
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ckan/ckan | api | 8,333 | Sometimes Internal Server Error is occurred on CKAN UI while adding Resource | ## CKAN version
2.10.1
I have set up the CKAN Docker setup by following this link: https://github.com/ckan/ckan-docker
## Describe the bug
While adding resources on the CKAN UI, getting 500 internal server error on the UI.
### Steps to reproduce
1. Login to CKAN UI
2. Add Organization and dataset
3. Try to ... | open | 2024-07-09T09:12:47Z | 2024-07-10T11:52:37Z | https://github.com/ckan/ckan/issues/8333 | [] | kumardeepak5 | 2 |
deepspeedai/DeepSpeed | deep-learning | 6,747 | Model Checkpoint docs are incorrectly rendered on deepspeed.readthedocs.io | The top google search hit for most deepspeed documentation searches is https://deepspeed.readthedocs.io/ or its various sub-pages. I assume this export is somehow maintained or at least enabled by the deepspeed team, hence this bug report.
The page on model checkpointing at https://deepspeed.readthedocs.io/en/latest/m... | open | 2024-11-12T19:52:24Z | 2024-11-22T21:18:29Z | https://github.com/deepspeedai/DeepSpeed/issues/6747 | [
"bug",
"documentation"
] | akeshet | 3 |
holoviz/colorcet | matplotlib | 3 | license of color scales | Hi, I think these color scales are great and would love to have them available to the Julia community. What license are they released under? I would like to copy the scales to the Julia package PlotUtils, which is under the MIT license. A reference to this repo would appear in the source file and in the documentation (... | closed | 2017-03-13T11:56:14Z | 2018-08-24T13:40:02Z | https://github.com/holoviz/colorcet/issues/3 | [] | mkborregaard | 3 |
huggingface/datasets | pytorch | 7,213 | Add with_rank to Dataset.from_generator | ### Feature request
Add `with_rank` to `Dataset.from_generator` similar to `Dataset.map` and `Dataset.filter`.
### Motivation
As for `Dataset.map` and `Dataset.filter`, this is useful when creating cache files using multi-GPU, where the rank can be used to select GPU IDs. For now, rank can be added in the `ge... | open | 2024-10-10T12:15:29Z | 2024-10-10T12:17:11Z | https://github.com/huggingface/datasets/issues/7213 | [
"enhancement"
] | muthissar | 0 |
ClimbsRocks/auto_ml | scikit-learn | 438 | [Parallel(n_jobs=-1)]: Using backend LokyBackend with 2 concurrent workers. BrokenProcessPool: A task has failed to un-serialize. Please ensure that the arguments of the function are all picklable. | open | 2021-02-11T07:48:07Z | 2023-10-13T02:28:14Z | https://github.com/ClimbsRocks/auto_ml/issues/438 | [] | elnurmmmdv | 1 | |
horovod/horovod | pytorch | 3,354 | Trying to get in touch regarding a security issue | Hey there!
I belong to an open source security research community, and a member (@srikanthprathi) has found an issue, but doesn’t know the best way to disclose it.
If not a hassle, might you kindly add a `SECURITY.md` file with an email, or another contact method? GitHub [recommends](https://docs.github.com/en/code-s... | closed | 2022-01-09T00:13:04Z | 2022-01-19T19:25:36Z | https://github.com/horovod/horovod/issues/3354 | [] | JamieSlome | 3 |
coqui-ai/TTS | python | 2,744 | [Bug] Config for bark cannot be found | ### Describe the bug
Attempting to use Bark through TTS API [Using tts = TTS("tts_models/multilingual/multi-dataset/bark"] throws the following error.
```
Traceback (most recent call last):
File "c:\Users\timeb\Desktop\BarkAI\Clone and Product TTS.py", line 7, in <module>
tts = TTS("tts_models/multilingual/m... | closed | 2023-07-06T23:15:51Z | 2023-07-11T19:21:48Z | https://github.com/coqui-ai/TTS/issues/2744 | [
"bug"
] | JLPiper | 5 |
fastapi/sqlmodel | fastapi | 346 | SQLAlchemy-Continuum compatibility | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2022-05-19T13:34:36Z | 2024-12-05T19:03:11Z | https://github.com/fastapi/sqlmodel/issues/346 | [
"question"
] | petyunchik | 9 |
flasgger/flasgger | flask | 35 | Change "no content" response from 204 status | Hi,
is it possible to change the response body when the code is 204?
The only way that I found it was change the javascript code.
| closed | 2016-10-14T19:27:35Z | 2017-03-24T20:19:49Z | https://github.com/flasgger/flasgger/issues/35 | [
"enhancement",
"help wanted"
] | andryw | 1 |
paulbrodersen/netgraph | matplotlib | 56 | Hyperlink or selectable text from annotations? | Hey,
I'm currently using the library on a project and have a usecase for linking to a URL based on node attributes. I have the annotation showing on node click, but realized that the link is not selectable or clickable. Would it be possible to do either of those (hyperlinks would be preferred but selectable text is ... | closed | 2022-12-16T04:13:00Z | 2022-12-23T20:43:33Z | https://github.com/paulbrodersen/netgraph/issues/56 | [] | a-arbabian | 6 |
marshmallow-code/flask-smorest | rest-api | 491 | grafana + Prometheus + smorest integration | how could we integrate grafana and Prometheus with smorest? is there easy solution for it? or is there something to monitor smorest? Prometheus is well integrated with flask-restful?! | closed | 2023-04-16T21:46:46Z | 2023-08-18T15:58:55Z | https://github.com/marshmallow-code/flask-smorest/issues/491 | [
"question"
] | justfortest-sketch | 2 |
dpgaspar/Flask-AppBuilder | rest-api | 1,741 | update docs website for Flask-AppBuilder `3.4.0` | Flask-AppBuilder 3.4.0 was [released 2 days ago](https://github.com/dpgaspar/Flask-AppBuilder/releases/tag/v3.4.0), but the https://flask-appbuilder.readthedocs.io/en/latest/index.html website still only has `3.3.0` visible under the `latest` tag. | closed | 2021-11-12T02:54:43Z | 2021-11-14T17:46:25Z | https://github.com/dpgaspar/Flask-AppBuilder/issues/1741 | [] | thesuperzapper | 2 |
reloadware/reloadium | pandas | 189 | Hot reloading of HTML files not working with reloadium (works fine with just webpack-dev-server and python manage.py runserver) | ## Describe the bug*
I have a Django project that uses webpack to serve some frontend assets and for hotreloading js/css/html files.
Hotreloading of HTML files work great when I run django normally.
However, when I run the project using Pycharm addon of Reloadium, the hotreloading of HTML files doesn't work.
The pa... | closed | 2024-04-03T17:38:26Z | 2024-05-20T23:42:57Z | https://github.com/reloadware/reloadium/issues/189 | [] | antoineprobst | 2 |
quantmind/pulsar | asyncio | 15 | Profiling task | Add functionality to profile a task run using the python profiler.
| closed | 2012-02-10T12:06:14Z | 2012-12-13T22:06:20Z | https://github.com/quantmind/pulsar/issues/15 | [
"taskqueue"
] | lsbardel | 1 |
PeterL1n/RobustVideoMatting | computer-vision | 67 | 前景预测 | 请问在训练阶段,有遇到第一阶段前景预测图整体偏红或者偏绿的情况吗?有什么解决办法吗? | closed | 2021-10-08T04:45:12Z | 2021-12-16T01:24:48Z | https://github.com/PeterL1n/RobustVideoMatting/issues/67 | [] | lyc6749 | 10 |
chaos-genius/chaos_genius | data-visualization | 1,007 | [BUG] Dependency conflict for PyArrow | ## Describe the bug
PyAthena installs version of PyArrow that is incompatible with Snowflake's Pyarrow requirement
## Explain the environment
- **Chaos Genius version**: 0.9.0 development build
- **OS Version / Instance**: any
- **Deployment type**: any
## Current behavior
warning while pip install
## Ex... | closed | 2022-06-27T11:16:43Z | 2022-06-29T12:39:08Z | https://github.com/chaos-genius/chaos_genius/issues/1007 | [] | rjdp | 0 |
explosion/spaCy | nlp | 13,712 | thinc conflicting versions | ## How to reproduce the behaviour
I had an issue with thinc when updated I numpy:
`thinc 8.3.2 has requirement numpy<2.1.0,>=2.0.0; python_version >= "3.9", but you have numpy 2.1.3.`
Therefore I updated thinc to its latest version `9.1.1` but now I'm having an issue with spaCy
`spacy 3.8.2 depends on thinc<8.4... | open | 2024-12-09T16:43:01Z | 2024-12-10T16:43:18Z | https://github.com/explosion/spaCy/issues/13712 | [] | kimlizette | 1 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 176 | Add a way of computing logits easily during inference | Right now you can only compute the loss, but there are cases where people want to do classification using the logits (see https://github.com/KevinMusgrave/pytorch-metric-learning/issues/175) | closed | 2020-08-11T04:18:20Z | 2020-09-14T09:56:47Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/176 | [
"enhancement",
"fixed in dev branch"
] | KevinMusgrave | 0 |
xuebinqin/U-2-Net | computer-vision | 149 | Taking Too Much CPU and Memory (RAM) on CPU | @NathanUA Thank you very much for such a good contribution.I am using the u2netp model which is 4.7 mb size
for inferences on the webcam video feed. I am running it on my CPU device but it is taking too much memory and processing power of CPU Device .My Device get slower while doing testing , Can you help me how I c... | open | 2021-01-20T16:38:19Z | 2021-03-17T09:36:08Z | https://github.com/xuebinqin/U-2-Net/issues/149 | [] | NaeemKhan333 | 1 |
graphistry/pygraphistry | jupyter | 50 | FAQ / guide on exporting | cc @thibaudh @padentomasello @briantrice
| closed | 2016-01-11T21:50:51Z | 2020-06-10T06:46:52Z | https://github.com/graphistry/pygraphistry/issues/50 | [
"enhancement"
] | lmeyerov | 0 |
pydata/xarray | pandas | 10,166 | Updating zarr causes errors when saving to zarr. | ### What is your issue?
xarray version 2024.9.0
zarr version 3.0.5
When attempting to save to zarr, the error below results. I can save the same file to zarr happily using zarr version 2.18.4. I've checked and the same thing happens for a wide range of files. Reseting the encoding has no effect.
[tas_AUST-04_ERA5_hi... | closed | 2025-03-24T04:27:09Z | 2025-03-24T04:32:47Z | https://github.com/pydata/xarray/issues/10166 | [
"needs triage"
] | bweeding | 1 |
klen/mixer | sqlalchemy | 37 | Create a way to define custom Types and Generators and error descriptively when Types are not recognized. | I defined a couple custom SQLAlchemy types with [`sqlalchemy.types.TypeDecorator`](http://docs.sqlalchemy.org/en/rel_0_9/core/custom_types.html#augmenting-existing-types), and immediately Mixer choked on them. I had to reverse-engineer the system and monkey-patch my custom types in order to get it working.
Here's a li... | closed | 2015-02-06T09:29:40Z | 2015-08-12T15:01:27Z | https://github.com/klen/mixer/issues/37 | [] | wolverdude | 1 |
jschneier/django-storages | django | 1,129 | Empty SpooledTemporaryFile` created when `closed` property is used multiple times | When `GoogleCloudFile`'s `closed` property is used multiple times, the spooled temporary `_file` is created when its previously closed. This is because https://github.com/django/django/blob/6f453cd2981525b33925faaadc7a6e51fa90df5c/django/core/files/utils.py#L53 uses `self.file` which triggers a creation of `_file` rega... | open | 2022-04-22T07:17:38Z | 2022-04-22T07:17:38Z | https://github.com/jschneier/django-storages/issues/1129 | [] | skylander86 | 0 |
encode/apistar | api | 543 | is this a bug? | 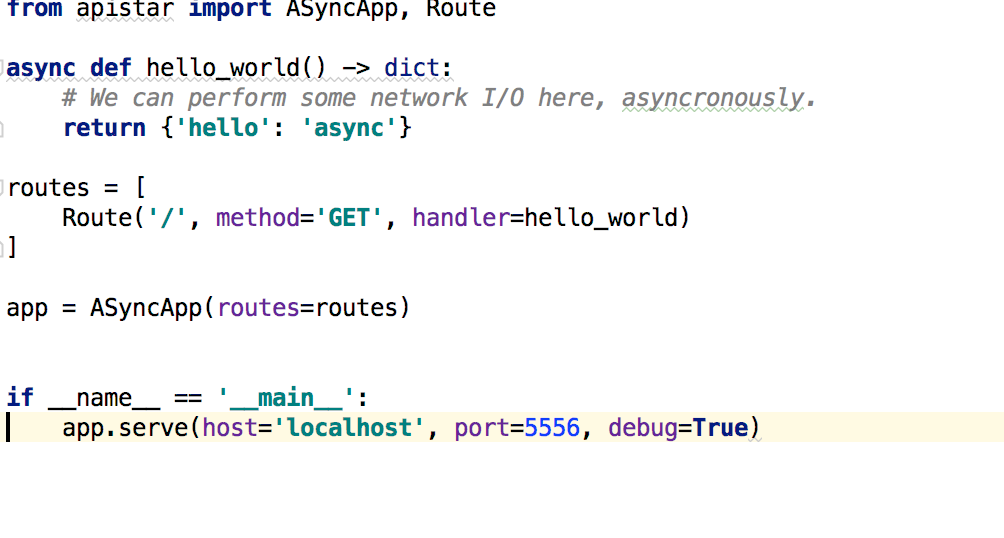
got an error where visit localhost:5556/docs
Could not build url for endpoint 'static' with values ['filename']. Did you mean 'serve_static_asgi' instead?
**and i find self.map._rules_by_endpoint not conta... | closed | 2018-05-15T10:49:54Z | 2018-05-18T02:40:17Z | https://github.com/encode/apistar/issues/543 | [] | goushicui | 4 |
apify/crawlee-python | web-scraping | 403 | Evaluate the efficiency of opening new Playwright tabs versus windows | Try to experiment with [PlaywrightBrowserController](https://github.com/apify/crawlee-python/blob/master/src/crawlee/browsers/playwright_browser_controller.py) to determine whether opening new Playwright pages in tabs offers better performance compared to opening them in separate windows (current state). | open | 2024-08-06T07:47:10Z | 2024-08-06T08:31:05Z | https://github.com/apify/crawlee-python/issues/403 | [
"t-tooling",
"solutioning"
] | vdusek | 1 |
ansible/awx | django | 14,918 | variables and source_vars expect dictionary but apply as yaml (multiple modules) | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software pro... | open | 2024-02-25T08:27:40Z | 2024-02-25T08:32:12Z | https://github.com/ansible/awx/issues/14918 | [
"type:bug",
"component:awx_collection",
"needs_triage",
"community"
] | kk-at-redhat | 0 |
microsoft/MMdnn | tensorflow | 832 | Convert trained yolov3 Darknet-53 custom model to tensorflow model | Platform: ubuntu 16.04
Python version: 3.6
Source framework: mxnet (gluon-cv)
Destination framework: Tensorflow
Model Type: Object detection
Pre-trained model path: [https://gluon-cv.mxnet.io/build/examples_detection/demo_yolo.html#sphx-glr-build-examples-detection-demo-yolo-py](url)
I have trained a custom yo... | open | 2020-05-07T14:13:04Z | 2020-05-08T18:15:42Z | https://github.com/microsoft/MMdnn/issues/832 | [] | analyticalrohit | 1 |
chainer/chainer | numpy | 8,199 | flaky test: `chainerx_tests/unit_tests/routines_tests/test_normalization.py::test_BatchNorm` | ERROR: type should be string, got "https://travis-ci.org/chainer/chainer/jobs/591364861\r\n\r\n`FAIL tests/chainerx_tests/unit_tests/routines_tests/test_normalization.py::test_BatchNorm_param_0_{contiguous=None}_param_0_{decay=None}_param_0_{eps=2e-05}_param_0_{param_dtype='float16'}_param_0_{x_dtype='float16'}_param_3_{axis=None, reduced_shape=(3, 4, 5, 2), x_shape=(2, 3, 4, 5, 2)}[native:0]`\r\n\r\n```\r\n[2019-09-30 08:05:44] E chainer.testing.function_link.FunctionTestError: Outputs do not match the expected values.\r\n[2019-09-30 08:05:44] E Indices of outputs that do not match: 0\r\n[2019-09-30 08:05:44] E Expected shapes and dtypes: (2, 3, 4, 5, 2):float16\r\n[2019-09-30 08:05:44] E Actual shapes and dtypes: (2, 3, 4, 5, 2):float16\r\n[2019-09-30 08:05:44] E \r\n[2019-09-30 08:05:44] E \r\n[2019-09-30 08:05:44] E Error details of output [0]:\r\n[2019-09-30 08:05:44] E \r\n[2019-09-30 08:05:44] E Not equal to tolerance rtol=0.1, atol=0.1\r\n[2019-09-30 08:05:44] E \r\n[2019-09-30 08:05:44] E (mismatch 0.4166666666666714%)\r\n[2019-09-30 08:05:44] E x: array([-0.1726 , 0.3286 , 0.4915 , 1.105 , 0.2152 , 0.587 ,\r\n[2019-09-30 08:05:44] E -0.2905 , -0.012695, 0.554 , -1.178 , -0.3076 , -0.4988 ,\r\n[2019-09-30 08:05:44] E -0.3975 , 0.4343 , 0.813 , 1.951 , 0.2693 , 0.758 ,...\r\n[2019-09-30 08:05:44] E y: array([-0.1726 , 0.3286 , 0.4915 , 1.105 , 0.2155 , 0.587 ,\r\n[2019-09-30 08:05:44] E -0.2905 , -0.012695, 0.554 , -1.178 , -0.3071 , -0.4988 ,\r\n[2019-09-30 08:05:44] E -0.3975 , 0.4343 , 0.813 , 1.951 , 0.269 , 0.758 ,...\r\n[2019-09-30 08:05:44] E \r\n[2019-09-30 08:05:44] E assert_allclose failed: \r\n[2019-09-30 08:05:44] E shape: (2, 3, 4, 5, 2) (2, 3, 4, 5, 2)\r\n[2019-09-30 08:05:44] E dtype: float16 float16\r\n[2019-09-30 08:05:44] E i: (0, 2, 0, 4, 1)\r\n[2019-09-30 08:05:44] E x[i]: 0.070556640625\r\n[2019-09-30 08:05:44] E y[i]: -0.03399658203125\r\n[2019-09-30 08:05:44] E relative error[i]: 3.076171875\r\n[2019-09-30 08:05:44] E absolute error[i]: 0.10455322265625\r\n:\r\n```" | closed | 2019-09-30T08:25:24Z | 2019-10-29T04:56:41Z | https://github.com/chainer/chainer/issues/8199 | [
"cat:test",
"prio:high"
] | niboshi | 1 |
mwaskom/seaborn | matplotlib | 2,861 | Legends don't represent additional visual properties | This is a meta issue replacing the following (exhaustive) list of reports:
- #2852
- #2005
- #1763
- #940
The basic issue is that artists in seaborn legends typically do not look exactly like artists in the plot in cases where additional matplotlib keyword arguments have been passed. This is semi-intentional (... | closed | 2022-06-15T02:53:19Z | 2023-09-11T01:18:03Z | https://github.com/mwaskom/seaborn/issues/2861 | [
"rough-edge",
"plots"
] | mwaskom | 0 |
seleniumbase/SeleniumBase | web-scraping | 3,266 | Add a full range of scroll methods for CDP Mode | ### Add a full range of scroll methods for CDP Mode
----
Once this task is completed, we should expect to see all these methods:
```python
sb.cdp.scroll_into_view(selector) # Scroll to the element
sb.cdp.scroll_to_y(y) # Scroll to the y-position
sb.cdp.scroll_to_top() # Scroll to the top
sb.cdp.sc... | closed | 2024-11-14T19:25:54Z | 2024-11-14T21:45:09Z | https://github.com/seleniumbase/SeleniumBase/issues/3266 | [
"enhancement",
"UC Mode / CDP Mode"
] | mdmintz | 1 |
django-oscar/django-oscar | django | 4,225 | Sandbox site is down | [Sandbox](http://latest.oscarcommerce.com/) is down. Sandbox site was using heroku for deployments I assume heroku's free tier was being used but they changed their policy awhile ago or their credits have run out.
[Removal of Heroku Free Product Plans FAQ](https://help.heroku.com/RSBRUH58/removal-of-heroku-free-pro... | open | 2024-01-14T19:44:28Z | 2024-02-29T12:20:45Z | https://github.com/django-oscar/django-oscar/issues/4225 | [] | Hisham-Pak | 1 |
google-research/bert | tensorflow | 920 | How to print learning_rate? | How to print `learning_rate` so that I could see it if decay.
Thank you! | closed | 2019-11-15T07:21:51Z | 2021-03-12T03:35:37Z | https://github.com/google-research/bert/issues/920 | [] | guotong1988 | 2 |
tqdm/tqdm | jupyter | 1,523 | AttributeError Exception under a console-less PyInstaller build | - [x] I have marked all applicable categories:
+ [x] exception-raising bug
+ [ ] visual output bug
- [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [x] I have mentioned version numbers, operating syste... | open | 2023-10-13T19:42:40Z | 2023-10-13T19:42:40Z | https://github.com/tqdm/tqdm/issues/1523 | [] | rlaphoenix | 0 |
iperov/DeepFaceLab | machine-learning | 5,613 | Attribute Error Message Upon Installation | Trying to re-download deepfacelive and deep facelab and every time i try to run the batch file after unzip it gives be this error message “ AttributeError: module "cv2' has no attribute gapi
Press any key to continue”
i’ve tried deleting it and reinstalling but the same thing happens. tried restarting my computer and... | open | 2023-01-23T11:41:45Z | 2023-06-08T23:19:26Z | https://github.com/iperov/DeepFaceLab/issues/5613 | [] | heyxur | 1 |
bigscience-workshop/petals | nlp | 250 | Inference timeout on larger input prompts | ### Currently using the chatbot example where session id is saved and inference occurs one token at a time:
```python
with models[model_name][1].inference_session(max_length=512) as sess:
print(f"Thread Start -> {threading.get_ident()}")
output[model_name] = ""
inputs = models[model_nam... | closed | 2023-02-04T00:22:26Z | 2023-02-27T14:25:54Z | https://github.com/bigscience-workshop/petals/issues/250 | [] | gururise | 6 |
ultralytics/yolov5 | pytorch | 12,468 | How to analyze remote machine training results with Comet? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I'm trying to analyze my yolov5 training with Comet, generated in a HPC machine. After ge... | closed | 2023-12-05T10:14:54Z | 2024-01-16T00:21:24Z | https://github.com/ultralytics/yolov5/issues/12468 | [
"question",
"Stale"
] | unrue | 4 |
lukasmasuch/streamlit-pydantic | streamlit | 68 | The type of the following property is currently not supported: Multi Selection | ### Checklist
- [X] I have searched the [existing issues](https://github.com/lukasmasuch/streamlit-pydantic/issues) for similar issues.
- [X] I added a very descriptive title to this issue.
- [X] I have provided sufficient information below to help reproduce this issue.
### Summary
In examples in https://st-pydantic... | open | 2025-01-10T18:34:15Z | 2025-02-14T05:03:56Z | https://github.com/lukasmasuch/streamlit-pydantic/issues/68 | [
"type:bug",
"status:needs-triage"
] | alikaz3mi | 1 |
ultralytics/yolov5 | pytorch | 12,990 | No detections on custom data training | ### Search before asking
- [ ] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I'm trying to train yolov5 with custom data. I'm using very few images just to test every... | closed | 2024-05-08T16:47:38Z | 2024-10-20T19:45:27Z | https://github.com/ultralytics/yolov5/issues/12990 | [
"question",
"Stale"
] | Just1813 | 3 |
sammchardy/python-binance | api | 786 | support coin margined future operations | currently, all the future operations are limited to usd margined futures, which is on /fapi/v1/. coin margined futures operations are on /dapi/v1/. | open | 2021-04-23T07:16:59Z | 2021-04-23T07:16:59Z | https://github.com/sammchardy/python-binance/issues/786 | [] | ZhiminHeGit | 0 |
pytest-dev/pytest-xdist | pytest | 515 | INTERNALERROR> TypeError: unhashable type: 'ExceptionChainRepr' | Running pytest with `-n4` and `--doctest-modules` together with import errors leads to this misleading error which hides what the actual error is.
```
(pytest-debug) :~/PycharmProjects/scratch$ py.test --pyargs test123 --doctest-modules -n4
=================================================== test session starts =... | closed | 2020-03-26T14:07:31Z | 2020-05-13T13:32:39Z | https://github.com/pytest-dev/pytest-xdist/issues/515 | [] | lusewell | 2 |
OthersideAI/self-operating-computer | automation | 151 | [BUG] Fedora system ,can't use it | Found a bug? Please fill out the sections below. 👍

My system Fedora 39
### Describe the bug
i can't use
Name: self-operating-computer
Version: 1.2.8
Summary:
Home-page:
Author:
Aut... | closed | 2024-01-30T20:42:58Z | 2024-03-25T15:51:44Z | https://github.com/OthersideAI/self-operating-computer/issues/151 | [
"bug"
] | Lori-Lin7 | 3 |
nltk/nltk | nlp | 3,152 | CategorizedMarkdownCorpusReader.sections() does not return final section of markdown | If you load a markdown corpus using CategorizedMarkdownCorpusReader, the object has a sections() method which returns a list of MarkdownSection objects. This function does not return the final section of *any* document I have tested.
Here is an example markdown, titled test.md
```
# Section One
This is a test sec... | open | 2023-05-08T18:53:21Z | 2023-05-11T09:30:15Z | https://github.com/nltk/nltk/issues/3152 | [] | nkuehnle | 1 |
dask/dask | scikit-learn | 11,376 | Slicing an array on the last chunk of an axis duplicates the number of chunks | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-09-06T01:07:30Z | 2024-09-06T01:44:39Z | https://github.com/dask/dask/issues/11376 | [
"needs triage"
] | josephnowak | 3 |
Sanster/IOPaint | pytorch | 264 | A question about the custom model ؟ | What should we do to add custom model to Google COLAB?
What should we do to add xformers to Google COLAB?
| open | 2023-04-03T17:14:05Z | 2023-04-03T23:15:34Z | https://github.com/Sanster/IOPaint/issues/264 | [] | kingal2000 | 0 |
unit8co/darts | data-science | 2,517 | [BUG] TFTModel predicts nan values when MapeLoss function is used | **Describe the bug**
When MapeLoss is used as loss function with a TFTModel (loss_fn parameter), the output of the training shows val_loss and train_loss = 0:
```python
from darts.utils.losses import MapeLoss
model = TFTModel(
...
loss_fn=MapeLoss(),
...
)
```
```
Epoch 4:... | closed | 2024-08-30T11:15:08Z | 2024-10-16T08:06:33Z | https://github.com/unit8co/darts/issues/2517 | [
"question"
] | akepa | 3 |
fastapi-users/fastapi-users | fastapi | 1,224 | Unable to install library on Mac M1 | ## Describe the bug
I'm trying to install the library in a virtualenv with the command
```
pip install 'fastapi-users[sqlalchemy]'
```
but I receive the following error
```
Collecting fastapi-users[sqlalchemy]
Using cached fastapi_users-11.0.0-py3-none-any.whl (38 kB)
Requirement already satisfied: ema... | closed | 2023-06-08T09:37:59Z | 2023-06-08T11:20:19Z | https://github.com/fastapi-users/fastapi-users/issues/1224 | [
"bug"
] | michele-grifa | 0 |
dmlc/gluon-cv | computer-vision | 1,095 | python 3.6 fails to build gluon-cv: 'ascii' codec can't decode byte 0xf0 | ```
Traceback (most recent call last):
File "<string>", line 1, in <module>
File "setup.py", line 45, in <module>
long_description = open('README.md').read()
File "/usr/local/lib/python3.6/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: ... | closed | 2019-12-15T20:18:32Z | 2021-06-07T07:04:35Z | https://github.com/dmlc/gluon-cv/issues/1095 | [
"Stale"
] | yurivict | 8 |
encode/httpx | asyncio | 1,772 | Add HTTPX to the Python documentation. | There are a couple of places in the Python documentation where `requests` is recommended for HTTP requests.
I think that we've done enough work on HTTPX now that we ought to look at getting `httpx` included here, or at *least* open the dialog up. Getting up into the Python docs for 3.10 onwards would seem to be a pr... | closed | 2021-07-26T10:41:21Z | 2022-03-14T19:58:20Z | https://github.com/encode/httpx/issues/1772 | [
"help wanted",
"docs",
"wontfix"
] | tomchristie | 4 |
iperov/DeepFaceLab | machine-learning | 947 | ValueError: cannot convert float NaN to integer | Hi, i got this
File "D:\Fakeapp\DeepFaceLab_OpenCL_SSE\_internal\DeepFaceLab\main.py", line 302, in <module>
arguments.func(arguments)
File "D:\Fakeapp\DeepFaceLab_OpenCL_SSE\_internal\DeepFaceLab\main.py", line 162, in process_train
Trainer.main(args, device_args)
File "D:\Fakeapp\DeepFaceLab_OpenCL... | open | 2020-11-12T13:26:33Z | 2023-06-08T21:36:25Z | https://github.com/iperov/DeepFaceLab/issues/947 | [] | 19DMT87 | 1 |
allenai/allennlp | data-science | 4,864 | Move ModelCard and TaskCard abstractions to the main repository | closed | 2020-12-14T21:51:22Z | 2020-12-22T22:00:01Z | https://github.com/allenai/allennlp/issues/4864 | [] | AkshitaB | 0 | |
sunscrapers/djoser | rest-api | 276 | /auth/me/ not working on production | In my local Django server, I can retrieve the user from /auth/me/ without any problem. But in production I recieve 401 (Unauthorized) error.
Do I need some special setting server-side to make it work properly? Thank you | closed | 2018-04-18T16:10:00Z | 2018-04-23T23:11:57Z | https://github.com/sunscrapers/djoser/issues/276 | [] | Zeioth | 1 |
HIT-SCIR/ltp | nlp | 500 | SRL示例问题 | closed | 2021-04-08T06:50:27Z | 2021-04-08T08:33:44Z | https://github.com/HIT-SCIR/ltp/issues/500 | [] | xinyubai1209 | 2 | |
vitalik/django-ninja | django | 769 | [BUG] The latest Django-ninja (0.22.1) doesn't support the latest Django-ninja (0.18.8) | The latest Django-ninja (0.22.1) doesn't support the latest Django-ninja (0.18.8) in connection with Poetry.
- Python version: 3.11.3
- Django version: 4.2
- Django-Ninja version: 0.22.1
--------------------------------------------------------------------------------------------------------------
Poetry ou... | closed | 2023-05-29T10:59:44Z | 2023-05-29T20:50:22Z | https://github.com/vitalik/django-ninja/issues/769 | [] | jankrnavek | 2 |
alteryx/featuretools | scikit-learn | 2,021 | Binary comparison primitives fail with Ordinal input if scalar value is not in the order values | The following primitives can fail when the input is an Ordinal column and the scalar value used for comparison is not one of the ordinal order values:
- `GreaterThanScalar`
- `GreaterThanEqualToScalar`
- `LessThanScalar`
- `LessThanEqualToScalar`
The primitive functions should be updated to confirm the value is ... | closed | 2022-04-19T19:33:08Z | 2022-04-20T22:33:39Z | https://github.com/alteryx/featuretools/issues/2021 | [
"bug"
] | thehomebrewnerd | 0 |
deeppavlov/DeepPavlov | nlp | 1,462 | levenshtein searcher works incorrectly |
**DeepPavlov version** (you can look it up by running `pip show deeppavlov`): 0.15.0
**Python version**: 3.7.10
**Operating system** (ubuntu linux, windows, ...): ubuntu 20.04
**Issue**: Levenshtein searcher does not take symbols replacements into account
**Command that led to error**:
```
>>> from ... | closed | 2021-07-04T21:39:27Z | 2023-07-10T11:45:40Z | https://github.com/deeppavlov/DeepPavlov/issues/1462 | [
"bug"
] | oserikov | 1 |
agronholm/anyio | asyncio | 500 | Creating Event when in from_thread.run_sync() context | When using `to_thread.run_sync` and then calling back again to the event loop with `from_thread.run_sync` I can't create an `anyio.Event` since sniffio fails to detect the running loop (no current_task is set in asyncio which of course is kindof true).
Reproduced in a gist here https://gist.github.com/tapetersen/e85... | closed | 2022-11-14T16:53:56Z | 2022-11-16T09:21:24Z | https://github.com/agronholm/anyio/issues/500 | [] | tapetersen | 1 |
apache/airflow | python | 47,452 | Rename DAG (from models/dag) to SchedulerDAG -- or remove it! | ### Body
It is easily confused with the DAG in task sdk.
Ideally we can remove. At least rename it.
comment from ash
> That should be renamed as SchedulerDAG really -- (or possibly it can be removed now) -- it's a) a compat import while that part isn't complete, and b) where scheduler specific DAG functions go
#... | open | 2025-03-06T15:01:54Z | 2025-03-06T15:04:11Z | https://github.com/apache/airflow/issues/47452 | [
"area:Scheduler",
"kind:meta"
] | dstandish | 0 |
plotly/dash | jupyter | 2,712 | dash_duo.get_logs() returns None instead of an empty list | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip l... | open | 2023-12-17T12:26:42Z | 2024-08-13T19:44:06Z | https://github.com/plotly/dash/issues/2712 | [
"bug",
"P3"
] | oegedijk | 1 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 3,597 | Replace merge with rebase for cleaner history | I'm suggesting to use rebase instead of merge when incorporating changes from one branch to another.
Rebase helps maintain a cleaner, linear commit history by replaying the commits from the current branch on top of the target branch. This approach avoids the creation of unnecessary merge commits and ensures a more ... | closed | 2025-01-12T15:29:10Z | 2025-01-13T14:06:22Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/3597 | [
"maintenance"
] | samyuh | 3 |
saulpw/visidata | pandas | 1,910 | [loaders] Support builtin data formats | This is meant to be an aspirational wishlist request. For developers who would like to contribute, this can be used as a map to what loaders could be added.
In https://github.com/saulpw/visidata/issues/1587#issuecomment-1369263933 it was suggested that:
> When Python includes the batteries, VisiData should as we... | closed | 2023-06-03T19:15:11Z | 2024-12-31T23:45:13Z | https://github.com/saulpw/visidata/issues/1910 | [
"wishlist"
] | frosencrantz | 3 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,585 | Training pix2pix with different input size | When I try to train the pix2pix model with the `--preprocess`, `--load_size` or `--crop_size` flag I run into an issue.
I try to train the pix2pix model on grayscale 400x400 images. For this I use those parameters: `'--model' 'pix2pix' '--direction' 'BtoA' '--input_nc' '1' '--output_nc' '1' '--load_size' '400' '--c... | open | 2023-06-27T15:38:42Z | 2024-06-05T07:18:53Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1585 | [] | MrMonk3y | 3 |
tensorpack/tensorpack | tensorflow | 804 | Inference with DoReFa-Net giving high top-1/top-5 error | Hi, I'm trying to do inference on DoReFa-Net with the ILSVRC2012 validation set as test data
(just to test the setup, not normally a "correct" practice I guess, but should give better-than-actual results right?),
and I'm getting really high top-1/top-5 error rate.
For the first 100 test data, I'm getting top-1/top... | closed | 2018-06-28T05:19:25Z | 2018-11-27T04:30:55Z | https://github.com/tensorpack/tensorpack/issues/804 | [
"bug",
"examples"
] | sammhho | 13 |
ShishirPatil/gorilla | api | 591 | [BFCL] Potential bug in calculating accuracy | **Describe the issue**
A clear and concise description of what the issue is.
**What is the issue**
I find the calculation of the simple AST score in the non-live part in v2 is not consistent with that in v1.
v1: scores of python, java and js are summed with `calculate_weighted_accuracy`
v2: scores of python... | closed | 2024-08-21T10:40:10Z | 2024-09-02T06:43:30Z | https://github.com/ShishirPatil/gorilla/issues/591 | [
"BFCL-General"
] | XuHwang | 1 |
strawberry-graphql/strawberry | django | 3,428 | Add support for framework's specific upload type | From https://github.com/strawberry-graphql/strawberry/pull/3389
We should allow users to do things like this:
```python
import strawberry
from starlette.datastructures import UploadFile
@strawberry.type
class Mutation:
@strawberry.mutation
class upload(self, file: UploadFile) -> str:
retu... | open | 2024-03-30T15:25:51Z | 2025-03-20T15:56:39Z | https://github.com/strawberry-graphql/strawberry/issues/3428 | [
"feature-request"
] | patrick91 | 0 |
geex-arts/django-jet | django | 201 | Feature request: more flexible dashboard layout. | * It would be nice if the size of the dashboard modules could be decoupled from the available number of columns
* Have a button (or slider) in the interface to increment or decrement the number of columns.
* Be able to automatically ad a new column, when dragging and dropping a widget to the right of the last column.... | open | 2017-04-08T18:23:20Z | 2017-08-15T16:01:58Z | https://github.com/geex-arts/django-jet/issues/201 | [] | Ismael-VC | 5 |
agronholm/anyio | asyncio | 376 | UNIX socket server hangs on asyncio | I have written the following code, trying to create a task that runs a unix-socket-based server for testing. I want to be able to dictate what the server will send when the client tries to read, but for testing I want to be able to get back what was sent to the server. Therefore, I am using a MemoryObjectStream to echo... | closed | 2021-10-09T20:23:19Z | 2021-10-10T19:09:53Z | https://github.com/agronholm/anyio/issues/376 | [
"bug",
"asyncio"
] | tarcisioe | 6 |
stanford-oval/storm | nlp | 342 | [FEATURE] Define model used for embeddings (esp. also azure endpoints) | **Describe the bug**
Currently the embedding model is hard-coded in https://github.com/stanford-oval/storm/blob/e80d9bbea7362141a479940dabb751c1f244e4b6/knowledge_storm/encoder.py#L83
This can be an issue in many ways:
- You want to use different model providers
- You don't have enough quota on `text-embedding-3-small... | open | 2025-03-19T11:33:26Z | 2025-03-19T11:33:42Z | https://github.com/stanford-oval/storm/issues/342 | [] | danieldekay | 0 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,391 | Multi-site feature, after first signup the main site is unavailable. | ### What version of GlobaLeaks are you using?
Latest - new install
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Linux
### Describe the issue
I’ve recently installed Globaleaks – when I active the multisite feature, the singup form is available... | closed | 2023-03-20T12:53:23Z | 2023-03-22T07:58:55Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3391 | [] | SJD-DK | 8 |
miguelgrinberg/Flask-Migrate | flask | 116 | flask-migrate not detecting 'compare_server_default' in env.py | When setting up a new database, my initial migration script does not contain the defaults i put in the model. For example, if in my model.py I have:
`class Devices(db.Model):`
`id = db.Column(db.Integer, primary_key=True, autoincrement=True)`
`name = db.Column(db.String(255), unique=True, nullable=False)`
`enabled = d... | closed | 2016-06-13T13:36:50Z | 2016-06-14T05:48:35Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/116 | [
"invalid"
] | kilgorejd | 4 |
JaidedAI/EasyOCR | deep-learning | 1,303 | Fine-tuning the model for reading both English and Arabic | I am working on a project where the text is a mix of English and Arabic and even though EasyOCR is made to recognize both I am facing the following issue:
Once the model comes across a slightly unclear English character, it immediately switches to Arabic and starts giving indecipherable results. However those same ex... | open | 2024-09-06T05:41:44Z | 2024-09-06T05:41:44Z | https://github.com/JaidedAI/EasyOCR/issues/1303 | [] | mariam-alsaleh | 0 |
wger-project/wger | django | 942 | Unable to locate static assets while running in container | When running in a Docker container on Kubernetes, I am seeing errors about not being able to find static assets like CSS and Javascript files. It was originally running correctly, and I'm not sure at all what changed when it stopped finding them. I have all static assets stored on a persistent volume mounted to /home/w... | open | 2022-01-13T03:46:13Z | 2024-09-17T04:53:07Z | https://github.com/wger-project/wger/issues/942 | [] | venom85 | 7 |
pyg-team/pytorch_geometric | pytorch | 9,685 | Distributed error when using 4 nodes | ### 🐛 Describe the bug
I encountered an issue while testing `examples/distributed/pyg/node_ogb_cpu.py` with four nodes and small batch sizes (e.g., 10). Using `batch_size=1` triggers the error immediately. The script fails if all source nodes belong to the same partition when executing the following line in `torch_ge... | open | 2024-10-01T16:59:15Z | 2024-10-03T18:10:13Z | https://github.com/pyg-team/pytorch_geometric/issues/9685 | [
"bug",
"distributed"
] | seakkas | 0 |
pallets/flask | python | 5,268 | When was 'Blueprint.before_app_first_request' deprecated and what replaces it? | I have resumed work on a Flask 1.x-based project after some time has passed, and sorting through deprecations and removals that have happened in the interim. The first place I got stuck was the `@bp.before_app_first_request` decorator.
Except to note that <q>`app.before_first_request` and `bp.before_app_first_reques... | closed | 2023-09-29T23:06:44Z | 2023-10-15T00:06:15Z | https://github.com/pallets/flask/issues/5268 | [] | ernstki | 1 |
youfou/wxpy | api | 325 | 请问自动处理消息能对回复信息进行处理吗? | 比如以某关键字开头的进入自动处理消息函数,然后返回文本等用户回复“是"或”否",回复"是“继续处理,”否“则不处理,继续监听下一个请求?请问如何取得返回文本并进行处理? | open | 2018-07-23T09:57:20Z | 2018-07-24T07:10:20Z | https://github.com/youfou/wxpy/issues/325 | [] | fireclaw | 2 |
google/seq2seq | tensorflow | 206 | Evaluation takes too much time. Is it normal? | The dev data contains 5000 sequences.
============================================================
INFO:tensorflow:Creating ZeroBridge in mode=eval
INFO:tensorflow:
ZeroBridge: {}
INFO:tensorflow:Starting evaluation at 2017-05-04-07:43:55
I tensorflow/core/common_runtime/gpu/gpu_device.cc:975] Creating TensorF... | closed | 2017-05-04T09:57:28Z | 2017-05-17T15:00:36Z | https://github.com/google/seq2seq/issues/206 | [] | yezhejack | 6 |
ageitgey/face_recognition | machine-learning | 873 | Error while installing face_recognition | * face_recognition version:-
* Python version:3.5.3
* Operating System:Raspbian Stretch
### Description
I'm a beginner to all this, i need to install face recognition on Raspberry Pi 3 B+, but this error comes.. can somebody provide a solution for this
### What I Did
I have followed Adrian's tutorial (ht... | closed | 2019-07-03T11:13:39Z | 2019-07-15T14:41:08Z | https://github.com/ageitgey/face_recognition/issues/873 | [] | Sanjaiii | 3 |
roboflow/supervision | pytorch | 1,339 | draw wrong OrientedBoxAnnotator with InferenceSlicer | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
I'm using official yolov8m_obb.pt and if I write code like below
```python
def callback(image_slice: np.ndarray) -> sv.Detections:
result = model(... | closed | 2024-07-10T05:52:36Z | 2024-07-18T13:46:39Z | https://github.com/roboflow/supervision/issues/1339 | [
"bug"
] | DawnMagnet | 7 |
indico/indico | flask | 6,120 | Room Booking: Horizontal padding of `timeline-occurrence` causes visual / selectability issues in monthly view | Due to the horizontal padding in:
https://github.com/indico/indico/blob/8ff31c228008a9847a10cbe70952c160f8c79630/indico/modules/rb/client/js/common/timeline/TimelineItem.module.scss#L21
bookings which are close to each other overlap in the monthly view, for example:
,
paramwise_cfg=dict(
custom_keys={'backbone': dict(lr_mult=0.1,... | open | 2024-05-08T15:33:30Z | 2024-05-08T15:33:48Z | https://github.com/open-mmlab/mmdetection/issues/11691 | [] | Pixie8888 | 0 |
thp/urlwatch | automation | 665 | How can i add a custom reporter in the urlwatch?like wechat? | I want to push the msg to WeChat. The official account on WeChat provides a means, its web:`http://pushplus.hxtrip.com/message`, which needs to be cleared by using WeChat account.
to be clear,its Call method is very easy.just need token and content,then it submit a post or get request to the server,and my wechat accou... | open | 2021-08-29T11:33:22Z | 2021-11-07T09:02:22Z | https://github.com/thp/urlwatch/issues/665 | [
"question"
] | ZJahon | 1 |
google-deepmind/graph_nets | tensorflow | 15 | EncodeProcessDecode model documentation | Hi,
I've been trying to understand the EncodeProcessDecode model parameters, however, the documentation is a little scarce on the parameters (edge_output_size, node_output_size, global_output_size) in this case.
In the code I found the following comment `# Transforms the outputs into the appropriate shapes.` but th... | closed | 2018-11-07T21:15:42Z | 2018-11-10T19:51:25Z | https://github.com/google-deepmind/graph_nets/issues/15 | [] | ferreirafabio | 7 |
OpenInterpreter/open-interpreter | python | 957 | Open-Interpreter not Starting | ### Describe the bug
When I run the `interpreter` command, I get:
`Traceback (most recent call last):
File "/usr/local/bin/interpreter", line 5, in <module>
from interpreter import interpreter
File "/usr/local/lib/python3.10/site-packages/interpreter/__init__.py", line 1, in <module>
from .core.core... | closed | 2024-01-22T00:36:09Z | 2024-02-12T10:41:02Z | https://github.com/OpenInterpreter/open-interpreter/issues/957 | [
"Bug"
] | mayowaosibodu | 2 |
keras-team/keras | machine-learning | 20,388 | Inconsistent loss/metrics with jax backend | Training an LSTM-based model with `mean_squared_error` loss, I got the following training results, for which the math doesn't add up: the values of the loss (MSE) and metric (RMSE) are inconsistent.
Would anyone have an insight as to what could be happening here? Thank you in advance.
<img width="1859" alt="Scree... | closed | 2024-10-21T21:37:52Z | 2024-11-12T12:39:49Z | https://github.com/keras-team/keras/issues/20388 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | dkgaraujo | 9 |
gevent/gevent | asyncio | 1,816 | Calling gevent.sleep from a thread creates an anon_inode and eventually "too many files open" error | * gevent version: 1.4.0 and 21.8.0 on Raspberry Pi installed using pip3
* Python version: 3.7.3
* Operating System: Please be as specific as possible. For example,
"Raspbian Buster"
### Description:
When gevent.sleep() is called from another thread, an anon_inode is created. If this happens... | closed | 2021-08-28T14:37:35Z | 2021-08-30T20:42:54Z | https://github.com/gevent/gevent/issues/1816 | [
"Type: Question"
] | aaknitt | 2 |
capitalone/DataProfiler | pandas | 415 | Unable to get Month as a label | Using DP version **c1-dataprofiler[ml]==0.7.1**
DP with data that has month it is labelled as `unknown`
Below the example that can be used.
`dp.Profiler(['MARCH']*30).report()` | open | 2021-09-16T20:30:39Z | 2021-09-16T20:30:39Z | https://github.com/capitalone/DataProfiler/issues/415 | [] | dipika-m | 0 |
streamlit/streamlit | machine-learning | 10,745 | Support masked input in `st.text_input` | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Allow the user to specify a `mask` for `st.text_input` to enforce specific input formats:

2.I got correct Respons result in web test.
3.`drf-yasg` shows the Respons result by the original `rest_framework.pag... | open | 2021-02-03T16:56:38Z | 2025-03-07T12:13:28Z | https://github.com/axnsan12/drf-yasg/issues/698 | [
"triage"
] | MrBeike | 7 |
deepinsight/insightface | pytorch | 1,798 | Resume training ArcFace-Torchh but it starts all from beginning and epoch is set to 0 | Hi, Thanks for your nice work!
I am using Colab to train ArcFace-Torch on Asian-Celeb dataset. After Colab disconects, I want to continue training from where it left by setting config.resume = True and successfully loading the latest backbone.pth file. However, the training process starts all over from epoch 0, acc ... | open | 2021-10-22T09:26:53Z | 2021-10-22T10:20:58Z | https://github.com/deepinsight/insightface/issues/1798 | [] | gradient1706 | 1 |
quokkaproject/quokka | flask | 133 | replace Misake with Mistune | https://github.com/lepture/mistune
| closed | 2014-02-28T20:18:51Z | 2015-07-16T02:56:34Z | https://github.com/quokkaproject/quokka/issues/133 | [
"enhancement"
] | rochacbruno | 2 |
davidsandberg/facenet | computer-vision | 1,213 | Broken link | The link to the Training dataset is attached to the readme is broken
https://github.com/davidsandberg/facenet#training-data | open | 2021-12-17T12:56:49Z | 2021-12-17T12:56:49Z | https://github.com/davidsandberg/facenet/issues/1213 | [] | owos | 0 |
xinntao/Real-ESRGAN | pytorch | 726 | Real-ESRGAN Not Using my GPU | Hello, I've been having this issue since I restored my computer, Im not sure if there's something missing but when I start the process (to reescale a image), I get this error/message:
(base) D:\Ai\bycloud\Real-ESRGAN-master>python inference_realesrgan.py --model_path experiments/pretrained_models/RealESRGAN_x4plus.p... | open | 2023-11-30T06:41:50Z | 2023-11-30T06:41:50Z | https://github.com/xinntao/Real-ESRGAN/issues/726 | [] | St33pFx | 0 |
apachecn/ailearning | python | 212 | Adaboost多类别分类问题 | 你好!感谢你的代码,请问Adaboost 用作多类别分类时该怎么实现?比如我这边有20个类别。 | closed | 2017-11-21T05:37:35Z | 2017-11-21T10:51:53Z | https://github.com/apachecn/ailearning/issues/212 | [] | lxtGH | 1 |
Nemo2011/bilibili-api | api | 323 | [漏洞] login 异常 | 
| closed | 2023-06-05T23:56:56Z | 2023-06-08T01:52:40Z | https://github.com/Nemo2011/bilibili-api/issues/323 | [
"bug"
] | z0z0r4 | 4 |
deepfakes/faceswap | machine-learning | 735 | ERROR Caught exception in thread: 'training_0'//original type is ok,but any other model cannot succeed | wanqi@amax:~/Desktop/faceswap-master$ python faceswap.py train -A faces/source -B faces/lyf -m models/lyf-128/ -p -t realface
05/22/2019 09:57:53 INFO Log level set to: INFO
Using TensorFlow backend.
05/22/2019 09:57:57 INFO Model A Directory: /home/wanqi/Desktop/faceswap-master/faces/source
05/22/2019 09:5... | closed | 2019-05-22T02:09:24Z | 2019-06-01T13:50:36Z | https://github.com/deepfakes/faceswap/issues/735 | [] | Jinwanqi | 3 |
autogluon/autogluon | computer-vision | 4,852 | [timeseries] Add sample_weight support to TimeSeriesPredictor | ## Description
Add an option to customize the sample weight used by time series forecasting metrics.
There are two types of weighting that would be interesting:
- [ ] #4854
- [ ] #4855
## References
- [ ] Find examples in other forecasting libraries to find reasonable names in the API. | open | 2025-01-30T16:36:23Z | 2025-02-20T14:09:18Z | https://github.com/autogluon/autogluon/issues/4852 | [
"enhancement",
"module: timeseries"
] | shchur | 0 |
sqlalchemy/alembic | sqlalchemy | 603 | Unable to specify relative revision in command.downgrade API | I'd like to execute a single downgrade (to previous revision) programmatically, so mimicking the command line functionality I did:
```python
alembic_cfg = Config(os.path.join(APP_ROOT, 'alembic.ini'))
command.downgrade(alembic_cfg, '-1')
```
Unfortunately it is not going through as expected:
```python... | closed | 2019-09-25T12:57:27Z | 2021-04-25T15:59:19Z | https://github.com/sqlalchemy/alembic/issues/603 | [
"question"
] | babaMar | 6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.