
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
tensorly/tensorly | numpy | 99 | Non-Negative Decompositions not available | I was looking at the docs and I saw there are a couple of non-negative decomposition, but when I installed tensorly I could not find them. Actually, the package looks a lot different than what I saw from the docs. | closed | 2019-02-25T15:54:08Z | 2019-02-25T16:37:03Z | https://github.com/tensorly/tensorly/issues/99 | [] | temuller | 1 |
graphql-python/gql | graphql | 463 | [Feature] Support Subscriptions HTTP Multipart Protocol | Apollo recently introduced [HTTP callback protocol for GraphQL subscriptions](https://www.apollographql.com/docs/router/executing-operations/subscription-callback-protocol/) which utilizes the HTTP Multipart protocol instead of websockets.
Apollo Client [supports it out of the box](https://www.apollographql.com/docs... | open | 2024-02-05T18:02:37Z | 2024-02-06T22:52:37Z | https://github.com/graphql-python/gql/issues/463 | [
"type: feature"
] | andrewmcgivery | 6 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 688 | Add flake8 and/or other style helpers | See https://github.com/pallets/werkzeug/blob/master/.pre-commit-config.yaml for reference. | closed | 2019-03-08T23:56:35Z | 2022-09-18T18:10:44Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/688 | [] | rsyring | 2 |
graphistry/pygraphistry | jupyter | 367 | [BUG] frozen ai deps for dirty-cat ci failures | Commit https://github.com/graphistry/pygraphistry/commit/e1be5e46d25d6224ed80f1b5c5012470c9b08212 requires, for umap/ai installs: py3.8+ (vs 3.6), scikit-learn 1.0+ (vs 0.2x), and froze dirty-cat to 0.2.0 (disallows 0.2.1)
This is to work around CI fail `FAILED graphistry/tests/test_umap_utils.py::TestUMAPFitTransfo... | open | 2022-06-23T05:38:18Z | 2022-06-23T05:39:39Z | https://github.com/graphistry/pygraphistry/issues/367 | [
"bug"
] | lmeyerov | 0 |
gradio-app/gradio | data-visualization | 10,347 | [ImageEditor] - tracking issue | The current ImageEditor work is being tackled in the following. way:
- [x] **Sizing redesign**
A number of bugs and features actually relate to sizing. We have several different ideas of what sizing means that is causing both confusion and bugs. We think of sizing in terms of container size, natural image/canvas si... | open | 2025-01-13T18:08:16Z | 2025-01-24T01:26:45Z | https://github.com/gradio-app/gradio/issues/10347 | [
"tracking",
"🖼️ ImageEditor"
] | pngwn | 5 |
ultralytics/yolov5 | pytorch | 13,176 | Training with HIP/ROCm | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar feature requests.
### Description
As pytorch 2.3 seems to support ROC https://pytorch.org/docs/stable/notes/hip.html
With minimal code changes (only TF32 support is not present, b... | open | 2024-07-08T21:51:50Z | 2024-10-20T19:49:45Z | https://github.com/ultralytics/yolov5/issues/13176 | [
"enhancement",
"Stale"
] | JijaProGamer | 3 |
predict-idlab/plotly-resampler | data-visualization | 341 | Dash Callback says FigureResampler is not JSON serializable | Apologies, this is more of a "this broke and I don't know what went wrong" type of issue. What it looks like so far is that everything in the dash dashboard ive made works except for the plotting. This is the exception i get:
```
dash.exceptions.InvalidCallbackReturnValue: The callback for `[<Output `data-plot.figure`>... | closed | 2025-03-05T20:37:21Z | 2025-03-06T18:06:15Z | https://github.com/predict-idlab/plotly-resampler/issues/341 | [] | FDSRashid | 1 |
ymcui/Chinese-BERT-wwm | tensorflow | 25 | 模型转换失效,请求提供pytorch版本 | 可能由于操作原因,我使用pytorch-transformers进行模型转化,然而tf checkpoints转为pytorch模型后,发生模型无效果,基本等同于随机的现象,希望能够提供转换好的版本,麻烦您啦
转换命令为:
` sudo python3 convert.py --tf_checkpoint_path ./bert_model.ckpt.index --bert_config_file bert_config.json --pytorch_dump_path ./pytorch_bert.bin
`
其中convert.py的代码为:
[https://github.com/huggingface/py... | closed | 2019-08-01T03:22:11Z | 2019-08-01T10:57:36Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/25 | [] | braveryCHR | 3 |
ray-project/ray | pytorch | 51,071 | [core] Only one of the threads in a thread pool will be initialized as a long-running Python thread | ### What happened + What you expected to happen
Currently, only one of the threads in a thread pool will be initialized as a long-running Python thread. I should also investigate whether it's possible to call `PyGILState_Release` on a different thread other than the one calls `PyGILState_Ensure` in the thread pool.
#... | open | 2025-03-04T22:03:14Z | 2025-03-04T23:02:20Z | https://github.com/ray-project/ray/issues/51071 | [
"bug",
"core"
] | kevin85421 | 0 |
flaskbb/flaskbb | flask | 601 | Attachments | Add support for uploading files and pictures | open | 2021-09-10T18:20:59Z | 2021-09-10T18:20:59Z | https://github.com/flaskbb/flaskbb/issues/601 | [] | sh4nks | 0 |
comfyanonymous/ComfyUI | pytorch | 6,511 | SamplerCustomAdvanced: The size of tensor a (3072) must match the size of tensor b (4096) at non-singleton dimension 2 | ### Your question
**I haven't been able to find any solution so far. I got this error when trying to use the following workflow: https://civitai.com/models/929131/flux-pulid-face-swap-inpainting-consistent-character-workflow**
# ComfyUI Error Report
## Error Details
- **Node ID:** 48
- **Node Type:** SamplerCustomAdv... | closed | 2025-01-18T13:47:18Z | 2025-03-01T11:40:04Z | https://github.com/comfyanonymous/ComfyUI/issues/6511 | [
"User Support",
"Custom Nodes Bug"
] | Felix0C | 1 |
BayesWitnesses/m2cgen | scikit-learn | 127 | add support for declarative languages | It seems that especially for functional languages it is very common to write `Score()` function and apply it to some data.
At present, assemblers make assumption about that target language is imperative. | closed | 2019-12-13T00:59:58Z | 2020-04-24T21:48:29Z | https://github.com/BayesWitnesses/m2cgen/issues/127 | [] | StrikerRUS | 4 |
QuivrHQ/quivr | api | 3,553 | Implement first version of retrieval/generation evaluation | For a list of potential datasets for retrieval see [CORE-325](https://linear.app/getquivr/issue/CORE-325/retrieval-datasets) and [Notion](https://www.notion.so/getquivr/Retrieval-generation-evaluation-189312462d4b800eb9cedff39777e80c?pvs=4)
# Evaluation steps for CI/CD
1. Select a subset (1 to 20) .Each subset contai... | open | 2025-01-22T11:11:58Z | 2025-02-05T13:56:47Z | https://github.com/QuivrHQ/quivr/issues/3553 | [
"enhancement"
] | jacopo-chevallard | 1 |
d2l-ai/d2l-en | pytorch | 1,728 | chapter 16 (recommender systems) needs translation to pytorch | chapter 16 (recommender systems) needs translation to pytorch | open | 2021-04-19T23:59:57Z | 2022-01-19T04:09:59Z | https://github.com/d2l-ai/d2l-en/issues/1728 | [] | murphyk | 5 |
jina-ai/clip-as-service | pytorch | 914 | TensorRT support for openai/clip-vit-large-patch14-336 | Is there a fundamental technical limitation on not being able to support TensorRT for openai/clip-vit-large-patch14-336 ? Just wanna understand why most 768-dim embedding models are not supported according to https://clip-as-service.jina.ai/user-guides/server/#model-support | open | 2023-05-09T02:48:36Z | 2023-05-09T03:38:49Z | https://github.com/jina-ai/clip-as-service/issues/914 | [] | junwang-wish | 1 |
iperov/DeepFaceLab | machine-learning | 545 | Openfaceswap gui issue when training | 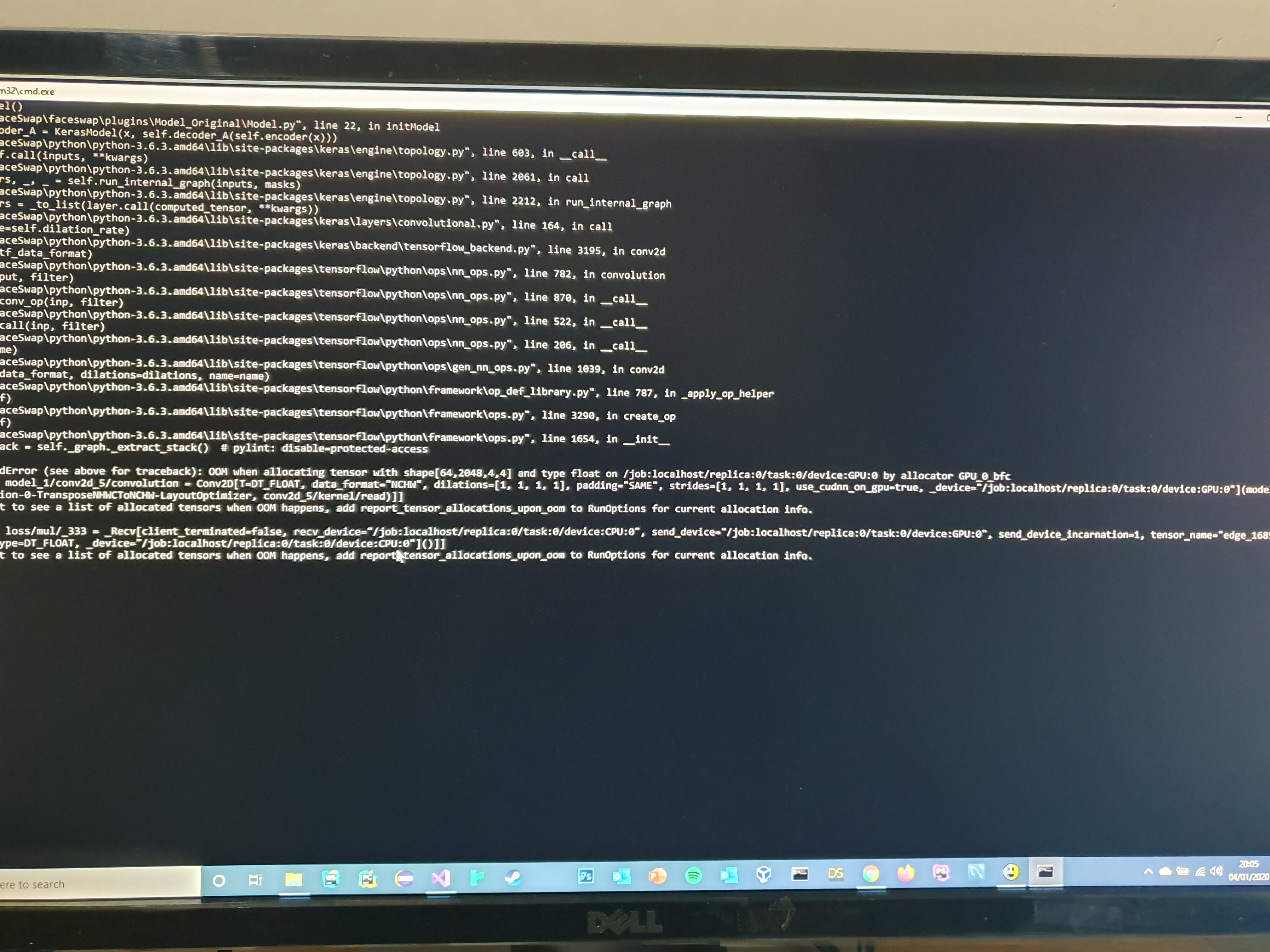
It just gets stuck on this part then nothing happens no matter how long i leave it for of any one has any ideas it would be a good help thanks. | closed | 2020-01-04T20:08:36Z | 2020-03-28T05:42:17Z | https://github.com/iperov/DeepFaceLab/issues/545 | [] | badat1223 | 4 |
mwaskom/seaborn | data-science | 3,462 | seaborn/_oldcore.py generating Futurewarning for deprecated pandas `is_categorical_dtype` and `use_inf_as_na` usage | This is more informational than a true "issue" as everything appears to be working.
I installed Ultralytics 8.0.170 in a new `venv` and at the start of training, received numerous `FutureWarnings` when `trainer` started plotting labels. Screenshot shows sample of output (continues for several more lines).
![Scre... | closed | 2023-09-05T10:03:41Z | 2023-10-01T11:54:54Z | https://github.com/mwaskom/seaborn/issues/3462 | [] | glenn-jocher | 4 |
ipython/ipython | data-science | 13,959 | %debug magic doesn't capture the locals | To reproduce:
1 - create a file `test.ipy`:
```python
def fun():
res = 1
%debug print(res)
fun()
```
2 - run with `ipython test.ipy`
3 - After pressing continue on the pdb promt, I get:
`NameError: name 'res' is not defined`
This is in contrast with the following code, which works:
```python
def ... | closed | 2023-03-04T06:17:35Z | 2023-03-13T10:35:54Z | https://github.com/ipython/ipython/issues/13959 | [] | impact27 | 0 |
jofpin/trape | flask | 255 | Ngrok tunnels never seem to load. | The startup and execution of trape seem to be fine (apart from a warning about being a development server, could possibly be the problem, I don't know), but whenever I try to use my public ngrok link (or my local IP address for that matter), the page seems to just infinitely load until I close the tunnel, which then re... | open | 2020-08-14T11:22:58Z | 2020-08-14T11:22:58Z | https://github.com/jofpin/trape/issues/255 | [] | jethr0-1 | 0 |
zappa/Zappa | django | 935 | [Migrated] Zappa init error: Access is denied (windows) | Originally from: https://github.com/Miserlou/Zappa/issues/2203 by [merlinnaidoo](https://github.com/merlinnaidoo)
(venv) C:\Users\zappa>zappa init
Access is denied.
(cannot run this to run to get json)
(venv) C:\Users\zappa>zappa
Access is denied.
python -m zappa
C:\Users\merlinn\PycharmProjects\lambdazappt... | closed | 2021-02-20T13:24:44Z | 2022-07-16T04:47:22Z | https://github.com/zappa/Zappa/issues/935 | [] | jneves | 1 |
jrieke/traingenerator | streamlit | 7 | New template: Image classification with Keras/Tensorflow | Opening up this issue to coordinate work on a new keras/tensorflow template – @jaymody and @EteimZ have shown interest in this. Guys, please feel free to share here if/how you want to work on this and coordinate :)
The template could probably take a lot of the code from the existing [pytorch template](https://githu... | open | 2021-01-03T01:55:31Z | 2021-01-03T04:49:56Z | https://github.com/jrieke/traingenerator/issues/7 | [
"new template"
] | jrieke | 1 |
omnilib/aiomultiprocess | asyncio | 90 | how multi processes can be used for each task? | ### Description
I test the following two methods, method_1 can show multiprocessing is involved for task dispatching. While in method_2, all tasks are involved in a single process, can anyone show me a way out for involving multiprocesses in method_2? Thx in advanced.
### Details
```
async def get(url):
... | open | 2021-03-22T00:48:17Z | 2021-03-22T03:22:39Z | https://github.com/omnilib/aiomultiprocess/issues/90 | [] | doncat99 | 1 |
sanic-org/sanic | asyncio | 2,443 | app.add_signal() AttributeError: 'method' object has no attribute '__requirements__' | **Describe the bug**
```
AttributeError: 'method' object has no attribute '__requirements__'
```
```
File "server.py", line 56, in start
self.app.add_signal( self.stop , "server.shutdown.after" )
File "/venv/lib/python3.9/site-packages/sanic/mixins/signals.py", line 76, in add_signal
self.signal(event... | closed | 2022-04-30T21:47:14Z | 2022-05-17T14:55:31Z | https://github.com/sanic-org/sanic/issues/2443 | [
"information required"
] | 48723247842 | 3 |
flavors/django-graphql-jwt | graphql | 327 | Case sensitive Username | We are using Postgres backend which is case sensitive unlike MSSQL. That means middleware fails to fetch a user if the username is not passed exactly like stored in db.
Is there a way or setting to configure to disable case sensitivity?
| open | 2024-01-12T13:58:36Z | 2024-01-12T13:58:36Z | https://github.com/flavors/django-graphql-jwt/issues/327 | [] | hirensoni913 | 0 |
JaidedAI/EasyOCR | deep-learning | 502 | Why don't you support refine model in text detection like CRAFT? | As I know, CRAFT supports refine model to merge box. It helps result more accuracy. Why didnot easyocr do it?
Thank you so much | closed | 2021-07-30T15:42:47Z | 2021-10-06T09:04:24Z | https://github.com/JaidedAI/EasyOCR/issues/502 | [] | vneseresearcher | 1 |
mitmproxy/mitmproxy | python | 7,279 | How can I change mitmweb style? | 1、How can I change "comment" style in mitmweb, such as put the value in the center or color it red?

2、May I add a new web column in mitmweb? So I can easily notice the error response.
| closed | 2024-10-27T10:27:08Z | 2024-10-27T12:21:18Z | https://github.com/mitmproxy/mitmproxy/issues/7279 | [
"kind/triage"
] | Stephen0910 | 1 |
pytest-dev/pytest-html | pytest | 193 | [Feature Request] Need report object in pytest_html_results_summary hook to extend the summary section | It would be too good if we add "report" object to the pytest_html_results_summary hook, so that in runtime can use the objects in report like outcome, location,sections,for customization option. If we added it then it would be good to create the test summary table section consists of test_group_name,total tests in fold... | open | 2019-01-12T16:17:33Z | 2020-11-22T14:56:58Z | https://github.com/pytest-dev/pytest-html/issues/193 | [
"enhancement",
"feature"
] | kvenkat88 | 9 |
pydantic/logfire | fastapi | 636 | Logfire does not have exception info | ### Description
If I configure my StructLog processors like this
```
structlog.configure(
processors=[
structlog.contextvars.merge_contextvars,
structlog.processors.add_log_level,
structlog.processors.TimeStamper(fmt="iso"),
logfire.StructlogProcessor(),
structlo... | closed | 2024-11-30T23:01:02Z | 2024-12-04T12:30:40Z | https://github.com/pydantic/logfire/issues/636 | [] | vikigenius | 1 |
QingdaoU/OnlineJudge | django | 262 | 一些良好的发展建言 | 非常喜欢这个评测系统
有以下几点建议:
1.一键导出导入全部数据
2.题目选择OI制时像洛谷一样非常突出得分情况
3.题目加入标程按钮,出题人可以附加标程供无法AC的同学点击参考
4.加入题目讨论区和选手个人博客
5.选手可以自选是否加入代码公开计划,方便其他人学习AC的代码。
6.比赛支持Hack
7.题目导入后支持批量加标签和开启显示
8.部分题目导入时报错,希望修复兼容
9.后台管理可以设置未登录的游客访问时看到中文还是英文界面
10.支持后台更换主题,专业用户可以编写主题上传社区
11.支持打卡签到,Noip/noi/acm赛事倒计时显示等
12.Github上挂好二维码,方便大家打赏支持这个开源项目... | open | 2019-09-09T16:36:41Z | 2019-09-22T04:57:26Z | https://github.com/QingdaoU/OnlineJudge/issues/262 | [] | CrazyBoyM | 19 |
jumpserver/jumpserver | django | 15,098 | [Question] Custom applet | ### Product Version
4
### Product Edition
- [x] Community Edition
- [ ] Enterprise Edition
- [ ] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [x] Offline Package Installation
- [ ] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
### Envir... | open | 2025-03-22T08:39:37Z | 2025-03-24T03:29:54Z | https://github.com/jumpserver/jumpserver/issues/15098 | [
"⏳ Pending feedback",
"🤔 Question"
] | hellsangell | 1 |
plotly/dash | data-visualization | 2,606 | [BUG] Duplicate callback outputs error when background callbacks or long_callbacks share a cancel input | **Describe your context**
Currently I am trying to migrate a Dash application from using versions 2.5.1 to a newer one, and as suggested for Dash >2.5.1 I am moving from using ```long_callbacks``` to using the ```dash.callback``` with ```background=True```, along with moving to using ```background_callback_manager```.... | closed | 2023-07-31T19:02:22Z | 2023-08-01T11:57:05Z | https://github.com/plotly/dash/issues/2606 | [] | C-C-Shen | 1 |
zappa/Zappa | flask | 729 | [Migrated] Timeout without a "Zappa event" | Originally from: https://github.com/Miserlou/Zappa/issues/1843 by [nihaals](https://github.com/nihaals)
## Context
When I send a request to my Zappa page I get an `Internal server error`, but my logs simply say:
```
[1553875874136] Instancing..
[1553875879150] 2019-03-29T16:11:19.138Z b3b3a6b7-6ee5-4ea6-a5f3-f8112... | closed | 2021-02-20T12:41:20Z | 2024-04-13T18:14:44Z | https://github.com/zappa/Zappa/issues/729 | [
"no-activity",
"auto-closed"
] | jneves | 2 |
gradio-app/gradio | data-science | 10,863 | Support for a favicon | - [ X] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
not a problem, just an improvement.
**Describe the solution you'd like**
eg ```demo.launch(favicon="/path/to/favicon.ico')```
**Additional context**
Add any other context or sc... | closed | 2025-03-22T16:42:06Z | 2025-03-23T21:31:12Z | https://github.com/gradio-app/gradio/issues/10863 | [] | rbpasker | 1 |
hankcs/HanLP | nlp | 833 | word2vec 训练工具参数文档描述不准确 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2018-05-18T05:59:11Z | 2020-01-01T10:50:15Z | https://github.com/hankcs/HanLP/issues/833 | [
"ignored"
] | linuxsong | 2 |
autogluon/autogluon | computer-vision | 4,595 | Bump transformers and accelerate versions | ## Description
- The incoming Chronos version depends on `accelerate` version 0.32 and runs stable with version 0.34, which is the last version of `accelerate` before its v1.0 release. In AG, accelerate is capped at v0.22.
- Transformers dependency is also now 5 minor versions behind. Chronos runs stable with v4.39. ... | closed | 2024-10-29T16:50:20Z | 2024-11-14T19:03:17Z | https://github.com/autogluon/autogluon/issues/4595 | [
"enhancement",
"module: timeseries",
"module: multimodal",
"dependency",
"priority: 0"
] | canerturkmen | 1 |
python-arq/arq | asyncio | 29 | add trove classifier | see https://github.com/aio-libs/aiohttp-devtools/pull/68 | closed | 2017-04-22T11:10:53Z | 2017-05-06T10:35:31Z | https://github.com/python-arq/arq/issues/29 | [] | samuelcolvin | 0 |
xonsh/xonsh | data-science | 5,312 | semicolon + newline + space in subprocess mode results in SyntaxError | ## xonfig
<details>
```
+------------------+-----------------+
| xonsh | 0.14.0 |
| Python | 3.10.12 |
| PLY | 3.11 |
| have readline | True |
| prompt toolkit | 3.0.38 |
| shell type | prompt_toolkit |
| history... | open | 2024-03-24T17:11:27Z | 2024-03-25T10:58:28Z | https://github.com/xonsh/xonsh/issues/5312 | [
"parser",
"integration-with-other-tools"
] | jahschwa | 1 |
frol/flask-restplus-server-example | rest-api | 158 | Unable to build docker image from Dockerfile | It seems many APIs and packages are out of date so I cannot build an image all by myself from the dockerfile. Can you help to update it or show the correct version of each dependencies? | closed | 2024-04-04T15:58:09Z | 2024-04-06T02:07:17Z | https://github.com/frol/flask-restplus-server-example/issues/158 | [] | iridium-soda | 2 |
miguelgrinberg/Flask-Migrate | flask | 191 | hello,python db_create.py db upgrade cmd error | sqlalchemy.exc.InternalError: (pymysql.err.InternalError) (1050, "Table 'userinfo' already exists") [SQL: '\nCREATE TABLE `UserInfo` (\n\tid INTEGER NOT NULL AUTO_INCREMENT, \n\t`userName` VARCHAR(80), \n\t`userPassword_hash` VARCHAR(120) NOT NULL, \n\t`userEmail` VARCHAR(120), \n\t`userNickName` VARCHAR(40) NOT NULL, ... | closed | 2018-03-12T13:48:23Z | 2018-03-12T14:53:27Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/191 | [] | MDreamStars | 2 |
serengil/deepface | machine-learning | 483 | Deep face takes all GPU memory | OS: Ubuntu 20.04 LTS
CPU: Intel(R) Core(TM) i9-10900K CPU @ 3.70GHz
GPU: NVIDIA GeForce RTX 3090
RAM: 32G
Python version: 3.6.9
model: `VGG-Face`
detector backend: `opencv`
deep face version: 0.0.75
install: from pip
I was just try to run a simple face verify task with:
```python
from d... | closed | 2022-05-19T22:37:16Z | 2022-05-20T10:06:28Z | https://github.com/serengil/deepface/issues/483 | [
"dependencies"
] | ASSANDHOLE | 1 |
pyjanitor-devs/pyjanitor | pandas | 703 | Add ability to generate boolean flags about data quality | I just came across ```pyjanitor``` as I was trying to do some research around publicly available data-cleaning libraries in Python. First of all, thanks a lot for all the effort that has been made in developing this package and the continued effort that goes into maintaining it.
I would like to propose the addition... | closed | 2020-07-21T23:37:47Z | 2020-07-28T17:24:08Z | https://github.com/pyjanitor-devs/pyjanitor/issues/703 | [
"triage"
] | UGuntupalli | 11 |
lundberg/respx | pytest | 228 | Router does not honor `assert_all_called` | I'm using the router like so:
```python
import pytest
import httpx
import respx
from syncer.workitem import WorkItem
@pytest.fixture
def router():
router = respx.Router(base_url="https://dev.azure.com/")
router.get(
path__regex=r"\/workitems\/\d+$",
name="get",
)
rou... | closed | 2023-05-04T20:23:27Z | 2023-07-21T14:22:49Z | https://github.com/lundberg/respx/issues/228 | [] | BeyondEvil | 5 |
deezer/spleeter | deep-learning | 187 | [Discussion] your question: confuse about GPU when Itry to train the model . | <!-- Please respect the title [Discussion] tag. -->
the command is :CUDA_VISIBLE_DEVICES='1' python __main__.py train -p /home/tae/spleeter_master/configs/4stems/base_config.json -d /home/tae/musdb18hq , using the tensorflow-gpu,But the utilization ratio is zero.How can I use the GPU to train my own model through the... | closed | 2019-12-17T11:49:40Z | 2019-12-30T10:12:13Z | https://github.com/deezer/spleeter/issues/187 | [
"question"
] | DaerTaeKook | 1 |
PaddlePaddle/ERNIE | nlp | 372 | 关于num_seqs Variable的一个小问题 | 请问finetune/classifier.py中的num_seqs是一个var tensor 也不在feedlist中 怎么就直接获取了batch_size | closed | 2019-11-22T06:39:07Z | 2020-05-28T09:52:37Z | https://github.com/PaddlePaddle/ERNIE/issues/372 | [
"wontfix"
] | wq343580510 | 2 |
allure-framework/allure-python | pytest | 404 | Can't use allure report with pytest under mac | Hi, I'm having trouble with allure reports using pytest. It seems allure command is recognized but somehow when I add it in the pytest command as a parameter it causes an error and exits. Maybe I'm missing something, here's command line:
`pytest.main("--maxfail=50 /Users/distiller/project/tests --alluredir=/Users/di... | closed | 2019-07-16T18:07:54Z | 2019-07-19T21:06:48Z | https://github.com/allure-framework/allure-python/issues/404 | [] | ashea | 20 |
jacobgil/pytorch-grad-cam | computer-vision | 270 | The color of the background | Thanks for your work.
I use the code of [EigenCAM for YOLO5.ipynb]
I test one image by using your example. But the color of the feature map for the background is red. In your example, the background should be blue.
the result looks as follows:
I want to know the reason
<img width="1726" alt="result" src="https:/... | closed | 2022-06-19T08:24:57Z | 2023-08-22T18:36:40Z | https://github.com/jacobgil/pytorch-grad-cam/issues/270 | [] | Dongjiuqing | 3 |
qubvel-org/segmentation_models.pytorch | computer-vision | 37 | No module named 'segmentation_models_pytorch.common.blocks' | Hi,
I'm working in a internet restricted system. I've installed segmentation_models.pytorch using source code using `pip install ..`
Now when I try to import it, I get following error:
```
---------------------------------------------------------------------------
ModuleNotFoundError Traceb... | closed | 2019-08-06T19:13:09Z | 2019-10-15T15:04:03Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/37 | [] | pyaf | 0 |
ipython/ipython | data-science | 13,875 | Annoying venv warning | Hi!
Using `ipython` 8.7.0 I just identified that the block below always triggers the annoying warning when I run `ipython` within a `pyenv` venv.
https://github.com/ipython/ipython/blob/d38397b078b744839b8510f7ac9ab4fa40450a4f/IPython/core/interactiveshell.py#L886-L890
The instance variable `warn_venv` occurs ... | open | 2022-12-23T14:16:15Z | 2023-10-09T15:08:51Z | https://github.com/ipython/ipython/issues/13875 | [] | jamilraichouni | 7 |
zappa/Zappa | flask | 792 | [Migrated] Issue while deploying Django project | Originally from: https://github.com/Miserlou/Zappa/issues/1943 by [CapturedCarbon](https://github.com/CapturedCarbon)
<!--- Provide a general summary of the issue in the Title above -->
Fails while deploy a django project
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a... | closed | 2021-02-20T12:42:30Z | 2022-07-16T06:16:20Z | https://github.com/zappa/Zappa/issues/792 | [] | jneves | 1 |
sqlalchemy/alembic | sqlalchemy | 1,230 | postgresql ExcludeConstraint behave differently with --autogenerate compare to sqlalchemy Base.metadata.create_all | **Describe the bug**
when running `alembic revision --autogenerate`, on a table with
``` python
ExcludeConstraint(
(func.tstzrange(effective_time, expiry_time), "&&"),
using="gist",
)
```
it generates
``` python
postgresql.ExcludeConstraint(('tstzrange(effective_time, expiry_time)', '&&'), using=... | closed | 2023-04-28T05:46:53Z | 2023-05-03T13:19:24Z | https://github.com/sqlalchemy/alembic/issues/1230 | [
"bug",
"autogenerate - rendering",
"postgresql"
] | tc-yu | 2 |
ageitgey/face_recognition | python | 793 | Dlib has no attribute get frontal face_detector | * face_recognition version:1.23.
* Python version:3.6.5
* Operating System:windows 7
### Description
Describe what you were trying to get done.
Tell us what happened, what went wrong, and what you expected to happen.
IMPORTANT: If your issue is related to a specific picture, include it so others can reproduce... | open | 2019-04-03T08:43:51Z | 2019-06-20T10:10:45Z | https://github.com/ageitgey/face_recognition/issues/793 | [] | HemanthKumarGadi | 1 |
Yorko/mlcourse.ai | scikit-learn | 709 | Issue on page /book/topic02/topic02_visual_data_analysis.html | item 5 is missing.

https://github.com/Yorko/mlcourse.ai/blob/54bca0f807481af872ca3245225c5084df5375d1/book/topic02/topic02_visual_data_analysis.html#L806 | closed | 2022-07-15T15:57:26Z | 2022-08-27T17:37:44Z | https://github.com/Yorko/mlcourse.ai/issues/709 | [] | KingAndJoker | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 860 | Disable cookies | How can I disable cookies? | closed | 2022-10-27T13:22:32Z | 2023-07-01T09:25:55Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/860 | [] | MazenTayseer | 1 |
huggingface/datasets | deep-learning | 6,720 | TypeError: 'str' object is not callable | ### Describe the bug
I am trying to get the HPLT datasets on the hub. Downloading/re-uploading would be too time- and resource consuming so I wrote [a dataset loader script](https://huggingface.co/datasets/BramVanroy/hplt_mono_v1_2/blob/main/hplt_mono_v1_2.py). I think I am very close but for some reason I always get ... | closed | 2024-03-07T11:07:09Z | 2024-03-08T07:34:53Z | https://github.com/huggingface/datasets/issues/6720 | [] | BramVanroy | 2 |
rio-labs/rio | data-visualization | 144 | Add Hover Height to `Card` | For consistency, add a hover height effect for `Card's` similar to the one in the `Rectangle` component. Same as for Rectangle: e.g. shadow_radius=3 | open | 2024-09-18T14:41:34Z | 2024-09-18T14:41:41Z | https://github.com/rio-labs/rio/issues/144 | [
"enhancement"
] | Sn3llius | 0 |
django-import-export/django-import-export | django | 1,834 | Breaking change due to _check_import_id_fields | **Describe the bug**
This is a breaking change in 4.0 vs 3.x.
In my resource, I've declared a `before_import_row()` to add another column 'Object' to the row, which is used as an identifier.
```
object = resources.Field(column_name="Object", attribute="object")
def before_import_row(self, row, **kwargs):
... | closed | 2024-05-14T17:27:21Z | 2024-05-15T08:48:42Z | https://github.com/django-import-export/django-import-export/issues/1834 | [
"bug"
] | jameslao | 2 |
pyeve/eve | flask | 1,200 | Add GitHub metadata and documentation link to PyPI | For reference, take a look at [Flask page on PyPI](http://docs.python-eve.org/en/latest/changelog.html)
<img width="297" alt="image" src="https://user-images.githubusercontent.com/512968/46522611-8e642980-c883-11e8-9532-11162d773b98.png">
| closed | 2018-10-05T07:47:15Z | 2019-04-11T09:01:48Z | https://github.com/pyeve/eve/issues/1200 | [
"enhancement"
] | nicolaiarocci | 3 |
robotframework/robotframework | automation | 4,864 | Process: Make warning about processes hanging if output buffers get full more visible | Related to #3661,
Before finding the related issue above, my binary hung when using the `RUN PROCESS`. It has consumed a lot of my time investigating whether the robot test has found a bug or not. I found out that it is a limitation or weird behavior on RF based on the related issue. It could really help other devel... | closed | 2023-09-11T10:30:57Z | 2023-11-07T09:14:55Z | https://github.com/robotframework/robotframework/issues/4864 | [
"enhancement",
"priority: low",
"alpha 1",
"effort: small"
] | pat0026 | 3 |
plotly/dash-recipes | dash | 11 | download-raw-data.py doesn't work in IE11 | URI links aren't allowed in IE11, so the download CSV links don't work. Is there an alternative that is easy to implement with Dash? Maybe some of the answers from [this stackoverflow question](https://stackoverflow.com/q/3916191/6068036) would help, like using another JavaScript library like downloadify.js or downlo... | closed | 2018-06-22T14:33:00Z | 2018-06-22T14:40:46Z | https://github.com/plotly/dash-recipes/issues/11 | [] | amarvin | 4 |
pandas-dev/pandas | pandas | 60,954 | BUG: Segmentation Fault when changing a column name in a DataFrame | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [ ] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2025-02-18T10:07:42Z | 2025-03-11T16:49:36Z | https://github.com/pandas-dev/pandas/issues/60954 | [
"Docs",
"Index"
] | cvr | 8 |
plotly/dash | flask | 2,359 | Auto sizing a single axis not properly handled | **Describe your context**
Plotly 5.11.0
Dash 2.7.0
Python 3.10
Dockerfile:
```
FROM debian:bullseye
RUN apt update && apt install -y --no-install-recommends python3 python3-pip
RUN pip install plotly==5.11.0 dash==2.7.0 dash-bootstrap-components==1.2.1 pandas==1.5.2
COPY swap_charts.py /tmp
EXPOSE 8050
C... | open | 2022-12-08T15:50:48Z | 2024-08-13T19:24:13Z | https://github.com/plotly/dash/issues/2359 | [
"bug",
"P3"
] | mneilly | 1 |
iterative/dvc | machine-learning | 10,703 | `dvc pull` takes ~20 minutes with no console output for 15 minutes unless run with `-v -v` | # Bug Report: `dvc pull` Takes ~20 Minutes With No Progress Unless Using Double Verbosity
## Description
We have a repository that stores about **31GB** of data in a Google Cloud Storage remote. Approximately **15GB** comes from ~60 main data files, and another **16GB** is apparently from 33 “temp” files that do not ... | open | 2025-03-13T17:31:04Z | 2025-03-14T03:59:48Z | https://github.com/iterative/dvc/issues/10703 | [
"triage"
] | vishvadesai9 | 0 |
vanna-ai/vanna | data-visualization | 813 | Number of requested results 10 is greater than number of elements in index 0, updating n_results = 0 | Number of requested results 10 is greater than number of elements in index 0, updating n_results = 0
一直出现上诉问题,而且ddl通过train加入之后,问了很多简单问题都回答不了,这是怎么回事呢?大佬知道问题出在哪里吗?我的表结构字段比较多,每张表有200个字段,共有6张表。 @pygeek @wgong @livenson @prady00 @gquental | open | 2025-03-14T11:01:17Z | 2025-03-15T03:00:55Z | https://github.com/vanna-ai/vanna/issues/813 | [] | wuxiaolianggit | 2 |
PablocFonseca/streamlit-aggrid | streamlit | 38 | "Open in Streamlit" Examples do not seem to work | Hi there @PablocFonseca!
I am a big fan of this streamlit component and am currently learning how to use it as I build out an application for internal company use. It is a huge improvement over the standard dataframe rendering offered by streamlit. Thank you!
During my learning process, I am referring to your ex... | closed | 2021-10-12T23:55:59Z | 2021-10-26T21:15:57Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/38 | [] | connorferster | 2 |
praw-dev/praw | api | 1,521 | difference between "hot" and "top"? | Hi! thanks for the app!
I have a question on the definition difference between "hot" and "top".
It seems top comes from the most upvote, but how does count hot items?
Best
Joseph Jin | closed | 2020-06-05T07:15:51Z | 2020-06-05T07:31:39Z | https://github.com/praw-dev/praw/issues/1521 | [] | dryjins | 1 |
jina-ai/serve | fastapi | 5,690 | Introduce Job concepts to make Executors suitable for 1-time Request | **Describe the feature**
Provide this:
```python
job = Job(uses=Executor, retries=3, ...)
job.run(on='/foo', inputs='s3....', output='s3....')
job.to_kubernetes_yaml() # should map to a K8s BatchJob
``` | closed | 2023-02-14T16:10:36Z | 2024-06-23T00:21:11Z | https://github.com/jina-ai/serve/issues/5690 | [
"Stale"
] | JoanFM | 6 |
reiinakano/scikit-plot | scikit-learn | 115 | Regarding the scikit-plot.metrics.plot_roc function | In you code I noticed that if we pass classes in the form of their actual meaning instead of (0,1,2 .. ) and we pass it as (c,b,a) then np.unique(y_true) makes the classes in the form of its alphabetical format and this changes the position of the classes that the model was trained on
classes = np.unique(y_true)
`... | open | 2021-07-23T13:46:02Z | 2022-11-04T15:12:46Z | https://github.com/reiinakano/scikit-plot/issues/115 | [] | Akshay1-6180 | 1 |
huggingface/datasets | deep-learning | 7,116 | datasets cannot handle nested json if features is given. | ### Describe the bug
I have a json named temp.json.
```json
{"ref1": "ABC", "ref2": "DEF", "cuts":[{"cut1": 3, "cut2": 5}]}
```
I want to load it.
```python
ds = datasets.load_dataset('json', data_files="./temp.json", features=datasets.Features({
'ref1': datasets.Value('string'),
'ref2': datasets.Value... | closed | 2024-08-20T12:27:49Z | 2024-09-03T10:18:23Z | https://github.com/huggingface/datasets/issues/7116 | [] | ljw20180420 | 3 |
cvat-ai/cvat | tensorflow | 9,211 | Migration of backend data to external storage services (e.g. AWS S3) | Hello everyone!
We are currently using CVAT `v2.7.4` in Kubernetes.
In this installation, the backend server pods use a single PV with `AccessMode: ReadWriteMany` for all these pods. This is a very specific type of volume in our infrastructure and we try not to use them unless absolutely necessary.
I would like to clar... | closed | 2025-03-14T11:20:54Z | 2025-03-17T19:10:16Z | https://github.com/cvat-ai/cvat/issues/9211 | [] | obervinov | 2 |
pydantic/FastUI | pydantic | 82 | class_name.py throws TypeError | Hi,
Interesting library! I am a newby and tried a hello-world app, with the default code. I run the code in a Docker container on Python 3.9. I get this TypeError:
File "/usr/local/lib/python3.9/site-packages/fastui/class_name.py", line 6, in <module>
ClassName = Annotated[str | list[str] | dict[str, bool... | closed | 2023-12-08T07:12:22Z | 2023-12-13T09:35:25Z | https://github.com/pydantic/FastUI/issues/82 | [] | jorritsma | 4 |
kizniche/Mycodo | automation | 451 | Overheating ? Others experience ? | Version 5.7.2
More of a query of others experience to explain my results ?
We had our first warm day of the year today and as luck would have it I was out all day....and returned to find my pi stopped recording for the hottest part of the day
So my pi got fried, in the image below you can see that once the pi re... | closed | 2018-04-18T23:48:17Z | 2018-05-02T13:45:36Z | https://github.com/kizniche/Mycodo/issues/451 | [] | drgrumpy | 4 |
aiortc/aiortc | asyncio | 1,264 | pull whep problem player = MediaPlayer("http://*****:1985/rtc/v1/whep/?app=live&stream=100") |
player = MediaPlayer("http://***:1985/rtc/v1/whep/?app=live&stream=100")
video = VideoTransformTrack(relay.subscribe(player.video),transform="airec")
if video:
pc.addTrack(video)
pc.addTrack(player.audio)
error :
File "E:\ProgramData\miniconda3\envs\mygpt39\lib\site-packages\... | open | 2025-03-02T01:56:54Z | 2025-03-02T01:57:08Z | https://github.com/aiortc/aiortc/issues/1264 | [] | gg22mm | 0 |
comfyanonymous/ComfyUI | pytorch | 6,344 | reactor workflow not working | ### Expected Behavior
workflow to work
### Actual Behavior
not working
### Steps to Reproduce
just insert ReActor 🌌 Fast Face Swap nodi in worklow, connect what is needed and that is it
### Debug Logs
```powershell
got prompt
[ReActor] 16:05:31 - STATUS - Working: source face index [0], target face index [0]
... | closed | 2025-01-04T14:09:39Z | 2025-02-07T00:04:17Z | https://github.com/comfyanonymous/ComfyUI/issues/6344 | [
"Potential Bug",
"Custom Nodes Bug"
] | dule1970 | 4 |
polyaxon/traceml | data-visualization | 5 | Add LICENSE to MANIFEST.in | Could you please add the license to MANIFEST.in so that it will be included in sdists and other packages? This came up during [packaging](https://github.com/conda-forge/staged-recipes/pull/1355/) of pandas-summary in [conda-forge](conda-forge.github.io).
| closed | 2016-08-25T18:49:52Z | 2016-08-26T10:51:19Z | https://github.com/polyaxon/traceml/issues/5 | [] | proinsias | 1 |
qwj/python-proxy | asyncio | 114 | Headers | Is possible to get headers of the request? | open | 2021-02-23T08:34:19Z | 2021-02-24T17:29:44Z | https://github.com/qwj/python-proxy/issues/114 | [] | 4you2see | 2 |
koxudaxi/fastapi-code-generator | pydantic | 277 | Special input parameter support | An error is reported when a function variable is a Python keyword. Like this:
```text
"parameters": [
{
"name": "from",
"in": "query",
"description": "起点坐标,39.071510,117.190091",
"required": true,
"schema": {
"type": "string"
... | open | 2022-09-11T04:04:23Z | 2022-09-11T04:04:23Z | https://github.com/koxudaxi/fastapi-code-generator/issues/277 | [] | Chise1 | 0 |
huggingface/pytorch-image-models | pytorch | 1,231 | [BUG] Convnext inference key error | Hi,
I use the train.py scripts to train the Convnext-B, it work well, but when I want to use the checkpoint pth to inference, the error occur, it says RuntimeError: Error(s) in loading state_dict for DPN:
Missing key(s) in state_dict: "features.conv1_1.conv.weight" ....
I don't know why it occur
| closed | 2022-04-24T01:55:28Z | 2022-04-24T02:01:36Z | https://github.com/huggingface/pytorch-image-models/issues/1231 | [
"bug"
] | 523997931 | 0 |
Yorko/mlcourse.ai | seaborn | 382 | Topic 3. Decision tree regressor, MSE | В примере по DecisionTreeRegressor неправильный расчет MSE в названии графика:
`plt.title("Decision tree regressor, MSE = %.2f" % np.sum((y_test - reg_tree_pred) ** 2))`
Нужно ещё поделить на количество наблюдений, предлагаю поправить так:
`plt.title("Decision tree regressor, MSE = %.4f" % (np.sum((y_test - reg_tree... | closed | 2018-10-17T08:08:32Z | 2018-10-17T21:34:04Z | https://github.com/Yorko/mlcourse.ai/issues/382 | [
"minor_fix"
] | lalimpiev | 1 |
Nekmo/amazon-dash | dash | 156 | confirmation with URL | Put an `x` into all the boxes [ ] relevant to your *issue* (like this: `[x]`)
### What is the purpose of your *issue*?
- [ ] Bug report (encountered problems with amazon-dash)
- [x] Feature request (request for a new functionality)
- [ ] Question
- [ ] Other
#### Description
with telegram and pushbulle... | open | 2020-05-11T15:46:18Z | 2020-05-11T15:46:18Z | https://github.com/Nekmo/amazon-dash/issues/156 | [] | Fraborak | 0 |
modelscope/data-juicer | data-visualization | 128 | 去哪儿可以获取到en_core_web_md-3.5.0.zip模型 | ### Before Asking 在提问之前
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully. 我已经仔细阅读了 [README](https://github.com/alibaba/data-juicer/blob/main/README_ZH.md) 上的操作指引。
- [X] I have pulled the latest code of main branch to run again and the problem still existed. 我已经拉取了主分... | closed | 2023-12-11T05:33:21Z | 2024-01-06T09:31:58Z | https://github.com/modelscope/data-juicer/issues/128 | [
"question",
"stale-issue"
] | ZengJin123 | 4 |
flairNLP/fundus | web-scraping | 256 | Rename `HTMLSource`'s `url_filter` parameter to `url_filters` and type hint accordingly | Type-hinting `self.url_filter` would help since it differs from the past `url_filter`. Also, we could allow `Optional[list[URLFilter]]` in the first place. Then `url_filters` instead of `url_filter` would be more fitting. This is not really related to async, so maybe for another PR?
_Originally posted ... | closed | 2023-07-03T12:45:23Z | 2023-08-29T15:09:30Z | https://github.com/flairNLP/fundus/issues/256 | [] | MaxDall | 0 |
mwaskom/seaborn | pandas | 3,299 | Swarmplots fail with numpy v1.22 for dataframes with repeating indices | With numpy v1.22, swarmplots fail when the index of the dataframe has repeating elements (works for 1.23+):
(I'm using seaborn 0.12.1 and matplotlib 3.7.1)
```
File "/[]/seaborn/categorical.py", line 346, in plot_swarms
dodge_move = offsets[sub_data["hue"].map(self._hue_map.levels.index)]
File "[]/pandas/co... | closed | 2023-03-21T01:28:46Z | 2023-03-21T12:55:26Z | https://github.com/mwaskom/seaborn/issues/3299 | [] | uri-t | 1 |
fugue-project/fugue | pandas | 292 | [FEATURE] Implement a real DuckDB engine | Currently, DuckDB engine is just a NativeExecutionEngine + DuckDB SQL Engine. It's not optimal because the data will be trasferred between duckdb and pandas whenever there is a new SQL statement. So we need to have a real DuckDBExecutionEngine, in which the dataframe can be kept inside DuckDB in most of the steps. This... | closed | 2022-01-17T04:02:22Z | 2022-01-17T07:49:52Z | https://github.com/fugue-project/fugue/issues/292 | [
"enhancement",
"duckdb"
] | goodwanghan | 0 |
babysor/MockingBird | deep-learning | 684 | 调整完batch_size之后需要其他的操作吗? | 调整了batch_size的大小但是占用率没有变化 | closed | 2022-07-27T19:49:41Z | 2023-07-01T02:46:28Z | https://github.com/babysor/MockingBird/issues/684 | [] | yunqi777 | 1 |
autokey/autokey | automation | 913 | Missing wiki page - Contributed Scripts 3 | ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is thi... | closed | 2023-08-15T19:05:41Z | 2023-08-17T18:50:48Z | https://github.com/autokey/autokey/issues/913 | [] | Elliria | 6 |
xuebinqin/U-2-Net | computer-vision | 311 | GPU memory increases during training | I am using the [refactored U-2-Net](https://github.com/xuebinqin/U-2-Net/blob/master/model/u2net_refactor.py) and the GPU memory increases every few iterations during training. I noticed in the code that there are function definitions in the forward functions such as [here](https://github.com/xuebinqin/U-2-Net/blob/ebb... | open | 2022-06-15T07:02:26Z | 2022-06-20T05:36:19Z | https://github.com/xuebinqin/U-2-Net/issues/311 | [] | kenmbkr | 1 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,288 | driver.find_element(By.XPATH, '//*[contains( text(), "Sign In")]').click() triggers antibot but if clicking manually it works | Apologies if I missed something here.
When trying to scrape a site, if i use the 'driver.find_element(By.XPATH, '//*[contains( text(), "Sign In")]').click()' command, I get asked to prove I am human, but if i click the website in manually i can browse through it without any ab verification.
Can't share the site a... | open | 2023-05-24T06:56:00Z | 2023-08-12T00:31:42Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1288 | [] | MGSolu | 2 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,348 | [Bug]: SDXL Lowram flag is broken (Probably) | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | open | 2024-03-21T20:10:10Z | 2024-03-22T19:40:27Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15348 | [
"bug-report"
] | Les-Tin | 1 |
pytest-dev/pytest-qt | pytest | 158 | waitForWindowShown doesn't handle timeout | Qt's [`qWaitForWindowShown`](https://doc.qt.io/qt-5/qtest-obsolete.html#qWaitForWindowShown) (or [`qWaitForWindowExposed`](https://doc.qt.io/qt-5/qtest.html#qWaitForWindowExposed) which supersedes it since Qt 5.0) has a `timeout` argument, and returns a `bool` saying if the waiting has timed out or not.
pytest-qt's wr... | closed | 2016-09-15T12:17:51Z | 2016-10-19T00:07:59Z | https://github.com/pytest-dev/pytest-qt/issues/158 | [] | The-Compiler | 2 |
python-gino/gino | sqlalchemy | 387 | Binding postgres url with sslcert and sslmode does not work | * GINO version: 0.800
* Python version: 3.6.5
* asyncpg version: 0.18.1
* aiocontextvars version: 2.3
* PostgreSQL version: 10.5
### Description
`async def main():
await db.set_bind(f'postgres://admin:pwd@amazingco.aivencloud.com:18629/prod?sslmode=verify&sslcert={ctx}')`
Keeps throwing this error.
`as... | closed | 2018-11-09T12:51:54Z | 2018-11-17T10:50:52Z | https://github.com/python-gino/gino/issues/387 | [
"question"
] | willyhakim | 4 |
falconry/falcon | api | 1,721 | Remove browser warning in unset_cookie | Currently unset cookie returns this warning on firefox when used in http:
`Cookie “<name-here>” will be soon rejected because it has the “sameSite” attribute set to “none” or an invalid value, without the “secure” attribute. To know more about the “sameSite“ attribute, read https://developer.mozilla.org/docs/Web/HTTP/... | closed | 2020-05-12T16:26:27Z | 2020-06-10T15:20:12Z | https://github.com/falconry/falcon/issues/1721 | [
"bug"
] | CaselIT | 5 |
aeon-toolkit/aeon | scikit-learn | 1,919 | [DOC] Outdated Classification Notebook | ### Describe the issue linked to the documentation
I was reading the classification notebook to learn more about classifiers, there were some confusing parts so I reached out on the slack for some help. It seems though as the classification notebook guides are completely outdated.
Notebook in discussion: https:... | closed | 2024-08-07T11:05:26Z | 2024-11-28T11:17:24Z | https://github.com/aeon-toolkit/aeon/issues/1919 | [
"documentation"
] | Moonzyyy | 1 |
computationalmodelling/nbval | pytest | 21 | Smarter picking of kernel to start | Currently, nbval always starts the default Python kernel, though this is not necessarily running in the same Python environment as nbval itself (see discussion on #6).
1. In the default case, we should probably pick the kernel to start based on notebook metadata, like nbconvert does for `--execute`. This would allow... | closed | 2016-12-21T22:48:07Z | 2017-01-17T10:13:14Z | https://github.com/computationalmodelling/nbval/issues/21 | [
"enhancement"
] | takluyver | 1 |
proplot-dev/proplot | matplotlib | 21 | Non-mercator ticks available in cartopy | FYI @lukelbd , looks like tick labeling is available for non-mercator projections now. https://github.com/SciTools/cartopy/pull/1117 was just merged. It's not in the conda/pip release yet, though. | closed | 2019-06-19T17:39:34Z | 2020-05-11T10:18:11Z | https://github.com/proplot-dev/proplot/issues/21 | [
"feature",
"high priority"
] | bradyrx | 2 |
mwaskom/seaborn | data-visualization | 3,003 | Documentation archive dropup only works on homepage | Needs to be changed to use absolute paths. | closed | 2022-09-06T22:25:00Z | 2022-09-09T01:50:34Z | https://github.com/mwaskom/seaborn/issues/3003 | [
"docs"
] | mwaskom | 1 |
matterport/Mask_RCNN | tensorflow | 2,816 | Unable to open file (truncated file: eof = 28999680, sblock->base_addr = 0, stored_eof = 257557808) | open | 2022-04-23T09:42:02Z | 2022-04-23T09:42:02Z | https://github.com/matterport/Mask_RCNN/issues/2816 | [] | remembersu | 0 | |
jupyter/nbgrader | jupyter | 1,033 | Manual grading after interrupted kernel |
### Operating system
Ubuntu 18.04 LTS
### `nbgrader --version`
Python version 3.6.6 | packaged by conda-forge | (default, Jul 26 2018, 09:53:17)
[GCC 4.8.2 20140120 (Red Hat 4.8.2-15)]
nbgrader version 0.5.4
### `jupyterhub --version` (if used with JupyterHub)
0.9.4
### `jupyter notebook --version... | open | 2018-10-20T22:07:35Z | 2022-06-23T10:21:12Z | https://github.com/jupyter/nbgrader/issues/1033 | [
"enhancement"
] | adibaba | 3 |
ibis-project/ibis | pandas | 10,022 | bug: BigQuery Create table with partition_by argument is not working | ### What happened?
I am trying to use the BigQuery backend to create a table with a partition by expression, ibis is raising exception.
here is a simple code to reproduce the error:
```
import ibis
c = ibis.bigquery.connect(...)
schema = ibis.schema([ ("c1", "date"), ("c2", "int")])
c.create_table('test_tb', par... | open | 2024-09-04T22:59:38Z | 2024-10-23T15:26:05Z | https://github.com/ibis-project/ibis/issues/10022 | [
"bug",
"bigquery"
] | ruiyang2015 | 7 |
jonaswinkler/paperless-ng | django | 412 | Use existing folder structure | I am interested in using paperless-ng, however I already have a existing folder structure in place where I organize everything.
Additionally to documents I keep other correlating data there so it is not easily possible to get rid of the existing structure.
I am also hesitant to dump everything into paperless-ng becau... | closed | 2021-01-23T07:40:39Z | 2021-01-24T06:07:29Z | https://github.com/jonaswinkler/paperless-ng/issues/412 | [] | spacemanspiff2007 | 4 |
plotly/dash | plotly | 2,641 | [BUG] Reset View Button in Choropleth Mapbox Shows Old Data | Hello,
I've built a dash app (https://www.greenspace.city), which uses the Plotly Choropleth Mapbox to visualise spatial data. The map is centered on the selected suburb (dropdown value).
Unfortunately, when I switch the data (i.e. select a different suburb or city from the dropdown) and hit the reset view butto... | closed | 2023-09-12T07:31:44Z | 2024-07-25T13:42:09Z | https://github.com/plotly/dash/issues/2641 | [] | masands | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.