
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
huggingface/transformers | tensorflow | 36,352 | Implement Titans Architecture with GRPO Fine-Tuning | ### Model description
It would be highly valuable to extend the Transformers library with an implementation of the Titans model—a hybrid architecture that combines traditional attention-based processing with a dedicated long-term memory module (for test-time memorization) and fine-tuning using a Group Relative Policy ... | open | 2025-02-23T09:32:17Z | 2025-02-24T14:42:43Z | https://github.com/huggingface/transformers/issues/36352 | [
"New model"
] | rajveer43 | 2 |
paulbrodersen/netgraph | matplotlib | 88 | Add multiple edges simultaneously | Hi guys, I hope you're well.
I work on a project called [GraphFilter](https://github.com/GraphFilter), where we use your library (we've even opened some issues here). Recently, a user asked us about the possibility of adding [multiple edges simultaneously](https://github.com/GraphFilter/GraphFilter/issues/453). I'd ... | open | 2024-04-09T21:09:23Z | 2024-06-19T10:16:59Z | https://github.com/paulbrodersen/netgraph/issues/88 | [
"enhancement"
] | fsoupimenta | 14 |
Guovin/iptv-api | api | 329 | m3u中存在使用错误的地址 | CCTV-5+频道中出现以下地址,地址本身可响应,但返回内容中存在404错误
Name: CCTV-5+, URL: http://220.179.68.222:9901/tsfile/live/0016_1.m3u8?key=txiptv&playlive=1&authid=0, Date: None, Resolution: None, Response Time: 34 ms
`{"timestamp":"2024-09-20T17:08:33.979+0800","status":404,"error":"Not Found","message":"Not Found","path":"/tsfile/live/... | closed | 2024-09-20T09:12:18Z | 2024-09-23T01:43:24Z | https://github.com/Guovin/iptv-api/issues/329 | [
"enhancement"
] | zid99825 | 1 |
schemathesis/schemathesis | graphql | 2,713 | [BUG] "ignored_auth" check causes SSLError exception when verify is set to False in the case | ### Checklist
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [x] I am using the latest version of Schemathesis
### ... | closed | 2025-01-30T13:31:42Z | 2025-02-03T10:07:30Z | https://github.com/schemathesis/schemathesis/issues/2713 | [
"Type: Bug",
"Status: Needs Triage"
] | lugi0 | 5 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 719 | Replacing synthesizer from Tacotron to Non Attentive Tacotron | Working on it! | closed | 2021-04-02T07:59:16Z | 2021-04-20T03:01:11Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/719 | [] | Garvit-32 | 2 |
coqui-ai/TTS | pytorch | 3,264 | [Bug] XTTS v2 keeps downloading model | ### Describe the bug
model = 'tts_models/multilingual/multi-dataset/xtts_v2'
tts = TTS(model).to(device)
everytime I call this i get it redownloads the model
### To Reproduce
Running TTS generation
### Expected behavior
_No response_
### Logs
_No response_
### Environment
```shell
{
"CUDA": {
... | closed | 2023-11-18T20:57:06Z | 2023-11-20T08:41:36Z | https://github.com/coqui-ai/TTS/issues/3264 | [
"bug"
] | darkzbaron | 2 |
dgtlmoon/changedetection.io | web-scraping | 1,672 | (changed) and (into) string | How to get rid of "(changed)" and "(into)" string in order to leave changed things alone? | closed | 2023-07-04T17:36:05Z | 2023-07-04T19:34:36Z | https://github.com/dgtlmoon/changedetection.io/issues/1672 | [] | lukaskrol7 | 0 |
Morizeyao/GPT2-Chinese | nlp | 35 | Fail to run train_single | Great repo. However, the train_single script seems to be broken.
```Traceback (most recent call last):
File "train_single.py", line 223, in <module>
main()
File "train_single.py", line 74, in main
full_tokenizer = tokenization_bert.BertTokenizer(vocab_file=args.tokenizer_path)
UnboundLocalError: lo... | closed | 2019-08-24T12:30:35Z | 2019-08-25T14:58:49Z | https://github.com/Morizeyao/GPT2-Chinese/issues/35 | [] | diansheng | 1 |
quokkaproject/quokka | flask | 270 | Filter problem at the post list admin page | These options of filter: Title, Summary, Created At, Available At aren't working well. The first time that page is loaded and some filter is added, the filter wasn't work.
| closed | 2015-07-20T02:51:21Z | 2016-03-02T15:18:06Z | https://github.com/quokkaproject/quokka/issues/270 | [
"bug",
"EASY"
] | felipevolpone | 2 |
noirbizarre/flask-restplus | api | 233 | Swagger doesn't support converters with optional arguments | If one defines a route with optional arguments, http://werkzeug.pocoo.org/docs/0.11/routing/#rule-format, i.e., `@api.route('/my-resource/<string(length=2):id>')`, Swagger raises a `ValueError` (swagger.py#L82) because in senses the type converter is unsupported, i.e.,
```python
from flask import Flask
from flask_... | closed | 2017-02-03T23:43:52Z | 2017-03-04T20:49:48Z | https://github.com/noirbizarre/flask-restplus/issues/233 | [] | john-bodley | 0 |
piskvorky/gensim | data-science | 2,608 | AttributeError in Doc2vec when compute_loss=True | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/forum/#!forum/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that d... | closed | 2019-09-25T11:03:29Z | 2019-09-28T13:37:40Z | https://github.com/piskvorky/gensim/issues/2608 | [] | Infinity1008 | 2 |
deezer/spleeter | tensorflow | 626 | [Bug] Spleeter Separate on custom trained model tries to download another model |
## Description
I have trained a custom model and the separate function does not work as intended as it tries to download the model from a nonexisting url.
## Step to reproduce
1. Created custom model training data / specs annotated in the custom_model_config.json
2. Trained model (succesfully, apparently) u... | closed | 2021-05-29T16:33:08Z | 2021-05-31T09:36:24Z | https://github.com/deezer/spleeter/issues/626 | [
"bug",
"invalid"
] | andresC98 | 4 |
litestar-org/litestar | pydantic | 3,396 | Enhancement: SQLAdmin Support | ### Summary
SQLAdmin has a fork for litestar, but it isn't properly supported and there are no issues or discussions around its limitations. Is there support for making this better integrated in the litestar community?
### Basic Example
When using both litestar sqlalchemy plugin and the sqladmin fork https://github.... | closed | 2024-04-16T16:34:28Z | 2025-03-20T15:54:36Z | https://github.com/litestar-org/litestar/issues/3396 | [
"Enhancement"
] | colebaileygit | 5 |
AutoGPTQ/AutoGPTQ | nlp | 521 | [BUG] Loading Saved Marlin Quantized Models Fails | **Describe the bug**
After saving a marlin model to disk with `save_pretrained`, reloading the model fails since the quantization config still has gptq in in.
**Hardware details**
A100
**Software version**
Current main
**To Reproduce**
1. Load a model in marlin format and save to disk
```python
from auto... | closed | 2024-01-24T18:51:57Z | 2024-02-12T13:51:07Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/521 | [
"bug"
] | robertgshaw2-redhat | 4 |
ivy-llc/ivy | tensorflow | 27,868 | Fix Frontend Failing Test: paddle - tensor.torch.Tensor.__gt__ | closed | 2024-01-07T23:37:49Z | 2024-01-07T23:48:41Z | https://github.com/ivy-llc/ivy/issues/27868 | [
"Sub Task"
] | NripeshN | 0 | |
python-restx/flask-restx | flask | 377 | Basic Auth for Swagger UI | Any suggestions on how to password protect the swagger UI with basic auth? I was going to use something like flask-httpauth or maybe just write my own wrapper but the Swagger UI route isn't exposed in an obvious way. If you wondering why, I may have to have my API available publicly and don't want anyone who isn't supp... | open | 2021-09-22T14:56:42Z | 2023-06-26T14:33:10Z | https://github.com/python-restx/flask-restx/issues/377 | [
"question"
] | Bxmnx | 2 |
paperless-ngx/paperless-ngx | machine-learning | 8,289 | [BUG] File permissions are not set correctly after e.g. deleting a page from a PDF | ### Description
When deleting a page from a scanned PDF the newly created PDF does not inherrit the permissions from the folder. After deleting the file other process are not able to work with thenew file because of access issue.
### Steps to reproduce
1. Create a job / cron job which regularly syncs the file... | closed | 2024-11-15T14:16:19Z | 2024-12-16T03:19:27Z | https://github.com/paperless-ngx/paperless-ngx/issues/8289 | [
"not a bug"
] | Kopierwichtel | 3 |
xinntao/Real-ESRGAN | pytorch | 87 | Sample images | input

output

Of course the quality of this picture is very low, but these thr... | open | 2021-09-21T10:56:50Z | 2021-09-26T02:52:17Z | https://github.com/xinntao/Real-ESRGAN/issues/87 | [] | tumuyan | 4 |
FactoryBoy/factory_boy | sqlalchemy | 1,044 | Unusable password generator for Django | #### The problem
The recently added `Password` generator for Django is helpful, but it's not clear how to use it to create an unusable password (similar to calling `set_unusable_password` on the generated user).
#### Proposed solution
Django's `set_unusable_password` is a call to `make_password` with `None` as... | closed | 2023-09-20T07:47:12Z | 2023-09-26T06:50:38Z | https://github.com/FactoryBoy/factory_boy/issues/1044 | [
"Doc",
"BeginnerFriendly"
] | jaap3 | 1 |
sktime/sktime | data-science | 7,224 | [BUG] DartsLinearRegression fails instead of giving warning message | **Describe the bug**
`DartsLinearRegressionModel` fails when a warning should be raised
**To Reproduce**
```python
from sktime.datasets import load_airline
from sktime.forecasting.darts import DartsLinearRegressionModel
y = load_airline()
forecaster = DartsLinearRegressionModel(output_chunk_length=6,likeli... | closed | 2024-10-04T16:56:02Z | 2024-10-11T09:21:09Z | https://github.com/sktime/sktime/issues/7224 | [
"bug",
"module:forecasting"
] | wilsonnater | 2 |
davidsandberg/facenet | computer-vision | 1,001 | classifier problem | I trained the model with my own images (10k images, 1k classes) by train_softmax.py,
My settings :
`
--max_nrof_epochs 100 \
--epoch_size 100 \
--batch_size 30 \
`
Other settings are default: (emb size is 128)
I got Accuracy ~0.98 at epoch 80, Loss ~ 1.7
But when I use this trained model to calculate 128... | open | 2019-03-30T08:02:17Z | 2019-03-30T08:02:17Z | https://github.com/davidsandberg/facenet/issues/1001 | [] | ducnguyen96 | 0 |
rthalley/dnspython | asyncio | 277 | In macos dnspython can not resolve some TLD domains. | In macos Sierra 10.12.4
pip list |grep dns
dnspython (1.15.0)

In Kali linux
pip list |grep dns
dnspython (1.15.0)
 of type object or array such as approval_list in the below code.
```
Create new Deployment Unit
---
tags:
- Deployment Unit
parameters:
- name: Token
in: header
description: API... | open | 2017-08-03T10:12:24Z | 2018-10-01T17:31:30Z | https://github.com/flasgger/flasgger/issues/141 | [
"hacktoberfest"
] | VjSng | 2 |
xinntao/Real-ESRGAN | pytorch | 905 | After executing ”python inference_realesrgan.py -n RealESRGAN_x4plus -i inputs” command, it gets stuck and there is no other information | **The environment is as follows:**
(ml-env) PS C:\workspace\ml\Real-ESRGAN\Real-ESRGAN> pip list
Package Version Editable project location
----------------------- --------------- ---------------------------------------
absl-py 2.1.0
addict 2.4.0
autocommand ... | open | 2025-03-19T06:08:30Z | 2025-03-19T08:29:04Z | https://github.com/xinntao/Real-ESRGAN/issues/905 | [] | Le1q | 1 |
encode/databases | sqlalchemy | 161 | Getting row count from an update | I'm aware of e.g. #108 but I'm wondering what the best way to get the row count for an update or delete is for now? On Postgres if it makes a difference. | open | 2019-11-15T15:00:25Z | 2019-12-11T11:11:26Z | https://github.com/encode/databases/issues/161 | [] | knyghty | 6 |
Lightning-AI/LitServe | fastapi | 121 | during manual local testing, the processes are not killed if the test fails | We need to terminate the processes if test fails for whatsoever reason:
## Current
```python
def test_e2e_default_batching(killall):
process = subprocess.Popen(
["python", "tests/e2e/default_batching.py"],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL,
stdin=subproce... | closed | 2024-05-31T12:02:02Z | 2024-06-03T18:46:25Z | https://github.com/Lightning-AI/LitServe/issues/121 | [
"bug",
"good first issue",
"ci / tests"
] | aniketmaurya | 0 |
donnemartin/system-design-primer | python | 691 | can you make it be a book? | open | 2022-07-25T03:27:19Z | 2023-10-02T12:12:55Z | https://github.com/donnemartin/system-design-primer/issues/691 | [
"needs-review"
] | aexftf | 2 | |
albumentations-team/albumentations | deep-learning | 1,973 | Supported mask formats with Albumentations | ## Your Question
From the documentation, both API reference and [user guide] (https://albumentations.ai/docs/getting_started/mask_augmentation/) sections, it's not straightforward to understand which kind of mask format is supported and more importantly, if different mask formats can lead to different transformation... | open | 2024-10-07T16:07:00Z | 2024-10-08T20:13:27Z | https://github.com/albumentations-team/albumentations/issues/1973 | [
"question"
] | PRFina | 1 |
FlareSolverr/FlareSolverr | api | 1,085 | Error solving the challenge. Timeout after 60.0 seconds | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2024-02-20T19:48:46Z | 2024-02-20T19:50:46Z | https://github.com/FlareSolverr/FlareSolverr/issues/1085 | [] | nickydd9 | 1 |
deepset-ai/haystack | nlp | 8,366 | Remove deprecated `Pipeline` init argument `debug_path` | The argument `debug_path` has been deprecate with PR #8364 and will be released with Haystack `2.6.0`.
We need to remove it before releasing version `2.7.0`. | closed | 2024-09-16T07:52:13Z | 2024-09-30T15:11:50Z | https://github.com/deepset-ai/haystack/issues/8366 | [
"breaking change",
"P3"
] | silvanocerza | 0 |
fugue-project/fugue | pandas | 377 | [FEATURE] Create bag | Fugue has been built on top of the DataFrame concept. Although a collection of arbitrary objects can be converted to DataFrame to be distributed in Fugue, it is not always efficient or intuitive to do so. Looking at Spark (RDD), Dask (Bag) and even Ray, they all have separate ways to handle a distributed collection of ... | closed | 2022-10-22T05:14:59Z | 2022-11-17T05:32:59Z | https://github.com/fugue-project/fugue/issues/377 | [
"enhancement",
"high priority",
"programming interface",
"core feature",
"bag"
] | goodwanghan | 0 |
zappa/Zappa | flask | 1,111 | “python_requires” should be set with “>=3.6, <3.10”, as zappa 0.54.1 is not compatible with all Python versions. | Currently, the keyword argument **python_requires** of **setup()** is not set, and thus it is assumed that this distribution is compatible with all Python versions.
However, I found the following code checking Python compatibility locally in **zappa/\_\_init\_\_.py**
```python
SUPPORTED_VERSIONS = [(3, 6), (3, 7), ... | closed | 2022-02-22T03:46:22Z | 2022-08-05T10:36:23Z | https://github.com/zappa/Zappa/issues/1111 | [] | PyVCEchecker | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 789 | conda install dependencies: downgrade python to 2.x | I am a conda user.
When I try './scripts/conda_deps.sh' to install dependencies.
It try to downgrade my python from 3.x to 2.x
`The following packages will be DOWNGRADED:
python: 3.6.5-hc3d631a_2 --> 2.7.16-h9bab390_7 `
| open | 2019-10-11T09:03:11Z | 2019-10-12T08:54:54Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/789 | [] | H0icky | 2 |
Evil0ctal/Douyin_TikTok_Download_API | api | 284 | [BUG] /tiktok_profile_videos 没有定义get_tiktok_user_profile_videos方法 | ***发生错误的平台?***
TikTok /tiktok_profile_videos/ 没有定义get_tiktok_user_profile_videos方法
***发生错误的端点?***
如:API-V1/API-V2/Web APP
***提交的输入值?***
短视频链接
***是否有再次尝试?***
如:是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述文件或接口文档吗?***
如:有,并且很确定该问题是程序导致的。
| closed | 2023-09-28T07:14:00Z | 2023-09-29T10:46:02Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/284 | [
"BUG"
] | wahahababaozhou | 1 |
littlecodersh/ItChat | api | 22 | 有没有办法将个人名片或自己关注的公众号名片转发出去? | 本issue记录个人名片、公众号、文章转发的相关讨论。
| closed | 2016-06-18T13:48:56Z | 2016-11-13T12:13:35Z | https://github.com/littlecodersh/ItChat/issues/22 | [
"enhancement",
"help wanted"
] | jireh-he | 12 |
AntonOsika/gpt-engineer | python | 134 | [windows] File system "permission denied" | I downloaded the new repo today, and when running a prompt i receive the following error.
It worked fine last night on the old repo of the previous day.
I have full administrative rights.
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", lin... | closed | 2023-06-18T01:23:25Z | 2023-07-12T12:00:32Z | https://github.com/AntonOsika/gpt-engineer/issues/134 | [] | DoLife | 4 |
biolab/orange3 | scikit-learn | 6,769 | Unable to run when there is a logging.py in the directory Orange is launched in | Similar issue to https://github.com/jupyter/notebook/issues/4892 | closed | 2024-03-21T09:09:14Z | 2024-04-12T07:20:43Z | https://github.com/biolab/orange3/issues/6769 | [
"bug report"
] | zactionn | 3 |
coqui-ai/TTS | python | 3,360 | [Bug] Cannot restore from checkpoint | ### Describe the bug
I'm training a vits model , when continue a training process using
````
python TTS/bin/train_tts.py --continue_path path/to/training/model/ouput/checkpoint/
````
the code in function _restore_best_loss ( trainer.py: line 1720 ) did not check type of ch["model_loss"] .
Restoring from best_... | closed | 2023-12-04T02:53:38Z | 2023-12-07T13:21:33Z | https://github.com/coqui-ai/TTS/issues/3360 | [
"bug"
] | YuboLong | 2 |
JoeanAmier/XHS-Downloader | api | 9 | 可以输入作者主页链接,然后下载作者全部作品吗? | 可以在xhs.txt中填写作者主页链接,实现批量下载 | open | 2023-11-04T08:12:59Z | 2023-11-05T06:24:16Z | https://github.com/JoeanAmier/XHS-Downloader/issues/9 | [] | wwkk2580 | 3 |
cvat-ai/cvat | computer-vision | 8,899 | Problem with exporting annotations to Datumaro | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
When exporting my annotations to datumaro format I get the following error: ValueError: could not broadcast input array fr... | closed | 2025-01-06T15:50:04Z | 2025-01-06T22:10:28Z | https://github.com/cvat-ai/cvat/issues/8899 | [
"bug"
] | toolambr | 1 |
ludwig-ai/ludwig | computer-vision | 3,915 | Ray parallelization does not work | **Describe the bug**
Does not work model parallelization with Ray and a custom model from huggingface.
**To Reproduce**
I want to train a neural network using ludwig and molecular encoder from huggingface. My config is:
```
model_type: ecd
input_features:
- name: Smiles
type: text
preprocessing... | open | 2024-01-24T16:41:35Z | 2024-10-21T18:51:06Z | https://github.com/ludwig-ai/ludwig/issues/3915 | [
"bug",
"ray",
"dependency"
] | sergsb | 1 |
graphql-python/graphene-django | graphql | 970 | ManyToMany through model handling via edges | Reopening with reference to: https://github.com/graphql-python/graphene/issues/83
To quote @adamcharnock from https://github.com/graphql-python/graphene/issues/83
> When a DjangoConnectionField traverses a many-to-many field it would be nice to have the option to expose the fields of any through-table on the edges ... | open | 2020-05-23T11:05:55Z | 2024-06-23T09:07:23Z | https://github.com/graphql-python/graphene-django/issues/970 | [
"✨enhancement",
"help wanted"
] | Eraldo | 8 |
stanfordnlp/stanza | nlp | 473 | To what degree is Stanford Stanza case sensitive? | In most languages, upper-case letters can sometimes be used as indicators about the part-of-speech of a word (e.g. proper names). In German particularly, "Gehen Sie?" is second person formal, and "Gehen sie?" is third person plural - the only way to know what is meant (apart from context) is the casing.
NLP tools li... | closed | 2020-09-24T21:20:59Z | 2020-11-06T16:45:56Z | https://github.com/stanfordnlp/stanza/issues/473 | [
"question"
] | yolpsoftware | 2 |
ionelmc/pytest-benchmark | pytest | 3 | Warn if benchmarks in the same group have different options | It's quite a bad idea to compare tests that don't have same `disable_gc` settings at least.
| open | 2014-12-15T00:39:13Z | 2015-08-17T22:42:01Z | https://github.com/ionelmc/pytest-benchmark/issues/3 | [] | ionelmc | 0 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,098 | Date selection in "Postpone expiration date" is not working | I'm in the process of creating a user manual, and has discovered, that the date selection feature in "Postpone expiration date" only allows to postpone 1 day
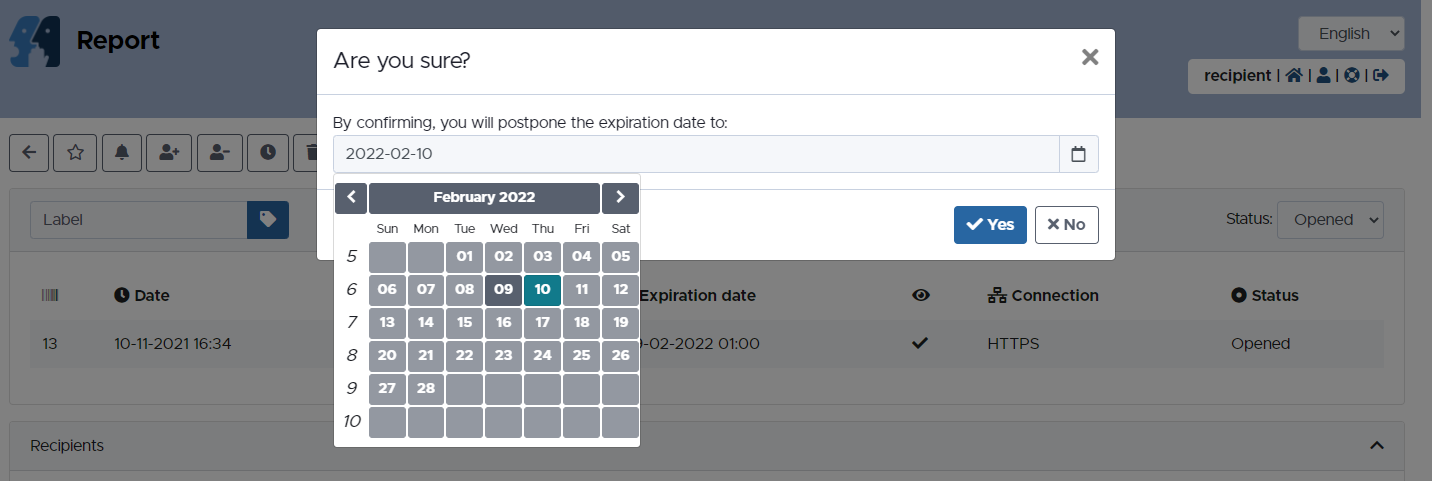
It is not possible to select another date in... | closed | 2021-11-11T05:59:26Z | 2021-11-11T14:58:00Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3098 | [] | schris-dk | 8 |
marshmallow-code/flask-smorest | rest-api | 543 | Pagination documentation example is incorrect | The pagination docs example for cursor pagination is incorrect as written: https://flask-smorest.readthedocs.io/en/latest/pagination.html#cursor-pager
The example used will always raise exceptions using SQLAlchemy or Mongoengine (the two examples provided):
```python
from flask_smorest import Page
class Cur... | closed | 2023-08-18T18:20:14Z | 2024-03-11T23:30:34Z | https://github.com/marshmallow-code/flask-smorest/issues/543 | [
"documentation"
] | brendan-morin | 3 |
flavors/django-graphql-jwt | graphql | 3 | Protecting Mutation or Queries | This is a helpful project, I just have one question, is there a way to protect mutations and queries from unauthorized uses? | closed | 2018-01-27T07:16:04Z | 2023-10-24T06:38:24Z | https://github.com/flavors/django-graphql-jwt/issues/3 | [
"enhancement",
"question"
] | CBinyenya | 11 |
huggingface/transformers | nlp | 36,745 | Gemma 3 1B - TypeError: 'NoneType' object is not callable | ### System Info
I'm trying to run Gemma3 using pipeline, and after updating Transformers to the latest version, making sure my token is set up to work with gated repositories, I still can't run Gemma 3.
Environment:
```
- `transformers` version: 4.50.0.dev0
- Platform: Linux-4.4.0-19041-Microsoft-x86_64-with-glibc2.39... | open | 2025-03-15T23:41:51Z | 2025-03-18T13:14:21Z | https://github.com/huggingface/transformers/issues/36745 | [
"bug"
] | amemov | 8 |
inventree/InvenTree | django | 8,649 | Access project information on stock item labels. | ### Body of the issue
Hi,
Hope my question is posted at the right place.
I am responsible implementing Inventree at the company I work for. Currently I am developing label templates.
Our operation includes installing equipment in racks. These racks are serialized stock items. They are the output of a build order. ... | closed | 2024-12-10T08:29:04Z | 2024-12-10T12:23:31Z | https://github.com/inventree/InvenTree/issues/8649 | [
"question",
"report"
] | akrly | 2 |
plotly/dash | data-visualization | 2,907 | Differences in dcc.Store storage_type performance with dash 2.17.1 | Background callback running correctly (loading animations appearing, print statements appearing too, etc) buut when it finishes it errors out (no output is returned) with this error in the console:
```
Failed to execute 'setItem' on 'Storage': Setting the value of 'flag_storage' exceeded the quota.
```
It was res... | open | 2024-06-28T08:29:16Z | 2024-08-13T14:19:36Z | https://github.com/plotly/dash/issues/2907 | [
"feature",
"P3"
] | celia-lm | 0 |
ivy-llc/ivy | numpy | 27,966 | Fix Ivy Failing Test: jax - elementwise.maximum | closed | 2024-01-20T16:16:20Z | 2024-01-25T09:54:26Z | https://github.com/ivy-llc/ivy/issues/27966 | [
"Sub Task"
] | samthakur587 | 0 | |
torchbox/wagtail-grapple | graphql | 63 | Issue with GraphQLColletion model when required | # 🐛 Bug Report
I'm having an issue with the `GraphQLColletion` grapple model. When `required=True` is passed, all `QuerySetList` arguments disappear.
## 💻 Code Sample
When we add a `GraphQLColletion` to the `graphql_fields` list, we get something like this on the GraphQL schema by default:
```python
class ... | closed | 2020-04-08T21:24:00Z | 2020-04-17T09:58:11Z | https://github.com/torchbox/wagtail-grapple/issues/63 | [] | ruisaraiva19 | 0 |
streamlit/streamlit | deep-learning | 10,126 | `st.close()` or `st.end()` to close or mark the end of a container and remove stale elements (like a frontend version of `st.stop()`) | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
Call `st.close()` to immediately discard all existing elements that follow (within whatever container ... | open | 2025-01-07T20:23:29Z | 2025-01-07T21:18:40Z | https://github.com/streamlit/streamlit/issues/10126 | [
"type:enhancement",
"area:utilities"
] | sfc-gh-dmatthews | 4 |
Yorko/mlcourse.ai | numpy | 764 | topic01 - small section of python code doesn't run - out of sync with main content | Seems like the latest mlcourse.ai/mlcourse_ai_jupyter_book/book/topic01/topic01_pandas_data_analysis.md already has this change but the Jupyter notebook doesn't.
Here is what is on the website and in the .md file:
```
What are the average values of numerical features for churned users?
Here we’l resort to an ad... | closed | 2024-08-03T19:10:26Z | 2024-08-19T15:09:15Z | https://github.com/Yorko/mlcourse.ai/issues/764 | [] | j-silv | 0 |
matterport/Mask_RCNN | tensorflow | 2,183 | How to display result using OpenCV? | Hello everyone, anybody know how to I display the detection using OpenCV? | open | 2020-05-14T05:09:32Z | 2020-06-01T04:28:37Z | https://github.com/matterport/Mask_RCNN/issues/2183 | [] | sgbatman | 4 |
chaoss/augur | data-visualization | 2,894 | Celery : Handle Task Error (issue in `dev`) | It looks as though an array of integers are being passed for comparison to a `repo_git` parameter in a query, and that's a string:
```bash
File "/home/ubuntu/github/augur/augur/tasks/init/celery_app.py", line 105, in on_failure
self.augur_handle_task_failure(exc, task_id, repo_git, "core_task_failure")
File "/h... | open | 2024-08-14T19:47:25Z | 2024-08-14T19:49:44Z | https://github.com/chaoss/augur/issues/2894 | [
"bug",
"server"
] | sgoggins | 0 |
wkentaro/labelme | computer-vision | 1,040 | Not working in Ubuntu 22.04 | As soon as I just installed it from the gnome store, it opens and closes immediately. Any chance to export the project to flatpak? | closed | 2022-06-22T23:56:29Z | 2022-09-26T14:53:33Z | https://github.com/wkentaro/labelme/issues/1040 | [
"issue::bug"
] | ffreitas-dev | 2 |
facebookresearch/fairseq | pytorch | 4,691 | Unable to load Wav2Vec 2.0 models - wav2vec2_vox_960h_new.pt | ## 🐛 Bug
Hello.
Firstly , thank you for sharing all of the work and results and code. Its no small task.
I am attempting to load `wav2vec2_vox_960h_new.pt` but am getting the following errors:
`TypeError: object of type 'NoneType' has no len()`
after calling
`model, cfg, task = fairseq.checkpoint_u... | open | 2022-09-01T21:00:08Z | 2022-10-25T09:26:59Z | https://github.com/facebookresearch/fairseq/issues/4691 | [
"bug",
"needs triage"
] | vade | 5 |
tortoise/tortoise-orm | asyncio | 1,445 | database connection not established after calling Tortoise.init | **Describe the bug**
I configure the orm with Tortoise.init. I can specify any connection data (host, port, user, password) there and no exception will be thrown
**To Reproduce**
```
host = "wrong_host"
port = 1234
user = "wrong_user"
password = "wrong_password"
sslmode = "require"
con_str = f"postgres://"... | open | 2023-07-31T21:35:50Z | 2023-09-14T10:34:11Z | https://github.com/tortoise/tortoise-orm/issues/1445 | [] | Prof1-web | 1 |
miguelgrinberg/Flask-Migrate | flask | 75 | Add edit command | Alembic added an edit command, which seems very useful. It opens a migration, by default the last one, in the default editor. It would be cool if this command was added to flask-migrate as well.
| closed | 2015-08-20T09:57:07Z | 2015-09-17T18:39:13Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/75 | [] | JelteF | 0 |
BlinkDL/RWKV-LM | pytorch | 232 | RWKV 5 supported vLLM?LMdeploy?TGI?Fastllm?FasterTransformer? | RWKV 5 supported vLLM?LMdeploy?TGI?Fastllm?FasterTransformer?
What should I do to get the inference performance?like throughput, token latency and latency? | open | 2024-03-19T10:44:12Z | 2024-09-25T01:23:23Z | https://github.com/BlinkDL/RWKV-LM/issues/232 | [] | lanzhoushaobing | 2 |
autogluon/autogluon | data-science | 4,806 | [BUG] Some unit tests cannot be run externally | **Bug Report Checklist**
<!-- Please ensure at least one of the following to help the developers troubleshoot the problem: -->
- [x] I provided code that demonstrates a minimal reproducible example. <!-- Ideal, especially via source install -->
- [x] I confirmed bug exists on the latest mainline of AutoGluon via sour... | closed | 2025-01-16T23:28:43Z | 2025-01-17T20:34:41Z | https://github.com/autogluon/autogluon/issues/4806 | [
"bug",
"module: multimodal"
] | TRNWWZ | 3 |
axnsan12/drf-yasg | rest-api | 556 | [BUG] Missing endpints | file: drf_yasg/generators.py
func: EndpointEnumerator.get_api_endpoints
line: 102-110
code:
path = self.replace_version(path, callback)
# avoid adding endpoints that have already been seen,
# as Django resolves urls in top-down order
if path in ignored_endpoints:
con... | open | 2020-03-10T06:06:35Z | 2025-03-07T12:15:25Z | https://github.com/axnsan12/drf-yasg/issues/556 | [
"triage"
] | daleeg | 0 |
PaddlePaddle/ERNIE | nlp | 687 | ERINIE-doc的预训练数据 | 请问,ERINIE-doc的预训练数据的CC-NEWS和STORIES的获取和处理方式能分享一下吗? | closed | 2021-05-30T09:32:32Z | 2021-08-06T08:26:42Z | https://github.com/PaddlePaddle/ERNIE/issues/687 | [
"wontfix"
] | xyltt | 3 |
jacobgil/pytorch-grad-cam | computer-vision | 134 | AttributeError: 'GradCAM' object has no attribute 'activations_and_grads' | I used this code to convit model,and ues my own datasets.But get a problem.
The problem is:
cam = methods[args.method](model=model,
File "D:\anaconda\anaconda\envs\ViT\lib\site-packages\grad_cam-1.3.2-py3.8.egg\pytorch_grad_cam\grad_cam.py", line 8, in __init__
File "D:\anaconda\anaconda\envs\ViT\lib\site-pa... | closed | 2021-09-13T15:09:54Z | 2023-01-03T11:18:36Z | https://github.com/jacobgil/pytorch-grad-cam/issues/134 | [] | Joker-ZXR | 7 |
gevent/gevent | asyncio | 1,510 | gevent.subprocess communicate suppresses UnicodeDecodeError and returns empty string instead | * gevent version: 1.4.0
* Python version: cPython 3.7.5 (default, Dec 18 2019, 12:57:24) \n[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)]
* Operating System: CentOS Linux release 7.7.1908 (Core)
### Description:
Running `gevent.subprocess.Popen.communicate()`, where text is expected but fails to decode, results in a tra... | closed | 2020-01-14T10:15:42Z | 2020-01-14T20:29:51Z | https://github.com/gevent/gevent/issues/1510 | [
"Type: Bug"
] | koreno | 0 |
openapi-generators/openapi-python-client | rest-api | 984 | Timeout issues due to client.beta.threads.runs.retrieve() | ~ Snip ~
Had the wrong repo. | closed | 2024-02-29T23:02:23Z | 2024-02-29T23:11:46Z | https://github.com/openapi-generators/openapi-python-client/issues/984 | [] | JeretSB | 1 |
gee-community/geemap | jupyter | 854 | The feature export problem by Map.draw_features | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information
- geemap version: the least version
- Python version: 3.8
- Operating System: Windows
### Description
I used the code showed in following:
"Map = geemap.Map()
Map"
to show a map and selected some poi... | closed | 2022-01-07T08:43:44Z | 2022-01-07T13:42:10Z | https://github.com/gee-community/geemap/issues/854 | [
"bug"
] | Godjobgerry | 1 |
developmentseed/lonboard | jupyter | 312 | [EPIC] Optimize user notebook experience | ## Context
Keeping our dependencies and development environment trimmed to what is necessary can keep our project tidy and help load times and execution times.
## Issue
Let's remove unnecessary dependencies and optimize the notebook experience.
## Acceptance-Criteria
List the tasks that need to be completed or... | closed | 2024-01-11T15:42:12Z | 2024-09-24T19:43:08Z | https://github.com/developmentseed/lonboard/issues/312 | [
"python"
] | emmalu | 1 |
yt-dlp/yt-dlp | python | 12,013 | [BiliBili] Circumvent 412 Error (Request is blocked by server) & Possible fix for no-account downloads. | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [X] I'm reporting that yt-dlp is broken on a **supported** site
- [X] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | closed | 2025-01-06T19:28:45Z | 2025-01-26T00:54:34Z | https://github.com/yt-dlp/yt-dlp/issues/12013 | [
"duplicate",
"site-bug"
] | pxssy | 3 |
autokey/autokey | automation | 920 | Keyboard keys not importing or loading in. | ### AutoKey is a Xorg application and will not function in a Wayland session. Do you use Xorg (X11) or Wayland?
Xorg
### Has this issue already been reported?
- [X] I have searched through the existing issues.
### Is this a question rather than an issue?
- [X] This is not a question.
### What type of issue is thi... | open | 2023-11-08T03:26:48Z | 2023-11-18T09:21:46Z | https://github.com/autokey/autokey/issues/920 | [] | ArcSpammer | 5 |
iperov/DeepFaceLab | machine-learning | 5,341 | Issue with quick96 training model | Hello im having problems with my training model ! For some reason my dfl is not remembering my trained model .Even though I saved it and I am currently around at 71000 iteration
It says no saved model found
Please help me out

```
Related code that enforces `gfpgan/weights`:
```
self.face_helper = FaceRestoreHelper(
upscale,
face_size=512,
... | closed | 2023-06-15T11:41:38Z | 2025-01-22T23:52:35Z | https://github.com/TencentARC/GFPGAN/issues/399 | [] | henryruhs | 2 |
explosion/spaCy | deep-learning | 12,854 | morph reading in token is not merged properly when using merge_entities pipeline | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
```
import spacy
import json
import fileinput
from pprint import pprint
# returns start and end index, end not inclusive
def process(nlp, texts):
docs = list(nlp.pipe(texts,... | closed | 2023-07-24T19:06:54Z | 2023-07-25T06:24:01Z | https://github.com/explosion/spaCy/issues/12854 | [
"feat / doc",
"feat / morphology"
] | lawctan | 2 |
tflearn/tflearn | tensorflow | 255 | fix accuray for binary_crossentropy | There is a bug when calculating 'accuracy' metric along with binary_crossentropy. 'accuracy' should have different behavior if incoming tensor is 1-D or 2-D.
| closed | 2016-08-03T00:10:18Z | 2016-08-31T19:41:41Z | https://github.com/tflearn/tflearn/issues/255 | [
"bug"
] | aymericdamien | 2 |
PaddlePaddle/ERNIE | nlp | 222 | BERT、ERNIE、TextCNN做文本分类任务性能对比 | 以下模型的推理速度、内存占用等均在‘CPU’上考察
【TextCNN、pytorch_bert、tensorflow_bert、ERNIE文本分类任务性能对比】
【以下性能考察结果均经过多次测试】
推理时的数据最长文本有75万中文字符,利用100个文本进行测试。
从内存占用及推理速度指标来看,四种算法中,TextCNN均是最优的。
由于bert及ERNIE并未经过多次fine-tune就已经达到较好泛化效果,因此可以认为其泛化能力会相对textcnn更好些。
pytorch_bert、tensorflow_bert、ERNIE三者相比较,在内存占用方面相差不是很大;但ERNIE在推理速度方面稍差(**这个蛮重要**)... | closed | 2019-07-24T03:48:11Z | 2020-05-28T09:52:45Z | https://github.com/PaddlePaddle/ERNIE/issues/222 | [
"wontfix"
] | Biaocsu | 17 |
aio-libs/aiomysql | sqlalchemy | 605 | Sometimes it broke by concurrent.futures._base.CancelledError | When I using Aiomysql in a sanic high concurrency web server:
``` python
async with self._pool.acquire() as conn:
async with conn.cursor() as cur:
await cur.execute(query, param)
if is_all:
res = await cur.fetchall()
else:
res = await cur.fetchone()
```
So... | open | 2021-08-09T02:27:00Z | 2023-04-12T02:22:44Z | https://github.com/aio-libs/aiomysql/issues/605 | [
"bug"
] | yanjieee | 5 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,252 | Define Dropout Value for Cycle & Pix2Pix | I have managed to turn dropout on for both pix2pix and cycle gan during training and in inference.
I would now like to explore the impact different values for dropout has on the predictions that are drawn from of each of the two models when running inference on the same dataset multiple times. How can I determine ... | open | 2021-03-12T15:58:05Z | 2021-04-14T15:56:44Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1252 | [] | Tonks684 | 1 |
graphql-python/gql | graphql | 391 | Is there a reason TransportQueryError doesn't extend TransportError? | I expected all exceptions to be captured by `gql.exceptions.TransportError`:
```python
from gql.exceptions import TransportError
try:
...
except TransportError as e:
...
```
But `TransportQueryError` extends from `Exception`:
https://github.com/graphql-python/gql/blob/2827d887db4c6951899a8e242a... | closed | 2023-02-23T13:19:11Z | 2023-02-23T17:09:56Z | https://github.com/graphql-python/gql/issues/391 | [
"type: bug"
] | helderco | 2 |
deepset-ai/haystack | nlp | 8,437 | Support Claude Sonnet 3.5 for AmazonBedrockGenerator | **Is your feature request related to a problem? Please describe.**
We'd like to use Sonnet 3.5 in Bedrock for some of our projects but need Haystack to support it (if it doesn't already)
**Describe the solution you'd like**
Haystack supports Sonnet 3 in Bedrock but we'd like support for Sonnet 3.5
**Describe a... | closed | 2024-10-02T22:00:14Z | 2024-10-10T14:21:08Z | https://github.com/deepset-ai/haystack/issues/8437 | [] | jkruzek | 3 |
deepset-ai/haystack | nlp | 8,649 | Importing `FileTypeRouter` imports all converters | **Describe the bug**
When using/importing `FileTypeRouter` all converters are imported as well. This makes it a heavier operation than necessary and can increase the probability for further issues (e.g. cyclic dependencies, load-time, import deadlocks when used in multithreaded env). E.g. importing `AzureOCRDocumentCo... | closed | 2024-12-17T11:56:49Z | 2025-02-17T07:50:00Z | https://github.com/deepset-ai/haystack/issues/8649 | [
"P2"
] | tstadel | 0 |
NullArray/AutoSploit | automation | 339 | Unhandled Exception (3b02048a5) | Autosploit version: `3.0`
OS information: `Linux-4.18.0-kali3-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py`
Error meesage: `global name 'Except' is not defined`
Error traceback:
```
Traceback (most recent call):
File "/root/Github/AutoSploit/autosploit/main.py", line 113, in main
... | closed | 2019-01-06T09:54:33Z | 2019-01-14T18:06:36Z | https://github.com/NullArray/AutoSploit/issues/339 | [] | AutosploitReporter | 0 |
ivy-llc/ivy | tensorflow | 28,066 | Fix Frontend Failing Test: torch - tensor.torch.Tensor.__mul__ | ToDo: https://github.com/unifyai/ivy/issues/27498
Type: Priority | closed | 2024-01-27T08:02:17Z | 2024-01-27T09:01:23Z | https://github.com/ivy-llc/ivy/issues/28066 | [
"Sub Task"
] | Aryan8912 | 1 |
awtkns/fastapi-crudrouter | fastapi | 134 | Question: Model with different look than the Input SCHEMA | I have an API that for some reasons has a certain structure which is different from what the route receives from external actors (they send with their schema which is a json from mongodb), how do I handle the conversion from this different schema to my model? | open | 2022-01-06T18:44:09Z | 2022-01-06T18:44:09Z | https://github.com/awtkns/fastapi-crudrouter/issues/134 | [] | jeanlst | 0 |
ageitgey/face_recognition | python | 929 | Can we make face_recognition.face_encodings a bit faster | * face_recognition version:
* Python version 3.6:
* Windows 10
GTX 1060
16 gb ram
I have notices ` face_recognition.face_encodings` takes a lot of time, is there a way to make it bit faster? | open | 2019-09-13T20:28:05Z | 2019-10-15T01:45:11Z | https://github.com/ageitgey/face_recognition/issues/929 | [] | talhaanwarch | 2 |
google-research/bert | nlp | 461 | Reduce prediction time for question answering | Hi,
i am executing BERT solution on machine with GPU (Tesla K80 - 12 GB) . for question answering prediction for single question is taking more than 5 seconds. Can we reduce it to below 1 second.
Do we need to configure any thing to make it possible ?
Thank you | open | 2019-02-28T09:28:09Z | 2019-09-19T04:36:36Z | https://github.com/google-research/bert/issues/461 | [] | shivamani-ans | 9 |
pydantic/pydantic | pydantic | 10,787 | `TypeAdapter.json_schema()` unable to render schema for custom `Annotated` type having a pydantic type in `PlainValidator.json_schema_input_type` | ### Initial Checks
- [X] I confirm that I'm using Pydantic V2
### Description
I define a custom Pydantic type with `typing.Annotated` + `pydantic.PlainValidator(func, json_schema_input_type=OtherType)` syntax :
- Validation of this custom type works as expected
- but I am unable to render its **JSON schem... | closed | 2024-11-07T16:35:22Z | 2024-12-05T19:47:46Z | https://github.com/pydantic/pydantic/issues/10787 | [
"bug V2"
] | emaheuxPEREN | 5 |
OWASP/Nettacker | automation | 991 | test coverage for `api/core.py` |
 | open | 2025-01-20T16:54:41Z | 2025-01-20T16:58:46Z | https://github.com/OWASP/Nettacker/issues/991 | [] | nitinawari | 1 |
ray-project/ray | deep-learning | 51,071 | [core] Only one of the threads in a thread pool will be initialized as a long-running Python thread | ### What happened + What you expected to happen
Currently, only one of the threads in a thread pool will be initialized as a long-running Python thread. I should also investigate whether it's possible to call `PyGILState_Release` on a different thread other than the one calls `PyGILState_Ensure` in the thread pool.
#... | open | 2025-03-04T22:03:14Z | 2025-03-04T23:02:20Z | https://github.com/ray-project/ray/issues/51071 | [
"bug",
"core"
] | kevin85421 | 0 |
vastsa/FileCodeBox | fastapi | 290 | Cannot read properties of undefined reading ‘digest‘ | 因为内部站点没有域名,纯ip访问所以是用的http访问
能否兼容http的情况

 | closed | 2025-03-13T08:44:23Z | 2025-03-15T15:42:39Z | https://github.com/vastsa/FileCodeBox/issues/290 | [] | BlackWhite2000 | 1 |
serengil/deepface | deep-learning | 542 | What is the target_size = (224, 224) for each of the models? | What value of target_size should I use for each of the models?
"VGG-Face",
"Facenet",
"Facenet512",
"OpenFace",
"DeepFace",
"DeepID",
"ArcFace",
"Dlib",
"SFace",
]
| closed | 2022-08-20T08:28:51Z | 2022-08-20T09:25:38Z | https://github.com/serengil/deepface/issues/542 | [
"question"
] | martinenkoEduard | 1 |
tiangolo/uwsgi-nginx-flask-docker | flask | 140 | Image failing on start | Since the new change on nginx.conf we added the following line to our Dockerfile
`COPY ./nginx.conf /app/nginx.conf`
but now on startup we get the following errors
any ideas??
6/14/2019 4:06:30 PMworker 1 buried after 1 seconds
6/14/2019 4:06:30 PMworker 2 buried after 1 seconds
6/14/2019 4:06:30 PMgoodbye ... | closed | 2019-06-14T14:21:10Z | 2020-04-10T20:01:27Z | https://github.com/tiangolo/uwsgi-nginx-flask-docker/issues/140 | [] | sepharg | 1 |
MODSetter/SurfSense | fastapi | 11 | Problem | uvicorn server:app --host 0.0.0.0 --port 8000
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "C:\Users\forte\AppData\Local\Programs\Python\Python311\Scripts\uvicorn.exe\__main__.py", line 7, in <module>
File "C:\U... | closed | 2024-11-13T18:07:37Z | 2024-11-16T19:08:30Z | https://github.com/MODSetter/SurfSense/issues/11 | [] | Claudioappassionato | 1 |
chainer/chainer | numpy | 7,726 | `chainerx.flip` returns incorrect value for non-contiguous inputs | `chainerx.flip` (supported in #7065) sometimes returns incorrect value for non-contiguous inputs.
```py
>>> import chainerx
>>> chainerx.flip(chainerx.array([1, 2, 3, 4], dtype='int32')[::-1])
array([32534, 33, 0, 1], shape=(4,), dtype=int32, device='native:0')
``` | closed | 2019-07-09T04:11:49Z | 2019-07-10T08:46:18Z | https://github.com/chainer/chainer/issues/7726 | [
"cat:bug",
"pr-ongoing",
"ChainerX"
] | asi1024 | 1 |
matplotlib/matplotlib | data-science | 29,224 | [Bug]: Matplotlib don't take into account savefig.pad_inches when plt.plot(... transform=fig.dpi_scale_trans) | ### Bug summary
Hello! When I draw line from bottom left figure corner up to top right figure corner, I see then that there some figure paddings:
```pyhon
fig = plt.figure(facecolor='#ccc')
ax = fig.gca()
ax.set_axis_off()
line_1, = plt.plot([0, 1], [0, 1], transform=fig.transFigure, clip_on=False, lw=2, c='blu... | open | 2024-12-03T18:42:04Z | 2024-12-05T17:48:34Z | https://github.com/matplotlib/matplotlib/issues/29224 | [] | sindzicat | 12 |
clovaai/donut | computer-vision | 237 | ValueError: `num_beams` is set to 1 | Hi,
Thank you for your work.
I tried to use this demo on [CORD](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Donut/CORD/Fine_tune_Donut_on_a_custom_dataset_(CORD)_with_PyTorch_Lightning.ipynb) from Niels Rogge, but during the training, it says that:
ValueError: `num_bea... | open | 2023-08-09T12:03:20Z | 2024-03-07T19:30:56Z | https://github.com/clovaai/donut/issues/237 | [] | yonlas | 1 |
jina-ai/clip-as-service | pytorch | 878 | how to transform CLIP to TensorRT, ONNX, TorchScript? | Could you please share the processing code of converting the original CLIP to TensorRT, ONNX, TorchScript model? | closed | 2022-12-20T03:28:59Z | 2023-03-02T08:22:12Z | https://github.com/jina-ai/clip-as-service/issues/878 | [] | FD-Liekkas | 1 |
mage-ai/mage-ai | data-science | 5,183 | Allow for registration of custom pipeline notification listeners | **Is your feature request related to a problem? Please describe.**
Mage-AI allows for pipeline failure/success/etc. events on Slack, Discord, Teams, etc. Sometimes, however, we would like to be able to react in different ways to a pipeline event: perhaps dropping a message on a queue, talking to some other API, etc. C... | open | 2024-06-10T20:09:51Z | 2024-06-10T20:09:51Z | https://github.com/mage-ai/mage-ai/issues/5183 | [] | pholser | 0 |
wandb/wandb | data-science | 9,022 | [Bug]: Error 403 When Using Wandb in Accelerator | Apologies for the oversight; I’m a beginner. When I saw the example provided:
accelerator = Accelerator(
kwargs_handlers=[ddp_kwargs],
deepspeed_plugin=deepspeed_plugin,
log_with="wandb"
)
accelerator.init_trackers(
"Accelerator",
config=hps,
init_kwargs={
"wandb": {
"notes"... | closed | 2024-12-05T01:12:49Z | 2024-12-05T02:03:15Z | https://github.com/wandb/wandb/issues/9022 | [
"ty:bug",
"a:sdk"
] | MstarLioning | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.