

metadata
license: bsd-3-clause
library_name: braindecode
pipeline_tag: feature-extraction
tags:
- eeg
- biosignal
- pytorch
- neuroscience
- braindecode
- foundation-model
- transformer
PBT
Patched Brain Transformer (PBT) model from Klein et al (2025) [pbt].
Architecture-only repository. Documents the
braindecode.models.PBTclass. No pretrained weights are distributed here. Instantiate the model and train it on your own data.
Quick start
pip install braindecode
from braindecode.models import PBT
model = PBT(
n_chans=22,
sfreq=250,
input_window_seconds=4.0,
n_outputs=4,
)
The signal-shape arguments above are illustrative defaults — adjust to match your recording.
Documentation
- Full API reference: https://braindecode.org/stable/generated/braindecode.models.PBT.html
- Interactive browser (live instantiation, parameter counts): https://huggingface.co/spaces/braindecode/model-explorer
- Source on GitHub: https://github.com/braindecode/braindecode/blob/master/braindecode/models/patchedtransformer.py#L17
Architecture
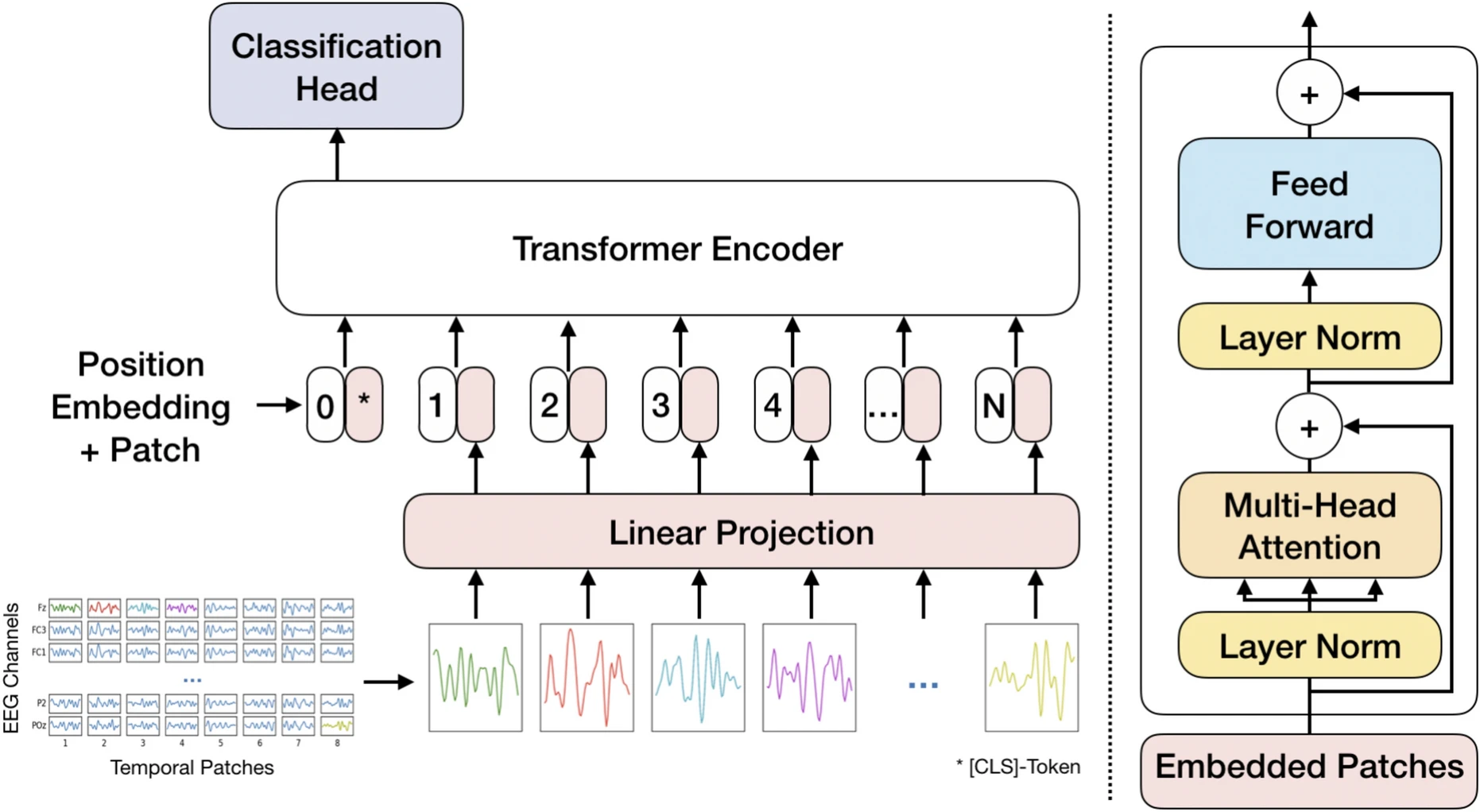
Parameters
| Parameter | Type | Description |
|---|---|---|
d_input |
int, optional | Size (in samples) of each patch (token) extracted along the time axis. |
embed_dim |
int, optional | Transformer embedding dimensionality. |
num_layers |
int, optional | Number of Transformer encoder layers. |
num_heads |
int, optional | Number of attention heads. |
drop_prob |
float, optional | Dropout probability used in Transformer components. |
learnable_cls |
bool, optional | Whether the classification token is learnable. |
bias_transformer |
bool, optional | Whether to use bias in Transformer linear layers. |
activation |
nn.Module, optional | Activation function class to use in Transformer feed-forward layers. |
References
- Klein, T., Minakowski, P., & Sager, S. (2025). Flexible Patched Brain Transformer model for EEG decoding. Scientific Reports, 15(1), 1-12. https://www.nature.com/articles/s41598-025-86294-3
- Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J. & Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations (ICLR).
- Krell, M. M., Kosec, M., Perez, S. P., & Fitzgibbon, A. (2021). Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance. arXiv preprint arXiv:2107.02027.
Citation
Cite the original architecture paper (see References above) and braindecode:
@article{aristimunha2025braindecode,
title = {Braindecode: a deep learning library for raw electrophysiological data},
author = {Aristimunha, Bruno and others},
journal = {Zenodo},
year = {2025},
doi = {10.5281/zenodo.17699192},
}
License
BSD-3-Clause for the model code (matching braindecode). Pretraining-derived weights, if you fine-tune from a checkpoint, inherit the licence of that checkpoint and its training corpus.