
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
serengil/deepface | machine-learning | 924 | Unable to find good face match with deepface and Annoy | Hi
I am using following code from Serengil's tutorial (you tube), for finding best face match. The embeddings are from deepface and Annoy's ANNS based search is used for find best matching face.
This code does not give good matching face, as was hightlighted in Serengil's you tube video.
Looking for help about... | closed | 2023-12-20T08:22:34Z | 2023-12-20T08:46:59Z | https://github.com/serengil/deepface/issues/924 | [
"question"
] | dumbogeorge | 2 |
mwaskom/seaborn | matplotlib | 2,821 | Calling `sns.heatmap()` changes matplotlib rcParams | See the following example
```python
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
mpl.rcParams["figure.dpi"] = 120
mpl.rcParams["figure.facecolor"] = "white"
mpl.rcParams["figure.figsize"] = (9, 6)
data = sns.load_dataset("iris")
print(mpl.rcParams["figure.dpi"])
p... | closed | 2022-05-25T19:16:45Z | 2022-05-27T11:13:29Z | https://github.com/mwaskom/seaborn/issues/2821 | [] | tomicapretto | 2 |
strawberry-graphql/strawberry | fastapi | 3,790 | Incorrect typing for the `type` decorator |
## Describe the Bug
The type function is decorated with
```
@dataclass_transform(
order_default=True, kw_only_default=True, field_specifiers=(field, StrawberryField)
)
```
Therefore mypy treats classes decorated with type as being dataclasses with ordering functions.
In particular, defining `__gt__` on such a ... | open | 2025-02-21T11:26:35Z | 2025-02-21T11:28:42Z | https://github.com/strawberry-graphql/strawberry/issues/3790 | [
"bug"
] | Corentin-Bravo | 0 |
521xueweihan/HelloGitHub | python | 2,078 | 【开源自荐】类似 rz / sz,支持 tmux 的文件传输工具 trzsz ( trz / tsz ) | ## 项目推荐
- 项目地址:https://github.com/trzsz/trzsz
- 类别:Python
- 项目后续更新计划:
* 支持 mac 以外的其他平台(例如 windows),要 SecureCRT、Xshell 等像 iTerm2 一样支持 [coprocesses](https://iterm2.com/documentation-coprocesses.html) 才能搞。
* 将进度条改成模态框,防止在文件传输过程中误触键盘导致传输失败,需要 iTerm2 支持显示 [mac 进度条](https://developer.apple.com/library/archive/do... | closed | 2022-01-16T08:50:39Z | 2022-01-28T01:21:25Z | https://github.com/521xueweihan/HelloGitHub/issues/2078 | [
"已发布",
"Python 项目"
] | lonnywong | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 1,014 | Using your own models with yellow brick | **Describe the issue**
If you create your own clustering algorithm that follows the sklearn pattern, is there anything I need to know to allow users to use the additional clustering methods to extend this package to my own sklearn like models? | closed | 2020-01-29T22:48:21Z | 2020-02-26T14:28:46Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1014 | [
"type: question"
] | achapkowski | 3 |
fa0311/TwitterInternalAPIDocument | graphql | 660 | Any idea how long each guest token is valid for? | I am using endpoints which can be viewed in incognito mode. I see each ip has a 95 request limit for a 13 minute window. But any idea how long a guest token remains valid before it starts giving 403?
I am caching the guest token in order to minimize requests but in production ended up getting 403 errors after sometime... | open | 2024-10-14T04:49:27Z | 2024-10-14T07:53:56Z | https://github.com/fa0311/TwitterInternalAPIDocument/issues/660 | [] | abhranil26 | 3 |
httpie/cli | python | 1,402 | can httpie support JSON5 (JSON for Humans) input? | ## Checklist
- [x] I've searched for similar feature requests.
---
## Enhancement request
trying to call httpie with post body including raw valid js objects,
http <url> metrics:='[{name: "activeUsers"}]'
got error:
'metrics:=[{name: "activeUsers"}]': Expecting property name enclosed in dou... | open | 2022-05-16T07:35:20Z | 2022-05-16T07:52:38Z | https://github.com/httpie/cli/issues/1402 | [
"enhancement",
"needs product design"
] | tx0c | 1 |
trevorstephens/gplearn | scikit-learn | 32 | Include logic regression | New estimator, needs much more research to see how/if it fits into `gplearn`'s API. No milestone yet. [Citation](http://kooperberg.fhcrc.org/logic/documents/logic-regression.pdf)
Add boolean/logical functions, conditional functions and potential to input a binary input dataset | closed | 2017-04-27T10:29:19Z | 2020-02-13T11:32:51Z | https://github.com/trevorstephens/gplearn/issues/32 | [
"enhancement"
] | trevorstephens | 3 |
django-oscar/django-oscar | django | 3,921 | Unable to access oscar on https://example.com:8443/oscar | ### Issue Summary
I followed [this guide](https://worldoscar.org/knowledge-base/oscar-19-installation/?epkb_post_type_1=oscar-19-installation) and I managed to install the most recent version [oscar_emr19-66~1881.deb](https://sourceforge.net/projects/oscarmcmaster/files/Oscar%20Debian%2BUbuntu%20deb%20Package/oscar_... | closed | 2022-05-01T16:35:58Z | 2022-05-02T04:03:02Z | https://github.com/django-oscar/django-oscar/issues/3921 | [] | jessicana | 1 |
dgtlmoon/changedetection.io | web-scraping | 2,174 | [feature] Sort tags / groups by alphabet | **Version and OS**
0.45.14 on Linux/Docker
**Is your feature request related to a problem? Please describe.**
To keep an overview about my watch jobs, I added tags / groups on them. In the meantime I work with 14 tags, and they are sorted by date created.
**Describe the solution you'd like**
It would be helpfu... | closed | 2024-02-10T08:21:00Z | 2024-03-10T10:10:57Z | https://github.com/dgtlmoon/changedetection.io/issues/2174 | [
"enhancement"
] | plangin | 3 |
deezer/spleeter | deep-learning | 186 | por favor su ayuda me sale esto |

| closed | 2019-12-16T22:48:17Z | 2019-12-18T14:18:10Z | https://github.com/deezer/spleeter/issues/186 | [
"bug",
"invalid"
] | excel77 | 1 |
predict-idlab/plotly-resampler | data-visualization | 60 | `FigureResampler` replace not working as it should when using a `go.Figure` | 
| closed | 2022-05-16T07:44:20Z | 2022-05-16T15:34:17Z | https://github.com/predict-idlab/plotly-resampler/issues/60 | [
"bug"
] | jonasvdd | 1 |
robotframework/robotframework | automation | 4,803 | Async support to dynamic and hybrid library APIs | For our Lib we are using framework that is async and we have to await for results.
our lib works similar to Remote Lib to get the keywords and arguments but communication is done using asyncio.
with RF 6.1 run_keyword can be made async but functions for getting keywords/arguments/etc. can't.
as a workaround I'm ... | closed | 2023-06-22T09:26:53Z | 2023-11-27T12:28:17Z | https://github.com/robotframework/robotframework/issues/4803 | [
"enhancement",
"priority: high",
"alpha 2",
"acknowledge"
] | WisniewskiP | 9 |
autogluon/autogluon | scikit-learn | 4,900 | [tabular] Add `num_cpus`, `num_gpus` to `predictor.predict` | Related: #4871
We should add ways for user to control num_cpus and num_gpus during model inference.
This also ties into adding parallel inference support. | open | 2025-02-17T21:05:37Z | 2025-02-17T21:05:37Z | https://github.com/autogluon/autogluon/issues/4900 | [
"enhancement",
"module: tabular"
] | Innixma | 0 |
plotly/dash | data-visualization | 2,765 | When moving the cursor, it will sometimes get stuck | **Describe your context**
Please provide us your environment, so we can easily reproduce the issue.¨
16 core 32 Thread dual CPU server, view selected to show all cores
Running in Docker on Ubuntu Server
- if frontend related, tell us your Browser, Version and OS
- OS: Windows
- Browser Chrome
- ... | closed | 2024-02-18T19:45:58Z | 2024-05-31T20:09:58Z | https://github.com/plotly/dash/issues/2765 | [
"bug",
"sev-2"
] | Spillebulle | 1 |
deeppavlov/DeepPavlov | nlp | 1,008 | Readme for /examples | Please add readme with short description of provided examples in
https://github.com/deepmipt/DeepPavlov/tree/master/examples
Please also add to the readme links to other resources to learn DeepPavlov -
https://github.com/deepmipt/dp_tutorials
https://github.com/deepmipt/dp_notebooks | closed | 2019-09-21T10:24:24Z | 2019-09-26T13:54:55Z | https://github.com/deeppavlov/DeepPavlov/issues/1008 | [] | DeepPavlovAdmin | 1 |
vitalik/django-ninja | rest-api | 818 | How to create Generic Schema for openapi? | ### Discussed in https://github.com/vitalik/django-ninja/discussions/817
<div type='discussions-op-text'>
<sup>Originally posted by **suuperhu** August 8, 2023</sup>
**I have the following piece of code, but there is a problem with openapi page, how should I solve it?**
_Code environment :
ubuntu 20.04
pyt... | closed | 2023-08-08T05:04:16Z | 2023-08-08T06:46:52Z | https://github.com/vitalik/django-ninja/issues/818 | [] | hushoujier | 1 |
huggingface/datasets | nlp | 7,041 | `sort` after `filter` unreasonably slow | ### Describe the bug
as the tittle says ...
### Steps to reproduce the bug
`sort` seems to be normal.
```python
from datasets import Dataset
import random
nums = [{"k":random.choice(range(0,1000))} for _ in range(100000)]
ds = Dataset.from_list(nums)
print("start sort")
ds = ds.sort("k")
print("f... | open | 2024-07-12T03:29:27Z | 2024-07-22T13:55:17Z | https://github.com/huggingface/datasets/issues/7041 | [] | Tobin-rgb | 1 |
piskvorky/gensim | machine-learning | 2,873 | Further focus/slim keyedvectors.py module | Pre-#2698, `keyedvectors.py` was 2500+ lines, including functionality over-specific to other models, & redundant classes. Post-#2698, with some added generic functionality, it's still over 1800 lines.
It should shed some other grab-bag utility functions that have accumulated, & don't logically fit inside the `Keyed... | open | 2020-07-06T20:00:39Z | 2021-03-09T07:59:52Z | https://github.com/piskvorky/gensim/issues/2873 | [] | gojomo | 8 |
3b1b/manim | python | 1,442 | Error installing manim and running a test program | ### Describe the error
<!-- A clear and concise description of what you want to make. -->
I installed ffmpeg from the APT package manager and PyOpenGL from pip3 in a virtual environment. Then, when I tried to install manim in the same virtual environment it gave the following error
However, in the end, it said tha... | open | 2021-03-21T09:19:49Z | 2022-06-13T16:52:39Z | https://github.com/3b1b/manim/issues/1442 | [] | kkin1995 | 6 |
tensorlayer/TensorLayer | tensorflow | 680 | Failed: TensorLayer (bfffb588) | *Sent by Read the Docs (readthedocs@readthedocs.org). Created by [fire](https://fire.fundersclub.com/).*
---
| TensorLayer build #7291120
---
| 
---
| Build Failed for TensorLayer (latest)
---
You can find out more about this failure here:
... | closed | 2018-06-04T14:24:24Z | 2018-06-04T14:56:34Z | https://github.com/tensorlayer/TensorLayer/issues/680 | [] | fire-bot | 0 |
RayVentura/ShortGPT | automation | 70 | 🐛 [Bug]: | ### What happened?
Step 9 _prepareBackgroundAssets
{'voiceover_audio_url': '.editing_assets/reddit_shorts_assets/b32f7d0a87944aa99dd1b826/audio_voice.wav', 'video_duration': None, 'background_video_url': 'https://rr3---sn-npoe7nez.googlevideo.com/videoplayback?expire=1690975098&ei=GufJZN7mJaei9fwPveCisA8&ip=194.156.1... | open | 2023-08-02T05:37:02Z | 2023-08-02T05:37:02Z | https://github.com/RayVentura/ShortGPT/issues/70 | [
"bug"
] | rpp-Little-pig | 0 |
raphaelvallat/pingouin | pandas | 209 | pairwise_nonparametric() | Hi, I was looking for non-parametric pairwise tests and only found the parameter `parametric=False` of the `pairwise_ttests()` after some time from the flowcharts. This seems confusing to me. I'd suggest adding function `pairwise_nonparametric()` for this purpose mainly because of discoverability and clarity. Also pls... | closed | 2021-11-10T10:45:33Z | 2022-03-12T23:51:51Z | https://github.com/raphaelvallat/pingouin/issues/209 | [
"docs/testing :book:",
"IMPORTANT❗"
] | michalkahle | 5 |
ymcui/Chinese-BERT-wwm | nlp | 146 | RoBERTa-wwm-ext-large能不能把mlm权重补充上? | 现在很多研究都表明MLM其实也是一个相当有用的语言模型,并不是纯粹的只有预训练的左右了,所以能不能麻烦一下把MLM的权重补上?
而且我最不能理解的就是,要是扔掉MLM的权重也就算了,为啥还要随机初始化一个放在那里,这不是容易误导人么? | closed | 2020-09-21T06:22:18Z | 2020-09-21T07:01:24Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/146 | [
"wontfix"
] | bojone | 1 |
newpanjing/simpleui | django | 43 | 左侧栏收起后无全屏缩小 | **bug描述**
简单的描述下遇到的bug:
**重现步骤**
1.
2.
3.
**环境**
1.操作系统:
2.python版本:
3.django版本:
4.simpleui版本:
**其他描述**
| closed | 2019-05-21T01:38:45Z | 2019-05-21T02:30:57Z | https://github.com/newpanjing/simpleui/issues/43 | [
"bug"
] | Qianzujin | 1 |
tqdm/tqdm | pandas | 749 | Logging from separate threads pushes tqdm bar up | Versions I'm using:
```
tqdm = 4.31.1
python = 3.7.3
OS: Ubuntu 19.04 (Linux: 5.0)
```
If we're processing an list of elements with a multiprocessing function, say applying `f` to the list with `pool.imap_unordered`, and log a message from within `f`, then the progress bar will be pushed up for each message lo... | open | 2019-05-23T12:51:57Z | 2019-06-17T16:43:02Z | https://github.com/tqdm/tqdm/issues/749 | [
"p3-enhancement 🔥",
"help wanted 🙏",
"need-feedback 📢",
"p2-bug-warning ⚠",
"synchronisation ⇶"
] | tupini07 | 1 |
huggingface/transformers | nlp | 36,217 | Albert does not use SDPA's Flash Attention since attention mask is always created | ### System Info
NA
### Who can help?
@ArthurZucker
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
https://github.... | closed | 2025-02-15T15:40:58Z | 2025-02-16T02:36:30Z | https://github.com/huggingface/transformers/issues/36217 | [
"bug"
] | gau-nernst | 1 |
plotly/dash-component-boilerplate | dash | 62 | capitalize component name | hi, while creating a new project it asks for component_name, if i give a name that starts with lowercase, it creates react component with lowercase, which is wrong from react component standards. React component must starts with uppercase. | open | 2019-03-13T01:14:51Z | 2019-03-13T01:14:51Z | https://github.com/plotly/dash-component-boilerplate/issues/62 | [] | rajeevmaster | 0 |
igorbenav/FastAPI-boilerplate | sqlalchemy | 138 | DB session from a worker function? | Hey, Im trying for 2 days now to make this work,
How do I pass the session from an endpoint to the background worker function?
My idea is to insert a record in the db from my endpoint then process it from the background function.
*Edit*
I made it work by creating another function with contextmanager
... | closed | 2024-05-21T13:16:39Z | 2024-06-02T14:05:30Z | https://github.com/igorbenav/FastAPI-boilerplate/issues/138 | [
"documentation",
"enhancement"
] | kaStoyanov | 4 |
ultralytics/yolov5 | machine-learning | 13,519 | Detection with Torch Hub Failing | ### Search before asking
- [x] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I have ML project on Python 3.7.8, it was working fine, but recently I am getting error w... | closed | 2025-02-25T04:56:37Z | 2025-02-27T23:58:53Z | https://github.com/ultralytics/yolov5/issues/13519 | [
"question",
"dependencies",
"detect"
] | llavkush | 4 |
WeblateOrg/weblate | django | 14,232 | Expose 'add comment' API endpoint | ### Describe the problem
We're migrating from another platform to Weblate, and would like to take along our comments. It's currently not possible to do this easily/programmatically. Consequently, we're using valuable contributor feedback on our strings.
### Describe the solution you would like
We'd like to have an A... | open | 2025-03-16T11:51:08Z | 2025-03-17T18:52:56Z | https://github.com/WeblateOrg/weblate/issues/14232 | [
"enhancement",
"undecided",
"Area: API"
] | keunes | 2 |
graphql-python/graphene-django | graphql | 1,116 | graphene-neo4j | I will be glad if you update graphene-neo4j with Django 3. | closed | 2021-02-15T19:17:27Z | 2021-02-16T06:12:03Z | https://github.com/graphql-python/graphene-django/issues/1116 | [
"🐛bug"
] | MajidHeydari | 1 |
3b1b/manim | python | 2,097 | Example Gallery Bug when Rendering High Quality | ### Describe the bug
For the Gallery Example with https://docs.manim.community/en/stable/examples.html#pointwithtrace
**Code**:
```py
from manim import *
class PointWithTrace(Scene):
def construct(self):
path = VMobject()
dot = Dot()
path.set_points_as_corners([dot.get_center(),... | open | 2024-01-29T04:51:34Z | 2024-01-29T04:53:52Z | https://github.com/3b1b/manim/issues/2097 | [
"bug"
] | wmstack | 1 |
ivy-llc/ivy | pytorch | 28,339 | Fix Frontend Failing Test: paddle - math.tensorflow.math.argmin | To-do List: https://github.com/unifyai/ivy/issues/27500 | closed | 2024-02-20T08:12:51Z | 2024-02-20T10:21:20Z | https://github.com/ivy-llc/ivy/issues/28339 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
gevent/gevent | asyncio | 1,962 | ImportError: cannot import name 'match_hostname' from 'ssl' (/usr/lib/python3.12/ssl.py) | * gevent version: 22.10.2 - fedora package
* Python version: 3.12.0b3
* Operating System: Fedora rawhide
### Description:
While trying to build the sphinx documentation for the x2go python module:
```
+ make -C docs SPHINXBUILD=/usr/bin/sphinx-build-3 html
make: Entering directory '/builddir/build/BUILD/p... | closed | 2023-06-26T23:33:53Z | 2023-07-10T15:30:56Z | https://github.com/gevent/gevent/issues/1962 | [] | opoplawski | 1 |
sinaptik-ai/pandas-ai | data-science | 686 | TypeError: 'NoneType' object is not callable . Retrying Unfortunately, I was not able to answer your question, because of the following error: No code found in the response | #### Error:-/usr/local/lib/python3.10/dist-packages/pandasai/llm/starcoder.py:28: UserWarning: Starcoder is deprecated and will be removed in a future release.
Please use langchain.llms.HuggingFaceHub instead, although please be
aware that it may perform poorly.
warnings.warn... | closed | 2023-10-25T12:07:05Z | 2024-06-01T00:20:12Z | https://github.com/sinaptik-ai/pandas-ai/issues/686 | [] | jaysinhpadhiyar | 1 |
matplotlib/matplotlib | data-science | 29,489 | [Bug]: Systematic test failures with ubuntu-22.04-arm pipeline | ### Bug summary
```
__________________________ test_errorbar_limits[svg] ___________________________
[gw2] linux -- Python 3.12.8 /opt/hostedtoolcache/Python/3.12.8/arm64/bin/python
args = ()
kwds = {'extension': 'svg', 'request': <FixtureRequest for <Function test_errorbar_limits[svg]>>}
@wraps(func)
def in... | closed | 2025-01-20T11:12:23Z | 2025-01-21T23:05:49Z | https://github.com/matplotlib/matplotlib/issues/29489 | [
"CI: testing"
] | timhoffm | 3 |
Gerapy/Gerapy | django | 74 | 在用admin进行user和group添加和修改时会出现TypeError | 前端显示:

后台报错:

主要原因是,在/server/core/TransformMiddleware中对所有request格式进行了转换,所以django自带处理方法中会出现类型错误。我... | open | 2018-07-26T04:37:27Z | 2018-07-26T04:37:27Z | https://github.com/Gerapy/Gerapy/issues/74 | [] | Fesbruk | 0 |
MilesCranmer/PySR | scikit-learn | 2 | [Question] Pure Julia package | Hi, Is there a plan to have pure Julia API and expose it Julia package? | closed | 2020-09-24T22:42:20Z | 2021-01-18T09:24:06Z | https://github.com/MilesCranmer/PySR/issues/2 | [
"implemented"
] | sheevy | 13 |
hbldh/bleak | asyncio | 1,419 | Qt timer can't stop bleak's notify. | * bleak version:0.20.0
* Python version: 3.11.4
* Operating System: windows 11
### Description
I integrated Bleak into a Qt application. I found that when using Qtimer to close the notification, there will be a problem and notify cannot be stopped.
### What I Did
My code
```python
class MainWindow(QMain... | closed | 2023-09-15T01:26:02Z | 2023-09-15T01:48:48Z | https://github.com/hbldh/bleak/issues/1419 | [] | ChienHao-Hung | 0 |
microsoft/nni | pytorch | 5,019 | where is scripts.compression_mnist_model | **Describe the issue**:
When I tried to run the demo from the doc here https://nni.readthedocs.io/en/stable/tutorials/quantization_speedup.html, I could not found `scripts.compression_mnist_model` in
`from scripts.compression_mnist_model import TorchModel, trainer, evaluator, device, test_trt`
**Environment**:
... | closed | 2022-07-25T23:37:38Z | 2022-11-23T03:09:31Z | https://github.com/microsoft/nni/issues/5019 | [
"user raised",
"documentation",
"support",
"ModelSpeedup",
"v2.9.1"
] | james20141606 | 4 |
neuml/txtai | nlp | 544 | Add support for custom scoring instances | Add support for custom scoring instances.
See implementations in ANNFactory, DatabaseFactory and GraphFactory. | closed | 2023-09-06T21:21:06Z | 2023-09-06T21:25:06Z | https://github.com/neuml/txtai/issues/544 | [] | davidmezzetti | 0 |
LAION-AI/Open-Assistant | python | 3,630 | Add Persian QA Dataset | After fine-tuning on [Farsi data](https://github.com/LAION-AI/Open-Assistant/pull/3629), I think adding QA Datasets like [this one](https://github.com/sajjjadayobi/PersianQA) can be helpful.
If the teams want to add support for Farsi, I will be glad to contribute and add this dataset in the standard format. | closed | 2023-08-02T10:30:53Z | 2023-08-03T19:24:31Z | https://github.com/LAION-AI/Open-Assistant/issues/3630 | [] | pourmand1376 | 0 |
adbar/trafilatura | web-scraping | 712 | setup: use `pyproject.toml` file | This is now standard for Python 3.8+ versions. | closed | 2024-10-07T10:33:18Z | 2024-10-10T11:12:05Z | https://github.com/adbar/trafilatura/issues/712 | [
"maintenance"
] | adbar | 0 |
Ehco1996/django-sspanel | django | 925 | 有一个请求不知道是什么 找不到,404 | **问题的描述**
有一个请求不知道是什么 找不到,404
**项目的配置文件**
**如何复现**
**相关截图/log**

**其他信息**
| closed | 2024-03-06T08:39:24Z | 2024-03-10T00:20:20Z | https://github.com/Ehco1996/django-sspanel/issues/925 | [] | wangxingsheng | 1 |
tableau/server-client-python | rest-api | 861 | Extracting "Who has seen the view"? | Hi,
I looked through the documentation, maybe it's there but i couldn't find it.
Is there a way to extract the breakdown of "Who has seen this view" for each view?
Thanks in advance!
| open | 2021-07-12T08:23:19Z | 2021-11-08T06:13:15Z | https://github.com/tableau/server-client-python/issues/861 | [
"enhancement",
"Server-Side Enhancement"
] | Zestsx | 2 |
jumpserver/jumpserver | django | 14,217 | [Bug] 配置LDAP会自动还原 | ### 产品版本
v4.1.0
### 版本类型
- [X] 社区版
- [ ] 企业版
- [ ] 企业试用版
### 安装方式
- [ ] 在线安装 (一键命令安装)
- [ ] 离线包安装
- [ ] All-in-One
- [ ] 1Panel
- [X] Kubernetes
- [ ] 源码安装
### 环境信息
helm 包安装
### 🐛 缺陷描述
admin账号登陆后,配置ldap登陆。配置信息填写完毕、开启ldap功能,选择提交。测试链接正常,可以获取到用户数;测试ldap用户登陆提示Authentication failed (before login check failed): no... | closed | 2024-09-23T06:45:24Z | 2024-09-26T10:01:03Z | https://github.com/jumpserver/jumpserver/issues/14217 | [
"🐛 Bug"
] | yulinor | 6 |
strawberry-graphql/strawberry | asyncio | 3,430 | Schema basics docs | https://strawberry.rocks/docs/general/schema-basics returns 500 error | closed | 2024-04-02T08:58:46Z | 2025-03-20T15:56:39Z | https://github.com/strawberry-graphql/strawberry/issues/3430 | [
"bug"
] | lorddaedra | 2 |
dmlc/gluon-cv | computer-vision | 1,582 | Top-1 accuracy on UCF101 dataset is bad? | I trained `i3d_nl5_resnet50_v1` on `UCF101` datasets with `Kinetics400` pretrained, the acc: `top-1=85.2%, top-5=95.4%`.
Params: `clip_len=32, input=224x224, lr=0.01, batch_size=8`.
It seems not so good, what is the possible reason? | closed | 2021-01-07T03:19:58Z | 2021-01-08T02:41:31Z | https://github.com/dmlc/gluon-cv/issues/1582 | [] | Tramac | 3 |
HIT-SCIR/ltp | nlp | 261 | 编译完成后在lib目录下并看不到segmentor_jni.so呀? | ltp编译完成后有个lib目录里面有很多so文件, 但是并看不到segmentor_jni.so等ltp4j使用的so?
这是为什么? 是因为ltp4j太久没人维护了吗? | closed | 2017-11-11T16:07:55Z | 2018-01-23T12:56:06Z | https://github.com/HIT-SCIR/ltp/issues/261 | [] | ambjlon | 1 |
PeterL1n/RobustVideoMatting | computer-vision | 127 | CUA | closed | 2022-01-12T11:35:10Z | 2022-01-14T06:39:23Z | https://github.com/PeterL1n/RobustVideoMatting/issues/127 | [] | HarrytheOrange | 0 | |
plotly/dash-core-components | dash | 475 | box plot issue with dcc.Graph? | Getting a few reports in the community forum that look valid, but I haven't attempted reproducing yet: https://community.plot.ly/t/boxplot-in-dash/19623/4 | open | 2019-03-05T15:00:28Z | 2019-03-05T15:00:28Z | https://github.com/plotly/dash-core-components/issues/475 | [] | chriddyp | 0 |
gradio-app/gradio | python | 10,255 | Bug of gr.ImageMask save image | ### Describe the bug
Hi, author.
I use gr.ImageMask met a bug. Wish you can solve this problem.
I set of ImageMask width and height, in the page save image from gr.ImageMask, but image size is compressed, not the width and height of the original upload.
### Have you searched existing issues? 🔎
- [X] I have searc... | closed | 2024-12-26T09:42:37Z | 2025-01-22T18:35:03Z | https://github.com/gradio-app/gradio/issues/10255 | [
"bug",
"🖼️ ImageEditor"
] | yaosheng216 | 1 |
satwikkansal/wtfpython | python | 137 | Is copy or reference in self recursion? | Hello, I not found in this repository about this grammar. so, I open this issue.
My CPython version is 3.7.1
- list recursion (reference )
```python
class C:
def f1(self, a):
if a[0][0] == 0:
return a
else:
a[0][0] -= 1
self.f1(a)
return a
... | closed | 2019-09-09T04:14:31Z | 2019-12-21T17:08:04Z | https://github.com/satwikkansal/wtfpython/issues/137 | [
"new snippets"
] | daidai21 | 1 |
plotly/dash-cytoscape | plotly | 175 | Graph nodes flocking to single point | #### Description
Nodes in graphs are shown correctly for a second before flocking to a single point, usually happens when inserting Cyto-components using callbacks. It is independent of any particular layout. This happens often.
Looks like this:
<img src="https://i.ibb.co/6WV2BF3/Screenshot-2022-05-17-at-16-15... | open | 2022-05-17T14:21:44Z | 2022-05-24T15:48:35Z | https://github.com/plotly/dash-cytoscape/issues/175 | [] | nilq | 3 |
aio-libs/aiomysql | asyncio | 979 | aiomysql raise InvalidRequestError: Cannot release a connection with not finished transaction | ### Describe the bug
When the database connection runs out and a new request is sent, an error occurd and the whole application goes down!
in the aiomysql/utils.py, line 137
```python3
async def __aexit__(self, exc_type, exc, tb):
try:
await self._pool.release(self._conn)
finally:
self... | open | 2024-03-07T09:01:24Z | 2024-03-07T09:06:15Z | https://github.com/aio-libs/aiomysql/issues/979 | [
"bug"
] | ShownYoung | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 370 | Does library supports load data from from torch.utils.data.Dataset? | closed | 2021-10-05T07:14:17Z | 2021-10-05T09:49:20Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/370 | [] | KennyTC | 1 | |
wandb/wandb | tensorflow | 9,198 | [Bug-App]: Sweep UI (Parallel Coordinates Plot, Parameter Importance Plot, etc.) Missing in W&B Dashboard | ### Describe the bug
Description:
I ran the following code from the sweep tutorial using the W&B library. While the logged score is visible on the W&B website, I cannot see the Sweep UI features such as the parallel coordinates plot or parameter importance plot.
Code:
```
# Import the W&B Python Library and log into ... | closed | 2025-01-07T12:15:07Z | 2025-01-09T12:36:42Z | https://github.com/wandb/wandb/issues/9198 | [
"ty:bug",
"c:sweeps",
"a:app"
] | hspark1212 | 2 |
tartiflette/tartiflette | graphql | 549 | Setup/teardown is failing when doing automated tests | This is a bug report about doing setup/teardown for running automated tests with Tartiflette (and tartiflette-aiohttp). It seems that the first test succeeds, but subsequent tests fail. I've created a repository with a minimal reproducible test case, which is here: https://github.com/singingwolfboy/tartiflette-test-bug... | open | 2021-12-02T17:54:09Z | 2021-12-02T17:54:09Z | https://github.com/tartiflette/tartiflette/issues/549 | [] | singingwolfboy | 0 |
httpie/cli | python | 966 | [Docs] `cv@` & `=@` are getting replaced in docsite with [email-protected] | 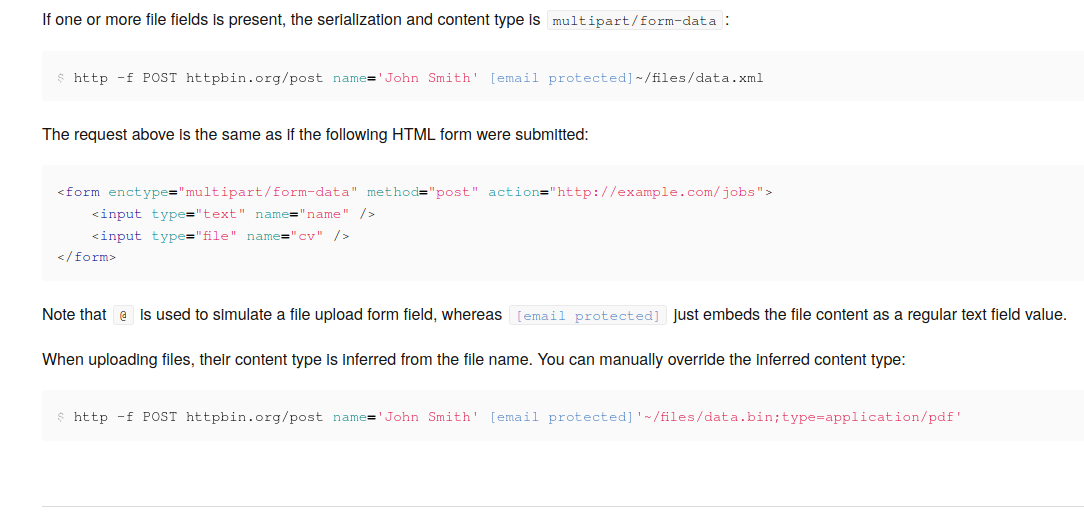
Clicking on the link in `[email-protected]` takes me to https://httpie.org/cdn-cgi/l/email-protection | closed | 2020-09-17T19:50:28Z | 2020-09-20T06:36:16Z | https://github.com/httpie/cli/issues/966 | [] | jskrzypek | 1 |
netbox-community/netbox | django | 17,940 | "Tagged VLANs" multiselect in Interface incomplete | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
v4.1.4
### Python Version
3.10
### Steps to Reproduce
Create more than 100 VLANs.
Create a Device with an Interface.
Set the 802.1q mode to tagged.
Open the "Tagged VLANs" multiselect and select VLANs.
### Expected Behavior
All e... | closed | 2024-11-06T09:23:59Z | 2025-02-06T03:03:46Z | https://github.com/netbox-community/netbox/issues/17940 | [] | georg-again | 2 |
matplotlib/mplfinance | matplotlib | 368 | Point and figure [pnf] - Reversal param | Hello,
Is it possible to change the PNF param "reversal" the same way as i can do with "box_size"? Is it even possible?
`mpf.plot(df, type='pnf', pnf_params=dict(box_size=7))`
| closed | 2021-04-01T14:54:53Z | 2021-04-25T18:06:50Z | https://github.com/matplotlib/mplfinance/issues/368 | [
"enhancement",
"released"
] | heytechv | 4 |
amisadmin/fastapi-amis-admin | sqlalchemy | 179 | 添加search_fields模糊搜索字段后报错 | 不添加页面正常显示,添加后页面为空报错

变量变成了[~]$样式

| closed | 2024-07-25T09:01:58Z | 2024-08-02T02:12:03Z | https://github.com/amisadmin/fastapi-amis-admin/issues/179 | [] | zeroChen00 | 1 |
pandas-dev/pandas | python | 60,656 | ENH: Add `date_format` and `date_unit` to `to_dict` similar to what exists in `to_json` | ### Feature Type
- [X] Adding new functionality to pandas
- [ ] Changing existing functionality in pandas
- [ ] Removing existing functionality in pandas
### Problem Description
`df.to_dict` is often (maybe even mostly) to post data via REST API.
My usual workflow for posting data looks like this:
```
df = pd.... | open | 2025-01-04T10:06:33Z | 2025-01-04T14:19:10Z | https://github.com/pandas-dev/pandas/issues/60656 | [
"Enhancement",
"IO Data",
"Closing Candidate"
] | lucasjamar | 1 |
huggingface/datasets | computer-vision | 6,689 | .load_dataset() method defaults to zstandard | ### Describe the bug
Regardless of what method I use, datasets defaults to zstandard for unpacking my datasets.
This is poor behavior, because not only is zstandard not a dependency in the huggingface package (and therefore, your dataset loading will be interrupted while it asks you to install the package), but it ... | closed | 2024-02-22T17:39:27Z | 2024-03-07T14:54:16Z | https://github.com/huggingface/datasets/issues/6689 | [] | ElleLeonne | 4 |
scrapfly/scrapfly-scrapers | web-scraping | 5 | Failed to register account | remind must be work email | closed | 2023-10-12T08:24:41Z | 2023-10-12T08:56:40Z | https://github.com/scrapfly/scrapfly-scrapers/issues/5 | [
"question"
] | lovelifelovejava | 0 |
microsoft/UFO | automation | 129 | AttributeError: 'AppAgentProcessor' object has no attribute 'update_step'. Did you mean: 'update_cost'? | I tried setting up and running the UFO first time with a basic task of sending an email to a gmail address with a simple question.
UFO does everything as expected until the last step when it asks the user for permission to send the email. That's where I received the error. Full traceback is pasted below:
[Input Requir... | open | 2024-10-27T10:39:11Z | 2024-11-23T13:00:25Z | https://github.com/microsoft/UFO/issues/129 | [] | HamzaAsiff | 8 |
adbar/trafilatura | web-scraping | 786 | Slow extraction after recent PRs | Hi @unsleepy22, I just ran tests on the benchmark with `pyinstrument tests/comparison_small.py` and there seems to be an issue with your PR which improve the results but have a major cost in terms of timing (say 3-4x as slow overall).
The problem seems to be in `determine_returnstring` > `xmltotxt` > `process_element`... | closed | 2025-02-10T16:38:09Z | 2025-02-17T16:29:13Z | https://github.com/adbar/trafilatura/issues/786 | [
"bug"
] | adbar | 0 |
piskvorky/gensim | data-science | 3,295 | Get coverage to work properly under Github Actions | See the suggestions here: https://github.com/RaRe-Technologies/gensim/pull/3286#issuecomment-1050561253 | open | 2022-02-25T07:01:04Z | 2022-02-25T07:13:39Z | https://github.com/piskvorky/gensim/issues/3295 | [
"housekeeping"
] | mpenkov | 0 |
miguelgrinberg/flasky | flask | 148 | Fix manage.py path problem on windows | > covdir = os.path.join(basedir, 'tmp/coverage')
> COV.html_report(directory=covdir)
> print('HTML version: file://%s/index.html' % covdir)
There is some problems on _windows_, coz path is '\'.
| closed | 2016-05-29T04:44:46Z | 2017-12-10T20:04:19Z | https://github.com/miguelgrinberg/flasky/issues/148 | [
"bug"
] | viprs | 1 |
Asabeneh/30-Days-Of-Python | matplotlib | 437 | Python Program | closed | 2023-08-23T10:27:38Z | 2023-08-23T10:28:38Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/437 | [] | xozayn | 0 | |
suitenumerique/docs | django | 332 | Web accessibility problems on document edition page | ## Bug Report
**Problematic behavior**
Here is the detailed analysis by Antoine : https://www.loom.com/share/3c9642546c2c4e5391b2ce04a5c3df93 | open | 2024-10-14T08:10:00Z | 2024-12-11T14:11:07Z | https://github.com/suitenumerique/docs/issues/332 | [
"good first issue",
"frontend"
] | virgile-dev | 1 |
tfranzel/drf-spectacular | rest-api | 904 | How can I use pagination in extend_schema_field? | I have a field in my serializer:
```
messages = serializers.SerializerMethodField()
```
and corresponding method:
```
def get_messages(self, obj):
```
that returns a list of paginated messages. I use `LimitOffsetPagination` class and my custom `MessageSerializer` serializer. I wish to define a type fo... | closed | 2022-12-23T09:18:55Z | 2022-12-23T16:06:27Z | https://github.com/tfranzel/drf-spectacular/issues/904 | [] | adybionka | 2 |
coqui-ai/TTS | deep-learning | 2,350 | ValueError(" [!] Unkown encoder type.") | ### Describe the bug
I am trying to load the pretrained glowtts model from the repo but I am stuck with this error when ***setup_model()*** function runs.
***ValueError(" [!] Unkown encoder type.")***
### To Reproduce
to reproduce simply load the config for the glowtts model and run setup_model:
config = load_... | closed | 2023-02-16T15:34:23Z | 2023-03-25T23:58:54Z | https://github.com/coqui-ai/TTS/issues/2350 | [
"bug",
"wontfix"
] | nicholasguimaraes | 1 |
onnx/onnx | deep-learning | 5,869 | Cannot install on windows 10 with pip - `test_data_set_0` folder is missing | # Bug Report
### Is the issue related to model conversion?
<!-- If the ONNX checker reports issues with this model then this is most probably related to the converter used to convert the original framework model to ONNX. Please create this bug in the appropriate converter's GitHub repo (pytorch, tensorflow-onnx, sk... | closed | 2024-01-19T20:11:58Z | 2024-01-25T14:20:05Z | https://github.com/onnx/onnx/issues/5869 | [
"bug"
] | Grsz | 3 |
plotly/dash | dash | 2,497 | select certain columns / rows that are False when cell_selectable=False | When I use dashtable with cell_selectable=False, all cells are not selectable. I am wondering if we can have the option to choose certain columns / rows that are not selectable? In my case, I only want 1 column that is selectable. Other columns should be disabled.
Using dash 2.9 | open | 2023-04-05T05:42:18Z | 2024-08-13T19:31:23Z | https://github.com/plotly/dash/issues/2497 | [
"feature",
"P3"
] | slyin87 | 0 |
chiphuyen/stanford-tensorflow-tutorials | tensorflow | 30 | advise to add a Jupyter Notebook | hi, here is a suggestion, how about add a "Jupyter Notebook" in example PATH? | open | 2017-06-18T09:05:43Z | 2017-07-11T17:47:48Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/30 | [] | DoneHome | 1 |
satwikkansal/wtfpython | python | 219 | Explain meaning of asterisk in heading titles | A lot of the headings end in a asterisk e.g. "First things first! *" does but "Strings can be tricky sometimes" does not. This suggests a footnote but after quite a bit of searching I can't find one. Perhaps it means something else like "new" or "reader contributed". Please explain on the page otherwise there's not muc... | closed | 2020-08-24T09:24:05Z | 2020-08-24T14:41:05Z | https://github.com/satwikkansal/wtfpython/issues/219 | [] | arthur-tacca | 1 |
onnx/onnx | pytorch | 6,168 | Any operation to convert "Tile" to "Slice" | I am working on some Low-Rank Adaptation (LoRA) models, in which two set of `torch.nn.Parameters` are initialized and then multiplied into a complete weight matrix of Conv/Attention during inference.
I noticed that, the weight of original Conv is converted into `Slice` type, while the torch.nn.Parameters designed f... | closed | 2024-06-11T07:29:08Z | 2024-07-10T05:41:22Z | https://github.com/onnx/onnx/issues/6168 | [
"question"
] | zw-xxx | 2 |
pyg-team/pytorch_geometric | deep-learning | 9,734 | `SetTransformerAggregation` has parameter incorrectly written | ### 📚 Describe the documentation issue
The page for the `nn.aggr.SetTransformerAggregation` class has a typo, where the parameter `layer_norm` is shown as `norm`.
### Suggest a potential alternative/fix
I will open a PR with an edit to that particular docstring. | closed | 2024-10-25T19:20:18Z | 2024-10-28T13:59:57Z | https://github.com/pyg-team/pytorch_geometric/issues/9734 | [
"documentation"
] | eurunuela | 1 |
BeanieODM/beanie | pydantic | 922 | Concerns and Suggestions Regarding Beanie Library | I wanted to raise some concerns regarding the current state of the Beanie library, particularly in its role as an async ODM in Python.
As a user of the library, I've noticed that the maintainer seems to be unavailable, which has raised some concerns about its suitability for use in our production environment. Addition... | closed | 2024-04-23T17:43:49Z | 2024-10-08T17:06:22Z | https://github.com/BeanieODM/beanie/issues/922 | [
"Stale"
] | alm0ra | 10 |
seleniumbase/SeleniumBase | pytest | 3,351 | how can I keep the browser open and keep it open? |
how can I keep the browser open and keep it open so that I can continue the secondary operation without having to restart the browser every time? | closed | 2024-12-19T04:23:13Z | 2025-01-12T14:16:55Z | https://github.com/seleniumbase/SeleniumBase/issues/3351 | [
"duplicate",
"question"
] | quyunet | 6 |
ymcui/Chinese-BERT-wwm | nlp | 111 | MaskedLM的head能开源吗? | 现在提供的模型只包含WWM fine tune 完成的BERT模型。能同时提供论文中用来fine tune 的MLM的linear head 吗? | closed | 2020-04-27T00:45:34Z | 2020-04-28T16:46:09Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/111 | [] | snakeztc | 3 |
ckan/ckan | api | 8,409 | Accessibility: <a> tags without href | Hi, there are a couple of `<a>` tags without `href` attributes in some of the templates. For example, https://github.com/ckan/ckan/blob/5117fbaeee5a60cf62e42abde2dcef19c747505a/ckan/templates/organization/snippets/info.html#L67
As per https://accessibleweb.com/question-answer/link-element-still-accessible-without-hr... | open | 2024-08-22T04:32:40Z | 2024-08-22T13:02:19Z | https://github.com/ckan/ckan/issues/8409 | [] | yawaramin | 0 |
iperov/DeepFaceLab | deep-learning | 847 | Inconsistent iterations times and issues with RW override in new version. | Expected behavior:
Correct me if I'm wrong but the recent updates should be overriding random warp setting state to disabled (n) as long as pretrain is enabled (y).
Actual behavior:
Despite this override update it seems like the behavior is not how one would expect, either explanation or bug fix is required, w... | open | 2020-08-03T12:39:58Z | 2023-06-08T23:12:09Z | https://github.com/iperov/DeepFaceLab/issues/847 | [] | ThomasBardem | 6 |
xonsh/xonsh | data-science | 4,960 | Web config tool includes \r in prompt | When using the web config (xonfig web), newlines are interpreted as "\r\n". On macOS (and Linux, I assume) this adds a "^M" to the prompt, before the newline.
## xonfig
```
+------------------+--------------------------------+
| xonsh | 0.13.3 |
| Python | 3.10.7 ... | closed | 2022-10-04T22:43:21Z | 2022-10-25T14:07:21Z | https://github.com/xonsh/xonsh/issues/4960 | [
"good first issue",
"xonfig-web"
] | JoBrad | 2 |
SYSTRAN/faster-whisper | deep-learning | 1,231 | Problem installing on macOS with Python 3.13.1 | This seems to be an issue with the av library being locked to a specific version. I can install av 14.1.0 just fine, but I believe faster-whisper is requiring a version below 13. I am on macOS in a virtualenv with nothing else installed and python 3.13.1.
.
According to the [documentation for Pokémon forms](https... | open | 2024-12-25T20:25:03Z | 2024-12-26T09:41:46Z | https://github.com/PokeAPI/pokeapi/issues/1178 | [] | Ferlow | 1 |
Farama-Foundation/PettingZoo | api | 1,143 | [Bug Report] MPE SimpleEnv continuous actions are the "other way" | ### Describe the bug
At the moment the simple env action.u computations are opposite to the discrete environment's. In the current setup when the agents recieve [0, 1, 0, 1, 0] for example they start moving to the top right, instead of the expected bottom left, based on `Agent and adversary action space: [no_action, m... | closed | 2023-12-02T13:14:48Z | 2023-12-07T14:42:28Z | https://github.com/Farama-Foundation/PettingZoo/issues/1143 | [
"bug"
] | mrxaxen | 3 |
Nike-Inc/koheesio | pydantic | 136 | [MAJOR] rename SynchronizeDeltaToSnowflakeTask to SynchronizeDeltaToSnowflakeStep in a future major release | Does it make sense to rename it SynchronizeDeltaToSnowflakeStep in a future major release?
_Originally posted by @riccamini in https://github.com/Nike-Inc/koheesio/pull/97#discussion_r1860832343_
| open | 2024-11-29T14:07:41Z | 2024-11-29T14:07:56Z | https://github.com/Nike-Inc/koheesio/issues/136 | [
"postponed"
] | dannymeijer | 0 |
flairNLP/flair | nlp | 3,626 | [Question]: Is it possible to add UMLS Metathesaurus as custom linking model | ### Question
On https://flairnlp.github.io/flair/v0.15.1/tutorial/tutorial-hunflair2/customize-linking.html there is example on how to add Human Phenotype Ontology.
Would it be possible to add UMLS Metathesaurus and how? | closed | 2025-03-04T17:35:28Z | 2025-03-22T11:01:25Z | https://github.com/flairNLP/flair/issues/3626 | [
"question"
] | darije | 3 |
PrefectHQ/prefect | data-science | 17,042 | Allow a List of Inputs for Prefect ECS Work Pool Start Commands | ### Bug summary
## Issue
Currently Prefect doesn't support a list of inputs as a custom start command. This functionality is natively supported by Docker and ECS.
## Example
Command: `['/bin/sh', '-c', 'python -m some.module', '&&', 'prefect flow-run execute']`
If I pass the above start command list to a Prefect ECS ... | open | 2025-02-07T14:53:33Z | 2025-02-07T14:53:33Z | https://github.com/PrefectHQ/prefect/issues/17042 | [
"bug"
] | skohlleffel | 0 |
Ehco1996/django-sspanel | django | 717 | 数据后台无法跳转 | **问题的描述**
我已经把页面功能启动来了,整体登录也OK,但是在看后端对接教程的时候,发现数据后台无法跳转,我看了代码里也没有在后台跳转处写跳转链接,包括html代码里也没有数据后台的添加SS链接等功能
**项目的配置文件**
**如何复现**
**相关截图/log**
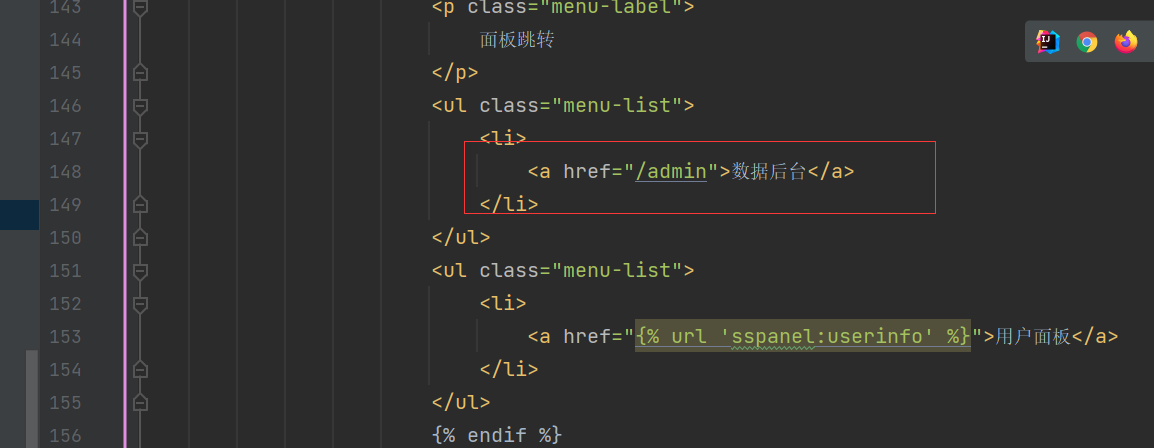
:
"""Arguments to create a pe... | open | 2018-02-09T05:44:41Z | 2018-04-24T18:13:29Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/112 | [] | alexisrolland | 3 |
schemathesis/schemathesis | pytest | 2,504 | Specifying --hypothesis-seed=# does not recreate tests with the same data | ### Checklist
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [x] I am using the latest version of Schemathesis
... | open | 2024-10-09T20:26:42Z | 2024-10-20T01:56:38Z | https://github.com/schemathesis/schemathesis/issues/2504 | [
"Type: Bug",
"Status: Needs Triage"
] | hydroculator | 2 |
pyg-team/pytorch_geometric | pytorch | 8,853 | Add Support for Pytorch 2.2 | ### 🚀 The feature, motivation and pitch
Pytorch 2.2 was released:
[Blog](https://pytorch.org/blog/pytorch2-2/)
[Release Notes](https://github.com/pytorch/pytorch/releases/tag/v2.2.0)
### Alternatives
_No response_
### Additional context
_No response_ | closed | 2024-02-02T09:40:55Z | 2024-02-03T10:13:11Z | https://github.com/pyg-team/pytorch_geometric/issues/8853 | [
"feature"
] | Foisunt | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.