
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
dask/dask | numpy | 11,226 | Negative lookahead suddenly incorrectly parsed | In Dask 2024.2.1 we suddenly have an issue with a regex with a negative lookahead. It somehow is invalid now.
```python
import dask.dataframe as dd
regex = 'negativelookahead(?!/check)'
ddf = dd.from_dict(
{
"test": ["negativelookahead", "negativelookahead/check/negativelookahead", ],
},
n... | closed | 2024-07-15T07:23:02Z | 2024-07-17T12:59:24Z | https://github.com/dask/dask/issues/11226 | [
"needs triage"
] | manschoe | 3 |
iperov/DeepFaceLab | deep-learning | 5,230 | DFL training on RTX 3090 produces error "illegal instruction, core dumped" Linux but also some Windows installations |
## Expected behavior
Training SAEHD or XSeg on DFL with RTX 3090, tensorflow 2.4.0
## Actual behavior
Python throws Error code of "illegal instruction, core dumped" on last line of DFL script which says "train"
This is despite Tensorflow 2.4.0 correctly recognising the RTX 3090, and despite cuda 11.0 or 11.... | closed | 2021-01-02T23:51:20Z | 2021-01-28T00:19:00Z | https://github.com/iperov/DeepFaceLab/issues/5230 | [] | Joe-121 | 2 |
deepset-ai/haystack | nlp | 8,177 | 🧪 Tools: support for tools in 4 Chat Generators | ```[tasklist]
### Tasks
- [ ] https://github.com/deepset-ai/haystack/issues/8178
- [ ] https://github.com/deepset-ai/haystack/issues/8190
- [ ] https://github.com/deepset-ai/haystack/issues/8261
- [ ] https://github.com/deepset-ai/haystack-experimental/pull/120
```
| closed | 2024-08-08T15:14:47Z | 2024-10-30T11:25:42Z | https://github.com/deepset-ai/haystack/issues/8177 | [
"P1"
] | anakin87 | 1 |
betodealmeida/shillelagh | sqlalchemy | 36 | Implement different modes for GSheets DML | See https://github.com/betodealmeida/shillelagh/pull/35 | closed | 2021-06-27T02:40:01Z | 2021-06-30T21:50:48Z | https://github.com/betodealmeida/shillelagh/issues/36 | [] | betodealmeida | 1 |
rthalley/dnspython | asyncio | 1,174 | custom verify path for dns.query.quic() and dns.query.https() (h3) only works for files, not dirs | **Describe the bug**
Providing a custom verify path for `dns.query.quic()` and `dns.query.https()` (h3 only) lookups only works when the path is a file because this call to `aioquic.quic.configuration.QuicConfiguration.load_verify_locations()`:
https://github.com/rthalley/dnspython/blob/19a5f048ec2fdd60ca6e5cd8b68d5b... | closed | 2025-01-12T21:24:51Z | 2025-01-29T19:37:10Z | https://github.com/rthalley/dnspython/issues/1174 | [
"Bug",
"Fixed"
] | tykling | 2 |
deepinsight/insightface | pytorch | 1,960 | blank | closed | 2022-04-04T08:29:03Z | 2022-04-04T13:56:50Z | https://github.com/deepinsight/insightface/issues/1960 | [] | huynhtruc0309 | 0 | |
pytorch/pytorch | machine-learning | 149,389 | [Docs] `torch.Library`'s `kind` is inconsistent with the code | ### 🐛 Describe the bug
The doc says that `kind` defaults to `IMPL` but it actually does not.
<img width="821" alt="Image" src="https://github.com/user-attachments/assets/2eb7b65a-d642-4a13-b111-edc43080b3a0" />
Calling `torch.library.Library("fsdp")` will get this:
```
TypeError: Library.__init__() missing 1 requi... | closed | 2025-03-18T08:40:02Z | 2025-03-21T04:42:13Z | https://github.com/pytorch/pytorch/issues/149389 | [
"triaged",
"actionable",
"module: library"
] | shink | 0 |
Guovin/iptv-api | api | 660 | 最近几天工作流运行到排序阶段,每次都是到90%400个左右地址时就卡死了 | ### Don't skip these steps
- [X] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
- [X] I have checked through the search that there are no similar issues that already exist
- [X] I will not submit any issues that are not related to this project
### Occurrence environm... | closed | 2024-12-12T08:07:40Z | 2024-12-12T08:31:06Z | https://github.com/Guovin/iptv-api/issues/660 | [
"duplicate",
"question"
] | zg4321 | 3 |
iterative/dvc | data-science | 10,306 | pull: "Fetching" step takes forever | # pull: "Fetching" takes forever
## Description
Since the update to the version 3.45, ``dvc pull`` started to spend a massive amount of time for "Fetching".
Can't tell precisely what is the reason, but at least the computation of the md5 of a large file is done repetitively within different ``dvc pull`` executions... | closed | 2024-02-16T16:01:25Z | 2024-04-26T15:36:46Z | https://github.com/iterative/dvc/issues/10306 | [
"bug",
"performance",
"regression"
] | zhf231298 | 5 |
ray-project/ray | data-science | 51,483 | CI test windows://python/ray/tests:test_ray_init_2 is consistently_failing | CI test **windows://python/ray/tests:test_ray_init_2** is consistently_failing. Recent failures:
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aad4-a541-45a9-b1ef-d27f9a1da383
- https://buildkite.com/ray-project/postmerge/builds/8965#0195aa03-5c4f-4168-a0da-6cbdc8cbd2df
DataCaseName-windows://python... | closed | 2025-03-18T23:07:30Z | 2025-03-19T21:54:11Z | https://github.com/ray-project/ray/issues/51483 | [
"bug",
"triage",
"core",
"flaky-tracker",
"ray-test-bot",
"ci-test",
"weekly-release-blocker",
"stability"
] | can-anyscale | 2 |
pytorch/pytorch | numpy | 149,037 | (Will PR if ok) Support generator returning values | ### 🐛 Describe the bug
Hi thanks for the library! It would be great if generators returning values could be supported. I will make a PR if this feature looks OK.
For example:
```python
import torch
def exhaust_generator(g):
ans = []
while True:
try:
ans.append(next(g))
except St... | open | 2025-03-12T12:17:33Z | 2025-03-13T06:30:28Z | https://github.com/pytorch/pytorch/issues/149037 | [
"triaged",
"oncall: pt2"
] | fzyzcjy | 6 |
JaidedAI/EasyOCR | machine-learning | 543 | Missing chars from latin model | Hi! There are missing characters in the latin model, as I cannot see the `ő` and `Ő` characters, that are otherwise available in hungarian. Can you add them and update your latin model?
OFF: The hungarian language file is incorrect, so I will provide a language update in a pull request later. | closed | 2021-09-21T07:21:22Z | 2022-05-31T12:03:41Z | https://github.com/JaidedAI/EasyOCR/issues/543 | [] | timurlenk07 | 3 |
nvbn/thefuck | python | 1,392 | Last history contained "\", and get fatal error | <!-- If you have any issue with The Fuck, sorry about that, but we will do what we
can to fix that. Actually, maybe we already have, so first thing to do is to
update The Fuck and see if the bug is still there. -->
<!-- If it is (sorry again), check if the problem has not already been reported and
if not, just op... | closed | 2023-07-27T13:00:47Z | 2023-10-02T13:42:07Z | https://github.com/nvbn/thefuck/issues/1392 | [] | badcast | 2 |
allenai/allennlp | nlp | 5,123 | Make sure that metrics in allennlp-models work in the distributed setting | closed | 2021-04-14T18:35:28Z | 2021-04-19T07:04:24Z | https://github.com/allenai/allennlp/issues/5123 | [] | AkshitaB | 1 | |
OthersideAI/self-operating-computer | automation | 174 | [FEATURE] Learning Process | If there is some learning process before the actual task it would be working accurately rather than navigating to unnecessary places or clicking on to wrong options.
Like AppAgent which is built for smartphone has a human intervention with learning feature which lets the user to navigate and show how the task is done ... | open | 2024-03-02T19:15:38Z | 2024-03-06T07:57:56Z | https://github.com/OthersideAI/self-operating-computer/issues/174 | [
"enhancement"
] | MirzaAreebBaig | 1 |
drivendataorg/cookiecutter-data-science | data-science | 278 | adding Citation files (CFF) to cookiecutter-data-science template | With the upcoming release of v2, I think this would be a nice addition.
With the addition of this CFF file Github enables academics and researchers to let people know how to correctly cite their work, especially in academic publications/materials. Originally proposed by the [research software engineering community... | closed | 2022-08-21T07:04:12Z | 2024-06-01T22:48:53Z | https://github.com/drivendataorg/cookiecutter-data-science/issues/278 | [] | kjgarza | 0 |
iperov/DeepFaceLab | machine-learning | 5,228 | "data_src faceset extract" Failing | Choose one or several GPU idxs (separated by comma).
[CPU] : CPU
[0] : GeForce GTX 960M
[0] Which GPU indexes to choose? :
0
[wf] Face type ( f/wf/head ?:help ) :
wf
[0] Max number of faces from image ( ?:help ) :
0
[512] Image size ( 256-2048 ?:help ) :
512
[90] Jpeg quality ( 1-100 ?:help ) :
90
... | open | 2021-01-02T11:18:19Z | 2023-06-08T21:53:08Z | https://github.com/iperov/DeepFaceLab/issues/5228 | [] | adam-eme | 2 |
ultralytics/yolov5 | pytorch | 12,850 | Inaccurate bounding boxes when detecting large images | ### Search before asking
- [x] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I‘m trying to detect a circle with a diameter of 40 in an image with a resolution ... | closed | 2024-03-25T12:48:34Z | 2024-10-20T19:42:15Z | https://github.com/ultralytics/yolov5/issues/12850 | [
"question",
"Stale"
] | kyoryuuu | 5 |
jupyter/nbgrader | jupyter | 1,305 | Error with late submission plugin class | <!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
### Operating system
Ubunt... | open | 2020-01-22T22:01:16Z | 2020-01-22T22:01:16Z | https://github.com/jupyter/nbgrader/issues/1305 | [] | amellinger | 0 |
onnx/onnxmltools | scikit-learn | 311 | keras2onnx doesn't support python 2 and renders pip installation fail. | Env: python 2.7.15
Steps to reproduce:
```
$ pip install onnxmltools
...
Collecting keras2onnx (from onnxmltools)
Could not find a version that satisfies the requirement keras2onnx (from onnxmltools) (from versions: )
No matching distribution found for keras2onnx (from onnxmltools)
``` | closed | 2019-06-09T01:06:35Z | 2019-09-25T17:32:33Z | https://github.com/onnx/onnxmltools/issues/311 | [] | turtleizzy | 3 |
streamlit/streamlit | data-visualization | 10,350 | st.logo randamly disappears after a while | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
My image that I rendered with st.logo (I am u... | closed | 2025-02-05T14:32:40Z | 2025-02-13T23:59:20Z | https://github.com/streamlit/streamlit/issues/10350 | [
"type:bug",
"status:confirmed",
"priority:P2",
"feature:st.fragment",
"feature:st.logo"
] | Martijn3161 | 4 |
proplot-dev/proplot | data-visualization | 22 | proplot having issues with `xarray` objects | Currently, when plotting values from an `xarray.DataArray`, `proplot` throws an error. Note that this didn't used to be an issue.
The following works (note `A.values` has to be called, but `A.time.values` does not. So this is only an issue with the actual data being plotted and not coordinates)
```python
import ... | closed | 2019-06-27T18:48:55Z | 2019-09-14T21:22:55Z | https://github.com/proplot-dev/proplot/issues/22 | [
"bug"
] | bradyrx | 4 |
matplotlib/matplotlib | matplotlib | 29,090 | [MNT]: More consistent color parameters for bar() | ### Summary
From #29072. `bar()` supports
- `color` : color or list of color
- `edgecolor` : color or list of color
- `facecolor`: color
i.e.
- `facecolor` cannot take a sequence
- there are no plural aliase (e.g. `edgecolors`)
- likely (t.b.c.) the aliases also do not support sequences, similar to #28884... | closed | 2024-11-05T22:53:22Z | 2024-11-30T19:54:18Z | https://github.com/matplotlib/matplotlib/issues/29090 | [
"Maintenance"
] | timhoffm | 1 |
tqdm/tqdm | jupyter | 1,192 | cannot install from source package tqdm-4.61.0.tar.gz | Because of my offline environment, I installed the tqdm with source package of pypi.
But after I "pip install tqdm-4.61.1.tar.gz", I got Successfully built UNKNOWN instead of tqdm, how can i fix it.
THANKS | closed | 2021-06-23T03:04:35Z | 2021-07-29T10:54:29Z | https://github.com/tqdm/tqdm/issues/1192 | [
"invalid ⛔",
"need-feedback 📢",
"p3-framework ⚒"
] | CnBDM-Su | 2 |
scrapy/scrapy | python | 6,561 | Improve the contribution documentation | It would be nice to have something like [this](https://github.com/scrapy/scrapy/issues/1615#issuecomment-2497663596) in a section of the contribution docs that we can link easily to such questions. | closed | 2024-11-25T10:52:01Z | 2024-12-12T10:38:31Z | https://github.com/scrapy/scrapy/issues/6561 | [
"enhancement",
"docs"
] | Gallaecio | 2 |
babysor/MockingBird | deep-learning | 31 | 使用预训练模型获得了奇怪的mel spectrogram和杂音 | 
voicepart1.mp3 是一段时长为10秒钟、含7个句子的录音片段

voicepart2.wav 是一段时长为5秒钟的类似片段
合成结果均为约2秒的背景杂音,无论输入内容长度。
... | closed | 2021-08-22T19:21:49Z | 2021-08-23T03:40:33Z | https://github.com/babysor/MockingBird/issues/31 | [] | wfjsw | 6 |
wger-project/wger | django | 1,180 | Server Error (500) on API /workout/:id/log_data | Hi,
I am testing the app and found an issue while investigating a bug with the mobile app (see wger-project/flutter#291) .
The endpoint in object always answers with 500 Internal Server Error.
After investigation it seems related to
```
wger/manager/api/views.py:106
```
In method `log_data` the object `Exercis... | closed | 2022-11-14T02:13:42Z | 2022-11-29T16:26:40Z | https://github.com/wger-project/wger/issues/1180 | [] | manto89 | 2 |
LAION-AI/Open-Assistant | python | 3,007 | Next Iteration Meeting (Friday, May 5, 2023 7:00pm UTC) | Topics for the next meeting | open | 2023-05-01T20:17:41Z | 2023-05-07T16:54:03Z | https://github.com/LAION-AI/Open-Assistant/issues/3007 | [
"meeting"
] | AbdBarho | 14 |
plotly/dash | dash | 3,023 | add tooling to show Dash memory usage | It would be useful to have a way for Dash to report how much memory it is using where. The report could be textual (CSV / JSON) or graphical (an introspective chart?). | open | 2024-10-02T16:52:20Z | 2024-10-02T16:52:20Z | https://github.com/plotly/dash/issues/3023 | [
"feature",
"P3"
] | gvwilson | 0 |
huggingface/transformers | nlp | 36,363 | 目前使用Ktransformers进行DEEPSEEK-R1满血版和4bit量化版模型进行推理,推理速度有多少tokens/s?对应的计算资源配置分别是多少? | 目前使用Ktransformers进行DEEPSEEK-R1满血版和4bit量化版模型进行推理,推理速度有多少tokens/s?对应的计算资源配置分别是多少?
目前本地部署测试能跑4bit量化版和Q2_K量化版,但推理速度只有不到0.1tokens/s,,(...o0^0o...),使用的配置如下:
GPU:tesla A10 24G X 2
CPU:Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10GHz X 100(--cpu_infer 100,支持AVX-512,不支持AMX)
MemTotal:256G
磁盘:12T (15000rpm gpt-1.00 partitioned parti... | open | 2025-02-24T03:30:06Z | 2025-02-24T03:33:54Z | https://github.com/huggingface/transformers/issues/36363 | [] | William-Cai123 | 0 |
Lightning-AI/pytorch-lightning | pytorch | 20,024 | Multiple subclassing levels required to use LightningDataModule in LightningCLI | ### Bug description
I get the following error message
```error: Parser key "data":
Import path data.snemi.SNEMIDataModule does not correspond to a subclass of LightningDataModule
```
with yaml config
```yaml
data:
class_path: data.snemi.SNEMIDataModule
```
when defining SNEMIDataModule as follows
```pyth... | open | 2024-06-27T21:57:17Z | 2024-06-28T12:29:17Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20024 | [
"bug",
"lightningcli"
] | jasonkena | 2 |
Kanaries/pygwalker | pandas | 20 | [Feat] Detect white-dark theme and use appropriate theme | Currently, using `pyg.walk(df)` on a Jupyter Notebook with a dark theme renders a white widget, where most text are so low contrast that they are effectively invisible. | closed | 2023-02-21T20:27:56Z | 2023-03-19T17:34:22Z | https://github.com/Kanaries/pygwalker/issues/20 | [
"enhancement",
"graphic-walker"
] | hyiltiz | 4 |
deezer/spleeter | tensorflow | 665 | 2.3.0 install uses cpu only | - [ ] I didn't find a similar issue already open.
- [ ] I read the documentation (README AND Wiki)
- [ ] I have installed FFMpeg
- [ ] My problem is related to Spleeter only, not a derivative product (such as Webapplication, or GUI provided by others)
## Description
<!-- Give us a clear and concise description... | open | 2021-09-22T10:52:41Z | 2022-02-21T03:29:20Z | https://github.com/deezer/spleeter/issues/665 | [
"bug",
"invalid"
] | yangxing5200 | 2 |
onnx/onnx | pytorch | 5,809 | Edit Input/Output Onnx file | # Ask a Question
### Question
Hi,
My goal is to change inputs/outputs names of Onnx file, I write this code:
`import onnx
onnx_model_path = "ostrack-256.onnx"
original_model = onnx.load(onnx_model_path)
for input in original_model.graph.input:
if input.name == "x":
input.name = "search"
el... | closed | 2023-12-18T13:32:02Z | 2023-12-18T13:50:20Z | https://github.com/onnx/onnx/issues/5809 | [
"question"
] | arielkantorovich | 0 |
Evil0ctal/Douyin_TikTok_Download_API | api | 127 | 抖音链接失效了 | https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=7175083035304398120
这个接口 无法访问了 | closed | 2022-12-22T12:38:22Z | 2023-08-02T03:06:43Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/127 | [
"BUG"
] | 5wcx | 22 |
Anjok07/ultimatevocalremovergui | pytorch | 1,011 | vocals separation stopped due to memory error | Last Error Received:
Process: Ensemble Mode
If this error persists, please contact the developers with the error details.
Raw Error Details:
MemoryError: "Unable to allocate 4.37 GiB for an array with shape (2, 769, 763136) and data type float32"
Traceback Error: "
File "UVR.py", line 6638, in process_s... | open | 2023-12-07T10:56:30Z | 2023-12-08T14:57:50Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1011 | [] | StephenBrahmi | 1 |
robotframework/robotframework | automation | 5,240 | [Setup] and [Teardown] in test steps overrides Test Setup and Test Teardown from Settings | Hi, given below example
```
*** Settings ***
Test Setup Log To Console test setup in settings
Test Teardown Log To Console test teardown in settings
*** Test Cases ***
Test
[Setup] Log To Console test setup in test steps
Comment just testing
[Teardown] Log To ... | closed | 2024-10-17T09:21:05Z | 2024-11-01T15:41:52Z | https://github.com/robotframework/robotframework/issues/5240 | [] | MarcinGmurczyk | 2 |
feature-engine/feature_engine | scikit-learn | 6 | DecisionTreeDiscretiser what page to read from CiML-v3-book.pdf | may you clarify what page from http://www.mtome.com/Publications/CiML/CiML-v3-book.pdf is relevant to read about
https://feature-engine.readthedocs.io/en/latest/discretisers/DecisionTreeDiscretiser.html?highlight=DecisionTreeDiscretiser
as you wrote
The methods is inspired by the following article from the winners ... | closed | 2019-08-06T17:02:59Z | 2019-09-04T08:03:12Z | https://github.com/feature-engine/feature_engine/issues/6 | [
"question"
] | Sandy4321 | 1 |
Miserlou/Zappa | django | 1,631 | multiple api resource with lambda trigger | <!--- Provide a general summary of the issue in the Title above -->
## Context
I am new to zappa world.
Can zappa create multiple api gateway resource and their method(GET,POST,PUT) allowing to trigger lambda using JSON settings.
Let me know if above statement made sense.
Thank you
## Expected Behavior
<!--- T... | open | 2018-10-03T09:32:22Z | 2018-10-03T18:50:15Z | https://github.com/Miserlou/Zappa/issues/1631 | [] | prashantbaditya | 2 |
quokkaproject/quokka | flask | 568 | themes: find a way to download single pelican-themes | re-host pelican themes individually for easier download?
https://github.com/rochacbruno/quokka_ng/issues/66 | closed | 2018-02-07T01:36:06Z | 2018-02-07T01:39:06Z | https://github.com/quokkaproject/quokka/issues/568 | [
"1.0.0",
"hacktoberfest"
] | rochacbruno | 0 |
nolar/kopf | asyncio | 309 | Unprocessable Entity | > <a href="https://github.com/brutus333"><img align="left" height="50" src="https://avatars0.githubusercontent.com/u/6450276?v=4"></a> An issue by [brutus333](https://github.com/brutus333) at _2020-02-10 14:15:34+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/issues/309
>
## Long story ... | open | 2020-08-18T20:03:21Z | 2020-08-23T20:55:24Z | https://github.com/nolar/kopf/issues/309 | [
"bug",
"archive"
] | kopf-archiver[bot] | 0 |
TencentARC/GFPGAN | deep-learning | 529 | For Free | Please make this site free. My father doesn't have much money. | open | 2024-03-20T04:30:08Z | 2024-06-16T21:28:42Z | https://github.com/TencentARC/GFPGAN/issues/529 | [] | md-roni-f | 3 |
assafelovic/gpt-researcher | automation | 245 | smart_token_limit Exceeds Max Tokens | ### Description
I've been experimenting with different output token limits for research purposes. However, I encountered an error when setting the `smart_token_limit` to 8000 in `gpt_researcher/config/config.py`.
### Error Encountered
The following error was thrown:Error code: 400 - {'error': {'message': 'max_tokens i... | closed | 2023-11-14T11:10:53Z | 2023-11-30T14:17:18Z | https://github.com/assafelovic/gpt-researcher/issues/245 | [] | outpost-caprice | 2 |
koxudaxi/datamodel-code-generator | fastapi | 1,762 | Two variations of syntaxes for defining dictionaries/free-form objects give different results | **Describe the bug**
According to [this OpenAPI guide](https://swagger.io/docs/specification/data-models/dictionaries/), there are two ways to define free-form objects (a.k.a., a dictionary with values of any type).
They are equivalent and we expect the code generator to produce the same results `Optional[Dict[str, A... | open | 2023-12-06T19:20:29Z | 2023-12-22T15:09:36Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1762 | [
"bug"
] | shuangwu5 | 1 |
bregman-arie/devops-exercises | python | 10,230 | Docker : is not available | docker is used in creating image of project | open | 2023-10-02T11:08:46Z | 2023-10-02T11:08:46Z | https://github.com/bregman-arie/devops-exercises/issues/10230 | [] | Madhurchandran | 0 |
gradio-app/gradio | data-visualization | 10,813 | ERROR: Exception in ASGI application after downgrading pydantic to 2.10.6 | ### Describe the bug
There were reports of the same error in https://github.com/gradio-app/gradio/issues/10662, and the suggestion is to downgrade pydantic, but even after I downgraded pydantic, I am still seeing the same error.
I am running my code on Kaggle
and the error
```
ERROR: Exception in ASGI applicati... | open | 2025-03-15T15:27:56Z | 2025-03-17T18:26:54Z | https://github.com/gradio-app/gradio/issues/10813 | [
"bug"
] | yumengzhao92 | 1 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 3,442 | Not possible to add a ServiceAccount to the Prepuller | ### Bug description
Even though `prepuller.hook.serviceaccount` is properly configured, these changes aren't applied in the pods
### How to reproduce
1. Configure `prepuller.hook.serviceaccount` with a service account
2. Apply the changes
3. Check that the pod `image-puller` uses the default service account, eve... | closed | 2024-06-23T11:06:34Z | 2024-10-15T09:20:46Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/3442 | [
"bug"
] | samyuh | 2 |
thtrieu/darkflow | tensorflow | 586 | Failed to use tiny yolo | Hi, i tried to use tiny-yolo.cfg and tiny-yolo.weights, when i run the command
`python3 flow --model cfg/tiny-yolo.cfg --load bin/tiny-yolo.weights`
I found some errors like this
> Parsing ./cfg/tiny-yolo.cfg
Parsing cfg/tiny-yolo.cfg
Loading bin/tiny-yolo.weights ...
Traceback (most recent call last):
Fi... | open | 2018-02-19T01:37:45Z | 2019-04-17T13:39:23Z | https://github.com/thtrieu/darkflow/issues/586 | [] | alfamousts | 4 |
dgtlmoon/changedetection.io | web-scraping | 2,336 | Text taken from wrong step of browser steps | **Describe the bug**
I'm having the same problem as issue #1911, except the text is being taken from step 3 of 4. I can see the saved snapshot is correct, but the saved text is not. When looking at the steps on disk that were grabbed, I can see the text matches step3.html, and the screenshot matches step4.html.
S... | closed | 2024-04-26T00:29:59Z | 2024-04-29T10:19:18Z | https://github.com/dgtlmoon/changedetection.io/issues/2336 | [
"triage",
"browser-steps"
] | fhriley | 2 |
nteract/papermill | jupyter | 253 | Hiding Ingested Parameters when executing with `--report-mode` | I want to be able to hide the ingested parameters at least when running in report mode. Since a new cell is created by papermill when feeding in params, there is no way to add metadata for that cell in the notebook. When you want to execute a notebook in order to generate some sort of report where no code is visible I ... | closed | 2018-11-13T20:14:04Z | 2018-11-14T16:55:23Z | https://github.com/nteract/papermill/issues/253 | [] | LeonardAukea | 2 |
nalepae/pandarallel | pandas | 264 | Memory usage increases across multiple `parallel_apply` | ## General
- **Operating System**: Linux
- **Python version**: 3.10.8
- **Pandas version**: 1.5.3
- **Pandarallel version**: 1.6.5
## Acknowledgement
- [x] My issue is **NOT** present when using `pandas` without alone (without `pandarallel`)
- [x] If I am on **Windows**, I read the [Troubleshooting page](h... | closed | 2024-03-04T19:56:13Z | 2024-07-23T15:06:52Z | https://github.com/nalepae/pandarallel/issues/264 | [] | hogan-roblox | 3 |
aminalaee/sqladmin | fastapi | 826 | Add Inline models like Django, Flask-Admin | 
| closed | 2024-10-07T07:26:15Z | 2024-10-14T15:33:15Z | https://github.com/aminalaee/sqladmin/issues/826 | [] | logicli0n | 1 |
scrapy/scrapy | python | 5,755 | 警报:Passing a 'spider' argument to ExecutionEngine | 请问大佬这个警报是什么意思啊,我该怎么解决
运行爬虫时:
2022-12-10 21:09:02 [py.warnings] WARNING: C:\Users\wsy\AppData\Roaming\Python\Python310\site-packages\scrapy_redis\spiders
.py:197: ScrapyDeprecationWarning: Passing a 'spider' argument to ExecutionEngine.crawl is deprecated
self.crawler.engine.crawl(req, spider=self)
| closed | 2022-12-11T09:06:22Z | 2022-12-12T10:51:08Z | https://github.com/scrapy/scrapy/issues/5755 | [] | maintain99 | 2 |
flairNLP/flair | pytorch | 3,450 | [Bug]: transformers 4.40.0 assumes infinite sequence length on many models and breaks | ### Describe the bug
This is due to a regression on the transformers side, see: https://github.com/huggingface/transformers/issues/30643 for details.
Flair uses the `tokenizer.model_max_length` in the TransformerEmbeddings to truncate (if `allow_long_sentences=False`) or split (if `allow_long_sentences=True`) long... | closed | 2024-05-03T17:35:23Z | 2024-12-31T13:38:55Z | https://github.com/flairNLP/flair/issues/3450 | [
"bug"
] | helpmefindaname | 3 |
encode/httpx | asyncio | 2,276 | GET method doesn't support body payload | It would be nice to be able to send a body with a GET request. I understand that this may not be considered a good practice, but this is necessary for the API that I have to work with.
RFC 2616, section 4.3 clearly states:
> A message-body **MUST NOT be included** in a request **if the specification of the reques... | closed | 2022-06-23T05:30:47Z | 2022-06-23T07:41:33Z | https://github.com/encode/httpx/issues/2276 | [] | ZhymabekRoman | 2 |
sherlock-project/sherlock | python | 2,369 | False positive for: HackenProof | ### Additional info
Searching `goslnt` reliably produces a false positive for HackenProof, and unreliably produced false positives for ArtStation (redirected to 404) and AskFM.
### Code of Conduct
- [X] I agree to follow this project's Code of Conduct | open | 2024-11-17T23:14:48Z | 2024-11-26T01:56:07Z | https://github.com/sherlock-project/sherlock/issues/2369 | [
"false positive"
] | sudo-nano | 3 |
google-research/bert | nlp | 559 | problem multiclass text classification | Hi,
I am trying to classify text in 34 mutually exclusive classes using BERT. After preparing train, dev and test TSV files, and I try to execute the command for training and testing
`!python bert/run_classifier.py \
--task_name=cola \
--do_train=true \
--do_eval=true \
--data_dir=./Bert_Input_Folder \
--voc... | open | 2019-04-07T02:13:04Z | 2020-09-13T14:47:59Z | https://github.com/google-research/bert/issues/559 | [] | 86mm86 | 14 |
flavors/django-graphql-jwt | graphql | 22 | graphql_jwt.relay.ObtainJSONWebToken returns token when wrong credentials are submitted and Authorization header is set | I ran into a case when I had two users, `A` and `B`, and was sending a valid token of `A` when trying to obtain a new token for `B`. The mutation doesn't return any error, but instead returns a new token for `A`.
I dig a little in the code and I found out it was because of using `authenticate` here: https://github.c... | closed | 2018-06-21T13:01:10Z | 2018-06-29T20:18:32Z | https://github.com/flavors/django-graphql-jwt/issues/22 | [
"bug"
] | vladcalin | 2 |
hankcs/HanLP | nlp | 1,214 | 感知机模型人名识别错误 | <!--
注意事项和版本号必填,否则不回复。若希望尽快得到回复,请按模板认真填写,谢谢合作。
-->
## 注意事项
请确认下列注意事项:
* 我已仔细阅读下列文档,都没有找到答案:
- [首页文档](https://github.com/hankcs/HanLP)
- [wiki](https://github.com/hankcs/HanLP/wiki)
- [常见问题](https://github.com/hankcs/HanLP/wiki/FAQ)
* 我已经通过[Google](https://www.google.com/#newwindow=1&q=HanLP)和[issue区检... | closed | 2019-06-28T03:36:45Z | 2020-03-20T10:09:38Z | https://github.com/hankcs/HanLP/issues/1214 | [
"question"
] | lingjiameng | 2 |
kizniche/Mycodo | automation | 490 | Feature: Dedicated AC/Heating Function | This thread is for the development of a dedicated AC/Heating Function that incorporates the benefits of PID control with the features required for operating an efficient AC/Heating system. Additionally, features that would enable low temperatures with a wall/compact AC system can be integrated ([coolbot](https://www.st... | closed | 2018-06-05T15:40:23Z | 2020-07-23T18:47:12Z | https://github.com/kizniche/Mycodo/issues/490 | [
"enhancement"
] | kizniche | 23 |
huggingface/datasets | tensorflow | 6,854 | Wrong example of usage when config name is missing for community script-datasets | As reported by @Wauplin, when loading a community dataset with script, there is a bug in the example of usage of the error message if the dataset has multiple configs (and no default config) and the user does not pass any config. For example:
```python
>>> ds = load_dataset("google/fleurs")
ValueError: Config name i... | closed | 2024-05-02T06:59:39Z | 2024-05-03T15:51:59Z | https://github.com/huggingface/datasets/issues/6854 | [
"bug"
] | albertvillanova | 0 |
ploomber/ploomber | jupyter | 859 | Shell script task with multiple products | I get the following error
```
Error: Failed to initialize task 'clean'
'Getitem' object has no attribute 'name'
```
when running the pipeline
### pipeline.yaml
```yaml
tasks:
- source: get_data.py
product:
nb: get_data.ipynb
data: data.csv
- source: clean.sh
product: o... | closed | 2022-06-16T15:42:26Z | 2022-06-17T15:05:02Z | https://github.com/ploomber/ploomber/issues/859 | [] | reesehopkins | 1 |
robotframework/robotframework | automation | 4,497 | Libdoc: Support setting dark or light mode explicitly | The HTML documentation generated by libdoc can be opened in an IDE, where many people use a dark theme. The contrast between the Robot Framework code on a dark background and the library documentation with a white background is unpleasant.
This problem can be solved if libdoc has a stylesheet parameter to specify t... | closed | 2022-10-06T11:01:38Z | 2022-10-11T17:37:11Z | https://github.com/robotframework/robotframework/issues/4497 | [
"enhancement",
"priority: medium",
"rc 2"
] | mardukbp | 16 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,457 | Pre-trained Model Archetecture | Hi @junyanz , I am using your pre-trained model to compare with my model.
I downloaded the models from [link](http://efrosgans.eecs.berkeley.edu/cyclegan/pretrained_models/), but I am confused by the structure of the models. How should I load the models?
It seems the .pth file contains parameters only and I could... | open | 2022-07-13T13:39:36Z | 2022-07-13T13:40:59Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1457 | [] | WuhaoStatistic | 0 |
tensorflow/tensor2tensor | deep-learning | 1,785 | Common Voice Clean dataset giving error when using t2t-datagen | ### Description
I've been trying to generate the common voice dataset to improve the ASR checkpoint that was trained on librispeech but when using the command it downloads the file properly but seems to not find cv_corpus_v1. I think it probably doesn't extract the .tar properly
### Environment information
```
... | closed | 2020-02-04T09:44:59Z | 2020-02-04T14:03:17Z | https://github.com/tensorflow/tensor2tensor/issues/1785 | [] | RegaliaXYZ | 0 |
ageitgey/face_recognition | machine-learning | 1,251 | Getting irregular output when running compare faces with lists | * face_recognition version: 1.3.0
* Python version: 3.9.0
* Operating System: Windows
I am trying to compare a sample face image with a list of encodings which are from stored in my files
When I ran the compare_faces function on the sample image encoding and the list of encodings (encodings for only 2 images) I... | closed | 2020-12-08T12:46:02Z | 2020-12-09T11:19:25Z | https://github.com/ageitgey/face_recognition/issues/1251 | [] | VedankPande | 0 |
tfranzel/drf-spectacular | rest-api | 749 | Question: Using `TypedDict` as response | Hi! I saw in another issue that now we can use `TypedDict` class in the response instead of a serializer. Is it possible to provide an example or a documentation link elaborating this behavior?
Thanks! | closed | 2022-05-30T20:52:53Z | 2022-06-18T13:37:21Z | https://github.com/tfranzel/drf-spectacular/issues/749 | [] | kmehran1106 | 1 |
apache/airflow | machine-learning | 47,501 | AIP-38 | Add API Endpoint to serve connection types and extra form meta data | ### Body
To be able to implement #47496 and #47497 the connection types and extra form elements meta data needs to be served by an additional API endpoint.
Note: The extra form parameters should be served in the same structure and format like the DAG params such that the form elements of FlexibleForm can be re-used i... | closed | 2025-03-07T14:54:17Z | 2025-03-12T22:28:20Z | https://github.com/apache/airflow/issues/47501 | [
"kind:feature",
"area:API",
"kind:meta"
] | jscheffl | 0 |
encode/uvicorn | asyncio | 1,230 | Bug: calling `WebSocketProtocol.asgi_receive` returns close frame even if there are data messages before close frame in read queue | ### Checklist
- [x] The bug is reproducible against the latest release and/or `master`.
- [x] There are no similar issues or pull requests to fix it yet.
### Describe the bug
Once a client sends a close frame, calling `WebSocketProtocol.asgi_receive` returns `{"type": "websocket.disconnect", "code": exc.code}... | closed | 2021-11-02T03:33:52Z | 2021-11-25T09:09:08Z | https://github.com/encode/uvicorn/issues/1230 | [] | kylebebak | 1 |
blacklanternsecurity/bbot | automation | 1,452 | Optimize Neo4j | @t94j0 I did some testing with Neo4j, and you're right that it's slow to insert events. In big scans especially, when the events are really flooding in, the Neo4j queue can get backed up.
To fix this, we'll need to figure out how to batch the cypher statements. | closed | 2024-06-12T13:31:35Z | 2024-08-01T19:47:41Z | https://github.com/blacklanternsecurity/bbot/issues/1452 | [
"enhancement"
] | TheTechromancer | 2 |
aeon-toolkit/aeon | scikit-learn | 2,304 | [test-pycatch22-allnighter] is STALE | @web-flow,
test-pycatch22-allnighter has had no activity for 254 days.
This branch will be automatically deleted in 0 days. | closed | 2024-11-04T01:28:25Z | 2024-11-11T01:28:39Z | https://github.com/aeon-toolkit/aeon/issues/2304 | [
"stale branch"
] | aeon-actions-bot[bot] | 0 |
CorentinJ/Real-Time-Voice-Cloning | python | 740 | Slow training on Tesla P40 | 
| closed | 2021-04-22T12:00:24Z | 2021-05-30T07:35:25Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/740 | [] | wy192 | 2 |
ansible/ansible | python | 84,726 | _set_composite_vars doesn't support disable_lookups handling. | ### Summary
The `_set_composite_vars` method of the Constructable class of the inventory plugin don't have disable_lookups in its parameters. Therefore, when this method calls the `_compose` function of the same class, it always does so with disable_lookups=True.
```
https://github.com/ansible/ansible/blob/devel/lib/... | open | 2025-02-18T09:17:19Z | 2025-02-18T15:01:05Z | https://github.com/ansible/ansible/issues/84726 | [
"feature",
"data_tagging"
] | jpaniorte | 5 |
replicate/cog | tensorflow | 1,406 | Cog compatible image/container spec / allow base image in cog.yaml | Hello!
I know that cog is aimed at research projects/researchers not super familiar with docker. However, I am investigating deploying models on replicate for the company I work for (i.e private models), and we already have a fully containerized workflow, which works with GPUs. It would be great if I could specify ... | open | 2023-11-30T01:31:27Z | 2023-12-16T22:39:24Z | https://github.com/replicate/cog/issues/1406 | [] | DeNeutoy | 5 |
marshmallow-code/flask-marshmallow | rest-api | 38 | Some change in the Docs required , for security reasons json can't pass arrray | Docs to serialise SQLAlchemy with multiple rows suggest the code bellow:
``` python
users_schema = UserSchema(many=True)
@app.route('/api/users/')
def users():
all_users = User.all()
result = users_schema.dump(all_users)
return jsonify(result.data)
# OR
# return user_schema.jsonify(all_users)
```
... | closed | 2016-04-23T04:04:03Z | 2016-04-23T14:29:30Z | https://github.com/marshmallow-code/flask-marshmallow/issues/38 | [] | karan1276 | 1 |
PokeAPI/pokeapi | api | 1,138 | Ability changes not recorded | <!--
Please search existing issues to avoid creating duplicates.
Describe the feature you'd like.
Certain abilities don't have their future generation effects
i.e
Prankster: Dark types are now immune to prankster speed up moves.
Scrappy: Is now immume to intimidate.
Thank you!
-->
| open | 2024-10-07T17:54:27Z | 2024-10-08T02:51:03Z | https://github.com/PokeAPI/pokeapi/issues/1138 | [] | XeenProof | 1 |
ets-labs/python-dependency-injector | flask | 820 | Cached Value | I want to have a Singleton which functions as a cache for a method call.
I want the field `file_content` in my container be initialized one time by calling a given method (`reader.read`). From then on always that result should be returned instead of calling the method again.
I have added a working code example be... | open | 2024-09-26T11:24:48Z | 2024-11-13T18:28:16Z | https://github.com/ets-labs/python-dependency-injector/issues/820 | [] | str-it | 1 |
pallets-eco/flask-sqlalchemy | flask | 959 | How do i define the model? | i use this way to connect to oracle
`SQLALCHEMY_DATABASE_URI = 'oracle://username:password@ip:port/servername'`
How to specify the library when writing Model?
`class MyselfModel(BaseModel):
__tablename__ = 'user'
username = db.Column(db.String(32))
`
How to specify the library corresponding to the user ... | closed | 2021-04-23T10:48:52Z | 2021-05-08T00:03:42Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/959 | [] | importTthis | 0 |
marcomusy/vedo | numpy | 398 | Find the inner and outer contour of a set of points | Hi again @marcomusy. I have a set of points that I want to find the inner and outer contour of these points. This means the inner and outer contour of the red points below. The points order aren't organized. This is so I can compute the deviation between the outer and inner contour to the blue lines. I have tried to r... | closed | 2021-05-18T13:49:15Z | 2021-05-24T07:58:16Z | https://github.com/marcomusy/vedo/issues/398 | [] | eivindtn | 12 |
autogluon/autogluon | computer-vision | 4,938 | Survival Analysis? | Possible to use this library to train Survival Analysis models? | open | 2025-02-26T00:11:58Z | 2025-03-01T01:31:32Z | https://github.com/autogluon/autogluon/issues/4938 | [
"enhancement"
] | austinmw | 1 |
serengil/deepface | machine-learning | 720 | deepface docker build issue | Hello,
I get the below error message when I try to build the deepface docker after cloning the repo:
=> ERROR [13/13] RUN pip install --trusted-host pypi.org --trusted-host pypi.python.org --trusted-host=files.pythonhosted.org -e . 2.2s
------
> [13/13] RUN pip install --t... | closed | 2023-04-13T00:53:46Z | 2023-04-13T08:22:58Z | https://github.com/serengil/deepface/issues/720 | [
"bug"
] | WisamAbbasi | 1 |
onnx/onnx | machine-learning | 6,140 | Error While Installing ONNX | # Bug Report
### Is the issue related to model conversion?
no
### System information
Ubuntu 14.04
onnx 1.9.0
python 2.7.6
protobuf 2.6.1
cmake 3.28.4
gcc 4.8.4
### Describe the bug
```
Building wheels for collected packages: onnx
Building wheel for onnx (PEP 517) ... error
ERROR: Command errore... | open | 2024-05-20T06:13:51Z | 2024-05-20T07:23:14Z | https://github.com/onnx/onnx/issues/6140 | [
"question"
] | jh97321 | 3 |
yihong0618/running_page | data-visualization | 63 | [TODO] add type to db | run, bike walk ......
user can select only run. | closed | 2020-12-16T00:55:17Z | 2022-01-07T05:24:06Z | https://github.com/yihong0618/running_page/issues/63 | [
"enhancement"
] | yihong0618 | 0 |
mwaskom/seaborn | matplotlib | 3,330 | Wrong handles in legend with boxplot | When trying to change the labels of the legend on a boxplot, there is a change on the symbol in the legend.
Here is my minimal code
```import seaborn as sns
import matplotlib.pyplot as plt
import pingouin as pg
data = pg.read_dataset('penguins')
fig, ax = plt.subplots(layout='tight')
fig.set_figwidth(8)
... | closed | 2023-04-19T08:59:19Z | 2023-04-25T21:41:52Z | https://github.com/mwaskom/seaborn/issues/3330 | [] | Djost43 | 1 |
AutoGPTQ/AutoGPTQ | nlp | 575 | [FEATURE] Add support for Phi models | Currently "phi" models don't seem to be supported
```
Traceback (most recent call last):
File "/home/mgoin/marlin-example/apply_gptq_save_marlin.py", line 44, in <module>
model = AutoGPTQForCausalLM.from_pretrained(
File "/home/mgoin/venvs/test/lib/python3.10/site-packages/auto_gptq/modeling/auto.py", li... | closed | 2024-03-02T01:09:08Z | 2024-03-19T06:41:24Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/575 | [
"enhancement"
] | mgoin | 0 |
tfranzel/drf-spectacular | rest-api | 768 | Spectacular ignores settings | **Describe the bug**
I set some parameters in my settings.py `SPECTACULAR_SETTINGS` but it wont get picked up
**To Reproduce**
I placed the example from the docs in my settings.py:
```
SPECTACULAR_SETTINGS = {
'TITLE': 'Your Project API',
'DESCRIPTION': 'Your project description',
'VERSION': '1.... | closed | 2022-07-13T13:13:39Z | 2022-07-15T18:12:19Z | https://github.com/tfranzel/drf-spectacular/issues/768 | [] | georgkrause | 4 |
aimhubio/aim | data-visualization | 3,251 | Failed to initialize Aim DB, Can't locate revision. | ## 🐛 Bug
I am getting the following error when using `aim up`:
ERROR [alembic.util.messaging] Can't locate revision identified by '3d5fd76e8485'
FAILED: Can't locate revision identified by '3d5fd76e8485'
Failed to initialize Aim DB. Please see the logs above for details.
### Environment
- Aim 3.25.1
-... | closed | 2024-11-19T16:52:58Z | 2025-01-07T12:05:16Z | https://github.com/aimhubio/aim/issues/3251 | [
"type / bug",
"help wanted"
] | maxbarton15 | 2 |
wkentaro/labelme | deep-learning | 960 | [BUG] | **Describe the bug**
when edit toll selected create rectangle and i clicl any object after i need change to create polygone and i make second click then app crashes
show video
https://youtu.be/kD-cFZ2YO0Y | closed | 2021-11-27T14:18:17Z | 2022-10-23T12:10:29Z | https://github.com/wkentaro/labelme/issues/960 | [] | doitauto | 1 |
yihong0618/running_page | data-visualization | 443 | python3 scripts/strava_sync.py 同步不了strava数据 | 日志是这样的
Access ok
Start syncing | closed | 2023-07-05T03:48:31Z | 2023-07-06T07:15:26Z | https://github.com/yihong0618/running_page/issues/443 | [] | leosj | 15 |
vastsa/FileCodeBox | fastapi | 127 | 后台登录页面的bug,提示:未授权或授权校验失败 | 复现页面:https://share.lanol.cn/#/admin
复现方法:第一次登录成功,退出登录后,在进行登录会提示:未授权或授权校验失败
查看控制台提示如下:

仔细查看报错路径,发现登录接口路径少了/#/
原登录接口:https://share.lanol.cn/#/admin/login
报错登录接口:https://share.lanol.cn/admin/login
包括在您的演... | closed | 2024-01-23T06:52:36Z | 2024-07-12T05:19:07Z | https://github.com/vastsa/FileCodeBox/issues/127 | [] | OuOumm | 4 |
Morizeyao/GPT2-Chinese | nlp | 2 | generate.py error | generate.py 第80行应该放在79行前面哟。 | closed | 2019-07-25T16:58:36Z | 2019-08-06T13:36:54Z | https://github.com/Morizeyao/GPT2-Chinese/issues/2 | [] | hackerxiaobai | 1 |
jofpin/trape | flask | 231 | TRACEBACK error while requirements are installed. | 
| open | 2020-04-28T21:40:21Z | 2020-04-28T21:40:21Z | https://github.com/jofpin/trape/issues/231 | [] | demaico | 0 |
mljar/mljar-supervised | scikit-learn | 329 | Add support for currencies features | If column have currency symbol it should be automatically detected and currency symbol should be removed. | closed | 2021-03-03T07:36:58Z | 2024-09-30T11:34:58Z | https://github.com/mljar/mljar-supervised/issues/329 | [] | pplonski | 0 |
graphql-python/graphene-django | django | 710 | Start warning if `fields` or `exclude` are not defined on `DjangoObjectType` | So that model fields aren't accidentally exposed through DjangoObjectType I propose that we start warning if either `fields` or `exclude` aren't defined with the intention to error completely in the future. This would also align the API more with Django Rest Framework which hopefully makes it more familiar to most deve... | closed | 2019-07-12T16:50:31Z | 2020-07-01T12:07:09Z | https://github.com/graphql-python/graphene-django/issues/710 | [
"✨enhancement",
"v3"
] | jkimbo | 6 |
SYSTRAN/faster-whisper | deep-learning | 196 | Where to put the model.bin and related files if I don't wanna them into C: disk? | https://huggingface.co/guillaumekln/faster-whisper-large-v2/tree/main
How should I set up these files if I don't want to put them on disk C? Who knows?
faster-whisper-large-v2
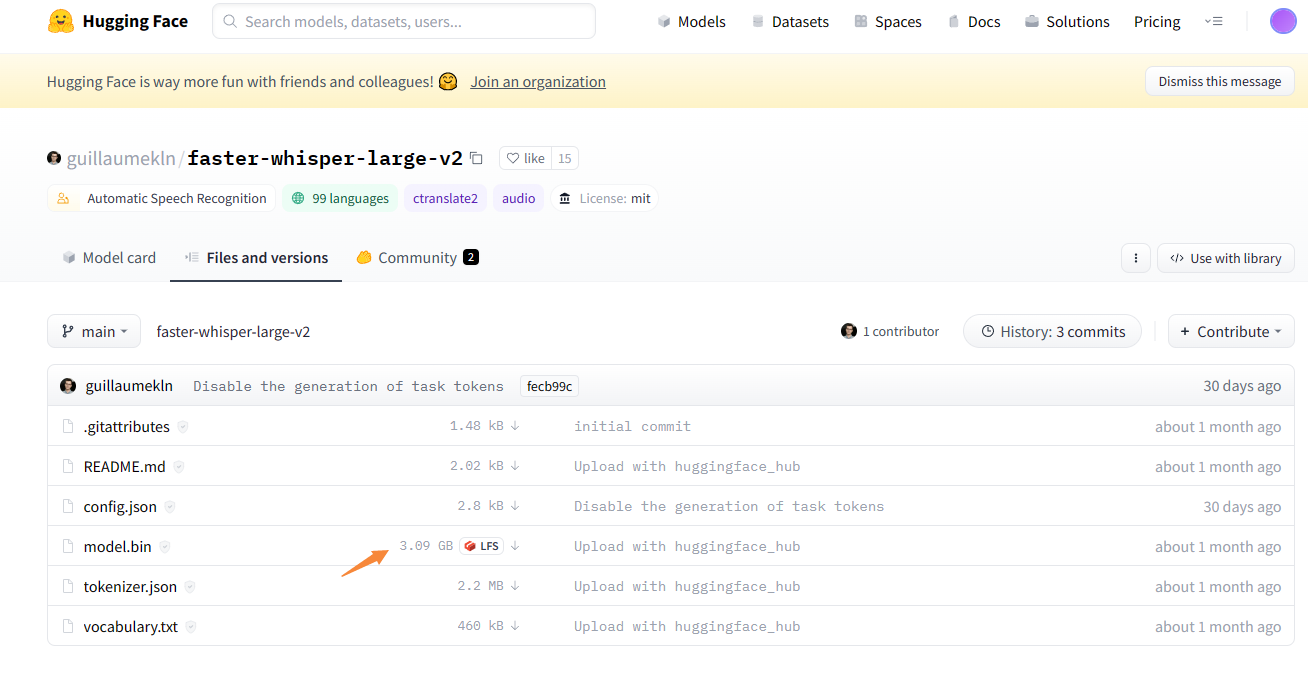
![... | closed | 2023-04-29T01:53:47Z | 2023-05-03T20:11:25Z | https://github.com/SYSTRAN/faster-whisper/issues/196 | [] | pendave | 1 |
kizniche/Mycodo | automation | 734 | Daemon log doesn't display in GUI when logrotate splits it | Develop a more reliable method for serving the latest lines from the daemon log. | closed | 2020-01-16T03:58:11Z | 2020-01-29T20:30:13Z | https://github.com/kizniche/Mycodo/issues/734 | [] | kizniche | 0 |
lux-org/lux | jupyter | 412 | Converting Timestamp: Error | Hi,
I am reading in a csv to my notebook, calling it df_plot. When I do a df_plot.head() it comes back saying that Timestamp maybe temperal. So I followed the suggested template and also tried a suggestion on the lux website. Neither works for me.
See attached image from my csv file of the timestamp
 | *Sent by Read the Docs (readthedocs@readthedocs.org). Created by [fire](https://fire.fundersclub.com/).*
---
| TensorLayer build #7116848
---
| 
---
| Build Failed for TensorLayer (latest)
---
You can find out more about this failure here:
... | closed | 2018-04-30T04:32:46Z | 2018-05-15T08:59:04Z | https://github.com/tensorlayer/TensorLayer/issues/539 | [] | fire-bot | 0 |
proplot-dev/proplot | matplotlib | 383 | The attribute fontsize in legend can not execute. | ### Description
When set fontsize=300 in legend, the attribute fontsize in legend can not execute, the legned fontsize unchanged.
```python
import proplot as pplt
labels = ['a', 'bb', 'ccc', 'ddddd', 'eeeee']
fig, axs = pplt.subplots(ncols=2, share=False, axwidth=3)
hs1, hs2 = [], []
state = n... | closed | 2022-08-15T14:25:14Z | 2023-03-28T23:57:18Z | https://github.com/proplot-dev/proplot/issues/383 | [
"already fixed"
] | NWPC-Whisperer | 2 |
gunthercox/ChatterBot | machine-learning | 2,248 | Parts of speech classification problem. | I'm just playing with chatterbot. I trained a model with chatterbot list trainer using the data of a conversation with a real person.
I was discovering how it works by seeing the contents of the sqlite database(which i used as the storage adapter). When I runned `SELECT * FROM statement` in sqlite shell, I saw that ... | closed | 2022-05-12T13:20:06Z | 2024-02-23T16:22:20Z | https://github.com/gunthercox/ChatterBot/issues/2248 | [] | SunPodder | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.