
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
babysor/MockingBird | pytorch | 764 | 如何解决colab炼丹每次都要上传数据集预处理数据集还爆磁盘的蛋疼问题 | 许多同鞋因为家里设备不佳训练模型效果不好,不得不去世界最大乞丐炼丹聚集地colab上训练。但是对于无法扩容google drive和升级colab的同鞋来说,上传数据集真的如同地狱一般,网速又慢空间又不够,而且每次重置都要上传,预处理令人头疼。我耗时9天终于解决了这个问题,现在给各位同学分享我的解决方案。
首先要去kaggle这个网站上面注册一个账号,然后获取token
我已经把预处理了的数据集(用的aidatatang_200zh)上传在上面了,但是下载数据集需要token,token需要注册账号,具体获取token的方法请自行百度,在此不过多赘述。
然后打开colab
修改-> 笔记本设置->运行时把 None 改成... | open | 2022-10-10T08:52:38Z | 2023-03-31T12:02:28Z | https://github.com/babysor/MockingBird/issues/764 | [] | HexBanana | 10 |
pyppeteer/pyppeteer | automation | 254 | Installation in docker fails | I am using Ubuntu bionic container (18.04)
```
Step 19/29 : RUN python3 -m venv .
---> Using cache
---> 921d12b1ff09
Step 20/29 : RUN python3 -m pip install setuptools
---> Using cache
---> 112749c3d9f4
Step 21/29 : RUN python3 -m pip install -U git+https://github.com/pyppeteer/pyppeteer@dev
---> Running ... | closed | 2021-05-11T06:49:12Z | 2021-05-11T08:03:34Z | https://github.com/pyppeteer/pyppeteer/issues/254 | [] | larytet | 1 |
polarsource/polar | fastapi | 5,156 | API Reference docs: validate/activate/deactivate license keys don't need a token | ### Discussed in https://github.com/orgs/polarsource/discussions/5155
The overlay matches every endpoints: https://github.com/polarsource/polar/blob/37646b3cab3219369bd48b3f105300893515ad9c/sdk/overlays/security.yml#L6-L10
We should exclude those endpoints. | closed | 2025-03-04T16:01:26Z | 2025-03-04T16:42:42Z | https://github.com/polarsource/polar/issues/5156 | [
"docs"
] | frankie567 | 0 |
tox-dev/tox | automation | 3,249 | tox seems to ignore part of tox.ini file | ## Issue
This PR of mine is failing: https://github.com/open-telemetry/opentelemetry-python/pull/3746
The issue seems to be that `tox` ignores part of the `tox.ini` file, from [this](https://github.com/open-telemetry/opentelemetry-python/pull/3746/files#diff-ef2cef9f88b4fe09ca3082140e67f5ad34fb65fb6e228f119d38122... | closed | 2024-03-21T01:12:26Z | 2024-04-12T20:43:57Z | https://github.com/tox-dev/tox/issues/3249 | [] | ocelotl | 2 |
strawberry-graphql/strawberry | asyncio | 3,613 | Hook for new results in subscription (and also on defer/stream) | From #3554
 | open | 2024-09-02T17:57:36Z | 2025-03-20T15:56:51Z | https://github.com/strawberry-graphql/strawberry/issues/3613 | [
"feature-request"
] | patrick91 | 0 |
qwj/python-proxy | asyncio | 112 | It works from command line but not from within a python script | Hello, thanks for pproxy, it's very useful. One problem I am facing is that the following command works well (I can browse the internet normally)...
```
C:\tools>pproxy -l http://127.0.0.1:12345 -r socks5://127.0.0.1:9050
Serving on 127.0.0.1:12345 by http
```
...but the following script, with the same schemes a... | closed | 2021-02-22T20:05:16Z | 2021-02-23T14:42:44Z | https://github.com/qwj/python-proxy/issues/112 | [] | analyserdmz | 2 |
aleju/imgaug | deep-learning | 186 | matplotlib to show is not convenient for some linux platform | when pip install,some error appear,such as:
Collecting matplotlib>=2.0.0 (from scikit-image>=0.11.0->imgaug==0.2.6)
Downloading http://10.123.98.50/pypi/web/packages/ec/06/def4fb2620cbe671ba0cb6462cbd8653fbffa4acd87d6d572659e7c71c13/matplotlib-3.0.0.tar.gz (36.3MB)
100% |################################| 36.... | open | 2018-09-26T09:19:44Z | 2018-10-02T19:27:56Z | https://github.com/aleju/imgaug/issues/186 | [] | sanren99999 | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 615 | TypeError: %d format: a number is required | Here is my example:
```python
from skopt import Optimizer
from skopt.utils import dimensions_aslist
from skopt.space import Integer, Categorical, Real
NN = {
'activation': Categorical(['identity', 'logistic', 'tanh', 'relu']),
'solver': Categorical(['adam', 'sgd', 'lbfgs']),
... | closed | 2018-01-25T14:28:05Z | 2018-04-19T12:09:11Z | https://github.com/scikit-optimize/scikit-optimize/issues/615 | [] | pavelkomarov | 1 |
ufoym/deepo | tensorflow | 120 | Building wheel for torchvision (setup.py): finished with status 'error' |
`$ docker build -f Dockerfile.pytorch-py36-cpu .`
Collecting git+https://github.com/pytorch/vision.git
Cloning https://github.com/pytorch/vision.git to /tmp/pip-req-build-8_0m83s6
Running command git clone -q https://github.com/pytorch/vision.git /tmp/pip-req-build-8_0m83s6
Requirement already satisfied, ... | closed | 2019-09-02T08:47:29Z | 2019-11-19T11:24:47Z | https://github.com/ufoym/deepo/issues/120 | [] | oiotoxt | 1 |
PokeAPI/pokeapi | graphql | 536 | Normalized entities in JSON data? | I asked about this in the Slack channel but didn't get any responses. I looked through the documentation but couldn't find any mention of this; is it possible to ask an endpoint for normalized entity data? Currently the entity relationships are eagerly fetched, so, for example, a berry has a list of flavors, and the fl... | closed | 2020-10-25T16:08:23Z | 2020-12-27T18:27:14Z | https://github.com/PokeAPI/pokeapi/issues/536 | [] | parkerault | 2 |
matterport/Mask_RCNN | tensorflow | 2,392 | Create environment | Could anyone help create the environment in anaconda? I've tried it in different ways and it shows error. I'm trying to create an environment using python 3.4, tensorflow 1.15.3 and keras 2.2.4 | open | 2020-10-16T11:10:13Z | 2022-03-08T14:59:50Z | https://github.com/matterport/Mask_RCNN/issues/2392 | [] | teixeirafabiano | 3 |
cupy/cupy | numpy | 8,269 | CuPy v14 Release Plan | ## Roadmap
```[tasklist]
## Planned Features
- [ ] #8306
- [ ] `complex32` support for limited APIs (restart [#4454](https://github.com/cupy/cupy/pull/4454))
- [ ] Support bfloat16
- [ ] Structured Data Type
- [ ] #8013
- [ ] #6986
- [ ] Drop support for Python 3.9 following [SPEC 0](https://scientific-python.org/spec... | open | 2024-04-03T02:51:19Z | 2025-02-13T08:02:10Z | https://github.com/cupy/cupy/issues/8269 | [
"issue-checked"
] | asi1024 | 1 |
matplotlib/matplotlib | data-visualization | 28,931 | [Bug]: plt.savefig incorrectly discarded z-axis label when saving Line3D/Bar3D/Surf3D images using bbox_inches='tight' | ### Bug summary
I drew a 3D bar graph in python3 using ax.bar3d and then saved the image to pdf under bbox_inches='tight' using plt.savefig, but the Z-axis label was missing in the pdf. Note that everything worked fine after switching matplotlib to version 3.5.0 without changing my python3 code.
### Code for reproduc... | closed | 2024-10-03T11:05:30Z | 2024-10-03T14:17:50Z | https://github.com/matplotlib/matplotlib/issues/28931 | [
"status: duplicate"
] | NJU-ZAD | 5 |
JoeanAmier/TikTokDownloader | api | 383 | unhandled exception,直接使用打包版exe,运行6,1,1,可获取视频数量,但无法下载 | 报错如下,使用的是打包版,是setting配置问题吗,可否帮忙看看,谢谢!
TikTokDownloader V5.5
Traceback (most recent call last):
File "main.py", line 19, in <module>
File "asyncio\runners.py", line 194, in run
File "asyncio\runners.py", line 118, in run
File "asyncio\base_events.py", line 686, in run_until_complete
File "main.py", line 10, ... | closed | 2025-01-22T03:25:34Z | 2025-01-22T07:18:57Z | https://github.com/JoeanAmier/TikTokDownloader/issues/383 | [] | WaymonHe | 2 |
gee-community/geemap | streamlit | 1,180 | Scrolling for layer panel | Hi,
Is there a way to scroll down the layer panel when we have a lot of layers?
Thanks,
Daniel
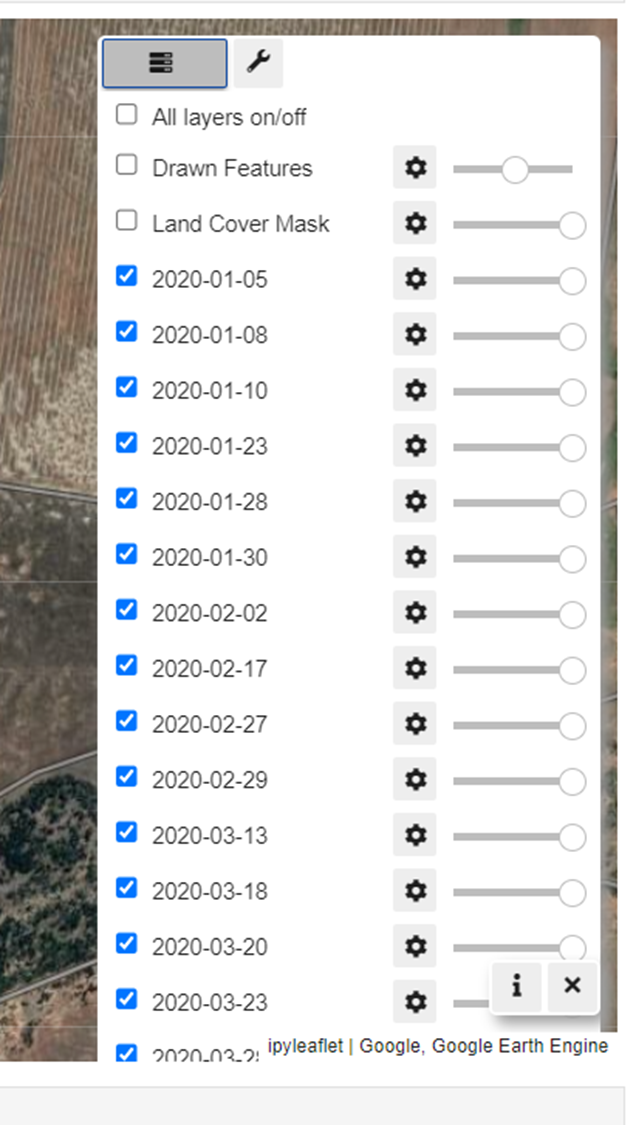
| closed | 2022-08-07T04:54:23Z | 2022-08-08T01:37:02Z | https://github.com/gee-community/geemap/issues/1180 | [
"Feature Request"
] | Daniel-Trung-Nguyen | 1 |
coqui-ai/TTS | python | 4,162 | [Bug] Python 3.12.0 | ### Describe the bug
Hi,
My version of python isn't supported by TTS 3.12.0 on Cygwin and 3.12 on Windows 10.
Also TTS isn't known when i try to install from pip: pip install TTS
### To Reproduce
tried installing from pip or manually
### Expected behavior
_No response_
### Logs
```shell
```
### Environment... | open | 2025-02-27T18:45:18Z | 2025-03-06T16:03:13Z | https://github.com/coqui-ai/TTS/issues/4162 | [
"bug"
] | TDClarke | 4 |
xlwings/xlwings | automation | 2,150 | Unable to embed code using version 0.28.9 | #### OS Windows 10
#### Versions of xlwings 0.28.9, Excel LTSC Professional Plus 2021 version 2108 and Python 3.8.6
#### I was able to embed my py code using the same setup with xlwings version 0.28.8. But it's not working with the latest version. I used noncommercial license of xlwings Pro with both versions.
#... | closed | 2023-01-22T19:36:29Z | 2023-01-25T00:54:53Z | https://github.com/xlwings/xlwings/issues/2150 | [] | MansuraKhanom | 4 |
encode/uvicorn | asyncio | 1,228 | Support Custom HTTP implementations protocols | ### Checklist
<!-- Please make sure you check all these items before submitting your feature request. -->
- [x] There are no similar issues or pull requests for this yet.
- [ ] I discussed this idea on the [community chat](https://gitter.im/encode/community) and feedback is positive.
### Is your feature relat... | closed | 2021-10-24T06:18:35Z | 2021-10-28T01:24:38Z | https://github.com/encode/uvicorn/issues/1228 | [] | kumaraditya303 | 1 |
ranaroussi/yfinance | pandas | 2,200 | yfinance - Unable to retrieve Ticker earnings_dates | ### Describe bug
Unable to retrieve Ticker earnings_dates
E.g. for NVDA, using Python get yf message back: $NVDA: possibly delisted; no earnings dates found
ditto for AMD and apparently all other valid ticker symbols: $AMD: possibly delisted; no earnings dates found
A list of all methods available for yf Ticker i... | closed | 2025-01-02T19:58:24Z | 2025-01-02T23:03:06Z | https://github.com/ranaroussi/yfinance/issues/2200 | [] | SymbReprUnlim | 1 |
python-restx/flask-restx | flask | 272 | Remove default HTTP 200 response code in doc | **Ask a question**
Hi, I was wondering if it's possible to remove the default "200 - Success" response in the swagger.json?
My model:
```
user_model = api.model(
"User",
{
"user_id": fields.String,
"project_id": fields.Integer(default=1),
"reward_points": fields.Integer(defaul... | closed | 2021-01-04T16:26:19Z | 2021-02-01T12:29:09Z | https://github.com/python-restx/flask-restx/issues/272 | [
"question"
] | mateusz-chrzastek | 2 |
flasgger/flasgger | api | 585 | a little miss | when i forget install this packet -> apispec
page will back err -> internal server error
just have not other tips, so i search the resource code,
in marshmallow_apispec.py

there have some import code, if err ... | open | 2023-06-27T07:43:36Z | 2023-06-27T07:45:55Z | https://github.com/flasgger/flasgger/issues/585 | [] | Spectator133 | 2 |
benlubas/molten-nvim | jupyter | 237 | [Feature Request] Option to show images only in output buffer | Option to show images only in the output buffer and not in the virtual text while still having virtual text enabled. This is because images can be very buggy in the virtual text compared to the buffer and it is nice to have the virtual text enabled for other types of output. This could be its own option where you speci... | closed | 2024-09-12T11:11:37Z | 2024-10-05T13:59:42Z | https://github.com/benlubas/molten-nvim/issues/237 | [
"enhancement"
] | michaelbrusegard | 0 |
keras-team/keras | machine-learning | 21,004 | Ensured torch import is properly handled | Before :
try:
import torch # noqa: F401
except ImportError:
pass
After :
try:
import torch # noqa: F401
except ImportError:
torch = None # Explicitly set torch to None if not installed
| open | 2025-03-07T19:58:17Z | 2025-03-13T07:09:01Z | https://github.com/keras-team/keras/issues/21004 | [
"type:Bug"
] | FNICKE | 1 |
huggingface/pytorch-image-models | pytorch | 1,477 | [FEATURE] Huge discrepancy between HuggingFace and timm in terms of the initialization of ViT | I see a huge discrepancy between HuggingFace and timm in terms of the initialization of ViT. Timm's implementation uses trunc_normal whereas huggingface uses "module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)". I noticed this cause a huge drop in performance when training ViT models on imagenet wi... | closed | 2022-09-28T18:57:06Z | 2023-02-02T04:45:09Z | https://github.com/huggingface/pytorch-image-models/issues/1477 | [
"enhancement"
] | Phuoc-Hoan-Le | 7 |
desec-io/desec-stack | rest-api | 223 | Send emails asynchronously | Currently, requests that trigger emails have to wait until the email has been sent. This is "not nice", and also opens a timing side channel for email enumeration at account registration or password reset.
Let's move to an asynchronous solution, like:
- https://pypi.org/project/django-celery-email/ (full-fledged)
... | closed | 2019-07-02T22:27:43Z | 2019-07-12T01:01:43Z | https://github.com/desec-io/desec-stack/issues/223 | [
"bug",
"api"
] | peterthomassen | 1 |
marcomusy/vedo | numpy | 1,035 | Adding text to screenshot | Hi there,
May I know how to adjust the size and text font of the text on a screenshot? Thank you so much
This is my code:
vp = Plotter(axes=0, offscreen=True)
text = str(lab)
vp.add(text)
vp.show(item, interactive=False, at=0)
screenshot(os.path.join(save_path,file_name)) | closed | 2024-01-25T07:43:40Z | 2024-01-25T09:16:36Z | https://github.com/marcomusy/vedo/issues/1035 | [] | priyabiswas12 | 2 |
AirtestProject/Airtest | automation | 1,150 | 执行了70来次才出现的一个问题,非常偶现 | Traceback (most recent call last):
File "/Users/administrator/jenkinsauto/workspace/autotest-IOS/initmain.py", line 35, in <module>
raise e
File "/Users/administrator/jenkinsauto/workspace/autotest-IOS/initmain.py", line 27, in <module>
t.pushtag_ios()
File "/Users/administrator/jenkinsauto/workspace... | open | 2023-07-28T09:15:06Z | 2023-07-28T09:15:06Z | https://github.com/AirtestProject/Airtest/issues/1150 | [] | z929151231 | 0 |
Evil0ctal/Douyin_TikTok_Download_API | api | 322 | [Feature request] Brief and clear description of the problem | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and conci... | closed | 2024-02-05T21:10:46Z | 2024-02-07T03:40:58Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/322 | [
"enhancement"
] | s6k6s6 | 0 |
ipyflow/ipyflow | jupyter | 40 | separate modes for prod / dev | closed | 2020-08-06T22:17:30Z | 2021-03-08T05:45:32Z | https://github.com/ipyflow/ipyflow/issues/40 | [] | smacke | 0 | |
nvbn/thefuck | python | 889 | how can you get the history for current terminal session | cuz it has not been written to the history file, how to get it? I'm very curious | open | 2019-03-03T10:49:49Z | 2023-10-30T20:00:47Z | https://github.com/nvbn/thefuck/issues/889 | [] | imroc | 1 |
donnemartin/system-design-primer | python | 235 | Anki Error on Launching using Ubuntu 18.10 | I'm using Ubuntu 18.10 on Lenovo Thinkpad:
I get this error right after the install using Ubuntu software install ....after installed ...when pressing Launch button:
_____________________________________________________
Error during startup:
Traceback (most recent call last):
File "/usr/share/anki/aqt/main.py", ... | open | 2018-11-17T16:17:20Z | 2019-04-10T00:51:09Z | https://github.com/donnemartin/system-design-primer/issues/235 | [
"help wanted",
"needs-review"
] | FunMyWay | 6 |
piskvorky/gensim | machine-learning | 3,154 | Yes, thanks. If it's really a bug with the FB model, not much we can do about it. | Yes, thanks. If it's really a bug with the FB model, not much we can do about it.
_Originally posted by @piskvorky in https://github.com/RaRe-Technologies/gensim/issues/2969#issuecomment-799811459_ | closed | 2021-05-19T22:08:58Z | 2021-05-19T23:05:28Z | https://github.com/piskvorky/gensim/issues/3154 | [] | Dino1981 | 0 |
streamlit/streamlit | data-visualization | 10,029 | st.radio label alignment and label_visibility issues in the latest versions | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
The st.radio widget has two unexpected behavi... | closed | 2024-12-16T12:28:53Z | 2024-12-16T16:06:20Z | https://github.com/streamlit/streamlit/issues/10029 | [
"type:bug",
"feature:st.radio",
"status:awaiting-team-response"
] | Panosero | 4 |
deeppavlov/DeepPavlov | tensorflow | 1,372 | Go-Bot: migrate to PyTorch (policy) | Moved to internal Trello | closed | 2021-01-12T11:19:57Z | 2021-11-30T10:16:57Z | https://github.com/deeppavlov/DeepPavlov/issues/1372 | [] | danielkornev | 0 |
jina-ai/clip-as-service | pytorch | 235 | Support for FP16 (mixed precision) trained models | I trained a little german BERT Model with FP16 and tensorflow, so the Nvidia suggestion https://github.com/google-research/bert/pull/255
the suggestions are hosted in this repository
https://github.com/thorjohnsen/bert/tree/gpu_optimizations
Training works fine, but bert-as-service doesn't work with that, because ... | closed | 2019-02-13T17:20:31Z | 2019-03-14T03:44:38Z | https://github.com/jina-ai/clip-as-service/issues/235 | [] | miweru | 1 |
ultralytics/ultralytics | computer-vision | 18,799 | YOLO导出TensorRT格式或许不支持JetPack 6.2 | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
你好!我目前发现我在将pytorch格式转成tensorRT格式时,程序会报错:
下面的错误表明似乎无法支持tensorRT,目前的jetson ori... | open | 2025-01-21T12:45:56Z | 2025-01-23T14:31:26Z | https://github.com/ultralytics/ultralytics/issues/18799 | [
"question",
"embedded",
"exports"
] | Vectorvin | 6 |
hpcaitech/ColossalAI | deep-learning | 5,601 | [FEATURE]: support multiple (partial) backward passes for zero | ### Describe the feature
In some vae training, users may use weight adaptive loss which may compute grad of some parameters twice, like

This will trigger backward hook twice.
Based on pytorch's document, we ma... | closed | 2024-04-16T05:02:06Z | 2024-04-16T09:49:22Z | https://github.com/hpcaitech/ColossalAI/issues/5601 | [
"enhancement"
] | ver217 | 0 |
exaloop/codon | numpy | 595 | Is there a way to use python Enum? | I cannot find an example : ( . | closed | 2024-09-30T07:21:46Z | 2024-09-30T07:28:37Z | https://github.com/exaloop/codon/issues/595 | [] | BeneficialCode | 0 |
mwaskom/seaborn | data-visualization | 3,584 | UserWarning: The figure layout has changed to tight self._figure.tight_layout(*args, **kwargs) | I have encountered a persistent `UserWarning` when using Seaborn's `pairplot` function, indicating a change in figure layout to tight.


| open | 2019-11-07T04:47:01Z | 2019-11-14T07:13:36Z | https://github.com/AirtestProject/Airtest/issues/595 | [] | abcdd12 | 5 |
gevent/gevent | asyncio | 1,679 | Python 3.8.6 and perhaps other recent Python 3.8 builds are incompatible | * gevent version: 1.4.0
* Python version: Please be as specific as possible: the `python:3.8` docker image as of 2020-09-24 6:30PM PST
* Operating System: Linux - ubuntu or Docker on Windows or Docker on Mac or Google container optimized linux
### Description:
Trying to boot a gunicorn worker with `--worker-cla... | closed | 2020-09-25T01:34:56Z | 2020-09-25T10:25:02Z | https://github.com/gevent/gevent/issues/1679 | [] | AaronFriel | 2 |
microsoft/nni | deep-learning | 5,651 | Can not download Tar when Build from Source | The tar package cannot be downloaded when the source code is used for building.
nni version: dev
python: 3.7.9
os: openeuler-20.03
How to reproduce it?
```
git clone https://github.com/microsoft/nni.git
cd nni
export NNI_RELEASE=2.0
python setup.py build_ts
```
 which uses code similar to yours for mAP@R calculation (I am not sure who's based on who, opening this issue on both).
I suspect there is a mistake in the implement... | closed | 2021-05-25T15:24:50Z | 2021-05-26T06:58:39Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/331 | [
"question"
] | drasros | 3 |
liangliangyy/DjangoBlog | django | 525 | 文章只是点播视频吗? | <!--
如果你不认真勾选下面的内容,我可能会直接关闭你的 Issue。
提问之前,建议先阅读 https://github.com/ruby-china/How-To-Ask-Questions-The-Smart-Way
-->
**我确定我已经查看了** (标注`[ ]`为`[x]`)
- [x] [DjangoBlog的readme](https://github.com/liangliangyy/DjangoBlog/blob/master/README.md)
- [x] [配置说明](https://github.com/liangliangyy/DjangoBlog/blob/master/bin... | closed | 2021-11-22T07:10:34Z | 2022-03-02T11:22:56Z | https://github.com/liangliangyy/DjangoBlog/issues/525 | [] | glinxx | 2 |
httpie/cli | rest-api | 1,247 | Test new httpie command on various actions | We have 2 actions that gets triggered when specific files are edited (for testing snap/brew works), they test the `http` but not `httpie`, so let's also test it too. | closed | 2021-12-21T17:32:58Z | 2021-12-23T18:55:40Z | https://github.com/httpie/cli/issues/1247 | [
"bug",
"new"
] | isidentical | 1 |
scrapy/scrapy | python | 6,378 | Edit Contributing.rst document to specify how to propose documentation suggestions | There are multiple types of contributions that the community can suggest including bug reports, feature requests, code improvements, security vulnerability reports, and documentation changes.
For the Scrapy.py project it was difficult to discern what process to follow to make a documentation improvement suggestion.... | closed | 2024-05-26T15:43:40Z | 2024-07-10T07:37:32Z | https://github.com/scrapy/scrapy/issues/6378 | [] | jtoallen | 11 |
pytorch/pytorch | machine-learning | 149,186 | torch.fx.symbolic_trace failed on deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B | ### 🐛 Describe the bug
I try to compile deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B to mlir with the following script.
```python
# Import necessary libraries
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from torch.export import export
import onnx
from torch_mlir import fx
# Load the DeepSee... | open | 2025-03-14T08:37:31Z | 2025-03-24T06:33:05Z | https://github.com/pytorch/pytorch/issues/149186 | [
"module: fx",
"oncall: pt2",
"oncall: export"
] | FlintWangacc | 4 |
gunthercox/ChatterBot | machine-learning | 2,190 | After my training using a third-party corpus, the robot was unable to answer accurately | I plan to use Chatterbot to build a chatbot. After training with a third-party corpus, MY questions cannot be answered accurately, and the error rate is almost 100%. How can I solve it | open | 2021-08-11T08:20:54Z | 2021-08-11T08:22:29Z | https://github.com/gunthercox/ChatterBot/issues/2190 | [] | jianwei923 | 1 |
gevent/gevent | asyncio | 1,981 | How to determine the saturation of the generated little green leaves | I want to observe how long the green applet waits in the ready queue for the loop to be dispatched.
Because I want to determine if I am generating too many greenlets | closed | 2023-08-03T12:14:10Z | 2023-08-03T13:10:35Z | https://github.com/gevent/gevent/issues/1981 | [] | xpf629629 | 3 |
davidteather/TikTok-Api | api | 612 | [BUG] - It seems that a csrf_session_id is now needed in cookies | `userPosts` endpoint stops to work on my side since several hours.
According to my first investigations, It seems a new cookie is now needed : csrf_session_id
I tried to fix that but was not able to make it work again for now
| closed | 2021-06-09T17:00:49Z | 2021-06-24T21:01:53Z | https://github.com/davidteather/TikTok-Api/issues/612 | [
"bug"
] | vdemay | 8 |
seleniumbase/SeleniumBase | pytest | 2,761 | Can the nodejs code in the integrations/nodejs directory be automatically generated? | closed | 2024-05-10T02:50:06Z | 2024-05-10T03:25:00Z | https://github.com/seleniumbase/SeleniumBase/issues/2761 | [
"question"
] | cloudswar | 1 | |
Textualize/rich | python | 2,512 | [BUG] Weird coloring when SSHed into a server | **Describe the bug**
So basically, when I am SSHed into a server, the coloring of text is not right
<br>
Here's the raw text:
```
[grey50][04/09/22 18:15:58][/] [blue3]122.161.67.108 [/] -- [magenta1]/ [/] [chartreuse4][/] -- [light_steel_blue]Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:104.0)... | closed | 2022-09-04T13:09:51Z | 2022-09-24T18:31:14Z | https://github.com/Textualize/rich/issues/2512 | [
"Needs triage"
] | msr8 | 4 |
deeppavlov/DeepPavlov | tensorflow | 1,338 | 404 in the docs | Our docs contain 404 links for nemo tutorials [here](http://docs.deeppavlov.ai/en/master/features/models/nemo.html) below in the model training section | closed | 2020-11-05T18:33:14Z | 2022-04-01T11:35:14Z | https://github.com/deeppavlov/DeepPavlov/issues/1338 | [
"bug"
] | oserikov | 2 |
Evil0ctal/Douyin_TikTok_Download_API | api | 431 | [BUG] 4.0.3版本更换了cookies依然无法获取视频的信息 | ***发生错误的平台?***
抖音
***发生错误的端点?***
/api/hybrid/video_data
***提交的输入值?***
[如:短视频链接](https://v.douyin.com/ijtxc3Go/)
***是否有再次尝试?***
是。
***你有查看本项目的自述文件或接口文档吗?***
有。log如下:
程序出现异常,请检查错误信息。
ERROR 无效响应类型。响应类型: <class 'NoneType'>
程序出现异常,请检查错误信息。
| closed | 2024-06-15T07:23:47Z | 2024-06-17T14:05:06Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/431 | [
"BUG"
] | ilucl | 12 |
slackapi/bolt-python | fastapi | 879 | Installation issue | I have noticed that anytime i update my code for my webhook that uses oauth that is deployed, it suddenly starts requesting for me to install the app again into the organisation. I don't think this is going to be sustainable once the app is actually published. What's the solution for this? my guess is slack pings it a ... | closed | 2023-04-08T00:01:47Z | 2023-04-08T09:18:08Z | https://github.com/slackapi/bolt-python/issues/879 | [] | smyja | 1 |
wiseodd/generative-models | tensorflow | 18 | loss compute | i think, should use `nn.BCEloss`, not `-(torch.mean(torch.log(D_real)) + torch.mean(torch.log(1 - D_fake)))` | closed | 2017-05-05T01:28:26Z | 2017-12-29T11:44:38Z | https://github.com/wiseodd/generative-models/issues/18 | [] | JiangWeixian | 0 |
strawberry-graphql/strawberry-django | graphql | 340 | optimizer over fetching rows | Hi,
It looks like Query Optimizer is over fetching rows when working with Relay connections. I works fine with List but not with Connections.
So when I build schema using List, query below gets executed as single SQL
But when using Connection, I get two SQLs. I guess thats how it works? Or could it be "optimized... | closed | 2023-08-16T22:25:21Z | 2025-03-20T15:57:17Z | https://github.com/strawberry-graphql/strawberry-django/issues/340 | [
"bug"
] | tasiotas | 12 |
piskvorky/gensim | data-science | 3,288 | Python 3.10 wheels | Hello!
Is there a reason why there are no wheels for python 3.10? See https://pypi.org/project/gensim/4.1.2/#files
If not, are you planning to add them?
Let me know if I can help in any way!
Best,
| closed | 2022-02-08T10:45:44Z | 2022-03-18T14:05:48Z | https://github.com/piskvorky/gensim/issues/3288 | [
"testing",
"reach MEDIUM",
"impact MEDIUM"
] | LouisTrezzini | 2 |
polakowo/vectorbt | data-visualization | 29 | Returns_Accessor | Is there a generic way to create a new method for these performance metrics, kind of how indicators has an indicator factory? Would be nice to be able to add these performance metrics and a generic way to implement new ones and add to the portfolio class.
I've only started implementing the examples so I might not... | closed | 2020-07-30T13:11:45Z | 2024-03-16T09:19:10Z | https://github.com/polakowo/vectorbt/issues/29 | [] | stevennevins | 8 |
tflearn/tflearn | tensorflow | 833 | Accuracy null and low loss | Hello everyone and thank you for looking at my question.
I have data made of date (one entry per minute) for the first column and congestion (value, between 0 and 200) for the 2nd. My goal is to feed it to my neural network and so be able to predict for the next week the congestion at each minute (my dataset is mor... | closed | 2017-07-12T08:29:35Z | 2017-07-20T05:58:42Z | https://github.com/tflearn/tflearn/issues/833 | [] | Erickira3 | 1 |
Sanster/IOPaint | pytorch | 429 | [BUG]pydantic_core._pydantic_core.ValidationError: 1 validation error for Config paint_by_example_example_image Input should be an instance of Image [type=is_instance_of, input_value=None, input_type=NoneType] | **Model**
LAMA
**Describe the bug**
[2024-01-24 09:36:41,914] ERROR in app: Exception on /inpaint [POST]
Traceback (most recent call last):
File "E:\wss\python\pycharm-work\lama-cleaner-0.37.0\venv\lib\site-packages\flask\app.py", line 2447, in wsgi_app
response = self.full_dispatch_request()
File "E:\... | closed | 2024-01-24T03:15:51Z | 2025-02-27T02:01:44Z | https://github.com/Sanster/IOPaint/issues/429 | [
"stale"
] | wang3680 | 3 |
PaddlePaddle/PaddleHub | nlp | 1,869 | 运行trainer.train()出现label should not out of bound, but gotTensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True, [2]) |
- 版本、环境信息
1)例如PaddleHub2.1.1,PaddlePaddle2.2.2.post101使用erine_tiny
2)系统环境:aistudio平台
- 复现信息:ValueError: label should not out of bound, but gotTensor(shape=[1], dtype=int64, place=CUDAPlace(0), stop_gradient=True,[2]
-
代码:https://aistudio.baidu.com/aistudio/datasetdetail/146374/0
| closed | 2022-05-14T02:57:07Z | 2022-05-25T01:56:52Z | https://github.com/PaddlePaddle/PaddleHub/issues/1869 | [] | fatepary | 2 |
viewflow/viewflow | django | 28 | right lookup over flow_task fields | Need to add full path to flow_task name
or
get_objects_or_404(Task, process__flow_cls=flow_task.flow_cls, flow_task=flow_task)
| closed | 2014-03-28T00:37:33Z | 2014-05-01T09:58:12Z | https://github.com/viewflow/viewflow/issues/28 | [
"request/enhancement"
] | kmmbvnr | 1 |
jpadilla/django-rest-framework-jwt | django | 368 | Validate and get the user using the jwt token inside a view or consumer | I am using django-rest-framework for the REST API. Also, for JSON web token authentication I am using django-rest-framework-jwt. After a successful login, the user is provided with a token. I have found how to [verify a token](https://getblimp.github.io/django-rest-framework-jwt/#verify-token) with the api call, but is... | open | 2017-09-15T02:24:36Z | 2018-08-20T05:28:08Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/368 | [] | robinlery | 1 |
biolab/orange3 | data-visualization | 6,173 | Feature Statistics - open issues | <!--
If something's not right with Orange, fill out the bug report template at:
https://github.com/biolab/orange3/issues/new?assignees=&labels=bug+report&template=bug_report.md&title=
If you have an idea for a new feature, fill out the feature request template at:
https://github.com/biolab/orange3/issues/new?assi... | closed | 2022-10-14T13:50:34Z | 2023-02-23T11:00:15Z | https://github.com/biolab/orange3/issues/6173 | [
"wish",
"snack"
] | lanzagar | 2 |
pytest-dev/pytest-xdist | pytest | 328 | Re-run errored tests on another node | With https://github.com/pytest-dev/pytest-xdist/issues/327 (errors due to out-of-memory), it would be useful if those tests could be run on another node automatically/optionally.
I guess that `--dist=each` would consider the test(s) to be OK if it failed only on one node, but I am using `--dist=loadfile` (for perfor... | open | 2018-08-02T05:27:24Z | 2018-08-02T08:19:31Z | https://github.com/pytest-dev/pytest-xdist/issues/328 | [] | blueyed | 4 |
marcomusy/vedo | numpy | 912 | linewidth in silhouette | problem: how to close linewidth in silhouette
mesh: [SMPL_A.txt](https://github.com/marcomusy/vedo/files/12273512/SMPL_A.txt)
code:
```
from vedo import settings, Plotter, Mesh
settings.use_depth_peeling = True
plt = Plotter()
path_mesh = "SMPL_A.obj"
mesh = Mesh(path_mesh).lighting("off").c("pink")... | closed | 2023-08-07T07:41:01Z | 2023-08-24T06:45:38Z | https://github.com/marcomusy/vedo/issues/912 | [] | LogWell | 3 |
jacobgil/pytorch-grad-cam | computer-vision | 22 | 'image not found' error | I see that several people get the image not found error.
Here is my solution: 'brew install libomp'
Added a comment to Readme:
https://github.com/punnerud/pytorch-grad-cam | closed | 2019-06-04T13:27:22Z | 2019-06-04T16:39:31Z | https://github.com/jacobgil/pytorch-grad-cam/issues/22 | [] | punnerud | 1 |
pallets-eco/flask-sqlalchemy | flask | 563 | many to many relationship, cann't add any data. | I use the case which was provided from official website (http://flask-sqlalchemy.pocoo.org/2.3/models/#many-to-many-relationships),this can create three tables, but when I add new data, they raise "AttributeError: 'tuple' object has no attribute 'foreign_keys'"
my code:
```
from flask import Flask
from flask_sqla... | closed | 2017-10-26T16:13:52Z | 2020-12-05T20:55:27Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/563 | [] | dreamsuifeng | 2 |
biolab/orange3 | pandas | 6,657 | Documentation for Table.from_list | <!--
This is an issue template. Please fill in the relevant details in the
sections below.
Wrap code and verbatim terminal window output into triple backticks, see:
https://help.github.com/articles/basic-writing-and-formatting-syntax/#quoting-code
If you're raising an issue about an add-on (e.g. installed via
... | closed | 2023-11-27T13:08:41Z | 2023-11-27T13:21:44Z | https://github.com/biolab/orange3/issues/6657 | [] | dhilst | 0 |
chezou/tabula-py | pandas | 198 | CalledProcessError after bundling Python script into executable with PyInstaller | <!--- Provide a general summary of your changes in the Title above -->
# Summary of your issue
I've been using tabula-py to convert a series of pdf tables into csv files for my program to parse through and collect some data. The code works perfectly when just in the script, but if I attempt to bundle my code into... | closed | 2019-12-17T00:34:05Z | 2023-04-06T01:40:51Z | https://github.com/chezou/tabula-py/issues/198 | [] | adammet | 5 |
seleniumbase/SeleniumBase | web-scraping | 2,178 | Unable to obtain multiple texts:self.get_text('li.el-menu-item') | 
I need to retrieve these files into a list, currently only the first one can be obtained
触发事件
流程列表
触发策略 | closed | 2023-10-11T11:04:28Z | 2023-10-12T02:33:52Z | https://github.com/seleniumbase/SeleniumBase/issues/2178 | [
"question"
] | luckyboy-wei | 2 |
miguelgrinberg/Flask-SocketIO | flask | 1,851 | Does the windows environment cause multiple client links to block | Hello, I am using Flask-SocketIO to process tasks, if a user sends multiple tasks, it will cause the link Flask-SocketIO to block, my environment is windows | closed | 2022-07-22T10:09:36Z | 2022-07-22T10:17:18Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1851 | [] | zhenzi0322 | 1 |
Lightning-AI/LitServe | api | 177 | Show warning if `batch` & `unbatch` is implemented but max_batch_size not set in `LitServer` | ## 🚀 Feature
<!-- A clear and concise description of the feature proposal -->
### Motivation
<!-- Please outline the motivation for the proposal. Is your feature request related to a problem? e.g., I'm always frustrated when [...]. If this is related to another GitHub issue, please link here too -->
### Pi... | closed | 2024-07-19T18:13:44Z | 2024-08-02T14:57:26Z | https://github.com/Lightning-AI/LitServe/issues/177 | [
"enhancement",
"good first issue",
"help wanted"
] | aniketmaurya | 2 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 667 | Dataset option is blur(not usable) in GUI | 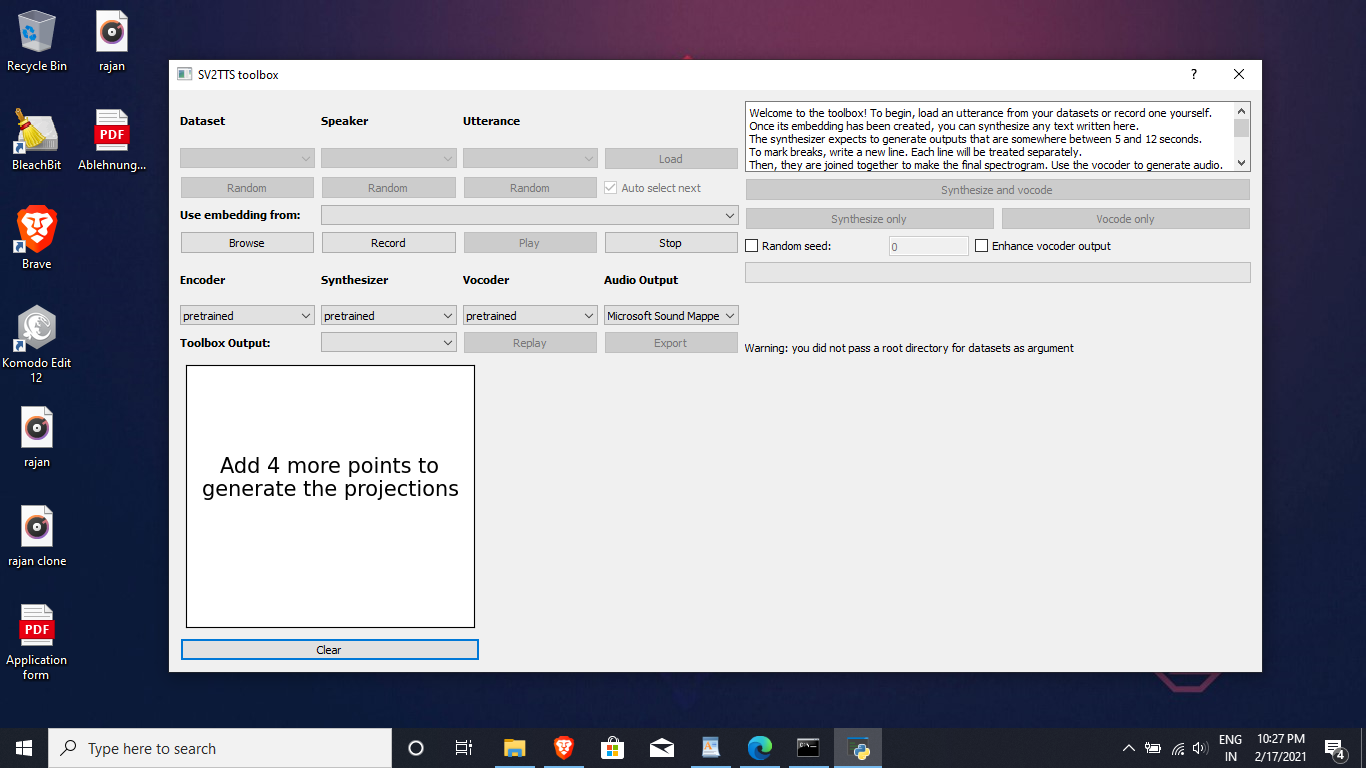
How to enable dataset option ? It is not usable in GUI. Where to extract data sets? <dataset_root> means any folder ? | closed | 2021-02-17T18:30:13Z | 2021-02-17T20:23:42Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/667 | [] | clonereal | 1 |
httpie/cli | rest-api | 1,523 | [macOS] Lag when piping stdout | When redirecting httpie output to a pipe, there is a significant lag in the total execution time:
1. Without pipe
```
time http http://localhost:8508/api/v1 > /dev/null
http http://localhost:8508/api/v1> /dev/null 0.12s user 0.05s system 59% cpu 0.282 total
```
2. With pipe
```
time http http://localhost... | closed | 2023-07-30T23:28:36Z | 2024-01-31T18:01:32Z | https://github.com/httpie/cli/issues/1523 | [
"bug",
"new"
] | gsakkis | 5 |
arogozhnikov/einops | numpy | 167 | [BUG] einops materializes tensors that could be views | **Describe the bug**
That a lot for this great library! My code looks much nicer now. Today I noticed that einops exhibits suboptimal behavior when repeating tensors in ways that could be views. In the example below, expanding with PyTorch creates a view that actually reuses the same memory as the original tensor. If ... | closed | 2022-01-19T17:23:03Z | 2022-01-19T18:53:09Z | https://github.com/arogozhnikov/einops/issues/167 | [
"bug"
] | martenlienen | 2 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 150 | sendkeys-elemwrite ? | File "C:\Users\Administrator\Desktop\Proxy-Changer-main\drivertest.py", line 83, in <module>
asyncio.run(main())
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python311\Lib\asyncio\runners.py", line 190, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "C:\Users\Administra... | closed | 2024-01-15T10:02:52Z | 2024-01-15T10:30:22Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/150 | [] | yemrekula0748 | 1 |
neuml/txtai | nlp | 377 | OpenMP issues with torch 1.13+ on macOS | macOS users are running into a compatibility issue between Faiss and Torch related to OpenMP. This has also affected the GitHub Actions build.
It would be great if a macOS user took a look at trying to figure out the root cause. See this comment for debugging ideas https://github.com/neuml/txtai/issues/498#issuecom... | closed | 2022-11-01T18:23:06Z | 2023-07-10T17:06:04Z | https://github.com/neuml/txtai/issues/377 | [
"bug"
] | davidmezzetti | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 243 | 我用cloudflare解析了域名,为什么无法访问,是不是我使用了泛解析,还是证书问题? | ***发生错误的平台?***
如:抖音/TikTok
***发生错误的端点?***
如:API-V1/API-V2/Web APP
***提交的输入值?***
如:短视频链接
***是否有再次尝试?***
如:是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述文件或接口文档吗?***
如:有,并且很确定该问题是程序导致的。
| closed | 2023-08-17T15:19:25Z | 2023-09-12T15:22:05Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/243 | [
"help wanted"
] | tiermove | 3 |
zappa/Zappa | flask | 738 | [Migrated] Zappa appears to fail silently when it can't create a bucket | Originally from: https://github.com/Miserlou/Zappa/issues/1860 by [fbidu](https://github.com/fbidu)
<!--- Provide a general summary of the issue in the Title above -->
## Context
I'm using Python 3.7 but that doesn't seem to affect the issue itself. In my initial config, I put a "bucket_name" that, by accident, alre... | closed | 2021-02-20T12:41:35Z | 2022-07-16T06:24:36Z | https://github.com/zappa/Zappa/issues/738 | [] | jneves | 1 |
Johnserf-Seed/TikTokDownload | api | 532 | 异常,本地网络请求异常。 异常: 0, message='Attempt to decode JSON with unexpected mimetype: text/plain; charset=utf-8', url=URL('https://www.douyin.com/aweme/v1/web/user/profile/other/?device_platform=webapp&aid=6383&sec_user_id=MS4wLjABAAAA4vgRHGrSG6rPlffm3RvwHWL8TBq7O4YnM5jHUNXz0-s&cookie_enabled=true& platform=PC&downlink=10&X-B... | **描述出现的错误**
遇到bug先在issues中搜索,没有得到解决方案再提交。
对出现bug的地方做清晰而简洁的描述。
**bug复现**
复现这次行为的步骤:
1.首先更改了什么什么
2.点击了什么什么
3.“……”
**截图**
如果适用,添加屏幕截图以帮助解释您的问题。
**桌面(请填写以下信息):**
-操作系统:[例如windows10 64bit]
-vpn代理:[例如开启、关闭]
-项目版本:[如1.4.2.2]
-py版本:[如3.11.1]
-依赖库的版本:[出错的库版本号]
**附文**
在此处添加有关此问题的其他备注。
| closed | 2023-08-31T16:45:48Z | 2023-09-01T13:03:57Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/532 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | Hkxuan | 1 |
amidaware/tacticalrmm | django | 1,229 | Request: Register all repos with OpenHub and Coverity Scan | Tactical RMM is already registered with OpenHub - https://www.openhub.net/p/tacticalrmm
It would be great for the project (and visibility) to register all the repos associated with Tactical RMM (core, agent, web) with both OpenHub and Coverity Scan - https://scan.coverity.com/ - a static analysis tool that is free f... | closed | 2022-07-28T13:40:57Z | 2022-10-26T12:09:47Z | https://github.com/amidaware/tacticalrmm/issues/1229 | [
"help wanted"
] | UranusBytes | 1 |
pallets/flask | flask | 4,604 | Update of the downloadable documentation of flask2.0 | I would love to be able to download the latest flask2.0 docs as it's always a good resource and since the update of flask the docs have been updated online but the downloadable versions are still in flask1.x.x
:
Traceback (most recent call last):
File "/home/pi/Mycodo/... | closed | 2021-05-30T15:24:59Z | 2021-06-05T16:32:42Z | https://github.com/kizniche/Mycodo/issues/1016 | [
"duplicate"
] | Fumetin | 1 |
google-research/bert | nlp | 1,010 | Finding results on STS Benchmark dataset | Hi,
Can someone tell how results on https://paperswithcode.com/sota/semantic-textual-similarity-on-sts-benchmark are found? What architecture BERT, ALBERT follow to get the output. | open | 2020-02-25T05:11:10Z | 2020-02-25T05:11:10Z | https://github.com/google-research/bert/issues/1010 | [] | dheerajiiitv | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 668 | Confusion with CycleGAN testing regarding domains | Hi I am trying to train a CycleGAN such that I can translate images from domain B to domain A. After training the initial model I wanted to test it on some out-of-training-set images from domain B. So I used:
`python test.py --dataroot datasets/my_proj/testB --name my_cyclegan_proj --model test --no_dropout`
Howe... | closed | 2019-06-06T16:47:18Z | 2024-09-02T16:54:27Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/668 | [] | patrick-han | 4 |
Anjok07/ultimatevocalremovergui | pytorch | 998 | UVR5 | Last Error Received:
Process: VR Architecture
Missing file error raised. Please address the error and try again.
If this error persists, please contact the developers with the error details.
Raw Error Details:
FileNotFoundError: "[WinError 2] The system cannot find the file specified"
Traceback Error: "... | closed | 2023-11-30T14:53:22Z | 2023-11-30T15:03:48Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/998 | [] | Soorenaca | 0 |
docarray/docarray | pydantic | 1,544 | Indexing field of DocList type (=subindex)is not yet supported. | I am creating database of the following format, but unable to index/search
User
-- Folder (multiple folders)
-- Document (multiple documents)
-- Sentences ( document split into sentences)
For the datastore, I get the error `Indexing field of DocList type (=subindex)is not yet supported.` wh... | closed | 2023-05-16T14:03:27Z | 2023-05-17T06:53:04Z | https://github.com/docarray/docarray/issues/1544 | [] | munish0838 | 4 |
ultralytics/ultralytics | pytorch | 18,853 | inference time | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi
Is there a script I can use to measure the inference time?
### Additiona... | open | 2025-01-23T16:08:44Z | 2025-01-23T20:42:35Z | https://github.com/ultralytics/ultralytics/issues/18853 | [
"question"
] | MuhabHariri | 5 |
strawberry-graphql/strawberry | graphql | 3,473 | Upgrade causes "no current event loop in thread" exception | Moving from 0.225.1 to 0.227.2, I get event loop exceptions like:
https://wedgworths-inc.sentry.io/share/issue/1ea8832512944d21b11adc8dedcacef7/
I don't use async so I'm confused why exception is in that area of the code.
I wonder if it has something to do with 63dfc89fc799e3b50700270fe243d3f53d543412 | closed | 2024-04-26T16:55:49Z | 2025-03-20T15:56:42Z | https://github.com/strawberry-graphql/strawberry/issues/3473 | [
"bug"
] | paltman | 1 |
miguelgrinberg/flasky | flask | 308 | Purpose of seed() in User model | ```python
class User(UserMixin, db.Model):
...
def generate_fake(count=100):
from sqlalchemy.exc import IntegrityError
from random import seed
import forgery_py
seed()
for i in range(count):
u = User(email=forgery_py.internet.email_address(),
... | closed | 2017-10-25T07:31:42Z | 2017-10-26T14:19:29Z | https://github.com/miguelgrinberg/flasky/issues/308 | [
"question"
] | noisytoken | 2 |
recommenders-team/recommenders | deep-learning | 1,616 | [BUG] Error in integration tests with SASRec | ### Description
<!--- Describe your issue/bug/request in detail -->
we got this error in the nightly integration tests:
```
tests/integration/examples/test_notebooks_gpu.py ..............F [100%]
=================================== FAILURES ===================================
_ test_sasrec_quickstart_in... | closed | 2022-01-19T14:14:01Z | 2022-01-19T20:12:33Z | https://github.com/recommenders-team/recommenders/issues/1616 | [
"bug"
] | miguelgfierro | 1 |
dask/dask | scikit-learn | 11,226 | Negative lookahead suddenly incorrectly parsed | In Dask 2024.2.1 we suddenly have an issue with a regex with a negative lookahead. It somehow is invalid now.
```python
import dask.dataframe as dd
regex = 'negativelookahead(?!/check)'
ddf = dd.from_dict(
{
"test": ["negativelookahead", "negativelookahead/check/negativelookahead", ],
},
n... | closed | 2024-07-15T07:23:02Z | 2024-07-17T12:59:24Z | https://github.com/dask/dask/issues/11226 | [
"needs triage"
] | manschoe | 3 |
ARM-DOE/pyart | data-visualization | 751 | There is a bug in pyart/io/cfradial.py | when I read the code of cfradial.py, I found that there is a value named 'radar_reciever_bandwidth' in pyart/io/cfradial.py line 62. This is wrong because you named it 'radar_receiver_bandwidth' in other file. It may cause other errors, I hope you can fix it soon. | closed | 2018-06-06T08:58:36Z | 2018-06-07T01:55:06Z | https://github.com/ARM-DOE/pyart/issues/751 | [] | YvZheng | 4 |
sunscrapers/djoser | rest-api | 46 | doesn't work is_authenticated() at the themplate | doesn't work is_authenticated() with 'rest_framework.authentication.TokenAuthentication' installed.
how to fix it?
| closed | 2015-05-12T17:22:57Z | 2015-05-13T08:28:52Z | https://github.com/sunscrapers/djoser/issues/46 | [] | ghost | 2 |
babysor/MockingBird | deep-learning | 437 | 【长期】训练克隆特定人声音&finetune | [AyahaShirane](https://github.com/AyahaShirane)
专项训练参照这个视频MockingBird数据集制作教程-手把手教你克隆海子姐的声线_哔哩哔哩_bilibili<https://www.bilibili.com/video/BV1dq4y137pH>
实测在已有模型基础上训练20K左右就能改变成想要的语音语调了。你如果是想要泛用型台湾口音的话,就尽可能收集更多人的数据集,否则会偏向特定某一个人的口音,而且断句和停顿似乎也会受到新数据集的影响
Reference: #380
> 作者却苦于近期精力限制只能势单力薄处理一些小的bug,也看到issue区有不少爱好与开发者想要学习... | open | 2022-03-07T15:14:08Z | 2023-11-20T06:15:40Z | https://github.com/babysor/MockingBird/issues/437 | [
"discussion"
] | babysor | 18 |
deeppavlov/DeepPavlov | nlp | 1,519 | Could not find a version that satisfies the requirement uvloop==0.14.0 (from deeppavlov) | Want to contribute to DeepPavlov? Please read the [contributing guideline](http://docs.deeppavlov.ai/en/master/devguides/contribution_guide.html) first.
Please enter all the information below, otherwise your issue may be closed without a warning.
**DeepPavlov version** (you can look it up by running `pip show ... | closed | 2022-01-28T09:16:07Z | 2022-04-01T11:46:48Z | https://github.com/deeppavlov/DeepPavlov/issues/1519 | [
"bug"
] | 645187919 | 2 |
aminalaee/sqladmin | fastapi | 776 | with ... as ... statement can make sesssion close,which will lead to DetachedInstanceError | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
sqladmin/models
```
def _run_query_sync(self, stmt: ClauseElement) -> Any:
with self.session_maker(expire_on_commit=False) as session:
... | open | 2024-05-30T08:41:13Z | 2024-06-07T05:06:09Z | https://github.com/aminalaee/sqladmin/issues/776 | [] | ChengChe106 | 8 |
TencentARC/GFPGAN | deep-learning | 279 | styleGAN 256x256 | hello, is there any pretrained styleGAN2 with 256x256 px that provided, as the FFHQ dataset is too large to download and it may take a long times for training. | open | 2022-10-04T02:16:00Z | 2022-10-09T03:21:44Z | https://github.com/TencentARC/GFPGAN/issues/279 | [] | greatbaozi001 | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.