
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
python-gino/gino | sqlalchemy | 141 | Handle SQLAlchemy prefetch | * GINO version: 0.5, 0.6
* Python version: 3.6
### Description
Some clause element may cause prefetch in SQLAlchemy, for example:
```
User.insert().values(nickname=random_name)
```
(without `returning`) | closed | 2018-02-18T09:17:09Z | 2018-03-19T08:59:02Z | https://github.com/python-gino/gino/issues/141 | [
"bug",
"help wanted"
] | fantix | 0 |
axnsan12/drf-yasg | django | 307 | Parameter 'items' property interferes with OrderedDict 'items' method | When trying to define an array parameter, the items definition is stored in an object property named `items`:
```
class Parameter(SwaggerDict):
def __init__(self, name, in_, description=None, required=None, schema=None,
type=None, format=None, enum=None, pattern=None, items=None, default=None, ... | closed | 2019-02-06T03:51:42Z | 2019-02-21T22:57:55Z | https://github.com/axnsan12/drf-yasg/issues/307 | [] | PaulWay | 1 |
blacklanternsecurity/bbot | automation | 1,457 | Occasional Newlines in URLs | ```
[URL_UNVERIFIED] https://uk.yahoo.com/news/ex-spandau-ballet-singer-complimented-080549530.html excavate (endpoint, extension-html, in-scope, spider-danger)
[URL_UNVERIFIED] https://tw.news.yahoo.com/ç©æ¡é
°å±
風波-éæ¤-éå½ç¼ç
§-æµåº-網åæ
[INFO] w... | closed | 2024-06-13T13:00:42Z | 2025-02-11T16:56:08Z | https://github.com/blacklanternsecurity/bbot/issues/1457 | [
"bug",
"low priority"
] | TheTechromancer | 2 |
laurentS/slowapi | fastapi | 111 | how to control limit by duration? | I want to set min duration between each requests. For example I want at least 30s duration between each request.How can I achieve it? | closed | 2022-08-30T01:14:12Z | 2022-08-31T12:39:35Z | https://github.com/laurentS/slowapi/issues/111 | [] | moo611 | 4 |
deepfakes/faceswap | deep-learning | 999 | Train Error: Caught exception in thread: '_training_0' | I get an error with training on Linux and Windows :
Linux:
When I train on Linux,I only get this:
```
Setting Faceswap backend to NVIDIA
03/27/2020 09:43:23 INFO Log level set to: INFO
Using TensorFlow backend.
```
Windows:
I get this error windows:
```
Setting Faceswap backend to NVIDIA
03/27/2020 09... | closed | 2020-03-27T02:13:31Z | 2020-12-06T05:08:11Z | https://github.com/deepfakes/faceswap/issues/999 | [] | Tian14267 | 6 |
sammchardy/python-binance | api | 568 | client order_market_buy call is failing | The client order_market_buy call is failing with this error
binance.exceptions.BinanceAPIException: APIError(code=-1106): Parameter 'quoteOrderQty' sent when not required.
**To Reproduce**
api_test_key = 'sjdflkdsjf'
api_test_secret = 'klfdsajflk'
client = Client(api_test_key, api_test_secret)
client.API_URL = ... | open | 2020-08-11T12:07:15Z | 2020-09-01T09:12:17Z | https://github.com/sammchardy/python-binance/issues/568 | [] | iamveritas | 3 |
explosion/spaCy | machine-learning | 13,551 | Italian & Spanish NER shouldn't extract "Google" or "Facebook"? | Extracting entities from news articles I've realized this behavior:

These words are present in articles but are not extracted by the models.
Does anyone know the reason?
## Info about spaCy
- **spaCy versio... | open | 2024-07-01T09:48:10Z | 2024-08-05T13:06:48Z | https://github.com/explosion/spaCy/issues/13551 | [] | davgargar | 1 |
robinhood/faust | asyncio | 128 | Fast creation of pandas dataframe from streamed data | Since you mentioned pandas also as an option to use together with faust in your documentation I was wondering if anybody can recommend a **fast** creation approach inside of an agent based on previously saved (rocksdb) and newly incoming stream data as an example.
Sample code also for later use as a cheatsheet in th... | open | 2018-08-02T10:33:54Z | 2020-02-27T23:19:23Z | https://github.com/robinhood/faust/issues/128 | [
"Status: Help Wanted",
"Component: Serializers",
"Component: Models",
"Issue Type: Documentation",
"Issue-Type: Feature Request"
] | trbck | 2 |
google-research/bert | nlp | 910 | `Whole Word Masking` does not work in this code at 'create_pretraining_data.py' | Hi, there :)
First of all, thanks for sharing such a nice code of bert for begginers to easily follow.
I made an issue to share that `whole word masking` does not work even though I set it as True.
As I read code at (
https://github.com/google-research/bert/blob/cc7051dc592802f501e8a6f71f8fb3cf9de95dc9/create... | open | 2019-11-12T06:58:34Z | 2022-12-21T17:10:32Z | https://github.com/google-research/bert/issues/910 | [] | alberto-hong | 3 |
RobertCraigie/prisma-client-py | pydantic | 1,008 | Improve error message when running prisma with an outdated client | ## Problem
When upgrading to a newer version of prisma python client - let's say, 0.13.1 to 0.14.0, if you forget to run `prisma generate` again, you'll get an error message like this
> File "/Users/adeel/Documents/GitHub/my-project/backend/utils/db.py", line 36, in get_db
_db = Prisma(auto_register=True, ... | open | 2024-08-11T16:16:51Z | 2024-08-18T16:18:34Z | https://github.com/RobertCraigie/prisma-client-py/issues/1008 | [
"kind/improvement",
"level/intermediate",
"priority/medium",
"topic: dx"
] | AdeelK93 | 0 |
FactoryBoy/factory_boy | django | 418 | How to implement a factory with a field of Foreign Key to self? | ```python
class EventType(models.Model):
"""Event Type Model"""
category = models.ForeignKey('EventType', null=True, blank=True, verbose_name='Category')
name = models.CharField(max_length=50, unique=True, verbose_name='Event Type')
```
How can I make a factory for this model? | closed | 2017-09-14T10:32:52Z | 2017-09-18T07:13:07Z | https://github.com/FactoryBoy/factory_boy/issues/418 | [] | NikosVlagoidis | 1 |
vimalloc/flask-jwt-extended | flask | 61 | Docs - porting from flask-jwt | Thanks for the hard work.
Looking though the docs it appears this extension is similar to flask-jwt but not identical. Would be nice to have a section in the docs on how to port to the newer library and any associated concerns there might be. So far I've noticed:
- JWT --> JWTManager(app)
- Need to create an a... | closed | 2017-07-03T21:22:25Z | 2017-10-13T19:32:55Z | https://github.com/vimalloc/flask-jwt-extended/issues/61 | [] | mixmastamyk | 1 |
zalandoresearch/fashion-mnist | computer-vision | 62 | Link in arxiv has extra period at the end | Hey guys,
Thank you for publishing this new dataset.
No an issue really wiht the dataset, but the link that you have in the arxiv's abstract has an extra period at the end.
Regards | closed | 2017-09-09T23:00:13Z | 2017-09-14T17:16:23Z | https://github.com/zalandoresearch/fashion-mnist/issues/62 | [] | DataWaveAnalytics | 1 |
google-deepmind/graph_nets | tensorflow | 2 | ImportError: No module named tensorflow_probability | Hi, I run into a problem about some **environmental** problem ...
I could not run your demo either on Colab on my local pc. All of them reports ModuleNotFoundError with respect to 'tensorflow_probability'.
For Colab of `shortest_path.ipynb`, change the install setting to be `install_graph_nets_library = "yes"`, it j... | closed | 2018-10-19T15:43:18Z | 2019-07-08T06:23:10Z | https://github.com/google-deepmind/graph_nets/issues/2 | [] | murphyyhuang | 3 |
gunthercox/ChatterBot | machine-learning | 1,721 | - | closed | 2019-04-29T23:06:10Z | 2023-04-14T23:44:29Z | https://github.com/gunthercox/ChatterBot/issues/1721 | [] | dtoxodm | 3 | |
plotly/dash | plotly | 3,065 | Dash in Jupyter tries to bind to $HOST set by conda, cannot override | **Summary**
Micromamba, and supposedly other python package managers set the HOST environment variable to something like x86_64-conda-linux-gnu. Then, when I try to run a dash app in Jupyter, I get an error as dash tries to bind to host "x86_64-conda-linux-gnu", which obviously doesn't resolve to a valid IP. Here's a ... | open | 2024-11-07T20:11:26Z | 2024-11-11T14:45:17Z | https://github.com/plotly/dash/issues/3065 | [
"bug",
"P2"
] | discapes | 0 |
Miksus/rocketry | automation | 193 | Passing a mongoclient to MongoRepo does not work. Rocketry.run() fails. | Hi, cool project, but is this supposed to work?
```
client= MongoClient(
"mongodb+srv://<user>:<pass>@<blabla>.a5qhe.mongodb.net/<SomeDb>?retryWrites=true&w=majority",
server_api=ServerApi("1"),
)
mongo_repo = MongoRepo(
client=client,
model=TaskRunRecord,
database="MyDatabase",
co... | open | 2023-02-16T15:12:20Z | 2023-02-20T10:26:03Z | https://github.com/Miksus/rocketry/issues/193 | [
"bug"
] | StigKorsnes | 1 |
exaloop/codon | numpy | 317 | Throws error on lines ending with backslash | A backslash at the end of a line seems to cause codon to throw an error: unexpected dedent. Python does not throw this error. Note that Python allows a backslash after a comma or a plus sign or the like, where it is obvious from the context that the line is incomplete. Codon does not accept this. Codon's parser should... | closed | 2023-04-02T21:06:46Z | 2023-04-12T22:14:02Z | https://github.com/exaloop/codon/issues/317 | [] | codeisnotcode | 2 |
litestar-org/litestar | api | 3,465 | Bug: Can't convert sqlalchemy model to pydantic model which is inherited from BaseModel | ### Description
**I tried to convert the sqlalchemy model to pydantic BaseModel but I get an error**:
using the `pydantic.type_adapter.TypeAdapter`:
```py
ValidationError: 1 validation error for list[User]
Input should be a valid list [type=list_type,
input_value=<app.database.models.user...t at 0x000002DCA... | closed | 2024-05-03T16:45:49Z | 2025-03-20T15:54:41Z | https://github.com/litestar-org/litestar/issues/3465 | [
"Bug :bug:"
] | monok8i | 1 |
flasgger/flasgger | flask | 266 | uiversion 3 with blank url after initializing default data | I overwrite the default data with following code:
```
# config.py
template = {
"swagger": "2.0",
"info": {
"title": "KG Service API & Algorithm API",
"description": "API for Knowledge Hub & Algorithm Hub",
"contact": {
"responsibleOrganization": "ME",
"responsibleDeveloper": "Me"... | closed | 2018-11-21T15:45:15Z | 2020-06-16T07:12:12Z | https://github.com/flasgger/flasgger/issues/266 | [] | huanghe314 | 1 |
wkentaro/labelme | deep-learning | 898 | No TIF support on Ubuntu 18.04 | I tried with your newest version and 4.2.9 as recommend in #675 but in no case i was able to open TIF images. Any suggestion?
It work normally with JPG.
in iPython
```
from` PyQt5.Qt import PYQT_VERSION_STR
PYQT_VERSION_STR
'5.10.1'
QImageReader.supportedImageFormats()
[PyQt5.QtCore.QByteArray(b'bmp'),
P... | closed | 2021-07-26T16:39:25Z | 2022-06-25T04:39:03Z | https://github.com/wkentaro/labelme/issues/898 | [] | Camilochiang | 4 |
gradio-app/gradio | machine-learning | 10,051 | `gr.Image` fullscreen button doesn't appear if `interactive=True` | ### Describe the bug
When using 'interactive=True' and 'show_fullscreen_button = Ture,
Fullscreen button doesnt appear
### Have you searched existing issues? 🔎
- [X] I have searched and found no existing issues
### Reproduction
```python
import gradio as gr
with gr.Blocks() as main:
image1 = gr.Image(... | closed | 2024-11-27T15:13:49Z | 2024-11-27T20:03:13Z | https://github.com/gradio-app/gradio/issues/10051 | [
"enhancement"
] | tripleS-Dev | 1 |
stanfordnlp/stanza | nlp | 919 | Constituency Parser does not produce output for every line | **Describe the bug**
English Constituency Parser does not produce output for every line.
**To Reproduce**
I am trying to compare the trees of a pair of documents.
`refdoc = open(os.path.join('.', 'drive', 'MyDrive', 'en.devtest'), 'r').read().split('\n')`
`hypdoc = open(os.path.join('.', 'drive', 'MyDrive', 'sw... | closed | 2022-01-09T15:27:27Z | 2022-01-11T02:45:03Z | https://github.com/stanfordnlp/stanza/issues/919 | [
"bug"
] | lhambrid | 5 |
indico/indico | sqlalchemy | 6,685 | Add fa_IR to Indico | **Is your feature request related to a problem? Please describe.**
Hello All.
Hope you're doing well.
I'm a student of Isfahan university of technology, Iran.
My university need Persian language for Indico and I'm going to translate it, but as I saw in docs, I should wait till Transifex bring Persian.
**Describe... | closed | 2025-01-02T02:08:30Z | 2025-01-05T21:23:35Z | https://github.com/indico/indico/issues/6685 | [
"enhancement"
] | aforouz | 6 |
charlesq34/pointnet | tensorflow | 238 | Preparing custom pointcloud dataset | Hey there, I have a Nuscenes point cloud dataset available and I will like to make use of it inside this Project. I looked at the `data_prep_util.py` script, however, I don't know where to start can anyone please help? | open | 2020-03-30T09:07:20Z | 2020-03-30T09:07:20Z | https://github.com/charlesq34/pointnet/issues/238 | [] | mtshikomba | 0 |
pytorch/pytorch | python | 149,422 | Pip-installed pytorch limits threads to 1 when setting GOMP_CPU_AFFINITY (likely due to bundled GOMP) | ### 🐛 Describe the bug
Pip-installed pytorch limits threads to 1 when setting GOMP_CPU_AFFINITY, while a pytorch build from source code will not have this problem. The pip-installed pytorch will use a bundled GOMP.
There is a cpp case can reproduce it.
```
#include <stdio.h>
#include <omp.h>
#include <torch/torch.h>
... | open | 2025-03-18T19:04:32Z | 2025-03-21T02:25:30Z | https://github.com/pytorch/pytorch/issues/149422 | [
"module: binaries",
"triaged"
] | yuchengliu1 | 4 |
FactoryBoy/factory_boy | django | 782 | Circular DjangoModelFactory RelatedFactory instances are not created | #### Description
I have two Django models that refer to eachother. StudentPhone has a ForeignKey relationship to Student, and a Student has a primary_phone field that refers to a StudentPhone. I want a StudentFactory that uses StudentPhoneFactory to create its primary_phone field. This is exactly the scenario shown in... | open | 2020-09-17T05:05:24Z | 2020-10-07T01:03:14Z | https://github.com/FactoryBoy/factory_boy/issues/782 | [
"Doc",
"Django"
] | incidentist | 3 |
modelscope/modelscope | nlp | 332 | ModelScope这个tts如何做流式呢?边转换,边播放 | 支持的,这周晚点最晚下周初github上更新一个issue会说明,其实现在code都是包含子函数的,但是我没有找到 | closed | 2023-06-14T01:48:24Z | 2024-07-28T01:56:53Z | https://github.com/modelscope/modelscope/issues/332 | [
"Stale",
"pending"
] | gsn516 | 7 |
fastapi-users/fastapi-users | fastapi | 747 | get_user_manager is not usable programmatically | ## Describe the bug
`get_user_manager` function proposed on official docs is not usable programmatically.
```
[...] in create_superuser
superuser = await user_manager.create(
AttributeError: 'generator' object has no attribute 'create'
```
## To Reproduce
Steps to reproduce the behavior:
1. Clone... | closed | 2021-09-27T10:35:26Z | 2021-09-30T07:15:29Z | https://github.com/fastapi-users/fastapi-users/issues/747 | [
"bug"
] | mlisthenewcool | 3 |
python-restx/flask-restx | api | 52 | CI is broken for Coveralls | ### **Repro Steps**
1. Create a PR
2. The tests run nicely in each environment
3. But suddenly, something goes wrong...
### **Expected Behavior**
The tests, coveralls, etc. should all pass.
### **Actual Behavior**
Coveralls does not pass
### **Error Messages/Stack Trace**
You can see an example failure [... | closed | 2020-02-10T21:13:59Z | 2020-02-11T15:09:45Z | https://github.com/python-restx/flask-restx/issues/52 | [
"bug",
"ci/cd"
] | plowman | 3 |
aio-libs/aiomysql | asyncio | 622 | i can use create_pool to query data,but why can't i query the new data that i manually inserted | i can use create_pool to query data,but why can't i query the new data that i manually inserted? | closed | 2021-10-08T08:59:48Z | 2022-02-18T14:26:55Z | https://github.com/aio-libs/aiomysql/issues/622 | [
"question"
] | Ray8716397 | 1 |
pywinauto/pywinauto | automation | 391 | Window hangging issue in windows 2012 while using Pywinauto 0.4 through Jep | Hi,
I am using jep code to launch a application window in windows 2012 system.
Sometimes the window which launches gets hanged immediately after opening and doesn't throw any exception.
The issue is inconsistent.
Is there any solution to this issue.
Thanks,
Elora | closed | 2017-07-19T06:48:18Z | 2019-05-12T11:35:46Z | https://github.com/pywinauto/pywinauto/issues/391 | [
"question"
] | eloraparija | 3 |
google/seq2seq | tensorflow | 304 | Could you please make the trained models available? | Could you please make the trained models available? | open | 2017-10-17T01:37:05Z | 2017-10-17T01:37:05Z | https://github.com/google/seq2seq/issues/304 | [] | LeenaShekhar | 0 |
FujiwaraChoki/MoneyPrinter | automation | 257 | Error: Response 403: Cloudflare detected | I get an error when generating.
 | closed | 2024-06-26T09:43:20Z | 2024-06-30T09:04:43Z | https://github.com/FujiwaraChoki/MoneyPrinter/issues/257 | [] | bqio | 5 |
pandas-dev/pandas | pandas | 60,308 | DOC: v2.2 offline documentation search button not work | ### Pandas version checks
- [X] I have checked that the issue still exists on the latest versions of the docs on `main` [here](https://pandas.pydata.org/docs/dev/)
### Location of the documentation
https://pandas.pydata.org/docs/pandas.zip
### Documentation problem
Mouse left click search button or Keyboard input... | open | 2024-11-14T01:09:51Z | 2024-12-22T11:22:12Z | https://github.com/pandas-dev/pandas/issues/60308 | [
"Docs"
] | jack6th | 3 |
pyg-team/pytorch_geometric | pytorch | 10,028 | Preserve and Subset Edge Features in KNNGraph Transform | ### 🚀 The feature, motivation and pitch
Currently, the `KNNGraph` transform in PyTorch Geometric constructs a k-nearest neighbors and returning only the `edge_index` tensor. However, if the input graph already has edge features(`edge_attr`), the transform does not subset or retain the corresponding edge attributes fo... | open | 2025-02-13T15:50:47Z | 2025-02-15T13:44:28Z | https://github.com/pyg-team/pytorch_geometric/issues/10028 | [
"feature",
"transform"
] | wesmail | 0 |
pyppeteer/pyppeteer | automation | 486 | can not get document object in evaluate function | i can not get document object in evaluate function, and get None;
```ptthon
res = await page.evaluate("""document""") # None
res = await page.evaluate("""document.querySelector('body')""") # None
```
but when i use page.querySelector('body'), the result is correct.
please help me。 i try some web pages and g... | open | 2024-11-26T09:39:06Z | 2024-11-26T09:39:06Z | https://github.com/pyppeteer/pyppeteer/issues/486 | [] | datuizhuang | 0 |
LibreTranslate/LibreTranslate | api | 8 | Limits to use the api on libre translate | Hello,
I am really interested to use the API on my project. First, I would like to introduce on a java lib that I created (https://github.com/stom79/mytransl). But, do you agree that I use your domain for my app (https://github.com/stom79/Fedilab)? | closed | 2021-01-10T13:08:40Z | 2021-01-19T07:14:01Z | https://github.com/LibreTranslate/LibreTranslate/issues/8 | [] | ghost | 7 |
localstack/localstack | python | 11,923 | bug: LS_LOG=error is extremely verbose | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
When I start the container localstack logs all my services configurations.

### Expec... | closed | 2024-11-25T16:39:56Z | 2024-11-26T09:12:51Z | https://github.com/localstack/localstack/issues/11923 | [
"type: bug",
"status: triage needed"
] | FezVrasta | 1 |
rasbt/watermark | jupyter | 89 | Include information about how Python was installed | Python can be installed in an number of ways. Limiting focus just to Linux, for example:
* Official system package
* On Ubuntu, deadsnakes PPA
* pyenv
* Conda (official default and conda-forge)
* `python` Docker image
Knowing how Python was installed can be useful at times for tools that have more intrusive i... | open | 2022-10-12T14:26:03Z | 2022-11-07T00:43:32Z | https://github.com/rasbt/watermark/issues/89 | [] | itamarst | 2 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 656 | Colab notebook is out of date | The colab notebook needs an update to keep up with the changes in #472.
Because no one is maintaining the notebook, I suggest we delete it. This will also reduce support questions for which we're not able to answer. | closed | 2021-02-14T16:35:00Z | 2021-02-14T20:55:55Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/656 | [] | ghost | 0 |
deepinsight/insightface | pytorch | 1,992 | RuntimeError: CUDA out of memory | 您好,我在训练glint360数据集的时候使用8卡V100 32G显存的一台服务器,batch_size设置为512的时候,第一张显卡显存会爆,提示RuntimeError: CUDA out of memory,但是剩余7张显卡都没有用满32G显存,请问下这个问题怎么解决呢?期待您的回复,十分感谢! | closed | 2022-04-29T00:53:59Z | 2022-04-30T02:09:25Z | https://github.com/deepinsight/insightface/issues/1992 | [] | quanh1990 | 2 |
d2l-ai/d2l-en | data-science | 2,431 | What is #@save mean and how does it work? | In the book, teacher says @save is used to save the function we design. I wonder how it work? Is it a character of python? Or it is designed by d2l?
There is a code here: https://github.com/d2l-ai/d2l-en/blob/master/d2l/torch.py
So the same name function will overwrite function here?
| closed | 2023-01-27T06:27:21Z | 2023-01-29T13:00:00Z | https://github.com/d2l-ai/d2l-en/issues/2431 | [] | likefallwind | 2 |
sinaptik-ai/pandas-ai | data-science | 1,384 | Error in Generating Text Output with Semantic Agents | While working with Semantic Agents, I want the output in text format. However, I am facing the following error. What can I do to get the output in text using Semantic Agents?
raise JSONDecodeError("Expecting value", s, err.value) from None
json.decoder.JSONDecodeError: Expecting value: line 1 column 1 (char 0)
<... | closed | 2024-10-01T07:30:45Z | 2025-01-07T16:08:20Z | https://github.com/sinaptik-ai/pandas-ai/issues/1384 | [
"bug"
] | muhammadshera71 | 1 |
vitalik/django-ninja | pydantic | 938 | [BUG] @model_validator(mode="before") issue | **Describe the bug**
When using something like this, `values` is a `DjangoGetter` instance which is somewhat unexpected to me. Prior to 1.0 and the pydantic update you would get a plain dictionary.
```python
class SomeSchema(Schema):
somevar:int
@model_validator(mode="before")
@classmethod... | open | 2023-11-20T23:04:02Z | 2023-12-21T05:46:20Z | https://github.com/vitalik/django-ninja/issues/938 | [] | shughes-uk | 2 |
Lightning-AI/pytorch-lightning | machine-learning | 19,618 | Validation runs during overfit, even when turned off | ### Bug description
I am attempting to overfit a model for demonstration. I am using the CLI and I am using trainer.overfit_batches=.125 and trainer.limit_val_batches=0.
If trainer.limit_val_batches=0 is run without the overfit_batches, the desired effect of turning off the validation dataloader and epoch is achieve... | closed | 2024-03-12T14:27:16Z | 2024-03-13T21:47:57Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19618 | [
"help wanted",
"docs",
"working as intended",
"trainer",
"ver: 2.1.x"
] | tkella47 | 2 |
LibrePhotos/librephotos | django | 589 | Date range selector | **Describe the enhancement you'd like**
I have uploaded thousands of pictures that I hope to use LibrePhotos to view, to replace Apple/Microsoft cloud based services, which I currently use. Both of these have an easy way to navigate to a point in time you wish to look at.
If I wanted to, for instance, go back to 20... | open | 2022-08-06T17:34:12Z | 2022-11-15T14:38:59Z | https://github.com/LibrePhotos/librephotos/issues/589 | [
"enhancement"
] | ubghacking | 1 |
tflearn/tflearn | data-science | 806 | Why is tflearn.data_utils.shuffle() not used in all CIFAR-10 Examples? | In the **covnet_cifar10.py** and **network_in_network.py** examples the CIFAR-10 data is shuffled after its loaded using the `tflearn.data_utils.shuffle()` function:
`from tflearn.datasets import cifar10`
`(X, Y), (X_test, Y_test) = cifar10.load_data()`
`X, Y = shuffle(X, Y)`
However, in the **residual_network... | open | 2017-06-22T16:39:56Z | 2017-06-26T03:21:19Z | https://github.com/tflearn/tflearn/issues/806 | [] | rhammell | 1 |
voxel51/fiftyone | computer-vision | 4,798 | [FR] How to host Fiftyone in AWS Amplify system? | ### Instructions
[AWS Amplify](https://aws.amazon.com/amplify) is a full stack development platform for web and mobile apps. I am not sure if we can host this in Amplify. If Fifityone can already host on Amplify, please let me know if there is some documentation.
### Proposal Summary
Allow hosting Fiftyone App... | open | 2024-09-13T22:02:47Z | 2024-09-13T22:02:47Z | https://github.com/voxel51/fiftyone/issues/4798 | [
"feature"
] | WuZhuoran | 0 |
SYSTRAN/faster-whisper | deep-learning | 894 | Update to Silero v5 | Silero v5 was recently released https://github.com/snakers4/silero-vad/tree/v5.0, and faster-whisper is still using v4. | closed | 2024-07-02T13:19:12Z | 2024-07-02T14:23:37Z | https://github.com/SYSTRAN/faster-whisper/issues/894 | [] | dorinclisu | 2 |
ageitgey/face_recognition | python | 1,473 | Save face in db | Hello everyone, tell me, can I somehow save the recognized face to the database and then get it from there to compare with the photo, I will be glad if some examples are presented | closed | 2023-02-17T00:54:10Z | 2023-02-27T19:12:40Z | https://github.com/ageitgey/face_recognition/issues/1473 | [] | Skreiphoff | 1 |
dask/dask | numpy | 11,188 | Bug in map_blocks when iterating over multiple arrays | **Describe the issue**:
When iterating over two arrays with map_blocks, I am running into an issue where each call to the function to process each chunk gets chunks with mismatching dimensions.
**Minimal Complete Verifiable Example**:
```python
from dask import array as da
array1 = da.zeros((100, 24)).rech... | closed | 2024-06-19T12:45:45Z | 2025-01-13T13:12:56Z | https://github.com/dask/dask/issues/11188 | [
"array"
] | astrofrog | 2 |
alteryx/featuretools | scikit-learn | 2,419 | Standardize Regular Expressions for Natural Language Primitives | Multiple primitives make use of regular expressions. Some of them define what punctuation to delimit on. We should standardize these. This would give users the confidence that Primitive A does not consider a string to be one word, while Primitive B considers it to be two. We could define the regexes in a common file an... | closed | 2022-12-20T00:20:38Z | 2023-01-03T17:35:13Z | https://github.com/alteryx/featuretools/issues/2419 | [
"refactor"
] | sbadithe | 0 |
erdewit/ib_insync | asyncio | 328 | Order held while securities are located | This is taken from ib_insync log:
Error 404, reqId 41686: Order held while securities are located.
Canceled order: Trade(contract=Contract(secType='STK', conId=416854744, symbol='DUST', exchange='SMART', primaryExchange='ARCA', currency='USD', localSymbol='DUST', tradingClass='DUST'), order=MarketOrder(orderId=4168... | closed | 2021-01-12T06:57:12Z | 2021-01-12T09:49:44Z | https://github.com/erdewit/ib_insync/issues/328 | [] | bandipapa | 0 |
fastapi/sqlmodel | pydantic | 221 | Circular Imports with Relationship | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | closed | 2022-01-13T16:10:56Z | 2022-01-14T06:57:45Z | https://github.com/fastapi/sqlmodel/issues/221 | [
"question"
] | laipz8200 | 1 |
nerfstudio-project/nerfstudio | computer-vision | 2,717 | floating things when training ngp model on ficus scene | Hi~I believe nerfstudio are using nerfacc to train instant-ngp models of nerf-synthetic dataset, when training on ficus dataset, I notice there are floating things in the scene cube, which hurt the psnr drastically, whereas no such things exist in scene like lego.
Here is a depth map picture rendered from ficus datase... | open | 2024-01-03T11:35:29Z | 2024-01-03T11:35:29Z | https://github.com/nerfstudio-project/nerfstudio/issues/2717 | [] | Moreland-cas | 0 |
Kanaries/pygwalker | plotly | 257 | Hide Visual Interface for Data Exploration in production environment | Hi,
I want to use pygwalker for dashboard creation in streamlit.
In development mode, I want Visual Interface for Data Exploration and chart creation.
However, I want to hide same in production environment. I just need chart with data filter.
Please guide me. | closed | 2023-10-07T03:54:48Z | 2023-10-21T14:13:32Z | https://github.com/Kanaries/pygwalker/issues/257 | [
"enhancement",
"P1"
] | mehtatejas | 3 |
comfyanonymous/ComfyUI | pytorch | 6,679 | AssertionError: Torch not compiled with CUDA enabled | ### Expected Behavior
Problem after updating ComfyUI using : update_comfyui_and_python_dependencies.bat. Then when i open it with :run_nvidia_gpu.bat it shows me this error. There was no problem when i checked it 2 weeks ago.
### Actual Behavior
c:\A\new_ComfyUI_windows_portable_nvidia_cu121_or_cpu>.\python_embede... | closed | 2025-02-02T18:11:34Z | 2025-02-02T20:06:52Z | https://github.com/comfyanonymous/ComfyUI/issues/6679 | [
"Potential Bug"
] | MarcinSoj | 3 |
mlfoundations/open_clip | computer-vision | 564 | why text unimodal of coca don't use casual mask self-attention? | Thanks for your great works. I have several questions on the coca model.
1. In the original paper, both the unimoal and the multimodal use causally-masked self-attention. However, the implement of unimodal in this repo use clip. If you donnot use causally-masked, the caption loss to be improperly computed since l... | closed | 2023-07-05T11:37:27Z | 2023-07-06T03:59:43Z | https://github.com/mlfoundations/open_clip/issues/564 | [] | PanXiebit | 2 |
deezer/spleeter | tensorflow | 96 | [Bug] Different audio duration after wave to mp3 | After converting the input mp3 file to wave the duration changes:
```
(.env) ip-192-168-23-184:spleeter loretoparisi$ ffprobe -i output/test/vocals.mp3
ffprobe version 4.0 Copyright (c) 2007-2018 the FFmpeg developers
built with Apple LLVM version 9.1.0 (clang-902.0.39.1)
configuration: --prefix=/usr/local/... | closed | 2019-11-14T17:33:40Z | 2019-11-14T22:41:33Z | https://github.com/deezer/spleeter/issues/96 | [
"bug",
"help wanted",
"question"
] | loretoparisi | 3 |
d2l-ai/d2l-en | data-science | 2,618 | [suggestion of presentation] pre-norm transformers | the figure&description in transformer.ipynb follows its historical post-norm version. Since (almost?) all modern projects uses pre-norm transformers, maybe it'd be presented head-up, not until in ViT section, to give newbies (like me) an optimized first-impression, and leave the historically significant version to a le... | open | 2024-08-30T13:57:12Z | 2024-08-30T13:57:12Z | https://github.com/d2l-ai/d2l-en/issues/2618 | [] | jkpjkpjkp | 0 |
albumentations-team/albumentations | deep-learning | 2,292 | [Speed up] Speed up Elastic | Benchmark shows that `imgaug` has faster Elastic implementations => need to learn from it and fix. | open | 2025-01-24T15:56:02Z | 2025-02-17T01:19:47Z | https://github.com/albumentations-team/albumentations/issues/2292 | [
"Speed Improvements"
] | ternaus | 2 |
mlfoundations/open_clip | computer-vision | 167 | Add jit save for ViT-H and ViT-g please | I tried new pretrained models, but they cannot be saved with torch jit script:
```model, _, preprocess = open_clip.create_model_and_transforms('ViT-g-14', 'laion2b_s12b_b42k', jit=True)```
Output:
```
File "/opt/conda/lib/python3.7/site-packages/open_clip/model.py", line 326
return self.attn(x, x, x,... | closed | 2022-09-16T08:49:37Z | 2022-09-16T15:06:27Z | https://github.com/mlfoundations/open_clip/issues/167 | [] | 25icecreamflavors | 1 |
google-research/bert | tensorflow | 695 | 1 | 1 | closed | 2019-06-13T07:34:52Z | 2019-06-13T07:43:57Z | https://github.com/google-research/bert/issues/695 | [] | sbmark | 0 |
httpie/cli | api | 1,105 | [Snap] Remove unused Pygments lexers | In the Snap package, we are bundling a lot of `Pygments` lexers that will never be used. Maybe should we take time to remove them at some point.
Here is the revelant output of `$ snapcraft --debug` (that builds the package):
```
(...)
Listing '/root/prime/lib/python3.8/site-packages/pygments'...
(...)
Listing '/r... | closed | 2021-07-05T12:01:07Z | 2021-08-27T11:07:03Z | https://github.com/httpie/cli/issues/1105 | [
"enhancement",
"packaging"
] | BoboTiG | 3 |
albumentations-team/albumentations | machine-learning | 2,447 | [Feature request] Add apply_to_images to CenterCrop | open | 2025-03-11T01:21:46Z | 2025-03-11T01:21:52Z | https://github.com/albumentations-team/albumentations/issues/2447 | [
"enhancement",
"good first issue"
] | ternaus | 0 | |
huggingface/pytorch-image-models | pytorch | 2,110 | [FEATURE] Add image backbones from `MobileCLIP` paper | [MobileCLIP](https://github.com/apple/ml-mobileclip/) is a really fast CLIP architecture for mobile inference - about 3x faster than the fastest publicly available CLIP backbone `convnext_base_w` for inference on iOS / macOS devices.
They introduce 3 novel image backbones: `mci{0|1|2}`. It would be amazing if these... | closed | 2024-03-16T10:24:56Z | 2024-06-14T19:29:02Z | https://github.com/huggingface/pytorch-image-models/issues/2110 | [
"enhancement"
] | rsomani95 | 7 |
wkentaro/labelme | deep-learning | 859 | Labelling z-stack images | I would like to label microscopic images that come as z-stack of several focus levels.
LabelMe does open such images but only shows the first layer. Is there any possibility to browse the other layers as well? Or could such option be added?
| closed | 2021-04-15T10:04:27Z | 2022-06-25T04:44:12Z | https://github.com/wkentaro/labelme/issues/859 | [] | MartinTheuerkauf | 0 |
horovod/horovod | tensorflow | 3,343 | [Error] horovod.common.exceptions.HorovodInternalError: ncclCommInitRank failed: unhandled system error | Hello, I am using the latest horovod docker for training deep learning models:
**Environment:**
1. Framework: (PyTorch)
2. Framework version:
3. Horovod version: Horovod v0.22.1
4. MPI version: mpirun (Open MPI) 3.0.0
5. CUDA version: cuda_11.2
6. NCCL version:
7. Python version: Python 3.7.5
10. OS and vers... | closed | 2022-01-04T09:14:28Z | 2022-01-04T13:06:59Z | https://github.com/horovod/horovod/issues/3343 | [] | RossStream | 5 |
pytest-dev/pytest-qt | pytest | 430 | BUG: Click Away from MenuBar does not Close MenuBar | ### System
**OS:** Windows 10
**Python:** 3.8.10
**Qt:** PySide6
**pytest-qt:** 4.0.2
### Problem
After clicking a `QMenuBar` item, clicking away from the menu does not close it when using `qtbot`.
### MRE
#### `myproj/main.py`
```python
from qtpy import QtWidgets
class View(QtWidgets.QMainWi... | open | 2022-06-07T23:58:00Z | 2022-06-08T16:30:56Z | https://github.com/pytest-dev/pytest-qt/issues/430 | [] | adam-grant-hendry | 3 |
holoviz/panel | jupyter | 7,605 | Several API reference docs are empty / missing content |
Examples:
https://panel.holoviz.org/api/panel.param.html
https://panel.holoviz.org/api/panel.pipeline.html
This page has headers, but no content, and a bunch of links to widgets in the right-hand sidebar, that do not error, but also don't lead to anywhere on the page.
Similar issue on this page:
https://panel.hol... | closed | 2025-01-08T06:55:49Z | 2025-01-23T17:02:06Z | https://github.com/holoviz/panel/issues/7605 | [
"type: docs"
] | Coderambling | 2 |
indico/indico | sqlalchemy | 6,795 | Multiple participant lists showing in 'lecture' after changing type of event | **Describe the bug**
In type 'lecture' I can not create several participants lists, in conference I can (e.g. participants list and waiting list). If I have two participant list in 'conference' and I change the type to 'lecture', then the second participant list is still display on the public event page, howver, in the... | open | 2025-03-11T08:53:21Z | 2025-03-17T14:21:41Z | https://github.com/indico/indico/issues/6795 | [
"enhancement"
] | geyslein | 2 |
PaddlePaddle/ERNIE | nlp | 503 | 生成中文词向量 | 你好,ERNIE模型能够生成中文的词级别向量,而不是生成字级别向量么? | closed | 2020-06-22T03:10:31Z | 2020-09-08T05:20:32Z | https://github.com/PaddlePaddle/ERNIE/issues/503 | [
"wontfix"
] | hvuehu | 4 |
tensorpack/tensorpack | tensorflow | 1,335 | Training stuck for faster rcnn on coco dataset for only person class. | I want to train faster rcnn on coco data using pretrained "COCO-MaskRCNN-R50FPN2x.npz" weights for person class only.
I am facing issue of training getting stuck. Please see the image below.
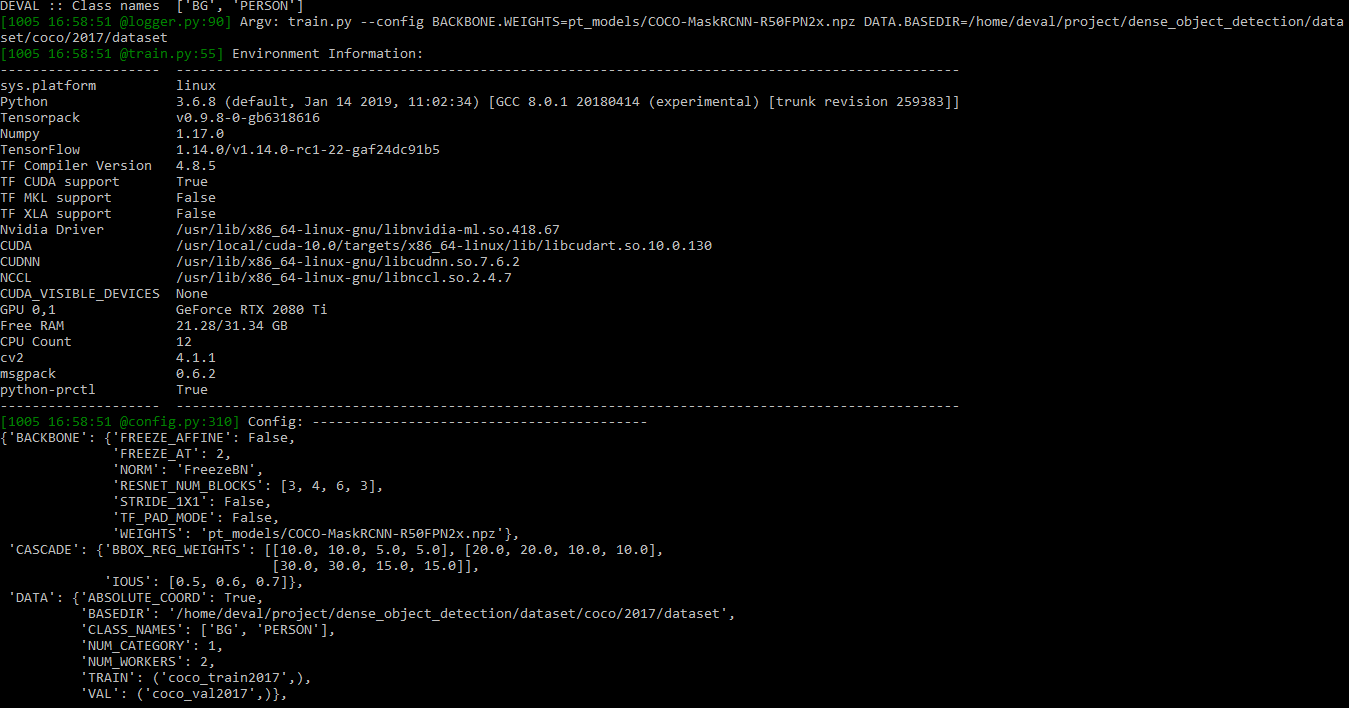
![erro... | closed | 2019-10-05T17:10:38Z | 2019-10-06T18:38:34Z | https://github.com/tensorpack/tensorpack/issues/1335 | [
"duplicate"
] | dvlshah | 4 |
developmentseed/lonboard | jupyter | 8 | `Map.save` for offline (outside of Python) use | - Serialize the Arrow table to a base64 string
- Create an HTML file with data, layer parameters, etc | closed | 2023-09-29T18:11:09Z | 2023-11-03T21:48:51Z | https://github.com/developmentseed/lonboard/issues/8 | [
"javascript"
] | kylebarron | 1 |
liangliangyy/DjangoBlog | django | 130 | 缓存文件404 | 缓存配置:
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'TIMEOUT': 10800,
'LOCATION': 'unique-snowflake',
}
}
错误如下:
[22/Jun/2018 22:05:14] "GET /static/CACHE/css/c9a7d7e6abbc.css HTTP/1.1" 404 2361
[22/Jun/2018 22:05:14] "GET /static/CACHE/css/2490f7c132d2.css HTTP/1.1" 4... | closed | 2018-06-22T14:08:04Z | 2018-06-22T14:12:50Z | https://github.com/liangliangyy/DjangoBlog/issues/130 | [] | jsuyanyong | 1 |
aiortc/aioquic | asyncio | 422 | pip install -e . error | I force the following error when i run the `pip install -e .`
```
Installing build dependencies ... done
Checking if build backend supports build_editable ... done
Getting requirements to build wheel ... done
Preparing metadata (pyproject.toml) ... done
Installing collected packages: UNKNOWN
Attempting... | closed | 2023-11-24T18:48:42Z | 2023-11-30T16:00:36Z | https://github.com/aiortc/aioquic/issues/422 | [] | EsmaeiliSina | 1 |
huggingface/transformers | pytorch | 36,516 | Object detection tutorial uses buggy dataset, may lead to crash during training | ### System Info
The [Object detection tutorial](https://huggingface.co/docs/datasets/object_detection) uses the [CPPE-5 dataset](https://huggingface.co/datasets/rishitdagli/cppe-5) to finetune a DETR model. This dataset contains multiple images with wrong annotations. This is clear when inspecting the [CPPE-5-v2 datas... | open | 2025-03-03T15:22:09Z | 2025-03-04T09:01:12Z | https://github.com/huggingface/transformers/issues/36516 | [
"Examples",
"bug",
"Vision"
] | LambdaP | 4 |
ARM-DOE/pyart | data-visualization | 1,406 | Mention Cfradial Version in read_cfradial | Currently, the API documentation of `read_cfradial` does not mention any version number of the Cfradial standard.
Although [Cfradial version 2](https://github.com/NCAR/CfRadial) officially still has draft status, it might be worth to mention which cfradial version is expected by `read_cfradial`, especially since versi... | closed | 2023-03-23T15:31:58Z | 2023-03-29T20:30:12Z | https://github.com/ARM-DOE/pyart/issues/1406 | [
"Docs"
] | Ockenfuss | 3 |
Gozargah/Marzban | api | 907 | arbitrary "path" for json subscription link | بالاخره توی نسخه 6.40 برنامه v2rayN امکان اضافه کردن چند کانفیگ کاستوم با استفاده لینک اشتراک اضافه شد. مشکلی که هست اینه که لینک اشتراک json را باید با اضافه کردن پسوند /v2ray - json به انتهای لینک اشتراکی که از پنل میگیریم، بسازیم. اینکار احتمال فیلتر شدن دامنه مورد استفاده برای لینک اشتراک را زیاد میکنه چون عبارت j... | closed | 2024-03-30T22:43:52Z | 2024-03-31T07:18:55Z | https://github.com/Gozargah/Marzban/issues/907 | [
"Invalid"
] | farshadl | 3 |
DistrictDataLabs/yellowbrick | matplotlib | 373 | Identity Estimator in Contrib | Create an Identify estimator to allow yellowbrick to use datasets that already contain predicted probabilities
```
from sklearn.base import BaseEstimator, ClassifierMixin
class Identity(BaseEstimator, ClassifierMixin):
def fit(self, X, y=None):
return self
def predict(self, X):
if... | open | 2018-03-28T23:51:40Z | 2018-04-04T19:06:37Z | https://github.com/DistrictDataLabs/yellowbrick/issues/373 | [
"type: feature",
"type: contrib"
] | ndanielsen | 0 |
ranaroussi/yfinance | pandas | 1,992 | [Volume] FutureWarning: Setting an item of incompatible dtype is deprecated and will raise an error in a future version of pandas. | ### Describe bug
The code can still work, but it shows warning. I used `yf.download()`, it happens more often if the interval is set to `1d`.
### Simple code that reproduces your problem
```python
def fetch_stock_data(tickers: List[str]) -> pd.DataFrame:
"""Fetch data of stock list using yfinance"""
t... | closed | 2024-07-19T07:16:43Z | 2024-07-19T08:03:19Z | https://github.com/ranaroussi/yfinance/issues/1992 | [] | makamto | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | pytorch | 1,508 | Question on semantic loss of CycleGANSemanticModel | Hi, I got a bit confused about the implementation of the semantic loss in the CycleGANSemanticModel. In your CyCADA paper, the semantic consistency loss is computed using a pretrained model fs. However, in this code I found that the semantic loss is directly computed using the target model ft. I just wonder why the imp... | closed | 2022-11-16T10:28:56Z | 2022-11-17T05:48:03Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1508 | [] | yklInverted | 0 |
JaidedAI/EasyOCR | machine-learning | 1,246 | Rely on a common/proven/maintained models retrieval logic | Every new OCR solution seems to rely on its own set of model. EasyOCR, DocTR, OpenMMLab's MMOCR, ...
It's even worst when model are not retrieved from their upstream/official location leading to all sort of question about performances, training, ... (Dozens of issues in the project bugtracker about dbnet18, dbnet50, c... | open | 2024-05-03T23:29:53Z | 2024-05-03T23:29:53Z | https://github.com/JaidedAI/EasyOCR/issues/1246 | [] | drzraf | 0 |
15r10nk/inline-snapshot | pytest | 98 | Broken "pytest integration" documentation page | All python code blocks are failing in https://15r10nk.github.io/inline-snapshot/pytest/
Error messages:
- `environment: line 10: pytest: command not found`
- `/usr/local/bin/python: No module named pytest` | closed | 2024-07-13T20:59:34Z | 2024-07-17T12:59:18Z | https://github.com/15r10nk/inline-snapshot/issues/98 | [] | tmlmt | 2 |
AutoGPTQ/AutoGPTQ | nlp | 715 | [BUG] The paths for the custom_bwd and custom_fwd methods have changed | **Describe the bug**
The paths for the custom_bwd and custom_fwd methods have changed, and their arguments have been updated.
Before
```
from torch.cuda.amp import custom_bwd, custom_fwd
```
After (need to change)
```
from torch.amp import custom_bwd, custom_fwd
```
**Hardware details**
CPU: ???
GPU: ... | open | 2024-07-26T17:30:22Z | 2024-07-28T14:22:23Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/715 | [
"bug"
] | russellgeum | 0 |
google-research/bert | tensorflow | 1,066 | BERT-Tiny,BERT-Mini,BERT-Small,BERT-Medium - TF 2.0 checkpoints | Hi All ,
I am looking at BERT checkpoint here - https://github.com/tensorflow/models/tree/master/official/nlp/bert for TF 2.0 .
Are checkpoints for BERT-Tiny,BERT-Mini,BERT-Small,BERT-Medium avaialbe in TF 2.0 ?
| closed | 2020-04-20T17:42:37Z | 2020-08-14T19:17:55Z | https://github.com/google-research/bert/issues/1066 | [] | 17patelumang | 2 |
Yorko/mlcourse.ai | numpy | 743 | AI learning | closed | 2023-04-23T07:20:16Z | 2023-05-03T09:07:35Z | https://github.com/Yorko/mlcourse.ai/issues/743 | [
"invalid"
] | manishikuma | 0 | |
alpacahq/alpaca-trade-api-python | rest-api | 318 | Erroneous historical bars - AAPL | I was using the data API to retrieve historical data (YTD) for AAPL, but the returned values look wrong.
Here is the code snippet:
```python
import pandas as pd
import alpaca_trade_api as tradeapi
api = tradeapi.REST()
bars = api.get_barset(
symbols="AAPL",
timeframe="day",
start="2020-01-01T... | closed | 2020-10-25T07:51:55Z | 2021-08-11T08:26:58Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/318 | [] | syltruong | 5 |
schemathesis/schemathesis | pytest | 2,371 | [FEATURE] Filling missing examples for basic data types | ## Description of Problem
`--contrib-openapi-fill-missing-examples` not working as expected along with `--hypothesis-phases=explicit`
let us say i have a field `name`, and i use `--hypothesis-phases=explicit` and `--contrib-openapi-fill-missing-examples`
schemathesis generates `name: ''` which is not valid json
... | open | 2024-07-24T19:07:25Z | 2024-07-28T09:08:55Z | https://github.com/schemathesis/schemathesis/issues/2371 | [
"Type: Feature"
] | ravy | 1 |
widgetti/solara | flask | 629 | Pyodide & Solara Integration? | I want to add Pyodide to Solara so the clients can run Python code in the browser.
Having a look over Solara code base i noticed this line:
`render_kwargs={"for_pyodide": True}`
What does it do? I found it [here](https://github.com/widgetti/solara/blob/cbf51712885642102b9dd6f3e48d1f60069f0413/solara/__main__.p... | open | 2024-05-02T19:25:52Z | 2024-05-08T15:11:18Z | https://github.com/widgetti/solara/issues/629 | [] | SuperPauly | 1 |
seleniumbase/SeleniumBase | web-scraping | 2,432 | can use chrome profile | can i use chrome profile path | closed | 2024-01-15T12:08:43Z | 2024-01-15T16:17:52Z | https://github.com/seleniumbase/SeleniumBase/issues/2432 | [
"duplicate",
"question"
] | raymomo | 1 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,230 | Can we train cycle GAN using paired dataset (Aligned dataset) | Sir , if we have a aligned dataset , can cycleGAN also show supervised learning behaviour ?
I mean can we add L1 loss between ground truth image (domain B) and generated image (domain B).
That is in simple words is it possible to include pix2pix kind of L1 loss using aligned dataset into CycleGAN for better results?
... | open | 2021-01-22T18:26:27Z | 2021-02-03T08:04:56Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1230 | [] | shivom9713 | 2 |
mlfoundations/open_clip | computer-vision | 435 | Train Model With Multiple Input Images | Is it possible to change the model to accept more than one image as the input?
If I'm not mistaken, CLIP takes an image and a text as the inputs, extracts the features of these two inputs and finally gives us the logits of the distance of the image to the text.
So, is it possible to give two (or more) input image... | open | 2023-02-18T10:42:05Z | 2023-02-18T22:01:06Z | https://github.com/mlfoundations/open_clip/issues/435 | [] | Neltherion | 3 |
httpie/cli | rest-api | 653 | How to get native terminal colors? | This used to work and now it's using its own set of really ugly colors (I've tried the different themes). I was under the impression `native` was supposed to use native terminal colors.
Thanks! | closed | 2018-02-17T14:26:42Z | 2018-08-24T18:52:50Z | https://github.com/httpie/cli/issues/653 | [] | 9mm | 16 |
biolab/orange3 | numpy | 7,050 | Widget documentation | In https://github.com/biolab/orange3-doc-visual-programming/pull/2, @ajdapretnar updated screenshots and some text, following similar contributions by @borondics. This was/is needed and long overdue, but documentation has other issues as well.
1. It looks awful, in particular because of image scaling: some retina imag... | open | 2025-03-15T10:52:31Z | 2025-03-15T12:38:37Z | https://github.com/biolab/orange3/issues/7050 | [
"needs discussion"
] | janezd | 1 |
modin-project/modin | pandas | 7,171 | BUG: ValueError: Length of values (3) does not match length of index (3001) | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [X] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthe... | closed | 2024-04-11T08:28:50Z | 2024-04-11T08:35:47Z | https://github.com/modin-project/modin/issues/7171 | [
"bug 🦗",
"pandas concordance 🐼"
] | YarShev | 1 |
RomelTorres/alpha_vantage | pandas | 253 | intraday data returned does not include current day | The `get_intraday` function returns data for the past 7 days, not including the current day in which the code is executed. Could we add functionality to retrieve the same data for the ongoing day up to the moment the function is called or are there other functions that already complete this action? | closed | 2020-08-28T17:18:56Z | 2020-08-28T17:23:35Z | https://github.com/RomelTorres/alpha_vantage/issues/253 | [] | sher85 | 1 |
sktime/pytorch-forecasting | pandas | 1,385 | [BUG] Unable to install with pip | - PyTorch-Forecasting version:
- PyTorch version: 2.0.1
- Python version: 3.11
- Operating System: Windows 11
### Expected behavior
I executed code `pip install pytorch-forecasting` to install the library
### Actual behavior
However, result was
```
Collecting pytorch-forecasting
Using cached pytorc... | closed | 2023-09-25T07:44:47Z | 2024-08-30T15:19:10Z | https://github.com/sktime/pytorch-forecasting/issues/1385 | [
"bug"
] | amrirasyidi | 5 |
viewflow/viewflow | django | 280 | Demo site https | http://viewflow.io
http://demo.viewflow.io
This sites doesn't have https in 2020. Had some issues with showing your solution for customer. | closed | 2020-06-19T07:04:42Z | 2023-02-09T10:17:25Z | https://github.com/viewflow/viewflow/issues/280 | [
"request/enhancement",
"dev/demo"
] | slavnycoder | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.