
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
hzwer/ECCV2022-RIFE | computer-vision | 221 | About LiteFlowNet's pre-trained model as the overpowered teacher in the leakage distillation | 您好,有一个问题想要请教一下您:如何在将LiteFlowNet的预训练模型作为overpowered teacher添加到代码中?我没有在代码中找到对LiteFlowNet预训练模型的调用。 | closed | 2021-12-11T08:50:41Z | 2021-12-17T11:57:51Z | https://github.com/hzwer/ECCV2022-RIFE/issues/221 | [] | Heroandzhang | 4 |
huggingface/diffusers | pytorch | 10,972 | Loading LoRA weights fails for OneTrainer Flux LoRAs | ### Describe the bug
Loading [OneTrainer](https://github.com/Nerogar/OneTrainer) style LoRAs, using diffusers commit #[dcd77ce22273708294b7b9c2f7f0a4e45d7a9f33](https://github.com/huggingface/diffusers/commit/dcd77ce22273708294b7b9c2f7f0a4e45d7a9f33), fails with error:
```
Traceback (most recent call last):
File "... | closed | 2025-03-05T13:07:40Z | 2025-03-06T08:33:34Z | https://github.com/huggingface/diffusers/issues/10972 | [
"bug"
] | spezialspezial | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,635 | Hello, | 谢谢
| closed | 2024-03-13T09:02:26Z | 2024-03-21T00:30:07Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1635 | [] | czh886 | 1 |
modin-project/modin | data-science | 6,712 | Copy `_shape_hint` in `query_complier.copy` function | closed | 2023-11-06T18:02:39Z | 2023-11-07T09:46:00Z | https://github.com/modin-project/modin/issues/6712 | [
"Performance 🚀"
] | anmyachev | 0 | |
graphql-python/gql | graphql | 207 | gql tests are failing with graphql-core 3.1.5 (cosmetic) | With graphql-core version 3.1.5:
* [print_ast() break arguments over multiple lines ](https://github.com/graphql-python/graphql-core/commit/ae923bb15ce58c7059e7e9f352e079ba8b23d3f9)
* [the check for the source argument was changed](https://github.com/graphql-python/graphql-core/commit/a9ae0d90fc25565dada6e363464ddc... | closed | 2021-05-11T11:29:52Z | 2021-05-22T21:41:45Z | https://github.com/graphql-python/gql/issues/207 | [
"type: tests"
] | leszekhanusz | 0 |
Lightning-AI/LitServe | fastapi | 366 | Info route | <!--
⚠️ BEFORE SUBMITTING, READ:
We're excited for your request! However, here are things we are not interested in:
- Decorators.
- Doing the same thing in multiple ways.
- Adding more layers of abstraction... tree-depth should be 1 at most.
- Features that over-engineer or complicate the code internals... | closed | 2024-11-21T10:29:09Z | 2024-11-27T17:31:26Z | https://github.com/Lightning-AI/LitServe/issues/366 | [
"enhancement"
] | lorenzomassimiani | 2 |
amdegroot/ssd.pytorch | computer-vision | 78 | in config.py, did min_sizes and max_sizes mean scale? | Nice work, thanks very much. But I have a little question:
```python
'min_sizes' : [30, 60, 111, 162, 213, 264],
'max_sizes' : [60, 111, 162, 213, 264, 315],
```
Did this mean the scale of default boxes in ssd? Why did you set in this way?why is it different with 0.2-0.95 in the original caffe implemen... | open | 2017-11-24T12:37:34Z | 2019-06-12T11:25:24Z | https://github.com/amdegroot/ssd.pytorch/issues/78 | [] | squirrel16 | 5 |
ultralytics/ultralytics | computer-vision | 19,232 | I found that training on dual GPU will load pre training weights, while in single GPU mode it seems that pretraining weights will not be loaded | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
### question1:
1. dual GPU mode (device)

Returning formatted text is toggled via the `format` boolean:
```python
inputs = processor(image, return_tensors="pt", format=True).to(device)
```
It only returns LaTeX. Can the model somehow return markdown or are t... | open | 2025-03-19T21:14:46Z | 2025-03-20T12:40:46Z | https://github.com/huggingface/transformers/issues/36836 | [] | piercelamb | 1 |
psf/black | python | 4,476 | Report error when processing folders on the command line | <!--
Please make sure that the bug is not already fixed either in newer versions or the
current development version. To confirm this, you have three options:
1. Update Black's version if a newer release exists: `pip install -U black`
2. Use the online formatter at <https://black.vercel.app/?version=main>, which w... | closed | 2024-10-10T15:40:16Z | 2024-10-10T15:56:45Z | https://github.com/psf/black/issues/4476 | [
"T: bug"
] | wevsty | 2 |
skypilot-org/skypilot | data-science | 4,506 | [bug] Task name is required when running `sky launch --docker` | <!-- Describe the bug report / feature request here -->
The documentation at https://docs.skypilot.co/en/latest/reference/yaml-spec.html#task-yaml states that the task name is optional; however, using the localdocker backend will result in an error if it is not specified.
```yaml
# Task name (optional), used for... | closed | 2024-12-25T14:03:33Z | 2024-12-26T00:15:09Z | https://github.com/skypilot-org/skypilot/issues/4506 | [] | gaocegege | 2 |
MaartenGr/BERTopic | nlp | 1,897 | Home page get_topic_info() function not understood | 

Why don't the two functions get the same topic name with the same label? In fact I think... | open | 2024-03-31T10:14:58Z | 2024-04-03T08:11:23Z | https://github.com/MaartenGr/BERTopic/issues/1897 | [] | EricIrving-chs | 5 |
dmlc/gluon-nlp | numpy | 1,552 | Operator npx.broadcast_like | ## Description
Currently, pr #1551 and pr #1545 are blocked by operator npx.broadcast_like. This will be fixed in https://github.com/apache/incubator-mxnet/pull/20169 | closed | 2021-04-15T04:26:31Z | 2021-06-03T17:44:45Z | https://github.com/dmlc/gluon-nlp/issues/1552 | [
"bug"
] | barry-jin | 3 |
cvat-ai/cvat | computer-vision | 8,576 | Grafana is not restarting as other containers (using docker) | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Install and start cvat on a new VM using docker (not Kubernetes)
2. On CVAT UI, go to "Analytics" tab (it's working)
3... | closed | 2024-10-22T09:02:56Z | 2024-10-22T11:27:30Z | https://github.com/cvat-ai/cvat/issues/8576 | [
"bug"
] | Gui-U | 0 |
huggingface/datasets | pytorch | 6,810 | Allow deleting a subset/config from a no-script dataset | As proposed by @BramVanroy, it would be neat to have this functionality through the API. | closed | 2024-04-15T07:53:26Z | 2025-01-11T18:40:40Z | https://github.com/huggingface/datasets/issues/6810 | [
"enhancement"
] | albertvillanova | 3 |
ivy-llc/ivy | pytorch | 28,717 | Fix Frontend Failing Test: tensorflow - logic.paddle.equal_all | To-do List: https://github.com/unifyai/ivy/issues/27499 | closed | 2024-04-01T13:15:46Z | 2024-04-09T04:31:30Z | https://github.com/ivy-llc/ivy/issues/28717 | [
"Sub Task"
] | ZJay07 | 0 |
pytest-dev/pytest-mock | pytest | 123 | Patches not stopped between tests. | Hi,
My patches seem to be leeking from one test to the other. Can you suggest why this is?
Tests below:
```python
import asyncio
import logging
import sys
import time
import pytest
import websockets
from asynctest import CoroutineMock, MagicMock
from pyskyq.status import Status
from .asynccontex... | closed | 2018-09-29T15:47:40Z | 2018-10-13T11:57:20Z | https://github.com/pytest-dev/pytest-mock/issues/123 | [
"question"
] | bradwood | 6 |
keras-team/keras | python | 20,574 | MeanIoU differ from custom IOU metrics implementation | Hi,
am running a segmentation training process and am using the following function as IoU Custom metrics:
```
@keras.saving.register_keras_serializable(package="glass_segm", name="custom_iou_metric")
def custom_iou_metric(y_true, y_pred, num_classes=3):
y_pred = tf.argmax(y_pred, axis=-1)
y_true = tf.... | closed | 2024-12-01T17:26:27Z | 2024-12-10T09:52:54Z | https://github.com/keras-team/keras/issues/20574 | [
"type:Bug"
] | edge7 | 12 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 859 | 添加词表 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.c... | closed | 2023-10-24T01:33:04Z | 2023-11-13T22:02:12Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/859 | [
"stale"
] | clclclaiggg | 6 |
openapi-generators/openapi-python-client | fastapi | 651 | Why required: [] generates an error | ```json
{
...
"components": {
"schemas": {
"ABC": {
"required": [],
...
},
...
}
}
}
```
this generates an error:
```
components -> schemas -> ABC -> required
ensure this value has at least 1 items (typ... | closed | 2022-08-11T02:52:56Z | 2024-10-27T18:52:24Z | https://github.com/openapi-generators/openapi-python-client/issues/651 | [
"🐞bug"
] | erdnax123 | 3 |
HumanSignal/labelImg | deep-learning | 143 | Can you tell me how to modify your code? | Hello !
I need to save other attributes as person wear glasser or not , I have append these attributes with QCheckBox.Can you tell me how to save these attributes ,I donot know how to append thess checks in shapes.
Thank you for your help !
:
@requests(on=... | closed | 2023-11-15T19:20:49Z | 2023-11-16T07:11:05Z | https://github.com/jina-ai/serve/issues/6109 | [] | that-rahul-guy | 2 |
laurentS/slowapi | fastapi | 2 | Limit rate issue | I've tested limit rate locally and it works fine.
After I deployed application on AWS, rates did't work at all until I set redis as storage.
But even with redis, rate limit seems to be broken.
Limit is exceeded after ~10th attempt, and I've set limit to 5.
I've checked redis value for the key inserted by limi... | closed | 2020-04-23T12:32:22Z | 2020-05-26T15:38:41Z | https://github.com/laurentS/slowapi/issues/2 | [] | ghost | 12 |
ageitgey/face_recognition | machine-learning | 1,022 | face verification | * face_recognition version: 1.2.3
* Python version:3.6
* Operating System: centos7
### Description
This work is very helpful to check if two images come from the same person. But my case is I have a pool of faces of same person. How can I improve the accuracy by comparing my probe image with the pool rather than ... | closed | 2020-01-10T03:18:50Z | 2021-08-09T10:27:02Z | https://github.com/ageitgey/face_recognition/issues/1022 | [] | flyingmrwang | 7 |
wkentaro/labelme | deep-learning | 807 | [QUESTION] | I have this in Python and it works fine.
subprocess.Popen(['labelme_json_to_dataset', json_path, '-o', out_path], stdout = subprocess.PIPE)
There is a way to run labelme_json_to_dataset from C#? | closed | 2020-11-30T22:33:02Z | 2020-12-07T10:43:56Z | https://github.com/wkentaro/labelme/issues/807 | [
"issue::bug"
] | Dzsepetto | 1 |
thtrieu/darkflow | tensorflow | 357 | Color change after 'resize_input' function | The 'resize_input' function in darkflow/net/yolo/predict.py,
there is one line 'imsz = imsz[:,:,::-1]'.
It seems like the image loses 'red' color after this line.
Anyone could answer why it is required to remove 'red' color from the image?
| open | 2017-07-27T04:20:42Z | 2017-07-27T04:20:42Z | https://github.com/thtrieu/darkflow/issues/357 | [] | nuitvolgit | 0 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,434 | [Bug]: pytorch rocm 6.0 with 7600xt = HSA_STATUS_ERROR_INVALID_ISA | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported ... | closed | 2024-04-03T03:59:29Z | 2025-02-24T14:28:38Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15434 | [
"bug-report"
] | neem693 | 15 |
zwczou/weixin-python | flask | 54 | python3中没有basestring | 环境:python3.7
微信消息推送出现
`NameError: name 'basestring' is not defined`
我目前解决方案是在msg.py 内添加了一行
```python3
basestring = (str, bytes)
``` | closed | 2019-10-19T11:51:15Z | 2019-10-20T09:51:53Z | https://github.com/zwczou/weixin-python/issues/54 | [] | vaakian | 2 |
modelscope/modelscope | nlp | 838 | Qwen1.5自我认知微调 官方教程运行报错ValueError: malformed node | 运行报错
[Qwen1.5自我认知微调 官方教程 ](https://modelscope.cn/docs/Qwen1.5%E5%85%A8%E6%B5%81%E7%A8%8B%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5)
ValueError: malformed node or string

.build(dashboard=dashboard).run()
### Code/Example... | closed | 2023-11-16T12:40:02Z | 2024-10-30T13:17:07Z | https://github.com/mckinsey/vizro/issues/175 | [
"General Question :question:"
] | gbabeleda | 5 |
Anjok07/ultimatevocalremovergui | pytorch | 1,098 | bugg | I cant procesing this music whyy pls fix it
| open | 2024-01-10T15:10:57Z | 2024-01-11T18:30:16Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1098 | [] | Plsdonthackmy | 1 |
netbox-community/netbox | django | 18,328 | 'GenericRel' object has no attribute 'verbose_name' error when trying to search something on Netbox | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
v4.2.0
### Python Version
3.10
### Steps to Reproduce
1. Upgrade Netbox
2. Connect as a user
3. Try to search something (like an IP adress) on the search bar
### Expected Behavior
Not having the issue below
### Observed Behavior
T... | closed | 2025-01-07T15:24:37Z | 2025-01-07T15:30:19Z | https://github.com/netbox-community/netbox/issues/18328 | [
"type: bug",
"status: duplicate"
] | TheGuardianLight | 1 |
jupyterhub/repo2docker | jupyter | 1,041 | Current RStudio version does not support R 4.1.0 graphics engine | ### Bug description
[RStudio v1.2.5001](https://github.com/jupyterhub/repo2docker/blob/81e1e39/repo2docker/buildpacks/_r_base.py#L7-L10) does not support the R graphics engine v14 that comes with R v4.1.0 ("Camp Pontanezen") (see [release notes](https://stat.ethz.ch/pipermail/r-announce/2021/000670.html)).
#### E... | closed | 2021-05-21T11:04:43Z | 2022-01-25T18:03:07Z | https://github.com/jupyterhub/repo2docker/issues/1041 | [] | fkohrt | 12 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 270 | 获取抖音视频数据失败!原因:SyntaxError: 缺少 ';' |
安装解析库:pip install douyin-tiktok-scraper
使用示例代码,Win10 本地测试运行成功,同样的脚本放到 Windows Server 2019 以及 Windows Server 2008 报错:
正在获取抖音视频数据...
获取抖音视频数据失败!原因:SyntaxError: 缺少 ';'
Win10的Python版本为:Python 3.11.0
pip安装包版本:Successfully installed Brotli-1.1.0 PyExecJS-1.5.1 douyin-tiktok-scraper-1.2.8 orjson-3.9.7
Windows Serv... | closed | 2023-09-11T15:41:22Z | 2023-09-12T01:47:38Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/270 | [
"BUG"
] | shimxx | 1 |
chainer/chainer | numpy | 8,210 | Apply pairwise parameterization selectively in tests | #8164 applied pairwise parameterization in tests unconditionally in `chainer_tests` and `chainerx_tests`, but I think it's too dangerous. Some tests might be designed carefully in a way that omitting some of their combination would lead to degradation of the tests.
Ideally we should apply pairwise testing only select... | closed | 2019-10-01T14:11:22Z | 2020-02-05T07:39:44Z | https://github.com/chainer/chainer/issues/8210 | [
"cat:test",
"stale",
"prio:low"
] | niboshi | 2 |
huggingface/peft | pytorch | 1,988 | TypeError: WhisperForConditionalGeneration.forward() got an unexpected keyword argument 'input_ids' | ### System Info
peft version = '0.12.0'
transformers version = '4.41.2'
accelerate version = '0.30.1'
bitsandbytes version = '0.43.3'
pytorch version = '2.1.2'
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An of... | closed | 2024-08-02T17:48:46Z | 2025-03-11T15:50:14Z | https://github.com/huggingface/peft/issues/1988 | [] | YOUSEFNANIS | 6 |
OFA-Sys/Chinese-CLIP | nlp | 35 | 基于提供的权重,无法复现clip_cn_vit-b-16结果 | 1. 使用你们提供的数据集(Flickr30k-CN)及pretrain权重,运行代码,无法得到预期结果。
{"score": 74.3, "mean_recall": 74.3, "r1": 54.42, "r5": 80.82000000000001, "r10": 87.66000000000001}}
<img width="434" alt="image" src="https://user-images.githubusercontent.com/19340566/209259689-5d4f7b4f-715c-4a4b-a1ea-1f7ad610a7b0.png">
<img width="1920" alt... | closed | 2022-12-23T02:37:36Z | 2022-12-23T02:48:27Z | https://github.com/OFA-Sys/Chinese-CLIP/issues/35 | [] | Maycbj | 2 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 191 | 训练报错,specified in either feed_devices or fetch_devices was not found in the Graph | 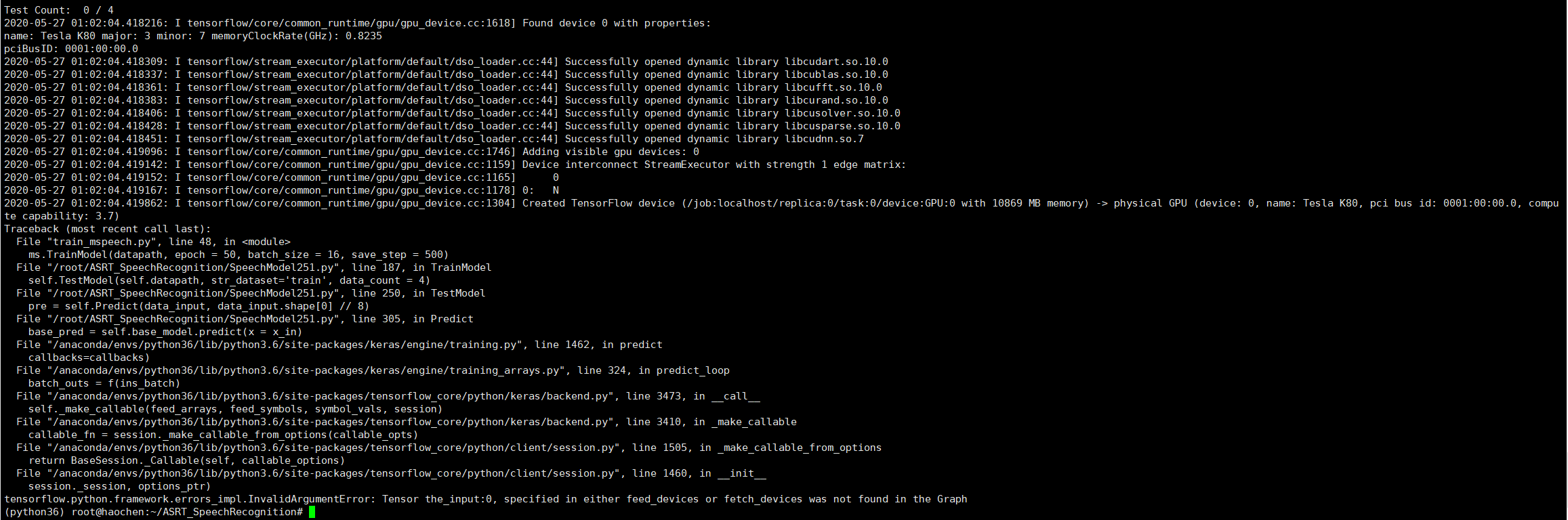
2020-05-27 01:02:04.419862: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1304] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10869 MB memory) -> physical GPU (device: 0,... | closed | 2020-05-27T01:15:55Z | 2020-05-27T04:22:35Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/191 | [] | JIANG3330 | 1 |
microsoft/unilm | nlp | 1,261 | DeltaLm: the model contains only the weights, where is model's config? | I am trying to use the model for inference using fairseq like:
import torch
from deltalm.models.deltalm import DeltaLMModel
model = DeltaLMModel.from_pretrained(
model_dir,
checkpoint_file=model_name,
bpe='sentencepiece',
sentencepiece_model=spm)
and I get this error :
RuntimeError: Neith... | open | 2023-08-21T04:31:02Z | 2023-08-27T03:39:10Z | https://github.com/microsoft/unilm/issues/1261 | [] | Khaled-Elsaka | 2 |
modin-project/modin | data-science | 6,767 | Provide the ability to use experimental functionality when experimental mode is not enabled globally via an environment variable. | Example where it can be useful:
```python
import modin.pandas as pd
df = pd.DataFrame([1,2,3,4])
# [some code]
with modin.utils.enable_exp_mode():
# this import has side effects that will need to be removed when leaving the context
# for example:
# 1. `IsExperimental.put(True)`
# 2. `set... | closed | 2023-11-23T16:07:58Z | 2023-12-08T16:31:15Z | https://github.com/modin-project/modin/issues/6767 | [
"new feature/request 💬",
"P1"
] | anmyachev | 0 |
graphql-python/graphene-django | django | 1,000 | v2.11.0: "lookup_required" with django_filters.LookupChoiceFilter() | v2.11.0 seems to have a problem with `django_filters.LookupChoiceFilter()` in a `django_filters.FilterSet` class.
A valid filter value in query will result in a `ValidationError: ['{"FooBar": [{"message": "Select a lookup.", "code": "lookup_required"}]}']`
I updated graphene-django from v2.10.1 to v2.11.0 in our ... | open | 2020-07-07T08:40:06Z | 2020-07-07T08:40:06Z | https://github.com/graphql-python/graphene-django/issues/1000 | [] | jedie | 0 |
streamlit/streamlit | machine-learning | 10,160 | Expose OAuth errors during `st.login` | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
We're soon launching native authentication in Streamlit (see #8518). One thing we left out for now is ... | open | 2025-01-10T23:32:58Z | 2025-01-10T23:33:46Z | https://github.com/streamlit/streamlit/issues/10160 | [
"type:enhancement",
"feature:st.user",
"feature:st.login"
] | jrieke | 1 |
ipython/ipython | jupyter | 14,489 | Do not use mixed units in timeit output | <!-- This is the repository for IPython command line, if you can try to make sure this question/bug/feature belong here and not on one of the Jupyter repositories.
If it's a generic Python/Jupyter question, try other forums or discourse.jupyter.org.
If you are unsure, it's ok to post here, though, there are few ... | open | 2024-07-25T09:29:21Z | 2024-10-16T02:04:51Z | https://github.com/ipython/ipython/issues/14489 | [] | maxnoe | 3 |
matterport/Mask_RCNN | tensorflow | 2,623 | Training for grayscale input | All layers training getting stopped | I am actually trying to run one experiment with grayscale input and for that I have already made required changes. The problem I am getting is that the code is able to run training for head epochs but it stopped for all layers training like after printing the layers' names there's no output related to anything, there's... | open | 2021-07-06T18:02:17Z | 2021-07-06T18:02:17Z | https://github.com/matterport/Mask_RCNN/issues/2623 | [] | Dartum08 | 0 |
rgerum/pylustrator | matplotlib | 17 | Missing community guidelines | As part of the JOSS review I could not find the community guide lines for contributing. The docs do say how to report bugs (although the text refers to bitbucket but links to github!). | closed | 2020-02-04T01:51:24Z | 2020-02-04T08:51:43Z | https://github.com/rgerum/pylustrator/issues/17 | [] | tacaswell | 1 |
ivy-llc/ivy | numpy | 28,334 | Fix Frontend Failing Test: tensorflow - math.tensorflow.math.is_strictly_increasing | To-do List: https://github.com/unifyai/ivy/issues/27499 | closed | 2024-02-19T17:27:12Z | 2024-02-20T09:26:02Z | https://github.com/ivy-llc/ivy/issues/28334 | [
"Sub Task"
] | Sai-Suraj-27 | 0 |
Johnserf-Seed/TikTokDownload | api | 291 | 直接运行 example.py 报错 | [ 💻 ]:Windows平台
[ 🗻 ]:获取最新版本号中!
[ 🚩 ]:目前 13043 版本已是最新
[ 警告 ]:未检测到命令,将使用配置文件进行批量下载!
[ 提示 ]:读取本地配置完成!
[ 提示 ]:为您下载多个视频!
[ 提示 ]:用户的sec_id=MS4wLjABAAAA3nckmLU8MKXB4Aao7ZOOLaHIRCJG5AzKMDRh_6WMkU4
[ 提示 ]:获取用户昵称失败! 请检查是否发布过作品,发布后请重新运行本程序!
[2023-01-19 20:25:29,460] - Log.py] - ERROR: [ 提示 ]:获取... | closed | 2023-01-19T12:27:32Z | 2023-01-22T09:06:22Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/291 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | liu-runsen | 2 |
microsoft/nni | pytorch | 5,663 | Does the trail_command in config file support the spaceholder? | I get a problem,I try to run my program with NNI Command "nnictl create --config config.yml --port 60001 --timestamp 88",and the trail-command in config.yml is "python framework.py --timestrap %timestrap%". | open | 2023-08-16T03:00:36Z | 2023-08-16T03:00:36Z | https://github.com/microsoft/nni/issues/5663 | [] | Nnnaqooooo | 0 |
sebp/scikit-survival | scikit-learn | 307 | LASSO Cox differences between packages | I have a list of genes and I have performed a Penalized Cox Model LASSO (cox_lasso = CoxnetSurvivalAnalysis(l1_ratio=1.0, alpha_min_ratio=0.01) to select the most useful prognostic genes to be included later in a multivariate Cox regression to generate a risk score.
I have also used the R package glmnet (with the par... | closed | 2022-09-20T21:07:04Z | 2022-09-21T15:22:19Z | https://github.com/sebp/scikit-survival/issues/307 | [] | alberto-mora | 0 |
qubvel-org/segmentation_models.pytorch | computer-vision | 782 | smp.utils module is deprecated | I am following the example [cars segmentation](https://github.com/qubvel/segmentation_models.pytorch/blob/master/examples/cars%20segmentation%20(camvid).ipynb)
In order to train my custom data, I have written a train.py
`
if __name__ == '__main__':
ENCODER = 'resnet34'
ENCODER_WEIGHTS = 'imagenet'
... | closed | 2023-06-13T02:40:48Z | 2023-10-02T01:49:15Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/782 | [
"Stale"
] | ningmenghongcha | 5 |
ipython/ipython | data-science | 14,157 | Magics with toplevel await | Hi,
It would be nice to be able to use top level await with magics, specifically `%time` and `%%time`.
For example:
```
async def foo():
return 'bar'
# This works
await foo()
# This fails with SyntaxError: 'await' outside function
%time await foo()
``` | closed | 2023-09-07T22:12:03Z | 2023-12-27T13:00:05Z | https://github.com/ipython/ipython/issues/14157 | [] | mlucool | 6 |
sunscrapers/djoser | rest-api | 813 | serializer for /users/me/ PATCH | Based on the [docs](https://djoser.readthedocs.io/en/latest/base_endpoints.html#user), we can make a `PATCH` request to `/users/me/` by giving `{{ User.FIELDS_TO_UPDATE }}`. I have `FIELDS_TO_UPDATE` defined in my custom user model:
```python
class CustomUser(AbstractBaseUser):
email = models.EmailField(
... | closed | 2024-04-12T14:22:07Z | 2024-04-13T10:45:51Z | https://github.com/sunscrapers/djoser/issues/813 | [] | andypal333 | 1 |
exaloop/codon | numpy | 642 | Unable to get Fast API working | See here:
I tried to get fast api working with codon. I like the idea of getting quite a bit of speed out of python.
https://github.com/fastapi/fastapi/discussions/10096
This is probably user error but I was not able to get their sample hello world running with codon. It might be a dependency issue?
Here is the ... | open | 2025-03-20T16:39:54Z | 2025-03-21T16:27:49Z | https://github.com/exaloop/codon/issues/642 | [] | michaelachrisco | 1 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,365 | [Bug]: protobuf==3.20.0 requirement breaks several extensions and offline mode | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [X] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported ... | open | 2024-08-11T09:24:02Z | 2024-11-26T21:20:27Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16365 | [
"bug-report"
] | neojam | 9 |
gradio-app/gradio | data-visualization | 9,923 | ChatInterface Appears Squished in Gradio Blocks | ### Describe the bug
I am experiencing an issue with the ChatInterface component within a Blocks layout in Gradio. The problem manifests as the chat interface appearing squished, not filling the height of the window as expected. Only a minimal portion of the chat content is visible, impacting usability.
Here's my r... | closed | 2024-11-09T22:45:03Z | 2025-01-17T22:54:25Z | https://github.com/gradio-app/gradio/issues/9923 | [
"bug"
] | dino1729 | 4 |
timkpaine/lantern | plotly | 176 | double check matplotlib bar widths | open | 2018-10-10T15:49:55Z | 2019-10-03T02:09:32Z | https://github.com/timkpaine/lantern/issues/176 | [
"bug",
"matplotlib/seaborn",
"backlog"
] | timkpaine | 0 | |
ultralytics/ultralytics | computer-vision | 19,642 | xywhr in OBB result have changed | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar bug report.
### Ultralytics YOLO Component
Predict
### Bug
Recently I updated my environment to the latest version of ultralytics and found that the xywhr result for... | closed | 2025-03-11T14:21:07Z | 2025-03-15T13:03:36Z | https://github.com/ultralytics/ultralytics/issues/19642 | [
"bug",
"OBB"
] | MarcelloCuoghi | 7 |
TencentARC/GFPGAN | deep-learning | 511 | Kushwaha | open | 2024-02-10T14:18:14Z | 2024-02-10T14:18:14Z | https://github.com/TencentARC/GFPGAN/issues/511 | [] | Vishvajeet9170 | 0 | |
roboflow/supervision | pytorch | 1,450 | Custom Symbol Annotators | ### Search before asking
- [x] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
A way to add custom symbols of annotators onto the image. Or possibly even other images.
### Use case
I want to be able to annotator multip... | closed | 2024-08-15T02:16:08Z | 2024-08-27T10:54:43Z | https://github.com/roboflow/supervision/issues/1450 | [
"enhancement"
] | mhsmathew | 2 |
pyppeteer/pyppeteer | automation | 445 | I am not able to connect to Bright Data's Scraping Browser.(their new proxy-zone) |
(CJ_test) kirancj@Home AcceptTransfer % python3 original_at.py
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.8/lib/python3.8/encodings/idna.py", line 165, in encode
raise UnicodeError("label empty or too long")
UnicodeError: label empty or too long
The above exc... | closed | 2023-07-12T10:30:26Z | 2024-02-09T06:00:27Z | https://github.com/pyppeteer/pyppeteer/issues/445 | [] | kiran-cj | 0 |
OWASP/Nettacker | automation | 119 | Security issue (try, except, pass) | Hello,
We've used many try, except, pass in our code and after I read the project review from codacy, I've to notice that it's a low-risk [security issue](https://docs.openstack.org/bandit/latest/plugins/b110_try_except_pass.html).
Regards.
| closed | 2018-04-23T19:45:59Z | 2021-02-02T20:23:34Z | https://github.com/OWASP/Nettacker/issues/119 | [
"enhancement",
"possible bug"
] | Ali-Razmjoo | 3 |
microsoft/qlib | machine-learning | 1,789 | Can we directly use the backtest function of qlib with our predictions? | I already have my prediction results, and I would like to use Qlib's backtest function, I wonder if it's easy to implement, cause Qlib apparently has its own data format and file format to save the results. | closed | 2024-05-21T03:33:24Z | 2024-05-24T05:43:44Z | https://github.com/microsoft/qlib/issues/1789 | [
"question"
] | TompaBay | 0 |
plotly/dash | data-science | 2,667 | Dropdown reordering options by value on search | dash 2.14.0, 2.9.2
Windows 10
Chrome 118.0.5993.71
**Description**
When entering a `search_value` in `dcc.Dropdown`, the matching options are ordered by _value_, ignoring the original option order. This behavior only happens when the option values are integers or integer-like strings (i.e. 3 or "3" or 3.0 but no... | open | 2023-10-18T20:02:10Z | 2024-08-13T19:41:22Z | https://github.com/plotly/dash/issues/2667 | [
"bug",
"P3"
] | TGeary | 0 |
keras-team/keras | machine-learning | 20,058 | "No gradients provided for any variable." when variable uses an integer data type | When using an integer data type for a trainable variable, training will always throw a "No gradients provided for any variable." `ValueError`. Here is a very simple example to reproduce the issue:
```python
import keras
import tensorflow as tf
import numpy as np
variable_dtype = tf.int32
# variable_dtype = tf... | closed | 2024-07-29T05:39:48Z | 2024-08-28T04:48:49Z | https://github.com/keras-team/keras/issues/20058 | [
"type:support"
] | solidDoWant | 9 |
akurgat/automating-technical-analysis | plotly | 7 | I am getting the following error in the system | File "/home/appuser/venv/lib/python3.9/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 564, in _run_script
exec(code, module.__dict__)
File "/app/automating-technical-analysis/Trade.py", line 9, in <module>
data_update()
File "/app/automating-technical-analysis/app/data_sourcing.py", li... | closed | 2023-01-22T11:36:32Z | 2023-01-22T12:12:35Z | https://github.com/akurgat/automating-technical-analysis/issues/7 | [] | tempest298 | 1 |
lepture/authlib | django | 609 | JWTBearerTokenValidator don't send parameters now and leeway to claim.validate |
```python
# authlib\oauth2\rfc7523\validator.py
class JWTBearerTokenValidator:
def authenticate_token(self, token_string):
try:
claims = jwt.decode( ... )
claims.validate()
return claims
except JoseError as error:
...
```
But:
```python
# authlib\jo... | open | 2023-12-21T07:58:03Z | 2025-02-20T20:15:21Z | https://github.com/lepture/authlib/issues/609 | [
"bug",
"good first issue",
"jose"
] | danilovmy | 0 |
qubvel-org/segmentation_models.pytorch | computer-vision | 210 | How to continue the train of the existing model and How to interpret accuracy of model on test dataset? | Hi,
I've trained model with custom dataset following example tutorial. Results are very good.
I have two question in this stage. I get following result when evaluate on test set. So should I interpret the success of the model as 98%? If not is there any way to get calculate accuracy of it?
.
Tested on Windows 10 / Ubuntu 20.04LTS
Tensorflow 2.4, 2.7.1
Python 3.7.11, 3.9.7
Latest DFL version. | open | 2022-03-19T10:32:18Z | 2023-06-08T23:18:47Z | https://github.com/iperov/DeepFaceLab/issues/5496 | [] | andyst75 | 1 |
TracecatHQ/tracecat | pydantic | 108 | [v0] Case management | closed | 2024-04-29T18:09:07Z | 2024-04-29T18:10:02Z | https://github.com/TracecatHQ/tracecat/issues/108 | [
"enhancement",
"frontend"
] | daryllimyt | 1 | |
chatanywhere/GPT_API_free | api | 60 | 能不能新增別的付款方式,國外的用戶用不了支付寶 | 如題,
能不能開個掏寶店家
或是串stripe金流? | closed | 2023-07-17T03:17:00Z | 2023-08-03T02:06:22Z | https://github.com/chatanywhere/GPT_API_free/issues/60 | [] | ooiplh20 | 1 |
open-mmlab/mmdetection | pytorch | 11,972 | 'DetDataSample' object has no attribute 'text' when finetune on grounding task | I try to train flickr30 dataset, but always got DetDataSample' object has no attribute 'text' . my training script is
`./tools/dist_train.sh configs/mm_grounding_dino/grounding_dino_swin-t_pretrain_obj365_goldg.py 1`
and in the grounding_dino_swin-t_pretrain_obj365_goldg.py, i just use flickr30 as the train dataset... | closed | 2024-09-25T06:32:49Z | 2024-09-25T06:40:11Z | https://github.com/open-mmlab/mmdetection/issues/11972 | [] | xingmimfl | 0 |
strawberry-graphql/strawberry | graphql | 3,129 | relay.node on subtype needs initialization | <!-- Provide a general summary of the bug in the title above. -->
Consider the code
```python
@strawberry.type
class Sub:
node: relay.Node = relay.node()
nodes: list[relay.Node] = relay.node()
@strawberry.type
class Query:
@strawberry.field
@staticmethod
def sub():
return Sub
schema... | open | 2023-10-02T13:04:02Z | 2025-03-20T15:56:24Z | https://github.com/strawberry-graphql/strawberry/issues/3129 | [
"bug"
] | devkral | 1 |
NVlabs/neuralangelo | computer-vision | 125 | switch to analytic gradients after delta is small enough? | would this bring any performance degradation?
or may speed up training a bit? | closed | 2023-09-25T08:25:38Z | 2023-09-26T04:50:17Z | https://github.com/NVlabs/neuralangelo/issues/125 | [] | blacksino | 1 |
recommenders-team/recommenders | deep-learning | 1,381 | [FEATURE] New versioning | ### Description
<!--- Describe your expected feature in detail -->
We are going to change the versioning name -> https://github.com/microsoft/recommenders/tags
| Original | Proposal |
|----------|-----------|
| 2021.2 | 0.5.0 |
| 2020.8 | 0.4.0 |
| 2019.09 | 0.3.1 |
| 2019.06 | 0.3.0 |
| 2019.02 | 0.2.0 |
|... | closed | 2021-04-22T13:49:28Z | 2021-05-04T12:12:31Z | https://github.com/recommenders-team/recommenders/issues/1381 | [
"enhancement"
] | miguelgfierro | 0 |
lyhue1991/eat_tensorflow2_in_30_days | tensorflow | 33 | 3-2在GPU上运行会报错,查了一下发现有人在CPU下可以运行 | 会报错如下
`` (0) Internal: No unary variant device copy function found for direction: 1 and Variant type_index: class tensorflow::data::`anonymous namespace'::DatasetVariantWrapper
[[{{node while_input_4/_12}}]]
(1) Internal: No unary variant device copy function found for direction: 1 and Variant type_index: cla... | closed | 2020-04-23T06:27:33Z | 2020-04-24T03:00:25Z | https://github.com/lyhue1991/eat_tensorflow2_in_30_days/issues/33 | [] | since2016 | 2 |
charlesq34/pointnet | tensorflow | 165 | about the dataset | hi,I'm very glad to see the excellent paper. It's very great. But I have some questions about this paper. Does it belong to Supervised classification and unsupervised classification? | open | 2019-03-10T02:46:06Z | 2019-05-21T19:58:53Z | https://github.com/charlesq34/pointnet/issues/165 | [] | zhonghuajiuzhou12138 | 1 |
satwikkansal/wtfpython | python | 370 | Add translation for Farsi | Expected time to finish: 3 weeks. I'll start working on it from ASAP after confirmation. | open | 2025-02-22T20:00:21Z | 2025-02-28T10:18:50Z | https://github.com/satwikkansal/wtfpython/issues/370 | [] | Alavi1412 | 10 |
allenai/allennlp | data-science | 5,495 | Updating model for Coreference Resolution | I noticed a new SoTA on Ontonotes 5.0 Coreference task on [paperswithcode](https://paperswithcode.com/paper/word-level-coreference-resolution#code)
The author provides the model (.pt) file in [their git repo](https://github.com/vdobrovolskii/wl-coref#preparation) and claims it to be faster (since it uses RoBERTa) wh... | closed | 2021-12-06T05:26:48Z | 2022-01-06T15:57:46Z | https://github.com/allenai/allennlp/issues/5495 | [
"question"
] | aakashb95 | 2 |
approximatelabs/sketch | pandas | 10 | Wrong result for query "Get the top 5 grossing states" in sample colab | According to data total value for every row should be calculated as Price Each * Quantity Ordered. In sample colab library summarizes prices but doesn't take in account quantity. | closed | 2023-01-27T08:34:38Z | 2023-01-27T22:08:53Z | https://github.com/approximatelabs/sketch/issues/10 | [] | lukyanenkomax | 1 |
streamlit/streamlit | streamlit | 10,022 | Setting max duration configuration parameter for st.audio_input() | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
The st.audio_input() is a great new addition to the Streamlit library, however it is missing a critical eleme... | open | 2024-12-13T23:34:50Z | 2024-12-16T21:03:21Z | https://github.com/streamlit/streamlit/issues/10022 | [
"type:enhancement",
"feature:st.audio_input"
] | iscoyd | 3 |
chezou/tabula-py | pandas | 42 | wrapper.py and tabula jar are missing | # Summary of your issue
I can import the library tabula, but the functions are still inaccessible. I checked the directory \site-packages\tabula. The wrapper.py and tabula jar file are missing.
# Environment
Write and check your environment.
- [x] `python --version`: Python 3.6.1 :: Anaconda 4.4.0 (64-bit)
- ... | closed | 2017-07-11T11:44:44Z | 2017-07-27T02:37:02Z | https://github.com/chezou/tabula-py/issues/42 | [] | Wind1002 | 2 |
iperov/DeepFaceLab | machine-learning | 931 | PC Stability | Hello. its me again, I am a little but concern about my PC.
My PC configurations are:-
MODEL:- HP Pavailion 15
PROCESSOR:- Intel(R) Core i7-9750H @ 2.60 GHz
RAM:- 8 GB DDR4
GRAPHICS CARD:- 4 GB NVIDIA GEFORCE GTX 1650
OPERATING SYSTEM:- Windows 10 x64 bit.
I am using SAEHD for training I mean the GPU for trainin... | open | 2020-10-29T08:09:45Z | 2023-06-08T21:22:01Z | https://github.com/iperov/DeepFaceLab/issues/931 | [] | Aeranstorm | 2 |
tensorflow/tensor2tensor | machine-learning | 1,639 | Decoder outputs blank lines for translation | ### Description
Using transformer model with transformer_base_single_gpu for En-De machine translation. For certain inputs, the decoder output is <EOS> <PAD> <PAD> .. .. (essentially a blank line) for certain translations. Tried to check the softmax output at the decoder end for the probabilities. I am unable to fin... | open | 2019-07-23T18:04:02Z | 2019-07-23T18:04:02Z | https://github.com/tensorflow/tensor2tensor/issues/1639 | [] | minump | 0 |
jmcarpenter2/swifter | pandas | 155 | No time gain | I have a data frame with 20k rows and I am applying a non-vectorizable function on each row. However, there is not benefit gained since it is fall back to normal pandas apply with a single process.
```python
ret = df.swifter.set_npartitions(npartitions=2).set_dask_threshold(dask_threshold=0.01).allow_dask_on_string... | closed | 2021-06-24T09:42:04Z | 2022-07-07T17:14:16Z | https://github.com/jmcarpenter2/swifter/issues/155 | [] | quancore | 3 |
QingdaoU/OnlineJudge | django | 101 | 使用nginx反向代理的时候静态资源会报404错误 | 在提交issue之前请
- 认真阅读文档 https://github.com/QingdaoU/OnlineJudge/wiki
- 搜索和查看历史issues
然后提交issue请写清楚下列事项
- 进行什么操作的时候遇到了什么问题
- 错误提示是什么,如果看不到错误提示,请去log文件夹查看。大段的错误提示请包在代码块标记里面。
- 你尝试修复问题的操作
- 页面问题请写清浏览器版本,尽量有截图
| closed | 2017-12-07T08:15:17Z | 2017-12-07T11:22:33Z | https://github.com/QingdaoU/OnlineJudge/issues/101 | [] | starfire-lzd | 0 |
chezou/tabula-py | pandas | 242 | how to read large table spread on multiple pages |
Iam using tabula_py to read tables on a pdf.
Some are big. I have a lot of cases where a table is on more than one page. Isuue is tabula_py is treating as new table for each page, instead of reading as one large table. | closed | 2020-06-12T18:15:12Z | 2020-06-12T18:15:27Z | https://github.com/chezou/tabula-py/issues/242 | [] | idea1002 | 1 |
deezer/spleeter | tensorflow | 767 | [Discussion] Help Docker on Synology | Hello,
Could someone please explain me how to set up and use Spleeter under Synology Docker ?
Add image => ok
Add volume => ok
Add env MODEL_DIRECTORY, AUDIO_OUT, AUDIO_IN => ok
On start => error :
```
spleeter: error: the following arguments are required: command
```
Thanks | open | 2022-05-23T20:36:49Z | 2022-05-31T07:58:10Z | https://github.com/deezer/spleeter/issues/767 | [
"question"
] | Silbad | 1 |
BeanieODM/beanie | asyncio | 644 | [BUG] get_settings() does not return the inherited settings | **Describe the bug**
When inheriting settings from a common class, get_settings() does not return the inherited settings.
**To Reproduce**
```
from beanie import Document, init_beanie
from motor.motor_asyncio import AsyncIOMotorClient
import asyncio
import datetime
class GlobalSettings(Document):
... | closed | 2023-08-07T13:06:04Z | 2023-08-22T10:09:04Z | https://github.com/BeanieODM/beanie/issues/644 | [] | piercsi | 4 |
sherlock-project/sherlock | python | 2,149 | Watson | ### Description
I created a GUI Assistant For Sherlock: [Watson](https://github.com/tf7software/Watson) | open | 2024-06-02T03:51:13Z | 2024-06-02T03:53:49Z | https://github.com/sherlock-project/sherlock/issues/2149 | [
"enhancement"
] | tf7software | 1 |
scikit-optimize/scikit-optimize | scikit-learn | 750 | Callback with Optimizer() | Hi, could one add a callback in the Optimizer() function for the Optimizer to be saved? (and loaded afterwards)?
Usecase
We have a set of 3 weights for a model which need to be optimized and all we do is measure the Click Through Rate, which has to be maximized. SInce we don't know the function of the CTR we use Op... | closed | 2019-03-06T13:37:13Z | 2019-04-21T18:33:28Z | https://github.com/scikit-optimize/scikit-optimize/issues/750 | [] | RakiP | 3 |
roboflow/supervision | machine-learning | 1,440 | Invalid validations on KeyPoints class? | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
I'm trying to use the KeyPoints class, with my xy data as [ [x1,y1], [x2,y1], .... ]
Based on the information in the docs string this seems to be input ... | closed | 2024-08-10T23:46:39Z | 2024-08-27T11:07:05Z | https://github.com/roboflow/supervision/issues/1440 | [
"bug"
] | Chappie74 | 7 |
yinkaisheng/Python-UIAutomation-for-Windows | automation | 237 | EditContral 把IsReadOnly设置为False | 我该怎么写才能把EditContral 把IsReadOnly设置为False ,然后setValue | open | 2023-02-15T10:12:19Z | 2023-03-18T13:31:24Z | https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/237 | [] | liyu133 | 1 |
3b1b/manim | python | 1,121 | Cannot set different color in specific Tex forms. | Let's say I have:
```
p_calc = TexMobject("p","=",r"\frac{n}{q}")
p_calc.set_color_by_tex_to_color_map({
"n": RED,
"p": BLUE,
"q": GREEN
})
```
which `p_calc ` is `p=n/q`.
I want p to be blue colored,n red colored and q green colored.
I have tri... | closed | 2020-06-02T05:03:36Z | 2020-06-03T05:15:22Z | https://github.com/3b1b/manim/issues/1121 | [] | JimChr-R4GN4R | 3 |
stanfordnlp/stanza | nlp | 1,223 | [QUESTION] How do declare an empty stanza.models.common.doc.Document | In my code I use a Stanza pipeline twice on two sections of an input document, imagine a TITLE and a BODY sections.
I normally insert the resulting Stanza Document in a MongoDB document.
It can happen that either the TITLE or the BODY sections are missing and therefore the corresponding Documents are too.
To a... | closed | 2023-03-22T16:38:00Z | 2023-03-22T16:58:33Z | https://github.com/stanfordnlp/stanza/issues/1223 | [
"question"
] | rjalexa | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.