
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ShishirPatil/gorilla | api | 567 | How to add a model that is not in vllm | Hi,
I am evaluating a new model which is not in vllm. How can I generate responses with this model since I find vllm is the only way for generate()?
Thank you! | closed | 2024-08-04T22:00:33Z | 2025-02-20T22:38:10Z | https://github.com/ShishirPatil/gorilla/issues/567 | [] | shizhediao | 5 |
allenai/allennlp | pytorch | 5,211 | Models loaded using the `from_archive` method need to be saved with original config | When `allennlp train` is used to fine-tune a pretrained model (`model A`) using `from_archive(path_to_A)`, the finetuned model (`model B`) is saved with the config that contains `from_archive`. This means that if you try to now finetune the `model B`, it needs the original `model A` at the exact `path_to_A`, as well as... | open | 2021-05-18T19:28:40Z | 2021-05-28T16:33:03Z | https://github.com/allenai/allennlp/issues/5211 | [
"bug"
] | AkshitaB | 1 |
modelscope/modelscope | nlp | 587 | Model Export Error. AttributeError: 'dict' object has no attribute 'model_dir' | **Description:**
When trying to use the `Model.from_pretrained()` method with the following code:
```python
from modelscope.models import Model
from modelscope.exporters import Exporter
model_id = 'damo/cv_unet_skin-retouching'
model = Model.from_pretrained(model_id)
output_files = Exporter.from_model(model)... | closed | 2023-10-16T05:53:45Z | 2023-10-20T09:40:18Z | https://github.com/modelscope/modelscope/issues/587 | [] | chiragsamal | 3 |
Farama-Foundation/PettingZoo | api | 1,215 | [Proposal] Integration of gfootball | ### Proposal
[gfootball](https://github.com/google-research/football) is widely used in SOTA MARL algorithms, e.g., https://arxiv.org/abs/2103.01955, https://arxiv.org/abs/2302.06205.
Will it be integrated in future releases?
### Motivation
_No response_
### Pitch
_No response_
### Alternatives
_No response_
... | closed | 2024-06-20T19:40:11Z | 2024-06-24T04:19:12Z | https://github.com/Farama-Foundation/PettingZoo/issues/1215 | [
"enhancement"
] | xihuai18 | 2 |
dbfixtures/pytest-postgresql | pytest | 303 | Windows support | ### What action do you want to perform
Hi, we are wanting to use the postgresql_proc fixture in our test suite and we ran into a few errors. Version 2.4.0 on Windows 10 and PostgreSQL version 11.
### What are the results
On the creation of PostgreSQLExecutor we find it errors when calling pg_ctl due to the quote... | open | 2020-07-16T13:51:47Z | 2022-08-01T17:01:33Z | https://github.com/dbfixtures/pytest-postgresql/issues/303 | [
"enhancement",
"help wanted"
] | pernlofgren | 5 |
coqui-ai/TTS | deep-learning | 3,587 | [Feature request] Move to MIT License | The company is shutting down and can no longer license this project for commercial purposes or benefit from such licensing. Suggest moving to MIT license for more permissive modification and redistribution by the community. | closed | 2024-02-17T11:23:38Z | 2025-01-06T02:42:59Z | https://github.com/coqui-ai/TTS/issues/3587 | [
"wontfix",
"feature request"
] | geofurb | 22 |
modin-project/modin | pandas | 6,783 | ModuleNotFoundError: No module named 'modin.pandas.testing' | This module is public and is used quite often.
It shouldn't be difficult to maintain, as it has a few functions:
```python
__all__ = [
"assert_extension_array_equal",
"assert_frame_equal",
"assert_series_equal",
"assert_index_equal",
]
``` | closed | 2023-11-29T22:16:12Z | 2024-03-11T19:15:46Z | https://github.com/modin-project/modin/issues/6783 | [
"new feature/request 💬",
"pandas concordance 🐼",
"P2"
] | anmyachev | 3 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 347 | Dependabot couldn't authenticate with https://pypi.python.org/simple/ | Dependabot couldn't authenticate with https://pypi.python.org/simple/.
You can provide authentication details in your [Dependabot dashboard](https://app.dependabot.com/accounts/marshmallow-code) by clicking into the account menu (in the top right) and selecting 'Config variables'.
[View the update logs](https://app.d... | closed | 2020-09-25T05:16:36Z | 2020-09-28T05:15:05Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/347 | [] | dependabot-preview[bot] | 0 |
serengil/deepface | deep-learning | 556 | Lot of False positives in Deepface | Hi @serengil ,
Kindly share your thoughts on why i am getting false positives in images repeatedly.
I have observed that setting threshold value to less than 0.40 gives lot of matches, I have extracted representations and calculated cosine score for images, but its giving me poor results in 2 images below, one imag... | closed | 2022-09-06T11:21:25Z | 2022-09-06T13:54:39Z | https://github.com/serengil/deepface/issues/556 | [
"question"
] | Risingabhi | 3 |
Anjok07/ultimatevocalremovergui | pytorch | 655 | ??? | Last Error Received:
Process: VR Architecture
If this error persists, please contact the developers with the error details.
Raw Error Details:
ValueError: "zero-size array to reduction operation maximum which has no identity"
Traceback Error: "
File "UVR.py", line 4719, in process_start
File "separat... | open | 2023-07-08T04:21:23Z | 2023-07-08T04:21:23Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/655 | [] | ToBeAnUncle | 0 |
roboflow/supervision | pytorch | 1,720 | The character's ID changed after a brief loss | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
Hello, I am using supervision ByteTrack, in the video, the male ID is 2 and the female ID is 3. However, when the female continues to move forwa... | closed | 2024-12-09T11:06:03Z | 2024-12-09T11:12:54Z | https://github.com/roboflow/supervision/issues/1720 | [
"question"
] | DreamerYinYu | 1 |
sammchardy/python-binance | api | 604 | is this repo supports for coin futures ? | is this repo supports for corn futures? I don't see any implementation related to **/dapi/v1/** | open | 2020-10-13T10:47:34Z | 2020-10-23T18:24:27Z | https://github.com/sammchardy/python-binance/issues/604 | [] | keerthankumar | 1 |
huggingface/transformers | python | 36,774 | Please support GGUF format for UMT5EncoderModel | ### Feature request
```python
import torch
from transformers import UMT5EncoderModel
from huggingface_hub import hf_hub_download
path = hf_hub_download(
repo_id="city96/umt5-xxl-encoder-gguf", filename="umt5-xxl-encoder-Q8_0.gguf"
)
text_encoder = UMT5EncoderModel.from_pretrained(
"Wan-AI/Wan2.1-I2V-14B-480P... | open | 2025-03-17T19:32:17Z | 2025-03-19T07:24:19Z | https://github.com/huggingface/transformers/issues/36774 | [
"Feature request"
] | nitinmukesh | 2 |
ivy-llc/ivy | numpy | 28,118 | Fix Frontend Failing Test: torch - tensor.torch.Tensor.reshape_as | To-do List: https://github.com/unifyai/ivy/issues/27498 | closed | 2024-01-30T09:55:24Z | 2024-01-30T10:01:24Z | https://github.com/ivy-llc/ivy/issues/28118 | [
"Sub Task"
] | Aryan8912 | 1 |
labmlai/annotated_deep_learning_paper_implementations | deep-learning | 275 | How to Contribute to This Repository | Hello,
I’ve been learning various AI/ML-related algorithms recently, and my notes are quite similar to the content of your repository. Also this excellent work has helped me understand some of the algorithms, and I’d love to contribute by adding papers such as those on VAE, CLIP, BLIP, etc.
But before I start, I ... | open | 2024-09-15T08:51:24Z | 2025-02-17T20:28:55Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/275 | [] | terancejiang | 4 |
iperov/DeepFaceLab | machine-learning | 695 | Merge Quick96 produces frames with original dst face | Hi, Everything seems to have worked up to to step 6- train Quick96. I did 120k iterations. I try to run step 7 to merge, and it simply keeping the original dst video face. It doesn't use the src face on any of the frames. I get this line: "no faces found for xxxxx.png, copying without faces" for all the frames.
thanks | closed | 2020-04-04T21:42:58Z | 2023-09-21T04:25:07Z | https://github.com/iperov/DeepFaceLab/issues/695 | [] | glueydoob1 | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 20,209 | ImportError: cannot import name '_TORCHMETRICS_GREATER_EQUAL_1_0_0' from 'pytorch_lightning.utilities.imports' | ### Bug description
─────────────────────────────── Traceback (most recent call last) ────────────────────────────────╮
│ /usr/local/lib/python3.10/dist-packages/IPython/core/interactiveshell.py:3553 in run_code │
│ ... | open | 2024-08-17T18:48:44Z | 2024-08-17T18:48:58Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20209 | [
"bug",
"needs triage",
"ver: 2.2.x",
"ver: 2.4.x",
"ver: 2.3.x"
] | Horizon-369 | 0 |
kennethreitz/responder | flask | 392 | Project status - doc URL broken | Is this repo the official one now?
https://python-responder.org/ not responding | closed | 2019-09-25T00:50:51Z | 2019-09-27T21:55:12Z | https://github.com/kennethreitz/responder/issues/392 | [] | michela | 1 |
Lightning-AI/pytorch-lightning | machine-learning | 19,780 | Does `fabric.save()` save on rank 0? | ### Bug description
I'm trying to save a simple object using `fabric.save()` but always get the same error and I don't know if I'm missing something about the way checkpoints are saved and loaded or if it's a bug. The error is caused when saving the model, and the `fabric.barrier()` produces that the state.pkl file i... | closed | 2024-04-15T20:05:40Z | 2024-04-16T11:45:38Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19780 | [
"question",
"fabric"
] | LautaroEst | 3 |
vitalik/django-ninja | django | 391 | Using a schema outside of Ninja | Firstly, I hope your well and safe!
I may have overlooked something but I am wondering how I can use a schema outside of Ninja.
My use case is using channels and it could just be that it's late here but I couldn't get it to parse. Any ideas? | closed | 2022-03-15T20:15:01Z | 2022-03-21T08:18:20Z | https://github.com/vitalik/django-ninja/issues/391 | [] | bencleary | 2 |
Nemo2011/bilibili-api | api | 130 | 【建议】将原先 session.py 中的 Picture 类移动到其他位置 | 现在b站视频评论已经可以发图片了,我在自己视频底下发了个测试的图片。
用以下代码获取到图片列表,并可通过键值对应为 Picture 类对象。
```python
from bilibili_api import comment, sync, bvid2aid
from bilibili_api.session import Picture
async def main():
c = await comment.get_comments(bvid2aid("BV1vU4y1r7VD"), comment.CommentResourceType.VIDEO, 1)
for cmt in c["rep... | closed | 2023-01-04T10:02:02Z | 2023-01-08T11:38:43Z | https://github.com/Nemo2011/bilibili-api/issues/130 | [] | Drelf2018 | 11 |
huggingface/transformers | python | 36,574 | After tokenizers upgrade, the length of the token does not correspond to the length of the model | ### System Info
#36532
1. My version is 4.48.1, a relatively new version. After referring to the document and executing it, my reasoning is still abnormal and the result is the same as the original reasoning
`import torch
import transformers
from transformers import PegasusForConditionalGeneration
# 加载 Pegasus 模型
#m... | open | 2025-03-06T06:18:28Z | 2025-03-06T06:18:28Z | https://github.com/huggingface/transformers/issues/36574 | [
"bug"
] | CurtainRight | 0 |
lukas-blecher/LaTeX-OCR | pytorch | 27 | The problms of mismatched evaluation metrics | Hi, thank you for your excellent work. I reproduce your work with the config file named default.yaml, but cannot get the same result(BLEU=0.74). And I found the train loss increased after a few epoches. Can you give some adivice?
 | closed | 2023-10-18T10:21:25Z | 2023-10-18T10:30:03Z | https://github.com/schemathesis/schemathesis/issues/1848 | [] | RayLXing | 2 |
InstaPy/InstaPy | automation | 6,595 | No such file _followedPool.csv [Win] | ## Expected Behavior
I expect to b**e able to save and load** the followed pool into csv, but it's not working on windows
## Current Behavior
**Doesn't saves the followed pool list.**
```
ERROR [2022-04-26 23:27:00] [XXXXXX] Error occurred while generating a user list from the followed pool!
b"[Errno 2] No such... | open | 2022-04-27T04:20:55Z | 2022-04-27T04:22:45Z | https://github.com/InstaPy/InstaPy/issues/6595 | [] | thekorko | 0 |
home-assistant/core | python | 141,124 | ZHA doesn't connect to Sonoff Zigbee dongle. Baud rate problem? | ### The problem
Can't get ZHA to connect to usb-Itead_Sonoff_Zigbee_3.0_USB_Dongle_Plus_V2_9c414fdf5bd9ee118970b24c37b89984-if00-port0. I noticed in the logs it is trying to connect at 460800 baud. I don't know if that has anything to do with it.
### What version of Home Assistant Core has the issue?
core-2025.3.4
... | open | 2025-03-22T16:25:57Z | 2025-03-23T15:39:35Z | https://github.com/home-assistant/core/issues/141124 | [
"integration: zha"
] | ncp1113 | 4 |
sktime/sktime | scikit-learn | 7,489 | [ENH] improved methodology test coverage for `DirectReductionForecaster` and `RecursiveReductionForecaster` | We should increase methodology test coverage for `DirectReductionForecaster` and `RecursiveReductionForecaster` - that is, testing across cases that indeed expected outputs are produced.
My suggest would be to do this in simple cases where we know the result and can calculate it by hand.
Example 1: window length ... | closed | 2024-12-06T20:25:17Z | 2025-03-22T14:12:19Z | https://github.com/sktime/sktime/issues/7489 | [
"module:forecasting",
"enhancement"
] | fkiraly | 2 |
lexiforest/curl_cffi | web-scraping | 34 | 和sanic使用时会报错 | ```
Exception in callback <bound method AsyncCurl.process_data of <curl_cffi.aio.AsyncCurl object at 0x7f1738a64310>>
handle: <TimerHandle AsyncCurl.process_data created at /home/alex/workspace/parse_server/venv/lib/python3.8/site-packages/curl_cffi/aio.py:39>
source_traceback: Object created at (most recent call la... | closed | 2023-03-29T16:39:24Z | 2023-04-18T14:54:05Z | https://github.com/lexiforest/curl_cffi/issues/34 | [] | alexliyu7352 | 6 |
oegedijk/explainerdashboard | plotly | 114 | AttributeError: 'str' object has no attribute 'shape' | * After using running the following code, and I also showed the data structure of the input parameters in second cell:

* I get the following error:
 arg 1 must be a class | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | open | 2022-04-23T23:47:10Z | 2022-04-24T21:43:04Z | https://github.com/fastapi/sqlmodel/issues/312 | [
"question"
] | Maypher | 1 |
vitalik/django-ninja | rest-api | 444 | Automated related ForeignKey Models in ModelSchema | Can related models be handled automatically?
**Model**
```
class ExampleModel(models.Model):
relation = models.ForeignKey(SomeOtherModel, on_delete=models.PROTECT, related_name='example')
```
**ModelSchema**
```
class ExampleSchema(ModelSchema):
class Config:
model = models.ExampleModel
... | open | 2022-05-11T12:07:11Z | 2024-11-18T11:56:27Z | https://github.com/vitalik/django-ninja/issues/444 | [] | 21adrian1996 | 8 |
coqui-ai/TTS | pytorch | 3,308 | [Bug] torch `weight_norm` issue | ### Describe the bug
In some of the model files, we use the `weight_norm` function which is imported as follows
```python
from torch.nn.utils.parametrizations import weight_norm
```
which is giving me the error:
```
ImportError: cannot import name 'weight_norm' from 'torch.nn.utils.parametrizations' (/data/saiak... | closed | 2023-11-25T07:30:43Z | 2024-02-08T11:03:38Z | https://github.com/coqui-ai/TTS/issues/3308 | [
"bug"
] | saiakarsh193 | 2 |
mwaskom/seaborn | pandas | 3,383 | Doc: Inheritance informations not shown | As an example see the [docu about `FacetGrid`](https://seaborn.pydata.org/generated/seaborn.FacetGrid.html?highlight=grid#seaborn.FacetGrid). There you don't see wich class it is inherited.
It is `Grid`.
That infos should be added somehow. | closed | 2023-06-14T10:27:38Z | 2023-06-14T11:28:37Z | https://github.com/mwaskom/seaborn/issues/3383 | [] | buhtz | 2 |
Kludex/mangum | asyncio | 101 | Document an example project that uses WebSockets | Probably will use Serverless Framework for this in a separate repo. Not sure yet. | closed | 2020-05-04T08:18:20Z | 2020-06-28T01:52:35Z | https://github.com/Kludex/mangum/issues/101 | [
"docs",
"websockets"
] | jordaneremieff | 1 |
nolar/kopf | asyncio | 368 | [PR] Fix an issue with client connection errors raised from initial request | > <a href="https://github.com/nolar"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/544296?v=4"></a> A pull request by [nolar](https://github.com/nolar) at _2020-05-26 09:59:06+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/pull/368
>
# What do these changes... | closed | 2020-08-18T20:04:50Z | 2020-09-09T22:04:19Z | https://github.com/nolar/kopf/issues/368 | [
"bug",
"archive"
] | kopf-archiver[bot] | 1 |
d2l-ai/d2l-en | machine-learning | 1,701 | suggestion: rename train_ch3 to something more generic | The [train_ch3](https://github.com/d2l-ai/d2l-en/blob/master/d2l/torch.py#L326) function could be renamed to 'train_loop_v1' or something like that, since it is quite generic, and is used in several chapters (eg sec 4.6 on dropout).
I would also suggest removing the hard-coded assertions about train/test accuracy fr... | closed | 2021-03-29T20:13:53Z | 2021-03-31T17:44:43Z | https://github.com/d2l-ai/d2l-en/issues/1701 | [] | murphyk | 1 |
mars-project/mars | scikit-learn | 2,917 | [BUG] mars client timeout after cancel subtask in notebook | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
When running following code in nodebook cell and cancel in the middle and re-execute it again, mars will throw timeout error::
```
urldf = df... | open | 2022-04-13T12:40:15Z | 2022-04-27T07:11:19Z | https://github.com/mars-project/mars/issues/2917 | [] | chaokunyang | 0 |
microsoft/nni | tensorflow | 5,325 | All Trial jobs failed from MNIST example of nni | **Describe the issue**:
All trail failed on "nnictl create --config nni-2.10\examples\trials\mnist-pytorch\config_detailed.yml".
But I can run it properly without nni
(base) C:\Users\vanil>python nni-2.10\examples\trials\mnist-pytorch\mnist.py
C:\Users\vanil\anaconda3\lib\site-packages\nni\runtime\platform\standalo... | closed | 2023-01-30T01:58:07Z | 2023-02-08T22:03:44Z | https://github.com/microsoft/nni/issues/5325 | [] | yiqiaoc11 | 3 |
openapi-generators/openapi-python-client | rest-api | 958 | Invalid code generated for nullable discriminated union | **Describe the bug**
Given the schema below, using the generated code like:
```python
from test_client.models.demo import Demo
from test_client.models.a import A
Demo(example_union=A()).to_dict()
```
fails with:
```
Traceback (most recent call last):
File "/Users/eric/Desktop/test/test.py", line 4... | closed | 2024-02-09T18:53:43Z | 2024-02-20T01:11:40Z | https://github.com/openapi-generators/openapi-python-client/issues/958 | [] | codebutler | 0 |
httpie/cli | api | 894 | HTML docs: anchor links broken on mobile | In the HTTPie website's [documentation ](https://httpie.org/doc) there are numerous instances of links to other sections of the documentation that use a standard `<a href="#section-name">` anchor link. Unfortunately, on at least the Firefox 68.7.0 and Chrome 80 mobile browsers, the links don't jump to the appropriate ... | closed | 2020-04-10T08:30:38Z | 2020-04-13T15:19:12Z | https://github.com/httpie/cli/issues/894 | [] | shanepelletier | 1 |
airtai/faststream | asyncio | 1,159 | Eliminate use of pytest-retry and pytest-timeout in tests/brokers/confluent/test_parser.py | closed | 2024-01-22T07:05:41Z | 2024-02-05T08:44:00Z | https://github.com/airtai/faststream/issues/1159 | [] | davorrunje | 0 | |
microsoft/JARVIS | deep-learning | 19 | suggestion to requirement.txt install failure | pip install controlnet-aux==0.0.1
requirement.txt 前3项如果出现安装问题,可以下载后,copy到javis环境目录
第三个,直接使用上面的pip安装。 | closed | 2023-04-04T08:05:12Z | 2023-04-06T19:41:23Z | https://github.com/microsoft/JARVIS/issues/19 | [] | samqin123 | 2 |
davidsandberg/facenet | computer-vision | 538 | How limit RAM usage | I'm following the topic: Classifier training of inception resnet v1
so when i run the step 5 my RAM isn't enough , is possible limit the memory ram usage? There's any parameter for setup this? | closed | 2017-11-16T16:17:27Z | 2017-12-13T11:37:14Z | https://github.com/davidsandberg/facenet/issues/538 | [] | ramonamorim | 2 |
numpy/numpy | numpy | 28,042 | BUG: Race in PyArray_UpdateFlags under free threading | ### Describe the issue:
thread-sanitizer reports a race in PyArray_UpdateFlags under free threading.
It may take a few runs to reproduce this race.
### Reproduce the code example:
```python
import concurrent.futures
import functools
import threading
import numpy as np
num_threads = 8
def closu... | closed | 2024-12-19T17:30:27Z | 2025-01-10T21:37:58Z | https://github.com/numpy/numpy/issues/28042 | [
"00 - Bug",
"sprintable - C",
"39 - free-threading"
] | hawkinsp | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,084 | The Close button in the "Request support" window is not translated. | When any other than English language is set, the "Request support" window is translated except the Close button, which is always in English.
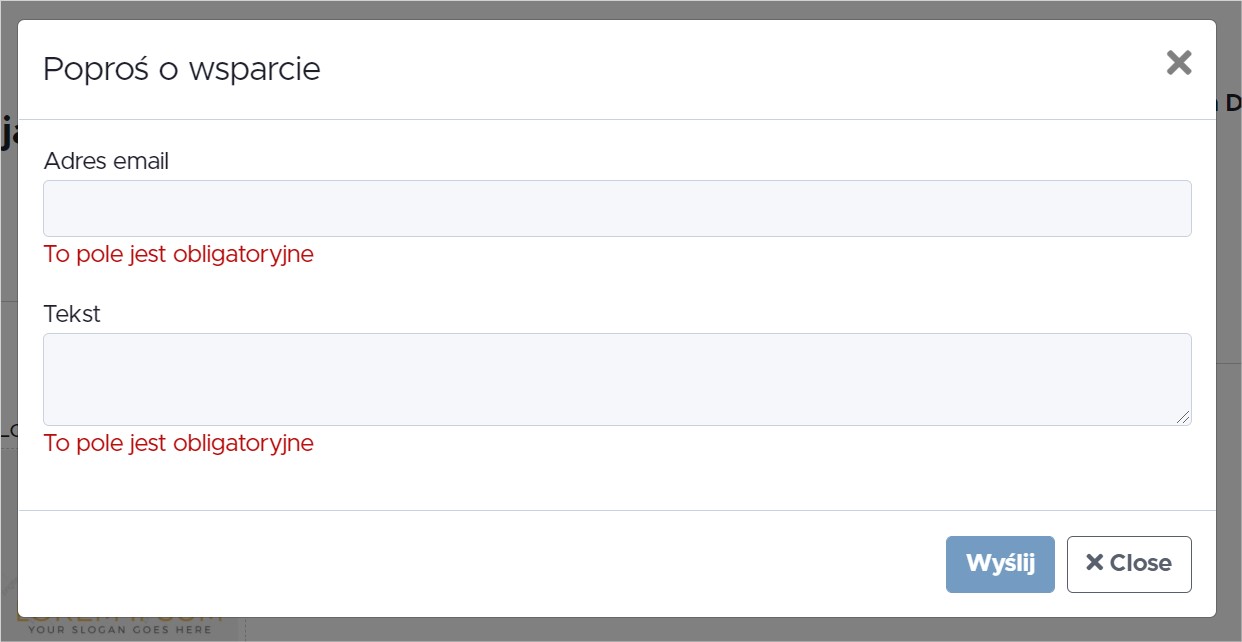
The "Request support" window is accessible via life... | closed | 2021-11-02T14:41:43Z | 2021-11-03T08:53:29Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3084 | [
"T: Bug",
"C: Client"
] | JackBRN | 1 |
microsoft/nni | tensorflow | 5,714 | Quantization with NAS | Does NNI support using NAS to quantify neural networks? To find the optimal bit width for each layer | open | 2023-11-23T04:50:21Z | 2023-11-23T04:50:21Z | https://github.com/microsoft/nni/issues/5714 | [] | lightup666 | 0 |
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 125 | 推理时base_model和lora_model精度不匹配报错 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[text-generation-webui... | closed | 2023-08-13T11:04:51Z | 2023-08-28T22:04:20Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/125 | [
"stale"
] | Celester | 2 |
NullArray/AutoSploit | automation | 1,310 | Unhandled Exception (15515d351) | Autosploit version: `4.0`
OS information: `Linux-5.10.0-kali9-amd64-x86_64-with-debian-kali-rolling`
Running context: `autosploit.py`
Error mesage: `can only concatenate list (not "str") to list`
Error traceback:
```
Traceback (most recent call):
File "/home/s/AutoSploit/AutoSploit/lib/term/terminal.py", line 719, in ... | open | 2022-01-24T16:48:18Z | 2022-01-24T16:48:18Z | https://github.com/NullArray/AutoSploit/issues/1310 | [] | AutosploitReporter | 0 |
lexiforest/curl_cffi | web-scraping | 144 | [BUG]使用headers自定义User Agent时,会自动转为小写。 | **Describe the bug**
你好,我不清楚这是不是需求导致的问题,我通过headers修改UserAgent时,curl_cffi会自动将我的User Agent转换为小写,导致我访问网站的时候被拦截。希望能够得到解决方案,谢谢。
curl_cffi/requests/headers.py:81行
```py
self._list = [
(
normalize_header_key(k, lower=False, encoding=encoding),
normalize_header... | closed | 2023-10-18T08:44:32Z | 2023-11-02T09:20:40Z | https://github.com/lexiforest/curl_cffi/issues/144 | [
"enhancement",
"good first issue"
] | AboutDark | 3 |
amdegroot/ssd.pytorch | computer-vision | 296 | when i training my dataset ,loss is very high. and don't converge.Please | open | 2019-03-04T10:59:56Z | 2019-03-05T04:35:03Z | https://github.com/amdegroot/ssd.pytorch/issues/296 | [] | tangdong1994 | 0 | |
nok/sklearn-porter | scikit-learn | 26 | Can't test accuracy in python and exported java code gives bad accuracy! | Hi, I started using your code to port a random forest estimator, first off I can't call the porter.integrity_score() function cause I get the following error:
```
Traceback (most recent call last):
File "C:/Python Project/Euler.py", line 63, in <module>
accuracy = porter.integrity_score(test_X)
File "C:\... | open | 2018-01-23T15:51:14Z | 2019-08-10T13:16:24Z | https://github.com/nok/sklearn-porter/issues/26 | [
"question",
"1.0.0"
] | Gizmomens | 13 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,178 | Warnings, exceptions and random crashes | I would really appreciate some help here I wanted to use this to help me with my Dyslexia, but it's too unreliable.
`
OS: Linux Mint 20.2 x86_64
Host: GA-78LMT-USB3 6.0
Kernel: 5.4.0-144-generic
Uptime: 5 hours, 29 mins
Packages: 2868 (dpkg), 7 (flatpak), 14 (snap)
Shell: bash 5.0.17
Resolu... | open | 2023-03-21T16:35:51Z | 2023-03-22T14:06:14Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1178 | [] | 007Srings | 1 |
gevent/gevent | asyncio | 2,086 | Question: How is the alignment of a thread and a hub in gevent? (Porting from asyncio) | * gevent version: gevent-24.11.2.dev0 (locally built from latest gevent sources, clang 17)
* Python version: 3.11.9, pyenv build
* Operating System: openSUSE LEAP 15.6, Linux kernel 6.4.0, x86_64
### Description:
If the question may not be too general, I wonder if one could ask if there may be any clarification... | closed | 2024-12-17T03:48:09Z | 2024-12-18T21:05:46Z | https://github.com/gevent/gevent/issues/2086 | [
"Type: Question"
] | spchamp | 1 |
arogozhnikov/einops | tensorflow | 55 | New pypi release (repeat not part of version installed by pip) | Is it possible to get out a new release of einops on pypi?
It seems like the version installable by pip doesn't include `repeat` (which is a very useful op). | closed | 2020-08-06T14:51:15Z | 2020-09-11T06:01:58Z | https://github.com/arogozhnikov/einops/issues/55 | [] | Froskekongen | 4 |
davidsandberg/facenet | computer-vision | 472 | OutOfRangeError (see above for traceback): FIFOQueue '_2_batch_join/fifo_queue' is closed and has insufficient elements (requested 1, current size 0) | **Notice:i need run grayscale picture**
**first:** i test my picture can be read and show

Secondly:i changed 'channels=3' to 'channels=1' .(All the places that involve channels=3)
meanwhile:i set ‘batc... | closed | 2017-09-28T08:20:08Z | 2017-11-29T12:15:05Z | https://github.com/davidsandberg/facenet/issues/472 | [] | rainy1798 | 1 |
graphql-python/graphene-django | django | 1,071 | Filtering based off of ManyToManyField | I'm trawling through the documentation and looking up what I know regarding Django Filters and Django, but there doesn't seem to be a way of filtering a `Node` object on a `ManyToMany` instance attribute ... e.g., RelatedName.name doesn't seem to be filterable within `filter_fields = {}` e.g.:
```
filter_fields = {... | open | 2020-11-30T13:12:44Z | 2020-11-30T13:12:44Z | https://github.com/graphql-python/graphene-django/issues/1071 | [
"✨enhancement"
] | asencis | 0 |
3b1b/manim | python | 1,976 | TypeError when running "manimgl example_scenes.py OpeningManimExample" | ### Describe the error
After a fresh install (macOS Ventura 13.1), the starting example does not work for me.
### Code and Error
**Code**:
```
manimgl example_scenes.py OpeningManimExample
```
**Error**:
```
ManimGL v1.6.1
[18:49:08] INFO Using the default configuration file, which you can modify in... | closed | 2023-01-29T02:50:47Z | 2023-02-03T22:54:54Z | https://github.com/3b1b/manim/issues/1976 | [] | bsubercaseaux | 2 |
scrapy/scrapy | python | 5,912 | Update Parsel output in docs/topics/selectors.rst | `docs/topics/selectors.rst` still contains `[<Selector xpath='//title/text()' data='Example website'>]` etc., it should be updated for the new Parsel version. Also I think it makes sense to modify it so that these examples are checked by tests like in docs/intro/tutorial.rst (probably an invisible code block loading do... | closed | 2023-04-27T10:06:56Z | 2023-05-04T13:30:35Z | https://github.com/scrapy/scrapy/issues/5912 | [
"enhancement",
"docs"
] | wRAR | 0 |
robinhood/faust | asyncio | 239 | Feature Pattern Matching / Join | Hi,
first of all a very interessting project of high quality. Good work !
One question concering planned features:
Are there any plans (if yes when? or do you have a roadmap or something similar) to implement some sort of complex event progressing. Like joining multiple streams based on a correlationid in a give t... | open | 2018-12-18T12:27:03Z | 2020-10-20T15:42:14Z | https://github.com/robinhood/faust/issues/239 | [
"Issue-Type: Feature Request"
] | FlorianKuckelkorn | 2 |
tqdm/tqdm | pandas | 639 | tensorflow/core/kernels/mkl_concat_op.cc:363] Check failed: dnn Concat Create_F32(&mkl_context.prim_concat, __null, N, &mkl_context.lt_inputs[0]) == E_SUCCESS (-1 vs. 0) | I am a freshman to the tensorflow, when I ran a deep nerualnetwork program, an error happen, I donot known, what can I do? Can you help me? | closed | 2018-11-11T13:36:54Z | 2018-11-14T01:35:26Z | https://github.com/tqdm/tqdm/issues/639 | [
"invalid ⛔"
] | yjyGo | 3 |
flairNLP/flair | nlp | 2,875 | Automatic mixed precision for TARS model | Hi can you please add apex=True as a parameter for training TARS also? I have seen it enabled for other models as described here: https://github.com/flairNLP/flair/pull/934#issuecomment-516775884
If such a feature already exists please provide appropriate documentation.
Thanks and regards,
Ujwal.
| closed | 2022-07-26T12:34:03Z | 2023-01-07T13:48:06Z | https://github.com/flairNLP/flair/issues/2875 | [
"wontfix"
] | Ujwal2910 | 1 |
Yorko/mlcourse.ai | pandas | 410 | topic 5 part 1 summation sign | [comment in ODS](https://opendatascience.slack.com/archives/C39147V60/p1541584422610100) | closed | 2018-11-07T10:57:25Z | 2018-11-10T16:18:10Z | https://github.com/Yorko/mlcourse.ai/issues/410 | [
"minor_fix"
] | Yorko | 1 |
Lightning-AI/pytorch-lightning | data-science | 19,801 | Construct objects from yaml by classmethod | ### Description & Motivation
Sometimes I want to construct an object from classmethods (e.g. `from_pretrained`) instead of `__init__`. But looks like currently lightning does not support it
### Pitch
```
model:
class_path: Model.from_pretrained
init_args:
...
```
### Alternatives
_No response_... | open | 2024-04-22T19:48:52Z | 2024-04-22T19:49:14Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19801 | [
"feature",
"needs triage"
] | Boltzmachine | 0 |
plotly/plotly.py | plotly | 4,298 | scatter plots with datetime x-axis and more than 1000 data points do not render all points | I believe this issue is similar to https://github.com/plotly/plotly_express/issues/145 .
I am using plotly 5.15.0 in jupyter lab 3.6.3.
My browsers (have tried firefox and chrome) support webgl.
When I render a scatter plot where the x-axis values are datetime objects,
if the plot has 1000 points, it render... | closed | 2023-07-27T15:19:11Z | 2024-02-23T16:06:52Z | https://github.com/plotly/plotly.py/issues/4298 | [] | cprice404 | 4 |
hankcs/HanLP | nlp | 572 | JDK1.6 portable包下报错 | ## 版本号
当前最新版本号是:hanlp-portable-1.3.4.jar
我使用的版本是:hanlp-portable-1.3.4.jar
## 我的问题
直接新建项目,加入引用hanlp-portable-1.3.4.jar,在jdk1.6环境下以下代码会报错
错误信息
```
2017-6-29 9:31:53 com.hankcs.hanlp.dictionary.TransformMatrixDictionary load
警告: 读取data/dictionary/CoreNatureDictionary.tr.txt失败java.lang.NullPointerException: I... | closed | 2017-06-29T01:39:13Z | 2018-04-10T08:51:33Z | https://github.com/hankcs/HanLP/issues/572 | [
"ignored"
] | AnyListen | 8 |
sigmavirus24/github3.py | rest-api | 527 | content-type: text/plain overwritten to None for GitHub.markdown() | When `raw=True` for `GitHub.markdown()`, `Content-Type` should be `text/plain`. However, `github3.models` overwrites the `Content-Type` on POST requests. I encountered this while completing the migration of `tests_github.py`.
### Unit Test assertion for markdown with raw=True
```
AssertionError: Expected call: post(... | closed | 2015-12-31T16:52:00Z | 2016-01-05T18:04:18Z | https://github.com/sigmavirus24/github3.py/issues/527 | [] | itsmemattchung | 4 |
taverntesting/tavern | pytest | 303 | Length of returned list was different than expected - expected 1 items, got 2 | Can anyone indicate me how can I match the first element of the array Categories -> "code: 1"
Actually, I got this error:
```
failed:
E - Value mismatch in body: Length of returned list was different than expected - expected 1 items, got 2 (expected["data"]["Categories"] = '[{'code': <tavern.util.l... | closed | 2019-03-08T20:01:09Z | 2019-04-20T17:26:47Z | https://github.com/taverntesting/tavern/issues/303 | [] | varayal | 2 |
pallets/flask | python | 4,466 | TaggedJSONSerializer doesn't round-trip naive datetimes | Since https://github.com/pallets/werkzeug/commit/265bad7, `parse_date` always returns an aware datetime. This can't be compared with naive datetimes, so will break a bunch of existing code.
```
>>> from flask.json.tag import TaggedJSONSerializer
>>> s = TaggedJSONSerializer()
>>> datetime.utcnow()
datetime.datet... | closed | 2022-02-25T02:01:22Z | 2022-03-12T00:04:45Z | https://github.com/pallets/flask/issues/4466 | [] | marksteward | 5 |
hzwer/ECCV2022-RIFE | computer-vision | 114 | Optical Flow Labels | Good evening!
Can you tell me how you generated the optical flow labels in the 100 sample subset of the vimeo-90k dataset?
I cannot reproduce these in the same way with [pytorch-liteflownet](https://github.com/sniklaus/pytorch-liteflownet)
This is the one I can generate with liteflownet
`python run.py --model... | closed | 2021-02-24T21:46:53Z | 2021-02-28T16:57:09Z | https://github.com/hzwer/ECCV2022-RIFE/issues/114 | [] | niklasAust | 2 |
dynaconf/dynaconf | flask | 768 | [RFC] Resolve depreciation warning for depreciated property kv | **Is your feature request related to a problem? Please describe.**
Yes, Currently we are hitting the depreciation warning in hvac 0.11 since the kv property is depreciated and adviced to use from `Client.secrets`
Clear Warning:
DeprecationWarning: Call to deprecated property 'kv'. This property will be removed in ... | closed | 2022-07-15T09:11:08Z | 2022-07-16T19:03:29Z | https://github.com/dynaconf/dynaconf/issues/768 | [
"Not a Bug",
"RFC"
] | jyejare | 0 |
lukas-blecher/LaTeX-OCR | pytorch | 42 | how to ocr low width latex image | 

If image width is too low, the ocr result will useless.
I have try to reduce patch_s... | closed | 2021-10-18T02:06:09Z | 2021-10-28T02:25:17Z | https://github.com/lukas-blecher/LaTeX-OCR/issues/42 | [] | daassh | 1 |
ets-labs/python-dependency-injector | flask | 551 | Dependencies are not injected when creating injections into a module using "providers.DependenciesContainer" | hello.
The following code tries to use SubContainer to perform dependency injection into a Service, but this code cannot be executed with the exception "exception: no description".
```python
from dependency_injector import containers, providers
from dependency_injector.wiring import Provide
class Service:
... | open | 2022-01-21T02:45:17Z | 2022-03-25T17:57:57Z | https://github.com/ets-labs/python-dependency-injector/issues/551 | [] | satodaiki | 1 |
sqlalchemy/alembic | sqlalchemy | 1,244 | v1.10.4 -> v1.11.0: pyright: "__setitem__" method not defined on type "Mapping[str, str]" | Hi Alembic and all,
There seems to be a type change (for better or for worse) that's being caught by `pyright` -- possibly others.
We have a migration `env.py` with a statement like `configuration["sqlalchemy.url"] = database` that's throwing the error when `pyright` runs. With v1.10.4, there's no such error. I'm... | closed | 2023-05-16T14:19:51Z | 2023-05-16T17:14:56Z | https://github.com/sqlalchemy/alembic/issues/1244 | [
"bug",
"pep 484"
] | gitpushdashf | 4 |
SciTools/cartopy | matplotlib | 2,339 | Cartopy 0.23 release | ### Description
Our last release was in August 2023, which means we haven't released since Python 3.12 has come out which I did not realize 😮
https://github.com/SciTools/cartopy/releases
I think we should aim for a release soon. Numpy 2.0 is coming out soon as well, so we will for sure need one after that. Sho... | closed | 2024-03-05T01:17:42Z | 2024-04-10T18:25:33Z | https://github.com/SciTools/cartopy/issues/2339 | [] | greglucas | 3 |
JaidedAI/EasyOCR | pytorch | 1,234 | Output of reader not shown in command window | Using this model through embedding it into C++ and the result of running the reader function does not show anything in the command line. This is how I run it:
```
PyRun_SimpleString("import easyocr");
PyRun_SimpleString("reader = easyocr.Reader(['ja'], gpu=True)");
PyRun_SimpleString("result = reader.readtext('./In... | open | 2024-03-25T17:58:13Z | 2024-03-25T17:58:13Z | https://github.com/JaidedAI/EasyOCR/issues/1234 | [] | danielzx2 | 0 |
feature-engine/feature_engine | scikit-learn | 845 | expand probe feature selection to derive importance with additional methods | At the moment it supports embedded methods and single feature models if i remember correctly. We could also rank features based on anova, correlation and mi and permutation. | open | 2025-02-03T15:42:57Z | 2025-02-20T07:37:13Z | https://github.com/feature-engine/feature_engine/issues/845 | [] | solegalli | 1 |
sinaptik-ai/pandas-ai | data-visualization | 721 | Inconsistentb datatype formation | ### System Info
Please share your system info with us.
OS version:Windows
Python version:3.11
The current version of pandasai being used:1.4
### 🐛 Describe the bug
using DataLake function the output type is in consistent, even after mentioning the output type the output comes as different one
example
dl.chat... | closed | 2023-11-02T06:59:10Z | 2023-11-15T10:23:36Z | https://github.com/sinaptik-ai/pandas-ai/issues/721 | [] | MuthusivamGS | 1 |
sinaptik-ai/pandas-ai | pandas | 1,392 | TypeError: e?.map is not a function | ### System Info
pandasai:2.2.15
python:3.12.4
masos
### 🐛 Describe the bug
```
> client@0.1.0 build
> next build
▲ Next.js 14.2.15
- Environments: .env
Creating an optimized production build ...
✓ Compiled successfully
Skipping linting
✓ Checking validity of types
✓ Collecting page data
... | closed | 2024-10-12T03:53:51Z | 2025-01-20T16:00:19Z | https://github.com/sinaptik-ai/pandas-ai/issues/1392 | [
"bug"
] | tangfei | 3 |
graphql-python/graphene | graphql | 1,400 | Python 3.10 support in v3 | * **What is the current behavior?**
Two tests fail on Python 3.10, with slightly different output on Python 3.10, that the tests do not expect.
```py
[ 101s] =================================== FAILURES ===================================
[ 101s] ___________________ test_objecttype_as_container_extra_args ___... | closed | 2022-01-11T03:33:20Z | 2022-06-14T14:57:23Z | https://github.com/graphql-python/graphene/issues/1400 | [
"🐛 bug"
] | jayvdb | 3 |
piskvorky/gensim | data-science | 3,493 | Search feature on website is broken | The title. | open | 2023-08-30T04:34:26Z | 2023-09-02T02:38:41Z | https://github.com/piskvorky/gensim/issues/3493 | [
"housekeeping"
] | mbarberry | 1 |
deepset-ai/haystack | machine-learning | 8,621 | Update materials to access `ChatMessage` `text` (instead of `content`) | part of https://github.com/deepset-ai/haystack/issues/8583
Since `content` will be removed in future in favor of `text` (and other types of content),
we are already transitioning to `text` to smooth the transition process.
```[tasklist]
### Materials to update
- [x] tutorials
- [x] cookbook (in review...)
- ... | closed | 2024-12-10T14:27:24Z | 2024-12-12T11:37:59Z | https://github.com/deepset-ai/haystack/issues/8621 | [] | anakin87 | 2 |
davidsandberg/facenet | tensorflow | 544 | A question about how to make a face verification? | Hello, now I have a new question: if I have an array of one people's face embeddings, how can I use these embeddings to make face verification?
I mean if I need do train these embeddings with a model and then give a new embeddings to verify, maybe there is a threshold, if the probability is greater than the threshol... | closed | 2017-11-22T10:47:47Z | 2017-11-23T08:05:16Z | https://github.com/davidsandberg/facenet/issues/544 | [] | xvdehao | 4 |
pyppeteer/pyppeteer | automation | 479 | is this supported by centOS? | Im asking this because playwright it's not supported by centOS | open | 2024-06-30T13:01:53Z | 2024-06-30T13:02:16Z | https://github.com/pyppeteer/pyppeteer/issues/479 | [] | juanfrilla | 0 |
iperov/DeepFaceLab | machine-learning | 5,262 | Graphic Card Recommendation | Hi there, I'm just beginner and want to upgrade my computer.
I was wondering if GeForce GC or Radeon would perform better, in the same price range I could get GeForce with 8/10 GB VRam or Radeon with 16GB VRam.
Any recommendations ?
| open | 2021-01-26T10:07:37Z | 2023-06-08T21:42:04Z | https://github.com/iperov/DeepFaceLab/issues/5262 | [] | Spoko-luzik | 2 |
coqui-ai/TTS | python | 3,235 | Slow deep voice after Vits training | ### Describe the bug
Hi,
I'm trying to train a model with my own voice. I recorded 150 samples with studio quality (44100Hz), which I reduced for training to 22050Hz. After 10000 epochs, I get a slow, deep voice far from the original voice.
What do I need to change to get a nearly original voice render?
Her... | closed | 2023-11-16T05:21:48Z | 2023-11-16T13:14:07Z | https://github.com/coqui-ai/TTS/issues/3235 | [
"bug"
] | o3web | 7 |
jschneier/django-storages | django | 621 | django-storage with dropbox breaks browser cache | I'm facing the same issue decribed [here](https://stackoverflow.com/questions/15668443/django-storage-with-s3-boto-break-browser-cache) but instead of amazon storage, I'm using the dropbox option. The current configuration works for a while with my cache configuration (cache_page), but after a while all the media files... | closed | 2018-10-24T15:33:05Z | 2018-10-25T13:56:26Z | https://github.com/jschneier/django-storages/issues/621 | [
"bug",
"dropbox"
] | JoabMendes | 2 |
scikit-optimize/scikit-optimize | scikit-learn | 1,007 | [QUESTION] Is existence of points provided by sampling method checked if already provided with x0/y0? | Hi,
I am sorry, I am not sure how to check this in the source code.
When using `forest_minimize`, I intend to use both options of:
- sampling the search space through Latin Hypercube
- providing known points by use of x0/y0 parameters
Because `func` to minimize is an expensive function to assess, it would be bes... | open | 2021-02-26T12:40:06Z | 2021-06-25T12:52:04Z | https://github.com/scikit-optimize/scikit-optimize/issues/1007 | [
"Question"
] | yohplala | 1 |
pytest-dev/pytest-django | pytest | 914 | docs(readme): update readme broken-links. | - line 58
- Manage test dependencies with pytest fixtures. <https://pytest.org/en/latest/fixture.html>
- line 62
- Make use of other `pytest plugins <https://pytest.org/en/latest/plugins.html>
Will submit a pull request for this. | closed | 2021-03-16T21:05:31Z | 2021-04-02T19:51:27Z | https://github.com/pytest-dev/pytest-django/issues/914 | [] | wearypossum4770 | 1 |
openapi-generators/openapi-python-client | fastapi | 773 | generated client doesn't support proxies | **Is your feature request related to a problem? Please describe.**
The generated client is nice - clean, ergonomic, and lean - but it doesn't provide the full ability to pass arguments through to `httpx`. In the case I care about right now, I need to pass a proxy configuration to it (and I need to do so in code, I c... | closed | 2023-06-27T02:09:34Z | 2023-07-23T19:38:28Z | https://github.com/openapi-generators/openapi-python-client/issues/773 | [
"✨ enhancement"
] | leifwalsh | 3 |
python-visualization/folium | data-visualization | 1,178 | Folium layer properties method | #### Please add a code sample or a nbviewer link, copy-pastable if possible
```python
mc = MarkerCluster(name='Stations')
for station in stationsgeo.iterrows():
popupstation = 'Name : {} ID : {}'.format(station[1]['englishNameStr'],station[1]['stationIDInt'])
mc.add_child(Marker([station[1]['latitudeFl... | closed | 2019-07-16T19:37:31Z | 2020-03-28T22:32:14Z | https://github.com/python-visualization/folium/issues/1178 | [] | itsgifnotjiff | 0 |
scrapy/scrapy | web-scraping | 6,188 | install scrapy for raspberry |

| closed | 2023-12-26T16:03:07Z | 2023-12-26T16:04:14Z | https://github.com/scrapy/scrapy/issues/6188 | [] | WangXinis | 0 |
dunossauro/fastapi-do-zero | pydantic | 126 | [MELHORIAS] Simplificação nas interações com o banco de dados via SQLAlchemy | A ideia principal dessa issue é tornar as relações com o banco de dados e sqlalchemy mais palatável para iniciantes.
### Problema da herança
Exemplo da aula 04:
```python
from sqlalchemy.orm import DeclarativeBase, Mapped, mapped_column
class Base(DeclarativeBase):
pass
class User(Base):
_... | closed | 2024-04-18T21:54:10Z | 2024-05-05T06:39:41Z | https://github.com/dunossauro/fastapi-do-zero/issues/126 | [] | dunossauro | 1 |
learning-at-home/hivemind | asyncio | 575 | How well does it scale? | Hello,
I am researching P2P solutions and am wondering how well Hivemind scales?
Thanks | open | 2023-07-20T01:37:29Z | 2023-07-20T20:50:52Z | https://github.com/learning-at-home/hivemind/issues/575 | [] | lonnietc | 2 |
jina-ai/serve | machine-learning | 5,622 | refactor: extract GrpcConnectionPool implementation into a package | Currently the `GrpcConnectionPool` class that handles gRPC channels and sending requests to targets in a single giant file. The goals of the refactor are:
- create a new networking package to extract inner classes to package inner classes.
- add unit tests to each inner class implementation.
- use correct synchorniz... | closed | 2023-01-25T08:33:30Z | 2023-02-01T12:26:01Z | https://github.com/jina-ai/serve/issues/5622 | [
"epic/gRPCTransport"
] | girishc13 | 1 |
davidsandberg/facenet | tensorflow | 1,172 | Get model graph in JSON | Hello, David! Your repo is really usefull in my neural networks' studying. I have done softmax training on my own dataset. But to use model with identical structure it's neccessary to get graph in json format. Used model is this: 20180402-114759 (trained on VGGFace). Please, help me to get it or show the way to it... | open | 2020-09-18T10:11:57Z | 2021-10-26T20:05:28Z | https://github.com/davidsandberg/facenet/issues/1172 | [] | Julia2505 | 1 |
vitalik/django-ninja | pydantic | 320 | Docs - file uploads | since this question is popped up very often -
add here (/tutorial/file-params/)
-1) an example how to store uploaded file to a model
-2) example File with form data(schema) | open | 2022-01-10T10:33:07Z | 2022-07-02T15:28:37Z | https://github.com/vitalik/django-ninja/issues/320 | [
"documentation"
] | vitalik | 0 |
babysor/MockingBird | deep-learning | 686 | 在作者模型上训练后再次训练报错 | 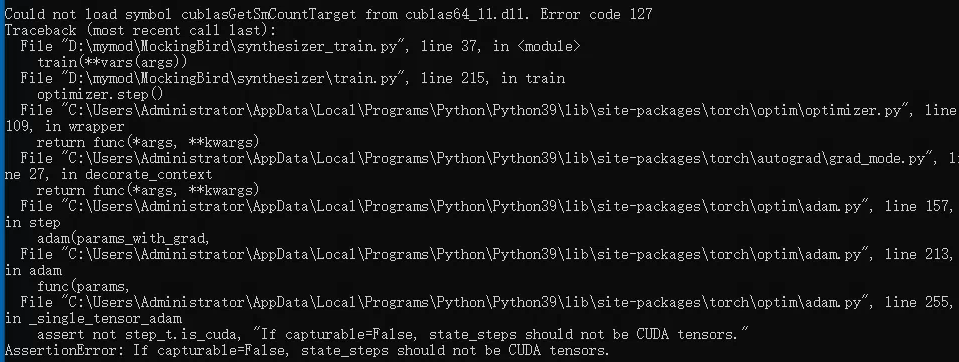
从cuda11.6降到cuda11.3还是不可以
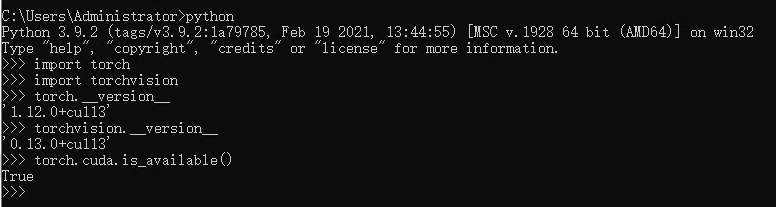
| open | 2022-07-28T23:12:53Z | 2022-07-29T04:32:49Z | https://github.com/babysor/MockingBird/issues/686 | [] | yunqi777 | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.