
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
vllm-project/vllm | pytorch | 14,403 | [Bug]: Error when Run Image Docker Vllm v0.7.3 - Unexpected error from cudaGetDeviceCount(). .... | ### Your current environment
<details>
<summary>
I have problem when start docker image with vllm v0.7.3 ( lasted now )

My docker-compose.yml file
### Docker Compose Configuration
```yaml
version: "3.8"
services:
vllm-o... | open | 2025-03-07T04:24:55Z | 2025-03-10T17:07:25Z | https://github.com/vllm-project/vllm/issues/14403 | [
"bug"
] | duytran1999 | 2 |
ets-labs/python-dependency-injector | asyncio | 692 | Selector should be able to select between different Configurations | Let's say I have this yaml configuration:
```
selected: option1
option1:
param1:...
param2:....
option2:
param1:...
param2:...
```
I want to be able to do something like this:
```
class Container(containers.DeclarativeContainer):
config = providers.Configuration()
parameters ... | open | 2023-03-31T21:09:27Z | 2023-04-01T13:12:34Z | https://github.com/ets-labs/python-dependency-injector/issues/692 | [] | andresi | 1 |
davidsandberg/facenet | tensorflow | 429 | Why the dataset has to be aligned | i ran the following script ,
`sudo python align_dataset_mtcnn.py /datasets/lfw/raw /datasets/lfw/lfw_mtcnnpy_160 --image_size 160 --margin 32 --random_order --gpu_memory_fraction 0.25 `
May I know what this script basically does? why do we have to align it? [This](https://github.com/davidsandberg/facenet/wiki/Val... | closed | 2017-08-20T11:52:26Z | 2017-08-23T17:35:39Z | https://github.com/davidsandberg/facenet/issues/429 | [] | Zumbalamambo | 2 |
amdegroot/ssd.pytorch | computer-vision | 56 | RunTime Error in Training with default values | `python train.py
Loading base network...
Initializing weights...
Loading Dataset...
Training SSD on VOC0712
Traceback (most recent call last):
File "train.py", line 232, in <module>
train()
File "train.py", line 181, in train
out = net(images)
File "/users/gpu/utkrsh/anaconda3/envs/pytorch/lib/... | closed | 2017-08-18T12:59:08Z | 2019-05-21T06:39:46Z | https://github.com/amdegroot/ssd.pytorch/issues/56 | [] | chauhan-utk | 13 |
graphql-python/graphene-sqlalchemy | graphql | 133 | Nested inputs in mutations | I'm failing to convert nested inputs into sqlalchemy models in mutations. Here's my example:
Let's say I want to create a quiz. For that I have the following code:
```
'''
GraphQL Models
'''
class Quiz(SQLAlchemyObjectType):
'''
GraphQL representation of a Quiz
'''
class Meta:
m... | open | 2018-05-22T19:21:42Z | 2018-05-22T19:49:08Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/133 | [] | NathanBWaters | 2 |
ultralytics/ultralytics | deep-learning | 19,574 | Use ray to tune | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Train
### Bug
Hi guys, I need your help with an issue I'm facing when using Ray to tune my YOLO model.
When using Ray, som... | closed | 2025-03-08T08:28:18Z | 2025-03-24T09:03:21Z | https://github.com/ultralytics/ultralytics/issues/19574 | [
"bug",
"enhancement"
] | csn223355 | 12 |
saulpw/visidata | pandas | 1,462 | Copy multiple columns across different files | Is there a way for me to copy multiple consecutive columns from one file and paste/insert them into another file? Thanks! | closed | 2022-08-09T23:22:38Z | 2022-08-09T23:29:03Z | https://github.com/saulpw/visidata/issues/1462 | [
"wishlist"
] | jingxixu | 1 |
tqdm/tqdm | pandas | 1,283 | `ipywidgets` variant broken | ```python
import sys, time, tqdm
for j in tqdm.trange(100, file=sys.stdout, leave=False, unit_scale=True, desc='loop'):
time.sleep(1)
```
works, but
```python
for j in tqdm.auto.tqdm(range(100), file=sys.stdout, leave=False, unit_scale=True, desc='loop'):
time.sleep(1)
````
shows a frozen progress bar... | open | 2021-12-22T22:20:23Z | 2022-09-14T15:03:40Z | https://github.com/tqdm/tqdm/issues/1283 | [
"invalid ⛔",
"need-feedback 📢",
"p2-bug-warning ⚠",
"submodule-notebook 📓"
] | OverLordGoldDragon | 5 |
databricks/koalas | pandas | 1,305 | Index.to_series() works not properly | When converting an Index to Series for comparing operation like the below,
there is something problem.
```python
>>> pidx = pd.Index([1, 2, 3, 4, 5])
>>> kidx1 = ks.Index([1, 2, 3, 4, 5])
>>> kidx2 = ks.Index(pidx)
>>> kidx3 = ks.from_pandas(pidx)
>>> kidx1.to_series() == kidx2.to_series() == kidx3.to_series... | closed | 2020-02-24T17:35:58Z | 2020-03-02T18:50:31Z | https://github.com/databricks/koalas/issues/1305 | [
"bug"
] | itholic | 0 |
django-cms/django-cms | django | 7,794 | [DOC] code update | Do you also want to take a look at https://github.com/django-cms/django-cms/blob/develop-4/docs/contributing/code.rst? There's still reference to aldryn-boilerplate (a bootstrap3 thing) | open | 2024-01-29T11:57:19Z | 2025-02-22T18:27:01Z | https://github.com/django-cms/django-cms/issues/7794 | [
"component: documentation"
] | marksweb | 1 |
vitalik/django-ninja | rest-api | 593 | How to define responses for the swagger | Hello!
I'm passing my API responses to schemas so that the corresponding responses and status appear in the swagger documentation.
In those that return a list with keys I have no problem, but in those that return a plain text, or a list without keys, how could I define it?
For example, an endpoint returning th... | closed | 2022-10-17T14:52:38Z | 2023-01-13T10:03:27Z | https://github.com/vitalik/django-ninja/issues/593 | [] | JFeldaca | 1 |
huggingface/datasets | machine-learning | 7,442 | Flexible Loader | ### Feature request
Can we have a utility function that will use `load_from_disk` when given the local path and `load_dataset` if given an HF dataset?
It can be something as simple as this one:
```
def load_hf_dataset(path_or_name):
if os.path.exists(path_or_name):
return load_from_disk(path_or_name)
... | open | 2025-03-09T16:55:03Z | 2025-03-17T20:35:07Z | https://github.com/huggingface/datasets/issues/7442 | [
"enhancement"
] | dipta007 | 2 |
zama-ai/concrete-ml | scikit-learn | 852 | [Feature Request] Support for threshold decryption | ## Feature request
Hi. Is there any plan to support Concrete-ML (or Concrete) with threshold decryption?
## Motivation
I came across this paper [https://eprint.iacr.org/2023/815.pdf](url). It seems that there has already been some research done by Zama about threshold decryption on TFHE. It would be good to a... | open | 2024-09-02T09:01:17Z | 2024-09-02T13:48:49Z | https://github.com/zama-ai/concrete-ml/issues/852 | [] | gy-cao | 1 |
pydantic/logfire | fastapi | 907 | Emit severity text in logRecord? | ### Question
Hello,
I'm trying to use logfire with an alternative backend, however I am having issues getting the severity level to show up in loki. When looking at the otel endpoint, the following is found in the trace attributes: `logfire.level_num`. However this doesn't translate to anything concrete. Is it possi... | closed | 2025-03-04T20:21:32Z | 2025-03-05T16:11:41Z | https://github.com/pydantic/logfire/issues/907 | [
"Question"
] | jonas-meyer | 5 |
aimhubio/aim | data-visualization | 2,659 | Unable to access Aim instance with a domain without specifying a port number | ### Describe the bug
When trying to access an Aim instance using a domain, the current implementation expects a port number to be included in the URL. However, in some cases, the port number might not be required, especially when using default ports (e.g., port 80 for HTTP). The current implementation of the _separate... | open | 2023-04-18T03:40:02Z | 2023-05-02T06:45:21Z | https://github.com/aimhubio/aim/issues/2659 | [] | ds-sebastian | 1 |
praw-dev/praw | api | 1,107 | Allow creating a userflair template with both a CSS class and a background color | ## Issue Description
When support was added for v2 flairs back in January (#1018), the Reddit API did not support defining new userflair templates that had both CSS classes and background colors defined. There are some checks in the code currently that throw errors if you try to do this (eg. praw/models/reddit/subre... | closed | 2019-07-15T21:20:55Z | 2019-07-29T02:08:40Z | https://github.com/praw-dev/praw/issues/1107 | [] | jenbanim | 1 |
CorentinJ/Real-Time-Voice-Cloning | python | 1,274 | How can I decrease speed for cloning? | I am using this model on aws ec2 instance but it takes approx 30 seconds to clone, but I want to clone it faster.
I have tried changing the instance types but that didn't worked.
I have tried g4, g5 and p3 instances but the time taken was same in all of them. | open | 2023-11-26T16:06:22Z | 2023-11-26T16:06:22Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1274 | [] | Satyam206 | 0 |
arogozhnikov/einops | tensorflow | 74 | [Feature suggestion] Add layer 'repeat_as' | In pytorch, we have 'expand_as' which check dim before expand.
I'm aware of 'repeat' layer as replace for 'expand' but could you add 'repeat_as' as expand for 'expand as' ?
Thanks. | closed | 2020-10-21T03:31:57Z | 2024-09-16T18:49:01Z | https://github.com/arogozhnikov/einops/issues/74 | [] | NguyenVanThanhHust | 1 |
marshmallow-code/flask-smorest | rest-api | 177 | Document file download | How can I document a file download (done with send_file from flask) in openapi.json? | closed | 2020-08-06T11:06:34Z | 2020-08-14T02:57:49Z | https://github.com/marshmallow-code/flask-smorest/issues/177 | [] | kettenbach-it | 1 |
noirbizarre/flask-restplus | api | 267 | upgrade swagger to 3.0 | https://github.com/swagger-api/swagger-ui/blob/master/dist/index.html
need a little fix on css

| closed | 2017-03-29T12:40:01Z | 2022-06-24T02:56:03Z | https://github.com/noirbizarre/flask-restplus/issues/267 | [] | tkizm1 | 3 |
davidsandberg/facenet | computer-vision | 964 | VGG19 Model | Can some one share VGG19 architecture, modified to run with facenet code? | open | 2019-01-29T09:44:52Z | 2019-03-20T12:21:00Z | https://github.com/davidsandberg/facenet/issues/964 | [] | Shahnawazgrewal | 1 |
akfamily/akshare | data-science | 5,593 | AKShare 接口问题报告 | ak.stock_zh_a_spot_em只能抓取200个股票了 | ak.stock_zh_a_spot_em 今天上午还能抓取5000多个股票的,下午变成只能抓取200个股票了。请问是什么问题,我akshare版本降级到1.15.84以后还是只能抓取200个。
序号 代码 名称 最新价 涨跌幅 涨跌额 成交量 ... 市净率 总市值 流通市值 涨速 5分钟涨跌 60日涨跌幅 年初至今涨跌幅
0 1 873167 新赣江 28.08 30.00 6.48 112559 ... 4.22 1989783900 1173234825 0.00 0.0... | closed | 2025-02-15T07:49:04Z | 2025-02-15T14:25:06Z | https://github.com/akfamily/akshare/issues/5593 | [
"bug"
] | diana518516 | 5 |
deezer/spleeter | tensorflow | 917 | [Bug] protobuf incompatibility | - [ ✅] I didn't find a similar issue already open.
- [ ✅] I read the documentation (README AND Wiki)
- [ ✅] I have installed FFMpeg
- [ ❌] My problem is related to Spleeter only, not a derivative product (such as Webapplication, or GUI provided by others)
## Description
I'm trying to build a streamlit web appl... | open | 2024-11-04T08:35:15Z | 2024-11-04T08:35:15Z | https://github.com/deezer/spleeter/issues/917 | [
"bug",
"invalid"
] | sahandkh1419 | 0 |
Gozargah/Marzban | api | 1,058 | nodes | سلام وقت بخیر
من یه مشکلی که دارم بعضی موقعا نود ام به قطع و وصلی میوفته مجبور میشم برم ssh بزنم به سرور node یه بار دستور ریستارت اجرا کنم
```
docker compose down --remove-orphans; docker compose up -d
```
تا مشکل حل بشه
کانفیگ داکر سرور نودم هم به این صورت هست
```
services:
marzban-node:
# build: .
... | closed | 2024-06-22T21:31:25Z | 2024-06-26T04:41:20Z | https://github.com/Gozargah/Marzban/issues/1058 | [
"Bug"
] | xmohammad1 | 0 |
onnx/onnx | tensorflow | 5,954 | How to export a yolov8 model to onnx format | open | 2024-02-23T03:23:33Z | 2024-02-23T03:23:33Z | https://github.com/onnx/onnx/issues/5954 | [
"question"
] | LeoYoung6k | 0 | |
jupyter/docker-stacks | jupyter | 1,775 | [BUG] - java & pyspark not pre-installed? | ### What docker image(s) are you using?
pyspark-notebook
### OS system and architecture running docker image
windows 11
### What Docker command are you running?
docker run --name pyspark -p 8888:8888 jupyter/scipy-notebook:latest
### How to Reproduce the problem?
from pyspark.sql import *
spark = SparkSession... | closed | 2022-08-21T16:06:07Z | 2022-08-21T16:30:34Z | https://github.com/jupyter/docker-stacks/issues/1775 | [
"type:Bug"
] | TBrannan | 3 |
keras-team/keras | deep-learning | 20,048 | keras.ops.map can't handle nested structures for TensorFlow backend | Keras: 3.4.1
TensorFlow: 2.17.0
As background, I am looking to leverage both `keras.ops.map` as well as `keras.ops.vectorize_map` for custom preprocessing layers. Certain layers require sequential mapping hence I use `keras.ops.map`. If I pass a nested input, `keras.ops.map` will fail when using TensorFlow backend.... | closed | 2024-07-26T14:59:47Z | 2024-08-11T22:24:16Z | https://github.com/keras-team/keras/issues/20048 | [
"type:Bug",
"backend:tensorflow"
] | apage224 | 2 |
BMW-InnovationLab/BMW-YOLOv4-Training-Automation | rest-api | 27 | FileNotFoundError: [Errno 2] No such file or directory: 'config/darknet/yolov4_default_weights/yolov4.weights' | Hi, I am facing this issue

Though we can see that the file exists there:

| closed | 2021-09-03T09:16:15Z | 2021-09-03T10:38:08Z | https://github.com/BMW-InnovationLab/BMW-YOLOv4-Training-Automation/issues/27 | [] | boredomed | 1 |
encode/databases | asyncio | 424 | Clarification on transaction isolation and management | Consider the following simulation of concurrent access:
```
# pylint: skip-file
import asyncio
import os
from databases import Database
async def tx1(db):
async with db.transaction():
await db.execute("INSERT INTO foo VALUES (1)")
await asyncio.sleep(1.5)
async def tx2(db):
... | closed | 2021-11-16T01:38:20Z | 2023-08-28T14:44:24Z | https://github.com/encode/databases/issues/424 | [
"clean up"
] | cochiseruhulessin | 6 |
freqtrade/freqtrade | python | 11,218 | ModuleNotFoundError: No module named 'freqtrade' | * Operating system: ____Linux 5.14.0-427.37.1.el9_4.x86_64
* Python Version: _____in openshift
* CCXT version: _____in openshift
* Freqtrade Version: ____ image: freqtradeorg/freqtrade:stable
The trying to install in openshift with "oc new-app freqtradeorg/freqtrade:stable" fails with the following error:
... | closed | 2025-01-12T07:28:17Z | 2025-01-15T02:40:16Z | https://github.com/freqtrade/freqtrade/issues/11218 | [
"Question",
"Install"
] | chmj | 2 |
zappa/Zappa | django | 569 | [Migrated] Flask 1.0 is out | Originally from: https://github.com/Miserlou/Zappa/issues/1493 by [mnp](https://github.com/mnp)
<!--- Provide a general summary of the issue in the Title above -->
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
<!--- Also, please make sure that you... | closed | 2021-02-20T12:22:54Z | 2022-07-16T07:04:54Z | https://github.com/zappa/Zappa/issues/569 | [] | jneves | 1 |
Neoteroi/BlackSheep | asyncio | 51 | Enrich the API for OpenAPI Docs | * support defining common responses to be shared across all operations
* support defining ~~security and~~ servers settings without subclassing `OpenAPIHandler` | closed | 2020-11-30T19:51:37Z | 2020-12-27T11:48:12Z | https://github.com/Neoteroi/BlackSheep/issues/51 | [
"enhancement"
] | RobertoPrevato | 0 |
jazzband/django-oauth-toolkit | django | 594 | [Question]: What is music? | I have questions
1. What is `scope` in the document context?
```python
OAUTH2_PROVIDER = {
# this is the list of available scopes
'SCOPES': {'read': 'Read scope', 'write': 'Write scope', 'groups': 'Access to your groups'}
}
```
Because `scopes` contain `verb`, and `plural nouns`. I... | closed | 2018-05-11T06:48:06Z | 2018-05-19T10:08:20Z | https://github.com/jazzband/django-oauth-toolkit/issues/594 | [
"question"
] | elcolie | 2 |
sktime/pytorch-forecasting | pandas | 1,753 | [BUG] temporal fusion transformer trained with GPU's then loaded with map_locations=torch.device('cpu') does not apply the correct device to loss metric | **Describe the bug**
<!--
A clear and concise description of what the bug is.
-->
**To Reproduce**
<!--
Add a Minimal, Complete, and Verifiable example (for more details, see e.g. https://stackoverflow.com/help/mcve
If the code is too long, feel free to put it in a public gist and link it in the issue: https... | closed | 2025-01-15T03:56:04Z | 2025-01-15T04:02:01Z | https://github.com/sktime/pytorch-forecasting/issues/1753 | [
"bug"
] | arizzuto | 0 |
koaning/scikit-lego | scikit-learn | 630 | [DOCS] Document KlusterFoldValidation | Related to https://www.linkedin.com/feed/update/urn:li:activity:7176859386554789888?commentUrn=urn%3Ali%3Acomment%3A%28activity%3A7176859386554789888%2C7176877653679894528%29&dashCommentUrn=urn%3Ali%3Afsd_comment%3A%287176877653679894528%2Curn%3Ali%3Aactivity%3A7176859386554789888%29
It doesn't help that it is missp... | closed | 2024-03-22T16:28:44Z | 2024-03-24T14:11:10Z | https://github.com/koaning/scikit-lego/issues/630 | [
"documentation"
] | koaning | 3 |
tfranzel/drf-spectacular | rest-api | 996 | Defining a static dict for an error response in @extend_schema returns "string" as the response body | **Describe the bug**
In instances where there is no available serializer, or the response returns a dict, I would like to be able to specify that dict as the response in my responses list under `extend_schema`. I understand this is not maybe how it should be expected to behave but I was also unable to figure out a sol... | closed | 2023-05-31T19:50:27Z | 2023-06-11T18:55:56Z | https://github.com/tfranzel/drf-spectacular/issues/996 | [] | dashdanw | 3 |
babysor/MockingBird | pytorch | 310 | 本人小白,语音合成时遇Errors in loading staste_dict for Tacotron 求解决方法 | 
| closed | 2022-01-03T05:10:55Z | 2022-01-03T05:51:36Z | https://github.com/babysor/MockingBird/issues/310 | [] | Kristen-PRC | 3 |
deepspeedai/DeepSpeed | pytorch | 6,951 | [REQUEST] Pipeline Parallelism support multi optimizer to train | **Is your feature request related to a problem? Please describe.**
i want to train big model gan, must shard to multi-gpu, but the pipeline_module seems not support multi-optimizer
**Describe the solution you'd like**
support
**Describe alternatives you've considered**
can control flow to which layer
**Additional con... | open | 2025-01-15T11:48:23Z | 2025-01-15T11:48:23Z | https://github.com/deepspeedai/DeepSpeed/issues/6951 | [
"enhancement"
] | whcjb | 0 |
amdegroot/ssd.pytorch | computer-vision | 251 | eval.py Error [ ValueError: not enough values to unpack (expected 2, got 0) ] | ../ssd.pytorch/layers/functions/detection.py", line 54, in forward
ids, count = nms(boxes, scores, self.nms_thresh, self.top_k)
ValueError: not enough values to unpack (expected 2, got 0)
What does that mean?
How to solve that problem? | closed | 2018-10-19T09:57:23Z | 2020-02-11T11:57:40Z | https://github.com/amdegroot/ssd.pytorch/issues/251 | [] | MakeToast | 7 |
microsoft/nlp-recipes | nlp | 74 | [Example] Named Entity Recognition using MT-DNN | closed | 2019-05-28T16:51:13Z | 2020-01-14T17:51:50Z | https://github.com/microsoft/nlp-recipes/issues/74 | [
"example"
] | saidbleik | 3 | |
gunthercox/ChatterBot | machine-learning | 1,950 | SpecificResponseAdapter "Not processing the statement" | I'm confused about how this adapter works. I'm using the example. The only thing I'm doing differently is using Mongo as storage.
Here is the log:
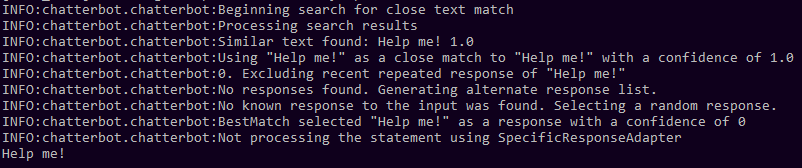
Am I missing something here? Do I need to set read only ... | open | 2020-04-19T01:20:33Z | 2020-04-19T01:20:44Z | https://github.com/gunthercox/ChatterBot/issues/1950 | [] | FallenSpaces | 0 |
babysor/MockingBird | pytorch | 994 | 预处理pre.py报错 |
Traceback (most recent call last):
File "/home_1/gaoyiyao/MockingBird-main/pre.py", line 74, in <module>
preprocess_dataset(**vars(args))
File "/home_1/gaoyiyao/MockingBird-main/models/synthesizer/preprocess.py", line 86, in preprocess_dataset
for speaker_metadata in tqdm(job, dataset, len(speaker_dir... | open | 2024-04-20T13:46:15Z | 2024-04-25T12:29:55Z | https://github.com/babysor/MockingBird/issues/994 | [] | gaoyiyao | 3 |
geopandas/geopandas | pandas | 2,872 | BUG: Different results between `GeoSeries.fillna` and `GeoDataFrame.fillna` | - [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of geopandas.
- [x] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
**Note**: Please read [this guide](https://matthewrocklin.com/blog/work/2018/0... | open | 2023-04-16T12:00:45Z | 2023-04-17T09:11:59Z | https://github.com/geopandas/geopandas/issues/2872 | [
"bug",
"enhancement"
] | Zeroto521 | 1 |
coqui-ai/TTS | deep-learning | 2,642 | [Bug] | ### Describe the bug
Problem when running yourtts training recipe with use_phonemes=True
Error -
```
> TRAINING (2023-05-30 17:28:48)
! Run is kept in /newvolume/souvik/yourtts_exp/TTS/recipes/vctk/yourtts/YourTTS-EN-VCTK-May-30-2023_05+28PM-2071088b
Traceback (most recent call last):
File "/newvolume/a... | closed | 2023-05-30T17:47:11Z | 2023-06-05T08:05:31Z | https://github.com/coqui-ai/TTS/issues/2642 | [
"bug"
] | souvikg544 | 2 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,864 | [Nodriver] Why does the number of browser.tabs remain unchanged after "Page" close? | browser = await uc.start()
page = await browser.get('url')
url2 = 'example.com'
#For special reasons, you need to use evaluate window.open to bypass Cloudflare
await page.evaluate(f'''window.open("{url2}", "_blank"); ''')
await page.close()
print(str(len(browser.tabs)))
#output len 2
page=browser.tabs[len(s... | open | 2024-05-04T01:52:52Z | 2024-05-04T01:52:52Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1864 | [] | mashien0201 | 0 |
LibrePhotos/librephotos | django | 664 | My Albums disappear and new ones are no longer created/visible : Showing 0 user created albums | # 🐛 Bug Report
* [X] 📁 I've Included a ZIP file containing my librephotos `log` files [gunicorn_django.log](https://github.com/LibrePhotos/librephotos/files/9791059/gunicorn_django.log)
* [X] ❌ I have looked for similar issues (including closed ones)
* [X] 🎬 (If applicable) I've provided pictures or links to vi... | closed | 2022-10-14T18:35:44Z | 2023-04-13T08:21:34Z | https://github.com/LibrePhotos/librephotos/issues/664 | [
"bug"
] | Circenn5130 | 7 |
ultralytics/yolov5 | machine-learning | 13,453 | conv2d() received an invalid combination of arguments | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
## environment
windows10
python3.8
## question
I used the trained model to detect. ... | open | 2024-12-08T13:24:11Z | 2024-12-13T10:18:27Z | https://github.com/ultralytics/yolov5/issues/13453 | [
"question",
"detect"
] | niusme | 3 |
nltk/nltk | nlp | 2,858 | Manually wrap output lines in HOWTO files | cf https://github.com/nltk/nltk/pull/2856#issuecomment-945193387 | open | 2021-10-18T10:02:18Z | 2024-10-07T16:34:36Z | https://github.com/nltk/nltk/issues/2858 | [
"good first issue",
"documentation"
] | stevenbird | 3 |
wkentaro/labelme | computer-vision | 1,448 | labels.txt not able to read the label 'car' | ### Provide environment information
python labelme2voc.py /home/amodpatil/semantic_dataset/segmentation /home/amodpatil/semantic_dataset/am --labels /home/amodpatil/pytorch-segmentation/datasets/labels.txt
Creating dataset: /home/amodpatil/semantic_dataset/am
Generating dataset from: /home/amodpatil/semantic_dataset... | open | 2024-06-11T11:44:14Z | 2024-06-11T11:44:14Z | https://github.com/wkentaro/labelme/issues/1448 | [
"issue::bug"
] | amodpatil1 | 0 |
biolab/orange3 | numpy | 6,553 | Nomogram and Predictions widget report different class probabilities for the same naive Bayesian model | **What's wrong?**
Given the same feature-value pairs for the data instances and the same model, nomogram should predict the same class probability as the Predict widget. It does not, and the numbers are different.
The attached workflow exemplifies this problem. I have considered the Titanic data set, create an inst... | closed | 2023-08-26T11:54:15Z | 2023-09-01T15:16:13Z | https://github.com/biolab/orange3/issues/6553 | [
"bug"
] | BlazZupan | 3 |
AirtestProject/Airtest | automation | 486 | find_element_by_xpath("//button[@type='submit']") 执行失败 | (请尽量按照下面提示内容填写,有助于我们快速定位和解决问题,感谢配合。否则直接关闭。)
**(重要!问题分类)**
* 测试开发环境AirtestIDE使用问题 -> https://github.com/AirtestProject/AirtestIDE/issues
* 控件识别、树状结构、poco库报错 -> https://github.com/AirtestProject/Poco/issues
* 图像识别、设备控制相关问题 -> 按下面的步骤
**描述问题bug**
(简洁清晰得概括一下遇到的问题是什么。或者是报错的traceback信息。)
1.当执行WEB端自动化的时候,采用airtestI... | closed | 2019-08-03T06:21:23Z | 2019-08-16T01:37:54Z | https://github.com/AirtestProject/Airtest/issues/486 | [] | chen072086 | 1 |
google-research/bert | tensorflow | 1,376 | Bert pre training approach | Hi,
I have stated working on Bert model. Do anyone know what was Bert pre-training accuracy(not fine tuned) using 100-0-0 masking approach vs 80-10-10 approach. I could not get it anywhere.
Basically I understand why 80-10-10 approach is implemented but did they do any experiments to figure this out | open | 2022-12-23T14:22:04Z | 2022-12-23T14:22:17Z | https://github.com/google-research/bert/issues/1376 | [] | shu1273 | 0 |
deezer/spleeter | deep-learning | 920 | [Discussion] is there any way to use spleeter in flutter ? | Flutter has a tensorflow lite version.
https://pub-web.flutter-io.cn/packages/tflite_flutter | open | 2024-12-09T12:25:23Z | 2024-12-09T12:25:23Z | https://github.com/deezer/spleeter/issues/920 | [
"question"
] | badboy-tian | 0 |
jupyter/nbviewer | jupyter | 272 | Notebooks with accents in the filename do not render | It seems that notebooks with accented characters in the filename do not render correctly. For example:
https://github.com/computo-fc/python_cientifico/blob/master/0.%20Por%20que%CC%81%20Python.ipynb
gives the following error:
```
404 : Not Found
You are requesting a page that does not exist!"
The remote resource ... | closed | 2014-05-05T21:57:30Z | 2014-05-06T21:03:19Z | https://github.com/jupyter/nbviewer/issues/272 | [] | dpsanders | 9 |
PokemonGoF/PokemonGo-Bot | automation | 5,859 | Automatic Installation | I don't understand why this is called "automatic" installation while we need to search and find and download ourselves some UNFOUNDABLE DLLs (encrypt.so and encrypt.dll or encrypt_64.dll) for whom you cannot give us links. | closed | 2017-01-05T21:22:33Z | 2017-01-08T12:29:19Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5859 | [] | mcferson | 6 |
roboflow/supervision | deep-learning | 686 | Class none person, how to remove it ? | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
I'm running this code on my raspberry pi 4 with picamera to detect and count people, using yolov8n, but sometimes it detects a class called none... | closed | 2023-12-21T05:05:40Z | 2023-12-28T12:25:28Z | https://github.com/roboflow/supervision/issues/686 | [
"question"
] | Rasantis | 1 |
plotly/dash-cytoscape | plotly | 162 | Background image | Is there a way to set a background image? | open | 2022-01-06T16:20:15Z | 2022-01-06T16:20:15Z | https://github.com/plotly/dash-cytoscape/issues/162 | [] | hitnik | 0 |
gradio-app/gradio | machine-learning | 10,021 | gr.State serializes pydantic BaseModel objects at initialization | ### Describe the bug
When passing an object based on the Pydantic BaseModel to gr.State during initalization of the gr.State the object gets serialized into a dictionary.
This doesn't happen for a regular class object.
Interestingly, when passing a Pydantic object into an already initialized gr.State the seriali... | closed | 2024-11-22T15:23:34Z | 2024-11-27T19:25:03Z | https://github.com/gradio-app/gradio/issues/10021 | [
"bug"
] | filiso | 0 |
huggingface/transformers | python | 36,014 | [Bug-Qwen2VL] Error when calling generate with fsdp2 | I have split Qwen2VL-2B using fsdp2 across 8 GPUs. Following the [official example](https://github.com/huggingface/transformers/blob/main/tests/generation/test_fsdp.py#L81-L101), I call the generate function, but encounter the following error:
```markdown
[rank7]: File "/software/mamba/envs/mm/lib/python3.11/site-pa... | closed | 2025-02-03T13:35:57Z | 2025-02-04T01:15:16Z | https://github.com/huggingface/transformers/issues/36014 | [
"bug",
"VLM"
] | mantle2048 | 2 |
davidsandberg/facenet | computer-vision | 404 | where to find the model file? | Hi, Experts
I had try to train the model. After the training finish, I can find some files under the folder of models, includes: .meta, .index, .data-00000-of-00001 and checkpoint, but can not find the .pb file.
Where can I get the .pb file, which can be used for compare. | closed | 2017-08-01T02:33:48Z | 2017-10-21T11:34:53Z | https://github.com/davidsandberg/facenet/issues/404 | [] | tonybaigang | 2 |
jofpin/trape | flask | 57 | trape showing issue | [2018-10-03 11:14:38,961] ERROR in app: Exception on /rl [GET]
Traceback (most recent call last):
File "/usr/local/lib/python2.7/dist-packages/flask/app.py", line 1982, in wsgi_app
response = self.full_dispatch_request()
File "/usr/local/lib/python2.7/dist-packages/flask/app.py", line 1614, in full_dispatch... | closed | 2018-10-03T15:15:21Z | 2018-11-24T01:54:59Z | https://github.com/jofpin/trape/issues/57 | [] | asciiterminal | 1 |
xuebinqin/U-2-Net | computer-vision | 308 | 3D Photo: New app on iOS using U-2-Net | Hey everyone,
Happy to share that we finished last week a new app using U-2-Net, that lets anyone create engaging animated video from any static photo. The app offers dozens of animated 3D motion styles. In seconds, you can turn a photo (or Live Photo) into an animated video using U-2-Net. Optionally add 3D layers, ap... | open | 2022-06-03T07:37:32Z | 2022-06-03T07:37:32Z | https://github.com/xuebinqin/U-2-Net/issues/308 | [] | adirkol | 0 |
lexiforest/curl_cffi | web-scraping | 325 | [BUG] KEY_USAGE_BIT_INCORRECT CHECK PLS PLS | https://github.com/yifeikong/curl_cffi/issues/323
Look, we need to solve this problem, I'm willing to pay 100-200$. Give me your contacts and we'll talk!
here's the solution on httpx, but I really want it to work in your library! It's all about the certificate, we need openssl, certifi.
import ssl
import ht... | closed | 2024-06-12T13:16:21Z | 2024-06-13T06:42:13Z | https://github.com/lexiforest/curl_cffi/issues/325 | [
"bug"
] | viskok-yuri | 1 |
JaidedAI/EasyOCR | deep-learning | 520 | How to train the recognition model? | I have a set of pictures, but the recognition accuracy of the existing model is not high. How can I train my own recognition model? | closed | 2021-08-18T09:30:42Z | 2022-03-02T09:25:33Z | https://github.com/JaidedAI/EasyOCR/issues/520 | [] | yourstar9 | 6 |
localstack/localstack | python | 11,454 | [INC-16] Certificate revocation for localhost.localstack.cloud | Updates for the ongoing issue (`INC-16`) with the certificate revocation for localhost.localstack.cloud[[1](https://localstack.statuspage.io/incidents/qcft2h8sffsb)][[2](https://localstack.statuspage.io/incidents/lpwmzs8x47y8)].
> [!IMPORTANT]
> We recommend **[updating to the latest LocalStack version](https://d... | closed | 2024-09-03T15:01:52Z | 2024-09-25T08:01:41Z | https://github.com/localstack/localstack/issues/11454 | [] | gtsiolis | 0 |
sebp/scikit-survival | scikit-learn | 473 | Histogram-based Gradient Boosting survival models | It would be great to have Histogram-based Gradient Boosting models on top of normal ones as it is much more scalable :
They are supported by scikit-learn:
- https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.HistGradientBoostingRegressor.html#sklearn.ensemble.HistGradientBoostingRegressor
| open | 2024-08-08T07:48:50Z | 2025-02-25T19:59:00Z | https://github.com/sebp/scikit-survival/issues/473 | [
"enhancement"
] | ogencoglu | 2 |
matplotlib/mplfinance | matplotlib | 523 | How to draw a hidden K-line with mplfinance? | @DanielGoldfarb :
When there are many K-line data, the drawing is not intuitive. I want to draw a hidden K-line.
The following figure shows the effect drawn with Matplotlib.
How to draw such an effect with mplfinance?
. In fact that seems to work for any file although I haven't actually t... | open | 2017-05-17T10:47:40Z | 2018-03-22T02:35:33Z | https://github.com/sigmavirus24/github3.py/issues/705 | [] | mjuenema | 1 |
coqui-ai/TTS | deep-learning | 3,488 | next steps after shutdown | According to the main site https://coqui.ai/ , coqui is shutting down, which is unfortunate as these open source libraries are great and could still be maintained. I'm wondering if there are any next steps to proceed, like if the license should allow for commercial use and the open source community could fork this repo... | open | 2024-01-03T14:38:14Z | 2025-03-15T11:51:33Z | https://github.com/coqui-ai/TTS/issues/3488 | [
"feature request"
] | bachittle | 31 |
Anjok07/ultimatevocalremovergui | pytorch | 1,710 | I've a problem to create the stems of every song | Last Error Received:
Process: Demucs
If this error persists, please contact the developers with the error details.
Raw Error Details:
RuntimeError: "Could not allocate tensor with 231211008 bytes. There is not enough GPU video memory available!"
Traceback Error: "
File "UVR.py", line 6638, in process_start
File... | open | 2025-01-22T15:55:08Z | 2025-02-02T20:10:26Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1710 | [] | Flavioalex75 | 2 |
keras-team/keras | deep-learning | 20,108 | Bug in `keras.src.saving.saving_lib._save_model_to_dir` | `tf.keras.__version__` -> "3.4.1"
If model is already saved then method call by `keras.src.models.model.Model.save` call `keras.src.saving.saving_lib._save_model_to_dir`, if model is already saved then `asset_store = DiskIOStore(assert_dirpath, mode="w")` ([Line - 178](https://github.com/keras-team/keras/blob/maste... | closed | 2024-08-10T13:12:49Z | 2024-08-15T05:33:26Z | https://github.com/keras-team/keras/issues/20108 | [
"stat:awaiting response from contributor",
"type:Bug"
] | MegaCreater | 6 |
deeppavlov/DeepPavlov | tensorflow | 896 | Bert_Squad context length longer than 512 tokens sequences | Hi,
Currently I have a long context and the answer cannot be extracted from the context when the context exceeds a certain length. Is there any python code to deal with long length context.
P.S. I am using BERT-based model for context question answering. | closed | 2019-06-23T14:37:55Z | 2020-05-13T11:41:45Z | https://github.com/deeppavlov/DeepPavlov/issues/896 | [] | Chunglwc | 2 |
litestar-org/litestar | api | 3,801 | Docs: improve "Improving performance with the codegen backend" docs in "DTOs" | ### Summary
Link: https://docs.litestar.dev/latest/usage/dto/0-basic-use.html#improving-performance-with-the-codegen-backend
Why do I think that it needs a refactor?
1. It was written when `experimental_codegen_backend` was not enabled by default
2. Right now it makes more sense to show how to turn it off
3. We ... | closed | 2024-10-15T13:44:27Z | 2025-03-20T15:54:58Z | https://github.com/litestar-org/litestar/issues/3801 | [
"Documentation :books:",
"DTOs"
] | sobolevn | 0 |
geex-arts/django-jet | django | 103 | The revenue model of Django JET | I think Django JET has the most potential of all the Django admin extensions available to date. Simply because it has the most complete responsive experience with easy integration.
That said, I question the renevue model of Django JET mr @f1nality.
Do you want this to be the product of a one-man army?
Or do you prefe... | closed | 2016-08-19T09:49:34Z | 2016-08-27T11:30:32Z | https://github.com/geex-arts/django-jet/issues/103 | [] | Zundrium | 2 |
marshmallow-code/flask-smorest | rest-api | 65 | Path parameters: document converters parameters | In FlaskPlugin, add min/max to number converters.
Manage negative values introduced in Werkzeug 0.15 (https://github.com/pallets/werkzeug/pull/1355). | closed | 2019-05-03T07:54:56Z | 2020-10-01T21:32:17Z | https://github.com/marshmallow-code/flask-smorest/issues/65 | [
"enhancement",
"help wanted",
"backwards incompat"
] | lafrech | 1 |
iperov/DeepFaceLab | machine-learning | 5,232 | pressing "L" key while in training preview switches to command window |
## Expected behavior
2021 releases - pressing "L" key is supposed to change the graph granularity in the training preview window
## Actual behavior
"L" key now just switches to command window or brings it to the front. Can get around by pressing shift+L in preview window
## Steps to reproduce
Just hit ... | closed | 2021-01-04T23:25:06Z | 2021-01-07T17:21:50Z | https://github.com/iperov/DeepFaceLab/issues/5232 | [] | frighte | 2 |
iMerica/dj-rest-auth | rest-api | 330 | Allauth creates migrations in site packages - Django 3.2.4 | Hi, it seems that Django 3.2.X is not properly supported due to a bug which I guess comes from allouth and seem to be fixed in the latest version as per https://github.com/pennersr/django-allauth/issues/2971
This results in migrations being created inside the `site-packages` of the virtual environment.
This has bee... | open | 2021-11-17T14:57:57Z | 2021-11-17T14:57:57Z | https://github.com/iMerica/dj-rest-auth/issues/330 | [] | 1oglop1 | 0 |
jazzband/django-oauth-toolkit | django | 1,018 | access django request in OAuth2Validator.get_additional_claims | In get_additional_claims I want to give url of users avatar, some thing like google claims...
But django image field just give path of file without domain
base on https://stackoverflow.com/questions/1451138/how-can-i-get-the-domain-name-of-my-site-within-a-django-template
I have to somehow access django request to f... | closed | 2021-10-01T14:42:47Z | 2023-10-04T15:01:06Z | https://github.com/jazzband/django-oauth-toolkit/issues/1018 | [
"question"
] | amirhoseinbidar | 1 |
PokeAPI/pokeapi | api | 734 | Add Pokemon strengths and weaknesses | Hey,
During my use of the API i also discovered that in a normal [Pokémon Request](https://pokeapi.co/api/v2/pokemon/1) no strengths and weaknesses are provided in the response json.
It would be really cool if you could expand on this.
Best Regards
| open | 2022-07-18T06:55:52Z | 2022-11-11T04:07:24Z | https://github.com/PokeAPI/pokeapi/issues/734 | [] | bidery | 1 |
mherrmann/helium | web-scraping | 52 | How to do multiple select? | Hi,
I am trying to select more than one option from a multi select element.
Right now, I've achieved this by writing a select command for each option like
``` Python
select(ComboBox('multi select element'), 'option 1')
select(ComboBox('multi select element'), 'option 2')
select(ComboBox('multi select element... | closed | 2020-12-19T19:15:33Z | 2020-12-21T04:14:48Z | https://github.com/mherrmann/helium/issues/52 | [] | some-sh | 1 |
CanopyTax/asyncpgsa | sqlalchemy | 60 | pip failed to install package | pip can't install **_asyncpgsa_** if it's part of requirements list alongside with **_asyncpg_** (in other words it requires _asyncpg_ to be installed before installing _asyncpgsa_). Is there a way to change version determination?
```
Collecting asyncpg==0.12.0 (from -r .meta/packages (line 5))
....
Collecting asyn... | closed | 2017-12-15T15:57:52Z | 2018-02-13T00:13:09Z | https://github.com/CanopyTax/asyncpgsa/issues/60 | [] | vayw | 2 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 90 | 找不到params.json 文件,模型文件里面也没有这个文件呀 | FileNotFoundError: [Errno 2] No such file or directory:
'/content/drive/MyDrive/model/7B/params.json' | closed | 2023-04-09T05:53:20Z | 2023-08-24T13:16:47Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/90 | [] | Song367 | 4 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 474 | 位置插值训练数据相关咨询 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://g... | closed | 2023-12-14T07:35:44Z | 2023-12-28T23:46:51Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/474 | [
"stale"
] | KyrieXu11 | 5 |
plotly/dash-cytoscape | dash | 206 | [BUG] CyLeaflet: Updating tile layer causes map to be initially blue before pan/zoom | <!--
Thanks for your interest in Plotly's Dash Cytoscape Component!
Note that GitHub issues in this repo are reserved for bug reports and feature
requests. Implementation questions should be discussed in our
[Dash Community Forum](https://community.plotly.com/c/dash).
Before opening a new issue, please search ... | closed | 2024-02-07T15:56:30Z | 2024-07-11T09:10:39Z | https://github.com/plotly/dash-cytoscape/issues/206 | [] | emilykl | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 10 | 多条视频链接下莫名卡在第六条 无报错。。 | ```
127.0.0.1 - - [17/Mar/2022 20:15:05] "GET /?app=index HTTP/1.1" 200 -
Sending request to:
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=7074510252833606925
Type = video
http://v95-a.douyinvod.com/3ae2fc443a268604e866b91136d7f97c/6233347a/video/tos/cn/tos-cn-ve-15c001-alinc2/0515dd92f27f421b8... | closed | 2022-03-17T12:22:32Z | 2022-03-17T18:10:21Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/10 | [] | wanghaisheng | 0 |
jupyter/nbviewer | jupyter | 554 | Slideviewer 400 errors. | Hi guys,
I'm attempting to view some test books to see if the slideviewer app is working (I remember Damian having said it was in development but haven't kept up to date on whether it's still functional.)
I was unable to get these notebooks to render a slideshow. I'm unsure if I'm just doing it incorrectly:
https://... | closed | 2015-12-21T06:28:28Z | 2015-12-21T14:09:17Z | https://github.com/jupyter/nbviewer/issues/554 | [] | mburke05 | 2 |
horovod/horovod | tensorflow | 2,956 | When using the ring-of-rings branch of horovod,Segmentation fault(MPI)will appear when running distributed programs. | 1. Framework: (using TensorFlow v1 (1.15) with Keras2.2.4)
2. OS and version: Ubuntu16.04 LTS
3. Horovod version: Branch ring-of-rings(horovod==0.12.2.dev0)
4. MPI version: OpenMPI 4.0.0
5. CUDA version:10.0
6. NCCL version:2.5.6
7. Python version:3.6.13(conda)
8. GCC version:5.4.0
9. CMake version:3.18.4
*... | open | 2021-06-07T09:53:38Z | 2021-06-07T09:53:38Z | https://github.com/horovod/horovod/issues/2956 | [
"bug"
] | Frank00001 | 0 |
Skyvern-AI/skyvern | api | 1,190 | Can you add a feature to capture specific network requests? | Can you add a feature to capture specific network requests? I need to get information from the network request headers. Also, it seems the F12 developer tools and bookmark creation are not supported. | closed | 2024-11-14T14:35:07Z | 2024-11-26T01:46:29Z | https://github.com/Skyvern-AI/skyvern/issues/1190 | [] | chaoqunxie | 8 |
mwaskom/seaborn | matplotlib | 3,365 | Change in Behavior for Python 3.12 for TestRegressionPlotter | Hi Team,
I would like to bring to your attention there is an expected change in behavior of of how variables are scoped inside comprehensions inside a class scope, details are here: https://discuss.python.org/t/pep-709-one-behavior-change-that-was-missed-in-the-pep
It has been identified in that thread (thanks to... | closed | 2023-05-14T13:35:54Z | 2023-05-15T23:17:55Z | https://github.com/mwaskom/seaborn/issues/3365 | [] | notatallshaw | 1 |
alteryx/featuretools | data-science | 2,368 | Revert changes for local docs build once related sphinx issue is closed | In MR #2367, changes were made in `docs/Makefile` to allow docs to be build locally using the `make html` command. This was needed due to errors that happened when attempting to built the docs with Featuretools installed in editable mode. Docs builds failing in editable mode *might* be related to an issue with sphinx.... | open | 2022-11-09T16:59:06Z | 2024-04-10T20:04:36Z | https://github.com/alteryx/featuretools/issues/2368 | [
"good first issue",
"documentation"
] | thehomebrewnerd | 10 |
mljar/mercury | data-visualization | 101 | Return URL address of HTML/PDF notebook after REST API excution | There should be an option to execute the notebook with REST API and return the address of the resulting HTML/PDF notebook.
It will create a lot of new possibilities for creating dynamic reports.
### The workflow
1. Create a notebook with variables editable in Mercury (variables in YAML header).
2. Share notebo... | closed | 2022-05-18T06:51:35Z | 2023-02-15T10:13:23Z | https://github.com/mljar/mercury/issues/101 | [
"enhancement",
"help wanted"
] | pplonski | 0 |
huggingface/diffusers | pytorch | 10,050 | Is there any img2img KDiffusion equivalent of StableDiffusionKDiffusionPipeline? | ### Model/Pipeline/Scheduler description
I'm working on result alignment between diffusers and A1111 webui.
In txt2img scene, I can achieve via `StableDiffusionKDiffusionPipeline`, refer to https://github.com/huggingface/diffusers/issues/3253.
But in img2img scene, is there any KDiffusion pipeline equivalent?
I... | open | 2024-11-29T07:47:11Z | 2024-12-29T15:03:05Z | https://github.com/huggingface/diffusers/issues/10050 | [
"stale"
] | juju812 | 2 |
JoeanAmier/XHS-Downloader | api | 39 | 如何把笔记的文案 保存到对应笔记的文件夹中 | 如何把笔记的文案 保存到对应笔记的文件夹中 | open | 2024-01-05T02:43:23Z | 2024-01-07T17:17:42Z | https://github.com/JoeanAmier/XHS-Downloader/issues/39 | [] | hackettk | 5 |
mwaskom/seaborn | data-visualization | 3,423 | Issue with lineplot - conflict with pandas | When trying to create a lineplot - with only x (datetime64 or simple int64) and y without any sophisticated arguments - the following error is raised:
> OptionError: No such keys(s): 'mode.use_inf_as_null'
This is the detailed reference to pandas:
> File [~/Documents/NeueFische/4_Capstone/capstone_solar_energy... | closed | 2023-07-20T22:31:12Z | 2023-08-02T11:20:03Z | https://github.com/mwaskom/seaborn/issues/3423 | [] | KathSe1984 | 3 |
huggingface/datasets | tensorflow | 7,073 | CI is broken for convert_to_parquet: Invalid rev id: refs/pr/1 404 error causes RevisionNotFoundError | See: https://github.com/huggingface/datasets/actions/runs/10095313567/job/27915185756
```
FAILED tests/test_hub.py::test_convert_to_parquet - huggingface_hub.utils._errors.RevisionNotFoundError: 404 Client Error. (Request ID: Root=1-66a25839-31ce7b475e70e7db1e4d44c2;b0c8870f-d5ef-4bf2-a6ff-0191f3df0f64)
Revision N... | closed | 2024-07-26T08:27:41Z | 2024-07-27T05:48:02Z | https://github.com/huggingface/datasets/issues/7073 | [] | albertvillanova | 9 |
graphistry/pygraphistry | jupyter | 321 | install pygraphistry togoogle colab | Hi,
I have used succesfully on my personal laptop, but I need to use in Colab. How I can use pygraphistry in Colab?
I have try to install in Google Colab with
`!pip install graphistry`
`!apt install graphistry`0
Every time it print that it successfully installed but then when running:
`import graphistry... | closed | 2022-03-18T14:15:22Z | 2022-03-21T20:12:49Z | https://github.com/graphistry/pygraphistry/issues/321 | [] | SalvatoreRa | 5 |
PaddlePaddle/ERNIE | nlp | 249 | bert 预训练代码有个小错误 | ERNIE/BERT/reader/pretraining.py
91行与162行应该统一吧
162行应该是大于号 | closed | 2019-08-01T11:25:24Z | 2019-08-19T02:54:35Z | https://github.com/PaddlePaddle/ERNIE/issues/249 | [] | zle1992 | 2 |
freqtrade/freqtrade | python | 11,216 | Problem with order/trade open price (wrong price) in dry run | Describe your environment
Operating system: Ubuntu 22.04.1 LTS
Python Version: > 3.10
Freqtrade 2024.7.1
Freqtrade running in docker
Exchange: Binance
Dry-run mode without new BNFCR features
I found a problem with order/trade open price.
Strategy is on 1m TF
Send an limit order for TRX/USDT:USDT at open_rate: 0.2444... | closed | 2025-01-11T07:52:04Z | 2025-01-11T15:21:22Z | https://github.com/freqtrade/freqtrade/issues/11216 | [
"Question"
] | dobremha | 2 |
AirtestProject/Airtest | automation | 553 | 关于iOS环境text()用法的疑问 | 想要跟set_text()一样的效果:输入框没有内容写入,输入框有内容直接覆盖
但是iOS不支持set_text(),也不支持用keyevent("KEYCODE_DEL")删除内容,请问还有什么办法可以实现直接覆盖输入框内容或者删除输入框内容吗? | open | 2019-10-11T07:07:05Z | 2020-09-06T13:19:28Z | https://github.com/AirtestProject/Airtest/issues/553 | [] | appp-deng | 3 |
stanfordnlp/stanza | nlp | 825 | Stanza Document model to dataframe | Hi, I got this following output from NER process. I want this in the form of a dataframe .In that case,"id,text,upos,xpos,ner" shoud be column names.Is that possible to convert into dataframe?
[
[
{
"id": 1,
"text": "[",
"upos": "PUNCT",
"xpos": "-LRB-",
"start_char": 0,
... | open | 2021-10-08T08:52:47Z | 2022-07-14T20:27:04Z | https://github.com/stanfordnlp/stanza/issues/825 | [
"enhancement",
"question"
] | sangeethsn | 10 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.