
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
HumanSignal/labelImg | deep-learning | 147 | Uable to select the small bounding box | I am working on ubuntu 16.04. I am able to select the bounding box and label them. But if the objects I have is smaller (about 10 x 10) px. then I am not able to select that bounding box and due to that I am not able to edit the label. It works for larger bounding box, but not for smaller bounding box.
| closed | 2017-08-21T09:18:38Z | 2017-08-25T05:46:17Z | https://github.com/HumanSignal/labelImg/issues/147 | [] | ghost | 0 |
SYSTRAN/faster-whisper | deep-learning | 722 | [INFO] Getting encoder output | I would like to extract the encoder output, so far, I did this:
```
from faster_whisper import WhisperModel
from datasets import load_dataset
from datasets import Audio
minds = load_dataset("PolyAI/minds14", name="de-DE", split="train")
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
model_si... | closed | 2024-02-28T20:49:59Z | 2024-07-08T02:23:57Z | https://github.com/SYSTRAN/faster-whisper/issues/722 | [] | ManilBen | 2 |
Lightning-AI/pytorch-lightning | data-science | 20,231 | torch.cuda.OutOfMemoryError after running tuner.scale_batch_size() in "binsearch" mode | ### Bug description
I am encountering a torch.cuda.OutOfMemoryError after using the tuner.scale_batch_size() method in "binsearch" mode to find the optimal batch size for my model. In contrast, when I use mode="power", the tuning process works without any issues, and I can successfully find an optimal batch size witho... | open | 2024-08-26T20:13:58Z | 2024-10-23T17:32:09Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20231 | [
"bug",
"needs triage",
"ver: 2.4.x"
] | rittik9 | 0 |
mirumee/ariadne | graphql | 660 | snake_case_fallback_resolvers not calling obj.get(attr_name) | **Ariadne version:** 0.13.0
**Python version:** 3.8.11
Hello. I am using the [databases](https://www.encode.io/databases/) package with an [asyncpg](https://magicstack.github.io/asyncpg/current/) backend to interact with a PostgreSQL database. The objects returned from my queries are of the type `databases.backends... | closed | 2021-08-31T22:54:18Z | 2021-09-03T22:52:35Z | https://github.com/mirumee/ariadne/issues/660 | [
"enhancement",
"roadmap"
] | RodrigoTMOLima | 1 |
biolab/orange3 | data-visualization | 6,001 | Recursive imputer | Use case: We have a model with 200 features. We apply a “Model base imputer (simple tree)” to fill in missing data.
Problem: The “Imputer” widget fills in just a part of the missing data (that's the limit of the default 1-NN regressor used).
Current workaround: We have chained 5 instances of the same imputer, tha... | closed | 2022-06-02T15:41:36Z | 2022-09-30T08:49:45Z | https://github.com/biolab/orange3/issues/6001 | [
"bug"
] | hydrastarmaster | 5 |
QuivrHQ/quivr | api | 3,192 | Remove knowledge from brain | * shouldn't remove knowledge from the KMS
* if KM is folder remove all subsequent children from brain
* Check what rules apply for the syncs vs local knowledge | closed | 2024-09-11T12:53:40Z | 2024-12-30T00:26:22Z | https://github.com/QuivrHQ/quivr/issues/3192 | [
"Stale",
"area: backend"
] | linear[bot] | 2 |
mlfoundations/open_clip | computer-vision | 505 | Information about BiomedCLIP-PubMedBERT config | I saw that a pull request had been made for BioMedCLIP model. I can also see that it has been merged. However, if I try to load the model using
`model, _, preprocess_val = open_clip.create_model_and_transforms("BiomedCLIP-PubMedBERT_256-vit_base_patch16_224")`
I get an error
`RuntimeError: Model config for Biom... | closed | 2023-04-22T13:36:55Z | 2023-06-29T20:37:44Z | https://github.com/mlfoundations/open_clip/issues/505 | [] | chinmay5 | 4 |
robotframework/robotframework | automation | 4,931 | Collapse long failure messages in log and report | Currently long failure messages (over 40 lines by default, configurable with `--max-error-lines` (#2576)) are cut from the middle. This is done to avoid huge messages messing up logs and reports, but the problem is that some valuable information may be lost. Another issue is that even the resulting messages are somewha... | open | 2023-11-06T17:11:28Z | 2024-03-25T22:19:45Z | https://github.com/robotframework/robotframework/issues/4931 | [
"enhancement",
"priority: medium",
"effort: medium"
] | pekkaklarck | 3 |
huggingface/datasets | deep-learning | 7,320 | ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['label'] | ### Describe the bug
I am trying to create a PEFT model from DISTILBERT model, and run a training loop. However, the trainer.train() is giving me this error: ValueError: You should supply an encoding or a list of encodings to this method that includes input_ids, but you provided ['label']
Here is my code:
### St... | closed | 2024-12-10T20:23:11Z | 2024-12-10T23:22:23Z | https://github.com/huggingface/datasets/issues/7320 | [] | atrompeterog | 1 |
zappa/Zappa | django | 510 | [Migrated] Be able to provide the path of the task as a string | Originally from: https://github.com/Miserlou/Zappa/issues/1333 by [michelorengo](https://github.com/michelorengo)
## Description
This is to be able to provide the function/task path as a string (and not use the inspection)
## GitHub Issues
#1332 1332
| closed | 2021-02-20T09:43:42Z | 2022-07-16T07:20:49Z | https://github.com/zappa/Zappa/issues/510 | [] | jneves | 1 |
mwaskom/seaborn | matplotlib | 3,544 | `CategoricalPlotter` broke statannotations | Hi,
I am using [`statannotations`](https://github.com/trevismd/statannotations) toolbox to perform statistics and add p<sub>value</sub> on a violin plot but it stopped working with `seaborn v0.13`.
Here is the issue faced:
`statannotations` relies on `seabon v0.11`, you can push up to `v0.12.2` but not `v0.13` as... | closed | 2023-11-02T16:18:18Z | 2024-09-04T14:15:31Z | https://github.com/mwaskom/seaborn/issues/3544 | [] | sjg2203 | 5 |
keras-team/keras | deep-learning | 20,390 | Empty model history logs when training with large `steps_per_execution` | Using the tensorflow backend, training with `steps_per_execution` larger than the training set results in empty logs.
Code to reproduce:
`!pip install keras-nightly`
```python
import numpy as np
import os
os.environ["KERAS_BACKEND"] = "tensorflow"
import keras
x = np.ones((10, 4))
y = np.ones((10, 1))... | closed | 2024-10-22T09:21:17Z | 2024-10-22T23:36:49Z | https://github.com/keras-team/keras/issues/20390 | [] | nicolaspi | 0 |
python-restx/flask-restx | api | 172 | No swagger related files after packaging | **Ask a question**
No swagger related files after packaging
**Additional context**
I pulled the source code of the project, packaged it through "python setup.py sdist bdist_wheel", and found that there are no swagger related files in the package. It is inaccessible to access http://127.0.0.1:8080/swagger
| open | 2020-07-09T06:38:08Z | 2020-09-14T19:45:01Z | https://github.com/python-restx/flask-restx/issues/172 | [
"question"
] | somta | 1 |
babysor/MockingBird | deep-learning | 388 | 这个只是学习音色?能学习说话风格语气么? | open | 2022-02-14T04:39:02Z | 2022-02-17T09:05:41Z | https://github.com/babysor/MockingBird/issues/388 | [] | SeedKunY | 1 | |
Sanster/IOPaint | pytorch | 292 | [BUG] When ControlNet is enabled I only get glitched/corrupted results in the inpainting area | **Model**
Realistic Vision 1.4
**Describe the bug**
When ControlNet is enabled I only get glitched/corrupted results in the inpainting area
**System Info**
Software version used
- lama-cleaner: 1.1.2
- pytorch: 2.0.0
I'm using mps, latest Mac OS Ventura 13.3.1
Screenshot:
![Arc - lama-cleaner - Ima... | open | 2023-04-23T19:58:43Z | 2023-04-25T01:26:25Z | https://github.com/Sanster/IOPaint/issues/292 | [] | alexzadeh | 1 |
huggingface/transformers | python | 36,124 | Speaker Verification: All Speakers Getting Perfect 1.000 Similarity Scores | ### System Info
### Bug Report
<!-- Important information -->
Model name (e.g. bert-base-cased): pyannote/embedding
Language (if applicable): English
Framework (PyTorch, TensorFlow, etc...): PyTorch
### Description
Using pyannote/embedding for speaker verification, getting perfect similarity scores (1.000) for all ... | closed | 2025-02-10T20:58:01Z | 2025-03-21T08:04:37Z | https://github.com/huggingface/transformers/issues/36124 | [
"bug"
] | misterpathologist | 2 |
alpacahq/alpaca-trade-api-python | rest-api | 660 | [Bug]: asyncio.run() cannot be called from a running event loop | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Current Behavior
when trying to run the historic_async.py in spyder keep getting the asyncio.run() running event loop error . I am running python 3.8
Could you kindly advice and help
### Expected Behavior
Expecting price data... | open | 2022-10-03T14:39:21Z | 2023-01-26T07:12:43Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/660 | [] | mehtap198 | 2 |
LibreTranslate/LibreTranslate | api | 687 | HelloGitHub Badge | Hi, We're thrilled to share that [your project](https://hellogithub.com/en/repository/a414dc09995f4b5188cf5acbe54c9107) has caught the attention of the HelloGitHub community and has been recognized for its merit. Your work is truly inspiring, and we'd like to invite you to participate in our [HelloGitHub Badge Program]... | closed | 2024-10-03T03:53:54Z | 2024-10-03T14:59:33Z | https://github.com/LibreTranslate/LibreTranslate/issues/687 | [] | 521xueweihan | 0 |
mage-ai/mage-ai | data-science | 5,408 | [BUG] Block fails to update metadatabase when running time is greater then idle_in_transaction_session_timeout | ### Mage version
0.9.73
### Describe the bug
We are using PostgreSQL as metadata storage for MageAI, our current orchestration tool. In the orchestrated pipelines, we have some blocks that can run for hours, in extreme cases, up to one day, as they orchestrate the processing of a massive amount of data.
What has... | open | 2024-09-11T21:11:58Z | 2024-09-13T12:00:07Z | https://github.com/mage-ai/mage-ai/issues/5408 | [
"bug"
] | messerzen | 0 |
geopandas/geopandas | pandas | 3,239 | REGR: incorrect order of left sjoin with within predicate | I think that #2353 has caused a regression when doing left join with within predicate:
```py
pts = gpd.GeoDataFrame(geometry=gpd.points_from_xy(*np.random.rand(2, 10)))
polys = gpd.GeoDataFrame({"id":[1, 2, 3, 4]}, geometry=[
box(0, 0, .5, .5),
box(0, .5, .5, 1),
box(.5, 0, 1, .5),
box(.5, .5, ... | closed | 2024-04-02T15:24:08Z | 2024-04-13T13:36:14Z | https://github.com/geopandas/geopandas/issues/3239 | [] | martinfleis | 1 |
napari/napari | numpy | 7,701 | Review these items for 0.6.0a1 | # Follow up items
- [ ] remove deprecated items #7550
- [ ] #7355
- [ ] Review feedback from #7700
- [ ] #7683
- [ ] #7665
- [ ] #7149
| open | 2025-03-14T23:48:11Z | 2025-03-15T01:14:51Z | https://github.com/napari/napari/issues/7701 | [
"feature"
] | willingc | 0 |
BlinkDL/RWKV-LM | pytorch | 290 | RWKV-6 and newer | To bring more awareness and adoption of RWKV, would it be possible to get benchmark scores on the Huggingface LLM leaderboard or on the model cards itself (For RWKV-6 and newer)?
https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/
Looks like they current track IFEval,BBH, MATH, GPQA, MUSR and MM... | open | 2025-02-09T23:00:45Z | 2025-02-16T10:02:28Z | https://github.com/BlinkDL/RWKV-LM/issues/290 | [] | DIGist | 1 |
strawberry-graphql/strawberry | django | 3,466 | Add better support for nested generics | This snippet is broken, because we don't check nested type var, we have done something similar here: https://github.com/strawberry-graphql/strawberry/pull/3463
```python
import strawberry
@strawberry.type
class Wrapper[T]:
value: T
@strawberry.type
class BlockRow[T]:
item: Wrapper[T]
@str... | open | 2024-04-20T20:11:11Z | 2025-03-20T15:56:42Z | https://github.com/strawberry-graphql/strawberry/issues/3466 | [] | patrick91 | 0 |
paperless-ngx/paperless-ngx | django | 8,317 | [BUG] trying to modify a specific correspondant item freeze the web page | ### Description
I have a correspondent in my list that causes the web page to freeze whenever I try to edit any correspondent.

In the screenshot above, it's the last one.
As soon as I apply a filter to remove this correspo... | closed | 2024-11-19T22:00:59Z | 2024-11-19T22:09:31Z | https://github.com/paperless-ngx/paperless-ngx/issues/8317 | [
"not a bug"
] | Underscan007 | 0 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,253 | Disabling of user not shown in audit log | Hi!
Would it be possible to add the date of disabeling of a user to the audit log? Currently it does not show up there. The disabeling is only shown in the Users log - but still with no date. The User log GUI could also benefit of a checkmark to verify a n account is active or disabled (Like the MFA column) | open | 2022-08-02T08:13:16Z | 2023-02-10T14:36:46Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3253 | [
"F: Audit Log"
] | schris-dk | 0 |
zappa/Zappa | django | 542 | [Migrated] Pipenv (if desired) | Originally from: https://github.com/Miserlou/Zappa/issues/1435 by [kennethreitz42](https://github.com/kennethreitz42)
Ran the tests, using only the provided `Pipfile.lock` — they mostly passed, so I assume everything is working as intended.
```
Ran 94 tests in 171.589s
FAILED (errors=2)
```
Please dismiss i... | closed | 2021-02-20T12:22:30Z | 2022-07-16T07:13:47Z | https://github.com/zappa/Zappa/issues/542 | [] | jneves | 1 |
biolab/orange3 | data-visualization | 6,999 | Crash on "Show help" and "Create report" | <!--
Thanks for taking the time to report a bug!
If you're raising an issue about an add-on (i.e., installed via Options > Add-ons), raise an issue in the relevant add-on's issue tracker instead. See: https://github.com/biolab?q=orange3
To fix the bug, we need to be able to reproduce it. Please answer the following qu... | closed | 2025-01-20T22:25:37Z | 2025-01-24T08:20:06Z | https://github.com/biolab/orange3/issues/6999 | [
"bug report"
] | GuidoBartoli | 5 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,382 | Warning: wandb package cannot be found. The option "--use_wandb" will result in error. | Warning: wandb package cannot be found. The option "--use_wandb" will result in error.
How can I solve the problem?
Thanks a lot. | closed | 2022-02-22T06:30:48Z | 2022-09-06T20:22:48Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1382 | [] | raylu1314coding | 6 |
vitalik/django-ninja | django | 1,207 | Returning alternate response objects | I have an endpoint that returns a profile details
```
@router.get("/profile/{id}", response=ProfileDetailsSchema)
```
to avoid leaking PPI, the ProfileDetailsSchema does not contain any fields containing personal details.
PPI details are accessed via
```
@router.get("/profile/{id}/private", response=... | open | 2024-06-26T11:00:04Z | 2024-06-27T16:00:56Z | https://github.com/vitalik/django-ninja/issues/1207 | [] | nhi-vanye | 1 |
python-gino/gino | asyncio | 668 | [question] Tornado fork mode with Gino | Hi, I am trying to create a REST API template based on Tornado and Gino and I would like your opinion/expertise on the fork mode.
is that likely to pose any problem?
when should I fork ? after import models ? before the set_bind ? no matter ?
what could be the side effect on the event loop ?
| closed | 2020-05-10T17:09:48Z | 2020-05-17T05:22:52Z | https://github.com/python-gino/gino/issues/668 | [
"question"
] | flapili | 2 |
pennersr/django-allauth | django | 3,634 | 'SyncToAsync.__call__' was never awaited session_check(request) | After upgrade to v0.61.0, i can see spurious warnings in logs:
```
.../lib/python3.12/site-packages/allauth/account/middleware.py:53: RuntimeWarning: coroutine 'SyncToAsync.__call__' was never awaited
session_check(request)
RuntimeWarning: Enable tracemalloc to get the object allocation traceback
```
Lookin... | closed | 2024-02-08T17:20:52Z | 2024-02-09T09:57:41Z | https://github.com/pennersr/django-allauth/issues/3634 | [] | stephane-martin | 2 |
lukas-blecher/LaTeX-OCR | pytorch | 8 | Error: Index out of range in self during the model training | I tried to train the model, in the CPU, but received the below error; not sure what could be the cause?
Loss: 1.0180: 2%|█▉ | 421/18013 [09:41<6:45:16, 1.38s/it]
Traceback (most recent call last):
File "train.py", line 94, in <m... | closed | 2021-05-02T19:32:04Z | 2021-05-03T15:33:02Z | https://github.com/lukas-blecher/LaTeX-OCR/issues/8 | [] | GopinathCool | 3 |
huggingface/datasets | computer-vision | 6,853 | Support soft links for load_datasets imagefolder | ### Feature request
Load_dataset from a folder of images doesn't seem to support soft links. It would be nice if it did, especially during methods development where image folders are being curated.
### Motivation
Images are coming from a complex variety of sources and we'd like to be able to soft link directly from ... | open | 2024-04-30T22:14:29Z | 2024-04-30T22:14:29Z | https://github.com/huggingface/datasets/issues/6853 | [
"enhancement"
] | billytcl | 0 |
jonra1993/fastapi-alembic-sqlmodel-async | sqlalchemy | 32 | Add a table self association example. | RT,
In the near future, I will add the following data tables:
``` python
class HeroComment:
id:
hero_id:
user_id:
content:
parent_id: -> point to other HeroComment
```
But before that, I want to discuss the problem of API path. Which of the following two forms is more appropriate?
- /comment/h... | closed | 2022-11-09T01:36:36Z | 2023-02-12T01:30:13Z | https://github.com/jonra1993/fastapi-alembic-sqlmodel-async/issues/32 | [] | dongfengweixiao | 3 |
modin-project/modin | pandas | 7,007 | How to Use Modin with ExtensionArrays and Accessors? | Pandas has an extension framework, how do you register the accessors and extension arrays with modin? My API has lots of custom dtypes and accessors to do specialized analysis and it would be great if modin honored those.
see: https://pandas.pydata.org/docs/development/extending.html | closed | 2024-03-05T11:48:48Z | 2024-03-07T14:07:35Z | https://github.com/modin-project/modin/issues/7007 | [
"question ❓"
] | achapkowski | 3 |
aio-libs-abandoned/aioredis-py | asyncio | 1,174 | [2.0] xread() halts when the connection is lost. | ### Describe the bug
If the connection with Redis is lost while the program is awaiting for `xread()` it get stuck until the connection is reestablished.
It doesn't raise any Exception, or at least timeout after the `block` time.
If I wrap `xread()` with `asyncio.wait_for()`, and force a disconnection, the `wait_f... | open | 2021-10-19T18:10:24Z | 2022-01-12T03:42:47Z | https://github.com/aio-libs-abandoned/aioredis-py/issues/1174 | [
"bug"
] | marciorasf | 1 |
fastapi/sqlmodel | pydantic | 57 | [BUG] Variables with annotation of 'typing.Literal' causes a panic | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2021-08-29T07:58:37Z | 2024-10-16T08:59:12Z | https://github.com/fastapi/sqlmodel/issues/57 | [
"question"
] | faresbakhit | 9 |
mljar/mljar-supervised | scikit-learn | 247 | Negative AUC and R2 | When optimized AUC eval_metric it has negative values. | closed | 2020-11-26T12:53:20Z | 2021-02-19T07:49:21Z | https://github.com/mljar/mljar-supervised/issues/247 | [
"bug"
] | pplonski | 1 |
ranaroussi/yfinance | pandas | 2,270 | throw exception when calling history() on a vietnamese stock which contains dividend record | ### Describe bug
When calling history() for Vietnamese stocks, if it contains dividend records, the dividend records will have a currency field, causing an exception. For example:
```
tk = yf.Ticker('PNJ.VN')
hist = tk.history(start='2024-11-01')
```
will cause:
```Traceback (most recent call last):
File "/Users... | open | 2025-02-17T07:13:40Z | 2025-03-08T11:45:44Z | https://github.com/ranaroussi/yfinance/issues/2270 | [] | alai04 | 2 |
xzkostyan/clickhouse-sqlalchemy | sqlalchemy | 247 | Release request | Hi! I'm starting to use your project. It looks awesome.
I noticed that the main branch has long had support for the asynch driver, but there was still no release.
When to expect it? It would help me a lot. Thanks! | closed | 2023-04-25T22:51:32Z | 2023-05-02T17:48:21Z | https://github.com/xzkostyan/clickhouse-sqlalchemy/issues/247 | [] | Noidor1 | 3 |
CPJKU/madmom | numpy | 70 | remove obsolete class constants | Formerly, most of these class constants were needed to set the default values for both the `__init__()` and the `add_arguments()` method. Since the latter moved to use `None` as default for most arguments, the class constants are more or less obsolete. We should remove them before someone starts using them.
| closed | 2016-01-25T13:53:30Z | 2016-03-07T14:38:50Z | https://github.com/CPJKU/madmom/issues/70 | [] | superbock | 1 |
microsoft/MMdnn | tensorflow | 112 | CaffeEmitter has not supported operator [Sequential] | Platform (like ubuntu 16.04/win10): ubuntu 14.04
Python version: 3.6
Source framework with version (like Tensorflow 1.4.1 with GPU): Keras 2.1.3
Destination framework with version (like CNTK 2.3 with GPU): Caffe
Pre-trained model path (webpath or webdisk path):
Running scripts:
I am trying to convert ... | closed | 2018-03-16T15:07:53Z | 2018-07-05T05:07:16Z | https://github.com/microsoft/MMdnn/issues/112 | [] | lamdawr | 1 |
miguelgrinberg/Flask-Migrate | flask | 494 | [4.0] app factory is called before click groups | **Describe the bug**
In 3.1.0, click groups declared with [FlaskGroup](https://flask.palletsprojects.com/en/2.2.x/api/#flask.cli.FlaskGroup) before the `create_app` factory of the group is called. In 4.0.0, this behavior changed and the app factory gets called before the click groups. This is a breaking change.
*... | closed | 2022-11-15T15:39:24Z | 2022-11-16T09:19:48Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/494 | [
"question"
] | gilbsgilbs | 6 |
NullArray/AutoSploit | automation | 398 | Unhandled Exception (3842f7fee) | Autosploit version: `3.0`
OS information: `Linux-4.18.0-kali2-amd64-x86_64-with-Kali-kali-rolling-kali-rolling`
Running context: `autosploit.py`
Error meesage: `global name 'Except' is not defined`
Error traceback:
```
Traceback (most recent call):
File "/root/Desktop/exploit 2018/Autosploit/autosploit/main.py", line ... | closed | 2019-01-21T21:40:12Z | 2019-04-02T20:27:08Z | https://github.com/NullArray/AutoSploit/issues/398 | [] | AutosploitReporter | 0 |
biolab/orange3 | data-visualization | 6,976 | Group By: add straightforward possiblility to do aggregations over all records | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
**What's your proposed solution?**
Sometimes it is useful to have several aggregations of selec... | open | 2025-01-02T15:54:33Z | 2025-01-13T09:47:36Z | https://github.com/biolab/orange3/issues/6976 | [
"meal"
] | wvdvegte | 5 |
suitenumerique/docs | django | 592 | Many file type not accepted as upload | ## Bug Report
**Problematic behavior**
.docx .mp4 .mov are not accepted
**Expected behavior/code**
I'd like to have the following to be accepted
MS (.docx, .pptx, .xlsx)
Vidéo (.mp4 . mov)
OpenDocument (.odt, .odp, .ods) | closed | 2025-01-29T10:18:17Z | 2025-03-03T19:58:41Z | https://github.com/suitenumerique/docs/issues/592 | [
"bug"
] | virgile-dev | 4 |
kubeflow/katib | scikit-learn | 1,802 | docker run is work. but katib trial don't work | /kind bug
`Error: failed to start container "tensorflow": Error response from daemon: OCI runtime create failed: container_linux.go:380: starting container process caused: exec: "--df_me=df_me.pkl": executable file not found in $PATH: unknown`
**What steps did you take and what happened:**
**1. docker build**
`... | closed | 2022-02-08T08:00:26Z | 2022-02-08T08:35:16Z | https://github.com/kubeflow/katib/issues/1802 | [
"kind/bug"
] | moey920 | 4 |
lexiforest/curl_cffi | web-scraping | 341 | [BUG] Curl.setopt() 中糟糕的类型传递 | 我尝试在aarch64 Android平台上运行这个项目,用最简单的方式测试:
```python
from curl_cffi import requests
res = requests.get("https://www.baidu.com")
print(res.text)
```
我得到了如下报错:
```
Traceback (most recent call last):
File "/data/user/0/coding.yu.pythoncompiler.new/files/default.py", line 3, in <module>
res = requests.get("htt... | closed | 2024-07-05T21:48:53Z | 2024-07-05T21:51:06Z | https://github.com/lexiforest/curl_cffi/issues/341 | [
"bug"
] | qishipai | 0 |
Nike-Inc/koheesio | pydantic | 114 | [BUG] Duplicate implementation of SynchronizeDeltaToSnowflakeTask | <!-- Please provide as much detail as possible to help us understand and reproduce the issue. This will enable us to address it more effectively. -->
## Describe the bug
There are two implementations of `SynchronizeDeltaToSnowflakeTask`
## Steps to Reproduce
Spark(Old): https://github.com/Nike-Inc/koheesio/blob... | closed | 2024-11-24T09:25:42Z | 2024-11-24T23:14:05Z | https://github.com/Nike-Inc/koheesio/issues/114 | [
"bug"
] | mikita-sakalouski | 0 |
plotly/dash-table | plotly | 491 | Changing one header cell changes all the header cells on the left | 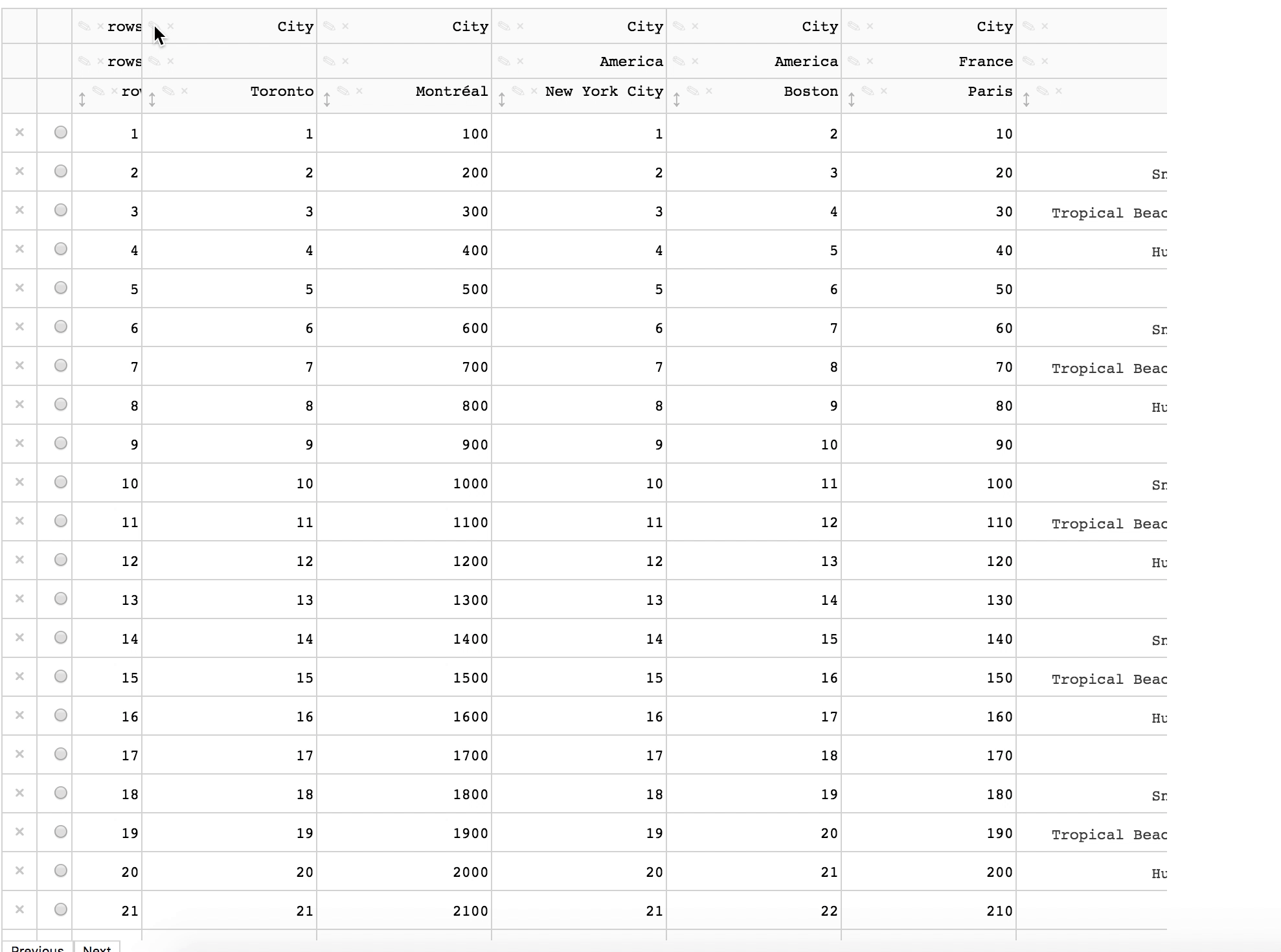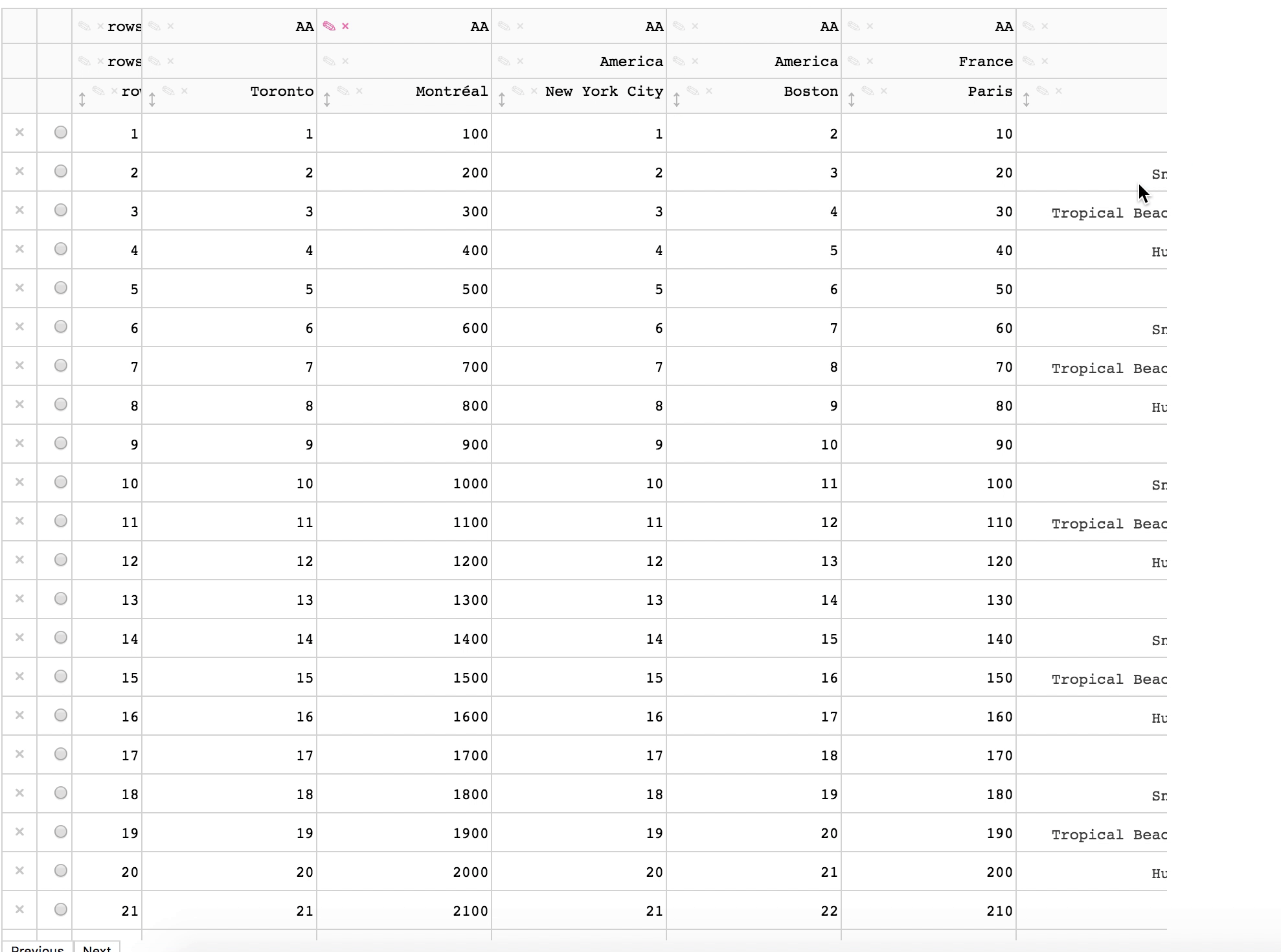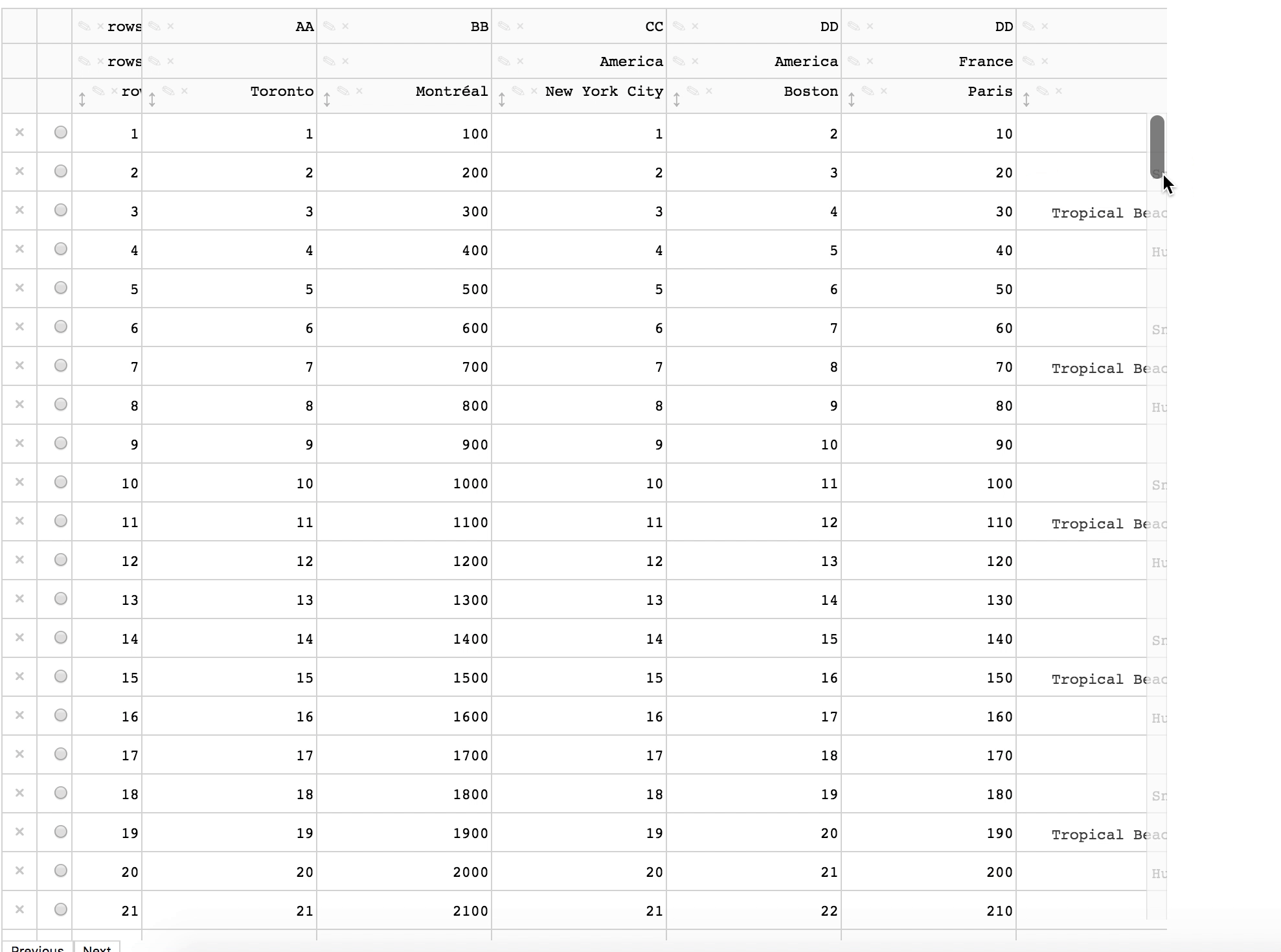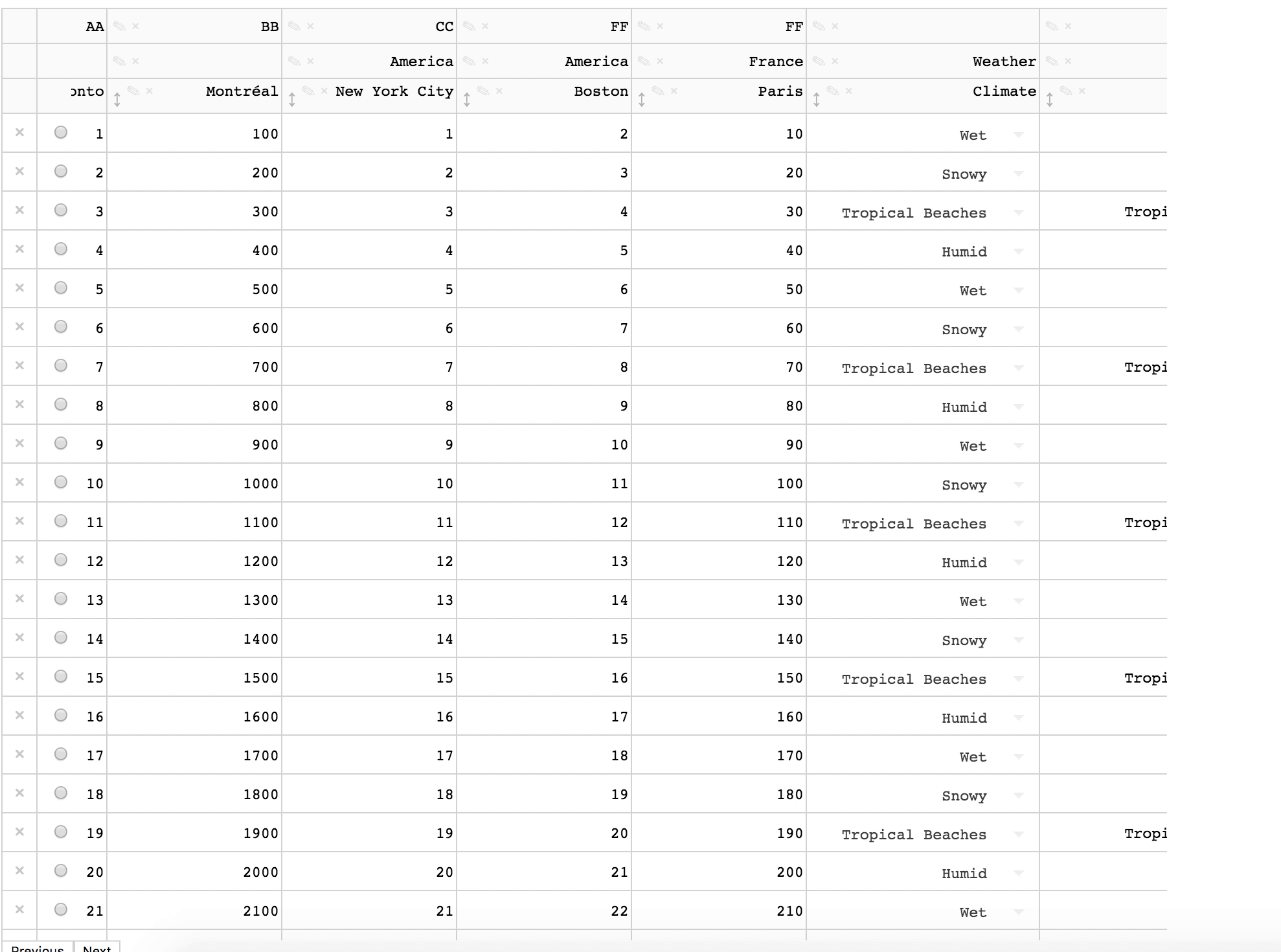
This only happened once when the cell is first changed. | closed | 2019-07-04T14:04:36Z | 2019-07-19T13:41:36Z | https://github.com/plotly/dash-table/issues/491 | [
"dash-type-bug",
"size: 1"
] | alinastarkov | 1 |
scrapy/scrapy | web-scraping | 6,354 | AttributeError: 'SelectReactor' object has no attribute '_handleSignals' | <!--
Thanks for taking an interest in Scrapy!
If you have a question that starts with "How to...", please see the Scrapy Community page: https://scrapy.org/community/.
The GitHub issue tracker's purpose is to deal with bug reports and feature requests for the project itself.
Keep in mind that by filing an iss... | closed | 2024-05-12T07:42:04Z | 2024-05-13T09:57:16Z | https://github.com/scrapy/scrapy/issues/6354 | [] | windY1Y | 2 |
modin-project/modin | data-science | 7,032 | `test_mixed_dtypes_groupby` failed due to different exception messages | Found in https://github.com/modin-project/modin/pull/6954 | open | 2024-03-07T15:10:40Z | 2024-03-07T15:13:23Z | https://github.com/modin-project/modin/issues/7032 | [
"bug 🦗",
"pandas concordance 🐼",
"P2"
] | anmyachev | 0 |
alteryx/featuretools | scikit-learn | 2,122 | release Featuretools 1.10.0 | - Release of Featuretools on June 21
- We want to get these PRs and issues in before the release:
- https://github.com/alteryx/featuretools/pull/2120
- https://github.com/alteryx/featuretools/pull/2099
- Instructions for release:
- https://github.com/alteryx/featuretools/blob/main/contributing.md | closed | 2022-06-17T21:27:04Z | 2022-06-24T15:50:42Z | https://github.com/alteryx/featuretools/issues/2122 | [] | gsheni | 1 |
pytest-dev/pytest-cov | pytest | 337 | Proposal: pytest-cov should do less | I've been working in the pytest-cov code recently to get it to support coverage.py 5.0 (pull request: #319), and also reviewing #330. The problems that have come up have brought me to a conclusion: pytest-cov does too many things.
The current code attempts to be a complete UI for coverage. I think this is a mistake.... | open | 2019-09-10T14:39:22Z | 2022-12-03T19:49:58Z | https://github.com/pytest-dev/pytest-cov/issues/337 | [] | nedbat | 47 |
jina-ai/serve | deep-learning | 5,963 | Docarray ValidationError when monitoring is enabled | **Describe the bug**
<!-- A clear and concise description of what the bug is. -->
When I run a schema'ed executor with custom docarray types as inputs and outputs with monitoring enabled, I get an error. I believe it is trying to cast the return value as the output type.
**Environment**
<!-- Run `jina --version-f... | closed | 2023-07-13T14:46:45Z | 2023-07-13T18:56:08Z | https://github.com/jina-ai/serve/issues/5963 | [] | NarekA | 2 |
vitalik/django-ninja | django | 1,390 | [BUG] 404 handler override not working as expected | **Describe the bug**
I have a simple demo Django-Ninja app working thanks to a helpful onboarding documentation on the related docs.
All of the endpoints in my simple demo work as expected.
However, the following code in my urls.py file does not produce the expected result based on the docs:
```
from djang... | open | 2025-01-12T00:50:36Z | 2025-02-24T20:05:57Z | https://github.com/vitalik/django-ninja/issues/1390 | [] | ErikPohl444 | 5 |
napari/napari | numpy | 7,552 | Add ability to draw circles Shapes from center | ## 🚀 Feature
Add ability to draw ellipses/circles from their center.
(Can also do rectangles)
## Motivation
This is a common feature in drawing programs. It can be convenient to be able to expand a shape from the center rather than corner to corner, particularly for circles.
In Adobe products and Pixelmator, `alt`... | open | 2025-01-22T22:06:30Z | 2025-01-22T22:06:30Z | https://github.com/napari/napari/issues/7552 | [
"feature"
] | psobolewskiPhD | 0 |
koxudaxi/datamodel-code-generator | fastapi | 1,796 | Property name in schema is the same as imported module name, causing RecursionError in pydantic | **Describe the bug**
This is not a bug so much as a question on how to workaround the issue without changing the schema.
**To Reproduce**
Example schema:
```json
{
"components": {
"schemas": {
"Request": {
"properties": {
... | closed | 2024-01-04T10:51:28Z | 2024-01-04T13:12:08Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1796 | [] | speksen-kb01 | 1 |
K3D-tools/K3D-jupyter | jupyter | 270 | Support rendering cell attributes | A far as I understand, k3d only supports vertex attributes. but in many cases we have simulation results assigned to cells rather than points/vertices. one solution would be to convert cell data to point data but its not always straightforward. It would be nice to add support for rendering cell attributes as well. Than... | closed | 2021-04-11T06:56:43Z | 2025-03-11T12:41:09Z | https://github.com/K3D-tools/K3D-jupyter/issues/270 | [
"Next release"
] | esalehim | 5 |
autogluon/autogluon | data-science | 3,924 | Request: Implement Feature Importance Explainability for Time-Series Module | ### Summary:
The AutoGluon time-series module has proven to be a powerful tool for forecasting tasks. However, one area that could significantly enhance its utility is the inclusion of feature importance explainability in terms of both global training as well as inclusion as covariates, akin to what is currently avail... | closed | 2024-02-15T16:00:13Z | 2024-04-09T16:41:52Z | https://github.com/autogluon/autogluon/issues/3924 | [
"enhancement",
"module: timeseries"
] | kristinakupf | 3 |
docarray/docarray | fastapi | 1,310 | change return type of `find_batched()` utility function | Currently, `find_batched()` has the following signature:
```python
def find_batched(
...
) -> List[FindResult]:
```
In order to align with `DocumentIndex`, it should be switched to:
```python
def find_batched(
...
) -> FindResultBatched:
```
**TODOs:**
- move the definition of `FindResultBatched` from `inde... | closed | 2023-03-29T12:41:30Z | 2023-04-14T15:51:05Z | https://github.com/docarray/docarray/issues/1310 | [
"DocArray v2",
"good-first-issue"
] | JohannesMessner | 4 |
scikit-image/scikit-image | computer-vision | 6,851 | skimage > 0.17.2 required | ### Description:
With skimage version '0.17.2' you get error: `binary_dilation() got an unexpected keyword argument 'footprint'` when using `gf.fill_rectangle(...)` function.
Upgrading to latest version of scikit-image fixes the error.
### Way to reproduce:
_No response_
### Version information:
```Shel... | closed | 2023-03-25T18:36:27Z | 2023-09-17T11:41:54Z | https://github.com/scikit-image/scikit-image/issues/6851 | [
":bug: Bug"
] | albe-jj | 1 |
TencentARC/GFPGAN | pytorch | 307 | NCNN | 是否有NCNN能用的模型下载? | open | 2022-11-17T04:32:34Z | 2022-11-17T04:32:34Z | https://github.com/TencentARC/GFPGAN/issues/307 | [] | skymailwu | 0 |
huggingface/datasets | pytorch | 6,744 | Option to disable file locking | ### Feature request
Commands such as `load_dataset` creates file locks with `filelock.FileLock`. It would be good if there was a way to disable this.
### Motivation
File locking doesn't work on all file-systems (in my case NFS mounted Weka). If the `cache_dir` only had small files then it would be possible to point ... | open | 2024-03-20T15:59:45Z | 2024-03-20T15:59:45Z | https://github.com/huggingface/datasets/issues/6744 | [
"enhancement"
] | VRehnberg | 0 |
ultralytics/yolov5 | machine-learning | 12,569 | Why does the learning rate suddenly increase | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Hello,
Why does my learning rate suddenly increase when I reach approximately 1739 e... | closed | 2024-01-02T08:32:39Z | 2024-02-16T00:19:59Z | https://github.com/ultralytics/yolov5/issues/12569 | [
"question",
"Stale"
] | Gary55555 | 3 |
plotly/dash | plotly | 3,023 | add tooling to show Dash memory usage | It would be useful to have a way for Dash to report how much memory it is using where. The report could be textual (CSV / JSON) or graphical (an introspective chart?). | open | 2024-10-02T16:52:20Z | 2024-10-02T16:52:20Z | https://github.com/plotly/dash/issues/3023 | [
"feature",
"P3"
] | gvwilson | 0 |
FujiwaraChoki/MoneyPrinter | automation | 225 | Design Modern UI with React | Please would you develop a modern and configurable (for example multilanguage, custom title, design etc.) UI ?
Best regards, | closed | 2024-02-13T17:58:31Z | 2024-02-13T19:05:35Z | https://github.com/FujiwaraChoki/MoneyPrinter/issues/225 | [] | Natgho | 2 |
deepfakes/faceswap | deep-learning | 1,145 | bug on require CPU (Mac Big Sur) | in the end of pip require....
Collecting pynvx==1.0.0
Using cached pynvx-1.0.0-cp39-cp39-macosx_10_9_x86_64.whl (119 kB)
ERROR: Could not find a version that satisfies the requirement tensorflow<2.5.0,>=2.2.0
ERROR: No matching distribution found for tensorflow<2.5.0,>=2.2.0
resolve? | closed | 2021-04-06T19:17:20Z | 2022-06-30T10:02:04Z | https://github.com/deepfakes/faceswap/issues/1145 | [
"bug"
] | SiNaPsEr0x | 8 |
mljar/mercury | data-visualization | 196 | add option to hide sidebar in notebook | closed | 2023-01-05T12:11:03Z | 2023-02-17T13:04:58Z | https://github.com/mljar/mercury/issues/196 | [] | pplonski | 1 | |
roboflow/supervision | tensorflow | 1,554 | Allow TIFF (and more) image formats in `load_yolo_annotations` | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Description
* Currently, `load_yolo_annotations` only allows `png,` `jpg`, and `jpeg` file formats. `load_yolo_annotations` is internally called b... | closed | 2024-09-28T15:04:57Z | 2025-01-19T13:02:38Z | https://github.com/roboflow/supervision/issues/1554 | [
"enhancement",
"hacktoberfest"
] | patel-zeel | 11 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 1,423 | Training related issues | Hello, I'm currently conducting training experiments. I have **17000** infrared images (trainA) and corresponding daytime results (trainB). The data resolution is **256 * 256**, 8 Tesla P4 graphics cards (**GPU Memory: 8*8GB = 64GB** ) and **batch_ Size = 16**. I have the following questions to ask you:
1. How many it... | open | 2022-05-23T08:35:42Z | 2022-06-14T19:57:17Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1423 | [] | songyn95 | 3 |
K3D-tools/K3D-jupyter | jupyter | 172 | k3d.plot().display() - can't change background color or axes labels | 
Hi, I attached a picture of wh... | closed | 2019-07-06T22:57:52Z | 2021-08-11T08:53:44Z | https://github.com/K3D-tools/K3D-jupyter/issues/172 | [] | tsj83 | 5 |
PrefectHQ/prefect | data-science | 17,230 | Self-hosted server not communicating with dashboard | ### Bug summary
I am running a Prefect 3.2.6 server and set a custom API host and URL via:
```
prefect config set PREFECT_SERVER_API_HOST="xx.xx.xx.xx"
prefect config set PREFECT_API_URL="http://xx.xx.xx.xx:4200/api"
```
As expected, running `prefect server start` yields
```
___ ___ ___ ___ ___ ___ _____
| _ \ _ \ __... | closed | 2025-02-21T15:37:25Z | 2025-02-21T15:39:41Z | https://github.com/PrefectHQ/prefect/issues/17230 | [
"bug"
] | Andrew-S-Rosen | 1 |
plotly/dash-table | plotly | 147 | Add derived properties `derived_virtual_selected_rows` and `derived_viewport_selected_rows` | `selected_rows` doesn't update on sort or filter
See this example: https://github.com/plotly/dash-docs/pull/232/files#diff-61a5d030fd2c372f3abe94110f039e85 | closed | 2018-10-22T16:42:20Z | 2018-11-08T17:56:07Z | https://github.com/plotly/dash-table/issues/147 | [
"dash-type-enhancement"
] | chriddyp | 6 |
babysor/MockingBird | deep-learning | 433 | 关于plot文件夹下自动生成的注意力图的含义求解 | 想知道plot文件夹下自动生成的注意力图里的横坐标、纵坐标分别是代表什么参数?为什么出现一条漂亮的斜线就是“出现了注意力机制”?如果两幅图都出现了注意力机制线条,那么能否以及如何比较他们的好坏?
目前查阅了一堆关于注意力机制的内容,都没有看到和这幅图相关的知识点,求解! | closed | 2022-03-07T11:47:21Z | 2022-03-15T10:45:39Z | https://github.com/babysor/MockingBird/issues/433 | [] | flysmart | 0 |
junyanz/pytorch-CycleGAN-and-pix2pix | deep-learning | 904 | Learning? | Hello,
Thank you for providing the code. I am using a custom dataset and generator, however my approach is based on pix2pix. I have noticed that the loss_D_fake and loss _D_real never oscillate after the first epoch! The average loss for these is around 0.25 for 21,000 images. According to [soumith point 10](https:... | open | 2020-01-23T13:12:41Z | 2020-01-27T18:45:37Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/904 | [] | DeepZono | 2 |
gee-community/geemap | streamlit | 1,100 | Please use Pythons style guide (Pep 8) | I would like to be able to use geemap in something close to production. To make our production apps robust we don't deploy if they fail basic tests. For example we use Pylint to test for Python style issue (https://peps.python.org/pep-0008/). This makes sure our teams code base looks and works in an aligned way.
As ... | closed | 2022-06-12T08:31:59Z | 2022-06-12T14:19:01Z | https://github.com/gee-community/geemap/issues/1100 | [
"Feature Request"
] | MarcSkovMadsen | 3 |
open-mmlab/mmdetection | pytorch | 11,147 | How to generate VOC format for custom dataset having original images and ground truth images for detection. | I am trying to implement my model for the **detection of disease** (mmdetection) in medical imaging. How I can convert my database into **VOC format?** Is there any supporting .py file available in the mmdetection database folder? If not, how I can do this? Can you please help me to sort out this issue?
My database ... | open | 2023-11-09T07:51:51Z | 2023-11-09T07:51:51Z | https://github.com/open-mmlab/mmdetection/issues/11147 | [] | ztahirzju | 0 |
Nemo2011/bilibili-api | api | 289 | 【提问】```user.get_user_info()```、```user.get_videos()```和```user.get_dynamics()```接口无法获取到有效信息,但是没有错误信息被抛出 | **Python 版本:** 3.11.2
**模块版本:** 15.4.2
**运行环境:** Windows
---
在bot内通过```user.get_user_info()```、```user.get_videos()```和```user.get_dynamics()```接口获取信息时经常没有获取到有效内容,但是也没有任何错误信息接收,单独运行类似代码时却能够正常获取信息
**部分代码**
该代码运行于一个**异步函数**中
```CREDENTIAL```是一个事先定义了的静态```Credential```对象,在我看来并不是问题的重点
```sub_list```是一个记... | closed | 2023-05-17T06:17:36Z | 2023-05-27T10:25:43Z | https://github.com/Nemo2011/bilibili-api/issues/289 | [
"bug"
] | WindowsSov8forUs | 16 |
dask/dask | numpy | 11,154 | dask.dataframe import error for Python 3.12.3 | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | closed | 2024-05-29T21:06:58Z | 2024-05-29T21:47:46Z | https://github.com/dask/dask/issues/11154 | [
"needs info"
] | jitingxu1 | 3 |
matplotlib/matplotlib | matplotlib | 28,898 | [Bug]: Matplotlib font error for negative data | ### Bug summary
When using a combination of text.usetex: True, font.family: 'serif', font.serif = 'Times', attempting to plot negative data results in a LookupError of the required font
### Code for reproduction
```Python
import matplotlib.pyplot as plt
plt.rcParams['text.usetex'] = True
plt.rcParams['font.famil... | closed | 2024-09-27T07:54:07Z | 2024-09-27T14:28:45Z | https://github.com/matplotlib/matplotlib/issues/28898 | [
"topic: text/usetex",
"topic: text/fonts"
] | JeltevL | 1 |
FactoryBoy/factory_boy | django | 811 | get_or_create fails with Trait | #### Description
If you use get_or_create and you use trait, the value of the trait will be ignored, an existing object without trait will be returned
#### To Reproduce
Failing test case here: https://github.com/FactoryBoy/factory_boy/pull/810
| open | 2020-11-02T18:03:04Z | 2020-11-02T18:03:04Z | https://github.com/FactoryBoy/factory_boy/issues/811 | [] | MRigal | 0 |
mwaskom/seaborn | data-science | 3,320 | LOWESS Smoother for The .objects Interface | Here's a LOWESS smoother for the .object interface. Like @tomicapretto, I slightly modified the PolyFit implementation. Until there is a release with a LOWESS smoother, this may do.
```
"""A smoother that has the same interface as the Seaborn PolyFit class."""
from __future__ import annotations
from dataclasse... | open | 2023-04-13T13:11:30Z | 2023-08-27T12:13:38Z | https://github.com/mwaskom/seaborn/issues/3320 | [
"wishlist"
] | tbpassin | 2 |
jmcnamara/XlsxWriter | pandas | 257 | Feature request: Add docs on timezone aware/naive datetime | Excel, and thus XlsxWriter, doesn't support timezones in dates/times.
The current recommendation is to remove or adjust the timezone from the datetime before passing it to XlsxWriter.
Something like this from the pytz docs:
``` python
dt = datetime(2005, 3, 1, 14, 13, 21, tzinfo=utc)
naive = dt.replace(tzinfo=None)
... | closed | 2015-05-20T07:22:48Z | 2016-12-02T21:56:14Z | https://github.com/jmcnamara/XlsxWriter/issues/257 | [
"feature request",
"documentation",
"ready to close",
"short term"
] | jmcnamara | 10 |
littlecodersh/ItChat | api | 785 | 已解决 | 彻底无法给好友发送消息 不知道什么情况
。。。
也删不掉好友
但是能收到好友发来的消息 | closed | 2019-01-24T02:53:54Z | 2019-06-27T02:26:47Z | https://github.com/littlecodersh/ItChat/issues/785 | [] | Liumxv | 2 |
MilesCranmer/PySR | scikit-learn | 126 | [Feature] Automatic Plotting + LaTeX rendering | It would be great if PySR would automatically generate plots for discovered expressions, as well as LaTeX of the expression form, during training. Then, one does not need to stop training to test the expressions - there would already be plots + generated latex for each expression.
This could be done occasionally, i... | open | 2022-04-25T17:15:59Z | 2023-04-20T06:07:09Z | https://github.com/MilesCranmer/PySR/issues/126 | [
"enhancement"
] | MilesCranmer | 0 |
nolar/kopf | asyncio | 1,030 | Embedding in shared event loop | ### Keywords
embed
### Problem
First of all - thank you for this project. Having framework for building operators in native Python is dope!
I have a question about embedding kopf.
Documentation states that kopf needs its own event loop because it considers all spawned tasks as its own. That would interfere with... | open | 2023-05-24T16:27:22Z | 2023-11-05T17:44:02Z | https://github.com/nolar/kopf/issues/1030 | [
"question"
] | scabala | 4 |
Significant-Gravitas/AutoGPT | python | 8,796 | integration test: Run a saved agent. | closed | 2024-11-27T02:03:26Z | 2024-12-06T04:44:35Z | https://github.com/Significant-Gravitas/AutoGPT/issues/8796 | [] | ntindle | 0 | |
flasgger/flasgger | flask | 124 | Release new version with decorating flasgger views support | Hey!
Could you release new version of flasgger? I want to use this https://github.com/rochacbruno/flasgger/pull/109 feature.
Thanks in advice. | closed | 2017-06-26T08:47:01Z | 2017-06-27T00:43:59Z | https://github.com/flasgger/flasgger/issues/124 | [] | rafal-jaworski | 2 |
cvat-ai/cvat | pytorch | 8,873 | Revisit undo/redo functionality in annotation UI | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
Currently, when creating composite shapes, such as polylines, points, skeletons... | open | 2024-12-25T11:04:39Z | 2025-01-14T10:00:45Z | https://github.com/cvat-ai/cvat/issues/8873 | [
"enhancement",
"ui/ux"
] | zhiltsov-max | 1 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 841 | 跑up的模型之后C盘爆满怎么解决 | 跑up的模型之后C盘爆满怎么解决 | open | 2024-10-16T07:32:13Z | 2024-11-09T07:03:59Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/841 | [] | zhy12123 | 2 |
qubvel-org/segmentation_models.pytorch | computer-vision | 318 | Reduce the model filesize if encoder depth is less than 5 | I noticed that if the depth of an encoder is set to a value less than 5, the unused nodes still remain in the graph and will be saved in checkpoints and torchscript files. This happens for example when the PSPNet is used with standard settings (extracting features after stage 3).
I think it could be beneficial to re... | closed | 2020-12-18T07:51:31Z | 2022-04-30T02:16:06Z | https://github.com/qubvel-org/segmentation_models.pytorch/issues/318 | [
"Stale"
] | winfried-ripken | 7 |
jupyterlab/jupyter-ai | jupyter | 530 | Improve API key error handling | ### Problem
API key error handling can be further improved:
> My high-level thought is that while this is a good starting point, this strategy is a little unintuitive. It requires manually detecting and handling API key exceptions. In the future, we should probably wrap the LangChain methods in an exception handl... | open | 2023-12-19T23:14:49Z | 2023-12-20T00:20:28Z | https://github.com/jupyterlab/jupyter-ai/issues/530 | [
"enhancement"
] | andrii-i | 1 |
OpenInterpreter/open-interpreter | python | 1,447 | VOICE MODEEEEEEEEEEEEEEEEEEEEEEEE | ### Is your feature request related to a problem? Please describe.
no
### Describe the solution you'd like
I've waited long enough for GPT-4o voice mode, so I’m curious if what you mentioned in your blog post about speech-to-speech models could be implemented sooner using Gemini 1.5 Pro. Could we use its audio input... | open | 2024-09-10T02:36:37Z | 2024-11-04T16:27:00Z | https://github.com/OpenInterpreter/open-interpreter/issues/1447 | [
"Enhancement"
] | OpenMachinesAI | 1 |
deeppavlov/DeepPavlov | tensorflow | 881 | NER problems with download=False | This code ```build_model(configs.ner.ner_rus, download=False)``` leads to following exception:
```
2019-06-14 14:51:45.158 INFO in 'deeppavlov.models.embedders.fasttext_embedder'['fasttext_embedder'] at line 67: [loading fastText embeddings from `/root/.deeppavlov/downloads/embeddings/lenta_lower_100.bin`]
INFO:de... | closed | 2019-06-14T14:55:03Z | 2019-06-27T15:02:24Z | https://github.com/deeppavlov/DeepPavlov/issues/881 | [] | bavadim | 4 |
mars-project/mars | pandas | 3,192 | [BUG] supervisor memory leak | <!--
Thank you for your contribution!
Please review https://github.com/mars-project/mars/blob/master/CONTRIBUTING.rst before opening an issue.
-->
**Describe the bug**
A clear and concise description of what the bug is.
, href=URL_REPO, target="_blank", style=icon_link_style),
html.A(html.H6("☕"), href=URL_KOFI, target="_blank"... | closed | 2020-04-24T17:00:13Z | 2020-04-27T13:29:04Z | https://github.com/mithi/hexapod-robot-simulator/issues/85 | [
"feature request",
"good first issue",
"low hanging fruit",
"code quality"
] | mithi | 4 |
taverntesting/tavern | pytest | 241 | Global variables are not correctly updated from ext function | I am trying to run tavern tests from a python script, for that matter I have a yaml file that tests an API call, the idea is to store the response in a global variable and use it latter.
```python
#My Python Script:
def login(host, login, password):
config = {
"variables": {
"host": ho... | closed | 2019-02-01T10:33:30Z | 2019-08-10T20:57:13Z | https://github.com/taverntesting/tavern/issues/241 | [] | ymouncef | 1 |
modelscope/data-juicer | streamlit | 388 | [Bug]: Loading checkpoint shards:的时候直接kill了是什么,是内存不够了吗 | ### Before Reporting 报告之前
- [X] I have pulled the latest code of main branch to run again and the bug still existed. 我已经拉取了主分支上最新的代码,重新运行之后,问题仍不能解决。
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully and no error occurred during the installation process. (Otherwise, w... | closed | 2024-08-18T04:18:12Z | 2024-08-18T04:52:12Z | https://github.com/modelscope/data-juicer/issues/388 | [
"bug"
] | ZHJ19970917 | 1 |
CorentinJ/Real-Time-Voice-Cloning | pytorch | 1,152 | train my dataset | can i train for custom dataset?? | closed | 2023-01-02T10:07:23Z | 2023-01-08T08:55:17Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1152 | [] | alidabaghi123 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.