
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
modin-project/modin | data-science | 6,849 | Possible to remove to_pandas calls in merge and join operations | In query_compiler.merge and query_compiler.join we use `to_pandas()` eg [right_pandas = right.to_pandas()](https://github.com/modin-project/modin/blob/7ef544f4467ddea18cfbb51ad2a6fcbbb12c0db3/modin/core/storage_formats/pandas/query_compiler.py#L525) in This operation in the main thread is blocking. This could be expens... | closed | 2024-01-10T14:04:22Z | 2024-01-11T16:18:29Z | https://github.com/modin-project/modin/issues/6849 | [] | arunjose696 | 1 |
aiortc/aiortc | asyncio | 201 | how can i get a certain channel and sample_rate like `channel=1 sample_rate=16000` when i use `MediaRecorder, MediaPlayer or AudioTransformTrack` to get audio frame ? | hi, i use MediaPlayer to read a wav file , and it not works when i change options parameters . to get origin data, i have to use channel=2 and sample_rate=48000 to save it .
does options works? please help me .
```python
async def save_wav(fine_name):
# player = MediaPlayer(fine_name, options={'channe... | closed | 2019-08-27T04:16:09Z | 2023-12-10T16:30:53Z | https://github.com/aiortc/aiortc/issues/201 | [] | supermanhuyu | 5 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 79 | Question about beamsearch | hello,
Your code is very clear! However, I have a quesion about beam search in your code. Why did you do two sorting operations in transformer/beam.py? Is there any special purpose?
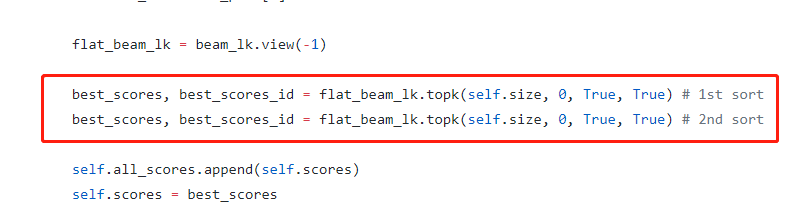
Thanks a lot! | closed | 2018-12-27T12:32:34Z | 2019-12-08T10:28:40Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/79 | [] | ZhengkunTian | 2 |
hzwer/ECCV2022-RIFE | computer-vision | 142 | 关于新添加的VGG模型 | 您好h佬,最近在试图训练RIFE时,发现RIFE更新了新的VGG损失函数相关代码,但在rife.py中相关代码被注释掉了。单纯的取消注释并修改相关代码后并不能顺利运行,想请问这部分工作是否是完成的。不胜感激。
就像这样
```
self.vgg = VGGPerceptualLoss().to(device)
# loss_G = loss_l1 + loss_cons + loss_ter
loss_G = self.vgg(pred, gt) + loss_cons + loss_ter
```
When trying to train RIFE recently, I found that RIFE ... | closed | 2021-04-19T01:05:32Z | 2021-04-21T09:03:28Z | https://github.com/hzwer/ECCV2022-RIFE/issues/142 | [] | 98mxr | 2 |
miguelgrinberg/python-socketio | asyncio | 455 | restricting access to socketio/client files with flask-socketio? | Hi,
i am having a problem where i am able to download certain socketio files from my flask application.
sending a call to https://localhost:port/socket.io/ downloads a file with 'sid' and other information.
Similarly i am able to download different socketio files like : socket.io.tar.gz and socket.io.arj and o... | closed | 2020-04-01T10:39:12Z | 2020-04-02T11:25:44Z | https://github.com/miguelgrinberg/python-socketio/issues/455 | [
"question"
] | raheel-ahmad | 4 |
strawberry-graphql/strawberry | django | 3,583 | pyinstrument extension doesn't seem to give detail breakdown | <!-- Provide a general summary of the bug in the title above. -->
I'm using strawberry with fastapi running everything in docker. I've tried using the pyinstrument extension as per the doc but am not getting breakdown of the execution.
<!--- This template is entirely optional and can be removed, but is here to help... | open | 2024-07-27T16:32:23Z | 2025-03-20T15:56:48Z | https://github.com/strawberry-graphql/strawberry/issues/3583 | [
"bug"
] | Vincent-liuwingsang | 0 |
deepspeedai/DeepSpeed | machine-learning | 6,692 | Installing DeepSpeed in WSL. | I am using Windows 11. I have Windows Subsystem for Linux activated (Ubuntu) as well as installed CUDA, and Visual Studio C++ Build tools. I am trying to install deepspeed. However, I am getting the following 2 errors. Could anybody please help resolve this?

I even tried to take column co-... | closed | 2019-06-26T13:17:36Z | 2019-06-27T01:54:53Z | https://github.com/chezou/tabula-py/issues/156 | [] | ayubansal1998 | 1 |
modin-project/modin | pandas | 6,849 | Possible to remove to_pandas calls in merge and join operations | In query_compiler.merge and query_compiler.join we use `to_pandas()` eg [right_pandas = right.to_pandas()](https://github.com/modin-project/modin/blob/7ef544f4467ddea18cfbb51ad2a6fcbbb12c0db3/modin/core/storage_formats/pandas/query_compiler.py#L525) in This operation in the main thread is blocking. This could be expens... | closed | 2024-01-10T14:04:22Z | 2024-01-11T16:18:29Z | https://github.com/modin-project/modin/issues/6849 | [] | arunjose696 | 1 |
mwaskom/seaborn | data-visualization | 3,219 | A violinplot in a FacetGrid can ignore the `split` argument | I try to produce a FacetGrid containing violin plots with the argument `split=True` but the violins are not split. See the following example:
```python
import numpy as np
import pandas as pd
import seaborn as sns
np.random.seed(42)
df = pd.DataFrame(
{
"value": np.random.rand(20),
"condit... | closed | 2023-01-10T15:20:58Z | 2023-01-10T23:40:53Z | https://github.com/mwaskom/seaborn/issues/3219 | [] | fabianegli | 4 |
matplotlib/mplfinance | matplotlib | 619 | PnF charts using just close. | I have a dataset with only 1 column that represents close price. I am unable to generate a PnF chart as it appears that PnF expects date, open, high, low & close.
PnF charts are drawn using either High/Low or just considering close.
Is there a way to generate a PnF with just close? | closed | 2023-05-29T16:10:02Z | 2023-05-30T10:22:51Z | https://github.com/matplotlib/mplfinance/issues/619 | [
"question"
] | boomkap | 4 |
NVlabs/neuralangelo | computer-vision | 28 | Cuda out of memory. Anyway to run training on 8GB GPU | Is there anyway to run training using nvidia gpu with only 8GB ? no matter how much time it take.
But because I can't train on my gpu nvidia 3070 with 8GB.
what parameters can I edit to solve this issue? | closed | 2023-08-16T15:09:57Z | 2023-08-25T06:24:26Z | https://github.com/NVlabs/neuralangelo/issues/28 | [] | parzoe | 14 |
ghtmtt/DataPlotly | plotly | 202 | scatterplot of time-data cross-connects | **Describe the bug**
a bug plotting time-plots. the "line cross connects" a few places and runs back to start.
**To Reproduce**
1. plot this data geopkg provided as a scatter plot
- [time-plot-bug.zip](https://github.com/ghtmtt/DataPlotly/files/4298541/time-plot-bug.zip)
2. use x-field: format_date( "dato_tid... | closed | 2020-03-06T13:38:54Z | 2020-03-11T12:03:49Z | https://github.com/ghtmtt/DataPlotly/issues/202 | [
"bug"
] | danpejobo | 5 |
mwaskom/seaborn | data-visualization | 3,542 | [BUG] Edge color with `catplot` with `kind=bar` | Hello,
When passing `edgecolor` to catplot for a bar, the argument doesn't reach the underlying `p.plot_bars` to generate the required output.
Currently there is a line
`edgecolor = p._complement_color(kwargs.pop("edgecolor", default), color, p._hue_map)`
is _not_ passed into the block `elif kind=="bar"`. ... | closed | 2023-10-27T07:33:09Z | 2023-11-04T16:09:47Z | https://github.com/mwaskom/seaborn/issues/3542 | [
"bug",
"mod:categorical"
] | prabhuteja12 | 5 |
onnx/onnx | deep-learning | 5,853 | Request for Swish Op | # Swish/SiLU
Do you have any plans to implement the Swish Op in ONNX?
### Describe the operator
Swish is a popular Activation fuction. Its mathematical definition could be found at https://en.wikipedia.org/wiki/Swish_function
TensorFLow has https://www.tensorflow.org/api_docs/python/tf/nn/silu
Keras has https:... | open | 2024-01-11T08:18:22Z | 2025-02-01T06:43:04Z | https://github.com/onnx/onnx/issues/5853 | [
"topic: operator",
"stale",
"contributions welcome"
] | vera121 | 7 |
sqlalchemy/sqlalchemy | sqlalchemy | 11,994 | missing type cast for jsonb in values for postgres? | ### Discussed in https://github.com/sqlalchemy/sqlalchemy/discussions/11990
<div type='discussions-op-text'>
<sup>Originally posted by **JabberWocky-22** October 12, 2024</sup>
I'm using `values` to update multi rows in single execution in postgres.
The sql failed due to type match on jsonb column, since it doe... | closed | 2024-10-13T09:00:38Z | 2024-12-03T08:43:54Z | https://github.com/sqlalchemy/sqlalchemy/issues/11994 | [
"postgresql",
"schema",
"use case"
] | CaselIT | 6 |
ageitgey/face_recognition | python | 968 | Crop image to preferred region to speed up detection | Hi everyone.
My problem is that I cannot resize the input image to smaller resolution (because faces then are to small to be detected) to apply cnn detection. My application scenario is that faces only appear in some specific region of a frame. Is it okay to keep the image the original size, but crop only the regio... | closed | 2019-11-05T03:56:06Z | 2019-11-05T07:42:59Z | https://github.com/ageitgey/face_recognition/issues/968 | [] | congphase | 2 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 300 | Error when using a Miner with ArcFaceLoss when training with Mixed Precision | I'm training my model with pytorch-lightning, using its mixed precision. When I tried to add a miner with the ArcFaceLoss, I got the following error:
```
File "/opt/conda/lib/python3.7/site-packages/pytorch_metric_learning/losses/base_metric_loss_function.py", line 34, in forward
loss_dict = self.compute_los... | closed | 2021-04-08T11:01:39Z | 2021-05-10T02:54:30Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/300 | [
"bug",
"fixed in dev branch"
] | fernandocamargoai | 2 |
quokkaproject/quokka | flask | 97 | Relase PyPi package and change the core architecture | closed | 2013-11-22T12:14:54Z | 2015-07-16T02:56:42Z | https://github.com/quokkaproject/quokka/issues/97 | [] | rochacbruno | 6 | |
deeppavlov/DeepPavlov | nlp | 1,628 | Predictions NER_Ontonotes_BERT_Mult for entities with interpunction | DeepPavlov version: 1.0.2
Python version: 3.8
Operating system: Ubuntu
**Issue**:
I am using the `ner_ontonotes_bert_mult` model to predict entities for text. For sentences with interpunction in the entities, this gives unexpected results. Before the 1.0.0 release, I used the [Deeppavlov docker image](https://hub... | closed | 2023-02-15T15:17:20Z | 2023-03-16T08:22:50Z | https://github.com/deeppavlov/DeepPavlov/issues/1628 | [
"bug"
] | ronaldvelzen | 3 |
marcomusy/vedo | numpy | 882 | Slice error | Examples with `msh.intersect_with_plane` (tried torus and bunny from `Mesh.slice`) produce the same error : AttributeError: module 'vedo.vtkclasses' has no attribute 'vtkPolyDataPlaneCutter' | closed | 2023-06-14T17:07:00Z | 2023-10-18T13:09:54Z | https://github.com/marcomusy/vedo/issues/882 | [] | mAxGarak | 5 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 176 | [BUG] Cannot read property 'JS_MD5_NO_COMMON_JS' of null | ***发生错误的平台?***
抖音
***发生错误的端点?***
API-V1
http://127.0.0.1:8000/api?url=
***提交的输入值?***
https://www.douyin.com/video/7153585499477757192
***是否有再次尝试?***
是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述文件或接口文档吗?***
有,并且很确定该问题是程序导致的。官网的接口也试过,报500
| closed | 2023-03-14T03:23:14Z | 2023-03-14T20:08:00Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/176 | [
"BUG"
] | WeiLi1201 | 3 |
pytest-dev/pytest-django | pytest | 790 | Tests do not run without django-configuration installed. | In my project I do not use django-configuration as I don't really need it.
When installing `pytest-django` I try to run my tests, here's what I've got:
```
pytest
Traceback (most recent call last):
File "/home/jakub/.virtualenvs/mobigol/bin/pytest", line 8, in <module>
sys.exit(main())
File "/home/ja... | closed | 2020-01-04T17:42:33Z | 2025-01-31T08:23:15Z | https://github.com/pytest-dev/pytest-django/issues/790 | [
"bug"
] | jakubjanuzik | 6 |
ranaroussi/yfinance | pandas | 2,155 | Wrong time stamp for 1h time frame for versions after 0.2.44 | ### Describe bug
Whenever I am trying to download stock data for 1h time frame it shows wrong time frame. This problem was not present in 0.2.44 and previous versions. It was easier to use when it used to give output in local time frames
### Simple code that reproduces your problem
import yfinance as yf
pri... | open | 2024-11-26T16:10:00Z | 2025-02-16T20:12:37Z | https://github.com/ranaroussi/yfinance/issues/2155 | [] | indra5534 | 10 |
nonebot/nonebot2 | fastapi | 2,924 | Plugin: LLOneBot-Master | ### PyPI 项目名
nonebot-plugin-llob-master
### 插件 import 包名
nonebot_plugin_llob_master
### 标签
[{"label":"LLOneBot","color":"#e3e9e9"},{"label":"Windows","color":"#1da6eb"}]
### 插件配置项
_No response_ | closed | 2024-08-25T08:15:27Z | 2024-08-27T13:20:46Z | https://github.com/nonebot/nonebot2/issues/2924 | [
"Plugin"
] | kanbereina | 5 |
smarie/python-pytest-cases | pytest | 91 | Enforce file naming pattern: automatically get cases from file named `test_xxx_cases.py` | We suggest this pattern in the doc, we could make it a default. | closed | 2020-06-02T12:57:26Z | 2020-07-09T09:18:12Z | https://github.com/smarie/python-pytest-cases/issues/91 | [
"enhancement"
] | smarie | 2 |
browser-use/browser-use | python | 668 | Unable to submit vulnerability report | ### Type of Documentation Issue
Incorrect documentation
### Documentation Page
https://github.com/browser-use/browser-use/security/policy
### Issue Description
The documentation states that security issues should be reported by creating a report at https://github.com/browser-use/browser-use/security/advisories/new... | closed | 2025-02-11T14:05:47Z | 2025-02-22T23:31:32Z | https://github.com/browser-use/browser-use/issues/668 | [
"documentation"
] | melonattacker | 5 |
jowilf/starlette-admin | sqlalchemy | 477 | Enhancement: Register Page | What about an out-of-the-box register page? We have a login page, why not have a register page? We can use `Fields` system to make the registration form more dynamic.
| open | 2024-01-17T12:20:00Z | 2024-01-27T20:55:33Z | https://github.com/jowilf/starlette-admin/issues/477 | [
"enhancement"
] | hasansezertasan | 0 |
snarfed/granary | rest-api | 122 | json feed: handle displayName as well as title | e.g. @aaronpk's articles feed: https://granary.io/url?input=html&output=jsonfeed&reader=false&url=http://aaronparecki.com/articles | closed | 2017-12-05T20:59:31Z | 2017-12-06T05:10:46Z | https://github.com/snarfed/granary/issues/122 | [] | snarfed | 0 |
eriklindernoren/ML-From-Scratch | deep-learning | 55 | Moore-Penrose pseudo-inverse in linear regression | Hi, I am reimplementing ml algorithms based on yours
But I am a little confused about the part of the calculation of Moore-Penrose pseudoinverse in linear regression.
https://github.com/eriklindernoren/ML-From-Scratch/blob/40b52e4edf9485c4e479568f5a41501914fdc55c/mlfromscratch/supervised_learning/regression.py#L... | open | 2019-06-21T03:27:28Z | 2019-11-20T16:09:03Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/55 | [] | liadbiz | 3 |
fastapi/sqlmodel | pydantic | 126 | max_length does not work in Fields | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2021-10-08T13:35:17Z | 2024-04-03T16:05:03Z | https://github.com/fastapi/sqlmodel/issues/126 | [
"question"
] | yudjinn | 7 |
ading2210/poe-api | graphql | 170 | KeyError: 'payload' | Getting the following error
```
INFO:root:Setting up session...
INFO:root:Downloading next_data...
Traceback (most recent call last):
File "/home/shubharthak/Desktop/apsaraAI/ChatGPT.py", line 10, in <module>
client = poe.Client(api)
File "/home/shubharthak/miniconda3/lib/python3.10/site-packages/poe.py... | closed | 2023-07-17T19:29:04Z | 2023-07-17T19:38:47Z | https://github.com/ading2210/poe-api/issues/170 | [] | shubharthaksangharsha | 0 |
OWASP/Nettacker | automation | 171 | Issue in getting results via discovery funstion in service scanner | I was trying to perform the same operation on my localhost and results were different everytime.
```python
In [1]: from lib.payload.scanner.service.engine import discovery
In [2]: discovery("127.0.0.1")
Out[2]: {443: 'UNKNOWN', 3306: 'UNKNOWN'}
In [3]: discovery("127.0.0.1")
Out[3]:
{80: 'http',
443: 'UNK... | closed | 2018-06-26T01:49:22Z | 2021-02-02T20:28:14Z | https://github.com/OWASP/Nettacker/issues/171 | [
"enhancement",
"possible bug"
] | shaddygarg | 8 |
newpanjing/simpleui | django | 512 | 包括但不限于base.less等多个样式表文件对用户模型依赖问题 | base.less 273 行:
```
#user_form{
background-color: white;
margin: 10px;
padding: 10px;
//color: #5a9cf8;
}
```
当用户模型User被swap以后,其名称不再是user,这个选择器将失效,从而导致样式有一些怪异。 | open | 2025-02-05T12:22:14Z | 2025-02-05T12:22:14Z | https://github.com/newpanjing/simpleui/issues/512 | [] | WangQixuan | 0 |
mljar/mljar-supervised | scikit-learn | 447 | Where can I find model details? | I want to see the best model parameters, preprocessing, etc so that I can reproduce it later or train the model again with the same parameters.
Thanks, | closed | 2021-07-30T19:37:58Z | 2021-08-28T19:56:47Z | https://github.com/mljar/mljar-supervised/issues/447 | [] | abdulwaheedsoudagar | 1 |
fohrloop/dash-uploader | dash | 73 | Uploading multiple files shows wrong total file count in case of errors | Affected version: f033683 (flow-dev branch)
Steps to reproduce
1. Use `max_file_size` for `du.Upload`
2. Upload multiple files (folder of files) where part of files (e.g. 2 files) are below `max_file_size` and part of files (e.g. 2 files) is above `max_file_size`
3. The upload text total files will reflect the ... | closed | 2022-02-24T19:23:56Z | 2022-02-24T19:29:21Z | https://github.com/fohrloop/dash-uploader/issues/73 | [
"bug"
] | fohrloop | 2 |
HumanSignal/labelImg | deep-learning | 748 | No module named 'libs.resources' | (ve) user1@comp1:~/path/to/labelImg$ python labelImg.py
Traceback (most recent call last):
File "labelImg.py", line 33, in <module>
from libs.resources import *
ModuleNotFoundError: No module named 'libs.resources'
Ubuntu
- **PyQt version:** 5
| closed | 2021-05-16T06:52:54Z | 2021-05-17T05:00:50Z | https://github.com/HumanSignal/labelImg/issues/748 | [] | waynemystir | 1 |
huggingface/diffusers | deep-learning | 10,080 | Proposal to add sigmas option to FluxPipeline | **Is your feature request related to a problem? Please describe.**
Flux's image generation is great, but it seems to have a tendency to remove too much detail.
**Describe the solution you'd like.**
Add the `sigmas` option to `FluxPipeline` to enable adjustment of the degree of noise removal.
**Additional contex... | closed | 2024-12-02T11:14:40Z | 2024-12-02T18:16:49Z | https://github.com/huggingface/diffusers/issues/10080 | [] | John6666cat | 3 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,773 | [Bug]: CUDA error: an illegal instruction was encountered | ### Checklist
- [ ] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-05-13T05:14:24Z | 2024-10-18T10:23:20Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15773 | [
"bug-report"
] | ClaudeRobbinCR | 1 |
tflearn/tflearn | data-science | 578 | possible typo line 584 | currently:
self.train_var = to_list(self.train_vars)
should it be this?
self.train_vars = to_list(self.train_vars)
| open | 2017-01-29T07:18:39Z | 2017-01-29T07:18:39Z | https://github.com/tflearn/tflearn/issues/578 | [] | ecohen1 | 0 |
pydantic/FastUI | pydantic | 165 | Proxy Support | I am running my fastapi behind a proxy. The issue I am running into:
assume my path is `https://example.com/proxy/8989/`
1. the root path is invoked
2. the HTMLResponse(prebuilt_html(title='FastUI Demo')) is sent
3. the following content is run
```
<!doctype html>
<html lang="en">
<head>
<meta charse... | closed | 2024-01-25T17:36:33Z | 2024-02-09T07:04:48Z | https://github.com/pydantic/FastUI/issues/165 | [] | stikkireddy | 1 |
facebookresearch/fairseq | pytorch | 5,244 | facebook/mbart-large-50 VS facebook/mbart-large-50-many-to-many-mmt | Hi!!
I am conducting some experiments for NMT on low resource languages, for this purpose I am fine tuning mbart for in a number for directions English to Sinhala, English to Tamil and SInhala to Tamil. I am using huggingface platform to perform this finetuning, while selecting the model i have 2 questions, i will hig... | open | 2023-07-09T11:23:31Z | 2023-07-09T11:23:31Z | https://github.com/facebookresearch/fairseq/issues/5244 | [
"question",
"needs triage"
] | vmenan | 0 |
pytest-dev/pytest-django | pytest | 964 | Drop support for unsupported Python and Django versions | closed | 2021-11-22T11:05:01Z | 2021-12-01T19:45:55Z | https://github.com/pytest-dev/pytest-django/issues/964 | [] | pauloxnet | 2 | |
QingdaoU/OnlineJudge | django | 51 | 批量建立使用者 | 请问有什么方法可以批量建立使用者
| closed | 2016-06-24T15:18:56Z | 2016-06-28T07:02:55Z | https://github.com/QingdaoU/OnlineJudge/issues/51 | [] | kevin50406418 | 1 |
littlecodersh/ItChat | api | 101 | 如何获得群里的群友的头像的图片具体binary数据? | 比如获得:
``` python
"HeadImgUrl": "/cgi-bin/mmwebwx-bin/webwxgetheadimg?seq=642242818&sername=@@21ec4b514edf3e7cb867e0512fb85f3a5e6deb657f4e8573d656bcd4558e3594&skey=",
```
但如何获得头像呢? 前面的域名应该是用什么?
| closed | 2016-10-16T20:31:54Z | 2017-02-02T14:45:39Z | https://github.com/littlecodersh/ItChat/issues/101 | [
"question"
] | 9cat | 4 |
graphql-python/graphene-mongo | graphql | 220 | Releases v0.2.16 and v0.3.0 missing on PyPI | Thanks for the work on this project, happy user here!
I noticed that there are releases on https://github.com/graphql-python/graphene-mongo/releases that are not on https://pypi.org/project/graphene-mongo/#history. Is this an oversight or is there something preventing you from releasing on PyPI?
In the meantime I... | open | 2023-05-02T14:55:36Z | 2023-07-31T07:20:21Z | https://github.com/graphql-python/graphene-mongo/issues/220 | [] | mathiasose | 4 |
Lightning-AI/pytorch-lightning | data-science | 20,391 | Error if SLURM_NTASKS != SLURM_NTASKS_PER_NODE | ### Bug description
Would it be possible for Lightning to raise an error if `SLURM_NTASKS != SLURM_NTASKS_PER_NODE` in case both are set?
With a single node the current behavior is:
* `SLURM_NTASKS == SLURM_NTASKS_PER_NODE`: Everything is fine
* `SLURM_NTASKS > SLURM_NTASKS_PER_NODE`: Slurm doesn't let you sche... | open | 2024-11-04T16:19:56Z | 2024-11-19T00:18:48Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20391 | [
"working as intended",
"ver: 2.4.x"
] | guarin | 1 |
taverntesting/tavern | pytest | 24 | Getting requests.exceptions.InvalidHeader: | In my test.tavern.yaml file
```
- name: Make sure signature is returned
request:
url: "{signature_url:s}"
method: PUT
headers:
content-type: application/json
content: {"ppddCode": "11","LIN": "123456789","correlationID":"{correlationId:s}","bodyTypeCode":"utv"}
... | closed | 2018-02-06T21:58:48Z | 2018-02-07T17:22:38Z | https://github.com/taverntesting/tavern/issues/24 | [] | sridharaiyer | 2 |
ansible/awx | django | 15,775 | How Do I Fail an Ansible Playbook Run or AWX Job when Hosts are Skipped? | ### Please confirm the following
- [x] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [x] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [x] I understand that AWX is open source software provide... | closed | 2025-01-27T08:36:31Z | 2025-02-05T18:11:39Z | https://github.com/ansible/awx/issues/15775 | [
"type:enhancement",
"needs_triage",
"community"
] | bskou | 1 |
keras-team/autokeras | tensorflow | 896 | How to specify the training batch_size? | When I train a StructuredDataClassifier model, I want to specify the training batch_size of input, should I specify the batch_size in fit function? I have try in fit function, but it seems not help. | closed | 2020-01-13T09:04:56Z | 2020-03-21T02:01:11Z | https://github.com/keras-team/autokeras/issues/896 | [
"bug report",
"wontfix"
] | Peng-wei-Yu | 2 |
slackapi/bolt-python | fastapi | 419 | Load testing an app - is there a way to disable or pass authorization | I am trying to implement load-testing for my Django app that utilizes Bolt.
I want to stress test it using Locust framework - basically firing http requests to the server running the app to see the response times. The app does not really have to call any requests to Slack API for that – I am planning to patch `App.c... | closed | 2021-07-23T02:37:28Z | 2021-08-06T09:50:54Z | https://github.com/slackapi/bolt-python/issues/419 | [
"question"
] | DataGreed | 4 |
ansible/ansible | python | 83,884 | uri module encodes uploaded file in base64 but it can't be handled by the server | ### Summary
I have the exact same issue as described in
https://github.com/ansible/ansible/issues/73621
Since that issue was closed and no more comments could be added.
So I have to create another issue to address it. Sorry for this.
I saw your comments in that issue. I agree base64 encoding is the standard ... | closed | 2024-09-02T04:36:01Z | 2024-09-17T13:00:02Z | https://github.com/ansible/ansible/issues/83884 | [
"module",
"bug",
"affects_2.14"
] | cwhuang | 6 |
voila-dashboards/voila | jupyter | 543 | Too many ipyleaflet layers fail to render | I noticed that notebooks with too many ipyleaflet layers cannot be properly rendered with Voila. Those notebooks are rendered on mybinder.org, so this could be a problem of my computer. That being said, I'd be happy if notebooks that can be rendered with JupyterLab locally can be rendered with Voila as well, or at leas... | open | 2020-02-15T19:32:37Z | 2022-01-20T06:07:12Z | https://github.com/voila-dashboards/voila/issues/543 | [] | yudai-nkt | 4 |
wagtail/wagtail | django | 12,703 | Stop sidebar re-rendering when clicking the page | Spotted as part of the [Wagtail 6.3 admin UI performance audit](https://github.com/wagtail/wagtail/discussions/12578). Our sidebar components are unnecessarily listening to click events on the whole page, most likely as part of their "click outside" logic.
We should either remove this unneeded event listening, or if i... | closed | 2024-12-17T11:08:11Z | 2025-01-20T07:34:00Z | https://github.com/wagtail/wagtail/issues/12703 | [
"type:Cleanup/Optimisation",
"🚀 Performance",
"component:Design system"
] | thibaudcolas | 0 |
kizniche/Mycodo | automation | 501 | DHT22 error | ## Mycodo Issue Report:
- Specific Mycodo Version: 6.1.4
Raspberry PI 3B+
16 GB SD Card Class10
System : Linux mycodo 4.14.52-v7+ #1123 SMP Wed Jun 27 17:35:49 BST 2018 armv7l GNU/Linux
Power 5v 2.0 Amp
Sensor : DHT22 ( 3 meters ) , DS18B20 , Original Atlas PH i2c
I've already tried everything.
other pins, ... | closed | 2018-07-10T15:32:01Z | 2018-10-13T14:47:37Z | https://github.com/kizniche/Mycodo/issues/501 | [] | pmunz75 | 5 |
gradio-app/gradio | data-visualization | 9,876 | Parameter passing of button.click() | ### Describe the bug
When using `button.click(fn=..., inputs=[],...)`, if the input parameter is a button component, the type of the component will change after being passed to the fn target function.
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```... | closed | 2024-10-31T08:29:56Z | 2024-11-01T01:43:12Z | https://github.com/gradio-app/gradio/issues/9876 | [
"bug"
] | Semper4u | 3 |
tqdm/tqdm | pandas | 953 | Provide a default computer unit handling (IEEE1541) | ```
4.45.0
3.7.5 (default, Oct 31 2019, 15:18:51) [MSC v.1916 64 bit (AMD64)]
win32 ## (but its a win10 x64 machine)
```
In the issue https://github.com/tqdm/tqdm/issues/952 I gave the following use case:
with TQDM 4.45.0, when I write some downloading code, I try to use IEEE1541 units.
So, I wrote this:
... | open | 2020-04-28T16:44:09Z | 2020-10-27T18:38:44Z | https://github.com/tqdm/tqdm/issues/953 | [
"p4-enhancement-future 🧨"
] | LoneWanderer-GH | 3 |
ydataai/ydata-profiling | jupyter | 995 | cannot import name 'soft_unicode' from 'markupsafe' | ### Current Behaviour
Used colab with 3.2.0
```
!pip install pandas-profiling==3.2.0
import numpy as np
import pandas as pd
from pandas_profiling import ProfileReport
df = pd.DataFrame(np.random.rand(100, 5), columns=["a", "b", "c", "d", "e"])
```
it shows
ImportError: cannot import name 'soft_unicode'... | closed | 2022-06-03T16:18:44Z | 2022-09-30T18:39:05Z | https://github.com/ydataai/ydata-profiling/issues/995 | [
"bug 🐛",
"code quality 📈"
] | DaiZack | 4 |
explosion/spaCy | machine-learning | 13,533 | [W030] Some entities could not be aligned in the text | Hi!
I tried training a custom Named Entity Recognition model using spaCy, but despite multiple trials, I get a warning telling me that there are misaligned entities in the training data that I had created.
```
import spacy
from spacy.training import Example
import random
nlp=spacy.load('en_core_web_sm')
tr... | closed | 2024-06-19T07:08:40Z | 2024-06-19T09:15:37Z | https://github.com/explosion/spaCy/issues/13533 | [
"usage"
] | NitGS | 1 |
plotly/dash-table | dash | 387 | Incorrect Filtering of Numeric Data with Decimal Points | Hello,
I have a pandas dataframe of data that I am displaying in a data-table with filtering enabled. Filtering seems to work okay on numeric columns that are whole numbers, but when I try to filter decimal point numbers it seems to ignore the values after the decimal.
ex - `eq num(1.5)` filters to rows with colu... | closed | 2019-02-27T14:05:17Z | 2019-02-27T17:29:06Z | https://github.com/plotly/dash-table/issues/387 | [
"dash-type-bug"
] | JAnderson419 | 1 |
strawberry-graphql/strawberry | django | 3,264 | Incongruity with the `Context` type across the library. | I'm developing an app using Django + Strawberry + Channels.
Until the introduction of Channels and related logic to manage subscriptions, I used a custom decorator to populate the `info.context` object of some selected queries and mutations with some extra stuff.
To be clear, something like this:
```py
from fun... | open | 2023-11-29T22:54:54Z | 2025-03-20T15:56:29Z | https://github.com/strawberry-graphql/strawberry/issues/3264 | [] | Byloth | 2 |
tqdm/tqdm | pandas | 786 | Suggestion: optionally redirect console logging to tqdm.write | This is somewhat related to #296, which is about stdout and stderr.
I believe the proposed example to redirect stdout and stderr doesn't work with logging, because it will already have saved the reference to stdout and stderr.
This seems to be a common "problem" with many related snippets. Rather than copy and pa... | closed | 2019-08-02T14:39:49Z | 2021-04-06T00:21:40Z | https://github.com/tqdm/tqdm/issues/786 | [
"p3-enhancement 🔥",
"submodule ⊂",
"to-merge ↰",
"c1-quick 🕐"
] | de-code | 4 |
matterport/Mask_RCNN | tensorflow | 2,677 | OSError: Unable to open file | Hi I'm unable to run training session. I'm using tensor flow 2.3 and modified model.py, utils.py and other files from some available accordingly. Any help would be highly appreciated
'' '' ''
OSError Traceback (most recent call last)
<ipython-input-15-ce3d0a98ce21> in <module>
... | closed | 2021-08-23T05:47:04Z | 2021-08-23T11:29:54Z | https://github.com/matterport/Mask_RCNN/issues/2677 | [] | chhigansharma | 2 |
ray-project/ray | data-science | 51,387 | [Train] Add support for NeMo Megatron strategy with lightning | ### Description
Similar to the [deepspeed lightning strategy with ray](https://docs.ray.io/en/latest/train/api/doc/ray.train.lightning.RayDeepSpeedStrategy.html#ray.train.lightning.RayDeepSpeedStrategy) I would like to integrate with the NeMo framework to use ray to manage feeding data to and orchestrating MegatronStr... | open | 2025-03-14T21:52:34Z | 2025-03-18T17:12:06Z | https://github.com/ray-project/ray/issues/51387 | [
"enhancement",
"triage",
"train"
] | sam-h-bean | 0 |
onnx/onnx | tensorflow | 6,302 | a) Feature Request: Function sample_dirichlet, b) State of probabilistic model support? | I am very interested in converting DeepLearning models, that contain the PowerSpherical function (https://github.com/andife/power_spherical) to ONNX.
Currently this fails because of the Dirichlet function (https://github.com/pytorch/pytorch/issues/116336).
After my research, I came across https://github.com/onnx/on... | open | 2024-08-17T04:38:43Z | 2024-09-30T21:38:34Z | https://github.com/onnx/onnx/issues/6302 | [] | andife | 6 |
yezz123/authx | pydantic | 626 | 🐛 Investigate TypeError: `coroutine` object is not callable | https://github.com/yezz123/authx/actions/runs/9650681836/job/26616841558?pr=625 | closed | 2024-06-24T18:47:04Z | 2024-06-30T15:05:39Z | https://github.com/yezz123/authx/issues/626 | [
"bug"
] | yezz123 | 0 |
python-gitlab/python-gitlab | api | 2,485 | Documentation wrong on page for "badges" | ## Description of the problem, including code/CLI snippet
Documentation seems to be wrong here:
https://python-gitlab.readthedocs.io/en/stable/gl_objects/badges.html#examples
-> "Update a badge"
## Expected Behavior
Update a badge:
badge.image_url = new_image_url
badge.link_url = new_link_url
badge.save()
... | closed | 2023-02-08T19:00:37Z | 2024-02-12T01:12:14Z | https://github.com/python-gitlab/python-gitlab/issues/2485 | [
"docs",
"good first issue"
] | stuff2use | 3 |
custom-components/pyscript | jupyter | 46 | Feature Request: access to sunset/sunrise in function | This works, but it's complicated to write and follow:
```python
@state_trigger('binary_sensor.dark == "on"')
@time_active("range(sunrise - 120min, sunset + 120min)")
def turn_on_dark():
turn_on()
@state_trigger('binary_sensor.downstairs_occupied == "on" and binary_sensor.dark == "on"')
def turn_on_occupied... | closed | 2020-10-16T11:34:32Z | 2023-04-10T07:40:06Z | https://github.com/custom-components/pyscript/issues/46 | [] | dlashua | 8 |
sigmavirus24/github3.py | rest-api | 723 | multiple test failures on develop branch | I'm at a bit of a loss as to why the unit tests are working under travis as I'm unable to to get a clean run locally. Eg.:
```
[develop] ~/github/github3.py $ virtualenv venv
New python executable in /home/jhoblitt/github/github3.py/venv/bin/python2
Also creating executable in /home/jhoblitt/github/github3.py/ven... | closed | 2017-08-01T16:17:07Z | 2017-08-01T16:22:16Z | https://github.com/sigmavirus24/github3.py/issues/723 | [] | jhoblitt | 1 |
vaexio/vaex | data-science | 2,383 | [BUG-REPORT] AssertionError while performing math operation on shifted columns | **Description**
Let's say I want to calculate something on a column and its shifted values (Lags or Leads). The basic one can be df.A - 2*df.A_shifted. It can easily be done in pandas: `df.A - df.A.shift(1)`. However, VAEX throws an exception saying ` AssertionError:`. Below is the code I used:
```
df = pd.DataFr... | open | 2023-07-11T11:08:42Z | 2023-07-11T11:08:42Z | https://github.com/vaexio/vaex/issues/2383 | [] | msat59 | 0 |
ageitgey/face_recognition | machine-learning | 781 | ValueError: operands could not be broadcast together with shapes (2,0) (128,) | open | 2019-03-23T17:30:24Z | 2019-06-20T10:17:52Z | https://github.com/ageitgey/face_recognition/issues/781 | [] | Profiiii | 1 | |
strawberry-graphql/strawberry-django | graphql | 658 | Implementing Object Level Permissions | <!--- Provide a general summary of the changes you want in the title above. -->
<!--- This template is entirely optional and can be removed, but is here to help both you and us. -->
<!--- Anything on lines wrapped in comments like these will not show up in the final text. -->
## Feature Request Type
- [ ] Core funct... | open | 2024-11-15T03:51:50Z | 2025-03-20T15:57:40Z | https://github.com/strawberry-graphql/strawberry-django/issues/658 | [] | moluwole | 2 |
serengil/deepface | machine-learning | 1,015 | Exclude Jupyter Notebooks from GitHub Programming Language Stats | GitHub's programming language statistics include Jupyter Notebooks, which may skew the results for repositories that heavily use them. This issue is created to address the need for excluding Jupyter Notebooks from the language statistics calculation.
### Proposed Solution
To exclude Jupyter Notebooks from language ... | closed | 2024-02-09T10:50:30Z | 2024-02-10T18:27:13Z | https://github.com/serengil/deepface/issues/1015 | [
"enhancement"
] | serengil | 1 |
streamlit/streamlit | python | 10,879 | Skills Vs Pay, Titles/Radio Buttons Wont Stay Stuck and Always Reset... | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Hey,
Apologies if this is confusing or obliv... | open | 2025-03-23T15:41:25Z | 2025-03-23T15:41:35Z | https://github.com/streamlit/streamlit/issues/10879 | [
"type:bug",
"status:needs-triage"
] | ipsaphoenix | 1 |
deepset-ai/haystack | pytorch | 8,118 | docs: clean up docstrings of OpenAIChatGenerator | closed | 2024-07-30T07:36:22Z | 2024-07-31T07:45:16Z | https://github.com/deepset-ai/haystack/issues/8118 | [] | agnieszka-m | 0 | |
praw-dev/praw | api | 1,447 | Revert commit 698b103514932424a222edfadd6ea735db76e954 | Per #1444 , those \`\`"..."\`\` should not have been removed. | closed | 2020-04-27T11:57:34Z | 2020-04-27T21:25:49Z | https://github.com/praw-dev/praw/issues/1447 | [
"Bug",
"Documentation"
] | PythonCoderAS | 0 |
flasgger/flasgger | rest-api | 122 | schema validation abort directly | schema validation abort directly
` try:
jsonschema.validate(data, main_def)
except ValidationError as e:
abort(Response(str(e), status=400))
`
should add option to only raise an exception and let the caller to handle it | closed | 2017-06-25T11:33:33Z | 2017-10-28T20:25:13Z | https://github.com/flasgger/flasgger/issues/122 | [
"enhancement"
] | ghost | 5 |
jofpin/trape | flask | 284 | ERROR: cannot import name json | I have error: cannot import name json, after I wrote python2 trape.py -h | open | 2020-12-25T13:52:42Z | 2021-01-31T12:08:28Z | https://github.com/jofpin/trape/issues/284 | [] | Gestohlener | 1 |
blacklanternsecurity/bbot | automation | 2,137 | Include IP, routing table in initial SCAN event | In order to correlate scan activity back to a specific agent / IP, we should include network interface information in the initial scan event.
@aconite33 @kerrymilan | open | 2025-01-07T16:03:23Z | 2025-02-06T00:02:28Z | https://github.com/blacklanternsecurity/bbot/issues/2137 | [
"enhancement"
] | TheTechromancer | 0 |
betodealmeida/shillelagh | sqlalchemy | 214 | Potential Issue with exact on Fields | The docs indicate that `exact=True` means no post filtering is needed:
https://github.com/betodealmeida/shillelagh/blob/97197bd564e96a23c5587be5c9e315f7c0e693ea/src/shillelagh/fields.py#L121-L125
however that value seems to be passed to apsw:
https://github.com/betodealmeida/shillelagh/blob/14579e4b8c3159adc4076b366... | closed | 2022-03-28T17:11:49Z | 2022-03-30T15:37:28Z | https://github.com/betodealmeida/shillelagh/issues/214 | [
"bug"
] | cancan101 | 3 |
Miserlou/Zappa | django | 1,914 | Passing non JSON serializable object to task throws cryptic error | Passing non JSON serializable object to task throws cryptic error and doesnt throw error when running locally.
## Context
I've recently noticed this when passing a Django model instance as a param to a task. The task ran fine when I was running the code locally but it failed when I deployed to lambda.
## Expecte... | open | 2019-08-06T10:26:09Z | 2019-08-06T10:26:09Z | https://github.com/Miserlou/Zappa/issues/1914 | [] | stan-sack | 0 |
miguelgrinberg/flasky | flask | 327 | can flask as a server and node.js as a web ? | i know ,node.js is a server frame,but i need it as a web ,can flask as a server and node.js as a web ? thanks | closed | 2018-01-02T07:57:03Z | 2018-10-14T22:22:50Z | https://github.com/miguelgrinberg/flasky/issues/327 | [
"question"
] | 744216212 | 1 |
microsoft/nni | pytorch | 5,773 | Which framework to use for Neural Architecture Search: NNI or Archai? | Hello,
I have been exploring the open source framework for NAS and came across NNI and Archai. How these two frameworks are different? As both are part of Microsoft research group so a clarification would be really helpful. Additionally, I would appreciate guidance on which framework would be more suitable for me as... | open | 2024-04-23T15:15:10Z | 2024-04-23T15:15:10Z | https://github.com/microsoft/nni/issues/5773 | [] | mkumar73 | 0 |
PeterL1n/BackgroundMattingV2 | computer-vision | 79 | question about the fourth output of basenet:hidden | What can it do? Why design this output? | closed | 2021-03-22T02:40:01Z | 2021-03-22T02:44:27Z | https://github.com/PeterL1n/BackgroundMattingV2/issues/79 | [] | nostayup | 1 |
deepset-ai/haystack | machine-learning | 8,035 | `OpenAPITool` fails to handle OpenAPI specs with `servers` under `paths` and missing `operationId` | ### Bug Report
**Describe the bug**
When using the `OpenAPITool` with a specific OpenAPI YAML specification, the tool fails to process the request properly. The issue arises due to the `servers` field being under the `paths` section and the absence of an `operationId` on the forecast path, which the tool does not h... | closed | 2024-07-17T07:11:19Z | 2024-07-18T15:57:31Z | https://github.com/deepset-ai/haystack/issues/8035 | [] | vblagoje | 0 |
deepspeedai/DeepSpeed | deep-learning | 5,945 | nv-nightly CI test failure | The Nightly CI for https://github.com/microsoft/DeepSpeed/actions/runs/10499491789 failed.
| closed | 2024-08-15T01:41:43Z | 2024-08-22T18:50:00Z | https://github.com/deepspeedai/DeepSpeed/issues/5945 | [
"ci-failure"
] | github-actions[bot] | 1 |
pyro-ppl/numpyro | numpy | 1,010 | HMM forward algorithm - 20x difference in performance between two comparable approaches | This issue links to the following thread:
https://forum.pyro.ai/t/intuition-for-the-difference-between-the-two-hmm-tutorials-forward-algo-vs-marginalization/2775
The following two tutorials for HMMs cover two alternative solutions via the forward algorithm (one explicit, one implicit):
1. [HMM Example semi-supe... | closed | 2021-04-14T21:15:35Z | 2021-04-28T18:22:25Z | https://github.com/pyro-ppl/numpyro/issues/1010 | [
"question"
] | svilupp | 2 |
tflearn/tflearn | data-science | 214 | Thread-specifc models in reinforcement Learning example | In the [reinforcement learning example](https://github.com/tflearn/tflearn/blob/master/examples/reinforcement_learning/atari_1step_qlearning.py), the note described that this example implemented the 1-step Q-learning algorithm from [this paper](http://arxiv.org/pdf/1602.01783v1.pdf). However, I found that the model doe... | closed | 2016-07-21T00:19:27Z | 2016-07-22T02:17:11Z | https://github.com/tflearn/tflearn/issues/214 | [] | yukezhu | 2 |
autogluon/autogluon | data-science | 4,573 | [BUG]Why can't we just specify the distributed operation of 'gloo' in hyperparameters | ['ddp', 'ddp_spawn', 'ddp_fork', 'ddp_notebook', 'ddp_find_unused_parameters_false', 'ddp_find_unused_parameters_true', 'ddp_spawn_find_unused_parameters_false', 'ddp_spawn_find_unused_parameters_true', 'ddp_fork_find_unused_parameters_false', 'ddp_fork_find_unused_parameters_true', 'ddp_notebook_find_unused_parameters... | open | 2024-10-23T14:58:55Z | 2024-10-23T14:58:55Z | https://github.com/autogluon/autogluon/issues/4573 | [
"bug: unconfirmed",
"Needs Triage"
] | Ultraman6 | 0 |
kymatio/kymatio | numpy | 454 | On output of 3D scattering | According to the following comment in #158, for a 3D input of size (B, M, N, O), the outputs , based on the method, would have the following dimensions:
> The 3D version returns different outputs for different versions.
>
> - "standard" would return `(B, P, M/2**J, N/2**J, O/2**J)`
> - "integral" would return `... | closed | 2019-11-21T01:57:35Z | 2022-06-20T20:17:50Z | https://github.com/kymatio/kymatio/issues/454 | [] | nshervt | 9 |
cupy/cupy | numpy | 8,973 | Use of cp.pad causes significant performance degradation in downstream code compared to np.pad | ### Description
When padding arrays directly on the GPU using `cp.pad`, I observed significantly slower performance in _subsequent_ code compared to padding on the CPU using `np.pad` and then transferring the data to the GPU with `cp.asarray`.
CuPy is awesome! Any help would be greatly appreciated! 😁
**What Happ... | open | 2025-02-20T17:15:58Z | 2025-02-26T19:44:10Z | https://github.com/cupy/cupy/issues/8973 | [
"issue-checked"
] | JohnHardy | 4 |
postmanlabs/httpbin | api | 100 | port to python 3 | it's time.
| closed | 2013-06-14T20:09:29Z | 2018-04-26T17:50:59Z | https://github.com/postmanlabs/httpbin/issues/100 | [] | kennethreitz | 6 |
ultralytics/yolov5 | deep-learning | 12,674 | KeyError: 'train' | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Transferred 308/362 items from yolov5\weights\yolov5s.pt
Traceback (most recent call las... | closed | 2024-01-27T10:18:24Z | 2024-10-20T19:38:19Z | https://github.com/ultralytics/yolov5/issues/12674 | [
"question",
"Stale"
] | 2ljz | 3 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 725 | Loss of Tacotron | May I ask what actually is the loss while training the synthesizers.
For the new Pytorch repo, as mentioned in #653 , the loss is the sum of:
1. L1 loss +L2 loss of decoder output
2. L2 loss of Mel spectrogram after Post-Net
3. Cross entropy of Stop Token
I can also see it in the code:
` # Backward pass `
... | closed | 2021-04-05T14:04:40Z | 2021-04-11T06:25:59Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/725 | [] | chankl3579 | 2 |
nicodv/kmodes | scikit-learn | 53 | kmodes package dependencies | Is it possible to install kmodes with following latest packages
numpy 1.13.1
scipy 0.19.1
scikit-learn 0.19.0 | closed | 2017-09-07T06:33:27Z | 2017-09-07T18:17:14Z | https://github.com/nicodv/kmodes/issues/53 | [
"question"
] | musharif | 1 |
gradio-app/gradio | data-science | 10,601 | change event doesn't be detected when value is component in gr.Dataframe | ### Describe the bug
I have a seven columns' dataframe, and the final column is html style selection component.
When I select the value in such column, change event cannot be detected.
### Have you searched existing issues? 🔎
- [x] I have searched and found no existing issues
### Reproduction
```python
import gr... | closed | 2025-02-17T04:14:08Z | 2025-03-04T19:16:16Z | https://github.com/gradio-app/gradio/issues/10601 | [
"bug",
"💾 Dataframe"
] | Yb2S3Man | 1 |
dask/dask | numpy | 10,842 | `make_meta` over a Dask Dataframe returns a reference, not a new object | **Describe the issue**:
Reading the documentation of [`make_meta`](https://docs.dask.org/en/stable/generated/dask.dataframe.utils.make_meta.html) it states that
> This method creates meta-data based on the type of x
so my understanding is that a new object is returned. However, one can check that when running ... | open | 2024-01-22T09:08:36Z | 2024-01-22T09:08:47Z | https://github.com/dask/dask/issues/10842 | [
"needs triage"
] | albarji | 0 |
encode/httpx | asyncio | 2,286 | Setting Cookies on request | Hello, i can't find the correct way to set all needed cookies. This is the cookie tab from the response:

Now i want to use client and tried a lot of different things to set the cookies but none of them s... | closed | 2022-06-30T22:18:51Z | 2022-07-01T08:08:06Z | https://github.com/encode/httpx/issues/2286 | [] | FuckingToasters | 0 |
gunthercox/ChatterBot | machine-learning | 1,582 | AttributeError: module 'chatterbot.logic' has no attribute 'UnitConversion' | While running the following example from the Git Example page,
``` Python
from chatterbot import ChatBot
bot = ChatBot(
'Unit Converter',
logic_adapters=[
'chatterbot.logic.UnitConversion',
]
)
questions = [
'How many meters are in a kilometer?',
'How many meters are in one ... | closed | 2019-01-23T08:50:21Z | 2019-11-21T09:23:17Z | https://github.com/gunthercox/ChatterBot/issues/1582 | [] | sarangjain40 | 2 |
stanfordnlp/stanza | nlp | 986 | AttributeError: 'NoneType' object has no attribute 'enum_types_by_name' | I got this error while running stanza
import stanza
from stanza.pipeline.core import Pipeline
from stanza.pipeline.constituency_processor import ConstituencyProcessor
import stanza.models.constituency.trainer as trainer
from stanza.server.parser_eval import EvaluateParser
from stanza.protobuf import to_text
fr... | closed | 2022-03-31T16:50:17Z | 2022-06-07T19:28:40Z | https://github.com/stanfordnlp/stanza/issues/986 | [
"question"
] | mennatallah644 | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.