
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
holoviz/panel | jupyter | 6,852 | Tabulator inputs trigger keyboard shortcuts | I'm experiencing the same issue as discussed in #6314, but only limited to Tabulator inputs
#### ALL software version info
Panel 1.4.2
JupyterLab 4.1.6
#### Description of expected behavior and the observed behavior
Expecting to enter any numbers without issues.
In reality, if I try to write numbers into ta... | closed | 2024-05-19T18:45:15Z | 2024-05-20T11:46:35Z | https://github.com/holoviz/panel/issues/6852 | [] | eaglesemanation | 1 |
aio-libs/aiopg | sqlalchemy | 356 | How to make concurrent queries to a database? | I'm probably missing sth really obvious .. I'm trying to make a few concurrent queries to a database in the following form:
```py
with (yield from request.app['pg_engine']) as conn:
tasks = []
tasks.append(conn.execute(tbl.insert().values(a=1,b=2....)
tasks.append(conn.execute(other_tbl.insert().valu... | closed | 2017-07-25T09:41:40Z | 2023-06-06T07:26:43Z | https://github.com/aio-libs/aiopg/issues/356 | [] | panagiks | 9 |
clovaai/donut | nlp | 181 | How did training with a batch size of 8 fit onto a single A100? | In the "Training" section, you mention you used a single A100 with the attached config yaml. An A100 has either 40 or 80GB of VRAM. The batch size is set to 8 in train_cord.yaml with a resolution of [1280, 960].
On a 24 GB 4090 with `torch.set_float32_matmul_precision('high')` and a resolution of around [1920, 1600... | open | 2023-04-13T12:16:41Z | 2023-05-04T15:27:27Z | https://github.com/clovaai/donut/issues/181 | [] | csanadpoda | 2 |
521xueweihan/HelloGitHub | python | 2,225 | 【开源自荐】基于golang开发的一款开箱即用的跨平台文件同步工具 | ## 项目推荐
- 项目地址:[https://github.com/no-src/gofs](https://github.com/no-src/gofs)
- 类别:Go
- 项目后续更新计划:
- 支持FTP、SFTP以及第三方云存储
- 内置中继模式支持
- 支持版本控制
- 支持自定义文件变更通知回调
- 新增Web管理以及监控平台
- 项目描述:
- gofs是基于golang开发的一款开箱即用的跨平台文件同步工具,支持在本地磁盘之间同步、从远程服务器同步变更到本地、将本地文件变更推送到远程服务器三种场景模式
- 通过第三方内网穿透工具进行中继,可以实现两台不... | closed | 2022-05-26T20:06:24Z | 2022-06-22T01:11:54Z | https://github.com/521xueweihan/HelloGitHub/issues/2225 | [
"Go 项目"
] | mstmdev | 1 |
biolab/orange3 | pandas | 6,879 | Python Script: example in widget help page causes warning | **What's wrong?**
The suggested code for the Zoo example in the Python Script help page causes a warning: "Direct calls to Table's constructor are deprecated and will be removed. Replace this call with Table.from_table":
**What's the solution?**
Rewrite the example code so that it conforms to tha latest version o... | open | 2024-08-21T13:27:31Z | 2024-09-06T07:18:23Z | https://github.com/biolab/orange3/issues/6879 | [
"bug report"
] | wvdvegte | 0 |
Esri/arcgis-python-api | jupyter | 1,767 | GeoSeriesAccessor.equals returns None in version 2.2 | **Describe the bug**
After updating to version: 2.2.0.1 of the API, the `GeoSeriesAccessor.equals()` method always returns `None`.
**To Reproduce**
```python
import pandas as pd
from arcgis.features import GeoAccessor, GeoSeriesAccessor
spatial_reference = {"wkid": 102100, "latestWkid": 3857}
df1 = pd.DataFr... | closed | 2024-02-29T20:24:08Z | 2024-03-27T06:53:24Z | https://github.com/Esri/arcgis-python-api/issues/1767 | [
"bug"
] | skykasko | 3 |
OFA-Sys/Chinese-CLIP | computer-vision | 21 | torch.load(args.resume, map_location="cpu") 加载clip_cn_rn50.pt时报错_pickle.UnpicklingError: invalid load key, '\xf7' | torch==1.9.0
torchvision==0.10.0
lmdb==1.3.0
cuda version 10.2
上面是我的环境配置,我跑默认的clip_cn_vit-b-16.pt是可以finetuing,但是换成clip_cn_rn50.pt就失败了。下面是启动脚本中修改的地方。
checkpoint=clip_cn_rn50.pt
vision_model=RN50
text_model=RBT3-chinese | closed | 2022-11-29T09:34:50Z | 2022-11-29T13:15:29Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/21 | [] | ZhaoyingAC | 7 |
roboflow/supervision | tensorflow | 1,144 | Multi-can tracking | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
I have 6 cams connected in a hallway and my task is to track and count people walking in it (there are always many people there), yet I do not u... | closed | 2024-04-26T11:54:47Z | 2024-04-26T12:09:35Z | https://github.com/roboflow/supervision/issues/1144 | [
"question"
] | Vdol22 | 1 |
fastapi-users/fastapi-users | asyncio | 566 | decode error | in route/verify.py
////
data = jwt.decode(
token,
verification_token_secret,
audience=VERIFY_USER_TOKEN_AUDIENCE,
algorithms=[JWT_ALGORITHM],
)
///
this cause error below:
raise InvalidAlgorithmError("The specified alg... | closed | 2021-03-24T15:26:27Z | 2021-03-24T15:57:25Z | https://github.com/fastapi-users/fastapi-users/issues/566 | [] | gavenwan | 1 |
521xueweihan/HelloGitHub | python | 2,289 | 【开源自荐】网页在线webrtc流媒体传输工具 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/iamtsm/tl-rtc-file
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:JS
<!... | closed | 2022-07-20T03:38:28Z | 2023-08-02T10:31:22Z | https://github.com/521xueweihan/HelloGitHub/issues/2289 | [
"JavaScript 项目"
] | iamtsm | 0 |
iterative/dvc | machine-learning | 9,997 | Unable to run dvc pull command | Cannot able to run the dvc pull command. Check the below description for it.
Error Message:
```
ERROR: failed to connect to azure - module 'lib' has no attribute 'OpenSSL_add_all_algorithms'
ERROR: failed to pull data from the cloud - 1 files failed to download
```
DVC and Deps Versions on python 3.8 (Ubuntu 20.... | closed | 2023-10-04T14:40:09Z | 2023-10-05T19:44:52Z | https://github.com/iterative/dvc/issues/9997 | [
"awaiting response"
] | khushkore | 6 |
predict-idlab/plotly-resampler | data-visualization | 276 | [FEAT] improve documentation of the aggregators | The documentation on how plotly-resampler works; i.e. the time-series data aggregation should be more clear (and less hidden). | closed | 2023-11-29T15:20:36Z | 2024-01-03T22:05:17Z | https://github.com/predict-idlab/plotly-resampler/issues/276 | [
"documentation",
"enhancement"
] | jonasvdd | 1 |
OWASP/Nettacker | automation | 819 | Only execute port_scan module on a local vm(metasploitable 2) | **OSes and version**: `Kali Linux 2023.04 WSL2` & `Ubuntu Core 22.04`
**Python Version**: `3.11.8`
_________________
I Tried with those module names:
- `all, *_scan` : These will just run the **port_scan**
- `*_vuln` : This even crazier, it just returned:
this scan module [*_vuln] not found!
I ... | closed | 2024-03-04T21:10:38Z | 2024-03-06T22:44:50Z | https://github.com/OWASP/Nettacker/issues/819 | [
"question"
] | dathtd119 | 3 |
sepandhaghighi/samila | matplotlib | 118 | Support transparent background | #### Description
Support transparent background
#### Steps/Code to Reproduce
```pycon
>>> from samila import *
>>> g = GenerativeImage()
>>> g.generate()
>>> g.plot(bgcolor="transparent")
```
#### Expected Behavior
Transparent background
#### Actual Behavior
```pycon
>>> g.bgcolor
'orangered'
```
#### O... | closed | 2022-04-20T07:31:59Z | 2022-06-01T12:22:50Z | https://github.com/sepandhaghighi/samila/issues/118 | [
"enhancement"
] | sepandhaghighi | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,219 | About the choice of final activation | Noticed that in both UnetGenerator and ResnetGenerator the final activation is Tanh. The codomain of Tanh is (-1, 1) yet the BaseDataset load images as in range (0, 1). The images are put into the generators and discriminators with (0, 1) values, but the generators ouput (-1, 1) values. Could there be some inconsistenc... | closed | 2020-12-30T11:16:05Z | 2021-01-03T05:49:46Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1219 | [] | feiyangsuo | 2 |
pydata/xarray | numpy | 9,704 | Support for astropy.units | ### Is your feature request related to a problem?
As described in [duck array requirements](https://docs.xarray.dev/en/stable/internals/duck-arrays-integration.html#duck-array-requirements), the [astropy.units.Quantity](https://docs.astropy.org/en/stable/api/astropy.units.Quantity.html#astropy.units.Quantity) object, ... | closed | 2024-11-03T02:23:20Z | 2024-11-18T07:11:18Z | https://github.com/pydata/xarray/issues/9704 | [
"enhancement"
] | tien-vo | 1 |
mjhea0/flaskr-tdd | flask | 72 | Circular depedency when adding SQLAlchemy | I ended up with circular dependency errors when adding SQLalchemy in:-
```
ImportError: cannot import name 'db' from partially initialized module 'flaskr_tdd.app' (most likely due to a circular import) (/Users/nigel/Tasks/learning/flaskr-tdd/flaskr_tdd/app.py)
```
I ended up changing the top of `models.py` to
... | closed | 2021-03-21T14:52:53Z | 2022-06-03T16:48:51Z | https://github.com/mjhea0/flaskr-tdd/issues/72 | [] | nigelm | 1 |
ultralytics/yolov5 | machine-learning | 12,468 | How to analyze remote machine training results with Comet? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I'm trying to analyze my yolov5 training with Comet, generated in a HPC machine. After ge... | closed | 2023-12-05T10:14:54Z | 2024-01-16T00:21:24Z | https://github.com/ultralytics/yolov5/issues/12468 | [
"question",
"Stale"
] | unrue | 4 |
onnx/onnx | tensorflow | 5,809 | Edit Input/Output Onnx file | # Ask a Question
### Question
Hi,
My goal is to change inputs/outputs names of Onnx file, I write this code:
`import onnx
onnx_model_path = "ostrack-256.onnx"
original_model = onnx.load(onnx_model_path)
for input in original_model.graph.input:
if input.name == "x":
input.name = "search"
el... | closed | 2023-12-18T13:32:02Z | 2023-12-18T13:50:20Z | https://github.com/onnx/onnx/issues/5809 | [
"question"
] | arielkantorovich | 0 |
google-research/bert | tensorflow | 819 | When will the Chinese BERT-large pre-training model be released? | When will the Chinese BERT-large pre-training model be released? | open | 2019-08-25T13:10:31Z | 2019-08-25T13:10:31Z | https://github.com/google-research/bert/issues/819 | [] | zhangsen-res | 0 |
dropbox/PyHive | sqlalchemy | 125 | Is there a way to define the application show in yarn resource manager? | Is there a way to define my own application on yarn resourcemanager using pyhive driver?
I want to konw what is running on the http://yarn_application_page/running the name column | closed | 2017-05-25T01:41:30Z | 2017-05-30T17:50:15Z | https://github.com/dropbox/PyHive/issues/125 | [] | darrkz | 1 |
streamlit/streamlit | data-science | 10,119 | Fullscreen label for `st.image` | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
A way for adding more context to images once they get clicked and enlarged. Currently trying to use the st.im... | open | 2025-01-07T01:28:26Z | 2025-01-08T02:13:51Z | https://github.com/streamlit/streamlit/issues/10119 | [
"type:enhancement",
"feature:st.image"
] | Walter909 | 3 |
AutoGPTQ/AutoGPTQ | nlp | 142 | How to load a LoRA for inference? | LoRAs are distributed on Hugging Face as folders containing two files:
```
$ ls kaiokendev_SuperCOT-7b
adapter_config.json
adapter_model.bin
```
How can such LoRA be loaded using the new peft functions in AutoGPTQ? Also, is it possible to
1) Load 2 or more LoRAs at the same time?
2) Unload a LoRA and retu... | open | 2023-06-05T20:45:48Z | 2023-11-23T05:30:09Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/142 | [] | oobabooga | 7 |
scrapy/scrapy | python | 6,177 | Switch to the latest sphinx | The docs fail to build with the current Sphinx (7.2.6):
```
reading sources... [ 48%] topics/downloader-middleware
Extension error (scrapydocs):
Handler <function collect_scrapy_settings_refs at 0x7f81fc663a60> for event 'doctree-read' threw an exception (exception: Next node is not a target)
```
So we should... | closed | 2023-12-12T21:43:22Z | 2025-01-19T12:25:02Z | https://github.com/scrapy/scrapy/issues/6177 | [
"enhancement",
"docs"
] | wRAR | 11 |
plotly/dash-core-components | dash | 208 | dcc.Interval as background process | Issue discovered in community: https://community.plot.ly/t/dash-working-as-a-background-process/10412
It looks like `dcc.Interval` freezes when the app is not in the foreground. once the app is the in the foreground again, the `dcc.Interval` process "catches up". This behavior appears to change depending on the brow... | open | 2018-05-24T19:44:07Z | 2023-04-24T19:55:06Z | https://github.com/plotly/dash-core-components/issues/208 | [
"Status: Discussion Needed"
] | charleyferrari | 6 |
tensorflow/tensor2tensor | machine-learning | 1,501 | --train_steps flag not working | ### Description
So I am running tensor2tensor framework with my own model, and I see that --train_steps flag not working., it keeps on training past 1000 that I have defined and stops above 200000 (sorry I could not track exactly when model stopped, but it does go beyond the set steps by a large margin)
```
t2t-t... | open | 2019-03-19T03:37:53Z | 2019-05-14T12:23:43Z | https://github.com/tensorflow/tensor2tensor/issues/1501 | [] | Eugen2525 | 1 |
nalepae/pandarallel | pandas | 103 | consider implementing parallelism with Ray | Ray has a lower overhead vs. python standard lib. multiple processing.
Is there any interest in moving in that direction for pandarallel? | open | 2020-07-29T17:56:27Z | 2020-11-25T14:51:13Z | https://github.com/nalepae/pandarallel/issues/103 | [] | bobcolner | 1 |
erdewit/ib_insync | asyncio | 649 | qualifyContractsAsync requires only 1 match per pattern | qualifyContractsAsync works in 4 steps:
(a) Retrieve qualified contracts from IB database based on a contract pattern argument
(b) Ensure that there is only one qualified contract per pattern
(c) Fix some faulty data fields of the qualified contract
(d) Copy its data into the initial argument's fields
However, t... | closed | 2023-10-17T09:33:58Z | 2023-10-17T17:06:35Z | https://github.com/erdewit/ib_insync/issues/649 | [] | rgeronimi | 4 |
graphistry/pygraphistry | jupyter | 31 | list class methods in documentation's table of contents | Unassigned -- @thibaudh and I are puzzled.
| closed | 2015-08-23T23:53:12Z | 2020-06-10T06:45:09Z | https://github.com/graphistry/pygraphistry/issues/31 | [
"enhancement"
] | lmeyerov | 0 |
plotly/dash-bio | dash | 538 | Background color Speck | Hi everyone,
Is there a way to change the background of the 3d molecular view using Speck?
Thanks a lot for the help! | closed | 2021-01-14T09:56:09Z | 2021-10-28T14:34:38Z | https://github.com/plotly/dash-bio/issues/538 | [] | raimon-fa | 1 |
JaidedAI/EasyOCR | pytorch | 721 | Output format of labels | open | 2022-05-07T04:09:01Z | 2022-05-07T04:09:26Z | https://github.com/JaidedAI/EasyOCR/issues/721 | [] | abhifanclash | 0 | |
biolab/orange3 | scikit-learn | 6,785 | Add-on download Orange | I have this issue

and here are the details "Traceback (most recent call last):
File "C:\Users\Fatima\AppData\Local\Programs\Orange\lib\concurrent\futures\thread.py", line 58, in run
result = self.fn(*self.args, ... | closed | 2024-04-22T09:26:35Z | 2024-05-10T07:30:41Z | https://github.com/biolab/orange3/issues/6785 | [] | FatimaAlKhatib | 3 |
tqdm/tqdm | jupyter | 810 | After using try/except method, the progress chart can not be refreshed in a single line. | This is my code:
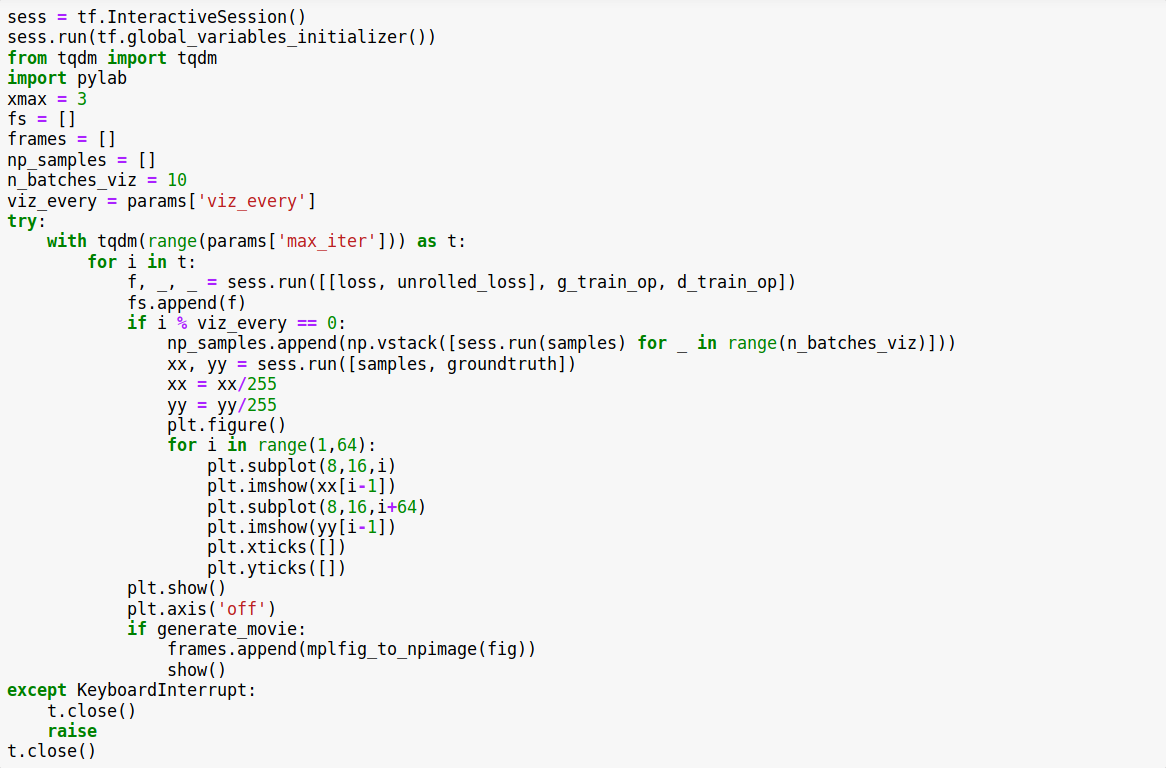
and problem reappears
I used ubuntu18.04+cuda10.0+cudnn7.4+tensorflow1.13 | closed | 2019-09-11T13:23:17Z | 2019-09-12T02:47:21Z | https://github.com/tqdm/tqdm/issues/810 | [
"duplicate 🗐",
"invalid ⛔"
] | shmilydy | 1 |
deepset-ai/haystack | pytorch | 8,732 | Bedrock ChatGenerator - support for Tool | closed | 2025-01-16T14:10:08Z | 2025-01-23T16:10:00Z | https://github.com/deepset-ai/haystack/issues/8732 | [
"P1"
] | anakin87 | 0 | |
roboflow/supervision | deep-learning | 1,415 | [InferenceSlicer] - it is hard to set specific tile dimensions | ### Description
I tried to use `InferenceSlicer` to divide the frame in four equally sized tiles and it turned out to be hard to do.
```python
import numpy as np
import supervision as sv
from inference import get_model
model = get_model(model_id="football-ball-detection-rejhg/3", api_key=ROBOFLOW_API_KEY)
... | closed | 2024-07-29T21:01:08Z | 2024-10-01T12:48:36Z | https://github.com/roboflow/supervision/issues/1415 | [
"bug"
] | SkalskiP | 8 |
openapi-generators/openapi-python-client | fastapi | 116 | Content type octet-stream | **Describe the bug**
I'm getting this parsing error:
```
MULTIPLE ERRORS WHILE PARSING:
ERROR parsing GET /api/v1/datasetversion/{dataSetVersionID}/read_data within datasetversion. Endpoint will not be generated.
{'content': {'application/octet-stream': {'schema': {'format': 'stream',
... | closed | 2020-08-03T15:32:55Z | 2020-08-13T19:51:02Z | https://github.com/openapi-generators/openapi-python-client/issues/116 | [
"✨ enhancement"
] | pawamoy | 3 |
python-restx/flask-restx | api | 409 | Wildcard dictionary omits keys with null values | The marshalled output of a model with wildcard field omits any member of the input dictionary whose value is None or whose key "comes before" a key whose value is None.
### **Repro Steps**
1. Run this:
```python
from flask_restx import marshal
from flask_restx.fields import Wildcard, String
wild = Wildcard(St... | open | 2022-02-02T00:14:14Z | 2022-02-02T20:48:06Z | https://github.com/python-restx/flask-restx/issues/409 | [
"bug"
] | dpeschman | 0 |
iam-abbas/FastAPI-Production-Boilerplate | rest-api | 19 | Authentication Dependency | The authentication dependency is not handling the authentication properly. the authentication middleware adds the auth and user to scope but these are not utilised in the the authentication dependency. The authentication protected urls are accessible with invalid token. | open | 2024-11-29T17:47:47Z | 2024-11-29T18:02:06Z | https://github.com/iam-abbas/FastAPI-Production-Boilerplate/issues/19 | [] | ajithpious | 0 |
google/trax | numpy | 982 | Support for windows |
Hi, is there gonna be any release soon which has support for windows?
| closed | 2020-08-29T07:35:30Z | 2020-09-10T02:59:10Z | https://github.com/google/trax/issues/982 | [] | Nishant-Pall | 2 |
strawberry-graphql/strawberry | graphql | 2,937 | refactoring: graphql_relay usage for more standard conformity | Is there a reason why strawberry doesn't use graphql-relay?
For standard conformity I would use the mentioned library (graphql-relay) and
use at least the to_global_id/from_global_id definitions as they are a bit more elaborated | open | 2023-07-11T10:04:47Z | 2025-03-20T15:56:17Z | https://github.com/strawberry-graphql/strawberry/issues/2937 | [] | devkral | 3 |
strawberry-graphql/strawberry | asyncio | 3,595 | allow permission_class instances | ## Feature Request Type
- [ ] Core functionality
- [x] Alteration (enhancement/optimization) of existing feature(s)
- [ ] New behavior
## Description
Currently it is not possible to use instances of PermissionClasses, leading to lots of boilerplate.
Usecase: I want to check for specific features, like thi... | open | 2024-08-09T06:16:16Z | 2025-03-20T15:56:49Z | https://github.com/strawberry-graphql/strawberry/issues/3595 | [] | Speedy1991 | 3 |
babysor/MockingBird | deep-learning | 955 | 生成的音频噪音有点大 | 即使把家里的门窗关了,风扇空调都关了,录制的音频没有噪音,但是合成的音频噪音挺大的,期待这块能优化一下
| open | 2023-09-05T12:54:09Z | 2023-11-01T01:31:58Z | https://github.com/babysor/MockingBird/issues/955 | [] | tailangjun | 3 |
plotly/dash | plotly | 2,337 | Add Individual Dismissible Error Messages in Debug=True | **Is your feature request related to a problem? Please describe.**
When trying to use the application in debug=True mode, not dealing with all errors one by one. If I have a components that I need to interact with on the right side of the screen, they become hidden by error messages, no longer being able to use withou... | open | 2022-11-27T02:50:48Z | 2025-02-19T19:09:27Z | https://github.com/plotly/dash/issues/2337 | [
"feature",
"P3"
] | BSd3v | 2 |
hankcs/HanLP | nlp | 1,002 | 使用HanLP.segment()分词导致python停止工作 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2018-10-19T11:25:50Z | 2020-01-01T10:56:18Z | https://github.com/hankcs/HanLP/issues/1002 | [
"ignored"
] | TJXTT | 2 |
davidsandberg/facenet | tensorflow | 998 | Clustering using facenet | I'm trying to use the clustering function to cluster the lfw images but the accuracy is so bad. did anyone face the same problem ?
Thank you. | open | 2019-03-28T14:21:49Z | 2019-04-09T09:38:47Z | https://github.com/davidsandberg/facenet/issues/998 | [] | khadijakhaldi | 1 |
BeanieODM/beanie | pydantic | 224 | How to bulk update with upsert=True? | Using `beanie==1.10.1`
Trying to preform bulk update with `upsert=True` with no luck.
```
async def run_test():
await init_mongo()
docs = [TestDoc(a=f"id_{i}", b=random.randint(1, 100)) for i in range(10)]
# docs = await insert_test_docs()
async with BulkWriter() as bulk_writer:
for d... | closed | 2022-03-22T12:10:25Z | 2023-04-18T19:31:41Z | https://github.com/BeanieODM/beanie/issues/224 | [
"Stale"
] | PATAPOsha | 14 |
OpenInterpreter/open-interpreter | python | 665 | Getting stuck at "Getting started..." when running local model on Windows PC | ### Describe the bug
Once the model and Ooba are downloaded, run interpreter --local will show print "Getting started..." then become stuck forever.
I thought some arguments might be bugged when calling oobabooga server. Up on checking llm.py, at line 44, there are:
```python
# Start oobabooga server
model_dir... | closed | 2023-10-20T19:18:05Z | 2023-11-14T22:07:27Z | https://github.com/OpenInterpreter/open-interpreter/issues/665 | [
"Bug"
] | xinranli0809 | 5 |
InstaPy/InstaPy | automation | 6,687 | has use instapy demo? | <!-- Did you know that we have a Discord channel ? Join us: https://discord.gg/FDETsht -->
<!-- Is this a Feature Request ? Please, check out our Wiki first https://github.com/timgrossmann/InstaPy/wiki -->
## Expected Behavior
## Current Behavior
## Possible Solution (optional)
## InstaPy configuration
| open | 2023-02-25T10:14:48Z | 2023-02-25T10:14:48Z | https://github.com/InstaPy/InstaPy/issues/6687 | [] | PalaChen | 0 |
aeon-toolkit/aeon | scikit-learn | 2,109 | [ENH] Add PyODAdapter-implementation for LOF | ### Describe the feature or idea you want to propose
The [`PyODAdapter`](https://github.com/aeon-toolkit/aeon/blob/main/aeon/anomaly_detection/_pyodadapter.py) in aeon allows us to use any outlier detector from [PyOD](https://github.com/yzhao062/pyod), which were originally proposed for relational data, also for tim... | closed | 2024-09-27T13:26:16Z | 2024-11-24T12:13:06Z | https://github.com/aeon-toolkit/aeon/issues/2109 | [
"enhancement",
"interfacing algorithms",
"anomaly detection"
] | SebastianSchmidl | 0 |
Miserlou/Zappa | django | 1,728 | Is it Possible to handle sessions using zappa in AWS Lambda | Hi,
I have created a web application and deployed on AWS using zappa. I was unable to handle the sessions. Is it possible to handle sessions using zappa on AWS? If possible, How?
Thanks & Regards,
N Sai Kumar | open | 2018-12-11T15:16:10Z | 2018-12-18T05:43:57Z | https://github.com/Miserlou/Zappa/issues/1728 | [] | saikumar-neelam | 5 |
geex-arts/django-jet | django | 379 | Popup Edit redirecting to new Window | Hello I am having troubles using popup edits in custom places.
Stack:
`Python 3.6.5`
`Django==2.1.4`
`django-jet==1.0.8`
I am using `ajax-select` in Django admin for 1:N selects, however when I try to insert the edit button manually to the row, it opens in new windows instead of the modal/popup.
I am format... | open | 2018-12-19T09:45:09Z | 2021-07-28T21:27:51Z | https://github.com/geex-arts/django-jet/issues/379 | [] | josefkorbel | 1 |
replicate/cog | tensorflow | 2,206 | Pydantic >2 and optional image Inputs | Hi,
I'm developing a cog model that requires a dependeny, which needs pydantic >2.
Now, I'm noticing an issue with optional image inputs. The model returns an error in that case. I'll provide a minimal working example:
```
from cog import BasePredictor, Path, Input
class Predictor(BasePredictor):
def predict(... | open | 2025-03-17T11:34:17Z | 2025-03-24T10:59:49Z | https://github.com/replicate/cog/issues/2206 | [] | jschoormans | 2 |
marcomusy/vedo | numpy | 126 | Displaying multiple volume objects | Thanks for this nice library. I am running into an issue while displaying multiple volumes. I am trying to superimpose CT scan and radiation dose distribution using the following code sample. I get the following warning and only one Volume object is rendered in jupyter notebook.
Warning: multirendering is not suppor... | closed | 2020-04-15T23:43:43Z | 2020-04-16T01:21:42Z | https://github.com/marcomusy/vedo/issues/126 | [] | cerr | 2 |
public-apis/public-apis | api | 3,942 | Fix: Old link of Jokes > Excuser API | the old heroku api is now down
This is the current one for [Excuser](https://github.com/public-apis/public-apis#entertainment:~:text=Excuser)
https://excuser-three.vercel.app
Repository: https://github.com/primeTanM/Excuser | open | 2024-07-23T11:20:00Z | 2024-07-23T11:27:26Z | https://github.com/public-apis/public-apis/issues/3942 | [] | RayyanNafees | 0 |
pandas-dev/pandas | python | 60,488 | BUG: no type provided for pandas.api.extensions.no_default | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [X] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2024-12-04T00:50:30Z | 2025-01-14T17:21:59Z | https://github.com/pandas-dev/pandas/issues/60488 | [
"Enhancement",
"Typing"
] | mballintijn | 3 |
OthersideAI/self-operating-computer | automation | 223 | Continuous development to reload app without re-install | Maybe this is there already, so please guide me. I searched various keywords to find developer mode or development framework of this app.
So basically, this app needs to be installed to run(i am on MAC). But for every change, I need to re-install to test the changes. Is there a way to develop in live-reload mechanism?... | open | 2025-01-15T21:56:38Z | 2025-01-23T14:07:03Z | https://github.com/OthersideAI/self-operating-computer/issues/223 | [
"enhancement"
] | humanely | 1 |
frappe/frappe | rest-api | 31,233 | [v16] must haves / good to have changes | Add your "must have" changes here for v16 so we can get them done before beta.
Previous list + few things I remembered:
- [ ] Separate the following modules into separate apps
- [ ] Social module - disabled by default, hardly used
- [ ] Offsite Backup solutions (huge size in installation and dependency churn)
... | open | 2025-02-11T12:05:09Z | 2025-03-15T06:01:00Z | https://github.com/frappe/frappe/issues/31233 | [
"meta",
"v16"
] | ankush | 8 |
gradio-app/gradio | machine-learning | 9,914 | guides with examples is fault | ### Describe the bug
https://www.gradio.app/guides/creating-a-chatbot-fast
in above tutorial,the example in gradio version 5.5.0 is fault,suggested update examples
### System Info
```shell
python 3.10.5
gradio 5.5.0
``` | closed | 2024-11-07T11:47:48Z | 2024-11-13T00:18:27Z | https://github.com/gradio-app/gradio/issues/9914 | [
"bug"
] | fishANDdog | 1 |
graphql-python/graphene-django | graphql | 1,463 | ModelInputObjecttypes | Can we Have sth like ModelInputObjecttypes for our Input | closed | 2023-09-16T10:31:31Z | 2023-09-16T16:06:48Z | https://github.com/graphql-python/graphene-django/issues/1463 | [
"✨enhancement"
] | elyashedayat0101 | 1 |
AutoGPTQ/AutoGPTQ | nlp | 371 | How to generate pytorch_model.bin.index.json or model.safetensors.index.json | from transformers import AutoTokenizer, TextGenerationPipeline, AutoConfig
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
import torch
pretrained_model_dir = "/root/ai/LLaMA-Efficient-Tuning/output_model"
quantized_model_dir = "/root/ai/AutoGPTQ/output_model"
tokenizer = AutoTokenizer.from_pretrai... | closed | 2023-10-18T08:58:51Z | 2024-08-25T08:20:36Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/371 | [
"chinese"
] | Fraudsterrrr | 2 |
jupyter-incubator/sparkmagic | jupyter | 97 | Allow user to return dataframes not constructed through SQL queries | A thought I just had: Currently we only return responses as dataframes if their query is a SQL query. Since we already have the code for parsing dataframes from JSON responses, we might provide an option that lets users say "I'm going to output a bunch of JSON here, please parse it and return it as a dataframe", even ... | closed | 2016-01-04T23:21:01Z | 2016-01-21T01:34:51Z | https://github.com/jupyter-incubator/sparkmagic/issues/97 | [
"kind:enhancement"
] | msftristew | 1 |
MolSSI/cookiecutter-cms | pytest | 57 | Duplicate Python versioning in Travis CI | Current in Travis we set:
```
- os: linux
python: 3.7
env: PYTHON_VER=3.7
```
This will both build a conda env and use a system 3.7 python. There is no need to set the Python version I believe, we may want to set the `name=` variable instead so that the display is correct.
We might also want ... | closed | 2019-01-05T01:05:03Z | 2019-06-05T15:48:53Z | https://github.com/MolSSI/cookiecutter-cms/issues/57 | [] | dgasmith | 1 |
jonaswinkler/paperless-ng | django | 508 | [Other] export task in Django Q scheduler | I would like to schedule the backup with the builtin scheduler. Is there a function for this or anynone knows how to add it?
If I click on "Add" I have to enter a function name. Maybe this could also be a good addition for others in the documentation :) | closed | 2021-02-07T07:18:10Z | 2021-02-07T12:46:23Z | https://github.com/jonaswinkler/paperless-ng/issues/508 | [] | igno2k | 1 |
smarie/python-pytest-cases | pytest | 134 | How to use builtin Pytest fixtures | I want to pass `tmp_path_factory ` from Pytest into my case. What is the recommended way to do this?
,Thanks | closed | 2020-09-11T08:33:24Z | 2020-09-11T09:54:49Z | https://github.com/smarie/python-pytest-cases/issues/134 | [] | 6Hhcy | 2 |
biolab/orange3 | scikit-learn | 6,057 | Implementing Numba in Python and Apple Accelerate (matrix processor support) in Numpy? | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
<!-- In other words, what's your pain point? -->
By using Numba and the Apple Accelerate (mat... | closed | 2022-07-11T13:24:43Z | 2023-01-10T10:59:35Z | https://github.com/biolab/orange3/issues/6057 | [] | stenerikbjorling | 1 |
marcomusy/vedo | numpy | 127 | cutting multiple overlapping volumes to display 2d slices | I am interested in slicing multiple 3d arrays and displaying 2D slices. Some of the options include using addCutterTool or volume.zSlice(index) . Can you please elaborate more on:
- displaying multiple overlapping volumes in addCutterTool.
- changing slices with volume.zSlice(index) using vtkplotter.addons.addSlider... | closed | 2020-04-16T03:01:20Z | 2023-09-09T03:17:20Z | https://github.com/marcomusy/vedo/issues/127 | [] | cerr | 1 |
onnx/onnx | scikit-learn | 6,093 | Using Pytorch Count of input_names provided during export not matching with session.get_inputs() | Hi,
I have trained a model using pytorch and trying to export it to a onnx file. I was able export it to onnx file with 5 input names and dynamic_axes. If I use the exported onnx file to run inference, the input_names provided are missing. Seeing only 2 out of 5 while doing session.get_inputs()
I used below code du... | closed | 2024-04-19T06:10:40Z | 2024-04-19T16:46:55Z | https://github.com/onnx/onnx/issues/6093 | [
"question"
] | v-ngangarapu | 1 |
inducer/pudb | pytest | 340 | py3.4 install failure due to latest pygments release | The latest pygments release appears to depend upon py3.5; since pudb just depends upon pygments`>=1.0`, then this causes pudb to now depend upon py3.5, and fails to install on py3.4.
In `zulip-term` we plan to pin pygments to an earlier version as a workaround for now, since we don't explicitly depend on pygments bu... | open | 2019-05-12T16:33:22Z | 2019-05-29T04:44:33Z | https://github.com/inducer/pudb/issues/340 | [] | neiljp | 3 |
tiangolo/uwsgi-nginx-flask-docker | flask | 172 | python3.7-alpine3.8 still uses python3.6 at runtime | Hi,
First of all, you do a great work with that images and they save me a lot of time :-)
Because I use the new asyncio API of Python 3.7 I recently needed to update to the python3.7-alpine3.8 image. And it seems the image still uses python3.6.9 at runtime.
At build time the Python path is configured to use Pyt... | closed | 2020-04-30T14:39:42Z | 2020-05-11T14:39:28Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/172 | [] | JuergenGutsch | 7 |
babysor/MockingBird | pytorch | 493 | 作者大佬,预处理报错 | 预处理报错,大佬帮忙看一下啥情况

| open | 2022-04-06T03:57:10Z | 2022-04-26T08:20:31Z | https://github.com/babysor/MockingBird/issues/493 | [
"help wanted"
] | 1239hy | 8 |
serengil/deepface | machine-learning | 1,345 | Why model cannot load in call verify before? | ### Before You Report a Bug, Please Confirm You Have Done The Following...
- [X] I have updated to the latest version of the packages.
- [X] I have searched for both [existing issues](https://github.com/serengil/deepface/issues) and [closed issues](https://github.com/serengil/deepface/issues?q=is%3Aissue+is%3Aclosed) ... | closed | 2024-09-24T02:05:24Z | 2024-09-24T07:48:20Z | https://github.com/serengil/deepface/issues/1345 | [
"bug",
"question"
] | ciaoyizhen | 3 |
Zeyi-Lin/HivisionIDPhotos | fastapi | 33 | Dockrfile构建的如何更新 | 感谢开发,已在群晖中成功部署后使用,但看更新日志2024.9.2: 更新调整照片 KB 大小,而hivision_modnet.onnx版本为Jul 3, 2023。
请问如何更新,谢谢! | closed | 2024-09-03T14:43:54Z | 2024-09-04T02:51:08Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/33 | [] | nageshuizeii | 1 |
jacobgil/pytorch-grad-cam | computer-vision | 446 | Swin Transformer cannot cam-->grad can be implicitly created only for scalar outputs | File "/home/xxx/Project/latested/camvisual.py", line 227, in <module>
grayscale_cam = cam(input_tensor=img_tensor, targets=target_category)
File "/home/xxx/miniconda3/lib/python3.10/site-packages/pytorch_grad_cam/base_cam.py", line 188, in __call__
return self.forward(input_tensor,
File "/home/xxx/minic... | open | 2023-08-06T13:38:43Z | 2023-12-03T08:30:19Z | https://github.com/jacobgil/pytorch-grad-cam/issues/446 | [] | woodszp | 2 |
NVlabs/neuralangelo | computer-vision | 212 | Calculation of PSNR value | Hello, author, thank you for your great contribution to the field of 3D reconstruction. In which directory are the rendered images saved? After I successfully ran the project, I found that there was no output of the rendered images. Is there a parameter in the code that is not set? Because I eventually want to compare ... | open | 2024-10-09T08:37:09Z | 2024-11-09T05:41:34Z | https://github.com/NVlabs/neuralangelo/issues/212 | [] | xsl316 | 0 |
waditu/tushare | pandas | 1,171 | 使用pro.daily_basic获取000925.SZ在20090429之前数据自由流通股本列和换手率数据类型是object,20090430之后是float64 | open | 2019-10-21T15:23:05Z | 2019-10-22T14:27:44Z | https://github.com/waditu/tushare/issues/1171 | [] | piaoyu51 | 1 | |
recommenders-team/recommenders | data-science | 1,394 | [FEATURE] Upgrade nni and scikit-learn | ### Description
<!--- Describe your expected feature in detail -->
- Upgrade nni from current version (1.5) so that we can use scikit-learn>=0.22.1
- Add nni back to the core option of the pypi package
| open | 2021-05-07T17:25:38Z | 2021-05-07T17:27:38Z | https://github.com/recommenders-team/recommenders/issues/1394 | [
"enhancement"
] | anargyri | 0 |
erdewit/ib_insync | asyncio | 103 | ib_insync with Tkinter: "RuntimeError: There is no current event loop in thread" |
I am working on a **Tkinter** GUI that utilizes IB API via **ib_insync** as a data source.
After a button click, I try to run **ib_insync** in a thread to regularly obtain _option chain_ of a specific asset.
I have written a class for this Tkinter app and following code block includes the methods that I invoke ... | closed | 2018-10-02T17:50:08Z | 2018-10-05T07:05:39Z | https://github.com/erdewit/ib_insync/issues/103 | [] | mcandar | 1 |
tensorpack/tensorpack | tensorflow | 1,080 | How to transfrom CKPT to savedmodel or pb format for classification task? |
As the title, how to convert the ckpt file obtained by the tensorpack training into a savedmodel or pb model file to complete online deployment, is there a reference code? | closed | 2019-02-13T13:43:17Z | 2019-02-24T08:54:18Z | https://github.com/tensorpack/tensorpack/issues/1080 | [
"usage"
] | lianyingteng | 1 |
charlesq34/pointnet | tensorflow | 143 | Training Issue for Semantic Segmentation | Hi,
I am trying to train the dataset for semantic segmentation. It makes crush my computer since I do not have enough memory. Also, when I decrease the batch size, it takes so much time. Is there any other option for that? Or is there any trained file of Area 6 available?
Thank you for any help.
Cheers. | open | 2018-10-12T13:46:38Z | 2019-01-03T09:55:08Z | https://github.com/charlesq34/pointnet/issues/143 | [] | Beril-1 | 1 |
ray-project/ray | python | 51,464 | CI test windows://python/ray/serve/tests:test_proxy is flaky | CI test **windows://python/ray/serve/tests:test_proxy** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa87-c07f-445d-9db6-96c5167fbcd8
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c50-4a37-b569-65a5282fdc15
DataCaseName-windows://pytho... | closed | 2025-03-18T20:15:02Z | 2025-03-20T03:42:19Z | https://github.com/ray-project/ray/issues/51464 | [
"bug",
"triage",
"serve",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 14 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 566 | MegaUpload model link not working | The MegaUpload link to the models is no longer working. maybe replace it with a new [mega.nz](url) link? | closed | 2020-10-19T08:57:59Z | 2020-10-24T17:34:48Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/566 | [] | ranshaa05 | 3 |
koxudaxi/datamodel-code-generator | fastapi | 2,093 | How to Generate Enums for OneOf in OpenAPI Schemas Similar to Enum Fields | **Describe the bug**
First of all, thank you for the great work on datamodel-code-generator! I have a question regarding how to handle oneOf in OpenAPI schemas, and I'm wondering if it’s possible to generate Python Enums from oneOf, similar to how they are generated from enum fields.
When I use enum in my schema,... | open | 2024-09-25T15:09:53Z | 2024-09-26T10:00:26Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2093 | [] | REZUCE | 0 |
marshmallow-code/flask-marshmallow | rest-api | 201 | How to integrate with PickleType | I want to pass a list to the schema which uses SQLAlchemy's `PickleType` column.
The json file will looks like this:
```
json_data = {uuid: '123456...', coords: [[x1, y1], [x2, y2]]}
```
But looks like `ma.SQLAlchemyAutoSchema` treat `PickleType` column as string so if I do `schema.load(json_data)` it will say `c... | open | 2020-10-02T08:10:40Z | 2021-10-15T15:06:28Z | https://github.com/marshmallow-code/flask-marshmallow/issues/201 | [] | kaito-albert | 1 |
Kav-K/GPTDiscord | asyncio | 278 | Self-Reflection | Give the bot functions like /gpt ask and etc a self-reflection function where GPT asks itself if its generated answer is suitable | closed | 2023-04-21T15:36:01Z | 2023-11-11T02:30:31Z | https://github.com/Kav-K/GPTDiscord/issues/278 | [
"help wanted",
"good first issue"
] | Kav-K | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 20,572 | auto_scale_batch_size arg not accept by lightning.Trainer | ### Bug description
The `auto_scale_batch_size` arg is not accept in `lightning.Trainer`, but accepted in `pytorch_lightning.Trainer`.
```
Error in call to target 'lightning.pytorch.trainer.trainer.Trainer':
TypeError("Trainer.__init__() got an unexpected keyword argument 'auto_scale_batch_size'")
```
### What vers... | open | 2025-02-03T22:58:59Z | 2025-02-03T22:59:11Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20572 | [
"bug",
"needs triage",
"ver: 2.5.x"
] | yc-tao | 0 |
keras-team/keras | data-science | 20,307 | ValueError when loading models that has reused weights | if I create a model wich reuses layers I get a Error when trying to load it again.
```python
import tensorflow as tf
from keras.models import load_model,save_model
from keras import layers
inputs = layers.Input(shape=(10,))
x=inputs
t=layers.Dense(10)
x = t(x)
x = layers.Dense(10)(x)
x = t(x)
model=tf.... | closed | 2024-09-30T16:50:04Z | 2024-10-22T16:41:10Z | https://github.com/keras-team/keras/issues/20307 | [
"type:Bug"
] | K1521 | 3 |
recommenders-team/recommenders | machine-learning | 2,153 | [BUG] Review new MIND tests | ### Description
<!--- Describe your issue/bug/request in detail -->
There is an error in staging, see https://github.com/recommenders-team/recommenders/issues/2147#issuecomment-2306967499
### In which platform does it happen?
<!--- Describe the platform where the issue is happening (use a list if needed) -->
<... | closed | 2024-08-23T12:48:23Z | 2024-08-26T14:39:01Z | https://github.com/recommenders-team/recommenders/issues/2153 | [
"bug"
] | miguelgfierro | 1 |
roboflow/supervision | pytorch | 1,333 | How to determine the source coordinates better in computer vision speed estimation | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
blog https://blog.roboflow.com/estimate-speed-computer-vision/
, and I'm not sure what the intended behavior is. In particular, `DVCFileSystem`'s `get_file` raises an error with `rpath=lpath` and `rev=None` from a non-default branch. But if exp... | open | 2024-12-10T00:13:00Z | 2024-12-17T18:50:00Z | https://github.com/iterative/dvc/issues/10647 | [] | adamliter | 0 |
tortoise/tortoise-orm | asyncio | 992 | ForeignKey fields, PydanticMeta - include should include the submodel | ```
class User(Model):
id = fields.IntField(pk=True)
username = fields.CharField(max_length=30, unique=True)
status = fields.ForeignKeyField('myapp.UserStatus')
class PydanticMeta:
include= ("username", "status_id") # Working
include= ("username", "status") # ERROR
```
As show... | open | 2021-11-28T19:15:18Z | 2022-05-20T20:19:48Z | https://github.com/tortoise/tortoise-orm/issues/992 | [] | alispa | 2 |
microsoft/qlib | machine-learning | 1,029 | What is the correspondence between the date of prediction and the dates during backtest? | Suppose that I use `Alpha360` for the input features, which contains data from day (T-59) to day T and by default the label is given as `Ref($close, -2) / Ref($close, -1) - 1`, thus what the model predicts on day T should be traded on T+2. Where is this time difference addressed in the backtest? I don't see any date ad... | closed | 2022-04-01T07:28:16Z | 2022-07-31T12:03:10Z | https://github.com/microsoft/qlib/issues/1029 | [
"question",
"stale"
] | Chlorie | 2 |
healthchecks/healthchecks | django | 1,041 | Feature request: support additional PostgreSQL DB SSL parameters via environment variables | It would be useful to support the following SSL parameters in postgresql DB connections, especially when using custom trusted CAs or certificate-based authentication.
* [`sslrootcert`](https://www.postgresql.org/docs/10/libpq-connect.html#LIBPQ-CONNECT-SSROOTCERT) - useful when using a custom certificate authority f... | closed | 2024-08-04T17:10:39Z | 2024-08-27T13:30:39Z | https://github.com/healthchecks/healthchecks/issues/1041 | [] | gclawes | 1 |
biolab/orange3 | scikit-learn | 6,745 | sklearn 1.1.3 can be upgraded? | Greetings!
This is to ask if the sklearn 1.1.3 can be upgraded to the latest on (i.e., 1.4) in Orange3 in which get_params can be used to extract the weights and biases of a trained neural network model?
As in the sklearn 1.1.3 the weights and biases are not available for further analyses in python.
Many thanks ... | closed | 2024-02-24T16:40:28Z | 2024-05-10T10:09:26Z | https://github.com/biolab/orange3/issues/6745 | [] | msokouti1 | 1 |
ultralytics/yolov5 | pytorch | 12,787 | Videostream on flask web | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
How can I apply the camera videostream to html with flask?
### Additional
_No response_ | closed | 2024-03-06T03:51:03Z | 2024-10-20T19:40:45Z | https://github.com/ultralytics/yolov5/issues/12787 | [
"question",
"Stale"
] | JosuaLimbu | 3 |
mkhorasani/Streamlit-Authenticator | streamlit | 156 | Cannot instantiate authenticator object in multiple pages: DuplicatedWidgetId | I'm following the documentation at steps 1 and 2, which states that one needs to recreate the Authenticator object and call the `login` method on each page of a multipage app.
I'm testing the functionality but cannot recreate the object in a different page. The exception is the following:
```
DuplicateWidgetID: Th... | closed | 2024-05-02T18:26:05Z | 2024-11-10T06:05:07Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/156 | [
"help wanted"
] | mattiatantardini | 15 |
ckan/ckan | api | 7,986 | libmagic error when CKAN 2.10.3 is installed from source | ## CKAN version
2.10.3 in Ubuntu 22.04 with Python 3.10.12
## Describe the bug
I'm trying to install CKAN 2.10.3 from source in Ubuntu 22.04 with Python 3.10.12 but when I run the `ckan` command in the virtual environment it returns an error related to python-magic (python-magic == 0.4.27) :
_ImportError: fai... | closed | 2023-12-15T10:16:41Z | 2024-01-17T17:38:57Z | https://github.com/ckan/ckan/issues/7986 | [
"Good for Contribution"
] | managume | 2 |
hzwer/ECCV2022-RIFE | computer-vision | 32 | Interpolating lead to poor quality and jamming | > https://pan.baidu.com/s/1m72KUBkUApodDDyrGZPhqQ 提取码: kivu
The 2x and 8x video is jamming in the 0:01..It's hard to say that the video after inserting frames has better MOS, but the speed has really improved a lot.
| closed | 2020-11-23T16:01:11Z | 2020-11-24T04:14:27Z | https://github.com/hzwer/ECCV2022-RIFE/issues/32 | [] | beiluo97 | 5 |
proplot-dev/proplot | matplotlib | 380 | Understanding autolayout and colorbar placement | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
I have been using proplot for the last few months and most of ... | closed | 2022-07-28T15:33:09Z | 2023-03-29T13:42:20Z | https://github.com/proplot-dev/proplot/issues/380 | [
"support"
] | cvanelteren | 3 |
Farama-Foundation/PettingZoo | api | 327 | Should RPS and RPSLS be merged? | Title. The reason they were split is that a very long time ago I wanted to increase the total number of environments supported in pettingzoo. The alternative is turning RPSLS into a flag of RPS. | closed | 2021-02-16T23:32:23Z | 2021-04-19T13:49:34Z | https://github.com/Farama-Foundation/PettingZoo/issues/327 | [] | jkterry1 | 0 |
widgetti/solara | fastapi | 183 | Set higher z-index on Solara 'reloading' overlay and 'refresh' dialogue | The Solara development mode 'reloading' overlay and 'refresh the page' dialogue appear underneath ipyleaflet maps because of their z-index. Since these overlays should supercede every element it would make sense to give them a very high z-index. | open | 2023-06-29T07:45:43Z | 2023-06-29T07:45:43Z | https://github.com/widgetti/solara/issues/183 | [] | mangecoeur | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.