
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pydantic/pydantic | pydantic | 11,590 | Mypy error when using `@model_validator(mode="after")` and `@final` | ### Initial Checks
- [x] I confirm that I'm using Pydantic V2
### Description
This is very similar to https://github.com/pydantic/pydantic/issues/6709, but occurs when the model class is decorated with `@typing.final`.
```console
$ mypy --cache-dir=/dev/null --strict bug.py
bug.py:10: error: Cannot infer function ... | closed | 2025-03-20T11:55:22Z | 2025-03-21T09:32:48Z | https://github.com/pydantic/pydantic/issues/11590 | [
"bug V2",
"pending"
] | ngnpope | 1 |
JaidedAI/EasyOCR | deep-learning | 957 | Unsupport Chinese path of images | It is obvious that EasyOCR goes down when it readtext from an image with Chinese path, just because it use python-opencv.
So I add some code peice into utils.py to solve this problem. Now the OCR system run smoothly.
def is_chinese(string):
"""
检查整个字符串是否包含中文
:param string: 需要检查的字符串
:return: boo... | open | 2023-03-01T02:31:50Z | 2023-03-01T02:31:50Z | https://github.com/JaidedAI/EasyOCR/issues/957 | [] | drrobincroft | 0 |
onnx/onnx | pytorch | 5,988 | Version converter: No Adapter From Version 16 for Identity | # Ask a Question
### Question
I meet the following issue while trying to convert the onnx model of Opset16 to Opset15 :
"**adapter_lookup: Assertion `false` failed: No Adapter From Version $16 for Identity**"
If I have to use an Opset15 and currently only have Opset16 version of the relevant onnx resources avai... | open | 2024-03-02T13:51:14Z | 2024-03-06T19:14:23Z | https://github.com/onnx/onnx/issues/5988 | [
"question"
] | lsp2 | 4 |
joke2k/django-environ | django | 410 | Default for keys in dictionary | With dict we can set defaults
```
MYVAR = env.dict(
"MYVAR",
{
'value': bool,
'cast': {
'ACTIVE': bool,
'URL': str,
}
},
default={
'ACTIVE': False,
'URL': "http://example.com",
})
```
now, the default are used IFF the ... | open | 2022-07-21T08:59:32Z | 2024-04-30T17:12:38Z | https://github.com/joke2k/django-environ/issues/410 | [] | esseti | 1 |
pennersr/django-allauth | django | 3,914 | Adding/changing email address with MFA enabled | It seems that it's impossible to add or change an email address while having MFA enabled, judging by this commit:
https://github.com/pennersr/django-allauth/pull/3383/commits/7bf4d5e6e4b188b7e0738652f2606b98804374ab
What is the logic behind this? What is the expected flow when a user needs to change an email addres... | closed | 2024-06-22T18:05:12Z | 2024-06-22T19:17:58Z | https://github.com/pennersr/django-allauth/issues/3914 | [] | eyalch | 2 |
lukasmasuch/streamlit-pydantic | streamlit | 74 | List of datatypes or Nested Models Not Displaying Correctly in `pydantic_input` form | ### Checklist
- [x] I have searched the [existing issues](https://github.com/lukasmasuch/streamlit-pydantic/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
### **Description:**
When using ... | open | 2025-02-21T20:00:22Z | 2025-02-25T13:33:12Z | https://github.com/lukasmasuch/streamlit-pydantic/issues/74 | [
"type:bug",
"status:needs-triage"
] | gaurav-brandscapes | 0 |
influxdata/influxdb-client-python | jupyter | 31 | Add support for /delete metrics endpoint | closed | 2019-11-01T15:09:05Z | 2019-11-04T09:32:01Z | https://github.com/influxdata/influxdb-client-python/issues/31 | [] | rhajek | 0 | |
pydantic/FastUI | pydantic | 253 | Demo in cities click "1" page not response. | this's component bug? | closed | 2024-03-21T13:13:59Z | 2024-03-21T13:18:26Z | https://github.com/pydantic/FastUI/issues/253 | [] | qq727127158 | 1 |
pallets-eco/flask-sqlalchemy | flask | 486 | Connecting multiple pre-exising databases via binds | Hi. I'm new to flask-sqlalchemy. I have multiple pre-existing mysql databases (for this example, two is enough). I have created a minimal example of what I'm trying to do below. I'm able to successful connect to one database using ```SQLALCHEMY_DATABASE_URI```. For the second database, I'm trying to use ```SQLALCHEMY_B... | closed | 2017-03-20T14:19:26Z | 2020-12-05T20:46:27Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/486 | [] | daniel-saunders | 3 |
plotly/dash-table | plotly | 448 | filtering not working in python or R | @rpkyle @Marc-Andre-Rivet Data Table filtering does not work when running the first example of the [docs](https://dash.plot.ly/datatable/interactivity) locally:

The gif above is from run... | closed | 2019-05-29T14:18:57Z | 2019-06-04T18:07:21Z | https://github.com/plotly/dash-table/issues/448 | [] | sacul-git | 2 |
dpgaspar/Flask-AppBuilder | rest-api | 1,574 | Invalid link in "about" of GitHub repo | Currently the "about" section has an invalid link to http://flaskappbuilder.pythonanywhere.com/:

Lets fix this and link to the docs: https://flask-appbuilder.readthedocs.io/en/... | closed | 2021-02-25T22:55:30Z | 2021-04-09T13:31:32Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1574 | [] | thesuperzapper | 3 |
dpgaspar/Flask-AppBuilder | rest-api | 1,559 | export only selected data using the @action method. | Hello, I'm desperately trying to export only selected data using the @action method.
The code actually works quite well, but only for one query.
`@action("export", "Export", "Select Export?", "fa-file-excel-o", single=False)
def export(self, items):
if isinstance(items, list):
urltools... | closed | 2021-02-07T17:47:31Z | 2021-02-12T08:25:50Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1559 | [] | pUC19 | 0 |
proplot-dev/proplot | matplotlib | 20 | eps figures save massive object outside of figure | Not really sure how to debug this, but something in your figure saving creates vector objects that extend to seemingly infinity off the screen.
You can see here in my illustrator screenshot. The bar object can't be modified by illustrator really because it says transforming it will make it too large. The blue outli... | closed | 2019-06-12T17:28:14Z | 2020-05-19T16:52:26Z | https://github.com/proplot-dev/proplot/issues/20 | [
"bug"
] | bradyrx | 4 |
pyg-team/pytorch_geometric | pytorch | 9,769 | Slack link no longer works | ### 📚 Describe the documentation issue
Slack link seems to be no longer active @rus
### Suggest a potential alternative/fix
_No response_ | closed | 2024-11-09T01:47:55Z | 2024-11-13T03:03:56Z | https://github.com/pyg-team/pytorch_geometric/issues/9769 | [
"documentation"
] | chiggly007 | 1 |
graphistry/pygraphistry | jupyter | 363 | [FEA] API personal key support | Need support for new api service keys:
- [x] `register(personal_key=...)`, used for files + datasets endpoints
- [x] add to `README.md`
+ testing uploads | open | 2022-06-10T23:24:15Z | 2023-02-10T09:12:05Z | https://github.com/graphistry/pygraphistry/issues/363 | [
"enhancement",
"p2"
] | lmeyerov | 1 |
statsmodels/statsmodels | data-science | 8,947 | How to completely remove training data from model. | Dear developers of statsmodels,
First of all, thank you so much for creating such an amazing package.
I've recently used statsmodels (0.14.0) to make a GLM model and I would like to share it with others so that they can input their own data and make predictions.
However, I am prohibited from sharing the data I h... | open | 2023-07-03T15:24:21Z | 2023-07-11T06:45:17Z | https://github.com/statsmodels/statsmodels/issues/8947 | [] | hiroki32 | 1 |
plotly/dash-table | plotly | 716 | Cell selection does not restore previous cell background after selection | I'm using a Dash table component with a custom background color (grey) defined with style_data_conditional. When I select any cell of my table the background color change to the selection color (hot-pink). When I then select another cell, the cell previously selected becomes white instead than the color I defined (grey... | open | 2020-03-06T12:04:25Z | 2020-03-06T12:04:25Z | https://github.com/plotly/dash-table/issues/716 | [] | claudioiac | 0 |
Urinx/WeixinBot | api | 259 | 请问入群欢迎是怎么实现的 | closed | 2018-07-11T05:04:37Z | 2018-07-13T07:44:32Z | https://github.com/Urinx/WeixinBot/issues/259 | [] | WellJay | 1 | |
litestar-org/litestar | pydantic | 3,752 | Enhancement: Allow multiple lifecycle hooks of each type to be run on any given request | ### Summary
Only having one lifecycle hook per request makes it impossible to use multiple plugins which both set the same hook, or makes it easy to inadvertently break plugins by overriding a hook that they install and depend on (whether at the root application or a lower layer).
It also places in application code... | open | 2024-09-21T17:50:29Z | 2025-03-20T15:54:55Z | https://github.com/litestar-org/litestar/issues/3752 | [
"Enhancement"
] | charles-dyfis-net | 2 |
pytorch/pytorch | deep-learning | 148,883 | Pytorch2.7+ROCm6.3 is 34.55% slower than Pytorch2.6+ROCm6.2.4 | The same hardware and software environment, only the versions of PyTorch+ROCm are different.
Use ComfyUI to run Hunyuan text to video:
ComfyUI:v0.3.24
ComfyUI plugin: teacache
49frames
480x960
20steps
CPU:i5-7500
GPU:AMD 7900XT 20GB
RAM:32GB
PyTorch2.6+ROCm6.2.4 Time taken: 348 seconds 14.7s/it
The VAE Decode Tile... | open | 2025-03-10T12:56:34Z | 2025-03-19T14:14:52Z | https://github.com/pytorch/pytorch/issues/148883 | [
"module: rocm",
"triaged"
] | testbug5577 | 6 |
igorbenav/fastcrud | sqlalchemy | 15 | Add Automatic Filters for Auto Generated Endpoints | **Is your feature request related to a problem? Please describe.**
I would like to be able to filter get_multi endpoint.
**Describe the solution you'd like**
I want to be filtering and searching in the get_multi endpoint. This is such a common feature in most CRUD system that I consider relevant. This is also avai... | closed | 2024-02-04T13:19:43Z | 2024-05-21T04:14:34Z | https://github.com/igorbenav/fastcrud/issues/15 | [
"enhancement",
"Automatic Endpoint"
] | AndreGuerra123 | 15 |
pydantic/FastUI | fastapi | 32 | Toggle switches | Similar to [this](https://getbootstrap.com/docs/5.1/forms/checks-radios/#switches), we should allow them as well as checkboxes in forms. | closed | 2023-12-01T19:07:40Z | 2023-12-04T13:07:19Z | https://github.com/pydantic/FastUI/issues/32 | [
"good first issue",
"New Component"
] | samuelcolvin | 2 |
pytest-dev/pytest-html | pytest | 7 | AttributeError: 'TestReport' object has no attribute 'extra' | Tried to add the code below, but got error - AttributeError: 'TestReport' object has no attribute 'extra'
from py.xml import html
from html import extras
def pytest_runtest_makereport(**multicall**, item):
report = **multicall**.execute()
extra = getattr(report, 'extra', [])
if report.when == 'call':
... | closed | 2015-05-26T14:27:45Z | 2015-05-26T15:27:00Z | https://github.com/pytest-dev/pytest-html/issues/7 | [] | reddypdl | 1 |
nschloe/tikzplotlib | matplotlib | 401 | Legend title is not converted to tikz | When creating a legend with a title, the title does not transform to tikz code.
Python code:
```
import matplotlib.pyplot as plt
from tikzplotlib import save as tikz_save
x=[-1,1]
y=[-1,1]
plt.figure()
plt.plot(x,y,label='my legend')
#plt.xlim([1e-3,5])
#plt.ylim([1e-3,1e2])
plt.legend(title='my title'... | open | 2020-04-12T11:30:57Z | 2023-07-25T12:12:37Z | https://github.com/nschloe/tikzplotlib/issues/401 | [] | Mpedrosab | 2 |
kennethreitz/responder | graphql | 323 | dealing with index.html location not in static directory | Responder is a great package, loving it so far!
Wanted to share some feedback on trouble that I ran into while trying to trying to deal with SPA, specifically dealing with serving up a React SPA bootstrapped by Create-React-App. The default webpack build scripts put the index.html in the parent folder of the static ... | closed | 2019-02-28T23:55:16Z | 2019-03-10T14:44:13Z | https://github.com/kennethreitz/responder/issues/323 | [
"discussion"
] | KenanHArik | 4 |
explosion/spaCy | deep-learning | 12,807 | Importing spacy (or thinc) breaks dot product | A very annoying bug that it took me forever to track down ... I'm at a loss for what might be going on here.
## How to reproduce the behaviour
```
import numpy as np
# works
small = np.random.randn(5, 6)
small.T @ small
# works
larger = np.random.randn(100, 110)
larger.T @ larger
import spacy # or im... | closed | 2023-07-08T22:05:46Z | 2023-08-19T00:02:07Z | https://github.com/explosion/spaCy/issues/12807 | [
"third-party"
] | jona-sassenhagen | 17 |
freqtrade/freqtrade | python | 11,053 | freqtrade 2024.10 backtesting short is not work……? | ```
{
"$schema": "https://schema.freqtrade.io/schema.json",
"max_open_trades": 100,
"stake_currency": "USDT",
"stake_amount": "unlimited",
"tradable_balance_ratio": 0.99,
"fiat_display_currency": "USD",
"dry_run": true,
"dry_run_wallet": 1000,
"cancel_open_orders_on_exit": false,
"trading_mode": "fu... | closed | 2024-12-07T12:46:38Z | 2024-12-10T03:21:43Z | https://github.com/freqtrade/freqtrade/issues/11053 | [
"Question"
] | Toney | 2 |
taverntesting/tavern | pytest | 791 | how to include saved value in the next stage request url | We have a service with the URL, https://www.domain.com/parallel/tests/uuid
I would like to run the test stage(name: Verify tests get API) with the saved value `newtest_uuid`
How can I use `newtest_uuid` in the second stage?
```
includes:
- !include includes.yaml
stages:
- name: Verify tests post API
r... | closed | 2022-06-15T09:19:00Z | 2022-06-16T03:09:09Z | https://github.com/taverntesting/tavern/issues/791 | [] | colinshin | 2 |
python-restx/flask-restx | api | 399 | the first time to open the swagger page will be very slow | After updating flask2.0.1 and restx0.5, start app.run(), the first time to open the swagger page will be very slow, about a few tens of seconds to a few minutes to wait, this problem is caused by too many registered routes, I tried to register only a few routes will not cause a problem. Why is the difference between 0.... | open | 2021-12-27T10:18:46Z | 2021-12-27T10:18:46Z | https://github.com/python-restx/flask-restx/issues/399 | [
"question"
] | sbigtree | 0 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,031 | [Bug]: cannot load SD2 checkpoint after performance update in dev branch | After the huge performance update in dev branch it is not possible to load sd2 model, while on master branch it works:
```
RuntimeError: mat1 and mat2 must have the same dtype, but got Half and Float
```
```
Loading weights [3f067a1b94] from /home/user/ai-apps/stable-diffusion-webui/models/Stable-diffusion/sd_... | open | 2024-06-16T15:03:44Z | 2024-06-23T15:23:07Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16031 | [
"bug-report"
] | light-and-ray | 5 |
dask/dask | scikit-learn | 10,949 | Issue repartitioning a time series by frequency when loaded from parquet file | **Describe the issue**:
When loading a parquet file that has a datetime index, I can't repartition based on frequency, getting the following error:
```
Traceback (most recent call last):
File "/Users/.../gitrepos/dask-exp/test_dask_issue.py", line 19, in <module>
df2 = df2.repartition(freq="1D")
File "/... | open | 2024-02-24T18:30:24Z | 2024-04-04T12:56:22Z | https://github.com/dask/dask/issues/10949 | [
"dataframe"
] | pvaezi | 5 |
grillazz/fastapi-sqlalchemy-asyncpg | pydantic | 98 | SQLAlchemy Engine disposal | I've come across your project and I really appreciate what you've done.
I have a question that bugs me for a long time and I've never seen any project addressing it, including yours.
When you create an `AsyncEngine`, you are supposed to [dispose](https://docs.sqlalchemy.org/en/13/core/connections.html#engine-dispos... | closed | 2023-07-13T19:17:29Z | 2023-07-20T08:25:35Z | https://github.com/grillazz/fastapi-sqlalchemy-asyncpg/issues/98 | [] | hmbui-noze | 1 |
pydantic/pydantic | pydantic | 11,335 | Unable to pip install pydantic | Hi,
I was trying to set up a repository from source that had `pydantic >= 2.9.0`, but I keep getting the following error -
<img width="917" alt="Image" src="https://github.com/user-attachments/assets/e0410efc-5fb7-494e-80e4-96231fff1489" />
I checked my internet connection a couple of times just before posting this... | closed | 2025-01-24T04:27:27Z | 2025-01-24T04:51:19Z | https://github.com/pydantic/pydantic/issues/11335 | [] | whiz-Tuhin | 1 |
allenai/allennlp | data-science | 4,855 | Models: missing None check in PrecoReader's text_to_instance method. | <!--
Please fill this template entirely and do not erase any of it.
We reserve the right to close without a response bug reports which are incomplete.
If you have a question rather than a bug, please ask on [Stack Overflow](https://stackoverflow.com/questions/tagged/allennlp) rather than posting an issue here.
--... | closed | 2020-12-09T14:16:36Z | 2020-12-10T20:30:06Z | https://github.com/allenai/allennlp/issues/4855 | [
"bug"
] | frcnt | 0 |
jumpserver/jumpserver | django | 14,140 | [Feature] ldap登录需要修改初始密码问题 | ### 产品版本
v3.10.9
### 版本类型
- [ ] 社区版
- [X] 企业版
- [ ] 企业试用版
### 安装方式
- [ ] 在线安装 (一键命令安装)
- [ ] 离线包安装
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] 源码安装
### ⭐️ 需求描述
ldap认证如果域控账号设置了初始密码,登录之后需要修改初始密码,我登录其他用域控密码的系统都会提示修改初始密码,同时弹出个修改密码的框,可是我登录堡垒机的时候没提示我修改初始密码,就直接提示密码错误,这个能不能改一下,让堡垒机登录域控账号的时候提示修改初始密码,同时弹出修改密码的框
... | closed | 2024-09-13T06:36:14Z | 2024-10-10T05:56:26Z | https://github.com/jumpserver/jumpserver/issues/14140 | [
"⭐️ Feature Request"
] | guoheng888 | 1 |
microsoft/unilm | nlp | 1,523 | All download links failed: vqkd_encoder pre-trained weight of beit2 | Please refer to https://github.com/microsoft/unilm/blob/master/beit2/TOKENIZER.md | closed | 2024-04-12T13:40:18Z | 2024-04-12T18:08:14Z | https://github.com/microsoft/unilm/issues/1523 | [] | JoshuaChou2018 | 2 |
NVIDIA/pix2pixHD | computer-vision | 206 | THCTensorScatterGather.cu line=380 error=59 : device-side assert triggered when using labels and nyuv2 dataset | Hello,
I trained a model using rgb values and the train folders train_A and train_B without any issues.
Now I wanted to use the nyuv2 dataset using the labels as input and rgb as outputs.
I extracted the label images with the class labels in each pixel for a total of 985 classes including 0 as a no class.
... | open | 2020-07-01T21:55:43Z | 2020-07-26T19:35:14Z | https://github.com/NVIDIA/pix2pixHD/issues/206 | [] | entrpn | 4 |
waditu/tushare | pandas | 1,515 | hk_hold 接口调用频次有问题 | 120积分报下面错误,加分到620分还是报下面错误。而且我的code里面已经等了32秒!
198 for day in days:
199 print(day)
200 df = pro.hk_hold(trade_date = day.replace('-',''))
201 if not df.empty:
202 df.to_csv(filename, mode='a', index=False, header=h_flag)
203
204 if ... | open | 2021-02-17T14:59:40Z | 2021-02-17T15:00:29Z | https://github.com/waditu/tushare/issues/1515 | [] | sq2309 | 1 |
adamerose/PandasGUI | pandas | 114 | Scatter size should handle null values | Using a column with null values (ie. demo data `penguins.body_mass`) on size in a scatter plot produces this error:
```
ValueError:
Invalid element(s) received for the 'size' property of scatter.marker
Invalid elements include: [nan]
The 'size' property is a number and may be specified as:
... | closed | 2021-03-03T13:39:16Z | 2021-06-27T08:43:49Z | https://github.com/adamerose/PandasGUI/issues/114 | [
"enhancement"
] | fdion | 4 |
hzwer/ECCV2022-RIFE | computer-vision | 381 | 使用X-TRAIN数据集训练RIFE | 作者您好,请问您尝试过使用高分辨率数据集(比如[X-TRAIN](https://github.com/JihyongOh/XVFI))训练RIFE吗?我在训练过程中遇到了一些问题。
实验设置如下:
1. 构造三帧组。X-TRAIN数据集中一个视频有65帧(索引为0到64),可以构造不同时间间隔的三帧组:0,1,2; 0,2,4; 0,3,6; 0,4,8; 0,5,10; ...; 0,32,64; 使用训练集中4408个视频共构造了400多万个三帧组。中间帧为ground truth. 训练时每个epoch会从这400多万个三帧组中随机选择48768个三帧组。
2. 数据预处理。随机裁剪至512x512.其他的数据增强方式... | closed | 2024-11-14T02:23:12Z | 2024-12-31T09:37:27Z | https://github.com/hzwer/ECCV2022-RIFE/issues/381 | [] | ZXMMD | 3 |
indico/indico | flask | 6,452 | Group members do not get notification on abstract comment/review | Indico 3.3.2
https://github.com/indico/indico/blob/e99185c27a0e1081d1f494ea706b8770d9a132c8/indico/modules/events/abstracts/controllers/reviewing.py#L188-L209
(Local) group members do not seem to be included in the recipient list. The group has permission *manage*' | open | 2024-07-23T11:50:58Z | 2024-10-30T10:55:46Z | https://github.com/indico/indico/issues/6452 | [] | paulmenzel | 1 |
deeppavlov/DeepPavlov | nlp | 1,467 | Windows support for DeepPavlov v0.14.1 and v0.15.0 | **DeepPavlov version** : 0.14.1 and 0.15.0
**Python version**: 3.7
**Operating system** (ubuntu linux, windows, ...): Windows 10
**Issue**:
Attempting to upgrade to v0.14.1 or v0.15.0 encounters an error on Windows as uvloop is not supported on Windows. Is this a noted issue or are there any workarounds?
See... | closed | 2021-07-21T19:24:20Z | 2022-11-09T00:15:14Z | https://github.com/deeppavlov/DeepPavlov/issues/1467 | [
"bug"
] | priyankshah7 | 6 |
Miserlou/Zappa | django | 1,277 | Not able to used "nested" project folter | ## Context
When using Zappa, I'm not able to structure the problem as this:
```
/zappa_settings.json
/project/manage.py
/project/project/settings.py
```
Even using `"django_settings": "project.project.settings.py"` won't work. Instead, I'm forced to do this:
```
/zappa_settings.json
/manage.py
/project/set... | closed | 2017-12-01T14:13:14Z | 2018-03-31T16:45:43Z | https://github.com/Miserlou/Zappa/issues/1277 | [] | jonatasbaldin | 4 |
redis/redis-om-python | pydantic | 464 | pydantic validators fail silently | This code works fine if the password conforms to the validator rules.
Especially during assignment of a parent JsonModel. However when I run a get() method to retrieve data I run into errors.
I have the follow EmbeddedJsonModel.
```
class identity(EmbeddedJsonModel):
'''
A Password|Token verification... | open | 2023-01-17T12:01:19Z | 2023-01-17T12:33:08Z | https://github.com/redis/redis-om-python/issues/464 | [] | XChikuX | 1 |
HIT-SCIR/ltp | nlp | 561 | 请问dep的解码过程用到的eisner是参考了哪篇论文? | closed | 2022-03-28T10:57:39Z | 2022-06-18T00:54:13Z | https://github.com/HIT-SCIR/ltp/issues/561 | [] | yhj997248885 | 1 | |
sqlalchemy/alembic | sqlalchemy | 584 | migration message does not support non ascii characters | When i try to create a migration that contains a non ascii characters in the message, the migration fail.
```python
Traceback (most recent call last):
File "/home/lohanna/digesto/op/venv/local/lib/python2.7/site-packages/alembic/util/pyfiles.py", line 14, in template_to_file
output = template.render_uni... | closed | 2019-07-03T16:38:27Z | 2019-07-03T17:40:53Z | https://github.com/sqlalchemy/alembic/issues/584 | [
"question"
] | lohxx | 3 |
awtkns/fastapi-crudrouter | fastapi | 55 | [FEAT] Ability to pass order_by column(s) | Right now you return the models ordered by id (or not really ordered didn't get into details of all backends, and without explicit order by the order in db is not guaranteed).
I would like to be able to pass a list of columns that should be used to, note that it should be treated as a default sorting, other function... | open | 2021-03-29T10:07:31Z | 2021-03-30T05:20:07Z | https://github.com/awtkns/fastapi-crudrouter/issues/55 | [] | collerek | 2 |
FactoryBoy/factory_boy | sqlalchemy | 688 | need revise docs Many-to-many for SQLAlchemy | #### The problem
Many-to-Many documentation is not work for SQLAlchemy.
This is described in #121
#### Proposed solution
[Simple Many-to-many relationship](https://factoryboy.readthedocs.io/en/latest/recipes.html#simple-many-to-many-relationship) in the docs should not use add but append.
#### Extra notes
Non... | closed | 2020-01-24T16:40:01Z | 2020-01-28T16:04:51Z | https://github.com/FactoryBoy/factory_boy/issues/688 | [
"Doc",
"SQLAlchemy"
] | kobayashi | 3 |
Lightning-AI/pytorch-lightning | deep-learning | 20,280 | SLURM resubmission crashes because of multiprocessing error | ### Bug description
Hello,
i am using `SLURMEnvironment` plugin to resubmit jobs automatically. So far it has been working seamlessly
on my academic cluster, but recently when the auto-requeue signal is sent, the python script fails because of some multiprocessing error.
It appears to me that workers in the dat... | open | 2024-09-13T15:00:13Z | 2024-11-09T18:34:42Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20280 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | antonzub99 | 2 |
allenai/allennlp | nlp | 4,675 | Have a single `TrainerCallback` that can handle both `BatchCallback` and `EpochCallback`. | Also, add another call at the end of the whole training run.
This should make it easier to hang on to state inside the callback.
See the discussion at the end of this issue: https://github.com/allenai/allennlp/pull/3970 | closed | 2020-09-25T23:00:34Z | 2020-10-26T17:22:41Z | https://github.com/allenai/allennlp/issues/4675 | [
"Contributions welcome",
"Feature request"
] | dirkgr | 7 |
simple-login/app | flask | 1,483 | Forbid to register with temporary adresses | Hello!
Please prohibit registering with a temporary email. There are a lot of people who abuse your service which causes their domains to get on spam lists.
Here is a list of all temporary emails. I hope it will be useful for you:
https://raw.githubusercontent.com/disposable-email-domains/disposable-email-doma... | open | 2022-12-09T16:37:11Z | 2022-12-13T13:17:27Z | https://github.com/simple-login/app/issues/1483 | [] | ghost | 1 |
Sanster/IOPaint | pytorch | 370 | [Feature Request] add image to prompt for anime or realistic image | i think Add this plugin can get better inpainting | closed | 2023-09-08T10:48:24Z | 2025-03-24T02:07:05Z | https://github.com/Sanster/IOPaint/issues/370 | [
"stale"
] | Kingal20000 | 2 |
Yorko/mlcourse.ai | data-science | 378 | Minor typo in the 3rd Assignment | > In our case there's only **_ine_** feature so ... | closed | 2018-10-16T12:43:37Z | 2018-10-17T21:34:04Z | https://github.com/Yorko/mlcourse.ai/issues/378 | [
"minor_fix"
] | foghegehog | 3 |
opengeos/leafmap | streamlit | 284 | Better documentation and approach for rescale parameter for multi-band COGs | ### Description
Two requests:
(1) multi-band COGs frequently need different rescaling for different bands. How to do this isn't documented in the API, but this
works because of how requests handles the params dictionary:
```
m.add_cog_layer(url, rescale=["164,223","130,211","99,212"])
```
so that `rescal... | closed | 2022-09-08T20:10:51Z | 2022-11-06T19:51:56Z | https://github.com/opengeos/leafmap/issues/284 | [
"Feature Request"
] | philvarner | 2 |
Farama-Foundation/Gymnasium | api | 717 | [Question] AssertionError when combining discrete and continious action space | ### Question
Hi all,
I have a gymnasium environment with a combiation of a discrete and a continious action space. So actually there are 3 actions to take. The first 2 ones are discrete in the range between 0 and `timeslots_for_state_load_percentages_costs`. The third one is a continious action between 0 and 50.
... | closed | 2023-09-19T16:36:43Z | 2023-09-19T18:54:36Z | https://github.com/Farama-Foundation/Gymnasium/issues/717 | [
"question"
] | PBerit | 1 |
inducer/pudb | pytest | 104 | bpython integration does not work | ``` pytb
File "/Users/aaronmeurer/anaconda/lib/python3.3/bdb.py", line 47, in trace_dispatch
return self.dispatch_line(frame)
File "/Users/aaronmeurer/anaconda/lib/python3.3/bdb.py", line 65, in dispatch_line
self.user_line(frame)
File "/Users/aaronmeurer/anaconda/lib/python3.3/site-packages/pudb/debugger... | closed | 2014-02-04T17:16:14Z | 2016-06-24T22:38:23Z | https://github.com/inducer/pudb/issues/104 | [] | asmeurer | 8 |
JaidedAI/EasyOCR | deep-learning | 393 | TypeError: super(type, obj): obj must be an instance or subtype of type | While initializing model according to README, I've got the following error:
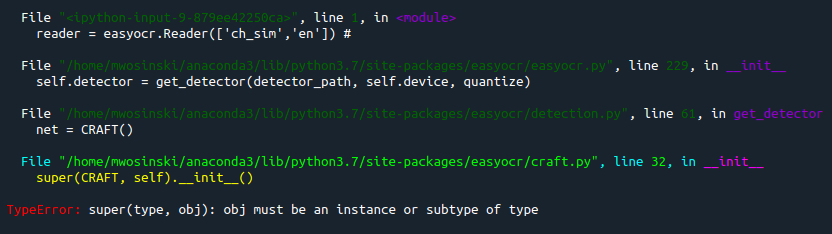
| closed | 2021-03-12T06:31:02Z | 2022-03-02T09:24:34Z | https://github.com/JaidedAI/EasyOCR/issues/393 | [] | mateuszwosinski | 1 |
gunthercox/ChatterBot | machine-learning | 1,758 | How to save train data | how to avoid train every time or how to save trained data | closed | 2019-06-18T11:47:47Z | 2020-08-29T20:31:24Z | https://github.com/gunthercox/ChatterBot/issues/1758 | [] | nikuraj006 | 1 |
alpacahq/alpaca-trade-api-python | rest-api | 604 | [Bug]: ModuleNotFoundError: No module named 'alpaca_trade_api.stream' | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
Trying to stream data but I keep getting the error
ModuleNotFoundError: No module named 'alpaca_trade_api.stream'
I’ve tried pip3 install alpaca_trade_api from here: https://stackoverflow.com/questions/... | closed | 2022-04-13T18:20:18Z | 2022-04-14T13:52:02Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/604 | [
"question"
] | EM5813 | 2 |
FactoryBoy/factory_boy | django | 403 | How to use RelatedFactory for a model without related_name? | ```
class User(Model):
name = CharField(max_length=100)
class Order(Model):
user = ForeignKey(User)
```
I access the list of orders for a user using as `user.order_set.all()` which is working for me. Ref: https://stackoverflow.com/a/42080970/1080135
But when I try to use the RelatedFactory as follows, I ... | closed | 2017-08-07T11:16:33Z | 2017-08-07T14:22:08Z | https://github.com/FactoryBoy/factory_boy/issues/403 | [
"Q&A",
"NeedInfo"
] | pavan-blackbuck | 2 |
kennethreitz/responder | graphql | 99 | On modularity & reusable ASGI components | So I've been following a general approach with the design of [Starlette](https://github.com/encode/starlette), that I'd love to see Responder follow on with. The aims are to keep complexity nicely bounded into smallish components, that then end up being reusable across different ASGI frameworks. Some examples:
* Sta... | closed | 2018-10-18T19:49:12Z | 2018-10-19T14:58:59Z | https://github.com/kennethreitz/responder/issues/99 | [
"feature"
] | tomchristie | 2 |
quantumlib/Cirq | api | 6,994 | Gauge compiling as a sweep: merge single qubit gates | **Problem Statement**
as_sweep() might transform a circuit with consecutive parameterized phxz operations.
Usually, after gauge_compiling, users would optimize the circuit by merging single qubit gates. While merging parameterized circuit isn't supported.
**Potential Solutions**
Support this in as_sweep() or mergin... | open | 2025-01-28T22:38:54Z | 2025-03-13T22:39:52Z | https://github.com/quantumlib/Cirq/issues/6994 | [
"kind/feature-request",
"triage/accepted",
"area/error-mitigation"
] | babacry | 3 |
scrapy/scrapy | python | 6,643 | Add support for async HTTP cache storages | https://stackoverflow.com/questions/79396472/how-to-extend-scrapy-with-custom-http-cache-which-needs-to-perform-asynchronous
It should be relatively easy to make it possible to have `HTTPCACHE_STORAGE` storages whose methods are asynchronous, because they are used only in `scrapy.downloadermiddlewares.httpcache.HttpCa... | open | 2025-01-31T15:03:52Z | 2025-02-11T20:18:29Z | https://github.com/scrapy/scrapy/issues/6643 | [
"enhancement",
"asyncio"
] | wRAR | 0 |
satwikkansal/wtfpython | python | 303 | Add notes for modifying class attributes | Relates to [class attributes and instance attributes](https://github.com/satwikkansal/wtfpython#-class-attributes-and-instance-attributes)
considering the following code:
```python
class Foo:
_count1 = 0
_count2 = 0
@staticmethod
def total():Foo._count2 += 1
@classmethod
def count(cls):... | open | 2022-12-31T03:38:32Z | 2023-01-05T14:38:26Z | https://github.com/satwikkansal/wtfpython/issues/303 | [] | ZeroRin | 2 |
litestar-org/litestar | pydantic | 3,133 | Enhancement: Support Websockets on the async tests client | ### Summary
Currently `websocket_connect` method is only available on the sync client.
Would be nice to support web sockets with the async client as well.
### Basic Example
```py
test_client = AsyncTestClient(get_application())
ws_session = test_client.websocket_connect()
```
### Drawbacks and Impact
_No resp... | closed | 2024-02-25T09:23:33Z | 2025-03-20T15:54:26Z | https://github.com/litestar-org/litestar/issues/3133 | [
"Enhancement"
] | nrbnlulu | 1 |
newpanjing/simpleui | django | 170 | 登录后打开其他菜单,点击菜单中的首页,出现两个首页标签 | **bug描述**
简单的描述下遇到的bug:
登录后打开其他菜单,点击菜单中的首页,出现两个首页标签
**重现步骤**
1.登录后,显示首页,地址栏连接没有#后缀;
2.点击菜单中其他任意项,打开新标签;
3.点击菜单中的首页,新增加了一个首页标签(总的显示两个),并且两个标签都是active状态;
**环境**
1.操作系统:MacOS 10.14.6
2.python版本:3.7.4
3.django版本:2.2.6
4.simpleui版本:3.2
**其他描述**
| closed | 2019-10-18T08:48:32Z | 2019-11-18T05:23:44Z | https://github.com/newpanjing/simpleui/issues/170 | [
"bug"
] | eshxcmhk | 0 |
qwj/python-proxy | asyncio | 133 | How to add username and pass --auth | what is the format of --auth , i tried but is not working | open | 2021-08-30T16:47:07Z | 2021-09-08T19:02:14Z | https://github.com/qwj/python-proxy/issues/133 | [] | apioff | 1 |
modelscope/modelscope | nlp | 812 | Modelscope导致datasets库无法正常载入数据集 | Thanks for your error report and we appreciate it a lot.
**Checklist**
* I have searched the tutorial on modelscope [doc-site](https://modelscope.cn/docs)
* I have searched related issues but cannot get the expected help.
* The bug has not been fixed in the latest version.
**Describe the bug**
modelscope 1... | closed | 2024-03-28T07:26:37Z | 2024-05-23T01:55:58Z | https://github.com/modelscope/modelscope/issues/812 | [
"Stale"
] | zodiacg | 5 |
babysor/MockingBird | pytorch | 65 | M1芯片下安装包报错的暂时性解决方案 | 本人设备m1 macbookair python3.9
在使用pip安装包时疯狂报错,通过其他方法安装完运行时报错的部分信息有“have:arm need:x86_64"。怀疑与arm兼容性有关。
解决方法:
1.安装x86版本的包使用rosetta2运行
在所需安装包命令前加上arch -x86_64
如arch -x86_64 pip install -r requirements.txt
最后启动时使用arch -x86_64 python demo_toolbox.py
或
2.安装windows虚拟机
~-~pd17真香 | open | 2021-08-30T15:43:50Z | 2022-04-05T10:02:54Z | https://github.com/babysor/MockingBird/issues/65 | [
"documentation"
] | msly5 | 5 |
tflearn/tflearn | tensorflow | 611 | loading saved model "NotFoundError" | I can save the model by: model.save("test.tfl")
INFO:tensorflow:./test.tfl is not in all_model_checkpoint_paths. Manually adding it.
Files appear under the same folder:
model.tfl.ckpt-500.data-00000-of-00001
model.tfl.ckpt-500.index
model.tfl.ckpt-500.meta
model.tfl.ckpt-860.data-00000-of-00001
model.tfl.ckpt-8... | closed | 2017-02-18T14:28:59Z | 2017-02-18T14:37:29Z | https://github.com/tflearn/tflearn/issues/611 | [] | edgedislocation | 0 |
albumentations-team/albumentations | machine-learning | 2,394 | [New feature] Add apply_to_images to CLAHE | open | 2025-03-11T00:59:04Z | 2025-03-11T00:59:11Z | https://github.com/albumentations-team/albumentations/issues/2394 | [
"enhancement",
"good first issue"
] | ternaus | 0 | |
amidaware/tacticalrmm | django | 1,057 | ENHANCEMENT: Add option to enable Proxy Protocol on TRMM Nginx Container | **Is your feature request related to a problem? Please describe.**
If TRMM is hosted behind a Load Balancer, it does not get the real IP of the client host in the logs.
**Describe the solution you'd like**
The solution to this problem is the use of `Proxy Protocol`, see https://docs.nginx.com/nginx/admin-guide/loa... | closed | 2022-04-08T18:40:48Z | 2022-06-21T04:22:00Z | https://github.com/amidaware/tacticalrmm/issues/1057 | [
"question"
] | joeldeteves | 8 |
aiogram/aiogram | asyncio | 835 | Bot API 5.7 | # Bot API 5.7
- Added support for Video Stickers.
- Added the field is_video to the classes Sticker and StickerSet.
- Added the parameter webm_sticker to the methods createNewStickerSet and addStickerToSet.
#Bot API 5.6
- Improved support for Protected Content.
- Added the parameter protect_content to the m... | closed | 2022-02-16T22:05:00Z | 2022-02-20T13:04:43Z | https://github.com/aiogram/aiogram/issues/835 | [] | JrooTJunior | 0 |
deeppavlov/DeepPavlov | nlp | 1,139 | Plans to trained bigger BERT/RoBERTa/T5 models for Russian language? | Hello!
Do you have any plans for training larger transformers models, something from the last architectures (Reformer specifically) or BERT?
Or maybe you have plans in the opposite direction: to train TinyBERT with https://github.com/huawei-noah/Pretrained-Language-Model/tree/master/TinyBERT ? | closed | 2020-02-26T22:07:28Z | 2020-04-30T11:07:19Z | https://github.com/deeppavlov/DeepPavlov/issues/1139 | [] | avostryakov | 2 |
custom-components/pyscript | jupyter | 58 | registered_triggers is not defined in new app | Using the below code for a new app and no matter what I try I can't get it to not throw an error on `registered_triggers`
```
registered_triggers = []
# start the app
@time_trigger('startup')
def personTrackerStartup():
loadApp('location', makePersonTracker)
def makePersonTracker(config):
global... | closed | 2020-10-27T17:35:20Z | 2020-10-29T01:12:58Z | https://github.com/custom-components/pyscript/issues/58 | [] | Nxt3 | 16 |
Textualize/rich | python | 2,461 | [REQUEST] Improved uninstall for `rich.traceback.install` and `rich.pretty.install` | We are very excited to have recently adopted rich on the Kedro framework. In short, our setup is:
```
logging.config.dictConfig(logging_config) # where logging_config uses rich logging handler
rich.traceback.install(show_locals=True, suppress=[click])
rich.pretty.install()
```
Some people have reported vario... | open | 2022-08-11T08:56:35Z | 2023-05-25T15:28:40Z | https://github.com/Textualize/rich/issues/2461 | [
"Needs triage"
] | antonymilne | 5 |
pytorch/vision | machine-learning | 8,126 | Models input/output conventions (shape, preproc/postproc, etc.) | Not an issue, just writing this down for reference.
(**TODO** perhaps it'd be useful to clarify whether models support arbitrary H and W)
## Img Classification
**Input**
Shape (N, C, H, W).
Must be scaled from [0, 1] into specific scale
**Output**
Shape (N, num_classes), logits
**preproc and postproc ... | open | 2023-11-20T14:24:08Z | 2023-11-20T14:24:49Z | https://github.com/pytorch/vision/issues/8126 | [] | NicolasHug | 0 |
seleniumbase/SeleniumBase | pytest | 2,883 | Improve multithreading with UC Mode 4.28.x | # Improve multithreading with UC Mode 4.28.x
In case you missed https://github.com/seleniumbase/SeleniumBase/issues/2865, `4.28.0` added a new UC Mode method: `uc_gui_handle_cf()`, which uses `pyautogui` to click Cloudflare checkboxes with the keyboard while the driver is disconnected from Chrome. For those of you w... | closed | 2024-06-28T20:03:57Z | 2024-07-01T01:41:13Z | https://github.com/seleniumbase/SeleniumBase/issues/2883 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 4 |
pyro-ppl/numpyro | numpy | 1,646 | Error when importing numpyro-0.13.1 | UPDATE: Bumping JAX to the latest version seems to fix the problem
jax version = 0.4.14
Reproducible example in google colab: https://colab.research.google.com/drive/1R444hZjVV0KDaaksTE6Gf72DaH8rUqZt?usp=sharing
```
[/usr/local/lib/python3.10/dist-packages/numpyro/__init__.py](https://localhost:8080/#) in <mo... | closed | 2023-09-22T20:55:32Z | 2023-09-22T22:46:23Z | https://github.com/pyro-ppl/numpyro/issues/1646 | [
"bug"
] | ziatdinovmax | 1 |
jacobgil/pytorch-grad-cam | computer-vision | 462 | If the target layer of model is encapsulated, and there are multiple outputs | how to set the value of target layer?
this is my target model:[https://github.com/HRNet/HRNet-Semantic-Segmentation](url) | open | 2023-10-23T03:15:06Z | 2023-10-23T03:16:56Z | https://github.com/jacobgil/pytorch-grad-cam/issues/462 | [] | douciyy | 0 |
mwaskom/seaborn | pandas | 3,253 | How to move the legend of sns.jointplot() with kind='kde'? | Hi,
I am trying to move the legend of a jointplot, but none of the methods works.
I tired
```
import seaborn as sns
penguins = sns.load_dataset("penguins")
sns.jointplot(data=penguins, x="bill_length_mm", y="bill_depth_mm", hue="species")
```
 fields as described in #385. As commented by @irsalmashhor (https://github.com/django-import-export/django-import-export/issues/385#issuecomment-385288150), I think we need to pass `row` value to `skip_row` to inspect M2M field in the instance. Any ideas?
| closed | 2020-03-17T03:05:34Z | 2021-05-05T20:36:55Z | https://github.com/django-import-export/django-import-export/issues/1098 | [] | okapies | 1 |
ndleah/python-mini-project | data-visualization | 279 | enhance the Dice Rolling Stimulator | # Description
In this issue I want to modify the game's functionality by introducing a "try again" feature and restructuring the code into a class. The objective is to enhance the user experience by providing the option to reroll the dice without restarting the entire program, and also add docstring and update the Rea... | open | 2024-06-10T09:56:08Z | 2024-06-10T11:16:14Z | https://github.com/ndleah/python-mini-project/issues/279 | [] | Gabriela20103967 | 0 |
ultralytics/yolov5 | machine-learning | 12,586 | ConfusionMatrix incorrect? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Validation
### Bug
I believe there is a problem in the ConfusionMatrix() method. It only counts the false positives if there are true positives.
... | closed | 2024-01-05T18:58:52Z | 2024-10-20T19:36:18Z | https://github.com/ultralytics/yolov5/issues/12586 | [
"bug",
"Stale"
] | GilSeamas | 3 |
microsoft/unilm | nlp | 804 | How layoutlmv3 makes train at the character level | **Describe**
Model I am using (LayoutLMv3):
The model train entities for each bbox, but my entity is a part of the text in a bbox, and there will be multiple entities in a bbox. How should I deal with this situation? | closed | 2022-07-26T12:33:51Z | 2022-08-25T06:58:45Z | https://github.com/microsoft/unilm/issues/804 | [] | 413542484 | 1 |
horovod/horovod | deep-learning | 2,941 | How to install Gloo on Ubuntu 18.04v? | I was trying to train my model on different hosts using this command:
`HOROVOD_WITH_TENSORFLOW=1 horovodrun --gloo -np 10 -H workstation-1:4,localhost:4 python train.py
`
However, I got this error:
`ValueError: Gloo support has not been built. If this is not expected, ensure CMake is installed and reinstall Hor... | closed | 2021-05-26T08:13:08Z | 2021-08-03T13:41:32Z | https://github.com/horovod/horovod/issues/2941 | [
"question",
"wontfix"
] | harrytrinh96 | 5 |
google-deepmind/sonnet | tensorflow | 245 | this portion of attention code looks incorrect | ` attention_mlp = basic.BatchApply(
mlp.MLP([self._mem_size] * self._attention_mlp_layers))`
`for _ in range(self._num_blocks):
attended_memory = self._multihead_attention(memory)`
shouldnt it be this
`attended_memory = memory`
`for _ in range(self._num_blocks):`
`attended_memory =... | open | 2022-06-14T07:38:51Z | 2022-06-14T07:40:17Z | https://github.com/google-deepmind/sonnet/issues/245 | [] | ava6969 | 0 |
skforecast/skforecast | scikit-learn | 566 | Usando Gaps en el pronóstico | Hola amigos:
Quiero ver la forma, y no he encontrado en el material muy bien preparado de skforecast, sobre cómo hacer un modelo de forecast que se entrene considerando un gap. Por ejemplo, El modelo considera las ventas de 5 días para predecir las ventas del séptimo, es decir hay un gap entre "y" y los rezagos del mo... | closed | 2023-10-03T20:08:15Z | 2023-11-02T08:18:06Z | https://github.com/skforecast/skforecast/issues/566 | [
"question"
] | GabrielCornejo | 1 |
Gozargah/Marzban | api | 1,384 | ClashMeta Bugs: Mux & HTTPUpgrade | Problem 1: Mux is disabled in mux template for clash meta (but enabled at host settings), mux will be enabled at clash meta config
Xray server does not support any mux except mux.cool, idk how clashmeta can still connect to my server using h2mux! maybe they have a fallback to disable mux if it's not supported by the s... | closed | 2024-10-18T23:07:36Z | 2024-11-04T05:27:57Z | https://github.com/Gozargah/Marzban/issues/1384 | [
"Bug",
"Core"
] | fodhelper | 3 |
plotly/dash | flask | 3,007 | Patten matching callbacks do not warn if no matches exist | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.18.1 A Python framework ...
dash-bootstrap-components 1.6.0 Bootstrap themed co.... | open | 2024-09-19T02:06:23Z | 2024-09-23T14:31:26Z | https://github.com/plotly/dash/issues/3007 | [
"bug",
"P3"
] | farhanhubble | 0 |
microsoft/nni | pytorch | 4,927 | RuntimeError: Has not supported replacing the module: `GroupNorm` | **Describe the issue**:
**Environment**:
- NNI version:
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version:
- PyTorch/TensorFlow version:
- Is conda/virtualenv/venv used?:
- Is running in Docker?:
**Configuration**:
- Experiment config ... | closed | 2022-06-12T12:44:15Z | 2022-09-16T09:19:36Z | https://github.com/microsoft/nni/issues/4927 | [
"user raised",
"support"
] | qhy991 | 2 |
lexiforest/curl_cffi | web-scraping | 27 | Can't install with poetry and pip | the latest version ( 0.4.0 ) can't be installed
My environment:
OS: MacOS 13.2.1 (22D68)
Python: 3.9.12
Pip: 22.3.1
poetry: 1.3.1
here is the error log
```
pip install curl_cffi ... | closed | 2023-03-13T04:22:04Z | 2023-03-13T05:24:32Z | https://github.com/lexiforest/curl_cffi/issues/27 | [] | MagicalBomb | 1 |
twopirllc/pandas-ta | pandas | 207 | Unable to Use in GCP | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
pandas-ta>=0.2.23b
```
**Upgrade.**
```sh
$ pip install -U git+https://github.com/twopirllc/pandas-ta
```
**Describe the bug**
A clear and concise description of what the bug is... | closed | 2021-02-02T06:03:32Z | 2021-05-18T03:03:48Z | https://github.com/twopirllc/pandas-ta/issues/207 | [
"help wanted",
"info"
] | jboshers1 | 6 |
voxel51/fiftyone | data-science | 5,520 | [BUG] Wrong Export of the KITTI dataset to YOLOv5 format | ### Describe the problem
Fiftyone does not export a compliant version of the [KITTI dataset](https://docs.voxel51.com/dataset_zoo/datasets.html#dataset-zoo-kitti) in [yolov5 format](https://docs.voxel51.com/user_guide/export_datasets.html#yolov5dataset-export) when train and test split should be exported. I orientated... | open | 2025-02-26T16:32:06Z | 2025-03-03T20:08:41Z | https://github.com/voxel51/fiftyone/issues/5520 | [
"bug"
] | DJE98 | 7 |
SciTools/cartopy | matplotlib | 1,778 | importing cartopy.crs in Binder fails | I'm trying to load my notebook in binder and I seem to have issues with importing cartopy.crs. I guess this is somehow similar to #1740 but in binder.
I'm using a minimal environment.yml to test this
```
name: test-environment
-python=3.7
channels:
- conda-forge
dependencies:
- numpy=1.20.2
- matplot... | closed | 2021-05-04T22:58:20Z | 2021-05-12T04:52:58Z | https://github.com/SciTools/cartopy/issues/1778 | [
"Type: Question",
"Component: installation"
] | vrx- | 7 |
gevent/gevent | asyncio | 1,886 | gevent.select.select still mark socket readable after all data is read on windows | * gevent version: 21.12 from pip
* Python version: cPython 3.7.6 downloaded from python.org
* Operating System: windows 7 x64
### Description:
It seems that there is a bug in `gevent.select.select` on windows. After a socket read all data from its peer, and run `select.select` again against it, it is still return... | open | 2022-05-19T09:24:38Z | 2022-10-07T01:46:17Z | https://github.com/gevent/gevent/issues/1886 | [
"Platform: Windows"
] | adamhj | 5 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.