
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
graphdeco-inria/gaussian-splatting | computer-vision | 473 | ValueError: too many values to unpack | I got an error when run train.py. It seems to occur in the GaussianRasterizer.
Optimizing
Output folder: ./output/92694154-4 [16/11 10:11:53]
Tensorboard not available: not logging progress [16/11 10:11:53]
Reading camera 2/2 [16/11 10:11:53]
Loading Training Cameras [16/11 10:11:53]
Loading Test Cameras [16/11 1... | closed | 2023-11-16T10:21:12Z | 2024-10-19T19:34:57Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/473 | [] | cfchi | 5 |
tensorflow/tensor2tensor | machine-learning | 962 | Timeseries problems on TPU throw exception "unexpected keyword argument 'drop_remainder'" | Hello,
When training on both timeseries problems, timeseries_toy_problem and timeseries_synthetic_data_series10_samples100k, I get an exception, unexpected keyword argument 'drop_remainder'. Any tips?
Thanks!
update: the following change in problem.py seems to solve the problem in this case:
dataset.batch(batch... | closed | 2018-07-29T20:53:51Z | 2019-07-24T18:31:52Z | https://github.com/tensorflow/tensor2tensor/issues/962 | [] | me-sh | 1 |
kymatio/kymatio | numpy | 632 | Indexing 2D (Request) | Hi,
When using for instance
```
J, L= 3,4
S = Scattering2D(J=J,shape=(64,64),L=L,backend='torch', max_order=2)
```
I have the coefficient in a array with typically such dimension [Cin,25,16,16]. Now, if I use `out_type='list'`, then I get a list of dictionary
```
Slist = Scattering2D(J=J,shape=(64,64),L=L,bac... | open | 2020-10-07T07:32:53Z | 2021-03-18T09:57:56Z | https://github.com/kymatio/kymatio/issues/632 | [] | jecampagne | 9 |
pydantic/logfire | pydantic | 542 | LLM tool call not shown for streamed response | ### Description
The Logfire UI nicely shows the tool call by an LLM for non-streamed responses
<img width="669" alt="image" src="https://github.com/user-attachments/assets/d363085f-ca73-4af9-a31f-9d74c0294836">
But for streamed responses the Assistant box is empty.
<img width="663" alt="image" src="https://... | closed | 2024-10-25T05:52:57Z | 2024-11-13T11:57:51Z | https://github.com/pydantic/logfire/issues/542 | [
"bug"
] | jackmpcollins | 2 |
matplotlib/matplotlib | matplotlib | 29,646 | [Bug]: Markers with string-type integer values are converted to integers in cycler and matplotlibrc | ### Bug summary
When creating a cycler with a `"marker"` property value contains strings that _could_ be converted to integers, they are always converted to integers, even if the string value is valid and the intended value. This is most obvious with the list `["1", "2"]`; which is distinctly different from `[1, 2]`. ... | open | 2025-02-19T12:48:32Z | 2025-02-20T15:21:29Z | https://github.com/matplotlib/matplotlib/issues/29646 | [] | conradhaupt | 6 |
netbox-community/netbox | django | 18,023 | Extend `register_model_view()` to handle list views | ### Proposed Changes
We currently use `register_model_view()` to register detail views (edit, delete, etc.) for models, which obviates the need to declare explicit URL paths for each. This could be extended to support list views as well. For example, a common set of views might look like this:
```python
# List vie... | closed | 2024-11-15T15:55:37Z | 2025-02-21T03:05:51Z | https://github.com/netbox-community/netbox/issues/18023 | [
"status: accepted",
"type: feature",
"topic: plugins",
"netbox"
] | jeremystretch | 1 |
PokemonGoF/PokemonGo-Bot | automation | 5,740 | [issue] [dev] Bot incubates shorter eggs first | ### Expected Behavior
`Bot Incubates longer eggs first, on both breakable and unbreakable`
### Actual Behavior
`Bot Incubates shorter eggs first.`
### Your FULL config.json (remove your username, password, gmapkey and any other private info)
```
{
"websocket_server": false,
"heartbeat_threshold": 10,
"en... | closed | 2016-09-30T09:43:34Z | 2016-10-03T07:12:09Z | https://github.com/PokemonGoF/PokemonGo-Bot/issues/5740 | [] | scarfield | 4 |
mckinsey/vizro | pydantic | 630 | [Docs] Py.Cafe code snippets to-do list | Here's an issue (public, so we can ask for contributions to it from our readers) to record the bits and pieces left to do on following the [introduction of py.cafe to our docs' examples](https://github.com/mckinsey/vizro/pull/569).
- [ ] Change the requirement in `hatch.toml` when py.cafe release their mkdocs plugin... | open | 2024-08-15T08:46:02Z | 2025-01-14T09:40:02Z | https://github.com/mckinsey/vizro/issues/630 | [
"Docs :spiral_notepad:"
] | stichbury | 1 |
AirtestProject/Airtest | automation | 818 | airtest.core.android.ADB.devices不返回ipv6远程连接的设备 | **描述问题bug**
airtest.core.android.ADB.devices不返回ipv6远程连接的设备
原因在于对应源码219行中的正则并未匹配这种情况
[ipv6ip%interface]:port
adb devices

源码

### Steps to Reproduce
1. Create a new project with some initial labels
2. After the project is created, add some more labels
3. Query ht... | closed | 2024-09-19T04:31:02Z | 2024-10-11T09:58:07Z | https://github.com/cvat-ai/cvat/issues/8457 | [
"bug"
] | BeanBagKing | 3 |
TracecatHQ/tracecat | fastapi | 467 | Sign in issue | I cant sign in to the default admin account using `admin@domain.com` and password `password` and sign up not working too

| closed | 2024-10-28T05:55:30Z | 2024-10-28T09:37:40Z | https://github.com/TracecatHQ/tracecat/issues/467 | [] | Harasisco | 16 |
modoboa/modoboa | django | 2,429 | Creating a disabled account imply an active (internal) alias | Testing against behavior similarly to #2120 it appears that creating a disabled account imply creation of an active (internal) alias.
# Impacted versions
* OS Type: Debian
* OS Version: Buster
* Database Type: PostgreSQL
* Database version: 11
* Modoboa: 1.17.3 (also on master branch)
# Steps to reproduce
... | closed | 2021-12-29T17:03:07Z | 2022-05-13T12:53:35Z | https://github.com/modoboa/modoboa/issues/2429 | [
"bug"
] | fpoulain | 6 |
comfyanonymous/ComfyUI | pytorch | 6,447 | MAC STUDIO M1MAX Torch not compiled with CUDA enabled | ### Your question
MAC STUDIO M1MAX run CogVideoX-5b-1.5 with ComfyUI,
Use python3 main.py --force-fp16 --use-split-cross-attentio --cpu to start ComfyUI.
But always throw exception -- AssertionError: Torch not compiled with CUDA enabled.
I was use CPU to run is model ,
and check pip3 install --pre torch torchvisi... | open | 2025-01-13T03:59:25Z | 2025-02-13T17:04:50Z | https://github.com/comfyanonymous/ComfyUI/issues/6447 | [
"User Support"
] | qinxiaoyi-stack | 6 |
albumentations-team/albumentations | machine-learning | 1,634 | [Tech debt] Improve interface for GridDropOut | * `unit_size_min`, `unit_size_max` => `unit_size_range`
* `shift_x`, `shift_y` => `shift`
=>
We can update transform to use new signature, keep old as working, but mark as deprecated.
----
PR could be similar to https://github.com/albumentations-team/albumentations/pull/1704 | closed | 2024-04-05T19:33:52Z | 2024-06-22T01:37:49Z | https://github.com/albumentations-team/albumentations/issues/1634 | [
"good first issue",
"Tech debt"
] | ternaus | 0 |
jadore801120/attention-is-all-you-need-pytorch | nlp | 89 | Missing $ on loop variable at preprocess.perl line 1. | Thanks for making this available. Trying to run this code on windows and getting the following error:
Missing $ on loop variable at preprocess.perl line 1.
When I run
for l in en de; do for f in data/multi30k/*.$l; do if [[ "$f" != *"test"* ]]; then sed -i "$ d" $f; fi; done; done
for l in en de; do for f in ... | closed | 2019-02-09T20:11:42Z | 2019-12-08T11:48:44Z | https://github.com/jadore801120/attention-is-all-you-need-pytorch/issues/89 | [] | ankur6ue | 4 |
huggingface/transformers | nlp | 36,292 | [Version: 4.49.0] Qwen2.5-VL is not supported in vLLM because of transformers | ### System Info
error: Model architectures Qwen2 5 VLForConditionalGeneration' failed to be inspected. Please check the logs for more details.

right now people say that they are using methods like:
1. pip install --upgrade git+... | closed | 2025-02-20T01:44:22Z | 2025-03-12T12:06:17Z | https://github.com/huggingface/transformers/issues/36292 | [
"bug"
] | usun1997 | 29 |
scikit-tda/kepler-mapper | data-visualization | 120 | Error in visualize (possibly) due to color_function scaling and histogram creation | Hi everyone,
I've been using kepler-mapper for analyzing some data, and found that certain choices of the color_function in mapper.visualize causes an error or incorrect output.
**To Reproduce**
The following is a minimal working example of the bug.
```
import kmapper as km
import numpy as np
import sklearn... | closed | 2018-10-31T07:56:03Z | 2018-11-02T15:27:55Z | https://github.com/scikit-tda/kepler-mapper/issues/120 | [] | emerson-escolar | 3 |
scikit-learn/scikit-learn | python | 30,950 | Potential Problem in the Computation of Adjusted Mutual Info Score | ### Describe the bug
It seems to me that for clusters of size 2 and 4, the AMI yields unexpected results of 0 instead of 1, if all items belong to different clusters.
### Steps/Code to Reproduce
Sample Code to Reproduce:
```python
>>> from sklearn.metrics.cluster import adjusted_mutual_info_score
>>> print(adjus... | open | 2025-03-06T09:01:58Z | 2025-03-24T10:57:51Z | https://github.com/scikit-learn/scikit-learn/issues/30950 | [
"Bug",
"Needs Investigation"
] | LinguList | 4 |
pandas-dev/pandas | pandas | 61,031 | BUG: `ValueError: ndarray is not C-contiguous` for `cummax` on nullable dtypes | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [x] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | open | 2025-03-02T16:21:03Z | 2025-03-05T01:44:09Z | https://github.com/pandas-dev/pandas/issues/61031 | [
"Bug",
"Groupby",
"NA - MaskedArrays",
"Transformations"
] | MarcoGorelli | 3 |
PokeAPI/pokeapi | api | 1,104 | Server is down | Schema no aviable in graphQL | closed | 2024-06-02T19:26:10Z | 2024-06-03T13:19:47Z | https://github.com/PokeAPI/pokeapi/issues/1104 | [] | Waanma | 1 |
yzhao062/pyod | data-science | 241 | COF and SOD huge bugs? | Hi all. Something is happening that I cannot understand, I'm doing hyperparameter tuning to all proximity based algorithms with RandomSearchCV form sklearn and only COF and SOD have problems. What is happening is the following: the constructor parameters are all None even though I'm passing values to it. I tried to ch... | closed | 2020-10-24T19:28:15Z | 2020-10-31T16:36:27Z | https://github.com/yzhao062/pyod/issues/241 | [] | dcabanas | 11 |
falconry/falcon | api | 2,157 | When following raw URL recipe based on RAW_URI, it breaks routing in TestClient | I'm building REST API with many %-encoded slashes in URI (i.e., as data, not path separator). For example, request URI `/book/baking-book/document/sweet%2Fcheescake.md` will never reach the route declared as `/book/{book}/document/{path}`.
I understand that's not Falcon's fault, but the WSGI server, which "eats" %-e... | closed | 2023-07-14T17:00:44Z | 2023-11-30T20:26:40Z | https://github.com/falconry/falcon/issues/2157 | [
"bug",
"good first issue"
] | liborjelinek | 5 |
django-oscar/django-oscar | django | 3,797 | Custom group prices | In a lot of ecommerce frameworks, customer group prices exists. Or even specific prices for a single user.
I think this can and should be a default feature in oscar.
Django groups already exists, so I guess this can be used for it.
Would this be something that can and may be implemented in oscar? | closed | 2021-10-30T20:48:01Z | 2023-06-23T13:45:06Z | https://github.com/django-oscar/django-oscar/issues/3797 | [] | thecodeiot | 2 |
geex-arts/django-jet | django | 313 | Wrong spelling of template variable | Since I've got the template options settings set to `'string_if_invalid': "<Couldn't render variable '%s'>"` I'm seeing an error that `'module.pre_contenta'` isn't found. It seems like it's a simple typo in the template:
https://github.com/geex-arts/django-jet/blob/552191c5be551741b3349aa104c92435702f62e5/jet/dashbo... | open | 2018-04-03T14:54:54Z | 2018-04-03T14:54:54Z | https://github.com/geex-arts/django-jet/issues/313 | [] | lauritzen | 0 |
JaidedAI/EasyOCR | deep-learning | 581 | Pypy support? | Has anyone tried using PyPy with this project? My attempts so far on windows with anaconda have been failures, wondering if I'm wasting time | closed | 2021-11-01T07:23:29Z | 2022-08-07T05:00:33Z | https://github.com/JaidedAI/EasyOCR/issues/581 | [] | ckcollab | 0 |
sherlock-project/sherlock | python | 1,601 | False Negative for twitter search | False negative when trying to scan usernames on that have attached twitters. This could lead to false reports and would be greatly appreciated if it's fixed. This is for every username I've tried that have valid accounts but show up as false negatives for example holiday8993
| closed | 2022-10-31T11:17:26Z | 2023-02-04T17:17:35Z | https://github.com/sherlock-project/sherlock/issues/1601 | [
"false negative"
] | Cr7pt0nic | 4 |
koaning/scikit-lego | scikit-learn | 218 | [BUG] fix gaussian methos | The gaussian methods are a bit nasty now.
- they use **kwargs instead of strict params
- they don't support the bayesian variant
it'd be great if these could be added. | closed | 2019-10-17T21:13:19Z | 2019-10-20T15:49:37Z | https://github.com/koaning/scikit-lego/issues/218 | [
"bug"
] | koaning | 0 |
pydantic/logfire | pydantic | 855 | LLM structured output support (client.beta.chat.completions.parse) | ### Description
Hi,
Structured output in https://platform.openai.com/docs/guides/structured-outputs has a different response format and is using a different method, which https://logfire.pydantic.dev/docs/integrations/llms/openai/#methods-covered does not seem to be supporting currently.
```python
completion = client... | open | 2025-02-11T12:18:05Z | 2025-02-11T12:18:05Z | https://github.com/pydantic/logfire/issues/855 | [
"Feature Request"
] | thedotedge | 0 |
pydata/bottleneck | numpy | 183 | bn.nansum on array with np.newaxis added dimension | Bottleneck's nansum (and nanmean, etc) doesn't seem to give the right answer when dimensions are added with np.newaxis. An example is:
In [27]: a = np.ones((2,2))
In [28]: a[1, :] = np.nan
In [29]: bn.nansum(a) # Correct
Out[29]: 2.0
In [30]: bn.nansum(a[..., np.newaxis]) # **Wrong**
Out[30]: 4.0
In [... | closed | 2018-01-02T17:28:09Z | 2018-01-03T16:47:45Z | https://github.com/pydata/bottleneck/issues/183 | [] | ng0 | 4 |
ymcui/Chinese-BERT-wwm | nlp | 80 | 能否获得其他维数的向量? | 例如50维或100维? | closed | 2019-12-31T08:01:10Z | 2019-12-31T09:04:57Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/80 | [] | lhy2749 | 2 |
netbox-community/netbox | django | 18,110 | Allow multiple config templates attached to a device | ### NetBox version
v4.1.7
### Feature type
Data model extension
### Triage priority
N/A
### Proposed functionality
Extend the config template field on a device/virtual machine to allow for attaching multiple config templates.
### Use case
We have multiple stages of a device lifespan, and one of the stages is t... | open | 2024-11-26T21:31:16Z | 2025-03-17T15:04:14Z | https://github.com/netbox-community/netbox/issues/18110 | [
"type: feature",
"status: under review"
] | rodvand | 4 |
abhiTronix/vidgear | dash | 28 | Bug: sys.stderr.close() throws ValueError bug in WriteGear class | ### Bug Description:
The use of `sys.stderr.close()` at line: https://github.com/abhiTronix/vidgear/blob/8d1fd2afec1e42b5583c37d411a29a9f25e0e2fb/vidgear/gears/writegear.py#L230 breaks stderr and throws `ValueError: I/O operation on closed file` at the output. This also results in hidden tracebacks, since tracebacks... | closed | 2019-07-07T17:47:01Z | 2019-07-08T02:51:04Z | https://github.com/abhiTronix/vidgear/issues/28 | [
"BUG :bug:",
"SOLVED :checkered_flag:"
] | abhiTronix | 1 |
InstaPy/InstaPy | automation | 6,310 | unfollow_users method isn't working. Activity is being restricted. | ## Expected Behavior
Unfollow users.
## Current Behavior
Showing an alert from instagram
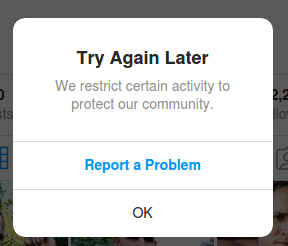
The unfollow action is not blocked on the account only with InstaPy, selenium and geckodriver.
I figu... | closed | 2021-09-11T07:51:33Z | 2021-09-19T17:19:31Z | https://github.com/InstaPy/InstaPy/issues/6310 | [] | Dieg0x17 | 1 |
amidaware/tacticalrmm | django | 1,342 | Default Option for "Take Control" | **Is your feature request related to a problem? Please describe.**
We generally do not want to take over a workstation unnoticed by the user. It's prone to error to remember to right click on the connect button and choose the appropriate option.
**Describe the solution you'd like**
An Option to change the default ... | closed | 2022-11-04T15:52:52Z | 2022-11-04T16:09:43Z | https://github.com/amidaware/tacticalrmm/issues/1342 | [] | Byolock | 1 |
Yorko/mlcourse.ai | data-science | 354 | Topic 9 Kaggle template broken | https://www.kaggle.com/kashnitsky/topic-9-part-2-time-series-with-facebook-prophet

| closed | 2018-09-24T12:50:54Z | 2018-10-04T14:12:09Z | https://github.com/Yorko/mlcourse.ai/issues/354 | [
"minor_fix"
] | Vozf | 1 |
scikit-learn/scikit-learn | python | 30,181 | DOC grammar issue in the governance page | ### Describe the issue linked to the documentation
In the governance page at line
https://github.com/scikit-learn/scikit-learn/blob/59dd128d4d26fff2ff197b8c1e801647a22e0158/doc/governance.rst?plain=1#L70
"GitHub" is referred to as `github`
However, in the other references, such as at
https://github.com/scikit-... | closed | 2024-10-30T20:01:44Z | 2024-11-05T07:31:27Z | https://github.com/scikit-learn/scikit-learn/issues/30181 | [
"Documentation"
] | AdityaInnovates | 5 |
vastsa/FileCodeBox | fastapi | 292 | 文本复制失败 | 点击按钮复制,会弹出失败。
我不确定是不是因为版本问题,因为我看官网demo是没有复制按钮的。
使用的是昨天装的 lanol/filecodebox:beta
 | closed | 2025-03-13T09:03:23Z | 2025-03-15T14:56:47Z | https://github.com/vastsa/FileCodeBox/issues/292 | [] | BlackWhite2000 | 0 |
rthalley/dnspython | asyncio | 574 | dnspython fails to see SRV record from headless Kubernetes service | NOTE: Also posted to [StackOverflow](https://stackoverflow.com/questions/63430708/dnspython-fails-to-see-srv-record-from-headless-kubernetes-service) in case the behavior described below is not a bug in `dnspython`.
I am able to retrieve the SRV record for a headless Kubernetes service from the command line, but I'm... | closed | 2020-08-15T20:58:05Z | 2020-08-15T22:00:37Z | https://github.com/rthalley/dnspython/issues/574 | [] | borenstein | 2 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,986 | [Bug]: Why does the quality on pics look bad? | ### Checklist
- [X] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-06-10T07:10:49Z | 2024-06-12T01:56:32Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15986 | [] | blehh666 | 3 |
vitalik/django-ninja | pydantic | 552 | [BUG] | **Describe the bug**
test_api.py turns off auth checking in the test for patient coverage.
we should restore the previous value at the end of the test, in case if affects other tests.
| closed | 2022-09-05T17:02:21Z | 2022-09-06T15:42:53Z | https://github.com/vitalik/django-ninja/issues/552 | [] | ntwyman | 1 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 1,185 | Can run demo_cli.py or demo_toolbox.py | I have followed the steps and I'm stuck here, couldn't find any similar issue either.
Traceback (most recent call last):
File "demo_toolbox.py", line 5, in <module>
from toolbox import Toolbox
File "C:\Users\SwedishMusic\Desktop\test\voice\Real-Time-Voice-Cloning\toolbox\__init__.py", line 9, in <module>
... | open | 2023-04-05T17:55:52Z | 2023-04-05T17:55:52Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1185 | [] | SwedishMusic | 0 |
taverntesting/tavern | pytest | 89 | py2.7 unicode problem | In the begin project, i set sys.defalutcoding to utf-8.
The expected body is {'body': {'message': u'\u624b\u673a\u53f7\u683c\u5f0f\u4e0d\u6b63\u786e'}}. they are unicode type.
however, actual body is Response: '<Response [400]>' ({
"message": "\u624b\u673a\u53f7\u683c\u5f0f\u4e0d\u6b63\u786e"
} . they are str ty... | closed | 2018-04-13T02:23:58Z | 2018-05-29T09:38:18Z | https://github.com/taverntesting/tavern/issues/89 | [] | Fosity | 2 |
matplotlib/matplotlib | data-visualization | 29,141 | [MNT]: Colormap refactoring | ### Summary
This is a collection of topics on colormaps to improve the API and also to eventually make colormaps immutable.
### Tasks
- [x] Deprecate parameter `ListedColormap(..., N=...)`
It's beyond the scope of `ListedColormap` to post-process the given list of colors.
PR: #29135
- [x] Narrow the type... | open | 2024-11-14T14:53:03Z | 2025-01-31T18:31:51Z | https://github.com/matplotlib/matplotlib/issues/29141 | [
"topic: color/color & colormaps",
"Maintenance"
] | timhoffm | 0 |
torchbox/wagtail-grapple | graphql | 169 | Object type and/or field level authentication? | Hello. Any pointers regarding applying (custom) authentication logic to object types or fields? Not quite sure where in the chain, if at all, this could be injected.
E.g. similarly to:
- https://docs.graphene-python.org/projects/django/en/latest/authorization/#user-based-queryset-filtering
- https://docs.graphen... | closed | 2021-04-17T20:06:05Z | 2021-08-21T21:20:48Z | https://github.com/torchbox/wagtail-grapple/issues/169 | [
"type: Feature"
] | PeterDekkers | 9 |
flasgger/flasgger | api | 74 | `import: external_yaml` should work for multiple paths | Ẁhen a function is decorated multiple times with `@swag_from` the `import` should take care of the original root_path.
reference: https://github.com/rochacbruno/flasgger/blob/master/flasgger/base.py#L65-L79 | open | 2017-03-30T01:38:12Z | 2018-09-10T05:31:54Z | https://github.com/flasgger/flasgger/issues/74 | [
"hacktoberfest"
] | rochacbruno | 0 |
microsoft/nni | data-science | 5,730 | mint | {
"p": "GRC20",
"op": "mint",
"tick": "GitHub",
"amt": "2000"
} | open | 2023-12-30T19:22:09Z | 2023-12-30T19:22:09Z | https://github.com/microsoft/nni/issues/5730 | [] | monirulnaim897 | 0 |
harry0703/MoneyPrinterTurbo | automation | 291 | docker安装 | $docker-compose up
ERROR: In file './docker-compose.yml', service 'x-common-volumes' must be a mapping not an array | closed | 2024-04-19T08:09:53Z | 2024-04-19T08:33:57Z | https://github.com/harry0703/MoneyPrinterTurbo/issues/291 | [] | a631069724 | 1 |
flasgger/flasgger | rest-api | 271 | Validate breaks when a property is referenced | Hello,
I am using a nested reference, which is documented successfully by Flasgger. However, Flasgger breaks when I try to use validation for it.
For example, this code doesn't allow the ```requestBody``` endpoint to be called:
```
# BOILER PLATE CODE:
from flask import Flask, jsonify, request
from flasgge... | closed | 2018-12-07T02:46:38Z | 2020-04-16T02:48:58Z | https://github.com/flasgger/flasgger/issues/271 | [] | josepablog | 4 |
autogluon/autogluon | computer-vision | 4,521 | [github] Add issue templates for bug reports per module | Add issue templates for bug reports per module so it is easier to track for developers and lowers ambiguity. | open | 2024-10-04T03:15:18Z | 2024-11-25T22:47:16Z | https://github.com/autogluon/autogluon/issues/4521 | [
"API & Doc"
] | Innixma | 0 |
slackapi/bolt-python | fastapi | 335 | Getting operation timeout after immediate ack() call | Hey!
In the api doc you says that i should return immediately wiht ack() method call to avoid operation timeout message.
I have an AWS lambda function with SlackRequestHandler, and I immediately call ack() after i receive a slash command, but i always get operation timeout message.
After ack() i have some business... | closed | 2021-05-10T15:46:10Z | 2021-05-12T07:44:25Z | https://github.com/slackapi/bolt-python/issues/335 | [
"question"
] | tomeszmh | 2 |
iperov/DeepFaceLab | deep-learning | 840 | Image turns black after GAN is turned on | Things have been going well with the new version but I just turned again on with my Titan video card and I got the image you see below. I did it on my RTX 8000 and it doesn’t do this.
 since we bumped to `numpy-1.20` (see .https://github.com/NixOS/nixpkgs/issues/118449). The problems seems to come to the fact that `numpy` adds new warnings, and some tests in `cartopy` re... | closed | 2021-04-11T19:35:09Z | 2021-04-11T23:37:12Z | https://github.com/SciTools/cartopy/issues/1760 | [] | lsix | 2 |
coqui-ai/TTS | pytorch | 3,347 | [Bug] Num. instances discarded samples: 252. VITS finetuning | ### Describe the bug
Hello, I'm finetuning the VITS model on my 979 audio dataset.
I have followed this tutorial (https://tts.readthedocs.io/en/latest/formatting_your_dataset.html) on how to format my dataset and it looks just fine.
I am able to start training but right before the first epoch I see the log:
... | closed | 2023-12-01T01:37:52Z | 2023-12-06T20:32:43Z | https://github.com/coqui-ai/TTS/issues/3347 | [
"bug"
] | nicholasguimaraes | 1 |
dynaconf/dynaconf | flask | 747 | [bug] Cannot merge using env var with dict that has empty string as its key | **SOLUTION IN** https://github.com/pulp/pulpcore/pull/3146/files
**Describe the bug**
I tried to use an env_var to merge a dictionary, but it has the key '' which is not able to work, although I expected it to work.
**To Reproduce**
I tried to set this variable:
` PULP_LOGGING={'dynaconf_merge': True, 'logg... | closed | 2022-05-03T14:55:40Z | 2022-08-29T17:08:13Z | https://github.com/dynaconf/dynaconf/issues/747 | [
"bug",
"Not a Bug"
] | bmbouter | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 891 | Not getting saved checkpoints on Google Colab | When I am trying to train on my dataset, I'm not getting checkpoints saved after every 5 epochs. I know the problem with google colab, that it has issues with visdom. I'm okay with visdom not working, but even the checkpoints aren't saved in the checkpoints directory. Please help. | closed | 2020-01-04T07:59:52Z | 2020-01-05T06:53:25Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/891 | [] | himansh1314 | 3 |
pytorch/pytorch | deep-learning | 148,938 | [triton 3.3] `AOTInductorTestABICompatibleGpu.test_triton_kernel_tma_descriptor_1d_dynamic_False_cuda` | ### 🐛 Describe the bug
1. Update triton to `release/3.3.x` https://github.com/triton-lang/triton/tree/release/3.3.x
2. run `python test/inductor/test_aot_inductor.py -vvv -k test_triton_kernel_tma_descriptor_1d_dynamic_False_cuda`
Possibly an easier repro is
```
TORCHINDUCTOR_CPP_WRAPPER=1 python test/inductor/test_... | open | 2025-03-11T02:00:45Z | 2025-03-13T16:58:07Z | https://github.com/pytorch/pytorch/issues/148938 | [
"oncall: pt2",
"module: inductor",
"upstream triton",
"oncall: export",
"module: aotinductor",
"module: user triton"
] | davidberard98 | 1 |
guohongze/adminset | django | 78 | 返回数据对象而不是数据 | 
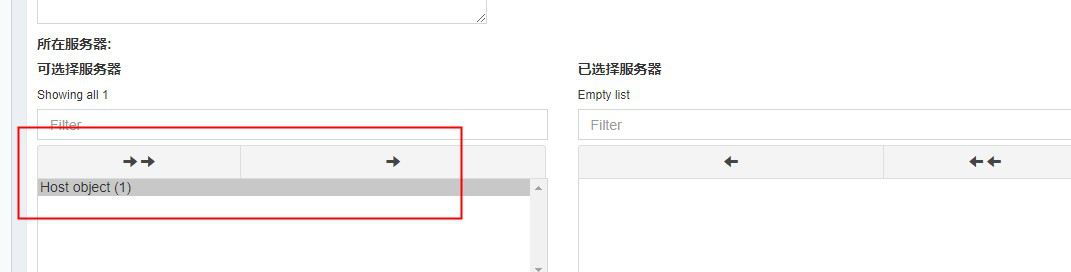
改成python3,mysql之后
所有外键返回的都是对象,而不是实际的数据
请介绍下这个bug的原理及修复方法(目前在静态页面上修改了几个明显的,其他的都没修改) | open | 2018-11-07T14:06:20Z | 2018-12-04T04:42:42Z | https://github.com/guohongze/adminset/issues/78 | [] | xiang5 | 4 |
hankcs/HanLP | nlp | 1,406 | 怎么查看GPU是否成功使用 | <!--
Please carefully fill out this form to bypass our spam filter. Please make sure that this is a bug. We only address bugs and feature requests issues on GitHub. Other questions should be posted on stackoverflow or https://bbs.hankcs.com/
以下必填,否则直接关闭。
-->
**Describe the bug**
pip安装之后,可以成功运行NER,但是增加batch后GPU的显... | closed | 2020-01-15T10:16:19Z | 2020-01-15T20:11:53Z | https://github.com/hankcs/HanLP/issues/1406 | [
"question"
] | PromptExpert | 1 |
chaos-genius/chaos_genius | data-visualization | 359 | Selecting a custom schema when adding KPIs | ## Tell us about the problem you're trying to solve
For postgres, there is data in custom schemas which is not being read. We cannot add KPIs directly using those tables via the TABLE functionality. In our case information from different sources lives in different schemas in the data warehouse.
## Describe the sol... | closed | 2021-11-01T20:30:17Z | 2022-01-04T07:27:59Z | https://github.com/chaos-genius/chaos_genius/issues/359 | [
"🔗 connectors",
"P1"
] | mvaerle | 3 |
nerfstudio-project/nerfstudio | computer-vision | 3,224 | can we just load any .ply file in the viewer | let's say if i just want to visualize the results can i load it direclty in the viewer the .ply file and also if there is other way to load it with other supported files | open | 2024-06-14T03:07:25Z | 2024-10-11T12:33:48Z | https://github.com/nerfstudio-project/nerfstudio/issues/3224 | [] | sumanttyagi | 2 |
roboflow/supervision | deep-learning | 1,392 | How do I get the current frame count | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
video.py : how to obtain the current video frame number,thanks
def get_video_frames_generator(
source_path: str, stride: int = 1, star... | closed | 2024-07-22T02:19:16Z | 2024-07-22T10:58:45Z | https://github.com/roboflow/supervision/issues/1392 | [
"question"
] | dearMOMO | 5 |
zappa/Zappa | flask | 1,240 | exclude_glob feature attempts to delete files outside the tmp_file_path |
## Context
When using the exclude_glob parameter to exclude files from the lambda file, if you set
exclude_glob = [ "/app/static/**"] (notice the leading forward slasj -- that is the problem )
then Zappa will delete the folder "/app/static" and everything in it.
## Expected Behavior
Setting exclude_g... | closed | 2023-05-01T17:09:50Z | 2024-03-13T01:20:07Z | https://github.com/zappa/Zappa/issues/1240 | [
"bug",
"next-release-candidate"
] | beon9273 | 1 |
modin-project/modin | data-science | 6,778 | BUG: Unable to read parquet files using fastparquet | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [x] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthe... | closed | 2023-11-28T21:36:18Z | 2023-12-01T16:50:22Z | https://github.com/modin-project/modin/issues/6778 | [
"bug 🦗",
"pandas concordance 🐼",
"External"
] | seydar | 12 |
ufoym/deepo | tensorflow | 145 | tensorflow 2.5.0 CUDA compatibility | The latest versions use `tensorflow==2.5.0`, `CUDA==10.2`, `cudnn7`.
Apparently, `tensorflow==2.5.0` seems to be not compatible with `CUDA==10.2`.
full log:
```
2021-06-22 06:10:01.725884: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcusparse.so.11'; dlerror... | closed | 2021-06-22T06:18:06Z | 2021-12-25T09:22:47Z | https://github.com/ufoym/deepo/issues/145 | [] | syncdoth | 6 |
jacobgil/pytorch-grad-cam | computer-vision | 13 | License | Hi,
Thanks for the great work.
Would it be possible for you to add an appropriate license to the work?
I noticed that your corresponding keras implementation is licensed under MIT: https://github.com/jacobgil/keras-grad-cam
Thanks,
Raghav | closed | 2018-10-11T16:15:00Z | 2020-01-27T06:47:44Z | https://github.com/jacobgil/pytorch-grad-cam/issues/13 | [] | raghavgoyal14 | 1 |
Teemu/pytest-sugar | pytest | 262 | Broken support for Python 3.6 | This commit breaks python 3.6 compatibility due to termcolor 2 requiring >= python 3.7.
- https://github.com/Teemu/pytest-sugar/pull/259
- https://github.com/Teemu/pytest-sugar/commit/6b82c48c4cadefc6f26eed3662863292e1c77101
And, seems you forgot to update tox.ini:
- https://github.com/Teemu/pytest-sugar/blob/b42... | closed | 2022-12-03T19:39:37Z | 2022-12-07T01:19:55Z | https://github.com/Teemu/pytest-sugar/issues/262 | [] | xkszltl | 15 |
google-research/bert | tensorflow | 616 | 650M corpus was splited to 40 files pass to create_pretraining_data, but it takes too long time | after 24 hours, it still runing.
python create_pretraining_data.py --input_file=BERT_BASE_DIR/all_file_merge.copyblock_notitle_linesplit.txt-6400* --output_file=BERT_BASE_DIR/tf_examples-64.tfrecord --vocab_file=chn_vocab --do_lower_case=True --max_seq_length=64 --max_predictions_per_seq=20 --masked_lm_prob=0.15 --r... | closed | 2019-05-03T06:55:00Z | 2019-05-04T01:02:28Z | https://github.com/google-research/bert/issues/616 | [] | SeekPoint | 3 |
sherlock-project/sherlock | python | 1,427 | # clone the repo
$ git clone https://github.com/sherlock-project/sherlock.git
# change the working directory to sherlock
$ cd sherlock
# install the requirements
$ python3 -m pip install -r requirements.txt | <!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE
######################################################################
-->
## Checklist
<!--
Put x into all boxes (like this [x]) once you have completed ... | closed | 2022-08-05T07:35:40Z | 2022-08-05T07:36:14Z | https://github.com/sherlock-project/sherlock/issues/1427 | [
"enhancement"
] | Darknessss19 | 0 |
taverntesting/tavern | pytest | 111 | Tavern create results as xml | Hello tavern-ci Team,
I'm using tavern in an open-source project because of the simplicity in the test creation. I really would like to use this solution with Jenkins. To this end, I need to generate the result output as XML. Since you are using pytest, I think would be easy to add this feature in further versions. ... | closed | 2018-05-29T11:31:40Z | 2018-06-13T16:53:38Z | https://github.com/taverntesting/tavern/issues/111 | [] | felipevicens | 2 |
Layout-Parser/layout-parser | computer-vision | 23 | AttributeError: 'Layout' object has no attribute 'sort' | Dear team, I was trying to implement https://github.com/Layout-Parser/layout-parser/blob/master/docs/example/deep_layout_parsing/index.rst but get the error "AttributeError: 'Layout' object has no attribute 'sort'". I see that I am easily able to write a sort function using "left_blocks._blocks[0].block.x_1" but just w... | closed | 2021-04-12T12:05:54Z | 2021-04-12T16:40:07Z | https://github.com/Layout-Parser/layout-parser/issues/23 | [] | mlamlamla | 0 |
sqlalchemy/alembic | sqlalchemy | 1,299 | `alembic merge` ignores `revision_environment` and cannot find the hooks defined in `env.py` | **Describe the bug**
As title says, `alembic merge` ignores `revision_environment` and cannot find the hooks defined in `env.py`.
**Expected behavior**
Custom hooks work the way they do when generating revisions
**To Reproduce**
```ini
# alembic.ini
revision_environment = true
hooks = ruff
ruff.type = ru... | closed | 2023-08-22T18:58:03Z | 2023-08-31T18:27:42Z | https://github.com/sqlalchemy/alembic/issues/1299 | [
"bug",
"command interface"
] | FeeeeK | 2 |
PaddlePaddle/PaddleHub | nlp | 1,642 | 使用paddlehub报错 | 使用如下代码
import paddlehub as hub
hub.version.hub_version
AttributeError: module 'paddlehub' has no attribute 'version'
i请问是我paddlehub版本不对吗
| open | 2021-10-03T10:30:42Z | 2023-09-15T08:57:41Z | https://github.com/PaddlePaddle/PaddleHub/issues/1642 | [
"installation"
] | jjchen460287 | 2 |
mwouts/itables | jupyter | 115 | itables does not work under Python 2 | closed | 2022-11-10T23:38:11Z | 2022-11-11T00:48:30Z | https://github.com/mwouts/itables/issues/115 | [] | mwouts | 0 | |
scrapy/scrapy | web-scraping | 6,525 | PIL Image Ignores Orientation in EXIF Data | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | open | 2024-11-04T16:45:45Z | 2025-01-10T12:29:31Z | https://github.com/scrapy/scrapy/issues/6525 | [
"needs more info",
"media pipelines"
] | hmandsager | 2 |
httpie/cli | python | 548 | Posting a form field string with spaces results in error | I'm currently trying to post to a form and the argument I'm trying to pass is a string with spaces in it.
```
$ http --form POST example.com name="John Smith"
```
But I keep getting this error back:
```
http: error: argument REQUEST_ITEM: "Smith" is not a valid value
```
I've seen this example on a coup... | closed | 2016-12-16T18:07:43Z | 2016-12-16T22:44:21Z | https://github.com/httpie/cli/issues/548 | [] | thornycrackers | 4 |
coqui-ai/TTS | pytorch | 3,510 | [Bug] impossible to resume train_gpt_xtts training | ### Describe the bug
When resuming training with train_gpt_xtts.py the GPTArgs in the saved config,json is deserialized incorretly as its parent XttsArgs, therefore not containing all required files.
### To Reproduce
Try resuming from checkpoint via setting continue_path
### Expected behavior
It trains
### Logs... | closed | 2024-01-10T19:06:06Z | 2024-03-09T10:40:03Z | https://github.com/coqui-ai/TTS/issues/3510 | [
"bug",
"wontfix"
] | KukumavMozolo | 3 |
kymatio/kymatio | numpy | 68 | 1D classif example now fails | Specifically, we get
```
TEST, average loss = nan, accuracy = 0.100
```
which is not very impressive. This used to work before (as of 5b41a31), giving
```
TEST, average loss = 0.092, accuracy = 0.973
```
but no longer... | closed | 2018-10-29T02:56:43Z | 2018-10-30T01:31:29Z | https://github.com/kymatio/kymatio/issues/68 | [
"bug"
] | janden | 7 |
kevlened/pytest-parallel | pytest | 60 | --exitfirst pytest CLI option is being ignored | Given the following pytest.ini configuration file:
```
[pytest]
addopts = --exitfirst --log-cli-level=debug --workers auto
```
I see the following when running my test suite containing an unhandled exception.
```
# ...
tests/unit/test_foo.py::test_foo /home/appuser/app
PASSED ... | open | 2019-12-11T15:15:20Z | 2019-12-11T15:15:20Z | https://github.com/kevlened/pytest-parallel/issues/60 | [] | ethagnawl | 0 |
Teemu/pytest-sugar | pytest | 192 | lots of project metadata is missing from setup.cfg | Current project listing on pypa is missing a lot of metadata including at least source code link, docs link, issue tracker link, list of open PRs/Bugs/starts.
Adding these should not be hard, just compare the setup.cfg with another project that lists them , example https://pypi.org/project/pytest-molecule/
| closed | 2020-03-30T08:25:28Z | 2020-08-25T18:10:32Z | https://github.com/Teemu/pytest-sugar/issues/192 | [] | ssbarnea | 1 |
miguelgrinberg/Flask-SocketIO | flask | 2,062 | Namespace catch-all handling of connect/disconnect events | **Is your feature request related to a problem? Please describe.**
I'd like to use dynamic namespaces, i.e. my server should respond to a client that connects on any arbitrary namespace. For that, the connection handler needs to accept and handle all namespaces with the '*' catch-all.
**Describe the solution you'd... | closed | 2024-05-05T17:37:24Z | 2024-05-10T06:50:58Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/2062 | [] | mooomooo | 1 |
graphql-python/graphene-django | django | 1,328 | SerializerMutation have output_fields with defination of return_field_name similar to DjangoModelFormMutation | **Is your feature request related to a problem? Please describe.**
A SerializerMutation provided by the package returns a output_fields as the serializer fields provided int serializer class. But as graphql we should be able to provided a DjangoObjectType of the required models. As looking into DjangoModelFormMutatio... | open | 2022-06-28T05:00:35Z | 2022-06-28T05:00:35Z | https://github.com/graphql-python/graphene-django/issues/1328 | [
"✨enhancement"
] | sushilkhadka165 | 0 |
coqui-ai/TTS | deep-learning | 2,386 | [Feature request] Add a hint on how to solve "not enough sample" | <!-- Welcome to the 🐸TTS project!
We are excited to see your interest, and appreciate your support! --->
**🚀 Feature Description**
Hi,
In section "SPeaker Adaptation" of [YourTTS paper](https://arxiv.org/pdf/2112.02418.pdf) it is mentioned that the experiment is conducted with eg 15 samples. I am trying to re... | closed | 2023-03-06T04:26:10Z | 2023-04-19T14:12:37Z | https://github.com/coqui-ai/TTS/issues/2386 | [
"help wanted",
"wontfix",
"feature request"
] | Ca-ressemble-a-du-fake | 3 |
sanic-org/sanic | asyncio | 2,918 | Unexpected behavior when using blueprint groups and app.url_for | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Describe the bug
When using `request.app.url_for` in combination with blueprint groups, the expected name cannot be used:
```
Traceback (most recent call last):
File "handle_request", line 97, in handle_request
File "###/b... | closed | 2024-02-17T12:03:58Z | 2024-04-01T13:22:39Z | https://github.com/sanic-org/sanic/issues/2918 | [
"bug"
] | asyte | 1 |
eamigo86/graphene-django-extras | graphql | 41 | How can I use the decorators in django-graphql-jwt ? | I am using [django-graphql-jwt](https://github.com/flavors/django-graphql-jwt) and it exposes a couple of decorators such as `@login_required` that are used to decorate the resolver functions to restrict their access.
How can I use such decorators with `DjangoSerializerType`, `.ListField()`, `RetrieveField()`, etc.... | closed | 2018-04-29T19:36:41Z | 2020-06-18T12:36:19Z | https://github.com/eamigo86/graphene-django-extras/issues/41 | [] | cidylle | 16 |
xinntao/Real-ESRGAN | pytorch | 57 | seal | it smudge
<img src="https://user-images.githubusercontent.com/16495490/131243595-c7ba962c-3c0e-493f-9df7-30db3438ffd0.png" width="500">
<img src="https://user-images.githubusercontent.com/16495490/131243629-0a2d1e1b-0d54-43ef-a942-7aa5894acd01.png" width="500">
| open | 2021-08-29T08:20:50Z | 2021-09-08T13:57:23Z | https://github.com/xinntao/Real-ESRGAN/issues/57 | [
"hard-samples reported"
] | OverLordGoldDragon | 3 |
zappa/Zappa | django | 1,267 | Provide configuration for reserved and provisioned concurrency | Lambda now provides a reserved and provisioned concurrency setting/configuration.
https://docs.aws.amazon.com/lambda/latest/dg/lambda-concurrency.html#reserved-and-provisioned
https://docs.aws.amazon.com/lambda/latest/dg/configuration-concurrency.html
zappa currently provides a `keep_warm` function to periodic... | closed | 2023-08-17T05:05:03Z | 2024-04-21T03:37:49Z | https://github.com/zappa/Zappa/issues/1267 | [
"no-activity",
"auto-closed"
] | monkut | 3 |
plotly/dash | flask | 2,399 | Document that a maximum 1 Dash instance is supported in a process at a time | Before Dash 2.0, it was possible to attach multiple `dash.Dash` app instances to a single `flask.Flask` server instance by passing the same Flask server in to each Dash app using the `server` param. This pattern was for a time [documented in the Dash docs](https://github.com/plotly/dash-docs/blob/master/dash_docs/chapt... | open | 2023-01-26T12:46:01Z | 2024-08-13T19:25:29Z | https://github.com/plotly/dash/issues/2399 | [
"documentation",
"feature",
"P3"
] | ned2 | 0 |
JaidedAI/EasyOCR | machine-learning | 1,316 | Fa (Persian) mismatch | some fonts and some car plate codes in Iran has mismatch detection
please let me contribute in Fa Persian dataset | open | 2024-10-12T09:49:21Z | 2024-10-12T09:49:21Z | https://github.com/JaidedAI/EasyOCR/issues/1316 | [] | mohamadkenway | 0 |
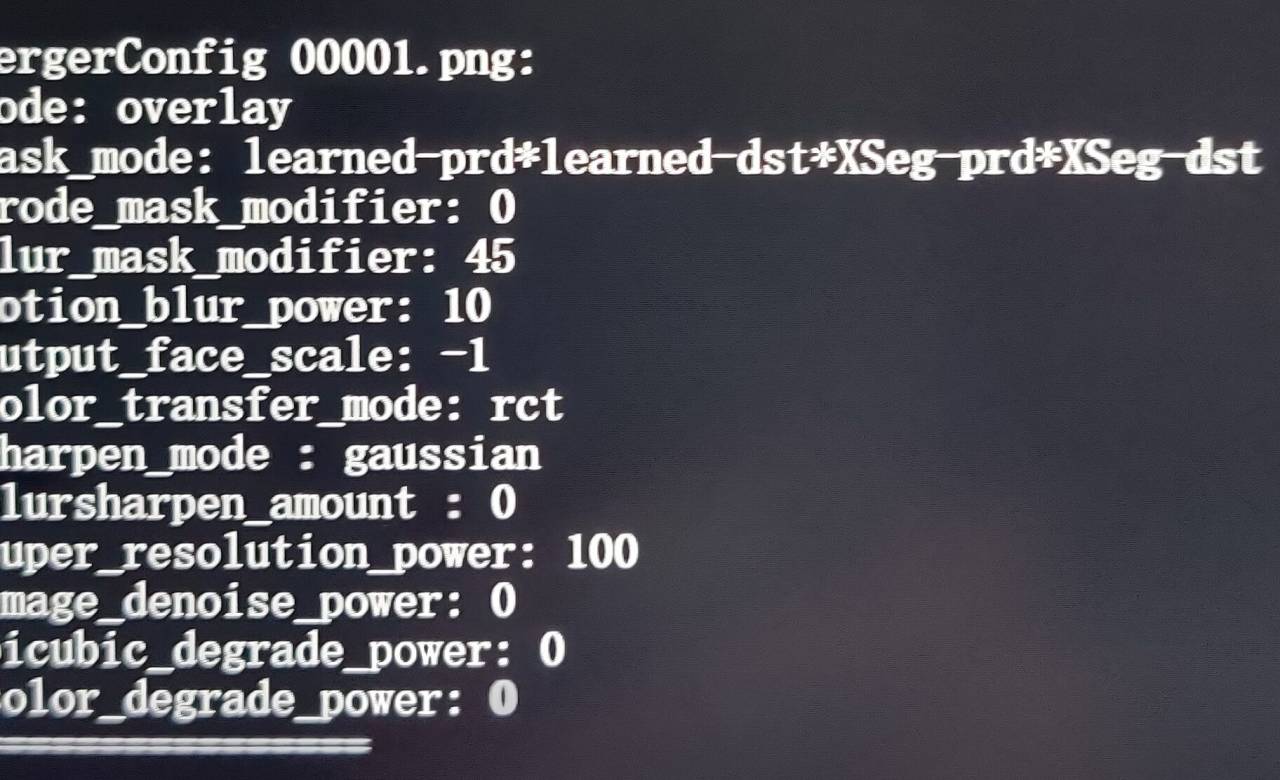
iperov/DeepFaceLab | deep-learning | 793 | The change of head is very fuzzy | I'm changing my head in the test. The effect is not good. After replacing the SRC image, it's very fuzzy. I'm using merge SAEHD.dat I set the parameter to: as shown in the following figure
| closed | 2020-06-18T12:08:45Z | 2023-09-21T15:37:36Z | https://github.com/iperov/DeepFaceLab/issues/793 | [] | stone100010 | 1 |
ultralytics/ultralytics | pytorch | 19,612 | YOLOv11 instance segmentation performance | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
As shown below, when I am using yolov11 for instance segmentation of pedestr... | open | 2025-03-10T07:27:10Z | 2025-03-12T10:38:36Z | https://github.com/ultralytics/ultralytics/issues/19612 | [
"question",
"segment"
] | WYL-Projects | 6 |
geopandas/geopandas | pandas | 3,137 | BUG: .to_parquet unable to write empty GeoDataFrame | - [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of geopandas.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
#### Code Sample, a copy-pastable example
```python
import geopandas as ... | open | 2024-01-10T15:05:33Z | 2024-01-10T17:51:16Z | https://github.com/geopandas/geopandas/issues/3137 | [
"bug"
] | kauevestena | 1 |
hbldh/bleak | asyncio | 1,278 | Disconnect causes "Event loop is closed" | * bleak version: 1.2.0
* Python version: 3.11.2
* Operating System: Windows 10
### Description
I am trying to use bleak without using the async context manager (I have found that with the bluetooth device I am using it causes a few issues with latency) as I will later use this to implement into a GUI.
While... | closed | 2023-04-13T19:34:38Z | 2023-04-13T20:03:21Z | https://github.com/hbldh/bleak/issues/1278 | [] | jacobbreen25 | 0 |
AirtestProject/Airtest | automation | 391 | Expand protected bundle identifier from iphone? | Can i know how to check iphone installed app bundle identifier?
Added star_app (bundle identifier). | closed | 2019-05-09T06:29:27Z | 2019-05-13T06:11:09Z | https://github.com/AirtestProject/Airtest/issues/391 | [] | JJunM | 2 |
seleniumbase/SeleniumBase | web-scraping | 3,027 | RuntimeError: You cannot reuse the ChromeOptions object | Getting the following error when trying to use user_data_dir.
The first run of the code (before user_data_dir is created) works, but then once its created and we try to use it, I get the error
```
Traceback (most recent call last):
File "//main.py", line 67, in <module>
Scrape().run()
File "/bots/scra... | closed | 2024-08-15T16:34:35Z | 2024-10-03T13:45:08Z | https://github.com/seleniumbase/SeleniumBase/issues/3027 | [
"duplicate",
"invalid usage",
"UC Mode / CDP Mode"
] | ttraxxrepo | 6 |
modin-project/modin | pandas | 7,217 | Update docs as to when Modin operators work best | closed | 2024-04-25T11:33:56Z | 2024-04-26T13:32:37Z | https://github.com/modin-project/modin/issues/7217 | [
"documentation 📜"
] | YarShev | 4 | |
awesto/django-shop | django | 431 | Demo store not building or running | I am trying to build a new django-shop app, as per the instructions at http://django-shop.readthedocs.io/en/latest/tutorial/intro.html and http://django-shop.readthedocs.io/en/latest/tutorial/quickstart.html#tutorial-quickstart
Here is my initial installation log.
```
(heroku) vagrant@vagrant:/vagrant/projects$ mkvir... | closed | 2016-09-30T13:46:54Z | 2018-01-13T08:36:06Z | https://github.com/awesto/django-shop/issues/431 | [
"blocker",
"bug",
"accepted",
"documentation"
] | petedermott | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.