
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pywinauto/pywinauto | automation | 887 | Error after 'from pywinauto.application import Application' | ## Expected Behavior
```
from pywinauto.application import Application
```
## Actual Behavior
```
Traceback (most recent call last):
File "d:\Devel\python\lib\ctypes\__init__.py", line 121, in WINFUNCTYPE
return _win_functype_cache[(restype, argtypes, flags)]
KeyError: (<class 'ctypes.HRESULT'>, (<clas... | closed | 2020-02-03T15:30:10Z | 2020-02-13T17:17:44Z | https://github.com/pywinauto/pywinauto/issues/887 | [
"duplicate",
"3rd-party issue"
] | arozehnal | 5 |
scikit-optimize/scikit-optimize | scikit-learn | 1,076 | ImportError when using skopt with scikit-learn 1.0 | When importing Scikit-optimize, the following ImportError is returned:
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python3.7/dist-packages/skopt/__init__.py", line 55, in <module>
from .searchcv import BayesSearchCV
File "/usr/local/lib/python3.7/dist-p... | closed | 2021-10-05T12:30:14Z | 2021-10-12T14:41:36Z | https://github.com/scikit-optimize/scikit-optimize/issues/1076 | [] | SenneDeproost | 3 |
s3rius/FastAPI-template | fastapi | 96 | Request object isn't passed as argument | Thanks for this package. I have created graphql app using template but getting below error. It seems fastapi doesn't pass request object.
```log
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/Users/test/Library/Caches/pypoetry/virtualenvs/fastapi-graphql-practice-1UuEp-7G-py3.... | closed | 2022-07-05T07:01:34Z | 2022-10-13T21:26:26Z | https://github.com/s3rius/FastAPI-template/issues/96 | [] | devNaresh | 16 |
unionai-oss/pandera | pandas | 1,261 | Fix to_script description | #### Location of the documentation
[DataFrameSchema.to_script](https://github.com/unionai-oss/pandera/blob/62bc4840508ff1ac0df595b57b2152737a1228a2/pandera/api/pandas/container.py#L1251)
#### Documentation problem
This method has the description for `from_yaml`.
#### Suggested fix for documentation
Somet... | closed | 2023-07-15T19:25:28Z | 2023-07-17T17:47:29Z | https://github.com/unionai-oss/pandera/issues/1261 | [
"docs"
] | tmcclintock | 1 |
onnx/onnx | pytorch | 5,926 | Add TopK node to a pretrained Brevitas model | We are working with FINN-ONNX, and we want the pretrained models from Brevitas that classify the MNIST images to output the index (class) instead of a probabilities tensor of dim 1x10.To our knowledge, the node responsible for this is the TopK.
Where do we have to add this layer, and what function can we add so the... | open | 2024-02-09T17:21:55Z | 2024-02-13T10:04:09Z | https://github.com/onnx/onnx/issues/5926 | [
"question"
] | abedbaltaji | 1 |
flasgger/flasgger | flask | 443 | Compatibility Proposal for OpenAPI 3 | This issue to discuss compatibility of OpenAPI3 in flasgger. Currently, the code differentiates them in runtime, and mixes up the processing of both specifications. In long term, I believe that this would lower code quality, and make the code harder to maintain. Please raise any suggestions or plans to make Flasgger wo... | open | 2020-11-21T18:15:27Z | 2021-11-14T08:53:02Z | https://github.com/flasgger/flasgger/issues/443 | [] | billyrrr | 3 |
nteract/papermill | jupyter | 575 | Some weird error messages when executing a notebook involving pytorch | I have a notebook for training a model using pytorch. The notebook runs fine if I run it from browser. But I ran into the following problem when executing it via papermill
```
Generating grammar tables from /home/ubuntu/anaconda3/envs/pytorch_p36/lib/python3.6/site-packages/blib2to3/Grammar.txt
Writing grammar tab... | closed | 2021-01-26T23:16:54Z | 2021-02-04T17:06:27Z | https://github.com/nteract/papermill/issues/575 | [
"question"
] | hongshanli23 | 12 |
twopirllc/pandas-ta | pandas | 807 | SyntaxWarning: invalid escape sequence '\g' return re_.sub("([a-z])([A-Z])","\g<1> \g<2>", x).title() | I got this warning after upgrade python from 3.11 to 3.12:
pandas_ta\utils\_core.py:14: SyntaxWarning: invalid escape sequence '\g'
return re_.sub("([a-z])([A-Z])","\g<1> \g<2>", x).title()
python 3.12.4
pandas_ta 0.3.14b
Do I need to downgrade to python 3.11 for now? | closed | 2024-07-02T05:57:48Z | 2024-12-01T22:06:59Z | https://github.com/twopirllc/pandas-ta/issues/807 | [
"bug"
] | kopes18 | 1 |
deepfakes/faceswap | deep-learning | 1,356 | Training collapse | *Note: For general usage questions and help, please use either our [FaceSwap Forum](https://faceswap.dev/forum)
or [FaceSwap Discord server](https://discord.gg/FC54sYg). General usage questions are liable to be closed without
response.*
**Crash reports MUST be included when reporting bugs.**
**Describe the bug... | closed | 2023-10-22T05:54:22Z | 2023-10-23T00:03:58Z | https://github.com/deepfakes/faceswap/issues/1356 | [] | Cashew-wood | 1 |
alteryx/featuretools | scikit-learn | 2,156 | release Featuretools v1.11.0 | - We can release **once these are merged in**
- https://github.com/alteryx/featuretools/pull/2136
- https://github.com/alteryx/featuretools/pull/2157
- The instructions for releasing:
- https://github.com/alteryx/featuretools/blob/main/release.md | closed | 2022-06-29T15:46:14Z | 2022-06-30T23:07:11Z | https://github.com/alteryx/featuretools/issues/2156 | [] | gsheni | 0 |
iperov/DeepFaceLab | machine-learning | 826 | Save ERROR |
The SAEHD and Quick96 training run as expected however it crashes every time I wanted to press save. This makes all of the previous progress useless. This error message pops up
2020-07-12 09:48:02.749598: E tensorflow/stream_executor/cuda/cuda_driver.cc:806] failed to allocate 517.44M (542572544 bytes) from devi... | closed | 2020-07-12T03:05:47Z | 2020-07-12T05:39:00Z | https://github.com/iperov/DeepFaceLab/issues/826 | [] | THE-MATT-222 | 1 |
dynaconf/dynaconf | flask | 993 | [bug] Default value on empty string | ## Problem
I have a nested structure whose value i need to set to a specific string when empy string or `None` is provided.
Take the following for example:
```python
from dynaconf import Dynaconf, Validator
settings = Dynaconf(
settings_files=[
'config.toml',
'.secrets.toml'
],
... | open | 2023-09-04T17:18:12Z | 2023-11-04T00:47:48Z | https://github.com/dynaconf/dynaconf/issues/993 | [
"Docs"
] | LukeSavefrogs | 9 |
kizniche/Mycodo | automation | 867 | compatible with DFRobot sensor/controller or other Chinese made sensors | **Is your feature request related to a problem? Please describe.**
Altas scientific is too costly even though it is very accurate and stable so i prefer cheaper one like DFRobot.
**Describe the solution you'd like**
will mycodo work with product from DFRobot or other Chinese brand? i am not sure if they are all st... | closed | 2020-10-18T09:32:21Z | 2020-11-17T03:11:01Z | https://github.com/kizniche/Mycodo/issues/867 | [
"question"
] | garudaonekh | 9 |
aimhubio/aim | data-visualization | 2,658 | Show the number of metrics (and system metrics) tracked on the Run page | ## 🚀 Feature
Add the number of tracked metrics on the Run metrics page.
### Motivation
It would be great to see how many metrics had been tracked.
A couple of use-cases:
- make sure the same number of metrics are shown as intended
- when metrics take time to load and lots are tracked, the number could help ... | open | 2023-04-17T23:34:35Z | 2023-04-17T23:34:35Z | https://github.com/aimhubio/aim/issues/2658 | [
"type / enhancement"
] | SGevorg | 0 |
ipython/ipython | data-science | 14,540 | add support for capturing entire ipython interaction [enhancement] | It would be good if IPython can support running exported Jupyter python notebooks in batch mode in a way that better matches the Jupyter output. In particular, being able to see the expressions that are evaluated along with the output would be beneficial, even when the output is not explicit. For example, there could b... | open | 2024-10-14T02:18:47Z | 2024-10-18T02:18:05Z | https://github.com/ipython/ipython/issues/14540 | [] | thomas-paul-ohara | 2 |
samuelcolvin/watchfiles | asyncio | 56 | [FEATURE] add ‘closed’ as change type | I have a server for file uploads. With low latency I need to trigger some python code that reads the incoming files and...
I have an issue right now though. Some times the files are empty and I think it’s because the upload is not done yet. How can I determine if the file is done being written to?
I think inotify... | closed | 2020-03-30T21:33:04Z | 2020-05-22T11:44:58Z | https://github.com/samuelcolvin/watchfiles/issues/56 | [] | NixBiks | 1 |
unionai-oss/pandera | pandas | 1,059 | Getting "TypeError: type of out argument not recognized: <class 'str'>" when using class function with Pandera decorator | Hi. I am having trouble to get Pandera work with classes.
First I create schemas:
```
from pandera import Column, Check
import yaml
in_ = pa.DataFrameSchema(
{
"Name": Column(object, nullable=True),
"Height": Column(object, nullable=True),
})
with open("./in_.yml", "w") as file:
... | closed | 2022-12-19T08:55:30Z | 2022-12-19T19:55:28Z | https://github.com/unionai-oss/pandera/issues/1059 | [
"question"
] | al-yakubovich | 1 |
pyeve/eve | flask | 964 | PyMongo 3.4.0 support | closed | 2017-01-15T16:54:21Z | 2017-01-15T16:58:25Z | https://github.com/pyeve/eve/issues/964 | [
"enhancement"
] | nicolaiarocci | 0 | |
gradio-app/gradio | python | 10,850 | Could not create share link. Please check your internet connection or our status page: https://status.gradio.app. | ### Describe the bug
Hi, I am using the latest version of Gradio.
But I encounter this problem:

Do you know how can I solve this problem? Thank you very much!
### Have you searched existing issues? 🔎
- [x] I have search... | closed | 2025-03-21T04:00:17Z | 2025-03-22T22:36:48Z | https://github.com/gradio-app/gradio/issues/10850 | [
"bug"
] | Allen-Zhou729 | 7 |
ultralytics/ultralytics | machine-learning | 19,781 | High CPU Usage with OpenVINO YOLOv8n on Integrated GPU – How Can I Reduce It? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi everyone,
I'm running inference using an OpenVINO-converted YOLOv8n mode... | open | 2025-03-19T10:56:05Z | 2025-03-20T01:34:16Z | https://github.com/ultralytics/ultralytics/issues/19781 | [
"question",
"detect",
"exports"
] | AlaaArboun | 2 |
facebookresearch/fairseq | pytorch | 4,754 | Forced decoding for translation | Hello,
Is there a flag in fairseq-cli to specify a prefix token for forced decoding? The [fairseq-generate](https://fairseq.readthedocs.io/en/latest/command_line_tools.html#fairseq-generate) documentation shows a flag to indicate the size *prefix-size* but I haven't found how to indicate what that token(s) is. Also l... | open | 2022-10-03T23:15:45Z | 2022-10-03T23:15:45Z | https://github.com/facebookresearch/fairseq/issues/4754 | [
"question",
"needs triage"
] | Pogayo | 0 |
nalepae/pandarallel | pandas | 244 | Some workers stuck while others finish 100% | ## General
- **Operating System**:
Centos 7
- **Python version**:
3.8
- **Pandas version**:
2.0.1
- **Pandarallel version**:
1.6.4
## Acknowledgement
- [x] My issue is **NOT** present when using `pandas` without alone (without `pandarallel`)
- [ ] If I am on **Windows**, I read the [Troubleshooting page]... | closed | 2023-06-12T13:36:37Z | 2023-06-28T08:41:51Z | https://github.com/nalepae/pandarallel/issues/244 | [] | SysuJayce | 5 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 531 | DistributedLossWrapper always requires labels | It shouldn't require labels if `indices_tuple` is provided. | closed | 2022-09-29T13:42:08Z | 2023-01-17T01:26:39Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/531 | [
"bug"
] | KevinMusgrave | 1 |
tatsu-lab/stanford_alpaca | deep-learning | 210 | Does this code still work when fine-tune with encoder-decoder (BLOOMZ or mT0) ? | I'm worry this code doesn't run when use pre-trained BLOOMZ or mT0 [https://github.com/bigscience-workshop/xmtf].
Have anyone fine-tuned this ? | open | 2023-04-14T02:30:27Z | 2023-04-14T02:30:27Z | https://github.com/tatsu-lab/stanford_alpaca/issues/210 | [] | nqchieutb01 | 0 |
iMerica/dj-rest-auth | rest-api | 542 | Get JWT secret used for encoding | How can i get the secret being used be library for encoding jwt tokens? | closed | 2023-09-01T13:15:25Z | 2023-09-01T13:19:25Z | https://github.com/iMerica/dj-rest-auth/issues/542 | [] | legalimpurity | 0 |
horovod/horovod | tensorflow | 3,707 | Reducescatter: Support ncclAvg op for averaging | Equivalently to #3646 for Allreduce | open | 2022-09-20T12:17:35Z | 2022-09-20T12:17:35Z | https://github.com/horovod/horovod/issues/3707 | [
"enhancement"
] | maxhgerlach | 0 |
mars-project/mars | numpy | 2,645 | [BUG] Groupby().agg() returned a DataFrame with index even as_index=False | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
Groupby().agg() returned a DataFrame with index even as_index=False.
**To Reproduce**
To help us reproducing this bug, please provide inf... | closed | 2022-01-21T07:58:47Z | 2022-01-21T09:26:23Z | https://github.com/mars-project/mars/issues/2645 | [
"type: bug",
"reso: invalid",
"mod: dataframe"
] | qinxuye | 1 |
graphql-python/graphene-mongo | graphql | 24 | Types are unaware of parent class attributes defined on child model | First of all, thank you for writing this library. I've been wanting to try GraphQL out with my current project but didn't want to have to create an entire new backend application from scratch. I can reuse my existing models thanks to this library, way cool 👍 🥇
Now for my issue...
I have a parent/child relation... | closed | 2018-04-01T13:42:14Z | 2018-04-02T13:59:45Z | https://github.com/graphql-python/graphene-mongo/issues/24 | [] | msholty-fd | 1 |
iterative/dvc | machine-learning | 10,064 | dvc pull: failed to load directory when first failed s3 connection | # Bug Report
<!--
## Issue name
Issue names must follow the pattern `command: description` where the command is the dvc command that you are trying to run. The description should describe the consequence of the bug.
Example: `repro: doesn't detect input changes`
-->
## Description
<!--
A clear and con... | closed | 2023-11-03T10:33:57Z | 2023-12-15T13:36:31Z | https://github.com/iterative/dvc/issues/10064 | [
"awaiting response"
] | fguiotte | 3 |
man-group/notebooker | jupyter | 134 | Add option to pass scheduled cron time to the notebook | Being able to read scheduled cron time from the notebook would improve the use case of using notebooker as tool to generate periodic reports. Might also need to maintain that time if same report is re-run. | open | 2023-02-02T20:41:31Z | 2023-10-11T15:34:27Z | https://github.com/man-group/notebooker/issues/134 | [] | marcinapostoluk | 1 |
ivy-llc/ivy | numpy | 28,764 | Fix Frontend Failing Test: tensorflow - pooling_functions.torch.nn.functional.max_pool2d | closed | 2024-06-15T20:44:58Z | 2024-07-15T02:29:34Z | https://github.com/ivy-llc/ivy/issues/28764 | [
"Sub Task"
] | nicolasb0 | 0 | |
waditu/tushare | pandas | 1,526 | 股票列表接口中没有标明请求所需积分值 | https://tushare.pro/document/2?doc_id=94
股票列表请求提示无权限,没有明确标明具体所需分值 | open | 2021-03-23T06:04:20Z | 2021-03-23T06:04:20Z | https://github.com/waditu/tushare/issues/1526 | [] | mestarshine | 0 |
microsoft/nni | pytorch | 5,309 | inputs is empty! | **Describe the bug**:
inputs is empty!As show in figure:

node-----> name: .aten::mul.146, type: func, op_type: aten::mul, sub_nodes: ['_aten::mul'], inputs: ['logvar'], outputs: ['809'], aux: None
node... | closed | 2023-01-05T10:33:19Z | 2023-01-06T02:19:42Z | https://github.com/microsoft/nni/issues/5309 | [] | Blakey-Gavin | 0 |
aleju/imgaug | machine-learning | 849 | Adding BlendAlphaSimplexNoise into an augmentation sequence fails to convert keypoints | Imgaug 0.4.0
Python 3.10
`iaa.BlendAlphaSimplexNoise` seems to cause problems when converting keypoints.
I have created an sequence of augmentations:
```python
seq = iaa.Sequential([
iaa.Affine(rotate=(-25, 25)),
iaa.AllChannelsCLAHE(clip_limit=(1, 3), tile_grid_size_px=(10, 25)),
iaa.BlendAlph... | open | 2024-05-03T12:39:05Z | 2024-05-03T12:39:05Z | https://github.com/aleju/imgaug/issues/849 | [] | vonaviv | 0 |
alteryx/featuretools | data-science | 2,047 | Investigate and resolve warnings related to pandas | - Our unit tests currently output these warnings.
- We should determine the cause of these warnings, and resolve them. | closed | 2022-04-29T20:47:16Z | 2022-05-13T21:24:26Z | https://github.com/alteryx/featuretools/issues/2047 | [] | gsheni | 1 |
google-research/bert | nlp | 372 | Two to Three mask word prediction at same sentence is very complex? | Two to Three mask word prediction at same sentence also very complex.
how to get good accuracy?
if i have to pretrained bert model and own dataset with **masked_lm_prob=0.25** (https://github.com/google-research/bert#pre-training-with-bert), what will happened?
Thanks.
| open | 2019-01-18T05:48:06Z | 2019-02-11T07:10:39Z | https://github.com/google-research/bert/issues/372 | [] | MuruganR96 | 1 |
JaidedAI/EasyOCR | deep-learning | 992 | EasyOCR failed when the picture has long height like long wechat snapshot contained several small snapshots | open | 2023-04-17T04:07:42Z | 2023-04-17T04:07:42Z | https://github.com/JaidedAI/EasyOCR/issues/992 | [] | crazyn2 | 0 | |
Yorko/mlcourse.ai | plotly | 406 | Topic 4. Part 4: Some modules are imported at the beginning, but are not used further in the text | 
It seems that _TfidfTransformer, TfidfVectorizer, LinearSVC_ were forgotten to be removed when preparing the final [article](https://mlcourse.ai/notebook... | closed | 2018-11-05T20:57:44Z | 2018-11-10T16:18:38Z | https://github.com/Yorko/mlcourse.ai/issues/406 | [
"minor_fix"
] | ptaiga | 1 |
taverntesting/tavern | pytest | 505 | Question: Any experience with using mocking with Tavern? | Would like to get head start on automating new api by mocking requests/responses while using Tavern and pytest. | closed | 2020-01-06T20:18:37Z | 2020-01-13T18:27:48Z | https://github.com/taverntesting/tavern/issues/505 | [] | pmneve | 2 |
horovod/horovod | pytorch | 4,110 | [+[!𝐅𝐔𝐋𝐋 𝐕𝐈𝐃𝐄𝐎𝐒!]+]Sophie Rain Spiderman Video Original Video Link Sophie Rain Spiderman Video Viral On Social Media X Trending Now | 20 seconds ago
L𝚎aked Video Sophie Rain Spiderman Original Video Viral Video L𝚎aked on X Twitter Telegram
..
..
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://usnews-daily.com/free-watch/)
..
..
[🔴 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🌐==►► 𝖣𝗈𝗐𝗇𝗅𝗈𝖺𝖽 𝖭𝗈𝗐](https://usnews-daily.com/free-watch/?t)... | closed | 2024-11-17T17:23:26Z | 2024-11-20T12:23:49Z | https://github.com/horovod/horovod/issues/4110 | [] | ghost | 1 |
dynaconf/dynaconf | fastapi | 823 | [bug] Validator cast happens before must_exist check | **Describe the bug**
The `Validator` `cast` function call happens before the `must_exist`, which doesn't make sense since you first want to ensure that the value has been provided, and then cast it into a different object.
**To Reproduce**
Steps to reproduce the behavior:
Having the following app code:
<deta... | closed | 2022-10-28T15:16:59Z | 2023-03-02T13:29:40Z | https://github.com/dynaconf/dynaconf/issues/823 | [
"bug"
] | Wenzel | 0 |
SciTools/cartopy | matplotlib | 2,311 | Chart Server dependency | Google chart server has been deprecated in 2012, and the notification for turning it down was in 2019:
https://groups.google.com/g/google-chart-api/c/rZtHTyYgyXI
The servers can be gone at any moment at this point.
These cartopy tests still seem to rely on the chart server API:
https://github.com/SciTools/... | open | 2024-01-08T22:09:19Z | 2024-01-09T00:18:47Z | https://github.com/SciTools/cartopy/issues/2311 | [] | rainwoodman | 1 |
ageitgey/face_recognition | python | 1,247 | Different domains | Hi guys, If I want to use images coming from different domains, e.g., webcamera and professional camera or identification cards, with different colors, what should be the best option/way to normalize images? face_encodings perform the normalization, really? It should be better to apply first an early normalization? | open | 2020-11-21T10:24:19Z | 2020-11-21T10:24:19Z | https://github.com/ageitgey/face_recognition/issues/1247 | [] | MarioProjects | 0 |
fastapi/fastapi | pydantic | 12,055 | Why can't the key of the returned value start with “_sa”? | ### Privileged issue
- [X] I'm @tiangolo or he asked me directly to create an issue here.
### Issue Content
```
import uvicorn
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def root():
return {"_sa": "Hello World", "status": "OK"}
if __name__ == '__main__':
uvicorn.run(app, ho... | closed | 2024-08-21T23:42:20Z | 2024-08-22T13:54:53Z | https://github.com/fastapi/fastapi/issues/12055 | [] | leafotto | 2 |
roboflow/supervision | pytorch | 1,052 | DetectionDataset.from_yolo bad conversion with autodistill_grounded_sam DetectionDataset object | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
The sv.DetectionDataset.from_yolo function has abnormal behavior when processing DetectionDataset objects from autodistil_grounded_sam
When I use... | closed | 2024-03-26T13:59:20Z | 2024-04-02T12:40:16Z | https://github.com/roboflow/supervision/issues/1052 | [
"bug"
] | Youho99 | 7 |
ymcui/Chinese-BERT-wwm | nlp | 132 | 预训练维基 繁/简体 | 您好:
感谢您提供预训练模型。想请教 BERT-wwm 在进行预训练时,使用的中文维基,是简体中文,还是繁体中文,还是两者都有?
| closed | 2020-07-23T08:16:17Z | 2020-07-23T11:12:37Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/132 | [] | d223302 | 1 |
Evil0ctal/Douyin_TikTok_Download_API | api | 161 | [BUG] 抖音接口应该是换了 | 抖音接口应该是换了 | closed | 2023-02-27T09:27:49Z | 2024-08-23T05:25:17Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/161 | [
"BUG",
"Fixed"
] | jw-star | 29 |
strawberry-graphql/strawberry | graphql | 3,119 | FastAPI GraphQL: Unknown type 'Upload' | <!--- Provide a general summary of the changes you want in the title above. -->
I'm getting an error `Unknown type 'Upload'` when calling my file upload API. Have I missed something? Or is it a bug?
Most of this code is based off the [Strawberry file upload guide](https://strawberry.rocks/docs/guides/file-upload)
... | closed | 2023-09-24T20:52:14Z | 2025-03-20T15:56:23Z | https://github.com/strawberry-graphql/strawberry/issues/3119 | [] | SquarerFive | 2 |
simple-login/app | flask | 2,292 | None of the SL domains accepted in www.studystream.live | Please note that this is only for bug report.
For help on your account, please reach out to us at hi[at]simplelogin.io. Please make sure to check out [our FAQ](https://simplelogin.io/faq/) that contains frequently asked questions.
For feature request, you can use our [forum](https://github.com/simple-login/app... | open | 2024-10-26T11:50:45Z | 2024-10-26T11:50:45Z | https://github.com/simple-login/app/issues/2292 | [] | homeostashish | 0 |
whitphx/streamlit-webrtc | streamlit | 1,254 | Webcam Stream not showing up | First of all, thank you very much for your really great work and contribution!!!
I currently need help accessing some of your demos and running my own App on the Streamlit Cloud.
When accessing the demos and starting the webcam (after granting access) it looks like this :
<img width="743" alt="image" src="http... | closed | 2023-05-10T20:38:48Z | 2024-05-05T04:59:15Z | https://github.com/whitphx/streamlit-webrtc/issues/1254 | [] | Martlgap | 2 |
yunjey/pytorch-tutorial | pytorch | 185 | there was a problem in language model | hello,when I try to run pytorch-tutorial/tutorials/02-intermediate/language_model/main.py this file,but I got some error,Firstly,when it comes to "ids = corpus.get_data('data/train.txt', batch_size)",it will display shape '[20,-1]' is invalid for input of size 929589,Is there any wrong with the train.txt? Secondly,sam... | open | 2019-07-27T09:35:45Z | 2019-12-17T22:47:25Z | https://github.com/yunjey/pytorch-tutorial/issues/185 | [] | TobeyLi | 1 |
serengil/deepface | machine-learning | 465 | OS error occurs when running DeepFace.stream() | Hello, I am completely new to deepface and I recently faced an error stated in this image when running DeepFace.stream(). I tried to reinstall deepface, keras and h5py packages but the problem still occurs. Any solutions for this?
This is what i ran,
[
 or, alternatively, setting it to Mode.
On that note, *Mode* is currently unavailable for c... | closed | 2022-08-04T08:29:16Z | 2022-08-04T09:08:02Z | https://github.com/biolab/orange3/issues/6089 | [
"bug report"
] | ajdapretnar | 1 |
guohongze/adminset | django | 96 | 持续交付 | 持续交付,发布代码支持版本回滚么 | open | 2019-02-21T07:00:08Z | 2019-02-22T03:49:30Z | https://github.com/guohongze/adminset/issues/96 | [] | frank0826 | 2 |
vllm-project/vllm | pytorch | 15,056 | [Bug]: [Minor] Forking happens after the creation of tokenizer | ### Your current environment
When testing prefix caching on TPU, we got the following in the log:
```text
huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...
To disable this warning, you can either:
- Avoid using `tokenizers... | closed | 2025-03-18T18:08:20Z | 2025-03-18T18:58:42Z | https://github.com/vllm-project/vllm/issues/15056 | [
"bug"
] | yarongmu-google | 3 |
pennersr/django-allauth | django | 3,391 | LinkedIn with OpenID Connect | First off, thank you for all your work on `django-allauth`. It is an indispensable addition to the Django ecosystem and I have been very happy with it for the past few years whenever I've needed the functionality.
I created a new LinkedIn App and wanted to use `django-allauth` to integrate with it. Newly created app... | closed | 2023-08-25T23:53:11Z | 2024-06-28T01:21:06Z | https://github.com/pennersr/django-allauth/issues/3391 | [] | adamghill | 9 |
Neoteroi/BlackSheep | asyncio | 341 | Cryptic error message when a list is expected and an object is received | Consider the following example:
```python
from dataclasses import dataclass
from blacksheep import Application, pretty_json
app = Application()
@dataclass
class Access:
id: int
name: str
permissions: list[str]
@app.router.post("/")
def set_access(data: list[Access]):
# Just an ... | closed | 2023-04-26T19:43:31Z | 2023-04-28T05:50:19Z | https://github.com/Neoteroi/BlackSheep/issues/341 | [] | RobertoPrevato | 1 |
ansible/ansible | python | 84,843 | ansible-config does not correclty validate all entries | ### Summary
Mostly the dynamic 'galaxy servers'
### Issue Type
Bug Report
### Component Name
ansible-config
### Ansible Version
```console
$ ansible --version
all
```
### Configuration
```console
# if using a version older than ansible-core 2.12 you should omit the '-t all'
$ ansible-config dump --only-change... | open | 2025-03-17T19:15:38Z | 2025-03-18T15:14:21Z | https://github.com/ansible/ansible/issues/84843 | [
"bug"
] | bcoca | 1 |
HumanSignal/labelImg | deep-learning | 666 | Unable to open previously saved .xml file |
- **OS: Mac
- **PyQt version: 5.15.1
- Python 3.8.6 Homebrew
Python crashes and this error appears when i "Open Dir > .xml file"
Traceback (most recent call last):
File "labelimg.py", line 1367, in openFile
self.loadFile(filename)
File "labelimg.py", line 1065, in loadFile
self.lineColor = QCo... | open | 2020-10-24T12:56:20Z | 2022-05-30T20:07:07Z | https://github.com/HumanSignal/labelImg/issues/666 | [] | zoehako | 3 |
plotly/dash | plotly | 3,218 | deselect all tabs in dcc tab component | I'm building an application that is using the tab dcc component. This component provide the option of not selecting anything as initial value. I want to take davantage of this feature to display specific information but if I interact with the tabs I have no way to go back to a "nothing selected" state.
The following ... | open | 2025-03-14T11:00:04Z | 2025-03-17T18:20:23Z | https://github.com/plotly/dash/issues/3218 | [
"feature",
"P3"
] | 12rambau | 2 |
recommenders-team/recommenders | machine-learning | 1,516 | Run tests in the appropriate extra dependencies. | ### Description
Our recommender package has several `extra` dependencies to address the different compute environments: `recommender[spark,gpu,example,dev]`. We should run our tests against the specific extra dependency so we can ensure users of the library would have minimum problems installing these extra dependenci... | closed | 2021-09-01T21:32:17Z | 2021-09-16T13:11:30Z | https://github.com/recommenders-team/recommenders/issues/1516 | [
"enhancement"
] | laserprec | 0 |
seleniumbase/SeleniumBase | web-scraping | 2,255 | Looks like Cloudflare found out about SeleniumBase UC Mode | The makers of the **Turnstile** have found out about **SeleniumBase UC Mode**:
<img width="480" alt="Screenshot 2023-11-08 at 5 47 30 PM" src="https://github.com/seleniumbase/SeleniumBase/assets/6788579/08fa67af-262e-48e4-8699-33e04c15ab54">
**To quote Dr. Emmett Brown from Back to the Future:**
> **"They found ... | closed | 2023-11-08T23:43:16Z | 2023-11-15T02:40:06Z | https://github.com/seleniumbase/SeleniumBase/issues/2255 | [
"News / Announcements",
"UC Mode / CDP Mode",
"Fun"
] | mdmintz | 10 |
pydantic/pydantic | pydantic | 11,361 | Override composed Field constraints not working when using AfterValidator | ### Initial Checks
- [x] I confirm that I'm using Pydantic V2
### Description
Hi!
First of all, thank you for all the time you put into building/maintaining this fantastic library!
I've noticed that when using shared annotated types with some sane default constraints/validation, later, when overriding the constrai... | open | 2025-01-30T10:38:29Z | 2025-02-12T20:00:27Z | https://github.com/pydantic/pydantic/issues/11361 | [
"change",
"bug V2",
"topic-annotations"
] | simonwahlgren | 7 |
fastapi/sqlmodel | fastapi | 475 | How to join tables across multiple schemas | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X] I al... | closed | 2022-10-21T11:28:47Z | 2022-11-26T11:04:32Z | https://github.com/fastapi/sqlmodel/issues/475 | [
"question",
"investigate"
] | christianholland | 3 |
s3rius/FastAPI-template | asyncio | 40 | Database is not initialized without migrations | If you choose to skip adding migrations, you'll face this issue.
We must add a function in application's startup that initializes database using metadata. | closed | 2021-10-10T05:57:07Z | 2021-10-13T10:03:45Z | https://github.com/s3rius/FastAPI-template/issues/40 | [
"bug"
] | s3rius | 2 |
kubeflow/katib | scikit-learn | 1,971 | Katib-DB-Manager is not automatically creating katib database in external mysql DB | /kind bug
**What steps did you take and what happened:**
When we point Katib-DB-manager to AWS RDS MySql Database, it is not automatically creating katib database automatically like pipeline/metadata pods
**What did you expect to happen:**
katib-db-manager to automatically create database in RDS mysql (external... | closed | 2022-10-05T15:58:08Z | 2023-09-14T00:17:37Z | https://github.com/kubeflow/katib/issues/1971 | [
"kind/bug",
"lifecycle/stale"
] | moorthy156 | 3 |
serengil/deepface | machine-learning | 996 | update illustration for detectors | We recently added yolo and yunet, add their outputs in the illustration | closed | 2024-02-01T11:51:09Z | 2024-02-03T10:49:18Z | https://github.com/serengil/deepface/issues/996 | [
"enhancement"
] | serengil | 1 |
dmlc/gluon-nlp | numpy | 1,008 | GPT2BPETokenizer produce strange symbol | ## Description
I ran code piece from
https://gluon-nlp.mxnet.io/model_zoo/bert/index.html
and the GPT2BPETokenizer produce a strange symbol Ġ
### Error Message
In [1]: import gluonnlp as nlp; import mxnet as mx;
...: model, vocab = nlp.model.get_model('roberta_12_768_12', dataset_name='openwebtext_ccnew
... | closed | 2019-11-14T09:38:41Z | 2020-10-26T22:48:10Z | https://github.com/dmlc/gluon-nlp/issues/1008 | [
"bug"
] | hutao965 | 9 |
flairNLP/flair | nlp | 3,543 | [Bug]: Cannot load pre-trained models after fine-tuning (Transformers) | ### Describe the bug
Hello,
I was trying to fine tune a mT5 model (google/mT5 series models) on a custom dataset that follows the text format given in your documentation for the column data loader. I have been trying to figure out what is happening but I think there is some problem in the way the model is being l... | closed | 2024-09-03T04:42:49Z | 2024-10-11T11:07:15Z | https://github.com/flairNLP/flair/issues/3543 | [
"bug"
] | DhruvSondhi | 1 |
pydata/xarray | numpy | 9,878 | multiindex + cftimeindex broken on pandas main | ### What happened?
This test fails on pandas main branch
https://github.com/pydata/xarray/blob/96e0ff7d70c605a1505ff89a2d62b5c4138b0305/xarray/tests/test_cftimeindex.py#L1191-L1195
I will xfail this test but it would be good to fix it
cc @spencerkclark
| open | 2024-12-11T23:16:05Z | 2024-12-13T19:32:03Z | https://github.com/pydata/xarray/issues/9878 | [
"bug",
"topic-cftime"
] | dcherian | 1 |
ydataai/ydata-profiling | jupyter | 733 | Slack links in the README.md are no longer valid | **Describe the bug**
The slack of Join the Slack community links on the README.md - both return an error saying the link is no longer valid
**To Reproduce**
Click the [Slack](https://join.slack.com/t/pandas-profiling/shared_invite/zt-l2iqwb92-9JpTEdFBijR2G798j2MpQw) link at the [beginning](https://github.com/p... | closed | 2021-03-25T12:55:29Z | 2021-03-27T19:23:16Z | https://github.com/ydataai/ydata-profiling/issues/733 | [] | owenlamont | 1 |
lanpa/tensorboardX | numpy | 258 | symbolic for max_pool2d_with_indices returned None for the output 1 (indicating conversion for that particular output is not supported), but the network uses this output later | Hi,
I am getting this error while adding a graph. Following is the stack trace
`---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-43-d96358ad8344> in <module>()
21 use_la... | open | 2018-10-24T10:12:35Z | 2019-07-04T18:55:51Z | https://github.com/lanpa/tensorboardX/issues/258 | [
"add_graph",
"wait for response"
] | shayansiddiqui | 9 |
donnemartin/data-science-ipython-notebooks | machine-learning | 71 | Data science | closed | 2020-06-06T12:05:25Z | 2020-06-06T12:06:27Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/71 | [] | Amine-OMRI | 0 | |
aiortc/aiortc | asyncio | 302 | Allow same track to be sent N times | In `rtcpeerconnection.py`:
```py
def __assertTrackHasNoSender(self, track: MediaStreamTrack) -> None:
for sender in self.getSenders():
if sender.track == track:
raise InvalidAccessError("Track already has a sender")
```
May I know why this constraint? is it artificial?... | closed | 2020-02-25T11:30:25Z | 2020-02-26T10:44:01Z | https://github.com/aiortc/aiortc/issues/302 | [] | ibc | 5 |
prkumar/uplink | rest-api | 119 | Class-level decorators on Consumer classes do not apply to inherited methods | **Describe the bug**
For consumer classes that inherit consumer methods (i.e., methods decorated with `@uplink.get`, `@uplink.post`, etc.) from one or more parent classes, uplink decorators such as`@response_handler` or `@timeout` are not applied to those inherited methods when these decorators are used as class-level... | closed | 2018-11-15T19:41:14Z | 2019-01-22T18:52:47Z | https://github.com/prkumar/uplink/issues/119 | [
"Bug",
"help wanted",
"good first issue"
] | prkumar | 1 |
ckan/ckan | api | 8,647 | `package_show` fallback to `name_or_id` does not work, requires `id` | ## CKAN version
2.11
## Describe the bug
The `package_show` API is supposed to allow `name_or_id` as a fallback for `id`, but it doesn't work on CKAN 2.11, giving an error if `id` is not present.
### Steps to reproduce
- Start a CKAN 2.11 instance.
- Create a public dataset named "Test".
- Go to `/api/action/packa... | open | 2025-02-04T06:14:05Z | 2025-02-04T13:21:20Z | https://github.com/ckan/ckan/issues/8647 | [] | ThrawnCA | 0 |
cvat-ai/cvat | computer-vision | 8,297 | Restoring task's backup which initially was created from file share fails | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
During development of #8287 the problem occured:
1. Connect file share to CVAT
2. Create a task with files from sh... | open | 2024-08-13T08:12:35Z | 2024-11-07T06:48:15Z | https://github.com/cvat-ai/cvat/issues/8297 | [
"bug"
] | klakhov | 2 |
OpenBB-finance/OpenBB | machine-learning | 6,720 | [🕹️] Create a Simple Sentiment Analysis for Stock Prices Notebook | # 📄 Task
Create a notebook that fetches sentiment data from financial news and correlates it with stock price movements.
---
### 📋 Requirements:
1. **Template**: Start by copying the [example template notebook](https://github.com/OpenBB-finance/OpenBB/blob/develop/examples/COMMUNITY_EXAMPLE_TEMPLATE.ipy... | closed | 2024-09-30T19:03:31Z | 2024-11-02T07:41:49Z | https://github.com/OpenBB-finance/OpenBB/issues/6720 | [
"🕹️ 300 points"
] | piiq | 54 |
JoeanAmier/TikTokDownloader | api | 76 | 如何批量获取达人所有视频的点赞和评论数 | 目前只能单独视频手动收入。 | open | 2023-10-26T07:30:33Z | 2023-11-13T15:11:29Z | https://github.com/JoeanAmier/TikTokDownloader/issues/76 | [] | myrainbowandsky | 1 |
serengil/deepface | machine-learning | 824 | analyze() detector_backends 'yolov8' and 'dlib' errors | Hey! I was just trying to test out all of the available backend detectors for the analyze function. I have managed to get them all to run except for yolov8 and dlib. Here are the errors:
shape_predictor_5_face_landmarks.dat.bz2 is going to be downloaded
Detector: dlib Error: 'content-type'
-and-
Detector: yolov8 ... | closed | 2023-08-15T20:30:57Z | 2023-08-18T15:32:52Z | https://github.com/serengil/deepface/issues/824 | [
"question"
] | Hipples | 2 |
AutoGPTQ/AutoGPTQ | nlp | 378 | 关于量化使用的数据最后没有eos的问题 | 在实例脚本中,下面这一段好像没有在每条数据的最后加入eos token?此处是否需要加eos token呢?
https://github.com/PanQiWei/AutoGPTQ/blob/e4b2493733d69a6e60e22cebc64b619be39feb0e/examples/quantization/quant_with_alpaca.py#L30-L40 | open | 2023-10-25T09:19:03Z | 2023-10-26T16:46:16Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/378 | [
"chinese"
] | sakura-umi | 0 |
chatopera/Synonyms | nlp | 93 | 效率过低,不知能否优化? | 使用该库来返回近义词,单核CPU一秒钟只能返回50个不相同的词的近义词,对于NLP任务效率过低,成为数据读取的瓶颈,不知能否进行优化? | closed | 2019-07-28T16:32:41Z | 2020-10-01T11:36:21Z | https://github.com/chatopera/Synonyms/issues/93 | [] | braveryCHR | 1 |
alteryx/featuretools | data-science | 2,284 | Add primitive for 2 digit Postal Code Prefix (US-only) | - As a user of Featuretools, I would like to do feature engineering for Postal Codes in USA.
- I would like to extract the 2 digit prefix:
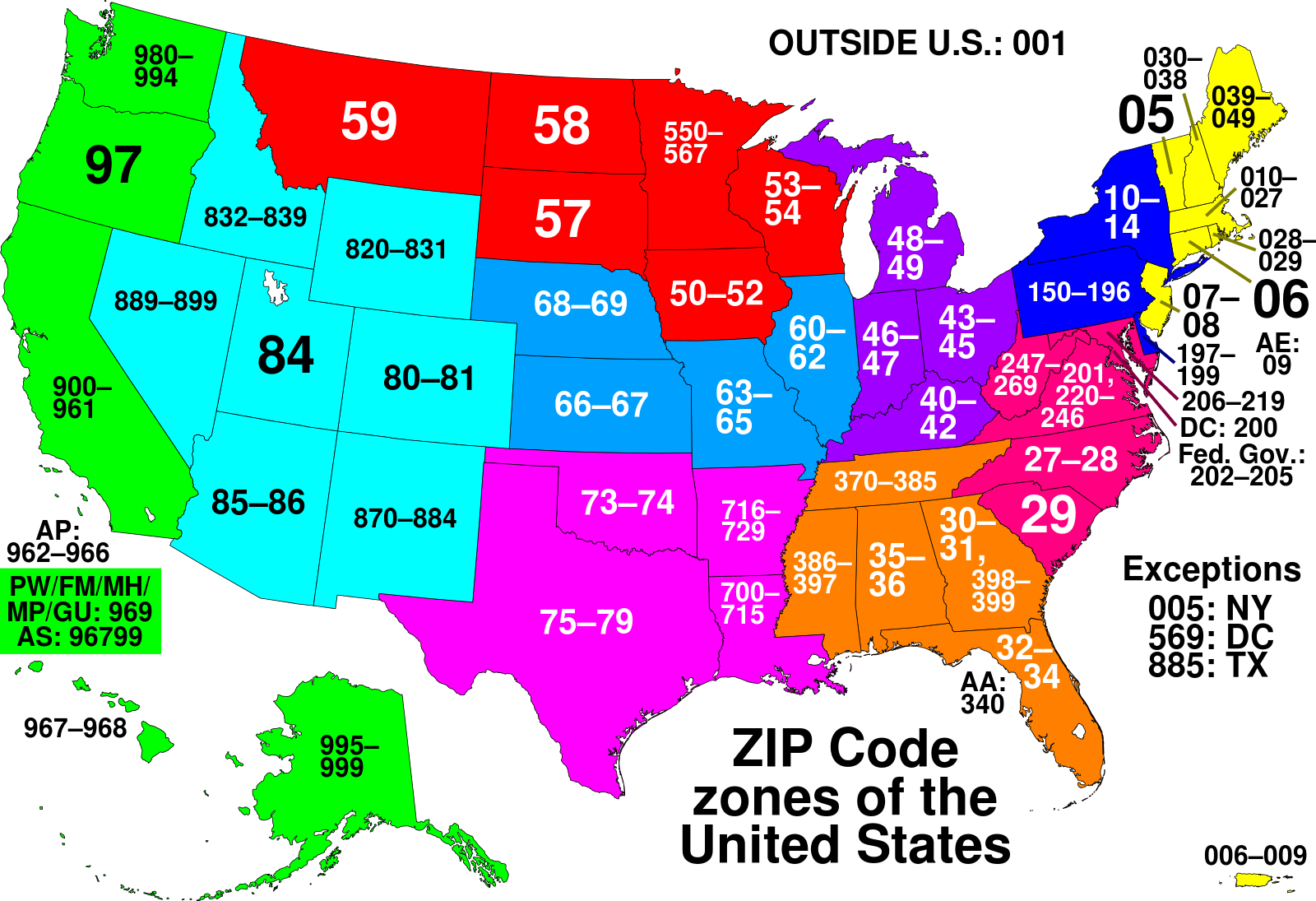
| closed | 2022-09-12T14:38:50Z | 2022-11-29T20:08:15Z | https://github.com/alteryx/featuretools/issues/2284 | [] | gsheni | 0 |
deepspeedai/DeepSpeed | machine-learning | 5,579 | [BUG] fp6 can‘t load qwen1.5-34b-chat | **Describe the bug**
NotImplementedError: Cannot copy out of meta tensor; no data!
`import mii
model_path = 'Qwen1.5-32B-Chat-hf'
pipe = mii.pipeline(model_path, quantization_mode='wf6af16')
response = pipe(["DeepSpeed is", "Seattle is"], max_new_tokens=128)
print(response)`
**System info (please complete the ... | open | 2024-05-29T07:32:04Z | 2024-05-29T07:32:42Z | https://github.com/deepspeedai/DeepSpeed/issues/5579 | [
"bug",
"inference"
] | pointerhacker | 0 |
PeterL1n/RobustVideoMatting | computer-vision | 78 | [Advice] Training in a Low RAM System | I am re-training this code in a 64GB RAM system. Do you have any recommendation on how to reduce the memory utilization? I've already reduced T to 4, but still a lot of swap memory usage, which is bottlenecking my training process.
| closed | 2021-10-12T17:52:34Z | 2021-10-14T14:58:30Z | https://github.com/PeterL1n/RobustVideoMatting/issues/78 | [] | SamHSlva | 2 |
aleju/imgaug | deep-learning | 705 | ValueError with Color Temperature Augmenter | I am using 0.4.0 installed from conda-forge and receive a ValueError in the last step of transform_kelvins_to_rgb_multipliers() in color.py. I am attempting to augment a batch of images. If it reshape and tile the "interpolation_factors" array, then the augmenter works as expected. Is this a bug, or am I using the augm... | open | 2020-07-29T20:06:07Z | 2020-09-18T03:39:50Z | https://github.com/aleju/imgaug/issues/705 | [] | wjacobward | 1 |
davidsandberg/facenet | tensorflow | 527 | how to set optional parameters for slim.batch_norm | here is my batch_norm_params, which is soon fed into normalizer_params.

however, when i print tf.trainable_variables, there are only mean, variance and beta for BN, missing gamma..
.
Is there currently a way to authenticate a token against a custom user model?
If so, please point me to the docs.
Thank you,
Michaela | open | 2017-05-15T18:55:11Z | 2017-08-27T09:59:16Z | https://github.com/jpadilla/django-rest-framework-jwt/issues/334 | [] | michaelaelise | 2 |
Lightning-AI/pytorch-lightning | machine-learning | 20,094 | Please allow automatic optimization for multiple optimizers again. | ### Description & Motivation
I'm suggesting allowing the old behavior to work again. While still giving users the option to use the new behavior if they set self.automatic_optimization=False. The old API was well designed and can allow for extremely simple implementations especially in situations where the training ... | open | 2024-07-16T02:49:09Z | 2024-07-19T16:45:13Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20094 | [
"feature",
"discussion"
] | profPlum | 2 |
deezer/spleeter | tensorflow | 273 | [Bug] Failed to load the native TensorFlow runtime. | ## Description
<!-- Hello. Every time I try to make a split, It always say that Failed to load the native TensorFlow runtime. Can someone help me on this -->
## Step to reproduce
<!-- Indicates clearly steps to reproduce the behavior: -->
1. Put the seperate command
2. Pressed enter
3. Got `Failed to load... | closed | 2020-02-15T23:21:02Z | 2020-04-05T12:09:00Z | https://github.com/deezer/spleeter/issues/273 | [
"bug",
"invalid"
] | ghost | 5 |
FlareSolverr/FlareSolverr | api | 274 | [yggtorrent] Exception (yggtorrent): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Cloudflare Error: Cloudflare has blocked this request. Probably your IP is banned for this site, check in your web browser.: Parse error (Test) | ### Environment
* **FlareSolverr version**: 2.1.0
* **Operating system**: Debian 10
* **Are you using Docker**: yes
* **Are you using a proxy or VPN?** no
* **Are you using Captcha Solver:** no
### Description
Hello suddenly FlareSolver stopped to work for on of my indexer. Can you please help me ?
### ... | closed | 2021-12-30T23:57:05Z | 2022-01-09T14:07:23Z | https://github.com/FlareSolverr/FlareSolverr/issues/274 | [] | MozkaGit | 2 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 62 | API Test | 图集链接:
https://www.tiktok.com/@pertcghy/video/7113056553556561195 | closed | 2022-08-08T23:44:10Z | 2022-08-09T01:20:59Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/62 | [] | Evil0ctal | 0 |
d2l-ai/d2l-en | computer-vision | 2,056 | multi-head Attention code has a big problem. | I only checked the pytorch version.
##################################################################
class MultiHeadAttention(nn.Module):
"""Multi-head attention.
Defined in :numref:`sec_multihead-attention`"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_he... | open | 2022-03-03T18:25:48Z | 2022-04-19T12:05:00Z | https://github.com/d2l-ai/d2l-en/issues/2056 | [] | Y-H-Joe | 2 |
thewhiteh4t/pwnedOrNot | api | 44 | Emails and password | closed | 2020-07-07T12:29:31Z | 2020-07-07T12:31:37Z | https://github.com/thewhiteh4t/pwnedOrNot/issues/44 | [
"invalid"
] | 33DarkStar | 0 | |
airtai/faststream | asyncio | 1,311 | Implement explicit methods annotations in Kafka and confluent brokers (Refer RabbitBroker) | closed | 2024-03-18T07:04:15Z | 2024-04-15T06:03:38Z | https://github.com/airtai/faststream/issues/1311 | [] | davorrunje | 1 | |
tflearn/tflearn | data-science | 484 | Mulitple outputs with weighted loss? | The loss of the objective function would be like loss = loss_output1 + weight2 * loss_output2.
Is there any way to implement this under the current framework?
Thanks,
Lisheng | open | 2016-11-27T22:48:15Z | 2016-12-29T18:38:03Z | https://github.com/tflearn/tflearn/issues/484 | [] | fufrank5 | 3 |
encode/databases | sqlalchemy | 404 | url parse error | Hi, my url is like this
```
mysql://jydb:G2W9iPwpAqF4R#202@rm-wz9s90lao15s6j4v2ro.mysql.rds.aliyuncs.com:3306/jydb
```
the database password contain `#`, but it split it into two pieces, what can I do for this situation except change the password, thanks. | closed | 2021-10-08T10:14:15Z | 2021-10-12T09:11:06Z | https://github.com/encode/databases/issues/404 | [
"question"
] | szj2ys | 2 |
gunthercox/ChatterBot | machine-learning | 1,419 | Time consumption for training is very high(reading from excel,55000 conversations) | I'm training data of 55000 questions and answers reading from excel with two columns,the time consumption for training the data is very high.Is there a solution for reducing time for training
alexa_bot=ChatBot("alexa_bot",trainer='chatterbot.trainers.ListTrainer',storage_adapter='chatterbot.storage.MongoDatabaseAd... | closed | 2018-09-21T13:28:46Z | 2019-08-07T23:45:17Z | https://github.com/gunthercox/ChatterBot/issues/1419 | [
"answered"
] | tghv | 2 |
piskvorky/gensim | data-science | 2,985 | Bug report of gensim official webpage | https://radimrehurek.com/gensim/auto_examples/core/run_similarity_queries.html#sphx-glr-auto-examples-core-run-similarity-queries-py
In this page, at the last second code part, the original code is :
sims = sorted(enumerate(sims), key=lambda item: -item[1])
for i, s in enumerate(sims):
print(s, documents[i])... | closed | 2020-10-19T06:31:07Z | 2020-10-19T08:09:17Z | https://github.com/piskvorky/gensim/issues/2985 | [] | yftadyz | 1 |
explosion/spaCy | machine-learning | 12,072 | How to get confidence score for each entity for custom NER model? |
* spaCy Version Used: 3.1
How to get confidence score for each entity for custom NER model?
| closed | 2023-01-09T06:27:20Z | 2023-01-10T12:12:13Z | https://github.com/explosion/spaCy/issues/12072 | [
"usage",
"feat / ner"
] | koyelseba | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.