
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ymcui/Chinese-LLaMA-Alpaca-2 | nlp | 500 | 关于chinese-alpaca-2-7b-64k模型在inference_hf.py推理部署中使用vllm报错的问题 | ### 提交前必须检查以下项目
- [X] 请确保使用的是仓库最新代码(git pull),一些问题已被解决和修复。
- [X] 我已阅读[项目文档](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki)和[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案。
- [x] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[LangChain](https://g... | closed | 2024-01-12T10:59:41Z | 2024-02-10T01:36:06Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/issues/500 | [
"stale"
] | hoohooer | 6 |
pywinauto/pywinauto | automation | 599 | Custom Type Object wont Take Click | Currently i'm using Pywinauto along with Behave to test a desktop application and i have encountered a road bump. at one point in my automation i need to use double click, currently i have it working as this:
```
@step("User selects {row} in Multi payment window")
def step_impl(context, row):
"""
:param ... | open | 2018-11-06T16:19:56Z | 2018-11-10T14:47:43Z | https://github.com/pywinauto/pywinauto/issues/599 | [
"question"
] | LeoDOD | 3 |
widgetti/solara | fastapi | 402 | Media placeholder Jupyter dashboard tutorial | closed | 2023-11-27T14:55:40Z | 2023-11-27T20:15:09Z | https://github.com/widgetti/solara/issues/402 | [] | maartenbreddels | 1 | |
feature-engine/feature_engine | scikit-learn | 786 | yeo-johnson inverse transform throws an erro | ```
InvalidIndexError Traceback (most recent call last)
File ~\Documents\Repositories\envs\fe_not\lib\site-packages\pandas\core\series.py:1289, in Series.__setitem__(self, key, value)
1288 try:
-> 1289 self._set_with_engine(key, value, warn=warn)
1290 except KeyError:
1291 ... | closed | 2024-07-17T09:14:48Z | 2024-08-23T17:21:04Z | https://github.com/feature-engine/feature_engine/issues/786 | [] | solegalli | 0 |
521xueweihan/HelloGitHub | python | 2,681 | 【开源自荐】CardCarousel - 最易用的 iOS 轮播组件 | - 项目地址:https://github.com/YuLeiFuYun/CardCarousel
- 类别:Swift
- 项目标题:一个功能强大且易于使用的轮播组件,支持使用咒语进行设置
- 项目描述:CardCarousel 可以让你对轮播进行更精细地控制,你可以设置滚动方向、页面尺寸、页间距、滚动停止时的页面对齐方式、自动滚动时的滚动动画效果、页面过渡效果、分页阈值和手动滚动时的页面减速速率等等。CardCarousel 可以在 UIKit 与 SwiftUI 中使用,支持链式调用,提供了丰富的初始化方法,参数可以通过点语法进行设置。更好的是,CardCarousel 还支持通过咒语进行设置。
- 亮... | closed | 2024-01-27T11:54:03Z | 2024-04-24T12:12:53Z | https://github.com/521xueweihan/HelloGitHub/issues/2681 | [] | YuLeiFuYun | 0 |
serengil/deepface | machine-learning | 884 | Memory usage in Windows Server is very high | i use this deepface package in windows server and this works well
but memory usage is very high
please tell me , this memory usage is normal?

| closed | 2023-11-04T19:41:38Z | 2023-11-05T19:20:25Z | https://github.com/serengil/deepface/issues/884 | [
"question"
] | ghost | 1 |
jschneier/django-storages | django | 603 | S3Boto3 listdir can no longer create buckets | Hi,
With the recent update of `listdir` in S3Boto3Backend, an undocumented behavior has also changed, I am not sure if this is a bug or if it is intended.
Formerly, when performing a `listdir` on a non-existing bucket, the function would call a `_get_or_create_bucket` which would create the bucket if `AWS_AUTO_C... | closed | 2018-09-20T14:18:03Z | 2020-02-03T06:08:02Z | https://github.com/jschneier/django-storages/issues/603 | [
"s3boto"
] | baldychristophe | 1 |
capitalone/DataProfiler | pandas | 856 | Add documentation for `sampling_ratio` option | Related to PR #845 add documentation around the new `sampling_ratio` option paramter | closed | 2023-06-05T17:40:23Z | 2023-06-28T17:24:04Z | https://github.com/capitalone/DataProfiler/issues/856 | [
"Documentation"
] | taylorfturner | 1 |
falconry/falcon | api | 1,950 | ASGI mount | Hi, I'm really glad to see Falcon supporting ASGI - great job!
In some other ASGI frameworks (for example FastAPI, Starlette and BlackSheep) there is the ability to mount other ASGI apps at a certain route. For example:
```python
asgi_app = falcon.asgi.App()
asgi_app.mount('/admin/', some_other_asgi_app)
```
... | open | 2021-08-14T22:17:27Z | 2023-07-24T10:34:26Z | https://github.com/falconry/falcon/issues/1950 | [
"enhancement",
"proposal",
"community"
] | dantownsend | 1 |
ansible/ansible | python | 84,680 | Cron module fails to properly work under some cases on systems with systemd-cron | ### Summary
Hi!
I've found strange situation and killed few days to debug it properly.
I started with strange problem that ansble's cron module failed to install any jobs for any users (as I thought), throwing be a (not very useful) python traceback and
```
CronTabError: Unable to read crontab
```
error.
Also I fou... | closed | 2025-02-06T15:09:38Z | 2025-02-25T14:00:07Z | https://github.com/ansible/ansible/issues/84680 | [
"module",
"bug",
"affects_2.18"
] | msva | 5 |
redis/redis-om-python | pydantic | 59 | list and tuple fields could have other types than strings | 'this Preview release, list and tuple fields can only contain strings. Problem field: . See docs: TODO' | closed | 2022-01-01T08:29:00Z | 2022-08-30T09:48:28Z | https://github.com/redis/redis-om-python/issues/59 | [] | gam-phon | 1 |
pydata/pandas-datareader | pandas | 383 | Eurostat - mismatched tag; | `eu_trade_since_2000 = web.DataReader("DS-043327", 'eurostat')`
gives the message
` File "<string>", line unknown
ParseError: mismatched tag: line 28, column 8`
That's not very informative. I have no idea what is going on at all. Part of the pip freeze output is:
>numpy==1.13.1
pandas==0.20.3
pandas-data... | closed | 2017-08-24T12:47:41Z | 2019-09-26T21:20:30Z | https://github.com/pydata/pandas-datareader/issues/383 | [] | HristoBuyukliev | 8 |
sczhou/CodeFormer | pytorch | 207 | Great job! How amazing, I was planning on reproducing the code myself today, but then it suddenly got updated! | open | 2023-04-19T15:17:09Z | 2023-04-19T15:20:10Z | https://github.com/sczhou/CodeFormer/issues/207 | [] | Liar-zzy | 1 | |
Sanster/IOPaint | pytorch | 376 | [Feature Request] Increase/decrease maximum base cursor size range. | Could it be possible to increase/decrease the maximum sizes for the cursor? I'd love to be able to make my cursor as small as 1px - 2px to get very exact in my masking for smaller images. If this can be adjusted on my own, I'd appreciate some guidance. And I don't mean that I need help figuring out how to work the norm... | closed | 2023-09-21T23:05:38Z | 2025-03-21T02:05:02Z | https://github.com/Sanster/IOPaint/issues/376 | [
"stale"
] | ArchAngelAries | 2 |
sammchardy/python-binance | api | 1,459 | python-binance ThreadedWebsocketManager not working with Python 3.11 or 3.12? | **Describe the bug**
When I run the following code in PyCharm, it doesn’t print any information. However, if I run it in debug mode, the information appears. This causes the code to not function properly on Python 3.11 or 3.12.
**To Reproduce**
```
from binance import ThreadedWebsocketManager
def handle_... | closed | 2024-10-29T08:17:14Z | 2024-10-30T01:11:17Z | https://github.com/sammchardy/python-binance/issues/1459 | [] | XiaoWXHang | 5 |
horovod/horovod | machine-learning | 4,043 | NVIDIA CUDA TOOLKIT version to run Horovod in Conda Environment | Hi Developers
I wish to install horovod inside Conda environment for which I require nccl from NVIDIA CUDA toolkit installed in system so I just wanted to know which is version of NVIDIA CUDA Toolkit is required to build horovod inside conda env to run Pytorch library.
Many Thanks
Pushkar | open | 2024-05-10T06:56:06Z | 2025-01-31T23:14:47Z | https://github.com/horovod/horovod/issues/4043 | [
"wontfix"
] | ppandit95 | 2 |
huggingface/datasets | computer-vision | 6,791 | `add_faiss_index` raises ValueError: not enough values to unpack (expected 2, got 1) | ### Describe the bug
Calling `add_faiss_index` on a `Dataset` with a column argument raises a ValueError. The following is the trace
```python
214 def replacement_add(self, x):
215 """Adds vectors to the index.
216 The index must be trained before vectors can be added to it.
217 Th... | closed | 2024-04-08T01:57:03Z | 2024-04-11T15:38:05Z | https://github.com/huggingface/datasets/issues/6791 | [] | NeuralFlux | 3 |
benbusby/whoogle-search | flask | 250 | [BUG] Whoogle spits out garbage when going to next page of search results | Whenever i try to go to the next page of a search (e.g. COVID-19) it spits out a ton of garbage
The exact string is the following
gAAAAABgZPRDBmNckg-txy85CufwUIccaLrnLWvW7gm9lyPJAXd8uFW1bFln-rKIyC3QxQAkoMDGjcZDgNlEtAS5_Kluz1OpGg==
It's the same no matter what search i do
Steps to reproduce the behavior:
1. S... | closed | 2021-03-31T22:19:16Z | 2021-04-27T13:46:19Z | https://github.com/benbusby/whoogle-search/issues/250 | [
"bug"
] | Rowan-Bird | 5 |
aiortc/aiortc | asyncio | 558 | Does the Raspberry PI 4B not support Google-CRC32C? | ity -Wdate-time -D_FORTIFY_SOURCE=2 -fPIC -I/usr/include/python3.7m -c src/google_crc32c/_crc32c.c -o build/temp.linux-aarch64-3.7/src/google_crc32c/_crc32c.o
src/google_crc32c/_crc32c.c:3:10: fatal error: crc32c/crc32c.h: No such file or directory
#include <crc32c/crc32c.h>
^~~~~~~~~~~~~~~~~
com... | closed | 2021-09-03T10:14:20Z | 2021-09-06T01:04:11Z | https://github.com/aiortc/aiortc/issues/558 | [] | Canees | 2 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,409 | Abouttransfer learning | closed | 2022-04-18T10:05:36Z | 2022-04-18T10:05:43Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1409 | [] | ZhenyuLiu-SYSU | 0 | |
deepfakes/faceswap | deep-learning | 722 | has installed cuDNN,but not found | **Describe the bug**
has installed cuDNN,but not found
**To Reproduce**
python setup.py
**Expected behavior**
WARNING Running without root/admin privileges
INFO The tool provides tips for installation
and installs required python packages
INFO Setup in Windows 10
INFO Installed Python: 3.6... | closed | 2019-05-10T15:00:49Z | 2019-05-10T15:09:23Z | https://github.com/deepfakes/faceswap/issues/722 | [] | chenkarl | 1 |
Nemo2011/bilibili-api | api | 698 | [提问]上传视频遇到问题 AttributeError: 'NoneType' object has no attribute '__dict__'. Did you mean: '__dir__'? | **Python 版本:** 3.10
**模块版本:** 16.2.0
**运行环境:** Windows
<!-- 务必提供模块版本并确保为最新版 -->
---
按照文档给的案例上传视频,credential和视频封面,视频文件都修改了,但是遇见这个问题
AttributeError: 'NoneType' object has no attribute '__dict__'. Did you mean: '__dir__'?
| closed | 2024-03-01T06:33:22Z | 2024-03-15T14:14:36Z | https://github.com/Nemo2011/bilibili-api/issues/698 | [
"bug",
"solved"
] | RickyCui010 | 8 |
snarfed/granary | rest-api | 46 | Duplicate in-reply-to links on Tweets | In the last week or so, I've noticed Twitter posts have started showing up with duplicated in-reply-to links:
```
<article class="h-entry h-as-note">
<span class="u-uid">tag:twitter.com:653670712104738816</span>
<time class="dt-published" datetime="2015-10-12T20:36:57+00:00">2015-10-12T20:36:57+00:00</time>
<div... | closed | 2015-10-13T15:55:00Z | 2015-10-13T18:05:29Z | https://github.com/snarfed/granary/issues/46 | [] | karadaisy | 4 |
CanopyTax/asyncpgsa | sqlalchemy | 101 | Asyncpg connection are not returning to a pool | An Asyncpg connection will not return to a pool connection if in the method __aenter__ was raised exception agter acquire_context.
```
async def __aenter__(self):
self.acquire_context = self.pool.acquire(timeout=self.timeout)
con = await self.acquire_context.__aenter__()
self.transaction... | closed | 2019-09-15T19:36:50Z | 2019-09-19T19:21:19Z | https://github.com/CanopyTax/asyncpgsa/issues/101 | [] | matemax | 0 |
numba/numba | numpy | 9,650 | Function with @guvectorize allow the index of array out of bound, not sure if this is in purpose | <!--
Thanks for opening an issue! To help the Numba team handle your information
efficiently, please first ensure that there is no other issue present that
already describes the issue you have
(search at https://github.com/numba/numba/issues?&q=is%3Aissue).
-->
## Reporting a bug
<!--
Before submittin... | closed | 2024-07-12T04:11:44Z | 2024-08-22T01:52:33Z | https://github.com/numba/numba/issues/9650 | [
"question",
"stale"
] | BixiongXiang | 3 |
tensorpack/tensorpack | tensorflow | 733 | The usage of dataflow | Will the get_data() and the reset_state() method be called only once or at the beginning of each epoch?
I want to do some curriculum learning. If the get_data() method is called every epoch, then I can record the epoch index in it and change the data as epoch number increases. Currently I have a data set consists of... | closed | 2018-04-20T01:23:23Z | 2018-05-30T20:59:41Z | https://github.com/tensorpack/tensorpack/issues/733 | [
"usage"
] | JesseYang | 3 |
aminalaee/sqladmin | asyncio | 415 | Protocol, Domain & port with request.get_url over just reporting the path | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
When using SQLAdmin behind a proxy, the URLs use 'http://' instead of 'https://'
This can be fixed by setting the Uvicorn proxy settings.
Howev... | closed | 2023-01-19T14:06:20Z | 2023-03-08T20:34:18Z | https://github.com/aminalaee/sqladmin/issues/415 | [
"waiting-for-feedback"
] | Jorricks | 5 |
davidsandberg/facenet | tensorflow | 729 | IndexError : index 1 is out of bounds for axis 0 with size 1 | class_index = class_indices[i] line 332 of tripletloss.py file
I am using LFW dataset people per batch = 45 and image per person 5 I have a user. when I have use image per person is 40 than I am also getting this error. | open | 2018-04-30T04:07:17Z | 2018-04-30T04:10:19Z | https://github.com/davidsandberg/facenet/issues/729 | [] | praveenkumarchandaliya | 0 |
ultralytics/ultralytics | pytorch | 18,892 | why cli results is different with python | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
.
[CPU] : CPU
[0] : NVID... | open | 2022-05-29T12:27:07Z | 2023-07-25T09:36:26Z | https://github.com/iperov/DeepFaceLab/issues/5526 | [] | huebez | 5 |
pandas-dev/pandas | python | 61,165 | BUG: `datetime64[s]` fails round trip using `.to_parquet` and `read_parquet` | ### Pandas version checks
- [x] I have checked that this issue has not already been reported.
- [x] I have confirmed this bug exists on the [latest version](https://pandas.pydata.org/docs/whatsnew/index.html) of pandas.
- [x] I have confirmed this bug exists on the [main branch](https://pandas.pydata.org/docs/dev/ge... | closed | 2025-03-21T23:39:25Z | 2025-03-22T11:19:48Z | https://github.com/pandas-dev/pandas/issues/61165 | [
"Bug",
"Datetime",
"IO Parquet"
] | noahblakesmith | 1 |
explosion/spaCy | nlp | 12,611 | support future pydantic v2 | Spacy uses an older version of pydantic, please lighten the pinning to support 1.10.x and the forthcoming version 2.0.0
| closed | 2023-05-08T17:00:15Z | 2023-09-08T00:02:11Z | https://github.com/explosion/spaCy/issues/12611 | [
"enhancement",
"third-party"
] | achapkowski | 8 |
httpie/cli | rest-api | 1,006 | Redirected output starts response headers on same line as request body | When I run a POST request without redirection, I see the response headers start on a new line:
```
}
}
}
}
HTTP/1.1 201
Date: Mon, 21 Dec 2020 13:39:00 GMT
Content-Length: 0
```
But when I redirect the output, I see the `HTTP/1.1 201` on the same line as the request:
```
... | closed | 2020-12-21T13:43:07Z | 2021-02-06T11:19:42Z | https://github.com/httpie/cli/issues/1006 | [
"bug"
] | hughpv | 5 |
man-group/arctic | pandas | 205 | stock tick data storing tutorial. | Hi, is there any tutorial for storing tick data and how to update the data for my symbols?
| closed | 2016-08-30T03:15:59Z | 2017-12-03T21:46:14Z | https://github.com/man-group/arctic/issues/205 | [] | leolle | 18 |
serengil/deepface | machine-learning | 980 | cv:resize issue for functions.extract_faces | Hi, there seems to be an issue with the `functions.extract_faces` method (using ssd).
```
File C:\ProgramData\anaconda3\Lib\site-packages\deepface\commons\functions.py:211, in extract_faces(img, target_size, detector_backend, grayscale, enforce_detection, align)
205 factor = min(factor_0, factor_1)
207 ds... | closed | 2024-01-28T20:28:28Z | 2024-01-31T09:12:05Z | https://github.com/serengil/deepface/issues/980 | [
"bug"
] | fechnologies-d | 7 |
pywinauto/pywinauto | automation | 932 | Panel | ## Expected Behavior
## Actual Behavior
Unable to get the Control in the Static Panel and open the child window
## Steps to Reproduce the Problem
1.
2.
3.
## Short Example of Code to Demonstrate the Problem
## Specifications
- Pywinauto version:
- Python version and bitness:
- Pla... | open | 2020-05-14T10:36:03Z | 2020-06-07T13:19:28Z | https://github.com/pywinauto/pywinauto/issues/932 | [
"question"
] | uvanesh | 3 |
explosion/spaCy | data-science | 13,264 | Regex doesn't work if less than 3 characters? | <!-- NOTE: For questions or install related issues, please open a Discussion instead. -->
## How to reproduce the behaviour
Taken and adjusted right from the docs:
```python
import spacy
from spacy.matcher import Matcher
nlp = spacy.blank("en")
matcher = Matcher(nlp.vocab, validate=True)
pattern = [
... | closed | 2024-01-23T16:14:48Z | 2024-02-23T00:05:21Z | https://github.com/explosion/spaCy/issues/13264 | [
"feat / matcher"
] | SHxKM | 3 |
joerick/pyinstrument | django | 168 | Feature request: cumulated time / total time / ncalls statistics + report | I used pyinstrument today to find bottlenecks in my optical simulation code, and found it overall very helpful. The HTML report is very usable and looks great!
One feature I was missing (or didn't find :-)) compared to builtin cProfile, is the possibility to sort / display **cumulative time for individual functions*... | closed | 2021-11-30T12:48:12Z | 2022-11-06T18:22:40Z | https://github.com/joerick/pyinstrument/issues/168 | [] | loehnertj | 4 |
dunossauro/fastapi-do-zero | sqlalchemy | 234 | Probleminha de versão do python na aula 10 | Fiz esse gist, pois tive problema por causa da versão do Python na aula 10
https://gist.github.com/fabiocasadossites/7194d9c6b36eed1452547d7ea8f24bef | closed | 2024-08-25T20:23:44Z | 2024-08-27T17:32:21Z | https://github.com/dunossauro/fastapi-do-zero/issues/234 | [] | fabiocasadossites | 2 |
dmlc/gluon-cv | computer-vision | 1,038 | Issue with "pose estimation" using GPU | For this tutorial: https://gluon-cv.mxnet.io/build/examples_pose/cam_demo.html.
I tried GPU, but failed with problems like :
```
[22:57:26] c:\jenkins\workspace\mxnet-tag\mxnet\src\operator\nn\cudnn\./cudnn_algoreg-inl.h:97: Running performance tests to find the best convolution algorithm, this can take a while... (... | closed | 2019-11-13T15:05:07Z | 2021-06-07T07:04:29Z | https://github.com/dmlc/gluon-cv/issues/1038 | [
"Stale"
] | dbsxdbsx | 4 |
CorentinJ/Real-Time-Voice-Cloning | python | 549 | Import Error | Hey, i am trying to run this code and everytime i run demo_toolbox.py there comes an error "failed to load qt binding" i tried reinstalling matplotlib and also tried installing PYQt5 .
Need Help !!!
| closed | 2020-10-06T20:23:24Z | 2020-10-12T09:55:04Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/549 | [] | jay-1104 | 5 |
Nemo2011/bilibili-api | api | 298 | 【建议】爬取视频弹幕时对cookies应该不设置要求 | 看了一下代码,发现爬取视频弹幕需要提供cookies,但是大部分视频不需要cookies即可获取弹幕,是否可以修改为若不提供credential也可以爬取弹幕。 | closed | 2023-05-22T00:03:54Z | 2023-05-24T11:17:20Z | https://github.com/Nemo2011/bilibili-api/issues/298 | [] | jhzgjhzg | 4 |
Avaiga/taipy | data-visualization | 2,293 | Have part or dialog centered to the element clicked | ### Description
Here, I have clicked on an icon and I have a dropdown menu of labels next to where I clicked:

Here, I have clicked on icon and I see a dialog/part showing up next to where I clicked:
. The API has changed, I think. See https://github.com/inducer/pudb/pull/83.
| open | 2013-08-13T04:34:13Z | 2014-01-25T20:17:55Z | https://github.com/inducer/pudb/issues/84 | [] | asmeurer | 1 |
gradio-app/gradio | data-visualization | 10,611 | thinking=true in some models | - [X] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
The IBM model granite has a setting which allows for reasoning or not. You set thinking=true or false.
It's like this:
```python
input_ids = tokenizer.apply_chat_template(conv, return_... | closed | 2025-02-17T20:09:40Z | 2025-02-17T21:10:44Z | https://github.com/gradio-app/gradio/issues/10611 | [] | surak | 2 |
3b1b/manim | python | 1,824 | Pip doesn't install a new enough numpy | ### Describe the bug
I ran
```
$ pip install manimgl
$ manimgl
```
and got the error
```
import numpy.typing as npt
ModuleNotFoundError: No module named 'numpy.typing'
```
### Additional context
I have numpy 1.19 and I numpy.typing requires numpy 1.20. I think the pip requirements files need to speci... | closed | 2022-06-02T21:51:49Z | 2022-06-04T08:04:34Z | https://github.com/3b1b/manim/issues/1824 | [
"bug"
] | thomasahle | 3 |
twopirllc/pandas-ta | pandas | 385 | Stochastic Rsi is very different from trading view values (again without proof) | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
**Upgrade.**
```sh
$ pip install -U git+https://github.com/twopirllc/pandas-ta
```
**Describe the bug**
I ran a simple call to stochastic rsi with the same... | closed | 2021-09-02T10:48:31Z | 2021-09-02T15:19:44Z | https://github.com/twopirllc/pandas-ta/issues/385 | [
"bug"
] | hosseinghafarian | 1 |
CorentinJ/Real-Time-Voice-Cloning | tensorflow | 1,198 | Error when training encoder | Hello, I am appealing to all who can and want to help. so I have a problem when I run encoder training, the first time everything is working fine and then gives an error. here it is:
..........
Step 110 Loss: 3.9845 EER: 0.4027 Step time: mean: 31023ms std: 39773ms
Average execution time over 10 steps:
... | open | 2023-04-19T10:38:46Z | 2023-04-19T10:38:46Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1198 | [] | terminatormlp | 0 |
scikit-image/scikit-image | computer-vision | 6,890 | Update Hausdorff Distance example to show usage as a segmentation metric and clarify docstring | ### Description:
## What is the issue?
The current version of [the Hausdorff Distance example](https://scikit-image.org/docs/stable/auto_examples/segmentation/plot_hausdorff_distance.html#hausdorff-distance) computes the distance on a set of four points. The example, however, is a bit confusing, as generally Haus... | open | 2023-04-13T08:28:20Z | 2023-10-26T11:48:50Z | https://github.com/scikit-image/scikit-image/issues/6890 | [
":pray: Feature request"
] | adfoucart | 9 |
axnsan12/drf-yasg | django | 762 | Not able to group any ListAPIView using Tags | I am not able to group any ListAPIView using Tags. This seems to be happening for only ListAPIView. There is no error or warning on Django debug console. The particular API gets grouped in the default untagged group. Any ideas on how to overcome this?
```
class GET_CurrencyList_API(generics.ListAPIView):
"""
... | open | 2021-12-21T06:22:39Z | 2025-03-21T10:49:34Z | https://github.com/axnsan12/drf-yasg/issues/762 | [
"bug",
"help wanted",
"1.21.x"
] | aibharata | 2 |
serengil/deepface | deep-learning | 537 | RAM leak with multiple calls | Hello @serengil, many thanks for this awesome library!
I noticed a non neglectible memory leak when calling `DeepFace.analyze()` multiple times. I've seen #78 and your suggestion to not use the function in a `for` loop and to use the `tf.keras.backend.clear_session()` to clear the tf graph.
Unfortunately, even ca... | closed | 2022-08-19T09:01:54Z | 2022-08-20T11:14:55Z | https://github.com/serengil/deepface/issues/537 | [
"question"
] | nicobonne | 6 |
nltk/nltk | nlp | 3,024 | nltk 3.7 requires explicit download of omw-1.4 on Linux | Consider the following script:
```
import nltk
nltk.download("wordnet")
nltk.corpus.wordnet.synsets("test")
```
This runs successfully on both Windows and Linux for nltk version 3.5, however for version 3.7 it only succeeds for Windows and produces the following error on Linux:
> [nltk_data] Downloading ... | closed | 2022-07-21T09:24:05Z | 2024-11-18T13:38:10Z | https://github.com/nltk/nltk/issues/3024 | [] | lanzkron | 8 |
facebookresearch/fairseq | pytorch | 5,142 | text after filtering OOV is empty output | Japanese TTS
downloaded the model with - wget https://dl.fbaipublicfiles.com/mms/tts/jvn.tar.gz
after running infer.py, there is no text after the line - text after filtering OOV:
What's the problem? | closed | 2023-05-24T03:02:51Z | 2023-05-25T01:20:41Z | https://github.com/facebookresearch/fairseq/issues/5142 | [
"bug",
"needs triage"
] | lisea2017 | 8 |
tensorlayer/TensorLayer | tensorflow | 535 | Failed: TensorLayer (b10975ab) | *Sent by Read the Docs (readthedocs@readthedocs.org). Created by [fire](https://fire.fundersclub.com/).*
---
| TensorLayer build #7116813
---
| 
---
| Build Failed for TensorLayer (latest)
---
Error: Problem parsing YAML configuration. Inval... | closed | 2018-04-30T04:12:23Z | 2018-04-30T04:26:32Z | https://github.com/tensorlayer/TensorLayer/issues/535 | [] | fire-bot | 0 |
lux-org/lux | pandas | 186 | [SETUP] Failed building wheel for scikit-learn | I am working on a Ubuntu 18.04.5 LTS machine, and I am trying to install lux-api using pip as described in the docs. My installation exits on the following error:
error: Command "x86_64-linux-gnu-gcc -pthread -Wno-unused-result -Wsign-compare -DNDEBUG -g -fwrapv -O2 -Wall -g -fstack-protector-strong -Wformat -Werro... | closed | 2020-12-23T20:01:14Z | 2021-01-06T09:21:17Z | https://github.com/lux-org/lux/issues/186 | [
"setup"
] | vmreyes12 | 1 |
d2l-ai/d2l-en | tensorflow | 1,779 | The `devices` argument in the TF implementation of d2l.predict_seq2seq | The TF implementation of `d2l.predict_seq2seq` in https://github.com/d2l-ai/d2l-en/pull/1768/files?file-filters%5B%5D=.md#diff-dbae7acee5140a9e76359207c8a1b718efcc82d4e7fbd194d6036ab0ee8e2130R883 removes `devices` argument with a note "We don't need the `device` argument in TF as TF uses available device automatically.... | open | 2021-06-08T01:42:02Z | 2023-10-31T14:20:58Z | https://github.com/d2l-ai/d2l-en/issues/1779 | [
"tensorflow-adapt-track"
] | astonzhang | 5 |
davidsandberg/facenet | computer-vision | 919 | Training on a small dataset | I have a small dataset and I get the OutOfRangeError after a few epochs. Is it possible to use the dataset multiple times (e.g. `dataset.repeat()` )? How should I modify the code? | open | 2018-11-13T14:20:13Z | 2019-04-25T07:23:45Z | https://github.com/davidsandberg/facenet/issues/919 | [] | FSet89 | 1 |
vaexio/vaex | data-science | 2,343 | [BUG-REPORT] rename when the new name is already a column has unexpected results | so this is a tricky little bug
Because we were renaming but not dropping the original columns, _sometimes_ vaex wouldn't overwrite correctly (I'll make an issue in the vaex github).
You can run these to understand the issue fully
```
import vaex
import numpy as np
df = vaex.example()[["x","y"]]
df["data_x"]... | open | 2023-02-24T16:42:20Z | 2023-02-24T16:42:47Z | https://github.com/vaexio/vaex/issues/2343 | [] | Ben-Epstein | 0 |
KevinMusgrave/pytorch-metric-learning | computer-vision | 727 | Numpy requirement | Hello,
pytorch-metric-learning has this numpy requirement that makes it hard to work with other package needing numpy > 2.0.
Would it be possible to loosen the numpy requirement ?
https://github.com/KevinMusgrave/pytorch-metric-learning/blob/60bab5ff9233de90b01a5c28d6a5c6cb02604640/setup.py#L42 | closed | 2024-10-31T14:49:41Z | 2024-11-04T09:32:39Z | https://github.com/KevinMusgrave/pytorch-metric-learning/issues/727 | [] | pchampio | 2 |
pytorch/vision | computer-vision | 8,270 | CocoDetection dataset incompatible with Faster R-CNN model Training and mAP calculation | ### 🐛 Describe the bug
### **🐛 Bug**
I would like to thank you for Object Detection Finetuning tutorial. The **CocoDetection** dataset appears to be incompatible with the Faster R-CNN model, I have been using **transforms-v2-end-to-end-object-detection-segmentation-example** for coco detection. The TorchVision Ob... | open | 2024-02-12T20:12:37Z | 2024-03-14T19:50:35Z | https://github.com/pytorch/vision/issues/8270 | [] | anirudh6415 | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 1,730 | GaboxR67/MelBandRoformers | Last Error Received:
Process: Ensemble Mode
If this error persists, please contact the developers with the error details.
Raw Error Details:
AttributeError: ""'norm'""
Traceback Error: "
File "UVR.py", line 9274, in process_start
File "separate.py", line 730, in seperate
File "separate.py", line 943, in demix... | open | 2025-02-06T10:13:20Z | 2025-02-11T14:12:35Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1730 | [] | infyplay | 1 |
mckinsey/vizro | data-visualization | 866 | Fix theme flickering | There's a quick theme change flickering that happens when the page is refreshed. It doesn't depend on the default theme set in the vm.Dashboard.
It looks like this started happening since the 0.1.25 version. | closed | 2024-11-12T10:14:20Z | 2024-11-13T14:05:31Z | https://github.com/mckinsey/vizro/issues/866 | [] | huong-li-nguyen | 0 |
InstaPy/InstaPy | automation | 6,570 | get_key = shared_data.get("entry_data").get("ProfilePage") - AttributeError: 'NoneType' object has no attribute 'get' | Just yesterday (3/28/2022) instapy stopped working for me:
with smart_run(session):
File "C:\Python39\lib\contextlib.py", line 119, in __enter__
return next(self.gen)
File "C:\Users\Eric\AppData\Roaming\Python\Python39\site-packages\instapy\util.py", line 1983, in smart_run
session.login()
File "... | closed | 2022-03-29T06:27:12Z | 2022-03-29T07:55:19Z | https://github.com/InstaPy/InstaPy/issues/6570 | [] | ersom | 1 |
plotly/dash-table | plotly | 560 | Renaming export button [feature suggestion] | Hi, the possibility to rename export button from "Export" to something custom could be necessary for apps where context suggests more elaborate naming or naming in another language.
Thank you:) | open | 2019-08-28T09:19:18Z | 2019-08-28T09:19:18Z | https://github.com/plotly/dash-table/issues/560 | [] | vetertann | 0 |
nonebot/nonebot2 | fastapi | 2,478 | Feature: 查看已安装插件及版本 | ### 希望能解决的问题
列出所有已安装的插件,以及查看已安装插件的版本
### 描述所需要的功能
列出所有已安装的插件,以及查看已安装插件的版本 | closed | 2023-12-04T02:51:25Z | 2023-12-10T10:13:48Z | https://github.com/nonebot/nonebot2/issues/2478 | [
"enhancement"
] | WindStill | 4 |
scikit-hep/awkward | numpy | 2,455 | `ak.flatten` flattens strings with `axis != None` | ### Version of Awkward Array
main
### Description and code to reproduce
We are leaning towards strings being a robust abstraction — if you want to erase a string, remove the parameters (or use `ak.enforce_type`).
However, there are some holes in this, notably with `ak.flatten`:
```python
>>> ak.flatten([... | closed | 2023-05-11T14:24:57Z | 2023-05-26T17:51:54Z | https://github.com/scikit-hep/awkward/issues/2455 | [
"bug (unverified)"
] | agoose77 | 0 |
huggingface/datasets | numpy | 7,047 | Save Dataset as Sharded Parquet | ### Feature request
`to_parquet` currently saves the dataset as one massive, monolithic parquet file, rather than as several small parquet files. It should shard large datasets automatically.
### Motivation
This default behavior makes me very sad because a program I ran for 6 hours saved its results using `to_... | open | 2024-07-12T23:47:51Z | 2024-07-17T12:07:08Z | https://github.com/huggingface/datasets/issues/7047 | [
"enhancement"
] | tom-p-reichel | 2 |
pytorch/vision | computer-vision | 8,087 | Custom coco format dataset | Hello! Can you suggest the structure of this dataset?
I want to use a custom dataset in coco format.
But I need to know what folder/file structure is needed for training.
```python
def get_args_parser(add_help=True):
import argparse
parser = argparse.ArgumentParser(description="PyTorch Detection Tra... | closed | 2023-11-02T10:18:15Z | 2023-11-07T15:01:36Z | https://github.com/pytorch/vision/issues/8087 | [] | Egorundel | 10 |
d2l-ai/d2l-en | machine-learning | 2,590 | Website of preview version is down. | Please fix. Thanks! | open | 2024-03-13T15:16:28Z | 2024-04-29T14:30:59Z | https://github.com/d2l-ai/d2l-en/issues/2590 | [] | Shujian2015 | 5 |
521xueweihan/HelloGitHub | python | 2,743 | 【项目推荐】一个简单易用,跨平台的通用版本管理器,VMR | ## 推荐项目
- 项目地址:https://github.com/gvcgo/version-manager
- 类别:Go
- 项目标题:一个简单易用,跨平台却非常强大的通用版本管理器,VMR
- 项目描述:
目前各种SDK版本管理器存在以下缺点:
- 各种语言的SDK版本管理器各自为政,彼此间差异较大,跨平台支持也不够完善。因此,作为多语言开发者,希望有一款开箱即用,能够支持多种常见编程语言的版本管理器。
- 现存的版本管理器很少有支持编程工具安装的,例如,很多发布在github上的好的开源工具,只能手动下载安装,比较麻烦。
- 现存的版本管理器都是直接从SDK列表页抓取然后下载... | open | 2024-05-06T02:29:34Z | 2024-06-05T03:29:18Z | https://github.com/521xueweihan/HelloGitHub/issues/2743 | [
"Go 项目"
] | moqsien | 0 |
pyqtgraph/pyqtgraph | numpy | 3,017 | Export to SVG with opacity on items | It would be very nice if the opacities of the items were respected when exporting to SVG.
Opacities are set with `setOpacity` method of the `ImageItem` (which very conveniently works with any other item).
Here is a minimal example where the resulting image is grey (black blended with white). However, the saved ... | open | 2024-05-02T10:31:58Z | 2024-05-02T10:37:24Z | https://github.com/pyqtgraph/pyqtgraph/issues/3017 | [
"enhancement",
"exporters",
"svg"
] | ElpadoCan | 0 |
Kludex/mangum | asyncio | 154 | [Question] What is a purpose of using asyncio.Queue() in HTTPCycle | https://github.com/jordaneremieff/mangum/blob/8763b9736a8ef60d16e10a204617f9b25fcd6a61/mangum/protocols/http.py#L45-L46 | closed | 2020-12-29T12:14:01Z | 2020-12-30T11:30:35Z | https://github.com/Kludex/mangum/issues/154 | [] | ediskandarov | 2 |
simple-login/app | flask | 2,015 | Private vulnerability reporting ? | Please, I sent you an email on Thu, Jan 11, 3:54 PM (7 days ago), regarding a vulnerability on the latest codebase with a severity of High 7.7. Could you please consider enabling GitHub private reporting for this repository, so that the process of private reporting go smooth?
https://docs.github.com/en/code-securit... | closed | 2024-01-18T15:24:00Z | 2024-01-19T17:52:20Z | https://github.com/simple-login/app/issues/2015 | [] | Sim4n6 | 0 |
tqdm/tqdm | jupyter | 1,237 | Add integration to prometheus pushgateway | - [x] I have marked all applicable categories:
+ [ ] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [x] new feature request
- [x] I have visited the [source website], and in particular
rea... | open | 2021-08-30T03:35:58Z | 2021-08-30T03:36:53Z | https://github.com/tqdm/tqdm/issues/1237 | [] | MartinForReal | 0 |
K3D-tools/K3D-jupyter | jupyter | 61 | Grid text overlays surface mesh | Image is pretty obvious. Let me know if you need an example to reproduce it, my current one requires external dependencies.

| closed | 2017-06-20T13:10:38Z | 2017-10-30T10:38:36Z | https://github.com/K3D-tools/K3D-jupyter/issues/61 | [] | martinal | 5 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 34 | Error: No module named 'selenium_driverless.pycdp' on Linux | Hi there,
Not sure if this is related to the other CDP bug reported on Linux but just in case:
trying out the examples provided in the readme give the following error (with or without async)
```
Error: ModuleNotFoundError: No module named 'selenium_driverless.pycdp'
```
Any idea what might be causing this? | closed | 2023-08-20T03:22:03Z | 2023-08-27T09:34:18Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/34 | [
"needs information"
] | alisawazrak | 2 |
Asabeneh/30-Days-Of-Python | python | 12 | Reference code for exercises | Thanks for the open source code, is there any reference code for the exercise? | closed | 2019-12-20T10:59:13Z | 2019-12-20T11:28:18Z | https://github.com/Asabeneh/30-Days-Of-Python/issues/12 | [] | Donaghys | 1 |
HIT-SCIR/ltp | nlp | 376 | batch处理的时候,分词会引入空字符 | 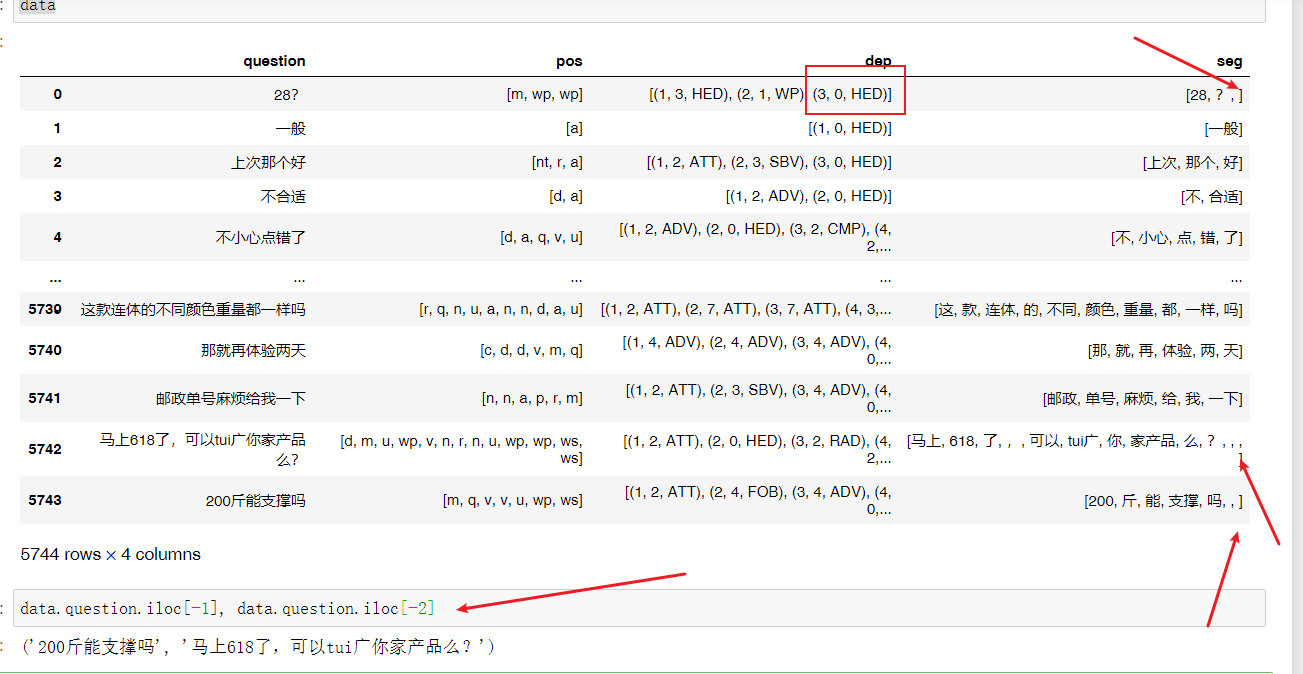
可以看到分词得到的结果,会有字段为空,从最后2个文本可以看到文本末尾并没有空格
这样会影响后续句法分析的结果,参见第1条文本 | closed | 2020-07-02T12:06:13Z | 2020-07-02T13:11:20Z | https://github.com/HIT-SCIR/ltp/issues/376 | [] | Nipi64310 | 3 |
microsoft/nni | tensorflow | 4,966 | Or(<function DoReFaQuantizer.validate_config.<locals>.<lambda> at 0x000001EF3142C9D0>) did not validate 'input' | I use the
>
configure_list = [{
'quant_types': ['weight','input','output'],
'quant_bits': {
'weight': 8,
'input': 8,
'output': 8
}, # you can just use `int` here because all `quan_types` share sa... | open | 2022-06-27T01:54:55Z | 2022-07-05T07:19:26Z | https://github.com/microsoft/nni/issues/4966 | [
"user raised",
"support",
"quantize"
] | sunpeil | 2 |
suitenumerique/docs | django | 416 | Add mermaid.js support | ## Feature Request
**Is your feature request related to a problem or unsupported use case? Please describe.**
This will allow users to do diagrams (and other cool stuff) in their docs.
This has been requested by a few users with a technical background.
**Describe the solution you'd like**
I'd like to add support of ... | open | 2024-11-12T14:12:22Z | 2025-03-18T15:10:25Z | https://github.com/suitenumerique/docs/issues/416 | [
"designed"
] | virgile-dev | 7 |
deepinsight/insightface | pytorch | 2,359 | C++ build on insightface | Can any one provide the same implementation in c++ because I want to run face detection and face recognition in c++ I am already using it in python but my requirement is to convert all code into c++ | open | 2023-07-03T12:46:19Z | 2023-07-06T06:38:19Z | https://github.com/deepinsight/insightface/issues/2359 | [] | AwaisPF | 3 |
iperov/DeepFaceLab | deep-learning | 568 | DFL 2.0 'copy' is not defined | Hi :)
First: i think thats the right direction u goes :)
if i start the DFl 2.0 i got an error:
Error: name 'copy' is not defined
Traceback (most recent call last):
File "N:\xy\_internal\DeepFaceLab\mainscripts\Trainer.py", line 57, in trainerThread
debug=debug,
File "N:\xy\_internal\DeepFaceLab\mode... | closed | 2020-01-22T19:48:15Z | 2020-01-23T06:44:20Z | https://github.com/iperov/DeepFaceLab/issues/568 | [] | blanuk | 1 |
twopirllc/pandas-ta | pandas | 466 | Problem with strategy (all) | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```python
import pandas_ta as ta
print(ta.version)
```
0.3.14b0
**Do you have _TA Lib_ also installed in your environment?**
```sh
$ pip list
```
Yes
TA-Lib 0.4.17
**Upgrade.**
``... | closed | 2022-01-20T12:36:09Z | 2022-01-22T00:17:18Z | https://github.com/twopirllc/pandas-ta/issues/466 | [
"question",
"wontfix",
"info"
] | hn2 | 26 |
google/seq2seq | tensorflow | 239 | No Speedup for Multiple GPUs? | I just switched to using an 8 GPU AWS instance from a 1 GPU machine, same instance. The log shows that tensorflow finds the additional GPUs, but the log makes it seem that there's no significant speedup using the additional GPUs. When I was using 1 GPU, it was about 150 seconds for 100 steps, and it's still about the s... | open | 2017-05-31T21:27:48Z | 2017-09-07T03:47:12Z | https://github.com/google/seq2seq/issues/239 | [] | npowell88 | 3 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 4,218 | The "enter a receipt interfaces" does not show up when a direct link to a context is used | ### What version of GlobaLeaks are you using?
5.0.11
### What browser(s) are you seeing the problem on?
All
### What operating system(s) are you seeing the problem on?
Linux
### Describe the issue
As reported by [sperti](https://github.com/esperti) the "enter a receipt interfaces" does not show up when a direct ... | closed | 2024-10-04T08:38:04Z | 2024-10-05T10:39:47Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/4218 | [
"T: Bug",
"C: Client"
] | evilaliv3 | 1 |
huggingface/text-generation-inference | nlp | 2,757 | The same model, but different loading methods will result in very different inference speeds? | ### System Info
TGI version latest;single NVIDIA GeForce RTX 3090;
### Information
- [X] Docker
- [ ] The CLI directly
### Tasks
- [X] An officially supported command
- [ ] My own modifications
### Reproduction
The first loading method (loading llama3 8B model from Hugging face):
```
model=meta-llama/Meta-Llam... | open | 2024-11-19T12:55:49Z | 2024-11-19T13:06:01Z | https://github.com/huggingface/text-generation-inference/issues/2757 | [] | hjs2027864933 | 1 |
explosion/spaCy | machine-learning | 13,293 | Install via `requirements.txt` documentation doesn't work | The docs [state](https://spacy.io/usage/models#models-download) I can specify the model like this in `requirements.txt`:
```
spacy>=3.0.0,<4.0.0
en_core_web_sm @ https://github.com/explosion/spacy-models/releases/download/en_core_web_sm-3.4.0/en_core_web_sm-3.4.0-py3-none-any.whl
```
This attempts to download ... | open | 2024-01-30T19:46:14Z | 2024-09-25T05:38:14Z | https://github.com/explosion/spaCy/issues/13293 | [
"docs",
"install"
] | SHxKM | 18 |
pytest-dev/pytest-django | pytest | 1,009 | assertRaisesMessage expects wrong excepted_exception type | I am trying to use `assertRaisesMessage` to test for `save()` raising an `IntegrityError`. However, the `expected_exception` expected type is `BaseException`.
vscode shows me `Type[Exception]` for `TestCase.assertRaisesMessage`.
Code snippet:
```python
from django.db.utils import IntegrityError
from pytest_d... | closed | 2022-04-21T14:50:12Z | 2022-04-26T08:57:23Z | https://github.com/pytest-dev/pytest-django/issues/1009 | [] | mschoettle | 0 |
datapane/datapane | data-visualization | 26 | token and graph plotting issues | So, the issue that I am facing is that I am not able to publish the report on the data pane server.
it is showing the token is invalid but that's not the case I have rechecked it and the token seems fine.
The second issue is when I am trying to display graphs only the first dp.Plot() method is working and other g... | closed | 2020-09-25T17:54:34Z | 2020-10-21T15:22:58Z | https://github.com/datapane/datapane/issues/26 | [] | pooja-anandani | 3 |
thp/urlwatch | automation | 332 | Can urlwatch do the same thing Website Watcher does? | Basically I can bulk import thousands of links into website watcher and it will detect and alert me if the link has any changes (without considering HTML tags -- just content)
Can urlwatch do the same thing? I need to be able to bulk import links and alert me if there's a content change in the website. I don't want ... | closed | 2018-12-06T19:57:49Z | 2020-07-10T13:34:04Z | https://github.com/thp/urlwatch/issues/332 | [] | majestique | 1 |
dask/dask | pandas | 11,145 | Concat with unknown divisions raises TypeError | **Describe the issue**:
When trying to concatenate multiple Dataframes without known divisions with Dask.Dataframe.multi.concat an error is raised as shown below.

After some digging in the codebase I found some logic causin... | closed | 2024-05-24T14:00:05Z | 2024-11-12T15:05:29Z | https://github.com/dask/dask/issues/11145 | [
"needs triage"
] | manschoe | 3 |
amidaware/tacticalrmm | django | 1,416 | Github does not want me to sponsor any more (drops PayPal). Alternative? | In some way this is a feature request,..
As Github drops PayPal from sponsoring (only), I cannot use it any more.
I don´t really like PayPal, but in this case it´s my only option. And I guess I´m not the only one.
Will there be an alternative?
| closed | 2023-01-25T20:17:40Z | 2023-02-20T20:46:10Z | https://github.com/amidaware/tacticalrmm/issues/1416 | [] | forti42 | 2 |
python-arq/arq | asyncio | 272 | Logging jobs info to database | I want to log job infomation to a database (PostgreSQL). Where is the best place to put it ? | closed | 2021-10-25T01:51:04Z | 2023-04-04T17:47:39Z | https://github.com/python-arq/arq/issues/272 | [] | hieulw | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,111 | Keeping a Socket.io connection on in the background | **Your question**
I currently have a Tweepy streaming api connected via flask socketio and everything is working fine (tweets are streaming in without any problems). Question: is it possible to configure socketio in such a manner that when a user lands on the webpage, the latest streamed tweets are already showing? Ri... | closed | 2019-11-25T21:21:40Z | 2019-11-26T01:38:57Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1111 | [
"question"
] | ghost | 1 |
plotly/dash | data-visualization | 2,882 | Switching back and forth between dcc.Tabs doesn't seem to release memory in the browser | In a dash app with a 50 000 point scatter chart in tab 1 and another in tab 2, switching back and forth between those tabs increases the memory footprint that I see in the Chrome task manager by about 100 MB every time but it doesn't look like any gets released.

### Steps to Reproduce

I saw that the default value of the parameter 'show_seconds' in the source code is true, Actually, the widget does not display the o... | open | 2025-03-21T08:35:29Z | 2025-03-21T08:35:29Z | https://github.com/odoo/odoo/issues/202837 | [] | a1061026202 | 0 |
ckan/ckan | api | 8,725 | DataStore Delete Uncaught ProgrammingErrors | ## CKAN version
master branch (2.11 ??)
## Describe the bug
pSQL ProgrammingErrors are not caught and re-raised as ValidationErrors in datastore_delete
### Steps to reproduce
Steps to reproduce the behavior:
- Have a datastore field that is a text field
- Insert some data
- Try to delete with filters on the text f... | open | 2025-03-17T18:22:22Z | 2025-03-19T19:20:06Z | https://github.com/ckan/ckan/issues/8725 | [] | JVickery-TBS | 3 |
thtrieu/darkflow | tensorflow | 917 | From Darknet to Darkflow and then Movidius | Hi,
I'm going to use a retrained model with darknet of YOLOv2Tiny on the Movidius NCS.
I cannot produce a .pb and .meta file from .cfg and .weights and I don't know why.
I use the command:
`python3 flow --model apple_tiny_yolov2/apple_tiny_yolov2.cfg --load apple_tiny_yolov2/apple_tiny_yolov2_1000.weights --sa... | open | 2018-10-08T08:46:13Z | 2018-10-08T08:46:13Z | https://github.com/thtrieu/darkflow/issues/917 | [] | keldrom | 0 |
nalepae/pandarallel | pandas | 135 | [Feature Request] Timer on Progress Bar | I'm switching to this package on places using tqdm.pandas earlier, think it would be nice to have a similar timer at the progress bar to track Estimated Time to Finish and monitor the speed. | open | 2021-02-12T22:00:19Z | 2024-04-27T07:48:12Z | https://github.com/nalepae/pandarallel/issues/135 | [] | zhenyulin | 5 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.