
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
inducer/pudb | pytest | 333 | No module named 'IPython.utils.warn' | I tried to use `%debug` in IPython, with this result:
```
In [3]: %debug
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-3-bc99e4ec804d> in <module>
----> 1 get_ipython().run_line_magic('debug', ... | closed | 2019-04-06T08:16:03Z | 2019-04-19T00:13:25Z | https://github.com/inducer/pudb/issues/333 | [] | alexeyr | 1 |
tflearn/tflearn | tensorflow | 546 | Python3 UnicodeDecodeError in oxflower17.load_data() | In python3, running the code:
```
>>> import tflearn.datasets.oxflower17 as oxflower17
>>> X, Y = oxflower17.load_data(one_hot=True, resize_pics=(227, 227))
```
Gives the error:
> File "/usr/local/lib/python3.4/dist-packages/tflearn/data_utils.py", line 339, in build_image_dataset_from_dir
> X, Y = pickl... | open | 2017-01-04T21:21:55Z | 2017-01-04T21:21:55Z | https://github.com/tflearn/tflearn/issues/546 | [] | rotemmairon | 0 |
ResidentMario/missingno | data-visualization | 37 | min() arg is an empty sequence | I have the following code, which has worked well up until today:
with PdfPages('Missing Data Report.pdf') as pdf:
for segment in SegDict_H1.keys():
matrix_fig = msno.matrix(SegDict_H1[segment],fontsize=12,inline=False)
matrix_fig.text(0,1.5,'{0} Segment Missing Data Matrix'.format(segment),sty... | closed | 2017-09-27T15:30:07Z | 2017-10-11T15:52:38Z | https://github.com/ResidentMario/missingno/issues/37 | [] | crooks3184 | 1 |
postmanlabs/httpbin | api | 207 | Incorrect URI scheme reported | As of some point within the last week the HTTPS version httpbin has started to report an incorrect URL with HTTPS swapped for HTTP, in its response JSON.
At a guess this the result of some reverse proxying? (use X-Forwarded-Proto?)
See example below, where `https://httpbin.org/post` becomes `http://httpbin.org/post`... | closed | 2015-01-26T10:42:29Z | 2018-04-26T17:51:05Z | https://github.com/postmanlabs/httpbin/issues/207 | [] | laurence-hudson-tessella | 4 |
modelscope/modelscope | nlp | 294 | No module named 'kantts' | from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
p = pipeline('text-to-speech', 'damo/speech_ptts_autolabel_16k')
`raceback (most recent call last):
File "/root/miniconda3/envs/modelscope/lib/python3.10/site-packages/modelscope/utils/import_utils.py", line 433, in _get_mod... | closed | 2023-05-10T09:58:17Z | 2023-07-29T01:50:06Z | https://github.com/modelscope/modelscope/issues/294 | [] | fuxishuyuan | 2 |
mwaskom/seaborn | data-science | 2,883 | Scatterplot y-axis inverts when column has None (object type) | Similar to https://stackoverflow.com/q/65206970/10447904:
(searched through GH issues with terms "None y axis inverted" as well as throwing in a "None"/"object" term in there, before opening this issue)
The simplest reproducing example I could find was:
```python
df = pd.DataFrame({'x': [0.0, 0.0, 0.3], 'y': [0... | closed | 2022-06-28T19:52:48Z | 2022-07-05T22:33:56Z | https://github.com/mwaskom/seaborn/issues/2883 | [] | loodvn | 2 |
pallets/flask | python | 5,372 | I'm seeing "GET /socket.io/?EIO=3&transport=polling&t=OozzqO3 HTTP/1.1" 404 errors running a simple flask app | I created a "Hello World" flask app (which can be found here: https://github.com/dhylands/flask-hello/tree/main
If I create a virtual environment and install flask and then do `flask run` I get the following output:
```
* Debug mode: off
WARNING: This is a development server. Do not use it in a production deploy... | closed | 2023-12-31T03:47:40Z | 2024-01-15T00:07:20Z | https://github.com/pallets/flask/issues/5372 | [] | dhylands | 2 |
pydata/xarray | numpy | 9,209 | Some complex aggregations broken with `numbagg` installed | ### What happened?
Some common aggregations (at least `min`, `max`, `var`, `std`) are broken with complex dtypes if `numbagg` is installed with the default `skipna=True`. Looks like this is the case since #8624.
### What did you expect to happen?
We either route to `bottleneck` or `numpy` [here](https://github.com/p... | closed | 2024-07-05T17:59:12Z | 2024-07-07T04:25:14Z | https://github.com/pydata/xarray/issues/9209 | [
"bug",
"needs triage"
] | slevang | 1 |
lanpa/tensorboardX | numpy | 444 | Flush_secs not working. | **Describe the bug**
SummaryWriter's flush_secs doesn't work as expected. If you set flush_secs=5, then it still outputs every 120 secs.
The reason is that SummaryWriter doesn't pass max_queue and flush_secs to FileWriter.
**Minimal runnable code to reproduce the behavior**
```
from tensorboardX import Summary... | closed | 2019-06-11T01:36:06Z | 2019-06-18T18:14:11Z | https://github.com/lanpa/tensorboardX/issues/444 | [] | geelin | 0 |
yt-dlp/yt-dlp | python | 12,587 | [BanBye.com] 404 error while video is available in browser | ### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same... | open | 2025-03-12T19:14:37Z | 2025-03-13T06:33:52Z | https://github.com/yt-dlp/yt-dlp/issues/12587 | [
"question"
] | nicolaasjan | 4 |
horovod/horovod | deep-learning | 3,842 | Problem with using MPI for training-related communications on Horovod + Ray | **Environment:**
1. Framework: PyTorch
2. Framework version: 1.5.0
3. Horovod version: 0.23.0
4. MPI version: MVAPICH2 2.3.7/mpi4py 3.1.4
5. CUDA version: 11.2
6. NCCL version: N/A
7. Python version: 3.7.15
8. Spark / PySpark version: N/A
9. Ray version: 2.2.0
10. OS and version: Centos 7
11. GCC version: 9... | closed | 2023-02-08T02:46:57Z | 2023-02-22T20:23:05Z | https://github.com/horovod/horovod/issues/3842 | [
"bug",
"ray"
] | KinanAlAttar | 0 |
miguelgrinberg/Flask-SocketIO | flask | 1,042 | Messages are being queued and being sent only when the server returns a 200 response. | I am working on a chat platform and I am using flask_socketio for that.
I am able to receive the messages on the chat interface just fine, but when there are more than one messages instead of sending the messages one by one. It sends all the three messages in a go.
After carefully looking into the issue it seems li... | closed | 2019-08-16T10:26:43Z | 2019-10-17T09:59:45Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1042 | [
"question"
] | sajil13 | 1 |
netbox-community/netbox | django | 18,893 | Same device types with different part numbers | ### NetBox version
v4.2.3
### Feature type
Data model extension
### Proposed functionality
We have some servers with same model (S2600WFT) and different part numbers (K91296-001 and K77844-002). I cannot add different device types because they are identified by device model, thus, Netbox considers them to be the s... | closed | 2025-03-13T12:11:58Z | 2025-03-20T19:27:08Z | https://github.com/netbox-community/netbox/issues/18893 | [
"type: feature"
] | wlnx | 1 |
SYSTRAN/faster-whisper | deep-learning | 1,128 | no_speech_prob always returns 0.0. | I'm using large-v3, and when I convert the audio to a numpy array and pass it to the model for transcription, the no_speech_prob returned is 0.0 every time, but with large-v2 there is a correct return.I can't fix this.Here's my sample code:
```python
def transcribe_audio(self, audio_numpy):
try:
... | open | 2024-11-12T06:21:42Z | 2024-11-26T14:13:40Z | https://github.com/SYSTRAN/faster-whisper/issues/1128 | [] | giaoyyds | 1 |
voila-dashboards/voila | jupyter | 989 | Wrong branch for latest version of documentation on `readthedocs` | Latest version of [Voila RTD](https://voila.readthedocs.io/en/latest/) is still pointing to `master` instead of `main` | closed | 2021-10-05T08:26:00Z | 2021-10-05T08:37:16Z | https://github.com/voila-dashboards/voila/issues/989 | [
"documentation"
] | trungleduc | 2 |
horovod/horovod | deep-learning | 3,994 | tensorflow hvd.DistributedOptimizer bug | **Environment:**
1. Framework: (TensorFlow)
2. Framework version:2.12
3. Horovod version: master
hvd.DistributedOptimizer bug,when set groups parma can reproduce error.
opt = hvd.DistributedOptimizer(opt, op=hvd.Sum, groups=4)
https://github.com/horovod/horovod/blob/master/horovod/tensorflow/__init__.py#L322... | open | 2023-10-12T09:26:51Z | 2023-10-12T09:26:51Z | https://github.com/horovod/horovod/issues/3994 | [
"bug"
] | Chenjingliang1 | 0 |
pywinauto/pywinauto | automation | 1,426 | QUESTION: Interfacing with 3 types of controls | Hi,
I am a novice in automation and still learning your software. At the moment I want to automate some music mastering software, specifically the window where the file export happens. I identify 3 elements, or controls. The **first** one is the filename field where you have to click on the text box, then enter a text... | open | 2025-01-23T10:02:47Z | 2025-01-23T10:02:47Z | https://github.com/pywinauto/pywinauto/issues/1426 | [] | QuantumCrazy | 0 |
Lightning-AI/pytorch-lightning | data-science | 20,654 | Fabric run CLI cannot launch python module | ### Description & Motivation
In Fabric run CLI, the script argument always assumes the input is an existed file path. However, users might need to launch a python module.
https://github.com/Lightning-AI/pytorch-lightning/blob/08266a9673cddf2d6ca39dc8de04d04bdf10cc7f/src/lightning/fabric/cli.py#L63
For example, the C... | open | 2025-03-18T20:40:12Z | 2025-03-18T20:40:32Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20654 | [
"feature",
"needs triage"
] | jhliu17 | 0 |
plotly/dash | dash | 2,515 | [BUG] tml : "In the callback for output(s):\n plot-update.id\nOutput 0 (plot-update.id) is already in use.\nTo resolve this, set `allow_duplicate=True` on\nduplicate outputs, or combine the outputs into\none callback function, distinguishing the trigger\nby using `dash.callback_context` if necessary." message : "Dup... | When I run my in a docker container in production, I get this error in the browser console and the app is fozen:
sh_renderer.v2_9_3m1682621169.min.js:2 {message: 'Duplicate callback outputs', html: 'In the callback for output(s):\n plot-update.id\nOu…er\nby using `dash.callback_context` if necessary.'}
Qo @ dash_r... | closed | 2023-04-27T19:15:32Z | 2024-05-23T10:11:03Z | https://github.com/plotly/dash/issues/2515 | [] | sorenwacker | 1 |
iperov/DeepFaceLab | machine-learning | 683 | OOM error with training | Tried to run training H128. Got an error message saying
Error: OOM when allocating tensor with shape [3,3,512,2048] and type float on /job:localhost
[[{{node training/adam/mul_73}} Mul[T=DT_float]
Also [[{{node loss/model_2_loss_1/Mean 3/_597}}]]
The bottom code said Hint: If you want to see a list of allocat... | closed | 2020-03-30T11:39:24Z | 2020-03-30T11:44:41Z | https://github.com/iperov/DeepFaceLab/issues/683 | [] | coastiestevie | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,150 | Dear Friends, I am facing segmentation fault | Dear Friends, I am facing segmentation fault
`
Segmentation fault (core dumped)`
while using
`$ python demo_toolbox.py`
There is nothing which happens other than this fault, no window popup or any other error. I tried several python versions and also torch versions. Same result.
I am using Centos 7. Earlier ... | closed | 2022-12-19T12:12:44Z | 2024-12-22T13:21:01Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1150 | [] | ImanuillKant1 | 1 |
pytorch/vision | machine-learning | 8,103 | Scheduled workflow failed | Oh no, something went wrong in the scheduled workflow tests/download.
Please look into it:
https://github.com/pytorch/vision/actions/runs/6795955113
Feel free to close this if this was just a one-off error.
cc @pmeier | closed | 2023-11-08T09:03:43Z | 2023-11-09T11:13:56Z | https://github.com/pytorch/vision/issues/8103 | [
"bug",
"module: datasets"
] | github-actions[bot] | 0 |
python-gino/gino | asyncio | 476 | Cascade delete? | ### Description
Suppose you have a set of models like the following
```py
db = Gino()
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Numeric(), primary_key=True)
username = db.Column(db.Unicode())
class Mod(db.Model):
__tablename__ = "mod"
id = db.Column(db.Numeri... | closed | 2019-05-01T12:36:49Z | 2019-05-11T03:28:37Z | https://github.com/python-gino/gino/issues/476 | [
"question"
] | Ovyerus | 2 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 700 | yolov3-spp 多gpu训练问题 一直提醒系统中没有rank 这个程序是需要在liunx上运行的么 | **System information**
* Have I written custom code:
* OS Platform(e.g., window10 or Linux Ubuntu 16.04):
* Python version:
* Deep learning framework and version(e.g., Tensorflow2.1 or Pytorch1.3):
* Use GPU or not:
* CUDA/cuDNN version(if you use GPU):
* The network you trained(e.g., Resnet34 network):
**Des... | open | 2022-11-28T07:39:58Z | 2022-12-05T04:55:11Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/700 | [] | Lexiaotian | 2 |
littlecodersh/ItChat | api | 227 | 群聊用户的微信账号(id)如何获取呢 | hi 大家好 群聊用户的微信账号(id)如何获取呢 | closed | 2017-02-11T10:42:56Z | 2017-02-12T03:27:48Z | https://github.com/littlecodersh/ItChat/issues/227 | [
"question"
] | wwj718 | 2 |
NullArray/AutoSploit | automation | 461 | Unhandled Exception (4f5600abe) | Autosploit version: `3.0`
OS information: `Linux-4.4.0-142-generic-x86_64-with-Ubuntu-16.04-xenial`
Running context: `autosploit.py`
Error meesage: `global name 'Except' is not defined`
Error traceback:
```
Traceback (most recent call):
File "/home/screamwre/wk/tool/AutoSploit-master/autosploit/main.py", line 113, in ... | closed | 2019-02-13T02:37:58Z | 2019-03-03T03:31:06Z | https://github.com/NullArray/AutoSploit/issues/461 | [] | AutosploitReporter | 0 |
xuebinqin/U-2-Net | computer-vision | 41 | How to change Input/Output image dimension from 320x320 to 640x640 | Dear Nathan ,
I hope you are doing well . Your results are really stunning thank you for sharing the project . It would be deeply appreciated if you can kindly answer the following question for me .
I want to change the model input image and output prediction size from 320x320 to 640x640 . Can you please guide me... | open | 2020-06-27T13:47:03Z | 2022-04-26T18:23:08Z | https://github.com/xuebinqin/U-2-Net/issues/41 | [] | kamalkantamaity | 11 |
n0kovo/fb_friend_list_scraper | web-scraping | 5 | Timed out waiting for friends count to load | 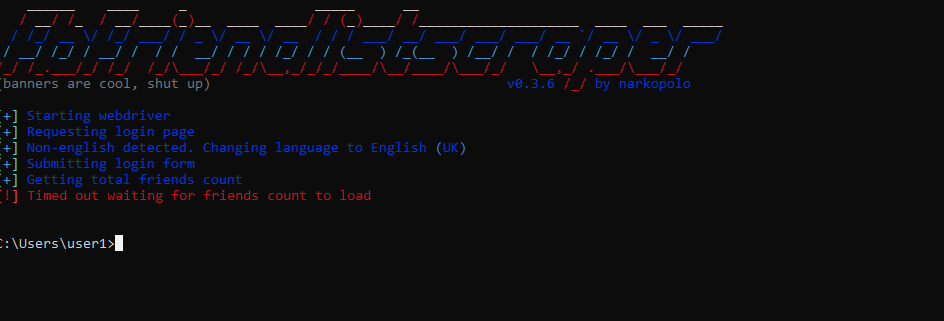
- Is it not able to read friends from a private profile?
AND/OR
- Do i need to install some firefox plugins? | closed | 2022-08-22T09:41:45Z | 2022-12-15T15:47:11Z | https://github.com/n0kovo/fb_friend_list_scraper/issues/5 | [] | jayjupdhig | 5 |
wger-project/wger | django | 1,742 | Unable to edit exercise | For some exercises that I created I am not able to edit them anymore.
## Steps to Reproduce
<!-- Please include as many steps to reproduce so that we can replicate the problem. -->
1. Go to an exercise page
2. Select Edit
**Expected results:** <!-- what did you expect to see? -->
The exercise editor for... | closed | 2024-07-26T13:05:47Z | 2024-12-12T19:38:15Z | https://github.com/wger-project/wger/issues/1742 | [] | seyfeb | 2 |
pallets/flask | python | 5,537 | `pyright` type checking seems to be unused. `mypy` still being used. | We added `pyright` in 3.0.3 (see: https://github.com/pallets/flask/pull/5457), but `mypy` is still being used for type checking https://github.com/pallets/flask/blob/main/tox.ini#L29-L32, and `pyright` is not.
If this was an intentional change of type checkers, then would expect that `mypy` be completely removed, an... | closed | 2024-07-31T04:29:38Z | 2024-11-08T00:07:41Z | https://github.com/pallets/flask/issues/5537 | [] | pygeek | 1 |
marshmallow-code/apispec | rest-api | 557 | Components are not referenced when combined with oneOf, anyOf, allOf, not | When combining multiple schemas with `oneOf`, `anyOf`, `allOf` or `not` that where previously added to components, they will not get referenced. I.e. running
```python
from pprint import pprint
from apispec import APISpec
spec = APISpec(
title="Gisty",
version="1.0.0",
openapi_version="3.0.2",
... | closed | 2020-04-25T11:41:17Z | 2021-07-26T15:03:37Z | https://github.com/marshmallow-code/apispec/issues/557 | [] | lfiedler | 10 |
mitmproxy/pdoc | api | 429 | one of the pytest doctests in a docstring not rendered correctly | #### Problem Description
One of the doctests in the example below isn´t rendered correctly. The behavior depends on indentation and on the --docformat command argument: see example below.
#### Steps to reproduce the behavior:
test script doctest_google.py:
```python
def bla():
"""Print bla.
Example... | closed | 2022-08-10T14:11:28Z | 2022-08-23T17:04:05Z | https://github.com/mitmproxy/pdoc/issues/429 | [
"bug",
"upstream"
] | tmeyier | 2 |
mitmproxy/mitmproxy | python | 6,645 | HTTP Request with Client Certificate doesn't work with IIS server (but works properly with other vendors) | #### Problem Description
Generate Client Certificate and use it to connect to IIS server get stuck (eventually it failed).
The same Client Certificate works properly with **NodeJS** Server and **Apache** Server.
#### Steps to reproduce the behavior:
1. Setup IIS Server
2. Generate Client Certificate
3. Try to r... | open | 2024-02-04T20:13:23Z | 2024-02-04T20:13:23Z | https://github.com/mitmproxy/mitmproxy/issues/6645 | [
"kind/triage"
] | Shnitzelil | 0 |
zappa/Zappa | flask | 994 | Maybe it would be more productive to make joint efforts with serverless framework and move Zappa features into plugins for it? | There are plugin and using it it's possible to achieve 90% of the Zappa functionality:
https://github.com/logandk/serverless-wsgi (it's based on Zappa btw)
Docker containers with auto build - deploy to ecr - are supported for several months
A lot of third-party-plugins
Zappa missing some critical features like ... | closed | 2021-06-25T11:48:58Z | 2022-07-16T04:30:36Z | https://github.com/zappa/Zappa/issues/994 | [] | ArtikUA | 3 |
huggingface/datasets | tensorflow | 7,440 | IterableDataset raises FileNotFoundError instead of retrying | ### Describe the bug
In https://github.com/huggingface/datasets/issues/6843 it was noted that the streaming feature of `datasets` is highly susceptible to outages and doesn't back off for long (or even *at all*).
I was training a model while streaming SlimPajama and training crashed with a `FileNotFoundError`. I can ... | open | 2025-03-07T19:14:18Z | 2025-03-22T21:48:02Z | https://github.com/huggingface/datasets/issues/7440 | [] | bauwenst | 5 |
numba/numba | numpy | 9,721 | @jit(target_backend='cpu') select loop mode for huge for loop |
can i use it like:
```
# loop_mode = 'cuda' or 'cpu'
def looper(loop_mode):
......
@jit(target_backend=loop_mode)
for i in range (......
.....
```
i mean can i use it like :
`@jit(target_backend='cpu')`
@jit(target_backend=loop_mode)
for making library for huge for loop... | closed | 2024-09-10T06:37:22Z | 2024-10-25T01:58:58Z | https://github.com/numba/numba/issues/9721 | [
"question",
"no action required",
"stale"
] | ganbaaelmer | 5 |
Lightning-AI/pytorch-lightning | pytorch | 20,358 | load data sequence is confusing | ### Bug description
I understand data consuming sequence in lightning is:
1, sanity check: call val_dataloader
2, training: call train_dataloader
3, validate: call val_dataloader
from above sequence I understand the cycle of a epoch is start from val_dataloader and end at train_dataloader, and the 3rd validate re... | open | 2024-10-22T14:08:12Z | 2024-10-22T14:37:08Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20358 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | workhours | 2 |
comfyanonymous/ComfyUI | pytorch | 7,025 | [Announcement] The frontend will no longer be shipped in the main ComfyUI repo, it will be a separate pip package instead. | Due to the frontend being a [separate project](https://github.com/Comfy-Org/ComfyUI_frontend) it doesn't make sense to continue shipping the frontend as part of the main repo.
To make our lives easier and prevent the main ComfyUI repo from becoming too large in size over time we have decided to start shipping the fron... | open | 2025-02-28T23:46:10Z | 2025-03-22T23:36:38Z | https://github.com/comfyanonymous/ComfyUI/issues/7025 | [
"Important"
] | comfyanonymous | 44 |
onnx/onnx | scikit-learn | 6,298 | Deprecation / Update Policy for onnx dependencies / Release Process? | Hello,
since Onnx has developed into a quasi-standard in some areas, I think it could makes sense
to write down how Onnx relates to other projects and what dependencies there are.
I want to avoid the expression _best practices_ and would therefore call it _good practices_ or _guidelines_.
When do we update/upg... | open | 2024-08-16T13:45:49Z | 2025-03-10T05:56:00Z | https://github.com/onnx/onnx/issues/6298 | [
"topic: documentation"
] | andife | 15 |
fastapi/fastapi | asyncio | 12,239 | Sponsor Badge CSS overflow issue on the docs | ### Discussed in https://github.com/fastapi/fastapi/discussions/12218
<div type='discussions-op-text'>
<sup>Originally posted by **nat236919** September 19, 2024</sup>
### First Check
- [X] I added a very descriptive title here.
- [X] I used the GitHub search to find a similar question and didn't find it.
-... | open | 2024-09-20T19:37:07Z | 2025-03-24T10:52:16Z | https://github.com/fastapi/fastapi/issues/12239 | [
"question"
] | Kludex | 1 |
microsoft/MMdnn | tensorflow | 599 | error: Tensorflow to caffe "caffe_emitter:emit_Constant" doesn't handle one dim tensor. | # Enviroment
Platform (like ubuntu 16.04/win10): ubuntu 16.04
Python version: python3.5
Source framework with version (like Tensorflow 1.4.1 with GPU): Tensorflow 1.13
Destination framework with version (like CNTK 2.3 with GPU): caffe
Pre-trained model path (webpath or webdisk path):
Running scripts... | closed | 2019-03-01T07:43:03Z | 2019-03-05T03:30:03Z | https://github.com/microsoft/MMdnn/issues/599 | [] | Alnlll | 3 |
miguelgrinberg/flasky | flask | 160 | how to initialize the "roles" table to insert the data? | I have encountered some error:
"application not registered on db instance and no application bound to current context"
when I call Role.insert_roles() to initialize the "roles" table. Can you help me to know how to do this in a right way? @miguelgrinberg
| closed | 2016-06-15T08:40:26Z | 2017-03-17T19:01:54Z | https://github.com/miguelgrinberg/flasky/issues/160 | [
"question"
] | onlyanyz | 2 |
deeppavlov/DeepPavlov | nlp | 799 | Remove KerasWrapper in favor of raw KerasModel | For now we have two basic classes: [KerasModel](https://github.com/deepmipt/DeepPavlov/blob/613d265f7371ba05365a7d44485066293c169674/deeppavlov/core/models/keras_model.py#L34-L36) and [KerasWrapper](https://github.com/deepmipt/DeepPavlov/blob/613d265f7371ba05365a7d44485066293c169674/deeppavlov/core/models/keras_model.p... | closed | 2019-04-15T11:43:52Z | 2019-07-09T07:37:13Z | https://github.com/deeppavlov/DeepPavlov/issues/799 | [] | yoptar | 2 |
ray-project/ray | data-science | 51,514 | [Autoscaler] Add Support for BatchingNodeProvider in Autoscaler Config Option | ### Description
[KubeRay](https://docs.ray.io/en/latest/cluster/kubernetes/user-guides/configuring-autoscaling.html#overview) currently uses the BatchingNodeProvider to manage clusters externally (using the KubeRay operator), which enables users to interact with external cluster management systems. However, to support... | open | 2025-03-19T06:51:24Z | 2025-03-19T22:23:54Z | https://github.com/ray-project/ray/issues/51514 | [
"enhancement",
"P2",
"core"
] | nadongjun | 0 |
pyqtgraph/pyqtgraph | numpy | 2,663 | AA | ```python
import pyqtgraph.opengl as gl
from pyqtgraph.Qt import QtCore, QtGui
import numpy as np
# create a 3D scatter plot
app = QtGui.QApplication([])
w = gl.GLViewWidget()
w.opts['distance'] = 20
w.show()
w.setWindowTitle('3D Scatter Plot')
pos = np.random.random((1000, 3))
color = np.random.random((... | closed | 2023-03-25T20:42:53Z | 2023-05-24T00:05:53Z | https://github.com/pyqtgraph/pyqtgraph/issues/2663 | [] | ISMAILJAOUA11 | 2 |
python-visualization/folium | data-visualization | 1,196 | Archiving documents containing folium maps | #### Problem description
I need to archive a Jupyter Notebook containing folium maps. Because technology changes and map tiles might move in 10 or 20 years, I would need to somehow save all the content into one file, which could be either XML, PDF or TIFF (or a mix of these). And I need to do this on a large scale, ... | closed | 2019-08-07T07:58:41Z | 2019-08-12T11:44:02Z | https://github.com/python-visualization/folium/issues/1196 | [] | 1kastner | 7 |
JaidedAI/EasyOCR | machine-learning | 1,266 | Request for Updated Pre-trained Models and Guidance on Fine-tuning EasyOCR | Hello,
I want to fine-tune EasyOCR for French (easyocr.Reader([fr])), and I followed the instructions provided in[ this note](https://github.com/JaidedAI/EasyOCR/blob/master/custom_model.md) by @rkcosmos and[ this article](https://pub.towardsai.net/how-to-fine-tune-easyocr-to-achieve-better-ocr-performance-1540f50764... | open | 2024-06-10T08:44:30Z | 2024-06-10T08:57:36Z | https://github.com/JaidedAI/EasyOCR/issues/1266 | [] | Meriem-DAHMANI | 0 |
flairNLP/flair | pytorch | 3,377 | [Question]: Difference Between `train` and `fine_tune` Methods in `ModelTrainer` | ### Question
I noticed the [documentation](https://github.com/flairNLP/flair/blob/master/docs/tutorial/tutorial-training/train-vs-fine-tune.md) on the difference between the ModelTrainer's train() and fine_tune() methods is empty. Based on this [example](https://github.com/flairNLP/flair/blob/master/docs/tutorial/tuto... | closed | 2023-11-27T15:58:18Z | 2023-11-28T10:17:46Z | https://github.com/flairNLP/flair/issues/3377 | [
"question"
] | AAnirudh07 | 2 |
google-deepmind/sonnet | tensorflow | 198 | VQ-VAE training example(v2) returned NAN loss | Dear Team Deepmind,
I am really grateful that you shared a vqvae_example with sonnet2. However, when running it, I currently encounter a problem of NAN vqvae loss from the beginning. The outcome is:
100 train loss: nan recon_error: 1.010 perplexity: 1.031 vqvae loss: nan
and so on.
The plot of the training set is... | open | 2021-02-13T06:41:58Z | 2021-09-06T09:36:37Z | https://github.com/google-deepmind/sonnet/issues/198 | [] | EBGU | 4 |
gee-community/geemap | streamlit | 1,614 | Possibly unused variables | `vis_params` and `url_format` variables e.g. [here](https://github.com/gee-community/geemap/blob/ccba6fd0185f5274c2a22ce5fdff8b0f9d04ee1e/geemap/ee_tile_layers.py#L70C5-L70C15) and [here](https://github.com/gee-community/geemap/blob/ccba6fd0185f5274c2a22ce5fdff8b0f9d04ee1e/geemap/ee_tile_layers.py#L109) appear unused.
... | closed | 2023-07-07T00:01:51Z | 2023-07-07T02:45:42Z | https://github.com/gee-community/geemap/issues/1614 | [
"cleanup"
] | jdbcode | 1 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,604 | add "create_type" to sqltypes.Enum ? | this type has a "name" argument that only applies to PostgreSQL. So the type already has "backend specific" arguments, and it having a name implies directly that there's a separate CREATE statement. so we should have create_type directly present. See https://github.com/sqlalchemy/alembic/issues/1347 | open | 2023-11-08T17:20:09Z | 2024-10-19T10:28:51Z | https://github.com/sqlalchemy/sqlalchemy/issues/10604 | [
"postgresql",
"datatypes"
] | zzzeek | 4 |
ClimbsRocks/auto_ml | scikit-learn | 86 | Allow the user to pass in a list of categorical variables as the value for a column | For example, item_ids in order.
We will then go through and manually one-hot-encode them.
So, we could pass in item_id: [5, 8, 12, 4, 6]. Then auto_ml would set row['item_id=5'] = True.
Obviously, this will not work for continuous variables (item cost). But it should at least be helpful for categorical variables ... | open | 2016-09-20T17:30:47Z | 2016-09-20T17:30:47Z | https://github.com/ClimbsRocks/auto_ml/issues/86 | [] | ClimbsRocks | 0 |
coqui-ai/TTS | pytorch | 3,246 | [Feature request] Could add a switch to disabled the remote config check that in check_if_configs_are_equal function in TTS/utils/manage.py file | Sometimes in Intranet which could not connect to Internet, the **check_if_configs_are_equal** function (in TTS/utils/manage.py file) check the local config version and the remote config version will failed and halt on so much time. Would it be possible to add a parameter setting to enable or disable this version of the... | closed | 2023-11-17T08:20:46Z | 2023-12-28T18:39:45Z | https://github.com/coqui-ai/TTS/issues/3246 | [
"wontfix",
"feature request"
] | listeng | 2 |
aeon-toolkit/aeon | scikit-learn | 2,324 | [ENH] Docker image for aeon with Numba caching | ### Describe the feature or idea you want to propose
Aeon should provide a Dockerfile or Docker image that showcases how to install and run aeon within Docker.
Additionally, aeon uses a lot of Numba-JITed code that gets compiled on first usage. This means that when using Docker, the functions are getting recompiled e... | open | 2024-11-08T14:29:19Z | 2025-03-22T15:02:01Z | https://github.com/aeon-toolkit/aeon/issues/2324 | [
"documentation",
"enhancement",
"maintenance"
] | SebastianSchmidl | 3 |
kymatio/kymatio | numpy | 490 | Add meta information to 2D and 3D | Right now, we have it in 1D by calling `Scattering1D.meta`. It would be good to have something similar in 2D and 3D. | open | 2020-01-23T20:08:17Z | 2020-03-03T16:59:58Z | https://github.com/kymatio/kymatio/issues/490 | [] | janden | 4 |
redis/redis-om-python | pydantic | 571 | AnyUrl & HttpUrl validation error | ### OS: Ubuntu 22.04.3 LTS (WSL2)
### Python: 3.11.6
### Redis: 7.2.2
Code sample:
from pydantic import HttpUrl, BaseModel
from redis_om import JsonModel
class Crush(BaseModel):
http: HttpUrl
class Test(JsonModel):
http: HttpUrl
Shell test:
ka... | closed | 2023-10-21T23:24:09Z | 2024-05-02T14:34:20Z | https://github.com/redis/redis-om-python/issues/571 | [] | rglKali | 0 |
pallets-eco/flask-sqlalchemy | flask | 1,177 | 'Lost connection to MySQL server during query' on database restart | When I restart my database (to simulate a timeout/network error/etc..), the next request my application process gets a 'Lost connection to MySQL server during query' error. Next requests process normally
Example code to reproduce:
```
import os
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
fro... | closed | 2023-03-07T14:40:02Z | 2023-03-22T01:05:44Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/1177 | [] | iTrooz | 4 |
robotframework/robotframework | automation | 5,198 | Require global settings to be defined before tests and keywords using them | Currently we support data like this so that the created test gets the setup and the template defined after the test itself:
```robotframework
*** Test Cases ***
Example
arg1 arg2
*** Settings ***
Test Setup Setup Keyword
Test Template Template Keyword
```
This syntax causes two problems:
1... | open | 2024-09-04T14:12:49Z | 2024-11-05T15:31:44Z | https://github.com/robotframework/robotframework/issues/5198 | [
"enhancement",
"priority: high",
"backwards incompatible"
] | pekkaklarck | 6 |
autogluon/autogluon | computer-vision | 4,706 | [BUG] AutoGluon v1.2 misconfigured libnvJitLink leads to Jupyter kernel crash on AL2 SageMaker notebooks | **To Reproduce**
Start a Jupyter notebook instance with the following startup script on SageMaker, and run AutoGluon-TimeSeries.
```
#!/bin/bash
set -e
ENV_NAME="ag"
PYTHON_VERSION="3.11"
source /home/ec2-user/anaconda3/bin/activate
conda create --yes --name $ENV_NAME python=$PYTHON_VERSION
source /home... | open | 2024-12-03T10:40:20Z | 2025-01-14T22:58:42Z | https://github.com/autogluon/autogluon/issues/4706 | [
"bug",
"install",
"dependency",
"priority: 1"
] | canerturkmen | 9 |
PokeAPI/pokeapi | graphql | 678 | Mega - Pokemon || Shadow - Pokemon | Hi I was wondering how do I get mega pokemon's info like a mega venusaur and like shadow pokemon is there anyway to get this info? | open | 2021-12-20T18:21:15Z | 2022-08-04T08:23:23Z | https://github.com/PokeAPI/pokeapi/issues/678 | [] | Flame101 | 5 |
biolab/orange3 | data-visualization | 6,576 | Distributions outputs wrong data | **What's wrong**
The widget's output does not match the selection.
**How can we reproduce the problem?**
Load Zoo and pass it to Distributions. Show "type" and check "Sort categories by frequency".
When selecting the n-th column, the widget outputs data referring to the n-th value of the variable in the or... | closed | 2023-09-14T14:45:06Z | 2023-09-20T20:21:07Z | https://github.com/biolab/orange3/issues/6576 | [
"bug",
"meal"
] | janezd | 4 |
jacobgil/pytorch-grad-cam | computer-vision | 350 | Hello! I used EigenCAM in YOLOX. I tried every layer of the network, and found that the effect was not good. I found that the distribution of the thermal map obtained by inputting different images was the same | open | 2022-10-25T03:33:56Z | 2022-10-25T03:33:56Z | https://github.com/jacobgil/pytorch-grad-cam/issues/350 | [] | Kyle-fang | 0 | |
LibrePhotos/librephotos | django | 1,121 | can not download models | we can not dowload models from dropbox in China, Can u store the models file elsewhere?
thx!
https://githubfast.com/LibrePhotos/librephotos/blob/dev/service/image_captioning/api/im2txt/README.md
| open | 2024-01-08T09:22:37Z | 2024-01-08T09:22:37Z | https://github.com/LibrePhotos/librephotos/issues/1121 | [
"enhancement"
] | yutao1129 | 0 |
pytorch/pytorch | python | 149,626 | `Segmentation Fault` in `torch.lstm_cell` | ### 🐛 Describe the bug
The following code snippet causes a `segmentation fault` when running torch.lstm_cell:
```
import torch
inp = torch.full((0, 8), 0, dtype=torch.float)
hx = torch.full((0, 9), 0, dtype=torch.float)
cx = torch.full((0, 9), 0, dtype=torch.float)
w_ih = torch.full((1, 8), 1.251e+12, dtype=torch.f... | open | 2025-03-20T15:24:09Z | 2025-03-21T07:08:54Z | https://github.com/pytorch/pytorch/issues/149626 | [
"module: crash",
"module: rnn",
"triaged",
"bug",
"module: empty tensor",
"topic: fuzzer"
] | vwrewsge | 1 |
tensorpack/tensorpack | tensorflow | 1,132 | Request help on debuging the running speed | I'm using the `FasterRCNN` module in Tensorpack and I modified the network by adding some other branch. The training data was saved in a NFS file system (in `png` format and `xml` format) and I run the code in a node of a cluster. The node has 4 K80 GPUs. When I run the `FasterRCNN` in this system. It seems the executa... | closed | 2019-04-07T08:39:10Z | 2019-04-13T07:18:58Z | https://github.com/tensorpack/tensorpack/issues/1132 | [
"performance"
] | Remember2018 | 4 |
clovaai/donut | nlp | 101 | Document Information Extraction in Production - How to know the confidence of each field? | Good afternoon, thank you very much for the incredible work!
I just wanted to know if there was an automatic way to know if the field is OK. Especially when other applications use the data extracted by the model. That way we could reduce the work of people in the loop as much as possible.
Other architectures like... | open | 2022-12-01T17:19:32Z | 2022-12-03T13:43:19Z | https://github.com/clovaai/donut/issues/101 | [] | WaterKnight1998 | 3 |
Farama-Foundation/Gymnasium | api | 652 | [Proposal] Inclusion of ActionRepeat wrapper | ### Proposal
I would like to propose `ActionRepeat` wrapper that would allow the wrapped environment to repeat `step()` for the specified number of times.
### Motivation
I am working on implementing models like PlaNet and Dreamer, and I'm working with MuJoCo environments mostly. In these implementations, there... | open | 2023-08-04T21:36:34Z | 2025-02-25T01:22:07Z | https://github.com/Farama-Foundation/Gymnasium/issues/652 | [
"enhancement",
"good first issue"
] | smmislam | 3 |
explosion/spaCy | nlp | 13,196 | Spacy dependency requirements are not met for pydantic versions ^2 | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
<!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. -->
Example pyproject.toml
```
[tool.poetry.dependencies]
python = "^3.7"
pyd... | closed | 2023-12-11T18:03:59Z | 2023-12-12T06:53:05Z | https://github.com/explosion/spaCy/issues/13196 | [
"install"
] | jacobmanderson | 1 |
django-import-export/django-import-export | django | 1,130 | Repeated ID in imported file does not cause error | Just to experiment, I created an XL with a repeated ID to see whether the import process would throw an error. My DB table already contains **IDs upto 4211**, and the table I created for import contained many rows with IDs as follows:
id
____
4210
4209
4210
4211
4212
4213
4214
...
When running the import... | closed | 2020-05-06T17:54:12Z | 2020-05-08T08:40:10Z | https://github.com/django-import-export/django-import-export/issues/1130 | [] | zehawki | 4 |
microsoft/nni | tensorflow | 5,767 | NNI console won't show after trialGpuNumber was set to 1 | **Describe the issue**:
NNI console won't show after trialGpuNumber was set to 1
**Environment**:
- NNI version: 3.0
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version: 2.1
- PyTorch/TensorFlow version:
- Is conda/virtualenv/venv used?:
- Is ru... | closed | 2024-04-02T21:54:41Z | 2024-04-03T01:56:05Z | https://github.com/microsoft/nni/issues/5767 | [] | yiqiaoc11 | 0 |
PokemonGoF/PokemonGo-Bot | automation | 6,116 | catch chance display | I have noticed that the bot displays the catch chance in a pretty weird manner:
[2017-07-23 20:33:18] [PokemonCatchWorker] [INFO] Threw a Pinap Berry! Catch rate with Greatball is now: 26.72
[2017-07-23 20:33:28] [PokemonCatchWorker] [INFO] Great Curveball throw! Used Ultraball, with chance 26.72 (42 left)
As far ... | open | 2017-07-23T17:42:02Z | 2017-07-24T07:42:42Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/6116 | [] | guenterneust | 1 |
piskvorky/gensim | data-science | 3,387 | n/a | n/a | closed | 2022-09-07T10:48:16Z | 2022-09-07T14:35:02Z | https://github.com/piskvorky/gensim/issues/3387 | [] | alabidi | 0 |
benbusby/whoogle-search | flask | 679 | [QUESTION] How to get the suggestions URL right? | I recently downloaded all of my data from Google Takeout and I noticed a peculiar field that Chrome doesn't show when adding/editing search engines, namely `suggestions_url` which in this case is set to `http://localhost:5000/autocomplete?q={searchTerms}`. Since chrome shows no way to change this field whatsoever I'm a... | closed | 2022-03-13T11:33:26Z | 2022-08-01T16:22:11Z | https://github.com/benbusby/whoogle-search/issues/679 | [
"question"
] | nocturn9x | 3 |
teamhide/fastapi-boilerplate | fastapi | 40 | Potential Performance Issue with Session Management in Repository Methods | I noticed that in the current implementation of the UserSQLAlchemyRepo, each repository method creates a new session using the session_factory() context manager. It can lead to potential performance issues when multiple repository methods are called sequentially within the same service layer function.
https:... | open | 2024-08-26T08:11:45Z | 2025-03-19T03:16:14Z | https://github.com/teamhide/fastapi-boilerplate/issues/40 | [] | vuxmai | 1 |
vitalik/django-ninja | rest-api | 373 | Parent URL resolver match parameters aren't handled (except when they are) | I have a soft tenant system where clients of the system each have their own `/company-slug/...` base URL. Probably not how I'd approach this today but this is where we are. All our URLs have a component that gets extracted and churned into a Company record (so we can do permissions checks, etc). I'm mounting my ninja ... | open | 2022-02-25T10:38:40Z | 2023-09-05T08:43:39Z | https://github.com/vitalik/django-ninja/issues/373 | [] | oliwarner | 4 |
pallets/flask | flask | 4,795 | flask crashed | Dears,
Hope all is well.
I have a project, you can say a big project has more than 168 API routes (/x /y /yyy ..etc)
each of these API routes has a specific function in my project I am facing a big problem that the flask crashed or the flask slower after sending about 1500 - 2000 req/second.
and I notch... | closed | 2022-08-31T17:19:22Z | 2022-08-31T17:27:55Z | https://github.com/pallets/flask/issues/4795 | [] | themeswordpress | 0 |
docarray/docarray | fastapi | 1,071 | docarray proto module cant be imported by child Processes | **Describe the bug**
docarray proto module cant be imported my child Processes
**To Reproduce**
script.py
```python
import torch
import multiprocessing as mp
from docarray import DocumentArray, BaseDocument
from docarray.typing import TorchTensor
class Meow(BaseDocument):
tensor: TorchTensor
def de... | closed | 2023-02-01T11:27:19Z | 2023-02-07T13:41:22Z | https://github.com/docarray/docarray/issues/1071 | [] | Jackmin801 | 1 |
flairNLP/flair | nlp | 3,283 | [Question]: Evaluating as a multi-label problem: False | ### Question
I'm training a SequenceTagger model for NER. My Corpus contains 13 different Labels. Training works and everything goes fine, but the evaluation during epochs seem off.
The Message "Evaluating as a multi-label problem: False" shows up and I think that's the reason why the F1-Scores are so bad. When ... | closed | 2023-07-19T09:13:22Z | 2023-07-24T06:30:14Z | https://github.com/flairNLP/flair/issues/3283 | [
"question"
] | sorth1992 | 1 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 1,120 | Victoria | LOVE | closed | 2022-09-29T01:01:14Z | 2022-09-29T01:01:32Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1120 | [] | ImanuillKant1 | 0 |
marcomusy/vedo | numpy | 66 | Points being plot as Lines | Hi,
First of all thanks you for such a great library with so many examples.
I am trying to plot points from an array. However, the resulting pic is always a line for this specific datapoints.
```python
from vtkplotter import show, Points
positions = array([[0.16621395, 0.28789101, 0. ],
[0. ... | closed | 2019-10-13T14:05:41Z | 2019-10-14T13:20:55Z | https://github.com/marcomusy/vedo/issues/66 | [
"bug",
"in-progress"
] | mahendra-ramajayam | 3 |
plotly/dash | jupyter | 2,457 | [BUG] DataTable containing List behaves inconsistently between display and export | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.8.1
dash-bootstrap-components 1.4.0
dash-core-components 2.0.0
dash-html-components 2.0.0
dash-renderer ... | closed | 2023-03-16T13:01:47Z | 2024-07-25T13:03:09Z | https://github.com/plotly/dash/issues/2457 | [
"dash-data-table"
] | avarsava | 2 |
graphql-python/graphene-django | graphql | 618 | How to provide an argument from DjangoFilterConnectionField to a node | ```
items = DjangoFilterConnectionField(ItemNode, userId=graphene.String())
...
class ItemNode(DjangoObjectType):
def resolve_something(self, info):
userId = ... ??? ...
if userId:
return self.something.filter(version__isnull=True)
return self.something.filter(version_... | closed | 2019-04-15T11:33:28Z | 2021-04-14T20:05:25Z | https://github.com/graphql-python/graphene-django/issues/618 | [
"question"
] | ulkoart | 2 |
scikit-learn-contrib/metric-learn | scikit-learn | 173 | Ensure that CalibratedClassifierCV works | Related to #168
scikit-learn's `CalibratedClassifierCV` should work with pairs classifier:
We should ensure that it return coherent results with our estimators (could be done in #168)
This could be finalized when `CalibratedClassifierCV` accept 3d arrays (see issue https://github.com/scikit-learn/scikit-lear... | open | 2019-02-22T11:06:16Z | 2019-04-02T13:50:04Z | https://github.com/scikit-learn-contrib/metric-learn/issues/173 | [] | wdevazelhes | 0 |
NVlabs/neuralangelo | computer-vision | 209 | Error wandb | I'm trying to run Neuralangelo with the test set "lego," but I haven't been able to get past the point where I invoke the command:
torchrun --nproc_per_node=${GPUS} train.py \
--logdir=logs/${GROUP}/${NAME} \
--config=${CONFIG} \
--show_pbar
This command throws an error for which I haven't been ab... | open | 2024-08-23T03:25:11Z | 2024-08-26T03:19:45Z | https://github.com/NVlabs/neuralangelo/issues/209 | [] | P-UnKnow08 | 1 |
tqdm/tqdm | pandas | 705 | Publish objects.inv file for use with intersphinx | It's possible to link to between Sphinx documentation sets by using the [intersphinx extension](http://www.sphinx-doc.org/en/master/usage/extensions/intersphinx.html), but when I try to do this with the tqdm docs, I get a file not found error for objects.inv. | open | 2019-03-28T20:29:39Z | 2019-04-22T21:11:36Z | https://github.com/tqdm/tqdm/issues/705 | [
"p4-enhancement-future 🧨"
] | tswast | 1 |
ccxt/ccxt | api | 25,151 | submit sell orders fails in gemini since Jan 31 | ### Operating System
Debian
### Programming Languages
Python
### CCXT Version
4.4.52
### Description
The order submission both buy and sell worked on Jan 30 and before, but does not work since .
### Code
```
This call returns json, but precision section in it is all null
markets = await exchange.loadMarket... | closed | 2025-02-02T19:35:14Z | 2025-02-19T21:39:15Z | https://github.com/ccxt/ccxt/issues/25151 | [] | vigorIv2 | 3 |
OFA-Sys/Chinese-CLIP | nlp | 105 | 请问demo中的图到图检索是如何实现的? | 我想实现图到图减速,但不知道怎么弄 | closed | 2023-05-11T10:25:08Z | 2023-11-27T07:26:25Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/105 | [] | yourfathermyson | 1 |
explosion/spaCy | deep-learning | 13,536 | Fail to call Python code using Matlab | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
<!-- Include a code example or the steps that led to the problem. Please try to be as specific as possible. -->
Python code: File name: test_spacy.py
```
import spacy
nlp = spacy.load(... | open | 2024-06-20T16:19:16Z | 2024-06-27T12:50:22Z | https://github.com/explosion/spaCy/issues/13536 | [] | Saswati-Project | 1 |
unit8co/darts | data-science | 2,193 | [QUESTION] Croston and add_encoders | Hi,
I cant get add_encoders functionality (for Croston) to work, see below

temporal_cv_lf basically just calls
m = Croston(**params)
**m.historical_forecasts**(series=series,
... | closed | 2024-01-27T11:07:01Z | 2024-09-02T09:48:21Z | https://github.com/unit8co/darts/issues/2193 | [
"bug",
"good first issue",
"pr_welcome"
] | sebros-sandvik | 5 |
axnsan12/drf-yasg | django | 877 | Showing the read_only fields in the serializer in the post /swagger template in (ForignKeyFields) | class MatchSerializer(serializers.ModelSerializer):
winner = AthleteWinnerSerializer(read_only=True)
class Meta:
model = Match
fields = ['uid', 'round_one', 'round_two', 'round_three', 'winner']
In this example the winner is generated in the body of the post api like the example below :
... | open | 2023-12-03T13:37:33Z | 2025-03-09T10:27:45Z | https://github.com/axnsan12/drf-yasg/issues/877 | [
"question",
"unanswered"
] | SamiTalebian | 1 |
ckan/ckan | api | 8,429 | UI Revamp: Displaying facet accordion with active options as expanded by default | Hello!
By request of the designers of the UI revamp, they would like the facets to appear as accordions. They have requested by default if there are no active options within a facet, it should be collapsed, otherwise it should be expanded.
Screenshots for context:
Default, facets with no active item

- [ ] A... | closed | 2024-10-05T02:00:27Z | 2024-10-05T18:00:30Z | https://github.com/dunossauro/fastapi-do-zero/issues/253 | [] | dunossauro | 1 |
huggingface/transformers | python | 36,642 | Is it correct that the repetition penalty is applied to the input_ids encompassing all inputs and outputs, rather than solely on the generated tokens? | ### System Info
- `transformers` version: 4.44.2
- Platform: Linux-3.10.0-1160.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.10.14
- Huggingface_hub version: 0.26.2
- Safetensors version: 0.4.5
- Accelerate version: 1.0.1
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1+cu124 (True)
### Who ca... | open | 2025-03-11T07:28:12Z | 2025-03-11T07:28:12Z | https://github.com/huggingface/transformers/issues/36642 | [
"bug"
] | Ostrichpie818 | 0 |
jupyterlab/jupyter-ai | jupyter | 907 | support multiple contexts within embeddings (configurable paths to embedding database). |
### Problem
The embedding interface (`/learn`, `/ask`) is really nice and remarkably useful. Currently though, it seems that a user can have only one active context at a time. This is fine for small contexts where I can, say, clone some GitHub project and start with `/learn` the docs of the project, and then `... | open | 2024-07-20T02:42:01Z | 2024-07-24T20:45:26Z | https://github.com/jupyterlab/jupyter-ai/issues/907 | [
"enhancement",
"scope:RAG"
] | cboettig | 0 |
tensorflow/tensor2tensor | machine-learning | 956 | cloud_tpu fails while another tpu is being created (ip = default) | when a tpu is being created it does not have an ip yet. if you try to create another one at the same time it will fail as cloud_tpu will try to parse 'default' as a valid ip
INFO:tensorflow:VM eyal-vm5-vm already exists, reusing.
Creating TPU instance eyal-vm5-tpu
multiprocessing.pool.RemoteTraceback:
"""
Trace... | open | 2018-07-25T01:28:54Z | 2018-07-25T01:29:04Z | https://github.com/tensorflow/tensor2tensor/issues/956 | [] | eyaler | 0 |
ultralytics/ultralytics | pytorch | 18,688 | Not all parameters in YOLO-World pretrained weights can be loaded | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Other
### Bug
When i init a YOLOv8s-World-v2 model from a .yaml configuration file and load pretrained weights, it seems t... | open | 2025-01-15T02:10:37Z | 2025-01-15T04:34:17Z | https://github.com/ultralytics/ultralytics/issues/18688 | [
"bug",
"detect"
] | chongkuiqi | 2 |
vitalik/django-ninja | rest-api | 797 | [BUG] Nested routers will overwrite the response if they are on the same path. | **Describe the bug**
If I define the response schema for the api path `/test` on router 1 as ATest,
and the response schema for the same path `/test` with the prefix `/api` on router 2 as BTest,
and then register to the router,
I get ATest as BTest in API Swagger.
My guess is that if the path is the same, the... | closed | 2023-07-19T02:23:53Z | 2023-07-29T06:18:04Z | https://github.com/vitalik/django-ninja/issues/797 | [] | ndjman7 | 3 |
pyeve/eve | flask | 1,011 | No primary available for writes | I have trouble on write in mongo cluster in `Eve 0.7.2`
On `Eve 0.6.4` works well but on I update this error occurs:
```
Traceback (most recent call last):
File "/var/www/articles-api/env/lib/python3.4/site-packages/eve/methods/patch.py", line 205, in patch_internal
resource, object_id, updates, original... | closed | 2017-04-18T16:38:41Z | 2018-05-18T17:19:47Z | https://github.com/pyeve/eve/issues/1011 | [
"stale"
] | luiscoms | 4 |
AirtestProject/Airtest | automation | 766 | 命令行/iOS真机/运行脚本时报错 json.decoder.JSONDecodeError |
**详细描述问题bug:**
```
======================================================================
ERROR: setUpClass (__main__.CustomAirtestCase)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/Users/xxx/anaconda3/envs/airtest_py3/lib/python3.7/site-pack... | closed | 2020-07-02T13:41:55Z | 2020-07-10T08:56:45Z | https://github.com/AirtestProject/Airtest/issues/766 | [] | IcyW | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.