

Replace with clean markdown card
Browse files
README.md
CHANGED
|
@@ -9,19 +9,17 @@ tags:
|
|
| 9 |
- neuroscience
|
| 10 |
- braindecode
|
| 11 |
- foundation-model
|
| 12 |
-
- convolutional
|
| 13 |
- transformer
|
| 14 |
---
|
| 15 |
|
| 16 |
# PBT
|
| 17 |
|
| 18 |
-
Patched Brain Transformer (PBT) model from Klein et al (2025) .
|
| 19 |
|
| 20 |
-
> **Architecture-only repository.**
|
| 21 |
> `braindecode.models.PBT` class. **No pretrained weights are
|
| 22 |
-
> distributed here**
|
| 23 |
-
> data
|
| 24 |
-
> separately.
|
| 25 |
|
| 26 |
## Quick start
|
| 27 |
|
|
@@ -40,257 +38,45 @@ model = PBT(
|
|
| 40 |
)
|
| 41 |
```
|
| 42 |
|
| 43 |
-
The signal-shape arguments above are
|
| 44 |
-
|
| 45 |
|
| 46 |
## Documentation
|
| 47 |
-
|
| 48 |
-
-
|
| 49 |
-
<https://braindecode.org/stable/generated/braindecode.models.PBT.html>
|
| 50 |
-
- Interactive browser with live instantiation:
|
| 51 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 52 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/patchedtransformer.py#L17>
|
| 53 |
|
| 54 |
-
## Architecture description
|
| 55 |
-
|
| 56 |
-
The block below is the rendered class docstring (parameters,
|
| 57 |
-
references, architecture figure where available).
|
| 58 |
-
|
| 59 |
-
<div class='bd-doc'><main>
|
| 60 |
-
<p>Patched Brain Transformer (PBT) model from Klein et al (2025) [pbt]_.</p>
|
| 61 |
-
<span style="display:inline-block;padding:2px 8px;border-radius:4px;background:#d9534f;color:white;font-size:11px;font-weight:600;margin-right:4px;">Foundation Model</span>
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
This implementation was based in https://github.com/timonkl/PatchedBrainTransformer/
|
| 66 |
-
|
| 67 |
-
.. figure:: https://raw.githubusercontent.com/timonkl/PatchedBrainTransformer/refs/heads/main/PBT_sketch.png
|
| 68 |
-
:align: center
|
| 69 |
-
:alt: Patched Brain Transformer Architecture
|
| 70 |
-
:width: 680px
|
| 71 |
-
|
| 72 |
-
PBT tokenizes EEG trials into per-channel patches, linearly projects each
|
| 73 |
-
patch to a model embedding dimension, prepends a classification token and
|
| 74 |
-
adds channel-aware positional embeddings. The token sequence is processed
|
| 75 |
-
by a Transformer encoder stack and classification is performed from the
|
| 76 |
-
classification token.
|
| 77 |
-
|
| 78 |
-
.. rubric:: Macro Components
|
| 79 |
-
|
| 80 |
-
- ``PBT.tokenization`` **(patch extraction)**
|
| 81 |
-
|
| 82 |
-
*Operations.* The pre-processed EEG signal :math:`X \in \mathbb{R}^{C \times T}`
|
| 83 |
-
(with :math:`C = \text{n_chans}` and :math:`T = \text{n_times}`) is divided into
|
| 84 |
-
non-overlapping patches of size :math:`d_{\text{input}}` along the time axis.
|
| 85 |
-
This process yields :math:`N` total patches, calculated as
|
| 86 |
-
:math:`N = C \left\lfloor \frac{T}{D} \right\rfloor` (where :math:`D = d_{\text{input}}`).
|
| 87 |
-
When time shifts are applied, :math:`N` decreases to
|
| 88 |
-
:math:`N = C \left\lfloor \frac{T - T_{\text{aug}}}{D} \right\rfloor`.
|
| 89 |
-
|
| 90 |
-
*Role.* Tokenizes EEG trials into fixed-size, per-channel patches so the model
|
| 91 |
-
remains adaptive to different numbers of channels and recording lengths.
|
| 92 |
-
Process is inspired by Vision Transformers [visualtransformer]_ and
|
| 93 |
-
adapted for GPT context from [efficient-batchpacking]_.
|
| 94 |
-
|
| 95 |
-
- ``PBT.patch_projection`` **(patch embedding)**
|
| 96 |
-
|
| 97 |
-
*Operations.* The linear layer ``PBT.patch_projection`` maps the tokens from dimension
|
| 98 |
-
:math:`d_{\text{input}}` to the Transformer embedding dimension :math:`d_{\text{model}}`.
|
| 99 |
-
Patches :math:`X_P` are projected as :math:`X_E = X_P W_E^\top`, where
|
| 100 |
-
:math:`W_E \in \mathbb{R}^{d_{\text{model}} \times D}`. In this configuration
|
| 101 |
-
:math:`d_{\text{model}} = 2D` with :math:`D = d_{\text{input}}`.
|
| 102 |
-
|
| 103 |
-
*Interpretability.* Learns periodic structures similar to frequency filters in
|
| 104 |
-
the first convolutional layers of CNNs (for example :class:`~braindecode.models.EEGNet`).
|
| 105 |
-
The learned filters frequently focus on the high-frequency range (20-40 Hz),
|
| 106 |
-
which correlates with beta and gamma waves linked to higher concentration levels.
|
| 107 |
-
|
| 108 |
-
- ``PBT.cls_token`` **(classification token)**
|
| 109 |
-
|
| 110 |
-
*Operations.* A classification token :math:`[c_{\text{ls}}] \in \mathbb{R}^{1 \times d_{\text{model}}}`
|
| 111 |
-
is prepended to the projected patch sequence :math:`X_E`. The CLS token can optionally
|
| 112 |
-
be learnable (see ``learnable_cls``).
|
| 113 |
-
|
| 114 |
-
*Role.* Acts as a dedicated readout token that aggregates information through the
|
| 115 |
-
Transformer encoder stack.
|
| 116 |
-
|
| 117 |
-
- ``PBT.pos_embedding`` **(positional embedding)**
|
| 118 |
-
|
| 119 |
-
*Operations.* Positional indices are generated by ``PBT.linear_projection``, an instance
|
| 120 |
-
of :class:`~braindecode.models.patchedtransformer._ChannelEncoding`, and mapped to vectors
|
| 121 |
-
through :class:`~torch.nn.Embedding`. The embedding table
|
| 122 |
-
:math:`W_{\text{pos}} \in \mathbb{R}^{(N+1) \times d_{\text{model}}}` is added to the token
|
| 123 |
-
sequence, yielding :math:`X_{\text{pos}} = [c_{\text{ls}}, X_E] + W_{\text{pos}}`.
|
| 124 |
-
|
| 125 |
-
*Role/Interpretability.* Introduces spatial and temporal dependence to counter the
|
| 126 |
-
position invariance of the Transformer encoder. The learned positional embedding
|
| 127 |
-
exposes spatial relationships, often revealing a symmetric pattern in central regions
|
| 128 |
-
(C1-C6) associated with the motor cortex.
|
| 129 |
-
|
| 130 |
-
- ``PBT.transformer_encoder`` **(sequence processing and attention)**
|
| 131 |
-
|
| 132 |
-
*Operations.* The token sequence passes through :math:`n_{\text{blocks}}` Transformer
|
| 133 |
-
encoder layers. Each block combines a Multi-Head Self-Attention (MHSA) module with
|
| 134 |
-
``num_heads`` attention heads and a Feed-Forward Network (FFN). Both MHSA
|
| 135 |
-
and FFN use parallel residual connections with Layer Normalization inside the blocks
|
| 136 |
-
and apply dropout (``drop_prob``) within the Transformer components.
|
| 137 |
-
|
| 138 |
-
*Role/Robustness.* Self-attention enables every token to consider all others, capturing
|
| 139 |
-
global temporal and spatial dependencies immediately and adaptively. This architecture
|
| 140 |
-
accommodates arbitrary numbers of patches and channels, supporting pre-training across
|
| 141 |
-
diverse datasets.
|
| 142 |
-
|
| 143 |
-
- ``PBT.final_layer`` **(readout)**
|
| 144 |
-
|
| 145 |
-
*Operations.* A linear layer operates on the processed CLS token only, and the model
|
| 146 |
-
predicts class probabilities as :math:`y = \operatorname{softmax}([c_{\text{ls}}] W_{\text{class}}^\top + b_{\text{class}})`.
|
| 147 |
-
|
| 148 |
-
*Role.* Performs the final classification from the information aggregated into the CLS
|
| 149 |
-
token after the Transformer encoder stack.
|
| 150 |
-
|
| 151 |
-
.. rubric:: Convolutional Details
|
| 152 |
-
|
| 153 |
-
PBT omits convolutional layers; equivalent feature extraction is carried out by the patch
|
| 154 |
-
pipeline and attention stack.
|
| 155 |
-
|
| 156 |
-
* **Temporal.** Tokenization slices the EEG into fixed windows of size :math:`D = d_{\text{input}}`
|
| 157 |
-
(for the default configuration, :math:`D=64` samples :math:`\approx 0.256\,\text{s}` at
|
| 158 |
-
:math:`250\,\text{Hz}`), while ``PBT.patch_projection`` learns periodic patterns within each
|
| 159 |
-
patch. The Transformer encoder then models long- and short-range temporal dependencies through
|
| 160 |
-
self-attention.
|
| 161 |
-
|
| 162 |
-
* **Spatial.** Patches are channel-specific, keeping the architecture adaptive to any electrode
|
| 163 |
-
montage. Channel-aware positional encodings :math:`W_{\text{pos}}` capture relationships between
|
| 164 |
-
nearby sensors; learned embeddings often form symmetric motifs across motor cortex electrodes
|
| 165 |
-
(C1–C6), and self-attention propagates information across all channels jointly.
|
| 166 |
-
|
| 167 |
-
* **Spectral.** ``PBT.patch_projection`` acts similarly to the first convolutional layer in
|
| 168 |
-
:class:`~braindecode.models.EEGNet`, learning frequency-selective filters without an explicit
|
| 169 |
-
Fourier transform. The highest-energy filters typically reside between :math:`20` and
|
| 170 |
-
:math:`40\,\text{Hz}`, aligning with beta/gamma rhythms tied to focused motor imagery.
|
| 171 |
-
|
| 172 |
-
.. rubric:: Attention / Sequential Modules
|
| 173 |
-
|
| 174 |
-
* **Attention Details.** ``PBT.transformer_encoder`` stacks :math:`n_{\text{blocks}}` Transformer
|
| 175 |
-
encoder layers with Multi-Head Self-Attention. Every token attends to all others, enabling
|
| 176 |
-
immediate global integration across time and channels and supporting heterogeneous datasets.
|
| 177 |
-
Attention rollout visualisations highlight strong activations over motor cortex electrodes
|
| 178 |
-
(C3, C4, Cz) during motor imagery decoding.
|
| 179 |
-
|
| 180 |
-
|
| 181 |
-
.. warning::
|
| 182 |
-
|
| 183 |
-
**Important:** As the other Foundation Models in Braindecode, :class:`PBT` is
|
| 184 |
-
designed for large-scale pre-training and fine-tuning. Training from
|
| 185 |
-
scratch on small datasets may lead to suboptimal results. Cross-Dataset
|
| 186 |
-
pre-training and subsequent fine-tuning is recommended to leverage the
|
| 187 |
-
full potential of this architecture.
|
| 188 |
-
|
| 189 |
-
Parameters
|
| 190 |
-
----------
|
| 191 |
-
d_input : int, optional
|
| 192 |
-
Size (in samples) of each patch (token) extracted along the time axis.
|
| 193 |
-
embed_dim : int, optional
|
| 194 |
-
Transformer embedding dimensionality.
|
| 195 |
-
num_layers : int, optional
|
| 196 |
-
Number of Transformer encoder layers.
|
| 197 |
-
num_heads : int, optional
|
| 198 |
-
Number of attention heads.
|
| 199 |
-
drop_prob : float, optional
|
| 200 |
-
Dropout probability used in Transformer components.
|
| 201 |
-
learnable_cls : bool, optional
|
| 202 |
-
Whether the classification token is learnable.
|
| 203 |
-
bias_transformer : bool, optional
|
| 204 |
-
Whether to use bias in Transformer linear layers.
|
| 205 |
-
activation : nn.Module, optional
|
| 206 |
-
Activation function class to use in Transformer feed-forward layers.
|
| 207 |
-
|
| 208 |
-
References
|
| 209 |
-
----------
|
| 210 |
-
.. [pbt] Klein, T., Minakowski, P., & Sager, S. (2025).
|
| 211 |
-
Flexible Patched Brain Transformer model for EEG decoding.
|
| 212 |
-
Scientific Reports, 15(1), 1-12.
|
| 213 |
-
https://www.nature.com/articles/s41598-025-86294-3
|
| 214 |
-
.. [visualtransformer] Dosovitskiy, A., Beyer, L., Kolesnikov, A.,
|
| 215 |
-
Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M.,
|
| 216 |
-
Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J. & Houlsby,
|
| 217 |
-
N. (2021). An Image is Worth 16x16 Words: Transformers for Image
|
| 218 |
-
Recognition at Scale. International Conference on Learning
|
| 219 |
-
Representations (ICLR).
|
| 220 |
-
.. [efficient-batchpacking] Krell, M. M., Kosec, M., Perez, S. P., &
|
| 221 |
-
Fitzgibbon, A. (2021). Efficient sequence packing without
|
| 222 |
-
cross-contamination: Accelerating large language models without
|
| 223 |
-
impacting performance. arXiv preprint arXiv:2107.02027.
|
| 224 |
-
|
| 225 |
-
.. rubric:: Hugging Face Hub integration
|
| 226 |
-
|
| 227 |
-
When the optional ``huggingface_hub`` package is installed, all models
|
| 228 |
-
automatically gain the ability to be pushed to and loaded from the
|
| 229 |
-
Hugging Face Hub. Install with::
|
| 230 |
-
|
| 231 |
-
pip install braindecode[hub]
|
| 232 |
-
|
| 233 |
-
**Pushing a model to the Hub:**
|
| 234 |
-
|
| 235 |
-
.. code::
|
| 236 |
-
from braindecode.models import PBT
|
| 237 |
-
|
| 238 |
-
# Train your model
|
| 239 |
-
model = PBT(n_chans=22, n_outputs=4, n_times=1000)
|
| 240 |
-
# ... training code ...
|
| 241 |
-
|
| 242 |
-
# Push to the Hub
|
| 243 |
-
model.push_to_hub(
|
| 244 |
-
repo_id="username/my-pbt-model",
|
| 245 |
-
commit_message="Initial model upload",
|
| 246 |
-
)
|
| 247 |
-
|
| 248 |
-
**Loading a model from the Hub:**
|
| 249 |
-
|
| 250 |
-
.. code::
|
| 251 |
-
from braindecode.models import PBT
|
| 252 |
-
|
| 253 |
-
# Load pretrained model
|
| 254 |
-
model = PBT.from_pretrained("username/my-pbt-model")
|
| 255 |
-
|
| 256 |
-
# Load with a different number of outputs (head is rebuilt automatically)
|
| 257 |
-
model = PBT.from_pretrained("username/my-pbt-model", n_outputs=4)
|
| 258 |
-
|
| 259 |
-
**Extracting features and replacing the head:**
|
| 260 |
|
| 261 |
-
|
| 262 |
-
import torch
|
| 263 |
|
| 264 |
-
|
| 265 |
-
# Extract encoder features (consistent dict across all models)
|
| 266 |
-
out = model(x, return_features=True)
|
| 267 |
-
features = out["features"]
|
| 268 |
|
| 269 |
-
# Replace the classification head
|
| 270 |
-
model.reset_head(n_outputs=10)
|
| 271 |
|
| 272 |
-
|
| 273 |
|
| 274 |
-
|
| 275 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 276 |
|
| 277 |
-
config = model.get_config() # all __init__ params
|
| 278 |
-
with open("config.json", "w") as f:
|
| 279 |
-
json.dump(config, f)
|
| 280 |
|
| 281 |
-
|
| 282 |
|
| 283 |
-
|
| 284 |
-
|
| 285 |
-
|
| 286 |
|
| 287 |
-
See :ref:`load-pretrained-models` for a complete tutorial.</main>
|
| 288 |
-
</div>
|
| 289 |
|
| 290 |
## Citation
|
| 291 |
|
| 292 |
-
|
| 293 |
-
*References* section above) and braindecode:
|
| 294 |
|
| 295 |
```bibtex
|
| 296 |
@article{aristimunha2025braindecode,
|
|
|
|
| 9 |
- neuroscience
|
| 10 |
- braindecode
|
| 11 |
- foundation-model
|
|
|
|
| 12 |
- transformer
|
| 13 |
---
|
| 14 |
|
| 15 |
# PBT
|
| 16 |
|
| 17 |
+
Patched Brain Transformer (PBT) model from Klein et al (2025) [pbt].
|
| 18 |
|
| 19 |
+
> **Architecture-only repository.** Documents the
|
| 20 |
> `braindecode.models.PBT` class. **No pretrained weights are
|
| 21 |
+
> distributed here.** Instantiate the model and train it on your own
|
| 22 |
+
> data.
|
|
|
|
| 23 |
|
| 24 |
## Quick start
|
| 25 |
|
|
|
|
| 38 |
)
|
| 39 |
```
|
| 40 |
|
| 41 |
+
The signal-shape arguments above are illustrative defaults — adjust to
|
| 42 |
+
match your recording.
|
| 43 |
|
| 44 |
## Documentation
|
| 45 |
+
- Full API reference: <https://braindecode.org/stable/generated/braindecode.models.PBT.html>
|
| 46 |
+
- Interactive browser (live instantiation, parameter counts):
|
|
|
|
|
|
|
| 47 |
<https://huggingface.co/spaces/braindecode/model-explorer>
|
| 48 |
- Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/patchedtransformer.py#L17>
|
| 49 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 50 |
|
| 51 |
+
## Architecture
|
|
|
|
| 52 |
|
| 53 |
+
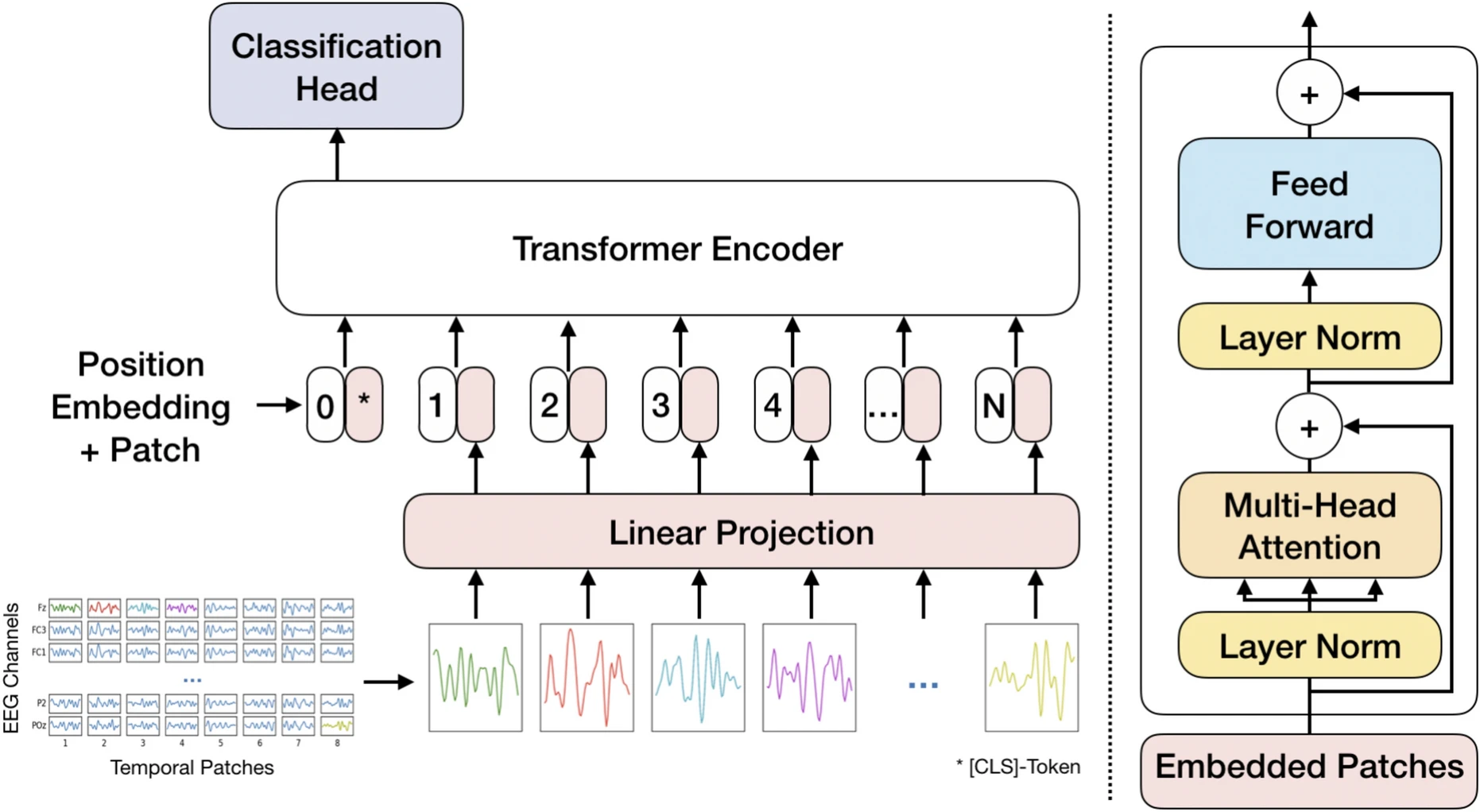
|
|
|
|
|
|
|
|
|
|
| 54 |
|
|
|
|
|
|
|
| 55 |
|
| 56 |
+
## Parameters
|
| 57 |
|
| 58 |
+
| Parameter | Type | Description |
|
| 59 |
+
|---|---|---|
|
| 60 |
+
| `d_input` | int, optional | Size (in samples) of each patch (token) extracted along the time axis. |
|
| 61 |
+
| `embed_dim` | int, optional | Transformer embedding dimensionality. |
|
| 62 |
+
| `num_layers` | int, optional | Number of Transformer encoder layers. |
|
| 63 |
+
| `num_heads` | int, optional | Number of attention heads. |
|
| 64 |
+
| `drop_prob` | float, optional | Dropout probability used in Transformer components. |
|
| 65 |
+
| `learnable_cls` | bool, optional | Whether the classification token is learnable. |
|
| 66 |
+
| `bias_transformer` | bool, optional | Whether to use bias in Transformer linear layers. |
|
| 67 |
+
| `activation` | nn.Module, optional | Activation function class to use in Transformer feed-forward layers. |
|
| 68 |
|
|
|
|
|
|
|
|
|
|
| 69 |
|
| 70 |
+
## References
|
| 71 |
|
| 72 |
+
1. Klein, T., Minakowski, P., & Sager, S. (2025). Flexible Patched Brain Transformer model for EEG decoding. Scientific Reports, 15(1), 1-12. https://www.nature.com/articles/s41598-025-86294-3
|
| 73 |
+
2. Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., Gelly, S., Uszkoreit, J. & Houlsby, N. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. International Conference on Learning Representations (ICLR).
|
| 74 |
+
3. Krell, M. M., Kosec, M., Perez, S. P., & Fitzgibbon, A. (2021). Efficient sequence packing without cross-contamination: Accelerating large language models without impacting performance. arXiv preprint arXiv:2107.02027.
|
| 75 |
|
|
|
|
|
|
|
| 76 |
|
| 77 |
## Citation
|
| 78 |
|
| 79 |
+
Cite the original architecture paper (see *References* above) and braindecode:
|
|
|
|
| 80 |
|
| 81 |
```bibtex
|
| 82 |
@article{aristimunha2025braindecode,
|