
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
Anjok07/ultimatevocalremovergui | pytorch | 669 | Install errors | No programmer here, I tried the **README.md** instructions:
~~~
> git clone https://github.com/Anjok07/ultimatevocalremovergui.git
> pip3 install -r requirements.txt
~~~
Then I get the following errors:
~~~
ERROR: Ignored the following versions that require a different python version: 0.36.0 Requires-Python >=... | open | 2023-07-17T15:36:47Z | 2023-07-30T19:23:39Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/669 | [] | Disonantemus | 1 |
huggingface/datasets | numpy | 6,436 | TypeError: <lambda>() takes 0 positional arguments but 1 was given | ### Describe the bug
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
[<ipython-input-35-7b6becee3685>](https://localhost:8080/#) in <cell line: 1>()
----> 1 from datasets import Dataset
9 frames
[/usr/lo... | closed | 2023-11-19T13:10:20Z | 2024-06-25T06:00:31Z | https://github.com/huggingface/datasets/issues/6436 | [] | ahmadmustafaanis | 2 |
seleniumbase/SeleniumBase | web-scraping | 2,429 | chromium_arg parameter "--disable-features" passed to seleniumbase.Driver() being ignored. | I'm creating a driver instance with code:
```python
dr = seleniumbase.Driver(uc=True,
proxy="user:pass@127.0.0.1:8090",
user_data_dir=user_data_dir,
extension_dir=ext_dirs,
agent=agent_string,
... | closed | 2024-01-14T20:08:16Z | 2024-01-19T03:22:42Z | https://github.com/seleniumbase/SeleniumBase/issues/2429 | [
"bug"
] | agp22888 | 2 |
yeongpin/cursor-free-vip | automation | 337 | [Bug]: machineid variable and not working on linux (ubuntu 24 LTS) | ### Commit before submitting
- [x] I understand that Issues are used to provide feedback and solve problems, not to complain in the comments section, and will provide more information to help solve the problem.
- [x] I have checked the top Issue and searched for existing [open issues](https://github.com/yeongpin/curso... | open | 2025-03-20T18:44:13Z | 2025-03-24T10:00:17Z | https://github.com/yeongpin/cursor-free-vip/issues/337 | [
"bug"
] | itsfarhan | 2 |
jupyter-incubator/sparkmagic | jupyter | 323 | [Question] ModuleNotFoundError when enabling the serverextension | I successfully invoked the following:
pip install sparkmagic
pip show sparkmagic
jupyter-kernelspec install sparkmagic/kernels/sparkkernel
jupyter-kernelspec install sparkmagic/kernels/pysparkkernel
jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel
jupyter-kernelspec install sparkmagic/kernels/sparkr... | closed | 2017-01-20T05:22:11Z | 2017-01-20T21:40:59Z | https://github.com/jupyter-incubator/sparkmagic/issues/323 | [] | javadba | 3 |
horovod/horovod | deep-learning | 3,650 | Can't pass-in edit_fields for TransformSpec in pytorch_lightning | **Environment:**
1. Framework: (TensorFlow, Keras, PyTorch, MXNet) pytorch_lightning
2. Framework version: 1.5.0
3. Horovod version: 0.25.0
4. MPI version:
5. CUDA version:
6. NCCL version:
7. Python version:
8. Spark / PySpark version: 3.2.0
9. Ray version:
10. OS and version:
11. GCC version:
12. CMake ve... | closed | 2022-08-15T08:10:36Z | 2022-08-17T22:09:45Z | https://github.com/horovod/horovod/issues/3650 | [
"bug"
] | serena-ruan | 1 |
DistrictDataLabs/yellowbrick | matplotlib | 714 | Add spec and verbose back to test configuration | See #712 for a more detailed discussion and the changes that relate to this issue.
The update to pytest 4.2, unfortunately, broke our tests in two ways:
1. The test object no longer has a `_genid` attribute, hurting our verbose names with parametrize
2. pytest-spec issues 1142 warnings making the test output un... | closed | 2019-02-01T01:45:27Z | 2020-06-21T02:17:36Z | https://github.com/DistrictDataLabs/yellowbrick/issues/714 | [
"type: technical debt",
"review"
] | bbengfort | 1 |
man-group/arctic | pandas | 439 | pymongo.errors.CursorNotFound when iterating over and processing large data | #### Arctic Version
1.54.0
#### Arctic Store
ChunkStore
#### Platform and version
Arch Linux x64, Python 3
#### Description of problem and/or code sample that reproduces the issue
I have a store and I'm storing three keys with chunk sizes 'M', 'W' and 'D' respectively. I have data in each key that ... | closed | 2017-10-15T13:52:02Z | 2020-07-20T14:36:41Z | https://github.com/man-group/arctic/issues/439 | [] | Zvezdin | 7 |
pallets-eco/flask-sqlalchemy | sqlalchemy | 501 | [API request] Proxy to current Flask-SQLAlchemy instance | Hi,
It seems that there isn't an easy way to access the current Flask-SQLAlchemy instance from separate python files (e.g. Pluggable Views).
Will there be a plan for a proxy similar to Flask's [current_app](http://flask.pocoo.org/docs/0.12/api/#flask.current_app) and Flask-Login's [current_user](https://flask-log... | closed | 2017-05-20T11:17:05Z | 2020-12-05T20:55:49Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/501 | [] | roniemartinez | 2 |
ranaroussi/yfinance | pandas | 1,700 | Importing yf fails if ~/.cache directory doesn't exist | ### Describe bug
Even though yf has a .set_tz_cache_location, simply importing yfinance fail if `~/.cache` directory doesn't exist
Simply importing yf should not have side-effects like creating a database, and especially should not fail before there is a chance to overwrite the cache directory.
This is particu... | closed | 2023-09-25T14:40:44Z | 2023-10-25T13:02:52Z | https://github.com/ranaroussi/yfinance/issues/1700 | [] | blackary | 14 |
ivy-llc/ivy | pytorch | 28,312 | householder_product | I will implement this as a composition function.
#28311 will be good to have for better implementation.
Conversation of torch.linealg locked! | closed | 2024-02-17T17:29:27Z | 2024-02-17T17:32:46Z | https://github.com/ivy-llc/ivy/issues/28312 | [
"Sub Task"
] | ZenithFlux | 0 |
tensorflow/datasets | numpy | 5,044 | Amazon dataset URLs are invalid! | Amazon reviews dataset is not accessible from the following URL:
```
https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_us_Books_v1_02.tsv.gz
```
So, TensorFlow Dataset cannot load the dataset:
```
DownloadError: Failed to get url https://s3.amazonaws.com/amazon-reviews-pds/tsv/amazon_reviews_us_Books... | open | 2023-08-09T17:20:18Z | 2023-08-10T22:46:48Z | https://github.com/tensorflow/datasets/issues/5044 | [
"bug"
] | xei | 2 |
serengil/deepface | deep-learning | 862 | [Feature Request]: Allow users to provide images of different formats other than "jpeg" and "png" | A long time ago I created a PR that would have refactored allowed image candidates (by format)
within `db_path` directory.
Specifically these lines would have been subject to change:
https://github.com/serengil/deepface/blob/fb8924e9849a943943ebac992eb5d3e175504981/deepface/DeepFace.py#L477C1-L484C49
I don't s... | closed | 2023-10-17T12:08:23Z | 2023-10-18T17:06:50Z | https://github.com/serengil/deepface/issues/862 | [
"question"
] | ekkolon | 6 |
dsdanielpark/Bard-API | api | 60 | Getting errors even on first request, even with large timeout | I tried running this, and I am getting the same kind of error. I didn't make a lot of requests, and this error persists whether I vary the following factors:
- session: Tried with and without
- timeout: Tried with and without
Here's what the errors are:
```
Session and timeout: Response Error: b')]}\'\n\n... | closed | 2023-06-12T18:17:16Z | 2023-06-13T18:01:26Z | https://github.com/dsdanielpark/Bard-API/issues/60 | [] | josh-ashkinaze | 6 |
gradio-app/gradio | data-science | 10,523 | [Dynamic components] - Calling dynamic rendering area events from the static code area | ### Describe the bug
I have a question that is really impacting me at the moment. I decided to work with dynamic components, and I don't know if I made the right choice. In fact, my interface became very complex and I had to do a lot of workarounds to get around certain behaviors. I managed to solve most of them, but ... | open | 2025-02-05T23:53:36Z | 2025-02-05T23:55:26Z | https://github.com/gradio-app/gradio/issues/10523 | [
"bug"
] | elismasilva | 0 |
Skyvern-AI/skyvern | api | 991 | Hi, can we support openrouter? openrouter has many visual models that can be used to test specific models on tasks of varying difficulty. Please consider it | open | 2024-10-17T02:05:20Z | 2024-10-17T02:06:10Z | https://github.com/Skyvern-AI/skyvern/issues/991 | [
"good first issue"
] | vencentml | 0 | |
Lightning-AI/pytorch-lightning | pytorch | 19,965 | Loading saved config file fails because of InterpolationMode | ### Bug description
In the `SaveConfigCallback`, the config file that was used to run the current experiment is saved to `config.yaml` with this command:
```
self.parser.save(
self.config, config_path, skip_none=False, overwrite=self.overwrite, multifile=self.multifile
)
```
If I try to reproduce the ex... | closed | 2024-06-10T18:08:05Z | 2024-06-11T13:24:25Z | https://github.com/Lightning-AI/pytorch-lightning/issues/19965 | [
"bug",
"needs triage"
] | iulialexandra | 1 |
vastsa/FileCodeBox | fastapi | 55 | . | closed | 2023-03-03T03:18:25Z | 2023-03-03T03:44:44Z | https://github.com/vastsa/FileCodeBox/issues/55 | [] | uu-xixi | 0 | |
saulpw/visidata | pandas | 1,497 | [alt-shift- ] The open-memos keyboard shortcut doesn't work | **Small description**
The open-memos keyboard shortcut doesn't work
**Expected result**
The open-memos keyboard shortcut would open the memo sheet.
**Actual result with screenshot**
https://asciinema.org/a/iFDKQSKcR6Sn9XTPsRCb3hb2f
**Steps to reproduce with sample data and a .vd**
`vd` then press `Alt+Sh... | closed | 2022-08-28T16:54:06Z | 2022-09-04T21:14:44Z | https://github.com/saulpw/visidata/issues/1497 | [
"bug",
"fixed"
] | frosencrantz | 4 |
Avaiga/taipy | data-visualization | 1,612 | [🐛 BUG] Can't submit scenario, "datanode not written" but it is | ### What went wrong? 🤔
I have a Taipy application, creating a scenario that triggers a callback that writes data to the data node "demand". The scenario viewer tells me I can't run the scenario because the "demand" data node is not written while it is. I can even see the written data in the data node viewer:
![image... | closed | 2024-07-30T17:22:29Z | 2024-07-31T09:06:03Z | https://github.com/Avaiga/taipy/issues/1612 | [
"Core",
"🖰 GUI",
"💥Malfunction",
"🟧 Priority: High"
] | AlexandreSajus | 1 |
mars-project/mars | pandas | 3,132 | [BUG] mars.learn.metrics.roc_curve can't execute when chunks is > 1 | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
When invokng mars.learn.metrics.roc_curve with inputs whose chunks is greater than 1, it throws `operands could not be broadcast together with ... | closed | 2022-06-10T06:59:32Z | 2022-06-12T01:04:52Z | https://github.com/mars-project/mars/issues/3132 | [
"type: bug",
"mod: learn"
] | chaokunyang | 0 |
PablocFonseca/streamlit-aggrid | streamlit | 218 | I can use only one AgGrid table on a page. Is it bug? | Hi,
Today, I'm facing the problem of using multiple agGrid table on a streamlit page. Specifically my code is as below:
```
# df1, df2 get from any source
tab_1, tab_2 = st.tabs(['Tab 1', 'Tab 2'])
with tab_1:
response_1 = AgGrid(df1, data_return_mode=DataReturnMode.FILTERED_AND_SORTED, height = 300)
... | open | 2023-05-09T11:12:55Z | 2024-03-21T18:32:24Z | https://github.com/PablocFonseca/streamlit-aggrid/issues/218 | [
"bug"
] | johnnyb1509 | 1 |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 15,482 | dreambooth plugin do not have test tab. | ### Checklist
- [X] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [ ] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-04-11T04:08:12Z | 2024-04-11T12:51:47Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/15482 | [
"bug-report"
] | whk6688 | 1 |
huggingface/datasets | pandas | 7,470 | Is it possible to shard a single-sharded IterableDataset? | I thought https://github.com/huggingface/datasets/pull/7252 might be applicable but looking at it maybe not.
Say we have a process, eg. a database query, that can return data in slightly different order each time. So, the initial query needs to be run by a single thread (not to mention running multiple times incurs mo... | open | 2025-03-21T04:33:37Z | 2025-03-21T04:33:37Z | https://github.com/huggingface/datasets/issues/7470 | [] | jonathanasdf | 0 |
miguelgrinberg/python-socketio | asyncio | 1,351 | AsyncClient automatically disconnects if not explicitly passing 'namespaces' | I'm testing out `python-socketio==5.11.2` with a Python client before plugging it into my real application. At first, I thought events other than `message` don't work, but after logging I found that the client automatically disconnect after the `connect` event handler finishes.
One more problem I found is that the c... | closed | 2024-06-18T18:42:45Z | 2024-06-18T22:39:13Z | https://github.com/miguelgrinberg/python-socketio/issues/1351 | [
"bug"
] | notnitsuj | 0 |
pydata/xarray | numpy | 9,379 | Simplify signature of `xr.open_dataset` using new `decoding_kwargs` dict | ### What is your issue?
The signature of [`xr.open_dataset`](https://docs.xarray.dev/en/stable/generated/xarray.open_dataset.html) is quite complicated, but many of the kwargs are really just immediately passed on to the public [`xr.decode_cf`](https://docs.xarray.dev/en/latest/generated/xarray.decode_cf.html) funct... | closed | 2024-08-18T20:26:01Z | 2024-08-19T16:07:41Z | https://github.com/pydata/xarray/issues/9379 | [
"API design",
"topic-backends",
"topic-CF conventions"
] | TomNicholas | 3 |
unionai-oss/pandera | pandas | 1,049 | MultiIndex with a str dtype schemas can produce invalid examples | Problem:
If you make a schema for a MultiIndex dataframe and some columns are `str`s but others are not, the example produced could have incorrect dtypes for the non-`str` indices and the resulting dataframe from `schema.example()` will not be valid according to the schema.
- [x] I have checked that this issue ha... | closed | 2022-12-11T22:00:03Z | 2024-02-19T04:11:05Z | https://github.com/unionai-oss/pandera/issues/1049 | [
"bug"
] | gsugar87 | 1 |
microsoft/qlib | deep-learning | 1,729 | Data is fetched twice in CSI500 index collector | https://github.com/microsoft/qlib/blob/98f569eed2252cc7fad0c120cad44f6181c3acf6/scripts/data_collector/cn_index/collector.py#L401-L408
`result` is overwritten with the call to `self.get_data_from_baostock(date)`, and that function contains exactly the same code as the lines above the overwrite. Might be an oversight... | open | 2024-01-08T07:16:12Z | 2024-01-11T12:31:34Z | https://github.com/microsoft/qlib/issues/1729 | [] | Chlorie | 1 |
simple-login/app | flask | 1,813 | Strange source code | Hello!
First I’m am writing here because I have some private concerns about Zendesk, so I don’t want to use it.
I found the following line in the SimpleLogin code:
```
"class ErrContactErrorUpgradeNeeded(SLException):
"""raised when user cannot create a contact because the plan doesn't allow it"""""
... | open | 2023-07-20T21:51:22Z | 2023-08-07T11:06:04Z | https://github.com/simple-login/app/issues/1813 | [] | ghost | 2 |
HumanSignal/labelImg | deep-learning | 696 | How can I use LabelImg on ARM64 Ubuntu18.04? | Hey. I want to compile this repo under a Jetson Xavier board, which equiped with a ARM64 ubuntu18.04 OS. I suffered a lot for the problem below. I'm hoping for your help, sincerely.
- **OS: ARM64, ubuntu18.04**
- **PyQt version: 5.12.2**
```
bafs@bafs-xavier:~/installer/labelImg$ sudo pip3 install -r requirem... | open | 2021-01-08T12:31:25Z | 2021-01-08T12:32:17Z | https://github.com/HumanSignal/labelImg/issues/696 | [] | wbzhang233 | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,472 | How to use a pre-trained model for training own dataset? | How to use a pre-trained model for training own dataset? | open | 2022-08-23T06:55:03Z | 2022-09-06T20:35:34Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1472 | [] | TinkingLoeng | 1 |
huggingface/transformers | deep-learning | 36,584 | Significant Increase in Computation Time When Using Attention Mask in SDPA Attention | ### System Info
`transformers` version: 4.46.3
- Platform: Linux-5.15.0-91-generic-x86_64-with-glibc2.10
- Python version: 3.8.18
- Huggingface_hub version: 0.25.2
- Safetensors version: 0.4.5
- Accelerate version: 1.0.1
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: DEEPSPEE... | closed | 2025-03-06T12:21:38Z | 2025-03-08T04:11:34Z | https://github.com/huggingface/transformers/issues/36584 | [
"bug"
] | tartarleft | 4 |
matplotlib/cheatsheets | matplotlib | 109 | 'right' and 'top' in plt.subplots_adjust() are not directly padding size | Very thankful of the cheatsheet, but I think there's a little problem.
In 'Axes adjustments' of the second cheatsheet, 'right' directly refers to the padding between **subplots' right edge** and **figure's right edge**. However it actually refers to the relative distance between **subplots' right edge** and **figure's... | open | 2022-05-05T15:11:21Z | 2022-05-07T06:48:51Z | https://github.com/matplotlib/cheatsheets/issues/109 | [
"cheatsheet"
] | K-gihu | 3 |
proplot-dev/proplot | data-visualization | 123 | Add back "miscellaneous" matplotlib colormaps | It would be nice to have by default all the colormaps from Matplotlib (https://matplotlib.org/examples/color/colormaps_reference.html) in particular the `jet` one for example that I was used to pick, because more visible than the `Spectral` one in Proplot. But the `terrain` one is also useful, etc. I don't know if ther... | closed | 2020-02-14T09:51:38Z | 2020-05-09T23:10:03Z | https://github.com/proplot-dev/proplot/issues/123 | [
"feature"
] | mickaellalande | 3 |
quantmind/pulsar | asyncio | 154 | Application can not call other module because pickle, is that in design? | I have following files:
main.py:
```
# -*- coding: utf-8 -*-
from pulsar.apps import wsgi, Application
import Run
import Proc
def app(environ, start_response):
print(Run)
print(Run.proc)
#Run.proc.do_something()
#need use the Run.proc object
start_response('200 OK', [('Content-type', 'text/plai... | closed | 2015-07-16T03:02:34Z | 2015-07-20T07:51:33Z | https://github.com/quantmind/pulsar/issues/154 | [] | sbant | 1 |
PokeAPI/pokeapi | api | 1,129 | Undocumented fields in API response | I have noticed that these fields in the JSON response appear to be undocumented at https://pokeapi.co/docs/v2.
- `PokemonSprites.other`
- `Type.sprites`
- `Pokemon.past_abilities`
You can see them in
https://pokeapi.co/api/v2/type/1/
and
https://pokeapi.co/api/v2/pokemon/25/ | open | 2024-09-14T23:46:44Z | 2024-09-14T23:46:44Z | https://github.com/PokeAPI/pokeapi/issues/1129 | [] | lunik1 | 0 |
aws/aws-sdk-pandas | pandas | 2,866 | Adding NotebookVersion Parameter as specified in official AWS Docs this parameter is necessary to create session using Spark | ### Describe the bug
Adding NotebookVersion Parameter as specified in official AWS Docs
https://docs.aws.amazon.com/athena/latest/APIReference/API_StartSession.html#athena-StartSession-request-NotebookVersion, this parameter is necessary to create session using Spark
Functions called from library
- run_spark_calc... | closed | 2024-06-21T10:12:56Z | 2024-06-24T14:02:39Z | https://github.com/aws/aws-sdk-pandas/issues/2866 | [
"bug"
] | DaxterXS | 0 |
python-gino/gino | asyncio | 299 | Checking for the existence of a row | * GINO version: 0.7.5
* Python version: 3.7.0
* asyncpg version: 0.17.0
* aiocontextvars version: 0.1.2
* PostgreSQL version: 10.4
### Description
Checking for the existence of a row
### What I Did
```
is_exists = await db.SomeModel.query.where(db.SomeModel.name == some_name).gino.first()
```
```
... | closed | 2018-08-07T05:32:37Z | 2018-08-15T10:32:31Z | https://github.com/python-gino/gino/issues/299 | [
"invalid"
] | ape364 | 2 |
modelscope/modelscope | nlp | 844 | ImportError: cannot import name 'VerificationMode' from 'datasets' | Thanks for your error report and we appreciate it a lot.
**Checklist**
* I have searched the tutorial on modelscope [doc-site](https://modelscope.cn/docs)
* I have searched related issues but cannot get the expected help.
* The bug has not been fixed in the latest version.
**Describe the bug**
root@f3db3... | closed | 2024-04-25T09:02:53Z | 2024-06-01T01:51:53Z | https://github.com/modelscope/modelscope/issues/844 | [
"Stale"
] | StochasticGame | 4 |
yunjey/pytorch-tutorial | deep-learning | 3 | Small understandability improvement in Pytorch basics | Hi!
First of all, really nice resource for learning pytorch and neural nets!
I am following your tutorial for preparing a short hands-on tutorial
During this process, I have identified a very small understandability issue here https://github.com/yunjey/pytorch-tutorial/blob/master/tutorials/00%20-%20PyTorch%20... | closed | 2017-03-13T10:06:28Z | 2017-03-13T10:18:21Z | https://github.com/yunjey/pytorch-tutorial/issues/3 | [] | dvsrepo | 1 |
lanpa/tensorboardX | numpy | 181 | Display of images in embedding visualization provides weird result | Hello,
when using the add_embedding functionality of the writer class, the following problem appears:
I am feeding in (3, 480, 640) sized RGB-images that I resize to (3, 299, 299). I collect a bunch of those and feed them into the add_embedding function, but instead of displaying the correctly colored sprites, th... | closed | 2018-06-29T23:56:50Z | 2018-08-10T14:12:28Z | https://github.com/lanpa/tensorboardX/issues/181 | [] | msieb1 | 1 |
SciTools/cartopy | matplotlib | 1,518 | Adopt NEP29: minimum dependency policy | After Cartopy 0.18, we will be dropping support for Python 2. Currently, for Python 3, we have a minimum of 3.5. This is somewhat problematic on conda-forge because they've already dropped support for it.
For the future, we should implement something like [NEP 29](https://numpy.org/neps/nep-0029-deprecation_policy.h... | closed | 2020-04-12T05:03:51Z | 2021-09-17T07:55:55Z | https://github.com/SciTools/cartopy/issues/1518 | [
"Type: Enhancement",
"Type: Infrastructure"
] | QuLogic | 3 |
google-research/bert | tensorflow | 917 | Eval every 100 steps during training. | How to implement?
It seems that evaluation is only done once after all training epochs have ended.
See https://github.com/google-research/bert/issues/636 | closed | 2019-11-14T03:46:26Z | 2021-03-12T03:35:52Z | https://github.com/google-research/bert/issues/917 | [] | guotong1988 | 3 |
RobertCraigie/prisma-client-py | pydantic | 34 | Add support for setting a field to null | ## Problem
<!-- A clear and concise description of what the problem is. Ex. I'm always frustrated when [...] -->
Optional database fields can be set to null, we currently don't support this as our query builder automatically removes `None` values and does not include them in the generated query.
## Suggested ... | closed | 2021-07-11T15:06:46Z | 2021-08-20T21:13:54Z | https://github.com/RobertCraigie/prisma-client-py/issues/34 | [
"kind/feature"
] | RobertCraigie | 0 |
deezer/spleeter | deep-learning | 425 | [Discussion] How to set GPU device | I have multiple GPU's but I can't figure out how to set which GPU device separator should use.
In my python script I've tried adding `os.environ['CUDA_VISIBLE_DEVICES'] = "1"` but it does nothing.
I've also tried adding `device_count={'GPU': 1}` to `ConfigProto`, but it does nothing either.
Has anyone got a cl... | open | 2020-06-18T15:35:58Z | 2020-06-22T13:01:50Z | https://github.com/deezer/spleeter/issues/425 | [
"question"
] | aidv | 2 |
deepset-ai/haystack | pytorch | 8,863 | Explain deprecation of `dataframe` field in documentation | We should explain here that dataframe is deprecated. https://docs.haystack.deepset.ai/docs/data-classes#document
We will need to fully remove the dataframe field from the explanation after the 2.11 release.
| closed | 2025-02-14T15:40:53Z | 2025-02-17T12:20:19Z | https://github.com/deepset-ai/haystack/issues/8863 | [
"type:documentation",
"P1"
] | julian-risch | 0 |
piskvorky/gensim | machine-learning | 3,496 | is the summarization module removed in the newest version of gensim, i find it nowhere in the documentation? | I actually want the keywords functionality | closed | 2023-09-15T04:00:15Z | 2023-09-15T15:11:21Z | https://github.com/piskvorky/gensim/issues/3496 | [] | zcsh | 1 |
deepinsight/insightface | pytorch | 2,240 | Ask for the official code to count FLOPS | May I ask for the official code to count FLOPS of a model? Thanks for your early reply! | open | 2023-02-13T12:29:51Z | 2023-02-13T14:30:27Z | https://github.com/deepinsight/insightface/issues/2240 | [] | 5RJ | 2 |
horovod/horovod | machine-learning | 3,404 | When would be next release of Horovod available? | Hello Horovod Team,
Just curious, I'm wondering when the next release of Horovod would be available on PyPI? And would it be a major or minor release?
Thank you very much and feel free to correct anything | closed | 2022-02-08T06:36:35Z | 2022-03-02T16:23:52Z | https://github.com/horovod/horovod/issues/3404 | [] | Tony-Feng | 7 |
noirbizarre/flask-restplus | flask | 566 | Is there a way to disable Automatically documented models in the swagger UI ? | Hello, I use models to describe some json inputs and ouputs of different methods.
I would like to disable the list of models in the Swagger documentation. | open | 2018-12-21T10:29:44Z | 2019-03-26T20:58:51Z | https://github.com/noirbizarre/flask-restplus/issues/566 | [
"question"
] | guissart | 0 |
ray-project/ray | deep-learning | 51,423 | Ray on kubernetes with custom image_uri is broken | ### What happened + What you expected to happen
Hi, I am trying to use a custom image on a kubernetes cluster. I am using this cluster: `https://github.com/ray-project/kuberay/blob/master/ray-operator/config/samples/ray-cluster.autoscaler.yaml`.
Unfortunately, it seems that ray uses podman to launch custom images (`h... | open | 2025-03-17T15:07:30Z | 2025-03-21T23:06:12Z | https://github.com/ray-project/ray/issues/51423 | [
"bug",
"triage",
"core"
] | CowKeyMan | 5 |
thp/urlwatch | automation | 146 | Make subfilter parameters configurable | For any given set of different method parameters, we would have to create a new function to support it. As it's the case with https://github.com/thp/urlwatch/pull/145 for just one simple extra configuration.
Maybe it would be better if we make it configurable, for example:
filter: html2text:pyhtml2text:body-w... | closed | 2017-04-07T13:30:48Z | 2017-06-28T10:26:25Z | https://github.com/thp/urlwatch/issues/146 | [] | vmassuchetto | 1 |
tableau/server-client-python | rest-api | 1,564 | ImageRequestOptions ignoring viz_height and viz_width | **Describe the bug**
The viz_height and viz_width options were added to ImageRequestOptions (this is the [merge](https://github.com/tableau/server-client-python/commit/d09a9ceeae33400536abcbc6c60393887fa03e04)). The resulting class has the properties, but it doesn't actually control the image resolution output.
**Vers... | closed | 2025-02-06T21:00:04Z | 2025-02-07T16:19:05Z | https://github.com/tableau/server-client-python/issues/1564 | [] | bnoffke-uwcu | 3 |
polakowo/vectorbt | data-visualization | 562 | Maybe a bug in `nb.sort_call_seq_nb` when provide `size` in group length. | I am using `.from_order_func`, my strategy is
1. select top 20 stocks base on rolling 10 `amount `( price*vol) every 100 days (control by select_interval below)
1. filter the stock by `entries` every 10 days. (control by segment_mask)
1. rebalance the portfolio (size)
```python
@njit
def topk_indices(arr... | open | 2023-02-10T04:39:17Z | 2024-02-26T01:48:30Z | https://github.com/polakowo/vectorbt/issues/562 | [
"stale"
] | eromoe | 4 |
sqlalchemy/sqlalchemy | sqlalchemy | 10,821 | Deprecate array any/all implementation specific implementations | These method have a peculiar signature that's quite different from the rest of the api.
Since there are alternatives these should be deprecated in 2.1 | open | 2024-01-03T00:03:24Z | 2024-01-03T00:03:25Z | https://github.com/sqlalchemy/sqlalchemy/issues/10821 | [
"task",
"sql",
"datatypes"
] | CaselIT | 0 |
microsoft/nni | data-science | 5,456 | 'Trainer' object has no attribute 'optimizer_frequencies' | **Describe the issue**: when running the experiment via experiment.run(config), this error throws :
AttributeError Traceback (most recent call last)
[<ipython-input-32-1486538249e8>](https://localhost:8080/#) in <module>
6 config = RetiariiExeConfig(execution_engine='oneshot')
... | open | 2023-03-16T16:55:02Z | 2023-05-29T02:15:29Z | https://github.com/microsoft/nni/issues/5456 | [] | yasmineLalabouali | 2 |
huggingface/transformers | pytorch | 36,730 | On MoE implementation in HuggingFace | On the Mixtral MoE implementation, I saw it mentioned that it is equivalent to `standard MoE with full capacity (no
dropped tokens)`. I just wonder where the token dropless logic is implemented?
Code reference: https://github.com/huggingface/transformers/blob/2c2495cc7b0e3e2942a9310f61548f40a2bc8425/src/transforme... | closed | 2025-03-14T20:31:26Z | 2025-03-17T09:20:55Z | https://github.com/huggingface/transformers/issues/36730 | [] | Neo9061 | 2 |
deeppavlov/DeepPavlov | tensorflow | 1,228 | Download models data from s3 | Привет.
Обученные модели я загружаю на s3, чтобы потом добавить их в конфиг в `"download"`. Проблема в том, что DeepPavlov не может скачивать данные по ссылкам на s3.
Данные из s3 можно загрузить создав временную ссылку на файл или сделав файл публичным, но это не очень удобно.
Было бы круто, если можно было заг... | closed | 2020-05-25T07:30:50Z | 2020-07-03T10:31:07Z | https://github.com/deeppavlov/DeepPavlov/issues/1228 | [] | pituganov | 2 |
krish-adi/barfi | streamlit | 50 | [Bug] - the commands argument in the st_flow function does not impact the UI. | As stated in the description. If the commands list is changed to just `commands = ["execute"]` the st_flow widget still has the Execute and Save buttons, both of which still function if you click on them. | open | 2025-02-12T14:08:40Z | 2025-02-12T14:08:40Z | https://github.com/krish-adi/barfi/issues/50 | [] | nwshell | 0 |
unit8co/darts | data-science | 2,500 | [BUG] How to prevent darts from caring about the date frequency | **Describe the bug**
I am trying to train TFT to predict the price movement of a stock given 10 other stocks. I removed after hours trading and non weekdays from my dataframe. Therefore, I only have data from monday to friday - from 9:30am to 4pm.
I do not need DARTS to populate these after hours dates with nan valu... | closed | 2024-08-14T16:06:00Z | 2024-08-15T10:43:30Z | https://github.com/unit8co/darts/issues/2500 | [
"question"
] | valentin-fngr | 2 |
pytorch/vision | computer-vision | 8,382 | Regarding IMAGENET1K_V1 and IMAGENET1K_V2 weights | ### 🐛 Describe the bug
I found a very strange "bug" while I was trying to find similiar instances in a vector database of pictures. The model I used is ResNet50. The problem occurs only when using the` IMAGENET1K_V2` weights, but does not appear when using the legacy `V1` weights (referring to https://pytorch.org/b... | open | 2024-04-17T09:30:50Z | 2024-04-17T09:33:44Z | https://github.com/pytorch/vision/issues/8382 | [] | asusdisciple | 0 |
ijl/orjson | numpy | 555 | Support for reading/writing directly to file objects | Seeing this has already been mentioned in #516, but did not get any comments there so opening a new issue.
I'm in a scenario where having `load`/`dump` support would probably be very helpful for us. I'm willing contribute the work on myself, but don't want to spend time on it unless you'd be willing to accept the chan... | closed | 2025-02-22T17:33:46Z | 2025-03-06T08:02:25Z | https://github.com/ijl/orjson/issues/555 | [
"Stale"
] | joburatti | 4 |
jmcnamara/XlsxWriter | pandas | 612 | Feature request: Option to lengthen worksheet names | Can an option be added to control the max length the worksheet name? Right now it's hard coded to limit at 31 characters (Excel Display limit), but I think the file format limit is 255 characters and LibreOffice displays longer names.
| closed | 2019-03-26T16:16:51Z | 2019-03-26T16:37:31Z | https://github.com/jmcnamara/XlsxWriter/issues/612 | [
"question"
] | kk49 | 1 |
ydataai/ydata-profiling | pandas | 1,490 | Bug Report - comparison of two time series reports | ### Current Behaviour
Hi,
I'm trying to compare two multivariate/univariate time series, with version 4.6.0 and python 3.10.13.
when I run `compare` I get an error
```
UnionMatchError: can not match type "list" to any type of "time_index_analysis.period" union: typing.Union[float, typing.List[float]]
```
Ful... | closed | 2023-10-30T10:09:15Z | 2024-01-08T12:18:13Z | https://github.com/ydataai/ydata-profiling/issues/1490 | [
"bug 🐛",
"needs-triage"
] | dean-sh | 0 |
onnx/onnx | scikit-learn | 6,069 | [Spec] DepthToSpace `mode` attribute is counter-intuitive | I want to discuss [our spec of the DepthToSpace operator](https://onnx.ai/onnx/operators/onnx__DepthToSpace.html#depthtospace-13). Please help to current me if any misunderstanding. Thanks! (I don't want to mark this as a _bug_ as it is not.)
For this operator, the `mode` attribute defaults to `DCR` is counter-intui... | open | 2024-04-08T03:10:35Z | 2025-03-10T06:09:46Z | https://github.com/onnx/onnx/issues/6069 | [
"question",
"topic: operator",
"topic: documentation",
"module: spec",
"topic: spec clarification",
"contributions welcome"
] | zhenhuaw-me | 1 |
tatsu-lab/stanford_alpaca | deep-learning | 107 | How to run the finetune code using the slurm launcher in the cluster? | open | 2023-03-20T13:02:59Z | 2023-03-20T13:02:59Z | https://github.com/tatsu-lab/stanford_alpaca/issues/107 | [] | tongwwt | 0 | |
holoviz/panel | plotly | 7,248 | Create Templates composed solely of Panel components | @philippjfr mentioned that the current generation of Panel templates are backed by Jinja2 templates initially because of a limitation in Bokeh where there can't be too many nested shadow roots(?), or else it would lag.
Now, I think this limitation is fixed(?). If so, we can steer away from Jinja2 templates and re-cr... | open | 2024-09-10T09:21:04Z | 2024-10-04T10:59:19Z | https://github.com/holoviz/panel/issues/7248 | [
"type: feature"
] | ahuang11 | 10 |
jonaswinkler/paperless-ng | django | 236 | Non-existing pre and post hooks stop consumption | Hi :wave:,
while I reconfigured my paperless-ng instance, I wrongly linked the pre and post hooks to a host path instead of a mapped docker container path.
Today, I tried to import new documents and it occurred to me that those documents were not imported.
The web UI logs as follows:
```bash
12/31/20, 3:51... | closed | 2020-12-31T15:17:37Z | 2022-06-25T13:07:45Z | https://github.com/jonaswinkler/paperless-ng/issues/236 | [
"bug",
"fixed in next release"
] | Tooa | 4 |
hzwer/ECCV2022-RIFE | computer-vision | 339 | Bad video output | Hi,
I just tried to use RIFE for the first time and the output video is simply broken. I followed the instructions from the README and ran the command `python3 inference_video.py --exp=2 --video=video.mp4`
I'm attaching the[ Google Drive Link here](https://drive.google.com/drive/folders/1A5eMb9SU51tEp6RmHQLPHEkRB... | open | 2023-10-18T16:31:46Z | 2023-10-18T16:31:46Z | https://github.com/hzwer/ECCV2022-RIFE/issues/339 | [] | matejhacin | 0 |
python-visualization/folium | data-visualization | 1,986 | Add zoomSnap parameter | I use folium to render maps for automatically generating figures but the lack of zoom granularity makes it difficult to generate nice figures that contain the bounds of the region of interest.
Add a parameter to folium.Map() to edit zoomSnap value
https://leafletjs.com/reference.html#map-zoomsnap
| closed | 2024-07-10T10:11:59Z | 2024-07-28T10:27:06Z | https://github.com/python-visualization/folium/issues/1986 | [] | Chris-airseed | 2 |
2noise/ChatTTS | python | 705 | 如何固定音色? | 由于我的语料较长,需要多次输入,这样会出现转语音时,不同段落转出来的音色值不同,声音不一致。 | closed | 2024-08-20T09:50:48Z | 2024-12-16T04:01:38Z | https://github.com/2noise/ChatTTS/issues/705 | [
"documentation",
"stale"
] | Shengrun2020 | 6 |
coqui-ai/TTS | pytorch | 4,006 | [Bug] Process *Killed* when executing parallel tts commands on different containers (Docker version) | ### Describe the bug
Trying to experiment a little bit with running multiple TTS instances at the same time using the docker image, I created 5 different containers, and trying to execute a TTS command on each of those running containers, but only 2 out of 5 produce an actual output, while the others simply log "Kille... | closed | 2024-10-04T16:25:01Z | 2024-12-28T11:58:13Z | https://github.com/coqui-ai/TTS/issues/4006 | [
"bug",
"wontfix"
] | khaldi-yass | 2 |
jupyter/nbgrader | jupyter | 1,306 | missing | <!--
Thanks for helping to improve nbgrader!
If you are submitting a bug report or looking for support, please use the below
template so we can efficiently solve the problem.
If you are requesting a new feature, feel free to remove irrelevant pieces of
the issue template.
-->
### Operating system
Ubunt... | closed | 2020-01-22T22:54:17Z | 2021-03-25T22:09:35Z | https://github.com/jupyter/nbgrader/issues/1306 | [
"bug",
"duplicate"
] | alexlopespereira | 8 |
huggingface/datasets | numpy | 6,950 | `Dataset.with_format` behaves inconsistently with documentation | ### Describe the bug
The actual behavior of the interface `Dataset.with_format` is inconsistent with the documentation.
https://huggingface.co/docs/datasets/use_with_pytorch#n-dimensional-arrays
https://huggingface.co/docs/datasets/v2.19.0/en/use_with_tensorflow#n-dimensional-arrays
> If your dataset consists of ... | closed | 2024-06-04T09:18:32Z | 2024-06-25T08:05:49Z | https://github.com/huggingface/datasets/issues/6950 | [
"documentation"
] | iansheng | 2 |
autogluon/autogluon | data-science | 4,195 | [timeseries] When saving predictor to a folder with an existing predictor, delete the old predictor | ## Description
- When the user sets `TimeSeriesPredictor(path="folder/with/existing/predictor")`, a lot of weird undocumented behaviors may occur (e.g., #4150). We currently log a warning in this case, but it's often ignored by the users, leading to confusion. A cleaner option would be to delete all the files related ... | closed | 2024-05-14T07:50:06Z | 2024-06-27T09:24:45Z | https://github.com/autogluon/autogluon/issues/4195 | [
"enhancement",
"module: timeseries"
] | shchur | 2 |
bauerji/flask-pydantic | pydantic | 45 | Is there any way to make custom response? | Hello! Thanks for awesome package.
I want to make custom response
ASIS
```
{
"validation_error": {
"query_params": [
{
"loc": ["age"],
"msg": "value is not a valid integer",
"type": "type_error.integer"
}
]
}
}
```
TOBE(or some other fomat, maybe)
```... | closed | 2021-12-11T14:42:35Z | 2022-09-25T08:04:27Z | https://github.com/bauerji/flask-pydantic/issues/45 | [] | matthew-cupist | 2 |
BeastByteAI/scikit-llm | scikit-learn | 121 | Add Structured Output support | Structured outputs allow users to define an output scheme using pydantic. OpenAI and most others support this now (see e.g. [OpenAI](https://openai.com/index/introducing-structured-outputs-in-the-api/) and their [docs](https://platform.openai.com/docs/guides/structured-outputs)).
~~~python
from pydantic import BaseMod... | open | 2025-01-23T15:03:11Z | 2025-01-23T15:03:11Z | https://github.com/BeastByteAI/scikit-llm/issues/121 | [] | AndreasKarasenko | 0 |
robotframework/robotframework | automation | 4,912 | Parsing model: Move `type` and `tokens` from `_fields` to `_attributes` | Our parsing model is based on Python's [ast](https://docs.python.org/3/library/ast.html). The `Statement` base class currently has `type` and `token` listed in its `_fields`. According to the [documentation](https://docs.python.org/3/library/ast.html#ast.AST._fields), `_fields` should contain names of the child nodes a... | closed | 2023-10-24T16:11:04Z | 2023-11-07T09:15:03Z | https://github.com/robotframework/robotframework/issues/4912 | [
"enhancement",
"priority: medium",
"backwards incompatible",
"alpha 1",
"effort: small"
] | pekkaklarck | 0 |
httpie/cli | python | 1,428 | Support different keywords for Bearer authentication | ## Checklist
- [x] I've searched for similar feature requests.
---
## Enhancement request
Adding support for different keywords than "Bearer" for Bearer authentication.
---
## Problem it solves
The default keyword in Falcon and Django REST Framework is "Token" instead of "Bearer". In HTTPie the onl... | open | 2022-08-19T20:09:07Z | 2022-11-30T21:53:57Z | https://github.com/httpie/cli/issues/1428 | [
"enhancement",
"new"
] | eraxeg | 1 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 289 | [BUG] does not collect Request after page load + does not always find the element, although it is loaded | Two problems:
1) It does not collect the request, after pressing the button, although it happens and in the network tab is displayed
2) The button is found once in a while, although it is always loaded after an error I check in the code of the element paths coincide.
Requests after button

ccxt.base.errors.NetworkError: 403, message='Invalid response status', url='wss://gateway.prod.vertexprotocol.com/v1/subscribe'
```
bitopro
```
wa... | closed | 2025-02-27T11:28:34Z | 2025-03-02T13:28:40Z | https://github.com/ccxt/ccxt/issues/25371 | [
"bug"
] | williamyizhu | 3 |
ultralytics/yolov5 | deep-learning | 13,066 | Labelling Objects Occluded objects in Extreme Environment | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I am dealing with object detection of objects with similar color that are occlude each ot... | closed | 2024-06-03T15:46:46Z | 2024-10-20T19:47:14Z | https://github.com/ultralytics/yolov5/issues/13066 | [
"question",
"Stale"
] | Avv22 | 5 |
TencentARC/GFPGAN | pytorch | 518 | ফাগুনের আগুন লেগেছে নবীন হৃদয়ে,সেজেছে বসন্ত আজ পলাশের রঙে । | open | 2024-02-16T17:06:05Z | 2024-02-16T19:17:52Z | https://github.com/TencentARC/GFPGAN/issues/518 | [] | lavlu2004 | 2 | |
deepfakes/faceswap | machine-learning | 1,002 | Convert Images has no face | Hello. Author, I get a problem when I convert my images. The output of my convert image has no face ,can you help me ?
The output pic just like this:

The order I input is:
`python faceswap.py convert -i=./... | closed | 2020-03-31T06:07:11Z | 2020-03-31T09:01:59Z | https://github.com/deepfakes/faceswap/issues/1002 | [] | Tian14267 | 4 |
gradio-app/gradio | data-science | 10,710 | API requests error | ### Describe the bug
Hello!
I am using SDK Gradio on on my Public space on Huggingface. I am deployed AI chat bot. WEB works OK. All requests and responses via terminal Bash - OK. But when I try to connect my telegram-bot to Gradio API - then i have error in log: server rejected WebSocket connection: HTTP 403.
... | closed | 2025-03-02T18:36:50Z | 2025-03-04T09:09:35Z | https://github.com/gradio-app/gradio/issues/10710 | [
"bug",
"pending clarification"
] | brokerelcom | 7 |
numpy/numpy | numpy | 28,434 | DOC: PyArray_CHKFLAGS protorype is wrong in the documentation | ### Issue with current documentation:
PyArray_CHKFLAGS is shown to receive a `PyObject *` argument in the documentation, but the actual function prototype is `PyArray_CHKFLAGS(const PyArrayObject *arr, int flags)`

This results ... | closed | 2025-03-05T17:25:53Z | 2025-03-07T15:28:38Z | https://github.com/numpy/numpy/issues/28434 | [
"04 - Documentation"
] | danielhrisca | 2 |
encode/apistar | api | 379 | Test client uses ImmutableDict from requests.Session for data | When using the apistar test client, data is passed as an `ImmutableDict`, so if you are trying to modify the `http.RequestData` in a view it will fail during tests. Only in a test situation like this would the data be passed as an `ImmutableDict` structure
```python
def create_account(request: http.Request, auth: A... | closed | 2017-12-26T22:37:43Z | 2018-04-17T12:49:56Z | https://github.com/encode/apistar/issues/379 | [] | audiolion | 0 |
nikitastupin/clairvoyance | graphql | 1 | Probe for Input Object type | Now we're probing only for (1) argument name and (2) it's type. However in case if argument of [INPUT_OBJECT](https://spec.graphql.org/June2018/#sec-Input-Object-Values) type we can probe for (3) fields too. | open | 2020-10-23T14:31:12Z | 2021-03-22T10:35:32Z | https://github.com/nikitastupin/clairvoyance/issues/1 | [
"enhancement"
] | nikitastupin | 2 |
automl/auto-sklearn | scikit-learn | 1,704 | calling model.show_models() give error as | ## Describe the bug ##
Please describe the bug you're experiencing is precise as possible.
## To Reproduce ##
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
## Expected behavior ##
A clear and concise description of what you expected to happen.
#... | open | 2023-11-13T07:10:25Z | 2023-11-13T07:10:25Z | https://github.com/automl/auto-sklearn/issues/1704 | [] | AhangarAamir | 0 |
vitalik/django-ninja | pydantic | 381 | AttributeError when running export_openapi_schema | Running
```
./manage.py export_openapi_schema
```
Results in the following error:
```
Traceback (most recent call last):
File "./manage.py", line 22, in <module>
main()
File "./manage.py", line 18, in main
execute_from_command_line(sys.argv)
File ".../venv/lib/python3.7/site-packages/djan... | closed | 2022-03-01T20:57:51Z | 2023-02-07T09:27:51Z | https://github.com/vitalik/django-ninja/issues/381 | [] | lausek | 1 |
Sanster/IOPaint | pytorch | 213 | I have problem with run "lama-clean" | I can't run "lama-clean". Could you help me, please?

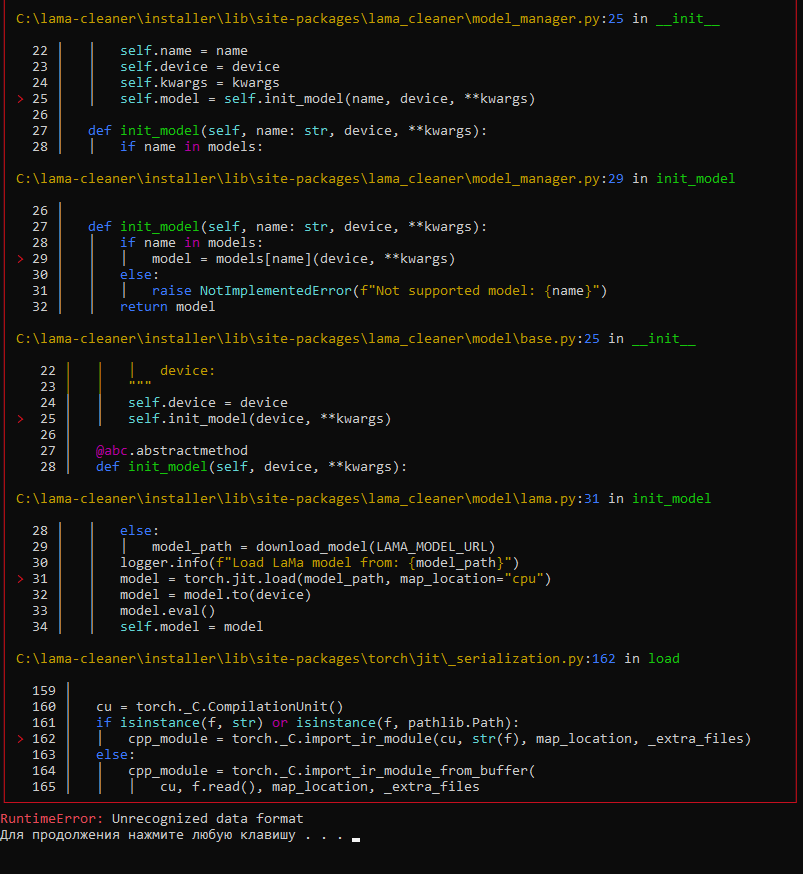
| open | 2023-02-13T17:12:41Z | 2023-04-21T02:18:36Z | https://github.com/Sanster/IOPaint/issues/213 | [
"bug",
"help wanted"
] | Ostruy | 12 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 58 | 请教合并模型merge_llama_with_chinese_lora.py的原理和中文LLaMA训练细节源码 | 你好,阅读了merge_llama_with_chinese_lora可是不太明白translate_state_dict_key背后的原理
以及请教中文LLaMA过程中词表扩充-预训练-指令精调的源代码学习学习,感谢~ | closed | 2023-04-04T09:48:44Z | 2023-04-18T14:07:44Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/58 | [] | jiangliqin | 1 |
marcomusy/vedo | numpy | 638 | mesh texture | DATA(rename `txt` to `zip`):
[mesh_tex.txt](https://github.com/marcomusy/vedo/files/8618771/mesh_tex.txt)
CODE:
```
from vedo import *
path_pfx = "/home/lab0/Pictures/mesh_tex"
path_obj = path_pfx + "/pro_img_ds_HR_00000_0.obj"
path_ply = path_pfx + "/cv_img_du_00000_0_mesh_inC.ply"
path_opt = path_pfx + ... | closed | 2022-05-04T08:27:22Z | 2022-05-04T13:31:10Z | https://github.com/marcomusy/vedo/issues/638 | [
"enhancement"
] | LogWell | 5 |
frol/flask-restplus-server-example | rest-api | 56 | Update Swagger UI to 3.x | The changes are quite radical, so it will take some time to get things going.
Just for the reference: https://github.com/noirbizarre/flask-restplus/issues/267 | open | 2017-04-04T15:42:03Z | 2019-02-06T10:33:11Z | https://github.com/frol/flask-restplus-server-example/issues/56 | [] | frol | 2 |
alyssaq/face_morpher | numpy | 59 | "Invalid HAAR feature" and no face in image error | Attempting to run facemorpher in a docker container [as described in the readme](https://github.com/alyssaq/face_morpher#try-out-in-a-docker-container),
```
root@6411e86f84bd:/# facemorpher --src=/images/alyssa.jpg --dest=/images/ian.jpg --plot
Failed finding face points: cascadedetect.cpp(569) : Unspecified erro... | open | 2019-10-18T03:54:04Z | 2020-05-03T08:45:06Z | https://github.com/alyssaq/face_morpher/issues/59 | [] | jstray | 3 |
mwaskom/seaborn | data-science | 3,598 | DOC: seaborn.set_context should note that it sets the global defaults for all plots using the matplotlib rcParams system | Unless I'm mistaken, the doc for [`seaborn.set_context`](https://seaborn.pydata.org/generated/seaborn.set_context.html) should note that it sets the global defaults for all plots using the matplotlib `rcParams` system. | closed | 2023-12-21T23:59:02Z | 2023-12-22T22:36:35Z | https://github.com/mwaskom/seaborn/issues/3598 | [] | rootsmusic | 6 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,667 | driver.quit not working | driver.quit closes the driver window but leaves the chromes in task manager which eat the CPU | open | 2023-11-18T09:26:49Z | 2024-08-22T14:10:26Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1667 | [] | tromotixc | 10 |
tflearn/tflearn | tensorflow | 192 | Dropout in RNNs | It seems there is a bug where dropout in RNNs are still applied at prediction time, investigating if it is coming from tflearn or tensorflow.
| closed | 2016-07-10T12:23:26Z | 2016-07-11T08:40:39Z | https://github.com/tflearn/tflearn/issues/192 | [
"bug"
] | aymericdamien | 2 |
xlwings/xlwings | automation | 2,125 | How to catch exceptions in VBA thrown from Python when using RunPython? | I'm using `RunPython` because it is simpler to setup. I haven't had luck running UDF as described here https://docs.xlwings.org/en/stable/udfs.html, on VBA always says `Syntax error` on the unknown UDF python function.
So I do from Python:
```
def test():
raise ValueError("test catching this")
```
then ... | closed | 2022-12-20T10:19:45Z | 2023-01-18T18:18:38Z | https://github.com/xlwings/xlwings/issues/2125 | [] | bravegag | 7 |
activeloopai/deeplake | tensorflow | 2,976 | [BUG] V4.0 breaking? | ### Severity
P0 - Critical breaking issue or missing functionality
### Current Behavior
Neither of these imports work with v4.0
```
from deeplake.core.vectorstore.deeplake_vectorstore import VectorStore
from deeplake.core.vectorstore import VectorStore
```
It looks like the docs aren't updated either. Is th... | closed | 2024-10-25T16:22:14Z | 2024-10-25T17:30:23Z | https://github.com/activeloopai/deeplake/issues/2976 | [
"bug"
] | logan-markewich | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.