
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
FactoryBoy/factory_boy | django | 136 | Default to null for nullable OneToOneField in Django | I can't figure from the docs how to achieve this.
I have a model with a 1to1 field, which is nullable. If I don't specify the relation somehow, I can't create the related model instance using __ syntax. But if I do, it appears to create the related mode no matter what.
How can I have it only create the related mode... | closed | 2014-02-28T02:46:51Z | 2014-09-03T21:44:34Z | https://github.com/FactoryBoy/factory_boy/issues/136 | [] | funkybob | 1 |
pandas-dev/pandas | pandas | 60,305 | API: how to check for "logical" equality of dtypes? | Assume you have a series, which has a certain dtype. In the case that this dtype is an instance of potentially multiple variants of a logical dtype (for example, string backed by python or backed by pyarrow), how do you check for the "logical" equality of such dtypes?
For checking the logical equality for one series... | open | 2024-11-13T18:00:22Z | 2024-12-25T16:19:32Z | https://github.com/pandas-dev/pandas/issues/60305 | [
"API Design"
] | jorisvandenbossche | 11 |
pytorch/pytorch | machine-learning | 148,939 | Whether the transposed tensor is contiguous affects the results of the subsequent Linear layer. | ### 🐛 Describe the bug
I found that whether the transposed tensor is contiguous affects the results of the subsequent Linear layer. I want to know if it is a bug or not?
```
import torch
from torch import nn
x = torch.randn(3, 4).transpose(0, 1) # 非连续张量(转置后)
linear = nn.Linear(3, 2)
y1 = linear(x) ... | open | 2025-03-11T02:39:40Z | 2025-03-18T02:47:42Z | https://github.com/pytorch/pytorch/issues/148939 | [
"needs reproduction",
"module: nn",
"triaged",
"module: intel"
] | pikerbright | 3 |
nerfstudio-project/nerfstudio | computer-vision | 2,863 | Splatfacto new POV image quality | Hi,
It not really a bug, but more a question about splatfacto image quality/parameters. If it is not the right place, just let me know.
I am working to reconstruct driving scene from pandaset. Camera poses are along a car trajectory. When I render an image from this trajectory (train or eval set) the quality is very ... | open | 2024-02-01T18:17:45Z | 2024-06-28T20:02:04Z | https://github.com/nerfstudio-project/nerfstudio/issues/2863 | [] | pierremerriaux-leddartech | 17 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 109 | 第一层的卷积核个数为什么选择32个 | closed | 2019-04-26T08:54:29Z | 2020-05-11T05:48:04Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/109 | [] | myrainbowandsky | 0 | |
GibbsConsulting/django-plotly-dash | plotly | 292 | "find apps" in admin creates almost duplicate app in django_plotly_dash_statelessapp | I have created the example app SimpleExample.
When running the django project for the first time, the table `django_plotly_dash_statelessapp` is empty.
When I first run the Dash app, the table contains a new row with `name="SimpleExample"` and `slug="simpleexample"`.
However, when I run the "find apps" command i... | closed | 2020-11-24T05:27:33Z | 2021-02-03T05:17:08Z | https://github.com/GibbsConsulting/django-plotly-dash/issues/292 | [] | sdementen | 1 |
plotly/dash | plotly | 2,744 | [BUG] Duplicate callback outputs | Hello:
I tried using the same `Input`, but there are some differences in the `Output`, but dash prompts me that I need to increase `allow_duplicate = True`。

example dash:
```python
from dash import Dash, html,callback,O... | closed | 2024-02-05T06:24:51Z | 2024-02-29T15:01:55Z | https://github.com/plotly/dash/issues/2744 | [] | Liripo | 4 |
jina-ai/serve | deep-learning | 5,422 | `metadata.uid` field doesn't exist in generated k8s YAMLs | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
In the [generated YAML file](https://github.com/jina-ai/jina/blob/master/jina/resources/k8s/template/deployment-executor.yml), it has a reference to `metadata.uid`: `fieldPath: metadata.uid`. But looks like in `metadata` there's no `uid... | closed | 2022-11-22T02:22:01Z | 2022-12-01T08:33:06Z | https://github.com/jina-ai/serve/issues/5422 | [] | zac-li | 0 |
BeanieODM/beanie | asyncio | 246 | _saved_state and _previous_revision_id saved in DB | These fields should not be stored in the database
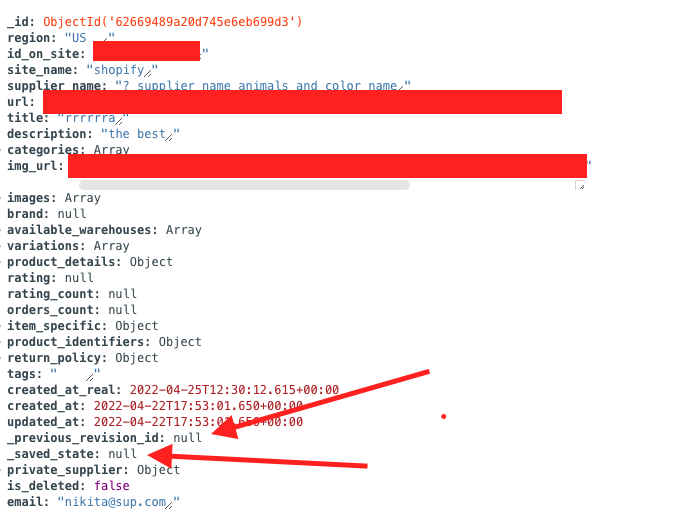
| closed | 2022-04-25T12:41:42Z | 2023-05-23T18:41:53Z | https://github.com/BeanieODM/beanie/issues/246 | [
"snippet requested"
] | nichitag | 3 |
PaddlePaddle/ERNIE | nlp | 76 | 关于msra标签增加报错 | 
分类报错.请问在什么地方可以更改分类数 | closed | 2019-04-04T07:24:54Z | 2019-04-17T16:16:49Z | https://github.com/PaddlePaddle/ERNIE/issues/76 | [] | jtyoui | 1 |
sinaptik-ai/pandas-ai | data-visualization | 1,455 | failed to solve: process "/bin/sh -c npm run build" did not complete successfully: exit code: 1 |
![Uploading Screenshot 2024-12-07 at 13.39.02.png…]()
------
> [client 6/6] RUN npm run build:
0.585 ... | closed | 2024-12-07T08:09:21Z | 2024-12-16T11:48:47Z | https://github.com/sinaptik-ai/pandas-ai/issues/1455 | [] | shivbhor | 2 |
recommenders-team/recommenders | machine-learning | 1,614 | [BUG] Error on als_movielens.ipynb | ### Description
<!--- Describe your issue/bug/request in detail -->
Hello :)
I found **two** bugs on [ALS Tutorial](https://github.com/microsoft/recommenders/blob/main/examples/00_quick_start/als_movielens.ipynb).
### 1. Error at `data = movielens.load_spark_df(spark, size=MOVIELENS_DATA_SIZE, schema=schema)`
This... | closed | 2022-01-19T13:36:18Z | 2022-01-20T02:44:10Z | https://github.com/recommenders-team/recommenders/issues/1614 | [
"bug"
] | Seyoung9304 | 2 |
plotly/dash | data-visualization | 2,916 | [BUG] TypeError: Cannot read properties of undefined (reading 'concat') in getInputHistoryState | **Context**
The following code is a simplified example of the real application. The layout initially contains a root div and inputs. By using **pattern matching** and **set_props** the callback function can be setup in a general manner. Anyway, when triggering the callback by a button the root div will be populated by... | closed | 2024-07-08T17:25:20Z | 2024-07-26T13:16:01Z | https://github.com/plotly/dash/issues/2916 | [] | wKollendorf | 2 |
robotframework/robotframework | automation | 5,146 | Warning with page screen shot | I am seeing the warning below in console and in html report while executing robot script.
Any way to hide or disable warning?
[ WARN ] Keyword 'Capture Page Screenshot' could not be run on failure: WebDriverException: Message: [Exception... "Data conversion failed because significant data would be lost" nsresult: ... | closed | 2024-06-09T11:33:15Z | 2024-06-11T16:35:16Z | https://github.com/robotframework/robotframework/issues/5146 | [] | aya-spec | 1 |
Asabeneh/30-Days-Of-Python | matplotlib | 565 | Duplicated exercises in Day 4 | There are some duplicated exercises in Day 4 ([30-Days-Of-Python](https://github.com/Asabeneh/30-Days-Of-Python/tree/master)/[04_Day_Strings](https://github.com/Asabeneh/30-Days-Of-Python/tree/master/04_Day_Strings)
/04_strings.md).
1. I believe exercise 23 and exercise 26 are nearly the same.
> 23. Use index or f... | open | 2024-07-23T08:25:04Z | 2024-07-24T07:00:01Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/565 | [] | chienchuanw | 1 |
s3rius/FastAPI-template | fastapi | 69 | Add psycopg support. | It would be super nice to have ability to generate project without ORM.
Since for highload it's really useful. | closed | 2022-04-12T22:16:11Z | 2022-04-15T20:41:15Z | https://github.com/s3rius/FastAPI-template/issues/69 | [] | s3rius | 1 |
huggingface/datasets | deep-learning | 6,912 | Add MedImg for streaming | ### Feature request
Host the MedImg dataset (similar to Imagenet but for biomedical images).
### Motivation
There is a clear need for biomedical image foundation models and large scale biomedical datasets that are easily streamable. This would be an excellent tool for the biomedical community.
### Your con... | open | 2024-05-22T00:55:30Z | 2024-09-05T16:53:54Z | https://github.com/huggingface/datasets/issues/6912 | [
"dataset request"
] | lhallee | 8 |
FactoryBoy/factory_boy | sqlalchemy | 400 | 'PostGenerationContext' object has no attribute 'items' | In https://github.com/FactoryBoy/factory_boy/commit/8dadbe20e845ae7e311edf2cefc4ce9e24c25370
PostGenerationContext was changed to a NamedTuple. This causes a crash in utils.log_pprint:110
AttributeError: 'PostGenerationContext' object has no attribute 'items'
PR with a quick fix here: https://github.com/FactoryB... | closed | 2017-07-31T18:31:48Z | 2017-07-31T18:34:36Z | https://github.com/FactoryBoy/factory_boy/issues/400 | [] | Fingel | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,185 | Not working as WebSocket on Windows 7 Ultimate | **Your question**
I'm trying to start a Websocket server with Flask and flask-socketio. It's working as ajax polling mode (Not WebSocket Mode). But It didn't work when I installed the eventlet module (for WebSocket Support).
**Logs**
Server initialized for eventlet.
Then nothing:`(
| closed | 2020-02-11T07:13:40Z | 2020-02-11T08:35:40Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1185 | [
"question"
] | fred913 | 2 |
streamlit/streamlit | data-visualization | 10,026 | Supress multiselect "Remove an option first". Message displays immediately upon reaching max selection. | ### Checklist
- [X] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [X] I added a descriptive title and summary to this issue.
### Summary
st.multiselect displays this message immediately upon reaching n = max_selections:
: ... | open | 2021-04-14T14:55:33Z | 2021-04-14T14:55:33Z | https://github.com/aleju/imgaug/issues/760 | [] | hgaiser | 0 |
allenai/allennlp | pytorch | 5,171 | No module named 'allennlp.data.tokenizers.word_splitter' |
I'm using python 3.7 in google colab. I install allennlp=2.4.0 and allennlp-models.
When I run my code:
from allennlp.data.tokenizers.word_splitter import SpacyWordSplitter
I get this error:
ModuleNotFoundError: No module named 'allennlp.data.tokenizers.word_splitter'
help me please.
| closed | 2021-04-30T17:11:44Z | 2021-05-17T16:10:36Z | https://github.com/allenai/allennlp/issues/5171 | [
"question",
"stale"
] | mitra8814 | 2 |
encode/httpx | asyncio | 2,660 | The `get_environment_proxies` function in _utils.py does not support IPv4, IPv6 correctly | Hi, I encountered error when my environment `no_proxy` includes IPv6 address like `::1`. It is wrongly transformed into `all://*::1` and causes urlparse error since the _urlparse.py parses the `:1` as port.
 TRAINING SYNTHETIZER | Can someone help me with this issue?
Traceback (most recent call last):
File "D:\PycharmProjects\Realtime\synthesizer_train.py", line 35, in <module>
train(**vars(args))
File "D:\PycharmProjects\Realtime\synthesizer\train.py", line 178, in train
m1_hat, m2_hat, attention, stop_pred = model(texts, m... | closed | 2021-09-25T14:39:20Z | 2021-09-27T18:22:49Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/852 | [] | ireneb612 | 3 |
ShishirPatil/gorilla | api | 88 | [bug] Hosted Gorilla: UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8a in position 9: invalid start byte | Hello,
I get this error when launching Gorilla on a Windows 10 PC:
`UnicodeDecodeError: 'utf-8' codec can't decode byte 0x8a in position 9: invalid start byte`
It seems like the output works though.
Thank you.
| open | 2023-08-07T16:46:52Z | 2023-08-08T09:43:49Z | https://github.com/ShishirPatil/gorilla/issues/88 | [
"hosted-gorilla"
] | giuliastro | 4 |
tqdm/tqdm | pandas | 1,432 | Multi processing with args | - [x ] I have marked all applicable categories:
+ [x ] exception-raising bug
+ [ x] visual output bug
- [ x] I have visited the [source website], and in particular
read the [known issues]
- [ x] I have searched through the [issue tracker] for duplicates
- [ x] I have mentioned version numbers, operating... | open | 2023-02-20T14:21:24Z | 2023-03-07T18:02:40Z | https://github.com/tqdm/tqdm/issues/1432 | [] | arist0v | 2 |
eriklindernoren/ML-From-Scratch | deep-learning | 108 | Naive Bayes | Shouldn't the coefficient be
coeff = 1.0 / math.pi * math.sqrt(2.0 * math.pi) + eps
In equation of normal equation the pi is outside of sqrt
| open | 2024-03-24T10:33:59Z | 2024-05-12T20:33:13Z | https://github.com/eriklindernoren/ML-From-Scratch/issues/108 | [] | StevenSopilidis | 2 |
miguelgrinberg/flasky | flask | 106 | How to apply login requirement in posts, users and comments api. | As you have mentioned in the book that use **@auth.login_required** to protect any resource. However, github repo does not show it being applied to resources in posts, comments and user apis in api_v1_0.
When I try to import from .authentication import auth and use @auth.login_required, it does not work. Could you ple... | closed | 2016-01-16T15:20:36Z | 2016-01-16T15:51:11Z | https://github.com/miguelgrinberg/flasky/issues/106 | [] | ibbad | 1 |
cvat-ai/cvat | tensorflow | 8,886 | "docker-compose up" got error... | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. git clone http://192.168.1.122:5000/polonii/cvat
### Expected Behavior
_No response_
### Possible Solution
_No respo... | closed | 2024-12-28T20:54:39Z | 2024-12-28T20:55:02Z | https://github.com/cvat-ai/cvat/issues/8886 | [
"bug"
] | PospelovDaniil | 0 |
rasbt/watermark | jupyter | 15 | Wrong package versions within virtualenv | I'm not sure how widespread this issue is, or if it's something particular to my setup, but when I use watermark to report package information (using -p) within a jupyter notebook that is running in a virtualenv, version information about system level packages are reported rather than packages installed within my envir... | closed | 2016-08-03T17:35:17Z | 2016-08-16T22:54:58Z | https://github.com/rasbt/watermark/issues/15 | [
"bug",
"help wanted"
] | mrbell | 17 |
Gozargah/Marzban | api | 1,544 | Can't get config via cli | I'm trying to get myself a config to paste it into FoxRay, and getting the following error:

| open | 2024-12-28T18:54:50Z | 2024-12-29T17:31:17Z | https://github.com/Gozargah/Marzban/issues/1544 | [] | subzero911 | 3 |
aleju/imgaug | machine-learning | 178 | Does this code use the gpu ? | Hi. I just found out that opencv-python doesn't actually use the gpu, even when properly compiled with cuda support on.
I'm currently actively looking for a package that does so. Does this repo expose a code that makes augmentations run on gpu ? | open | 2018-09-10T15:10:03Z | 2018-10-30T14:50:22Z | https://github.com/aleju/imgaug/issues/178 | [] | dmenig | 2 |
ultralytics/ultralytics | computer-vision | 19,547 | onnx-inference-for-segment-predict | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
HELLO, guys, when I using the @https://github.com/ultralytics/ultralytics/... | closed | 2025-03-06T08:16:34Z | 2025-03-15T03:40:42Z | https://github.com/ultralytics/ultralytics/issues/19547 | [
"question",
"fixed",
"segment",
"exports"
] | Keven-Don | 29 |
sammchardy/python-binance | api | 1,002 | ModuleNotFoundError: No module named 'binance.websockets' | whenever i try to run the pumpbot with the terminal i get this error
anyone know how i can fix it?

| open | 2021-08-29T21:12:03Z | 2022-08-05T17:28:29Z | https://github.com/sammchardy/python-binance/issues/1002 | [] | safwaanfazz | 1 |
TheKevJames/coveralls-python | pytest | 55 | LICENSE not included in source package | When running ./setup.py sdist the LICENSE file is not included. I opt to add it to MANIFEST.in.
| closed | 2015-02-07T09:10:31Z | 2015-02-19T06:09:56Z | https://github.com/TheKevJames/coveralls-python/issues/55 | [] | joachimmetz | 5 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 185 | 这是什么问题? | 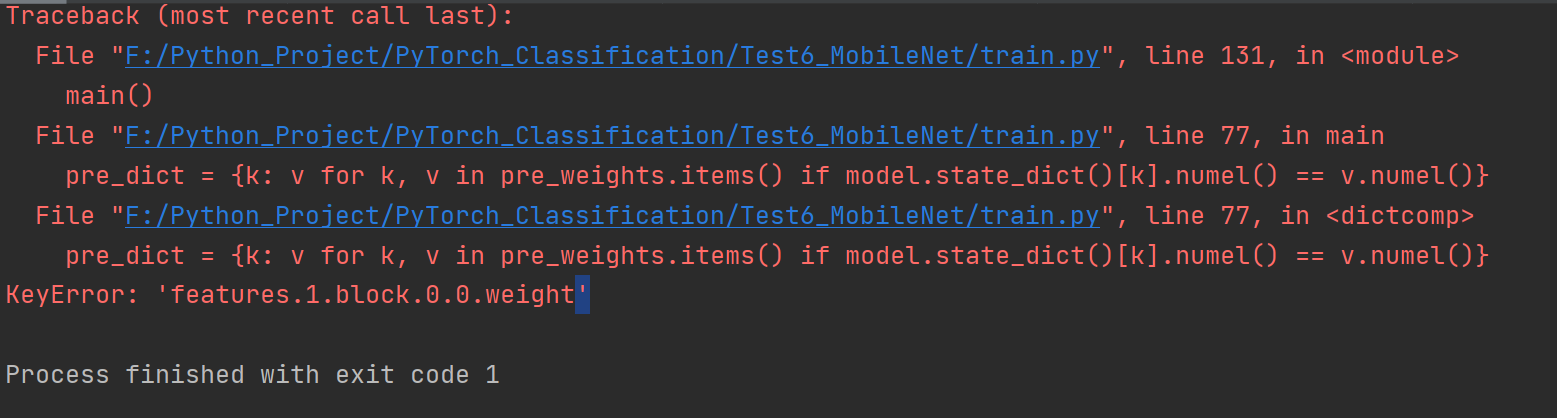

| closed | 2021-03-18T08:38:23Z | 2021-03-20T07:09:50Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/185 | [] | HuKai97 | 2 |
wagtail/wagtail | django | 12,062 | StructBlock missing a joining space when displaying multiple error messages | ### Issue Summary
When multiple errors are raised for a `StructBlock`, the error messages get joined with no separating space.
For example, given these error messages: `["one.", "two."]`, this would be displayed as follows:
* For a model field: `one. two.` (good 👍🏻)
* For a StructBlock: `one.two.` (not good... | closed | 2024-06-18T14:56:13Z | 2024-06-20T18:30:59Z | https://github.com/wagtail/wagtail/issues/12062 | [
"type:Bug",
"status:Unconfirmed"
] | kbayliss | 0 |
scikit-learn/scikit-learn | machine-learning | 30,525 | OPTICS.fit leaks memory when called under VS Code's built-in debugger | ### Describe the bug
Running clustering algorithm with n_jobs parameter set to more than 1 thread causes memory leak each time algorithm is run.
This simple code causes additional memory leak at each loop cycle. The issue will not occur if i replace manifold reduction algorithm with precomputed features.
### Ste... | open | 2024-12-21T15:50:53Z | 2024-12-31T14:12:54Z | https://github.com/scikit-learn/scikit-learn/issues/30525 | [
"Bug",
"Performance",
"Needs Investigation"
] | Probelp | 18 |
flairNLP/flair | pytorch | 3,036 | Support for Vietnamese | Hi, I am looking through Flair and wondering if it support Vietnamese or not. If not, will it in the future? Thank you!
_Originally posted by @longsc2603 in https://github.com/flairNLP/flair/issues/2#issuecomment-1354413764_
| closed | 2022-12-21T01:37:57Z | 2023-06-11T11:25:47Z | https://github.com/flairNLP/flair/issues/3036 | [
"wontfix"
] | longsc2603 | 1 |
Zeyi-Lin/HivisionIDPhotos | machine-learning | 211 | onnxruntime error | Hi, I am using slurm and I get the following issue:
```
[E:onnxruntime:Default, env.cc:234 ThreadMain] pthread_setaffinity_np failed for thread: 3131773, index: 22, mask: {23, }, error code: 22 error msg: Invalid argument. Specify the number of threads explicitly so the affinity is not set.#[m
#[1;31m2024-11-22 13:... | open | 2024-11-22T13:36:11Z | 2024-11-22T13:36:11Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/211 | [] | gebaltso | 0 |
babysor/MockingBird | deep-learning | 616 | MacBook在运行python demo_toolbox.py -d .\samples时报错 | 实际我是有安装PyQt5的,网上说了PyQt@5就是PyQt5。
<img width="491" alt="图片" src="https://user-images.githubusercontent.com/22427032/173240261-25972477-abf0-4017-a8bc-f40b8c7b423e.png">
<img width="491" alt="图片" src="https://user-images.githubusercontent.com/22427032/173240295-61d2ec48-a9a2-4fca-a336-3acf2b58df98.png">
| open | 2022-06-12T15:24:45Z | 2022-07-16T10:56:35Z | https://github.com/babysor/MockingBird/issues/616 | [] | iOS-Kel | 3 |
hootnot/oanda-api-v20 | rest-api | 45 | Version 0.2.1 | - [x] fix missing requirement
- [x] fix examples: candle-data.py | closed | 2016-11-15T18:44:19Z | 2016-11-15T19:03:01Z | https://github.com/hootnot/oanda-api-v20/issues/45 | [
"Release"
] | hootnot | 0 |
polakowo/vectorbt | data-visualization | 478 | Unable to move stop-loss in profit | Hi!
I'm using `Portfolio.from_signals` and trying to set up a moving stop-loss using supertrend. So for long position I want my stop-loss to move up with supertrend. I use `adjust_sl_func_nb` for that and everything works great untill the stop-loss moves in profit. There's a condition in `get_stop_price_nb` which does... | open | 2022-07-31T22:00:57Z | 2022-10-01T08:24:33Z | https://github.com/polakowo/vectorbt/issues/478 | [] | tossha | 1 |
reloadware/reloadium | django | 183 | pydevd_process_net_command.py this file frequently wrong as UnicodeDecodeError | def _on_run(self):
read_buffer = ""
try:
while not self.killReceived:
try:
r = self.sock.recv(1024)
except:
if not self.killReceived:
traceback.print_exc()
self... | open | 2024-02-26T17:26:45Z | 2024-02-26T17:26:45Z | https://github.com/reloadware/reloadium/issues/183 | [] | fangplu | 0 |
httpie/cli | python | 1,567 | Online doc error | https://httpie.io/docs/cli/non-string-json-fields
> hobbies:='["http", "pies"]' \ # Raw JSON — Array
In my test (PyPI ver.), it should be
```
hobbies='["http", "pies"]'
```
instead of
```
hobbies:='["http", "pies"]'
``` | closed | 2024-03-05T03:45:23Z | 2024-03-06T06:08:44Z | https://github.com/httpie/cli/issues/1567 | [
"new"
] | XizumiK | 3 |
pyeventsourcing/eventsourcing | sqlalchemy | 163 | Question: inject services into aggregates. | Hello
I am new to your library.
I want to create event sourced aggregate with service injected into the constructor of aggregates.
Say I want to create an aggregate that handles a command that contains a password.
I need to hash the password before constructing the event.
Something like this:
... | closed | 2018-10-17T07:57:03Z | 2018-11-01T02:01:01Z | https://github.com/pyeventsourcing/eventsourcing/issues/163 | [] | midnight-wonderer | 4 |
thp/urlwatch | automation | 58 | Automatically cleaning up cached content | Does urlwatch automatically clean up its cache? i.e. keep only the latest version of a page and delete any old versions.
| closed | 2016-03-11T11:39:19Z | 2016-03-12T12:34:41Z | https://github.com/thp/urlwatch/issues/58 | [] | Immortalin | 7 |
polakowo/vectorbt | data-visualization | 313 | Internal numba list grows with each iteration by ~10mb | Hi,
I have noticed that if I call `from_signals`/`from_random_signals` inside a loop, some internal numba list grows with each iteration by ~10mb. If you have a large loop, then this fills up your memory quite quickly.
Here is an example which shows this issue:
```Python
import vectorbt as vbt
import numpy as np
... | closed | 2021-12-30T11:09:28Z | 2022-01-02T13:55:29Z | https://github.com/polakowo/vectorbt/issues/313 | [] | FalsePositiv3 | 11 |
abhiTronix/vidgear | dash | 137 | Framerate < 1 fps, display of out of date frames, in example code "Using NetGear_Async with Variable Parameters" | ## Description
The client for the example [Using NetGear_Async with Variable Parameters](https://abhitronix.github.io/vidgear/gears/netgear_async/usage/) does:
1. display the first frame from the server on connection rather than the most recent
2. display frames updating at a frame rate < 1 per second
### Ack... | closed | 2020-06-13T19:10:22Z | 2020-06-25T00:54:05Z | https://github.com/abhiTronix/vidgear/issues/137 | [
"QUESTION :question:",
"SOLVED :checkered_flag:"
] | whogben | 11 |
InstaPy/InstaPy | automation | 5,842 | Index Error | When I try to run my code it seems to go fine for a while (around 40mins), and then I get this error:
`Traceback (most recent call last):
File "/Users/rafael/Documents/Projects/InstaPySimon/InstagramSimonSetup.py", line 92, in <module>
session.unfollow_users(amount=500, instapy_followed_enabled=True, insta... | closed | 2020-10-23T11:02:15Z | 2020-12-09T00:54:45Z | https://github.com/InstaPy/InstaPy/issues/5842 | [
"wontfix"
] | rafo | 2 |
erdewit/ib_insync | asyncio | 610 | ib.portfolio() request for specific subaccount fails? | Thanks for the great library @erdewit.
I am trying to load the portfolio for a specific sub-account.
I tried using:
`ib.portfolio()`
it returns a `[]` as the first portfolio is empty.
I checked the source for `ib.portfolio()` and modified it to take in a account argument.
```
def portfolio(self, account... | closed | 2023-06-29T12:26:44Z | 2023-06-29T13:30:16Z | https://github.com/erdewit/ib_insync/issues/610 | [] | SidGoy | 0 |
plotly/dash | dash | 3,062 | Improve Dependency Management by removing packages not needed at runtime | Dash runtime requirements inlcude some packages that are not needed at runtime.
See [requirements/install.txt](https://github.com/plotly/dash/blob/0d9cd2c2a611e1b8cce21d1d46b69234c20bdb11/requirements/install.txt)
**Is your feature request related to a problem? Please describe.**
Working in an enterprise setting ther... | open | 2024-11-06T07:36:03Z | 2024-11-11T14:44:18Z | https://github.com/plotly/dash/issues/3062 | [
"feature",
"P2"
] | waldemarmeier | 1 |
keras-team/autokeras | tensorflow | 928 | Loss starts from initial value every epoch for structured classifier | ### Bug Description
Loss starts from initial value every epoch for structured classifier:
> Train for 16 steps, validate for 4 steps
> 1/16 [>.............................] - ETA: 1s - loss: 2.3992 - accuracy: 0.8438
> 4/16 [======>.......................] - ETA: 0s - loss: 2.6361 - accuracy: 0.8281
> 7/16 [==... | closed | 2020-01-25T16:22:16Z | 2021-11-12T08:13:17Z | https://github.com/keras-team/autokeras/issues/928 | [
"bug report",
"wontfix"
] | SirJohnFranklin | 2 |
PaddlePaddle/ERNIE | nlp | 718 | Can't open VCR_resnet101_faster_rcnn_genome_pickle2.lmdb: ValueError: unsupported pickle protocol: 3 | I want to run the VCR inference(run_inference.sh) in python 2.7, however, this error occurred:
```
Traceback (most recent call last):
File "finetune.py", line 868, in <module>
main(args)
File "finetune.py", line 802, in main
graph_vars=model_outputs)
File "finetune.py", line 436, in predict_wrap... | closed | 2021-07-19T14:03:20Z | 2021-10-05T00:52:18Z | https://github.com/PaddlePaddle/ERNIE/issues/718 | [
"wontfix"
] | greeksharifa | 2 |
mljar/mercury | data-visualization | 59 | create rich demo | The rich package works in the notebook - it can be a nice demo with it.
https://github.com/Textualize/rich | closed | 2022-03-10T13:33:52Z | 2023-02-15T10:06:06Z | https://github.com/mljar/mercury/issues/59 | [] | pplonski | 0 |
miguelgrinberg/Flask-Migrate | flask | 291 | sqlalchemy.exc.IntegrityError: (sqlite3.IntegrityError) FOREIGN KEY constraint failed | What I am trying to do here is,
1. Add a column to the existing table that has constraints
2. Try to delete the recently added column
I am using flask-sqlalchemy for SQLite
[https://github.com/bstinsonmhk/duffy/commit/f3a31ecee236a10f2c694458975569fb4019be7b](https://github.com/bstinsonmhk/duffy/commit/f3a31ecee... | closed | 2019-09-17T18:08:54Z | 2020-01-19T18:47:20Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/291 | [
"question"
] | shivarajalagond | 4 |
babysor/MockingBird | pytorch | 826 | 训练时出现问题 | 使用nvidia官方pytorch23.01 docker镜像进行训练时,经常出现Floating point exception然后中断训练
python版本3.8.10

使用win11系统训练时会出现训练完一个epoch后卡住,不继续训练,任务管理器cuda占用降到0,ctrl+c无法结束,只能关掉cmd窗口重新打开,python版本3.9.0,显卡为RTX... | closed | 2023-02-12T15:44:15Z | 2023-02-18T02:56:12Z | https://github.com/babysor/MockingBird/issues/826 | [] | YuuLuo | 5 |
viewflow/viewflow | django | 83 | Cannot assign "<Process: <foo/bar/None> - NEW>": "Process" instance isn't saved in the database. | I was going though the documented hello word example, and created a lilttle accommodation booking system as a proof of concept and ran into this issue.
I added my entire [code example](https://www.dropbox.com/s/r1lwkgag0l7xcq9/flow.zip?dl=1).
The problem starts pops up, when I want to start a new process.
models.py
... | closed | 2015-04-29T12:33:35Z | 2015-07-31T08:24:34Z | https://github.com/viewflow/viewflow/issues/83 | [
"request/bug"
] | codingjoe | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,469 | The ONNX network's output '625' dimensions should be non-negative | Hello,
I am trying to convert a cyclegan model to onnx.
I referred [this answer](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1113#issuecomment-728681741) for onnx importing, and it worked without errors.
But the thing is, when I try to import the onnx file to the onnx runtime(Snap Lens Studio), ... | closed | 2022-08-11T19:09:05Z | 2025-01-05T14:46:48Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1469 | [] | youjin-c | 5 |
plotly/dash | flask | 2,511 | provide a command-line interface for Dash | Thanks so much for your interest in Dash!
Before posting an issue here, please check the Dash [community forum](https://community.plotly.com/c/dash) to see if the topic has already been discussed. The community forum is also great for implementation questions. When in doubt, please feel free to just post the issue h... | open | 2023-04-22T14:07:06Z | 2024-08-13T19:31:39Z | https://github.com/plotly/dash/issues/2511 | [
"feature",
"P3"
] | erdos2n | 0 |
youfou/wxpy | api | 30 | 如何移除指定的用户 | 我想@机器人 移除 某用户,这样该怎么写?
我写了一半如下:
@bot.register(teamgroup)
def remove_msg(msg):
if msg.is_at:
if '移除' in msg.text.lower():
remove_members( ) <------这个“某用户”的参数该如何传递?
| closed | 2017-04-14T03:34:34Z | 2017-04-14T04:57:15Z | https://github.com/youfou/wxpy/issues/30 | [] | nkta3m | 0 |
HumanSignal/labelImg | deep-learning | 54 | Can't open annotations with more than 6 boxes | We are using the prebuilt files (v1.2.1) for Windows and when entering more than 6 boxes than the annotations cannot be opened again. Everything looks fine for one up to 6 boxes but when a page contains 7 or more boxes then I cannot open the annotation again. Actually the following errors shows up in the command line w... | closed | 2017-02-17T16:10:49Z | 2017-02-20T09:33:03Z | https://github.com/HumanSignal/labelImg/issues/54 | [] | zuphilip | 6 |
microsoft/MMdnn | tensorflow | 133 | Caffe to Tensorflow model ,error! | caffemodel for ctpn
deploy.prototxt
[deploy.txt](https://github.com/Microsoft/MMdnn/files/1865306/deploy.txt)
error information:
I0331 08:47:32.099702 7859 net.cpp:228] relu1_1 does not need backward computation.
I0331 08:47:32.099707 7859 net.cpp:228] conv1_1 does not need backward computation.
I0331 08:47... | open | 2018-03-31T09:00:00Z | 2018-04-12T04:55:34Z | https://github.com/microsoft/MMdnn/issues/133 | [] | FakerYFX | 3 |
python-gino/gino | asyncio | 157 | Chinese Docs | Translations are supposed to be done on [Transifex](https://www.transifex.com/decentfox-studio/gino/), and the built docs can be found here: https://python-gino.org/docs/zh/master/index.html
Automated build is already set, only translation to go!
- [x] index (fantix)
- [x] tutorial (fantix)
- [ ] schema
- [ ] ... | open | 2018-03-14T08:26:43Z | 2020-04-20T22:53:00Z | https://github.com/python-gino/gino/issues/157 | [
"enhancement",
"help wanted"
] | fantix | 0 |
nonebot/nonebot2 | fastapi | 2,647 | Plugin: 飞花令 | ### PyPI 项目名
nonebot-plugin-fhl
### 插件 import 包名
nonebot_plugin_fhl
### 标签
[{"label":"飞花令","color":"#ea5252"}]
### 插件配置项
_No response_
| closed | 2024-04-17T12:42:52Z | 2024-04-18T06:10:12Z | https://github.com/nonebot/nonebot2/issues/2647 | [
"Plugin"
] | baiqwerdvd | 1 |
jina-ai/serve | fastapi | 5,474 | feat: silence or minimize output of jina ping command | **Describe the feature**
<!-- A clear and concise description of what the feature is. -->
The jina ping command is also used for the startup, readinesss and/or liveness probe. The command currently by default prints the jina logo and the arguments of the command which pollutes the kubernetes events logger and the pod... | closed | 2022-12-01T14:09:06Z | 2022-12-01T15:59:08Z | https://github.com/jina-ai/serve/issues/5474 | [] | girishc13 | 0 |
roboflow/supervision | computer-vision | 896 | IndexError:arrays used as indices must be of integer (or boolean) type | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
while running yolo-nas and sam for segmentation of my sample video i am getting error as
ERROR:
detections = detections[detections.area == np... | closed | 2024-02-13T16:25:29Z | 2024-02-14T11:13:50Z | https://github.com/roboflow/supervision/issues/896 | [
"question"
] | josh-001 | 4 |
deepspeedai/DeepSpeed | pytorch | 5,648 | RuntimeError: still have inflight params[BUG] | **Describe the bug**
Hello,Can some one get Help. I use V0.14.3, installed from source code tar.gz: https://github.com/melMass/DeepSpeed/releases
I use deepspeed Zero3, and training LLama Factory KTO task, under the training-evaluate stage get this problem.
**Launcher context**
deepspeed --num_gpus 1 --master_p... | closed | 2024-06-12T12:47:57Z | 2024-08-03T16:32:31Z | https://github.com/deepspeedai/DeepSpeed/issues/5648 | [
"bug",
"training"
] | iszengxin | 5 |
onnx/onnx | deep-learning | 6,352 | [Feature request] Better support for large models (>2GB) in extract_model | ### System information
1.16.2
### What is the problem that this feature solves?
Allows for extracting sub-models form a large model (>2GB). When using this function (both with the loaded model and the model path), we are forced to do 2 things:
* `infer_shapes` with the loaded model (in `Extractor` init). This... | open | 2024-09-09T08:58:13Z | 2024-10-23T03:36:51Z | https://github.com/onnx/onnx/issues/6352 | [
"topic: enhancement"
] | highly0 | 3 |
Nike-Inc/koheesio | pydantic | 42 | [DOC] Wrong package manager in Contributing guide | Contributing guide refers to poetry as package manager: https://github.com/Nike-Inc/koheesio/blob/main/CONTRIBUTING.md
| closed | 2024-06-07T14:57:21Z | 2024-06-21T19:15:42Z | https://github.com/Nike-Inc/koheesio/issues/42 | [
"bug",
"documentation"
] | riccamini | 0 |
ultralytics/ultralytics | python | 19,287 | FastSam output | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello,
I was trying FastSam on some images, but the outputs were not as I e... | closed | 2025-02-17T23:29:09Z | 2025-02-21T01:38:30Z | https://github.com/ultralytics/ultralytics/issues/19287 | [
"question",
"detect"
] | SebastianJanampa | 4 |
plotly/dash | flask | 2,406 | [BUG] JS Error for a multi-page dash application when upgrading to > `2.7` | Noticing JS errors with a Dash multi-page Application with dash upgrade. No JS errors on Dash v`2.6.2`
- replace the result of `pip list | grep dash` below
```
app==0.0.1
boto==2.49.0
boto3==1.20.23
botocore==1.23.26
census==0.8.18
censusgeocode==0.5.1
dash==2.7.1
dash_bootstrap_components==1.2.0
dash... | closed | 2023-01-31T23:10:41Z | 2023-02-01T02:41:24Z | https://github.com/plotly/dash/issues/2406 | [] | kevalshah90 | 3 |
keras-rl/keras-rl | tensorflow | 372 | DDPG worked well but not CDQN or NAF ! | I tried DDPG and everything worked well, now I am trying your NAF example model on my custom environment and I am getting this error:
```
---------------------------------------------------------------------------
InvalidArgumentError Traceback (most recent call last)
~\.conda\envs\sim\lib\si... | closed | 2020-12-30T15:10:27Z | 2021-01-02T10:44:17Z | https://github.com/keras-rl/keras-rl/issues/372 | [] | B-Yassine | 1 |
521xueweihan/HelloGitHub | python | 2,768 | 【开源自荐】一款功能强大的 WEB 端创意画板 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/LHRUN/paint-board
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别:JS
<!-... | closed | 2024-06-10T13:34:45Z | 2024-12-27T10:01:46Z | https://github.com/521xueweihan/HelloGitHub/issues/2768 | [
"已发布"
] | LHRUN | 0 |
Textualize/rich | python | 3,499 | [BUG] rich handler is documented In textual but not rich documentation | rich loggings handler does not print rich objects as [documented](https://textual.textualize.io/guide/devtools/#logging-handler) in Textual
"The logging library works with strings only, so you won't be able to log Rich renderables such as self.tree with the logging handler."
This is documented in Textual but not the ... | open | 2024-09-25T07:56:04Z | 2024-09-25T07:56:21Z | https://github.com/Textualize/rich/issues/3499 | [
"Needs triage"
] | KRRT7 | 1 |
pyg-team/pytorch_geometric | deep-learning | 9,176 | SNAPDataset ram usage | ### 🐛 Describe the bug
Ran the following code on python 3.10/3.11 and the process got killed by the os(tried on windows/wsl/mac)
for using too much RAM (tried to run both on a laptop with 16gb of memory and a desktop pc with 64gb of memory).
```python
from torch_geometric.datasets import SNAPDataset
dataset = S... | closed | 2024-04-09T11:31:36Z | 2024-04-12T12:57:08Z | https://github.com/pyg-team/pytorch_geometric/issues/9176 | [
"bug"
] | omrihaber | 2 |
ipython/ipython | data-science | 14,078 | IPython/terminal/ptutils.py", line 116, in get_completions exc_type, exc_value, exc_tb = sys.exc_info() NameError: name 'sys' is not defined | ```
...:
Traceback (most recent call last):
File "/root/anaconda3/lib/python3.8/site-packages/IPython/terminal/ptutils.py", line 113, in get_completions
yield from self._get_completions(body, offset, cursor_position, self.ipy_completer)
File "/root/anaconda3/lib/python3.8/site-packages/IPython/terminal... | open | 2023-05-14T13:14:46Z | 2023-05-14T13:14:46Z | https://github.com/ipython/ipython/issues/14078 | [] | QGB | 0 |
deepinsight/insightface | pytorch | 2,227 | How to use SCRFD detect() in latest insightface? | Hello,
I want to be able to call the detect here:
https://github.com/deepinsight/insightface/blob/6baaa7bcaf1a1624feec75270022e2dafeb6883b/detection/scrfd/tools/scrfd.py
I have this code:
```
detector = insightface.model_zoo.model_zoo.get_model('insightface/models/antelope/scrfd_10g_bnkps.onnx')
detector.... | closed | 2023-01-23T16:43:11Z | 2023-01-24T16:08:21Z | https://github.com/deepinsight/insightface/issues/2227 | [] | aesanchezgh | 5 |
google/seq2seq | tensorflow | 250 | Attention Context's Interaction with Decoder | Hi, I am looking into how AttentionDecoder exactly works. I know the attention_context is supposed to be concatenated with the hidden state from the previous time step (Line 128 in seq2seq/decoder/attention_decoder.py) and it is fed into the current time step. But I noticed that the "attention_context" variable is ALSO... | open | 2017-06-07T21:55:45Z | 2017-06-07T22:08:13Z | https://github.com/google/seq2seq/issues/250 | [] | ghost | 0 |
AirtestProject/Airtest | automation | 548 | Unable to launch the script in android 9 getting the below error RuntimeError: unable to launch AndroidUiautomationPoco | save log in '/private/var/folders/3r/j0yh54zj32b_pp_6336p9sx40000gp/T/AirtestIDE/scripts/f643ec8dd315e2d641f7865d1a6b739b'
[02:27:10][DEBUG]<airtest.core.android.adb> /Library/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/airtest/core/android/static/adb/mac/adb -P 5037 -s 5ab2fefd wait-for-devic... | open | 2019-10-01T09:00:33Z | 2020-04-14T01:37:15Z | https://github.com/AirtestProject/Airtest/issues/548 | [] | anandplay17 | 2 |
dgtlmoon/changedetection.io | web-scraping | 2,209 | 500 Internal Server Error | **Version**
0.45.14
I'm using changedetection.io Docker image. Unexpectedly, trying to access port 5000 results in receiving an Internal Server Error. In the container logs, the following error can be seen:
```
[2024-02-22 15:49:12,914] ERROR in app: Exception on / [GET]
Traceback (most recent call last):
F... | closed | 2024-02-22T16:05:19Z | 2024-02-25T09:26:58Z | https://github.com/dgtlmoon/changedetection.io/issues/2209 | [
"triage"
] | ghost | 2 |
skypilot-org/skypilot | data-science | 4,480 | [chore] Cleanup branches | <!-- Describe the bug report / feature request here -->
There are too many branches (~350) in the upstream, which makes forking and fetching quite messy. Could you please delete the merged branches? Thank you!
| open | 2024-12-18T07:52:24Z | 2024-12-19T23:08:30Z | https://github.com/skypilot-org/skypilot/issues/4480 | [] | gaocegege | 0 |
TencentARC/GFPGAN | deep-learning | 47 | Train with GPU and inference without GPU. Is it possible ? | Hello :)
One more - thank you very much for your beatifull project !
1. I trained model on my ouw dataset - mymodel.pth
2. I ran inference on CPU with your model - GFPGANCleanv1-NoCE-C2.pth
3. I see that GFPGANv1.pth (and mymodel.pth) has 2x size that GFPGANCleanv1-NoCE-C2.pth
So, how I can transform mymodel.p... | closed | 2021-08-18T22:53:00Z | 2021-08-23T23:21:31Z | https://github.com/TencentARC/GFPGAN/issues/47 | [] | MDYLL | 4 |
plotly/dash | data-visualization | 2,329 | Allow currency format for dcc.Input of type='number' | **Describe the solution you'd like**
Allow currency format for dcc.Input while keeping the value type as number and the arrows to increase/decrease it.
**Describe alternatives you've considered**
Clientside circular callback that updates the value format based on [this JS solution](https://stackoverflow.com/questi... | open | 2022-11-21T14:46:30Z | 2024-08-13T19:22:53Z | https://github.com/plotly/dash/issues/2329 | [
"feature",
"P3"
] | celia-lm | 0 |
pydata/xarray | numpy | 9,204 | DataTree.coords.__setitem__ is broken | > One messy thing is that it appears that assignment via `.coords` is broken on `DataTree` even at `main`.
Ah yes - I forgot there's a TODO deep somewhere for that 😅 I left it for later because it seemed like it might require changing the `DatasetCoordinates` class that `ds.coords` returns. (Surely that class could... | closed | 2024-07-01T22:42:50Z | 2024-09-11T04:03:34Z | https://github.com/pydata/xarray/issues/9204 | [
"bug",
"topic-DataTree"
] | shoyer | 1 |
BeanieODM/beanie | asyncio | 458 | [BUG] PydanticObjectId Serialization Issue When Beanie is Used With Starlite | **Describe the bug**
Starlite raises an HTTP 500 error when trying to return a Beanie `Document`. It seems to be due to the `PydanticObjectId` type not being JSON serializable. The issue was discussed [here](https://github.com/starlite-api/starlite/discussions/819) on the Starlite repo. Is this an issue that can be ... | closed | 2022-12-26T12:08:31Z | 2023-01-09T16:18:55Z | https://github.com/BeanieODM/beanie/issues/458 | [
"bug"
] | bwhli | 5 |
deeppavlov/DeepPavlov | tensorflow | 1,550 | refactor: tensorboard on pytorch | **What problem are we trying to solve?**:
```
Tensorboard used by tensorflow 1.15, that is going be removed.
```
**How can we solve it?**:
```
Rewrite tensorboard usage using pytorch api
``` | closed | 2022-04-12T07:06:31Z | 2022-06-22T06:12:13Z | https://github.com/deeppavlov/DeepPavlov/issues/1550 | [
"enhancement"
] | IgnatovFedor | 1 |
HIT-SCIR/ltp | nlp | 368 | 如何fine tune做自己的任务 | 你好,我在尝试用ltp来fine tune做自己的任务,我该如何从哪个文件fine tune我的模型,
我尝试使用 python __main__.py --config "./tiny/config.json"
报错:
Traceback (most recent call last):
File "__main__.py", line 23, in <module>
run()
File "__main__.py", line 19, in run
Fire(Command)
File "/home/ray.yao/anaconda2/envs/ltp_demo/lib/pytho... | closed | 2020-06-18T10:30:40Z | 2020-06-19T07:30:06Z | https://github.com/HIT-SCIR/ltp/issues/368 | [] | junrong1 | 0 |
microsoft/unilm | nlp | 1,336 | [kosmos-g] Problem about docker image setup | When installing xformers according to official instruction, it fails.
Low version of torch + high version of xformers is difficult to install.
Can anyone offer a docker image? | open | 2023-10-17T09:08:25Z | 2024-07-01T14:24:58Z | https://github.com/microsoft/unilm/issues/1336 | [] | caicj15 | 15 |
piskvorky/gensim | data-science | 3,520 | bug about remove_markup | #### Problem description
After calling gensim.corpora.wikicorpus.filter_wiki,there are still characters not been stripped.
```python
RE_P1 = re.compile(r'<ref([> ].*?)(</ref>|/>)', re.DOTALL | re.UNICODE)
```
Before stripping RE_P1, characters as following should be stripped.
```python
re.compile('(?:<br... | open | 2024-03-28T03:34:24Z | 2024-04-11T08:27:31Z | https://github.com/piskvorky/gensim/issues/3520 | [] | seadog-www | 2 |
chezou/tabula-py | pandas | 350 | dont ignore empty columns in tables spanning multiple pages | **Is your feature request related to a problem? Please describe.**
<!--- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
I have a pdf file with multiple pages. From page two to the end (page 29) I have one table basically spanning over all pages after page 2. now it ... | closed | 2023-06-26T16:44:31Z | 2023-06-26T16:51:42Z | https://github.com/chezou/tabula-py/issues/350 | [] | awesome-crab | 1 |
apache/airflow | machine-learning | 47,646 | Fix Connections Test Endpoint Should Allow None in the Request Body | ### Description
The test endpoint doesn't need `Connection Type` since the connection should already exist in the database.
### Are you willing to submit a PR?
- [x] Yes I am willing to submit a PR!
### Code of Conduct
- [x] I agree to follow this project's [Code of Conduct](https://github.com/apache/airflow/blob/... | closed | 2025-03-11T21:25:04Z | 2025-03-16T13:49:07Z | https://github.com/apache/airflow/issues/47646 | [
"area:API",
"type:bug-fix",
"priority:medium",
"affected_version:3.0.0beta"
] | bugraoz93 | 1 |
JaidedAI/EasyOCR | pytorch | 601 | Downloading detection model too slow | Hi, I when I run a code in Windows, it display "Downloading detection model, please wait. This may take several minutes depending upon your network connection."
Then it keep downloading for a long time.
even though I plug a VPN , its progress is very slow
I just use "pip install easyocr" to install
And the code is... | closed | 2021-11-27T07:12:11Z | 2022-08-07T05:01:23Z | https://github.com/JaidedAI/EasyOCR/issues/601 | [] | LiHangBing | 2 |
huggingface/datasets | nlp | 7,059 | None values are skipped when reading jsonl in subobjects | ### Describe the bug
I have been fighting against my machine since this morning only to find out this is some kind of a bug.
When loading a dataset composed of `metadata.jsonl`, if you have nullable values (Optional[str]), they can be ignored by the parser, shifting things around.
E.g., let's take this example
... | open | 2024-07-22T13:02:42Z | 2024-07-22T13:02:53Z | https://github.com/huggingface/datasets/issues/7059 | [] | PonteIneptique | 0 |
slackapi/python-slack-sdk | asyncio | 1,590 | Message ID from messages with files. | Hi!
`files_upload_v2` function does not return `ts` and `thread_ts` arguments. For my program, I need to know parent and child message ID. I tried to use `permalink `in blocks argument in `postMessage` function, but I get `invalid_blocks` error.
And for some reason there are two absolutely identical file objects in... | closed | 2024-11-10T23:26:07Z | 2024-11-10T23:35:16Z | https://github.com/slackapi/python-slack-sdk/issues/1590 | [
"question",
"duplicate",
"web-client",
"Version: 3x"
] | denikryt | 2 |
CPJKU/madmom | numpy | 364 | TypeError: frame indices must be slices or integers | ### Expected behaviour
madmom should iterate over `FramedSignal` independently how it is called.
### Actual behaviour
In Python 3 it fails if iterating over `np.arange`. | closed | 2018-04-17T13:27:02Z | 2018-04-18T07:13:49Z | https://github.com/CPJKU/madmom/issues/364 | [] | superbock | 0 |
youfou/wxpy | api | 72 | 可以发送收藏的表情吗? | 如果可以怎么发送? | closed | 2017-06-05T16:06:38Z | 2017-06-06T04:27:09Z | https://github.com/youfou/wxpy/issues/72 | [] | tchy | 1 |
numba/numba | numpy | 9,463 | How about unifying `int32` and `Literal[int](0)` as `int32`, rather than `int64` | code:
```python
import os
os.environ["NUMBA_DEBUG_TYPEINFER"] = "1"
from numba import njit
from numba.core import types
@njit
def foo(flag, v):
v2 = types.int32(v)
if flag:
return v2
else:
return 0
foo(True, 2)
```
the inferred return type is `int64`, can we consider u... | open | 2024-02-24T00:26:06Z | 2024-02-26T19:17:46Z | https://github.com/numba/numba/issues/9463 | [
"feature_request",
"Blocked awaiting long term feature",
"NumPy 2.0"
] | dlee992 | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.