
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Gozargah/Marzban | api | 1,086 | subscription v2ray-json does not support quic | Hi, this quic inbound works for v2ray format, but does not work for v2ray-json format, i mean subscription cannot update
inbound:
```
{
"listen": "0.0.0.0",
"port": 3636,
"protocol": "vless",
"settings": {
"clients": [],
"decryption": "none",
"fallbacks": ... | closed | 2024-07-04T23:32:48Z | 2024-08-13T21:35:09Z | https://github.com/Gozargah/Marzban/issues/1086 | [
"Bug"
] | m0x61h0x64i | 2 |
mars-project/mars | pandas | 2,585 | [BUG] TimeoutError: Timeout in request queue | When fetching dataframe to local, when chunks is greater than 200, following errors happen:
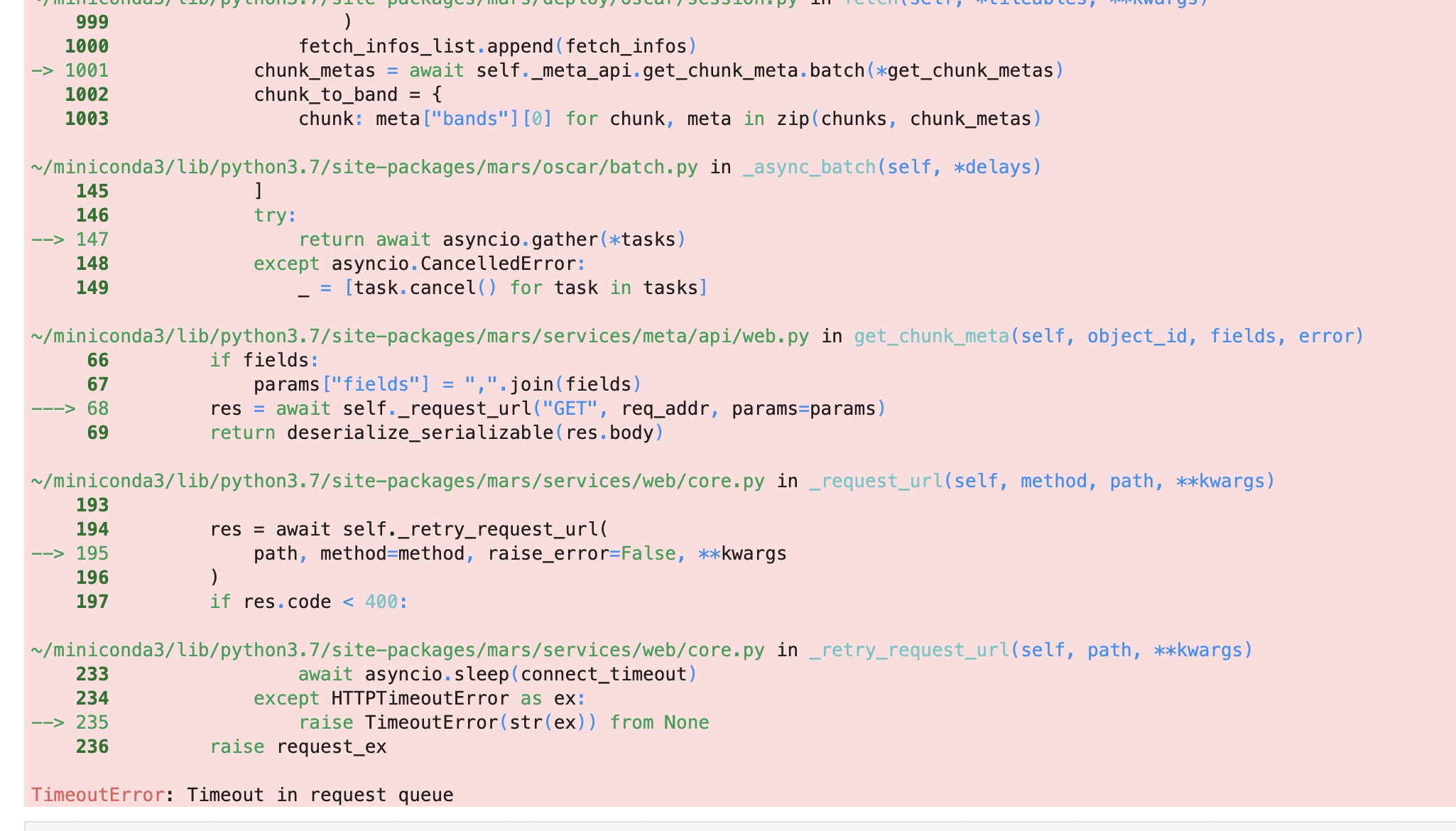 | open | 2021-11-25T10:35:52Z | 2021-11-25T10:35:52Z | https://github.com/mars-project/mars/issues/2585 | [] | chaokunyang | 0 |
roboflow/supervision | machine-learning | 1,694 | Crash when filtering empty detections: xyxy shape (0, 0, 4). | Reproduction code:
```python
import supervision as sv
import numpy as np
CLASSES = [0, 1, 2]
prediction = sv.Detections.empty()
prediction = prediction[np.isin(prediction["class_name"], CLASSES)]
```
Error:
```
Traceback (most recent call last):
File "/Users/linasko/.settler_workspace/pr/supervis... | closed | 2024-11-28T11:31:18Z | 2024-12-04T10:15:33Z | https://github.com/roboflow/supervision/issues/1694 | [
"bug"
] | LinasKo | 0 |
flasgger/flasgger | rest-api | 146 | OpenAPI 3.0 | https://www.youtube.com/watch?v=wBDSR0x3GZo | open | 2017-08-10T17:42:13Z | 2020-07-16T10:23:14Z | https://github.com/flasgger/flasgger/issues/146 | [
"hacktoberfest"
] | rochacbruno | 10 |
piskvorky/gensim | machine-learning | 3,536 | scipy probably not needed in [build-system.requires] table | <!--
**IMPORTANT**:
- Use the [Gensim mailing list](https://groups.google.com/g/gensim) to ask general or usage questions. Github issues are only for bug reports.
- Check [Recipes&FAQ](https://github.com/RaRe-Technologies/gensim/wiki/Recipes-&-FAQ) first for common answers.
Github bug reports that do not includ... | closed | 2024-06-06T13:42:33Z | 2024-07-18T12:03:09Z | https://github.com/piskvorky/gensim/issues/3536 | [
"awaiting reply"
] | filip-komarzyniec | 2 |
albumentations-team/albumentations | deep-learning | 2,097 | [Add transform] Add RandomJPEG | Add RandomJPEG which is a child of ImageCompression and has the same API as Kornia's
https://kornia.readthedocs.io/en/latest/augmentation.module.html#kornia.augmentation.RandomJPEG | closed | 2024-11-08T15:50:40Z | 2024-11-09T00:58:42Z | https://github.com/albumentations-team/albumentations/issues/2097 | [
"enhancement"
] | ternaus | 0 |
gyli/PyWaffle | data-visualization | 2 | width problems with a thousand blocks | When plotting a larger number of blocks, the width of the white space between them become unstable:
```
plt.figure(
FigureClass=Waffle,
rows=20,
columns=80,
values=[300, 700],
figsize=(18, 10)
);
plt.savefig('example.png')
```
 in v0.24 raises type object not subscriptable error | # Brief Description
The addition of deprecated_kwargs in version 0.23 causes a type object not subscriptable error.
# System Information
I'm using Python 3.8.12 on a sagemaker instance. I'm pretty sure this is the issue, that my company has us locked at 3.8.12 right now. Selecting the v.0.23 does solve the problem... | closed | 2022-11-14T16:11:14Z | 2022-11-21T06:04:41Z | https://github.com/pyjanitor-devs/pyjanitor/issues/1200 | [
"bug"
] | zykezero | 11 |
modelscope/modelscope | nlp | 1,122 | from modelscope.msdatasets import MsDataset 报错 | (Pdb) from modelscope.msdatasets import MsDataset
*** ModuleNotFoundError: No module named 'datasets.download'
(Pdb) import modelscope
(Pdb) modelscope.__version__
'1.17.0'
(Pdb) datasets.__version__
'2.0.0'
Python 3.10.15,ubuntu 22.04 系统
当前modescope 需要使用哪个版本的datasets ? | closed | 2024-12-04T10:15:02Z | 2024-12-19T12:13:28Z | https://github.com/modelscope/modelscope/issues/1122 | [] | robator0127 | 1 |
microsoft/UFO | automation | 190 | Batch Mode and Follower Mode get "No module named 'ufo.config'; 'ufo' is not a package" exception | When trying the steps with [Batch Mode](https://microsoft.github.io/UFO/advanced_usage/batch_mode/) and [Follower Mode](https://microsoft.github.io/UFO/advanced_usage/follower_mode/) based on the document, it will throw "ModuleNotFoundError: No module named 'ufo.config'; 'ufo' is not a package" exception which result t... | open | 2025-03-19T06:33:06Z | 2025-03-19T08:28:24Z | https://github.com/microsoft/UFO/issues/190 | [] | WeiweiCaiAcpt | 2 |
automl/auto-sklearn | scikit-learn | 1,573 | Add pylint linter | After we have removed all mypy ignores. | open | 2022-08-22T11:23:17Z | 2022-08-24T04:04:50Z | https://github.com/automl/auto-sklearn/issues/1573 | [
"maintenance"
] | mfeurer | 0 |
RobertCraigie/prisma-client-py | pydantic | 106 | Experimental support for the Decimal type | ## Why is this experimental?
Currently Prisma Client Python does not have access to the field metadata containing the precision of `Decimal` fields at the database level. This means that we cannot:
- Raise an error if you attempt to pass a `Decimal` value with a greater precision than the database supports, leadi... | closed | 2021-11-07T23:58:44Z | 2022-03-24T22:03:06Z | https://github.com/RobertCraigie/prisma-client-py/issues/106 | [
"topic: types",
"kind/feature",
"level/advanced",
"priority/medium"
] | RobertCraigie | 12 |
graphdeco-inria/gaussian-splatting | computer-vision | 986 | Error when installing the SIBR viewer on Ubuntu 22.04 | Hi! I had this error when I ran the installation command
`cmake -Bbuild . -DCMAKE_BUILD_TYPE=Release`
> There is no provided OpenCV library for your compiler, relying on find_package to find it
-- Found OpenCV: /usr (found suitable version "4.5.4", minimum required is "4.5")
-- Populating library imgui...
-- Po... | open | 2024-09-13T00:09:47Z | 2024-09-13T00:09:47Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/986 | [] | yiduohao | 0 |
koxudaxi/datamodel-code-generator | fastapi | 1,982 | AttributeError: 'FieldInfo' object has no attribute '<EnumName>' | **Describe the bug**
Generating from a schema with an Enum type causes `AttributeError: 'FieldInfo' object has no attribute '<EnumName>'`
**To Reproduce**
File structure after codegen should look like:
```
schemas/
├─ bean.json
├─ bean_type.json
src/
├─ __init__.py
├─ bean.py
├─ bean_type.py
main.py
```
... | closed | 2024-06-02T15:01:30Z | 2024-06-18T05:14:07Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1982 | [] | alpoi-x | 0 |
tensorflow/tensor2tensor | machine-learning | 1,523 | The evolved transformer code is the final graph or the whole procedure to find the best graph? | I'm new to neural architecture search. Thank you. | open | 2019-03-25T02:27:41Z | 2020-11-12T15:56:57Z | https://github.com/tensorflow/tensor2tensor/issues/1523 | [] | guotong1988 | 6 |
ghtmtt/DataPlotly | plotly | 257 | Display every record as a line in a scatter plot | Hi,
**Short Feature Explanation**
I am wondering if it would be possible to create a scatter plot that displays a line per record instead of a point per record.
This would be done by selecting two columns storing arrays of values for the x and y fields.
For example, with a table: Temp(xs int[], ys[]), selectin... | open | 2021-03-15T17:03:19Z | 2021-03-24T12:58:10Z | https://github.com/ghtmtt/DataPlotly/issues/257 | [
"enhancement"
] | mschoema | 6 |
apache/airflow | python | 47,970 | "consuming_dags" and "producing_tasks" do not correct account for Asset.ref | ### Body
They are direct SQLAlchemy relationships to only concrete references (DagAssetScheduleReference and TaskOutletAssetReference). Not quite sure how to fix this. Maybe they should be plain properties that return list-of-union instead? We don’t really need those relationships….
### Committer
- [x] I acknowledge... | open | 2025-03-19T18:23:11Z | 2025-03-19T18:29:31Z | https://github.com/apache/airflow/issues/47970 | [
"kind:bug",
"area:datasets"
] | uranusjr | 1 |
coqui-ai/TTS | deep-learning | 3,177 | [Bug] Loading XTTS via Xtts.load_checkpoint() | ### Describe the bug
When loading the model using `Xtts.load_checkpoint`, exception is raised as `Error(s) in loading state_dict for Xtts`, which leads to missing keys GPT embedding weights and size mismatch on Mel embedding. Even tried providing the directory which had base(v2) model checkpoints and got the same re... | closed | 2023-11-09T03:28:30Z | 2024-06-25T12:46:25Z | https://github.com/coqui-ai/TTS/issues/3177 | [
"bug"
] | caffeinetoomuch | 12 |
ultralytics/yolov5 | pytorch | 13,243 | Exporting trained yolov5 model (trained on custom dataset) to 'saved model' format changes the no. of classes and the name of classes to default coco128 values | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Export
### Bug
I trained yolov5s model to detect various logos (amazon, ups, fedex etc). The model detects the logos well.
The command used for tr... | open | 2024-08-05T07:38:31Z | 2024-10-27T13:30:48Z | https://github.com/ultralytics/yolov5/issues/13243 | [
"bug"
] | ssingh17j | 2 |
Lightning-AI/pytorch-lightning | deep-learning | 19,978 | Running `test` with LightningCLI, the program can quit before the test loop ends | ### Bug description
Within my `LightningModule`, I used `self.log_dict(metrics, on_step=True, on_epoch=True)` in `test_step`, and run with `python main.py test --config config.yaml`, with `main.py` containing only `cli = LightningCLI()`, and `config.yaml` providing both the datasets and model. The `TensorBoardLogger... | open | 2024-06-15T16:24:26Z | 2024-06-15T16:36:11Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19978 | [
"bug",
"needs triage"
] | t4rf9 | 0 |
autogluon/autogluon | computer-vision | 4,792 | [timeseries] Clarify the documentation for `known_covariates` during `predict()` | ## Description
We should clarify which values should be provided as `known_covariates` during prediction time.
The [current documentation](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-indepth.html) says:
"The timestamp index must include the values for prediction_length many time steps into the ... | open | 2025-01-14T08:03:33Z | 2025-01-14T08:05:06Z | https://github.com/autogluon/autogluon/issues/4792 | [
"API & Doc",
"enhancement",
"module: timeseries"
] | shchur | 0 |
pyeve/eve | flask | 711 | extra_response_fields should be after (not before) any on_inserted hooks on POST | Currently, `extra_response_fields` are processed after `on_insert` hooks are complete but before any `on_inserted` hooks.
It would be intuitive and great to have `extra_response_fields` processed after both of these hooks are complete - in case we changed something during `on_inserted`.
| closed | 2015-09-14T05:20:29Z | 2018-05-18T18:19:30Z | https://github.com/pyeve/eve/issues/711 | [
"enhancement",
"on hold",
"stale"
] | kenmaca | 2 |
DistrictDataLabs/yellowbrick | scikit-learn | 949 | Some plot directive visualizers not rendering in Read the Docs | Currently on Read the Docs (develop branch), a few of our visualizers that use the plot directive (#687) are not rendering the plots:
- [Classification Report](http://www.scikit-yb.org/en/develop/api/classifier/classification_report.html)
- [Silhouette Scores](http://www.scikit-yb.org/en/develop/api/cluster/silhoue... | closed | 2019-08-15T20:58:39Z | 2019-08-29T00:03:24Z | https://github.com/DistrictDataLabs/yellowbrick/issues/949 | [
"type: bug",
"type: documentation"
] | rebeccabilbro | 1 |
plotly/dash | flask | 2,754 | [BUG] Dropdown options not rendering on the UI even though it is generated | **Describe your context**
Python Version -> `3.8.18`
`poetry show | grep dash` gives the below packages:
```
dash 2.7.0 A Python framework for building reac...
dash-bootstrap-components 1.5.0 Bootstrap themed components for use ...
dash-core-components 2.0.0 Core... | closed | 2024-02-08T13:47:01Z | 2024-05-31T20:12:51Z | https://github.com/plotly/dash/issues/2754 | [] | malavika-menon | 2 |
nikitastupin/clairvoyance | graphql | 100 | 500 internal server error | Hey tool showing 500 ERROR on loop, i then burp Intercepted my clairvoyance traffic
clairvoyance -H "Authorization: Bearer" -H "X-api-key:" -x "127.1:8080" -k http://example.com/graphql
**Body it sending**
`{"query": "query { reporting essential myself tours platform load affiliate labor immediately admin nursin... | open | 2024-05-15T15:16:51Z | 2024-08-27T06:13:53Z | https://github.com/nikitastupin/clairvoyance/issues/100 | [
"bug"
] | 649abhinav | 1 |
predict-idlab/plotly-resampler | plotly | 341 | Dash Callback says FigureResampler is not JSON serializable | Apologies, this is more of a "this broke and I don't know what went wrong" type of issue. What it looks like so far is that everything in the dash dashboard ive made works except for the plotting. This is the exception i get:
```
dash.exceptions.InvalidCallbackReturnValue: The callback for `[<Output `data-plot.figure`>... | closed | 2025-03-05T20:37:21Z | 2025-03-06T18:06:15Z | https://github.com/predict-idlab/plotly-resampler/issues/341 | [] | FDSRashid | 1 |
matplotlib/matplotlib | matplotlib | 29,799 | [ENH]: set default color cycle to named color sequence | ### Problem
It would be great if I could put something like this in my matplotlibrc to use the petroff10 color sequence by default:
```
axes.prop_cycle : cycler('color', 'petroff10')
```
### Proposed solution
Currently if a single string is supplied we try to interpret as a list of single character colors
https://gi... | open | 2025-03-24T16:57:39Z | 2025-03-24T17:42:14Z | https://github.com/matplotlib/matplotlib/issues/29799 | [
"New feature",
"topic: rcparams",
"topic: color/cycle"
] | rcomer | 2 |
horovod/horovod | pytorch | 3,795 | Seen with tf-head: ModuleNotFoundError: No module named 'keras.optimizers.optimizer_v2' | Problem with tf-head / Keras seen in CI, for instance at https://github.com/horovod/horovod/actions/runs/3656223581/jobs/6180240570
```
___________ ERROR collecting test/parallel/test_tensorflow_keras.py ____________
ImportError while importing test module '/horovod/test/parallel/test_tensorflow_keras.py'.
Hint: ... | closed | 2022-12-09T14:25:50Z | 2022-12-10T09:54:00Z | https://github.com/horovod/horovod/issues/3795 | [
"bug"
] | maxhgerlach | 1 |
plotly/dash-table | plotly | 700 | `Backspace` on cell only reflects deleted content after cell selection changes | In the recording below, `backspace` is hit right after the cell selection and the displayed cell content only updates after the selected cell changed.

| open | 2020-02-20T17:08:28Z | 2024-01-25T21:34:23Z | https://github.com/plotly/dash-table/issues/700 | [
"dash-type-bug",
"regression"
] | Marc-Andre-Rivet | 2 |
AirtestProject/Airtest | automation | 1,205 | airtest自动安装的urllib3库, 需要旧版 (比如1.26.17) 才能通过uid连接ios手机 | **描述问题bug**
airtest自动安装的urllib3库, 需要旧版 (比如1.26.17) 才能通过uuid连接ios手机, 否则会提示wda未准备好并且在20秒等待后报错, 当你将 urllib3库改为旧版本可以解决这个问题, 控制端mac和windows 设备端ios15/16/17 下均是如此.
**python 版本:** `python3.11`
**airtest 版本:** `1.3.3`
**设备:**
- 手机型号: [iphone se2]
- 控制端: [mbp m1/windows11]
- 手机系统: [ios15/ios16/ios17]
| open | 2024-04-15T06:33:57Z | 2024-04-15T06:41:39Z | https://github.com/AirtestProject/Airtest/issues/1205 | [] | yh1121yh | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 2,155 | [NODRIVER] Add ability to capture and return screenshot as base64 - changes are ready to PR merge | Hello, I would like to create a PR to (as title suggest) giving the base64 of the screenshots instead of saving files locally
Here is the commit: https://github.com/falmar/nodriver/commit/d903cca8aac2406ff0c4462785b61d5ce474256c
it includes and demo example
EDIT: I'm unable to create PR on the nodriver [repository](... | closed | 2025-03-07T12:29:58Z | 2025-03-10T07:48:53Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/2155 | [] | falmar | 2 |
xinntao/Real-ESRGAN | pytorch | 209 | 希望能增加带去除扫描图片网纹的超分辨率算法 | 在进行扫图的杂志 周边 同人志等超分辨率的时候 网纹也会被放大得非常明显 不知道有没有办法先把网纹去除后再进行超分辨率呢? | open | 2022-01-02T15:53:01Z | 2022-01-02T15:53:01Z | https://github.com/xinntao/Real-ESRGAN/issues/209 | [] | sistinafibe | 0 |
2noise/ChatTTS | python | 3 | 运行到一半就自动停止了 | 
如图,运行到一半就停止了。。
系统:linux
python版本:3.12
另外建议写个requirements吧 | closed | 2024-05-28T02:50:19Z | 2024-05-28T11:29:23Z | https://github.com/2noise/ChatTTS/issues/3 | [] | luosaidage | 1 |
kizniche/Mycodo | automation | 442 | install mycodo error??? | what happen ?! How to install mycodo version lower to 5.6.10? I'm want to install mycodo version 5.5.24. how can i do?
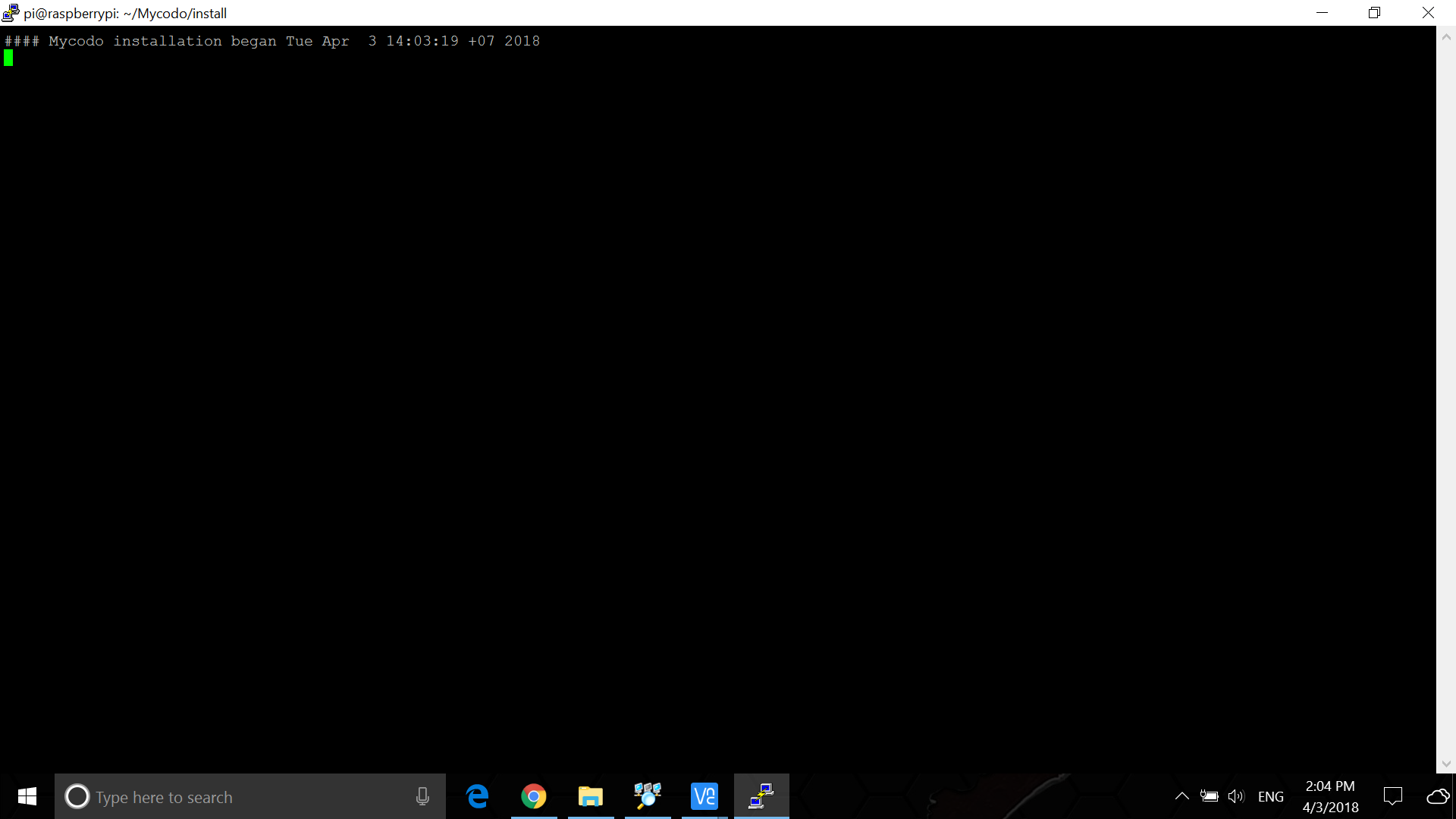 | closed | 2018-04-03T07:11:43Z | 2018-04-06T00:42:52Z | https://github.com/kizniche/Mycodo/issues/442 | [] | bike2538 | 4 |
InstaPy/InstaPy | automation | 6,296 | Not posting the comment when mentioning any account. |
## InstaPy configuration
InstaPy Version: 0.6.14-AS
I am trying to comment on a hashtag by mentioning some page with @..... but it seems like when I am using the @.... it doesn't post the comment instead it skips it. Anyone else is facing the same issue? What is the solution?
| open | 2021-08-16T09:16:11Z | 2021-10-10T00:35:52Z | https://github.com/InstaPy/InstaPy/issues/6296 | [] | moshema10 | 6 |
StackStorm/st2 | automation | 6,160 | Provide support for passing "=" in a string | **alias yaml**
`---
name: "launch_quasar"
action_ref: "quasar.quasar1"
description: "launch a quasar execution"
formats:
- display: "*<command>* *<payload>*"
representation:
- "{{ command }} {{ payload }}"
result:
format: |
```{{ execution.result.result }}```
`
**action yaml**
name: qu... | open | 2024-03-04T06:08:03Z | 2024-03-04T06:09:32Z | https://github.com/StackStorm/st2/issues/6160 | [] | sivudu47 | 0 |
assafelovic/gpt-researcher | automation | 645 | UnicodeEncodeError: 'charmap' codec can't encode character '\U0001f50e' in position 0: character maps to <undefined> | I'm testing a simple next.js/fastapi app on Windows 11, using the example FastAPI from https://docs.tavily.com/docs/gpt-researcher/pip-package (btw I think this example is missing the query parameter)
It's a very simple parameter report test with api call/url of
```
const query = encodeURIComponent("What is 4... | closed | 2024-07-06T05:39:07Z | 2024-07-07T03:38:54Z | https://github.com/assafelovic/gpt-researcher/issues/645 | [] | sonicviz | 5 |
gunthercox/ChatterBot | machine-learning | 2,033 | Creating a chatbot | Errors in importing the chatterbot and installing Chatbot to python
| closed | 2020-08-27T15:48:33Z | 2025-02-26T11:43:08Z | https://github.com/gunthercox/ChatterBot/issues/2033 | [] | Anwarite | 4 |
netbox-community/netbox | django | 18,327 | error after update to NetBox 4.2.0: requires_internet | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
v4.2.0
### Python Version
3.12
### Steps to Reproduce
After updating NetBox to 4.20 using the Git method. Login Page works fine if not logged in. After login the error occurs.
### Expected Behavior
Can Login norm... | closed | 2025-01-07T15:13:52Z | 2025-01-07T15:36:49Z | https://github.com/netbox-community/netbox/issues/18327 | [
"type: bug",
"status: duplicate"
] | Kujo01243 | 4 |
babysor/MockingBird | deep-learning | 794 | PPG训练时的报错,请帮忙看看 | PPG预处理很顺利,ppg2mel.yaml路径也改了,但是这个错误提示怎么都解决不了,请大家帮忙看看能否有经验分享下。
D:\MockingBird-main>python ppg2mel_train.py --config .\ppg2mel\saved_models\ppg2mel.yaml --oneshotvc
Traceback (most recent call last):
File "D:\MockingBird-main\ppg2mel_train.py", line 67, in <module>
main()
File "D:\MockingBird-main\ppg2mel_t... | open | 2022-12-01T14:03:43Z | 2022-12-03T02:45:27Z | https://github.com/babysor/MockingBird/issues/794 | [] | benny1227 | 1 |
psf/requests | python | 6,830 | PreparedRequests can't bypass URL normalization when proxies are used | Related to #5289, where [akmalhisyam found a way to bypass URL normalization using PreparedRequests](https://github.com/psf/requests/issues/5289#issuecomment-573632625), however, the solution doesn't work when you have proxies provided.
## Expected Result
This should be able to explicitly set the request URL with... | open | 2024-11-18T17:06:17Z | 2025-01-27T18:44:36Z | https://github.com/psf/requests/issues/6830 | [] | shelld3v | 1 |
microsoft/nlp-recipes | nlp | 285 | [ASK] Add ReadMe for subfolder unit under tests | ### Description
Add a ReadaMe file descriping the scope of all unit tests. Are we having full coverage of units tests for all utils and notebooks?
### Other Comments
**Principles of NLP Documentation**
Each landing page at the folder level should have a ReadMe which explains -
○ Summary of what this folder ... | closed | 2019-08-13T22:13:37Z | 2019-08-16T20:56:48Z | https://github.com/microsoft/nlp-recipes/issues/285 | [
"documentation",
"release-blocker"
] | dipanjan77 | 1 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,345 | Verify possibility to restrict the content security policy preventing usage of inline CSS styles | ### Proposal
This ticket is to keep track of the activities related to verify possibility to restrict the content security policy preventing usage of inline styles and the possible implementations necessary to achieve this goal on globaleaks v5 as previously achieved on client globaleaks 4.
At the moment it seems... | closed | 2024-12-03T13:44:20Z | 2024-12-06T16:14:48Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4345 | [
"T: Enhancement",
"C: Client",
"C: Backend",
"F: Security"
] | evilaliv3 | 1 |
bigscience-workshop/petals | nlp | 282 | http://health.petals.ml/ shows "broken" in the same timeframe i spin up a docker petals | Hi there.
I think your project is awesome and want to support you by sharing my resources.
I noticed an outage on bloom and bloomz, yesterday when i used a dockercompose to spin up a new docker image.
I noticed a second outage just now on bloom, when i started the colab on https://colab.research.google.com/drive... | closed | 2023-03-09T12:15:15Z | 2023-03-09T23:59:01Z | https://github.com/bigscience-workshop/petals/issues/282 | [] | worldpeaceenginelabs | 1 |
biolab/orange3 | pandas | 7,009 | Metavariables are not excluded in feature selection methods | A longstanding issue is that metavariables are not excluded from methods. For example, in "find informative projections" for scatter plots, they appear as suggestions. Also, in feature suggestions, the metas are included. If there are many, the automatic feature selection breaks down. This is a nuisance, as metas often... | open | 2025-01-30T13:21:18Z | 2025-02-19T10:01:28Z | https://github.com/biolab/orange3/issues/7009 | [
"needs discussion",
"bug report"
] | lareooreal | 4 |
scrapy/scrapy | python | 5,944 | Improve statscollector.py along with test_stats.py and test_link.py | ## Summary
Remove unused code from statscollector.py and improve test suits in test_stats.py and test_link.py
## Motivation
I was working with the project and reviewed some of the code trying to understand how the stats collection is working and I noticed that some of the code hasn't been implemented in the st... | closed | 2023-06-04T20:58:39Z | 2023-06-21T09:20:59Z | https://github.com/scrapy/scrapy/issues/5944 | [] | DeanDro | 1 |
chatopera/Synonyms | nlp | 56 | 请问下相似度计算公式是什么? | 请问下相似度计算公式是什么?
目前我用的多的是textrank + word2vec
请问本工具的算法是?我想做下对比,可能的话我把我的算法也pr过来
| closed | 2018-03-19T15:48:23Z | 2018-03-24T23:05:03Z | https://github.com/chatopera/Synonyms/issues/56 | [] | Wall-ee | 2 |
wkentaro/labelme | computer-vision | 459 | Add shortcut for ‘Add Point to Edge’ | Hello, i really appreciate your work, the software really helps me a lot.
I want to add shortcut for ‘Add Point to Edge’, but it does not work. The mouse needs to be in a specific location, how can I add shortcut? | closed | 2019-08-07T11:10:25Z | 2019-08-23T10:00:40Z | https://github.com/wkentaro/labelme/issues/459 | [] | stormlands | 2 |
mkhorasani/Streamlit-Authenticator | streamlit | 71 | Saving cookie failed when deploying the app with docker | Hey everybody,
I implemented the auth as described in your README and tested it locally on my machine - works fine. Then i deployed the same app using Docker and the authentification does not work as expected. Seems like the client-side cookies are not saved when using Docker.
Does anyone know the problem or ev... | open | 2023-06-12T07:23:31Z | 2024-07-27T14:42:48Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/71 | [
"help wanted"
] | ArnoSchiller | 3 |
QingdaoU/OnlineJudge | django | 50 | 2.0重构版规划 | 本OJ大约是1年前开始开发的,目前逐渐暴露出一些问题。打算进行一个比较大的重构,主要包括
- [x] vue.js重写所有前端页面
- [x] 前端后端的国际化,多语言和时区
- [x] 导入导出题目(但是目前考虑的hustoj的FPS格式还有些问题,可能在当前版本中也会做)
- [x] 更方便的添加多编程程序语言支持,统一配置规则(有些问题还没解决)题目选择可以使用的语言
- [x] 比赛的OI模式(排名,查看单独测试数据是否通过等)
- [x] SPJ更加方便的添加代码和测试
- [x] 超级管理员 - 管理所有 普通管理员- 默认创建小组内比赛和不能创建题目题目,但是可以通过两个选项允许
- [x]... | closed | 2016-06-24T05:32:44Z | 2019-01-05T06:15:41Z | https://github.com/QingdaoU/OnlineJudge/issues/50 | [] | virusdefender | 27 |
JaidedAI/EasyOCR | pytorch | 1,335 | FileNotFoundError in `download_and_unzip` when running multiple easyocr's concurrently | When we try to run two or more easyocr's concurrently, we get an error in the downloader. I am guessing that the download logic uses a fixed download filepath?
```shell
EasyOcrModel(
File ".../lib/python3.10/site-packages/docling/models self.reader = easyocr.Reader(config["lang"])
File ".../lib/python3.10/site-pa... | open | 2024-11-18T21:39:58Z | 2024-12-18T10:27:48Z | https://github.com/JaidedAI/EasyOCR/issues/1335 | [] | starpit | 2 |
tflearn/tflearn | tensorflow | 960 | TypeError: only integer scalar arrays can be converted to a scalar index | Exception in thread Thread-8:
Traceback (most recent call last):
File "C:\Users\Bhumit\Anaconda3\lib\threading.py", line 916, in _bootstrap_inner
self.run()
File "C:\Users\Bhumit\Anaconda3\lib\threading.py", line 864, in run
self._target(*self._args, **self._kwargs)
File "C:\Users\Bhumit\Anaconda3\lib\site-packag... | open | 2017-11-17T13:02:41Z | 2017-11-17T13:02:41Z | https://github.com/tflearn/tflearn/issues/960 | [] | AdivarekarBhumit | 0 |
blb-ventures/strawberry-django-plus | graphql | 256 | Using input_mutation with a None return type throws an exception | I have a mutation that looks something like
```python
@gql.django.input_mutation(permission_classes=[IsAdmin])
def mutate_thing(
self,
info: Info,
) -> None:
# do the thing
return None
```
This throws an exception when I try to generate my schema:
```
File "/Users... | open | 2023-07-02T21:39:36Z | 2023-07-03T13:15:57Z | https://github.com/blb-ventures/strawberry-django-plus/issues/256 | [] | taobojlen | 1 |
DistrictDataLabs/yellowbrick | matplotlib | 560 | Add 'Yellowbrick for Teachers' slidedeck to docs | **Describe the solution you'd like**
Add a sample slide deck to the docs for machine learning teachers to use in teaching model selection & visual diagnostics
**Is your feature request related to a problem? Please describe.**
I've been asked a few times by other teachers of machine learning if I had any slides or ... | closed | 2018-08-10T18:38:19Z | 2018-08-13T15:17:14Z | https://github.com/DistrictDataLabs/yellowbrick/issues/560 | [] | rebeccabilbro | 3 |
gee-community/geemap | jupyter | 2,011 | error with 'geemap.requireJS' | <!-- Please search existing issues to avoid creating duplicates. -->
### Environment Information

### Description
error with 'geemap.requireJS'
### What I Did
```
import geemap
WS = geemap.requireJ... | closed | 2024-05-14T02:45:35Z | 2024-05-16T18:05:29Z | https://github.com/gee-community/geemap/issues/2011 | [
"bug"
] | Dushuai12138 | 5 |
liangliangyy/DjangoBlog | django | 191 | Centos 7 + apache2 部署 | 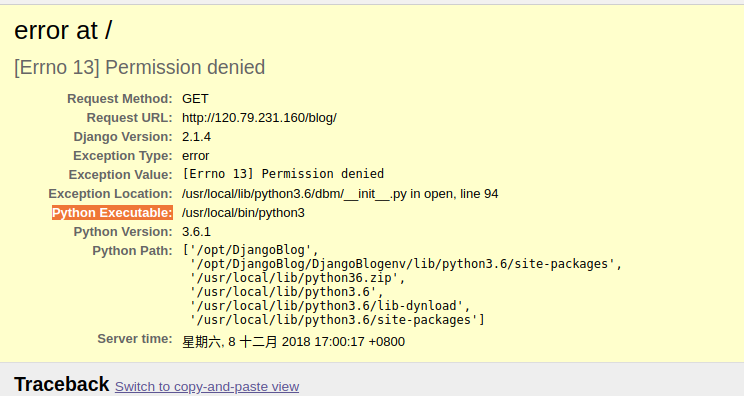
请问这是什么错误啊...弄了一天实在没头绪 | closed | 2018-12-08T09:11:07Z | 2018-12-11T10:22:49Z | https://github.com/liangliangyy/DjangoBlog/issues/191 | [] | FishWoWater | 5 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 166 | [BUG] Tiktok接口是挂了吗? | 最近发现接口频繁返回:{"status_code":0,"status_msg":"","block_code":2018},貌似现在强制性需要提供X-Argus、X-Ladon两个算参数才能返回了,但我发现douyin.wtf的接口是可以正常拿到数据的,有点疑惑,难道是因为ip的问题? | closed | 2023-03-08T02:24:42Z | 2023-03-09T02:35:00Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/166 | [
"BUG"
] | juedi998 | 5 |
pydantic/pydantic-ai | pydantic | 496 | Configuration and parameters for `all_messages()` and `new_messages()` | It would be helpful if the `all_messages()` and `new_messages()` methods had an option to exclude the system prompt like `all_messages(system_prompt=False)`. This would probably be a better default behavior too. Why?
Well, when do you use these methods?
### 1. Passing messages to the client/frontend
```python
... | open | 2024-12-19T12:06:26Z | 2025-02-17T04:24:12Z | https://github.com/pydantic/pydantic-ai/issues/496 | [
"Feature request"
] | pietz | 7 |
amidaware/tacticalrmm | django | 1,913 | tactical meshagent memory leak | **Server Info (please complete the following information):**
- OS: Ubuntu 22.04.4
- Browser: chrome
- RMM Version (as shown in top left of web UI): v0.18.2
**Installation Method:**
- [ x ] Standard
**Agent Info (please complete the following information):**
- Agent version (as shown in the 'Summary' tab... | closed | 2024-07-08T21:54:19Z | 2024-07-10T05:10:02Z | https://github.com/amidaware/tacticalrmm/issues/1913 | [] | slapplebags | 1 |
MaxHalford/prince | scikit-learn | 144 | Not compatible with pandas 2.0.0 | I'm having dependency conflicts when trying to install prince and pandas==2.0.0 in the same environment. | closed | 2023-04-17T20:42:03Z | 2023-04-18T12:56:10Z | https://github.com/MaxHalford/prince/issues/144 | [] | JuanCruzC97 | 4 |
scikit-learn/scikit-learn | python | 30,699 | Make scikit-learn OpenML more generic for the data download URL | According to https://github.com/orgs/openml/discussions/20#discussioncomment-11913122 our code hardcodes where to find the OpenML data.
I am not quite sure what needs to be done right now but maybe @PGijsbers has some suggestions (not urgent at all though, I am guessing you have bigger fish to fry right now 😉) or may... | closed | 2025-01-22T09:13:44Z | 2025-02-25T15:09:52Z | https://github.com/scikit-learn/scikit-learn/issues/30699 | [
"Enhancement",
"module:datasets"
] | lesteve | 3 |
oegedijk/explainerdashboard | dash | 147 | Add support to Imbalanced-learn pipelines in ClassifierExplainer | When I try to generate a `ClassifierExplainer``on a imblearn pipeline I get the following **error**:
```
TypeError: All intermediate steps should be transformers and implement fit and transform or be the string 'passthrough'
'SMOTETomek(random_state=42)' (type <class 'imblearn.combine._smote_tomek.SMOTETomek'>) does... | closed | 2021-09-17T12:18:59Z | 2021-12-26T21:25:17Z | https://github.com/oegedijk/explainerdashboard/issues/147 | [] | Abdelgha-4 | 6 |
jowilf/starlette-admin | sqlalchemy | 563 | Bug: sorting by datetime does not work | hi
postgres+asyncpg
starlette-admin==0.13.2
models.py
```python
class Log(Base):
created_at: Mapped[datetime] = mapped_column(DateTime(timezone=True), server_default=func.now())
...
```
```
2024-07-17 12:25:35.227 UTC [4632] ERROR: operator does not exist: timestamp with time zone >= character varyi... | open | 2024-07-17T12:29:13Z | 2025-03-19T14:43:56Z | https://github.com/jowilf/starlette-admin/issues/563 | [
"bug"
] | Kaiden0001 | 1 |
youfou/wxpy | api | 46 | 如何根据接收的消息在多线程中控制注册消息? | 文档中说明要在额外的线程控制开关注册消息。
但我在代码中测试过程中,发现在单个线程中也能个进行开关注册。
想问问作者多线程中如何实现,谢谢 | closed | 2017-05-04T09:37:39Z | 2017-05-06T08:20:56Z | https://github.com/youfou/wxpy/issues/46 | [
"question"
] | cxyfreedom | 1 |
coqui-ai/TTS | pytorch | 3,142 | Fairseq voice cloning | ### Describe the bug
There seems to be an issue of activating voice conversion in Coqui when using _Fairseq_ models. Argument `--speaker_wav` works fine on identical text with the XTTS model, but with Fairseq it seems to be ignored. Have tried both .wav and .mp3, different lengths, file locations/names, with and wit... | closed | 2023-11-05T17:02:20Z | 2024-11-28T20:16:24Z | https://github.com/coqui-ai/TTS/issues/3142 | [
"bug"
] | Poccapx | 21 |
ultralytics/ultralytics | computer-vision | 19,550 | Yolov11-12 tensorboard images section | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hello I'm collage student that using yolo models for object detection. I got... | open | 2025-03-06T09:53:21Z | 2025-03-11T17:57:57Z | https://github.com/ultralytics/ultralytics/issues/19550 | [
"question",
"detect"
] | MehmetKaTR | 7 |
sanic-org/sanic | asyncio | 2,982 | Github Actions need updating | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
GitHub actions for publishing a package are on an old version, which uses a deprecated version of Node JS.
<img width="1109" alt="image" src="https://github.com/sanic... | open | 2024-06-30T12:38:42Z | 2024-06-30T15:28:45Z | https://github.com/sanic-org/sanic/issues/2982 | [] | prryplatypus | 3 |
davidteather/TikTok-Api | api | 262 | great job!! I want post a comment under a post,is there have any api for this? | **Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear an... | closed | 2020-09-14T15:44:09Z | 2020-09-14T16:23:52Z | https://github.com/davidteather/TikTok-Api/issues/262 | [
"feature_request"
] | Gh-Levi | 3 |
thunlp/OpenPrompt | nlp | 140 | Use 2.1_conditional_generation.py , after fine-tuning, it only generates the same char. Why ? | use 2.1_conditional_generation.py in datasets/CondGen/webnlg_2017/
generated txt: ''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''''
| closed | 2022-04-15T10:08:09Z | 2022-05-30T09:14:56Z | https://github.com/thunlp/OpenPrompt/issues/140 | [] | 353xiong | 4 |
torchbox/wagtail-grapple | graphql | 297 | grapple vs wagtail-grapple | Initially I foundy myself confused by the difference between grapple and wagtail grapple. I had to pip install wagtail-grapple, but then import grapple in my code. It would be nice if the package only had one canonical name. | closed | 2023-01-13T15:09:56Z | 2024-09-20T09:49:55Z | https://github.com/torchbox/wagtail-grapple/issues/297 | [] | dopry | 14 |
marcomusy/vedo | numpy | 1,053 | Is delete_cells_by_point_index parallelisable? | Current code:
```
def delete_cells_by_point_index(self, indices):
"""
Delete a list of vertices identified by any of their vertex index.
See also `delete_cells()`.
Examples:
- [delete_mesh_pts.py](https://github.com/marcomusy/vedo/tree/master/examples/basic/delete_mesh_p... | open | 2024-02-16T02:52:30Z | 2024-02-16T12:22:56Z | https://github.com/marcomusy/vedo/issues/1053 | [] | JeffreyWardman | 1 |
matterport/Mask_RCNN | tensorflow | 2,191 | How to reduce inference detection time | I am using CPU for detection, when I run model.detect([image], verbose=1), it takes more than 25 seconds to detect for single image.
Is there any way to reduce the detection time? | open | 2020-05-17T15:32:42Z | 2020-11-19T10:31:00Z | https://github.com/matterport/Mask_RCNN/issues/2191 | [] | Dgs29 | 3 |
JaidedAI/EasyOCR | pytorch | 856 | TypeError: __init__() got an unexpected keyword argument 'detection' | Hi, I am trying to run this line ;
_reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
But it is throwing me the following error;
TypeError: __init__() got an unexpected keyword argument 'detection'
| closed | 2022-09-17T19:06:30Z | 2022-09-17T19:14:53Z | https://github.com/JaidedAI/EasyOCR/issues/856 | [] | sabaina-Haroon | 1 |
deezer/spleeter | deep-learning | 751 | [Discussion] your question |
ERROR: Cannot uninstall 'llvmlite'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall. | closed | 2022-04-17T21:48:13Z | 2022-04-29T09:14:45Z | https://github.com/deezer/spleeter/issues/751 | [
"question"
] | sstefanovski21 | 0 |
LAION-AI/Open-Assistant | machine-learning | 3,744 | Can't open dashboard | ERROR: type should be string, got "\r\nhttps://github.com/LAION-AI/Open-Assistant/assets/29770761/254db19d-a284-41ca-8612-99103df12fac\r\n\r\n" | closed | 2024-01-06T16:14:36Z | 2024-01-06T17:25:55Z | https://github.com/LAION-AI/Open-Assistant/issues/3744 | [] | DRYN07 | 1 |
benlubas/molten-nvim | jupyter | 291 | [Help] How to use cell magic like "%%time", "!ls" without pyright complaining? | First of all big thank you for this wonderful plugin. I'm trying to use cell magic like so:
<img width="726" alt="Image" src="https://github.com/user-attachments/assets/0c41a1ee-1e75-4429-be26-b8601487cac3" />
They would execute perfectly fine via ipython, but pyright complains about the syntax. Is there a way to sup... | closed | 2025-03-02T13:48:28Z | 2025-03-04T17:12:45Z | https://github.com/benlubas/molten-nvim/issues/291 | [] | kanghengliu | 6 |
kubeflow/katib | scikit-learn | 2,149 | Consolidate katib-cert-generator to katib-controller | /kind feature
**Describe the solution you'd like**
[A clear and concise description of what you want to happen.]
I would like to consolidate the katib-cert-generator to the katib-controller.
Currently, if we use the standalone cert-generator to generate self-signed certs for the webhooks, we can not use `Fail` ... | closed | 2023-04-24T13:40:15Z | 2023-08-04T19:31:23Z | https://github.com/kubeflow/katib/issues/2149 | [
"kind/feature",
"release/0.16"
] | tenzen-y | 4 |
huggingface/diffusers | deep-learning | 10,745 | Unloading multiple loras: norms do not return to their original values | When unloading from multiple loras on flux pipeline, I believe that the norm layers are not restored [here](https://github.com/huggingface/diffusers/blob/464374fb87610c53b2cf81e08d3df628fada3ce4/src/diffusers/loaders/lora_pipeline.py#L1575).
Shouldn't we have:
```python
if len(transformer_norm_state_dict) > 0... | open | 2025-02-07T15:43:12Z | 2025-03-17T15:03:25Z | https://github.com/huggingface/diffusers/issues/10745 | [
"stale"
] | christopher5106 | 26 |
ultralytics/yolov5 | pytorch | 13,044 | Parameters Fusion | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
How to integrate some parameters from imported external modules into the entire YOLOv5 mo... | closed | 2024-05-28T08:24:22Z | 2024-10-20T19:46:44Z | https://github.com/ultralytics/yolov5/issues/13044 | [
"question",
"Stale"
] | znmzdx-zrh | 9 |
JaidedAI/EasyOCR | pytorch | 1,028 | RuntimeError: DataLoader worker (pid(s) 4308) exited unexpectedly | I get this error on training and don't know what is causing it
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "C:\Users\FireAngelEmpire\anaconda3\lib\multiprocessing\spawn.py", line 116, in spawn_main
exitcode = _main(fd, parent_sentinel)
File "C:\Users\FireAngelEmpire\anaco... | open | 2023-05-23T22:58:06Z | 2025-01-21T13:53:56Z | https://github.com/JaidedAI/EasyOCR/issues/1028 | [] | deadworldisee | 1 |
kizniche/Mycodo | automation | 1,313 | Add "lock" feature to functions & outputs pages similar to Dashboard "lock" button function. | Sometimes when accessing the Mycodo web GUI from a phone, functions and outputs can accidentally get moved and jumbled if the drag handles are touched when trying to scroll the screen.
Would it be possible to add a lock feature like on the Dashboard pages that prevents any of the widgets from being moved?
I now h... | open | 2023-06-13T08:09:19Z | 2023-08-11T03:40:47Z | https://github.com/kizniche/Mycodo/issues/1313 | [
"enhancement"
] | LucidEye | 1 |
ultralytics/ultralytics | machine-learning | 19,838 | where is yolo3D? | ### Search before asking
- [x] I have searched the Ultralytics [issues](https://github.com/ultralytics/ultralytics/issues) and found no similar feature requests.
### Description
where is yolo3D?
### Use case
_No response_
### Additional
_No response_
### Are you willing to submit a PR?
- [ ] Yes I'd like to h... | open | 2025-03-24T08:35:01Z | 2025-03-24T10:43:16Z | https://github.com/ultralytics/ultralytics/issues/19838 | [
"enhancement",
"question"
] | xinsuinizhuan | 2 |
CPJKU/madmom | numpy | 92 | refactor add_arguments of all FilteredSpectrogramProcessor and MultiBandSpectrogramProcessor | Most of the duplicated code could be refactored to `audio.filters`.
| closed | 2016-02-18T12:56:16Z | 2016-02-24T08:21:30Z | https://github.com/CPJKU/madmom/issues/92 | [] | superbock | 0 |
iterative/dvc | data-science | 9,891 | dvc data status: handle broken symlinks to cache | Managing shared caches is difficult, and so sometimes we are naughty and just delete data from the cache directly. (This is much easier than trying to manage `dvc gc -p`.)
The result is dangling symlinks, and `dvc data status` trips over these with ...
```
ERROR: unexpected error - [Errno 2] No such file or direct... | open | 2023-08-31T04:51:52Z | 2023-09-06T03:26:34Z | https://github.com/iterative/dvc/issues/9891 | [] | johnyaku | 2 |
nvbn/thefuck | python | 1,177 | Feature Request: rvm | Would be great to add support for rvm, such as in the following example:
```
mensly ~> rvm use 2.7.2
Required ruby-2.7.2 is not installed.
To install do: 'rvm install "ruby-2.7.2"'
mensly ~> fuck
No fucks given
mensly ~> rvm install "ruby-2.7.2"
``` | open | 2021-03-22T02:41:38Z | 2021-07-23T16:31:17Z | https://github.com/nvbn/thefuck/issues/1177 | [
"help wanted",
"hacktoberfest"
] | mensly | 0 |
jupyter-book/jupyter-book | jupyter | 1,912 | Footnote does not show up with Utterances. | ### Describe the bug
Hi, I wish this is not a duplicated issue and I am sorry for my poor English in advance.
**context**
I have used Utterances as commenting service on my Jupyter Book and I just found out that a footnote does not show up with Utterances.
I would like to note that I have manually inserted Utte... | open | 2023-01-21T04:22:04Z | 2023-01-24T06:45:16Z | https://github.com/jupyter-book/jupyter-book/issues/1912 | [
"bug"
] | HiddenBeginner | 1 |
slackapi/bolt-python | fastapi | 350 | Problem with globals in Socket Mode + Flask? | Hi! I use SocketMode in my application in conjunction with Flask, in order to make a health check of the probes, so I use in this form:
```bash
@flask_app.route('/readiness')
def readiness():
return {"status": "Ok"}
if __name__ == "__main__":
SocketModeHandler(app, settings.slack_app_token).connect()
... | closed | 2021-05-25T13:34:29Z | 2021-06-19T01:52:34Z | https://github.com/slackapi/bolt-python/issues/350 | [
"question",
"area:adapter"
] | De1f364 | 7 |
tflearn/tflearn | tensorflow | 987 | Interface for 3D max pooling inconsistent. | `tflearn.layers.conv.max_pool_1d` and `tflearn.layers.conv.max_pool_2d` default strides is equal to the kernel size. For`tflearn.layers.conv.max_pool_3d` this is not the case, there the default strides equals to 1.
While not really a bug this could lead to confusion with people which are used to the 1d and 2d interf... | open | 2017-12-30T09:48:31Z | 2017-12-30T09:49:14Z | https://github.com/tflearn/tflearn/issues/987 | [] | deeplearningrobotics | 0 |
jowilf/starlette-admin | sqlalchemy | 391 | Enhancement: Customizable profile menu | **Is your feature request related to a problem? Please describe.**
The profile menu has only one button: logout. I'm proposing to implement a way to extend this menu from the python side. Maybe a hook like `auth_provider`. `profile_menu` could have a bunch of items in it and we could define the functionality with `exp... | closed | 2023-11-08T09:19:11Z | 2023-12-04T00:53:33Z | https://github.com/jowilf/starlette-admin/issues/391 | [
"enhancement"
] | hasansezertasan | 0 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 452 | [BUG] 一个星期前使用Web app过并且成功下载了200+视频,但是这个星期突然不行了,按照视频教程更换了Cookie,仍然不行 | ***发生错误的平台?***
如:抖音
***发生错误的端点?***
如:Web APP
***提交的输入值?***
如:短视频链接
***是否有再次尝试?***
如:是,发生错误后X时间后错误依旧存在。
***你有查看本项目的自述文件或接口文档吗?***
如:有,并且很确定该问题是程序导致的。
这是我的Cookie,已经按照了视频教程重复过多次,并且在一个星期前已经成功下载了200+视频,但是不知道为什么最近这几天突然出现视频教程中的情况突然不能解析了,有可能是我的Cookie除了问题吗?
ttwid=1%7C-0dflMMeBDApYTLvDCHU5M9zmhMbAw... | closed | 2024-07-17T08:47:35Z | 2024-07-27T21:53:09Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/452 | [
"BUG"
] | Losoy1 | 6 |
deeppavlov/DeepPavlov | tensorflow | 876 | DeepPavlov Bert 10x slower than Pytorch Pretrained Bert | Hi,
I modified the default DeepPavlov Bert to only output the pooled output (I followed the instructions given in [my previous issue](https://github.com/deepmipt/DeepPavlov/issues/825)).
However, this modified DeepPavlov Bert version is 10x slower than the [Pytorch Pretrained Bert](https://github.com/huggingface/... | closed | 2019-06-11T13:09:42Z | 2020-05-13T09:48:54Z | https://github.com/deeppavlov/DeepPavlov/issues/876 | [] | lcswillems | 1 |
pydata/pandas-datareader | pandas | 453 | RLS 0.6.0 | There have been a lot of changes in the past few days.
Please report any issues here. I there are none raised by the start of next week, 0.6.0 will be released then.
- [x] Add release date to what's new
- [x] Tag release | closed | 2018-01-18T16:36:28Z | 2018-01-29T21:42:08Z | https://github.com/pydata/pandas-datareader/issues/453 | [] | bashtage | 24 |
opengeos/streamlit-geospatial | streamlit | 39 | issue | how to download data from this app
and how to add districts,towns,etc
how to add lat and long from live APi | closed | 2022-04-12T16:39:32Z | 2022-05-19T13:15:40Z | https://github.com/opengeos/streamlit-geospatial/issues/39 | [] | Zar-Jamil | 1 |
lundberg/respx | pytest | 138 | Consider changing the badges | [](https://github.com/lundberg/respx/actions/workflows/test.yml) [](ht... | closed | 2021-03-03T21:13:58Z | 2021-07-06T08:37:35Z | https://github.com/lundberg/respx/issues/138 | [] | lundberg | 0 |
ets-labs/python-dependency-injector | asyncio | 865 | Implement Python dependency injector library in Azure Functions | ### Description of Issue
I am trying to implement the dependency injector for Python Azure functions.
i tried to implement it using a Python library called Dependency Injector.
pip install dependency-injector [https://python-dependency-injector.ets-labs.org](https://python-dependency-injector.ets-labs.org/)
However, ... | open | 2025-03-03T05:29:25Z | 2025-03-03T05:29:25Z | https://github.com/ets-labs/python-dependency-injector/issues/865 | [] | Ramkisubramanian | 0 |
pydantic/logfire | fastapi | 813 | Cannot incorporate VCS root_path | I am struggling to get the root_path component of my VCS configuration to work. I've tried configuring via `logfire.CodeSource()` as well as setting the `OTEL_RESOURCE_ATTRIBUTES` environment variable (not at the same time).
My current configuration is as follows -
```
logfire.configure(
environment=os.environ["E... | open | 2025-01-21T16:14:51Z | 2025-01-23T16:28:00Z | https://github.com/pydantic/logfire/issues/813 | [] | fwinokur | 6 |
PaddlePaddle/PaddleHub | nlp | 2,195 | paddlehub 引用sklearn 报 cannot load any more object with static TLS 错误 | 系统环境
paddle.__version__ 2.4.0-rc0
#### 具体代码
!/usr/bin/env python
#-*- coding=utf8 -*-
import os
import sys
import paddlehub as hub
module = hub.Module(name="lac")
test_text = '小明硕士毕业于中国科学院计算所,后在日本京都大学深造'
results = module.lexical_analysis(texts=test_text)
###############
Traceback (most recent ... | open | 2023-01-12T06:42:38Z | 2023-01-13T09:38:14Z | https://github.com/PaddlePaddle/PaddleHub/issues/2195 | [] | hnlslyp | 1 |
JaidedAI/EasyOCR | machine-learning | 746 | Export to ONNX and use ONNX Runtime, working. Guide. | This is an explanation of how to export the recognition model and the detection model to ONNX format. Then a brief explanation of how to use ONNX Runtime to use these models.
ONNX is an intercompatibility standard for AI models. It allows us to use the same model in different types of programming languages, operati... | open | 2022-06-05T22:38:00Z | 2025-03-05T11:58:29Z | https://github.com/JaidedAI/EasyOCR/issues/746 | [] | Kromtar | 42 |
rthalley/dnspython | asyncio | 599 | tsigkey not recognized by peer with 2.0.0 (but works with 1.16.0) | Something changed in how tsigkey names are transmitted to the DNS server. This is the exact same code with 2.0.0 vs 1.16.0:
> (pyddns) mira/scanner (64) $ ./dnspython-delete-name.py usenet CNAME kamidake
> Deleting key 'usenet', of type 'CNAME' with value 'kamidake' in 'apricot.com'
> Traceback (most recent call ... | closed | 2020-10-28T23:17:35Z | 2021-10-21T06:28:38Z | https://github.com/rthalley/dnspython/issues/599 | [] | scanner | 3 |
ansible/ansible | python | 84,075 | `ansible-test` host properties detection sometimes tracebacks in CI | ### Summary
Specifically, this https://github.com/ansible/ansible/blob/f1f0d9bd5355de5b45b894a9adf649abb2f97df5/test/lib/ansible_test/_internal/docker_util.py#L327C31-L327C37 causes an `IndexError`, meaning that blocks is sometimes a list of 2 elements and not 3.
### Issue Type
Bug Report
### Component Name... | open | 2024-10-08T13:34:04Z | 2025-02-24T19:00:57Z | https://github.com/ansible/ansible/issues/84075 | [
"bug",
"has_pr"
] | webknjaz | 14 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.