
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
sqlalchemy/sqlalchemy | sqlalchemy | 10,780 | name with flat for aliased() | ### Describe the use case
aliased() currently prohibits a name in conjunction with `flat=True`. Presumably this is because it would require some arbitrary naming convention. In reality, `flat=True` already has an arbitrary naming convention (suffix with numbers) which is useful for the query compiler, but not so much ... | open | 2023-12-19T18:26:30Z | 2023-12-19T21:18:10Z | https://github.com/sqlalchemy/sqlalchemy/issues/10780 | [
"sql",
"use case"
] | ericatkin | 3 |
waditu/tushare | pandas | 972 | 用Rstudio调取接口数据为空?积分是正好够的 | closed | 2019-03-22T09:43:04Z | 2019-03-25T13:10:56Z | https://github.com/waditu/tushare/issues/972 | [] | daisyldf | 2 | |
pytorch/pytorch | machine-learning | 149,502 | [Inductor] register_module_forward_pre_hook lead to compiled model produce wrong inference results | ### 🐛 Describe the bug
Given the same inputs, the inference results for the compiled models were not equivalent to the original model before/after the execution of `register_module_forward_pre_hook(pre_hook)` ,
Such results are bizarre!
```python
import torch
model = torch.nn.Sequential(
torch.nn.Linear(10, ... | open | 2025-03-19T11:13:23Z | 2025-03-19T22:03:42Z | https://github.com/pytorch/pytorch/issues/149502 | [
"high priority",
"triage review",
"oncall: pt2",
"module: pt2-dispatcher"
] | Cookiee235 | 2 |
mars-project/mars | pandas | 3,366 | [BUG]Build fails under Windows platform | **Bug description**
The MSVC team recently added Mars as part of RWC testing to detect compiler regression. Seems the project will fail to build under Windows due to error C1189: #error: unsupported platform. Could you please take a look?
**To Reproduce**
1. Open VS2022 x64 Tools command .
2. git clone C:\gitP\T... | open | 2024-05-11T08:18:43Z | 2024-05-14T02:39:33Z | https://github.com/mars-project/mars/issues/3366 | [] | brianGriifin114 | 1 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 611 | Quality of the voice | Hi, I am trying to clone the voice of famous people like Abdul Kalam, Modi. I collected their speeches from youtube videos. But the quality of the voice is very low. There is no similarity between the voice generated by the model and the target's voice.
I am attaching the generated audio file(.wav) and the audio file... | closed | 2020-11-30T00:18:59Z | 2020-12-05T08:04:57Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/611 | [] | sriharsha0806 | 2 |
google-research/bert | nlp | 631 | Train with bert_multi_cased OOM error, but works with bert_cased | Hi guys!
I'm working on a project where, basically, I add a CNN + maxpool + dense layer with softmax after the bert embeddings, to perform classification on different datasets. I'm running this locally on my computer, on my GPU. Until now, I was only working with English datasets (such as the TREC question dataset - w... | open | 2019-05-09T05:30:30Z | 2019-06-20T02:50:42Z | https://github.com/google-research/bert/issues/631 | [] | bernardoccordeiro | 1 |
nonebot/nonebot2 | fastapi | 2,461 | Docs: 建议插件商店新增一个更新排序 | ### 希望能解决的问题
有时候一些老旧的插件突然又更新了,可以从最近更新优先级进去看看更新了啥
### 描述所需要的功能
RT | closed | 2023-11-20T14:22:37Z | 2025-02-26T15:05:08Z | https://github.com/nonebot/nonebot2/issues/2461 | [
"documentation"
] | mmmjie | 1 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 862 | 扩充词表后加载 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.c... | closed | 2023-10-30T03:58:32Z | 2023-11-15T00:36:40Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/862 | [
"stale"
] | wzg-zhuo | 3 |
pallets/quart | asyncio | 375 | Type checking has been failing in CI for the last 6 months | Type checking doesn't pass when running tests for PRs
https://github.com/pallets/quart/actions/workflows/tests.yaml
https://github.com/pallets/quart/actions/runs/9331655216
| closed | 2024-11-13T22:16:19Z | 2024-11-29T00:26:12Z | https://github.com/pallets/quart/issues/375 | [] | JamesParrott | 5 |
hankcs/HanLP | nlp | 1,339 | HanLP多实例魔改中 | 由于早期设计局限,目前HanLP的`CustomDictionary`、`CoreDictionary`、`CoreBiGramTableDictionary`等都是静态资源类。而一些应用场景要求加载不同的词典,比如同一个JVM中不同用户实例,或者不同领域下加载不同的bigram模型。由于个人时间有限,这个功能让大家久等了。
现在,所有静态资源类正在逐步改造中。目前的进度如下:
- [x] `CustomDictionary`重构完毕
- 如果你不需要多实例,无需任何改动,1.x保持前向兼容
- 如果你需要多实例,可以为分词器`segment`或`analyzer`创建一个新的`DynamicCustomDi... | closed | 2019-12-05T05:15:29Z | 2023-03-22T06:20:13Z | https://github.com/hankcs/HanLP/issues/1339 | [
"ignored"
] | hankcs | 10 |
JaidedAI/EasyOCR | machine-learning | 619 | Doesn't it support macos? | My system is macOS Monterey, and the computer is mbp 2019 16inch. I tried to install it using both `pip install easyocr` and `pip install git+git://github.com/jaidedai/easyocr.git`.But just when I run `import easyocr`,zsh says "segmentation fault". I wonder if it supports macOS and whether I need to install it manually... | closed | 2021-12-10T13:49:45Z | 2021-12-10T14:03:36Z | https://github.com/JaidedAI/EasyOCR/issues/619 | [] | hengyuekang | 1 |
lucidrains/vit-pytorch | computer-vision | 281 | Potential regression with PT 2.0 and CUDA 12.2/CuDNN 8.9.4 | Hi we are benchmarking ViT on H100 GPUs but found it's slower with newer CUDA/CUDNN recommended by Nvidia.
PyTorch version: 2.0.1
model config: default (large)
datatype: bf16
### CUDA 12.2 + CUDNN 8.9.4 , avg throughput: 94.95987583, 3 runs:
"throughput": 95.0631667348959
"throughput": 94.94235140772204
"th... | closed | 2023-09-28T22:39:24Z | 2023-10-01T15:42:59Z | https://github.com/lucidrains/vit-pytorch/issues/281 | [] | roywei | 1 |
benbusby/whoogle-search | flask | 417 | [BUG] First result not shown sometimes | **Describe the bug**
When making a search Whoogle sometimes omits the first result.
**To Reproduce**
Search something like "Google" and you will see the second result on top. This only happens on some searches but not others. It will happen every time on certain search terms
I was not able to reproduce this using... | closed | 2021-09-05T20:13:38Z | 2021-10-27T21:15:17Z | https://github.com/benbusby/whoogle-search/issues/417 | [
"bug"
] | Mazawrath | 5 |
pytest-dev/pytest-django | pytest | 214 | Order in which tests are executed | pytest-django could / should probably use the same test ordering like Django: https://docs.djangoproject.com/en/1.7/topics/testing/overview/#order-in-which-tests-are-executed
This would mean to run all tests using the `db` fixture before tests using the `transactional_db` fixture, and then the remaining ones.
Django'... | closed | 2015-02-27T14:30:10Z | 2019-03-16T02:06:16Z | https://github.com/pytest-dev/pytest-django/issues/214 | [
"enhancement",
"bitesize"
] | blueyed | 21 |
JaidedAI/EasyOCR | deep-learning | 358 | easyocr.recognize is significantly slower when given several boxes to estimate, rather than running it several time with one box each time | Hello,
Thank you for this tool, it is great. I want to build on top of it, and execution time is a matter of importance for me (even on CPU).
I don't know if it's a bug or a *feature*, but I've noticed that `easyocr.recognize` is significantly slower when called once and given `n` boxes to estimate the text in, r... | closed | 2021-01-28T20:50:10Z | 2021-02-22T01:04:12Z | https://github.com/JaidedAI/EasyOCR/issues/358 | [] | fxmarty | 4 |
dynaconf/dynaconf | django | 1,102 | How to configure layered environments on files when confg.py is used. | The following section of the documentation https://www.dynaconf.com/settings_files/#layered-environments-on-files misses the example for `settings.py` (`py`-based settings). Can someone help me to understand how the configuration should be properly made? For example, I have the following config files:
```python
# set... | open | 2024-06-02T21:14:37Z | 2024-07-08T18:37:56Z | https://github.com/dynaconf/dynaconf/issues/1102 | [
"question",
"Docs",
"django"
] | oleksii-suprun | 4 |
modin-project/modin | pandas | 6,754 | Merge partial dtype caches on `concat(axis=0)` | we could have merged 'known_dtypes':
```python
import modin.pandas as pd
import numpy as np
from modin.core.dataframe.pandas.metadata import ModinDtypes, DtypesDescriptor
df1 = pd.DataFrame({"a": [1, 2, 3], "b": [3, 4, 5]})
df2 = pd.DataFrame({"a": [3.0, 4.0, 5.4], "b": [True, True, False]})
df2._query_compile... | closed | 2023-11-17T16:14:00Z | 2023-11-21T13:18:32Z | https://github.com/modin-project/modin/issues/6754 | [
"Performance 🚀",
"P2"
] | dchigarev | 0 |
idealo/image-super-resolution | computer-vision | 165 | visible padding border when run RDN artifact-cancelling net with "by_patch_size" | 
[pic]
just check this out
code:
```
rdn = RDN(weights='noise-cancel')
sr_img = rdn.predict(lr_img, by_patch_of_size=10)
```
using different "by_path_size" produces different sizes of blocks.
... | closed | 2020-12-23T14:14:45Z | 2021-01-08T10:58:55Z | https://github.com/idealo/image-super-resolution/issues/165 | [] | DeXtmL | 1 |
mlflow/mlflow | machine-learning | 14,153 | [FR] add asynchronous option to client log_artifact | ### Willingness to contribute
Yes. I would be willing to contribute this feature with guidance from the MLflow community.
### Proposal Summary
Most MlflowClient APIs have a `synchronous` bool kwarg, but log_artifact does not. The proposal is to add the option to MlflowClient.log_artifact
### Motivation
> #### What... | open | 2024-12-23T23:19:25Z | 2025-01-20T05:56:49Z | https://github.com/mlflow/mlflow/issues/14153 | [
"enhancement",
"area/artifacts",
"area/tracking"
] | garymm | 10 |
skypilot-org/skypilot | data-science | 4,659 | [Docs] Adding new clouds (DO, vast) to readme/docs | Like in #4573, we should add those new clouds to the doc.
Also we might need to update the cloud figure. | open | 2025-02-06T21:09:41Z | 2025-02-06T22:18:37Z | https://github.com/skypilot-org/skypilot/issues/4659 | [] | cblmemo | 2 |
tensorflow/tensor2tensor | deep-learning | 1,610 | Serving problem: Error parsing text-format tensorflow.SavedModel | I trained a transformer model about 3 months ago. Then I export and serve my model based on the tutorial. Everything was fine.
Now I want to train a new model. I can train a new model but during serving a strange error happened:
```
Error parsing text-format tensorflow.SavedModel: 134169:18: Message type "tensorflo... | open | 2019-06-23T06:59:10Z | 2019-08-12T11:43:55Z | https://github.com/tensorflow/tensor2tensor/issues/1610 | [] | zfallahnejad | 2 |
mirumee/ariadne | graphql | 251 | Add schema validation to make_executable_schema | GraphQL-Core-next implements `assert_valid_schema` function in `graphql.type.validate` that takes `GraphQLSchema` and validates its correctness.
Currently, this function is called as part of query execution, during query validation, but we could also run it inside the `make_executable_schema`, so developers get this... | closed | 2019-10-02T10:08:45Z | 2019-10-13T23:41:25Z | https://github.com/mirumee/ariadne/issues/251 | [
"enhancement",
"help wanted",
"roadmap"
] | rafalp | 6 |
twopirllc/pandas-ta | pandas | 158 | Question: just want to know why drawdown doesn't in the default strategy | closed | 2020-11-09T13:32:17Z | 2020-11-12T23:01:41Z | https://github.com/twopirllc/pandas-ta/issues/158 | [
"info"
] | tangxianrong | 1 | |
microsoft/hummingbird | scikit-learn | 3 | upgrade and test new sklearn version | we need to upgrade sklearn version. (currently scikit-learn==0.21.3). To do this, we need to accomodate some API changes in the newer version
ex: Imputer is deprecated (was in preprocessing). Now, do :from sklearn.impute import SimpleImputer
| closed | 2020-03-23T17:04:48Z | 2020-06-11T23:41:52Z | https://github.com/microsoft/hummingbird/issues/3 | [] | ksaur | 0 |
Lightning-AI/LitServe | fastapi | 26 | 504 gateway timeouts | Hi guys,
using one GPU works better than working with 4 GUPs e.g.
I am running it on LightningAI and not even one request goes through at all if running on 4 devices.
`server = LitServer(SimpleLitAPI(), accelerator="cuda", devices=1, timeout=60)`
vs
`server = LitServer(SimpleLitAPI(), accelerator="cuda", d... | closed | 2024-04-10T20:12:52Z | 2024-04-11T17:45:44Z | https://github.com/Lightning-AI/LitServe/issues/26 | [] | grumpyp | 7 |
litestar-org/polyfactory | pydantic | 514 | Bug: Invalid Coverage for Optional Fields with Annotated Constraint | ### Description
I was trying to produce coverage for a Pydantic model with Annotated Field constraints.
```py
class PartialA(BaseModel):
a: Annotated[str | None, Field(min_length=1, max_length=10)] = None
```
The coverage function does not yield proper attributes for field `a`.
I tracked it down to t... | open | 2024-03-28T02:25:41Z | 2025-03-20T15:53:15Z | https://github.com/litestar-org/polyfactory/issues/514 | [
"bug"
] | tharindurr | 0 |
JaidedAI/EasyOCR | deep-learning | 535 | memory keep increases (CPU) | I'm running this
```
def reader_text(thread_limiter,reader):
thread_limiter..acquire()
try:
results = reader.readtext(output)
----doing something----
finally:
limit.release()
return
threads=[]
reader = easyocr.Reader(['en'], gpu=False)
thread_limiter= thre... | closed | 2021-09-09T11:05:17Z | 2022-03-02T09:25:33Z | https://github.com/JaidedAI/EasyOCR/issues/535 | [] | BalajiArun004 | 2 |
kymatio/kymatio | numpy | 894 | Looks good but we're now missing docstring for `N`, `J` in `scattering_filter_factory`. | Looks good but we're now missing docstring for `N`, `J` in `scattering_filter_factory`.
_Originally posted by @janden in https://github.com/kymatio/kymatio/pull/863#pullrequestreview-1012149453_
So these docstrings need to be added. | closed | 2022-06-20T11:53:18Z | 2023-03-03T07:58:41Z | https://github.com/kymatio/kymatio/issues/894 | [
"doc"
] | janden | 0 |
twelvedata/twelvedata-python | matplotlib | 88 | [Bug]: Setuptools not installed as a requirement, but module won't load without it. | ```
from pkg_resources import get_distribution, DistributionNotFound
ModuleNotFoundError: No module named 'pkg_resources'
```
twelvedata python package depends on `setuptools` being installed to access pkg_resources, but does not define it as a dependency, so if setuptools is not installed due to an incidenta... | closed | 2024-08-29T12:18:03Z | 2024-08-30T08:28:38Z | https://github.com/twelvedata/twelvedata-python/issues/88 | [] | EdgyEdgemond | 1 |
akfamily/akshare | data-science | 5,179 | AKShare 接口问题报告 |
stock_zh_a_hist这个接口无法获取沪深300的数据,这是一个指数数据,现在的接口访问000300会直接报错,腾讯的接口可以通过sh000300获取到沪深300数据,但是每天更新的很慢
stock_zh_a_hist_tx_df = ak.stock_zh_a_hist_tx(symbol="sh000300", start_date="20240911",
end_date="20240911",
adju... | closed | 2024-09-12T06:58:14Z | 2024-09-12T07:33:55Z | https://github.com/akfamily/akshare/issues/5179 | [
"bug"
] | HolyLl | 2 |
nltk/nltk | nlp | 2,686 | Travis CI test fails with Python 3.9 | Travis CI now also tests with Python 3.9.
The output reveals that the XML Parser used by NLTK's corpus.reader is no longer compatible with the newest Python 3.9 version.
So all NLTK builds will fail Travis CI testing with Python 3.9 until this is fixed:
=================================== FAILURES ============... | closed | 2021-04-04T08:00:45Z | 2021-04-04T20:12:34Z | https://github.com/nltk/nltk/issues/2686 | [] | ekaf | 1 |
remsky/Kokoro-FastAPI | fastapi | 115 | Support more than 1 stream at the same time. | I noticed that when Kokoro is running, it does not use all of the GPU. However, the latency gets very bad if I send two requests simultaneously. Is there a way to optimize it to support more than one stream simultaneously?
P.S. This is a fantastic project! How do we give back? I don't see a donation link on the readme... | open | 2025-02-03T13:12:56Z | 2025-03-10T04:21:11Z | https://github.com/remsky/Kokoro-FastAPI/issues/115 | [
"in-progress"
] | sipvoip | 16 |
widgetti/solara | flask | 868 | Solara Dev Documentation is Buggy | **Issue:**
When I go to [solara docs](https://solara.dev/documentation/), I cannot immediately scroll on the web page. I see the left side panel open and the content, but I can not scroll. Sometimes, when the page is loading, I noticed that I could scroll, but then a quick "flash" of a grey popup shows and disappears... | open | 2024-11-21T16:03:56Z | 2024-11-22T09:47:55Z | https://github.com/widgetti/solara/issues/868 | [
"documentation"
] | jonkimdev | 1 |
OthersideAI/self-operating-computer | automation | 196 | Use gpt-4o instead of using gpt-4 turbo | The system by default is usng gpt4-turbo, is it possible to use gpt-4o instead, which is suppose to be better and less expensive?
thanks | closed | 2024-06-16T07:58:46Z | 2024-07-10T21:51:06Z | https://github.com/OthersideAI/self-operating-computer/issues/196 | [
"enhancement"
] | aicoder2048 | 1 |
tflearn/tflearn | tensorflow | 403 | openai gym render and tflearn, can't load any more object with static TLS | when using tflearn and rendering game in openAI gym, it gives me an error,
Unexpected error loading library libGL.so.1: dlopen: cannot load any more object with static TLS
| closed | 2016-10-18T00:16:57Z | 2016-11-19T20:57:12Z | https://github.com/tflearn/tflearn/issues/403 | [] | gabrieledcjr | 7 |
mwaskom/seaborn | data-visualization | 3,380 | Incorrect error bar offset in barplots | In whitegrid style, I've noticed the error bars in seaborn are plotted offset to the true end of the colored bar when using barplots (see images). This is caused by the default style parameter `'patch.edgecolor': 'w'` which makes a invisible border that the error bar is truely centered on (see offset.png). I like the w... | closed | 2023-06-06T19:20:09Z | 2023-06-07T01:12:12Z | https://github.com/mwaskom/seaborn/issues/3380 | [] | schmittlema | 3 |
pytorch/vision | machine-learning | 8,358 | Choose either 'long' or 'short' options for the resize anchor edge if the size variable is scalar | ### 🚀 The feature
Choose either 'long' or 'short' options for the resize anchor edge if the size variable is scalar
### Motivation, pitch
`torchvision.transforms.Resize()` does not provide a clean interface for resizing images based off the longer edge.
Consider the following use case - a user wants to re... | closed | 2024-03-28T00:00:06Z | 2024-06-05T11:49:29Z | https://github.com/pytorch/vision/issues/8358 | [] | sidijju | 8 |
graphql-python/flask-graphql | graphql | 56 | Incorrect request populated as context for mutation | I posted about this on stackoverflow, but figured I'd ask about it directly here as well: https://stackoverflow.com/questions/53233291/python-flask-and-graphene-incorrect-request-causes-security-issue
Basically, the issue is that when I try to perform a high volume of mutations as one user while another user is maki... | closed | 2018-11-09T21:24:21Z | 2019-12-30T22:28:49Z | https://github.com/graphql-python/flask-graphql/issues/56 | [] | maxlang | 0 |
jazzband/django-oauth-toolkit | django | 617 | Python 3.4 or Python 3.5 | The [README for 1.2.0](https://github.com/jazzband/django-oauth-toolkit/blob/86e8f9b22c9d5957b8ff6097208de69758a3c013/README.rst) states that the requirement is Python 3.5+.
However, the [Changelog](https://github.com/jazzband/django-oauth-toolkit/blob/master/CHANGELOG.md) states that the minimum is Python 3.4+. | closed | 2018-07-06T20:02:01Z | 2018-07-21T15:30:05Z | https://github.com/jazzband/django-oauth-toolkit/issues/617 | [] | robrap | 3 |
healthchecks/healthchecks | django | 187 | hc/settings.py template -> resolve from env variables | Is possible to do in hc/settings.py something like this ?
```
import os
...
if os.environ.get("DB_TYPE") == "mysql" or os.environ.get("DB_TYPE") == "postgres" :
DATABASES = {
'default': {
'ENGINE': 'django.db.backends' + os.environ['DB_TYPE'],
... | closed | 2018-09-19T12:41:08Z | 2018-10-22T14:27:17Z | https://github.com/healthchecks/healthchecks/issues/187 | [] | lukasmrtvy | 1 |
JoeanAmier/TikTokDownloader | api | 174 | tiktok 下载时出现——响应内容为空,可能是接口失效或者 Cookie 失效,请尝试更新 Cookie | 感谢作者开源的工具,使用遇到以下问题:
在键入1. 复制粘贴写入 Cookie
后出现
当前 Cookie 已登录
保存配置成功!
写入 Cookie 成功!
但是键入4. 终端交互模式出现
缓存数据文件不存在
然后再键入3. 批量下载链接作品(通用)
请输入作品链接: https://www.tiktok.com/@vueltaalmundoenmoto/video/7332886806339357984
出现问题:
响应内容为空,可能是接口失效或者 Cookie 失效,请尝试更新 Cookie
获取作品数据失败
正在尝试第 1 次重试
响应内容为空,可能是接口失效或者 Cookie 失效,请尝试更... | open | 2024-03-14T08:42:14Z | 2024-03-17T13:26:51Z | https://github.com/JoeanAmier/TikTokDownloader/issues/174 | [
"功能异常(bug)"
] | chlinfeng1997 | 5 |
simple-login/app | flask | 2,315 | SOLVED: On subdomains there is no creation of unique part before the @ | ## Bug report
**Describe the bug**
I decided to create an email domain. I've set it up to have the main domain pointing to protonmail.
emails would be @domain.xyz
Then I decided to add aliases to my setup. So I created a subdomain. "aliases.domain.xyz"
When I am creating an alias in the simplelogin extension o... | closed | 2024-11-11T07:57:07Z | 2024-11-11T08:02:20Z | https://github.com/simple-login/app/issues/2315 | [] | pyjoku | 0 |
ageitgey/face_recognition | machine-learning | 1,270 | Using a already loaded image with the recognition functions? | * face_recognition version: 1.3.0
* Python version: 3.8
* Operating System: Windows 10
### Description
I am trying to crop half the image out before running face recognition (The face is always in the top half) but I am unable to find a way to do this without saving the image after running the crop as there see... | closed | 2021-01-25T13:18:36Z | 2021-01-30T17:20:20Z | https://github.com/ageitgey/face_recognition/issues/1270 | [] | TristanBeer | 2 |
thtrieu/darkflow | tensorflow | 456 | Change labels? | I want to change the labels of the object. For example change the "person" label to "dog", but I can't seem to get it working.
Any help ? | closed | 2017-12-04T10:55:42Z | 2017-12-04T12:08:04Z | https://github.com/thtrieu/darkflow/issues/456 | [] | dankm8 | 2 |
mljar/mljar-supervised | scikit-learn | 34 | provide labels for true classes | When working with imbalanced datasets, a class may be underrepresented to the point where y_true and y_pred nearly always contain a different number of classes (for example, one class is missing from the predicted values). Because of this, mljar oftentimes cannot be used for imbalanced datasets.
I have attached the ... | closed | 2019-11-07T21:06:44Z | 2019-11-07T21:17:50Z | https://github.com/mljar/mljar-supervised/issues/34 | [] | Shoeboxam | 1 |
facebookresearch/fairseq | pytorch | 4,704 | How can I use fairseq on Apple M1 chip with GPU? | ## ❓ Questions and Help
I want to use fairseq on Apple M1 chip for BART model. I checked the document and optional arguments but I could not figure out the solution or setting about mps. So I need your help. Please give me some advice, thank you.
#### What's your environment?
- fairseq Version 0.9.0:
- PyTo... | open | 2022-09-08T08:38:21Z | 2024-10-09T17:01:35Z | https://github.com/facebookresearch/fairseq/issues/4704 | [
"question",
"needs triage"
] | sataketatsuya | 5 |
huggingface/datasets | pytorch | 7,037 | A bug of Dataset.to_json() function | ### Describe the bug
When using the Dataset.to_json() function, an unexpected error occurs if the parameter is set to lines=False. The stored data should be in the form of a list, but it actually turns into multiple lists, which causes an error when reading the data again.
The reason is that to_json() writes to the f... | open | 2024-07-10T09:11:22Z | 2024-09-22T13:16:07Z | https://github.com/huggingface/datasets/issues/7037 | [
"bug"
] | LinglingGreat | 2 |
vi3k6i5/flashtext | nlp | 48 | [bug] set of word boundary characters too restrictive | Hello there,
first of all: thanks for the amazing algorithm, it's really useful!
It turns out you use only a very restrictive set of characters as `non_word_boundaries`. For many languages this poses a problem. E.g. in German:
```python
from flashtext import KeywordProcessor
kwp = KeywordProcessor()
kwp.add... | open | 2018-03-19T15:41:05Z | 2018-03-19T16:04:13Z | https://github.com/vi3k6i5/flashtext/issues/48 | [] | aseifert | 1 |
allenai/allennlp | nlp | 5,441 | A problem about install allennlp | When i run allennlp in cmd, there was a wrong :
Traceback (most recent call last):
File "/dockerdata/username/anaconda3/bin/allennlp", line 8, in <module>
sys.exit(run())
File "/dockerdata/username/anaconda3/lib/python3.8/site-packages/allennlp/__main__.py", line 40, in run
from allennlp.commands im... | closed | 2021-10-21T12:36:35Z | 2021-10-21T13:16:03Z | https://github.com/allenai/allennlp/issues/5441 | [
"question"
] | lwgkzl | 1 |
jumpserver/jumpserver | django | 14,875 | [Question] JumpServer Kubernetes plugin can't handle container selection unlike Argo CD | ### Product Version
4.6.0
### Product Edition
- [x] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [x] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### E... | closed | 2025-02-12T09:38:20Z | 2025-02-20T02:47:12Z | https://github.com/jumpserver/jumpserver/issues/14875 | [
"⏳ Pending feedback",
"🤔 Question",
"📦 z~release:v4.7.0"
] | isjuye | 4 |
feature-engine/feature_engine | scikit-learn | 473 | mypy throws error on latest main | **Describe the bug**
I'm following the contribution guidelines, But when I run mypy on the latest main branch, I get type errors.The type errors are not related to the issues im working on.
**To Reproduce**
Steps to reproduce the behavior:
1. Pull the latest main branch.
2. Cd into feature-engine
3. Run mypy ... | closed | 2022-06-12T10:38:34Z | 2022-06-13T15:22:32Z | https://github.com/feature-engine/feature_engine/issues/473 | [] | SangamSwadiK | 11 |
albumentations-team/albumentations | deep-learning | 2,405 | [New feature] Add apply_to_images to GaussianBlur | open | 2025-03-11T01:04:42Z | 2025-03-11T01:04:52Z | https://github.com/albumentations-team/albumentations/issues/2405 | [
"enhancement",
"good first issue"
] | ternaus | 0 | |
MaartenGr/BERTopic | nlp | 1,671 | BERTopic n-gram words are not adjacent to each other | After setting the ngram_range=(2,2), the trained BERTopic model generates topics with 2-gram phrases such as Topic_1: {"Model Router", "Network Setup", etc}, but the individual words of each 2-gram are not adjacent to each other within the document and they are far away form each other. It seems that the BERTopic model... | open | 2023-12-07T06:59:43Z | 2023-12-13T15:24:14Z | https://github.com/MaartenGr/BERTopic/issues/1671 | [] | navidNickaan | 5 |
google-research/bert | tensorflow | 1,030 | BERT Large , 512 sequence length - Allocation of X exceeds Y% of system memory. | Hi ,
I am trying to run BERT Large model having 512 sequence length on CPU for inference. I have converted checkpoint file from BERT Large to savedModel format which has feature transformation ported to it as well.
However when I do the inference I can see warning message as
**"tensorflow/core/framework/cp... | closed | 2020-03-12T21:16:16Z | 2020-08-14T19:54:25Z | https://github.com/google-research/bert/issues/1030 | [] | 17patelumang | 7 |
httpie/cli | api | 691 | Running HTTPie from PyCharm | I would like to run the project in pycharm, but it doesn't work. When I run `__main__.py` which is in `httpie/` folder, it just raises the error: `ModuleNotFoundError: No module named '__main__.core'; '__main__' is not a package`.
So how should I do if I would like to run the code by myself? | closed | 2018-07-22T02:18:18Z | 2018-07-23T16:23:52Z | https://github.com/httpie/cli/issues/691 | [] | memdreams | 2 |
kornia/kornia | computer-vision | 2,574 | Error loading image | ### Describe the bug
I use code to load image:
```
img: Tensor = K.io.load_image(filepath, K.io.ImageLoadType.RGB32)
img = img[None]
x_gray = K.color.rgb_to_grayscale(img)
```
I get error:
```
File "edge_detector.py", line 7, in edge_detection
img: Tensor = K.io.load_image(filepa... | closed | 2023-09-27T04:09:56Z | 2023-10-04T01:55:52Z | https://github.com/kornia/kornia/issues/2574 | [
"help wanted"
] | phamkhactu | 5 |
gradio-app/gradio | data-visualization | 10,799 | Gradio whitelist FRPC | Was chatting with @cocktailpeanut about Gradio share links and how they are currently blocked in Windows due to Windows Defender.
There are programmatic ways to whitelist programs from Windows Defender, see https://stackoverflow.com/questions/40233123/windows-defender-add-exclusion-folder-programmatically
The idea wo... | open | 2025-03-12T22:12:12Z | 2025-03-13T00:16:56Z | https://github.com/gradio-app/gradio/issues/10799 | [
"enhancement"
] | abidlabs | 2 |
tiangolo/uwsgi-nginx-flask-docker | flask | 180 | Build problem | Hello
I tried to build a docker image from uwsgi-nginx-flask-docker but I have an error (of beginner ?):
My application tree is:
```
app/
app/
__init__.py
main.py
uwsgi.ini
Dockerfile
```
My Dockerfile is:
```
FROM tiangolo/uwsgi-nginx:python3.8-alpine
COPY ./app /app
WORKDIR /a... | closed | 2020-05-13T23:53:02Z | 2020-06-06T13:27:35Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/180 | [] | mlabarre | 2 |
PokemonGoF/PokemonGo-Bot | automation | 5,458 | Implementation of PokeSnipers | ### Short Description
Use Sniping websites like pokemon https://pokesnipers.com/ | pokesniper.org/ | pokesnipe.de/ to find uncommon/rare pokemons.
### Possible solution
http://pokeapi.pokesnipe.de/ this site offers a json api that can be implemented. after going to location and encountering the pokemon(DON'T CATCH IT... | closed | 2016-09-15T18:57:35Z | 2016-09-22T03:25:55Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5458 | [] | bhoot1234567890 | 2 |
ultralytics/yolov5 | deep-learning | 13,502 | Label detection | ### Search before asking
- [x] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I am using YOLO to detect labels and then extract the text within the detected regions. ... | open | 2025-01-30T13:57:20Z | 2025-02-06T23:01:24Z | https://github.com/ultralytics/yolov5/issues/13502 | [
"question",
"detect"
] | Uddeshya1052 | 6 |
widgetti/solara | fastapi | 851 | docs: more info on use_context and use of global reactives | would like to see more documentation on:
- how to avoid issues with sharing same object on a global reactive
- using `use_context` in solara (just duplicate the one from the reacton docs) | open | 2024-11-05T23:52:54Z | 2024-11-05T23:54:34Z | https://github.com/widgetti/solara/issues/851 | [] | rileythai | 0 |
deeppavlov/DeepPavlov | tensorflow | 907 | ner_model(['Bob Ross lived in Florida']) is giving error | raise type(e)(node_def, op, message)
InvalidArgumentError: Requested more than 0 entries, but params is empty. Params shape: [1,7,0] | closed | 2019-06-28T08:34:45Z | 2020-05-13T09:47:24Z | https://github.com/deeppavlov/DeepPavlov/issues/907 | [] | puneetkochar016 | 1 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 220 | List Index Out of Range | I tried two images. Both very old, one with lots of scratches, the other with some. I got `List Index Out of Range` both times. | open | 2022-01-13T02:05:42Z | 2022-12-04T10:16:40Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/220 | [] | yeasir2148 | 6 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 285 | AssertionError | while sythesizer_preprocess_audio.py running it intrupted by an assetion error at this point every time . can anyone tell me what is happening?
AssertionError
LibriSpeech: 21%|███▊ | 251/1172 [48:17<2:57:10, 11.54s/speakers] | closed | 2020-02-19T06:37:12Z | 2020-07-04T22:38:57Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/285 | [] | AmitBDA | 1 |
babysor/MockingBird | pytorch | 256 | demo_toolbox.py 出现 python.exe 中发生了未经处理的win32异常 | 点击 browse 加载音频文件时出错 系统是 win8.1 64位 显卡 amd python 3.7.9 pyQt5 版本 pyQt 5.12.0 会不会pyQt5 版本的问题呢?
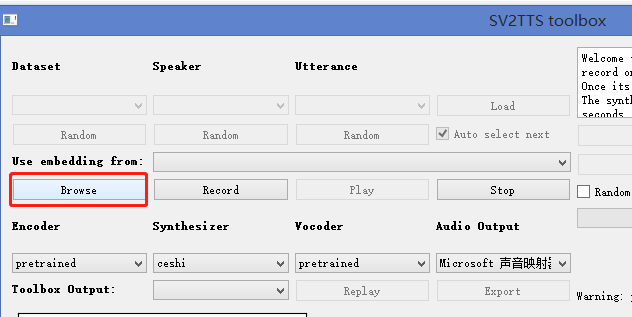
:
File "C:\Users\admin\AppData\Local\Programs\Python\Python37-32\lib\site-packages\airtest\aircv\sift.py", line 253, in _find_homography
M, mask = cv2.findHomography(sch_pts, src_pts, cv2.RANS... | closed | 2019-02-26T07:51:51Z | 2019-02-28T02:17:56Z | https://github.com/AirtestProject/Airtest/issues/284 | [
"wontfix"
] | JustinToken | 3 |
zappa/Zappa | flask | 489 | [Migrated] Refactor Let's Encrypt implementation to use available packages [proposed code] | Originally from: https://github.com/Miserlou/Zappa/issues/1300 by [rgov](https://github.com/rgov)
The Let's Encrypt integration works by invoking the `openssl` command line tool, creating various temporary files, and communicating with the Let's Encrypt certificate authority API directly.
The Python package that Le... | closed | 2021-02-20T09:43:23Z | 2024-04-13T16:36:18Z | https://github.com/zappa/Zappa/issues/489 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
google-research/bert | nlp | 1,373 | how much should be the accuracy of bert base cased on squad 2 | Hello
I finetuned the bert base cased on squad 2 with the following command:
python run_squad.py \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=config.json \
--init_checkpoint=bert_model.ckpt \
--do_train=True \
--train_file=$SQUAD_DIR/train-v2.0.json \
--do_predict=True \
--predict... | open | 2022-11-20T12:42:14Z | 2022-11-20T12:42:14Z | https://github.com/google-research/bert/issues/1373 | [] | navid72m | 0 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,495 | [Feature Request]: Button for 'Respect Preferred VAE" in XYZ plot | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
When using XYZ plot, it seems to use whatever VAE is selected in the UI, not the preferred VAE per checkpoint (as specified in JSON files etc).
Example case: Te... | open | 2024-04-12T04:48:15Z | 2024-04-12T04:48:15Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15495 | [
"enhancement"
] | ewebgh33 | 0 |
sanic-org/sanic | asyncio | 2,751 | queue.put faild with shared_ctx | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
run app:
python -m sanic aaa.app --workers=4
1. Add a multiprocessing.Queue to shared_ctx
2. make a request, then call queue.put(1)
then get error:
http: LogLevel.ERROR: ConnectionError: ('Connect... | closed | 2023-05-11T09:22:33Z | 2023-05-12T03:26:15Z | https://github.com/sanic-org/sanic/issues/2751 | [
"bug"
] | muyu525 | 1 |
graphistry/pygraphistry | pandas | 8 | Fix dependencies of pip package | We should probably depend on Pandas since nobody is going to use the direct json API.
| closed | 2015-06-25T21:31:49Z | 2015-08-06T13:53:52Z | https://github.com/graphistry/pygraphistry/issues/8 | [
"bug"
] | thibaudh | 1 |
httpie/cli | api | 1,323 | How to print part of the body | I post a URL and get body like this.
I just want to print the value of "token"
How can I do that?
<img width="709" alt="제목 없는 그림" src="https://user-images.githubusercontent.com/43262277/158118069-187f0c8b-ae85-4915-97f7-fae9ed096222.png">
| closed | 2022-03-14T06:40:05Z | 2022-03-15T06:52:50Z | https://github.com/httpie/cli/issues/1323 | [
"question"
] | zhaohanqing95 | 2 |
wkentaro/labelme | deep-learning | 374 | JSON to png | I know there is file corresponding script to do that https://github.com/wkentaro/labelme/tree/master/examples/semantic_segmentation
But how get png if I have opened json file:
I wrote somethink like this:
```
import json
with open(json_names[0], encoding = 'utf-8') as f:
data = json.load(f)
import nump... | closed | 2019-04-16T13:53:29Z | 2019-04-16T16:12:50Z | https://github.com/wkentaro/labelme/issues/374 | [] | Diyago | 1 |
marimo-team/marimo | data-science | 3,780 | datashader rasterize not supported? | ### Describe the bug
Would Marimo be able to support DataShader's rasterise()?
In Jupyter, plots with millions of points can be rasterized before being sent to the browser .
E.g. https://holoviews.org/user_guide/Large_Data.html when converted to Marimo, the rasterized plots are not re-rendered when zoomed in.
###... | open | 2025-02-13T07:04:19Z | 2025-02-24T08:51:02Z | https://github.com/marimo-team/marimo/issues/3780 | [
"bug"
] | Jzege | 6 |
521xueweihan/HelloGitHub | python | 2,786 | 【开源自荐】功能齐全的代码Diff View组件,支持React/Vue平台,参考Github | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/MrWangJustToDo/git-diff-view
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类... | open | 2024-07-31T08:17:38Z | 2024-08-16T02:17:19Z | https://github.com/521xueweihan/HelloGitHub/issues/2786 | [] | MrWangJustToDo | 1 |
openapi-generators/openapi-python-client | fastapi | 763 | openapi-python-client fails to load with typing-extensions==4.6.0 | **Describe the bug**
I bumped up (the pydantic dependency) `typing-extensions` from 4.5.0 to 4.6.0 in my project, and openapi-python-client fails to load.
Here's the stack trace:
```
File "/opt/hostedtoolcache/Python/3.9.16/x64/bin/openapi-python-client", line 5, in <module>
from openapi_python_client.cli i... | closed | 2023-05-23T19:24:59Z | 2023-05-27T00:58:46Z | https://github.com/openapi-generators/openapi-python-client/issues/763 | [
"🐞bug"
] | pacificsky | 1 |
KaiyangZhou/deep-person-reid | computer-vision | 10 | Problem evaluating Market | When i try to evaluate market i get the following error
File "/home/konstantinou/virtualenvs/pytorch_python2/local/lib/python2.7/site-packages/torch/nn/modules/linear.py", line 49, in reset_parameters
stdv = 1. / math.sqrt(self.weight.size(1))
RuntimeError: dimension out of range (expected to be in range of [... | closed | 2018-05-11T12:39:24Z | 2018-05-11T13:29:42Z | https://github.com/KaiyangZhou/deep-person-reid/issues/10 | [] | akonstantinou | 4 |
davidsandberg/facenet | computer-vision | 397 | how to get a picture‘s embedding vector? | I'm a newer , i want to get a new picture‘ vecotr, how should i do ? | closed | 2017-07-26T17:34:45Z | 2018-07-21T13:37:19Z | https://github.com/davidsandberg/facenet/issues/397 | [] | wjqy1510 | 4 |
onnx/onnx | tensorflow | 5,853 | Request for Swish Op | # Swish/SiLU
Do you have any plans to implement the Swish Op in ONNX?
### Describe the operator
Swish is a popular Activation fuction. Its mathematical definition could be found at https://en.wikipedia.org/wiki/Swish_function
TensorFLow has https://www.tensorflow.org/api_docs/python/tf/nn/silu
Keras has https:... | open | 2024-01-11T08:18:22Z | 2025-02-01T06:43:04Z | https://github.com/onnx/onnx/issues/5853 | [
"topic: operator",
"stale",
"contributions welcome"
] | vera121 | 7 |
Zeyi-Lin/HivisionIDPhotos | fastapi | 20 | Update List - 2024.9.2 | ## Gradio Demo
- [x] Support Set photo KB size
- [x] More Default size
- [x] DockerHub
- [x] Multiple languages
| closed | 2024-09-02T05:03:31Z | 2024-09-03T02:36:29Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/20 | [] | Zeyi-Lin | 0 |
facebookresearch/fairseq | pytorch | 4,654 | A question about adding audio samples to XLSR-53 |
I have already used XLSR-53 successfully, fine-tuning it according : https://huggingface.co/blog/fine-tune-xlsr-wav2vec2
However I have a lot of unlabeled data. I understand that building a Wav2Vec model from scratch does not make sense, so I want to train a model
With my audio but use XLSR-53 as a base - but I ... | open | 2022-08-16T07:56:35Z | 2022-08-16T07:56:35Z | https://github.com/facebookresearch/fairseq/issues/4654 | [
"question",
"needs triage"
] | arikhalperin | 0 |
CPJKU/madmom | numpy | 196 | downbeat activations should only contain beats & downbeats, not non-beats | closed | 2016-07-31T06:47:03Z | 2016-07-31T11:51:21Z | https://github.com/CPJKU/madmom/issues/196 | [] | superbock | 0 | |
2noise/ChatTTS | python | 22 | 建议出一个便携版,方便上手 | closed | 2024-05-28T12:51:41Z | 2024-06-29T06:17:14Z | https://github.com/2noise/ChatTTS/issues/22 | [
"stale",
"ad"
] | andyhebear | 1 | |
sammchardy/python-binance | api | 1,491 | Api removeal | https://github.com/vikky-wire | closed | 2024-12-01T07:45:14Z | 2024-12-01T14:51:38Z | https://github.com/sammchardy/python-binance/issues/1491 | [] | Tanimola50 | 1 |
keras-team/keras | deep-learning | 20,158 | Tensorboard callback is blocking process | I am unable to find the transferred issue: https://github.com/keras-team/tf-keras/issues/496
This issue is still occuring and creates performance bottleneck when writing to cloud storage | open | 2024-08-23T18:05:17Z | 2024-09-05T17:09:59Z | https://github.com/keras-team/keras/issues/20158 | [
"stat:awaiting keras-eng"
] | rivershah | 2 |
darrenburns/posting | rest-api | 72 | Feature request: cURL command parsing | It could be very helpful to have the ability to populate the different fields from a cURL command. It could be implemented in different ways but two that I can think of is either a floating pane where the command could be pasted, or allowing direct pasting of the command and detecting if it's a valid one. | closed | 2024-08-02T22:50:52Z | 2024-08-02T22:57:05Z | https://github.com/darrenburns/posting/issues/72 | [] | taha-yassine | 0 |
pyeventsourcing/eventsourcing | sqlalchemy | 109 | Support Redis streams | https://brandur.org/redis-streams | closed | 2017-11-14T11:27:24Z | 2019-06-12T22:30:18Z | https://github.com/pyeventsourcing/eventsourcing/issues/109 | [
"enhancement",
"help wanted"
] | johnbywater | 0 |
paperless-ngx/paperless-ngx | django | 7,737 | [BUG] Missing Repo for Helm-Chart | ### Description
In this PR @alexander-bauer wanted to create a dedicated Repo for Helm:
https://github.com/paperless-ngx/paperless-ngx/pull/2119#issuecomment-1374932540
### Steps to reproduce
1. create repo
2. put there the data
### Webserver logs
```bash
*
```
### Browser logs
_No response_
### Paperless-... | closed | 2024-09-18T22:12:14Z | 2024-10-20T03:12:03Z | https://github.com/paperless-ngx/paperless-ngx/issues/7737 | [
"not a bug"
] | genofire | 3 |
nolar/kopf | asyncio | 1,121 | Make Probes access logs configurable | ### Problem
With the current implementation of probes, the default logger, loggs every access request. While this can be beneficial in some cases, it is only noise in the long run. I would like to be able to disable access logs.
Example log entry that i am refering to:
```
{"message": "10.244.0.1 [04/Aug/2024:2... | open | 2024-08-04T21:05:59Z | 2024-08-04T21:06:21Z | https://github.com/nolar/kopf/issues/1121 | [
"enhancement"
] | Lerentis | 0 |
tensorlayer/TensorLayer | tensorflow | 753 | Typo in absolute different error function | ### New Issue Checklist
- [x] I have read the [Contribution Guidelines](https://github.com/tensorlayer/tensorlayer/blob/master/CONTRIBUTING.md)
- [x] I searched for [existing GitHub issues](https://github.com/tensorlayer/tensorlayer/issues)
### Issue Description
[Typo in absolute different error function]
... | closed | 2018-07-25T09:08:31Z | 2018-07-30T13:52:22Z | https://github.com/tensorlayer/TensorLayer/issues/753 | [] | thangvubk | 2 |
xinntao/Real-ESRGAN | pytorch | 152 | 训练log | 非常感谢~按照您给的训练指导文档,我将超分模型替换成XLSR模型,l_pix loss只能够降低到e-2级别,validation效果不理想,请问一下您能够给下您的realesrnet的training log嘛?
将模型应用到移动端,您有什么建议嘛?
谢谢! | open | 2021-11-09T07:48:29Z | 2021-11-09T07:48:29Z | https://github.com/xinntao/Real-ESRGAN/issues/152 | [] | liujianisme | 0 |
coqui-ai/TTS | python | 2,872 | [Bug] AttributeError: 'NoneType' object has no attribute 'hop_length' | ### Describe the bug
I am trying to train the following dataset and I am getting the following error during training:
**train.py**
```
import korean
import os
os.environ['CUDA_VISIBLE_DEVICES'] ="0"
import torch
from trainer import Trainer, TrainerArgs
from TTS.utils.audio import AudioProcessor
from... | closed | 2023-08-14T09:53:11Z | 2023-08-21T08:35:25Z | https://github.com/coqui-ai/TTS/issues/2872 | [
"bug"
] | zhanglina94 | 0 |
chatopera/Synonyms | nlp | 78 | windows下能安装吗 | closed | 2019-03-17T08:54:46Z | 2019-04-21T01:04:11Z | https://github.com/chatopera/Synonyms/issues/78 | [] | SeekPoint | 1 | |
SYSTRAN/faster-whisper | deep-learning | 518 | Can faster-whisper support TPU? | Kaggle and colab both supply TPU, it is much faster than T4. So can faster-whisper support it? | closed | 2023-10-19T10:16:02Z | 2023-11-26T01:40:51Z | https://github.com/SYSTRAN/faster-whisper/issues/518 | [] | ILG2021 | 4 |
strawberry-graphql/strawberry | asyncio | 3,470 | endless integrations with all python framworks | Explain to me why developers make integrations with other frameworks? for example, graphene integrated with sqlalchemy, django, flask, and so on. However, sqlalchemy does not integrate with anyone. after all, a good library is one that does not create unnecessary dependencies but simply fits perfectly with any technolo... | closed | 2024-04-23T08:23:42Z | 2025-03-20T15:56:42Z | https://github.com/strawberry-graphql/strawberry/issues/3470 | [] | ArtemIsmagilov | 1 |
great-expectations/great_expectations | data-science | 11,032 | Optional limitation to 200 records for UnexpectedRowsExpectation | **Is your feature request related to a problem? Please describe.**
I need to retrieve ALL rows that failed the UnexpectedRowsExpectation. Currently, unexpected_rows is limited to 200 rows.
**Describe the solution you'd like**
I need the possibility to disable the limit. An additional boolean parameter would be suffici... | open | 2025-03-17T13:26:30Z | 2025-03-17T18:21:41Z | https://github.com/great-expectations/great_expectations/issues/11032 | [
"feature-request"
] | HOsthues | 0 |
pyqtgraph/pyqtgraph | numpy | 2,790 | Niggles with pen parameter | <!-- In the following, please describe your issue in detail! -->
<!-- If some sections do not apply, just remove them. -->
### Short description
<!-- This should summarize the issue. -->
When adding a pen parameter to a parameter list, the following behavior is observed:
1. The name (title row) is rendered in **... | open | 2023-08-01T11:51:03Z | 2023-08-09T02:11:29Z | https://github.com/pyqtgraph/pyqtgraph/issues/2790 | [
"parameterTree"
] | MrBeee | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.