
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
huggingface/datasets | nlp | 6,728 | Issue Downloading Certain Datasets After Setting Custom `HF_ENDPOINT` | ### Describe the bug
This bug is triggered under the following conditions:
- datasets repo ids without organization names trigger errors, such as `bookcorpus`, `gsm8k`, `wikipedia`, rather than in the form of `A/B`.
- If `HF_ENDPOINT` is set and the hostname is not in the form of `(hub-ci.)?huggingface.co`.
- T... | closed | 2024-03-11T09:06:38Z | 2024-03-15T14:52:07Z | https://github.com/huggingface/datasets/issues/6728 | [] | padeoe | 3 |
home-assistant/core | python | 140,688 | Webdav Integration for backup does not work | ### The problem
Backup with remote storage via webDAV integration does not work.
### What version of Home Assistant Core has the issue?
core-2025.3.3
### What was the last working version of Home Assistant Core?
core-2025.3.3
### What type of installation are you running?
Home Assistant OS
### Integration caus... | closed | 2025-03-15T20:46:17Z | 2025-03-15T23:25:12Z | https://github.com/home-assistant/core/issues/140688 | [
"needs-more-information",
"integration: webdav"
] | holger-tangermann | 7 |
AntonOsika/gpt-engineer | python | 182 | Doesn't quite work right on windows: tries to run .sh file | ```
Do you want to execute this code?
If yes, press enter. Otherwise, type "no"
Executing the code...
run.sh: /mnt/c/Users/jeff/.pyenv/pyenv-win/shims/pip: /bin/sh^M: bad interpreter: No such file or directory
run.sh: line 2: $'\r': command not found
run.sh: line 3: syntax error near unexpected token `<'
'... | closed | 2023-06-19T02:47:53Z | 2023-06-21T13:12:19Z | https://github.com/AntonOsika/gpt-engineer/issues/182 | [] | YEM-1 | 7 |
huggingface/peft | pytorch | 1,452 | peft/utils/save_and_load.py try to connect to the hub even when HF_HUB_OFFLINE=1 | ### System Info
peft 0.8.2
axolotl v0.4.0
export HF_DATASETS_OFFLINE=1
export TRANSFORMERS_OFFLINE=1
export HF_HUB_OFFLINE=1
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `e... | closed | 2024-02-09T18:59:45Z | 2024-02-12T13:41:37Z | https://github.com/huggingface/peft/issues/1452 | [] | LsTam91 | 1 |
ultralytics/ultralytics | pytorch | 19,105 | Impossible to use custom YOLOv8 when loading model | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
I tried to use my own train model for inference but instead of that I download and use a new yolov8n... | open | 2025-02-06T16:10:50Z | 2025-02-06T17:22:03Z | https://github.com/ultralytics/ultralytics/issues/19105 | [] | nlsferrara | 2 |
biolab/orange3 | data-visualization | 6,809 | do you have any examples that use Orange3 for brain image analysis and network analysis? | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
<!-- In other words, what's your pain point? -->
<!-- Is your request related to a problem, or ... | closed | 2024-05-21T17:09:38Z | 2024-06-06T15:53:35Z | https://github.com/biolab/orange3/issues/6809 | [] | cosmosanalytics | 1 |
iperov/DeepFaceLab | deep-learning | 5,463 | Wont use GPU | I have a Geforce RTX 2060 and it wont work with quick train 96 any way to fix? | open | 2022-01-18T17:16:20Z | 2023-06-08T23:18:36Z | https://github.com/iperov/DeepFaceLab/issues/5463 | [] | YGT72 | 5 |
proplot-dev/proplot | matplotlib | 309 | Latest proplot version incompatible with matplotlib 3.5 | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
I think v0.9.5 might be incompatible with matplotlib 3.5.0. ... | closed | 2021-12-10T21:29:15Z | 2023-03-03T12:57:40Z | https://github.com/proplot-dev/proplot/issues/309 | [
"bug",
"dependencies"
] | beckermr | 7 |
huggingface/pytorch-image-models | pytorch | 1,497 | [DOC] Add Link to the recipe for each model | Adding the recipe used to train each model would be a step forward in the documentation. | closed | 2022-10-16T10:49:03Z | 2024-08-20T19:29:23Z | https://github.com/huggingface/pytorch-image-models/issues/1497 | [
"enhancement"
] | mjack3 | 1 |
BeanieODM/beanie | pydantic | 187 | Validation error when getting the doc and it's linked document is deleted. | I have looked on the docs and according to [docs](https://roman-right.github.io/beanie/tutorial/relations/) "If a direct link is referred to a non-existent document, after the fetching it will stay the object of the Link class." But in my case it's raising ValidationError when the Linked document is deleted. Here is a ... | closed | 2022-01-16T19:23:53Z | 2023-05-23T18:40:31Z | https://github.com/BeanieODM/beanie/issues/187 | [
"bug"
] | runetech0 | 3 |
graphql-python/graphene-mongo | graphql | 180 | Switch Mongoengine DB at run time | I have a requirement where each client's data is stored in a different DB. The schema is the same for all clients in this case. So I need to switch_db while the query is being processed.
Is there any way to configure graphQL to select DB to be used? | open | 2021-07-12T03:54:33Z | 2021-07-12T03:54:33Z | https://github.com/graphql-python/graphene-mongo/issues/180 | [] | harsh04 | 0 |
encode/databases | sqlalchemy | 221 | "asyncpg.exceptions.PostgresSyntaxError" While using sqlalchemy is_(None) method in query | Hai friends,
I am using `sqlalchemy core + databases` for building and executing query in my project.\
My steps to build the query is like
```python
from sqlalchemy import *
from databases import Database
url = 'postgresql://username:password@localhost:5432/db_name'
meta = MetaData()
eng = create_engine(url... | open | 2020-06-16T15:47:20Z | 2021-07-21T14:03:44Z | https://github.com/encode/databases/issues/221 | [] | balukrishnans | 1 |
mckinsey/vizro | data-visualization | 459 | Relationship analysis chart in demo has no flexibility in Y axis | ### Description
If we look at [relationship analysis page of the demo UI](https://vizro.mckinsey.com/relationship-analysis), it provides explicit controls of what variables to put on axis:
<img width="243" alt="Screenshot 2024-05-06 at 9 58 43 PM" src="https://github.com/mckinsey/vizro/assets/102987839/9dda54f5-d98... | closed | 2024-05-06T20:04:00Z | 2024-06-04T13:11:17Z | https://github.com/mckinsey/vizro/issues/459 | [] | yury-fedotov | 10 |
skypilot-org/skypilot | data-science | 4,922 | [API server] Helm warning: annotation "kubernetes.io/ingress.class" is deprecated | ```
W0310 23:08:14.543122 97112 warnings.go:70] annotation "kubernetes.io/ingress.class" is deprecated, please use 'spec.ingressClassName' instead
NAME: skypilot
```
We can choose the field to set based on the server version | open | 2025-03-10T15:16:26Z | 2025-03-10T15:16:32Z | https://github.com/skypilot-org/skypilot/issues/4922 | [
"good first issue",
"good starter issues"
] | aylei | 0 |
miguelgrinberg/python-socketio | asyncio | 1,077 | keep trying to reconnect | **Describe the bug**
Analyze the log of PING pong, the connection has been successful, but it is constantly trying to reconnect, check the traceback, socketio.exceptions.ConnectionError: Already connected
**To Reproduce**
Please fill the following code example:
Socket.IO server version: `4.1.z`
*Server*
... | closed | 2022-10-27T07:24:18Z | 2024-01-04T20:08:11Z | https://github.com/miguelgrinberg/python-socketio/issues/1077 | [
"question"
] | dly667 | 9 |
s3rius/FastAPI-template | fastapi | 199 | PEP 604 Optional[] | Python 3.10+ introduces the | union operator into type hinting, see [PEP 604](https://www.python.org/dev/peps/pep-0604/). Instead of Union[str, int] you can write str | int. In line with other type-hinted languages, the preferred (and more concise) way to denote an optional argument in Python 3.10 and up, is now Type |... | open | 2023-12-13T08:58:02Z | 2023-12-15T14:05:27Z | https://github.com/s3rius/FastAPI-template/issues/199 | [] | Spirit412 | 3 |
graphql-python/graphene-sqlalchemy | graphql | 152 | Serializing native Python enums does not work | Currently using SQL enums works well, unless you use a `enum.Enum` as base for the enum. For example using this model:
```python
class Hairkind(enum.Enum):
LONG = 'long'
SHORT = 'short'
class Pet(Base):
__tablename__ = 'pets'
id = Column(Integer(), primary_key=True)
hair_kind = Column(En... | closed | 2018-07-31T12:47:07Z | 2023-02-25T06:58:33Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/152 | [] | wichert | 6 |
microsoft/unilm | nlp | 712 | Isn't LayoutXLM-large is the public model? | Hi, Thank you for sharing your work. I'm using the layoutxlm-base model.
I wanna check the layoutxlm-large too, but I can't find the models in huggingface.
Can't I try the model? | closed | 2022-05-11T09:05:47Z | 2022-05-13T00:17:49Z | https://github.com/microsoft/unilm/issues/712 | [] | yellowjs0304 | 2 |
flaskbb/flaskbb | flask | 548 | pip install -r requirements.txt doesn't work | Last output of `pip install -r requirements.txt`
```
Collecting Mako==1.0.7
Using cached Mako-1.0.7.tar.gz (564 kB)
Collecting MarkupSafe==1.0
Using cached MarkupSafe-1.0.tar.gz (14 kB)
ERROR: Command errored out with exit status 1:
command: /home/<user>/flaskbb/.venv/bin/python -c 'import sys, setu... | closed | 2020-04-17T19:44:40Z | 2020-06-04T18:29:32Z | https://github.com/flaskbb/flaskbb/issues/548 | [] | trick2011 | 4 |
pydantic/pydantic-ai | pydantic | 846 | ollama_example.py not working from docs | openai.OpenAIError: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variable | closed | 2025-02-04T05:35:14Z | 2025-02-04T18:11:48Z | https://github.com/pydantic/pydantic-ai/issues/846 | [] | saipr0 | 2 |
cle-b/httpdbg | rest-api | 155 | Feature Request: Counter for List of Requests | Just learned about httpdbg and have been enjoying using it. This is a small suggestion, but it would be nice to have a counter in the UI displaying the number of recorded requests.
Thanks for the great tool! | closed | 2024-10-31T00:48:49Z | 2024-11-01T17:50:41Z | https://github.com/cle-b/httpdbg/issues/155 | [] | erikcw | 2 |
sunscrapers/djoser | rest-api | 306 | Allow optional user fields to be set on registration | It would be very helpful if optional user fields like `first_name` and `last_name` could be set in `POST /users/`. The available fields would depend on the serializer being used. | closed | 2018-09-14T23:09:47Z | 2019-01-18T17:48:30Z | https://github.com/sunscrapers/djoser/issues/306 | [] | ferndot | 2 |
axnsan12/drf-yasg | rest-api | 260 | Detect ChoiceField type based on choices | ### Background
According to DRF documentation and source code, `ChoiceField` class supports different values types.
`ChoiceFieldInspector` considers ChoiceField to be of string type in all cases (except ModelSerializer case).
### Goal
Detect field type based on provided choices types.
When all choices are intege... | closed | 2018-12-04T08:15:45Z | 2018-12-07T12:11:14Z | https://github.com/axnsan12/drf-yasg/issues/260 | [] | mofr | 5 |
RobertCraigie/prisma-client-py | pydantic | 107 | Add support for the Unsupported type | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Prisma supports an `Unsupported` type that means types that Prisma does not support yet can still be represented in the schema.
We should support it too.
[https://www.prisma.io/docs/reference/api-referen... | open | 2021-11-08T00:16:59Z | 2022-02-01T15:38:21Z | https://github.com/RobertCraigie/prisma-client-py/issues/107 | [
"topic: types",
"kind/feature",
"level/advanced",
"priority/low"
] | RobertCraigie | 0 |
modin-project/modin | data-science | 7,249 | how to take down ray and put up again in local mode | My program has memory risk, and part of it seems to come from memory leak (idling ray workers holding a big chunk of memory). I have a for loop to independently run chunks of csv file on a series of tasks, I wish to kill ray after each iteration to release memory, and let Modin to put it up again with fresh ray workers... | closed | 2024-05-09T09:06:03Z | 2024-06-15T21:00:33Z | https://github.com/modin-project/modin/issues/7249 | [
"new feature/request 💬"
] | SiRumCz | 14 |
iMerica/dj-rest-auth | rest-api | 499 | Not getting `id_token` in response: Apple authentication. | I am using 3.0.0 and now I am confused about `id_token` for apple authentication. This [issue](https://github.com/iMerica/dj-rest-auth/issues/201#issue-774050426) says to use both `access_token` and `id_token` for login. When I hit the [authorisation url](https://developer.apple.com/documentation/sign_in_with_apple/req... | open | 2023-03-30T01:03:34Z | 2023-05-04T05:19:08Z | https://github.com/iMerica/dj-rest-auth/issues/499 | [] | haccks | 1 |
jupyter/nbviewer | jupyter | 673 | Error 503: GitHub API rate limit exceeded. Try again soon. | I am getting this error on a few notebooks, but I can't imagine that I have reached any traffic limits
[http://nbviewer.jupyter.org/github/MaayanLab/single_cell_RNAseq_Visualization/blob/master/Single%20Cell%20RNAseq%20Visualization%20Example.ipynb](http://nbviewer.jupyter.org/github/MaayanLab/single_cell_RNAseq_Vis... | closed | 2017-02-22T15:50:40Z | 2019-10-07T17:37:41Z | https://github.com/jupyter/nbviewer/issues/673 | [] | cornhundred | 10 |
plotly/dash-bio | dash | 422 | dash bio installation error in R | **Description of the bug**
Error when installing dash-bio in R, problem with dashHtmlComponents.
**To Reproduce**
```
> remotes::install_github("plotly/dash-bio")
Downloading GitHub repo plotly/dash-bio@master
✔ checking for file ‘/tmp/Rtmp3t2YC5/remotes1be9102a356f/plotly-dash-bio-447ebbe/DESCRIPTION’ ...
─ ... | closed | 2019-10-01T14:55:42Z | 2019-10-01T17:18:31Z | https://github.com/plotly/dash-bio/issues/422 | [] | Ebedthan | 3 |
keras-team/keras | machine-learning | 20,432 | TorchModuleWrapper object has no attribute 'train' (Keras3) | **Description**
I am trying to integrate a `torch.nn.Module` together with Keras Layers in my neural architecture using the `TorchModuleWrapper` layer. For this, I tried to reproduce the example reported in the [documentation](https://keras.io/api/layers/backend_specific_layers/torch_module_wrapper/).
To make the... | closed | 2024-10-31T13:04:18Z | 2024-11-01T07:40:06Z | https://github.com/keras-team/keras/issues/20432 | [] | MicheleCattaneo | 4 |
chiphuyen/stanford-tensorflow-tutorials | nlp | 143 | How to change the output of style_transfer? | After running the code successfully it cut off the image which wasn't desired.How to change the scale on which i want to do style transfer.I used different images as input.
I am working on ubuntu 18.04 | open | 2019-03-08T14:16:55Z | 2019-03-08T16:41:01Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/143 | [] | ghost | 0 |
ultralytics/ultralytics | machine-learning | 19,099 | How to deploy YOLO11 detection model on CVAT nuclio? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Any sample .yaml I can follow?
### Additional
_No response_ | open | 2025-02-06T11:18:43Z | 2025-02-06T14:07:29Z | https://github.com/ultralytics/ultralytics/issues/19099 | [
"question",
"detect"
] | patricklau12 | 4 |
ARM-DOE/pyart | data-visualization | 1,245 | plot_ppi_map with lat/lon | I have some code that I've been using successfully on a Debian 10 machine running pyart v1.11.2. I've tried running it on a Debian 11 machine running pyart v1.12.5 and I get plots but no lat/lon information. See my code and two attached images. Can you explain what I might be missing?
`import os
import sys
im... | closed | 2022-08-17T21:07:02Z | 2024-05-14T18:55:02Z | https://github.com/ARM-DOE/pyart/issues/1245 | [
"Question",
"component: pyart.graph"
] | srbrodzik | 27 |
strawberry-graphql/strawberry | django | 3,158 | Default values for scalar arguments passed as string | When declaring an optional argument with a scalar type, its default value is passed as a string in the resulting schema. This makes Strawberry-declared schemas incompatible with externally connected GraphQL consumers with strict schema checkers, such as Hasura.
The following code:
```python
from typing import Opti... | closed | 2023-10-18T09:52:49Z | 2025-03-20T15:56:26Z | https://github.com/strawberry-graphql/strawberry/issues/3158 | [
"bug"
] | ichorid | 7 |
joke2k/django-environ | django | 548 | ReadTheDocs build is broken | https://app.readthedocs.org/projects/django-environ/?utm_source=django-environ&utm_content=flyout
As a result the updates for v.0.12.0 have not been uploaded to ReadTheDocs | closed | 2025-01-15T21:18:52Z | 2025-01-16T22:15:58Z | https://github.com/joke2k/django-environ/issues/548 | [] | dgilmanAIDENTIFIED | 2 |
donnemartin/system-design-primer | python | 203 | DNS layer to elect loadbalancer health | How about to dns layer work as service discovery? Wich load balaner must be elect ?
Load balancer network may cuase problem or even might be any problem such as any layer of system.

DNS layer can work via simple mechanism to figure it out wich load ... | open | 2018-08-19T19:42:11Z | 2020-01-18T21:01:23Z | https://github.com/donnemartin/system-design-primer/issues/203 | [
"needs-review"
] | mhf-ir | 2 |
wkentaro/labelme | computer-vision | 1,029 | rectangle mouse line cross | rectangle
I want the mouse to show a cross
Convenient for me to locate
<img width="408" alt="微信截图_20220602200358" src="https://user-images.githubusercontent.com/6490927/171625270-8646ab55-a5d3-44df-a935-279a72cb156a.png">
| closed | 2022-06-02T12:05:15Z | 2022-06-25T04:09:24Z | https://github.com/wkentaro/labelme/issues/1029 | [] | monkeycc | 0 |
MycroftAI/mycroft-core | nlp | 2,511 | Unable to install on latest Ubuntu |
Hello! Thanks for your time :-)
## software, hardware and version
* master pull of the mycroft-core codebase
## steps that we can use to replicate the Issue
For example:
1. Clone the repo to a machine running the latest version of ubuntu
2. Try to install/run the program with `dev_setup.sh` or `start... | closed | 2020-03-24T21:03:53Z | 2020-04-27T08:54:34Z | https://github.com/MycroftAI/mycroft-core/issues/2511 | [] | metasoarous | 8 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 967 | [FEATURE]: add undetected - chrome driver | ### Feature summary
adding undetected - chrome driver
### Feature description
https://github.com/ultrafunkamsterdam/undetected-chromedriver
### Motivation
_No response_
### Alternatives considered
_No response_
### Additional context
_No response_ | closed | 2024-11-28T16:02:20Z | 2024-12-01T15:07:48Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/967 | [
"enhancement",
"hotfix needed"
] | surapuramakhil | 2 |
HIT-SCIR/ltp | nlp | 435 | dlopen: cannot load any more object with static TLS | python 3.6.3
ltp 4.0.9
GCC 4.8.4
Traceback (most recent call last):
File "pre_app.py", line 39, in <module>
from wenlp.sentence_analyser import process_long_sentence,sub_pre_comma,del_nonsense,change_negative_is_positive
File "/data/welab/nlp/speech_bot_venv/venv/lib/python3.6/site-packages/webot_nlp-... | closed | 2020-11-10T01:24:59Z | 2020-11-16T01:55:54Z | https://github.com/HIT-SCIR/ltp/issues/435 | [] | liuchenbaidu | 1 |
roboflow/supervision | machine-learning | 1,281 | Machine vision | closed | 2024-06-13T19:07:39Z | 2024-06-14T13:12:04Z | https://github.com/roboflow/supervision/issues/1281 | [] | Romu10 | 0 | |
pydantic/FastUI | pydantic | 339 | FastUI provides raw json object instead of rendered interface | First of all, congratulations for this outstanding framework, you rock! I wrote the small app, below, on a file `main.py` with routes `/users` and `/users/{id}`. For some reason I do not know why is my app displaying "Request Error: Response not valid JSON" when I hit endpoint `/` and the raw json on available routes i... | closed | 2024-07-13T19:55:31Z | 2024-07-14T16:05:40Z | https://github.com/pydantic/FastUI/issues/339 | [] | brunolnetto | 3 |
ultralytics/ultralytics | pytorch | 19,476 | YOLOv10 or YOLO11 Pruning, Masking and Fine-Tuning | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello, I have a question. After pruning, I wanna fine-tuning with the traine... | open | 2025-02-28T08:23:13Z | 2025-03-03T02:00:36Z | https://github.com/ultralytics/ultralytics/issues/19476 | [
"enhancement",
"question"
] | Thaising-Taing | 6 |
viewflow/viewflow | django | 33 | Separate declarative and state code | closed | 2014-04-09T10:17:04Z | 2014-05-01T09:58:12Z | https://github.com/viewflow/viewflow/issues/33 | [
"request/enhancement"
] | kmmbvnr | 2 | |
deepspeedai/DeepSpeed | machine-learning | 6,838 | nv-ds-chat CI test failure | The Nightly CI for https://github.com/microsoft/DeepSpeed/actions/runs/12226557524 failed.
| closed | 2024-12-09T00:21:33Z | 2024-12-11T00:08:34Z | https://github.com/deepspeedai/DeepSpeed/issues/6838 | [
"ci-failure"
] | github-actions[bot] | 0 |
quantmind/pulsar | asyncio | 283 | HTTP Tunneling | * **pulsar version**: 2.0
* **python version**: 3.5+
* **platform**: any
## Description
With pulsar 2.0, the HTTP tunnel does not work across different event loops. Since we use the uvloop as almost the default loop we need to find an implementation that works properly. In the mean time SSL tunneling (ssl behin... | closed | 2017-11-14T22:29:07Z | 2017-11-16T21:21:37Z | https://github.com/quantmind/pulsar/issues/283 | [
"http",
"bug"
] | lsbardel | 0 |
man-group/arctic | pandas | 662 | VersionStore static method is_serializable | #### Arctic Version
```
1.72.0
```
#### Arctic Store
```
VersionStore
```
#### Description of problem and/or code sample that reproduces the issue
Following up the change where "can_write_type" static methods were added to all VersionStore handlers:
https://github.com/manahl/arctic/pull/622
we ca... | open | 2018-11-20T11:09:49Z | 2018-11-20T11:13:26Z | https://github.com/man-group/arctic/issues/662 | [
"enhancement",
"feature"
] | dimosped | 0 |
plotly/dash | data-visualization | 2,891 | [Feature Request] tabIndex of Div should also accept number type | In the origin React, parameter `tabIndex` could accept number type:

It would be better to add number type support for `tabIndex`:

databricks
### Versions of Apache Airflow Providers
apache-airflow-providers-databricks==7.2.0
### Apache Airflow version
2.10.5
### Operating System
Debian Bookworm
### Deployment
Official Apache Airflow Helm Chart
### Deployment details
_No response_
### What happened
When... | open | 2025-03-11T13:20:57Z | 2025-03-24T02:01:18Z | https://github.com/apache/airflow/issues/47614 | [
"kind:bug",
"area:providers",
"provider:databricks"
] | pacmora | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 378 | [Question] How use intra_var_miner for multiclass | Firstly, thank you for your great package and modules.
It works very fine, well documented.
Nevertheless, I struggle to determine what kind of loss I can use for binary or multiclass.
For example, I'm trying to create a kind of "anomaly" detector through metric learning.
In the ideal world, in the embedding space... | closed | 2021-11-04T16:49:55Z | 2021-11-16T11:05:40Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/378 | [
"question"
] | cfrancois7 | 5 |
holoviz/panel | plotly | 7,554 | Perspective pane collapses rows when updating data | #### ALL software version info
panel 1.5.4
Windows, MacOS, Chrome, Edge
#### Description of expected behavior and the observed behavior
There appears to be a bug with the perspective pane automatically collapsing the hierarchy when the underlying data object is updated - **this only seems to happen _after_ clicking ... | open | 2024-12-16T23:33:25Z | 2025-01-20T21:35:52Z | https://github.com/holoviz/panel/issues/7554 | [] | rob-tay | 0 |
akfamily/akshare | data-science | 5,415 | 关于AKShare的接口get_futures_daily在条件market='INE'时获取2018年3月以前的数据出错问题 | **当前使用Python 3.13.0,AKShare版本为1.15.45,AKTools版本为0.0.89,运行环境为64位的Windows 10 终端下执行:**
>python
>>> import akshare as ak
>>> df = ak.get_futures_daily(start_date='20180301', end_date='20180331', market='DCE')
>>> df = ak.get_futures_daily(start_date='20180301', end_date='20180331', market='CFFEX')
>>> df = ak.get_futu... | closed | 2024-12-12T12:17:38Z | 2024-12-14T09:00:38Z | https://github.com/akfamily/akshare/issues/5415 | [] | dahong38 | 3 |
svc-develop-team/so-vits-svc | pytorch | 55 | epch 到10000停止了,但是推理时有很严重的噪音 | 到10000后训练就停止,推理时还会有严重的噪音,但可以隐约听到说话声音了
是否需要把配置文件中的"epochs": 10000, 调高让他接着练呢?还是说有哪一步可能做错了呢?
我确实没有使用Pre-trained model files: G_0.pth D_0.pth, 不知道是否和这个有关呢?
| closed | 2023-03-19T01:14:32Z | 2023-03-31T07:14:03Z | https://github.com/svc-develop-team/so-vits-svc/issues/55 | [] | Max-Liu | 7 |
Aeternalis-Ingenium/FastAPI-Backend-Template | sqlalchemy | 30 | TypeError: MultiHostUrl.__new__() got an unexpected keyword argument 'scheme' | backend_app | File "/usr/backend/src/api/dependencies/session.py", line 11, in <module>
backend_app | from src.repository.database import async_db
backend_app | File "/usr/backend/src/repository/database.py", line 43, in <module>
backend_app | async_db: AsyncDatabase = AsyncDatabase()
backen... | open | 2023-11-28T11:29:43Z | 2024-11-12T10:25:00Z | https://github.com/Aeternalis-Ingenium/FastAPI-Backend-Template/issues/30 | [] | eshpilevskiy | 1 |
tortoise/tortoise-orm | asyncio | 994 | how to use tortoise-orm in django3 | Django3 does not support asynchronous ORM, how can I use tortoise-orm in django3, I can't find an example of that.
Thanks! | open | 2021-11-30T10:03:22Z | 2021-11-30T10:20:39Z | https://github.com/tortoise/tortoise-orm/issues/994 | [] | lastshusheng | 2 |
Evil0ctal/Douyin_TikTok_Download_API | api | 210 | 部署问题 | 在docker部署的时候,发生错误,以下都是docker报的错误和一些配置截图,求大佬解答



2. Framework version: Tensorflow-gpu 2.1.0 / Keras 2.3.1
3. Horovod version: 0.21.3
4. MPI version: OpenMPI 4.1.1 / MPI API 3.1.0
5. CUDA version: 10.1
6. NCCL version: 2.5.7.1
7. Python version: 3.7
8. Spark / PySpark version:
9. Ray version:
10. OS and vers... | closed | 2021-10-01T09:55:26Z | 2022-12-02T17:10:42Z | https://github.com/horovod/horovod/issues/3189 | [
"wontfix"
] | SHEELE41 | 2 |
healthchecks/healthchecks | django | 939 | Truncate beginning of long request bodies instead of the end | I've started making use of the [feature to send log data to healthchecks](https://healthchecks.io/docs/attaching_logs/). I like that I get a truncated copy of the logs in my notification provider.
Under most circumstances I can imagine, an error in the script would show up at the end, and typically this error is tru... | open | 2024-01-08T00:22:40Z | 2024-04-11T17:41:29Z | https://github.com/healthchecks/healthchecks/issues/939 | [] | StevenMassaro | 5 |
ludwig-ai/ludwig | computer-vision | 3,218 | [FR] Allow users to set the unmarshalling mode as RAISE for BaseConfig | **Is your feature request related to a problem? Please describe.**
Currently, when loading the user config, Ludwig allows unknown attributes to be set. There is a TODO item in the code at `ludwig/schema/utils.py:161`
```
unknown = INCLUDE # TODO: Change to RAISE and update descriptions once we want to enforce str... | closed | 2023-03-07T13:14:49Z | 2023-03-17T21:12:20Z | https://github.com/ludwig-ai/ludwig/issues/3218 | [
"feature"
] | dragosmc | 5 |
xinntao/Real-ESRGAN | pytorch | 747 | The OST dataset has many sub folders, have all the images been used for training? | closed | 2024-02-07T01:21:00Z | 2024-02-08T01:54:51Z | https://github.com/xinntao/Real-ESRGAN/issues/747 | [] | Note-Liu | 0 | |
PaddlePaddle/models | computer-vision | 5,254 | PaddleCV模型库下的3D检测里的M3D-RPN模型文档有问题 | 这个目录下的文档
快速开始目录下的cd M3D-RPN后
运行ln -s /path/to/kitti dataset/kitti提示:
ln:failed to create symbolic link "dataset/kitti":没有这个目录
另外:本模型是在1.8下开发的,什么时候能提供个2.0的版本呢
| open | 2021-02-01T03:26:28Z | 2024-02-26T05:09:17Z | https://github.com/PaddlePaddle/models/issues/5254 | [] | Sqhttwl | 2 |
plotly/dash | jupyter | 3,208 | Add support for retrieving `HTMLElement` by Dash component ID in clientside callbacks. | This has been [discussed on the forum](https://community.plotly.com/t/how-to-use-document-queryselector-with-non-string-ids-in-clientside-callback/91146). A feature request seems more appropriate.
**Is your feature request related to a problem? Please describe.**
When using clientside callbacks and pattern matching, t... | open | 2025-03-11T12:59:20Z | 2025-03-11T13:58:18Z | https://github.com/plotly/dash/issues/3208 | [
"feature",
"P2"
] | ctdunc | 1 |
InstaPy/InstaPy | automation | 6,241 | Already unfollowed 'username'! or a private user that rejected your req | <!-- Did you know that we have a Discord channel ? Join us: https://discord.gg/FDETsht -->
<!-- Is this a Feature Request ? Please, check out our Wiki first https://github.com/timgrossmann/InstaPy/wiki -->
## Expected Behavior
## Current Behavior
```
INFO [2021-06-19 17:23:14] [my.account] Ongoing Unfollow [1/4... | open | 2021-06-19T15:25:31Z | 2021-07-21T00:19:18Z | https://github.com/InstaPy/InstaPy/issues/6241 | [
"wontfix"
] | Tr1pke | 1 |
vaexio/vaex | data-science | 1,229 | [BUG-REPORT] Columns with spaces throw error with from_dict | Description
There seems to be a problem with columns that have spaces in them. I provided an example below that clearly demonstrates it.
df_pd = {}
df_pd['A'] = [0]
df_pd['SHORT VOLUME'] = ['4563']
df_pd['SHORT_VOLUME'] = ['4563']
df = vaex.from_dict(df_pd)
displ... | open | 2021-02-25T15:41:53Z | 2021-03-09T23:52:43Z | https://github.com/vaexio/vaex/issues/1229 | [
"priority: high"
] | foooooooooooooooobar | 3 |
StackStorm/st2 | automation | 5,908 | Keystore RBAC Configuration Issues | ## SUMMARY
Changes to the RBAC to incorporate the keystore items has created various issues with the config that cannot be corrected aside from assigning users "admin" roles. First, actions/workflows that are grant permission to a user by RBAC role config to DO NOT apply to keystore operations that are executed wit... | open | 2023-02-20T16:39:28Z | 2023-02-20T20:07:00Z | https://github.com/StackStorm/st2/issues/5908 | [] | jamesdreid | 2 |
vitalik/django-ninja | rest-api | 1,290 | [BUG] JWTAuth() is inconsistent with django authentication? | ```
@api.get(
path="/hello-user",
response=UserSchema,
auth=[JWTAuth()]
)
def hello_user(request):
return request.user
>>>
"GET - hello_user /api/hello-user"
Unauthorized: /api/hello-user
```
When disabling auth
```
@api.get(
path="/hello-user",
response=UserSchema,
... | open | 2024-09-02T08:53:50Z | 2024-09-21T06:03:49Z | https://github.com/vitalik/django-ninja/issues/1290 | [] | neldivad | 1 |
httpie/cli | rest-api | 960 | Convert Httpie to other http requests | Excuse me, how can I convert Httpie to other http requests, such as cURL etc.. | closed | 2020-08-20T06:04:06Z | 2020-08-20T12:11:46Z | https://github.com/httpie/cli/issues/960 | [] | wnjustdoit | 1 |
aminalaee/sqladmin | asyncio | 875 | Add RichTextField to any field, control in ModelView | ### Checklist
- [x] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
The current solution for CKEditor is not suitable (or reusable) if I have a model with two fields that requires CKEditor. Or any other model, that have different field name, not `... | open | 2025-01-24T13:20:50Z | 2025-01-24T13:20:50Z | https://github.com/aminalaee/sqladmin/issues/875 | [] | mmzeynalli | 0 |
jupyter-book/jupyter-book | jupyter | 1,787 | Convert admonitions to html when launching notebook | ### Context
Problem: a note/tip/admonition is not rendered properly when the notebook is opened with Binder/Colab/...
### Proposal
Automatically convert note/tip/admonition to HTML standalone in the notebook (with the corresponding <style>).
### Tasks and updates
I can try to do it, but I am not sure on the feasib... | closed | 2022-07-21T16:30:58Z | 2022-07-22T17:36:04Z | https://github.com/jupyter-book/jupyter-book/issues/1787 | [
"enhancement"
] | fortierq | 0 |
polakowo/vectorbt | data-visualization | 394 | Having trouble implementing backtesting, pf.stat(),pf.order.records_readable can't generate the result | Hi, I encounter some problem while running my strategy,these are the correct result. It works fine yesterday
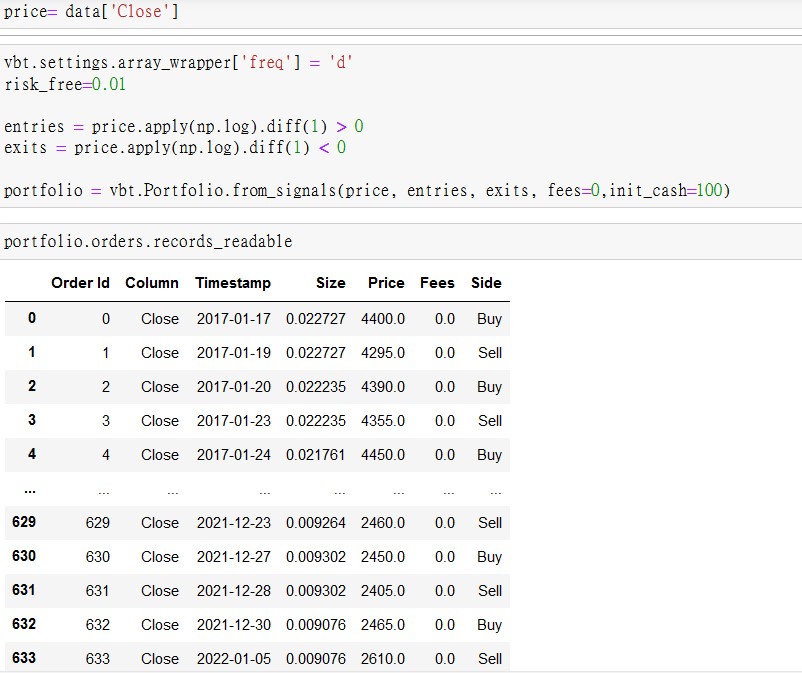

| closed | 2021-05-06T09:36:22Z | 2021-06-27T19:45:28Z | https://github.com/miguelgrinberg/python-socketio/issues/680 | [
"question"
] | yathartharora | 1 |
Miserlou/Zappa | flask | 1,533 | NameError: name 'LAMBDA_CLIENT' is not defined | ## Context
Python 3.6
I'm trying to run async tasks with Zappa. The details of my environment are probably causing the issue, but my problem is more with the absence of error messages.
## Expected Behavior
If `boto3` can't initialize a session, I would expect to get a clear error about it.
## Actual Beha... | open | 2018-06-14T13:21:21Z | 2019-03-21T21:50:52Z | https://github.com/Miserlou/Zappa/issues/1533 | [] | charlax | 3 |
PedroBern/django-graphql-auth | graphql | 64 | [Error!]: Invalid Token in verifyAccount Mutation | # Prerequisites
* [x] Is it a bug?
* [ ] Is it a new feature?
* [ ] Is it a a question?
* [x] Can you reproduce the problem?
* [x] Are you running the latest version?
* [ ] Did you check for similar issues?
* [ ] Did you perform a cursory search?
For more information, see the [CONTRIBUTING](https://github.c... | closed | 2020-09-05T22:45:22Z | 2022-03-29T13:19:20Z | https://github.com/PedroBern/django-graphql-auth/issues/64 | [] | nietzscheson | 5 |
PokeAPI/pokeapi | graphql | 904 | Missing data for distortion world location areas | Hi ! There is no data for `areas` when calling the API on `https://pokeapi.co/api/v2/location/distortion-world/`. This implies that `giratina-origin` doesn't have any encounter data.
Steps to Reproduce:
1. Go to `https://pokeapi.co/api/v2/location/distortion-world` and see the empty `areas` array
2. Go to `https... | closed | 2023-07-17T13:58:49Z | 2023-07-17T21:47:05Z | https://github.com/PokeAPI/pokeapi/issues/904 | [] | truite-codeuse | 4 |
tensorlayer/TensorLayer | tensorflow | 525 | tensorlayer output | Is there a function to return the probability of the outputs? I searched utils.py and couldn't find what I wanted. | closed | 2018-04-23T12:45:51Z | 2018-04-26T10:16:18Z | https://github.com/tensorlayer/TensorLayer/issues/525 | [] | kodayu | 1 |
cleanlab/cleanlab | data-science | 773 | Add support for detecting label errors in Instance Segmentation data | Many users have requested this functionality.
For now, you should be able to use the existing code for semantic segmentation label error detection by converting your instance segmentation labels & predictions into semantic segmentation labels & predictions. That approach may not capture all possible types of label er... | open | 2023-07-13T22:45:20Z | 2024-09-03T02:30:23Z | https://github.com/cleanlab/cleanlab/issues/773 | [
"enhancement",
"help-wanted"
] | jwmueller | 7 |
amdegroot/ssd.pytorch | computer-vision | 455 | how can we train on custom VOC dataset?? | I want to train on custom dataset with VOC format
| open | 2020-01-06T14:08:15Z | 2021-11-16T12:27:34Z | https://github.com/amdegroot/ssd.pytorch/issues/455 | [] | ayaelalfy | 6 |
RasaHQ/rasa | machine-learning | 13,114 | How to Handle Out of Context Messeges and Unclear Messges in Chat | Your input -> hello
Hey there! What's your name?
Your input -> my name is john
In which city do you live?
Your ... | open | 2025-03-18T18:14:29Z | 2025-03-18T18:14:29Z | https://github.com/RasaHQ/rasa/issues/13114 | [] | Vishwa-ud | 0 |
xzkostyan/clickhouse-sqlalchemy | sqlalchemy | 274 | Bug in _reflect_table() support for alembic versions < 1.11.0 | **Describe the bug**
Versions of alembic lower than 1.11.0 will fail with syntax error when trying to produce a migration script.

```
migration = produce_migrations(mi... | closed | 2023-11-08T23:29:44Z | 2024-03-25T07:22:19Z | https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/274 | [] | DicksonChi | 0 |
InstaPy/InstaPy | automation | 6,177 | Only Like Posts if Their Authors Belong to a Set of Users | I was hoping to write a bot that likes posts only by certain users. I noticed there's a function `session.set_ignore_users()` that ignores any user in a given list, and I am wondering if there is a function that behaves in a reversed way, i.e. it ignores any other users not specified by a given list. Thanks in advance.... | closed | 2021-05-10T04:36:12Z | 2021-06-26T19:00:11Z | https://github.com/InstaPy/InstaPy/issues/6177 | [
"wontfix"
] | georgezywang | 2 |
dsdanielpark/Bard-API | nlp | 14 | How to get BARD_API_KEY ? | I saw the usage, but idk how to get my BARD_API_KEY ? | closed | 2023-05-17T18:10:30Z | 2023-05-17T18:51:58Z | https://github.com/dsdanielpark/Bard-API/issues/14 | [] | SKbarbon | 1 |
koaning/scikit-lego | scikit-learn | 187 | [DOCS] duplicate images in docs | We now have an issue that is similar to [this](https://github.com/spatialaudio/nbsphinx/issues/162) one. Certain images get overwritten. From console;
```
reading sources... [100%] preprocessing ... | closed | 2019-09-08T19:35:50Z | 2019-09-19T07:00:49Z | https://github.com/koaning/scikit-lego/issues/187 | [
"documentation"
] | koaning | 3 |
deepset-ai/haystack | pytorch | 8,925 | Remove the note "Looking for documentation for Haystack 1.x? Visit the..." from documentation pages | closed | 2025-02-25T10:53:16Z | 2025-02-26T14:21:58Z | https://github.com/deepset-ai/haystack/issues/8925 | [
"P1"
] | julian-risch | 0 | |
sqlalchemy/alembic | sqlalchemy | 1,090 | Migration generated always set enum nullable to true | **Describe the bug**
I have a field with enum type and I want to set nullable to False, however, the migration generated is always set nullable to True
**Expected behavior**
If the field contains nullable = False, migration generated should set nullable = False
**To Reproduce**
```py
import enum
from sqlmo... | closed | 2022-09-23T04:51:44Z | 2022-10-09T14:25:56Z | https://github.com/sqlalchemy/alembic/issues/1090 | [
"awaiting info",
"cant reproduce"
] | yixiongngvsys | 3 |
christabor/flask_jsondash | flask | 5 | Remove jquery, bootstrap, etc.. from blueprint, put into requirements and example app. | The user will likely have them in their main app.
| closed | 2016-05-02T19:52:03Z | 2016-05-03T18:24:08Z | https://github.com/christabor/flask_jsondash/issues/5 | [] | christabor | 0 |
flairNLP/flair | nlp | 2,683 | Wrong Detection - person entity | **Describe the bug**
For any person entity, the prediction are added along with "hey"
Eg: "Hey Karthick"
**To Reproduce**
Model name - ner-english-fast, ner-english
Steps to reproduce the behavior (e.g. which model did you train? what parameters did you use? etc.).
**Expected behavior**
Eg: "Hey Karthick"
P... | closed | 2022-03-21T08:22:26Z | 2022-09-09T02:02:36Z | https://github.com/flairNLP/flair/issues/2683 | [
"bug",
"wontfix"
] | karthicknarasimhan98 | 1 |
autogluon/autogluon | scikit-learn | 3,944 | Ray error when using preset `good_quality` | ### Discussed in https://github.com/autogluon/autogluon/discussions/3943
<div type='discussions-op-text'>
<sup>Originally posted by **ArijitSinghEDA** February 22, 2024</sup>
I am using the preset `good_quality` in my `TabularPredictor`, but it gives the following error:
```
2024-02-22 13:57:06,461 WARNING w... | closed | 2024-02-22T08:32:39Z | 2024-02-22T08:58:10Z | https://github.com/autogluon/autogluon/issues/3944 | [] | ArijitSinghEDA | 0 |
zalandoresearch/fashion-mnist | computer-vision | 21 | Adding Japanese README translation | I found a Japanese translation of README.md on http://tensorflow.classcat.com/category/fashion-mnist/
Seems pretty complete to me. I sent a email to the website and asking for the permission to use it as official README-jp.md.
Still waiting their reply. | closed | 2017-08-28T14:45:28Z | 2017-08-29T09:02:47Z | https://github.com/zalandoresearch/fashion-mnist/issues/21 | [] | hanxiao | 0 |
zihangdai/xlnet | nlp | 57 | Has the data been split into segments for pretraining | The paper says
> During the pretraining phase, following BERT, we randomly sample two segments (either from the same context or not) and treat the concatenation of two segments as one sequence to perform permutation language modeling.
I don't really get this, if there is no next sentence prediction what is the... | closed | 2019-06-25T23:12:02Z | 2019-07-07T20:14:04Z | https://github.com/zihangdai/xlnet/issues/57 | [] | rakshanda22 | 3 |
katanaml/sparrow | computer-vision | 1 | How to save the predicted output from LayoutLM or LayoutLMv2 ? | I trained LayoutLM for my dataset and I am getting predictions at the word level like in the image "ALVARO FRANCISCO MONTOYA" is true labeled as "party_name_1" but while prediction "ALVARO " is tagged as "party_name_1", "FRANCISCO" is tagged as "party_name_1", "MONTOYA" is tagged as "party_name_1". In short, i am get... | closed | 2022-03-31T11:05:15Z | 2022-03-31T15:55:52Z | https://github.com/katanaml/sparrow/issues/1 | [] | karndeepsingh | 3 |
blacklanternsecurity/bbot | automation | 1,815 | Excavate IPv6 URLs | We should have a test for excavating IPv6 URLs.
originally suggested by @colin-stubbs | open | 2024-10-02T18:38:46Z | 2025-02-28T15:02:40Z | https://github.com/blacklanternsecurity/bbot/issues/1815 | [
"enhancement"
] | TheTechromancer | 0 |
onnx/onnx | tensorflow | 5,885 | [Feature request] Provide a means to convert to numpy array without byteswapping | ### System information
ONNX 1.15
### What is the problem that this feature solves?
Issue onnx/tensorflow-onnx#1902 in tf2onnx occurs on big endian systems, and it is my observation that attributes which end up converting to integers are incorrectly byteswapped because the original data resided within a tensor. If `n... | closed | 2024-01-31T20:58:56Z | 2024-02-02T16:52:35Z | https://github.com/onnx/onnx/issues/5885 | [
"topic: enhancement"
] | tehbone | 4 |
mirumee/ariadne | graphql | 121 | Support content type "application/graphql" | > If the "application/graphql" Content-Type header is present, treat the HTTP POST body contents as the GraphQL query string. | closed | 2019-03-26T19:07:04Z | 2024-04-03T09:15:39Z | https://github.com/mirumee/ariadne/issues/121 | [] | rafalp | 3 |
aleju/imgaug | machine-learning | 102 | Background Image Processing Hangs If Ungraceful Exit | A process using background image processing will hang if runtime is terminated before background image processing is complete.
### System:
- Operating System: Ubuntu 16.04
- Python: 2.7.12
- imgaug: 0.2.5
### Code to Reproduce
```python
import imgaug as ia
import numpy as np
def batch_generator():
f... | closed | 2018-03-07T16:15:56Z | 2018-03-08T19:20:27Z | https://github.com/aleju/imgaug/issues/102 | [] | AustinDoolittle | 2 |
dmlc/gluon-nlp | numpy | 724 | PrefetcherIter with worker_type='process' may hang | I noticed that using PrefetcherIter with worker_type='process' may leave the prefetching process hang. Specifically, if I do
```
kill $PARENT_PID
```
I will observe that the parent process exits, and that child process still runs. And the child process runs till https://github.com/dmlc/gluon-nlp/blob/master/src/gl... | closed | 2019-05-23T06:46:27Z | 2020-10-15T20:16:10Z | https://github.com/dmlc/gluon-nlp/issues/724 | [
"bug"
] | eric-haibin-lin | 5 |
erdewit/ib_insync | asyncio | 314 | QEventDispatcherWin32::wakeUp: Failed to post a message (Not enough quota is available to process this command.) | I am working with a pyqt5 application with ib_insync. I am loading a set of open orders and showing them in a table one I press the connect button. Worked fine so far.
I increased the number of open orders to around 50-60. Now, once I press the connect button, I get an endless stdout of messages with the text:
`QEv... | closed | 2020-11-09T13:55:13Z | 2020-11-11T20:31:37Z | https://github.com/erdewit/ib_insync/issues/314 | [] | romanrdgz | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,131 | Socket.io not establishing connection with load balancer : timeout error | **Your question**
Hi Miguel, We are in the process of moving our cloud instance from Linode to Google Cloud Platform. Our entire web app uses socket.io for most frontend behavior. When we hit the domain on the GCP instance we are experiencing extremely slow speeds. In addition we are experiencing a server disconnect e... | closed | 2019-12-18T22:42:45Z | 2020-06-30T22:52:00Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1131 | [
"question"
] | jtopel | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.