
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
pytorch/vision | computer-vision | 8,730 | release for python 3.13 | ### 🚀 The feature
Any plans to release for python 3.13?
thanks
### Motivation, pitch
torch is already compatible with 3.13
### Alternatives
_No response_
### Additional context
_No response_ | closed | 2024-11-14T08:41:04Z | 2025-02-27T10:40:56Z | https://github.com/pytorch/vision/issues/8730 | [] | dpinol | 6 |
wagtail/wagtail | django | 12,408 | Streamfield migrations fail on revisions that don't have target field | ### Issue Summary
`wagtail.blocks.migrations.migrate_operation.MigrateStreamData` does not gracefully handle revisions that do not contain the field that is being operated on. This may occur when running a migration on a model that has revisions from before the creation of the field on the model. We do support limitin... | open | 2024-10-12T11:03:21Z | 2024-12-01T03:58:01Z | https://github.com/wagtail/wagtail/issues/12408 | [
"type:Bug",
"component:Streamfield"
] | jams2 | 2 |
xinntao/Real-ESRGAN | pytorch | 328 | 请问在哪可以看到生成器的网络结构 | 作者您好,我没有在代码中找到生成器的arch文件,basicsr的arch文件夹下也没有ESRGAN的arch文件
请问在哪里可以看到ESRGAN的arch文件 | closed | 2022-05-12T10:41:16Z | 2023-02-15T07:34:34Z | https://github.com/xinntao/Real-ESRGAN/issues/328 | [] | EgbertMeow | 1 |
miguelgrinberg/Flask-Migrate | flask | 73 | The multidb is not putting changes in the correct database. | I am having an issue where my schema changes are not showing up in the correct database. Furthermore, the test_multidb_migrate_upgrade fails when running "python setup.py test".
When I run these commands:
``` sh
cd tests
rm *.db && rm -rf migrations # cleanup
python app_multidb.py db init --multidb
python app_multidb... | closed | 2015-08-17T18:38:27Z | 2015-09-04T17:57:35Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/73 | [
"bug"
] | espositocode | 3 |
jina-ai/serve | fastapi | 5,994 | Dynamic k8s namespace for generating kubernetes yaml | **Describe the feature**
The current implementation for to_kubernetes_yaml flow [takes `k8s_namespace` to be explicitly specified somewhere otherwise it outputs as `default` namespace](https://github.com/jina-ai/jina/blob/34664ee8db0a0e593a6c71dd6476cbf266a80641/jina/orchestrate/flow/base.py#L2772C69-L2772C69). The na... | closed | 2023-07-30T11:05:54Z | 2024-06-06T00:18:51Z | https://github.com/jina-ai/serve/issues/5994 | [
"Stale"
] | sansmoraxz | 25 |
suitenumerique/docs | django | 113 | 🐛Editor difference with PDF | ## Bug Report
Some properties of the editor are not reflected to the PDF (color / bg / alignment)
An issue was opened about it:
- [x] https://github.com/TypeCellOS/BlockNote/issues/893
## Demo

## Co... | closed | 2024-07-01T12:50:13Z | 2024-08-02T15:34:03Z | https://github.com/suitenumerique/docs/issues/113 | [
"bug",
"enhancement",
"frontend"
] | AntoLC | 0 |
agronholm/anyio | asyncio | 418 | 'get_coro' doesn't apply to a 'Task' object | Don't know if I should file it under `anyio` or `httpx`.
I have a FastAPI web app that makes some external calls with `httpx`. I sometimes (timeout involved? loop terminated elsewhere?) get the following error. I was unsuccessful at reproducing it in a minimal example, so please forgive me for just pasting the trace... | closed | 2022-02-10T10:26:31Z | 2022-05-08T19:08:01Z | https://github.com/agronholm/anyio/issues/418 | [] | jacopo-exact | 7 |
pytest-dev/pytest-cov | pytest | 605 | Maximum coverage in minimal time | # Summary
Given a project where tests have been added incrementally over time and there is a significant amount of overlap between tests,
I'd like to be able to generate a list of tests that creates maximum coverage in minimal time. Clearly this is a pure coverage approach and doesn't guarantee that functional cov... | closed | 2023-08-10T11:57:49Z | 2023-12-11T09:26:55Z | https://github.com/pytest-dev/pytest-cov/issues/605 | [] | masaccio | 5 |
horovod/horovod | deep-learning | 3,162 | Spark with Horovod fails with py4j.protocol.Py4JJavaError | **Environment:**
1. Framework: TensorFlow, Keras
2. Framework version: tensorflow-2.4.3, keras-2.6.0
3. Horovod version: horovod-0.22.1
4. MPI version:
5. CUDA version:
6. NCCL version:
7. Python version: python-3.6.9
8. Spark / PySpark version: Spark-3.1.2
9. Ray version:
10. OS and version: Ubuntu 18
11. G... | open | 2021-09-13T05:06:05Z | 2021-09-14T22:34:34Z | https://github.com/horovod/horovod/issues/3162 | [
"bug"
] | aakash-sharma | 2 |
scikit-optimize/scikit-optimize | scikit-learn | 569 | ImportError: cannot import name MaskedArray | I got scikit-optimize from your pypi release [here](https://pypi.python.org/pypi/scikit-optimize), where it says I need scikit-learn >= 0.18. "I'm in luck." thought I, for 0.18 I have. But trying to import skopt I get an error that MaskedArray can not be imported from sklearn.utils.fixes, and trying to import that clas... | closed | 2017-12-11T19:31:36Z | 2023-06-20T19:06:05Z | https://github.com/scikit-optimize/scikit-optimize/issues/569 | [] | pavelkomarov | 25 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 138 | How to use a queue of negative samples as done in MoCo | Hi Kevin,
I wonder if such an extended NT-Xent loss could be implemented?
The NT-Xent implemented in this package can return the pairwise loss when given a mini-batch and a label array. I wonder if for the purpose of increasing negative samples to make the task harder, could we directly use this package?
To be... | closed | 2020-07-14T01:22:43Z | 2020-07-25T14:21:05Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/138 | [
"Frequently Asked Questions",
"question"
] | CSerxy | 13 |
inventree/InvenTree | django | 9,196 | [FR] PUI: Please add IPN to supplier parts table | ### Please verify that this feature request has NOT been suggested before.
- [x] I checked and didn't find a similar feature request
### Problem statement
With reference to #9179: The IPN is missing in the supplierpart table. In CUI it was combined with the name. An
additional column is also fine.
### Suggested so... | closed | 2025-02-27T06:56:01Z | 2025-02-27T12:18:00Z | https://github.com/inventree/InvenTree/issues/9196 | [
"enhancement",
"User Interface"
] | SergeoLacruz | 3 |
graphql-python/graphene-django | graphql | 750 | Bug: Supposedly wrong types in query with filter_fields since 2.4.0 | ### Problem
When using filter_fields I get an error about using wrong types which started appearing in 2.4.0.
`Variable "startedAtNull" of type "Boolean" used in position expecting type "DateTime".` The error does not occur with graphene-django 2.3.2
### Context
- using django-filter 2.2.0
- django 2.4.0
###
... | closed | 2019-08-16T09:43:08Z | 2019-10-10T08:20:16Z | https://github.com/graphql-python/graphene-django/issues/750 | [
"🐛bug"
] | lassesteffen | 10 |
plotly/dash-table | dash | 600 | Incorrect cell validation / coercion | 1 - Validation default is not applied correctly when its value is `0` (number) -- the value is falsy and trips the default case
2 - Deleting cell content with `backspace` does not run validation
1 - This is simple, update https://github.com/plotly/dash-table/blob/dev/src/dash-table/type/reconcile.ts#L67 to do a `R.... | closed | 2019-09-24T12:34:57Z | 2019-09-24T16:28:50Z | https://github.com/plotly/dash-table/issues/600 | [
"dash-type-bug",
"size: 0.5"
] | Marc-Andre-Rivet | 0 |
stanfordnlp/stanza | nlp | 808 | Stanza sluggish with multiprocessing | Down below testcase.
Stanza is fast if `parallel == 1`, but becomes sluggish when distributed among processes.
````
import os, multiprocessing, time
import stanza
parallel = os.cpu_count()
language = 'cs'
sentence = 'ponuže dobře al ja nemam i zpětlou vas dbu od policiei teto ty teto věci najitam spravným or... | closed | 2021-09-16T12:41:13Z | 2021-09-20T12:35:40Z | https://github.com/stanfordnlp/stanza/issues/808 | [
"bug"
] | doublex | 1 |
deepinsight/insightface | pytorch | 2,328 | batch SimilarityTransform | The following code implements face alignment using functions from the `skimage` library. In cases where there are a small number of faces, using this function for face alignment can yield satisfactory results. However, when dealing with a large collection of faces, I'm looking for a method to calculate similarity trans... | open | 2023-06-06T03:29:15Z | 2023-07-11T02:55:29Z | https://github.com/deepinsight/insightface/issues/2328 | [] | muqishan | 1 |
python-visualization/folium | data-visualization | 1,850 | export / save Folium map as static image (PNG) | Code:
```python
colormap = branca.colormap.linear.plasma.scale(vmin, vmax).to_step(100)
r_map = folium.Map(location=[lat, long], tiles='openstreetmap')
for i in range(0, len(df)):
r_lat = ...
r_long = ...
r_score = ...
Circle(location=[r_lat, r_long], radius=5, color=colormap(r_score)).add_to(... | closed | 2023-12-22T21:15:47Z | 2024-05-25T14:11:19Z | https://github.com/python-visualization/folium/issues/1850 | [] | FlorinAndrei | 5 |
tradingstrategy-ai/web3-ethereum-defi | pytest | 125 | Error when loading last N blocks using JSONRPCReorganisationMonitor | How do you only load the last N blocks? This code wants to loads only last 5 blocks i believe, however it errors when adding new blocks.
```
reorg_mon = JSONRPCReorganisationMonitor(web3, check_depth=30)
reorg_mon.load_initial_block_headers(block_count=5)
while True:
try:
# ... | closed | 2023-05-18T09:10:38Z | 2023-08-08T11:47:19Z | https://github.com/tradingstrategy-ai/web3-ethereum-defi/issues/125 | [] | bryaan | 2 |
graphdeco-inria/gaussian-splatting | computer-vision | 850 | basic question from beginner of 3d reconstruction using 3DGS | Hello! I am trying to start 3d reconstruction with your 3DGS software.
I'd like to ask some basic questions.
1. Does 3DGS needs camera intrinsic parameter? It just helps 3D quality, or it is must to have?
2. I am using Colmap to make SfM as prerequisite before train.py used to make 3DGS .ply file. I put 2800 imag... | open | 2024-06-15T15:19:30Z | 2024-06-18T11:58:18Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/850 | [] | RickMaruyama | 1 |
hankcs/HanLP | nlp | 1,806 | 文件流未正确关闭 | <!--
感谢找出bug,请认真填写下表:
-->
**Describe the bug**
A clear and concise description of what the bug is.
VectorsReader类的readVectorFile()方法未正确关闭文件流,导致资源泄漏
**Code to reproduce the issue**
Provide a reproducible test case that is the bare minimum necessary to generate the problem.
使用Word2VecTrainer的train方法,或者new 一个Wor... | closed | 2023-02-24T13:40:24Z | 2023-02-25T01:02:15Z | https://github.com/hankcs/HanLP/issues/1806 | [
"bug"
] | zjqer | 3 |
NullArray/AutoSploit | automation | 406 | Unhandled Exception (e195f1bf9) | Autosploit version: `3.0`
OS information: `Linux-4.18.0-kali2-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py`
Error meesage: `global name 'Except' is not defined`
Error traceback:
```
Traceback (most recent call):
File "/root/Puffader/Autosploit/autosploit/main.py", line 113, in main... | closed | 2019-01-24T09:40:39Z | 2019-04-02T20:27:09Z | https://github.com/NullArray/AutoSploit/issues/406 | [] | AutosploitReporter | 0 |
piskvorky/gensim | machine-learning | 2,973 | phrases.export_phrases() doesn't yield all bigrams | Hallo and thank you for this tool,
phrases.export_phrases() doesn't yield all bigrams when some are part of a bigger n-gram.
If I create a Phrases object with
`phrases = gensim.models.phrases.Phrases(sentences, min_count=1, threshold=10, delimiter=b' ', scoring='default')`
on the following two sentences
... | closed | 2020-10-06T03:28:57Z | 2020-10-09T00:04:27Z | https://github.com/piskvorky/gensim/issues/2973 | [] | o-nc | 3 |
cvat-ai/cvat | pytorch | 8,431 | Toggle switch for mask point does not work anymore | For instance segmentation, I used to draw the first mask. For the second mask which would always overlap the first mask, I usually used CTRL to make the points of mask 1 appear to have a suitable overlap in annotation.
Now, the function of making the points of mask 1 appear is gone?! I can not turn the points on wit... | closed | 2024-09-11T10:24:34Z | 2024-09-11T11:11:25Z | https://github.com/cvat-ai/cvat/issues/8431 | [] | hasano20 | 2 |
encode/apistar | api | 71 | Interactive API Documentation | We'll be pulling in REST framework's existing interactive API docs.
It's gonna be ✨fabulous✨. | closed | 2017-04-20T14:07:21Z | 2017-08-04T15:06:37Z | https://github.com/encode/apistar/issues/71 | [
"Baseline feature"
] | tomchristie | 6 |
pytorch/pytorch | machine-learning | 149,516 | ```StateDictOptions``` in combination with ```cpu_offload=True``` and ```strict=False``` not working | ### 🐛 Describe the bug
When running the following for distributed weight loading:
```
options = StateDictOptions(
full_state_dict=True,
broadcast_from_rank0=True,
strict=False,
cpu_offload=True,
)
set_model_state_dict(model=model, model_state_dict=weights, options=options)
```
I am getting `KeyErr... | open | 2025-03-19T14:53:37Z | 2025-03-20T19:19:49Z | https://github.com/pytorch/pytorch/issues/149516 | [
"oncall: distributed checkpointing"
] | psinger | 0 |
getsentry/sentry | django | 86,783 | Add ttid_contribution_rate() function | ### Problem Statement
Add ttid_contribution_rate() to eap via rpc
### Solution Brainstorm
_No response_
### Product Area
Unknown | closed | 2025-03-11T13:16:41Z | 2025-03-11T17:46:36Z | https://github.com/getsentry/sentry/issues/86783 | [] | DominikB2014 | 0 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 98 | I can't use shortcuts on ios | I have updated to the latest 6.0 version but the shortcut still says to update, it makes me unable to download videos on tiktok
I use iphone X iOS 15.5
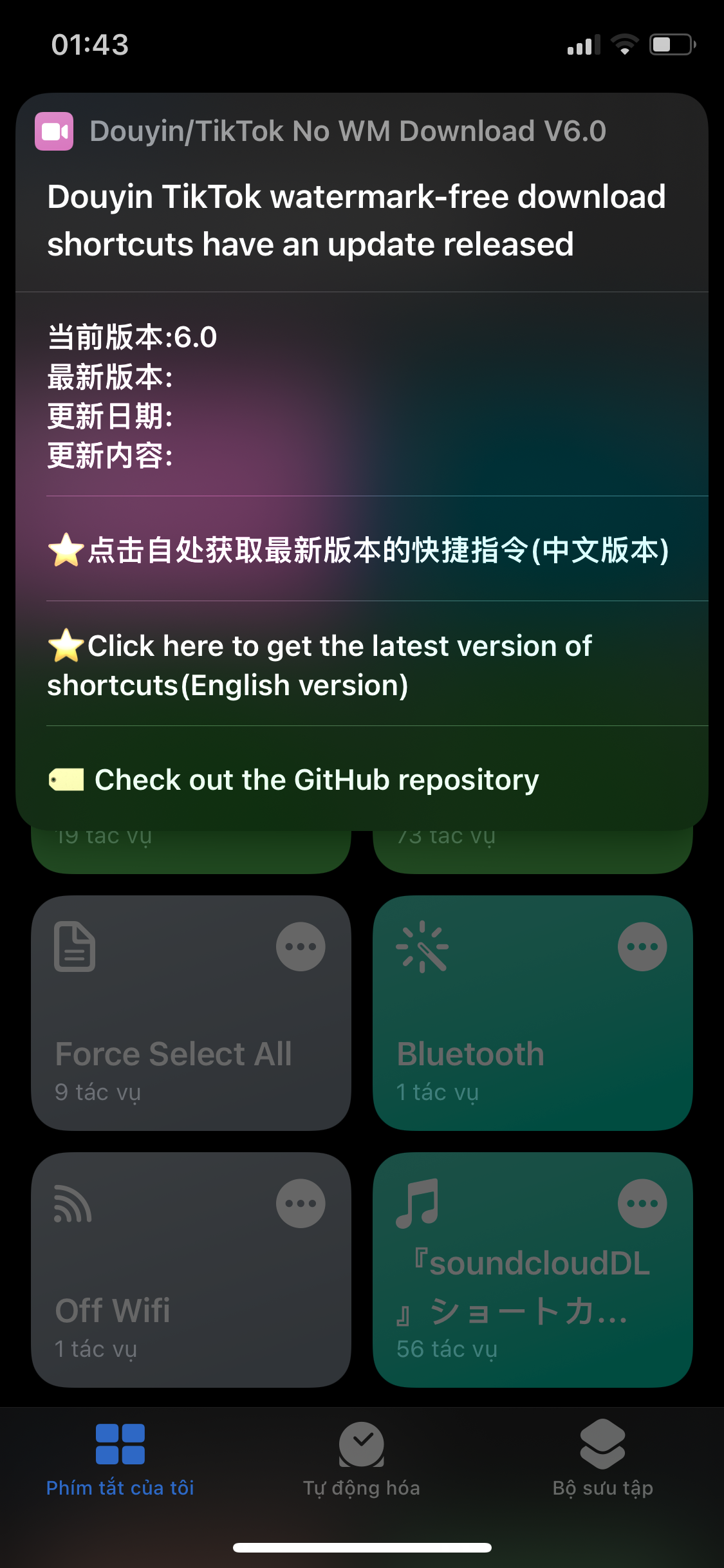 | closed | 2022-11-08T18:48:19Z | 2022-11-10T08:00:58Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/98 | [
"API Down",
"Fixed"
] | beelyhot5 | 1 |
timkpaine/lantern | plotly | 169 | Chop out email to separate jlab plugin | closed | 2018-07-22T17:57:18Z | 2018-08-10T19:55:22Z | https://github.com/timkpaine/lantern/issues/169 | [
"feature"
] | timkpaine | 2 | |
deepspeedai/DeepSpeed | deep-learning | 6,729 | GPU mem doesn't release after delete tensors in optimizer.bit16groups | I'm developing a peft algorithm, basically it does the following:
Say the training process has 30 steps in total,
1. For global step 0\~9: train `lmhead` + `layer_0`
2. For global step 10\~19: train `lmhead` + `layer_1`
3. For global step 20\~29: train `lmhead` + `layer_0`
The key point is that, after the switch, the... | closed | 2024-11-08T11:42:49Z | 2024-12-06T21:59:52Z | https://github.com/deepspeedai/DeepSpeed/issues/6729 | [] | wheresmyhair | 2 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 575 | 跑run_pt.sh时,使用--deepspeed ds_zero2_no_offload.json运行卡住了 | peft使用的指定的0.3.0dev,运行run_pt.sh时,参数都是默认配置,只修改了模型和token路径,运行后读取数据正常,但卡在下面这里不动了,试了几次都如此,但删除--deepspeed ${deepspeed_config_file}后不会卡住,单报其他错误,感觉问题可能出在deepspeed脚本上,下面是卡住时的log:
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████... | closed | 2023-06-12T11:04:47Z | 2023-06-13T03:51:24Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/575 | [] | guijuzhejiang | 6 |
holoviz/panel | plotly | 7,517 | JSComponent not working in Jupyter | I'm on panel==1.5.4 panel-copy-paste==0.0.4
The `render_fn` cannot be found and the component does not display.

```python
import panel as pn
from panel_copy_paste import PasteToDataFrameButton
import pandas as pd
ACCENT = "#ff... | open | 2024-11-25T06:35:13Z | 2025-01-21T10:50:40Z | https://github.com/holoviz/panel/issues/7517 | [
"more info needed"
] | MarcSkovMadsen | 2 |
donnemartin/data-science-ipython-notebooks | matplotlib | 13 | Command to run mrjob s3 log parser is incorrect | Current:
```
python mr-mr_s3_log_parser.py -r emr s3://bucket-source/ --output-dir=s3://bucket-dest/"
```
Should be:
```
python mr_s3_log_parser.py -r emr s3://bucket-source/ --output-dir=s3://bucket-dest/"
```
| closed | 2015-07-31T22:52:18Z | 2015-12-28T13:14:13Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/13 | [
"bug"
] | donnemartin | 1 |
google-research/bert | tensorflow | 782 | InvalidArgumentError (see above for traceback): Found Inf or NaN global norm. : Tensor had NaN values [[{{node VerifyFinite/CheckNumerics}} = CheckNumerics[T=DT_FLOAT, message="Found Inf or NaN global norm.", _device="/job:localhost/replica:0/task:0/device:GPU:0"](global_norm/global_norm)]] | I add POS tag feature to the BERT model and meet the following problem,I tried to reduce the batch_size, but it was useless.
python run_oqmrc_POS.py --task_name=MyPro --do_train=true --do_eval=true --data_dir=./data --vocab_file=chinese_bert/vocab.txt --pos_tag_vocab_file=pyltp_data/pos_tag_vocab.txt --bert_config_f... | open | 2019-07-23T07:18:52Z | 2019-07-23T07:18:52Z | https://github.com/google-research/bert/issues/782 | [] | daishu7 | 0 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 15,870 | [Bug]: Stable Diffusion is now very slow and won't work at all | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-05-23T05:24:37Z | 2024-05-28T22:59:12Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15870 | [
"bug-report"
] | MichaelDeathBringer | 8 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,122 | a trouble when testing cyclegan | Hi, appreciating your open source code, it's really a masterpiece.
I've met some trouble when I run the test.py using cyclegan, like this:

my input data are images with [256,256,3], I keep some flags th... | closed | 2020-08-08T20:52:50Z | 2020-08-09T14:40:49Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1122 | [] | bearxiong333 | 7 |
sigmavirus24/github3.py | rest-api | 1,111 | The search result `total_count` is always 0 | I'm trying to use GitHub3.py to find the number of total issues in a repository. For that, I want to use the Search API to search for the issues in a particular repository.
For example, with the raw GitHub API, I can request [https://api.github.com/search/issues?q=repo%3Asigmavirus24/github3.py](https://api.github.c... | open | 2022-09-28T14:25:29Z | 2022-09-28T14:25:29Z | https://github.com/sigmavirus24/github3.py/issues/1111 | [] | theoctober19th | 0 |
MagicStack/asyncpg | asyncio | 655 | Does not work on ASGI servers | <!--
Thank you for reporting an issue/feature request.
If this is a feature request, please disregard this template. If this is
a bug report, please answer to the questions below.
It will be much easier for us to fix the issue if a test case that reproduces
the problem is provided, with clear instructions on ... | closed | 2020-11-21T09:29:53Z | 2023-04-24T16:37:54Z | https://github.com/MagicStack/asyncpg/issues/655 | [] | cheesycod | 5 |
psf/requests | python | 5,994 | ca_certs zip file extraction permission issue with multiple users on Python 3.6 | When you have multiple users on a machine that each use `requests` from zipapps with `certifi`, one user running a request should not block other users from successfully performing requests. This issue only appears when using a zipapp on python3.6. For python3.7+ the certifi library handles the tempfile and `requests.u... | closed | 2021-12-01T00:00:05Z | 2022-04-02T17:01:56Z | https://github.com/psf/requests/issues/5994 | [] | Peter200lx | 2 |
JaidedAI/EasyOCR | machine-learning | 1,301 | numpy 2 | hey, got issue related to numpy 1/2 binary builds
can you confirm that Numpy 2 is supported, and, if not, please provide ETA for support | open | 2024-09-05T00:06:22Z | 2024-12-09T17:46:17Z | https://github.com/JaidedAI/EasyOCR/issues/1301 | [] | Napolitain | 1 |
alpacahq/alpaca-trade-api-python | rest-api | 588 | [WARNING] data websocket error, restarting connection: no close frame received or sent | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
websocket connection on sip is unusable for me, a connection lost every 10 seconds, one of tow errors
- [WARNING] data websocket error, restarting connection: no close frame received or sent
- [WARNING] da... | open | 2022-03-15T16:12:23Z | 2022-12-14T20:12:40Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/588 | [] | kimboox44 | 11 |
yihong0618/running_page | data-visualization | 380 | 【keep】为啥会存在轨迹缺失的问题 | `actions` 倒没报错,但好像没获取`gpx`到数据,不太清楚原因,今天晚上再跑个步测试一下看看是不是脚本的问题。
<img width="1512" alt="image" src="https://user-images.githubusercontent.com/79169717/221772616-3a2623d8-65ff-4bb8-9729-02eb15ee04e5.png">
还有这个彩蛋,左边的样式是不是有点问题。
<img width="1512" alt="image" src="https://user-images.githubusercontent.com/79169717/2217... | closed | 2023-02-28T06:34:49Z | 2023-10-21T11:22:41Z | https://github.com/yihong0618/running_page/issues/380 | [] | sun0225SUN | 5 |
modelscope/modelscope | nlp | 900 | MsDataset.load报错 |
我执行下列代码加载数据集:
from modelscope.msdatasets import MsDataset
# Loading dataset
hf_ds = MsDataset.load(
'ICASSP_2021_DNS_Challenge', namespace='modelscope',split='test')
出现以下报错:
2024-07-04 13:20:42,801 - modelscope - INFO - PyTorch version 1.11.0+cu113 Found.
2024-07-04 13:20:42,801 - modelscope - INFO - L... | closed | 2024-07-04T05:26:54Z | 2024-08-11T01:58:34Z | https://github.com/modelscope/modelscope/issues/900 | [
"Stale"
] | tianqiong123 | 3 |
jupyterhub/repo2docker | jupyter | 1,289 | Container engine initialization error, unclear why | <!-- Thank you for contributing. These HTML commments will not render in the issue, but you can delete them once you've read them if you prefer! -->
### Bug description
<!-- Use this section to clearly and concisely describe the bug. -->
I ran this command: `jupyter-repo2docker .` and apparently it cannot find... | closed | 2023-06-14T21:46:01Z | 2024-09-16T15:22:03Z | https://github.com/jupyterhub/repo2docker/issues/1289 | [] | startakovsky | 13 |
neuml/txtai | nlp | 138 | Add korean translation to README.md | Hi! ! I'm South Korean and I want to help you translate README.md to Korean.
Is it okay to translate your README.md?
Thank you. | closed | 2021-11-07T15:45:15Z | 2021-11-14T12:53:51Z | https://github.com/neuml/txtai/issues/138 | [] | 0206pdh | 1 |
ccxt/ccxt | api | 25,285 | XT.com Futures - pagination in fetch_ohlcv | ### Operating System
Windows
### Programming Languages
Python
### CCXT Version
4.4.59
### Description
The current implementation of `fetch_ohlcv` for XT.com does not support pagination (`params.paginate`) unlike most exchanges. Would it be possible to add it?
https://github.com/ccxt/ccxt/blob/99fc65ec7aa5b8b88c... | open | 2025-02-15T03:55:50Z | 2025-02-19T10:59:10Z | https://github.com/ccxt/ccxt/issues/25285 | [] | krasnyd | 3 |
2noise/ChatTTS | python | 93 | 数字、标点符号,字母,都会出错 | 数字、标点符号,字母,都会出错 | closed | 2024-05-30T09:51:14Z | 2024-08-04T04:02:16Z | https://github.com/2noise/ChatTTS/issues/93 | [
"stale"
] | weiyi88 | 5 |
sinaptik-ai/pandas-ai | pandas | 917 | Streamlit UI example for pandaAI | ### 🚀 The feature
To add example of UI for pandasAI. I can share source of my own UI - https://pva-ask-my-data-eqwdqswwf.streamlit.app/. Inside it's pandasAI.
### Motivation, pitch
Maybe it can be useful for other people who use pandasAI
### Alternatives
_No response_
### Additional context
_No response_ | closed | 2024-01-31T15:35:40Z | 2024-03-16T16:20:48Z | https://github.com/sinaptik-ai/pandas-ai/issues/917 | [] | PavelAgurov | 3 |
plotly/dash-core-components | dash | 626 | Feature request: Rangeslider and slider to support datetime format | I've done some testing, and as far as I can see the sliders in Dash don't support datetime formats, only numerical formats. This would be great to have.
It would be especially handy when working with time series data in pandas.
https://dash.plot.ly/dash-core-components/slider
https://dash.plot.ly/dash-core-compo... | open | 2018-11-27T15:40:55Z | 2019-08-30T16:13:44Z | https://github.com/plotly/dash-core-components/issues/626 | [] | Judochopalots | 1 |
dsdanielpark/Bard-API | nlp | 57 | Responce error | Response code not 200. Response Status is 302 | closed | 2023-06-08T04:44:37Z | 2023-06-08T12:26:00Z | https://github.com/dsdanielpark/Bard-API/issues/57 | [] | Ridoy302583 | 1 |
seleniumbase/SeleniumBase | web-scraping | 3,569 | Setting the `lang` arg via the `cdp_driver` isn't taking effect | ## Setting the `lang` arg via the `cdp_driver` isn't taking effect
https://github.com/seleniumbase/SeleniumBase/blob/5d732a412f1a1c5da10345bdb29f160182d00450/seleniumbase/undetected/cdp_driver/cdp_util.py#L235
This is the pure CDP Mode equivalent of setting the `locale` / `locale_code`. | closed | 2025-02-26T05:35:48Z | 2025-02-26T22:43:23Z | https://github.com/seleniumbase/SeleniumBase/issues/3569 | [
"bug",
"UC Mode / CDP Mode"
] | mdmintz | 1 |
jupyterhub/jupyterhub-deploy-docker | jupyter | 91 | 'make build' fails with Conda | Followed all the configurations and then it fails in build stage with error - ModuleNotFoundError: No module named 'conda'.
Below is the full error trace,
make build
docker-compose build
hub-db uses an image, skipping
Building hub
Step 1/9 : ARG JUPYTERHUB_VERSION
Step 2/9 : FROM jupyterhub/jupyterhub-onbuil... | closed | 2019-08-26T12:00:41Z | 2021-04-27T10:50:58Z | https://github.com/jupyterhub/jupyterhub-deploy-docker/issues/91 | [] | karthi4k | 9 |
clovaai/donut | computer-vision | 115 | Train script hangs with no errors | ```bash
root@spot-a100-1670595978:/app# python3 train.py --config config/train_cord.yaml --pretrained_model_name_or_path
"naver-clova-ix/donut-base" --dataset_name_or_paths "['/app/jsonl']" --exp_version "abay_experiment"
resume_from_checkpoint_path: None
result_path: ./result
pretrained_model_name_or_path: na... | closed | 2022-12-28T02:52:05Z | 2024-12-16T10:05:42Z | https://github.com/clovaai/donut/issues/115 | [] | abaybektursun | 8 |
ranaroussi/yfinance | pandas | 1,609 | KeyError: shortName | My program needs to get the name for a stock. This is done in finance by getting the shortName value in the dictionary. This worked until version 0.2.22. However, after updating to 0.2.24 due to missing values, I am getting a KeyError for the shortName. I am guessing that after the update, shortName is not included in ... | closed | 2023-07-16T08:21:43Z | 2023-07-28T17:12:38Z | https://github.com/ranaroussi/yfinance/issues/1609 | [] | vismoh2010 | 5 |
Yorko/mlcourse.ai | scikit-learn | 370 | locally built docker image doesn't work | I've created docker image locally, using docker image build and then tried to run it like this:
`python run_docker_jupyter.py -t mlc_local`
got this:
```
Running command
docker run -it --rm -p 5022:22 -p 4545:4545 -v "/home/egor/private/mlcourse.ai":/notebooks -w /notebooks mlc_local jupyter
Command: jupyt... | closed | 2018-10-10T12:50:06Z | 2018-10-11T13:59:36Z | https://github.com/Yorko/mlcourse.ai/issues/370 | [
"enhancement"
] | eignatenkov | 7 |
matterport/Mask_RCNN | tensorflow | 2,815 | Differences in results for this model on TF2.0CPU and TF2.7 GPU | Hi,
I ran this model on a custom dataset TF2.0 CPU and TF2.7GPU. Got good results on test data for object detection on TF2.0 but TF2.7 GPU results are totally bad. Not a single object was identified after same number of epochs. Is it because MRCNN model is not ported to TF2.7 as yet. | open | 2022-04-22T00:07:16Z | 2022-11-10T14:06:55Z | https://github.com/matterport/Mask_RCNN/issues/2815 | [] | suraj123 | 3 |
axnsan12/drf-yasg | rest-api | 518 | Add type hints | HI! I started a https://github.com/intgr/drf-yasg-stubs repository since drf-yasg was the only major component in my project that did not include type stubs. For now it's still quite incomplete (some of it is still auto-generated files with `Any` types).
I'm wondering what are your opinions on type stubs? [PEP 561](... | open | 2019-12-24T11:37:34Z | 2025-03-07T12:15:19Z | https://github.com/axnsan12/drf-yasg/issues/518 | [
"triage"
] | intgr | 8 |
widgetti/solara | flask | 131 | test/ci issue: coverage slows down some tests | After 172cdefeabd88f166d451873ea4582589a4cbb9b the test_memoize_hook fails more regularly. We've seen it fail before, but now it's almost 90%. Therefore we disabled coverage in CI for now.
If we want to enable it again, 172cdefeabd88f166d451873ea4582589a4cbb9b might give a clue.
This fails about 50% of the time on my... | open | 2023-05-31T21:25:06Z | 2023-06-01T06:43:48Z | https://github.com/widgetti/solara/issues/131 | [
"help wanted"
] | maartenbreddels | 1 |
Kludex/mangum | asyncio | 151 | Slash at end of endpoint | I've been updated to version `0.10.0` and suddenly all my endpoints on custom domain doesn't work more. I had to add `/` at end of url to back to work.
Is it a normal or a bug? | closed | 2020-12-04T21:43:35Z | 2022-12-28T13:07:37Z | https://github.com/Kludex/mangum/issues/151 | [
"more info needed"
] | sergiors | 3 |
aiortc/aioquic | asyncio | 6 | Understanding packet header construction | Hi,
I am working on a project, which requires modifying packet headers, especially for the ack packets.
Can you please help me understand the code flow via which I can modify the headers and add custom key values.
Thanks. | closed | 2019-05-28T11:30:06Z | 2019-06-01T02:02:53Z | https://github.com/aiortc/aioquic/issues/6 | [] | massvoice | 2 |
openapi-generators/openapi-python-client | fastapi | 1,203 | Read-only `src_dict` dictionary in `from_dict` methods should be typed as `Mapping[str, Any]` | **Describe the bug**
Generated classmethod `from_dict`
https://github.com/openapi-generators/openapi-python-client/blob/5cfe4e1d594951725844ea470fc9d61f40c08093/openapi_python_client/templates/model.py.jinja#L131-L132
should probably be annotated as
```python
@classmethod
def from_dict(cls: type[T], src_dic... | closed | 2025-02-08T21:21:44Z | 2025-03-15T19:00:56Z | https://github.com/openapi-generators/openapi-python-client/issues/1203 | [] | edgarrmondragon | 0 |
proplot-dev/proplot | data-visualization | 288 | Manually specify `title` and `abc` coordinate positions | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
Hi, is it possible to make the abc labels slightly offset to... | open | 2021-09-27T22:08:14Z | 2022-07-08T15:54:21Z | https://github.com/proplot-dev/proplot/issues/288 | [
"feature"
] | scottstanie | 6 |
pinry/pinry | django | 156 | problem uploading image | I tried to set up pinry myself using apache and mod_wsgi and I got the server running but could post any pins - kept getting an error 'proplem saving image'. Looking at the requests I could see that any call to /api/v2/... was returning a 403 error.
Thinking that maybe it was my lack of knowledge of django and how ... | closed | 2019-10-03T04:03:16Z | 2019-12-08T19:19:30Z | https://github.com/pinry/pinry/issues/156 | [] | t1v0 | 2 |
sinaptik-ai/pandas-ai | data-visualization | 1,291 | LLM Call response of JudgeAgent not always returning <Yes> or <No> | ### System Info
macos = 14.5
python = 3.10.13
pandasai = 2.2.12
### 🐛 Describe the bug
Using AzureOpenAI agent in combination with JudgeAgent.
```
llm = AzureOpenAI(...)
judge = JudgeAgent(config={"llm": llm, "verbose": True})
agent = Agent("filepath", config={"llm": llm, "verbose": True}, judge=judge)
... | closed | 2024-07-24T13:18:52Z | 2024-11-04T16:08:30Z | https://github.com/sinaptik-ai/pandas-ai/issues/1291 | [
"bug"
] | sschrijver-pon | 2 |
FlareSolverr/FlareSolverr | api | 1,141 | [yggtorrent] (updating) The cookies provided by FlareSolverr are not valid | ### Have you checked our README?
- [X] I have checked the README
### Have you followed our Troubleshooting?
- [X] I have followed your Troubleshooting
### Is there already an issue for your problem?
- [X] I have checked older issues, open and closed
### Have you checked the discussions?
- [X] I have read the Dis... | closed | 2024-04-02T18:37:42Z | 2024-04-02T19:14:35Z | https://github.com/FlareSolverr/FlareSolverr/issues/1141 | [
"more information needed"
] | daniwalter001 | 2 |
ray-project/ray | machine-learning | 50,827 | CI test linux://python/ray/data:test_transform_pyarrow is flaky | CI test **linux://python/ray/data:test_transform_pyarrow** is flaky. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8496#01952c44-0d09-4aa4-b1f3-e432b7ebfca1
- https://buildkite.com/ray-project/postmerge/builds/8495#01952b30-22c6-4a0f-9857-59a7988f67d8
- https://buildkite.com/ray-project/post... | closed | 2025-02-22T06:46:30Z | 2025-03-04T09:29:49Z | https://github.com/ray-project/ray/issues/50827 | [
"bug",
"triage",
"data",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 31 |
pywinauto/pywinauto | automation | 680 | Updating table cell with pywinauto | Hello all,
I am currently using pywinauto to step through a tree and print the contents of the table in each children. I would like to know if i can use pywinauto to push in a text file which would go and update the changed cells.

r1 = Router()
r2 = Router()
r3 = Router()
clas... | closed | 2023-01-28T15:06:38Z | 2023-02-07T09:22:53Z | https://github.com/vitalik/django-ninja/issues/666 | [] | aasiffaizal | 1 |
deezer/spleeter | deep-learning | 812 | [Discussion] Does Spleeter tech powers Apple Music Sing? | Can we confirm yet if Apple Music's newest exciting Karaoke feature called "Apple Music Sing" is **_powered by Spleeter's tech?_**

> Ever since the launch of the [Live L... | open | 2022-12-10T12:39:45Z | 2022-12-12T17:32:09Z | https://github.com/deezer/spleeter/issues/812 | [
"question"
] | Mancerrss | 1 |
deepfakes/faceswap | machine-learning | 715 | I got some UnicodeEncodeError issues. How can I slove it? |
File "C:\Users\jho60\AppData\Local\Programs\Python\Python36\lib\configparser.py", line 931, in _write_section
fp.write("{}{}\n".format(key, value))
**UnicodeEncodeError: 'cp949' codec can't encode character '\u2013' in position 159: illegal multibyte sequence**
File "C:\faceswap\lib\logger.py", line 155, i... | closed | 2019-04-28T12:19:37Z | 2019-04-29T05:52:08Z | https://github.com/deepfakes/faceswap/issues/715 | [] | ghost | 4 |
gradio-app/gradio | deep-learning | 10,783 | Gradio: predict() got an unexpected keyword argument 'message' | ### Describe the bug
Trying to connect my telegram-bot(webhook) via API with my public Gradio space on Huggingface.
Via terminal - all works OK.
But via telegram-bot always got the same issue: Error in connection Gradio: predict() got an unexpected keyword argument 'message'.
What should i use to work it properl... | closed | 2025-03-11T12:12:43Z | 2025-03-18T10:28:21Z | https://github.com/gradio-app/gradio/issues/10783 | [
"bug",
"needs repro"
] | brokerelcom | 11 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 229 | [BUG] issue with TikTok video download | Hello!
First, I want to thank the author for such a wonderful project, but in the process of getting to know him, I had an error related to uploading a video
I am running project in docker desktop
When i insert TikTok video link in WebAPP interface and go to the parsing results page, after clicking on the Video ... | closed | 2023-07-27T13:50:54Z | 2023-08-04T09:31:15Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/229 | [
"BUG",
"enhancement"
] | spac3orange | 1 |
ultralytics/ultralytics | pytorch | 19,357 | Train and val losses became "NaN" but metrics do not update accordingly. | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
This seems that this is slightly related to #18521
During training several... | closed | 2025-02-21T08:40:28Z | 2025-02-25T14:19:57Z | https://github.com/ultralytics/ultralytics/issues/19357 | [
"enhancement",
"question",
"fixed",
"detect"
] | mayrajeo | 13 |
WeblateOrg/weblate | django | 14,279 | Batch Automatic Translation on Component and Project | ### Describe the problem
Currently, automatic translation can only be performed in the language page, then if we have many languages, when we add some new text on template language, we need to go to each language page and click Automatic Translation, so if we have Batch Automatic Translation button on component tools,... | open | 2025-03-20T03:50:05Z | 2025-03-20T09:42:28Z | https://github.com/WeblateOrg/weblate/issues/14279 | [
"enhancement",
"hacktoberfest",
"help wanted",
"good first issue",
"Area: Automated translation"
] | kingshuaishuai | 2 |
rthalley/dnspython | asyncio | 601 | How to start | closed | 2020-11-06T10:00:19Z | 2020-11-07T22:58:57Z | https://github.com/rthalley/dnspython/issues/601 | [] | DarkLand-Chen | 1 | |
aiogram/aiogram | asyncio | 700 | Refactor exceptions | closed | 2021-09-21T21:35:25Z | 2021-09-21T21:53:00Z | https://github.com/aiogram/aiogram/issues/700 | [
"enhancement",
"breaking",
"3.x"
] | JrooTJunior | 0 | |
google-research/bert | tensorflow | 716 | How to run prediction on text classification task on GPU | I used the fine-tuned model to predict txt, but I seems like to run on CPU, for it takes 5s on each txt(which have nearly 2000 words). and I see log like this below, is there something wrong I do.
Instructions for updating:
Use keras.layers.dense instead.
2019-06-25 10:27:33.731101: I tensorflow/core/platform/cpu_... | closed | 2019-06-25T02:46:52Z | 2019-07-10T01:09:05Z | https://github.com/google-research/bert/issues/716 | [] | Biaocsu | 2 |
rougier/scientific-visualization-book | matplotlib | 80 | BUG: showcase textspiral, assignment destination is read-only | I try to replicate `shocase/text-spiral.py` in my laptop.
I tried to run the following code.
```python
import mpmath
mpmath.mp.dps = 15000
text = str(mpmath.pi)
path = TextPath((0, 0), text, size=6, ) #, prop=FontProperties(family="Source Serif Pro"))
#path.vertices.setflags(write=1)
Vx, Vy = path.vertic... | open | 2023-01-20T12:03:59Z | 2023-02-02T12:47:50Z | https://github.com/rougier/scientific-visualization-book/issues/80 | [] | toshiakiasakura | 1 |
ethanopp/fitly | dash | 20 | Rolling window of strava activities? | Hi,
Curious if there's a way to configure a "rolling window" of strava activities, like optionally only keeping the past 13 months, as an example.
Thanks! | open | 2021-03-14T03:30:57Z | 2021-03-14T03:30:57Z | https://github.com/ethanopp/fitly/issues/20 | [] | spawn-github | 0 |
kymatio/kymatio | numpy | 309 | Ill-conditioning in `scattering3d_qm7.py` | When running this, I get
```
...
Ridge regression, alpha: 1.0, MAE: 5.897314548492432, RMSE: 8.19788932800293
/mnt/xfs1/home/janden/local/anaconda3/envs/kymatio_cuda90/lib/python3.7/site-packages/sklearn/linear_model/ridge.py:125: LinAlgWarning: scipy.linalg.solve
Ill-conditioned matrix detected. Result is not gua... | closed | 2019-01-17T15:10:46Z | 2020-02-19T07:25:30Z | https://github.com/kymatio/kymatio/issues/309 | [
"3D"
] | janden | 4 |
remsky/Kokoro-FastAPI | fastapi | 116 | docker compose fails because of `entrypoint.sh` EOL sequence | **Describe the bug**
As the title says, when running `docker compose --up build` on a Windows host, the command fails towards the end.
**Screenshots or console output**
```
kokoro-tts-1 | /opt/nvidia/nvidia_entrypoint.sh: /app/docker/scripts/entrypoint.sh: /bin/sh^M: bad interpreter: No such file or directory
kokoro-... | closed | 2025-02-03T16:44:23Z | 2025-02-17T09:33:13Z | https://github.com/remsky/Kokoro-FastAPI/issues/116 | [] | Puncia | 2 |
lepture/authlib | django | 567 | The expires_in function needs to have a timedelta to avoid tokenExpiry errors for milliseconds | **Describe the bug**
I am using the OAuth2session object
```
client = OAuth2Session(client_id=client_id, client_secret=client_secret, token_endpoint=token_url, grant_type='client_credentials')
client.fetch_token(token_url)
client.get(<MY_PROTECTED_URL>)
```
Here, the library behavior is that the token gets... | closed | 2023-07-24T08:47:18Z | 2024-04-08T16:58:45Z | https://github.com/lepture/authlib/issues/567 | [
"bug",
"good first issue"
] | pghole | 2 |
noirbizarre/flask-restplus | api | 428 | flask request RequestParser bundle error=True is not working as expected | ```
from flask import Flask
from flask_restplus import Api, Resource, reqparse
app = Flask(name)
api = Api(app)
parser = reqparse.RequestParser(bundle_errors=False)
parser.add_argument('username', type=list, required=True, help="Missing Username", location="json")
parser.add_argument('password', type=list, r... | open | 2018-05-04T05:44:29Z | 2021-10-12T11:18:44Z | https://github.com/noirbizarre/flask-restplus/issues/428 | [] | vimox-shah | 8 |
allenai/allennlp | data-science | 4,775 | Ask for further integration with Optuna | Hello, I'm a member of Optuna dev and the author of the allennlp-guide chapter on hyperparameter optimization.
Recently, I created [allennlp-optuna](https://github.com/himkt/allennlp-optuna), a prototype of a wrapper for Optuna to enable users to optimize hyperparameter of AllenNLP model. It provides a way to use O... | closed | 2020-11-07T13:25:21Z | 2020-11-11T00:12:06Z | https://github.com/allenai/allennlp/issues/4775 | [
"question"
] | himkt | 2 |
django-import-export/django-import-export | django | 1,020 | Prevent new items. Update only. | Is there any setting that will allow me to ignore any new items. I would only want to import to update. But let's say that there is a new ID that does not currently exists in the database, I would want to ignore that. | closed | 2019-10-21T20:56:38Z | 2019-11-19T18:16:42Z | https://github.com/django-import-export/django-import-export/issues/1020 | [] | jangeador | 2 |
Zeyi-Lin/HivisionIDPhotos | machine-learning | 98 | HivisionIDPhotos Api调用问题 | INFO: [127.0.0.1:52124](http://127.0.0.1:52124/) - "POST /add_background HTTP/1.1" 500 Internal Server Error
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "C:\Users\zdy\AppData\Local\anaconda3\Lib\site-packages\uvicorn\protocols\http\httptools_impl.py", line 435, in run_asgi
... | closed | 2024-09-11T03:04:28Z | 2024-09-11T06:06:44Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/98 | [] | OuTaMan | 9 |
man-group/arctic | pandas | 830 | Have a restore_version api that supports operations with uncompressed chunks | Currently in restore_version we read and write the entire data to a new version. There was a more efficient implementation of this but that was reverted as it might cause corruptions.
What we want is to have a version that just reads and writes uncompressed chunks to save up on memory blowing up due to the new bytea... | open | 2019-12-02T11:59:58Z | 2019-12-02T12:10:58Z | https://github.com/man-group/arctic/issues/830 | [
"VersionStore"
] | shashank88 | 1 |
saleor/saleor | graphql | 16,872 | Bug: Saleor apps installed using django command do not show up in the Saleor Dashboard | ### What are you trying to achieve?
Saleor apps installed using the Django command `manage.py install_app --activate <manifest_url>` do not show up in the Saleor Dashboard under Apps / Installed Apps, even if the installation using the Django command completed successfully.
### Steps to reproduce the problem
1. ... | closed | 2024-10-11T12:40:54Z | 2024-10-14T08:16:33Z | https://github.com/saleor/saleor/issues/16872 | [
"bug",
"triage"
] | ceresnam | 2 |
pytest-dev/pytest-mock | pytest | 245 | Since 3.3.0 github is missing releases confusing users | When you visit https://github.com/pytest-dev/pytest-mock you only see version 3.3.0 as latest. Even if you click releases page you still see the same.
While after while you may be lucky to discover that tags for newer versions exists, that does not provide the best experience.
Ideally github releases should be cr... | closed | 2021-05-18T08:16:35Z | 2021-05-18T11:56:29Z | https://github.com/pytest-dev/pytest-mock/issues/245 | [] | ssbarnea | 1 |
huggingface/pytorch-image-models | pytorch | 1,482 | [BUG] Wrong Repo Id | This is regarding the new models (vit CLIP)
the URL for their weights is wrong
```
Repository Not Found for url: https://huggingface.co/CLIP-ViT-g-14-laion2B-s12B-b42K/resolve/main/open_clip_pytorch_model.bin.
Please make sure you specified the correct `repo_id` and `repo_type`.
If the repo is private, make sure y... | closed | 2022-10-05T14:23:34Z | 2022-10-05T16:00:23Z | https://github.com/huggingface/pytorch-image-models/issues/1482 | [
"bug"
] | MohamedAliRashad | 1 |
nteract/testbook | pytest | 59 | More examples documentation | We could use more examples for how to use testbook in different scenarios. This would have a strong lasting effect for adoption and resuse of the project over other efforts. | open | 2020-08-18T17:01:56Z | 2021-05-20T09:49:46Z | https://github.com/nteract/testbook/issues/59 | [
"documentation",
"sprint-friendly"
] | MSeal | 1 |
litestar-org/polyfactory | pydantic | 566 | Bug: RecursionError With constrained 0 length lists | ### Description
When constraining a list to be empty (max_length=0):
```python
from pydantic import BaseModel, Field
from polyfactory.factories.pydantic_factory import ModelFactory
class TestModel(BaseModel):
empty_list_field: list = Field(default=[], max_length=0)
class TestModelFactory(ModelFactory):
... | closed | 2024-07-16T09:30:48Z | 2025-03-20T15:53:18Z | https://github.com/litestar-org/polyfactory/issues/566 | [
"bug"
] | tom300z | 1 |
Lightning-AI/pytorch-lightning | deep-learning | 19,772 | Sanitize object params before they get logged from argument-free classes | ### Description & Motivation
The motivation for this proposal is as follows: when you store classes (not-yet instantiated, but from the main file) in a module's hyperparameters to instantiate them later, the related entries in the dictionary are not sanitized.
### Pitch
For example, let's say my configuration ... | closed | 2024-04-12T20:16:34Z | 2024-06-06T18:51:56Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19772 | [
"feature"
] | V0XNIHILI | 0 |
PaddlePaddle/PaddleHub | nlp | 1,555 | ace2p分割模型GPU推理时发生错误 | ```
代码:
module = hub.Module(name='ace2p', version='1.0.0')
while flag:
input_dict = {'image': [path_jpg_in]}
_ = module.segmentation(data=input_dict, use_gpu=True, output_dir=masked_path, batch_size=7)
**问题1**:
batch_size大于等于8时就出错。
-------------------------------------- ... | open | 2021-07-28T02:18:21Z | 2021-08-10T12:58:31Z | https://github.com/PaddlePaddle/PaddleHub/issues/1555 | [
"cv"
] | justzhanghong | 1 |
ipython/ipython | jupyter | 14,120 | IPython file error | ```
Traceback (most recent call last):
File "/home/me_user/.cache/pypoetry/virtualenvs/advent-of-code-XSxK3i_Q-py3.11/lib/python3.11/site-packages/traitlets/traitlets.py", line 656, in get
value = obj._trait_values[self.name]
~~~~~~~~~~~~~~~~~^^^^^^^^^^^
KeyError: 'ipython_dir'
During handling... | open | 2023-07-24T11:03:15Z | 2023-07-24T11:08:19Z | https://github.com/ipython/ipython/issues/14120 | [] | Vasile-Hij | 0 |
Buuntu/fastapi-react | sqlalchemy | 28 | Add React login page | closed | 2020-05-25T02:19:46Z | 2020-05-25T15:18:52Z | https://github.com/Buuntu/fastapi-react/issues/28 | [
"enhancement"
] | Buuntu | 0 | |
plotly/dash | plotly | 2,852 | [BUG] set_props called multiple times only keep the last props. | For regular callbacks, when multiple call of `set_props` to the same component id, only the last call is saved.
Example:
```
from dash import Dash, Input, html, set_props
app = Dash()
app.layout = [
html.Button("start", id="start"),
html.Div("initial", id="output"),
]
@app.callback(
Input(... | closed | 2024-05-07T16:35:57Z | 2024-05-15T19:22:04Z | https://github.com/plotly/dash/issues/2852 | [
"bug",
"sev-1"
] | T4rk1n | 0 |
proplot-dev/proplot | data-visualization | 105 | More issues with "thin" fonts | @bradyrx In your example (#103) it looks like matplotlib may be picking up [a "thin" font again](https://github.com/lukelbd/proplot/issues/94) :/. Could you run the following:
```python
from matplotlib.font_manager import findfont, FontProperties
print(findfont(FontProperties(['sans-serif'])))
```
and post the... | closed | 2020-01-09T05:54:48Z | 2020-01-09T09:30:29Z | https://github.com/proplot-dev/proplot/issues/105 | [
"bug"
] | lukelbd | 1 |
yuka-friends/Windrecorder | streamlit | 57 | feat: 为托盘的更新提示添加“更新日志”入口 | https://github.com/yuka-friends/Windrecorder/pull/46
在程序有可用更新时,在更新选项下添加一个“查看更新日志(what's new)”的选项,点击后浏览器打开 GitHub 上的 CHANGELOG 文件(和浏览器访问 localhost:xxxx 进入页面那个选项一致) | closed | 2023-12-04T14:42:12Z | 2024-02-09T11:18:33Z | https://github.com/yuka-friends/Windrecorder/issues/57 | [
"enhancement",
"P0"
] | Antonoko | 0 |
simple-login/app | flask | 1,982 | Remove sensitive words | I will make a PR | closed | 2023-12-29T19:54:47Z | 2024-01-02T11:33:28Z | https://github.com/simple-login/app/issues/1982 | [] | ghost | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.