
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
SciTools/cartopy | matplotlib | 2,482 | indicate_inset_zoom not working on some projections | ### Description
On most non-standard projections (like `TransverseMercator`) the connectors to an inset axis are not drawn correctly.
#### Code to reproduce
```python
map_proj = ccrs.TransverseMercator()
fig, ax = plt.subplots(
figsize=(15, 15),
subplot_kw={
"projection": map_proj
... | open | 2024-11-21T09:19:33Z | 2024-11-22T21:15:22Z | https://github.com/SciTools/cartopy/issues/2482 | [
"Component: Geometry transforms"
] | guidocioni | 4 |
jonaswinkler/paperless-ng | django | 1,548 | [BUG] Consume stops after initial run | **Describe the bug**
I am importing documents from my scanner to the consume directory. I've noticed that files are not picked up until I restart the container (running in Docker). After a restart, all files present are consumed correctly. After that initial run, if I continue placing files in the consume directory, n... | closed | 2022-01-14T13:02:36Z | 2022-01-20T09:41:10Z | https://github.com/jonaswinkler/paperless-ng/issues/1548 | [] | PhilippCh | 2 |
sinaptik-ai/pandas-ai | data-visualization | 1,488 | Local LLM pandasai.json | ### System Info
"name": "pandasai-all",
"version": "1.0.0",
MacOS (15.1.1)
The code is run directly as Poetry run. and not in a docker.
### 🐛 Describe the bug
I'm trying to use a local LLM but it keeps defaulting to BamboLLM
Here how the pandasai.json at the root directory looks like
Regardless what... | closed | 2024-12-19T10:45:00Z | 2025-01-20T10:09:51Z | https://github.com/sinaptik-ai/pandas-ai/issues/1488 | [
"bug"
] | ahadda5 | 7 |
slackapi/python-slack-sdk | asyncio | 1,261 | blocks/attachments as str for chat.* API calls should be clearly supported | The use case reported at https://github.com/slackapi/python-slack-sdk/pull/1259#issuecomment-1237007209 has been supported for a long time but it was **not by design**.
```python
client = WebClient(token="....")
client.chat_postMessage(text="fallback", blocks="{ JSON string here }")
```
The `blocks` and `atta... | closed | 2022-09-06T04:44:42Z | 2022-09-06T06:41:40Z | https://github.com/slackapi/python-slack-sdk/issues/1261 | [
"enhancement",
"web-client",
"Version: 3x"
] | seratch | 0 |
lk-geimfari/mimesis | pandas | 1,583 | Replace black with ruff. | Ruff would be a good fit for us. | open | 2024-07-19T13:24:33Z | 2024-07-19T13:25:11Z | https://github.com/lk-geimfari/mimesis/issues/1583 | [] | lk-geimfari | 0 |
tensorflow/tensor2tensor | machine-learning | 1,449 | ImportError: No module named 'mesh_tensorflow.transformer' | ### Description
Importing `t2t_trainer` is not working in `1.12.0`.
I have just updated my t2t version to `1.12.0` and noticed that I cannot import `t2t_trainer` anymor as I am getting
> `ImportError: No module named 'mesh_tensorflow.transformer'`
which was not the case in `1.11.0`.
...
### Reproduce
... | closed | 2019-02-13T08:41:16Z | 2019-02-13T08:45:50Z | https://github.com/tensorflow/tensor2tensor/issues/1449 | [] | stefan-falk | 1 |
microsoft/nni | machine-learning | 5,431 | Can not prune model TypeError: 'model' object is not iterable | **Describe the issue**:
**Environment**:
- NNI version: 2.6.1
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote mode only):
- Python version:
- PyTorch/TensorFlow version:
- Is conda/virtualenv/venv used?:
- Is running in Docker?:
**Configuration**:
- Experiment c... | closed | 2023-03-10T07:29:46Z | 2023-03-13T07:47:34Z | https://github.com/microsoft/nni/issues/5431 | [] | Kracozebr | 5 |
TheAlgorithms/Python | python | 12,217 | Add a index priority queue to Data Structures | ### Feature description
As there is no IPQ implementation in the standard python library, I wish to add one to TheAlgorithms. | closed | 2024-10-21T04:59:16Z | 2024-10-21T05:03:04Z | https://github.com/TheAlgorithms/Python/issues/12217 | [
"enhancement"
] | alessadroc | 1 |
flairNLP/flair | nlp | 2,859 | module 'conllu' has no attribute TokenList |

This did not happen till today . I have been using this basic code for 6 months and this bug is new and did not appear anytime before today.
Please resolve quickly | closed | 2022-07-12T18:03:37Z | 2022-11-14T15:03:52Z | https://github.com/flairNLP/flair/issues/2859 | [
"bug"
] | yash-rathore | 10 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 992 | Error in loading state_dict for SpeakerEncoder: size mismatch | Hi! I trained a synthesizer a month ago and I could synthesize my voice, too mechanical though, but now I got this error. How can I fix this?
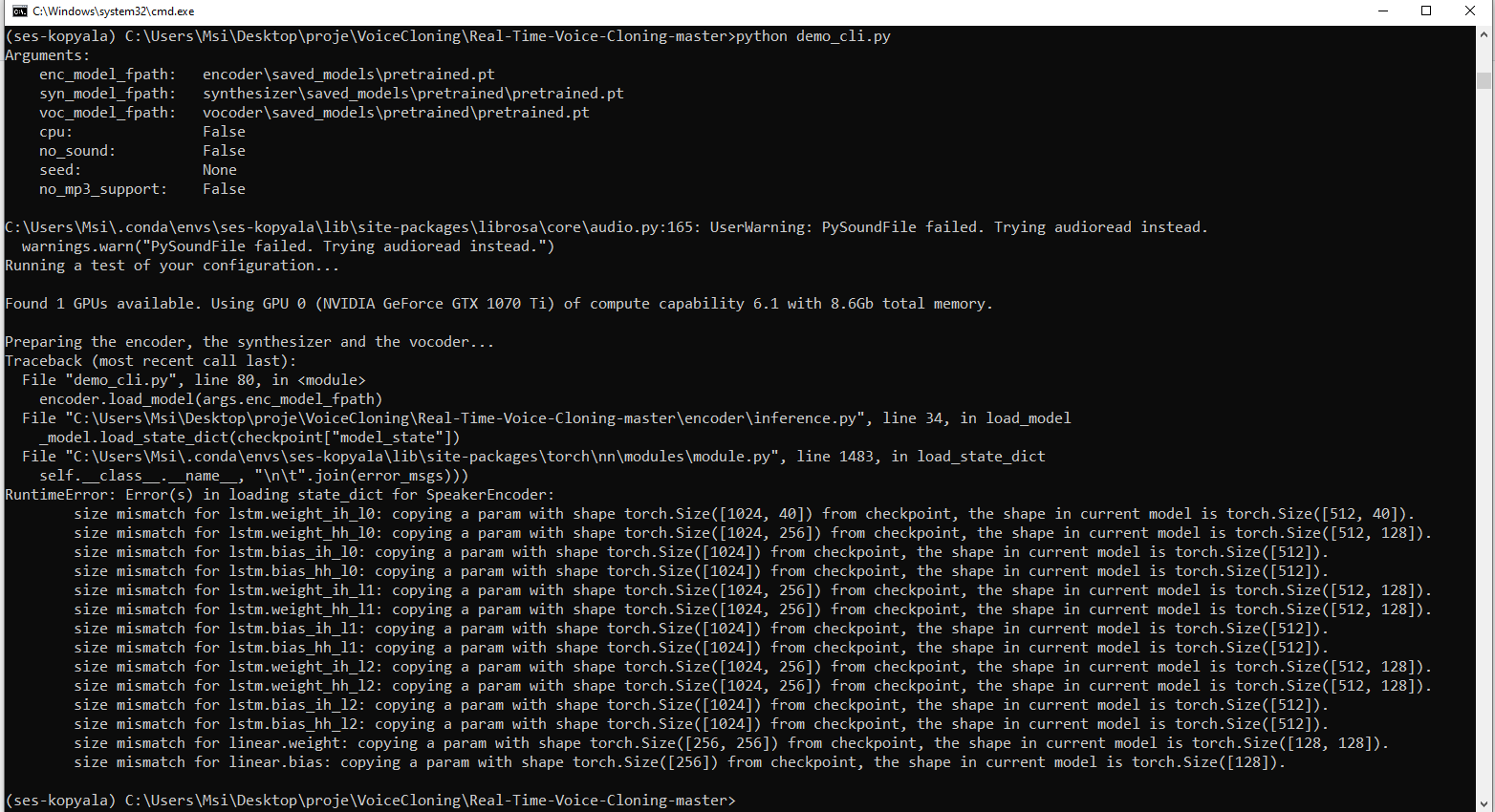
| closed | 2022-01-23T15:40:31Z | 2022-01-28T19:41:32Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/992 | [] | EkinUstundag | 1 |
openapi-generators/openapi-python-client | fastapi | 338 | Add support for recursively defined schemas | **Describe the bug**
I tried to create a python client from an OpenApi-Spec with the command `openapi-python-client generate --path secret_server_openapi3.json`. Then I got multple warnings:
- invalid data in items of array settings
- Could not find reference in parsed models or enums
- Cannot parse response for st... | closed | 2021-02-17T13:27:58Z | 2022-11-12T17:49:54Z | https://github.com/openapi-generators/openapi-python-client/issues/338 | [
"✨ enhancement",
"🐲 here there be dragons"
] | sp-schoen | 13 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 730 | FileNotFoundError: [Errno 2] No such file or directory: './save_weights/ssd300-14.pth' | 有没有大哥可以分享一下训练好的ssd300-14.pth | open | 2023-03-30T09:50:36Z | 2023-03-30T09:50:36Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/730 | [] | ANXIOUS-7 | 0 |
roboflow/supervision | tensorflow | 1,044 | [ByteTrack] add `minimum_consecutive_frames` to limit the number of falsely assigned tracker IDs | ### Description
Expand the `ByteTrack` API by adding the `minimum_consecutive_frames` argument.
It will specify how many consecutive frames an object must be detected to be assigned a tracker ID. This will help prevent the creation of accidental tracker IDs in cases of false detection or double detection. Until de... | closed | 2024-03-25T15:29:06Z | 2024-04-24T22:25:19Z | https://github.com/roboflow/supervision/issues/1044 | [
"enhancement",
"api:tracker"
] | SkalskiP | 3 |
voila-dashboards/voila | jupyter | 940 | UI Tests: Update to the new Galata setup | <!--
Welcome! Thanks for thinking of a way to improve Voilà. If this solves a problem for you, then it probably solves that problem for lots of people! So the whole community will benefit from this request.
Before creating a new feature request please search the issues for relevant feature requests.
-->
### P... | closed | 2021-09-02T06:58:02Z | 2021-09-03T16:02:02Z | https://github.com/voila-dashboards/voila/issues/940 | [
"maintenance"
] | jtpio | 1 |
HumanSignal/labelImg | deep-learning | 180 | Image in portrait mode | I have some images which are took in portrait mode like this
https://imgur.com/baVUII8
But after I load the image, it becomes landscape mode
https://imgur.com/EQUGKIW
If it is in landscape mode, I cant label eyes and nose
both Win10 and Ubuntu16.04+python2+QT4 happened
How to fix this problem?
Thanks f... | closed | 2017-10-23T06:25:10Z | 2017-10-23T07:54:22Z | https://github.com/HumanSignal/labelImg/issues/180 | [] | nerv3890 | 1 |
mkhorasani/Streamlit-Authenticator | streamlit | 10 | Password modification | Great job !
Do you plan to add a "forgot password" option ? | closed | 2022-05-16T13:32:30Z | 2022-06-25T15:15:33Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/10 | [] | axel-prl-mrtg | 2 |
neuml/txtai | nlp | 41 | Enhance API to fully support all txtai functionality | Currently, the API supports a subset of functionality in the embeddings module. Fully support embeddings and add methods qa extraction and labeling.
This will enable network-based implementations of txtai in other programming languages. | closed | 2020-11-20T17:31:08Z | 2021-05-13T15:04:12Z | https://github.com/neuml/txtai/issues/41 | [] | davidmezzetti | 0 |
quantmind/pulsar | asyncio | 195 | Deprecate async function and replace with ensure_future | First step towards new syntax
| closed | 2016-01-30T20:38:38Z | 2016-03-17T08:01:08Z | https://github.com/quantmind/pulsar/issues/195 | [
"design decision",
"enhancement"
] | lsbardel | 1 |
learning-at-home/hivemind | asyncio | 507 | [BUG] Tests for compression fail on GPU servers with bitsandbytes installed | **Describe the bug**
While working on https://github.com/learning-at-home/hivemind/pull/490, I found that if I have bitsandbytes installed in a GPU-enabled environment, I get an error when running [test_adaptive_compression](https://github.com/learning-at-home/hivemind/blob/master/tests/test_compression.py#L152), whic... | open | 2022-09-10T14:59:04Z | 2022-09-10T14:59:04Z | https://github.com/learning-at-home/hivemind/issues/507 | [
"bug",
"ci"
] | mryab | 0 |
dynaconf/dynaconf | fastapi | 772 | [bug] Setting auto_cast in instance options is ignored | **Affected version:** 3.1.9
**Describe the bug**
Setting **auto_cast** option inside `config.py` to **False** is ignored, even though the docs say otherwise.
**To Reproduce**
Add **auto_cast** to Dynaconf initialization.
```
from dynaconf import Dynaconf
settings = Dynaconf(
settings_files=["settings.... | closed | 2022-07-22T15:43:41Z | 2022-09-22T12:49:36Z | https://github.com/dynaconf/dynaconf/issues/772 | [
"bug"
] | pvmm | 1 |
Lightning-AI/pytorch-lightning | deep-learning | 20,511 | Cannot import OptimizerLRSchedulerConfig or OptimizerLRSchedulerConfigDict | ### Bug description
Since I bumped up `lightning` to `2.5.0`, the `configure_optimizers` has been failing the type checker. I saw that `OptimizerLRSchedulerConfig` had been replaced with `OptimizerLRSchedulerConfigDict`, but I cannot import any of them.
### What version are you seeing the problem on?
v2.5
#... | closed | 2024-12-20T15:18:27Z | 2024-12-21T01:42:58Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20511 | [
"bug",
"ver: 2.5.x"
] | zordi-youngsun | 4 |
iterative/dvc | machine-learning | 10,452 | Getting timeout in DVC pull | I have a large file arround 3GB
When I try to do dvc pull from inside a docker environment, I get this below error.
ERROR: unexpected error - The difference between the request time and the current time is too large.: An error occurred (RequestTimeTooSkewed) when calling the GetObject operation: The difference be... | closed | 2024-06-07T12:12:01Z | 2025-01-12T15:10:47Z | https://github.com/iterative/dvc/issues/10452 | [
"awaiting response",
"A: data-sync"
] | bhaswa | 6 |
minimaxir/textgenrnn | tensorflow | 161 | What version(s) of tensorflow are supported? | open | 2019-12-14T03:32:11Z | 2019-12-17T08:37:26Z | https://github.com/minimaxir/textgenrnn/issues/161 | [] | marcusturewicz | 1 | |
ymcui/Chinese-LLaMA-Alpaca | nlp | 642 | 关于lora 精调 Alpaca-7B-Plus模型时为何不需要设置Lora参数的疑惑 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [X] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [X] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.c... | closed | 2023-06-20T05:28:01Z | 2023-06-27T23:56:01Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/642 | [
"stale"
] | jjyu-ustc | 2 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 232 | Issue with primary keys that are also foreign keys | I have a case where marshmallow-sqlalchemy causes an SQLAlchemy FlushError at session commit time.
This is the error I get:
```
sqlalchemy.orm.exc.FlushError: New instance <Parent at 0x7f790f4832b0> with identity key (<class '__main__.Parent'>, (1,), None) conflicts with persistent instance <Parent at 0x7f790f48... | closed | 2019-08-05T15:18:31Z | 2025-01-12T05:37:10Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/232 | [] | elemoine | 3 |
dmlc/gluon-cv | computer-vision | 865 | Any channel pruning examples? | Hi there, I'm trying some channel pruning ideas in mxnet.
However it's hard to get some simple tutorials or examples I can start with.
So is there some basic examples showing how to do channel pruning (freezing)
during training?
An example of channel pruning is **Learning Efficient Convolutional Networks throug... | closed | 2019-07-14T09:50:16Z | 2021-05-24T07:52:30Z | https://github.com/dmlc/gluon-cv/issues/865 | [
"Stale"
] | zeakey | 1 |
geopandas/geopandas | pandas | 3,512 | BUG: to_arrow conversion should write crs as PROJJSON object and not string. | - [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the latest version of geopandas.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
#### Code Sample, a copy-pastable example
```python
import geopandas
import nanoarrow... | closed | 2025-02-13T05:30:49Z | 2025-02-18T14:27:06Z | https://github.com/geopandas/geopandas/issues/3512 | [
"bug"
] | paleolimbot | 1 |
davidsandberg/facenet | tensorflow | 383 | face authentication using custom dataset | Hi All,
I have trained set of images for which am able to create .pkl file. Now i need to authenticate with single image. Tried with existing code(classifier.py) but could not able to achieve the same.
Pls suggest the way forward
Thanks
vij
| open | 2017-07-18T15:43:44Z | 2019-11-10T06:06:33Z | https://github.com/davidsandberg/facenet/issues/383 | [] | myinzack | 2 |
piccolo-orm/piccolo | fastapi | 593 | Email column type | We don't have an email column type at the moment. It's because Postgres doesn't have an email column type.
However, I think it would be useful to designate a column as containing an email.
## Option 1
We can define a new column type, which basically just inherits from `Varchar`:
```python
class Email(Varch... | closed | 2022-08-19T20:23:16Z | 2022-08-20T21:42:11Z | https://github.com/piccolo-orm/piccolo/issues/593 | [
"enhancement",
"good first issue",
"proposal - input needed"
] | dantownsend | 5 |
hbldh/bleak | asyncio | 815 | Distinguish Advertisement Data and Scan Response Data | * bleak version: 0.14.2
### Description
Could you clarify about a limitation of the library, is it possible to distinguish data, received by the first advertisement packet (PDU type: `ADV_IND`) and the subsequent scan response packet (PDU type: `SCAN_RSP`) from a specific device? Right now, launching the example ... | closed | 2022-04-26T01:26:10Z | 2022-04-26T07:42:13Z | https://github.com/hbldh/bleak/issues/815 | [] | RAlexeev | 2 |
httpie/cli | python | 518 | h | o | closed | 2016-09-12T07:11:16Z | 2020-04-27T07:20:57Z | https://github.com/httpie/cli/issues/518 | [] | ghost | 2 |
neuml/txtai | nlp | 512 | Add support for configurable text/object fields | Currently, the `text` and `object` fields are hardcoded throughout much of the code. This change will make the text and object fields configurable. | closed | 2023-07-29T02:11:45Z | 2023-07-29T02:17:45Z | https://github.com/neuml/txtai/issues/512 | [] | davidmezzetti | 0 |
InstaPy/InstaPy | automation | 6,147 | Can't follow private accounts (even after enabling the option) | ## Expected Behavior
I want to be able to follow private accounts, any help will be really appreciated!
## Current Behavior
I get this message: "is private account, by default skip"
Even after adding:
```
session.set_skip_users(skip_private=False,
skip_no_profile_pic=True,
... | closed | 2021-04-12T17:50:17Z | 2021-07-21T05:18:53Z | https://github.com/InstaPy/InstaPy/issues/6147 | [
"wontfix"
] | hecontreraso | 1 |
gradio-app/gradio | deep-learning | 10,252 | Browser get Out of Memory when using Plotly for plotting. | ### Describe the bug
I used Gradio to create a page for monitoring an image that needs to be refreshed continuously. When I used Plotly for plotting and set the refresh rate to 10 Hz, the browser showed an "**Out of Memory**" error after running for less than 10 minutes.
I found that the issue is caused by the `Plo... | closed | 2024-12-25T05:16:18Z | 2025-02-08T00:56:23Z | https://github.com/gradio-app/gradio/issues/10252 | [
"bug"
] | Reflux00 | 0 |
KaiyangZhou/deep-person-reid | computer-vision | 351 | significant GPU memory cost on PRID | Here is my configuration.
```python
model:
name: 'resnet50'
pretrained: True
data:
type: 'video'
sources: ['prid2011']
targets: ['prid2011']
height: 224
width: 112
combineall: False
transforms: ['random_flip']
save_dir: 'log/osnet_x1_0_prid2011_softmax_cosinelr'
loss:
name: 'sof... | open | 2020-07-03T11:51:54Z | 2020-07-04T14:37:56Z | https://github.com/KaiyangZhou/deep-person-reid/issues/351 | [] | deropty | 1 |
RafaelMiquelino/dash-flask-login | plotly | 5 | current_user.is_authenticated returns false in deployment | Hello,
Thanks for making this repository.
I have been using it with success on a localhost, but as soon as I deploy it, on a hosted server, the user authentication stops behaving. As the user logs in, it registers that the user is authenticated, but within less than a 1s the bool current_user.is_authenticated is... | closed | 2020-06-04T07:39:04Z | 2020-06-09T09:23:49Z | https://github.com/RafaelMiquelino/dash-flask-login/issues/5 | [] | max454545 | 12 |
3b1b/manim | python | 1,498 | AnimationGroup height visual issue | I am trying to create a cool effect where the text is getting written and zoom in at the same time.
I tried to use the `AnimationGroup` object for that but this is how it renders :
https://user-images.githubusercontent.com/2827383/115975871-e9a4b700-a568-11eb-8194-fed4927fcfd2.mp4
First, the letters appear re... | open | 2021-04-24T23:55:57Z | 2021-06-17T00:43:57Z | https://github.com/3b1b/manim/issues/1498 | [] | vdegenne | 1 |
graphql-python/graphene | graphql | 1,361 | Interfaces are ignored when define Mutation. | Hello.
First of all, thanks for all graphene developers and contributors.
* **What is the current behavior?**
Interface is ignored when define mutation. This is my code.
```python
class CreatePlan(Mutation):
class Meta:
interfaces = (PlanInterface, )
class Arguments:
name = String(req... | open | 2021-09-03T07:13:50Z | 2021-09-03T07:13:50Z | https://github.com/graphql-python/graphene/issues/1361 | [
"🐛 bug"
] | maintain1210 | 0 |
aio-libs/aiomysql | sqlalchemy | 203 | Mistake :( | closed | 2017-08-07T17:33:19Z | 2017-08-07T17:39:54Z | https://github.com/aio-libs/aiomysql/issues/203 | [] | paccorsi | 0 | |
yihong0618/running_page | data-visualization | 710 | 小米运动健康App导出的TCX文件结构与TCXReader解析格式不兼容,导致无法获取心率信息 | Edit: tcx同步到strava
小米运动健康导出的tcx结构:
```
<TrainingCenterDatabase creator="Mi Fitness" version="1.0" xsi:schemaLocation="http://www.garmin.com/xmlschemas/TrainingCenterDatabase/v2 http://www.garmin.com/xmlschemas/TrainingCenterDatabasev2.xsd">
<script/>
<Activities>
<Activity Sport="">
<Id>2024-09-08T19:08:07.000... | closed | 2024-09-08T15:02:34Z | 2024-11-10T12:06:00Z | https://github.com/yihong0618/running_page/issues/710 | [] | RiverOnVenus | 11 |
pydata/pandas-datareader | pandas | 197 | Docs bug | The [usage examples](http://pandas-datareader.readthedocs.org/en/latest/remote_data.html#yahoo-finance-options) for Yahoo Finance options contain a couple errors.
| closed | 2016-04-24T09:22:19Z | 2016-04-24T09:55:49Z | https://github.com/pydata/pandas-datareader/issues/197 | [] | andportnoy | 3 |
Textualize/rich | python | 2,572 | [BUG] Hyperlinks in logger messages don't work on VS Code | You may find a solution to your problem in the [docs](https://rich.readthedocs.io/en/latest/introduction.html) or [issues](https://github.com/textualize/rich/issues).
**Describe the bug**
The hyperlinks in the logger messages don't work in VS Code.
**Platform**
<details>
<summary>Click to expand</summary>
... | closed | 2022-10-11T14:10:41Z | 2024-08-26T14:29:55Z | https://github.com/Textualize/rich/issues/2572 | [
"Needs triage"
] | ma-sadeghi | 3 |
dask/dask | numpy | 11,574 | Masked Array reductions and numpy 2+ | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-12-03T04:40:34Z | 2024-12-18T12:03:37Z | https://github.com/dask/dask/issues/11574 | [
"needs triage"
] | Kirill888 | 1 |
ClimbsRocks/auto_ml | scikit-learn | 309 | make sure compare_all_algos lives up to the name | and if so, remove duplicate tests for compare all models | open | 2017-08-02T01:29:12Z | 2017-08-02T01:29:12Z | https://github.com/ClimbsRocks/auto_ml/issues/309 | [] | ClimbsRocks | 0 |
alteryx/featuretools | scikit-learn | 2,115 | Feature serialization and deserialization improvements | The serialization and deserialization of features should be improved.
For serialization we should update the approach so we are not duplicating primitive serialized primitive information. Currently if there are features that share the same primitive, each serialized feature contains the information needed to deseria... | closed | 2022-06-16T21:27:11Z | 2022-07-06T17:58:54Z | https://github.com/alteryx/featuretools/issues/2115 | [] | thehomebrewnerd | 0 |
xlwings/xlwings | automation | 2,135 | Error exporting cmap formatted DF to Excel | #### OS (e.g. Windows 10 or macOS Sierra)
Windows 10
#### Versions of xlwings, Excel and Python (e.g. 0.11.8, Office 365, Python 3.7)
Running on Jupyter Notebook
#### Describe your issue (incl. Traceback!)
Hi, I am having an issue pasting dataframes that is formatted via background_gradient through pandas into... | closed | 2023-01-06T07:38:38Z | 2023-01-17T10:42:58Z | https://github.com/xlwings/xlwings/issues/2135 | [] | russwongg | 5 |
slackapi/python-slack-sdk | asyncio | 913 | Updated pop up modal view seen for a second and closed immediately | ### Description
Not sure what’s is missing , pasting the exact code.When I use below method I'm able to see pop getting update on click of submit button but its closing within approximately 2 seconds
```python
def send_views(user_name):
form_json = json.loads(request.form.get('payload'))
open_dialog1 =... | closed | 2021-01-11T19:52:32Z | 2021-01-14T15:11:42Z | https://github.com/slackapi/python-slack-sdk/issues/913 | [
"question",
"web-client"
] | ravi7271973 | 10 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,052 | WaterColor Style transfer, the generated image is not obvious... | Hello, I'm using cycleGAN to do watercolor style transfer, and I have collected many watercolor style images (about 3500) of different scenes with different objects. But the generated image is just no different of the original.
Some questions in my mind:
1) should the training set keep in the similar scene or simi... | open | 2020-06-01T03:40:14Z | 2020-06-01T06:01:50Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1052 | [] | Rancherzhang | 2 |
wkentaro/labelme | deep-learning | 435 | Feedback————How can I change the color of the 'label_viz' background? | Hello, wkentaro. I want to implement some display functions about my data, but I don't know how to get it.
I will get a folder in command line with " labelme_json_to_dataset /path ", this folder contains an image called 'label_viz'.
.values():
if param._data is None:
param.initialize()
```
However, the error remains still. Please advise. Thanks for your help.
### Terminal output (Powershell) f... | closed | 2019-12-02T21:53:08Z | 2020-02-04T19:28:33Z | https://github.com/dmlc/gluon-cv/issues/1071 | [] | NamTran838P | 11 |
d2l-ai/d2l-en | deep-learning | 2,440 | Wrong epanechikov kernel | Chapter 11.2. It is triangular kernel. | open | 2023-02-12T15:50:31Z | 2023-02-12T15:50:31Z | https://github.com/d2l-ai/d2l-en/issues/2440 | [] | yongduek | 0 |
jofpin/trape | flask | 376 | Hey | closed | 2023-03-11T18:34:19Z | 2023-03-11T18:46:06Z | https://github.com/jofpin/trape/issues/376 | [] | Baggy79 | 1 | |
seleniumbase/SeleniumBase | pytest | 2,910 | Add advanced UC Mode PyAutoGUI clicking methods | ## Add advanced UC Mode PyAutoGUI clicking methods
```python
driver.uc_gui_click_x_y(x, y, timeframe=0.25) # PyAutoGUI click screen
driver.uc_gui_click_cf(frame="iframe", retry=False, blind=False) # (*)
```
👤 `driver.uc_gui_click_x_y(x, y, timeframe=0.25)` uses `PyAutoGUI` to click the screen at the coord... | closed | 2024-07-06T06:24:50Z | 2024-07-08T21:24:39Z | https://github.com/seleniumbase/SeleniumBase/issues/2910 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 2 |
voila-dashboards/voila | jupyter | 1,486 | Broken rendering of math/LaTeX using HTMLMath widget since 0.5.5 | Hello!
First of all, thanks for this tool it is awesome.
## Description
`HTMLMath` widget has not rendered Math/LaTeX content correctly since `0.5.5`.
<img width="960" alt="repro-0 5 5-bad" src="https://github.com/user-attachments/assets/eef21090-88ab-48b7-9b3d-94f8cacc52fb">
Going back to `0.5.4` it rend... | closed | 2024-08-01T23:09:37Z | 2024-10-09T20:54:11Z | https://github.com/voila-dashboards/voila/issues/1486 | [
"bug"
] | akielbowicz | 1 |
piskvorky/gensim | nlp | 2,728 | [QUESTION] Update LDA model | ## Problem description
Update an existing LDA model with an incremental approach. We create a LDA model for a collection of documents on demand basis. We save the resulting model file on the cloud. When a new LDA request arrives with fresh data, I need a way to incrementally update the model (live training) wit the th... | closed | 2020-01-16T13:23:23Z | 2020-01-23T07:40:12Z | https://github.com/piskvorky/gensim/issues/2728 | [] | loretoparisi | 1 |
samuelcolvin/dirty-equals | pytest | 38 | Include documentation on how this works | I find this functionality quite interesting and think it could be useful.
But I'm a bit hesitant to include a library with "magical" behavior that I don't understand.
My main question is, why is the `__eq__` method of the right operand used?
The [python documentation](https://docs.python.org/3/reference/datamodel.... | closed | 2022-05-09T11:04:01Z | 2022-05-13T14:01:32Z | https://github.com/samuelcolvin/dirty-equals/issues/38 | [] | Marco-Kaulea | 3 |
strawberry-graphql/strawberry-django | graphql | 712 | Cannot find 'assumed_related_name' on 'YourRelatedModel' object, 'assumed_related_name' is an invalid parameter to prefetch_related() | ## The Bug
When defining models in django, it is often assumed that we provide the `related_name` field. Usually, it is a plural of the name of the model we are pointing from. In `strawberry-django`, if this plural name is not provided for `related_name`, we are thrown the error:
```shell
Cannot find 'transactions' o... | closed | 2025-02-24T07:49:40Z | 2025-02-24T08:10:22Z | https://github.com/strawberry-graphql/strawberry-django/issues/712 | [
"bug"
] | jamietdavidson | 1 |
frappe/frappe | rest-api | 31,155 | Asset Image can't be changed/removed once uploaded and Saved. Draft/Submitted | **Description:** The Image Field in the Asset is an "Allow on Submit" Field, allowing users to Add/Change the Image after Submitting. But once a User uploads an Image, it can't be removed or changed even though the option is there, it is not working.
**Pre-Requisites:** Create an Asset(Either Draft or Submitted).
**S... | open | 2025-02-06T05:10:53Z | 2025-02-06T05:11:41Z | https://github.com/frappe/frappe/issues/31155 | [
"bug"
] | ransikerandeni | 0 |
ghtmtt/DataPlotly | plotly | 33 | Animations are available for offline | A bit complicated to implement, but the code is more or less straightforward:
```python
f1 = [125.7, 219.12, 298.55, 132.32, 520.6, 3435.49, 2322.61, 1891.63, 216.97, 383.98, 82.01, 365.56, 199.98, 308.71, 217.58, 436.09, 711.77]
f2 = [1046.67, 1315.0, 1418.0, 997.33, 2972.3, 9700.0, 6726.0, 6002.5, 2096.0, 2470... | open | 2017-07-07T13:05:38Z | 2021-08-26T05:56:17Z | https://github.com/ghtmtt/DataPlotly/issues/33 | [
"enhancement"
] | ghtmtt | 5 |
Python3WebSpider/ProxyPool | flask | 18 | zincrby 新的版本redis-py有改动 | zincrby(name, amount, value)
需要将源代码中的zincrby第二、三参数换个顺序 | closed | 2018-12-24T12:47:51Z | 2020-02-19T16:57:53Z | https://github.com/Python3WebSpider/ProxyPool/issues/18 | [] | duolk | 1 |
graphql-python/gql | graphql | 188 | Customizable ExecutionResult, or how to get other API response parts | https://github.com/graphql-python/gql/blob/459d5ebacce95c817effcd18be152d6cf360cf2b/gql/transport/requests.py#L174
### Case:
The GraphQL API that I need to make requests to, responds with some other useful information, except of `data` block:
```json
{
"data": {...},
"extensions": {
"pageInfo": {... | closed | 2021-01-23T10:45:35Z | 2021-11-24T09:10:03Z | https://github.com/graphql-python/gql/issues/188 | [
"type: feature"
] | extrin | 7 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 295 | 合并词表报错 | 合并词表时我用了redpajama的tokenizer替换了llama的tokenizer,报错:
<img width="882" alt="image" src="https://github.com/ymcui/Chinese-LLaMA-Alpaca/assets/69674181/e4547f0e-f57d-4a6d-b20c-dc5436483d9d">
请问如何解决这种报错、或者说有什么解决的思路吗 | closed | 2023-05-10T06:55:26Z | 2023-05-20T22:02:04Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/295 | [
"stale"
] | han508 | 5 |
sktime/sktime | scikit-learn | 7,950 | [BUG] Link to documentation in ExpandingGreedySplitter display goes to incorrect URL | **Describe the bug**
The image displayed with you instantiate an `ExpandingGreedySplitter` object has a `?` icon in the top right that links to the API reference for the object. However rather than link to the `latest` or `stable` page, it links to the version of `sktime` that you have installed. In my case, it is `v0.... | open | 2025-03-07T17:55:13Z | 2025-03-22T14:23:35Z | https://github.com/sktime/sktime/issues/7950 | [
"bug",
"documentation"
] | gbilleyPeco | 5 |
feature-engine/feature_engine | scikit-learn | 446 | [ENHANCEMENT] change pandas.corr() by numpy alternative in correlation selectors | **Is your feature request related to a problem? Please describe.**
For the following feature selectors:
- [SmartCorrelatedSelection](https://feature-engine.readthedocs.io/en/1.3.x/api_doc/selection/SmartCorrelatedSelection.html)
- [DropCorrelatedFeatures](https://feature-engine.readthedocs.io/en/1.3.x/api_doc/sele... | closed | 2022-05-08T04:28:21Z | 2024-02-18T17:24:28Z | https://github.com/feature-engine/feature_engine/issues/446 | [
"enhancement"
] | lauradang | 1 |
recommenders-team/recommenders | machine-learning | 1,562 | [BUG] ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject | ### The benchmark notebook got a Numpy error while running, like this:
<!--- Describe your issue/bug/request in detail -->
```
ValueError: numpy.ndarray size changed, may indicate binary incompatibility. Expected 88 from C header, got 80 from PyObject
```
I searched from the stackoverflow, it seems that I got th... | closed | 2021-11-01T12:17:39Z | 2021-11-02T19:54:44Z | https://github.com/recommenders-team/recommenders/issues/1562 | [
"bug"
] | mokeeqian | 1 |
qwj/python-proxy | asyncio | 101 | api_* tests require an internet connection | It would be helpful for distro packaging if the api_* tests had a non-internet tunnel endpoint, such as a dedicated test local service which could be stood up for the purpose of testing, e.g. `httpbin`, which is available as a pytest plugin `pytest-httpbin` | open | 2020-12-07T18:39:50Z | 2020-12-07T18:39:50Z | https://github.com/qwj/python-proxy/issues/101 | [] | jayvdb | 0 |
pytest-dev/pytest-cov | pytest | 456 | .coveragerc sometimes ignored | # Summary
In jaraco/skeleton, I've configured my projects to [ignore .tox](https://github.com/jaraco/skeleton/blob/86efb884f805a9e1f64661ec758f3bd084fed515/.coveragerc#L2) for coverage. Despite this setting, I often see `.tox` in the coverage results. ([example](https://github.com/jaraco/cssutils/runs/2082642025?che... | closed | 2021-03-11T02:58:38Z | 2021-10-03T23:58:05Z | https://github.com/pytest-dev/pytest-cov/issues/456 | [] | jaraco | 4 |
MycroftAI/mycroft-core | nlp | 2,651 | Custom wake up word is only detected once during the "start-mycroft.sh debug" and not detected at all after that | Hi Team,
I have trained my custom wake up word "mokato" using precise models. When I test it with "precise-listen -b mokato.net" I see many ! (positive detection) and the output of "precise-test mokato.net mokato" is also good (100% postive), I am pasting all info below. Now when I start the "start-mycroft.sh debug" i... | closed | 2020-08-07T18:41:14Z | 2020-12-09T05:42:07Z | https://github.com/MycroftAI/mycroft-core/issues/2651 | [] | abhisek-mishra | 4 |
zihangdai/xlnet | tensorflow | 274 | What is the function of _sample_mask method? | 
It seems XLNet do not have MASK. | closed | 2020-09-29T09:55:44Z | 2020-09-29T12:06:19Z | https://github.com/zihangdai/xlnet/issues/274 | [] | guotong1988 | 1 |
mars-project/mars | pandas | 3,176 | [BUG] session creation error | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
session creation error
**To Reproduce**
To help us reproducing this bug, please provide information below:
1. Python 3.7.13
2. Mars 9.0
... | closed | 2022-06-29T13:04:47Z | 2023-03-31T05:00:52Z | https://github.com/mars-project/mars/issues/3176 | [] | Ukon233 | 2 |
jwkvam/bowtie | plotly | 42 | ant looks nice | https://ant.design/docs/react/introduce
strongly considering just always using ant.design styling for bowtie because
1. They have all the widgets I need as far as I can tell.
2. I like the UX of their components more than palantir's blueprint.
3. It looks nice.
4. More professional looking to have components w... | closed | 2016-11-28T21:27:34Z | 2016-12-05T08:34:17Z | https://github.com/jwkvam/bowtie/issues/42 | [] | jwkvam | 1 |
autogluon/autogluon | data-science | 4,129 | Make `timm` an optional dependency | We should see if we can make `timm` an optional dependency in the multimodal module.
- [ ] Lazy import timm only when it is used
- [ ] Make timm an optional dependency
- [ ] Ensure presets work appropriately when timm is not present
- [ ] Ensure informative error message if timm is required but not installed for ... | open | 2024-04-23T20:26:23Z | 2024-11-02T02:14:19Z | https://github.com/autogluon/autogluon/issues/4129 | [
"module: multimodal",
"dependency",
"priority: 0"
] | Innixma | 1 |
python-arq/arq | asyncio | 417 | Function level keep_result_s not respected for errors | In `finish_failed_job`, there's only a check on self.keep_result_s, not the value configured from the function. As a result, any failed tasks are stored for potentially a very long time and cannot be re-enqueued with the same job id, even if configured on the function level to not store a result.
This also relates t... | open | 2023-10-22T08:55:06Z | 2023-10-22T08:55:06Z | https://github.com/python-arq/arq/issues/417 | [] | SoftMemes | 0 |
deepset-ai/haystack | machine-learning | 8,067 | docs: clean up docstrings of InMemoryEmbeddingRetriever | closed | 2024-07-24T11:01:57Z | 2024-07-25T11:24:01Z | https://github.com/deepset-ai/haystack/issues/8067 | [] | agnieszka-m | 0 | |
bmoscon/cryptofeed | asyncio | 740 | There is a simple error in this line, need to put Decimal() into the left side of the / . | https://github.com/bmoscon/cryptofeed/blob/6bb55d30a46f50ff9d28e6297e1c0f97f4040825/cryptofeed/exchanges/binance.py#L498 | closed | 2021-12-10T14:21:38Z | 2021-12-11T15:01:17Z | https://github.com/bmoscon/cryptofeed/issues/740 | [] | badosanjos | 2 |
microsoft/nni | tensorflow | 5,744 | Not training enough times | Stopped training after only running 6 times, although it displayed as RUING, there was no issue with memory usage.
Ubuntu 22.04.3 LTS
python 3.8.18
nni 3.0b2

: GTK
Installed via: Mint's Software Manager
Linux Distribution: Mint Cinnamon
## Summary
Summary of the problem.
## Steps to Reproduce (if applicable)
1. Right-c... | closed | 2021-07-23T18:27:11Z | 2024-11-10T05:03:10Z | https://github.com/autokey/autokey/issues/585 | [
"enhancement",
"autokey-gtk",
"help-wanted",
"user interface",
"easy fix"
] | KeronCyst | 5 |
pyg-team/pytorch_geometric | deep-learning | 9,346 | Examples folder refactor | ### 🛠 Proposed Refactor
Hi, I am a beginner of PyG, and I get myself familiar with PyG through the documentation, now I want to try to run some examples, I felt a little confused on the current example folder in the repo. The following are my current thoughts, I put it here for your reference, looking forward to he... | open | 2024-05-22T07:54:23Z | 2024-05-27T07:24:22Z | https://github.com/pyg-team/pytorch_geometric/issues/9346 | [
"help wanted",
"0 - Priority P0",
"refactor",
"example"
] | zhouyu5 | 1 |
tensorpack/tensorpack | tensorflow | 1,543 | Applying quantization to the CNN for CIFAR net with BNReLU gives 0.1 validation accuracy | ### 1. What you did:
(1) Trained the CNN in the /examples/basics for CIFAR net and added quantization layers
### 2. What you observed:
(1) The validation accuracy does not increase above 0.1

Hi,
... | closed | 2021-09-24T18:43:03Z | 2021-09-25T14:02:34Z | https://github.com/tensorpack/tensorpack/issues/1543 | [] | Abhishek2271 | 1 |
pytest-dev/pytest-qt | pytest | 211 | blocker.all_signals_and_args is empty when using PySide2 | First and foremost, pytest-qt has been tremendously useful. Thank you!
I am working on a UI that needs to be compatible with both PyQt5 and PySide2. When testing I noticed that with PyQt5, the all_signals_and_args seems to be populated correctly with the args from the multile signals, however, when testing with PySi... | closed | 2018-05-15T22:45:46Z | 2020-05-14T19:43:42Z | https://github.com/pytest-dev/pytest-qt/issues/211 | [
"bug :bug:"
] | zephmann | 4 |
huggingface/transformers | machine-learning | 35,957 | Cannot import 'GenerationOutput' in 4.48.1 | ### System Info
- `transformers` version: 4.48.1
- Platform: Linux-5.15.167.4-microsoft-standard-WSL2-x86_64-with-glibc2.31
- Python version: 3.9.5
- Huggingface_hub version: 0.28.0
- Safetensors version: 0.5.2
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.5.1+cu124 (Tr... | closed | 2025-01-29T13:22:00Z | 2025-03-13T08:03:51Z | https://github.com/huggingface/transformers/issues/35957 | [
"bug"
] | inthree3 | 4 |
flasgger/flasgger | rest-api | 624 | security-parameter missing for Authorization header | So maybe I'm doing something wrong, but I couldn't get the the Swagger-UI to actually send the Authorization header.
My configuration includes both necessary definitions imo:
```
"securityDefinitions": {
"Bearer": {
"type": "apiKey",
"name": "Authorization",
"in"... | open | 2024-09-23T13:06:16Z | 2024-09-23T13:09:18Z | https://github.com/flasgger/flasgger/issues/624 | [] | wiseboar | 0 |
coqui-ai/TTS | pytorch | 2,927 | [Bug] Unable to run tts-server or server/server.py with Bark | ### Describe the bug
Hi,
Thank you for making such excellent software.
However, maybe due to my lack of familiarity with Docker and Python, I am running into the following errors. I ran:
`docker run --rm -it -p 5002:5002 --gpus all --entrypoint /bin/bash ghcr.io/coqui-ai/tts`
`python3 TTS/server/server.py ... | closed | 2023-09-05T16:52:47Z | 2025-01-15T16:57:36Z | https://github.com/coqui-ai/TTS/issues/2927 | [
"bug",
"help wanted",
"wontfix"
] | aindilis | 9 |
SALib/SALib | numpy | 207 | Unable to install SALib | When I execute 'pip install SALib' on centOS 7, it is giving an error of "distutils.errors.DistutilsError: Could not find suitable distribution for Requirement.parse('pyscaffold<2.6a0,>=2.5a0')".
After installed pyscaffold (2.5.2), it is giving error of "your setuptools version is too old(<12)",but my setuptools vers... | closed | 2018-09-11T08:08:52Z | 2019-03-14T15:45:55Z | https://github.com/SALib/SALib/issues/207 | [] | valwu | 6 |
dmlc/gluon-nlp | numpy | 1,242 | [Numpy Refactor] Tokenizers wishlist | We revised the implementation of tokenizers in the new version of GluonNLP.
Basically we have integrated the following tokenizers:
- whitespace
- spacy
- jieba
- SentencePiece
- YTTM
- HuggingFaceBPE
- HuggingFaceByteBPE
- HuggingFaceWordPiece
For all tokenizers, we support the following methods:
- Enc... | open | 2020-06-10T07:25:57Z | 2020-06-10T16:13:11Z | https://github.com/dmlc/gluon-nlp/issues/1242 | [
"enhancement",
"numpyrefactor"
] | sxjscience | 0 |
microsoft/nni | data-science | 4,783 | please add the ppo_tuner performance in comparison of hpo algorithms | **Describe the issue**:
Hi,
Could you please add the ppo_tuner performance in comparison of hpo algorithms:
https://nni.readthedocs.io/en/latest/sharings/hpo_comparison.html
Thanks a lot!
**Environment**:
- NNI version:
- Training service (local|remote|pai|aml|etc):
- Client OS:
- Server OS (for remote... | open | 2022-04-20T13:18:47Z | 2022-04-24T08:56:03Z | https://github.com/microsoft/nni/issues/4783 | [] | southisland | 1 |
FlareSolverr/FlareSolverr | api | 297 | Can't access property "documentTitle", this.browsingContext.currentWindowGlobal is null | This issue is reported with FlareSolverr 2.2.0 in Windows and CentOS.
I think it's not related to user permissions but a Firefox bug. We are using the latest nightly.
I'm not able to reproduce the issue, just once.
Related #295 #286 #289 #282 | closed | 2022-02-06T10:56:15Z | 2023-01-05T11:19:13Z | https://github.com/FlareSolverr/FlareSolverr/issues/297 | [
"more information needed",
"confirmed"
] | ngosang | 3 |
miguelgrinberg/Flask-Migrate | flask | 456 | Add timezone support | #### What's the problem this feature will solve?
If you try to generate a migration that requires a DateTime with timezone support you'll get the following error:
```
ERROR: MainProcess<flask_migrate> Error: The library 'python-dateutil' is required for timezone support
```
It seems `python-dateutil` is opti... | closed | 2022-03-16T12:07:10Z | 2022-03-16T15:21:40Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/456 | [
"question"
] | atugushev | 2 |
deezer/spleeter | tensorflow | 493 | [Discussion] updating Python dependencies | Some Python packages listed in `setup.py` are a little bit old:
- pandas is now `1.1.2` as opposed to `0.25.1`
- librosa is now `0.8.0` as opposed to `0.7.2`
- it now requires `numba==0.48.0` for itself, so unless you're using numba in the actual project, you can remove it
Also, I think you can:
- safely r... | closed | 2020-09-13T20:23:43Z | 2020-10-09T15:32:56Z | https://github.com/deezer/spleeter/issues/493 | [
"question"
] | flriancu | 3 |
flaskbb/flaskbb | flask | 170 | Performance issues | I am creating a general topic for this and posting the first performance issue I encountered.
Using standard install in production mode with redis configured I am seeing very consistently slow response times. With plain "hello world" nginx + uwsgi the response time is 0.309 ms
When using flask BB the response time is... | closed | 2016-01-09T14:35:01Z | 2018-04-15T07:47:37Z | https://github.com/flaskbb/flaskbb/issues/170 | [] | abshkd | 6 |
chaoss/augur | data-visualization | 2,752 | Stability of our production SAAS instance of Augur | As we look to expand our SAAS offerings within CHAOSS, I wonder if we could get some additional funding that would allow us to run our "production" instance in a completely separate environment that wouldn't be impacted by issues like the one we just had with a dev instance getting overloaded and taking other instances... | open | 2024-03-26T16:30:34Z | 2024-03-28T16:54:09Z | https://github.com/chaoss/augur/issues/2752 | [
"feature-request",
"deployed version",
"CHAOSS",
"documentation",
"usability",
"server",
"database",
"add-feature",
"devops"
] | geekygirldawn | 1 |
thp/urlwatch | automation | 97 | how to enable color diffs? | Hi,
What is the configuration to enable color diffs? I don't find it in the readme.
Thanks.
| closed | 2016-09-30T11:01:28Z | 2016-10-02T09:58:46Z | https://github.com/thp/urlwatch/issues/97 | [] | monperrus | 1 |
praw-dev/praw | api | 2,004 | Installing praw from source or sdist fails due to importing runtime deps at build time | ### Describe the Bug
Same issue as praw-dev/prawcore#164 and @LilSpazJoekp requested followup from praw-dev/prawcore#165
Due to the use of Flit's fallback automatic metadata version extraction needing to dynamically import the package `__init__.py` instead of reading it statically (see pypa/flit#386 ) , since the... | open | 2023-12-15T22:19:44Z | 2025-03-17T06:26:44Z | https://github.com/praw-dev/praw/issues/2004 | [] | CAM-Gerlach | 12 |
pydata/xarray | numpy | 9,653 | Dataset.to_dataframe() dimension order is not alphabetically sorted by default | ### What happened?
Hi, I noticed that the [documentation](https://docs.xarray.dev/en/stable/generated/xarray.Dataset.to_dataframe.html) for `Dataset.to_dataframe()` says that "by default, dimensions are sorted alphabetically". This is contrast with [`DataArray.to_dataframe()`](https://docs.xarray.dev/en/stable/gener... | closed | 2024-10-21T11:33:00Z | 2024-10-23T08:09:16Z | https://github.com/pydata/xarray/issues/9653 | [
"topic-documentation"
] | mgunyho | 4 |
Farama-Foundation/PettingZoo | api | 600 | StopIteration | Hi, i have a problem and i don't know how to solve it, could you give me some advice?
File "/home/user/anaconda3/lib/python3.6/site-packages/supersuit/utils/make_defaultdict.py", line 5, in make_defaultdict
dd = defaultdict(type(next(iter(d.values()))))
StopIteration
| closed | 2022-01-01T17:14:00Z | 2022-01-28T17:38:43Z | https://github.com/Farama-Foundation/PettingZoo/issues/600 | [] | xiaominy | 3 |
autogluon/autogluon | scikit-learn | 4,314 | Error during TabularPredictor's `predict_proba` | I am using `TabularPredictor` for a classification problem. I am using the method `TabularPredictor.predict`, which throws the error:
```
OSError: libgomp.so.1: cannot open shared object file: No such file or directory
```
On further reading the traceback, the problem starts when it internally calls `predict_pr... | closed | 2024-07-08T05:02:51Z | 2024-07-10T05:06:16Z | https://github.com/autogluon/autogluon/issues/4314 | [
"module: tabular",
"OS: Mac",
"install"
] | ArijitSinghEDA | 3 |
Farama-Foundation/PettingZoo | api | 434 | Pygame rendering/observing returns a reference rather than a new object in Cooperative Pong | According to the pygame documentation for pygame.surfarray.pixels3d:
> Create a new 3D array that directly references the pixel values in a Surface. Any changes to the array will affect the pixels in the Surface. This is a fast operation since no data is copied.
Any environment with a render function that directl... | closed | 2021-07-30T18:20:45Z | 2021-07-30T18:30:54Z | https://github.com/Farama-Foundation/PettingZoo/issues/434 | [] | RyanNavillus | 0 |
voxel51/fiftyone | computer-vision | 5,492 | [FR] Support more image codecs in `fiftyone.utils.image.read` | ### Proposal Summary
Support more codecs when reading images from `fiftyone.utils.image.read`
### What areas of FiftyOne does this feature affect?
- [ ] App: FiftyOne application
- [x] Core: Core `fiftyone` Python library
- [ ] Server: FiftyOne server
### Details
`read` uses opencv, which doesn't support `.a... | open | 2025-02-14T14:24:48Z | 2025-02-14T16:53:14Z | https://github.com/voxel51/fiftyone/issues/5492 | [
"feature"
] | Laurent2916 | 1 |
ymcui/Chinese-BERT-wwm | nlp | 82 | Chinese-BERT-wwm与Chinese-PreTrained-XLNet的模型下载地址有错误 | 其中两者的base版模型的讯飞云下载地址发生了交错。 | closed | 2020-01-01T22:29:18Z | 2020-01-02T00:41:31Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/82 | [] | fungxg | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.