
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ARM-DOE/pyart | data-visualization | 872 | Speed up of "estimate_noise_hs74" | Hi all,
In my own version of Py-ART I have modified the code of pyart/util/hildebrand_sekhon.py in order to speed it up. Check out:
https://github.com/meteoswiss-mdr/pyart/blob/master/pyart/util/hildebrand_sekhon.py
The resultant code is significantly faster. You may want to add it up in Py-ART.
Greetings f... | closed | 2019-10-18T11:47:35Z | 2019-11-11T15:36:59Z | https://github.com/ARM-DOE/pyart/issues/872 | [] | meteoswiss-mdr | 3 |
wagtail/wagtail | django | 12,718 | Sass @import to @use module system migration | Part of #12717. We need to migrate our Sass code to the language’s `@use` module system, as `@import` is deprecated. `@use` is more explicit in its behavior and more featureful, but there are some aspects of how we use `@import` that will require more than a 1:1 refactoring.
See [wagtail.org#483](https://github.com/wa... | closed | 2024-12-19T13:32:03Z | 2025-02-24T15:17:12Z | https://github.com/wagtail/wagtail/issues/12718 | [
"type:Cleanup/Optimisation",
"Compatibility"
] | thibaudcolas | 7 |
wkentaro/labelme | deep-learning | 1,002 | Program shutted down after clicked ‘OK' for changing the label in Windows latest release version | Program shutted down after clicked ‘OK' for changing the label in Windows latest release version. It happend for all my Windows10 system devices.
```
Traceback (most recent call last):
File "d:\libraries\anaconda3\lib\site-packages\labelme\app.py", line 1075, in editLabel
self._update_shape_color(shape)
... | open | 2022-03-14T01:53:06Z | 2024-12-30T12:47:56Z | https://github.com/wkentaro/labelme/issues/1002 | [
"issue::bug"
] | Zaoyee | 1 |
flasgger/flasgger | api | 347 | Return list as response | Hello everyone,
in the example of https://github.com/flasgger/flasgger/blob/master/README.md#using-marshmallow-schemas it shows how to use nested to define a list as response. It returns e.g.
```
{
'cmyk': ['cian', 'magenta', 'yellow', 'black']
}
```
How can I modify it such that it returns directly a lis... | closed | 2019-11-20T09:40:29Z | 2019-12-18T08:51:17Z | https://github.com/flasgger/flasgger/issues/347 | [] | sschiessl-bcp | 2 |
babysor/MockingBird | deep-learning | 735 | Could not load symbol cublasGetSmCountTarget from cublas64_11.dll. Error code 127 | 训练时提示
Could not load symbol cublasGetSmCountTarget from cublas64_11.dll. Error code 127
但仍可以继续,这是什么情况?
| open | 2022-09-06T15:03:56Z | 2022-09-06T15:03:56Z | https://github.com/babysor/MockingBird/issues/735 | [] | kensukwok | 0 |
matplotlib/matplotlib | matplotlib | 29,319 | [Bug]: Legend with location set to ‘best’ overlaps with the title when the titles is moved down | ### Bug summary
If I adjust the y-position of a plot title to move it down, and then I add a legend with loc set to `best`, the legend overlaps with the title.
### Code for reproduction
```Python
import matplotlib.pyplot as plt
plt.close('all')
plt.plot((1,2,3), label='Just a very long legend')
plt.title('Jus... | open | 2024-12-16T08:25:31Z | 2024-12-17T10:14:19Z | https://github.com/matplotlib/matplotlib/issues/29319 | [
"Documentation: API"
] | aweinstein | 6 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,199 | [Feature Request]: Add Ascend NPU npu_fusion_attention to accelerate training | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
- a simple description of npu_fusion_attention operator
- add Ascend NPU npu_fusion_attention to accelerate training
### Proposed workflow
1. Go to add descript... | open | 2024-07-12T08:52:41Z | 2024-07-24T08:48:30Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16199 | [
"enhancement"
] | kevin19891229 | 2 |
InstaPy/InstaPy | automation | 5,789 | Bot not working at all with docker-compose | See error log below (username and password are correct):
```InstaPy Version: 0.6.10
._. ._. ._. ._. ._. ._. ._.
Workspace in use: "/code/InstaPyN"
2445kb [00:03, 754.76kb/s]
Traceback (most recent call last):
File "docker_quickstart.py", line 19, in <module>
bot = InstaPy(username=insta_username,... | closed | 2020-09-19T16:01:34Z | 2021-05-10T04:46:53Z | https://github.com/InstaPy/InstaPy/issues/5789 | [
"wontfix"
] | wsdt | 2 |
dnouri/nolearn | scikit-learn | 275 | Convolutional Autoencoder NaN | Hi! I'm trying to make a convolutional autoencoder based off of VGG-S (https://github.com/Lasagne/Recipes/blob/master/modelzoo/vgg_cnn_s.py).
For some reason, learning always converges to NaN almost immediately. I think my architecture is correct from VGG-S, so I'm not sure why this is happening.
<img width="504" alt... | closed | 2016-06-09T17:09:39Z | 2016-08-28T03:10:50Z | https://github.com/dnouri/nolearn/issues/275 | [] | sampepose | 2 |
datapane/datapane | data-visualization | 30 | Style formatted Pandas Dataframe with , | Hi ,
I am using datapane table populated with formatted pandas dataframe. The issue is out of 6 column , one column transforms to date. Rest of the 5 columns display correctly with , formatted. | closed | 2020-10-23T16:22:21Z | 2021-01-12T16:48:34Z | https://github.com/datapane/datapane/issues/30 | [
"bug"
] | kumarmisra | 2 |
StackStorm/st2 | automation | 6,215 | Inquiries with invalid schema go to blank page | ## SUMMARY
If there's any issues with the JSON schema for an inquiry, when you click on the inquiry in the UI, it sends you to a blank page
### STACKSTORM VERSION
st2 3.8.1, on Python 3.9.13
##### OS, environment, install method
Post what OS you are running this on, along with any other relevant informat... | open | 2024-06-26T06:36:47Z | 2024-06-26T11:03:13Z | https://github.com/StackStorm/st2/issues/6215 | [] | lexiismadd | 1 |
scikit-learn-contrib/metric-learn | scikit-learn | 222 | Deprecate use_pca for lmnn | There is still a `use_pca` attribute for LMNN, that needs to be deprecated | closed | 2019-06-17T07:15:10Z | 2019-07-04T06:48:28Z | https://github.com/scikit-learn-contrib/metric-learn/issues/222 | [] | wdevazelhes | 0 |
proplot-dev/proplot | data-visualization | 137 | Would you add the "readshapefile" method in proplot? | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
[Description of the bug or feature.]
### Steps to reprodu... | closed | 2020-04-07T04:14:20Z | 2020-04-22T23:15:45Z | https://github.com/proplot-dev/proplot/issues/137 | [
"feature"
] | sfhua | 2 |
JaidedAI/EasyOCR | pytorch | 386 | build failed on AArch64, Fedora 33 | [jw@cn05 easyocr]$ sudo python3 setup.py install --verbose
running install
running bdist_egg
running egg_info
writing easyocr.egg-info/PKG-INFO
writing dependency_links to easyocr.egg-info/dependency_links.txt
writing entry points to easyocr.egg-info/entry_points.txt
writing requirements to easyocr.egg-info/requ... | closed | 2021-03-03T10:52:30Z | 2021-06-22T10:34:25Z | https://github.com/JaidedAI/EasyOCR/issues/386 | [] | LutzWeischerFujitsu | 1 |
matplotlib/matplotlib | data-visualization | 29,534 | [Bug]: missing graph | ### Bug summary
Good day, I'm having issues with my graphs showing after running my command, I only get axis but no graph

### Code for reproduction
```Python
Gby_plt.plot()
```
### Actual outcome
 based on the current request. This is different from #3274 where we allow people to customise fields at schema build time.
... | open | 2024-01-16T11:36:50Z | 2025-03-20T15:56:34Z | https://github.com/strawberry-graphql/strawberry/issues/3343 | [
"feature-request"
] | patrick91 | 0 |
ultralytics/ultralytics | computer-vision | 18,896 | Excuse me, how can I solve the problem that the confidence level is only 0.1 after switching to the ONNX model? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug

### Envir... | open | 2025-01-26T07:53:15Z | 2025-01-26T13:48:03Z | https://github.com/ultralytics/ultralytics/issues/18896 | [
"exports"
] | CanhaoL | 2 |
fastapi/fastapi | pydantic | 12,290 | Chrome does not display Swagger UI | ### Privileged issue
- [X] I'm @tiangolo or he asked me directly to create an issue here.
### Issue Content

Chrome does not display Swagger UI, but Edge can.
Is this a bug?
| closed | 2024-09-28T13:51:40Z | 2024-09-28T13:55:37Z | https://github.com/fastapi/fastapi/issues/12290 | [] | soevai | 0 |
tfranzel/drf-spectacular | rest-api | 1,271 | How is it possible to close all groups at Swagger's opening? | Maybe it's a silly question, but how can I inform DRF-Spectacular to make all groups closed when opening Swagger? It seems that every time I request Swagger, it opens all groups, and since I have a lot of APIs, navigation becomes a real disaster. Is there any setting?
Thanks for your great module. Best regards. | closed | 2024-08-05T20:32:28Z | 2024-08-09T20:43:31Z | https://github.com/tfranzel/drf-spectacular/issues/1271 | [] | amirhoseinbidar | 2 |
sgl-project/sglang | pytorch | 3,719 | [Bug] v0.4.3 performance degradation 2x8xH100 | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [ ] 2. The bug has not been fixed in the latest version.
- [ ] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | open | 2025-02-20T03:48:02Z | 2025-02-20T05:04:39Z | https://github.com/sgl-project/sglang/issues/3719 | [] | Hugh-yw | 2 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,074 | [Bug]: 283 settings changed after click to save | ### Checklist
- [X] The issue exists after disabling all extensions
- [x] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported ... | closed | 2024-06-23T02:10:13Z | 2024-06-24T08:36:29Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16074 | [
"asking-for-help-with-local-system-issues"
] | HenryEvan | 5 |
miguelgrinberg/Flask-SocketIO | flask | 990 | Getting 404 error when using gunicorn/eventlet in prod | Hi, I've spent several hours looking online and reading through the issues posted but have not found a solution.
This totally works on dev without gunicorn and eventlet
websocket request return the following error:
~~~~
{
"error": "404 Not Found: The requested URL was not found on the server. If you entered ... | closed | 2019-05-31T02:26:32Z | 2019-05-31T15:00:51Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/990 | [
"question"
] | jcuna | 6 |
opengeos/leafmap | plotly | 661 | NAIP STAC Item added to map as layer disappears on zoom out, needs a very close zoom level to appear. | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- leafmap version: 0.30.1
- Python version: 3.10
- Operating System: Ubuntu
### Description
I want to zoom out and see my image on the map. But it disappears at far away zoom levels. Also the default zoo... | closed | 2024-01-16T22:29:36Z | 2024-02-06T15:32:44Z | https://github.com/opengeos/leafmap/issues/661 | [
"bug"
] | rbavery | 1 |
miguelgrinberg/python-socketio | asyncio | 554 | Update connect_error documentation | Hello,
I would like to suggest you mention in the documentation that the `connect_error` handler can get arguments. Now, it is only shown not getting arguments, [here](https://python-socketio.readthedocs.io/en/latest/client.html?highlight=connect_error#defining-event-handlers).
As you stated in issue [#508](https:... | closed | 2020-10-13T10:53:03Z | 2021-05-04T22:09:46Z | https://github.com/miguelgrinberg/python-socketio/issues/554 | [
"documentation"
] | turicfr | 1 |
lexiforest/curl_cffi | web-scraping | 17 | Bug: Request header is 'application/x-www-form-urlencoded' but use json as request body | Request header is 'application/x-www-form-urlencoded' but use json as request body when requests.post have both json and data parameter,
here are code
```python
requests.post("https://httpbin.org/post", data={"data": 1}, json={"json": 1}).json()
```
here are output
```json
{'args': {},
'data': '',
'files... | closed | 2023-03-03T13:13:08Z | 2023-09-29T12:25:30Z | https://github.com/lexiforest/curl_cffi/issues/17 | [] | MagicalBomb | 3 |
gevent/gevent | asyncio | 1,419 | ImportError: cannot import name _corecffi | I installed gevent using `pip install gevent` and have the latest version 1.4.0. I would like to compare the speed between all event loops but don't manage to use libuv. Is there a specific installation to do ?
```
>>> import gevent
>>> gevent.config.loop = 'libuv'
Traceback (most recent call last):
File "<stdin... | closed | 2019-05-04T15:50:43Z | 2019-05-04T16:27:03Z | https://github.com/gevent/gevent/issues/1419 | [] | maingoh | 2 |
nolar/kopf | asyncio | 227 | [PR] Switch to `aiohttp` and full asynchronous I/O in the core | > <a href="https://github.com/nolar"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> A pull request by [nolar](https://github.com/nolar) at _2019-11-13 10:31:58+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/pull/227
> Merged by [nolar](https://githu... | closed | 2020-08-18T20:01:14Z | 2020-08-23T20:51:34Z | https://github.com/nolar/kopf/issues/227 | [
"enhancement",
"archive",
"refactoring"
] | kopf-archiver[bot] | 0 |
shaikhsajid1111/social-media-profile-scrapers | web-scraping | 10 | The pinterest scraper doesn't work. | it returns:
'country'
None
| open | 2022-07-06T10:57:07Z | 2022-07-06T17:07:16Z | https://github.com/shaikhsajid1111/social-media-profile-scrapers/issues/10 | [] | meatloaf4u | 2 |
reloadware/reloadium | pandas | 52 | Plugin 0.8.6 (with Relodium 0.9.3) breaks with PyCharm 2022.2.3 | **Describe the bug**
Relodium breaks.
I had relodium installed and upgraded both PyCharm and Relodium versions.
After the upgrade, the plugin fails when running. Because code is obfuscated I cannot see where it breaks, but I attached the log console.
**Screenshots**
 - Beanie and FastAPI collaboration demonstration. CRUD and Aggregation.
- [Indexes Demo](https://github.com/roman-right/beanie-index-demo) - Regular and Geo Indexes usage example wrapped to a microservice.
B... | closed | 2021-07-10T20:13:54Z | 2023-04-16T02:26:00Z | https://github.com/BeanieODM/beanie/issues/90 | [
"good first issue",
"Stale"
] | roman-right | 3 |
allenai/allennlp | data-science | 5,043 | bug | <!--
Please fill this template entirely and do not erase any of it.
We reserve the right to close without a response bug reports which are incomplete.
If you have a question rather than a bug, please ask on [Stack Overflow](https://stackoverflow.com/questions/tagged/allennlp) rather than posting an issue here.
--... | closed | 2021-03-07T20:55:37Z | 2021-03-08T19:06:41Z | https://github.com/allenai/allennlp/issues/5043 | [
"bug"
] | apsiriwat | 0 |
ghtmtt/DataPlotly | plotly | 244 | Overlay two graphics on atlas | **Describe the bug**
I am trying to overlay two graphics in the atlas.
I think that should be done from element properties by adding two graphics (screenshot 1).
I have an atlas with 100 points. I am interested in representing in the same graphic the 100 points and in another color (superimposing) the point t... | closed | 2020-12-19T12:30:27Z | 2021-03-18T07:24:32Z | https://github.com/ghtmtt/DataPlotly/issues/244 | [
"bug"
] | cesarcorreo | 12 |
KaiyangZhou/deep-person-reid | computer-vision | 25 | How to set the parameters of xent+htri that use the densenet-121 | Thanks for provide the elegant code;
When I train the densenet 121 with xent+htri loss, I set 80 epoch ;
I train it for three times ,but got not good result:
batch size = 32,epoch = 80 :rank1 = 60.6%
batch size = 16,epoch = 80 :rank1 = 61.2%
batch size = 48,epoch = 60 :rank1 = 58.4%
I don't know why the re... | closed | 2018-06-13T09:56:53Z | 2018-06-21T22:27:33Z | https://github.com/KaiyangZhou/deep-person-reid/issues/25 | [] | jianwu585218 | 4 |
ycd/manage-fastapi | fastapi | 147 | Is this repo still maintained? | Hey @ycd , @Kludex 👋🏻
I was curious about what your plans are with this repo. It looks like the maintenance stopped a year ago and there are [some important issues ](https://github.com/ycd/manage-fastapi/issues/146)that makes the tool practically unusable, and multiple PRs waiting open for a while.
If you don'... | open | 2024-10-24T14:28:19Z | 2024-10-24T14:28:19Z | https://github.com/ycd/manage-fastapi/issues/147 | [] | ulgens | 0 |
jschneier/django-storages | django | 963 | mistake | sorry, mistake to open. Please delete... | closed | 2020-12-11T08:28:05Z | 2020-12-11T08:52:29Z | https://github.com/jschneier/django-storages/issues/963 | [] | sakimyto | 0 |
python-gino/gino | asyncio | 636 | Query Filters, Pagination and Sorting | * GINO version: 0.8.6
* Python version: 3.7.0
* asyncpg version: 0.20.1
* aiocontextvars version: 0.2.2
* PostgreSQL version: 11
### Description
I'm trying to find solution in **Gino** for **filtering**, **pagination**, and **sorting**. Like this one which is for **SQL Alchemy**:
[sqlalchemy-filters](https:/... | closed | 2020-03-10T15:15:23Z | 2020-09-07T21:08:06Z | https://github.com/python-gino/gino/issues/636 | [
"question"
] | Psykepro | 8 |
predict-idlab/plotly-resampler | plotly | 274 | Python 3.12 support | closed | 2023-11-22T18:29:44Z | 2024-02-05T15:30:35Z | https://github.com/predict-idlab/plotly-resampler/issues/274 | [
"enhancement",
"installation"
] | jvdd | 4 | |
huggingface/transformers | tensorflow | 36,561 | Improving expected test results | Several tests use the concept of "expected" results.
Sometimes the expected results are dependant on the environment.
We've used `torch.cuda.get_device_capability()` to differentiate between different cuda environments, and this has worked fairly well so far.
I recently started adding expected results for AMD devices ... | open | 2025-03-05T13:34:16Z | 2025-03-05T13:34:16Z | https://github.com/huggingface/transformers/issues/36561 | [] | ivarflakstad | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 764 | Training Time | Hi,
I have been training pix2pix with unet256 as generator. My training data is 10000 images of 256*256 resolution.
Each epoch is taking around 25000 seconds (7.25 hrs)
I am running experiments on two 1080 Ti cards with batch size 32
May I know if it is usually the case?
Thanks for any help,
| closed | 2019-09-11T05:36:50Z | 2024-05-25T12:17:03Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/764 | [] | jsaisagar | 3 |
miguelgrinberg/flasky | flask | 82 | Errata: if current_user.is_authenticated() | `Tag: 12a`
In the book the `if current_user.is_authenticated()` field in template `user.html` contains parentheses.
The correct thing without the parenthesis.
Cause the error:

The code on GitHub is correct... | closed | 2015-10-14T18:59:21Z | 2017-03-17T18:54:27Z | https://github.com/miguelgrinberg/flasky/issues/82 | [] | ghost | 4 |
deepinsight/insightface | pytorch | 2,073 | [Inference using model trained on mnet25 backbone] Operands cannot be broadcasted together | insightface->detection->retinaface->retinaface.py (line 464)
bbox_pred (line 761)
Dimension issue

| open | 2022-08-10T12:24:50Z | 2022-08-10T12:24:50Z | https://github.com/deepinsight/insightface/issues/2073 | [] | iqraJilani | 0 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,378 | [Feature Request]: Please add support for the FLUX model, thank you! | ### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What would your feature do ?
The FLUX model's hand processing and prompt accuracy are incredibly powerful, and it's been super popular recently!
### Proposed workflow
1. thank you!
2. thank... | open | 2024-08-13T08:33:37Z | 2024-12-06T01:08:19Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16378 | [
"enhancement"
] | divineblessing | 14 |
syrupy-project/syrupy | pytest | 333 | Incorrect unused snapshot detection for targeting single case in parameterized test | **To Reproduce**
- Create a parameterized test case, for example test_dict in tests/test_extension_amber.py.
- Run pytest targeting one case: `pytest tests/test_extension_amber.py::test_dict[actual4]`
Syrupy says 1 snapshot passed, and the rest are unused.
**Expected behavior**
One snapshot should pass. No... | closed | 2020-08-24T20:52:29Z | 2020-10-30T02:58:21Z | https://github.com/syrupy-project/syrupy/issues/333 | [
"bug",
"released"
] | noahnu | 1 |
ufoym/deepo | jupyter | 133 | theano gpu not working | Hi,
I've followed instructions of how to run theano gpu using the deepo; unfortuantely i'm not able to run the theano code with gpu. it uses the cpu instead
steps that I took
`docker run --gpus all -it ufoym/deepo:theano bash`
and I'm running the following test code (from theano documentations)
```
# Code ... | closed | 2020-05-05T19:42:47Z | 2021-12-27T14:58:36Z | https://github.com/ufoym/deepo/issues/133 | [] | sedghi | 1 |
pyg-team/pytorch_geometric | pytorch | 9,530 | None edge_attr assertion in GeneralConv | ### 🐛 Describe the bug
The `GeneralConv` layer is raising an assertion when only a node array (`x`) and adjacency (`edge_index`) are provided. I expect the layer to return a result when I don't provide `edge_attr` (default is None).
Context: I'm writing unit tests for a model that is composed of many layers. I've... | open | 2024-07-22T15:53:49Z | 2024-08-19T14:56:46Z | https://github.com/pyg-team/pytorch_geometric/issues/9530 | [
"bug"
] | bgeier | 2 |
frappe/frappe | rest-api | 31,183 | Add a Bidirectional Link FieldType for automatic Two-Way Relationships Between DocTypes | **Is your feature request related to a problem? Please describe.**
Right now, there’s no easy way to create a two-way link between DocTypes in Frappe. For example, let’s say I have a `Job` DocType and a `Task` DocType:
- In the `Job` form, I have a `child_tasks` field where I can select multiple tasks.
- In the... | open | 2025-02-07T13:52:50Z | 2025-02-13T07:12:02Z | https://github.com/frappe/frappe/issues/31183 | [
"feature-request"
] | Waishnav | 1 |
jonaswinkler/paperless-ng | django | 381 | Mail consumer - "It is not a file" | Couldn't seem to see this on another bug.
Just set up the imap consumer to pull from a folder. Action to move it to another one. Processing attachments only, and using the attachment filename as the document title.
The following appears in the logs for all the files. These files consume fine when uploading the pd... | closed | 2021-01-18T16:52:00Z | 2021-01-22T11:15:16Z | https://github.com/jonaswinkler/paperless-ng/issues/381 | [
"bug"
] | rknightion | 10 |
flaskbb/flaskbb | flask | 163 | Ask for confirmation before deleting things? | I love how it asks "Are you sure?" before letting you unban a banned user but will cheerfully blow away a category and all forums below it with a single click.
Would you like me to have a bit of a poke at the admin section and add some "Are you sure?" dialogues?
| closed | 2015-12-30T03:28:05Z | 2018-04-15T07:47:37Z | https://github.com/flaskbb/flaskbb/issues/163 | [] | gordonjcp | 1 |
google-research/bert | tensorflow | 858 | when using c++ to do inference, tensorflow::session->Run error | open | 2019-09-18T08:26:54Z | 2019-12-01T13:26:01Z | https://github.com/google-research/bert/issues/858 | [] | Jiayuforfreeo | 0 | |
plotly/plotly.py | plotly | 4,507 | go.Scatter3d doesn't display a given tensor | # Issue
While plotting an np.ndarray of type fp64, it is not displayed.
It is so funny that we could reproduce it only for one specific array.
Thigs that make the script work:
- If we add epsilon (as in the commented line), then the pointcloud is displayed properly.
- If we cast to fp32 it works.
- If we add ... | open | 2024-02-06T16:07:02Z | 2024-08-13T13:08:34Z | https://github.com/plotly/plotly.py/issues/4507 | [
"bug",
"sev-2",
"P3"
] | JuanFMontesinos | 3 |
chainer/chainer | numpy | 7,797 | Release Tasks for v7.0.0b3 / v6.3.0 | This is an issue to track-down release-blocker tasks.
- [x] #7741 NumPy 1.17 support
- [x] Python 2 drop
- [x] chainer #7826
- [x] cupy https://github.com/cupy/cupy/pull/2343
- [x] blog https://github.com/chainer/chainer.org/pull/110
Merge after release:
- ~Separate parameter combinations betwe... | closed | 2019-07-23T11:14:21Z | 2019-10-01T07:21:06Z | https://github.com/chainer/chainer/issues/7797 | [
"release-blocker",
"prio:high"
] | kmaehashi | 0 |
xinntao/Real-ESRGAN | pytorch | 169 | Unexpected key(s) in state_dict error | 我按照Training.md.教學訓練了RealESRGANmodel
將python inference_realesrgan.py --model_path experiments/pretrained_models/RealESRGAN_x4plus.pth --input inputs --face_enhance
換成訓練的model
得到了這個錯誤
| closed | 2021-11-29T20:30:04Z | 2021-11-29T20:35:08Z | https://github.com/xinntao/Real-ESRGAN/issues/169 | [] | 610821216 | 0 |
mwaskom/seaborn | data-science | 3,373 | Standard seaborn.objects printouts are inaccessible in some ways on Macs | Alright, this one involves like four different pieces of software to isolate. But I *think* the issue here is in **seaborn** rather than one of those other places. Here's the issue:
1. I have a Jupyter notebook containing two **seaborn.objects** graphs. The first one is printed using **matplotlib** (`fig = plt.figur... | closed | 2023-05-25T22:46:46Z | 2023-05-26T16:49:43Z | https://github.com/mwaskom/seaborn/issues/3373 | [] | NickCH-K | 2 |
slackapi/bolt-python | fastapi | 327 | Custom Select Menu-- Payload Too Big | I'm using a custom select menu in socket mode, like this: https://slack.dev/bolt-python/concepts#options and am getting the error:
```
slack_sdk/socket_mode/builtin/internals.py", line 411, in _build_data_frame_for_sending
header += struct.pack("!BH", b2, payload_length)
struct.error: 'H' format requires 0 <=... | closed | 2021-05-07T21:32:17Z | 2021-05-10T16:31:40Z | https://github.com/slackapi/bolt-python/issues/327 | [
"question"
] | mariebarrramsey | 5 |
explosion/spaCy | nlp | 12,566 | CLI benchmark accuracy doesn't save rendered displacy htmls | The accuracy benchmark of my model does not save rendered displacy htmls as requested. Benchmark works that's why I'm confused. The model contains only **transformers** and **spancat** components. Does **spancat** is not yet supported? 😞
DocBin does not contain any empty docs
CLI output:
```powershell
$ pyth... | closed | 2023-04-23T21:40:47Z | 2023-05-29T00:02:17Z | https://github.com/explosion/spaCy/issues/12566 | [
"bug",
"feat / cli",
"feat / spancat"
] | jamnicki | 3 |
activeloopai/deeplake | computer-vision | 2,848 | [BUG] I cannot create an empty dataset on custom s3 location due to signed header | ### Severity
P0 - Critical breaking issue or missing functionality
### Current Behavior
Trying to create an empty dataset using the s3 provider with a custom endpoint I fail with following error
`
Traceback (most recent call last):
File "... | closed | 2024-05-08T14:24:41Z | 2024-05-10T15:13:03Z | https://github.com/activeloopai/deeplake/issues/2848 | [
"bug"
] | hoshimura | 5 |
pydata/xarray | numpy | 10,157 | Selecting point closest to (lon0, lat0) when lon,lat coordinates are 2D | It's very common to want to extract a time series at a specified coordinate location, and I'm wondering whether xarray could support this directly without using xoak. Currently I'm using xoak, as in this reproducible example:
``` python
import xarray as xr
import intake
import xoak
intake_catalog_url = 'https://usgs... | open | 2025-03-20T15:42:46Z | 2025-03-21T10:14:00Z | https://github.com/pydata/xarray/issues/10157 | [
"enhancement"
] | rsignell | 5 |
ploomber/ploomber | jupyter | 805 | add did you mean feature to `ploomber examples` | We should add the "did you mean?" feature when executing `ploomber examples`
```sh
ploomber examples -n cookbook/fileclient -o fileclient
```
```txt
There is no example named "cookbook/fileclient", did you mean "cookbook/file-client"?
```
for reference: We already have this built-in in other places http... | closed | 2022-05-22T04:44:22Z | 2022-07-19T18:08:47Z | https://github.com/ploomber/ploomber/issues/805 | [] | edublancas | 1 |
jackmpcollins/magentic | pydantic | 38 | Proposal: Custom base url/parameters environment variables for AI gateways | Would be neat to support environment variables for base url and necessary key/value parameters to support AI gateways, like Cloudflare's offering!
> ### AI Gateway
> [Cloudflare AI Gateway Documentation](https://developers.cloudflare.com/ai-gateway/)
> Cloudflare’s AI Gateway allows you to gain visibility and cont... | closed | 2023-10-04T14:46:05Z | 2024-03-04T01:03:12Z | https://github.com/jackmpcollins/magentic/issues/38 | [] | peteallport | 3 |
hankcs/HanLP | nlp | 1,236 | 执行from pyhanlp import * 报错”A fatal error has been detected by the Java Runtime Environment:“ | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-07-09T12:47:07Z | 2020-01-01T10:49:17Z | https://github.com/hankcs/HanLP/issues/1236 | [
"ignored"
] | ferrior30 | 3 |
AntonOsika/gpt-engineer | python | 462 | Statistics: collection of learnings did not work as intended | this line is expecting 1 arguments, might need to specify the `open_ssl` version
https://github.com/AntonOsika/gpt-engineer/blob/main/gpt_engineer/collect.py#L39
## Expected Behavior
Collection of data should have been submitted
## Current Behavior
What is the current behavior?
To help gpt-engineer learn,... | closed | 2023-07-01T15:39:58Z | 2023-07-02T15:37:37Z | https://github.com/AntonOsika/gpt-engineer/issues/462 | [] | eleijonmarck | 2 |
huggingface/datasets | deep-learning | 6,851 | load_dataset('emotion') UnicodeDecodeError | ### Describe the bug
**emotions = load_dataset('emotion')**
_UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8b in position 1: invalid start byte_
### Steps to reproduce the bug
load_dataset('emotion')
### Expected behavior
succese
### Environment info
py3.10
transformers 4.41.0.dev0
datasets 2.... | open | 2024-04-30T09:25:01Z | 2024-09-05T03:11:04Z | https://github.com/huggingface/datasets/issues/6851 | [] | L-Block-C | 2 |
ExpDev07/coronavirus-tracker-api | rest-api | 488 | Coronavirus data missing for Finland | Having downloaded the data from the beginning of the pandemic, I have notices in the last 10 days or so than Finland data are zero. No data from the 15th January to present day. (15-16 January would normally be zero as it is a weekend)
just thought I would point it out.
KEEP UP THE GOOD WORK AND THANKS. | closed | 2022-01-26T09:58:39Z | 2023-09-10T11:24:33Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/488 | [] | PRRH | 1 |
Farama-Foundation/PettingZoo | api | 1,262 | [Proposal] Flexibility with _was_dead_step | ### Proposal
Hello,
I propose to modify how AECEnv (and possibly ParrallelEnv, but I have not worked with it so I'm not sure how its handled there) handles dropping out of agents.
I've been working with the current method (_was_dead_step) for the past couple of weeks and perhaps I think I understand its purpose and ... | open | 2025-02-10T23:36:08Z | 2025-02-10T23:36:08Z | https://github.com/Farama-Foundation/PettingZoo/issues/1262 | [
"enhancement"
] | AlexAdrian-Hamazaki | 0 |
tensorflow/datasets | numpy | 5,448 | etils.epy.lazy_imports not found | When running the import of version 4.9.5,
it complains that etils.epy.lazy_imports() is not found.
My version of etils is 1.7.0.
(etils==1.9.0 would require Python 3.11 and I still have Python 3.10.)
Importing version 4.9.4 works fine --- I notice it is also the current default in Colab.
| closed | 2024-06-04T00:51:52Z | 2024-06-04T16:15:50Z | https://github.com/tensorflow/datasets/issues/5448 | [
"bug"
] | hhoppe | 5 |
DistrictDataLabs/yellowbrick | matplotlib | 1,065 | issue in installation in ubuntu | **try:
import deepmatcher
except:
!pip install -qqq deepmatcher
While running the above code in python 3.6 i am getting the error mention below
File "/home/vikrant/anaconda2/lib/python2.7/site-packages/deepmatcher/data/field.py", line 163
def build_vocab(self, *args, **vectors=None**, cache=None, **kwargs... | closed | 2020-05-13T15:25:16Z | 2020-05-13T15:49:27Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1065 | [
"invalid"
] | parulmishra19 | 1 |
mitmproxy/pdoc | api | 127 | After installing pdoc with pip it not recognised as an executable on Windows | Tried navigating to \Scripts, same result. | closed | 2017-04-14T07:26:29Z | 2021-02-26T00:02:35Z | https://github.com/mitmproxy/pdoc/issues/127 | [] | epogrebnyak | 16 |
ranaroussi/yfinance | pandas | 1,425 | _get_decryption_keys_from_yahoo_js(soup) got yfinance failed to decrypt Yahoo data response error | # IMPORTANT
Confirm by running:
tf version : 0.2.12
python version : 3.9.7
using ticker: "AAPL"
Thank you update quickely 0.2.11 -> 0.2.12
but i found error " " in scraper.py
tk = TickerData("AAPL")
tk._get_decryption_keys_from_yahoo_js(soup)
```python
from yfinance.data import decrypt_cryptojs_a... | closed | 2023-02-17T01:47:32Z | 2023-02-18T11:38:58Z | https://github.com/ranaroussi/yfinance/issues/1425 | [] | seohyunjun | 2 |
pyg-team/pytorch_geometric | pytorch | 9,520 | Take too long to install PyG on Colab | ### 😵 Describe the installation problem
I used to install the required packages on Colab to run PyG using the following codes within 2 minutes.
```
import torch
def format_pytorch_version(version):
return version.split('+')[0]
TORCH_version = torch.__version__
TORCH = format_pytorch_version(TORCH_vers... | open | 2024-07-19T03:41:35Z | 2024-09-19T15:48:02Z | https://github.com/pyg-team/pytorch_geometric/issues/9520 | [
"installation"
] | xubingze | 4 |
InstaPy/InstaPy | automation | 6,657 | Login XPaths are broken | ## Expected Behavior
Can login and execute program
## Current Behavior
Cannot login and program fails. Console logs:
```
InstaPy Version: 0.6.16
._. ._. ._. ._. ._. ._. ._. ._. ._.
Workspace in use: "C:/Users/admin/InstaPy"
OOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
INFO [2022-11-30 11... | open | 2022-11-30T16:41:17Z | 2023-03-11T16:23:10Z | https://github.com/InstaPy/InstaPy/issues/6657 | [] | thEpisode | 4 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,650 | [Bug]: Error when loading v-pred model on dev branch | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [X] The issue has not been reported ... | closed | 2024-11-13T01:22:58Z | 2024-11-19T07:00:06Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16650 | [
"bug",
"upstream"
] | quicks1lver42 | 5 |
scikit-hep/awkward | numpy | 2,936 | Test against NumPy 2.0 | Ruff has tools for this, and there are NumPy 2.0 prereleases (or there will be soon). | closed | 2024-01-11T16:28:10Z | 2024-04-01T18:18:40Z | https://github.com/scikit-hep/awkward/issues/2936 | [] | jpivarski | 8 |
lundberg/respx | pytest | 36 | Fixture / global level mocking | Is it possible to do the respx setup in a fixture so that it can be used by all test functions instead of one setup per function?
Thanks and excellent work on this. | closed | 2019-12-30T23:42:46Z | 2020-01-27T09:09:14Z | https://github.com/lundberg/respx/issues/36 | [
"documentation"
] | dave-brennan | 3 |
minimaxir/textgenrnn | tensorflow | 230 | why train_from_file generate text ? | look at the name | closed | 2021-05-18T16:32:47Z | 2021-05-24T16:16:12Z | https://github.com/minimaxir/textgenrnn/issues/230 | [] | SomeMinecraftModder | 0 |
jupyter/nbgrader | jupyter | 961 | Document how to set up nbgrader for multiple graders when running without JupyterHub | There is already documentation on how to use nbgrader with [multiple graders with JupyterHub](http://nbgrader.readthedocs.io/en/master/configuration/jupyterhub_config.html#example-use-case-one-class-multiple-graders), but not when *not* using JupyterHub.
Briefly, the answer is that you still need access to a shared ... | open | 2018-05-09T20:34:30Z | 2022-12-02T14:20:19Z | https://github.com/jupyter/nbgrader/issues/961 | [
"documentation"
] | jhamrick | 1 |
Farama-Foundation/PettingZoo | api | 1,181 | [Bug Report] AgileRL tutorials broken | ### Describe the bug
AgileRL updated to version 0.1.20 a couple days ago. The changes break the example tutorials in PettingZoo
for example: `python agilerl_maddpg.py`
gives
```
Traceback (most recent call last):
File "/opt/home/code/PettingZoo/tutorials/AgileRL/agilerl_maddpg.py", line 86, in <module>
... | closed | 2024-02-11T22:44:09Z | 2024-03-13T18:35:22Z | https://github.com/Farama-Foundation/PettingZoo/issues/1181 | [
"bug"
] | dm-ackerman | 1 |
aeon-toolkit/aeon | scikit-learn | 2,211 | [BUG] RandomIntervalClassifier and SupervisedIntervalClassifier do not set n_jobs in contained scikit learn estimator | ### Describe the bug
found when writing tests. These classifiers set the contained estimators n_jobs as follows
```python
self._estimator = _clone_estimator(
(
RandomForestClassifier(n_estimators=200)
if self.estimator is None
else self.estima... | closed | 2024-10-16T10:27:15Z | 2024-10-18T13:18:36Z | https://github.com/aeon-toolkit/aeon/issues/2211 | [
"bug",
"classification"
] | TonyBagnall | 2 |
hpcaitech/ColossalAI | deep-learning | 5,359 | [DOC]: Fix typo for 1D 张量并行 | ### 📚 The doc issue
The sentence "这就是所谓的行并行方式" should be placed on a new line:

In the English documentation, the layout is correct:
 for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Issue is only in MS Edge Browser:
When pressin... | open | 2025-02-26T08:43:56Z | 2025-03-03T11:49:27Z | https://github.com/streamlit/streamlit/issues/10521 | [
"type:bug",
"feature:st.dataframe",
"status:confirmed",
"priority:P3",
"feature:st.download_button",
"feature:st.data_editor"
] | LazerLars | 2 |
axnsan12/drf-yasg | rest-api | 299 | Support nested coreschema in CoreAPI compat layer | ```python
class MyFilterBackend(BaseFilterBackend):
def get_schema_fields(self, view):
return [coreapi.Field(
name="values"
required=False,
schema=coreschema.Array(items=coreschema.Integer(), unique_items=True),
location='query'
)]
```
Result:
![2019-01-22... | open | 2019-01-22T08:18:42Z | 2025-03-07T12:16:45Z | https://github.com/axnsan12/drf-yasg/issues/299 | [
"triage"
] | khomyakov42 | 1 |
AntonOsika/gpt-engineer | python | 594 | Issue with tiktoken ''Could not automatically map gpt-4 to a tokeniser. Please use `tiktok.get_encoding` to explicitly get the tokeniser you expect.'' | I have tried using both the dev and production versions and get the same error. I have followed the windows guide for setting ENV variables and installed all dependencies. I am on Windows 10 and python 3.11. Full version of the error:
... | open | 2024-12-23T14:55:54Z | 2024-12-23T15:24:32Z | https://github.com/widgetti/solara/issues/950 | [] | Ben-Epstein | 3 |
microsoft/unilm | nlp | 1,106 | VALL-E demo page missing/404 | VALL-E demo page is missing/404.
It was initially working.
Plz can you fix?
https://valle-demo.github.io/ | closed | 2023-05-27T05:46:01Z | 2023-06-14T11:51:15Z | https://github.com/microsoft/unilm/issues/1106 | [] | rickkadamss | 0 |
TheKevJames/coveralls-python | pytest | 232 | Python coverage not reported to https://coveralls.io/ | I'm running:
```bash
coverage run --source=. -m pytest cvise/tests/
coverage report -m
COVERALLS_REPO_TOKEN=xyz coveralls -n
```
where I see:
```
============================= test session starts ==============================
platform linux -- Python 3.8.3, pytest-5.4.3, py-1.9.0, pluggy-0.13.1
rootdir: ... | closed | 2020-07-23T08:12:02Z | 2020-07-25T00:29:54Z | https://github.com/TheKevJames/coveralls-python/issues/232 | [] | marxin | 4 |
microsoft/hummingbird | scikit-learn | 237 | Random forest in LightGBM | I want to clarify, now hummingbird is no support random forest in LightGBM? Is it planned?
When I convert from lgbm to onnx this model, I get an error
lgb.LGBMClassifier(boosting_type='rf', n_estimators = 128, max_depth = 5, subsample = 0.3, bagging_freq = 1)
File "/venv/lib/python3.6/site-packages/hummingbird/m... | open | 2020-08-17T13:25:46Z | 2020-11-11T01:51:43Z | https://github.com/microsoft/hummingbird/issues/237 | [
"bug"
] | arfangeta | 12 |
dmlc/gluon-cv | computer-vision | 835 | transfer learning for classification | Hello @zhreshold,
As you told me in this issue: #746 to do the fine tuning of 'resnet50_v1b' I should replace the 'finetune_net.output' with 'finetune_net.fc' and it works. But for some classifiers I need to use 'finetune_net.output', so can you explain what's the difference between the 'output' and 'fc' and why some... | closed | 2019-06-25T07:33:56Z | 2019-07-02T08:02:52Z | https://github.com/dmlc/gluon-cv/issues/835 | [] | FAFACHR | 8 |
yihong0618/running_page | data-visualization | 121 | 功能建议:加入月度统计数据展示 | yihong 您好,
刚刚在看 @geekplux 的 running page 的时候发现 geekplus 在首页中加入了月统计柱状图,主要显示了 跑步,徒步,骑行的月度统计数据。
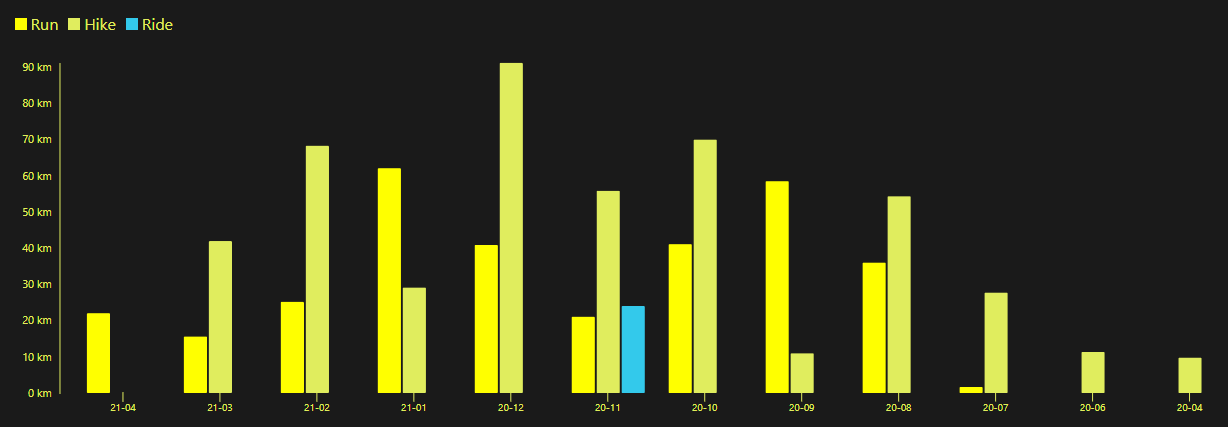
私以为相比于年度和每日统计数据来说,**月度统计能够在一个更加折中的频率上展示统计数据,也丰富了展示效果**。
所以就依照 geekplus 本人的仓库尝试将此柱状图进行迁移,但是由于我并不曾深入研究学习过... | closed | 2021-04-17T10:47:51Z | 2021-04-19T08:56:27Z | https://github.com/yihong0618/running_page/issues/121 | [] | MFYDev | 3 |
flasgger/flasgger | rest-api | 586 | Async/await in Flask 2.0+ breaks due to decorator order | | Name | Version |
|--|--|
| Flasgger | 0.9.7.1 |
| Flask | 2.3.2 |
| Python | 3.9, 3.10 |
| OS | macOS 13.3 |
I'm setting up a basic Flask project with an asynchronous route. I want to fetch information online using the `selenium` package, and this requires the Flask route to await for the task to finish.
... | open | 2023-06-30T14:00:46Z | 2024-12-02T19:16:39Z | https://github.com/flasgger/flasgger/issues/586 | [] | phil-chp | 2 |
mckinsey/vizro | plotly | 630 | [Docs] Py.Cafe code snippets to-do list | Here's an issue (public, so we can ask for contributions to it from our readers) to record the bits and pieces left to do on following the [introduction of py.cafe to our docs' examples](https://github.com/mckinsey/vizro/pull/569).
- [ ] Change the requirement in `hatch.toml` when py.cafe release their mkdocs plugin... | open | 2024-08-15T08:46:02Z | 2025-01-14T09:40:02Z | https://github.com/mckinsey/vizro/issues/630 | [
"Docs :spiral_notepad:"
] | stichbury | 1 |
ivy-llc/ivy | pytorch | 28,517 | Fix Frontend Failing Test: torch - math.paddle.heaviside | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-03-09T14:58:00Z | 2024-03-14T21:29:22Z | https://github.com/ivy-llc/ivy/issues/28517 | [
"Sub Task"
] | ZJay07 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.