
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Textualize/rich | python | 3,068 | [REQUEST] | Please add a way to center/align the Progress module. Currently from what I've seen it can only align to the left but I would love for it to be able to be centered. | closed | 2023-07-30T09:04:38Z | 2023-07-30T20:53:16Z | https://github.com/Textualize/rich/issues/3068 | [
"Needs triage"
] | KingKDot | 4 |
deezer/spleeter | deep-learning | 290 | Command not found: Spleeter | <img width="568" alt="Screen Shot 2020-03-12 at 9 33 25 AM" src="https://user-images.githubusercontent.com/58147163/76526825-87602400-6444-11ea-9ec2-a16ea279bd02.png">
Any ideas? I followed all the instructions. | closed | 2020-03-12T13:34:49Z | 2020-05-25T19:25:21Z | https://github.com/deezer/spleeter/issues/290 | [
"bug",
"invalid"
] | chrisgauthier9 | 2 |
ultralytics/ultralytics | computer-vision | 18,758 | Cannot export model to edgetpu on linux machine | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Other, Export
### Bug
The export to edgetpu works in google colab, however I cannot reproduce the model export in a person... | open | 2025-01-19T11:22:22Z | 2025-01-20T15:54:53Z | https://github.com/ultralytics/ultralytics/issues/18758 | [
"bug",
"exports"
] | Lorsu | 3 |
graphql-python/graphene-django | django | 1,515 | Documentation Mismatch for Testing API Calls with Django | **What is the current behavior?**
The documentation for testing API calls with Django on the official website of [Graphene-Django](https://docs.graphene-python.org/projects/django/en/latest/testing/) shows incorrect usage of a parameter named **op_name** in the code examples for unit tests and pytest integration. How... | open | 2024-04-06T05:32:32Z | 2024-07-03T18:44:00Z | https://github.com/graphql-python/graphene-django/issues/1515 | [
"🐛bug"
] | hamza-m-farooqi | 1 |
FlareSolverr/FlareSolverr | api | 1,288 | [yggtorrent] (testing) Exception (yggtorrent): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the challenge. Timeout after 55.0 seconds.: FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the chall... | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I hav... | closed | 2024-07-25T18:54:10Z | 2024-07-25T20:19:26Z | https://github.com/FlareSolverr/FlareSolverr/issues/1288 | [
"duplicate"
] | touzenesmy | 4 |
PaddlePaddle/PaddleHub | nlp | 2,254 | AttributeError: module 'paddle' has no attribute '__version__' | 欢迎您反馈PaddleHub使用问题,非常感谢您对PaddleHub的贡献!
在留下您的问题时,辛苦您同步提供如下信息:
- 版本、环境信息
1)PaddleHub和PaddlePaddle版本:请提供您的PaddleHub和PaddlePaddle版本号,例如PaddleHub1.4.1,PaddlePaddle1.6.2
2)系统环境:请您描述系统类型,例如Linux/Windows/MacOS/,python版本
- 复现信息:如为报错,请给出复现环境、复现步骤
| closed | 2023-05-15T06:40:12Z | 2023-09-15T08:45:13Z | https://github.com/PaddlePaddle/PaddleHub/issues/2254 | [] | HuangXinzhe | 3 |
Kanaries/pygwalker | plotly | 252 | When deploying the streamlit apllication the graph is not visible in browser the api calls are going st_core which is not there in directory | closed | 2023-09-29T02:17:29Z | 2023-10-17T11:37:29Z | https://github.com/Kanaries/pygwalker/issues/252 | [
"bug",
"fixed but needs feedback"
] | JeevankumarDharmalingam | 13 | |
geex-arts/django-jet | django | 289 | Page not found (404) | Hi, I make download of the project later, I try to run the project and I have the next issue when try to surf of the dashboard.
Using the URLconf defined in jet.tests.urls, Django tried these URL patterns, in this order:
url: http://127.0.0.1:8000/admin/jet
^jet/
^jet/dashboard/
^admin/doc/
^admin... | open | 2018-01-31T13:36:45Z | 2019-01-24T20:31:13Z | https://github.com/geex-arts/django-jet/issues/289 | [] | JorgeSevilla | 10 |
ultralytics/ultralytics | python | 19,292 | Colab default setting could not covert to tflite | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
Few weeks ago I can convert the yolo11n.pt to tflite, but now the colab default python setting will ... | open | 2025-02-18T09:09:13Z | 2025-02-21T01:35:52Z | https://github.com/ultralytics/ultralytics/issues/19292 | [
"bug",
"non-reproducible",
"exports"
] | kris-himax | 5 |
koxudaxi/datamodel-code-generator | fastapi | 2,232 | [PydanticV2] Add parameter to use Python Regex Engine in order to support look-around | **Is your feature request related to a problem? Please describe.**
1. I wrote a valid JSON Schema with many properties
2. Some properties' pattern make use of look-ahead and look-behind, which are supported by JSON Schema specifications.
See: [JSON Schema supported patterns](https://json-schema.org/understanding-js... | open | 2024-12-17T15:39:44Z | 2025-02-06T20:06:51Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2232 | [
"bug",
"help wanted"
] | ilovelinux | 4 |
deezer/spleeter | deep-learning | 88 | [Bug] Colab Runtime Disconnected | <!-- PLEASE READ THIS CAREFULLY :
- Any issue which does not respect following template or lack of information will be considered as invalid and automatically closed
- First check FAQ from wiki to see if your problem is not already known
-->
## Description
Was having trouble installing for local use, so I deci... | closed | 2019-11-14T01:02:26Z | 2024-03-19T16:51:17Z | https://github.com/deezer/spleeter/issues/88 | [
"bug",
"invalid",
"wontfix"
] | tiwonku | 3 |
proplot-dev/proplot | data-visualization | 332 | ticklabels of log scale axis should be 'log' by default? | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
I feel it might be more natural to use 'log' for ticklabels when log scale is u... | open | 2022-01-29T16:56:23Z | 2022-01-29T18:41:10Z | https://github.com/proplot-dev/proplot/issues/332 | [
"enhancement"
] | syrte | 6 |
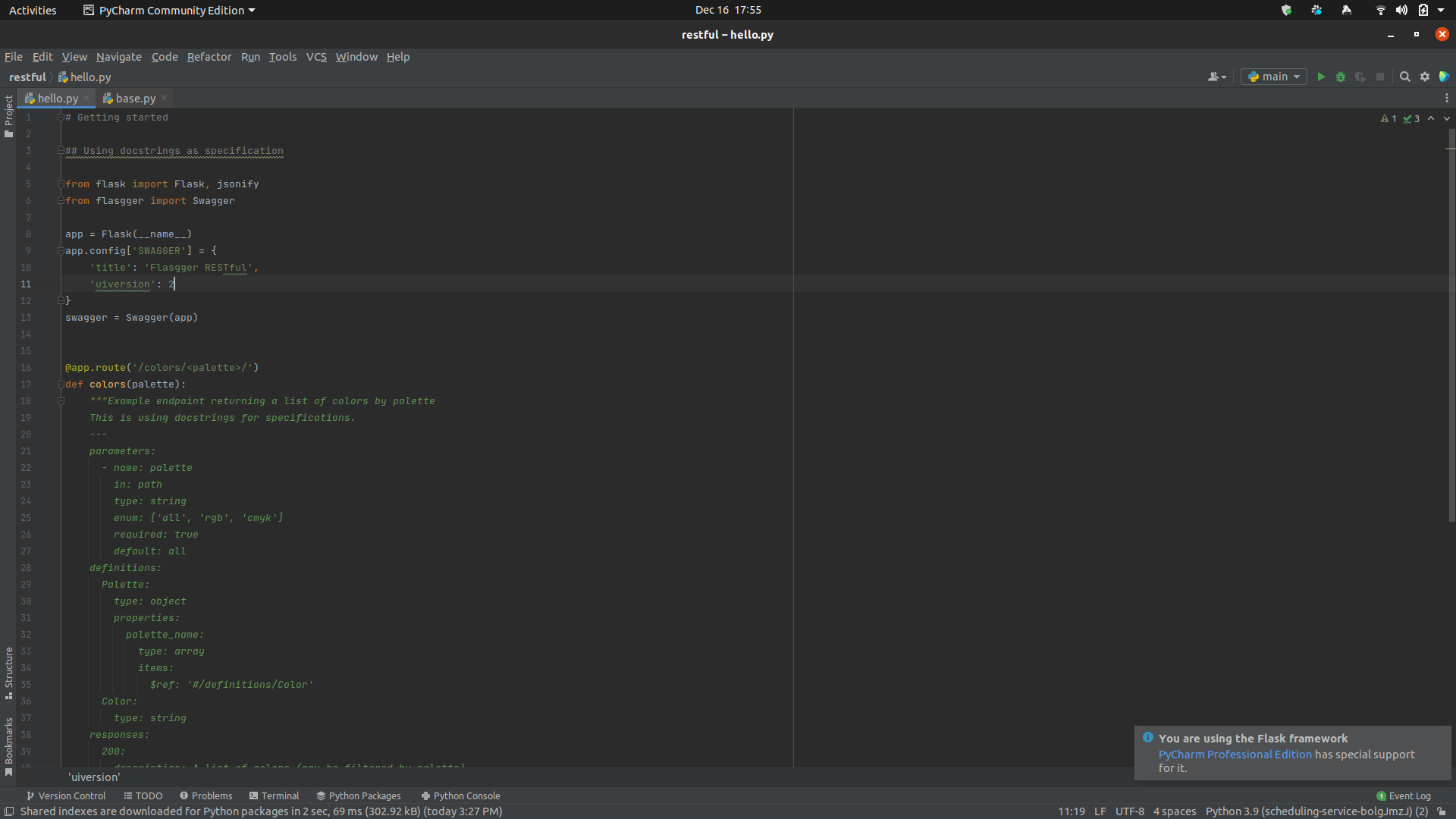
flasgger/flasgger | flask | 512 | Flasgger Not Working | I tried to use colors.py example of the app, but it isn't working

| closed | 2024-08-22T08:20:58Z | 2024-08-22T08:21:14Z | https://github.com/vastsa/FileCodeBox/issues/198 | [] | qiuyu2547 | 0 |
OFA-Sys/Chinese-CLIP | computer-vision | 192 | 怎么利用这个工具实现图像描述任务 | closed | 2023-08-28T07:33:08Z | 2023-08-28T13:01:42Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/192 | [] | yazheng0307 | 2 | |
sktime/sktime | scikit-learn | 7,134 | [ENH] `polars` schema checks - address performance warnings | The current schema checks for lazy `polars` based data types raise performance warnings, e.g.,
```
sktime/datatypes/tests/test_check.py::test_check_metadata_inference[Table-polars_lazy_table-fixture:1]
/home/runner/work/sktime/sktime/sktime/datatypes/_adapter/polars.py:234: PerformanceWarning: Determining the wi... | closed | 2024-09-18T12:55:28Z | 2024-10-06T19:35:47Z | https://github.com/sktime/sktime/issues/7134 | [
"good first issue",
"module:datatypes",
"enhancement"
] | fkiraly | 0 |
chatanywhere/GPT_API_free | api | 200 | 付费API key报错429错误 | **Describe the bug 描述bug**
付费API key报错429错误
**To Reproduce 复现方法**
发了一条信息之后, 接着询问时出现的. 之前没有遇到过这样的问题
**Screenshots 截图**

**Tools or Programming Language 使用的工具或编程语言**
Botgem
**Additional context 其他内容**
... | closed | 2024-03-25T05:31:15Z | 2024-03-25T19:30:00Z | https://github.com/chatanywhere/GPT_API_free/issues/200 | [] | Sanguine-00 | 1 |
open-mmlab/mmdetection | pytorch | 11,411 | infer error about visualizer | mmdetection/mmdet/visualization/local_visualizer.py", line 153, in _draw_instances
label_text = classes[
IndexError: tuple index out of range
https://github.com/open-mmlab/mmdetection/blob/44ebd17b145c2372c4b700bfb9cb20dbd28ab64a/mmdet/visualization/local_visualizer.py#L153-L154
| open | 2024-01-19T19:15:23Z | 2024-01-20T04:53:14Z | https://github.com/open-mmlab/mmdetection/issues/11411 | [] | dongfeicui | 1 |
peerchemist/finta | pandas | 31 | EMA calculation not matching with Tv output | Hi
Can you please check EMA calculation the output is close but not matching with Tv outputs.
Better to test this with TV and realign the code.
| closed | 2019-06-08T08:41:44Z | 2020-01-19T12:56:15Z | https://github.com/peerchemist/finta/issues/31 | [] | mbmarx | 2 |
lepture/authlib | flask | 408 | authorize_access_token broken POST? | Hello, I'm really not sure if it is a bug, but when I am trying to use authorize_access_token there is no params in POST body, as I understand they are sending in a new TCP packet (see a tcpdump picture)?
```
oauth = OAuth()
oauth.register(
'zoom',
client_id=os.environ['ZOOM_CLIENT_ID'],
client_secr... | closed | 2021-12-04T07:35:07Z | 2022-03-15T10:28:31Z | https://github.com/lepture/authlib/issues/408 | [
"bug"
] | akam-it | 2 |
flasgger/flasgger | flask | 497 | TypeError: issubclass() arg 2 must be a class or tuple of classes (when apispec not installed) | I defined Schema using marshmallow, however I was not able to see swaggerUI (having not installed apispec), thus ending with very vague error
`File "C:\gryton\projects\turbo_auta_z_usa\venv\Lib\site-packages\flasgger\marshmallow_apispec.py", line 118, in convert_schemas
if inspect.isclass(v) and issubclass(v, Sch... | open | 2021-09-23T14:21:16Z | 2021-09-23T14:21:16Z | https://github.com/flasgger/flasgger/issues/497 | [] | Gryton | 0 |
serengil/deepface | machine-learning | 897 | Got an assertion error when installing deepface | i got an error like this when installing deepface
```
#13 138.8 Building wheel for fire (setup.py): finished with status 'done'
#13 138.8 Created wheel for fire: filename=fire-0.5.0-py2.py3-none-any.whl size=116951 sha256=f36f3a2c5b1987dda9e4c020d73b1617adb6c59ae81200fcf4920bd419c4a21f
#13 138.8 Stored in dir... | closed | 2023-11-29T05:12:49Z | 2023-11-29T05:13:08Z | https://github.com/serengil/deepface/issues/897 | [] | ghost | 0 |
tfranzel/drf-spectacular | rest-api | 1,382 | Inconsistency between [AllowAny] and [] with permission_classes in schema generation | **Describe the bug**
When using AllowAny or IsAuthenticatedOrReadOnly, opening the openapi doc using swagger looks like this:

**To Reproduce**
Create an APIView or an @api_view that overrides the permission_classes with [AllowAn... | open | 2025-02-17T12:46:12Z | 2025-02-17T17:50:07Z | https://github.com/tfranzel/drf-spectacular/issues/1382 | [] | ldeluigi | 6 |
Lightning-AI/LitServe | rest-api | 195 | move `wrap_litserve_start` to utils | > I would rather reserve `conftest` for fixtures and this (seems to be) general functionality move to another utils module
_Originally posted by @Borda in https://github.com/Lightning-AI/LitServe/pull/190#discussion_r1705957686_
| closed | 2024-08-06T18:39:12Z | 2024-08-12T10:49:09Z | https://github.com/Lightning-AI/LitServe/issues/195 | [
"good first issue",
"help wanted"
] | aniketmaurya | 5 |
proplot-dev/proplot | data-visualization | 301 | Colormaps Docs Error | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
The latest docs have error in Colormaps section https://prop... | closed | 2021-11-06T19:09:17Z | 2021-11-09T18:19:22Z | https://github.com/proplot-dev/proplot/issues/301 | [
"bug"
] | pratiman-91 | 2 |
getsentry/sentry | django | 87,159 | Solve bolding of starred projects | closed | 2025-03-17T10:12:00Z | 2025-03-17T12:52:06Z | https://github.com/getsentry/sentry/issues/87159 | [] | matejminar | 0 | |
Avaiga/taipy | data-visualization | 2,388 | Add Taipy-specific and hidden parameters to navigate() | ### Description
We had a request to allow a Taipy application to query another Taipy application page, potentially served by another Taipy GUI application.
This can be done using the *params* parameter to `navigate()` but then the URL is complemented with the query string that the requestee is willing to hide, for se... | open | 2025-01-09T13:55:18Z | 2025-01-31T13:27:58Z | https://github.com/Avaiga/taipy/issues/2388 | [
"🖰 GUI",
"🟧 Priority: High",
"✨New feature",
"📝Release Notes"
] | FabienLelaquais | 1 |
marimo-team/marimo | data-visualization | 3,869 | Code Is Repeated after Minimizing Marimo Interface | ### Describe the bug
Whenever Multitasking with marimo and other tools, once i go back to marimo after minimizing it, the code in all cells are repeated multiple times making the usage of the Marimo not very friendly.
I tried to upgrade to newer version. Same issue persists/
### Environment
<details>
```
{
"mar... | closed | 2025-02-21T10:04:25Z | 2025-02-25T02:00:27Z | https://github.com/marimo-team/marimo/issues/3869 | [
"bug"
] | Nashat90 | 1 |
huggingface/transformers | python | 36,769 | Add Audio inputs available in apply_chat_template | ### Feature request
Hello, I would like to request support for audio processing in the apply_chat_template function.
### Motivation
With the rapid advancement of multimodal models, audio processing has become increasingly crucial alongside image and text inputs. Models like Qwen2-Audio, Phi-4-multimodal, and various... | open | 2025-03-17T17:05:46Z | 2025-03-17T20:41:41Z | https://github.com/huggingface/transformers/issues/36769 | [
"Feature request"
] | junnei | 1 |
mlfoundations/open_clip | computer-vision | 761 | Gradient accumulation may requires scaling before backward | In function train_one_epoch, in the file [src/training/train.py ](https://github.com/mlfoundations/open_clip/blob/main/src/training/train.py#L159)from line 156 to 162, as shown below:
```python
losses = loss(**inputs, **inputs_no_accum, output_dict=True)
del... | open | 2023-12-12T17:46:49Z | 2023-12-22T01:25:45Z | https://github.com/mlfoundations/open_clip/issues/761 | [] | yonghanyu | 1 |
widgetti/solara | jupyter | 206 | Add release notes | As the Solars package gains wider adoption, it becomes increasingly important to provide users with a convenient way to track changes and make informed decisions when selecting versions. Adding release notes would greatly benefit users. | open | 2023-07-11T12:39:34Z | 2023-10-02T17:01:31Z | https://github.com/widgetti/solara/issues/206 | [] | lp9052 | 3 |
3b1b/manim | python | 2,125 | No video is generated | Showing the following error
Manim Extension XTerm
Serves as a terminal for logging purpose.
Extension Version 0.2.13
MSV d:\All document\VS Code\Python>"manim" "d:\All document\VS Code\Python\new2.py" CreateCircle
Manim Community v0.18.0
Animation 0: Create(Circle): 0%| | 0/60 [00:00<?, ?it/s][... | closed | 2024-04-26T19:50:07Z | 2024-04-26T20:16:04Z | https://github.com/3b1b/manim/issues/2125 | [] | ghost | 0 |
ultralytics/ultralytics | deep-learning | 19,632 | about precision --Yolov11--fromdocker | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
# baout preciseion
I't's been my first time to use ultarlytics in dokcer way... | open | 2025-03-11T04:57:45Z | 2025-03-11T05:15:52Z | https://github.com/ultralytics/ultralytics/issues/19632 | [
"question",
"detect"
] | deadwoodeatmoon | 2 |
sigmavirus24/github3.py | rest-api | 641 | Strict option for branch protection | The [protected branches API](https://developer.github.com/v3/repos/branches/) now contains a new option called _strict_, which defines whether the branch that is being merged into a protected branch has to be rebased before. Since github3.py doesn't have this feature implemented yet, it is automatically set to _true_, ... | closed | 2016-10-20T14:37:30Z | 2021-11-01T01:08:43Z | https://github.com/sigmavirus24/github3.py/issues/641 | [] | kristian-lesko | 7 |
d2l-ai/d2l-en | tensorflow | 2,308 | Add chapter on diffusion models | GANs are the most advanced topic currently discussed in d2l.ai. However, diffusion models have taken the image generation mantle from GANs. Holding up GANs as the final chapter of the book and not discussing diffusion models at all feels like a clear indication of dated content. Additionally, fast.ai just announced tha... | open | 2022-09-16T21:41:12Z | 2023-05-15T13:48:32Z | https://github.com/d2l-ai/d2l-en/issues/2308 | [
"feature request"
] | dmarx | 4 |
litestar-org/litestar | pydantic | 3,601 | Bug: Custom plugin with lifespan breaks channel startup hook | ### Description
I wrote a simple plugin with a lifespan based on a context manager. When I add the custom plugin and the channels plugin, the channels plugin does not initialize properly. If I remove the lifespan from the custom plugin it works.
### URL to code causing the issue
_No response_
### MCVE
``... | closed | 2024-06-26T10:19:20Z | 2025-03-20T15:54:48Z | https://github.com/litestar-org/litestar/issues/3601 | [
"Bug :bug:"
] | TheZwieback | 1 |
cleanlab/cleanlab | data-science | 400 | Update links between tutorial notebook and example notebook | Update links between [tutorial notebook](https://github.com/cleanlab/cleanlab/blob/master/docs/source/tutorials/token_classification.ipynb) and [example notebook](https://github.com/cleanlab/examples/pull/7) so these properly point at each other (across all future versions of cleanlab).
| closed | 2022-09-06T00:45:17Z | 2022-09-15T13:42:01Z | https://github.com/cleanlab/cleanlab/issues/400 | [] | elisno | 1 |
pytorch/pytorch | machine-learning | 149,275 | torch.onnx.export Dynamic shapes output not working | ### 🐛 Describe the bug
export not working when using `nvidia/nv-embed-v2` model, if i remove `sentence_embeddings` from the input, it would make the input static
```python
!pip install datasets==3.3.2
!pip install onnx==1.17.0 onnxscript==0.2.2 torch==2.6.0 torchvision==0.21.0 onnxruntime-gpu==1.21.0
!git clone htt... | closed | 2025-03-16T15:19:49Z | 2025-03-17T03:30:06Z | https://github.com/pytorch/pytorch/issues/149275 | [] | ducknificient | 3 |
keras-team/keras | deep-learning | 20,475 | Cannot generate heatmaps using Gradcam library | import numpy as np
import tensorflow as tf
from tf_explain.core.grad_cam import GradCAM
import matplotlib.pyplot as plt
# Initialize Grad-CAM explainer
explainer = GradCAM()
# Specify the layer for Grad-CAM in the VGG16 model (vgg16_tr)
conv_layer_name = 'block5_conv2' # Adjusted to use 'block5_conv2'
# ... | open | 2024-11-08T23:10:43Z | 2024-12-03T08:15:10Z | https://github.com/keras-team/keras/issues/20475 | [
"type:Bug"
] | jeev0306 | 4 |
modin-project/modin | pandas | 7,023 | `test_corr_non_numeric` failed due to different exception messages | Also `test_cov_numeric_only`.
Found in https://github.com/modin-project/modin/pull/6954 | open | 2024-03-07T12:02:02Z | 2024-03-07T14:11:24Z | https://github.com/modin-project/modin/issues/7023 | [
"bug 🦗",
"pandas concordance 🐼",
"P2"
] | anmyachev | 0 |
erdewit/ib_insync | asyncio | 243 | examples/tk.py fails with "RuntimeError: Cannot run the event loop while another loop is running" | Hi Ewald,
seems to be very nice library which I am starting to use now. Running the examples with single modification of my local host, port, and client_id in the IB.connect() line.
examples/qt_ticker_table.py runs fine
examples/tk.py fails:
```
rusakov@dfk78:~/mcai/github/ib_insync (master)$ python examples... | closed | 2020-04-29T08:41:56Z | 2020-05-04T11:37:52Z | https://github.com/erdewit/ib_insync/issues/243 | [] | drusakov778 | 6 |
NullArray/AutoSploit | automation | 584 | Unhandled Exception (55ded4728) | Autosploit version: `3.0`
OS information: `Linux-4.18.0-kali2-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py`
Error meesage: `argument of type 'NoneType' is not iterable`
Error traceback:
```
Traceback (most recent call):
File "/root/Desktop/AutoSploit/autosploit/main.py", line 117, ... | closed | 2019-03-24T02:05:49Z | 2019-04-02T20:25:18Z | https://github.com/NullArray/AutoSploit/issues/584 | [] | AutosploitReporter | 0 |
marcomusy/vedo | numpy | 1,121 | Smooth boundary line of a mesh | Hi, I'm looking to smooth just the boundary line of a mesh (not the entire mesh), I was wondering if there's any functionality in vedo to achieve this? Thanks! | closed | 2024-05-17T01:26:33Z | 2024-06-13T18:35:26Z | https://github.com/marcomusy/vedo/issues/1121 | [] | sean-d-zydex | 2 |
dpgaspar/Flask-AppBuilder | rest-api | 1,567 | Running tests: DB Creation and initialization failed | I don't know if this is a flask_appbuilder issue, probably not. But I do need to solve this in order to be able to run tests via bash (so I can write and test tests and finish my pull request according to the new reset password functions).
### Environment
Flask-Appbuilder version: 3.1.1
pip freeze output:
... | closed | 2021-02-11T12:10:07Z | 2021-02-12T08:23:25Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1567 | [] | runoutnow | 1 |
biolab/orange3 | pandas | 6,675 | File widget: add option to skip a range of rows not holding headers or data | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
Many datasets that are available online as open data have rows that are not column headers or ac... | closed | 2023-12-13T14:28:02Z | 2024-01-05T10:38:14Z | https://github.com/biolab/orange3/issues/6675 | [] | wvdvegte | 5 |
pyppeteer/pyppeteer | automation | 136 | Downloading a file (into memory) with pyppeteer | I'm navigating a site in pyppeteer that contains logic in which file download links must be followed in the same session in which they're surfaced. It's complex enough such that simply replaying the requests with postman fails and is not worth reverse-engineering. This means that I need to use pyppeteer to follow a dir... | open | 2020-06-13T15:56:26Z | 2020-10-21T01:08:32Z | https://github.com/pyppeteer/pyppeteer/issues/136 | [
"bug",
"fixed-in-2.1.1"
] | jessrosenfield | 5 |
waditu/tushare | pandas | 1,039 | [BUG]前复权数据与同花顺不一致 | 代码:
df_bar = ts.pro_bar(ts_code='603156.SH', adj='qfq', start_date='20190507', end_date='20190509')
print(df_bar)
结果:
ts_code trade_date open high ... change pct_chg vol amount
0 603156.SH 20190509 35.75 35.77 ... -1.18 -3.21 25671.86 89925.308
1 603156.SH 20190508 35.77 ... | closed | 2019-05-12T00:45:49Z | 2019-05-12T12:26:05Z | https://github.com/waditu/tushare/issues/1039 | [] | ghost0917 | 2 |
waditu/tushare | pandas | 1,231 | 做了访问限制吗?google vm无法访问http://file.tushare.org | 一天只调用一次get_stock_basics,没有暴力爬,今天突然就不行了?connection reset by peer,而国内网就没问题 | closed | 2019-12-23T05:12:41Z | 2019-12-24T01:46:57Z | https://github.com/waditu/tushare/issues/1231 | [] | sidazhang123 | 0 |
MycroftAI/mycroft-core | nlp | 2,363 | Error during paring | After I pair, it gives me this error
```bash
21:01:28.914 | ERROR | 5174 | mycroft.skills.settings:_issue_api_call:310 | Failed to upload skill settings meta for mycroft-pairing|19.08
Traceback (most recent call last):
File "/root/mycroft-core/mycroft/skills/settings.py", line 307, in _issue_api_call
se... | closed | 2019-10-12T02:04:23Z | 2019-11-18T21:46:20Z | https://github.com/MycroftAI/mycroft-core/issues/2363 | [
"Type: Bug - complex"
] | weathon | 6 |
biolab/orange3 | scikit-learn | 6,835 | Orange3 version 3.37.0 of the graph_ranks function is replaced by what | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2024-06-15T02:54:18Z | 2024-07-05T07:12:15Z | https://github.com/biolab/orange3/issues/6835 | [
"bug report"
] | CandB1314 | 1 |
developmentseed/lonboard | jupyter | 293 | Troubleshooting docs page | - if you see an error like "model not found", reload your _browser tab_ (not the Jupyter kernel) and try again | closed | 2023-12-06T18:44:28Z | 2024-09-24T21:06:18Z | https://github.com/developmentseed/lonboard/issues/293 | [] | kylebarron | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 37 | 宝塔部署里面只能选一个启动文件 | Web启动文件选择web_zh.py
API启动文件选择web_api.py
尝试创建了2个项目好像后面那个启动不成功
那这样是Web和Api是需要2台服务器分别来部署吗? | closed | 2022-06-08T08:31:33Z | 2022-06-11T02:42:41Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/37 | [] | chris-ss | 2 |
ray-project/ray | data-science | 51,496 | CI test windows://python/ray/tests:test_advanced_4 is consistently_failing | CI test **windows://python/ray/tests:test_advanced_4** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aaf1-9737-4a02-a7f8-1d7087c16fb1
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c4f-4156-97c5-9793049512c1
DataCaseName-windows://python... | closed | 2025-03-19T00:05:32Z | 2025-03-19T21:52:09Z | https://github.com/ray-project/ray/issues/51496 | [
"bug",
"triage",
"core",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 3 |
tflearn/tflearn | tensorflow | 1,131 | QuickStart tutorial can use columns_to_ignore in load_csv() function call | load_csv line can be since there's `columns_to_ignore` param's supported
```
data, labels = load_csv('titanic_dataset.csv', target_column=0, columns_to_ignore=[2, 7], categorical_labels=True, n_classes=2)
```
and we don't need to do that in preprocess()
```
def preprocess(passengers):
for i in range(len(pass... | open | 2019-06-13T17:36:47Z | 2019-06-13T17:36:47Z | https://github.com/tflearn/tflearn/issues/1131 | [] | nicechester | 0 |
idealo/image-super-resolution | computer-vision | 187 | Different scaling factors depending on model used | I've tried running the code provided here https://github.com/idealo/image-super-resolution#prediction on a sample image. My code is as follows
import numpy as np
from PIL import Image
from ISR.models import RDN, RRDN
img = Image.open('data/input/0001.png')
lr_img = np.array(img)
mode... | open | 2021-03-14T12:43:59Z | 2021-03-14T12:43:59Z | https://github.com/idealo/image-super-resolution/issues/187 | [] | axymeus | 0 |
pytest-dev/pytest-cov | pytest | 290 | Ok, it appears to be as you explained in https://github.com/pytest-dev/pytest-cov/issues/285#issuecomment-488733091 | Ok, it appears to be as you explained in https://github.com/pytest-dev/pytest-cov/issues/285#issuecomment-488733091
in fact against current master the following patch is sufficient to not cause an error:
```diff
diff --git a/proj/app/__init__.py b/proj/app/__init__.py
index e69de29..7ec32ee 100644
--- a/proj/app... | closed | 2019-05-13T12:57:15Z | 2019-05-13T12:57:43Z | https://github.com/pytest-dev/pytest-cov/issues/290 | [] | TauPan | 1 |
Miserlou/Zappa | flask | 2,130 | documentation link is not working | *Zappa documentation link is not working*
I tried to acccess https://blog.zappa.io/, but its not loading | closed | 2020-06-30T06:57:55Z | 2021-02-08T17:45:07Z | https://github.com/Miserlou/Zappa/issues/2130 | [] | avinash-bhosale | 8 |
cvat-ai/cvat | computer-vision | 9,157 | [Question] how can i fetch frames with annotation via APIs? | So, I have our CVAT running locally and for a certain Job X i want to fetch all the frames with annotation via APIs
 | closed | 2025-02-27T19:47:49Z | 2025-03-03T09:12:33Z | https://github.com/cvat-ai/cvat/issues/9157 | [
"question"
] | prabaljainn | 4 |
apify/crawlee-python | web-scraping | 549 | Add init script for Playwright browser context | - For now, let's use a data file containing fingerprints \(or at minimum user agents\) from the Apify fingerprint dataset.
- Use the init script from the [fingerprint suite](https://github.com/apify/fingerprint-suite/blob/master/packages/fingerprint-injector/src/utils.js).
- A fingerprint, selected based on parameters ... | closed | 2024-09-27T18:02:14Z | 2025-02-05T15:04:06Z | https://github.com/apify/crawlee-python/issues/549 | [
"enhancement",
"t-tooling",
"product roadmap"
] | vdusek | 0 |
nerfstudio-project/nerfstudio | computer-vision | 2,998 | Train model from custom data without COLMAP | Hi, I'm trying to build some NeRF models from images acquired with the [PyRep](https://github.com/stepjam/PyRep) simulator and I cannot use COLMAP to extract camera intrinsics and extrinsics.
I'm currently filling a transform.json with intrinsic and extrinsic parameters from the simulator, but I don't manage to trai... | closed | 2024-03-12T11:12:37Z | 2024-08-06T07:15:10Z | https://github.com/nerfstudio-project/nerfstudio/issues/2998 | [] | fedeceola | 2 |
LibreTranslate/LibreTranslate | api | 130 | Submit translations | How can translations be provided to improve the LibreTranslate application?
| English | magyar (Hungarian) incorrect | magyar (Hungarian) correct |
|----|----|----|
| bootstrap | bootstrap | rendszerindítás |
| queue | sor | várakozási sor |
| script | szkript | parancsfájl |
| server | szerver | kiszolgáló |
... | closed | 2021-09-05T23:24:30Z | 2021-10-09T14:13:25Z | https://github.com/LibreTranslate/LibreTranslate/issues/130 | [
"enhancement"
] | ovari | 2 |
ScrapeGraphAI/Scrapegraph-ai | machine-learning | 411 | Groq example results in context_length_exceeded error | **Describe the bug**
I'm getting an error when running the Groq example on the repo. I confirmed my Groq key works when making a normal request.
*Code*
```python
from scrapegraphai.graphs import SearchGraph
import os
groq_key = os.getenv("GROQ_API_KEY")
# Define the configuration for the graph
graph_co... | closed | 2024-06-26T22:13:20Z | 2024-07-10T10:36:02Z | https://github.com/ScrapeGraphAI/Scrapegraph-ai/issues/411 | [] | yngwz | 2 |
taverntesting/tavern | pytest | 21 | Logger format issue in python 2.7 | In the **entry.py** file, **line 63**, the logger format is as follows:
`{asctime:s} [{levelname:s}]: ({name:s}:{lineno:d}) {message:s}`
Any logging output will just print the line above and not the actual variables.
A quick fix is by replacing it with the following:
`%(asctime)s [%(levelname)s]: (%(name)s:%(l... | closed | 2018-01-25T14:07:11Z | 2018-01-25T16:32:05Z | https://github.com/taverntesting/tavern/issues/21 | [] | JadedLlama | 1 |
Textualize/rich | python | 2,762 | [BUG] rich.progress.Progress transient option not working when exception is thrown within context | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
... | open | 2023-01-18T22:40:05Z | 2023-01-21T03:19:54Z | https://github.com/Textualize/rich/issues/2762 | [
"Needs triage"
] | TerranWorks | 1 |
babysor/MockingBird | pytorch | 996 | 请问作者大大,encoder如何训练? | 看了知乎链接的教程,尝试训练encoder

练了半天,这结果似乎没什么变化

`, a lot of weird undocumented behaviors may occur (e.g., #4150). We currently log a warning in this case, but it's often ignored by the users, leading to confusion. A cleaner option would be to delete all the files related ... | closed | 2024-05-14T07:50:06Z | 2024-06-27T09:24:45Z | https://github.com/autogluon/autogluon/issues/4195 | [
"enhancement",
"module: timeseries"
] | shchur | 2 |
dunossauro/fastapi-do-zero | pydantic | 180 | Link do Projecto | https://github.com/HulitosCode/fast_zero | closed | 2024-06-18T11:54:23Z | 2024-06-18T12:00:02Z | https://github.com/dunossauro/fastapi-do-zero/issues/180 | [] | HulitosCode | 0 |
localstack/localstack | python | 11,537 | bug: EventBridge pattern using suffix generates incorrect rule | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
I'm trying to create an EventBridge rule using the `suffix` matcher, with CDK:
```javascript
new Rule(this, "TestRule", {
eventPattern: {
source: ["aws.s3"],
detailType: ["Object Created"],
d... | closed | 2024-09-18T18:41:45Z | 2024-12-05T13:54:19Z | https://github.com/localstack/localstack/issues/11537 | [
"type: bug",
"aws:cloudformation",
"status: backlog"
] | arshsingh | 3 |
localstack/localstack | python | 12,019 | bug: Secret exists but is not found | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
We have a couple of secrets that we store in the Secrets Manager using a localstack image. When we fetch the secret through AWS's SDK, it returns a 400 ResoureNotFoundException.
.get("ignore_register_page"):
LookupError: <Co... | closed | 2022-10-09T21:15:14Z | 2023-03-21T18:42:12Z | https://github.com/plotly/dash/issues/2266 | [] | SKnight79 | 1 |
ageitgey/face_recognition | python | 1,199 | Problem regarding installation of face_recognition API | * face_recognition version: 1.3.0
* Python version: 3.8.2
* Operating System: Ubuntu 20.04
### Description
I wanted to install `face_recognition` api with the command `pip3 install face_recognition` and every time I do this, I get an error as following:
```
Collecting face_recognition
Using cached face_r... | open | 2020-08-12T17:43:29Z | 2020-08-13T02:10:40Z | https://github.com/ageitgey/face_recognition/issues/1199 | [] | Pritam-Pagla | 1 |
deeppavlov/DeepPavlov | tensorflow | 844 | Setting `DP_MODELS_PATH` and `DP_DOWNLOADS_PATH` variables doesn't really work | All configs in DeepPavlov library have their own way of what is written in `MODELS_PATH`:
* some configs have just `{ROOT_PATH}/models`
* some configs have one more folder, ex. `{ROOT_PATH}/models/kbqa_mix_lowercase`
* some configs have a lot of additional folders, ex. `{ROOT_PATH}/models/classifiers/insults_kaggle_... | closed | 2019-05-15T17:32:06Z | 2019-06-26T11:05:14Z | https://github.com/deeppavlov/DeepPavlov/issues/844 | [
"bug"
] | my-master | 1 |
scikit-learn/scikit-learn | machine-learning | 31,032 | `weighted_percentile` should error/warn when all sample weights 0 | ### Describe the bug
Noticed while working on #29431
### Steps/Code to Reproduce
See the following test:
https://github.com/scikit-learn/scikit-learn/blob/cd0478f42b2c873853e6317e3c4f2793dc149636/sklearn/utils/tests/test_stats.py#L67-L73
### Expected Results
Error or warning should probably be given. You'... | open | 2025-03-20T01:57:45Z | 2025-03-21T17:30:17Z | https://github.com/scikit-learn/scikit-learn/issues/31032 | [
"Bug"
] | lucyleeow | 1 |
nteract/papermill | jupyter | 660 | nbclient.exceptions.DeadKernelError if Python Warnings Filter set to 'default' | ## Question
<!-- A clear and concise description of what the bug is. -->
:wave: Hi. While trying to get a nightly notebook `pytest` test working again with modern `papermill` and `scrapbook` (c.f. https://github.com/scikit-hep/pyhf/pull/1841) I noticed that if I have [Python filter warnings](https://docs.python.o... | open | 2022-04-06T08:40:12Z | 2022-04-06T14:29:06Z | https://github.com/nteract/papermill/issues/660 | [
"bug",
"help wanted"
] | matthewfeickert | 0 |
ultralytics/yolov5 | deep-learning | 12,519 | index: 2 Got: 384 Expected: 640 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I have been using the Ultralytics Python module to use my yolov5 model made with U... | closed | 2023-12-17T17:45:54Z | 2024-02-09T04:05:16Z | https://github.com/ultralytics/yolov5/issues/12519 | [
"question",
"Stale"
] | DylDevs | 13 |
allenai/allennlp | pytorch | 5,274 | allennlp.common.checks.ConfigurationError: srl not in acceptable choices for dataset_reader | ```
from allennlp.models import load_archive
from allennlp.predictors.predictor import Predictor
import allennlp
def get_srl_predictor():
if torch.cuda.is_available():
archive = allennlp.models.archival.load_archive("https://s3-us-west-2.amazonaws.com/allennlp/models/bert-base-srl-2019.06.17.tar.gz"... | closed | 2021-06-20T07:10:09Z | 2022-06-01T21:21:45Z | https://github.com/allenai/allennlp/issues/5274 | [
"question"
] | jeevana28 | 6 |
mckinsey/vizro | plotly | 584 | Custom data does not get picked up if directly defined inside custom chart | ### Which package?
vizro
### Package version
0.1.18
### Description
If this is supposed to be like this, then I think we need to raise an error earlier or document it somewhere. Optimally this should work though: https://py.cafe/huong-li-nguyen/vizro-bug-filter-interaction
If the custom data argument is defined... | closed | 2024-07-14T18:17:07Z | 2024-07-15T06:28:43Z | https://github.com/mckinsey/vizro/issues/584 | [
"Bug Report :bug:",
"Needs triage :mag:"
] | huong-li-nguyen | 1 |
christabor/flask_jsondash | plotly | 85 | Clear api results field on modal popup | Just to prevent any confusion as to what is loaded there.
| closed | 2017-03-01T19:04:52Z | 2017-03-02T20:28:18Z | https://github.com/christabor/flask_jsondash/issues/85 | [
"enhancement"
] | christabor | 0 |
Anjok07/ultimatevocalremovergui | pytorch | 630 | Got this error getting vocals from long webm video | Last Error Received:
Process: MDX-Net
The application was unable to allocate enough system memory to use this model.
Please do the following:
1. Restart this application.
2. Ensure any CPU intensive applications are closed.
3. Then try again.
Please Note: Intel Pentium and Intel Celeron processors do n... | open | 2023-06-23T17:43:18Z | 2023-06-23T17:43:18Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/630 | [] | Comput3rUs3r | 0 |
NVlabs/neuralangelo | computer-vision | 207 | Direct point cloud extraction. Mesh extraction: addressing different results | Hi,
I was wondering if there is a way to directly extract a point cloud without extracting the mesh first?
I am seeing different results in the mesh during training and after extracting the mesh. Do you have any idea why this is happening?
Thank you! | open | 2024-07-29T15:11:36Z | 2024-07-29T15:11:36Z | https://github.com/NVlabs/neuralangelo/issues/207 | [] | camolina2 | 0 |
cleanlab/cleanlab | data-science | 638 | Whether cleanlab can be used for graph link prediction? | As the official documentation says, cleanlab can handle image, text, audio, or tabular data, so can it be used for graph data, like link prediction? | closed | 2023-02-19T06:50:46Z | 2023-05-31T22:05:21Z | https://github.com/cleanlab/cleanlab/issues/638 | [
"question"
] | xioacd99 | 2 |
django-import-export/django-import-export | django | 1,168 | What is the right way to import specific sheet in excel?? | I would like to import specific sheet in excel file...
what is the correct way to implement this??
| closed | 2020-07-28T15:19:40Z | 2020-07-31T20:13:55Z | https://github.com/django-import-export/django-import-export/issues/1168 | [
"question"
] | rmControls | 1 |
pallets-eco/flask-wtf | flask | 345 | cannot import name 'FlaskForm' | When I run
`from flask_wtf import FlaskForm`
I get:
```pytb
Traceback (most recent call last):
File "F:/Dokumente/Programmierung/Python/wtforms/wtforms.py", line 5, in <module>
from flask_wtf import FlaskForm
File "C:\Users\Niklas\Documents\venvs\testenv\lib\site-packages\flask_wtf\__init__.py", line... | closed | 2018-07-29T17:44:17Z | 2020-04-21T06:24:40Z | https://github.com/pallets-eco/flask-wtf/issues/345 | [] | Toxenum | 1 |
deepset-ai/haystack | pytorch | 8,483 | Use of meta data of documents inside components | **Problem Description**
When using a set of documents in a component like DocumentSplitter esp in a pipeline, the current working is that the same parameters of the component like split_by, split_length etc are applied to all documents. But that may not always be the case, as it is for my need.
**Suggested Solution... | open | 2024-10-23T13:17:16Z | 2025-01-09T07:30:31Z | https://github.com/deepset-ai/haystack/issues/8483 | [
"P3"
] | rmrbytes | 2 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,067 | Options suggestions to disable reminder emails | ### Proposal
This suggestion is to request the possibility to:
1. stop sending reminder notification (report settings) email when a report is in "closed" status, or checkbox option to set it in the status change panel.
2. stop sending the default notification reminder (channel settings) email when at least one r... | open | 2024-05-06T13:15:01Z | 2024-08-05T16:06:35Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4067 | [
"C: Client",
"C: Backend",
"T: Feature"
] | larrykind | 7 |
paperless-ngx/paperless-ngx | django | 8,096 | Dokumenten Export über NAS zeigt Warnung | ### Description
Ich bekomme diese Warnung angezeigt.
Was kann denn das sein?
WARNINGS:
?: Filename format {created_year}/{correspondent}/{title} is using the old style, please update to use double curly brackets
HINT: {{ created_year }}/{{ correspondent }}/{{ title }}
### Steps to reproduce
Nach jeder si... | closed | 2024-10-29T06:58:54Z | 2024-12-04T03:17:50Z | https://github.com/paperless-ngx/paperless-ngx/issues/8096 | [
"not a bug"
] | totocotonio | 3 |
allure-framework/allure-python | pytest | 730 | `allure.dynamic.title` does not create an appropriate title if fixture steps fail | **Describe the bug**
No appropriate title in case of test's fixture fail
**To Reproduce**
1. Create failed fixture
2. Add fixture to the test
3. Add parametrized test with title param
4. Add `allure.dynamic.title` based on parametrized title
5. Run the test
**Expected behavior**
Title of the failed test sa... | closed | 2023-02-07T06:30:19Z | 2023-02-08T09:33:17Z | https://github.com/allure-framework/allure-python/issues/730 | [
"theme:pytest"
] | storenth | 3 |
supabase/supabase-py | flask | 681 | Advice or example of mocking the client for tests | **Is your feature request related to a problem? Please describe.**
- I'm working on a FastAPI project that uses the `supabase-py` client.
- I am writing tests focused on API interaction (payload validation, return structure, etc).
- Many of the endpoints interact with the supabase client to fetch data, perform some... | closed | 2024-02-02T00:16:46Z | 2024-10-26T08:14:12Z | https://github.com/supabase/supabase-py/issues/681 | [] | philliphartin | 6 |
babysor/MockingBird | deep-learning | 614 | hifigan的训练无法直接使用cpu,且修改代码后无法接着训练 | **Summary[问题简述(一句话)]**
A clear and concise description of what the issue is.
hifigan的训练无法直接使用cpu,且修改代码后无法接着训练
**Env & To Reproduce[复现与环境]**
描述你用的环境、代码版本、模型
最新环境、代码版本,模型:hifigan
**Screenshots[截图(如有)]**
If applicable, add screenshots to help
将MockingBird-main\vocoder\hifigan下trian.py中41行torch.cuda.manual_seed(h.s... | open | 2022-06-12T01:52:36Z | 2022-07-02T04:57:25Z | https://github.com/babysor/MockingBird/issues/614 | [] | HSQhere | 2 |
huggingface/diffusers | deep-learning | 10,872 | [Feature request] Please add from_single_file support in SanaTransformer2DModel to support first Sana Apache licensed model | **Is your feature request related to a problem? Please describe.**
We all know Sana model is very good but unfortunately the LICENSE is restrictive.
Recently a Sana finetuned model is released under Apache LICENSE. Unfortunately SanaTransformer2DModel does not support from_single_file to use it
**Describe the solution... | closed | 2025-02-23T11:36:21Z | 2025-03-10T03:08:32Z | https://github.com/huggingface/diffusers/issues/10872 | [
"help wanted",
"Good second issue",
"contributions-welcome",
"roadmap"
] | nitinmukesh | 5 |
SALib/SALib | numpy | 102 | Negative sobol indices | Hi,
I wonder how to interpret negative numbers for the values of sensitivity indices. For example in one of my results, a parameter x has S1 = -71.6 and ST = 0.52. Likewise I saw that the example here gives negative indices:
https://waterprogramming.wordpress.com/2013/08/05/running-sobol-sensitivity-analysis-using-sal... | closed | 2016-09-26T08:38:39Z | 2016-10-25T15:50:11Z | https://github.com/SALib/SALib/issues/102 | [
"question"
] | rJonatan | 4 |
yzhao062/pyod | data-science | 2 | AUC Score & Precision score are different why not same? | from pyod.utils.data import evaluate_print
# evaluate and print the results
print("\nOn Training Data:")
evaluate_print(clf_name, y_true, y_scores)
On Training Data:
KNN ROC:0.9352, precision @ rank n:0.568
from sklearn import metrics
print("Accuracy Score",round(metrics.accuracy_score(y_true, y_pred),2))
p... | closed | 2018-06-04T19:35:54Z | 2022-01-07T03:12:09Z | https://github.com/yzhao062/pyod/issues/2 | [
"question"
] | vchouksey | 8 |
jupyterhub/repo2docker | jupyter | 682 | Provide 'podman' as a build backend | ### Proposed change
Currently, only docker is available to build images. We should:
1. Abstract the interface that builds a Dockerfile
2. Implement docker (via docker-py) as the default implementation
3. Allow [podman](https://podman.io/) to be the second implementation, so we can make sure our design isn't doc... | closed | 2019-05-20T20:42:47Z | 2021-07-02T12:44:27Z | https://github.com/jupyterhub/repo2docker/issues/682 | [
"enhancement",
"needs: discussion"
] | yuvipanda | 3 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 574 | yolo spp | 导儿,我完整下载你的项目,运行yolospp,为啥这边飘红啊
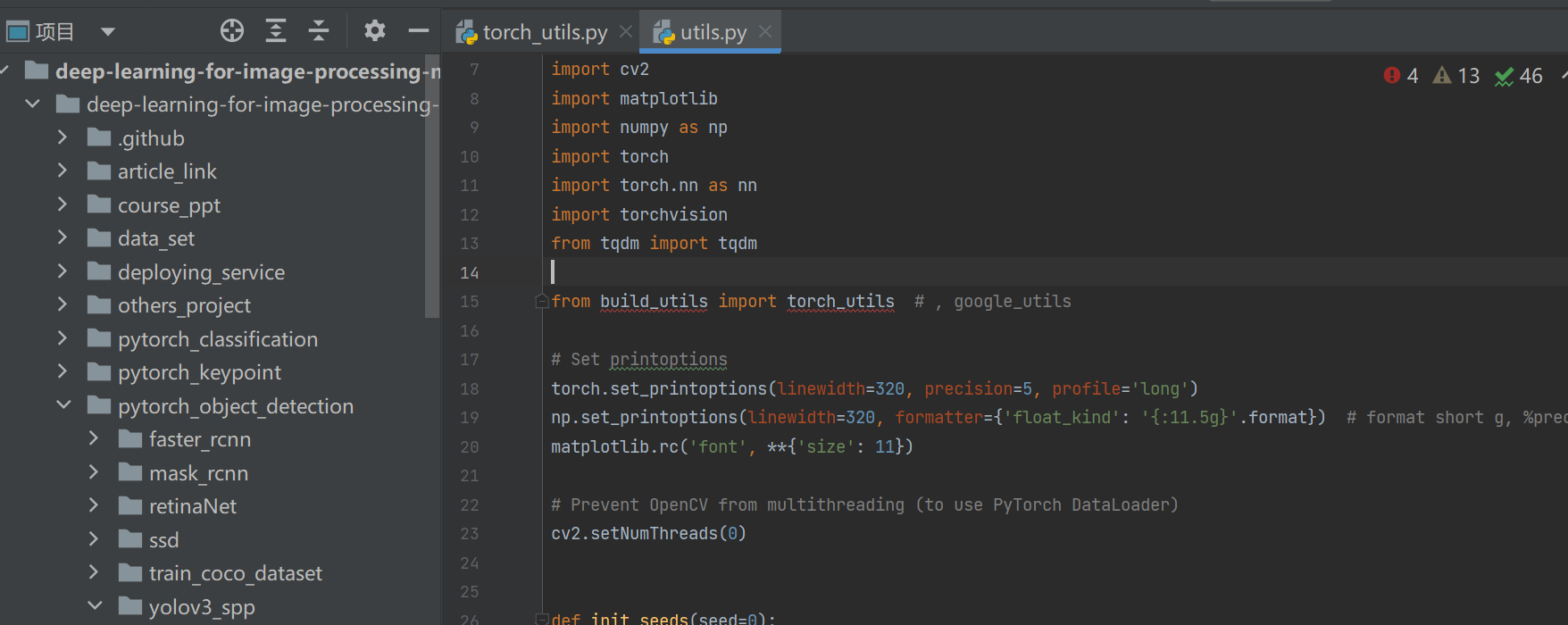
我改成import torch_utils,确实不飘红了
但是运行的时候,变成了这样
 call seems to work for all my tables on my first tab;
but in my second tab, it sometimes reduces the first few columns of my AgGrid to minimum width.
And if I use the suppressColumnVirtualisation:True option, it reduces all t... | open | 2024-02-20T06:59:30Z | 2024-03-21T17:22:32Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/249 | [
"bug"
] | spiritdncyer | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.