
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
DistrictDataLabs/yellowbrick | matplotlib | 979 | Visualize the results without fitting the model | Let's say I have to visualize a confusion matrix.
I can use yellowbrick and use the LogisticRegression and visualize like this:
https://www.scikit-yb.org/en/latest/api/classifier/confusion_matrix.html
```
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split as tts
from skl... | closed | 2019-10-12T18:26:54Z | 2019-10-12T18:48:32Z | https://github.com/DistrictDataLabs/yellowbrick/issues/979 | [
"type: question"
] | bhishanpdl | 1 |
jmcnamara/XlsxWriter | pandas | 170 | Issue with DataLabels Position in Column Chart | I'm trying to position the data labels at the top of each column in a column chart, however doing so creates an Excel file with invalid XML that Excel won't process. I'm using XlsxWriter version 0.5.7 with Python version 2.7.6.
Here's a sample that will create such a file:
``` python
from xlsxwriter import Workbook
... | closed | 2014-10-15T18:28:30Z | 2014-10-29T02:21:50Z | https://github.com/jmcnamara/XlsxWriter/issues/170 | [
"bug",
"documentation",
"ready to close"
] | MitsuharuEishi | 3 |
blb-ventures/strawberry-django-plus | graphql | 84 | I don't see why we need to install a new dependency django-choices-field | https://github.com/blb-ventures/strawberry-django-plus/blob/9f06e1169f6ce696a9439bec52abd546ef380b29/strawberry_django_plus/types.py#L208
Hey there, I'm currently trying the lib here, I'm enjoying it so far, hopefully it gets merged with the main lib soon.
Regarding the above, can't you just do something like t... | open | 2022-07-17T02:00:16Z | 2022-07-19T22:18:36Z | https://github.com/blb-ventures/strawberry-django-plus/issues/84 | [
"question"
] | mhdismail | 5 |
marshmallow-code/apispec | rest-api | 176 | Can't use apispec tornado plugin icw complex paths | I'm trying to use apispec icw the 'apispec.ext.tornado' and 'apispec.ext.marshmallow' plugins.
Only i'm getting the following error:
```
Traceback (most recent call last):
File "D:\JetBrains\PyCharm 2017.2.4\helpers\pydev\pydevd.py", line 1599, in <module>
globals = debugger.run(setup['file'], None, None, is... | closed | 2017-12-11T19:41:43Z | 2018-11-03T14:33:19Z | https://github.com/marshmallow-code/apispec/issues/176 | [] | p0psicles | 2 |
ray-project/ray | python | 51,642 | [core] Unify `CoreWorker::Exit` and `CoreWorker::Shutdown` | ### Description
See https://github.com/ray-project/ray/pull/51582#discussion_r2010500080 for more details.
### Use case
_No response_ | open | 2025-03-24T16:52:35Z | 2025-03-24T16:52:44Z | https://github.com/ray-project/ray/issues/51642 | [
"enhancement",
"core"
] | kevin85421 | 0 |
FlareSolverr/FlareSolverr | api | 1,223 | [yggtorrent] (testing) Exception (yggtorrent): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the challenge. Timeout after 55.0 seconds.: FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Error solving the chall... | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2024-06-21T09:21:23Z | 2024-06-21T09:26:08Z | https://github.com/FlareSolverr/FlareSolverr/issues/1223 | [
"duplicate"
] | eejag | 1 |
python-gino/gino | sqlalchemy | 351 | Release GINO 0.7.6 and 0.8 | I'm planning to release GINO 0.8 (1.0-rc) from current master, and close `v0.6.x` branch and support. @wwwjfy anything to add please? | closed | 2018-09-29T03:28:29Z | 2018-10-17T07:41:56Z | https://github.com/python-gino/gino/issues/351 | [
"task"
] | fantix | 11 |
coqui-ai/TTS | deep-learning | 3,840 | [Bug] can not load the checkpoints when do fine-tune with XTTS_v2 | ### Describe the bug
Hello, community and @eginhard,
For the XTTS fine-tuning, I manually downloaded `dvae.pth, mel_stats.pth, model.pth` and `vocab.json` in `train_gpt_xtts.py`.
Further, below is the command line for fine-tuning XTTS_v2.
```
CUDA_VISIBLE_DEVICES="0" python recipes/mshop/xtts_v2/train_gpt_x... | closed | 2024-07-29T14:10:11Z | 2024-07-29T18:46:28Z | https://github.com/coqui-ai/TTS/issues/3840 | [
"bug"
] | kaen2891 | 4 |
jina-ai/serve | fastapi | 5,613 | Error reporting when DNS exists, but route is not valid | When an external Executor/Flow is down, but there is no DNS error (e.g. because it is behind an API gateway), then the error reporting does not show which Executor is the failing one.
**Reproduce:**
```python
from jina import Flow
from docarray import DocumentArray, Document
f = Flow().add(host='https://blah.w... | closed | 2023-01-20T12:05:32Z | 2023-01-24T11:40:54Z | https://github.com/jina-ai/serve/issues/5613 | [] | JohannesMessner | 0 |
tensorflow/tensor2tensor | deep-learning | 1,640 | mismatch of tensor2tensor.layers.common_audio.compute_mel_filterbank_features with tensorflow audio_ops.mfcc | ### Description
...
### Environment information
```
OS: Ubuntu 18.04
$ pip freeze | grep tensor
tensorflow: 1.14.0
$ python -V
3.6.8
```
### For bugs: reproduction and error logs
```
# Steps to reproduce:
import tensorflow as tf
tf.enable_eager_execution()
from tensorflow.contrib.framework.... | open | 2019-07-24T09:07:23Z | 2019-07-24T09:07:23Z | https://github.com/tensorflow/tensor2tensor/issues/1640 | [] | cahuja1992 | 0 |
custom-components/pyscript | jupyter | 420 | Enhancement request: wildcards in @state_trigger | Can `@state_trigger` be changed to support wildcards?
I am wanting to do:
````
@state_trigger('sensor.ble_temperature_*')
```` | closed | 2022-12-31T17:36:05Z | 2023-01-01T04:21:16Z | https://github.com/custom-components/pyscript/issues/420 | [] | fovea1959 | 3 |
PrefectHQ/prefect | automation | 16,917 | Prefect UI only shows blank white screen | > Hey! I'm getting the same result by running prefect inside a uv venv on linux, commands used:
> ```
> uv venv --python 3.12 && source .venv/bin/activate
> uv pip install -U prefect
> prefect server start
> ```
>
> Visiting localhost or 127.0.0.1 gives the same result, /docs works as intended. Screenshot with error:
... | open | 2025-01-30T21:58:40Z | 2025-01-30T21:58:40Z | https://github.com/PrefectHQ/prefect/issues/16917 | [] | aaazzam | 0 |
tflearn/tflearn | tensorflow | 215 | validation_set doesn't seem to run through Image Augmentation | I'm trying to use validation_set=0.1 with the below tflearn image augmentation pipeline, but I get the following error which makes it seem like tflearn is trying to run the metric on the original image (128,128,3) instead of an augmented one (112,112,3):
Cannot feed value of shape (128, 128, 128, 3) for Tensor u'Input... | open | 2016-07-21T11:33:56Z | 2016-07-21T17:01:23Z | https://github.com/tflearn/tflearn/issues/215 | [] | tetmin | 3 |
iMerica/dj-rest-auth | rest-api | 67 | Docs Improvement: Register users from admin panel in a compatible way. | Hi, I went through the documentation for this library. But didn't find an answer for my question.
So I implemented dj-rest-auth and everything is smooth AF.
Thank you so much for this amazing library.
So a user can register via my web app..but I want to be able to add users from my admin application. How can I g... | open | 2020-05-12T05:53:04Z | 2022-03-30T10:08:55Z | https://github.com/iMerica/dj-rest-auth/issues/67 | [
"enhancement"
] | Goutam192002 | 9 |
milesmcc/shynet | django | 329 | Docker-less troubles | Edit: updated instructions to fix my own problem. And help anyone who finds this.
As discussed in #9, I've been trying to get shynet up and running without docker in order to submit a PR with documentation. I'm using RHEL but once done the instructions can easily be translated into Debian or any other Linux flavor.
... | closed | 2024-07-16T15:56:46Z | 2024-07-20T21:49:57Z | https://github.com/milesmcc/shynet/issues/329 | [] | CarlSinclair | 3 |
pydata/xarray | pandas | 9,608 | xarray can open a nc file with open_dataset, but fails to load this nc file with load | ### What is your issue?
Recently, I have downloaded chla data from copernicus marine service, and tried to regrid it with xarray. The sad thing is that the data always goes wrong in the load phase. I have checked that variables in test dataset could be plotted normally. I do know what happen to this. Any advice is ... | open | 2024-10-11T10:29:44Z | 2024-10-25T01:33:57Z | https://github.com/pydata/xarray/issues/9608 | [
"needs info"
] | onion5376 | 3 |
TencentARC/GFPGAN | pytorch | 564 | Problem about finetuning GFPGAN v1.4 | Hello Xintao,
We found that the direct inferencing based on GFPGAN v1.4 performs pretty well on our own datasets, whilst GFPGAN v1 inferencing is not high-quality.
However, when we tried to finetune this model, we found that only the related files of training GFPGAN v1 was released.
Could you please share the... | open | 2024-08-03T09:29:59Z | 2024-08-23T10:33:21Z | https://github.com/TencentARC/GFPGAN/issues/564 | [] | leonsylarfang | 4 |
mars-project/mars | numpy | 3,211 | [BUG] Ray executor auto merge chunk may raise KeyError | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
```python
mars/deploy/oscar/tests/test_ray_dag.py:189 (test_merge_groupby[before-None])... | closed | 2022-08-09T02:51:44Z | 2022-08-19T03:30:10Z | https://github.com/mars-project/mars/issues/3211 | [
"type: bug",
"mod: ray integration"
] | fyrestone | 0 |
vimalloc/flask-jwt-extended | flask | 502 | Jwt_required and optional == True | This appears to be a bug unless I'm missing the requirement/intended functionality: If optional is True, I'm expecting jwt-extended not to raise any errors - however, I'm still getting a 401 - token missing error. I dug in a bit deeper in the code, and the issue seems to be that the verify_jwt_in_request method's error... | closed | 2022-11-15T19:08:50Z | 2022-12-22T22:52:30Z | https://github.com/vimalloc/flask-jwt-extended/issues/502 | [] | hooverdirt | 1 |
sktime/sktime | scikit-learn | 7,652 | [BUG] AttributeError in SubLOF with novelty=False when calling fit_transform or fit_predict | When using SubLOF from the sktime library with novelty=False and calling fit_transform or fit_predict, an AttributeError is raised. The error indicates that the predict method is not available when novelty=False, which contradicts the documentation's recommendation to use fit_predict for outlier detection on the traini... | open | 2025-01-17T07:44:33Z | 2025-03-15T23:17:41Z | https://github.com/sktime/sktime/issues/7652 | [
"bug",
"module:detection"
] | axisrow | 4 |
ryfeus/lambda-packs | numpy | 21 | Lamda Packs for Tensorflow 1.6 based on Python 3 | Hi, I'm trying to create a lamda pack for tensorflow 1.6 based on Python 3.
However I am not able to compress the pack to be less than 50 MB.
Can you please share your taught's on how to do that. | closed | 2018-05-23T07:28:04Z | 2018-12-13T18:13:50Z | https://github.com/ryfeus/lambda-packs/issues/21 | [] | SumanthReddyKaliki | 1 |
aminalaee/sqladmin | fastapi | 172 | Be able to hook into the fastAPI subapp | ### Checklist
- [X] There are no similar issues or pull requests for this yet.
### Is your feature related to a problem? Please describe.
Hello, great work ! :)
I would like to be able to add my own url paths below the root endpoint of the admin app.
For example I would like to be able to do a POST on the homepa... | open | 2022-06-08T16:18:35Z | 2022-06-24T12:18:34Z | https://github.com/aminalaee/sqladmin/issues/172 | [
"waiting-for-feedback"
] | lebrunthibault | 5 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 347 | Phone number and country did not change | I have changed the phone number and the country in plain_text_resume.yaml but when i see the bot applying to jobs , It write italy in the country and different phone number.
I apply with my own pdf using python main.py --resume /path/to/your/resume.pdf
 is the use of [QtPy: Abstraction layer for PyQt5/PyQt4/PySide2/PySide](https://github.com/spyder-ide/qtpy).
I propose a set of minor changes to ensure all the calls to Qt bindi... | open | 2021-08-29T08:44:43Z | 2021-08-29T21:19:40Z | https://github.com/adamerose/PandasGUI/issues/168 | [] | EmanueleCannizzaro | 1 |
mljar/mercury | data-visualization | 417 | Option to hide the RunMercury switch at the top black bar | Hello:
I have been testing this product and it's wonderful... Only issues I had are with:
- Share button: in some cases, I would prefer not to have our users sharing the links for security reasons.
- The RunMercury switch at the top blank bar, might not be good in those cases where you don't want the users to chec... | closed | 2024-02-04T23:17:10Z | 2024-02-15T13:37:14Z | https://github.com/mljar/mercury/issues/417 | [] | gregcode123 | 3 |
MorvanZhou/tutorials | tensorflow | 78 | 建议 | 建议课程中多讲一点理论,比如数学基础等。感谢提供教程 | closed | 2019-03-08T03:01:44Z | 2019-03-08T03:03:35Z | https://github.com/MorvanZhou/tutorials/issues/78 | [] | ustcerlik | 0 |
jschneier/django-storages | django | 869 | ""Unicode-objects must be encoded before hashing" when i try upload a .m3u8 file using storages|s3 instead local storage. | **Describe the bug**
**COMPLETE CODE AND SETTINGS IN THE END OF THE FILE**
**the upload works when i add the .m3u8 file directly in the aws s3 site**
I was able to send the video normally to my local machine, but when I changed the storage settings, I just started getting this error.
The error points to the l... | closed | 2020-04-05T17:52:16Z | 2020-04-05T18:17:47Z | https://github.com/jschneier/django-storages/issues/869 | [] | marcosfromrio | 3 |
explosion/spaCy | data-science | 12,982 | RuntimeError: Error(s) in loading state_dict for RobertaModel: Unexpected key(s) in state_dict: "embeddings.position_ids". | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
```py
import spacy
nlp = spacy.load('en_core_web_trf')
```
Full traceback:
```
---------------------------------------------------------------------------
RuntimeError ... | closed | 2023-09-14T14:08:37Z | 2023-10-19T00:02:09Z | https://github.com/explosion/spaCy/issues/12982 | [
"install",
"feat / transformer"
] | dzenilee | 6 |
zappa/Zappa | flask | 775 | [Migrated] 'exclude' setting in config excludes all occurrences also for dependencies | Originally from: https://github.com/Miserlou/Zappa/issues/1917 by [themmes](https://github.com/themmes)
<!--- Provide a general summary of the issue in the Title above -->
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
I do not understand why I am ... | closed | 2021-02-20T12:42:15Z | 2024-04-13T18:37:15Z | https://github.com/zappa/Zappa/issues/775 | [
"no-activity",
"auto-closed"
] | jneves | 3 |
zappa/Zappa | django | 695 | [Migrated] Flask-like app factory support | Originally from: https://github.com/Miserlou/Zappa/issues/1775 by [fcicc](https://github.com/fcicc)
# Description
How to use application factories in Zappa:
* app.py
`def create_app():`
`app = Flask()`
`#define settings, db, routes, ...`
&nbs... | closed | 2021-02-20T12:33:03Z | 2022-07-16T06:37:34Z | https://github.com/zappa/Zappa/issues/695 | [
"needs-user-testing"
] | jneves | 1 |
hootnot/oanda-api-v20 | rest-api | 90 | "Connection: Keep-Alive" question | This is more a question than an issue. It's about the best practices section of the developer references (http://developer.oanda.com/rest-live-v20/best-practices/).
They say that you should add a http header with the following content `Connection: Keep-Alive`. However I ran `grep -rn "Connection" .` in this repository... | closed | 2017-07-19T18:37:45Z | 2017-07-20T07:49:16Z | https://github.com/hootnot/oanda-api-v20/issues/90 | [] | silgon | 3 |
tqdm/tqdm | pandas | 859 | fractional total keyword can cause AssertionError in version 4.40 |
In the newest version, a fractional total can produce an AssertionError, where in previous versions it worked as expected. The documentation suggests that `total` can be a floating point value, so the error appears to be a bug. Here is a minimal reproducible example:
```python
import sys, tqdm
print(tqdm.__versi... | closed | 2019-12-05T16:49:54Z | 2019-12-06T11:29:57Z | https://github.com/tqdm/tqdm/issues/859 | [
"p0-bug-critical ☢",
"duplicate 🗐"
] | aronnem | 2 |
mwaskom/seaborn | data-visualization | 3,784 | [Feature Request] style parameter in `displot`, `catplot` and `lmplot` similar to `relplot` | Currently, `relplot` has `style` parameter that provides an additional way to "facet" the data beyond col, row and hue using `linestyle`. It would be nice if this was extended to the other figure plot types. This would also lead to a more consistent API across the different facet grid plots.
- `displot` - kdeplot ... | closed | 2024-11-13T21:48:27Z | 2024-11-13T22:56:40Z | https://github.com/mwaskom/seaborn/issues/3784 | [] | hguturu | 4 |
fastapi/fastapi | python | 13,067 | poor quality traceback / useful stack frames not present when exceptions raised in sync dependencies | ### Privileged issue
- [X] I'm ~@tiangolo or he asked me directly to create an issue here~ a liar, but the discussion template was crazy onerous, and I'm confident I can write a decent, succinct issue description that's worth reading here ;-)
### Issue Content
If I apply this diff to the [full-stack-fastapi-te... | closed | 2024-12-13T08:04:35Z | 2024-12-14T10:42:04Z | https://github.com/fastapi/fastapi/issues/13067 | [] | cjw296 | 7 |
deepfakes/faceswap | machine-learning | 1,085 | Being informed on manual preview refresh | On slower hardware and with demanding model configurations it can take several minutes until a manual preview refresh actually completes.
For that reason I suggest that another message "Refresh preview done" will be added, so that the user can focus on other things in the meantime and still reliably tell whether the... | closed | 2020-11-10T10:37:25Z | 2021-05-30T10:48:41Z | https://github.com/deepfakes/faceswap/issues/1085 | [
"feature"
] | OreSeq | 1 |
rasbt/watermark | jupyter | 1 | Error in the date with the options -u -n -t -z | Hello Sebastian,
I noticed that with `%watermark -u -n -t -z` the date is incorrect, the day takes the same value as the minute. Here is, for comparison, the outputs I have with different options:
---
- Output of %watermark
01/10/2014 14:17:34
CPython 2.7.3
IPython 2.2.0
compiler : GCC 4.2.1 (Apple Inc. build 56... | closed | 2014-10-01T12:21:08Z | 2014-10-01T17:46:57Z | https://github.com/rasbt/watermark/issues/1 | [] | TaurusOlson | 1 |
521xueweihan/HelloGitHub | python | 2,187 | 微信聊天记录年度报告 | ## 项目推荐
- 项目地址:https://github.com/myth984/wechat-report
- 类别:JS
- 项目后续更新计划:
- 项目描述:
- 必写:和女朋友微信聊天记录统计年度报告
- 描述长度(不包含示例代码): 一步一步的教你生成和女朋友的微信聊天记录年度报告
- 推荐理由:各个APP都有年度报告 给女朋友也出一个报告吧
- 截图:

... | closed | 2022-04-29T07:51:20Z | 2022-05-27T01:22:32Z | https://github.com/521xueweihan/HelloGitHub/issues/2187 | [
"已发布",
"JavaScript 项目"
] | myth984 | 1 |
mwaskom/seaborn | data-science | 3,592 | Add more detailed errorbar type (ci, pi, se, sd) description to the documentation | I propose adding a short explanation of the options ci, pi, sd, and se to every function description that uses the errorbar keyword.
Like a link to the tutorial section for example, since that page never shows up in my search queries.
Showing the equations used behind the different types woul also be a benefit, as ... | closed | 2023-12-14T13:36:39Z | 2023-12-17T22:43:51Z | https://github.com/mwaskom/seaborn/issues/3592 | [] | rk-exxec | 1 |
microsoft/unilm | nlp | 882 | BEIT v3 code | I am very interested in the BEIT v3 paper. When will the code be publicly available? Thanks! | closed | 2022-09-28T12:24:09Z | 2023-03-13T13:58:55Z | https://github.com/microsoft/unilm/issues/882 | [] | DecstionBack | 2 |
babysor/MockingBird | deep-learning | 128 | RuntimeError: CUDA out of memory. Tried to allocate 58.00 MiB (GPU 0; 6.00 GiB total capacity; 1.83 GiB already allocated; 2.49 GiB free; 2.02 GiB reserved in total by PyTorch) | {| Epoch: 1/1 (121/15311) | Loss: 1.719 | 0.73 steps/s | Step: 0k | }Traceback (most recent call last):
出现错误
RuntimeError: CUDA out of memory. Tried to allocate 58.00 MiB (GPU 0; 6.00 GiB total capacity; 1.83 GiB already allocated; 2.49 GiB free; 2.02 GiB reserved in total by PyTorch)
显示显存不足
已经修改### Tacotron Traini... | open | 2021-10-08T14:47:59Z | 2022-01-18T12:00:47Z | https://github.com/babysor/MockingBird/issues/128 | [] | yinjia823 | 4 |
Anjok07/ultimatevocalremovergui | pytorch | 1,577 | I have this error code, It wont go away, no matter what i try | Last Error Received:
Process: MDX-Net
Missing file error raised. Please address the error and try again.
If this error persists, please contact the developers with the error details.
Raw Error Details:
FileNotFoundError: "[WinError 2] Das System kann die angegebene Datei nicht finden"
Traceback Error: "... | open | 2024-10-05T08:41:42Z | 2024-10-05T08:41:42Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1577 | [] | Elias02345 | 0 |
facebookresearch/fairseq | pytorch | 4,633 | Transformer's pad token has non-zero embedding | ## 🐛 Bug
By default a transformer's token embedding layer has `padding_idx=1` indicating that the embedding of this token should be a 0 vector and should not contribute to loss. However, transformers trained using fairseq have non-zero pad token embeddings.
### To Reproduce
Steps to reproduce the behavior (**... | open | 2022-08-07T00:03:59Z | 2022-08-09T13:53:12Z | https://github.com/facebookresearch/fairseq/issues/4633 | [
"bug",
"needs triage"
] | erip | 3 |
lux-org/lux | jupyter | 94 | Improve general sampling strategy in PandasExecutor | The current sampling strategy is crude and largely based on random sampling. We should investigate the performance degradation of Lux across various large datasets to select better sampling strategies, as well as exposing tunable parameters in the API to allow users to adjust for different sampling parameters and strat... | closed | 2020-09-25T08:49:56Z | 2021-01-08T10:03:58Z | https://github.com/lux-org/lux/issues/94 | [] | dorisjlee | 1 |
gevent/gevent | asyncio | 1,777 | SSLContext recursion when initialized before patching | Simple repro:
```python
import gevent.monkey
import ssl
ctx = ssl.SSLContext()
ctx.options |= ssl.Options.OP_NO_TICKET
gevent.monkey.patch_all()
ctx.options |= ssl.Options.OP_NO_TICKET # infinite recursion here
```
Perhaps a way to solve it would be to restructure `gevent._ssl3.SSLContext` to **copy** SSL... | closed | 2021-03-03T20:01:21Z | 2021-03-04T02:03:24Z | https://github.com/gevent/gevent/issues/1777 | [] | ikonst | 4 |
google-research/bert | tensorflow | 706 | Couldn't train BERT with SQUAD 1.1 | I created VM (n1-standard-2) and Cloud TPU (v3-8) using ctpu tool.
I have created a Storage bucket and mounted it in VM using GCSfuse.
Tried to run it. Failed.
```
python run_squad.py \
> --vocab_file=$BERT_BASE_DIR/vocab.txt \
> --bert_config_file=$BERT_BASE_DIR/bert_config.json \
> --init_checkpoint=$BER... | closed | 2019-06-19T06:13:50Z | 2023-02-17T04:17:26Z | https://github.com/google-research/bert/issues/706 | [] | JeevaTM | 4 |
mlfoundations/open_clip | computer-vision | 261 | Investigate memory usage for HF models | mt5 xl non frozen + H/14 frozen uses > 40GB at batch size 1
that seems wrong, something is probably off | closed | 2022-11-28T01:39:05Z | 2024-10-30T16:32:06Z | https://github.com/mlfoundations/open_clip/issues/261 | [
"bug",
"important"
] | rom1504 | 2 |
vitalik/django-ninja | rest-api | 436 | Make `NinjaAPI().add_router` idempotent | **Problem**
I have a project where we attach/register routes/urls during `apps.ready`. Which becomes problematic to keep doing when using `django-ninja` while also having test cases calling
```python
with django.test.utils.modify_settings(INSTALLED_APPS={"append": ["django-app"]}):
...
```
As that'll tr... | open | 2022-05-04T07:50:31Z | 2022-05-04T07:50:31Z | https://github.com/vitalik/django-ninja/issues/436 | [] | flaeppe | 0 |
RobertCraigie/prisma-client-py | asyncio | 259 | Create with required relation is incorrectly typed | <!--
Thanks for helping us improve Prisma Client Python! 🙏 Please follow the sections in the template and provide as much information as possible about your problem, e.g. by enabling additional logging output.
See https://prisma-client-py.readthedocs.io/en/stable/reference/logging/ for how to enable additional log... | open | 2022-02-01T01:16:11Z | 2022-02-02T03:11:40Z | https://github.com/RobertCraigie/prisma-client-py/issues/259 | [
"bug/2-confirmed",
"kind/bug",
"level/intermediate",
"priority/high"
] | RobertCraigie | 0 |
recommenders-team/recommenders | data-science | 1,597 | [BUG] Error when publishing to pypi with pymanopt | ### Description
<!--- Describe your issue/bug/request in detail -->
When publishing to pypi the current code, I get an error:
```
$ twine upload lib/*
Uploading distributions to https://upload.pypi.org/legacy/
/anaconda/envs/py38_default/lib/python3.8/site-packages/twine/auth.py:66: UserWarning: Failed to create ... | closed | 2021-12-21T13:26:08Z | 2022-01-10T14:50:40Z | https://github.com/recommenders-team/recommenders/issues/1597 | [
"bug"
] | miguelgfierro | 7 |
syrupy-project/syrupy | pytest | 438 | How to use pytest.approx() with syrupy | We have a bunch of tests that perform computations using pandas, numpy, and other scientific libraries and produce a dictionary containing the resulting key-value pairs. Some of the values are slightly different when run on different platforms (i.e. macOS vs Linux), so we wrap those values with `pytest.approx()` to acc... | closed | 2020-12-01T00:30:51Z | 2020-12-03T17:30:22Z | https://github.com/syrupy-project/syrupy/issues/438 | [
"question"
] | hashstat | 5 |
Textualize/rich | python | 3,441 | [REQUEST] Support python -m rich.traceback myscript.py | **How would you improve Rich?**
The Python debugger `pdb` supports running a script with debugging enabled by changing the command line call from `python myscript.py --args` to `python -m pdb myscript.py --args`. It would be great to have the same functionality for running a script with rich tracebacks installed: `p... | closed | 2024-08-02T05:59:18Z | 2024-08-26T14:58:35Z | https://github.com/Textualize/rich/issues/3441 | [
"Needs triage"
] | f0k | 3 |
Guovin/iptv-api | api | 640 | 分类指的是?这个地址作为订阅源我试了是可以获取结果的 | 分类指的是?这个地址作为订阅源我试了是可以获取结果的
_Originally posted by @Guovin in https://github.com/Guovin/iptv-api/issues/637#issuecomment-2530116885_
是可以在每个大类上细分,如咪咕分类下有CCTV1-17,卫视等等,还有IPV6分类下有CCTV1-17,卫视等等。有没可能按照链接上的来分类 | closed | 2024-12-10T07:40:13Z | 2024-12-10T07:41:34Z | https://github.com/Guovin/iptv-api/issues/640 | [] | alantang1977 | 0 |
ml-tooling/opyrator | pydantic | 94 | Issue regarding determine uploaded file types on MIME | Hi, i played a bit with the project and noticed one potential issue. In this [function](https://github.com/ml-tooling/opyrator/blob/3f443f05b6b21f00685c2b9bba16cf080edf2385/src/opyrator/ui/streamlit_ui.py#L242), the mime type could be manipulated by remote user, hence he could upload any file with a manipulated MIME he... | closed | 2024-02-18T20:04:21Z | 2024-11-08T02:33:18Z | https://github.com/ml-tooling/opyrator/issues/94 | [
"question",
"stale"
] | nevercodecorrect | 3 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 166 | 老照片 | 老照片 | closed | 2021-05-15T16:23:15Z | 2021-05-24T11:02:35Z | https://github.com/microsoft/Bringing-Old-Photos-Back-to-Life/issues/166 | [] | 56518 | 0 |
pyro-ppl/numpyro | numpy | 1,916 | `MCMC.run` gets error after `MCMC.warmup` with `AIES` | Hi, I get an error when I `MCMC.run` after `warmup` with `AIES`.
Here is the example
```
import jax
import jax.numpy as jnp
import numpyro
from numpyro.infer import MCMC, AIES
import numpyro.distributions as dist
n_dim, num_chains = 5, 100
mu, sigma = jnp.zeros(n_dim), jnp.ones(n_dim)
def model(mu, sigma)... | closed | 2024-11-25T14:53:29Z | 2024-11-29T01:52:21Z | https://github.com/pyro-ppl/numpyro/issues/1916 | [
"bug"
] | xiesl97 | 2 |
aiogram/aiogram | asyncio | 1,103 | Documentation mistake for PreCheckoutQuery type. | ### Checklist
- [x] I am sure the error is coming from aiogram code
- [X] I have searched in the issue tracker for similar bug reports, including closed ones
### Operating system
Windows 11 21H2
### Python version
3.11.1
### aiogram version
2.24
### Expected behavior
When I open documentation for [types.PreChe... | closed | 2023-01-21T12:44:49Z | 2023-08-14T20:23:56Z | https://github.com/aiogram/aiogram/issues/1103 | [
"bug"
] | iamnalinor | 1 |
sinaptik-ai/pandas-ai | data-visualization | 841 | Conversational/Follow Up questions for Agent still takes the base dataframe for code generation | ### System Info
python==3.10.13
pandasai==1.5.11
Windows OS
### 🐛 Describe the bug
I initialized pandasai agent for conversation capabilities. Gave the base dataframe and Azure OpenAI LLM. Agent answers first question well, but when I ask follow up question it runs/build the python code on base dataframe rather... | closed | 2023-12-29T05:11:32Z | 2024-06-01T00:20:42Z | https://github.com/sinaptik-ai/pandas-ai/issues/841 | [] | chaituValKanO | 0 |
itamarst/eliot | numpy | 144 | Allow passing existing `Field`s to `fields` | As it stands combining previously defined `Field`s with `fields` is a bit of a mess:
``` python
BAR = Field(u'bar', ...)
LOG_FOO = ActionType(u'example:foo', [BAR, ...] + fields(reason=int, ...), [BAR, ...] + fields(result=int), ...)
```
It would be convenient if `fields` accepted positional arguments of `Field` inst... | closed | 2015-02-24T09:43:19Z | 2018-09-22T20:59:16Z | https://github.com/itamarst/eliot/issues/144 | [] | jonathanj | 1 |
keras-team/autokeras | tensorflow | 828 | [Question] Project Algorithms Milestones and its relations to Kerastuner | Hi,
You seem to be using RandomSearch and params band search (HyperBand) from kerastuner as algorithms. You are planning to deploy other popular NAS/AutoML as Reinforcement Learning and Meta-Heuristic Search (GA e.g.) ? Does keras-team plans to do all the algorithms in kerastuner or in this module ? Do you have a r... | closed | 2019-11-07T19:04:30Z | 2020-02-08T14:39:21Z | https://github.com/keras-team/autokeras/issues/828 | [
"wontfix"
] | Uiuran | 6 |
rougier/scientific-visualization-book | numpy | 7 | Visualizations | open | 2021-08-11T23:06:12Z | 2021-08-11T23:06:12Z | https://github.com/rougier/scientific-visualization-book/issues/7 | [] | morr-debug | 0 | |
floodsung/Deep-Learning-Papers-Reading-Roadmap | deep-learning | 85 | UnicodeEncodeError: 'charmap' codec can't encode | [3] "Reducing the dimensionality of data with neur [...] (http://www.cs.toronto.edu/~hinton/science.pdf)
Traceback (most recent call last):
File "download.py", line 102, in <module>
print_title(point.text)
File "download.py", line 50, in print_title
print('\n'.join(("", title, pattern * len(title))))
... | open | 2017-12-05T15:37:13Z | 2019-06-10T12:47:44Z | https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap/issues/85 | [] | Vyomax | 4 |
tensorpack/tensorpack | tensorflow | 782 | ops are assigned to gpu when run DistributedTrainerParameterServer | I want to run DistributedTrainerParameterServer example , so I modify thr examples/basics/mnist-convnet.py as below:
launch_train_with_config(config, SyncMultiGPUTrainerParameterServer(gpus=args.gpu.split(",")))
===>
cluster = tf.train.ClusterSpec({"ps":["localhost:2222"], "worker":["localhost:2223"]})
... | closed | 2018-06-06T09:47:26Z | 2018-06-15T07:40:19Z | https://github.com/tensorpack/tensorpack/issues/782 | [
"usage",
"upstream issue"
] | yogurfrul | 5 |
DistrictDataLabs/yellowbrick | scikit-learn | 1,087 | Show ROC for train and test + hide macro/micro in binary classification. | Hi! Thanks (again) for this incredible package 👍
I hope not to be missing heavily with this feature, I read all of the documentation + google + stackoverflow. Please if I'm wrong to point me in the right direction (=> URL)
Normally we check train data vs test data. I see that ROC feature only shows the data for... | closed | 2020-07-18T23:39:51Z | 2020-10-02T17:43:27Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1087 | [
"type: question"
] | pablo14 | 4 |
timkpaine/lantern | plotly | 201 | Add conda recipe | closed | 2020-02-18T19:59:13Z | 2024-02-03T21:42:36Z | https://github.com/timkpaine/lantern/issues/201 | [
"feature",
"backlog"
] | timkpaine | 0 | |
fastapi/sqlmodel | sqlalchemy | 95 | How to deal with column type needed situation? | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2021-09-14T08:05:54Z | 2023-09-03T20:43:36Z | https://github.com/fastapi/sqlmodel/issues/95 | [
"question"
] | Ma233 | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 757 | Fail: "[ONNXRuntimeError] | Last Error Received:
Process: Ensemble Mode
If this error persists, please contact the developers with the error details.
Raw Error Details:
Fail: "[ONNXRuntimeError] : 1 : FAIL : Non-zero status code returned while running FusedConv node. Name:'Conv_0' Status Message: CUDNN error executing cudnnFindConvolu... | open | 2023-08-22T13:58:07Z | 2023-08-22T19:10:34Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/757 | [] | dimadt | 3 |
tartiflette/tartiflette | graphql | 256 | .cook() is not idempotent | * [x] **Explain with a simple sentence the expected behavior**: it should be possible to call `.cook()` multiple times without it failing with hard-to-debug error tracebacks.
* [x] **Tartiflette version:** 0.11.2
* [x] **Python version:** 3.7.2
* [x] **Executed in docker:** No
* [x] **Is it a regression from a prev... | closed | 2019-07-02T07:49:57Z | 2019-07-02T22:30:07Z | https://github.com/tartiflette/tartiflette/issues/256 | [
"enhancement"
] | florimondmanca | 8 |
vanna-ai/vanna | data-visualization | 228 | Ask Snowflake - Couldn't run sql: 'NoneType' object has no attribute 'fetchall' | I am running vn.ask(question="some natual language questions") to query Snowflake table, and it returns the following error.
None
WARNING:snowflake.connector.cursor:execute: no query is given to execute
Couldn't run sql: 'NoneType' object has no attribute 'fetchall' | closed | 2024-02-02T10:29:33Z | 2024-03-02T04:13:22Z | https://github.com/vanna-ai/vanna/issues/228 | [] | boyuanqian | 0 |
hankcs/HanLP | nlp | 1,162 | 关于简繁转换的问题 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-04-26T07:19:26Z | 2019-04-26T07:38:17Z | https://github.com/hankcs/HanLP/issues/1162 | [] | humiao8sz | 1 |
python-visualization/folium | data-visualization | 1,286 | How to open the popup automatically when a search is found for a GeoJson layer? | #### Please add a code sample or a nbviewer link, copy-pastable if possible
```python
# Your code here
import folium
import branca
import geopandas
from folium.plugins import Search
print(folium.__version__)
states = geopandas.read_file(
'https://rawcdn.githack.com/PublicaMundi/MappingAPI/master/data... | open | 2020-04-10T04:18:51Z | 2022-11-28T16:56:55Z | https://github.com/python-visualization/folium/issues/1286 | [
"bug"
] | RenchengDong | 1 |
onnx/onnx | pytorch | 6,013 | AttributeError while installing ONNX | # Bug Report
### Is the issue related to model conversion?
<!-- If the ONNX checker reports issues with this model then this is most probably related to the converter used to convert the original framework model to ONNX. Please create this bug in the appropriate converter's GitHub repo (pytorch, tensorflow-onnx, sk... | closed | 2024-03-11T14:02:25Z | 2024-07-31T16:01:36Z | https://github.com/onnx/onnx/issues/6013 | [
"question",
"topic: build"
] | Tom-Teamo | 13 |
svc-develop-team/so-vits-svc | pytorch | 126 | [Help]: 每次训练都在 Epoch: 2 [42%], step: 800 的位置报错退出 | ### 请勾选下方的确认框。
- [x] 我已仔细阅读[README.md](https://github.com/svc-develop-team/so-vits-svc/blob/4.0/README_zh_CN.md)和[wiki中的Quick solution](https://github.com/svc-develop-team/so-vits-svc/wiki/Quick-solution)。
- [X] 我已通过各种搜索引擎排查问题,我要提出的问题并不常见。
- [X] 我未在使用由第三方用户提供的一键包/环境包。
### 系统平台版本号
Windows 10 家庭版
### GPU 型号
NVIDIA G... | closed | 2023-04-05T18:59:38Z | 2023-04-13T04:03:13Z | https://github.com/svc-develop-team/so-vits-svc/issues/126 | [
"help wanted"
] | AGuanDao | 5 |
jina-ai/serve | machine-learning | 5,744 | Torch error in Jcloud http flow | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
Posting to the below flow in jcloud http protocol will throw a torch module not found error. Grpc is fine.
```
from jina import DocumentArray, Executor, requests
import torch
class dummy_torch(Executor):
@requests
de... | closed | 2023-03-07T12:01:10Z | 2023-03-13T21:55:46Z | https://github.com/jina-ai/serve/issues/5744 | [] | ZiniuYu | 0 |
nolar/kopf | asyncio | 966 | Replay resources doesn't work | ### Keywords
_No response_
### Problem
Hello, my use case manages two CRDs (DNS instance and DNS records). My operator allows removing the DNS instance leaving the associated DNS records present just in case it obeys to a temporary need.
After recreating the DNS instance I planned to simply run "kubectl get ... | closed | 2022-10-30T10:32:38Z | 2022-11-07T19:14:30Z | https://github.com/nolar/kopf/issues/966 | [
"question"
] | davidp1404 | 2 |
google-research/bert | tensorflow | 1,148 | Can RoBERTa be fine-tuned on unlabeled data? | Im new working with language models, need some help
Can i pre train RoBERTa with data set having just one column i-e sentences and no labels or anything? | open | 2020-09-16T06:39:13Z | 2020-09-16T06:39:13Z | https://github.com/google-research/bert/issues/1148 | [] | HamzaYounis | 0 |
aeon-toolkit/aeon | scikit-learn | 1,931 | [ENH] Improvements to write_to_tsfile | ### Describe the feature or idea you want to propose
just writing some data to file and will note anything here that could be better
### Describe your proposed solution
1. More informative errors
2. Data precision option: it currently creates big files
3. Doesnt work with univariate data in 2D format
| closed | 2024-08-08T10:07:40Z | 2024-11-23T08:46:43Z | https://github.com/aeon-toolkit/aeon/issues/1931 | [
"enhancement",
"datasets"
] | TonyBagnall | 0 |
cobrateam/splinter | automation | 570 | Unexpected behavior from setting profiles and extensions. | Python = 2.7.10 (mac OS X Sierra)
Tried:
browser = Browser('firefox', extensions=['/full/path/to/ext.xpi', '/full/path/to/ext2.xpi'])
browser = Browser('firefox', extensions=['./ext.xpi', './ext2.xpi'])
With and without escape characters because it's in 'Application Support'
browser = Browser('firefox', profile=... | closed | 2017-11-01T01:52:34Z | 2021-07-22T21:59:15Z | https://github.com/cobrateam/splinter/issues/570 | [
"NeedsInvestigation"
] | orange-tsai | 2 |
noirbizarre/flask-restplus | flask | 466 | App runs locally but returns 500 error on Heroku | There doesn't seem to be any documentation on deploying to Heroku with flask-restplus. I've just deployed an app and am getting the following: `Error: INTERNAL SERVER ERROR`.
My Procfile is set to `web: gunicorn app:app` and my app is set as `api = Api(app)`, `app.wsgi_app = ProxyFix(app.wsgi_app)`, and `app = Flask... | closed | 2018-06-05T15:44:07Z | 2024-03-20T17:15:35Z | https://github.com/noirbizarre/flask-restplus/issues/466 | [] | rah-ool | 39 |
Esri/arcgis-python-api | jupyter | 1,815 | License.all() returns incorrect results for orgs with >10,000 users | In an ArcGIS Online organization with >10,000 users, the License.all() method returns only the first 10,000 users that have a particular license. There does not seem to be a way to page results or otherwise access the users above the first 10,000.
You can reproduce this issue in any org with more than 10,000 users, ... | open | 2024-04-28T14:56:37Z | 2024-06-24T18:21:50Z | https://github.com/Esri/arcgis-python-api/issues/1815 | [
"enhancement"
] | knoopum | 0 |
waditu/tushare | pandas | 1,617 | 数据获取工具获取上市公司管理层信息报错 | 环境:Chrome浏览器
功能点击:Tushare数据获取工具,获取上市公司管理层 时,报错,错误没有完全显示
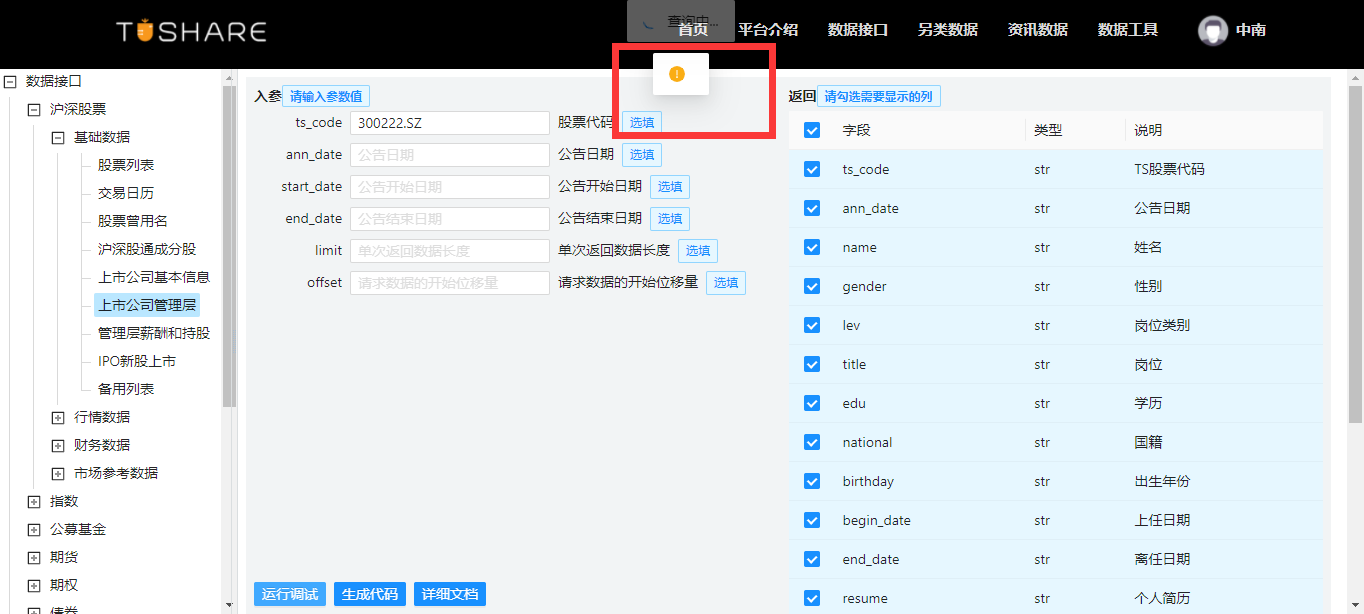
缺陷提交人:494037935@qq.com
| open | 2022-01-01T12:25:39Z | 2022-01-01T12:26:02Z | https://github.com/waditu/tushare/issues/1617 | [] | znufe2010 | 0 |
microsoft/JARVIS | pytorch | 45 | Would it support Azure OpenAI? | Hi, I only saw OpenAI API key in config.yml. Does it support Azure OpenAI? Or is there any plans to support Azure OpenAI? | closed | 2023-04-05T14:51:30Z | 2023-04-10T05:22:04Z | https://github.com/microsoft/JARVIS/issues/45 | [] | Ko-Ko-Kirk | 2 |
pennersr/django-allauth | django | 3,679 | Assertion Error for Existing Users After Registering New User with Social Account | Hello,
I've encountered an issue where, after registering a new user through a social account integration, all existing users are unable to log in and are met with an AssertionError. This problem persists across all stored users and makes it impossible for them to log in after a new user registers via a social accou... | closed | 2024-03-11T15:33:23Z | 2025-02-23T07:45:56Z | https://github.com/pennersr/django-allauth/issues/3679 | [] | YuchenTOR | 4 |
koxudaxi/datamodel-code-generator | pydantic | 2,130 | The class "Extra" is deprecated Extra is deprecated. Use literal values instead (e.g. `extra='allow'`) | **Describe the bug**
This is not a bug **yet**, but I think I should report it.
So, I just installed `datamodel-code-generator` to be able to convert a JSON schema to a dataclass.
Here's the dependencies
```
datamodel-code-generator 0.26.2
...
pydantic 2.9.2
pydantic_core 2.2... | closed | 2024-10-21T15:06:26Z | 2024-10-22T17:04:00Z | https://github.com/koxudaxi/datamodel-code-generator/issues/2130 | [] | nbro10 | 2 |
ultralytics/ultralytics | pytorch | 19,310 | Device selection on export on multi-gpu systems | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
_No response_
### Bug
Greatings! 🚀
Sorry for my English. I ran into issue (latest version, February, 19th) when choosing ... | closed | 2025-02-19T10:30:55Z | 2025-02-20T18:39:51Z | https://github.com/ultralytics/ultralytics/issues/19310 | [
"exports"
] | liwtw | 4 |
pywinauto/pywinauto | automation | 511 | Maintaining control identifiers in centralized location | When desktop application is very large and has 10k identifiers,then how should one maintain and access then from centralized location (file) in python.
Please give suggestions.
Earlier we were using QTP for automation which has its own utility of object repository... For pywinauto how can we create similar utility ... | open | 2018-06-26T15:42:37Z | 2024-01-09T07:14:02Z | https://github.com/pywinauto/pywinauto/issues/511 | [
"enhancement",
"Priority-Critical",
"good first issue"
] | NeJaiswal | 12 |
FactoryBoy/factory_boy | django | 598 | Changes introduced in #345 altered how django_get_or_create behaves | Upgrading to 2.12.0 broke some of the tests we had, and I'm pretty sure either the docs for django_get_or_create are incorrect or the change in behavior was unintended. The change that seems to be causing the problem is https://github.com/FactoryBoy/factory_boy/pull/345
We have a model with three fields marked as un... | closed | 2019-05-24T19:20:35Z | 2019-05-28T14:38:48Z | https://github.com/FactoryBoy/factory_boy/issues/598 | [
"Bug",
"Django"
] | mkokotovich | 1 |
encode/httpx | asyncio | 3,334 | Document `Authentication` header is stripped on redirection | - [x] Initially raised as discussion #3291
| open | 2024-10-08T01:44:02Z | 2024-10-28T21:27:39Z | https://github.com/encode/httpx/issues/3334 | [
"docs"
] | findmyway | 0 |
google-research/bert | nlp | 674 | Not compatible with tensorflow 2.0 | Is Bert not compatible with tensorflow 2.0 ?
AttributeError Traceback (most recent call last)
<ipython-input-4-1b957e7a053a> in <module>()
1 import modeling
----> 2 import optimization
3 import run_classifier
4 import run_classifier_with_tfhub
5 import tokeniz... | closed | 2019-06-04T05:55:20Z | 2020-09-02T09:56:05Z | https://github.com/google-research/bert/issues/674 | [] | makaveli10 | 5 |
CorentinJ/Real-Time-Voice-Cloning | python | 816 | Is this supposed to happen? am I supposed to put an audio file next to this? | Hello, I get this error in Ubuntu on my WSL 2 implementation and Ubuntu Docker NOVNC container. Please place more details or a pathway in documentation to help with error resolution
See below
############
**gitpod /workspace/Real-Time-Voice-Cloning $** python demo_cli.py
Arguments:
enc_model_fpath: en... | closed | 2021-08-11T20:51:14Z | 2021-08-25T08:48:55Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/816 | [] | Hi-ip | 1 |
akfamily/akshare | data-science | 5,227 | AKShare 接口问题报告 - stock_board_industry_index_ths |
**详细问题描述**
1. 请先详细阅读文档对应接口的使用方式:https://akshare.akfamily.xyz
2. 操作系统版本:Win11 64位
3. Python 版本:3.8 以上的版本
4. AKShare 版本:最新版
5. 接口的名称和相应的调用代码
接口名称:stock_board_industry_index_ths
调用:http://127.0.0.1:8080/api/public/stock_board_industry_index_ths?symbol=元件&start_date=20100930&end_date=20241009
7. 接口报错的截图或描述
其他的... | closed | 2024-10-07T13:06:43Z | 2024-10-11T14:11:52Z | https://github.com/akfamily/akshare/issues/5227 | [
"bug"
] | jiataocai | 2 |
QingdaoU/OnlineJudge | django | 463 | 纯小白求助 | 请问大家是怎么进行二次开发的呢 我在ubuntu上部署了FE和onlinejudge,在ubuntu上只能看到前端页面,也进不去后台管理,课设需要在青岛oj上开发,不太了解这种架构的开发方式,部署完了,怎么对前端和后端二次开发,有没有对这个项目有过二开经验的大佬,求有偿指导
| closed | 2024-04-15T14:15:40Z | 2024-04-17T08:35:50Z | https://github.com/QingdaoU/OnlineJudge/issues/463 | [] | t1yifang | 1 |
strawberry-graphql/strawberry | django | 2,864 | Problems with from __future__ import annotations and relay | <!-- Provide a general summary of the bug in the title above. -->
The novel relay module is not compatible with `from __future__ import annotations`.
I build a simple demo:
https://github.com/devkral/graphene-protector/tree/demo/withresolve_bug (see first section how to reproduce)
Somehow the field cannot be... | open | 2023-06-19T09:13:50Z | 2025-03-20T15:56:15Z | https://github.com/strawberry-graphql/strawberry/issues/2864 | [
"bug"
] | devkral | 3 |
paperless-ngx/paperless-ngx | django | 9,192 | [BUG] Deleting a Split in Multi-Split Documents Deletes the Wrong Split | ### Description
When splitting documents I ran into this problem where if you have a document with many splits and then try to delete a split, it will fail to delete the selected split.
### Steps to reproduce
1. Download this sample pdf [bla4.pdf](https://github.com/user-attachments/files/18921583/bla4.pdf). Having ... | closed | 2025-02-22T10:34:24Z | 2025-02-22T15:28:27Z | https://github.com/paperless-ngx/paperless-ngx/issues/9192 | [
"bug",
"frontend"
] | gooney47 | 2 |
mars-project/mars | scikit-learn | 2,758 | make mars type inference optional | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Is your feature request related to a problem? Please describe.**
Mars type inferrence will generate mock data, then feed the data into user provided function, if ... | closed | 2022-02-25T10:40:07Z | 2022-02-28T06:15:22Z | https://github.com/mars-project/mars/issues/2758 | [
"type: enhancement",
"mod: dataframe"
] | chaokunyang | 0 |
pyeve/eve | flask | 605 | GridFSMediaStorage does not save filename | `GridFSMediaStorage.put` method is saving the filename from the keyword argument, however `store_media_files` in `eve.methods.common` does not specify anything for filename argument.
I have a workaround currently by subclassing `GridFSMediaStorage.put` method but default behavior should also specify the filename for k... | closed | 2015-04-18T02:32:03Z | 2015-04-18T07:07:23Z | https://github.com/pyeve/eve/issues/605 | [] | slamuu | 0 |
sqlalchemy/alembic | sqlalchemy | 369 | ORM session creates a subtransaction on get_bind()? this interferes w/ things ? | **Migrated issue, originally created by chris7 ([@chris7](https://github.com/chris7))**
I am trying to run a trivial migration, and alembic will migrate the database, but is not updating the database version. To update alembic_version, it requires me to run the migration again.
Here's the script I am running:
```pyth... | closed | 2016-04-17T15:17:38Z | 2017-02-23T16:36:39Z | https://github.com/sqlalchemy/alembic/issues/369 | [
"bug"
] | sqlalchemy-bot | 10 |
aio-libs/aiomysql | sqlalchemy | 102 | Connecting via URL instead of separate connection values | Could we connect by passing the connection details via an URL instead of having separate host, port, etc. variables? [Similar to what aioamqp has with its from_url function](https://github.com/Polyconseil/aioamqp/blob/b1d11024c658e03722bee57f97a9ced8e3e6b1bc/aioamqp/__init__.py#L76).
| closed | 2016-09-01T11:35:57Z | 2021-10-01T00:18:14Z | https://github.com/aio-libs/aiomysql/issues/102 | [] | ghost | 3 |
postmanlabs/httpbin | api | 285 | test_post_body_unicode fails on PyPy 3 with UnicodeDecodeError | PyPy 3 raises an exception during `test_post_body_unicode`
```
RPython traceback:
...
Fatal RPython error: UnicodeDecodeError
```
Is httpbin interested in fixes for PyPy 3?
| closed | 2016-05-02T03:46:08Z | 2018-04-26T17:51:10Z | https://github.com/postmanlabs/httpbin/issues/285 | [] | jayvdb | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.