
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
lepture/authlib | django | 376 | CSRF Warning! State not equal in request and response | **Describe the bug**
It happens when using authlib to configure Keycloak for Apache Superset. Everything works perfectly up until redirecting back from Keycloak to Superset.
**Error Stacks**
```
Traceback (most recent call last):
File "/home/abc/.local/lib/python3.8/site-packages/flask/app.py", line 2447, ... | closed | 2021-08-18T12:06:46Z | 2024-11-11T13:40:19Z | https://github.com/lepture/authlib/issues/376 | [
"bug"
] | nl2412 | 25 |
Miserlou/Zappa | flask | 2,230 | [Question] Is there a way to set the API Gateway stage on AWS different from the 'stage name' in the config? | I have 3 stages... dev, staging, and prod. But I would like each of the three API Gateway endpoints to have a single API Gateway stage name of 'api' so that my app is accessible at '/api' on all three instead of '/dev', '/staging', and '/prod'.
I know about custom domains but this doesn't work for me because I share... | open | 2021-10-25T17:20:47Z | 2021-10-25T17:20:47Z | https://github.com/Miserlou/Zappa/issues/2230 | [] | dsmurrell | 0 |
aio-libs/aiomysql | asyncio | 62 | Enable by default utf8 encoding | Hi,
If I import this SQL file in MySQL DB with this line: https://github.com/TechEmpower/FrameworkBenchmarks/blob/master/config/create.sql#L110
When I retrieve this line with aiomysql, I have **??????????????** string instead of **フレームワークのベンチマーク**.
Except if I add two parameters in the aiomysql connection:
```
... | closed | 2016-02-14T22:00:19Z | 2016-02-16T11:17:17Z | https://github.com/aio-libs/aiomysql/issues/62 | [] | ludovic-gasc | 4 |
feature-engine/feature_engine | scikit-learn | 41 | Discretiser - return interval boundaries | I would like to suggest discretiser had an option to return interval boundaries instead of an integer, it turns more understandable the variable content output.
for example: outputs 1, 3, 2 turns (0,10] , (20,30], (10,20]
Thanks in advance | closed | 2020-05-12T14:33:21Z | 2020-05-14T17:33:57Z | https://github.com/feature-engine/feature_engine/issues/41 | [] | pellanda | 1 |
minimaxir/textgenrnn | tensorflow | 31 | ValueError: Layer #1 (named "embedding") | Hi,
After I train the model with the following config:
num_epochs: 1000
gen_epochs: 10
batch_size: 128
prop_keep: 1.0
new_model: True
model_config:
rnn_layers: 2
rnn_size: 128
rnn_bidirectional: False
max_length: 40
dim_embeddings: 100
word_level: False
I am trying to generate some text... | closed | 2018-06-10T02:23:06Z | 2018-06-10T02:29:46Z | https://github.com/minimaxir/textgenrnn/issues/31 | [] | ihavetoomanyquestions | 1 |
Gozargah/Marzban | api | 1,216 | مشکل اتصال اپراتور همراه اول | دوستان من زمانی که پینگ میگیرم با CMD، کاملا هم آیپی هم دامنه اوکیه ولی نه پنل واسم با همراه اول بالا میاد، نه سرورها واسم کار میکنه. با آیپی مستقیم هم پنل بالا نمیاد روی همراه اول.
خیلی اوکی میتونم ssh بزنم بهش با اینترنت همراه اول،
اما پنل X-UI رو هم که نصب کردم همین شکلی بود
راهی هست واسهی این قضیه که این محدود... | closed | 2024-08-03T21:33:44Z | 2024-08-04T04:46:57Z | https://github.com/Gozargah/Marzban/issues/1216 | [] | MatinSenPai | 1 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 499 | Real Time Voice Cloning Issue | after i have done everything and whin i put code [python demo_toolbox.py] to run tool box it shows ImportError : DLL Load Failed:The specified module could not be found.
How to Fix this problem | closed | 2020-08-20T21:22:24Z | 2020-08-23T13:50:29Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/499 | [] | Jason3018 | 3 |
hankcs/HanLP | nlp | 739 | 分词问题:自定义词典有时会失效 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2018-01-10T07:07:05Z | 2020-01-01T10:51:04Z | https://github.com/hankcs/HanLP/issues/739 | [
"ignored"
] | kjdongzh | 6 |
biosustain/potion | sqlalchemy | 140 | Cross resource fields.Inline does not updates the schema accordingly | I have a resource with a Route that instead of returning the own schema, should return the schema of another ModelResource. I'll explain with some code that is purely a demo but should give the idea:
```
class UserResource(ModelResource):
class Meta:
model = User
class AuthResource(Resource):
... | closed | 2018-07-18T15:16:02Z | 2018-07-20T11:29:10Z | https://github.com/biosustain/potion/issues/140 | [] | dappiu | 0 |
plotly/dash | plotly | 2,583 | Inline callback exceptions in Jupyter Notebook | closed | 2023-07-04T21:20:27Z | 2023-07-04T21:38:36Z | https://github.com/plotly/dash/issues/2583 | [] | mcstarioni | 0 | |
labmlai/annotated_deep_learning_paper_implementations | machine-learning | 61 | torch version to run a demo code for FNet | Hi guys! Thanks for the awesome work! I am excited to play with the code. Here is the gist
https://gist.github.com/ra312/f3c895aba6e8954985258de10e9be52f
At the first attempt, I am encountered this exception
<img width="863" alt="image" src="https://user-images.githubusercontent.com/12486277/122645152-bd598100-d1... | closed | 2021-06-19T14:15:10Z | 2022-07-02T10:03:29Z | https://github.com/labmlai/annotated_deep_learning_paper_implementations/issues/61 | [
"enhancement"
] | ra312 | 6 |
ultralytics/yolov5 | deep-learning | 12,894 | How to remove a detection layer? | ### Search before asking
- [x] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I am using YOLOv5 to create a detection model. The model will only see small objects (box... | closed | 2024-04-08T12:09:44Z | 2024-10-20T19:43:12Z | https://github.com/ultralytics/yolov5/issues/12894 | [
"question",
"Stale"
] | nachoogriis | 3 |
lux-org/lux | jupyter | 240 | Extend support for ordinal data type | Ordinal data are common in rating scales for surveys, as well as attributes like Age or number of years for X.
Ordinal data currently gets classified as categorical, especially if the column contains NaN values.
The [young people survey dataset](https://www.kaggle.com/miroslavsabo/young-people-survey) on Kaggle is a... | open | 2021-01-23T08:55:59Z | 2021-03-02T13:09:40Z | https://github.com/lux-org/lux/issues/240 | [
"easy"
] | dorisjlee | 1 |
activeloopai/deeplake | tensorflow | 2,320 | deeplake.util.exceptions.TransformError | ## 🐛🐛 Bug Report
I'm attempting to load some Documents and get a `TransformError` - could someone please point me in the right direction? Thanks!
I'm afraid the traceback doesn't mean much to me.
```python
db = DeepLake(dataset_path=deeplake_path, embedding_function=embeddings)
db.add_documents(texts)
```
... | closed | 2023-04-27T09:10:31Z | 2023-05-27T16:43:44Z | https://github.com/activeloopai/deeplake/issues/2320 | [
"bug"
] | CharlesFr | 3 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,322 | [Bug]: Adding "txt2img" to "Hidden UI tabs" makes img2img no longer function | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | open | 2024-08-02T19:34:02Z | 2024-10-29T15:11:44Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16322 | [
"bug"
] | 1cheez | 2 |
mars-project/mars | pandas | 2,930 | [BUG] `dask.persist` cannot work on dask-on-mars | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
`dask.persist` cannot work on dask-on-mars.
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Your ... | closed | 2022-04-18T13:35:17Z | 2022-04-24T02:19:24Z | https://github.com/mars-project/mars/issues/2930 | [
"type: bug",
"dask-on-mars"
] | qinxuye | 4 |
statsmodels/statsmodels | data-science | 8,652 | ENH/REF/SUMM: enhance, refactor power classes | triggered by #8646 and #8651
see also #8159 for power classes without effect size
related issues: ...
The semi-generic power classes were written initially based on effect sizes and packages GPower and R pwr.
Design decisions were based on those packages with the generic structure it is often not "obvious" how to... | open | 2023-02-06T15:39:16Z | 2023-02-25T18:31:35Z | https://github.com/statsmodels/statsmodels/issues/8652 | [
"type-enh",
"comp-stats"
] | josef-pkt | 4 |
comfyanonymous/ComfyUI | pytorch | 7,286 | Installing requirements.txt fails due to missing RECORD for tokenizers | ### Your question
I have recently synced the latest ComfyUI (commit ID 50614f1b7), and I am trying to install and run using the instructions here: [](https://docs.comfy.org/installation/manual_install#nvidia)
I am encountering an error when I run the `pip install -r requirements.txt` command. Here's my output:
```
.... | closed | 2025-03-17T21:48:49Z | 2025-03-18T15:30:59Z | https://github.com/comfyanonymous/ComfyUI/issues/7286 | [
"User Support"
] | sipkode | 1 |
saulpw/visidata | pandas | 1,557 | 2.10.2 unavailable in PyPI | <img width="1728" alt="Screen Shot 2022-10-08 at 1 21 43 PM" src="https://user-images.githubusercontent.com/11388735/194719825-b3e6cdeb-da92-4370-aa62-6e47cdf113a9.png">
I installed the dev branch of Visidata to get around [1550](https://github.com/saulpw/visidata/issues/1550).
```sh
pipx install git+https://g... | closed | 2022-10-08T17:24:12Z | 2022-10-08T17:56:19Z | https://github.com/saulpw/visidata/issues/1557 | [
"question"
] | zachvalenta | 4 |
pykaldi/pykaldi | numpy | 232 | Clif build fails on Ubuntu 20.04 | I tried some configurations to build clif and i had issues that clif doesnt build with Ubuntu 20.04 and Python 3.6, 3.7 and 3.8.
I get the same error message in Ubuntu 20.04 with Python 3.6 and 3.7 on two different virtual machines:
`
[324/490] Building CXX object tools/llvm-as/CMakeFiles/llvm-as.dir/llvm-as.cpp.o
... | closed | 2020-08-15T10:58:49Z | 2021-06-13T16:14:53Z | https://github.com/pykaldi/pykaldi/issues/232 | [] | Alienmaster | 4 |
FlareSolverr/FlareSolverr | api | 435 | [mteamtp] (updating) Error connecting to FlareSolverr server | **Please use the search bar** at the top of the page and make sure you are not creating an already submitted issue.
Check closed issues as well, because your issue may have already been fixed.
### How to enable debug and html traces
[Follow the instructions from this wiki page](https://github.com/FlareSolverr/Fl... | closed | 2022-07-20T08:41:41Z | 2022-07-24T03:22:15Z | https://github.com/FlareSolverr/FlareSolverr/issues/435 | [
"invalid",
"more information needed"
] | bing81620 | 1 |
collerek/ormar | sqlalchemy | 1,014 | Lost connection to MySQL server during query | When my application throws an exception and I try to access an endpoint again, it returns the error "(2013, 'Lost connection to MySQL server during query ([Errno 104] Connection reset by peer)')".
It is as if it were not connected to the database or as if it did not refresh. Using SQLAlchemist I edited the parameter... | closed | 2023-02-15T08:59:56Z | 2024-04-29T13:08:09Z | https://github.com/collerek/ormar/issues/1014 | [
"bug"
] | alexol91 | 1 |
arnaudmiribel/streamlit-extras | streamlit | 136 | 🐛 [BUG] - Markdownlit | ### Description
In Markdownlit it uses "st.experimental_memo" which should be changed to "st.cache_data". Using st.experimental_memo I've found that my app crashes on importing markdownlit (from markdownlit import mdlit) with the error "streamlit.errors.StreamlitAPIException: `set_page_config()` can only be called onc... | closed | 2023-04-04T07:41:13Z | 2023-05-11T15:28:00Z | https://github.com/arnaudmiribel/streamlit-extras/issues/136 | [
"bug"
] | ditlevjoergensen | 1 |
dsdanielpark/Bard-API | api | 241 | BardAsync with continuous conversation | bard = BardAsync(token=tokenBard, session=session, timeout = 60)
jawaban = await bard.get_answer(q)
return jawaban
#res: __init__() got an unexpected keyword argument 'session | closed | 2023-12-06T04:28:48Z | 2024-01-01T13:33:09Z | https://github.com/dsdanielpark/Bard-API/issues/241 | [] | ahmadkeren | 7 |
schemathesis/schemathesis | graphql | 1,994 | [FEATURE] graphql not required handling | Currently when fields in graphql schemas are not required, schemathesis can send `null` to them.
According to the graphql specs this is valid and it is useful to find bugs.
But sometimes it would be easier to not send null values
Is there a way to turn the null value sending behavior off? It would be nice to hav... | closed | 2024-01-25T12:08:38Z | 2024-08-06T19:23:32Z | https://github.com/schemathesis/schemathesis/issues/1994 | [
"Priority: Medium",
"Type: Feature",
"Specification: GraphQL",
"Difficulty: Intermediate"
] | devkral | 2 |
graphql-python/gql | graphql | 304 | Infinite Recursion Error | **Describe the bug**
So when constructing my gql client, I am able to do that successfully. When doing do, I also set `fetch_schema_from_transport=True` in there. When doing so, I try to access a query using dot notation but I get an infinite recursion error.
```
client = Client(
transport=RequestsHTTPT... | closed | 2022-02-23T20:10:14Z | 2022-02-23T22:13:33Z | https://github.com/graphql-python/gql/issues/304 | [
"type: question or discussion"
] | alexmaguilar25 | 10 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 1,200 | webrtcvad wont install | When I try to install webrtcvad with pip install webrtcvad it throws out
Collecting webrtcvad
Using cached webrtcvad-2.0.10.tar.gz (66 kB)
Preparing metadata (setup.py) ... done
Building wheels for collected packages: webrtcvad
Building wheel for webrtcvad (setup.py) ... error
error: subprocess-exited... | open | 2023-04-21T22:17:25Z | 2024-08-06T16:59:22Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1200 | [] | zamonster | 6 |
qubvel-org/segmentation_models.pytorch | computer-vision | 47 | cannot import name 'cfg' from 'torchvision.models.vgg' | Hi, there is an error.
```
~/anaconda3/envs/dl/lib/python3.7/site-packages/segmentation_models_pytorch/encoders/vgg.py in <module>
2 from torchvision.models.vgg import VGG
3 from torchvision.models.vgg import make_layers
----> 4 from torchvision.models.vgg import cfg
ImportError: cannot import name 'c... | closed | 2019-08-22T07:17:01Z | 2019-08-26T14:44:13Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/47 | [] | JimWang97 | 1 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 164 | 发现一个挺搞笑的东西 | words=FXXK_U_ByteDance
# 从安卓apk中提取到的新API,目前可用,支持视频,图集,笔记的解析(2022年12月25日)
api_url = f"https://www.iesdouyin.com/aweme/v1/web/aweme/detail/?aweme_id={video_id}&aid=1128&version_name=23.5.0&device_platform=android&os_version=2333&Github=Evil0ctal&words=FXXK_U_ByteDance"
| closed | 2023-03-06T09:33:44Z | 2023-03-11T00:43:53Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/164 | [
"enhancement"
] | xyfacai | 1 |
ultralytics/yolov5 | machine-learning | 12,949 | How to change annotations indices in memory without changing the dataset locally? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello! 😊
I have a large dataset and I would like to change the annotations before sta... | closed | 2024-04-22T09:46:36Z | 2024-06-02T00:23:54Z | https://github.com/ultralytics/yolov5/issues/12949 | [
"question",
"Stale"
] | killich8 | 4 |
hbldh/bleak | asyncio | 1,507 | KeyError: 'org.bluez.Device1' | - raspberry pi 4B
- debian bookworm
- bleak 0.20.2-1 from python3-bleak package
- bluetoothctl: 5.66
I'm having a very hard time getting my code to run stable; i'm basically round-robin polling about 60 bluetooth devices (For details of my setup see #1500)
Apart from the occasional problem at the kernel/driver... | closed | 2024-02-12T13:54:37Z | 2024-02-20T03:54:41Z | https://github.com/hbldh/bleak/issues/1507 | [
"bug",
"Backend: BlueZ"
] | zevv | 11 |
dynaconf/dynaconf | django | 1,157 | [RFC]Change the semantics of layered environments | Dynaconf was designed to have multiple environments (sections) on the same file
```toml
[default]
a = 1
[dev]
a = 2
[prod]
a = 3
```
It looks like this approach is not the best one, and not the one adopted by industry,
what I see in the deployments are the usage of the same name settings files that vary... | open | 2024-07-08T16:32:19Z | 2024-07-08T18:38:26Z | https://github.com/dynaconf/dynaconf/issues/1157 | [
"Not a Bug",
"RFC",
"4.0-breaking-change"
] | rochacbruno | 0 |
recommenders-team/recommenders | data-science | 1,342 | Cannot replicate LSTUR results for MIND large test | Hello, I cannot replicate the results of LSTUR model with MIND test set. I used the scripts provided to generate `embedding.npy`, `word_dict.pkl` and `uid2index.pkl` for test set because they are not provided with MINDlarge_utils.zip.
I use the last lines of code in lstur_MIND.pynb to make predictions in test set, bu... | closed | 2021-03-11T21:03:05Z | 2021-04-19T09:07:02Z | https://github.com/recommenders-team/recommenders/issues/1342 | [] | albertobezzon | 3 |
kizniche/Mycodo | automation | 454 | Can't read DHT22 - power output error | ## Mycodo Issue Report:
- Specific Mycodo Version: 6.0.4
#### Problem Description
Please list:
Read input from DHT22 on GPIO 2
Fresh install of Raspbian Stretch Lite did update/upgrade/dist-upgrade before installing Mycodo
### Errors
2018-04-21 23:17:44,643 - mycodo.inputs.dht22_1 - INFO - Turning on... | closed | 2018-04-21T21:37:20Z | 2018-04-28T01:05:13Z | https://github.com/kizniche/Mycodo/issues/454 | [] | MrDeadBeef | 1 |
iMerica/dj-rest-auth | rest-api | 545 | Module import error with all-auth latest version | File "/home/fotoley-anup/blog-project/blogzine/venv/lib/python3.10/site-packages/dj_rest_auth/registration/urls.py", line 4, in <module>
from .views import RegisterView, VerifyEmailView, ResendEmailVerificationView
File "/home/fotoley-anup/blog-project/blogzine/venv/lib/python3.10/site-packages/dj_rest_auth/r... | open | 2023-09-05T13:12:37Z | 2023-09-08T21:41:11Z | https://github.com/iMerica/dj-rest-auth/issues/545 | [] | anupsingh3292 | 1 |
facebookresearch/fairseq | pytorch | 4,648 | Question about implementation of sinusoidal positional embedding | Is there any reason why not shuffling sin and cos values when calculating positional embedding?
Because to the best of my knowledge, "attention is all you need" used shuffled sinusoidal positional embedding values.
e.g.) sin, cos, sin, cos ...
But I see the implementation be like: torch.cat([sin,cos], dim=-1)... | open | 2022-08-12T09:50:43Z | 2022-08-12T09:51:27Z | https://github.com/facebookresearch/fairseq/issues/4648 | [
"question",
"needs triage"
] | rlawjdghek | 0 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,395 | Questions in different languages | ### What version of GlobaLeaks are you using?
4.11.0
### What browser(s) are you seeing the problem on?
_No response_
### What operating system(s) are you seeing the problem on?
Windows
### Describe the issue
Hello, is it possible to offer the questions in different languages or do I have to open an extra channe... | closed | 2023-03-23T07:57:33Z | 2023-03-23T08:49:52Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3395 | [] | nicogithub22 | 1 |
tox-dev/tox | automation | 3,326 | Document all config expansions in a single page | ## Issue
I want to have one documentation page that lists all expansions made by tox when loading its config, with the kind of values they would have. Example:
- `basepython` - full path to python interpreter
- `env_name` - name of the environment
- `env_dir` - path to the environment
- `env_tmp_dir` - {work... | open | 2024-08-13T18:34:58Z | 2024-08-13T18:38:48Z | https://github.com/tox-dev/tox/issues/3326 | [] | ssbarnea | 1 |
qubvel-org/segmentation_models.pytorch | computer-vision | 301 | how to use UnetPlusPlus |
model = smp.UnetPlusPlus()
AttributeError: module 'segmentation_models_pytorch' has no attribute 'UnetPlusPlus'
| closed | 2020-12-08T06:26:39Z | 2020-12-08T09:35:16Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/301 | [] | picEmily | 2 |
huggingface/peft | pytorch | 1,824 | Fix PeftMixedModel example | ### Feature request
The `PeftMixedModel` docstring references `get_peft_model` and imports it in its example but doesn't use it:
https://github.com/huggingface/peft/blob/ad8f7cb59ee7ca4b9ca1c9048711038ac36b31b8/src/peft/mixed_model.py#L97-L107
### Motivation
The unused import in the docstring is confusing.
### Y... | closed | 2024-06-04T23:34:16Z | 2024-06-12T12:27:16Z | https://github.com/huggingface/peft/issues/1824 | [] | ringohoffman | 2 |
giotto-ai/giotto-tda | scikit-learn | 659 | Correlation dimension | Is there a way to compute the correlation dimension for a given embedding dimension in this framework?
Let's say that if I were to take `x` time series of the Lorenz system and compute the correlation dimension for each embedding dimension then I would get a plot where the correlation dimension would increase with t... | closed | 2023-02-14T08:05:07Z | 2023-02-14T08:27:01Z | https://github.com/giotto-ai/giotto-tda/issues/659 | [] | qubit0 | 0 |
tflearn/tflearn | tensorflow | 447 | GPUs | I've been following threads about using GPUs with tflearn---does that happen now automatically or is that feature to come? If not, how do I indicate I want GPUs to be used. Thanks. | open | 2016-11-07T04:59:00Z | 2016-11-09T23:28:56Z | https://github.com/tflearn/tflearn/issues/447 | [] | arshavir | 1 |
explosion/spaCy | nlp | 13,248 | Cannot train Arabic models with a custom tokenizer | This issue was initially about a possible bug in the _training pipeline_, related to the _parser_ (see below). But now I believe that posing preliminary questions is more appropriate:
- is it possible to create a completely _custom tokenizer_, which does not define custom rules and a few methods, but just redefines ... | open | 2024-01-18T21:32:32Z | 2024-02-09T22:44:40Z | https://github.com/explosion/spaCy/issues/13248 | [
"lang / ar",
"feat / tokenizer"
] | gtoffoli | 3 |
pydantic/logfire | fastapi | 264 | Specifying `http_client` in openai client options causing `TypeError` with `instrument_httpx` | ### Description
If I use `instrument_httpx()`, and then construct an OpenAI client with a custom httpx client, openai will raise an TypeError:
```py
TypeError: Invalid `http_client` argument; Expected an instance of `httpx.AsyncClient` but got <class 'httpx.AsyncClient'>
```
### Python, Logfire & OS Versions, re... | closed | 2024-06-14T12:09:36Z | 2024-07-18T07:02:11Z | https://github.com/pydantic/logfire/issues/264 | [
"bug",
"OTel Issue"
] | CNSeniorious000 | 5 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 107 | [BUG] tiktok有个视频的下载,总是出错。 | ***发生错误的平台?***
TikTok
***发生错误的端点?***
三个都试过,一样的,API-V1/API-V2/Web APP
***提交的输入值?***
https://vm.tiktok.com/ZMFHSEp6J/
https://www.tiktok.com/@user5875741980434/video/7166974134272970011
这两个网址是同一个视频,视频内容是女生和一条狗。可是解析出来的视频,都不是这个原视频,下载的视频也不是原视频
***是否有再次尝试?***
是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述... | closed | 2022-11-22T06:41:17Z | 2022-11-22T21:46:07Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/107 | [
"help wanted"
] | wzboyer | 1 |
huggingface/datasets | nlp | 6,671 | CSV builder raises deprecation warning on verbose parameter | CSV builder raises a deprecation warning on `verbose` parameter:
```
FutureWarning: The 'verbose' keyword in pd.read_csv is deprecated and will be removed in a future version.
```
See:
- https://github.com/pandas-dev/pandas/pull/56556
- https://github.com/pandas-dev/pandas/pull/57450 | closed | 2024-02-16T14:23:46Z | 2024-02-19T09:20:23Z | https://github.com/huggingface/datasets/issues/6671 | [] | albertvillanova | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 478 | Multi language cloning | Hi,
is it possible to train the model for multilingual voice cloning?
Is there any trained model available.
Or can you help with the parameters to train the model in multilingual using language database.
Thanks | closed | 2020-08-10T05:28:05Z | 2020-08-10T06:12:08Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/478 | [] | sid0791 | 1 |
mwaskom/seaborn | data-science | 2,775 | Inconsistent pointplot documentation/functionality | The pointplot documentation (https://seaborn.pydata.org/generated/seaborn.pointplot.html) suggests you can pass **kwargs, presumably to an underlying scatter or line plot, but there's no argument description on that page for **kwargs and in the source code there's no **kwargs either. The ax.scatter() just takes argumen... | closed | 2022-03-30T13:34:35Z | 2022-06-15T00:17:10Z | https://github.com/mwaskom/seaborn/issues/2775 | [
"mod:categorical",
"ux"
] | abpoll | 2 |
ivy-llc/ivy | pytorch | 28,253 | Fix Ivy Failing Test: jax - shape.shape__radd__ | closed | 2024-02-12T15:46:44Z | 2024-02-13T09:32:13Z | https://github.com/ivy-llc/ivy/issues/28253 | [] | fnhirwa | 0 | |
jonaswinkler/paperless-ng | django | 1,545 | [BUG] Ansible Installation fails at "get commit for target tag" task | **Describe the bug**
I am trying to install Paperless NG with Ansible.
The installation fails at the step "get commit for target tag" with the following error:
"You need to install \"jmespath\" prior to running json_query filter"
I tried to install jmespath on the target manually (pip3 install jmespath) but t... | open | 2022-01-13T10:54:50Z | 2022-01-23T18:06:07Z | https://github.com/jonaswinkler/paperless-ng/issues/1545 | [] | moxli | 1 |
pytest-dev/pytest-cov | pytest | 117 | Incorrect coverage report | Using `py.test --cov-config .coveragerc --cov nengo -n 6 nengo` a lot of lines that should be hit get reported as missed (like class and function definitions in a module). This might be related to #19 as the project has a conftest file importing other modules from the project.
Using `coverage run --rcfile .coveragerc... | closed | 2016-05-11T22:04:47Z | 2017-10-28T01:48:33Z | https://github.com/pytest-dev/pytest-cov/issues/117 | [] | jgosmann | 21 |
seleniumbase/SeleniumBase | pytest | 2,962 | SeleniumBase A.I. detected a CF Turnstile change (update needed) | ### SeleniumBase A.I. detected a CF Turnstile change (update needed)
<img width="610" alt="Screenshot" src="https://github.com/user-attachments/assets/b761801e-78fb-4b4e-b7ae-4f607f379837">
That change is preventing UC Mode from bypassing the CAPTCHAs.
The proposed update will be shipped in the next release to... | closed | 2024-07-25T18:59:43Z | 2024-07-25T21:16:48Z | https://github.com/seleniumbase/SeleniumBase/issues/2962 | [
"UC Mode / CDP Mode"
] | mdmintz | 3 |
jupyter/docker-stacks | jupyter | 1,517 | Make the start script fail loudly with an error where it makes sense | This issue represents the following comments from another PR, so we can mark them as resolved without forgetting them.
~https://github.com/jupyter/docker-stacks/pull/1512#discussion_r745520508~ fixed
https://github.com/jupyter/docker-stacks/pull/1512#discussion_r745526275 | closed | 2021-11-09T22:18:05Z | 2024-01-07T15:08:28Z | https://github.com/jupyter/docker-stacks/issues/1517 | [
"type:Enhancement"
] | consideRatio | 1 |
marcomusy/vedo | numpy | 1,056 | test_core2 fails: 'NoneType' object has no attribute 'GetData' | test_core2.py in vedo 2024.5.1 fails (with the debian build of vtk 9.1.0)
```
$ python3 test_core2.py
2024-02-19 14:01:08.512 ( 0.520s) [ 7FD21040] vtkXMLParser.cxx:375 ERR| vtkXMLDataParser (0x1e40440): Error parsing XML in stream at line 24, column 32, byte index 1540: not well-formed (invalid t... | open | 2024-02-19T12:57:09Z | 2024-06-13T18:49:20Z | https://github.com/marcomusy/vedo/issues/1056 | [
"possible bug"
] | drew-parsons | 3 |
eamigo86/graphene-django-extras | graphql | 121 | V2.6 Version is not compatible | Graphene-django updated to 2.6, adding "DjangoListField only accepts DjangoObjectType types" causes version incompatibility。 | closed | 2019-09-28T16:32:03Z | 2019-10-16T09:24:53Z | https://github.com/eamigo86/graphene-django-extras/issues/121 | [] | grusirna | 4 |
ultralytics/yolov5 | machine-learning | 12,597 | imgsz,iou_thres and conf_thres | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello,
I have a few questions during training YOLO v5 and would like to ask for advice:
... | closed | 2024-01-08T10:39:13Z | 2024-02-19T00:21:08Z | https://github.com/ultralytics/yolov5/issues/12597 | [
"question",
"Stale"
] | Gary55555 | 4 |
deeppavlov/DeepPavlov | nlp | 1,164 | How do I train slot filler using 'slotfill_dstc2.json' config on custom data | I have created a dataset following the strucutre of the dstc2 dataset.
Then I sucessfully trained gobot using "gobot_simple_dstc2.json" slot filler component.
But when I train gobot with "slotfill_dstc2.json" I get an error. How?
First I try to train the NER using "slotfill_dstc2.json" using the default param... | closed | 2020-03-31T04:00:19Z | 2020-03-31T07:13:10Z | https://github.com/deeppavlov/DeepPavlov/issues/1164 | [] | Eugen2525 | 1 |
albumentations-team/albumentations | deep-learning | 2,446 | [Feature request] Add apply_to_images to BboxSafeRandomCrop | open | 2025-03-11T01:21:28Z | 2025-03-11T01:21:34Z | https://github.com/albumentations-team/albumentations/issues/2446 | [
"enhancement",
"good first issue"
] | ternaus | 0 | |
Johnserf-Seed/TikTokDownload | api | 415 | [BUG]闪退 | 请问这是什么问题?
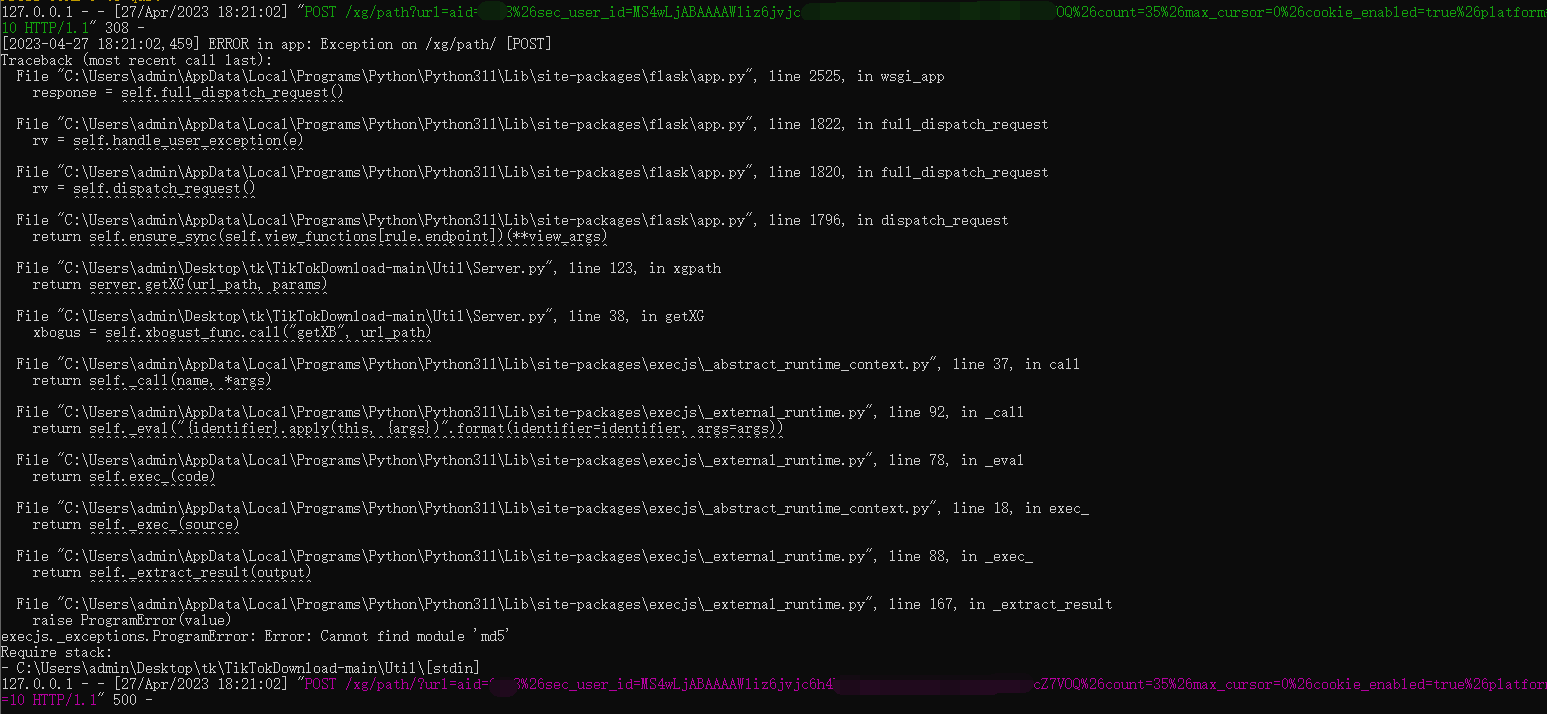 | closed | 2023-04-27T10:23:20Z | 2023-05-27T10:28:10Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/415 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | summer990 | 2 |
bmoscon/cryptofeed | asyncio | 958 | Too much request | **Describe the bug**
Connecting more than 400 pairs on Binance leads to a connection error that looks like: {"code":-1003,"msg":"Too much request weight used; current limit is 1200 request weight per 1 MINUTE. Please use WebSocket Streams for live updates to avoid polling the API."}
**To Reproduce**
```python
fro... | closed | 2023-03-04T12:20:45Z | 2023-03-05T11:42:56Z | https://github.com/bmoscon/cryptofeed/issues/958 | [
"bug"
] | ghost | 2 |
coqui-ai/TTS | python | 2,590 | [Bug] TTS loads a corrupted model instead of redownloading | ### Describe the bug
If I interrupt model downloading and rerun the code, the corrupted model will be loaded instead of re-downloading. In that case, I need to find the cached file on the disk myself and delete it.
### To Reproduce
1. Run `tts = TTS(model_name="tts_models/de/thorsten/tacotron2-DDC", progress_bar=Tru... | closed | 2023-05-05T15:11:35Z | 2024-03-17T12:35:47Z | https://github.com/coqui-ai/TTS/issues/2590 | [
"bug"
] | adrianboguszewski | 3 |
microsoft/nni | pytorch | 5,333 | Can't speed up model when pruning mT5 model | **Describe the issue**:
I use TaylorFOWeightPruner to prune mT5_base model, but the errors happened when speed up model.
pruner = TaylorFOWeightPruner(attention_pruned_model, ffn_config_list, evaluator, taylor_pruner_steps)
_, ffn_masks = pruner.compress()
renamed_ffn_masks = {}
... | open | 2023-02-03T03:31:20Z | 2023-02-15T07:24:45Z | https://github.com/microsoft/nni/issues/5333 | [] | Kathrine94 | 4 |
roboflow/supervision | tensorflow | 1,243 | Request: PolygonZone determination using object recognition | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
I am currently using supervision in my thesis to analyse driving behavior in different videos and its super useful. But the PolygonZone array... | closed | 2024-05-29T12:20:02Z | 2024-05-29T12:44:24Z | https://github.com/roboflow/supervision/issues/1243 | [
"enhancement"
] | pasionline | 1 |
deepinsight/insightface | pytorch | 1,905 | [arcface_torch] Problems with distributed training in arcface_torch | Good Afternoon,
I have a current setup of two machines in the same network, each of them presenting a RTX3090 GPU, and despite intializing a process in each of the machines (Checked with nvidia-smi), and the master machine printing "Training YYYY-MM-DD HH:MM:SS,MS-rank_id: 0" both processes seem to freeze (power us... | closed | 2022-02-07T20:20:53Z | 2022-05-11T20:25:07Z | https://github.com/deepinsight/insightface/issues/1905 | [] | luisfmnunes | 2 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 181 | Error running the bot: Failed to initialize browser: Message: unknown error: cannot find Chrome binary Stacktrace | Runtime error: Error running the bot: Failed to initialize browser: Message: unknown error: cannot find Chrome binary
Stacktrace:
Backtrace:
GetHandleVerifier [0x00B0A813+48355]
(No symbol) [0x00A9C4B1]
(No symbol) [0x009A5358]
(No symbol) [0x009C1A9E]
(No symbol) [0x009C0... | closed | 2024-08-31T07:48:49Z | 2024-09-07T13:00:05Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/181 | [] | Jasmeer57 | 1 |
facebookresearch/fairseq | pytorch | 5,460 | How did you train the k-means clustering model on the HuBERT model? | ## ❓ Questions and Help
### My question
Hello, due to my downstream task requirements, I need to perform k-means clustering on the output of Contentvec model, that has the same structure as the HuBERT model but with a different training idea. I have performed feature extraction on my dataset on Contentvec and learnt ... | open | 2024-03-16T10:41:14Z | 2024-07-08T11:40:36Z | https://github.com/facebookresearch/fairseq/issues/5460 | [
"question",
"needs triage"
] | Remaxic | 1 |
allure-framework/allure-python | pytest | 601 | Multiple runs for same test case is showing as separate results | [//]: # (
. Note: for support questions, please use Stackoverflow or Gitter**.
. This repository's issues are reserved for feature requests and bug reports.
.
. In case of any problems with Allure Jenkins plugin** please use the following repository
. to create an issue: https://github.com/jenkinsci/allure-plugi... | closed | 2021-06-18T01:23:55Z | 2022-12-29T10:38:27Z | https://github.com/allure-framework/allure-python/issues/601 | [
"theme:pytest-bdd"
] | budsee | 2 |
mirumee/ariadne-codegen | graphql | 204 | Add full support for skip/include directives | GQL spec defines [skip](https://spec.graphql.org/June2018/#sec--skip) and [include](https://spec.graphql.org/June2018/#sec--include) directives. They are not fully supported cause generated pydantic types cannot parse server-side responses (e.g. skipped part of the query is missing and pydantic raises validation error)... | closed | 2023-09-04T14:13:42Z | 2023-09-07T12:44:29Z | https://github.com/mirumee/ariadne-codegen/issues/204 | [] | jakub-bacic | 4 |
Yorko/mlcourse.ai | seaborn | 408 | Topic 2.2: For new versions, add sns.set() to apply styles throughout notebook | 
In the [article](https://mlcourse.ai/notebooks/blob/master/jupyter_english/topic02_visual_data_analysis/topic2_additional_seaborn_matplotlib_plotly.ipynb... | closed | 2018-11-05T21:52:35Z | 2018-11-10T16:18:38Z | https://github.com/Yorko/mlcourse.ai/issues/408 | [
"minor_fix"
] | ptaiga | 1 |
pytest-dev/pytest-html | pytest | 743 | is it possible to create report with filtering ability based on log levels? | Looking for ability to filter logs when expanded based on the log-level chosen (debug, info, error) etc., Is it possible to create that filter in the HTML report? | open | 2023-09-29T05:32:47Z | 2023-10-31T00:02:13Z | https://github.com/pytest-dev/pytest-html/issues/743 | [] | jdilipan | 1 |
gee-community/geemap | streamlit | 2,048 | Add UI tests with Galata | Galata is a set of helpers and fixtures for JupyterLab UI Testing. ipyleaflet and bqplot uses Galata for UI tests. We can add UI tests using Galata as well.
- https://github.com/jupyterlab/jupyterlab/tree/main/galata
- https://github.com/jupyter-widgets/ipyleaflet/tree/master/ui-tests
- https://github.com/bqplot/... | open | 2024-06-16T03:50:25Z | 2024-06-16T03:50:25Z | https://github.com/gee-community/geemap/issues/2048 | [
"Feature Request"
] | giswqs | 0 |
aio-libs/aiopg | sqlalchemy | 911 | Can't create a connection pool when running the example from the README | ### Describe the bug
For some reason, running your example runs into a NotImplementedError of asyncio when it tries to create a connection pool. The PostgreSQL psycopg2 package works just fine when I use it directly without aiopg.
### To Reproduce
As already said, the code is just the first example of the README wit... | open | 2024-08-21T09:27:56Z | 2024-08-21T09:37:56Z | https://github.com/aio-libs/aiopg/issues/911 | [
"bug"
] | Bonifatius94 | 1 |
huggingface/diffusers | deep-learning | 10,411 | How to call the training of lora weights obtained from examples/concestency_stiffness/train_lcm-distill-lora_std_wds. py | I followed https://github.com/huggingface/diffusers/tree/main/examples/consistency_distillation The provided tutorial trained the final Lora weight, but did not find a way to call it. May I ask if you can provide me with a demo of running and calling this weight? Thank you very much!
the training set:
```
#!/bin/bas... | closed | 2024-12-30T12:06:07Z | 2024-12-31T07:21:40Z | https://github.com/huggingface/diffusers/issues/10411 | [] | yangzhenyu6 | 0 |
TencentARC/GFPGAN | pytorch | 607 | NameError: name 'fused_act_ext' is not defined | After using export BASICSR_JIT=True, when running python basicsr/train.py -opt ..., the terminal gets stuck and doesn't proceed. Is there anyone who can help me solve this issue? | closed | 2025-03-08T09:55:14Z | 2025-03-08T09:57:49Z | https://github.com/TencentARC/GFPGAN/issues/607 | [] | WangYJ-WYJ | 0 |
microsoft/nni | pytorch | 5,503 | Load data once and use it afterwards for multiple trails | **What would you like to be added**: Data file that is loaded once and used for multiple trails instead of loading data individually for each trail.
**Why is this needed**: As I have a lot of data for the hyperparameter, I don't want to load data for each trail. I was wondering if it is possible to do so in this bui... | open | 2023-04-04T11:15:24Z | 2023-04-07T02:35:27Z | https://github.com/microsoft/nni/issues/5503 | [] | TayyabaZainab0807 | 0 |
PaddlePaddle/ERNIE | nlp | 702 | 一年多了中文ernie-gen还不开源吗? | closed | 2021-06-21T06:32:57Z | 2021-07-04T02:47:39Z | https://github.com/PaddlePaddle/ERNIE/issues/702 | [] | cedar33 | 1 | |
ycd/manage-fastapi | fastapi | 96 | Remove support of python 3.6 | As long as the FastAPI version has been bumped to 0.85.0 and it also drops the support to the python version 3.6 as mentionned here : https://fastapi.tiangolo.com/release-notes/ , shouldn't we drop the support within the package (This will make it also possible to make some updates on the packages such as Black, pydant... | closed | 2022-10-03T09:33:31Z | 2023-01-01T16:26:01Z | https://github.com/ycd/manage-fastapi/issues/96 | [] | kaieslamiri | 2 |
joeyespo/grip | flask | 373 | Create CONTRIBUTION.md to guide open source developers to contribute to this project | In order to develop, people need to know:
- How to run code locally
- Program subsystems
- ...
Thanks for making this useful tool :) | open | 2023-05-20T21:07:39Z | 2023-05-20T21:09:42Z | https://github.com/joeyespo/grip/issues/373 | [] | anhtumai | 0 |
python-security/pyt | flask | 108 | Feature Request: Whitelist lines ending in # nosec | So both [detect-secrets](https://github.com/Yelp/detect-secrets/blob/master/detect_secrets/plugins/high_entropy_strings.py#L41) and Bandit have the concept of whitelisting a line by putting a comment at the end, similar to how you've probably seen people do `# noqa: F401` or whatever, with pylint.
Let us steal once ... | closed | 2018-04-14T18:27:20Z | 2018-04-28T18:38:34Z | https://github.com/python-security/pyt/issues/108 | [
"feature request"
] | KevinHock | 7 |
skforecast/skforecast | scikit-learn | 495 | Feature importance ForecasterAutoregMultiVariate - regressor LightGBM | Hi all,
When I try to retrieve the important features of an AutoRegressive Multivariate model (Direct Multi Step forecasting, step=3), it works with all regressors except LightGBM.
Indeed, for the same data, the feature importances of the model trained using XGB or Ridge regressors work (positive/negative value... | closed | 2023-06-26T19:24:06Z | 2023-11-02T08:18:42Z | https://github.com/skforecast/skforecast/issues/495 | [
"question"
] | jouet-leon | 1 |
ghtmtt/DataPlotly | plotly | 94 | Speeding up the plot with many points | Using `go.Scattergl` should help but it seems not working nicely in DataPlotly. As standalone script no problem.
To test in DataPlotly just change the https://github.com/ghtmtt/DataPlotly/blob/master/data_plotly_plot.py#L160 from `go.Scatter` to `go.Scattergl`.
Here a standalone snippet working in python:
```... | open | 2019-03-08T16:59:08Z | 2019-10-11T13:03:32Z | https://github.com/ghtmtt/DataPlotly/issues/94 | [
"enhancement"
] | ghtmtt | 1 |
DistrictDataLabs/yellowbrick | scikit-learn | 1,089 | Parallel Plot with independent vline | **Describe the solution you'd like**
`ParallelCoordinates` plots each vline using a shared y scale. Instead of normalizing the values (using the parameter normalize), I'd like to keep original values, and allow each vline to have its own scale (scaling / moving the axis in order to fit current figsize)
**Examples**... | closed | 2020-07-28T17:38:09Z | 2020-10-02T17:27:34Z | https://github.com/DistrictDataLabs/yellowbrick/issues/1089 | [
"type: question",
"level: expert"
] | franperezlopez | 1 |
FactoryBoy/factory_boy | django | 908 | Setup for flask - unexpected behavior probably due to session management | #### The problem
I'm trying to use _flask, flask-sqlalchemy, factory-boy,_ and _pytest,_ but I'm having some kind of trouble with sessions (I think). Could anyone help me?
I've prepared a minimal example to show the problem I'm having. Tests are working only because I put the _factory-boy_ class (named _ExampleFa... | closed | 2022-02-24T12:54:54Z | 2024-04-08T16:36:08Z | https://github.com/FactoryBoy/factory_boy/issues/908 | [] | lmtani | 0 |
huggingface/datasets | deep-learning | 7,457 | Document the HF_DATASETS_CACHE env variable | ### Feature request
Hello,
I have a use case where my team is sharing models and dataset in shared directory to avoid duplication.
I noticed that the [cache documentation for datasets](https://huggingface.co/docs/datasets/main/en/cache) only mention the `HF_HOME` environment variable but never the `HF_DATASETS_CACHE`... | open | 2025-03-17T12:24:50Z | 2025-03-20T10:36:46Z | https://github.com/huggingface/datasets/issues/7457 | [
"enhancement"
] | LSerranoPEReN | 4 |
freqtrade/freqtrade | python | 11,090 | problem with Hyperliquid, data-download and trade | ## Describe your environment
* Operating system: ____Ubuntu 24.04.1 LTS
* Python Version: _____ 3.12.3
* CCXT version: _____ 4.4.35
* Freqtrade Version: ____ 2024.11
Note: All issues other than enhancement requests will be closed without further comment if the above template is deleted or not filled out.
#... | closed | 2024-12-14T14:55:12Z | 2024-12-16T09:09:08Z | https://github.com/freqtrade/freqtrade/issues/11090 | [
"Question"
] | 0xh0551 | 5 |
dunossauro/fastapi-do-zero | sqlalchemy | 304 | Adicionar mais questões aos quizes | O ideal seria que todos os quizes tivessem o mesmo número de questões. Como a maioria tem 10, podemos normalizar nesse número. Alguns quizes que não têm 10 questões.
- 09, com 5
Os não listados já foram contempladas | closed | 2025-02-10T09:48:12Z | 2025-03-11T20:02:53Z | https://github.com/dunossauro/fastapi-do-zero/issues/304 | [] | dunossauro | 2 |
ultralytics/ultralytics | computer-vision | 19,151 | locking on to a single person in a multi-person frame | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi, I am using yolo11-pose to assess power lifts (squats) against standards ... | closed | 2025-02-10T05:05:48Z | 2025-02-15T02:37:39Z | https://github.com/ultralytics/ultralytics/issues/19151 | [
"question",
"track",
"pose"
] | mkingopng | 8 |
albumentations-team/albumentations | deep-learning | 2,070 | [Bug] RandomShadow + shadow_intensity | In RandomShadow large values of shadow_intensity correspond to lighter shadow and visa versa. | closed | 2024-11-07T21:20:03Z | 2024-11-08T23:50:18Z | https://github.com/albumentations-team/albumentations/issues/2070 | [
"bug"
] | ternaus | 0 |
mlfoundations/open_clip | computer-vision | 875 | [1,512] data | What is the meaning of the [1,512] data obtained from the clip encoder. | closed | 2024-05-09T01:30:09Z | 2024-05-09T05:07:03Z | https://github.com/mlfoundations/open_clip/issues/875 | [] | lwtgithublwt | 1 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 296 | How can I deserialize from either of two JSON fields into the same DB field | Hi,
I have this problem that I've been trying to solve for a few hours.
I'm using marshmallow-sqlalchemy to deserialize json into SQLAlchemy models
So far, I had a schema that contained a nested relationship :
category = Nested(CategorySchema)
So far so good.
However now the API evolves and has to accomod... | closed | 2020-03-18T15:33:21Z | 2020-03-21T16:27:22Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/296 | [] | eino | 1 |
yt-dlp/yt-dlp | python | 12,482 | [youtube] SSAP interference - missing formats, only itag 18 available | ### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instructions](https://github.com/yt-dlp/yt-dlp#update-channels))
- [x] I've checked that all provided URLs are playable in a browser with the same IP and same... | open | 2025-02-26T06:58:37Z | 2025-02-26T06:58:37Z | https://github.com/yt-dlp/yt-dlp/issues/12482 | [
"help-wanted",
"site-bug",
"needs-investigating",
"site:youtube"
] | coletdjnz | 0 |
remsky/Kokoro-FastAPI | fastapi | 15 | High VRAM usage | Running with `docker compose up` I get 1020 MiB of VRAM usage `/usr/bin/python3 1020MiB`.
Is this normal? Given the size of the model, I was expecting less VRAM used and was wondering if there is a way to trim this?
| closed | 2025-01-08T18:57:05Z | 2025-01-10T02:42:43Z | https://github.com/remsky/Kokoro-FastAPI/issues/15 | [
"enhancement"
] | cduk | 3 |
matplotlib/mplfinance | matplotlib | 121 | Bug Report: When calculating mean average, -1 need to be converted into np.NaN | **Describe the bug**
In https://github.com/matplotlib/mplfinance/blob/master/src/mplfinance/plotting.py#L340
```python
mavprices = pd.Series(closes).rolling(mav).mean().values
```
I believe the code need to filter `-1`, for example
```python
mavprices = pd.Series(c if c >= 0 else np.NaN for c in closes).ro... | closed | 2020-05-04T14:20:56Z | 2020-05-04T14:26:29Z | https://github.com/matplotlib/mplfinance/issues/121 | [
"bug"
] | char101 | 1 |
piskvorky/gensim | nlp | 3,325 | AttributeError: 'KeyedVectors' object has no attribute 'add' |
#### Problem description
```
Using backend: pytorch
Traceback (most recent call last):
File "train.py", line 88, in <module>
main(config)
File "train.py", line 17, in main
train_data_loader = config.initialize('train_data_loader', module_data, "train")
File "/gpfs/home/chenzhiqiang_stu/taxoE/p... | closed | 2022-04-13T14:01:25Z | 2022-04-14T04:39:57Z | https://github.com/piskvorky/gensim/issues/3325 | [] | GitHubBoys | 2 |
StratoDem/sd-material-ui | dash | 57 | Remove PropTypes from package in favor of newly-supported Flow metadata.json in dash | ### Description
https://github.com/plotly/dash/pull/207 updates to support flow types in [v0.21.0](https://github.com/plotly/dash/blob/ff93d2c4331a576b445be87bb3b77576f18b030a/CHANGELOG.md)
Dash now supports React components that use Flow. To support Flow, component_loader now has the following behavior to create d... | closed | 2018-02-22T13:59:33Z | 2018-02-22T15:45:22Z | https://github.com/StratoDem/sd-material-ui/issues/57 | [
"Tech: JS",
"Priority: Medium",
"Tech: Architecture",
"Type: Enhancement"
] | mjclawar | 0 |
gunthercox/ChatterBot | machine-learning | 1,666 | how to hide the elements which are in loop in either javascript or jquery | Hi everyone,
I want to know how to hide and show the elements from the for loop in java script/J query
Thanks in advance....
Happy codding...... | closed | 2019-03-13T05:58:38Z | 2020-02-06T03:22:34Z | https://github.com/gunthercox/ChatterBot/issues/1666 | [] | mady143 | 6 |
FujiwaraChoki/MoneyPrinter | automation | 168 | Stuck with an OSError | 
Can anybody help me fix this? I am kinda lost | closed | 2024-02-11T00:15:29Z | 2024-02-11T02:04:55Z | https://github.com/FujiwaraChoki/MoneyPrinter/issues/168 | [] | Kempius | 0 |
paperless-ngx/paperless-ngx | machine-learning | 9,121 | [BUG] Webhook URL doesn't accept hostname without dots | ### Description
I have both `paperless-ngx` and `paperless-ai` running in Docker containers. Trying to use `http://paperless-ai:3000/api/webhook/document` as a webhook URL throws "Enter a valid URL":
```
{"headers":{"normalizedNames":{},"lazyUpdate":null},"status":400,"statusText":"Bad Request","url":"http://danhome.i... | closed | 2025-02-16T02:41:03Z | 2025-03-24T03:17:54Z | https://github.com/paperless-ngx/paperless-ngx/issues/9121 | [
"bug",
"backend"
] | Daniel15 | 6 |
plotly/jupyterlab-dash | dash | 29 | jupyterlab-dash@0.1.0-alpha.2" is not compatible with the current JupyterLab 1.0 | Hi,
I'm trying to install jupyterlab-dash with jupyterlab 1.0.0, but am getting the following error:
```
build 01-Jul-2019 14:15:16 The following NEW packages will be INSTALLED:
build 01-Jul-2019 14:15:16
build 01-Jul-2019 14:15:16 json5: 0.8.4-py_0
build 01-Jul-2019 14:15:16 jupyterlab... | closed | 2019-07-01T20:09:58Z | 2019-09-13T14:08:29Z | https://github.com/plotly/jupyterlab-dash/issues/29 | [] | cw6515 | 5 |
chiphuyen/stanford-tensorflow-tutorials | tensorflow | 49 | 03_linear_regression_sol.py can't run with errors as follows | Traceback (most recent call last):
File "D:/stanford_tensorflow_tutorials/tf_oreilly/01_linear_regression_sol.py", line 19, in <module>
book = xlrd.open_workbook(DATA_FILE, encoding_override="utf-8")
File "C:\Anaconda3\lib\site-packages\xlrd\__init__.py", line 441, in open_workbook
ragged_rows=ragged_ro... | open | 2017-08-12T13:35:06Z | 2017-08-12T13:35:06Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/49 | [] | WoNiuHu | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.