
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
comfyanonymous/ComfyUI | pytorch | 6,331 | No more real-time preview SamplerCustomAdvanced node after update? | ### Your question
How do I enable it? I cant seem to find the option.

### Logs
_No response_
### Other
_No response_ | closed | 2025-01-03T12:01:54Z | 2025-01-03T13:06:43Z | https://github.com/comfyanonymous/ComfyUI/issues/6331 | [
"User Support"
] | Orenji-Tangerine | 2 |
pydata/xarray | numpy | 9,084 | Release 2024.06.0 | ### What is your issue?
We should get this out before numpy 2 (June 16).
@keewis, thanks for [volunteering!](https://github.com/pydata/xarray/pull/8946#issuecomment-2158022820) | closed | 2024-06-10T15:52:19Z | 2024-06-14T10:18:53Z | https://github.com/pydata/xarray/issues/9084 | [
"Release"
] | dcherian | 2 |
deepset-ai/haystack | machine-learning | 8,622 | Update serialization in HuggingFace Generators to include missing parameters | **Is your feature request related to a problem? Please describe.**
Certain initialization parameters, such as `chat_template` in `HuggingFaceLocalChatGenerator` and `stop_words` in `HuggingFaceAPIChatGenerator`, are not included in the serialization process. This omission can result in inconsistent behavior when deser... | closed | 2024-12-10T16:27:55Z | 2024-12-19T14:12:14Z | https://github.com/deepset-ai/haystack/issues/8622 | [
"P2",
"2.x"
] | Amnah199 | 1 |
charlesq34/pointnet | tensorflow | 174 | The visi | closed | 2019-04-22T06:59:13Z | 2019-04-22T06:59:59Z | https://github.com/charlesq34/pointnet/issues/174 | [] | Liu-Feng | 0 | |
huggingface/datasets | machine-learning | 7,053 | Datasets.datafiles resolve_pattern `TypeError: can only concatenate tuple (not "str") to tuple` | ### Describe the bug
in data_files.py, line 332,
`fs, _, _ = get_fs_token_paths(pattern, storage_options=storage_options)`
If we run the code on AWS, as fs.protocol will be a tuple like: `('file', 'local')`
So, `isinstance(fs.protocol, str) == False` and
`protocol_prefix = fs.protocol + "://" if fs.protocol != ... | closed | 2024-07-18T13:42:35Z | 2024-07-18T15:17:42Z | https://github.com/huggingface/datasets/issues/7053 | [] | MatthewYZhang | 2 |
numpy/numpy | numpy | 28,216 | numpy import issue with python 3.13.1 over nfs [Windows] | ### Describe the issue:
opening a new bug as I could not able to reopen previous bug #28207 (numpy 2.0.1 on python 3.12.6 vs 3.13.1)
As mentioned in this bug , I built numpy 2.1.0 with python 3.13.1 but still getting same import error -
from numpy._core._multiarray_umath import (
add_docstring, _get_imp... | closed | 2025-01-22T11:35:13Z | 2025-01-24T23:39:36Z | https://github.com/numpy/numpy/issues/28216 | [
"00 - Bug"
] | Ganeshkumhar1 | 9 |
ultralytics/yolov5 | machine-learning | 12,677 | Cant understand how does yolov5 work. | Hello.I dont understand some basic principles of the yolov5 work and need help.Could you, please, answer my questions?
As far as i am concerned, convolutional neural network always has fully connected layer on its exit to predict the class of the object, but i dont see it on this picture.It seems yolov5 output consi... | closed | 2024-01-28T12:41:51Z | 2024-10-20T19:38:23Z | https://github.com/ultralytics/yolov5/issues/12677 | [] | Aflexg | 4 |
ckan/ckan | api | 7,548 | CKAN bulk_update_delete not reflecting changes in frontend | ## CKAN 2.9
## Made a request to bulk_update_delete endpoint, received success:true, but packages are not deleted when I check the site.
A clear and concise description of what the bug is.
### Steps to reproduce
Steps to reproduce the behavior:
data_dict = {
"id": f"{id}",
"organizati... | closed | 2023-04-14T19:26:44Z | 2023-05-27T19:54:49Z | https://github.com/ckan/ckan/issues/7548 | [] | jamxiao2025 | 1 |
google-research/bert | nlp | 801 | Intended Behaviour for Impossible (out-of-span) SQuAD 1.1 Features | Hello! We have a quick question regarding the featurization for BERT on SQuAD 1.1 specifically.
We noticed a confusing contradiction in your current `run_squad` implementation: regardless of how the `version_2_with_negative` flag is set, you do not discard “impossible” features (chunks of a context). Instead of disc... | open | 2019-08-13T01:55:15Z | 2019-08-13T01:55:15Z | https://github.com/google-research/bert/issues/801 | [] | Shayne13 | 0 |
vaexio/vaex | data-science | 2,062 | [BUG-REPORT] (Major) vaex hdf5 incompatible with number 1.22.4 | Thank you for reaching out and helping us improve Vaex!
Before you submit a new Issue, please read through the [documentation](https://docs.vaex.io/en/latest/). Also, make sure you search through the Open and Closed Issues - your problem may already be discussed or addressed.
**Description**
Vaex cannot export h... | closed | 2022-05-24T14:44:17Z | 2023-02-16T14:54:09Z | https://github.com/vaexio/vaex/issues/2062 | [] | Ben-Epstein | 14 |
developmentseed/lonboard | data-visualization | 593 | support classification schemes | Hi folks, thanks for all your work on this; lonboard has been lovely! I'm curious if there is interest in supporting commonly-used map classification schemes (a-la the `scheme` argument in geopandas's plot function) under the hood (particularly in the `viz` API)? We just added [a small function in mapclassify](https://... | closed | 2024-08-13T22:51:57Z | 2024-08-14T19:09:26Z | https://github.com/developmentseed/lonboard/issues/593 | [] | knaaptime | 6 |
raphaelvallat/pingouin | pandas | 298 | `pairwise_tests` producing array of t values internally | I occasionally get mysterious crashes when using the pairwise t-test, e.g:
```
.../pingouin/pairwise.py", line 397, in pairwise_tests
df_ttest = ttest(
.../pingouin/parametric.py", line 310, in ttest
bf = bayesfactor_ttest(tval, nx, ny, paired=paired, alternative=alternative, r=r)
.../pingouin/bayes... | closed | 2022-08-26T00:04:18Z | 2022-09-09T22:37:28Z | https://github.com/raphaelvallat/pingouin/issues/298 | [
"bug :boom:"
] | George3d6 | 4 |
mitmproxy/pdoc | api | 723 | Support `#:` annotation | #### Problem Description
Document variables in a compatible and terse way.
#### Proposal
Generate documentation from comments that start with `#:`
#### Alternatives
Triple-quote on a new line below the variable declaration. Which is rather confusing...
#### Additional context
This code:
```py
class Dog:
... | closed | 2024-08-08T12:32:38Z | 2024-08-09T12:25:57Z | https://github.com/mitmproxy/pdoc/issues/723 | [
"enhancement"
] | savchenko | 3 |
axnsan12/drf-yasg | django | 554 | Missing validation of query parameters in a GET request | I’m developing an app with Django 3.
I have an endpoint that I’m trying to use in this way:
`/queryenpoint/?entity=A&id=1`
In my view, that I want to use just for GET requests (at least for now), I have the following configuration for the swagger_auto_schema decorator:
```
@swagger_auto_schema(manual_paramet... | open | 2020-03-06T08:46:27Z | 2025-03-07T12:15:25Z | https://github.com/axnsan12/drf-yasg/issues/554 | [
"triage"
] | MartaLopesGomes | 0 |
NVIDIA/pix2pixHD | computer-vision | 241 | question about fp16 | Warning: multi_tensor_applier fused unscale kernel is unavailable, possibly because apex was installed without --cuda_ext --cpp_ext. Using Python fallback. Original ImportError was: ModuleNotFoundError("No module named 'amp_C'")
Gradient overflow. Skipping step, loss scaler 0 reducing loss scale to 32768.0
Gradie... | open | 2021-02-17T01:11:31Z | 2021-02-25T02:33:42Z | https://github.com/NVIDIA/pix2pixHD/issues/241 | [] | najingligong1111 | 1 |
ageitgey/face_recognition | machine-learning | 885 | How to Enrol Face Timeout | * face_recognition version:
* Python version: 3
* Operating System: raspian stretch
### Description
I am trying to make a simple face enrolment script, after user id entered the person is asked to look at the camera.
If there is no face detected on the camera, say after 5 seconds, i wish the script to go to th... | open | 2019-07-12T20:07:41Z | 2019-07-12T20:09:12Z | https://github.com/ageitgey/face_recognition/issues/885 | [] | akeilox | 0 |
ultralytics/yolov5 | deep-learning | 13,349 | Why is the GPU usage low and the CPU usage high when training the model? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello, I train my data with Yolov5.7, it works well. But I find that the GPU usage... | open | 2024-10-09T09:24:22Z | 2024-10-27T13:30:33Z | https://github.com/ultralytics/yolov5/issues/13349 | [
"question"
] | Assassintears | 3 |
dynaconf/dynaconf | fastapi | 491 | Error with dynaconf+django+pytest | I have a Django project with pytest and dynaconf.
In `conftest.py` I force the dynaconf environment as seen in the dynaconf documentation https://www.dynaconf.com/advanced/#a-python-program
```python
@pytest.fixture(scope="session", autouse=True)
def set_test_settings():
from dynaconf import settings
se... | closed | 2020-12-15T09:33:24Z | 2021-08-20T19:14:20Z | https://github.com/dynaconf/dynaconf/issues/491 | [
"bug",
"django",
"backport3.1.5"
] | alexander-jacob | 4 |
dnouri/nolearn | scikit-learn | 271 | 'RuntimeError: maximum recursion depth exceeded' when trying to serialize model | When I try
``` python
joblib.dump(model, 'my_model.pkl', compress=9)
```
or to pickle the model, I get:
```
File "/home/moose/.local/lib/python2.7/site-packages/sklearn/externals/joblib/numpy_pickle.py", line 280, in save
return Pickler.save(self, obj)
File "/usr/lib/python2.7/pickle.py", line 331, in save
... | closed | 2016-05-27T09:18:04Z | 2016-11-02T15:37:09Z | https://github.com/dnouri/nolearn/issues/271 | [] | MartinThoma | 6 |
deeppavlov/DeepPavlov | nlp | 907 | ner_model(['Bob Ross lived in Florida']) is giving error | raise type(e)(node_def, op, message)
InvalidArgumentError: Requested more than 0 entries, but params is empty. Params shape: [1,7,0] | closed | 2019-06-28T08:34:45Z | 2020-05-13T09:47:24Z | https://github.com/deeppavlov/DeepPavlov/issues/907 | [] | puneetkochar016 | 1 |
ploomber/ploomber | jupyter | 660 | Pipeline can't be run with env file having .yml suffix | ## Description
Pipeline can't be run with env.yml file. It seems it won't get read at all since variables stated in the env.yml are unknown to the pipeline run. Renaming file to env.yaml solved the issue for me.
## Replication
Files for replication of minimal example are attached [here](https://github.com/ploo... | closed | 2022-03-18T14:42:16Z | 2022-03-18T14:42:45Z | https://github.com/ploomber/ploomber/issues/660 | [] | edublancas | 1 |
ray-project/ray | machine-learning | 51,642 | [core] Unify `CoreWorker::Exit` and `CoreWorker::Shutdown` | ### Description
See https://github.com/ray-project/ray/pull/51582#discussion_r2010500080 for more details.
### Use case
_No response_ | open | 2025-03-24T16:52:35Z | 2025-03-24T16:52:44Z | https://github.com/ray-project/ray/issues/51642 | [
"enhancement",
"core"
] | kevin85421 | 0 |
FlareSolverr/FlareSolverr | api | 802 | Challenge not detected! - (There is no challenge but the cookies wont work) | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2023-06-16T00:42:08Z | 2023-06-17T04:01:12Z | https://github.com/FlareSolverr/FlareSolverr/issues/802 | [
"more information needed"
] | Nixitov | 11 |
streamlit/streamlit | streamlit | 10,815 | st.html inside an st.tab does not render for the inactive tabs at the moment of rendering | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
I have tested it on:
python 3.11.10
streamlit... | closed | 2025-03-18T10:45:22Z | 2025-03-18T22:13:50Z | https://github.com/streamlit/streamlit/issues/10815 | [
"type:bug",
"status:confirmed",
"priority:P2",
"feature:st.tabs"
] | colin-kerkhof | 3 |
giotto-ai/giotto-tda | scikit-learn | 695 | !! Someone please build python wheels for giotto-tda on aarch64 (Nvidia Jetson) |
The problem: Can't install giotto-tda, giotto-ph, giotto-time etc on aarch64 (NVIDIA Jetson) architectures. I get the error:
ERROR: Could not build wheels for giotto-tda.
The reason: Allowing us to use giotto-based analysis tools on embedded platforms such as Nvidia Jetson will certainly spotlight this amazing ... | open | 2024-04-10T15:54:28Z | 2024-05-31T20:59:27Z | https://github.com/giotto-ai/giotto-tda/issues/695 | [
"enhancement"
] | silent-code | 3 |
LAION-AI/Open-Assistant | python | 3,223 | Cannot open other tabs with custom preset | Cannot open other tabs with custom preset
https://www.youtube.com/watch?v=jTUiHbFnbP8 | open | 2023-05-24T13:03:30Z | 2024-05-25T13:47:31Z | https://github.com/LAION-AI/Open-Assistant/issues/3223 | [
"bug",
"website"
] | echo0x22 | 2 |
PokeAPI/pokeapi | graphql | 948 | Generation 8 BDSP doesn't have a Pokedex associated to the VersionGroup | Similar issue to the other bug I reported, only simpler:
BDSP don't have a Pokedex associated to the Version Group
`api/v2/version-group/brilliant-diamond-and-shining-pearl`
Not sure if it should be 'original-sinnoh' or 'extended-sinnoh' or someething else

I am working on a multi-agent system using Pydantic AI, where I have two agents: a `dice_game_agent` and a `record_agent`. The `dice_game_agent` calls the `record_agent` when needed. However, when I try to... | closed | 2024-12-17T21:53:28Z | 2024-12-18T13:00:19Z | https://github.com/pydantic/pydantic-ai/issues/401 | [] | ishswar | 1 |
ray-project/ray | pytorch | 50,925 | [Core] Cleanup ray.init() logging related options | 1. Currently there are multiple log related options in `ray.init()`, they should be reevaluated and be cleaned up if needed
2. We should also reevaluate the `logging_config` options to see whether it should still be experimental | open | 2025-02-26T20:50:31Z | 2025-02-26T20:50:31Z | https://github.com/ray-project/ray/issues/50925 | [
"P1",
"core",
"observability"
] | MengjinYan | 0 |
iperov/DeepFaceLab | deep-learning | 5,572 | Cant get SAEHD to work | THIS IS NOT TECH SUPPORT FOR NEWBIE FAKERS
POST ONLY ISSUES RELATED TO BUGS OR CODE
## Expected behavior
Im trying to train with SAEHD. Quick96 works fine, however saehd will not work for me at all. Im using a Ryzen 9 5900x and Nvidia RTX 3060 Ti.
## Actual behavior
Getting error after error. Sometimes it ... | open | 2022-10-25T17:34:32Z | 2023-06-08T23:19:03Z | https://github.com/iperov/DeepFaceLab/issues/5572 | [] | fzrdfl | 1 |
LibrePhotos/librephotos | django | 826 | librephotos-proxy wrong filename encoding when downloading file | # 🐛 Bug Report
Everything works fine, except for downloading images. I get 404 and this in the librephotos-proxy log :
`2023/04/16 14:55:37 [error] 25#25: *63854 open() "/data//xxxx/2023-01-H�st-Vinter-Jul-Taj-10�r/DSC_0240.JPG" failed (2: No such file or directory), client: 172.23.0.1, server: , request: "GET /... | closed | 2023-04-16T15:09:40Z | 2023-04-17T18:43:51Z | https://github.com/LibrePhotos/librephotos/issues/826 | [
"bug"
] | nowheretobefound | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 13 | 咋回事 | 抖音快捷指令开始让输入文本,最终url错误 | closed | 2022-04-05T14:52:14Z | 2022-04-06T18:50:33Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/13 | [] | zsjsleep | 2 |
pytorch/vision | computer-vision | 8,904 | Setting more than 2 elements to `ratio` argument of `RandomResizedCrop()` works | ### 🐛 Describe the bug
Setting more than 2 elements to `ratio` argument of [RandomResizedCrop()](https://pytorch.org/vision/main/generated/torchvision.transforms.v2.RandomResizedCrop.html) works as shown below. *`ratio` argument should accept 2 elements:
```python
from torchvision.transforms.v2 import RandomResizedC... | closed | 2025-02-08T15:49:15Z | 2025-02-28T11:02:06Z | https://github.com/pytorch/vision/issues/8904 | [] | hyperkai | 1 |
plotly/dash | dash | 2,335 | [BUG] `dash-generate-components` / `react-docgen` do not resolve imported prop types | **Describe your context**
```
dash 2.7.0
react-docgen 5.4.3
```
**Describe the bug**
Issue #2096 does not seem to be fixed yet.
Given the code below:
`structure.js`
```javascript
import PropTypes from "prop-types";
export const StructurePropTypes = { test: PropTypes.string.isRequired };
... | closed | 2022-11-23T15:49:01Z | 2023-03-10T21:11:01Z | https://github.com/plotly/dash/issues/2335 | [] | rubenthoms | 1 |
FactoryBoy/factory_boy | sqlalchemy | 264 | RelatedFactory lazy arguments from parent | The dot-notation which is in the docs w.r.t Subfactories for getting a parent attribute, does not work for RelatedFactory.
For example:
``` python
class SearchFactory(ActivityFactory):
"""A complete search field factory for testing search"""
class Meta:
model = models.Activity
exclude = ('tit... | closed | 2016-01-19T14:33:35Z | 2018-07-06T18:03:47Z | https://github.com/FactoryBoy/factory_boy/issues/264 | [
"Bug",
"Doc"
] | bryanph | 2 |
deeppavlov/DeepPavlov | tensorflow | 1,133 | Unable to load pre-trained model | Hi
I'm trying to use a pre-trained model for NER,and once the model got downloaded,
I'm getting the below issue.
```
from deeppavlov import configs, build_model
ner_model = build_model(configs.ner.ner_ontonotes_bert, download=True)
2020-02-18 17:45:34.88 ERROR in 'deeppavlov.core.common.params'['params']... | closed | 2020-02-18T12:21:35Z | 2020-05-26T20:32:57Z | https://github.com/deeppavlov/DeepPavlov/issues/1133 | [] | MaheshChandrra | 6 |
tqdm/tqdm | jupyter | 1,472 | ”screen“ command environment is different from base environment | Hello, thanks for the great library!
I found a very magical thing when using the tqdm library . Since I deal with a lot of data, I use “screen” command. When not using the “screen” environment, the output is a normal progress bar.
 need a string or byte-like object. | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
In the File sanic/mixins/route.py, the type of the variable "file_path"(line:836) is PosixPath but mimetypes.guess_type() need a string or byte-like object.
In python 3.7.2, the Signature of the function guess... | closed | 2023-02-13T07:32:00Z | 2023-04-02T11:04:23Z | https://github.com/sanic-org/sanic/issues/2683 | [
"bug"
] | xSandie | 4 |
dask/dask | pandas | 11,167 | Improve documentation for `dd.from_map(...)` | There are two main ways to load dataframe partitions via custom functions:
* `dd.from_map`
* `dd.from_delayed`
For some reason, users seem to prefer `dd.from_delayed` over `dd.from_map` even though the latter is much simpler and most often suffices for their use cases. `dd.from_delayed` on the other hand, is more ... | closed | 2024-06-11T13:19:22Z | 2024-06-21T12:58:15Z | https://github.com/dask/dask/issues/11167 | [
"documentation",
"enhancement"
] | hendrikmakait | 1 |
miguelgrinberg/Flask-SocketIO | flask | 2,095 | Add support for wildcard events | I would like to listen to generic events to be able to handle them myself. Wildcard events are supported by the underlying python socketio library since version 5.4.1
I would love it if we could have "*" events which would trigger every time no other event handler was registered for the event.
```
socketio.on("*... | closed | 2024-09-29T05:36:23Z | 2024-09-30T02:13:24Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/2095 | [] | Dubidu1212 | 2 |
electricitymaps/electricitymaps-contrib | data-visualization | 6,957 | [Data Issue]: Italian data appears to be 100% estimated | ### When did this happen?
2024-06-22
### What zones are affected?
IT-NO, IT-CNO, IT-CSO, IT-SO, IT-SIC, IT-SAR
### What is the problem?
All the data appears to be estimated since the 22nd of June 2024.
I don't know if Terna updated their transparency section or if this project even uses their API (https://develop... | closed | 2024-07-04T16:39:21Z | 2024-08-06T20:43:30Z | https://github.com/electricitymaps/electricitymaps-contrib/issues/6957 | [
"data",
"external"
] | Gianfilippo980 | 3 |
pyeve/eve | flask | 549 | document_link() takes a passed resource, but calls resource_link() which uses the current resource | The offending line is here in `document_link(resource, ..)`:
`'href': '%s/%s%s' % (resource_link(), document_id, version_part)}`
This creates a link that is based on the current resource, instead of whichever resource is passed in to `document_link`.
Currently, all uses of `document_link` are called with the resourc... | closed | 2015-01-19T23:34:59Z | 2015-01-20T07:59:28Z | https://github.com/pyeve/eve/issues/549 | [
"bug"
] | mkandalf | 3 |
akfamily/akshare | data-science | 5,686 | AKShare 接口问题报告 | AKShare Interface Issue Report stock_board_concept_hist_em 这个接口也存在问题 |
版本Version: 1.16.3
 | closed | 2025-02-18T04:53:51Z | 2025-02-18T11:07:52Z | https://github.com/akfamily/akshare/issues/5686 | [
"bug"
] | fweiger | 2 |
adamerose/PandasGUI | pandas | 232 | Filter Export/Import Option | When using pandasgui, I generally want to use similar or the same filters. Adding an option to export filters to an external file for re-importing when viewing another dataframe would be fantastic for the way I use pandasgui. | open | 2023-06-28T15:15:21Z | 2023-06-28T15:15:21Z | https://github.com/adamerose/PandasGUI/issues/232 | [
"enhancement"
] | ggfiorillo | 0 |
onnx/onnx | pytorch | 6,562 | ONNX failing to build from source with external Protobuf and Abseil-cpp | # Bug Report
### Is the issue related to model conversion?
No
### Describe the bug
When I tried to built Onnx v1.17.0 with external protobuf v4.25.3 and abseil 20240116.2. I have built protobuf with this version abseil and while trying to build Onnx with this, I see this error.
```
[ 95%] Building CXX objec... | closed | 2024-11-29T14:02:16Z | 2024-12-03T05:14:01Z | https://github.com/onnx/onnx/issues/6562 | [
"bug"
] | Aman-Surkar | 1 |
openapi-generators/openapi-python-client | fastapi | 107 | Optionally disable validation | **Is your feature request related to a problem? Please describe.**
It seems that some OpenAPI specifications aren't always correct, but it might be helpful to allow generation anyway.
For example, I installed the latest version from the `main` branch using:
```bash
poetry add git+https://github.com/triaxtec/open... | closed | 2020-07-28T05:58:59Z | 2023-10-17T15:07:40Z | https://github.com/openapi-generators/openapi-python-client/issues/107 | [
"✨ enhancement"
] | multimeric | 5 |
ultralytics/yolov5 | pytorch | 13,485 | Significant Differences in Evaluation Results on the Validation Set Between `train.py` During Training and `test.py` in YOLOv5 5.0 | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
# [YOLOv5 5.0版本](https://github.com/ultralytics/yolov5/releases/tag/v5.0)在train.py训练过程中在验... | open | 2025-01-09T12:21:19Z | 2025-01-10T02:56:45Z | https://github.com/ultralytics/yolov5/issues/13485 | [
"question",
"detect"
] | 3210448723 | 2 |
aimhubio/aim | tensorflow | 3,230 | Visualize multiple images of the same step | ## 🚀 Feature
It would be super useful to visualize on the same view multiple stored images of the same step.
### Motivation
Often you need to visually compare input, GT and prediction and it seems currently not possible to visualize all these images for a specific step on the same page.
### Pitch
It would be nice... | open | 2024-09-29T10:21:30Z | 2024-09-29T10:21:30Z | https://github.com/aimhubio/aim/issues/3230 | [
"type / enhancement"
] | bhack | 0 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,040 | Text 2 Speech | closed | 2022-03-17T17:24:32Z | 2022-03-17T17:24:43Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1040 | [] | domoskanonos | 0 | |
widgetti/solara | jupyter | 827 | Version check crashes with ValueError: invalid literal for int() with base 10: '0a0' for ipykernel 7.0.0a0 | This line broke when pre-release is available (e.g., `ipykernel==7.0.0a0`):
https://github.com/widgetti/solara/blob/eb8b827a20586a7e1db716ea532b0d686ef94cee/solara/server/kernel.py#L76
```
> ipykernel_version = tuple(map(int, ipykernel.__version__.split(".")))
E ValueError: invalid literal for int() with ba... | closed | 2024-10-22T14:06:14Z | 2024-12-03T13:35:08Z | https://github.com/widgetti/solara/issues/827 | [] | pllim | 5 |
DistrictDataLabs/yellowbrick | scikit-learn | 722 | data folder not created | As said earlier, python -m yellowbrick.download downloads datasets to yellowbrick/yellowbrick/datasets/fixtures rather not creating data folder in the current directory.The path of download is already set.when i type in the following command
data = pd.read_csv('data/concrete/concrete.csv')
error occurs
python
Pyth... | closed | 2019-02-03T12:18:58Z | 2019-02-13T14:40:30Z | https://github.com/DistrictDataLabs/yellowbrick/issues/722 | [
"type: question"
] | dnabanita7 | 5 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,167 | Fine tuning a downloaded pre-trained cyclegan model | Hello,
First of all, thanks for this amazing repo!
After going through tips&tricks, and the first few pages of issues I haven't found out how I can start with one of your pretrained cyclegan models and then resume training on my own dataset.
Specifically, it seems that for a given pretrained model (here style_... | open | 2020-10-21T10:31:55Z | 2020-10-30T09:31:32Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1167 | [] | SebastianPartarrieu | 0 |
Asabeneh/30-Days-Of-Python | numpy | 177 | Hi Asabeneh, | I have not been able to do the course for some time now due to unforeseen circumstances, but I am now ready and willing to commit. I hope I can still get into this course and do my best and complete it. Please let me know if there are any issues. If not I'm going full steam ahead. I hope you are ready for all my questi... | open | 2021-09-26T02:50:01Z | 2021-09-26T02:50:01Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/177 | [] | Aaron-1974 | 0 |
google-deepmind/graph_nets | tensorflow | 136 | Support Apple Silicon | Hi, is it possible that this library one day will be usable in the new generation of architecture Apple Silicon M1?
I tried to install it in a _conda_ environment (through _miniforge_) after having installed also TensorFlow 2.4 benchmark on Mac M1, but it doesn't work! It gives an error related with _bazel_. | closed | 2021-01-28T19:17:59Z | 2021-07-29T09:28:33Z | https://github.com/google-deepmind/graph_nets/issues/136 | [] | tribustale | 6 |
JoeanAmier/TikTokDownloader | api | 66 | 建议增加批零评论采集! | 可以批量采集主页作品,那肯定也就爬取了所有得作品链接,有了作品链接,做个批量采集评论,应该可以把。🙆♂️ | open | 2023-09-18T04:42:29Z | 2023-09-18T13:14:23Z | https://github.com/JoeanAmier/TikTokDownloader/issues/66 | [] | aminggoodboy | 1 |
google-research/bert | tensorflow | 830 | Loss keep going up and down | 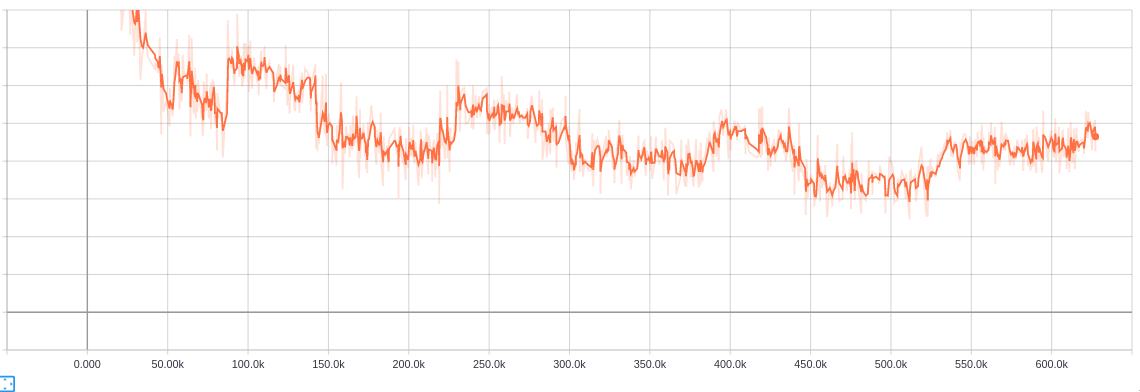
this is my train command
```
python run_pretraining.py
--input_file="data/wikipedia_corpus/final_tfrecords_sharded/tf_examples.tfrecord000*"
--output_dir=results/
--do_train=True
--do_eval=Tru... | open | 2019-08-30T05:02:14Z | 2019-11-15T05:04:26Z | https://github.com/google-research/bert/issues/830 | [] | AnakTeka | 1 |
pydantic/pydantic-ai | pydantic | 581 | Import "pydantic_ai.usage" could not be resolved | In the flight booking example:
```python
from pydantic_ai.usage import Usage, UsageLimits
``` | closed | 2025-01-01T13:54:56Z | 2025-01-13T17:20:52Z | https://github.com/pydantic/pydantic-ai/issues/581 | [
"question",
"more info"
] | HamzaFarhan | 5 |
pytorch/pytorch | numpy | 149,501 | Inductor produce significantly different inference results with the originl original model | ### 🐛 Describe the bug
```python
import torch
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear = torch.nn.Linear(3, 3)
self.linear.weight = torch.nn.Parameter(torch.eye(3))
self.linear.bias = torch.nn.Parameter(torch.zeros(3))
def fo... | open | 2025-03-19T10:42:37Z | 2025-03-20T08:53:28Z | https://github.com/pytorch/pytorch/issues/149501 | [
"oncall: pt2",
"oncall: cpu inductor"
] | Cookiee235 | 2 |
browser-use/browser-use | python | 661 | Request Multiple times to model | ### Bug Description
**### IMPORTANT!**
I am directly addressing the developer and I'd like to let you know.
While I was developing my solution, I came to know that At each step it sends separate request to the AI model,
I am using Anthropic Claude sonnet 3.5, which is costly, as it supports images,
Why is that so? Why... | open | 2025-02-11T06:55:05Z | 2025-02-24T05:05:53Z | https://github.com/browser-use/browser-use/issues/661 | [
"bug"
] | faizanhameed-vf | 8 |
FactoryBoy/factory_boy | sqlalchemy | 972 | bug with django 4.1 | #### Description
we are using factory boy with django unit test but when we upgraded from 4.0.4 to 4.1.1
i got the following errors
```
Traceback (most recent call last):
File "/opt/atlassian/pipelines/agent/build/.venv/lib/python3.9/site-packages/django/db/models/query.py", line 928, in get_or_create
retur... | closed | 2022-09-19T06:07:36Z | 2022-11-16T08:00:40Z | https://github.com/FactoryBoy/factory_boy/issues/972 | [] | hishamkaram | 14 |
asacristani/fastapi-rocket-boilerplate | pytest | 27 | Feature Suggestion: Adapter for multiples autentications | A suggested feature would be to add support for adapters that would allow integrating various forms of authentication, jwt, oauth, open id connect (oidc) and others | open | 2023-10-11T11:58:41Z | 2023-10-11T11:58:41Z | https://github.com/asacristani/fastapi-rocket-boilerplate/issues/27 | [] | dyohan9 | 0 |
microsoft/unilm | nlp | 850 | BEiT v2 pretrained checkpoints links are not working | Hey,
Thanks for releasing the BEiT v2 code. However, the pretrained checkpoints are not working, I am getting an error that says "blob doesn't exist" when I try to download any of the four variants of the pretrained models. Below are the links that are not working:
- BEiT-base: [beitv2_base_patch16_224_pt1k_ft21k](... | closed | 2022-09-04T08:11:43Z | 2022-09-05T03:13:23Z | https://github.com/microsoft/unilm/issues/850 | [] | eliahuhorwitz | 2 |
albumentations-team/albumentations | machine-learning | 1,876 | affine with fit_output set to true does not scale bounding boxes correctly | ## Describe the bug
Bounding boxes are not augmented as expected when fit_output=True.
### To Reproduce
perform affine augmentation with fit_output=True and observe the decoupling of bounding boxes and objects
### Expected behavior
Bounding boxes should be augmented such that the final image is correctly... | closed | 2024-08-13T21:45:47Z | 2024-08-15T23:16:59Z | https://github.com/albumentations-team/albumentations/issues/1876 | [
"bug"
] | dominicdill | 1 |
Avaiga/taipy | data-visualization | 2,022 | I was visit the website | **updates new things**
●Updates new fonts
●Create new features
●Add the white mood
●add chatbot
| closed | 2024-10-11T12:52:25Z | 2024-10-11T13:06:09Z | https://github.com/Avaiga/taipy/issues/2022 | [] | kamali1331 | 0 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 15 | 找不到文件问题 | 您好,上次我发现一直出现找不到文件的错误,我发现是不是readdata22-2.py 文件中GetData函数没有当self.type==dev时读取文件的程序,才导致speechmodel.py210行测试程序出错,找不到文件。当我把210行注释掉后就可以在window下运行了。但是在Linux下,我直接把程序复制过去在服务器gpu跑时,又出现找不到路径的问题FileNotFoundError: [Errno 2] No such file or directory: 'dataset/wav/train/A11/A11_183.WAV'
,可是路径下是有该音频的。想问下window和Linux下有什么需要注意修改的地方吗 | closed | 2018-05-12T14:08:25Z | 2018-05-27T17:16:41Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/15 | [] | huanzoey | 3 |
lorien/grab | web-scraping | 218 | Error installing | When you run the code gives error:
> Requirement already satisfied: grab in /usr/local/lib/python2.7/dist-packages
> Requirement already satisfied: weblib>=0.1.23 in /usr/local/lib/python2.7/dist-packages (from grab)
> Requirement already satisfied: six in /usr/local/lib/python2.7/dist-packages (from grab)
> Requir... | closed | 2017-01-30T22:33:30Z | 2017-02-03T08:35:37Z | https://github.com/lorien/grab/issues/218 | [] | DenoBY | 7 |
biolab/orange3 | pandas | 6,099 | EntropyMDL._normalize does not account if X is 0's | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following... | closed | 2022-08-18T22:42:23Z | 2022-08-22T09:33:10Z | https://github.com/biolab/orange3/issues/6099 | [
"bug report"
] | davzaman | 3 |
JaidedAI/EasyOCR | machine-learning | 1,103 | Japanese Kanji character | I found that the Japanese character "絆" is missing in the file "ja_char.txt".And I cannot recognize this Japanese Kanji character using the Japanese model. | open | 2023-08-02T15:20:34Z | 2023-08-02T15:20:34Z | https://github.com/JaidedAI/EasyOCR/issues/1103 | [] | 98andpeople | 0 |
google-research/bert | nlp | 799 | Why estimator.predict didn't really run inference graph? | I want to evaluate inference time of bert. I found wired things when I executed code below
```python
t_start = time.time()
result = estimator.predict(input_fn=predict_input_fn)
t_consumed = time.time() - t_start
print("Time consumed after 'estimator.predict' is %f" % t_consumed)
output_predi... | open | 2019-08-12T05:04:04Z | 2019-08-14T02:30:44Z | https://github.com/google-research/bert/issues/799 | [] | DataTerminatorX | 1 |
keras-team/keras | python | 20,335 | Floating point exception (core dumped) with onednn opt on tensorflow backend | As shown in this [colab](https://colab.research.google.com/drive/1XjoAtDP4SC2qyLWslW8qWzqQusn9eDOu?usp=sharing), the kernel, not the program, crashes if the OneDNN OPT is on and the output tensor shape contains a zero dimension.
As discussed in tensorflow/tensorflow#77131, and also shown in the above colab, we found... | closed | 2024-10-09T08:41:45Z | 2024-11-14T02:01:52Z | https://github.com/keras-team/keras/issues/20335 | [
"type:bug/performance",
"stat:awaiting response from contributor",
"stale",
"backend:tensorflow"
] | Shuo-Sun20 | 4 |
ExpDev07/coronavirus-tracker-api | rest-api | 235 | Thank you for your great API! | Hi, thank you for your great API
I have develop simple Android app
https://github.com/kiyosuke/corona-grapher
Thank you :) | closed | 2020-03-30T08:56:43Z | 2020-04-19T18:26:29Z | https://github.com/ExpDev07/coronavirus-tracker-api/issues/235 | [
"user-created"
] | kiyosuke | 0 |
pandas-dev/pandas | data-science | 60,573 | BUG: NameError: name 'pa' is not defined despite `pyarrow` is installed | ### Pandas version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [X] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | open | 2024-12-15T11:15:59Z | 2025-02-21T02:22:42Z | https://github.com/pandas-dev/pandas/issues/60573 | [
"Bug",
"Arrow"
] | emmansh | 10 |
Lightning-AI/pytorch-lightning | deep-learning | 19,696 | LightningCLI docs example for EarlyStopping missing required args in config file | ### 📚 Documentation
# Error Description
In the lightning CLI tutorial (https://lightning.ai/docs/pytorch/stable/cli/lightning_cli_advanced_3.html), misleading error exists in the tutorial on how to set callbacks in yaml files.
## How to fix?
The original tutorial gives the following simple configuration file tha... | closed | 2024-03-25T13:37:37Z | 2024-03-27T22:16:30Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19696 | [
"help wanted",
"docs",
"lightningcli"
] | Lunamos | 2 |
sanic-org/sanic | asyncio | 2,832 | Outdated docs on http to https redirection | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
I needed to set up http-to-https redirection for my app and came across this:
https://sanic.dev/en/guide/how-to/tls.html#redirect-http-to-https-with-certificate-requests-still-over-http
But it fails because ... | open | 2023-10-05T17:07:00Z | 2023-10-05T17:07:00Z | https://github.com/sanic-org/sanic/issues/2832 | [
"bug"
] | dfb | 0 |
tableau/server-client-python | rest-api | 1,430 | TSC.SubscriptionItem, Payload is either malformed or incomplete. (0x5CE10192 : Specifying subscription attachments not allowed.) | Hello, I'm trying to create a subscription for a user on a view. I put this piece of code,
schedule_id = '60c392fc-d902-44b0-92cf-cfa3b512630f'
user_id = df[0].values[i]
# Create the new SubscriptionItem object with variables from above.
new_sub = TSC.SubscriptionItem('EssaiGD', schedule_id... | closed | 2024-07-29T14:45:30Z | 2024-10-04T23:35:15Z | https://github.com/tableau/server-client-python/issues/1430 | [
"help wanted"
] | gdrau | 11 |
iperov/DeepFaceLab | deep-learning | 883 | Error when applying XSeg Mask. Help would be appreciated ASAP | Full terminal window & error message:
Applying trained XSeg model to aligned/ folder.
Traceback (most recent call last):
File "C:\Users\Joshua Waghorn\Documents\DeepFaceLab_NVIDIA\_internal\python-3.6.8\lib\site-packages\tensorflow\python\client\session.py", line 1334, in _do_call
return fn(*args)
File "... | open | 2020-09-04T06:30:57Z | 2023-06-08T21:18:14Z | https://github.com/iperov/DeepFaceLab/issues/883 | [] | Xlectron | 6 |
graphistry/pygraphistry | jupyter | 546 | [BUG] gfql e not exported | **Describe the bug**
```
import pandas as pd
import graphistry
from graphistry import (
# graph operators
n, e_undirected, e_forward, e_reverse, e,
# attribute predicates
is_in, ge, startswith, contains, match as match_re
)
```
==>
```
ImportError: cannot import name 'e' from ... | closed | 2024-02-22T23:22:54Z | 2024-02-25T01:04:50Z | https://github.com/graphistry/pygraphistry/issues/546 | [
"bug",
"p3",
"gfql"
] | lmeyerov | 0 |
TencentARC/GFPGAN | deep-learning | 589 | not running | python inference_gfpgan.py -i inputs/whole_imgs -o results -v 1.4 -s 2
Traceback (most recent call last):
File "/home/MKN/GFPGAN/inference_gfpgan.py", line 7, in <module>
from basicsr.utils import imwrite
File "/home/MKN/GFPGAN/myenv/lib/python3.12/site-packages/basicsr-1.4.2-py3.12.egg/basicsr/__init__.py"... | open | 2024-10-24T14:25:04Z | 2024-10-30T20:52:07Z | https://github.com/TencentARC/GFPGAN/issues/589 | [] | mkn1212 | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,262 | Can you provide the pretrained model in pytorch? | I'm sorry. I have tried many times, but none of them succeeded.
These days,I want to use cyclegan to transfer GTA5 images to CityScapes style.But I don't know the hyperparameters,such as epoches,crop size,load size etc.
By the way,due to insufficient storage space, I just used 7500 GTA5 pictures.Will this have an imp... | open | 2021-03-27T15:10:19Z | 2021-03-27T15:10:19Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1262 | [] | ALEX13679173326 | 0 |
pytest-dev/pytest-xdist | pytest | 855 | New `LoadScheduling` batch distribution logic doesn't work for long-running tests | The PR https://github.com/pytest-dev/pytest-xdist/pull/812 that implemented new batch distribution logic (and that is now released in 3.0.2) disregards long-running tests.
I have several modules with long-running tests and many of these tests are now scheduled on single worker, instead of being distributed evenly ac... | closed | 2022-12-10T01:15:18Z | 2023-01-13T11:52:57Z | https://github.com/pytest-dev/pytest-xdist/issues/855 | [] | mkoura | 8 |
rougier/numpy-100 | numpy | 9 | Better way of showing the numpy configuration | In exercise 2, I think `np.show_config()` is a better way of showing the configuration than `np.__config__.show()`.
| closed | 2016-03-09T07:24:06Z | 2016-03-09T09:31:42Z | https://github.com/rougier/numpy-100/issues/9 | [] | Dapid | 1 |
tox-dev/tox | automation | 3,071 | Stale egg-info used to build packages? | First of all, thanks for the great tool!
I'm not sure if this is an issue in tox, something that can be configured, or my misunderstanding of how tox and/or Python packaging work - I would appreciate some clarity.
When an egg-info directory is present, tox seems to use that to build the package, rather than gener... | closed | 2023-07-27T16:59:02Z | 2023-07-27T19:57:34Z | https://github.com/tox-dev/tox/issues/3071 | [] | njiles | 2 |
pywinauto/pywinauto | automation | 504 | How to retrieve the content of an item in Combobox in pywinauto ? | closed | 2018-06-04T01:10:51Z | 2019-05-12T11:58:24Z | https://github.com/pywinauto/pywinauto/issues/504 | [
"invalid",
"question"
] | hulei545 | 5 | |
holoviz/panel | jupyter | 7,630 | Examples on homepage don't work | The examples at the top of the homepage https://panel.holoviz.org/ don't work, they return "404 page not found" errors, for example,
https://panel-gallery.holoviz-demo.anaconda.com/portfolio_analyzer | closed | 2025-01-18T12:54:56Z | 2025-01-20T19:03:59Z | https://github.com/holoviz/panel/issues/7630 | [] | faysou | 2 |
feature-engine/feature_engine | scikit-learn | 524 | reduce running time of tests for feature selection module | open | 2022-09-21T16:21:29Z | 2023-03-01T12:38:03Z | https://github.com/feature-engine/feature_engine/issues/524 | [] | solegalli | 6 | |
aiortc/aioquic | asyncio | 163 | WebTransport over HTTP/3 support | Hi,
We are developing WebTransport over HTTP/3 which replaces WebTransport over QUIC (a.k.a. QUICTransport). I would like to use aioquic to [implement a test server for web-platform tests](https://github.com/w3c/webtransport/issues/125) (similar to what I did, writing a QuicTransport server on top of aioquic for tes... | closed | 2021-03-02T09:30:02Z | 2024-06-23T17:24:04Z | https://github.com/aiortc/aioquic/issues/163 | [] | yutakahirano | 19 |
graphql-python/graphene-mongo | graphql | 230 | outdated version number in package | The version of the package specified in \_\_init__.py is still [version 0.1.1](https://github.com/graphql-python/graphene-mongo/blob/a084895d270cb8f9865ee33daab5356fc3ab3ba1/graphene_mongo/__init__.py#L7). While this can be fixed simply, fixing it right now does not change much (though suggested). Rather, there is a ne... | closed | 2024-01-01T17:27:29Z | 2024-02-24T09:43:57Z | https://github.com/graphql-python/graphene-mongo/issues/230 | [] | WeepingClown13 | 0 |
Kanaries/pygwalker | pandas | 210 | I've got 2 warning message |

## 1st Warning
```
WARNING: parse invoke code failed, This may affect feature of export code.
```
I am unsure about the cause of the first message.
## 2nd Warning
```
WARNING: parse invoke code failed, T... | closed | 2023-08-25T09:03:31Z | 2023-08-28T04:06:39Z | https://github.com/Kanaries/pygwalker/issues/210 | [] | Erimus-Koo | 16 |
idealo/image-super-resolution | computer-vision | 118 | strange error on training | I am trying to run the sample training, as per provided notebbok. I use a dataset of 3361 training images (both lr and hr) and 40 validation images (900x900, 3 band RGB)
I declared the trainer as follows:
```
trainer = Trainer(
generator=rrdn,
discriminator=discr,
feature_extractor=f_ext,
lr_tr... | open | 2020-04-15T10:31:45Z | 2023-05-27T14:58:56Z | https://github.com/idealo/image-super-resolution/issues/118 | [] | procton | 2 |
matplotlib/matplotlib | matplotlib | 29,050 | [Bug]: LogFormatter(minor_thresholds=...) should count actually drawn ticks, not number of decades spanned by axes | ### Bug summary
The first minor_threshold (called `subset`, defaulting to 1) in LogFormatter is documented as "If ``numdec > subset`` then no minor ticks will be labeled" (where `numdec`) is the number of decades spanned by the axes. Unfortunately, even if an axes spans more than one decade, there may be a single maj... | closed | 2024-10-31T10:58:43Z | 2024-12-19T03:34:04Z | https://github.com/matplotlib/matplotlib/issues/29050 | [
"topic: ticks axis labels"
] | anntzer | 0 |
dynaconf/dynaconf | django | 583 | Allow disabling the toml parsing [was:Environment variables in JSON format get parsed as TOML] | **Describe the bug**
Environment variables that contain valid TOML are parsed with [parse_with_toml()](https://github.com/rochacbruno/dynaconf/blob/6c6fda4950a1a403b71503c8940692aeb3725cdf/dynaconf/utils/parse_conf.py#L244) even if it is not desired.
**To Reproduce**
Steps to reproduce the behavior:
The easiest... | open | 2021-05-11T09:21:42Z | 2022-09-06T17:45:01Z | https://github.com/dynaconf/dynaconf/issues/583 | [
"RFC"
] | o-fedorov | 1 |
huggingface/datasets | pytorch | 6,642 | Differently dataset object saved than it is loaded. | ### Describe the bug
Differently sized object is saved than it is loaded.
### Steps to reproduce the bug
Hi, I save dataset in a following way:
```
dataset = load_dataset("json",
data_files={
"train": os.path.join(input_folder, f"{task_met... | closed | 2024-02-05T17:28:57Z | 2024-02-06T09:50:19Z | https://github.com/huggingface/datasets/issues/6642 | [] | MFajcik | 2 |
davidsandberg/facenet | tensorflow | 452 | An issue with the accuracy of facenet | Hi- I use a pipeline based on mtcnn for face detection and then facenet for face recognition (I did test both 20170511-185253.pb and 20170512-110547.pb). I perform this process in a while loop for 2 minutes in which frames/images are captured using opencv video capture function! Finally, I compare my own images/faces d... | open | 2017-09-08T11:00:35Z | 2018-11-05T22:32:30Z | https://github.com/davidsandberg/facenet/issues/452 | [] | github4f | 16 |
hzwer/ECCV2022-RIFE | computer-vision | 340 | How to avoid interpolating scene changes? | Hello, I noticed that sometimes the model attempts to interpolate scene changes, which leads to bad results. This is very noticeable when watching the videos (see the example below). Simply not doing the interpolation in these cases would be enough to greatly improve results. Is there any parameter to avoid interpolati... | closed | 2023-10-21T20:33:56Z | 2023-10-23T21:20:13Z | https://github.com/hzwer/ECCV2022-RIFE/issues/340 | [] | hsilva664 | 2 |
microsoft/JARVIS | deep-learning | 22 | Can Nvidia's 40 series graphics card be used for the current project? | Can Nvidia's 40 series graphics card be used for the current project?
as I can see that the System Requirements is as follows:
Ubuntu 16.04 LTS
NVIDIA GeForce RTX 3090 * 1
RAM > 24GB | closed | 2023-04-04T11:56:24Z | 2023-04-06T19:41:52Z | https://github.com/microsoft/JARVIS/issues/22 | [] | GothicFox | 5 |
microsoft/hummingbird | scikit-learn | 778 | backorder message after product into cart | hello
in hummingdird 0.2, when product add to cart in out of stock, then message shows.
I think like with classic, when we increase the quantity, the increase message should be displayed over stock, not after adding to cart.
![Uploading dddd.png…]()
| closed | 2024-06-09T11:21:39Z | 2024-06-10T14:47:37Z | https://github.com/microsoft/hummingbird/issues/778 | [] | hogo20 | 1 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 10 | TypeError: cat() takes no keyword arguments | Traceback (most recent call last):
File "train.py", line 266, in <module>
main()
File "train.py", line 263, in main
train(transformer, training_data, validation_data, crit, optimizer, opt)
File "train.py", line 124, in train
train_loss, train_accu = ... | closed | 2017-07-05T06:42:02Z | 2017-08-14T12:29:04Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/10 | [] | susht3 | 2 |
Yorko/mlcourse.ai | numpy | 169 | Missing image on Lesson 3 notebook | Hey,
Image _credit_scoring_toy_tree_english.png_ is missing on the topic3_decision_trees_kNN notebook. | closed | 2018-02-19T11:17:20Z | 2018-08-04T16:08:25Z | https://github.com/Yorko/mlcourse.ai/issues/169 | [
"minor_fix"
] | henriqueribeiro | 3 |
dgtlmoon/changedetection.io | web-scraping | 2,909 | [feature] Comments for steps | **Version and OS**
v0.48.5 on docker
**Is your feature request related to a problem? Please describe.**
I would love to attach comments to each step.
**Describe the solution you'd like**
An optional textbox just above the three buttons in each step. Even expandable, so it doesn't take too much step. Happy for it to b... | open | 2025-01-17T22:16:48Z | 2025-01-20T11:38:31Z | https://github.com/dgtlmoon/changedetection.io/issues/2909 | [
"enhancement",
"browser-steps"
] | hoopyfrood | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.