
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Nemo2011/bilibili-api | api | 241 | 【提问】关于comment模块无法爬取所有评论 | **Python 版本:** 3.8
**模块版本:** 15.3.1
**运行环境:** Windows
---
依照文档里的范例直接爬取,试过不同视频都只显示总评论在200多条左右,实际评论都超过这个数量。
而且爬取下来的也只有部分评论,请问是接口那边更新了导致失效吗

 blocks | Hello! I am new to tensorflow and when I run your model TextCNN, I get a issue, that is, sess.run() blocks.
I can only get the print before the code: "curr_loss,curr_acc,_=sess.run([textCNN.loss_val,textCNN.accuracy,textCNN.train_op],feed_dict=feed_dict)" and then , the program blocks! I already make sure the input d... | closed | 2017-07-16T15:11:14Z | 2017-07-17T01:13:17Z | https://github.com/brightmart/text_classification/issues/2 | [] | scutzck033 | 2 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 160 | [TODO] serve docs | github pages seems to be active
but i dont see the result at
[kaliiiiiiiiii.github.io/Selenium-Driverless](https://kaliiiiiiiiii.github.io/Selenium-Driverless/)
where is it...?
the link should be in the "about" section of
[github.com/kaliiiiiiiiii/Selenium-Driverless](https://github.com/kaliiiiiiiiii/Selenium-Dr... | closed | 2024-02-01T13:37:43Z | 2024-02-02T10:02:57Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/160 | [
"documentation"
] | milahu | 4 |
Buuntu/fastapi-react | sqlalchemy | 86 | [Feature Request] Add Storybook support | Any thoughts on adding [Storybook](https://storybook.js.org/) support as part of a development workflow? | closed | 2020-07-15T13:33:48Z | 2020-07-24T22:00:55Z | https://github.com/Buuntu/fastapi-react/issues/86 | [] | inactivist | 3 |
huggingface/datasets | tensorflow | 7,196 | concatenate_datasets does not preserve shuffling state | ### Describe the bug
After concatenate datasets on an iterable dataset, the shuffling state is destroyed, similar to #7156
This means concatenation cant be used for resolving uneven numbers of samples across devices when using iterable datasets in a distributed setting as discussed in #6623
I also noticed th... | open | 2024-10-03T14:30:38Z | 2025-03-18T10:56:47Z | https://github.com/huggingface/datasets/issues/7196 | [] | alex-hh | 1 |
explosion/spaCy | nlp | 13,252 | Vocab Issue | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
<!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. -->
:
both
AUR repo: https://aur.archlinux.org/packages/autokey
Linux Distribution:
Manjaro Linux XFCE 64 bit, kernel 4.14.170-1-MANJARO
## What happens:
Yestard... | closed | 2020-02-18T07:10:01Z | 2023-05-07T19:45:09Z | https://github.com/autokey/autokey/issues/368 | [] | MR-Diamond | 8 |
plotly/dash | data-science | 2,803 | [Feature Request] Global set_props in backend callbacks. | Add a global `dash.set_props` to be used in callbacks to set arbitrary props not defined in the callbacks outputs, similar to the clientside `dash_clientside.set_props`.
Example:
```
app.layout = html.Div([
html.Div(id="output"),
html.Div(id="secondary-output"),
html.Button("click", id="clicker")... | closed | 2024-03-20T16:26:14Z | 2024-05-03T13:20:34Z | https://github.com/plotly/dash/issues/2803 | [] | T4rk1n | 2 |
ultralytics/yolov5 | pytorch | 13,141 | how to convert pt to onnx to trt | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
how to convert pt to onnx to trt
### Additional
im doing this
python export.py --wei... | closed | 2024-06-27T03:11:08Z | 2024-12-16T10:28:50Z | https://github.com/ultralytics/yolov5/issues/13141 | [
"question",
"Stale"
] | gdfapokgdpafog | 8 |
pyro-ppl/numpyro | numpy | 1,744 | Adding HMCECS proxy functions | Hi,
I'm working on a neural proxy function for HMCECS and have a Taylor expansion proxy with an approximate Hessian. However, the file is becoming somewhat unruly as the proxies are currently in `hmc_gibbs.py`. If I move (only) the proxy functions to a separate file under `contrib` and keep using the static method i... | closed | 2024-02-23T11:08:06Z | 2024-02-28T08:07:15Z | https://github.com/pyro-ppl/numpyro/issues/1744 | [
"discussion"
] | OlaRonning | 2 |
neuml/txtai | nlp | 585 | Add support for binary indexes to Faiss ANN | This change will add support for [Faiss binary indexes](https://github.com/facebookresearch/faiss/wiki/Binary-indexes). Binary indexes will be used to index scalar quantized data. | closed | 2023-10-27T09:52:56Z | 2023-10-27T19:21:38Z | https://github.com/neuml/txtai/issues/585 | [] | davidmezzetti | 1 |
tfranzel/drf-spectacular | rest-api | 1,326 | Weird issue when generating the schema | **Describe the bug**
I'm having a hard time but when I generate the schema from the Swagger UI, I got the correct schema (that includes the filter fields that I defined in a FilteSet class).

T... | closed | 2024-11-07T07:53:41Z | 2024-11-10T13:16:58Z | https://github.com/tfranzel/drf-spectacular/issues/1326 | [] | yoelfme | 7 |
lepture/authlib | flask | 328 | PKCE check | https://github.com/lepture/authlib/blob/51261de795cddb93d5e5206d8206bfd87917c5b3/authlib/oauth2/rfc6749/grants/authorization_code.py#L207
Hi.
here when the request is "PKCE token request" as client is public and client credentials are not sent, shouldn't we skip client authentication and just check client_id instea... | closed | 2021-03-05T21:49:14Z | 2021-03-06T03:56:58Z | https://github.com/lepture/authlib/issues/328 | [] | shahabGh77 | 1 |
custom-components/pyscript | jupyter | 492 | Response Data | With the recent introduction for Home Assistant allowing service calls to respond with data, I am curious if this is a planned feature for pyscript? | closed | 2023-07-18T20:48:48Z | 2023-07-30T18:02:41Z | https://github.com/custom-components/pyscript/issues/492 | [] | Sian-Lee-SA | 1 |
gradio-app/gradio | python | 10,711 | Should not try to get_node_path() if SSR mode is disabled. | ### Describe the bug
In Gradio code, the lines https://github.com/gradio-app/gradio/blob/54fd90703e74bd793668dda62fd87c4ef2cfff03/gradio/blocks.py#L2560 and https://github.com/gradio-app/gradio/blob/54fd90703e74bd793668dda62fd87c4ef2cfff03/gradio/routes.py#L1737 call `get_node_path()` prematurely. The call to `get_nod... | closed | 2025-03-03T03:12:59Z | 2025-03-04T03:11:47Z | https://github.com/gradio-app/gradio/issues/10711 | [
"bug",
"good first issue"
] | anirbanbasu | 2 |
scikit-multilearn/scikit-multilearn | scikit-learn | 194 | Getting ValueError: Can only tuple-index with a MultiIndex | I am trying to stratify my multi-label data, `total` is all my data. contains 20 columns, 1st column is text(X) and rest of 19 cols are labels( each col represent a class, if present for an example,set to 1 else set to 0). `total` is a csv file if this info is needed
```
from skmultilearn.model_selection import itera... | closed | 2019-12-30T07:09:55Z | 2023-03-14T17:05:30Z | https://github.com/scikit-multilearn/scikit-multilearn/issues/194 | [] | adiv5 | 6 |
tensorflow/tensor2tensor | machine-learning | 1,914 | Error: AttributeError: module 'tensorflow.compat.v2.__internal__' has no attribute 'monitoring' | ### How to resolve this error?
I am running this code on Jupyter notebook.
I have imported `tensor2tensor` and `tensorflow` packages, however, this error arises. Can anyone assist what is the reason?
```
from tensor2tensor.data_generators.problem import Problem
...
```
```
ttributeError ... | open | 2022-07-18T08:02:14Z | 2022-07-18T08:02:14Z | https://github.com/tensorflow/tensor2tensor/issues/1914 | [] | qm-intel | 0 |
jacobgil/pytorch-grad-cam | computer-vision | 391 | Explanation scores using Remove and debias is none | During the reproduction of the blog: [https://jacobgil.github.io/pytorch-gradcam-book/CAM%20Metrics%20And%20Tuning%20Tutorial.html#road-remove-and-debias], I found the scores calculated by cam_metric using remove and debias is always none. I have located the source of the error, the "NoisyLinearImputer" function will p... | open | 2023-02-19T00:36:44Z | 2025-03-11T10:35:55Z | https://github.com/jacobgil/pytorch-grad-cam/issues/391 | [] | MasterEndless | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 19,526 | Model stuck after saving a checkpoing when using the FSDPStrategy | ### Bug description
I'm training a GPT model using Fabric. Below are the setups for Fabric
It works well if I'm running without saving a checkpoint. However, if I save a checkpoint using ethier `torch.save` with `fabric.barrier()` or with `fabric.save()` the training will stuck.
I saw `torch.distributed.barrie... | closed | 2024-02-24T20:07:41Z | 2024-07-27T12:44:27Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19526 | [
"bug",
"strategy: fsdp",
"ver: 2.1.x",
"repro needed"
] | charlesxu90 | 3 |
deezer/spleeter | tensorflow | 508 | no tag entry for v2[Bug] name your bug | you have not a releases entry for v2. and when models was updated at last time? | open | 2020-10-27T18:01:11Z | 2020-10-27T18:01:11Z | https://github.com/deezer/spleeter/issues/508 | [
"bug",
"invalid"
] | ilyapashuk | 0 |
Asabeneh/30-Days-Of-Python | matplotlib | 392 | day 4_result is not correct | https://github.com/Asabeneh/30-Days-Of-Python/blame/c8656171d69e79b5dfc743f425991f46b7d1423e/04_Day_Strings/04_strings.md#L331
For this program the result should be 5 for ('y') and 0 for ('th')
challenge = 'thirty days of python'
print(challenge.find('y')) # 16
print(challenge.find('th')) # 17 | closed | 2023-05-09T18:09:54Z | 2023-07-08T21:47:18Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/392 | [] | Galio54 | 1 |
LAION-AI/Open-Assistant | python | 3,368 | Add Support for Language Dialect Consistency in Conversations | Hello,
I’m reaching out to propose a new feature that I believe would enhance the user experience.
### Issue
Currently, when selecting a language, the system does not differentiate between language variants. For instance, when Spanish is selected, dialogues are mixed between European Spanish (Spain) and Latin ... | closed | 2023-06-09T19:20:23Z | 2023-06-10T09:10:38Z | https://github.com/LAION-AI/Open-Assistant/issues/3368 | [] | salvacarrion | 0 |
horovod/horovod | deep-learning | 3,883 | Installation failure | **Environment:**
1. Framework: PyTorch
2. Framework version: 1.11.0
3. Horovod version: 0.27.0
4. MPI version: openmpi-4.1.4
5. CUDA version: 11.3
6. NCCL version: 2.9.9_1
7. Python version: 3.9
8. Spark / PySpark version:
9. Ray version:
10. OS and version: ubuntu18.04
11. GCC version:9.3.0
12. CMake versi... | closed | 2023-04-07T14:54:33Z | 2023-12-15T04:10:50Z | https://github.com/horovod/horovod/issues/3883 | [
"wontfix"
] | Dairhepon | 2 |
vaexio/vaex | data-science | 1,911 | [FEATURE-REQUEST] Is there an equivalent of creating multiple virtual columns from function returning tuples? | Is there the equivalent of doing this in Pandas, in vaex?
```python
df = pd.DataFrame(data={'num': range(10)})
print(df)
num
0 0
1 1
2 2
3 3
4 4
def powers(x):
return x, x**2
df['p1'], df['p2'] = zip(*df['num'].map(powers))
print(df)
num p1 p2
0 0 0 0
1 1 1 1
... | closed | 2022-02-11T19:49:17Z | 2022-02-14T13:06:45Z | https://github.com/vaexio/vaex/issues/1911 | [] | tdeboer-ilmn | 1 |
waditu/tushare | pandas | 1,244 | [Bug][get_sz50s] Throw exception - read_excel() got an unexpected keyword argument `parse_cols` | [root cause]
There is no parameter `parse_cols` in read_excell() of pandas 0.25.3, since has been deprecated.
| open | 2020-01-03T08:01:27Z | 2020-01-08T05:55:51Z | https://github.com/waditu/tushare/issues/1244 | [] | bradleetw | 1 |
kensho-technologies/graphql-compiler | graphql | 150 | Unable to resolve dependencies for pipenv lock | Off a clean master branch, running `pipenv lock` throws error:
```
Locking [dev-packages] dependencies...
Warning: Your dependencies could not be resolved. You likely have a mismatch in your sub-dependencies.
You ... | closed | 2019-01-02T19:49:33Z | 2019-01-03T02:00:19Z | https://github.com/kensho-technologies/graphql-compiler/issues/150 | [
"bug"
] | jmeulemans | 0 |
jacobgil/pytorch-grad-cam | computer-vision | 492 | How should I assign a value to the "targets" when I draw the heatmap of yolov8-pose? | 
I don't think "targets=None" is right. in the "base_cam.py",
```
if targets is None:
target_categories = np.argmax(outputs.cpu().data.numpy(), axis=-2)
targets = [ClassifierOutputTarget(
c... | open | 2024-03-15T03:42:07Z | 2024-10-27T08:05:20Z | https://github.com/jacobgil/pytorch-grad-cam/issues/492 | [] | Xavier-W | 1 |
omar2535/GraphQLer | graphql | 81 | [Enhancement] Materialize only SCALARs after MAX_DEPTH | # Overview
Currently, the materializer which creates queries and mutations to materialize will end when MAX_DEPTH is hit. However, this doesn't guarantee a valid query due to NON_NULL constraints (since NON_NULLs could be at various depths of a payload).
IE.
**Schema:**
```sh
type User {
id: ID!
name: St... | closed | 2024-07-22T12:28:03Z | 2024-08-06T05:51:54Z | https://github.com/omar2535/GraphQLer/issues/81 | [
"➕enhancement",
"❕ Critical"
] | omar2535 | 0 |
matterport/Mask_RCNN | tensorflow | 2,599 | Writing Mask R-CNN prediction pixel co-ordinates to text file | Does anyone know how to write the predicted mask co-ordinates to a text file? I want to import my prediction results to GIS. | open | 2021-06-15T01:04:39Z | 2022-05-06T08:53:03Z | https://github.com/matterport/Mask_RCNN/issues/2599 | [] | ghost | 1 |
flasgger/flasgger | rest-api | 90 | Handling Collections of Objects with marshmallow | In marshmallow I can handle many collections of an object. For the
https://github.com/rochacbruno/flasgger/blob/master/examples/marshmallow_apispec.py
example how do I handle a collection of "User" and have it reflect in the apidocs? | closed | 2017-04-23T11:12:53Z | 2017-04-24T18:17:41Z | https://github.com/flasgger/flasgger/issues/90 | [
"question"
] | wobeng | 1 |
sammchardy/python-binance | api | 1,214 | bot sets TAKE_PROFIT_MARKET too high 🤨 | Because when my bot opens a MARKET order with a take profit of 0.001 percent, it sets the TAKE_PROFIT_MARKET much higher, like 0.03 percent. And it goes both ways LONG and SHORT.

| open | 2022-07-11T00:46:41Z | 2022-07-11T00:46:41Z | https://github.com/sammchardy/python-binance/issues/1214 | [] | DrakoAI | 0 |
python-arq/arq | asyncio | 425 | Task Progress | In Python RQ there is this `job.meta` dictionary that can be used to set some custom task progress indication which is useful for showing in the UI, does ARQ have this?
https://python-rq.org/docs/jobs/ | open | 2023-12-29T13:27:28Z | 2024-03-09T01:56:42Z | https://github.com/python-arq/arq/issues/425 | [] | ronbeltran | 1 |
noirbizarre/flask-restplus | flask | 752 | CSS injection security vulnerability in swagger-ui | closed | 2019-11-26T17:04:37Z | 2020-01-07T15:20:39Z | https://github.com/noirbizarre/flask-restplus/issues/752 | [
"bug"
] | khsu528 | 0 | |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 5 | Colab "Try it on your own photos!" fails to save output | When running the section `"Try it on your own photos!"` the upload of the photo works fine:
```
EMILIA 78.png(image/png) - 6794251 bytes, last modified: 19/9/2020 - 100% done
Saving EMILIA 78.png to EMILIA 78.png
```
and even the pipeline seems to work:
```
Running Stage 1: Overall restoration
Now you are... | closed | 2020-09-19T18:23:35Z | 2020-09-19T18:36:24Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/5 | [] | loretoparisi | 0 |
geopandas/geopandas | pandas | 3,210 | BUG: up to 4 times slower in Linux compared to Windows when using gpd.read_file to read vector data |
It is very very slow to read vector data (including ESRI ShapeFile, ESRI Geodatabase) with gpd.read_file in Linux (Including Ubuntu, Rocky linux). I have reproduced this issue in several different Linux servers with high performace and Windows PCs, so it seemed that it is not a question involving the performace of de... | closed | 2024-03-06T10:09:26Z | 2024-03-07T06:37:03Z | https://github.com/geopandas/geopandas/issues/3210 | [
"bug",
"needs triage"
] | kwtk86 | 6 |
numba/numba | numpy | 9,903 | Iteration over a C-order array yields subarrays without C-order property | Using a `for` loop to iterate over the first axis of a C-order array yields subarrays that are not C-order, even though they should be (and likely are).
A workaround is to iterate over a range of indices and then extract the subarray in another statement.
See this example code:
```python
import numba
import numpy as ... | open | 2025-01-23T06:10:49Z | 2025-01-28T12:26:20Z | https://github.com/numba/numba/issues/9903 | [
"bug - typing"
] | hhoppe | 1 |
abhiTronix/vidgear | dash | 356 | [Question]: How to set hwaccel to StreamGear for utilizing GPU, Using the option ? | ### Issue guidelines
- [X] I've read the [Issue Guidelines](https://abhitronix.github.io/vidgear/latest/contribution/issue/#submitting-an-issue-guidelines) and wholeheartedly agree.
### Issue Checklist
- [X] I have searched open or closed [issues](https://github.com/abhiTronix/vidgear/issues) for my problem and foun... | closed | 2023-04-01T03:46:24Z | 2023-04-04T09:12:26Z | https://github.com/abhiTronix/vidgear/issues/356 | [
"QUESTION :question:",
"ANSWERED IN DOCS :book:"
] | PraveenSuryawanshi-Dev | 2 |
PrefectHQ/prefect | data-science | 17,384 | DaskTaskRunner does not handle Dask exceptions | ### Bug summary
In `PrefectDaskFuture.wait`, it's assumed (per [this comment](https://github.com/PrefectHQ/prefect/blob/eb9d51f7c507adeed73a460c234594a815c9b4c0/src/integrations/prefect-dask/prefect_dask/task_runners.py#L120)) that either `future.result()` returns a `State` or times out. But there are other possible ... | open | 2025-03-05T15:26:03Z | 2025-03-05T15:26:42Z | https://github.com/PrefectHQ/prefect/issues/17384 | [
"bug"
] | bnaul | 0 |
sczhou/CodeFormer | pytorch | 78 | Error CUDA out of memory. | **Pls howto fix memory error?**
"Error CUDA out of memory. Tried to allocate 930.00 MiB (GPU 0; 3.82 GiB total capacity; 849.56 MiB already allocated; 938.75 MiB free; 1.66 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentati... | closed | 2022-12-04T19:18:06Z | 2022-12-31T07:14:42Z | https://github.com/sczhou/CodeFormer/issues/78 | [] | idanka | 6 |
d2l-ai/d2l-en | machine-learning | 2,048 | \n disappears when using if tab.selected | 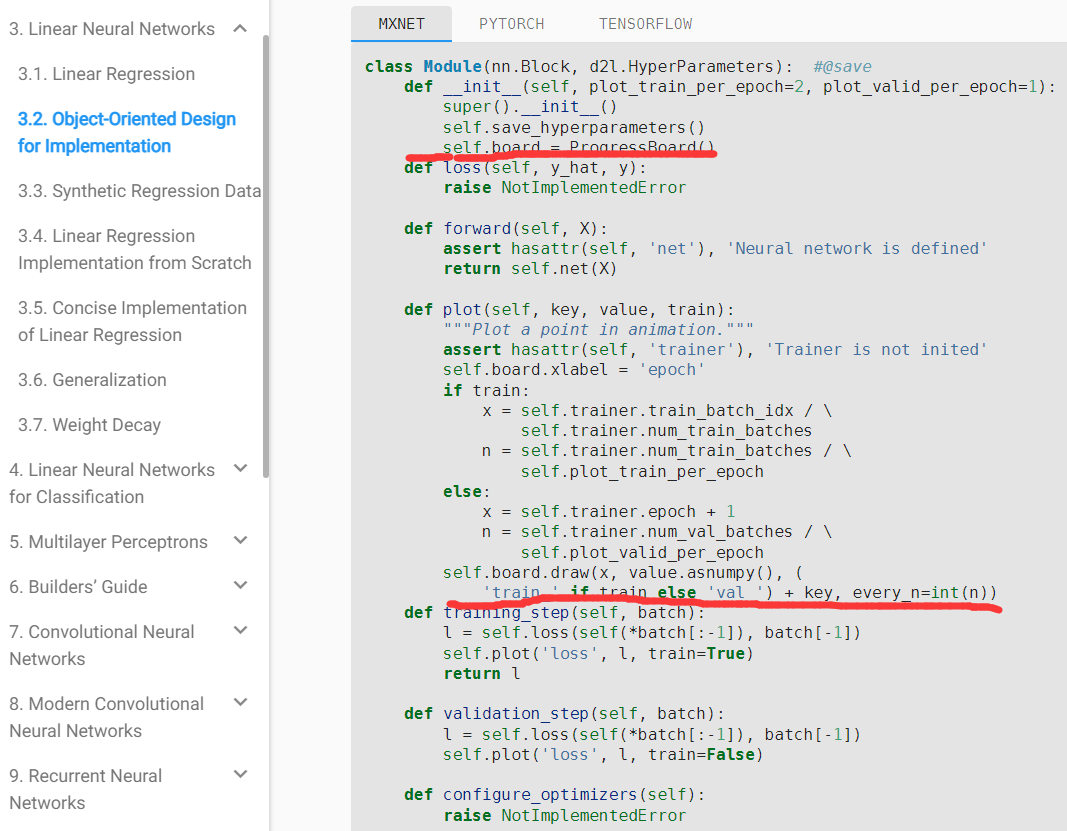
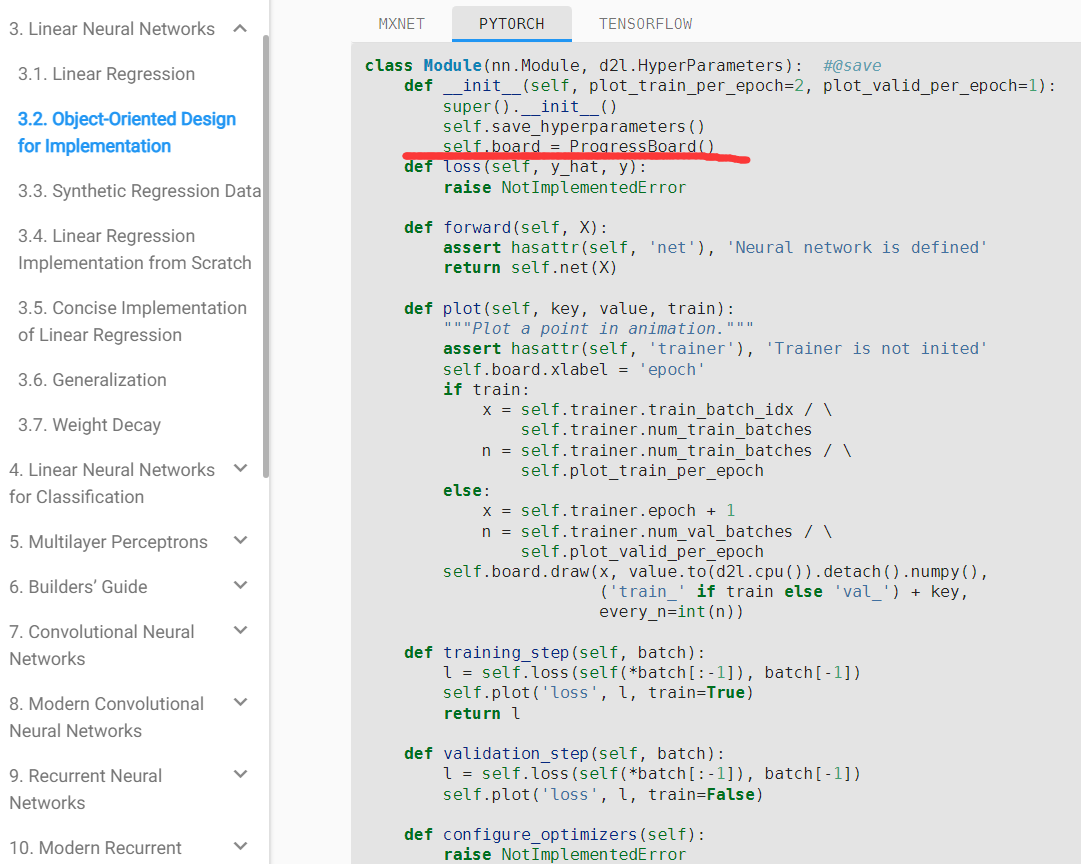
:
......
......msg.body = render_template( template + 'txt', *_kwarg)
......
......mail.send(msg)
In the book says that: "... | closed | 2016-01-22T17:18:22Z | 2016-05-19T17:27:16Z | https://github.com/miguelgrinberg/flasky/issues/107 | [
"question"
] | masaguaro | 3 |
OWASP/Nettacker | automation | 111 | wappalyzer_scan bug - nothing found on target | Hey, just want to inform you of this bug.
```
[+] checking https://www.owasp.org ...
[+] category: Wikis, frameworks: MediaWiki found!
[+] category: Video Players, frameworks: YouTube found!
[+] nothing found on https://www.owasp.org in wappalyzer_scan!
```
Regards.
_________________
**OS**: `Windows`
*... | closed | 2018-04-22T14:25:53Z | 2018-05-19T19:42:20Z | https://github.com/OWASP/Nettacker/issues/111 | [
"bug",
"done",
"bug fixed"
] | Ali-Razmjoo | 1 |
biolab/orange3 | data-visualization | 6,094 | REST interface component - receiving JSON data into models | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
<!-- In other words, what's your pain point? -->
<!-- Is your request related to a problem, or ... | closed | 2022-08-13T10:37:36Z | 2022-10-11T09:27:20Z | https://github.com/biolab/orange3/issues/6094 | [] | stenerikbjorling | 2 |
nonebot/nonebot2 | fastapi | 3,022 | Plugin: PM帮助 | ### PyPI 项目名
nonebot-plugin-pmhelp
### 插件 import 包名
nonebot_plugin_pmhelp
### 标签
[{"label":"帮助","color":"#ea5252"}]
### 插件配置项
_No response_ | closed | 2024-10-16T09:32:22Z | 2024-10-18T14:39:52Z | https://github.com/nonebot/nonebot2/issues/3022 | [
"Plugin"
] | CM-Edelweiss | 12 |
scikit-optimize/scikit-optimize | scikit-learn | 1,205 | Scikit optimize abandoned? | open | 2024-02-23T07:08:31Z | 2024-02-28T15:16:21Z | https://github.com/scikit-optimize/scikit-optimize/issues/1205 | [] | jobs-git | 2 | |
ResidentMario/geoplot | matplotlib | 190 | Cannot plot with projection | I try to run plotting_with_geoplot.py with available on [](http://geopandas.org/gallery/plotting_with_geoplot.html) in python3.7. The result could not appear but got a message below.
```
Geometry must be a Point or LineString
python: geos_ts_c.cpp:4038: int GEOSCoordSeq_getSize_r(GEOSContextHandle_t, const geos:... | closed | 2019-11-19T01:43:12Z | 2019-11-21T16:06:19Z | https://github.com/ResidentMario/geoplot/issues/190 | [] | sdayu | 6 |
babysor/MockingBird | deep-learning | 404 | 预处理失败,求助 | C:\Users\Administrator\Downloads\MockingBird-main\MockingBird-main>python pre.py C:\Users\Administrator\Downloads -d aidatatang_200zh -n 6
Using data from:
C:\Users\Administrator\Downloads\aidatatang_200zh\corpus\train
Traceback (most recent call last):
File "C:\Users\Administrator\Downloads\MockingBird-main\... | closed | 2022-02-25T14:46:34Z | 2022-07-17T15:11:44Z | https://github.com/babysor/MockingBird/issues/404 | [] | Xlbnas | 5 |
geex-arts/django-jet | django | 98 | Wrong dashboard settings documentation | Hi, i'm working in a project and i set the other questions:
``` python
JET_INDEX_DASHBOARD = 'jet.dashboard.DefaultIndexDashboard'
JET_APP_INDEX_DASHBOARD = 'jet.dashboard.DefaultAppIndexDashboard'
```
Put this settings in my settings file and i get this problem:
 pointing to [this example implementation](https://github.com/tmbdev-archive/webdataset-l... | open | 2024-08-01T15:48:48Z | 2024-08-03T09:44:57Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20149 | [
"help wanted",
"docs",
"ver: 2.2.x"
] | cgebbe | 0 |
Yorko/mlcourse.ai | data-science | 718 | Bad view in Feature importance | In the [feature importance article](https://mlcourse.ai/book/topic05/topic5_part3_feature_importance.html) there is some problem with the representation of sklearn Impurity Reduction algo. It seems like some indentations are not shown properly.
Actually, in [English ntbk](https://github.com/Yorko/mlcourse.ai/blob/mai... | closed | 2022-09-12T10:32:39Z | 2022-09-13T23:01:38Z | https://github.com/Yorko/mlcourse.ai/issues/718 | [] | aulasau | 1 |
piskvorky/gensim | data-science | 3,017 | Inconsistency within documentation | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2020-12-27T13:07:01Z | 2020-12-27T15:44:47Z | https://github.com/piskvorky/gensim/issues/3017 | [] | JakovGlavac | 1 |
streamlit/streamlit | python | 10,384 | st.html() Injects CSS but It Does Not Take Effect in Streamlit 1.42.1 (Worked in 1.37) | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
<h4><strong>Summary</strong></h4>
<p>In <str... | closed | 2025-02-12T20:40:06Z | 2025-02-13T06:32:36Z | https://github.com/streamlit/streamlit/issues/10384 | [
"type:bug",
"status:needs-triage"
] | ishswar | 3 |
joke2k/django-environ | django | 413 | Add support for CONN_HEALTH_CHECKS and OPTIONS | Hello!
How to convert my config to django-environ? I'm worry about CONN_HEALTH_CHECKS and OPTIONS.
```
DATABASES = types.MappingProxyType({
'default': {
'ENGINE': 'django.db.backends.postgresql',
'HOST': '127.0.0.1',
'NAME': 'devdatabase',
'CONN_MAX_AGE': None,
'... | closed | 2022-08-22T07:58:29Z | 2024-04-17T18:41:24Z | https://github.com/joke2k/django-environ/issues/413 | [
"enhancement"
] | lorddaedra | 12 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 1,197 | Others | Hello. How i can add Brazilian portuguese to this program? | open | 2023-04-18T13:09:31Z | 2023-04-18T13:09:31Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1197 | [] | jvzin8040 | 0 |
miguelgrinberg/python-socketio | asyncio | 340 | "event" method with AsyncSever | The Sanic example shows a call with an event method being used as a decorator function; however, upon inspecting the library, the method doesn't exist... is there something that I am missing?
| closed | 2019-08-27T10:38:58Z | 2019-11-17T19:05:56Z | https://github.com/miguelgrinberg/python-socketio/issues/340 | [
"question"
] | leehol | 4 |
Avaiga/taipy | automation | 1,777 | Improve editing capabilities of Taipy tables | ### Description
I'm looking for a way to enable immediate editing for all editable columns or cells of a table. Instead of clicking the pencil icon for each cell I want to edit, I would like to have a single button that makes all cells in the table ready for editing.
This was asked by a user.
### Requested Featu... | open | 2024-09-11T12:47:48Z | 2025-03-14T13:51:54Z | https://github.com/Avaiga/taipy/issues/1777 | [
"🖰 GUI",
"🆘 Help wanted",
"🟩 Priority: Low",
"✨New feature"
] | FlorianJacta | 12 |
LibreTranslate/LibreTranslate | api | 706 | Community forum is down | Hello, i have a question about LibreTranslate (how to only download one specific model with a self hosted instance) but community.libretranslate.com does not work. So i hope im allowed to ask this question here and also report the issue about the community page. | closed | 2024-11-02T15:19:44Z | 2024-11-02T15:22:17Z | https://github.com/LibreTranslate/LibreTranslate/issues/706 | [] | Hallilogod | 3 |
Sanster/IOPaint | pytorch | 414 | lama cleaner memory usage increase every clean cycle in docker container deployed kubernetes | Hi,
I tried to deploy lama cleaner docker container in kubernetes cluster (in machine using CPU).
Lama cleaner works well. But every cleaning cycle, memory usage of container keep increasing.
When restart container, memory usage become default state. I could set memory limit of the container and restart container w... | closed | 2023-12-19T04:51:29Z | 2025-03-01T02:05:48Z | https://github.com/Sanster/IOPaint/issues/414 | [
"stale"
] | kmpartner | 2 |
tiangolo/uwsgi-nginx-flask-docker | flask | 109 | Here's how uWSGI is configured, from the base image: https://github.com/tiangolo/uwsgi-nginx-docker | From what I understand, having a configuration like:
>program:uwsgi]
>environment=PATH='/opt/conda/envs/conda_environment/bin:/opt/conda/bin'
>command=/opt/conda/bin/uwsgi --ini /etc/uwsgi/uwsgi.ini --die-on-term --need-app --processes 4
>master = true
>stdout_logfile=/dev/stdout
>stdout_logfile_maxbytes=0
>stde... | closed | 2018-11-20T11:40:31Z | 2019-01-01T20:00:07Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/109 | [] | hadjichristslave | 3 |
dynaconf/dynaconf | django | 203 | Document the use of pytest with dynaconf | For testing in my project i want to add in my conftest.py something like that:
```
import pytest
import os
@pytest.fixture(scope='session', autouse=True)
def settings():
os.environ['ENV_FOR_DYNACONF'] = 'testing'
```
But this is not work ;-(. What can you advise me ?
I dont want start my test like th... | closed | 2019-08-08T10:41:39Z | 2020-02-26T18:04:26Z | https://github.com/dynaconf/dynaconf/issues/203 | [
"enhancement",
"question",
"Docs",
"good first issue"
] | dyens | 12 |
man-group/arctic | pandas | 448 | Context Manager | Can I please know if we have context manger in Arctic, e.g., drop connections or clear cache?
| closed | 2017-11-06T16:48:37Z | 2017-12-03T21:28:33Z | https://github.com/man-group/arctic/issues/448 | [] | johnjihong | 3 |
aimhubio/aim | tensorflow | 2,433 | Add a community discord link in the sidebar | ## 🚀 Feature
Add a community discord link in the `Sidebar`
### Motivation
Provide users the ability to easily navigate to the `Aim discord` community channel from the `Sidebar`
### Pitch
Display a link to the discord with an icon in the `Sidebar`.
| closed | 2022-12-15T11:37:57Z | 2023-01-31T11:13:59Z | https://github.com/aimhubio/aim/issues/2433 | [
"type / enhancement",
"area / Web-UI",
"phase / shipped"
] | arsengit | 0 |
explosion/spaCy | deep-learning | 12,982 | RuntimeError: Error(s) in loading state_dict for RobertaModel: Unexpected key(s) in state_dict: "embeddings.position_ids". | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
```py
import spacy
nlp = spacy.load('en_core_web_trf')
```
Full traceback:
```
---------------------------------------------------------------------------
RuntimeError ... | closed | 2023-09-14T14:08:37Z | 2023-10-19T00:02:09Z | https://github.com/explosion/spaCy/issues/12982 | [
"install",
"feat / transformer"
] | dzenilee | 6 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 289 | How do I use my own mp3? | I'm playing with the demo, and I only have an option to record, how do I import an audio file?
tnx.
| closed | 2020-02-26T00:24:56Z | 2020-07-04T22:35:07Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/289 | [] | orenong | 10 |
openapi-generators/openapi-python-client | fastapi | 839 | `UnexpectedStatus` contains an uninformative message | ### Problem
Now when we set
```python
raise_on_unexpected_status=True
```
in the client, we will only see `Unexpected status code: 400` (or smt like) when any unexpected status is received. But in fact, this is an uninformative message. To find out what is the reason for this exception, we should try to reproduc... | closed | 2023-08-16T07:55:10Z | 2023-08-16T15:56:38Z | https://github.com/openapi-generators/openapi-python-client/issues/839 | [] | M1troll | 0 |
hpcaitech/ColossalAI | deep-learning | 5,421 | [BUG]: ColossalEval/AGIEvalDataset loader causing IndexError when few shot is disabled | ### 🐛 Describe the bug
## Describe the bug
AGIEvalDataset loader in ColossalEval incorrectly set `few_shot_data` to `[]` when `few_shot` is disabled, causing IndexError at https://github.com/hpcaitech/ColossalAI/blob/main/applications/ColossalEval/colossal_eval/utils/conversation.py#L126.
## To Reproduce
Use... | closed | 2024-03-03T20:40:29Z | 2024-03-05T13:48:56Z | https://github.com/hpcaitech/ColossalAI/issues/5421 | [
"bug"
] | starcatmeow | 0 |
Evil0ctal/Douyin_TikTok_Download_API | api | 417 | Cookie更换频率和请求频率 | 我在尝试使用自己部署的服务爬取TikTok的视频评论。我想请教一下作者:为了避免被平台控,Cookie推荐多长时间换一次?以及请求频率推荐为多快?此外,是否有其他的避免被控的注意事项?谢谢~ | open | 2024-06-03T14:35:58Z | 2024-06-09T08:00:00Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/417 | [] | scn0901 | 9 |
sunscrapers/djoser | rest-api | 91 | possible E-mail improvement | I want to quickly say first Djoser is a great package to kickoff DRF REST API projects and I've used it to its absolute maximal intent and beyond. Great job!
I figure I would add my 2cents on some improvements though. Well, actually it's just one, the rest I found very flexible and inline with OOP/DRY.
With respect t... | closed | 2015-11-03T01:17:21Z | 2017-09-25T21:12:32Z | https://github.com/sunscrapers/djoser/issues/91 | [
"enhancement"
] | ghost | 7 |
onnx/onnx | machine-learning | 6,475 | source code question | Why not optimize this by determining if the index is already in the set?

| closed | 2024-10-20T08:50:58Z | 2024-11-01T14:54:16Z | https://github.com/onnx/onnx/issues/6475 | [
"question"
] | XiaBing992 | 1 |
pytest-dev/pytest-xdist | pytest | 176 | AttributeError when using --showlocals with -d | Sorry if I putting this issue in wrong place. Maybe it related to pytest (core).
I am searching around the issue database but did not find anything similar.
This is the first time when I am playing with ssh support of xdist plugin. So maybe I am doing something wrong.
My problem is I have got a traceback when am u... | closed | 2017-06-30T08:09:59Z | 2017-07-06T00:20:22Z | https://github.com/pytest-dev/pytest-xdist/issues/176 | [
"bug"
] | mitzkia | 8 |
Johnserf-Seed/TikTokDownload | api | 113 | [BUG]pip安装依赖报错 | **描述出现的错误**
git clone 后运行源码安装pip3 install -r requirements.txt 报错
**报错代码截图**
<a href="https://imgtu.com/i/qsNAq1"><img src="https://s1.ax1x.com/2022/03/28/qsNAq1.png" alt="qsNAq1.png" border="0" /></a>
**桌面(请填写以下信息):**
-操作系统:arm64
-版本 latest
| closed | 2022-03-28T15:20:08Z | 2022-04-02T08:49:21Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/113 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | Jakob-Boy | 1 |
ultralytics/ultralytics | machine-learning | 19,662 | yolo Model training problems | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
)' )
lib_dir=$( python -c 'import paddle; print(paddle.sysconfig.get_lib())' )
echo $in... | open | 2021-09-16T11:35:20Z | 2024-02-26T05:08:43Z | https://github.com/PaddlePaddle/models/issues/5346 | [] | zjuncd | 1 |
ansible/ansible | python | 84,408 | ansible requires that LC_ALL is set on Linux | ### Summary
All ansible commands fail with an error message regarding "unsupported locale setting".
```sh
$ ansible --version
ERROR: Ansible could not initialize the preferred locale: unsupported locale setting
```
I am forced to prefix the commands with LC_ALL
```sh
$ LC_ALL=en_GB.UTF-8 ansible --version
... | closed | 2024-11-29T22:01:12Z | 2024-12-14T14:00:02Z | https://github.com/ansible/ansible/issues/84408 | [] | red-lichtie | 3 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,170 | OperationalError: Database or disk is full on GlobaLeaks Despite Sufficient Disk Space |
### What version of GlobaLeaks are you using?
v4.14.8
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Linux
### Describe the issue
We are encountering a persistent OperationalError on our GlobaLeaks installation, specifically ve... | closed | 2024-08-27T12:04:02Z | 2024-08-29T13:12:55Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4170 | [] | willskymaker | 5 |
microsoft/unilm | nlp | 1,373 | [KOSMOS-2] The visual-pretrained ckpt for kosmos-2 training | **Describe**
i want to finetune the kosmos-2,where can i find it?thank you very much
| closed | 2023-11-23T09:28:40Z | 2023-11-23T09:34:03Z | https://github.com/microsoft/unilm/issues/1373 | [] | bill4689 | 0 |
ydataai/ydata-profiling | jupyter | 1,499 | Add SECURITY.md | Hello 👋
I run a security community that finds and fixes vulnerabilities in OSS. A researcher (@zer0h-bb) has found a potential issue, which I would be eager to share with you.
Could you add a `SECURITY.md` file with an e-mail address for me to send further details to? GitHub [recommends](https://docs.github.com/en/c... | open | 2023-11-12T21:30:04Z | 2023-12-04T19:28:09Z | https://github.com/ydataai/ydata-profiling/issues/1499 | [
"code quality 📈"
] | psmoros | 0 |
microsoft/qlib | deep-learning | 1,487 | Download source data fail when executing python collector.py | I am trying to build a customized dataset from k-line data. I execute qlib/scripts/data_collector/yahoo/collector.py using command `python collector.py normalize_data --source_dir ~/.qlib/stock_data/source/cn_1min --normalize_dir ~/.qlib/stock_data/source/cn_1min_nor --region CN --interval 1min`.
I find this script wo... | closed | 2023-04-09T02:17:18Z | 2023-07-13T06:02:08Z | https://github.com/microsoft/qlib/issues/1487 | [
"question",
"stale"
] | ziangqin-stu | 1 |
pytest-dev/pytest-cov | pytest | 465 | Ensure COV_CORE_SRC is an absolute path before exporting to the environment | # Summary
When COV_CORE_SRC is a relative directory and a subprocess first changes its working directory
before invoking Python then coverage won't associate the
## Expected vs actual result
Get proper coverage reporting, but coverage is not reported properly.
# Reproducer
* specifiy the test directory... | open | 2021-04-26T08:09:28Z | 2022-11-11T20:29:44Z | https://github.com/pytest-dev/pytest-cov/issues/465 | [] | ctheune | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,068 | How to add loss function only for G_A | Hi~ I'm confused about is G_A and G_B using same loss function? If it is, why can we get two different generator.
Besides, How can I add a loss function only for G_A, I just did not find similar question in Issues. | closed | 2020-06-12T11:57:04Z | 2020-06-13T00:46:17Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1068 | [] | Iarkii | 2 |
jkrusina/SoccerPredictor | dash | 20 | ValueError: Value must be a nonnegative integer or None | ```py
Traceback (most recent call last):
File "C:\Users\usr\Downloads\SoccerPredictor-master\main.py", line 21, in <module>
pd.set_option("display.max_colwidth", -1)
File "C:\Users\usr\AppData\Local\Programs\Python\Python311\Lib\site-packages\pandas\_config\config.py", line 261, in __call__
return self... | open | 2023-08-29T18:13:46Z | 2023-08-29T18:13:46Z | https://github.com/jkrusina/SoccerPredictor/issues/20 | [] | indicts | 0 |
huggingface/datasets | pytorch | 6,995 | ImportError when importing datasets.load_dataset | ### Describe the bug
I encountered an ImportError while trying to import `load_dataset` from the `datasets` module in Hugging Face. The error message indicates a problem with importing 'CommitInfo' from 'huggingface_hub'.
### Steps to reproduce the bug
1. pip install git+https://github.com/huggingface/datasets
2. f... | closed | 2024-06-24T17:07:22Z | 2024-11-14T01:42:09Z | https://github.com/huggingface/datasets/issues/6995 | [] | Leo-Lsc | 9 |
lux-org/lux | jupyter | 439 | Loading Lux library into StreamLit Cloud | **Is your feature request related to a problem? Please describe.**
Trying to deploy my data project with Lux visualisations in the streamlit cloud, but no idea what to put in the requirements.txt or packages.txt file so keep getting deployment errors.
**Describe the solution you'd like**
The ability to get lux wor... | closed | 2021-12-08T22:35:52Z | 2022-01-06T20:19:40Z | https://github.com/lux-org/lux/issues/439 | [] | djswoosh | 2 |
QuivrHQ/quivr | api | 2,985 | Make Anthropic compatible with Quivr Core | Currently Anthropic is not OpenAI API compatible
<img src="https://uploads.linear.app/51e2032d-a488-42cf-9483-a30479d3e2d0/e9a817c8-b304-4009-a1a9-05e3bdde63e7/55401dbc-49f7-43d7-8794-4100976d67e5?signature=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJwYXRoIjoiLzUxZTIwMzJkLWE0ODgtNDJjZi05NDgzLWEzMDQ3OWQzZTJkMC9lOWE4MTdjOC1... | closed | 2024-08-08T21:50:15Z | 2024-09-24T07:21:30Z | https://github.com/QuivrHQ/quivr/issues/2985 | [
"enhancement"
] | StanGirard | 1 |
robotframework/robotframework | automation | 4,604 | Listeners do not get source information for keywords executed with `Run Keyword` | This was initially reported as a regression (#4599), but it seems source information has never been properly sent to listeners for keywords executed with `Run Keyword` or its variants like `Run Keyword If`. | closed | 2023-01-15T16:39:42Z | 2023-03-15T12:50:22Z | https://github.com/robotframework/robotframework/issues/4604 | [
"bug",
"priority: medium",
"alpha 1",
"effort: small"
] | pekkaklarck | 1 |
pallets/quart | asyncio | 370 | Program still not closing on Ctrl+C on Windows | I still experience the issue that Ctrl+C on Windows does not work with the current version (0.19.8).
This was already reported and addressed in #282, but not fully fixed.
<!--
Describe the expected behavior that should have happened but didn't.
-->
For an example please look at the original issue.
Environment... | closed | 2024-11-11T18:16:03Z | 2024-11-28T00:26:23Z | https://github.com/pallets/quart/issues/370 | [] | Shadow-Devil | 1 |
Miksus/rocketry | automation | 150 | BUG TaskRunnable is missing __str__ | **Describe the bug**
When using Rocketry with FastAPI, I return all tasks using such code: return `rocketry_app.session.tasks` .
But if I dynamically create task (`rocketry_app.session.create_task(...)`) and set its `start_cond` to `conds.cron(...)`, then endpoint raises exception on returning tasks:
`AttributeErro... | closed | 2022-11-21T12:44:44Z | 2022-11-28T21:04:44Z | https://github.com/Miksus/rocketry/issues/150 | [
"bug"
] | egisxxegis | 2 |
tqdm/tqdm | jupyter | 981 | Minor documentation issue: allmychanges.com is dead(?) | There's a link here to a defunct website (allmychanges.com): https://github.com/tqdm/tqdm#changelog | closed | 2020-06-01T18:53:20Z | 2020-06-28T22:25:10Z | https://github.com/tqdm/tqdm/issues/981 | [
"question/docs ‽",
"to-merge ↰"
] | roger- | 1 |
ultralytics/ultralytics | deep-learning | 19,111 | YOLO with dinov2 as backbone | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello @Y-T-G ,
I saw your code to support different backbones from torchvis... | open | 2025-02-06T23:57:42Z | 2025-02-14T13:34:43Z | https://github.com/ultralytics/ultralytics/issues/19111 | [
"enhancement",
"question"
] | SebastianJanampa | 6 |
pytorch/pytorch | machine-learning | 149,472 | torch.compile(mode="max-autotune") produces different outputs from eager mode | ### 🐛 Describe the bug
I'm encountering a result mismatch between eager mode and `torch.compile(mode="max-autotune")`.
The outputs differ beyond acceptable tolerances (e.g., `torch.allclose` fails), and this behavior persists in both stable and nightly builds.
### Related Discussion
I initially posted this issue o... | open | 2025-03-19T02:15:53Z | 2025-03-24T11:21:07Z | https://github.com/pytorch/pytorch/issues/149472 | [
"triaged",
"oncall: pt2",
"module: inductor",
"topic: fuzzer"
] | tinywisdom | 3 |
deepinsight/insightface | pytorch | 2,095 | Why the params of IResNet50 is larger than ResNet50? | IResNet50 vs ResNet50(in object detection): 43.77M vs 33.71M | open | 2022-09-01T15:53:20Z | 2022-09-01T16:36:34Z | https://github.com/deepinsight/insightface/issues/2095 | [] | Icecream-blue-sky | 1 |
benbusby/whoogle-search | flask | 904 | [BUG] Most of the search terms are not bold in Chinese results | **Describe the bug**
Most of the search terms are not bold in Chinese results.
Whoogle results:
<img width="819" alt="Screenshot 2022-12-11 at 6 43 14 PM" src="https://user-images.githubusercontent.com/33184148/206899969-b2d72332-7eee-44ca-88ec-b126492d361e.png">
Google results for reference:
<img width="936" ... | closed | 2022-12-11T11:09:16Z | 2023-01-09T19:54:43Z | https://github.com/benbusby/whoogle-search/issues/904 | [
"bug"
] | whaler-ragweed | 6 |
miguelgrinberg/Flask-SocketIO | flask | 1,107 | emit message from server to client on a particular time using python-socketio | I want to emit message on a particular time to a particular client. is that possible ??? is possible to make standard connection between client and server in socket io up to that time??? | closed | 2019-11-22T08:56:55Z | 2020-06-30T22:51:59Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1107 | [
"question"
] | harsha2041 | 7 |
ghtmtt/DataPlotly | plotly | 146 | Add data defined property 'Use feature subset' | I would like to suggest to add a data defined property named 'Use feature subset' below the layer selection combo box. It is applied to filter the features in the layer and can replace the 'use only selected features' checkbox. | closed | 2019-10-15T11:20:08Z | 2019-10-25T00:02:08Z | https://github.com/ghtmtt/DataPlotly/issues/146 | [
"enhancement"
] | SGroe | 1 |
lk-geimfari/mimesis | pandas | 1,096 | Publish v5.0.0 version to pypi | # Release request
## Version Info
- version: 5.0.0
## Expected
- Version 5.0.0 appears in [mimesis release history](https://pypi.org/project/mimesis/#history) of pypi
| closed | 2021-09-26T09:00:03Z | 2022-01-04T13:40:11Z | https://github.com/lk-geimfari/mimesis/issues/1096 | [] | blakegao | 5 |
Anjok07/ultimatevocalremovergui | pytorch | 1,006 | Remove Guitar | Hello, I'm new to this world of mixing.
Is there any way, through this software, to remove just the guitar from a song?
I know how to remove the battery.
But I would like to learn how to remove the guitar.
Can anyone with any advice help me and help the community?
Thanks. | closed | 2023-12-05T23:54:47Z | 2023-12-10T23:29:47Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1006 | [] | DEV7Kadu | 2 |
deepfakes/faceswap | deep-learning | 1,202 | faceswap graph crashes | The training module of faceswap used to have a broken line statistical chart. Now I click the chart, and the program crashes and exits | closed | 2022-01-01T23:46:30Z | 2022-06-30T09:52:22Z | https://github.com/deepfakes/faceswap/issues/1202 | [] | wangyifan349 | 3 |
explosion/spaCy | nlp | 13,673 | `spacy download nl_core_news_sm` downgrades transformers installation | Since models are in fact pip modules, it makes sense that they have their own dependencies. However, I was very surprised to find out that `nl_core_news_sm` required me to downgrade my `transformers` version. I am running on the main branch of `transformers` so ahead of 4.45.2 (`4.46.0.dev0`). yet when installing `nl-c... | open | 2024-10-19T21:45:34Z | 2024-10-19T21:45:34Z | https://github.com/explosion/spaCy/issues/13673 | [] | BramVanroy | 0 |
astrofrog/mpl-scatter-density | matplotlib | 15 | Does not work with inline matplotlib on Jupyter-Notebooks | MWE:
In a Jupyter Notebook,
```
%matplotlib inline
import mpl_scatter_density
import numpy as np
import matplotlib.pyplot as plt
N = 10000000
x = np.random.normal(4, 2, N)
y = np.random.normal(3, 1, N)
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1, projection='scatter_density')
ax.scatter_de... | open | 2018-04-20T20:36:29Z | 2018-06-19T22:04:47Z | https://github.com/astrofrog/mpl-scatter-density/issues/15 | [
"bug"
] | ijoseph | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.