
branch_name stringclasses 149 values | text stringlengths 23 89.3M | directory_id stringlengths 40 40 | languages listlengths 1 19 | num_files int64 1 11.8k | repo_language stringclasses 38 values | repo_name stringlengths 6 114 | revision_id stringlengths 40 40 | snapshot_id stringlengths 40 40 |
|---|---|---|---|---|---|---|---|---|
refs/heads/master | <repo_name>starlightjy/CustomView<file_sep>/app/src/main/java/share/imooc/com/customview/TuyaView.java
package share.imooc.com.customview;
import android.content.Context;
import android.content.Intent;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Paint;
import android.graphics.Path;
import android.graphics.PorterDuff;
import android.graphics.PorterDuffXfermode;
import android.net.Uri;
import android.os.Environment;
import android.util.AttributeSet;
import android.util.Log;
import android.view.MotionEvent;
import android.view.View;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Date;
import java.util.Iterator;
import java.util.List;
import java.util.logging.SimpleFormatter;
/**
* Created by asus- on 2017/4/21.
*/
public class TuyaView extends View{
private SaveImageLister saveImageLister;
private Context context;
private Bitmap mBitmap;
private Canvas mCanvas;
private Paint mPaint;//画布的画笔
private Paint mBitmapPaint;//真实的画笔
private Path mPath;
private float mX,mY;//临时点坐标
private static final float TOUCH_TOLERANCE = 4;
// 保存Path路径的集合
private static List<DrawPath>savepath;
// 保存已删除Path路径的集合
private static List<DrawPath> deletePath;
// 记录Path路径的对象
private DrawPath dp;
private int screenWidth,screenHeight;
private int currentColor= Color.RED;
private int currentSize=5;
private int currentStyle=1;
//颜色集合
private int[]paintColor;
private class DrawPath {
public Path path;// 路径
public Paint paint;// 画笔
}
public TuyaView(Context context, int w,int h) {
super(context);
this.context=context;
screenWidth=w;
screenHeight=h;
paintColor=new int[]{Color.RED, Color.BLUE, Color.GREEN, Color.YELLOW, Color.BLACK, Color.GRAY, Color.CYAN };
//设置默认样式,去除dis-in的黑色方框以及clear模式的黑线效果
setLayerType(LAYER_TYPE_SOFTWARE,null);
initCanvas();
savepath = new ArrayList<DrawPath>();
deletePath = new ArrayList<DrawPath>();
}
private void initCanvas() {
setPaintStyle();
mBitmapPaint=new Paint(Paint.DITHER_FLAG);
mBitmap=Bitmap.createBitmap(screenWidth,screenHeight,Bitmap.Config.ARGB_8888);
//把图片设置成透明
mBitmap.eraseColor(Color.argb(0,0,0,0));
mCanvas = new Canvas(mBitmap); //所有mCanvas画的东西都被保存在了mBitmap中
mCanvas.drawColor(Color.TRANSPARENT);
}
//初始化画笔样式
private void setPaintStyle() {
mPaint = new Paint();
mPaint.setStyle(Paint.Style.STROKE);
mPaint.setStrokeJoin(Paint.Join.ROUND);// 设置外边缘
mPaint.setStrokeCap(Paint.Cap.ROUND);// 形状
//设置抗锯齿
mPaint.setAntiAlias(true);
//该方法是设置防抖动。
mPaint.setDither(true);
//普通画笔
if (currentStyle == 1) {
mPaint.setStrokeWidth(currentSize);
mPaint.setColor(currentColor);
}
//橡皮擦
else {
mPaint.setAlpha(0);
mPaint.setXfermode(new PorterDuffXfermode(PorterDuff.Mode.DST_IN));
mPaint.setColor(Color.TRANSPARENT);
mPaint.setStrokeWidth(50);
}
}
@Override
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
canvas.drawBitmap(mBitmap,0,0,mBitmapPaint);
if (mPath!=null){
// 实时的显示
canvas.drawPath(mPath,mPaint);
}
}
@Override
public boolean onTouchEvent(MotionEvent event) {
float x=event.getX();
float y=event.getY();
switch (event.getAction()){
case MotionEvent.ACTION_DOWN:
// 每次down下去重新new一个Path
mPath=new Path();
//每一次记录的路径对象是不一样的
dp = new DrawPath();
dp.path=mPath;
dp.paint=mPaint;
touch_start(x,y);
invalidate();
break;
case MotionEvent.ACTION_MOVE:
touch_move(x, y);
invalidate();
break;
case MotionEvent.ACTION_UP:
touch_up();
invalidate();
break;
}
return true;
}
private void touch_up() {
mPath.lineTo(mX,mY);
mCanvas.drawPath(mPath,mPaint);
//将一条完整的路径保存下来
savepath.add(dp);
mPath = null;// 重新置空
}
private void touch_move(float x, float y) {
float dx=Math.abs(mX-x);
float dy= Math.abs(y-mY);
if (dx>=TOUCH_TOLERANCE||dy>=TOUCH_TOLERANCE){
mPath.quadTo(mX,mY,(mX+x)/2,(mY+y)/2);
mX = x;
mY = y;
}
}
private void touch_start(float x, float y) {
mPath.moveTo(x,y);
mX = x;
mY = y;
}
/* 撤销
撤销的核心思想就是将画布清空,
将保存下来的Path路径最后一个移除掉,
重新将路径画在画布上面。
* */
public void undo(){
if (savepath!=null&&savepath.size()>0){
DrawPath lastDrawPath=savepath.get(savepath.size()-1);
deletePath.add(lastDrawPath);
savepath.remove(savepath.size()-1);
redrawOnBitmap();
}
}
private void redrawOnBitmap() {
initCanvas();//清空画布
//重新将路径画在画布上面
Iterator<DrawPath> iterator=savepath.iterator();
while (iterator.hasNext()){
DrawPath drawPath=iterator.next();
mCanvas.drawPath(drawPath.path,drawPath.paint);
}
invalidate();
}
//重做
public void redo(){
if (savepath!=null&&savepath.size()>0){
savepath.clear();
redrawOnBitmap();
}
}
//恢复,恢复的核心就是将删除的那条路径重新添加到savapath中重新绘画即可
public void recover(){
if (deletePath!=null&&deletePath.size()>0){
//将删除的路径列表中的最后一个,也就是最顶端路径取出(栈),并加入路径保存列表中
DrawPath drawPath=deletePath.get(deletePath.size()-1);
savepath.add(drawPath);
//将取出的路径重绘在画布上
mCanvas.drawPath(drawPath.path, drawPath.paint);
//将该路径从删除的路径列表中去除
deletePath.remove(deletePath.size() - 1);
invalidate();
}
}
//以下为样式修改内容
//设置画笔样式
public void selectPaintStyle(int which){
//选择画笔
if (which==0){
currentStyle=1;
setPaintStyle();
} //当选择的是橡皮擦时,设置颜色为白色
else if(which==1) {
currentStyle = 2;
setPaintStyle();
}
}
//选择画笔大小
public void selectPaintSize(int which){
currentSize=which;
setPaintStyle();
}
//设置画笔颜色
public void selectPaintColor(int which){
currentColor=paintColor[which];
setPaintStyle();
}
//保存到sd卡
public void saveToSDCard(){
//获得系统当前时间,并以该时间作为文件名
SimpleDateFormat simpleDateFormat=new SimpleDateFormat("yyyyMMddHHmmss");
Date curDate=new Date(System.currentTimeMillis());
String str=simpleDateFormat.format(curDate)+"paint.png";
File file = new File(Environment.getExternalStorageDirectory().getAbsolutePath()+"/" + str);
FileOutputStream fos=null;
try {
fos=new FileOutputStream(file);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
mBitmap.compress(Bitmap.CompressFormat.PNG,100,fos);
//发送Sd卡的就绪广播,要不然在手机图库中不存在
/* Intent intent=new Intent(Intent.ACTION_MEDIA_MOUNTED);
intent.setData(Uri.fromFile(Environment.getExternalStorageDirectory()));
context.sendBroadcast(intent);*/
try {
fos.close();
saveImageLister.onSaveFinshed(file.getAbsolutePath());
} catch (IOException e) {
e.printStackTrace();
}
Log.e("TAG", "图片已保存");
}
public void setSaveImageLister(SaveImageLister saveImageLister){
this.saveImageLister=saveImageLister;
}
}
| 98d3a820b0f9d39f445517a57aa083fff7c6ce1f | [
"Java"
] | 1 | Java | starlightjy/CustomView | 399ec64db6370eac01c5e339c02f249d61951e48 | 9bf93023cea35ca6c784de7d3862a4b7dc4ef7da |
refs/heads/master | <file_sep>from django.db import models
# Create your models here.
class News(models.Model):
news_title = models.CharField(max_length=255)
news_url = models.CharField(max_length=255)
timestamp = models.CharField(max_length=255)
<file_sep>CREATE DATABASE news ENCODING="utf8";
GRANT ALL PRIVILEGES ON DATABASE "news" to docker;
\c news;
CREATE TABLE IF NOT EXISTS sina_news (
title character varying(255) NOT NULL,
url character varying(255),
timestamp timestamp default current_timestamp
);
<file_sep>#!/bin/bash
python3 manage.py makemigrations selenium_view
python3 manage.py migrate
echo "from django.contrib.auth.models import User; User.objects.create_superuser('admin', '<EMAIL>', '<PASSWORD>')" | python3 manage.py shell
python3 manage.py runserver 0.0.0.0:8000
<file_sep># Python dependancy
FROM python:3
ENV PYTHONUNBUFFERED 1
RUN mkdir /code
WORKDIR /code
ADD requirements.txt /code/
RUN pip install -r requirements.txt
# Run updates and install deps
RUN apt-get update
# Install phantomjs
RUN apt-get install -y -q --no-install-recommends \
apt-transport-https \
build-essential \
ca-certificates \
curl \
g++ \
gcc \
git \
make \
nginx \
sudo \
wget \
&& rm -rf /var/lib/apt/lists/* \
&& apt-get -y autoclean
ENV NVM_DIR /usr/local/nvm
ENV NODE_VERSION 5.1.0
# Install nvm with node and npm
RUN curl -o- https://raw.githubusercontent.com/creationix/nvm/v0.29.0/install.sh | bash \
&& /bin/bash -c "source $NVM_DIR/nvm.sh && nvm install $NODE_VERSION && nvm alias default $NODE_VERSION && nvm use default"
# Set up our PATH correctly so we don't have to long-reference npm, node, &c.
ENV NODE_PATH $NVM_DIR/versions/node/v$NODE_VERSION/lib/node_modules
ENV PATH $NVM_DIR/versions/node/v$NODE_VERSION/bin:$PATH
RUN npm -g install phantomjs-prebuilt
ADD ./mysite /code/
<file_sep>from django.test import LiveServerTestCase
from selenium import webdriver
import logging
class SinaTestCase(LiveServerTestCase):
def setUp(self):
self.selenium = webdriver.PhantomJS()
super(SinaTestCase, self).setUp()
def tearDown(self):
self.selenium.quit()
super(SinaTestCase, self).tearDown()
def test_content(self):
selenium = self.selenium
#Opening the link we want to test
url = '{}/compare/'.format(self.live_server_url)
selenium.get(url)
print("URL is : {}".format(url))
#find the form element
page_html = selenium.page_source
print(page_html)
xpath = '//ul[contains(@class, "list-a news_top")]'
news_list = selenium.find_element_by_xpath(xpath)
#print(news_list)
assert news_list is not None, "new list is empty"
# Create your tests here.
<file_sep>Django>=1.8,<2.0
psycopg2
selenium
lxml
<file_sep>from django.shortcuts import render
from django.http import HttpResponse
import lxml.html
from .models import News
from django.utils import timezone
from django.shortcuts import render
from .utils import Utils
import re
# Create your views here.
def index(request):
# Try to read from database for today's news
print("Trying to read from database...")
current_date = str(timezone.now().date())
current_news = News.objects.filter(timestamp=current_date)
if len(current_news) == 0:
# Cannot find today's news, retrieve form website
print("Cannot find today's news from database, read from website")
url = "http://www.sina.com.cn"
top_news_l = Utils.get_top_news(url)
regex = '<a target="_blank" href="([^"]+)">([^<]+)</a>'
for _news in top_news_l:
found = re.match(regex, _news.strip())
if not found:
continue
news_title = found.group(2)
news_url = found.group(1)
n = News(news_title=news_title, news_url=news_url, timestamp=current_date)
n.save()
else:
print("Found from database")
# Read from database
print("Read from database")
values = Utils.read_from_db()
return render(request, 'index.html', {'values': values})
def test(request):
return HttpResponse("Hello World!")
<file_sep>"""Define all util functions"""
import lxml.html
import urllib.request
from .models import News
class Utils():
@classmethod
def get_top_news(self, url):
fp = urllib.request.urlopen(url)
mybytes = fp.read()
html = mybytes.decode("utf8")
fp.close()
root = lxml.html.document_fromstring(html)
top_news = root.xpath('//ul[contains(@class, "list-a news_top")]')[0]
tmp_top_news = lxml.html.tostring(top_news).decode("utf-8")
tmp_top_news = tmp_top_news.replace("</li>", "<li>")
return tmp_top_news.split("<li>")
@classmethod
def read_from_db(self):
entries = News.objects.all()
dates = []
values = []
# Construct a dict like this:
"""
[
{"date":date, "values": news_entries}
]
"""
for entry in entries:
if len(dates) == 0:
dates.append(entry.timestamp)
elif entry.timestamp not in dates:
dates.append(entry.timestamp)
for i in range(len(dates)):
date = dates[i]
news_entries = News.objects.filter(timestamp=date)
tmp_dict = {
'date': date,
'values': news_entries
}
values.append(tmp_dict)
return values
<file_sep>from django.apps import AppConfig
class SeleniumViewConfig(AppConfig):
name = 'selenium_view'
| 49d352f22fffdf09a8447612cb58234b9ea4e77f | [
"SQL",
"Python",
"Text",
"Dockerfile",
"Shell"
] | 9 | Python | nancyli03/news_digest_web | 564456be0f358ef2d191d132baf83c8ac0b2d414 | 129593d1c5c0dfa181eb0cdf3173b54be4c134cc |
refs/heads/master | <repo_name>patrickbaber/theme-one<file_sep>/views/blog/post.php
<?php $view->script('post', 'blog:app/bundle/post.js', 'vue') ?>
<article class="uk-article tm-container-small">
<?php if ($image = $post->get('image.src')): ?>
<img src="<?= $image ?>" alt="<?= $post->get('image.alt') ?>">
<?php endif ?>
<h1 class="uk-article-title"><?= $post->title ?></h1>
<div class="uk-margin"><?= $post->content ?></div>
<?= $view->render('blog/comments.php') ?>
</article>
| 87046344a8574c0afe0304f7e09da3ea32a771b7 | [
"PHP"
] | 1 | PHP | patrickbaber/theme-one | c0d479a9aeda6dd3074c4abc449331e27208fe07 | aa39353ffb72b8d7f7c61105e53e05a3f544ac09 |
refs/heads/master | <repo_name>krystianwolanski/TreeNodes<file_sep>/README.md
# TreeNodes
Wykonane w ASP.Net MVC
<p>
<img src="Photo1.PNG">
</p>
<file_sep>/Models/TreeDB.cs
namespace Tree.Models
{
using System;
using System.Data.Entity;
using System.Linq;
public class TreeDB : DbContext
{
// Your context has been configured to use a 'Model1' connection string from your application's
// configuration file (App.config or Web.config). By default, this connection string targets the
// 'Tree.Models.Model1' database on your LocalDb instance.
//
// If you wish to target a different database and/or database provider, modify the 'Model1'
// connection string in the application configuration file.
public TreeDB()
: base("name=TreeDB")
{
}
// Add a DbSet for each entity type that you want to include in your model. For more information
// on configuring and using a Code First model, see http://go.microsoft.com/fwlink/?LinkId=390109.
public virtual DbSet<Node> NodeEntities { get; set; }
//protected override void OnModelCreating(DbModelBuilder modelBuilder)
//{
// modelBuilder.Entity<Node>().HasRequired<Node>(a => a.Parent).WithMany().WillCascadeOnDelete(true);
//}
}
}<file_sep>/Controllers/HomeController.cs
using System;
using System.Collections.Generic;
using System.Data.Entity.Infrastructure;
using System.Data.SqlClient;
using System.Linq;
using System.Web;
using System.Web.Mvc;
using Tree.Models;
namespace Tree.Controllers
{
public class HomeController : Controller
{
private TreeDB _context;
public HomeController()
{
_context = new TreeDB();
}
protected override void Dispose(bool disposing)
{
_context.Dispose();
}
[HttpGet]
public ActionResult Index(int? id)
{
var items = _context.NodeEntities.Where(x => x.ParentId == id);
ViewBag.ParentId = id;
return View(items);
}
public ActionResult Wstecz(int? parentId)
{
var item = _context.NodeEntities.Single(x => x.Id == parentId);
return RedirectToAction("Index", new { id = item.ParentId });
}
[HttpPost]
public ActionResult Save(Node node, int? parentId)
{
if (node.Id == 0)
{
node.ParentId = parentId;
_context.NodeEntities.Add(node);
}
else
{
Node nodeInDb = _context.NodeEntities.Single(n => n.Id == node.Id);
nodeInDb.Name = node.Name;
}
_context.SaveChanges();
return RedirectToAction("Index", new { id = node.ParentId });
}
private void Remove(Node node)
{
var listOfNodes = _context.NodeEntities.Where(a => a.ParentId == node.Id);
if (listOfNodes != null)
foreach (var node3 in listOfNodes)
Remove(node3);
_context.NodeEntities.Remove(node);
}
[HttpPost]
public HttpStatusCodeResult Delete(int id)
{
Node nodeInDb = _context.NodeEntities.Single(n => n.Id == id);
Remove(nodeInDb);
//_context.NodeEntities.Remove(nodeInDb);
_context.SaveChanges();
return new HttpStatusCodeResult(System.Net.HttpStatusCode.OK);
//return RedirectToAction("Index", new { nodeInDb.ParentId });
}
public PartialViewResult NodeForm(int? id)
{
Node node = _context.NodeEntities.FirstOrDefault(x => x.Id == id);
return PartialView("_NodeForm", node);
}
}
} | 21b0ef23ed4af164cee6846c45e2464eba3a2d6d | [
"Markdown",
"C#"
] | 3 | Markdown | krystianwolanski/TreeNodes | 8ba67a09875e361349fd098000241f8e51d12cdb | 1dadfe8d61449471304c8b9fdfcdeedbf893b1c8 |
refs/heads/master | <repo_name>bevzuk/react<file_sep>/pluralsight/react-fundamentals/01.components/app.js
(function () {
'use strict';
var Quiz = React.createClass({
//getDefaultState: function() {};
//getDefaultProps: function() {};
//propTypes: - validate property type
propTypes: {
books: React.PropTypes.array.isRequired
},
render: function() {
return <div>
{this.props.books.map(function(book) {
return <Book title={book} key={book}></Book>;
})}
</div>;
}
});
var Book = React.createClass({
propTypes: {
title: React.PropTypes.string.isRequired
},
render: function() {
return <div><h4>{this.props.title}</h4></div>;
}
});
ReactDOM.render(
<Quiz books={['The lord of the rings', 'War and Peace']}/>,
document.getElementById('container')
);
})(); | 901d7dffe44d82e27d9189f75fb0a9fbcacdfe87 | [
"JavaScript"
] | 1 | JavaScript | bevzuk/react | a15c54d94d3759fb8f0ad6bdea1ddaff47e107df | 45ebfbea186f9dc3d5b597570472f9b542156bbf |
refs/heads/master | <repo_name>LucasSSales/GerenciamentoDeFaltas<file_sep>/app/src/main/java/projectp3/studio/com/gerenciamentodefaltas/MainActivity.java
package projectp3.studio.com.gerenciamentodefaltas;
import android.app.Activity;
import android.content.DialogInterface;
import android.content.Intent;
import android.database.sqlite.SQLiteDatabase;
import android.net.Uri;
import android.os.AsyncTask;
import android.os.Bundle;
import android.support.v7.app.AlertDialog;
import android.support.v7.app.NotificationCompat;
import android.view.View;
import android.widget.Button;
import android.widget.Toast;
import java.io.UnsupportedEncodingException;
import java.net.URLEncoder;
public class MainActivity extends Activity {
private Button addMat;
private Button addF;
private Button verF;
private Button share;
private SQLiteDatabase banco;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
addMat = (Button) findViewById(R.id.addMat);
addF = (Button) findViewById(R.id.addF);
verF = (Button) findViewById(R.id.verF);
share = (Button) findViewById(R.id.share);
banco = openOrCreateDatabase("GerencFaltas", MODE_PRIVATE, null);
banco.execSQL("CREATE TABLE IF NOT EXISTS materias (id INTEGER PRIMARY KEY AUTOINCREMENT, nome VARCHAR, cargaHoraria INT(2), maxFaltas INT(2), faltas INT(2))");
addMat.setOnClickListener(new View.OnClickListener(){
@Override
public void onClick(View v){
startActivity(new Intent(MainActivity.this, AddMateria.class));
}
});
addF.setOnClickListener(new View.OnClickListener(){
@Override
public void onClick(View v){
startActivity(new Intent(MainActivity.this, AddFalta.class));
}
});
verF.setOnClickListener(new View.OnClickListener(){
@Override
public void onClick(View v){
startActivity(new Intent(MainActivity.this, Situacao.class));
}
});
share.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
AlertDialog.Builder dialog = new AlertDialog.Builder(MainActivity.this);
dialog.setTitle("Compartilhar em The Dank Network");
dialog.setMessage("Deseja divulgar o app através de uma postagem em The Dank Network?");
dialog.setCancelable(false);
dialog.setNegativeButton("Não", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {}
});
dialog.setPositiveButton("Sim", new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
String encoded = "";
String imgURL = "";
try {
encoded= URLEncoder.encode("Estou usando o Gerenciador de Faltas! Confira na seção apps", "utf-8").replace("+", "%20");
imgURL = URLEncoder.encode("https://orig00.deviantart.net/107e/f/2017/299/8/2/gerenciadordefaltaslogo_by_lucsales-dbrtnz5.png", "utf-8");
startActivity(new Intent(Intent.ACTION_VIEW, Uri.parse("https://the-dank-network.herokuapp.com/post?content=" + encoded+
"&imageUrl="+imgURL)));
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
}
});
dialog.create();
dialog.show();
}
});
}
}
<file_sep>/app/src/main/java/projectp3/studio/com/gerenciamentodefaltas/SituDaMat.java
package projectp3.studio.com.gerenciamentodefaltas;
import android.app.Activity;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.util.Log;
import android.view.View;
import android.widget.ArrayAdapter;
import android.widget.Button;
import android.widget.TextView;
import android.widget.Toast;
import java.util.ArrayList;
import Strategy.InfosDB;
import Strategy.StrategyFuncs;
public class SituDaMat extends Activity {
private TextView nomeMat;
private TextView faltasRest;
private TextView faltasAtuais;
private TextView status;
private Button voltar;
private StrategyFuncs s;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_situ_da_mat);
s = new StrategyFuncs(SituDaMat.this);
nomeMat = (TextView) findViewById(R.id.NomeMat);
faltasRest = (TextView) findViewById(R.id.RestF);
faltasAtuais = (TextView) findViewById(R.id.FaltasAt);
status = (TextView) findViewById(R.id.status);
voltar = (Button) findViewById(R.id.voltar);
Bundle extra = getIntent().getExtras();
if(extra != null){
ArrayList<String> dados = extra.getStringArrayList("Dados");
Integer faltasR = Integer.parseInt(dados.get(2)) - Integer.parseInt(dados.get(1));
nomeMat.setText(dados.get(0));
faltasAtuais.setText(dados.get(1));
if(faltasR < 0)
faltasR = 0;
faltasRest.setText(faltasR.toString());
status.setText(s.calcStatus(Integer.parseInt(dados.get(1)) , Integer.parseInt(dados.get(2))));
}
//Botão Voltar
voltar.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
finish();
}
});
}
}<file_sep>/app/src/main/java/Strategy/InfosDB.java
package Strategy;
import android.content.Context;
import android.database.Cursor;
import android.database.sqlite.SQLiteDatabase;
import android.widget.ArrayAdapter;
import android.widget.ListView;
import android.widget.Toast;
import java.util.ArrayList;
/**
* Created by Lucas on 22/10/2017.
*/
public class InfosDB {
private Context context;
private Cursor cursor;
private ArrayAdapter<String> listaMaterias;
private ArrayList<String> mat;
private ArrayList<Integer> ids;
private ArrayList<String> faltasA;
private ArrayList<String> faltasMax;
public InfosDB (Context context){
this.context = context;
}
public ListView recuperarInfo(SQLiteDatabase banco, ListView listaMat){
try{
cursor = banco.rawQuery("SELECT id, nome,faltas,maxFaltas FROM materias", null);
int indexNome = cursor.getColumnIndex("nome");
int indexId = cursor.getColumnIndex("id");
int indexFaltas = cursor.getColumnIndex("faltas");
int indexMaxF = cursor.getColumnIndex("maxFaltas");
cursor.moveToFirst();
//Adapter
mat = new ArrayList<String>();
ids = new ArrayList<Integer>();
faltasA = new ArrayList<String>();
faltasMax = new ArrayList<String>();
listaMaterias = new ArrayAdapter<String>(context, android.R.layout.simple_list_item_2, android.R.id.text2, mat);
listaMat.setAdapter(listaMaterias);
while(cursor != null){
mat.add( cursor.getString(indexNome) );
ids.add( Integer.parseInt(cursor.getString(indexId)) );
faltasA.add( cursor.getString(indexFaltas) );
faltasMax.add( cursor.getString(indexMaxF) );
cursor.moveToNext();
}
}catch(Exception e){}
finally {
return listaMat;
}
}
public ArrayList<String> getDados (int position){
ArrayList<String> extra = new ArrayList<String>();
extra.add(mat.get(position));
extra.add(faltasA.get(position));
extra.add(faltasMax.get(position));
return extra;
}
public void updateFaltas (SQLiteDatabase banco, int f, ListView listaMat, Integer id){
try{
banco.execSQL("UPDATE materias SET faltas="+ f +" WHERE id=" + id);
Toast.makeText(context, "Falta adicionada!", Toast.LENGTH_LONG).show();
recuperarInfo(banco, listaMat);
}catch(Exception e){
e.printStackTrace();;
}
}
public Context getContext() {
return context;
}
public Cursor getCursor() {
return cursor;
}
public ArrayAdapter<String> getListaMaterias() {
return listaMaterias;
}
public ArrayList<String> getMat() {
return mat;
}
public ArrayList<Integer> getIds() {
return ids;
}
public ArrayList<String> getFaltasA() {
return faltasA;
}
public ArrayList<String> getFaltasMax() {
return faltasMax;
}
}
<file_sep>/app/src/main/java/Strategy/StrategyFuncs.java
package Strategy;
import android.app.Activity;
import android.app.NotificationManager;
import android.app.PendingIntent;
import android.content.Context;
import android.content.Intent;
import android.database.Cursor;
import android.database.CursorIndexOutOfBoundsException;
import android.database.sqlite.SQLiteDatabase;
import android.media.Ringtone;
import android.media.RingtoneManager;
import android.net.Uri;
import android.support.v7.app.NotificationCompat;
import android.view.View;
import android.widget.ArrayAdapter;
import android.widget.Button;
import android.widget.ListView;
import android.widget.Toast;
import java.util.ArrayList;
import projectp3.studio.com.gerenciamentodefaltas.AddFalta;
import projectp3.studio.com.gerenciamentodefaltas.R;
import projectp3.studio.com.gerenciamentodefaltas.SituDaMat;
/**
* Created by Lucas on 17/10/2017.
*/
public class StrategyFuncs extends Activity {
private Context context;
public StrategyFuncs(Context c){
this.context = c;
}
public String calcStatus(Integer fA, Integer maxF){
//ACEITAVEL -> ate 50% [0, 50)
//PERIGOSO -> entre 50% e 90% [50, 90)
//CRITICO -> mais de 90% [90, 100]
//ULTRAPASSADO -> mais de 100% (100, +inf)
int nvl = (int)((fA*100)/maxF);
if( nvl < 50 ){
return "ACEITÁVEL";
}else if (nvl >= 50 && nvl < 80){
return "PERIGOSO!";
}else if (nvl >= 80 && nvl <= 100){
return "CRÍTICO!!!";
}else{
return "LIMITE ULTRAPASSADO!";
}
}
public boolean hasNext (Cursor c){
try{
c.moveToNext();
return true;
}catch (CursorIndexOutOfBoundsException e){
return false;
}
}
}
| c713f8379dd13f4ecd87246b91bef28cfae4d629 | [
"Java"
] | 4 | Java | LucasSSales/GerenciamentoDeFaltas | b1ece981c9c3b2b9ce084f51462468493dbe8e18 | cfe7f75f164942439e501780c0ee53dbd7dab0a8 |
refs/heads/master | <repo_name>shouaya/minios<file_sep>/minios/src/main/java/com/jialu/minios/process/LineRequest.java
package com.jialu.minios.process;
import java.io.IOException;
import java.io.InputStream;
import org.apache.http.HttpResponse;
import org.apache.http.ParseException;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.ContentType;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.util.EntityUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.dropbox.core.DbxException;
import com.dropbox.core.v2.DbxClientV2;
import com.dropbox.core.v2.files.WriteMode;
import com.dropbox.core.v2.sharing.SharedLinkMetadata;
import com.jialu.minios.utility.MiniConstants;
public class LineRequest {
private static final Logger LOGGER = LoggerFactory.getLogger(LineRequest.class);
public static String reply(String accessToken, String postData) throws ParseException, IOException {
LOGGER.info("postData:" + postData);
HttpClient httpClient = HttpClientBuilder.create().build();
HttpPost post = new HttpPost(MiniConstants.LINE_REPLY_URL);
StringEntity se = new StringEntity(postData, ContentType.APPLICATION_JSON);
post.setEntity(se);
post.addHeader("Authorization", "Bearer " + accessToken);
post.addHeader("Content-Type", "application/json;charset=UTF-8");
HttpResponse response = httpClient.execute(post);
String body = EntityUtils.toString(response.getEntity(), "UTF-8");
LOGGER.info("returnData:" + body);
return body;
}
public static String upload(DbxClientV2 dbx, String accessToken, String contentId, String type)
throws ClientProtocolException, IOException {
String url = String.format("https://api.line.me/v2/bot/message/%s/content", contentId);
HttpClient httpClient = HttpClientBuilder.create().build();
HttpGet get = new HttpGet(url);
get.addHeader("Authorization", "Bearer " + accessToken);
HttpResponse response = httpClient.execute(get);
String retUrl = null;
try (InputStream in = response.getEntity().getContent()) {
String remoteFile = "/test/" + contentId;
if ("image".equals(type)) {
remoteFile = remoteFile + ".jpeg";
} else if ("audio".equals(type)) {
remoteFile = remoteFile + ".m4a";
} else if ("video".equals(type)) {
remoteFile = remoteFile + ".mp4";
}
dbx.files().uploadBuilder(remoteFile).withMode(WriteMode.OVERWRITE).uploadAndFinish(in);
SharedLinkMetadata sharedLinkMetadata = dbx.sharing().createSharedLinkWithSettings(remoteFile);
retUrl = sharedLinkMetadata.getUrl().replace("?dl=0", "?dl=1");
} catch (DbxException e) {
LOGGER.error("upload error", e);
}
return retUrl;
}
public static String getUserProfile(String accessToken, String userId) throws ParseException, IOException {
String url = String.format("https://api.line.me/v2/bot/profile/%s", userId);
HttpClient httpClient = HttpClientBuilder.create().build();
HttpGet get = new HttpGet(url);
get.addHeader("Authorization", "Bearer " + accessToken);
get.addHeader("Content-Type", "application/json;charset=UTF-8");
HttpResponse response = httpClient.execute(get);
String body = EntityUtils.toString(response.getEntity(), "UTF-8");
LOGGER.info("returnData:" + body);
return body;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/model/Education.java
package com.jialu.minios.model;
import java.io.Serializable;
import java.sql.Timestamp;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.NamedQuery;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonBackReference;
/**
* 学歴.
*
*/
@Entity
@Table(name = "education")
@NamedQuery(name = "Education.findAll", query = "SELECT m FROM Education m")
public class Education implements Serializable {
private static final long serialVersionUID = 1L;
// 学校名称/学部/専門
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private Timestamp ctime;
private String cuser;
private Timestamp utime;
private String uuser;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getBeginYmd() {
return beginYmd;
}
public void setBeginYmd(String beginYmd) {
this.beginYmd = beginYmd;
}
public String getEndYmd() {
return endYmd;
}
public void setEndYmd(String endYmd) {
this.endYmd = endYmd;
}
public String getSchool() {
return school;
}
public void setSchool(String school) {
this.school = school;
}
public String getDepartment() {
return department;
}
public void setDepartment(String department) {
this.department = department;
}
public String getExpert() {
return expert;
}
public void setExpert(String expert) {
this.expert = expert;
}
public Timestamp getCtime() {
return ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getCuser() {
return cuser;
}
public void setCuser(String cuser) {
this.cuser = cuser;
}
public Timestamp getUtime() {
return utime;
}
public void setUtime(Timestamp utime) {
this.utime = utime;
}
public String getUuser() {
return uuser;
}
public void setUuser(String uuser) {
this.uuser = uuser;
}
// 期間
@Column(name = "begin_ymd")
private String beginYmd;
@Column(name = "end_ymd")
private String endYmd;
// 学校名称
private String school;
// 学部
private String department;
// 専門
private String expert;
@ManyToOne
@JoinColumn(name = "cv_id", nullable = true, insertable = false, updatable = false)
@JsonBackReference
private CurriculumVitae curriculumVitae;
}
<file_sep>/minios/src/main/java/com/jialu/minios/resource/Line.java
package com.jialu.minios.resource;
import java.io.IOException;
import javax.ws.rs.GET;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.QueryParam;
import javax.ws.rs.core.Cookie;
import javax.ws.rs.core.MediaType;
import javax.ws.rs.core.NewCookie;
import javax.ws.rs.core.Response;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.codahale.metrics.annotation.Timed;
import com.fasterxml.jackson.databind.DeserializationFeature;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.datatype.jsr310.JavaTimeModule;
import com.jialu.minios.configuration.MiniConfiguration;
import com.jialu.minios.dao.LineUserDao;
import com.jialu.minios.model.LineUser;
import com.jialu.minios.process.LineProcess;
import com.jialu.minios.view.StaticView;
import com.linecorp.bot.model.event.CallbackRequest;
import com.linecorp.bot.model.event.Event;
import io.dropwizard.hibernate.UnitOfWork;
@Path("/line")
public class Line {
private static final Logger LOGGER = LoggerFactory.getLogger(Line.class);
private MiniConfiguration config;
public Line(MiniConfiguration config) {
this.config = config;
}
@POST
@Timed
@UnitOfWork
@Produces("application/json; charset=utf-8")
public Response message(String json) {
try {
LOGGER.info(json);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
objectMapper.registerModule(new JavaTimeModule())
.configure(DeserializationFeature.READ_DATE_TIMESTAMPS_AS_NANOSECONDS, false);
CallbackRequest callbackRequest = objectMapper.readValue(json, CallbackRequest.class);
for (Event event : callbackRequest.getEvents()) {
LineProcess.eventProcess(event, config);
}
} catch (IOException e) {
LOGGER.error("line callback ", e);
}
return Response.ok().build();
}
@GET
@Timed
@UnitOfWork
@Path("/regist")
public Response authorization(@QueryParam("uid") String uid, @QueryParam("token") String token) {
LineUserDao dao = config.getDao(LineUserDao.class);
LineUser user = dao.findByIdAndToken(uid, token);
if (user == null) {
StaticView view = new StaticView("error.mustache", "regist_error");
return Response.ok(view, MediaType.TEXT_HTML).build();
}
StaticView view = new StaticView("success.mustache", "regist_success");
Cookie cookieUid = new Cookie("uid", uid, "/" , config.getHost());
Cookie cookieToken = new Cookie("token", token, "/" , config.getHost());
NewCookie cookieU = new NewCookie(cookieUid);
NewCookie cookieT = new NewCookie(cookieToken);
return Response.ok(view, MediaType.TEXT_HTML).cookie(cookieU, cookieT).build();
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/model/LineUser.java
package com.jialu.minios.model;
import java.io.Serializable;
import java.sql.Timestamp;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.NamedQueries;
import javax.persistence.NamedQuery;
import javax.persistence.OneToOne;
import javax.persistence.Table;
/**
* save line user.
*
*/
@Entity
@Table(name = "line_user")
@NamedQueries({
@NamedQuery(name = "LineUser.findByOpenid", query = "SELECT e FROM LineUser e WHERE e.userId = :user_id ORDER BY e.id"),
@NamedQuery(name = "LineUser.findByIdAndToken", query = "SELECT e FROM LineUser e WHERE e.userId = :uid and e.token = :token ORDER BY e.id") })
public class LineUser implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private Timestamp ctime;
private String cuser;
private Timestamp utime;
private String uuser;
@Column(name = "user_id", unique = true, nullable = false)
private String userId;
@Column(name = "display_name")
private String displayName;
@Column(name = "picture_url")
private String pictureUrl;
@Column(name = "status_message")
private String statusMessage;
private String token;
@OneToOne(mappedBy = "lineUser")
private LinkedinUser linkedinUser;
@OneToOne(mappedBy = "lineUser")
private GithubUser githubUser;
@OneToOne(mappedBy = "lineUser")
private CurriculumVitae cv;
public LineUser() {
}
public Integer getId() {
return this.id;
}
public void setId(Integer id) {
this.id = id;
}
public Timestamp getCtime() {
return this.ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getCuser() {
return this.cuser;
}
public void setCuser(String cuser) {
this.cuser = cuser;
}
public Timestamp getUtime() {
return this.utime;
}
public void setUtime(Timestamp utime) {
this.utime = utime;
}
public String getUuser() {
return this.uuser;
}
public void setUuser(String uuser) {
this.uuser = uuser;
}
public String getUserId() {
return userId;
}
public void setUserId(String userId) {
this.userId = userId;
}
public String getDisplayName() {
return displayName;
}
public void setDisplayName(String displayName) {
this.displayName = displayName;
}
public String getPictureUrl() {
return pictureUrl;
}
public void setPictureUrl(String pictureUrl) {
this.pictureUrl = pictureUrl;
}
public String getStatusMessage() {
return statusMessage;
}
public void setStatusMessage(String statusMessage) {
this.statusMessage = statusMessage;
}
public String getToken() {
return token;
}
public void setToken(String token) {
this.token = token;
}
public LinkedinUser getLinkedinUser() {
return linkedinUser;
}
public void setLinkedinUser(LinkedinUser linkedinUser) {
this.linkedinUser = linkedinUser;
}
public CurriculumVitae getCv() {
return cv;
}
public void setCv(CurriculumVitae cv) {
this.cv = cv;
}
public GithubUser getGithubUser() {
return githubUser;
}
public void setGithubUser(GithubUser githubUser) {
this.githubUser = githubUser;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/dao/LineMessageDao.java
package com.jialu.minios.dao;
import java.sql.Timestamp;
import org.hibernate.SessionFactory;
import com.jialu.minios.model.LineMessage;
import com.jialu.minios.utility.MiniConstants;
import io.dropwizard.hibernate.AbstractDAO;
/**
* The persistent class for the wechat_user database table.
*
*/
public class LineMessageDao extends AbstractDAO<LineMessage> {
public LineMessageDao(SessionFactory factory) {
super(factory);
}
public LineMessage findById(Integer id) {
return get(id);
}
public long save(LineMessage message) {
message.setCuser(MiniConstants.APP_NAME);
message.setCtime(new Timestamp(System.currentTimeMillis()));
message.setUuser(MiniConstants.APP_NAME);
message.setUtime(new Timestamp(System.currentTimeMillis()));
return persist(message).getId();
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/configuration/GithubConfiguration.java
package com.jialu.minios.configuration;
import javax.validation.Valid;
import javax.validation.constraints.NotNull;
import com.fasterxml.jackson.annotation.JsonProperty;
public class GithubConfiguration {
@Valid
@NotNull
@JsonProperty
private String url;
@Valid
@NotNull
@JsonProperty
private String appId;
@Valid
@NotNull
@JsonProperty
private String appSecret;
public String getUrl() {
return url;
}
public String getAppSecret() {
return appSecret;
}
public String getAppId() {
return appId;
}
}
<file_sep>/minios/src/main/resources/message.properties
regist_success.page_title=\u767B\u9332\u5B8C\u4E86
regist_success.msg_title=\u767B\u9332\u6B63\u5E38\u5B8C\u4E86\u3057\u307E\u3057\u305F\u3002
regist_success.msg_desc=\u4F7F\u3044\u306A\u304C\u3089\u899A\u3048\u3061\u3083\u304A\u3046\uFF01\u3068\u3044\u3046\u3053\u3068\u3067\u3001\u65E9\u901F\u4F7F\u3063\u3066\u307F\u307E\u3057\u3087\u3046\u3002
regist_success.btn_title=閉じる
regist_success.footer_title=便利な履歴書
regist_error.page_title=登録エラー
regist_error.msg_title=エラー発生しました。
regist_error.msg_desc=
regist_error.btn_title=閉じる
regist_error.footer_title=エラー発生しました。
404_error.page_title=未検出エラー
404_error.msg_title=ページ見つかりません。
404_error.msg_desc=
404_error.btn_title=閉じる
404_error.footer_title=便利な履歴書
401_error.page_title=認証エラー
401_error.msg_title=認証に失敗しました。
401_error.msg_desc=哈哈哈
401_error.btn_title=閉じる
401_error.footer_title=便利な履歴書
500_error.page_title=サーバーエラー
500_error.msg_title=エラー発生しました。
500_error.msg_desc=
500_error.btn_title=閉じる
500_error.footer_title=便利な履歴書<file_sep>/minios/src/main/java/com/jialu/minios/model/LinkedinUser.java
package com.jialu.minios.model;
import java.io.Serializable;
import java.sql.Timestamp;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.NamedQueries;
import javax.persistence.NamedQuery;
import javax.persistence.OneToOne;
import javax.persistence.Table;
import com.fasterxml.jackson.annotation.JsonBackReference;
/**
* save linkedin user.
*
*/
@Entity
@Table(name = "linkedin_user")
@NamedQueries({
@NamedQuery(name = "LinkedinUser.findByOpenid", query = "SELECT e FROM LinkedinUser e WHERE e.openid = :openid ORDER BY e.id") })
public class LinkedinUser implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private Timestamp ctime;
private String cuser;
@Column(name = "first_name")
private String firstName;
private String headline;
@Column(name = "last_name")
private String lastName;
@Column(unique = true, nullable = false)
private String openid;
private String site;
@Column(name = "linkedin_token")
private String linkedinToken;
@Column(name = "linkedin_token_expires")
private Timestamp linkedinTokenExpires;
private Timestamp utime;
private String uuser;
@OneToOne
@JoinColumn(name = "line_id")
@JsonBackReference
private LineUser lineUser;
public LinkedinUser() {
}
public Integer getId() {
return this.id;
}
public void setId(Integer id) {
this.id = id;
}
public Timestamp getCtime() {
return this.ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getCuser() {
return this.cuser;
}
public void setCuser(String cuser) {
this.cuser = cuser;
}
public String getFirstName() {
return this.firstName;
}
public void setFirstName(String firstName) {
this.firstName = firstName;
}
public String getHeadline() {
return this.headline;
}
public void setHeadline(String headline) {
this.headline = headline;
}
public String getLastName() {
return this.lastName;
}
public void setLastName(String lastName) {
this.lastName = lastName;
}
public String getOpenid() {
return this.openid;
}
public void setOpenid(String openid) {
this.openid = openid;
}
public String getSite() {
return this.site;
}
public void setSite(String site) {
this.site = site;
}
public Timestamp getUtime() {
return this.utime;
}
public void setUtime(Timestamp utime) {
this.utime = utime;
}
public String getUuser() {
return this.uuser;
}
public void setUuser(String uuser) {
this.uuser = uuser;
}
public String getLinkedinToken() {
return linkedinToken;
}
public void setLinkedinToken(String linkedinToken) {
this.linkedinToken = linkedinToken;
}
public Timestamp getLinkedinTokenExpires() {
return linkedinTokenExpires;
}
public void setLinkedinTokenExpires(Timestamp linkedinTokenExpires) {
this.linkedinTokenExpires = linkedinTokenExpires;
}
public LineUser getLineUser() {
return lineUser;
}
public void setLineUser(LineUser lineUser) {
this.lineUser = lineUser;
}
}
<file_sep>/minios/src/test/java/minios/LinkedinTest.java
package minios;
//import java.io.IOException;
//
//import org.junit.Test;
//
//import com.fasterxml.jackson.databind.ObjectMapper;
//import com.jialu.minios.utility.LinkedinRequest;
//import com.jialu.minios.vo.LinkedinShareData;
//
//import twitter4j.JSONException;
//import twitter4j.JSONObject;
public class LinkedinTest {
// private static String TOKEN =
// "<KEY>";
// @Test
// public void testRestApi(){
// ObjectMapper mapper = new ObjectMapper();
// String json = "";
// LinkedinShareData lsd = new LinkedinShareData();
// lsd.setComment("this is a test from minios 4");
// lsd.getContent().put("title", "title test");
// lsd.getContent().put("description", "description test");
// lsd.getContent().put("submitted-url",
// "http://www.wingarc.com/product/svf/demo/");
// //80 x 150px
// lsd.getContent().put("submitted-image-url",
// "http://astrodeo.com/blog/wp-content/uploads/2010/04/simulator-80x150.png");
// try {
// json = mapper.writeValueAsString(lsd);
// JSONObject jo = LinkedinRequest.share(TOKEN, json);
// System.out.println(jo.toString());
// } catch (IOException | JSONException e) {
// e.printStackTrace();
// }
// }
//
// @Test
// public void getUserInfo(){
// try {
// JSONObject jo = LinkedinRequest.getPerson(TOKEN);
// System.out.println(jo.toString());
// } catch (IOException | JSONException e) {
// e.printStackTrace();
// }
// }
}
<file_sep>/minios/src/main/java/com/jialu/minios/dao/GithubUserDao.java
package com.jialu.minios.dao;
import java.sql.Timestamp;
import java.util.List;
import org.hibernate.SessionFactory;
import com.jialu.minios.model.GithubUser;
import com.jialu.minios.utility.MiniConstants;
import io.dropwizard.hibernate.AbstractDAO;
public class GithubUserDao extends AbstractDAO<GithubUser> {
public GithubUserDao(SessionFactory factory) {
super(factory);
}
public GithubUser findById(Integer id) {
return get(id);
}
public long save(GithubUser inUser) {
inUser.setCuser(MiniConstants.APP_NAME);
inUser.setCtime(new Timestamp(System.currentTimeMillis()));
inUser.setUuser(MiniConstants.APP_NAME);
inUser.setUtime(new Timestamp(System.currentTimeMillis()));
return persist(inUser).getId();
}
public GithubUser findByOpenId(String openid) {
List<GithubUser> list = list(namedQuery("GithubUser.findByOpenid").setParameter("openid", openid));
if (list == null) {
return null;
}
if (list.size() == 0) {
return null;
}
return list.get(0);
}
}
<file_sep>/minios/src/test/java/minios/ResourcesTest.java
package minios;
//import static org.assertj.core.api.Assertions.assertThat;
//import javax.ws.rs.client.Client;
//import javax.ws.rs.core.Response;
//
//import org.apache.commons.lang3.builder.ToStringBuilder;
//import org.assertj.core.util.Lists;
//import org.dozer.DozerBeanMapper;
//import org.dozer.Mapper;
//import org.junit.ClassRule;
//import org.junit.Test;
//
//import com.jialu.minios.MiniApp;
//import com.jialu.minios.configuration.MiniConfiguration;
//import com.jialu.minios.model.WeiboUser;
//import com.jialu.minios.utility.MiniProperties;
//import com.jialu.minios.vo.WeiboInfo;
//
//import io.dropwizard.client.JerseyClientBuilder;
//import io.dropwizard.testing.ResourceHelpers;
//import io.dropwizard.testing.junit.DropwizardAppRule;
public class ResourcesTest {
// @ClassRule
// public static final DropwizardAppRule<MiniConfiguration> RULE = new DropwizardAppRule<MiniConfiguration>(
// MiniApp.class, ResourceHelpers.resourceFilePath("mini.yml"));
//
// @Test
// public void loginHandlerRedirectsAfterPost() {
// Client client = new JerseyClientBuilder(RULE.getEnvironment()).build("test client");
//
// Response response = client.target(String.format("http://localhost:%d/profile/info", RULE.getLocalPort()))
// .request().get();
//
// assertThat(response.getStatus()).isEqualTo(401);
// }
//
// @Test
// public void testConfigData() {
// String job = MiniProperties.getJobPosition("OP");
//
// assertThat(job).isEqualTo("オペレーター");
// }ß
//
// @Test
// public void testMappingData() {
// WeiboUser sourceObject = new WeiboUser();
// sourceObject.setOpenid("test");
// Mapper mapper = new DozerBeanMapper(Lists.newArrayList("dozerMappings.xml"));
// WeiboInfo destObject = mapper.map(sourceObject, WeiboInfo.class);
// System.out.println(ToStringBuilder.reflectionToString(destObject));
//
// assertThat(destObject.getOpenid()).isEqualTo(sourceObject.getOpenid());
// }
}
<file_sep>/minios/src/main/java/com/jialu/minios/view/StaticView.java
package com.jialu.minios.view;
import java.util.HashMap;
import com.jialu.minios.utility.PropertiesUtil;
import io.dropwizard.views.View;
public class StaticView extends View {
private HashMap<String, String> page;
public StaticView(String viewName, String pageName) {
super(viewName);
mappingPageMessage(pageName);
}
public HashMap<String, String> getPage() {
return page;
}
private void mappingPageMessage(String pageName){
page = PropertiesUtil.getMsgProperty(pageName);
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/dao/LinkedinUserDao.java
package com.jialu.minios.dao;
import java.sql.Timestamp;
import java.util.List;
import org.hibernate.SessionFactory;
import com.jialu.minios.model.LinkedinUser;
import com.jialu.minios.utility.MiniConstants;
import io.dropwizard.hibernate.AbstractDAO;
public class LinkedinUserDao extends AbstractDAO<LinkedinUser> {
public LinkedinUserDao(SessionFactory factory) {
super(factory);
}
public LinkedinUser findById(Integer id) {
return get(id);
}
public long save(LinkedinUser inUser) {
inUser.setCuser(MiniConstants.APP_NAME);
inUser.setCtime(new Timestamp(System.currentTimeMillis()));
inUser.setUuser(MiniConstants.APP_NAME);
inUser.setUtime(new Timestamp(System.currentTimeMillis()));
return persist(inUser).getId();
}
public LinkedinUser findByOpenId(String openid) {
List<LinkedinUser> list = list(namedQuery("LinkedinUser.findByOpenid").setParameter("openid", openid));
if (list == null) {
return null;
}
if (list.size() == 0) {
return null;
}
return list.get(0);
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/utility/MiniProperties.java
package com.jialu.minios.utility;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.dataformat.yaml.YAMLFactory;
import com.jialu.minios.vo.ConfigData;
import com.jialu.minios.vo.GerenralData;
public class MiniProperties {
private static final Logger LOGGER = LoggerFactory.getLogger(MiniProperties.class);
private static ConfigData configData = new ConfigData();
static {
try (InputStream is = MiniProperties.class.getClassLoader().getResourceAsStream(MiniConstants.CONFIGFILE)) {
final ObjectMapper mapper = new ObjectMapper(new YAMLFactory());
configData = mapper.readValue(is, ConfigData.class);
} catch (IOException e) {
LOGGER.error("MiniProperties ", e);
}
}
public static List<GerenralData> getJobPosition() {
return configData.getJobPosition();
}
public static String getJobPosition(String key) {
return getValueByKey(key, configData.getJobPosition());
}
public static List<GerenralData> getJobProcess() {
return configData.getJobProcess();
}
public static String getJobProcess(String key) {
return getValueByKey(key, configData.getJobProcess());
}
public static List<GerenralData> getSkill() {
return configData.getSkill();
}
public static String getSkill(String key) {
return getValueByKey(key, configData.getSkill());
}
private static String getValueByKey(String key, List<GerenralData> list) {
for (GerenralData gd : list) {
if (gd.getCode().equals(key)) {
return gd.getValue();
}
}
return null;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/resource/Github.java
package com.jialu.minios.resource;
import java.io.IOException;
import java.io.UnsupportedEncodingException;
import java.net.URI;
import java.net.URISyntaxException;
import java.net.URLEncoder;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.QueryParam;
import javax.ws.rs.container.ContainerRequestContext;
import javax.ws.rs.core.Context;
import javax.ws.rs.core.Response;
import org.apache.http.ParseException;
import org.json.JSONException;
import org.json.JSONObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.codahale.metrics.annotation.Timed;
import com.jialu.minios.configuration.MiniConfiguration;
import com.jialu.minios.dao.GithubUserDao;
import com.jialu.minios.dao.LineUserDao;
import com.jialu.minios.model.LineUser;
import com.jialu.minios.process.GithubProcess;
import com.jialu.minios.process.GithubRequest;
import com.jialu.minios.utility.MiniConstants;
import com.jialu.minios.view.LineProfileView;
import com.jialu.minios.view.StaticView;
import io.dropwizard.hibernate.UnitOfWork;
@Path("/github")
public class Github {
private static final Logger LOGGER = LoggerFactory.getLogger(Github.class);
private MiniConfiguration config;
public Github(MiniConfiguration config) {
this.config = config;
}
@GET
@Timed
@Path("/authorization")
public Response authorization(@Context ContainerRequestContext context) throws URISyntaxException {
String url = MiniConstants.GITHUB_AUTHORIZATION_URL;
try {
LineUser wxUser = (LineUser) context.getProperty(MiniConstants.WECHAT_USER);
url += "&client_id=" + this.config.getGithub().getAppId() + "&redirect_uri="
+ URLEncoder.encode(this.config.getGithub().getUrl(), "UTF-8") + "&state=" + wxUser.getUserId();
LOGGER.info(url);
} catch (UnsupportedEncodingException e) {
LOGGER.error("github authorization ", e);
}
return Response.seeOther(new URI(url)).build();
}
@GET
@Timed
@UnitOfWork
@Path("/callback")
public StaticView callback(@Context ContainerRequestContext context, @QueryParam("code") String code,
@QueryParam("state") String wxopenid) {
LineProfileView view = new LineProfileView("profile.mustache", "profile");
try {
JSONObject accessTokenJson = GithubRequest.getAccessToken(code, this.config.getGithub());
LineUserDao wuDao = this.config.getDao(LineUserDao.class);
GithubUserDao ghDao = this.config.getDao(GithubUserDao.class);
LineUser user = GithubProcess.saveGithubUser(wuDao, ghDao, accessTokenJson, wxopenid);
view.setUser(user);
} catch (ParseException | IOException | JSONException e) {
LOGGER.error("github callback ", e);
}
return view;
}
}
<file_sep>/minios/src/main/resources/check.properties
cookie_check=github/authorization,/github/callback,linkedin/authorization,linkedin/callback<file_sep>/minios/pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jialu</groupId>
<artifactId>minios</artifactId>
<packaging>jar</packaging>
<version>0.0.1</version>
<name>minios</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<dropwizard.version>1.0.5</dropwizard.version>
</properties>
<dependencies>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-core</artifactId>
<version>${dropwizard.version}</version>
</dependency>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-assets</artifactId>
<version>${dropwizard.version}</version>
</dependency>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-views-mustache</artifactId>
<version>${dropwizard.version}</version>
</dependency>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-hibernate</artifactId>
<version>${dropwizard.version}</version>
</dependency>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-testing</artifactId>
<version>${dropwizard.version}</version>
</dependency>
<dependency>
<groupId>io.dropwizard</groupId>
<artifactId>dropwizard-client</artifactId>
<version>${dropwizard.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.reflections</groupId>
<artifactId>reflections</artifactId>
<version>0.9.10</version>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>
<dependency>
<groupId>me.chanjar</groupId>
<artifactId>weixin-java-mp</artifactId>
<version>1.3.3</version>
</dependency>
<dependency>
<groupId>org.json</groupId>
<artifactId>json</artifactId>
<version>20160810</version>
</dependency>
<dependency>
<groupId>com.dropbox.core</groupId>
<artifactId>dropbox-core-sdk</artifactId>
<version>2.0.6</version>
</dependency>
<dependency>
<groupId>postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.1-901.jdbc4</version>
</dependency>
<dependency>
<groupId>com.linecorp.bot</groupId>
<artifactId>line-bot-model</artifactId>
<version>1.3.0</version>
<exclusions>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</exclusion>
<exclusion>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<finalName>minios</finalName>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.3</version>
<configuration>
<createDependencyReducedPom>true</createDependencyReducedPom>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.jialu.minios.MiniApp</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>2.4</version>
<configuration>
<archive>
<manifest>
<addDefaultImplementationEntries>true</addDefaultImplementationEntries>
</manifest>
</archive>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.3</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
<file_sep>/minios/src/main/java/com/jialu/minios/dao/LineUserDao.java
package com.jialu.minios.dao;
import java.sql.Timestamp;
import java.util.List;
import org.hibernate.SessionFactory;
import com.jialu.minios.model.LineUser;
import com.jialu.minios.utility.MiniConstants;
import io.dropwizard.hibernate.AbstractDAO;
public class LineUserDao extends AbstractDAO<LineUser> {
public LineUserDao(SessionFactory factory) {
super(factory);
}
public LineUser findById(Integer id) {
return get(id);
}
public long save(LineUser inUser) {
inUser.setCuser(MiniConstants.APP_NAME);
inUser.setCtime(new Timestamp(System.currentTimeMillis()));
inUser.setUuser(MiniConstants.APP_NAME);
inUser.setUtime(new Timestamp(System.currentTimeMillis()));
return persist(inUser).getId();
}
public LineUser findByOpenId(String openid) {
List<LineUser> list = list(namedQuery("LineUser.findByOpenid").setParameter("user_id", openid));
if (list == null) {
return null;
}
if (list.size() == 0) {
return null;
}
return list.get(0);
}
public LineUser findByIdAndToken(String uid, String token) {
List<LineUser> list = list(
namedQuery("LineUser.findByIdAndToken").setParameter("uid", uid).setParameter("token", token));
if (list == null) {
return null;
}
if (list.size() == 0) {
return null;
}
return list.get(0);
}
}
<file_sep>/README.md
# minios
<i>new project connect wechat and linkedin</i>
* <font color="red"><b>attention</b></font> wechat
* Graphic or other click or menu prompt <font color="red"><b>attention</b></font> linkedin
* view<font color="red"><b> all user</b></font>
* <font color="red"><b>invite</b></font> friend
* bind linkedin
* edit <font color="red"><b> profiles </b></font> bind to linkedin
* edit <font color="red"><b> head portrait </b></font> upload image
* view other ,add <font color="red"><b>skill or blog </b></font>to my linkedin
* <font color="red"><b> invite yourself </b></font>to wechat,<font color="red"><b> ask for </b></font>evaluation
<file_sep>/minios/src/main/java/com/jialu/minios/vo/GithubInfo.java
package com.jialu.minios.vo;
import java.io.Serializable;
public class GithubInfo implements Serializable {
private static final long serialVersionUID = 1L;
private Integer id;
private String openid;
private String scope;
private String uuser;
private String avatarUrl;
private String url;
private String htmlUrl;
private String type;
private String name;
private String company;
private String blog;
private String location;
private String email;
private String bio;
private String publicRepos;
private String publicGists;
private String followers;
private String following;
private String totalPrivateRepos;
private String ownedPrivateRepos;
private String privateGists;
private String diskUsage;
private String collaborators;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getOpenid() {
return openid;
}
public void setOpenid(String openid) {
this.openid = openid;
}
public String getScope() {
return scope;
}
public void setScope(String scope) {
this.scope = scope;
}
public String getUuser() {
return uuser;
}
public void setUuser(String uuser) {
this.uuser = uuser;
}
public String getAvatarUrl() {
return avatarUrl;
}
public void setAvatarUrl(String avatarUrl) {
this.avatarUrl = avatarUrl;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public String getHtmlUrl() {
return htmlUrl;
}
public void setHtmlUrl(String htmlUrl) {
this.htmlUrl = htmlUrl;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getCompany() {
return company;
}
public void setCompany(String company) {
this.company = company;
}
public String getBlog() {
return blog;
}
public void setBlog(String blog) {
this.blog = blog;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public String getBio() {
return bio;
}
public void setBio(String bio) {
this.bio = bio;
}
public String getPublicRepos() {
return publicRepos;
}
public void setPublicRepos(String publicRepos) {
this.publicRepos = publicRepos;
}
public String getPublicGists() {
return publicGists;
}
public void setPublicGists(String publicGists) {
this.publicGists = publicGists;
}
public String getFollowers() {
return followers;
}
public void setFollowers(String followers) {
this.followers = followers;
}
public String getFollowing() {
return following;
}
public void setFollowing(String following) {
this.following = following;
}
public String getTotalPrivateRepos() {
return totalPrivateRepos;
}
public void setTotalPrivateRepos(String totalPrivateRepos) {
this.totalPrivateRepos = totalPrivateRepos;
}
public String getOwnedPrivateRepos() {
return ownedPrivateRepos;
}
public void setOwnedPrivateRepos(String ownedPrivateRepos) {
this.ownedPrivateRepos = ownedPrivateRepos;
}
public String getPrivateGists() {
return privateGists;
}
public void setPrivateGists(String privateGists) {
this.privateGists = privateGists;
}
public String getDiskUsage() {
return diskUsage;
}
public void setDiskUsage(String diskUsage) {
this.diskUsage = diskUsage;
}
public String getCollaborators() {
return collaborators;
}
public void setCollaborators(String collaborators) {
this.collaborators = collaborators;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/utility/MiniConstants.java
package com.jialu.minios.utility;
public class MiniConstants {
public static final String APP_NAME = "minios";
public static final String COOKIE_OPENID = "openid";
public static final String COOKIE_AUTH_TOKEN = "mini_token";
public static final String NOTAUTHORIZEDEXCEPTION = "not allow";
public static final String WECHAT_USER = "wechat_user";
public static final String LINKEDIN_AUTHORIZATION_URL = "https://www.linkedin.com/oauth/v2/authorization?response_type=code";
public static final String LINKEDIN_ACCESSTOKEN_URL = "https://www.linkedin.com/oauth/v2/accessToken";
public static final String LINKEDIN_SHARE_URL = "https://api.linkedin.com/v1/people/~/shares?format=json";
public static final String LINKEDIN_PEOPLE_URL = "https://api.linkedin.com/v1/people/~?format=json";
public static final String GITHUB_AUTHORIZATION_URL = "https://github.com/login/oauth/authorize?response_type=code";
public static final String GITHUB_ACCESSTOKEN_URL = "https://github.com/login/oauth/access_token";
public static final String GITHUB_PEOPLE_URL = "https://api.github.com/user";
public static final String LINE_REPLY_URL = "https://api.line.me/v2/bot/message/reply";
public static final String MODEL_PACKAGE = "com.jialu.minios.model";
public static final String RESOURCE_PACKAGE = "com.jialu.minios.resource";
public static final String DAO_PACKAGE = "com.jialu.minios.dao";
public static final String CONFIGFILE = "config.yml";
public static final String MAPPERPATH = "dozerMappings.xml";
}
<file_sep>/minios/src/main/java/com/jialu/minios/RequestFilter.java
package com.jialu.minios;
import java.io.IOException;
import java.net.URI;
import java.util.List;
import java.util.Map;
import javax.ws.rs.NotAuthorizedException;
import javax.ws.rs.container.ContainerRequestContext;
import javax.ws.rs.container.ContainerRequestFilter;
import javax.ws.rs.core.Cookie;
import javax.ws.rs.ext.Provider;
import org.hibernate.CacheMode;
import org.hibernate.FlushMode;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.context.internal.ManagedSessionContext;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.jialu.minios.configuration.MiniConfiguration;
import com.jialu.minios.dao.LineUserDao;
import com.jialu.minios.model.LineUser;
import com.jialu.minios.utility.MiniConstants;
import com.jialu.minios.utility.PropertiesUtil;
import io.dropwizard.hibernate.UnitOfWork;
@Provider
public class RequestFilter implements ContainerRequestFilter {
private static final Logger LOGGER = LoggerFactory.getLogger(RequestFilter.class);
private MiniConfiguration config;
private SessionFactory sessionFactory;
RequestFilter(MiniConfiguration config, SessionFactory sessionFactory) {
this.config = config;
this.sessionFactory = sessionFactory;
}
@Override
@UnitOfWork
public void filter(ContainerRequestContext context) throws IOException {
URI uri = context.getUriInfo().getRequestUri();
LOGGER.info(uri.toString());
String path = context.getUriInfo().getPath();
List<String> checkCookie = PropertiesUtil.getCheckProperty("cookie_check");
if (!checkCookie.contains(path)) {
LOGGER.info(" AUTH: needless ");
return;
}
Session session = getSession();
Map<String, Cookie> cookies = context.getCookies();
if (cookies.get("uid") == null || cookies.get("token") == null) {
LOGGER.error(" AUTH: no line cookie");
throw new NotAuthorizedException("no line cookie");
}
try {
LineUserDao wxdao = this.config.getDao(LineUserDao.class);
LineUser model = wxdao.findByIdAndToken(cookies.get("uid").getValue(), cookies.get("token").getValue());
if (model == null) {
LOGGER.error(" AUTH: no line user");
throw new NotAuthorizedException("no line user");
}
context.setProperty(MiniConstants.WECHAT_USER, model);
} finally {
session.close();
}
}
private Session getSession() {
Session session = sessionFactory.openSession();
session.setDefaultReadOnly(true);
session.setCacheMode(CacheMode.NORMAL);
session.setFlushMode(FlushMode.MANUAL);
ManagedSessionContext.bind(session);
return session;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/utility/MiniHibernateBundle.java
package com.jialu.minios.utility;
import javax.persistence.Entity;
import org.reflections.Reflections;
import com.google.common.collect.ImmutableList;
import com.jialu.minios.configuration.MiniConfiguration;
import io.dropwizard.ConfiguredBundle;
import io.dropwizard.db.PooledDataSourceFactory;
import io.dropwizard.hibernate.HibernateBundle;
import io.dropwizard.hibernate.SessionFactoryFactory;
public class MiniHibernateBundle extends HibernateBundle<MiniConfiguration>
implements ConfiguredBundle<MiniConfiguration> {
public MiniHibernateBundle() {
super(getEntities(MiniConstants.MODEL_PACKAGE), new SessionFactoryFactory());
}
private static ImmutableList<Class<?>> getEntities(String pageName) {
Reflections reflections = new Reflections(pageName);
ImmutableList<Class<?>> entities = ImmutableList.copyOf(reflections.getTypesAnnotatedWith(Entity.class));
return entities;
}
@Override
public PooledDataSourceFactory getDataSourceFactory(MiniConfiguration configuration) {
return configuration.getDatabase();
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/process/GithubRequest.java
package com.jialu.minios.process;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.apache.http.HttpResponse;
import org.apache.http.NameValuePair;
import org.apache.http.ParseException;
import org.apache.http.client.HttpClient;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.HttpGet;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils;
import org.json.JSONObject;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.jialu.minios.configuration.GithubConfiguration;
import com.jialu.minios.utility.MiniConstants;
public class GithubRequest {
private static final Logger LOGGER = LoggerFactory.getLogger(GithubRequest.class);
public static JSONObject getAccessToken(String code, GithubConfiguration config)
throws ParseException, IOException {
HttpClient httpClient = HttpClientBuilder.create().build();
HttpPost method = new HttpPost(MiniConstants.GITHUB_ACCESSTOKEN_URL);
List<NameValuePair> requestParams = new ArrayList<NameValuePair>();
requestParams.add(new BasicNameValuePair("code", code));
requestParams.add(new BasicNameValuePair("redirect_uri", config.getUrl()));
requestParams.add(new BasicNameValuePair("client_id", config.getAppId()));
requestParams.add(new BasicNameValuePair("client_secret", config.getAppSecret()));
method.setHeader("Accept", "application/json");
method.setEntity(new UrlEncodedFormEntity(requestParams));
LOGGER.info("GithubRequest.getAccessToken header:" + method.getEntity());
HttpResponse response = httpClient.execute(method);
String body = EntityUtils.toString(response.getEntity(), "UTF-8");
LOGGER.info("GithubRequest.getAccessToken body:" + body);
JSONObject json = new JSONObject(body);
return json;
}
public static JSONObject getPerson(String access_token) throws ParseException, IOException {
HttpClient httpClient = HttpClientBuilder.create().build();
String url = MiniConstants.GITHUB_PEOPLE_URL + "?access_token=" + access_token;
LOGGER.info("GithubRequest.getPerson url:" + url);
HttpGet get = new HttpGet(url);
get.setHeader("Accept", "application/json");
HttpResponse response = httpClient.execute(get);
String body = EntityUtils.toString(response.getEntity(), "UTF-8");
LOGGER.info("GithubRequest.getPerson body:" + body);
JSONObject json = new JSONObject(body);
return json;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/model/Project.java
package com.jialu.minios.model;
import java.io.Serializable;
import java.sql.Timestamp;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.NamedQuery;
import javax.persistence.Table;
/**
* 案件.
*
*/
@Entity
@Table(name = "project")
@NamedQuery(name = "Project.findAll", query = "SELECT m FROM Project m")
public class Project implements Serializable {
private static final long serialVersionUID = 1L;
// 案件名
// 勤務地
// 参画時期
// 勤務時間
// スキル
// 作業経験
// 備考
// 連絡先
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Integer id;
private Timestamp ctime;
private String cuser;
private Timestamp utime;
private String uuser;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Timestamp getCtime() {
return ctime;
}
public void setCtime(Timestamp ctime) {
this.ctime = ctime;
}
public String getCuser() {
return cuser;
}
public void setCuser(String cuser) {
this.cuser = cuser;
}
public Timestamp getUtime() {
return utime;
}
public void setUtime(Timestamp utime) {
this.utime = utime;
}
public String getUuser() {
return uuser;
}
public void setUuser(String uuser) {
this.uuser = uuser;
}
}
<file_sep>/minios/src/main/java/com/jialu/minios/configuration/MiniConfiguration.java
package com.jialu.minios.configuration;
import io.dropwizard.Configuration;
import io.dropwizard.db.DataSourceFactory;
import io.dropwizard.hibernate.AbstractDAO;
import me.chanjar.weixin.mp.api.WxMpService;
import java.util.HashMap;
import javax.validation.Valid;
import javax.validation.constraints.NotNull;
import com.dropbox.core.v2.DbxClientV2;
import com.fasterxml.jackson.annotation.JsonProperty;
public class MiniConfiguration extends Configuration {
private WxMpService wxMpService;
private HashMap<String, AbstractDAO<?>> daoList = new HashMap<String, AbstractDAO<?>>();
@SuppressWarnings("unchecked")
public <T> T getDao(Class<T> type) {
AbstractDAO<?> baseDao = daoList.get(type.getName());
return (T) baseDao;
}
private DbxClientV2 dropboxService;
@Valid
@NotNull
@JsonProperty
private DataSourceFactory database = new DataSourceFactory();
@Valid
@NotNull
@JsonProperty
private String name;
@Valid
@NotNull
@JsonProperty
private String host;
@Valid
@NotNull
@JsonProperty
private Boolean debug;
@Valid
@NotNull
@JsonProperty
private LinkedinConfiguration linkedin = new LinkedinConfiguration();
@Valid
@NotNull
@JsonProperty
private DropboxConfiguration dropbox = new DropboxConfiguration();
@Valid
@NotNull
@JsonProperty
private GithubConfiguration github = new GithubConfiguration();
@Valid
@NotNull
@JsonProperty
private LineConfiguration line = new LineConfiguration();
public DropboxConfiguration getDropbox() {
return dropbox;
}
public void setDropbox(DropboxConfiguration dropbox) {
this.dropbox = dropbox;
}
public LinkedinConfiguration getLinkedin() {
return linkedin;
}
public void setLinkedin(LinkedinConfiguration linkedin) {
this.linkedin = linkedin;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public WxMpService getWxMpService() {
return wxMpService;
}
public void setWxMpService(WxMpService wxMpService) {
this.wxMpService = wxMpService;
}
public Boolean getDebug() {
return debug;
}
public void setDebug(Boolean debug) {
this.debug = debug;
}
public DataSourceFactory getDatabase() {
return database;
}
public void setDatabase(DataSourceFactory database) {
this.database = database;
}
public String getHost() {
return host;
}
public void setHost(String host) {
this.host = host;
}
public DbxClientV2 getDropboxService() {
return dropboxService;
}
public void setDropboxService(DbxClientV2 dropboxService) {
this.dropboxService = dropboxService;
}
public GithubConfiguration getGithub() {
return github;
}
public void setGithub(GithubConfiguration github) {
this.github = github;
}
public HashMap<String, AbstractDAO<?>> getDaoList() {
return daoList;
}
public void setDaoList(HashMap<String, AbstractDAO<?>> daoList) {
this.daoList = daoList;
}
public LineConfiguration getLine() {
return line;
}
public void setLine(LineConfiguration line) {
this.line = line;
}
}
| 68150a5c371a4347b392d254c0544b228a86b3cd | [
"Markdown",
"Java",
"Maven POM",
"INI"
] | 26 | Java | shouaya/minios | 94cca4b5bf277588f997ec4e24955581eb2d776f | 8cc2ba9ae99c2fd9788fba42faf07344d4a7ea6a |
refs/heads/master | <file_sep>package ru.tulupov.alex.medalmanah.view.fragments;
import android.app.Activity;
import android.app.Dialog;
import android.content.DialogInterface;
import android.support.v4.app.DialogFragment;
import android.support.v7.app.AlertDialog;
import android.content.res.Resources;
import android.os.Bundle;
import java.util.List;
import ru.tulupov.alex.medalmanah.model.dao.ListSpecialities;
import ru.tulupov.alex.medalmanah.R;
import ru.tulupov.alex.medalmanah.model.dao.Speciality;
public class FragmentSpecialitiesDialog extends DialogFragment implements DialogInterface.OnClickListener {
Speciality[] specialitiesArray;
String[] specialitiesTitle;
SelectSpeciality listener;
int selectedItem = 0;
@Override
public Dialog onCreateDialog(Bundle savedInstanceState) {
Resources res = getResources();
AlertDialog.Builder builder = new AlertDialog.Builder(getActivity());
if (specialitiesArray != null && specialitiesTitle != null) {
builder.setTitle(res.getString(R.string.selectSpecialities))
.setSingleChoiceItems(specialitiesTitle, selectedItem, this)
.setNegativeButton(res.getString(R.string.cancel), new DialogInterface.OnClickListener() {
@Override
public void onClick(DialogInterface dialogInterface, int i) {
dismiss();
}
});
}
return builder.create();
}
public void setArraySpecialities (ListSpecialities specialities) {
if (specialities == null) {
return;
}
List<Speciality> list = specialities.getSpecialties();
specialitiesArray = new Speciality[list.size()];
specialitiesTitle = new String[list.size()];
for (int i = 0; i < list.size(); i++) {
specialitiesArray[i] = list.get(i);
specialitiesTitle[i] = list.get(i).getTitle();
}
}
public void setSelectedItem(Speciality speciality) {
if (speciality == null || specialitiesArray == null) {
return;
}
for(int i = 0; i < specialitiesArray.length; i++) {
if (speciality.getId() == specialitiesArray[i].getId()) {
selectedItem = i;
break;
}
}
}
@Override
public void onClick(DialogInterface dialogInterface, int i) {
listener.selectSpeciality(specialitiesArray[i]);
dismiss();
}
@Override
public void onAttach(Activity activity) {
super.onAttach(activity);
try {
listener = (SelectSpeciality) activity;
} catch (ClassCastException e) {
throw new ClassCastException(activity.toString()
+ " must implement " + FragmentSpecialitiesDialog.SelectSpeciality.class.getName());
}
}
public interface SelectSpeciality {
void selectSpeciality(Speciality speciality);
}
}
<file_sep>package ru.tulupov.alex.medalmanah.presenter.callbacks;
import ru.tulupov.alex.medalmanah.model.dao.ListPublications;
public interface CallbackPublications {
void setPublications(ListPublications publications);
void failPublications();
}
<file_sep>package ru.tulupov.alex.medalmanah.view.activties;
import android.support.annotation.NonNull;
import android.support.design.widget.NavigationView;
import android.support.v4.widget.DrawerLayout;
import android.support.v7.app.ActionBarDrawerToggle;
import android.support.v7.app.AppCompatActivity;
import android.support.v7.widget.Toolbar;
import android.view.MenuItem;
import ru.tulupov.alex.medalmanah.R;
public class BaseActivity extends AppCompatActivity {
protected DrawerLayout drawerLayout;
protected Toolbar toolbar;
protected NavigationView navigationView;
protected void initToolbar(String title) {
toolbar = (Toolbar) findViewById(R.id.toolbar);
toolbar.setTitle(title);
setSupportActionBar(toolbar);
}
protected void initNavigationView() {
drawerLayout = (DrawerLayout) findViewById(R.id.drawer_layout);
ActionBarDrawerToggle toggle =
new ActionBarDrawerToggle(this, drawerLayout, toolbar, R.string.open, R.string.close);
drawerLayout.addDrawerListener(toggle);
toggle.syncState();
navigationView = (NavigationView) findViewById(R.id.navigationView);
navigationView.setNavigationItemSelectedListener(new NavigationView.OnNavigationItemSelectedListener() {
@Override
public boolean onNavigationItemSelected(@NonNull MenuItem item) {
drawerLayout.closeDrawers();
return true;
}
});
}
}
<file_sep>package ru.tulupov.alex.medalmanah.presenter.callbacks;
import ru.tulupov.alex.medalmanah.model.dao.ListSpecialities;
public interface CallbackSpecialities {
void setSpecialities (ListSpecialities specialities);
void failSpecialities ();
}
<file_sep>package ru.tulupov.alex.medalmanah.model.dao;
import com.google.gson.annotations.Expose;
import com.google.gson.annotations.SerializedName;
public class Speciality {
@SerializedName("id")
@Expose
protected int id;
@SerializedName("title")
@Expose
protected String title;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
@Override
public String toString() {
return title;
}
}
<file_sep>package ru.tulupov.alex.medalmanah.view.adapters;
import android.support.v4.app.Fragment;
import android.support.v4.app.FragmentManager;
import android.support.v4.app.FragmentPagerAdapter;
import ru.tulupov.alex.medalmanah.view.fragments.EventFragment;
import ru.tulupov.alex.medalmanah.view.fragments.NewsFragment;
public class TabsMainAdapter extends FragmentPagerAdapter {
public static final int TAB_NEWS = 0;
public static final int TAB_EVENTS = 1;
private String[] titleTabs;
private NewsFragment newsFragment;
private EventFragment eventFragment;
public TabsMainAdapter(FragmentManager fm, String[] titleTabs) {
super(fm);
this.titleTabs = titleTabs;
newsFragment = NewsFragment.getInstance();
eventFragment = EventFragment.getInstance();
}
@Override
public Fragment getItem(int position) {
switch (position) {
case TAB_NEWS:
return newsFragment;
case TAB_EVENTS:
return eventFragment;
}
return null;
}
@Override
public CharSequence getPageTitle(int position) {
return titleTabs[position];
}
@Override
public int getCount() {
return titleTabs.length;
}
public NewsFragment getNewsFragment() {
return newsFragment;
}
public EventFragment getEventFragment() {
return eventFragment;
}
}
<file_sep>package ru.tulupov.alex.medalmanah.di;
import dagger.Module;
import dagger.Provides;
import retrofit.RestAdapter;
import ru.tulupov.alex.medalmanah.model.api.ApiNews;
import ru.tulupov.alex.medalmanah.presenter.NewsPresenter;
@Module
public class NewsModule {
protected String baseUrl;
public NewsModule(String bseUrl) {
this.baseUrl = bseUrl;
}
@Provides
NewsPresenter provideNewsPresenter() {
return new NewsPresenter();
}
@Provides
ApiNews provideApiNews() {
RestAdapter adapter = new RestAdapter.Builder().setEndpoint(baseUrl).build();
return adapter.create(ApiNews.class);
}
}
<file_sep>package ru.tulupov.alex.medalmanah.model.dao;
import android.os.Parcel;
import android.os.Parcelable;
public class SearchEventParameters implements Parcelable {
private Speciality speciality;
private int location = 0;
private String searchLine;
private String start;
private String end;
public SearchEventParameters() {}
protected SearchEventParameters(Parcel in) {
location = in.readInt();
searchLine = in.readString();
start = in.readString();
end = in.readString();
speciality = new Speciality();
speciality.setId(in.readInt());
speciality.setTitle(in.readString());
}
public Speciality getSpeciality() {
return speciality;
}
public void setSpeciality(Speciality speciality) {
this.speciality = speciality;
}
public int getLocation() {
return location;
}
public void setLocation(int location) {
this.location = location;
}
public String getSearchLine() {
return searchLine;
}
public void setSearchLine(String searchLine) {
this.searchLine = searchLine;
}
public String getStart() {
return start;
}
public void setStart(String start) {
this.start = start;
}
public String getEnd() {
return end;
}
public void setEnd(String end) {
this.end = end;
}
public static final Creator<SearchEventParameters> CREATOR = new Creator<SearchEventParameters>() {
@Override
public SearchEventParameters createFromParcel(Parcel in) {
return new SearchEventParameters(in);
}
@Override
public SearchEventParameters[] newArray(int size) {
return new SearchEventParameters[size];
}
};
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel parcel, int i) {
parcel.writeInt(location);
parcel.writeString(searchLine);
parcel.writeString(start);
parcel.writeString(end);
parcel.writeInt(speciality.getId());
parcel.writeString(speciality.getTitle());
}
}
<file_sep>package ru.tulupov.alex.medalmanah;
import android.app.Application;
import ru.tulupov.alex.medalmanah.di.AppComponent;
import ru.tulupov.alex.medalmanah.di.DaggerAppComponent;
import ru.tulupov.alex.medalmanah.di.EventModule;
import ru.tulupov.alex.medalmanah.di.NewsModule;
public class App extends Application {
public static final String DOMAIN = "https://medalmanah.ru";
private static AppComponent component;
public static AppComponent getComponent() {
return component;
}
protected AppComponent buildComponent() {
return DaggerAppComponent.builder().newsModule(new NewsModule(DOMAIN))
.eventModule(new EventModule(DOMAIN)).build();
}
@Override
public void onCreate() {
super.onCreate();
component = buildComponent();
}
}
<file_sep>package ru.tulupov.alex.medalmanah.presenter;
import javax.inject.Inject;
import ru.tulupov.alex.medalmanah.App;
import ru.tulupov.alex.medalmanah.model.ModelImpl;
import ru.tulupov.alex.medalmanah.model.dao.ListPublications;
import ru.tulupov.alex.medalmanah.presenter.callbacks.CallbackPublications;
import ru.tulupov.alex.medalmanah.view.fragments.NewsView;
public class NewsPresenter implements Presenter {
private NewsView newsView;
@Inject
protected ModelImpl model;
public void onCreate(NewsView newsView) {
this.newsView = newsView;
App.getComponent().inject(this);
}
public void showNews () {
model.getListPublicationsByPage(1, new CallbackPublications() {
@Override
public void setPublications(ListPublications publications) {
newsView.showNews(publications);
}
@Override
public void failPublications() {
newsView.failShowNews();
}
});
}
@Override
public void onStop() {
this.newsView = null;
}
}
<file_sep>package ru.tulupov.alex.medalmanah.model.dao;
import java.util.List;
import com.google.gson.annotations.Expose;
import com.google.gson.annotations.SerializedName;
public class ListSpecialities {
@SerializedName("specialties")
@Expose
protected List<Speciality> specialties;
public ListSpecialities(List<Speciality> specialties) {
this.specialties = specialties;
}
public ListSpecialities() {}
public List<Speciality> getSpecialties() {
return specialties;
}
public void setSpecialties(List<Speciality> specialties) {
this.specialties = specialties;
}
@Override
public String toString() {
return specialties.toString();
}
}
<file_sep>package ru.tulupov.alex.medalmanah.view.fragments;
import android.support.v4.app.Fragment;
/**
* Created by tulup on 30.10.2016.
*/
public class BaseFragment extends Fragment {
}
<file_sep>package ru.tulupov.alex.medalmanah.view.activties;
import android.content.Intent;
import android.content.res.Resources;
import android.os.Bundle;
import android.support.design.widget.FloatingActionButton;
import android.support.design.widget.TabLayout;
import android.support.v4.view.ViewPager;
import android.util.Log;
import android.view.View;
import android.view.animation.Animation;
import android.view.animation.AnimationUtils;
import ru.tulupov.alex.medalmanah.R;
import ru.tulupov.alex.medalmanah.model.dao.SearchEventParameters;
import ru.tulupov.alex.medalmanah.view.adapters.TabsMainAdapter;
import static ru.tulupov.alex.medalmanah.Constants.MY_TAG;
public class MainActivity extends BaseActivity {
TabsMainAdapter tabsMainAdapter;
FloatingActionButton fab;
ViewPager.OnPageChangeListener pageChangeListener = new ViewPager.OnPageChangeListener() {
@Override
public void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {
}
@Override
public void onPageSelected(int position) {
if (position != 1) {
Animation animation = AnimationUtils.loadAnimation(getApplication(), R.anim.fab_event_filter_hide);
fab.startAnimation(animation);
fab.setVisibility(View.GONE);
} else {
Animation animation = AnimationUtils.loadAnimation(getApplication(), R.anim.fab_event_filter_start);
fab.startAnimation(animation);
fab.setVisibility(View.VISIBLE);
}
}
@Override
public void onPageScrollStateChanged(int state) {
}
};
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Resources resources = getResources();
initToolbar(resources.getString(R.string.app_name));
initNavigationView();
initTabs();
fab = (FloatingActionButton) findViewById(R.id.fabEvents);
fab.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Intent intent = new Intent(MainActivity.this, SearchEventsActivity.class);
startActivityForResult(intent, 200);
}
});
}
private void initTabs() {
ViewPager viewPager = (ViewPager) findViewById(R.id.viewPager);
TabLayout tabLayout = (TabLayout) findViewById(R.id.tabLayout);
String[] tabsTitle = getResources().getStringArray(R.array.tabs_main);
tabsMainAdapter = new TabsMainAdapter(getSupportFragmentManager(), tabsTitle);
viewPager.setAdapter(tabsMainAdapter);
viewPager.addOnPageChangeListener(pageChangeListener);
tabLayout.setupWithViewPager(viewPager);
}
@Override
protected void onActivityResult(int requestCode, int resultCode, Intent data) {
if (requestCode == 200 && data != null) {
SearchEventParameters parameters =
(SearchEventParameters) data.getParcelableExtra(SearchEventsActivity.SEARCH_PARAMETERS);
Log.d(MY_TAG, parameters.getSpeciality().getTitle());
/**
* TODO add argument for searching
*/
tabsMainAdapter.getEventFragment().searchEvents();
}
}
}
<file_sep>package ru.tulupov.alex.medalmanah.presenter;
import ru.tulupov.alex.medalmanah.view.fragments.EventView;
public class EventsPresenter implements Presenter {
protected EventView eventView;
public void onCreate(EventView eventView) {
this.eventView = eventView;
}
@Override
public void onStop() {
}
}
| c83a9b138047ec78c830169ea55c7c434858be59 | [
"Java"
] | 14 | Java | Algresh/Medalmanah | ceb370a9f4b6a2189d691d4f137ebda0db921630 | 36b0324c3b96712abd7a1aeb0245f5b6aeea11cb |
refs/heads/main | <repo_name>Cali93/quadratic-diplomacy-homepage<file_sep>/next-seo.config.js
/** @type {import('next-seo').DefaultSeoProps} */
const defaultSEOConfig = {
title: "quadratic-diplomacy",
titleTemplate: "%s | quadratic-diplomacy",
defaultTitle: "quadratic-diplomacy",
description:
"Distribute tokens among your team members based on quadratic voting.",
canonical: "https://quadratic-diplomacy.com",
openGraph: {
url: "https://quadratic-diplomacy.com",
title: "quadratic-diplomacy",
description:
"Distribute tokens among your team members based on quadratic voting.",
//TODO: replace with qd image
images: [
{
url: "",
alt: "quadratic-diplomacy.com og-image",
},
],
site_name: "quadratic-diplomacy",
},
twitter: {
handle: "@moonshotcollect",
cardType: "summary_large_image",
},
};
export default defaultSEOConfig;
| b09b88338f5f830c8b43342042790adf1209ee76 | [
"JavaScript"
] | 1 | JavaScript | Cali93/quadratic-diplomacy-homepage | 46bcfa92dc192ab7e0f01470a6defd92e7750a6e | 7df86ae60768a206ac17595ee6109902f37cd7c0 |
refs/heads/master | <file_sep><?php
$dir = dirname(__FILE__) . DS;
// Let the FuelPHP autoloader handle loading for Doctrine classes
Autoloader::add_namespace("Doctrine", $dir . 'Doctrine' . DS, true);
Autoloader::add_namespace("Symfony", $dir . 'Doctrine/Symfony' . DS, true);
// Set up wrapper namespace
Autoloader::add_namespace('Doctrine_Fuel', $dir . 'classes' . DS);
Autoloader::alias_to_namespace('Doctrine_Fuel\Doctrine_Fuel');<file_sep><?php
namespace Doctrine_Fuel;
/**
* Convenience class to wrap Doctrine configuration with FuelPHP features.
* I'm only trying to handle relatively simple usage here, so if your configuration needs
* are more complicated, just extend/replace in your application
*
* Example:
*
* <code>
* $em = Doctrine_Fuel::manager();
* $em->createQuery(...);
* </code>
*
* Or to use a defined connection other than 'default'
* <code>
* $em = Doctrine_Fuel::manager('connection_name');
* $em->createQuery(...);
* </code>
*
*/
class Doctrine_Fuel
{
/** @var array */
protected static $_managers;
/** @var array */
protected static $_connections;
/** @var array */
protected static $settings;
/**
* Map cache types to class names
* Memcache/Memcached can't be set up automatically the way the other types can, so they're not included
*
* @var array
*/
protected static $cache_drivers = array(
'array'=>'ArrayCache',
'apc'=>'ApcCache',
'xcache'=>'XcacheCache',
'wincache'=>'WinCache',
'zend'=>'ZendDataCache'
);
/**
* Map metadata driver types to class names
*/
protected static $metadata_drivers = array(
'annotation'=>'', // We'll use the factory method; just here for the exception check
'php'=>'PHPDriver',
'simplified_xml'=>'SimplifiedXmlDriver',
'simplified_yaml'=>'SimplifiedYamlDriver',
'xml'=>'XmlDriver',
'yaml'=>'YamlDriver'
);
/**
* Read configuration and set up EntityManager singleton
*/
public static function _init()
{
\Config::load('doctrine', true);
static::$settings = \Config::get('doctrine');
}
public static function _init_manager($connection)
{
$settings = static::$settings;
if ( ! isset($settings[$connection]))
{
throw new Exception('No connection configuration for '.$connection);
}
$config = new \Doctrine\ORM\Configuration();
$cache = static::_init_cache();
if ($cache)
{
$config->setMetadataCacheImpl($cache);
$config->setQueryCacheImpl($cache);
}
$config->setProxyDir($settings['proxy_dir']);
$config->setProxyNamespace($settings['proxy_namespace']);
$config->setAutoGenerateProxyClasses($settings['auto_generate_proxy_classes']);
$config->setMetadataDriverImpl(static::_init_metadata($config));
static::$_managers[$connection] = \Doctrine\ORM\EntityManager::create($settings[$connection]['connection'], $config);
if ( ! empty($settings[$connection]['profiling']))
{
static::$_managers[$connection]->getConnection()->getConfiguration()->setSQLLogger(new Logger($connection));
}
}
public static function _init_connection($connection)
{
$settings = static::$settings;
if ( ! isset($settings[$connection]))
{
throw new Exception('No connection configuration for '.$connection);
}
$config = new \Doctrine\DBAL\Configuration();
static::$_connections[$connection] = \Doctrine\DBAL\DriverManager::getConnection($settings[$connection]['connection'], $config);
if ( ! empty($settings[$connection]['profiling']))
{
static::$_connections[$connection]->getConnection()->getConfiguration()->setSQLLogger(new Logger($connection));
}
}
/**
* @return \Doctrine\Common\Cache|false
*/
protected static function _init_cache()
{
$type = \Arr::get(static::$settings, 'cache_driver', 'array');
if ($type)
{
if ( ! array_key_exists($type, static::$cache_drivers))
{
throw new \Exception('Invalid Doctrine2 cache driver: ' . $type);
}
$class = '\\Doctrine\\Common\\Cache\\' . static::$cache_drivers[$type];
return new $class();
}
return false;
}
/**
* @return \Doctrine\ORM\Mapping\Driver\Driver
*/
protected static function _init_metadata($config)
{
$type = \Arr::get(static::$settings, 'metadata_driver', 'annotation');
if ( ! array_key_exists($type, static::$metadata_drivers))
{
throw new \Exception('Invalid Doctrine2 metadata driver: ' . $type);
}
if ($type == 'annotation')
{
return $config->newDefaultAnnotationDriver(static::$settings['metadata_path']);
}
$class = '\\Doctrine\\ORM\\Mapping\\Driver\\' . static::$metadata_drivers[$type];
return new $class($settings['metadata_path']);
}
/**
* @return \Doctrine\ORM\EntityManager
*/
public static function manager($connection = 'default')
{
if ( ! isset(static::$_managers[$connection]))
{
static::_init_manager($connection);
}
return static::$_managers[$connection];
}
/**
* @return Doctrine\DBAL\Connection
*/
public static function connection($connection = 'default')
{
if ( ! isset(static::$_connections[$connection]))
{
static::_init_connection($connection);
}
return static::$_connections[$connection];
}
/**
* @return array Doctrine version information
*/
public static function version_check()
{
return array(
'common' => \Doctrine\Common\Version::VERSION,
'dbal' => \Doctrine\DBAL\Version::VERSION,
'orm' => \Doctrine\ORM\Version::VERSION
);
}
}
<file_sep><?php
namespace Doctrine_Fuel;
/**
* Log Doctrine DBAL queries to FuelPHP profiler
*/
class Logger implements \Doctrine\DBAL\Logging\SQLLogger
{
/** @var string */
protected $db_name;
/** @var mixed */
protected $benchmark;
/**
* @param string $db_name database name to save in profiler
*/
public function __construct($db_name = '')
{
$this->db_name = $db_name;
}
public function startQuery($sql, array $params = null, array $types = null)
{
$this->benchmark = false;
if (substr($sql, 0, 7) == 'EXPLAIN') // Don't re-log EXPLAIN statements from profiler
return;
if ($params)
{
// Attempt to replace placeholders so that we can log a final SQL query for profiler's EXPLAIN statement
// (this is not perfect-- getPlaceholderPositions has some flaws-- but it should generally work with ORM-generated queries)
$is_positional = is_numeric(key($params));
list($sql, $params, $types) = \Doctrine\DBAL\SQLParserUtils::expandListParameters($sql, $params, $types);
$placeholders = \Doctrine\DBAL\SQLParserUtils::getPlaceholderPositions($sql, $is_positional);
if ($is_positional)
$map = array_flip($placeholders);
else
{
$map = array();
foreach ($placeholders as $name=>$positions)
{
foreach ($positions as $pos)
$map[$pos] = $name;
}
}
ksort($map);
$src_pos = 0;
$final_sql = '';
foreach ($map as $pos=>$replace_name)
{
$final_sql .= substr($sql, $src_pos, $pos-$src_pos);
$src_pos = $pos + strlen($replace_name);
$final_sql .= Doctrine_Fuel::manager()->getConnection()->quote( $params[ ltrim($replace_name, ':') ] );
}
$final_sql .= substr($sql, $src_pos);
$sql = $final_sql;
}
$this->benchmark = \Profiler::start("Database (Doctrine: $this->db_name)", $sql);
}
public function stopQuery()
{
if ($this->benchmark)
{
\Profiler::stop($this->benchmark);
$this->benchmark = null;
}
}
}
| 004a670f6c66ed63090e21f965159f2d3a7ce5af | [
"PHP"
] | 3 | PHP | monsonis/fuel-doctrine2 | b9dde5bace2f6223de3d8b83a7435e8acc9bc928 | 156eada9ccc590532a57a4d09844367f092e2f51 |
refs/heads/master | <file_sep>(function (define, beforeEach) {
'use strict';
define([
'angular',
'app/app'
], function (angular, app) {
beforeEach(function () {
// This function registers a module configuration code.
// It collects the configuration information which will be used when the injector is created by inject.
angular.mock.module('app');
});
return app;
});
}(this.define, this.beforeEach));
<file_sep>(function (define, describe, it, expect) {
'use strict';
define([], function () {
describe('True test', function () {
it('Should be true', function () {
expect(true).toBeTruthy();
});
});
});
}(this.define, this.describe, this.it, this.expect));
<file_sep>[](https://travis-ci.org/devw/angular-requirejs-karma-showcase)
## angular-requirejs-karma-showcase
1. Copy the repository named angular-karma-requirejs
> git clone ......
2. Install the libraries
>npm install
>bower install
3. Remove the existing karma.conf.js and generate another one responding to the questions in this way:
>node_modules/karma/bin/karma init
Which testing framework do you want to use ? jasmine
Do you want to use Require.js ? yes
What is the location of your source and test files ? test/*js
Do you wanna generate a bootstrap file for RequireJS? yes
4. Try to run the test
> node_modules/karma/bin/karma start # you should get an error because some package is missing
> npm install <missing package> --save
> node_modules/karma/bin/karma start # it should run succesfully the test/test.js
5. Write the test using the IIFE pattern
# test/test.js
(function (define, describe, it) {
define([
], function () {
describe('True test', function() {
it('Should be true', function() {
expect(true).toBeTruthy();
});
});
});
}(define, describe, it));
Suggestions:
1. the missing package of (4) is karma-requirejs
<file_sep>(function (define, describe, beforeEach, it, expect) {
'use strict';
define([
'angular',
'test/app.spec'
], function (angular) {
describe('pieController', function () {
var $scope = {};
beforeEach(function () {
angular.mock.inject(function ($controller) {
// The injector unwraps the underscores (_) from around the parameter names when matching
$controller('pieController', { $scope: $scope });
});
});
describe('Initialization', function () {
it('should instantiate slice to 8', function () {
expect($scope.slices).toEqual(8);
});
});
describe('$scope.slices', function () {
it('sets the strength to "strong" if the password length is >8 chars', function () {
$scope.eatSlice();
expect($scope.slices).toEqual(7);
});
});
});
});
}(this.define, this.describe, this.beforeEach, this.it, this.expect));
<file_sep>/*global angular*/
(function () {
define([], function () {
return ['$scope', function pieController ($scope) {
'use strict';
$scope.slices = 8;
$scope.eatSlice = function () {
if ($scope.slices) {
$scope.slices = $scope.slices - 1;
}
};
}];
});
}());
<file_sep>(function (define) {
'use strict';
define([
'../controllers/password.controller',
'text!../templates/home.html'
], function (passwordController, homeTemplate) {
console.log(passwordController);
return {
url: '/',
template: homeTemplate,
controller: passwordController
};
});
}(this.define)); | eb574c9be2117d761f0e48d6da3d05f80b7d8d7d | [
"JavaScript",
"Markdown"
] | 6 | JavaScript | devw/angular-requirejs-karma-showcase | 07adf795a238a7f3aebb499337ff1c30249b98f0 | 8cd4a05bd6b59256597636b471462549d33078db |
refs/heads/master | <file_sep>if true
puts 'hi'
else
puts 'goodbye'
end
if false
puts 'hi'
else
puts 'goodbye'
end
num = 5
# => 5
num < 10
# => true
(num < 10).class
# => TrueClass
<file_sep>/*
Problem:
take mxn matrix
'rotate it by 90 degrees'
transpose the matrix and flip it on its edge
Expectations:
var matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6],
];
3 4 1
9 7 5
6 2 8
Algorithm:
using previous algorithm
transpose an mxn matrix
reverse each of the subarrays
*/
function transpose(matrix) {
var subArrays = {};
matrix.forEach(function (oneSub) {
oneSub.forEach(function (elem, idx) {
subArrays[idx] = [];
});
});
var result = [];
matrix.forEach(function (oneSub) {
oneSub.forEach(function (elem, idx) {
subArrays[idx].push(elem);
});
});
Object.values(subArrays).forEach(oneSub => result.push(oneSub));
return result;
}
function rotate90(matrix) {
return transpose(matrix).map(oneSub => oneSub.reverse());
}
var matrix1 = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6],
];
var matrix2 = [
[3, 7, 4, 2],
[5, 1, 0, 8],
];
var newMatrix1 = rotate90(matrix1);
var newMatrix2 = rotate90(matrix2);
var newMatrix3 = rotate90(rotate90(rotate90(rotate90(matrix2))));
console.log(newMatrix1);
// [[3, 4, 1], [9, 7, 5], [6, 2, 8]]
console.log(newMatrix2);
// [[5, 3], [1, 7], [0, 4], [8, 2]]
console.log(newMatrix3);
// `matrix2` --> [[3, 7, 4, 2], [5, 1, 0, 8]]
<file_sep>def sequence(count, num2)
1.upto(count).map {|a| a * num2}
end
sequence(5, 1) == [1, 2, 3, 4, 5]
sequence(4, -7) == [-7, -14, -21, -28]
sequence(3, 0) == [0, 0, 0]
sequence(0, 1000000) == []
<file_sep>def sum(num)
num = num.to_s.chars
sumz = 0
num.each do |num|
sumz += num.to_i
end
sumz
end
puts sum(23) == 5
puts sum(496) == 19
puts sum(123_456_789) == 45
# Their version:
# def sum(number)
# number.to_s.chars.map(&:to_i).reduce(:+)
# end<file_sep># The formula verifies a number against its included check digit,
# which is usually appended to a partial number to generate the full number.
# This number must pass the following test:
# Counting from rightmost digit (which is the check digit) and moving left,
# double the value of every second digit.
# For any digits that thus become 10 or more, subtract 9 from the result.
# 1111 becomes 2121.
# 8763 becomes 7733 (from 2×6=12 → 12-9=3 and 2×8=16 → 16-9=7).
# Add all these digits together.
# 1111 becomes 2121 sums as 2+1+2+1 to give a checksum of 6.
# 8763 becomes 7733, and 7+7+3+3 is 20.
# rightmost digit = check digit
# double the value of every second digit
# [1, 1, 1, 1] [2, 1, 2, 1] reverse and double odds
# then reduce to add to 6
# the number has to end in 0 in order to be valid in the Luhn formula
# 20 is valid, 6 is not
# program needs to:
# check if it is valid per the Luhn formula
# valid example: "2323 2005 7766 3554"
# return the checksum, or the remainder using the Luhn formula
# 20 is checksum, 4 is remainder for 6 checksum
# add a digit to make valid checksum
# "2323 2005 7766 3554" in response to "2323 2005 7766 355".
# addends, valid?, checksum, create(sum)
# luhn = Luhn.new(201_773)
# assert_equal 21, luhn.checksum
require 'pry'
class Luhn
attr_reader :interpretation
def initialize(num)
@interpretation = num.to_s.chars
@number = num
end
def checksum
addends.reduce(&:+)
end
def valid?
checksum.to_s[-1].to_i.zero?
end
def addends
# take @interpretation, reverse, double each second #, unreverse
# subtract 9 from result if a digit is 10 or more
# 8763 becomes 7733 (from 2×6=12 → 12-9=3 and 2×8=16 → 16-9=7)
self.interpretation.reverse.map.with_index do |n, idx|
if idx.odd?
n = n.to_i * 2
n > 10 ? n - 9 : n
else
n.to_i
end
end.reverse
end
def validate
count = 0
test = @number.to_s
test = test + count.to_s
until Luhn.new(test.to_i).valid?
test[-1] = count.to_s
count += 1
end
test.to_i
end
def self.create(num)
Luhn.new(num).validate
end
end
luhn = Luhn.new(201_773)
# binding.pry
<file_sep>function domTreeTracer(id) {
var current = document.getElementById(String(id));
var result = [];
var level;
while (current !== document.body) {
level = [].slice.call(current.parentNode.childNodes);
result.push(level.map(function (node) { return node.tagName }).filter(function (name) {
return name && name !== 'SCRIPT'
}));
current = current.parentNode;
}
return result;
}
console.log(domTreeTracer(1));
//= [["ARTICLE"]]
console.log(domTreeTracer(2));
//= [["HEADER", "MAIN", "FOOTER"], ["ARTICLE"]]
console.log(domTreeTracer(22));
//= [["A"], ["STRONG"], ["SPAN", "SPAN"], ["P", "P"],
// ["SECTION", "SECTION"], ["HEADER", "MAIN", "FOOTER"], ["ARTICLE"]]
<file_sep>
JavaScript Promises: an Introduction
<NAME>
By <NAME>
Human boy working on web standards at Google
Developers, prepare yourself for a pivotal moment in the history of web development.
[Drumroll begins]
Promises have arrived natively in JavaScript!
[Fireworks explode, glittery paper rains from above, the crowd goes wild]
At this point you fall into one of these categories:
People are cheering around you, but you're not sure what all the fuss is about. Maybe you're not even sure what a "promise" is. You'd shrug, but the weight of glittery paper is weighing down on your shoulders. If so, don't worry about it, it took me ages to work out why I should care about this stuff. You probably want to begin at the beginning.
You punch the air! About time right? You've used these Promise things before but it bothers you that all implementations have a slightly different API. What's the API for the official JavaScript version? You probably want to begin with the terminology.
You knew about this already and you scoff at those who are jumping up and down like it's news to them. Take a moment to bask in your own superiority, then head straight to the API reference.
What's all the fuss about?
JavaScript is single threaded, meaning that two bits of script cannot run at the same time; they have to run one after another. In browsers, JavaScript shares a thread with a load of other stuff that differs from browser to browser. But typically JavaScript is in the same queue as painting, updating styles, and handling user actions (such as highlighting text and interacting with form controls). Activity in one of these things delays the others.
As a human being, you're multithreaded. You can type with multiple fingers, you can drive and hold a conversation at the same time. The only blocking function we have to deal with is sneezing, where all current activity must be suspended for the duration of the sneeze. That's pretty annoying, especially when you're driving and trying to hold a conversation. You don't want to write code that's sneezy.
You've probably used events and callbacks to get around this. Here are events:
var img1 = document.querySelector('.img-1');
img1.addEventListener('load', function() {
// woo yey image loaded
});
img1.addEventListener('error', function() {
// argh everything's broken
});
This isn't sneezy at all. We get the image, add a couple of listeners, then JavaScript can stop executing until one of those listeners is called.
Unfortunately, in the example above, it's possible that the events happened before we started listening for them, so we need to work around that using the "complete" property of images:
var img1 = document.querySelector('.img-1');
function loaded() {
// woo yey image loaded
}
if (img1.complete) {
loaded();
}
else {
img1.addEventListener('load', loaded);
}
img1.addEventListener('error', function() {
// argh everything's broken
});
This doesn't catch images that error'd before we got a chance to listen for them; unfortunately the DOM doesn't give us a way to do that. Also, this is loading one image, things get even more complex if we want to know when a set of images have loaded.
Events aren't always the best way
Events are great for things that can happen multiple times on the same object—keyup, touchstart etc. With those events you don't really care about what happened before you attached the listener. But when it comes to async success/failure, ideally you want something like this:
img1.callThisIfLoadedOrWhenLoaded(function() {
// loaded
}).orIfFailedCallThis(function() {
// failed
});
// and…
whenAllTheseHaveLoaded([img1, img2]).callThis(function() {
// all loaded
}).orIfSomeFailedCallThis(function() {
// one or more failed
});
This is what promises do, but with better naming. If HTML image elements had a "ready" method that returned a promise, we could do this:
img1.ready().then(function() {
// loaded
}, function() {
// failed
});
// and…
Promise.all([img1.ready(), img2.ready()]).then(function() {
// all loaded
}, function() {
// one or more failed
});
At their most basic, promises are a bit like event listeners except:
A promise can only succeed or fail once. It cannot succeed or fail twice, neither can it switch from success to failure or vice versa.
If a promise has succeeded or failed and you later add a success/failure callback, the correct callback will be called, even though the event took place earlier.
This is extremely useful for async success/failure, because you're less interested in the exact time something became available, and more interested in reacting to the outcome.
Promise terminology
<NAME> proof read the first draft of this article and graded me "F" for terminology. He put me in detention, forced me to copy out States and Fates 100 times, and wrote a worried letter to my parents. Despite that, I still get a lot of the terminology mixed up, but here are the basics:
A promise can be:
fulfilled - The action relating to the promise succeeded
rejected - The action relating to the promise failed
pending - Hasn't fulfilled or rejected yet
settled - Has fulfilled or rejected
The spec also uses the term thenable to describe an object that is promise-like, in that it has a then method. This term reminds me of ex-England Football Manager Terry Venables so I'll be using it as little as possible.
Promises arrive in JavaScript!
Promises have been around for a while in the form of libraries, such as:
Q
when
WinJS
RSVP.js
The above and JavaScript promises share a common, standardized behaviour called Promises/A+. If you're a jQuery user, they have something similar called Deferreds. However, Deferreds aren't Promise/A+ compliant, which makes them subtly different and less useful, so beware. jQuery also has a Promise type, but this is just a subset of Deferred and has the same issues.
Although promise implementations follow a standardized behaviour, their overall APIs differ. JavaScript promises are similar in API to RSVP.js. Here's how you create a promise:
var promise = new Promise(function(resolve, reject) {
// do a thing, possibly async, then…
if (/* everything turned out fine */) {
resolve("Stuff worked!");
}
else {
reject(Error("It broke"));
}
});
The promise constructor takes one argument, a callback with two parameters, resolve and reject. Do something within the callback, perhaps async, then call resolve if everything worked, otherwise call reject.
Like throw in plain old JavaScript, it's customary, but not required, to reject with an Error object. The benefit of Error objects is they capture a stack trace, making debugging tools more helpful.
Here's how you use that promise:
promise.then(function(result) {
console.log(result); // "Stuff worked!"
}, function(err) {
console.log(err); // Error: "It broke"
});
then() takes two arguments, a callback for a success case, and another for the failure case. Both are optional, so you can add a callback for the success or failure case only.
JavaScript promises started out in the DOM as "Futures", renamed to "Promises", and finally moved into JavaScript. Having them in JavaScript rather than the DOM is great because they'll be available in non-browser JS contexts such as Node.js (whether they make use of them in their core APIs is another question).
Although they're a JavaScript feature, the DOM isn't afraid to use them. In fact, all new DOM APIs with async success/failure methods will use promises. This is happening already with Quota Management, Font Load Events, ServiceWorker, Web MIDI, Streams, and more.
Browser support & polyfill
There are already implementations of promises in browsers today.
As of Chrome 32, Opera 19, Firefox 29, Safari 8 & Microsoft Edge, promises are enabled by default.
To bring browsers that lack a complete promises implementation up to spec compliance, or add promises to other browsers and Node.js, check out the polyfill (2k gzipped).
Compatibility with other libraries
The JavaScript promises API will treat anything with a then() method as promise-like (or thenable in promise-speak sigh), so if you use a library that returns a Q promise, that's fine, it'll play nice with the new JavaScript promises.
Although, as I mentioned, jQuery's Deferreds are a bit … unhelpful. Thankfully you can cast them to standard promises, which is worth doing as soon as possible:
var jsPromise = Promise.resolve($.ajax('/whatever.json'))
Here, jQuery's $.ajax returns a Deferred. Since it has a then() method, Promise.resolve() can turn it into a JavaScript promise. However, sometimes deferreds pass multiple arguments to their callbacks, for example:
var jqDeferred = $.ajax('/whatever.json');
jqDeferred.then(function(response, statusText, xhrObj) {
// ...
}, function(xhrObj, textStatus, err) {
// ...
})
Whereas JS promises ignore all but the first:
jsPromise.then(function(response) {
// ...
}, function(xhrObj) {
// ...
})
Thankfully this is usually what you want, or at least gives you access to what you want. Also, be aware that jQuery doesn't follow the convention of passing Error objects into rejections.
Complex async code made easier
Right, let's code some things. Say we want to:
Start a spinner to indicate loading
Fetch some JSON for a story, which gives us the title, and urls for each chapter
Add title to the page
Fetch each chapter
Add the story to the page
Stop the spinner
… but also tell the user if something went wrong along the way. We'll want to stop the spinner at that point too, else it'll keep on spinning, get dizzy, and crash into some other UI.
Of course, you wouldn't use JavaScript to deliver a story, serving as HTML is faster, but this pattern is pretty common when dealing with APIs: Multiple data fetches, then do something when it's all done.
To start with, let's deal with fetching data from the network:
Promisifying XMLHttpRequest
Old APIs will be updated to use promises, if it's possible in a backwards compatible way. XMLHttpRequest is a prime candidate, but in the mean time let's write a simple function to make a GET request:
function get(url) {
// Return a new promise.
return new Promise(function(resolve, reject) {
// Do the usual XHR stuff
var req = new XMLHttpRequest();
req.open('GET', url);
req.onload = function() {
// This is called even on 404 etc
// so check the status
if (req.status == 200) {
// Resolve the promise with the response text
resolve(req.response);
}
else {
// Otherwise reject with the status text
// which will hopefully be a meaningful error
reject(Error(req.statusText));
}
};
// Handle network errors
req.onerror = function() {
reject(Error("Network Error"));
};
// Make the request
req.send();
});
}
var URL = "https://launchschool.com/";
get(URL).then(function(response) {
console.log("Success!", response);
}, function(error) {
console.error("Failed!", error);
});
<file_sep>def rolling_buffer1(buffer, max_buffer_size, new_element)
buffer << new_element
buffer.shift if buffer.size > max_buffer_size
buffer
end
def rolling_buffer2(input_array, max_buffer_size, new_element)
buffer = input_array + [new_element]
buffer.shift if buffer.size > max_buffer_size
buffer
end
# In rolling buffer two, the method does not mutate the caller
# In rolling buffer 1, the caller is mutated,
# it can be called independently, and the code is simpler<file_sep>function makeList() {
var theList = [];
return {
add: function(item) {
theList.push(item);
console.log(item + ' added!');
},
remove: function(item) {
var idx = theList.indexOf(item);
if (idx === -1) {
return "Item doesn't exist"
} else {
theList.splice(idx, 1);
console.log(item + ' removed!');
}
},
clear: function() {
theList = [];
console.log('all items deleted!');
},
list: function() {
return theList.forEach(function(i) { console.log(i) });
}
}
}
var list = makeList();
list.add('peas');
list.list();
list.add('corn');
list.list();
list.remove('peas');
list.list();
<file_sep>require 'erb'
template_file = File.read('example2.erb')
erb = ERB.new(template_file)
erb.result
<file_sep>def rps(fist1, fist2)
if fist1 == "rock"
(fist2 == "paper") ? "paper" : "rock"
elsif fist1 == "paper"
(fist2 == "scissors") ? "scissors" : "paper"
else
(fist2 == "rock") ? "rock" : "scissors"
end
end
puts rps(rps(rps("rock", "paper"), rps("rock", "scissors")), "rock")
# "paper"
# The internally nested method starts first, paper beats rock
# Then Paper faces off against the winner of rock v. scissors, rock
# Paper beats rock again
# Finally, the outermost method is paper vs. rock again, paper beats rock
# Computer Outputs Paper<file_sep>def missing(num_array)
ret_array = []
return ret_array if num_array.size < 2
iterates = (num_array[0]..num_array[-1])
iterates.each {|num| ret_array << num if !num_array.include?(num)}
ret_array
end
missing([-3, -2, 1, 5]) == [-1, 0, 2, 3, 4]
missing([1, 2, 3, 4]) == []
missing([1, 5]) == [2, 3, 4]
missing([6]) == []
# good user solution:
def missing(arr)
(arr.first...arr.last).reject { |num| arr.include?(num) }
end
<file_sep># A featured number (something unique to this exercise) is:
# 1. an odd number
# 2. that is a multiple of 7
# 3. whose digits occur exactly once each.
# Pseudo
# create validation method for featured numbers
# create featured method
# take argument and calculate upto the next number that is validated by initial method
# if no number works, return error message
def valid_featured?(num)
num % 7 == 0 && num.odd? && num.to_s.chars.uniq.join.to_i == num
end
def featured(arg)
return "There is no possible number that fulfills those requirements" if arg >= 9_876_543_210
arg += 1
until valid_featured?(arg)
arg += 1
end
arg
end
featured(12) == 21
featured(20) == 21
featured(21) == 35
featured(997) == 1029
featured(1029) == 1043
featured(999_999) == 1_023_547
featured(999_999_987) == 1_023_456_987
featured(9_999_999_999) # -> There is no possible number that fulfills those requirements<file_sep>function isBalanced(string) {
var count = 0;
var tracker = [];
if (string.split('').filter(p => p === ')').length !== string.split('').filter(p => p === '(').length) {
return false;
}
string.split('').forEach(function (char) {
if (char === '(' && count === 0) {
count += 1;
tracker.push(char);
} else if (char === ')' && tracker.filter(p => p === ')').length !== tracker.filter(p => p === '(').length) {
count -= 1;
tracker.push(char);
}
});
return count === 0;
}
isBalanced('What (is) this?'); // true
isBalanced('What is) this?'); // false
isBalanced('What (is this?'); // false
isBalanced('((What) (is this))?'); // true
isBalanced('((What)) (is this))?'); // false
isBalanced('Hey!'); // true
isBalanced(')Hey!('); // false
isBalanced('What ((is))) up('); // false<file_sep>function startCountLog() {
var i = 1;
return function() {
console.log(i);
return i++;
};
}
var startCounting = startCountLog();
var log = setInterval(startCounting, 1000);
function stopCounting(func) {
clearInterval(func);
}
// stopCounting(log);
<file_sep>var $operator = '+';
var $numerator = 0;
var $denominator = 0;
var $result;
$(function() {
// handle operator condition
// on select
// if select.val() ===
// var $x = Number($('#numerator'.val())) + Number($('#denominator'.val()))
// $('h1').text(String($x));
// parsefloat for divide
$result = $('h1');
$('#operator').change(function(event) {
$operator = $('#operator *:selected').val();
});
$('#calc').submit(function (event) {
event.preventDefault();
$numerator = Number($('#numerator').val());
$denominator = Number($('#denominator').val());
if ($operator === '+') {
$result.text(String($numerator + $denominator));
} else if ($operator === '-') {
$result.text(String($numerator - $denominator));
} else if ($operator === '*') {
$result.text(String($numerator * $denominator));
} else if ($operator === '/') {
$result.text(String(parseFloat($numerator) / parseFloat($denominator)));
} else {
$result.text('invalid');
}
});
});<file_sep>function substring(string, start, end) {
var i;
var final = '';
if (!end) { end = string.length; }
if (start < 0 || !Number(start)) {
start = 0;
} else if (end < 0 || !Number(end)) {
end = 0;
}
if (start <= 0 && end <= 0) { return final }
// standard version
if (start >= 0 && end >= 0 && start < end) {
for (i = 0; i < string.length; i++) {
if (i === start) {
while (i < end && i < string.length) {
final += string[i];
i++;
}
}
}
} else if (start > end) {
// backwards version
for (i = 0; i < string.length; i++) {
if (i === start) {
while (i >= end && i >= 0) {
i--;
final += string[i];
if (i === end || i === 0) {
return final;
}
}
}
}
}
return final;
}
// If both start and end are positive integers, start is less than end,
// and both are within the boundary of the string, return the substring
// from the start index (inclusive), to the end index (NOT inclusive).
// If the value of start is greater than end, swap the values of the two,
// then return the substring as described above.
// If start is equal to end, return an empty string.
// If end is omitted, the end variable inside the function is undefined.
// Return the substring starting at position start up through (and including) the end of the string.
// If either start or end is less than 0 or NaN, treat it as 0.
// If either start or end is greater than the length of the string, treat it as equal to the string length.
<file_sep>require 'spec_helper'
describe Video do
it { should belong_to(:category) }
it { should validate_presence_of(:title) }
describe "::search_by_title" do
it "searches exact title" do
Video.create(title: "Family Guy")
vid = Video.search_by_title("Family Guy").first
vid.title.should == "Family Guy"
end
it "searches partial title case insensitive" do
Video.create(title: "Family Guy")
vid = Video.search_by_title("guy").first
vid.title.should == "Family Guy"
end
it "returns empty when no match" do
vid = Video.search_by_title("um")
vid.should == []
end
it "sorts by created date" do
Video.create(title: "pop")
Video.create(title: "top")
vids = Video.search_by_title("op")
vids.first.created_at.should < vids.last.created_at
end
end
end<file_sep>module Boss
def delegate
puts "#{name} is delegating"
end
end
module FullTime
def take_vacation
self.vacation_days = self.vacation_days - 1
end
end
class Employee
attr_reader :name, :serial_number, :desk, :status
attr_accessor :vacation_days
def initialize(name)
@name = name
@serial_number = rand(10000..99999)
end
def to_s
attributes = ["Name: #{name}", "Type: #{self.class}", "Serial number: #{serial_number}", "Vacation days: #{vacation_days}", "Desk: #{desk}"]
attributes.join("\n")
end
end
class Executive < Employee
include Boss
include FullTime
def initialize(name)
super
@status = "Full Time"
@desk = "Corner Office"
@vacation_days = 20
end
end
class Manager < Employee
include Boss
include FullTime
def initialize(name)
super
@status = "Full Time"
@desk = "Private Office"
@vacation_days = 14
end
end
class Regular < Employee
include FullTime
def initialize(name)
super
@status = "Full Time"
@desk = "Cubicle Farm"
@vacation_days = 10
end
end
class PartTime < Employee
def initialize(name)
super
@status = "Part Time"
@desk = "None"
@vacation_days = 0
end
end
boss = Executive.new("Jerry")
puts boss
boss.delegate
underboss = Manager.new("Adam")
puts underboss
underboss.delegate
joe = Regular.new("Joe")
puts joe
joe.take_vacation
puts joe.vacation_days
<file_sep>def find_fibonacci_index_by_length(num)
fib = [1, 1]
new_fib = ''
count = 0
until new_fib.length == num
sum = fib.reduce(&:+)
fib << sum
fib.slice!(0)
new_fib = fib[-1].to_s
count += 1
end
count + 2
end
find_fibonacci_index_by_length(2) == 7
find_fibonacci_index_by_length(10) == 45
find_fibonacci_index_by_length(100) == 476
find_fibonacci_index_by_length(1000) == 4782
find_fibonacci_index_by_length(10000) == 47847<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
require_relative 'odd'
class OddTest < MiniTest::Test
def setup
@odd = Odd.new(2)
end
def test_odd
assert_equal(true, @odd.num.odd?)
end
end
<file_sep># setter
class Person
def initialize(n)
@name = n
end
end
bob = Person.new('bob')
joe = Person.new('joe')
puts bob.inspect
# => #<Person:0x007f9c830e5f70 @name="bob">
puts joe.inspect
# => #<Person:0x007f9c830e5f20 @name="joe">
# getter
class Person
def initialize(n)
@name = n
end
def get_name
@name # is the @name i-var accessible here?
end
end
bob = Person.new('bob')
bob.get_name # => "bob"
# uninitialized
class Person
def get_name
@name # the @name i-var is not initialized anywhere
end
end
bob = Person.new
bob.get_name # => nil
# class instance variables (useful later)
class Person
@name = "bob" # class level initialization
def get_name
@name
end
end
bob = Person.new
bob.get_name # => nil
<file_sep>class Cat
def initialize(name)
puts "I'm a cat!"
end
end
kitty = Cat.new<file_sep>class Person
attr_accessor :first_name, :last_name
def initialize(name)
@name = name
self.first_name = name.split.first
end
def last_name=(name)
@last_name = name
@name += ' ' + last_name
end
def name=(name)
@name = name
first_name = @name.split.first
@name.split.size > 1 ? @last_name = @name.split.last : last_name = ''
end
end
bob = Person.new('Robert')
bob.name # => 'Robert'
bob.first_name # => 'Robert'
bob.last_name # => ''
bob.last_name = 'Smith'
bob.name # => '<NAME>'
bob.name = "<NAME>"
bob.first_name # => 'John'
bob.last_name # => 'Adams'
# LS Solution: Note that they wrote an accessor method and interpolated the two names
# also note they created a method to split the string and define first & last name variables
# also note that within parse_full_name they create a separate variable within the private method
# that variable is called parts, and that splits the string
class Person
attr_accessor :first_name, :last_name
def initialize(full_name)
parse_full_name(full_name)
end
def name
"#{first_name} #{last_name}".strip
end
def name=(full_name)
parse_full_name(full_name)
end
private
def parse_full_name(full_name)
parts = full_name.split
self.first_name = parts.first
self.last_name = parts.size > 1 ? parts.last : ''
end
end<file_sep>advice = "Few things in life are as important as house training your pet dinosaur."
advice = advice.replace(important) "urgent"
# or advice.replace!('important', 'urgent')<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
class NumericTest < MiniTest::Test
def test_numeric
assert_instance_of(Numeric, Numeric.new)
end
end
<file_sep>var name = 'Julian';
function greet() {
function say() {
console.log(name);
}
say();
}
var country = 'Spain';
function update() {
country = 'Liechtenstein';
}
console.log(country); // logs: Spain
update();
console.log(country); // logs: Liechtenstein
// global var assignment. undeclared vars can hold values...
function assign() {
var country1 = 'Liechtenstein';
country2 = 'Spain';
}
assign();
console.log(country2); // logs: Spain
<file_sep># puts "the value of 40 + 2 is " + (40 + 2)
# this is an error because you cant add an integer to a string
# 2 fixes
puts "the value of 40 + 2 is " + (40 + 2).to_s
puts "the value of 40 + 2 is #{(40 + 2)}"<file_sep>hex_collection = 'a'.upto('z').to_a + 0.upto(9).to_a
section_1 = ''
section_2 = ''
section_3 = ''
section_4 = ''
section_5 = ''
8.times {section_1 << hex_collection.sample.to_s.chomp}
4.times {section_2 << hex_collection.sample.to_s.chomp}
4.times {section_3 << hex_collection.sample.to_s.chomp}
4.times {section_4 << hex_collection.sample.to_s.chomp}
12.times {section_5 << hex_collection.sample.to_s.chomp}
uuid = [section_1, section_2, section_3, section_4, section_5]
uuid = uuid.join('-')
uuid<file_sep>// constructor function
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName || '';
this.fullName = function() {
return (this.firstName + ' ' + this.lastName).trim();
};
}
var john = new Person('John', 'Doe');
var jane = new Person('Jane');
john.fullName(); // "<NAME>"
jane.fullName(); // "Jane"
john.constructor; // function Person(..)
jane.constructor; // function Person(..)
john instanceof Person; // true
jane instanceof Person; // true
<file_sep>hash = { a: 'ant', b: 'bear' }
hash.shift
# => [:a, 'ant']
# takes first k-v pair away from hash, returns it as an array<file_sep># 1, 5, 8
# 4, 7, 2
# 3, 9, 6
# 3 4 1
# 9 7 5
# 6 2 8
# each row is simply the reverse of the transposed array
matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
]
def rotate90(array)
indexes = {}
array.each_with_index do |row, idx|
row.each_with_index {|num, idx2| idx == 0 ? indexes[idx2] = [num] : indexes[idx2] << num}
end
indexes.values.map {|row| row.reverse}
end
matrix1 = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
]
matrix2 = [
[3, 7, 4, 2],
[5, 1, 0, 8]
]
new_matrix1 = rotate90(matrix1)
new_matrix2 = rotate90(matrix2)
new_matrix3 = rotate90(rotate90(rotate90(rotate90(matrix2))))
p new_matrix1 == [[3, 4, 1], [9, 7, 5], [6, 2, 8]]
p new_matrix2 == [[5, 3], [1, 7], [0, 4], [8, 2]]
# further exploration
def rotate_matrix(array, degree)
indexes = {}
array.each_with_index do |row, idx|
row.each_with_index {|num, idx2| idx == 0 ? indexes[idx2] = [num] : indexes[idx2] << num}
end
new_array = indexes.values.map {|row| row.reverse}
degree > 90 ? rotate_matrix(new_array, degree - 90) : new_array
end
matrix1 = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
]
rotate_matrix(matrix1, 180)<file_sep># you can chain as many expressions as you'd like with &&, and it will be evaluated left to right.
# If any expression is false, the entire && chain will return false.
# Short Circuiting: the && and || operators exhibit a behavior called short circuiting,
# which means it will stop evaluating expressions once it can guarantee the return value.
false && 3/0
# => false
true || 3/0
# => true
# false || 3/0
# ZeroDivisionError: divided by 0
name = false
if name && name.valid?
puts "great name!"
else
puts "either couldn't find name or it's invalid"
end
<file_sep>class Array
def zip(addons)
self.map do |before|
[before, addons[self.index(before)]]
end
end
end
[1, 2, 3].zip([4, 5, 6]) == [[1, 4], [2, 5], [3, 6]]
def zip(ary1, ary2)
ary1.map {|before| [before, ary2[ary1.index(before)]]}
end
zip([1, 2, 3], [4, 5, 6]) == [[1, 4], [2, 5], [3, 6]]
<file_sep>// Example 1 (let vs const):
// let is block-scoped variable
// const is block-scoped constant
function f() {
{
let x;
{
// this is ok since it's a block scoped name
const x = "sneaky";
// error, was just defined with `const` above
x = "foo";
}
// this is ok since it was declared with `let`
x = "bar";
// error, already declared above in this block
let x = "inner";
}
}
// Example 2 (var vs let):
// let holds lexical scoping rules, hoisting does not occur
{
console.log(c); // undefined. Due to hoisting
var c = 2;
}
{
console.log(b); // ReferenceError: b is not defined
let b = 3;
}
// Example 3: const variables are mutable, even though they can't be reassigned
const person = {
name: 'Wes',
age: 28
}
person.age = 29
// Example 4: all blocks, even if/while/for/switch, can be scoped with let
let points = 50;
let winner = false;
if (points > 40) {
let winner = true;
}
// 2 separate winner variables
<file_sep>def interleave(ary1, ary2)
ary3 = []
counter = 0
loop do
ary3 << ary1[counter]
ary3 << ary2[counter]
counter += 1
break if counter == ary2.size
end
ary3
end
interleave([1, 2, 3], ['a', 'b', 'c']) == [1, 'a', 2, 'b', 3, 'c']<file_sep># number, to_s
# invalid = '0' * 10
class PhoneNumber
attr_reader :number
INVALID = '0' * 10
def initialize(num)
@number = validate(num)
end
def area_code
number[0, 3]
end
def to_s
"(#{number[0, 3]}) #{number[3, 3]}-#{number[6, 4]}"
end
private
def validate(num)
num = num.split(/[ .()\-]/).join
if num.size == 11 && num[0] == '1'
num[1..-1]
elsif num =~ /[^0-9]/ || num.size != 10
INVALID
else
num
end
end
end
<file_sep>function trim(str) {
return str.split('').filter((char)=> char !== ' ').join('');
}<file_sep>def word_cap(string)
string = string.split.map {|s| s[0] =~ /[^a-zA-Z]/ ? s : s.capitalize! }.join (' ')
string.split.each {|s| string.index(s) < 0 ? s.downcase! : s}.join(' ')
end
word_cap('four score and seven') == 'Four Score And Seven'
word_cap('the javaScript language') == 'The Javascript Language'
word_cap('this is a "quoted" word') == 'This Is A "quoted" Word'
<file_sep>def stringy(num = 1)
result = ''
if num.zero?
result = '0'
else
for i in 1..num do
if i.odd?
result << '1'
else
result << '0'
end
end
end
result
end
puts stringy(6) == '101010'
puts stringy(9) == '101010101'
puts stringy(4) == '1010'
puts stringy(7) == '1010101'
puts stringy == '1'
puts stringy(0) == '0'
<file_sep>def longest_sentence(text_file)
lines = File.readlines(text_file)
lines.map!(&:chomp) ; lines = lines.join(' ') ; lines = lines.split(/[.|?|!]/) ;
lines.map!(&:split) ; longest = lines.map(&:size).max
p lines.select {|l| l.size == longest}.join(' ')
p longest
end
longest_sentence("Gettysburg.txt")
# Launch School Solution (They use a good method, Enumerable#max_by, line 3)
=begin
text = File.read('sample_text.txt')
sentences = text.split(/\.|\?|!/)
largest_sentence = sentences.max_by { |sentence| sentence.split.size }
largest_sentence = largest_sentence.strip
number_of_words = largest_sentence.split.size
puts "#{largest_sentence}"
puts "Containing #{number_of_words} words"
=end<file_sep>function substr(string, start, length) {
var i;
var final = '';
for (i = 0; i < string.length; i++) {
if (i === start || (i - string.length) === start) {
var j = 1;
while (j <= length && i < string.length) {
final += string[i];
i++;
j++;
}
}
}
return final;
}
var string = 'hello world';
substr(string, 2, 4);
substr(string, -3, 2);
substr(string, 8, 20);
substr(string, 0, -20);
substr(string, 0, 0);<file_sep>index = -1
flintstones = ["Fred", "Barney", "Wilma", "Betty", "Pebbles", "BamBam"]
flintstones.each_with_object({}) do |(key, value), hash|
hash[key] = index += 1
hash[value] = key
hash.delete_if {|k,v| k == nil}
end
=begin
Launch School Solution:
flintstones_hash = {}
flintstones.each_with_index do |name, index|
flintstones_hash[name] = index
end
=end<file_sep>=begin
The <=> Method
Any object in a collection that we want to sort must implement a <=> method.
This method performs comparison between two objects of the same type and returns
a -1, 0, or 1, depending on whether the first object is less than, equal to, or greater than
the second object; if the two objects cannot be compared then nil is returned.
=end
2 <=> 1 # => 1
1 <=> 2 # => -1
2 <=> 2 # => 0
'b' <=> 'a' # => 1
'a' <=> 'b' # => -1
'b' <=> 'b' # => 0
1 <=> 'a' # => nil
<file_sep>def oddities(array)
array.select do |i|
array.rindex(i).even?
end
end
oddities([2, 3, 4, 5, 6]) == [2, 4, 6]
oddities(['abc', 'def']) == ['abc']
oddities([123]) == [123]
oddities([]) == []<file_sep># Let's try to write out a description of the game.
=begin
Tic Tac Toe is a 2 player game played on a 3x3 board.
Each player takes a turn and marks a square on the board.
First player to reach 3 squares in a row, including diagonals, wins.
If all 9 squares are marked and no player has 3 squares in a row,
then the game is a tie.
=end
# outline the sequence of the gameplay a little more.
=begin
1. Display the initial empty 3x3 board.
2. Ask the user to mark a square.
3. Computer marks a square.
4. Display the updated board state.
5. If winner, display winner.
6. If board is full, display tie.
7. If neither winner nor board is full, go to #2
8. Play again?
9. If yes, go to #1
10. Good bye!
=end
# there are two main loops -- one at step #7 and one at # 9<file_sep>class ReviewsController < ApplicationController
before_action :access_granted?
def create
@video = Video.find(params[:video_id])
@review = Review.new(review_params)
@review.user = current_user
if @review.save
@video.reviews << @review
flash[:notice] = "Your review was successful"
redirect_to video_path(@video)
else
flash[:alert] = "Something went wrong"
redirect_to :back
end
end
private
def review_params
params.require(:review).permit(:rating, :description)
end
end<file_sep>class Category < ActiveRecord::Base
has_many :videos
validates :name, presence: true, uniqueness: true
def recent_videos
videos.sort_by(&:created_at).reverse.first(6)
end
end<file_sep>def string_to_signed_integer(string)
if string.include?('-')
number =
string.bytes[1..-1].reduce(0) do |acc, chaar|
acc*10 + chaar - 48
end
number = number - (number*2)
elsif string.include?('+')
string.bytes[1..-1].reduce(0) do |acc, chaar|
acc*10 + chaar - 48
end
else
string.bytes.reduce(0) do |acc, chaar|
acc*10 + chaar - 48
end
end
end
string_to_signed_integer('4321') == 4321
string_to_signed_integer('-570') == -570
string_to_signed_integer('+100') == 100<file_sep>function createNum(str) {
var spl = str.split('.');
var decimal = spl.slice(1).join('');
return Number(spl[0] + '.' + decimal);
}
function compareVersions(version1, version2) {
if (String(version1).match(/([^0-9.]|^\.|\.\.|\.$)/g) || String(version2).match(/([^0-9.]|^\.|\.\.|\.$)/g)) {
return null;
}
var result = [];
Array.prototype.slice.call(arguments).forEach(function (arg) {
if (String(arg).length === 1) {
result.push(Number(arg));
} else {
result.push(createNum(String(arg)));
}
});
if (result[0] === result[1]) {
return 0;
} else if (result[0] > result[1]) {
return 1;
} else {
return -1;
}
}
console.log(compareVersions('10', '1')); // 1
console.log(compareVersions('10.2', '10.2')); // 0
console.log(compareVersions('10.2', '10.23')); // -1
console.log(compareVersions('1.1', '1.0')); // 1
console.log(compareVersions('2.3.4', '2.3.5')); // -1
console.log(compareVersions('1.a', '1')); // null
console.log(compareVersions('.1', '1')); // null
console.log(compareVersions('1.', '2')); // null
console.log(compareVersions('1..0', '2.0')); // null
console.log(compareVersions('1.0', '1.0.0')); // 0
console.log(compareVersions('1.0.0', '1.1')); // -1
console.log(compareVersions('1.0', '1.0.5'));
//sort
// take 2 version numbers
// return null if not [0-9] or .
//convert to string
//split by period
//each . add a 0 to number
// convert to number
// compare numbers
// If version1 > version2, we should return 1.
// If version1 < version2, we should return -1.
// If version1 === version2, we should return 0.<file_sep>def letter_percentages(string)
size = []
result = {lowercase: 0, uppercase: 0, neither: 0}
string.each_char {|ch| size << ch}
size = size.size
string.each_char do |letter|
case
when letter =~ /[a-z]/
result[:lowercase] += 1
when letter =~ /[A-Z]/
result[:uppercase] += 1
when letter !~ /[a-zA-Z]/
result[:neither] += 1
end
end
result.map do |k, v|
v = (v.to_f / size.to_f) * 100
v == v.to_i.to_f ? result[k] = v.to_i : result[k] = v
end
result
end
letter_percentages('abCdef 123') == { lowercase: 50, uppercase: 10, neither: 40 }
letter_percentages('AbCd +Ef') == { lowercase: 37.5, uppercase: 37.5, neither: 25 }
letter_percentages('123') == { lowercase: 0, uppercase: 0, neither: 100 }<file_sep>part_1 = WINNING_LINES.select {|w| w.select {|l| brd[l].count(INITIAL_MARKER) == 1}.count == 1}
part_2 = WINNING_LINES.select {|w| w.map {|l| brd[l].count(PLAYER_MARKER)}.count(1) == 2}
part_3 = part_1.flatten.select {|p| brd[p] == INITIAL_MARKER}.uniq
part_4 = part_2.flatten.select {|p| brd[p] == INITIAL_MARKER}.uniq
part_3 && part_4 != []
# part 5 (when the condition is met):
new = WINNING_LINES.select {|w| w.map {|l| brd[l].count(PLAYER_MARKER)}.count(1) == 2}
move = new.map {|n| n.select {|s| brd[s] == INITIAL_MARKER} }
square = move.flatten.first
brd[square] = COMPUTER_MARKER<file_sep>def swap(string)
string = string.split.each {|s| s.prepend(s[-1]) ; s.chop!; if s.length > 2 then s << s[1] && s.slice!(1) end}.join(' ')
string
end
swap('Oh what a wonderful day it is') == 'hO thaw a londerfuw yad ti si'
swap('Abcde') == 'ebcdA'
swap('a') == 'a'<file_sep>class VideosController < ApplicationController
before_action :access_granted?
def index
@videos = Video.all
@categories = Category.all
end
def create; end
def new; end
def edit; end
def show
@video ||= Video.find(params[:id])
redirect_to home_path unless @video
@reviews = @video.reviews
@average = Review.average(@video.id)
@review = Review.new
@qcount = qrement
end
def update; end
def destroy; end
def search
@vids = Video.search_by_title(params[:query])
end
private
def qrement
logged_in? ? current_user.queue_items.count + 1 : nil
end
end<file_sep># Group 1
def check_return_with_proc
my_proc = proc { return }
my_proc.call
puts "This will never output to screen."
end
check_return_with_proc
# nil
# the return value of the proc is executed and ends the method execution
# Group 2
my_proc = proc { return }
def check_return_with_proc_2(my_proc)
my_proc.call
end
check_return_with_proc_2(my_proc)
#unexpected return LocalJumpError
# if the proc is defined outside of the scope of the method,
# its execution will cause an error with return
# Group 3
def check_return_with_lambda
my_lambda = lambda { return }
my_lambda.call
puts "This will be output to screen."
end
check_return_with_lambda
# the return is ignored and the method executes
# Group 4
my_lambda = lambda { return }
def check_return_with_lambda(my_lambda)
my_lambda.call
puts "This will be output to screen."
end
check_return_with_lambda(my_lambda)
# the return value of the lambda is ignored by the method, unlike the proc
# method executes all the way
# Group 5
def block_method_3
yield
end
block_method_3 { return }
# LocalJump - unexpected return
=begin
LS Answer:
Group 1
If we return from within a Proc, and that Proc is defined within a method.
Then, we will immediately exit that method(we return from the method).
Group 2
If we return from within a Proc and that Proc is defined outside of a method.
Then, an error will be thrown when we call that Proc.
This occurs because program execution jumps to where the Proc was defined when we call that Proc.
We cannot return from the top level of the program.
Group 3
If we return from within a Lambda, and that Lambda is defined within a method,
then program execution jumps to where the Lambda code is defined.
After that, code execution then proceeds to the next line of the method after the #call to that lambda.
Group 4
If we return from within a Lambda and that Lambda is defined outside a method,
then program execution continues to the next line after the call to that Lambda.
This is the same effect as the code in group 3.
Group 5
If we return from an implicit block that is yielded to a method,
then an error will be thrown.
The reason for this error is the same as the one mentioned for group 2.
We are trying to return from some code in our program that isn't in a method.
Comparison
Procs and implicit blocks sometimes have the same behavior when we return from them.
If a Proc is defined outside a method, and we return from it, then we'll get an error.
The same thing occurs if we try to return from an implicit block,
where the block itself isn't defined in a method.
An error is thrown if we try to return from it.
If we try to return from within a Proc that is defined within a method,
then we immediately exit the method.
If we try to return from a Lambda, the same outcome occurs,
regardless of whether the Lambda is defined outside a method or inside of it.
Eventually, program execution will proceed to the next line after the #call to that lambda.
<file_sep>class Integer
def binlib
counter = 0
library = []
until counter == 1000
library << (2 ** counter)
counter += 1
end
library
end
def to_binary
final_string = ''
bins = binlib.select {|n| n <= self}.reverse
return '0' if bins.empty?
return '1' if bins[0] == 1
final_string << '1'
difference = self - bins[0]
bins[1..-1].each do |bin|
if difference >= bin
final_string << '1'
difference -= bin
else
final_string << '0'
end
end
final_string
end
end
# loop
# find closest value in binlib to self
# get index
# add 1 to string collection
# binlib[0..idx].reverse
# iterate each
# add 0 if it is greater than difference
# add 1 if it is less than difference
# subtract binlib value from self
# until difference == 0<file_sep>flintstones = %w(<NAME> Wilma Betty BamBam Pebbles)
flintstones.each_index { |index| puts index if flintstones[index].start_with?("Be") }
# flintstones.index { |name| name[0, 2] == "Be" }<file_sep>// Simple example:
var promise = new Promise(function(resolve, reject) {
// do a thing, possibly async, then…
if (/* everything turned out fine */) {
resolve("Stuff worked!");
}
else {
reject(Error("It broke"));
}
});
promise.then(function(result) {
console.log(result); // "Stuff worked!"
}, function(err) {
console.log(err); // Error: "It broke"
});
// MDN Example:
function doSomething() {
return new Promise((resolve, reject) => {
console.log("It is done.");
// Succeed half of the time.
if (Math.random() > .5) {
resolve("SUCCESS")
} else {
reject("FAILURE")
}
})
}
const promise = doSomething();
promise.then(successCallback, failureCallback);
//…or simply:
doSomething().then(successCallback, failureCallback);
// Chaining - add a catch() for failure conditions:
doSomething()
.then(result => doSomethingElse(result))
.then(newResult => doThirdThing(newResult))
.then(finalResult => console.log(`Got the final result: ${finalResult}`))
.catch(failureCallback);
<file_sep>def average(array)
sum = 0.0
array.each do |num|
sum += num
end
result = sum / array.size
result
end
puts average([1, 5, 87, 45, 8, 8])
puts average([9, 47, 23, 95, 16, 52])
# Their version:
# def average(numbers)
# sum = numbers.reduce { |sum, number| sum + number }
# sum / numbers.count
# end<file_sep>function splitString(string, delimiter) {
if (delimiter === undefined) {
return console.log('ERROR: no delimiter');
}
var i;
var loggedString = '';
for (i = 0; i < string.length; i++) {
if (string[i] === delimiter) {
console.log(loggedString);
loggedString = '';
} else if (delimiter === '') {
loggedString += string[i];
console.log(loggedString);
loggedString = '';
} else if (i === (string.length - 1)) {
loggedString += string[i];
console.log(loggedString);
} else {
loggedString += string[i];
}
}
}<file_sep># Define a class Meetup with a constructor taking a month and a year
# and a method day(weekday, schedule)
# where weekday is one of :monday, :tuesday, etc
# and schedule is :first, :second, :third, :fourth, :last or :teenth.
require 'date'
class Meetup
attr_reader :month, :year
def initialize(month, year)
@month = month
@year = year
end
def day(weekday, schedule)
if schedule == :teenth
find_dates(19, 12).select(&"#{weekday.to_s}?".to_sym)[0]
elsif schedule == :last
monthday(weekday)[-1]
else
monthday(weekday)[count(schedule)]
end
end
private
def count(symbol)
[:first, :second, :third, :fourth].index(symbol)
end
def monthday(weekday)
find_dates(Date.new(year, month, -1).day).select(&"#{weekday.to_s}?".to_sym)
end
def find_dates(max, date = 0)
Date.new(year, month).upto(Date.new(year, month, max)).select {|cal| cal.day > date}
end
end
may = Meetup.new(5, 2013)
may.day(:thursday, :third)
<file_sep>var module = {
age: 30,
foo: function() {
setTimeout(() => {
console.log(this.age);
}, 100);
}
}
module.foo();
// automatic context binding
<file_sep>class MyCar
attr_reader :year
attr_accessor :color
def initialize(year, color, model)
@year = year
@color = color
@model = model
@speed = 0
end
def speed_up
@speed += 25
end
def brake
@speed -= 25
end
def stop_car
@speed = 0
end
def spray_paint(new_color)
self.color = (new_color)
end
def show_info
"#{@model}, #{year}, #{color}, going #{@speed} mph."
end
end
chevy = MyCar.new(2017, 'Black', 'Silverado')
puts chevy.color
chevy.spray_paint('Yellow')
puts chevy.show_info
<file_sep>def fib(first_num, second_num, limit)
while second_num < limit
sum = first_num + second_num
first_num = second_num
second_num = sum
end
sum
end
result = fib(0, 1, 15)
puts "result is #{result}"
# Methods contain their own internal scope.
# Limit was initialized outside of the method.
# Need to initialize limit within the method.
# Or add it as an argument to the method.<file_sep>require 'pry'
class Board
WINNING_LINES = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] +
[[1, 4, 7], [2, 5, 8], [3, 6, 9]] +
[[1, 5, 9], [3, 5, 7]]
def initialize
@squares = {}
(1..9).each { |n| @squares[n] = Square.new }
end
# rubocop:disable Metrics/AbcSize
def draw
puts ""
puts " | |"
puts " #{@squares[1]} | #{@squares[2]} | #{@squares[3]}"
puts " | |"
puts "-----+-----+-----+"
puts " | |"
puts " #{@squares[4]} | #{@squares[5]} | #{@squares[6]}"
puts " | |"
puts "-----+-----+-----+"
puts " | |"
puts " #{@squares[7]} | #{@squares[8]} | #{@squares[9]}"
puts " | |"
puts ""
end
# rubocop:enable Metrics/AbcSize
def empty_squares
@squares.keys.select { |key| @squares[key].unmarked? }
end
def full?
empty_squares.empty?
end
def someone_won?
!!winning_marker
end
def [](key)
@squares[key].marker
end
def []=(key, marker)
@squares[key].marker = marker
end
def winning_marker # return winning marker or nil
WINNING_LINES.each do |line|
return @squares[line[0]].marker if line.all? do |move|
@squares[move].marker != Square::INITIAL_MARKER &&
@squares[line[0]].marker == @squares[move].marker
end
end
nil
end
end
class Square
INITIAL_MARKER = " "
attr_accessor :marker
def initialize(marker = INITIAL_MARKER)
@marker = marker
end
def to_s
@marker
end
def unmarked?
marker == INITIAL_MARKER
end
end
class Player
attr_reader :marker
attr_accessor :wins
def initialize(marker)
@marker = marker
@wins = 0
end
end
class TTTGame
HUMAN_MARKER = "X"
COMPUTER_MARKER = "O"
attr_accessor :board
attr_reader :human, :computer
def initialize
@board = Board.new
@human = Player.new(HUMAN_MARKER)
@computer = Player.new(COMPUTER_MARKER)
@current_player = 0
end
def play
display_welcome_message
loop do
loop do
display_board
loop do
current_player_moves
break if board.someone_won? || board.full?
clear_screen_and_display_board
end
display_result
break if human.wins == 5 || computer.wins == 5
reset
end
display_game_results
break unless play_again?
reset
human.wins = 0
computer.wins = 0
display_play_again_message
end
display_goodbye_message
end
private
def display_welcome_message
puts "Welcome to Tic Tac Toe!"
puts ""
end
def joinor(array)
array[-1] = array[-1].to_s.prepend("or ") unless array.size == 1
if array.size > 2
array.join(', ')
else array.join(' ')
end
end
def clear
system "cls"
end
def display_board
puts "You are #{human.marker}, and the CPU is #{computer.marker}"
board.draw
end
def clear_screen_and_display_board
clear
display_board
end
def human_moves
square = nil
puts "Pick a square: #{joinor(board.empty_squares)}"
loop do
square = gets.chomp.to_i
break if board.empty_squares.include?(square)
puts "Sorry, that's not a valid choice. Please try again."
end
board[square] = human.marker
end
def next_move
result = nil
Board::WINNING_LINES.each do |line|
line_map = line.map {|sq| board[sq]}
empties = board.empty_squares & line
line.each do |number|
if empties.size == 1
if line_map.count(HUMAN_MARKER) == 2 || line_map.count(COMPUTER_MARKER) == 2
result = empties[0]
end
elsif empties.size == 2
if line_map.count(COMPUTER_MARKER) == 1
result = empties[0] if result.nil?
end
end
end
end
return result unless result.nil?
board.empty_squares.sample
end
def computer_moves
board[next_move] = computer.marker
end
def current_player_moves
case @current_player
when 0
human_moves
@current_player += 1
when 1
computer_moves
@current_player -= 1
end
end
def display_result
clear_screen_and_display_board
case board.winning_marker
when human.marker
puts "You won!"
human.wins = human.wins + 1
when computer.marker
puts "CPU won!"
computer.wins = computer.wins + 1
else
puts "It's a tie."
end
puts "Press Enter to Continue"
gets
clear
display_score
end
def play_again?
puts "Do you want to play again? (y/n)"
answer = gets.chomp.downcase
return answer if answer.start_with?('y')
nil
end
def display_score
puts "Your Score: #{human.wins}, Computer Score: #{computer.wins}"
end
def display_game_results
if human.wins == 5
puts "You Won The Game!"
else puts "CPU Won The Game"
end
end
def reset
@current_player = 0
self.board = Board.new
end
def display_play_again_message
puts "Let's Play Again!"
puts ""
end
def display_goodbye_message
puts "Thanks for playing Tic Tac Toe! Goodbye!"
end
end
game = TTTGame.new
game.play
<file_sep># == is not an operator in Ruby, like the = assignment operator.
# Instead, it's actually an instance method available on all objects.
# compares values being referenced by two objects
# str1.==(str2)
45 == 45.00 # => true
# in custom classes, using == will compare references of the actual object b/w two classes
class Person
attr_accessor :name
end
bob = Person.new
bob.name = "bob"
bob2 = Person.new
bob2.name = "bob"
bob == bob2 # => false
bob_copy = bob
bob == bob_copy # => true
# overriding == so it measures whether or not the argument references the same object
class Person
attr_accessor :name
def ==(other)
name == other.name # relying on String#== here
end
end
bob = Person.new
bob.name = "bob"
bob2 = Person.new
bob2.name = "bob"
bob == bob2
# One final note: when you define a == method, you also get the != for free.
# You should also realize that 45 == 45.00 is not the same as 45.00 == 45
<file_sep># methods: Clock.at(hour, min = 0), Clock#-(integer),
# Clock#+(integer), Clock#to_s #=> '01:00'
# army time, wraps around 24
# reformat string at the end of methods
# hour - 1 * 60 + min
# minus: 60 - min
# Clock.totalmin - num
# edge cases
require 'pry'
class Timestring < String
DAY_MIN = 1440
def -(num)
Clock.totalmin - num < 0 ? new_time = (DAY_MIN + Clock.totalmin) - num : new_time = Clock.totalmin - num
new_hour = new_time / 60
new_min = new_time % 60
Clock.at(new_hour, new_min)
end
def +(num)
new_time = Clock.totalmin + num
new_hour = new_time / 60
new_min = new_time % 60
Clock.at(new_hour, new_min)
end
end
class Clock
alias_method :at, :to_s
RESET = 24
def self.at(hour, min = 0)
@hour = hour
@min = min
@hourstring = hour.to_s
@minstring = min.to_s
configure_hour
configure_minutes
@timestring = Timestring.new("#{@hourstring}:#{@minstring}")
end
private
def self.configure_hour
@hour = (@hour % RESET) if @hour >= RESET
return @hourstring = "0#{@hour}" if @hour < 10
@hourstring = @hour.to_s
end
def self.configure_minutes
@min < 10 ? @minstring = "0#{@min}" : @minstring = @min.to_s
end
def self.totalmin
@hour * 60 + @min
end
end
seven_thirty = Clock.at(8, 30) - 60
nine_thirty = Clock.at(8) + 90
#binding.pry
<file_sep>class Person
def initialize(name)
@name = name
end
def name=(name)
@name = name
end
end
bob = Person.new('bob')
bob.name # => 'bob'
bob.name = 'Robert'
bob.name # => 'Robert'
# ls with attr_accessor
class Person
attr_accessor :name
def initialize(n)
@name = n
end
end<file_sep>class SecretFile
# replace attr_reader with custom getter method to log data
def initialize(secret_data, log) # log takes collaborator custom object as an argument
@data = secret_data
@log = log
end
def data
log.create_log_entry
@data
end
end
class SecurityLogger
def create_log_entry
# enter some information
end
end
new_file = SecretFile([1, 2, 3], SecurityLogger.new)
<file_sep>puts "Enter the length of the room in feet:"
length = gets.to_f
puts "Enter the width of the room in feet:"
width = gets.to_f
area = length * width
area_message = <<-MSG
The area of the room is #{area.round(2)} square feet,
or #{(area / 10.7639).round(2)} square meters,
or #{(area * 12).round(2)} square inches,
or #{(area / 0.107369).round(2)} square centimeters.
MSG
puts area_message<file_sep>require 'spec_helper'
describe UsersController do
describe "POST create" do
it "should work with good user" do
post :create, user: { username: "user", email: "<EMAIL>", password: "<PASSWORD>" }
response.should redirect_to '/home'
end
it "should not work with bad user" do
post :create, user: { username: "user", email: "<EMAIL>", password: "s" }
response.should_not redirect_to '/home'
end
end
end<file_sep>Andy's version of the Launch School Reddit clone:
Additions:
- Ability to delete posts
- Alternative category adding/changing
- Better upvoting and downvoting (unvoting/vote changes)<file_sep>def repeater(string)
string.gsub!(' ', ' ')
split_string = string.split(/ /)
split_string.map! {|s| s != "" ? s.chars.flat_map {|char| [char, char]} : s = ' '}.join
end
repeater('Hello') == "HHeelllloo"
repeater("Good job!") == "GGoooodd jjoobb!!"
repeater('') == ''
=begin
Their solution:
def repeater(string)
result = ''
string.each_char do |char|
result << char << char
end
result
end
=end<file_sep>def step(range_begins, range_ends, step_value)
counter = 0
(range_begins..range_ends).each do |number|
yield(number) if number == range_begins || number == range_ends || counter % step_value == 0
counter += 1
end
(range_begins..range_ends)
end
step(1, 10, 3) { |value| puts "value = #{value}" }
# value = 1
# value = 4
# value = 7
# value = 10
<file_sep>arr = [1, 2, 3, 4, 5]
counter = 0
loop do
arr[counter] += 1
counter += 1
break if counter == arr.size
end
arr # => [2, 3, 4, 5, 6]
loop do
number = rand(1..10) # a random number between 1 and 10
puts 'Hello!'
if number == 5
puts 'Exiting...'
break
end
end
counter = 0
loop do
puts 'Hello!'
counter += 1
break if counter == 5
end
# Here we shortened the if statement by changing it to an if modifier.
# An if modifier is implemented by appending the keyword if and the condition to a statement.
# In this case, the statement is break.
# if modifier should only be used in a one-line block
counter = 0
loop do
counter += 1
next if counter.odd?
puts counter
break if counter > 5
end
# when next is executed, any code after it (within the loop) will be ignored.
alphabet = 'abcdefghijklmnopqrstuvwxyz'
counter = 0
loop do
break if counter >= alphabet.size
puts alphabet[counter]
counter += 1
end
colors = ['green', 'blue', 'purple', 'orange']
counter = 0
# >= size accounts for any condition, including space characters, preventing an infinite loop.
loop do
break if counter == colors.size
puts "I'm the color #{colors[counter]}!"
counter += 1
end
# Below, example of multiple object types.
objects = ['hello', :key, 10, []]
counter = 0
loop do
break if counter == objects.size
puts objects[counter].class
counter += 1
end
# hashes are more difficult to loop because they use k-v pairs instead of a 0-based index
number_of_pets = {
'dogs' => 2,
'cats' => 4,
'fish' => 1
}
pets = number_of_pets.keys # => ['dogs', 'cats', 'fish']
counter = 0
loop do
break if counter == number_of_pets.size
current_pet = pets[counter]
current_pet_number = number_of_pets[current_pet]
puts "I have #{current_pet_number} #{current_pet}!"
counter += 1
end
# To remedy this, we have to create an array containing all of the keys in the hash.
# The important thing to realize here is that this is a two step process.
# First, we're iterating over the array of keys, pets, and saving each key into the current_pet variable.
# We then use the current_pet key to retrieve the appropriate value out of the number_of_pets hash.
<file_sep>birds = %w(raven finch hawk eagle)
p birds # => ['raven','finch','hawk','eagle']
# If we want to assign every element to a
# separate variable, we can do that too:
raven, finch, hawk, eagle = %w(raven finch hawk eagle)
p raven # => 'raven'
p finch # => 'finch'
p hawk # => 'hawk'
p eagle # => 'eagle'
raven, finch, *raptors = %w(raven finch hawk eagle)
p raven # => 'raven'
p finch # => 'finch'
p raptors # => ['hawk','eagle']
# write a method that takes an array as an argument
# The method should yield the contents of the array
# to a block
# which should assign your block variables
# in such a way that it ignores the first two elements,
# and groups all remaining elements as a raptors array.
def contents(array)
yield(array[2..-1]).flatten!
end
raptors = []
contents(%w(raven finch hawk eagle)) { |items| raptors << items }
# ls solution
birds = ['crow', 'finch', 'hawk', 'eagle', 'osprey']
def types(birds)
yield birds
end
types(birds) do |_, _, *raptors|
puts "Raptors: #{raptors.join(', ')}."
end
<file_sep>function afterNSeconds(func, n) {
setTimeout(func, n * 1000);
}
function log() {
console.log('Waited 10');
}
afterNSeconds(log, 10);<file_sep>function triangle(angle1, angle2, angle3) {
var angles = Array.prototype.slice.call(arguments);
var angleSum = angles.reduce(function (sum, angle) { return sum + angle });
if (angles.length !== 3 || angleSum !== 180 || angles.some(function (corner) { return corner <= 0 })) {
return "invalid";
} else if (angles.filter(function (angle) { return angle === 90 }).length === 1) {
return "right";
} else if (angles.filter(function (angle) { return angle < 90 }).length === 3) {
return "acute";
} else if (angles.filter(function (angle) { return angle > 90 }).length === 1) {
return "obtuse";
} else {
return "invalid";
}
}
triangle(60, 70, 50); // "acute"
triangle(30, 90, 60); // "right"
triangle(120, 50, 10); // "obtuse"
triangle(0, 90, 90); // "invalid"
triangle(50, 50, 50); // "invalid"<file_sep>def word_sizes(string)
diff_lengths = {}
length_array = string.split
length_array.map! {|c| c.chars.delete_if {|l| l =~ /\p{^alpha}/}.join}
length_array.map! {|i| i.length }
unique_array = length_array.uniq
unique_array.map {|i| diff_lengths[i] = length_array.count{|x| x == i}}
diff_lengths
end
word_sizes('Four score and seven.') == { 3 => 1, 4 => 1, 5 => 2 }
word_sizes('Hey diddle diddle, the cat and the fiddle!') == { 3 => 5, 6 => 3 }
word_sizes("What's up doc?") == { 5 => 1, 2 => 1, 3 => 1 }
word_sizes('') == {}<file_sep>FACE = ['two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten', 'jack', 'queen', 'king', 'ace']
deck = FACE * 4
card_value = 0
player_hand = []
computer_hand = []
def reshuffle!(dck)
dck.shuffle!
end
def draw_cards!(dck, hnd)
hnd << dck.slice!(0..1)
hnd.flatten!
end
def stringhand(hnd)
hnd = hnd.select! {|h| h.class == String}
end
def determine_value(hnd)
values = [2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10]
non_ace = FACE[0..-2]
if hnd.include?('ace')
hnd = hnd.unshift(1, 11)
end
non_ace.each {|f| hnd.include?(f)? hnd << (values[non_ace.index(f)]) : f}
dup = hnd.select{|element| hnd.count(element) > 1}
if !dup.empty?
non_ace.map {|f| hnd.include?(f)? hnd << (values[non_ace.index(f)]) : f}
end
new_hnd = hnd.select {|h| h.integer? rescue false}
if new_hnd.include?(11)
unless new_hnd == [1, 11]
new_hnd[2..-1].inject(&:+) >= 22 ? new_hnd.delete(11) : new_hnd.delete(1)
end
end
stringhand(hnd)
new_hnd.size == 4 ? sum = new_hnd[0..1].inject(&:+) : sum = new_hnd.inject(&:+)
end
def busted?(crd)
crd > 21
end
def hit(dck, hnd, curr)
new_card = dck.slice!(0)
hnd << new_card
unless new_card == 'ace'
curr += determine_value([new_card])
else
curr + 11 >= 22 ? curr += 1 : curr += 11
end
curr
end
shuffled_deck = reshuffle!(deck)
draw_cards!(shuffled_deck, player_hand)
card_value = determine_value(player_hand)
card_value = hit(shuffled_deck, player_hand, card_value)
player_hand
busted?(card_value)
player_turn<file_sep>def letter_case_count(string)
cases = {}
cases[:lowercase] = string.chars.select{|a| a =~ /[a-z]/}.size
cases[:uppercase] = string.chars.select{|a| a =~ /[A-Z]/}.size
cases[:neither] = string.chars.select{|a| a =~ /[^a-zA-z]/}.size
cases
end
letter_case_count('abCdef 123') == { lowercase: 5, uppercase: 1, neither: 4 }
letter_case_count('AbCd +Ef') == { lowercase: 3, uppercase: 3, neither: 2 }
letter_case_count('123') == { lowercase: 0, uppercase: 0, neither: 3 }
letter_case_count('') == { lowercase: 0, uppercase: 0, neither: 0 }
<file_sep>def one?(array)
counter = 0
onesies = 0
while counter < array.size
onesies += 1 if yield(array[counter])
counter += 1
end
onesies == 1
end
one?([1, 3, 5, 6]) { |value| value.even? } # -> true
one?([1, 3, 5, 7]) { |value| value.odd? } # -> false
one?([2, 4, 6, 8]) { |value| value.even? } # -> false
one?([1, 3, 5, 7]) { |value| value % 5 == 0 } # -> true
one?([1, 3, 5, 7]) { |value| true } # -> false
one?([1, 3, 5, 7]) { |value| false } # -> false
one?([]) { |value| true } # -> false
<file_sep># Group 1
my_proc = proc { |thing| puts "This is a #{thing}." }
puts my_proc
puts my_proc.class
my_proc.call
# This is a .
my_proc.call('cat')
# This is a cat.
# You can call a proc without arguments
# Group 2
my_lambda = lambda { |thing| puts "This is a #{thing}" }
my_second_lambda = -> (thing) { puts "This is a #{thing}" } # lambda shorthand, does same as first
puts my_lambda
puts my_second_lambda
puts my_lambda.class
my_lambda.call('dog')
# this is a dog
my_lambda.call
# ArgumentError
my_third_lambda = Lambda.new { |thing| puts "This is a #{thing}" }
# Uninitialized constant
# You need arguments for lambdas, lambda objects are Procs
# Group 3
def block_method_1(animal)
yield
end
block_method_1('seal') { |seal| puts "This is a #{seal}."}
block_method_1('seal')
# argument error, no block given, need to use if #block_given?
# Group 4
def block_method_2(animal)
yield(animal)
end
block_method_2('turtle') { |turtle| puts "This is a #{turtle}."}
block_method_2('turtle') do |turtle, seal|
puts "This is a #{turtle} and a #{seal}."
end
block_method_2('turtle') { puts "This is a #{animal}."}
# block parameters need to be defined as method arguments, if not enough
# arguments are given, the code will still execute but the second argument won't be processed
=begin
LS Description
Group 1:
A new Proc object can be created with a call of proc instead of Proc.new
A Proc is an object of class Proc
A Proc object does not require that the correct number of arguments are passed to it.
If nothing is passed, then nil is assigned to the block variable.
Group 2:
A new Lambda object can be created with a call to lambda or ->.
We cannot create a new Lambda object with Lambda.new
A Lambda is actually a different variety of Proc.
While a Lambda is a Proc, it maintains a separate identity from a plain Proc.
This can be seen when displaying a Lambda:
the string displayed contains an extra "(lambda)" that is not present for regular Procs.
A lambda enforces the number of arguments.
If the expected number of arguments are not passed to it, then an error is thrown.
Group 3:
A block passed to a method does not require the correct number of arguments.
If a block variable is defined, and no value is passed to it,
then nil will be assigned to that block variable.
If we have a yield and no block is passed, then an error is thrown.
Group 4:
If we pass too few arguments to a block, then the remaining ones are assigned a nil value.
Blocks will throw an error if a variable is referenced that doesn't exist in the block's scope.
Comparison:
Lambdas are types of Proc's.
Technically they are both Proc objects.
An implicit block is a grouping of code, a type of closure, it is not an Object.
Lambdas enforce the number of arguments passed to them.
Implicit block and Procs do not enforce the number of arguments passed in.
=end
<file_sep>class Person
attr_accessor :first_name
attr_writer :last_name
def first_equals_last?
first_name == last_name
end
# Public methods, like first_equals_last?,
# can be used to access @last_name through the private accessor method.
private
attr_reader :last_name
# only Person has access to this method.
end
person1 = Person.new
person1.first_name = 'Dave'
person1.last_name = 'Smith'
puts person1.first_equals_last?
<file_sep>require 'pry'
class Board
WINNING_LINES = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] +
[[1, 4, 7], [2, 5, 8], [3, 6, 9]] +
[[1, 5, 9], [3, 5, 7]]
def initialize
@squares = {}
(1..9).each {|n| @squares[n] = Square.new}
end
def get_square(key)
@squares[key]
end
def set_square(key, marker)
@squares[key].marker = marker
end
def empty_squares
@squares.keys.select {|key| @squares[key].unmarked?}
end
def full?
empty_squares.empty?
end
def someone_won?
!!detect_winner
end
def detect_winner # return winning marker or nil
WINNING_LINES.each do |line|
return TTTGame::HUMAN_MARKER if line.all? { |key| @squares[key].marker == TTTGame::HUMAN_MARKER }
return TTTGame::COMPUTER_MARKER if line.all? { |key| @squares[key].marker == TTTGame::COMPUTER_MARKER }
end
nil
end
end
class Square
INITIAL_MARKER = " "
attr_accessor :marker
def initialize(marker = INITIAL_MARKER)
@marker = marker
end
def to_s
@marker
end
def unmarked?
marker == INITIAL_MARKER
end
end
class Player
attr_reader :marker
def initialize(marker)
@marker = marker
end
def mark
end
end
class TTTGame
HUMAN_MARKER = "X"
COMPUTER_MARKER = "O"
attr_accessor :board
attr_reader :human, :computer
def initialize
@board = Board.new
@human = Player.new(HUMAN_MARKER)
@computer = Player.new(COMPUTER_MARKER)
end
def display_welcome_message
puts "Welcome to Tic Tac Toe!"
puts ""
end
def display_board(clear = true)
system "cls" if clear
puts "You are #{human.marker}, and the CPU is #{computer.marker}"
puts ""
puts " | |"
puts " #{board.get_square(1)} | #{board.get_square(2)} | #{board.get_square(3)}"
puts " | |"
puts "-----+-----+-----+"
puts " | |"
puts " #{board.get_square(4)} | #{board.get_square(5)} | #{board.get_square(6)}"
puts " | |"
puts "-----+-----+-----+"
puts " | |"
puts " #{board.get_square(7)} | #{board.get_square(8)} | #{board.get_square(9)}"
puts " | |"
puts ""
end
def human_moves
square = nil
puts "Please choose a square. Choose one of the following: #{board.empty_squares.join(', ')}"
loop do
square = gets.chomp.to_i
break if board.empty_squares.include?(square)
puts "Sorry, that's not a valid choice."
end
board.set_square(square, human.marker)
end
def computer_moves
board.set_square(board.empty_squares.sample, computer.marker)
end
def display_result
display_board
case board.detect_winner
when human.marker
puts "You won!"
when computer.marker
puts "CPU won!"
else
puts "It's a tie."
end
end
def play_again?
puts "Do you want to play again? (y/n)"
answer = gets.chomp.downcase
return answer if answer.start_with?('y')
nil
end
def display_goodbye_message
puts "Thanks for playing Tic Tac Toe! Goodbye!"
end
def play
display_welcome_message
loop do
display_board(false)
loop do
human_moves
break if board.someone_won? || board.full?
computer_moves
break if board.someone_won? || board.full?
display_board
end
display_result
break unless play_again?
self.board = Board.new
system "cls"
puts "Let's Play Again!" ; puts
end
display_goodbye_message
end
end
game = TTTGame.new
game.play<file_sep>def rotate_array(ary)
ary[1..-1] << ary.slice(0)
end
rotate_array([7, 3, 5, 2, 9, 1]) == [3, 5, 2, 9, 1, 7]
rotate_array(['a', 'b', 'c']) == ['b', 'c', 'a']
rotate_array(['a']) == ['a']
x = [1, 2, 3, 4]
rotate_array(x) == [2, 3, 4, 1] # => true
x == [1, 2, 3, 4] # => true
<file_sep>def substrings(string)
subs = []
string.chars.each {|letter| string.chars.each_with_index {|other_lets, idx| idx >= string.index(letter) ? subs << string[string.index(letter)..idx] : idx}}
subs
end
substrings('abcde') == [
'a', 'ab', 'abc', 'abcd', 'abcde',
'b', 'bc', 'bcd', 'bcde',
'c', 'cd', 'cde',
'd', 'de',
'e'
]<file_sep>def titlesize(title)
title.split.each {|word| word.capitalize}.join(" ")
end
words = "the flintstones rock"
puts titlesize(words)<file_sep>puts "What is the bill?"
bill = gets.to_f
puts "What is the tip percentage?"
tip_percent = gets.to_f
tip = ((tip_percent / 100) * bill).round(2)
total = (bill += tip).round(2)
puts "The tip is #{tip}"
puts "The total is #{total}"
<file_sep>[[1, 2], [3, 4]].map do |arr|
puts arr.first
arr.first
end
=begin
Line 1
Action: map
Object: the outer array
Side Effect: none
Return Value: [1, 3]
Return Used: No
Line 1-3
Action: block execution
Object: each sub array
Side Effect: none
Return Value: [1, 3]
Return Used: Yes, by map
Line 2
Action: puts
Object: integer at index 0 of each sub array
Side Effect: outputs 1 and 3
Return Value: nil
Return Used: no
Line 2:
Action: first
Object: each sub array
Side Effect: none
Return Value: [1, 3]
Return Used: Yes, by puts
Line 3:
Action: first
Object: each sub array
Side effect: None
Return Value: [1,3]
Return Used: Yes, to determine the return value of the block<file_sep>// #1
function getDefiningObject(object, propKey) {
var parent = object;
while (parent !== Object.prototype) {
if (parent.hasOwnProperty(String(propKey))) { return parent }
parent = Object.getPrototypeOf(parent);
}
return null;
}
var foo = {
a: 1,
b: 2,
};
var bar = Object.create(foo);
var baz = Object.create(bar);
var qux = Object.create(baz);
bar.c = 3;
console.log(getDefiningObject(qux, 'c') === bar); // true
console.log(getDefiningObject(qux, 'e')); // null
// #2
function shallowCopy(object) {
var result = Object.create(Object.getPrototypeOf(object));
var prop;
for (prop in object) {
if (Object.prototype.hasOwnProperty.call(object, prop)) {
result[prop] = object[prop];
}
}
return result;
}
var foo = {
a: 1,
b: 2,
};
var bar = Object.create(foo);
bar.c = 3;
bar.say = function() {
console.log('c is ' + this.c);
};
var baz = shallowCopy(bar);
console.log(baz.a); // 1
baz.say(); // "c is 3"
// #3
function extend(destination) {
var objs = [].slice.call(arguments).slice(1);
objs.forEach(function(o) {
for (prop in o) {
if (!Object.prototype.hasOwnProperty.call(destination, prop)) {
destination[prop] = o[prop];
}
}
});
return destination;
}
var foo = {
a: 0,
b: {
x: 1,
y: 2,
},
};
var joe = {
name: 'Joe'
};
var funcs = {
sayHello: function() {
console.log('Hello, ' + this.name);
},
sayGoodBye: function() {
console.log('Goodbye, ' + this.name);
},
};
var object = extend({}, foo, joe, funcs);
console.log(object.b.x); // 1
object.sayHello(); // "Hello, Joe"
<file_sep>class Integer
def prime?
(2...self).each do |n|
return false if self % n == 0
end
true
end
end
class Sieve
def initialize(num)
@num = num
end
def primes
result = []
(2..@num).each {|n| result << n if n.prime?}
result
end
end
<file_sep># Launch School Answer:
def egyptian(target_value)
denominators = []
unit_denominator = 1
until target_value == 0
unit_fraction = Rational(1, unit_denominator)
if unit_fraction <= target_value
target_value -= unit_fraction
denominators << unit_denominator
end
unit_denominator += 1
end
denominators
end
def unegyptian(denominators)
denominators.inject(Rational(0)) do |accum, denominator|
accum + Rational(1, denominator)
end
end
# A Rational Number is any number that can be represented as the result of
# the division between two integers, e.g., 1/3, 3/2, 22/7, etc.
# The number to the left is called the numerator, and the number to the right is called the denominator.
# A Unit Fraction is a rational number where the numerator is 1.
# An Egyptian Fraction is the sum of a series
# of distinct unit fractions (no two are the same), such as:
# 1 1 1 1
# - + - + -- + --
# 2 3 13 15
# Every positive rational number can be written as an Egyptian fraction. For example:
# 1 1 1 1
# 2 = - + - + - + -
# 1 2 3 6
# NOTICE that it's 1, then 1 divided by 2, then 1 divided by 3, and the remainder is 1/6
# egyptian(Rational(3, 1)) => [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 230, 57960]
# Write two methods: one that takes a Rational number as an argument,
# and returns an Array of the denominators that are part
# of an Egyptian Fraction representation of the number,
# and another that takes an Array of numbers in the same format,
# and calculates the resulting Rational number.
# You will need to use the Rational class provided by Ruby.
# DATA STRUCTURES:
# Given two integers, calculate the egyptian fraction denominators and place them into an array
# Transform the argument into a set of rationals
# Rationals - according to Ruby API, this is how Rationals are calculated
# Rational(1) #=> (1/1)
# Rational(2, 3) #=> (2/3)
# Rational(4, -6) #=> (-2/3)
# '2/3'.to_r #=> (2/3)
# Rational(2, 3).fdiv(1) #=> 0.6666666666666666
# Array to pass in denominators to create correct return value
# Algorithms: increment the integer until 1/integer is greater than the desired number
# Then find the next available integer to hit the number exactly
# If that is not available - find the integer that will get closest to the number without going over
# 3/4 = 1/2 + 1/4
=begin
I was able to get egyptian to work on sample tests, then had to create conditionals for proper fractions, but
was not able to figure out the entire problem when I tried to create unegyptian
first version (works on sample tests):
def egyptian(n)
denominator = Rational(n).denominator
numerator = Rational(n).numerator
desired = n.to_f
numerator = 1
denominator = 1
result = [denominator]
quotient = (numerator.to_f / denominator.to_f)
quotients = [0]
until desired == numerator + quotients.reduce(&:+)
if desired >= (numerator + quotients.reduce(&:+) + (numerator.to_f/(denominator + 1).to_f))
denominator += 1
quotient = (numerator.to_f / denominator.to_f)
quotients << quotient
result << denominator
else
denominator += 1
end
end
result
end
egyptian(Rational(2, 1)) # -> [1, 2, 3, 6]
egyptian(Rational(137, 60)) # -> [1, 2, 3, 4, 5]
egyptian(Rational(3, 1)) # -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 230, 57960]
Second version: Works with Some Fractions Less than 1
def egyptian(n)
denominator = Rational(n).denominator
numerator = Rational(n).numerator
desired = n.to_f
if numerator > denominator
numerator = 1
denominator = 1
result = [denominator]
quotient = (numerator.to_f / denominator.to_f)
quotients = [quotient]
until desired == quotients.reduce(&:+)
if desired >= quotients.reduce(&:+) + (numerator.to_f/(denominator + 1).to_f)
denominator += 1
quotient = (numerator.to_f / denominator.to_f)
quotients << quotient
result << denominator
else
denominator += 1
end
end
else
numerator = 1
denominator = 2
result = [denominator]
quotient = (numerator.to_f / denominator.to_f)
return result if desired == quotient
quotients = [quotient]
until desired == quotients.reduce(&:+)
if desired >= quotients.reduce(&:+) + (numerator.to_f/(denominator + 1).to_f)
denominator += 1
quotient = (numerator.to_f / denominator.to_f)
quotients << quotient
result << denominator
else
denominator += 1
end
end
end
result
end
egyptian(Rational(5, 8))
egyptian(Rational(1, 3))
egyptian(Rational(2, 1)) # -> [1, 2, 3, 6]
egyptian(Rational(137, 60)) # -> [1, 2, 3, 4, 5]
egyptian(Rational(3, 1)) # -> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 230, 57960]
egyptian(Rational(3, 4)) # -> [2, 4]
egyptian(Rational(5, 8))
def unegyptian(array)
numerator = array.map {|den| 1.0 / den.to_f}.reduce(&:+)
sum = array.reduce(&:+)
second_sum = numerator / sum
third_sum = second_sum / numerator
denominator = (third_sum / second_sum) * numerator
"#{numerator.to_i}/#{denominator.to_i}".to_r
end
unegyptian(egyptian(Rational(1, 2)))
unegyptian(egyptian(Rational(2, 1)))
unegyptian(egyptian(Rational(137, 60)))
=end
<file_sep>off_part_1 = WINNING_LINES.select {|w| w.map {|l| brd[l].count(COMPUTER_MARKER)}.count(1) == 2}
off_part_2 = off_part_1.flatten.select {|p| brd[p] == INITIAL_MARKER}.uniq.first
# elsif condition
off_part_3 = WINNING_LINES.select {|w| w.map {|l| brd[l].count(COMPUTER_MARKER)}.count(1) == 1}
off_part_4 = WINNING_LINES.select {|w| w.map {|l| brd[l].count(PLAYER_MARKER)}.count(1) == 0}
if off_part_3 && off_part_4 != []
move = off_part_4.map {|n| n.select {|s| brd[s] == INITIAL_MARKER} }
square = move.flatten.first
brd[square] = COMPUTER_MARKER
elsif off_part_3.empty? && !off_part_4.empty?
move = off_part_3.map {|n| n.select {|s| brd[s] == INITIAL_MARKER} }
square = move.flatten.first
end<file_sep>$(function() {
$('#team-links li').on('click', function(event) {
event.preventDefault();
var $elf = $(this);
if (!$elf.hasClass('modal') ) {
$elf.fadeOut(0, function() {
$elf.addClass('modal');
$elf.fadeIn('fast');
});
} else if ($(event.target).hasClass('hideclose') || event.target === event.currentTarget) {
$elf.fadeOut('fast', function() {
$elf.removeClass('modal');
$elf.css('display', 'inline-block');
});
}
});
});<file_sep>function isPrime(n) {
if (n <= 1) {
return false;
}
var i;
for (i = 2; i < n; i++) {
if (i <= 1) {
continue;
}
else if (n % i === 0) {
return false;
}
}
return true;
}
function checkGoldberg(n) {
if (n < 4 || n % 2 === 1) {
console.log(null);
return;
}
var i;
for (i = 1; i < n; i++) {
if (isPrime(i)) {
var saved = i;
var x;
for (x = 1; x < i; x++) {
if (isPrime(x) && (x + i === n)) {
var final = String(x) + ' ' + String(i);
console.log(final);
}
}
}
}
if (!final) {
console.log(null);
}
}<file_sep># Strings use an integer-based index that represents each character in the string.
str = 'abcdefghi'
str[2] # => "c"
# You can also reference multiple characters within a string
# by using an index starting point and the number of characters to return.
str[2, 3] # => "cde"
# String#slice alternate shorthand
# chaining methods on a string collection element reference
str[2, 3][0] # => "c"
# Here we are actually calling [0] on the return value
# of str[2, 3] (which is 'cde') so this is effectively the same as 'cde'[0].
str = 'The grass is green'
str[4, 5] # => 'grass'
<file_sep>module Truckbed
def truckbed?
"The #{@model} has a truckbed."
end
end
class Vehicle
attr_accessor :color, :year, :make, :model
@@number_of_cars = 0
def initialize(year, color, model)
@year = year
@color = color
@model = model
@speed = 0
@@number_of_cars += 1
end
def self.miles_per_gallon(gallons, miles)
@@mpg = miles / gallons
puts "#{miles / gallons} miles per gallon of gas"
end
def speed_up
@speed += 25
end
def brake
@speed -= 25
end
def stop_car
@speed = 0
end
def spray_paint(new_color)
self.color = (new_color)
end
def to_s
"#{@model}, #{year}, #{color}, going #{@speed} mph."
end
end
class MyCar < Vehicle
VEHICLE_TYPE = 'car'
def to_s
super + " The #{model} is a #{VEHICLE_TYPE}. Number of cars: #{@@number_of_cars}."
end
end
class MyTruck < Vehicle
include Truckbed
VEHICLE_TYPE = 'truck'
def to_s
puts truckbed?
super + " The #{model} is a #{VEHICLE_TYPE}. Number of cars: #{@@number_of_cars}."
end
end
chevy = MyCar.new(2017, 'Black', 'Camaro')
puts chevy
ford = MyTruck.new(2015, 'Red', 'F150')
puts ford
<file_sep>arr1 = [1, [2, 3], 4]
arr1.map! {|i| i.class == Array ? i.map! {|x| x == 3 ? x = 4 : x = x} : i == 3 ? i = 4 : i = i }
arr1[1][1] = 4
arr1
arr2 = [{a: 1}, {b: 2, c: [7, 6, 5], d: 4}, 3]
arr2.map {|i| i.to_s.size > 1 ? i.map {|x, y| i[x].to_s.size > 1 ? i[x].map! {|z| z == 3 ? z = 4 : z = z} : y == 3 ? i[x] = 4 : y = y} : if i == 3 then arr2[arr2.rindex(i)] = 4 end}
arr2[2] = 4
arr2
hsh1 = {first: [1, 2, [3]]}
hsh1[:first].map! {|v| v.class == Array ? v.map {|y| y == 3 ? v[v.rindex(y)] = 4 : y = y} : v == 3 ? v = 4 : v = v}
hsh1[:first][2][0] = 4
hsh1
hsh2 = {['a'] => {a: ['1', :two, 3], b: 4}, 'b' => 5}
hsh2.map {|o, p| p.class == Hash ? p.map {|x, y| y.class == Array ? y.map!{|z| z == 3 ? z = 4 : z = z} : y == 3 ? hsh2[['a']][x] = 4 : y = y} : p == 3 ? hsh2[o] = 4 : p = p}
hsh2[['a']][:a][2] = 4
hsh2<file_sep># available to subclasses
class Animal
@@total_animals = 0
def initialize
@@total_animals += 1
end
end
class Dog < Animal
def total_animals
@@total_animals
end
end
spike = Dog.new
spike.total_animals # => 1
# Class variables can be reassigned in subclasses
class Vehicle
@@wheels = 4
def self.wheels
@@wheels
end
end
Vehicle.wheels # => 4
class Motorcycle < Vehicle
@@wheels = 2
end
Motorcycle.wheels # => 2
Vehicle.wheels # => 2 Yikes!
<file_sep>puts "Enter the first number"
number_1 = gets.chomp.to_i
puts "Enter the second number"
number_2 = gets.chomp.to_i
puts "#{number_1} + #{number_2} is #{(number_1 + number_2)}"
puts "#{number_1} - #{number_2} is #{(number_1 - number_2)}"
puts "#{number_1} * #{number_2} is #{(number_1 * number_2)}"
puts "#{number_1} / #{number_2} is #{(number_1 / number_2)}"
puts "#{number_1} % #{number_2} is #{(number_1 % number_2)}"
puts "#{number_1} ** #{number_2} is #{(number_1 ** number_2)}"<file_sep># Hashes, instead of using an integer-based index, use key-value pairs,
# where the key or the value can be any type of Ruby object.
hsh = { 'fruit' => 'apple', 'vegetable' => 'carrot' }
hsh['fruit'] # => "apple"
hsh['fruit'][0] # => "a"
# It is important to note that the [0] part of hsh['fruit'][0] in the above
# example is string element reference.
# The string 'apple' is returned by hsh['fruit'] and [0] is called on that return value.
# keys can not be duplicated
hsh = { 'fruit' => 'apple', 'vegetable' => 'carrot', 'fruit' => 'pear' }
# (irb):1: warning: key :fruit is duplicated and overwritten on line 1
# => {"fruit"=>"pear", "vegetable"=>"carrot"}
# Ruby will overrwrite the key with following duplicates
# values can be duplicated
hsh = { 'apple' => 'fruit', 'carrot' => 'vegetable', 'pear' => 'fruit' }
# accessing keys and values:
country_capitals = { uk: 'London', france: 'Paris', germany: 'Berlin' }
country_capitals.keys # => [:uk, :france, :germany]
country_capitals.values # => ["London", "Paris", "Berlin"]
country_capitals.values[0] # => "London"
# Although both hash keys and values can be any object in Ruby,
# it is common practice to use symbols as the keys.
# Symbols in Ruby can be thought of as immutable strings.
<file_sep>class Television
def self.manufacturer
puts "Sony"
end
def model
# method logic
end
end
Television::manufacturer
Television.manufacturer
<file_sep># loop
numbers = [1, 2, 3]
counter = 0
loop do
break if counter == numbers.size
puts numbers[counter]
counter += 1
end
# vs each
[1, 2, 3].each do |num|
puts num
end
# The code within the block is executed for each iteration.
# For each iteration, each sends the value of the current element to the block in the form of an argument.
# num represents the current element
# select
[1, 2, 3].select do |num|
num.odd?
end
# select evaluates the return value of the block
# If the return value of the block is "truthy", then the element during that iteration will be selected.
[1, 2, 3].select do |num|
num + 1
puts num
end
# => []
# puts returns nil
# map
# map, like select, evaluates the return value of the block
[1, 2, 3].map do |num|
num * 2
end
# The return value of the block is the product of num and 2.
# map then takes this value and places it in a new collection.
# This process is repeated for each element in the original collection.
[1, 2, 3].map do |num|
num.odd?
end
# => [true, false, true]<file_sep># This file should contain all the record creation needed to seed the database with its default values.
# The data can then be loaded with the rake db:seed (or created alongside the db with db:setup).
#
# Examples:
#
# cities = City.create([{ name: 'Chicago' }, { name: 'Copenhagen' }])
# Mayor.create(name: 'Emanuel', city: cities.first)
category1 = Category.find_or_initialize_by(name: "Animation")
category2 = Category.find_or_initialize_by(name: "Comedies")
video1 = Video.find_or_initialize_by(title: "South Park")
video1.description = "A Cartoon"
video1.small_cover_url = "/tmp/south_park.jpg"
video1.large_cover_url = "https://via.placeholder.com/665x375/000000/0613A1"
video1.category = category1
video1.save!
video2 = Video.find_or_initialize_by(title: "Family Guy")
video2.description = "A Cartoon"
video2.small_cover_url = "/tmp/family_guy.jpg"
video2.large_cover_url = "https://via.placeholder.com/665x375/000000/0613A1"
video2.category = category1
video2.save!
video3 = Video.find_or_initialize_by(title: "Futurama")
video3.description = "A Cartoon"
video3.small_cover_url = "/tmp/futurama.jpg"
video3.large_cover_url = "https://via.placeholder.com/665x375/000000/0613A1"
video3.category = category1
video3.save!
video4 = Video.find_or_initialize_by(title: "Monk")
video4.description = "Not A Cartoon"
video4.small_cover_url = "/tmp/monk.jpg"
video4.large_cover_url = "https://via.placeholder.com/665x375/000000/0613A1"
video4.category = category2
video4.save!
<file_sep>class Computer
attr_accessor :template
def create_template
@template = "template 14231"
end
def show_template
template
end
end
class Computer
attr_accessor :template
def create_template
self.template = "template 14231"
end
def show_template
self.template
end
end
# create_template in the first version changes the instance variable
# create_template in the second version calls the setter method instead
# both methods achieve the same result
# self is not needed in the second show_template
# it is recommended to use self only when necessary in ruby
<file_sep>def triangle(a, b, c)
case
when [a, b, c].sort[0..1].reduce(&:+) <= [a, b, c].sort[-1]
:invalid
when a == b && b == c && c == a
:equilateral
when [a, b, c].count(a) == 2 || [a, b, c].count(b) == 2 || [a, b, c].count(c) == 2
:isosceles
when [a, b, c].sort.uniq.size == 3
:scalene
end
end
triangle(3, 3, 3) == :equilateral
triangle(3, 3, 1.5) == :isosceles
triangle(3, 4, 5) == :scalene
triangle(0, 3, 3) == :invalid
triangle(3, 1, 1) == :invalid<file_sep>class Fruit
def initialize(name)
name = name
end
end
class Pizza
def initialize(name)
@name = name
end
end
# Pizza has an instance variable, we know because of the @ sign
# L_S Notes, object#instance_variables reveals instance variables
=begin
hot_pizza.instance_variables
=> [:@name]
orange.instance_variables
=> []
=end
<file_sep>function letterCaseCount(str) {
result = {
lowercase: 0,
uppercase: 0,
neither: 0
}
str.split('').forEach(function (char) {
if (/[A-Z]/.test(char)) {
result.uppercase += 1;
} else if (/[a-z]/.test(char)) {
result.lowercase += 1;
} else {
result.neither += 1;
}
});
return result;
}
letterCaseCount('abCdef 123'); // { lowercase: 5, uppercase: 1, neither: 4 }
letterCaseCount('AbCd +Ef'); // { lowercase: 3, uppercase: 3, neither: 2 }
letterCaseCount('123'); // { lowercase: 0, uppercase: 0, neither: 3 }
letterCaseCount(''); // { lowercase: 0, uppercase: 0, neither: 0 }<file_sep>function generatePattern(n) {
var i;
var nums = '';
for(i = 1; i <= n; i++) {
nums += String(i);
var stars = '*'.repeat(n - i);
var numstars = nums + stars;
console.log(numstars);
}
}<file_sep>def compute(&block)
return 'Does not compute.' if !block_given?
yield
end
compute { 5 + 3 } == 8
compute { 'a' + 'b' } == 'ab'
compute == 'Does not compute.'
<file_sep># loop selection as a method
def select_vowels(str)
selected_chars = ''
counter = 0
loop do
current_char = str[counter]
if 'aeiouAEIOU'.include?(current_char)
selected_chars << current_char
end
counter += 1
break if counter == str.size
end
selected_chars
end
select_vowels('the quick brown fox') # => "euioo"
sentence = 'I wandered lonely as a cloud'
select_vowels(sentence) # => "Iaeeoeaaou"
# now we can chain methods
number_of_vowels = select_vowels('hello world').size
number_of_vowels # => 3<file_sep>class Game
def play
"Start the game!"
end
end
class Bingo < Game
def play
end
def rules_of_play
#rules of play
end
end
# if you call play on a Bingo object, the Bingo#play method will be called
<file_sep>class Animal
def initialize(name)
@name = name
end
end
class Dog < Animal
def dog_name
"bark! bark! #{@name} bark! bark!"
# can @name be referenced here?
end
end
teddy = Dog.new("Teddy")
puts teddy.dog_name # => bark! bark! Teddy bark! bark!
# Since the Dog class doesn't have an initialize instance method,
# the method lookup path went to the super class, Animal
class Animal
def initialize(name)
@name = name
end
end
class Dog < Animal
def initialize(name); end
def dog_name
"bark! bark! #{@name} bark! bark!"
# can @name be referenced here?
end
end
teddy = Dog.new("Teddy")
puts teddy.dog_name # => bark! bark! bark! bark!
# modules are different, no inheritance
module Swim
def enable_swimming
@can_swim = true
end
end
class Dog
include Swim
def swim
"swimming!" if @can_swim
end
end
teddy = Dog.new
teddy.swim # => nil
# @can_swim was never init in Dog Class
teddy = Dog.new
teddy.enable_swimming
teddy.swim # now it works
<file_sep>def double_consonants(string)
string.gsub!(' ', ' ')
split_string = string.split(/ /)
split_string.map! {|s| s != "" ? s.chars.flat_map {|char| char =~ /[aeiou]/ || char =~ /[^[:alpha:]]/ ? [char] : [char, char]} : s = ' '}.join
end
double_consonants('String') == "SSttrrinngg"
double_consonants("Hello-World!") == "HHellllo-WWorrlldd!"
double_consonants("July 4th") == "JJullyy 4tthh"
double_consonants('') == ""<file_sep># make school class
# methods: to_h, add, grade (returns an array)
# data structures:
# to h returns a hash with integer keys and array values
# add(student, grade) school[grade] << student
class School
def initialize
@roster = {}
end
def add(student, grade, classes = [])
@roster[grade] = classes if @roster[grade].nil?
@roster[grade] << student
sort_roster
end
def grade(num)
return [] if @roster[num].nil?
@roster[num]
end
def to_h
@roster
end
private
def sort_roster
new_roster = {}
@roster.keys.sort.each do |grade|
new_roster[grade] = @roster[grade].sort
end
@roster = new_roster
end
end
<file_sep>[[1, 2], [3, 4]].map do |arr|
arr.map do |num|
num * 2
end
end
=begin
Line 1
Action: Method Call, Map
Object: Outer Array
Side effect: none
Return value: New, transformed array
Return used: No, it is the one using (top level)
Line 1-4
Action: Block Execution
Object: Each Sub Array As an Index
Side Effect: None
Return Value: New, Transformed Array
Return Used: Yes, by outer map method for transformation
Line 2:
Action: Method Call, Map
Object: Sub Arrays
Return Value: New, Transformed Array
Return Used: Yes, to determine outer block's return value
Line 2-3
Action: Block Execution
Object: Each Index of Each Sub Array
Return Value: New Integers
Return Used: Yes, by inner map for transformation
Line 3
Action: num * 2
Object: Each Integer
Return Value: New Integers
Return Used: Yes, used to determine return value for inner block<file_sep>def multisum(number)
sums = []
for i in 1..number do
if (i % 3 == 0 || i % 5 == 0)
sums << i
end
end
sums.inject(:+)
end
multisum(3) == 3
multisum(5) == 8
multisum(10) == 33
multisum(1000) == 234168<file_sep>module Speed
def go_fast
puts "I am a #{self.class} and going super fast!"
end
end
class Car
include Speed
def go_slow
puts "I am safe and driving slow."
end
end
small_car = Car.new
small_car.go_fast
# => I am a Car and going super fast!
# By interpolating self.class we are calling upon the class of the current object
# L_S Explanation
=begin
We use self.class in the method and this works the following way:
1. self refers to the object itself, in this case either a Car or Truck object.
2. We ask self to tell us its class with .class. It tells us.
3. We don't need to use to_s here because it is inside of a string
and is interpolated which means it will take care of the to_s for us.
=end<file_sep>def mess_with_vars(one, two, three)
one = two
two = three
three = one
end
one = "one"
two = "two"
three = "three"
mess_with_vars(one, two, three)
puts "one is: #{one}"
puts "two is: #{two}"
puts "three is: #{three}"
# they all print as expected: "one", "two", "three" - initialized independent of method
def mess_with_vars(one, two, three)
one = "two"
two = "three"
three = "one"
end
one = "one"
two = "two"
three = "three"
mess_with_vars(one, two, three)
puts "one is: #{one}"
puts "two is: #{two}"
puts "three is: #{three}"
# "one", "two", "three" - Assignment does not mutate variables
def mess_with_vars(one, two, three)
one.gsub!("one","two")
two.gsub!("two","three")
three.gsub!("three","one")
end
one = "one"
two = "two"
three = "three"
mess_with_vars(one, two, three)
puts "one is: #{one}"
puts "two is: #{two}"
puts "three is: #{three}"
# "two", "three", "one" - gsub! is a method that mutates the variable,
# now reference different strings<file_sep>=begin
Write a method that takes a string with one or more space separated words
and returns a hash that shows the number of words of different sizes.
Words consist of any string of characters that do not include a space.
=end
def word_sizes(string)
diff_lengths = {}
length_array = string.split
length_array.map! {|i| i.length }
unique_array = length_array.uniq
unique_array.map {|i| diff_lengths[i] = length_array.count{|x| x == i}}
diff_lengths
end
word_sizes('Four score and seven.') == { 3 => 1, 4 => 1, 5 => 1, 6 => 1 }
word_sizes('Hey diddle diddle, the cat and the fiddle!') == { 3 => 5, 6 => 1, 7 => 2 }
word_sizes("What's up doc?") == { 6 => 1, 2 => 1, 4 => 1 }
word_sizes('') == {}<file_sep>/*
The program has a list of random words
associated with word types
The program will take an input text and
line by line, replace highlighted word with
a randomized word from the program.
Math.random * Math.floor(num) is the best way to
get randomized outputs
Expectations:
// These examples use the following list of replacement texts:
adjectives: quick lazy sleepy noisy hungry
nouns: fox dog head leg tail
verbs: jumps lifts bites licks pats
adverbs: easily lazily noisily excitedly
------
madlibs(template1);
// The "sleepy" brown "cat" "noisily"
// "licks" the "sleepy" yellow
// "dog", who "lazily" "licks" his
// "tail" and looks around.
madlibs(template1);
// The "hungry" brown "cat" "lazily"
// "licks" the "noisy" yellow
// "dog", who "lazily" "licks" his
// "leg" and looks around.
madlibs(template2); // The "fox" "bites" the "dog"'s "tail".
madlibs(template2); // The "cat" "pats" the "cat"'s "head".
Data:
The template should be a string
The program splits the text into an array by newline
then splits each of the elements by words
The templates will have all caps words for word types
There will be an object within the template that has
the word types associated with a list of strings
the strings will be replaced and the output will be
a new string with a randomized madlib
Algorithm:
Define object with word types and words (word types caps)
Take input string, split via \n
reassign the array to a mapped array of arrays (split by space)
take reassigned array
map through it
map through each of the subarrays
then foreach through Object.keys(wordTypes)
new RegExp("\\b" + word + "\\b", g)
if regex.test(word)
idx = Math.floor(Math.random() * Math.floor(wordTypes[type].length - 1))
return word.replace(word, wordTypes[type][idx])
may need to concat the nonword parts of string
join all strings via space
join all lines via newline
return new string
*/
function madlibs(template) {
wordTypes = {
"ADJECTIVE": ['quick', 'lazy', 'sleepy', 'noisy', 'hungry'],
"NOUN": ['fox', 'dog', 'head', 'leg', 'tail'],
"VERB": ['jumps', 'lifts', 'bites', 'licks', 'pats'],
"ADVERB": ['easily', 'lazily', 'noisily', 'excitedly']
}
var typeKeys = Object.keys(wordTypes);
var i;
var currentKey;
var idx;
template = template.split("/n");
template = template.map(line => line.split(' '));
return template.map(function (line) {
return line.map(function (word) {
for (i = 0; i < typeKeys.length; i += 1) {
currentKey = new RegExp("\\b" + typeKeys[i] + "\\b", 'g');
if (currentKey.test(word)) {
idx = Math.floor(Math.random() * Math.floor(wordTypes[typeKeys[i]].length - 1));
return word.replace(currentKey, wordTypes[typeKeys[i]][idx]);
}
}
return word;
}).join(' ');
}).join("/n");
}
var template1 = "The ADJECTIVE brown NOUN ADVERB \n" +
"VERB the ADJECTIVE yellow \n" +
"NOUN, who ADVERB VERB his \n" +
"NOUN and looks around.";
var template2 = "The NOUN VERB the NOUN's NOUN.";
madlibs(template1);
madlibs(template2);<file_sep># === is an instance method, not an operator
num = 25
case num
when 1..50
puts "small number"
when 51..100
puts "large number"
else
puts "not in range"
end
# Behind the scenes, the case statement is using the === method to compare each when clause with num
num = 25
if (1..50) === num
puts "small number"
elsif (51..100) === num
puts "large number"
else
puts "not in range"
end
# When === compares two objects, such as (1..50) and 25, it's essentially asking
# "if (1..50) is a group, would 25 belong in that group?"
String === "hello" # => true
String === 15 # => false
# On line 1, true is returned because "hello" is an instance of String,
# even though "hello" doesn't equal String.
# Similarly, false is returned on line 2 because 15 is an integer,
# which doesn't equal String and isn't an instance of the String class.
<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
class NilTest < MiniTest::Test
def test_nil
assert_nil(nil)
assert_nil(true)
end
end
<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: calls; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE calls (
id integer NOT NULL,
"when" timestamp without time zone NOT NULL,
duration integer NOT NULL,
contact_id integer NOT NULL
);
ALTER TABLE calls OWNER TO postgres;
--
-- Name: calls_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE calls_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE calls_id_seq OWNER TO postgres;
--
-- Name: calls_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE calls_id_seq OWNED BY calls.id;
--
-- Name: contacts; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE contacts (
id integer NOT NULL,
first_name text NOT NULL,
last_name text NOT NULL,
number character varying(10) NOT NULL
);
ALTER TABLE contacts OWNER TO postgres;
--
-- Name: contacts_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE contacts_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE contacts_id_seq OWNER TO postgres;
--
-- Name: contacts_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE contacts_id_seq OWNED BY contacts.id;
--
-- Name: calls id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY calls ALTER COLUMN id SET DEFAULT nextval('calls_id_seq'::regclass);
--
-- Name: contacts id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY contacts ALTER COLUMN id SET DEFAULT nextval('contacts_id_seq'::regclass);
--
-- Data for Name: calls; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY calls (id, "when", duration, contact_id) FROM stdin;
1 2016-01-02 04:59:00 1821 6
2 2016-01-08 15:30:00 350 17
3 2016-01-11 11:06:00 111 25
4 2016-01-13 18:13:00 2521 25
5 2016-01-17 09:43:00 982 17
6 2016-01-18 14:47:00 632 6
7 2016-01-17 11:52:00 175 26
8 2016-01-18 21:22:00 79 27
\.
--
-- Data for Name: contacts; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY contacts (id, first_name, last_name, number) FROM stdin;
6 William Swift 7204890809
17 Yuan Ku 2195677796
25 Tamila Chichigov 5702700921
26 Merve Elk 6343511126
27 Sawa Fyodorov 6125594874
\.
--
-- Name: calls_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('calls_id_seq', 8, true);
--
-- Name: contacts_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('contacts_id_seq', 28, true);
--
-- Name: calls calls_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY calls
ADD CONSTRAINT calls_pkey PRIMARY KEY (id);
--
-- Name: contacts contacts_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY contacts
ADD CONSTRAINT contacts_pkey PRIMARY KEY (id);
--
-- Name: contacts uniq_num; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY contacts
ADD CONSTRAINT uniq_num UNIQUE (number);
--
-- Name: calls calls_contact_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY calls
ADD CONSTRAINT calls_contact_id_fkey FOREIGN KEY (contact_id) REFERENCES contacts(id);
--
-- PostgreSQL database dump complete
--
<file_sep># A module allows us to group reusable code into one place.
# We use modules in our classes by using the include reserved word,
# followed by the module name.
# Modules are also used as a namespace.
module Study
end
class MyClass
include Study
end
my_obj = MyClass.new<file_sep>function makeList() {
var theList = {};
return function(todo) {
if (arguments.length === 0) {
if (Object.keys(theList).length > 0) {
return Object.keys(theList).forEach(item => console.log(item));
} else {
return console.log('The list is empty.')
}
}
if (!Object.keys(theList).includes(String(todo))) {
theList[String(todo)] = false;
return console.log(todo + ' added!')
} else {
delete theList[String(todo)];
return console.log(todo + ' removed!')
}
}
}
var list = makeList();
list();
list('make breakfast');
list('read book');
list();
list('make breakfast');
list();<file_sep>Object.getPrototypeOf([]) === Array.prototype; // true
function NewArray() {}
NewArray.prototype = Object.create(Object.getPrototypeOf([]));
NewArray.prototype.constructor = NewArray;
NewArray.prototype.first = function() {
return this[0];
};
var newArr = new NewArray();
var oldArr = new Array();
oldArr.push(5);
newArr.push(5);
oldArr.push(2);
newArr.push(2);
console.log(newArr.first()); // 5
console.log(oldArr.first); // undefined
<file_sep>function transactionsFor(idNum, objAry) {
return objAry.filter(obj => obj.id === idNum);
}
function isItemAvailable(idNum, objAry) {
var result = 0;
transactionsFor(idNum, objAry).forEach(function (item) {
if (item.movement === 'out') {
result -= item.quantity;
} else {
result += item.quantity;
}
});
return result > 0;
}
var transactions = [ { id: 101, movement: 'in', quantity: 5 },
{ id: 105, movement: 'in', quantity: 10 },
{ id: 102, movement: 'out', quantity: 17 },
{ id: 101, movement: 'in', quantity: 12 },
{ id: 103, movement: 'out', quantity: 15 },
{ id: 102, movement: 'out', quantity: 15 },
{ id: 105, movement: 'in', quantity: 25 },
{ id: 101, movement: 'out', quantity: 18 },
{ id: 102, movement: 'in', quantity: 22 },
{ id: 103, movement: 'out', quantity: 15 }, ];
isItemAvailable(101, transactions);
isItemAvailable(105, transactions);<file_sep>=begin
Create a class called MyCar.
When you initialize a new instance or object of the class,
allow the user to define some instance variables that
tell us the year, color, and model of the car.
Create an instance variable that is set to 0 during instantiation
of the object to track the current speed of the car as well.
Create instance methods that allow the car to speed up, brake, and shut the car off.
=end
class MyCar
def initialize(year, color, model)
@year = year
@color = color
@model = model
@speed = 0
end
def speed_up
@speed += 25
end
def brake
@speed -= 25
end
def stop_car
@speed = 0
end
def show_info
"#{@model}, #{@year}, #{@color}, going #{@speed} mph."
end
end
chevy = MyCar.new(2017, 'Black', 'Silverado')
puts chevy.show_info
2.times {chevy.speed_up}
puts chevy.show_info
chevy.brake
puts chevy.show_info
chevy.stop_car
puts chevy.show_info
<file_sep>function add(first, second) {
return first + second;
}
function repeat(count, string) {
var result = '';
var i;
for (i = 0; i < count; i += 1) {
result += string;
}
return result;
}
function partial(primary, arg1) {
return function(arg2) {
return primary(arg1, arg2);
};
}
var add1 = partial(add, 1);
add1(2); //3
var threeTimes = partial(repeat, 3);
threeTimes('Hello'); //HelloHelloHello
<file_sep>def staggered_case(string)
string = string.chars
string.each_index {|s| s.even? ? string[s].upcase! : string[s].downcase!}.join
end
staggered_case('I Love Launch School!') == 'I LoVe lAuNcH ScHoOl!'
staggered_case('ALL_CAPS') == 'AlL_CaPs'
staggered_case('ignore 77 the 444 numbers') == 'IgNoRe 77 ThE 444 NuMbErS'
<file_sep>[1, 2, 3].each { |num| "do nothing" } # still returns [1, 2, 3]
# So what happens is that the Array#each method
# iterates through the array, yielding each element to the block,
# where the block can do whatever it needs to do to each element.
# Then, the method returns the calling object.
# This is so developers can chain methods on afterwards, like this:
[1, 2, 3].each{|num| "do nothing"}.select{ |num| num.odd? } # => [1, 3]
# Make-your-own Each
def each(array)
counter = 0
while counter < array.size
yield(array[counter]) # yield to the block, passing in the current element to the block
counter += 1
end
array # returns the `array` parameter, similar in spirit to how `Array#each` returns the caller
end
each([1, 2, 3, 4, 5]) do |num|
puts num
end
# 1
# 2
# 3
# 4
# 5
# => [1, 2, 3, 4, 5]
each([1, 2, 3, 4, 5]) {|num| "do nothing"}.select{ |num| num.odd? } # => [1, 3, 5]
# our each method is solely focused on iterating and not on anything beyond that
<file_sep>// preventing bar call on line 12 from changing this context
var obj = {
a: 'hello',
b: 'world',
foo: function() {
var self = this;
function bar() {
console.log(self.a + ' ' + self.b);
}
bar();
}
};
obj.foo(); // hello world
// Also can use bind on a function expression
var obj = {
a: 'hello',
b: 'world',
foo: function() {
var bar = function() {
console.log(this.a + ' ' + this.b);
}.bind(this);
// some lines of code
bar();
// more lines of code
bar();
// ...
}
};
obj.foo(); // hello world<file_sep>class Cat
attr_accessor :name
COLOR = ['red', 'blue', 'yellow', 'green'].sample
def initialize(name)
@name = name
end
def greet
puts "Hello! My name's #{name} and I'm a #{COLOR} cat!"
end
end
kitty = Cat.new('Sophie')
kitty.greet
<file_sep>function makeMultipleLister(n) {
return function() {
if (n < 1) { return console.log('needs to be postitive') }
var i = 1;
for (i; i < 100; i++) {
if (i % n === 0) { console.log(i) }
}
}
}
var lister = makeMultipleLister(13);
lister();<file_sep>class Pet
attr_reader :name
def initialize(name)
@name = name.to_s
end
def to_s
"My name is #{@name.upcase}."
end
end
new_name = 'Fluffy'
fluffy = Pet.new(new_name)
puts fluffy.name
puts fluffy
puts fluffy.name
puts new_name
# further exploration
name = 42
fluffy = Pet.new(name)
name += 1
puts fluffy.name
puts fluffy
puts fluffy.name
puts name
# when this Pet object is initialized, it references
# the name variable pointing to 42
# then the name variable is reassigned to a different object, 43
# fluffy.name references the 42 passed into fluffy
# name still references 43 when called at the end
<file_sep>arr = [['1', '8', '11'], ['2', '6', '13'], ['2', '12', '15'], ['1', '8', '9']]
# We know that we want to sort at the level of the outer array, but we can't simply call sort on it
# arr.sort # => [["1", "8", "11"], ["1", "8", "9"], ["2", "12", "15"], ["2", "6", "13"]]
# What We Want:
# Each of the inner arrays is compared with the other inner arrays.
# The way those arrays are compared is by comparing the elements within them
arr.sort_by do |sub_arr|
sub_arr.map do |num|
num.to_i
end
end
# => [["1", "8", "9"], ["1", "8", "11"], ["2", "6", "13"], ["2", "12", "15"]]
=begin
In this case, each time the top-level block is called,
we call map on the sub-array for that iteration,
within the map block we call to_i on each string within that particular sub-array,
which returns a new array with integers and leaves the original sub-array unmodified.
This ends up sorting the outer array by comparing the transformed integers in the inner arrays,
which is what we're looking to do, without any side effects.
=end<file_sep>// #1
function Triangle(a, b, c) {
this.a = a,
this.b = b,
this.c = c,
this.type = "triangle",
this.getPerimeter = function() {
return this.a + this.b + this.c;
},
this.getType = function() {
return this.type;
}
}
var shape = Triangle.prototype;
var t = new Triangle(1, 2, 3);
t.constructor;
// Triangle(a, b, c)
shape.isPrototypeOf(t);
// true
t.getPerimeter();
// 6
t.getType();
// "triangle"
/*
their version:
var shape = {
getType: function() {
return this.type;
},
};
function Triangle(a, b, c) {
this.type = 'triangle';
this.a = a;
this.b = b;
this.c = c;
}
Triangle.prototype = shape;
Triangle.prototype.getPerimeter = function() {
return this.a + this.b + this.c;
};
Triangle.prototype.constructor = Triangle;
*/
// #2
function User(first, last) {
this.prototype = {
name: first + ' ' + last
}
return this.prototype;
}
var name = '<NAME>';
var user1 = new User('John', 'Doe');
var user2 = User('John', 'Doe');
console.log(name); // <NAME>
console.log(user1.name); // <NAME>
console.log(user2.name); // <NAME>
/* Their version:
function User(first, last){
if (!(this instanceof User)) {
return new User(first, last);
}
this.name = first + ' ' + last;
}
var name = '<NAME>';
var user = User('John', 'Doe');
console.log(name); // <NAME>
console.log(user.name); // <NAME>
*/
// #3
function createObject(obj) {
function Func() {}
Func.prototype = obj;
return new Func();
}
var foo = {
a: 1
};
var bar = createObject(foo);
foo.isPrototypeOf(bar); // true
// #4
Object.prototype.begetObject = function() {
function Func() {};
Func.prototype = this;
return new Func();
}
var foo = {
a: 1,
};
var bar = foo.begetObject();
foo.isPrototypeOf(bar);
// #5
function neww(constructor, args) {
var object = Object.create(constructor.prototype);
var result = constructor.apply(object, args);
return result === undefined ? object : result;
}
function Person(firstName, lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
Person.prototype.greeting = function() {
console.log('Hello, ' + this.firstName + ' ' + this.lastName);
};
var john = neww(Person, ['John', 'Doe']);
john.greeting(); // Hello, <NAME>
john.constructor; // Person(firstName, lastName) {...}<file_sep>Myflix::Application.routes.draw do
root to: 'application#front', as: 'front'
get '/home', to: 'videos#index', as: 'home'
get '/login', to: 'sessions#new', as: 'login'
post '/login', to: 'sessions#create'
get '/logout', to: 'sessions#destroy', as: 'logout'
get '/queue', to: 'queue_items#index', as: 'queue'
post '/queue', to: 'queue_items#create', as: 'add_queue'
get 'ui(/:action)', controller: 'ui'
post 'batch', controller: 'queue_items'
resources :videos, except: [:index] do
collection do
get 'search'
end
resources :reviews, only: :create
end
resources :categories, only: :show
resources :users
resources :queue_items, only: :destroy
end
<file_sep>var stringVar = 'string reference';
var numberVar = 42; // number reference
function functionVar() {
return 'function reference';
}
console.log(typeof stringVar); // string
console.log(typeof numberVar); // number
console.log(typeof functionVar); // function
// Reassignment works as expected:
stringVar = functionVar; // `stringVar` now references a function
functionVar = 'string reference'; // `functionVar` now references a string
console.log(typeof stringVar); // function
console.log(typeof functionVar); // string
// function expressions
var hello = function () {
return 'hello';
};
console.log(typeof hello); // function
console.log(hello()); // hello
//
var foo = function () {
return function () { // function expression as return value
return 1;
};
};
var bar = foo(); // bar is assigned to the returned function
bar(); // 1
// named function expressions
var hello = function foo() {
console.log(typeof foo); // function
};
hello();
foo(); // Uncaught ReferenceError: foo is not defined
<file_sep>function transpose(matrix) {
var subArrays = {};
matrix.forEach(function (oneSub) {
oneSub.forEach(function (elem, idx) {
subArrays[idx] = [];
});
});
var result = [];
matrix.forEach(function (oneSub) {
oneSub.forEach(function (elem, idx) {
subArrays[idx].push(elem);
});
});
Object.values(subArrays).forEach(oneSub => result.push(oneSub));
return result;
}
transpose([[1, 2, 3, 4]]);
transpose([[1], [2], [3], [4]]);
transpose([[1]]);
transpose([[1, 2, 3, 4, 5], [4, 3, 2, 1, 0], [3, 7, 8, 6, 2]]);<file_sep>=begin
How to calculate:
Convert 35.72° to degrees, minutes, and seconds.
35° is the whole part. We convert the 0.72 to minutes and seconds.
We have 0.72 of a degree,
which is 0.72 x 1° = 0.72 x 60 minutes = 43.2 minutes.
So, this is 35° 43.2 minutes.
We can change the 0.2 minutes to seconds the same way.
0.2 x 1 minute = 0.2 x 60 seconds = 12 seconds.
Therefore, this is 35 0 43 minutes and 12 seconds, also written 35 0 43’ 12”.
=end
DEGREE = "\x00\xB0"
# Using ^ to represent degree symbol
def decimals(number)
numstring = number.to_s
numstring[numstring.index('.')..-1]
end
def dms(number)
numstring = number.to_s
if numstring.include?('.')
new_decimals = decimals(numstring)
minutes = (new_decimals[0..-1].to_f * 60)
dec_count = new_decimals[1..-1].chars.size
if dec_count == 1
seconds = 0
else
seconds = decimals(minutes).to_f * 60
end
minutes < 10 ? minutes = "0#{minutes.to_i}" : minutes = "#{minutes.to_i}"
seconds < 10 ? seconds = "0#{seconds.to_i}" : seconds = "#{seconds.to_i}"
degree_string = "#{number.to_i}^#{minutes}'#{seconds}\""
else
degree_string = "#{numstring}^00'00\""
end
degree_string
end
dms(30) == %(30^00'00")
dms(76.73) == %(76^43'48")
dms(254.6) == %(254^36'00")
dms(93.034773) == %(93^02'05")
dms(0) == %(0^00'00")
dms(360) == %(360^00'00") || dms(360) == %(0^00'00")
# Their Solution
# DEGREE = "\x00\xB0"
# MINUTES_PER_DEGREE = 60
# SECONDS_PER_MINUTE = 60
# SECONDS_PER_DEGREE = MINUTES_PER_DEGREE * SECONDS_PER_MINUTE
# 1. Starts converting the number of degrees to seconds;
# this makes it easier to compute the whole number of degrees, minutes, and seconds.
# 2. Next, we use divmod to get the whole number of degrees,
# and a remainder that represents the number of seconds
# 3. We then use divmod again to split the remainder
# into a whole number of minutes, and a whole number of seconds.
# 4. The final step puts everything together with #Kernel.format.
# Ruby provides a variety of ways to deal with quotes inside strings; the easiest uses %(), %q() or %Q()
# def dms(degrees_float)
# 1:
# total_seconds = (degrees_float * SECONDS_PER_DEGREE).round
# 2:
# degrees, remaining_seconds = total_seconds.divmod(SECONDS_PER_DEGREE)
# 3:
# minutes, seconds = remaining_seconds.divmod(SECONDS_PER_MINUTE)
# 4:
# format(%(#{degrees}#{DEGREE}%02d'%02d"), minutes, seconds)
# end
<file_sep>class QueueItem < ActiveRecord::Base
belongs_to :video
belongs_to :user
validates_uniqueness_of :video, scope: :user_id
delegate :category, to: :video
delegate :title, to: :video, prefix: :video
delegate :name, to: :category, prefix: :category
def rating
review = video.reviews.find_by(user_id: user_id)
review.rating if review
end
end<file_sep>def fibonacci(num, placeholder = 3, fib = [1, 1])
return 1 if num <= 2
sum = fib[-2..-1].reduce(&:+)
return sum if placeholder == num
placeholder += 1
fib << sum
fibonacci(num, placeholder, fib)
end
fibonacci(1) == 1
fibonacci(2) == 1
fibonacci(3) == 2
fibonacci(4) == 3
fibonacci(5) == 5
fibonacci(12) == 144
fibonacci(20) == 6765<file_sep># return an array which contains only the hashes where all the integers are even
arr = [{a: [1, 2, 3]}, {b: [2, 4, 6], c: [3, 6], d: [4]}, {e: [8], f: [6, 10]}]
arr2 = []
arr.map do |i|
i.map {|k, v| v.all? {|n| n.even?} ? arr2 << {k: v} : v = v}
end
arr2<file_sep>/*
star(7);
// logs
* * *
* * *
***
*******
***
* * *
* * *
star(9);
// logs
* * *
* * *
* * *
***
*********
***
* * *
* * *
* * *
Problem:
8-pointed star
min 7X7 grid
odd int supplied, >= 7
Data:
given int
create array for half
str for middle
reversed array
return set of strings, rows of star
Algorithm:
'*'.repeat(n) for middle
first row: 0 spaces
second row: one space
helper function makeRow(spaces)
var arr = []
arr.push(('*' + ' '.repeat(spaces)).repeat(3).slice(0, -spaces))
return arr
var half = (n - 7) / 2
helper function makeHalf(half)
result = []
for (i = 1; i <= (3 + half); i += 1)
result.concat(result, makeRow(i))
}
return result }
var final = makehalf(half).concat('*'.repeat(n), makehalf(half).slice(0).reverse())
final.forEach(function (line) {console.log(line)});
*/
function makeRow(spaces, n) {
var arr = [];
var tab = ((n - 7) / 2) + 2;
arr.push((' '.repeat(tab - spaces) + ('*' + ' '.repeat(spaces)).repeat(3) + ' '.repeat(tab - spaces)));
return arr;
}
function makeHalf(half, n) {
result = [];
for (i = (3 + half) -1; i >= 0; i -= 1) {
result.push(makeRow(i, n));
}
return result;
}
function star(n) {
var final = [];
var half = (n - 7) / 2;
makeHalf(half, n).forEach(function (line) { final.push(line) });
final.push(['*'.repeat(n)]);
makeHalf(half, n).slice(0).reverse().forEach(function (line) { final.push(line) });
final.forEach(function (line) { line.forEach(function (row) { console.log(row) }) });
}
star(7);
star(9);
star(15);
star(21);
<file_sep>class Person
def initialize
@age = nil
end
def age
@age * 2
end
def age=(age)
@age = age * 2
end
end
person1 = Person.new
person1.age = 20
puts person1.age
# L_S further discussion, extract calculation to private method
class Person
def age=(age)
@age = double(age)
end
def age
double(@age)
end
private
def double(value)
value * 2
end
end
<file_sep>=begin
RNA: "AUGUUUUCU" => translates to
Codons: "AUG", "UUU", "UCU"
=> which become a polypeptide with the following sequence =>
Protein: "Methionine", "Phenylalanine", "Serine"
Codon Protein
AUG Methionine
UUU, UUC Phenylalanine
UUA, UUG Leucine
UCU, UCC, UCA, UCG Serine
UAU, UAC Tyrosine
UGU, UGC Cysteine
UGG Tryptophan
UAA, UAG, UGA STOP
=end
# take RNA
# break RNA into Sequences of 3
# take those values and find the ones matching a specific protein
# 'Tryptophan', Translation.of_codon('UGG')
# assert_equal 'STOP', Translation.of_codon(codon)
# strand = 'AUGUUUUAA'
# assert_equal expected, Translation.of_rna(strand)
# class is Translation
# class methods: of_codon(codon_string), of_rna(strand_string)
# each protein is a hash item, paired with an array of strings of possible combinations
# an rna string is broken down with #scan /.{3}/ to create a string every 3 spaces
# PAIRS.keys.each {|key| return PAIRS[key] if PAIRS[key].include?(string)}
# if PAIRS[key] == STOP stop sequence
# else return_string << PAIRS[key]
class InvalidCodonError < TypeError
end
require 'pry'
class Translation
PAIRS = {'Methionine': ['AUG'], 'Phenylalanine': ['UUU', 'UUC'], 'Leucine': ['UUA', 'UUG'],
'Serine': ['UCU', 'UCC', 'UCA', 'UCG'], 'Tyrosine': ['UAU', 'UAC'],
'Cysteine': ['UGU', 'UGC'], 'Tryptophan': ['UGG'], 'STOP': ['UAA', 'UAG', 'UGA']}
STOP = ['UAA', 'UAG', 'UGA']
def self.of_codon(codon)
raise InvalidCodonError, 'Invalid Codon' if codon =~ /[^UAGC]/
PAIRS.each do |k, v|
return k.to_s if v.include?(codon)
end
end
def self.of_rna(strand)
raise InvalidCodonError, 'Invalid Codon' if strand =~ /[^UAGC]/
return_array = []
strand_array = strand.scan(/.{3}/)
strand_array.each do |seq|
return return_array if STOP.include?(seq)
PAIRS.each do |k, v|
return_array << k.to_s if v.include?(seq)
end
end
return_array
end
end
strand = 'AUGUUUUAA'
#binding.pry
<file_sep>function doubleConsonants(str) {
return str.split('').map(function (ch) {
return /([aeiou]|[^a-z])/i.test(ch) ? ch : ch + ch;
}).join('');
}
doubleConsonants('String'); // "SSttrrinngg"
doubleConsonants('Hello-World!'); // "HHellllo-WWorrlldd!"
doubleConsonants('July 4th'); // "JJullyy 4tthh"
doubleConsonants(''); // ""<file_sep>// Set() is an iterable collection of unique values
// Set() does not have keys or indexes
const set1 = new Set();
set1.add(42);
set1.add(42);
set1.add(13);
for (let item of set1) {
console.log(item);
// expected output: 42
// expected output: 13
}
<file_sep>def string_to_integer(string)
string.bytes.reduce(0) do |acc, chaar|
acc*10 + chaar - 48
end
end
string_to_integer('4321') == 4321
string_to_integer('570') == 570
# 48 is the byte code for character '0'.
=begin
Their Solution:
DIGITS = {
'0' => 0, '1' => 1, '2' => 2, '3' => 3, '4' => 4,
'5' => 5, '6' => 6, '7' => 7, '8' => 8, '9' => 9
}
def string_to_integer(string)
digits = string.chars.map { |char| DIGITS[char] }
value = 0
digits.each { |digit| value = 10 * value + digit }
value
end
The actual computation of the numeric value of string is mechanical.
We take each digit and add it to 10 times the previous value,
which yields the desired result in almost no time.
For example, if we have 4, 3, and 1, we compute the result as:
10 * 0 + 4 -> 4
10 * 4 + 3 -> 43
10 * 43 + 1 -> 431
=end<file_sep>my_arr = [[18, 7], [3, 12]].each do |arr|
arr.each do |num|
if num > 5
puts num
end
end
end
=begin
Line 1
Action: variable assignment
Object: n/a
Side effect: none
Return value: full aray
Return used: no
Line 1
Action: method call, each
Object: outer array
Side effect: none
Return Value: full array
Return used: yes
Lines 1-5
Action: block execution
Object: outer array
Side effect: none
Return value: full array
Return used: no
Line 2:
Action: method call, each
Object: inner arrays
Side effect: none
return value: inner arrays
return used: yes, to determine value of inner block
Line 2:
Action: block execution
Object: each element of the sub array during the current iteration
Side effect: none
return value: each sub array of the current iteration
return used: no
Line 3:
Action: if condition
Object: each element of inner arrays
Side effect: none
return value: nil
return used: yes, to determine value of inner block
Line 4:
Action: method call, puts
Object: elements of inner arrays matching condition
Side effect: Outputs to screen
Return value: nil
Return used: yes, used to determine return value of inner block (cus it's on last line)
There are 4 return values to pay attention to here: the return value of both calls to each
and the return value of both blocks.
When determining what these return values will be
it's important to understand how the method used in the example actually works.
In this case we're using each, which ignores the return value of the block.
This lets us quickly see that the value of my_arr will be the array that each was called on.
Because each ignores the block's return value, this was a relatively straight forward example.
=end<file_sep>var STONES = {
"January": "garnet",
"February": "amethyst",
"March": "aquamarine or bloodstone",
"April": "diamond",
"May": "emerald",
"June": "pearl, moonstone, or alexandrite",
"July": "ruby",
"August": "peridot",
"September": "sapphire",
"October": "opal or tourmaline",
"November": "topaz or citrine",
"December": "turquoise, zircon, or tanzanite"
}
function validateCard(cc_number) {
var odd_total = 0;
var even_total = 0;
cc_number = cc_number.split("").reverse();
for (var i = 0, len = cc_number.length; i < len; i++) {
if (i % 2 == 1) {
cc_number[i] = (+cc_number[i] * 2) + "";
if (cc_number[i].length > 1) {
cc_number[i] = +cc_number[i][0] + +cc_number[i][1];
} else {
cc_number[i] = +cc_number[i];
}
odd_total += cc_number[i];
} else { even_total += +cc_number[i] }
}
return (odd_total + even_total) % 10 === 0;
}
$(function() {
var clicked;
var $ul = $('ul ul');
$("nav").hover(function() { $ul.show() }, function() { $ul.hide() });
$("main p").first().click(function(event) {
event.preventDefault();
$(event.target).addClass('clicked');
});
$(".toggle").on("click", function(e) {
e.preventDefault();
$(this).next(".accordion").toggleClass("opened");
});
$("form").submit(function(e) {
e.preventDefault();
var cc_number = $(this).find(":text").val();
var valid = validateCard(cc_number);
$(this).find(".success").toggle(valid);
$(this).find(".error").toggle(!valid);
});
$("ul a").on("click", function(e) {
e.preventDefault();
var month = $(this).text();
$("#birthstone").text("Your birthstone is " + STONES[month] + ".");
});
});
<file_sep>def multiply(number1, number2)
number1 * number2
end
def square(number)
multiply(number, number)
end
square(5) == 25
square(-8) == 64<file_sep>require 'pry'
class PokerHand
attr_reader :hand
def initialize(new_cards = randomize_hand)
@hand = new_cards
@hand = randomize_hand(new_cards) if hand.class == Deck
end
def print
@hand.each {|card| puts card.to_s}
end
def randomize_hand(the_deck)
@hand = []
5.times {@hand << the_deck.draw}
hand
end
def evaluate
case
when royal_flush? then 'Royal flush'
when straight_flush? then 'Straight flush'
when four_of_a_kind? then 'Four of a kind'
when full_house? then 'Full house'
when flush? then 'Flush'
when straight? then 'Straight'
when three_of_a_kind? then 'Three of a kind'
when two_pair? then 'Two pair'
when pair? then 'Pair'
else 'High card'
end
end
private
def royal_flush?
flush? && straight? && hand.all? {|card| card > Card.new(9, 'Clubs')}
end
def straight_flush?
flush? && straight?
end
def four_of_a_kind?
hand_count = @hand.map(&:rank)
!hand_count.select {|card| hand_count.count(card) == 4}.empty?
end
def full_house?
ranks = @hand.map(&:rank)
uniques = ranks.uniq
ranks.count(uniques[0]) == 3 && ranks.count(uniques[1]) == 2
end
def flush?
@hand.all? {|card| card.suit == hand[0].suit}
end
def straight?
straight = []
@hand.sort.each_cons(2) do |a, b|
straight << 1 if Card::RANK_ORDER.key(b.rank) - 1 == Card::RANK_ORDER.key(a.rank)
end
straight.size == 4
end
def three_of_a_kind?
hand_count = @hand.map(&:rank)
!hand_count.select {|card| hand_count.count(card) == 3}.empty?
end
def two_pair?
hand_count = @hand.map(&:rank)
hand_count.select {|card| hand_count.count(card) == 2}.uniq.size == 2
end
def pair?
hand_count = @hand.map(&:rank)
!hand_count.select {|card| hand_count.count(card) == 2}.empty?
end
end
class Deck
attr_reader :new_deck
attr_accessor :counter
RANKS = (2..10).to_a + %w(Jack Queen King Ace).freeze
SUITS = %w(Hearts Clubs Diamonds Spades).freeze
def initialize
@new_deck = []
init_deck
@counter = -1
end
def init_deck
SUITS.each {|suit| RANKS.each {|rank| @new_deck << Card.new(rank, suit)}}
@new_deck.shuffle!
end
def draw
@counter += 1
if counter > 51
@new_deck.shuffle!
self.counter = 0
end
@new_deck[counter]
end
end
class Card < Deck
attr_reader :rank, :suit
include Comparable
RANK_ORDER = {1 => 2, 2 => 3, 3 => 4, 4 => 5, 5 => 6, 6 => 7, 7 => 8, 8 => 9, 9 => 10, 10 => 'Jack', 11 => 'Queen', 12 => 'King', 13 => 'Ace'}
def initialize(rank, suit)
@rank = rank
@suit = suit
end
def <=>(other_card)
RANK_ORDER.key(rank) <=> RANK_ORDER.key(other_card.rank)
end
def to_s
"#{rank} of #{suit}"
end
end
hand = PokerHand.new(Deck.new)
hand.print
puts hand.evaluate
# Danger danger danger: monkey
# patching for testing purposes.
class Array
alias_method :draw, :pop
end
# Test that we can identify each PokerHand type.
hand = PokerHand.new([
Card.new(10, 'Hearts'),
Card.new('Ace', 'Hearts'),
Card.new('Queen', 'Hearts'),
Card.new('King', 'Hearts'),
Card.new('Jack', 'Hearts')
])
puts hand.evaluate == 'Royal flush'
hand = PokerHand.new([
Card.new(8, 'Clubs'),
Card.new(9, 'Clubs'),
Card.new('Queen', 'Clubs'),
Card.new(10, 'Clubs'),
Card.new('Jack', 'Clubs')
])
puts hand.evaluate == 'Straight flush'
hand = PokerHand.new([
Card.new(3, 'Hearts'),
Card.new(3, 'Clubs'),
Card.new(5, 'Diamonds'),
Card.new(3, 'Spades'),
Card.new(3, 'Diamonds')
])
puts hand.evaluate == 'Four of a kind'
hand = PokerHand.new([
Card.new(3, 'Hearts'),
Card.new(3, 'Clubs'),
Card.new(5, 'Diamonds'),
Card.new(3, 'Spades'),
Card.new(5, 'Hearts')
])
puts hand.evaluate == 'Full house'
hand = PokerHand.new([
Card.new(10, 'Hearts'),
Card.new('Ace', 'Hearts'),
Card.new(2, 'Hearts'),
Card.new('King', 'Hearts'),
Card.new(3, 'Hearts')
])
puts hand.evaluate == 'Flush'
hand = PokerHand.new([
Card.new(8, 'Clubs'),
Card.new(9, 'Diamonds'),
Card.new(10, 'Clubs'),
Card.new(7, 'Hearts'),
Card.new('Jack', 'Clubs')
])
puts hand.evaluate == 'Straight'
hand = PokerHand.new([
Card.new(3, 'Hearts'),
Card.new(3, 'Clubs'),
Card.new(5, 'Diamonds'),
Card.new(3, 'Spades'),
Card.new(6, 'Diamonds')
])
puts hand.evaluate == 'Three of a kind'
hand = PokerHand.new([
Card.new(9, 'Hearts'),
Card.new(9, 'Clubs'),
Card.new(5, 'Diamonds'),
Card.new(8, 'Spades'),
Card.new(5, 'Hearts')
])
puts hand.evaluate == 'Two pair'
hand = PokerHand.new([
Card.new(2, 'Hearts'),
Card.new(9, 'Clubs'),
Card.new(5, 'Diamonds'),
Card.new(9, 'Spades'),
Card.new(3, 'Diamonds')
])
puts hand.evaluate == 'Pair'
hand = PokerHand.new([
Card.new(2, 'Hearts'),
Card.new('King', 'Clubs'),
Card.new(5, 'Diamonds'),
Card.new(9, 'Spades'),
Card.new(3, 'Diamonds')
])
puts hand.evaluate == 'High card'
<file_sep>
function calculateGrade() {
var i;
var grades = [];
for (i = 0; i < 3; i++) {
var newGrade = prompt('What did you score?');
grades.push(Number(newGrade));
}
var sum = grades.reduce((total, amount) => total + amount);
var average = sum / grades.length;
var finalGrade;
if (average >= 90) {
finalGrade = 'A';
} else if (average >= 70 && average < 90) {
finalGrade = 'B';
} else if (average >= 50 && average < 70) {
finalGrade = 'C';
} else {
finalGrade = 'F';
}
console.log('Based on the average of your 3 scores your letter grade is "' +
finalGrade + '".');
}<file_sep># array with nested hashes
arr = [{ a: 'ant' }, { b: 'bear' }]
# assignment
arr[0][:c] = 'cat'
arr # => [{ :a => "ant", :c => "cat" }, { :b => "bear" }]
arr = [['a', ['b']], { b: 'bear', c: 'cat' }, 'cab']
arr[0] # => ["a", ["b"]]
arr[0][1][0] # => "b"
arr[1] # => { :b => "bear", :c => "cat" }
arr[1][:b] # => "bear"
arr[1][:b][0] # => "b"
arr[2][2] # => "b"
<file_sep>class Video < ActiveRecord::Base
belongs_to :category
has_many :reviews
has_many :queue_items
validates :title, presence: true, uniqueness: true
def self.search_by_title(ttl)
return [] if ttl.blank?
where(["title ILIKE ?", "%#{ttl}%"]).sort_by(&:created_at)
end
end<file_sep>hsh = {first: ['the', 'quick'], second: ['brown', 'fox'], third: ['jumped'], fourth: ['over', 'the', 'lazy', 'dog']}
vowels = ''
hsh.each_value do |value|
value.each do |string|
string.chars.each do |characters|
characters =~ /a|e|i|o|u/ ? vowels << characters : characters
end
end
end
puts vowels<file_sep>/*
Problems: 1-4
var account = {
balance: 0,
transactions: [],
deposit: function (n) {
this.balance += n;
this.transactions.push({type: "deposit", amount: n});
return n;
},
withdraw: function (n) {
this.balance -= n;
if (this.balance < 0) {
n += this.balance;
this.balance = 0;
}
this.transactions.push({type: "withdrawal", amount: n});
return n;
}
};
account.deposit(81);
account.balance;
account.withdraw(91);
account.balance;
*/
function makeAccount() {
var balance = 0;
var transactions = [];
return {
balance: function() { return balance },
transactions: function() { return transactions },
deposit: function (n) {
balance += n;
transactions.push({type: "deposit", amount: n});
return n;
},
withdraw: function (n) {
balance -= n;
if (balance < 0) {
n += balance;
balance = 0;
}
transactions.push({type: "withdrawal", amount: n});
return n;
}
};
}
var account = makeAccount();
account.deposit(15);
account.balance();
var otherAccount = makeAccount();
otherAccount.balance();
function makeBank() {
var starter = 101;
var accounts = [];
return {
openAccount: function() {
var acct = makeAccount();
acct.number = function() { return starter }
accounts.push(acct);
starter += 1;
return acct;
},
transfer: function(givr, recvr, amt) {
givr.withdraw(amt);
recvr.deposit(amt);
return amt;
}
}
}
var bank = makeBank();
var account = bank.openAccount();
account.number();
//= 101
//bank.accounts;
//= [{...}]
//bank.accounts[0];
//= {number: 101, balance: 0, transactions: Array[0]}
var secondAccount = bank.openAccount();
secondAccount.number();
var bank = makeBank();
var source = bank.openAccount();
source.deposit(10);
//= 10
var destination = bank.openAccount();
bank.transfer(source, destination, 7);
//= 7
source.balance();
//= 3
destination.balance();
//= 7
var bank = makeBank();
var account = bank.openAccount();
account.balance();
//= 0
account.deposit(17);
//= 17
var secondAccount = bank.openAccount();
secondAccount.number();
//= 102
account.transactions();
//> [Object]<file_sep>arr = [[1, 6, 7], [1, 4, 9], [1, 8, 3]]
arr.sort! do |a, b|
a.select {|i| i.odd?}
b.select {|i| i.odd?}
a <=> b
end<file_sep># dup allows objects within the copied object to be modified.
arr1 = ["a", "b", "c"]
arr2 = arr1.dup
arr2[1].upcase!
arr2 # => ["a", "B", "c"]
arr1 # => ["a", "B", "c"]
# clone works the same way.
arr1 = ["abc", "def"]
arr2 = arr1.clone
arr2[0].reverse!
arr2 # => ["cba", "def"]
arr1 # => ["cba", "def"]
# It's important to understand that the reason this happens
# is because the destructive methods (String#upcase! and String#reverse!)
# were called on the object within the array rather than the array itself.
# Example 1 (whole array)
arr1 = ["a", "b", "c"]
arr2 = arr1.dup
arr2.map! do |char|
char.upcase
end
arr1 # => ["a", "b", "c"]
arr2 # => ["A", "B", "C"]
# Example 2 (objects within the array)
arr1 = ["a", "b", "c"]
arr2 = arr1.dup
arr2.each do |char|
char.upcase!
end
arr1 # => ["A", "B", "C"]
arr2 # => ["A", "B", "C"]<file_sep>/*
the 3x3 matrix shown below:
1 5 8
4 7 2
3 9 6
var matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6],
];
var matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
];
var newMatrix = transpose(matrix);
console.log(newMatrix); // [[1, 4, 3], [5, 7, 9], [8, 2, 6]]
console.log(matrix); // [[1, 5, 8], [4, 7, 2], [3, 9, 6]]
Problem:
Take nested array
return 'transposed' version of that array
transposed means that the elements facing 'up and down'
are returned as subarrays, rather than those facing 'left and right'
do not mutate the array
Expectations:
Input: nested array
output: new nested array that's 'transposed'
console.log(newMatrix); // [[1, 4, 3], [5, 7, 9], [8, 2, 6]]
console.log(matrix); // [[1, 5, 8], [4, 7, 2], [3, 9, 6]]
var matrix2 = [['a', 'b', 'c'], ['e', 'f', 'g'], ['h', 'i', 'j']]
var newMatrix2 = transpose(matrix2);
matrices are always three by three so this example should suffice
Data structures:
nested array input
create new result array
create object with keys for each index,
empty array values
push subarrays and transposed values to object
push object values to result array
return the result array
Algorithm:
define subarray object with values of 1, 2, and 3
define result array
take nested array
iterate through nested array with map
map each subarray with idx
subArrays[idx].push(elem)
Object.values(subarrays).forEach(result.push(subarray));
return result
*/
function transpose(matrix) {
var subArrays = {0: [], 1: [], 2: []};
var result = [];
matrix.forEach(function (oneSub) {
oneSub.forEach(function (elem, idx) {
subArrays[idx].push(elem);
});
});
Object.values(subArrays).forEach(oneSub => result.push(oneSub));
return result;
}
var matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
];
var newMatrix = transpose(matrix);
console.log(newMatrix);
console.log(matrix);
var matrix2 = [['a', 'b', 'c'], ['e', 'f', 'g'], ['h', 'i', 'j']]
var newMatrix2 = transpose(matrix2);
console.log(newMatrix2);
console.log(matrix2);
<file_sep>function anagram(word, list) {
function sorted(str) { return str.split('').slice(0).sort().join('') }
return list.filter(function (tester) {
return sorted(word) === sorted(tester);
});
}
anagram('listen', ['enlists', 'google', 'inlets', 'banana']);
anagram('listen', ['enlist', 'google', 'inlets', 'banana']);
// blank array
// create array of letters for arg1, sort sliced array, join
// push to array if array of arg2.split.slice(0).sort ===<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: devices; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE devices (
id integer NOT NULL,
name text NOT NULL,
created_at timestamp without time zone DEFAULT now()
);
ALTER TABLE devices OWNER TO postgres;
--
-- Name: devices_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE devices_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE devices_id_seq OWNER TO postgres;
--
-- Name: devices_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE devices_id_seq OWNED BY devices.id;
--
-- Name: parts; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE parts (
id integer NOT NULL,
part_number integer NOT NULL,
device_id integer
);
ALTER TABLE parts OWNER TO postgres;
--
-- Name: parts_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE parts_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE parts_id_seq OWNER TO postgres;
--
-- Name: parts_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE parts_id_seq OWNED BY parts.id;
--
-- Name: devices id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY devices ALTER COLUMN id SET DEFAULT nextval('devices_id_seq'::regclass);
--
-- Name: parts id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY parts ALTER COLUMN id SET DEFAULT nextval('parts_id_seq'::regclass);
--
-- Data for Name: devices; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY devices (id, name, created_at) FROM stdin;
1 Accelerometer 2017-12-26 17:25:22.424829
2 Gyroscope 2017-12-26 17:25:22.424829
\.
--
-- Data for Name: parts; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY parts (id, part_number, device_id) FROM stdin;
4 12 1
5 14 1
6 16 1
7 31 2
8 33 2
9 35 2
10 37 2
11 39 2
12 50 \N
13 54 \N
14 58 \N
\.
--
-- Name: devices_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('devices_id_seq', 2, true);
--
-- Name: parts_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('parts_id_seq', 14, true);
--
-- Name: devices devices_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY devices
ADD CONSTRAINT devices_pkey PRIMARY KEY (id);
--
-- Name: parts parts_part_number_key; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY parts
ADD CONSTRAINT parts_part_number_key UNIQUE (part_number);
--
-- Name: parts parts_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY parts
ADD CONSTRAINT parts_pkey PRIMARY KEY (id);
--
-- Name: parts parts_device_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY parts
ADD CONSTRAINT parts_device_id_fkey FOREIGN KEY (device_id) REFERENCES devices(id);
--
-- PostgreSQL database dump complete
--
<file_sep>function greet(arg1, arg2) {
var greeting1 = arg1[0].toUpperCase() + arg1.slice(1) + ', ';
var greeting2 = arg2[0].toUpperCase() + arg2.slice(1) + '!';
console.log(greeting1 + greeting2);
}
greet('howdy', 'Joe');
greet('good morning', 'Sue');
function partial(primary, arg1) {
return function(arg2) {
return primary(arg1, arg2);
};
}
var sayHello = partial(greet, 'hello');
sayHello('Brandon');
var sayHi = partial(greet, 'hi');
sayHi('Sarah');
<file_sep>def multiply(numbers, multiply_by)
new_numbers = []
counter = 0
loop do
current_number = numbers[counter]
new_numbers << current_number * multiply_by
counter += 1
break if counter == numbers.size
end
new_numbers
end
my_numbers = [1, 4, 3, 7, 2, 6]
multiply(my_numbers, 3) # => [3, 12, 9, 21, 6, 18]<file_sep>function wordToDigit(phrase) {
var numWords = {'one': 1, 'two': 2, 'three': 3, 'four': 4, 'five': 5, 'six': 6, 'seven': 7, 'eight': 8, 'nine': 9, 'zero': 0};
return phrase.split(' ').map(function (word) {
var cleaned = word.replace(/[^a-z]/ig, '');
if (Object.keys(numWords).some(function (k) { return new RegExp(cleaned, 'ig').test(k) })) {
return String(numWords[cleaned]) + word.replace(/[a-z]/ig, '');
} else {
return word;
}
}).join(' ');
}
wordToDigit('Please call me at five five five one two three four. Thanks.');<file_sep>WORD_TYPE = {
gname: ["Sarah", "Lindsey", "Rebecca", "Darlene", "Karen", "Stacy", "Tiffany"],
bname: ["John", "Mike", "Andrew", "Sam", "Tyler", "Brandon", "Ezekiel"],
noun: ["dog", "cat", "man", "bicyle", "squirrel", "spoon", "spindle", "cloud"],
adjective: ["bouncy", "stupid", "cynical", "fancy", "buoyant", "splendifferous"],
adverb: ["jokingly", "spitefully", "willingly", "painfully", "ignorantly", "gleefully"],
ingverb: ["speaking", "carrying", "spamming", "eating", "swinging", "spiraling"],
verb: ["run", "jump", "fly", "eat", "spin", "swim", "dazzle"]
}
def madlib(text_file)
lines = File.read(text_file).split
lines.each do |word|
WORD_TYPE.keys.each do |type|
word == type.to_s.upcase || word.chop == type.to_s.upcase ? word.gsub!(type.to_s.upcase, WORD_TYPE[type].sample) : type
end
end
lines.join(' ')
end
p madlib("madlib.txt")
# Take Text File
# Take lists of randomized nouns, verbs, adjectives
# Insert randomized strings from the appropriate list into that text
# input -> One day, princess NAME sat on her ADJECTIVE NOUN VERB-ING NOUN.
# madlib(file_name) -> One day, princess Antonia sat on her scruffy couch eating Cheetos.
# Rules: Lists can come directly from program, but need to be used in appropriate cases
# Data Structures:
# Lists: arrays titled with correct word type and list of words appropriate to that type
# File Text: File text will also be displayed in an array per line
# text will then be transformed into a string,
# the word will be replaced, then it will go back to an array
# the line will go back to a string one there are no more cued words on that line
# a case statement will direct flow control to find the appropriate word type
# Algorithms:
# readlines the file to turn each line into an array
# loop
# iterate with find to find next appropriate word
# case statement - when word type is ___
# then join line, reassign to string
# gsub! word_type.sample
# break loop if there are no more triggers
# else split line back into array
# end loop
# join whole file, print whole file
# Abstractions:
# Create Arrays of Randomized Words for Each Word Type
# Create Arrays for Each Line of a File
# Iterate over those arrays to replace words when the words match one of the word type arrays
# Print contents of file with replaced words<file_sep># class - Palindromes
# initialize takes one argument, a hash
# max_factor: 9, min_factor: 1
# methods
# generate => returns array of palindromes
# create range
# within said range, find every number that is a palindrome
# is_palindrome?
# to_s.reverse.join.to_i
# (1..9) 9 is the largest factor
# 1*1, 1*2 ...etc
# take each number in range
# multiply that number by every other number
# largest
# Integer#factors
# returns [[[3, 3], [1, 9]], [[1, 9], [3, 3]]] nested array
require 'pry'
class Palindromes
def initialize(hash)
@hash = hash.to_h
if @hash.include?(:max_factor) && @hash.include?(:min_factor)
@range = (@hash[:min_factor]..@hash[:max_factor])
else
@range = (1..@hash[:max_factor])
end
end
def generate
all_products = @range.map do |number|
@range.map do |other_number|
number * other_number
end
end.flatten
all_products.select { |product| is_palindrome? product }
end
def largest
NumberVal.new(generate.max, @range)
end
def smallest
NumberVal.new(generate.min, @range)
end
def is_palindrome?(num)
num.to_s.reverse.to_i == num
end
end
class NumberVal
attr_reader :value
def initialize(num, orig_range)
@value = num
@range = (1..num)
@orig = orig_range
end
def factors
result = []
@range.each do |n|
(1..n).each do |other_n|
result << [n, other_n] if n * other_n == @value
end
end
result.select { |fact| @orig.include?(fact[0]) && @orig.include?(fact[1]) }.map(&:sort)
end
end
<file_sep>class Odd
attr_accessor :num
def initialize(num)
@num = num
end
end
<file_sep>class Series
def initialize(string)
@string = string
end
def slices(n)
raise ArgumentError, 'Argument larger than string.' if n > @string.length
result = []
@string.split('').each_cons(n) do |ch, *others|
result << [ch.to_i, others.map(&:to_i).flatten].flatten
end
result
end
end
series = Series.new('01234')
series.slices(3)<file_sep>var request = new XMLHttpRequest();
var data;
request.open('GET', 'https://api.github.com/repos/rails/rails');
request.responseType = 'json';
request.addEventListener('load', function(event) {
// request.response will be the result of parsing the JSON response body
// or null if the body couldn't be parsed or another error
// occurred.
data = request.response;
console.log(request.status);
if (!String(request.status)[0].match(/[2-3]/)) {
console.log('The request could not be completed!');
}
});
/*
Could use built-in JSON.parse() but need error handling:
request.addEventListener('load', function(event) {
try {
var data = JSON.parse(request.response);
// do something with the data
} catch(e) {
console.log('Cannot parse the received response as JSON.')
}
});
'error' event listener to handle errors as well:
request.addEventListener('error', function(event) {
console.log('The request could not be completed!');
});
*/
request.send();
setTimeout(function() { console.log(data.open_issues) }, 400);
<file_sep>class BankAccount
attr_reader :balance
def initialize(starting_balance)
@balance = starting_balance
end
def positive_balance?
balance >= 0
end
end
# no need for an @ because attr_reader creates a getter method
# positive_balance? references the method balance
<file_sep>def multiply(number1, number2)
number1 * number2
end
multiply(5, 3) == 15<file_sep>var turk = {
firstName: 'Christopher',
lastName: 'Turk',
occupation: 'Surgeon',
getDescription: function() {
return this.firstName + ' ' + this.lastName + ' is a ' + this.occupation + '.';
}
};
function logReturnVal(func, obj) {
var returnVal = func.bind(obj)();
console.log(returnVal);
}
logReturnVal(turk.getDescription, turk);
TESgames.listGames();
var TESgames = {
titles: ['Arena', 'Daggerfall', 'Morrowind', 'Oblivion', 'Skyrim'],
seriesTitle: 'The Elder Scrolls',
listGames: function() {
this.titles.forEach(function(title) {
console.log(this.seriesTitle + ' ' + title);
}, this); // how the thisArg argument is used
}
};
TESgames.listGames(TESgames);
var foo = {
a: 0,
incrementA: function() {
var self = this;
function increment() {
self.a += 1;
}
increment();
}
};
foo.incrementA();
foo.incrementA();
foo.incrementA();
foo.a;
var foo = {
a: 0,
incrementA: function() {
function increment() {
this.a += 3;
}
increment.bind(this)();
}
};
foo.incrementA();
foo.a;
<file_sep>def not_so_tricky_method(a_string_param, an_array_param)
a_string_param += "rutabaga"
an_array_param += ["rutabaga"]
# consistent operator
return a_string_param, an_array_param
# explicit return of multiple variables
end
my_string = "pumpkins"
my_array = ["pumpkins"]
# assigning multiple variables
my_string, my_array = not_so_tricky_method(my_string, my_array)
puts "My string looks like this now: #{my_string}"
puts "My array looks like this now: #{my_array}"
<file_sep>require "sinatra"
require "sinatra/reloader"
require "tilt/erubis"
require "redcarpet"
require "yaml"
require "bcrypt"
def data_path
if ENV["RACK_ENV"] == "test"
File.expand_path("../test/data", __FILE__)
else
File.expand_path("../data", __FILE__)
end
end
def credentials_path
if ENV["RACK_ENV"] == "test"
File.expand_path("../test/users.yml", __FILE__)
else
File.expand_path("../users.yml", __FILE__)
end
end
def load_users
Psych.load_file(credentials_path)
end
def encrypt(pw)
BCrypt::Password.create(pw)
end
def decrypt(pw)
BCrypt::Password.new(pw)
end
def add_user(name, pw)
File.open(credentials_path, "a") { |yml| yml << "\n#{name}: #{encrypt(pw)}" }
end
def check_signin
unless session[:success]
session[:message] = "You must be signed in to do that."
redirect "/login"
end
end
configure do
enable :sessions
set :session_secret, 'secret2'
end
before do
pattern = File.join(data_path, "*")
@files = Dir.glob(pattern).map do |path|
File.basename(path)
end.sort
@markdown = Redcarpet::Markdown.new(Redcarpet::Render::HTML)
end
get "/" do
redirect "/login" unless session[:success]
erb :home, layout: :layout
end
get "/index/:file" do
check_signin
file_path = File.join(data_path, params[:file])
if !@files.include? params[:file]
session[:message] = "#{params[:file]} does not exist."
redirect "/"
end
if params[:file][-3, 3] == ".md"
headers["Content-Type"] = "text/html;charset=utf-8"
@markdown.render(File.read(file_path))
else
headers["Content-Type"] = "text/plain"
File.read(file_path)
end
end
get "/index/:file/edit" do
check_signin
file_path = File.join(data_path, params[:file])
@file = params[:file]
@read = File.read(file_path)
erb :edit, layout: :layout
end
post "/index/:file/save" do
check_signin
file_path = File.join(data_path, params[:file])
@file = params[:file]
File.open(file_path, "w+") { |file| file.write(params[:edit_file]) }
session[:message] = "Your changes to #{@file} were saved."
redirect "/"
end
get "/create" do
check_signin
erb :create, layout: :layout
end
post "/create" do
check_signin
@new = params[:new]
if @new.empty? || !@new.include?(".")
session[:message] = "Please enter a valid file name."
redirect "/create"
else
file_path = File.join(data_path, @new)
File.write(file_path, "")
session[:message] = "New file created: #{@new}"
redirect "/"
end
end
post "/delete" do
check_signin
@destroy = params[:destroy]
file_path = File.join(data_path, @destroy)
File.delete(file_path)
session[:message] = "#{@destroy} was deleted"
redirect "/"
end
get "/login" do
erb :login, layout: :layout
end
post "/login" do
username = params[:username]
password = params[:password]
if username.empty? || password.empty?
session[:message] = "Please enter username and password."
status 422
erb :login, layout: :layout
elsif !load_users.nil? && load_users.key?(username) && decrypt(load_users[username]) == password
session[:user] = username
session[:message] = "Welcome!"
session[:success] = true
redirect "/"
else
session[:message] = "Invalid Credentials."
status 422
erb :login, layout: :layout
end
end
post "/logout" do
session[:user] = nil
session[:success] = false
session[:message] = "Logged Out."
redirect "/login"
end
get "/users/new" do
# Add in registration functionality
erb :usernew, layout: :layout
end
post "/users/new" do
username = params[:username]
password = params[:<PASSWORD>]
if !load_users.nil? && load_users.key?(username)
session[:message] = "Username Taken."
status 422
erb :usernew, layout: :layout
else
add_user(username, password)
session[:user] = username
session[:message] = "Welcome!"
session[:success] = true
redirect "/"
end
end<file_sep>def is_odd?(num)
if num % 2 == 0
puts 1 == 2
else puts 1 == 1
end
end
puts is_odd?(2) # => false
puts is_odd?(5) # => true
puts is_odd?(-17) # => true
puts is_odd?(-8) # => false
puts is_odd?(0) # => false
# their version
# def is_odd?(number)
# number % 2 == 1
# end<file_sep># All of these collection classes include the Enumerable module,
# which means they have access to an each method,
# as well as many other iterative methods such as map, reduce, select, and more.
class Tree
include Enumerable
def initialize
@collection = []
end
def <<(item)
@collection << item
end
def each
counter = 0
while counter < @collection.size
yield(@collection[counter])
counter += 1
end
@collection
end
end
# tree << 1
# => [1]
# tree << 2
# => [1, 2]
# tree << 3
# => [1, 2, 3]
# Custom each method:
# tree.each {|item| puts item}
# 1
# 2
# 3
# => [1, 2, 3]
# Incorporating non-custom Enumerable methods
# tree.select {|item| item.odd?}
# => [1, 3]<file_sep># Again, using a counter to iterate, but transform instead of select
# Adding an 's' at the end of each string
fruits = ['apple', 'banana', 'pear']
transformed_elements = []
counter = 0
loop do
current_element = fruits[counter]
# transformation criteria (below)
transformed_elements << current_element + 's' # appends transformed string into array
counter += 1
break if counter == fruits.size
end
transformed_elements # => ["apples", "bananas", "pears"]
=begin
Note that, in this example, we perform the transformation on a new array
and leave the original array unchanged.
When performing transformation,
it's always important to pay attention to whether the original collection was mutated
or if a new collection was returned.
=end<file_sep># A circular buffer, cyclic buffer or ring buffer
# is a data structure that uses a single, fixed-size buffer
# as if it were connected end-to-end.
# [ ][ ][ ][ ][ ][ ][ ]
# [ ][ ][ ][1][ ][ ][ ]
# [ ][ ][ ][1][2][3][ ]
# [ ][ ][ ][ ][ ][3][ ]
# If the buffer has 7 elements then it is completely full:
# [6][7][8][9][3][4][5]
# The client can opt to overwrite the oldest data with a forced write.
# In this case, two more elements — A & B — are added and they overwrite the 3 & 4:
# [6][7][8][9][A][B][5]
# if two elements are now removed then what would be returned is not 3 & 4 but 5 & 6
# [ ][7][8][9][A][B][ ]
# 4 methods
# read, write, write! and clear
# read returns the oldest element and removes it
# 2 errors
# BufferEmptyException
# BufferFullException
# read takes oldest item, returns and eliminates it
# write adds new item
# count = 0
# oldest = @buffer[count]
# if count == 2, second_oldest = @buffer[count]
# buffer.read
# buffer.calculate_oldest
# calculate_oldest deletes oldest value
# add each count as index into record
class CircularBuffer
class BufferEmptyException < StandardError; end
class BufferFullException < StandardError; end
def initialize(num)
@num = num
@buffer = []
@order = {}
end
def read
raise BufferEmptyException if @buffer.empty?
oldest = @order.values.first
@order.delete(@order.keys.first)
@buffer.slice!(@buffer.find_index(oldest))
end
def write(ch)
return if ch.nil?
raise BufferFullException if @buffer.size == num
@buffer << ch
sleep_add(ch)
end
def write!(ch)
return if ch.nil?
return write(ch) unless @buffer.size == num
oldest = @order.values.first
@order.delete(@order.keys.first)
@buffer[@buffer.find_index(oldest)] = ch
sleep_add(ch)
end
def clear
@buffer.clear
end
private
attr_reader :num
def sleep_add(item)
sleep 1
@order[Time.new] = item
end
end
<file_sep>arr = [['b', 'c', 'a'], [2, 1, 3], ['blue', 'black', 'green']]
for i in arr[0..-1] do
i.sort!.reverse!
end
# their solution
arr.map do |sub_arr|
sub_arr.sort do |a, b|
b <=> a
end
end<file_sep>def transpose(array)
new_array = [
[array[0][0], array[1][0], array[2][0]].flatten,
[[array[0][1], array[1][1], array[2][1]]].flatten,
[array[0][2], array[1][2], array[2][2]].flatten
]
end
matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
]
new_matrix = transpose(matrix)
p new_matrix == [[1, 4, 3], [5, 7, 9], [8, 2, 6]]
p matrix == [[1, 5, 8], [4, 7, 2], [3, 9, 6]]
def transpose!(array)
new_array = [
[array[0][0], array[1][0], array[2][0]].flatten,
[[array[0][1], array[1][1], array[2][1]]].flatten,
[array[0][2], array[1][2], array[2][2]].flatten
]
array.replace(new_array)
end
matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
]
transpose!(matrix)
# other version:
def transpose(array)
row1, row2, row3 = [], [], []
array.each_with_index do |row, idx|
row.each_with_index do |num, idx2|
case
when idx2 == 0
row1 << num
when idx2 == 1
row2 << num
when idx2 == 2
row3 << num
end
end
end
[row1, row2, row3]
end
matrix = [
[1, 5, 8],
[4, 7, 2],
[3, 9, 6]
]
transpose(matrix)
=begin
Launch School Version (Uses Separate 0..2 Ranges to Delegate Indices):
def transpose(matrix)
result = []
(0..2).each do |column_index|
new_row = (0..2).map { |row_index| matrix[row_index][column_index] }
result << new_row
end
result
end
=end<file_sep># Arrays are lists of elements that are ordered by index, where each element can be any object.
arr = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
arr[2] # => 'c'
arr = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
# => ['a', 'b', 'c', 'd', 'e', 'f', 'g']
arr[2, 3]
# Array#slice
# => ['c', 'd', 'e']
arr[2, 3][0]
# => 'c'
# String#slice returns a new string whereas Array#slice returns a new array.
arr = [1, 'two', :three, '4']
arr[3] # => "4"
# Array#[] method; this returns the object at index 3 of arr
arr[3, 1] # => ["4"]
# Array#slice
<file_sep>def merge(ary1, ary2)
(ary1 + ary2).uniq
end
merge([1, 3, 5], [3, 6, 9]) == [1, 3, 5, 6, 9]
# their solution:
# def merge(array_1, array_2)
# array_1 | array_2
# end
<file_sep>class WordProblem
def initialize(sentence)
@sentence = sentence
end
def answer
operators!(@sentence)
cut_out!(@sentence)
raise ArgumentError unless @sentence !~ /[a-zA-Z]/
equate(@sentence)
end
private
def operators!(string)
string.gsub!('plus', '+')
string.gsub!('minus', '-')
string.gsub!('multiplied by', '*')
string.gsub!('divided by', '/')
end
def cut_out!(string)
string.delete!('Whatis?')
end
def equate(string)
equation = string.split
sum = equation[0].to_i
equation.each_with_index do |n, idx|
next if n =~ /[0-9 ]/
sum = sum.send(n, equation[idx + 1].to_i)
end
sum
end
end
#WordProblem.new('What is 1 multiplied by 3?').answer
#WordProblem.new('What is 53 cubed?').answer
<file_sep>def sum_square_difference(num)
1.upto(num).reduce(&:+)**2 - 1.upto(num).map{|n| n**2}.reduce(&:+)
end
sum_square_difference(3) == 22
# -> (1 + 2 + 3)**2 - (1**2 + 2**2 + 3**2)
sum_square_difference(10) == 2640
sum_square_difference(1) == 0
sum_square_difference(100) == 25164150
<file_sep>[{ a: 'ant', b: 'elephant' }, { c: 'cat' }].select do |hash|
hash.all? do |key, value|
value[0] == key.to_s
end
end
# => [{ :c => "cat" }]
=begin
Line: 1
Action: Method Call, Select
Object: The Outer Array
Side Effects: None
Return Value: A New Array with the Selected Hash K-V pairs
Return Used: No, Select is the one Using
Line: 1-5
Action: Block Execution
Object: Each Sub Hash
Side Effects: None
Return Value: Selected Hash
Return Used: Yes, By Select
Line: 2
Action: Method Call, All?
Object: Each Sub Hash
Side Effects: None
Return Value: [False, True]
Return Used: Yes, to determine return value of outer block
Line: 2-4
Action: Block Execution
Object: Each Sub Hash
Side Effects: None
Return Value: [False, True]
Return Used: Yes, By All?
Line: 3
Action: value[0] == key.to_s
Object: Each Index of Each Sub Hash
Side Effects: None
Return Value: [[False], [True]]
Return Used: Yes, to determine return value of inner block<file_sep>=begin
what is != and where should you use it?
!= translates to 'not equal to.'
It works well for conditionals.
put ! before something, like !user_name
The bang operator before an operand reverses
the state of the operand.
ex: !(a && b) is false
This would make a & b true.
put ! after something, like words.uniq!
Any time you want to mutate an object,
putting the bang operator after a class method
will typically do the trick.
put ? before something
A ternary operator, meaning it will
execute an if...else statement in one line.
put ? after something
Usually used as a styling convention for methods,
'?' indicates that the method will return a boolean value.
put !! before something, like !!user_name
The double bang operator will turn
the operand into a boolean value.
=end
<file_sep>class PigLatin
def self.translate(phrase)
phrase.split.map do |word|
if word[0] =~ /[aeiouAEIOU]/ || word[0] =~ /[yxYX]/ && word[1] =~ /[^aeiouAEIOU]/
word + 'ay'
elsif word[0, 3] =~ /(sch|thr|squ)/
ending = word[0, 3] + 'ay'
word[3..-1] + ending
elsif word[0, 2] =~ /(ch|sh|th|qu)/
ending = word[0, 2] + 'ay'
word[2..-1] + ending
else
ending = word[0] + 'ay'
word[1..-1] + ending
end
end.join(' ')
end
end
# extra rules
# sh, ch, th also go to end + ay
# single word v phrase<file_sep>function substringsAtStart(str) {
var result = [];
str = str.split('');
str.map(function (num, idx) {
result.push(str.slice(0, (idx + 1)).join(''));
});
return result;
}
function substrings(str) {
var result = []
var i = 0;
while(i < str.length) {
substringsAtStart(str.slice(i)).forEach(char => result.push(char));
i += 1;
}
return result;
}
substrings('abcde');<file_sep>def transpose(array)
indexes = {}
array.each_with_index do |row, idx|
row.each_with_index do |num, idx2|
if idx == 0
indexes[idx2] = [num]
else
indexes[idx2] << num
end
end
end
indexes.values
end
transpose([[1, 2, 3, 4]]) == [[1], [2], [3], [4]]
transpose([[1], [2], [3], [4]]) == [[1, 2, 3, 4]]
transpose([[1, 2, 3, 4, 5], [4, 3, 2, 1, 0], [3, 7, 8, 6, 2]]) ==
[[1, 4, 3], [2, 3, 7], [3, 2, 8], [4, 1, 6], [5, 0, 2]]
transpose([[1]]) == [[1]]<file_sep># minimum number of point mutations
# GAGCCTACTAACGGGAT
# CATCGTAATGACGGCCT
# ^ ^ ^ ^ ^ ^^
class DNA
def initialize(sequence)
@sequence = sequence
@seq_arr = sequence.chars
end
def hamming_distance(other)
count = 0
new_seq = other.chars
new_seq.each_with_index do |letter, idx|
break if idx + 1 > @seq_arr.size
count += 1 if letter != @seq_arr[idx]
end
count
end
end
<file_sep>class Person
attr_accessor :name, :age
def initialize(name, age)
@name = name
@age = age
end
def >(other_person)
age > other_person.age
end
end
bob = Person.new("Bob", 49)
kim = Person.new("Kim", 33)
puts "bob is older" if bob > kim # => "bob is older"
puts "bob is older" if bob.>(kim) # => "bob is older"
# overriding <<
class Team
attr_accessor :name, :members
def initialize(name)
@name = name
@members = []
end
def <<(person)
members.push person
end
end
cowboys = Team.new("Dallas Cowboys")
emmitt = Person.new("<NAME>", 46) # suppose we're using the Person class from earlier
cowboys << emmitt # will this work?
cowboys.members # => [#<Person:0x007fe08c209530>]
# overriding +
class Team
attr_accessor :name, :members
def initialize(name)
@name = name
@members = []
end
def <<(person)
members.push person
end
def +(other_team)
members + other_team.members
end
end
# we'll use the same Person class from earlier
cowboys = Team.new("Dallas Cowboys")
cowboys << Person.new("<NAME>", 48)
cowboys << Person.new("<NAME>", 46)
cowboys << Person.new("<NAME>", 49)
niners = Team.new("San Francisco 49ers")
niners << Person.new("<NAME>", 59)
niners << Person.new("<NAME>", 52)
niners << Person.new("<NAME>", 47)
dream_team = cowboys + niners
<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: films; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE films (
title character varying(255) NOT NULL,
year integer NOT NULL,
genre character varying(100) NOT NULL,
duration integer NOT NULL,
director_id integer NOT NULL,
CONSTRAINT title_length CHECK ((length((title)::text) >= 1)),
CONSTRAINT year_range CHECK (((year >= 1900) AND (year <= 2100)))
);
ALTER TABLE films OWNER TO postgres;
--
-- Data for Name: films; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY films (title, year, genre, duration, director_id) FROM stdin;
Die Hard 1988 action 132 1
Casablanca 1942 drama 102 2
The Conversation 1974 thriller 113 3
1984 1956 scifi 90 4
Tinker Tailor Soldier Spy 2011 espionage 127 5
The Birdcage 1996 comedy 118 6
\.
--
-- Name: films title_unique; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films
ADD CONSTRAINT title_unique UNIQUE (title);
--
-- Name: films films_director_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films
ADD CONSTRAINT films_director_id_fkey FOREIGN KEY (director_id) REFERENCES directors(id);
--
-- PostgreSQL database dump complete
--
<file_sep>def cleanup(line)
line.gsub(/\p{^alpha}/, ' ').squeeze(' ')
end
cleanup("---what's my +*& line?") == ' what s my line '
=begin
squeeze([other_str]*) → new_str
Builds a set of characters from the other_str parameter(s)
using the procedure described for String#count.
Returns a new string where runs of the same character
that occur in this set are replaced by a single character.
If no arguments are given, all runs of identical characters
are replaced by a single character.
=end<file_sep># Pseudo
# 2 ideas - regex for non alnum, OR char the word and find out if parantheses occur within indices
# Regex sounds way simpler
# Find out if paranthases do not match
# if so, return false
# measure if all parentheses are closed
# my version
def balanced?(string)
return true if string !~ /[(|)]/
return false if (string.count('(') + string.count(')')).odd?
return false if string.chars.each_index.select {|idx| string[idx] == '('}.last > string.chars.each_index.select {|idx| string[idx] == ')'}.last
return true if (string.count('(') == string.count(')'))
false
end
balanced?('What (is) this?') == true
balanced?('What is) this?') == false
balanced?('What (is this?') == false
balanced?('((What) (is this))?') == true
balanced?('((What)) (is this))?') == false
balanced?('Hey!') == true
balanced?(')Hey!(') == false
balanced?('What ((is))) up(') == false
#ls solutuion
def balanced?(string)
parens = 0
string.each_char do |char|
parens += 1 if char == '('
parens -= 1 if char == ')'
break if parens < 0
end
parens.zero?
end
<file_sep>def repeat (str, num)
num.times do
puts str
end
end
repeat('Hello', 3)<file_sep>=begin
diamond(3)
*
***
*
diamond(9)
*
***
*****
*******
*********
*******
*****
***
*
what do they have in common?
will always be an odd integer
each line has the next odd number
=end
# PSEUDO
# create method, pick number of asterisks at center
# center each line
def diamond(odd_num)
rows = (1..odd_num).select {|n| n.odd?}
padding = rows[-1] + 1
rows += rows.reverse[1..-1]
rows.each {|n| puts ("*" * n).center(padding)}
end
diamond(25)<file_sep>def triangle(num)
output = ''
num.times {puts output.prepend("*").rjust(num)}
end
def flip_triangle(num)
output = ("*" * num)
num.times {puts output.rjust(num); output.slice!(0)}
end
def corner_triangle(num, corner)
if corner == "top left"
output = ("*" * num)
num.times {puts output.ljust(num); output.slice!(0)}
elsif corner == "bottom left"
output = ''
num.times {puts output.prepend("*").ljust(num)}
elsif corner == "bottom right"
output = ''
num.times {puts output.prepend("*").rjust(num)}
elsif corner == "top right"
output = ("*" * num)
num.times {puts output.rjust(num); output.slice!(0)}
end
end
triangle(5)
triangle(9)
flip_triangle(5)
corner_triangle(5, "bottom left")
corner_triangle(5, "top left")
corner_triangle(5, "bottom right")
corner_triangle(5, "top right")<file_sep>var foo = {
bar: 1,
baz: 2
}
// instead of var bar = foo.bar; var baz = foo.baz;
var { bar, baz } = foo;
var { bar } = foo;
// with an array
var tenses = ["me", "you", "he"];
var [ firstperson ] = tenses; // assigns "me"
// As function args (with es6 default values)
function calcBmi({ weight, height, max = 25, callback }) {
var bmi = weight / Math.pow(height, 2);
if (bmi > max) {
console.log("You're overweight");
}
if (callback) {
callback(bmi);
}
}
calcBmi({ weight: 32000000, height: 60, max: 28 });
calcBmi({ weight: 40, height: 50, callback: function(arg) {console.log(arg)} });
<file_sep>def each_cons(array)
array[0..-2].each_with_index { |item, idx| yield(item, array[idx + 1]) } ; nil
end
hash = {}
result = each_cons([1, 3, 6, 10]) do |value1, value2|
hash[value1] = value2
end
result == nil
hash == { 1 => 3, 3 => 6, 6 => 10 }
hash = {}
each_cons([]) do |value1, value2|
hash[value1] = value2
end
hash == {}
hash = {}
each_cons(['a', 'b']) do |value1, value2|
hash[value1] = value2
end
hash == {'a' => 'b'}
<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
require_relative 'swap_letters'
class SwapTest < MiniTest::Test
def setup
@sample_text = File.open('./the_sample.txt', 'r')
@text = Text.new(@sample_text.read)
@replacement = <<-REPLACE
Lorem ipsum doxor sit amet, consectetur adipiscing exit. Cras sed vuxputate ipsum.
Suspendisse commodo sem arcu. Donec a nisi exit. Nuxxam eget nisi commodo, voxutpat
quam a, viverra mauris. Nunc viverra sed massa a condimentum. Suspendisse ornare justo
nuxxa, sit amet moxxis eros soxxicitudin et. Etiam maximus moxestie eros, sit amet dictum
doxor ornare bibendum. Morbi ut massa nec xorem tincidunt exementum vitae id magna. Cras
et varius mauris, at pharetra mi.
REPLACE
end
def test_swap
assert_equal(@replacement, @text.swap('l','x'))
end
def test_word_count
assert_equal(72, @text.word_count)
end
def teardown
@sample_text.close
end
end <file_sep>numbers = [1, 2, 3, 4]
numbers.each do |number|
p number
numbers.shift(1)
end
# here's what's happening with each iteration
numbers = [1, 2, 3, 4]
numbers.each_with_index do |number, index|
p "#{index} #{numbers.inspect} #{number}"
numbers.shift(1)
end
# "0 [1, 2, 3, 4] 1" ; array is 1,2,3,4, prints 1 and deletes 1 item, shifts left
# "1 [2, 3, 4] 3" ; array is now modified as 2,3,4 prints 3 and deletes 1 item, shifts left
# => [3, 4] skips over the last 2 items because the length of the array has been shortened
numbers = [1, 2, 3, 4]
numbers.each do |number|
p number
numbers.pop(1)
end
# => [1, 2]
# In our second example, we are shortening the array each pass just as in
# the first example...but the items removed are beyond the point we are
# sampling from in the abbreviated loop.<file_sep># How would you order this array of number strings by descending numeric value?
arr = ['10', '11', '9', '7', '8']
arr.map {|a| a.to_i}.sort.reverse!.map! {|a| a.to_s}
# best solution
arr.sort {|a,b| b.to_i <=> a.to_i}
# => ["11", "10", "9", "8", "7"]
# by doing b, 'spaceship', a, the reverse order is achieved
# see ../sort.rb for more examples<file_sep>class PostsController < ApplicationController
before_action :require_user, except: [:index, :show]
before_action :set_post, only: [:show, :edit, :update, :destroy, :vote]
before_action :current_posts, only: :index
def index
@n = @all_posts.size
if params[:page]
@posts = params[:page].idx @all_posts
else
@posts = @all_posts[0]
end
end
def create
new_cat_name = params[:post][:categories]
@post = Post.new(post_params)
@post.creator = current_user
if !new_cat_name.empty? # validate/create new category
@category = Category.new(name: new_cat_name)
if Category.exists?(name: @category.name) # existing category
flash.now[:alert] = "The category, #{new_cat_name}, already exists, please use the check box."
return render 'new'
else # new category
if @category.save
@post.categories << @category
else
flash.now[:alert] = "Category validation issue. Please try again"
return render 'new'
end
end
end
if @post.save
flash[:notice] = "Your post was created"
redirect_to posts_path
else
render 'new'
end
end
def new
@post = Post.new
end
def show
@comment = Comment.new
@commented = @post.comments
if @commented.size > 0
@commented = @commented.sort_by(&:total_votes).reverse
end
end
def edit
end
def update
if @post.update(post_params)
flash[:notice] = "Your post was updated"
redirect_to posts_path
else
render 'edit'
end
end
def destroy
@post.destroy
flash[:notice] = "Post Deleted!"
redirect_to :back
end
def vote
@vote = Vote.create(voteable: @post, creator: current_user, vote: params[:vote])
if @vote.valid?
flash[:notice] = 'Your vote was counted'
elsif Vote.exists?(voteable: @post, creator: current_user)
@vote = Vote.find_by(voteable: @post, creator: current_user)
if params[:vote] != @vote.vote.to_s
@vote.vote = !@vote.vote
@vote.save
flash[:notice] = 'Your vote has changed'
else
@vote.delete
flash[:notice] = 'Unvoted'
end
else
flash[:notice] = 'Your vote did not count'
end
@message = flash.notice
respond_to do |format|
format.html { redirect_to :back }
format.js
end
end
private
def post_params
params.require(:post).permit(:title, :url, :description, :category_ids => [])
end
def set_post
@post = Post.find_by(slug: params[:id])
end
end
<file_sep>if false
greeting = “hello world”
end
greeting
# =>
# a variable will print nil when initialized within an 'if' block, even outside of that block<file_sep>def rotate_array(ary)
ary[1..-1] << ary.slice(0)
end
def rotate_rightmost_digits(digits, count)
digarray = digits.to_s.chars
rotated_nums = digarray[-count..-1]
rotated_nums = rotate_array(rotated_nums)
digarray = digarray[0...-count] + rotated_nums
digarray.join.to_i
end
rotate_rightmost_digits(735291, 2)
rotate_rightmost_digits(735291, 1)
rotate_rightmost_digits(735291, 1) == 735291
rotate_rightmost_digits(735291, 2) == 735219
rotate_rightmost_digits(735291, 3) == 735912
rotate_rightmost_digits(735291, 4) == 732915
rotate_rightmost_digits(735291, 5) == 752913
rotate_rightmost_digits(735291, 6) == 352917
<file_sep>class User < ActiveRecord::Base
has_secure_password validations: false
validates :username, presence: true, uniqueness: true
validates :email, presence: true, uniqueness: true
validates :password, presence: true, on: :create, length: {minimum: 3}
has_many :reviews
has_many :queue_items
end<file_sep>statement = "The Flintstones Rock"
statement.downcase!.delete!(" ")
statement_array = statement.chars
statement_array.each_with_object({}) do |(key, value), hash|
hash[key] = statement_array.count(key)
end<file_sep>def xor?(arg1, arg2)
if (arg1 && arg2)
false
elsif (arg1 || arg2)
true
else
false
end
end
xor?(5.even?, 4.even?) == true
xor?(5.odd?, 4.odd?) == true
xor?(5.odd?, 4.even?) == false
xor?(5.even?, 4.odd?) == false
# def xor?(value1, value2)
# (value1 && !value2) || (value2 && !value1)
# end<file_sep>require "sinatra"
require "sinatra/reloader"
require "tilt/erubis"
def find_chapnum(str)
str[-6..-5].include?('p') ? str[-5] : str[-6..-5]
end
before do
@chapters = File.readlines("data/toc.txt")
end
get "/" do
@title = "The Adventures of Sherlock Holmes"
erb :home
end
get "/chapters/:number" do
@title = "Chapter #{params[:number]}"
number = params[:number].to_i
redirect "/" unless (1..@chapters.size).cover? number
@chap_text = File.read("data/chp#{params[:number]}.txt")
@chap_ary = @chap_text.split("\n\n")
erb :chp1
end
get "/search" do
@query = params[:query]
@chaps_unsorted = Dir.glob("data/chp*").map { |file| File.basename(file) }
@chap_files = @chaps_unsorted.sort do |a, b|
a = find_chapnum(a)
b = find_chapnum(b)
a.to_i <=> b.to_i
end
erb :search
end
get "/show/:name" do
params[:name]
end
helpers do
def in_paragraphs(text, argument, chapnum)
text.split("\n\n").map.with_index do |par, idx|
next unless par.downcase.include?(argument)
path = "href=/chapters/#{chapnum}##{idx}"
par = par.gsub(argument, "<strong>#{argument}</strong>")
par = par.gsub(argument.capitalize, "<strong>#{argument.capitalize}</strong>")
par = par.gsub(argument.upcase, "<strong>#{argument.upcase}</strong>")
"<li><a #{path}>#{par}</a></li>"
end.join
end
def run_search
return nil if @query.nil?
result = @chap_files.map do |text|
chapnum = find_chapnum(text)
chtitle = @chapters[chapnum.to_i - 1]
chapstring = File.read("data/#{text}")
if chapstring.downcase.include?(@query.downcase)
"<li><strong>#{chtitle}</strong><ul>#{in_paragraphs(chapstring, @query, chapnum)}</ul></li>"
else
next
end
end.join
result.empty? ? "<p>Sorry, no matches were found.</p>" : "<ul>#{result}</ul>"
end
end
not_found do
redirect "/"
end
<file_sep>[1, 2, 3].reduce do |acc, num|
acc + num
end
# => 6
# it sets the accumulator to the return value of the block,
# and then passes the accumulator to the block on the next yield.
def reduce(input_array, accum = 0)
counter = 0
while counter < input_array.size
accum = yield(accum, input_array[counter])
counter += 1
end
accum
end
array = [1, 2, 3, 4, 5]
reduce(array) { |acc, num| acc + num } # => 15
reduce(array, 10) { |acc, num| acc + num } # => 25
<file_sep>class Greeting
def greet(sentence)
puts sentence
end
end
class Hello < Greeting
def initialize
@sentence = "Hello"
end
def hi
greet(@sentence)
end
end
class Goodbye < Greeting
def initialize
@sentence = "Goodbye"
end
def bye
greet(@sentence)
end
end
salutations = Hello.new
salutations.hi
farewell = Goodbye.new
farewell.bye
<file_sep>var me = {
firstname: 'Andy',
lastname: 'Rosenberg'
}
function fullName(person) {
console.log(person.firstName + ' ' + person.lastName);
}
fullName(me);
var friend = {
firstname: 'Derp',
lastname: 'DerpDerp'
}
fullName(friend);
var mother = {
firstname: 'Lisa',
lastname: 'Rosenberg'
}
var father = {
firstname: 'Phil',
lastname: 'Rosenberg'
}
fullName(mother);
fullName(father);
var people = [];
people.push(me);
people.push(friend);
people.push(mother);
people.push(father);
function rollCall(collection) {
collection.forEach(function(item) {
fullName(item);
});
}
rollCall(people);
// since forEach expects a function argument, just do this!
function rollCall(collection) {
collection.forEach(fullName);
}
rollCall(people);
// new, larger object
var people = {
collection: [me, friend, mother, father],
fullName: function(person) {
console.log(person.firstName + ' ' + person.lastName);
},
rollCall: function() {
people.collection.forEach(people.fullName);
},
};
people.rollCall();
people.rollCall = function() {
this.collection.forEach(this.fullName);
}
people.add = function(person) {
this.collection.push(person);
}
people.getIndex = function(person) {
return this.collection.indexOf(person);
}
people.remove = function(person) {
var index = this.getIndex(person);
console.log(index);
}
// updated getIndex
people.getIndex = function(person) {
var index = -1;
this.collection.forEach(function (comparator, i) {
if (comparator.firstname === person.firstname &&
comparator.lastname === person.lastname) {
index = i;
}
});
return index;
}
people.remove = function(person) {
var index = this.getIndex(person);
if (index === -1) {
return;
}
this.collection.splice(index, 1);
}
people.isValidPerson = function(person) {
return typeof person.firstName === 'string';
}
people.remove = function(person) {
var index = this.getIndex(person);
if (this.isValidPerson(person)){
return;
}
if (index === -1) {
return;
}
this.collection.splice(index, 1);
}
people.isInvalidPerson = function(person) {
return typeof person.firstName !== 'string' || typeof person.lastName !== 'string';
},
people.remove = function(person) {
if (this.isInvalidPerson(person)) {
return;
}
}
people.add = function(person) {
if (this.isInvalidPerson(person)) {
return;
}
this.collection.push(person);
}
people.get = function(person) {
if (this.isInvalidPerson(person)) {
return;
}
return this.collection[this.getIndex(person)];
}
people.update = function(person) {
if (this.isInvalidPerson(person)) {
return;
}
var existingPersonId = this.getIndex(person);
if (existingPersonId === -1) {
this.add(person);
} else {
this.collection[existingPersonId] = person;
}
}<file_sep>def calculate_bonus(salary, get_bonus)
unless get_bonus == false
bonus = salary/2
else
bonus = 0
end
bonus
end
puts calculate_bonus(2800, true) == 1400
puts calculate_bonus(1000, false) == 0
puts calculate_bonus(50000, true) == 25000
# Their version:
# def calculate_bonus(salary, bonus)
# bonus ? (salary / 2) : 0
# end<file_sep>@vehicles = ['car', 'car', 'truck', 'car', 'SUV', 'truck', 'motorcycle', 'motorcycle', 'car', 'truck']
@car = []
@truck = []
@motorcycle = []
@suv = []
def count_occurences(vehicles)
@vehicles.each do |v|
case v
when 'car'
@car << 'car'
when 'truck'
@truck << 'truck'
when 'motorcycle'
@motorcycle << 'motorcycle'
when 'SUV'
@suv << 'SUV'
end
end
puts "car => #{@car.size}"
puts "truck => #{@truck.size}"
puts "SUV => #{@suv.size}"
puts "motorcycle => #{@motorcycle.size}"
end
count_occurences(@vehicles)
=begin
Their solution:
def count_occurrences(array)
occurrences = {}
array.each do |element|
occurrences[element] = array.count(element)
end
occurrences.each do |element, count|
puts "#{element} => #{count}"
end
end
=end<file_sep>function buyFruit(nest) {
var result = [];
var times;
nest.forEach(function (fruit){
times = fruit[1];
while (times > 0) {
result.push(fruit[0]);
times -= 1;
}
});
return result;
}
buyFruit([['apple', 3], ['orange', 1], ['banana', 2]]);<file_sep># Use Kernel#raise to raise exceptions
raise TypeError.new("Something went wrong!")
raise TypeError, "Something went wrong!"
# Will default to RuntimeError if no error specified
def validate_age(age)
raise("invalid age") unless (0..105).include?(age)
end
# Handling Manual Exceptions
begin
validate_age(age)
rescue RuntimeError => e
puts e.message #=> "invalid age"
end
# Custom Exception Classes
class ValidateAgeError < StandardError; end
# ValidateAgeError now has access to all of the built-in exception object
# behaviors Ruby provides, including Exception#message and Exception#backtrace
# Most often you will want to inherit from StandardError.
# In Practice:
def validate_age(age)
raise ValidateAgeError, "invalid age" unless (0..105).include?(age)
end
begin
validate_age(age)
rescue ValidateAgeError => e
# take action
end
<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: weather; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE weather (
date date NOT NULL,
low integer NOT NULL,
high integer NOT NULL,
rainfall numeric(6,3) DEFAULT 0
);
ALTER TABLE weather OWNER TO postgres;
--
-- Data for Name: weather; Type: TABLE DATA; Schema: public; Owner: postgres
--
INSERT INTO weather VALUES ('2016-03-01', 34, 43, 0.100);
INSERT INTO weather VALUES ('2016-03-02', 32, 44, 0.100);
INSERT INTO weather VALUES ('2016-03-03', 31, 47, 0.200);
INSERT INTO weather VALUES ('2016-03-04', 33, 42, 0.100);
INSERT INTO weather VALUES ('2016-03-05', 39, 46, 0.300);
INSERT INTO weather VALUES ('2016-03-06', 32, 43, 0.100);
INSERT INTO weather VALUES ('2016-03-09', 17, 18, 0.000);
INSERT INTO weather VALUES ('2016-03-07', 29, 32, 0.000);
INSERT INTO weather VALUES ('2016-03-08', 23, 31, 0.000);
--
-- PostgreSQL database dump complete
--
<file_sep>function guessEngine() {
function guessPassword() {
var i;
for (i = 0; i < 3; i++) {
var guess = prompt('What is the password');
if (guess === 'password') { return true; }
}
return false;
}
if (guessPassword()) {
console.log('You have successfully logged in.');
} else {
console.log('You have been denied access.');
}
}<file_sep>puts "What is your name?"
name = gets.chomp.capitalize!
if name == nil
puts "Teddy is #{rand(20..201)} years old!"
else
puts "#{name} is #{rand(20..201)} years old!"
end<file_sep>class ChangePermissionsInUsersForDefaultValues < ActiveRecord::Migration
def change
change_column :users, :permissions, :string, :default => 'user'
end
end
<file_sep># in Ruby Array and Hash includes the Enumerable module.
# Enumerable#any? looks for truthiness in the return value of the block, if any items are truthy
%w[ant bear cat].any? { |word| word.length >= 3 } #=> true
%w[ant bear cat].any? { |word| word.length >= 4 } #=> true
[nil, true, 99].any? #=> true
[].any? #=> false
[1, 2, 3].any? do |num|
num > 2
end
# => true
{ a: "ant", b: "bear", c: "cat" }.any? do |key, value|
value.size > 4
end
# => false
# Enumerable#all? also looks for truthiness in the return value of the block, but all items have to be truthy
[1, 2, 3].all? do |num|
num > 2
end
# => false
{ a: "ant", b: "bear", c: "cat" }.all? do |key, value|
value.length >= 3
end
# => true
# Enumerable#each_with_index
# takes a second argument to represent index
[1, 2, 3].each_with_index do |num, index|
puts "The index of #{num} is #{index}."
end
# The index of 1 is 0.
# The index of 2 is 1.
# The index of 3 is 2.
# => [1, 2, 3]
# useful for hash because it can call each k-v pair
{ a: "ant", b: "bear", c: "cat" }.each_with_index do |pair, index|
puts "The index of #{pair} is #{index}."
end
# The index of [:a, "ant"] is 0.
# The index of [:b, "bear"] is 1.
# The index of [:c, "cat"] is 2.
# => { :a => "ant", :b => "bear", :c => "cat" }
# Enumerable#each_with_object
[1, 2, 3].each_with_object([]) do |num, array|
array << num if num.odd?
end
# => [1, 3]
# In the above example, array is initialized to an empty array, [].
# Inside the block, we can now manipulate array.
# In this case, we're just appending the current num into it if it's odd.
# calling the last element of each k,v pair in a hash, placing into an array
{ a: "ant", b: "bear", c: "cat" }.each_with_object([]) do |pair, array|
array << pair.last
end
# => ["ant", "bear", "cat"]
# switching the values on a hash, putting them into a new hash
{ a: "ant", b: "bear", c: "cat" }.each_with_object({}) do |(key, value), hash|
hash[value] = key
end
# => { "ant" => :a, "bear" => :b, "cat" => :c }
# Enumerable#first
[1, 2, 3].first
# => 1
{ a: "ant", b: "bear", c: "cat" }.first(2)
# => [[:a, "ant"], [:b, "bear"]]
# since Ruby 1.9, order is preserved according to the order of insertion. Hashes have order.
# Enumerable#include?
[1, 2, 3].include?(1)
# => true
# Only checks keys, not the values:
{ a: "ant", b: "bear", c: "cat" }.include?("ant")
# => false
{ a: "ant", b: "bear", c: "cat" }.include?(:a)
# => true
# Enumerable#partition
# Partition divides up elements in the current collection
# into two collections, depending on the block's return value.
[1, 2, 3].partition do |num|
num.odd?
end
# => [[1, 3], [2]]
odd, even = [1, 2, 3].partition do |num|
num.odd?
end
odd # => [1, 3]
even # => [2]
# Partition always returns an array
long, short = { a: "ant", b: "bear", c: "cat" }.partition do |key, value|
value.size > 3
end
# => [[[:b, "bear"]], [[:a, "ant"], [:c, "cat"]]]
# need to use to_h to turn back into a hash<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: customers; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE customers (
id integer NOT NULL,
name text NOT NULL,
payment_token character varying(8) NOT NULL,
CONSTRAINT p_t_letters CHECK (((payment_token)::text !~ '[^A-Z]'::text))
);
ALTER TABLE customers OWNER TO postgres;
--
-- Name: customers_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE customers_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE customers_id_seq OWNER TO postgres;
--
-- Name: customers_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE customers_id_seq OWNED BY customers.id;
--
-- Name: customers_services; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE customers_services (
id integer NOT NULL,
customer_id integer,
service_id integer
);
ALTER TABLE customers_services OWNER TO postgres;
--
-- Name: customers_services_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE customers_services_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE customers_services_id_seq OWNER TO postgres;
--
-- Name: customers_services_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE customers_services_id_seq OWNED BY customers_services.id;
--
-- Name: services; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE services (
id integer NOT NULL,
description text NOT NULL,
price numeric(10,2) NOT NULL,
CONSTRAINT not_neg CHECK ((price >= 0.00))
);
ALTER TABLE services OWNER TO postgres;
--
-- Name: services_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE services_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE services_id_seq OWNER TO postgres;
--
-- Name: services_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE services_id_seq OWNED BY services.id;
--
-- Name: customers id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY customers ALTER COLUMN id SET DEFAULT nextval('customers_id_seq'::regclass);
--
-- Name: customers_services id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY customers_services ALTER COLUMN id SET DEFAULT nextval('customers_services_id_seq'::regclass);
--
-- Name: services id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY services ALTER COLUMN id SET DEFAULT nextval('services_id_seq'::regclass);
--
-- Data for Name: customers; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY customers (id, name, payment_token) FROM stdin;
1 <NAME> XHGOAHEQ
2 <NAME> JKWQPJKL
3 <NAME> KLZXWEEE
5 <NAME> UUEAPQPS
6 <NAME> XKJEYAZA
7 <NAME> EYODHLCN
\.
--
-- Data for Name: customers_services; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY customers_services (id, customer_id, service_id) FROM stdin;
1 1 1
2 1 2
3 1 3
4 3 1
5 3 2
6 3 3
7 3 4
8 3 5
11 5 1
12 5 2
13 5 6
14 6 1
15 6 6
17 7 1
18 7 2
19 7 3
\.
--
-- Data for Name: services; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY services (id, description, price) FROM stdin;
1 Unix Hosting 5.95
2 DNS 4.95
3 Whois Registration 1.95
4 High Bandwidth 15.00
5 Business Support 250.00
6 Dedicated Hosting 50.00
8 One-to-one Training 999.00
\.
--
-- Name: customers_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('customers_id_seq', 7, true);
--
-- Name: customers_services_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('customers_services_id_seq', 19, true);
--
-- Name: services_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('services_id_seq', 8, true);
--
-- Name: customers customers_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY customers
ADD CONSTRAINT customers_pkey PRIMARY KEY (id);
--
-- Name: customers_services customers_services_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY customers_services
ADD CONSTRAINT customers_services_pkey PRIMARY KEY (id);
--
-- Name: services services_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY services
ADD CONSTRAINT services_pkey PRIMARY KEY (id);
--
-- Name: customers_services customers_services_customer_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY customers_services
ADD CONSTRAINT customers_services_customer_id_fkey FOREIGN KEY (customer_id) REFERENCES customers(id);
--
-- Name: customers_services customers_services_services_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY customers_services
ADD CONSTRAINT customers_services_services_id_fkey FOREIGN KEY (service_id) REFERENCES services(id);
--
-- PostgreSQL database dump complete
--
<file_sep>class Cube
attr_reader :volume
def initialize(volume)
@volume = volume
end
end
Cube.new(3).volume
# L_S Explanation, Great method #instance_variable_get
=begin
big_cube = Cube.new(5000)
>> big_cube.instance_variable_get("@volume")
=> 5000
=end<file_sep>// XMLHttpRequest constructor
var request = new XMLHttpRequest();
request.open('GET', '/path');
request.send();
// null values before request completes
request.responseText; // => null
request.status; // => null
request.statusText; // => null
// once request completes:
request.responseText; // body of response
request.status; // status code of response
request.statusText; // status text from response
request.getResponseHeader('Content-Type'); // response header
request.readyState; // more on this later...
// event listener
request.addEventListener('load', function(event) {
var request = event.target; // the XMLHttpRequest object
request.responseText; // body of response
request.status; // status code
request.statusText; // status text from response
request.getResponseHeader('Content-Type'); // response header
request.readyState; // more on this later...
});
// Best format:
request.open('GET', '/path');
// For POST:
var request2 = new XMLHttpRequest();
request2.open('POST', 'http://example.test/path');
var data = 'this is a test';
// like data attr in $.ajax()
request2.send(data);
// Or if there was no data to send
// request.send();
// With event listener:
var request3 = new XMLHttpRequest();
request3.open('POST', 'http://ls-230-book-catalog.herokuapp.com/books');
request3.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
var data2 = 'title=Effective%20JavaScript&author=David%20Herman';
request3.addEventListener('load', function() {
if (request3.status === 201) {
// A 201 status means the resource was added successfully on the server
console.log('This book was added to the catalog: ' + request3.responseText);
}
});
request3.send(data2);
<file_sep># returns the result of concatenating
# the shorter string, the longer string, and the shorter string once again.
def short_long_short(string_1, string_2)
if string_1.length > string_2.length
long, short = string_1, string_2
else
short, long = string_1, string_2
end
old_string = short.freeze
new_string = old_string.dup.concat(long)
new_string = new_string.concat(old_string)
end
short_long_short('abc', 'defgh') == "abcdefghabc"
short_long_short('abcde', 'fgh') == "fghabcdefgh"
short_long_short('', 'xyz') == "xyz"
# Good User Solution:
# def short_long_short(str1, str2)
# str1 < str2 ? str1+str2+str1 : str2+str1+str2
# end<file_sep>require_relative 'to_binary'
class SecretHandshake
attr_reader :commands
def initialize(num)
if num.class == String
@binary = num
@commands = calculate_commands(num)
elsif num.class == Integer
@binary = num.to_binary
@commands = calculate_commands(@binary)
else
raise ArgumentError, 'Argument Needs to be a String or Integer'
end
end
private
def calculate_commands(bin)
return [] if !validate_binary
commands = bin.chars
unreversed = true
result = bin.chars.map.with_index do |b, idx|
next if b == '0'
size = commands[idx..-1].size
if size > 4
unreversed = false
next
elsif size == 4
b = 'jump'
elsif size == 3
b = 'close your eyes'
elsif size == 2
b = 'double blink'
else
b = 'wink'
end
end
result.compact!
result.reverse! if unreversed
result
end
def validate_binary
return false if @binary =~ /[^01]/
true
end
end
number = SecretHandshake.new(9)
string = SecretHandshake.new("11001")
<file_sep>def reversed_number(num)
num = num.to_s.chars.select {|n| !n.to_i.zero?}
num.reverse.join.to_i
end
reversed_number(12345) == 54321
reversed_number(12213) == 31221
reversed_number(456) == 654
reversed_number(12000) == 21 # Note that zeros get dropped!
reversed_number(1) == 1<file_sep>var inventory;
(function() {
inventory = {
collection: [],
setDate: function() {
$('#order_date').text(new Date().toDateString());
},
init: function() {
this.setDate();
this.template = $('#inventory_item').html();
$(document).remove('#inventory_item');
},
add: function(item) {
this.collection.push(item);
},
update: function(idx, key, value) {
this.collection[idx][key] = value;
},
del: function(idx) {
this.collection.splice(idx, 1);
},
};
})();
$(inventory.init.bind(inventory));
function findID(event) {
return Number($(event.target).parents('tr').find('[type=hidden]').val());
}
function findInvIdx(numID) {
return inventory.collection.findIndex(function(item) {
return item.id === numID;
});
}
$(function() {
var seqID = 0;
var $temp = $('#inventory_item').remove();
inventory.template = Handlebars.compile($temp.html());
$('button').click(function(e) {
e.preventDefault();
seqID += 1;
inventory.add({
id: seqID,
name: '',
"stock number": '',
quantity: 1
});
var $item = $(inventory.template({ id: seqID }));
$('#inventory').append($item);
});
$('#inventory').on('blur', 'input', function(e) {
var id = findID(e);
var idx = findInvIdx(id);
var key = $(this).parent().find('label').text().toLowerCase();
var value = key === "quantity" ? Number($(this).val()) : $(this).val();
inventory.update(idx, key, value);
});
$('#inventory').on('click', '.delete', function(e) {
e.preventDefault();
var id = findID(e);
var idx = findInvIdx(id);
inventory.del(idx);
$(this).parents('tr').remove();
});
});
<file_sep>famous_words = "seven years ago..."
other_famous_words = "Four score and"
other_famous_words << famous_words
"Four score and" + famous_words
# good example in their answer
famous_words.prepend("Four score and")<file_sep># triple-nested array:
[[[1], [2], [3], [4]], [['a'], ['b'], ['c']]].map do |element1|
element1.each do |element2|
element2.partition do |element3|
element3.size > 0
end
end
end
# => [[[1], [2], [3], [4]], [["a"], ["b"], ["c"]]]
=begin
Line: 1
Action: Method Call, Map
Object: 1st-level Singular Array
Side Effects: None
Return Value: New, Full Array
Return Used: No
Line: 1-7
Action: 1st-level block execution
Object: 2nd level Sub Arrays
Side-effects: None
Return Value: New, Full Array
Return Used: yes, by map
Line: 2
Action: Method call, Each
Object: Each of the 2 arrays on the 2nd level
Side Effects: None
Return Value: 2 sub arrays, organized according to partition
Return Used: No
Line: 2-6
Action: 2nd-level block execution
Object: 3rd level singular arrays
Side Effects: None
Return Value: 3rd level arrays organized by partition
Return Used: Yes, to determine the return value of 1st level block
Line: 3
Action: Method Call, Partition
Object: 3rd level arrays
Side Effects: None
Return Value: Reorganized Arrays on the 3rd level
Return Used: Yes, to determine return value of the 2nd block
Lines: 3-4
Action: Block Execution
Object: Each element in the singular 3rd level arrays
Side Effects: None
Return Value: Reorganized 3rd Level Arrays
Return Used: Yes, to determine the return value of 3rd level block
Line: 4
Action: Method Call, Size
Object: Each Element in the singular 3rd level arrays
Side Effects: None
Return Value: 1 for each element on the 3rd level arrays
Return Used: Yes, to determine the return value of the third level block
Line: 4
Action: Element3.size > 0
Object: Each element in the singular 3rd level arrays
Side Effects: none
Return Value: True for each block
Return used: Yes, by partition to determine the order of the new arrays
=end<file_sep>// Dog.prototype --> Animal.prototype --> Object.prototype
function Animal(animalType) {
this.animalType = animalType; // values for this can be land, air, or water
}
Animal.prototype.move = function() {
console.log('Animal is moving.');
};
var Dog = function() {};
// Assign prototype to return value of constructor function
Dog.prototype = new Animal('land');
Dog.prototype.say = function() {
console.log(this.name + ' says Woof!');
};
Dog.prototype.run = function() {
console.log(this.name + ' runs away.');
};
// or Dog.prototype = Object.create(Animal.prototype);
// need to reset constructor pointer
// manually after instantiation.
var myDog = new Dog;
myDog.constructor; // returns `Animal` constructor function
Dog.prototype.constructor = Dog;
<file_sep>=begin
# You have a bank of switches before you numbered from 1 to 1000.
# Each switch is connected to exactly one light that is initially off.
# You walk down the row of switches, and turn every one of them on.
# Then, you go back to the beginning and toggle switches 2, 4, 6, and so on.
# Repeat this for switches 3, 6, 9, and so on,
# and keep going until you have been through 1000 repetitions of this process.
# with 5 switches
# round 1: every light is turned on
# round 2: turn off all evens >= 2, lights 2 and 4 are now off; 1, 3, 5 are on
# round 3: turn off all odds >= 3 lights 2, 3, and 4 are now off; 1 and 5 are on
# round 4: toggle all evens >= 4, lights 2 and 3 are now off; 1, 4, and 5 are on
# round 5: toggle all odds >= 5, lights 2, 3, and 5 are now off; 1 and 4 are on
=end
# PSEUDO
# Make two conditions, on and off
# Make 1000 lights
# put them into a collection, probably a hash with on and off conditions
# lights start as off
# Iterate through the collection, each time skipping through a greater number of switches
# i.e. skip 1 (all lights) skip 2, skip 3...
# toggle until there have been 1000 repetitions
counter = 1
def toggle(value)
value == "Off" ? value.gsub!("Off", "On") : value.gsub!("On", "Off")
end
def switch(hsh, start)
hsh.map do |k, v|
if k % start == 0
toggle(v)
end
end
hsh
end
lights = Hash[(1..1000).map { |num| [num, "Off"] }]
loop do
break if counter == 1000
switch(lights, counter)
counter += 1
end
p lights.select {|k, v| v == "On"}.keys
<file_sep>class Expander
def initialize(string)
@string = string
end
def to_s
self.expand(3)
end
protected
def expand(n)
@string * n
end
end
expander = Expander.new('xyz')
puts expander
# puts originally was called on an instance of an object accessing a private method
# which produced an error, making it protected allows us to access the method in an instance
# their solution
class Expander
def to_s
expand(3)
end
end
# private methods can not be called with a receiver, even if that receiver is self
# a reveiver could be the class or instance variable
<file_sep>def player_turn
loop do
puts "hit or stay?"
answer = gets.chomp
break if answer == 'stay' || busted?(card_value)
card_value = hit(shuffled_deck, player_hand, card_value)
puts "Your hand has #{player_deck.join(', '), totaling #{current_value}"
end
end
<file_sep># this loop is a nice alternative to each for selection purposes
# use a counter with a loop to select g out of the sequence
alphabet = 'abcdefghijklmnopqrstuvwxyz'
selected_chars = ''
counter = 0
loop do
current_char = alphabet[counter]
if current_char == 'g' # selection criteria
selected_chars << current_char # appends current_char into the selected_chars string
end
counter += 1
break if counter == alphabet.size
end
selected_chars # => "g"
<file_sep>class GuessingGame
attr_accessor :guesses, :win_game
LIMIT = 7
def initialize
@number = rand(1..LIMIT)
@winner = rand(1..100)
@win_game = false
end
def guess_number
return puts "You have #{@number} guesses remaining" unless @number == 1
puts "You have 1 guess remaining"
end
def validated?(guess)
guess > 0 && guess < 100
end
def evaluate(guess)
puts "Your guess is too high" if guess > @winner
puts "Your guess is too low" if guess < @winner
end
def turn
answer = nil
loop do
guess_number
loop do
puts "Enter a number between 1 and 100:"
answer = gets.chomp.to_i
break if validated?(answer)
puts "Invalid Guess."
end
evaluate(answer)
@number -= 1
break if answer == @winner || @number.zero?
end
self.win_game = true if answer == @winner
end
def play
turn
return puts "You Win!" if win_game
puts "You are out of guesses. You lose."
end
end
game = GuessingGame.new
game.play
=begin
You have 7 guesses remaining.
Enter a number between 1 and 100: 104
Invalid guess. Enter a number between 1 and 100: 50
Your guess is too low
You have 6 guesses remaining.
Enter a number between 1 and 100: 75
Your guess is too low
You have 5 guesses remaining.
Enter a number between 1 and 100: 85
Your guess is too high
You have 4 guesses remaining.
Enter a number between 1 and 100: 0
Invalid guess. Enter a number between 1 and 100: 80
You have 3 guesses remaining.
Enter a number between 1 and 100: 81
You win!
game.play
You have 7 guesses remaining.
Enter a number between 1 and 100: 50
Your guess is too high
You have 6 guesses remaining.
Enter a number between 1 and 100: 25
Your guess is too low
You have 5 guesses remaining.
Enter a number between 1 and 100: 37
Your guess is too high
You have 4 guesses remaining.
Enter a number between 1 and 100: 31
Your guess is too low
You have 3 guesses remaining.
Enter a number between 1 and 100: 34
Your guess is too high
You have 2 guesses remaining.
Enter a number between 1 and 100: 32
Your guess is too low
You have 1 guesses remaining.
Enter a number between 1 and 100: 32
Your guess is too low
You are out of guesses. You lose.
=end
<file_sep>WORD_DIGITS = {"zero": 0, "one": 1, "two": 2, "three": 3, "four": 4, "five": 5, "six": 6, "seven": 7, "eight": 8, "nine": 9}
def word_to_digit(string)
string = string.split
string.map do |word|
WORD_DIGITS.select do |k, v|
if word.include?(k.to_s)
if word[-1] !~ /a-zA-Z0-9/
word.gsub!(/[a-zA-Z]/, v.to_s).squeeze!
else
word.gsub!(/\b#{word}\b/, v.to_s)
end
end
end
end
string.join(' ')
end
word_to_digit('Please call me at five five five one two three four. Thanks.')<file_sep>FACE = ['two', 'three', 'four', 'five', 'six', 'seven', 'eight', 'nine', 'ten', 'jack', 'queen', 'king', 'ace']
hearts = FACE.map { |f| f + ' of hearts' }
spades = FACE.map { |f| f + ' of spades' }
clubs = FACE.map { |f| f + ' of clubs' }
diamonds = FACE.map { |f| f + ' of diamonds' }
deck = hearts + spades + clubs + diamonds
player_hand = []
computer_hand = []
usable_deck = deck.clone
deck.freeze
player_wins = []
computer_wins = []
WIN_AMOUNT = 21
STAY_AMOUNT = 17
def reshuffle!(dck)
dck.clone.shuffle!
end
def draw_cards!(dck, hnd)
hnd << dck.slice!(0..1)
hnd.flatten!
end
def determine_value(hnd)
hnd = hnd.map { |h| h.split[0] }
values = [2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10]
non_ace = FACE[0..-2]
if hnd.include?('ace')
hnd = hnd.unshift(1, 11)
end
non_ace.each { |f| hnd.include?(f) ? hnd << (values[non_ace.index(f)]) : f }
dup = hnd.select { |element| hnd.count(element) > 1 }
if !dup.empty?
non_ace.map { |f| hnd.include?(f) ? hnd << (values[non_ace.index(f)]) : f }
end
new_hnd = hnd.select { |h| h.integer? rescue false }
if new_hnd.include?(11)
unless new_hnd == [1, 11]
new_hnd[2..-1].inject(&:+) >= 22 ? new_hnd.delete(11) : new_hnd.delete(1)
end
end
new_hnd.size == 4 ? new_hnd[0..1].inject(&:+) : new_hnd.inject(&:+)
end
def busted?(crd)
crd > WIN_AMOUNT
end
def hit(dck, hnd, c_val)
new_card = dck.slice!(0)
hnd << new_card
crd = new_card.split[0]
if crd != 'ace'
c_val += determine_value([new_card])
else
c_val + 11 > WIN_AMOUNT ? c_val += 1 : c_val += 11
end
c_val
end
loop do
puts "First to Five Wins!"
loop do
break if player_wins.size == 5 || computer_wins.size == 5
loop do
shuffled_deck = reshuffle!(usable_deck)
draw_cards!(shuffled_deck, player_hand)
player_card_value = determine_value(player_hand)
draw_cards!(shuffled_deck, computer_hand)
# player turn
puts "Player Score: #{player_wins.size}, Dealer Score: #{computer_wins.size}"
puts "Press Enter To Continue"
enter = gets
system "cls"
puts "Both Players Draw Their Cards..."
puts "Dealer is showing the #{computer_hand[0]}."
puts "Your hand: #{player_hand.join(' and ')}. Total: #{player_card_value}."
loop do
puts "hit or stay?"
answer = ''
loop do
answer = gets.chomp
break if answer.downcase.start_with?('h', 's')
puts 'Invalid choice. Hit or stay?'
end
break if answer.downcase.start_with?('s')
puts "Player Hits..."
player_card_value = hit(shuffled_deck, player_hand, player_card_value)
puts "Your hand: #{player_hand.join(', ')}. Total: #{player_card_value}."
break if busted?(player_card_value)
end
loser = ''
if busted?(player_card_value)
puts "You busted, sucka."
loser = "Player"
computer_wins << loser
break
else
puts "You chose to stay at #{player_card_value}."
end
# dealer turn
dealer_card_value = determine_value(computer_hand)
next if !loser.empty?
puts "Dealer Shows Cards..."
puts "Dealer hand: #{computer_hand.join(' and ')}. Total: #{dealer_card_value}."
loop do
break if busted?(dealer_card_value) || dealer_card_value >= STAY_AMOUNT
puts "Dealer Hits..."
dealer_card_value = hit(shuffled_deck, computer_hand, dealer_card_value)
puts "Dealer hand: #{computer_hand.join(', ')}. Total: #{dealer_card_value}."
end
if dealer_card_value <= WIN_AMOUNT
puts "Dealer chooses to stay at #{dealer_card_value}."
else
puts "Dealer Busts!"
loser = "Dealer"
player_wins << loser
end
if !busted?(dealer_card_value) && !busted?(player_card_value)
if player_card_value == dealer_card_value
winner = "Tie!"
elsif player_card_value > dealer_card_value
winner = "Player Wins!"
player_wins << winner
else winner = "Dealer Wins!"
computer_wins << winner
end
puts winner
break
else
puts "#{loser} Loses!"
end
break if !loser.empty?
end
player_hand.clear
computer_hand.clear
usable_deck = deck.dup
end
player_wins.size == 5 ? game_winner = "Player" : game_winner = "Dealer"
system "cls"
puts "#{game_winner} wins the game!"
puts "Play Again? (y or n)"
play_again = gets.chomp
break unless play_again.downcase.start_with?('y')
player_wins.clear
computer_wins.clear
end
puts "Thanks for Playing #{WIN_AMOUNT}. Goodbye!"
<file_sep>function isUppercase(str) {
if (!str) { return true }
return str.split('').every(function (char) {return char === char.toUpperCase()});
}
isUppercase('t'); // false
isUppercase('T'); // true
isUppercase('Four Score'); // false
isUppercase('FOUR SCORE'); // true
isUppercase('4SCORE!'); // true
isUppercase(''); // true <file_sep>function delayLog() {
function log() {
var i = 1;
return function() {
console.log(i);
i++;
return i;
};
}
var runLog = log();
var j;
for (j = 1; j < 11; j++) {
setTimeout(runLog, (j * 1000))
}
}
delayLog();<file_sep>def reverse(list)
list.sort_by {|i| -list.index(i)}
end
reverse([1,2,3,4]) == [4,3,2,1] # => true
reverse(%w(a b c d e)) == %w(e d c b a) # => true
reverse(['abc']) == ['abc'] # => true
reverse([]) == [] # => true
list = [1, 2, 3] # => [1, 2, 3]
new_list = reverse(list) # => [3, 2, 1]
list.object_id != new_list.object_id # => true
list == [1, 2, 3] # => true
new_list == [3, 2, 1] # => true
<file_sep>function indexOf(firstString, secondString) {
var i;
for (i = 0; i < firstString.length; i++) {
if (firstString[i] === secondString[0]) {
var save = i;
var j;
for (j = 1; j < secondString.length; j++) {
i++;
if (secondString[j] !== firstString[i]) {
return -1;
}
}
return save;
}
}
return -1;
}
function lastIndexOf(firstString, secondString) {
var i;
for (i = 0; i < firstString.length; i++) {
if (firstString[i] === secondString[0]) {
var save = i;
var k = i;
var j;
for (j = 1; j < secondString.length; j++) {
k++;
if (secondString[j] !== firstString[k]) {
return -1;
}
}
}
}
if (!save) {
return -1;
} else {
return save;
}
}
<file_sep>words = {}
def prompt(word_type, hash)
puts "Enter a #{word_type}:"
answer = gets.chomp
hash[word_type] = answer
end
prompt(:noun, words)
prompt(:verb, words)
prompt(:adjective, words)
prompt(:adverb, words)
puts "Do you #{words[:verb]} your #{words[:adjective]} #{words[:noun]} #{words[:adverb]}? That's hilarious!"
<file_sep># A bubble sort works by making multiple passes (iterations) through the Array.
# On each pass, each pair of consecutive elements is compared.
# If the first of the two elements is greater than the second, then the two elements are swapped.
def bubble_sort!(array)
until array == array.sort
array.each_cons(2) {|a, b| a > b ? array[array.index(a)] = [a, b].sort : a}
array.flatten!.uniq!
end
array
end
array = [5, 3]
bubble_sort!(array)
array == [3, 5]
array = [6, 2, 7, 1, 4]
bubble_sort!(array)
array == [1, 2, 4, 6, 7]
array = %w(<NAME> <NAME>)
bubble_sort!(array)
array == %w(<NAME> Kim <NAME> <NAME>)
<file_sep># The main difference between dup and clone is that clone preserves the frozen state of the object.
arr1 = ["a", "b", "c"].freeze
arr2 = arr1.clone
arr2 << "d"
# => RuntimeError: can't modify frozen Array
# dup doesn't preserve the frozen state of the object.
arr1 = ["a", "b", "c"].freeze
arr2 = arr1.dup
arr2 << "d"
arr2 # => ["a", "b", "c", "d"]
arr1 # => ["a", "b", "c"]
# In Ruby, objects can be frozen in order to prevent them from being modified.
str = "abc".freeze
str << "d"
# => RuntimeError: can't modify frozen String
# frozen?
5.frozen? # => true
# freeze only freezes the object it's called on.
# If the object it's called on contains other objects, those objects won't be frozen.
arr = [[1], [2], [3]].freeze
arr[2] << 4
arr # => [[1], [2], [3, 4]]
arr = ["a", "b", "c"].freeze
arr[2] << "d"
arr # => ["a", "b", "cd"]<file_sep>def century(year)
year = year.to_i
if year.to_s.end_with?('00')
year = year/100
else
year = (year/100) + 1
end
year = year.to_s
if year[-2] == '1'
year = year + 'th'
else
if year.end_with?('1')
year = year + 'st'
elsif year.end_with?('2')
year = year + 'nd'
elsif year.end_with?('3')
year = year + 'rd'
else
year = year + 'th'
end
end
year
end
century(2000) == '20th'
century(2001) == '21st'
century(1965) == '20th'
century(256) == '3rd'
century(5) == '1st'
century(10103) == '102nd'
century(1052) == '11th'
century(1127) == '12th'
century(11201) == '113th'
=begin
Their Version:
def century(year)
century = year / 100 + 1
century -= 1 if year % 100 == 0
century.to_s + century_suffix(century)
end
def century_suffix(century)
return 'th' if [11, 12, 13].include?(century % 100)
last_digit = century % 10
case last_digit
when 1 then 'st'
when 2 then 'nd'
when 3 then 'rd'
else 'th'
end
end
=end<file_sep>for i in (1..99) do
if i.odd?
puts i
end
end<file_sep>var identifier = 0;
var SHAPE1 = '<div class="container-shape" id="';
var SHAPE2 = 'id"><div class="';
var SHAPE3 = '"></div></div>';
$(function() {
$('form').submit(function(e) {
e.preventDefault();
identifier += 1;
var chosen = SHAPE1 + String(identifier) +
SHAPE2 + $(':radio:checked').val() + SHAPE3;
$(chosen).appendTo('#canvas');
var current = $('#' + String(identifier) + 'id');
var x = Number(current.css('left').slice(0, -2));
var y = Number(current.css('top').slice(0, -2));
current.data('outx', x);
current.data('outy', y);
current.css('left', String(x + Number($('#startx').val())) + 'px');
current.data('startx', current.css('left'));
current.css('top', String(y + Number($('#starty').val())) + 'px');
current.data('starty', current.css('top'));
current.data('endx', Number($('#endx').val()));
current.data('endy', Number($('#endy').val()));
current.data('duration', Number($('#duration').val()));
});
$('#startlink').click(function(e) {
e.preventDefault();
if (!$('[id*=id]').get(0)) {
alert('Please add a shape before pressing start.');
} else {
$('[id*=id]').each(function(i) {
var endx = $(this).data('endx');
var outx = $(this).data('outx');
var endy = $(this).data('endy');
var outy = $(this).data('outy');
var duration = $(this).data('duration');
$(this).animate({
left: String(endx + outx) + 'px',
top: String(endx + outy) + 'px'
}, (duration || 400));
});
}
});
$('#stoplink').click(function(e) {
e.preventDefault();
$('[id*=id]').each(function() {
$(this).stop();
$(this).css('left', $(this).data('startx'));
$(this).css('top', $(this).data('starty'));
});
});
});
<file_sep>function say() {
if (false) {
var a = 'hello from inside a block';
}
console.log(a);
}
say();
// Scoping in JavaScript is function-level, not block-level.
//Since we declare but never assign a, line 7 logs undefined.
function hello() {
a = 'hello';
console.log(a);
if (false) {
var a = 'hello again';
}
}
hello();
console.log(a);
//hello
//Uncaught ReferenceError: a is not defined
//a's scope is the body of hello().
//Since there is no global variable named a, line 13 raises an error.
var a = 'hello';
for (var i = 0; i < 5; i += 1) {
var a = i;
}
console.log(a);
//a = 4
var a = 1;
function foo() {
a = 2;
function bar() {
a = 3;
return 4;
}
return bar();
}
console.log(foo());
console.log(a);
var a = 'global';
function checkScope() {
var a = 'local';
function nested() {
var a = 'nested';
function superNested() {
a = 'superNested';
return a;
}
return superNested();
}
return nested();
}
console.log(checkScope());
console.log(a);
//supernested
//global
//not a trick question
var a = 'outer';
var b = 'outer';
console.log(a);
console.log(b);
setScope(a);
console.log(a);
console.log(b);
function setScope(foo) {
foo = 'inner';
b = 'inner';
}
//outer outer outer inner
//not a trick question
var total = 50;
var increment = 15;
function incrementBy(increment) {
total += increment;
}
console.log(total);
incrementBy(10);
console.log(total);
console.log(increment);
// 50 60 15
//not a trick question
var a = 'outer';
console.log(a);
setScope();
console.log(a);
var setScope = function () {
a = 'inner';
};
//outer
//uncaught typerror: setscope is not a function
// this is an unnamed function<file_sep># BOB
# BOB
# both variables reference the same string object, and the string has been mutated
=begin
irb(main):001:0> name = 'Bob'
=> "Bob"
irb(main):002:0> save_name = name
=> "Bob"
irb(main):003:0> save_name.object_id
=> 23564860
irb(main):004:0> name.upcase!
=> "BOB"
irb(main):005:0> name.object_id
=> 23564860
=end<file_sep>function isValidEmail(email) {
if (email.match(/\.\./) || !email.match(/\./)) {
return false;
}
var dots = email.split('.');
var first = dots[0].match(/^[a-z0-9]+[a-z0-9]+@{1}[a-z0-9]{2}/ig);
var second = dots.slice(1).every(domain => domain.length >= 2 && !domain.match(/[^a-z]/ig));
if (first && second) {
return true;
}
return false;
}
function isValidEmail(email){
return !!email.match(/^\w+[@][a-zA-Z]{2,}\.[a-zA-Z]{2,}(\.[a-zA-Z]{2,})*/);
}
isValidEmail('<EMAIL>'); // returns true
isValidEmail('<EMAIL>'); // returns true
isValidEmail('<EMAIL>'); // returns true
isValidEmail('<EMAIL>'); // returns true
isValidEmail('HELLO123@baz'); // returns false
isValidEmail('<EMAIL>'); // returns false
isValidEmail('foo@baz.'); // returns false
isValidEmail('foo_bat@baz'); // returns false
isValidEmail('<EMAIL>'); // returns false
isValidEmail('<EMAIL>'); // returns false
isValidEmail('<EMAIL>'); // returns false<file_sep>def count(array)
array.select {|item| yield(item)}.size
end
count([1,2,3,4,5]) { |value| value.odd? } == 3
count([1,2,3,4,5]) { |value| value % 3 == 1 } == 2
count([1,2,3,4,5]) { |value| true } == 5
count([1,2,3,4,5]) { |value| false } == 0
count([]) { |value| value.even? } == 0
count(%w(Four score and seven)) { |value| value.size == 5 } == 2
<file_sep>function makeCounterLogger(n) {
return function(x) {
function counter(op1, op2, operator) {
var i;
if (operator === '-') {
for (i = op2; i >= op1; i-= 1) { console.log(i) }
} else {
for (i = op2; i <= op1; i+= 1) { console.log(i) }
}
}
return x >= n ? counter(n, x, '-') : counter(n, x);
}
}
var countlog = makeCounterLogger(5);
countlog(8);
countlog(2);<file_sep>[[1, 2], [3, 4]].each do |arr|
puts arr.first
end
# 1
# 3
# => [[1, 2], [3, 4]]
# The Array#each method is being called on the multi-dimensional array [[1, 2], [3, 4]]
# Each inner array is passed to the block in turn and assigned to the local variable arr.
# The Array#first method is called on arr and returns the object at index 0 of the current array
# in this case the integers 1 and 3, respectively.
# The puts method then outputs a string representation of the integer.
# puts returns nil and, since this is the last evaluated statement within the block,
# the return value of the block is therefore nil.
# each doesn't do anything with this returned value though,
# and since the return value of each is the calling object
# in this case the nested array [[1, 2], [3, 4]] - this is what is ultimately returned.
=begin
When evaluating code like this, ask the following questions:
What is the type of action being performed (method call, block, conditional, etc..)?
What is the object that action is being performed on?
What is the side-effect of that action (e.g. output or destructive action)?
What is the return value of that action?
Is the return value used by whatever instigated the action?
=end
<file_sep>def palindrome?(word)
word == word.reverse
end
palindrome?('madam') == true
palindrome?('Madam') == false
palindrome?("madam i'm adam") == false
palindrome?('356653') == true<file_sep>class PerfectNumber
def self.sum(num)
result = []
(1...num).each do |n|
result << n if num % n == 0
end
result.reduce(&:+)
end
def self.classify(num)
raise RuntimeError if num < 0
case PerfectNumber::sum(num) <=> num
when 1
'abundant'
when -1
'deficient'
when 0
'perfect'
end
end
end
PerfectNumber.classify(28)
<file_sep>var bill = parseFloat(prompt("What is the bill?"));
var tip = (parseFloat(prompt("What is the tip percentage?")) / 100) * bill;
var total = bill + tip;
console.log("The tip is $" + tip.toFixed(2));
console.log("The bill is $" + total.toFixed(2));<file_sep>/*
Problem:
Determine how many lights are on with n switches and repetitions
all switches off
all switches on, divisible by 1
all switches divisible by 2 are toggled (turned off)
all switches divisible by 3 are toggled
keep doing this until n is reached,
return an array of the lights turned on
Expectation:
Input - number of lights and turns
Output - array of lights on
lightsOn(5); // [1, 4]
lightsOn(100); // [1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
Data structures
array of objects with a number and a boolean
[{1: true}, {2: false}]
Algorithm
create array of hashes
for loop, i = 1, i <= num, i++
forEach within loop w idx
if (idx + 1) % i === 0
n[idx + 1] = !n[idx + 1]
return keys that have true values in array
*/
function lightsOn(switches) {
var switchboard = [];
var i;
for (i = 1; i <= switches; i += 1) {
switchboard.push({});
switchboard[i - 1][i] = false;
}
for (i = 1; i <= switches; i += 1) {
switchboard.forEach(function (obj, idx) {
for (num in obj) {
if (num % i === 0) {
obj[num] = !obj[num];
}
}
});
}
var result = [];
switchboard.forEach(function (obj) {
for (num in obj) {
if (obj[num]) {
result.push(Number(num));
}
}
});
return result;
}
lightsOn(5);
lightsOn(100);
<file_sep>str1 = "something"
str2 = "something"
str1 == str2 # => true
int1 = 1
int2 = 1
int1 == int2 # => true
sym1 = :something
sym2 = :something
sym1 == sym2 # => true
str1 = str1 + " else"
str1 # => "something else"
str1 == str2 # => false
# What we're asking is "are the values within the two objects the same?"
# and not "are the two objects the same?".
str1 = "something"
str2 = "something"
str1_copy = str1
# comparing the string objects' values
str1 == str2 # => true
str1 == str1_copy # => true
str2 == str1_copy # => true
# comparing the actual objects
str1.equal? str2 # => false
str1.equal? str1_copy # => true
str2.equal? str1_copy # => false
# str1_copy & str1 both reference the same string object, str2 does not reference str1
# the == method compares the two variables' values
# whereas the equal? method determines whether the two variables point to the same object.<file_sep>var sum = 0;
var numbers;
sum += 10;
sum += 31;
numbers = [1, 7, -3, 3];
sum += (function sum(arr) {
return arr.reduce(function(sum, number) {
sum += number;
return sum;
}, 0);
})(numbers);
//
function countdown(n) {
var i;
(function() {
for (i = n; i >=0; i--) {
console.log(i);
}
})(n);
console.log('Done!');
}
countdown(7);
function countdown(n) {
return (function() {
console.log(n)
n === 0 ? console.log('Done!') : countdown(n - 1);
})(n);
}
countdown(7);
<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
class EmptyTest < MiniTest::Test
def test_nil
array = []
assert_empty(array)
array << 1
assert(array.empty?)
end
end
<file_sep>=begin
# "102012"
1 0 2 0 1 2 # the number
1*3^5 + 0*3^4 + 2*3^3 + 0*3^2 + 1*3^1 + 2*3^0 # the value
243 + 0 + 54 + 0 + 3 + 2 = 302
=end
class Trinary
def initialize(num_string)
@num_string = num_string
@num_array = num_string.chars.map(&:to_i)
@num_size = @num_array.size
end
def to_decimal
return 0 if @num_string =~ /[^0-2]/
counter = @num_size
@num_array.map do |number|
counter -= 1
number * (3**counter)
end.reduce(&:+)
end
end
<file_sep>$(function() {
var $form = $('form');
var $quant;
$form.submit(function(event) {
event.preventDefault();
$quant = $('#quantity').val().match(/[0-9]/ig) ? $('#quantity').val() : "1";
$("<li>" + $quant + ' ' + $('#name').val() + "</li>").appendTo('ul');
$form[0].reset();
});
});<file_sep>var text = 'The quick brown fox jumps over the lazy dog.';
function countWordInText(word, text) {
// `replace` creates a new string
var textArray = text.replace(/[^a-z ]/ig, '').split(' ');
//ig means case-insensitive and global (returns all matches)
// filter/select only the needed words
return textArray.filter(function (wordInText) {
return word.toLowerCase() === wordInText.toLowerCase();
}).length;
}
countWordInText('the', text); // 2
countWordInText('dog', text); // 1<file_sep>puts "Please write word or multiple words:"
words = gets.chomp
puts "There are #{words.delete(' ').chars.size} characters in #{words}"<file_sep>require "pg"
require "date"
require "io/console"
require "bcrypt"
class ExpenseData
attr_reader :connection, :id_vals, :size
include BCrypt
def initialize
@connection = PG.connect(dbname: "expenses", host: "localhost", password: "<PASSWORD>")
@id_vals = @connection.exec("SELECT * FROM expenses").map { |tuple| tuple["id"] }
@size = @id_vals.size
setup_schema
end
def add_expense(price, text)
date = Date.today
sql = "INSERT INTO expenses (amount, memo, created_on) VALUES ($1, $2, $3)"
connection.exec_params(sql, [price, text, date])
end
def list_expenses
return puts "There are no expenses." if id_vals.empty?
puts "There are #{size} expenses."
result = connection.exec("SELECT * FROM expenses ORDER BY created_on ASC")
display(result)
sum = connection.exec("SELECT SUM(amount) FROM expenses")
show_total(sum)
end
def show_total(sql)
puts ("-" * 40)
puts "Total" + "#{sql.values[0][0]}".rjust(35)
end
def search_expenses(column, name)
if column == "id"
sql = "SELECT * FROM expenses WHERE id = $1"
result = connection.exec_params(sql, [name])
display(result)
else
sql = "SELECT * FROM expenses WHERE #{column} ILIKE $1"
result = connection.exec_params(sql, ["%#{name}%"])
result_size = result.map { |tuple| tuple }.size
return puts "No expenses match your query." if result_size < 1
puts "Search results: #{result_size} expense/s."
display(result)
total = "SELECT SUM(amount) FROM expenses WHERE #{column} ILIKE $1"
show_total(connection.exec_params(total, ["%#{name}%"]))
end
end
def delete_expense(id_num)
puts "The following expense has been deleted:"
search_expenses("id", id_num)
sql = "DELETE FROM expenses WHERE id = $1"
connection.exec_params(sql, ["#{id_num}"])
end
def help
puts <<~MSG
Commands:
add AMOUNT MEMO [DATE] - record a new expense
clear - delete all expenses
list - list all expenses
delete NUMBER - remove expense with id NUMBER
search QUERY - list expenses with a matching memo field
MSG
end
def clear_table
puts "Are you sure you want to do this? (y/n)"
answer = $stdin.getch
if answer == 'y'
delete_all_expenses
else
puts "Ok then."
end
end
def delete_all_expenses
connection.exec("DELETE FROM expenses")
puts "Deleted All Expenses."
end
def display(result_object)
result_object.each do |tuple|
columns = [ tuple["id"].rjust(3),
tuple["created_on"].rjust(10),
tuple["amount"].rjust(12),
tuple["memo"] ]
puts columns.join(" | ")
end
end
def setup_schema
result = connection.exec <<~SQL
SELECT COUNT(*) FROM information_schema.tables
WHERE table_schema = 'public' AND table_name = 'expenses';
SQL
if result.values[0][0] == "0"
connection.exec <<~SQL
CREATE TABLE expenses (
id serial PRIMARY KEY,
amount numeric(6,2) NOT NULL CHECK (amount >= 0.01),
memo text NOT NULL,
created_on date NOT NULL
);
SQL
end
end
end
class CLI
attr_reader :db
def initialize
@db = ExpenseData.new
end
def run(args)
if args[0] == "list"
db.list_expenses
elsif args[0] == "clear"
db.clear_table
db.list_expenses
elsif args[0] == "search"
if args.size == 1
puts "Please specify your search."
else
db.search_expenses("memo", args[1])
end
elsif args[0] == "delete"
if args.size == 1 || db.id_vals.none? { |id| id == args[1] } || args[1].to_i < 1
puts "You must provide an id number within the list. See below:"
db.list_expenses
else
db.delete_expense(args[1])
end
elsif args[0] == "add"
if args.size == 1
puts "You must provide an amount and memo."
else
db.add_expense(args[1], args[2])
puts "Expense Added: #{args[2]}"
end
else
db.help
end
end
end
<file_sep>['ant', 'bat', 'caterpillar'].count do |str|
str.length < 4
end
# => 2
# count counts the number of truthy iterations of a block, returns an integer <file_sep>/*
Write a JavaScript function that takes an array containing
repeated elements and returns a two dimensional array.
Each subarray contains the repeated elements grouped together
groupDuplicates([1,1, 2, 2, 3]) // -> [[1, 1], [2, 2], [3]]
Problem:
given an array
array contains duplicate elements
create an chunked nested array
returns nested array with duplicate elements chunked together
Data structures:
given an array
return new array, nested subarrays grouped by duplicate elements
object
{String(elem): [1, 1],
Algorithm:
groupDublicates(arr)
var previous = {}
arr.forEach elem
previous[String(elem)] = [];
arr.forEach elem
previous[String(elem)].push(elem)
return Object.values(previous);
*/
function groupDuplicates(arr) {
var previousElems = {};
arr.forEach(function (currentElem) {
if (previousElems[typeof currentElem + String(currentElem)] === undefined) {
previousElems[typeof currentElem + String(currentElem)] = [];
}
});
arr.forEach(function (currentElem) {
previousElems[typeof currentElem + String(currentElem)].push(currentElem);
});
return Object.values(previousElems);
}
console.log(groupDuplicates([1,1, 2, 2, 3, 3, "1"]));
// -> [[1, 1], [2, 2], [3, 3], ["1"]]
console.log(groupDuplicates([undefined, 1, 2, undefined, 3, 3]));
// [[undefined, undefined], [1], [2], [3, 3]]
console.log(groupDuplicates(['a', 'b', 'a', 'c', 'b']));
//[['a', 'a'], ['b', 'b'], ['c']]<file_sep>class GuessingGame
attr_accessor :guesses, :win_game, :min, :max
def initialize(min, max)
@min = min
@max = max
@winner = rand(min..max)
@number = Math.log2((min..max).size).to_i + 1
@win_game = false
end
def guess_number
return puts "You have #{@number} guesses remaining" unless @number == 1
puts "You have 1 guess remaining"
end
def validated?(guess)
guess > min && guess < max
end
def evaluate(guess)
puts "Your guess is too high" if guess > @winner
puts "Your guess is too low" if guess < @winner
end
def turn
answer = nil
loop do
guess_number
loop do
puts "Enter a number between #{min} and #{max}:"
answer = gets.chomp.to_i
break if validated?(answer)
puts "Invalid Guess."
end
evaluate(answer)
@number -= 1
break if answer == @winner || @number.zero?
end
self.win_game = true if answer == @winner
end
def play
turn
return puts "You Win!" if win_game
puts "You are out of guesses. You lose."
end
end
game = GuessingGame.new(501, 1500)
game.play
<file_sep># Write a program that, given a number, can find the
# sum of all the multiples of particular numbers up to but not including that number.
# If we list all the natural numbers up to but not including 20 that
# are multiples of either 3 or 5, we get 3, 5, 6, 9, 10, 12, 15, and 18.
class SumOfMultiples
@multiples = [3, 5]
attr_reader :multiples
def initialize(*numbers)
@multiples = numbers.to_a
end
def self.to(nd)
result = [0]
(1...nd).each do |mult|
@multiples.each do |test|
result << mult if mult % test == 0
break if mult % test == 0
end
end
result.reduce(&:+)
end
def to(nd)
result = [0]
(1...nd).each do |mult|
self.multiples.each do |test|
result << mult if mult % test == 0
break if mult % test == 0
end
end
result.reduce(&:+)
end
end
<file_sep>function acronym(string) {
return string.match(/(\b[A-Z]|\-[a-z])/ig).map(char => char.toUpperCase()).join('').replace(/\-/, '');
}
acronym('Portable Network Graphics'); // "PNG"
acronym('First In, First Out'); // "FIFO"
acronym('PHP: HyperText Preprocessor'); // "PHP"
acronym('Complementary metal-oxide semiconductor'); // "CMOS"
acronym('Hyper-text Markup Language'); // "HTML"<file_sep>/*
Write a function that computes the difference between
the square of the sum of the first n positive integers and
the sum of the squares of the first n positive integers.
var result1 = [];
var result2 = [];
for (i = 1; i <= num; i += 1) {
result1.push(i);
result2.push(Math.pow(i, 2));
}
var squared1 = Math.pow(result1.reduce(function (sum, n) { return sum + n }), 2);
var squared2 = result2.reduce(function (sum, n) { return sum + n });
return squared1 - squared2
*/
function sumSquareDifference(num) {
var result1 = [];
var result2 = [];
for (i = 1; i <= num; i += 1) {
result1.push(i);
result2.push(Math.pow(i, 2));
}
var squared1 = Math.pow(result1.reduce(function (sum, n) { return sum + n }), 2);
var squared2 = result2.reduce(function (sum, n) { return sum + n });
return squared1 - squared2;
}
sumSquareDifference(3); // 22 --> (1 + 2 + 3)**2 - (1**2 + 2**2 + 3**2)
sumSquareDifference(10); // 2640
sumSquareDifference(1); // 1**2 - 1 **2 = 0
sumSquareDifference(100); // 25164150<file_sep>[[8, 13, 27], ['apple', 'banana', 'cantaloupe']].map do |arr|
arr.select do |item|
if item.to_s.to_i == item # if it's an integer
item > 13
else
item.size < 6
end
end
end
# => [[27], ["apple"]]
# Why map is called on outer, then select on sub arrays
# map accesses return values to appropriately return new array based on select's criteria
# select uses 2 conditions to select values from the sub arrays
# 1. an integer greater than 13
# or 2. an object with a character length less than 6
# relying on the truthiness of the conditions, select returns a new array with sub arrays
# with the selected values
=begin
At first you might think to reach for the select method to perform selection,
but since we're working with a nested array, that won't work.
We first need to access the nested arrays before we can select the value we want.
In order to select the specified values in the requirement,
we need to first determine if an element is an integer;
there are lots of ways to do this,
we just went with the imperfect item.to_s.to_i == item test.
One of the main reasons map is used in this example is
not only to iterate over the array and access the nested arrays,
but to return a new array containing the selected values.
If we used each instead we wouldn't have the desired return value,
and would need an extra variable to collect the desired results.
=end<file_sep>require "test/unit"
class RefutationTest < Test::Unit::TestCase
def test_refutation
list = ['xyz']
refute_includes(list, 'xyz')
end
end
<file_sep>for i in (1..99) do
if i.even?
puts i
end
end<file_sep>class Television
def self.manufacturer
# method logic
end
def model
# method logic
end
end
tv = Television.new
tv.manufacturer
# error
tv.model
# success
Television.manufacturer
# success
Television.model
# error
<file_sep>#! /usr/bin/env ruby
require_relative "app_logic"
commands = CLI.new
commands.run(ARGV)
<file_sep>[[1, 2], [3, 4]].map do |arr|
puts arr.first
end
# 1
# 3
# => [nil, nil]
=begin
Line: 1
Action: Method Call, Map
Object: The Outer Array
Side Effects: None
Return Value: New Array [Nil, Nil]
Return Used: No, it is the one using
Lines: 1-2
Action: Block Execution
Object: Each Sub Array
Side Effects: None
Return Value: Nil
Return Used: Yes, By Map
Line: 2
Action: Method Call, Puts
Object: Element at index 0 of each Sub Array
Side Effect: Prints To Screen
Return Value: Nil
Return Used: Yes, to determine return value of block
Line: 2
Action: Method Call, First
Object: Each Sub Array
Side effects: None
Return Value: 1, 3
Return Used: Yes, by puts<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: planets; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE planets (
id integer NOT NULL,
designation character varying(1),
mass integer,
star_id integer NOT NULL
);
ALTER TABLE planets OWNER TO postgres;
--
-- Name: planets_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE planets_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE planets_id_seq OWNER TO postgres;
--
-- Name: planets_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE planets_id_seq OWNED BY planets.id;
--
-- Name: stars; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE stars (
id integer NOT NULL,
name character varying(50) NOT NULL,
distance integer NOT NULL,
spectral_type character varying(1),
companions integer NOT NULL,
CONSTRAINT companions_no_negatives CHECK ((companions >= 0)),
CONSTRAINT distance_positive CHECK ((distance > 0))
);
ALTER TABLE stars OWNER TO postgres;
--
-- Name: stars_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE stars_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE stars_id_seq OWNER TO postgres;
--
-- Name: stars_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE stars_id_seq OWNED BY stars.id;
--
-- Name: planets id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY planets ALTER COLUMN id SET DEFAULT nextval('planets_id_seq'::regclass);
--
-- Name: stars id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY stars ALTER COLUMN id SET DEFAULT nextval('stars_id_seq'::regclass);
--
-- Data for Name: planets; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY planets (id, designation, mass, star_id) FROM stdin;
\.
--
-- Data for Name: stars; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY stars (id, name, distance, spectral_type, companions) FROM stdin;
1 Alpha Centauri B 4 K 3
\.
--
-- Name: planets_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('planets_id_seq', 1, false);
--
-- Name: stars_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('stars_id_seq', 1, true);
--
-- Name: planets planets_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY planets
ADD CONSTRAINT planets_pkey PRIMARY KEY (id);
--
-- Name: stars stars_name_key; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY stars
ADD CONSTRAINT stars_name_key UNIQUE (name);
--
-- Name: stars stars_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY stars
ADD CONSTRAINT stars_pkey PRIMARY KEY (id);
--
-- Name: planets planets_star_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY planets
ADD CONSTRAINT planets_star_id_fkey FOREIGN KEY (star_id) REFERENCES stars(id);
--
-- PostgreSQL database dump complete
--
<file_sep>function fibonacci(n) {
fib = [1, 1];
for (i = 3; i <= n; i += 1) {
fib.push(fib.slice(-2)[0] + fib.slice(-1)[0]);
}
return fib.slice(-1)[0];
}
fibonacci(20); // 6765
fibonacci(50); // 12586269025
fibonacci(100); // 354224848179261915075<file_sep>class Team
attr_accessor :name, :members
def initialize(name)
@name = name
@members = []
end
def <<(person)
members.push person
end
def +(other_team)
temp_team = Team.new("Temporary Team")
temp_team.members = members + other_team.members
temp_team
end
end
# we'll use the same Person class from earlier
cowboys = Team.new("Dallas Cowboys")
cowboys << Person.new("<NAME>", 48)
cowboys << Person.new("<NAME>", 46)
cowboys << Person.new("<NAME>", 49)
niners = Team.new("San Francisco 49ers")
niners << Person.new("<NAME>", 59)
niners << Person.new("<NAME>", 52)
niners << Person.new("<NAME>", 47)
dream_team = niners + cowboys
puts dream_team.inspect # => #<Team:0x007fac3b9eb878 @name="Temporary Team"
# Array#[] and Array#[]= are getter and setter array methods
ary = [1, 2, 3]
ary.[](2) == ary[2]
ary.[]=(3, "Four") # => [1, 2, 3, "Four"]
# in use
class Team
attr_accessor :name, :members
def initialize(name)
@name = name
@members = []
end
def <<(person)
members.push person
end
def +(other_team)
temp_team = Team.new("Temporary Team")
temp_team.members = members + other_team.members
temp_team
end
def [](idx)
members[idx]
end
def []=(idx, obj)
members[idx] = obj
end
end
cowboys.members # => ... array of 3 Person objects
cowboys[1] # => #<Person:0x007fae9295d830 @name="<NAME>", @age=46>
cowboys[3] = Person.new("JJ", 72)
cowboys[3] # => #<Person:0x007fae9220fa88 @name="JJ", @age=72>
<file_sep>var frameLength = 13; // delay between each frame in milliseconds
var speed = 400; // duration of animation in milliseconds
var steps = Math.round(speed / frameLength);
var endTop = 250;
var endLeft = 500;
var paragraph = document.querySelector('p'); // p has "position: absolute" for this snippet
var i = 0;
var update = function() {
paragraph.style.top = endTop * (i / steps) + 'px';
paragraph.style.left = endLeft * (i / steps) + 'px';
i += 1;
i < steps && setTimeout(update, frameLength);
};
update(); // kick off the animation loop
<file_sep>def twice(number)
number.to_s[0...(number.to_s.size/2)] == number.to_s[(number.to_s.size/2)..-1] ? number : number * 2
end
twice(37) == 74
twice(44) == 44
twice(334433) == 668866
twice(444) == 888
twice(107) == 214
twice(103103) == 103103
twice(3333) == 3333
twice(7676) == 7676
twice(123_456_789_123_456_789) == 123_456_789_123_456_789
twice(5) == 10<file_sep>x = 0
sum = 0
product = 1
ans = ''
puts "Please enter an integer greater than 0:"
loop do
x = gets.chomp.to_i
break unless x <= 0
puts "Please enter an integer greater than 0:"
end
puts "Enter 's' to compute the sum, 'p' to compute the product."
loop do
ans = gets.chomp
if ans == 's'
for i in (1..x) do
sum += i
end
puts "The sum of the integers between 1 and #{x} is #{sum}."
elsif ans == 'p'
for i in (1..x) do
product *= i
end
puts "The product of the integers between 1 and #{x} is #{product}."
else
puts "Please enter 'p' or 's'"
end
break
end<file_sep>function staggeredCase(str) {
var i = 0;
var j = 0;
var result = [];
while (i < str.length) {
if (/[a-z]/i.test(str[i])) {
(j === 0 || j % 2 === 0) ? result.push(str[i].toUpperCase()) : result.push(str[i].toLowerCase());
j += 1;
} else {
result.push(str[i]);
}
i += 1;
}
return result.join('');
}
staggeredCase('I Love Launch School!'); // "I lOvE lAuNcH sChOoL!"
staggeredCase('ALL CAPS'); // "AlL cApS"
staggeredCase('ignore 77 the 444 numbers'); // "IgNoRe 77 ThE 444 nUmBeRs"<file_sep>DIGITS = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
def signed_integer_to_string(number)
result = ''
original_number = number
loop do
number, remainder = number.abs.divmod(10)
# divmod returns integer quotient, remainder in an array
# 2.divmod(10) = [0, 2]
# 562.divmod(10) = [56, 2]
result.prepend(DIGITS[remainder])
# DIGITS[2] = '2'
# loop breaks off last number until none are left, then number == 0
break if number == 0
end
if original_number < 0
result.prepend('-')
elsif original_number > 0
result.prepend('+')
else
result = '0'
end
result
end
signed_integer_to_string(4321) == '+4321'
signed_integer_to_string(-123) == '-123'
signed_integer_to_string(0) == '0'<file_sep>def fibonacci(num, fib = [1, 1])
(num - 2).times do
sum = fib[-2..-1].reduce(&:+)
fib << sum
end
fib[-1]
end
fibonacci(20) == 6765
fibonacci(100) == 354224848179261915075
fibonacci(100_001) # => 4202692702.....8285979669707537501<file_sep>require 'spec_helper'
describe SessionsController do
let(:user) { User.create(username: "user", email: "<EMAIL>", password: "<PASSWORD>") }
describe "POST create" do
it "should work with good user" do
user
post :create, { email: user.email, password: user.password }
response.should redirect_to '/'
session[:user_id].should == user.id
end
it "should not work with bad login" do
user
post :create, { email: user.email, password: 'bad' }
response.should_not redirect_to '/home'
session[:user_id].should be_nil
end
end
describe "GET destroy" do
it "logout" do
user
session[:user_id] = user.id
get :destroy
response.should redirect_to '/'
session[:user_id].should be_nil
end
end
end<file_sep># pascal's triangle
# classes
# Triangle
# takes 1 argument, number of rows
# methods
# rows
# returns nested array of rows
# rules
# each number is calculated by elements
# to right and left of position in PREVIOUS row
# 1
# 1 1
# 1 2 1
# 1 3 3 1
# 1 4 6 4 1
# 1 5 10 10 5 1
# 1 6 15 20 15 6 1
# every row is greater than the last
# create_row method
# save the last row as a variable
# new_row[2] = last_row[0..1].reduce(&:+)
# @structure = ary
# triangle 2.rows = [[1], [1, 1]]
# start with those two given
# @structure << create_row(@structure.last)
class Triangle
ONE = [1]
def initialize(num)
@amount = num
@all = [ONE]
end
def rows
until @all.size == @amount
@all << create_row(@all.last)
end
@all
end
def create_row(row)
spaces = row.size + 1
new_row = []
spaces.times { new_row << nil }
new_row.map.with_index do |n, idx|
if idx == 0 || idx == row.size
n = 1
else
n = row[idx] + row[idx - 1]
end
end
end
end<file_sep>function countOccurrences(arr) {
var result = {};
arr.forEach(function (elem) {
if (result[elem] === undefined) {
result[elem] = 1;
} else {
result[elem] += 1;
}
});
return result;
}
var vehicles = ['car', 'car', 'truck', 'car', 'SUV', 'truck',
'motorcycle', 'motorcycle', 'car', 'truck'];
countOccurrences(vehicles);<file_sep>function isXor(first, second) {
var testFirst = Boolean(first);
var testSecond = Boolean(second);
if (testFirst && testSecond) { return false; }
if (testFirst || testSecond) { return true; }
return false;
}
isXor(false, 3);
isXor('a', undefined);
isXor(null, '');
isXor('2', 23);<file_sep>def merge(ary1, ary2)
result = []
new = ary1 + ary2
counter = 1
loop do
break if result.size == new.size
result << new.min(counter)[-1]
counter += 1
end
result
end
merge([1, 5, 9], [2, 6, 8]) == [1, 2, 5, 6, 8, 9]
merge([1, 1, 3], [2, 2]) == [1, 1, 2, 2, 3]
merge([], [1, 4, 5]) == [1, 4, 5]
merge([1, 4, 5], []) == [1, 4, 5]
<file_sep>puts "What is your age?"
age = gets.to_i
puts "At what age would you like to retire?"
retire_age = gets.to_i
year = Time.now.year.to_i
retire_year = (retire_age - age) + year
years_left = retire_year - year
puts "It's #{year}. You will retire in #{retire_year}."
puts "You have only #{years_left} years of work to go!"<file_sep># Sort an array of passed in values using merge sort.
# You can assume that this array may contain only one type of data.
# And that data may be either all numbers or all strings.
# Merge sort is a recursive sorting algorithm that
# works by breaking down the array elements into nested sub-arrays,
# then recombining those nested sub-arrays in sorted order.
# It is best shown by example. For instance,
# let's merge sort the array [9,5,7,1].
# Breaking this down into nested sub-arrays, we get:
# [9, 5, 7, 1] ->
# [[9, 5], [7, 1]] ->
# [[[9], [5]], [[7], [1]]]
# We then work our way back to a flat array by merging each pair of nested sub-arrays:
# [[[9], [5]], [[7], [1]]] ->
# [[5, 9], [1, 7]] ->
# [1, 5, 7, 9]
# Given an array of all strings or all numbers
# break this array down into sub arrays with 2 elements each,
# break down into one element each
# merge back to two elements each, now sorted
# merge back into a single flat array
def merge(ary1, ary2)
result = []
new = ary1 + ary2
counter = 1
loop do
break if result.size == new.size
result << new.min(counter)[-1]
counter += 1
end
result
end
def merge_sort(array)
array = [array[0...(array.size/2)], array[(array.size/2)..-1]]
ary1, ary2 = array[0...(array.size/2)], array[(array.size/2)..-1]
array.all? {|elem| elem.size > 1} ? array.map! {|a| merge_sort(a)} : array.merge(ary1, ary2).flatten
array.merge(array[0], array[1])
end
merge_sort([9, 5, 7, 1])
merge_sort([9, 5, 7, 1]) == [1, 5, 7, 9]
merge_sort([5, 3]) == [3, 5]
merge_sort([6, 2, 7, 1, 4]) == [1, 2, 4, 6, 7]
merge_sort(%w(Sue <NAME> <NAME>)) == %w(<NAME> Kim <NAME> <NAME>)
merge_sort([7, 3, 9, 15, 23, 1, 6, 51, 22, 37, 54, 43, 5, 25, 35, 18, 46]) == [1, 3, 5, 6, 7, 9, 15, 18, 22, 23, 25, 35, 37, 43, 46, 51, 54]<file_sep>require 'erb'
def random_number
(0..9).to_a.sample
end
content1 = ERB.new("<html><body><p>The number is: <%= random_number %>!</p></body></html>")
content1.result
content2 = ERB.new("<html><body><p>The number is: <%= random_number %>!</p></body></html>")
content2.result
<file_sep>//section 1
var kGex = /K/g;
'Kx BlacK kelly'.match(kGex);
var hGex = /h/ig;
'Henry perch golf'.match(hGex);
var dragonGex = /dragon/g;
'snapdragon bearded dragon dragoon'.match(dragonGex);
var fruitGex = /(apple|orange|banana|strawberry)/g;
'banana orange pineapples strawberry raspberry grappler'.match(fruitGex);
var comSpaceGex = /[ ,]/g;
'This line has spacesThis,line,has,commas,No-spaces-or-commas'.match(comSpaceGex);
var berryGex = /(black|blue)+berry/g;
'blueberry blackberry black berry strawberry'.match(berryGex);
//section 2
var kGex2 = /[kKs]/g;
'Kitchen Kaboodle Reds and blues kitchen Servers'.match(kGex2);
var subs = /(cat|cot|cut|bat|bot|but)/ig;
var text = 'My cats, Butterscotch and Pudding, like to sleep on my cot with me, but they cut my sleep short with acrobatics when breakfast time rolls around. I need a robotic cat feeder.';
text.match(subs);
var base20 = /[a-j0-9]/ig;
'0xDEADBEEF 1234.5678 Jamaica plow ahead'.match(base20);
var notX = /([a-w]|[y-z])/ig;
var xTest = '0x1234 Too many XXXXXXXXXXxxxxxxXXXXXXXXXXXX to count. The quick brown fox jumps over the lazy dog THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG';
xTest.match(notX);
var notLetter = /[^a-z]/ig;
var testForLetters = "0x1234abcd 1,000,000,000s and 1,000,000,000s. THE quick BROWN fox JUMPS over THE lazy DOG!";
testForLetters.match(notLetter);
var alphabet1 = /(ABC|abc)/g;
var alphabet2 = /[aA][bB][cC]/g;
var alphaString = 'Abc';
alphaString.match(alphabet1);
alphaString.match(alphabet2);
var negatedMatch = /(\/\[\^a\-z\]\/|\/\[\^0\-9\]\/)/ig;
'The regex /[^a-z]/i matches any character that is'.match(negatedMatch);
'not a letter. Similarly, /[^0-9]/ matches any'.match(negatedMatch);
'non-digit while /[^A-Z]/ matches any character'.match(negatedMatch);
'that is not an uppercase letter. Beware: /[^+-<]/'.match(negatedMatch);
'is at best obscure, and may even be wrong.'.match(negatedMatch);
// Section 3
var threeNonWhite = /(\s\S|^\S)\S\S\s/g;
'reds and blues'.match(threeNonWhite);
'the lazy cat sleeps'.match(threeNonWhite);
var betterNonWhite = /\s...\s/g;
'Doc in a big red box.'.match(betterNonWhite);
'Hup! 2 3 4'.match(betterNonWhite);
var hex = /\s[a-f0-9][a-f0-9][a-f0-9][a-f0-9]\s/ig;
'Hello 4567 bye CDEF - cdef 0x1234 0x5678 0xABCD 1F8A done'.match(hex);
var threeLetters = /[a-z][a-z][a-z]/ig;
'The red d0g chases the b1ack cat. a_b c_d'.match(threeLetters);
// Section 4
var theBeginning = /^the\b/i;
'The lazy cat sleeps.'.match(theBeginning);
'The number 623 is not a word.'.match(theBeginning);
'Then, we went to the movies.'.match(theBeginning);
'Ah. The bus has arrived.'.match(theBeginning);
var catEnd = /\bcat$/;
'The lazy cat sleeps'.match(catEnd);
'The number 623 is not a cat'.match(catEnd);
'The Alaskan drives a snowcat'.match(catEnd);
var threeWord = /\b[a-z][a-z][a-z]\b/ig;
'reds and blues'.match(threeWord);
'The lazy cat sleeps.'.match(threeWord);
'The number 623 is not a word. Or is it?'.match(threeWord);
var challengeThe = /(a|the)\s[a-z][a-z][a-z][a-z]\s(dog|cat)/ig;
'A grey cat'.match(challengeThe);
'The lazy dog'.match(challengeThe);
'The white cat'.match(challengeThe);
'A loud dog'.match(challengeThe);
'Go away dog'.match(challengeThe);
'The ugly rat'.match(challengeThe);
'The lazy, loud dog'.match(challengeThe);
var be = /\bb*[a-z]+e\b/g;
'To be or not to be'.match(be);
'Be a busy bee'.match(be);
'I brake for animals.'.match(be);
var question = /\?$/;
"What's up, doc?".match(question);
"Say what? No way.".match(question);
"?".match(question);
"Who? What? Where? When? How?".match(question);
question = /^.+\?$/;
"What's up, doc?".match(question);
"Say what? No way.".match(question);
"?".match(question);
"Who? What? Where? When? How?".match(question);
var url = /^https?:\/\/\S*$/;
"http://launchschool.com/".match(url);
"https://mail.google.com/mail/u/0/#inbox".match(url);
"htpps://example.com".match(url);
"Go to http://launchschool.com/".match(url);
"https://user.example.com/test.cgi?a=p&c=0&t=0&g=0 hello".match(url);
" http://launchschool.com/".match(url);
url = /^\s*https?:\/\/\S*$/;
"http://launchschool.com/".match(url);
" http://launchschool.com/".match(url);
url = /\bhttps?:\/\/\S*/;
var letterI = /\b[a-z]*([a-z]*i){3}\S*\b/gi;
'Mississippi ziti 0minimize7 inviting illegal iridium'.match(letterI);
var lastWord = /\b\S+$/;
"What's up, doc?".match(lastWord);
"I tawt I taw a putty tat!".match(lastWord);
"Thufferin' thuccotath!".match(lastWord);
"Oh my darling, Clementine!".match(lastWord);
"Camptown ladies sing this song, doo dah.'".match(lastWord);
var commas = /^,(\d+,){3,6}$/g;
',123,456,789,123,345,'.match(commas);
',123,456,,789,123,'.match(commas);
',23,56,7,'.match(commas);
',13,45,78,23,45,34,'.match(commas);
',13,45,78,23,45,34,56,'.match(commas);
commas = /^(\d+,){2,5}\d+$/g;
'123,456,789,123,345'.match(commas);
// Section 5
function isUrl(str) {
var url = /^https?:\/\/\S*$/;
return str.match(url);
}
function fields(str) {
return str.split(/[ \t,]+/);
}
function mysteryMath(eq) {
return eq.slice(0).replace(/[*+\/\-/, '?');
}
function mysteriousMath(eq) {
return eq.slice(0).replace(/[*+\/\-/g, '?');
}
function danish(str) {
return str.replace(/\b(apple|cherry|blueberry)\b/g, 'danish');
}
function formatDate(date) {
return date.split('.').reverse.join('.').replace(/[.]/g, '-');
}
function formatDate(date) {
if (date.match(/[\-]/) && date.match(/[\/]/)) {
return date;
} else if (date.match(/[\-]/)) {
return date.split('-').reverse().join('-').replace(/[\-]/g, '.');
} else {
return date.split('/').reverse().join('/').replace(/[\/]/g, '.');
}
}
formatDate('2016-06-17');
<file_sep># 1..Math.sqrt(num)
class Integer
def determine_prime
(2..Math.sqrt(self)).select do |n|
self % n == 0
end.empty?
end
end
class Prime
def self.nth(num)
raise ArgumentError if num.zero?
return 2 if num == 1
primes = (2..(num * 50)).select { |int| int.determine_prime }
primes[(num - 1)]
end
end
<file_sep>function substringsAtStart(str) {
var result = [];
str = str.split('');
str.map(function (num, idx) {
result.push(str.slice(0, (idx + 1)).join(''));
});
return result;
}
function substrings(str) {
var result = []
var i = 0;
while(i < str.length) {
substringsAtStart(str.slice(i)).forEach(char => result.push(char));
i += 1;
}
return result;
}
function palindromes(str) {
var result = [];
substrings(str).forEach(function (sub) {
if (sub.length > 1 && sub === sub.split('').reverse().join('')) {
result.push(sub);
}
});
return result;
}
palindromes('madam'); // [ "madam", "ada" ]
palindromes('abcd'); // []
palindromes('hello-madam-did-madam-goodbye');
// returns
[ "ll", "-madam-", "-madam-did-madam-", "madam", "madam-did-madam", "ada",
"adam-did-mada", "dam-did-mad", "am-did-ma", "m-did-m", "-did-", "did",
"-madam-", "madam", "ada", "oo" ]
palindromes('knitting cassettes');
// returns
[ "nittin", "itti", "tt", "ss", "settes", "ette", "tt" ]<file_sep>require 'spec_helper'
describe VideosController do
let(:user) { User.create(username: "user", email: "<EMAIL>", password: "<PASSWORD>") }
let(:video) { Video.create(title: "pass") }
describe "GET show" do
it "should render show correctly" do
session[:user_id] = user.id
get :show, id: video.id
response.should render_template :show
assigns(:video).should == video
end
end
describe "GET search" do
it "should render search correctly" do
session[:user_id] = user.id
video
get :search, query: "pass"
response.should render_template :search
assigns(:vids).first.should == video
end
end
end<file_sep>class TextAnalyzer
def process
file_string = File.open('sample.txt') {|f| f.read}
yield(file_string)
end
end
analyzer = TextAnalyzer.new
analyzer.process {|file_string| puts "#{file_string.split("\n\n").size} paragraphs" }
analyzer.process {|file_string| puts "#{file_string.split("\n").size} lines" }
analyzer.process {|file_string| puts "#{file_string.split.size} words" }
<file_sep>=begin
Letter Value
'A', 'E', 'I', 'O', 'U', 'L', 'N', 'R', 'S', 'T' 1
'D', 'G' 2
'B', 'C', 'M', 'P' 3
'F', 'H', 'V', 'W', 'Y' 4
K 5
'J', 'X' 8
'Q', 'Z' 10
=end
# data structures:
# hash - key array - value integer
# input.upcase.each_char |ch|
# LETTERS.keys.each |x| score += LETTERS[x] if x.include? ch
class Scrabble
LETTERS = {['A', 'E', 'I', 'O', 'U', 'L', 'N', 'R', 'S', 'T'] => 1,
['D', 'G'] => 2,
['B', 'C', 'M', 'P'] => 3,
['F', 'H', 'V', 'W', 'Y'] => 4,
['K'] => 5,
['J', 'X'] => 8,
['Q', 'Z'] => 10}
def initialize(word)
@word = word
@score = 0
end
def score
return 0 if @word.nil? || @word.empty?
@word.upcase.each_char do |ch|
LETTERS.keys.each {|ltr| @score += LETTERS[ltr] if ltr.include?(ch)}
end
@score
end
def self.score(new_word)
Scrabble.new(new_word).score
end
end
Scrabble.new(nil).score
Scrabble.new('street').score<file_sep>arr = [[2], [3, 5, 7], [9], [11, 13, 15]]
for i in arr[0..-1] do
i.select! {|n| n % 3 == 0}
end
# their reject solution
arr.map do |element|
element.reject do |num|
num % 3 != 0
end
end<file_sep>function add(previousValue, element) {
return previousValue + element;
}
var count = [1, 2, 3, 4, 5];
count.reduce(add);
function add(previousValue, element) {
var sum = previousValue + element;
console.log(previousValue, element, sum);
return sum;
}
console.log(count.reduce(add));
// diy
function myReduce(array, func, initial) {
var value;
var index;
if (initial === undefined) {
value = array[0];
index = 1;
} else {
value = initial;
index = 0;
}
array.slice(index).forEach(function (element) {
value = func(value, element);
});
return value;
}
// using diy within other functions
function longestWord(words) {
return myReduce(words, longest);
}
var longest = function (result, currentWord) {
return currentWord.length >= result.length ? currentWord : result;
};
longestWord(['abc', 'launch', 'targets', '']);
<file_sep>233 # decimal
# = 2*10^2 + 3*10^1 + 3*10^0
# = 2*100 + 3*10 + 3*1
# => 233
233 # octal
# = 2*8^2 + 3*8^1 + 3*8^0
# = 2*64 + 3*8 + 3*1
# = 128 + 24 + 3
# => 155
# 1, 5, 5
class Octal
attr_reader :num_array
def initialize(num_string)
@num_string = num_string
@num_array = num_string.chars.map(&:to_i)
@num_size = @num_array.size
end
def to_decimal
return 0 if @num_string =~ /[a-zA-Z8-9]/
num_array.map do |number|
@num_size -= 1
exponent = 8**@num_size
number * exponent
end.reduce(&:+)
end
end
=begin
LS Solution:
Solution 1
class Octal
BASE = 8
INVALID_OCTAL = /\D|[8-9]/
attr_reader :octal_string
def initialize(octal_string)
@octal_string = octal_string
end
def to_decimal
octal_string =~ INVALID_OCTAL ? 0 : calculate
end
private
def calculate
decimal = 0
octal_string.reverse.each_char.with_index do |char, index|
decimal += char.to_i * (BASE ** index)
end
decimal
end
end
=end<file_sep>def palindromic_number?(number)
number.to_s.chars == number.to_s.chars.reverse
end
palindromic_number?(34543) == true
palindromic_number?(123210) == false
palindromic_number?(22) == true
palindromic_number?(5) == true<file_sep>def tricky_method(a_string_param, an_array_param)
a_string_param += "rutabaga"
an_array_param << "rutabaga"
end
my_string = "pumpkins"
my_array = ["pumpkins"]
tricky_method(my_string, my_array)
puts "My string looks like this now: #{my_string}"
puts "My array looks like this now: #{my_array}"
# My string looks like this now: pumpkins
# My array looks like this now: ["pumpkins", "rutabaga"]
# Only << mutated the original caller, which was called in the last 2 lines
=begin
LS Explanation:
The String#+= operation is re-assignment and creates a new String object.
The reference to this new object is assigned to a_string_param.
The local variable a_string_param now points to "pumpkinsrutabaga", not "pumpkins".
It has been re-assigned by the String#+= operation.
This means that a_string_param and my_string no longer point to the same object.
=end<file_sep>function sumOfSums(arr) {
var result = [];
arr.map(function (num, idx) {
result.push(arr.slice(0, (idx + 1)).reduce((sum, n) => sum + n));
});
return result.reduce((sum, n) => sum + n);
}
sumOfSums([3, 5, 2]); // (3) + (3 + 5) + (3 + 5 + 2) --> 21
sumOfSums([1, 5, 7, 3]); // (1) + (1 + 5) + (1 + 5 + 7) + (1 + 5 + 7 + 3) --> 36
sumOfSums([4]); // 4
sumOfSums([1, 2, 3, 4, 5]);<file_sep>(function() {
var _ = function(element) {
var u = {
last: function() {
return element[element.length - 1];
},
first: function() {
return element[0];
},
without: function(items) {
var args = [].slice.call(arguments);
var result = element.slice(0);
args.forEach(function(item) {
result = result.filter(function(i) { return i !== item });
});
return result;
}, lastIndexOf: function(val) {
return element.lastIndexOf(val);
},
sample: function(quant) {
var result = [];
var working = element.slice(0);
if (quant === undefined) {
var idx = Math.round(Math.random() * Math.round(element.length - 1));
return element[idx];
} else {
for (i = 1; i <= quant; i++) {
var idx = Math.round(Math.random() * Math.round(element.length - 1));
result.push(working[idx]);
working.splice(idx, 1);
}
return result;
}
},
findWhere: function(testObj) {
return element.find(function(obj) {
return Object.keys(testObj).every(function(k) {
return obj[k] === testObj[k];
});
});
},
where: function(testObj) {
var result = [];
element.forEach(function(obj) {
if (_([obj]).findWhere(testObj)) {
result.push(obj);
}
});
return result;
},
pluck: function(key) {
var result = [];
element.forEach(function(item) {
for (i in item) {
if (i === key) {
result.push(item[i]);
}
}
});
return result;
},
keys: function() {
return Object.keys(element);
},
values: function() {
return Object.values(element);
},
pick: function(prop) {
var args = [].slice.call(arguments);
var result = {};
args.forEach(function(arg) {
result[arg] = element[arg];
});
return result;
},
omit: function(prop) {
var args = [].slice.call(arguments);
var result = {};
args.forEach(function(arg) {
for (i in element) {
if (i !== arg) {
result[i] = element[i];
}
}
});
return result;
},
has: function(prop) {
for (key in element) {
if (key === prop) {
return true;
}
}
return false;
},
isElement: function(element) {
return element.nodeType === 1;
},
isArray: function() {
return Array.isArray(element);
},
isObject: function() {
return typeof element === "object" || typeof elem === "function";
},
isFunction: function() {
return typeof element === "function";
},
isBoolean: function() {
return typeof element === "boolean" ||
(typeof element === "object" &&
(String(element) === "true" || String(element) === "false"));
},
isString: function() {
return typeof element === "string" || element.constructor === String;
},
isNumber: function(elem) {
return typeof elem === "number" || elem.constructor === Number;
}
};
return u;
};
_.range = function(nums) {
var args = [].slice.call(arguments);
var result = [];
var i;
if (args.length === 1) {
for (i = 0; i < nums; i++) {
result.push(i);
}
} else if (args.length === 2) {
for (i = args[0]; i < args[1]; i++) {
result.push(i);
}
}
return result;
}
_.extend = function(oldObj, newObj) {
var args = [].slice.call(arguments).slice(1);
args.forEach(function(miniObj) {
for (i in miniObj) {
oldObj[i] = miniObj[i];
}
});
return oldObj;
}
_.isElement = function(elem) {
return elem.nodeType === 1;
}
_.isArray = function(elem) {
return Array.isArray(elem);
}
_.isObject = function(elem) {
return typeof elem === "object" || typeof elem === "function";
}
_.isFunction = function(elem) {
return typeof elem === "function";
}
_.isBoolean = function(elem) {
return typeof elem === "boolean" ||
(typeof elem === "object" &&
(String(elem) === "true" || String(elem) === "false"));
}
_.isString = function(elem) {
return typeof elem === "string" || elem.constructor === String;
}
_.isNumber = function(elem) {
return typeof elem === "number" || elem.constructor === Number;
}
window._ = _;
})();
<file_sep>true.class # => TrueClass
true.nil? # => false
true.to_s # => "true"
true.methods # => list of methods you can call on the true object
false.class # => FalseClass
false.nil? # => false
false.to_s # => "false"
false.methods # => list of methods you can call on the false object<file_sep>ary = [{a: 1}, {b: 2, c: 3}, {d: 4, e: 5, f: 6}]
ary.map {|hash| hash.map {|k,v| hash[k] += 1}}<file_sep>def include?(ary, num)
!!ary.find_index(num)
end
include?([1,2,3,4,5], 3) == true
include?([1,2,3,4,5], 6) == false
include?([], 3) == false
include?([nil], nil) == true
include?([], nil) == false
# find_index(obj)
# Returns the index of the first object in ary such that the object is == to obj.
<file_sep>function staggeredCase(str) {
return str.split(' ').map(function (word) {
return word.split('').map(function (char, idx) {
char = (/[a-z]/i.test(char) && (idx % 2 === 1)) ? char.toLowerCase() : /[a-z]/i.test(char) ? char.toUpperCase() : char;
return char;
}).join('');
}).join(' ');
}
staggeredCase('I Love Launch School!'); // "I LoVe lAuNcH ScHoOl!"
staggeredCase('ALL_CAPS'); // "AlL_CaPs"
staggeredCase('ignore 77 the 444 numbers'); // "IgNoRe 77 ThE 444 NuMbErS"<file_sep>class MyCar
attr_reader :year
attr_accessor :color
def initialize(year, color, model)
@year = year
@color = color
@model = model
@speed = 0
end
def self.miles_per_gallon(gallons, miles)
@@mpg = miles / gallons
puts "#{miles / gallons} miles per gallon of gas"
end
def speed_up
@speed += 25
end
def brake
@speed -= 25
end
def stop_car
@speed = 0
end
def spray_paint(new_color)
self.color = (new_color)
end
def to_s
"#{@model}, #{year}, #{color}, going #{@speed} mph."
end
end
chevy = MyCar.new(2017, 'Black', 'Silverado')
puts chevy
<file_sep>def reverse_words(words)
words.split.each {|w| w.reverse! unless w.length < 5}.join(' ')
end
puts reverse_words('Professional') # => lanoisseforP
puts reverse_words('Walk around the block') # => Walk dnuora the kcolb
puts reverse_words('Launch School') # => hcnuaL loohcS<file_sep>// Todo Object
var Todo = (function() {
var identification = 0;
function Todo(todoObj) {
identification += 1;
this.id = identification;
for (property in todoObj) {
this[property] = todoObj[property];
}
this.completed = false;
}
Todo.prototype.isWithinMonthYear = function(mo, yr) {
return this.month === mo && this.year === yr;
};
return Todo;
})();
//todoList object
var TodoList = (function() {
var dup;
var id = 0;
var todoStore = {};
function duplicate(item) {
dup = Object.assign({}, item);
Object.setPrototypeOf(dup, Object.getPrototypeOf(item));
return dup;
}
function TodoList(set) {
id += 1;
todoStore[this.listID = id] = [];
if (Array.isArray(set)) {
set = set.map(function(item) { return new Todo(item) })
set.forEach(function (item) { todoStore[id].push(duplicate(item)) });
}
}
TodoList.prototype = {
forDisplay: function() {
return todoStore[this.listID].map(function (item) {
return duplicate(item);
});
},
add: function(item) {
return todoStore[this.listID].push(duplicate(item));
},
remove: function(ident) {
var found = todoStore[this.listID].find(function(item) {
return item.id === ident;
});
todoStore[this.listID] = todoStore[this.listID].filter(function(item) {
return item.id !== ident;
});
return found === undefined ? false : duplicate(found);
},
find: function(ident) {
var found = todoStore[this.listID].find(function(item) {
return item.id === ident
});
return found === undefined ? false : duplicate(found);
},
update: function(ident, property, changes) {
if (property === 'id') { return 'Can Not Change ID' }
var found = this.find(ident);
if (found !== false && found[property] !== undefined) {
found = todoStore[this.listID].find(function(item) {
return item.id === ident;
});
found[property] = changes;
console.log('Item Updated!');
} else {
console.log('Item Not Found.');
}
return duplicate(todoStore[this.listID]);
}
}
return TodoList;
})();
// Todo Manager Object
var todoManager = {
display: function(listObj) {
return listObj.forDisplay();
},
completed: function(listObj) {
return this.display(listObj).filter(function (item) {
return item.completed;
});
},
byDate: function(listObj, mo, yr) {
return this.display(listObj).filter(function (item) {
return item.isWithinMonthYear(mo, yr);
});
},
completedDate: function(listObj, mo, yr) {
return this.display(listObj).filter(function (item) {
return item.isWithinMonthYear(mo, yr) && item.completed;
});
}
}
var todoData1 = {
title: 'Buy Milk',
month: '1',
year: '2017',
description: 'Milk for baby',
};
var todoData2 = {
title: 'Buy Apples',
month: '',
year: '2017',
description: 'An apple a day keeps the doctor away',
};
var todoData3 = {
title: 'Buy chocolate',
month: '1',
year: '',
description: 'For the cheat day',
};
var todoData4 = {
title: 'Buy Veggies',
month: '',
year: '',
description: 'For the daily fiber needs',
};
var todoSet = [todoData1, todoData2, todoData3, todoData4];
// Tests:
// test 1: Todo item takes object as argument, returns Todo object
var todo1 = new Todo(todoData1);
console.log(todoData1);
console.log(todo1);
var todo2 = new Todo(todoData2);
console.log(todo2);
console.log(todo1 === todo2);
// test 2: Todo items have unique id's
var todo3 = new Todo(todoData3);
console.log(todo3.id);
var todo4 = new Todo(todoData3);
console.log(todo4.id);
var todo5 = new Todo(todoData3);
// test 3: TodoList takes set of todos, returns new object with todos
var testList1 = new TodoList(todoSet);
console.log(testList1.forDisplay());
var testList2 = new TodoList;
console.log(testList2.forDisplay());
// test 4: Items in TodoList are unmodifiable by direct interaction
testList1.forDisplay()[0].completed = true;
testList1.forDisplay()[0].description = '';
console.log(testList1);
console.log(testList1.forDisplay()[0]);
// test 5: TodoList methods return copies of objects
var todoSet2 = [todoData2, todoData4];
var testList3 = new TodoList(todoSet2);
console.log(testList3);
console.log(testList3.forDisplay());
console.log(testList3.forDisplay()[0]);
console.log(testList3.forDisplay()[0] === testList3.forDisplay()[0]);
// test 6: TodoList can add items
testList3.add(new Todo(todoData1));
console.log(testList3.forDisplay());
testList3.add(new Todo(todoData1));
console.log(testList3.forDisplay());
// test 7: TodoList can remove items
console.log(testList3.remove(13));
console.log(testList3.forDisplay());
console.log(testList3.remove(13));
// test 8: TodoList can update items
console.log(testList3.forDisplay()[0]);
testList3.update(10, 'title', 'Walk the dogs.');
testList3.update(10, 'description', 'They need the exercise.');
testList3.update(10, 'completed', true);
console.log(testList3.forDisplay()[0]);
console.log(testList3.update(10, 'id', 12));
// test 9: TodoList can find items
console.log(testList3.find(11));
console.log(testList3.find(13));
// test 10: Todo method isWithinMonthYear() works properly
var todo3 = new Todo(todoData1);
console.log(todo3.isWithinMonthYear('1', '2017'));
console.log(todo3.isWithinMonthYear('2', '2017'));
var todo4 = new Todo(todoData3);
console.log(todo4.isWithinMonthYear('1', ''));
// test 11: TodoManager object takes TodoList object, can return list
console.log(todoManager.display(testList1));
console.log(todoManager.display(testList3));
// test 12: TodoManager can not interact with list directly, can only query
console.log(todoManager.testList1);
console.log(todoManager.testList3);
// test 13: TodoManager completed method works properly
console.log(todoManager.completed(testList1));
console.log(todoManager.completed(testList3));
// test 14: TodoManager by date works properly
console.log(todoManager.byDate(testList1, '1', '2017'));
console.log(todoManager.byDate(testList1, '', ''));
console.log(todoManager.byDate(testList1, '1', ''));
console.log(todoManager.byDate(testList1, '', '2017'));
// test 15: TodoManager completed/date method works properly
testList3.update(12, 'completed', true);
console.log(todoManager.completedDate(testList3, '1', '2017'));
<file_sep>advice = "Few things in life are as important as house training your pet dinosaur."
advice.slice!("house training your pet dinosaur.")<file_sep>numbers = [1, 2, 2, 3]
numbers.uniq
puts numbers
# answer:
# 1
# 2
# 2
# 3
# Array#uniq did not change the value of the array, Array#uniq! would have
<file_sep>class Student
attr_accessor :grade
def initialize
@grade = get_grade
end
def better_grade_than?(student_2)
@grade > student_2.grade
end
private
def get_grade
rand(50..100)
end
end
joe = Student.new
puts joe.grade
bob = Student.new
puts bob.grade
puts "Well done!" if joe.better_grade_than?(bob)<file_sep>array = [1, 2, 3, 4, 5]
array.select { |num| num.odd? } # => [1, 3, 5]
array.select { |num| puts num } # => [], because "puts num" returns nil and evaluates to false
array.select { |num| num + 1 } # => [1, 2, 3, 4, 5], because "num + 1" evaluates to true
def select(input_array)
counter = 0
return_array = []
while counter < input_array.size
return_array << input_array[counter] if yield(input_array[counter])
counter += 1
end
return_array
end
array = [1, 2, 3, 4, 5]
select(array) { |num| num.odd? } # => [1, 3, 5]
select(array) { |num| puts num } # => [], because "puts num" returns nil and evaluates to false
select(array) { |num| num + 1 } # => [1, 2, 3, 4, 5], because "num + 1" evaluates to true
<file_sep>def multiply_list(ary1, ary2)
ary3 = []
ary1.each_index {|a| ary3 << ary1[a] * ary2[a]}
ary3
end
multiply_list([3, 5, 7], [9, 10, 11]) == [27, 50, 77]<file_sep>function logMultiples(n) {
var i;
for (i = 100; i >=1; i--) {
if (i % n === 0 && i % 2 === 1) {
console.log(i);
}
}
}
logMultiples(17);<file_sep>numbers = []
puts "Enter the first number"
numbers << gets.chomp.to_i
puts "Enter the second number"
numbers << gets.chomp.to_i
puts "Enter the third number"
numbers << gets.chomp.to_i
puts "Enter the fourth number"
numbers << gets.chomp.to_i
puts "Enter the fifth number"
numbers << gets.chomp.to_i
puts "Enter the last number"
search = gets.chomp.to_i
if numbers.include?(search)
puts "#{search} is in #{numbers}"
else
puts "#{search} is not in #{numbers}"
end<file_sep>def real_palindrome?(word)
word = word.chars.delete_if{|c| c !~ /\p{Alnum}/}.join
word.downcase == word.downcase.reverse
end
real_palindrome?('madam') == true
real_palindrome?('Madam') == true # (case does not matter)
real_palindrome?("Madam, I'm Adam") == true # (only alphanumerics matter)
real_palindrome?('356653') == true
real_palindrome?('356a653') == true
real_palindrome?('123ab321') == false
=begin
def real_palindrome?(string)
string = string.downcase.delete('^a-z0-9')
palindrome?(string)
end
=end
<file_sep># problematic code
def dot_separated_ip_address?(input_string)
dot_separated_words = input_string.split(".")
while dot_separated_words.size > 0 do
word = dot_separated_words.pop
break unless is_an_ip_number?(word)
end
return true
end
# fixed code
def dot_separated_ip_address?(input_string)
dot_separated_words = input_string.split(".")
return false unless dot_separated_words.size == 4
while dot_separated_words.size > 0 do
word = dot_separated_words.pop
return false unless is_an_ip_number?(word)
end
true
end
=begin
There are several ways to fix this.
To determine if there are exactly 4 dot-separated "words" in the string,
you can simply add a check for dot_separated_words.size after splitting the string.
The other error in Ben's code is that instead of returning
false upon encountering a non-numeric component,
he used break to break out of the while loop.
Once he breaks, control falls through to the return true statement.
He can fix this by performing return false instead of break.
=end<file_sep># Class variables start with @@ and are scoped
# at the class level. They exhibit two main behaviors:
# all objects share 1 copy of the class variable.
# (This also implies objects can access class variables
# by way of instance methods.)
# class methods can access class variables,
# regardless of where it's initialized.
class Person
@@total_people = 0 # initialized at the class level
def self.total_people
@@total_people # accessible from class method
end
def initialize
@@total_people += 1 # mutable from instance method
end
def total_people
@@total_people # accessible from instance method
end
end
Person.total_people # => 0
Person.new
Person.new
Person.total_people # => 2
bob = Person.new
bob.total_people # => 3
joe = Person.new
joe.total_people # => 4
Person.total_people # => 4
<file_sep>class Integer
ROMAN_NUMERALS = {"I": 1, "V": 5, "X": 10, "L": 50, "C": 100, "D": 500, "M": 1000}
def to_roman
ROMAN_NUMERALS.each do |key, value|
return key.to_s if value == self
end
numstring = self.to_s
final_string = ''
numstring.each_char.with_index do |char, idx|
next if char == '0'
val = char + ('0' * (numstring[idx..-1].size - 1))
val = val.to_i
max_div = ROMAN_NUMERALS.key(ROMAN_NUMERALS.select {|k, v| val / v == 0}.values[0]).to_s
current_max = ROMAN_NUMERALS.select {|k, v| val % v == 0}.values[-1]
result = ROMAN_NUMERALS.key(current_max).to_s
one_below = ROMAN_NUMERALS.select {|k, v| val % v == 0}.values[-2]
below = ROMAN_NUMERALS.key(one_below).to_s
if char == '9' || char == '4'
final_string << max_div.prepend(result)
elsif idx <= numstring.size - 2 && val >= 50 && val < 90
final_string << "L#{'X' * (val / (("1#{val.to_s[1..-1]}".to_i)) - 5)}"
elsif idx <= numstring.size - 2
val.to_s[0].to_i >= 5 ? final_string << "#{result}#{below * (val / (("1#{val.to_s[1..-1]}".to_i)) - 5)}" : final_string << "#{result * (val / (("1#{val.to_s[1..-1]}".to_i)))}"
else
val >= 5 ? final_string << "V#{'I' * (val - 5)}" : final_string << 'I' * val
end
end
final_string
end
end
456.to_roman
14.to_roman
9.to_roman
3.to_roman
49.to_roman
# each_char, prepend I if number is 4 or 9
# 1 = I
# 5 = V
# 10 = X
# 50 = L
# 100 = C
# 500 = D
# 1000 = M
# 1000=M
# 900=CM
# 90=XC
<file_sep>[1, 2, 3].map do |num|
if num > 1
puts num
else
num
end
end
# => [1, nil, nil]
# For the rest of the elements in the array,
# num > 1 evaluates to true,
# which means puts num is the last statement evaluated,
# which in turn, means that the block's return value is nil for those iterations.<file_sep>require "test/unit"
class List
attr_reader :process
def initialize(process)
@process = process
end
def object_id
@process.object_id
end
end
class TestProcess < Test::Unit::TestCase
def test_process
list = List.new("process")
assert_equal(list.object_id, list.process.object_id)
end
end
# assert_same will test for same object
<file_sep>['cot', 'bed', 'mat'].sort_by do |word|
word[1]
end
# => ["mat", "bed", "cot"]
# sorting a hash
people = { Kate: 27, john: 25, Mike: 18 }
people.sort_by do |name, age|
age
end
# => [[:Mike, 18], [:john, 25], [:Kate, 27]]
# sort by keys
# Symbol#<=> calls to_s, then compares
# By using Symbol#<=> we are effectively comparing strings.
# if cases dont match:
people.sort_by do |name, age|
name.capitalize
end
# => [[:john, 25], [:Kate, 27], [:Mike, 18]]
# Array#sort and Array#sort_by have a equivalent destructive methods Array#sort! and Array#sort_by!
# With these methods, rather then returning a new collection, the same collection is returned but sorted.
<file_sep>var count = [1, 2, 3, 4, 5];
function iterate(array, callback) {
var i;
for (i = 0; i < array.length; i += 1) { // for each element in the Array
callback(array[i]); // invoke callback and pass the element
}
}
iterate(count, function (number) { console.log(number); });
//forEach is applicable this way
function oddOrEven(array) {
array.forEach(function (number) {
if (number % 2 === 0) {
console.log('even');
} else {
console.log('odd');
}
});
}<file_sep># Which of the following are objects in Ruby? If they are objects,
# how can you find out what class they belong to?
# All are objects, object#class to find out
true
# Boolean
"hello"
# String
[1, 2, 3, "happy days"]
# Array
142
# Integer
<file_sep># Normal times method
5.times do |num|
puts num
end
# Invoking the Integer#times method produces this output:
# 0
# 1
# 2
# 3
# 4
# => 5
# Make-your-own times version 1:
# method implementation
def times(number)
counter = 0
while counter < number do
yield(counter)
counter += 1
end
number # return the original method argument to match behavior of `Integer#times`
end
# method invocation
times(5) do |num|
puts num
end
# execution path: Line 28 - 17 - 18 - 19 - 20 - 28 - 29 - 30 - 21 -
# (repeat 19 - 20 - 28 - 29 - 30 - 21 until 19 returns false) - 22 - 23 - 24 - 25
<file_sep>class Phrase
def initialize(sentence)
@sentence = sentence
@words = sentence.split(/[ ,]/).map(&:downcase).map { |w| w = w.gsub(/[^a-z0-9']/, "") }
@count = {}
end
def word_count
@words.each { |word| word.delete!("'") if word.start_with?("'") && word.end_with?("'") }
@words.each { |word| @count[word] = @words.count(word) unless word.empty?}
@count
end
end
Phrase.new('one fish two fish red fish blue fish').word_count
<file_sep>str1 = "something"
str2 = "something"
str1.object_id # => 70186013144280
str2.object_id # => 70186013536580
arr1 = [1, 2, 3]
arr2 = [1, 2, 3]
arr1.object_id == arr2.object_id # => false
sym1 = :something
sym2 = :something
sym1.object_id == sym2.object_id # => true
int1 = 5
int2 = 5
int1.object_id == int2.object_id # => true
# If two symbols or two integers have the same value, they are also the same object.
<file_sep>$(function() {
var $blinds = $('[id^=blind]');
var $blind;
var $delay = 0;
function startAnim() {
$blinds.each(function(i) {
$blind = $blinds.eq(i);
$blind.delay($delay).animate({
top: (Number($blind.css('top').slice(0, -2)) + Number($blind.css('height').slice(0, -2))),
height: 0
}, {
duration: 250
});
$delay += 1500;
});
}
startAnim();
$('a').click(function(e) {
e.preventDefault();
$blinds.finish();
$delay = 0;
$blinds.removeAttr('style');
startAnim();
});
});<file_sep>def reverse_sentence(words = '')
words = words.split
words = words.reverse!
words = words.join(' ')
end
puts reverse_sentence('') == ''
puts reverse_sentence('Hello World') == 'World Hello'
puts reverse_sentence('Reverse these words') == 'words these Reverse'
=begin
Their Solution:
def reverse_sentence(string)
string.split.reverse.join(' ')
end
=end<file_sep>class Review < ActiveRecord::Base
default_scope { order(created_at: :desc) }
belongs_to :user
belongs_to :video
validates_presence_of :rating, :description
validates_uniqueness_of :user, scope: :video_id
def self.average(vid_id)
vid_reviews = where(video_id: vid_id)
return 0.0 if (!vid_id || vid_reviews.blank?)
denominator = vid_reviews.length.to_f
numerator = vid_reviews.map(&:rating).reduce(&:+).to_f
(numerator / denominator).round(1)
end
end<file_sep>def sum_of_sums(ary)
sums = [ary[0]]
ary.each_with_index do |num, idx|
idx == 0 ? next : sums << ary[0..idx].reduce(&:+)
end
sums.reduce(&:+)
end
sum_of_sums([3, 5, 2]) == (3) + (3 + 5) + (3 + 5 + 2) # -> (21)
sum_of_sums([1, 5, 7, 3]) == (1) + (1 + 5) + (1 + 5 + 7) + (1 + 5 + 7 + 3) # -> (36)
sum_of_sums([4]) == 4
sum_of_sums([1, 2, 3, 4, 5]) == 35<file_sep>def select_fruit(variable)
counter = 0
fruit_collection = {}
current = variable.keys
loop do
break if counter == variable.size
current_val = current[counter]
if variable.values_at(current_val).include?('Fruit')
fruit_collection[current_val] = 'Fruit'
end
counter += 1
end
fruit_collection
end
produce = {
'apple' => 'Fruit',
'carrot' => 'Vegetable',
'pear' => 'Fruit',
'broccoli' => 'Vegetable'
}
p select_fruit(produce) # => {"apple"=>"Fruit", "pear"=>"Fruit"}
=begin
def select_fruit(produce_list)
produce_keys = produce_list.keys
counter = 0
selected_fruits = {}
loop do
# this has to be at the top in case produce_list is empty hash
break if counter == produce_keys.size
current_key = produce_keys[counter]
current_value = produce_list[current_key]
if current_value == 'Fruit'
selected_fruits[current_key] = current_value
end
counter += 1
end
selected_fruits
end
=end<file_sep>require "sinatra"
require "sinatra/reloader"
require "tilt/erubis"
get "/" do
@counter = 0
@title = "Dynamic Index"
@files = Dir.glob("public/images/*").map { |file| File.basename(file) }.sort
@files.reverse! if params[:sort] == "desc"
erb :home
end
get "/image/" do
@name = params[:file]
erb :image
end
<file_sep>var count = [1, 2, 3, 4, 5];
var filtered = count.filter(function (number, index, array) {
return number % 2 === 0; // look for the even numbers
});
console.log(filtered); // logs [ 2, 4 ]
// diy filter
function myFilter(array, func) {
var result = [];
array.forEach(function (value) {
if (func(value)) {
result.push(value);
}
});
return result;
}
var isPythagoreanTriple = function (triple) {
return Math.pow(triple.a, 2) + Math.pow(triple.b, 2) === Math.pow(triple.c, 2);
};
myFilter([{ a: 3, b: 4, c: 5 },
{ a: 5, b: 12, c: 13 },
{ a: 1, b: 2, c: 3 },], isPythagoreanTriple);
// using diy filter in other functions
function multiplesOfThreeOrFive(values) {
return myFilter(values, isMultipleOfThreeOrFive);
}
var isMultipleOfThreeOrFive = function (value) {
return value % 5 === 0 || value % 3 === 0;
};
multiplesOfThreeOrFive([1, 3, 5, 7, 11, 18, 16, 15]);
<file_sep>[1, 2, 3].reject do |num|
puts num
end
# => [1, 2, 3]
# puts returns nil, nothing gets rejected<file_sep>var total = 0;
function add(n) {
total += n;
return console.log(total);
}
function subtract(n) {
total -= n;
return console.log(total);
}
add(1);
add(42);
subtract(39);
add(6);<file_sep>def print_in_box(string = ' ', arg1 = '--', arg2 = ' ')
if !string.empty?
arg1 = arg1.squeeze * string.chars.size
arg2 = arg2.squeeze * string.chars.size
else
string = string.prepend(' ')
string << ' '
end
puts ""
puts "+#{arg1}+"
puts "|#{arg2}|"
puts "|#{string}|"
puts "|#{arg2}|"
puts "+#{arg1}+"
puts ""
end
print_in_box('To boldly go where no one has gone before.')
print_in_box('')
=begin
puts "+--------------------------------------------+"
puts "| |"
puts "| |"
puts "| |"
puts "+--------------------------------------------+"
=end<file_sep># Write a method that takes an Array of numbers,
# and returns an Array with the same number of elements,
# and each element has the running total from the original Array.
def running_total(array)
the_total = []
sum = 0
array.each do |i|
sum += i
the_total << sum
end
the_total
end
running_total([2, 5, 13]) == [2, 7, 20]
running_total([14, 11, 7, 15, 20]) == [14, 25, 32, 47, 67]
running_total([3]) == [3]
running_total([]) == []
=begin
Their Solution:
def running_total(array)
sum = 0
array.map { |value| sum += value }
end
=end<file_sep>flintstones = %w(<NAME> Wilma Betty BamBam Pebbles)
flintstones.each {|name| name.slice!(3..-1)}
# flintstones.map! { |name| name[0,3] }<file_sep>factorial = Enumerator.new do |yielder|
accumulator = 1
number = 0
loop do
accumulator = number.zero? ? 1 : accumulator * number
yielder << accumulator
# a “yielder” object, given as block parameter,
# can be used to yield a value by calling the yield method
# (aliased as +<<+):
number += 1
end
end
7.times { puts factorial.next } # Enumerable#next
factorial.rewind # Enumerable#rewind, rewinds to beginning
factorial.each_with_index do |number, index|
puts number
break if index == 6
end
<file_sep>def max_by(array)
return nil if array.empty?
winning_index = 0 ; winner = yield(array[0])
array.each_with_index do |item, idx|
if yield(item) > winner
winning_index = idx
winner = yield(item)
end
end
array[winning_index]
end
max_by([1, 5, 3]) { |value| value + 2 } == 5
max_by([1, 5, 3]) { |value| 9 - value } == 1
max_by([1, 5, 3]) { |value| (96 - value).chr } == 1
max_by([[1, 2], [3, 4, 5], [6]]) { |value| value.size } == [3, 4, 5]
max_by([-7]) { |value| value * 3 } == -7
max_by([]) { |value| value + 5 } == nil
<file_sep>time = ''
def time_of_day(num)
hours, minutes = num.abs.divmod(60)
# negative route
if num < 0
if hours > 24
hours = 24 - ((hours - 24*(hours/24)) + 1)
else
unless hours == 23
hours = (24 - hours)
if hours == 24
hours = 23
end
else
hours = 0
end
end
minutes = (60 - minutes)
if minutes == 60
minutes = 0
end
else
# positive route
if hours > 24
hours = hours % 24
end
end
# creating the time string
hours >= 24 ? hours = "#{(hours - 24)}" : "#{hours}"
hours.to_i < 10 ? hours = "0#{hours}" : "#{hours}"
minutes.to_i < 10 ? minutes = "0#{minutes}" : minutes = "#{minutes}"
time = "#{hours}:#{minutes}"
if num.zero?
time = "00:00"
end
time
end
time_of_day(0) == "00:00"
time_of_day(-3) == "23:57"
time_of_day(35) == "00:35"
time_of_day(-1437) == "00:03"
time_of_day(3000) == "02:00"
time_of_day(800) == "13:20"
time_of_day(-4231) == "01:29"
# Their version:
# MINUTES_PER_HOUR = 60
# HOURS_PER_DAY = 24
# MINUTES_PER_DAY = HOURS_PER_DAY * MINUTES_PER_HOUR
# def time_of_day(delta_minutes)
# delta_minutes = delta_minutes % MINUTES_PER_DAY
# hours, minutes = delta_minutes.divmod(MINUTES_PER_HOUR)
# format('%02d:%02d', hours, minutes)
# end
<file_sep>var string = 'A';
asciiNumeric = string.charCodeAt(0);
asciiNumeric += 32;
string = String.fromCharCode(asciiNumeric);
function toLowerCase(string) {
var i;
var final = '';
for (i = 0; i < string.length; i++) {
if (string[i].charCodeAt(0) > 96 || string[i].charCodeAt(0) < 65) {
final += string[i];
} else {
var mini = string[i];
var asciiNumeric = mini.charCodeAt(0);
asciiNumeric += 32;
mini = String.fromCharCode(asciiNumeric);
final += mini;
}
}
return final;
}<file_sep>munsters_description = "The Munsters are creepy in a good way."
munsters_description.capitalize!
munsters_description.swapcase!
munsters_description.downcase!
munsters_description.upcase!
<file_sep># General Exception Handling:
begin
# some code at risk of failing
rescue TypeError
# take action
rescue ArgumentError
# take a different action
end
# StandardError:
begin
# code at risk of failing here
rescue StandardError => e # storing the exception object in e
puts e.message # output error message
end
# ensure:
# the ensure clause serves as a single exit point for the block and allows you to put all of your cleanup code in one place
file = open(file_name, 'w')
begin
# do something with file
rescue
# handle exception
rescue
# handle a different exception
ensure
file.close
# executes every time
end
# retry:
RETRY_LIMIT = 5
begin
attempts = attempts || 0
# do something
rescue
attempts += 1
retry if attempts < RETRY_LIMIT
end
# Exception class hierarchy:
=begin
Exception
NoMemoryError
ScriptError
LoadError
NotImplementedError
SyntaxError
SecurityError
SignalException
Interrupt
StandardError
ArgumentError
UncaughtThrowError
EncodingError
FiberError
IOError
EOFError
IndexError
KeyError
StopIteration
LocalJumpError
NameError
NoMethodError
RangeError
FloatDomainError
RegexpError
RuntimeError
SystemCallError
Errno::*
ThreadError
TypeError
ZeroDivisionError
SystemExit
SystemStackError
fatal
=end
<file_sep>class InvoiceEntry
attr_accessor :quantity, :product_name
def initialize(product_name, number_purchased)
@quantity = number_purchased
@product_name = product_name
end
def update_quantity(updated_count)
# prevent negative quantities from being set
self.quantity = updated_count if updated_count >= 0
end
end
# nothing wrong with fixing it this way
# however, there are now two methods that use the setter quantity= because of attr_accessor
# this could mess with the code down the line
<file_sep>function rotateRightmostDigits(num, start) {
var copy = String(num).split('');
var affected = copy.slice(-start);
var shifted = affected.shift();
affected.push(shifted);
return Number(copy.slice(0, copy.length - start).join('') + affected.join(''));
}
rotateRightmostDigits(735291, 1); // 735291
rotateRightmostDigits(735291, 2); // 735219
rotateRightmostDigits(735291, 3); // 735912
rotateRightmostDigits(735291, 4); // 732915
rotateRightmostDigits(735291, 5); // 752913
rotateRightmostDigits(735291, 6); // 352917<file_sep>var LOOKUP = {
'0': 'zero',
'1': 'one',
'2': 'two',
'3': 'three',
'4': 'four',
'5': 'five',
'6': 'six',
'7': 'seven',
'8': 'eight',
'9': 'nine',
'10': 'ten',
'11': 'eleven',
'12': 'twelve',
'13': 'thirteen',
'14': 'fourteen',
'15': 'fifteen',
'16': 'sixteen',
'17': 'seventeen',
'18': 'eighteen',
'19': 'nineteen'
}
function alphabeticNumberSort(arr) {
return arr.slice(0).sort(function (a, b) {
if (LOOKUP[String(a)] < LOOKUP[String(b)]) {
return -1;
}
if (LOOKUP[String(a)] > LOOKUP[String(b)]) {
return 1;
}
if (LOOKUP[String(a)] === LOOKUP[String(b)]) {
return 1;
}
});
}
alphabeticNumberSort(
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]);<file_sep>def substrings_at_start(string)
starts = [string[0]]
string.chars.each_with_index do |str, idx|
idx == 0 ? next : starts << string[0..idx]
end
starts
end
substrings_at_start('abc') == ['a', 'ab', 'abc']
substrings_at_start('a') == ['a']
substrings_at_start('xyzzy') == ['x', 'xy', 'xyz', 'xyzz', 'xyzzy']
<file_sep>def show_multiplicative_average(ary)
average = (ary.reduce(&:*).to_f/ary.size.to_f)
format('%.3f', average)
end
show_multiplicative_average([3, 5])
# The result is 7.500
show_multiplicative_average([6])
# The result is 6.000
show_multiplicative_average([2, 5, 7, 11, 13, 17])
# The result is 28361.667
<file_sep>var $p = $('p');
// Fades:
$p.fadeOut();
$p.fadeIn();
$p.fadeToggle();
$p.fadeTo(400, .5);
$p.fadeIn(250, function() {
$(this).addClass('visible');
});
// Slides:
$p.slideDown();
$p.slideUp(250);
$p.slideToggle(400, function() {
console.log('Sliding complete!');
});
// object as argument
// easing defaults to 'swing', other value is 'linear'
$p.slideToggle({
duration: 400,
easing: 'linear',
complete: function() {
console.log('Sliding complete!');
}
});
// Custom Animations:
$p.animate({
left: 500,
top: 250
}, 400, function() {
$(this).text('All done!');
});
// 2 objects as args, first w/ css properties, second with jq options
$p.animate({
left: 500,
top: 250
}, {
duration: 1000,
complete: function() {
$(this).text('All done!');
}
});
// Chaining animations (one method completes at a time)
$p.slideUp(250).fadeIn();
$p.slideUp(250).delay(500).slideDown(250);
// Element will immediately be visible and will be in position 50, 50
$p.fadeIn(200).animate({
left: 50,
top: 50
}).finish();
// stop(true) stops all animations in sequence
// stop(true, true) and finish() stops and jumps to endframe
// $.fx.off = true; turns off all animations, usually for testing
<file_sep>/*
Write a function that implements a miniature stack-and-register-based
programming language that has the following commands
(also called operations or tokens):
stack of values
register is current value, not part of stack
2 value operations:
the operation removes the most recently pushed value from the stack,
operates on the popped value and the register value,
and stores the result back in the register.
[3, 6, 4] MULT register (7)
4 * 7 = 28
stack = [3, 6]
n : Place a value, n, in the register. Do not modify the stack.
PUSH : Push the register value onto the stack.
Leave the value in the register.
ADD : Pop a value from the stack and
add it to the register value, storing the result in the register.
SUB : Pop a value from the stack and subtract it from the register value,
storing the result in the register.
MULT : Pop a value from the stack and multiply it by the register value,
storing the result in the register.
DIV : Pop a value from the stack and divide it into the register value,
storing the integer result in the register.
MOD : Pop a value from the stack and divide it into the register value,
storing the integer remainder of the division in the register.
POP : Remove the topmost item from the stack and place it in the register.
PRINT : Print the register value.
All operations deal with full integers
All arguments are supplied as strings
Initialize the stack and register to the values [] and 0, respectively.
stack = []
register = 0
----
Problem: take set of string commands
apply functions for each command to stack and register values
PRINT logs the value of the register to the console
No validation required, assume operations are correct and have correct datatypes
Account for negative values
Expectations:
minilang('5 PUSH 3 MULT PRINT');
// 15
minilang('-3 PUSH 5 SUB PRINT');
// 8
minilang('3 PUSH 4 PUSH 5 PUSH PRINT ADD PRINT POP PRINT ADD PRINT');
// 5 - 5 is last placed as register
// 10 - 5 is added to 5, last item in stack
// 4 - pop replaces register with last item in stack
// 7 - last item in stack is added to register
input, string of commands,
output, logged register values
datatypes:
Input:
string to start
string becomes array
string elements become commands associated with functions
stringnums are converted to numbers (match)
print logs values in register
Stack & register:
array and int
operations can interact with register, register never 'goes away'
PUSH for example places register value in stack but register stays the same
Algorithms:
function push(stack, register) {
stack.push(register);
}
function pop(stack, register) {
register = stack.pop();
}
function add(stack, register) {
register += stack.pop();
}
function sub(stack, register) {
register -= stack.pop();
}
function mult(stack, register) {
register *= stack.pop();
}
function div(stack, register) {
register /= Math.round(stack.pop());
}
function mod(stack, register) {
register %= stack.pop();
}
function print(register {
console.log(register);
}
stack = []
register = 0
string.split(' ')
.forEach(function command)
if command.match(/[0-9]/g)
register = command
else if command.match(/print/ig)
else if command.match(/push/ig)
else if command.match(/pop/ig)
else if command.match(/add/ig)
else if command.match(/sub/ig)
else if command.match(/mult/ig)
else if command.match(/div/ig)
else if command.match(/mod/ig)
*/
function push(stack, register) {
return stack.push(register);
}
function pop(stack, register) {
return stack.pop();
}
function add(stack, register) {
return register += stack.pop();
}
function sub(stack, register) {
return register -= stack.pop();
}
function mult(stack, register) {
return register *= stack.pop();
}
function div(stack, register) {
return Math.floor(register /= stack.pop());
}
function mod(stack, register) {
return Math.floor(register %= stack.pop());
}
function print(register) {
console.log(register);
}
function minilang(commands) {
var realStack = [];
var realRegister = 0;
commands.split(' ').forEach(function (comm) {
if (comm.match(/[0-9]/g)) {
realRegister = Number(comm);
} else if (comm.match(/print/ig)) {
print(realRegister);
} else if (comm.match(/push/ig)) {
push(realStack, realRegister);
} else if (comm.match(/pop/ig)) {
realRegister = pop(realStack, realRegister);
} else if (comm.match(/add/ig)) {
realRegister = add(realStack, realRegister);
} else if (comm.match(/sub/ig)) {
realRegister = sub(realStack, realRegister);
} else if (comm.match(/mult/ig)) {
realRegister = mult(realStack, realRegister);
} else if (comm.match(/div/ig)) {
realRegister = div(realStack, realRegister);
} else if (comm.match(/mod/ig)) {
realRegister = mod(realStack, realRegister);
}
})
}
minilang('PRINT');
minilang('5 PUSH 3 MULT PRINT');
minilang('5 PRINT PUSH 3 PRINT ADD PRINT');
minilang('5 PUSH POP PRINT');
minilang('3 PUSH 4 PUSH 5 PUSH PRINT ADD PRINT POP PRINT ADD PRINT');
minilang('3 PUSH PUSH 7 DIV MULT PRINT');
minilang('4 PUSH PUSH 7 MOD MULT PRINT');
minilang('-3 PUSH 5 SUB PRINT');
minilang('6 PUSH');<file_sep># find min
# find max
# to_s outputs 'suit of rank'
class Card
attr_reader :rank, :suit
include Comparable
RANK_ORDER = {1 => 2, 2 => 3, 3 => 4, 4 => 5, 5 => 6, 6 => 7, 7 => 8, 8 => 9, 9 => 10, 10 => 'Jack', 11 => 'Queen', 12 => 'King', 13 => 'Ace'}
def initialize(rank, suit)
@rank = rank
@suit = suit
end
def <=>(other_card)
RANK_ORDER.key(rank) <=> RANK_ORDER.key(other_card.rank)
end
def to_s
"#{rank} of #{suit}"
end
end
cards = [Card.new(2, 'Hearts'),
Card.new(10, 'Diamonds'),
Card.new('Ace', 'Clubs')]
puts cards
puts cards.min == Card.new(2, 'Hearts')
puts cards.max == Card.new('Ace', 'Clubs')
cards = [Card.new(5, 'Hearts')]
puts cards.min == Card.new(5, 'Hearts')
puts cards.max == Card.new(5, 'Hearts')
cards = [Card.new(4, 'Hearts'),
Card.new(4, 'Diamonds'),
Card.new(10, 'Clubs')]
puts cards.min.rank == 4
puts cards.max == Card.new(10, 'Clubs')
cards = [Card.new(7, 'Diamonds'),
Card.new('Jack', 'Diamonds'),
Card.new('Jack', 'Spades')]
puts cards.min == Card.new(7, 'Diamonds')
puts cards.max.rank == 'Jack'
cards = [Card.new(8, 'Diamonds'),
Card.new(8, 'Clubs'),
Card.new(8, 'Spades')]
puts cards.min.rank == 8
puts cards.max.rank == 8
=begin
Output:
2 of Hearts
10 of Diamonds
Ace of Clubs
true
true
true
true
true
true
true
true
true
true
=end<file_sep>def tricky_method_two(a_string_param, an_array_param)
a_string_param << 'rutabaga'
an_array_param = ['pumpkins', 'rutabaga']
end
my_string = "pumpkins"
my_array = ["pumpkins"]
tricky_method_two(my_string, my_array)
puts "My string looks like this now: #{my_string}"
puts "My array looks like this now: #{my_array}"
# My string looks like this now: pumpkinsrutabaga
# My array looks like this now: ["pumpkins"]
# Assignment is not mutation
# an_array_params values stay inside the method
# LS
# With the Array#= assignment,
# our literal ['pumpkins', 'rutabaga'] array is a new object,
# and we are assigning it to the local variable an_array_param.<file_sep># stack is collection of values
# register is current value, has not been added to the stack
# Ruby's push and pop methods add to and subtract from the stack
# Operations that require two values pop the topmost item from the stack
# (that is, the operation removes the most recently pushed value from the stack),
# perform the operation using the popped value and the register value,
# and then store the result back in the register.
# pop, push new value, push popped value
=begin
Consider a MULT operation in a stack-and-register language.
It multiplies the stack value with the register value, removes the value from the stack,
and then stores the result back in the register.
Thus, if we start with a stack of 3 6 4 (where 4 is the topmost item in the stack),
and a register value of 7, then the MULT operation will transform things to 3 6 on the stack
(the 4 is removed), and the result of the multiplication, 28, is left in the register.
If we do another MULT at this point, then the stack is transformed to 3,
and the register is left with the value 168.
=end
=begin
Write a method that implements a miniature stack-and-register-based programming language
that has the following commands:
n - Place a value n in the "register". Do not modify the stack.
PUSH - Push the register value on to the stack. Leave the value in the register.
ADD - Pops a value from the stack and adds it to the register value, storing the result in the register.
SUB - Pops a value from the stack and subtracts it from the register value, storing the result in the register.
MULT - Pops a value from the stack and multiplies it by the register value, storing the result in the register.
DIV - Pops a value from the stack and divides it into the register value, storing the integer result in the register.
MOD - Pops a value from the stack and divides it into the register value, storing the integer remainder of the division in the register.
POP - Remove the topmost item from the stack and place in register
PRINT - Print the register value
=end
# PSEUDO
# Split String Input
# Turn Numbers into Integers
# Run Case for Each of the Commands
def minilang(string)
stack = []
register = []
commands = string.split
commands.map! {|word| word =~ /[1-9]/ ? word.to_i : word}
commands.each_with_index do |word, idx|
if word.class == Integer || word.class == Fixnum
register << word
elsif word == 'PUSH'
stack << register.slice(-1)
elsif word == 'PRINT'
if register.empty?
puts 0
else puts register[-1]
end
elsif word == 'POP'
register << stack.pop
elsif word == 'ADD'
register << (register.pop + stack.pop)
register.slice!(-2)
elsif word == 'MULT'
register << (register.pop * stack.pop)
register.slice!(-2)
elsif word == 'SUB'
register << (register.pop - stack.pop)
register.slice!(-2)
elsif word == 'DIV'
register << (register.pop / stack.pop)
register.slice!(-2)
elsif word == 'MOD'
register << (register.pop % stack.pop)
register.slice!(-2)
end
end
end
minilang('PRINT')
# 0
minilang('5 PUSH 3 MULT PRINT')
# 15
minilang('5 PRINT PUSH 3 PRINT ADD PRINT')
# 5
# 3
# 8
minilang('5 PUSH POP PRINT')
# 5
minilang('3 PUSH 4 PUSH 5 PUSH PRINT ADD PRINT POP PRINT ADD PRINT')
# 5
# 10
# 4
# 7
minilang('3 PUSH PUSH 7 DIV MULT PRINT ')
# 6
minilang('4 PUSH PUSH 7 MOD MULT PRINT ')
# 12
minilang('-3 PUSH 5 SUB PRINT')
# 8
minilang('6 PUSH')
# (nothing printed; no PRINT commands)
# Their Solution:
=begin
def minilang(program)
stack = []
register = 0
program.split.each do |token|
case token
when 'ADD' then register += stack.pop
when 'DIV' then register /= stack.pop
when 'MULT' then register *= stack.pop
when 'MOD' then register %= stack.pop
when 'SUB' then register -= stack.pop
when 'PUSH' then stack.push(register)
when 'POP' then register = stack.pop
when 'PRINT' then puts register
else register = token.to_i
end
end
end
=end<file_sep># character setting of letters, spaces, and a point
# words can range from 1-20 letters
# input text = one or more words separated from each other by one or more spaces
# words are terminated by 0 or more spaces, text always ends with a point
# odd words must be copied and reversed, odd words have a single space
# take string input
# split string with regex spaces
def odd_words(string)
string.split(/[ .]/).reject(&:empty?).map.with_index {|item, idx| idx.odd? ? item.reverse : item}.join(' ') + '.'
end
odd_words('What is the matter with kansas.')
odd_words("How is the weather today.")
odd_words('My name is Andy, how are you doing.')
# bonus
def input(string)
final_string = ''
string.each_char.with_index do |ch, idx|
final_string << ch unless (ch == ' ' && string[idx + 1] == ' ')
end
final_string
end
input('My name is Andy, how are you doing.')
def output(string)
final_string = ''
reversal = []
word_count = 0
string = input(string)
string.each_char.with_index do |ch, idx|
if word_count.odd?
if ch == ' ' || idx == string.size - 1
final_string << reversal.reverse.join
reversal.clear
else
reversal << ch
end
end
final_string << ch if ch == ' ' || word_count.even?
word_count += 1 if ch == ' '
end
final_string + '.'
end
output('My name is Andy, how are you doing.')
output('What is the matter with kansas.')
<file_sep>def triangle(a, b, c)
case
when (a + b + c) != 180 || [a,b,c].any? {|num| num <= 0}
:invalid
when [a,b,c].any? {|num| num == 90}
:right
when [a,b,c].all? {|num| num < 90}
:acute
when [a,b,c].any? {|num| num > 90}
:obtuse
end
end
triangle(60, 70, 50) == :acute
triangle(30, 90, 60) == :right
triangle(120, 50, 10) == :obtuse
triangle(0, 90, 90) == :invalid
triangle(50, 50, 50) == :invalid
<file_sep>module ApplicationHelper
def fix_url(str)
str.downcase.starts_with?('http') ? str : "http://#{str}"
end
end
<file_sep>def ascii_value(string)
string.chars.map{|s| s.ord}.reduce(0, :+)
end
ascii_value('Four score') == 984
ascii_value('Launch School') == 1251
ascii_value('a') == 97
ascii_value('') == 0<file_sep>function logOddNumbers(n) {
var i;
for (i = 0; i <= n; i ++) {
if (i % 2 !== 0) {
console.log(i);
}
}
}
logOddNumbers(19);<file_sep>function negative(num) {
if (num === 0) {return "-0"}
return num < 0 ? num : Number("-" + String(num));
}
negative(5); // -5
negative(-3); // -3
negative(0); // -0<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
class IncludeTest < MiniTest::Test
def test_nil
array = ['xyz']
assert_includes(array, 'xyz')
end
end
<file_sep>sum = 0
ages = { "Herman" => 32, "Lily" => 30, "Grandpa" => 5843, "Eddie" => 10, "Marilyn" => 22, "Spot" => 237 }
ages.each_value do |num|
sum += num
end
sum
=begin
Hash#each
total_ages = 0
ages.each { |_,age| total_ages += age }
total_ages # => 6174
Another option would be to use a Enumerable#inject method.
ages.values.inject(:+) # => 6174<file_sep>MINUTES_IN_DAY = 24 * 60
def after_midnight(string)
string.delete!(":")
hours = string[0, 2].to_i
minutes = string[2, 2].to_i
time = hours * 60 + minutes
if time == MINUTES_IN_DAY
time = 0
end
time
end
def before_midnight(string)
string.delete!(":")
hours = string[0, 2].to_i
minutes = string[2, 2].to_i
time = (MINUTES_IN_DAY - ((hours * 60) + minutes)).abs
if time == MINUTES_IN_DAY
time = 0
end
time
end
after_midnight('00:00') == 0
before_midnight('00:00') == 0
after_midnight('12:34') == 754
before_midnight('12:34') == 686
after_midnight('24:00') == 0
before_midnight('24:00') == 0
=begin
Their Version:
HOURS_PER_DAY = 24
MINUTES_PER_HOUR = 60
MINUTES_PER_DAY = HOURS_PER_DAY * MINUTES_PER_HOUR
def after_midnight(time_str)
hours, minutes = time_str.split(':').map(&:to_i)
(hours * MINUTES_PER_HOUR + minutes) % MINUTES_PER_DAY
end
def before_midnight(time_str)
delta_minutes = MINUTES_PER_DAY - after_midnight(time_str)
delta_minutes = 0 if delta_minutes == MINUTES_PER_DAY
delta_minutes
end
=end
# Quick way to transform values in a collection!
# .map(&:method)
# .map(&:to_i); it's a shorthand way of doing this:
# something.map { |string| string.to_i }<file_sep>def divisors(num)
(1..num).select {|int| num % int == 0}
end
divisors(1) == [1]
divisors(7) == [1, 7]
divisors(12) == [1, 2, 3, 4, 6, 12]
divisors(98) == [1, 2, 7, 14, 49, 98]
divisors(99400891) == [1, 9967, 9973, 99400891] # may take a minute
<file_sep>=begin
Improved "join"
If we run the current game, we'll see the following prompt:
=> Choose a position to place a piece: 1, 2, 3, 4, 5, 6, 7, 8, 9
This is ok, but we'd like for this message to read a little better. We want to separate the last item with a "or", so that it reads:
=> Choose a position to place a piece: 1, 2, 3, 4, 5, 6, 7, 8, or 9
Currently, we're using the Array#join method, which can only
insert a delimiter between the array elements,
and isn't smart enough to display a joining word for the last element.
Write a method called joinor that will produce the following result:
=end
def joinor(array, conjunct = ', ', symbol = 'or')
array = array.join(conjunct)
unless array.split.size == 1
array[1, 2] = ' ' if array.split.map(&:to_i).count{|x| x / 1 == x} < 3
array[-2] = " #{symbol} "
end
array
end
joinor([1, 2]) # => "1 or 2"
joinor([1, 2, 3]) # => "1, 2, or 3"
joinor([1, 2, 3], '; ') # => "1; 2; or 3"
joinor([1, 2, 3], ', ', 'and') # => "1, 2, and 3"<file_sep>class CategoriesController < ApplicationController
before_action :set_post, except: :show
before_action :set_cat, only: [:show, :destroy]
before_action :require_user, except: [:show]
def new
@category = Category.new
end
def create
@category = Category.new(params.require(:category).permit!)
if Category.exists?(name: @category.name) # existing category
@category = Category.where(name: @category.name).first
if PostCategory.exists?(post_id: @post.id, category_id: @category.id)
flash[:notice] = "The post already has this category: #{@category.name}"
redirect_to :back # change this to flash.now[:alert] and return render
else
add_category
end
else # new category
if @category.save
add_category
else
render 'new'
end
end
end
def show
end
def destroy
delete_category
end
private
def set_post
@post = Post.find_by(slug: params[:post_id])
end
def set_cat
@category = Category.find_by(slug: params[:id])
end
def add_category
@post.categories << @category
flash[:notice] = "New category added!"
redirect_to post_path(@post)
end
def delete_category
@post.categories.delete(@category)
flash[:notice] = "Category #{@category.name} deleted"
redirect_to :back
end
end<file_sep>/* Differences of Map() vs Object()
1. Key field: in Object, it follows the rule of normal dictionary.
The keys MUST be simple types — either integer or string or symbols.
Nothing more. But in Map it can be any data type (an object, an array, etc…).
2. Element order: in Map, original order of elements (pairs)
is preserved, while in Object, it isn’t.
3. Inheritance: Map is an instance of Object (surprise surprise!),
but Object is definitely not an instance of Map.
*/
var map1 = new Map();
map1.set('bar', 'foo');
console.log(map1.get('bar'));
// expected output: "foo"
console.log(map1.get('baz'));
// expected output: undefined
// also, no new key is defined
<file_sep>class Cat
attr_accessor :type, :age
def initialize(type)
@type = type
@age = 0
end
def make_one_year_older
self.age += 1
end
end
# self refers to the current calling object, an instance of the class Cat
# L_S:
# Keeping this in mind the use of self here is referencing the instance
# (object) that called the method - the calling object.
<file_sep>def buy_fruit(nested_ary)
new_ary = []
nested_ary.map {|item| item[-1].times {new_ary << item[0]}}
new_ary
end
buy_fruit([["apples", 3], ["orange", 1], ["bananas", 2]]) ==
["apples", "apples", "apples", "orange", "bananas","bananas"]
# Launch School Version:
def buy_fruit(list)
list.map { |fruit, quantity| [fruit] * quantity }.flatten
end
<file_sep>function showMultiplicativeAverage(arr) {
var mult = arr.reduce(function (prod, n) {return prod * n}) / arr.length;
return mult.toPrecision(String(Math.floor(mult)).length + 3);
}
showMultiplicativeAverage([3, 5]); // "7.500"
showMultiplicativeAverage([2, 5, 7, 11, 13, 17]); // "28361.667"<file_sep>arr = [1, 2, 3, 4, 5]
arr.take(2)
# non-destructive, just returns n elements of array<file_sep>[1, 2, 3].any? do |num|
puts num
num.odd?
end
# prints 1
# => true
=begin
Since the Array#any? method returns true if the block ever returns
a value other than false or nil, and the block returns true on the first iteration,
we know that any? will return true. What is also interesting here is any?
stops iterating after this point since there is no need to evaluate the remaining
items in the array; therefore, puts num is only ever invoked for the first item in the array: 1.
=end<file_sep>def multiply_all_pairs(ary1, ary2)
products = []
ary1.each {|a| products << ary2.map(&a.method(:*))}
products.flatten.sort
end
multiply_all_pairs([2, 4], [4, 3, 1, 2]) == [2, 4, 4, 6, 8, 8, 12, 16]<file_sep>def crunch(string)
string.chars.chunk{|character| character}.map(&:first).join
end
crunch('ddaaiillyy ddoouubbllee')
crunch('ddaaiillyy ddoouubbllee') == 'daily double'
crunch('4444abcabccba') == '4abcabcba'
crunch('ggggggggggggggg') == 'g'
crunch('a') == 'a'
crunch('') == ''
# Enumerable#chunk
# Enumerates over the items, chunking them together
# based on the return value of the block.
# Consecutive elements which return the same block value
# are chunked together.
# broken down version
# def crunch(string)
# string = string.chars
# string = string.chunk{|m| m}
# string.map{|m| m.first}.join
# end<file_sep>=begin
The sort method
As we have already seen, we can simply call sort on an array,
which returns a new array of ordered items; when we do this,
comparisons are carried out using the <=> method on the items being sorted.
=end
[2, 5, 3, 4, 1].sort do |a, b|
a <=> b
end
# => [1, 2, 3, 4, 5]
[2, 5, 3, 4, 1].sort do |a, b|
b <=> a
end
# => [5, 4, 3, 2, 1]
[2, 5, 3, 4, 1].sort do |a, b|
puts "a is #{a} and b is #{b}"
a <=> b
end
# a is 2 and b is 5
# a is 4 and b is 1
# a is 3 and b is 1
# a is 3 and b is 4
# a is 2 and b is 1
# a is 2 and b is 3
# a is 5 and b is 3
# a is 5 and b is 4
# => [1, 2, 3, 4, 5]
[['a', 'cat', 'b', 'c'], ['b', 2], ['a', 'car', 'd', 3], ['a', 'car', 'd']].sort
# => [["a", "car", "d"], ["a", "car", "d", 3], ["a", "cat", "b", "c"], ["b", 2]]
=begin
The documentation states the "Each object in each array is compared...
in an 'element-wise' manner", so the first object in all of the arrays is compared initially.
Since three of the arrays have the string 'a' at their first index,
these all come before the array that has the string 'b' at its first index.
=end
<file_sep>a = 'hi'
# 'hi'
english_greetings = ['hello', a, 'good morning']
# greetings index 1 references a
greetings = {
french: ['bonjour', 'salut', 'allo'],
english: english_greetings,
italian: ['buongiorno', 'buonasera', 'ciao']
}
# greetings value at key :english references a at index 1
greetings[:english][1] = 'hey'
# changes value of index 1 in english_greetings, but doesn't modify original reference
greetings.each do |language, greeting_list|
greeting_list.each { |greeting| greeting.upcase! }
end
# destructive method placed on elements in greetings hash & english_greetings array
# does not modify original object
puts a
puts english_greetings[1]
puts greetings[:english][1]<file_sep>comparator = proc { |a, b| b <=> a }
# array.sort(comparator) fails
array.sort(&comparator) # works
# problem
def convert_to_base_8(n)
n.to_s(8).to_i # replace these two method calls
end
# The correct type of argument must be used below
base8_proc = convert_to_base_8(:convert_to_base_8).to_proc
# We'll need a Proc object to make this code work. Replace `a_proc`
# with the correct object
[8,10,12,14,16,33].map(&base8_proc)
# [10, 12, 14, 16, 20, 41]
<file_sep>class Flight
# delete attr_accessor, no need for the methods, makes data too easily accessible
def initialize(flight_number)
@database_handle = Database.init
@flight_number = flight_number
end
end
<file_sep>class Banner
def initialize(message)
@message = message
@corner = '+'
@dash = '-'
@border = '|'
@empty = ' '
end
def to_s
[horizontal_rule, empty_line, message_line, empty_line, horizontal_rule].join("\n")
end
private
def horizontal_rule
# use this method to determine the width of the banner, +--+
@corner + (@dash * (message_line.length - 2)) + @corner
end
def empty_line
# use the horizontal rule for the width, but use | for each edge
@border + (@empty * (message_line.length - 2)) + @border
end
def message_line
"#{@border} #{@message} #{@border}"
end
end
banner = Banner.new('To boldly go where no one has gone before.')
puts banner
banner = Banner.new('')
puts banner
# Complete this class so that the test cases shown below work as intended.
# You are free to add any methods or instance variables you need.
# However, do not make the implementation details public.
=begin
banner = Banner.new('To boldly go where no one has gone before.')
puts banner
+--------------------------------------------+
| |
| To boldly go where no one has gone before. |
| |
+--------------------------------------------+
banner = Banner.new('')
puts banner
+--+
| |
| |
| |
+--+
=end
# version 2:
class Banner
TOP = '-'
SIDE = '|'
CORNER = '+'
SPACE = ' '
attr_reader :message
def initialize(message)
@message = message
@spaces = @message.length
end
def to_s
[horizontal_rule, empty_line, message_line, empty_line, horizontal_rule].join("\n")
end
private
def horizontal_rule
CORNER + TOP + (TOP * @spaces) + TOP + CORNER
end
def empty_line
SIDE + SPACE + (SPACE * @spaces) + SPACE + SIDE
end
def message_line
"| #{message} |"
end
end
<file_sep>10.times { |number| puts (" " * number) + "The Flintstones Rock!" }
=begin
space = " "
phrase = "The Flintstones Rock!"
for i in 1..10 do
puts (space * i) + phrase
end
=end<file_sep>// factory function
function makeObj() {
var obj = {};
obj.propA = 10;
obj.propB = 20;
return obj;
}
// factory function with object literal syntax
function makeObj() {
return {
propA: 10,
probB: 20,
};
}
// examples for #3
var invoice = {
phone: 3000,
internet: 6500,
};
var payment = {
phone: 1300,
internet: 5500,
};
var invoiceTotal = invoice.phone + invoice.internet;
var paymentTotal = payment.phone + payment.internet;
var remainingDue = invoiceTotal - paymentTotal;
console.log(paymentTotal); // 6800
console.log(remainingDue); // 2700
// #3
function createInvoice(services) {
services = arguments.length < 1 ? {} : services;
services.phone = !services.phone ? 3000 : services.phone;
services.internet = !services.internet ? 5500 : services.internet;
services.total = function(){ return Object.values(services).filter(function(x) { return typeof x === "number" }).reduce(function(sum, inv) { return sum + inv }) };
return services;
}
function invoiceTotal(invoices) {
var total = 0;
var i;
for (i = 0; i < invoices.length; i += 1) {
total += invoices[i].total();
}
return total;
}
var invoices = [];
invoices.push(createInvoice());
invoices.push(createInvoice({
internet: 6500,
}));
invoices.push(createInvoice({
phone: 2000,
}));
invoices.push(createInvoice({
phone: 1000,
internet: 4500,
}));
console.log(invoiceTotal(invoices));
// 31000
//# 4
function createPayment(services) {
services = arguments.length < 1 ? {initial: 0} : services;
services.total = function(){ return Object.values(services).filter(function(x) { return typeof x === "number" }).reduce(function(sum, inv) { return sum + inv }) };
return services;
}
function paymentTotal(payments) {
var total = 0;
var i;
for (i = 0; i < payments.length; i += 1) {
total += payments[i].total();
}
return total;
}
var payments = [];
payments.push(createPayment());
payments.push(createPayment({
internet: 6500,
}));
payments.push(createPayment({
phone: 2000,
}));
payments.push(createPayment({
phone: 1000,
internet: 4500.
}));
payments.push(createPayment({
amount: 10000,
}));
console.log(paymentTotal(payments)); // 24000
// #5
function createInvoice(services) {
services = arguments.length < 1 ? {} : services;
services.paid = 0;
services.phone = !services.phone ? 3000 : services.phone;
services.internet = !services.internet ? 5500 : services.internet;
services.total = function(){ return Object.values(services).filter(function(x) { return typeof x === "number" }).reduce(function(sum, inv) { return sum + inv }) };
services.addPayment = function(payment) { services.paid = services.paid - payment.total() }
services.addPayments = function(paymentsArr) { paymentsArr.forEach(function(pmt) { services.addPayment(pmt) }) };
services.amountDue = function() { return services.total() };
return services;
}
function createPayment(services) {
services = arguments.length < 1 ? {initial: 0} : services;
services.total = function(){ return Object.values(services).filter(function(x) { return typeof x === "number" }).reduce(function(sum, inv) { return sum + inv }) };
return services;
}
var invoice = createInvoice({
phone: 1200,
internet: 4000,
});
var payment1 = createPayment({
amount: 2000
});
var payment2 = createPayment({
phone: 1000,
internet: 1200,
});
var payment3 = createPayment({
phone: 1000,
});
invoice.addPayment(payment1);
invoice.addPayments([payment2, payment3]);
invoice.amountDue(); // this should return 0
<file_sep>function walk(node) {
console.log(node.nodeName); // do something with node
var i;
for (i = 0; i < node.childNodes.length; i++) { // for each child node
walk(node.childNodes[i]); // recursively call walk()
}
}
walk(document.body); // log nodeName of every node
// Here's a version that takes customized functions as arguments:
// walk() calls the function "callback" once for each node
function walk(node, callback) {
callback(node); // do something with node
var i;
for (i = 0; i < node.childNodes.length; i++) { // for each child node
walk(node.childNodes[i], callback); // recursively call walk()
}
}
walk(document.body, function(node) { // log nodeName of every node
console.log(node.nodeName);
});
<file_sep># numbers.delete_at(1)
# this will delete the value at index 1 in the aray
# AKA the second value
# numbers.delete(1)
# this will delete all occurences of 1 in the array<file_sep>require 'pry'
class Participant
attr_accessor :hand, :name
def initialize(name)
@hand = []
@name = name
end
def <<(cards)
@hand << cards
end
def total
hand.map(&:value).reduce(&:+)
end
def to_sym
@name.to_sym
end
def busted?
total > 21
end
end
class Player < Participant
def hit(current_deck, player)
hand << Card.new(current_deck.shift, player.to_sym)
puts "You drew a #{hand[-1].name}. Your total is #{total}."
end
def stay
puts "You chose to stay at #{total}."
end
end
class Dealer < Participant
def deal(player, current_deck)
2.times { player << Card.new(current_deck.shift, player.to_sym) }
end
def hit(current_deck, player)
hand << Card.new(current_deck.shift, player.to_sym)
puts "Dealer draws a #{hand[-1].name}."
puts "Dealer's total is #{total}."
end
def stay
puts "Dealer stays at #{total}."
end
end
class Deck
attr_reader :new_deck
FACE = ['two', 'three', 'four', 'five', 'six', 'seven',
'eight', 'nine', 'ten', 'jack', 'queen', 'king', 'ace']
HEARTS = FACE.map { |f| f + ' of hearts' }
SPADES = FACE.map { |f| f + ' of spades' }
CLUBS = FACE.map { |f| f + ' of clubs' }
DIAMONDS = FACE.map { |f| f + ' of diamonds' }
def initialize
@new_deck = (HEARTS + SPADES + CLUBS + DIAMONDS).shuffle
end
def shift
new_deck.shift
end
end
class Card
attr_reader :type, :name
attr_accessor :value
@@drawn_cards_human = []
@@drawn_cards_comp = []
def initialize(name, player)
@name = name
@face = name.split[-1]
@type = name.split[0]
@numbers = {}
number_values
@player = player
@value = determine_value
end
def human?
@player == :human
end
def number_values
counter = 2
Deck::FACE[0..8].each do |word|
@numbers[word] = counter
counter += 1
end
end
def determine_value
if @numbers.keys.include?(type)
value = @numbers[type]
elsif type == 'ace'
value = determine_ace
else
value = 10
end
@@drawn_cards_human << value if human?
@@drawn_cards_comp << value if !human?
value
end
def determine_ace
if human?
if @@drawn_cards_human.empty? || ace_calculation(@@drawn_cards_human)
return 11
end
else
if @@drawn_cards_comp.empty? || ace_calculation(@@drawn_cards_comp)
return 11
end
end
1
end
def ace_calculation(drawn_cards)
drawn_cards.reduce(&:+) + 11 < 21
end
end
class Game
attr_reader :game_deck, :human, :computer, :move
def initialize
@game_deck = Deck.new
@human = Player.new(:human)
@computer = Dealer.new(:computer)
end
def deal_cards
computer.deal(human, game_deck)
computer.deal(computer, game_deck)
end
def show_initial_cards
puts "Your hand: #{human.hand[0].name} & #{human.hand[1].name}."
puts "Current total is #{human.total}."
puts "Your opponent is showing the #{computer.hand[1].name}."
end
def hit_or_stay_prompt
loop do
puts "Do you want to hit or stay?"
@move = gets.chomp.downcase
break if move.start_with?('h', 's')
puts "Please type hit or stay."
end
end
def player_turn
loop do
hit_or_stay_prompt
human.hit(game_deck, :human) if move.start_with?('h')
break if move.start_with?('s') || human.busted?
end
end
def dealer_turn
loop do
break if computer.total >= 17
computer.hit(game_deck, :computer)
end
computer.stay unless computer.busted?
end
def determine_winner
@winner = 'You' if human.total > computer.total
@winner = 'Dealer' if computer.total > human.total
end
def show_result
if human.busted?
puts "You busted!"
elsif computer.busted?
puts "Dealer busted!"
else
determine_winner
puts "#{@winner} won!"
end
end
def start
deal_cards
show_initial_cards
player_turn
dealer_turn unless human.busted?
show_result
end
end
Game.new.start
<file_sep>def staggered_case(string)
string.downcase!
counter = 0
string = string.chars.each do |s|
if s =~ /[a-zA-Z]/
counter +=1
if counter.odd?
s.upcase!
else s.downcase!
end
elsif nil
next
end
end
string.join
end
staggered_case('I Love Launch School!') == 'I lOvE lAuNcH sChOoL!'
staggered_case('ALL CAPS') == 'AlL cApS'
staggered_case('ignore 77 the 444 numbers') == 'IgNoRe 77 ThE 444 nUmBeRs'
<file_sep>function swapName(name) {
return name.split(' ').reverse().join(', ');
}
function swapName(name) {
var multifirst = name.split(' ').length > 2 ? name.split(' ').slice(0, name.split(' ').length - 1).join(' ') : name.split(' ')[0];
return name.split(' ')[name.split(' ').length - 1] + ', ' + multifirst;
}
swapName('<NAME>');
swapName('<NAME>');<file_sep>def rotate_array(ary)
ary[1..-1] << ary.slice(0)
end
def rotate_rightmost_digits(digits, count)
digarray = digits.to_s.chars
rotated_nums = digarray[-count..-1]
rotated_nums = rotate_array(rotated_nums)
digarray = digarray[0...-count] + rotated_nums
digarray.join.to_i
end
def max_rotation(new_digits)
number_size = new_digits.to_s.size
return new_digits if number_size == 1
new_digits = rotate_rightmost_digits(new_digits, number_size)
count = 1
loop do
break if count == (number_size - 1)
new_digits = rotate_rightmost_digits(new_digits, (number_size - count))
count += 1
end
new_digits
end
max_rotation(735291) == 321579
max_rotation(3) == 3
max_rotation(35) == 53
max_rotation(105) == 15 # the leading zero gets dropped
max_rotation(8_703_529_146) == 7_321_609_845
<file_sep>var a = 'outer';
function testScope() {
var a = 'inner';
console.log(a);
}
console.log(a);
testScope();
console.log(a);
//outer
//inner
//outer
var a = 'outer';
function testScope() {
a = 'inner';
console.log(a);
}
console.log(a);
testScope();
console.log(a);
//outer
//inner
//inner
var basket = 'empty';
function goShopping() {
function shop1() {
basket = 'tv';
}
console.log(basket);
function shop2() {
basket = 'computer';
}
function shop3() {
var basket = 'play station';
console.log(basket);
}
shop1();
shop2();
shop3();
console.log(basket);
}
goShopping();
//empty
//play station
//computer
function hello() {
a = 'hello';
}
hello();
console.log(a);
//hello
function hello() {
var a = 'hello';
}
hello();
console.log(a);
//Uncaught ReferenceError: a is not defined
console.log(a);
var a = 1;
//undefined, hoising puts var a above the log call, then the assignment
console.log(a);
function hello() {
a = 1;
}
//Uncaught ReferenceError: a is not defined<file_sep>answer = 42
def mess_with_it(some_number)
some_number += 8
end
new_answer = mess_with_it(answer)
p answer - 8
# Outputs 34. 42-8=34
# The last line asks the computer to print answer - 8
# new_answer was a changed number, but it called the original variable <file_sep>greetings = { a: 'hi' }
# id 24187160
informal_greeting = greetings[:a]
# id 24187160
informal_greeting << ' there'
puts informal_greeting # => "hi there"
puts greetings # => "hi there"
=begin
If instead of modifying the original object,
we wanted to only modify informal_greeting but not greetings, there are a couple of options:
we could initialize informal_greeting with a reference to a new object
containing the same value by informal_greeting = greetings[:a].clone.
we can use string concatenation, informal_greeting = informal_greeting + ' there',
which returns a new String object instead of modifying the original object.
=end<file_sep>class Rot13
LETTERS = {1 => 'A', 2 => 'B', 3 => 'C', 4 => 'D', 5 => 'E', 6 => 'F', 7 => 'G',
8 => 'H', 9 => 'I', 10 => 'J', 11 => 'K', 12 => 'L', 13 => 'M', 14 => 'N',
15 => 'O', 16 => 'P', 17 => 'Q', 18 => 'R', 19 => 'S', 20 => 'T', 21 => 'U',
22 => 'V', 23 => 'W', 24 => 'X', 25 => 'Y', 26 => 'Z', 27 => ' ', 28 => '-'}
attr_accessor :string
def initialize(string)
@string = string
self.decode
end
def encode(phrase)
new_values = []
phrase.each_char do |ch|
new_values << (LETTERS.key(ch.upcase) - 13) unless ch == ' ' || ch == '-'
new_values << 27 if ch == ' '
new_values << 28 if ch == '-'
end
new_values.map(&:to_i).map {|num| num < 1 ? 26 + num : num}
end
def decode
new_string = ''
encode(@string).each_with_index do |new_char, idx|
current = @string[idx]
if new_char > 26 || current == current.upcase
new_string << LETTERS[new_char]
else
new_string << LETTERS[new_char].downcase
end
end
self.string = new_string
end
def to_s
@string
end
end
names = ['<NAME>', '<NAME>', '<NAME>', '<NAME>', '<NAME>',
'<NAME> ny-Xujnevmzv', '<NAME>', 'Ybvf Unvog',
'<NAME>', '<NAME>', 'Ov<NAME>ngrf', 'G<NAME>', '<NAME>',
'X<NAME>', '<NAME>', '<NAME>', 'Lhxvuveb Zngfhzbgb',
'Un<NAME>', '<NAME>']
names.each {|name| puts Rot13.new(name)}
<file_sep>def count(*values)
array = values.to_a
counter = 0
array.each {|item| counter += 1 if yield(item)}
counter
end
count(1, 3, 6) { |value| value.odd? } == 2
count(1, 3, 6) { |value| value.even? } == 1
count(1, 3, 6) { |value| value > 6 } == 0
count(1, 3, 6) { |value| true } == 3
count() { |value| true } == 0
count(1, 3, 6) { |value| value - 6 } == 3
# LS solution - You can treat these arguments like an array object
def count(*arguments)
total = 0
arguments.each { |item| total += 1 if yield(item) }
total
end
<file_sep>
# Rules
# Smallest Star You'll Need is a 7 X 7 Grid
# look at diamond problem (below)
# 1st row of star 7 is 1,4,7
# 1 skip skip 2 skip skip 3
# skip 1 skip 2 skip 3
# 1 2 3
# 1234567 then the opposite
# star 9 has 2 more spaces and one more row upward
# 1 skip skip skip 2 skip skip skip 3
# skip 1 skip skip 2 skip skip 3 skip
# skip skip 1 skip 2 skip 3 skip skip
# skip skip skip 123 skip skip skip
# 123456789
# Take number
# Each row you go down, 2 less skips on inside, 2 more on outside (one on each end)
# [outside][inside][outside]
# skip
def star(num = 7)
outside1, outside2 = '', ''
spaces = ' ' * ((num - 7) / 2)
inside = "* #{spaces}* #{spaces}*"
puts inside
until inside == '***'
outside1 << inside.slice!(1)
outside2 << inside.slice!(-2)
puts outside1 + inside + outside2
end
puts '*' * num # middle
puts inside.center(num + 1)
until outside1.empty?
inside[1] = inside[1].prepend(outside1.slice!(0))
inside[-2] += outside2.slice!(0)
puts outside1 + inside + outside2
end
end
star
star(9)
=begin
def diamond(odd_num)
rows = (1..odd_num).select {|n| n.odd?}
padding = rows[-1] + 1
rows += rows.reverse[1..-1]
rows.each {|n| puts ("*" * n).center(padding)}
end
=end
star(7)
* * *
* * *
***
*******
***
* * *
* * *
star(9)
* * *
* * *
* * *
***
*********
***
* * *
* * *
* * *<file_sep>function repeater(str) {
return str.split('').map(ch => ch + ch).join('');
}
repeater('Hello'); // "HHeelllloo"
repeater('Good job!'); // "GGoooodd jjoobb!!"
repeater(''); // ""<file_sep>class Deck
attr_reader :new_deck
attr_accessor :counter
RANKS = (2..10).to_a + %w(Jack Queen King Ace).freeze
SUITS = %w(Hearts Clubs Diamonds Spades).freeze
def initialize
@new_deck = []
init_deck
@counter = -1
end
def init_deck
SUITS.each {|suit| RANKS.each {|rank| @new_deck << Card.new(rank, suit)}}
@new_deck.shuffle!
end
def draw
@counter += 1
if counter > 51
@new_deck.shuffle!
self.counter = 0
end
@new_deck[counter]
end
end
class Card < Deck
attr_reader :rank, :suit
include Comparable
RANK_ORDER = {1 => 2, 2 => 3, 3 => 4, 4 => 5, 5 => 6, 6 => 7, 7 => 8, 8 => 9, 9 => 10, 10 => 'Jack', 11 => 'Queen', 12 => 'King', 13 => 'Ace'}
def initialize(rank, suit)
@rank = rank
@suit = suit
end
def <=>(other_card)
RANK_ORDER.key(rank) <=> RANK_ORDER.key(other_card.rank)
end
def to_s
"#{rank} of #{suit}"
end
end
deck = Deck.new
drawn = []
52.times { drawn << deck.draw }
drawn.count { |card| card.rank == 5 } == 4
drawn.count { |card| card.suit == 'Hearts' } == 13
drawn2 = []
52.times { drawn2 << deck.draw }
drawn != drawn2 # Almost always.
<file_sep># every method can take an optional block as an implicit parameter.
def echo(str)
str
end
echo("hello!") { puts "world" }
# => "hello!"
def echo_with_yield(str)
yield
str
end
echo_with_yield("hello!") { puts "world" }
# world
# => "hello!" (returned)
def echo_with_yield(str)
yield if block_given?
str
end
echo_with_yield("hello!")
# => "hello!"
echo_with_yield("hello!") { puts "world" }
# world
# => "hello!"
def say(words)
yield if block_given?
puts "> " + words
end
# method invocation
say("hi there") do
system 'cls'
end
# clears screen first, then outputs "> hi there"
# with an argument
# method implementation
def increment(number)
if block_given?
yield(number + 1)
else
number + 1
end
end
# method invocation
increment(5) do |num|
puts num
end
# outputs 6
# assigned variable to the return
# value of a block via yield
def compare(str)
puts "Before: #{str}"
after = yield(str)
puts "After: #{after}"
end
# method invocation
compare('hello') { |word| word.upcase }
# Before: hello
# After: HELLO
# => nil
# use case: before/after
def time_it
time_before = Time.now
yield # execute the implicit block
time_after= Time.now
puts "It took #{time_after - time_before} seconds."
end
time_it { sleep(3) } # It took 3.003767 seconds.
# => nil
time_it { "hello world" } # It took 3.0e-06 seconds.
# => nil
<file_sep>def all?(array)
counter = 0
truthies = 0
while counter < array.size
truthies += 1 if yield(array[counter])
counter += 1
end
truthies == array.size
end
all?([1, 3, 5, 6]) { |value| value.odd? } == false
all?([1, 3, 5, 7]) { |value| value.odd? } == true
all?([2, 4, 6, 8]) { |value| value.even? } == true
all?([1, 3, 5, 7]) { |value| value % 5 == 0 } == false
all?([1, 3, 5, 7]) { |value| true } == true
all?([1, 3, 5, 7]) { |value| false } == false
all?([]) { |value| false } == true
# ls solution
def all?(collection)
collection.each { |item| return false unless yield(item) }
true
end
<file_sep>function letterPercentages(str) {
var result = {lowercase: 0, uppercase: 0, neither: 0};
var count = 0;
str.split('').forEach(function (char) {
if (/[a-z]/.test(char)) {
result.lowercase += 1;
} else if (/[A-Z]/.test(char)) {
result.uppercase += 1;
} else {
result.neither += 1;
}
count += 1;
});
Object.keys(result).forEach(function (key) {
result[key] = String(((result[key] / count) * 100).toFixed(2));
console.log(key);
})
return result;
}
letterPercentages('abCdef 123');
// { lowercase: "50.00", uppercase: "10.00", neither: "40.00" }
letterPercentages('AbCd +Ef');
// { lowercase: "37.50", uppercase: "37.50", neither: "25.00" }
letterPercentages('123');
// { lowercase: "0.00", uppercase: "0.00", neither: "100.00" }<file_sep>arr = [[:a, 1], ['b', 'two'], ['sea', {c: 3}], [{a: 1, b: 2, c: 3, d: 4}, 'D']]
new_hash = {}
arr.map do |ary|
new_hash[ary[0]] = ary[1]
end
new_hash<file_sep>def fibonacci_last(num, fib = [1, 1])
(num - 2).times do
sum = fib[-2..-1].reduce(&:+)
fib << sum.to_s[-1].to_i
end
fib[-1]
end
fibonacci_last(15) # -> 0 (the 15th Fibonacci number is 610)
fibonacci_last(20) # -> 5 (the 20th Fibonacci number is 6765)
fibonacci_last(100) # -> 5 (the 100th Fibonacci number is 354224848179261915075)
fibonacci_last(100_001) # -> 1 (this is a 20899 digit number)
fibonacci_last(1_000_007) # -> 3 (this is a 208989 digit number)
fibonacci_last(123456789) # -> 4
# Their Solution
=begin
def fibonacci_last(nth)
last_2 = [1, 1]
3.upto(nth) do
last_2 = [last_2.last, (last_2.first + last_2.last) % 10]
end
last_2.last
end
=end<file_sep>require "sinatra"
require "sinatra/reloader"
require "tilt/erubis"
require "yaml"
get "/" do
redirect "/names"
end
get "/names" do
@data = parse_yaml
erb :names
end
get "/user" do
@data = parse_yaml
@name = params[:id]
erb :user
end
helpers do
def parse_yaml
Psych.load_file("data/users.yaml")
end
def display_users
@data.keys.map do |name|
"<p><a href=/user?id=#{name}>#{name.to_s.capitalize}</a><p>"
end.join
end
def count_interests
@data.map do |k, v|
v.map do |k2, v2|
next unless k2 == :interests
v2.size
end.compact.reduce(&:+)
end.reduce(&:+)
end
def display_interests
@data[@name.to_sym][:interests].join(', ')
end
def other_users
@data.keys.map do |name|
"<a href=/user?id=#{name}>#{name.to_s.capitalize}</a>"
end.select {|link| !link.include?(@name.to_s.capitalize)}.join(' ')
end
end<file_sep>class QueueItemsController < ApplicationController
before_action :access_granted?
def index
@queue_items = current_user.queue_items.sort_by(&:position)
end
def create
@queue_item = QueueItem.create(queue_item_params)
flash[:notice] = @queue_item.save ? "Added to queue" : "Something went wrong"
redirect_to :back
end
def destroy
QueueItem.delete(params[:id])
current_user.queue_items.each do |item|
item.update_column('position', (item.position - 1)) unless item.position == 1
end
flash[:notice] = "Item Deleted"
redirect_to :back
end
def batch
begin
ActiveRecord::Base.transaction do
params[:items].each do |item_param|
full_item = QueueItem.find(item_param[:id])
full_item.update_attributes!(position: item_param[:position])
determine_q_rev(full_item.video_id, item_param[:rating])
end
current_user.queue_items.each_with_index do |item, idx|
item.update_attributes!(position: idx + 1)
end
flash[:notice] = "Success"
end
rescue ActiveRecord::RecordInvalid
flash[:error] = "Invalid Entry"
end
redirect_to queue_path
end
private
def queue_item_params
params.require(:queue_item).permit!
end
def determine_q_rev(vid_id, param)
if Review.exists?(user_id: current_user.id, video_id: vid_id)
review = Review.where(user: current_user, video_id: vid_id).first
review.update_column(:rating, param)
else
rew = Review.new(user_id: current_user.id, video_id: vid_id, rating: param)
rew.save(validate: false)
end
end
end<file_sep>def swapcase(string)
string.split.map {|s| s = s.chars}.map {|a| a.map { |l| l =~ /[a-zA-Z]/ ? l == l.upcase ? l = l.downcase! : l = l.upcase! : l}.join }.join(' ')
end
swapcase('CamelCase') == 'cAMELcASE'
swapcase('Tonight on XYZ-TV') == 'tONIGHT ON xyz-tv'<file_sep>def foo(param = "no")
"yes"
end
def bar(param = "no")
param == "no" ? "yes" : "no"
end
bar(foo)
# Foo's return value is "yes"
# Putting that into the second method as an argument,
# the parameter will not be equal to no, thus printing "no"<file_sep>class BeerSong
attr_accessor :beer
ENDING = "No more bottles of beer on the wall, no more bottles of beer.\n" \
"Go to the store and buy some more, 99 bottles of beer on the wall.\n"
def initialize
@beer = 99
end
def bottle
self.beer != 1 ? 'bottles' : 'bottle'
end
def one
self.beer != 1 ? 'one' : 'it'
end
def countdown
self.beer = (self.beer - 1)
return "no more" if self.beer == 0
self.beer
end
def verse(start)
return ENDING if start == 0
self.beer = start
"#{beer} #{bottle} of beer on the wall, #{beer} #{bottle} of beer.\n" \
"Take #{one} down and pass it around, #{countdown} #{bottle} of beer on the wall.\n" \
end
def verses(start, nd)
final_string = verse(start) + "\n"
while self.beer > nd
final_string << verse(@beer) + "\n"
end
if self.beer == 'no more'
final_string << ENDING
else
final_string << verse(@beer)
end
final_string
end
def lyrics
verses(99, 0)
end
end
BeerSong.new.verse(99)<file_sep>/* ABC
B:O X:K D:Q C:P N:A
G:T R:E F:S J:W H:U
V:I L:Y Z:M
Problem:
Only one letter oer block, one block per word
otherwise false
Expectation:
Take string
return boolean
Data structure:
nested array
object for count
Algorithm
nested.some (ary)
str.includes(ary[0].toUpperCase()) && str.includes(ary[1].toUpperCase())
str.split(/[^a-z]/i).join.split('') for loop
if obj[str[i].toLowerCase()]
return false
else
obj[str[i].toLowerCase()] = 1
end
return true
*/
var BLOCKS = [['B', 'O'], ['X', 'K'], ['D', 'Q'], ['C', 'P'], ['N', 'A'], ['G', 'T'], ['R', 'E'], ['F', 'S'], ['J', 'W'], ['H', 'U'], ['V', 'I'], ['L', 'Y'], ['Z', 'M']]
function isBlockWord(str) {
var doubled = BLOCKS.some(function (ary) {
return str.toUpperCase().includes(ary[0]) && str.toUpperCase().includes(ary[1]);
});
if (doubled) {return false}
var obj = {};
var i;
for (i = 0; i < str.length; i += 1) {
if (obj[str[i].toLowerCase()]) {
return false;
} else {
obj[str[i].toLowerCase()] = 1;
}
}
return true;
}
isBlockWord('BATCH'); // true
isBlockWord('BUTCH'); // false
isBlockWord('jest'); // true
isBlockWord('floW'); // true
isBlockWord('APPLE'); // false
isBlockWord('apple'); // false
isBlockWord('apPLE'); // false
isBlockWord('Box'); // false
<file_sep>function walk(node, callback) {
callback(node);
var i;
for (i = 0; i < node.childNodes.length; i++) {
walk(node.childNodes[i], callback);
}
}
var html = document.childNodes[1];
var body = html.lastChild;
var heading = body.childNodes[1];
heading.style.fontSize = '48px';
heading.style.color = 'Red';
var count = 0;
function countP(node) {
if (node instanceof HTMLParagraphElement) {
count += 1;
console.log(node);
}
return count;
}
walk(body, countP);
console.log(count);
var firstWords = [];
function countParFirsts(node) {
if (node instanceof HTMLParagraphElement) {
firstWords.push(node.childNodes[0].data.trim().split(/[^a-z]/ig)[0]);
}
return firstWords;
}
walk(body, countParFirsts);
console.log(firstWords);
var count = 0;
function setStanzas(node) {
if (node instanceof HTMLParagraphElement) {
if (count > 0) {
node.setAttribute('class', 'stanza');
console.log(node);
}
count += 1;
}
}
walk(body, setStanzas);
<file_sep>var Car = {
name: 'Car',
brand: 'Unknown',
speed: 0,
rate: 5,
speedometer: function() {
console.log('Your car is going' + String(this.speed) + 'miles per hour.');
},
brake: function() {
this.speed -= 5;
console.log('You slowed down to' + String(this.speed) + 'miles per hour.');
},
accelerate: function() {
this.speed += 5;
console.log('You sped up to' + String(this.speed) + 'miles per hour.');
},
init: function(name, brand) {
this.name = name;
this.brand = brand;
console.log('You are now driving a ' + this.name + ' ' + this.brand);
return this;
}
}
var porsche = Object.create(Car).init('Porsche', 'Carerra');
var Truck = Object.create(Car);
Truck.hasTowing = true;
Truck.towingCapacity = '6 tons.';
var f150 = Object.create(Truck).init('Ford', 'F150');
function Engine(hp, tq) {
this.horsepower = hp;
this.torque = tq;
}
Engine.prototype.wearDown = function() {
this.torque -= 5;
this.horsepower -= 5;
console.log('The Engine is wearing down.');
}
Engine.prototype.displayStats = function() {
console.log("The engine has " + String(this.torque) + " torque & " + String(this.horsepower) + " horsepower.")
}
Car.engine = new Engine(120, 253);
f150.engine.displayStats();
Truck.engine = new Engine(200, 275);
porsche.engine.displayStats();
f150.engine.displayStats();
function maxCap(aCar) {
var hp = aCar.engine.horsepower;
return (function(carObj) {
console.log('This ' + carObj.name + ' ' + carObj.brand + ' has an engine with a horsepower of ' + hp);
})(aCar)
}
maxCap(porsche);
var increaseCap = function(aCar) {
var hp = aCar.engine.horsepower;
return function(){
hp += 1;
console.log('HP is now ' + hp);
return hp;
}
}
var nextCap = increaseCap(porsche);
nextCap();
nextCap();
nextCap();
<file_sep>=begin
You start with a normal 52-card deck consisting of the 4 suits
(hearts, diamonds, clubs, and spades),
and 13 values (2, 3, 4, 5, 6, 7, 8, 9, 10, jack, queen, king, ace).
The goal of Twenty-One is to try to get as close to 21 as possible, without going over.
If you go over 21, it's a "bust" and you lose.
Setup: the game consists of a "dealer" and a "player".
Both participants are initially dealt 2 cards.
The player can see their 2 cards, but can only see one of the dealer's cards.
Card values: all of the card values are pretty straightforward, except for the ace.
The numbers 2 through 10 are worth their face value.
The jack, queen, and king are each worth 10, and the ace can be worth 1 or 11.
The ace's value is determined each time a new card is drawn from the deck.
For example, if the hand contains a 2, an ace, and a 5, then the total value of the hand is 18.
In this case, the ace is worth 11 because the sum of the hand (2 + 11 + 5) doesn't exceed 21.
Now, say another card is drawn and it happens to be an ace.
Your program will have to determine the value of both aces.
If the sum of the hand (2 + 11 + 5 + 11) exceeds 21 then one of the aces must be worth 1,
resulting in the hand's total value be deing 19.
What happens if another card is drawn and it also happens to be an ace?
It can get tricky if there are multiple aces in a hand, so your program must account for that.
=end
# step 1: create deck of cards
# 1a deck must have 4 of each kind, 13 options
# faces are 10, aces are 1/11
# step 2: player draws 2 cards
# 2a: program determines sum of cards
# step 3: computer draws 2 cards
# 3a: program determines sum of cards
# step 4: player decides whether to hit or stay, loop until stay or bust
# 4a: program determines sum of cards
# game ends if sum <= 21, bust, comp wins
# step 5: decides whether to hit or stay, loop until stay or bust
# 5a: program determines sum of cards
# 5b: stay if computer sum >= 17
# game ends if sum <= 21, bust, player wins
# step 6: player & computer get sums added up
# step 7: winner is determined by closest to 21
# step 8: play again?<file_sep>def valid_number(num)
/^\d+$/.match(num) || (/\d/.match(num) && /^\d*\.?\d*$/.match(num))
end
name = ''
loan_amount = 0
annual_apr = 0
annual_duration = 0
puts "Welcome to the loan calculator! What's your name?"
loop do
name = gets.chomp
if name.empty?
puts "Please use a valid name. What is your name?"
else
break
end
end
puts "Hi #{name}. Congrats on the home! I just need some more info:"
puts "First thing I will need to know...what is the loan amount?"
loop do
loan_amount = gets.chomp
if valid_number(loan_amount)
break
else
puts "Please use a valid number. What is the loan amount?"
end
end
loan_amount = loan_amount.to_f
puts "What is the APR? Please enter the full number (EX: 5.25% as '5.25'):"
loop do
annual_apr = gets.chomp
if valid_number(annual_apr)
break
else
puts "Please use a valid number. What is the APR?"
end
end
annual_apr = annual_apr.to_f / 100
puts "What is the loan duration (in years)?"
loop do
annual_duration = gets.chomp
if valid_number(annual_duration)
break
else
puts "Please use a valid number. What is the loan amount?"
end
end
annual_duration = annual_duration.to_f
puts "Thank you, now calculating..."
monthly_apr = (annual_apr / 12)
monthly_duration = (annual_duration * 12)
monthly_payment = loan_amount * (monthly_apr / (1 - (1 + monthly_apr)**-monthly_duration))
puts "Your monthly payment is: $#{monthly_payment.round(2)}"
<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: orders; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE orders (
id integer NOT NULL,
product_id integer NOT NULL,
quantity integer NOT NULL
);
ALTER TABLE orders OWNER TO postgres;
--
-- Name: orders_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE orders_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE orders_id_seq OWNER TO postgres;
--
-- Name: orders_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE orders_id_seq OWNED BY orders.id;
--
-- Name: products; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE products (
id integer NOT NULL,
name text NOT NULL
);
ALTER TABLE products OWNER TO postgres;
--
-- Name: products_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE products_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE products_id_seq OWNER TO postgres;
--
-- Name: products_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE products_id_seq OWNED BY products.id;
--
-- Name: reviews; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE reviews (
id integer NOT NULL,
body text NOT NULL,
product_id integer
);
ALTER TABLE reviews OWNER TO postgres;
--
-- Name: reviews_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE reviews_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE reviews_id_seq OWNER TO postgres;
--
-- Name: reviews_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE reviews_id_seq OWNED BY reviews.id;
--
-- Name: orders id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY orders ALTER COLUMN id SET DEFAULT nextval('orders_id_seq'::regclass);
--
-- Name: products id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY products ALTER COLUMN id SET DEFAULT nextval('products_id_seq'::regclass);
--
-- Name: reviews id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY reviews ALTER COLUMN id SET DEFAULT nextval('reviews_id_seq'::regclass);
--
-- Data for Name: orders; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY orders (id, product_id, quantity) FROM stdin;
1 1 10
2 2 25
3 1 15
\.
--
-- Data for Name: products; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY products (id, name) FROM stdin;
1 small bolt
2 large bolt
\.
--
-- Data for Name: reviews; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY reviews (id, body, product_id) FROM stdin;
1 a little small 1
2 very round 1
3 could have been smaller 2
\.
--
-- Name: orders_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('orders_id_seq', 6, true);
--
-- Name: products_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('products_id_seq', 2, true);
--
-- Name: reviews_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('reviews_id_seq', 3, true);
--
-- Name: orders orders_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY orders
ADD CONSTRAINT orders_pkey PRIMARY KEY (id);
--
-- Name: products products_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY products
ADD CONSTRAINT products_pkey PRIMARY KEY (id);
--
-- Name: reviews reviews_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY reviews
ADD CONSTRAINT reviews_pkey PRIMARY KEY (id);
--
-- Name: products unique_name; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY products
ADD CONSTRAINT unique_name UNIQUE (name);
--
-- Name: orders orders_product_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY orders
ADD CONSTRAINT orders_product_id_fkey FOREIGN KEY (product_id) REFERENCES products(id);
--
-- Name: reviews reviews_product_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY reviews
ADD CONSTRAINT reviews_product_id_fkey FOREIGN KEY (product_id) REFERENCES products(id);
--
-- PostgreSQL database dump complete
--
<file_sep>var length = Number(prompt("Enter the length of the room in meters:"));
var width = Number(prompt("Enter the width of the room in meters:"));
var areaMeters = length * width;
var areaFeet = areaMeters * 10.7639;
console.log("The area of the room is " + areaMeters.toFixed(2) + " square meters (" + areaFeet.toFixed(2) + " square feet).");<file_sep>items = ['apples', 'corn', 'cabbage', 'wheat']
def gather(items)
puts "Let's start gathering food."
yield(items)
puts "We've finished gathering!"
end
gather(items) do |*others, last|
puts others.join(', ')
puts last
end
# Let's start gathering food.
# apples, corn, cabbage
# wheat
# We've finished gathering!
gather(items) do | first, *others, last|
puts first
puts others.join(', ')
puts last
end
# Let's start gathering food.
# apples
# corn, cabbage
# wheat
# We've finished gathering!
gather(items) do | first, *others |
puts first
puts others.join(', ')
end
# Let's start gathering food.
# apples
# corn, cabbage, wheat
# We've finished gathering!
gather(items) do | one, two, three, four |
puts "#{one}, #{two}, #{three}, and #{four}"
end
# Let's start gathering food.
# apples, corn, cabbage, and wheat
# We've finished gathering!
<file_sep>def center_of(string)
string.each_char.size.odd? ? string[string.each_char.size/2] : string[(string.each_char.size/2) - 1, 2]
end
center_of('I love ruby') == 'e'
center_of('Launch School') == ' '
center_of('Launch') == 'un'
center_of('Launchschool') == 'hs'
center_of('x') == 'x'<file_sep>def color_valid(color)
color == "blue" || color == "green"
end
color_valid("blue")
color_valid("green")
color_valid("red")<file_sep>class Transform
attr_reader :letters
def initialize(letters)
@letters = letters
end
def uppercase
letters.upcase
end
def self.lowercase(string = letters)
string.downcase
end
end
my_data = Transform.new('abc')
puts my_data.uppercase
puts Transform.lowercase('XYZ')
<file_sep># We create an object by defining a class
# and instantiating it by using the .new method
# to create an instance, also known as an object.
class MyClass
end
my_obj = MyClass.new<file_sep>var h2s = [].slice.call(document.querySelectorAll('h2'));
var countArr = h2s.map(function (headline) { return headline.textContent.split(' ').length });
var count = countArr.reduce(function (sum, n) { return sum + n });
var contents = document.querySelector('div#toc');
contents = document.querySelectorAll('div#toc')[0];
contents = document.getElementsByClassName('toc')[0];
var contentsList = [].slice.call(document.querySelectorAll('#toc a'));
contentsList = contentsList.filter(function (link, idx) { return idx % 2 === 1 });
contentsList.forEach(function (link) { link.style.color = 'green' });
var thumbText = [].slice.call(document.querySelectorAll('.thumbcaption'));
thumbText = thumbText.map(function (cap) { return cap.textContent.trim() });
// elements 6-12 in tbody have classifications
var classifications = document.querySelector('tbody');
classifications = [].slice.call(classifications.querySelectorAll('tr'));
classifications = classifications.filter(function (row, idx) { return idx > 4 && idx < 12 });
var bearStats = {};
var statName;
var statVal;
classifications.forEach(function (row) {
statName = row.querySelectorAll('td')[0].textContent.trim().slice(0, -1);
statVal = row.querySelectorAll('td')[1].textContent.trim();
bearStats[statName] = statVal;
});
<file_sep>=begin
Use a class to create a circular queue
P1 P2 P3 Comments
All positions are initially empty
1 Add 1 to the queue
1 2 Add 2 to the queue
2 Remove oldest item from the queue (1)
2 3 Add 3 to the queue
4 2 3 Add 4 to the queue, queue is now full
4 3 Remove oldest item from the queue (2)
4 5 3 Add 5 to the queue, queue is full again
4 5 6 Add 6 to the queue, replaces oldest element (3)
7 5 6 Add 7 to the queue, replaces oldest element (4)
7 6 Remove oldest item from the queue (5)
7 Remove oldest item from the queue (6)
Remove oldest item from the queue (7)
Remove non-existent item from the queue (nil)
=end
# add, add, remove oldest, add, add (q full), remove oldest, add, add - replace oldest,
# add - replace oldest - last item,
# then remove all 3 oldest to newest, remove non-existent items
class CircularQueue
attr_writer :oldest
attr_reader :array
def initialize(num)
@array = [nil] * num
@oldest = nil
@counter = 0
@tracker = {}
end
def enqueue(num)
if @array.any?(&:nil?)
@array[@array.find_index(&:nil?)] = num
else self.oldest = find_oldest
@array[@array.index(oldest)] = num
end
@counter += 1
@tracker[@counter] = num
end
def find_oldest
@tracker.keys.select {|count| @array.include?(@tracker[count])}.min
end
def dequeue
return nil if @array.all?(&:nil?)
@array[@array.index(oldest)] = nil
self.oldest = find_oldest
@tracker.keys.select {|count| @array.include?(count) == false}.max
end
end
queue = CircularQueue.new(3)
puts queue.dequeue == nil
queue.enqueue(1)
queue.enqueue(2)
puts queue.dequeue == 1
queue.enqueue(3)
queue.enqueue(4)
puts queue.dequeue == 2
queue.enqueue(5)
queue.enqueue(6)
queue.enqueue(7)
puts queue.dequeue == 5
puts queue.dequeue == 6
puts queue.dequeue == 7
puts queue.dequeue == nil
queue = CircularQueue.new(4)
puts queue.dequeue == nil
queue.enqueue(1)
queue.enqueue(2)
puts queue.dequeue == 1
queue.enqueue(3)
queue.enqueue(4)
puts queue.dequeue == 2
queue.enqueue(5)
queue.enqueue(6)
queue.enqueue(7)
puts queue.dequeue == 4
puts queue.dequeue == 5
puts queue.dequeue == 6
puts queue.dequeue == 7
puts queue.dequeue == nil
<file_sep># element assigment permanently modifies variables
str = "joe's favorite color is blue"
str[0] = 'J'
str # => "Joe's favorite color is blue"
str[6] = 'F'
str[15] = 'C'
str[21] = 'I'
str[24] = 'B'
str # => "Joe's Favorite Color Is Blue"
arr = [1, 2, 3, 4, 5]
arr[0] += 1 # => 2
arr # => [2, 2, 3, 4, 5]
arr[1] += 1
arr[2] += 1
arr[3] += 1
arr[4] += 1
arr # => [2, 3, 4, 5, 6]
hsh = { apple: 'Produce', carrot: 'Produce', pear: 'Produce', broccoli: 'Produce' }
hsh[:apple] = 'Fruit'
hsh # => { :apple => "Fruit", :carrot => "Produce", :pear => "Produce", :broccoli => "Produce" }
hsh[:carrot] = 'Vegetable'
hsh[:pear] = 'Fruit'
hsh[:broccoli] = 'Vegetable'
hsh # => { :apple => "Fruit", :carrot => "Vegetable", :pear => "Fruit", :broccoli => "Vegetable" }
<file_sep>[[[1, 2], [3, 4]], [5, 6]].map do |arr|
arr.map do |el|
if el.to_s.size == 1 # it's an integer
el + 1
else # it's an array
el.map do |n|
n + 1
end
end
end
end
# => [[[2,3] [4,5]], [6, 7]]
=begin
Line: 1
Action: Method Call, Map
Object: 1st level array, 2 elements (1-4) (5-6)
Side Effects: None
Return Value: New, Full Array
Return Used: No, map is the one using
Line: 1-11
Action: 1st Block Execution
Object: Each Index of the 1st level array (2nd level arrays)
Side Effects: None
Return Value: New, full array
Return Used: Yes, used by map
Line: 2
Action: Method Call, Map
Object: Second Level Arrays
Side Effects: None
Return value: two new sub arrays
Return Used: Yes, to determine value of first level block
Line: 2-10
Action: Block Execution
Object: Indexes of 2nd level arrays, for 1-4: indexes [1,2], [3,4] then for 5-6: elements 5,6
Side Effects: None
Return value: two new sub arrays
Return Used: Yes, to determine return of the second level block
Line: 3-9
Action: If Conditional Block
Object: Each index of 2nd level array elements
Side Effects: None
Return Value: [False], [False], [True]
Return Used: Yes, to determine action of the conditional block
Line: 4
Action: El + 1
Object: Each truthy object of the if condition: 5,6
Side Effects: None
Return Value [6,7]
Return Used: Yes, to determine values of second level array matching this condition
Line: 6-8
Action: Method Call, Map
Object: Each falsey object of the conditional block: [1,2] and [3,4]
Side Effects: None
Return value: new sub arrays on the 3rd level [[2,3],[4,5]]
Return Used: Yes, to determine values of second level array with falsey condition
Line: 7
Action: n + 1
Object: Each element in the sub arrays on the 3rd level in the falsey condition
Side effects: None
Return Value: [2,3] [4,5]
Return Used: Yes, to determine values of second level array with falsey condition
=end<file_sep>class MinilangRuntimeError < RuntimeError; end
class BadTokenError < MinilangRuntimeError; end
class EmptyStackError < MinilangRuntimeError; end
class Minilang
attr_reader :commands
def initialize(string)
@commands = string.split.map {|word| word =~ /[1-9]/ ? word.to_i : word}
@stack = []
@register = []
end
def delegate(command)
case command
when 'PRINT'
print
when 'PUSH'
push
when 'POP'
raise EmptyStackError, "Empty stack!" if @stack.empty?
pop
when 'MULT'
equate(:*)
when 'ADD'
equate(:+)
when 'SUB'
equate(:-)
when 'DIV'
equate(:/)
when 'MOD'
equate(:%)
else
raise BadTokenError, "Invalid Token: #{command}"
end
end
def eval
commands.each do |cmd|
if cmd.class == Integer
@register << cmd
else
delegate(cmd)
end
end
end
private
def print
return p 0 if @register.empty?
p @register[-1]
end
def push
@stack << @register.slice(-1)
end
def pop
@register << @stack.pop
end
def equate(op)
@register << (@register.pop.send(op, @stack.pop))
@register.slice!(-2)
end
end
Minilang.new('PRINT').eval
Minilang.new('5 PUSH 3 MULT PRINT').eval
Minilang.new('5 PRINT PUSH 3 PRINT ADD PRINT').eval
Minilang.new('5 PUSH 10 PRINT POP PRINT').eval
Minilang.new('5 PUSH POP POP PRINT').eval
Minilang.new('3 PUSH PUSH 7 DIV MULT PRINT ').eval
Minilang.new('4 PUSH PUSH 7 MOD MULT PRINT ').eval
Minilang.new('-3 PUSH 5 XSUB PRINT').eval
Minilang.new('-3 PUSH 5 SUB PRINT').eval
Minilang.new('6 PUSH').eval
<file_sep>function halvsies(arr) {
var middle = Math.ceil(arr.length / 2);
var result1 = [];
var result2 = [];
arr.forEach(function (elem, idx) {
idx < middle ? result1.push(elem) : result2.push(elem);
});
return [result1, result2];
}
halvsies([1, 2, 3, 4]); // [[1, 2], [3, 4]]
halvsies([1, 5, 2, 4, 3]); // [[1, 5, 2], [4, 3]]
halvsies([5]); // [[5], []]
halvsies([]); // [[], []]<file_sep>function gcd(num1, num2) {
var i;
var divisor;
for (i = 1; (i <= num1 || i <= num2); i++) {
if (num1 % i === 0 && num2 % i === 0) {
divisor = i;
}
}
return divisor;
}<file_sep># A constant initialized in a super-class is
# inherited by the sub-class, and can be accessed
# by both class and instance methods.
# if its a separate class, it is uninitialized
class Dog
LEGS = 4
end
class Cat
def legs
LEGS
end
end
kitty = Cat.new
kitty.legs # => NameError: uninitialized constant Cat::LEGS
# initialized by referencing other class variable
class Dog
LEGS = 4
end
class Cat
def legs
Dog::LEGS # added the :: namespace resolution operator
end
end
kitty = Cat.new
kitty.legs # => 4
# They work in subclasses
class Vehicle
WHEELS = 4
end
class Car < Vehicle
def self.wheels
WHEELS
end
def wheels
WHEELS
end
end
Car.wheels # => 4
a_car = Car.new
a_car.wheels
# modules & constants
module Maintenance
def change_tires
"Changing #{WHEELS} tires."
end
end
class Vehicle
WHEELS = 4
end
class Car < Vehicle
include Maintenance
end
a_car = Car.new
a_car.change_tires # => NameError: uninitialized constant Maintenance::WHEELS
# fixes
module Maintenance
def change_tires
"Changing #{Vehicle::WHEELS} tires." # this fix works
end
end
# or
module Maintenance
def change_tires
"Changing #{Car::WHEELS} tires." # surprisingly, this also works
end
end
<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
require 'pry'
class NoExperienceError < TypeError
end
class Employee
def initialize(experience)
@experience = experience
end
def hire
raise NoExperienceError, "Need Experience, Sorry." unless @experience > 0
end
end
class HireTest < MiniTest::Test
def test_error
# binding.pry
assert_raises(NoExperienceError) {Employee.new(0).hire}
end
end
<file_sep>=begin
For example, write out pseudo-code (both casual and formal) that does the following:
1. a method that returns the sum of two integers
Given two integers
Add integers together
Return the sum
START
SET integer_1 = 4
SET integer_2 = 6
SET sum = integer_1 + integer_2
PRINT sum
END
2. a method that takes an array of strings, and returns a string that is all those strings concatenated together
Given an array of strings
Use an array method to print all of the strings together
START
SET arr = ["This", "is", "an", "array"]
SET str_arr = arr as one concatenated string
PRINT str_arr
END
3. a method that takes an array of integers, and returns a new array with every other element
Given an array of integers
Transform the array of integers into every other kind of object
Return a new array with the new values
START
SET arr = [1, 2, 3, 4]
PRINT IF arr index is odd
END
=end<file_sep>require 'spec_helper'
describe Category do
it { should have_many(:videos) }
it { should validate_presence_of(:name) }
describe "#recent_videos" do
it "returns the most recent video first" do
vid1 = Video.create(title: "vid1")
vid2 = Video.create(title: "vid2")
cat = Category.create(name: "cat")
cat.videos << vid1
cat.videos << vid2
cat.recent_videos[0].should == vid2
end
it "returns an empty array if no vids" do
cat = Category.create(name: "cat")
cat.recent_videos.should == []
end
end
end<file_sep>class Anagram
attr_reader :word, :letters
def initialize(word)
@word = word
@letters = word.chars.map(&:downcase).sort
end
def match(array)
results = []
array.each do |test_word|
next if test_word == word || test_word == word.upcase || test_word == word.capitalize
results << test_word if test_word.chars.map(&:downcase).sort == letters
end
results
end
end
detector = Anagram.new('Orchestra')
anagrams = detector.match %w(cashregister Carthorse radishes)
<file_sep>// All cars start out not moving, and sedans
// can accelerate about 8 miles per hour per second (mph/s).
var sedan = {
speed: 0,
rate: 8,
};
sedan = {
speed: 0,
rate: 8,
// To accelerate, add the rate of acceleration
// to the current speed.
accelerate: function() {
this.speed += this.rate;
},
};
sedan;
//= Object {speed: 0, rate: 8}
sedan.accelerate();
sedan;
//= Object {speed: 8, rate: 8}
var coupe = {
speed: 0,
rate: 12,
accelerate: function() {
this.speed += this.rate;
},
};
sedan.accelerate();
sedan.speed;
//= 8
coupe.accelerate();
coupe.speed;
//= 12
function makeCar(carRate, decRate) {
return {
speed: 0,
rate: carRate,
deceleration: decRate,
accelerate: function() {
this.speed += this.rate;
},
brake: function() {
this.speed -= this.deceleration;
if (this.speed <= 0) { this.speed = 0 }
}
};
}
var sedan = makeCar(8);
sedan.accelerate();
sedan.speed;
//= 8
var coupe = makeCar(12);
coupe.accelerate();
coupe.speed;
//= 12
var hatchBack = makeCar(9);
<file_sep>function interleave(arr1, arr2) {
var result = [];
arr1.forEach(function (elem1, idx1) {
result.push(elem1);
arr2.forEach(function (elem2, idx2) {
if (idx1 === idx2) { result.push(elem2) }
});
});
return result;
}
interleave([1, 2, 3], ['a', 'b', 'c']);<file_sep>class ApplicationController < ActionController::Base
protect_from_forgery with: :exception
helper_method :current_user, :logged_in?, :access_granted
def front
redirect_to home_path if logged_in?
end
def current_user
@current_user ||= User.find(session[:user_id]) if session[:user_id]
end
def logged_in?
!!current_user
end
def access_granted?
redirect_to front_path unless logged_in?
end
end
<file_sep>def full_year(start_year, ary)
year = Time.new(start_year, 1, 1)
ary << year
start_month = 1
counter = 1
until start_month == 12 && counter == 31
counter += 1
new_date = Time.new(start_year, start_month, counter) rescue "end month"
if new_date == "end month"
counter = 0
start_month += 1
else
ary << new_date
end
end
ary.uniq!
end
def friday_13th(year)
dates = []
full_year(year, dates)
dates.select {|date| date.friday? && date.day == 13}.size
end
friday_13th(2015) == 3
friday_13th(1986) == 1
friday_13th(2019) == 2
# Their solution (uses Ruby's Date class)
=begin
require 'date'
def friday_13th(year)
unlucky_count = 0
thirteenth = Date.new(year, 1, 13)
12.times do
unlucky_count += 1 if thirteenth.friday?
thirteenth = thirteenth.next_month
end
unlucky_count
end
=end
<file_sep>--
-- PostgreSQL database dump
--
-- Dumped from database version 10.1
-- Dumped by pg_dump version 10.1
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SET check_function_bodies = false;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: plpgsql; Type: EXTENSION; Schema: -; Owner:
--
CREATE EXTENSION IF NOT EXISTS plpgsql WITH SCHEMA pg_catalog;
--
-- Name: EXTENSION plpgsql; Type: COMMENT; Schema: -; Owner:
--
COMMENT ON EXTENSION plpgsql IS 'PL/pgSQL procedural language';
SET search_path = public, pg_catalog;
SET default_tablespace = '';
SET default_with_oids = false;
--
-- Name: directors; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE directors (
id integer NOT NULL,
name text NOT NULL,
CONSTRAINT valid_name CHECK (((length(name) >= 1) AND ("position"(name, ' '::text) > 0)))
);
ALTER TABLE directors OWNER TO postgres;
--
-- Name: directors_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE directors_id_seq
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE directors_id_seq OWNER TO postgres;
--
-- Name: directors_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE directors_id_seq OWNED BY directors.id;
--
-- Name: films; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE films (
title character varying(255) NOT NULL,
year integer NOT NULL,
genre character varying(100) NOT NULL,
duration integer NOT NULL,
id integer NOT NULL,
CONSTRAINT title_length CHECK ((length((title)::text) >= 1)),
CONSTRAINT year_range CHECK (((year >= 1900) AND (year <= 2100)))
);
ALTER TABLE films OWNER TO postgres;
--
-- Name: films_directors; Type: TABLE; Schema: public; Owner: postgres
--
CREATE TABLE films_directors (
film_id integer,
director_id integer,
id integer NOT NULL
);
ALTER TABLE films_directors OWNER TO postgres;
--
-- Name: films_directors_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE films_directors_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE films_directors_id_seq OWNER TO postgres;
--
-- Name: films_directors_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE films_directors_id_seq OWNED BY films_directors.id;
--
-- Name: films_id_seq; Type: SEQUENCE; Schema: public; Owner: postgres
--
CREATE SEQUENCE films_id_seq
AS integer
START WITH 1
INCREMENT BY 1
NO MINVALUE
NO MAXVALUE
CACHE 1;
ALTER TABLE films_id_seq OWNER TO postgres;
--
-- Name: films_id_seq; Type: SEQUENCE OWNED BY; Schema: public; Owner: postgres
--
ALTER SEQUENCE films_id_seq OWNED BY films.id;
--
-- Name: directors id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY directors ALTER COLUMN id SET DEFAULT nextval('directors_id_seq'::regclass);
--
-- Name: films id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films ALTER COLUMN id SET DEFAULT nextval('films_id_seq'::regclass);
--
-- Name: films_directors id; Type: DEFAULT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films_directors ALTER COLUMN id SET DEFAULT nextval('films_directors_id_seq'::regclass);
--
-- Data for Name: directors; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY directors (id, name) FROM stdin;
1 <NAME>
2 <NAME>
3 <NAME>
4 <NAME>
5 <NAME>
6 <NAME>
7 <NAME>
8 <NAME>
9 <NAME>
10 <NAME>
11 <NAME>
12 <NAME>
\.
--
-- Data for Name: films; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY films (title, year, genre, duration, id) FROM stdin;
Die Hard 1988 action 132 1
Casablanca 1942 drama 102 2
The Conversation 1974 thriller 113 3
1984 1956 scifi 90 4
Tinker Tailor Soldier Spy 2011 espionage 127 5
The Birdcage 1996 comedy 118 6
The Godfather 1972 crime 175 7
12 Angry Men 1957 drama 96 8
Wayne's World 1992 comedy 95 9
Let the Right One In 2008 horror 114 10
Fargo 1996 comedy 98 11
No Country for Old Men 2007 western 122 12
Sin City 2005 crime 124 13
Spy Kids 2001 scifi 88 14
\.
--
-- Data for Name: films_directors; Type: TABLE DATA; Schema: public; Owner: postgres
--
COPY films_directors (film_id, director_id, id) FROM stdin;
1 1 1
2 2 2
3 3 3
4 4 4
5 5 5
6 6 6
7 3 7
8 7 8
9 8 9
10 4 10
11 9 11
12 9 12
12 10 13
13 11 14
13 12 15
14 12 16
\.
--
-- Name: directors_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('directors_id_seq', 12, true);
--
-- Name: films_directors_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('films_directors_id_seq', 16, true);
--
-- Name: films_id_seq; Type: SEQUENCE SET; Schema: public; Owner: postgres
--
SELECT pg_catalog.setval('films_id_seq', 14, true);
--
-- Name: directors directors_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY directors
ADD CONSTRAINT directors_pkey PRIMARY KEY (id);
--
-- Name: films_directors films_directors_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films_directors
ADD CONSTRAINT films_directors_pkey PRIMARY KEY (id);
--
-- Name: films films_pkey; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films
ADD CONSTRAINT films_pkey PRIMARY KEY (id);
--
-- Name: films title_unique; Type: CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films
ADD CONSTRAINT title_unique UNIQUE (title);
--
-- Name: films_directors films_directors_director_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films_directors
ADD CONSTRAINT films_directors_director_id_fkey FOREIGN KEY (director_id) REFERENCES directors(id);
--
-- Name: films_directors films_directors_film_id_fkey; Type: FK CONSTRAINT; Schema: public; Owner: postgres
--
ALTER TABLE ONLY films_directors
ADD CONSTRAINT films_directors_film_id_fkey FOREIGN KEY (film_id) REFERENCES films(id);
--
-- PostgreSQL database dump complete
--
<file_sep>def halvsies(ary)
ary.size.even? ? [ary[0...(ary.size/2)], ary[(ary.size/2)..-1]] : [ary[0..(ary.size/2)], ary[(ary.size/2 + 1)..-1]]
end
halvsies([1, 2, 3, 4]) == [[1, 2], [3, 4]]
halvsies([1, 5, 2, 4, 3]) == [[1, 5, 2], [4, 3]]
halvsies([5]) == [[5], []]
halvsies([]) == [[], []]<file_sep>require 'minitest/autorun'
require "minitest/reporters"
Minitest::Reporters.use!
class NumericTest < MiniTest::Test
def test_numeric
number = 1
assert_equal(Numeric, number.class.superclass)
end
end
# assert_kind_of(Numeric, value) would work as well
<file_sep>function Circle(rad) {
return {
radius: rad,
area: function() { return Math.PI * Math.pow(this.radius, 2) }
}
}
var a = new Circle(3);
var b = new Circle(4);
console.log(a.area().toFixed(2)); // 28.27
console.log(b.area().toFixed(2)); // 50.27
/* their version:
var Circle = function(radius) {
this.radius = radius;
};
Circle.prototype.area = function() {
return Math.PI * this.radius * this.radius;
};
*/
var ninjaA;
var ninjaB;
function Ninja() {
this.swung = false;
}
ninjaA = new Ninja();
ninjaB = new Ninja();
Ninja.prototype.swing = function() {
this.swung = true;
return this;
}
console.log(ninjaA.swing().swung); // this needs to be true
console.log(ninjaB.swing().swung); // this needs to be true
var ninjaA = (function() {
function Ninja(){};
return new Ninja();
})();
var ninjaB = {};
ninjaA(ninjaB);
console.log(ninjaB.constructor === ninjaA.constructor); // this should be true
var ninjaA = (function() {
function Ninja(){};
return new Ninja();
})();
var ninjaB = Object.create(ninjaA);
console.log(ninjaB.constructor === ninjaA.constructor);
| 3b456a1faeac6175349deb7e70b2a247cbe2845c | [
"JavaScript",
"SQL",
"RDoc",
"Ruby"
] | 450 | Ruby | AndyRosenberg/Launch-School | 5a9dc8e9d83b6e0039b3cf8e4c0a9f1ecfccc940 | c25942b403642fefcf47b168395e552dade73080 |
refs/heads/master | <repo_name>fmuller85/mi_bugligue_mobile<file_sep>/mobile/vues/v_modifierbug.php
<div data-role="page">
<div data-role="header">
<div data-role="controlgroup" data-type="horizontal">
<a data-icon="plus" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=dash" data-theme="b">Accueil</a>
<a data-icon="delete" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=deconnexion" data-theme="b">Se déconnecter</a>
</div>
</div>
<div data-role="content">
<a id="<?php echo $the_bug->getId(); ?>" class="bt-rapport" data-icon="edit" data-role="button" data-transition="slide" href="index.php?uc=dash&action=rapport&idbug=<?php echo $idBug; ?>" data-theme="b">Créer un rapport</a>
<h4>Bienvenue sur votre console de gestion</h4>
<div>
<p>Date d'ajout : <?php echo $the_bug->getCreated()->format('d.m.Y'); ?></p>
<?php
$engineer = "<select data-theme='b' id='".$the_bug->getId()."' class='select-tech' name='technicien'>";
Foreach($liste_techniciens as $technicien){
if($the_bug->getEngineer() != null){
if($the_bug->getEngineer()->getId() == $technicien->getId()){
$selected = "selected='true'";
}else{
$selected = "";
}
}else{
$selected = "";
}
$engineer .= "<option $selected value='".$technicien->getId()."'>".$technicien->getName()."</option>";
}
$engineer .= "</select>";
$datelimite = "";
if($the_bug->getDatelimite() != null){
$datelimite = $the_bug->getDatelimite()->format('d.m.Y');
}
$listeproduct = "";
foreach ($the_bug->getProducts() as $product) {
$listeproduct .= "- ".$product->getName()." ";
}
?>
<p>Produit concerné : <?php echo $listeproduct; ?></p>
<p>Description : <?php echo $the_bug->getDescription(); ?></p>
<form action="index.php?uc=dash&action=modifierbug" method="POST">
<p>Affecté à : <?php echo $engineer; ?> </p>
<?php echo $datelimite; ?>
<p>Date limite : <input data-theme="b" type="date" name="datelimite" id="date" value="<?php echo $datelimite; ?>" ></p>
<p><input data-theme="b" type="hidden" name="idbug" value="<?php echo $the_bug->getId(); ?>"></p>
<p><input data-theme="b" type="submit" name="valider" value="Valider les changements"></p>
</form>
</div>
</div>
<div data-role="footer" data-position="fixed" data-theme="b">
<h4>Pied de page</h4>
</div>
</div>
<div data-role="dialog" id="ticket_dialog">
<div data-role="header">
<h1>Detail du ticket <div id="id_ticket"></div></h1>
</div>
<div data-role="content">
<div id="descri_ticket"></div>
<hr/>
<div id="solution_ticket"></div>
</div>
</div>
<script>
jQuery(function($){
alert('coucou !!');
$(".bt-rapport").click(function(){
alert('coucou');
/*var idbug = $(this).attr('id');
$.mobile.changePage('index.php?uc=dash&action=rapport', {
type : 'POST',
data : 'idbug='+idbug
});*/
});
})
</script>
</body>
</html><file_sep>/mobile/controleurs/c_dashboard_club.php
<?php
/**
* Created by JetBrains PhpStorm.
* User: Eric
* Date: 20/02/14
* Time: 19:10
* To change this template use File | Settings | File Templates.
*/
if(!isset($_REQUEST['action']))
$action = 'list';
else
$action = $_REQUEST['action'];
switch($action){
case 'list':{
$the_bugs = getBugsOpenByUser($_SESSION['login']['id']);
$bugs_en_cours = $the_bugs[0];
$bugs_fermes = $the_bugs[1];
include("vues/v_dashclub.php");
break;
}
case 'nouveau':{
if (isset($_POST['objet'])){
$message = ajouterNewBug();
include("vues/v_message.php");
}
$the_products = getAllProducts();
include("vues/v_new_bug.php");
break;
}
case 'detailbug':{
$idBug = $_POST['idbug'];
$the_bug = getBugById($idBug);
/*if(isset($_POST['valider'])){
if(isset($_POST['rapport'])){
$message = ajouterRapport($idBug);
include("vues/v_message.php");
}
}*/
include("vues/v_detailbug.php");
break;
}
}
<file_sep>/mobile/controleurs/c_dashboard_resp.php
<?php
if(!isset($_REQUEST['action']))
$action = 'list';
else
$action = $_REQUEST['action'];
switch($action){
case 'list':{
$the_bugs = getAllBugs();
$bugs_en_cours = $the_bugs[0];
$bugs_fermes = $the_bugs[1];
$liste_techniciens = getAllTech();
include("vues/v_dashresp.php");
break;
}
case 'nouveau':{
if (isset($_POST['objet'])){
$message = ajouterNewBug();
include("vues/v_message.php");
}
$the_products = getAllProducts();
include("vues/v_new_bug.php");
break;
}
/*case 'reparer':{
$idBug = $_GET['idBug'];
$the_bug = getBugById($idBug);
if(isset($_POST['valider'])){
if(isset($_POST['rapport'])){
$message = ajouterRapport($idBug);
include("vues/v_message.php");
}
}
include("vues/v_rapport_bug.php");
break;
}*/
case 'modifierbug':{
if(isset($_POST['idbug'])){
if(isset($_POST['valider'])){
$datelimite = $_POST['datelimite'];
$technicien = $_POST['technicien'];
$idBug = $_POST['idbug'];
$message = updatebug($idBug, $technicien, $datelimite);
include("vues/v_message.php");
}else{
$idBug = $_POST['idbug'];
$the_bug = getBugById($idBug);
$liste_techniciens = getAllTech();
/*if(isset($_POST['valider'])){
if(isset($_POST['rapport'])){
$message = ajouterRapport($idBug);
include("vues/v_message.php");
}
}*/
include("vues/v_modifierbug.php");
}
}else{
$message = "Bug non trouvé";
include("vues/v_message.php");
}
break;
}
case 'rapport':{
if(isset($_POST['valider'])){
if(isset($_POST['rapport'])){
$idBug = $_POST['idbug'];
$message = ajouterRapport($idBug);
include("vues/v_message.php");
echo "<script> window.location='index.php?uc=dash';</script>";
}
}else{
$idBug = $_GET['idbug'];
$the_bug = getBugById($idBug);
include("vues/v_rapport.php");
}
break;
}
}
?><file_sep>/vues/v_rapport_bug.php
<?php
$bugDescription = $the_bug->getDescription();
foreach ($the_bug->getProducts() as $product) {
$productName = $product->getName();
}
?>
<article>
<form name="new_rapport" method="POST" action="index.php?uc=dash&action=reparer&idBug=<?php echo $the_bug->getId(); ?>" >
<h3>Enregistrement d'un rapport</h3>
<ul>
<li>
<label>Nom de l'appli : </label>
<label><?php echo $productName; ?></label>
</li>
<li>
<label>Description du problème : </label>
<label><?php echo $bugDescription; ?></label>
</li>
<li>
<label for="text">Rapport : </label>
<textarea id="text" name="rapport" size="500" maxlength="500"></textarea>
</li>
</ul>
<p>
<input class="action" type="submit" value="Valider" name="valider">
<input id="bt_retour" type="button" value="Retour" name="retour">
</p>
</form>
</article>
<script>
jQuery(function($){
$('#bt_retour').click(function(){
window.location="index.php?uc=dash";
});
})
</script><file_sep>/mobile/vues/v_message.php
<div data-role="page">
<div data-role="header"></div>
<div data-role="content">
<?php echo $message; ?>
<div data-role="fieldcontain">
<a class="retour" data-icon="check" data-role="button" data-theme="c" rel="external" href="index.php?uc=dash">Retour à l'accueil</a>
</div>
</div>
<div data-role="footer" data-position="fixed" data-theme="b"></div>
</div>
<script>
jQuery(function($){
})
</script>
</body>
</html><file_sep>/vues/v_dashboard_resp.php
<puissante>elle existe vraiment</puissante>
<div id="liste_tickets">
<h2>Tickets en cours</h2>
<br />
<table>
<tr><th></th><th >Affecté à</th><th class="col-produit" >Produit</th><th class="col-date">Date de création</th><th class="col-date">Date limite</th><th class="col-description">Description</th><th class="col-rapport">Rapport</th></tr>
<?php
foreach ($bugs_en_cours as $bug) {
if ($bug->getEngineer() != null){
$engineer = $bug->getEngineer()->getName();
}else{
$engineer = "<select id='".$bug->getId()."' class='select-tech' name='technicien'>";
Foreach($liste_techniciens as $technicien){
$engineer .= "<option value='".$technicien->getId()."'>".$technicien->getName()."</option>";
}
$engineer .= "</select>";
}
if($bug->getDatelimite() != null){
$datelimite = $bug->getDatelimite()->format('d.m.Y');
if($bug->getDatelimite()->getTimeStamp() >= $bug->getCreated()->getTimeStamp()){
$nbJourRestant = date('d', $bug->getDatelimite()->getTimeStamp() - $bug->getCreated()->getTimeStamp())."j ";
$nbMoisRestant = date('m', $bug->getDatelimite()->getTimeStamp() - $bug->getCreated()->getTimeStamp());
$nbMoisRestant = intval($nbMoisRestant)-1;
$nbMoisRestant .= "m restant(s)";
}else{
$nbJourRestant = "";
$nbMoisRestant = "";
}
}else{
$nbJourRestant = "";
$nbMoisRestant = "";
$datelimite = "<input style='width: 100px;' type='text' class='datepicker' placeholder='0000-00-00'>";
}
echo "<tr class='unticket' value='".$bug->getId()."'>";
echo "<td><img src='./images/en_cours.png' width='30px' height='30px'/></td>";
echo "<td><span class='nomTechnicien' >".$engineer."</span> <img class='deverouiller' src='./images/cadena2.png'></td>";
echo "<td>";
foreach ($bug->getProducts() as $product) {
echo "".$product->getName()." ";
}
echo "</td>";
echo "<td>".$bug->getCreated()->format('d.m.Y')."</td>";
echo "<td><span class='dateLimite'>".$datelimite."</span><img class='icoCalendrier' src='images/iconeCalendrier.gif' title='modifier la date' />".$nbJourRestant.$nbMoisRestant."</td>";
echo "<td><span class='bt-voir-description'>Voir description</span></td>";
echo "<td><a href='index.php?uc=dash&action=reparer&idBug=".$bug->getId()."'> Créer un rapport de résolution</a></td>";
if ($bug->getEngineer() == null){
}
echo "</tr>";
echo "<tr id='description".$bug->getId()."' class='description hidden'><td colspan='6'><img src='".$bug->getScreen()."' />".$bug->getDescription()."</td></tr>";
}
?>
</table>
</div>
<br />
<br />
<div id="liste_tickets">
<h2>Tickets fermés</h2>
<br />
<table>
<tr><th></th><th >Affecté à</th><th class="col-produit" >Produit</th><th class="col-date">Date de création</th><th class="col-date">Date de résolution</th><th class="col-description">Description</th></tr>
<?php
foreach ($bugs_fermes as $bug) {
if ($bug->getEngineer() != null){
$engineer = $bug->getEngineer()->getName();
}else{
$engineer = "Non affecté";
}
echo "<tr class='unticket' value='".$bug->getId()."'>";
echo "<td><img src='./images/ferme.png' width='30px' height='30px'/></td>";
echo "<td><span class='nomTechnicien' >".$engineer."</span></td>";
echo "<td>";
foreach ($bug->getProducts() as $product) {
echo "".$product->getName()." ";
}
echo "</td>";
echo "<td>".$bug->getCreated()->format('d.m.Y')."</td>";
echo "<td>".$bug->getRapport()->getCreated()->format('d.m.Y')."</td>";
echo "<td><span class='bt-voir-description'>Voir description</span></td>";
if ($bug->getEngineer() == null){
}
echo "</tr>";
echo "<tr id='description".$bug->getId()."' class='description hidden'><td colspan='6'><img src='".$bug->getScreen()."' />".$bug->getDescription()."</td></tr>";
}
?>
</table>
</div>
<script>
jQuery(function($){
var listeTechnicien = $('.select-tech');
/*listeTechnicien.on('change', function(){
var idbug = $(this).attr('id');
var idbug = id.replace('list', "");
alert(idbug);
});*/
$( "body" ).on( "click",'option', function() {
var idTech = $(this).val();
var idbug = $(this).parent().parent().parent().parent().attr('value');
$.ajax({
type:"POST",
url:"/mi_bugligue_mobile/util/traitements_JSON.php",
dataType:"json",
data:"action=affecter_technicien&tech_id="+idTech+"&bug_id="+idbug,
success: function(data){
alert('Technicien affecté');
window.location='index.php?uc=dash';
}
});
});
$('.deverouiller').click(function(){ // con on click sur deverouiller
var emplacementTech = $(this).parent().find('.nomTechnicien');
emplacementTech.html('');
$.ajax({
type:"POST",
url:"/mi_bugligue_mobile/util/traitements_JSON.php",
dataType:"json",
data:"action=liste_technicien",
success: function(data){
var i = 0;
var select = document.createElement("select");
emplacementTech.append(select);
while(i < data.length){
var option = document.createElement("option");
var nom = data[i].nom;
option.setAttribute('value', data[i].id);
option.innerHTML = nom;
select.appendChild(option);
i++;
}
}
});
});
$( "body" ).on( "click",'.bt-voir-description', function() {
$('.description').hide();
var idbug = $(this).parent().parent().attr('value');
$('.bt-cacher-description').each(function(){
$(this).parent().html('<span class="bt-voir-description">Voir description</span>');
});
var description = $('#description'+idbug);
description.slideDown();
$(this).parent().html('<span class="bt-cacher-description">Cacher description</span>');
});
$( "body" ).on( "click",'.bt-cacher-description', function() {
var idbug = $(this).parent().parent().attr('value');
$('.description').hide();
$(this).parent().html('<span class="bt-voir-description">Voir description</span>');
});
$( ".datepicker" ).datepicker({
onSelect: function(date) {
var idbug = $(this).parent().parent().parent().attr('value');
$.ajax({
type:"POST",
url:"/mi_bugligue_mobile/util/traitements_JSON.php",
data:"action=set_date_limite&bug_id="+idbug+"&date_limite="+date,
success: function(data){
window.location='index.php?uc=dash';
}
});
/*$.post("/ppe5/PPE5_MI/util/traitements_JSON.php",
{action: "set_date_limite", bug_id: idbug, date_limite: date },
function(data){
window.location='index.php?uc=dash';
}
);*/
},
dateFormat:"yy-mm-dd"
});
$( "body" ).on( "click",'.icoCalendrier', function() {
var champDate = $(this).parent().find('.dateLimite');
var date = champDate.text();
champDate.html("<input style='width: 100px;' type='text' class='datepicker' placeholder='"+date+"'>");
$( ".datepicker" ).datepicker({
onSelect: function(date) {
var idbug = $(this).parent().parent().parent().attr('value');
/*$.post("/ppe5/PPE5_MI/util/traitements_JSON.php",
{action: "set_date_limite", bug_id: idbug, date_limite: date },
function(data){
champDate.html(date);
}
);*/
$.ajax({
type:"POST",
url:"/mi_bugligue_mobile/util/traitements_JSON.php",
data:"action=set_date_limite&bug_id="+idbug+"&date_limite="+date,
success: function(data){
window.location='index.php?uc=dash';
}
});
},
dateFormat:"yy-mm-dd"
});
});
});
</script><file_sep>/src/BugTest.php
<?php
/**
* Created by PhpStorm.
* User: Flo
* Date: 11/04/14
* Time: 16:08
*/
class BugTest extends PHPUnit_Framework_TestCase {
public function testAssignToProduct()
{
$bug = new Bug();
$bug->setCreated(new DateTime());
$bug->setScreen(null);
$bug->setDatelimite();
// Arrange
$product = new Money(1);
// Assert
$this->assertEquals(-1, $b->getAmount());
}
}
<file_sep>/mobile/vues/v_new_bug.php
<a data-mini="true" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=dash" data-theme="c"><span class="ui-btn-inner"><span class="ui-btn-text">Dashboard Club</span></span></a>
<form name="new_bug" method="POST" action="index.php?uc=dash&action=nouveau" data-rel="dialog">
<fieldset>
<legend>Signalement d'un nouveau bug</legend>
<div data-role="fieldcontain">
<label for="objet">Objet : </label>
<input id="objet" type="text" name="objet" size="50" maxlength="50">
</div>
<div data-role="fieldcontain">
<label for="libelle">Description du problème : </label>
<textarea id="libelle" name="libelle" size="500" maxlength="500"></textarea>
</div>
<div data-role="fieldcontain">
<label for="apps">Application(s) concernées : </label>
<select data-native-menu="false" multiple id="apps" name="apps[]">
<?php
foreach($the_products as $p){
echo '<option value="'.$p->getId().'">'.$p->getName().'</option>';
}
?>
</select>
</div>
<p>
<input data-theme="b" type="submit" value="Valider" name="valider">
<input data-theme="b" type="reset" id='bt-annuler' value="Annuler" name="annuler">
</p>
</fieldset>
</form>
<script>
$('#bt-annuler').click(function(){
window.location="index.php?uc=dash";
});
</script><file_sep>/util/traitements_JSON.php
<?php
switch($_POST['action']){
case 'affecter_technicien':{
include_once('../bootstrap.php');
$bugId = $_POST['bug_id'];
$techId = $_POST['tech_id'];
$bug = $entityManager->find("Bug", $bugId);
$tech = $entityManager->find("User", $techId);
$bug->setEngineer($tech);
$entityManager->persist($bug);
$entityManager->flush();
break;
}
case 'liste_technicien':{
include_once('../bootstrap.php');
$dql = "SELECT u FROM User u WHERE u.fonction = 'Technicien' OR u.fonction = 'Responsable'";
$query = $entityManager->createQuery($dql);
$lesTechniciens = $query->getResult();
$tableauTechnicien = array();
Foreach($lesTechniciens as $technicien){
$tableauTechnicien[] = $technicien->toString();
}
echo json_encode($tableauTechnicien);
exit();
break;
}
case 'set_date_limite':{
include_once('../bootstrap.php');
$bugId = $_POST['bug_id'];
$dateLimite = $_POST['date_limite'];
$bug = $entityManager->find("Bug", $bugId);
$bug->setDateLimite(new DateTime($dateLimite));
$entityManager->persist($bug);
$entityManager->flush();
break;
}
}<file_sep>/mobile/vues/v_detailbug.php
<div data-role="page">
<div data-role="header">
<h1>En-tête</h1>
</div>
<div data-role="content">
<h4>Bienvenue sur votre console de gestion</h4>
<div data-role="controlgroup" data-type="horizontal">
<a style="width: 50%;" data-icon="plus" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=dash&action=nouveau" data-theme="b">Nouveau bug</a>
<a style="width: 50%;" data-icon="delete" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=deconnexion" data-theme="b">Se déconnecter</a>
</div>
<div>
<p>Date d'ajout : <?php echo $the_bug->getCreated()->format('d.m.Y'); ?></p>
<p>Affecté à : <?php if ($the_bug->getEngineer() != null){
echo $the_bug->getEngineer()->getName();
}else{
echo "non affecté";
} ?>
</p>
<p>Description : <?php echo $the_bug->getDescription(); ?></p>
</div>
</div>
<div data-role="footer" data-position="fixed" data-theme="b">
<h4>Pied de page</h4>
</div>
</div>
<div data-role="dialog" id="ticket_dialog">
<div data-role="header">
<h1>Detail du ticket <div id="id_ticket"></div></h1>
</div>
<div data-role="content">
<div id="descri_ticket"></div>
<hr/>
<div id="solution_ticket"></div>
</div>
</div>
<script>
jQuery(function($){
})
</script>
</body>
</html><file_sep>/src/Rapport.php
<?php
use Doctrine\Common\Collections\ArrayCollection;
// src/Rapport.php
/**
* @Entity @Table(name="Rapport")
**/
class Rapport
{
/**
* @Id @Column(type="integer") @GeneratedValue
**/
protected $id;
/**
* @Column(type="string",nullable=true)
**/
protected $resume;
/**
* @Column(type="datetime")
**/
protected $created;
/**
* @OneToOne(targetEntity="Bug", mappedBy="rapport")
*/
protected $bug;
public function __construct()
{
}
/**
* @param mixed $id
*/
public function setId($id)
{
$this->id = $id;
}
/**
* @return mixed
*/
public function getId()
{
return $this->id;
}
/**
* @param mixed $resume
*/
public function setResume($resume)
{
$this->resume = $resume;
}
/**
* @return mixed
*/
public function getResume()
{
return $this->resume;
}
/**
* @param mixed $bug
*/
public function setBug($bug)
{
$this->bug = $bug;
}
/**
* @return mixed
*/
public function getBug()
{
return $this->bug;
}
/**
* @param mixed $created
*/
public function setCreated($created)
{
$this->created = $created;
}
/**
* @return mixed
*/
public function getCreated()
{
return $this->created;
}
}
<file_sep>/README.md
mi_bugligue_mobile
==================
<file_sep>/mobile/vues/v_rapport.php
<div data-role="page">
<div data-role="header">
<div data-role="controlgroup" data-type="horizontal">
<a data-icon="plus" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=dash" data-theme="b">Accueil</a>
<a data-icon="delete" data-inline="true" data-role="button" data-transition="slide" href="index.php?uc=deconnexion" data-theme="b">Se déconnecter</a>
</div>
</div>
<div data-role="content">
<h4>Créer un rapport</h4>
<div>
<form action="index.php?uc=dash&action=rapport" method="POST">
<label for="rapport">Rapport : </label>
<textarea id="rapport" name="rapport"></textarea>
<input type="hidden" name="idbug" value="<?php echo $idBug ?>"/>
<input data-theme="b" type="submit" name="valider" value="Enregistrer le rapport"/>
</form>
</div>
</div>
<div data-role="footer" data-position="fixed" data-theme="b">
<h4>Pied de page</h4>
</div>
</div>
<div data-role="dialog" id="ticket_dialog">
<div data-role="header">
<h1>Detail du ticket <div id="id_ticket"></div></h1>
</div>
<div data-role="content">
<div id="descri_ticket"></div>
<hr/>
<div id="solution_ticket"></div>
</div>
</div>
<script>
jQuery(function($){
$(".bt-rapport").click(function(){
var idbug = $(this).attr('id');
$.mobile.changePage('index.php?uc=dash&action=rapport', {
type : 'POST',
data : 'idbug='+idbug
});
});
})
</script>
</body>
</html><file_sep>/vues/v_dashboard_club.php
<div id="liste_tickets">
<h2>Tickets en cours</h2>
<br />
<table>
<tr><th></th><th >Affecté à</th><th class="col-produit" >Produit</th><th class="col-date">Date de création</th><th class="col-description">Description</th></tr>
<?php
foreach ($bugs_en_cours as $bug) {
if ($bug->getEngineer() != null){
$engineer = $bug->getEngineer()->getName();
}else{
$engineer = "Non affecté";
}
echo "<tr class='unticket' value='".$bug->getId()."'>";
echo "<td><img src='./images/en_cours.png' width='30px' height='30px'/></td>";
echo "<td><span class='nomTechnicien' >".$engineer."</span></td>";
echo "<td>";
foreach ($bug->getProducts() as $product) {
echo "".$product->getName()." ";
}
echo "</td>";
echo "<td>".$bug->getCreated()->format('d.m.Y')."</td>";
echo "<td><span class='bt-voir-description'>Voir description</span></td>";
if ($bug->getEngineer() == null){
}
echo "</tr>";
echo "<tr id='description".$bug->getId()."' class='description hidden'><td colspan='6'><img src='".$bug->getScreen()."' />".$bug->getDescription()."</td></tr>";
}
?>
</table>
</div>
<br />
<br />
<div id="liste_tickets">
<h2>Tickets fermés</h2>
<br />
<table>
<tr><th></th><th >Affecté à</th><th class="col-produit" >Produit</th><th class="col-date">Date de création</th><th class="col-date">Date de résolution</th><th class="col-description">Description</th></tr>
<?php
foreach ($bugs_fermes as $bug) {
if ($bug->getEngineer() != null){
$engineer = $bug->getEngineer()->getName();
}else{
$engineer = "Non affecté";
}
echo "<tr class='unticket' value='".$bug->getId()."'>";
echo "<td><img src='./images/ferme.png' width='30px' height='30px'/></td>";
echo "<td><span class='nomTechnicien' >".$engineer."</span></td>";
echo "<td>";
foreach ($bug->getProducts() as $product) {
echo "".$product->getName()." ";
}
echo "</td>";
echo "<td>".$bug->getCreated()->format('d.m.Y')."</td>";
echo "<td>".$bug->getRapport()->getCreated()->format('d.m.Y')."</td>";
echo "<td><span class='bt-voir-description'>Voir description</span></td>";
if ($bug->getEngineer() == null){
}
echo "</tr>";
echo "<tr id='description".$bug->getId()."' class='description hidden'><td colspan='6'><img src='".$bug->getScreen()."' />".$bug->getDescription()."</td></tr>";
}
?>
</table>
</div>
<script>
jQuery(function($){
$( "body" ).on( "click",'.bt-voir-description', function() {
$('.description').hide();
var idbug = $(this).parent().parent().attr('value');
$('.bt-cacher-description').each(function(){
$(this).parent().html('<span class="bt-voir-description">Voir description</span>');
});
var description = $('#description'+idbug);
description.slideDown();
$(this).parent().html('<span class="bt-cacher-description">Cacher description</span>');
});
$( "body" ).on( "click",'.bt-cacher-description', function() {
var idbug = $(this).parent().parent().attr('value');
$('.description').hide();
$(this).parent().html('<span class="bt-voir-description">Voir description</span>');
});
});
</script><file_sep>/src/Bug.php
<?php
use Doctrine\Common\Collections\ArrayCollection;
// src/Bug.php
/**
* @Entity @Table(name="bugs")
**/
class Bug
{
/**
* @Id @Column(type="integer") @GeneratedValue
**/
protected $id;
/**
* @Column(type="string")
**/
protected $description;
/**
* @Column(type="datetime")
**/
protected $created;
/**
* @Column(type="string")
**/
protected $status;
/**
* @Column(type="datetime",nullable=true)
**/
protected $datelimite;
/**
* @Column(type="string",nullable=true)
**/
protected $screen;
/**
* @ManyToOne(targetEntity="User", inversedBy="assignedBugs", cascade={"persist"})
* @ORM\JoinColumn(name="engineer_id", referencedColumnName="id", nullable="true")
**/
protected $engineer;
/**
* @ManyToOne(targetEntity="User", inversedBy="reportedBugs")
**/
protected $reporter;
/**
* @ManyToMany(targetEntity="Product")
**/
protected $products;
/**
* @OneToOne(targetEntity="Rapport", inversedBy="bug")
* @JoinColumn(name="rapport_id", referencedColumnName="id")
*/
protected $rapport;
public function getId()
{
return $this->id;
}
public function getDescription()
{
return $this->description;
}
public function setDescription($description)
{
$this->description = $description;
}
public function setCreated(DateTime $created)
{
$this->created = $created;
}
public function getCreated()
{
return $this->created;
}
public function setStatus($status)
{
$this->status = $status;
}
public function getStatus()
{
return $this->status;
}
public function __construct()
{
$this->products = new ArrayCollection();
}
public function setEngineer($engineer)
{
$engineer->assignedToBug($this);
$this->engineer = $engineer;
}
public function setReporter($reporter)
{
$reporter->addReportedBug($this);
$this->reporter = $reporter;
}
public function getEngineer()
{
return $this->engineer;
}
public function getReporter()
{
return $this->reporter;
}
public function assignToProduct($product)
{
$this->products[] = $product;
}
public function getProducts()
{
return $this->products;
}
public function close()
{
$this->status = "CLOSE";
}
/**
* @param mixed $rapports
*/
public function setRapport($rapports)
{
$this->rapport = $rapports;
}
/**
* @return mixed
*/
public function getRapport()
{
return $this->rapport;
}
/**
* @param mixed $screen
*/
public function setScreen($screen)
{
$this->screen = $screen;
}
/**
* @return mixed
*/
public function getScreen()
{
return $this->screen;
}
/**
* @param mixed $datelimite
*/
public function setDatelimite($datelimite)
{
$this->datelimite = $datelimite;
}
/**
* @return mixed
*/
public function getDatelimite()
{
return $this->datelimite;
}
}<file_sep>/vues/v_dashboard_tech.php
<div id="liste_tickets">
<h2>Tickets en cours</h2>
<table>
<tr><th></th><th >Affecté à</th><th class="col-produit" >Produit</th><th class="col-date">Date de création</th><th class="col-date">Date limite</th><th class="col-description">Description</th><th class="col-rapport">Rapport</th></tr>
<?php
foreach ($bugs_en_cours as $bug) {
if ($bug->getEngineer() != null){
$engineer = $bug->getEngineer()->getName();
}else{
$engineer = "Non affecté";
}
if($bug->getDatelimite() != null){
$datelimite = $bug->getDatelimite()->format('d.m.Y');
if($bug->getDatelimite()->getTimeStamp() <= $bug->getCreated()->getTimeStamp()){
$nbJourRestant = date('d', $bug->getDatelimite()->getTimeStamp() - $bug->getCreated()->getTimeStamp())."j ";
$nbMoisRestant = date('m', $bug->getDatelimite()->getTimeStamp() - $bug->getCreated()->getTimeStamp());
$nbMoisRestant = intval($nbMoisRestant)-1;
$nbMoisRestant .= "m restant(s)";
}else{
$nbJourRestant = "";
$nbMoisRestant = "";
}
}else{
$datelimite = "non défini";
$nbJourRestant = "";
$nbMoisRestant = "";
}
echo "<tr class='unticket' value='".$bug->getId()."'>";
echo "<td><img src='./images/en_cours.png' width='30px' height='30px'/></td>";
echo "<td><span class='nomTechnicien' >".$engineer."</span></td>";
echo "<td>";
foreach ($bug->getProducts() as $product) {
echo "".$product->getName()." ";
}
echo "</td>";
echo "<td>".$bug->getCreated()->format('d.m.Y')."</td>";
echo "<td><span class='dateLimite'>".$datelimite."</span>".$nbJourRestant.$nbMoisRestant."</td>";
echo "<td><span class='bt-voir-description'>Voir description</span></td>";
echo "<td><a href='index.php?uc=dash&action=reparer&idBug=".$bug->getId()."'> Créer un rapport de résolution</a></td><br>";
if ($bug->getEngineer() == null){
}
echo "</tr>";
echo "<tr id='description".$bug->getId()."' class='description hidden'><td colspan='6'><img src='".$bug->getScreen()."' />".$bug->getDescription()."</td></tr>";
}
?>
</table>
</div>
<br />
<br />
<div id="liste_tickets">
<h2>Tickets résolus</h2>
<br />
<table>
<tr><th></th><th >Affecté à</th><th class="col-produit" >Produit</th><th class="col-date">Date de création</th><th class="col-date">Date de résolution</th><th class="col-date">Date limite</th><th class="col-description">Description</th></tr>
<?php
foreach ($bugs_fermes as $bug) {
if ($bug->getEngineer() != null){
$engineer = $bug->getEngineer()->getName();
}else{
$engineer = "Non affecté";
}
if($bug->getDatelimite() != null){
$datelimite = $bug->getDatelimite()->format('d.m.Y');
}else{
$datelimite = '00-00-0000';
}
echo "<tr class='unticket' value='".$bug->getId()."'>";
echo "<td><img src='./images/ferme.png' width='30px' height='30px'/></td>";
echo "<td><span class='nomTechnicien' >".$engineer."</span></td>";
echo "<td>";
foreach ($bug->getProducts() as $product) {
echo "".$product->getName()." ";
}
echo "</td>";
echo "<td>".$bug->getCreated()->format('d.m.Y')."</td>";
echo "<td>".$bug->getRapport()->getCreated()->format('d.m.Y')."</td>";
echo "<td>".$datelimite."</td>";
echo "<td><span class='bt-voir-description'>Voir description</span></td>";
if ($bug->getEngineer() == null){
}
echo "</tr>";
echo "<tr id='description".$bug->getId()."' class='description hidden'><td colspan='6'><img src='".$bug->getScreen()."' />".$bug->getDescription()."</td></tr>";
}
?>
</table>
</div>
<script>
jQuery(function($){
$( "body" ).on( "click",'.bt-voir-description', function() {
$('.description').hide();
var idbug = $(this).parent().parent().attr('value');
$('.bt-cacher-description').each(function(){
$(this).parent().html('<span class="bt-voir-description">Voir description</span>');
});
var description = $('#description'+idbug);
description.slideDown();
$(this).parent().html('<span class="bt-cacher-description">Cacher description</span>');
});
$( "body" ).on( "click",'.bt-cacher-description', function() {
var idbug = $(this).parent().parent().attr('value');
$('.description').hide();
$(this).parent().html('<span class="bt-voir-description">Voir description</span>');
});
});
</script><file_sep>/exemples/create_user.php
<?php
// create_user.php
require_once "../bootstrap.php";
$newUserName = $argv[1];
$newUserPrenom = $argv[2];
$newUserFonction = $argv[3];
$newUserLogin = $argv[4];
$newUserPass = $argv[5];
$newUserMail = $argv[6];
$user = new User();
$user->setName($newUserName);
$user->setPrenom($newUserPrenom);
$user->setFonction($newUserFonction);
$user->setLogin($newUserLogin);
$user->setMdp($newUserPass);
$user->setCourriel($newUserMail);
$entityManager->persist($user);
$entityManager->flush();
echo "Created User with ID " . $user->getId() . "\n"; | 2c7758ff0a0afedd523d675af4ac6fb2550f13c0 | [
"Markdown",
"PHP"
] | 17 | PHP | fmuller85/mi_bugligue_mobile | 8811fcf83f05d5d61c2957d9d335909cb458719a | 56f7b3fc3fc0eb2f52bffb4b2fbe4b0c514c7f9d |
refs/heads/main | <file_sep>package pronom
import (
"path/filepath"
"reflect"
"sort"
"testing"
"github.com/richardlehane/siegfried/pkg/config"
)
var dataPath string = filepath.Join("..", "..", "cmd", "roy", "data")
var minimalPronom = []string{"fmt/1", "fmt/3", "fmt/5", "fmt/11", "fmt/14"}
func TestNew(t *testing.T) {
config.SetHome(dataPath)
_, err := NewPronom()
if err != nil {
t.Error(err)
}
}
// TestFormatInfos inspects the values loaded into a PRONOM identifier
// from a minimal PRONOM dataset, i.e. fewer than loading all of PRONOM.
func TestFormatInfos(t *testing.T) {
config.SetHome(dataPath)
config.SetLimit(minimalPronom)()
i, err := NewPronom()
if err != nil {
t.Error(err)
}
const minReports int = 5
if len(i.Infos()) != minReports {
t.Error("Unexpected number of reports for PRONOM minimal tests")
}
expectedPuids := []string{
"fmt/1",
"fmt/3",
"fmt/5",
"fmt/11",
"fmt/14",
}
expectedNames := []string{
"Broadcast WAVE",
"Graphics Interchange Format",
"Audio/Video Interleaved Format",
"Portable Network Graphics",
"Acrobat PDF 1.0 - Portable Document Format",
}
expectedVersions := []string{
"0 Generic",
"87a",
"",
"1.0",
"1.0",
}
expectedMimes := []string{
"image/gif",
"video/x-msvideo",
"image/png",
"application/pdf",
"audio/x-wav",
}
expectedTypes := []string{
"Audio",
"Image (Raster)",
"Audio, Video",
"Image (Raster)",
"Page Description",
}
puids := make([]string, 0)
names := make([]string, 0)
versions := make([]string, 0)
mimes := make([]string, 0)
types := make([]string, 0)
for puid := range i.Infos() {
puids = append(puids, puid)
names = append(names, i.Infos()[puid].(formatInfo).name)
versions = append(versions, i.Infos()[puid].(formatInfo).version)
mimes = append(mimes, i.Infos()[puid].(formatInfo).mimeType)
types = append(types, i.Infos()[puid].(formatInfo).class)
}
sort.Strings(puids)
sort.Strings(expectedPuids)
if !reflect.DeepEqual(puids, expectedPuids) {
t.Error("PUIDs from minimal PRONOM set do not match expected values")
}
sort.Strings(names)
sort.Strings(expectedNames)
if !reflect.DeepEqual(names, expectedNames) {
t.Errorf("Format names from minimal PRONOM set do not match expected values; expected %v, got %v", expectedNames, names)
}
sort.Strings(versions)
sort.Strings(expectedVersions)
if !reflect.DeepEqual(versions, expectedVersions) {
t.Error("Format versions from minimal PRONOM set do not match expected values")
}
sort.Strings(mimes)
sort.Strings(expectedMimes)
if !reflect.DeepEqual(mimes, expectedMimes) {
t.Error("MIMETypes from minimal PRONOM set do not match expected values")
}
sort.Strings(types)
sort.Strings(expectedTypes)
if !reflect.DeepEqual(types, expectedTypes) {
t.Error("Format types from minimal PRONOM set do not match expected values")
}
config.Clear()()
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package bytematcher
import (
"fmt"
"github.com/richardlehane/match/dwac"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/pkg/config"
)
func (b *Matcher) addSignature(sig frames.Signature) error {
// todo: add cost to the Segment - or merge segments based on cost?
segments := sig.Segment(config.Distance(), config.Range(), config.Cost(), config.Repetition())
// apply config no eof option
if config.NoEOF() {
var hasEof bool
var x int
for i, segment := range segments {
c := segment.Characterise()
if c > frames.Prev {
hasEof = true
x = i
break
}
}
if hasEof {
if x == 0 {
b.keyFrames = append(b.keyFrames, []keyFrame{})
return nil
}
segments = segments[:x] // Otherwise trim segments to the first SUCC/EOF segment
}
}
kf := make([]keyFrame, len(segments))
clstr := newCluster(b)
for i, segment := range segments {
var pos frames.Position
c := segment.Characterise()
switch c {
case frames.Unknown:
return fmt.Errorf("zero length segment: signature %d, %v, segment %d", len(b.keyFrames), sig, i)
case frames.BOFZero:
pos = frames.BOFLength(segment, config.Choices())
case frames.EOFZero:
pos = frames.EOFLength(segment, config.Choices())
default:
pos = frames.VarLength(segment, config.Choices())
}
if pos.Length < 1 {
switch c {
case frames.BOFZero, frames.BOFWindow:
kf[i] = b.addToFrameSet(segment, i, b.bofFrames, 0, 1)
case frames.EOFZero, frames.EOFWindow:
kf[i] = b.addToFrameSet(segment, i, b.eofFrames, len(segment)-1, len(segment))
default:
return fmt.Errorf("variable offset segment encountered that can't be turned into a sequence: signature %d, segment %d", len(b.keyFrames), i)
}
} else {
switch c {
case frames.BOFZero, frames.BOFWild:
clstr = clstr.commit()
kf[i] = clstr.add(segment, i, pos)
case frames.BOFWindow:
if i > 0 {
kfB, _, _ := toKeyFrame(segment, pos)
if crossOver(kf[i-1], kfB) {
clstr = clstr.commit()
}
} else {
clstr = clstr.commit()
}
kf[i] = clstr.add(segment, i, pos)
case frames.Prev:
kf[i] = clstr.add(segment, i, pos)
case frames.Succ:
if !clstr.rev {
clstr = clstr.commit()
clstr.rev = true
}
kf[i] = clstr.add(segment, i, pos)
case frames.EOFZero, frames.EOFWindow, frames.EOFWild:
if !clstr.rev {
clstr = clstr.commit()
clstr.rev = true
}
kf[i] = clstr.add(segment, i, pos)
clstr = clstr.commit()
clstr.rev = true
}
}
}
clstr.commit()
updatePositions(kf)
unknownBOF, unknownEOF := unknownBOFandEOF(len(b.keyFrames), kf)
if len(unknownBOF) > 0 {
b.unknownBOF = append(b.unknownBOF, unknownBOF...)
}
if len(unknownEOF) > 0 {
b.unknownBOF = append(b.unknownEOF, unknownEOF...)
}
b.maxBOF = maxBOF(b.maxBOF, kf)
b.maxEOF = maxEOF(b.maxEOF, kf)
b.keyFrames = append(b.keyFrames, kf)
return nil
}
type cluster struct {
rev bool
kfs []keyFrame
b *Matcher
w dwac.Seq
ks []int
lefts [][]frames.Frame
rights [][]frames.Frame
}
func newCluster(b *Matcher) *cluster {
return &cluster{b: b}
}
func (c *cluster) add(seg frames.Signature, i int, pos frames.Position) keyFrame {
sequences := frames.NewSequencer(c.rev)
k, left, right := toKeyFrame(seg, pos)
c.kfs = append(c.kfs, k)
var seqs [][]byte
// do it all backwards
if c.rev {
for j := pos.End - 1; j >= pos.Start; j-- {
seqs = sequences(seg[j])
}
c.w.Choices = append([]dwac.Choice{dwac.Choice(seqs)}, c.w.Choices...)
c.ks = append([]int{i}, c.ks...)
c.lefts = append([][]frames.Frame{left}, c.lefts...)
c.rights = append([][]frames.Frame{right}, c.rights...)
} else {
for _, f := range seg[pos.Start:pos.End] {
seqs = sequences(f)
}
c.w.Choices = append(c.w.Choices, dwac.Choice(seqs))
c.ks = append(c.ks, i)
c.lefts = append(c.lefts, left)
c.rights = append(c.rights, right)
}
return k
}
func (c *cluster) commit() *cluster {
// commit nothing if the cluster is empty
if len(c.w.Choices) == 0 {
return newCluster(c.b)
}
updatePositions(c.kfs)
c.w.MaxOffsets = make([]int64, len(c.kfs))
if c.rev {
for i := range c.w.MaxOffsets {
c.w.MaxOffsets[i] = c.kfs[len(c.kfs)-1-i].key.pMax
}
} else {
for i, v := range c.kfs {
c.w.MaxOffsets[i] = v.key.pMax
}
}
var ss *seqSet
if c.rev {
ss = c.b.eofSeq
} else {
ss = c.b.bofSeq
}
hi := ss.add(c.w, len(c.b.tests))
l := len(c.ks)
if hi == len(c.b.tests) {
for i := 0; i < l; i++ {
c.b.tests = append(c.b.tests, &testTree{})
}
}
for i := 0; i < l; i++ {
c.b.tests[hi+i].add([2]int{len(c.b.keyFrames), c.ks[i]}, c.lefts[i], c.rights[i])
}
return newCluster(c.b)
}
func (b *Matcher) addToFrameSet(segment frames.Signature, i int, fs *frameSet, start, end int) keyFrame {
k, left, right := toKeyFrame(segment, frames.Position{Length: 0, Start: start, End: end})
hi := fs.add(segment[start], len(b.tests))
if hi == len(b.tests) {
b.tests = append(b.tests, &testTree{})
}
b.tests[hi].add([2]int{len(b.keyFrames), i}, left, right)
return k
}
<file_sep>package pronom
import (
"encoding/json"
"errors"
"fmt"
"path/filepath"
"strings"
"testing"
"github.com/richardlehane/siegfried/pkg/config"
)
// DROID parsing is tested by comparing it against Report parsing
func TestParseDroid(t *testing.T) {
config.SetHome(filepath.Join("..", "..", "cmd", "roy", "data"))
d, err := newDroid(config.Droid())
if err != nil {
t.Fatal(err)
}
r, err := newReports(d.IDs(), d.idsPuids())
if err != nil {
t.Fatal(err)
}
dsigs, dpuids, err := d.Signatures()
if err != nil {
t.Fatal(err)
}
rsigs, rpuids, err := r.Signatures()
if err != nil {
t.Fatal(err)
}
if len(dpuids) != len(rpuids) {
t.Errorf("Parse Droid: Expecting length of reports and droid to be same, got %d, %d, %s", len(rpuids), len(dpuids), dpuids[len(dpuids)-8])
}
for i, v := range rpuids {
if v != dpuids[i] {
t.Errorf("Parse Droid: Expecting slices of puids to be identical but at index %d, got %s for reports and %s for droid", i, v, dpuids[i])
}
}
if len(dsigs) != len(rsigs) {
t.Errorf("Parse Droid: Expecting sig length of reports and droid to be same, got %d, %d", len(rsigs), len(dsigs))
}
errs := []string{}
for i, v := range rsigs {
if !v.Equals(dsigs[i]) {
errs = append(errs, fmt.Sprintf("Parse Droid: signatures for %s are not equal:\nReports: %s\n Droid: %s", rpuids[i], v, dsigs[i]))
}
}
dpmap, rpmap := d.Priorities(), r.Priorities()
for k, v := range rpmap {
w, ok := dpmap[k]
if !ok {
errs = append(errs, fmt.Sprintf("Parse Droid: Can't find %s in droid priorities", k))
continue
}
if len(v) != len(w) {
errs = append(errs, fmt.Sprintf("Parse Droid: priorites for %s are not equal:\nReports: %v\nDroid: %v", k, v, w))
continue
}
for i, vv := range v {
if w[i] != vv {
errs = append(errs, fmt.Sprintf("Parse Droid: priorites for %s are not equal:\nReports: %v\nDroid: %v", k, v, w))
break
}
}
}
if len(errs) != 0 {
t.Skip(strings.Join(errs, "\n"))
}
}
func fiJSON(infos map[string]formatInfo) error {
for k, v := range infos {
if !json.Valid([]byte("\"" + v.name + "\"")) {
return errors.New(k + " has bad JSON: \"" + v.name + "\"")
}
if !json.Valid([]byte("\"" + v.version + "\"")) {
return errors.New(k + " has bad JSON: \"" + v.version + "\"")
}
if !json.Valid([]byte("\"" + v.mimeType + "\"")) {
return errors.New(k + " has bad JSON: \"" + v.mimeType + "\"")
}
}
return nil
}
// Check for any issues in format infos that would break JSON encoding
// See: https://github.com/richardlehane/siegfried/issues/186
func TestJSON(t *testing.T) {
config.SetHome(filepath.Join("..", "..", "cmd", "roy", "data"))
d, err := newDroid(config.Droid())
if err != nil {
t.Fatal(err)
}
err = fiJSON(infos(d.Infos()))
if err != nil {
t.Fatalf("JSON error in DROID file: %v", err)
}
r, err := newReports(d.IDs(), d.idsPuids())
if err != nil {
t.Fatal(err)
}
err = fiJSON(infos(r.Infos()))
if err != nil {
t.Fatalf("JSON error in PRONOM reports: %v", err)
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Registration of different file-format signature sequence encodings
// that we might discover e.g. from sources such as Wikidata.
package converter
import (
"github.com/richardlehane/siegfried/pkg/config"
)
// Encoding enumeration to return unambiguous values for encoding from
// the mapping lookup below.
const (
// UnknownEncoding provides us with a default to work with.
UnknownEncoding = iota
// HexEncoding describes magic numbers written in plain-hexadecimal.
HexEncoding
// PronomEncoding describe PRONOM based file format signatures.
PronomEncoding
// PerlEncoding describe PERL regular expression encoded signatures.
PerlEncoding
// ASCIIEncoding encoded patterns are those written entirely in plain ASCII.
ASCIIEncoding
// GUIDEncoding are globally unique identifiers.
GUIDEncoding
)
// Encoding constants. IRIs from Wikidata mean that we don't need to
// encode i18n differences. IRIs must have http:// scheme, and link to
// the data entity, i.e. not the "page", e.g.
//
// * Hex data entity: http://www.wikidata.org/entity/Q82828
// * Hex page: https://www.wikidata.org/wiki/Q82828
//
const (
// Hexadecimal.
hexadecimal = "http://www.wikidata.org/entity/Q82828"
// Globally unique identifier.
guid = "http://www.wikidata.org/entity/Q254972"
// ASCII.
ascii = "http://www.wikidata.org/entity/Q8815"
// Perl compatible regular expressions 2.
perl = "http://www.wikidata.org/entity/Q98056596"
// Unknown encoding.
unknown = "unknown encoding"
)
// PRONOM internal signature. This is not a constant as it can be read
// into Roy from wikibase.json.
var pronom string = config.WikibasePronom()
// GetPronomURIFromConfig will read the current value of the PRONOM
// property from the configuration, e.g. after being updated using a
// custom SPARQL query.
func GetPronomURIFromConfig() {
pronom = config.WikibasePronom()
}
// GetPronomEncoding returns the PRONOM encoding URI as is set locally in
// the package.
func GetPronomEncoding() string { return pronom }
// LookupEncoding will return a best-guess encoding type for a supplied
// encoding string.
func LookupEncoding(encoding string) int {
encoding = encoding
switch encoding {
case hexadecimal:
return HexEncoding
case pronom:
return PronomEncoding
case perl:
return PerlEncoding
case ascii:
return ASCIIEncoding
case guid:
return GUIDEncoding
}
return UnknownEncoding
}
// ReverseEncoding can provide a human readable string for us if we
// ever need it, e.g. if we need to debug this module.
func ReverseEncoding(encoding int) string {
switch encoding {
case HexEncoding:
return hexadecimal
case PronomEncoding:
return pronom
case PerlEncoding:
return perl
case ASCIIEncoding:
return ascii
case GUIDEncoding:
return guid
}
return unknown
}
<file_sep>package frames_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
. "github.com/richardlehane/siegfried/internal/bytematcher/patterns/tests"
)
func TestFixed(t *testing.T) {
f2 := NewFrame(BOF, TestSequences[0], 0, 0)
f3 := NewFrame(BOF, TestSequences[0], 0)
if !TestFrames[0].Equals(f2) {
t.Error("Fixed fail: Equality")
}
if TestFrames[0].Equals(f3) {
t.Error("Fixed fail: Equality")
}
if !TestFrames[0].Equals(TestFrames[1]) {
t.Error("Fixed fail: Equality")
}
num, rem, _ := f2.MaxMatches(10)
if num != 1 {
t.Errorf("Fixed fail: MaxMatches should have one match, got %d", num)
}
if rem != 6 {
t.Errorf("Fixed fail: MaxMatches should have rem value 6, got %d", rem)
}
}
func TestWindow(t *testing.T) {
w2 := NewFrame(BOF, TestSequences[0], 0, 5)
w3 := NewFrame(BOF, TestSequences[0], 0)
if !TestFrames[5].Equals(w2) {
t.Error("Window fail: Equality")
}
if TestFrames[5].Equals(w3) {
t.Error("Window fail: Equality")
}
num, rem, _ := w2.MaxMatches(16)
if num != 2 {
t.Errorf("Window fail: MaxMatches should have two matches, got %d", num)
}
if rem != 12 {
t.Errorf("Window fail: MaxMatches should have rem value 12, got %d", rem)
}
}
func TestWild(t *testing.T) {
w2 := NewFrame(BOF, TestSequences[0])
w3 := NewFrame(BOF, TestSequences[0], 1)
if !TestFrames[9].Equals(w2) {
t.Error("Wild fail: Equality")
}
if TestFrames[9].Equals(w3) {
t.Error("Wild fail: Equality")
}
num, rem, _ := w2.MaxMatches(10)
if num != 3 {
t.Errorf("Wild fail: MaxMatches should have three matches, got %d", num)
}
if rem != 6 {
t.Errorf("Wild fail: MaxMatches should have rem value 6, got %d", rem)
}
}
func TestWildMin(t *testing.T) {
w2 := NewFrame(BOF, TestSequences[0], 5)
w3 := NewFrame(BOF, TestSequences[0], 0, 5)
if !TestFrames[11].Equals(w2) {
t.Error("Wild fail: Equality")
}
if TestFrames[11].Equals(w3) {
t.Error("Wild fail: Equality")
}
num, rem, _ := w2.MaxMatches(10)
if num != 1 {
t.Errorf("WildMin fail: MaxMatches should have one matches, got %d", num)
}
if rem != 1 {
t.Errorf("WildMin fail: MaxMatches should have rem value 1, got %d", rem)
}
}
<file_sep>package config
import (
"errors"
"io/fs"
"io/ioutil"
"os"
"path/filepath"
"testing"
)
// TestProps makes sure the properties do not skew without deliberate
// consideration when doing so.
func TestProps(t *testing.T) {
pronom := "http://www.wikidata.org/entity/Q35432091"
bof := "http://www.wikidata.org/entity/Q35436009"
eof := "http://www.wikidata.org/entity/Q1148480"
if WikibasePronom() != pronom {
t.Errorf(
"Pronom property '%s' is not '%s'",
WikibasePronom(),
pronom,
)
}
if WikibaseBOF() != bof {
t.Errorf(
"BOF property '%s' is not '%s'",
WikibaseBOF(),
bof,
)
}
if WikibaseEOF() != eof {
t.Errorf(
"EOF property '%s' is not '%s'",
WikibaseEOF(),
eof,
)
}
}
// TestSetCustomWikibaseQuery provides a way to verify some of the basic
// handling required for updating our SPARQL query for a custom Wikibase.
func TestSetCustomWikibaseQuery(t *testing.T) {
var testSPARQL = "select ?s ?p ?o where { ?s ?p ?o. }"
tempDir, _ := ioutil.TempDir("", "wikidata-test-dir-*")
defer os.RemoveAll(tempDir)
err := os.Mkdir(filepath.Join(tempDir, "wikidata"), 0755)
if err != nil {
t.Fatal(err)
}
SetHome(tempDir)
customSPARQLFile := filepath.Join(tempDir, "wikidata", "wikibase.sparql")
err = ioutil.WriteFile(customSPARQLFile, []byte(testSPARQL), 0755)
if err != nil {
t.Fatal(err)
}
err = SetCustomWikibaseQuery()
if err != nil {
t.Errorf(
"Unexpected error setting custom wikibase query %s",
err,
)
}
if WikidataSPARQL() != testSPARQL {
t.Errorf(
"Query not updated from custom SPARQL as expected: '%s'",
WikidataSPARQL(),
)
}
err = os.Remove(customSPARQLFile)
err = SetCustomWikibaseQuery()
if !errors.Is(err, fs.ErrNotExist) {
t.Errorf(
"Expected error loading wikibase.sparql but received: %s",
err,
)
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package bytematcher
import (
"bytes"
"io"
"sort"
"github.com/richardlehane/match/dwac"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/siegreader"
)
// Sequence Sets and Frame Sets
// As far as possible, signatures are flattened into simple byte sequences grouped into two sets: BOF and EOF sets.
// When a byte sequence is matched, the TestTree is examined for keyframe matches and to conduct further tests.
type seqSet struct {
set []dwac.Seq
//entanglements map[int]entanglement // not persisted yet
testTreeIndex []int // The index of the testTree for the first choices. For subsequence choices, add the index of that choice to the test tree index.
}
func (ss *seqSet) save(ls *persist.LoadSaver) {
ls.SaveSmallInt(len(ss.set))
for _, v := range ss.set {
ls.SaveBigInts(v.MaxOffsets)
ls.SaveSmallInt(len(v.Choices))
for _, w := range v.Choices {
ls.SaveSmallInt(len(w))
for _, x := range w {
ls.SaveBytes(x)
}
}
}
ls.SaveInts(ss.testTreeIndex)
}
func loadSeqSet(ls *persist.LoadSaver) *seqSet {
ret := &seqSet{}
le := ls.LoadSmallInt()
if le == 0 {
_ = ls.LoadInts() // discard the empty testtreeindex list too
return ret
}
ret.set = make([]dwac.Seq, le)
for i := range ret.set {
ret.set[i].MaxOffsets = ls.LoadBigInts()
ret.set[i].Choices = make([]dwac.Choice, ls.LoadSmallInt())
for j := range ret.set[i].Choices {
ret.set[i].Choices[j] = make(dwac.Choice, ls.LoadSmallInt())
for k := range ret.set[i].Choices[j] {
ret.set[i].Choices[j][k] = ls.LoadBytes()
}
}
}
ret.testTreeIndex = ls.LoadInts()
return ret
}
// helper funcs to test equality of wac.Seq
func choiceExists(a []byte, b dwac.Choice) bool {
for _, v := range b {
if bytes.Equal(a, v) {
return true
}
}
return false
}
func seqEquals(a dwac.Seq, b dwac.Seq) bool {
if len(a.MaxOffsets) != len(b.MaxOffsets) || len(a.Choices) != len(b.Choices) {
return false
}
for i := range a.MaxOffsets {
if a.MaxOffsets[i] != b.MaxOffsets[i] {
return false
}
}
for i := range a.Choices {
if len(a.Choices[i]) != len(b.Choices[i]) {
return false
}
for _, v := range a.Choices[i] {
if !choiceExists(v, b.Choices[i]) {
return false
}
}
}
return true
}
func (ss *seqSet) exists(seq dwac.Seq) (int, bool) {
for i, v := range ss.set {
if seqEquals(seq, v) {
return i, true
}
}
return -1, false
}
// Add sequence to set. Provides latest testTreeIndex, returns actual testTreeIndex for hit insertion.
func (ss *seqSet) add(seq dwac.Seq, hi int) int {
i, ok := ss.exists(seq)
if ok {
return ss.testTreeIndex[i]
}
ss.set = append(ss.set, seq)
ss.testTreeIndex = append(ss.testTreeIndex, hi)
return hi
}
// Reduce creates a reduced seqSet based on limited slice of test tree indexes.
// Used for dynamic matching.
func (ss *seqSet) indexes(tti []int) []dwac.SeqIndex {
sort.Ints(tti)
uniq := make(map[int]bool)
ret := make([]dwac.SeqIndex, 0, len(tti))
outer:
for _, v := range tti {
for idx, w := range ss.testTreeIndex {
if w <= v && v-w < len(ss.set[idx].Choices) {
if !uniq[w] {
ret = append(ret, dwac.SeqIndex{idx, v - w})
uniq[w] = true
}
continue outer
}
}
}
return ret
}
// Some signatures cannot be represented by simple byte sequences. The first or last frames from these sequences are added to the BOF or EOF frame sets.
// Like sequences, frame matches are referred to the TestTree for further testing.
type frameSet struct {
set []frames.Frame
testTreeIndex []int
}
func (fs *frameSet) save(ls *persist.LoadSaver) {
ls.SaveSmallInt(len(fs.set))
for _, f := range fs.set {
f.Save(ls)
}
ls.SaveInts(fs.testTreeIndex)
}
func loadFrameSet(ls *persist.LoadSaver) *frameSet {
ret := &frameSet{}
le := ls.LoadSmallInt()
if le == 0 {
_ = ls.LoadInts()
return ret
}
ret.set = make([]frames.Frame, le)
for i := range ret.set {
ret.set[i] = frames.Load(ls)
}
ret.testTreeIndex = ls.LoadInts()
return ret
}
// Add frame to set. Provides current testerIndex, returns actual testerIndex for hit insertion.
func (fs *frameSet) add(f frames.Frame, hi int) int {
for i, f1 := range fs.set {
if f1.Equals(f) {
return fs.testTreeIndex[i]
}
}
fs.set = append(fs.set, f)
fs.testTreeIndex = append(fs.testTreeIndex, hi)
return hi
}
type fsmatch struct {
idx int
off int64
length int
}
func (fs *frameSet) index(buf *siegreader.Buffer, rev bool, quit chan struct{}) chan fsmatch {
ret := make(chan fsmatch)
go func() {
for i, f := range fs.set {
select {
case <-quit:
close(ret)
return
default:
}
var matches []int
if rev {
slc, err := buf.EofSlice(0, frames.TotalLength(f))
if err != nil && err != io.EOF {
close(ret)
return
}
matches = f.MatchR(slc)
} else {
slc, err := buf.Slice(0, frames.TotalLength(f))
if err != nil && err != io.EOF {
close(ret)
return
}
matches = f.Match(slc)
}
//if len(matches) > 0 { TODO: WTF???
// var min int
// if !rev {
// min, _ = f.Length()
// }
for _, off := range matches {
ret <- fsmatch{i, int64(f.Min), off - f.Min}
}
//}
}
close(ret)
}()
return ret
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package bytematcher
import (
"sort"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/persist"
)
// Test trees link byte sequence and frame matches (from the sequence and frame sets) to keyframes. This link is sometimes direct if there are no
// further test to perform. Follow-up tests may be required to the left or to the right of the match.
type testTree struct {
complete []keyFrameID
incomplete []followUp
maxLeftDistance int
maxRightDistance int
left []*testNode
right []*testNode
}
func saveTests(ls *persist.LoadSaver, tts []*testTree) {
ls.SaveSmallInt(len(tts))
for _, tt := range tts {
ls.SaveSmallInt(len(tt.complete))
for _, kfid := range tt.complete {
ls.SaveSmallInt(kfid[0])
ls.SaveSmallInt(kfid[1])
}
ls.SaveSmallInt(len(tt.incomplete))
for _, fu := range tt.incomplete {
ls.SaveSmallInt(fu.kf[0])
ls.SaveSmallInt(fu.kf[1])
ls.SaveBool(fu.l)
ls.SaveBool(fu.r)
}
ls.SaveInt(tt.maxLeftDistance)
ls.SaveInt(tt.maxRightDistance)
saveTestNodes(ls, tt.left)
saveTestNodes(ls, tt.right)
}
}
func loadTests(ls *persist.LoadSaver) []*testTree {
l := ls.LoadSmallInt()
ret := make([]*testTree, l)
for i := range ret {
ret[i] = &testTree{}
ret[i].complete = make([]keyFrameID, ls.LoadSmallInt())
for j := range ret[i].complete {
ret[i].complete[j][0] = ls.LoadSmallInt()
ret[i].complete[j][1] = ls.LoadSmallInt()
}
ret[i].incomplete = make([]followUp, ls.LoadSmallInt())
for j := range ret[i].incomplete {
ret[i].incomplete[j].kf[0] = ls.LoadSmallInt()
ret[i].incomplete[j].kf[1] = ls.LoadSmallInt()
ret[i].incomplete[j].l = ls.LoadBool()
ret[i].incomplete[j].r = ls.LoadBool()
}
ret[i].maxLeftDistance = ls.LoadInt()
ret[i].maxRightDistance = ls.LoadInt()
ret[i].left = loadTestNodes(ls)
ret[i].right = loadTestNodes(ls)
}
return ret
}
type followUp struct {
kf keyFrameID
l bool // have a left test
r bool // have a right test
}
type followupMatch struct {
followUp int
distances []int
}
type testNode struct {
frames.Frame
success []int // followUp id
tests []*testNode
}
func saveTestNodes(ls *persist.LoadSaver, tns []*testNode) {
ls.SaveSmallInt(len(tns))
for _, n := range tns {
n.Frame.Save(ls)
ls.SaveInts(n.success)
saveTestNodes(ls, n.tests)
}
}
func loadTestNodes(ls *persist.LoadSaver) []*testNode {
l := ls.LoadSmallInt()
if l == 0 {
return nil
}
ret := make([]*testNode, l)
for i := range ret {
ret[i] = &testNode{
frames.Load(ls),
ls.LoadInts(),
loadTestNodes(ls),
}
}
return ret
}
func newtestNode(f frames.Frame) *testNode {
return &testNode{
Frame: f,
}
}
func hasTest(t []*testNode, f frames.Frame) (*testNode, bool) {
for _, nt := range t {
if nt.Frame.Equals(f) {
return nt, true
}
}
return nil, false
}
func appendTests(ts []*testNode, f []frames.Frame, fu int) []*testNode {
// if our signature segment is empty just return ts
if len(f) < 1 {
return ts
}
nts := make([]*testNode, len(ts))
copy(nts, ts)
var t *testNode
if nt, ok := hasTest(nts, f[0]); ok {
t = nt
} else {
t = newtestNode(f[0])
nts = append(nts, t)
}
if len(f) > 1 {
for _, f1 := range f[1:] {
if nt, ok := hasTest(t.tests, f1); ok {
t = nt
} else {
nt := newtestNode(f1)
t.tests = append(t.tests, nt)
t = nt
}
}
}
t.success = append(t.success, fu)
return nts
}
func (t *testTree) add(kf keyFrameID, l []frames.Frame, r []frames.Frame) {
if len(l) == 0 && len(r) == 0 {
t.complete = append(t.complete, kf)
return
}
var fl, fr bool
if len(l) > 0 {
fl = true
}
if len(r) > 0 {
fr = true
}
t.incomplete = append(t.incomplete, followUp{kf, fl, fr})
fu := len(t.incomplete) - 1
if fl {
t.left = appendTests(t.left, l, fu)
}
if fr {
t.right = appendTests(t.right, r, fu)
}
}
func (t *testNode) length() int {
return frames.TotalLength(t.Frame)
}
func maxLength(ts []*testNode) int {
var max int
var delve func(t *testNode, this int)
delve = func(t *testNode, this int) {
if len(t.tests) == 0 {
if this+t.length() > max {
max = this + t.length()
}
}
for _, nt := range t.tests {
delve(nt, this+t.length())
}
}
for _, t := range ts {
delve(t, 0)
}
return max
}
/*
Consider adding new calculated values for maxLeftIter and maxRightIter. These would use the new MaxMatches methods on the Frames
to determine the theoretical max times we'd have to iterate in order to generate all the possible followUp hits.
*/
func maxMatches(ts []*testNode, l int) int {
if len(ts) == 0 || l == 0 {
return 0
}
var iters int
maxes := make(map[int]int)
var delve func(t *testNode, this int)
delve = func(t *testNode, this int) {
if iters > 1000 {
return
}
iters++
mm, rem, min := t.MaxMatches(this)
for mm > 0 {
for _, fu := range t.success {
maxes[fu]++
}
for _, nt := range t.tests {
delve(nt, rem)
}
mm--
rem = rem - min
}
}
for _, t := range ts {
delve(t, l)
}
if iters > 1000 {
return iters
}
maxSlc := make([]int, len(maxes))
var iter int
for _, v := range maxes {
maxSlc[iter] = v
iter++
}
sort.Ints(maxSlc)
return maxSlc[len(maxSlc)-1]
}
// TODO: This recursive function can overload the stack. Replace with a lazy approach
// Could it return a closure that itself returns one followupMatch per keyframe ID?
func matchTestNodes(ts []*testNode, b []byte, rev bool) []followupMatch {
ret := []followupMatch{}
if b == nil {
return ret
}
var match func(t *testNode, o int)
match = func(t *testNode, o int) {
if o >= len(b) {
return
}
var offs []int
if rev {
offs = t.MatchR(b[:len(b)-o])
} else {
offs = t.Match(b[o:])
}
if len(offs) > 0 {
for i := range offs {
offs[i] = offs[i] + o
}
for _, s := range t.success {
ret = append(ret, followupMatch{s, offs})
}
for _, off := range offs {
for _, test := range t.tests {
match(test, off)
}
}
}
}
for _, t := range ts {
match(t, 0)
}
return ret
}
// KeyFrames returns a list of all KeyFrameIDs that are included in the test tree, including completes and incompletes
// Used in scorer.go
func (t *testTree) keyFrames() []keyFrameID {
ret := make([]keyFrameID, len(t.complete), len(t.complete)+len(t.incomplete))
copy(ret, t.complete)
for _, v := range t.incomplete {
ret = append(ret, v.kf)
}
return ret
}
// FilterTests returns indexes into the main slice of testTree, given a slice of keyframe IDs.
// Used in scorer.go to select a subset of sequences and tests for dynamic matching.
func filterTests(ts []*testTree, kfids []keyFrameID) []int {
ret := make([]int, 0, len(kfids)) // will return length always equal kfids (no multiple kfids could attach to a single tt, so may be less)? would it be faster to do the outer loop on kfids. Current each tt can onlya appear once
outer:
for idx, tt := range ts {
for _, c := range tt.complete {
for _, k := range kfids {
if c == k {
ret = append(ret, idx)
continue outer
}
}
}
for _, ic := range tt.incomplete {
for _, k := range kfids {
if ic.kf == k {
ret = append(ret, idx)
continue outer
}
}
}
}
return ret
}
<file_sep>package pronom
import (
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
)
func TestRange(t *testing.T) {
rng := Range{[]byte{1}, []byte{3}}
rng2 := Range{[]byte{1}, []byte{3}}
rng3 := Range{[]byte{11, 250}, []byte{12, 1}}
if !rng.Equals(rng2) {
t.Error("Range fail: Equality")
}
if r, _ := rng.Test([]byte{1}); len(r) != 1 || r[0] != 1 {
t.Error("Range fail: Test")
}
if r, _ := rng.Test([]byte{2}); len(r) != 1 || r[0] != 1 {
t.Error("Range fail: Test")
}
if r, _ := rng.Test([]byte{3}); len(r) != 1 || r[0] != 1 {
t.Error("Range fail: Test")
}
if r, _ := rng.Test([]byte{4}); len(r) > 0 {
t.Error("Range fail: Test should fail")
}
if r, _ := rng3.Test([]byte{11, 251}); len(r) != 1 || r[0] != 2 {
t.Errorf("Range fail: Test multibyte range, got %d, %d", len(r), r[0])
}
if rng.NumSequences() != 3 {
t.Error("Range fail: NumSequences")
}
if rng3.NumSequences() != 8 {
t.Error("Range fail: NumSequences; expecting 8 got ", rng3.NumSequences())
}
}
func TestNotRange(t *testing.T) {
rng := patterns.Not{Range{[]byte{1}, []byte{3}}}
rng2 := patterns.Not{Range{[]byte{1}, []byte{3}}}
if !rng.Equals(rng2) {
t.Error("NotRange fail: Equality")
}
if r, _ := rng.Test([]byte{1}); len(r) != 0 {
t.Error("Not Range fail: Test")
}
if r, _ := rng.Test([]byte{2}); len(r) != 0 {
t.Error("Not Range fail: Test")
}
if r, _ := rng.Test([]byte{3}); len(r) != 0 {
t.Error("Not Range fail: Test")
}
if r, _ := rng.Test([]byte{4}); len(r) != 1 || r[0] != 1 {
t.Error("Not Range fail: 4 falls outside range so should succeed")
}
if rng.NumSequences() != 253 {
t.Error("Not Range fail: NumSequences; expecting 253 got", rng.NumSequences())
}
seqs := rng.Sequences()
if len(seqs) != 253 {
t.Error("Not Range fail: Sequences")
}
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package writer
import (
"bufio"
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"os"
"strings"
"testing"
"time"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
var testValues = []string{"pronom",
"fmt/43",
"JPEG File Interchange Format",
"1.01",
"image/jpeg",
"extension match jpg; byte match at [[[0 14]] [[75201 2]]]",
""}
type testErr struct{}
func (t testErr) Error() string { return "mscfb: bad OLE" }
type testID struct{}
func (t testID) String() string { return testValues[1] }
func (t testID) Known() bool { return true }
func (t testID) Warn() string { return "" }
func (t testID) Values() []string { return testValues }
func (t testID) Archive() config.Archive { return 0 }
func makeFields() []string {
return []string{"namespace",
"id",
"format",
"version",
"mime",
"basis",
"warning"}
}
var controlCharacters = []string{"\u0000", "\u0001", "\u0002", "\u0003",
"\u0004", "\u0005", "\u0006", "\u0007", "\u0008", "\u0009", "\u000A",
"\u000B", "\u000C", "\u000D", "\u000E", "\u000F", "\u0010", "\u0011",
"\u0012", "\u0013", "\u0014", "\u0015", "\u0016", "\u0017", "\u0018",
"\u0019",
}
var nonControlCharacters = []string{"\u0020", "\u1F5A4", "\u265B", "\u1F0A1",
"\u262F",
}
// TestJSONControlCharacters tests control characters that are valid but
// need special treatment from the writer and makes sure that they
// create invalid JSON.
func TestControlCharacters(t *testing.T) {
buf := &bytes.Buffer{}
js := JSON(buf)
js.Head("", time.Time{}, time.Time{}, [3]int{}, [][2]string{{"pronom", ""}}, [][]string{makeFields()}, "")
// Loop through the control characters to make sure the JSON output
// is valid.
for _, val := range controlCharacters {
js.File(fmt.Sprintf("path/%sto/file", val), 1, "2015-05-24T16:59:13+10:00", nil, testErr{}, []core.Identification{testID{}})
}
js.Tail()
if !json.Valid(buf.Bytes()) {
t.Errorf("Invalid JSON:\n%s", buf.String())
}
}
// TestNonControlCharacters tests valid characters and simply makes sure
// that the JSON output is correct.
func TestNonControlCharacters(t *testing.T) {
buf := &bytes.Buffer{}
js := JSON(buf)
js.Head("", time.Time{}, time.Time{}, [3]int{}, [][2]string{{"pronom", ""}}, [][]string{makeFields()}, "")
// Loop through the non control characters to make sure the JSON output
// is valid.
for _, val := range nonControlCharacters {
js.File(fmt.Sprintf("path/%sto/file", val), 1, "2015-05-24T16:59:13+10:00", nil, testErr{}, []core.Identification{testID{}})
}
js.Tail()
if !json.Valid(buf.Bytes()) {
t.Errorf("Invalid JSON:\n%s", buf.String())
}
}
func TestYAMLHeader(t *testing.T) {
expect := " - ns : %v\n id : %v\n format : %v\n version : %v\n mime : %v\n basis : %v\n warning : %v\n"
ret := header(makeFields())
if expect != ret {
t.Errorf("Expecting header to return %s\nGot: %s", expect, ret)
}
}
func TestYAMLMultilineString(t *testing.T) {
buf := &bytes.Buffer{}
yml := YAML(buf)
yml.Head("", time.Time{}, time.Time{}, [3]int{}, [][2]string{{"pronom", ""}}, [][]string{makeFields()}, "")
yml.File("example.\ndoc", 1, "2015-05-24T16:59:13+10:00", nil, testErr{}, []core.Identification{testID{}})
yml.Tail()
expect :=
`---
siegfried : 0.0.0
scandate : 0001-01-01T00:00:00Z
signature :
created : 0001-01-01T00:00:00Z
identifiers :
- name : 'pronom'
details : ''
---
filename : "example.\ndoc"
filesize : 1
modified : 2015-05-24T16:59:13+10:00
errors : 'mscfb: bad OLE'
matches :
- ns : 'pronom'
id : 'fmt/43'
format : 'JPEG File Interchange Format'
version : '1.01'
mime : 'image/jpeg'
basis : 'extension match jpg; byte match at [[[0 14]] [[75201 2]]]'
warning :
`
ret := buf.String()
if expect != ret {
var detail string
if len(expect) != len(ret) {
detail = fmt.Sprintf("Strings differ in length, %d vs %d", len(expect), len(ret))
} else {
for i := range expect {
if expect[i] != ret[i] {
detail = fmt.Sprintf("Strings differ at index %d, %d vs %d", i, expect[i], ret[i])
}
}
}
t.Errorf("Expecting return: %s\nGot: %s\n%s", expect, ret, detail)
}
}
// TestDroidHeader ensures that the DROID header is output consistently
// and matches the DROID CSV specification.
func TestDroidHeader(t *testing.T) {
buf := &bytes.Buffer{}
droid := Droid(buf)
droid.Head("", time.Time{}, time.Time{}, [3]int{}, [][2]string{{"pronom", ""}}, [][]string{makeFields()}, "md5")
droid.Tail()
// DROID identification result isn't tested here as the paths output
// are absolute and require a bit of finessing in SF to get right.
expected := `ID,PARENT_ID,URI,FILE_PATH,NAME,METHOD,STATUS,SIZE,TYPE,EXT,LAST_MODIFIED,EXTENSION_MISMATCH,MD5_HASH,FORMAT_COUNT,PUID,MIME_TYPE,FORMAT_NAME,FORMAT_VERSION`
res := strings.Trim(buf.String(), "\n")
if res != expected {
t.Errorf("DROID output didn't output as expected: \n'%s' got: \n'%s'", res, expected)
}
}
func ExampleYAML() {
yml := YAML(ioutil.Discard)
yml.Head("", time.Time{}, time.Time{}, [3]int{}, [][2]string{{"pronom", ""}}, [][]string{makeFields()}, "")
yml.(*yamlWriter).w = bufio.NewWriter(os.Stdout)
yml.File("example.doc", 1, "2015-05-24T16:59:13+10:00", nil, testErr{}, []core.Identification{testID{}})
yml.Tail()
// Output:
// ---
// filename : 'example.doc'
// filesize : 1
// modified : 2015-05-24T16:59:13+10:00
// errors : 'mscfb: bad OLE'
// matches :
// - ns : 'pronom'
// id : 'fmt/43'
// format : 'JPEG File Interchange Format'
// version : '1.01'
// mime : 'image/jpeg'
// basis : 'extension match jpg; byte match at [[[0 14]] [[75201 2]]]'
// warning :
}
func ExampleJSON() {
js := JSON(ioutil.Discard)
js.Head("", time.Time{}, time.Time{}, [3]int{}, [][2]string{{"pronom", ""}}, [][]string{makeFields()}, "")
js.(*jsonWriter).w = bufio.NewWriter(os.Stdout)
js.File("example.doc", 1, "2015-05-24T16:59:13+10:00", nil, testErr{}, []core.Identification{testID{}})
js.Tail()
// Output:
// {"filename":"example.doc","filesize": 1,"modified":"2015-05-24T16:59:13+10:00","errors": "mscfb: bad OLE","matches": [{"ns":"pronom","id":"fmt/43","format":"JPEG File Interchange Format","version":"1.01","mime":"image/jpeg","basis":"extension match jpg; byte match at [[[0 14]] [[75201 2]]]","warning":""}]}]}
}
<file_sep>//go:build ignore
// +build ignore
// Copyright 2020 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// gen.go updates signature and sets files
// invoke using `go generate`
package main
import (
"flag"
"fmt"
"os"
"path/filepath"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/loc"
"github.com/richardlehane/siegfried/pkg/mimeinfo"
"github.com/richardlehane/siegfried/pkg/pronom"
"github.com/richardlehane/siegfried/pkg/sets"
"github.com/richardlehane/siegfried/pkg/wikidata"
)
var genhome = flag.String("home", "data", "override the default home directory")
type job func() error
func main() {
jobs := []job{
makeDefault,
makeLoc,
makeTika,
makeFreedesktop,
makeDeluxe,
makeArchivematica,
makeSets,
makeWikidata,
}
for i, j := range jobs {
fmt.Printf("Running job %d\n", i)
if err := j(); err != nil {
fmt.Println(err)
os.Exit(0)
}
}
}
func writeSigFile(name string, identifiers ...core.Identifier) error {
s := siegfried.New()
for _, id := range identifiers {
if err := s.Add(id); err != nil {
return err
}
}
return s.Save(filepath.Join("data", name))
}
func makeDefault() error {
config.SetHome(*genhome)
p, err := pronom.New()
if err != nil {
return err
}
return writeSigFile(config.SignatureBase(), p)
}
func makeLoc() error {
config.SetHome(*genhome)
l, err := loc.New(config.SetLOC(""))
if err != nil {
return err
}
return writeSigFile("loc.sig", l)
}
func makeTika() error {
config.SetHome(*genhome)
m, err := mimeinfo.New(config.SetMIMEInfo("tika"))
if err != nil {
return err
}
return writeSigFile("tika.sig", m)
}
func makeFreedesktop() error {
config.SetHome(*genhome)
m, err := mimeinfo.New(config.SetMIMEInfo("freedesktop"))
if err != nil {
return err
}
return writeSigFile("freedesktop.sig", m)
}
func makeDeluxe() error {
config.SetHome(*genhome)
p, err := pronom.New(config.Clear())
if err != nil {
return err
}
m, err := mimeinfo.New(config.SetMIMEInfo("tika"))
if err != nil {
return err
}
f, err := mimeinfo.New(config.SetMIMEInfo("freedesktop"))
if err != nil {
return err
}
l, err := loc.New(config.SetLOC(""))
if err != nil {
return err
}
wikidataOpts := []config.Option{config.SetWikidataNamespace()}
wikidataOpts = append(wikidataOpts, config.SetWikidataNoPRONOM())
w, err := wikidata.New(wikidataOpts...)
if err != nil {
return err
}
return writeSigFile("deluxe.sig", p, m, f, l, w)
}
func makeArchivematica() error {
config.SetHome(*genhome)
p, err := pronom.New(
config.SetName("archivematica"),
config.SetExtend(sets.Expand("archivematica-fmt2.xml,archivematica-fmt3.xml,archivematica-fmt4.xml,archivematica-fmt5.xml")))
if err != nil {
return err
}
return writeSigFile("archivematica.sig", p)
}
func makeSets() error {
config.SetHome(*genhome)
releases, err := pronom.LoadReleases(config.Local("release-notes.xml"))
if err == nil {
err = pronom.ReleaseSet("pronom-changes.json", releases)
}
if err == nil {
err = pronom.TypeSets("pronom-all.json", "pronom-families.json", "pronom-types.json")
}
if err == nil {
err = pronom.ExtensionSet("pronom-extensions.json")
}
return err
}
func makeWikidata() error {
config.SetHome(*genhome)
wikidataOpts := []config.Option{
config.Clear(),
config.SetWikidataNamespace(),
config.SetWikidataNoPRONOM(),
}
w, err := wikidata.New(wikidataOpts...)
if err != nil {
return err
}
return writeSigFile("wikidata.sig", w)
}
<file_sep>package bytematcher
import (
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
"github.com/richardlehane/siegfried/internal/persist"
)
var TesttestNodes = []*testNode{
{
Frame: tests.TestFrames[3],
success: []int{},
tests: []*testNode{
{
Frame: tests.TestFrames[1],
success: []int{0},
tests: []*testNode{},
},
},
},
{
Frame: tests.TestFrames[6],
success: []int{},
tests: []*testNode{
{
Frame: tests.TestFrames[2],
success: []int{0},
tests: []*testNode{},
},
},
},
}
var TestTestTree = &testTree{
complete: []keyFrameID{},
incomplete: []followUp{
{
kf: keyFrameID{1, 0},
l: true,
r: true,
},
},
maxLeftDistance: 10,
maxRightDistance: 30,
left: []*testNode{TesttestNodes[0]},
right: []*testNode{TesttestNodes[1]},
}
func TestMaxLength(t *testing.T) {
test := &testTree{}
test.add([2]int{0, 0}, []frames.Frame{}, []frames.Frame{tests.TestFrames[0], tests.TestFrames[3], tests.TestFrames[6]})
test.add([2]int{0, 0}, []frames.Frame{}, []frames.Frame{tests.TestFrames[1], tests.TestFrames[3]})
saver := persist.NewLoadSaver(nil)
saveTests(saver, []*testTree{test, test})
loader := persist.NewLoadSaver(saver.Bytes())
tests := loadTests(loader)
test = tests[1]
if maxLength(test.right) != 33 {
t.Errorf("maxLength fail: expecting 33 got %v", maxLength(test.right))
}
}
func TestMaxMatches(t *testing.T) {
test := &testTree{}
test.add([2]int{0, 0}, []frames.Frame{}, []frames.Frame{tests.TestFrames[0], tests.TestFrames[3], tests.TestFrames[6]})
test.add([2]int{0, 0}, []frames.Frame{}, []frames.Frame{tests.TestFrames[1], tests.TestFrames[3]})
mm := maxMatches(test.right, 33)
if mm != 3 {
t.Errorf("maxMatches fail: expecting 3 got %d", mm)
}
}
func TestMaxMatches134(t *testing.T) {
test := &testTree{}
test.add([2]int{0, 0}, []frames.Frame{}, tests.TestFmts[134][1:])
mm := maxMatches(test.right, maxLength(test.right))
if mm != 1001 {
t.Errorf("maxMatches fail: expecting 1001 got %d", mm)
}
}
func TestMatchLeft(t *testing.T) {
left := matchTestNodes(TestTestTree.left, Sample[:8], true)
if len(left) != 1 {
t.Errorf("expecting one match, got %v", len(left))
}
if left[0].followUp != 0 {
t.Errorf("expecting 0, got %v", left[0].followUp)
}
}
func TestMatchRight(t *testing.T) {
right := matchTestNodes(TestTestTree.right, Sample[8+5:], false)
if len(right) != 1 {
t.Errorf("expecting one match, got %v", len(right))
}
if right[0].followUp != 0 {
t.Errorf("expecting 0, got %v", right[0].followUp)
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package patterns
import (
"bytes"
"github.com/richardlehane/siegfried/internal/persist"
)
// BMH turns patterns into BMH sequences if possible.
func BMH(p Pattern, rev bool) Pattern {
s, ok := p.(Sequence)
if !ok {
return p
}
if rev {
return NewRBMHSequence(s)
}
return NewBMHSequence(s)
}
// BMHSequence is an optimised version of the regular Sequence pattern.
// It is used behind the scenes in the Bytematcher package to speed up matching and should not be used directly in other packages (use the plain Sequence instead).
type BMHSequence struct {
Seq Sequence
advance int
Shift [256]int
}
// NewBMHSequence turns a Sequence into a BMHSequence.
func NewBMHSequence(s Sequence) *BMHSequence {
var shift [256]int
for i := range shift {
shift[i] = len(s)
}
last := len(s) - 1
for i := 0; i < last; i++ {
shift[s[i]] = last - i
}
return &BMHSequence{s, Overlap(s), shift}
}
// Test bytes against the pattern.
func (s *BMHSequence) Test(b []byte) ([]int, int) {
if len(b) < len(s.Seq) {
return nil, 0
}
for i := len(s.Seq) - 1; i > -1; i-- {
if b[i] != s.Seq[i] {
return nil, s.Shift[b[len(s.Seq)-1]]
}
}
return []int{len(s.Seq)}, s.advance
}
// Test bytes against the pattern in reverse.
func (s *BMHSequence) TestR(b []byte) ([]int, int) {
if len(b) < len(s.Seq) {
return nil, 0
}
if bytes.Equal(s.Seq, b[len(b)-len(s.Seq):]) {
return []int{len(s.Seq)}, s.advance
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (s *BMHSequence) Equals(pat Pattern) bool {
seq2, ok := pat.(*BMHSequence)
if ok {
return bytes.Equal(s.Seq, seq2.Seq)
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (s *BMHSequence) Length() (int, int) {
return len(s.Seq), len(s.Seq)
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (s *BMHSequence) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (s *BMHSequence) Sequences() []Sequence {
return []Sequence{s.Seq}
}
func (s *BMHSequence) String() string {
return "seq " + Stringify(s.Seq)
}
// Save persists the pattern.
func (s *BMHSequence) Save(ls *persist.LoadSaver) {
ls.SaveByte(bmhLoader)
ls.SaveBytes(s.Seq)
ls.SaveSmallInt(s.advance)
for _, v := range s.Shift {
ls.SaveSmallInt(v)
}
}
func loadBMH(ls *persist.LoadSaver) Pattern {
bmh := &BMHSequence{}
bmh.Seq = Sequence(ls.LoadBytes())
bmh.advance = ls.LoadSmallInt()
for i := range bmh.Shift {
bmh.Shift[i] = ls.LoadSmallInt()
}
return bmh
}
// RBMHSequence is a variant of the BMH sequence designed for reverse (R-L) matching.
// It is used behind the scenes in the Bytematcher package to speed up matching and should not be used directly in other packages (use the plain Sequence instead).
type RBMHSequence struct {
Seq Sequence
advance int
Shift [256]int
}
// NewRBMHSequence create a reverse matching BMH sequence (apply the BMH optimisation to TestR rather than Test).
func NewRBMHSequence(s Sequence) *RBMHSequence {
var shift [256]int
for i := range shift {
shift[i] = len(s)
}
last := len(s) - 1
for i := 0; i < last; i++ {
shift[s[last-i]] = last - i
}
return &RBMHSequence{s, Overlap(s), shift}
}
// Test bytes against the pattern.
func (s *RBMHSequence) Test(b []byte) ([]int, int) {
if len(b) < len(s.Seq) {
return nil, 0
}
if bytes.Equal(s.Seq, b[:len(s.Seq)]) {
return []int{len(s.Seq)}, s.advance
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (s *RBMHSequence) TestR(b []byte) ([]int, int) {
if len(b) < len(s.Seq) {
return nil, 0
}
for i, v := range b[len(b)-len(s.Seq):] {
if v != s.Seq[i] {
return nil, s.Shift[b[len(b)-len(s.Seq)]]
}
}
return []int{len(s.Seq)}, s.advance
}
// Equals reports whether a pattern is identical to another pattern.
func (s *RBMHSequence) Equals(pat Pattern) bool {
seq2, ok := pat.(*RBMHSequence)
if ok {
return bytes.Equal(s.Seq, seq2.Seq)
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (s *RBMHSequence) Length() (int, int) {
return len(s.Seq), len(s.Seq)
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (s *RBMHSequence) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (s *RBMHSequence) Sequences() []Sequence {
return []Sequence{s.Seq}
}
func (s *RBMHSequence) String() string {
return "seq " + Stringify(s.Seq)
}
// Save persists the pattern.
func (s *RBMHSequence) Save(ls *persist.LoadSaver) {
ls.SaveByte(rbmhLoader)
ls.SaveBytes(s.Seq)
ls.SaveSmallInt(s.advance)
for _, v := range s.Shift {
ls.SaveSmallInt(v)
}
}
func loadRBMH(ls *persist.LoadSaver) Pattern {
rbmh := &RBMHSequence{}
rbmh.Seq = Sequence(ls.LoadBytes())
rbmh.advance = ls.LoadSmallInt()
for i := range rbmh.Shift {
rbmh.Shift[i] = ls.LoadSmallInt()
}
return rbmh
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Tests to ensure the efficacy of the converter package.
package converter
import (
"encoding/hex"
"encoding/json"
"testing"
)
// signature is the structure we're using to express different information
// about these tests.
type signature struct {
Signature string // Signature represents the original byte sequence.
Encoding string // Signature represents the original encoding, e.g. Hexadecimal, ASCII, PRONOM.
NewEncoding string // NewEncoding represents the converted encoding of the sequence we input.
NewSignature string // NewSignature represents the converted form of the sequence we input.
Comment string // Comment field to potentially replay information to the user if a test fails.
Fail bool // Fail flag to enable us to know when a test is expected to pass or fail.
Converted bool // Converted will tell us whether the signature should have been converted or not.
}
// TestParse provides us with a way to loop through our fixtures and
// make sure the results are as expected.
func TestParse(t *testing.T) {
var sigs []signature
err := json.Unmarshal([]byte(testPatterns), &sigs)
if err != nil {
t.Error("Failed to load fixtures:", err)
}
for _, sig := range sigs {
signature, converted, encoding, err := Parse(sig.Signature, LookupEncoding(sig.Encoding))
if sig.Converted != converted {
t.Errorf("Signature '%s' should not have been converted", sig.Signature)
}
if sig.NewEncoding != "" {
if converted != true && sig.Converted {
t.Error("Converted flag should be set to 'true'")
}
newEncodingReversed := ReverseEncoding(encoding)
if sig.NewEncoding != newEncodingReversed {
t.Errorf("Encoding conversion didn't work got '%s' expected '%s'", newEncodingReversed, sig.NewEncoding)
}
if sig.NewSignature != signature {
t.Errorf("Newly encoded signature should be '%s' not '%s'", sig.NewSignature, signature)
}
}
if err != nil && sig.Fail != true {
t.Error("Failed to parse signature:", err, sig.Signature)
}
}
}
// TestParseEmojiRoundTrip is a little bit of a hangover from the
// olden-days. Make sure that we can round-trip strings without a loss
// of fidelity.
func TestParseEmojiRoundTrip(t *testing.T) {
const chessEmoji = "♕♖♗♘♙♚♛♜♝♞♟"
val, _, _, err := Parse(chessEmoji, ASCIIEncoding)
if err != nil {
t.Error("Failed to parse signature:", err)
}
roundTrip, err := hex.DecodeString(val)
if string(roundTrip) != chessEmoji || err != nil {
t.Errorf("Round tripping emoji failed, expected '%s', actual: '%s' (%s)", chessEmoji, val, err)
}
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mappings
import (
"fmt"
"strings"
)
type FDD struct {
ID string `xml:"id,attr"`
Name string `xml:"titleName,attr"`
LongName string `xml:"identificationAndDescription>fullName"`
Extensions []string `xml:"fileTypeSignifiers>signifiersGroup>filenameExtension>sigValues>sigValue"`
MIMEs []string `xml:"fileTypeSignifiers>signifiersGroup>internetMediaType>sigValues>sigValue"`
Magics []string `xml:"fileTypeSignifiers>signifiersGroup>magicNumbers>sigValues>sigValue"`
Others []Other `xml:"fileTypeSignifiers>signifiersGroup>other"`
Relations []Relation `xml:"identificationAndDescription>relationships>relationship"`
Updates []string `xml:"properties>updates>date"`
Links []string `xml:"usefulReferences>urls>url>urlReference>link"`
}
type Other struct {
Tag string `xml:"tag"`
Values []string `xml:"values>sigValues>sigValue"`
}
func (o Other) String() string {
return fmt.Sprintf("[tag: %s; vals: %s]", o.Tag, strings.Join(o.Values, ","))
}
func ostr(os []Other) []string {
ret := make([]string, len(os))
for i, v := range os {
ret[i] = v.String()
}
return ret
}
type Relation struct {
Typ string `xml:"typeOfRelationship"`
Value string `xml:"relatedTo>id"`
}
func (r Relation) String() string {
return fmt.Sprintf("[typ: %s; val: %s]", r.Typ, r.Value)
}
func rstr(rs []Relation) []string {
ret := make([]string, len(rs))
for i, v := range rs {
ret[i] = v.String()
}
return ret
}
func (f FDD) String() string {
return fmt.Sprintf("ID: %s\nName: %s\nLong Name: %s\nExts: %s\nMIMEs: %s\nMagics: %s\nOthers: %s\nRelations: %s\nPUIDs: %s",
f.ID,
f.Name,
f.LongName,
strings.Join(f.Extensions, ", "),
strings.Join(f.MIMEs, ", "),
strings.Join(f.Magics, ", "),
strings.Join(ostr(f.Others), ", "),
strings.Join(rstr(f.Relations), ", "),
strings.Join(f.PUIDs(), ", "),
)
}
func (f FDD) PUIDs() []string {
var puids []string
for _, l := range f.Links {
if strings.HasPrefix(l, "http://apps.nationalarchives.gov.uk/pronom/") {
puids = append(puids, strings.TrimPrefix(l, "http://apps.nationalarchives.gov.uk/pronom/"))
} else if strings.HasPrefix(l, "http://www.nationalarchives.gov.uk/pronom/") {
puids = append(puids, strings.TrimPrefix(l, "http://www.nationalarchives.gov.uk/pronom/"))
}
}
return puids
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package containermatcher
import (
"fmt"
"path/filepath"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
func (m Matcher) Identify(n string, b *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
res := make(chan core.Result)
// check trigger
buf, err := b.Slice(0, 8)
if err != nil {
close(res)
return res, nil
}
divhints := m.divideHints(hints)
for i, c := range m {
if c.trigger(buf) {
rdr, err := c.rdr(b)
if err != nil {
close(res)
return res, err
}
go c.identify(n, rdr, res, divhints[i]...)
return res, nil
}
}
// nothing ... move on
close(res)
return res, nil
}
// ranges allows referencing a container hit back to a specific container matcher (used by divideHints)
// returns running number / matcher index / identifier index
func (m Matcher) ranges() [][3]int {
var l int
for _, c := range m {
l += len(c.startIndexes)
}
ret := make([][3]int, l)
var prev, this, idx, jdx int
for i := range ret {
prev = this
this = m[idx].startIndexes[jdx]
ret[i] = [3]int{prev + this, idx, jdx}
idx++
if idx >= len(m) {
jdx++
idx = 0
}
}
return ret
}
func findID(id int, rng [][3]int) (int, int) {
var idx int
for idx = range rng {
if rng[idx][0] > id {
if idx > 0 {
idx--
}
break
}
}
return rng[idx][1], rng[idx][2]
}
func (m Matcher) divideHints(hints []core.Hint) [][]core.Hint {
ret := make([][]core.Hint, len(m))
rng := m.ranges()
for _, h := range hints {
if len(h.Pivot) == 0 {
continue
}
first := make([]bool, len(m))
for _, p := range h.Pivot {
midx, iidx := findID(p, rng)
if !first[midx] {
first[midx] = true
_, excl := m[midx].priorities.Index(p - m[midx].startIndexes[iidx])
ret[midx] = append(ret[midx], core.Hint{excl, nil})
}
ret[midx][len(ret[midx])-1].Pivot = append(ret[midx][len(ret[midx])-1].Pivot, p-m[midx].startIndexes[iidx])
}
}
return ret
}
type identifier struct {
partsMatched [][]hit // hits for parts
ruledOut []bool // mark additional signatures as negatively matched
waitSet *priority.WaitSet
hits []hit // shared buffer of hits used when matching
result bool
}
func (c *ContainerMatcher) newIdentifier(numParts int, hints ...core.Hint) *identifier {
return &identifier{
make([][]hit, numParts),
make([]bool, numParts),
c.priorities.WaitSet(hints...),
make([]hit, 0, 1),
false,
}
}
func (c *ContainerMatcher) identify(n string, rdr Reader, res chan core.Result, hints ...core.Hint) {
// safe to call on a nil matcher (i.e. container matching switched off)
if c == nil {
close(res)
return
}
id := c.newIdentifier(len(c.parts), hints...)
var err error
for err = rdr.Next(); err == nil; err = rdr.Next() {
ct, ok := c.nameCTest[rdr.Name()]
if !ok {
continue
}
if config.Debug() {
fmt.Fprintf(config.Out(), "{Name match - %s (container %d))}\n", rdr.Name(), c.conType)
}
// name has matched, let's test the CTests
// ct.identify will generate a slice of hits which pass to
// processHits which will return true if we can stop
if c.processHits(ct.identify(c, id, rdr, rdr.Name()), id, ct, rdr.Name(), res) {
break
}
}
// send a default hit if no result and extension matches
if c.extension != "" && !id.result && filepath.Ext(n) == "."+c.extension {
res <- defaultHit(-1 - int(c.conType))
}
close(res)
}
func (ct *cTest) identify(c *ContainerMatcher, id *identifier, rdr Reader, name string) []hit {
// reset hits
id.hits = id.hits[:0]
for _, h := range ct.satisfied {
if id.waitSet.Check(h) {
id.hits = append(id.hits, hit{h, name, "name only"})
}
}
if ct.unsatisfied != nil && !rdr.IsDir() {
buf, err := rdr.SetSource(c.entryBufs)
if buf == nil {
rdr.Close()
if config.Debug() {
fmt.Fprintf(config.Out(), "{Container error - %s (container %d)); error: %v}\n", rdr.Name(), c.conType, err)
}
return id.hits
}
bmc, _ := ct.bm.Identify("", buf)
for r := range bmc {
h := ct.unsatisfied[r.Index()]
if id.waitSet.Check(h) && id.checkHits(h) {
id.hits = append(id.hits, hit{h, name, r.Basis()})
}
}
rdr.Close()
c.entryBufs.Put(buf)
}
return id.hits
}
// process the hits from the ctest: adding hits to the parts matched, checking priorities
// return true if satisfied and can quit
func (c *ContainerMatcher) processHits(hits []hit, id *identifier, ct *cTest, name string, res chan core.Result) bool {
// if there are no hits, rule out any sigs in the ctest
if len(hits) == 0 {
for _, v := range ct.satisfied {
id.ruledOut[v] = true
}
for _, v := range ct.unsatisfied {
id.ruledOut[v] = true
}
return false
}
for _, h := range hits {
id.partsMatched[h.id] = append(id.partsMatched[h.id], h)
if len(id.partsMatched[h.id]) == c.parts[h.id] {
if id.waitSet.Check(h.id) {
idx, _ := c.priorities.Index(h.id)
res <- toResult(c.startIndexes[idx], id.partsMatched[h.id]) // send a Result here
id.result = true // mark id as having a result (for zip default)
// set a priority list and return early if can
if id.waitSet.Put(h.id) {
return true
}
}
}
}
// if nothing ruled out by this test, then we must continue
if len(hits) == len(ct.satisfied)+len(ct.unsatisfied) {
return false
}
// we can rule some possible matches out...
for _, v := range ct.satisfied {
if len(id.partsMatched[v]) == 0 || id.partsMatched[v][len(id.partsMatched[v])-1].name != name {
id.ruledOut[v] = true
}
}
for _, v := range ct.unsatisfied {
if len(id.partsMatched[v]) == 0 || id.partsMatched[v][len(id.partsMatched[v])-1].name != name {
id.ruledOut[v] = true
}
}
// if we haven't got a waitList yet, then we should return false
waitingOn := id.waitSet.WaitingOn()
if waitingOn == nil {
return false
}
// loop over the wait list, seeing if they are all ruled out
for _, v := range waitingOn {
if !id.ruledOut[v] {
return false
}
}
return true
}
// eliminate duplicate hits - must do this since rely on number of matches for each sig as test for full match
func (id *identifier) checkHits(i int) bool {
for _, h := range id.hits {
if i == h.id {
return false
}
}
return true
}
func toResult(i int, h []hit) result {
if len(h) == 0 {
return result(h)
}
h[0].id += i
return result(h)
}
type result []hit
func (r result) Index() int {
if len(r) == 0 {
return -1
}
return r[0].id
}
func (r result) Basis() string {
var basis string
for i, v := range r {
if i < 1 {
basis += "container "
} else {
basis += "; "
}
basis += "name " + v.name
if len(v.basis) > 0 {
basis += " with " + v.basis
}
}
return basis
}
type hit struct {
id int
name string
basis string
}
type defaultHit int
func (d defaultHit) Index() int {
return int(d)
}
func (d defaultHit) Basis() string {
return "container match with trigger and default extension"
}
<file_sep>// Copyright 2019 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package patterns
// func Overlap calculates the max distance before a possible overlap with multiple matches of the same Pattern
// e.g. 0xAABBAA has a length of 3 but returns 2
func Overlap(p Pattern) int {
return aggregateOverlap(p, overlap)
}
// func OverlapR calculates the max distance before a possible overlap with multiple matches of the same Pattern,
// matching in reverse
// e.g. EOFE has a length of 4 but returns 3
func OverlapR(p Pattern) int {
return aggregateOverlap(p, overlapR)
}
func aggregateOverlap(p Pattern, of overlapFunc) int {
seqs := p.Sequences()
if len(seqs) < 1 {
return 1
}
ret := len(seqs[0])
for _, v := range seqs {
for _, vv := range seqs {
if r := of(v, vv); r < ret {
ret = r
}
}
}
return ret
}
type overlapFunc func([]byte, []byte) int
func overlap(a, b []byte) int {
var ret int = 1
for ; ret < len(a); ret++ {
success := true
for i := 0; ret+i < len(a) && i < len(b); i++ {
if a[ret+i] != b[i] {
success = false
break
}
}
if success {
break
}
}
return ret
}
func overlapR(a, b []byte) int {
var ret int = 1
for ; ret < len(a); ret++ {
success := true
for i := 0; ret+i < len(a) && i < len(b); i++ {
if a[len(a)-ret-i-1] != b[len(b)-i-1] {
success = false
break
}
}
if success {
break
}
}
return ret
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"fmt"
"io"
"strconv"
"strings"
"time"
"github.com/richardlehane/siegfried/internal/checksum"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
const (
unknownWarn = "no match"
extWarn = "match on extension only"
extMismatch = "extension mismatch"
)
type Reader interface {
Head() Head
Next() (File, error)
}
type Head struct {
ResultsPath string
SignaturePath string
Scanned time.Time
Created time.Time
Version [3]int
Identifiers [][2]string
Fields [][]string
HashHeader string
}
type File struct {
Path string
Size int64
Mod time.Time
Hash []byte
Err error
IDs []core.Identification
}
type record struct {
attributes map[string]string
listFields []string
listValues []string
}
func toVersion(str string) ([3]int, error) {
var ret [3]int
if str == "" {
return ret, nil
}
nums := strings.Split(str, ".")
if len(nums) != len(ret) {
return ret, fmt.Errorf("bad version; got %d numbers", len(nums))
}
for i, v := range nums {
var err error
ret[i], err = strconv.Atoi(v)
if err != nil {
return ret, fmt.Errorf("bad version; got %v", err)
}
}
return ret, nil
}
func getHead(rec record) (Head, error) {
head, err := newHeadMap(rec.attributes)
head.Identifiers = getIdentifiers(rec.listValues)
return head, err
}
func newHeadMap(m map[string]string) (Head, error) {
return newHead(m["results"], m["signature"], m["scandate"], m["created"], m["siegfried"])
}
func newHead(resultsPath, sigPath, scanned, created, version string) (Head, error) {
var err error
h := Head{
ResultsPath: resultsPath,
SignaturePath: sigPath,
}
h.Version, err = toVersion(version)
if scanned != "" {
h.Scanned, err = time.Parse(time.RFC3339, scanned)
}
if created != "" {
h.Created, err = time.Parse(time.RFC3339, created)
}
return h, err
}
func newFile(path, sz, mod, hash, e string) (File, error) {
var err error
file := File{
Path: path,
IDs: make([]core.Identification, 0, 1),
}
if mod != "" {
file.Mod, err = time.Parse(time.RFC3339, mod)
if err != nil {
file.Mod, err = time.Parse(droidTime, mod)
}
}
if err != nil {
err = fmt.Errorf("bad field, mod: %s, err: %v", mod, err)
}
if len(hash) > 0 {
file.Hash = []byte(hash)
}
if e != "" {
file.Err = fmt.Errorf("%s", e)
}
if sz == "" {
return file, nil
}
fs, fserr := strconv.Atoi(sz)
file.Size = int64(fs)
if fserr != nil {
err = fmt.Errorf("bad field, sz: %s, err: %v", sz, err)
}
return file, err
}
func getFile(rec record) (File, error) {
var hh string
for k := range rec.attributes {
if h := checksum.GetHash(k); h >= 0 {
hh = k
break
}
}
f, err := newFile(rec.attributes["filename"],
rec.attributes["filesize"],
rec.attributes["modified"],
rec.attributes[hh],
rec.attributes["errors"],
)
if err != nil {
return f, err
}
var sidx, eidx int
for i, v := range rec.listFields {
if v == "ns" {
eidx = i
if eidx > sidx {
f.IDs = append(f.IDs, newDefaultID(rec.listFields[sidx:eidx], rec.listValues[sidx:eidx]))
sidx = eidx
}
}
}
f.IDs = append(f.IDs, newDefaultID(rec.listFields[sidx:len(rec.listFields)], rec.listValues[sidx:len(rec.listFields)]))
return f, nil
}
func getIdentifiers(vals []string) [][2]string {
ret := make([][2]string, 0, len(vals)/2)
for i, v := range vals {
if i%2 == 0 {
ret = append(ret, [2]string{v, ""})
} else {
ret[len(ret)-1][1] = v
}
}
return ret
}
func getHash(m map[string]string) string {
for k := range m {
if h := checksum.GetHash(k); h >= 0 {
return h.String()
}
}
return ""
}
func getFields(keys, vals []string) [][]string {
ret := make([][]string, 0, 1)
var ns string
var consume bool
for i, v := range keys {
if v == "ns" || v == "namespace" {
if ns == vals[i] {
consume = false
} else {
ns = vals[i]
consume = true
ret = append(ret, []string{})
v = "namespace" // always store as namespace
}
}
if consume {
ret[len(ret)-1] = append(ret[len(ret)-1], v)
}
}
return ret
}
type peekReader struct {
unread bool
peek byte
rdr io.Reader
}
func (pr *peekReader) Read(b []byte) (int, error) {
if pr.unread {
if len(b) < 1 {
return 0, nil
}
b[0] = pr.peek
pr.unread = false
if len(b) == 1 {
return 1, nil
}
i, e := pr.rdr.Read(b[1:])
return i + 1, e
}
return pr.rdr.Read(b)
}
func New(rdr io.Reader, path string) (Reader, error) {
buf := make([]byte, 1)
if _, err := rdr.Read(buf); err != nil {
return nil, err
}
pr := &peekReader{true, buf[0], rdr}
switch buf[0] {
case '-':
return newYAML(pr, path)
case 'f':
return newCSV(pr, path)
case '{':
return newJSON(pr, path)
case 'O', 'K':
return newFido(pr, path)
case 'D':
return newDroidNp(pr, path)
case '"', 'I':
return newDroid(pr, path)
}
return nil, fmt.Errorf("not a valid results file, bad char %d", int(buf[0]))
}
type defaultID struct {
id int
warn int
known bool
values []string
}
func (did *defaultID) String() string { return did.values[did.id] }
func (did *defaultID) Known() bool { return did.known }
func (did *defaultID) Warn() string {
if did.warn > 0 {
return did.values[did.warn]
}
return ""
}
func (did *defaultID) Values() []string { return did.values }
func (did *defaultID) Archive() config.Archive { return config.None }
func newDefaultID(fields, values []string) *defaultID {
did := &defaultID{values: values}
for i, v := range fields {
switch v {
case "id", "identifier", "ID":
did.id = i
switch values[i] {
case "unknown", "UNKNOWN", "":
default:
did.known = true
}
case "warn", "warning":
did.warn = i
}
}
return did
}
<file_sep>package siegreader
type source interface {
IsSlicer() bool
Slice(off int64, l int) ([]byte, error)
EofSlice(off int64, l int) ([]byte, error)
Size() int64
}
// an external buffer is a non-file stream that implements the Slice() etc. methods
// this is used to prevent unnecessary copying of webarchive WARC/ARC readers
type external struct{ source }
func newExternal() interface{} { return &external{} }
func (e *external) setSource(src source) error {
e.source = src
if e.Size() == 0 {
return ErrEmpty
}
return nil
}
// SizeNow is a non-blocking Size().
func (e *external) SizeNow() int64 { return e.Size() }
func (e *external) CanSeek(off int64, whence bool) (bool, error) {
if e.Size() < off {
return false, nil
}
return true, nil
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mimeinfo
import (
"fmt"
"sort"
"strings"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
func init() {
core.RegisterIdentifier(core.MIMEInfo, Load)
}
type Identifier struct {
infos map[string]formatInfo
*identifier.Base
}
func (i *Identifier) Save(ls *persist.LoadSaver) {
ls.SaveByte(core.MIMEInfo)
ls.SaveSmallInt(len(i.infos))
for k, v := range i.infos {
ls.SaveString(k)
ls.SaveString(v.comment)
ls.SaveBool(v.text)
ls.SaveInts(v.globWeights)
ls.SaveInts(v.magicWeights)
}
i.Base.Save(ls)
}
func Load(ls *persist.LoadSaver) core.Identifier {
i := &Identifier{}
i.infos = make(map[string]formatInfo)
le := ls.LoadSmallInt()
for j := 0; j < le; j++ {
i.infos[ls.LoadString()] = formatInfo{
ls.LoadString(),
ls.LoadBool(),
ls.LoadInts(),
ls.LoadInts(),
}
}
i.Base = identifier.Load(ls)
return i
}
func contains(ss []string, str string) bool {
for _, s := range ss {
if s == str {
return true
}
}
return false
}
func New(opts ...config.Option) (core.Identifier, error) {
for _, v := range opts {
v()
}
mi, err := newMIMEInfo(config.MIMEInfo())
if err != nil {
return nil, err
}
// add extensions
for _, v := range config.Extend() {
e, err := newMIMEInfo(v)
if err != nil {
return nil, fmt.Errorf("MIMEinfo: error loading extension file %s; got %s", v, err)
}
mi = identifier.Join(mi, e)
}
// apply config
mi = identifier.ApplyConfig(mi)
// get version
// return identifier
return &Identifier{
infos: infos(mi.Infos()),
Base: identifier.New(mi, config.ZipMIME(), config.MIMEVersion()...),
}, nil
}
func (i *Identifier) Fields() []string {
return []string{"namespace", "id", "format", "mime", "basis", "warning"}
}
func (i *Identifier) Recorder() core.Recorder {
return &Recorder{
Identifier: i,
ids: make(ids, 0, 1),
}
}
type Recorder struct {
*Identifier
ids ids
satisfied bool
globActive bool
mimeActive bool
textActive bool
}
func (r *Recorder) Active(m core.MatcherType) {
if r.Identifier.Active(m) {
switch m {
case core.NameMatcher:
r.globActive = true
case core.MIMEMatcher:
r.mimeActive = true
case core.TextMatcher:
r.textActive = true
}
}
}
func (r *Recorder) Record(m core.MatcherType, res core.Result) bool {
switch m {
default:
return false
case core.NameMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
r.ids = add(r.ids, r.Name(), id, r.infos[id], res.Basis(), m, rel(r.Place(core.NameMatcher, res.Index())))
return true
} else {
return false
}
case core.MIMEMatcher, core.XMLMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
r.ids = add(r.ids, r.Name(), id, r.infos[id], res.Basis(), m, 0)
return true
} else {
return false
}
case core.ByteMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
if r.satisfied {
return true
}
basis := res.Basis()
p, t := r.Place(core.ByteMatcher, res.Index())
if t > 1 {
basis = basis + fmt.Sprintf(" (signature %d/%d)", p, t)
}
r.ids = add(r.ids, r.Name(), id, r.infos[id], basis, m, p-1)
return true
} else {
return false
}
case core.TextMatcher:
if hit, _ := r.Hit(m, res.Index()); hit {
if r.satisfied {
return true
}
if len(r.IDs(m)) > 0 {
r.ids = bulkAdd(r.ids, r.Name(), r.IDs(m), r.infos, res.Basis(), core.TextMatcher, 0)
}
return true
} else {
return false
}
}
}
func rel(prev, post int) int {
return prev - 1
}
func (r *Recorder) Satisfied(mt core.MatcherType) (bool, core.Hint) {
if r.NoPriority() {
return false, core.Hint{}
}
sort.Sort(r.ids)
if len(r.ids) > 0 && (r.ids[0].xmlMatch || (r.ids[0].magicScore > 0 && r.ids[0].ID != config.TextMIME())) {
if mt == core.ByteMatcher {
return true, core.Hint{Exclude: r.Start(mt), Pivot: nil}
}
return true, core.Hint{}
}
return false, core.Hint{}
}
func (r *Recorder) Report() []core.Identification {
// no results
if len(r.ids) == 0 {
return []core.Identification{Identification{
Namespace: r.Name(),
ID: "UNKNOWN",
Warning: "no match",
}}
}
sort.Sort(r.ids)
// exhaustive
if r.Multi() == config.Exhaustive {
ret := make([]core.Identification, len(r.ids))
for i, v := range r.ids {
ret[i] = r.updateWarning(v)
}
return ret
}
// if we've only got weak matches (match is filename/mime only) report only the first
if !r.ids[0].xmlMatch && r.ids[0].magicScore == 0 {
var nids []Identification
if len(r.ids) == 1 || r.ids.Less(0, 1) { // // Less reports whether the element with index i (0) should sort before the element with index j
if r.ids[0].ID != config.TextMIME() || r.ids[0].textMatch || !r.textActive {
nids = []Identification{r.ids[0]}
}
}
var conf string
if len(nids) != 1 {
lowConfidence := confidenceTrick()
poss := make([]string, len(r.ids))
for i, v := range r.ids {
poss[i] = v.ID
conf = lowConfidence(v)
}
return []core.Identification{Identification{
Namespace: r.Name(),
ID: "UNKNOWN",
Warning: fmt.Sprintf("no match; possibilities based on %s are %v", conf, strings.Join(poss, ", ")),
}}
}
r.ids = nids
}
// handle single result only
if r.Multi() == config.Single && len(r.ids) > 1 && !r.ids.Less(0, 1) {
poss := make([]string, 0, len(r.ids))
for i, v := range r.ids {
if i > 0 && r.ids.Less(i-1, i) {
break
}
poss = append(poss, v.ID)
}
return []core.Identification{Identification{
Namespace: r.Name(),
ID: "UNKNOWN",
Warning: fmt.Sprintf("multiple matches %v", strings.Join(poss, ", ")),
}}
}
ret := make([]core.Identification, len(r.ids))
for i, v := range r.ids {
if i > 0 {
switch r.Multi() {
case config.Single:
return ret[:i]
case config.Conclusive:
if r.ids.Less(i-1, i) {
return ret[:i]
}
default:
if !v.xmlMatch && v.magicScore == 0 { // if weak
return ret[:i]
}
}
}
ret[i] = r.updateWarning(v)
}
return ret
}
func (r *Recorder) updateWarning(i Identification) Identification {
// weak match
if !i.xmlMatch && i.magicScore == 0 {
lowConfidence := confidenceTrick()
if len(i.Warning) > 0 {
i.Warning += "; " + "match on " + lowConfidence(i) + " only"
} else {
i.Warning = "match on " + lowConfidence(i) + " only"
}
// if the match has no corresponding byte or xml signature...
if r.HasSig(i.ID, core.XMLMatcher, core.ByteMatcher) {
i.Warning += "; byte/xml signatures for this format did not match"
}
}
// apply mismatches
if r.globActive && i.globScore == 0 {
for _, v := range r.IDs(core.NameMatcher) {
if i.ID == v {
if len(i.Warning) > 0 {
i.Warning += "; filename mismatch"
} else {
i.Warning = "filename mismatch"
}
break
}
}
}
if r.mimeActive && !i.mimeMatch {
if len(i.Warning) > 0 {
i.Warning += "; MIME mismatch"
} else {
i.Warning = "MIME mismatch"
}
}
return i
}
func confidenceTrick() func(i Identification) string {
var ls = make([]string, 0, 1)
return func(i Identification) string {
if i.globScore > 0 && !contains(ls, "filename") {
ls = append(ls, "filename")
}
if i.mimeMatch && !contains(ls, "MIME") {
ls = append(ls, "MIME")
}
if i.textMatch && !contains(ls, "text") {
ls = append(ls, "text")
}
switch len(ls) {
case 0:
return ""
case 1:
return ls[0]
case 2:
return ls[0] + " and " + ls[1]
default:
return strings.Join(ls[:len(ls)-1], ", ") + " and " + ls[len(ls)-1]
}
}
}
type Identification struct {
Namespace string
ID string
Name string
Basis []string
Warning string
archive config.Archive
xmlMatch bool
magicScore int
globScore int
mimeMatch bool
textMatch bool
textDefault bool
}
func (id Identification) String() string {
return id.ID
}
func (id Identification) Known() bool {
return id.ID != "UNKNOWN"
}
func (id Identification) Warn() string {
return id.Warning
}
func (id Identification) Values() []string {
var basis string
if len(id.Basis) > 0 {
basis = strings.Join(id.Basis, "; ")
}
return []string{
id.Namespace,
id.ID,
id.Name,
id.ID,
basis,
id.Warning,
}
}
func (id Identification) Archive() config.Archive {
return id.archive
}
type ids []Identification
func (m ids) Len() int { return len(m) }
func tieBreak(m1, m2, t1, t2, td1, td2 bool, gs1, gs2 int) bool {
switch {
case m1 && !m2:
return true
case m2 && !m1:
return false
}
if gs1 == gs2 {
if t1 && !t2 {
return true
}
if t2 && !t1 {
return false
}
if td1 && !td2 {
return true
}
}
return gs2 < gs1
}
func multisignal(m, t bool, ms, gs int) bool {
switch {
case m && ms > 0:
return true
case ms > 0 && gs > 0:
return true
case m && t:
return true
case t && gs > 0:
return true
}
return false
}
func (m ids) Less(i, j int) bool {
switch {
case m[i].xmlMatch && !m[j].xmlMatch:
return true
case !m[i].xmlMatch && m[j].xmlMatch:
return false
case m[i].xmlMatch && m[j].xmlMatch:
return tieBreak(m[i].mimeMatch, m[j].mimeMatch, m[i].textMatch, m[j].textMatch, m[i].textDefault, m[j].textDefault, m[i].globScore, m[j].globScore)
}
msi, msj := multisignal(m[i].mimeMatch, m[i].textMatch, m[i].magicScore, m[i].globScore), multisignal(m[j].mimeMatch, m[j].textMatch, m[j].magicScore, m[j].globScore)
switch {
case msi && !msj:
return true
case !msi && msj:
return false
}
switch {
case m[i].magicScore > m[j].magicScore:
return true
case m[i].magicScore < m[j].magicScore:
return false
}
return tieBreak(m[i].mimeMatch, m[j].mimeMatch, m[i].textMatch, m[j].textMatch, m[i].textDefault, m[j].textDefault, m[i].globScore, m[j].globScore)
}
func (m ids) Swap(i, j int) { m[i], m[j] = m[j], m[i] }
func applyScore(id Identification, info formatInfo, t core.MatcherType, rel int) Identification {
switch t {
case core.NameMatcher:
score := info.globWeights[rel]
if score > id.globScore {
id.globScore = score
}
case core.MIMEMatcher:
id.mimeMatch = true
case core.XMLMatcher:
id.xmlMatch = true
case core.ByteMatcher:
score := info.magicWeights[rel]
if score > id.magicScore {
id.magicScore = score
}
case core.TextMatcher:
id.textMatch = true
if id.ID == config.TextMIME() {
id.textDefault = true
}
}
return id
}
func bulkAdd(m ids, ns string, bids []string, infs map[string]formatInfo, basis string, t core.MatcherType, rel int) ids {
nids := make(ids, len(m), len(m)+len(bids))
for _, bid := range bids {
var has bool
for i, v := range m {
if v.ID == bid {
m[i].Basis = append(m[i].Basis, basis)
m[i] = applyScore(m[i], infs[bid], t, rel)
has = true
break
}
}
if !has {
md := Identification{
Namespace: ns,
ID: bid,
Name: infs[bid].comment,
Basis: []string{basis},
Warning: "",
archive: config.IsArchive(bid),
}
nids = append(nids, applyScore(md, infs[bid], t, rel))
}
}
copy(nids, m)
return nids
}
func add(m ids, ns string, id string, info formatInfo, basis string, t core.MatcherType, rel int) ids {
for i, v := range m {
if v.ID == id {
m[i].Basis = append(m[i].Basis, basis)
m[i] = applyScore(m[i], info, t, rel)
return m
}
}
md := Identification{
Namespace: ns,
ID: id,
Name: info.comment,
Basis: []string{basis},
Warning: "",
archive: config.IsArchive(id),
}
return append(m, applyScore(md, info, t, rel))
}
<file_sep>package frames_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
func TestBlock(t *testing.T) {
segs := Signature(TestSignatures[7]).Segment(1000, 500, 500, 5)
if len(segs) != 3 {
t.Fatalf("Expecting three frames after running segment, got %d", len(segs))
}
blocks := Blockify(segs[0])
if len(blocks) != 1 {
t.Fatalf("Expecting one frame after running blockify, got %d, %v", len(blocks), blocks)
}
blk, ok := blocks[0].Pattern.(*Block)
if !ok {
t.Fatal("The pattern should be a block!")
}
hits, ju := blk.Test([]byte("test01234test"))
if len(hits) != 1 || hits[0] != 13 || ju != 3 {
t.Errorf("Expecting a single hit, length 13, with a jump of 3; got %v and %d", hits, ju)
}
blocks = Blockify(segs[1])
if _, ok := blocks[0].Pattern.(*Block); ok {
t.Fatal("Second segment should not be a block!")
}
blocks = Blockify(segs[2])
if len(blocks) != 1 {
t.Fatalf("Expecting one frame after running blockify, got %d", len(blocks))
}
blk, ok = blocks[0].Pattern.(*Block)
if !ok {
t.Fatalf("Last segment should be a block!")
}
hits, ju = blk.TestR([]byte("testy23"))
if len(hits) != 1 || hits[0] != 7 || ju != 5 {
t.Errorf("Expecting a single hit, length 7, with a jump of 5; got %v and %d", hits, ju)
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package containermatcher
import (
"encoding/binary"
"errors"
"fmt"
"github.com/richardlehane/siegfried/internal/bytematcher"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
type containerType int
const (
Zip containerType = iota // Zip container type e.g. for .docx etc.
Mscfb // Mscfb container type e.g. for .doc etc.
)
// Matcher is a slice of container matchers
type Matcher []*ContainerMatcher
// Load returns a container Matcher
func Load(ls *persist.LoadSaver) core.Matcher {
if !ls.LoadBool() {
return nil
}
ret := make(Matcher, ls.LoadTinyUInt())
for i := range ret {
ret[i] = loadCM(ls)
ret[i].ctype = ctypes[ret[i].conType]
ret[i].entryBufs = siegreader.New()
}
return ret
}
// Save encodes a container Matcher
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveBool(false)
return
}
m := c.(Matcher)
if m.total(-1) == 0 {
ls.SaveBool(false)
return
}
ls.SaveBool(true)
ls.SaveTinyUInt(len(m))
for _, v := range m {
v.save(ls)
}
}
type SignatureSet struct {
Typ containerType
NameParts [][]string
SigParts [][]frames.Signature
}
func Add(c core.Matcher, ss core.SignatureSet, l priority.List) (core.Matcher, int, error) {
var m Matcher
if c == nil {
m = Matcher{newZip(), newMscfb()}
} else {
m = c.(Matcher)
}
sigs, ok := ss.(SignatureSet)
if !ok {
return nil, 0, fmt.Errorf("container matcher error: cannot convert signature set to CM signature set")
}
err := m.addSigs(int(sigs.Typ), sigs.NameParts, sigs.SigParts, l)
if err != nil {
return nil, 0, err
}
return m, m.total(-1), nil
}
// calculate total number of signatures present in the matcher. Provide -1 to get the total sum, or supply an index of an individual matcher to exclude that matcher's total
func (m Matcher) total(i int) int {
var t int
for j, v := range m {
// don't include the count for the ContainerMatcher in question
if i > -1 && j == i {
continue
}
t += len(v.parts)
}
return t
}
func (m Matcher) addSigs(i int, nameParts [][]string, sigParts [][]frames.Signature, l priority.List) error {
if len(m) < i+1 {
return fmt.Errorf("container: missing container matcher")
}
var err error
if len(nameParts) != len(sigParts) {
return fmt.Errorf("container: expecting equal name and persist parts")
}
// give as a starting index the current total of signatures in the matcher, except those in the ContainerMatcher in question
m[i].startIndexes = append(m[i].startIndexes, m.total(i))
for j, n := range nameParts {
err = m[i].addSignature(n, sigParts[j])
if err != nil {
return err
}
}
for _, v := range m[i].nameCTest {
err = v.commit()
if err != nil {
return err
}
}
m[i].priorities.Add(l, len(nameParts), 0, 0)
return nil
}
func (m Matcher) String() string {
var str string
for _, c := range m {
str += c.String()
}
return str
}
type ContainerMatcher struct {
ctype
startIndexes []int // added to hits - these place all container matches in a single slice
conType containerType
nameCTest map[string]*cTest
parts []int // corresponds with each signature: represents the number of CTests for each sig
priorities *priority.Set
extension string
entryBufs *siegreader.Buffers
}
func loadCM(ls *persist.LoadSaver) *ContainerMatcher {
return &ContainerMatcher{
startIndexes: ls.LoadInts(),
conType: containerType(ls.LoadTinyUInt()),
nameCTest: loadCTests(ls),
parts: ls.LoadInts(),
priorities: priority.Load(ls),
extension: ls.LoadString(),
}
}
func (c *ContainerMatcher) save(ls *persist.LoadSaver) {
ls.SaveInts(c.startIndexes)
ls.SaveTinyUInt(int(c.conType))
saveCTests(ls, c.nameCTest)
ls.SaveInts(c.parts)
c.priorities.Save(ls)
ls.SaveString(c.extension)
}
func (c *ContainerMatcher) String() string {
str := "\nContainer matcher:\n"
str += fmt.Sprintf("Type: %d\n", c.conType)
str += fmt.Sprintf("Priorities: %v\n", c.priorities)
str += fmt.Sprintf("Parts: %v\n", c.parts)
for k, v := range c.nameCTest {
str += "-----------\n"
str += fmt.Sprintf("Name: %v\n", k)
str += fmt.Sprintf("Satisfied: %v\n", v.satisfied)
str += fmt.Sprintf("Unsatisfied: %v\n", v.unsatisfied)
if v.bm == nil {
str += "Bytematcher: None\n"
} else {
str += "Bytematcher:\n" + v.bm.String()
}
}
return str
}
type ctype struct {
trigger func([]byte) bool
rdr func(*siegreader.Buffer) (Reader, error)
}
var ctypes = []ctype{
{
zipTrigger,
zipRdr, // see zip.go
},
{
mscfbTrigger,
mscfbRdr, // see mscfb.go
},
}
func zipTrigger(b []byte) bool {
return binary.LittleEndian.Uint32(b[:4]) == 0x04034B50
}
func newZip() *ContainerMatcher {
return &ContainerMatcher{
ctype: ctypes[0],
conType: Zip,
nameCTest: make(map[string]*cTest),
priorities: &priority.Set{},
extension: "zip",
entryBufs: siegreader.New(),
}
}
func mscfbTrigger(b []byte) bool {
return binary.LittleEndian.Uint64(b) == 0xE11AB1A1E011CFD0
}
func newMscfb() *ContainerMatcher {
return &ContainerMatcher{
ctype: ctypes[1],
conType: Mscfb,
nameCTest: make(map[string]*cTest),
priorities: &priority.Set{},
entryBufs: siegreader.New(),
}
}
func (c *ContainerMatcher) addSignature(nameParts []string, sigParts []frames.Signature) error {
if len(nameParts) != len(sigParts) {
return errors.New("container matcher: nameParts and sigParts must be equal")
}
c.parts = append(c.parts, len(nameParts))
for i, nm := range nameParts {
ct, ok := c.nameCTest[nm]
if !ok {
ct = &cTest{}
c.nameCTest[nm] = ct
}
ct.add(sigParts[i], len(c.parts)-1)
}
return nil
}
// a container test is a the basic element of container matching
type cTest struct {
satisfied []int // satisfied persists are immediately matched: i.e. a name without a required bitstream
unsatisfied []int // unsatisfied persists depend on bitstreams as well as names matching
buffer []frames.Signature // temporary - used while creating CTests
bm core.Matcher // bytematcher
}
func loadCTests(ls *persist.LoadSaver) map[string]*cTest {
ret := make(map[string]*cTest)
l := ls.LoadSmallInt()
for i := 0; i < l; i++ {
ret[ls.LoadString()] = &cTest{
satisfied: ls.LoadInts(),
unsatisfied: ls.LoadInts(),
bm: bytematcher.Load(ls),
}
}
return ret
}
func saveCTests(ls *persist.LoadSaver, ct map[string]*cTest) {
ls.SaveSmallInt(len(ct))
for k, v := range ct {
ls.SaveString(k)
ls.SaveInts(v.satisfied)
ls.SaveInts(v.unsatisfied)
bytematcher.Save(v.bm, ls)
}
}
func (ct *cTest) add(s frames.Signature, t int) {
if s == nil {
ct.satisfied = append(ct.satisfied, t)
return
}
ct.unsatisfied = append(ct.unsatisfied, t)
ct.buffer = append(ct.buffer, s)
}
// call for each key after all signatures added
func (ct *cTest) commit() error {
if ct.buffer == nil {
return nil
}
var err error
ct.bm, _, err = bytematcher.Add(ct.bm, bytematcher.SignatureSet(ct.buffer), nil) // don't need to add priorities
ct.buffer = nil
return err
}
func (m Matcher) InspectTestTree(ct int, nm string, idx int) []int {
for _, c := range m {
if c.conType == containerType(ct) {
if ctst, ok := c.nameCTest[nm]; ok {
bmt := ctst.bm.(*bytematcher.Matcher).InspectTestTree(idx)
ret := make([]int, len(bmt))
for i, v := range bmt {
s, _ := c.priorities.Index(ctst.unsatisfied[v])
ret[i] = ctst.unsatisfied[v] + c.startIndexes[s]
}
return ret
}
return nil
}
}
return nil
}
<file_sep>package frames_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
func TestSequencer(t *testing.T) {
sequencer := NewSequencer(false)
byts := sequencer(TestFrames[0])
if len(byts) != 1 {
t.Error("Sequencer: expected only one sequence")
}
if len(byts[0]) != 4 {
t.Error("Sequencer: expected an initial sequence length of 5")
}
byts = sequencer(TestFrames[2])
if len(byts) != 1 {
t.Error("Sequencer: expected only one sequence")
}
if len(byts[0]) != 9 {
t.Error("Sequencer: expected a final sequence length of 9")
}
}
<file_sep>// Copyright 2019 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package frames
import (
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/persist"
)
func singleLen(f Frame) bool {
min, max := f.Length()
if min == max {
return true
}
return false
}
// Blockify takes a signature segment, identifies any blocks within (frames linked by fixed offsets),
// converts those frames to block patterns within window frames (the window frame of the first frame in the block),
// but with a new length), and returns a new segment.
// If no blocks are within a segment, the original segment will be returned.
func Blockify(seg Signature) Signature {
if len(seg) < 2 {
return seg
}
ret := make(Signature, 0, len(seg))
lst := seg[0]
blk := []Frame{lst}
for _, f := range seg[1:] {
if lnk, _, _ := f.Linked(lst, -1, 0); lnk && singleLen(lst) && singleLen(f) {
blk = append(blk, f)
} else {
ret = append(ret, blockify(blk))
blk = []Frame{f}
}
lst = f
}
return append(ret, blockify(blk))
}
func blockify(seg []Frame) Frame {
if len(seg) == 1 {
return seg[0]
}
// identify Key by looking for longest Sequence Pattern within the segment
var kf, kfl int
for i, f := range seg {
if _, ok := f.Pattern.(patterns.Sequence); ok { // we want to BMH the key, so this will only work on seqs
l, _ := f.Length()
if l > kfl {
kfl = l
kf = i
}
}
}
blk := &Block{}
var fr Frame
// Frame is the first frame in a BOF/PREV segment, or the last if a EOF/SUCC segment
typ := Signature(seg).Characterise()
// BMHify the Key and populate (switching) the L and R frames
if typ <= Prev {
fr = seg[0]
blk.Key = patterns.BMH(seg[kf].Pattern, false)
if kf < len(seg)-1 {
blk.R = seg[kf+1:]
}
blk.L = make([]Frame, kf)
for i := 0; i < kf; i++ {
blk.L[i] = SwitchFrame(seg[i+1], seg[i].Pattern)
}
} else {
fr = seg[len(seg)-1]
blk.Key = patterns.BMH(seg[kf].Pattern, true)
if kf > 0 {
blk.L = seg[:kf]
}
blk.R = make([]Frame, len(seg)-kf-1)
idx := len(blk.R) - 1
for i := len(seg) - 1; i > kf; i-- {
blk.R[idx] = SwitchFrame(seg[i-1], seg[i].Pattern)
idx--
}
}
// calc block length by tallying TotalLength of L and R frames plus length of the pattern
blk.Le, _ = blk.Key.Length()
for _, f := range blk.L {
blk.Le += TotalLength(f)
blk.Off += TotalLength(f)
}
for _, f := range blk.R {
blk.Le += TotalLength(f)
blk.OffR += TotalLength(f)
}
fr.Pattern = blk
return fr
}
// Block combines Frames that are linked to each other by a fixed offset into a single Pattern
// Patterns within a block must have a single length (i.e. no Choice patterns with varying lengths).
// Blocks are used within the Machine pattern to cluster frames to identify repetitions & optimise searching.
type Block struct {
L []Frame
R []Frame
Key patterns.Pattern
Le int // Pattern length
Off int // fixed offset of the Key, relative to the first frame in the block
OffR int // fixed offset of the Key, relative to the last frame in the block
}
func (bl *Block) Test(b []byte) ([]int, int) {
if bl.Off >= len(b) {
return nil, 0
}
ls, jmp := bl.Key.Test(b[bl.Off:])
if len(ls) < 1 {
return nil, jmp
}
ld := bl.Off
for i := len(bl.L) - 1; i >= 0; i-- {
if ld < 0 {
return nil, jmp
}
j, _ := bl.L[i].MatchNR(b[:ld], 0)
if j < 0 {
return nil, jmp
}
ld -= j
}
rd := bl.Off + ls[0]
for _, rf := range bl.R {
if rd > len(b)-1 {
return nil, jmp
}
j, _ := rf.MatchN(b[rd:], 0)
if j < 0 {
return nil, jmp
}
rd += j
}
return []int{bl.Le}, jmp
}
func (bl *Block) TestR(b []byte) ([]int, int) {
if bl.OffR >= len(b) {
return nil, 0
}
ls, jmp := bl.Key.TestR(b[:len(b)-bl.OffR])
if len(ls) < 1 {
return nil, jmp
}
ld := bl.OffR + ls[0]
for i := len(bl.L) - 1; i >= 0; i-- {
if ld < 0 {
return nil, jmp
}
j, _ := bl.L[i].MatchNR(b[:ld], 0)
if j < 0 {
return nil, jmp
}
ld -= j
}
rd := len(b) - bl.OffR
for _, rf := range bl.R {
if rd > len(b)-1 {
return nil, jmp
}
j, _ := rf.MatchN(b[rd:], 0)
if j < 0 {
return nil, jmp
}
rd += j
}
return []int{bl.Le}, jmp
}
func (bl *Block) Equals(pat patterns.Pattern) bool {
bl2, ok := pat.(*Block)
if !ok {
return false
}
if !bl.Key.Equals(bl2.Key) {
return false
}
if len(bl.L) != len(bl2.L) || len(bl.R) != len(bl2.R) ||
bl.Le != bl2.Le || bl.Off != bl2.Off || bl.OffR != bl2.OffR {
return false
}
for i, v := range bl.L {
if !v.Equals(bl2.L[i]) {
return false
}
}
for i, v := range bl.R {
if !v.Equals(bl2.R[i]) {
return false
}
}
return true
}
func (bl *Block) Length() (int, int) {
return bl.Le, bl.Le
}
// Blocks are used where sequence matching inefficient
func (bl *Block) NumSequences() int { return 0 }
func (bl *Block) Sequences() []patterns.Sequence { return nil }
func (bl *Block) String() string {
str := bl.Key.String()
if len(bl.L) > 0 {
str += "; L:"
}
for i, v := range bl.L {
if i > 0 {
str += " | "
}
str += v.String()
}
if len(bl.R) > 0 {
str += "; R:"
}
for i, v := range bl.R {
if i > 0 {
str += " | "
}
str += v.String()
}
return "b {" + str + "}"
}
func (bl *Block) Save(ls *persist.LoadSaver) {
ls.SaveByte(blockLoader)
ls.SaveSmallInt(len(bl.L))
for _, f := range bl.L {
f.Save(ls)
}
ls.SaveSmallInt(len(bl.R))
for _, f := range bl.R {
f.Save(ls)
}
bl.Key.Save(ls)
ls.SaveInt(bl.Le)
ls.SaveInt(bl.Off)
ls.SaveInt(bl.OffR)
}
func loadBlock(ls *persist.LoadSaver) patterns.Pattern {
bl := &Block{}
bl.L = make([]Frame, ls.LoadSmallInt())
for i := range bl.L {
bl.L[i] = Load(ls)
}
bl.R = make([]Frame, ls.LoadSmallInt())
for i := range bl.R {
bl.R[i] = Load(ls)
}
bl.Key = patterns.Load(ls)
bl.Le = ls.LoadInt()
bl.Off = ls.LoadInt()
bl.OffR = ls.LoadInt()
return bl
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package config
import (
"fmt"
"strings"
)
// Archive is a file format capable of decompression by sf.
type Archive int
// Archive type enum.
const (
None Archive = iota // None means the format cannot be decompressed by sf.
Zip // Zip describes a Zip type archive.
Gzip // Gzip describes a Gzip type archive. .
Tar // Tar describes a Tar type archive
ARC // ARC describes an ARC web archive.
WARC // WARC describes a WARC web archive.
)
const (
zipArc = "zip"
tarArc = "tar"
gzipArc = "gzip"
warcArc = "warc"
arcArc = "arc"
)
// ArcZipTypes returns a string array with all Zip identifiers Siegfried
// can match and decompress.
func ArcZipTypes() []string {
return []string{
pronom.zip,
mimeinfo.zip,
loc.zip,
}
}
// ArcGzipTypes returns a string array with all Gzip identifiers
// Siegfried can match and decompress.
func ArcGzipTypes() []string {
return []string{
pronom.gzip,
mimeinfo.gzip,
wikidata.gzip,
}
}
// ArcTarTypes returns a string array with all Tar identifiers Siegfried
// can match and decompress.
func ArcTarTypes() []string {
return []string{
pronom.tar,
mimeinfo.tar,
wikidata.tar,
}
}
// ArcArcTypes returns a string array with all Arc identifiers Siegfried
// can match and decompress.
func ArcArcTypes() []string {
return []string{
pronom.arc,
pronom.arc1_1,
mimeinfo.arc,
loc.arc,
wikidata.arc,
wikidata.arc1_1,
}
}
// ArcWarcTypes returns a string array with all Arc identifiers
// Siegfried can match and decompress.
func ArcWarcTypes() []string {
return []string{
pronom.warc,
mimeinfo.warc,
loc.warc,
wikidata.warc,
}
}
// ListAllArcTypes returns a list of archive file-format extensions that
// can be used to filter the files Siegfried will decompress to identify
// the contents of.
func ListAllArcTypes() string {
return fmt.Sprintf("%s, %s, %s, %s, %s",
zipArc,
tarArc,
gzipArc,
warcArc,
arcArc,
)
}
var permissiveFilter []string
// SetArchiveFilterPermissive will take our comma separated list of
// archives we want to extract from the Siegfried command-line and use
// the values to construct a permissive filter. Anything not in the
// slice returned at the end of this function will not be extracted when
// -z flag is used.
func SetArchiveFilterPermissive(value string) []string {
arr := []string{}
arcList := strings.Split(value, ",")
for _, arc := range arcList {
switch strings.TrimSpace(strings.ToLower(arc)) {
case zipArc:
arr = append(arr, ArcZipTypes()...)
case tarArc:
arr = append(arr, ArcTarTypes()...)
case gzipArc:
arr = append(arr, ArcGzipTypes()...)
case warcArc:
arr = append(arr, ArcWarcTypes()...)
case arcArc:
arr = append(arr, ArcArcTypes()...)
}
}
permissiveFilter = arr
return arr
}
// archiveFilterPermissive provides a getter for the configured
// zip-types we want to extract and identify the contents of.
func archiveFilterPermissive() []string {
return permissiveFilter
}
func (a Archive) String() string {
switch a {
case Zip:
return "zip"
case Gzip:
return "gzip"
case Tar:
return "tar"
case ARC:
return "ARC"
case WARC:
return "WARC"
}
return ""
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package logger
import (
"fmt"
"io"
"os"
"path/filepath"
"sort"
"strings"
"time"
"github.com/richardlehane/siegfried/internal/chart"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/sets"
)
const (
fileString = "[FILE]"
errString = "[ERROR]"
warnString = "[WARN]"
timeString = "[TIME]"
)
// Logger logs characteristics of the matching process depending on options set by user.
type Logger struct {
progress, e, warn, known, unknown bool
fmts map[string]bool
cht map[string]map[string]int
w io.Writer
start time.Time
// mutate
fp bool
}
// New creates a new Logger.
func New(opts string) (*Logger, error) {
lg := &Logger{w: os.Stderr}
if opts == "" {
return lg, nil
}
var items []string
for _, o := range strings.Split(opts, ",") {
switch o {
case "stderr":
case "stdout", "out", "o":
lg.w = os.Stdout
case "progress", "p":
lg.progress = true
case "time", "t":
lg.start = time.Now()
case "error", "err", "e":
lg.e = true
case "warning", "warn", "w":
lg.warn = true
case "debug", "d":
config.SetDebug()
case "slow", "s":
config.SetSlow()
case "unknown", "u":
lg.unknown = true
case "known", "k":
lg.known = true
case "chart", "c":
lg.cht = make(map[string]map[string]int)
default:
items = append(items, o)
}
}
if len(items) > 0 {
lg.fmts = make(map[string]bool)
for _, v := range sets.Sets(items...) {
lg.fmts[v] = true
}
}
if config.Debug() || config.Slow() {
lg.progress = false // progress reported internally
config.SetOut(lg.w)
}
return lg, nil
}
// IsOut reports if the logger is writing to os.Stdout
func (lg *Logger) IsOut() bool {
return lg.w == os.Stdout
}
// Elapsed logs time elapsed since logger created.
func (lg *Logger) Elapsed() {
if !lg.start.IsZero() {
fmt.Fprintf(lg.w, "%s %v\n", timeString, time.Since(lg.start))
}
}
// Chart prints a chart of formats matched
func (lg *Logger) Chart() {
if lg.cht == nil {
return
}
sections := make([]string, 0, len(lg.cht))
for k := range lg.cht {
sections = append(sections, k)
}
sort.Strings(sections)
fieldT, fieldR := make(map[string]int), make(map[int][]string)
for _, m := range lg.cht {
for k, v := range m {
fieldT[k] += v
}
}
for k, v := range fieldT {
fieldR[v] = append(fieldR[v], k)
}
fields, totals := make([]string, 0, len(fieldT)), make([]int, 0, len(fieldR))
for k, v := range fieldR {
totals = append(totals, k)
sort.Strings(v)
}
sort.Sort(sort.Reverse(sort.IntSlice(totals)))
for _, k := range totals {
fields = append(fields, fieldR[k]...)
}
fmt.Fprint(lg.w, chart.Chart("[Chart]", sections, fields, map[string]bool{}, lg.cht))
}
// Close prints and chart and time elapsed
func (lg *Logger) Close() {
lg.Chart()
lg.Elapsed()
}
// Progress prints file name and resets.
func (lg *Logger) Progress(p string) {
lg.fp = false
if lg.progress {
lg.fp = printFile(lg.fp, lg.w, p)
}
}
// Error logs errors.
func (lg *Logger) Error(p string, e error) {
if lg.e && e != nil {
lg.fp = printFile(lg.fp, lg.w, p)
fmt.Fprintf(lg.w, "%s %v\n", errString, e)
}
}
// IDs logs warnings, known, unknown and reports matches against supplied formats.
func (lg *Logger) IDs(p string, ids []core.Identification) {
if !lg.warn && !lg.known && !lg.unknown && lg.fmts == nil && lg.cht == nil {
return
}
var kn bool
for _, id := range ids {
if id.Known() {
kn = true
}
if lg.warn {
if w := id.Warn(); w != "" {
lg.fp = printFile(lg.fp, lg.w, p)
fmt.Fprintf(lg.w, "%s %s\n", warnString, w)
}
}
if lg.fmts[id.String()] {
fmt.Fprintln(lg.w, abs(p))
}
if lg.cht != nil {
if lg.cht[id.Values()[0]] == nil {
lg.cht[id.Values()[0]] = make(map[string]int)
}
lg.cht[id.Values()[0]][id.String()]++
}
}
if (lg.known && kn) || (lg.unknown && !kn) {
fmt.Fprintln(lg.w, abs(p))
}
}
// helpers
func abs(p string) string {
np, _ := filepath.Abs(p)
if np == "" {
return p
}
return np
}
func printFile(done bool, w io.Writer, p string) bool {
if !done {
fmt.Fprintf(w, "%s %s\n", fileString, abs(p))
}
return true
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package persist marshals and unmarshals siegfried signatures as binary data
package persist
import (
"encoding/binary"
"errors"
"time"
)
type LoadSaver struct {
buf []byte
i int
Err error
}
func NewLoadSaver(b []byte) *LoadSaver {
if len(b) == 0 {
b = make([]byte, 16)
}
return &LoadSaver{
b,
0,
nil,
}
}
func (l *LoadSaver) Bytes() []byte {
return l.buf[:l.i]
}
func (l *LoadSaver) get(i int) []byte {
if l.Err != nil || i == 0 {
return nil
}
if l.i+i > len(l.buf) {
l.Err = errors.New("error loading signature file, overflowed")
return nil
}
l.i += i
return l.buf[l.i-i : l.i]
}
func (l *LoadSaver) put(b []byte) {
if l.Err != nil || len(b) == 0 {
return
}
if len(b)+l.i > len(l.buf) {
nbuf := make([]byte, (len(b)+l.i)*2)
copy(nbuf, l.buf[:l.i])
l.buf = nbuf
}
copy(l.buf[l.i:len(b)+l.i], b)
l.i += len(b)
}
const (
_int8 byte = iota
_uint8
_int16
_uint16
_int32
_uint32
)
const (
min8, max8 = -128, 128
maxu8 = 256
min16, max16 = -32768, 32768
maxu16 = 65536
min32, max32 = -2147483648, 2147483648
maxu32 = 4294967296
maxu23 = 256 * 256 * 128 // used by collection refs = approx 8mb address space
)
func (l *LoadSaver) LoadByte() byte {
le := l.get(1)
if le == nil {
return 0
}
return le[0]
}
func (l *LoadSaver) SaveByte(b byte) {
l.put([]byte{b})
}
func (l *LoadSaver) LoadBool() bool {
b := l.LoadByte()
if b == 0xFF {
return true
}
return false
}
func (l *LoadSaver) SaveBool(b bool) {
if b {
l.SaveByte(0xFF)
} else {
l.SaveByte(0)
}
}
const (
_a = 1 << iota
_b
_c
_d
_e
_f
_g
_h
)
func (l *LoadSaver) LoadBoolField() (a bool, b bool, c bool, d bool, e bool, f bool, g bool, h bool) {
byt := l.LoadByte()
if byt&_a == _a {
a = true
}
if byt&_b == _b {
b = true
}
if byt&_c == _c {
c = true
}
if byt&_d == _d {
d = true
}
if byt&_e == _e {
e = true
}
if byt&_f == _f {
f = true
}
if byt&_g == _g {
g = true
}
if byt&_h == _h {
h = true
}
return
}
func (l *LoadSaver) SaveBoolField(a bool, b bool, c bool, d bool, e bool, f bool, g bool, h bool) {
var byt byte
if a {
byt |= _a
}
if b {
byt |= _b
}
if c {
byt |= _c
}
if d {
byt |= _d
}
if e {
byt |= _e
}
if f {
byt |= _f
}
if g {
byt |= _g
}
if h {
byt |= _h
}
l.SaveByte(byt)
}
func (l *LoadSaver) LoadTinyInt() int {
i := int(l.LoadByte())
if i > max8 {
return i - maxu8
}
return i
}
func (l *LoadSaver) SaveTinyInt(i int) {
if i <= min8 || i >= max8 {
l.Err = errors.New("int overflows byte")
return
}
l.SaveByte(byte(i))
}
func (l *LoadSaver) LoadTinyUInt() int {
return int(l.LoadByte())
}
func (l *LoadSaver) SaveTinyUInt(i int) {
if i < 0 || i >= maxu8 {
l.Err = errors.New("int overflows byte as a uint")
return
}
l.SaveByte(byte(i))
}
func (l *LoadSaver) LoadSmallInt() int {
le := l.get(2)
if le == nil {
return 0
}
i := int(binary.LittleEndian.Uint16(le))
if i > max16 {
return i - maxu16
}
return i
}
func (l *LoadSaver) SaveSmallInt(i int) {
if i <= min16 || i >= max16 {
l.Err = errors.New("int overflows int16")
return
}
buf := make([]byte, 2)
binary.LittleEndian.PutUint16(buf, uint16(i))
l.put(buf)
}
func (l *LoadSaver) LoadInt() int {
le := l.get(4)
if le == nil {
return 0
}
i := int64(binary.LittleEndian.Uint32(le))
if i > max32 {
return int(i - maxu32)
}
return int(i)
}
func (l *LoadSaver) SaveInt(i int) {
if int64(i) <= min32 || int64(i) >= max32 {
l.Err = errors.New("int overflows uint32")
return
}
buf := make([]byte, 4)
binary.LittleEndian.PutUint32(buf, uint32(i))
l.put(buf)
}
func (l *LoadSaver) getCollection() []byte {
if l.Err != nil {
return nil
}
le := l.LoadSmallInt()
return l.get(le)
}
func (l *LoadSaver) putCollection(b []byte) {
if l.Err != nil {
return
}
l.SaveSmallInt(len(b))
l.put(b)
}
func characterise(is []int) (byte, error) {
f := func(i, max int, sign bool) (int, bool) {
if i < 0 {
sign = true
i *= -1
}
if i > max {
return i, sign
}
return max, sign
}
var m int
var s bool
for _, v := range is {
m, s = f(v, m, s)
}
switch {
case m < max8:
return _int8, nil
case m < maxu8 && !s:
return _uint8, nil
case m < max16:
return _int16, nil
case m < maxu16 && !s:
return _uint16, nil
case int64(m) < max32:
return _int32, nil
case int64(m) < maxu32 && !s:
return _uint32, nil
default:
return 0, errors.New("integer overflow when building signature - need 64 bit int types!")
}
}
func (l *LoadSaver) convertInts(is []int) []byte {
if len(is) == 0 {
return nil
}
typ, err := characterise(is)
if err != nil {
l.Err = err
return nil
}
var ret []byte
switch typ {
case _int8, _uint8:
ret = make([]byte, len(is))
for i := range ret {
ret[i] = byte(is[i])
}
case _int16, _uint16:
ret = make([]byte, len(is)*2)
for i := range is {
binary.LittleEndian.PutUint16(ret[i*2:], uint16(is[i]))
}
case _int32, _uint32:
ret = make([]byte, len(is)*4)
for i := range is {
binary.LittleEndian.PutUint32(ret[i*4:], uint32(is[i]))
}
}
return append([]byte{typ}, ret...)
}
func makeInts(b []byte) []int {
if len(b) == 0 {
return nil
}
var ret []int
typ := b[0]
b = b[1:]
switch typ {
case _int8:
ret = make([]int, len(b))
for i := range ret {
ret[i] = int(b[i])
if ret[i] > max8 {
ret[i] -= maxu8
}
}
case _uint8:
ret = make([]int, len(b))
for i := range ret {
ret[i] = int(b[i])
}
case _int16:
ret = make([]int, len(b)/2)
for i := range ret {
ret[i] = int(binary.LittleEndian.Uint16(b[i*2:]))
if ret[i] > max16 {
ret[i] -= maxu16
}
}
case _uint16:
ret = make([]int, len(b)/2)
for i := range ret {
ret[i] = int(binary.LittleEndian.Uint16(b[i*2:]))
}
case _int32:
ret = make([]int, len(b)/4)
for i := range ret {
n := int64(binary.LittleEndian.Uint32(b[i*4:]))
if n > max32 {
n -= maxu32
}
ret[i] = int(n)
}
case _uint32:
ret = make([]int, len(b)/4)
for i := range ret {
ret[i] = int(binary.LittleEndian.Uint32(b[i*4:]))
}
}
return ret
}
func (l *LoadSaver) LoadInts() []int {
return makeInts(l.getCollection())
}
func (l *LoadSaver) SaveInts(i []int) {
l.putCollection(l.convertInts(i))
}
func (l *LoadSaver) LoadBigInts() []int64 {
is := makeInts(l.getCollection())
if is == nil {
return nil
}
ret := make([]int64, len(is))
for i := range is {
ret[i] = int64(is[i])
}
return ret
}
func (l *LoadSaver) SaveBigInts(is []int64) {
n := make([]int, len(is))
for i := range is {
n[i] = int(is[i])
}
l.SaveInts(n)
}
func (l *LoadSaver) LoadBytes() []byte {
return l.getCollection()
}
func (l *LoadSaver) SaveBytes(b []byte) {
l.putCollection(b)
}
func (l *LoadSaver) LoadString() string {
return string(l.getCollection())
}
func (l *LoadSaver) SaveString(s string) {
l.putCollection([]byte(s))
}
func (l *LoadSaver) LoadStrings() []string {
le := l.LoadSmallInt()
if le == 0 {
return nil
}
ret := make([]string, le)
for i := range ret {
ret[i] = string(l.getCollection())
}
return ret
}
func (l *LoadSaver) SaveStrings(ss []string) {
l.SaveSmallInt(len(ss))
for _, s := range ss {
l.putCollection([]byte(s))
}
}
func (l *LoadSaver) SaveTime(t time.Time) {
byts, err := t.MarshalBinary()
if err != nil {
l.Err = err
return
}
l.put(byts)
}
func (l *LoadSaver) LoadTime() time.Time {
buf := l.get(15)
t := &time.Time{}
l.Err = t.UnmarshalBinary(buf)
return *t
}
func (l *LoadSaver) SaveFourCC(cc [4]byte) {
l.put(cc[:])
}
func (l *LoadSaver) LoadFourCC() [4]byte {
buf := l.get(4)
var ret [4]byte
copy(ret[:], buf)
return ret
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package bytematcher
import (
"fmt"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/pkg/config"
)
// positioning information: min/max offsets (in relation to BOF or EOF) and min/max lengths
type keyFramePos struct {
// Minimum and maximum position
pMin int64
pMax int64
// Minimum and maximum length
lMin int
lMax int
}
// Each segment in a signature is represented by a single keyFrame. A slice of keyFrames represents a full signature.
// The keyFrame includes the range of offsets that need to match for a successful hit.
// The segment (Seg) offsets are relative (to preceding/succeding segments or to BOF/EOF if the first or last segment).
// The keyframe (Key) offsets are absolute to the BOF or EOF.
type keyFrame struct {
typ frames.OffType // BOF|PREV|SUCC|EOF
seg keyFramePos // relative positioning info for segment as a whole (min/max length and offset in relation to BOF/EOF/PREV/SUCC)
key keyFramePos // absolute positioning info for keyFrame portion of segment (min/max length and offset in relation to BOF/EOF)
}
func loadKeyFrames(ls *persist.LoadSaver) [][]keyFrame {
kfs := make([][]keyFrame, ls.LoadSmallInt())
for i := range kfs {
kfs[i] = make([]keyFrame, ls.LoadSmallInt())
for j := range kfs[i] {
kfs[i][j].typ = frames.OffType(ls.LoadByte())
kfs[i][j].seg.pMin = int64(ls.LoadInt())
kfs[i][j].seg.pMax = int64(ls.LoadInt())
kfs[i][j].seg.lMin = ls.LoadSmallInt()
kfs[i][j].seg.lMax = ls.LoadSmallInt()
kfs[i][j].key.pMin = int64(ls.LoadInt())
kfs[i][j].key.pMax = int64(ls.LoadInt())
kfs[i][j].key.lMin = ls.LoadSmallInt()
kfs[i][j].key.lMax = ls.LoadSmallInt()
}
}
return kfs
}
func saveKeyFrames(ls *persist.LoadSaver, kfs [][]keyFrame) {
ls.SaveSmallInt(len(kfs))
for _, v := range kfs {
ls.SaveSmallInt(len(v))
for _, kf := range v {
ls.SaveByte(byte(kf.typ))
ls.SaveInt(int(kf.seg.pMin))
ls.SaveInt(int(kf.seg.pMax))
ls.SaveSmallInt(kf.seg.lMin)
ls.SaveSmallInt(kf.seg.lMax)
ls.SaveInt(int(kf.key.pMin))
ls.SaveInt(int(kf.key.pMax))
ls.SaveSmallInt(kf.key.lMin)
ls.SaveSmallInt(kf.key.lMax)
}
}
}
func (kf keyFrame) String() string {
return fmt.Sprintf("%s Seg Min:%d Seg Max:%d; Abs Min:%d Abs Max:%d", frames.OffString[kf.typ], kf.seg.pMin, kf.seg.pMax, kf.key.pMin, kf.key.pMax)
}
// A double index: the first int is for the signature's position within the set of all signatures,
// the second int is for the keyFrames position within the segments of the signature.
type keyFrameID [2]int
func (kf keyFrameID) String() string {
return fmt.Sprintf("[%d:%d]", kf[0], kf[1])
}
func loadKeyFrameIDs(ls *persist.LoadSaver) []keyFrameID {
l := ls.LoadSmallInt()
if l == 0 {
return nil
}
ret := make([]keyFrameID, l)
for i := range ret {
ret[i][0] = ls.LoadSmallInt()
ret[i][1] = ls.LoadSmallInt()
}
return ret
}
func saveKeyFrameIDs(ls *persist.LoadSaver, kfids []keyFrameID) {
ls.SaveSmallInt(len(kfids))
for _, kfid := range kfids {
ls.SaveSmallInt(kfid[0])
ls.SaveSmallInt(kfid[1])
}
}
type kfFilter struct {
idx int
fdx int
kfs []keyFrameID
nfs []keyFrameID
}
func (k *kfFilter) Next() int {
if k.idx >= len(k.kfs) {
return -1
}
k.idx++
return k.kfs[k.idx-1][0]
}
func (k *kfFilter) Mark(t bool) {
if t {
k.nfs[k.fdx] = k.kfs[k.idx-1]
k.fdx++
}
}
func filterKF(kfs []keyFrameID, ws *priority.WaitSet) []keyFrameID {
f := &kfFilter{kfs: kfs, nfs: make([]keyFrameID, len(kfs))}
ws.ApplyFilter(f)
return f.nfs[:f.fdx]
}
// Turn a signature segment into a keyFrame and left and right frame slices.
// The left and right frame slices are converted into BMH sequences where possible
func toKeyFrame(seg frames.Signature, pos frames.Position) (keyFrame, []frames.Frame, []frames.Frame) {
var left, right []frames.Frame
var typ frames.OffType
var segPos, keyPos keyFramePos
segPos.lMin, segPos.lMax = calcLen(seg)
keyPos.lMin, keyPos.lMax = calcLen(seg[pos.Start:pos.End])
// BOF and PREV segments
if seg[0].Orientation() < frames.SUCC {
typ, segPos.pMin, segPos.pMax = seg[0].Orientation(), int64(seg[0].Min), int64(seg[0].Max)
keyPos.pMin, keyPos.pMax = segPos.pMin, segPos.pMax
for i, f := range seg[:pos.Start+1] {
if pos.Start > i {
min, max := f.Length()
keyPos.pMin += int64(min)
keyPos.pMin += int64(seg[i+1].Min)
if keyPos.pMax > -1 {
keyPos.pMax += int64(max)
keyPos.pMax += int64(seg[i+1].Max)
}
left = append([]frames.Frame{frames.SwitchFrame(seg[i+1], f.Pattern)}, left...)
}
}
if pos.End < len(seg) {
right = seg[pos.End:]
}
return keyFrame{typ, segPos, keyPos}, frames.BMHConvert(left, true), frames.BMHConvert(right, false)
}
// EOF and SUCC segments
typ, segPos.pMin, segPos.pMax = seg[len(seg)-1].Orientation(), int64(seg[len(seg)-1].Min), int64(seg[len(seg)-1].Max)
keyPos.pMin, keyPos.pMax = segPos.pMin, segPos.pMax
if pos.End < len(seg) {
for i, f := range seg[pos.End:] {
min, max := f.Length()
keyPos.pMin += int64(min)
keyPos.pMin += int64(seg[pos.End+i-1].Min)
if keyPos.pMax > -1 {
keyPos.pMax += int64(max)
keyPos.pMax += int64(seg[pos.End+i-1].Max)
}
right = append(right, frames.SwitchFrame(seg[pos.End+i-1], f.Pattern))
}
}
for _, f := range seg[:pos.Start] {
left = append([]frames.Frame{f}, left...)
}
return keyFrame{typ, segPos, keyPos}, frames.BMHConvert(left, true), frames.BMHConvert(right, false)
}
// calculate minimum and maximum lengths for a segment (slice of frames)
func calcLen(fs []frames.Frame) (int, int) {
var min, max int
if fs[0].Orientation() < frames.SUCC {
for i, f := range fs {
fmin, fmax := f.Length()
min += fmin
max += fmax
if i > 0 {
min += f.Min
max += f.Max
}
}
return min, max
}
for i := len(fs) - 1; i > -1; i-- {
f := fs[i]
fmin, fmax := f.Length()
min += fmin
max += fmax
if i < len(fs)-1 {
min += f.Min
max += f.Max
}
}
return min, max
}
func calcMinMax(min, max int64, sp keyFramePos) (int64, int64) {
min = min + sp.pMin + int64(sp.lMin)
if max < 0 || sp.pMax < 0 {
return min, -1
}
max = max + sp.pMax + int64(sp.lMax)
return min, max
}
// update the absolute positional information (distance from the BOF or EOF)
// for keyFrames based on the other keyFrames in the signature
func updatePositions(ks []keyFrame) {
var min, max int64
// first forwards, for BOF and PREV
for i := range ks {
if ks[i].typ == frames.BOF {
min, max = calcMinMax(0, 0, ks[i].seg)
// Apply max bof
if config.MaxBOF() > 0 {
if ks[i].key.pMax < 0 || ks[i].key.pMax > int64(config.MaxBOF()) {
ks[i].key.pMax = int64(config.MaxBOF())
}
}
}
if ks[i].typ == frames.PREV {
ks[i].key.pMin = min + ks[i].key.pMin
if max > -1 && ks[i].key.pMax > -1 {
ks[i].key.pMax = max + ks[i].key.pMax
} else {
ks[i].key.pMax = -1
}
min, max = calcMinMax(min, max, ks[i].seg)
// Apply max bof
if config.MaxBOF() > 0 {
if ks[i].key.pMax < 0 || ks[i].key.pMax > int64(config.MaxBOF()) {
ks[i].key.pMax = int64(config.MaxBOF())
}
}
}
}
// now backwards for EOF and SUCC
min, max = 0, 0
for i := len(ks) - 1; i >= 0; i-- {
if ks[i].typ == frames.EOF {
min, max = calcMinMax(0, 0, ks[i].seg)
// apply max eof
if config.MaxEOF() > 0 {
if ks[i].key.pMax < 0 || ks[i].key.pMax > int64(config.MaxEOF()) {
ks[i].key.pMax = int64(config.MaxEOF())
}
}
}
if ks[i].typ == frames.SUCC {
ks[i].key.pMin = min + ks[i].key.pMin
if max > -1 && ks[i].key.pMax > -1 {
ks[i].key.pMax = max + ks[i].key.pMax
} else {
ks[i].key.pMax = -1
}
min, max = calcMinMax(min, max, ks[i].seg)
// apply max eof
if config.MaxEOF() > 0 {
if ks[i].key.pMax < 0 || ks[i].key.pMax > int64(config.MaxEOF()) {
ks[i].key.pMax = int64(config.MaxEOF())
}
}
}
}
}
// returns keyframeIDs of unexcludable wildcard BOF or EOF keyframe segments
func unknownBOFandEOF(firstIdx int, ks []keyFrame) ([]keyFrameID, []keyFrameID) {
var bof, eof []keyFrameID
b := getMax(-1, func(t frames.OffType) bool { return t == frames.BOF }, ks, true)
if b < 0 {
e := getMax(-1, func(t frames.OffType) bool { return t == frames.EOF }, ks, true)
if e < 0 {
bof = make([]keyFrameID, 0, len(ks))
eof = make([]keyFrameID, 0, len(ks))
for idx, kf := range ks {
if kf.typ < frames.SUCC {
bof = append(bof, keyFrameID{firstIdx, idx})
} else {
eof = append(eof, keyFrameID{firstIdx, idx})
}
}
}
}
return bof, eof
}
func getMax(max int, t func(frames.OffType) bool, ks []keyFrame, localMin bool) int {
for _, v := range ks {
if t(v.typ) {
if v.key.pMax < 0 {
if !localMin {
return -1
}
continue
}
this := int(v.key.pMax) + v.key.lMax
if localMin {
if max < 0 || this < max {
max = this
}
} else if this > max {
max = this
}
}
}
return max
}
// for doing a running total of the maxBOF:
// is the maxBOF we already have, further from the BOF than the maxBOF of the current signature?
func maxBOF(max int, ks []keyFrame) int {
if max < 0 {
return max
}
return getMax(max, func(t frames.OffType) bool { return t < frames.SUCC }, ks, false)
}
func maxEOF(max int, ks []keyFrame) int {
if max < 0 {
return max
}
return getMax(max, func(t frames.OffType) bool { return t > frames.PREV }, ks, false)
}
func crossOver(a, b keyFrame) bool {
if a.key.pMax == -1 {
return true
}
if a.key.pMax+int64(a.key.lMax) > b.key.pMin {
return true
}
return false
}
// quick check performed before applying a keyFrame ID
func (kf keyFrame) check(o int64) bool {
if kf.key.pMin > o {
return false
}
if kf.key.pMax == -1 {
return true
}
if kf.key.pMax < o {
return false
}
return true
}
// can we gather just a single hit for this keyframe?
func oneEnough(id int, kfs []keyFrame) bool {
kf := kfs[id]
// if this is a BOF frame or a wild PREV frame we can ...
if kf.typ == frames.BOF || (kf.typ == frames.PREV && kf.seg.pMax == -1 && kf.seg.pMin == 0) {
// unless this isn't the last frame and the next frame is a non-wild PREV frame
if id+1 < len(kfs) {
next := kfs[id+1]
if next.typ == frames.PREV && (next.seg.pMax > -1 || next.seg.pMin > 0) {
return false
}
}
return true
}
// if this is an EOF frame or SUCC frame we can ...
if id > 0 {
// so long as there isn't a previous frame that is a non-wild SUCC frame
prev := kfs[id-1]
if prev.typ == frames.SUCC && (prev.seg.pMax > -1 || prev.seg.pMin > 0) {
return false
}
}
return true
}
func checkRelated(thisKf, prevKf, nextKf keyFrame, thisOff, prevOff [][2]int64) ([][2]int64, []int, bool) {
switch thisKf.typ {
case frames.BOF:
return thisOff, make([]int, len(thisOff)), true
case frames.EOF, frames.SUCC:
if prevKf.typ == frames.SUCC && !(prevKf.seg.pMax == -1 && prevKf.seg.pMin == 0) {
ret := make([][2]int64, 0, len(thisOff))
idx := make([]int, 0, len(prevOff))
success := false
for _, v := range thisOff {
for i, v1 := range prevOff {
dif := v[0] - v1[0] - v1[1]
if dif > -1 {
if dif < prevKf.seg.pMin || (prevKf.seg.pMax > -1 && dif > prevKf.seg.pMax) {
continue
} else {
ret = append(ret, v)
idx = append(idx, i)
success = true
// if this type is EOF, we only need one match
if thisKf.typ == frames.EOF {
return ret, idx, success
}
}
}
}
}
return ret, idx, success
} else {
return thisOff, make([]int, len(thisOff)), true
}
default:
if thisKf.seg.pMax == -1 && thisKf.seg.pMin == 0 {
return thisOff, make([]int, len(thisOff)), true
}
ret := make([][2]int64, 0, len(thisOff))
idx := make([]int, 0, len(prevOff))
success := false
for _, v := range thisOff {
for i, v1 := range prevOff {
dif := v[0] - v1[0] - v1[1] // current offset, minus previous offset, minus previous length
if dif > -1 {
if dif < thisKf.seg.pMin || (thisKf.seg.pMax > -1 && dif > thisKf.seg.pMax) {
continue
} else {
ret = append(ret, v)
idx = append(idx, i)
success = true
// if the next type isn't a non-wild PREV, we only need one match
if nextKf.typ != frames.PREV || (nextKf.seg.pMax == -1 && nextKf.seg.pMin == 0) {
return ret, idx, success
}
}
}
}
}
return ret, idx, success
}
}
<file_sep>package main
import (
"bytes"
"errors"
"flag"
"fmt"
"os"
"path/filepath"
"strings"
"testing"
"time"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/pronom"
)
var (
testhome = flag.String("testhome", "../roy/data", "override the default home directory")
testdata = flag.String("testdata", filepath.Join(".", "testdata"), "override the default test data directory")
)
var s *siegfried.Siegfried
func setup(opts ...config.Option) error {
if opts == nil && s != nil {
return nil
}
var err error
s = siegfried.New()
config.SetHome(*testhome)
opts = append(opts, config.SetDoubleUp())
p, err := pronom.New(opts...)
if err != nil {
return err
}
return s.Add(p)
}
func identifyT(s *siegfried.Siegfried, p string) ([]string, error) {
ids := make([]string, 0)
file, err := os.Open(p)
if err != nil {
return nil, fmt.Errorf("failed to open %v, got: %v", p, err)
}
t := time.Now()
c, _ := s.Identify(file, p, "")
for _, i := range c {
ids = append(ids, i.String())
}
err = file.Close()
if err != nil {
return nil, err
}
if len(ids) > 10 {
fmt.Printf("test file %s has %d ids\n", p, len(ids))
}
tooLong := time.Millisecond * 500
elapsed := time.Since(t)
if elapsed > tooLong {
fmt.Printf("[WARNING] time to match %s was %s\n", p, elapsed.String())
}
return ids, nil
}
func multiIdentifyT(s *siegfried.Siegfried, r string) ([][]string, error) {
set := make([][]string, 0)
wf := func(path string, info os.FileInfo, err error) error {
if info.IsDir() {
if *nr && path != r {
return filepath.SkipDir
}
return nil
}
ids, err := identifyT(s, path)
if err != nil {
return err
}
set = append(set, ids)
return nil
}
err := filepath.Walk(r, wf)
return set, err
}
func matchString(i []string) string {
str := "[ "
for _, v := range i {
str += v
str += " "
}
return str + "]"
}
func TestSuite(t *testing.T) {
err := setup()
if err != nil {
t.Error(err)
}
expect := make([]string, 0)
names := make([]string, 0)
wf := func(path string, info os.FileInfo, err error) error {
if info.IsDir() {
return nil
}
last := strings.Split(path, string(os.PathSeparator))
path = last[len(last)-1]
var idx int
idx = strings.Index(path, "container")
if idx < 0 {
idx = strings.Index(path, "signature")
}
if idx < 0 {
idx = len(path)
}
strs := strings.Split(path[:idx-1], "-")
if len(strs) == 2 {
expect = append(expect, strings.Join(strs, "/"))
} else if len(strs) == 3 {
expect = append(expect, "x-fmt/"+strs[2])
} else {
return errors.New("long string encountered: " + path)
}
names = append(names, path)
return nil
}
suite := filepath.Join(*testdata, "skeleton-suite")
_, err = os.Stat(suite)
if err != nil {
t.Fatal(err)
}
err = filepath.Walk(suite, wf)
if err != nil {
t.Fatal(err)
}
matches, err := multiIdentifyT(s, suite)
if err != nil {
t.Fatal(err)
}
if len(expect) != len(matches) {
t.Error("Expect should equal matches")
}
var iter int
for i, v := range expect {
if !check(v, matches[i]) {
t.Errorf("Failed to match signature %v; got %v; expected %v", names[i], matchString(matches[i]), v)
} else {
iter++
}
}
if iter != len(expect) {
t.Errorf("Matched %v out of %v signatures", iter, len(expect))
}
}
func TestTip(t *testing.T) {
expect := "fmt/669"
err := setup()
if err != nil {
t.Error(err)
}
buf := bytes.NewReader([]byte{0x00, 0x4d, 0x52, 0x4d, 0x00})
c, _ := s.Identify(buf, "test.mrw", "")
for _, i := range c {
if i.String() != expect {
t.Errorf("First buffer: expecting %s, got %s", expect, i)
}
}
buf = bytes.NewReader([]byte{0x00, 0x4d, 0x52, 0x4d, 0x00})
c, _ = s.Identify(buf, "test.mrw", "")
for _, i := range c {
if i.String() != expect {
t.Errorf("Second buffer: expecting %s, got %s", expect, i)
}
}
buf = bytes.NewReader([]byte{0x00, 0x4d, 0x52, 0x4d, 0x00})
c, _ = s.Identify(buf, "test.mrw", "")
for _, i := range c {
if i.String() != expect {
t.Errorf("Third buffer: expecting %s, got %s", expect, i)
}
}
}
// TestDROID tests -multi DROID. Samples from https://github.com/richardlehane/siegfried/issues/146
func TestDROID(t *testing.T) {
if err := setup(config.SetMulti("droid")); err != nil {
t.Fatal(err)
}
expect1 := []string{"fmt/41", "fmt/96"}
jpghtml := [60]uint8{
0xFF, 0xD8, 0xFF, 0x3C, 0x68, 0x74, 0x6D, 0x6C, 0x3E, 0x54, 0x48, 0x49,
0x53, 0x20, 0x46, 0x49, 0x4C, 0x45, 0x20, 0x53, 0x48, 0x4F, 0x55, 0x4C,
0x44, 0x20, 0x49, 0x44, 0x45, 0x4E, 0x54, 0x49, 0x46, 0x59, 0x20, 0x41,
0x53, 0x20, 0x4A, 0x50, 0x45, 0x47, 0x20, 0x41, 0x4E, 0x44, 0x20, 0x48,
0x54, 0x4D, 0x4C, 0x3C, 0x2F, 0x68, 0x74, 0x6D, 0x6C, 0x3E, 0xFF, 0xD9,
}
expect2 := []string{"fmt/41", "x-fmt/384"}
jpgmov := [69]uint8{
0xFF, 0xD8, 0xFF, 0x00, 0x6D, 0x6F, 0x6F, 0x76, 0x00, 0x00, 0x00, 0x00,
0x6D, 0x76, 0x68, 0x64, 0x54, 0x48, 0x49, 0x53, 0x20, 0x46, 0x49, 0x4C,
0x45, 0x20, 0x53, 0x48, 0x4F, 0x55, 0x4C, 0x44, 0x20, 0x49, 0x44, 0x45,
0x4E, 0x54, 0x49, 0x46, 0x59, 0x20, 0x41, 0x53, 0x20, 0x51, 0x55, 0x49,
0x43, 0x4B, 0x54, 0x49, 0x4D, 0x45, 0x20, 0x4D, 0x4F, 0x56, 0x20, 0x41,
0x4E, 0x44, 0x20, 0x4A, 0x50, 0x45, 0x47, 0xFF, 0xD9,
}
buf := bytes.NewReader(jpghtml[:])
c, _ := s.Identify(buf, "test.jpg", "")
if len(c) != len(expect1) || (c[0].String() != expect1[0] && c[0].String() != expect1[1]) || (c[1].String() != expect1[0] && c[1].String() != expect1[1]) {
t.Errorf("-multi DROID: expected %v; got %v", expect1, c)
}
buf = bytes.NewReader(jpgmov[:])
c, _ = s.Identify(buf, "test.mov", "")
if len(c) != len(expect2) || (c[0].String() != expect2[0] && c[0].String() != expect2[1]) || (c[1].String() != expect2[0] && c[1].String() != expect2[1]) {
t.Errorf("-multi DROID: expected %v; got %v", expect2, c)
}
setup(config.Clear())
}
func Test363(t *testing.T) {
repetitions := 10000
iter := 0
expect := "fmt/363"
err := setup()
if err != nil {
t.Error(err)
}
segy := func(l int) []byte {
b := make([]byte, l)
for i := range b {
if i > 21 {
break
}
b[i] = 64
}
copy(b[l-9:], []byte{01, 00, 00, 00, 01, 00, 00, 01, 00})
return b
}
se := segy(3226)
for i := 0; i < repetitions; i++ {
buf := bytes.NewReader(se)
c, _ := s.Identify(buf, "test.seg", "")
for _, i := range c {
iter++
if i.String() != expect {
t.Errorf("first buffer on %d iteration: expecting %s, got %s", iter, expect, i)
}
}
}
iter = 0
se = segy(3626)
for i := 0; i < repetitions; i++ {
buf := bytes.NewReader(se)
c, _ := s.Identify(buf, "test2.seg", "")
for _, i := range c {
iter++
if i.String() != expect {
t.Errorf("Second buffer on %d iteration: expecting %s, got %s", iter, expect, i)
}
}
}
}
// Benchmarks
func benchidentify(ext string) {
setup()
file := filepath.Join(*testdata, "benchmark", "Benchmark")
file += "." + ext
identifyT(s, file)
}
func BenchmarkACCDB(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("accdb")
}
}
func BenchmarkBMP(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("bmp")
}
}
func BenchmarkDOCX(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("docx")
}
}
func BenchmarkGIF(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("gif")
}
}
func BenchmarkJPG(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("jpg")
}
}
func BenchmarkMSG(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("msg")
}
}
func BenchmarkODT(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("odt")
}
}
func BenchmarkPDF(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("pdf")
}
}
func BenchmarkPNG(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("png")
}
}
func BenchmarkPPTX(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("pptx")
}
}
func BenchmarkRTF(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("rtf")
}
}
func BenchmarkTIF(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("tif")
}
}
func BenchmarkXLSX(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("xlsx")
}
}
func BenchmarkXML(bench *testing.B) {
for i := 0; i < bench.N; i++ {
benchidentify("xml")
}
}
func BenchmarkMulti(bench *testing.B) {
dir := filepath.Join(*testdata, "benchmark")
for i := 0; i < bench.N; i++ {
multiIdentifyT(s, dir)
}
}
<file_sep>// Copyright 2022 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//go:generate go run gen.go
package static
import (
"bytes"
"github.com/richardlehane/siegfried"
)
func New() *siegfried.Siegfried {
rc := bytes.NewBuffer(sfcontent)
sf, _ := siegfried.LoadReader(rc)
return sf
}
<file_sep>// The bulk of this lexer code is taken from http://golang.org/src/pkg/text/template/parse/lex.go
// Described in a talk by <NAME>: http://cuddle.googlecode.com/hg/talk/lex.html#title-slide and http://www.youtube.com/watch?v=HxaD_trXwRE
//
// Copyright 2011 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file. (Available here: http://golang.org/LICENSE)
//
// For the remainder of the file:
// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package pronom
import (
"fmt"
"strings"
"unicode/utf8"
)
type item struct {
typ itemType
pos int
val string
}
func (i item) String() string {
switch {
case i.typ == itemEOF:
return "EOF"
case i.typ == itemError:
return i.val
}
return fmt.Sprintf("%q", i.val)
}
type itemType int
const (
itemError itemType = iota
itemEOF
itemCurlyLeft
itemCurlyRight
itemWildStart
itemSlash
itemWildEnd
itemWildSingle //??
itemWild //*
itemUnprocessedText
itemEnterGroup
itemExitGroup
itemChoiceMarker
itemNotMarker
itemRangeMarker
itemMaskMarker
itemAnyMaskMarker
itemHexText
itemQuoteText
itemQuote
itemSpace
)
const (
leftBracket = '['
rightBracket = ']'
leftParens = '('
rightParens = ')'
leftCurly = '{'
rightCurly = '}'
wildSingle = '?'
wild = '*'
not = '!'
colon = ':'
slash = '-'
pipe = '|'
quot = '\''
space = ' '
tab = '\t'
amp = '&'
tilda = '~'
newline = '\n'
carriage = '\r'
)
const digits = "0123456789"
const hexadecimal = digits + "abcdefABCDEF"
const hexnonquote = hexadecimal + " " + "\n" + "\r"
const digitswild = digits + "*"
const eof = -1
type stateFn func(*lexer) stateFn
// lexer holds the state of the scanner.
type lexer struct {
name string
input string
state stateFn
pos int
start int
width int
lastPos int
items chan item
}
// next returns the next rune in the input.
func (l *lexer) next() rune {
if int(l.pos) >= len(l.input) {
l.width = 0
return eof
}
r, w := utf8.DecodeRuneInString(l.input[l.pos:])
l.width = w
l.pos += l.width
return r
}
// peek returns but does not consume the next rune in the input.
func (l *lexer) peek() rune {
r := l.next()
l.backup()
return r
}
// backup steps back one rune. Can only be called once per call of next.
func (l *lexer) backup() {
l.pos -= l.width
}
// emit passes an item back to the client.
func (l *lexer) emit(t itemType) {
l.items <- item{t, l.start, l.input[l.start:l.pos]}
l.start = l.pos
}
// acceptRun consumes a run of runes from the valid set.
func (l *lexer) acceptRun(valid string) {
for strings.IndexRune(valid, l.next()) >= 0 {
}
l.backup()
}
// acceptText consumes a run of runes that are deemed to be plain sequences (hex or quoted values)
func (l *lexer) acceptText(group bool) error {
valid := hexnonquote
if group {
valid = hexadecimal
}
for {
l.acceptRun(valid)
switch l.peek() {
default:
return nil
case quot:
r := l.next()
for r = l.next(); r != eof && r != quot; r = l.next() {
}
if r != quot {
return fmt.Errorf("expected closing quote, got %v", r)
}
}
}
}
// errorf returns an error token and terminates the scan by passing
// back a nil pointer that will be the next state, terminating l.nextItem.
func (l *lexer) errorf(format string, args ...interface{}) stateFn {
l.items <- item{itemError, l.start, fmt.Sprintf("Lex error in "+l.name+": "+format, args...)}
return nil
}
// nextItem returns the next item from the input.
func (l *lexer) nextItem() item {
item := <-l.items
l.lastPos = item.pos
return item
}
// lex creates a new scanner for the input string.
func lex(name, input string, start stateFn) *lexer {
l := &lexer{
name: name,
input: input,
items: make(chan item),
}
go l.run(start)
return l
}
// run runs the state machine for the lexer.
func (l *lexer) run(start stateFn) {
for l.state = start; l.state != nil; {
l.state = l.state(l)
}
}
// lexer for PRONOM signature files - reports, container and droid
func lexPRONOM(name, input string) *lexer {
return lex(name, input, insideText)
}
func insideText(l *lexer) stateFn {
if err := l.acceptText(false); err != nil {
return l.errorf(err.Error())
}
if l.pos > l.start {
l.emit(itemUnprocessedText)
}
r := l.next()
switch r {
default:
return l.errorf("encountered invalid character %q", r)
case eof:
l.emit(itemEOF)
return nil
case leftBracket:
l.emit(itemEnterGroup)
return insideLeftBracket
case leftParens:
l.emit(itemEnterGroup)
return insideLeftParens
case leftCurly:
l.emit(itemCurlyLeft)
return insideWild
case wildSingle:
return insideWildSingle
case wild:
l.emit(itemWild)
return insideText
}
}
func (l *lexer) insideGroup(boundary itemType) stateFn {
depth := 1
for {
if err := l.acceptText(true); err != nil {
return l.errorf(err.Error())
}
if l.pos > l.start {
l.emit(itemUnprocessedText)
}
r := l.next()
switch r {
default:
return l.errorf("encountered invalid character %q", r)
case leftBracket:
l.emit(itemEnterGroup)
depth++
case rightBracket:
l.emit(itemExitGroup)
depth--
if depth == 0 {
if boundary != rightBracket {
return l.errorf("expected group to close with %q, got %q", boundary, r)
}
return insideText
}
case rightParens:
if boundary != rightParens {
return l.errorf("expected group to close with %q, got %q", boundary, r)
}
l.emit(itemExitGroup)
return insideText
case not:
l.emit(itemNotMarker)
case pipe, space, tab:
l.emit(itemChoiceMarker)
case colon, slash:
l.emit(itemRangeMarker)
case amp:
l.emit(itemMaskMarker)
case tilda:
l.emit(itemAnyMaskMarker)
}
}
}
func insideLeftBracket(l *lexer) stateFn {
return l.insideGroup(rightBracket)
}
func insideLeftParens(l *lexer) stateFn {
return l.insideGroup(rightParens)
}
func insideWildSingle(l *lexer) stateFn {
r := l.next()
if r == wildSingle {
l.emit(itemWildSingle)
return insideText
}
return l.errorf("expecting a double '?', got %q", r)
}
func insideWild(l *lexer) stateFn {
l.acceptRun(digits) // don't accept a '*' as start of range
if l.pos > l.start {
l.emit(itemWildStart)
}
r := l.next()
if r == slash {
l.emit(itemSlash)
l.acceptRun(digitswild)
if l.pos > l.start {
l.emit(itemWildEnd)
}
r = l.next()
}
if r == rightCurly {
l.emit(itemCurlyRight)
return insideText
}
return l.errorf("expecting a closing bracket, got %q", r)
}
// text lexer
func lexText(input string) *lexer {
return lex("textProcessor", input, insideUnprocessedText)
}
func insideUnprocessedText(l *lexer) stateFn {
for {
l.acceptRun(hexadecimal)
if l.pos > l.start {
l.emit(itemHexText)
}
switch l.next() {
default:
l.backup()
return l.errorf("unexpected character in text: %q", l.next())
case eof:
l.emit(itemEOF)
return nil
case quot:
l.emit(itemQuote)
return insideQuoteText
case space, tab, newline, carriage:
l.emit(itemSpace)
}
}
}
func insideQuoteText(l *lexer) stateFn {
r := l.next()
for ; r != eof && r != quot; r = l.next() {
}
if r == quot {
l.backup()
l.emit(itemQuoteText)
l.next()
l.emit(itemQuote)
return insideUnprocessedText
}
return l.errorf("expected closing quote, reached end of string")
}
<file_sep>package priority
import (
"testing"
"github.com/richardlehane/siegfried/internal/persist"
)
func TestAdd(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("apple", "banana")
m.Add("apple", "orange")
l := m["apple"]
if len(l) != 2 {
t.Errorf("Priority: expecting two superiors, got %d", len(l))
}
}
func TestComplete(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("orange", "banana")
m.Add("orange", "grapes")
m.Add("banana", "grapes")
m.Add("banana", "grapefruit")
m.Add("grapes", "banana") // "banana shouldn't be added as superior to self"
m.Complete()
l := m["apple"]
if len(l) != 4 {
t.Errorf("Priority: expecting four superiors, got %d", len(l))
}
l = m["orange"]
if len(l) != 3 {
t.Errorf("Priority: expecting three superiors, got %d", len(l))
}
}
func TestApply(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("orange", "banana")
m.Add("orange", "grapes")
m.Add("banana", "grapes")
m.Add("banana", "grapefruit")
m.Complete()
hits := m.Apply([]string{"apple", "grapes", "orange", "grapefruit"})
if len(hits) != 2 {
t.Fatalf("Priority: expecting two superior hits, got %d", len(hits))
}
if hits[0] != "grapes" || hits[1] != "grapefruit" {
t.Errorf("Priority: expecting grapes and grapefruit, got %v", hits)
}
}
func TestList(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("orange", "banana")
m.Add("orange", "grapes")
m.Add("banana", "grapes")
m.Add("banana", "grapefruit")
m.Complete()
list := m.List([]string{"apple", "grapes", "grapes", "banana", "banana", "apple"})
if len(list) != 6 {
t.Errorf("Priority: expecting six sets of indexes, got %d", len(list))
}
if len(list[0]) != 4 {
t.Errorf("Priority: expecting four indexes for apple, got %v", len(list[0]))
}
if len(list[5]) != 4 {
t.Errorf("Priority: expecting four indexes for apple, got %v", len(list[5]))
}
}
func TestSubset(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("orange", "banana")
m.Add("orange", "grapes")
m.Add("banana", "grapes")
m.Add("banana", "grapefruit")
m.Complete()
list := m.List([]string{"apple", "grapes", "grapes", "banana", "banana", "apple"})
sub := list.Subset([]int{0, 3, 5}, 0)
if len(sub) != 3 {
t.Errorf("Priority: expecting 3 in the subset list, got %d", len(sub))
}
if len(sub[0]) != 1 {
t.Errorf("Priority: expecting one index for apple subset, got %v", len(sub[0]))
}
if len(sub[2]) != 1 {
t.Errorf("Priority: expecting one index for apple subset, got %v", len(sub[2]))
}
}
func TestSet(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("orange", "banana")
m.Add("orange", "grapes")
m.Add("banana", "grapes")
m.Add("banana", "grapefruit")
m.Complete()
list := m.List([]string{"apple", "grapes", "grapes", "banana", "banana", "apple"})
list2 := m.List([]string{"grapefruit", "banana", "grapes"})
s := &Set{}
s.Add(list, len(list), -1, -1)
s.Add(list2, len(list2), -1, -1)
// test save/load
saver := persist.NewLoadSaver(nil)
s.Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
s = Load(loader)
// now test the waitset
w := s.WaitSet()
if !w.Check(8) {
t.Error("Priority: should get continue signal")
}
if w.Put(8) {
t.Error("Priority: should not be satisfied")
}
if !w.Put(1) {
t.Error("Priority: should be satisfied")
}
w.Put(7)
if !w.Check(6) {
t.Error("Priority: expecting to be waiting on grapefruits")
}
wo := w.WaitingOn()
if len(wo) != 2 {
t.Error("Priority: expecting to be waiting on two")
}
if wo[0] != 6 {
t.Error("Priority: expecting to be waiting on grapefruits")
}
l := w.Filter([]int{5, 6})
if len(l) != 1 {
t.Error("Priority: bad filter, expecting to be waiting on grapefruits")
}
if l[0] != 6 {
t.Error("Priority: bad filter, expecting to be waiting on grapefruits")
}
l = w.Filter([]int{1, 2})
if l != nil {
t.Error("Priority: bad filter, nil list")
}
}
func TestMapFilter(t *testing.T) {
m := make(Map)
m.Add("apple", "orange")
m.Add("orange", "banana")
m.Add("orange", "grapes")
m.Add("banana", "grapes")
m.Add("banana", "grapefruit")
m.Add("grapes", "grapefruit")
m.Complete()
m = m.Filter([]string{"apple", "orange", "banana"})
l := m["banana"]
if len(l) != 0 {
t.Errorf("Not expecting any superiors for banana got %v", l)
}
l = m["apple"]
if len(l) != 2 {
t.Errorf("Expecting 2 superiors for apple got %v", l)
}
_, ok := m["grapes"]
if ok {
t.Errorf("not expecting any grapes")
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package pronom
import (
"encoding/hex"
"errors"
"strconv"
"strings"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/pkg/pronom/internal/mappings"
)
// This code produces siegfried bytematcher signatures from the relevant parts of PRONOM, Droid and Container XML signature files
const (
pronombof = "Absolute from BOF"
pronomeof = "Absolute from EOF"
pronomvry = "Variable"
droidbof = "BOFoffset"
droideof = "EOFoffset"
)
// helper
func decodeNum(num string) (int, error) {
if strings.TrimSpace(num) == "" {
return 0, nil
}
return strconv.Atoi(num)
}
// PROCompatSequence (compatibility) provides access to the PRONON
// primitive mappings.ByteSequence for custom identifier types that
// want to make use of PRONOM's level of expression.
type PROCompatSequence = mappings.ByteSequence
// BeginningOfFile provides access to PRONOM's BOF const.
const BeginningOfFile = pronombof
// EndOfFile provides access to PRONOM's EOF const.
const EndOfFile = pronomeof
// FormatPRONOM is an external helper function for enabling the
// processing of a significant number of signature types compatible with
// the PRONOM standard from plain-old hex, to more complex PRONOM regex.
func FormatPRONOM(id string, ps []PROCompatSequence) (frames.Signature, error) {
signature := mappings.Signature{}
signature.ByteSequences = ps
return processPRONOM(id, signature)
}
// PRONOM
func processPRONOM(puid string, s mappings.Signature) (frames.Signature, error) {
sig := make(frames.Signature, 0, 1)
for _, bs := range s.ByteSequences {
// check if <Offset> or <MaxOffset> elements are present
min, err := decodeNum(bs.Offset)
if err != nil {
return nil, err
}
max, err := decodeNum(bs.MaxOffset)
if err != nil {
return nil, err
}
// lack of a max offset implies a fixed offset for BOF and EOF seqs (not VAR)
if max == 0 {
max = min
} else {
max = max + min // the max offset in a PRONOM report is relative to the "offset" value, not to the BOF/EOF
}
var eof bool
if bs.Position == pronomeof {
eof = true
}
// parse the hexstring
seg, lmin, lmax, err := process(puid, bs.Hex, eof)
if err != nil {
return nil, err
}
// check position and add patterns to signature
switch bs.Position {
case pronombof:
if seg[0].Min != 0 || seg[0].Max != 0 {
// some signatures may begin with offsets e.g. {0-8} see e.g. fmt/1741
min, max = seg[0].Min+min, seg[0].Max+max
}
seg[0] = frames.NewFrame(frames.BOF, seg[0].Pattern, min, max)
case pronomvry:
if max == 0 {
max = -1
}
if seg[0].Min != 0 || seg[0].Max != 0 {
// this seems iffy?
min, max = seg[0].Min, seg[0].Max
}
if min == max {
max = -1
}
seg[0] = frames.NewFrame(frames.BOF, seg[0].Pattern, min, max)
case pronomeof:
if len(seg) > 1 {
for i, f := range seg[:len(seg)-1] {
seg[i] = frames.NewFrame(frames.SUCC, f.Pattern, seg[i+1].Min, seg[i+1].Max)
}
}
// handle edge case where there is a {x-y} at end of EOF seq e.g. x-fmt/263
if lmin != 0 || lmax != 0 {
min, max = lmin, lmax
}
seg[len(seg)-1] = frames.NewFrame(frames.EOF, seg[len(seg)-1].Pattern, min, max)
default:
return nil, errors.New("Pronom parse error: invalid ByteSequence position " + bs.Position)
}
// add the segment to the complete signature
sig = appendSig(sig, seg, bs.Position)
}
return sig, nil
}
// merge two segments into a signature. Provide s2's pos
func appendSig(s1, s2 frames.Signature, pos string) frames.Signature {
if len(s1) == 0 {
return s2
}
// if s2 is an EOF - just append it
if pos == pronomeof || pos == droideof {
return append(s1, s2...)
}
// if s1 has an EOF segment, and s2 is a BOF or Var, prepend that s2 segment before it, but after any preceding segments
for i, f := range s1 {
orientation := f.Orientation()
if orientation == frames.SUCC || orientation == frames.EOF {
s3 := make(frames.Signature, len(s1)+len(s2))
copy(s3, s1[:i])
copy(s3[i:], s2)
copy(s3[i+len(s2):], s1[i:])
return s3
}
}
// default is just to append it
return append(s1, s2...)
}
// DROID & Container
func processDROID(puid string, s []mappings.ByteSeq) (frames.Signature, error) {
var sig frames.Signature
for _, b := range s {
var eof, vry bool
ref := b.Reference
if ref == droideof {
eof = true
} else if ref == "" {
vry = true
}
var zeroIndexed bool // fmt/1190 bug in containers: https://github.com/richardlehane/siegfried/issues/175
for _, ss := range b.SubSequences {
if ss.Position == 0 {
zeroIndexed = true
}
if zeroIndexed {
ss.Position += 1
}
ns, err := processSubSequence(puid, ss, eof, vry)
if err != nil {
return nil, err
}
sig = appendSig(sig, ns, ref)
}
}
return sig, nil
}
func processSubSequence(puid string, ss mappings.SubSequence, eof, vry bool) (frames.Signature, error) {
sig, _, _, err := process(puid, ss.Sequence, eof)
if err != nil {
return nil, err
}
if len(ss.LeftFragments) > 0 {
sig, err = appendFragments(puid, sig, ss.LeftFragments, true, eof)
if err != nil {
return nil, err
}
}
if len(ss.RightFragments) > 0 {
sig, err = appendFragments(puid, sig, ss.RightFragments, false, eof)
if err != nil {
return nil, err
}
}
if ss.Position > 1 {
vry = true
}
calcOffset := func(minS, maxS string, vry bool) (int, int, error) {
min, err := decodeNum(minS)
if err != nil {
return 0, 0, err
}
if maxS == "" {
if vry {
return min, -1, nil
}
return min, min, nil // if not var - max should be at least min (which is prob 0)
}
max, err := decodeNum(maxS)
if err != nil {
return 0, 0, err
}
if max == 0 { // fix bug fmt/837 where has a min but no max
max = min
}
return min, max, nil
}
min, max, err := calcOffset(ss.SubSeqMinOffset, ss.SubSeqMaxOffset, vry)
if err != nil {
return nil, err
}
if eof {
if ss.Position == 1 {
sig[len(sig)-1] = frames.NewFrame(frames.EOF, sig[len(sig)-1].Pattern, min, max)
} else {
sig[len(sig)-1] = frames.NewFrame(frames.SUCC, sig[len(sig)-1].Pattern, min, max)
}
} else {
if ss.Position == 1 {
sig[0] = frames.NewFrame(frames.BOF, sig[0].Pattern, min, max)
} else {
sig[0] = frames.NewFrame(frames.PREV, sig[0].Pattern, min, max)
}
}
return sig, nil
}
// append a slice of fragments (left or right) to the central droid sequence
func appendFragments(puid string, sig frames.Signature, frags []mappings.Fragment, left, eof bool) (frames.Signature, error) {
// First off, group the fragments:
// droid fragments (right or left) can share positions. If such fragments have same offsets, they are a patterns.Choice. If not, then err.
var maxPos int
for _, f := range frags {
if f.Position == 0 {
return nil, errors.New("Pronom: encountered fragment without a position, puid " + puid)
}
if f.Position > maxPos {
maxPos = f.Position
}
}
fs := make([][]mappings.Fragment, maxPos)
for _, f := range frags {
fs[f.Position-1] = append(fs[f.Position-1], f)
}
for _, r := range fs {
max, min := r[0].MaxOffset, r[0].MinOffset
for _, v := range r {
if v.MaxOffset != max || v.MinOffset != min {
return nil, errors.New("Pronom: encountered fragments at same positions with different offsets, puid " + puid)
}
}
}
typ := frames.PREV
if eof {
typ = frames.SUCC
}
var choice patterns.Choice
offs := make([][2]int, len(fs))
ns := make([]frames.Signature, len(fs))
// iterate over the grouped fragments
for i, v := range fs {
if len(v) > 1 {
choice = patterns.Choice{}
for _, c := range v {
pats, _, _, err := process(puid, c.Value, eof)
if err != nil {
return nil, err
}
if len(pats) > 1 {
list := make(patterns.List, len(pats))
for i, v := range pats {
list[i] = v.Pattern
}
choice = append(choice, list)
} else {
choice = append(choice, pats[0].Pattern)
}
}
ns[i] = frames.Signature{frames.NewFrame(typ, choice, 0, 0)}
} else {
pats, _, _, err := process(puid, v[0].Value, eof)
if err != nil {
return nil, err
}
ns[i] = pats
}
min, err := decodeNum(v[0].MinOffset)
if err != nil {
return nil, err
}
var max int
if v[0].MaxOffset == "" {
max = -1
} else {
max, err = decodeNum(v[0].MaxOffset)
if err != nil {
return nil, err
}
}
offs[i] = [2]int{min, max}
}
// Now make the frames by adding in offset information (if left fragments, this needs to be taken from their neighbour)
if left {
if eof {
for i, v := range ns {
v[len(v)-1] = frames.NewFrame(frames.SUCC, v[len(v)-1].Pattern, offs[i][0], offs[i][1])
sig = append(v, sig...)
}
} else {
for i, v := range ns {
sig[0] = frames.NewFrame(frames.PREV, sig[0].Pattern, offs[i][0], offs[i][1])
sig = append(v, sig...)
}
}
} else {
if eof {
for i, v := range ns {
sig[len(sig)-1] = frames.NewFrame(frames.SUCC, sig[len(sig)-1].Pattern, offs[i][0], offs[i][1])
sig = append(sig, v...)
}
} else {
for i, v := range ns {
v[0] = frames.NewFrame(frames.PREV, v[0].Pattern, offs[i][0], offs[i][1])
sig = append(sig, v...)
}
}
}
return sig, nil
}
// Shared code for processing raw lex outputs in PRONOM/Container pattern language
func process(puid, seq string, eof bool) (frames.Signature, int, int, error) {
if seq == "" {
return nil, 0, 0, errors.New("parse error " + puid + ": empty sequence")
}
typ := frames.PREV
if eof {
typ = frames.SUCC
}
var min, max int
l := lexPRONOM(puid, seq)
sig := frames.Signature{}
for i := l.nextItem(); i.typ != itemEOF; i = l.nextItem() {
switch i.typ {
case itemError:
return nil, 0, 0, errors.New("parse error " + puid + ": " + i.String())
case itemWildSingle:
min++
max++
case itemWildStart:
min, _ = decodeNum(i.val)
case itemCurlyRight: //detect {n} wildcards by checking if the max value has been set
if max == 0 {
max = min
}
case itemWildEnd:
if i.val == "*" {
max = -1
} else {
max, _ = decodeNum(i.val)
}
case itemWild:
max = -1
case itemEnterGroup:
pat, err := processGroup(l)
if err != nil {
return nil, 0, 0, errors.New("parse error " + puid + ": " + err.Error())
}
sig = append(sig, frames.NewFrame(typ, pat, min, max))
min, max = 0, 0
case itemUnprocessedText:
sig = append(sig, frames.NewFrame(typ, patterns.Sequence(processText(i.val)), min, max))
min, max = 0, 0
}
}
return sig, min, max, nil
}
func processText(hx string) []byte {
var buf []byte
l := lexText(hx)
for i := range l.items {
switch i.typ {
case itemHexText:
byts, _ := hex.DecodeString(i.val)
buf = append(buf, byts...)
case itemQuoteText:
buf = append(buf, []byte(i.val)...)
case itemError:
panic(i.val)
case itemEOF:
return buf
}
}
// ignore err, the hex string has been lexed
return buf
}
// groups are chunks of PRONOM/Droid patterns delimited by parentheses or brackets
// these chunks represent any non-sequence pattern (choices, ranges, bitmasks, not-patterns etc.)
func processGroup(l *lexer) (patterns.Pattern, error) {
var (
list patterns.List // bucket to stuff patterns into
choice patterns.Choice // bucket to stuff choices into
val []byte // bucket to stuff text values
not, mask, anyMask, rng bool // retains state from previous tokens
)
// when commit a pattern (to the list), go back to zero state
reset := func() {
val = []byte{}
not, mask, anyMask, rng = false, false, false, false
}
// make a pattern based on the current state
makePat := func() patterns.Pattern {
if len(val) == 0 {
return nil
}
var pat patterns.Pattern
switch {
case mask:
pat = patterns.Mask(val[0])
case anyMask:
pat = patterns.AnyMask(val[0])
default:
pat = patterns.Sequence(val)
}
if not {
pat = patterns.Not{pat}
}
reset()
return pat
}
// add patterns to the choice
addChoice := func() (patterns.Choice, error) {
switch len(list) {
case 0:
return nil, errors.New(l.name + " has choice marker without preceding pattern")
case 1:
choice = append(choice, list[0])
default:
choice = append(choice, list)
}
list = patterns.List{}
return choice, nil
}
for {
i := <-l.items
switch i.typ {
default:
return nil, errors.New(l.name + " encountered unexpected token " + i.val)
case itemEnterGroup: // recurse e.g. for a range nested within a choice
if pat := makePat(); pat != nil {
list = append(list, pat)
}
pat, err := processGroup(l)
if err != nil {
return nil, err
}
list = append(list, pat)
case itemExitGroup:
if pat := makePat(); pat != nil {
list = append(list, pat)
}
if len(choice) > 0 {
return addChoice()
} else {
switch len(list) {
case 0:
return nil, errors.New(l.name + " has group with no legal pattern")
case 1:
return list[0], nil
default:
return list, nil
}
}
case itemRangeMarker:
rng = true
case itemChoiceMarker:
if pat := makePat(); pat != nil {
list = append(list, pat)
}
_, err := addChoice()
if err != nil {
return nil, err
}
case itemNotMarker:
not = true
case itemMaskMarker:
mask = true
case itemAnyMaskMarker:
anyMask = true
case itemUnprocessedText:
v := processText(i.val)
// if it is a range, we need values before and after the range marker, so add it here
if rng {
r := Range{val, v}
if not {
list = append(list, patterns.Not{r})
} else {
list = append(list, r)
}
reset()
} else {
val = v
}
}
}
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mappings
import (
"bytes"
"encoding/json"
"encoding/xml"
)
type Releases struct {
XMLName xml.Name `xml:"release_notes"`
Releases []Release `xml:"release_note"`
}
type Release struct {
ReleaseDate string `xml:"release_date"`
SignatureName string `xml:"signature_filename"`
Outlines []Outline `xml:"release_outline"`
}
type Outline struct {
Typ string `xml:"name,attr"`
Puids []Puid `xml:"format>puid"`
}
type Puid struct {
Typ string `xml:"type,attr"`
Val string `xml:",chardata"`
}
type KeyVal struct {
Key string
Val []string
}
// OrderedMap define an ordered map
type OrderedMap []KeyVal
// Implement the json.Marshaler interface
func (omap OrderedMap) MarshalJSON() ([]byte, error) {
var buf bytes.Buffer
buf.WriteString("{")
for i, kv := range omap {
if i != 0 {
buf.WriteString(",")
}
// marshal key
key, err := json.MarshalIndent(kv.Key, "", " ")
if err != nil {
return nil, err
}
buf.Write(key)
buf.WriteString(":")
// marshal value
val, err := json.MarshalIndent(kv.Val, "", " ")
if err != nil {
return nil, err
}
buf.Write(val)
}
buf.WriteString("}")
return buf.Bytes(), nil
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Pre-process and process Wikidata signatures and enable the return of
// linting information that describe whether the information retrieved
// from the service can be processed correctly.
// WIKIDATA TODO: preValidateSignatures, updateSequences are two
// functions in need of some decent testing because they direct the
// logic of how we build the identifier. They are also responsible for
// making sure we get the bulk of the linting messages out of this
// package. The more accurate and precise we can make these functions
// (and probably a handful of others in this file) the better we can
// make the Wikidata identifier as well as the Wikidata sources.
package wikidata
import (
"github.com/richardlehane/siegfried/pkg/wikidata/internal/converter"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/mappings"
"github.com/ross-spencer/wikiprov/pkg/spargo"
)
// ByteSequence provides an alias for the mappings.ByteSequence object.
type ByteSequence = mappings.ByteSequence
// handleLinting ensures that our sequence error arrays are added to
// following the validation of the information.
func handleLinting(uri string, lint linting) {
if lint != nle {
addLinting(uri, lint)
}
}
// newSignature will parse signature information from the Spargo Item
// structure and create a new Signature structure to be returned. If
// there is an error we log it out with the format identifier so that
// more work can be done on the source data.
func newByteSequence(wikidataItem map[string]spargo.Item) ByteSequence {
tmpSequence := ByteSequence{}
uri := wikidataItem[uriField].Value
// Add relativity to sequence.
relativity, lint, _ := validateAndReturnRelativity(
wikidataItem[relativityField].Value)
handleLinting(uri, lint)
tmpSequence.Relativity = relativity
// Add offset to sequence.
offset, lint := validateAndReturnOffset(
wikidataItem[offsetField].Value, wikidataItem[offsetField].Type)
handleLinting(uri, lint)
tmpSequence.Offset = offset
// Add encoding to sequence.
encoding, lint := validateAndReturnEncoding(
wikidataItem[encodingField].Value)
handleLinting(uri, lint)
tmpSequence.Encoding = encoding
// Add the signature to the sequence.
signature, lint, _ := validateAndReturnSignature(
wikidataItem[signatureField].Value, encoding)
handleLinting(uri, lint)
tmpSequence.Signature = signature
return tmpSequence
}
// updateSignatures will create a new ByteSequence and associate it
// with either an existing Signature or create a brand new Signature.
// If there is a problem processing that means the sequence shouldn't be
// added to the identifier for the sake of consistency then a linting
// error is returned and we should stop processing.
func updateSequences(wikidataItem map[string]spargo.Item, wd *wikidataRecord) linting {
// Pre-process the encoding.
encoding, lint := validateAndReturnEncoding(
wikidataItem[encodingField].Value)
handleLinting(wd.URI, lint)
// Pre-process the relativity.
relativity, lint, _ := validateAndReturnRelativity(
wikidataItem[relativityField].Value)
handleLinting(wd.URI, lint)
// Pre-process the sequence.
signature, lint, _ := validateAndReturnSignature(
wikidataItem[signatureField].Value, encoding)
handleLinting(wd.URI, lint)
// WIKIDATA FUTURE it's nearly impossible to tease apart sequences
// in Wikidata right now to determine which duplicate sequences are
// new signatures or which belong to the same group. Provenance
// could differ but three can be multiple provenances, different
// sequences which they're returned from the service, etc.
if !sequenceInSignatures(wd.Signatures, signature) {
if relativityAlreadyInSignatures(wd.Signatures, relativity) {
if relativity == relativeBOF {
// Create a new record...
sig := Signature{}
bs := newByteSequence(wikidataItem)
sig.ByteSequences = append(sig.ByteSequences, bs)
prov, lint := validateAndReturnProvenance(wikidataItem[referenceField].Value)
handleLinting(wd.URI, lint)
sig.Source = parseProvenance(prov)
sig.Date, lint = validateAndReturnDate(wikidataItem[dateField].Value)
handleLinting(wd.URI, lint)
wd.Signatures = append(wd.Signatures, sig)
return nle
}
// We've a bad heuristic and can't piece together a
// valid signature.
return heuWDE01
}
// Append to record...
idx := len(wd.Signatures)
sig := &wd.Signatures[idx-1]
if checkEncodingCompatibility(wd.Signatures[idx-1], encoding) {
bs := newByteSequence(wikidataItem)
sig.ByteSequences = append(sig.ByteSequences, bs)
return nle
}
// We've a bad heuristic and can't piece together a
// valid signature.
return heuWDE01
}
// Sequence already in signatures, no need to process, no errors of
// note.
return nle
}
// sequenceInSignatures will tell us if there are any duplicate byte
// sequences. At which point we can stop processing.
func sequenceInSignatures(signatures []Signature, signature string) bool {
for _, sig := range signatures {
for _, seq := range sig.ByteSequences {
if signature == seq.Signature {
return true
}
}
}
return false
}
// relativityInSlice helps us to identify if the needle: relativity is
// in the slice which we use for validation.
func relativityAlreadyInSignatures(signatures []Signature, relativity string) bool {
for _, sig := range signatures {
for _, seq := range sig.ByteSequences {
if relativity == seq.Relativity {
return true
}
}
}
return false
}
// checkEncodingCompatibility should work for now and just makes sure
// we're not trying to combine encodings that don't match, i.e. anything
// not PRONOM or HEX. ASCII should work too because we'll have encoded
// it as hex by now 🤞.
func checkEncodingCompatibility(signature Signature, givenEncoding int) bool {
for _, seq := range signature.ByteSequences {
if (seq.Encoding == converter.GUIDEncoding &&
givenEncoding != converter.GUIDEncoding) ||
(seq.Encoding == converter.PerlEncoding &&
givenEncoding != converter.PerlEncoding) {
return false
}
}
return true
}
// preValidateSignatures performs some rudimentary validation of the
// sequences belonging to a Wikidata record. The sequences are stepped
// through as logically as possible to provide a sensible filter
// heuristic.
func preValidateSignatures(preProcessedSequences []preProcessedSequence) bool {
// Map our values into slices to analyze cross-sectionally.
var encoding []string
var relativity []string
var offset []string
var signature []string
for _, value := range preProcessedSequences {
encoding = append(encoding, value.encoding)
if value.relativity != "" {
relativity = append(relativity, value.relativity)
}
offset = append(offset, value.offset)
signature = append(signature, value.signature)
_, _, err := validateAndReturnRelativity(value.relativity)
if err != nil {
return false
}
_, _, err = validateAndReturnSignature(
value.signature, converter.LookupEncoding(value.encoding))
if err != nil {
return false
}
}
// Maps act like sets when we're only interested in the keys. We
// want to use sets to understand more about the unique values in
// each of the records.
var relativityMap = make(map[string]bool)
var signatureMap = make(map[string]bool)
var encodingMap = make(map[string]bool)
for _, value := range signature {
signatureMap[value] = true
}
for _, value := range relativity {
relativityMap[value] = true
}
for _, value := range encoding {
encodingMap[value] = true
}
if len(preProcessedSequences) == 2 {
// The most simple validation we can do. If both we have two
// values and two different relativities we can let the
// signature through.
if len(relativityMap) == 2 {
return true
}
// If the relativities don't differ or aren't available then we
// can then check to see if the signatures are different
// because we will create two new records the the sequences.
// They will both be beginning of file sequences.
if len(signatureMap) == 2 {
return true
}
}
// We are going to start wrestling with a sensible heuristic with
// sequences over 2 in length. Validate those.
if len(preProcessedSequences) > 2 {
// Processing starts to get too complicated if we have to work
// out whether multiple encodings are valid when combined.
if len(encodingMap) != 1 && len(encodingMap) != 0 {
return false
}
// If we haven't a uniform relativity then we can't easily
// guess how to combine signatures, e.g. how do we pair a single
// EOF with one of three BOF sequences? Albeit an unlikely
// scenario. but also, What if the EOF was not meant to be
// paired?
if len(relativityMap) != 1 && len(relativityMap) != 0 {
return false
}
}
// We should have enough information in these records to be able to
// write a signature that is reliable.
if len(signature) == len(encoding) && len(offset) == len(signature) {
if len(relativity) == 0 || len(relativity) == len(signature) {
return true
}
}
// Anything else, we can't guarantee enough about the sequences to
// write a signature. We may still have issues with the one's we've
// pre-processed even, but we can give ourselves a chance.
return false
}
// addSignatures tells us whether a signature can be added to the
// wikidata identifier after some level of validation.
func addSignatures(wikidataItems []map[string]spargo.Item, id string) bool {
var preProcessedSequences []preProcessedSequence
for _, wikidataItem := range wikidataItems {
if getID(wikidataItem[uriField].Value) == id {
if wikidataItem[signatureField].Value != "" {
preProcessed := preProcessedSequence{}
preProcessed.signature = wikidataItem[signatureField].Value
preProcessed.offset = wikidataItem[offsetField].Value
preProcessed.encoding = wikidataItem[encodingField].Value
preProcessed.relativity = wikidataItem[relativityField].Value
if len(preProcessedSequences) == 0 {
preProcessedSequences =
append(preProcessedSequences, preProcessed)
}
found := false
for _, value := range preProcessedSequences {
if preProcessed == value {
found = true
break
}
}
if !found {
preProcessedSequences =
append(preProcessedSequences, preProcessed)
}
}
}
}
var add bool
if len(preProcessedSequences) > 0 {
add = preValidateSignatures(preProcessedSequences)
}
return add
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Package wikidata contains the majority of the functions needed to
// build a Wikidata identifier (compiled signature file) compatible with
// Siegfried. Package Wikidata then also contains the majority of the
// functions required to enable Siegfried to consume that same
// identifier. The ability to do this is enabled by implementing
// Siegfried's Identifier and Parseable interfaces.
package wikidata
import (
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/pronom"
)
// wikidataDefinitions contains the file format information retrieved
// from the Wikidata definitions file, e.g. the name, URI, extensions,
// PUIDs that are associated with a Wikidata record. The structure also
// contains an implementation of parseable which we will attempt to
// satisfy, and a default implementation of parseable to take care of
// parts of the interface we don't complete (I think!).
type wikidataDefinitions struct {
formats []wikidataRecord
parseable identifier.Parseable
identifier.Blank
}
// newWikidata will call the functions required to load Wikidata
// definitions from disk and parse them into an identifier compatible
// structure. newWikidata will also add the data needed to also use
// native PRONOM identification patterns before finally collecting a
// list of PUIDs to be used in constructing provenance about each /
// signature.
func newWikidata() (identifier.Parseable, []string, error) {
var puids []string
var wikiParseable identifier.Parseable = identifier.Blank{}
var err error
// Process Wikidata report from disk and read into a report
// structure.
reportMappings, err := createMappingFromWikidata()
if err != nil {
return nil, []string{}, err
}
if config.GetWikidataNoPRONOM() {
logln(
"Roy (Wikidata): Not building identifiers set from PRONOM",
)
} else {
logln(
"Roy (Wikidata): Building identifiers set from PRONOM",
)
wikiParseable, err = pronom.NewPronom()
if err != nil {
return nil, []string{}, err
}
// Collect the PRONOM identifiers we want to work with in this
// identifier for use in generating provenance that will be
// displayed in the source field.
_, puids, _ = wikiParseable.Signatures()
}
return wikidataDefinitions{
reportMappings, // Wikidata formats.
wikiParseable, // Implementation of Parseable.
identifier.Blank{}, // Blank Parseable implementation.
}, puids, nil
}
<file_sep>package pronom
import (
"bytes"
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/pkg/pronom/internal/mappings"
)
var bsStub1 = mappings.ByteSequence{
Position: "Absolute from BOF",
Offset: "0",
MaxOffset: "",
Hex: "02{2}[01:1C][01:1F]????[00:03]([41:5A][61:7A]){10}(43|4E|4C)",
}
var bsStub2 = mappings.ByteSequence{
Position: "Absolute from BOF",
Offset: "0",
MaxOffset: "",
Hex: "02{2}000000??[00:03]([41:5A]|[61:7A]){10}(43|4E|4C)",
}
var bsStub3 = mappings.ByteSequence{
Position: "Absolute from BOF",
Offset: "0",
MaxOffset: "",
Hex: "5033(20|09|0D0A|0A)",
}
var bsStub4 = mappings.ByteSequence{
Position: "Absolute from EOF",
Offset: "0",
MaxOffset: "4",
Hex: "(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)(30|31|32|33|34|35|36|37|38|39|20|0A|0D)20",
}
var bsStub5 = mappings.ByteSequence{
Position: "Absolute from BOF",
Offset: "0",
MaxOffset: "264",
Hex: "7E56*564552532E*322E*(4C4153|43574C53)20(4C4F47204153434949205354414E44415244|4C6F67204153434949205374616E64617264|6C6F67204153434949205374616E64617264|4C4153){1-3}56(455253494F4E|657273696F6E)20322E[30:31]*7E57*7E43{5-*}7E41",
}
var bsStub6 = mappings.ByteSequence{
Position: "Absolute from BOF",
Offset: "0",
MaxOffset: "",
Hex: "2F322E[30:33](0D0A|0A)2850726F6A6563742E31(0D0A|0A)094E616D653A0922",
}
var csStub = mappings.SubSequence{
Position: 1,
SubSeqMinOffset: "0",
SubSeqMaxOffset: "128",
Sequence: "'office:document-content'",
}
var csStub1 = mappings.SubSequence{
Position: 2,
SubSeqMinOffset: "0",
SubSeqMaxOffset: "",
Sequence: "'office:version=' [22 27] '1.0' [22 27]",
}
var csStub3 = mappings.SubSequence{
Position: 1,
SubSeqMinOffset: "40",
SubSeqMaxOffset: "1064",
Sequence: "0F 00 00 00 'MSProject.MPP9' 00",
}
var ciStub = mappings.InternalSignature{
ByteSequences: []mappings.ByteSeq{{
SubSequences: []mappings.SubSequence{csStub, csStub1}}},
}
var ciStub1 = mappings.InternalSignature{
ByteSequences: []mappings.ByteSeq{{
SubSequences: []mappings.SubSequence{csStub3}}},
}
var sStub1 = mappings.Signature{[]mappings.ByteSequence{bsStub1}}
var sStub2 = mappings.Signature{[]mappings.ByteSequence{bsStub2}}
var sStub3 = mappings.Signature{[]mappings.ByteSequence{bsStub3, bsStub4}}
var sStub4 = mappings.Signature{[]mappings.ByteSequence{bsStub5}}
var sStub5 = mappings.Signature{[]mappings.ByteSequence{bsStub6}}
var rStub1 = &mappings.Report{Signatures: []mappings.Signature{sStub1, sStub2}, Identifiers: []mappings.FormatIdentifier{{Typ: "PUID", Id: "x-fmt/8"}}}
var rStub2 = &mappings.Report{Signatures: []mappings.Signature{sStub3}, Identifiers: []mappings.FormatIdentifier{{Typ: "PUID", Id: "x-fmt/178"}}}
var rStub3 = &mappings.Report{Signatures: []mappings.Signature{sStub4}, Identifiers: []mappings.FormatIdentifier{{Typ: "PUID", Id: "fmt/390"}}}
var rStub4 = &mappings.Report{Signatures: []mappings.Signature{sStub5}, Identifiers: []mappings.FormatIdentifier{{Typ: "PUID", Id: "x-fmt/317"}}}
func TestProcessText(t *testing.T) {
byts := processText(csStub3.Sequence)
if !bytes.Equal(byts, []byte{15, 0, 0, 0, 77, 83, 80, 114, 111, 106, 101, 99, 116, 46, 77, 80, 80, 57, 0}) {
t.Fatalf("Got %v", byts)
}
}
func TestProcessGroup(t *testing.T) {
// try PRONOM form
l := lexPRONOM("test", "(FF|10[!00:10])")
<-l.items // discard group entry
pat, err := processGroup(l)
if err != nil {
t.Fatal(err)
}
expect := patterns.Choice{
patterns.Sequence([]byte{255}),
patterns.List{
patterns.Sequence([]byte{16}),
patterns.Not{Range{[]byte{0}, []byte{16}}},
},
}
if !pat.Equals(expect) {
t.Errorf("expecting %v, got %v", expect, pat)
}
// try container form
l = lexPRONOM("test2", "[10 'cats']")
<-l.items
pat, err = processGroup(l)
if err != nil {
t.Fatal(err)
}
expect = patterns.Choice{
patterns.Sequence([]byte{16}),
patterns.Sequence([]byte("cats")),
}
if !pat.Equals(expect) {
t.Errorf("expecting %v, got %v", expect, pat)
}
// try simple
l = lexPRONOM("test3", "[00:10]")
<-l.items
pat, err = processGroup(l)
if err != nil {
t.Fatal(err)
}
rng := Range{[]byte{0}, []byte{16}}
if !pat.Equals(rng) {
t.Errorf("expecting %v, got %v", expect, rng)
}
}
func TestParseHex(t *testing.T) {
ts, _, _, err := process("x-fmt/8", bsStub1.Hex, false)
if err != nil {
t.Error("Parse items: Error", err)
}
if len(ts) != 6 {
t.Error("Parse items: Expecting 6 patterns, got", len(ts))
}
tok := ts[5]
if tok.Min != 10 || tok.Max != 10 {
t.Error("Parse items: Expecting 10,10, got", tok.Min, tok.Max)
}
tok = ts[3]
if tok.Min != 2 || tok.Max != 2 {
t.Error("Parse items: Expecting 2,2, got", tok.Min, tok.Max)
}
if !tok.Pattern.Equals(Range{[]byte{0}, []byte{3}}) {
t.Error("Parse items: Expecting [00:03], got", tok.Pattern)
}
ts, _, _, _ = process("fmt/390", bsStub5.Hex, false)
tok = ts[12]
if tok.Min != 5 || tok.Max != -1 {
t.Error("Parse items: Expecting 5-0, got", tok.Min, tok.Max)
}
if !tok.Pattern.Equals(patterns.Sequence(processText("7E41"))) {
t.Error("Parse items: Expecting 7E41, got", tok.Pattern)
}
ts, _, _, _ = process("x-fmt/317", bsStub6.Hex, false)
seqs := ts[2].Pattern.Sequences()
if !seqs[0].Equals(patterns.Sequence(processText("0D0A"))) {
t.Error("Parse items: Expecting [13 10], got", []byte(seqs[0]))
}
}
func TestParseReports(t *testing.T) {
r := &reports{[]string{"test1", "test2", "test3", "test4"}, []*mappings.Report{rStub1, rStub2, rStub3, rStub4}, nil, identifier.Blank{}}
_, _, err := r.Signatures()
if err != nil {
t.Error(err)
}
}
func TestParseContainer(t *testing.T) {
sig, err := processDROID("fmt/123", ciStub.ByteSequences)
if err != nil {
t.Error(err)
}
if len(sig) != 5 {
t.Error("Expecting 5 patterns! Got ", sig)
}
sig, err = processDROID("fmt/123", ciStub1.ByteSequences)
if err != nil {
t.Error(err)
}
if min, _ := sig[0].Length(); min != 19 {
t.Error("Expecting a sequence with a length of 19! Got ", sig)
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package siegreader implements multiple independent Readers (and ReverseReaders) from a single Buffer.
//
// Example:
// buffers := siegreader.New()
// buffer, err := buffers.Get(io.Reader)
// if err != nil {
// log.Fatal(err)
// }
// rdr := siegreader.ReaderFrom(buffer)
// second_rdr := siegreader.ReaderFrom(buffer)
// brdr := siegreader.LimitReaderFrom(buffer, -1)
// rrdr, err := siegreader.LimitReverseReaderFrom(buffer, 16000)
// i, err := rdr.Read(slc)
// i2, err := second_rdr.Read(slc2)
// i3, err := rrdr.ReadByte()
package siegreader
import (
"errors"
"io"
"github.com/richardlehane/characterize"
)
var (
ErrEmpty = errors.New("empty source")
ErrQuit = errors.New("siegreader: quit chan closed while awaiting EOF")
ErrNilBuffer = errors.New("siegreader: attempt to SetSource on a nil buffer")
)
const (
readSz int = 4096 // 8192
initialRead = readSz * 2
eofSz = readSz * 2
wheelSz = readSz * 16
smallFileSz = readSz * 16
streamSz = smallFileSz * 1024
)
type bufferSrc interface {
Slice(off int64, l int) ([]byte, error)
EofSlice(off int64, l int) ([]byte, error)
Size() int64
SizeNow() int64
CanSeek(off int64, rev bool) (bool, error)
}
// Buffer allows multiple readers to read from the same source.
// Readers include reverse (from EOF) and limit readers.
type Buffer struct {
Quit chan struct{} // when this channel is closed, readers will return io.EOF
texted bool
text characterize.CharType
bufferSrc
}
// Bytes returns a byte slice for a full read of the buffered file or stream.
// Returns nil on error
func (b *Buffer) Bytes() []byte {
sz := b.SizeNow()
// check for int overflow
if int64(int(sz)) != sz {
return nil
}
s, err := b.Slice(0, int(sz))
if err != nil {
return nil
}
return s
}
// Text returns the CharType of the first 4096 bytes of the Buffer.
func (b *Buffer) Text() characterize.CharType {
if b.texted {
return b.text
}
b.texted = true
buf, err := b.Slice(0, readSz)
if err == nil || err == io.EOF {
b.text = characterize.Detect(buf)
}
return b.text
}
// Reader exposes a Reader for the Buffer.
// This is to support external uses of this internal package.
func (b *Buffer) Reader() *Reader {
return ReaderFrom(b)
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package containermatcher
import "github.com/richardlehane/siegfried/internal/siegreader"
type Reader interface {
Next() error // when finished, should return io.EOF
Name() string // return name of the object with paths concatenated with / character
SetSource(*siegreader.Buffers) (*siegreader.Buffer, error)
Close() // close files
IsDir() bool // report if a directory
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package textmatcher
import (
"bytes"
"fmt"
"testing"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
type unit struct {
label string
rdr *bytes.Buffer
expect string
results int
}
var suite = []unit{
{
label: "bindata",
rdr: bytes.NewBuffer([]byte{0, 1, 50, 255}),
expect: "nada",
results: 0,
},
{
label: "utf8",
rdr: bytes.NewBuffer([]byte("ᚠᛇᚻ᛫ᛒᛦᚦ᛫ᚠᚱᚩᚠ")),
expect: "text match UTF-8 Unicode",
results: 3,
},
{
label: "ascii",
rdr: bytes.NewBuffer([]byte("hello world")),
expect: "text match ASCII",
results: 3,
},
}
var testMatcher *Matcher
func new(i int) (core.Matcher, error) {
var m core.Matcher
for j := 1; j < i+1; j++ {
var idx int
m, idx, _ = Add(m, SignatureSet{}, nil)
if idx != j {
return nil, fmt.Errorf("Error adding signature set, expecting index %d got %d", j, idx)
}
}
return m, nil
}
func TestNewMatcher(t *testing.T) {
m, err := new(5)
if err != nil {
t.Fatal(err)
}
if tm := m.(*Matcher); *tm != 5 {
t.Fatalf("Expecting a matcher equalling %d, got %d", 5, tm)
}
}
func TestSuite(t *testing.T) {
ids := 3
m, _ := new(ids)
bufs := siegreader.New()
for _, u := range suite {
buf, _ := bufs.Get(u.rdr)
res, _ := m.Identify("", buf)
var i int
for r := range res {
i++
if r.Index() != i || r.Basis() != u.expect {
t.Fatalf("Expecting result %d for %s, got %d with %s", i, u.label, r.Index(), r.Basis())
}
}
if i != u.results {
t.Fatalf("Expecting a total of %d results, got %d", u.results, i)
}
}
}
<file_sep>package main
import (
"bytes"
"encoding/json"
"flag"
"os"
"path/filepath"
"strings"
"testing"
"time"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/wikidata"
"github.com/richardlehane/siegfried/pkg/writer"
)
// Path components associated with the Roy command folder.
const wikidataTestDefinitions = "wikidata-test-definitions"
const wikidataDefinitionsBaseDir = "definitionsBaseDir"
var royTestData = filepath.Join("..", "roy", "data")
// Path components within the Siegfried command folder.
const wikidataNamespace = "wikidata"
const siegfriedTestData = "testdata"
const wikidataTestData = "wikidata"
const wikidataPRONOMSkeletons = "pro"
const wikidataCustomSkeletons = "wd"
const wikidataArcSkeletons = "arc"
const wikidataExtensionMismatches = "ext_mismatch"
const wikidataContainerMatches = "container"
const wikidataCuriosityMatches = "curiosities"
var (
wikidataDefinitions = flag.String(
wikidataDefinitionsBaseDir,
royTestData,
"Creates an flag var that is compatible with the config functions...",
)
)
func resetWikidata() {
config.SetWikidataEndpoint("https://query.wikidata.org/sparql")
propPronom := "http://www.wikidata.org/entity/Q35432091"
propBOF := "http://www.wikidata.org/entity/Q35436009"
propEOF := "http://www.wikidata.org/entity/Q1148480"
config.SetProps(propPronom, propBOF, propEOF)
wikidata.GetBOFandEOFFromConfig()
wikidata.GetPronomURIFromConfig()
}
func setupWikidata(pronom bool) (*siegfried.Siegfried, error) {
var wdSiegfried *siegfried.Siegfried
resetWikidata()
wdSiegfried = siegfried.New()
config.SetHome(*wikidataDefinitions)
config.SetWikidataDefinitions(wikidataTestDefinitions)
opts := []config.Option{config.SetWikidataNamespace()}
if pronom != true {
opts = append(opts, config.SetWikidataNoPRONOM())
} else {
opts = append(opts, config.SetWikidataPRONOM())
}
identifier, err := wikidata.New(opts...)
if err != nil {
return wdSiegfried, err
}
wdSiegfried.Add(identifier)
return wdSiegfried, nil
}
// identificationTests provides our structure for table driven tests.
type identificationTests struct {
fname string
label string
qid string
extMatch bool
byteMatch bool
containerMatch bool
error bool
}
var skeletonSamples = []identificationTests{
identificationTests{
filepath.Join(wikidataPRONOMSkeletons, "fmt-11-signature-id-58.png"),
"Portable Network Graphics", "Q178051", true, true, false, false},
identificationTests{
filepath.Join(wikidataPRONOMSkeletons, "fmt-279-signature-id-295.flac"),
"Free Lossless Audio Codec", "Q27881556", true, true, false, false},
identificationTests{
filepath.Join(wikidataCustomSkeletons, "Q10287816.gz"),
"GZIP", "Q10287816", true, true, false, false},
identificationTests{
filepath.Join(wikidataCustomSkeletons, "Q28205479.info"),
"Amiga Workbench icon", "Q28205479", true, true, false, false},
identificationTests{
filepath.Join(wikidataCustomSkeletons, "Q42591.mp3"),
"إم بي 3", "Q42591", true, true, false, false},
identificationTests{
filepath.Join(wikidataCustomSkeletons, "Q42332.pdf"),
"পোর্টেবল ডকুমেন্ট ফরম্যাট", "Q42332", true, true, false, false},
}
// Rudimentary consts that can help us determine the method of
// identification. Can also add "container name" here for when we want
// to validate PRONOM alongside Wikidata.
const extensionMatch = "extension match"
const byteMatch = "byte match"
const extensionMismatch = "extension mismatch"
const containerMatch = "container name"
// TestWikidataBasic will perform some rudimentary tests using some
// simple Skeleton files and the Wikidata identifier without PRONOM.
func TestWikidataBasic(t *testing.T) {
wdSiegfried, err := setupWikidata(false)
if err != nil {
t.Error(err)
}
for _, test := range skeletonSamples {
path := filepath.Join(siegfriedTestData, wikidataTestData, test.fname)
siegfriedRunner(wdSiegfried, path, test, t)
}
}
var archiveSamples = []identificationTests{
identificationTests{
filepath.Join(wikidataArcSkeletons, "fmt-289-signature-id-305.warc"),
"Web ARChive", "Q7978505", true, true, false, false},
identificationTests{
filepath.Join(wikidataArcSkeletons, "fmt-410-signature-id-580.arc"),
"Internet Archive ARC, version 1.1", "Q27824065", true, true, false, false},
identificationTests{
filepath.Join(wikidataArcSkeletons, "x-fmt-219-signature-id-525.arc"),
"Internet Archive ARC, version 1.0", "Q27824060", true, true, false, false},
identificationTests{
filepath.Join(wikidataArcSkeletons, "x-fmt-265-signature-id-265.tar"),
"tar", "Q283579", true, true, false, false},
identificationTests{
filepath.Join(wikidataArcSkeletons, "x-fmt-266-signature-id-201.gz"),
"GZIP", "Q10287816", true, true, false, false},
}
func TestArchives(t *testing.T) {
wdSiegfried, err := setupWikidata(true)
if err != nil {
t.Error(err)
}
for _, test := range archiveSamples {
path := filepath.Join(siegfriedTestData, wikidataTestData, test.fname)
siegfriedRunner(wdSiegfried, path, test, t)
}
}
var extensionMismatchSamples = []identificationTests{
identificationTests{
filepath.Join(wikidataExtensionMismatches, "fmt-11-signature-id-58.jpg"),
"Portable Network Graphics", "Q178051", false, true, false, false},
identificationTests{
filepath.Join(wikidataExtensionMismatches, "fmt-279-signature-id-295.wav"),
"Free Lossless Audio Codec", "Q27881556", false, true, false, false},
}
func TestExtensionMismatches(t *testing.T) {
wdSiegfried, err := setupWikidata(false)
if err != nil {
t.Error(err)
}
for _, test := range extensionMismatchSamples {
path := filepath.Join(siegfriedTestData, wikidataTestData, test.fname)
siegfriedRunner(wdSiegfried, path, test, t)
}
}
var containerSamples = []identificationTests{
identificationTests{
filepath.Join(wikidataContainerMatches, "fmt-292-container-signature-id-8010.odp"),
"OpenDocument Presentation, version 1.1", "Q27203973", true, true, true, false},
identificationTests{
filepath.Join(wikidataContainerMatches, "fmt-482-container-signature-id-14000.ibooks"),
"Apple iBooks format", "Q49988096", true, true, true, false},
identificationTests{
filepath.Join(wikidataContainerMatches, "fmt-680-container-signature-id-22120.ppp"),
"Serif PagePlus Publication file format, version 12", "Q47520869", true, true, true, false},
identificationTests{
filepath.Join(wikidataContainerMatches, "fmt-998-container-signature-id-32000.ora"),
"OpenRaster", "Q747906", true, true, true, false},
}
func TestContainers(t *testing.T) {
wdSiegfried, err := setupWikidata(true)
if err != nil {
t.Error(err)
}
for _, test := range containerSamples {
path := filepath.Join(siegfriedTestData, wikidataTestData, test.fname)
siegfriedRunner(wdSiegfried, path, test, t)
}
}
var curiositySamples = []identificationTests{
identificationTests{
// curiosity.1 should match with Q000000 in the sample signature
// file which has source information including lots of strange
// characters as well as emoji.
filepath.Join(wikidataCuriosityMatches, "curiosity.1"),
"curiosity", "Q000000", true, true, false, false},
}
func TestCurious(t *testing.T) {
wdSiegfried, err := setupWikidata(true)
if err != nil {
t.Error(err)
}
for _, test := range curiositySamples {
path := filepath.Join(siegfriedTestData, wikidataTestData, test.fname)
siegfriedRunner(wdSiegfried, path, test, t)
}
}
func siegfriedRunner(wdSiegfried *siegfried.Siegfried, path string, test identificationTests, t *testing.T) {
file, err := os.Open(path)
if err != nil {
t.Fatalf("failed to open %v, got: %v", path, err)
}
defer file.Close()
res, err := wdSiegfried.Identify(file, path, "")
if err != nil && !test.error {
t.Fatal(err)
}
if len(res) > 1 {
t.Errorf("Match length greater than one: '%d'", len(res))
}
namespace := res[0].Values()[0]
if namespace != wikidataNamespace {
t.Errorf("Namespace error, expected: '%s' received: '%s'",
wikidataNamespace, namespace,
)
}
// res is a an array of JSON values. We're interested in the first
// result (index 0), and then the following three fields
id := res[0].Values()[1]
label := res[0].Values()[2]
permalink := res[0].Values()[4]
basis := res[0].Values()[6]
warning := res[0].Values()[7]
if id != test.qid {
t.Errorf(
"QID match different than anticipated: '%s' expected '%s'",
id,
test.qid,
)
}
if label != test.label {
t.Errorf(
"Label match different than anticipated: '%s' expected '%s'",
label,
test.label,
)
}
const placeholderPermalink = "https://www.wikidata.org/w/index.php?oldid=1287431117&title=Q12345"
if permalink != placeholderPermalink {
t.Errorf(
"There has been a problem parsing the permalink for '%s' from Wikidata/Wikiprov: %s",
test.qid,
permalink,
)
}
if test.extMatch && !strings.Contains(basis, extensionMatch) {
t.Errorf(
"Extension match not returned by identifier: %s",
basis,
)
}
if test.byteMatch && !strings.Contains(basis, byteMatch) {
t.Errorf(
"Byte match not returned by identifier: %s",
basis,
)
}
if test.containerMatch && !strings.Contains(basis, containerMatch) {
t.Errorf(
"Container match not returned by identifier: %s",
basis,
)
}
if !test.extMatch && !strings.Contains(warning, extensionMismatch) {
t.Errorf(
"Expected an extension mismatch but it wasn't returned: %s",
warning,
)
}
// Implement a basic Writer test for some of the data coming out of
// the Wikidata identifier. CSV and YAML will need a little more
// thought.
var w writer.Writer
buf := new(bytes.Buffer)
w = writer.JSON(buf)
w.Head(
"path/to/file",
time.Now(),
time.Now(),
[3]int{0, 0, 0},
wdSiegfried.Identifiers(),
wdSiegfried.Fields(),
"md5",
)
w.File("testName", 10, "testMod", []byte("d41d8c"), nil, res)
w.Tail()
if !json.Valid([]byte(buf.String())) {
t.Fatalf("Output from JSON writer is invalid: %s", buf.String())
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Helper functions for creating the sets of signatures that will be
// processed into the Wikidata identifier. As Wikidata entries are
// processed records are either created new, or appended/updated.
package wikidata
import (
"fmt"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/mappings"
"github.com/ross-spencer/wikiprov/pkg/spargo"
)
// wikidataRecord provides an alias for the mappings.Wikidata object.
type wikidataRecord = mappings.Wikidata
// getProvenance will return the permalink, and provenance entry for
// a Wikidata record given a QID. If a provenance entry doesn't exist
// for an entry an error is returned.
func getProvenance(id string, provenance wikiProv) (string, string, error) {
const noValueFound = ""
for _, value := range provenance {
if value.Title == fmt.Sprintf("Item:%s", id) {
// Verbose Item prefix, used by default Wikimedia installs.
return value.Permalink, fmt.Sprintf("%s", value), nil
} else if value.Title == fmt.Sprintf("%s", id) {
// Non-verbose, but looks like it is used in Wikidata flavor
// Wikimedia, i.e. specifically Wikidata.
return value.Permalink, fmt.Sprintf("%s", value), nil
}
}
return noValueFound, noValueFound, fmt.Errorf("Roy (Wikidata): Provenance not found for: %s", id)
}
// newRecord creates a Wikidata record with the values received from
// Wikidata itself.
func newRecord(wikidataItem map[string]spargo.Item, provenance wikiProv, addSigs bool) wikidataRecord {
wd := wikidataRecord{}
wd.ID = getID(wikidataItem[uriField].Value)
wd.Name = wikidataItem[formatLabelField].Value
wd.URI = wikidataItem[uriField].Value
wd.PRONOM = append(wd.PRONOM, wikidataItem[puidField].Value)
if wikidataItem[extField].Value != "" {
wd.Extension = append(wd.Extension, wikidataItem[extField].Value)
}
wd.Mimetype = append(wd.Mimetype, wikidataItem[mimeField].Value)
if wikidataItem[signatureField].Value != "" {
if !addSigs {
// Pre-processing has determined that no particular
// heuristic will help us here and so let's make sure we can
// report on that at the end, as well as exit early.
addLinting(wd.URI, heuWDE01)
wd.DisableSignatures()
return wd
}
sig := Signature{}
sig.Source = parseProvenance(wikidataItem[referenceField].Value)
sig.Date = wikidataItem[dateField].Value
wd.Signatures = append(wd.Signatures, sig)
bs := newByteSequence(wikidataItem)
wd.Signatures[0].ByteSequences = append(
wd.Signatures[0].ByteSequences, bs)
}
perma, prov, err := getProvenance(wd.ID, provenance)
if err != nil {
logln("Roy (Wikidata):", err) // Q. (RL) Is it safe to ignore this error and just log it? Or should this func return an error?
}
wd.Permalink, wd.RevisionHistory = perma, prov
return wd
}
// updateRecord manages a format record's repeating properties.
// exceptions and adds them to the list if it doesn't already exist.
func updateRecord(wikidataItem map[string]spargo.Item, wd wikidataRecord) wikidataRecord {
if contains(wd.PRONOM, wikidataItem[puidField].Value) == false {
wd.PRONOM = append(wd.PRONOM, wikidataItem[puidField].Value)
}
if contains(wd.Extension, wikidataItem[extField].Value) == false &&
wikidataItem[extField].Value != "" {
wd.Extension = append(wd.Extension, wikidataItem[extField].Value)
}
if contains(wd.Mimetype, wikidataItem[mimeField].Value) == false {
wd.Mimetype = append(wd.Mimetype, wikidataItem[mimeField].Value)
}
if wikidataItem[signatureField].Value != "" {
if !wd.SignaturesDisabled() {
lintingErr := updateSequences(wikidataItem, &wd)
// WIKIDATA FUTURE: If we can re-organize the signatures in
// Wikidata so that they are better encapsulated from each
// other then we don't need to be as strict about not
// processing the value. Right now, there's not enough
// consistency in records that mix signatures with multiple
// sequences, types, offsets and so forth.
if lintingErr != nle {
wd.Signatures = nil
wd.DisableSignatures()
addLinting(wd.URI, lintingErr)
}
}
}
return wd
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"encoding/base64"
"fmt"
"io"
"net/http"
"os"
"sync"
"time"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/internal/checksum"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/writer"
)
func handleErr(w http.ResponseWriter, status int, e error) {
w.WriteHeader(status)
w.Header().Set("Content-Type", "text/plain; charset=utf-8")
io.WriteString(w, fmt.Sprintf("SF server error; got %v\n", e))
}
func decodePath(s, b64 string) (string, error) {
if len(s) < 11 {
return "", fmt.Errorf("path too short, expecting at least 11 characters got %d", len(s))
}
if b64 == "true" {
data, err := base64.URLEncoding.DecodeString(s[10:])
if err != nil {
return "", fmt.Errorf("Error base64 decoding file path, error message %v", err)
}
return string(data), nil
}
return s[10:], nil
}
func parseRequest(w http.ResponseWriter, r *http.Request, s *siegfried.Siegfried, wg *sync.WaitGroup) (string, writer.Writer, bool, bool, bool, checksum.HashTyp, *siegfried.Siegfried, getFn, error) {
// json, csv, droid or yaml
paramsErr := func(field, expect string) (string, writer.Writer, bool, bool, bool, checksum.HashTyp, *siegfried.Siegfried, getFn, error) {
return "", nil, false, false, false, -1, nil, nil, fmt.Errorf("bad request; in param %s got %s; valid values %s", field, r.FormValue(field), expect)
}
var (
mime string
wr writer.Writer
d bool
frmt int
)
switch {
case *jsono:
frmt = 1
case *csvo:
frmt = 2
case *droido:
frmt = 3
}
if v := r.FormValue("format"); v != "" {
switch v {
case "yaml":
frmt = 0
case "json":
frmt = 1
case "csv":
frmt = 2
case "droid":
frmt = 3
default:
return paramsErr("format", "yaml, json, csv or droid")
}
}
if accept := r.Header.Get("Accept"); accept != "" {
switch accept {
case "application/x-yaml":
frmt = 0
case "application/json":
frmt = 1
case "text/csv", "application/csv":
frmt = 2
case "application/x-droid":
frmt = 3
}
}
switch frmt {
case 0:
wr = writer.YAML(w)
mime = "application/x-yaml"
case 1:
wr = writer.JSON(w)
mime = "application/json"
case 2:
wr = writer.CSV(w)
mime = "text/csv"
case 3:
wr = writer.Droid(w)
d = true
mime = "application/x-droid"
}
// no recurse
norec := *nr
if v := r.FormValue("nr"); v != "" {
switch v {
case "true":
norec = true
case "false":
norec = false
default:
paramsErr("nr", "true or false")
}
}
// continue on error
coerr := *coe
if v := r.FormValue("coe"); v != "" {
switch v {
case "true":
coerr = true
case "false":
coerr = false
default:
paramsErr("coe", "true or false")
}
}
// archive
z := *archive
if v := r.FormValue("z"); v != "" {
switch v {
case "true":
z = true
case "false":
z = false
default:
paramsErr("z", "true or false")
}
}
// checksum
h := *hashf
if v := r.FormValue("hash"); v != "" {
h = v
}
ht := checksum.GetHash(h)
// sig
sf := s
if v := r.FormValue("sig"); v != "" {
if _, err := os.Stat(config.Local(v)); err != nil {
return "", nil, false, false, false, -1, nil, nil, fmt.Errorf("bad request; sig param should be path to a signature file (absolute or relative to home); got %v", err)
}
nsf, err := siegfried.Load(config.Local(v))
if err == nil {
sf = nsf
}
}
gf := func(path, mime string, mod time.Time, sz int64) *context {
c := ctxPool.Get().(*context)
c.path, c.mime, c.mod, c.sz = path, mime, mod, sz
c.s, c.wg, c.w, c.d, c.z, c.h = sf, wg, wr, d, z, checksum.MakeHash(ht)
return c
}
return mime, wr, coerr, norec, d, ht, sf, gf, nil
}
func handleIdentify(w http.ResponseWriter, r *http.Request, s *siegfried.Siegfried, ctxts chan *context) {
wg := &sync.WaitGroup{}
mime, wr, coerr, nrec, d, ht, sf, gf, err := parseRequest(w, r, s, wg)
if err != nil {
handleErr(w, http.StatusNotFound, err)
return
}
if r.Method == "POST" {
f, h, err := r.FormFile("file")
if err != nil {
handleErr(w, http.StatusNotFound, err)
return
}
defer f.Close()
var sz int64
var mod time.Time
osf, ok := f.(*os.File)
if ok {
info, err := osf.Stat()
if err != nil {
handleErr(w, http.StatusInternalServerError, err)
}
sz = info.Size()
mod = info.ModTime()
} else {
sz = r.ContentLength
}
w.Header().Set("Content-Type", mime)
wr.Head(config.SignatureBase(), time.Now(), sf.C, config.Version(), sf.Identifiers(), sf.Fields(), ht.String())
wg.Add(1)
ctx := gf(h.Filename, "", mod, sz)
ctxts <- ctx
identifyRdr(f, ctx, ctxts, gf)
wg.Wait()
wr.Tail()
return
}
path, err := decodePath(r.URL.Path, r.FormValue("base64"))
if err == nil {
_, err = os.Stat(path)
}
if err != nil {
handleErr(w, http.StatusNotFound, err)
return
}
w.Header().Set("Content-Type", mime)
wr.Head(config.SignatureBase(), time.Now(), sf.C, config.Version(), sf.Identifiers(), sf.Fields(), ht.String())
err = identify(ctxts, path, "", coerr, nrec, d, gf)
wg.Wait()
wr.Tail()
if _, ok := err.(walkError); ok { // only dump out walk errors, other errors reported in result
io.WriteString(w, err.Error())
}
}
const usage = `
<html>
<head>
<title>Siegfried server</title>
</head>
<body>
<h1><a name="top">Siegfried server usage</a></h1>
<p>The siegfried server has two modes of identification:
<ul><li><a href="#get_request">GET request</a>, where a file or directory path is given in the URL and the server retrieves the file(s);</li>
<li><a href="#post_request">POST request</a>, where the file is sent over the network as form-data.</li></ul></p>
<p>The update command can also be issued as a GET request to <a href="/update">/update</a>. This fetches an updated signature file and hot patches the running siegfried instance.</p>
<p>If PRONOM isn't being used as the underlying identifier, the update command can be qualified with the name of a different identifer e.g. <a href="/update">/update/wikidata</a>.</p>
<h2>Default settings</h2>
<p>When starting the server, you can use regular sf flags to set defaults for the <i>nr</i>, <i>format</i>, <i>hash</i>, <i>z</i>, and <i>sig</i> parameters that will apply to all requests unless overridden. Logging options can also be set.<p>
<p>E.g. sf -nr -z -hash md5 -sig pronom-tika.sig -log p,w,e -serve localhost:5138</p>
<hr>
<h2><a name="get_request">GET request</a></h2>
<p><strong>GET</strong> <i>/identify/[file or folder name (percent encoded)](?base64=false&nr=true&format=yaml&hash=md5&z=true&sig=locfdd.sig)</i></p>
<p>E.g. http://localhost:5138/identify/c%3A%2FUsers%2Frichardl%2FMy%20Documents%2Fhello%20world.docx?format=json</p>
<h3>Parameters</h3>
<p><i>base64</i> (optional) - use <a href="https://tools.ietf.org/html/rfc4648#section-5">URL-safe base64 encoding</a> for the file or folder name with base64=true.</p>
<p><i>coe</i> (optional) - continue directory scans even when fatal file access errors are encountered with coe=true.</p>
<p><i>nr</i> (optional) - stop sub-directory recursion when a directory path is given with nr=true.</p>
<p><i>format</i> (optional) - select the output format (csv, yaml, json, droid). Default is yaml. Alternatively, HTTP content negotiation can be used.</p>
<p><i>hash</i> (optional) - calculate file checksum (md5, sha1, sha256, sha512, crc)</p>
<p><i>z</i> (optional) - scan archive formats (zip, tar, gzip, warc, arc) with z=true. Default is false.</p>
<p><i>sig</i> (optional) - load a specific signature file. Default is default.sig.</p>
<h3>Example</h2>
<!-- set the get target for the example form using js function at bottom page-->
<h4>File/ directory:</h4>
<p><input type="text" id="filename"> (provide the path to a file or directory e.g. c:\My Documents\file.doc. It will be percent encoded by this form.)</p>
<h4>Parameters:</h4>
<form method="get" id="get_example">
<p>Use base64 encoding (base64): <input type="radio" name="base64" value="true"> true <input type="radio" name="base64" value="false" checked> false</p>
<p>Continue on error (coe): <input type="radio" name="coe" value="true"> true <input type="radio" name="nr" value="false" checked> false</p>
<p>No directory recursion (nr): <input type="radio" name="nr" value="true"> true <input type="radio" name="nr" value="false" checked> false</p>
<p>Format (format): <select name="format">
<option value="json">json</option>
<option value="yaml">yaml</option>
<option value="csv">csv</option>
<option value="droid">droid</option>
</select></p>
<p>Hash (hash): <select name="hash">
<option value="none">none</option>
<option value="md5">md5</option>
<option value="sha1">sha1</option>
<option value="sha256">sha256</option>
<option value="sha512">sha512</option>
<option value="crc">crc</option>
</select></p>
<p>Scan archive (z): <input type="radio" name="z" value="true"> true <input type="radio" name="z" value="false" checked> false</p>
<p>Signature file (sig): <input type="text" name="sig"></p>
<p><input type="submit" value="Submit"></p>
</form>
<p><a href="#top">Back to top</p>
<hr>
<h2><a name="post_request">POST request</a></h2>
<p><strong>POST</strong> <i>/identify(?format=yaml&hash=md5&z=true&sig=locfdd.sig)</i> Attach a file as form-data with the key "file".</p>
<p>E.g. curl "http://localhost:5138/identify?format=json&hash=crc" -F file=@myfile.doc</p>
<h3>Parameters</h3>
<p><i>format</i> (optional) - select the output format (csv, yaml, json, droid). Default is yaml. Alternatively, HTTP content negotiation can be used.</p>
<p><i>hash</i> (optional) - calculate file checksum (md5, sha1, sha256, sha512, crc)</p>
<p><i>z</i> (optional) - scan archive formats (zip, tar, gzip, warc, arc) with z=true. Default is false.</p>
<p><i>sig</i> (optional) - load a specific signature file. Default is default.sig.</p>
<h3>Example</h2>
<form action="/identify" enctype="multipart/form-data" method="post">
<h4>File:</h4>
<p><input type="file" name="file"></p>
<h4>Parameters:</h4>
<p>Format (format): <select name="format">
<option value="json">json</option>
<option value="yaml">yaml</option>
<option value="csv">csv</option>
<option value="droid">droid</option>
</select></p>
<p>Hash (hash): <select name="hash">
<option value="none">none</option>
<option value="md5">md5</option>
<option value="sha1">sha1</option>
<option value="sha256">sha256</option>
<option value="sha512">sha512</option>
<option value="crc">crc</option>
</select></p>
<p>Scan archive (z): <input type="radio" name="z" value="true"> true <input type="radio" name="z" value="false" checked> false</p>
<p>Signature file (sig): <input type="text" name="sig"></p>
<p><input type="submit" value="Submit"></p>
</form>
<p><a href="#top">Back to top</p>
<script>
var input = document.getElementById('filename');
input.addEventListener('input', function()
{
var frm = document.getElementById('get_example');
frm.action = "/identify/" + encodeURIComponent(input.value);
});
</script>
</body>
</html>
`
func handleMain(w http.ResponseWriter, r *http.Request) {
w.Header().Set("Content-Type", "text/html")
io.WriteString(w, usage)
}
func handleUpdate(w http.ResponseWriter, r *http.Request, m *muxer) {
args := []string{}
if len(r.URL.Path) > 8 {
args = append(args, r.URL.Path[8:])
}
updated, msg, err := updateSigs("", args)
if err != nil {
handleErr(w, http.StatusInternalServerError, err)
return
}
if updated {
defer func() {
if r := recover(); r != nil {
handleErr(w, http.StatusInternalServerError, fmt.Errorf("panic: %v", r))
}
}()
nsf, err := siegfried.Load(config.Signature()) // may panic
if err == nil {
m.s = nsf // hot swap the siegfried!
w.WriteHeader(http.StatusOK)
w.Header().Set("Content-Type", "text/plain; charset=utf-8")
io.WriteString(w, msg)
return
} else {
handleErr(w, http.StatusInternalServerError, err)
return
}
}
w.WriteHeader(http.StatusNotModified)
w.Header().Set("Content-Type", "text/plain; charset=utf-8")
io.WriteString(w, msg)
}
type muxer struct {
s *siegfried.Siegfried
ctxts chan *context
mut sync.RWMutex
}
func (m *muxer) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if (len(r.URL.Path) == 0 || r.URL.Path == "/") && r.Method == "GET" {
handleMain(w, r)
return
}
if len(r.URL.Path) >= 9 && r.URL.Path[:9] == "/identify" {
m.mut.RLock()
handleIdentify(w, r, m.s, m.ctxts)
m.mut.RUnlock()
return
}
if len(r.URL.Path) >= 7 && r.URL.Path[:7] == "/update" {
m.mut.Lock()
handleUpdate(w, r, m)
m.mut.Unlock()
return
}
handleErr(w, http.StatusNotFound, fmt.Errorf("valid paths are /, /update, /update/*, /identify and /identify/*"))
}
func listen(port string, s *siegfried.Siegfried, ctxts chan *context) {
mux := &muxer{
s: s,
ctxts: ctxts,
}
http.ListenAndServe(port, mux)
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package mappings contains struct mappings to unmarshal three
// different PRONOM XML formats: the DROID signature file format, the report
// format, and the container format.
package mappings
import "encoding/xml"
type Droid struct {
XMLName xml.Name `xml:"FFSignatureFile"`
Version int `xml:",attr"`
Signatures []InternalSignature `xml:"InternalSignatureCollection>InternalSignature"`
FileFormats []FileFormat `xml:"FileFormatCollection>FileFormat"`
}
type InternalSignature struct {
ID int `xml:"ID,attr"`
ByteSequences []ByteSeq `xml:"ByteSequence"`
}
type ByteSeq struct {
Reference string `xml:"Reference,attr"`
SubSequences []SubSequence `xml:"SubSequence"`
}
type SubSequence struct {
Position int `xml:",attr"`
SubSeqMinOffset string `xml:",attr"` // and empty int values are unmarshalled to 0
SubSeqMaxOffset string `xml:",attr"` // uses string rather than int because value might be empty
Sequence string
LeftFragments []Fragment `xml:"LeftFragment"`
RightFragments []Fragment `xml:"RightFragment"`
}
type Fragment struct {
Value string `xml:",chardata"`
MinOffset string `xml:",attr"`
MaxOffset string `xml:",attr"`
Position int `xml:",attr"`
}
type FileFormat struct {
XMLName xml.Name `xml:"FileFormat"`
ID int `xml:"ID,attr"`
Puid string `xml:"PUID,attr"`
Name string `xml:",attr"`
Version string `xml:",attr"`
MIMEType string `xml:",attr"`
Extensions []string `xml:"Extension"`
Signatures []int `xml:"InternalSignatureID"`
Priorities []int `xml:"HasPriorityOverFileFormatID"`
}
<file_sep>package siegreader
func mmapable(sz int64) bool {
return false
}
func (m *mmap) mapFile() error {
var err error
return err
}
func (m *mmap) unmap() error {
var err error
return err
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mimeinfo
import (
"encoding/binary"
"encoding/hex"
"encoding/xml"
"errors"
"io/ioutil"
"regexp"
"strconv"
"strings"
"unicode/utf16"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/mimeinfo/internal/mappings"
)
func versions() []string {
return nil
}
type mimeinfo struct {
m []mappings.MIMEType
identifier.Blank
}
func newMIMEInfo(path string) (identifier.Parseable, error) {
buf, err := ioutil.ReadFile(path)
if err != nil {
return nil, err
}
mi := &mappings.MIMEInfo{}
err = xml.Unmarshal(buf, mi)
if err != nil {
return nil, err
}
index := make(map[string]int)
errs := []string{}
for i, v := range mi.MIMETypes {
if _, ok := index[v.MIME]; ok {
errs = append(errs, v.MIME)
}
index[v.MIME] = i
}
if len(errs) > 0 {
return nil, errors.New("Can't parse mimeinfo file, duplicated IDs: " + strings.Join(errs, ", "))
}
for i, v := range mi.MIMETypes {
if len(v.SuperiorClasses) == 1 && v.SuperiorClasses[0].SubClassOf != config.TextMIME() { // subclasses of text/plain shouldn't inherit text magic
sup := index[v.SuperiorClasses[0].SubClassOf]
if len(mi.MIMETypes[sup].XMLPattern) > 0 {
mi.MIMETypes[i].XMLPattern = append(mi.MIMETypes[i].XMLPattern, mi.MIMETypes[sup].XMLPattern...)
}
if len(mi.MIMETypes[sup].Magic) > 0 {
nm := make([]mappings.Magic, len(mi.MIMETypes[sup].Magic))
copy(nm, mi.MIMETypes[sup].Magic)
for i, w := range nm {
if len(w.Priority) > 0 {
num, err := strconv.Atoi(w.Priority)
if err == nil {
nm[i].Priority = strconv.Itoa(num - 1)
continue
}
}
nm[i].Priority = "49"
}
mi.MIMETypes[i].Magic = append(mi.MIMETypes[i].Magic, nm...)
}
}
}
return mimeinfo{mi.MIMETypes, identifier.Blank{}}, nil
}
func (mi mimeinfo) IDs() []string {
ids := make([]string, len(mi.m))
for i, v := range mi.m {
ids[i] = v.MIME
}
return ids
}
type formatInfo struct {
comment string
text bool
globWeights []int
magicWeights []int
}
func (f formatInfo) String() string {
return f.comment
}
// turn generic FormatInfo into mimeinfo formatInfo
func infos(m map[string]identifier.FormatInfo) map[string]formatInfo {
i := make(map[string]formatInfo, len(m))
for k, v := range m {
i[k] = v.(formatInfo)
}
return i
}
func textMIMES(m map[string]identifier.FormatInfo) []string {
ret := make([]string, 1, len(m))
ret[0] = config.TextMIME() // first one is the default
for k, v := range m {
if v.(formatInfo).text {
ret = append(ret, k)
}
}
return ret
}
func (mi mimeinfo) Infos() map[string]identifier.FormatInfo {
fmap := make(map[string]identifier.FormatInfo, len(mi.m))
for _, v := range mi.m {
fi := formatInfo{}
if len(v.Comment) > 0 {
fi.comment = v.Comment[0]
} else if len(v.Comments) > 0 {
fi.comment = v.Comments[0]
}
var magicWeight int
for _, mg := range v.Magic {
magicWeight += len(mg.Matches)
}
fi.globWeights, fi.magicWeights = make([]int, len(v.Globs)), make([]int, 0, magicWeight)
for i, w := range v.Globs {
if len(w.Weight) > 0 {
num, err := strconv.Atoi(w.Weight)
if err == nil {
fi.globWeights[i] = num
continue
}
}
fi.globWeights[i] = 50
}
for _, w := range v.Magic {
weight := 50
if len(w.Priority) > 0 {
if num, err := strconv.Atoi(w.Priority); err == nil {
weight = num
}
}
for _, s := range w.Matches {
ss, _ := toSigs(s)
for _, sig := range ss {
if sig != nil {
fi.magicWeights = append(fi.magicWeights, weight)
}
}
}
}
if len(v.SuperiorClasses) == 1 && v.SuperiorClasses[0].SubClassOf == config.TextMIME() {
fi.text = true
}
fmap[v.MIME] = fi
}
return fmap
}
func (mi mimeinfo) Globs() ([]string, []string) {
globs, ids := make([]string, 0, len(mi.m)), make([]string, 0, len(mi.m))
for _, v := range mi.m {
for _, w := range v.Globs {
globs, ids = append(globs, w.Pattern), append(ids, v.MIME)
}
}
return globs, ids
}
func (mi mimeinfo) MIMEs() ([]string, []string) {
mimes, ids := make([]string, 0, len(mi.m)), make([]string, 0, len(mi.m))
for _, v := range mi.m {
mimes, ids = append(mimes, v.MIME), append(ids, v.MIME)
for _, w := range v.Aliases {
mimes, ids = append(mimes, w.Alias), append(ids, v.MIME)
}
}
return mimes, ids
}
func (mi mimeinfo) Texts() []string {
return textMIMES(mi.Infos())
}
// slice of root/NS
func (mi mimeinfo) XMLs() ([][2]string, []string) {
xmls, ids := make([][2]string, 0, len(mi.m)), make([]string, 0, len(mi.m))
for _, v := range mi.m {
for _, w := range v.XMLPattern {
xmls, ids = append(xmls, [2]string{w.Local, w.NS}), append(ids, v.MIME)
}
}
return xmls, ids
}
func (mi mimeinfo) Signatures() ([]frames.Signature, []string, error) {
var errs []error
sigs, ids := make([]frames.Signature, 0, len(mi.m)), make([]string, 0, len(mi.m))
for _, v := range mi.m {
for _, w := range v.Magic {
for _, s := range w.Matches {
ss, err := toSigs(s)
for _, sig := range ss {
if sig != nil {
sigs, ids = append(sigs, sig), append(ids, v.MIME)
}
}
if err != nil {
errs = append(errs, err)
}
}
}
}
var err error
if len(errs) > 0 {
errStrs := make([]string, len(errs))
for i, e := range errs {
errStrs[i] = e.Error()
}
err = errors.New(strings.Join(errStrs, "; "))
}
return sigs, ids, err
}
func toSigs(m mappings.Match) ([]frames.Signature, error) {
f, err := toFrames(m)
if err != nil || f == nil {
return nil, err
}
if len(m.Matches) == 0 {
return []frames.Signature{frames.Signature(f)}, nil
}
subs := make([][]frames.Signature, 0, len(m.Matches))
for _, m2 := range m.Matches {
frs, err := toSigs(m2)
if err != nil {
return nil, err
}
if frs != nil {
subs = append(subs, frs)
}
}
var l, idx int
for _, v := range subs {
l += len(v)
}
ss := make([]frames.Signature, l)
for _, v := range subs {
for _, w := range v {
ss[idx] = append(frames.Signature(f), w...)
idx++
}
}
return ss, nil
}
func toFrames(m mappings.Match) ([]frames.Frame, error) {
pat, min, max, err := toPattern(m)
if err != nil || pat == nil {
return nil, err
}
mask, ok := pat.(Mask)
if !ok {
return []frames.Frame{frames.NewFrame(frames.BOF, pat, min, max)}, nil
}
pats, ints := unmask(mask)
f := []frames.Frame{frames.NewFrame(frames.BOF, pats[0], min+ints[0], max+ints[0])}
if len(pats) > 1 {
for i, p := range pats[1:] {
f = append(f, frames.NewFrame(frames.PREV, p, ints[i+1], ints[i+1]))
}
}
return f, nil
}
func toPattern(m mappings.Match) (patterns.Pattern, int, int, error) {
min, max, err := toOffset(m.Offset)
if err != nil {
return nil, min, max, err
}
var pat patterns.Pattern
switch m.Typ {
case "byte":
i, err := strconv.ParseInt(m.Value, 0, 16)
if err != nil {
return nil, min, max, err
}
pat = Int8(i)
case "big16":
i, err := strconv.ParseInt(m.Value, 0, 32)
if err != nil {
return nil, min, max, err
}
pat = Big16(i)
case "little16":
i, err := strconv.ParseInt(m.Value, 0, 32)
if err != nil {
return nil, min, max, err
}
pat = Little16(i)
case "host16":
i, err := strconv.ParseInt(m.Value, 0, 32)
if err != nil {
return nil, min, max, err
}
pat = Host16(i)
case "big32":
i, err := strconv.ParseInt(m.Value, 0, 64)
if err != nil {
return nil, min, max, err
}
pat = Big32(i)
case "little32":
i, err := strconv.ParseInt(m.Value, 0, 64)
if err != nil {
return nil, min, max, err
}
pat = Little32(i)
case "host32":
i, err := strconv.ParseInt(m.Value, 0, 64)
if err != nil {
return nil, min, max, err
}
pat = Host32(i)
case "string", "": // if no type given, assume string
pat = patterns.Sequence(unquote(m.Value))
case "stringignorecase":
pat = IgnoreCase(unquote(m.Value))
case "unicodeLE":
uints := utf16.Encode([]rune(string(unquote(m.Value))))
buf := make([]byte, len(uints)*2)
for i, u := range uints {
binary.LittleEndian.PutUint16(buf[i*2:], u)
}
pat = patterns.Sequence(buf)
case "regex":
return nil, min, max, nil // ignore regex magic
default:
return nil, min, max, errors.New("unknown magic type: " + m.Typ + " val: " + m.Value)
}
if len(m.Mask) > 0 {
pat = Mask{pat, unquote(m.Mask)}
}
return pat, min, max, err
}
func toOffset(off string) (int, int, error) {
var min, max int
var err error
if off == "" {
return min, max, err
}
idx := strings.IndexByte(off, ':')
switch {
case idx < 0:
min, err = strconv.Atoi(off)
max = min
case idx == 0:
max, err = strconv.Atoi(off[1:])
default:
min, err = strconv.Atoi(off[:idx])
if err == nil {
max, err = strconv.Atoi(off[idx+1:])
}
}
return min, max, err
}
var (
rpl = strings.NewReplacer("\\ ", " ", "\\n", "\n", "\\t", "\t", "\\r", "\r", "\\b", "\b", "\\f", "\f", "\\v", "\v", "\\\\", "\\")
rgx = regexp.MustCompile(`\\([0-9]{1,3}|x[0-9A-Fa-f]{1,2})`)
)
func numReplace(b []byte) []byte {
var i uint64
var err error
if b[1] == 'x' {
i, err = strconv.ParseUint(string(b[2:]), 16, 8)
} else {
// octal
if len(b) == 4 {
i, err = strconv.ParseUint(string(b[1:]), 8, 8)
} else { // decimal
i, err = strconv.ParseUint(string(b[1:]), 10, 8)
}
}
if err != nil {
panic(b)
}
return []byte{byte(i)}
}
func unquote(input string) []byte {
// deal with hex first
if len(input) > 2 && input[:2] == "0x" {
h, err := hex.DecodeString(input[2:])
if err == nil {
return h
} else {
panic(input + " " + err.Error())
}
}
return rgx.ReplaceAllFunc([]byte(rpl.Replace(input)), numReplace)
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package checksum
import (
"crypto/md5"
"crypto/sha1"
"crypto/sha256"
"crypto/sha512"
"hash"
"hash/crc32"
)
const HashChoices = "'md5', 'sha1', 'sha256', 'sha512', 'crc'"
type HashTyp int
const (
md5Hash HashTyp = iota
sha1Hash
sha256Hash
sha512Hash
crcHash
)
func GetHash(typ string) HashTyp {
switch typ {
case "", "false":
case "md5", "MD5":
return md5Hash
case "sha1", "SHA1":
return sha1Hash
case "sha256", "SHA256":
return sha256Hash
case "sha512", "SHA512":
return sha512Hash
case "crc", "CRC":
return crcHash
}
return -1
}
func MakeHash(typ HashTyp) hash.Hash {
switch typ {
case md5Hash:
return md5.New()
case sha1Hash:
return sha1.New()
case sha256Hash:
return sha256.New()
case sha512Hash:
return sha512.New()
case crcHash:
return crc32.NewIEEE()
}
return nil
}
func (typ HashTyp) String() string {
switch typ {
case md5Hash:
return "md5"
case sha1Hash:
return "sha1"
case sha256Hash:
return "sha256"
case sha512Hash:
return "sha512"
case crcHash:
return "crc"
}
return ""
}
<file_sep>package identifier
import (
"reflect"
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
)
// Globals to enable testing and comparison of Parseable results.
var sigs []frames.Signature
var ids []string
var f0, f1, f2, f3, f4, f5, f6 frames.Signature
func init() {
sigs = make([]frames.Signature, 0, 7)
ids = make([]string, 0, 7)
hx := "Hex: 4D 4D 00 2A"
var pat = patterns.Sequence(hx)
f0 = frames.Signature{frames.NewFrame(frames.BOF, pat, 0, 0)}
f1 = frames.Signature{frames.NewFrame(frames.BOF, pat, 1, 1)}
f2 = frames.Signature{frames.NewFrame(frames.BOF, pat, 2, 2)}
f3 = frames.Signature{frames.NewFrame(frames.BOF, pat, 3, 3)}
f4 = frames.Signature{frames.NewFrame(frames.BOF, pat, 4, 4)}
f5 = frames.Signature{frames.NewFrame(frames.BOF, pat, 5, 5)}
f6 = frames.Signature{frames.NewFrame(frames.BOF, pat, 6, 6)}
sigs = append(sigs, f6)
sigs = append(sigs, f2)
sigs = append(sigs, f1)
sigs = append(sigs, f4)
sigs = append(sigs, f5)
sigs = append(sigs, f0)
sigs = append(sigs, f3)
// IDs deliberately out of order so that they are reordered during
// Parseable's sort.
ids = append(ids, "text/x-go")
ids = append(ids, "fdd000002")
ids = append(ids, "fdd000001")
ids = append(ids, "fmt/1")
ids = append(ids, "fmt/2")
ids = append(ids, "application/x-elf")
ids = append(ids, "fdd000002")
}
func TestFind(t *testing.T) {
testBase := &Base{
gids: &indexes{
start: 50,
ids: []string{
"fmt/1",
"fmt/2",
"fmt/3",
"fmt/4",
"fmt/1",
"fmt/5",
},
},
}
expect := []int{50, 54, 52}
lookup := testBase.Lookup(core.NameMatcher, []string{"fmt/1", "fmt/3"})
if len(lookup) != len(expect) || lookup[0] != expect[0] || lookup[1] != expect[1] || lookup[2] != expect[2] {
t.Fatalf("Failed lookup: got %v, expected %v", lookup, expect)
}
}
// Utilize Parseable's Blank identifier so that we can override
// Signatures() for the purposes of testing.
type testParseable struct{ Blank }
func (b testParseable) Signatures() ([]frames.Signature, []string, error) {
return sigs, ids, nil
}
// TestSorted tests the Parseable sort mechanism that will be shared
// across identifiers. Identifiers each contain a Parseable.
func TestSorted(t *testing.T) {
sigsBeforeSort := []frames.Signature{f6, f2, f1, f4, f5, f0, f3}
sigsAfterSort := []frames.Signature{f0, f1, f2, f3, f4, f5, f6}
idsBeforeSort := []string{
"text/x-go",
"fdd000002",
"fdd000001",
"fmt/1",
"fmt/2",
"application/x-elf",
"fdd000002",
}
idsAfterSort := []string{
"application/x-elf",
"fdd000001",
"fdd000002",
"fdd000002",
"fmt/1",
"fmt/2",
"text/x-go",
}
identifier := &Base{}
identifier.p = testParseable{}
sigs, ids, err := identifier.p.Signatures()
if err != nil {
t.Error("Signatures() should not have returned an error", err)
}
for idx, val := range sigs {
if !reflect.DeepEqual(sigsBeforeSort[idx], val) {
t.Error("Results should not have been sorted")
t.Errorf("Returned: %+v expected: %+v", sigs, sigsBeforeSort)
}
}
if !reflect.DeepEqual(ids, idsBeforeSort) {
t.Error("Results should not have been sorted")
t.Errorf("Returned: %s expected: %s", ids, idsBeforeSort)
}
identifier.p = ApplyConfig(identifier.p)
sigs, ids, err = identifier.p.Signatures()
if err != nil {
t.Error("Signatures() should not have returned an error", err)
}
for idx, val := range sigs {
if !reflect.DeepEqual(sigsAfterSort[idx], val) {
t.Error("Results should have been sorted")
t.Errorf("Returned: %+v expected: %+v", sigs, sigsAfterSort)
}
}
if !reflect.DeepEqual(ids, idsAfterSort) {
t.Error("Results should not have been sorted")
t.Errorf("Returned: %s expected: %s", ids, idsAfterSort)
}
}
<file_sep>package namematcher
import (
"testing"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/core"
)
var fmts = SignatureSet{"*.wav", "*.doc", "*.xls", "*.pdf", "*.ppt", "*.adoc.txt", "README"}
var sm core.Matcher
func init() {
sm, _, _ = Add(nil, fmts, nil)
}
func TestWavMatch(t *testing.T) {
res, _ := sm.Identify("hello/apple.wav", nil)
e := <-res
if e.Index() != 0 {
t.Errorf("Expecting 0, got %v", e)
}
e, ok := <-res
if ok {
t.Error("Expecting a length of 1")
}
}
func TestAdocMatch(t *testing.T) {
res, _ := sm.Identify("hello/apple.adoc.txt", nil)
e := <-res
if e.Index() != 5 {
t.Errorf("Expecting 5, got %v", e)
}
e, ok := <-res
if ok {
t.Error("Expecting a length of 1")
}
}
func TestREADMEMatch(t *testing.T) {
res, _ := sm.Identify("hello/README", nil)
e, ok := <-res
if ok {
if e.Index() != 6 {
t.Errorf("Expecting 6, got %v", e)
}
} else {
t.Error("Expecting 5, got nothing")
}
e, ok = <-res
if ok {
t.Error("Expecting a length of 1")
}
}
func TestNoMatch(t *testing.T) {
res, _ := sm.Identify("hello/apple.tty", nil)
_, ok := <-res
if ok {
t.Error("Should not match")
}
}
func TestNoExt(t *testing.T) {
res, _ := sm.Identify("hello/apple", nil)
_, ok := <-res
if ok {
t.Error("Should not match")
}
}
func TestIO(t *testing.T) {
sm, _, _ = Add(nil, SignatureSet{"*.bla", "*.doc", "*.ppt"}, nil)
str := sm.String()
saver := persist.NewLoadSaver(nil)
Save(sm, saver)
if len(saver.Bytes()) < 10 {
t.Errorf("Save string matcher: too small, only got %v", saver.Bytes())
}
loader := persist.NewLoadSaver(saver.Bytes())
newsm := Load(loader)
str2 := newsm.String()
if str != str2 {
t.Errorf("Load string matcher: expecting first matcher (%v), to equal second matcher (%v)", str, str2)
}
}
var fnames = []string{
"README",
"README",
"",
"\\this\\directory\\file.txt",
"file.txt",
"txt",
"c:\\docs\\SONG.MP3",
"SONG.MP3",
"mp3",
"Climate/Existential.pdf",
"Existential.pdf",
"pdf",
"/Volumes/Public/bearbeiten/Dateien/ermitteln Dateityp/Salzburger Nachtstudio.2019-06-19 - Kulturkampf im Klassenzimmer?.mp3",
"Salzburger Nachtstudio.2019-06-19 - Kulturkampf im Klassenzimmer?.mp3",
"mp3",
"http://www.archive.org/about/faq.php?faq_id=243 172.16.31.10",
"faq.php",
"php",
"http://www.archive.org/images/wayback-election2000.gif",
"wayback-election2000.gif",
"gif",
"http://www.example.org/foo.html#bar",
"foo.html",
"html",
"/root/corpora/ipres-systems-showcase-files/IAH-20080430204825-00000-blackbook.warc#20080430205011/http://www.archive.org/about/faq.php?faq_id=257",
"faq.php",
"php",
}
func TestNormalise(t *testing.T) {
for i := 0; i < len(fnames); i += 3 {
fname, ext := normalise(fnames[i])
if fname != fnames[i+1] {
t.Errorf("normalise filename error\ninput: %s\nexpect: %s\ngot: %s", fnames[i], fnames[i+1], fname)
}
if ext != fnames[i+2] {
t.Errorf("normalise ext error\ninput: %s\nexpect: %s\ngot: %s", fnames[i], fnames[i+2], ext)
}
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package tests exports shared patterns for use by the other bytematcher packages
package tests
import . "github.com/richardlehane/siegfried/internal/bytematcher/patterns"
// TestSequences are exported so they can be used by the other bytematcher packages.
var TestSequences = []Sequence{
Sequence("test"),
Sequence("test"),
Sequence("testy"),
Sequence("TEST"),
Sequence("TESTY"),
Sequence("YNESS"), //5
{'a'},
{'b'},
{'c'},
{'d'},
{'e'},
{'f'},
{'g'},
{'h'},
{'i'},
{'j'},
Sequence("junk"), // 16
Sequence("23"),
}
// TestNotSequences are exported so they can be used by the other bytematcher packages.
var TestNotSequences = []Not{
{Sequence("test")},
{Sequence("test")},
{Sequence{255}},
{Sequence{0}},
{Sequence{10}},
}
// TestLists are exported so they can be used by the other bytematcher packages.
var TestLists = []List{
{TestSequences[0], TestSequences[2]},
{TestSequences[3], TestSequences[4]},
}
// Test Choices are exported so they can be used by the other bytematcher packages.
var TestChoices = []Choice{
{TestSequences[0], TestSequences[2]},
{TestSequences[2], TestSequences[0]},
{TestSequences[4], TestSequences[5]},
{TestSequences[3]},
{
TestSequences[6],
TestSequences[7],
TestSequences[8],
TestSequences[9],
TestSequences[10],
TestSequences[11],
TestSequences[12],
TestSequences[13],
TestSequences[14],
TestSequences[15],
},
{TestSequences[0], TestLists[0]},
{TestSequences[3], TestSequences[4]},
}
var TestMasks = []Mask{Mask(0xAA)}
var TestAnyMasks = []AnyMask{AnyMask(0xAA)}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Structures and helpers for Wikidata processing and validation.
package wikidata
import (
"encoding/json"
"fmt"
"github.com/richardlehane/siegfried/pkg/config"
)
// Summary of the identifier once processed.
type Summary struct {
AllSparqlResults int // All rows of data returned from our SPARQL request.
CondensedSparqlResults int // All unique records once the SPARQL is processed.
SparqlRowsWithSigs int // All SPARQL rows with signatures (SPARQL necessarily returns duplicates).
RecordsWithPotentialSignatures int // Records that have signatures that can be processed.
FormatsWithBadHeuristics int // Formats that have bad heuristics that we can't process.
RecordsWithSignatures int // Records remaining that were processed.
MultipleSequences int // Records that have been parsed out into multiple signatures per record.
AllLintingMessages []string // All linting messages returned.
AllLintingMessageCount int // Count of all linting messages output.
RecordCountWithLintingMessages int // A count of the records that have linting messages to investigate.
}
// String will serialize the summary report as JSON to be printed.
func (summary Summary) String() string {
report, err := json.MarshalIndent(summary, "", " ")
if err != nil {
return ""
}
return fmt.Sprintf("%s", report)
}
// analyseWikidataRecords will parse the processed Wikidata mapping and
// populate the summary structure to enable us to report on the identifier.
func analyseWikidataRecords(wikidataMapping wikidataMappings, summary *Summary) {
recordsWithLinting, allLinting, badHeuristics := countLintingErrors()
summary.RecordCountWithLintingMessages = recordsWithLinting
summary.AllLintingMessageCount = allLinting
summary.FormatsWithBadHeuristics = badHeuristics
for _, wd := range wikidataMapping {
if len(wd.Signatures) > 0 {
summary.RecordsWithSignatures++
}
for _, sigs := range wd.Signatures {
if len(sigs.ByteSequences) > 1 {
summary.MultipleSequences++
}
}
}
if config.WikidataDebug() {
summary.AllLintingMessages = lintingToString()
} else {
const debugMessage = "Use the `-wikidataDebug` flag to build the identifier to see linting messages"
summary.AllLintingMessages = []string{debugMessage}
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package config
import (
"encoding/json"
"io/ioutil"
"path/filepath"
)
var mimeinfo = struct {
mi string
name string
versions string
zip string
gzip string
tar string
arc string
warc string
text string
}{
versions: "mime-info.json",
zip: "application/zip",
gzip: "application/gzip",
tar: "application/x-tar",
arc: "application/x-arc",
warc: "application/x-warc",
text: "text/plain",
}
// MIMEInfo returns the location of the MIMEInfo signature file.
func MIMEInfo() string {
if filepath.Dir(mimeinfo.mi) == "." {
return filepath.Join(siegfried.home, mimeinfo.mi)
}
return mimeinfo.mi
}
func MIMEVersion() []string {
byt, err := ioutil.ReadFile(filepath.Join(siegfried.home, mimeinfo.versions))
m := make(map[string][]string)
if err == nil {
err = json.Unmarshal(byt, &m)
if err == nil {
return m[mimeinfo.mi]
}
}
return nil
}
func ZipMIME() string {
return mimeinfo.zip
}
func TextMIME() string {
return mimeinfo.text
}
func SetMIMEInfo(mi string) func() private {
return func() private {
wikidata.namespace = "" // reset wikidata to prevent pollution
loc.fdd = "" // reset loc to prevent pollution
switch mi {
case "tika", "tika-mimetypes.xml":
mimeinfo.mi = "tika-mimetypes.xml"
mimeinfo.name = "tika"
case "freedesktop", "freedesktop.org", "freedesktop.org.xml":
mimeinfo.mi = "freedesktop.org.xml"
mimeinfo.name = "freedesktop.org"
default:
mimeinfo.mi = mi
mimeinfo.name = "mimeinfo"
}
return private{}
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
package wikidatasparql
// wikidatasparql encapsulates SPARQL functions required for generating
// the Wikidata identifier in Roy.
import (
"strings"
)
// languateTemplate gives us a field which we can replace with a
// language code of our own configuration.
const languageTemplate = "<<lang>>"
// Number of replacements to make when replacing the SPARQL fields with
// the values that we have configured.
const numberReplacements = 1
// Default language for the Wikidata SPARQL query.
var wikidataLang = "en"
// sparql represents the query required to pull all file format records
// and signatures from the Wikidata query service.
const sparql = `
# Return all file format records from Wikidata.
#
select distinct ?uri ?uriLabel ?puid ?extension ?mimetype ?encoding ?referenceLabel ?date ?relativity ?offset ?sig
where
{
?uri wdt:P31/wdt:P279* wd:Q235557. # Return records of type File Format.
optional { ?uri wdt:P2748 ?puid. } # PUID is used to map to PRONOM signatures proper.
optional { ?uri wdt:P1195 ?extension. }
optional { ?uri wdt:P1163 ?mimetype. }
optional { ?uri p:P4152 ?object; # Format identification pattern statement.
optional { ?object pq:P3294 ?encoding. } # We don't always have an encoding.
optional { ?object ps:P4152 ?sig. } # We always have a signature.
optional { ?object pq:P2210 ?relativity. } # Relativity to beginning or end of file.
optional { ?object pq:P4153 ?offset. } # Offset relative to the relativity.
optional { ?object prov:wasDerivedFrom ?provenance;
optional { ?provenance pr:P248 ?reference;
pr:P813 ?date.
}
}
}
service wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE], <<lang>>". }
}
order by ?uri
`
// WikidataSPARQL returns the SPARQL query needed to pull file-format
// signatures from Wikidata replacing various template values as we
// go.
func WikidataSPARQL() string {
return strings.Replace(sparql, languageTemplate, wikidataLang, numberReplacements)
}
// WikidataLang will return to the caller the ISO language code
// currently configured for this module.
func WikidataLang() string {
return wikidataLang
}
// SetWikidataLang will set the Wikidata language to one supplied by
// the user. The language should be an ISO language code such as fr.
// de. jp. etc.
func SetWikidataLang(lang string) {
wikidataLang = lang
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"bufio"
"errors"
"flag"
"fmt"
"hash"
"io"
"log"
"os"
"path/filepath"
"runtime"
"strings"
"sync"
"time"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/internal/checksum"
"github.com/richardlehane/siegfried/internal/logger"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/decompress"
"github.com/richardlehane/siegfried/pkg/reader"
"github.com/richardlehane/siegfried/pkg/writer"
)
// defaults
const maxMulti = 1024
// flags
var (
updateShort = flag.Bool("u", false, "update or install the default signature file")
update = flag.Bool("update", false, "update or install the default signature file")
versionShort = flag.Bool("v", false, "display version information")
version = flag.Bool("version", false, "display version information")
logf = flag.String("log", "error", "log errors, warnings, debug or slow output, knowns or unknowns to stderr or stdout e.g. -log error,warn,unknown,stdout")
nr = flag.Bool("nr", false, "prevent automatic directory recursion")
_ = flag.Bool("yaml", true, "YAML output format") // yaml is the default, need a flag so can overwrite config (see conf.go)
csvo = flag.Bool("csv", false, "CSV output format")
jsono = flag.Bool("json", false, "JSON output format")
droido = flag.Bool("droid", false, "DROID CSV output format")
sig = flag.String("sig", config.SignatureBase(), "set the signature file")
home = flag.String("home", config.Home(), "override the default home directory")
serve = flag.String("serve", "", "start siegfried server e.g. -serve localhost:5138")
multi = flag.Int("multi", 1, "set number of parallel file ID processes")
archive = flag.Bool("z", false, fmt.Sprintf("scan archive formats: (%s)", config.ListAllArcTypes()))
selectArchives = flag.String("zs", "", fmt.Sprintf("select archive formats to scan: (%s)", config.ListAllArcTypes()))
hashf = flag.String("hash", "", "calculate file checksum with hash algorithm; options "+checksum.HashChoices)
throttlef = flag.Duration("throttle", 0, "set a time to wait between scanning files e.g. 50ms")
utcf = flag.Bool("utc", false, "report file modified times in UTC, rather than local, TZ")
coe = flag.Bool("coe", false, "continue on fatal errors during directory walks (this may result in directories being skipped)")
replay = flag.Bool("replay", false, "replay one (or more) results files to change output or logging e.g. sf -replay -csv results.yaml")
list = flag.Bool("f", false, "scan one (or more) lists of filenames e.g. sf -f myfiles.txt")
name = flag.String("name", "", "provide a filename when scanning a stream e.g. sf -name myfile.txt -")
conff = flag.String("conf", "", "set the configuration file")
setconff = flag.Bool("setconf", false, "record flags used with this command in configuration file")
)
var (
throttle *time.Ticker
ctxPool *sync.Pool
)
type modeError os.FileMode
func (me modeError) Error() string {
typ := "unknown"
switch {
case os.FileMode(me)&os.ModeDir == os.ModeDir:
typ = "directory"
case os.FileMode(me)&os.ModeSymlink == os.ModeSymlink:
typ = "symlink"
case os.FileMode(me)&os.ModeNamedPipe == os.ModeNamedPipe:
typ = "named pipe"
case os.FileMode(me)&os.ModeSocket == os.ModeSocket:
typ = "socket"
case os.FileMode(me)&os.ModeDevice == os.ModeDevice:
typ = "device"
case os.FileMode(me)&256 == 0:
return "file does not have user read permissions; and cannot be scanned"
}
return fmt.Sprintf("file is of type %s; only regular files can be scanned", typ)
}
type walkError struct {
path string
err error
}
func (we walkError) Error() string {
return fmt.Sprintf("[FATAL] file access error for %s: %v", we.path, we.err)
}
func setCtxPool(s *siegfried.Siegfried, wg *sync.WaitGroup, w writer.Writer, d, z bool, h checksum.HashTyp) {
ctxPool = &sync.Pool{
New: func() interface{} {
return &context{
s: s,
wg: wg,
w: w,
d: d,
z: z,
h: checksum.MakeHash(h),
res: make(chan results, 1),
}
},
}
}
type getFn func(string, string, time.Time, int64) *context
func getCtx(path, mime string, mod time.Time, sz int64) *context {
c := ctxPool.Get().(*context)
if c.h != nil {
c.h.Reset()
}
c.path, c.mime, c.mod, c.sz = path, mime, mod, sz
return c
}
type context struct {
s *siegfried.Siegfried
wg *sync.WaitGroup
w writer.Writer
d bool // droid
// opts
z bool
h hash.Hash
// info
path string
mime string
mod time.Time
sz int64
// results
res chan results
}
type results struct {
err error
cs []byte
ids []core.Identification
}
func printer(ctxts chan *context, lg *logger.Logger) {
for ctx := range ctxts {
lg.Progress(ctx.path)
// block on the results
res := <-ctx.res
lg.Error(ctx.path, res.err)
lg.IDs(ctx.path, res.ids)
if *utcf {
ctx.mod = ctx.mod.UTC()
}
// write the result
ctx.w.File(ctx.path, ctx.sz, ctx.mod.Format(time.RFC3339), res.cs, res.err, res.ids)
ctx.wg.Done()
ctxPool.Put(ctx) // return the context to the pool
}
}
// convenience function for printing files we haven't ID'ed (e.g. dirs or errors)
func printFile(ctxs chan *context, ctx *context, err error) {
ctx.res <- results{err, nil, nil}
ctx.wg.Add(1)
ctxs <- ctx
}
// identify() defined in longpath.go and longpath_windows.go
func readFile(ctx *context, ctxts chan *context, gf getFn) {
f, err := os.Open(ctx.path)
if err != nil {
f, err = retryOpen(ctx.path, err) // retry open in case is a windows long path error
if err != nil {
ctx.res <- results{err, nil, nil}
return
}
}
identifyRdr(f, ctx, ctxts, gf)
f.Close()
}
func identifyFile(ctx *context, ctxts chan *context, gf getFn) {
wg := ctx.wg
wg.Add(1)
ctxts <- ctx
if *multi == 1 || ctx.z || config.Slow() || config.Debug() {
readFile(ctx, ctxts, gf)
return
}
wg.Add(1)
go func() {
readFile(ctx, ctxts, gf)
wg.Done()
}()
}
func identifyRdr(r io.Reader, ctx *context, ctxts chan *context, gf getFn) {
s := ctx.s
b, berr := s.Buffer(r)
defer s.Put(b)
ids, err := s.IdentifyBuffer(b, berr, ctx.path, ctx.mime)
if ids == nil {
ctx.res <- results{err, nil, nil}
return
}
// calculate checksum
var cs []byte
if ctx.h != nil {
var i int64
l := ctx.h.BlockSize()
for ; ; i += int64(l) {
buf, _ := b.Slice(i, l)
if buf == nil {
break
}
ctx.h.Write(buf)
}
cs = ctx.h.Sum(nil)
}
// decompress if an archive format
if !ctx.z {
ctx.res <- results{err, cs, ids}
return
}
arc := decompress.IsArc(ids)
if arc == config.None {
ctx.res <- results{err, cs, ids}
return
}
d, err := decompress.New(arc, b, ctx.path, ctx.sz)
if err != nil {
ctx.res <- results{fmt.Errorf("failed to decompress, got: %v", err), cs, ids}
return
}
// send the result
zpath := ctx.path
ctx.res <- results{err, cs, ids}
// decompress and recurse
for err = d.Next(); err == nil; err = d.Next() {
if ctx.d {
for _, v := range d.Dirs() {
printFile(ctxts, gf(v, "", time.Time{}, -1), nil)
}
}
nctx := gf(d.Path(), d.MIME(), d.Mod(), d.Size())
nctx.wg.Add(1)
ctxts <- nctx
identifyRdr(d.Reader(), nctx, ctxts, gf)
}
if err != io.EOF && err != nil {
printFile(ctxts, gf(decompress.Arcpath(zpath, ""), "", time.Time{}, 0), fmt.Errorf("error occurred during decompression: %v", err))
}
}
func openFile(path string) (*os.File, error) {
if path == "-" {
return os.Stdin, nil
}
return os.Open(path)
}
var firstReplay sync.Once
func replayFile(path string, ctxts chan *context, w writer.Writer) error {
f, err := openFile(path)
if err != nil {
return err
}
defer f.Close()
rdr, err := reader.New(f, path)
if err != nil {
return fmt.Errorf("[FATAL] error reading results file %s; got %v", path, err)
}
hd := rdr.Head()
if *droido && (len(hd.Identifiers) != 1 || len(hd.Fields[0]) != 7) {
return errors.New("[FATAL] DROID output is limited to signature files with a single PRONOM identifier")
}
firstReplay.Do(func() {
w.Head(hd.SignaturePath, hd.Scanned, hd.Created, hd.Version, hd.Identifiers, hd.Fields, hd.HashHeader)
})
var rf reader.File
for rf, err = rdr.Next(); err == nil; rf, err = rdr.Next() {
ctx := getCtx(rf.Path, "", rf.Mod, rf.Size)
ctx.res <- results{rf.Err, rf.Hash, rf.IDs}
ctx.wg.Add(1)
ctxts <- ctx
}
if err != nil && err != io.EOF {
return fmt.Errorf("[FATAL] error reading results file %s; got %v", path, err)
}
return nil
}
func main() {
flag.Parse()
// configure home
if *home != config.Home() {
config.SetHome(*home)
}
// conf funcs - setconff saves flags as configuration; readconf reads defaults
if *conff != "" {
config.SetConf(*conff)
}
if *setconff {
msg, err := setconf()
if err != nil {
log.Fatalf("[FATAL] failed to set configuration file, %v", err)
}
if msg == "" {
fmt.Printf("No flags to save, deleted config file (if it exists) at %s\n", config.Conf())
return
}
fmt.Printf("Saved flags (%s) in config file at %s\n", msg, config.Conf())
return
}
if err := readconf(); err != nil {
log.Fatalf("[FATAL] error reading configuration file, %v", err)
}
// configure signature
var usig string
if *sig != config.SignatureBase() {
config.SetSignature(*sig)
usig = *sig
}
// handle -update
if *update || *updateShort {
_, msg, err := updateSigs(usig, flag.Args())
if err != nil {
log.Fatalf("[FATAL] failed to update signature file, %v", err)
}
fmt.Println(msg)
return
}
// handle -hash error
hashT := checksum.GetHash(*hashf)
if *hashf != "" && hashT < 0 {
log.Fatalf("[FATAL] invalid hash type; choose from %s", checksum.HashChoices)
}
// load and handle signature errors
var (
s *siegfried.Siegfried
err error
)
if !*replay || *version || *versionShort || *fprflag || *serve != "" {
s, err = load(config.Signature())
}
if err != nil {
log.Fatalf("[FATAL] error loading signature file, got: %v", err)
}
// handle -version
if *version || *versionShort {
version := config.Version()
fmt.Printf("siegfried %d.%d.%d\n", version[0], version[1], version[2])
fmt.Printf("%s (%s)\nidentifiers: \n", config.Signature(), s.C.Format(time.RFC3339))
for _, id := range s.Identifiers() {
fmt.Printf(" - %s: %s\n", id[0], id[1])
}
confflags, _ := getconf()
if len(confflags) > 0 {
fmt.Print("config: \n")
for k, v := range confflags {
fmt.Printf(" - %s: %s\n", k, v)
}
}
return
}
// handle -z and -zs
if *archive || *selectArchives != "" {
*archive = true // if zs flag given, no need to also give z flag
if *selectArchives == "" {
config.SetArchiveFilterPermissive(config.ListAllArcTypes())
} else {
config.SetArchiveFilterPermissive(*selectArchives)
}
}
// handle -fpr
if *fprflag {
log.Printf("FPR server started at %s. Use CTRL-C to quit.\n", config.Fpr())
serveFpr(config.Fpr(), s)
return
}
// check -multi
if *multi > maxMulti || *multi < 1 || (*archive && *multi > 1) {
log.Println("[WARN] -multi must be > 0 and =< 1024. If -z, -multi must be 1. Resetting -multi to 1")
*multi = 1
}
// start logger
lg, err := logger.New(*logf)
if err != nil {
log.Fatalln(err)
}
if config.Slow() || config.Debug() {
if *serve != "" || *fprflag {
log.Fatalln("[FATAL] debug and slow logging cannot be run in server mode")
}
}
// start throttle
if *throttlef != 0 {
throttle = time.NewTicker(*throttlef)
defer throttle.Stop()
}
// start the printer
lenCtxts := *multi
if lenCtxts == 1 {
lenCtxts = 8
}
ctxts := make(chan *context, lenCtxts)
go printer(ctxts, lg)
// set default writer
var w writer.Writer
var d bool
switch {
case lg.IsOut():
w = writer.Null()
case *csvo:
w = writer.CSV(os.Stdout)
case *jsono:
w = writer.JSON(os.Stdout)
case *droido:
if !*replay && (len(s.Fields()) != 1 || len(s.Fields()[0]) < 7) {
close(ctxts)
log.Fatalln("[FATAL] DROID output is limited to signature files with a single PRONOM identifier")
}
decompress.SetDroid()
w = writer.Droid(os.Stdout)
d = true
default:
w = writer.YAML(os.Stdout)
}
// setup default waitgroup
wg := &sync.WaitGroup{}
// setup context pool
setCtxPool(s, wg, w, d, *archive, hashT)
// handle -serve
if *serve != "" {
log.Printf("Starting server at %s. Use CTRL-C to quit.\n", *serve)
listen(*serve, s, ctxts)
return
}
// handle no file/directory argument
if flag.NArg() < 1 {
close(ctxts)
log.Fatalln("[FATAL] expecting one or more file or directory arguments (or '-' to scan stdin)")
}
if !*replay {
w.Head(config.SignatureBase(), time.Now(), s.C, config.Version(), s.Identifiers(), s.Fields(), hashT.String())
}
for _, v := range flag.Args() {
if *list {
f, err := openFile(v)
if err != nil {
break
}
scanner := bufio.NewScanner(f)
for scanner.Scan() {
if *replay {
err = replayFile(scanner.Text(), ctxts, w)
if err != nil {
break
}
} else {
err = identify(ctxts, scanner.Text(), "", *coe, *nr, d, getCtx)
if err != nil {
printFile(ctxts,
getCtx(scanner.Text(), "", time.Time{}, 0),
fmt.Errorf("failed to identify %s: %v", scanner.Text(), err))
err = nil
}
}
}
f.Close()
} else if *replay {
err = replayFile(v, ctxts, w)
} else if v == "-" {
ctx := getCtx(*name, "", time.Time{}, 0)
ctx.wg.Add(1)
ctxts <- ctx
identifyRdr(os.Stdin, ctx, ctxts, getCtx)
} else {
// As a workaround for https://github.com/richardlehane/siegfried/issues/227 only do glob matching on Windows _after_ a direct match has been tried and the name contains characters that indicate a possible pattern
if runtime.GOOS == "windows" && strings.ContainsAny(v, "*?[\\") {
err = tryStat(v)
if err != nil {
// Since patterns aren't assumed to be the main argument form and a bad pattern can still be a valid filename (e.g. `file[.txt`) that just wasn't found ignore the returned error and just handle found matches
matches, _ := filepath.Glob(v)
if matches != nil {
for _, match := range matches {
err = identify(ctxts, match, "", *coe, *nr, d, getCtx)
if err != nil {
printFile(ctxts, getCtx(v, "", time.Time{}, 0), fmt.Errorf("failed to identify %s: %v", v, err))
err = nil
}
}
continue
}
err = walkError{v, err}
break
}
}
err = identify(ctxts, v, "", *coe, *nr, d, getCtx)
}
if err != nil {
break
}
}
wg.Wait()
close(ctxts)
w.Tail()
// log time elapsed and chart
lg.Close()
if err != nil {
log.Fatal(err)
}
os.Exit(0)
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package frames
import "github.com/richardlehane/siegfried/internal/bytematcher/patterns"
// Sequencer turns sequential frames into a set of plain byte sequences. The set represents possible choices.
type Sequencer func(Frame) [][]byte
// NewSequencer creates a Sequencer (reversed if true).
func NewSequencer(rev bool) Sequencer {
var ret [][]byte
return func(f Frame) [][]byte {
var s []patterns.Sequence
if rev {
s = f.Sequences()
for i := range s {
s[i] = s[i].Reverse()
}
} else {
s = f.Sequences()
}
ret = appendSeq(ret, s)
return ret
}
}
func appendSeq(b [][]byte, s []patterns.Sequence) [][]byte {
var c [][]byte
if len(b) == 0 {
c = make([][]byte, len(s))
for i, seq := range s {
c[i] = make([]byte, len(seq))
copy(c[i], []byte(seq))
}
} else {
c = make([][]byte, len(b)*len(s))
iter := 0
for _, seq := range s {
for _, orig := range b {
c[iter] = make([]byte, len(orig)+len(seq))
copy(c[iter], orig)
copy(c[iter][len(orig):], []byte(seq))
iter++
}
}
}
return c
}
<file_sep>//go:build static
package main
import (
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/static"
)
func load(path string) (*siegfried.Siegfried, error) {
return static.New(), nil
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package loc
import "testing"
var magicTests = [][]string{
{
`Hex: 52 49 46 46 xx xx xx xx 57 41 56 45 66 6D 74 20`,
`ASCII: RIFF....WAVEfmt`,
},
{
`Hex: 46 4F 52 4D 00`,
`ASCII: FORM`,
},
{
`Hex: 06 0E 2B 34 02 05 01 01 0D 01 02 01 01 02`,
`ASCII: ..+4`,
},
{
`Hex: 0xFF 0xD8`,
},
{
`Hex: FF D8 FF E0 xx xx 4A 46 49 46 00`,
`ASCII: ÿØÿè..JFIF.`,
},
{
`Hex: FF D8 FF E8 xx xx 53 50 49 46 46 00 `,
`ASCII: ÿØÿè..SPIFF`,
},
{
`Hex: 49 49 2A 00`,
`Hex: 49 49`,
`ASCII: II`,
`Hex: 4D 4D 00 2A`,
`ASCII: MM`,
},
{
`Hex: 4F 67 67 53 00 02 00 00 00 00 00 00 00 00`,
`ASCII: OggS`,
},
{
`Hex: 30 26 B2 75 8E 66 CF 11 A6 D9 00 AA 00 62 CE 6C`,
`ASCII: 0&²u.fÏ.¦Ù.ª.bÎl`,
},
{
`Hex: 00 00 01 Bx`,
`ASCII: ....`,
},
{
`Hex: 25 50 44 46`,
`ASCII: %PDF`,
},
{
`ASCII: msid`,
},
{
`Hex: 00 00 01 Bx`,
`ASCII: ....`,
},
{
`Hex: 2E 52 4D 46`,
`ASCII: .RMF`,
`Hex: 2E 52 4D 46 00 00 00 12 00`,
`ASCII: .RMF`,
},
{
`Hex: 2E 52 4D 46`,
`ASCII: .RMF`,
`Hex: 2E 52 4D 46 00 00 00 12 00`,
`ASCII: .RMF`,
},
{
`Hex: xx xx xx xx 6D 6F 6F 76`,
`ASCII: ....moov`,
},
{
`Hex: 52 49 46 46 xx xx xx xx 41 56 49 20 4C 49 53 54`,
`ASCII: RIFF....AVILIST`,
},
{
`Hex: 30 26 B2 75 8E 66 CF 11 A6 D9 00 AA 00 62 CE 6C`,
`ASCII: 0&²u.fÏ.¦Ù.ª.bÎl`,
},
{
`Hex: 30 26 B2 75 8E 66 CF 11 A6 D9 00 AA 00 62 CE 6C`,
`ASCII: 0&²u.fÏ.¦Ù.ª.bÎl`,
},
{
`Hex: FF FB 30`,
},
{
`Hex: 46 4F 52 4D 00`,
`ASCII: FORM`,
},
{
`Hex: 52 49 46 46`,
`ASCII: RIFF`,
},
{
`Hex: 4D 54 68 64`,
`ASCII: MThd`,
},
{
`Hex: 52 49 46 46 xx xx xx xx 52 4D 49 44 64 61 74 61`,
`ASCII: RIFF....RMIDdata`,
},
{
`Hex: 58 4D 46 5F`,
`ASCII: XMF_`,
},
{
`Hex: 4A 4E`,
`ASCII: JN`,
` Hex: 69 66`,
`ASCII: if`,
`Hex: 44 44 4D 46`,
`ASCII: DDMF`,
`Hex: 46 41 52 FE`,
`ASCII: FAR`,
`Hex: 49 4D 50 4D`,
`ASCII: IMPM`,
`Hex: 4D 4D 44`,
`ASCII: MMD`,
`Hex: 4D 54 4D`,
`ASCII: MTM`,
`Hex: 4F 4B 54 41 53 4F 4E 47 43 4D 4F 44`,
` ASCII: OKTASONGCMOD`,
`Hex (position 25): 00 00 00 1A 10 00 00`,
`Hex: 45 78 74 65 6E 64 65 64 20 6D 6F 64 75 6C 65 3A 20`,
`ASCII: Extended module:`,
},
{
`12 byte string: X'0000 000C 6A50 2020 0D0A 870A'`,
},
{
`Hex: 46 57 53`,
`ASCII: FWS`,
`Hex: 43 57 53`,
`ASCII: CWS`,
},
{
`Hex: 46 4C 56`,
`ASCII: FLV`,
},
{
`Hex: D0 CF 11 E0 A1 B1 1A E1 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00`,
},
{
`Hex: 47 49 46 38 39 61`,
`ASCII: GIF89a`,
},
{
`Hex: 00 00 00 0C 6A 50 20 20 0D 0A 87 0A 00 00 00 14 66 74 79 70 6A 70 32`,
},
{
`Hex: 49 20 49`,
`ASCII: I<space>I`,
},
{
`HEX: FF D8 FF E1 xx xx 45 78 69 66 00`,
` ASCII: ÿØÿà..EXIF.`,
},
{
`Hex: 0xFF 0xD8`,
},
{
`Hex: 0xFF 0xD8`,
},
{
`Hex: 0xFF 0xD8`,
},
{
`Hex: 89 50 4e 47 0d 0a 1a 0a`,
`ASCII: \211 P N G \r \n \032 \n`,
},
{
`Hex: 0x53445058`,
`ASCII: SDPX`,
`Hex: 0x58504453`,
`ASCII: XPDS`,
},
{
`BM`,
},
{
`Hex: 66 4C 61 43 00 00 00 22`,
`ASCII: fLaC`,
},
{
`Hex: 61 6A 6B 67 02 FB`,
`ASCII: ajkg`,
},
{
`Hex: 0E 03 13 01`,
},
{
`Hex: 89 48 44 46 0d 0a 1a 0a`,
`ASCII: \211 HDF \r \n \032 \n`,
},
{
`Not applicable`,
},
{
`Hex: 49 49 1A 00 00 00 48 45 41 50 43 43 44 52 02 00 01`,
`ASCII: II [null] HEAPCCDR`,
`Hex: 00 4D 52 4D`,
`ASCII: .MRM`,
`Hex: 46 4F 56 62`,
`ASCII: FOVb`,
},
{
`Hex: 49 49 BC`,
`ASCII: II.`,
},
{
`Hex: 46 57 53`,
`ASCII: FWS`,
`Hex: 43 57 53`,
`ASCII: CWS`,
},
{
`Hex: 0x2321414d520a`,
`ASCII: #!AMR\n `,
`Hex: 00 00 00`,
},
{
`Hex: 0x2321414d522d57420a`,
`ASCII: #!AMR-WB\n`,
},
{
`Hex: 4F 67 67 53 00 02 00 00 00 00 00 00 00 00`,
`ASCII: OggS`,
},
{
` Hex: 00 00 27 0A 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00`,
`ASCII: ' `,
},
{
`HEX: 53 49 4d 50 4c 45`,
`ASCII: SIMPLE`,
`HEX: 53 49 4d 50 4c 45 20 20 3d {20 bytes of Hex 20} 54`,
`ASCII: SIMPLE {2 spaces} = {20 spaces} T`,
},
{
`Hex: 43 44 46 01`,
`ASCII: CDF \x01`,
`Hex: 43 44 46 02`,
`ASCII: CDF \x02`,
},
{
`Hex: 0xFF 0xD8`,
},
{
`Hex: 0xFF 0xD8`,
},
{
`Hex: 00 00 01 Bx`,
`ASCII: ....`,
},
{
`1A 45 DF A3 93 42 82 88
6D 61 74 72 6F 73 6B 61`,
},
{
`Hex: 43 44 30 30 31`,
`ASCII: CD001`,
},
{
`Hex: 21 42 44 4E`,
`ASCII: !BDN`,
},
{
`00 0D BB A0`,
},
{
`Hex: 45 56 46 09 0D 0A FF 00`,
`ASCII: EVF...ÿ.`,
},
{
`Hex: 45 56 46 09 0D 0A FF 00`,
`ASCII: EVF...ÿ.`,
},
{
`Hex: 4C 56 46 09 0D 0A FF 00`,
`ASCII: LVF...ÿ.`,
},
{
`Hex: 45 56 46 32 0D 0A 81 00`,
`ASCII: EVF2....`,
},
{
`Hex: 4C 45 46 32 0D 0A 81 00`,
`ASCII: LEF2....`,
},
{
`Hex: 41 46 46`,
`ASCII: AFF`,
},
{
`LASF`,
},
{
`Hex: 53 51 4c 69 74 65 20 66 6f 72 6d 61 74 20 33 00`,
`ASCII: SQLite format 3`,
},
{
`ASCII: EHFA_HEADER_TAG`,
`ASCII: ERDAS_IMG_EXTERNAL_RASTER`,
},
{
`1A 00 00 04 00 00`,
},
{
`Hex: 4D 41 54 4C 41 42 20 35 2E 30 20 4D 41 54 2D 66 69 6C 65 2C 20 50 6C 61 74 66 6F 72 6D 3A 20`,
`ASCII: MATLAB 5.0 MAT-file, Platform:`,
},
}
func TestMagic(t *testing.T) {
for _, v := range magicTests {
_, err := magics(v)
if err != nil {
t.Fatalf("Error parsing: %v; got %v", v, err)
}
}
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package loc
import (
"fmt"
"path/filepath"
"testing"
"time"
"github.com/richardlehane/siegfried/pkg/config"
)
func TestLOC(t *testing.T) {
var dump, dumpmagic bool // set to true to print out LOC sigs
config.SetHome(filepath.Join("..", "..", "cmd", "roy", "data"))
config.SetLOC("")()
l, err := newLOC(config.LOC())
if l != nil {
if dump {
fdd := l.(fdds)
for _, v := range fdd.f {
fmt.Println(v)
fmt.Println("****************")
}
} else if dumpmagic {
fdd := l.(fdds)
for _, v := range fdd.f {
if len(v.Magics) > 0 {
fmt.Println("{")
for _, m := range v.Magics {
fmt.Println("`" + m + "`,")
}
fmt.Println("},")
}
}
}
if _, _, err = l.Signatures(); err != nil {
t.Fatal(err)
}
} else {
t.Fatalf("Expecting a LOC, got nothing! Error: %v", err)
}
}
func TestUpdated(t *testing.T) {
config.SetHome(filepath.Join("..", "..", "cmd", "roy", "data"))
l, err := newLOC(config.LOC())
if err != nil || l == nil {
t.Fatalf("couldn't parse LOC file: %v", err)
}
expect, _ := time.Parse(dateFmt, "2016-01-01")
f := l.(fdds)
if !f.Updated().After(expect) {
t.Fatalf("expected %v, got %v", expect, f.Updated())
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"os"
"path/filepath"
"strings"
"time"
)
// longpath code derived from https://github.com/docker/docker/tree/master/pkg/longpath
// prefix is the longpath prefix for Windows file paths.
const prefix = `\\?\`
func longpath(path string) string {
if !strings.HasPrefix(path, prefix) {
if strings.HasPrefix(path, `\\`) {
// This is a UNC path, so we need to add 'UNC' to the path as well.
path = prefix + `UNC` + path[1:]
} else {
abs, err := filepath.Abs(path)
if err != nil {
return path
}
path = prefix + abs
}
}
return path
}
// attempt to reconstitute original path
func shortpath(long, short string) string {
if short == "" {
return long
}
i := strings.Index(long, short)
if i == -1 {
return long
}
return long[i:]
}
func tryStat(path string) error {
_, err := os.Lstat(path)
if err != nil {
_, err = retryStat(path, err)
}
return err
}
func retryStat(path string, err error) (os.FileInfo, error) {
if strings.HasPrefix(path, prefix) { // already a long path - no point retrying
return nil, err
}
info, e := os.Lstat(longpath(path)) // filepath.Walk uses Lstat not Stat
if e != nil {
return nil, err
}
return info, nil
}
func retryOpen(path string, err error) (*os.File, error) {
if strings.HasPrefix(path, prefix) { // already a long path - no point retrying
return nil, err
}
file, e := os.Open(longpath(path))
if e != nil {
return nil, err
}
return file, nil
}
func identify(ctxts chan *context, root, orig string, coerr, norecurse, droid bool, gf getFn) error {
walkFunc := func(path string, info os.FileInfo, err error) error {
var retry bool
var lp, sp string
if *throttlef > 0 {
<-throttle.C
}
if err != nil {
info, err = retryStat(path, err) // retry stat in case is a windows long path error
if err != nil {
if coerr {
printFile(ctxts, gf(path, "", time.Time{}, 0), walkError{path, err})
return nil
}
return walkError{path, err}
}
lp, sp = longpath(path), path
retry = true
}
if info.IsDir() {
if norecurse && path != root {
return filepath.SkipDir
}
if retry { // if a dir long path, restart the recursion with a long path as the new root
return identify(ctxts, lp, sp, coerr, norecurse, droid, gf)
}
if droid {
printFile(ctxts, gf(shortpath(path, orig), "", info.ModTime(), -1), nil)
}
return nil
}
if !info.Mode().IsRegular() {
printFile(ctxts, gf(path, "", info.ModTime(), info.Size()), modeError(info.Mode()))
return nil
}
identifyFile(gf(shortpath(path, orig), "", info.ModTime(), info.Size()), ctxts, gf)
return nil
}
return filepath.Walk(root, walkFunc)
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Satisfies the Parseable interface to enable Roy to process Wikidata
// signatures into a Siegfried compatible identifier.
package config
import (
"testing"
)
// Valid archive UIDs.
var proZipUID = "x-fmt/263"
var locArcUID = "fdd000235"
var mimeTarUID = "application/x-tar"
var mimeWarcUID = "application/x-warc"
var mimeGzipUID = "application/gzip"
// Non-archive UID.
var nonArcUID = "fmt/1000"
// arcTest defines the structure needed for our table driven testing.
type arcTest struct {
filter string // The set of zip-type files to provide SetArchiveFilterPermissive(...)
uid string // A UID (PUID, FDD) that identifies a zip-type file.
result Archive // The anticipated result from our test.
}
// isArcTests provide us a slice of tests and results to loop through.
var isArcTests = []arcTest{
// Positive tests should return valid Archive values.
arcTest{ListAllArcTypes(), proZipUID, Zip},
arcTest{"TAR", mimeTarUID, Tar},
arcTest{"gZip", mimeGzipUID, Gzip},
arcTest{"warc,zip,tar", mimeWarcUID, WARC},
arcTest{"zip,arc", locArcUID, ARC},
// Negative tests should all return None.
arcTest{"zip,arc", mimeWarcUID, None},
arcTest{"zip,arc", mimeGzipUID, None},
arcTest{ListAllArcTypes(), nonArcUID, None},
arcTest{"", nonArcUID, None},
}
// TestIsArchivePositive tests cases where the archive filter should
// return a positive match.
func TestIsArchivePositive(t *testing.T) {
for _, test := range isArcTests {
SetArchiveFilterPermissive(test.filter)
arc := IsArchive(test.uid)
if arc != test.result {
t.Errorf(
"Unexpected test result '%s', expected '%s'",
arc, test.result,
)
}
}
}
var arcTypes = [...]Archive{Zip, Gzip, Tar, ARC, WARC}
const noneType = None
// TestIsArchiveGreaterThanNone is a test to to ensure that legacy
// functions relying on `id.Archive() > config.None`.
func TestIsArchiveGreaterThanNone(t *testing.T) {
for _, item := range arcTypes {
if item <= None {
t.Errorf("Archive is evaluating less than 0")
}
}
if noneType != 0 {
t.Errorf("Archive 0 type should equal zero not %d", noneType)
}
}
<file_sep>package pronom
import "testing"
type testpattern struct {
name string
pattern string
}
var good = []testpattern{
{
"dbf",
"02{2}[01:1C][01:1F]????[00:03]([41:5A]|[61:7A]){10}(43|4E|4C)",
},
{
"dcx",
"0004000000000000000000000A00[!00]{1009}03000200FFFFFFFFFFFFFFFF{1}01FFFF{2}0F0F{491}[41:5A]000A{502}2B00[0B:0F]0000002B00{512}[!00]00[!00]00FFFFFFFFFFFFFFFF",
},
{
"igs",
"53(202020202020|303030303030)31(0D0A|0A){72}(5320202020202032|5330303030303032|4720202020202031|4730303030303031)",
},
{
"mif",
"56(45|65)(52|72)(53|73)(49|69)??(4E|6E){5-6}(43|63)(48|68)(41|61)(52|72)(53|73)(45|65)(54|74)*43(4F|6F)(4C|6C)(55|75)(4D|6D)(4E|6E)(53|73)",
},
{
"zip",
"504B01{43-65531}504B0506{18-65531}",
},
{
"ani",
"52494646{4}41434F4E{0-*}616E69682400000024000000[!00]*4C495354{4}6672616D69636F6E",
},
{
"cel",
"1991[!4001C80000000000]",
},
{
"notrange",
"1991[!01:02]", // made this up, haven't seen any in the wild with a not range
},
{
"notchoice",
"1991(!65|[!01:02])",
},
{
"rangechoice",
"1991(6500|52[01:02])", // with a list
},
{
"OOXML",
`'C'00 'o'00 'n'00 't'00 'e'00 'n'00 't'00 'T'00 'y'00 'p'00 'e'00 '='00 '"'00 'a'00 'p'00 'p'00 'l'00 'i'00 'c'00 'a'00 't'00 'i'00 'o'00 'n'00 '/'00 'v'00 'n'00 'd'00 '.'00 'o'00 'p'00 'e'00 'n'00 'x'00 'm'00 'l'00 'f'00 'o'00 'r'00 'm'00 'a'00 't'00 's'00 '-'00 'o'00 'f'00 'f'00 'i'00 'c'00 'e'00 'd'00 'o'00 'c'00 'u'00 'm'00 'e'00 'n'00 't'00 '.'00 'w'00 'o'00 'r'00 'd'00 'p'00 'r'00 'o'00 'c'00 'e'00 's'00 's'00 'i'00 'n'00 'g'00 'm'00 'l'00 '.'00 'd'00 'o'00 'c'00 'u'00 'm'00 'e'00 'n'00 't'00 '.'00 'm'00 'a'00 'i'00 'n'00 '+'00 'x'00 'm'00 'l'00 '"'00`,
},
{
"WORD",
`10 00 00 00 'Word.Document.' ['6'-'7'] 00`,
},
{
"ODT",
`'office:version=' [22 27] '1.0' [22 27]`,
},
{
"VISIO",
`'Visio (TM) Drawing'0D0A`,
},
}
var bad = []testpattern{
{
"badchar",
"1991[!4001C80000000000]y",
},
{
"singlewild",
"1991?ACCD",
},
{
"badwild",
"1991{ABCD}ABDC",
},
{
"unclosed",
"1991[!4001",
},
}
func TestGood(t *testing.T) {
for _, v := range good {
l := lexPRONOM(v.name, v.pattern)
for i := l.nextItem(); i.typ != itemEOF; i = l.nextItem() {
if i.typ == itemError {
t.Error(i)
break
}
}
}
}
func TestBad(t *testing.T) {
for _, v := range bad {
l := lexPRONOM(v.name, v.pattern)
i := l.nextItem()
for ; i.typ != itemEOF; i = l.nextItem() {
if i.typ == itemError {
break
}
}
if i.typ != itemError {
t.Error(v.name)
}
}
}
func TestAcceptText(t *testing.T) {
test := `'C'00 'o'00 'n'00 't'00 'e'00 'n'00 't'00 'T'00 'y'00 'p'00 'e'00 '='00 '"'00 'a'00 'p'00 'p'00 'l'00 'i'00 'c'00 'a'00 't'00 'i'00 'o'00 'n'00 '/'00 'v'00 'n'00 'd'00 '.'00 'o'00 'p'00 'e'00 'n'00 'x'00 'm'00 'l'00 'f'00 'o'00 'r'00 'm'00 'a'00 't'00 's'00 '-'00 'o'00 'f'00 'f'00 'i'00 'c'00 'e'00 'd'00 'o'00 'c'00 'u'00 'm'00 'e'00 'n'00 't'00 '.'00 'w'00 'o'00 'r'00 'd'00 'p'00 'r'00 'o'00 'c'00 'e'00 's'00 's'00 'i'00 'n'00 'g'00 'm'00 'l'00 '.'00 'd'00 'o'00 'c'00 'u'00 'm'00 'e'00 'n'00 't'00 '.'00 'm'00 'a'00 'i'00 'n'00 '+'00 'x'00 'm'00 'l'00 '"'00 `
l := &lexer{
name: "test",
input: test,
items: make(chan item, 1),
}
e := l.acceptText(false)
if e != nil {
t.Error(e)
}
l.emit(itemUnprocessedText)
i := <-l.items
if i.val != test {
t.Errorf("Expecting %s, got %s", test, i.val)
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mappings
import "encoding/xml"
type MIMEInfo struct {
XMLName xml.Name `xml:"mime-info"`
MIMETypes []MIMEType `xml:"mime-type"`
}
type MIMEType struct {
MIME string `xml:"type,attr"`
Globs []struct {
Pattern string `xml:"pattern,attr"`
Weight string `xml:"weight,attr"`
} `xml:"glob"`
XMLPattern []struct {
Local string `xml:"localName,attr"`
NS string `xml:"namespaceURI,attr"`
} `xml:"root-XML"`
Magic []Magic `xml:"magic"`
Aliases []struct {
Alias string `xml:"type,attr"`
} `xml:"alias"`
SuperiorClasses []struct {
SubClassOf string `xml:"type,attr"`
} `xml:"sub-class-of"`
Comment []string `xml:"_comment"`
Comments []string `xml:"comment"`
Acronym []string `xml:"acronym"`
Superior bool `xml:"-"`
}
type Magic struct {
Matches []Match `xml:"match"`
Priority string `xml:"priority,attr"`
}
type Match struct {
Typ string `xml:"type,attr"`
Offset string `xml:"offset,attr"`
Value string `xml:"value,attr"`
Mask string `xml:"mask,attr"`
Matches []Match `xml:"match"`
}
// Some string methods just for debugging the mappings - delete once confirmed
type stringMaker [][]string
func (sm stringMaker) stringify() string {
if len(sm) == 0 {
return ""
}
str := "["
for i, item := range sm {
if i > 0 {
str += " | "
}
for j, field := range item {
if j > 0 && field != "" {
str += "; "
}
str += field
}
}
return str + "]"
}
func matchString(m Match) string {
str := "{"
str += "type:" + m.Typ
str += ",off:" + m.Offset
str += ",pat:" + m.Value
if m.Mask != "" {
str += ",mask:" + m.Mask
}
if len(m.Matches) > 0 {
str += " ==> "
for i, sub := range m.Matches {
if i > 0 {
str += " | "
}
str += matchString(sub)
}
}
return str + "}"
}
func (m MIMEType) String() string {
glob := make(stringMaker, len(m.Globs))
for i, g := range m.Globs {
glob[i] = []string{g.Pattern, g.Weight}
}
xmlPat := make(stringMaker, len(m.XMLPattern))
for i, x := range m.XMLPattern {
xmlPat[i] = []string{x.Local, x.NS}
}
var magic string
if len(m.Magic) > 0 {
magic = "["
for i, mg := range m.Magic {
if i > 0 {
magic += " || "
}
if mg.Priority != "" {
magic += "priority: " + mg.Priority + " "
}
for _, mt := range mg.Matches {
magic += matchString(mt)
}
}
magic += "]"
}
return m.MIME + " " + glob.stringify() + " " + xmlPat.stringify() + magic
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Fixtures for testing converter capability.
package converter
// testPatterns for Converter. The list is created from the Wikidata
// sources at the time of writing and minimized to a sensible number.
//
// Custom patterns have also been added as required.
//
// IRIs are followed by un-exported note fields, e.g. encodingNote or
// newEncodingNote to identify clearly for the reader what the IRI
// represents.
var testPatterns = `[
{
"Signature": "DONOTCONVERT",
"Encoding": "http://www.wikidata.org/entity/Q98056596",
"encodingNote": "PERL",
"Comment": "Do not convert because for now PERL conversion should be limited...",
"Fail": true,
"Converted": false
}, {
"Signature": "ACDC1",
"Encoding": "http://www.wikidata.org/entity/Q82828",
"encodingNote": "Hexadecimal",
"Comment": "This should fail as it is an uneven length HEX string",
"Fail": true,
"Converted": false
}, {
"Signature": "♕♖♗♘♙♚♛♜♝♞♟",
"Encoding": "http://www.wikidata.org/entity/Q8815",
"encodingNote": "ASCII",
"Comment": "A decent chunk of Unicode to test (Chess 1 emoji)",
"Fail": false,
"Converted": true
}, {
"Signature": "\u2655\u2656\u2657\u2658\u2659\u265A\u265B\u265C\u265D\u265E\u265F",
"Encoding": "http://www.wikidata.org/entity/Q8815",
"encodingNote": "ASCII",
"Comment": "A decent chunk of Unicode to test (Chess 2 code-points)",
"Fail": false,
"Converted": true
}, {
"Signature": "424D{4}00000000{4}28000000{8}0100(01|04|08|18|20)00(00|01|02)000000",
"Encoding": "http://www.wikidata.org/entity/Q35432091",
"encodingNote": "PRONOM",
"Fail": false,
"Converted": false
}, {
"Signature": "00 61 73 6d",
"Encoding": "",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "0061736D",
"Converted": true
}, {
"Signature": "7573746172",
"Encoding": "http://www.wikidata.org/entity/Q82828",
"encodingNote": "Hexadecimal",
"Converted": false
}, {
"Signature": "786D6C6E733A7064666169643D(22|27)687474703A2F2F7777772E6169696D2E6F72672F706466612F6E732F6964*7064666169643A70617274(3D22|3D27|3E)33(22|27|3C2F7064666169643A706172743E){0-11}7064666169643A636F6E666F726D616E6365(3E|3D22|3D27)42(22|27|3C2F7064666169643A636F6E666F726D616E63653E)",
"Encoding": "http://www.wikidata.org/entity/Q35432091",
"encodingNote": "PRONOM",
"Converted": false
}, {
"Signature": "255044462D312E[30:37]",
"Encoding": "http://www.wikidata.org/entity/Q35432091",
"encodingNote": "PRONOM",
"Converted": false
}, {
"Signature": "63616666",
"Encoding": "http://www.wikidata.org/entity/Q82828",
"encodingNote": "Hexadecimal",
"Converted": false
}, {
"Signature": "424D{4}00000000{4}6C000000{8}0100(01|04|08|10|18|20)00(00|01|02|03)00000000",
"Encoding": "http://www.wikidata.org/entity/Q35432091",
"encodingNote": "PRONOM",
"Converted": false
}, {
"Signature": "GIF89a",
"Encoding": "http://www.wikidata.org/entity/Q8815",
"encodingNote": "ASCII",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "474946383961",
"Converted": true
}, {
"Signature": "BLENDER_",
"Encoding": "http://www.wikidata.org/entity/Q8815",
"encodingNote": "ASCII",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "424C454E4445525F",
"Converted": true
}, {
"Signature": "ý7zXZ",
"Encoding": "http://www.wikidata.org/entity/Q8815",
"encodingNote": "ASCII",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "C3BD377A585A",
"Converted": true
}, {
"Signature": "FD 37 7A 58 5A 00",
"Encoding": "http://www.wikidata.org/entity/Q82828",
"encodingNote": "Hexadecimal",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "FD377A585A00",
"Comment": "Semantics! Hexadecimal sequences with spaces aren't converted per se, but are normalized.",
"Converted": false
}, {
"Signature": "325E1010",
"Encoding": "",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "325E1010",
"Converted": true
}, {
"Signature": "B297E169",
"Encoding": "",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "B297E169",
"Converted": true
}, {
"Signature": "RIFF.{4}WEBPVP8\\x20",
"Encoding": "http://www.wikidata.org/entity/Q98056596",
"encodingNote": "PERL",
"NewEncoding": "http://www.wikidata.org/entity/Q35432091",
"newEncodingNote": "PRONOM",
"NewSignature": "52494646{4}5745425056503820",
"Converted": true
}, {
"Signature": "RIFF.{4}WEBPVP8L",
"Encoding": "http://www.wikidata.org/entity/Q98056596",
"encodingNote": "PERL",
"NewEncoding": "http://www.wikidata.org/entity/Q35432091",
"newEncodingNote": "PRONOM",
"NewSignature": "52494646{4}574542505650384C",
"Converted": true
}, {
"Signature": "RIFF.{4}WEBPVP8X",
"Encoding": "http://www.wikidata.org/entity/Q98056596",
"encodingNote": "PERL",
"NewEncoding": "http://www.wikidata.org/entity/Q35432091",
"newEncodingNote": "PRONOM",
"NewSignature": "52494646{4}5745425056503858",
"Converted": true
}, {
"Signature": "RIFF.{4}WEBP",
"Encoding": "http://www.wikidata.org/entity/Q98056596",
"encodingNote": "PERL",
"NewEncoding": "http://www.wikidata.org/entity/Q35432091",
"newEncodingNote": "PRONOM",
"NewSignature": "52494646{4}57454250",
"Converted": true
}, {
"Signature": "00 61 73 6d",
"Encoding": "",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "0061736D",
"Converted": true
}, {
"Signature": "badf00d1",
"Encoding": "Nonsense encoding...",
"NewEncoding": "http://www.wikidata.org/entity/Q82828",
"newEncodingNote": "Hexadecimal",
"NewSignature": "BADF00D1",
"Converted": true
}, {
"Signature": "00021401-0000-0000-c000-000000000046",
"Encoding": "http://www.wikidata.org/entity/Q254972",
"encodingNote": "GUID",
"Fail": true,
"Converted": false
}]`
<file_sep>package containermatcher
import (
"bytes"
"io"
"testing"
"github.com/richardlehane/siegfried/internal/siegreader"
)
type node struct {
name string
stream []byte
}
type testReader struct {
nodes []*node
idx int
}
func (tr *testReader) Next() error {
tr.idx++
if tr.idx >= len(tr.nodes)-1 {
return io.EOF
}
return nil
}
func (tr *testReader) Name() string {
return tr.nodes[tr.idx].name
}
func (tr *testReader) SetSource(b *siegreader.Buffers) (*siegreader.Buffer, error) {
return b.Get(bytes.NewReader(tr.nodes[tr.idx].stream))
}
func (tr *testReader) Close() {}
func (tr *testReader) IsDir() bool { return false }
func (tr *testReader) Quit() {}
var ns []*node = []*node{
{
"one",
[]byte("test12345678910YNESSjunktestyjunktestytest12345678910111223"),
},
{
"two",
[]byte("test12345678910YNESSjunktestyjunktestytest12345678910111223"),
},
{
"three",
[]byte("test12345678910YNESSjunktestyjunktestytest12345678910111223"),
},
}
var tr *testReader = &testReader{nodes: ns}
func newTestReader(buf *siegreader.Buffer) (Reader, error) {
tr.idx = -1
return tr, nil
}
func TestReader(t *testing.T) {
tr.idx = -1
err := tr.Next()
if err != nil {
t.Error(err)
}
_ = tr.Next()
err = tr.Next()
if err != io.EOF {
t.Error("expecting EOF")
}
}
<file_sep># Siegfried
[Siegfried](http://www.itforarchivists.com/siegfried) is a signature-based file format identification tool, implementing:
- the National Archives UK's [PRONOM](http://www.nationalarchives.gov.uk/pronom) file format signatures
- freedesktop.org's [MIME-info](https://freedesktop.org/wiki/Software/shared-mime-info/) file format signatures
- the Library of Congress's [FDD](http://www.digitalpreservation.gov/formats/fdd/descriptions.shtml) file format signatures (*beta*).
- Wikidata (*beta*).
### Version
1.10.1
[](https://godoc.org/github.com/richardlehane/siegfried) [](https://goreportcard.com/report/github.com/richardlehane/siegfried)
## Usage
### Command line
sf file.ext
sf *.ext
sf DIR
#### Options
sf -csv file.ext | *.ext | DIR // Output CSV rather than YAML
sf -json file.ext | *.ext | DIR // Output JSON rather than YAML
sf -droid file.ext | *.ext | DIR // Output DROID CSV rather than YAML
sf -nr DIR // Don't scan subdirectories
sf -z file.zip | *.ext | DIR // Decompress and scan zip, tar, gzip, warc, arc
sf -zs gzip,tar file.tar.gz | *.ext | DIR // Selectively decompress and scan
sf -hash md5 file.ext | *.ext | DIR // Calculate md5, sha1, sha256, sha512, or crc hash
sf -sig custom.sig *.ext | DIR // Use a custom signature file
sf - // Scan stream piped to stdin
sf -name file.ext - // Provide filename when scanning stream
sf -f myfiles.txt // Scan list of files and directories
sf -v | -version // Display version information
sf -home c:\junk -sig custom.sig file.ext // Use a custom home directory
sf -serve hostname:port // Server mode
sf -throttle 10ms DIR // Pause for duration (e.g. 1s) between file scans
sf -multi 256 DIR // Scan multiple (e.g. 256) files in parallel
sf -log [comma-sep opts] file.ext // Log errors etc. to stderr (default) or stdout
sf -log e,w file.ext | *.ext | DIR // Log errors and warnings to stderr
sf -log u,o file.ext | *.ext | DIR // Log unknowns to stdout
sf -log d,s file.ext | *.ext | DIR // Log debugging and slow messages to stderr
sf -log p,t DIR > results.yaml // Log progress and time while redirecting results
sf -log fmt/1,c DIR > results.yaml // Log instances of fmt/1 and chart results
sf -replay -log u -csv results.yaml // Replay results file, convert to csv, log unknowns
sf -setconf -multi 32 -hash sha1 // Save flag defaults in a config file
sf -setconf -serve :5138 -conf srv.conf // Save/load named config file with '-conf filename'
#### Example
[](https://asciinema.org/a/ernm49loq5ofuj48ywlvg7xq6)
#### Signature files
By default, siegfried uses the latest PRONOM signatures without buffer limits (i.e. it may do full file scans). To use MIME-info or LOC signatures, or to add buffer limits or other customisations, use the [roy tool](https://github.com/richardlehane/siegfried/wiki/Building-a-signature-file-with-ROY) to build your own signature file.
## Install
### With go installed:
go install github.com/richardlehane/siegfried/cmd/sf@latest
sf -update
### Or, without go installed:
#### Win:
Download a pre-built binary from the [releases page](https://github.com/richardlehane/siegfried/releases). Unzip to a location in your system path. Then run:
sf -update
#### Mac Homebrew (or [Linuxbrew](http://brew.sh/linuxbrew/)):
brew install mistydemeo/digipres/siegfried
Or, for the most recent updates, you can install from this fork:
brew install richardlehane/digipres/siegfried
#### Ubuntu/Debian (64 bit):
curl -sL "http://keyserver.ubuntu.com/pks/lookup?op=get&search=0x20F802FE798E6857" | gpg --dearmor | sudo tee /usr/share/keyrings/siegfried-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/siegfried-archive-keyring.gpg] https://www.itforarchivists.com/ buster main" | sudo tee -a /etc/apt/sources.list.d/siegfried.list
sudo apt-get update && sudo apt-get install siegfried
#### FreeBSD:
pkg install siegfried
#### Arch Linux:
git clone https://aur.archlinux.org/siegfried.git
cd siegfried
makepkg -si
## Changes
### v1.10.1 (2023-04-24)
### Fixed
- glob expansion now only on Windows & when no explicit path match. Implemented by [<NAME>](https://github.com/richardlehane/siegfried/pull/229)
- compression algorithm for debian packages changed back to xz. Implemented by [<NAME>](https://github.com/richardlehane/siegfried/pull/230)
- `-multi droid` setting returned empty results when priority lists contained self-references. See [#218](https://github.com/richardlehane/siegfried/issues/218)
- CGO disabled for debian package and linux binaries. See [#219](https://github.com/richardlehane/siegfried/issues/219)
### v1.10.0 (2023-03-25)
### Added
- format classification included as "class" field in PRONOM results. Requested by [<NAME>](https://github.com/richardlehane/siegfried/discussions/207). Implemented by [<NAME>pencer](https://github.com/richardlehane/siegfried/commit/7f695720a752ac5fca3e1de8ba034b92ab6da1d9)
- `-noclass` flag added to roy build command. Use this flag to build signatures that omit the new "class" field from results.
- glob paths can be used in place of file or directory paths for identification (e.g. `sf *.jpg`). Implemented by [<NAME>](https://github.com/richardlehane/siegfried/commit/54bf6596c5fe7d1c9858348f0170d0dd7365fc8f)
- `-multi droid` setting for roy build command. Applies priorities after rather than during identification for more DROID-like results. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/146)
- `/update` command for server mode. Requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/208)
### Changed
- new algorithm for dynamic multi-sequence matching for improved wildcard performance
- update PRONOM to v111
- update LOC to 2023-01-27
- update tika-mimetypes to v2.7.0
- minimum go version to build siegfried is now 1.18
### Fixed
- archivematica extensions built into wikidata signatures. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/210)
- trailing slash for folder paths in URI field in droid output. Reported by <NAME>
- crash when using `sf -replay` with droid output
### v1.9.6 (2022-11-06)
### Changed
- update PRONOM to v109
### v1.9.5 (2022-09-13)
### Added
- `roy inspect` now takes a `-droid` flag to allow easier inspection of old or custom DROID files
- github action to update siegfried docker deployment [https://github.com/keeps/siegfried-docker]. Implemented by [Keep Solutions](https://github.com/richardlehane/siegfried/pull/201)
### Changed
- update PRONOM to v108
- update tika-mimetype signatures to v2.4.1
- update LOC signatures to 2022-09-01
### Fixed
- incorrect encoding of YAML strings containing line endings; [#202](https://github.com/richardlehane/siegfried/issues/202).
- parse signatures with offsets and offsets in patterns e.g. fmt/1741; [#203](https://github.com/richardlehane/siegfried/issues/203)
### v1.9.4 (2022-07-18)
### Added
- new pkg/static and static builds. This allows direct use of sf API and self-contained binaries without needing separate signature files.
### Changed
- update PRONOM to v106
### Fixed
- inconsistent output for `roy inspect priorities`. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/192)
### v1.9.3 (2022-05-23)
### Added
- JS/WASM build support contributed by [<NAME>](https://github.com/richardlehane/siegfried/pull/188)
- wikidata signature added to `-update`. Contributed by [<NAME>](https://github.com/richardlehane/siegfried/pull/178)
- `-nopronom` flag added to `roy inspect` subcommand. Contributed by [<NAME>](https://github.com/richardlehane/siegfried/pull/185)
### Changed
- update PRONOM to v104
- update LOC signatures to 2022-05-09
- update Wikidata to 2022-05-20
- update tika-mimetypes signatures to v2.4.0
- update freedesktop.org signatures to v2.2
### Fixed
- invalid JSON output for fmt/1472 due to tab in MIME field. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/186)
- panic on corrupt Zip containers. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/181)
### v1.9.2 (2022-02-07)
### Added
- Wikidata definition file specification has been updated and now includes endpoint (users will need to harvest Wikidata again)
- Custom Wikibase endpoint can now be specified for harvesting when paired with a custom SPARQL query and property mappings
- Wikidata identifier includes permalinks in results
- Wikidata revision history visible using `roy inspect`
- roy inspect returns format ID with name
### Changed
- update PRONOM to v100
- update LOC signatures to 2022-02-01
- update tika-mimetypes signatures to v2.1
- update freedesktop.org signatures to v2.2.1
### Fixed
- parse issues for container files where zero indexing used for Position. Spotted by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/175)
- sf -droid output can't be read by sf (e.g. for comparing results). Reported by [ostnatalie](https://github.com/richardlehane/siegfried/issues/174)
- panic when running in server mode due to race condition. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/172)
- panic when reading malformed MSCFB files. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/171)
- unescaped control characters in JSON output. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/165)
- zip file names with null terminated strings prevent ID of Serif formats. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/150)
### v1.9.1 (2020-10-11)
### Changed
- update PRONOM to v97
- zs flag now activates -z flag
### Fixed
- details text in PRONOM identifier
- `roy` panic when building signatures with empty sequences. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/149)
### v1.9.0 (2020-09-22)
### Added
- a new Wikidata identifier, harvesting information from the Wikidata Query Service. Implemented by [Ross Spencer](https://github.com/richardlehane/siegfried/commit/dfb579b4ae46ae6daa814fc3fc74271d768f2f9c).
- select which archive types (zip, tar, gzip, warc, or arc) are unpacked using the -zs flag (sf -zs tar,zip). Implemented by [Ross Spencer](https://github.com/richardlehane/siegfried/commit/88dd43b55e5f83304705f6bcd439d502ef08cd38).
### Changed
- update LOC signatures to 2020-09-21
- update tika-mimetypes signatures to v1.24
- update freedesktop.org signatures to v2.0
### Fixed
- incorrect basis for some signatures with multiple patterns. Reported and fixed by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/142).
See the [CHANGELOG](CHANGELOG.md) for the full history.
## Rights
Copyright 2020 <NAME>, <NAME>
Licensed under the [Apache License, Version 2.0](http://www.apache.org/licenses/LICENSE-2.0)
## Announcements
Join the [Google Group](https://groups.google.com/d/forum/sf-roy) for updates, signature releases, and help.
## Contributing
Like siegfried and want to get involved in its development? That'd be wonderful! There are some notes on the [wiki](https://github.com/richardlehane/siegfried/wiki) to get you started, and please get in touch.
## Thanks
Thanks TNA for http://www.nationalarchives.gov.uk/pronom/ and http://www.nationalarchives.gov.uk/information-management/projects-and-work/droid.htm
Thanks Ross for https://github.com/exponential-decay/skeleton-test-suite-generator and http://exponentialdecay.co.uk/sd/index.htm, both are very handy!
Thanks Misty for the brew and ubuntu packaging
Thanks Steffen for the FreeBSD and Arch Linux packaging
<file_sep>package siegreader
import (
"bytes"
"fmt"
"io"
"io/ioutil"
"math/rand"
"os"
"path/filepath"
"strings"
"testing"
)
const testString = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
var (
testBytes = []byte(testString)
testfile = filepath.Join("..", "..", "cmd", "sf", "testdata", "benchmark", "Benchmark.docx")
testBigFile = filepath.Join("..", "..", "cmd", "sf", "testdata", "benchmark", "Benchmark.xml")
testSmallFile = filepath.Join("..", "..", "cmd", "sf", "testdata", "benchmark", "Benchmark.gif")
bufs = New()
)
func TestNewBufferPool(t *testing.T) {
b := New()
if b == nil {
t.Error("Failed to make a new Buffer pool nil")
}
}
func setup(r io.Reader, t *testing.T) *Buffer {
buf, err := bufs.Get(r)
if err != nil && err != io.EOF {
t.Fatalf("Read error: %v", err)
}
q := make(chan struct{})
buf.Quit = q
return buf
}
func (b *Buffer) setbigfile() {
b.bufferSrc.(*file).once.Do(func() {
b.bufferSrc.(*file).data = b.bufferSrc.(*file).pool.bfpool.get().(*bigfile)
b.bufferSrc.(*file).data.(*bigfile).setSource(b.bufferSrc.(*file))
})
}
func (b *Buffer) setsmallfile() {
b.bufferSrc.(*file).once.Do(func() {
b.bufferSrc.(*file).data = b.bufferSrc.(*file).pool.sfpool.get().(*smallfile)
b.bufferSrc.(*file).data.(*smallfile).setSource(b.bufferSrc.(*file))
})
}
func TestStrSource(t *testing.T) {
r := strings.NewReader(testString)
b := setup(r, t)
defer bufs.Put(b)
b.Slice(0, readSz)
if b.Size() != int64(len(testString)) {
t.Errorf("String read: size error, expecting %d got %d", b.Size(), int64(len(testString)))
}
}
func TestBytSource(t *testing.T) {
r := bytes.NewBuffer(testBytes)
b := setup(r, t)
defer bufs.Put(b)
b.Slice(0, readSz)
if b.Size() != int64(len(testBytes)) {
t.Error("String read: size error")
}
if len(b.Bytes()) != len(testBytes) {
t.Error("String read: Bytes() error")
}
}
func TestMMAPFile(t *testing.T) {
r, err := os.Open(testfile)
defer r.Close()
if err != nil {
t.Fatal(err)
}
b := setup(r, t)
defer bufs.Put(b)
stat, _ := r.Stat()
if len(b.Bytes()) != int(stat.Size()) {
t.Error("File read: Bytes() error")
}
}
func TestBigFile(t *testing.T) {
f, err := os.Open(testBigFile)
defer f.Close()
if err != nil {
t.Fatal(err)
}
b := setup(f, t)
defer bufs.Put(b)
b.setbigfile()
stat, _ := f.Stat()
if len(b.Bytes()) != int(stat.Size()) {
t.Error("File read: Bytes() error")
}
r := ReaderFrom(b)
results := make(chan int)
go drain(r, results)
if i := <-results; i != int(stat.Size()) {
t.Errorf("Expecting %d, got %d", int(stat.Size()), i)
}
}
func TestSmallFile(t *testing.T) {
r, err := os.Open(testSmallFile)
defer r.Close()
if err != nil {
t.Fatal(err)
}
b := setup(r, t)
defer bufs.Put(b)
b.setsmallfile()
stat, _ := r.Stat()
if len(b.Bytes()) != int(stat.Size()) {
t.Error("File read: Bytes() error")
}
}
// The following tests generate temp files filled with random data and compare io.ReadAt()
// calls with Slice() and EofSlice() calls for the various Buffer types (mmap file, big file,
// small file, big stream and small stream).
func TestMMAPFileRand(t *testing.T) {
tf, err := makeTmp(100000)
if err != nil {
t.Fatal(err)
}
defer os.Remove(tf.Name())
defer tf.Close()
b := setup(tf, t)
defer bufs.Put(b)
if err := testBuffer(t, 1000, tf, b); err != nil {
t.Fatal(err)
}
}
func TestSmallFileRand(t *testing.T) {
tf, err := makeTmp(10000)
if err != nil {
t.Fatal(err)
}
defer os.Remove(tf.Name())
defer tf.Close()
b := setup(tf, t)
b.setsmallfile()
defer bufs.Put(b)
err = testBuffer(t, 10, tf, b)
if err := testBuffer(t, 1000, tf, b); err != nil {
t.Fatal(err)
}
}
func TestBigFileRand(t *testing.T) {
tf, err := makeTmp(100000)
if err != nil {
t.Fatal(err)
}
defer os.Remove(tf.Name())
defer tf.Close()
b := setup(tf, t)
b.setbigfile()
defer bufs.Put(b)
if err := testBuffer(t, 1000, tf, b); err != nil {
t.Fatal(err)
}
}
func TestSmallStreamRand(t *testing.T) {
var sz int64 = 100000
tf, err := makeTmp(sz)
if err != nil {
t.Fatal(err)
}
defer os.Remove(tf.Name())
defer tf.Close()
lr := io.LimitReader(tf, sz)
b := setup(lr, t)
defer bufs.Put(b)
if err := testBuffer(t, 1000, tf, b); err != nil {
t.Fatal(err)
}
}
func TestBigStreamRand(t *testing.T) {
var sz int64 = 1000000000 // 1GB
tf, err := makeTmp(sz)
if err != nil {
t.Fatal(err)
}
defer os.Remove(tf.Name())
defer tf.Close()
lr := io.LimitReader(tf, sz)
b := setup(lr, t)
defer bufs.Put(b)
if err := testBuffer(t, 1000, tf, b); err != nil {
t.Fatal(err)
}
}
func makeTmp(sz int64) (f *os.File, err error) {
tf, err := ioutil.TempFile("", "sftest")
if err != nil {
return nil, err
}
rnd := rand.New(rand.NewSource(rand.Int63()))
wr, err := io.CopyN(tf, rnd, sz)
if wr != sz {
return nil, fmt.Errorf("didn't write rands successfully: tried %d, got %d", sz, wr)
}
if err != nil {
return nil, err
}
nm := tf.Name()
tf.Close() // force the flush
return os.Open(nm)
}
func eofOff(sz, off int64, l int) (int64, int) {
bof := sz - off - int64(l)
if bof >= 0 {
return bof, l
}
return 0, l + int(bof)
}
func joinErrs(errs []error) error {
if len(errs) == 0 {
return nil
}
strs := make([]string, len(errs))
for i := range strs {
strs[i] = errs[i].Error()
}
return fmt.Errorf("Got %d errors: %s", len(strs), strings.Join(strs, "\n"))
}
func testBuffer(t *testing.T, checks int, tf *os.File, bs *Buffer) error {
stat, err := tf.Stat()
if err != nil {
return err
}
sz := stat.Size()
lens := make([][]byte, 10)
for i := range lens {
lens[i] = make([]byte, rand.Intn(10000))
}
offs := make([]int64, checks)
for i := range lens {
offs[i] = rand.Int63n(sz)
}
var errs []error
// test Slice()
for _, o := range offs {
rb := lens[rand.Intn(len(lens))]
wi, rerr := tf.ReadAt(rb, o)
slc, serr := bs.Slice(o, len(rb))
if !bytes.Equal(rb[:wi], slc) {
var samplea, sampleb []byte
if wi >= 3 {
samplea = rb[:3]
}
if len(slc) >= 3 {
sampleb = slc[:3]
}
errs = append(errs, fmt.Errorf("Bad Slice() read at offset %d, len %d; got %v & %v, errs reported %v & %v", o, len(rb), samplea, sampleb, rerr, serr))
}
}
if bsz := bs.SizeNow(); bsz != sz {
errs = append(errs, fmt.Errorf("SizeNow() does not match: got %d, expecting %d", bsz, sz))
}
// test EofSlice()
for _, o := range offs {
rb := lens[rand.Intn(len(lens))]
off, l := eofOff(sz, o, len(rb))
wi, rerr := tf.ReadAt(rb[:l], off)
slc, serr := bs.EofSlice(o, len(rb))
if !bytes.Equal(rb[:wi], slc) {
var samplea, sampleb []byte
if wi >= 3 {
samplea = rb[:3]
}
if len(slc) >= 3 {
sampleb = slc[:3]
}
errs = append(errs, fmt.Errorf("Bad EofSlice() read at EOF offset %d (real %d), len %d (real %d); got %v & %v, errs reported %v & %v", o, off, len(rb), l, samplea, sampleb, rerr, serr))
}
}
return joinErrs(errs)
}
<file_sep>package frames_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
const cost = 250000
const repetition = 4
// [BOF 0:test], [P 10-20:TESTY|YNESS], [S *:test|testy], [S 0:testy], [E 10-20:test|testy]
func TestSignatureOne(t *testing.T) {
s := TestSignatures[0].Segment(8192, 2059, cost, repetition)
if len(s) != 3 {
t.Errorf("Segment fail: expecting 3 segments, got %d", len(s))
}
// [BOF 0:test], [P 10-20:TESTY|YNESS]
if len(s[0]) != 2 {
t.Errorf("Segment fail: expecting the first segment to have two frames, got %d", len(s[0]))
}
if s[0].Characterise() != BOFZero {
t.Errorf("Characterise fail: expecting the first segment to be BOFZero, it is %v", s[0].Characterise())
}
pos := Position{4, 0, 1}
if BOFLength(s[0], 64) != pos {
t.Errorf("bofLength fail: expecting position %v, to equal %v", BOFLength(s[0], 64), pos)
}
// [S *:test|testy]
if len(s[1]) != 1 {
t.Errorf("Segment fail: expecting the second segment to have a single frame, got %d", len(s[0]))
}
if s[1].Characterise() != Succ {
t.Errorf("Characterise fail: expecting the second segment to be Succ, it is %v", s[1].Characterise())
}
// the length in varLength reports the minimum, not the maximum length
pos = Position{4, 0, 1}
if VarLength(s[1], 64) != pos {
t.Errorf("varLength fail: expecting position %v, to equal %v", VarLength(s[1], 64), pos)
}
// [S 0:testy], [E 10-20:test|testy]
if len(s[2]) != 2 {
t.Errorf("Segment fail: expecting the last segment to have two frames, got %d", len(s[2]))
}
if s[2].Characterise() != EOFWindow {
t.Errorf("Characterise fail: expecting the last segment to be eofWindow, it is %v", s[2].Characterise())
}
pos = Position{9, 0, 2}
if VarLength(s[2], 64) != pos {
t.Errorf("varLength fail: expecting position %v, to equal %v", VarLength(s[2], 64), pos)
}
}
// [BOF 0:test], [P 10-20:TESTY|YNESS], [P 0-1:TEST], [S 0:testy], [S *:test|testy], [E 0:23]
func TestSignatureTwo(t *testing.T) {
s := TestSignatures[1].Segment(8192, 2059, cost, repetition)
if len(s) != 3 {
t.Errorf("Segment fail: expecting 3 segments, got %d", len(s))
}
// [BOF 0:test], [P 10-20:TESTY|YNESS], [P 0-1:TEST]
if len(s[0]) != 3 {
t.Errorf("Segment fail: expecting the first segment to have three frames, got %d", len(s[0]))
}
if s[0].Characterise() != BOFZero {
t.Errorf("Characterise fail: expecting the first segment to be bofzero, it is %v", s[0].Characterise())
}
pos := Position{4, 0, 1}
if BOFLength(s[0], 64) != pos {
t.Errorf("bofLength fail: expecting position %v, to equal %v", BOFLength(s[0], 64), pos)
}
// [S 0:testy], [S *:test|testy]
if len(s[1]) != 2 {
t.Errorf("Segment fail: expecting the second segment to have two frames, got %d", len(s[1]))
}
if s[1].Characterise() != Succ {
t.Errorf("Characterise fail: expecting the second segment to be succ, it is %v", s[1].Characterise())
}
pos = Position{9, 0, 2}
if VarLength(s[1], 64) != pos {
t.Errorf("varLength fail: expecting position %v, to equal %v", BOFLength(s[1], 64), pos)
}
}
// [BOF 0-5:a|b|c...|j], [P *:test]
func TestSignatureThree(t *testing.T) {
s := TestSignatures[2].Segment(8192, 2059, cost, repetition)
if len(s) != 2 {
t.Errorf("Segment fail: expecting 2 segments, got %d", len(s))
}
// [BOF 0-5:a|b]
if s[0].Characterise() != BOFWindow {
t.Errorf("Characterise fail: expecting the first segment to be bofWindow, it is %v", s[0].Characterise())
}
pos := Position{1, 0, 1}
if VarLength(s[0], 64) != pos {
t.Errorf("varLength fail: expecting position %v, to equal %v", VarLength(s[0], 64), pos)
}
// [P *:test]
if len(s[1]) != 1 {
t.Errorf("Segment fail: expecting the second segment to have one frame, got %d", len(s[1]))
}
if s[1].Characterise() != Prev {
t.Errorf("Characterise fail: expecting the second segment to be prev, it is %v", s[1].Characterise())
}
pos = Position{4, 0, 1}
if VarLength(s[1], 64) != pos {
t.Errorf("varLength fail: expecting position %v, to equal %v", VarLength(s[1], 64), pos)
}
}
// [BOF 0:test], [P 10-20:TESTY|YNESS], [BOF *:test]
func TestSignatureFour(t *testing.T) {
s := TestSignatures[3].Segment(8192, 2059, cost, repetition)
if len(s) != 2 {
t.Errorf("Segment fail: expecting 2 segments, got %d", len(s))
}
// [BOF 0:test], [P 10-20:TESTY|YNESS]
if s[0].Characterise() != BOFZero {
t.Errorf("Characterise fail: expecting the first segment to be bofWindow, it is %v", s[0].Characterise())
}
pos := Position{4, 0, 1}
if BOFLength(s[0], 64) != pos {
t.Errorf("bofLength fail: expecting position %v, to equal %v", BOFLength(s[0], 64), pos)
}
// [BOF *:test]
if len(s[1]) != 1 {
t.Errorf("Segment fail: expecting the second segment to have one frame, got %d", len(s[1]))
}
if s[1].Characterise() != BOFWild {
t.Errorf("Characterise fail: expecting the second segment to be prev, it is %v", s[1].Characterise())
}
pos = Position{4, 0, 1}
if VarLength(s[1], 64) != pos {
t.Errorf("varLength fail: expecting position %v, to equal %v", VarLength(s[1], 64), pos)
}
}
func TestFmt418(t *testing.T) {
s := TestFmts[418].Segment(2000, 500, cost, repetition)
if len(s) != 2 {
t.Errorf("fmt418 fail: expecting 2 segments, got %d", len(s))
}
if s[0].Characterise() != BOFZero {
t.Errorf("fmt418 fail: expecting the first segment to be bofzero, got %v", s[0].Characterise())
}
pos := Position{14, 0, 1}
if BOFLength(s[0], 2) != pos {
t.Errorf("fmt418 fail: expecting the first segment to have pos %v, got %v", pos, BOFLength(s[0], 2))
}
if s[1].Characterise() != Prev {
t.Errorf("fmt418 fail: expecting the second segment to be prev, got %v", s[1].Characterise())
}
pos = Position{33, 0, 2}
if VarLength(s[1], 2) != pos {
t.Errorf("fmt418 fail: expecting the second segment to have pos %v, got %v", pos, BOFLength(s[1], 2))
t.Error(s[1])
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Organizes the format identification results from the Wikidata
// package.
// WIKIDATA TODO: This part of an identifier is still somewhat
// unfamiliar to me so I need to spend a bit longer on it at some point.
package wikidata
import (
"fmt"
"sort"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
const (
extScore = 1 << iota
mimeScore
textScore
incScore
)
type matchIDs []Identification
// Len needed to satisfy the sort interface for sorting the slice during
// reporting.
func (matches matchIDs) Len() int { return len(matches) }
// Less needed to satisfy the sort interface for sorting the slice during
// reporting.
func (matches matchIDs) Less(i, j int) bool { return matches[j].confidence < matches[i].confidence }
// Swap needed to satisfy the sort interface for sorting the slice during
// reporting.
func (matches matchIDs) Swap(i, j int) { matches[i], matches[j] = matches[j], matches[i] }
// Recorder comment...
type Recorder struct {
*Identifier
ids matchIDs
cscore int
satisfied bool
extActive bool
mimeActive bool
textActive bool
}
// Active tells the recorder what matchers are active which helps when
// providing a detailed response to the caller.
func (recorder *Recorder) Active(matcher core.MatcherType) {
if recorder.Identifier.Active(matcher) {
switch matcher {
case core.NameMatcher:
recorder.extActive = true
case core.MIMEMatcher:
recorder.mimeActive = true
case core.TextMatcher:
recorder.textActive = true
}
}
}
// Record will build possible results sets associated with an
// identification.
func (recorder *Recorder) Record(matcher core.MatcherType, result core.Result) bool {
switch matcher {
default:
return false
case core.NameMatcher:
return recordNameMatcher(recorder, matcher, result)
case core.ContainerMatcher:
return recordContainerMatcher(recorder, matcher, result)
case core.ByteMatcher:
return recordByteMatcher(recorder, matcher, result)
}
}
// add appends identifications to a matchIDs slice.
func add(matches matchIDs, id string, wikidataID string, info formatInfo, basis string, confidence int) matchIDs {
for idx, match := range matches {
// WIKIDATA TODO: This function is looping too much, especially
// with extension matches which might point to a part of this
// implementation running sub-optimally. Or it might be expected
// of extension matches.
//
// Run with: fmt.Fprintf(os.Stderr, "LOOPING: %#v\n", v)
//
if match.ID == wikidataID {
matches[idx].confidence += confidence
matches[idx].Basis = append(matches[idx].Basis, basis)
return matches
}
}
return append(
matches, Identification{
Namespace: id,
ID: wikidataID,
Name: info.name,
LongName: info.uri,
Permalink: info.permalink,
MIME: info.mime,
Basis: []string{basis},
Warning: "",
archive: config.IsArchive(wikidataID),
confidence: confidence,
})
}
// recordNameMatcher ...
func recordNameMatcher(recorder *Recorder, matcher core.MatcherType, result core.Result) bool {
if hit, id := recorder.Hit(matcher, result.Index()); hit {
recorder.ids = add(
recorder.ids,
recorder.Name(),
id,
recorder.infos[id],
result.Basis(),
extScore,
)
return true
}
return false
}
// recordByteMatcher ...
func recordByteMatcher(recorder *Recorder, matcher core.MatcherType, result core.Result) bool {
var hit bool
var id string
if hit, id = recorder.Hit(matcher, result.Index()); !hit {
return false
}
if recorder.satisfied {
// This is never set for this identifier yet which might be
// related to the issue we're seeing in add(...)
return true
}
recorder.cscore += incScore
basis := result.Basis()
position, total := recorder.Place(core.ByteMatcher, result.Index())
// Depending on how defensive we are being, we might check:
//
// position-1 >= len(recorder.infos[id].sources)
//
// where identifiers and "source" slices need to align 1:1 to output
// correctly. See: richardlehane/siegfried#142
source := fmt.Sprintf("%s", recorder.infos[id].sources[position-1])
if total > 1 {
basis = fmt.Sprintf(
"%s (signature %d/%d)", basis, position, total,
)
} else {
if source != "" {
basis = fmt.Sprintf("%s", basis)
}
}
basis = fmt.Sprintf("%s (%s)", basis, source)
recorder.ids = add(
recorder.ids,
recorder.Name(),
id,
recorder.infos[id],
basis,
recorder.cscore,
)
return true
}
// recordContainerMatcher ...
func recordContainerMatcher(recorder *Recorder, matcher core.MatcherType, result core.Result) bool {
if result.Index() < 0 {
if recorder.ZipDefault() {
recorder.cscore += incScore
recorder.ids = add(
recorder.ids,
recorder.Name(),
config.ZipPuid(),
recorder.infos[config.ZipPuid()],
result.Basis(),
recorder.cscore,
)
}
return false
}
if hit, id := recorder.Hit(matcher, result.Index()); hit {
recorder.cscore += incScore
basis := result.Basis()
position, total := recorder.Place(
core.ContainerMatcher, result.Index(),
)
source := ""
if position-1 >= len(recorder.infos[id].sources) {
// Container provenance isn't working as anticipated in the
// Wikidata identifier yet. We use a placeholder here in
// their place.
source = pronomOfficialContainer
} else {
source = fmt.Sprintf(
"%s", recorder.infos[id].sources[position-1],
)
}
if total > 1 {
basis = fmt.Sprintf(
"%s (signature %d/%d)", basis, position, total,
)
} else {
if source != "" {
basis = fmt.Sprintf("%s", basis)
}
}
basis = fmt.Sprintf("%s (%s)", basis, source)
recorder.ids = add(
recorder.ids,
recorder.Name(),
id,
recorder.infos[id],
basis,
recorder.cscore,
)
return true
}
return false
}
// Satisfied is drawn from the PRONOM identifier and tells us whether or not
// we should continue with any particular matcher...
func (recorder *Recorder) Satisfied(mt core.MatcherType) (bool, core.Hint) {
if recorder.NoPriority() {
return false, core.Hint{}
}
if recorder.cscore < incScore {
if len(recorder.ids) == 0 {
return false, core.Hint{}
}
if mt == core.ContainerMatcher ||
mt == core.ByteMatcher ||
mt == core.XMLMatcher ||
mt == core.RIFFMatcher {
if mt == core.ByteMatcher ||
mt == core.ContainerMatcher {
keys := make([]string, len(recorder.ids))
for i, v := range recorder.ids {
keys[i] = v.String()
}
return false, core.Hint{recorder.Start(mt), recorder.Lookup(mt, keys)}
}
return false, core.Hint{}
}
for _, res := range recorder.ids {
if res.ID == config.TextPuid() {
return false, core.Hint{}
}
}
}
recorder.satisfied = true
if mt == core.ByteMatcher {
return true, core.Hint{recorder.Start(mt), nil}
}
return true, core.Hint{}
}
// Report organizes the identification output so that the highest
// priority results are output first.
func (recorder *Recorder) Report() []core.Identification {
// Happy path for zero results...
if len(recorder.ids) == 0 {
return []core.Identification{Identification{
Namespace: recorder.Name(),
ID: "UNKNOWN",
Warning: "no match",
}}
}
// Sort IDs by confidence to return highest first.
sort.Sort(recorder.ids)
confidence := recorder.ids[0].confidence
ret := make([]core.Identification, len(recorder.ids))
for i, v := range recorder.ids {
if i > 0 {
switch recorder.Multi() {
case config.Single:
return ret[:i]
case config.Conclusive:
if v.confidence < confidence {
return ret[:i]
}
default:
if v.confidence < incScore {
return ret[:i]
}
}
}
ret[i] = recorder.updateWarning(v)
}
return ret
}
// updateWarning is used to add precision to the identification. A
// classic example is the application of an extension mismatch to an
// identification when the binary match works but the extension is
// known to be in all likelihood incorrect.
func (recorder *Recorder) updateWarning(identification Identification) Identification {
// Apply mismatches to the identification result.
if recorder.extActive && (identification.confidence&extScore != extScore) {
for _, v := range recorder.IDs(core.NameMatcher) {
if identification.ID == v {
if len(identification.Warning) > 0 {
identification.Warning += "; extension mismatch"
} else {
identification.Warning = "extension mismatch"
}
break
}
}
}
return identification
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is dis tributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package identifier
import (
"sort"
"strings"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/pkg/config"
)
// FormatInfo is Identifier-specific information to be retained for the Identifier.
type FormatInfo interface {
String() string
}
// Parseable is something we can parse to derive filename, MIME, XML and byte signatures.
type Parseable interface {
IDs() []string // list of all IDs in identifier
Infos() map[string]FormatInfo // identifier specific information
Globs() ([]string, []string) // signature set and corresponding IDs for globmatcher
MIMEs() ([]string, []string) // signature set and corresponding IDs for mimematcher
XMLs() ([][2]string, []string) // signature set and corresponding IDs for xmlmatcher
Signatures() ([]frames.Signature, []string, error) // signature set and corresponding IDs for bytematcher
Zips() ([][]string, [][]frames.Signature, []string, error) // signature set and corresponding IDs for container matcher - Zip
MSCFBs() ([][]string, [][]frames.Signature, []string, error) // signature set and corresponding IDs for container matcher - MSCFB
RIFFs() ([][4]byte, []string) // signature set and corresponding IDs for riffmatcher
Texts() []string // IDs for textmatcher
Priorities() priority.Map // priority map
}
type inspectErr []string
func (ie inspectErr) Error() string {
return "can't find " + strings.Join(ie, ", ")
}
// inspect returns string representations of the format signatures within a parseable
func inspect(p Parseable, ids ...string) (string, error) {
var (
ie = inspectErr{}
fmts = make([]string, 0, len(ids))
gs, gids = p.Globs()
ms, mids = p.MIMEs()
xs, xids = p.XMLs()
bs, bids, _ = p.Signatures()
zns, zbs, zids, _ = p.Zips()
msns, msbs, msids, _ = p.MSCFBs()
rs, rids = p.RIFFs()
tids = p.Texts()
pm = p.Priorities()
)
has := func(ss []string, s string) bool {
for _, v := range ss {
if s == v {
return true
}
}
return false
}
get := func(ss, rs []string, s string) []string {
ret := make([]string, 0, len(ss))
for i, v := range ss {
if s == v {
ret = append(ret, rs[i])
}
}
return ret
}
getX := func(ss []string, rs [][2]string, s string) []string {
ret := make([]string, 0, len(ss))
for i, v := range ss {
if s == v {
ret = append(ret, "root: "+rs[i][0]+"; ns: "+rs[i][1])
}
}
return ret
}
getS := func(ss []string, rs []frames.Signature, s string) []string {
ret := make([]string, 0, len(ss))
for i, v := range ss {
if s == v {
ret = append(ret, rs[i].String())
}
}
return ret
}
getC := func(ss []string, cn [][]string, cb [][]frames.Signature, s string) []string {
ret := make([]string, 0, len(ss))
for i, v := range ss {
if s == v {
cret := make([]string, len(cn[i]))
for j, n := range cn[i] {
cret[j] = n
if cb[i][j] != nil {
cret[j] += " | " + cb[i][j].String()
}
}
ret = append(ret, strings.Join(cret, "; "))
}
}
return ret
}
getR := func(ss []string, rs [][4]byte, s string) []string {
ret := make([]string, 0, len(ss))
for i, v := range ss {
if s == v {
ret = append(ret, string(rs[i][:]))
}
}
return ret
}
for _, id := range ids {
lines := make([]string, 0, 10)
info, ok := p.Infos()[id]
if ok {
if strings.Contains(info.String(), "\n") { // for wikidata output
lines = append(lines, id, info.String(), "Signatures:")
} else {
lines = append(lines, strings.ToUpper(info.String()+" ("+id+")"))
}
if has(gids, id) {
lines = append(lines, "globs: "+strings.Join(get(gids, gs, id), ", "))
}
if has(mids, id) {
lines = append(lines, "mimes: "+strings.Join(get(mids, ms, id), ", "))
}
if has(xids, id) {
lines = append(lines, "xmls: "+strings.Join(getX(xids, xs, id), ", "))
}
if has(bids, id) {
lines = append(lines, "sigs: "+strings.Join(getS(bids, bs, id), "\n "))
}
if has(zids, id) {
lines = append(lines, "zip sigs: "+strings.Join(getC(zids, zns, zbs, id), "\n "))
}
if has(msids, id) {
lines = append(lines, "mscfb sigs: "+strings.Join(getC(msids, msns, msbs, id), "\n "))
}
if has(rids, id) {
lines = append(lines, "riffs: "+strings.Join(getR(rids, rs, id), ", "))
}
if has(tids, id) {
lines = append(lines, "text signature")
}
// Priorities
ps, ok := pm[id]
if ok && len(ps) > 0 {
lines = append(lines, "superiors: "+strings.Join(ps, ", "))
} else {
lines = append(lines, "superiors: none")
}
} else {
ie = append(ie, id)
}
fmts = append(fmts, strings.Join(lines, "\n"))
}
if len(ie) > 0 {
return strings.Join(fmts, "\n\n"), ie
}
return strings.Join(fmts, "\n\n"), nil
}
// Blank parseable can be embedded within other parseables in order to include default nil implementations of the interface
type Blank struct{}
func (b Blank) IDs() []string { return nil }
func (b Blank) Infos() map[string]FormatInfo { return nil }
func (b Blank) Globs() ([]string, []string) { return nil, nil }
func (b Blank) MIMEs() ([]string, []string) { return nil, nil }
func (b Blank) XMLs() ([][2]string, []string) { return nil, nil }
func (b Blank) Signatures() ([]frames.Signature, []string, error) { return nil, nil, nil }
func (b Blank) Zips() ([][]string, [][]frames.Signature, []string, error) { return nil, nil, nil, nil }
func (b Blank) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
return nil, nil, nil, nil
}
func (b Blank) RIFFs() ([][4]byte, []string) { return nil, nil }
func (b Blank) Texts() []string { return nil }
func (b Blank) Priorities() priority.Map { return nil }
// Joint allows two parseables to be logically joined.
type joint struct {
a, b Parseable
}
// Join two Parseables.
func Join(a, b Parseable) joint {
return joint{a, b}
}
// IDs returns a list of all the IDs in an identifier.
func (j joint) IDs() []string {
ids := make([]string, len(j.a.IDs()), len(j.a.IDs())+len(j.b.IDs()))
copy(ids, j.a.IDs())
for _, id := range j.b.IDs() {
var present bool
for _, ida := range j.a.IDs() {
if id == ida {
present = true
break
}
}
if !present {
ids = append(ids, id)
}
}
return ids
}
// Infos returns a map of identifier specific information.
func (j joint) Infos() map[string]FormatInfo {
infos := j.a.Infos()
for k, v := range j.b.Infos() {
infos[k] = v
}
return infos
}
func joinStrings(a func() ([]string, []string), b func() ([]string, []string)) ([]string, []string) {
c, d := a()
e, f := b()
return append(c, e...), append(d, f...)
}
// Globs returns a signature set with corresponding IDs for the globmatcher.
func (j joint) Globs() ([]string, []string) {
return joinStrings(j.a.Globs, j.b.Globs)
}
// MIMEs returns a signature set with corresponding IDs for the mimematcher.
func (j joint) MIMEs() ([]string, []string) {
return joinStrings(j.a.MIMEs, j.b.MIMEs)
}
// XMLs returns a signature set with corresponding IDs for the xmlmatcher.
func (j joint) XMLs() ([][2]string, []string) {
a, b := j.a.XMLs()
c, d := j.b.XMLs()
return append(a, c...), append(b, d...)
}
// Signatures returns a signature set with corresponding IDs for the bytematcher.
func (j joint) Signatures() ([]frames.Signature, []string, error) {
s, p, err := j.a.Signatures()
if err != nil {
return nil, nil, err
}
t, q, err := j.b.Signatures()
if err != nil {
return nil, nil, err
}
return append(s, t...), append(p, q...), nil
}
// Priorities returns a priority map.
func (j joint) Priorities() priority.Map {
ps := j.a.Priorities()
for k, v := range j.b.Priorities() {
for _, w := range v {
ps.Add(k, w)
}
}
return ps
}
func (j joint) Zips() ([][]string, [][]frames.Signature, []string, error) {
n, s, i, err := j.a.Zips()
if err != nil {
return nil, nil, nil, err
}
m, q, k, err := j.b.Zips()
if err != nil {
return nil, nil, nil, err
}
return append(n, m...), append(s, q...), append(i, k...), nil
}
func (j joint) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
n, s, i, err := j.a.MSCFBs()
if err != nil {
return nil, nil, nil, err
}
m, q, k, err := j.b.MSCFBs()
if err != nil {
return nil, nil, nil, err
}
return append(n, m...), append(s, q...), append(i, k...), nil
}
func (j joint) RIFFs() ([][4]byte, []string) {
a, b := j.a.RIFFs()
c, d := j.b.RIFFs()
return append(a, c...), append(b, d...)
}
func (j joint) Texts() []string {
txts := make([]string, len(j.a.Texts()), len(j.a.Texts())+len(j.b.Texts()))
copy(txts, j.a.Texts())
for _, t := range j.a.Texts() {
var present bool
for _, u := range j.b.Texts() {
if t == u {
present = true
break
}
}
if !present {
txts = append(txts, t)
}
}
return txts
}
// Filtered allows us to apply limit and exclude filters to a parseable (in both cases - provide the list of ids we want to show).
type filtered struct {
ids []string
p Parseable
}
// Filter restricts a Parseable to the supplied ids. Enables limit and exclude filters.
func Filter(ids []string, p Parseable) filtered {
return filtered{ids, p}
}
// IDs returns a list of all the IDs in an identifier.
func (f filtered) IDs() []string {
ret := make([]string, 0, len(f.ids))
for _, v := range f.p.IDs() {
for _, w := range f.ids {
if v == w {
ret = append(ret, v)
break
}
}
}
return ret
}
// Infos returns a map of identifier specific information.
func (f filtered) Infos() map[string]FormatInfo {
ret, infos := make(map[string]FormatInfo), f.p.Infos()
for _, v := range f.IDs() {
ret[v] = infos[v]
}
return ret
}
func filterStrings(a func() ([]string, []string), ids []string) ([]string, []string) {
ret, retp := make([]string, 0, len(ids)), make([]string, 0, len(ids))
e, p := a()
for i, v := range p {
for _, w := range ids {
if v == w {
ret, retp = append(ret, e[i]), append(retp, v)
break
}
}
}
return ret, retp
}
// Globs returns a signature set with corresponding IDs for the globmatcher.
func (f filtered) Globs() ([]string, []string) {
return filterStrings(f.p.Globs, f.IDs())
}
// MIMEs returns a signature set with corresponding IDs for the mimematcher.
func (f filtered) MIMEs() ([]string, []string) {
return filterStrings(f.p.MIMEs, f.IDs())
}
// XMLs returns a signature set with corresponding IDs for the xmlmatcher.
func (f filtered) XMLs() ([][2]string, []string) {
ret, retp := make([][2]string, 0, len(f.IDs())), make([]string, 0, len(f.IDs()))
e, p := f.p.XMLs()
for i, v := range p {
for _, w := range f.IDs() {
if v == w {
ret, retp = append(ret, e[i]), append(retp, v)
break
}
}
}
return ret, retp
}
// Signatures returns a signature set with corresponding IDs and weights for the bytematcher.
func (f filtered) Signatures() ([]frames.Signature, []string, error) {
s, p, err := f.p.Signatures()
if err != nil {
return nil, nil, err
}
ret, retp := make([]frames.Signature, 0, len(f.IDs())), make([]string, 0, len(f.IDs()))
for i, v := range p {
for _, w := range f.IDs() {
if v == w {
ret, retp = append(ret, s[i]), append(retp, v)
break
}
}
}
return ret, retp, nil
}
func (f filtered) Zips() ([][]string, [][]frames.Signature, []string, error) {
n, s, i, err := f.p.Zips()
if err != nil {
return nil, nil, nil, err
}
nret, sret, iret := make([][]string, 0, len(f.IDs())), make([][]frames.Signature, 0, len(f.IDs())), make([]string, 0, len(f.IDs()))
for idx, v := range i {
for _, w := range f.IDs() {
if v == w {
nret, sret, iret = append(nret, n[idx]), append(sret, s[idx]), append(iret, v)
break
}
}
}
return nret, sret, iret, nil
}
func (f filtered) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
n, s, i, err := f.p.MSCFBs()
if err != nil {
return nil, nil, nil, err
}
nret, sret, iret := make([][]string, 0, len(f.IDs())), make([][]frames.Signature, 0, len(f.IDs())), make([]string, 0, len(f.IDs()))
for idx, v := range i {
for _, w := range f.IDs() {
if v == w {
nret, sret, iret = append(nret, n[idx]), append(sret, s[idx]), append(iret, v)
break
}
}
}
return nret, sret, iret, nil
}
func (f filtered) RIFFs() ([][4]byte, []string) {
ret, retp := make([][4]byte, 0, len(f.IDs())), make([]string, 0, len(f.IDs()))
r, p := f.p.RIFFs()
for i, v := range p {
for _, w := range f.IDs() {
if v == w {
ret, retp = append(ret, r[i]), append(retp, v)
break
}
}
}
return ret, retp
}
func (f filtered) Texts() []string {
txts := make([]string, 0, len(f.p.Texts()))
for _, t := range f.p.Texts() {
for _, u := range f.IDs() {
if t == u {
txts = append(txts, t)
break
}
}
}
return txts
}
// Priorities returns a priority map.
func (f filtered) Priorities() priority.Map {
m := f.p.Priorities()
return m.Filter(f.IDs())
}
// Mirror reverses the PREV wild segments within signatures as SUCC/EOF wild segments so they match at EOF as well as BOF.
type Mirror struct{ Parseable }
// Signatures returns a signature set with corresponding IDs and weights for the bytematcher.
func (m Mirror) Signatures() ([]frames.Signature, []string, error) {
sigs, ids, err := m.Parseable.Signatures()
if err != nil {
return sigs, ids, err
}
rsigs := make([]frames.Signature, 0, len(sigs)+100)
rids := make([]string, 0, len(sigs)+100)
for i, v := range sigs {
rsigs = append(rsigs, v)
rids = append(rids, ids[i])
mirror := v.Mirror()
if mirror != nil {
rsigs = append(rsigs, mirror)
rids = append(rids, ids[i])
}
}
return rsigs, rids, nil
}
type noName struct{ Parseable }
func (nn noName) Globs() ([]string, []string) { return nil, nil }
type noMIME struct{ Parseable }
func (nm noMIME) MIMEs() ([]string, []string) { return nil, nil }
type noXML struct{ Parseable }
func (nx noXML) XMLs() ([][2]string, []string) { return nil, nil }
type noByte struct{ Parseable }
func (nb noByte) Signatures() ([]frames.Signature, []string, error) { return nil, nil, nil }
type noContainers struct{ Parseable }
func (nc noContainers) Zips() ([][]string, [][]frames.Signature, []string, error) {
return nil, nil, nil, nil
}
func (nc noContainers) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
return nil, nil, nil, nil
}
type noRIFF struct{ Parseable }
func (nr noRIFF) RIFFs() ([][4]byte, []string) { return nil, nil }
type noText struct{ Parseable }
func (nt noText) Texts() []string { return nil }
type noPriority struct{ Parseable }
func (np noPriority) Priorities() priority.Map { return nil }
// sorted sorts signatures by their index so that runs of signatures
// e.g. fmt/1, fmt/1, fmt/2, fmt/1 can be properly placed.
type sorted struct{ Parseable }
func (s sorted) Signatures() ([]frames.Signature, []string, error) {
sigs, ids, err := s.Parseable.Signatures()
if err != nil {
return sigs, ids, err
}
retSigs := make([]frames.Signature, len(sigs))
retIds := make([]string, len(ids))
copy(retIds, ids)
sort.Strings(retIds)
var last string
var nth int
for i, this := range retIds {
if this == last {
nth++
} else {
nth = 0
last = this
}
var cursor int
for j, str := range ids {
if this != str {
continue
}
if cursor == nth {
retSigs[i] = sigs[j]
break
}
cursor++
}
}
return retSigs, retIds, nil
}
func ApplyConfig(p Parseable) Parseable {
if config.NoName() {
p = noName{p}
}
if config.NoMIME() {
p = noMIME{p}
}
if config.NoXML() {
p = noXML{p}
}
if config.NoByte() {
p = noByte{p}
}
if config.NoContainer() {
p = noContainers{p}
}
if config.NoRIFF() {
p = noRIFF{p}
}
if config.NoText() {
p = noText{p}
}
if config.NoPriority() {
p = noPriority{p}
}
// mirror PREV wild segments into EOF if maxBof and maxEOF set
if config.MaxBOF() > 0 && config.MaxEOF() > 0 {
p = Mirror{p}
}
if config.HasLimit() || config.HasExclude() {
ids := p.IDs()
if config.HasLimit() {
ids = config.Limit(ids)
} else {
ids = config.Exclude(ids)
}
p = Filter(ids, p)
}
// Sort Parseable so runs of signatures are contiguous.
p = sorted{p}
return p
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package containermatcher
import (
"strings"
"github.com/richardlehane/mscfb"
"github.com/richardlehane/siegfried/internal/siegreader"
)
type mscfbReader struct {
rdr *mscfb.Reader
entry *mscfb.File
}
func mscfbRdr(b *siegreader.Buffer) (Reader, error) {
m, err := mscfb.New(siegreader.ReaderFrom(b))
if err != nil {
return nil, err
}
return &mscfbReader{rdr: m}, nil
}
func (m *mscfbReader) Next() error {
var err error
m.entry, err = m.rdr.Next()
return err
}
func (m *mscfbReader) Name() string {
if m.entry == nil {
return ""
}
return strings.Join(append(m.entry.Path, m.entry.Name), "/")
}
func (m *mscfbReader) SetSource(b *siegreader.Buffers) (*siegreader.Buffer, error) {
return b.Get(m.entry)
}
func (m *mscfbReader) Close() {}
func (m *mscfbReader) IsDir() bool {
if m.entry == nil {
return false
}
return m.entry.FileInfo().IsDir()
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package loc
import (
"encoding/hex"
"fmt"
"strings"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
)
func magics(m []string) ([]frames.Signature, error) {
hx, ascii, hxx, asciix, err := characterise(m)
if err != nil {
return nil, err
}
if len(hx) > 0 {
sigs := make([]frames.Signature, len(hx))
for i, v := range hx {
byts, offs, masks, err := dehex(v, hxx[i])
if err != nil {
return nil, err
}
sigs[i] = make(frames.Signature, len(byts))
for ii, vv := range byts {
rel := frames.BOF
if ii > 0 {
rel = frames.PREV
}
var pat patterns.Pattern
if masks[ii] {
pat = patterns.Mask(vv[0])
} else {
pat = patterns.Sequence(vv)
}
sigs[i][ii] = frames.NewFrame(rel, pat, offs[ii], offs[ii])
}
}
return sigs, nil
} else if len(ascii) > 0 {
sigs := make([]frames.Signature, len(ascii))
for i, v := range ascii {
pat := patterns.Sequence(v)
sigs[i] = frames.Signature{frames.NewFrame(frames.BOF, pat, asciix[i], asciix[i])}
}
return sigs, nil
}
return nil, nil
}
// return raw hex and ascii signatures (ascii to be used only if no hex)
func characterise(m []string) ([]string, []string, []int, []int, error) {
hx, ascii := []string{}, []string{}
hxx, asciix := []int{}, []int{}
for _, v := range m {
tokens := strings.SplitN(v, ": ", 2)
switch len(tokens) {
case 1:
if v == "Not applicable" { // special case fdd000230
continue
}
_, _, _, err := dehex(v, 0)
if err == nil {
hx = append(hx, v)
hxx = append(hxx, 0)
continue
}
ascii = append(ascii, v)
asciix = append(asciix, 0)
case 2:
switch strings.TrimSpace(tokens[0]) { // special case fdd000147
case "Hex", "HEX":
hx = append(hx, tokens[1])
hxx = append(hxx, 0)
case "ASCII":
ascii = append(ascii, tokens[1])
asciix = append(asciix, 0)
case "12 byte string": // special case fdd000127
hx = append(hx, strings.TrimSuffix(strings.TrimPrefix(tokens[1], "X'"), "'"))
hxx = append(hxx, 0)
case "Hex (position 25)": // special case fdd000126
hx = append(hx, tokens[1])
hxx = append(hxx, 25)
default:
return hx, ascii, hxx, asciix, fmt.Errorf("loc: can't characterise signature (value: %v), unexpected label %s", v, tokens[0])
}
default:
return hx, ascii, hxx, asciix, fmt.Errorf("loc: can't characterise signature (value: %v), unexpected token number %d", v, len(tokens))
}
}
return hx, ascii, hxx, asciix, nil
}
func dehex(h string, off int) ([][]byte, []int, []bool, error) { // return bytes, offsets, and masks
repl := strings.NewReplacer("0x", "", " ", "", "\n", "", "\t", "", "\r", "", "{20 bytes of Hex 20}", "2020202020202020202020202020202020202020") // special case fdd000342 (nl tab within the hex)
h = repl.Replace(h)
if len(h)%2 != 0 {
return nil, nil, nil, fmt.Errorf("loc: can't dehex %s", h)
}
h = strings.ToLower(h)
var (
idx int
byts [][]byte = [][]byte{{}}
offs []int = []int{0}
masks []bool = []bool{false}
)
for i := 0; i < len(h); i += 2 {
switch {
case h[i:i+2] == "xx":
if off == 0 && i > 0 {
idx++
byts = append(byts, []byte{})
offs = append(offs, 0)
masks = append(masks, false)
}
off++
case h[i] == 'x' || h[i+1] == 'x':
if len(byts[idx]) > 0 {
idx++
byts = append(byts, []byte{})
offs = append(offs, 0)
masks = append(masks, false)
}
if off > 0 {
offs[idx] = off
off = 0
}
masks[idx] = true
if h[i] == 'x' {
byts[idx] = append(byts[idx], '0', h[i+1])
} else {
byts[idx] = append(byts[idx], h[i], '0')
}
if i+2 < len(h) {
idx++
byts = append(byts, []byte{})
offs = append(offs, 0)
masks = append(masks, false)
}
default:
if off > 0 {
offs[idx] = off
off = 0
}
byts[idx] = append(byts[idx], h[i], h[i+1])
}
}
for i, s := range byts {
byt, err := hex.DecodeString(string(s))
if err != nil {
return nil, nil, nil, err
}
byts[i] = byt
}
return byts, offs, masks, nil
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"bufio"
"bytes"
"fmt"
"io"
"strings"
)
type sfYAML struct {
replacer *strings.Replacer
dblReplacer *strings.Replacer
buf *bufio.Reader
head Head
peek record
err error
}
const (
divide = iota
keyval
item // e.g. -
)
type token struct {
typ int
key string
val string
}
func advance(buf *bufio.Reader, repl, dbl *strings.Replacer) (token, error) {
byts, err := buf.ReadBytes('\n')
if err != nil {
return token{}, err
}
if bytes.Equal(byts, []byte("---\n")) {
return token{typ: divide}, nil
}
var tok token
if bytes.HasPrefix(byts, []byte(" - ")) {
tok.typ = item
byts = byts[4:]
} else {
tok.typ = keyval
}
split := bytes.SplitN(byts, []byte(":"), 2)
tok.key = string(bytes.TrimSpace(split[0]))
if len(split) == 2 {
val := bytes.TrimSpace(split[1])
if len(val) > 0 {
if val[0] == '"' {
tok.val = dbl.Replace(string(bytes.TrimSuffix(bytes.TrimPrefix(val, []byte("\"")), []byte("\""))))
} else {
tok.val = repl.Replace(string(bytes.TrimSuffix(bytes.TrimPrefix(val, []byte("'")), []byte("'"))))
}
}
}
return tok, nil
}
func consumeList(buf *bufio.Reader, repl, dbl *strings.Replacer, tok token) ([]string, []string, error) {
fields, values := []string{tok.key}, []string{tok.val}
var err error
for tok, err = advance(buf, repl, dbl); err == nil && tok.typ != divide; tok, err = advance(buf, repl, dbl) {
fields, values = append(fields, tok.key), append(values, tok.val)
}
return fields, values, err
}
func consumeRecord(buf *bufio.Reader, repl, dbl *strings.Replacer) (record, error) {
var (
rec record
tok token
err error
)
m := make(map[string]string)
for tok, err = advance(buf, repl, dbl); err == nil && tok.typ == keyval; tok, err = advance(buf, repl, dbl) {
m[tok.key] = tok.val
}
if err != nil || tok.typ != item {
if err == nil {
return rec, fmt.Errorf("unexpected token got %d", tok.typ)
}
return rec, err
}
ks, vs, err := consumeList(buf, repl, dbl, tok)
if err != nil && err != io.EOF {
return rec, err
}
return record{m, ks, vs}, nil
}
func newYAML(r io.Reader, path string) (Reader, error) {
sfy := &sfYAML{
replacer: strings.NewReplacer("''", "'"),
dblReplacer: strings.NewReplacer(
"\\0", "\x00",
"\\a", "\x07",
"\\b", "\x08",
"\\n", "\x0A",
"\\v", "\x0B",
"\\f", "\x0C",
"\\r", "\x0D",
"\\e", "\x1B",
"\\\"", "\x22",
"\\/", "\x2F",
"\\\\", "\x5c",
),
buf: bufio.NewReader(r),
}
return sfy.makeHead(path)
}
func (sfy *sfYAML) Head() Head {
return sfy.head
}
func (sfy *sfYAML) makeHead(path string) (*sfYAML, error) {
tok, err := advance(sfy.buf, sfy.replacer, sfy.dblReplacer)
if err != nil || tok.typ != divide {
return nil, fmt.Errorf("invalid YAML; got %v", err)
}
rec, err := consumeRecord(sfy.buf, sfy.replacer, sfy.dblReplacer)
if err != nil {
return nil, fmt.Errorf("invalid YAML; got %v", err)
}
rec.attributes["results"] = path
sfy.head, err = getHead(rec)
sfy.peek, sfy.err = consumeRecord(sfy.buf, sfy.replacer, sfy.dblReplacer)
sfy.head.HashHeader = getHash(sfy.peek.attributes)
sfy.head.Fields = getFields(sfy.peek.listFields, sfy.peek.listValues)
return sfy, err
}
func (sfy *sfYAML) Next() (File, error) {
r, e := sfy.peek, sfy.err
if e != nil {
return File{}, e
}
sfy.peek, sfy.err = consumeRecord(sfy.buf, sfy.replacer, sfy.dblReplacer)
return getFile(r)
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package chart
import (
"fmt"
)
func ExampleChart() {
fmt.Print(Chart("Census",
[]string{"1950", "1951", "1952"},
[]string{"deaths", "births", "marriages"},
map[string]bool{},
map[string]map[string]int{"1950": {"births": 11, "deaths": 49}, "1951": {"deaths": 200, "births": 9}},
))
// Output:
// CENSUS
// 1950
// deaths: ■ ■ (49)
// births: ■ (11)
//
// 1951
// deaths: ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ (200)
// births: ■ (9)
}
<file_sep>// +build !windows
// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"flag"
"log"
"net"
"os"
"strings"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
)
var fprflag = flag.Bool("fpr", false, "start siegfried fpr server at "+config.Fpr())
func reply(s string) []byte {
if len(s) > 1024 {
return []byte(s[:1024])
}
return []byte(s)
}
func fpridentify(s *siegfried.Siegfried, path string) []byte {
fi, err := os.Open(path)
defer fi.Close()
if err != nil {
return reply("error: failed to open " + path + "; got " + err.Error())
}
ids, err := s.Identify(fi, path, "")
if ids == nil {
return reply("error: failed to scan " + path + "; got " + err.Error())
}
switch len(ids) {
case 0:
return reply("error: scanning " + path + ": no formats returned")
case 1:
if !ids[0].Known() {
return reply("error: format unknown; got " + ids[0].Warn())
}
return reply(ids[0].String())
default:
strs := make([]string, len(ids))
for i, v := range ids {
strs[i] = v.String()
}
return reply("error: multiple formats returned; got " + strings.Join(strs, ", "))
}
}
func serveFpr(addr string, s *siegfried.Siegfried) {
// remove the socket file if it exists
if _, err := os.Stat(addr); err == nil {
os.Remove(addr)
}
uaddr, err := net.ResolveUnixAddr("unix", addr)
if err != nil {
log.Fatalf("FPR error: failed to get address: %v", err)
}
lis, err := net.ListenUnix("unix", uaddr)
if err != nil {
log.Fatalf("FPR error: failed to listen: %v", err)
}
buf := make([]byte, 4024)
for {
conn, err := lis.Accept()
if err != nil {
log.Fatalf("FPR error: bad connection: %v", err)
}
l, err := conn.Read(buf)
if err != nil {
conn.Write([]byte("error reading from connection: " + err.Error()))
} else {
conn.Write(fpridentify(s, string(buf[:l])))
}
conn.Close()
}
}
<file_sep>package wikidata
import (
"errors"
"io/fs"
"io/ioutil"
"os"
"path/filepath"
"strings"
"testing"
"github.com/richardlehane/siegfried/pkg/config"
)
type idTestsStruct struct {
uri string
res string
}
var idTests = []idTestsStruct{
idTestsStruct{"http://www.wikidata.org/entity/Q1023647", "Q1023647"},
idTestsStruct{"http://www.wikidata.org/entity/Q336284", "Q336284"},
idTestsStruct{"http://www.wikidata.org/entity/Q9296340", "Q9296340"},
}
// TestGetID is a rudimentary test to make sure that we can retrieve
// QUIDs reliably from a Wikidata URI.
func TestGetID(t *testing.T) {
for _, v := range idTests {
res := getID(v.uri)
if res != v.res {
t.Errorf("Expected to generate QID '%s' but received '%s'", v.res, res)
}
}
}
// TestOpenWikidata simply verifies the different anticipated behavior
// of openWikidata so that behavior is predictable for the end user.
func TestOpenWikidata(t *testing.T) {
var testDefinitions = `
{
"endpoint": "%replaceMe%",
"head": {},
"results": {
"bindings": []
},
"provenance": []
}
`
var testJSON = `
{
"PronomProp": "http://wikibase.example.com/entity/Q2",
"BofProp": "http://wikibase.example.com/entity/Q3",
"EofProp": "http://wikibase.example.com/entity/Q4"
}
`
var replaceMe = "%replaceMe%"
var defaultEndpoint = "https://query.wikidata.org/sparql"
tempDir, _ := ioutil.TempDir("", "wikidata-test-dir-*")
defer os.RemoveAll(tempDir)
err := os.Mkdir(filepath.Join(tempDir, "wikidata"), 0755)
if err != nil {
t.Fatal(err)
}
config.SetHome(tempDir)
defsWithCustomEndpoint := filepath.Join(tempDir, "wikidata", "wikidata-definitions")
err = ioutil.WriteFile(defsWithCustomEndpoint, []byte(testDefinitions), 0755)
if err != nil {
t.Fatal(err)
}
config.SetWikidataDefinitions("wikidata-definitions")
// At this point wikibase.json doesn't exist and so we want to
// receive an error.
_, err = openWikidata()
if !errors.Is(err, fs.ErrNotExist) {
t.Errorf(
"Expected error loading wikibase.json but received: %s",
err,
)
}
// Now make sure wikibase.json exists, there should be no error.
wikibaseJSON := filepath.Join(tempDir, "wikidata", "wikibase.json")
err = ioutil.WriteFile(wikibaseJSON, []byte(testJSON), 0755)
if err != nil {
t.Fatal(err)
}
// Wikidata should now open without error and complete processing.
// Even though we have a definitions file with no actionable data,
// it's not actually an error.
_, err = openWikidata()
if err != nil {
t.Fatal(err)
}
// Test defaults, by first removing custom JSON and then setting up
// a default definitions file.
err = os.Remove(wikibaseJSON)
if err != nil {
t.Fatal(err)
}
defaultDefinitions := strings.Replace(testDefinitions, replaceMe, defaultEndpoint, 1)
config.SetHome(tempDir)
defsWithDefaultEndpoint := filepath.Join(tempDir, "wikidata", "wikidata-definitions")
err = ioutil.WriteFile(defsWithDefaultEndpoint, []byte(defaultDefinitions), 0755)
if err != nil {
t.Fatal(err)
}
// Open the good definitions now, there should be no issue.
_, err = openWikidata()
if err != nil {
t.Fatal(err)
}
// Finally let's put some really un-useful information into the path
// for the definitions and try that.
config.SetWikidataDefinitions("/path/🙅/does/🙅/not/🙅/exist/🙅/")
_, err = openWikidata()
if err == nil {
t.Errorf(
"Anticipating error with non-existent path, but got: 'nil'",
)
}
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package config
// Multi defines how identifiers treat multiple results.
type Multi int
const (
Single Multi = iota // Return a single result. If there is more than one result with the highest score, return UNKNOWN and a warning
Conclusive // Default. Return only the results with the highest score.
Positive // Return any result with a strong score (or if only weak results, return all). This means a byte match, container match or XML match. Text/MIME/extension-only matches are considered weak.
Comprehensive // Same as positive but also turn off the priority rules during byte matching.
Exhaustive // Turn off priority rules during byte matching and return all weak as well as strong results.
DROID // Turn off priority rules during byte matching but apply priorities to results with strong score after matching
)
func (m Multi) String() string {
switch m {
case Single:
return "single (0)"
case Conclusive:
return "conclusive (1)"
case Positive:
return "positive (2)"
case Comprehensive:
return "comprehensive (3)"
case Exhaustive:
return "exhaustive (4)"
case DROID:
return "droid (5)"
}
return ""
}
<file_sep>package containermatcher
import (
"bytes"
"io"
"os"
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
func TestIdentify(t *testing.T) {
// testTrigger defined in container_test and just returns true
// newTestReader defined in reader_test and returns a test reader
// This test works because the outside file (bytes 0..8) is just a
// meaningless wrapper. The matcher always detects container (due to testTrigger)
// and newTestReader has the content we actually test against.
config.SetOut(os.Stderr)
config.SetDebug()
ctypes = []ctype{{testTrigger, newTestReader}}
// test adding
count++
testMatcher, _, err := Add(Matcher{testContainerMatcher},
SignatureSet{
0,
[][]string{
{"one", "two"},
{"one"},
},
[][]frames.Signature{
{tests.TestSignatures[3], tests.TestSignatures[4]}, // {[BOF 0:test], [P 10-20:TESTY|YNESS], [BOF *:test]}, {[BOF *:junk]}
{tests.TestSignatures[2]}, // {[BOF 0-5:a|b|c..j], [P *:test]}
},
},
nil,
)
/*
// The file content is always: "test12345678910YNESSjunktestyjunktestytest12345678910111223"
The signatures are processed as these sequences:
"one": [ {Offsets: 0; Choices: [test]} {Offsets: -1; Choices: [test]}
{Offsets: 5, -1; Choices: [a | b | c | d | e | f | g | h | i | j], [test]}
]
"two" [{Offsets: -1; Choices: [junk]}]
// Issue (1) we have a signature of *junk - this signature is never sent to resume as no hits indicated it. Need to add a list of non-anchored wildcard signatures.
// Issue (2) the signature at 2[1] isn't being sent on the resume channel. Or it is being sent but ends up with wrong test index.
*/
if err != nil {
t.Fatal(err)
}
r := bytes.NewBuffer([]byte("012345678"))
bufs := siegreader.New()
b, err := bufs.Get(r)
if err != nil && err != io.EOF {
t.Fatal(err)
}
res, _ := testMatcher.Identify("example.tt", b)
var collect []core.Result
for r := range res {
collect = append(collect, r)
}
expect := count * 2
if len(collect) != expect {
t.Errorf("Expecting %d results, got %d", expect, len(collect))
for _, r := range collect {
t.Error(r.Basis())
}
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package bytematcher
import (
"fmt"
"github.com/richardlehane/match/dwac"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
// identify function - brings a new matcher into existence
func (b *Matcher) identify(buf *siegreader.Buffer, quit chan struct{}, r chan core.Result, hints ...core.Hint) {
buf.Quit = quit
waitSet := b.priorities.WaitSet(hints...)
maxBOF, maxEOF := b.maxBOF, b.maxEOF
if len(hints) > 0 {
var hasExclude bool
for _, h := range hints {
if h.Pivot == nil {
hasExclude = true
break
}
}
if hasExclude {
maxBOF, maxEOF = waitSet.MaxOffsets()
}
}
incoming, resume := b.scorer(buf, waitSet, quit, r)
rdr := siegreader.LimitReaderFrom(buf, maxBOF)
// First test BOF frameset
bfchan := b.bofFrames.index(buf, false, quit)
for bf := range bfchan {
if config.Debug() {
fmt.Fprintln(config.Out(), strike{b.bofFrames.testTreeIndex[bf.idx], 0, bf.off, bf.length, false, true})
}
incoming <- strike{b.bofFrames.testTreeIndex[bf.idx], 0, bf.off, bf.length, false, true}
}
select {
case <-quit: // the matcher has called quit
close(incoming)
return
default:
}
// start bof matcher if not yet started
b.bmu.Do(func() {
b.bAho = dwac.New(b.bofSeq.set)
})
var resuming bool
var bofOffset int64
// Do an initial check of BOF sequences (until resume signal)
bchan, rchan := b.bAho.Index(rdr)
for br := range bchan {
if br.Index[0] == -1 { // if we got a resume signal
resuming = true
bofOffset = br.Offset
break
} else {
if config.Debug() {
fmt.Fprintln(config.Out(), strike{b.bofSeq.testTreeIndex[br.Index[0]], br.Index[1], br.Offset, br.Length, false, false})
}
incoming <- strike{b.bofSeq.testTreeIndex[br.Index[0]], br.Index[1], br.Offset, br.Length, false, false}
}
}
select {
case <-quit: // the matcher has called quit
close(rchan)
close(incoming)
return
default:
}
// check the EOF
if maxEOF != 0 {
_, _ = buf.CanSeek(0, true) // force a full read to enable EOF scan to proceed for streams
// EOF frame tests (should be none)
efchan := b.eofFrames.index(buf, true, quit)
for ef := range efchan {
if config.Debug() {
fmt.Fprintln(config.Out(), strike{b.eofFrames.testTreeIndex[ef.idx], 0, ef.off, ef.length, true, true})
}
incoming <- strike{b.eofFrames.testTreeIndex[ef.idx], 0, ef.off, ef.length, true, true}
}
// EOF sequences
b.emu.Do(func() {
b.eAho = dwac.New(b.eofSeq.set)
})
rrdr := siegreader.LimitReverseReaderFrom(buf, maxEOF)
echan, erchan := b.eAho.Index(rrdr) // todo: handle the possibility of wild EOF segments
// Scan complete EOF
for er := range echan {
if er.Index[0] == -1 { // handle EOF wilds (should be none!)
incoming <- strike{-1, -1, er.Offset, 0, true, false} // send resume signal
kfids := <-resume
dynSet := b.eofSeq.indexes(filterTests(b.tests, kfids))
erchan <- dynSet
continue
}
if config.Debug() {
fmt.Fprintln(config.Out(), strike{b.eofSeq.testTreeIndex[er.Index[0]], er.Index[1], er.Offset, er.Length, true, false})
}
incoming <- strike{b.eofSeq.testTreeIndex[er.Index[0]], er.Index[1], er.Offset, er.Length, true, false}
}
select {
case <-quit: // the matcher has called quit
close(rchan)
close(incoming)
return
default:
}
}
if !resuming {
close(incoming)
return
}
// Finally, finish BOF scan looking for wilds only
incoming <- strike{-1, -1, bofOffset, 0, false, false} // send resume signal
kfids := <-resume
dynSet := b.bofSeq.indexes(filterTests(b.tests, kfids))
rchan <- dynSet
for br := range bchan {
if config.Debug() {
fmt.Fprintln(config.Out(), strike{b.bofSeq.testTreeIndex[br.Index[0]], br.Index[1], br.Offset, br.Length, false, false})
}
incoming <- strike{b.bofSeq.testTreeIndex[br.Index[0]], br.Index[1], br.Offset, br.Length, false, false}
}
close(incoming)
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package chart
import (
"bytes"
"fmt"
"strings"
)
const max = 10
func squares(num int, rel float64, abs bool) string {
if rel < 1 && !abs {
nnum := int(float64(num) * rel)
if nnum == 0 && num > 0 {
nnum = 1
}
num = nnum
}
s := make([]string, num)
for i := 0; i < num; i++ {
s[i] = "\xE2\x96\xA0"
}
return strings.Join(s, " ")
}
func Chart(title string, sections, fields []string, abs map[string]bool, frequencies map[string]map[string]int) string {
buf := &bytes.Buffer{}
if len(title) > 0 {
buf.WriteString(strings.ToUpper(title))
}
var pad int // pad to length longest field
for _, v := range fields {
if len(v) > pad {
pad = len(v) + 1
}
}
template := fmt.Sprintf("%%-%ds %%s (%%d)\n", pad)
var rel float64 = 1
for _, m := range frequencies {
for _, num := range m {
if num > max && float64(max)/float64(num) < rel {
rel = float64(max) / float64(num)
}
}
}
for _, k := range sections {
if m, ok := frequencies[k]; ok {
fmt.Fprintf(buf, "\n%s\n", k)
for _, label := range fields {
if num, ok := m[label]; ok {
fmt.Fprintf(buf, template, label+":", squares(num, rel, abs[label]), num)
}
}
}
}
return buf.String()
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"encoding/csv"
"fmt"
"io"
)
type sfCSV struct {
rdr *csv.Reader
hh string
path string
fields [][]string
identifiers [][2]string
peek []string
err error
}
func newCSV(r io.Reader, path string) (Reader, error) {
rdr := csv.NewReader(r)
rec, err := rdr.Read()
if err != nil || rec[0] != "filename" || len(rec) < 5 {
return nil, fmt.Errorf("bad or invalid CSV: %v", err)
}
sfc := &sfCSV{
rdr: rdr,
path: path,
}
var (
fieldStart = 4
fieldIdx = -1
fields = make([][]string, 0, 1)
)
if rec[fieldStart] != "namespace" {
sfc.hh = rec[4]
fieldStart++
}
if rec[fieldStart] != "namespace" {
return nil, fmt.Errorf("bad CSV, expecting field 'namespace' got %s", rec[fieldStart])
}
for _, v := range rec[fieldStart:] {
if v == "namespace" {
fieldIdx++
fields = append(fields, make([]string, 0, 7))
}
fields[fieldIdx] = append(fields[fieldIdx], v)
}
sfc.fields = fields
sfc.peek, err = rdr.Read()
sfc.identifiers = make([][2]string, 0, 1)
if err != nil {
return nil, fmt.Errorf("bad CSV, no results; got %v", err)
}
for i, v := range sfc.peek {
if rec[i] == "namespace" {
sfc.identifiers = append(sfc.identifiers, [2]string{v, ""})
}
}
return sfc, nil
}
func (sfc *sfCSV) Head() Head {
return Head{
ResultsPath: sfc.path,
Identifiers: sfc.identifiers,
Fields: sfc.fields,
HashHeader: sfc.hh,
}
}
func (sfc *sfCSV) Next() (File, error) {
if sfc.peek == nil || sfc.err != nil {
return File{}, sfc.err
}
fieldStart := 4
var hash string
if sfc.hh != "" {
hash = sfc.peek[fieldStart]
fieldStart++
}
file, err := newFile(sfc.peek[0], sfc.peek[1], sfc.peek[2], hash, sfc.peek[3])
if err != nil {
return file, err
}
fn := sfc.peek[0]
for {
idStart := fieldStart
for _, v := range sfc.fields {
vals := sfc.peek[idStart : idStart+len(v)]
if vals[0] != "" {
file.IDs = append(file.IDs, newDefaultID(v, vals))
}
idStart += len(v)
}
sfc.peek, sfc.err = sfc.rdr.Read()
if sfc.peek == nil || sfc.err != nil || fn != sfc.peek[0] {
break
}
}
return file, nil
}
<file_sep>package bytematcher
import (
"testing"
"github.com/richardlehane/match/dwac"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
var TestSeqSetBof = &seqSet{
set: []dwac.Seq{},
testTreeIndex: []int{},
}
var TestSeqSetEof = &seqSet{
set: []dwac.Seq{},
testTreeIndex: []int{},
}
var TestFrameSetBof = &frameSet{
set: []frames.Frame{},
testTreeIndex: []int{},
}
func TestSeqSet(t *testing.T) {
s := &seqSet{}
c1 := dwac.Seq{MaxOffsets: []int64{0}, Choices: []dwac.Choice{{[]byte{'a', 'p', 'p', 'l', 'e'}}}}
c2 := dwac.Seq{MaxOffsets: []int64{0}, Choices: []dwac.Choice{{[]byte{'a', 'p', 'p', 'l', 'e'}}}}
c3 := dwac.Seq{MaxOffsets: []int64{-1}, Choices: []dwac.Choice{{[]byte{'a', 'p', 'p', 'l', 'e'}}}}
c4 := dwac.Seq{MaxOffsets: []int64{-1}, Choices: []dwac.Choice{{[]byte{'a', 'p', 'p', 'l', 'e', 's'}}}}
s.add(c1, 0)
i := s.add(c2, 1)
if i != 0 {
t.Error("Adding identical byte sequences should return a single TestTree index")
}
i = s.add(c3, 1)
if i != 1 {
t.Error("A different offset, should mean a different TestTree index")
}
i = s.add(c4, 2)
if i != 2 {
t.Error("A different choice slice, should mean a different TestTree index")
}
i = s.add(c2, 3)
if i != 0 {
t.Error("Adding identical byte sequences should return a single TestTree index")
}
}
func TestFrameSet(t *testing.T) {
f := &frameSet{}
f.add(tests.TestFrames[0], 0)
i := f.add(tests.TestFrames[0], 1)
if i != 0 {
t.Error("Adding identical frame sequences should return a single TestTree index")
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Define custom patterns (implementing the siegfried.Pattern interface) for the different patterns allowed by the PRONOM spec.
package pronom
import (
"bytes"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/persist"
)
func init() {
patterns.Register(rangeLoader, loadRange)
}
const (
rangeLoader byte = iota + 8
)
type Range struct {
From, To []byte
}
func (r Range) Test(b []byte) ([]int, int) {
if len(b) < len(r.From) || len(b) < len(r.To) {
return nil, 0
}
if bytes.Compare(r.From, b[:len(r.From)]) < 1 {
if bytes.Compare(r.To, b[:len(r.To)]) > -1 {
return []int{len(r.From)}, 1
}
}
return nil, 1
}
func (r Range) TestR(b []byte) ([]int, int) {
if len(b) < len(r.From) || len(b) < len(r.To) {
return nil, 0
}
if bytes.Compare(r.From, b[len(b)-len(r.From):]) < 1 {
if bytes.Compare(r.To, b[len(b)-len(r.To):]) > -1 {
return []int{len(r.From)}, 1
}
}
return nil, 1
}
func (r Range) Equals(pat patterns.Pattern) bool {
rng, ok := pat.(Range)
if ok {
if bytes.Equal(rng.From, r.From) {
if bytes.Equal(rng.To, r.To) {
return true
}
}
}
return false
}
func (r Range) Length() (int, int) {
return len(r.From), len(r.From)
}
func (r Range) NumSequences() int {
l := len(r.From)
if l > 2 || l < 1 {
return 0
}
if l == 2 {
if r.To[0]-r.From[0] > 1 {
return 0
}
return 256*int(r.To[0]-r.From[0]) + int(r.To[1]) - int(r.From[1]) + 1
}
return int(r.To[0]-r.From[0]) + 1
}
func (r Range) Sequences() []patterns.Sequence {
num := r.NumSequences()
seqs := make([]patterns.Sequence, num)
if num < 1 {
return seqs
}
if len(r.From) == 2 {
if r.From[0] == r.To[0] {
for i := 0; i < num; i++ {
seqs[i] = patterns.Sequence{r.From[0], r.From[1] + byte(i)}
}
return seqs
}
max := 256 - int(r.From[1])
for i := 0; i < max; i++ {
seqs[i] = patterns.Sequence{r.From[0], r.From[1] + byte(i)}
}
for i := 0; max < num; max++ {
seqs[max] = patterns.Sequence{r.To[0], byte(0 + i)}
i++
}
return seqs
}
for i := 0; i < num; i++ {
seqs[i] = patterns.Sequence{r.From[0] + byte(i)}
}
return seqs
}
func (r Range) String() string {
return "r " + patterns.Stringify(r.From) + " - " + patterns.Stringify(r.To)
}
func (r Range) Save(ls *persist.LoadSaver) {
ls.SaveByte(rangeLoader)
ls.SaveBytes(r.From)
ls.SaveBytes(r.To)
}
func loadRange(ls *persist.LoadSaver) patterns.Pattern {
return Range{
ls.LoadBytes(),
ls.LoadBytes(),
}
}
<file_sep>package bytematcher
import (
"bytes"
"io"
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
var TestSample1 = []byte("test12345678910YNESSjunktestyjunktestytest12345678910111223") // should match sigs 0, 1 and 2
var TestSample2 = []byte("test12345678910YNESSjTESTunktestyjunktestytest12345678910111223") // should match all 4 sigs
func TestIO(t *testing.T) {
bm, _, err := Add(nil, SignatureSet(tests.TestSignatures), nil)
if err != nil {
t.Error(err)
}
saver := persist.NewLoadSaver(nil)
Save(bm, saver)
if len(saver.Bytes()) < 100 {
t.Errorf("Save bytematcher: too small, only got %v", len(saver.Bytes()))
}
newbm := Load(persist.NewLoadSaver(saver.Bytes()))
nsaver := persist.NewLoadSaver(nil)
Save(newbm, nsaver)
if len(nsaver.Bytes()) != len(saver.Bytes()) {
t.Fatalf("expecting the bms to match length: %d and %d", len(saver.Bytes()), len(nsaver.Bytes()))
}
if string(nsaver.Bytes()) != string(saver.Bytes()) {
t.Errorf("Load bytematcher: expecting first bytematcher (%v), to equal second bytematcher (%v)", bm.String(), newbm.String())
}
}
func contains(a []core.Result, b []int) bool {
for _, v := range a {
var present bool
for _, w := range b {
if v.Index() == w {
present = true
}
}
if !present {
return false
}
}
return true
}
func TestMatch(t *testing.T) {
bm, _, err := Add(nil, SignatureSet(tests.TestSignatures), nil)
if err != nil {
t.Error(err)
}
bufs := siegreader.New()
buf, err := bufs.Get(bytes.NewBuffer(TestSample1))
if err != nil && err != io.EOF {
t.Error(err)
}
res, _ := bm.Identify("", buf)
results := make([]core.Result, 0)
for i := range res {
results = append(results, i)
}
if !contains(results, []int{0, 2, 3, 4}) {
t.Errorf("Missing result, got: %v, expecting:%v\n", results, bm)
}
buf, err = bufs.Get(bytes.NewBuffer(TestSample2))
if err != nil && err != io.EOF {
t.Error(err)
}
res, _ = bm.Identify("", buf)
results = results[:0]
for i := range res {
results = append(results, i)
}
if !contains(results, []int{0, 1, 2, 3, 4}) {
t.Errorf("Missing result, got: %v, expecting:%v\n", results, bm)
}
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package riffmatcher
import (
"fmt"
"sort"
"strings"
"golang.org/x/image/riff"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
type Matcher struct {
riffs map[riff.FourCC][]int
priorities *priority.Set
}
func Load(ls *persist.LoadSaver) core.Matcher {
le := ls.LoadSmallInt()
if le == 0 {
return nil
}
riffs := make(map[riff.FourCC][]int)
for i := 0; i < le; i++ {
k := riff.FourCC(ls.LoadFourCC())
r := make([]int, ls.LoadSmallInt())
for j := range r {
r[j] = ls.LoadSmallInt()
}
riffs[k] = r
}
return &Matcher{
riffs: riffs,
priorities: priority.Load(ls),
}
}
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveSmallInt(0)
return
}
m := c.(*Matcher)
ls.SaveSmallInt(len(m.riffs))
if len(m.riffs) == 0 {
return
}
for k, v := range m.riffs {
ls.SaveFourCC(k)
ls.SaveSmallInt(len(v))
for _, w := range v {
ls.SaveSmallInt(w)
}
}
m.priorities.Save(ls)
}
type SignatureSet [][4]byte
func Add(c core.Matcher, ss core.SignatureSet, p priority.List) (core.Matcher, int, error) {
sigs, ok := ss.(SignatureSet)
if !ok {
return nil, -1, fmt.Errorf("RIFFmatcher: can't cast persist set")
}
if len(sigs) == 0 {
return c, 0, nil
}
var m *Matcher
if c == nil {
m = &Matcher{
riffs: make(map[riff.FourCC][]int),
priorities: &priority.Set{},
}
} else {
m = c.(*Matcher)
}
var length int
// unless it is a new matcher, calculate current length by iterating through all the result values
if len(m.riffs) > 0 {
for _, v := range m.riffs {
for _, w := range v {
if w > length {
length = w
}
}
}
length++ // add one - because the result values are indexes
}
for i, v := range sigs {
cc := riff.FourCC(v)
_, ok := m.riffs[cc]
if ok {
m.riffs[cc] = append(m.riffs[cc], i+length)
} else {
m.riffs[cc] = []int{i + length}
}
}
// add priorities
m.priorities.Add(p, len(sigs), 0, 0)
return m, length + len(sigs), nil
}
type result struct {
idx int
cc riff.FourCC
}
func (r result) Index() int {
return r.idx
}
func (r result) Basis() string {
return "fourCC matches " + string(r.cc[:])
}
func (m Matcher) Identify(na string, b *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
buf, err := b.Slice(0, 8)
if err != nil || buf[0] != 'R' || buf[1] != 'I' || buf[2] != 'F' || buf[3] != 'F' {
res := make(chan core.Result)
close(res)
return res, nil
}
rcc, rrdr, err := riff.NewReader(siegreader.ReaderFrom(b))
if err != nil {
res := make(chan core.Result)
close(res)
return res, nil
}
// now make structures for testing
uniqs := make(map[riff.FourCC]bool)
res := make(chan core.Result)
waitset := m.priorities.WaitSet(hints...)
// send and report if satisified
send := func(cc riff.FourCC) bool {
if config.Debug() {
fmt.Fprintf(config.Out(), "riff match %s\n", string(cc[:]))
}
if uniqs[cc] {
return false
}
uniqs[cc] = true
for _, hit := range m.riffs[cc] {
if waitset.Check(hit) {
if config.Debug() {
fmt.Fprintf(config.Out(), "sending riff match %s\n", string(cc[:]))
}
res <- result{hit, cc}
if waitset.Put(hit) {
return true
}
}
}
return false
}
// riff walk
var descend func(*riff.Reader) bool
descend = func(r *riff.Reader) bool {
for {
chunkID, chunkLen, chunkData, err := r.Next()
if err != nil || send(chunkID) {
return true
}
if chunkID == riff.LIST {
listType, list, err := riff.NewListReader(chunkLen, chunkData)
if err != nil || send(listType) {
return true
}
if descend(list) {
return true
}
}
}
}
// go time
go func() {
if send(rcc) {
close(res)
return
}
descend(rrdr)
close(res)
}()
return res, nil
}
func (m Matcher) String() string {
keys := make([]string, 0, len(m.riffs))
for k := range m.riffs {
keys = append(keys, string(k[:]))
}
sort.Strings(keys)
return fmt.Sprintf("RIFF matcher: %s\n", strings.Join(keys, ", "))
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package xmlmatcher
import (
"fmt"
"github.com/richardlehane/xmldetect"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
type Matcher map[[2]string][]int
type SignatureSet [][2]string // slice of root, namespace (both optional)
func Load(ls *persist.LoadSaver) core.Matcher {
le := ls.LoadSmallInt()
if le == 0 {
return nil
}
ret := make(Matcher)
for i := 0; i < le; i++ {
k := [2]string{ls.LoadString(), ls.LoadString()}
r := make([]int, ls.LoadSmallInt())
for j := range r {
r[j] = ls.LoadSmallInt()
}
ret[k] = r
}
return ret
}
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveSmallInt(0)
return
}
m := c.(Matcher)
ls.SaveSmallInt(len(m))
for k, v := range m {
ls.SaveString(k[0])
ls.SaveString(k[1])
ls.SaveSmallInt(len(v))
for _, w := range v {
ls.SaveSmallInt(w)
}
}
}
func Add(c core.Matcher, ss core.SignatureSet, p priority.List) (core.Matcher, int, error) {
var m Matcher
if c == nil {
m = make(Matcher)
} else {
m = c.(Matcher)
}
sigs, ok := ss.(SignatureSet)
if !ok {
return nil, -1, fmt.Errorf("Xmlmatcher: can't cast persist set")
}
var length int
// unless it is a new matcher, calculate current length by iterating through all the result values
if len(m) > 0 {
for _, v := range m {
for _, w := range v {
if w > length {
length = w
}
}
}
length++ // add one - because the result values are indexes
}
for i, v := range sigs {
_, ok := m[v]
if ok {
m[v] = append(m[v], i+length)
} else {
m[v] = []int{i + length}
}
}
return m, length + len(sigs), nil
}
func (m Matcher) Identify(s string, b *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
rdr := siegreader.TextReaderFrom(b)
_, root, ns, err := xmldetect.Root(rdr)
if err != nil {
res := make(chan core.Result)
close(res)
return res, nil
}
both := m[[2]string{root, ns}]
var nsonly []int
var rootonly []int
if ns != "" {
nsonly = m[[2]string{"", ns}]
rootonly = m[[2]string{root, ""}]
}
res := make(chan core.Result, len(both)+len(rootonly)+len(nsonly))
for _, v := range both {
res <- makeResult(v, root, ns)
}
for _, v := range rootonly {
res <- makeResult(v, root, ns)
}
for _, v := range nsonly {
res <- makeResult(v, root, ns)
}
close(res)
return res, nil
}
func makeResult(idx int, root, ns string) result {
switch {
case root == "":
return result{idx, "xml match with ns " + ns}
case ns == "":
return result{idx, "xml match with root " + root}
}
return result{idx, fmt.Sprintf("xml match with root %s and ns %s", root, ns)}
}
type result struct {
idx int
basis string
}
func (r result) Index() int {
return r.idx
}
func (r result) Basis() string {
return r.basis
}
func (m Matcher) String() string {
var str string
for k, v := range m {
str += fmt.Sprintf("%s %s: %v\n", k[0], k[1], v)
}
return str
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package pronom implements the TNA's PRONOM signatures as a siegfried identifier
package pronom
import (
"encoding/json"
"encoding/xml"
"fmt"
"io/ioutil"
"net/http"
"os"
"path/filepath"
"sort"
"strconv"
"strings"
"sync"
"time"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/pronom/internal/mappings"
)
type pronom struct {
identifier.Parseable
c identifier.Parseable
}
// add container IDs to the DROID IDs (this ensures container extensions register)
func (p *pronom) IDs() []string {
ids := make([]string, len(p.Parseable.IDs()), len(p.Parseable.IDs())+len(p.c.IDs()))
copy(ids, p.Parseable.IDs())
for _, id := range p.c.IDs() {
var present bool
for _, ida := range p.Parseable.IDs() {
if id == ida {
present = true
break
}
}
if !present {
ids = append(ids, id)
}
}
return ids
}
func (p *pronom) Zips() ([][]string, [][]frames.Signature, []string, error) {
return p.c.Zips()
}
func (p *pronom) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
return p.c.MSCFBs()
}
// return a PRONOM object without applying the config
func raw() (identifier.Parseable, error) {
p := &pronom{
c: identifier.Blank{},
}
// apply no container rule
if !config.NoContainer() {
if err := p.setContainers(); err != nil {
return nil, fmt.Errorf("pronom: error loading containers; got %s\nUnless you have set `-nocontainer` you need to download a container signature file", err)
}
}
if err := p.setParseables(); err != nil {
return nil, err
}
return p, nil
}
// Pronom creates a pronom object
func NewPronom() (identifier.Parseable, error) {
p, err := raw()
if err != nil {
return nil, err
}
return identifier.ApplyConfig(p), nil
}
// set identifiers joins signatures in the DROID signature file with any extra reports and adds that to the pronom object
func (p *pronom) setParseables() error {
d, err := newDroid(config.Droid())
if err != nil {
return fmt.Errorf("Pronom: error loading Droid file; got %s\nYou must have a Droid file to build a signature", err)
}
// if noreports set
if config.Reports() == "" {
p.Parseable = d
} else { // otherwise build from reports
// get list of puids that applies limit or exclude filters (actual filtering of Parseable delegated to core/identifier)
puids := d.IDs()
if config.HasLimit() {
puids = config.Limit(puids)
} else if config.HasExclude() {
puids = config.Exclude(puids)
}
r, err := newReports(puids, d.idsPuids())
if err != nil {
return fmt.Errorf("Pronom: error loading reports; got %s\nYou must download PRONOM reports to build a signature (unless you use the -noreports flag). You can use `roy harvest` to download reports", err)
}
p.Parseable = r
}
// add extensions
for _, v := range config.Extend() {
e, err := newDroid(v)
if err != nil {
return fmt.Errorf("Pronom: error loading extension file; got %s", err)
}
p.Parseable = identifier.Join(p.Parseable, e)
}
// exclude byte signatures where also have container signatures, unless doubleup set
if !config.DoubleUp() {
p.Parseable = doublesFilter{
config.ExcludeDoubles(p.IDs(), p.c.IDs()),
p.Parseable,
}
}
return nil
}
func newDroid(path string) (*droid, error) {
d := &mappings.Droid{}
if err := openXML(path, d); err != nil {
return nil, err
}
return &droid{d, identifier.Blank{}}, nil
}
func newReports(reps []string, idsPuids map[int]string) (*reports, error) {
r := &reports{reps, make([]*mappings.Report, len(reps)), idsPuids, identifier.Blank{}}
if len(reps) == 0 {
return r, nil // empty signatures
}
indexes := make(map[string]int)
for i, v := range reps {
indexes[v] = i
}
apply := func(puid string) error {
idx := indexes[puid]
r.r[idx] = &mappings.Report{}
return openXML(reportPath(puid), r.r[idx])
}
errs := applyAll(200, reps, apply)
if len(errs) > 0 {
strs := make([]string, len(errs))
for i, v := range errs {
strs[i] = v.Error()
}
return nil, fmt.Errorf(strings.Join(strs, "\n"))
}
return r, nil
}
func reportPath(puid string) string {
return filepath.Join(config.Reports(), strings.Replace(puid, "/", "", 1)+".xml")
}
// setContainers adds containers to a pronom object. It takes as an argument the path to a container signature file
func (p *pronom) setContainers() error {
c := &mappings.Container{}
err := openXML(config.Container(), c)
if err != nil {
return err
}
for _, ex := range config.ExtendC() {
c1 := &mappings.Container{}
err = openXML(ex, c1)
if err != nil {
return err
}
c.ContainerSignatures = append(c.ContainerSignatures, c1.ContainerSignatures...)
c.FormatMappings = append(c.FormatMappings, c1.FormatMappings...)
}
p.c = &container{c, identifier.Blank{}}
return nil
}
// UTILS
// Harvest fetches PRONOM reports listed in the DROID file
func Harvest() []error {
d, err := newDroid(config.Droid())
if err != nil {
return []error{err}
}
apply := func(puid string) error {
url, _, _, _ := config.HarvestOptions()
return save(puid, url, config.Reports())
}
return applyAll(5, d.IDs(), apply)
}
func nameType(in string) string {
switch in {
case "New Records":
return "new"
case "Updated Records":
return "updated"
case "New Signatures", "Signatures":
return "signatures"
}
return in
}
func checkType(in string) bool {
switch in {
case "New Records", "Updated Records", "New Signatures", "Signatures":
return true
}
return false
}
func GetReleases(path string) error {
byts, err := getHttp(config.ChangesURL())
if err != nil {
return err
}
return ioutil.WriteFile(path, byts, os.ModePerm)
}
func LoadReleases(path string) (*mappings.Releases, error) {
releases := &mappings.Releases{}
err := openXML(path, releases)
return releases, err
}
func Releases(releases *mappings.Releases) ([]string, []string, map[string]map[string]int) {
changes := make(map[string]map[string]int)
fields := []string{"number releases", "new records", "updated records", "new signatures"}
for _, release := range releases.Releases {
trimdate := strings.TrimSpace(release.ReleaseDate)
yr := trimdate[len(trimdate)-4:]
if changes[yr] == nil {
changes[yr] = make(map[string]int)
}
changes[yr][fields[0]]++
for _, bit := range release.Outlines {
if !checkType(bit.Typ) {
continue
}
switch nameType(bit.Typ) {
case "new":
changes[yr][fields[1]] += len(bit.Puids)
case "updated":
changes[yr][fields[2]] += len(bit.Puids)
case "signatures":
changes[yr][fields[3]] += len(bit.Puids)
}
}
}
yrs := make([]int, 0, len(changes))
for k := range changes {
i, _ := strconv.Atoi(k)
yrs = append(yrs, i)
}
sort.Ints(yrs)
years := make([]string, len(yrs))
for i, v := range yrs {
years[i] = strconv.Itoa(v)
}
return years, fields, changes
}
func makePuids(in []mappings.Puid) []string {
out := make([]string, len(in))
for i, v := range in {
out[i] = v.Typ + "/" + v.Val
}
return out
}
// ReleaseSet writes a changes sets file based on the latest PRONOM release file
func ReleaseSet(path string, releases *mappings.Releases) error {
output := mappings.OrderedMap{}
for _, release := range releases.Releases {
bits := []mappings.KeyVal{}
name := strings.TrimSuffix(strings.TrimPrefix(release.SignatureName, "DROID_SignatureFile_V"), ".xml")
top := mappings.KeyVal{
Key: name,
Val: []string{},
}
for _, bit := range release.Outlines {
if !checkType(bit.Typ) {
continue
}
this := name + nameType(bit.Typ)
top.Val = append(top.Val, "@"+this)
bits = append(bits, mappings.KeyVal{
Key: this,
Val: makePuids(bit.Puids),
})
}
output = append(output, top)
output = append(output, bits...)
}
out, err := json.MarshalIndent(output, "", " ")
if err != nil {
return err
}
return ioutil.WriteFile(filepath.Join(config.Local("sets"), path), out, 0666)
}
// TypeSets writes three sets files based on PRONOM reports:
// an all sets files, with all PUIDs; a families sets file with FormatFamilies; and a types sets file with FormatTypes.
func TypeSets(p1, p2, p3 string) error {
d, err := newDroid(config.Droid())
if err != nil {
return err
}
r, err := newReports(d.IDs(), d.idsPuids())
if err != nil {
return err
}
families, types := r.FamilyTypes()
all := r.Labels()
out, err := json.MarshalIndent(map[string][]string{"all": all}, "", " ")
if err != nil {
return err
}
if err := ioutil.WriteFile(filepath.Join(config.Local("sets"), p1), out, 0666); err != nil {
return err
}
out, err = json.MarshalIndent(families, "", " ")
if err != nil {
return err
}
if err := ioutil.WriteFile(filepath.Join(config.Local("sets"), p2), out, 0666); err != nil {
return err
}
out, err = json.MarshalIndent(types, "", " ")
if err != nil {
return err
}
return ioutil.WriteFile(filepath.Join(config.Local("sets"), p3), out, 0666)
}
// Extension set writes a sets file that links extensions to IDs.
func ExtensionSet(path string) error {
d, err := newDroid(config.Droid())
if err != nil {
return err
}
r, err := newReports(d.IDs(), d.idsPuids())
if err != nil {
return err
}
exts, puids := r.Globs()
extM := make(map[string][]string)
for i, e := range exts {
if len(e) > 0 {
e = strings.TrimPrefix(e, "*")
extM[e] = append(extM[e], puids[i])
}
}
out, err := json.MarshalIndent(extM, "", " ")
if err != nil {
return err
}
return ioutil.WriteFile(filepath.Join(config.Local("sets"), path), out, 0666)
}
func openXML(path string, els interface{}) error {
buf, err := ioutil.ReadFile(path)
if err != nil {
return err
}
return xml.Unmarshal(buf, els)
}
func applyAll(max int, reps []string, apply func(puid string) error) []error {
ch := make(chan error, len(reps))
wg := sync.WaitGroup{}
queue := make(chan struct{}, max) // to avoid hammering TNA
_, _, tf, _ := config.HarvestOptions()
var throttle *time.Ticker
if tf > 0 {
throttle = time.NewTicker(tf)
defer throttle.Stop()
}
for _, puid := range reps {
if tf > 0 {
<-throttle.C
}
wg.Add(1)
go func(puid string) {
queue <- struct{}{}
defer wg.Done()
if err := apply(puid); err != nil {
ch <- err
}
<-queue
}(puid)
}
wg.Wait()
close(ch)
var errors []error
for err := range ch {
errors = append(errors, err)
}
return errors
}
func getHttp(url string) ([]byte, error) {
req, err := http.NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
_, timeout, _, transport := config.HarvestOptions()
req.Header.Add("User-Agent", "siegfried/roybot (+https://github.com/richardlehane/siegfried)")
timer := time.AfterFunc(timeout, func() {
transport.CancelRequest(req)
})
defer timer.Stop()
client := http.Client{
Transport: transport,
}
resp, err := client.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
return ioutil.ReadAll(resp.Body)
}
func save(puid, url, path string) error {
b, err := getHttp(url + puid + ".xml")
if err != nil {
return err
}
return ioutil.WriteFile(filepath.Join(path, strings.Replace(puid, "/", "", 1)+".xml"), b, os.ModePerm)
}
<file_sep>package main
import (
"encoding/hex"
"path/filepath"
"reflect"
"sort"
"testing"
"testing/fstest"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/pronom"
)
var DataPath string = filepath.Join("..", "..", "cmd", "roy", "data")
// pronomIdentificationTests provides our structure for table driven tests.
type pronomIdentificationTests struct {
identiifer string
puid string
label string
version string
mime string
types string
details string
error string
}
var skeletons = make(map[string]*fstest.MapFile)
var minimalPronom = []string{"fmt/1", "fmt/3", "fmt/5", "fmt/11", "fmt/14"}
// Populate the global skeletons map from string-based byte-sequences to
// save having to store skeletons on disk and read from them.
func makeSkeletons() {
var files = make(map[string]string)
files["fmt-11-signature-id-58.png"] = "89504e470d0a1a0a0000000d494844520000000049454e44ae426082"
files["fmt-14-signature-id-123.pdf"] = "255044462d312e302525454f46"
files["fmt-1-signature-id-1032.wav"] = ("" +
"524946460000000057415645000000000000000000000000000000000000" +
"000062657874000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"000000000000000000000000000000000000000000000000000000000000" +
"00000000000000000000000000000000000000000000000000000000" +
"")
files["fmt-5-signature-id-51.avi"] = ("" +
"524946460000000041564920000000000000000000000000000000000000" +
"00004c495354000000006864726c61766968000000000000000000000000" +
"00000000000000004c495354000000006d6f7669" +
"")
files["fmt-3-signature-id-18.gif"] = "4749463837613b"
files["badf00d.unknown"] = "badf00d"
for key, val := range files {
data, _ := hex.DecodeString(val)
skeletons[key] = &fstest.MapFile{Data: []byte(data)}
}
}
var pronomIDs = []pronomIdentificationTests{
{
"pronom",
"UNKNOWN",
"",
"",
"",
"",
"",
"no match",
},
{
"pronom",
"fmt/1",
"Broadcast WAVE",
"0 Generic",
"audio/x-wav",
"Audio",
"extension match wav; byte match at [[0 12] [32 356]]",
"",
},
{
"pronom",
"fmt/11",
"Portable Network Graphics",
"1.0",
"image/png",
"Image (Raster)",
"extension match png; byte match at [[0 16] [16 12]]",
"",
},
{
"pronom",
"fmt/14",
"Acrobat PDF 1.0 - Portable Document Format",
"1.0",
"application/pdf",
"Page Description",
"extension match pdf; byte match at [[0 8] [8 5]]",
"",
},
{
"pronom",
"fmt/3",
"Graphics Interchange Format",
"87a",
"image/gif",
"Image (Raster)",
"extension match gif; byte match at [[0 6] [6 1]]",
"",
},
{
"pronom",
"fmt/5",
"Audio/Video Interleaved Format",
"",
"video/x-msvideo",
"Audio, Video",
"extension match avi; byte match at [[0 12] [32 16] [68 12]]",
"",
},
}
// TestPronom looks to see if PRONOM identification results for a
// minimized PRONOM dataset are correct and contain the information we
// anticipate.
func TestPronom(t *testing.T) {
sf := siegfried.New()
config.SetHome(DataPath)
identifier, err := pronom.New(config.SetLimit(minimalPronom))
if err != nil {
t.Errorf("Error creating new PRONOM identifier: %s", err)
}
sf.Add(identifier)
makeSkeletons()
skeletonFS := fstest.MapFS(skeletons)
testDirListing, err := skeletonFS.ReadDir(".")
if err != nil {
t.Fatalf("Error reading test files directory: %s", err)
}
const resultLen int = 8
results := make([]pronomIdentificationTests, 0)
for _, val := range testDirListing {
testFilePath := filepath.Join(".", val.Name())
reader, _ := skeletonFS.Open(val.Name())
res, _ := sf.Identify(reader, testFilePath, "")
result := res[0].Values()
if len(result) != resultLen {
t.Errorf("Result len: %d not %d", len(result), resultLen)
}
idResult := pronomIdentificationTests{
result[0], // identifier
result[1], // PUID
result[2], // label
result[3], // version
result[4], // mime
result[5], // types
result[6], // details
result[7], // error
}
results = append(results, idResult)
}
// Sort expected results and received results to make them
// comparable.
sort.Slice(pronomIDs, func(i, j int) bool {
return pronomIDs[i].puid < pronomIDs[j].puid
})
sort.Slice(results, func(i, j int) bool {
return results[i].puid < results[j].puid
})
// Compare results on a result by result basis.
for idx, res := range results {
//t.Error(res)
if !reflect.DeepEqual(res, pronomIDs[idx]) {
t.Errorf("Results not equal for %s; expected %v; got %v", res.puid, pronomIDs[idx], res)
}
}
config.Clear()()
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package config
import (
"fmt"
"io/ioutil"
"net/http"
"path/filepath"
"strconv"
"strings"
"time"
)
var pronom = struct {
name string
droid string // name of droid file e.g. DROID_SignatureFile_V78.xml
container string // e.g. container-signature-19770502.xml
reports string // directory where PRONOM reports are stored
noclass bool // omit class from the format info
doubleup bool // include byte signatures for formats that also have container signatures
extendc []string //container extensions
changesURL string
harvestURL string
harvestTimeout time.Duration
harvestThrottle time.Duration
harvestTransport *http.Transport
// archive puids
zip string
tar string
gzip string
arc string
arc1_1 string
warc string
// text puid
text string
}{
name: "pronom",
reports: "pronom",
changesURL: "http://www.nationalarchives.gov.uk/aboutapps/pronom/release-notes.xml",
harvestURL: "http://www.nationalarchives.gov.uk/pronom/",
harvestTimeout: 120 * time.Second,
harvestTransport: &http.Transport{Proxy: http.ProxyFromEnvironment},
zip: "x-fmt/263",
tar: "x-fmt/265",
gzip: "x-fmt/266",
arc: "x-fmt/219",
arc1_1: "fmt/410",
warc: "fmt/289",
text: "x-fmt/111",
}
// GETTERS
// Droid returns the location of the DROID signature file.
// If not set, infers the latest file.
func Droid() string {
if pronom.droid == "" {
droid, err := latest("DROID_SignatureFile_V", ".xml")
if err != nil {
return ""
}
return filepath.Join(siegfried.home, droid)
}
if filepath.Dir(pronom.droid) == "." {
return filepath.Join(siegfried.home, pronom.droid)
}
return pronom.droid
}
// DroidBase returns the base filename of the DROID signature file.
// If not set, infers the latest file.
func DroidBase() string {
if pronom.droid == "" {
droid, err := latest("DROID_SignatureFile_V", ".xml")
if err != nil {
return ""
}
return droid
}
return pronom.droid
}
// Container returns the location of the DROID container signature file.
// If not set, infers the latest file.
func Container() string {
if pronom.container == "" {
container, err := latest("container-signature-", ".xml")
if err != nil {
return ""
}
return filepath.Join(siegfried.home, container)
}
if filepath.Dir(pronom.container) == "." {
return filepath.Join(siegfried.home, pronom.container)
}
return pronom.container
}
// ContainerBase returns the base filename of the DROID container signature file.
// If not set, infers the latest file.
func ContainerBase() string {
if pronom.container == "" {
container, err := latest("container-signature-", ".xml")
if err != nil {
return ""
}
return container
}
return pronom.container
}
func latest(prefix, suffix string) (string, error) {
var hits []string
var ids []int
files, err := ioutil.ReadDir(siegfried.home)
if err != nil {
return "", err
}
for _, f := range files {
nm := f.Name()
if strings.HasPrefix(nm, prefix) && strings.HasSuffix(nm, suffix) {
hits = append(hits, nm)
id, err := strconv.Atoi(strings.TrimSuffix(strings.TrimPrefix(nm, prefix), suffix))
if err != nil {
return "", err
}
ids = append(ids, id)
}
}
if len(hits) == 0 {
return "", fmt.Errorf("Config: no file in %s with prefix %s", siegfried.home, prefix)
}
if len(hits) == 1 {
return hits[0], nil
}
max, idx := ids[0], 0
for i, v := range ids[1:] {
if v > max {
max = v
idx = i + 1
}
}
return hits[idx], nil
}
// Reports returns the location of the PRONOM reports directory.
func Reports() string {
if pronom.reports == "" {
return ""
}
return filepath.Join(siegfried.home, pronom.reports)
}
// NoClass reports whether the noclass flag has been set. This will cause class to be omitted from format infos
func NoClass() bool {
return pronom.noclass
}
// DoubleUp reports whether the doubleup flag has been set. This will cause byte signatures to be built for formats where container signatures are also provided.
func DoubleUp() bool {
return pronom.doubleup
}
// ExcludeDoubles takes a slice of puids and a slice of container puids and excludes those that are in the container slice, if nodoubles is set.
func ExcludeDoubles(puids, cont []string) []string {
return exclude(puids, cont)
}
// ExtendC reports whether a set of container signature extensions has been provided.
func ExtendC() []string {
return extensionPaths(pronom.extendc)
}
// ChangesURL returns the URL for the PRONOM release notes.
func ChangesURL() string {
return pronom.changesURL
}
// HarvestOptions reports the PRONOM url, timeout and transport.
func HarvestOptions() (string, time.Duration, time.Duration, *http.Transport) {
return pronom.harvestURL, pronom.harvestTimeout, pronom.harvestThrottle, pronom.harvestTransport
}
// ZipPuid reports the puid for a zip archive.
func ZipPuid() string {
return pronom.zip
}
// TextPuid reports the puid for a text file.
func TextPuid() string {
return pronom.text
}
// SETTERS
// SetDroid sets the name and/or location of the DROID signature file.
// I.e. can provide a full path or a filename relative to the HOME directory.
func SetDroid(d string) func() private {
return func() private {
pronom.droid = d
return private{}
}
}
// SetContainer sets the name and/or location of the DROID container signature file.
// I.e. can provide a full path or a filename relative to the HOME directory.
func SetContainer(c string) func() private {
return func() private {
pronom.container = c
return private{}
}
}
// SetNoReports instructs roy to build from the DROID signature file alone (and not from the PRONOM reports).
func SetNoReports() func() private {
return func() private {
pronom.reports = ""
return private{}
}
}
// SetNoClass causes class to be omitted from the format info
func SetNoClass() func() private {
return func() private {
pronom.noclass = true
return private{}
}
}
// SetDoubleUp causes byte signatures to be built for formats where container signatures are also provided.
func SetDoubleUp() func() private {
return func() private {
pronom.doubleup = true
return private{}
}
}
// SetExtendC adds container extension signatures to the build.
func SetExtendC(l []string) func() private {
return func() private {
pronom.extendc = l
return private{}
}
}
// unlike other setters, these are only relevant in the roy tool so can't be converted to the Option type
// SetHarvestTimeout sets a time limit on PRONOM harvesting.
func SetHarvestTimeout(d time.Duration) {
pronom.harvestTimeout = d
}
// SetHarvestThrottle sets a throttle value for downloading DROID reports.
func SetHarvestThrottle(d time.Duration) {
pronom.harvestThrottle = d
}
// SetHarvestTransport sets the PRONOM harvesting transport.
func SetHarvestTransport(t *http.Transport) {
pronom.harvestTransport = t
}
<file_sep>// Copyright 2018 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"bufio"
"bytes"
"flag"
"fmt"
"io/ioutil"
"os"
"strings"
"github.com/richardlehane/siegfried/pkg/config"
)
var (
// list of flags that can be configured
setableFlags = []string{"coe", "csv", "droid", "hash", "json", "log", "multi", "nr", "serve", "sig", "throttle", "yaml", "z", "zs"}
// list of flags that control output - these are exclusive of each other
outputFlags = []string{"csv", "droid", "json", "yaml"}
)
// also used in sf_test.go
func check(s string, ss []string) bool {
for _, v := range ss {
if s == v {
return true
}
}
return false
}
// if -setconf flag set, write settable flags to a conf file. Returns flag names set and an error.
func setconf() (string, error) {
buf := &bytes.Buffer{}
var settables []string
flag.Visit(func(fl *flag.Flag) {
if !check(fl.Name, setableFlags) {
return
}
fmt.Fprintf(buf, "%s:%s\n", fl.Name, fl.Value.String())
settables = append(settables, fl.Name)
})
if len(settables) > 0 {
return strings.Join(settables, ", "), ioutil.WriteFile(config.Conf(), buf.Bytes(), 0644)
}
// no flags - so we delete the conf file if it exists
if _, err := os.Stat(config.Conf()); err != nil {
if os.IsNotExist(err) {
return "", nil
}
return "", err
}
return "", os.Remove(config.Conf())
}
// if it exists, read defaults from the conf file.
func getconf() (map[string]string, error) {
if _, err := os.Stat(config.Conf()); err != nil {
if os.IsNotExist(err) {
return nil, nil
}
return nil, err
}
f, err := os.Open(config.Conf())
if err != nil {
return nil, err
}
defer f.Close()
ret := make(map[string]string)
scanner := bufio.NewScanner(f)
for scanner.Scan() {
kv := strings.SplitN(scanner.Text(), ":", 2)
if len(kv) != 2 {
continue
}
ret[kv[0]] = kv[1]
}
return ret, nil
}
// if it exists, read defaults from the conf file. Overwrite defaults with any flags explictly set
func readconf() error {
confFlags, err := getconf()
if len(confFlags) == 0 {
return err
}
// remove conf values for any flags explictly set
flag.Visit(func(fl *flag.Flag) {
// if an output flag has been explicitly set, delete any that may be in the conf file
if check(fl.Name, outputFlags) {
for _, v := range outputFlags {
delete(confFlags, v)
}
} else {
delete(confFlags, fl.Name)
}
})
for k, v := range confFlags {
if err = flag.Set(k, v); err != nil {
return err
}
}
return nil
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Provides configuration structures and helpers for the Siegfried
// Wikidata functionality.
package config
import (
"fmt"
"net/url"
"os"
"path/filepath"
"github.com/richardlehane/siegfried/pkg/config/internal/wikidatasparql"
)
// Wikidata configuration fields. NB. In alphabetical order.
var wikidata = struct {
// archive formats that Siegfried should be able to decompress via
// the Wikidata identifier.
arc string
arc1_1 string
gzip string
tar string
warc string
// debug provides a way for users to output errors and warnings
// associated with Wikidata records.
debug bool
// definitions stores the name of the file for the Wikidata
// signature definitions. The definitions file is the raw SPARQL
// output from Wikidata which will then be processed into an
// identifier that can be consumed by Siegfried.
definitions string
// endpoint stores the URL of the SPARQL endpoint to pull
// definitions from.
endpoint string
// filemode describes the file-mode we want to use to access the
// Wikidata definitions file.
filemode os.FileMode
// namespace acts as a flag to tell us that we're using the Wikidata
// identifier and describes and distinguishes it in reports.
namespace string
// nopronom determines whether the identifier will be build without
// patterns from PRONOM sources outside of Wikidata.
nopronom bool
// propPronom should be the URL needed to resolve PRONOM encoded
// signatures in the Wikidata identifier.
propPronom string
// propBOF should be the URL needed to resolve signatures to BOF
// in the Wikidata identifier.
propBOF string
// propEOF should be the URL needed to resolve signatures to EOF
// in the Wikidata identifier.
propEOF string
// revisionHistoryLen provides a way to configure the amount of
// history returned from a Wikibase instance. More history will
// slow down query time. Less history will speed it up.
revisionHistoryLen int
// revisionHistoryThreads provides a way to configure the number of
// threads used to download revision history from a Wikibase instance.
// Theoretically this value can speed up the Wikidata harvest process
// but it isn't guaranteed.
revisionHistoryThreads int
// sparqlParam refers to the SPARQL parameter (?param) that returns
// the QID for the record that we want to return revision history
// and permalink for. E.g. ?uriLabl may return QID: Q12345. This
// will then be used to query Wikibase for its revision history.
// This should be the subject/IRI of the file format record in
// Wikidata.
sparqlParam string
// wikidatahome describes the name of the wikidata directory withing
// $SFHOME.
wikidatahome string
// wikibaseSparql is a placeholder for custom queries to be provided
// to a custom Wikibase instance.
wikibaseSparql string
// wikibaseSparqlFile points to the wikibase.sparql file required to
// query a custom Wikibase endpoint.
wikibaseSparqlFile string
// wikibasePropsFile is a JSON file that stores all the properties
// needed for Roy to interpret a custom Wikibase SPARQL result.
wikibasePropsFile string
// wikibaseURL is the base URL needed by Wikibase for permalinks to
// resolve and for revision history to be retrieved. The URL will be
// augmented with /w/index.php or /w/api.php via Wikiprov (so do not
// add this!). Wikiprov is the package used to make revision history
// and permalinks happen.
wikibaseURL string
}{
arc: "Q7978505",
arc1_1: "Q27824065",
gzip: "Q27824060",
tar: "Q283579",
warc: "Q10287816",
definitions: "wikidata-definitions-3.0.0",
endpoint: "https://query.wikidata.org/sparql",
filemode: 0644,
propPronom: "http://www.wikidata.org/entity/Q35432091",
propBOF: "http://www.wikidata.org/entity/Q35436009",
propEOF: "http://www.wikidata.org/entity/Q1148480",
revisionHistoryLen: 5,
revisionHistoryThreads: 10,
sparqlParam: "uri",
wikidatahome: "wikidata",
wikibaseSparql: "",
wikibaseSparqlFile: "wikibase.sparql",
wikibasePropsFile: "wikibase.json",
wikibaseURL: "https://www.wikidata.org/",
}
// WikidataHome describes where files needed by Siegfried and Roy for
// its Wikidata component resides.
func WikidataHome() string {
return filepath.Join(siegfried.home, wikidata.wikidatahome)
}
// Namespace to be used in the Siegfried identification reports.
const wikidataNamespace = "wikidata"
// SetWikidataNamespace will set the Wikidata namespace. One reason
// this isn't set already is that Roy's idiom is to use it as a signal
// to say this identifier is ON/OFF and should be used, i.e. when
// this function is called, we want to use a Wikidata identifier.
func SetWikidataNamespace() func() private {
return func() private {
loc.fdd = "" // reset loc to avoid pollution
mimeinfo.mi = "" // reset mimeinfo to avoid pollution
wikidata.namespace = wikidataNamespace
return private{}
}
}
// GetWikidataNamespace will return the Wikidata namespace field to the
// caller.
func GetWikidataNamespace() string {
return wikidata.namespace
}
// SetWikidataDebug turns linting messages on when compiling the
// identifier
func SetWikidataDebug() func() private {
wikidata.debug = true
return SetWikidataNamespace()
}
// WikidataDebug will return the status of the debug flag, i.e.
// true for debug linting messages, false for none.
func WikidataDebug() bool {
return wikidata.debug
}
// SetWikidataDefinitions is a setter to enable us to elect to use a
// different signature file name, e.g. as a setter during testing.
func SetWikidataDefinitions(definitions string) {
wikidata.definitions = definitions
}
// WikidataDefinitionsFile returns the name of the file used to store
// the signature definitions.
func WikidataDefinitionsFile() string {
return wikidata.definitions
}
// WikidataDefinitionsPath is a helper for convenience from callers to
// point directly at the definitions path for reading/writing as
// required.
func WikidataDefinitionsPath() string {
return filepath.Join(WikidataHome(), WikidataDefinitionsFile())
}
// WikidataFileMode returns the file-mode required to save the
// definitions file.
func WikidataFileMode() os.FileMode {
return wikidata.filemode
}
// SetWikidataEndpoint enables the use of another Wikibase instance if
// one is available. If there is an error with the URL then summary
// information will be returned to the caller and the default endpoint
// will be used.
func SetWikidataEndpoint(endpoint string) (func() private, error) {
_, err := url.ParseRequestURI(endpoint)
if err != nil {
return func() private { return private{} }, fmt.Errorf(
"URL provided is invalid: '%w' default Wikidata Query Service will be used instead",
err,
)
}
wikidata.endpoint = endpoint
return func() private {
return private{}
}, err
}
// WikidataEndpoint returns the SPARQL endpoint to call when harvesting
// Wikidata definitions.
func WikidataEndpoint() string {
return wikidata.endpoint
}
// WikidataSPARQL returns the SPARQL query required to harvest Wikidata
// definitions.
func WikidataSPARQL() string {
if wikidata.wikibaseSparql != "" {
return wikidata.wikibaseSparql
}
return wikidatasparql.WikidataSPARQL()
}
// WikidataLang returns the language we want to return results in from
// Wikidata.
func WikidataLang() string {
return wikidatasparql.WikidataLang()
}
// SetWikidataLang sets the language that we want to return results in
// from Wikidata. The default is en.
func SetWikidataLang(lang string) {
wikidatasparql.SetWikidataLang(lang)
}
// SetWikidataNoPRONOM will turn native PRONOM patterns off in the final
// identifier output.
func SetWikidataNoPRONOM() func() private {
return func() private {
wikidata.nopronom = true
return private{}
}
}
// SetWikidataPRONOM will turn native PRONOM patterns on in the final
// identifier output.
func SetWikidataPRONOM() func() private {
return func() private {
wikidata.nopronom = false
return private{}
}
}
// GetWikidataNoPRONOM will tell the caller whether or not to use native
// PRONOM patterns inside the identifier.
func GetWikidataNoPRONOM() bool {
return wikidata.nopronom
}
// SetWikibaseURL lets the default value for the Wikibase URL to be
// overridden. The URL should be that which enables permalinks to be
// returned from Wikibase, e.g. for Wikidata this URL needs to be:
//
// e.g. https://www.wikidata.org/w/index.php
//
func SetWikibaseURL(baseURL string) (func() private, error) {
_, err := url.ParseRequestURI(baseURL)
if err != nil {
return func() private { return private{} }, fmt.Errorf(
"URL provided is invalid: '%w' default Wikibase URL be used instead but may not work",
err,
)
}
wikidata.wikibaseURL = baseURL
return func() private {
return private{}
}, err
}
// WikidataWikibaseURL returns the SPARQL endpoint to call when harvesting
// Wikidata definitions.
func WikidataWikibaseURL() string {
return wikidata.wikibaseURL
}
// WikidataSPARQLRevisionParam returns the SPARQL parameter (?param) that
// returns the QID for the record that we want to return revision
// history and permalink for. E.g. ?uriLabl may return QID: Q12345.
// This will then be used to query Wikibase for its revision history.
func WikidataSPARQLRevisionParam() string {
return wikidata.sparqlParam
}
// GetWikidataRevisionHistoryLen will return the length of the Wikibase
// history to retrieve to the caller.
func GetWikidataRevisionHistoryLen() int {
return wikidata.revisionHistoryLen
}
// GetWikidataRevisionHistoryThreads will return the number of threads
// to use to retrieve Wikibase history to the caller.
func GetWikidataRevisionHistoryThreads() int {
return wikidata.revisionHistoryThreads
}
// WikibaseSparqlFile returns the file path expected for a custom
// Wikibase sparql query file. This file is needed to query a custom
// instance in the majority of cases. It is unlikely a host Wikibase
// will use the same configured properties and entities.
func WikibaseSparqlFile() string {
return filepath.Join(WikidataHome(), wikidata.wikibaseSparqlFile)
}
// SetWikibaseSparql sets the SPARQL placeholder for custom Wikibase
// queries.
func SetWikibaseSparql(query string) func() private {
wikidata.wikibaseSparql = query
return func() private {
return private{}
}
}
// checkWikibaseURL guides the user to set the Wikibase/Wikimedia server
// URL when using a custom endpoint. This URL should be a valid
// Wikimedia URL. Roy will connect to the Wikimedia API via this URL.
func checkWikibaseURL(customEndpointURL string, customWikibaseURL string) error {
if customWikibaseURL == WikidataWikibaseURL() {
return fmt.Errorf(
"Wikibase server URL for '%s' needs to be configured, can't be: '%s'",
customEndpointURL,
customWikibaseURL,
)
}
return nil
}
// SetCustomWikibaseEndpoint sets a custom Wikibase endpoint if provided
// by the caller.
func SetCustomWikibaseEndpoint(customEndpointURL string, customWikibaseURL string) error {
err := checkWikibaseURL(customEndpointURL, customWikibaseURL)
if err != nil {
return err
}
_, err = SetWikidataEndpoint(customEndpointURL)
if err != nil {
return err
}
_, err = SetWikibaseURL(customWikibaseURL)
if err != nil {
return err
}
return nil
}
// SetCustomWikibaseQuery checks for a custom query file and then sets
// the configuration to point to that file if it finds one.
func SetCustomWikibaseQuery() error {
wikibaseSparqlPath := WikibaseSparqlFile()
sparqlFile, err := os.ReadFile(wikibaseSparqlPath)
if os.IsNotExist(err) {
return fmt.Errorf(
"Setting custom Wikibase SPARQL: cannot find file '%s' in '%s': %w",
wikibaseSparqlPath,
WikidataHome(),
err,
)
}
if err != nil {
return fmt.Errorf(
"Setting custom Wikibase SPARQL: unexpected error opening '%s' has occurred: %w",
wikibaseSparqlPath,
err,
)
}
// Read the contents and assign to our query field in our config.
SetWikibaseSparql(string(sparqlFile))
return nil
}
// WikibasePropsPath returns the file path expected for the
// configuration needed to tell roy how to interpret results from a
// custom Wikibase query.
//
// Example:
//
// {
// "PronomProp": "http://wikibase.example.com/entity/Q2",
// "BofProp": "http://wikibase.example.com/entity/Q3",
// "EofProp": "http://wikibase.example.com/entity/Q4"
// }
//
func WikibasePropsPath() string {
return filepath.Join(WikidataHome(), wikidata.wikibasePropsFile)
}
// SetWikibasePropsPath allows the WikidataPropsPath to be overwritten,
// e.g. for testing, and if it becomes needed, in the primary Roy code base.
func SetWikibasePropsPath(propsPath string) func() private {
wikidata.wikibasePropsFile = propsPath
return func() private {
return private{}
}
}
// WikibasePronom will return the configured PRONOM property from the
// Wikibase configuration.
func WikibasePronom() string {
return wikidata.propPronom
}
// WikibaseBOF will return the configured BOF property from the Wikibase
// configuration.
func WikibaseBOF() string {
return wikidata.propBOF
}
// WikibaseEOF will return the configured EOF property from the Wikibase
// configuration.
func WikibaseEOF() string {
return wikidata.propEOF
}
// testPropURL provides a helper for testing the properties being set by
// SetProps.
func testPropURL(propURL string) error {
_, err := url.ParseRequestURI(propURL)
if err != nil {
return fmt.Errorf(
"URL provided '%s' is invalid: '%w' custom Wikibase instances need this value to be correct",
propURL,
err,
)
}
return nil
}
// SetProps will set the three minimum properties needed to run Roy/SF
// with a custom Wikibase instance.
func SetProps(pronom string, bof string, eof string) error {
if err := testPropURL(pronom); err != nil {
return err
}
if err := testPropURL(bof); err != nil {
return err
}
if err := testPropURL(eof); err != nil {
return err
}
wikidata.propPronom = pronom
wikidata.propBOF = bof
wikidata.propEOF = eof
return nil
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Helper functions for cleaning up provenance "source" information in
// the Wikidata identifier.
package wikidata
import ()
// Source strings from Wikidata. We may have a use-case to normalize
// them, but also, we can do this via ShEx on a long-enough time-line.
const (
// Wikidata source strings are those returned by Wikidata
// specifically.
prePronom = "PRONOM"
preKessler = "<NAME> File Signature Table"
// Normalized source strings are those that we want to return from
// the Wikidata identifier to the user so that they can be parsed
// consistently by the consumer.
tnaPronom = "PRONOM (TNA)"
wdPronom = "PRONOM (Wikidata)"
wdNone = "Wikidata reference is empty"
// Provenance to include in source information when the PRONOM
// signatures are being used to compliment those in the Wikidata
// identifier.
pronomOfficial = "PRONOM (Official (%s))"
pronomOfficialContainer = "PRONOM (Official container ID)"
)
// parseProvenance normalizes the provenance string and let's us know
// if the value is in-fact empty.
func parseProvenance(prov string) string {
if prov == prePronom {
prov = wdPronom
}
if prov == "" {
prov = wdNone
}
return prov
}
<file_sep>package siegreader
import (
"io"
"io/ioutil"
"os"
"sync"
)
type stream struct {
b *Buffer
src io.Reader
sz int64
buf []byte
tf *os.File // temp backing file - used when stream exceeds streamSz
tfBuf []byte
eofc chan struct{}
mu sync.Mutex
i int // marks how much of buf we have filled
eof bool
}
func newStream() interface{} {
return &stream{buf: make([]byte, readSz*2), tfBuf: make([]byte, readSz)}
}
func (s *stream) setSource(src io.Reader, b *Buffer) error {
s.b = b
s.src = src
s.sz = 0
s.eofc = make(chan struct{})
s.i = 0
s.eof = false
_, err := s.fill()
return err
}
// close and delete temp file, if exists
func (s *stream) cleanUp() {
if s.tf == nil {
return
}
s.tf.Close()
os.Remove(s.tf.Name())
s.tf = nil
}
// Size returns the buffer's size, which is available immediately for files. Must wait for full read for streams.
func (s *stream) Size() int64 {
select {
case <-s.eofc:
return s.sz
case <-s.b.Quit:
return 0
}
}
// SizeNow is a non-blocking Size(). Will force a full read of a stream.
func (s *stream) SizeNow() int64 {
var err error
for _, err = s.fill(); err == nil; _, err = s.fill() {
}
return s.sz
}
func (s *stream) grow() error {
if s.tf != nil { // return if we already have a temp file
return nil
}
c := cap(s.buf) * 2
if c > streamSz {
if cap(s.buf) < streamSz {
c = streamSz
} else { // if we've exceeded streamSz, use a temp file to copy remainder
var err error
s.tf, err = ioutil.TempFile("", "siegfried")
return err
}
}
buf := make([]byte, c)
copy(buf, s.buf[:s.i]) // don't care about unlocking as grow() is only called by fill()
s.buf = buf
return nil
}
func (s *stream) fill() (int64, error) {
// have already scanned to the end of the stream
if s.eof {
return s.sz, io.EOF
}
// if we've run out of room in buf, & there is no backing file, grow the buffer
if len(s.buf)-readSz < s.i && s.tf == nil {
s.grow()
}
// now let's read
var err error
if s.tf != nil {
// if we have a backing file, fill that
var wi int64
wi, err = io.CopyBuffer(s.tf, io.LimitReader(s.src, int64(readSz)), s.tfBuf)
if wi < int64(readSz) && err == nil {
err = io.EOF
}
// update s.sz
s.sz += wi
} else {
// otherwise, fill the slice
var i int
i, err = io.ReadFull(s.src, s.buf[s.i:s.i+readSz])
s.i += i
s.sz += int64(i)
if err == io.ErrUnexpectedEOF {
err = io.EOF
}
}
if err != nil {
close(s.eofc)
s.eof = true
if err == io.EOF && s.sz == 0 {
err = ErrEmpty
}
}
return s.sz, err
}
// Slice returns a byte slice from the buffer that begins at offset off and has length l.
func (s *stream) Slice(off int64, l int) ([]byte, error) {
s.mu.Lock()
defer s.mu.Unlock()
var err error
var bound int64
furthest := off + int64(l)
if furthest > s.sz {
for bound, err = s.fill(); furthest > bound && err == nil; bound, err = s.fill() {
}
}
if err != nil && err != io.EOF {
return nil, err
}
if err == io.EOF {
// in the case of an empty file
if s.sz == 0 {
return nil, io.EOF
}
if furthest > s.sz {
if off >= s.sz {
return nil, io.EOF
}
l = int(s.sz - off)
} else {
err = nil
}
}
// slice is wholly in buf
if off+int64(l) <= int64(len(s.buf)) {
return s.buf[int(off) : int(off)+l], err
}
ret := make([]byte, l)
// if slice crosses border, copy first bit from end of buf
var ci int
if off < int64(len(s.buf)) {
ci = copy(ret, s.buf[int(off):])
off = 0
} else {
off -= int64(len(s.buf))
}
_, rerr := s.tf.ReadAt(ret[ci:], off)
if rerr != nil {
err = rerr
}
return ret, err
}
// EofSlice returns a slice from the end of the buffer that begins at offset s and has length l.
// Blocks until the slice is available (which may be until the full stream is read).
func (s *stream) EofSlice(o int64, l int) ([]byte, error) {
// block until the EOF is available or we quit
select {
case <-s.b.Quit:
return nil, ErrQuit
case <-s.eofc:
}
if o >= s.sz {
return nil, io.EOF
}
var err error
if o+int64(l) > s.sz {
l = int(s.sz - o)
err = io.EOF
}
slc, serr := s.Slice(s.sz-o-int64(l), l)
if serr != nil {
err = serr
}
return slc, err
}
// fill until a seek to a particular offset is possible, then return true, if it is impossible return false
func (s *stream) CanSeek(o int64, rev bool) (bool, error) {
s.mu.Lock()
defer s.mu.Unlock()
if rev {
var err error
for _, err = s.fill(); err == nil; _, err = s.fill() {
}
if err != io.EOF {
return false, err
}
if o >= s.sz {
return false, nil
}
return true, nil
}
var err error
var bound int64
if o > s.sz {
for bound, err = s.fill(); o > bound && err == nil; bound, err = s.fill() {
}
}
if err == nil {
return true, nil
}
if err == io.EOF {
if o > s.sz {
return false, err
}
return true, nil
}
return false, err
}
<file_sep>package patterns_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/patterns"
. "github.com/richardlehane/siegfried/internal/bytematcher/patterns/tests"
)
func TestBMH(t *testing.T) {
b := NewBMHSequence(TestSequences[0])
b1 := NewBMHSequence(TestSequences[0])
if !b.Equals(b1) {
t.Error("BMH equality fail")
}
ok, l := b.Test([]byte("test"))
if len(ok) != 1 || ok[0] != 4 {
t.Errorf("Expecting bmh match length to be 4, got %d", l)
}
ok, l = b.Test([]byte("tost"))
if len(ok) > 0 {
t.Error("Not expecting bmh to match tost")
}
if l != 3 {
t.Errorf("Expecting bmh skip to be 3, got %d", l)
}
}
func TestRBMH(t *testing.T) {
b := NewRBMHSequence(TestSequences[0])
ok, l := b.TestR([]byte("tosttest"))
if len(ok) != 1 || ok[0] != 4 {
t.Errorf("Expecting bmh match length to be 4, got %d", l)
}
ok, l = b.TestR([]byte("testtost"))
if len(ok) > 0 {
t.Error("Not expecting bmh to match tost")
}
if l != 3 {
t.Errorf("Expecting bmh skip to be 3, got %d", l)
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Tests for the Wikidata SPARQL helper functions.
package wikidatasparql
import (
"fmt"
"strings"
"testing"
)
// TestDefaultLang the simplest test to make sure that 'some' default
// language is set.
func TestDefaultLang(t *testing.T) {
expected := "en"
if wikidataLang != "en" {
t.Errorf(
"Default language is incorrect, expected '%s' got '%s'",
expected,
wikidataLang,
)
}
}
// TestReturnWDSparql ensures that the language `<<lang>>` template is
// present in the SPARQL query required to harvest Wikidata results. The
// language template is a functional component required to generate
// results in different languages including English.
func TestReturnWDSparql(t *testing.T) {
template := "<<lang>>"
if !strings.Contains(sparql, template) {
t.Errorf(
"Lang replacement template '%s' is missing from SPARQL request string:\n%s",
template,
sparql,
)
}
res := WikidataSPARQL()
defaultLang := "\"[AUTO_LANGUAGE], en\""
if !strings.Contains(res, defaultLang) {
t.Errorf(
"Default language `en` missing from SPARQL request string:\n%s",
res,
)
}
// Change the language string and ensure that replacement occurs.
newLang := "jp"
SetWikidataLang(newLang)
newLangReplacement := fmt.Sprintf("\"[AUTO_LANGUAGE], %s\".", newLang)
res = WikidataSPARQL()
if !strings.Contains(res, newLangReplacement) {
t.Errorf(
"Language replacement '%s' hasn't been done in returned SPARQL request string:\n%s",
newLangReplacement,
res,
)
}
}
<file_sep>package siegreader
import "log"
type smallfile struct {
*file
buf [smallFileSz]byte
}
func newSmallFile() interface{} {
return &smallfile{}
}
func (sf *smallfile) setSource(f *file) {
sf.file = f
i, err := sf.src.ReadAt(sf.buf[:], 0)
if i != int(sf.sz) {
log.Fatalf("Siegreader fatal error: failed to read %s, got %d bytes of %d, error: %v\n", sf.src.Name(), i, sf.sz, err)
}
}
func (sf *smallfile) slice(off int64, l int) []byte {
return sf.buf[int(off) : int(off)+l]
}
func (sf *smallfile) eofSlice(off int64, l int) []byte {
o := int(sf.sz - off)
return sf.buf[o-l : o]
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Convert file-format signature sequences to something compatible with
// Siegfried's identifiers.
package converter
import (
"encoding/hex"
"fmt"
"strings"
)
// Parse will take a signature and convert it into something that can
// be used. If the signature needs to be converted then the function
// will inform the caller and return the new encoding value.
func Parse(signature string, encoding int) (string, bool, int, error) {
switch encoding {
case HexEncoding:
hex, err := HexParse(signature)
if err != nil {
return "", false, encoding, err
}
return hex, false, encoding, nil
case ASCIIEncoding:
hexEncoded := ASCIIParser(signature)
return hexEncoded, true, HexEncoding, nil
case PerlEncoding:
pronomEncoded, converted := PERLParser(signature)
if converted {
return pronomEncoded, converted, PronomEncoding, nil
}
return "", false, encoding, fmt.Errorf("Not processing PERL")
case PronomEncoding:
return signature, false, encoding, nil
case GUIDEncoding:
return "",
false,
encoding, fmt.Errorf("Not processing GUID")
case UnknownEncoding:
hex, err := HexParse(signature)
if err != nil {
return "",
false,
encoding,
fmt.Errorf("Unknown conversion to hex failed: %s", err)
}
return hex, true, HexEncoding, nil
}
return "", false, encoding, nil
}
// preprocessHex will perform some basic operations on a hexadecimal
// string to give it a greater chance of being decoded.
func preprocessHex(signature string) string {
// Remove non-encoded spaces from HEX e.g. `AC DC` -> `ACDC`.
signature = strings.Replace(signature, " ", "", -1)
if strings.HasPrefix(signature, "0x") {
// Remove 0x prefix some values have.
signature = strings.Replace(signature, "0x", "", 1)
}
// Convert the hex string to upper-case to be consistent.
signature = strings.ToUpper(signature)
return signature
}
// HexParse will take a hexadecimal based signature and do something
// useful with it...
func HexParse(signature string) (string, error) {
signature = preprocessHex(signature)
// Validate the hexadecimal
_, err := hex.DecodeString(signature)
return signature, err
}
// ASCIIParser returns a hexadecimal representation of a signature
// written using ASCII encoding.
func ASCIIParser(signature string) string {
return strings.ToUpper(hex.EncodeToString([]byte(signature)))
}
// PERLParser will take a very limited range of PERL syntax and convert
// it to something PRONOM compatible.
func PERLParser(signature string) (string, bool) {
const perlSpace = "\\x20"
const perlWildcardFour = ".{4}"
if strings.Contains(signature, perlSpace) {
signature = strings.Replace(signature, perlSpace, " ", 1)
}
if strings.Contains(signature, perlWildcardFour) {
split := strings.Split(signature, perlWildcardFour)
if len(split) == 2 {
s1 := strings.ToUpper(hex.EncodeToString([]byte(split[0])))
s2 := strings.ToUpper(hex.EncodeToString([]byte(split[1])))
return fmt.Sprintf("%s{4}%s", s1, s2), true
}
}
return "", false
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package loc
import (
"archive/zip"
"encoding/xml"
"errors"
"io/ioutil"
"path/filepath"
"strings"
"time"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/loc/internal/mappings"
"github.com/richardlehane/siegfried/pkg/pronom"
)
type fdds struct {
f []mappings.FDD
p identifier.Parseable
identifier.Blank
}
func newLOC(path string) (identifier.Parseable, error) {
rc, err := zip.OpenReader(path)
if err != nil {
return nil, errors.New("reading " + path + "; " + err.Error())
}
defer rc.Close()
fs := make([]mappings.FDD, 0, len(rc.File))
for _, f := range rc.File {
dir, nm := filepath.Split(f.Name)
if dir == "fddXML/" && nm != "" && filepath.Ext(nm) == ".xml" && !strings.Contains(nm, "test") {
res := mappings.FDD{}
rdr, err := f.Open()
if err != nil {
return nil, err
}
buf, err := ioutil.ReadAll(rdr)
rdr.Close()
if err != nil {
return nil, err
}
err = xml.Unmarshal(buf, &res)
if err != nil {
return nil, err
}
fs = append(fs, res)
}
}
var p identifier.Parseable = identifier.Blank{}
if !config.NoPRONOM() {
p, err = pronom.NewPronom()
if err != nil {
return nil, err
}
}
return fdds{fs, p, identifier.Blank{}}, nil
}
const dateFmt = "2006-01-02"
func (f fdds) Updated() time.Time {
t, _ := time.Parse(dateFmt, "2000-01-01")
for _, v := range f.f {
for _, u := range v.Updates {
tt, err := time.Parse(dateFmt, u)
if err == nil && tt.After(t) {
t = tt
}
}
}
return t
}
func (f fdds) IDs() []string {
ids := make([]string, len(f.f))
for i, v := range f.f {
ids[i] = v.ID
}
return ids
}
type formatInfo struct {
name string
longName string
mimeType string
}
func (f formatInfo) String() string {
return f.name
}
// turn generic FormatInfo into fdd formatInfo
func infos(m map[string]identifier.FormatInfo) map[string]formatInfo {
i := make(map[string]formatInfo, len(m))
for k, v := range m {
i[k] = v.(formatInfo)
}
return i
}
func (f fdds) Infos() map[string]identifier.FormatInfo {
fmap := make(map[string]identifier.FormatInfo, len(f.f))
for _, v := range f.f {
var mime string
if len(v.MIMEs) > 0 {
mime = v.MIMEs[0]
}
fi := formatInfo{
name: v.Name,
longName: v.LongName,
mimeType: mime,
}
fmap[v.ID] = fi
}
return fmap
}
func (f fdds) Globs() ([]string, []string) {
globs, ids := make([]string, 0, len(f.f)), make([]string, 0, len(f.f))
for _, v := range f.f {
for _, w := range v.Extensions {
globs, ids = append(globs, "*."+w), append(ids, v.ID)
}
}
return globs, ids
}
func (f fdds) MIMEs() ([]string, []string) {
mimes, ids := make([]string, 0, len(f.f)), make([]string, 0, len(f.f))
for _, v := range f.f {
for _, w := range v.MIMEs {
mimes, ids = append(mimes, w), append(ids, v.ID)
}
}
return mimes, ids
}
func (f fdds) Signatures() ([]frames.Signature, []string, error) {
var errs []error
var puidsIDs map[string][]string
if len(f.p.IDs()) > 0 {
puidsIDs = make(map[string][]string)
}
sigs, ids := make([]frames.Signature, 0, len(f.f)), make([]string, 0, len(f.f))
for _, v := range f.f {
ss, e := magics(v.Magics)
if e != nil {
errs = append(errs, e)
}
for _, s := range ss {
sigs = append(sigs, s)
ids = append(ids, v.ID)
}
if puidsIDs != nil {
for _, puid := range v.PUIDs() {
puidsIDs[puid] = append(puidsIDs[puid], v.ID)
}
}
}
if puidsIDs != nil {
puids := make([]string, 0, len(puidsIDs))
for p := range puidsIDs {
puids = append(puids, p)
}
np := identifier.Filter(puids, f.p)
ns, ps, e := np.Signatures()
if e != nil {
errs = append(errs, e)
}
for i, v := range ps {
for _, id := range puidsIDs[v] {
sigs = append(sigs, ns[i])
ids = append(ids, id)
}
}
}
var err error
if len(errs) > 0 {
errStrs := make([]string, len(errs))
for i, e := range errs {
errStrs[i] = e.Error()
}
err = errors.New(strings.Join(errStrs, "; "))
}
return sigs, ids, err
}
func (f fdds) containers(typ string) ([][]string, [][]frames.Signature, []string, error) {
if _, ok := f.p.(identifier.Blank); ok {
return nil, nil, nil, nil
}
puidsIDs := make(map[string][]string)
for _, v := range f.f {
for _, puid := range v.PUIDs() {
puidsIDs[puid] = append(puidsIDs[puid], v.ID)
}
}
puids := make([]string, 0, len(puidsIDs))
for p := range puidsIDs {
puids = append(puids, p)
}
np := identifier.Filter(puids, f.p)
names, sigs, ids := make([][]string, 0, len(f.f)), make([][]frames.Signature, 0, len(f.f)), make([]string, 0, len(f.f))
var (
ns [][]string
ss [][]frames.Signature
is []string
err error
)
switch typ {
default:
err = errors.New("Unknown container type " + typ)
case "ZIP":
ns, ss, is, err = np.Zips()
case "OLE2":
ns, ss, is, err = np.MSCFBs()
}
if err != nil {
return nil, nil, nil, err
}
for i, puid := range is {
for _, id := range puidsIDs[puid] {
names = append(names, ns[i])
sigs = append(sigs, ss[i])
ids = append(ids, id)
}
}
return names, sigs, ids, nil
}
func (f fdds) Zips() ([][]string, [][]frames.Signature, []string, error) {
return f.containers("ZIP")
}
func (f fdds) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
return f.containers("OLE2")
}
func (f fdds) RIFFs() ([][4]byte, []string) {
riffs, ids := make([][4]byte, 0, len(f.f)), make([]string, 0, len(f.f))
for _, v := range f.f {
for _, w := range v.Others {
if w.Tag == "Microsoft FOURCC" {
for _, x := range w.Values {
if len(x) == 4 {
val := [4]byte{}
copy(val[:], x[:])
riffs, ids = append(riffs, val), append(ids, v.ID)
}
}
}
}
}
return riffs, ids
}
func (f fdds) Priorities() priority.Map {
p := make(priority.Map)
for _, v := range f.f {
for _, r := range v.Relations {
switch r.Typ {
case "Subtype of", "Modification of", "Version of", "Extension of", "Has earlier version":
p.Add(v.ID, r.Value)
}
}
}
p.Complete()
return p
}
<file_sep>package bytematcher
import (
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
var TestKeyFrames = []keyFrame{
{
typ: frames.BOF,
seg: keyFramePos{
pMin: 8,
pMax: 12,
},
},
{
typ: frames.PREV,
seg: keyFramePos{
pMin: 5,
pMax: 5,
},
},
{
typ: frames.PREV,
seg: keyFramePos{
pMin: 0,
pMax: -1,
},
},
{
typ: frames.SUCC,
seg: keyFramePos{
pMin: 5,
pMax: 10,
},
},
{
typ: frames.EOF,
seg: keyFramePos{
pMin: 0,
pMax: 0,
},
},
}
func TestKeyFrame(t *testing.T) {
_, left, right := toKeyFrame(tests.TestSignatures[1], frames.Position{Length: 1, Start: 1, End: 2})
if len(left) != 1 {
t.Error("KeyFrame: expecting only one frame on the left")
}
seq := left[0].Pattern.Sequences()
if seq[0][1] != 'e' {
t.Error("KeyFrame: expecting the left frame's pattern to have been reversed")
}
if len(right) != 4 {
t.Errorf("KeyFrame: expecting three frames on the right, got %d", len(right))
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Package mappings provides data structures and helpers that describe
// Wikidata signature resources that we want to work with.
package mappings
import (
"encoding/json"
"fmt"
)
// Wikidata stores information about something which constitutes a
// format resource in Wikidata. I.e. Anything which has a URI and
// describes a file-format.
type Wikidata struct {
ID string // Wikidata short name, e.g. Q12345 can be appended to a URI to be dereferenced.
Name string // Name of the format as described in Wikidata.
URI string // URI is the absolute URL in Wikidata terms that can be dereferenced.
PRONOM []string // 1:1 mapping to PRONOM wherever possible.
Extension []string // Extension returned by Wikidata.
Mimetype []string // Mimetype as recorded by Wikidata.
Signatures []Signature // Signature associated with a record which we will convert to a new Type.
Permalink string // Permalink associated with a record when the definitions were downloaded.
RevisionHistory string // RevisionHistory is a human readable block of JSON for use in roy inspect functions.
disableSignatures bool // If a bad heuristic was found we can't reliably add signatures to the record.
}
// Signature describes a complete signature resource, i.e. a way to
// identify a file format using Wikidata information.
type Signature struct {
ByteSequences []ByteSequence // A signature is made up of multiple byte sequences that encode a position and a pattern, e.g. BOF and EOF.
Source string // Source (provenance) of the signature in Wikidata.
Date string // Date the signature was submitted.
}
// ByteSequence describes a sequence that goes into a signature, where
// a signature is made up of 1..* sequences. Usually up to three.
type ByteSequence struct {
Signature string // Signature byte sequence.
Offset int // Offset used by the signature.
Encoding int // Signature encoding, e.g. Hexadecimal, ASCII, PRONOM.
Relativity string // Position relative to beginning or end of file, or elsewhere.
}
// Serialize the signature component of our record to a string for
// debugging purposes.
func (signature Signature) String() string {
report, err := json.MarshalIndent(signature, "", " ")
if err != nil {
return ""
}
return fmt.Sprintf("%s", report)
}
// Serialize the byte sequence component of our record to a string for
// debugging purposes.
func (byteSequence ByteSequence) String() string {
report, err := json.MarshalIndent(byteSequence, "", " ")
if err != nil {
return ""
}
return fmt.Sprintf("%s", report)
}
// DisableSignatures is used when processing Wikidata records when a
// critical error is discovered with a record that needs to be looked
// into beyond what Roy can do for us.
func (wikidata *Wikidata) DisableSignatures() {
wikidata.disableSignatures = true
}
// SignaturesDisabled tells us whether the signatures are disabled for
// a given record.
func (wikidata Wikidata) SignaturesDisabled() bool {
return wikidata.disableSignatures
}
// PUIDs enables the Wikidata format records to be mapped to existing
// PRONOM records when run in PRONOM mode, i.e. not just with Wikidata
// signatures.
func (wikidata Wikidata) PUIDs() []string {
var puids []string
for _, puid := range wikidata.PRONOM {
puids = append(puids, puid)
}
return puids
}
// NewWikidata creates new map for adding Wikidata records to.
func NewWikidata() map[string]Wikidata {
return make(map[string]Wikidata)
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package sets
import (
"encoding/json"
"errors"
"io/ioutil"
"log"
"os"
"path/filepath"
"sort"
"strconv"
"strings"
"sync"
"github.com/richardlehane/siegfried/pkg/config"
)
var (
sets map[string][]string
setsMu = &sync.Once{}
)
// Keys returns a list of all the format sets
func Keys() []string {
load(config.Local("sets"))
l := make([]string, 0, len(sets))
for k := range sets {
l = append(l, k)
}
return l
}
// Expand takes a comma separated string of fmts and sets (e.g. fmt/1,@pdf,fmt/2) and expand any sets within.
func Expand(l string) []string {
return Sets(strings.Split(l, ",")...)
}
// Sets takes a slice of fmts and sets (e.g. []{"fmt/1","@pdf","fmt/2"}) and expand any sets within.
func Sets(items ...string) []string {
uniqs := make(map[string]struct{}) // drop any duplicates with this map
for _, v := range items {
item := strings.TrimSpace(v)
if strings.HasPrefix(item, "@") {
load(config.Local("sets"))
list, err := getSets(strings.TrimPrefix(item, "@"))
if err != nil {
log.Fatalf("error interpreting sets: %v", err)
}
for _, v := range list {
uniqs[v] = struct{}{}
}
} else if len(item) > 0 {
uniqs[item] = struct{}{}
}
}
ret := make([]string, 0, len(uniqs))
for k := range uniqs {
ret = append(ret, k)
}
return sortFmts(ret)
}
// a plain string sort doesn't work e.g. get fmt/1,fmt/111/fmt/2 - need to sort on ints
func sortFmts(s []string) []string {
fmts := make(map[string][]int)
others := []string{}
addFmt := func(str, prefix string) bool {
if strings.HasPrefix(str, prefix+"/") {
no, err := strconv.Atoi(strings.TrimPrefix(str, prefix+"/"))
if err == nil {
fmts[prefix] = append(fmts[prefix], no)
} else {
others = append(others, str)
}
return true
}
return false
}
for _, v := range s {
if !addFmt(v, "fmt") {
if !addFmt(v, "x-fmt") {
others = append(others, v)
}
}
}
var ret []string
appendFmts := func(prefix string) {
f, ok := fmts[prefix]
if ok {
sort.Ints(f)
for _, i := range f {
ret = append(ret, prefix+"/"+strconv.Itoa(i))
}
}
}
appendFmts("fmt")
appendFmts("x-fmt")
sort.Strings(others)
return append(ret, others...)
}
func getSets(key string) ([]string, error) {
// recursively build a list of all values for the key
attempted := make(map[string]bool) // prevent cycles by bookkeeping with attempted map
var f func(string) ([]string, error)
f = func(k string) ([]string, error) {
if ok := attempted[k]; ok {
return nil, nil
}
attempted[k] = true
l, ok := sets[k]
if !ok {
return nil, errors.New("sets: unknown key " + k)
}
var nl []string
for _, k2 := range l {
if strings.HasPrefix(k2, "@") {
l2, err := f(strings.TrimPrefix(k2, "@"))
if err != nil {
return nil, err
}
nl = append(nl, l2...)
} else {
nl = append(nl, k2)
}
}
return nl, nil
}
return f(key)
}
func load(path string) {
setsMu.Do(func() {
// load all json files in the sets directory and add them to a single map
sets = make(map[string][]string)
wf := func(path string, info os.FileInfo, err error) error {
if err != nil {
return errors.New("error walking sets directory, must have a 'sets' directory in siegfried home: " + err.Error())
}
if info.IsDir() {
return nil
}
switch filepath.Ext(path) {
default:
return nil // ignore non json files
case ".json":
}
set := make(map[string][]string)
byts, err := ioutil.ReadFile(path)
if err != nil {
return errors.New("error loading " + path + " " + err.Error())
}
err = json.Unmarshal(byts, &set)
if err != nil {
return errors.New("error unmarshalling " + path + " " + err.Error())
}
for k, v := range set {
k = stripComment(k)
v = stripComments(v)
sort.Strings(v)
m, ok := sets[k]
if !ok {
sets[k] = v
} else {
// if we already have this key, add any new items in its list to the existing list
for _, w := range v {
idx := sort.SearchStrings(m, w)
if idx == len(m) || m[idx] != w {
m = append(m, w)
}
}
sort.Strings(m)
sets[k] = m
}
}
return nil
}
if err := filepath.Walk(path, wf); err != nil {
log.Fatal(err)
}
})
}
func stripComment(in string) string {
ws := strings.Index(in, " ")
if ws < 0 {
return in
} else {
return in[:ws]
}
}
func stripComments(in []string) []string {
out := make([]string, len(in))
for i, v := range in {
out[i] = stripComment(v)
}
return out
}
<file_sep>// Copyright 2022 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import "C"
import (
"os"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/static"
)
func init() {
sf = static.New()
}
var sf *siegfried.Siegfried
//export Identify
func Identify(path string) ([][][2]string, error) {
f, err := os.Open(path)
if err != nil {
return nil, err
}
ids, err := sf.Identify(f, path, "")
if err != nil {
return nil, err
}
ret := make([][][2]string, len(ids))
for i := range ret {
ret[i] = sf.Label(ids[i])
}
return ret, nil
}
func main() {}
<file_sep>package patterns_test
import (
"testing"
"github.com/richardlehane/siegfried/internal/persist"
. "github.com/richardlehane/siegfried/internal/bytematcher/patterns/tests"
)
func TestSequence(t *testing.T) {
if !TestSequences[0].Equals(TestSequences[1]) {
t.Error("Seq fail: Equality")
}
if r, _ := TestSequences[0].Test([]byte{'t', 'o', 'o', 't'}); len(r) > 0 {
t.Error("Sequence fail: shouldn't match")
}
if r, _ := TestSequences[2].Test([]byte{'t', 'e', 's', 't', 'y'}); len(r) != 1 || r[0] != 5 {
t.Error("Sequence fail: should match")
}
reverseSeq := TestSequences[2].Reverse()
if reverseSeq[1] != 't' || reverseSeq[2] != 's' || reverseSeq[3] != 'e' || reverseSeq[4] != 't' {
t.Error("Sequence fail: Reverse")
}
saver := persist.NewLoadSaver(nil)
TestSequences[0].Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loader.LoadBytes()
if len(p) != 4 {
t.Errorf("expecting %v, got %v", TestSequences[0], string(p))
}
}
func TestChoice(t *testing.T) {
if !TestChoices[0].Equals(TestChoices[1]) {
t.Error("Choice fail: Equality")
}
if r, _ := TestChoices[0].Test([]byte{'t', 'e', 's', 't'}); len(r) != 1 || r[0] != 4 {
t.Error("Choice test fail: Test")
}
if TestChoices[0].NumSequences() != 2 {
t.Error("Choice fail: NumSequences; expecting 2 got", TestChoices[0].NumSequences())
}
seqs := TestChoices[0].Sequences()
if seqs[0][0] != 't' || seqs[1][0] != 't' {
t.Error("Choice fail: Sequences; expecting t, t got ", seqs[0][0], seqs[1][0])
}
}
func TestList(t *testing.T) {
if TestLists[0].Equals(TestLists[1]) {
t.Error("List fail: equality")
}
if r, _ := TestLists[0].Test([]byte{'t', 'e', 's', 't', 't', 'e', 's', 't', 'y'}); len(r) != 1 || r[0] != 9 {
t.Error("List test fail: Test")
}
if TestLists[0].NumSequences() != 1 {
t.Error("List fail: NumSequences; expecting 1 got", TestLists[0].NumSequences())
}
seqs := TestLists[0].Sequences()
if seqs[0][0] != 't' || seqs[0][8] != 'y' {
t.Error("List fail: Sequences; expecting t, y got ", seqs[0][0], seqs[0][8])
}
}
func TestNotSequence(t *testing.T) {
if !TestNotSequences[0].Equals(TestNotSequences[1]) {
t.Error("NotSequence fail: Equality test")
}
if r, _ := TestNotSequences[0].Test([]byte{'t', 'e', 's', 't'}); len(r) > 0 {
t.Error("NotSequence fail: Test shouldn't match")
}
if r, _ := TestNotSequences[0].Test([]byte{'t', 'o', 'o', 't'}); len(r) != 1 || r[0] != 4 {
t.Error("NotSequence fail: Test should match")
}
seqs := TestNotSequences[2].Sequences()
if len(seqs) != 255 {
t.Error("NotSequence fail: Sequences")
}
seqs = TestNotSequences[3].Sequences()
if len(seqs) != 255 {
t.Error("NotSequence fail: Sequences")
}
seqs = TestNotSequences[4].Sequences()
if len(seqs) != 255 {
t.Error("NotSequence fail: Sequences")
}
}
func TestMask(t *testing.T) {
mask := TestMasks[0]
if r, _ := mask.Test([]byte{0xEE}); len(r) != 1 || r[0] != 1 {
t.Errorf("mask fail: 0xEE should match")
}
if r, _ := mask.Test([]byte{0x0A}); len(r) > 0 {
t.Errorf("mask fail: expected 0x0A not to match!")
}
num := mask.NumSequences()
if num != 16 {
t.Fatal("mask fail: expecting 16 sequences")
}
seqs := mask.Sequences()
if len(seqs) != 16 {
t.Fatal("mask fail: expecting 16 sequences")
}
for i, v := range seqs {
if v[0] == 0xEE {
break
}
if i == len(seqs)-1 {
t.Fatal("mask fail: expecting 0xEE amongst sequences")
}
}
}
func TestAnyMask(t *testing.T) {
amask := TestAnyMasks[0]
if r, _ := amask.Test([]byte{0x0A}); len(r) != 1 || r[0] != 1 {
t.Errorf("any mask fail: 0x0A should match")
}
if r, _ := amask.Test([]byte{5}); len(r) > 0 {
t.Errorf("any mask fail: expected 5 not to match!")
}
num := amask.NumSequences()
if num != 240 {
t.Fatal("any mask fail: expecting 240 sequences")
}
seqs := amask.Sequences()
if len(seqs) != 240 {
t.Fatal("any mask fail: expecting 240 sequences")
}
for i, v := range seqs {
if v[0] == 0x0A {
break
}
if i == len(seqs)-1 {
t.Fatal("any mask fail: expecting 0x0A amongst sequences")
}
}
}
<file_sep>package siegreader
import (
"io"
"os"
"sync"
)
type file struct {
peek [initialRead]byte
sz int64
src *os.File
once *sync.Once
data
pool *datas // link to the data pool
}
func newFile() interface{} { return &file{once: &sync.Once{}} }
type data interface {
slice(offset int64, length int) []byte
eofSlice(offset int64, length int) []byte
}
func (f *file) setSource(src *os.File, p *datas) error {
// reset
f.once = &sync.Once{}
f.data = nil
f.pool = p
f.src = src
info, err := f.src.Stat()
if err != nil {
return err
}
f.sz = info.Size()
i, err := f.src.Read(f.peek[:])
if i < initialRead && (err == nil || err == io.EOF) {
if i == 0 {
return ErrEmpty
}
if err == nil {
return io.EOF
}
}
return err
}
// Size returns the buffer's size, which is available immediately for files. Must wait for full read for streams.
func (f *file) Size() int64 { return f.sz }
// SizeNow is a non-blocking Size().
func (f *file) SizeNow() int64 { return f.sz }
func (f *file) CanSeek(off int64, whence bool) (bool, error) {
if f.sz < off {
return false, nil
}
return true, nil
}
// Slice returns a byte slice from the buffer that begins at offset off and has length l.
func (f *file) Slice(off int64, l int) ([]byte, error) {
// return EOF if offset is larger than the file size
if off >= f.sz {
return nil, io.EOF
}
// shorten the length, if necessary
var err error
if off+int64(l) > f.sz {
l = int(f.sz - off)
err = io.EOF
}
// the slice falls entirely in the bof segment
if off+int64(l) <= int64(initialRead) {
return f.peek[int(off) : int(off)+l], err
}
f.once.Do(func() {
f.data = f.pool.get(f)
})
ret := f.slice(off, l)
return ret, err
}
// EofSlice returns a slice from the end of the buffer that begins at offset s and has length l.
// May block until the slice is available.
func (f *file) EofSlice(off int64, l int) ([]byte, error) {
// if the offset is larger than the file size, it is invalid
if off >= f.sz {
return nil, io.EOF
}
// shorten the length, if necessary
var err error
if off+int64(l) > f.sz {
l = int(f.sz - off)
err = io.EOF
}
// the slice falls entirely in the bof segment
if f.sz-off <= int64(initialRead) {
return f.peek[int(f.sz-off)-l : int(f.sz-off)], err
}
f.once.Do(func() {
f.data = f.pool.get(f)
})
ret := f.eofSlice(off, l)
return ret, err
}
<file_sep># Change Log
## v1.10.1 (2023-04-24)
### Fixed
- glob expansion now only on Windows & when no explicit path match. Implemented by [<NAME>](https://github.com/richardlehane/siegfried/pull/229)
- compression algorithm for debian packages changed back to xz. Implemented by [<NAME>](https://github.com/richardlehane/siegfried/pull/230)
- `-multi droid` setting returned empty results when priority lists contained self-references. See [#218](https://github.com/richardlehane/siegfried/issues/218)
- CGO disabled for debian package and linux binaries. See [#219](https://github.com/richardlehane/siegfried/issues/219)
## v1.10.0 (2023-03-25)
### Added
- format classification included as "class" field in PRONOM results. Requested by [<NAME>](https://github.com/richardlehane/siegfried/discussions/207). Implemented by [<NAME>](https://github.com/richardlehane/siegfried/commit/7f695720a752ac5fca3e1de8ba034b92ab6da1d9)
- `-noclass` flag added to roy build command. Use this flag to build signatures that omit the new "class" field from results.
- glob paths can be used in place of file or directory paths for identification (e.g. `sf *.jpg`). Implemented by [Ross Spencer](https://github.com/richardlehane/siegfried/commit/54bf6596c5fe7d1c9858348f0170d0dd7365fc8f)
- `-multi droid` setting for roy build command. Applies priorities after rather than during identificaiton for more DROID-like results. Reported by [David Clipsham](https://github.com/richardlehane/siegfried/issues/146)
- `/update` command for server mode. Requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/208)
### Changed
- new algorithm for dynamic multi-sequence matching for improved wildcard performance
- update PRONOM to v111
- update LOC to 2023-01-27
- update tika-mimetypes to v2.7.0
- minimum go version to build siegfried is now 1.18
### Fixed
- archivematica extensions built into wikidata signatures. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/210)
- trailing slash for folder paths in URI field in droid output. Reported by <NAME>
- crash when using `sf -replay` with droid output
## v1.9.6 (2022-11-06)
### Changed
- update PRONOM to v109
## v1.9.5 (2022-09-12)
### Added
- `roy inspect` now takes a `-droid` flag to allow easier inspection of old or custom DROID files
- github action to update siegfried docker deployment [https://github.com/keeps/siegfried-docker]. Implemented by [Keep Solutions](https://github.com/richardlehane/siegfried/pull/201)
### Changed
- update PRONOM to v108
- update tika-mimetype signatures to v2.4.1
- update LOC signatures to 2022-09-01
### Fixed
- incorrect encoding of YAML strings containing line endings; [#202](https://github.com/richardlehane/siegfried/issues/202).
- parse signatures with offsets and offsets in patterns e.g. fmt/1741; [#203](https://github.com/richardlehane/siegfried/issues/203)
## v1.9.4 (2022-07-18)
### Added
- new pkg/static and static builds. This allows direct use of sf API and self-contained binaries without needing separate signature files.
### Changed
- update PRONOM to v106
### Fixed
- inconsistent output for `roy inspect priorities`. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/192)
## v1.9.3 (2022-05-23)
### Added
- JS/WASM build support contributed by [<NAME>](https://github.com/richardlehane/siegfried/pull/188)
- wikidata signature added to `-update`. Contributed by [<NAME>](https://github.com/richardlehane/siegfried/pull/178)
- `-nopronom` flag added to `roy inspect` subcommand. Contributed by [<NAME>](https://github.com/richardlehane/siegfried/pull/185)
### Changed
- update PRONOM to v104
- update LOC signatures to 2022-05-09
- update Wikidata to 2022-05-20
- update tika-mimetypes signatures to v2.4.0
- update freedesktop.org signatures to v2.2
### Fixed
- invalid JSON output for fmt/1472 due to tab in MIME field. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/186)
- panic on corrupt Zip containers. Reported by [A. Diamond](https://github.com/richardlehane/siegfried/issues/181)
## v1.9.2 (2022-02-07)
### Added
- Wikidata definition file specification has been updated and now includes endpoint (users will need to harvest Wikidata again)
- Custom Wikibase endpoint can now be specified for harvesting when paired with a custom SPARQL query and property mappings
- Wikidata identifier includes permalinks in results
- Wikidata revision history visible using `roy inspect`
- roy inspect returns format ID with name
### Changed
- update PRONOM to v100
- update LOC signatures to 2022-02-01
- update tika-mimetypes signatures to v2.2.1
- update freedesktop.org signatures to v2.1
### Fixed
- parse issues for container files where zero indexing used for Position. Spotted by [<NAME>](https://github.com/richardlehane/siegfried/issues/175)
- sf -droid output can't be read by sf (e.g. for comparing results). Reported by [ostnatalie](https://github.com/richardlehane/siegfried/issues/174)
- panic when running in server mode due to race condition. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/172)
- panic when reading malformed MSCFB files. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/171)
- unescaped control characters in JSON output. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/165)
- zip file names with null terminated strings prevent ID of Serif formats. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/150)
## v1.9.1 (2020-10-11)
### Changed
- update PRONOM to v97
- zs flag now activates -z flag
### Fixed
- details text in PRONOM identifier
- `roy` panic when building signatures with empty sequences. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/149)
## v1.9.0 (2020-09-22)
### Added
- a new Wikidata identifier, harvesting information from the Wikidata Query Service. Implemented by [Ross Spencer](https://github.com/richardlehane/siegfried/commit/dfb579b4ae46ae6daa814fc3fc74271d768f2f9c).
- select which archive types (zip, tar, gzip, warc, or arc) are unpacked using the -zs flag (sf -zs tar,zip). Implemented by [Ross Spencer](https://github.com/richardlehane/siegfried/commit/88dd43b55e5f83304705f6bcd439d502ef08cd38).
### Changed
- update LOC signatures to 2020-09-21
- update tika-mimetypes signatures to v1.24
- update freedesktop.org signatures to v2.0
### Fixed
- incorrect basis for some signatures with multiple patterns. Reported and fixed by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/142).
## v1.8.0 (2020-01-22)
### Added
- utc flag returns file modified dates in UTC e.g. `sf -utc FILE | DIR`. Requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/136)
- new cost and repetition flags to control segmentation when building signatures
### Changed
- update PRONOM to v96
- update LOC signatures to 2019-12-18
- update tika-mimetypes signatures to v1.23
- update freedesktop.org signatures to v1.15
### Fixed
- XML namespaces detected by prefix on root tag, as well as default namespace (for mime-info spec)
- panic when scanning certain MS-CFB files. Reported separately by <NAME> and <NAME>
- file with many FF xx sequences grinds to a halt. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/128)
## v1.7.13 (2019-08-18)
### Added
- the `-f` flag now scans directories, as well as files. Requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/130)
### Changed
- update LOC signatures to 2019-06-16
- update tika-mimetypes signatures to v1.22
### Fixed
- filenames with "?" were parsed as URLs; reported by [workflowsguy](https://github.com/richardlehane/siegfried/issues/129)
## v1.7.12 (2019-06-15)
### Changed
- update PRONOM to v95
- update LOC signatures to 2019-05-20
- update tika-mimetypes signatures to v1.21
### Fixed
- .docx files with .doc extensions panic due to bug in division of hints in container matcher. Thanks to <NAME> for [reporting and sharing samples](https://github.com/richardlehane/siegfried/issues/126) and to VAIarchief for [additional report with example](https://github.com/richardlehane/siegfried/issues/127).
- mime-info signatures panic on some files due to duplicate entries in the freedesktop and tika signature files; spotted during an attempt at pair coding with <NAME>... thanks Ross and sorry for hogging the laptop! [#125](https://github.com/richardlehane/siegfried/issues/125)
## v1.7.11 (2019-02-16)
### Changed
- update LOC signatures to 2019-01-06
- update tika-mimetypes signatures to v1.20
### Fixed
- container matching can now match against directory names. Thanks <NAME> for [reporting](https://github.com/richardlehane/siegfried/issues/123) and for the sample SIARD signature file. Thanks <NAME>, <NAME> and <NAME> for contributions on the ticket.
- fixes to travis.yml for auto-deploy of debian release; [#124](https://github.com/richardlehane/siegfried/issues/124)
## v1.7.10 (2018-09-19)
### Added
- print configuration defaults with `sf -version`
### Changed
- update PRONOM to v94
### Fixed
- LOC identifier fixed after regression in v1.7.9
- remove skeleton-suite files triggering malware warnings by adding to .gitignore; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/118)
- release built with Go version 11, which includes a fix for a CIFS error that caused files to be skipped during file walk; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/115)
## v1.7.9 (2018-08-30)
### Added
- save defaults in a configuration file: use the -setconf flag to record any other flags used into a config file. These defaults will be loaded each time you run sf. E.g. `sf -multi 16 -setconf` then `sf DIR` (loads the new multi default)
- use `-conf filename` to save or load from a named config file. E.g. `sf -multi 16 -serve :5138 -conf srv.conf -setconf` and then `sf -conf srv.conf`
- added `-yaml` flag so, if you set json/csv in default config :(, you can override with YAML instead. Choose the YAML!
### Changed
- the `roy compare -join` options that join on filepath now work better when comparing results with mixed windows and unix paths
- exported decompress package to give more functionality for users of the golang API; requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/119)
- update LOC signatures to 2018-06-14
- update freedesktop.org signatures to v1.10
- update tika-mimetype signatures to v1.18
### Fixed
- misidentifications of some files e.g. ODF presentation due to sf quitting early on strong matches. Have adjusted this algorithm to make sf wait longer if there is evidence (e.g. from filename) that the file might be something else. Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/112)
- read and other file errors caused sf to hang; reports by [<NAME> and <NAME>](https://github.com/richardlehane/siegfried/issues/113); fix contributed by [<NAME>](https://github.com/richardlehane/siegfried/commit/ea5300d3639d741a451522958e8b99912f7d639d)
- bug reading streams where EOF returned for reads exactly adjacent the end of file
- bug in mscfb library ([race condition for concurrent access to a global variable](https://github.com/richardlehane/siegfried/issues/117))
- some matches result in extremely verbose basis fields; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/111). Partly fixed: basis field now reports a single basis for a match but work remains to speed up matching for these cases.
## v1.7.8 (2017-12-02)
### Changed
- update LOC signatures to 2017-09-28
- update PRONOM signatures to v93
## v1.7.7 (2017-11-30)
### Added
- version information for MIME-info signatures (freedesktop.org and tika-mimetypes) now recorded in mime-info.json file and presented in results
- new sets file for PRONOM extensions. This creates sets like @.doc and @.txt (i.e. all PUIDs with those extensions). Allows you to do commands like `roy build -limit @.doc,@.docx`, `roy inspect @.txt` and `sf -log @.pdf,o DIR`
### Changed
- update freedesktop.org signatures to v1.9
### Fixed
- out of memory error when using `sf -z` on compressed files that contain very large files; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/109)
- report errors that occur during file decompression. Previously, only fatal errors encountered when a compressed file is first opened were reported. Now errors that are encountered while attempting to walk the contents of a compressed file are also reported.
- report errors for 'roy inspect' when roy can't find anything to inspect; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/108)
## v1.7.6 (2017-10-04)
### Added
- continue on error flag (-coe) can now be used to continue scans despite fatal file errors that would normally cause scanning to halt. This may be useful e.g. for big directory scans over unreliable networks. Usage: `sf -coe DIR`
### Changed
- update PRONOM signatures to v92
### Fixed
- file scanning is now restricted to regular files (i.e. not symlinks, sockets, devices etc.). Reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/107).
- windows longpath fix now works for paths that appear short
## v1.7.5 (2017-08-12)
### Added
- `sf -update` flag can now be used to download/update non-PRONOM signatures. Options are "loc", "tika", "freedesktop", "pronom-tika-loc", "deluxe" and "archivematica". To update a non-PRONOM signature, include the signature name as an argument after the flags e.g. `sf -update freedesktop`. This command will overwrite 'default.sig' (the default signature file that sf loads). You can preserve your default signature file by providing an alternative `-sig` target e.g. `sf -sig notdefault.sig -update loc`. If you use one of the signature options as a filename (with or without a .sig extension), you can omit the signature argument i.e. `sf -update -sig loc.sig` is equivalent to `sf -sig loc.sig -update loc`. Feature requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/103).
- `sf -update` now does SHA-256 hash verification of updates and communication with the update server is via HTTPS.
### Changed
- update PRONOM signatures to v91
### Fixed
- fixes to config package where global variables are polluted with subsquent calls to the Add(Identifier) function
- fix to reader package where panic triggered by illegal slice access in some cases
## v1.7.4 (2017-07-14)
### Added
- `roy build` and `roy add` now take a `-nobyte` flag to omit byte signatures from the identifier; requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/102)
### Changed
- update Tika MIMEInfo signatures to 1.16
- update LOC to 2017-06-10
## v1.7.3-(x) (2017-05-30)
### Fixed
- no changes since v1.7.3, repairing Travis-CI auto-deploy of Debian packages
## v1.7.3 (2017-05-20)
### Added
- sf now accepts multiple files or directories as input e.g. `sf myfile1.doc mydir myfile3.txt`
- LOC signature update
### Changed
- code re-organisation to export reader and writer packages
- `sf -replay` can now take lists of results files with `-f` flag e.g. `sf -replay -f list-of-results.txt`
### Fixed
- the command `sf -replay -` now works on Windows as expected e.g. `sf myfiles | sf -replay -json -`
- text matcher not allocating hits to correct identifiers; fixes [#101](https://github.com/richardlehane/siegfried/issues/101)
- unescaped YAML field contains quote; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/100)
## v1.7.2 (2017-04-4)
### Added
- PRONOM v90 update
### Fixed
- the -home flag was being overriden for roy subcommands due to interaction other flags
## v1.7.1 (2017-03-12)
### Added
- signature updates for PRONOM, LOC and tika-mimetypes
### Changed
- `roy inspect` accepts space as well as comma-separated lists of formats e.g. `roy inspect fmt/1 fmt/2`
## v1.7.0 (2017-02-17)
### Added
- log files that match particular formats with `-log fmt/1,@set2` (comma separated list of format IDs/format sets). These can be mixed with regular log options e.g. `-log unknown,fmt/1,chart`
- generate a summary view of formats matched during a scan with `-log chart` (or just `-log c`)
- replay scans from results files with `sf -replay`: load one or more results files to replay logging or to convert to a different output format e.g. `sf -replay -csv results.yaml` or `sf -replay -log unknown,chart,stdout results1.yaml results2.csv`
- compare results with `roy compare` subcommand: view the difference between two or more results e.g. `roy compare results1.yaml results2.csv droid.csv ...`
- `roy sets` subcommand: `roy sets` creates pronom-all.json, pronom-families.json, and pronom-types.json sets files;
`roy sets -changes` creates a pronom-changes.json sets file from a PRONOM release-notes.xml file; `roy sets -list @set1,@set2` lists contents of a comma-separated list of format sets
- `roy inspect releases` provides a summary view of a PRONOM release-notes.xml file
### Changed
- the `sf -` command now scans stdin e.g. `cat mypdf.pdf | sf -`. You can pass a filename in to supplement the analysis with the `-name` flag. E.g. `cat myfile.pdf | sf -name myfile.pdf -`. In previous versions of sf, the dash argument signified treating stdin as a newline separated list of filenames for scanning. Use the new `-f` flag for this e.g. `sf -f myfiles.txt` or `cat myfiles.txt | sf -f -`; change requested by [pm64](https://github.com/richardlehane/siegfried/issues/96)
### Fixed
- some files cause endless scanning due to large numbers of signature hits; reported by [workflowsguy](https://github.com/richardlehane/siegfried/issues/94)
- null bytes can be written to output due to bad zip filename decoding; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/95)
## v1.6.7 (2016-11-23)
### Added
- enable -hash, -z, and -log flags for -serve and -multi modes
- new hash, z, and sig params for -serve mode (to control per-request)
- enable droid output in -serve mode
- GET requests in -serve mode now just percent encoded (with base64 option as a param)
- -serve mode landing page now includes example forms
### Changed
- code re-organisation using /internal directory to hide internal packages
- Identify method now returns a slice rather than channel of IDs (siegfried pkg change)
## v1.6.6 (2016-10-25)
### Added
- graph implicit and missing priorities with `roy inspect implicit-priorities` and `roy inspect missing-priorities`
### Fixed
- error parsing mimeinfo signatures with double backslashes (e.g. rtf signatures)
## v1.6.5 (2016-09-28)
### Added
- new sets files (pronom-families.json and pronom-types) automatically created from PRONOM classficiations. Removed redundant sets (database, audio, etc.).
### Fixed
- debbuilder.sh fix: debian packages were copying roy data to wrong directory
### Changed
- roy inspect priorities command now includes "orphan" fmts in graphs
- update PRONOM urls from apps. to www.
## v1.6.4 (2016-09-05)
### Added
- roy inspect FMT command now inspects sets e.g. roy inspect @pdfa
- roy inspect priorities command generates graphs of priority relations
### Fixed
- [container matcher running when empty](https://github.com/richardlehane/siegfried/issues/90) (i.e. for freedesktop/tika signature files and when -nocontainer flag used with PRONOM)
- [-doubleup flag preventing signature extensions loading](https://github.com/richardlehane/siegfried/issues/92): since v1.3.0 signature extensions included with the -extend flag haven't been loading properly due to interaction with the doubles filter (which prevents byte signatures loading for formats that also have container signatures defined)
### Changed
- use fwac rather than wac package for performance
- roy inspect FMT command speed up by building without reports and without the doubles filter
- -reports flag removed for roy harvest and roy build commands
- -reports flag changed for roy inspect command, now a boolean that, if set, will cause the signature(s) to be built from the PRONOM report(s), rather than the DROID XML file. This is slower but can be a more accurate representation.
## v1.6.3 (2016-08-18)
### Added
- roy inspect FMT command now gives details of all signatures, [including container signatures](https://github.com/richardlehane/siegfried/issues/88)
### Fixed
- misidentification: [x-fmt/45 files misidentified as fmt/40](https://github.com/richardlehane/siegfried/issues/89) due to repetition of elements in container file
- roy build -noreports includes blank extensions that generate false matches; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/87)
## v1.6.2 (2016-08-08)
### Fixed
- poor performance unknowns due to interaction of -bof/-eof flags with known BOF/EOF calculation; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/86)
- [unnecessary warnings for mimeinfo identifier](https://github.com/richardlehane/siegfried/issues/84)
- add fddXML.zip to .gitattributes to preserve newlines
- various [Go Report Card](https://goreportcard.com/report/github.com/richardlehane/siegfried) issues
## v1.6.1 (2016-07-06)
### Added
- Travis and Appveyor CI automated deployment to Github releases and Bintray
- PRONOM v85 signatures
- LICENSE.txt, CHANGELOG.md
- [Go Report Card](https://goreportcard.com/report/github.com/richardlehane/siegfried)
### Fixed
- golang.org/x/image/riff bug (reported [here](https://github.com/golang/go/issues/16236))
- misspellings reported by Go Report Card
- ineffectual assignments reported by Go Report Card
## v1.6.0 (2016-06-26)
### Added
- implement Library of Congress FDD signatures (*beta*)
- implement RIFF matcher
- -multi flag replaces -nopriority; based on report by [<NAME>](https://github.com/richardlehane/siegfried/issues/75)
### Changed
- change to -z output: use hash as filepath separator (and unix slash for webarchives); requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/81)
### Fixed
- parsing fmt/837 signature; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/80)
## v1.5.0 (2016-03-14)
### Added
- implement freedesktop.org MIME-info signatures (and the Apache Tika variant)
- implement XML matcher
- file name matcher now supports glob patterns as well as file extensions
### Changed
- default signature file now "default.sig" (was "pronom.sig")
- changes to YAML and JSON output: "ns" (for namespace) replaces "id", and "id" replaces "puid"
- changes to CSV output: multi-identifiers now displayed in extra columns, not extra rows
## v1.4.5 (2016-02-06)
### Added
- summarise os errors; requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/65)
- code quality: vendor external packages; implemented by [Misty de Meo](https://github.com/richardlehane/siegfried/pull/71)
### Fixed
- [big file handling](https://github.com/richardlehane/siegfried/commit/b348c4628ac8edf8e93208e9100bd15616f72e41)
- [file handle leak](https://github.com/richardlehane/siegfried/commit/47144fd33a4ddd260bdcd5dd15c132525c3bd113); reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/66)
- [mscfb](https://github.com/richardlehane/mscfb/commit/e19fa67f7571388d3dc956f7c6b4547bfb635072); reported by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/68)
## v1.4.4 (2016-01-09)
### Changed
- code quality: refactor textmatcher package
- code quality: refactor siegreader package
- code quality: documentation
### Fixed
- speed regression in TIFF mis-identification patch last release
## v1.4.3 (2015-12-19)
### Added
- measure time elapsed with -log time
### Fixed
- [percent encode file URIs in droid output](https://github.com/richardlehane/siegfried/issues/63)
- long windows directory paths (further work on bug fixed in 1.4.2); reported by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/58)
- mscfb panic; reported by [Ro<NAME>](https://github.com/richardlehane/siegfried/issues/62)
- **TIFF mis-identifications** due to an [early halt error](https://github.com/richardlehane/siegfried/commit/5f0ccd477c467186c350e762f8fddda888d987bf)
## v1.4.2 (2015-11-27)
### Added
- new -throttle flag; requested by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/61)
### Changed
- errors logged to stderr by default (to quieten use -log ""); requested by [Ross Spencer](https://github.com/richardlehane/siegfried/issues/60)
- mscfb update: [lazy reading](https://github.com/richardlehane/mscfb/commit/f909cfa596c7880c650ed5440df90e5474f08b29)
- webarchive update: [decode Transfer-Encoding and Content-Encoding](https://github.com/richardlehane/webarchive/commit/2f125b9bece4d7d119ea029aa8c942a41962ecf4); requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/55)
### Fixed
- long windows paths; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/58)
- 32-bit file size overflow; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/59)
## v1.4.1 (2015-11-06)
### Changed
- **-log replaces -debug, -slow, -unknown and -known flags** (see usage above)
- highlight empty file/stream with error and warning
- negative text match overrides extension-only plain text match
## v1.4.0 (2015-10-31)
### Added
- new MIME matcher; requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/55)
- support warc continuations
- add all.json and tiff.json sets
### Changed
- minor speed-up
- report less redundant basis information
- report error on empty file/stream
## v1.3.0 (2015-09-27)
### Added
- scan within warc and arc files with -z flag; reqested by [<NAME>](https://github.com/richardlehane/siegfried/issues/43)
- sf -slow FILE | DIR reports slow signatures
- sf -version describes signature file; requested by [Michelle Lindlar](https://github.com/richardlehane/siegfried/issues/54)
### Changed
- [quit scanning earlier on known unknowns](https://github.com/richardlehane/siegfried/commit/f7fedf6b629048e1c41a694f4428e94deeffd3ee)
- don't include byte signatures where formats have container signatures (unless -doubleup flag is given); fixes a mis-identification reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/52)
- sf -debug output simplified
- roy -limit and -exclude now operate on text and default zip matches
- roy -nopriority re-configured to return more results
### Fixed
- upgraded versions of sf panic when attempting to read old signature files; reported by [Stefan](https://github.com/richardlehane/siegfried/issues/49)
- panic mmap'ing files over 1GB on Win32; reported by [Duncan](https://github.com/richardlehane/siegfried/issues/50)
- reporting extensions for folders with "."; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/51)
## v1.2.2 (2015-08-15)
### Added
- -noext flag to roy to suppress extension matching; requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/46)
- -known and -unknown flags for sf to output lists of recognised and unknown files respectively; requested by [<NAME>](https://github.com/richardlehane/siegfried/issues/47)
## v1.2.1 (2015-08-11)
### Added
- support annotation of sets.json files; requested by <NAME>
- add warning when use -extendc without -extend
### Fixed
- report container extensions in details; reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/48)
## v1.2.0 (2015-07-31)
### Added
- text matcher (i.e. sf README will now report a 'Plain Text File' result)
- -notext flag to suppress text matcher (roy build -notext)
- all outputs now include file last modified time
- -hash flag with choice of md5, sha1, sha256, sha512, crc (e.g. sf -hash md5 FILE)
- -droid flag to mimic droid output (sf -droid FILE)
### Fixed
- [detect encoding of zip filenames](https://github.com/richardlehane/siegfried/commit/0c92c52d3d709e1a9b2822fa182ebd1847a6c394) reported by [Drag<NAME>](https://github.com/richardlehane/siegfried/issues/42)
- [mscfb](https://github.com/richardlehane/mscfb/commit/f790430b648469e862b40f599171e361e30442e7) reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/41)
## v1.1.0 (2015-05-17)
### Added
- scan within archive formats (zip, tar, gzip) with -z flag
- format sets (e.g. roy build -exclude @pdfa)
- support bitmask patterns
### Changed
- leaner, faster signature format
- mirror bof patterns as eof patterns where both roy -bof and -eof limits set
### Fixed
- ([mscfb](https://github.com/richardlehane/mscfb/commit/22552265cefc80b400ff64156155f53a5d5751e6)) reported by [<NAME>](https://github.com/richardlehane/siegfried/issues/32)
- race condition in scorer (affected tip golang)
## v1.0.0 (2015-03-22)
### Changed
- [user documentation](http://github.com/richardlehane/siegfried/wiki)
- bugfixes (mscfb, match/wac and sf)
- QA using [comparator](http://github.com/richardlehane/comparator)
## v0.8.2 (2015-02-22)
### Added
- json output
- server mode
## v0.8.1 (2015-02-01)
### Fixed
- single quote YAML output
## v0.8.0 (2015-01-26)
### Changed
- optimisations (mmap, multithread, etc.)
## v0.7.1 (2014-12-09)
### Added
- csv output
### Changed
- periodic priority checking to stop searches earlier
### Fixed
- range/distance/choices bugfix
## v0.7.0 (2014-11-24)
### Changed
- change to signature file format
## v0.6.1 (2014-11-21)
### Added
- roy (r2d2 rename) signature customisation
- parse Droid signature (not just PRONOM reports)
- support extension signatures
## v0.6.0 (2014-11-11)
### Added
- support multiple identifiers
- config package
### Changed
- license info in srcs (no change to license; this allows for attributing authorship for non-Richard contribs)
- default home change to "$HOME/siegfried" (no longer ".siegfried")
### Fixed
- mscfb bugfixes
## v0.5.0 (2014-10-01)
### Added
- container matching
## v0.4.3 (2014-09-23)
### Fixed
- cross-compile was broken (because of use of os/user). Now doing native builds on the three platforms so the download binaries should all work now.
## v0.4.2 (2014-09-16)
### Fixed
- bug in processing code caused really bad matching profile for MP3 sigs. No need to update the tool for this, but please do a sieg -update to get the latest signature file.
## v0.4.1 (2014-09-14)
### Added
- sf command line: descriptive output in YAML, including basis for matches
### Changed
- optimisations inc. initial BOF loop before main matching loop
## v0.4.0 (2014-08-24)
### Added
- sf command line changes: -version and -update flags now enabled
- over-the-wire updates of signature files from www.itforarchivists.com/siegfried
## v0.3.0 (2014-08-19)
### Changed
- replaced ac matcher with wac matcher
- re-write of bytematcher code
- some benchmarks slower but fewer really poor edge cases (see cmd/sieg/testdata/bench_results.txt)... so a win!
- but still too slow!
## v0.2.0 (2014-03-26)
### Added
- an Identifier type that controls the matching process and stops on best possible match (i.e. no longer require a full file scan for all files)
- name/extension matching
- a custom reader (pkg/core/siegreader)
### Changed
- benchmarks (cmd/sieg/testdata)
- simplifications to the sieg command and signature file
- optimisations that have boosted performance (see cmd/sieg/testdata/bench_results.txt). But still too slow!
## v0.1.0 (2014-02-28)
### Added
- First release. Parses PRONOM signatures and performs byte matching. Bare bones CLI. Glacially slow!
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package persist
import (
"testing"
"time"
)
func TestByte(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveByte(5)
saver.SaveBool(true)
saver.SaveBool(false)
loader := NewLoadSaver(saver.Bytes())
i := loader.LoadByte()
if i != 5 {
t.Errorf("expecting %d, got %d", 5, i)
}
b := loader.LoadBool()
if !b {
t.Error("expecting true, got false")
}
b = loader.LoadBool()
if b {
t.Error("expecting false, got true")
}
}
func TestBoolField(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveBoolField(true, false, false, true, false, true, true, true)
loader := NewLoadSaver(saver.Bytes())
a, b, c, d, e, f, g, h := loader.LoadBoolField()
if !a || b || c || !d || e || !f || !g || !h {
t.Errorf("expecting 'true, false, false, true, false, true, true, true', got %v, %v, %v, %v, %v, %v, %v, %v", a, b, c, d, e, f, g, h)
}
}
func TestTinyInt(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveTinyInt(5)
saver.SaveTinyInt(-1)
saver.SaveTinyInt(127)
saver.SaveTinyInt(0)
saver.SaveTinyInt(-127)
saver.SaveInts([]int{5, -1, 127, 0, -127})
loader := NewLoadSaver(saver.Bytes())
i := loader.LoadTinyInt()
if i != 5 {
t.Errorf("expecting %d, got %d", 5, i)
}
i = loader.LoadTinyInt()
if i != -1 {
t.Errorf("expecting %d, got %d", -1, i)
}
i = loader.LoadTinyInt()
if i != 127 {
t.Errorf("expecting %d, got %d", 127, i)
}
i = loader.LoadTinyInt()
if i != 0 {
t.Errorf("expecting %d, got %d", 0, i)
}
i = loader.LoadTinyInt()
if i != -127 {
t.Errorf("expecting %d, got %d", -127, i)
}
is := loader.LoadInts()
if len(is) != 5 {
t.Errorf("expecting 5 ints got %d", len(is))
}
switch {
case is[0] != 5:
t.Errorf("expecting 5, got %d", is[0])
case is[1] != -1:
t.Errorf("expecting -1, got %d", is[1])
case is[2] != 127:
t.Errorf("expecting 127, got %d", is[2])
case is[3] != 0:
t.Errorf("expecting 0, got %d", is[3])
case is[4] != -127:
t.Errorf("expecting -127, got %d", is[4])
}
}
func TestSmallInt(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveSmallInt(5)
saver.SaveSmallInt(-1)
saver.SaveSmallInt(32767)
saver.SaveSmallInt(0)
saver.SaveSmallInt(-32767)
saver.SaveInts([]int{-1, 32767, 0, -32767})
loader := NewLoadSaver(saver.Bytes())
i := loader.LoadSmallInt()
if i != 5 {
t.Errorf("expecting %d, got %d", 5, i)
}
i = loader.LoadSmallInt()
if i != -1 {
t.Errorf("expecting %d, got %d", -1, i)
}
i = loader.LoadSmallInt()
if i != 32767 {
t.Errorf("expecting %d, got %d", 32767, i)
}
i = loader.LoadSmallInt()
if i != 0 {
t.Errorf("expecting %d, got %d", 0, i)
}
i = loader.LoadSmallInt()
if i != -32767 {
t.Errorf("expecting %d, got %d", -32767, i)
}
c := loader.LoadInts()
if len(c) != 4 {
t.Fatalf("expecting 4 results got %v", c)
}
if c[0] != -1 {
t.Errorf("expecting -1, got %v", c[0])
}
if c[1] != 32767 {
t.Errorf("expecting 32767, got %v", c[1])
}
if c[2] != 0 {
t.Errorf("expecting 0, got %v", c[2])
}
if c[3] != -32767 {
t.Errorf("expecting -32767, got %v", c[3])
}
}
func TestInt(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveInt(5)
saver.SaveInt(-1)
saver.SaveInt(2147483647)
saver.SaveInt(0)
saver.SaveInt(-2147483647)
saver.SaveInts([]int{5, -2147483647, 2147483647, 0})
loader := NewLoadSaver(saver.Bytes())
i := loader.LoadInt()
if i != 5 {
t.Errorf("expecting %d, got %d", 5, i)
}
i = loader.LoadInt()
if i != -1 {
t.Errorf("expecting %d, got %d", -1, i)
}
i = loader.LoadInt()
if i != 2147483647 {
t.Errorf("expecting %d, got %d", 2147483647, i)
}
i = loader.LoadInt()
if i != 0 {
t.Errorf("expecting %d, got %d", 0, i)
}
i = loader.LoadInt()
if i != -2147483647 {
t.Errorf("expecting %d, got %d", -2147483647, i)
}
c := loader.LoadInts()
if len(c) != 4 {
t.Fatalf("expecting 4 results got %v", c)
}
if c[0] != 5 {
t.Errorf("expecting 5, got %v", c[0])
}
if c[1] != -2147483647 {
t.Errorf("expecting -1, got %v", c[1])
}
if c[2] != 2147483647 {
t.Errorf("expecting 2147483647, got %v", c[2])
}
if c[3] != 0 {
t.Errorf("expecting 0, got %v", c[3])
}
}
func TestString(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveString("apple")
saver.SaveString("banana")
loader := NewLoadSaver(saver.Bytes())
s := loader.LoadString()
if s != "apple" {
t.Errorf("expecting %s, got %s", "apple", s)
}
s = loader.LoadString()
if s != "banana" {
t.Errorf("expecting %s, got %s", "banana", s)
}
}
func TestStrings(t *testing.T) {
saver := NewLoadSaver(nil)
saver.SaveString("apple")
saver.SaveStrings([]string{"banana", "orange"})
saver.SaveStrings([]string{"banana", "grapefruit"})
loader := NewLoadSaver(saver.Bytes())
s := loader.LoadString()
if s != "apple" {
t.Errorf("expecting %s, got %s", "apple", s)
}
ss := loader.LoadStrings()
if len(ss) != 2 {
t.Errorf("expecting a slice of two strings got %v", ss)
}
if ss[0] != "banana" {
t.Errorf("expecting %s, got %s", "banana", ss[0])
}
if ss[1] != "orange" {
t.Errorf("expecting %s, got %s", "orange", ss[1])
}
s2 := loader.LoadStrings()
if len(s2) != 2 {
t.Errorf("expecting a slice of two strings got %v", s2)
}
if s2[0] != "banana" {
t.Errorf("expecting %s, got %s", "banana", s2[0])
}
if s2[1] != "grapefruit" {
t.Errorf("expecting %s, got %s", "grapefruit", s2[1])
}
}
func TestTime(t *testing.T) {
saver := NewLoadSaver(nil)
now := time.Now()
saver.SaveTime(now)
loader := NewLoadSaver(saver.Bytes())
then := loader.LoadTime()
if now.Round(0).String() != then.String() {
t.Errorf("expecting %s to equal %s, errs %v & %v, raw: %v", now, then, loader.Err, saver.Err, saver.Bytes())
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package textmatcher
import (
"github.com/richardlehane/characterize"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
type Matcher int
func Load(ls *persist.LoadSaver) core.Matcher {
m := Matcher(ls.LoadSmallInt())
return &m
}
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveSmallInt(0)
return
}
ls.SaveSmallInt(int(*c.(*Matcher)))
}
type SignatureSet struct{}
func Add(c core.Matcher, ss core.SignatureSet, p priority.List) (core.Matcher, int, error) {
var m *Matcher
if c == nil {
z := Matcher(0)
m = &z
} else {
m = c.(*Matcher)
}
*m++
return m, int(*m), nil
}
type result struct {
idx int
basis string
}
func (r result) Index() int {
return r.idx
}
func (r result) Basis() string {
return r.basis
}
func (m *Matcher) Identify(na string, buf *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
if *m > 0 {
tt := buf.Text()
if tt != characterize.DATA {
res := make(chan core.Result, *m)
for i := 1; i < int(*m)+1; i++ {
res <- result{
idx: i,
basis: "text match " + tt.String(),
}
}
close(res)
return res, nil
}
}
res := make(chan core.Result)
close(res)
return res, nil
}
func (m *Matcher) String() string {
return "text matcher"
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mappings
import "encoding/xml"
// Container
type Container struct {
XMLName xml.Name `xml:"ContainerSignatureMapping"`
ContainerSignatures []ContainerSignature `xml:"ContainerSignatures>ContainerSignature"`
FormatMappings []FormatMapping `xml:"FileFormatMappings>FileFormatMapping"`
TriggerPuids []TriggerPuid `xml:"TriggerPuids>TriggerPuid"`
}
type ContainerSignature struct {
Id int `xml:",attr"`
ContainerType string `xml:",attr"`
Description string
Files []File `xml:"Files>File"`
}
type File struct {
Path string
Signature InternalSignature `xml:"BinarySignatures>InternalSignatureCollection>InternalSignature"` // see Droid mapping file
}
type FormatMapping struct {
Id int `xml:"signatureId,attr"`
Puid string `xml:",attr"`
}
type TriggerPuid struct {
ContainerType string `xml:",attr"`
Puid string `xml:",attr"`
}
func (c *Container) Puids() []string {
if c == nil {
return []string{}
}
ids := make([]int, len(c.ContainerSignatures))
for i, v := range c.ContainerSignatures {
ids[i] = v.Id
}
hasId := func(id int) bool {
for _, v := range ids {
if id == v {
return true
}
}
return false
}
puids := make([]string, 0, len(c.FormatMappings))
addPuid := func(p string) {
for _, v := range puids {
if v == p {
return
}
}
puids = append(puids, p)
}
for _, v := range c.FormatMappings {
if hasId(v.Id) {
addPuid(v.Puid)
}
}
return puids
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package config
import (
"fmt"
"path/filepath"
"strings"
)
// Name of the default identifier as well as settings for how a new identifer will be built
var identifier = struct {
name string // Name of the default identifier
details string // a short string describing the signature e.g. with what DROID and container file versions was it built?
maxBOF int // maximum offset from beginning of file to scan
maxEOF int // maximum offset from end of file to scan
noEOF bool // trim end of file segments from signatures
noByte bool // don't build with byte signatures
noContainer bool // don't build with container signatures
multi Multi // define how many results identifiers should return
noText bool // don't build with text signatures
noName bool // don't build with filename signatures
noMIME bool // don't build with MIME signatures
noXML bool // don't build with XML signatures
noRIFF bool // don't build with RIFF signatures
limit []string // limit signature to a set of included PRONOM reports
exclude []string // exclude a set of PRONOM reports from the signature
extensions string // directory where custom signature extensions are stored
extend []string // list of custom signature extensions
verbose bool // verbose output when building signatures
}{
multi: Conclusive,
extensions: "custom",
}
// GETTERS
const emptyNamespace = ""
// Name returns the name of the identifier.
func Name() string {
switch {
case identifier.name != emptyNamespace:
return identifier.name
case mimeinfo.mi != emptyNamespace:
return mimeinfo.name
case loc.fdd != emptyNamespace:
return loc.name
case GetWikidataNamespace() != emptyNamespace:
return GetWikidataNamespace()
default:
return pronom.name
}
}
// Details returns a description of the identifier. This is auto-populated if not set directly.
// Extra information from signatures such as date last modified can be given to this function.
func Details(extra ...string) string {
// if the details string has been explicitly set, return it
if len(identifier.details) > 0 {
return identifier.details
}
// ... otherwise create a default string based on the identifier settings chosen
var str string
if len(mimeinfo.mi) > 0 {
str = mimeinfo.mi
} else if len(loc.fdd) > 0 {
str = loc.fdd
if !loc.nopronom {
extra = append(extra, DroidBase())
if !identifier.noContainer {
extra = append(extra, ContainerBase())
}
}
} else if wikidata.namespace != "" {
str = wikidata.definitions
if !wikidata.nopronom {
extra = append(extra, DroidBase())
if !identifier.noContainer {
extra = append(extra, ContainerBase())
}
}
} else {
str = DroidBase()
if !identifier.noContainer {
str += "; " + ContainerBase()
}
}
if len(extra) > 0 {
str += " (" + strings.Join(extra, ", ") + ")"
}
if identifier.maxBOF > 0 {
str += fmt.Sprintf("; max BOF %d", identifier.maxBOF)
}
if identifier.maxEOF > 0 {
str += fmt.Sprintf("; max EOF %d", identifier.maxEOF)
}
if identifier.noEOF {
str += "; no EOF signature parts"
}
if identifier.noByte {
str += "; no byte signatures"
}
if identifier.noContainer {
str += "; no container signatures"
}
if identifier.multi != Conclusive {
str += "; multi set to " + identifier.multi.String()
}
if identifier.noText {
str += "; no text matcher"
}
if identifier.noName {
str += "; no filename matcher"
}
if identifier.noMIME {
str += "; no MIME matcher"
}
if identifier.noXML {
str += "; no XML matcher"
}
if identifier.noRIFF {
str += "; no RIFF matcher"
}
if pronom.reports == "" {
str += "; built without reports"
}
if pronom.doubleup {
str += "; byte signatures included for formats that also have container signatures"
}
if HasLimit() {
str += "; limited to ids: " + strings.Join(identifier.limit, ", ")
}
if HasExclude() {
str += "; excluding ids: " + strings.Join(identifier.exclude, ", ")
}
if len(identifier.extend) > 0 {
str += "; extensions: " + strings.Join(identifier.extend, ", ")
}
if len(pronom.extendc) > 0 {
str += "; container extensions: " + strings.Join(pronom.extendc, ", ")
}
return str
}
// MaxBOF returns any BOF buffer limit set.
func MaxBOF() int {
return identifier.maxBOF
}
// MaxEOF returns any EOF buffer limit set.
func MaxEOF() int {
return identifier.maxEOF
}
// NoEOF reports whether end of file segments of signatures should be trimmed.
func NoEOF() bool {
return identifier.noEOF
}
// NoByte reports whether byte signatures should be omitted.
func NoByte() bool {
return identifier.noByte
}
// NoContainer reports whether container signatures should be omitted.
func NoContainer() bool {
return identifier.noContainer
}
// NoPriority reports whether priorities between signatures should be omitted.
func NoPriority() bool {
return identifier.multi >= Comprehensive
}
// GetMulti returns the multi setting
func GetMulti() Multi {
return identifier.multi
}
// NoText reports whether text signatures should be omitted.
func NoText() bool {
return identifier.noText
}
// NoName reports whether filename signatures should be omitted.
func NoName() bool {
return identifier.noName
}
// NoMIME reports whether MIME signatures should be omitted.
func NoMIME() bool {
return identifier.noMIME
}
// NoXML reports whether XML signatures should be omitted.
func NoXML() bool {
return identifier.noXML
}
// NoRIFF reports whether RIFF FOURCC signatures should be omitted.
func NoRIFF() bool {
return identifier.noRIFF
}
// HasLimit reports whether a limited set of signatures has been selected.
func HasLimit() bool {
return len(identifier.limit) > 0
}
// Limit takes a slice of puids and returns a new slice containing only those puids in the limit set.
func Limit(ids []string) []string {
ret := make([]string, 0, len(identifier.limit))
for _, v := range identifier.limit {
for _, w := range ids {
if v == w {
ret = append(ret, v)
}
}
}
return ret
}
// HasExclude reports whether an exlusion set of signatures has been provided.
func HasExclude() bool {
return len(identifier.exclude) > 0
}
func exclude(ids, ex []string) []string {
ret := make([]string, 0, len(ids))
for _, v := range ids {
excluded := false
for _, w := range ex {
if v == w {
excluded = true
break
}
}
if !excluded {
ret = append(ret, v)
}
}
return ret
}
// Exclude takes a slice of puids and omits those that are also in the identifier.exclude slice.
func Exclude(ids []string) []string {
return exclude(ids, identifier.exclude)
}
func extensionPaths(e []string) []string {
ret := make([]string, len(e))
for i, v := range e {
if filepath.Dir(v) == "." {
ret[i] = filepath.Join(siegfried.home, identifier.extensions, v)
} else {
ret[i] = v
}
}
return ret
}
// Extend reports whether a set of signature extensions has been provided.
func Extend() []string {
return extensionPaths(identifier.extend)
}
// Verbose reports whether to build signatures with verbose logging output
func Verbose() bool {
return identifier.verbose
}
// Return true if value 'v' is contained in slice 's'.
func contains(v string, s []string) bool {
for _, n := range s {
if v == n {
return true
}
}
return false
}
// IsArchive returns an Archive that corresponds to the provided id (or none if no match).
func IsArchive(id string) Archive {
if !contains(id, archiveFilterPermissive()) {
return None
}
switch {
case contains(id, ArcZipTypes()):
return Zip
case contains(id, ArcGzipTypes()):
return Gzip
case contains(id, ArcTarTypes()):
return Tar
case contains(id, ArcArcTypes()):
return ARC
case contains(id, ArcWarcTypes()):
return WARC
}
return None
}
// SETTERS
// Clear clears loc and mimeinfo details to avoid pollution when creating multiple identifiers in same session
func Clear() func() private {
return func() private {
identifier.name = ""
identifier.extend = nil
identifier.limit = nil
identifier.exclude = nil
identifier.multi = Conclusive
loc.fdd = ""
mimeinfo.mi = ""
return private{}
}
}
// SetName sets the name of the identifier.
func SetName(n string) func() private {
return func() private {
identifier.name = n
return private{}
}
}
// SetDetails sets the identifier's description. If not provided, this description is
// automatically generated based on options set.
func SetDetails(d string) func() private {
return func() private {
identifier.details = d
return private{}
}
}
// SetBOF limits the number of bytes to scan from the beginning of file.
func SetBOF(b int) func() private {
return func() private {
identifier.maxBOF = b
return private{}
}
}
// SetEOF limits the number of bytes to scan from the end of file.
func SetEOF(e int) func() private {
return func() private {
identifier.maxEOF = e
return private{}
}
}
// SetNoEOF will cause end of file segments to be trimmed from signatures.
func SetNoEOF() func() private {
return func() private {
identifier.noEOF = true
return private{}
}
}
// SetNoByte will cause byte signatures to be omitted.
func SetNoByte() func() private {
return func() private {
identifier.noByte = true
return private{}
}
}
// SetNoContainer will cause container signatures to be omitted.
func SetNoContainer() func() private {
return func() private {
identifier.noContainer = true
return private{}
}
}
// SetMulti defines how identifiers report multiple results.
func SetMulti(m string) func() private {
return func() private {
switch m {
case "0", "single", "top":
identifier.multi = Single
case "1", "conclusive":
identifier.multi = Conclusive
case "2", "positive":
identifier.multi = Positive
case "3", "comprehensive":
identifier.multi = Comprehensive
case "4", "exhaustive":
identifier.multi = Exhaustive
case "5", "droid":
identifier.multi = DROID
default:
identifier.multi = Conclusive
}
return private{}
}
}
// SetNoText will cause text signatures to be omitted.
func SetNoText() func() private {
return func() private {
identifier.noText = true
return private{}
}
}
// SetNoName will cause extension signatures to be omitted.
func SetNoName() func() private {
return func() private {
identifier.noName = true
return private{}
}
}
// SetNoMIME will cause MIME signatures to be omitted.
func SetNoMIME() func() private {
return func() private {
identifier.noMIME = true
return private{}
}
}
// SetNoXML will cause XML signatures to be omitted.
func SetNoXML() func() private {
return func() private {
identifier.noXML = true
return private{}
}
}
// SetNoRIFF will cause RIFF FOURCC signatures to be omitted.
func SetNoRIFF() func() private {
return func() private {
identifier.noRIFF = true
return private{}
}
}
// SetLimit limits the set of signatures built to the list provide.
func SetLimit(l []string) func() private {
return func() private {
identifier.limit = l
return private{}
}
}
// SetExclude excludes the provided signatures from those built.
func SetExclude(l []string) func() private {
return func() private {
identifier.exclude = l
return private{}
}
}
// SetExtend adds extension signatures to the build.
func SetExtend(l []string) func() private {
return func() private {
identifier.extend = l
return private{}
}
}
// SetVerbose controls logging verbosity when building signatures
func SetVerbose(v bool) func() private {
return func() private {
identifier.verbose = v
return private{}
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package siegreader
import "sync"
// pool of precons - just a simple free list
type pool struct {
mu *sync.Mutex
fn func() interface{}
head *item
}
type item struct {
next *item
val interface{}
}
func newPool(f func() interface{}) *pool {
return &pool{
mu: &sync.Mutex{},
fn: f,
}
}
func (p *pool) get() interface{} {
p.mu.Lock()
defer p.mu.Unlock()
if p.head == nil {
return p.fn()
}
ret := p.head.val
p.head = p.head.next
return ret
}
func (p *pool) put(v interface{}) {
p.mu.Lock()
p.head = &item{p.head, v}
p.mu.Unlock()
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package siegfried identifies file formats
//
// Example:
// s, err := siegfried.Load("pronom.sig")
// if err != nil {
// log.Fatal(err)
// }
// f, err := os.Open("file")
// if err != nil {
// log.Fatal(err)
// }
// defer f.Close()
// ids, err := s.Identify(f, "filename.ext", "application/xml")
// if err != nil {
// log.Fatal(err)
// }
// for _, id := range ids {
// fmt.Println(id)
// }
package siegfried
import (
"bytes"
"compress/flate"
"fmt"
"io"
"io/ioutil"
"os"
"strings"
"time"
"github.com/richardlehane/siegfried/internal/bytematcher"
"github.com/richardlehane/siegfried/internal/containermatcher"
"github.com/richardlehane/siegfried/internal/mimematcher"
"github.com/richardlehane/siegfried/internal/namematcher"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/riffmatcher"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/internal/textmatcher"
"github.com/richardlehane/siegfried/internal/xmlmatcher"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/loc"
"github.com/richardlehane/siegfried/pkg/mimeinfo"
"github.com/richardlehane/siegfried/pkg/pronom"
// Load Wikidata into a Siegfried...
"github.com/richardlehane/siegfried/pkg/wikidata"
)
var ( // for side effect - register their patterns/ signature loaders
_ = pronom.Range{}
_ = mimeinfo.Int8(0)
_ = loc.Identifier{}
// Is this what we want to do here..?
_ = wikidata.Identifier{}
)
// Siegfried structs are persisent objects that can be serialised to disk and
// used to identify file formats.
// They contain three matchers as well as a slice of identifiers. When identifiers
// are added to a Siegfried struct, they are registered with each matcher.
type Siegfried struct {
// immutable fields
C time.Time // signature create time
nm core.Matcher // namematcher
mm core.Matcher // mimematcher
cm core.Matcher // containermatcher
xm core.Matcher // bytematcher
rm core.Matcher // riffmatcher
bm core.Matcher // bytematcher
tm core.Matcher // textmatcher
// mutatable fields
ids []core.Identifier // identifiers
buffers *siegreader.Buffers
}
// New creates a new Siegfried struct. It initializes the three matchers.
//
// Example:
// s := New()
// p, err := pronom.New() // create a new PRONOM identifier
// if err != nil {
// log.Fatal(err)
// }
// err = s.Add(p) // add the identifier to the Siegfried
// if err != nil {
// log.Fatal(err)
// }
// err = s.Save("pronom.sig") // save the Siegfried
func New() *Siegfried {
return &Siegfried{
C: time.Now(),
buffers: siegreader.New(),
}
}
// Add adds an identifier to a Siegfried struct.
func (s *Siegfried) Add(i core.Identifier) error {
for _, v := range s.ids {
if v.Name() == i.Name() {
return fmt.Errorf("siegfried: identifiers must have unique names, you already have an identifier named %s. Use the -name flag to assign a new name e.g. `roy add -name richard`", i.Name())
}
}
var err error
if s.nm, err = i.Add(s.nm, core.NameMatcher); err != nil {
return err
}
if s.mm, err = i.Add(s.mm, core.MIMEMatcher); err != nil {
return err
}
if s.cm, err = i.Add(s.cm, core.ContainerMatcher); err != nil {
return err
}
if s.xm, err = i.Add(s.xm, core.XMLMatcher); err != nil {
return err
}
if s.rm, err = i.Add(s.rm, core.RIFFMatcher); err != nil {
return err
}
if s.bm, err = i.Add(s.bm, core.ByteMatcher); err != nil {
return err
}
if s.tm, err = i.Add(s.tm, core.TextMatcher); err != nil {
return err
}
s.ids = append(s.ids, i)
return nil
}
// Save persists a Siegfried struct to disk (path)
func (s *Siegfried) Save(path string) error {
f, err := os.Create(path)
if err != nil {
return err
}
err = s.SaveWriter(f)
if err != nil {
return err
}
return f.Close()
}
// SaveWriter persists a Siegfried struct to an io.Writer
func (s *Siegfried) SaveWriter(w io.Writer) error {
// sprinkle magic
_, err := w.Write(append(config.Magic(), byte(config.Version()[0]), byte(config.Version()[1])))
if err != nil {
return err
}
// persist the siegfried
ls := persist.NewLoadSaver(nil)
ls.SaveTime(s.C)
namematcher.Save(s.nm, ls)
mimematcher.Save(s.mm, ls)
containermatcher.Save(s.cm, ls)
xmlmatcher.Save(s.xm, ls)
riffmatcher.Save(s.rm, ls)
bytematcher.Save(s.bm, ls)
textmatcher.Save(s.tm, ls)
ls.SaveTinyUInt(len(s.ids))
for _, i := range s.ids {
i.Save(ls)
}
if ls.Err != nil {
return ls.Err
}
// compress
z, err := flate.NewWriter(w, 1)
if err != nil {
return err
}
_, err = z.Write(ls.Bytes())
if err != nil {
return err
}
return z.Close()
}
// Load creates a Siegfried struct and loads content from path
func Load(path string) (*Siegfried, error) {
f, err := os.Open(path)
if err != nil {
return nil, fmt.Errorf("siegfried: error opening signature file, got %v; try running `sf -update`", err)
}
sf, err := LoadReader(f)
if err != nil {
return nil, err
}
return sf, f.Close()
}
// LoadReader creates a Siegfried struct and loads content from a reader
func LoadReader(r io.Reader) (*Siegfried, error) {
errReading := "siegfried: error reading signature file, got %v; try running `sf -update`"
errNotSig := "siegfried: not a siegfried signature file; try running `sf -update`"
errUpdateSig := "siegfried: signature file is incompatible with this version of sf; try running `sf -update`"
fbuf, err := ioutil.ReadAll(r)
if err != nil {
return nil, err
}
if len(fbuf) < len(config.Magic())+2 {
return nil, fmt.Errorf(errNotSig)
}
if string(fbuf[:len(config.Magic())]) != string(config.Magic()) {
return nil, fmt.Errorf(errNotSig)
}
if major, minor := fbuf[len(config.Magic())], fbuf[len(config.Magic())+1]; major < byte(config.Version()[0]) || (major == byte(config.Version()[0]) && minor < byte(config.Version()[1])) {
return nil, fmt.Errorf(errUpdateSig)
}
rb := bytes.NewBuffer(fbuf[len(config.Magic())+2:])
rc := flate.NewReader(rb)
buf, err := ioutil.ReadAll(rc)
rc.Close()
if err != nil {
return nil, fmt.Errorf(errReading, err)
}
return load(buf)
}
func load(buf []byte) (*Siegfried, error) {
ls := persist.NewLoadSaver(buf)
return &Siegfried{
C: ls.LoadTime(),
nm: namematcher.Load(ls),
mm: mimematcher.Load(ls),
cm: containermatcher.Load(ls),
xm: xmlmatcher.Load(ls),
rm: riffmatcher.Load(ls),
bm: bytematcher.Load(ls),
tm: textmatcher.Load(ls),
ids: func() []core.Identifier {
ids := make([]core.Identifier, ls.LoadTinyUInt())
for i := range ids {
ids[i] = core.LoadIdentifier(ls)
}
return ids
}(),
buffers: siegreader.New(),
}, ls.Err
}
// Identifiers returns a slice of the names and details of each identifier.
func (s *Siegfried) Identifiers() [][2]string {
ret := make([][2]string, len(s.ids))
for i, v := range s.ids {
ret[i][0] = v.Name()
ret[i][1] = v.Details()
}
return ret
}
// Fields returns a slice of the names of the fields in each identifier.
func (s *Siegfried) Fields() [][]string {
ret := make([][]string, len(s.ids))
for i, v := range s.ids {
ret[i] = v.Fields()
}
return ret
}
// Buffer gets a siegreader buffer from the pool
func (s *Siegfried) Buffer(r io.Reader) (*siegreader.Buffer, error) {
buffer, err := s.buffers.Get(r)
if err == io.EOF {
err = nil
}
return buffer, err
}
// Put returns a siegreader buffer to the pool
func (s *Siegfried) Put(buffer *siegreader.Buffer) {
s.buffers.Put(buffer)
}
func satisfied(mt core.MatcherType, recs []core.Recorder) (bool, []core.Hint) {
sat := true
var hints []core.Hint
if mt == core.ByteMatcher || mt == core.ContainerMatcher {
hints = make([]core.Hint, 0, len(recs))
}
for _, rec := range recs {
ok, h := rec.Satisfied(mt)
if mt == core.ByteMatcher || mt == core.ContainerMatcher {
if !ok {
sat = false
if len(h.Pivot) > 0 {
hints = append(hints, h)
}
} else { // if this matcher is satisfied, append a hint with a nil Pivot (which priority knows is satisifed)
hints = append(hints, h)
}
} else if !ok {
sat = false
break
}
}
return sat, hints
}
// IdentifyBuffer identifies a siegreader buffer. Supply the error from Get as the second argument.
func (s *Siegfried) IdentifyBuffer(buffer *siegreader.Buffer, err error, name, mime string) ([]core.Identification, error) {
if err != nil && err != siegreader.ErrEmpty {
return nil, fmt.Errorf("siegfried: error reading file; got %v", err)
}
recs := make([]core.Recorder, len(s.ids))
for i, v := range s.ids {
recs[i] = v.Recorder()
if name != "" {
recs[i].Active(core.NameMatcher)
}
if mime != "" {
recs[i].Active(core.MIMEMatcher)
}
if err == nil {
recs[i].Active(core.XMLMatcher)
recs[i].Active(core.TextMatcher)
}
}
// Log name for debug/slow
if config.Debug() || config.Slow() {
fmt.Fprintf(config.Out(), "[FILE] %s\n", name)
}
// Name Matcher
if len(name) > 0 && s.nm != nil {
nms, _ := s.nm.Identify(name, nil) // we don't care about an error here
for v := range nms {
for _, rec := range recs {
if rec.Record(core.NameMatcher, v) {
break
}
}
}
}
// MIME Matcher
if len(mime) > 0 && s.mm != nil {
mms, _ := s.mm.Identify(mime, nil) // we don't care about an error here
for v := range mms {
for _, rec := range recs {
if rec.Record(core.MIMEMatcher, v) {
break
}
}
}
}
// Container Matcher
_, hints := satisfied(core.ContainerMatcher, recs)
if s.cm != nil {
if config.Debug() {
fmt.Fprintln(config.Out(), ">>START CONTAINER MATCHER")
}
cms, cerr := s.cm.Identify(name, buffer, hints...)
for v := range cms {
for _, rec := range recs {
if rec.Record(core.ContainerMatcher, v) {
break
}
}
}
if err == nil {
err = cerr
}
}
sat, _ := satisfied(core.XMLMatcher, recs)
// XML Matcher
if s.xm != nil && !sat {
if config.Debug() {
fmt.Fprintln(config.Out(), ">>START XML MATCHER")
}
xms, xerr := s.xm.Identify("", buffer)
for v := range xms {
for _, rec := range recs {
if rec.Record(core.XMLMatcher, v) {
break
}
}
}
if err == nil {
err = xerr
}
}
sat, _ = satisfied(core.RIFFMatcher, recs)
// RIFF Matcher
if s.rm != nil && !sat {
if config.Debug() {
fmt.Fprintln(config.Out(), ">>START RIFF MATCHER")
}
rms, rerr := s.rm.Identify("", buffer)
for v := range rms {
for _, rec := range recs {
if rec.Record(core.RIFFMatcher, v) {
break
}
}
}
if err == nil {
err = rerr
}
}
sat, hints = satisfied(core.ByteMatcher, recs)
// Byte Matcher
if s.bm != nil && !sat {
if config.Debug() {
fmt.Fprintln(config.Out(), ">>START BYTE MATCHER")
}
ids, _ := s.bm.Identify("", buffer, hints...) // we don't care about an error here
for v := range ids {
for _, rec := range recs {
if rec.Record(core.ByteMatcher, v) {
break
}
}
}
}
sat, _ = satisfied(core.TextMatcher, recs)
// Text Matcher
if s.tm != nil && !sat {
ids, _ := s.tm.Identify("", buffer) // we don't care about an error here
for v := range ids {
for _, rec := range recs {
if rec.Record(core.TextMatcher, v) {
break
}
}
}
}
if len(recs) < 2 {
return recs[0].Report(), err
}
var res []core.Identification
for idx, rec := range recs {
if config.Slow() || config.Debug() {
for _, id := range rec.Report() {
fmt.Fprintf(config.Out(), "matched: %s\n", id.String())
}
}
if idx == 0 {
res = rec.Report()
continue
}
res = append(res, rec.Report()...)
}
return res, err
}
// Identify identifies a stream or file object.
// It takes an io.Reader and the name and mimetype of the file/stream (if unknown, give empty strings).
// It returns a slice of identifications and an error.
func (s *Siegfried) Identify(r io.Reader, name, mime string) ([]core.Identification, error) {
buffer, err := s.Buffer(r)
defer s.buffers.Put(buffer)
return s.IdentifyBuffer(buffer, err, name, mime)
}
// Label takes the values of a core.Identification and returns a slice that pairs these values with the
// relevant identifier's field labels.
func (s *Siegfried) Label(id core.Identification) [][2]string {
ret := make([][2]string, len(id.Values()))
for i, p := range s.Identifiers() {
if p[0] == id.Values()[0] {
for j, l := range s.Fields()[i] {
ret[j][0] = l
ret[j][1] = id.Values()[j]
}
return ret
}
}
return nil
}
// Blame checks with the byte matcher to see what identification results subscribe to a particular result or test
// tree index. It can be used when identifying in a debug mode to check which identification results trigger
// which strikes.
func (s *Siegfried) Blame(idx, ct int, cn string) string {
toID := func(i int, typ core.MatcherType) string {
for _, id := range s.ids {
if ok, str := id.Recognise(typ, i); ok {
return str
}
}
return ""
}
toIDs := func(iis []int, typ core.MatcherType) []string {
res := make([]string, len(iis))
for i, v := range iis {
res[i] = toID(v, typ)
}
return res
}
if idx < 0 {
buf := &bytes.Buffer{}
if idx < -1 {
fmt.Fprint(buf, "KEY FRAMES\n")
bm := s.bm.(*bytematcher.Matcher)
for i := 0; i < bm.KeyFramesLen(); i++ {
fmt.Fprintf(buf, "---\n%s\n%s\n", toID(i, core.ByteMatcher), strings.Join(bm.DescribeKeyFrames(i), "\n"))
}
} else {
fmt.Fprint(buf, "TEST TREES\n")
bm := s.bm.(*bytematcher.Matcher)
for i := 0; i < bm.TestTreeLen(); i++ {
cres, ires, maxL, maxR, maxLM, maxRM := bm.DescribeTestTree(i)
fmt.Fprintf(buf, "---\nTest Tree %d\nCompletes: %s\nIncompletes: %s\nMax Left Distance: %d\nMax Right Distance: %d\nMax Left Matches: %d\nMax Right Matches: %d\n",
i, strings.Join(toIDs(cres, core.ByteMatcher), ", "), strings.Join(toIDs(ires, core.ByteMatcher), ", "), maxL, maxR, maxLM, maxRM)
}
}
return buf.String()
}
matcher := "BYTE MATCHER"
var ttis []int
if cn != "" {
matcher = "CONTAINER MATCHER"
cm := s.cm.(containermatcher.Matcher)
ttis = cm.InspectTestTree(ct, cn, idx)
res := toIDs(ttis, core.ContainerMatcher)
ttiNames := "not recognised"
if len(res) > 0 {
ttiNames = strings.Join(res, ",")
}
return fmt.Sprintf("%s\nHits at %d: %s (identifies hits reported by -debug)", matcher, idx, ttiNames)
}
bm := s.bm.(*bytematcher.Matcher)
resName := "not recognised"
for _, id := range s.ids {
if ok, str := id.Recognise(core.ByteMatcher, idx); ok {
resName = str
break
}
}
ttiNames := "not recognised"
res := toIDs(bm.InspectTestTree(idx), core.ByteMatcher)
if len(res) > 0 {
ttiNames = strings.Join(res, ",")
}
return fmt.Sprintf("%s\nResults at %d: %s (identifies results reported by -slow)\nHits at %d: %s (identifies hits reported by -debug)", matcher, idx, resName, idx, ttiNames)
}
// Inspect returns a string containing detail about the various matchers in the Siegfried struct.
func (s *Siegfried) Inspect(t core.MatcherType) string {
switch t {
case core.ByteMatcher:
if s.bm != nil {
return s.bm.String()
}
case core.NameMatcher:
if s.nm != nil {
return s.nm.String()
}
case core.MIMEMatcher:
if s.mm != nil {
return s.mm.String()
}
case core.ContainerMatcher:
if s.cm != nil {
return s.cm.String()
}
case core.RIFFMatcher:
if s.rm != nil {
return s.rm.String()
}
case core.TextMatcher:
if s.tm != nil {
return s.tm.String()
}
case core.XMLMatcher:
if s.xm != nil {
return s.xm.String()
}
default:
return fmt.Sprintf("Identifiers\n%s",
func() string {
var str string
for _, i := range s.ids {
str += i.String()
}
return str
}())
}
return "matcher not present in this signature"
}
<file_sep>//go:build !static
package main
import "github.com/richardlehane/siegfried"
func load(path string) (*siegfried.Siegfried, error) {
return siegfried.Load(path)
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"encoding/csv"
"fmt"
"io"
"os"
"sort"
"strconv"
"strings"
"time"
)
const (
Path int = iota
Filename
FilenameSize
FilenameMod
FilenameHash
Hash
)
func isSep(c uint8) bool {
return c == '\\' || c == '/'
}
// like filepath.Base but simplified + works with unix or win separators
func Base(path string) string {
// remove trailing
for len(path) > 0 && isSep(path[len(path)-1]) {
path = path[0 : len(path)-1]
}
i := len(path) - 1
for i >= 0 && !isSep(path[i]) {
i--
}
if i >= 0 {
return path[i+1:]
}
return path
}
func keygen(join int, fi File) string {
switch join {
default:
return fi.Path
case Filename:
return Base(fi.Path)
case FilenameSize:
return Base(fi.Path) + strconv.FormatInt(fi.Size, 10)
case FilenameMod:
return Base(fi.Path) + fi.Mod.Format(time.RFC3339)
case FilenameHash:
return Base(fi.Path) + string(fi.Hash)
case Hash:
return string(fi.Hash)
}
}
func idStr(fi File) string {
ids := make([]string, len(fi.IDs))
for i, id := range fi.IDs {
ids[i] = id.String()
}
sort.Strings(ids)
return strings.Join(ids, ";")
}
func matches(res []string) bool {
if len(res) < 3 {
return false
}
m := res[1]
for _, r := range res[2:] {
if r != m {
return false
}
}
return true
}
func Compare(w io.Writer, join int, paths ...string) error {
if len(paths) < 2 {
return fmt.Errorf("at least two results files must be provided for comparison; got %d", len(paths))
}
readers := make([]Reader, len(paths))
for i, v := range paths {
f, err := os.Open(v)
if err != nil {
return err
}
defer f.Close()
rdr, err := New(f, v)
if err != nil {
return err
}
readers[i] = rdr
}
files := make([]string, 0, 1000)
results := make(map[string][]string)
for i, rdr := range readers {
for f, e := rdr.Next(); e == nil; f, e = rdr.Next() {
key := keygen(join, f)
_, ok := results[key]
if !ok {
files = append(files, key)
def := make([]string, len(readers)+1)
def[0] = f.Path
for i := range def[1:] {
def[i+1] = "MISSING"
}
results[key] = def
}
results[key][i+1] = idStr(f)
}
}
wrt := csv.NewWriter(w)
var complete bool = true
for _, f := range files {
if !matches(results[f]) {
complete = false
if err := wrt.Write(results[f]); err != nil {
return err
}
}
}
wrt.Flush()
if complete {
fmt.Fprint(w, "COMPLETE MATCH\n")
}
return nil
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package frames describes the Frame interface.
// A set of standard frames are also defined in this package. These are: Fixed, Window, Wild and WildMin.
package frames
import (
"strconv"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/persist"
)
// Frame encapsulates a pattern with offset information, mediating between the pattern and the bytestream.
type Frame struct {
Min int
Max int
OffType
patterns.Pattern
}
// OffType is the type of offset
type OffType uint8
// Four offset types are supported
const (
BOF OffType = iota // beginning of file offset
PREV // offset from previous frame
SUCC // offset from successive frame
EOF // end of file offset
)
// OffString is an exported array of strings representing each of the four offset types
var OffString = [...]string{"B", "P", "S", "E"}
// Orientation returns the offset type of the frame which must be either BOF, PREV, SUCC or EOF
func (o OffType) Orientation() OffType {
return o
}
// SwitchOff returns a new offset type according to a given set of rules. These are:
// - PREV -> SUCC
// - SUCC and EOF -> PREV
// This is helpful when changing the orientation of a frame (for example to allow right-left searching).
func (o OffType) SwitchOff() OffType {
switch o {
case PREV:
return SUCC
case SUCC, EOF:
return PREV
default:
return o
}
}
// NewFrame generates Fixed, Window, Wild and WildMin frames. The offsets argument controls what type of frame is created:
// - for a Wild frame, give no offsets or give a max offset of < 0 and a min of < 1
// - for a WildMin frame, give one offset, or give a max offset of < 0 and a min of > 0
// - for a Fixed frame, give two offsets that are both >= 0 and that are equal to each other
// - for a Window frame, give two offsets that are both >= 0 and that are not equal to each other.
func NewFrame(typ OffType, pat patterns.Pattern, offsets ...int) Frame {
switch len(offsets) {
case 0:
return Frame{0, -1, typ, pat}
case 1:
if offsets[0] > 0 {
return Frame{offsets[0], -1, typ, pat}
}
return Frame{0, -1, typ, pat}
}
if offsets[1] < 0 {
if offsets[0] > 0 {
return Frame{offsets[0], -1, typ, pat}
}
return Frame{0, -1, typ, pat}
}
if offsets[0] < 0 {
offsets[0] = 0
}
return Frame{offsets[0], offsets[1], typ, pat}
}
// SwitchFrame returns a new frame with a different orientation (for example to allow right-left searching).
func SwitchFrame(f Frame, p patterns.Pattern) Frame {
return NewFrame(f.SwitchOff(), p, f.Min, f.Max)
}
// BMHConvert converts the patterns within a slice of frames to BMH sequences if possible.
func BMHConvert(fs []Frame, rev bool) []Frame {
nfs := make([]Frame, len(fs))
for i, f := range fs {
nfs[i] = NewFrame(f.Orientation(), patterns.BMH(f.Pattern, rev), f.Min, f.Max)
}
return nfs
}
// NonZero checks whether, when converted to simple byte sequences, this frame's pattern is all 0 bytes.
func NonZero(f Frame) bool {
for _, seq := range f.Sequences() {
allzeros := true
for _, b := range seq {
if b != 0 {
allzeros = false
}
}
if allzeros {
return false
}
}
return true
}
// TotalLength is sum of the maximum length of the enclosed pattern and the maximum offset.
func TotalLength(f Frame) int {
// a wild frame has no total length
if f.Max < 0 {
return -1
}
_, l := f.Length()
return l + f.Max
}
// Match the enclosed pattern against the byte slice in a L-R direction.
// Returns a slice of offsets for where a successive match by a related frame should begin.
func (f Frame) Match(b []byte) []int {
ret := make([]int, 0, 1)
min, max := f.Min, f.Max
if max < 0 || max > len(b) {
max = len(b)
}
for min <= max {
lengths, adv := f.Test(b[min:])
for _, l := range lengths {
ret = append(ret, min+l)
}
if adv < 1 {
break
}
min += adv
}
return ret
}
// For the nth match (per above), return the offset for successive match by related frame and bytes that can advance to make a successive test by this frame.
func (f Frame) MatchN(b []byte, n int) (int, int) {
var i int
min, max := f.Min, f.Max
if max < 0 || max > len(b) {
max = len(b)
}
for min <= max {
lengths, adv := f.Test(b[min:])
for _, l := range lengths {
if i == n {
return min + l, min + adv
}
i++
}
if adv < 1 {
break
}
min += adv
}
return -1, 0
}
// Match the enclosed pattern against the byte slice in a reverse (R-L) direction. Returns a slice of offsets for where a successive match by a related frame should begin.
func (f Frame) MatchR(b []byte) []int {
ret := make([]int, 0, 1)
min, max := f.Min, f.Max
if max < 0 || max > len(b) {
max = len(b)
}
for min <= max {
lengths, adv := f.TestR(b[:len(b)-min])
for _, l := range lengths {
ret = append(ret, min+l)
}
if adv < 1 {
break
}
min += adv
}
return ret
}
// For the nth match (per above), return the offset for successive match by related frame and bytes that can advance to make a successive test by this frame.
func (f Frame) MatchNR(b []byte, n int) (int, int) {
var i int
min, max := f.Min, f.Max
if max < 0 || max > len(b) {
max = len(b)
}
for min <= max {
lengths, adv := f.TestR(b[:len(b)-min])
for _, l := range lengths {
if i == n {
return min + l, min + adv
}
i++
}
if adv < 1 {
break
}
min += adv
}
return -1, 0
}
func (f Frame) Equals(f1 Frame) bool {
if f.Min == f1.Min && f.Max == f1.Max && f.OffType == f1.OffType && f.Pattern.Equals(f1.Pattern) {
return true
}
return false
}
func (f Frame) String() string {
var rng string
if f.Min == f.Max {
rng = strconv.Itoa(f.Min)
} else {
if f.Max < 0 {
rng = strconv.Itoa(f.Min) + "..*"
}
rng = strconv.Itoa(f.Min) + ".." + strconv.Itoa(f.Max)
}
return OffString[f.OffType] + ":" + rng + " " + f.Pattern.String()
}
// MaxMatches returns:
// - the max number of times a frame can match, given a byte slice of length 'l'
// - the maximum remaining slice length
// - the minimum length of a successful pattern match
func (f Frame) MaxMatches(l int) (int, int, int) {
min, _ := f.Length()
rem := l - min - f.Min
if rem < 0 && l >= 0 {
return 0, 0, 0
}
// handle fixed
if f.Min == f.Max || (l < 0 && f.Max < 0) {
return 1, rem, min
}
var ov int
if f.OffType <= PREV {
ov = patterns.Overlap(f.Pattern)
} else {
ov = patterns.OverlapR(f.Pattern)
}
if f.Max < 0 || (l > 0 && f.Max+min > l) {
return rem/ov + 1, rem, min
}
return (f.Max-f.Min)/ov + 1, rem, min
}
// Linked tests whether a frame is linked to a preceding frame (by a preceding or succeding relationship) with an offset and range that is less than the supplied ints.
// If -1 is given for maxDistance & maxRange, then will check if frame is linked to a preceding frame via a PREV or SUCC relationship.
// If -1 is given for maxDistance, but not maxRange, then will check if frame linked without regard to distance (only range),
// this is useful because if give maxRange of 0 you can tell if it is a fixed relationship
func (f Frame) Linked(prev Frame, maxDistance, maxRange int) (bool, int, int) {
switch f.OffType {
case PREV:
if maxDistance < 0 && f.Max > -1 && (maxRange < 0 || f.Max-f.Min <= maxRange) {
return true, maxDistance, maxRange
}
if f.Max < 0 || f.Max > maxDistance || f.Max-f.Min > maxRange {
return false, 0, 0
}
return true, maxDistance - f.Max, maxRange - (f.Max - f.Min)
case SUCC, EOF:
if prev.Orientation() != SUCC || prev.Max < 0 {
return false, 0, 0
}
if maxDistance < 0 && (maxRange < 0 || prev.Max-prev.Min <= maxRange) {
return true, maxDistance, maxRange
}
if prev.Max > maxDistance || prev.Max-prev.Min > maxRange {
return false, 0, 0
}
return true, maxDistance - prev.Max, maxRange - (prev.Max - prev.Min)
default:
return false, 0, 0
}
}
func (f Frame) Save(ls *persist.LoadSaver) {
ls.SaveInt(f.Min)
ls.SaveInt(f.Max)
ls.SaveByte(byte(f.OffType))
f.Pattern.Save(ls)
}
func Load(ls *persist.LoadSaver) Frame {
return Frame{
ls.LoadInt(),
ls.LoadInt(),
OffType(ls.LoadByte()),
patterns.Load(ls),
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package priority creates a subordinate-superiors map of identifications.
// These maps can be flattened into sorted lists for use by the bytematcher and containermatcher engines.
// Multiple priority lists can be added to priority sets. These contain the priorities of different identifiers within a bytematcher or containermatcher.
package priority
import (
"fmt"
"sort"
"sync"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/core"
)
// a priority map links subordinate results to a list of priority results
type Map map[string][]string
func (m Map) Difference(mb Map) Map {
mc := make(Map)
for k, v := range m {
vb, ok := mb[k]
if !ok {
mc[k] = v
continue
}
e := extras(v, vb)
if len(e) > 0 {
mc[k] = e
}
}
return mc
}
func (m Map) Elements() [][2]string {
fmts := make(map[string]bool)
elements := make([][2]string, 0, len(m)*3)
for k, v := range m {
for _, sup := range v {
elements = append(elements, [2]string{k, sup})
fmts[sup] = true
}
}
for k, v := range m {
if len(v) == 0 && !fmts[k] {
elements = append(elements, [2]string{k, ""})
}
}
return elements
}
func containsStr(ss []string, s string) bool {
for _, v := range ss {
if v == s {
return true
}
}
return false
}
func addStr(ss []string, s string) []string {
if containsStr(ss, s) {
return ss
}
return append(ss, s)
}
// make sure that a set of superiors doesn't include self
func trimSelf(ss []string, s string) []string {
if !containsStr(ss, s) {
return ss
}
ret := make([]string, 0, len(ss))
for _, v := range ss {
if v != s {
ret = append(ret, v)
}
}
return ret
}
// add a subordinate-superior relationship to the priority map
func (m Map) Add(subordinate string, superior string) {
if subordinate == "" || superior == "" || subordinate == superior {
return
}
_, ok := m[subordinate]
if ok {
m[subordinate] = addStr(m[subordinate], superior)
return
}
m[subordinate] = []string{superior}
}
// create a list of all strings that appear in 'a' but not 'b', 'c', 'd', ...
func extras(a []string, bs ...[]string) []string {
ret := make([]string, 0, len(a))
for _, v := range a {
var exists bool
outer:
for _, b := range bs {
for _, v1 := range b {
if v == v1 {
exists = true
break outer
}
}
}
if !exists {
ret = append(ret, v)
}
}
return ret
}
func (m Map) priorityWalk(k string) []string {
tried := make([]string, 0)
ret := make([]string, 0)
var walkFn func(string)
walkFn = func(id string) {
vals, ok := m[id]
if !ok {
return
}
for _, v := range vals {
// avoid cycles
if containsStr(tried, v) {
continue
}
tried = append(tried, v)
priorityPriorities := m[v]
ret = append(ret, extras(priorityPriorities, vals, ret)...)
walkFn(v)
}
}
walkFn(k)
return ret
}
// After adding all priorities, walk the priority map to make sure that it is consistent,
// i.e. that for any format with a superior fmt, then anything superior
// to that superior fmt is also marked as superior to the base fmt, all the way down the tree
func (m Map) Complete() {
for k := range m {
extraPriorities := m.priorityWalk(k)
extraPriorities = trimSelf(extraPriorities, k)
m[k] = append(m[k], extras(extraPriorities, m[k])...)
sort.Strings(m[k])
}
}
// because keys can be duplicated in the slice given to List(), the list of superior indexes may be larger than the list of superior keys
func (m Map) expand(key string, iMap map[string][]int) []int {
// use an empty, rather than nil slice for ret. This means a priority.List will never contain a nil slice.
ret := make([]int, 0)
superiors := m[key]
for _, k := range superiors {
ret = append(ret, iMap[k]...)
}
sort.Ints(ret)
return ret
}
// Filter returns a new Priority Map that just contains formats in the provided slice
func (m Map) Filter(fmts []string) Map {
ret := make(Map)
for _, v := range fmts {
l := m[v]
n := []string{}
for _, w := range l {
for _, x := range fmts {
if w == x {
n = append(n, w)
break
}
}
}
ret[v] = n
}
return ret
}
// is this a superior result? (it has no superiors among the set of intial hits)
func superior(sups, hits []string) bool {
for _, sup := range sups {
for _, hit := range hits {
if sup == hit {
return false
}
}
}
return true
}
// Apply checks a list of hits against a priority map and returns a subset of that list for any hits
// that don't have superiors also in that list
func (m Map) Apply(hits []string) []string {
ret := make([]string, 0, len(hits))
for _, hit := range hits {
if superior(m[hit], hits) {
ret = append(ret, hit)
}
}
return ret
}
// return a priority list using the indexes from the supplied slice of keys (keys can be duplicated in that slice)
func (m Map) List(keys []string) List {
if m == nil {
return nil
}
// build a map of keys to their indexes in the supplied slice
iMap := make(map[string][]int)
for _, k := range keys {
// continue on if the key has already been added
_, ok := iMap[k]
if ok {
continue
}
var indexes []int
for i, v := range keys {
if v == k {
indexes = append(indexes, i)
}
}
iMap[k] = indexes
}
l := make(List, len(keys))
for i, k := range keys {
l[i] = m.expand(k, iMap)
}
return l
}
type List [][]int
// take a list of indexes, subtract the length of the previous priority list in a set (or 0) to get relative indexes,
// then map those against a priority list. Re-number according to indexes and return the common subset.
func (l List) Subset(indexes []int, prev int) List {
if l == nil {
return nil
}
submap := make(map[int]int)
for i, v := range indexes {
submap[v-prev] = i
}
subset := make(List, len(indexes))
for i, v := range indexes {
ns := make([]int, 0, len(l[v-prev]))
for _, w := range l[v-prev] {
if idx, ok := submap[w]; ok {
ns = append(ns, idx)
}
}
subset[i] = ns
}
return subset
}
func (l List) String() string {
if l == nil {
return "priority list: nil"
}
return fmt.Sprintf("priority list: %v", [][]int(l))
}
// A priority set holds a number of priority lists
type Set struct {
idx []int
lists []List
maxOffsets [][2]int
}
func (s *Set) Save(ls *persist.LoadSaver) {
ls.SaveInts(s.idx)
ls.SaveSmallInt(len(s.lists))
for _, v := range s.lists {
ls.SaveSmallInt(len(v))
for _, w := range v {
ls.SaveInts(w)
}
}
ls.SaveSmallInt(len(s.maxOffsets))
for _, v := range s.maxOffsets {
ls.SaveInt(v[0])
ls.SaveInt(v[1])
}
}
func Load(ls *persist.LoadSaver) *Set {
set := &Set{}
set.idx = ls.LoadInts()
set.lists = make([]List, ls.LoadSmallInt())
for i := range set.lists {
le := ls.LoadSmallInt()
if le == 0 {
continue
}
set.lists[i] = make(List, le)
for j := range set.lists[i] {
set.lists[i][j] = ls.LoadInts()
}
}
set.maxOffsets = make([][2]int, ls.LoadSmallInt())
for i := range set.maxOffsets {
set.maxOffsets[i] = [2]int{ls.LoadInt(), ls.LoadInt()}
}
return set
}
// Add a priority list to a set. The length is the number of signatures the priority list applies to, not the length of the priority list.
// This length will only differ when no priorities are set for a given set of signatures.
func (s *Set) Add(l List, length, bof, eof int) {
var last int
if len(s.idx) > 0 {
last = s.idx[len(s.idx)-1]
}
s.idx = append(s.idx, length+last)
s.lists = append(s.lists, l)
s.maxOffsets = append(s.maxOffsets, [2]int{bof, eof})
}
func (s *Set) list(i, j int) []int {
if s.lists[i] == nil {
return nil
} else {
l := s.lists[i][j]
if l == nil {
l = []int{}
}
return l
}
}
// at given BOF and EOF offsets, should we still wait on a given priority set?
func (s *Set) await(idx int, bof, eof int64) bool {
if s.maxOffsets[idx][0] < 0 || (s.maxOffsets[idx][0] > 0 && int64(s.maxOffsets[idx][0]) >= bof) {
return true
}
if s.maxOffsets[idx][1] < 0 || (s.maxOffsets[idx][1] > 0 && int64(s.maxOffsets[idx][1]) >= eof) {
return true
}
return false
}
// Index return the index of the s.lists for the wait list, and return the previous tally
// previous tally is necessary for adding to the values in the priority list to give real priorities
func (s *Set) Index(i int) (int, int) {
var prev int
for idx, v := range s.idx {
if i < v {
return idx, prev
}
prev = v
}
// should never get here. Signal error
return -1, -1
}
// A wait set is a mutating structure that holds the set of indexes that should be waited for while matching underway
type WaitSet struct {
*Set
wait [][]int // a nil list means we're not waiting on anything yet; an empty list means nothing to wait for i.e. satisifed
this []int // record last hit so can avoid pivotting to weaker matches
pivot [][]int // a pivot list is a list of indexes that we could potentially pivot to. E.g. for a .pdf file that has mp3 signatures, but is actually a PDF
m *sync.RWMutex
}
// WaitSet creates a new WaitSet given a list of hints
func (s *Set) WaitSet(hints ...core.Hint) *WaitSet {
ws := &WaitSet{
s,
make([][]int, len(s.lists)),
make([]int, len(s.lists)),
make([][]int, len(s.lists)),
&sync.RWMutex{},
}
for _, h := range hints {
idx, _ := s.Index(h.Exclude)
if h.Pivot == nil { // if h.Pivot is nil (as opposed to empty slice), it is a signal that that matcher is satisfied
ws.wait[idx] = []int{}
} else {
ws.pivot[idx] = h.Pivot
}
}
return ws
}
// MaxOffsets returns max/min offset info in order to override the max/min offsets set on the bytematcher when
// any identifiers have been excluded.
func (w *WaitSet) MaxOffsets() (int, int) {
var bof, eof int
for i, v := range w.wait {
if v == nil {
if bof >= 0 && (w.maxOffsets[i][0] < 0 || bof < w.maxOffsets[i][0]) {
bof = w.maxOffsets[i][0]
}
if eof >= 0 && (w.maxOffsets[i][1] < 0 || eof < w.maxOffsets[i][1]) {
eof = w.maxOffsets[i][1]
}
}
}
return bof, eof
}
func inPivot(i int, ii []int) bool {
for _, v := range ii {
if i == v {
return true
}
}
return false
}
func mightPivot(i int, ii []int) bool {
return len(ii) > 0 && !inPivot(i, ii)
}
// Set the priority list & return a boolean indicating whether the WaitSet is satisfied such that matching can stop (i.e. no priority list is nil, and all are empty)
func (w *WaitSet) Put(i int) bool {
idx, prev := w.Index(i)
l := w.list(idx, i-prev)
// no priorities for this set, return false immediately
if l == nil {
return false
}
w.m.Lock()
defer w.m.Unlock()
// set the wait list
w.wait[idx] = l
// set this
w.this[idx] = i - prev
mp := mightPivot(i, w.pivot[idx])
if !mp {
w.pivot[idx] = nil // ditch the pivot list if it is just confirming a match or empty
}
// if we have any priorities, then we aren't satisified
if len(l) > 0 || mp {
return false
}
// if l is 0, and we have only one priority set, and we're not going to pivot, then we are satisfied
if len(w.wait) == 1 && !mp {
return true
}
// otherwise, let's check all the other priority sets for wait sets or pivot lists
for i, v := range w.wait {
if i == idx {
continue
}
if v == nil || len(v) > 0 || len(w.pivot[i]) > 0 {
return false
}
}
return true
}
// Set the priority list & return a boolean indicating whether the WaitSet is satisfied such that matching can stop (i.e. no priority list is nil, and all are empty)
func (w *WaitSet) PutAt(i int, bof, eof int64) bool {
idx, prev := w.Index(i)
l := w.list(idx, i-prev)
// no priorities for this set, return false immediately
if l == nil && w.await(idx, bof, eof) {
return false
}
w.m.Lock()
defer w.m.Unlock()
// set the wait list
w.wait[idx] = l
// set this
w.this[idx] = i - prev
mp := mightPivot(i, w.pivot[idx])
if !mp {
w.pivot[idx] = nil // ditch the pivot list if it is just confirming a match or empty
}
// if we have any priorities, then we aren't satisified
if (len(l) > 0 || mp) && w.await(idx, bof, eof) {
return false
}
// if l is 0, and we have only one priority set, and we're not going to pivot, then we are satisfied
if len(w.wait) == 1 && !mp {
return true
}
// otherwise, let's check all the other priority sets
for i, v := range w.wait {
if i == idx {
continue
}
if w.await(i, bof, eof) {
if v == nil || len(v) > 0 || len(w.pivot[i]) > 0 {
return false
}
}
}
return true
}
// Check a signature index against the appropriate priority list. Should we continue trying to match this signature?
func (w *WaitSet) Check(i int) bool {
idx, prev := w.Index(i)
w.m.RLock()
defer w.m.RUnlock()
return w.check(i, idx, prev)
}
func (w *WaitSet) check(i, idx, prev int) bool {
if w.wait[idx] == nil {
return true
}
j := sort.SearchInts(w.wait[idx], i-prev)
if j == len(w.wait[idx]) || w.wait[idx][j] != i-prev {
if inPivot(i, w.pivot[idx]) {
l := w.list(idx, i-prev)
k := sort.SearchInts(l, w.this[idx])
if k < len(l) && l[k] == w.this[idx] {
return false
}
return true
}
return false
}
return true
}
// Filter a waitset with a list of potential matches, return only those that we are still waiting on. Return nil if none.
func (w *WaitSet) Filter(l []int) []int {
ret := make([]int, 0, len(l))
w.m.RLock()
defer w.m.RUnlock()
for _, v := range l {
idx, prev := w.Index(v)
if w.check(v, idx, prev) {
ret = append(ret, v)
}
}
if len(ret) == 0 {
return nil
}
return ret
}
type Filterable interface {
Next() int
Mark(bool)
}
func (w *WaitSet) ApplyFilter(f Filterable) {
w.m.RLock()
defer w.m.RUnlock()
for i := f.Next(); i > -1; i = f.Next() {
idx, prev := w.Index(i)
f.Mark(w.check(i, idx, prev))
}
}
// For periodic checking - what signatures are we currently waiting on?
// Accumulates values from all the priority lists within the set.
// Returns nil if *any* of the priority lists is nil.
func (w *WaitSet) WaitingOn() []int {
w.m.RLock()
defer w.m.RUnlock()
var l int
for i, v := range w.wait {
if v == nil {
return nil
}
l = l + len(v) + len(w.pivot[i])
}
ret := make([]int, l)
var prev, j int
for i, v := range w.wait {
for _, x := range v {
ret[j] = x + prev
j++
}
copy(ret[j:], w.pivot[i])
j += len(w.pivot[i])
prev = w.idx[i]
}
return ret
}
<file_sep>package reader
import (
"bytes"
"os"
"testing"
)
const (
ipresFiles = 2190
ipresFidoIDs = 2984
ipresDroidIDs = 2451
ipresDroidNpIDs = 2192
)
func TestSF(t *testing.T) {
f1, err := os.Open("examples/multi/multi.csv")
defer f1.Close()
sfc, err := New(f1, "examples/multi/multi.csv")
if err != nil {
t.Fatal(err)
}
f2, err := os.Open("examples/multi/multi.yaml")
defer f2.Close()
sfy, err := New(f2, "examples/multi/multi.yaml")
if err != nil {
t.Fatal(err)
}
f3, err := os.Open("examples/multi/multi.json")
defer f3.Close()
sfj, err := New(f3, "examples/multi/multi.json")
if err != nil {
t.Fatal(err)
}
for f, e := sfc.Next(); e == nil; f, e = sfc.Next() {
y, e1 := sfy.Next()
if e1 != nil {
t.Errorf("got a YAML error for a valid CSV %s; %v", f.Path, e1)
}
j, e2 := sfj.Next()
if e2 != nil {
t.Errorf("got a JSON error for a valid CSV %s; %v", f.Path, e2)
}
if len(f.IDs) != len(y.IDs) || len(f.IDs) != len(j.IDs) {
t.Errorf("JSON, YAML and CSV IDs don't match for %s; got %d, %d and %d", f.Path, len(j.IDs), len(y.IDs), len(f.IDs))
}
}
}
func testRdr(t *testing.T, path string, expectFiles, expectIDs int) {
f, err := os.Open(path)
if err != nil {
t.Fatal(err)
}
defer f.Close()
rdr, err := New(f, path)
if err != nil {
t.Fatal(err)
}
var i, j int
var ff File
var e error
for ff, e = rdr.Next(); e == nil; ff, e = rdr.Next() {
i++
j += len(ff.IDs)
}
if i != expectFiles || j != expectIDs {
t.Errorf("Expecting %d files and %d IDs, got %d files and %d IDs; error: %v", expectFiles, expectIDs, i, j, e)
}
}
func TestFido(t *testing.T) {
testRdr(t, "examples/ipresShowcase/fido.csv", ipresFiles, ipresFidoIDs)
}
func TestDroid(t *testing.T) {
testRdr(t, "examples/ipresShowcase/droid-gui-m.csv", ipresFiles, ipresDroidIDs)
testRdr(t, "examples/ipresShowcase/droid-gui-s.csv", ipresFiles, ipresDroidIDs)
testRdr(t, "examples/ipresShowcase/droid-np.csv", ipresFiles, ipresDroidNpIDs)
}
func TestCompare(t *testing.T) {
w := &bytes.Buffer{}
if err := Compare(w, 0, "examples/ipresShowcase/droid-gui-m.csv", "examples/ipresShowcase/droid-gui-s.csv"); err != nil {
t.Fatal(err)
}
if string(w.Bytes()) != "COMPLETE MATCH\n" {
t.Fatalf("expecting a complete match; got %s", string(w.Bytes()))
}
}
<file_sep>module github.com/richardlehane/siegfried
go 1.18
require (
github.com/richardlehane/characterize v1.0.0
github.com/richardlehane/match v1.0.5
github.com/richardlehane/mscfb v1.0.4
github.com/richardlehane/webarchive v1.0.0
github.com/richardlehane/xmldetect v1.0.2
github.com/ross-spencer/wikiprov v0.2.0
golang.org/x/image v0.6.0
golang.org/x/sys v0.6.0
)
require (
github.com/richardlehane/msoleps v1.0.3 // indirect
github.com/ross-spencer/spargo v0.4.1 // indirect
golang.org/x/text v0.8.0 // indirect
)
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package bytematcher
import (
"fmt"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
// Strikes
// strike is a raw hit from either the WAC matchers or the BOF/EOF frame matchers
// progress strikes aren't hits: and have -1 for idxa, they just report how far we have scanned
type strike struct {
idxa int
idxb int // a test tree index = idxa + idxb
offset int64 // offset of match
length int
reverse bool
frame bool // is it a frameset match?
}
func (st strike) String() string {
strikeOrientation := "BOF"
if st.reverse {
strikeOrientation = "EOF"
}
strikeType := "sequence"
if st.frame {
strikeType = "frametest"
}
return fmt.Sprintf("{%s %s hit - index: %d [%d], offset: %d, length: %d}", strikeOrientation, strikeType, st.idxa+st.idxb, st.idxb, st.offset, st.length)
}
// strikes are cached in a map of strikeItems indexed by strikes' idxa + idxb fields
type strikeItem struct {
first strike
idx int // allows us to 'pop' strikes off the strikeItem and records where we are in the successive slice
successive [][2]int64
}
// have we exhausted the strikeItem i.e. popped off all the available strikes?
func (s *strikeItem) hasPotential() bool {
return s.idx+1 <= len(s.successive)
}
func (s *strikeItem) numPotentials() int {
return len(s.successive) - s.idx
}
func (s *strikeItem) pop() strike {
s.idx++
if s.idx > 0 {
s.first.offset, s.first.length = s.successive[s.idx-1][0], int(s.successive[s.idx-1][1])
}
return s.first
}
// potential hits (signature matches) are marked in a map of hitItems indexed by keyframeID[0]
type hitItem struct {
potentialIdxs []int // indexes to the strike cache
partials [][][2]int64 // for each keyframe in a signature, a slice of offsets and lengths of matches
matched bool // if we've already matched, mark so don't return
}
// search a set of partials for a complete match
func searchPartials(partials [][][2]int64, kfs []keyFrame) (bool, string) {
res := make([][][2]int64, len(partials))
idxs := make([][]int, len(partials))
prevOff := partials[0]
var idx []int
ok := false
res[0] = prevOff
for i, kf := range kfs[1:] {
var nextKf keyFrame
if i+2 < len(kfs) {
nextKf = kfs[i+2]
}
prevOff, idx, ok = checkRelated(kf, kfs[i], nextKf, partials[i+1], prevOff)
if !ok {
return false, ""
}
res[i+1] = prevOff
idxs[i+1] = idx
}
basis := make([][2]int64, len(partials))
basis[len(basis)-1] = res[len(res)-1][0]
j := idxs[len(idxs)-1][0]
for i := len(idxs) - 1; i > 0; i-- {
basis[i-1] = res[i-1][j]
if i > 1 {
j = idxs[i-1][j]
}
}
return true, fmt.Sprintf("byte match at %v", basis)
}
// returns the next strike for testing and true if should continue/false if done
func (h *hitItem) nextPotential(s map[int]*strikeItem) (strike, bool) {
if h == nil || !h.potentiallyComplete(-1, s) {
return strike{}, false
}
var minIdx, min int
for i, v := range h.potentialIdxs {
// first try sending only when we don't have any corresponding partial matches
if h.partials[i] == nil {
return s[v-1].pop(), true
}
// otherwise, if all are potential, start with the fewest potentials first (so as to exclude)
if v > 0 && s[v-1].hasPotential() && (min == 0 || s[v-1].numPotentials() < min) {
minIdx, min = v-1, s[v-1].numPotentials()
}
}
// in case we are all partials, no potentials
if min == 0 {
return strike{}, false
}
return s[minIdx].pop(), true
}
// is a hit item potentially complete? - i.e. has at least one potential strike,
// and either partial matches or strikes for all segments
func (h *hitItem) potentiallyComplete(idx int, s map[int]*strikeItem) bool {
if h.matched { // if matched, we don't want to resatisfy it
return false
}
for i, v := range h.potentialIdxs {
if i == idx {
continue
}
if (v == 0 || !s[v-1].hasPotential()) && h.partials[i] == nil {
return false
}
}
return true
}
// return list of all hits, however fragmentary
func all(m map[int]*hitItem) []int {
ret := make([]int, len(m))
i := 0
for k := range m {
ret[i] = k
i++
}
return ret
}
// kfHits are returned by the testStrike function defined in the scorer method below. They give offsets and lengths for hits on signatures' keyframes.
type kfHit struct {
id keyFrameID
offset int64
length int
}
// partials are used within the testStrike function defined in the scorer method below.
// they mirror the testTree incompletes slice to record distances for hits to left and right of the matching segment
type partial struct {
ldistances []int
rdistances []int
}
// result is the bytematcher implementation of the Result interface.
type result struct {
index int
basis string
}
func (r result) Index() int {
return r.index
}
func (r result) Basis() string {
return r.basis
}
func (b *Matcher) scorer(buf *siegreader.Buffer, waitSet *priority.WaitSet, q chan struct{}, r chan<- core.Result) (chan<- strike, <-chan []keyFrameID) {
incoming := make(chan strike)
resume := make(chan []keyFrameID)
hits := make(map[int]*hitItem)
strikes := make(map[int]*strikeItem)
var bof int64
var eof int64
var quitting bool
quit := func() {
close(q)
close(resume)
quitting = true
}
newHit := func(i int) *hitItem {
l := len(b.keyFrames[i])
hit := &hitItem{
potentialIdxs: make([]int, l),
partials: make([][][2]int64, l),
}
hits[i] = hit
return hit
}
// Used for dwac
dynamicSeqs := func(w []int) []keyFrameID {
dynSeqs := make([]keyFrameID, 0, 20)
for _, v := range w {
kf := b.keyFrames[v]
for i, f := range kf {
var waitfor, excludable bool
if f.key.pMax == -1 {
waitfor = true
} else if hit, ok := hits[v]; ok {
if hit.partials[i] != nil {
waitfor = true
} else if hit.potentialIdxs[i] > 0 && strikes[hit.potentialIdxs[i]-1].hasPotential() {
waitfor, excludable = true, true
}
}
// if we've got to the end of the signature, and have determined this is a live one - return immediately & continue scan
if waitfor {
if i == len(kf)-1 {
if config.Slow() {
fmt.Fprintf(config.Out(), "waiting on: %d, potentially excludable: %t\n", v, excludable)
}
for ii, ff := range kf {
if ff.key.pMax == -1 {
dynSeqs = append(dynSeqs, keyFrameID{v, ii})
}
}
}
continue // we've got one, now get more!
}
break // no reason to keep checking this signature
}
}
return dynSeqs
}
testStrike := func(st strike) []kfHit {
// the offsets we *record* are always BOF offsets - these can be interpreted as EOF offsets when necessary
off := st.offset
if st.reverse {
off = buf.Size() - st.offset - int64(st.length)
}
// grab the relevant testTree
t := b.tests[st.idxa+st.idxb]
res := make([]kfHit, 0, 10)
// immediately apply key frames for the completes
for _, kf := range t.complete {
if b.keyFrames[kf[0]][kf[1]].check(st.offset) && waitSet.Check(kf[0]) {
res = append(res, kfHit{kf, off, st.length})
}
}
// if there are no incompletes, we are done
if len(t.incomplete) < 1 {
return res
}
// see what incompletes are worth pursuing
var checkl, checkr bool
for _, v := range t.incomplete {
if checkl && checkr {
break
}
if b.keyFrames[v.kf[0]][v.kf[1]].check(st.offset) && waitSet.Check(v.kf[0]) {
if v.l {
checkl = true
}
if v.r {
checkr = true
}
}
}
if !checkl && !checkr {
return res
}
// calculate the offset and lengths for the left and right test slices
var lslc, rslc []byte
var lpos, rpos int64
var llen, rlen int
if st.reverse {
lpos, llen = st.offset+int64(st.length), t.maxLeftDistance
rpos, rlen = st.offset-int64(t.maxRightDistance), t.maxRightDistance
if rpos < 0 {
rlen = rlen + int(rpos)
rpos = 0
}
} else {
lpos, llen = st.offset-int64(t.maxLeftDistance), t.maxLeftDistance
rpos, rlen = st.offset+int64(st.length), t.maxRightDistance
if lpos < 0 {
llen = llen + int(lpos)
lpos = 0
}
}
// the partials slice has a mirror entry for each of the testTree incompletes
partials := make([]partial, len(t.incomplete))
// test left (if there are valid left tests to try)
if checkl {
if st.reverse {
lslc, _ = buf.EofSlice(lpos, llen)
} else {
lslc, _ = buf.Slice(lpos, llen)
}
left := matchTestNodes(t.left, lslc, true)
for _, lp := range left {
if partials[lp.followUp].ldistances == nil {
partials[lp.followUp].ldistances = lp.distances
} else {
partials[lp.followUp].ldistances = append(partials[lp.followUp].ldistances, lp.distances...)
}
}
}
// test right (if there are valid right tests to try)
if checkr {
if st.reverse {
rslc, _ = buf.EofSlice(rpos, rlen)
} else {
rslc, _ = buf.Slice(rpos, rlen)
}
right := matchTestNodes(t.right, rslc, false)
for _, rp := range right {
if partials[rp.followUp].rdistances == nil {
partials[rp.followUp].rdistances = rp.distances
} else {
partials[rp.followUp].rdistances = append(partials[rp.followUp].rdistances, rp.distances...)
}
}
}
// now iterate through the partials, checking whether they fulfil any of the incompletes
for i, p := range partials {
if (len(p.ldistances) > 0) == t.incomplete[i].l && (len(p.rdistances) > 0) == t.incomplete[i].r {
kf := t.incomplete[i].kf
if b.keyFrames[kf[0]][kf[1]].check(st.offset) && waitSet.Check(kf[0]) {
if p.ldistances == nil {
p.ldistances = []int{0}
}
if p.rdistances == nil {
p.rdistances = []int{0}
}
// oneEnough is defined in keyframes.go and checks whether segments of a signature are anchored to other segments
if oneEnough(kf[1], b.keyFrames[kf[0]]) {
res = append(res, kfHit{kf, off - int64(p.ldistances[0]), p.ldistances[0] + st.length + p.rdistances[0]})
continue
}
for _, ldistance := range p.ldistances {
for _, rdistance := range p.rdistances {
res = append(res, kfHit{kf, off - int64(ldistance), ldistance + st.length + rdistance})
}
}
}
}
}
return res
}
applyKeyFrame := func(hit kfHit) (bool, string) {
kfs := b.keyFrames[hit.id[0]]
if len(kfs) == 1 {
return true, fmt.Sprintf("byte match at %d, %d", hit.offset, hit.length)
}
h, ok := hits[hit.id[0]]
if !ok {
h = newHit(hit.id[0])
}
if h.partials[hit.id[1]] == nil {
h.partials[hit.id[1]] = [][2]int64{{hit.offset, int64(hit.length)}}
} else {
h.partials[hit.id[1]] = append(h.partials[hit.id[1]], [2]int64{hit.offset, int64(hit.length)})
}
for _, p := range h.partials {
if p == nil {
return false, ""
}
}
return searchPartials(h.partials, kfs)
}
go func() {
for in := range incoming {
// if we've got a positive result, drain any remaining strikes from the matchers
if quitting {
continue
}
// HANDLE RESUME
if in.idxa == -1 {
w := waitSet.WaitingOn() // todo: this uses bof/eof which are less relevant I don't store progress
if w == nil {
w = all(hits)
}
if in.reverse {
resume <- append(dynamicSeqs(w), b.unknownEOF...)
continue
}
resume <- append(dynamicSeqs(w), b.unknownBOF...)
continue
}
// HANDLE MATCH STRIKES
var hasPotential bool
potentials := filterKF(b.tests[in.idxa+in.idxb].keyFrames(), waitSet)
for _, pot := range potentials {
// if any of the signatures are single keyframe we can satisfy immediately and skip cache
if len(b.keyFrames[pot[0]]) == 1 {
hasPotential = true
break
}
if hit, ok := hits[pot[0]]; ok && hit.potentiallyComplete(pot[1], strikes) {
hasPotential = true
break
}
}
if !hasPotential {
// cache the strike
s, ok := strikes[in.idxa+in.idxb]
if !ok {
s = &strikeItem{in, -1, nil}
strikes[in.idxa+in.idxb] = s
} else {
if s.successive == nil {
s.successive = make([][2]int64, 0, 10)
}
s.successive = append(s.successive, [2]int64{in.offset, int64(in.length)})
}
// range over the potentials, linking to the strike
for _, pot := range potentials {
if b.keyFrames[pot[0]][pot[1]].check(in.offset) {
hit, ok := hits[pot[0]]
if !ok {
hit = newHit(pot[0])
}
hit.potentialIdxs[pot[1]] = in.idxa + in.idxb + 1
}
}
goto end
}
// satisfy the strike
for {
ks := testStrike(in)
for _, k := range ks {
if match, basis := applyKeyFrame(k); match {
if waitSet.Check(k.id[0]) {
r <- result{k.id[0], basis}
if waitSet.PutAt(k.id[0], bof, eof) {
quit()
goto end
}
}
if h, ok := hits[k.id[0]]; ok {
h.matched = true
}
}
}
// given waitset, check if any potential matches remain to wait for
potentials = filterKF(potentials, waitSet)
var ok bool
for _, pot := range potentials {
in, ok = hits[pot[0]].nextPotential(strikes)
if ok {
break
}
}
if !ok {
break
}
}
end: // keep looping until incoming is closed
}
close(r)
}()
return incoming, resume
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package pronom
import (
"strings"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/pronom/internal/mappings"
)
type formatInfo struct {
name string
version string
mimeType string
class string
}
func (f formatInfo) String() string {
return f.name
}
// turn generic FormatInfo into PRONOM formatInfo. TODO: use real generics
func infos(m map[string]identifier.FormatInfo) map[string]formatInfo {
i := make(map[string]formatInfo, len(m))
for k, v := range m {
i[k] = v.(formatInfo)
}
return i
}
// DoublesFilter removes the byte signatures where container signatures are also defined
type doublesFilter struct {
ids []string
identifier.Parseable
}
func (db doublesFilter) Signatures() ([]frames.Signature, []string, error) {
filter := identifier.Filter(db.ids, db.Parseable)
return filter.Signatures()
}
// REPORTS
type reports struct {
p []string
r []*mappings.Report
ip map[int]string
identifier.Blank
}
func word(w string) string {
w = strings.TrimSpace(w)
w = strings.ToLower(w)
ws := strings.Split(w, " ")
w = ws[0]
if len(ws) > 1 {
for _, s := range ws[1:] {
s = strings.TrimSuffix(strings.TrimPrefix(s, "("), ")")
s = strings.Replace(s, "-", "", 1)
w += strings.Title(s)
}
}
return w
}
func normalise(ws string) []string {
ss := strings.Split(ws, ",")
for i, s := range ss {
ss[i] = word(s)
}
if len(ss) == 1 && ss[0] == "" {
return nil
}
return ss
}
func (r *reports) FamilyTypes() (map[string][]string, map[string][]string) {
retf, rett := make(map[string][]string), make(map[string][]string)
for i, v := range r.r {
f, t := normalise(v.Families), normalise(v.Types)
this := v.Label(r.p[i])
for _, fs := range f {
retf[fs] = append(retf[fs], this)
}
for _, ts := range t {
rett[ts] = append(rett[ts], this)
}
}
return retf, rett
}
func (r *reports) Labels() []string {
ret := make([]string, len(r.p))
for i, v := range r.r {
ret[i] = v.Label(r.p[i])
}
return ret
}
func (r *reports) IDs() []string {
return r.p
}
func (r *reports) Infos() map[string]identifier.FormatInfo {
infos := make(map[string]identifier.FormatInfo)
for i, v := range r.r {
infos[r.p[i]] = formatInfo{
name: strings.TrimSpace(v.Name),
version: strings.TrimSpace(v.Version),
mimeType: strings.TrimSpace(v.MIME()),
class: strings.TrimSpace(v.Types),
}
}
return infos
}
func globify(s []string) []string {
ret := make([]string, 0, len(s))
for _, v := range s {
if len(v) > 0 {
ret = append(ret, "*."+v)
}
}
return ret
}
func (r *reports) Globs() ([]string, []string) {
exts := make([]string, 0, len(r.r))
puids := make([]string, 0, len(r.p))
for i, v := range r.r {
for _, e := range globify(v.Extensions) {
exts = append(exts, e)
puids = append(puids, r.p[i])
}
}
return exts, puids
}
func (r *reports) MIMEs() ([]string, []string) {
mimes, puids := make([]string, 0, len(r.r)), make([]string, 0, len(r.p))
for i, v := range r.r {
if len(v.MIME()) > 0 {
mimes, puids = append(mimes, v.MIME()), append(puids, r.p[i])
}
}
return mimes, puids
}
func (r *reports) XMLs() ([][2]string, []string) {
return nil, nil
}
func (r *reports) Texts() []string {
return []string{config.TextPuid()}
}
func (r *reports) idsPuids() map[int]string {
if r.ip != nil {
return r.ip
}
idsPuids := make(map[int]string)
for i, v := range r.r {
idsPuids[v.Id] = r.p[i]
}
return idsPuids
}
func (r *reports) Priorities() priority.Map {
idsPuids := r.idsPuids()
pMap := make(priority.Map)
for i, v := range r.r {
this := r.p[i]
for _, sub := range v.Subordinates() {
pMap.Add(idsPuids[sub], this)
}
for _, sup := range v.Superiors() {
pMap.Add(this, idsPuids[sup])
}
}
pMap.Complete()
return pMap
}
func (r *reports) Signatures() ([]frames.Signature, []string, error) {
sigs, puids := make([]frames.Signature, 0, len(r.r)*2), make([]string, 0, len(r.r)*2)
for i, rep := range r.r {
puid := r.p[i]
for _, v := range rep.Signatures {
s, err := processPRONOM(puid, v)
if err != nil {
return nil, nil, err
}
sigs = append(sigs, s)
puids = append(puids, puid)
}
}
return sigs, puids, nil
}
// DROID
type droid struct {
*mappings.Droid
identifier.Blank
}
func (d *droid) IDs() []string {
puids := make([]string, len(d.FileFormats))
for i, v := range d.FileFormats {
puids[i] = v.Puid
}
return puids
}
func (d *droid) Infos() map[string]identifier.FormatInfo {
infos := make(map[string]identifier.FormatInfo)
for _, v := range d.FileFormats {
infos[v.Puid] = formatInfo{
name: strings.TrimSpace(v.Name),
version: strings.TrimSpace(v.Version),
mimeType: strings.TrimSpace(v.MIMEType),
}
}
return infos
}
func (d *droid) Globs() ([]string, []string) {
p := d.IDs()
exts, puids := make([]string, 0, len(d.FileFormats)), make([]string, 0, len(p))
for i, v := range d.FileFormats {
if len(v.Extensions) > 0 {
for _, e := range globify(v.Extensions) {
exts = append(exts, e)
puids = append(puids, p[i])
}
}
}
return exts, puids
}
func (d *droid) MIMEs() ([]string, []string) {
p := d.IDs()
mimes, puids := make([]string, 0, len(d.FileFormats)), make([]string, 0, len(p))
for i, v := range d.FileFormats {
if len(v.MIMEType) > 0 {
mimes, puids = append(mimes, v.MIMEType), append(puids, p[i])
}
}
return mimes, puids
}
func (d *droid) XMLs() ([][2]string, []string) {
return nil, nil
}
func (d *droid) Texts() []string {
return []string{config.TextPuid()}
}
func (d *droid) idsPuids() map[int]string {
idsPuids := make(map[int]string)
for _, v := range d.FileFormats {
idsPuids[v.ID] = v.Puid
}
return idsPuids
}
func (d *droid) puidsInternalIds() map[string][]int {
puidsIIds := make(map[string][]int)
for _, v := range d.FileFormats {
if len(v.Signatures) > 0 {
sigs := make([]int, len(v.Signatures))
copy(sigs, v.Signatures)
puidsIIds[v.Puid] = sigs
}
}
return puidsIIds
}
func (d *droid) Priorities() priority.Map {
idsPuids := d.idsPuids()
pMap := make(priority.Map)
for _, v := range d.FileFormats {
superior := v.Puid
for _, w := range v.Priorities {
subordinate := idsPuids[w]
pMap.Add(subordinate, superior)
}
}
pMap.Complete()
return pMap
}
func (d *droid) Signatures() ([]frames.Signature, []string, error) {
if len(d.Droid.Signatures) == 0 {
return nil, nil, nil
}
sigs, puids := make([]frames.Signature, 0, len(d.Droid.Signatures)), make([]string, 0, len(d.Droid.Signatures))
// first a map of internal sig ids to bytesequences
seqs := make(map[int][]mappings.ByteSeq)
for _, v := range d.Droid.Signatures {
seqs[v.ID] = v.ByteSequences
}
m := d.puidsInternalIds()
var err error
for _, v := range d.IDs() {
for _, w := range m[v] {
sig, err := processDROID(v, seqs[w])
if err != nil {
return nil, nil, err
}
sigs = append(sigs, sig)
puids = append(puids, v)
}
}
return sigs, puids, err
}
// Containers
type container struct {
*mappings.Container
identifier.Blank
}
func (c *container) IDs() []string {
return c.Puids()
}
func (c *container) containerSigs(t string) ([][]string, [][]frames.Signature, []string, error) {
// store all the puids in a map
cpuids := make(map[int]string)
for _, fm := range c.FormatMappings {
cpuids[fm.Id] = fm.Puid
}
cp := len(c.ContainerSignatures)
names := make([][]string, 0, cp)
sigs := make([][]frames.Signature, 0, cp)
puids := make([]string, 0, cp)
for _, c := range c.ContainerSignatures {
if c.ContainerType != t {
continue
}
puid := cpuids[c.Id]
ns, ss := make([]string, 0, len(c.Files)), make([]frames.Signature, 0, len(c.Files))
for _, f := range c.Files {
sig, err := processDROID(puid, f.Signature.ByteSequences)
if err != nil {
return nil, nil, nil, err
}
// write over a File if it exists: address bug x-fmt/45 (# issues 89)
var replace bool
for i, nm := range ns {
if nm == f.Path {
if sig != nil {
ss[i] = sig
}
replace = true
}
}
if !replace {
ns = append(ns, f.Path)
ss = append(ss, sig)
}
}
names = append(names, ns)
sigs = append(sigs, ss)
puids = append(puids, cpuids[c.Id])
}
return names, sigs, puids, nil
}
func (c *container) Zips() ([][]string, [][]frames.Signature, []string, error) {
return c.containerSigs("ZIP")
}
func (c *container) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
return c.containerSigs("OLE2")
}
<file_sep>package bytematcher
// TODO: something!
/*
import "testing"
// Partial keyframes
var (
Pstub = [][][2]int{
[][2]int{
[2]int{10, 5},
[2]int{7, 2},
},
[][2]int{
[2]int{20, 5},
[2]int{20, 10},
},
[][2]int{
[2]int{24, 5},
[2]int{40, 5},
},
[][2]int{
[2]int{50, 5},
},
[][2]int{
[2]int{60, 10},
[2]int{62, 8},
},
}
)
func TestIdentify(t *testing.T) {}
*/
<file_sep>package bytematcher
import (
"sync"
"testing"
"github.com/richardlehane/match/dwac"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/pkg/config"
)
var TestProcessObj = &Matcher{
keyFrames: [][]keyFrame{},
tests: []*testTree{},
bofFrames: nil,
eofFrames: nil,
bofSeq: nil,
eofSeq: nil,
}
var Sample = []byte("testTESTMATCHAAAAAAAAAAAYNESStesty")
func newMatcher() *Matcher {
return &Matcher{
bofFrames: &frameSet{},
eofFrames: &frameSet{},
bofSeq: &seqSet{},
eofSeq: &seqSet{},
priorities: &priority.Set{},
bmu: &sync.Once{},
emu: &sync.Once{},
}
}
func TestProcess(t *testing.T) {
b := newMatcher()
config.SetDistance(8192)()
config.SetRange(2059)()
config.SetChoices(9)()
for i, v := range tests.TestSignatures {
err := b.addSignature(v)
if err != nil {
t.Errorf("Unexpected error adding persist; sig %v; error %v", i, v)
}
}
saver := persist.NewLoadSaver(nil)
Save(b, saver)
loader := persist.NewLoadSaver(saver.Bytes())
b = Load(loader).(*Matcher)
if len(b.keyFrames) != 8 {
t.Errorf("Expecting 8 keyframe slices, got %d", len(b.keyFrames))
}
var tl int
for _, v := range b.keyFrames {
tl += len(v)
}
if tl != 16 {
t.Errorf("Expecting a total of 16 keyframes, got %d", tl)
}
if len(b.tests) != 12 {
t.Errorf("Expecting a total of 12 tests, got %d", len(b.tests))
}
if len(b.bofSeq.set) != 5 {
t.Errorf("Expecting 5 BOF seqs, got %d", len(b.bofSeq.set))
}
e1 := dwac.Seq{MaxOffsets: []int64{0}, Choices: []dwac.Choice{{[]byte{'t', 'e', 's', 't'}}}}
if !seqEquals(b.bofSeq.set[0], e1) {
t.Errorf("Expecting %v to equal %v", b.bofSeq.set[0], e1)
}
e2 := dwac.Seq{MaxOffsets: []int64{-1}, Choices: []dwac.Choice{{[]byte{'t', 'e', 's', 't'}}}}
if seqEquals(b.bofSeq.set[0], e2) {
t.Errorf("Not expecting %v to equal %v", b.bofSeq.set[0], e2)
}
if len(b.eofSeq.set) != 3 {
t.Errorf("Expecting 3 EOF seqs, got %d, first is %v", len(b.eofSeq.set), b.eofSeq.set[0])
}
if len(b.bofFrames.set) != 1 {
t.Errorf("Expecting one BOF Frame, got %d", len(b.bofFrames.set))
}
if len(b.eofFrames.set) != 0 {
t.Errorf("Expecting no EOF frame, got %d", len(b.eofFrames.set))
}
}
func TestProcessFmt418(t *testing.T) {
b := newMatcher()
config.SetDistance(2000)()
config.SetRange(500)()
config.SetChoices(10)()
b.addSignature(tests.TestFmts[418])
saver := persist.NewLoadSaver(nil)
Save(b, saver)
loader := persist.NewLoadSaver(saver.Bytes())
b = Load(loader).(*Matcher)
if len(b.keyFrames[0]) != 2 {
t.Errorf("Expecting 2, got %d", len(b.keyFrames[0]))
}
}
func TestProcessFmt134(t *testing.T) {
b := newMatcher()
config.SetDistance(1000)
config.SetRange(500)
config.SetChoices(3)
b.addSignature(tests.TestFmts[134])
saver := persist.NewLoadSaver(nil)
Save(b, saver)
loader := persist.NewLoadSaver(saver.Bytes())
b = Load(loader).(*Matcher)
if len(b.keyFrames[0]) != 1 {
t.Errorf("Expecting 1, got %d", len(b.keyFrames[0]))
}
for _, t := range b.tests {
t.maxLeftDistance = maxLength(t.left)
t.maxRightDistance = maxLength(t.right)
}
if len(b.tests) != 1 {
t.Errorf("Expecting 1 test, got %d", len(b.tests))
}
}
func TestProcessFmt363(t *testing.T) {
b := newMatcher()
b.addSignature(tests.TestFmts[363])
saver := persist.NewLoadSaver(nil)
Save(b, saver)
loader := persist.NewLoadSaver(saver.Bytes())
b = Load(loader).(*Matcher)
if len(b.keyFrames[0]) != 2 {
for _, v := range b.keyFrames[0] {
t.Errorf("%s\n", v)
}
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package frames
import "fmt"
// Segment divides signatures into signature segments.
// This separation happens on wildcards or when the distance between frames is deemed too great.
// E.g. a signature of [BOF 0: "ABCD"][PREV 0-20: "EFG"][PREV Wild: "HI"][EOF 0: "XYZ"]
// has three segments:
// 1. [BOF 0: "ABCD"][PREV 0-20: "EFG"]
// 2. [PREV Wild: "HI"]
// 3. [EOF 0: "XYZ"]
// The Distance and Range options control the allowable distance and range between frames
// (i.e. a fixed offset of 5000 distant might be acceptable, where a range of 1-2000 might not be).
var costCount = 1
func (s Signature) Segment(dist, rng, cost, repetition int) []Signature {
// first pass: segment just on wild, then check cost of further segmentation
wildSegs := s.segment(-1, -1)
ret := make([]Signature, 0, 1)
for _, v := range wildSegs {
if v.costly(cost) && v.repetitive(repetition) {
ret = append(ret, machinify(v))
} else {
segs := v.segment(dist, rng)
for _, se := range segs {
ret = append(ret, se)
}
}
}
return ret
}
func (s Signature) costly(cost int) bool {
price := 1
for _, v := range s {
mm, _, _ := v.MaxMatches(-1)
price = price * mm
if cost < price {
return true
}
}
return false
}
func (s Signature) repetitive(repetition int) bool {
var price int
ns := Blockify(s)
if len(ns) < 2 {
return false
}
pat := ns[0].Pattern
for _, v := range ns[1:] {
if v.Pattern.Equals(pat) {
price += 1
}
pat = v.Pattern
}
return price > repetition
}
func (s Signature) segment(dist, rng int) []Signature {
if len(s) <= 1 {
return []Signature{s}
}
segments := make([]Signature, 0, 1)
segment := Signature{s[0]}
thisDist, thisRng := dist, rng
var lnk bool
for i, frame := range s[1:] {
if lnk, thisDist, thisRng = frame.Linked(s[i], thisDist, thisRng); lnk {
segment = append(segment, frame)
} else {
segments = append(segments, segment)
segment = Signature{frame}
thisDist, thisRng = dist, rng
}
}
return append(segments, segment)
}
type SigType int
const (
Unknown SigType = iota
BOFZero // fixed offset, zero length from BOF
BOFWindow // offset is a window or fixed value greater than zero from BOF
BOFWild
Prev
Succ
EOFZero
EOFWindow
EOFWild
)
// Simple characterisation of a segment: is it relative to the BOF, or the EOF, or is it a prev/succ segment.
func (seg Signature) Characterise() SigType {
if len(seg) == 0 {
return Unknown
}
switch seg[len(seg)-1].Orientation() {
case SUCC:
return Succ
case EOF:
off := seg[len(seg)-1].Max
switch {
case off == 0:
return EOFZero
case off < 0:
return EOFWild
default:
return EOFWindow
}
}
switch seg[0].Orientation() {
case PREV:
return Prev
case BOF:
off := seg[0].Max
switch {
case off == 0:
return BOFZero
case off < 0:
return BOFWild
}
}
return BOFWindow
}
// position of a key frame in a segment: the length (minimum length in bytes), start and end indexes.
// The keyframe can span multiple frames in the segment (if they are immediately adjacent and can make sequences)
// which is why there is a start and end index
// If length is 0, the segment goes to the frame matcher
type Position struct {
Length int
Start int
End int
}
func (p Position) String() string {
return fmt.Sprintf("POS Length: %d; Start: %d; End: %d", p.Length, p.Start, p.End)
}
func VarLength(seg Signature, max int) Position {
var cur int
var current, greatest Position
num := seg[0].NumSequences()
if num > 0 && num <= max && NonZero(seg[0]) {
current.Length, _ = seg[0].Length()
greatest = Position{current.Length, 0, 1}
cur = num
}
if len(seg) > 1 {
for i, f := range seg[1:] {
if lnk, _, _ := f.Linked(seg[i], 0, 0); lnk {
num = f.NumSequences()
if num > 0 && num <= max {
if current.Length > 0 && cur*num <= max {
l, _ := f.Length()
current.Length += l
current.End = i + 2
cur = cur * num
} else {
current.Length, _ = f.Length()
current.Start, current.End = i+1, i+2
cur = num
}
} else {
current.Length = 0
}
} else {
num = f.NumSequences()
if num > 0 && num <= max && NonZero(seg[i+1]) {
current.Length, _ = f.Length()
current.Start, current.End = i+1, i+2
cur = num
} else {
current.Length = 0
}
}
if current.Length > greatest.Length {
greatest = current
}
}
}
return greatest
}
func BOFLength(seg Signature, max int) Position {
var cur int
var pos Position
num := seg[0].NumSequences()
if num > 0 && num <= max {
pos.Length, _ = seg[0].Length()
pos.Start, pos.End = 0, 1
cur = num
}
if len(seg) > 1 {
for i, f := range seg[1:] {
if lnk, _, _ := f.Linked(seg[i], 0, 0); lnk {
num = f.NumSequences()
if num > 0 && num <= max {
if pos.Length > 0 && cur*num <= max {
l, _ := f.Length()
pos.Length += l
pos.End = i + 2
cur = cur * num
continue
}
}
}
break
}
}
return pos
}
func EOFLength(seg Signature, max int) Position {
var cur int
var pos Position
num := seg[len(seg)-1].NumSequences()
if num > 0 && num <= max {
pos.Length, _ = seg[len(seg)-1].Length()
pos.Start, pos.End = len(seg)-1, len(seg)
cur = num
}
if len(seg) > 1 {
for i := len(seg) - 2; i >= 0; i-- {
f := seg[i]
if lnk, _, _ := seg[i+1].Linked(f, 0, 0); lnk {
num = f.NumSequences()
if num > 0 && num <= max {
if pos.Length > 0 && cur*num <= max {
l, _ := f.Length()
pos.Length += l
pos.Start = i
cur = cur * num
continue
}
}
}
break
}
}
return pos
}
<file_sep>// Copyright 2018 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package decompress provides zip, tar, gzip and webarchive decompression/unpacking
package decompress
import (
"fmt"
"io"
"path/filepath"
"strings"
"time"
"archive/tar"
"archive/zip"
"compress/gzip"
"github.com/richardlehane/characterize"
"github.com/richardlehane/webarchive"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
// package flag for changing functionality of Arcpath func if droid output flag is used
var droidOutput bool
func SetDroid() {
droidOutput = true
}
func IsArc(ids []core.Identification) config.Archive {
var arc config.Archive
for _, id := range ids {
if id.Archive() > config.None {
return id.Archive()
}
}
return arc
}
type Decompressor interface {
Next() error // when finished, should return io.EOF
Reader() io.Reader
Path() string
MIME() string
Size() int64
Mod() time.Time
Dirs() []string
}
func New(arc config.Archive, buf *siegreader.Buffer, path string, sz int64) (Decompressor, error) {
switch arc {
case config.Zip:
return newZip(siegreader.ReaderFrom(buf), path, sz)
case config.Gzip:
return newGzip(buf, path)
case config.Tar:
return newTar(siegreader.ReaderFrom(buf), path)
case config.ARC:
return newARC(siegreader.ReaderFrom(buf), path)
case config.WARC:
return newWARC(siegreader.ReaderFrom(buf), path)
}
return nil, fmt.Errorf("Decompress: unknown archive type %v", arc)
}
type zipD struct {
idx int
p string
rdr *zip.Reader
rc io.ReadCloser
written map[string]bool
}
func newZip(ra io.ReaderAt, path string, sz int64) (Decompressor, error) {
zr, err := zip.NewReader(ra, sz)
return &zipD{idx: -1, p: path, rdr: zr}, err
}
func (z *zipD) close() {
if z.rc == nil {
return
}
z.rc.Close()
}
func (z *zipD) Next() error {
z.close() // close the previous entry, if any
// proceed
z.idx++
// scan past directories
for ; z.idx < len(z.rdr.File) && z.rdr.File[z.idx].FileInfo().IsDir(); z.idx++ {
}
if z.idx >= len(z.rdr.File) {
return io.EOF
}
var err error
z.rc, err = z.rdr.File[z.idx].Open()
return err
}
func (z *zipD) Reader() io.Reader {
return z.rc
}
func (z *zipD) Path() string {
return Arcpath(z.p, filepath.FromSlash(characterize.ZipName(z.rdr.File[z.idx].Name)))
}
func (z *zipD) MIME() string {
return ""
}
func (z *zipD) Size() int64 {
return int64(z.rdr.File[z.idx].UncompressedSize64)
}
func (z *zipD) Mod() time.Time {
return z.rdr.File[z.idx].ModTime()
}
func (z *zipD) Dirs() []string {
if z.written == nil {
z.written = make(map[string]bool)
}
return dirs(z.p, characterize.ZipName(z.rdr.File[z.idx].Name), z.written)
}
type tarD struct {
p string
hdr *tar.Header
rdr *tar.Reader
written map[string]bool
}
func newTar(r io.Reader, path string) (Decompressor, error) {
return &tarD{p: path, rdr: tar.NewReader(r)}, nil
}
func (t *tarD) Next() error {
var err error
// scan past directories
for t.hdr, err = t.rdr.Next(); err == nil && t.hdr.FileInfo().IsDir(); t.hdr, err = t.rdr.Next() {
}
return err
}
func (t *tarD) Reader() io.Reader {
return t.rdr
}
func (t *tarD) Path() string {
return Arcpath(t.p, filepath.FromSlash(t.hdr.Name))
}
func (t *tarD) MIME() string {
return ""
}
func (t *tarD) Size() int64 {
return t.hdr.Size
}
func (t *tarD) Mod() time.Time {
return t.hdr.ModTime
}
func (t *tarD) Dirs() []string {
if t.written == nil {
t.written = make(map[string]bool)
}
return dirs(t.p, t.hdr.Name, t.written)
}
type gzipD struct {
sz int64
p string
read bool
rdr *gzip.Reader
}
func newGzip(b *siegreader.Buffer, path string) (Decompressor, error) {
b.Quit = make(chan struct{}) // in case a stream with a closed quit channel, make a new one
_ = b.SizeNow() // in case a stream, force full read
buf, err := b.EofSlice(0, 4) // gzip stores uncompressed size in last 4 bytes of the stream
if err != nil {
return nil, err
}
sz := int64(uint32(buf[0]) | uint32(buf[1])<<8 | uint32(buf[2])<<16 | uint32(buf[3])<<24)
g, err := gzip.NewReader(siegreader.ReaderFrom(b))
return &gzipD{sz: sz, p: path, rdr: g}, err
}
func (g *gzipD) Next() error {
if g.read {
g.rdr.Close()
return io.EOF
}
g.read = true
return nil
}
func (g *gzipD) Reader() io.Reader {
return g.rdr
}
func (g *gzipD) Path() string {
name := g.rdr.Name
if len(name) == 0 {
switch filepath.Ext(g.p) {
case ".gz", ".z", ".gzip", ".zip":
name = strings.TrimSuffix(filepath.Base(g.p), filepath.Ext(g.p))
default:
name = filepath.Base(g.p)
}
}
return Arcpath(g.p, name)
}
func (g *gzipD) MIME() string {
return ""
}
func (g *gzipD) Size() int64 {
return g.sz
}
func (g *gzipD) Mod() time.Time {
return g.rdr.ModTime
}
func (t *gzipD) Dirs() []string {
return nil
}
func trimWebPath(p string) string {
d, f := filepath.Split(p)
clean := strings.TrimSuffix(d, string(filepath.Separator))
_, f1 := filepath.Split(clean)
if f == strings.TrimSuffix(f1, filepath.Ext(clean)) {
return clean
}
return p
}
type wa struct {
p string
rec webarchive.Record
rdr webarchive.Reader
}
func newARC(r io.Reader, path string) (Decompressor, error) {
arcReader, err := webarchive.NewARCReader(r)
return &wa{p: trimWebPath(path), rdr: arcReader}, err
}
func newWARC(r io.Reader, path string) (Decompressor, error) {
warcReader, err := webarchive.NewWARCReader(r)
return &wa{p: trimWebPath(path), rdr: warcReader}, err
}
func (w *wa) Next() error {
var err error
w.rec, err = w.rdr.NextPayload()
return err
}
func (w *wa) Reader() io.Reader {
return webarchive.DecodePayload(w.rec)
}
func (w *wa) Path() string {
return Arcpath(w.p, w.rec.Date().Format(webarchive.ARCTime)+"/"+w.rec.URL())
}
func (w *wa) MIME() string {
return w.rec.MIME()
}
func (w *wa) Size() int64 {
return w.rec.Size()
}
func (w *wa) Mod() time.Time {
return w.rec.Date()
}
func (w *wa) Dirs() []string {
return nil
}
func dirs(path, name string, written map[string]bool) []string {
ds := strings.Split(filepath.ToSlash(name), "/")
if len(ds) > 1 {
var ret []string
for _, p := range ds[:len(ds)-1] {
path = path + string(filepath.Separator) + p
if !written[path] {
ret = append(ret, path)
written[path] = true
}
}
return ret
}
return nil
}
// per https://github.com/richardlehane/siegfried/issues/81
// construct paths for compressed objects acc. to KDE hash notation
func Arcpath(base, path string) string {
if droidOutput {
return base + string(filepath.Separator) + path
}
return base + "#" + path
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package frames
import "github.com/richardlehane/siegfried/internal/bytematcher/patterns"
// Signature is just a slice of frames.
type Signature []Frame
func (s Signature) String() string {
var str string
for i, v := range s {
if i > 0 {
str += " | "
}
str += v.String()
}
return "(" + str + ")"
}
func (s Signature) OneEnough() bool {
for _, f := range s {
if f.Min != f.Max {
return false
}
}
return true
}
// Equals tests equality of two signatures.
func (s Signature) Equals(s1 Signature) bool {
if len(s) != len(s1) {
return false
}
for i, v := range s {
if !v.Equals(s1[i]) {
return false
}
}
return true
}
// add ints together & if any are -1 (wildcard) then return -1
func addWilds(i ...int) int {
var j int
for _, k := range i {
if k == -1 {
return -1
}
j += k
}
return j
}
// return the min and max legal offsets for a frame. If it is a BOF sequence the first variable returned is true.
func (s Signature) position(idx int) (bool, int, int) {
var min, max int
f := s[idx]
if f.Orientation() >= SUCC {
for j := len(s) - 1; j >= 0; j-- {
f = s[j]
if f.Orientation() == EOF {
min, max = 0, 0
}
if j == idx {
return false, addWilds(min, f.Min), addWilds(max, f.Max)
}
minl, maxl := f.Length()
min, max = addWilds(min, f.Min, minl), addWilds(max, f.Max, maxl)
}
}
for i, f := range s {
if f.Orientation() == BOF {
min, max = 0, 0
}
if i == idx {
return true, addWilds(min, f.Min), addWilds(max, f.Max)
}
minl, maxl := f.Length()
min, max = addWilds(min, f.Min, minl), addWilds(max, f.Max, maxl)
}
// should not get here
return false, -1, -1
}
// test whether two positions overlap. Positions are marked by BOF/EOF and min/max ints
func overlap(a bool, amin, amax int, b bool, bmin, bmax int) bool {
if a != b {
return false
}
if amax > -1 && (amax < bmin || amax < amin) {
return false
}
if bmax > -1 && bmax < amin {
return false
}
return true
}
// Contains tests whether a signature wholly contains the segments of another signature.
func (s Signature) Contains(s1 Signature) bool {
if len(s1) > len(s) {
return false
}
var numEquals int
for i, f := range s {
if idx := patterns.Index(f.Pattern, s1[numEquals].Pattern); idx >= 0 {
a, amin, amax := s.position(i)
amin += idx
b, bmin, bmax := s1.position(numEquals)
if overlap(a, amin, amax, b, bmin, bmax) {
numEquals++
if numEquals == len(s1) {
break
}
}
}
}
return numEquals == len(s1)
}
// turn a wild prev into a succ segment
func (s Signature) reverse(last bool, min int) Signature {
ret := make(Signature, len(s))
for i := range s[:len(s)-1] {
ret[i] = SwitchFrame(s[i+1], s[i].Pattern)
}
typ := SUCC
if last {
typ = EOF
}
ret[len(ret)-1] = NewFrame(typ, s[len(s)-1].Pattern, min)
return ret
}
// Mirror returns a signature in which wildcard previous segments are turned into wildcard succ/eof segments.
// If no wildcard previous segments are present, nil is returned.
func (s Signature) Mirror() Signature {
segments := s.segment(-1, -1)
var hasWild = -1
for i, v := range segments {
if v[0].Orientation() < SUCC && v[0].Max == -1 {
if v[0].Orientation() < PREV && v[0].Min > 0 {
hasWild = -1 // reset on BOF min wild
} else {
if hasWild < 0 {
hasWild = i // get the first wild segment
}
}
}
}
if hasWild < 0 {
return nil
}
ret := make(Signature, 0, len(s))
for i, v := range segments {
if i >= hasWild && v[0].Orientation() < SUCC && v[0].Max == -1 {
var last bool
var min int
if i == len(segments)-1 {
last = true
} else {
next := segments[i+1][0]
if next.Orientation() < SUCC {
min = next.Min
}
}
ret = append(ret, v.reverse(last, min)...)
} else {
ret = append(ret, v...)
}
}
return ret
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"bufio"
"bytes"
"encoding/csv"
"fmt"
"io"
"strconv"
"strings"
"github.com/richardlehane/siegfried/internal/checksum"
)
const droidTime = "2006-01-02T15:04:05"
var (
droidIDs = [][2]string{{"pronom", ""}}
droidFields = [][]string{{"ns", "id", "format", "version", "mime", "basis", "warning"}}
droidNpFields = [][]string{{"ns", "id", "warning"}}
)
type droid struct {
rdr *csv.Reader
hh string
path string
peek []string
err error
}
func newDroid(r io.Reader, path string) (Reader, error) {
rdr := csv.NewReader(r)
rdr.FieldsPerRecord = -1
//rdr.LazyQuotes = true
rec, err := rdr.Read()
if err != nil || rec[0] != "ID" || len(rec) < 17 {
return nil, fmt.Errorf("bad or invalid DROID CSV: %v", err)
}
dr := &droid{
rdr: rdr,
path: path,
}
cs := checksum.GetHash(strings.TrimSuffix(rec[12], "_HASH"))
if cs >= 0 {
dr.hh = cs.String()
}
return dr, dr.nextFile()
}
func (dr *droid) nextFile() error {
for {
dr.peek, dr.err = dr.rdr.Read()
if dr.err != nil {
return fmt.Errorf("bad or invalid DROID CSV: %v", dr.err)
}
if len(dr.peek) > 8 && dr.peek[8] != "Folder" {
return nil
}
}
}
func (dr *droid) Head() Head {
return Head{
ResultsPath: dr.path,
Identifiers: droidIDs,
Fields: droidFields,
HashHeader: dr.hh,
}
}
func didVals(puid, format, version, mime, basis, mismatch string) []string {
var warn string
if mismatch == "true" {
warn = extMismatch
} else if basis == "Extension" {
warn = extWarn
} else if puid == "" {
warn = unknownWarn
}
if puid == "" {
puid = "UNKNOWN"
}
return []string{droidIDs[0][0], puid, format, version, mime, strings.ToLower(basis), warn}
}
func (dr *droid) Next() (File, error) {
if dr.peek == nil || dr.err != nil {
return File{}, dr.err
}
file, err := newFile(dr.peek[3], dr.peek[7], dr.peek[10], dr.peek[12], "")
fn := dr.peek[3]
for {
file.IDs = append(file.IDs, newDefaultID(droidFields[0],
didVals(dr.peek[14], dr.peek[16], dr.peek[17], dr.peek[15], dr.peek[5], dr.peek[11])))
// single line multi ids
if len(dr.peek) > 18 {
num, err := strconv.Atoi(dr.peek[13])
if err == nil && num > 1 {
for i := 1; i < num; i++ {
file.IDs = append(file.IDs, newDefaultID(droidFields[0],
didVals(dr.peek[14+i*4], dr.peek[16+i*4], dr.peek[17+i*4], dr.peek[15+i*4], dr.peek[5], dr.peek[11])))
}
}
}
// multi line multi ids
err := dr.nextFile()
if err != nil || fn != dr.peek[3] {
break
}
}
return file, err
}
type droidNp struct {
buf *bufio.Reader
path string
ids [][2]string
peek []string
err error
}
func newDroidNp(r io.Reader, path string) (Reader, error) {
dnp := &droidNp{
buf: bufio.NewReader(r),
path: path,
ids: make([][2]string, 1),
}
dnp.ids[0][0] = droidIDs[0][0]
var (
sigs []string
byts []byte
err error
)
for {
byts, err = dnp.buf.ReadBytes('\n')
if err != nil {
return nil, err
}
if bytes.HasPrefix(byts, []byte("Binary signature file: ")) {
sigs = append(sigs, string(byts))
} else if bytes.HasPrefix(byts, []byte("Container signature file: ")) {
sigs = append(sigs, string(byts))
}
if !bytes.Contains(byts, []byte(": ")) {
break
}
}
dnp.ids[0][1] = strings.Join(sigs, "; ")
return dnp, dnp.setPeek(byts)
}
func (dnp *droidNp) advance() {
byts, err := dnp.buf.ReadBytes('\n')
if err != nil {
dnp.err = err
return
}
dnp.err = dnp.setPeek(byts)
}
func (dnp *droidNp) setPeek(byts []byte) error {
idx := bytes.LastIndex(byts, []byte{','})
if idx < 0 {
if strings.TrimSpace(string(byts)) == "" {
return io.EOF
}
return fmt.Errorf("bad droid no profile file; line without comma separator: %v", byts)
}
var fn, puid string
fn = string(byts[:idx])
if idx < len(byts)-2 {
puid = strings.TrimSpace(string(byts[idx+1:]))
}
dnp.peek = []string{fn, puid}
return nil
}
func (dnp *droidNp) Head() Head {
return Head{
ResultsPath: dnp.path,
Identifiers: dnp.ids,
Fields: droidNpFields,
}
}
func (dnp *droidNp) Next() (File, error) {
if dnp.peek == nil || dnp.err != nil {
return File{}, dnp.err
}
file, err := newFile(dnp.peek[0], "", "", "", "")
fn := dnp.peek[0]
for {
var puid, warn string
puid = dnp.peek[1]
if puid == "Unknown" {
puid = "UNKNOWN"
warn = unknownWarn
}
file.IDs = append(file.IDs, newDefaultID(droidNpFields[0],
[]string{droidIDs[0][0], puid, warn}))
// multi line multi ids
dnp.advance()
if dnp.err != nil || fn != dnp.peek[0] {
break
}
}
return file, err
}
<file_sep>//go:generate go run gen.go
// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"flag"
"fmt"
"log"
"os"
"path/filepath"
"strconv"
"strings"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/internal/chart"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/loc"
"github.com/richardlehane/siegfried/pkg/mimeinfo"
"github.com/richardlehane/siegfried/pkg/pronom"
wd "github.com/richardlehane/siegfried/pkg/wikidata"
"github.com/richardlehane/siegfried/pkg/reader"
"github.com/richardlehane/siegfried/pkg/sets"
)
var usage = `
Usage:
roy build -help
roy add -help
roy harvest -help
roy inspect -help
roy sets -help
roy compare -help
`
var inspectUsage = `
Usage of inspect:
roy inspect
Inspect the default signature file.
roy inspect SIGNATURE
Inspect a named signature file e.g. roy inspect archivematica.sig
roy inspect MATCHER
Inspect contents of a matcher e.g. roy inspect bytematcher.
Short aliases work too e.g. roy inspect bm
Current matchers are bytematcher (or bm), containermatcher (cm),
xmlmatcher (xm), riffmatcher (rm), namematcher (nm), textmatcher (tm).
roy inspect INTEGER
Identify the signatures related to the numerical hits reported by the
sf debug and slow flags (sf -log d,s). E.g. roy inspect 100
To inspect hits within containermatchers, give the index for the
container type with the -ct flag, and the name of the container
sub-folder with the -cn flag.
The container types are 0 for XML and 1 for MSCFB.
E.g. roy inspect -ct 0 -cn [Content_Types].xml 0
roy inspect FMT
Inspect a file format signature e.g. roy inspect fmt/40
MIME-info and LOC FDD file format signatures can be inspected too.
Also accepts comma separated lists of formats or format sets.
E.g. roy inspect fmt/40,fmt/41 or roy inspect @pdfa
roy inspect priorities
Create a graph of priority relations (in graphviz dot format).
The graph is built from the set of defined priority relations.
Short alias is roy inspect p.
View graph with a command e.g. roy inspect p | dot -Tpng -o priorities.png
If you don't have dot installed, can use http://www.webgraphviz.com/.
roy inspect missing-priorities
Create a graph of relations that can be inferred from byte signatures,
but that are not in the set of defined priority relations.
Short alias is roy inspect mp.
View graph with a command e.g. roy inspect mp | dot -Tpng -o missing.png
roy inspect implicit-priorities
Create a graph of relations that can be inferred from byte signatures,
regardless of whether they are in the set of defined priority relations.
Short alias is roy inspect ip.
View graph with a command e.g. roy inspect ip | dot -Tpng -o implicit.png
roy inspect releases
Summary view of a PRONOM release-notes.xml file (which must be in your
siegfried home directory).
Additional flags:
The roy inspect FMT and roy inspect priorities sub-commands both accept
the following flags. These flags mirror the equivalent flags for the
roy build subcommand and you can find more detail with roy build -help.
-extend, -extendc
Add additional extension and container extension signature files.
Useful for inspecting test signatures during development.
E.g. roy inspect -extend my-groovy-sig.xml dev/1
-limit, -exclude
Limit signatures to a comma-separated list of formats (or sets).
Useful for priority graphs.
E.g. roy inspect -limit @pdfa priorities
-mi, -loc, -fdd
Specify particular MIME-info or LOC FDD signature files for inspecting
formats or viewing priorities.
-reports
Build from PRONOM reports files (rather than just using the DROID XML
file as input). A bit slower but can be more accurate for a small set
of formats like FLAC.
-home
Use a different siegfried home directory.
`
var (
// BUILD, ADD flag sets
build = flag.NewFlagSet("build | add", flag.ExitOnError)
home = build.String("home", config.Home(), "override the default home directory")
droid = build.String("droid", config.Droid(), "set name/path for DROID signature file")
mi = build.String("mi", "", "set name/path for MIMEInfo signature file")
fdd = build.String("fdd", "", "set name/path for LOC FDD signature file")
locfdd = build.Bool("loc", false, "build a LOC FDD signature file")
wikidata = build.Bool("wikidata", false, "build a Wikidata identifier")
wikidataDebug = build.Bool("wikidatadebug", false, "build a Wikidata identifier in debug mode")
noPRONOM = build.Bool("nopronom", false, "don't include PRONOM sigs with LOC or Wikidata signature file")
container = build.String("container", config.Container(), "set name/path for Droid Container signature file")
name = build.String("name", "", "set identifier name")
details = build.String("details", config.Details(), "set identifier details")
extend = build.String("extend", "", "comma separated list of additional signatures")
extendc = build.String("extendc", "", "comma separated list of additional container signatures")
include = build.String("limit", "", "comma separated list of PRONOM signatures to include")
exclude = build.String("exclude", "", "comma separated list of PRONOM signatures to exclude")
bof = build.Int("bof", 0, "define a maximum BOF offset")
eof = build.Int("eof", 0, "define a maximum EOF offset")
noeof = build.Bool("noeof", false, "ignore EOF segments in signatures")
multi = build.String("multi", "", "control how identifiers treat multiple results")
nobyte = build.Bool("nobyte", false, "skip byte signatures")
nocontainer = build.Bool("nocontainer", false, "skip container signatures")
notext = build.Bool("notext", false, "skip text matcher")
noname = build.Bool("noname", false, "skip filename matcher")
nomime = build.Bool("nomime", false, "skip MIME matcher")
noxml = build.Bool("noxml", false, "skip XML matcher")
noriff = build.Bool("noriff", false, "skip RIFF matcher")
noreports = build.Bool("noreports", false, "build directly from DROID file rather than PRONOM reports")
noclass = build.Bool("noclass", false, "omit format classes from the signature file")
doubleup = build.Bool("doubleup", false, "include byte signatures for formats that also have container signatures")
rng = build.Int("range", config.Range(), "define a maximum range for segmentation")
distance = build.Int("distance", config.Distance(), "define a maximum distance for segmentation")
choices = build.Int("choices", config.Choices(), "define a maximum number of choices for segmentation")
cost = build.Int("cost", config.Cost(), "define a maximum tolerable cost in the worst case for segmentation (overrides distance/range/choices)")
repetition = build.Int("repetition", config.Repetition(), "define a maximum tolerable repetition in a segment, used in combination with cost to determine segmentation")
quiet = build.Bool("quiet", false, "lower verbosity level of logging output when building signatures")
// HARVEST
harvest = flag.NewFlagSet("harvest", flag.ExitOnError)
harvestHome = harvest.String("home", config.Home(), "override the default home directory")
harvestDroid = harvest.String("droid", config.Droid(), "set name/path for DROID signature file")
harvestChanges = harvest.Bool("changes", false, "harvest the latest PRONOM release-notes.xml file")
_, htimeout, _, _ = config.HarvestOptions()
timeout = harvest.Duration("timeout", htimeout, "set duration before timing-out harvesting requests e.g. 120s")
throttlef = harvest.Duration("throttle", 0, "set a time to wait HTTP requests e.g. 50ms")
harvestWikidataSig = harvest.Bool("wikidata", false, "harvest a static Wikidata report")
harvestWikidataLang = harvest.String("lang", config.WikidataLang(), "two-letter language-code to download Wikidata strings, e.g. \"de\"")
harvestWikidataEndpoint = harvest.String("wikidataendpoint", config.WikidataEndpoint(), "the endpoint to use to harvest Wikidata definitions from")
harvestWikidataWikibaseURL = harvest.String("wikibaseurl", config.WikidataWikibaseURL(), "the permalink baseURL for the Wikibase server")
// INSPECT (roy inspect | roy inspect fmt/121 | roy inspect usr/local/mysig.sig | roy inspect 10)
inspect = flag.NewFlagSet("inspect", flag.ExitOnError)
inspectHome = inspect.String("home", config.Home(), "override the default home directory")
inspectDroid = inspect.String("droid", config.Droid(), "set name/path for DROID signature file")
inspectReports = inspect.Bool("reports", false, "build signatures from PRONOM reports (rather than DROID xml)")
inspectExtend = inspect.String("extend", "", "comma separated list of additional signatures")
inspectExtendc = inspect.String("extendc", "", "comma separated list of additional container signatures")
inspectInclude = inspect.String("limit", "", "when inspecting priorities, comma separated list of PRONOM signatures to include")
inspectExclude = inspect.String("exclude", "", "when inspecting priorities, comma separated list of PRONOM signatures to exclude")
inspectMI = inspect.String("mi", "", "set name/path for MIMEInfo signature file to inspect")
inspectFDD = inspect.String("fdd", "", "set name/path for LOC FDD signature file to inspect")
inspectLOC = inspect.Bool("loc", false, "inspect a LOC FDD signature file")
inspectCType = inspect.Int("ct", 0, "provide container type to inspect container hits")
inspectCName = inspect.String("cn", "", "provide container name to inspect container hits")
inspectWikidata = inspect.Bool("wikidata", false, "inspect a Wikidata signature file")
inspectNoPRONOM = inspect.Bool("nopronom", false, "don't include PRONOM sigs when inspecting LOC or Wikidata signature file")
// SETS
setsf = flag.NewFlagSet("sets", flag.ExitOnError)
setsHome = setsf.String("home", config.Home(), "override the default home directory")
setsDroid = setsf.String("droid", config.Droid(), "set name/path for DROID signature file")
setsChanges = setsf.Bool("changes", false, "create a pronom-changes.json sets file")
setsList = setsf.String("list", "", "expand comma separated list of format sets")
// COMPARE
comparef = flag.NewFlagSet("compare", flag.ExitOnError)
compareJoin = comparef.Int("join", 0, "control which field(s) are used to link results files. Default is 0 (full file path). Other options are 1 (filename), 2, (filename + size), 3 (filename + modified), 4 (filename + hash), 5 (hash)")
)
func savereps() error {
file, err := os.Open(config.Reports())
if err != nil {
err = os.Mkdir(config.Reports(), os.ModePerm)
if err != nil {
return fmt.Errorf("roy: error making reports directory %s", err)
}
}
file.Close()
errs := pronom.Harvest()
if len(errs) > 0 {
return fmt.Errorf("roy: errors saving reports to disk %s", errs)
}
return nil
}
func makegob(s *siegfried.Siegfried, opts []config.Option) error {
var id core.Identifier
var err error
if *mi != "" {
id, err = mimeinfo.New(opts...)
} else if *locfdd || *fdd != "" {
id, err = loc.New(opts...)
} else if *wikidata || *wikidataDebug {
id, err = wd.New(opts...)
} else {
id, err = pronom.New(opts...)
}
if err != nil {
return err
}
if id != nil {
err = s.Add(id)
if err != nil {
return err
}
} else {
log.Println("Identifier returned nil, not adding to a Siegfried")
}
return s.Save(config.Signature())
}
func inspectSig(t core.MatcherType) error {
if *inspectHome != config.Home() {
config.SetHome(*inspectHome)
}
s, err := siegfried.Load(config.Signature())
if err == nil {
fmt.Print(s.Inspect(t))
}
return err
}
func inspectFmts(fmts []string) error {
var id core.Identifier
var err error
fs := sets.Expand(strings.Join(fmts, ","))
if len(fs) == 0 {
return fmt.Errorf("nothing to inspect")
}
opts := append(getOptions(), config.SetDoubleUp()) // speed up by allowing sig double ups
if *inspectMI != "" {
id, err = mimeinfo.New(opts...)
} else if strings.HasPrefix(fs[0], "fdd") || *inspectLOC || (*inspectFDD != "") {
if *inspectFDD == "" && !*inspectLOC {
opts = append(opts, config.SetLOC(""))
}
id, err = loc.New(opts...)
} else if strings.HasPrefix(fs[0], "Q") || *inspectWikidata {
opts = append(opts, config.SetVerbose(false)) // only print fmt information
id, err = wd.New(opts...)
} else {
if !*inspectReports {
opts = append(opts, config.SetNoReports()) // speed up by building from droid xml
}
id, err = pronom.New(opts...)
}
if err != nil {
return err
}
rep, err := id.Inspect(fs...)
if err == nil {
fmt.Println(rep)
}
return err
}
func graphPriorities(typ int) error {
var id core.Identifier
var err error
opts := append(getOptions(), config.SetDoubleUp()) // speed up by allowing sig double ups
if *inspectMI != "" {
id, err = mimeinfo.New(opts...)
} else if *inspectLOC || (*inspectFDD != "") {
id, err = loc.New(opts...)
} else {
if !*inspectReports {
opts = append(opts, config.SetNoReports()) // speed up by building from droid xml
}
id, err = pronom.New(opts...)
}
if err == nil {
fmt.Println(id.GraphP(typ))
}
return err
}
func blameSig(i int) error {
if *inspectHome != config.Home() {
config.SetHome(*inspectHome)
}
s, err := siegfried.Load(config.Signature())
if err == nil {
fmt.Println(s.Blame(i, *inspectCType, *inspectCName))
}
return err
}
func viewReleases() error {
xm, err := pronom.LoadReleases(config.Local("release-notes.xml"))
if err != nil {
return err
}
years, fields, releases := pronom.Releases(xm)
fmt.Println(chart.Chart("PRONOM releases",
years,
fields,
map[string]bool{"number releases": true},
releases))
return nil
}
func getOptions() []config.Option {
opts := []config.Option{}
// build options
if *droid != config.Droid() {
opts = append(opts, config.SetDroid(*droid))
}
if *container != config.Container() {
opts = append(opts, config.SetContainer(*container))
}
if *mi != "" {
opts = append(opts, config.SetMIMEInfo(*mi))
}
if *fdd != "" {
opts = append(opts, config.SetLOC(*fdd))
}
if *locfdd {
opts = append(opts, config.SetLOC(""))
}
if *wikidata {
opts = append(opts, config.SetWikidataNamespace())
}
if *wikidataDebug {
opts = append(opts, config.SetWikidataDebug())
}
if *noPRONOM || *inspectNoPRONOM {
opts = append(opts, config.SetNoPRONOM())
opts = append(opts, config.SetWikidataNoPRONOM())
}
if *name != "" {
opts = append(opts, config.SetName(*name))
}
if *details != config.Details() {
opts = append(opts, config.SetDetails(*details))
}
if *extend != "" {
opts = append(opts, config.SetExtend(sets.Expand(*extend)))
}
if *extendc != "" {
if *extend == "" {
fmt.Println(
`roy: warning! Unless the container extension only extends formats defined in
the DROID signature file you should also include a regular signature extension
(-extend) that includes a FileFormatCollection element describing the new formats.`)
}
opts = append(opts, config.SetExtendC(sets.Expand(*extendc)))
}
if *include != "" {
opts = append(opts, config.SetLimit(sets.Expand(*include)))
}
if *exclude != "" {
opts = append(opts, config.SetExclude(sets.Expand(*exclude)))
}
if *bof != 0 {
opts = append(opts, config.SetBOF(*bof))
}
if *eof != 0 {
opts = append(opts, config.SetEOF(*eof))
}
if *noeof {
opts = append(opts, config.SetNoEOF())
}
if *multi != "" {
opts = append(opts, config.SetMulti(strings.ToLower(*multi)))
}
if *nobyte {
opts = append(opts, config.SetNoByte())
}
if *nocontainer {
opts = append(opts, config.SetNoContainer())
}
if *notext {
opts = append(opts, config.SetNoText())
}
if *noname {
opts = append(opts, config.SetNoName())
}
if *nomime {
opts = append(opts, config.SetNoMIME())
}
if *noxml {
opts = append(opts, config.SetNoXML())
}
if *noriff {
opts = append(opts, config.SetNoRIFF())
}
if *noreports {
opts = append(opts, config.SetNoReports())
}
if *noclass {
opts = append(opts, config.SetNoClass())
}
if *doubleup {
opts = append(opts, config.SetDoubleUp())
}
if *rng != config.Range() {
opts = append(opts, config.SetRange(*rng))
}
if *distance != config.Distance() {
opts = append(opts, config.SetDistance(*distance))
}
if *choices != config.Choices() {
opts = append(opts, config.SetChoices(*choices))
}
if *cost != config.Cost() {
opts = append(opts, config.SetCost(*cost))
}
if *repetition != config.Repetition() {
opts = append(opts, config.SetRepetition(*repetition))
}
if *quiet == config.Verbose() {
opts = append(opts, config.SetVerbose(!*quiet)) // do the opposite, because the flag is quiet and the setting is verbose!
}
// inspect options
if *inspectDroid != config.Droid() {
opts = append(opts, config.SetDroid(*inspectDroid))
}
if *inspectMI != "" {
opts = append(opts, config.SetMIMEInfo(*inspectMI))
}
if *inspectFDD != "" {
opts = append(opts, config.SetLOC(*fdd))
}
if *inspectLOC {
opts = append(opts, config.SetLOC(""))
}
if *inspectWikidata {
opts = append(opts, config.SetWikidataNamespace())
}
if *inspectInclude != "" {
opts = append(opts, config.SetLimit(sets.Expand(*inspectInclude)))
}
if *inspectExclude != "" {
opts = append(opts, config.SetExclude(sets.Expand(*inspectExclude)))
}
if *inspectExtend != "" {
opts = append(opts, config.SetExtend(sets.Expand(*inspectExtend)))
}
if *inspectExtendc != "" {
if *inspectExtend == "" {
fmt.Println(
`roy: warning! Unless the container extension only extends formats defined in
the DROID signature file you should also include a regular signature extension
(-extend) that includes a FileFormatCollection element describing the new formats.`)
}
opts = append(opts, config.SetExtendC(sets.Expand(*inspectExtendc)))
}
// set home
if *home != config.Home() {
config.SetHome(*home)
} else if *inspectHome != config.Home() {
config.SetHome(*inspectHome)
}
return opts
}
func setHarvestOptions() {
if *harvestDroid != config.Droid() {
config.SetDroid(*harvestDroid)()
}
if *harvestHome != config.Home() {
config.SetHome(*harvestHome)
}
if *timeout != htimeout {
config.SetHarvestTimeout(*timeout)
}
if *throttlef > 0 {
config.SetHarvestThrottle(*throttlef)
}
if *harvestWikidataLang != "" {
config.SetWikidataLang(*harvestWikidataLang)
}
if *harvestWikidataEndpoint != config.WikidataEndpoint() {
// Configure Siegfried to connect to a custom Wikibase instance.
if err := configureCustomWikibase(); err != nil {
log.Printf("Roy (Wikibase): %s", err)
os.Exit(1)
}
}
}
func setSetsOptions() {
if *setsDroid != config.Droid() {
config.SetDroid(*setsDroid)()
}
if *setsHome != config.Home() {
config.SetHome(*setsHome)
}
}
func main() {
var err error
if len(os.Args) < 2 {
log.Fatal(usage)
}
switch os.Args[1] {
case "build":
err = build.Parse(os.Args[2:])
if err == nil {
if build.Arg(0) != "" {
config.SetSignature(build.Arg(0))
}
s := siegfried.New()
err = makegob(s, getOptions())
}
case "add":
err = build.Parse(os.Args[2:])
if err == nil {
if build.Arg(0) != "" {
config.SetSignature(build.Arg(0))
}
var s *siegfried.Siegfried
s, err = siegfried.Load(config.Signature())
if err == nil {
err = makegob(s, getOptions())
}
}
case "harvest":
err = harvest.Parse(os.Args[2:])
if err == nil {
setHarvestOptions()
if *harvestChanges {
err = pronom.GetReleases(config.Local("release-notes.xml"))
} else if *harvestWikidataSig {
err = harvestWikidata()
} else {
err = savereps()
}
}
case "inspect":
inspect.Usage = func() { fmt.Print(inspectUsage) }
err = inspect.Parse(os.Args[2:])
if err == nil {
input := inspect.Arg(0)
switch {
case input == "":
err = inspectSig(-1)
case input == "bytematcher", input == "bm":
err = inspectSig(core.ByteMatcher)
case input == "containermatcher", input == "cm":
err = inspectSig(core.ContainerMatcher)
case input == "namematcher", input == "nm":
err = inspectSig(core.NameMatcher)
case input == "mimematcher", input == "mm":
err = inspectSig(core.MIMEMatcher)
case input == "riffmatcher", input == "rm":
err = inspectSig(core.RIFFMatcher)
case input == "xmlmatcher", input == "xm":
err = inspectSig(core.XMLMatcher)
case input == "textmatcher", input == "tm":
err = inspectSig(core.TextMatcher)
case input == "priorities", input == "p":
err = graphPriorities(0)
case input == "missing-priorities", input == "mp":
err = graphPriorities(1)
case input == "implicit-priorities", input == "ip":
err = graphPriorities(2)
case input == "releases":
err = viewReleases()
case input == "testtrees":
err = blameSig(-1)
case input == "keyframes":
err = blameSig(-2)
case filepath.Ext(input) == ".sig":
config.SetSignature(input)
err = inspectSig(-1)
default:
var i int
i, err = strconv.Atoi(input)
if err == nil {
err = blameSig(i)
} else {
err = inspectFmts(inspect.Args())
}
}
}
if err != nil {
err = fmt.Errorf("%s\nUsage: `roy inspect -help`", err.Error())
}
case "sets":
err = setsf.Parse(os.Args[2:])
if err != nil {
break
}
setSetsOptions()
if *setsList != "" {
fmt.Println(strings.Join(sets.Expand(*setsList), "\n"))
} else if *setsChanges {
releases, rerr := pronom.LoadReleases(config.Local("release-notes.xml"))
if rerr != nil {
err = rerr
break
}
err = pronom.ReleaseSet("pronom-changes.json", releases)
} else {
err = pronom.TypeSets("pronom-all.json", "pronom-families.json", "pronom-types.json")
if err == nil {
err = pronom.ExtensionSet("pronom-extensions.json")
}
}
case "compare":
err = comparef.Parse(os.Args[2:])
if err == nil {
err = reader.Compare(os.Stdout, *compareJoin, comparef.Args()...)
}
default:
log.Fatal(usage)
}
if err != nil {
log.Fatal(err)
}
os.Exit(0)
}
<file_sep>package siegreader
import "log"
type mmap struct {
*file
handle uintptr // for windows unmap
buf []byte
}
func newMmap() interface{} {
return &mmap{}
}
func (m *mmap) setSource(f *file) error {
m.file = f
return m.mapFile()
}
func (m *mmap) slice(off int64, l int) []byte {
return m.buf[int(off) : int(off)+l]
}
func (m *mmap) eofSlice(off int64, l int) []byte {
o := int(m.sz - off)
return m.buf[o-l : o]
}
func (m *mmap) reset() {
err := m.unmap()
if err != nil {
log.Fatalf("Siegfried: fatal error while unmapping: %s; error: %v\n", m.src.Name(), err) // not polite of this package to panic - consider deprecate
}
m.buf = nil
return
}
<file_sep>#!/usr/bin/env sh
set -ev # exit early on error
# setup dirs
mkdir -p $SF_PATH/DEBIAN
mkdir -p $SF_PATH/usr/bin
mkdir -p $SF_PATH/usr/share/siegfried
ls $SF_PATH
# copy binaries and assets
cp $BIN_PATH/sf $SF_PATH/usr/bin/
cp $BIN_PATH/roy $SF_PATH/usr/bin/
cp -R cmd/roy/data/. $SF_PATH/usr/share/siegfried
# write control file
SIZE=$(du -s "${SF_PATH}/usr" | cut -f1)
cat >$SF_PATH/DEBIAN/control << EOA
Package: siegfried
Version: $VERSION-1
Architecture: amd64
Maintainer: <NAME> <<EMAIL>>
Installed-Size: $SIZE
Depends: libc6 (>= 2.2.5)
Section: misc
Priority: optional
Description: signature-based file identification tool
EOA
# make deb; explicit 'xz' is for compatibility with Debian "bullseye";
# see:
#
# https://github.com/richardlehane/siegfried/issues/222
#
dpkg-deb -Zxz --build $SF_PATH
<file_sep>// Copyright 2011 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// +build linux darwin dragonfly freebsd netbsd openbsd
package siegreader
import "golang.org/x/sys/unix"
func mmapable(sz int64) bool {
if int64(int(sz+4095)) != sz+4095 {
return false
}
return true
}
func (m *mmap) mapFile() error {
var err error
m.buf, err = unix.Mmap(int(m.src.Fd()), 0, int(m.sz), unix.PROT_READ, unix.MAP_SHARED)
return err
}
func (m *mmap) unmap() error {
return unix.Munmap(m.buf)
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package loc
import (
"fmt"
"sort"
"strings"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
func init() {
core.RegisterIdentifier(core.LOC, Load)
}
type Identifier struct {
infos map[string]formatInfo
*identifier.Base
}
func (i *Identifier) Save(ls *persist.LoadSaver) {
ls.SaveByte(core.LOC)
ls.SaveSmallInt(len(i.infos))
for k, v := range i.infos {
ls.SaveString(k)
ls.SaveString(v.name)
ls.SaveString(v.longName)
ls.SaveString(v.mimeType)
}
i.Base.Save(ls)
}
func Load(ls *persist.LoadSaver) core.Identifier {
i := &Identifier{}
i.infos = make(map[string]formatInfo)
le := ls.LoadSmallInt()
for j := 0; j < le; j++ {
i.infos[ls.LoadString()] = formatInfo{
ls.LoadString(),
ls.LoadString(),
ls.LoadString(),
}
}
i.Base = identifier.Load(ls)
return i
}
func New(opts ...config.Option) (core.Identifier, error) {
for _, v := range opts {
v()
}
loc, err := newLOC(config.LOC())
if err != nil {
return nil, err
}
// set updated
updated := loc.(fdds).Updated().Format(dateFmt)
// add extensions
for _, v := range config.Extend() {
e, err := newLOC(v)
if err != nil {
return nil, fmt.Errorf("LOC: error loading extension file %s; got %s", v, err)
}
loc = identifier.Join(loc, e)
}
// apply config
loc = identifier.ApplyConfig(loc)
// return identifier
return &Identifier{
infos: infos(loc.Infos()),
Base: identifier.New(loc, config.ZipLOC(), updated),
}, nil
}
func (i *Identifier) Fields() []string {
return []string{"namespace", "id", "format", "full", "mime", "basis", "warning"}
}
func (i *Identifier) Recorder() core.Recorder {
return &Recorder{
Identifier: i,
ids: make(pids, 0, 1),
}
}
type Recorder struct {
*Identifier
ids pids
cscore int
satisfied bool
extActive bool
mimeActive bool
textActive bool
}
const (
extScore = 1 << iota
mimeScore
textScore
incScore
)
func (r *Recorder) Active(m core.MatcherType) {
if r.Identifier.Active(m) {
switch m {
case core.NameMatcher:
r.extActive = true
case core.MIMEMatcher:
r.mimeActive = true
case core.TextMatcher:
r.textActive = true
}
}
}
func (r *Recorder) Record(m core.MatcherType, res core.Result) bool {
switch m {
default:
return false
case core.NameMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
r.ids = add(r.ids, r.Name(), id, r.infos[id], res.Basis(), extScore)
return true
} else {
return false
}
case core.MIMEMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
r.ids = add(r.ids, r.Name(), id, r.infos[id], res.Basis(), mimeScore)
return true
} else {
return false
}
case core.ContainerMatcher:
// add zip default
if res.Index() < 0 {
if r.ZipDefault() {
r.cscore += incScore
r.ids = add(r.ids, r.Name(), config.ZipLOC(), r.infos[config.ZipLOC()], res.Basis(), r.cscore)
}
return false
}
if hit, id := r.Hit(m, res.Index()); hit {
r.cscore += incScore
basis := res.Basis()
p, t := r.Place(core.ContainerMatcher, res.Index())
if t > 1 {
basis = basis + fmt.Sprintf(" (signature %d/%d)", p, t)
}
r.ids = add(r.ids, r.Name(), id, r.infos[id], basis, r.cscore)
return true
} else {
return false
}
case core.RIFFMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
if r.satisfied {
return true
}
r.cscore += incScore
r.ids = add(r.ids, r.Name(), id, r.infos[id], res.Basis(), r.cscore)
return true
} else {
return false
}
case core.ByteMatcher:
if hit, id := r.Hit(m, res.Index()); hit {
if r.satisfied {
return true
}
r.cscore += incScore
basis := res.Basis()
p, t := r.Place(core.ByteMatcher, res.Index())
if t > 1 {
basis = basis + fmt.Sprintf(" (signature %d/%d)", p, t)
}
r.ids = add(r.ids, r.Name(), id, r.infos[id], basis, r.cscore)
return true
} else {
return false
}
}
}
func (r *Recorder) Satisfied(mt core.MatcherType) (bool, core.Hint) {
if r.NoPriority() {
return false, core.Hint{}
}
if r.cscore < incScore {
if mt == core.ContainerMatcher || mt == core.ByteMatcher || mt == core.XMLMatcher || mt == core.RIFFMatcher {
return false, core.Hint{}
}
if len(r.ids) == 0 {
return false, core.Hint{}
}
}
r.satisfied = true
if mt == core.ByteMatcher {
return true, core.Hint{r.Start(mt), nil}
}
return true, core.Hint{}
}
func lowConfidence(conf int) string {
var ls = make([]string, 0, 1)
if conf&extScore == extScore {
ls = append(ls, "extension")
}
if conf&mimeScore == mimeScore {
ls = append(ls, "MIME")
}
if conf&textScore == textScore {
ls = append(ls, "text")
}
switch len(ls) {
case 0:
return ""
case 1:
return ls[0]
case 2:
return ls[0] + " and " + ls[1]
default:
return strings.Join(ls[:len(ls)-1], ", ") + " and " + ls[len(ls)-1]
}
}
func (r *Recorder) Report() []core.Identification {
// no results
if len(r.ids) == 0 {
return []core.Identification{Identification{
Namespace: r.Name(),
ID: "UNKNOWN",
Warning: "no match",
}}
}
sort.Sort(r.ids)
// exhaustive
if r.Multi() == config.Exhaustive {
ret := make([]core.Identification, len(r.ids))
for i, v := range r.ids {
ret[i] = r.updateWarning(v)
}
return ret
}
conf := r.ids[0].confidence
// if we've only got extension / mime matches, check if those matches are ruled out by lack of byte match
// only permit a single extension or mime only match
// add warnings too
if conf <= textScore {
nids := make([]Identification, 0, 1)
for _, v := range r.ids {
// if overall confidence is greater than mime or ext only, then rule out any lesser confident matches
if conf > mimeScore && v.confidence != conf {
break
}
// if the match has no corresponding byte or RIFF signature...
if ok := r.HasSig(v.ID, core.RIFFMatcher, core.ByteMatcher); !ok {
// break immediately if more than one match
if len(nids) > 0 {
nids = nids[:0]
break
}
nids = append(nids, v)
}
}
if len(nids) != 1 {
poss := make([]string, len(r.ids))
for i, v := range r.ids {
poss[i] = v.ID
conf = conf | v.confidence
}
return []core.Identification{Identification{
Namespace: r.Name(),
ID: "UNKNOWN",
Warning: fmt.Sprintf("no match; possibilities based on %v are %v", lowConfidence(conf), strings.Join(poss, ", ")),
}}
}
r.ids = nids
}
// handle single result only
if r.Multi() == config.Single && len(r.ids) > 1 && r.ids[0].confidence == r.ids[1].confidence {
poss := make([]string, 0, len(r.ids))
for _, v := range r.ids {
if v.confidence < conf {
break
}
poss = append(poss, v.ID)
}
return []core.Identification{Identification{
Namespace: r.Name(),
ID: "UNKNOWN",
Warning: fmt.Sprintf("multiple matches %v", strings.Join(poss, ", ")),
}}
}
ret := make([]core.Identification, len(r.ids))
for i, v := range r.ids {
if i > 0 {
switch r.Multi() {
case config.Single:
return ret[:i]
case config.Conclusive:
if v.confidence < conf {
return ret[:i]
}
default:
if v.confidence < incScore {
return ret[:i]
}
}
}
ret[i] = r.updateWarning(v)
}
return ret
}
func (r *Recorder) updateWarning(i Identification) Identification {
// apply low confidence
if i.confidence <= textScore {
if len(i.Warning) > 0 {
i.Warning += "; " + "match on " + lowConfidence(i.confidence) + " only"
} else {
i.Warning = "match on " + lowConfidence(i.confidence) + " only"
}
}
// apply mismatches
if r.extActive && (i.confidence&extScore != extScore) {
for _, v := range r.IDs(core.NameMatcher) {
if i.ID == v {
if len(i.Warning) > 0 {
i.Warning += "; extension mismatch"
} else {
i.Warning = "extension mismatch"
}
break
}
}
}
if r.mimeActive && (i.confidence&mimeScore != mimeScore) {
for _, v := range r.IDs(core.MIMEMatcher) {
if i.ID == v {
if len(i.Warning) > 0 {
i.Warning += "; MIME mismatch"
} else {
i.Warning = "MIME mismatch"
}
break
}
}
}
return i
}
type Identification struct {
Namespace string
ID string
Name string
LongName string
MIME string
Basis []string
Warning string
archive config.Archive
confidence int
}
func (id Identification) String() string {
return id.ID
}
func (id Identification) Known() bool {
return id.ID != "UNKNOWN"
}
func (id Identification) Warn() string {
return id.Warning
}
func (id Identification) Values() []string {
var basis string
if len(id.Basis) > 0 {
basis = strings.Join(id.Basis, "; ")
}
return []string{
id.Namespace,
id.ID,
id.Name,
id.LongName,
id.MIME,
basis,
id.Warning,
}
}
func (id Identification) Archive() config.Archive {
return id.archive
}
type pids []Identification
func (p pids) Len() int { return len(p) }
func (p pids) Less(i, j int) bool { return p[j].confidence < p[i].confidence }
func (p pids) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func add(p pids, id string, f string, info formatInfo, basis string, c int) pids {
for i, v := range p {
if v.ID == f {
p[i].confidence += c
p[i].Basis = append(p[i].Basis, basis)
return p
}
}
return append(p, Identification{id, f, info.name, info.longName, info.mimeType, []string{basis}, "", config.IsArchive(f), c})
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package core defines a set of core interfaces: Identifier, Recorder, Identification, and Matcher
package core
import (
"errors"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
)
// Identifier describes the implementation of a signature format. E.g. there is a PRONOM identifier that implements the TNA's PRONOM format.
type Identifier interface {
Add(Matcher, MatcherType) (Matcher, error)
Recorder() Recorder // return a recorder for matching
Name() string
Details() string
Fields() []string // Fields of an Identification, first element must be "namespace"
Save(*persist.LoadSaver)
String() string // A string representation of the global identifier
Inspect(...string) (string, error) // String representation of format signatures within the identifier
GraphP(int) string // a dot graph representation of the identifier's priorities, missing priorities or implicit priorities
Recognise(MatcherType, int) (bool, string) // do you recognise this result index?
}
// Add additional identifier types here
const (
Pronom byte = iota // Pronom is the TNA's PRONOM file format registry
MIMEInfo
LOC
Wikidata
)
// IdentifierLoader unmarshals an Identifer from a LoadSaver.
type IdentifierLoader func(*persist.LoadSaver) Identifier
var loaders = [8]IdentifierLoader{nil, nil, nil, nil, nil, nil, nil, nil}
// RegisterIdentifier allows external packages to add new IdentifierLoaders.
func RegisterIdentifier(id byte, l IdentifierLoader) {
loaders[int(id)] = l
}
// LoadIdentifier applies the appropriate IdentifierLoader to load an identifier.
func LoadIdentifier(ls *persist.LoadSaver) Identifier {
id := ls.LoadByte()
l := loaders[int(id)]
if l == nil {
if ls.Err == nil {
ls.Err = errors.New("bad identifier loader")
}
return nil
}
return l(ls)
}
// Hint is a structure provided by a Recorder before a matcher is run, when asked if it is Satisfied().
// A hint identifies if that recorder can be excluded or if there is a pivot list.
type Hint struct {
Exclude int
Pivot []int
}
// Recorder is a mutable object generated by an identifier. It records match results and sends identifications.
type Recorder interface {
Record(MatcherType, Result) bool // Record results for each matcher; return true if match recorded (siegfried will iterate through the identifiers until an identifier returns true).
Satisfied(MatcherType) (bool, Hint) // Called before matcher starts - should we continue onto this matcher? Should we pass any hints (exclude or pivot) to this matcher?
Report() []Identification // Return results as slice
Active(MatcherType) // Instruct Recorder that can expect results of type MatcherType.
}
// Identification is sent by an identifier when a format matches
type Identification interface {
String() string // short text that is displayed to indicate the format match
Known() bool // does this identifier produce a match
Warn() string // identification warning message
Values() []string // match response. Slice can be any length, but must be same length as Fields() returned by Identifier
Archive() config.Archive // does this format match any of the archive formats (zip, gzip, tar, warc, arc)
}
// Matcher does the matching (against the name/mime string or the byte stream) and sends results
type Matcher interface {
Identify(string, *siegreader.Buffer, ...Hint) (chan Result, error) // Given a name/MIME string and bytes, identify the file. Include the collected Hints
String() string
}
// MatcherType is used by recorders to tell which type of matcher has sent a result
type MatcherType int
// Add additional Matchers here
const (
NameMatcher MatcherType = iota
MIMEMatcher
ContainerMatcher
ByteMatcher
TextMatcher
XMLMatcher
RIFFMatcher
)
// SignatureSet is added to a matcher. It can take any form, depending on the matcher.
type SignatureSet interface{}
// Result is a raw hit that matchers pass on to Identifiers
type Result interface {
Index() int
Basis() string
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package identifier
import (
"fmt"
"strings"
"sync"
"github.com/richardlehane/siegfried/internal/bytematcher"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/containermatcher"
"github.com/richardlehane/siegfried/internal/mimematcher"
"github.com/richardlehane/siegfried/internal/namematcher"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/riffmatcher"
"github.com/richardlehane/siegfried/internal/textmatcher"
"github.com/richardlehane/siegfried/internal/xmlmatcher"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
// A base identifier that can be embedded in other identifier
type Base struct {
p Parseable
name string
details string
multi config.Multi
zipDefault bool
gids, mids, cids, xids, bids, rids, tids *indexes
}
type indexes struct {
start int
ids []string
once sync.Once
lookup map[string][]int
}
func (ii *indexes) find(ks []string) []int {
ii.once.Do(func() {
ii.lookup = make(map[string][]int)
for i, v := range ii.ids {
ii.lookup[v] = append(ii.lookup[v], ii.start+i)
}
})
ret := make([]int, 0, len(ks)*2)
for _, k := range ks {
ret = append(ret, ii.lookup[k]...)
}
return ret
}
func (ii *indexes) hit(i int) (bool, string) {
if i >= ii.start && i < ii.start+len(ii.ids) {
return true, ii.ids[i-ii.start]
}
return false, ""
}
func (ii *indexes) first(i int) (bool, string) {
if i == ii.start && len(ii.ids) > 0 {
return true, ii.ids[0]
}
return false, ""
}
func (ii *indexes) save(ls *persist.LoadSaver) {
ls.SaveInt(ii.start)
ls.SaveStrings(ii.ids)
}
func (ii *indexes) place(i int) (int, int) {
if i >= ii.start && i < ii.start+len(ii.ids) {
idx, id := i-ii.start, ii.ids[i-ii.start]
var prev, post int
for j := idx - 1; j > -1 && ii.ids[j] == id; j-- {
prev++
}
for j := idx + 1; j < len(ii.ids) && ii.ids[j] == id; j++ {
post++
}
return prev + 1, prev + post + 1
}
return -1, -1
}
func loadIndexes(ls *persist.LoadSaver) *indexes {
return &indexes{
start: ls.LoadInt(),
ids: ls.LoadStrings(),
}
}
func New(p Parseable, zip string, extra ...string) *Base {
return &Base{
p: p,
name: config.Name(),
details: config.Details(extra...),
multi: config.GetMulti(),
zipDefault: contains(p.IDs(), zip),
gids: &indexes{}, mids: &indexes{}, cids: &indexes{}, xids: &indexes{}, bids: &indexes{}, rids: &indexes{}, tids: &indexes{},
}
}
func (b *Base) Save(ls *persist.LoadSaver) {
ls.SaveString(b.name)
ls.SaveString(b.details)
ls.SaveTinyInt(int(b.multi))
ls.SaveBool(b.zipDefault)
b.gids.save(ls)
b.mids.save(ls)
b.cids.save(ls)
b.xids.save(ls)
b.bids.save(ls)
b.rids.save(ls)
b.tids.save(ls)
}
func Load(ls *persist.LoadSaver) *Base {
return &Base{
name: ls.LoadString(),
details: ls.LoadString(),
multi: config.Multi(ls.LoadTinyInt()),
zipDefault: ls.LoadBool(),
gids: loadIndexes(ls),
mids: loadIndexes(ls),
cids: loadIndexes(ls),
xids: loadIndexes(ls),
bids: loadIndexes(ls),
rids: loadIndexes(ls),
tids: loadIndexes(ls),
}
}
func (b *Base) Name() string {
return b.name
}
func (b *Base) Details() string {
return b.details
}
func (b *Base) String() string {
str := fmt.Sprintf("Name: %s\nDetails: %s\n", b.name, b.details)
str += fmt.Sprintf("Number of filename signatures: %d \n", len(b.gids.ids))
str += fmt.Sprintf("Number of MIME signatures: %d \n", len(b.mids.ids))
str += fmt.Sprintf("Number of container signatures: %d \n", len(b.cids.ids))
str += fmt.Sprintf("Number of XML signatures: %d \n", len(b.xids.ids))
str += fmt.Sprintf("Number of byte signatures: %d \n", len(b.bids.ids))
str += fmt.Sprintf("Number of RIFF signatures: %d \n", len(b.rids.ids))
str += fmt.Sprintf("Number of text signatures: %d \n", len(b.tids.ids))
return str
}
func (b *Base) Inspect(ids ...string) (string, error) {
return inspect(b.p, ids...)
}
func graphP(p priority.Map, infos map[string]FormatInfo) string {
elements := p.Elements()
lines := make([]string, len(elements))
for i, v := range elements {
if v[1] == "" {
lines[i] = fmt.Sprintf("\"%s (%s)\"", infos[v[0]].String(), v[0])
continue
}
lines[i] = fmt.Sprintf("\"%s (%s)\" -> \"%s (%s)\"", infos[v[0]].String(), v[0], infos[v[1]].String(), v[1])
}
return "digraph {\n " + strings.Join(lines, "\n ") + "\n}"
}
const (
Priorities int = iota
Missing
Implicit
)
func (b *Base) GraphP(i int) string {
p := b.p.Priorities()
if p == nil && i < Implicit {
return "no priorities set"
}
switch i {
case Missing:
p = implicit(b.p.Signatures()).Difference(p)
case Implicit:
p = implicit(b.p.Signatures())
}
return graphP(p, b.p.Infos())
}
func implicit(sigs []frames.Signature, ids []string, e error) priority.Map {
pm := make(priority.Map)
if e != nil {
return pm
}
for i, v := range sigs {
for j, w := range sigs {
if i == j || ids[i] == ids[j] {
continue
}
if w.Contains(v) {
pm.Add(ids[i], ids[j])
}
}
}
return pm
}
func (b *Base) NoPriority() bool {
return b.multi >= config.Comprehensive
}
func (b *Base) Multi() config.Multi {
return b.multi
}
func (b *Base) ZipDefault() bool {
return b.zipDefault
}
func (b *Base) Hit(m core.MatcherType, idx int) (bool, string) {
switch m {
default:
return false, ""
case core.NameMatcher:
return b.gids.hit(idx)
case core.MIMEMatcher:
return b.mids.hit(idx)
case core.ContainerMatcher:
return b.cids.hit(idx)
case core.XMLMatcher:
return b.xids.hit(idx)
case core.ByteMatcher:
return b.bids.hit(idx)
case core.RIFFMatcher:
return b.rids.hit(idx)
case core.TextMatcher:
return b.tids.first(idx) // textmatcher is unique as only returns a single hit per identifier
}
}
func (b *Base) Place(m core.MatcherType, idx int) (int, int) {
switch m {
default:
return -1, -1
case core.NameMatcher:
return b.gids.place(idx)
case core.MIMEMatcher:
return b.mids.place(idx)
case core.ContainerMatcher:
return b.cids.place(idx)
case core.XMLMatcher:
return b.xids.place(idx)
case core.ByteMatcher:
return b.bids.place(idx)
case core.RIFFMatcher:
return b.rids.place(idx)
case core.TextMatcher:
return b.tids.place(idx)
}
}
func (b *Base) Lookup(m core.MatcherType, keys []string) []int {
switch m {
default:
return nil
case core.NameMatcher:
return b.gids.find(keys)
case core.MIMEMatcher:
return b.mids.find(keys)
case core.ContainerMatcher:
return b.cids.find(keys)
case core.XMLMatcher:
return b.xids.find(keys)
case core.ByteMatcher:
return b.bids.find(keys)
case core.RIFFMatcher:
return b.rids.find(keys)
case core.TextMatcher:
return b.tids.find(keys)
}
}
func (b *Base) Recognise(m core.MatcherType, idx int) (bool, string) {
h, id := b.Hit(m, idx)
if h {
return true, b.name + ": " + id
}
return false, ""
}
func (b *Base) Add(m core.Matcher, t core.MatcherType) (core.Matcher, error) {
var l int
var err error
switch t {
default:
return nil, fmt.Errorf("identifier: unknown matcher type %d", t)
case core.NameMatcher:
var globs []string
globs, b.gids.ids = b.p.Globs()
m, l, err = namematcher.Add(m, namematcher.SignatureSet(globs), nil)
if err != nil {
return nil, err
}
b.gids.start = l - len(b.gids.ids)
case core.ContainerMatcher:
znames, zsigs, zids, err := b.p.Zips()
if err != nil {
return nil, err
}
m, _, err = containermatcher.Add(
m,
containermatcher.SignatureSet{
Typ: containermatcher.Zip,
NameParts: znames,
SigParts: zsigs,
},
b.p.Priorities().List(zids),
)
if err != nil {
return nil, err
}
mnames, msigs, mids, err := b.p.MSCFBs()
if err != nil {
return nil, err
}
m, l, err = containermatcher.Add(
m,
containermatcher.SignatureSet{
Typ: containermatcher.Mscfb,
NameParts: mnames,
SigParts: msigs,
},
b.p.Priorities().List(mids),
)
if err != nil {
return nil, err
}
b.cids.ids = append(zids, mids...)
b.cids.start = l - len(b.cids.ids)
case core.MIMEMatcher:
var mimes []string
mimes, b.mids.ids = b.p.MIMEs()
m, l, err = mimematcher.Add(m, mimematcher.SignatureSet(mimes), nil)
if err != nil {
return nil, err
}
b.mids.start = l - len(b.mids.ids)
case core.XMLMatcher:
var xmls [][2]string
xmls, b.xids.ids = b.p.XMLs()
m, l, err = xmlmatcher.Add(m, xmlmatcher.SignatureSet(xmls), nil)
if err != nil {
return nil, err
}
b.xids.start = l - len(b.xids.ids)
case core.ByteMatcher:
var sigs []frames.Signature
var err error
sigs, b.bids.ids, err = b.p.Signatures()
if err != nil {
return nil, err
}
m, l, err = bytematcher.Add(m, bytematcher.SignatureSet(sigs), b.p.Priorities().List(b.bids.ids))
if err != nil {
return nil, err
}
b.bids.start = l - len(b.bids.ids)
case core.RIFFMatcher:
var riffs [][4]byte
riffs, b.rids.ids = b.p.RIFFs()
m, l, err = riffmatcher.Add(m, riffmatcher.SignatureSet(riffs), b.p.Priorities().List(b.rids.ids))
if err != nil {
return nil, err
}
b.rids.start = l - len(b.rids.ids)
case core.TextMatcher:
b.tids.ids = b.p.Texts()
if len(b.tids.ids) > 0 {
m, l, _ = textmatcher.Add(m, textmatcher.SignatureSet{}, nil)
b.tids.start = l
}
}
return m, nil
}
func (b *Base) Active(m core.MatcherType) bool {
switch m {
default:
return false
case core.NameMatcher:
return len(b.gids.ids) > 0
case core.MIMEMatcher:
return len(b.mids.ids) > 0
case core.ContainerMatcher:
return len(b.cids.ids) > 0
case core.XMLMatcher:
return len(b.xids.ids) > 0
case core.ByteMatcher:
return len(b.bids.ids) > 0
case core.RIFFMatcher:
return len(b.rids.ids) > 0
case core.TextMatcher:
return len(b.tids.ids) > 0
}
}
func (b *Base) Start(m core.MatcherType) int {
switch m {
default:
return 0
case core.NameMatcher:
return b.gids.start
case core.MIMEMatcher:
return b.mids.start
case core.ContainerMatcher:
return b.cids.start
case core.XMLMatcher:
return b.xids.start
case core.ByteMatcher:
return b.bids.start
case core.RIFFMatcher:
return b.rids.start
case core.TextMatcher:
return b.tids.start
}
}
func (b *Base) IDs(m core.MatcherType) []string {
switch m {
default:
return nil
case core.NameMatcher:
return b.gids.ids
case core.MIMEMatcher:
return b.mids.ids
case core.ContainerMatcher:
return b.cids.ids
case core.XMLMatcher:
return b.xids.ids
case core.ByteMatcher:
return b.bids.ids
case core.RIFFMatcher:
return b.rids.ids
case core.TextMatcher:
return b.tids.ids
}
}
func (b *Base) HasSig(id string, ms ...core.MatcherType) bool {
for _, m := range ms {
for _, i := range b.IDs(m) {
if id == i {
return true
}
}
}
return false
}
func contains(strs []string, s string) bool {
for _, v := range strs {
if s == v {
return true
}
}
return false
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mimeinfo
import (
"bytes"
"encoding/binary"
"encoding/hex"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/persist"
)
func init() {
patterns.Register(int8Loader, loadInt8)
patterns.Register(big16Loader, loadBig16)
patterns.Register(big32Loader, loadBig32)
patterns.Register(little16Loader, loadLittle16)
patterns.Register(little32Loader, loadLittle32)
patterns.Register(host16Loader, loadHost16)
patterns.Register(host32Loader, loadHost32)
patterns.Register(ignoreCaseLoader, loadIgnoreCase)
patterns.Register(maskLoader, loadMask)
}
const (
int8Loader = iota + 16
big16Loader
big32Loader
little16Loader
little32Loader
host16Loader
host32Loader
ignoreCaseLoader
maskLoader
)
type Int8 byte
// Test bytes against the pattern.
func (n Int8) Test(b []byte) ([]int, int) {
if len(b) < 1 {
return nil, 0
}
if b[0] == byte(n) {
return []int{1}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Int8) TestR(b []byte) ([]int, int) {
if len(b) < 1 {
return nil, 0
}
if b[len(b)-1] == byte(n) {
return []int{1}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Int8) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Int8)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Int8) Length() (int, int) {
return 1, 1
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Int8) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Int8) Sequences() []patterns.Sequence {
return []patterns.Sequence{{byte(n)}}
}
func (n Int8) String() string {
return "int8 " + hex.EncodeToString([]byte{byte(n)})
}
// Save persists the pattern.
func (n Int8) Save(ls *persist.LoadSaver) {
ls.SaveByte(int8Loader)
ls.SaveByte(byte(n))
}
func loadInt8(ls *persist.LoadSaver) patterns.Pattern {
return Int8(ls.LoadByte())
}
type Big16 uint16
// Test bytes against the pattern.
func (n Big16) Test(b []byte) ([]int, int) {
if len(b) < 2 {
return nil, 0
}
if binary.BigEndian.Uint16(b[:2]) == uint16(n) {
return []int{2}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Big16) TestR(b []byte) ([]int, int) {
if len(b) < 2 {
return nil, 0
}
if binary.BigEndian.Uint16(b[len(b)-2:]) == uint16(n) {
return []int{2}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Big16) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Big16)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Big16) Length() (int, int) {
return 2, 2
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Big16) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Big16) Sequences() []patterns.Sequence {
seq := make(patterns.Sequence, 2)
binary.BigEndian.PutUint16([]byte(seq), uint16(n))
return []patterns.Sequence{seq}
}
func (n Big16) String() string {
buf := make([]byte, 2)
binary.BigEndian.PutUint16(buf, uint16(n))
return "big16 " + hex.EncodeToString(buf)
}
// Save persists the pattern.
func (n Big16) Save(ls *persist.LoadSaver) {
ls.SaveByte(big16Loader)
buf := make([]byte, 2)
binary.BigEndian.PutUint16(buf, uint16(n))
ls.SaveBytes(buf)
}
func loadBig16(ls *persist.LoadSaver) patterns.Pattern {
return Big16(binary.BigEndian.Uint16(ls.LoadBytes()))
}
type Big32 uint32
// Test bytes against the pattern.
func (n Big32) Test(b []byte) ([]int, int) {
if len(b) < 4 {
return nil, 0
}
if binary.BigEndian.Uint32(b[:4]) == uint32(n) {
return []int{4}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Big32) TestR(b []byte) ([]int, int) {
if len(b) < 4 {
return nil, 0
}
if binary.BigEndian.Uint32(b[len(b)-4:]) == uint32(n) {
return []int{4}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Big32) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Big32)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Big32) Length() (int, int) {
return 4, 4
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Big32) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Big32) Sequences() []patterns.Sequence {
seq := make(patterns.Sequence, 4)
binary.BigEndian.PutUint32([]byte(seq), uint32(n))
return []patterns.Sequence{seq}
}
func (n Big32) String() string {
buf := make([]byte, 4)
binary.BigEndian.PutUint32(buf, uint32(n))
return "big32 " + hex.EncodeToString(buf)
}
// Save persists the pattern.
func (n Big32) Save(ls *persist.LoadSaver) {
ls.SaveByte(big32Loader)
buf := make([]byte, 4)
binary.BigEndian.PutUint32(buf, uint32(n))
ls.SaveBytes(buf)
}
func loadBig32(ls *persist.LoadSaver) patterns.Pattern {
return Big32(binary.BigEndian.Uint32(ls.LoadBytes()))
}
type Little16 uint16
// Test bytes against the pattern.
func (n Little16) Test(b []byte) ([]int, int) {
if len(b) < 2 {
return nil, 0
}
if binary.LittleEndian.Uint16(b[:2]) == uint16(n) {
return []int{2}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Little16) TestR(b []byte) ([]int, int) {
if len(b) < 2 {
return nil, 0
}
if binary.LittleEndian.Uint16(b[len(b)-2:]) == uint16(n) {
return []int{2}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Little16) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Little16)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Little16) Length() (int, int) {
return 2, 2
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Little16) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Little16) Sequences() []patterns.Sequence {
seq := make(patterns.Sequence, 2)
binary.LittleEndian.PutUint16([]byte(seq), uint16(n))
return []patterns.Sequence{seq}
}
func (n Little16) String() string {
buf := make([]byte, 2)
binary.LittleEndian.PutUint16(buf, uint16(n))
return "little16 " + hex.EncodeToString(buf)
}
// Save persists the pattern.
func (n Little16) Save(ls *persist.LoadSaver) {
ls.SaveByte(little16Loader)
buf := make([]byte, 2)
binary.LittleEndian.PutUint16(buf, uint16(n))
ls.SaveBytes(buf)
}
func loadLittle16(ls *persist.LoadSaver) patterns.Pattern {
return Little16(binary.LittleEndian.Uint16(ls.LoadBytes()))
}
type Little32 uint32
// Test bytes against the pattern.
func (n Little32) Test(b []byte) ([]int, int) {
if len(b) < 4 {
return nil, 0
}
if binary.LittleEndian.Uint32(b[:4]) == uint32(n) {
return []int{4}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Little32) TestR(b []byte) ([]int, int) {
if len(b) < 4 {
return nil, 0
}
if binary.LittleEndian.Uint32(b[len(b)-4:]) == uint32(n) {
return []int{4}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Little32) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Little32)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Little32) Length() (int, int) {
return 4, 4
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Little32) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Little32) Sequences() []patterns.Sequence {
seq := make(patterns.Sequence, 4)
binary.LittleEndian.PutUint32([]byte(seq), uint32(n))
return []patterns.Sequence{seq}
}
func (n Little32) String() string {
buf := make([]byte, 4)
binary.LittleEndian.PutUint32(buf, uint32(n))
return "little32 " + hex.EncodeToString(buf)
}
// Save persists the pattern.
func (n Little32) Save(ls *persist.LoadSaver) {
ls.SaveByte(little32Loader)
buf := make([]byte, 4)
binary.LittleEndian.PutUint32(buf, uint32(n))
ls.SaveBytes(buf)
}
func loadLittle32(ls *persist.LoadSaver) patterns.Pattern {
return Little32(binary.LittleEndian.Uint32(ls.LoadBytes()))
}
type Host16 uint16
// Test bytes against the pattern.
func (n Host16) Test(b []byte) ([]int, int) {
if len(b) < 2 {
return nil, 0
}
if binary.LittleEndian.Uint16(b[:2]) == uint16(n) {
return []int{2}, 1
}
if binary.BigEndian.Uint16(b[:2]) == uint16(n) {
return []int{2}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Host16) TestR(b []byte) ([]int, int) {
if len(b) < 2 {
return nil, 0
}
if binary.LittleEndian.Uint16(b[len(b)-2:]) == uint16(n) {
return []int{2}, 1
}
if binary.BigEndian.Uint16(b[len(b)-2:]) == uint16(n) {
return []int{2}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Host16) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Host16)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Host16) Length() (int, int) {
return 2, 2
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Host16) NumSequences() int {
return 2
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Host16) Sequences() []patterns.Sequence {
seq, seq2 := make(patterns.Sequence, 2), make(patterns.Sequence, 2)
binary.LittleEndian.PutUint16([]byte(seq), uint16(n))
binary.BigEndian.PutUint16([]byte(seq2), uint16(n))
return []patterns.Sequence{seq, seq2}
}
func (n Host16) String() string {
buf := make([]byte, 2)
binary.BigEndian.PutUint16(buf, uint16(n))
return "host16 " + hex.EncodeToString(buf)
}
// Save persists the pattern.
func (n Host16) Save(ls *persist.LoadSaver) {
ls.SaveByte(host16Loader)
buf := make([]byte, 2)
binary.LittleEndian.PutUint16(buf, uint16(n))
ls.SaveBytes(buf)
}
func loadHost16(ls *persist.LoadSaver) patterns.Pattern {
return Host16(binary.LittleEndian.Uint16(ls.LoadBytes()))
}
type Host32 uint32
// Test bytes against the pattern.
func (n Host32) Test(b []byte) ([]int, int) {
if len(b) < 4 {
return nil, 0
}
if binary.LittleEndian.Uint32(b[:4]) == uint32(n) {
return []int{4}, 1
}
if binary.BigEndian.Uint32(b[:4]) == uint32(n) {
return []int{4}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Host32) TestR(b []byte) ([]int, int) {
if len(b) < 4 {
return nil, 0
}
if binary.LittleEndian.Uint32(b[len(b)-4:]) == uint32(n) {
return []int{4}, 1
}
if binary.BigEndian.Uint32(b[len(b)-4:]) == uint32(n) {
return []int{4}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Host32) Equals(pat patterns.Pattern) bool {
n2, ok := pat.(Host32)
if ok {
return n == n2
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Host32) Length() (int, int) {
return 4, 4
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Host32) NumSequences() int {
return 2
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Host32) Sequences() []patterns.Sequence {
seq, seq2 := make(patterns.Sequence, 4), make(patterns.Sequence, 4)
binary.LittleEndian.PutUint32([]byte(seq), uint32(n))
binary.BigEndian.PutUint32([]byte(seq2), uint32(n))
return []patterns.Sequence{seq, seq2}
}
func (n Host32) String() string {
buf := make([]byte, 4)
binary.BigEndian.PutUint32(buf, uint32(n))
return "host32 " + hex.EncodeToString(buf)
}
// Save persists the pattern.
func (n Host32) Save(ls *persist.LoadSaver) {
ls.SaveByte(host32Loader)
buf := make([]byte, 4)
binary.LittleEndian.PutUint32(buf, uint32(n))
ls.SaveBytes(buf)
}
func loadHost32(ls *persist.LoadSaver) patterns.Pattern {
return Host32(binary.LittleEndian.Uint32(ls.LoadBytes()))
}
type IgnoreCase []byte
func (c IgnoreCase) Test(b []byte) ([]int, int) {
if len(b) < len(c) {
return nil, 0
}
for i, v := range c {
if v != b[i] {
if 'a' <= v && v <= 'z' && b[i] == v-'a'-'A' {
continue
}
if 'A' <= v && v <= 'Z' && b[i] == v+'a'-'A' {
continue
}
return nil, 1
}
}
return []int{len(c)}, 1
}
func (c IgnoreCase) TestR(b []byte) ([]int, int) {
if len(b) < len(c) {
return nil, 0
}
for i, v := range c {
if v != b[len(b)-len(c)+i] {
if 'a' <= v && v <= 'z' && b[len(b)-len(c)+i] == v-'a'-'A' {
continue
}
if 'A' <= v && v <= 'Z' && b[len(b)-len(c)+i] == v+'a'-'A' {
continue
}
return nil, 1
}
}
return []int{len(c)}, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (c IgnoreCase) Equals(pat patterns.Pattern) bool {
c2, ok := pat.(IgnoreCase)
if ok && bytes.Equal(bytes.ToLower(c), bytes.ToLower(c2)) {
return true
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (c IgnoreCase) Length() (int, int) {
return len(c), len(c)
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (c IgnoreCase) NumSequences() int {
i := 1
for _, v := range c {
if 'A' <= v && v <= 'z' {
i *= 2
}
}
return i
}
// Sequences converts the pattern into a slice of plain sequences.
func (c IgnoreCase) Sequences() []patterns.Sequence {
var ret []patterns.Sequence
for _, v := range c {
switch {
case 'a' <= v && v <= 'z':
ret = sequences(ret, v, v-('a'-'A'))
case 'A' <= v && v <= 'Z':
ret = sequences(ret, v, v+('a'-'A'))
default:
ret = sequences(ret, v)
}
}
return ret
}
func (c IgnoreCase) String() string {
return "ignore case " + string(c)
}
// Save persists the pattern.
func (c IgnoreCase) Save(ls *persist.LoadSaver) {
ls.SaveByte(ignoreCaseLoader)
ls.SaveBytes(c)
}
func loadIgnoreCase(ls *persist.LoadSaver) patterns.Pattern {
return IgnoreCase(ls.LoadBytes())
}
func sequences(pats []patterns.Sequence, opts ...byte) []patterns.Sequence {
if len(pats) == 0 {
pats = []patterns.Sequence{{}}
}
ret := make([]patterns.Sequence, len(opts)*len(pats))
var i int
for _, b := range opts {
for _, p := range pats {
seq := make(patterns.Sequence, len(p)+1)
copy(seq, p)
seq[len(p)] = b
ret[i] = seq
i++
}
}
return ret
}
type Mask struct {
pat patterns.Pattern
val []byte // masks for numerical types can be any number; masks for strings must be in base16 and start with 0x
}
func (m Mask) Test(b []byte) ([]int, int) {
if len(b) < len(m.val) {
return nil, 0
}
t := make([]byte, len(m.val))
for i := range t {
t[i] = b[i] & m.val[i]
}
return m.pat.Test(t)
}
func (m Mask) TestR(b []byte) ([]int, int) {
if len(b) < len(m.val) {
return nil, 0
}
t := make([]byte, len(m.val))
for i := range t {
t[i] = b[len(b)-len(t)+i] & m.val[i]
}
return m.pat.TestR(t)
}
// Equals reports whether a pattern is identical to another pattern.
func (m Mask) Equals(pat patterns.Pattern) bool {
m2, ok := pat.(Mask)
if ok && m.pat.Equals(m2.pat) && bytes.Equal(m.val, m2.val) {
return true
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (m Mask) Length() (int, int) {
return m.pat.Length()
}
func validMasks(a, b byte) []byte {
var ret []byte
var byt byte
for ; ; byt++ {
if a&byt == b {
ret = append(ret, byt)
}
if byt == 255 {
break
}
}
return ret
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (m Mask) NumSequences() int {
if n := m.pat.NumSequences(); n != 1 {
return 0
}
seq := m.pat.Sequences()[0]
if len(m.val) != len(seq) {
return 0
}
var ret int
for i, b := range m.val {
ret *= len(validMasks(b, seq[i]))
}
return ret
}
// Sequences converts the pattern into a slice of plain sequences.
func (m Mask) Sequences() []patterns.Sequence {
if n := m.pat.NumSequences(); n != 1 {
return nil
}
seq := m.pat.Sequences()[0]
if len(m.val) != len(seq) {
return nil
}
var ret []patterns.Sequence
for i, b := range m.val {
ret = sequences(ret, validMasks(b, seq[i])...)
}
return ret
}
func (m Mask) String() string {
return "mask " + hex.EncodeToString(m.val) + " (" + m.pat.String() + ")"
}
// Save persists the pattern.
func (m Mask) Save(ls *persist.LoadSaver) {
ls.SaveByte(maskLoader)
m.pat.Save(ls)
ls.SaveBytes(m.val)
}
func loadMask(ls *persist.LoadSaver) patterns.Pattern {
return Mask{
pat: patterns.Load(ls),
val: ls.LoadBytes(),
}
}
func repairMask(m Mask) (Mask, bool) {
seq := m.pat.Sequences()[0]
for _, b := range m.val {
if b != 0xFF && b != 0x00 {
return m, false
}
}
for i, b := range seq {
if b == '.' {
break
}
if i == len(seq)-1 {
return m, false
}
}
nv := make([]byte, len(seq))
for i, v := range seq {
if v == '.' {
nv[i] = 0x00
} else {
nv[i] = 0xFF
}
}
return Mask{seq, nv}, true
}
// Unmask turns 0xFF00 masks into a slice of patterns and slice of distances between those patterns.
func unmask(m Mask) ([]patterns.Pattern, []int) {
if m.pat.NumSequences() != 1 {
return []patterns.Pattern{m}, []int{0}
}
seq := m.pat.Sequences()[0]
if len(seq) != len(m.val) {
var ok bool
m, ok = repairMask(m)
if !ok {
return []patterns.Pattern{m}, []int{0}
}
}
pret, iret := []patterns.Pattern{}, []int{}
var slc, skip int
for idx, byt := range m.val {
switch byt {
case 0xFF:
slc++
case 0x00:
if slc > 0 {
pat := make(patterns.Sequence, slc)
copy(pat, seq[idx-slc:idx])
pret = append(pret, pat)
iret = append(iret, skip)
slc, skip = 0, 0
}
skip++
default:
if slc > 0 {
pat := make(patterns.Sequence, slc)
copy(pat, seq[idx-slc:idx])
pret = append(pret, pat)
iret = append(iret, skip)
slc, skip = 0, 0
}
pat := make(patterns.Sequence, len(m.val)-idx)
copy(pat, seq[idx:])
pret = append(pret, Mask{pat: pat, val: m.val[idx:]})
iret = append(iret, skip)
return pret, iret
}
}
if slc > 0 {
pat := make(patterns.Sequence, slc)
copy(pat, seq[len(m.val)-slc:])
pret = append(pret, pat)
iret = append(iret, skip)
}
return pret, iret
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package bytematcher builds a matching engine from a set of signatures and performs concurrent matching against an input siegreader.Buffer.
package bytematcher
import (
"fmt"
"sync"
"github.com/richardlehane/match/dwac"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
// Matcher matches byte signatures against the siegreader.Buffer.
type Matcher struct {
// the following fields are persisted
keyFrames [][]keyFrame
tests []*testTree
bofFrames *frameSet
eofFrames *frameSet
bofSeq *seqSet
eofSeq *seqSet
unknownBOF []keyFrameID // slice of IDs for wild segments that can't be excluded by other segments in a signature at defined offsets
unknownEOF []keyFrameID // ditto but for EOF wild segments (of which PRONOM has none)
maxBOF int
maxEOF int
priorities *priority.Set
// remaining fields are not persisted
bmu *sync.Once
emu *sync.Once
bAho *dwac.Dwac
eAho *dwac.Dwac
}
// SignatureSet for a bytematcher is a slice of frames.Signature.
type SignatureSet []frames.Signature
// Load loads a Matcher.
func Load(ls *persist.LoadSaver) core.Matcher {
if !ls.LoadBool() {
return nil
}
return &Matcher{
keyFrames: loadKeyFrames(ls),
tests: loadTests(ls),
bofFrames: loadFrameSet(ls),
eofFrames: loadFrameSet(ls),
bofSeq: loadSeqSet(ls),
eofSeq: loadSeqSet(ls),
unknownBOF: loadKeyFrameIDs(ls),
unknownEOF: loadKeyFrameIDs(ls),
maxBOF: ls.LoadInt(),
maxEOF: ls.LoadInt(),
priorities: priority.Load(ls),
bmu: &sync.Once{},
emu: &sync.Once{},
}
}
// Save persists a Matcher.
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveBool(false)
return
}
b := c.(*Matcher)
ls.SaveBool(true)
saveKeyFrames(ls, b.keyFrames)
saveTests(ls, b.tests)
b.bofFrames.save(ls)
b.eofFrames.save(ls)
b.bofSeq.save(ls)
b.eofSeq.save(ls)
saveKeyFrameIDs(ls, b.unknownBOF)
saveKeyFrameIDs(ls, b.unknownEOF)
ls.SaveInt(b.maxBOF)
ls.SaveInt(b.maxEOF)
b.priorities.Save(ls)
}
type sigErrors []error
func (se sigErrors) Error() string {
str := "bytematcher.Signatures errors:"
for _, v := range se {
str += v.Error()
str += "\n"
}
return str
}
// Add a set of signatures to a bytematcher.
// The priority list should be of equal length to the signatures, or nil (if no priorities are to be set).
//
// Example:
//
// m, n, err := Add(bm, []frames.Signature{frames.Signature{frames.NewFrame(frames.BOF, patterns.Sequence{'p','d','f'}, 0, 0)}}, nil)
func Add(c core.Matcher, ss core.SignatureSet, priorities priority.List) (core.Matcher, int, error) {
var b *Matcher
if c == nil {
b = &Matcher{
bofFrames: &frameSet{},
eofFrames: &frameSet{},
bofSeq: &seqSet{},
eofSeq: &seqSet{},
priorities: &priority.Set{},
bmu: &sync.Once{},
emu: &sync.Once{},
}
} else {
b = c.(*Matcher)
}
sigs, ok := ss.(SignatureSet)
if !ok {
return nil, -1, fmt.Errorf("byte matcher: can't convert signature set to BM signature set")
}
if len(sigs) == 0 {
return c, len(b.keyFrames), nil // return same matcher as given (may be nil) if no signatures to add
}
var se sigErrors
// process each of the sigs, adding them to b.Sigs and the various seq/frame/testTree sets
var bof, eof int
for _, sig := range sigs {
if err := b.addSignature(sig); err == nil {
// get the local max bof and eof by popping last keyframe and testing
kf := b.keyFrames[len(b.keyFrames)-1]
bof, eof = maxBOF(bof, kf), maxEOF(eof, kf)
} else {
se = append(se, err)
}
}
if len(se) > 0 {
return nil, -1, se
}
// set the maximum distances for this test tree so can properly size slices for matching
for _, t := range b.tests {
t.maxLeftDistance = maxLength(t.left)
t.maxRightDistance = maxLength(t.right)
}
// add the priorities to the priority set
b.priorities.Add(priorities, len(sigs), bof, eof)
return b, len(b.keyFrames), nil
}
// Identify matches a Matcher's signatures against the input siegreader.Buffer.
// Results are passed on the returned channel.
//
// Example:
//
// ret := bm.Identify("", buf)
// for v := range ret {
// if v.Index() == 0 {
// fmt.Print("Success! It is signature 0!")
// }
// }
func (b *Matcher) Identify(name string, sb *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
quit, ret := make(chan struct{}), make(chan core.Result)
go b.identify(sb, quit, ret, hints...)
return ret, nil
}
// String returns information about the Bytematcher including the number of BOF, VAR and EOF sequences, the number of BOF and EOF frames, and the total number of tests.
func (b *Matcher) String() string {
str := fmt.Sprintf("BOF seqs: %v\n", len(b.bofSeq.set))
str += fmt.Sprintf("EOF seqs: %v\n", len(b.eofSeq.set))
str += fmt.Sprintf("BOF frames: %v\n", len(b.bofFrames.set))
str += fmt.Sprintf("EOF frames: %v\n", len(b.eofFrames.set))
str += fmt.Sprintf("Total Test Trees: %v\n", len(b.tests))
var c, ic, l, r, ml, mr int
for _, t := range b.tests {
c += len(t.complete)
ic += len(t.incomplete)
l += len(t.left)
if ml < t.maxLeftDistance {
ml = t.maxLeftDistance
}
r += len(t.right)
if mr < t.maxRightDistance {
mr = t.maxRightDistance
}
}
str += fmt.Sprintf("Complete Tests: %v\n", c)
str += fmt.Sprintf("Incomplete Tests: %v\n", ic)
str += fmt.Sprintf("Left Tests: %v\n", l)
str += fmt.Sprintf("Right Tests: %v\n", r)
str += fmt.Sprintf("Maximum Left Distance: %v\n", ml)
str += fmt.Sprintf("Maximum Right Distance: %v\n", mr)
str += fmt.Sprintf("Number of unexcludable wild BOF segments: %v\n", len(b.unknownBOF))
str += fmt.Sprintf("Number of unexcludable wild EOF segments: %v\n", len(b.unknownEOF))
str += fmt.Sprintf("Maximum BOF Distance: %v\n", b.maxBOF)
str += fmt.Sprintf("Maximum EOF Distance: %v\n", b.maxEOF)
str += fmt.Sprintf("priorities: %v\n", b.priorities)
return str
}
// InspectTestTree reports which signatures are linked to a given index in the test tree.
// This is used by the -log debug and -log slow options for sf.
func (b *Matcher) InspectTestTree(i int) []int {
cres, ires, _, _, _, _ := b.DescribeTestTree(i)
return append(cres, ires...)
}
func (b *Matcher) DescribeTestTree(i int) ([]int, []int, int, int, int, int) {
if i < 0 || i >= len(b.tests) {
return nil, nil, 0, 0, 0, 0
}
t := b.tests[i]
cres := make([]int, len(t.complete))
for i, v := range t.complete {
cres[i] = v[0]
}
ires := make([]int, len(t.incomplete))
for i, v := range t.incomplete {
ires[i] = v.kf[0]
}
return cres, ires, t.maxLeftDistance, t.maxRightDistance, maxMatches(t.left, t.maxLeftDistance), maxMatches(t.right, t.maxRightDistance)
}
func (b *Matcher) TestTreeLen() int {
return len(b.tests)
}
func (b *Matcher) DescribeKeyFrames(i int) []string {
if i < 0 || i >= len(b.keyFrames) {
return nil
}
ret := make([]string, len(b.keyFrames[i]))
for j := range ret {
ret[j] = b.keyFrames[i][j].String()
}
return ret
}
func (b *Matcher) KeyFramesLen() int {
return len(b.keyFrames)
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Satisfies the Parseable interface to enable Roy to process Wikidata
// signatures into a Siegfried compatible identifier.
package wikidata
import (
"errors"
"fmt"
"strconv"
"strings"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/mappings"
"github.com/richardlehane/siegfried/pkg/pronom"
)
// Globs match based on some pattern in the filename of a file. For
// Wikidata this means we'll use the extensions returned by the service
// to match formats by that.
func (wdd wikidataDefinitions) Globs() ([]string, []string) {
logln(
"Roy (Wikidata): Adding Glob signatures to identifier...",
)
globs, ids := make(
[]string, 0, len(wdd.formats)),
make([]string, 0, len(wdd.formats))
for _, v := range wdd.formats {
for _, w := range v.Extension {
globs, ids = append(globs, "*."+w), append(ids, v.ID)
}
}
return globs, ids
}
// Signatures maps our standard non-container binary signatures into the
// Wikidata identifier.
func (wdd wikidataDefinitions) Signatures() ([]frames.Signature, []string, error) {
frames, ids, err := processSIgnatures(wdd)
return frames, ids, err
}
// collectPUIDs identifies the PUIDs we have at our disposal in the
// Wikidata report and collects them into a map to be processed into
// the identifier to augment the identifiers capabilities with PRONOM
// binary signatures.
func collectPUIDs(puidsIDs map[string][]string, v mappings.Wikidata) map[string][]string {
if puidsIDs != nil {
for _, puid := range v.PUIDs() {
puidsIDs[puid] = append(puidsIDs[puid], v.ID)
}
}
return puidsIDs
}
// byteSequences provides an alias for the mappings ByteSequence object.
type byteSequences = []mappings.ByteSequence
// pronomSequence provides an alias for the PRONOM compatibility object.
type pronomSequence = pronom.PROCompatSequence
// processForPronom maps Wikidata byte sequences into a slice that can
// be processed through the PRONOM identifier which is enabled by the
// PRONOM compatibility sequence, PROCompatSequence.
func processForPronom(bs byteSequences) []pronomSequence {
var pronomSlice []pronomSequence
for _, b := range bs {
ps := pronomSequence{}
switch b.Relativity {
case relativeBOF:
ps.Position = pronom.BeginningOfFile
case relativeEOF:
ps.Position = pronom.EndOfFile
default:
// We might otherwise return an error. I don't think there
// is a high risk with the pre-processing work we do for the
// identifier, and other errors will be caught below.
}
ps.Hex = b.Signature
ps.Offset = strconv.Itoa(b.Offset)
pronomSlice = append(pronomSlice, ps)
}
return pronomSlice
}
// processSignatures processes the Wikidata signatures into an
// identifier and returns a slice of Signature frames, IDs, and errors
// collected along the way.
func processSIgnatures(wdd wikidataDefinitions) ([]frames.Signature, []string, error) {
logln(
"Roy (Wikidata): Adding Wikidata Byte signatures to identifier...",
)
var errs []error
var puidsIDs map[string][]string
if len(wdd.parseable.IDs()) > 0 {
puidsIDs = make(map[string][]string)
}
sigs := make([]frames.Signature, 0, len(wdd.formats))
ids := make([]string, 0, len(wdd.formats))
for _, wd := range wdd.formats {
puidsIDs = collectPUIDs(puidsIDs, wd)
for _, v := range wd.Signatures {
ps := processForPronom(v.ByteSequences)
frames, err := pronom.FormatPRONOM(wd.ID, ps)
if err != nil {
errs = append(errs, err)
}
sigs = append(sigs, frames)
ids = append(ids, wd.ID)
}
}
// Add PRONOM into the mix.
if puidsIDs != nil {
puids := make([]string, 0, len(puidsIDs))
for p := range puidsIDs {
puids = append(puids, p)
}
newParseable := identifier.Filter(puids, wdd.parseable)
pronomSignatures, pronomIdentifiers, err :=
newParseable.Signatures()
if err != nil {
errs = append(errs, err)
}
for i, v := range pronomIdentifiers {
for _, id := range puidsIDs[v] {
sigs = append(sigs, pronomSignatures[i])
ids = append(ids, id)
}
}
}
var err error
if len(errs) > 0 {
errStrs := make([]string, len(errs))
for i, e := range errs {
errStrs[i] = e.Error()
}
err = errors.New(strings.Join(errStrs[:], "; "))
}
return sigs, ids, err
}
// Zips adds ZIP based container signatures to the identifier.
func (wdd wikidataDefinitions) Zips() ([][]string, [][]frames.Signature, []string, error) {
return wdd.containers("ZIP")
}
// MSCFBs adds OLE2 based container signatures to the identifier.
func (wdd wikidataDefinitions) MSCFBs() ([][]string, [][]frames.Signature, []string, error) {
return wdd.containers("OLE2")
}
// Wikidata doesn't have its own concept of container format
// identification just yet and so we do this via PRONOM's in-build
// methods. This mimics that of the Library of Congress identifier.
// Wikidata container modeling is in-progress.
func (wdd wikidataDefinitions) containers(typ string) ([][]string, [][]frames.Signature, []string, error) {
logln(
"Roy (Wikidata): Adding container signatures to identifier...",
)
if _, ok := wdd.parseable.(identifier.Blank); ok {
return nil, nil, nil, nil
}
puidsIDs := make(map[string][]string)
for _, v := range wdd.formats {
for _, puid := range v.PUIDs() {
puidsIDs[puid] = append(puidsIDs[puid], v.ID)
}
}
puids := make([]string, 0, len(puidsIDs))
for p := range puidsIDs {
puids = append(puids, p)
}
np := identifier.Filter(puids, wdd.parseable)
names, sigs, ids :=
make([][]string, 0, len(wdd.formats)),
make([][]frames.Signature, 0, len(wdd.formats)),
make([]string, 0, len(wdd.formats))
var (
ns [][]string
ss [][]frames.Signature
is []string
err error
)
switch typ {
default:
err = fmt.Errorf("Unknown container type: %s", typ)
case "ZIP":
ns, ss, is, err = np.Zips()
case "OLE2":
ns, ss, is, err = np.MSCFBs()
}
if err != nil {
return nil, nil, nil, err
}
for i, puid := range is {
for _, id := range puidsIDs[puid] {
names = append(names, ns[i])
sigs = append(sigs, ss[i])
ids = append(ids, id)
}
}
return names, sigs, ids, nil
}
<file_sep>package patterns
import "testing"
func TestOverlap(t *testing.T) {
res := overlap([]byte{'p', 'd', 'f', 'a'}, []byte{'d', 'f', 'a', 'b'})
if res != 1 {
t.Errorf("FAIL: expect 1, got %d\n", res)
}
res = overlap([]byte{'p', 'd', 'f', 'a'}, []byte{'f', 'a', 'b'})
if res != 2 {
t.Errorf("FAIL: expect 2, got %d\n", res)
}
res = overlap([]byte{'p', 'd', 'f', 'a'}, []byte{'a', 'b'})
if res != 3 {
t.Errorf("FAIL: expect 3, got %d\n", res)
}
res = overlap([]byte{'p', 'd', 'f', 'a'}, []byte{'b'})
if res != 4 {
t.Errorf("FAIL: expect 4, got %d\n", res)
}
}
func TestOverlapR(t *testing.T) {
res := overlapR([]byte{'e', 'o', 'f', 'a'}, []byte{'d', 'e', 'o', 'f'})
if res != 1 {
t.Errorf("FAIL: expect 1, got %d\n", res)
}
res = overlapR([]byte{'e', 'o', 'f', 'a'}, []byte{'d', 'e', 'o'})
if res != 2 {
t.Errorf("FAIL: expect 2, got %d\n", res)
}
res = overlapR([]byte{'e', 'o', 'f', 'a'}, []byte{'d', 'e'})
if res != 3 {
t.Errorf("FAIL: expect 3, got %d\n", res)
}
res = overlapR([]byte{'e', 'o', 'f', 'a'}, []byte{'a'})
if res != 4 {
t.Errorf("FAIL: expect 4, got %d\n", res)
}
}
<file_sep>//go:build !windows
// +build !windows
// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"os"
"path/filepath"
"time"
)
func retryOpen(path string, err error) (*os.File, error) {
return nil, err
}
func tryStat(path string) error {
_, err := os.Lstat(path)
return err
}
func identify(ctxts chan *context, root, orig string, coerr, norecurse, droid bool, gf getFn) error {
walkFunc := func(path string, info os.FileInfo, err error) error {
if *throttlef > 0 {
<-throttle.C
}
if err != nil {
if coerr {
printFile(ctxts, gf(path, "", time.Time{}, 0), walkError{path, err})
return nil
}
return walkError{path, err}
}
if info.IsDir() {
if norecurse && path != root {
return filepath.SkipDir
}
if droid {
printFile(ctxts, gf(path, "", info.ModTime(), -1), nil)
}
return nil
}
// zero user read permissions mask, octal 400 (decimal 256)
if !info.Mode().IsRegular() || info.Mode()&256 == 0 {
printFile(ctxts, gf(path, "", info.ModTime(), info.Size()), modeError(info.Mode()))
return nil
}
identifyFile(gf(path, "", info.ModTime(), info.Size()), ctxts, gf)
return nil
}
return filepath.Walk(root, walkFunc)
}
<file_sep>// +build archivematica
package config
func init() {
siegfried.home = "/usr/share/siegfried"
siegfried.signature = "archivematica.sig"
identifier.name = "archivematica"
identifier.extend = []string{"archivematica-fmt2.xml", "archivematica-fmt3.xml", "archivematica-fmt4.xml", "archivematica-fmt5.xml"}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package siegreader
import "sync"
// bigfile handles files that are too large to mmap (normally encountered on 32-bit machines)
type bigfile struct {
*file
eof [eofSz]byte
wheel [wheelSz]byte
mu sync.Mutex
i int // wheel offset for next write
start, end, progress int64 // start and end are file offsets for the head and tail of the wheel; progress is file offset for the last call to progressSlice
}
func newBigFile() interface{} {
return &bigfile{progress: int64(initialRead)}
}
func (bf *bigfile) setSource(f *file) {
bf.file = f
// reset
bf.i = 0
bf.progress = int64(initialRead)
// fill the EOF slice
bf.src.ReadAt(bf.eof[:], bf.sz-int64(eofSz))
}
func (bf *bigfile) progressSlice(o int64) []byte {
if bf.i == 0 {
bf.start = o
i, _ := bf.src.Read(bf.wheel[:])
bf.end = bf.start + int64(i)
if i < readSz {
return nil
}
}
slc := bf.wheel[bf.i : bf.i+readSz]
bf.i += readSz
if bf.i == wheelSz {
bf.i = 0
}
return slc
}
func (bf *bigfile) slice(o int64, l int) []byte {
// if within the eof, return from there
if bf.sz-o <= int64(eofSz) {
x := eofSz - int(bf.sz-o)
return bf.eof[x : x+l] // (l is safe because read lengths already confirmed as legal)
}
bf.mu.Lock()
defer bf.mu.Unlock()
if l == readSz && bf.progress == o { // if adjacent to last progress read and right length, assume this is a progress read
bf.progress += int64(readSz)
return bf.progressSlice(o)
}
ret := make([]byte, l)
// if within the wheel, copy
if o >= bf.start && o+int64(l) <= bf.end { // within wheel
copy(ret, bf.wheel[int(o-bf.start):int(o-bf.start)+l])
return ret
}
// otherwise we just expose the underlying reader at
bf.src.ReadAt(ret, o)
return ret
}
func (bf *bigfile) eofSlice(o int64, l int) []byte {
if o+int64(l) > int64(eofSz) {
ret := make([]byte, l)
bf.mu.Lock()
defer bf.mu.Unlock()
bf.src.ReadAt(ret, bf.sz-o-int64(l))
return ret
}
return bf.eof[eofSz-int(o)-l : eofSz-int(o)]
}
<file_sep>package containermatcher
import (
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/frames"
"github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
)
func testTrigger([]byte) bool {
return true
}
var testContainerMatcher *ContainerMatcher = &ContainerMatcher{
ctype: ctype{testTrigger, newTestReader},
conType: 0,
nameCTest: make(map[string]*cTest),
priorities: &priority.Set{},
startIndexes: []int{0},
entryBufs: siegreader.New(),
}
var count int
func TestMatcher(t *testing.T) {
ctypes = []ctype{{testTrigger, newTestReader}}
// test adding
count++
testMatcher, _, err := Add(Matcher{testContainerMatcher},
SignatureSet{
0,
[][]string{{"one", "two"}, {"one"}},
[][]frames.Signature{{tests.TestSignatures[3], tests.TestSignatures[4]}, {tests.TestSignatures[2]}},
},
nil,
)
if err != nil {
t.Fatal(err)
}
// test IO
str := testMatcher.String()
saver := persist.NewLoadSaver(nil)
Save(testMatcher, saver)
if len(saver.Bytes()) < 100 {
t.Errorf("Save container: too small, only got %v", len(saver.Bytes()))
}
newcm := Load(persist.NewLoadSaver(saver.Bytes()))
str2 := newcm.String()
if len(str) != len(str2) {
t.Errorf("Load container: expecting first matcher (%v), to equal second matcher (%v)", str, str2)
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Satisfies the Identifier interface: functions responsible for PERSIST
// (saving and loading data structures to the Siegfried signature file).
// Also creates the structures we are going to use to inspect the
// signature file which also get converted to Siegfried result sets,
// including provenance and revision history.
package wikidata
import (
"fmt"
"strings"
"time"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/mappings"
)
// Alias for the FormatInfo interface in Parseable to make it easier to
// reference.
type parseableFormatInfo = map[string]identifier.FormatInfo
// Save will write a Wikidata identifier to the Siegfried signature
// file using the persist package to save primitives in the identifier's
// data structure.
func (i *Identifier) Save(ls *persist.LoadSaver) {
// Save the Wikidata magic enum from core.
ls.SaveByte(core.Wikidata)
// Save the no. formatInfo entries to read.
ls.SaveSmallInt(len(i.infos))
// Save the information in the formatInfo records.
for idx, value := range i.infos {
ls.SaveString(idx)
ls.SaveString(value.name)
ls.SaveString(value.uri)
ls.SaveString(value.mime)
ls.SaveStrings(value.sources)
ls.SaveString(value.permalink)
ls.SaveString(value.revisionHistory)
}
i.Base.Save(ls)
}
// Load back into memory from the signature file the same information
// that we wrote to the file using Save().
func Load(ls *persist.LoadSaver) core.Identifier {
i := &Identifier{}
le := ls.LoadSmallInt()
i.infos = make(map[string]formatInfo)
for j := 0; j < le; j++ {
i.infos[ls.LoadString()] = formatInfo{
ls.LoadString(), // name.
ls.LoadString(), // URI.
ls.LoadString(), // mime.
ls.LoadStrings(), // sources.
ls.LoadString(), // permalink.
ls.LoadString(), // revision history.
}
}
i.Base = identifier.Load(ls)
return i
}
// formatInfo can hold absolutely anything and can be used to return
// that information to the user. So we could also map to PUID or LoC
// identifier here if there was a strong link. Other information might
// exist in Wikidata (does exist in Wikidata) that we might want to map
// here, e.g. file formats capable of rendering the identified file.
type formatInfo struct {
// name is the Name as retrieved from Wikidata. Name usually
// incorporates version too in Wikidata which is why there isn't a
// separate field for that.
name string
// uri is Wikidata IRI, e.g. http://www.wikidata.org/entity/Q1069215
uri string
// mime is a semi-colon separated list of the MIMETypes which are
// also associated with a file format.
mime string
// sources describes the source of a signature retrieved from
// Wikidata.
sources []string
// permalink refers to the Wikibase permalink for a Wikidata record.
// The data at the permalink represents the specific version of the
// record used to derive the information used by Siegfried, e.g.
// signature definition.
permalink string
// revisionHistory refers to a bigger chunk of JSON which can be
// displayed to a user to describe the history of a format
// definition.
revisionHistory string
}
// infos turns the generic formatInfo into the structure that will be
// written into the Siegfried identifier.
func infos(formatInfoMap parseableFormatInfo) map[string]formatInfo {
idx := make(map[string]formatInfo, len(formatInfoMap))
for key, value := range formatInfoMap {
idx[key] = value.(formatInfo)
}
return idx
}
// Serialize formatInfo as a string for the roy --inspect function and
// debugging.
func (f formatInfo) String() string {
sources := ""
if len(f.sources) > 0 {
sources = strings.Join(f.sources, " ")
}
return fmt.Sprintf(
"Name: '%s'\nMIMEType: '%s'\nSources: '%s' \nRevision History: %s\n---",
f.name,
f.mime,
sources,
f.revisionHistory,
)
}
// Infos arranges summary information about formats within an Identifier
// into a structure suitable for output in a Siegfried signature file.
//
// Infos provides a mechanism for a placing any other information about
// formats that you'd like to talk about in an identifier.
func (wdd wikidataDefinitions) Infos() parseableFormatInfo {
logf(
"Roy (Wikidata): In Infos()... length formats: '%d' no-pronom: '%t'\n",
len(wdd.formats),
config.GetWikidataNoPRONOM(),
)
formatInfoMap := make(
map[string]identifier.FormatInfo, len(wdd.formats),
)
for _, value := range wdd.formats {
var mime = value.Mimetype[0]
if len(value.Mimetype) > 1 {
// Q24907733 is a good example with mimes:
//
// `image/heif-sequence`; `image/heif`;
// `image/heic-sequence`; `image/heic...`
//
for idx, value := range value.Mimetype {
if idx == 0 {
continue
}
mime = fmt.Sprintf("%s; %s", mime, value)
}
}
sources := prepareSources(value)
fi := formatInfo{
name: value.Name,
uri: value.URI,
mime: mime,
sources: sources,
permalink: value.Permalink,
revisionHistory: value.RevisionHistory,
}
formatInfoMap[value.ID] = fi
}
return formatInfoMap
}
// prepareSources prepares a slice of sources that will be used to
// return some sort of source information (provenance of datum in
// Wikidata) for positive matches returned by the Wikidata identifier.
// We need to return a slice here as order of processing is important
// and matches the order which they will be processed into the
// identifier in the other identifier functions.
//
// We also want to take into account the native PRONOM sources here.
//
// What is also strange about this function is that it happens before
// Parseable processes the signatures for this identifier and so there
// is a potential for things to go wrong. If we start seeing issues in
// Parseable with the data, we might also need to consider how we
// interact with signature sources to modify them on the fly.
//
// We currently return a slice of strings but in-time there might well
// be value in using a struct here. The struct could then encode
// "source" information in different fields and could in future encode
// information of increasing complexity. The structure would also need
// to be compatible with Siegfried's/Roy's persist package.
func prepareSources(wdMapping mappings.Wikidata) []string {
// Output the source date consistently.
const provDateFormat = "2006-01-02"
sources := []string{}
// We need at least one signature to write a source for.
if len(wdMapping.Signatures) > 0 {
// Records like MACH-0 (Q2627217) are good examples of records
// with multiple signatures that can potentially have different
// sources.
for idx := range wdMapping.Signatures {
prov := wdMapping.Signatures[idx].Source
date := wdMapping.Signatures[idx].Date
if date != "" {
date, _ := time.Parse(time.RFC3339, date)
prov = fmt.Sprintf("%s (source date: %s)", prov, date.Format(provDateFormat))
}
sources = append(sources, prov)
}
}
if !config.GetWikidataNoPRONOM() {
// Bring PRONOM sources into the identifier.
for _, exid := range wdMapping.PRONOM {
// We have PRONOM identifiers to work with so we need to extend the
// slice further.
for _, value := range sourcePuids {
if exid == value {
sources = append(sources, fmt.Sprintf(pronomOfficial, exid))
}
}
}
}
return sources
}
<file_sep>package main
import (
"encoding/json"
"errors"
"flag"
"io/fs"
"strings"
"testing"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/loc"
"github.com/richardlehane/siegfried/pkg/mimeinfo"
"github.com/richardlehane/siegfried/pkg/pronom"
"github.com/richardlehane/siegfried/pkg/sets"
wd "github.com/richardlehane/siegfried/pkg/wikidata"
)
var testhome = flag.String("home", "data", "override the default home directory")
func TestDefault(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
p, err := pronom.New()
if err != nil {
t.Fatal(err)
}
err = s.Add(p)
if err != nil {
t.Fatal(err)
}
}
func TestLoc(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
l, err := loc.New(config.SetLOC(""))
if err != nil {
t.Fatal(err)
}
err = s.Add(l)
if err != nil {
t.Fatal(err)
}
}
func TestTika(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
m, err := mimeinfo.New(config.SetMIMEInfo("tika"))
if err != nil {
t.Fatal(err)
}
err = s.Add(m)
if err != nil {
t.Fatal(err)
}
}
func TestFreedesktop(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
m, err := mimeinfo.New(config.SetMIMEInfo("freedesktop"))
if err != nil {
t.Fatal(err)
}
err = s.Add(m)
if err != nil {
t.Fatal(err)
}
}
func TestWikidata(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
config.SetWikidataDefinitions("wikidata-test-definitions")
m, err := wd.New(config.SetWikidataNamespace())
if err != nil {
t.Fatal(err)
}
err = s.Add(m)
if err != nil {
t.Fatal(err)
}
}
func TestWikibaseNoEndpoint(t *testing.T) {
config.SetHome(*testhome)
config.SetWikidataDefinitions("custom-wikibase-test-definitions-no-endpoint")
_, err := wd.New(config.SetWikidataNamespace())
if !errors.Is(err, wd.ErrNoEndpoint) {
t.Fatalf(
"Expected 'ErrNoEndpoint' trying to open custom Wikibase definitions, but got: '%s'",
err,
)
}
}
func TestWikibaseNoProps(t *testing.T) {
config.SetHome(*testhome)
config.SetWikibasePropsPath("/path/does/not/exist.json")
config.SetWikidataDefinitions("custom-wikibase-test-definitions")
_, err := wd.New(config.SetWikidataNamespace())
if !errors.Is(err, fs.ErrNotExist) {
t.Fatalf(
"Expected an error trying to open custom Wikibase properties, but got: '%s'",
err,
)
}
}
func TestWikibase(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
// Default wouldn't normally need to be set, but may be overridden
// through other tests.
config.SetWikibasePropsPath("wikibase.json")
config.SetWikidataDefinitions("custom-wikibase-test-definitions")
m, err := wd.New(config.SetWikidataNamespace())
if err != nil {
t.Fatal(err)
}
err = s.Add(m)
if err != nil {
t.Fatal(err)
}
}
func TestPronomTikaLoc(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
p, err := pronom.New(config.Clear())
if err != nil {
t.Fatal(err)
}
err = s.Add(p)
if err != nil {
t.Fatal(err)
}
m, err := mimeinfo.New(config.SetMIMEInfo("tika"))
if err != nil {
t.Fatal(err)
}
err = s.Add(m)
if err != nil {
t.Fatal(err)
}
l, err := loc.New(config.SetLOC(""))
if err != nil {
t.Fatal(err)
}
err = s.Add(l)
if err != nil {
t.Fatal(err)
}
}
func TestDeluxe(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
p, err := pronom.New(config.Clear())
if err != nil {
t.Fatal(err)
}
err = s.Add(p)
if err != nil {
t.Fatal(err)
}
m, err := mimeinfo.New(config.SetMIMEInfo("tika"))
if err != nil {
t.Fatal(err)
}
err = s.Add(m)
if err != nil {
t.Fatal(err)
}
f, err := mimeinfo.New(config.SetMIMEInfo("freedesktop"))
if err != nil {
t.Fatal(err)
}
err = s.Add(f)
if err != nil {
t.Fatal(err)
}
l, err := loc.New(config.SetLOC(""))
if err != nil {
t.Fatal(err)
}
err = s.Add(l)
if err != nil {
t.Fatal(err)
}
}
func TestArchivematica(t *testing.T) {
s := siegfried.New()
config.SetHome(*testhome)
p, err := pronom.New(
config.SetName("archivematica"),
config.SetExtend(sets.Expand("archivematica-fmt2.xml,archivematica-fmt3.xml,archivematica-fmt4.xml,archivematica-fmt5.xml")))
if err != nil {
t.Fatal(err)
}
err = s.Add(p)
if err != nil {
t.Fatal(err)
}
}
// TestAddEndpoint makes sure that valid JSON is still output when we
// add the endpoint to the SPARQL JSON.
func TestAddEndpoint(t *testing.T) {
simpleJSON := `
{
"key_one": "value_one",
"key_two": "value_two"
}
`
resJSON := `
{
"endpoint": "http://example.com:8834/proxy/wdqs/bigdata/namespace/wdq/sparql?",
"key_one": "value_one",
"key_two": "value_two"
}
`
res := addEndpoint(
simpleJSON,
"http://example.com:8834/proxy/wdqs/bigdata/namespace/wdq/sparql?",
)
// Try to see if adding endpoint works, and is equal to our sample
// JSON before checking whether or not it is valid.
if res != resJSON {
t.Errorf(
"Replacement result '%s' does not match what was expected '%s'",
res,
resJSON,
)
}
valid := json.Valid([]byte(res))
if !valid {
t.Fatalf("Add endpoint returned invalid JSON: '%s'", res)
}
// Lets flatten the JSON structure a bit and see if we can cause
// more problems this way,
res = addEndpoint(
strings.ReplaceAll(simpleJSON, "\n", ""),
"http://example.com:8834/proxy/wdqs/bigdata/namespace/wdq/sparql?",
)
if strings.ReplaceAll(res, "\n", "") !=
strings.ReplaceAll(resJSON, "\n", "") {
t.Errorf(
"Replacement result '%s' does not match what was expected '%s'",
res,
resJSON,
)
}
valid = json.Valid([]byte(res))
if !valid {
t.Fatalf(
"Add endpoint returned invalid JSON: '%s'",
res,
)
}
}
// invokeOptions cycles through an options slice and invokes each of
// their functions to set them within their respective configs.
func invokeOptions(opts []config.Option) {
// Invoke the options we're trying to test.
for _, value := range opts {
value()
}
}
// TestNoPRONOM makes sure that the InspectNoPronom flag is set for the
// identifiers that use it.
func TestInspectNoPRONOM(t *testing.T) {
opts := getOptions()
invokeOptions(opts)
if config.NoPRONOM() != false {
t.Errorf("LoC NoPRONOM default is incorrect: %t", config.NoPRONOM())
}
if config.GetWikidataNoPRONOM() != false {
t.Errorf("Wikidata NoPRONOM default is incorrect: %t", config.GetWikidataNoPRONOM())
}
*inspectNoPRONOM = true
opts = getOptions()
invokeOptions(opts)
if config.NoPRONOM() != true {
t.Errorf("LoC NoPRONOM not set as anticipated: %t", config.NoPRONOM())
}
if config.GetWikidataNoPRONOM() != true {
t.Errorf("Wikidata NoPRONOM not set as anticipated: %t", config.GetWikidataNoPRONOM())
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Package patterns describes the Pattern interface.
// Standard patterns are also defined in this package: Sequence (as well as BMH and reverse BMH Sequence), Choice, List and Not.
package patterns
import (
"bytes"
"encoding/hex"
"errors"
"fmt"
"strconv"
"unicode/utf8"
"github.com/richardlehane/siegfried/internal/persist"
)
func init() {
Register(sequenceLoader, loadSequence)
Register(choiceLoader, loadChoice)
Register(listLoader, loadList)
Register(notLoader, loadNot)
Register(bmhLoader, loadBMH)
Register(rbmhLoader, loadRBMH)
Register(maskLoader, loadMask)
Register(anyMaskLoader, loadAnyMask)
}
// Stringify returns a string version of a byte slice.
// If all bytes are UTF8, an ASCII string is returned
// Otherwise a hex string is returned.
func Stringify(b []byte) string {
if utf8.Valid(b) {
return strconv.QuoteToASCII(string(b))
}
return hex.EncodeToString(b)
}
// Patterns are the smallest building blocks of a format signature.
// Exact byte sequence matches are a type of pattern, as are byte ranges, non-sequence matches etc.
// You can define custom patterns (e.g. for W3C date type) by implementing this interface.
type Pattern interface {
Test([]byte) ([]int, int) // For a positive match, returns slice of lengths of the match and bytes to advance for a subsequent test. For a negative match, returns nil or empty slice and the bytes to advance for subsequent test (or 0 if the length of the pattern is longer than the length of the slice).
TestR([]byte) ([]int, int) // Same as Test but for testing in reverse (from the right-most position of the byte slice).
Equals(Pattern) bool // Test equality with another pattern
Length() (int, int) // Minimum and maximum lengths of the pattern
NumSequences() int // Number of simple sequences represented by a pattern. Return 0 if the pattern cannot be represented by a defined number of simple sequence (e.g. for an indirect offset pattern) or, if in your opinion, the number of sequences is unreasonably large.
Sequences() []Sequence // Convert the pattern to a slice of sequences. Return an empty slice if the pattern cannot be represented by a defined number of simple sequences.
String() string
Save(*persist.LoadSaver) // encode the pattern into bytes for saving in a persist file
}
// Loader loads a Pattern.
type Loader func(*persist.LoadSaver) Pattern
const (
sequenceLoader byte = iota
choiceLoader
listLoader
notLoader
bmhLoader
rbmhLoader
maskLoader
anyMaskLoader
)
var loaders = [32]Loader{}
// Register a new Loader (provide an id higher than 16).
func Register(id byte, l Loader) {
loaders[int(id)] = l
}
// Load loads the Pattern, choosing the correct Loader by the leading id byte.
func Load(ls *persist.LoadSaver) Pattern {
id := ls.LoadByte()
l := loaders[int(id)]
if l == nil {
if ls.Err == nil {
ls.Err = errors.New("bad pattern loader")
}
return nil
}
return l(ls)
}
// Index reports the offset of one pattern within another (or -1 if not contained)
func Index(a, b Pattern) int {
if a.Equals(b) {
return 0
}
seq1, ok := a.(Sequence)
seq2, ok2 := b.(Sequence)
if ok && ok2 {
return bytes.Index(seq1, seq2)
}
return -1
}
// Sequence is a matching sequence of bytes.
type Sequence []byte
// Test bytes against the pattern.
func (s Sequence) Test(b []byte) ([]int, int) {
if len(b) < len(s) {
return nil, 0
}
if bytes.Equal(s, b[:len(s)]) {
return []int{len(s)}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (s Sequence) TestR(b []byte) ([]int, int) {
if len(b) < len(s) {
return nil, 0
}
if bytes.Equal(s, b[len(b)-len(s):]) {
return []int{len(s)}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (s Sequence) Equals(pat Pattern) bool {
seq2, ok := pat.(Sequence)
if ok {
return bytes.Equal(s, seq2)
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (s Sequence) Length() (int, int) {
return len(s), len(s)
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (s Sequence) NumSequences() int {
return 1
}
// Sequences converts the pattern into a slice of plain sequences.
func (s Sequence) Sequences() []Sequence {
return []Sequence{s}
}
func (s Sequence) String() string {
return "seq " + Stringify(s)
}
// The Reverse method is unique to this pattern. It is used for the EOF byte sequence set
func (s Sequence) Reverse() Sequence {
p := make(Sequence, len(s))
for i, j := 0, len(s)-1; j > -1; i, j = i+1, j-1 {
p[i] = s[j]
}
return p
}
// Save persists the pattern.
func (s Sequence) Save(ls *persist.LoadSaver) {
ls.SaveByte(sequenceLoader)
ls.SaveBytes(s)
}
func loadSequence(ls *persist.LoadSaver) Pattern {
return Sequence(ls.LoadBytes())
}
// Choice is a slice of patterns, any of which can test successfully for the pattern to succeed. For advance, returns shortest
type Choice []Pattern
func (c Choice) test(b []byte, f func(Pattern, []byte) ([]int, int)) ([]int, int) {
var r, res []int
var tl, fl, adv int // trueLen and falseLen
for _, pat := range c {
res, adv = f(pat, b)
if len(res) > 0 {
r = append(r, res...)
if tl == 0 || (adv > 0 && adv < tl) {
tl = adv
}
} else if fl == 0 || (adv > 0 && adv < fl) {
fl = adv
}
}
if len(r) > 0 {
return r, tl
}
return nil, fl
}
// Test bytes against the pattern.
func (c Choice) Test(b []byte) ([]int, int) {
return c.test(b, Pattern.Test)
}
// Test bytes against the pattern in reverse.
func (c Choice) TestR(b []byte) ([]int, int) {
return c.test(b, Pattern.TestR)
}
// Equals reports whether a pattern is identical to another pattern.
func (c Choice) Equals(pat Pattern) bool {
c2, ok := pat.(Choice)
if ok {
if len(c) == len(c2) {
for _, p := range c {
ident := false
for _, p2 := range c2 {
if p.Equals(p2) {
ident = true
}
}
if !ident {
return false
}
}
return true
}
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (c Choice) Length() (int, int) {
var min, max int
if len(c) > 0 {
min, max = c[0].Length()
}
for _, pat := range c {
min2, max2 := pat.Length()
if min2 < min {
min = min2
}
if max2 > max {
max = max2
}
}
return min, max
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (c Choice) NumSequences() int {
var s int
for _, pat := range c {
num := pat.NumSequences()
if num == 0 { // if any of the patterns can't be converted to sequences, don't return any
return 0
}
s += num
}
return s
}
// Sequences converts the pattern into a slice of plain sequences.
func (c Choice) Sequences() []Sequence {
num := c.NumSequences()
seqs := make([]Sequence, 0, num)
for _, pat := range c {
seqs = append(seqs, pat.Sequences()...)
}
return seqs
}
func (c Choice) String() string {
s := "c["
for i, pat := range c {
s += pat.String()
if i < len(c)-1 {
s += ","
}
}
return s + "]"
}
// Save persists the pattern.
func (c Choice) Save(ls *persist.LoadSaver) {
ls.SaveByte(choiceLoader)
ls.SaveSmallInt(len(c))
for _, pat := range c {
pat.Save(ls)
}
}
func loadChoice(ls *persist.LoadSaver) Pattern {
l := ls.LoadSmallInt()
choices := make(Choice, l)
for i := range choices {
choices[i] = Load(ls)
}
return choices
}
// List is a slice of patterns, all of which must test true sequentially in order for the pattern to succeed.
type List []Pattern
// Test bytes against the pattern.
func (l List) Test(b []byte) ([]int, int) {
if len(l) < 1 {
return nil, 0
}
totals := []int{0}
for _, pat := range l {
nts := make([]int, 0, len(totals))
for _, t := range totals {
les, _ := pat.Test(b[t:])
for _, le := range les {
nts = append(nts, t+le)
}
}
if len(nts) < 1 {
return nil, 1
}
totals = nts
}
return totals, 1
}
// Test bytes against the pattern in reverse.
func (l List) TestR(b []byte) ([]int, int) {
if len(l) < 1 {
return nil, 0
}
totals := []int{0}
for i := len(l) - 1; i >= 0; i-- {
nts := make([]int, 0, len(totals))
for _, t := range totals {
les, _ := l[i].TestR(b[:len(b)-t])
for _, le := range les {
nts = append(nts, t+le)
}
}
if len(nts) < 1 {
return nil, 1
}
totals = nts
}
return totals, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (l List) Equals(pat Pattern) bool {
l2, ok := pat.(List)
if ok {
if len(l) == len(l2) {
for i, p := range l {
if !p.Equals(l2[i]) {
return false
}
}
}
}
return true
}
// Length returns a minimum and maximum length for the pattern.
func (l List) Length() (int, int) {
var min, max int
for _, pat := range l {
pmin, pmax := pat.Length()
min += pmin
max += pmax
}
return min, max
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (l List) NumSequences() int {
s := 1
for _, pat := range l {
num := pat.NumSequences()
if num == 0 { // if any of the patterns can't be converted to sequences, don't return any
return 0
}
s *= num
}
return s
}
// Sequences converts the pattern into a slice of plain sequences.
func (l List) Sequences() []Sequence {
total := l.NumSequences()
seqs := make([]Sequence, total)
for _, pat := range l {
num := pat.NumSequences()
times := total / num
idx := 0
for _, seq := range pat.Sequences() {
for i := 0; i < times; i++ {
seqs[idx] = append(seqs[idx], seq...)
idx++
}
}
}
return seqs
}
func (l List) String() string {
s := "l["
for i, pat := range l {
s += pat.String()
if i < len(l)-1 {
s += ","
}
}
return s + "]"
}
// Save persists the pattern.
func (l List) Save(ls *persist.LoadSaver) {
ls.SaveByte(listLoader)
ls.SaveSmallInt(len(l))
for _, pat := range l {
pat.Save(ls)
}
}
func loadList(ls *persist.LoadSaver) Pattern {
le := ls.LoadSmallInt()
list := make(List, le)
for i := range list {
list[i] = Load(ls)
}
return list
}
// Not contains a pattern and reports the opposite of that pattern's result when testing.
type Not struct{ Pattern }
// Test bytes against the pattern.
func (n Not) Test(b []byte) ([]int, int) {
min, _ := n.Pattern.Length()
if len(b) < min {
return nil, 0
}
ok, _ := n.Pattern.Test(b)
if len(ok) < 1 {
return []int{min}, 1
}
return nil, 1
}
// Test bytes against the pattern in reverse.
func (n Not) TestR(b []byte) ([]int, int) {
min, _ := n.Pattern.Length()
if len(b) < min {
return nil, 0
}
ok, _ := n.Pattern.TestR(b)
if len(ok) < 1 {
return []int{min}, 1
}
return nil, 1
}
// Equals reports whether a pattern is identical to another pattern.
func (n Not) Equals(pat Pattern) bool {
n2, ok := pat.(Not)
if ok {
return n.Pattern.Equals(n2.Pattern)
}
return false
}
// Length returns a minimum and maximum length for the pattern.
func (n Not) Length() (int, int) {
min, _ := n.Pattern.Length()
return min, min
}
// NumSequences reports how many plain sequences are needed to represent this pattern.
func (n Not) NumSequences() int {
_, max := n.Pattern.Length()
if max > 1 {
return 0
}
num := n.Pattern.NumSequences()
if num == 0 {
return 0
}
return 256 - num
}
// Sequences converts the pattern into a slice of plain sequences.
func (n Not) Sequences() []Sequence {
num := n.NumSequences()
if num < 1 {
return nil
}
seqs := make([]Sequence, 0, num)
pseqs := n.Pattern.Sequences()
allBytes := make([]Sequence, 256)
for i := 0; i < 256; i++ {
allBytes[i] = Sequence{byte(i)}
}
for _, v := range allBytes {
eq := false
for _, w := range pseqs {
if v.Equals(w) {
eq = true
break
}
}
if eq {
continue
}
seqs = append(seqs, v)
}
return seqs
}
func (n Not) String() string {
return "not[" + n.Pattern.String() + "]"
}
// Save persists the pattern.
func (n Not) Save(ls *persist.LoadSaver) {
ls.SaveByte(notLoader)
n.Pattern.Save(ls)
}
func loadNot(ls *persist.LoadSaver) Pattern {
return Not{Load(ls)}
}
type Mask byte
func (m Mask) Test(b []byte) ([]int, int) {
if len(b) == 0 {
return nil, 0
}
if byte(m)&b[0] == byte(m) {
return []int{1}, 1
}
return nil, 1
}
func (m Mask) TestR(b []byte) ([]int, int) {
if len(b) == 0 {
return nil, 0
}
if byte(m)&b[len(b)-1] == byte(m) {
return []int{1}, 1
}
return nil, 1
}
func (m Mask) Equals(pat Pattern) bool {
msk, ok := pat.(Mask)
if ok {
if m == msk {
return true
}
}
return false
}
func (m Mask) Length() (int, int) {
return 1, 1
}
func countBits(b byte) int {
var count uint
for b > 0 {
b &= b - 1
count++
}
return 256 / (1 << count)
}
func allBytes() []byte {
all := make([]byte, 256)
for i := range all {
all[i] = byte(i)
}
return all
}
func (m Mask) NumSequences() int {
return countBits(byte(m))
}
func (m Mask) Sequences() []Sequence {
seqs := make([]Sequence, 0, m.NumSequences())
for _, b := range allBytes() {
if byte(m)&b == byte(m) {
seqs = append(seqs, Sequence{b})
}
}
return seqs
}
func (m Mask) String() string {
return fmt.Sprintf("m %#x", byte(m))
}
func (m Mask) Save(ls *persist.LoadSaver) {
ls.SaveByte(maskLoader)
ls.SaveByte(byte(m))
}
func loadMask(ls *persist.LoadSaver) Pattern {
return Mask(ls.LoadByte())
}
type AnyMask byte
func (am AnyMask) Test(b []byte) ([]int, int) {
if len(b) == 0 {
return nil, 0
}
if byte(am)&b[0] != 0 {
return []int{1}, 1
}
return nil, 1
}
func (am AnyMask) TestR(b []byte) ([]int, int) {
if len(b) == 0 {
return nil, 0
}
if byte(am)&b[len(b)-1] != 0 {
return []int{1}, 1
}
return nil, 1
}
func (am AnyMask) Equals(pat Pattern) bool {
amsk, ok := pat.(AnyMask)
if ok {
if am == amsk {
return true
}
}
return false
}
func (am AnyMask) Length() (int, int) {
return 1, 1
}
func (am AnyMask) NumSequences() int {
return 256 - countBits(byte(am))
}
func (am AnyMask) Sequences() []Sequence {
seqs := make([]Sequence, 0, am.NumSequences())
for _, b := range allBytes() {
if byte(am)&b != 0 {
seqs = append(seqs, Sequence{b})
}
}
return seqs
}
func (am AnyMask) String() string {
return fmt.Sprintf("am %#x", byte(am))
}
func (am AnyMask) Save(ls *persist.LoadSaver) {
ls.SaveByte(anyMaskLoader)
ls.SaveByte(byte(am))
}
func loadAnyMask(ls *persist.LoadSaver) Pattern {
return AnyMask(ls.LoadByte())
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"encoding/json"
"io"
"strconv"
)
type sfJSON struct {
dec *json.Decoder
head Head
peek record
err error
}
func next(dec *json.Decoder) ([]string, []string, error) {
var (
tok json.Token
err error
i int
)
keys, vals := make([]string, 0, 10), make([]string, 0, 10)
for tok, err = dec.Token(); err == nil; tok, err = dec.Token() {
switch tok := tok.(type) {
case string:
if i%2 == 0 {
keys = append(keys, tok)
} else {
vals = append(vals, tok)
}
i++
case float64:
i++
vals = append(vals, strconv.FormatFloat(tok, 'f', 0, 32))
case json.Delim:
if tok.String() == "[" || tok.String() == "]" {
return keys, vals, nil
}
}
}
return nil, nil, err
}
func jsonRecord(dec *json.Decoder) (record, error) {
keys, vals, err := next(dec)
if err != nil {
return record{}, err
}
m := make(map[string]string)
for i, v := range vals {
m[keys[i]] = v
}
keys, vals, err = next(dec)
if err != nil {
return record{}, err
}
return record{m, keys, vals}, nil
}
func newJSON(r io.Reader, path string) (Reader, error) {
sfj := &sfJSON{dec: json.NewDecoder(r)}
rec, err := jsonRecord(sfj.dec)
if err != nil {
return nil, err
}
rec.attributes["results"] = path
sfj.head, err = getHead(rec)
if err != nil {
return nil, err
}
next(sfj.dec) // throw away "files": [
sfj.peek, sfj.err = jsonRecord(sfj.dec)
sfj.head.HashHeader = getHash(sfj.peek.attributes)
sfj.head.Fields = getFields(sfj.peek.listFields, sfj.peek.listValues)
return sfj, nil
}
func (sfj *sfJSON) Head() Head {
return sfj.head
}
func (sfj *sfJSON) Next() (File, error) {
r, e := sfj.peek, sfj.err
if e != nil {
return File{}, e
}
sfj.peek, sfj.err = jsonRecord(sfj.dec)
return getFile(r)
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Satisfies the Identifier interface.
package wikidata
import (
"encoding/json"
"fmt"
"strings"
"time"
"github.com/richardlehane/siegfried/internal/identifier"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
const unknown = "UNKNOWN"
const identifierDateFormat = "2006-01-02"
// Initialize the variables needed by this file.
func init() {
core.RegisterIdentifier(core.Wikidata, Load)
}
// Identifier contains a set of Wikidata records and an implementation
// of the identifier interface for consuming.
type Identifier struct {
infos map[string]formatInfo
*identifier.Base
}
// Global that allows us to do is keep track of the PUIDs going to be
// output in the identifier which need provenance. At least it felt
// needed at the time, but need to look at in more detail. We may
// eventually delete this in favor of something "less-global".
var sourcePuids []string
// New is the entry point for an Identifier when it is compiled by the Roy tool
// to a brand new signature file.
//
// New will read a Wikidata report, and parse its information into structures
// suitable for compilation by Roy.
//
// New will also update its identification information with provenance-like
// info. It will enable signature extensions to be added by the utility, and
// enables configuration to be applied as well.
func New(opts ...config.Option) (core.Identifier, error) {
for _, v := range opts {
v()
}
logln("Roy (Wikidata): Congratulations: doing something with the Wikidata identifier package!")
wikidata, puids, err := newWikidata()
if err != nil {
return nil, fmt.Errorf("Error in Wikidata New(): %w", err)
}
// Having retrieved our PUIDs from newWikidata, assign them to our
// provenance global to generate source information from Wikidata.
sourcePuids = puids
updatedDate := time.Now().Format(identifierDateFormat)
wikidata = identifier.ApplyConfig(wikidata)
base := identifier.New(
wikidata,
"Wikidata Name: I don't think this field is used...",
updatedDate,
)
infos := infos(wikidata.Infos())
return &Identifier{
infos: infos,
Base: base,
}, nil
}
// Recorder provides a recorder for matching.
func (i *Identifier) Recorder() core.Recorder {
return &Recorder{
Identifier: i,
ids: make(matchIDs, 0, 1),
}
}
// Identification contains the result of a single ID for a file. There may be
// multiple, per file. The identification to the user looks something like as
// follows:
//
// - ns : 'wikidata'
// id : 'Q1343830'
// format : 'Executable and Linkable Format'
// URI : 'http://www.wikidata.org/entity/Q1343830'
// mime :
// basis : 'byte match at 0, 4 (signature 1/5); byte match at 0, 7 (signature 4/5)'
// source : 'Gary Kessler”s File Signature Table (source date: 2017-08-08) PRONOM (Official (fmt/689))'
// warning :
type Identification struct {
Namespace string // Namespace of the identifier, e.g. this will be the 'wikidata' namespace.
ID string // QID of the file format according to Wikidata.
Name string // Complete name of the format identification. Often includes version.
LongName string // IRI of the Wikidata record.
MIME string // MIMEtypes associated with the record.
Basis []string // Basis for the result returned by Siegfried.
Source []string // Provenance information associated with the result.
Permalink string // Permalink from the Wikibase record used to build the signature definition.
Warning string // Warnings generated by Siegfried.
archive config.Archive // Is it an Archive format?
confidence int // Identification confidence for sorting.
}
// String creates a human readable representation of an identifier for output
// by fmt-like functions.
func (id Identification) String() string {
str, err := json.MarshalIndent(id, "", " ")
if err != nil {
return ""
}
return fmt.Sprintf("%s", str)
}
// Fields describes a portion of YAML that will be output by Siegfried's
// identifier for an individual match. E.g.
//
// matches :
// - ns : 'wikidata'
// id : 'Q475488'
// format : 'EPUB'
// ... : '...'
// ... : '...'
// custom : 'your custom field'
// custom : '...'
//
// siegfried/pkg/writer/writer.go normalizes the output of this field
// grouping so that if it sees certain fields, e.g. namespace, then it
// can convert that to something anticipated by the consumer,
//
// e.g. namespace => becomes => ns
func (i *Identifier) Fields() []string {
// Result fields. Basis is used by Wikidata to reflect both the
// details of the signature used to match (or other identifiers) as
// well as the source of binary signatures.
//
// e.g. byte match at 0, 4 (Gary Kessler''s File Signature Table (source date: 2017-08-08))
//
return []string{
"namespace",
"id",
"format",
"URI",
"permalink",
"mime",
"basis",
"warning",
}
}
// Archive should tell us if any identifiers match those considered to
// be an archive format so that they can be extracted and the contents
// identified.
func (id Identification) Archive() config.Archive {
return id.archive
}
// Known returns false if the ID isn't recognized or true if so.
func (id Identification) Known() bool {
return id.ID != unknown
}
// Warn returns the warning associated with an identification.
func (id Identification) Warn() string {
return id.Warning
}
// Values returns a string slice containing each of the identifier segments.
func (id Identification) Values() []string {
var basis string
if len(id.Basis) > 0 {
basis = strings.Join(id.Basis, "; ")
}
// Slice must match the order of resultsFueldsWithoutSource.
return []string{
id.Namespace,
id.ID,
id.Name,
id.LongName,
id.Permalink,
id.MIME,
basis,
id.Warning,
}
}
<file_sep>package mimematcher
import (
"testing"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/core"
)
var fmts = SignatureSet{"application/json", "application/json;v1", "text/plain", "x-world/x-3dmf", "application/x-cocoa"}
var sm core.Matcher
func init() {
sm, _, _ = Add(nil, fmts, nil)
}
func TestJsonMatch(t *testing.T) {
res, _ := sm.Identify("application/json;v1", nil)
e := <-res
if e.Index() != 1 {
t.Errorf("Expecting 0, got %v", e)
}
e = <-res
if e.Index() != 0 {
t.Errorf("Expecting 1, got %v", e)
}
_, ok := <-res
if ok {
t.Error("Expecting a length of 2")
}
}
func TestNoMatch(t *testing.T) {
res, _ := sm.Identify("application/java", nil)
_, ok := <-res
if ok {
t.Error("Should not match")
}
}
func TestIO(t *testing.T) {
str := sm.String()
saver := persist.NewLoadSaver(nil)
Save(sm, saver)
if len(saver.Bytes()) < 10 {
t.Errorf("Save mime matcher: too small, only got %v", saver.Bytes())
}
loader := persist.NewLoadSaver(saver.Bytes())
newsm := Load(loader)
str2 := newsm.String()
if str != str2 {
t.Errorf("Load mime matcher: expecting first matcher (%v), to equal second matcher (%v)", str, str2)
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package siegreader
import (
"fmt"
"io"
"github.com/richardlehane/characterize"
)
// Reader implements the io.Reader, io.Seeker, io.ByteReader and io.ReaderAt interfaces
// The special thing about a siegreader.Reader is that you can have a bunch of them all reading independently from the one buffer.
//
// Example:
// buffers := siegreader.New()
// buffer := buffers.Get(underlying_io_reader)
// rdr := siegreader.ReaderFrom(buffer)
// second_rdr := siegreader.ReaderFrom(buffer)
// limit_rdr := siegreader.LimitedReaderFrom(buffer, 4096)
// reverse_rdr := siegreader.ReverseReaderFrom(buffer)
type Reader struct {
i int64
j int
scratch []byte
end bool // buffer adjoins the end of the file
*Buffer
}
// ReaderFrom returns a Reader reading from the Buffer.
func ReaderFrom(b *Buffer) *Reader {
// A BOF reader may not have been used, trigger a fill if necessary.
return &Reader{0, 0, nil, false, b}
}
func (r *Reader) setBuf(o int64) error {
var err error
r.scratch, err = r.Slice(o, readSz)
if err == io.EOF {
r.end = true
}
return err
}
// ReadByte implements the io.ByteReader interface.
// Checks the quit channel every 4096 bytes.
func (r *Reader) ReadByte() (byte, error) {
if r.j >= len(r.scratch) {
if r.end {
return 0, io.EOF
}
// every slice len check on quit channel
select {
case <-r.Quit:
return 0, io.EOF
default:
}
err := r.setBuf(r.i)
if err != nil && err != io.EOF {
return 0, err
}
if len(r.scratch) == 0 {
return 0, io.EOF
}
r.j = 0
}
b := r.scratch[r.j]
r.i++
r.j++
return b, nil
}
// Read implements the io.Reader interface.
func (r *Reader) Read(b []byte) (int, error) {
var slc []byte
var err error
if len(b) > len(r.scratch)-r.j {
slc, err = r.Slice(r.i, len(b))
if err != nil {
if err != io.EOF {
return 0, err
}
r.end = true
}
} else {
slc = r.scratch[r.j : r.j+len(b)]
}
n := copy(b, slc)
r.i += int64(n)
r.j += n
return len(slc), err
}
// ReadAt implements the io.ReaderAt interface.
func (r *Reader) ReadAt(b []byte, off int64) (int, error) {
var slc []byte
var err error
// if b is already covered by the scratch slice
if off >= r.i-int64(r.j) && off+int64(len(b)) <= r.i-int64(r.j+len(r.scratch)) {
s := int(off-r.i) - r.j
slc = r.scratch[s : s+len(b)]
} else {
slc, err = r.Slice(off, len(b))
if err != nil {
if err != io.EOF {
return 0, err
}
r.end = true
}
}
copy(b, slc)
return len(slc), err
}
// Seek implements the io.Seeker interface.
func (r *Reader) Seek(offset int64, whence int) (int64, error) {
var rev bool
switch whence {
case 0:
case 1:
offset = offset + int64(r.i)
case 2:
rev = true
default:
return 0, fmt.Errorf("Siegreader: Seek error, whence value must be one of 0,1,2 got %v", whence)
}
success, err := r.CanSeek(offset, rev)
if success {
if rev {
offset = r.Size() - offset
}
d := offset - r.i
r.i = offset
r.j += int(d) // add the jump distance to r.j PROBLEM - WHAT IF r.j < 0!!
return offset, err
}
return 0, err
}
// ReverseReader implements the io.Reader and io.ByteReader interfaces, but for each it does so from the end of the io source working backwards.
// Like Readers, you can have multiple ReverseReaders all reading independently from the same buffer.
type ReverseReader struct {
i int64
j int
scratch []byte
end bool // if buffer is adjacent to the BOF, i.e. we have scanned all the way back to the beginning
*Buffer
}
// ReverseReaderFrom returns a ReverseReader reading from the Buffer.
func ReverseReaderFrom(b *Buffer) *ReverseReader {
return &ReverseReader{0, 0, nil, false, b}
}
func (r *ReverseReader) setBuf(o int64) error {
var err error
r.scratch, err = r.EofSlice(o, readSz)
if err == io.EOF {
r.end = true
}
return err
}
// Read implements the io.Reader interface.
func (r *ReverseReader) Read(b []byte) (int, error) {
if r.i == 0 {
r.setBuf(0)
}
var slc []byte
var err error
if len(b) > len(r.scratch)-r.j {
slc, err = r.EofSlice(r.i, len(b))
if err != nil {
if err != io.EOF {
return 0, err
}
r.end = true
}
} else {
slc = r.scratch[len(r.scratch)-len(b) : len(r.scratch)-r.j]
}
n := copy(b, slc)
r.i += int64(n)
r.j += n
return len(slc), err
}
// ReadByte implements the io.ByteReader interface.
func (r *ReverseReader) ReadByte() (byte, error) {
if r.j >= len(r.scratch) {
if r.end {
return 0, io.EOF
}
// every slice len check quit channel
select {
case <-r.Quit:
return 0, io.EOF
default:
}
err := r.setBuf(r.i)
if err != nil && err != io.EOF {
return 0, err
}
if len(r.scratch) == 0 {
return 0, io.EOF
}
r.j = 0
}
b := r.scratch[len(r.scratch)-r.j-1]
r.i++
r.j++
return b, nil
}
// LimitReader allows you to set an early limit for the ByteReader.
// At limit, ReadByte() returns 0, io.EOF.
type LimitReader struct {
limit int
*Reader
}
// LimitReaderFrom returns a new LimitReader reading from Buffer.
func LimitReaderFrom(b *Buffer, l int) io.ByteReader {
// A BOF reader may not have been used, trigger a fill if necessary.
r := &Reader{0, 0, nil, false, b}
if l < 0 {
return r
}
return &LimitReader{l, r}
}
// ReadByte implements the io.ByteReader interface.
// Once limit is reached, returns 0, io.EOF.
func (l *LimitReader) ReadByte() (byte, error) {
if l.i >= int64(l.limit) {
return 0, io.EOF
}
return l.Reader.ReadByte()
}
// LimitReverseReader allows you to set an early limit for the ByteReader.
// At limit, REadByte() returns 0, io.EOF.
type LimitReverseReader struct {
limit int
*ReverseReader
}
// LimitReverseReaderFrom returns a new LimitReverseReader reading from Buffer.
func LimitReverseReaderFrom(b *Buffer, l int) io.ByteReader {
if l < 0 {
return &ReverseReader{0, 0, nil, false, b}
}
return &LimitReverseReader{l, &ReverseReader{0, 0, nil, false, b}}
}
// ReadByte implements the io.ByteReader interface.
// Once limit is reached, returns 0, io.EOF.
func (r *LimitReverseReader) ReadByte() (byte, error) {
if r.i >= int64(r.limit) {
return 0, io.EOF
}
return r.ReverseReader.ReadByte()
}
type nullReader struct{}
func (n nullReader) ReadByte() (byte, error) { return 0, io.EOF }
func (n nullReader) Read(b []byte) (int, error) { return 0, io.EOF }
type utf16Reader struct{ *Reader }
func (u *utf16Reader) ReadByte() (byte, error) {
_, err := u.Reader.ReadByte()
if err != nil {
return 0, err
}
return u.Reader.ReadByte()
}
func utf16leReaderFrom(b *Buffer) *utf16Reader {
r := ReaderFrom(b)
r.ReadByte()
return &utf16Reader{r}
}
func utf16beReaderFrom(b *Buffer) *utf16Reader {
r := ReaderFrom(b)
r.ReadByte()
r.ReadByte()
return &utf16Reader{r}
}
func TextReaderFrom(b *Buffer) io.ByteReader {
switch b.Text() {
case characterize.ASCII, characterize.UTF8, characterize.LATIN1, characterize.EXTENDED:
return ReaderFrom(b)
case characterize.UTF16BE:
return utf16beReaderFrom(b)
case characterize.UTF16LE:
return utf16leReaderFrom(b)
case characterize.UTF8BOM:
r := ReaderFrom(b)
for i := 0; i < 3; i++ {
r.ReadByte()
}
return r
case characterize.UTF7:
r := ReaderFrom(b)
for i := 0; i < 4; i++ {
r.ReadByte()
}
return r
}
return nullReader{}
}
type reverseUTF16Reader struct {
*ReverseReader
first bool
}
func (u *reverseUTF16Reader) ReadByte() (byte, error) {
if u.first {
u.first = false
return u.ReverseReader.ReadByte()
}
if _, err := u.ReverseReader.ReadByte(); err != nil {
return 0, err
}
return u.ReverseReader.ReadByte()
}
func reverseUTF16leReaderFrom(b *Buffer) *reverseUTF16Reader {
r := ReverseReaderFrom(b)
r.ReadByte()
return &reverseUTF16Reader{r, true}
}
func reverseUTF16beReaderFrom(b *Buffer) *reverseUTF16Reader {
return &reverseUTF16Reader{ReverseReaderFrom(b), true}
}
func TextReverseReaderFrom(b *Buffer) io.ByteReader {
switch b.Text() {
case characterize.ASCII, characterize.UTF8, characterize.LATIN1, characterize.EXTENDED, characterize.UTF8BOM, characterize.UTF7:
return ReaderFrom(b)
case characterize.UTF16BE:
return reverseUTF16beReaderFrom(b)
case characterize.UTF16LE:
return reverseUTF16leReaderFrom(b)
}
return nullReader{}
}
<file_sep>package sets
import (
"flag"
"fmt"
"strings"
"testing"
"github.com/richardlehane/siegfried/pkg/config"
)
var testhome = flag.String("testhome", "../../cmd/roy/data", "override the default home directory")
func TestSets(t *testing.T) {
config.SetHome(*testhome)
list := "fmt/1,fmt/2,@pdfa,x-fmt/19"
expect := "fmt/1,fmt/2,fmt/95,fmt/354,fmt/476,fmt/477,fmt/478,fmt/479,fmt/480,fmt/481,x-fmt/19"
res := strings.Join(Expand(list), ",")
if res != expect {
t.Errorf("expecting %s, got %s", expect, res)
}
pdfs := strings.Join(Expand("@pdf"), ",")
expect = "fmt/14,fmt/15,fmt/16,fmt/17,fmt/18,fmt/19,fmt/20,fmt/95,fmt/144,fmt/145,fmt/146,fmt/147,fmt/148,fmt/157,fmt/158,fmt/276,fmt/354,fmt/476,fmt/477,fmt/478,fmt/479,fmt/480,fmt/481,fmt/488,fmt/489,fmt/490,fmt/491,fmt/492,fmt/493"
if pdfs != expect {
t.Errorf("expecting %s, got %s", expect, pdfs)
}
compression := strings.Join(Expand("@compression"), ",")
expect = "fmt/626,x-fmt/266,x-fmt/267,x-fmt/268"
if compression != expect {
t.Errorf("expecting %s, got %s", expect, compression)
}
}
var testSet = map[string][]string{
"t": {"a", "a", "b", "c"},
"u": {"b", "d"},
"v": {"@t", "@u"},
}
func TestDupeSets(t *testing.T) {
orig := sets
sets = testSet
expect := "a,b,c,d"
res := strings.Join(Expand("@v"), ",")
if res != expect {
t.Errorf("expecting %s, got %s", expect, res)
}
sets = orig
}
var (
tika = []string{"x-fmt/111", "@pdf", "@msword"}
fnName string = "IsText"
)
func ExampleSets() {
fmt.Printf("func %s(puid string) bool {\n switch puid {\n case \"%s\":\n return true\n }\n return false\n}", fnName, strings.Join(Sets(tika...), "\",\""))
// Output:
//func IsText(puid string) bool {
// switch puid {
// case "fmt/14","fmt/15","fmt/16","fmt/17","fmt/18","fmt/19","fmt/20","fmt/37","fmt/38","fmt/39","fmt/40","fmt/95","fmt/144","fmt/145","fmt/146","fmt/147","fmt/148","fmt/157","fmt/158","fmt/276","fmt/354","fmt/412","fmt/473","fmt/476","fmt/477","fmt/478","fmt/479","fmt/480","fmt/481","fmt/488","fmt/489","fmt/490","fmt/491","fmt/492","fmt/493","fmt/523","fmt/597","fmt/599","fmt/609","fmt/754","x-fmt/45","x-fmt/111","x-fmt/273","x-fmt/274","x-fmt/275","x-fmt/276":
// return true
// }
// return false
//}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Accesses the harvested signature definitions from Wikidata and
// processes them into mappings structures which will be processed by
// Roy to create the identifier that will be consumed by Siegfried.
package wikidata
import (
"encoding/json"
"errors"
"fmt"
"io/ioutil"
"log"
"os"
"strings"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/converter"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/mappings"
"github.com/ross-spencer/wikiprov/pkg/spargo"
"github.com/ross-spencer/wikiprov/pkg/wikiprov"
)
type wikidataMappings = map[string]mappings.Wikidata
// Alias our spargo Item for ease of referencing.
type wikidataItem = []map[string]spargo.Item
// Alias our wikiprov Provenance structure.
type wikiProv = []wikiprov.Provenance
// wikiItemProv helpfully collects item and provenance data.
type wikiItemProv struct {
items wikidataItem
prov wikiProv
}
// Signature provides an alias for mappings.Signature for convenience.
type Signature = mappings.Signature
// Fields which are used in the Wikidata SPARQL query which we will
// access via JSON mapping.
const (
uriField = "uri"
formatLabelField = "uriLabel"
puidField = "puid"
locField = "ldd"
extField = "extension"
mimeField = "mimetype"
signatureField = "sig"
offsetField = "offset"
encodingField = "encoding"
relativityField = "relativity"
dateField = "date"
referenceField = "referenceLabel"
)
// helper functions to control logging output
// Verbose output is default for roy but not when running tests etc.
func logf(format string, v ...any) {
if config.Verbose() {
log.Printf(format, v...)
}
}
func logln(v ...any) {
if config.Verbose() {
log.Println(v...)
}
}
// getID returns the QID from the IRI of the record that we're
// processing.
func getID(wikidataURI string) string {
splitURI := strings.Split(wikidataURI, "/")
return splitURI[len(splitURI)-1]
}
// contains will look for the appearance of a string item in slice of
// strings items.
func contains(items []string, item string) bool {
for i := range items {
if items[i] == item {
return true
}
}
return false
}
// endpointJSON provides a helper to us to read the harvest results from a
// Wikibase and read the endpoint specifically. This is a special use feature
// of Roy/Siegfried and doesn't yet exist in the Wikiprov internals.
type endpointJSON struct {
Endpoint string `json:"endpoint"`
}
// ErrNoEndpoint provides a method of validating the error received from
// this package when the custom SPARQL endpoint cannot be read from
// the harvest data.
var ErrNoEndpoint = errors.New("Endpoint in custom Wikibase sparql results not set")
// customEndpoint checks whether or not a custom "endpoint" is set in
// the Wikidata harvest results. If the endpoint doesn't match the default
// for Wikidata then we have a signal that we need to do more work to
// default endpoint then we need to do more work to make things run.
func customEndpoint(jsonFile []byte) (bool, error) {
var endpoint endpointJSON
err := json.Unmarshal([]byte(jsonFile), &endpoint)
if err != nil {
return false, fmt.Errorf(
"Cannot parse JSON in Wikidata file: %w",
err,
)
}
if endpoint.Endpoint == "" {
return false, fmt.Errorf("%w", ErrNoEndpoint)
}
if endpoint.Endpoint != config.WikidataEndpoint() {
return true, nil
}
return false, nil
}
// openWikidata accesses the signatures definitions we harvested from
// Wikidata which are stored in SPARQL JSON and initiates their
// processing into the structures required by Roy to process into an
// identifier to be consumed by Siegfried.
func openWikidata() (wikiItemProv, error) {
path := config.WikidataDefinitionsPath()
logf("Roy (Wikidata): Opening Wikidata definitions: %s\n", path)
jsonFile, err := ioutil.ReadFile(path)
if err != nil {
return wikiItemProv{}, fmt.Errorf(
"cannot open Wikidata file (check, or try harvest again): %w",
err,
)
}
custom, err := customEndpoint(jsonFile)
if err != nil {
return wikiItemProv{}, err
}
if custom {
logln("Roy (Wikidata): Using a custom endpoint for results")
err := setCustomWikibaseProperties()
if err != nil {
return wikiItemProv{}, fmt.Errorf("setting custom Wikibase properties: %w", err)
}
logf(
"Roy (Wikidata): Custom PRONOM encoding loaded; config: '%s' => local: '%s'",
config.WikibasePronom(),
converter.GetPronomEncoding(),
)
logf(
"Roy (Wikidata): Custom BOF loaded; config: '%s' => local: '%s'",
config.WikibaseBOF(),
relativeBOF,
)
logf(
"Roy (Wikidata): Custom EOF loaded; config: '%s' => local: '%s'",
config.WikibaseEOF(),
relativeEOF,
)
}
var sparqlReport spargo.WikiProv
err = json.Unmarshal(jsonFile, &sparqlReport)
if err != nil {
return wikiItemProv{}, fmt.Errorf(
"cannot open Wikidata file: %w",
err,
)
}
return wikiItemProv{
items: sparqlReport.Binding.Bindings,
prov: sparqlReport.Provenance,
}, nil
}
// processWikidata iterates over the Wikidata signature definitions and
// creates or updates records as it goes. The global wikidataMapping
// stores the Roy ready definitions to turn into an identifier. The
// summary data structure is returned to the caller so that it can be
// used to replay the results of processing, e.g. so the caller can
// access the stored linting results.
func processWikidata(itemProv wikiItemProv) (Summary, wikidataMappings) {
var wikidataMapping = mappings.NewWikidata()
var summary Summary
var expectedRecordsWithSignatures = make(map[string]bool)
for _, item := range itemProv.items {
id := getID(item[uriField].Value)
if item[signatureField].Value != "" {
summary.SparqlRowsWithSigs++
expectedRecordsWithSignatures[item[uriField].Value] = true
}
if wikidataMapping[id].ID == "" {
okayToAdd := addSignatures(itemProv.items, id)
wikidataMapping[id] = newRecord(item, itemProv.prov, okayToAdd)
} else {
wikidataMapping[id] =
updateRecord(item, wikidataMapping[id])
}
}
summary.AllSparqlResults = len(itemProv.items)
summary.CondensedSparqlResults = len(wikidataMapping)
summary.RecordsWithPotentialSignatures =
len(expectedRecordsWithSignatures)
return summary, wikidataMapping
}
// createMappingFromWikidata encapsulates the functions needed to load
// parse, and process the Wikidata records from our definitions file.
// After processing the summary results are output by Roy.
func createMappingFromWikidata() ([]wikidataRecord, error) {
itemProv, err := openWikidata()
if err != nil {
return []wikidataRecord{}, err
}
summary, wikidataMapping := processWikidata(itemProv)
analyseWikidataRecords(wikidataMapping, &summary)
reportMapping := createReportMapping(wikidataMapping)
// Log summary before leaving the function.
logf("%s\n", summary)
return reportMapping, nil
}
// createReportMapping iterates over our Wikidata records to return a
// mapping `reportMappings` that can later be used to map PRONOM
// signatures into the Wikidata identifier. reportMappings is used to
// map Wikidata identifiers to PRONOM so that PRONOM native patterns can
// be incorporated into the identifier when it is first created.
func createReportMapping(wikidataMapping wikidataMappings) []wikidataRecord {
var reportMappings = []wikidataRecord{
/* Examples:
{"Q12345", "PNG", "http://wikidata.org/q12345", "fmt/11", "png"},
{"Q23456", "FLAC", "http://wikidata.org/q23456", "fmt/279", "flac"},
{"Q34567", "ICO", "http://wikidata.org/q34567", "x-fmt/418", "ico"},
{"Q45678", "SIARD", "http://wikidata.org/q45678", "fmt/995", "siard"},
*/
}
for _, wd := range wikidataMapping {
reportMappings = append(reportMappings, wd)
}
return reportMappings
}
// There are three sets of properties to lookup in a configuration
// file, those for PRONOM, BOF and EOF values.
const (
pronomProp = "PronomProp"
bofProp = "BofProp"
eofProp = "EofProp"
)
// setCustomWikibaseProperties sets the properties needed by Roy to
// parse the results coming from a custom Wikibase endpoint.
func setCustomWikibaseProperties() error {
logln("Roy (Wikidata): Looking for existence of wikibase.json in Siegfried home")
wikibasePropsPath := config.WikibasePropsPath()
propsFile, err := os.ReadFile(wikibasePropsPath)
if os.IsNotExist(err) {
return fmt.Errorf(
"cannot find file '%s' in '%s': %w",
wikibasePropsPath,
config.WikidataHome(),
err,
)
}
if err != nil {
return fmt.Errorf(
"a different error handling '%s' has occurred: %w",
wikibasePropsPath,
err,
)
}
propsMap := make(map[string]string)
if err == nil {
err = json.Unmarshal(propsFile, &propsMap)
if err != nil {
return err
}
}
pronom := propsMap[pronomProp]
bof := propsMap[bofProp]
eof := propsMap[eofProp]
// Set the properties globally in the config and then request they are
// re-read from the module so that they are updated prior to building the
// signature file.
err = config.SetProps(pronom, bof, eof)
if err != nil {
return err
}
GetPronomURIFromConfig()
GetBOFandEOFFromConfig()
logf(
"Roy (Wikidata): Properties set for PRONOM: '%s', BOF: '%s', EOF: '%s'",
pronom,
bof,
eof,
)
return nil
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package writer
import (
"bufio"
"encoding/csv"
"encoding/hex"
"fmt"
"io"
"path/filepath"
"strconv"
"strings"
"time"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
)
type Writer interface {
Head(path string, scanned, created time.Time, version [3]int, ids [][2]string, fields [][]string, hh string) // path := filepath.Base(path)
File(name string, sz int64, mod string, checksum []byte, err error, ids []core.Identification) // if a directory give a negative sz
Tail()
}
func Null() Writer {
return null{}
}
type null struct{}
func (n null) Head(path string, scanned, created time.Time, version [3]int, ids [][2]string, fields [][]string, hh string) {
}
func (n null) File(name string, sz int64, mod string, cs []byte, err error, ids []core.Identification) {
}
func (n null) Tail() {}
type csvWriter struct {
recs [][]string
names []string
w *csv.Writer
}
func CSV(w io.Writer) Writer {
return &csvWriter{w: csv.NewWriter(w)}
}
func (c *csvWriter) Head(path string, scanned, created time.Time, version [3]int, ids [][2]string, fields [][]string, hh string) {
c.names = make([]string, len(fields))
l := 4
if hh != "" {
l++
}
for i, f := range fields {
l += len(f)
c.names[i] = f[0]
}
c.recs = make([][]string, 1)
c.recs[0] = make([]string, l)
c.recs[0][0], c.recs[0][1], c.recs[0][2], c.recs[0][3] = "filename", "filesize", "modified", "errors"
idx := 4
if hh != "" {
c.recs[0][4] = hh
idx++
}
for _, f := range fields {
copy(c.recs[0][idx:], f)
idx += len(f)
}
c.w.Write(c.recs[0])
}
func (c *csvWriter) File(name string, sz int64, mod string, checksum []byte, err error, ids []core.Identification) {
var errStr string
if err != nil {
errStr = err.Error()
}
c.recs[0][0], c.recs[0][1], c.recs[0][2], c.recs[0][3] = name, strconv.FormatInt(sz, 10), mod, errStr
idx := 4
if checksum != nil {
c.recs[0][4] = hex.EncodeToString(checksum)
idx++
}
if len(ids) == 0 {
empty := make([]string, len(c.recs[0])-idx)
if checksum != nil {
c.recs[0][4] = ""
}
copy(c.recs[0][idx:], empty)
c.w.Write(c.recs[0])
return
}
var thisName string
var rowIdx, colIdx, prevLen int
colIdx = idx
for _, id := range ids {
fields := id.Values()
if thisName == fields[0] {
rowIdx++
} else {
thisName = fields[0]
rowIdx = 0
colIdx += prevLen
prevLen = len(fields)
}
if rowIdx >= len(c.recs) {
c.recs = append(c.recs, make([]string, len(c.recs[0])))
copy(c.recs[rowIdx][:idx], c.recs[0][:idx])
}
copy(c.recs[rowIdx][colIdx:], fields)
}
for _, r := range c.recs {
c.w.Write(r)
}
c.recs = c.recs[:1]
}
func (c *csvWriter) Tail() { c.w.Flush() }
type yamlWriter struct {
replacer *strings.Replacer
dblReplacer *strings.Replacer
w *bufio.Writer
hh string
hstrs []string
vals [][]interface{}
}
const nonPrintables = "\x00\x07\x08\x0A\x0B\x0C\x0D\x1B"
func YAML(w io.Writer) Writer {
return &yamlWriter{
replacer: strings.NewReplacer("'", "''"),
dblReplacer: strings.NewReplacer(
"\x00", "\\0",
"\x07", "\\a",
"\x08", "\\b",
"\x0A", "\\n",
"\x0B", "\\v",
"\x0C", "\\f",
"\x0D", "\\r",
"\x1B", "\\e",
"\x22", "\\\"",
"\x2F", "\\/",
"\x5c", "\\\\",
),
w: bufio.NewWriter(w),
}
}
func header(fields []string) string {
headings := make([]string, len(fields))
var max int
for _, v := range fields {
if v != "namespace" && len(v) > max {
max = len(v)
}
}
pad := fmt.Sprintf("%%-%ds", max)
for i, v := range fields {
if v == "namespace" {
v = "ns"
}
headings[i] = fmt.Sprintf(pad, v)
}
return " - " + strings.Join(headings, " : %v\n ") + " : %v\n"
}
func (y *yamlWriter) Head(path string, scanned, created time.Time, version [3]int, ids [][2]string, fields [][]string, hh string) {
y.hh = hh
y.hstrs = make([]string, len(fields))
y.vals = make([][]interface{}, len(fields))
for i, f := range fields {
y.hstrs[i] = header(f)
y.vals[i] = make([]interface{}, len(f))
}
fmt.Fprintf(y.w,
"---\nsiegfried : %d.%d.%d\nscandate : %v\nsignature : %s\ncreated : %v\nidentifiers : \n",
version[0], version[1], version[2],
scanned.Format(time.RFC3339),
y.replacer.Replace(path),
created.Format(time.RFC3339))
for _, id := range ids {
fmt.Fprintf(y.w, " - name : '%v'\n details : '%v'\n", id[0], id[1])
}
}
func (y *yamlWriter) File(name string, sz int64, mod string, checksum []byte, err error, ids []core.Identification) {
var (
errStr string
h string
fname string
thisName string
idx int = -1
)
if err != nil {
errStr = "'" + y.replacer.Replace(err.Error()) + "'"
}
if checksum != nil {
h = fmt.Sprintf("%-8s : %s\n", y.hh, hex.EncodeToString(checksum))
}
if strings.ContainsAny(name, nonPrintables) {
fname = "\"" + y.dblReplacer.Replace(name) + "\""
} else {
fname = "'" + y.replacer.Replace(name) + "'"
}
fmt.Fprintf(y.w, "---\nfilename : %s\nfilesize : %d\nmodified : %s\nerrors : %s\n%smatches :\n", fname, sz, mod, errStr, h)
for _, id := range ids {
values := id.Values()
if values[0] != thisName {
idx++
thisName = values[0]
}
for i, v := range values {
if v == "" {
y.vals[idx][i] = ""
continue
}
y.vals[idx][i] = "'" + y.replacer.Replace(v) + "'"
}
fmt.Fprintf(y.w, y.hstrs[idx], y.vals[idx]...)
}
}
func (y *yamlWriter) Tail() { y.w.Flush() }
type jsonWriter struct {
subs bool
replacer *strings.Replacer
w *bufio.Writer
hh string
hstrs []func([]string) string
}
func JSON(w io.Writer) Writer {
return &jsonWriter{
replacer: strings.NewReplacer(
`\`, `\\`,
`"`, `\"`,
"\u0000", `\u0000`,
"\u0001", `\u0001`,
"\u0002", `\u0002`,
"\u0003", `\u0003`,
"\u0004", `\u0004`,
"\u0005", `\u0005`,
"\u0006", `\u0006`,
"\u0007", `\u0007`,
"\u0008", `\u0008`,
"\u0009", `\u0009`,
"\u000A", `\u000A`,
"\u000B", `\u000B`,
"\u000C", `\u000C`,
"\u000D", `\u000D`,
"\u000E", `\u000E`,
"\u000F", `\u000F`,
"\u0010", `\u0010`,
"\u0011", `\u0011`,
"\u0012", `\u0012`,
"\u0013", `\u0013`,
"\u0014", `\u0014`,
"\u0015", `\u0015`,
"\u0016", `\u0016`,
"\u0017", `\u0017`,
"\u0018", `\u0018`,
"\u0019", `\u0019`,
),
w: bufio.NewWriter(w),
}
}
func jsonizer(fields []string) func([]string) string {
for i, v := range fields {
if v == "namespace" {
fields[i] = "\"ns\":\""
continue
}
fields[i] = "\"" + v + "\":\""
}
vals := make([]string, len(fields))
return func(values []string) string {
for i, v := range values {
vals[i] = fields[i] + v
}
return "{" + strings.Join(vals, "\",") + "\"}"
}
}
func (j *jsonWriter) Head(path string, scanned, created time.Time, version [3]int, ids [][2]string, fields [][]string, hh string) {
j.hh = hh
j.hstrs = make([]func([]string) string, len(fields))
for i, f := range fields {
j.hstrs[i] = jsonizer(f)
}
fmt.Fprintf(j.w,
"{\"siegfried\":\"%d.%d.%d\",\"scandate\":\"%v\",\"signature\":\"%s\",\"created\":\"%v\",\"identifiers\":[",
version[0], version[1], version[2],
scanned.Format(time.RFC3339),
path,
created.Format(time.RFC3339))
for i, id := range ids {
if i > 0 {
j.w.WriteString(",")
}
fmt.Fprintf(j.w, "{\"name\":\"%s\",\"details\":\"%s\"}", id[0], id[1])
}
j.w.WriteString("],\"files\":[")
}
func (j *jsonWriter) File(name string, sz int64, mod string, checksum []byte, err error, ids []core.Identification) {
if j.subs {
j.w.WriteString(",")
}
var (
errStr string
h string
thisName string
idx int = -1
)
if err != nil {
errStr = err.Error()
}
if checksum != nil {
h = fmt.Sprintf("\"%s\":\"%s\",", j.hh, hex.EncodeToString(checksum))
}
fmt.Fprintf(j.w, "{\"filename\":\"%s\",\"filesize\": %d,\"modified\":\"%s\",\"errors\": \"%s\",%s\"matches\": [", j.replacer.Replace(name), sz, mod, errStr, h)
for i, id := range ids {
if i > 0 {
j.w.WriteString(",")
}
values := id.Values()
if values[0] != thisName {
idx++
thisName = values[0]
}
j.w.WriteString(j.hstrs[idx](values))
}
j.w.WriteString("]}")
j.subs = true
}
func (j *jsonWriter) Tail() {
j.w.WriteString("]}\n")
j.w.Flush()
}
type droidWriter struct {
id int
parents map[string]parent
rec []string
w *csv.Writer
}
type parent struct {
id int
uri string
archive string
}
func Droid(w io.Writer) Writer {
return &droidWriter{
parents: make(map[string]parent),
rec: make([]string, 18),
w: csv.NewWriter(w),
}
}
// "identifier", "id", "format name", "format version", "mimetype", "basis", "warning"
func (d *droidWriter) Head(path string, scanned, created time.Time, version [3]int, ids [][2]string, fields [][]string, hh string) {
if hh == "" {
hh = "no"
}
d.w.Write([]string{
"ID", "PARENT_ID", "URI", "FILE_PATH", "NAME",
"METHOD", "STATUS", "SIZE", "TYPE", "EXT",
"LAST_MODIFIED", "EXTENSION_MISMATCH", strings.ToUpper(hh) + "_HASH", "FORMAT_COUNT",
"PUID", "MIME_TYPE", "FORMAT_NAME", "FORMAT_VERSION"})
}
func (d *droidWriter) File(p string, sz int64, mod string, checksum []byte, err error, ids []core.Identification) {
d.id++
d.rec[0], d.rec[6], d.rec[10] = strconv.Itoa(d.id), "Done", mod
if err != nil {
d.rec[6] = err.Error()
}
d.rec[1], d.rec[2], d.rec[3], d.rec[4], d.rec[9] = d.processPath(p)
// if folder (has sz -1) or error
if sz < 0 || ids == nil {
d.rec[5], d.rec[7], d.rec[12], d.rec[13], d.rec[14], d.rec[15], d.rec[16], d.rec[17] = "", "", "", "", "", "", "", ""
if sz < 0 {
d.rec[8], d.rec[9], d.rec[11] = "Folder", "", "false"
d.parents[d.rec[3]] = parent{d.id, d.rec[2], ""}
d.rec[3] = clearArchivePath(d.rec[2], d.rec[3])
d.rec[2] = d.rec[2] + "/" // add a trailing slash if a folder URI
} else {
d.rec[8], d.rec[11] = "", ""
d.rec[3] = clearArchivePath(d.rec[2], d.rec[3])
}
d.w.Write(d.rec)
return
}
// size
d.rec[7] = strconv.FormatInt(sz, 10)
if checksum == nil {
d.rec[12] = ""
} else {
d.rec[12] = hex.EncodeToString(checksum)
}
// leave early for unknowns
if len(ids) < 1 || !ids[0].Known() {
d.rec[5], d.rec[8], d.rec[11], d.rec[13] = "", "File", "FALSE", "0"
d.rec[14], d.rec[15], d.rec[16], d.rec[17] = "", "", "", ""
d.rec[3] = clearArchivePath(d.rec[2], d.rec[3])
d.w.Write(d.rec)
return
}
d.rec[13] = strconv.Itoa(len(ids))
for _, id := range ids {
if id.Archive() > config.None {
d.rec[8] = "Container"
d.parents[d.rec[3]] = parent{d.id, d.rec[2], id.Archive().String()}
} else {
d.rec[8] = "File"
}
fields := id.Values()
d.rec[5], d.rec[11] = getMethod(fields[len(fields)-2]), mismatch(fields[len(fields)-1])
d.rec[14], d.rec[15], d.rec[16], d.rec[17] = fields[1], fields[4], fields[2], fields[3]
d.rec[3] = clearArchivePath(d.rec[2], d.rec[3])
d.w.Write(d.rec)
}
}
func (d *droidWriter) Tail() { d.w.Flush() }
func (d *droidWriter) processPath(p string) (parent, uri, path, name, ext string) {
path, _ = filepath.Abs(p)
path = strings.TrimSuffix(path, string(filepath.Separator))
name = filepath.Base(path)
dir := filepath.Dir(path)
par, ok := d.parents[dir]
if ok {
parent = strconv.Itoa(par.id)
uri = toUri(par.uri, par.archive, escape(name))
} else {
puri := "file:/" + escape(filepath.ToSlash(dir))
uri = toUri(puri, "", escape(name))
}
ext = strings.TrimPrefix(filepath.Ext(p), ".")
return
}
func toUri(parenturi, parentarc, base string) string {
if len(parentarc) > 0 {
parenturi = parentarc + ":" + parenturi + "!"
}
return parenturi + "/" + base
}
// uri escaping adapted from https://golang.org/src/net/url/url.go
func shouldEscape(c byte) bool {
if 'A' <= c && c <= 'Z' || 'a' <= c && c <= 'z' || '0' <= c && c <= '9' {
return false
}
switch c {
case '-', '_', '.', '~', '/', ':':
return false
}
return true
}
func escape(s string) string {
var hexCount int
for i := 0; i < len(s); i++ {
c := s[i]
if shouldEscape(c) {
hexCount++
}
}
if hexCount == 0 {
return s
}
t := make([]byte, len(s)+2*hexCount)
j := 0
for i := 0; i < len(s); i++ {
if c := s[i]; shouldEscape(c) {
t[j] = '%'
t[j+1] = "0123456789ABCDEF"[c>>4]
t[j+2] = "0123456789ABCDEF"[c&15]
j += 3
} else {
t[j] = s[i]
j++
}
}
return string(t)
}
func clearArchivePath(uri, path string) string {
if strings.HasPrefix(uri, config.Zip.String()) ||
strings.HasPrefix(uri, config.Tar.String()) ||
strings.HasPrefix(uri, config.Gzip.String()) {
path = ""
}
return path
}
func getMethod(basis string) string {
switch {
case strings.Contains(basis, "container"):
return "Container"
case strings.Contains(basis, "byte"):
return "Signature"
case strings.Contains(basis, "extension"):
return "Extension"
case strings.Contains(basis, "text"):
return "Text"
}
return ""
}
func mismatch(warning string) string {
if strings.Contains(warning, "extension mismatch") {
return "TRUE"
}
return "FALSE"
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mimematcher
import (
"fmt"
"sort"
"strings"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
// Matcher matches provided MIME-types against MIME-types associated with formats.
// This is an extra signal for identification akin to a file extension.
// It is used, for example, for web archive files (WARC) where you have declared
// MIME-types which you might want to verify.
type Matcher map[string][]int
// Load returns a MIMEMatcher
func Load(ls *persist.LoadSaver) core.Matcher {
le := ls.LoadSmallInt()
if le == 0 {
return nil
}
ret := make(Matcher)
for i := 0; i < le; i++ {
k := ls.LoadString()
r := make([]int, ls.LoadSmallInt())
for j := range r {
r[j] = ls.LoadSmallInt()
}
ret[k] = r
}
return ret
}
// Save encodes a MIMEMatcher
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveSmallInt(0)
return
}
m := c.(Matcher)
ls.SaveSmallInt(len(m))
for k, v := range m {
ls.SaveString(k)
ls.SaveSmallInt(len(v))
for _, w := range v {
ls.SaveSmallInt(w)
}
}
}
// SignatureSet for a MIMEMatcher is a slice of MIME-types
type SignatureSet []string
// Add adds a set of MIME-type signatures to a MIMEMatcher
func Add(c core.Matcher, ss core.SignatureSet, p priority.List) (core.Matcher, int, error) {
var m Matcher
if c == nil {
m = make(Matcher)
} else {
m = c.(Matcher)
}
sigs, ok := ss.(SignatureSet)
if !ok {
return nil, -1, fmt.Errorf("MIMEmatcher: bad signature set")
}
var length int
// unless it is a new matcher, calculate current length by iterating through all the result values
if len(m) > 0 {
for _, v := range m {
for _, w := range v {
if int(w) > length {
length = int(w)
}
}
}
length++ // add one - because the result values are indexes
}
for i, v := range sigs {
m.add(v, i+length)
}
return m, length + len(sigs), nil
}
func (m Matcher) add(s string, fmt int) {
_, ok := m[s]
if ok {
m[s] = append(m[s], fmt)
return
}
m[s] = []int{fmt}
}
// Identify tests the supplied MIME-type against the MIMEMatcher. The Buffer is not used.
func (m Matcher) Identify(s string, na *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
var (
fmts, tfmts []int
idx int
)
if len(s) > 0 {
fmts = m[s]
idx = strings.LastIndex(s, ";")
if idx > 0 {
tfmts = m[s[:idx]]
}
}
res := make(chan core.Result, len(fmts)+len(tfmts))
for _, v := range fmts {
res <- Result{
idx: v,
mime: s,
}
}
for _, v := range tfmts {
res <- Result{
idx: v,
Trimmed: true,
mime: s[:idx],
}
}
close(res)
return res, nil
}
// String representation of a MIMEMatcher
func (m Matcher) String() string {
var str string
var keys []string
for k := range m {
keys = append(keys, k)
}
sort.Strings(keys)
for _, v := range keys {
str += fmt.Sprintf("%v: %v\n", v, m[v])
}
return str
}
// Result reports a MIME-type match. If Trimmed is true, then the supplied MIME-type
// was trimmed of text following a ";" before matching
type Result struct {
idx int
Trimmed bool
mime string
}
// Index of the MIME-type match
func (r Result) Index() int {
return r.idx
}
// Basis for a MIME-type match is always just that the mime matched
func (r Result) Basis() string {
return "mime match " + r.mime
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Core siegfried defaults
package config
import (
"io"
"net/http"
"path/filepath"
"time"
)
var siegfried = struct {
version [3]int // Siegfried version (i.e. of the sf tool)
home string // Home directory used by both sf and roy tools
signature string // Name of signature file
conf string // Name of the conf file
magic []byte // Magic bytes to ID signature file
// Defaults for processing bytematcher signatures. These control the segmentation.
distance int // The acceptable distance between two frames before they will be segmented (default is 8192)
rng int // The acceptable range between two frames before they will be segmented (default is 0-2049)
choices int // The acceptable number of plain sequences generated from a single segment
cost int // The acceptable cost of a signature segement, in terms of the times that it might match in a worst case
repetition int // The acceptable repetition within a signature segment, used in combination with cost to determine segmentation.
// Config for using the update service.
updateURL string // URL for the update service (a JSON file that indicates whether update necessary and where can be found)
updateTimeout time.Duration
updateTransport *http.Transport
// Archivematica format policy registry service
fpr string
// DEBUG and SLOW modes
debug bool
slow bool
out io.Writer
checkpoint int64
userAgent string
}{
version: [3]int{1, 10, 1},
signature: "default.sig",
conf: "sf.conf",
magic: []byte{'s', 'f', 0x00, 0xFF},
distance: 8192,
rng: 4096,
choices: 128,
cost: 25600000,
repetition: 4,
updateURL: "https://www.itforarchivists.com/siegfried/update", // "http://localhost:8081/siegfried/update",
updateTimeout: 30 * time.Second,
updateTransport: &http.Transport{Proxy: http.ProxyFromEnvironment},
fpr: "/tmp/siegfried",
checkpoint: 524288, // point at which to report slow signatures (must be power of two)
userAgent: "siegfried/siegbot (+https://github.com/richardlehane/siegfried)",
}
// GETTERS
// Version reports the siegfried version.
func Version() [3]int {
return siegfried.version
}
// Home reports the siegfried HOME location (e.g. /usr/home/siegfried).
func Home() string {
return siegfried.home
}
// Home makes a path local to Home() if it is relative
func Local(base string) string {
if filepath.Dir(base) == "." {
return filepath.Join(siegfried.home, base)
}
return base
}
// Signature returns the path to the siegfried signature file.
func Signature() string {
return Local(siegfried.signature)
}
// SignatureBase returns the filename of the siegfried signature file.
func SignatureBase() string {
return siegfried.signature
}
// Conf returns the path to the siegfried configuration file.
func Conf() string {
return Local(siegfried.conf)
}
// Magic returns the magic string encoded at the start of a siegfried signature file.
func Magic() []byte {
return siegfried.magic
}
// Distance is a bytematcher setting. It controls the absolute widths at which segments in signatures are split.
// E.g. if segments are separated by a minimum of 50 and maximum of 100 bytes, the distance is 100.
// A short distance means a smaller Aho Corasick search tree and more patterns to follow-up.
// A long distance means a larger Aho Corasick search tree and more signatures immediately satisfied without follow-up pattern matching.
func Distance() int {
return siegfried.distance
}
// Range is a bytematcher setting. It controls the relative widths at which segments in signatures are split.
// E.g. if segments are separated by a minimum of 50 and maximum of 100 bytes, the range is 50.
// A small range means a smaller Aho Corasick search tree and more patterns to follow-up.
// A large range means a larger Aho Corasick search tree and more signatures immediately satisfied without follow-up pattern matching.
func Range() int {
return siegfried.rng
}
// Choices is a bytematcher setting. It controls the number of tolerable strings produced by processing signature segments.
// E.g. signature has two adjoining frames ("PDF") and ("1.1" OR "1.2") it can be processed into two search strings: "PDF1.1" and "PDF1.2".
// A low number of choices means a smaller Aho Corasick search tree and more patterns to follow-up.
// A large of choices means a larger Aho Corasick search tree and more signatures immediately satisfied without follow-up pattern matching.
func Choices() int {
return siegfried.choices
}
// Choices is a bytematcher setting. It controls the number of tolerable matches in a worst case scenario for a signature segement.
// If this cost is exceeded, then segmentation won't happen and the choices/range/distance preferences will be ignored.
func Cost() int {
return siegfried.cost
}
// Repetitition is a bytematcher setting. It is used in combination with Cost to determine segmentation.
func Repetition() int {
return siegfried.repetition
}
// UpdateOptions returns the update URL, timeout and transport for the sf -update command.
func UpdateOptions() (string, time.Duration, *http.Transport) {
return siegfried.updateURL, siegfried.updateTimeout, siegfried.updateTransport
}
// Fpr reports whether sf is being run in -fpr (Archivematica format policy registry) mode.
func Fpr() string {
return siegfried.fpr
}
// Debug reports whether debug logging is activated.
func Debug() bool {
return siegfried.debug
}
// Slow reports whether slow logging is activated.
func Slow() bool {
return siegfried.slow
}
// Out reports the target for logging messages (STDOUT or STDIN).
func Out() io.Writer {
return siegfried.out
}
// Checkpoint reports the offset at which slow logging should trigger.
func Checkpoint(i int64) bool {
return i == siegfried.checkpoint
}
// UserAgent returns the siegbot User-Agent string for http requests.
func UserAgent() string {
return siegfried.userAgent
}
// SETTERS
// SetHome sets the siegfried HOME location (e.g. /usr/home/siegfried).
func SetHome(h string) {
siegfried.home = h
}
// SetSignature sets the signature filename or filepath.
func SetSignature(s string) {
siegfried.signature = s
}
// SetConf sets the configuration filename or filepath.
func SetConf(s string) {
siegfried.conf = s
}
// SetDistance sets the distance variable for the bytematcher.
func SetDistance(i int) func() private {
return func() private {
siegfried.distance = i
return private{}
}
}
// SetRange sets the range variable for the bytematcher.
func SetRange(i int) func() private {
return func() private {
siegfried.rng = i
return private{}
}
}
// SetChoices sets the choices variable for the bytematcher.
func SetChoices(i int) func() private {
return func() private {
siegfried.choices = i
return private{}
}
}
// SetCost sets the cost variable for the bytematcher.
func SetCost(i int) func() private {
return func() private {
siegfried.cost = i
return private{}
}
}
// SetRepetition sets the repetitition variable for the bytematcher.
func SetRepetition(i int) func() private {
return func() private {
siegfried.repetition = i
return private{}
}
}
// SetDebug sets degub logging on.
func SetDebug() {
siegfried.debug = true
}
// SetSlow sets slow logging on.
func SetSlow() {
siegfried.slow = true
}
// SetOut sets the target for logging.
func SetOut(o io.Writer) {
siegfried.out = o
}
<file_sep>// Copyright 2019 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package frames
import (
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/persist"
)
func init() {
patterns.Register(machineLoader, loadMachine)
patterns.Register(blockLoader, loadBlock)
}
const (
machineLoader byte = iota + 12 // mimeinfo patterns start at 16
blockLoader
)
func machinify(seg Signature) Signature {
seg = Blockify(seg)
switch seg.Characterise() {
case BOFZero, BOFWindow, BOFWild:
return Signature{NewFrame(BOF, Machine(seg), 0, 0)}
case EOFZero, EOFWindow, EOFWild:
return Signature{NewFrame(EOF, Machine(seg), 0, 0)}
default: //todo handle Prev and Succ wild
}
return seg
}
// A Machine is a segment of a signature that implements the patterns interface
type Machine Signature
func (m Machine) Test(b []byte) ([]int, int) {
var iter int
offs := make([]int, len(m))
for {
if iter < 0 {
return nil, 1
}
if offs[iter] >= len(b) {
iter--
continue
}
length, adv := m[iter].MatchN(b[offs[iter]:], 0)
if length < 0 {
iter--
continue
}
// success!
if iter == len(offs)-1 {
offs[iter] += length
break
}
offs[iter+1] = offs[iter] + length
offs[iter] += adv
iter++
}
return []int{offs[iter]}, 1
}
func (m Machine) TestR(b []byte) ([]int, int) {
iter := len(m) - 1
offs := make([]int, len(m))
for {
if iter >= len(m) {
return nil, 0
}
if offs[iter] >= len(b) {
iter++
continue
}
length, adv := m[iter].MatchNR(b[:len(b)-offs[iter]], 0)
if length < 0 {
iter++
continue
}
// success!
if iter == 0 {
offs[iter] += length
break
}
offs[iter-1] = offs[iter] + length
offs[iter] += adv
iter--
}
return []int{offs[iter]}, 1
}
func (m Machine) Equals(pat patterns.Pattern) bool {
m2, ok := pat.(Machine)
if !ok || len(m) != len(m2) {
return false
}
for i, f := range m {
if !f.Equals(m2[i]) {
return false
}
}
return true
}
func (m Machine) Length() (int, int) {
var min, max int
for _, f := range m {
pmin, pmax := f.Length()
min += f.Min
min += pmin
max += f.Max
max += pmax
}
return min, max
}
// Machines are used where sequence matching inefficient
func (m Machine) NumSequences() int { return 0 }
func (m Machine) Sequences() []patterns.Sequence { return nil }
func (m Machine) String() string {
var str string
for i, v := range m {
if i > 0 {
str += " | "
}
str += v.String()
}
return "m {" + str + "}"
}
func (m Machine) Save(ls *persist.LoadSaver) {
ls.SaveByte(machineLoader)
ls.SaveSmallInt(len(m))
for _, f := range m {
f.Save(ls)
}
}
func loadMachine(ls *persist.LoadSaver) patterns.Pattern {
m := make(Machine, ls.LoadSmallInt())
for i := range m {
m[i] = Load(ls)
}
return m
}
<file_sep>package siegreader
import (
"io"
"os"
"strings"
"testing"
)
func TestRead(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := ReaderFrom(b)
buf := make([]byte, 62)
i, err := r.Read(buf)
if err != nil {
t.Errorf("Read error: %v", err)
}
if i != 62 {
t.Errorf("Read error: expecting a read length of 62, got %v", i)
}
if string(buf) != testString {
t.Errorf("Read error: %s should equal %s", string(buf), testString)
}
bufs.Put(b)
}
func readAt(t *testing.T, r *Reader) {
buf := make([]byte, 5)
i, err := r.ReadAt(buf, 4)
if err != nil {
t.Errorf("Read error: %v", err)
}
if i != 5 {
t.Errorf("Read error: expecting a read length of 5, got %d", i)
}
if string(buf) != "45678" {
t.Errorf("Read error: %s should equal %s", string(buf), "45678")
}
}
func TestReadAt(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := ReaderFrom(b)
readAt(t, r)
bufs.Put(b)
}
func readByte(t *testing.T, r *Reader) {
c, err := r.ReadByte()
if err != nil {
t.Errorf("Read error: %v", err)
}
if c != '0' {
t.Errorf("Read error: expecting '0', got %s", string(c))
}
c, err = r.ReadByte()
if err != nil {
t.Errorf("Read error: %v", err)
}
if c != '1' {
t.Errorf("Read error: expecting '1', got %s", string(c))
}
}
func TestReadByte(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := ReaderFrom(b)
readByte(t, r)
bufs.Put(b)
}
func seek(t *testing.T, r *Reader) {
_, err := r.Seek(6, 0)
if err != nil {
t.Errorf("Read error: %v", err)
}
c, err := r.ReadByte()
if err != nil {
t.Errorf("Read error: %v", err)
}
if c != '6' {
t.Errorf("Read error: expecting '6', got %s", string(c))
}
}
func TestSeek(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := ReaderFrom(b)
seek(t, r)
bufs.Put(b)
}
func TestReuse(t *testing.T) {
r, err := os.Open(testfile)
if err != nil {
t.Fatal(err)
}
b, err := bufs.Get(r)
if err != nil {
t.Fatal(err)
}
bufs.Put(b)
r.Close()
nr := strings.NewReader(testString)
q := make(chan struct{})
b, err = bufs.Get(nr)
if err != nil && err != io.EOF {
t.Fatal(err)
}
b.Quit = q
if err != nil && err != io.EOF {
t.Errorf("Read error: %v", err)
}
reuse := ReaderFrom(b)
readByte(t, reuse)
seek(t, reuse)
bufs.Put(b)
}
func drain(r io.ByteReader, results chan int) {
var i int
for _, e := r.ReadByte(); e == nil; _, e = r.ReadByte() {
i++
}
results <- i
}
func TestDrain(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := ReaderFrom(b)
results := make(chan int)
go drain(r, results)
if i := <-results; i != 62 {
t.Errorf("Expecting 62, got %v", i)
}
bufs.Put(b)
}
func TestDrainFile(t *testing.T) {
r, err := os.Open(testfile)
if err != nil {
t.Fatal(err)
}
b := setup(r, t)
first := ReaderFrom(b)
results := make(chan int)
go drain(first, results)
if i := <-results; i != 24040 {
t.Errorf("Expecting 24040, got %v", i)
}
r.Close()
bufs.Put(b)
}
func TestMultiple(t *testing.T) {
r, err := os.Open(testfile)
if err != nil {
t.Fatal(err)
}
b := setup(r, t)
first := ReaderFrom(b)
second := ReaderFrom(b)
results := make(chan int)
go drain(first, results)
go drain(second, results)
if i := <-results; i != 24040 {
t.Errorf("Expecting 24040, got %v", i)
}
if i := <-results; i != 24040 {
t.Errorf("Expecting 24040, got %v", i)
}
bufs.Put(b)
}
func TestReverse(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := ReverseReaderFrom(b)
first := ReaderFrom(b)
results := make(chan int)
go drain(first, results)
<-results
c, err := r.ReadByte()
if err != nil {
t.Fatalf("Read error: %v", err)
}
if c != 'Z' {
t.Fatalf("Read error: expecting 'Z', got %s", string(c))
}
c, err = r.ReadByte()
if err != nil {
t.Fatalf("Read error: %v", err)
}
if c != 'Y' {
t.Fatalf("Read error: expecting 'Y', got %s", string(c))
}
bufs.Put(b)
}
func TestReverseDrainFile(t *testing.T) {
r, err := os.Open(testfile)
if err != nil {
t.Fatal(err)
}
b := setup(r, t)
quit := make(chan struct{})
b.Quit = quit
first := ReaderFrom(b)
firstResults := make(chan int, 1)
last := ReverseReaderFrom(b)
lastResults := make(chan int)
go drain(first, firstResults)
go drain(last, lastResults)
if i := <-lastResults; i != 24040 {
t.Errorf("Expecting 24040, got %v", i)
}
<- firstResults // make sure we've finished in both directions before closing file
r.Close()
bufs.Put(b)
}
func TestLimit(t *testing.T) {
b := setup(strings.NewReader(testString), t)
r := LimitReaderFrom(b, 5)
results := make(chan int)
go drain(r, results)
if i := <-results; i != 5 {
t.Errorf("Expecting 5, got %d", i)
}
bufs.Put(b)
}
func TestReverseLimit(t *testing.T) {
b := setup(strings.NewReader(testString), t)
l := LimitReaderFrom(b, -1)
firstResults := make(chan int, 1)
go drain(l, firstResults)
r := LimitReverseReaderFrom(b, 5)
results := make(chan int)
go drain(r, results)
if i := <-results; i != 5 {
t.Errorf("Expecting 5, got %d", i)
}
bufs.Put(b)
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package xmlmatcher
import (
"strings"
"testing"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
var (
testSet = SignatureSet{
{"MD_metadata", ""},
{"MD_metadata", "http://www.isotc211.org/2005/gmd"},
{"", "http://purl.org/rss/1.0/"},
}
testCases = []struct {
name string
val string
expect []int
}{
{"notXML", "this is not xml!", []int{}},
{"mdXML", "<MD_metadata>bla bla", []int{0}},
{"mdXMLns", "<MD_metadata xmlns='http://www.isotc211.org/2005/gmd'>bla bla", []int{1, 0}},
{"rssXMLns", "<atom xmlns='http://purl.org/rss/1.0/'>", []int{2}},
}
)
func TestAdd(t *testing.T) {
_, i, err := Add(nil, testSet, nil)
if err != nil || i != 3 {
t.Errorf("expecting no errors and three signatures added, got %v and %d", err, i)
}
}
func identifyString(m Matcher, s string) ([]core.Result, error) {
rdr := strings.NewReader(s)
bufs := siegreader.New()
buf, _ := bufs.Get(rdr)
res, err := m.Identify("", buf)
if err != nil {
return nil, err
}
ret := []core.Result{}
for r := range res {
ret = append(ret, r)
}
return ret, nil
}
func TestIdentify(t *testing.T) {
m, i, e := Add(nil, testSet, nil)
if i != 3 || e != nil {
t.Fatal("failed to create matcher")
}
for _, tc := range testCases {
res, err := identifyString(m.(Matcher), tc.val)
if err != nil {
t.Fatalf("error identifying %s: %v", tc.name, err)
}
if len(res) == len(tc.expect) {
for i := range res {
if res[i].Index() != tc.expect[i] {
t.Errorf("bad results for %s: got index %d, expected %d, basis %s", tc.name, res[i].Index(), tc.expect[i], res[i].Basis())
}
}
} else {
t.Errorf("bad results for %s: got %d results, expected %d %s %d %s %d ", tc.name, len(res), len(tc.expect), res[0].Basis(), res[0].Index(), res[1].Basis(), res[1].Index())
}
}
}
<file_sep>// +build brew
package config
func init() {
siegfried.home = "/usr/share/siegfried"
}
<file_sep>// Copyright 2017 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package reader
import (
"encoding/csv"
"fmt"
"io"
)
var (
fidoIDs = [][2]string{{"fido", ""}}
fidoFields = [][]string{{"ns", "id", "format", "full", "mime", "basis", "warning", "time"}}
)
type fido struct {
rdr *csv.Reader
path string
peek []string
err error
}
func newFido(r io.Reader, path string) (Reader, error) {
fi := &fido{
rdr: csv.NewReader(r),
path: path,
}
fi.peek, fi.err = fi.rdr.Read()
if fi.err == nil && len(fi.peek) < 9 {
fi.err = fmt.Errorf("not a valid fido results file, need 9 fields, got %d", len(fi.peek))
}
return fi, fi.err
}
func (fi *fido) Head() Head {
return Head{
ResultsPath: fi.path,
Identifiers: fidoIDs,
Fields: fidoFields,
}
}
func idVals(known, puid, format, full, mime, basis, time string) []string {
var warn string
if known == "KO" {
puid = "UNKNOWN"
warn = unknownWarn
} else if basis == "extension" {
warn = extWarn
}
if mime == "None" {
mime = ""
}
return []string{"fido", puid, format, full, mime, basis, warn, time}
}
func (fi *fido) Next() (File, error) {
if fi.peek == nil || fi.err != nil {
return File{}, fi.err
}
file, err := newFile(fi.peek[6], fi.peek[5], "", "", "")
fn := fi.peek[6]
for {
file.IDs = append(file.IDs, newDefaultID(fidoFields[0],
idVals(fi.peek[0], fi.peek[2], fi.peek[3], fi.peek[4], fi.peek[7], fi.peek[8], fi.peek[1])))
fi.peek, fi.err = fi.rdr.Read()
if fi.peek == nil || fi.err != nil || fn != fi.peek[6] {
break
}
}
return file, err
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package siegreader
import (
"io"
"os"
)
// Buffers is a combined pool of stream, external and file buffers
type Buffers struct {
spool *pool // Pool of stream Buffers
fpool *pool // Pool of file Buffers
epool *pool // Pool of external buffers
fdatas *datas // file datas
}
// New creates a new pool of stream, external and file buffers
func New() *Buffers {
return &Buffers{
spool: newPool(newStream),
fpool: newPool(newFile),
epool: newPool(newExternal),
fdatas: &datas{
newPool(newBigFile),
newPool(newSmallFile),
newPool(newMmap),
},
}
}
// Get returns a Buffer reading from the provided io.Reader.
// Get returns a Buffer backed by a stream, external or file
// source buffer depending on the type of reader.
// Source buffers are re-cycled where possible.
func (b *Buffers) Get(src io.Reader) (*Buffer, error) {
f, ok := src.(*os.File)
if ok {
stat, err := f.Stat()
if err != nil || stat.Mode()&os.ModeType != 0 {
ok = false
}
}
if !ok {
e, ok := src.(source)
if !ok || !e.IsSlicer() {
stream := b.spool.get().(*stream)
buf := &Buffer{}
err := stream.setSource(src, buf)
buf.bufferSrc = stream
return buf, err
}
ext := b.epool.get().(*external)
err := ext.setSource(e)
return &Buffer{bufferSrc: ext}, err
}
fbuf := b.fpool.get().(*file)
err := fbuf.setSource(f, b.fdatas)
return &Buffer{bufferSrc: fbuf}, err
}
// Put returns a Buffer to the pool for re-cycling.
func (b *Buffers) Put(i *Buffer) {
switch v := i.bufferSrc.(type) {
default:
panic("Siegreader: unknown buffer type")
case *stream:
v.cleanUp()
b.spool.put(v)
case *file:
b.fdatas.put(v.data)
b.fpool.put(v)
case *external:
b.epool.put(v)
}
}
// data pool (used by file)
// pool of big files, small files, and mmap files
type datas struct {
bfpool *pool
sfpool *pool
mpool *pool
}
func (d *datas) get(f *file) data {
if mmapable(f.sz) {
m := d.mpool.get().(*mmap)
if err := m.setSource(f); err == nil {
return m
}
d.mpool.put(m) // replace on error and get big file instead
}
if f.sz <= int64(smallFileSz) {
sf := d.sfpool.get().(*smallfile)
sf.setSource(f)
return sf
}
bf := d.bfpool.get().(*bigfile)
bf.setSource(f)
return bf
}
func (d *datas) put(i data) {
if i == nil {
return
}
switch v := i.(type) {
default:
panic("Siegreader: unknown data type")
case *bigfile:
d.bfpool.put(v)
case *smallfile:
d.sfpool.put(v)
case *mmap:
v.reset()
d.mpool.put(v)
}
return
}
<file_sep>// Copyright 2011 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
package siegreader
import (
"os"
"reflect"
"syscall"
"unsafe"
)
func mmapable(sz int64) bool {
if int64(int(sz+4095)) != sz+4095 {
return false
}
return true
}
func (m *mmap) mapFile() error {
h, err := syscall.CreateFileMapping(syscall.Handle(m.src.Fd()), nil, syscall.PAGE_READONLY, uint32(m.sz>>32), uint32(m.sz), nil)
if err != nil {
return err
}
m.handle = uintptr(h) // for later unmapping
addr, err := syscall.MapViewOfFile(h, syscall.FILE_MAP_READ, 0, 0, 0)
if err != nil {
return err
}
m.buf = []byte{}
slcHead := (*reflect.SliceHeader)(unsafe.Pointer(&m.buf))
slcHead.Data = addr
slcHead.Len = int(m.sz)
slcHead.Cap = int(m.sz)
return nil
}
func (m *mmap) unmap() error {
slcHead := (*reflect.SliceHeader)(unsafe.Pointer(&m.buf))
err := syscall.UnmapViewOfFile(slcHead.Data)
if err != nil {
return err
}
return os.NewSyscallError("CloseHandle", syscall.CloseHandle(syscall.Handle(m.handle)))
}
<file_sep>package main
import (
"bytes"
"encoding/json"
"os"
"path/filepath"
"strings"
"testing"
"time"
"github.com/richardlehane/siegfried"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/wikidata"
"github.com/richardlehane/siegfried/pkg/writer"
)
// Path components associated with the Roy command folder.
const wikibaseTestDefinitions = "custom-wikibase-test-definitions"
const wikibaseCustomSkeletons = "wikibase"
func setupWikibase() (*siegfried.Siegfried, error) {
config.SetWikidataEndpoint("https://query.wikidata.org/sparql")
// resetWikidata sets state for the standard Wikidata tests because
// it isn't set during normal runtime like the Wikibase config. This
// function is good to call here anyway as it helps verify that
// runtime config for Wikibase regardless.
resetWikidata()
var wbSiegfried *siegfried.Siegfried
wbSiegfried = siegfried.New()
config.SetHome(*wikidataDefinitions)
config.SetWikidataDefinitions(wikibaseTestDefinitions)
opts := []config.Option{config.SetWikidataNamespace()}
opts = append(opts, config.SetWikidataNoPRONOM())
wbIdentifier, err := wikidata.New(opts...)
if err != nil {
return wbSiegfried, err
}
wbSiegfried.Add(wbIdentifier)
return wbSiegfried, nil
}
// wbIdentificationTests provides our structure for table driven tests.
type wbIdentificationTests struct {
fname string
label string
qid string
extMatch bool
byteMatch bool
containerMatch bool
error bool
hasExt bool
}
var wbSkeletonSamples = []wbIdentificationTests{
wbIdentificationTests{
filepath.Join(wikibaseCustomSkeletons, "badf00d.badf00d"),
"FFIFF", "Q6", false, true, false, false, true},
wbIdentificationTests{
filepath.Join(wikibaseCustomSkeletons, "ba53ba11.ff2"),
"FFIIFF", "Q7", true, true, false, false, true},
wbIdentificationTests{
filepath.Join(wikibaseCustomSkeletons, "FFIIIFF"),
"FFIIIFF", "Q9", true, true, false, false, false},
wbIdentificationTests{
filepath.Join(wikibaseCustomSkeletons, "FITS"),
"Flexible Image Transport System (FITS), Version 3.0", "Q8",
true, true, false, false, false,
},
}
// TestWikidataBasic will perform some rudimentary tests using some
// simple Skeleton files and the Wikibase identifier.
func TestWikibaseBasic(t *testing.T) {
wbSiegfried, err := setupWikibase()
if err != nil {
t.Error(err)
}
for _, test := range wbSkeletonSamples {
path := filepath.Join(siegfriedTestData, wikidataTestData, test.fname)
wbSiegfriedRunner(wbSiegfried, path, test, t)
}
}
func wbSiegfriedRunner(wbSiegfried *siegfried.Siegfried, path string, test wbIdentificationTests, t *testing.T) {
file, err := os.Open(path)
if err != nil {
t.Fatalf("failed to open %v, got: %v", path, err)
}
defer file.Close()
res, err := wbSiegfried.Identify(file, path, "")
if err != nil && !test.error {
t.Fatal(err)
}
if len(res) > 1 {
t.Errorf("Match length greater than one: '%d'", len(res))
}
namespace := res[0].Values()[0]
if namespace != wikidataNamespace {
t.Errorf("Namespace error, expected: '%s' received: '%s'",
wikidataNamespace, namespace,
)
}
// res is a an array of JSON values. We're interested in the first
// result (index 0), and then the following fields
id := res[0].Values()[1]
label := res[0].Values()[2]
permalink := res[0].Values()[4]
basis := res[0].Values()[6]
warning := res[0].Values()[7]
if id != test.qid {
t.Errorf(
"QID match different than anticipated: '%s' expected '%s'",
id,
test.qid,
)
}
if label != test.label {
t.Errorf(
"Label match different than anticipated: '%s' expected '%s'",
label,
test.label,
)
}
const placeholderPermalink = "http://wikibase.example.com/w/index.php?oldid=58&title=Item%3AQ6"
if permalink != placeholderPermalink {
t.Errorf(
"There has been a problem parsing the permalink for '%s' from Wikidata/Wikiprov: %s",
test.qid,
permalink,
)
}
if test.extMatch && !strings.Contains(basis, extensionMatch) {
if test.hasExt {
t.Errorf(
"Extension match not returned by identifier: %s",
basis,
)
}
}
if test.byteMatch && !strings.Contains(basis, byteMatch) {
t.Errorf(
"Byte match not returned by identifier: %s",
basis,
)
}
if !test.extMatch && !strings.Contains(warning, extensionMismatch) {
t.Errorf(
"Expected an extension mismatch but it wasn't returned: %s",
warning,
)
}
// Implement a basic Writer test for some of the data coming out of
// the Wikidata identifier. CSV and YAML will need a little more
// thought.
var w writer.Writer
buf := new(bytes.Buffer)
w = writer.JSON(buf)
w.Head(
"path/to/file",
time.Now(),
time.Now(),
[3]int{0, 0, 0},
wbSiegfried.Identifiers(),
wbSiegfried.Fields(),
"md5",
)
w.File("testName", 10, "testMod", []byte("d41d8c"), nil, res)
w.Tail()
if !json.Valid([]byte(buf.String())) {
t.Fatalf("Output from JSON writer is invalid: %s", buf.String())
}
}
<file_sep>package frames_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
func TestMachine(t *testing.T) {
machine := Machine(TestFmts[13405])
if machine.NumSequences() != 0 {
t.Errorf("Expecting 0 sequences, got %d", machine.NumSequences())
}
// test BOF matching
l, _ := machine.Test(TestMP3)
if len(l) < 1 {
t.Error("Expecting the machine to match the MP3")
}
if l[0] != 5218 {
t.Errorf("Expecting length of the match to be 5218, got %d", l)
}
// check for pernicious slowdown
l, _ = machine.Test(TestBumper)
if len(l) > 0 {
t.Error("Expecting the machine not to match bumper")
}
// test EOF matching
rmachine := Machine(TestFmts[13401])
if rmachine.NumSequences() != 0 {
t.Errorf("Expecting 0 sequences, got %d", machine.NumSequences())
}
l, _ = rmachine.TestR(TestMP3)
if len(l) < 1 {
t.Error("Expecting the machine to match the MP3")
}
if l[0] != 5218 {
t.Errorf("Expecting length of the match to be 5218, got %d", l)
}
min, max := rmachine.Length()
if min != 344 || max != 10450 {
t.Errorf("Got lengths %d and %d", min, max)
}
}
func TestMultiLenMatching(t *testing.T) {
machine := Machine(TestSignatures[6])
l, _ := machine.Test(TestMultiLen)
if len(l) < 1 || l[0] != 9 {
t.Error("Expected the machine to match the multi-len string TESTYNESS")
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mappings
import (
"encoding/xml"
"strings"
)
// PRONOM Report
type Report struct {
XMLName xml.Name `xml:"PRONOM-Report"`
Id int `xml:"report_format_detail>FileFormat>FormatID"`
Name string `xml:"report_format_detail>FileFormat>FormatName"`
Version string `xml:"report_format_detail>FileFormat>FormatVersion"`
Description string `xml:"report_format_detail>FileFormat>FormatDescription"`
Families string `xml:"report_format_detail>FileFormat>FormatFamilies"`
Types string `xml:"report_format_detail>FileFormat>FormatTypes"`
Identifiers []FormatIdentifier `xml:"report_format_detail>FileFormat>FileFormatIdentifier"`
Signatures []Signature `xml:"report_format_detail>FileFormat>InternalSignature"`
Extensions []string `xml:"report_format_detail>FileFormat>ExternalSignature>Signature"`
Relations []RelatedFormat `xml:"report_format_detail>FileFormat>RelatedFormat"`
}
type Signature struct {
ByteSequences []ByteSequence `xml:"ByteSequence"`
}
func (s Signature) String() string {
var p string
for i, v := range s.ByteSequences {
if i > 0 {
p += "\n"
}
p += v.String()
}
return p
}
type ByteSequence struct {
Position string `xml:"PositionType"`
Offset string
MaxOffset string
IndirectLoc string `xml:"IndirectOffsetLocation"`
IndirectLen string `xml:"IndirectOffsetLength"`
Endianness string
Hex string `xml:"ByteSequenceValue"`
}
func trim(label, s string) string {
s = strings.TrimSpace(s)
if s == "" {
return s
}
return label + ":" + s + " "
}
func (bs ByteSequence) String() string {
return trim("Pos", bs.Position) + trim("Min", bs.Offset) + trim("Max", bs.MaxOffset) + trim("Hex", bs.Hex)
}
type RelatedFormat struct {
Typ string `xml:"RelationshipType"`
Id int `xml:"RelatedFormatID"`
}
func appendUniq(is []int, i int) []int {
for _, v := range is {
if i == v {
return is
}
}
return append(is, i)
}
func (r *Report) Superiors() []int {
sups := []int{}
for _, v := range r.Relations {
if v.Typ == "Has lower priority than" || v.Typ == "Is supertype of" {
sups = appendUniq(sups, v.Id)
}
}
return sups
}
func (r *Report) Subordinates() []int {
subs := []int{}
for _, v := range r.Relations {
if v.Typ == "Has priority over" || v.Typ == "Is subtype of" {
subs = appendUniq(subs, v.Id)
}
}
return subs
}
type FormatIdentifier struct {
Typ string `xml:"IdentifierType"`
Id string `xml:"Identifier"`
}
func (r *Report) MIME() string {
for _, v := range r.Identifiers {
if v.Typ == "MIME" {
return v.Id
}
}
return ""
}
func (r *Report) Label(puid string) string {
name, version := strings.TrimSpace(r.Name), strings.TrimSpace(r.Version)
switch {
case name == "" && version == "":
return puid
case name == "":
return puid + " (" + version + ")"
case version == "":
return puid + " (" + name + ")"
}
return puid + " (" + name + " " + version + ")"
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mimeinfo
import (
//"fmt"
"path/filepath"
"testing"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/config"
)
func TestNew(t *testing.T) {
config.SetHome(filepath.Join("..", "..", "cmd", "roy", "data"))
config.SetMIMEInfo("freedesktop.org.xml")()
mi, err := newMIMEInfo(config.MIMEInfo())
if err != nil {
t.Fatal(err)
}
config.SetMIMEInfo("tika-mimetypes.xml")()
mi, err = newMIMEInfo(config.MIMEInfo())
if err != nil {
t.Fatal(err)
}
sigs, ids, err := mi.Signatures()
if err != nil {
t.Error(err)
}
for i, v := range sigs {
if len(v) == 0 {
t.Errorf("Empty signature: %s", ids[i])
}
}
id, _ := New()
str := id.String()
saver := persist.NewLoadSaver(nil)
id.Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
id2 := Load(loader)
if str != id2.String() {
t.Errorf("Load identifier fail: got %s, expect %s", str, id2.String())
}
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
package main
import (
"encoding/json"
"fmt"
"io/ioutil"
"log"
"os"
"strings"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/ross-spencer/wikiprov/pkg/spargo"
"github.com/ross-spencer/wikiprov/pkg/wikiprov"
)
// configureCustomWikibase captures all the functions needed to harvest
// signature information from a custom Wikibase instance. It only
// impacts 'harvest'. Roy's 'build' stage needs to be managed differently.
func configureCustomWikibase() error {
if err := config.SetCustomWikibaseEndpoint(
*harvestWikidataEndpoint,
*harvestWikidataWikibaseURL); err != nil {
return err
}
if err := config.SetCustomWikibaseQuery(); err != nil {
return err
}
return nil
}
// jsonEscape can be used to escape a string for adding to a JSON structure
// without fear of letting unescaped special characters slip by.
func jsonEscape(str string) string {
jsonStr, err := json.Marshal(str)
if err != nil {
panic(err)
}
str = string(jsonStr)
return str[1 : len(str)-1]
}
// addEndpoint is designed to augment the harvest data from Wikidata
// with the source endpoint used. This information provides greater
// context for the caller.
//
// In the fullness of time, this might also be added to Wikiprov, and
// if it is, it will make the process more reliable, and this function
// redundant.
func addEndpoint(repl string, endpoint string) string {
replacement := fmt.Sprintf(
"{\n \"endpoint\": \"%s\",",
jsonEscape(endpoint),
)
return strings.Replace(repl, "{", replacement, 1)
}
// harvestWikidata will connect to the configured Wikidata query service
// and save the results of the configured query to disk.
func harvestWikidata() error {
log.Printf(
"Roy (Wikidata): Harvesting Wikidata definitions: lang '%s'",
config.WikidataLang(),
)
err := os.MkdirAll(config.WikidataHome(), os.ModePerm)
if err != nil {
return fmt.Errorf(
"Roy (Wikidata): Error harvesting Wikidata definitions: '%s'",
err,
)
}
log.Printf(
"Roy (Wikidata): Harvesting definitions from: '%s'",
config.WikidataEndpoint(),
)
// Set the Wikibase server URL for wikiprov to construct index.php
// and api.php links for permalinks and revision history.
wikiprov.SetWikibaseURLs(config.WikidataWikibaseURL())
log.Printf(
"Roy (Wikidata): Harvesting revision history from: '%s'",
config.WikidataWikibaseURL(),
)
res, err := spargo.SPARQLWithProv(
config.WikidataEndpoint(),
config.WikidataSPARQL(),
config.WikidataSPARQLRevisionParam(),
config.GetWikidataRevisionHistoryLen(),
config.GetWikidataRevisionHistoryThreads(),
)
if err != nil {
return fmt.Errorf(
"Error trying to retrieve SPARQL with revision history: %s",
err,
)
}
// Create a modified JSON output containing the endpoint the query
// was run against. In future this could be added to Wikiprov.
modifiedJSON := addEndpoint(
fmt.Sprintf("%s", res), config.WikidataEndpoint(),
)
path := config.WikidataDefinitionsPath()
err = ioutil.WriteFile(
path,
[]byte(fmt.Sprintf("%s", modifiedJSON)),
config.WikidataFileMode(),
)
if err != nil {
return fmt.Errorf(
"Error harvesting Wikidata: '%s'",
err,
)
}
log.Printf(
"Roy (Wikidata): Harvesting Wikidata definitions '%s' complete",
path,
)
return nil
}
<file_sep>package frames_test
import (
"testing"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames"
. "github.com/richardlehane/siegfried/internal/bytematcher/frames/tests"
)
func TestContains(t *testing.T) {
if !TestSignatures[0].Contains(TestSignatures[0]) {
t.Error("Contains: expecting identical signatures to be contained")
}
}
func TestMirror(t *testing.T) {
mirror := TestSignatures[2].Mirror()
if len(mirror) < 2 || mirror[1].Orientation() != EOF {
t.Errorf("Mirror fail: got %v", mirror)
}
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package mimeinfo
import (
"encoding/binary"
"testing"
"github.com/richardlehane/siegfried/internal/bytematcher/patterns"
"github.com/richardlehane/siegfried/internal/persist"
)
var (
i8 byte = 8
i16 int16 = -5000
i32 int32 = 12345678
b16, l16 = make([]byte, 2), make([]byte, 2)
b32, l32 = make([]byte, 4), make([]byte, 4)
)
func init() {
binary.BigEndian.PutUint16(b16, uint16(i16))
binary.LittleEndian.PutUint16(l16, uint16(i16))
binary.BigEndian.PutUint32(b32, uint32(i32))
binary.LittleEndian.PutUint32(l32, uint32(i32))
}
func TestInt8(t *testing.T) {
if !Int8(i8).Equals(Int8(i8)) {
t.Error("Int8 fail: Equality")
}
if r, _ := Int8(i8).Test([]byte{7}); len(r) > 0 {
t.Error("Int8 fail: shouldn't match")
}
if r, _ := Int8(i8).Test([]byte{i8}); len(r) != 1 || r[0] != 1 {
t.Error("Int8 fail: should match")
}
if r, _ := Int8(i8).TestR([]byte{i8}); len(r) != 1 || r[0] != 1 {
t.Error("Int8 fail: should match reverse")
}
saver := persist.NewLoadSaver(nil)
Int8(i8).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadInt8(loader)
if !p.Equals(Int8(i8)) {
t.Errorf("expecting %d, got %s", i8, p)
}
}
func TestBig16(t *testing.T) {
if !Big16(i16).Equals(Big16(i16)) {
t.Error("Big16 fail: Equality")
}
if r, _ := Big16(i16).Test(l16); len(r) > 0 {
t.Error("Big16 fail: shouldn't match")
}
if r, _ := Big16(i16).Test(b16); len(r) != 1 || r[0] != 2 {
t.Error("Big16 fail: should match")
}
if r, _ := Big16(i16).TestR(b16); len(r) != 1 || r[0] != 2 {
t.Error("Big16 fail: should match reverse")
}
saver := persist.NewLoadSaver(nil)
Big16(i16).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadBig16(loader)
if !p.Equals(Big16(i16)) {
t.Errorf("expecting %d, got %s", i16, p)
}
}
func TestLittle16(t *testing.T) {
if !Little16(i16).Equals(Little16(i16)) {
t.Error("Little16 fail: Equality")
}
if r, _ := Little16(i16).Test(b16); len(r) > 0 {
t.Error("Little16 fail: shouldn't match")
}
if r, _ := Little16(i16).Test(l16); len(r) != 1 || r[0] != 2 {
t.Error("Little16 fail: should match")
}
if r, _ := Little16(i16).TestR(l16); len(r) != 1 || r[0] != 2 {
t.Error("Little16 fail: should match reverse")
}
saver := persist.NewLoadSaver(nil)
Little16(i16).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadLittle16(loader)
if !p.Equals(Little16(i16)) {
t.Errorf("expecting %d, got %s", i16, p)
}
}
func TestHost16(t *testing.T) {
if !Host16(i16).Equals(Host16(i16)) {
t.Error("Host16 fail: Equality")
}
if r, _ := Host16(i16).Test(b32); len(r) > 0 {
t.Error("Host16 fail: shouldn't match")
}
if r, _ := Host16(i16).Test(l16); len(r) != 1 || r[0] != 2 {
t.Error("Host16 fail: should match")
}
if r, _ := Host16(i16).Test(b16); len(r) != 1 || r[0] != 2 {
t.Error("Host16 fail: should match")
}
if r, _ := Host16(i16).TestR(l16); len(r) != 1 || r[0] != 2 {
t.Error("Host16 fail: should match reverse")
}
if r, _ := Host16(i16).TestR(b16); len(r) != 1 || r[0] != 2 {
t.Error("Host16 fail: should match reverse")
}
saver := persist.NewLoadSaver(nil)
Host16(i16).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadHost16(loader)
if !p.Equals(Host16(i16)) {
t.Errorf("expecting %d, got %s", i16, p)
}
}
func TestBig32(t *testing.T) {
if !Big32(i32).Equals(Big32(i32)) {
t.Error("Big32 fail: Equality")
}
if r, _ := Big32(i32).Test(l32); len(r) > 0 {
t.Error("Big32 fail: shouldn't match")
}
if r, _ := Big32(i32).Test(b32); len(r) != 1 || r[0] != 4 {
t.Error("Big32 fail: should match")
}
if r, _ := Big32(i32).TestR(b32); len(r) != 1 || r[0] != 4 {
t.Error("Big32 fail: should match")
}
saver := persist.NewLoadSaver(nil)
Big32(i32).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadBig32(loader)
if !p.Equals(Big32(i32)) {
t.Errorf("expecting %d, got %s", i32, p)
}
}
func TestLittle32(t *testing.T) {
if !Little32(i32).Equals(Little32(i32)) {
t.Error("Little32 fail: Equality")
}
if r, _ := Little32(i32).Test(b32); len(r) > 0 {
t.Error("Big32 fail: shouldn't match")
}
if r, _ := Little32(i32).Test(l32); len(r) != 1 || r[0] != 4 {
t.Error("Little32 fail: should match")
}
if r, _ := Little32(i32).TestR(l32); len(r) != 1 || r[0] != 4 {
t.Error("Little32 fail: should match")
}
saver := persist.NewLoadSaver(nil)
Little32(i32).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadLittle32(loader)
if !p.Equals(Little32(i32)) {
t.Errorf("expecting %d, got %s", i32, p)
}
}
func TestHost32(t *testing.T) {
if !Host32(i32).Equals(Host32(i32)) {
t.Error("Host32 fail: Equality")
}
if r, _ := Host32(i32).Test(b16); len(r) > 0 {
t.Error("Host32 fail: shouldn't match")
}
if r, _ := Host32(i32).Test(l32); len(r) != 1 || r[0] != 4 {
t.Error("Host32 fail: should match")
}
if r, _ := Host32(i32).Test(b32); len(r) != 1 || r[0] != 4 {
t.Error("Host32 fail: should match")
}
if r, _ := Host32(i32).TestR(l32); len(r) != 1 || r[0] != 4 {
t.Error("Host32 fail: should match reverse")
}
if r, _ := Host32(i32).TestR(b32); len(r) != 1 || r[0] != 4 {
t.Error("Host32 fail: should match reverse")
}
saver := persist.NewLoadSaver(nil)
Host32(i32).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadHost32(loader)
if !p.Equals(Host32(i32)) {
t.Errorf("expecting %d, got %s", i32, p)
}
}
func TestIgnoreCase(t *testing.T) {
apple := []byte("AppLe")
apple2 := []byte("apple")
if !IgnoreCase(apple).Equals(IgnoreCase(apple2)) {
t.Error("IgnoreCase fail: Equality")
}
if r, _ := IgnoreCase(apple).Test([]byte("banana")); len(r) > 0 {
t.Error("IgnoreCase fail: shouldn't match")
}
if r, _ := IgnoreCase(apple).Test(IgnoreCase(apple2)); len(r) != 1 || r[0] != 5 {
t.Error("IgnoreCase fail: should match")
}
if r, _ := IgnoreCase(apple).TestR(IgnoreCase(apple2)); len(r) != 1 || r[0] != 5 {
t.Error("IgnoreCase fail: should match reverse")
}
if i := IgnoreCase("!bYt*e").NumSequences(); i != 16 {
t.Errorf("IgnoreCase fail: numsequences expected %d, got %d", 16, i)
}
saver := persist.NewLoadSaver(nil)
IgnoreCase(apple).Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadIgnoreCase(loader)
if !p.Equals(IgnoreCase(apple)) {
t.Errorf("expecting %v, got %v", IgnoreCase(apple), p)
}
if seqs := IgnoreCase([]byte("a!cd")).Sequences(); len(seqs) != 8 {
t.Errorf("IgnoreCase sequences %v", seqs)
}
}
func TestMask(t *testing.T) {
apple := Mask{
pat: patterns.Sequence{'a', 'p', 'p', 0, 0, 'l', 'e'},
val: []byte{255, 255, 255, 0, 0, 255, 255},
}
apple2 := Mask{
pat: patterns.Sequence{'a', 'p', 'p', 0, 0, 'l', 'e'},
val: []byte{255, 255, 255, 0, 0, 255, 255},
}
if !apple.Equals(apple2) {
t.Error("Mask fail: Equality")
}
if r, _ := apple.Test([]byte("apPyzle")); len(r) > 0 {
t.Error("Mask fail: shouldn't match")
}
if r, _ := apple.Test([]byte("appyzle")); len(r) != 1 || r[0] != 7 {
t.Error("Mask fail: should match")
}
if r, _ := apple.TestR([]byte("appyzle")); len(r) != 1 || r[0] != 7 {
t.Error("Mask fail: should match reverse")
}
saver := persist.NewLoadSaver(nil)
apple.Save(saver)
loader := persist.NewLoadSaver(saver.Bytes())
_ = loader.LoadByte()
p := loadMask(loader)
if !p.Equals(apple) {
t.Errorf("expecting %s, got %s", apple, p)
}
seqsTest := Mask{
pat: patterns.Sequence("ap"),
val: []byte{0xFF, 0xFE},
}
if seqs := seqsTest.Sequences(); len(seqs) != 2 || seqs[1][1] != 'q' {
t.Error(seqs)
}
pats, ints := unmask(apple)
if len(ints) != 2 || ints[0] != 0 || ints[1] != 2 {
t.Errorf("Unmask fail, got ints %v", ints)
}
if len(pats) != 2 || !pats[0].Equals(patterns.Sequence("app")) || !pats[1].Equals(patterns.Sequence("le")) {
t.Errorf("Unmask fail, got pats %v", pats)
}
pats, ints = unmask(Mask{
pat: patterns.Sequence{'A', 'C', '0', '0', '0', '0'},
val: []byte{0xFF, 0xFF, 0xF0, 0xF0, 0xF0, 0xF0},
})
if len(ints) != 2 || ints[0] != 0 || ints[1] != 0 {
t.Errorf("Unmask fail, got ints %v", ints)
}
if len(pats) != 2 || !pats[0].Equals(patterns.Sequence("AC")) || !pats[1].Equals(Mask{
pat: patterns.Sequence{'0', '0', '0', '0'},
val: []byte{0xF0, 0xF0, 0xF0, 0xF0},
}) {
t.Errorf("Unmask fail, got pats %v", pats)
}
}
<file_sep>package siegfried
import (
"bytes"
"testing"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/pronom"
)
func TestLoad(t *testing.T) {
s := New()
config.SetHome("./cmd/roy/data")
p, err := pronom.New()
if err != nil {
t.Fatal(err)
}
err = s.Add(p)
if err != nil {
t.Fatal(err)
}
}
func TestIdentify(t *testing.T) {
s := New()
s.nm = testEMatcher{}
s.bm = testBMatcher{}
s.cm = nil
s.ids = append(s.ids, testIdentifier{})
c, err := s.Identify(bytes.NewBufferString("test"), "test.doc", "")
if err != nil {
t.Error(err)
}
i := c[0]
if i.String() != "fmt/3" {
t.Error("expecting fmt/3")
}
}
func TestLabel(t *testing.T) {
s := &Siegfried{ids: []core.Identifier{testIdentifier{}}}
res := s.Label(testIdentification{})
if len(res) != 2 ||
res[0][0] != "namespace" ||
res[0][1] != "a" ||
res[1][0] != "id" ||
res[1][1] != "fmt/3" {
t.Errorf("bad label, got %v", res)
}
}
// extension matcher test stub
type testEMatcher struct{}
func (t testEMatcher) Identify(n string, sb *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
ret := make(chan core.Result)
go func() {
ret <- testResult(0)
close(ret)
}()
return ret, nil
}
func (t testEMatcher) String() string { return "" }
// byte matcher test stub
type testBMatcher struct{}
func (t testBMatcher) Identify(nm string, sb *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
ret := make(chan core.Result)
go func() {
ret <- testResult(1)
ret <- testResult(2)
close(ret)
}()
return ret, nil
}
func (t testBMatcher) String() string { return "" }
type testResult int
func (tr testResult) Index() int { return int(tr) }
func (tr testResult) Basis() string { return "" }
// identifier test stub
type testIdentifier struct{}
func (t testIdentifier) Add(m core.Matcher, mt core.MatcherType) (core.Matcher, error) {
return nil, nil
}
func (t testIdentifier) Recorder() core.Recorder { return testRecorder{} }
func (t testIdentifier) Name() string { return "a" }
func (t testIdentifier) Details() string { return "b" }
func (t testIdentifier) Fields() []string { return []string{"namespace", "id"} }
func (t testIdentifier) Save(l *persist.LoadSaver) {}
func (t testIdentifier) String() string { return "" }
func (t testIdentifier) Inspect(s ...string) (string, error) { return "", nil }
func (t testIdentifier) GraphP(i int) string { return "" }
func (t testIdentifier) Recognise(m core.MatcherType, i int) (bool, string) { return false, "" }
// recorder test stub
type testRecorder struct{}
func (t testRecorder) Active(m core.MatcherType) {}
func (t testRecorder) Record(m core.MatcherType, r core.Result) bool { return true }
func (t testRecorder) Satisfied(m core.MatcherType) (bool, core.Hint) { return false, core.Hint{} }
func (t testRecorder) Report() []core.Identification {
return []core.Identification{testIdentification{}}
}
// identification test stub
type testIdentification struct{}
func (t testIdentification) String() string { return "fmt/3" }
func (t testIdentification) Warn() string { return "" }
func (t testIdentification) Known() bool { return true }
func (t testIdentification) Values() []string { return []string{"a", "fmt/3"} }
func (t testIdentification) Archive() config.Archive { return 0 }
<file_sep>package riffmatcher
import (
"flag"
"os"
"path/filepath"
"testing"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
)
var testdata = flag.String("testdata", filepath.Join("..", "..", "cmd", "sf", "testdata"), "override the default test data directory")
var fmts = SignatureSet{
[4]byte{'a', 'f', 's', 'p'},
[4]byte{'I', 'C', 'R', 'D'},
[4]byte{'I', 'S', 'F', 'T'},
[4]byte{'I', 'C', 'M', 'T'},
[4]byte{'f', 'a', 'c', 't'},
[4]byte{'f', 'm', 't', ' '},
[4]byte{'d', 'a', 't', 'a'},
[4]byte{'I', 'N', 'F', 'O'},
[4]byte{'W', 'A', 'V', 'E'},
}
var rm core.Matcher
func init() {
rm, _, _ = Add(rm, fmts, nil)
}
func TestMatch(t *testing.T) {
f, err := os.Open(filepath.Join(*testdata, "benchmark", "Benchmark.wav"))
if err != nil {
t.Fatal(err)
}
bufs := siegreader.New()
b, _ := bufs.Get(f)
res, err := rm.Identify("", b)
if err != nil {
t.Fatal(err)
}
var hits []int
for h := range res {
hits = append(hits, h.Index())
}
if len(hits) != len(fmts) {
t.Fatalf("Expecting %d hits, got %d", len(fmts), len(hits))
}
}
func TestIO(t *testing.T) {
str := rm.String()
saver := persist.NewLoadSaver(nil)
Save(rm, saver)
if len(saver.Bytes()) < 10 {
t.Errorf("Save riff matcher: too small, only got %v", saver.Bytes())
}
loader := persist.NewLoadSaver(saver.Bytes())
newrm := Load(loader)
str2 := newrm.String()
if str != str2 {
t.Errorf("Load riff matcher: expecting first matcher (%v), to equal second matcher (%v)", str, str2)
}
}
<file_sep>// Copyright 2014 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package containermatcher
import (
"archive/zip"
"io"
"strings"
"github.com/richardlehane/siegfried/internal/siegreader"
)
type zipReader struct {
idx int
rdr *zip.Reader
rc io.ReadCloser
}
func (z *zipReader) Next() error {
z.idx++
if z.idx >= len(z.rdr.File) {
return io.EOF
}
return nil
}
func (z *zipReader) Name() string {
return strings.TrimSuffix(z.rdr.File[z.idx].Name, "\x00") // non-spec zip files may have null terminated strings
}
func (z *zipReader) SetSource(bufs *siegreader.Buffers) (*siegreader.Buffer, error) {
var err error
z.rc, err = z.rdr.File[z.idx].Open()
if err != nil {
return nil, err
}
return bufs.Get(z.rc)
}
func (z *zipReader) Close() {
if z.rc == nil {
return
}
z.rc.Close()
}
func (z *zipReader) IsDir() bool {
if z.idx < len(z.rdr.File) {
return z.rdr.File[z.idx].FileHeader.FileInfo().IsDir()
}
return false
}
func zipRdr(b *siegreader.Buffer) (Reader, error) {
r, err := zip.NewReader(siegreader.ReaderFrom(b), b.SizeNow())
return &zipReader{idx: -1, rdr: r}, err
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package main
import (
"bytes"
"compress/flate"
"crypto/sha256"
"encoding/hex"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"os"
"path/filepath"
"strings"
"time"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/pkg/config"
)
type Update struct {
Version [3]int `json:"sf"`
Created string `json:"created"`
Hash string `json:"hash"`
Size int `json:"size"`
Path string `json:"path"`
}
func current(buf []byte, utime string) bool {
ut, err := time.Parse(time.RFC3339, utime)
if err != nil {
return false
}
if len(buf) < len(config.Magic())+2+15 {
return false
}
rc := flate.NewReader(bytes.NewBuffer(buf[len(config.Magic())+2:]))
nbuf := make([]byte, 15)
if n, _ := rc.Read(nbuf); n < 15 {
return false
}
rc.Close()
ls := persist.NewLoadSaver(nbuf)
tt := ls.LoadTime()
if ls.Err != nil {
return false
}
return !ut.After(tt)
}
func same(buf []byte, usize int, uhash string) bool {
if len(buf) != usize {
return false
}
h := sha256.New()
h.Write(buf)
return hex.EncodeToString(h.Sum(nil)) == uhash
}
func uptodate(utime, uhash string, usize int) bool {
fbuf, err := ioutil.ReadFile(config.Signature())
if err != nil {
return false
}
if current(fbuf, utime) && same(fbuf, usize, uhash) {
return true
}
return false
}
func location(base, sig string, args []string) string {
if len(args) > 0 && len(args[0]) > 0 {
if args[0] == "freedesktop.org" { // freedesktop.org is more correct, but we don't use it in update service
args[0] = "freedesktop"
}
return base + "/" + args[0]
}
if len(sig) > 0 {
return base + "/" + strings.TrimSuffix(filepath.Base(sig), filepath.Ext(sig))
}
return base
}
func updateSigs(sig string, args []string) (bool, string, error) {
url, _, _ := config.UpdateOptions()
if url == "" {
return false, "Update is not available for this distribution of siegfried", nil
}
response, err := getHttp(location(url, sig, args))
if err != nil {
return false, "", err
}
var u Update
if err := json.Unmarshal(response, &u); err != nil {
return false, "", err
}
version := config.Version()
if version[0] < u.Version[0] || (version[0] == u.Version[0] && version[1] < u.Version[1]) || // if the version is out of date
u.Version == [3]int{0, 0, 0} || u.Created == "" || u.Size == 0 || u.Path == "" { // or if the unmarshalling hasn't worked and we have blank values
return false, "Your version of siegfried is out of date; please install latest from http://www.itforarchivists.com/siegfried before continuing.", nil
}
if uptodate(u.Created, u.Hash, u.Size) {
return false, "You are already up to date!", nil
}
// this hairy bit of golang exception handling is thanks to Ross! :)
if _, err = os.Stat(config.Home()); err != nil {
if os.IsNotExist(err) {
err = os.MkdirAll(config.Home(), os.ModePerm)
if err != nil {
return false, "", fmt.Errorf("Siegfried: cannot create home directory %s, %v", config.Home(), err)
}
} else {
return false, "", fmt.Errorf("Siegfried: error opening directory %s, %v", config.Home(), err)
}
}
fmt.Println("... downloading latest signature file ...")
response, err = getHttp(u.Path)
if err != nil {
return false, "", fmt.Errorf("Siegfried: error retrieving %s.\nThis may be a network or firewall issue. See https://github.com/richardlehane/siegfried/wiki/Getting-started for manual instructions.\nSystem error: %v", config.SignatureBase(), err)
}
if !same(response, u.Size, u.Hash) {
return false, "", fmt.Errorf("Siegfried: error retrieving %s; SHA256 hash of response doesn't match %s", config.SignatureBase(), u.Hash)
}
err = ioutil.WriteFile(config.Signature(), response, os.ModePerm)
if err != nil {
return false, "", fmt.Errorf("Siegfried: error writing to directory, %v", err)
}
fmt.Printf("... writing %s ...\n", config.Signature())
return true, "Your signature file has been updated", nil
}
func getHttp(url string) ([]byte, error) {
req, err := http.NewRequest("GET", url, nil)
if err != nil {
return nil, err
}
_, timeout, transport := config.UpdateOptions()
req.Header.Add("User-Agent", config.UserAgent())
req.Header.Add("Cache-Control", "no-cache")
timer := time.AfterFunc(timeout, func() {
transport.CancelRequest(req)
})
defer timer.Stop()
client := http.Client{
Transport: transport,
}
resp, err := client.Do(req)
if err != nil {
return nil, err
}
defer resp.Body.Close()
return ioutil.ReadAll(resp.Body)
}
<file_sep>// Copyright 2020 <NAME>, <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
// implied. See the License for the specific language governing
// permissions and limitations under the License.
// Perform some linting on the SPARQL we receive from Wikidata. This is
// all preliminary stuff where we will still need to wrangle the
// signatures to be useful in aggregate. Using that as a rule then we
// only do enough work here to make that wrangling a bit easier later
// on.
package wikidata
import (
"fmt"
"strconv"
"github.com/richardlehane/siegfried/pkg/config"
"github.com/richardlehane/siegfried/pkg/wikidata/internal/converter"
)
// Create a map to store linting results per Wikidata URI.
var linter = make(map[string]map[lintingResult]bool)
// lintingResult provides a data structure to store information about
// errors encountered while trying to process Wikidata records.
type lintingResult struct {
URI string // URI of the Wikidata record.
Value linting // Linting error.
Critical bool // Critical, true or false.
}
// addLinting adds linting errors to our linter map when the function
// is called.
func addLinting(uri string, value linting) {
if value == nle {
return
}
critical := false
switch value {
case offWDE02:
case relWDE02:
case heuWDE01:
critical = true
}
linting := lintingResult{}
linting.URI = uri
linting.Value = value
linting.Critical = critical
if linter[uri] == nil {
lMap := make(map[lintingResult]bool)
lMap[linting] = critical
linter[uri] = lMap
return
}
linter[uri][linting] = critical
}
// lintingToString will output our linting errors in an easy to consume
// slice.
func lintingToString() []string {
var lintingMessages []string
for _, result := range linter {
for res := range result {
s := fmt.Sprintf(
"%s: URI: %s Critical: %t", lintingLookup(res.Value),
res.URI,
res.Critical,
)
lintingMessages = append(lintingMessages, s)
}
}
return lintingMessages
}
// countLintingErrors will count all the linting errors returned during
// processing. It will return two counts, that of all the records with
// at least one error, and that of all the individual errors.
func countLintingErrors() (int, int, int) {
var recordCount, individualCount, badHeuristicCount int
for _, result := range linter {
recordCount++
for res := range result {
if res.Value == heuWDE01 || res.Value == heuWDE02 {
badHeuristicCount++
}
individualCount++
}
}
return recordCount, individualCount, badHeuristicCount
}
type linting int
// nle provides a nil for no lint errors.
const nle = noLintingError
// Linting enumerator. This approach feels like it might be a little
// old fashioned but it lets us capture as many of the data issues we're
// seeing in Wikidata as they come up so that they can be fixed. Once
// we can find better control of the source data I think we'll be able
// to get rid of this and use a much simpler approach for compiling
// the set of signatures for the identifier.
const (
noLintingError linting = iota // noLintingError encodes No linting error.
// Offset based linting issues.
offWDE01 // offWDE01 encodes ErrNoOffset
offWDE02 // offWDE02 encodes ErrCannotParseOffset
offWDE03 // offWDE03 encodes ErrBlankNodeOffset
// Relativity based linting issues.
relWDE01 // relWDE01 encodes ErrEmptyStringRelativity
relWDE02 // relWDE02 encodes ErrUnknownRelativity
// Encoding based linting issues.
encWDE01 // encWDE01 encodes ErrNoEncoding
// Provenance based linting issues.
proWDE01 // proWDE01 encodes ErrNoProvenance
proWDE02 // proWDE02 encodes ErrNoDate
// Sequence based linting issues.
seqWDE01 // seqWDE01 encodes ErrDuplicateSequence
// Heuristic errors. We have to give up on this record.
heuWDE01 // heuWDE01 encodes ErrNoHeuristic
heuWDE02 // heuWDE02 encodes ErrCannotProcessSequence
)
// lintingLookup returns a plain-text string for the type of errors or
// issues that we encounter when trying to process Wikidata records
// into an identifier.
func lintingLookup(lint linting) string {
switch lint {
case offWDE01:
return "Linting: WARNING no offset"
case offWDE02:
return "Linting: ERROR cannot parse offset"
case offWDE03:
return "Linting: ERROR blank node returned for offset"
case relWDE01:
return "Linting: WARNING no relativity"
case relWDE02:
return "Linting: ERROR unknown relativity"
case encWDE01:
return "Linting: WARNING no encoding"
case seqWDE01:
return "Linting: ERROR duplicate sequence"
case proWDE01:
return "Linting: WARNING no provenance"
case proWDE02:
return "Linting: WARNING no provenance date"
case heuWDE01:
return "Linting: ERROR bad heuristic"
case heuWDE02:
return "Linting: ERROR cannot process sequence"
case noLintingError:
return "Linting: INFO no linting errors"
}
return "Linting: ERROR unknown linting error"
}
// preProcessedSequence gives us a way to hold temporary information
// about the signature associated with a record.
type preProcessedSequence struct {
signature string
offset string
relativity string
encoding string
}
// Relativities as encoded in Wikidata records. IRIs from Wikidata mean
// that we don't need to encode i18n differences. IRIs must have
// http:// scheme, and link to the data entity, i.e. not the "page",
// e.g.
//
// * BOF data entity: http://www.wikidata.org/entity/Q35436009
// * BOF page: https://www.wikidata.org/wiki/Q35436009
//
var relativeBOF string = config.WikibaseBOF()
var relativeEOF string = config.WikibaseEOF()
// GetBOFandEOFFromConfig will read the current value of the BOF/EOF
// properties from the configuration, e.g. after being updated using a
// custom SPARQL query.
func GetBOFandEOFFromConfig() {
relativeBOF = config.WikibaseBOF()
relativeEOF = config.WikibaseEOF()
}
// GetPronomURIFromConfig will read the current value of the PRONOM
// properties from the configuration, e.g. after being updated using a
// custom SPARQL query.
func GetPronomURIFromConfig() {
converter.GetPronomURIFromConfig()
}
// validateAndReturnProvenance performs some arbitrary validation on
// provenance as recorded by Wikidata and let's us know any issues
// with it. Right now we can only really say if the provenance field
// is empty, it's not going to be very useful to us.
func validateAndReturnProvenance(value string) (string, linting) {
if value == "" {
return value, proWDE01
}
return value, nle
}
// validateAndReturnDate will perform some validation on the provenance
// date we are able to access from Wikidata records. If the value is
// blank for example, it will return a linting warning.
func validateAndReturnDate(value string) (string, linting) {
if value == "" {
return value, proWDE02
}
return value, nle
}
// validateAndReturnEncoding asks whether the encoding we can access
// from Wikidata is known to Siegfried. If it isn't then we know for
// now that we cannot handle it. If we cannot handle it, we either need
// to correct the Wikidata record, or add capability to Siegfried or
// the converter package.
func validateAndReturnEncoding(value string) (int, linting) {
encoding := converter.LookupEncoding(value)
if encoding == converter.UnknownEncoding {
return encoding, encWDE01
}
return encoding, nle
}
// validateAndReturnRelativity will return a string and an error based
// on whether the relativity of a format identification pattern, e.g.
// BOF, EOF is known. If it isn't then it makes it more difficult to
// process in Roy/Siegfried.
func validateAndReturnRelativity(value string) (string, linting, error) {
const unknownRelativity = "Received an unknown relativity"
if value == "" {
// Assume beginning of file.
return relativeBOF, relWDE01, nil
} else if value == relativeBOF {
return relativeBOF, nle, nil
} else if value == relativeEOF {
return relativeEOF, nle, nil
}
return value, relWDE02, fmt.Errorf("%s: '%s'", unknownRelativity, value)
}
// validateAndReturnOffset will return an integer and an error based on
// whether we can use the offset delivered by Wikidata.
func validateAndReturnOffset(value string, nodeType string) (int, linting) {
const blankNodeType = "bnode"
const blankNodeErr = "Received a blank node type instead of offset"
var offset int
if value == "" {
return offset, nle
} else if nodeType == blankNodeType {
return offset, offWDE03
}
offset, err := strconv.Atoi(value)
if err != nil {
return offset, offWDE02
}
return offset, nle
}
// validateAndReturnSignature calls the converter functions to normalize
// our signature. We need to do this so that we can compare signatures
// and remove duplicates and identify other errors.
func validateAndReturnSignature(value string, encoding int) (string, linting, error) {
value, _, _, err := converter.Parse(value, encoding)
if err != nil {
return value, heuWDE02, err
}
return value, nle, nil
}
<file_sep>// Copyright 2016 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package namematcher
// todo: add a precise map[string][]int to take out bulk of globs which are exact names e.g. README
import (
"fmt"
"net/url"
"path/filepath"
"sort"
"strings"
"github.com/richardlehane/siegfried/internal/persist"
"github.com/richardlehane/siegfried/internal/priority"
"github.com/richardlehane/siegfried/internal/siegreader"
"github.com/richardlehane/siegfried/pkg/core"
"github.com/richardlehane/siegfried/pkg/reader"
)
type Matcher struct {
extensions map[string][]int
globs []string // use filepath.Match(glob, name) https://golang.org/pkg/path/filepath/#Match
globIdx [][]int
}
func Load(ls *persist.LoadSaver) core.Matcher {
if !ls.LoadBool() {
return nil
}
le := ls.LoadSmallInt()
var ext map[string][]int
if le > 0 {
ext = make(map[string][]int)
for i := 0; i < le; i++ {
k := ls.LoadString()
r := make([]int, ls.LoadSmallInt())
for j := range r {
r[j] = ls.LoadSmallInt()
}
ext[k] = r
}
}
globs := ls.LoadStrings()
globIdx := make([][]int, ls.LoadSmallInt())
for i := range globIdx {
globIdx[i] = ls.LoadInts()
}
return &Matcher{
extensions: ext,
globs: globs,
globIdx: globIdx,
}
}
func Save(c core.Matcher, ls *persist.LoadSaver) {
if c == nil {
ls.SaveBool(false)
return
}
m := c.(*Matcher)
ls.SaveBool(true)
ls.SaveSmallInt(len(m.extensions))
for k, v := range m.extensions {
ls.SaveString(k)
ls.SaveSmallInt(len(v))
for _, w := range v {
ls.SaveSmallInt(int(w))
}
}
ls.SaveStrings(m.globs)
ls.SaveSmallInt(len(m.globIdx))
for _, v := range m.globIdx {
ls.SaveInts(v)
}
}
type SignatureSet []string
func Add(c core.Matcher, ss core.SignatureSet, p priority.List) (core.Matcher, int, error) {
var m *Matcher
if c == nil {
m = &Matcher{extensions: make(map[string][]int), globs: []string{}, globIdx: [][]int{}}
} else {
m = c.(*Matcher)
}
sigs, ok := ss.(SignatureSet)
if !ok {
return nil, -1, fmt.Errorf("Namematcher: can't cast persist set")
}
var length int
// unless it is a new matcher, calculate current length by iterating through all the result values
if len(m.extensions) > 0 || len(m.globs) > 0 {
for _, v := range m.extensions {
for _, w := range v {
if int(w) > length {
length = int(w)
}
}
}
for _, v := range m.globIdx {
for _, w := range v {
if int(w) > length {
length = int(w)
}
}
}
length++ // add one - because the result values are indexes
}
for i, v := range sigs {
m.add(v, i+length)
}
return m, length + len(sigs), nil
}
func (m *Matcher) add(s string, fmt int) {
// handle extension globs first
if strings.HasPrefix(s, "*.") && strings.LastIndex(s, ".") == 1 {
ext := strings.ToLower(strings.TrimPrefix(s, "*."))
if _, ok := m.extensions[ext]; ok {
m.extensions[ext] = append(m.extensions[ext], fmt)
} else {
m.extensions[ext] = []int{fmt}
}
return
}
for i, v := range m.globs {
if v == s {
m.globIdx[i] = append(m.globIdx[i], fmt)
return
}
}
m.globs = append(m.globs, s)
m.globIdx = append(m.globIdx, []int{fmt})
}
// normalise returns a path's base name (e.g. README.txt) and extension (e.g. txt)
func normalise(s string) (string, string) {
// check if this might be a URL (i.e. if source is from a WARC or ARC)
i := strings.Index(s, "://")
if i > 0 {
// backup until hit first non-ASCII alpha char (so we can trim the string to start with scheme)
for i > 0 {
i--
if s[i] < 65 || s[i] > 122 || (s[i] > 90 && s[i] < 97) {
i++
break
}
}
u, err := url.Parse(s[i:])
if err == nil && u.Scheme != "" {
// make sure it really is a URL
switch u.Scheme {
case "http", "https", "ftp", "mailto", "file", "data", "irc":
// grab the path (trims any trailing query string from the URL)
s = u.Path
}
}
}
base := reader.Base(s)
return base, strings.ToLower(strings.TrimPrefix(filepath.Ext(base), "."))
}
func (m *Matcher) Identify(s string, na *siegreader.Buffer, hints ...core.Hint) (chan core.Result, error) {
var efmts, gfmts []int
base, ext := normalise(s)
var glob string
if len(s) > 0 {
efmts = m.extensions[ext]
for i, g := range m.globs {
if ok, _ := filepath.Match(g, base); ok {
glob = g
gfmts = m.globIdx[i]
break
}
}
}
res := make(chan core.Result, len(efmts)+len(gfmts))
for _, fmt := range efmts {
res <- result{
idx: fmt,
matches: ext,
}
}
for _, fmt := range gfmts {
res <- result{
glob: true,
idx: fmt,
matches: glob,
}
}
close(res)
return res, nil
}
func (m *Matcher) String() string {
var str string
keys := make([]string, len(m.extensions))
var i int
for k := range m.extensions {
keys[i] = k
i++
}
sort.Strings(keys)
for _, v := range keys {
str += fmt.Sprintf("%s: %v\n", v, m.extensions[v])
}
for i, v := range m.globs {
str += fmt.Sprintf("%s: %v\n", v, m.globIdx[i])
}
return str
}
type result struct {
glob bool
idx int
matches string
}
func (r result) Index() int {
return r.idx
}
func (r result) Basis() string {
if r.glob {
return "glob match " + r.matches
}
return "extension match " + r.matches
}
<file_sep>// Copyright 2015 <NAME>. All rights reserved.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package config
import "path/filepath"
var loc = struct {
fdd string
def string // default
nopronom bool
name string
zip string
gzip string // n/a
tar string // n/a
arc string
warc string
text string // n/a
}{
def: "fddXML.zip",
name: "loc",
zip: "fdd000354",
arc: "fdd000235",
warc: "fdd000236",
}
// LOC returns the location of the LOC signature file.
func LOC() string {
if loc.fdd == loc.def {
return filepath.Join(siegfried.home, loc.def)
}
if filepath.Dir(loc.fdd) == "." {
return filepath.Join(siegfried.home, loc.fdd)
}
return loc.fdd
}
func ZipLOC() string {
return loc.zip
}
func NoPRONOM() bool {
return loc.nopronom
}
func SetNoPRONOM() func() private {
return func() private {
loc.nopronom = true
return private{}
}
}
func SetLOC(fdd string) func() private {
return func() private {
wikidata.namespace = "" // reset wikidata to prevent pollution
mimeinfo.mi = "" // reset mimeinfo to prevent pollution
if fdd == "" {
fdd = loc.def
}
loc.fdd = fdd
return private{}
}
}
| bb8eef023547ce372f3b3f01bce9d8e8114be671 | [
"Markdown",
"Go Module",
"Go",
"Shell"
] | 172 | Go | richardlehane/siegfried | 637f684eddcb8194866e0c4e8a65ccc191238042 | a75924faf50dbee4dc1932c8bde055160afc4fc1 |
refs/heads/master | <repo_name>hitanshud123/SudokuSolverWithCNN<file_sep>/README.md
# SudokuSolverWithCNN
This program can take images of sudoku boards as an input and output it's solution. It has an incredibly fast algorithm that uses recursion and backtracking to get the solution in miliseconds.
Manual Input:
In order to manually input the board, enter each number the board row by row in one line. For blank spaces, input a 0.
Sample input: 010020300004005060070000008006900070000100002030048000500006040000800106008000000
Image Input:
To input an image, enter to directory of the image. The image must be alligned and croped so that the image only consists of the board. You can use the sample images in the imgs directory as guidlines.
Editing:
If you or the program made a small error in inputting the board, instead of reinputtting the board, you may edit small mistakes. This can be done by entering the row and column of the mistake and the number that you wan't to change it to. The rows and columns start at 1 and end at 9. These values must be separated by a comma. You may also include more than one edit by separating them with a semicolon. Please do not include any spaces.
Example:
row,column,change;row,col,change;row,col,change
2,3,4;8,4,9;1,9,0
<file_sep>/SudokuSolver.py
import copy
import math
import imgProcessing
import os
def is_valid_input(inputb):
if (len(inputb) != 81):
return False
for i in inputb:
if (i != '0' and i != '1' and i != '2' and i != '3' and i != '4' and i != '5' and i != '6' and i != '7' and i != '8' and i != '9'):
return False
return True
def manual_input():
sudoku_code = input('Input:\n')
while(not is_valid_input(sudoku_code)):
print('\nInvalid input')
sudoku_code = input('Input:\n')
return sudoku_code
def image_input():
img_dir = input('\nEnter image directory: ')
while(not os.path.exists(img_dir)):
print('\nInvalid Directory')
img_dir = input('Enter image directory: ')
inputb = imgProcessing.getInput(img_dir)
return inputb
def parse_board(inputb):
board = []
k = 0;
for i in range(int(math.sqrt(len(inputb)))):
board.append([])
for j in range(int(math.sqrt(len(inputb)))):
board[i].append(int(inputb[k]))
k += 1
return board
def edit_board(board, edits):
edits = edits.split(';')
for edit in edits:
edit = edit.split(',')
board[int(edit[0])-1][int(edit[1])-1] = int(edit[2])
def print_board(board, title):
print(title)
for i in range(len(board)):
if (i%3 == 0):
print('--------------------------')
for j in range(len(board[i])):
if (j%3 == 0):
print('| ', end='')
if (board[i][j] == 0):
print('_ ', end='')
else:
print(str(board[i][j])+' ',end='')
print('| ')
if(i == 8):
print('--------------------------')
def is_valid(board, value, pos):
for i in range(len(board[pos[0]])):
if (i != pos[1]) and (board[pos[0]][i] == value):
return False
for i in range(len(board)):
if (i != pos[0]) and (board[i][pos[1]] == value):
return False
for i in range(pos[0]//3*3, pos[0]//3*3+3):
for j in range(pos[1]//3*3, pos[1]//3*3+3):
if ((i,j) != pos) and (board[i][j] == value):
return False
return True
def solve_board(board, iterations):
for i in range(len(board)):
for j in range(len(board[i])):
if (board[i][j] == 0):
for k in range(1,10):
if(is_valid(board, k, (i,j))):
board[i][j] = k
if(solve_board(board, iterations+1)):
return True
board[i][j] = 0
return False
return True
def main():
input_type = int(input('\nSelect your input type (1=manual, 2=image):'))
while(input_type != 1 and input_type != 2):
print('\nInvalid input')
input_type = int(input('Select your input type (1=manual, 2=image):'))
if(input_type == 1):
inputb = manual_input()
else:
inputb = image_input()
board = parse_board(inputb)
print_board(board, '\n\nYour Input:')
reinput = 1
while(reinput != 3):
reinput = int(input('\nEnter 1 to re-input, Enter 2 to edit, Enter 3 to continue:'))
if (reinput == 1):
input_type = int(input('\nSelect your input type (1=manual, 2=image):'))
while(input_type != 1 and input_type != 2):
print('\nInvalid input')
input_type = int(input('Select your input type (1=manual, 2=image):'))
if(input_type == 1):
inputb = manual_input()
else:
inputb = image_input()
board = parse_board(inputb)
print_board(board, '\n\nYour Input:')
if (reinput == 2):
edits = input('\nEnter your edits:\n')
edit_board(board, edits)
print_board(board, '\n\nYour Input:')
solution = copy.deepcopy(board)
print_board(board, '\n\nYour Input:')
input('Hit Enter to solve')
print('Solving...')
solved = True
for i in range(len(board)):
for j in range(len(board[i])):
if(not is_valid(board, board[i][j], (i,j)) and (board[i][j] != 0)):
solved = False
if(solved):
solved = solve_board(solution,1)
if(solved == False):
print('\nThis sudoku grid is unsolvable')
else:
print_board(solution, '\n\nThe Solution:')
if __name__ == '__main__':
main()
<file_sep>/imgProcessing.py
from PIL import Image
import os
from numpy import *
from matplotlib import pyplot as plt
import time
import filetype
import tensorflow.keras.models as models
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Conv2D, Dropout, Flatten, MaxPooling2D
def process(img1_name, grid_dir, cell_dir):
file_type = filetype.guess(img1_name).extension
img1 = Image.open(img1_name)
img2 = img1.resize((252,252))
os.makedirs(grid_dir)
os.makedirs(cell_dir)
img2_name = grid_dir + 'sudokuGrid.' + file_type
img2.save(img2_name)
slice_image(img2, 9, 9, cell_dir, file_type)
def slice_image(img, rows, cols, new_path, file_type):
width, height = img.size
for i in range(rows):
for j in range(cols):
box = (j*int(width/rows),i*int(height/cols), j*int(width/rows)+int(width/rows), i*int(height/cols)+int(height/cols))
cell = img.crop(box)
cell = cell.crop((3,3,25,25))
cell = cell.resize((28,28))
cell.save(new_path + 'sudokuCell' + str(i) + str(j) + '.' + file_type)
def create_data(cell_dir):
test = []
for cell in os.listdir(cell_dir):
cell = Image.open(cell_dir + cell).convert('L')
test.append(array(cell).flatten())
test = (255-reshape(test, (81, 28, 28, 1)).astype('float32'))/255
return test
def remove(grid_dir, cell_dir):
for x in os.listdir(cell_dir):
os.unlink(cell_dir + x)
os.rmdir(cell_dir)
for x in os.listdir(grid_dir):
os.unlink(grid_dir + x)
os.rmdir(grid_dir)
def getInput(img1_name):
grid_dir = img1_name + '/../grid_fromSudokuSolver/'
cell_dir = grid_dir + 'cells_fromSudokuSolver/'
process(img1_name, grid_dir, cell_dir)
data = create_data(cell_dir)
remove(grid_dir, cell_dir)
model = models.load_model('digit_reader_for_sudoku.model')
# plt.figure()
j= 1
inputb = ''
for i in data:
# plt.subplot(9,9, j)
j += 1
# plt.imshow(i.reshape(28, 28),cmap='Greys')
pred = model.predict(i.reshape(1, 28, 28, 1))
# plt.title(str(pred.argmax()))
if (pred.argmax() == 10):
inputb += '0'
else:
inputb += str(pred.argmax())
plt.show()
return inputb
| efd21cde0a767a8114c60ecfbed62a50c412e777 | [
"Markdown",
"Python"
] | 3 | Markdown | hitanshud123/SudokuSolverWithCNN | f64c6dce2cf4e1cc4eb15a9ce59c7151c1e2d1f4 | d2b87fe2dbd1a7bb23135161160c0e9da4d2baf2 |
refs/heads/master | <repo_name>VolkovCode/hw04_tests<file_sep>/posts/views.py
from django.core.paginator import Paginator
from django.shortcuts import render, get_object_or_404
from django.shortcuts import redirect
from .models import Post, Group, User
from .forms import PostForm
def index(request):
post_list = Post.objects.order_by("-pub_date").all()
paginator = Paginator(post_list, 10) # показывать по 10 записей на странице.
page_number = request.GET.get('page') # переменная в URL с номером запрошенной страницы
page = paginator.get_page(page_number) # получить записи с нужным смещением
return render(request, 'posts/index.html', {'page': page, 'paginator': paginator})
def group_posts(request, slug):
group = get_object_or_404(Group, slug=slug)
posts = Post.objects.filter(group=group).order_by("-pub_date")[:12]
paginator = Paginator(posts, 10)
page_number = request.GET.get('page')
page = paginator.get_page(page_number)
return render(request, "group.html", {"group": group, 'page': page, 'paginator': paginator})
def new_post(request):
user = request.user
form = PostForm(request.POST)
if not request.user.is_authenticated:
return redirect(index)
if request.method == 'POST':
if form.is_valid():
n_post = form.save(commit=False)
n_post.author = user
n_post.save()
return redirect('index')
return render(request, 'posts/new_post.html', {'form': form})
form = PostForm()
return render(request, 'posts/new_post.html', {'form': form})
def profile(request, username):
author = get_object_or_404(User, username = username)
post_list = Post.objects.filter(author = author).order_by('-pub_date')
paginator = Paginator(post_list, 10) # показывать по 10 записей на странице.
page_number = request.GET.get('page') # переменная в URL с номером запрошенной страницы
page = paginator.get_page(page_number) # получить записи с нужным смещением
count = post_list.count
return render(request, "posts/profile.html", {'count':count, 'author':author, 'page': page, 'paginator': paginator})
def post_view(request, username, post_id):
author = get_object_or_404(User, username = username)
post = Post.objects.get(pk=post_id)
posts = Post.objects.filter(author = author).order_by('-pub_date')
count = posts.count
return render(request, "posts/post.html", {'post':post, 'count':count, 'author':author})
def post_edit(request, username, post_id):
post = get_object_or_404(Post, id = post_id)
if request.user != post.author:
return redirect("post", username, post_id)
form = PostForm(request.POST)
if form.is_valid():
post.text = form.cleaned_data['text']
post.group = form.cleaned_data['group']
post.save()
return redirect("post", username, post_id)
form = PostForm()
return render(request, "posts/post_edit.html", {"form": form, 'post':post})
<file_sep>/posts/tests.py
from django.test import TestCase
from django.test import Client
from .models import User
from . import views
from django.urls import reverse
class ProfileTest(TestCase):
def setUp(self):
self.client = Client()
self.user = User.objects.create_user(
username="sarah", email="<EMAIL>", password="<PASSWORD>")
def test_profile(self): # проверка на создание персональной страницы
response = self.client.post('/auth/signup/', {'first_name': "Alexey",
'last_name': 'Volkov', 'username': 'AGV', 'email': '<EMAIL>',
"password1": "<PASSWORD>", 'password2': '<PASSWORD>'}, follow=True)
response = self.client.get("/AGV/")
self.assertEqual(response.status_code, 200)
def test_new(self):
self.client.login(username='sarah', password='<PASSWORD>')
response = self.client.post(reverse('new_post'), {'text': 'FirstPost'}, follow=True) # авторизованный пользователь может опубликовать пост
response = self.client.get('/') # проверка на публикацию поста
self.assertContains(response, text='FirstPost', status_code=200)
response = self.client.get("/sarah/")
self.assertContains(response, text='FirstPost', status_code=200)
response = self.client.get("/sarah/1/")
self.assertContains(response, text='FirstPost', status_code=200)
def test_edit(self):
self.client.login(username='sarah', password='<PASSWORD>')
response = self.client.post(reverse('new_post'), {'text': 'FirstPost'}, follow=True)
response = self.client.post(reverse('post_edit', kwargs={'username': 'sarah', 'post_id': '1'}),
{'text': 'EditPost'}, follow=True) # проверка на изменение поста
response = self.client.get('/')
self.assertContains(response, text='EditPost', status_code=200)
response = self.client.get("/sarah/")
self.assertContains(response, text='EditPost', status_code=200)
response = self.client.get("/sarah/1/")
self.assertContains(response, text='EditPost', status_code=200)
class test_not_auth(TestCase): # Неавторизованный посетитель не может опубликовать пост
def setUp(self):
self.client = Client()
def test_redirect(self):
response = self.client.get('/new/')
self.assertRedirects(response, '/')
<file_sep>/users/tests.py
from django.test import TestCase
from django.test import Client
from .forms import User
class ProfileTest(TestCase):
def setUp(self):
self.client = Client()
self.user = User.objects.create_user(
username="sarah", email="<EMAIL>", password="<PASSWORD>")
def test_profile(self): #проверка на создание персональной страницы
response = self.client.post('/auth/singup/', {'first_name': "EditPost", 'last_name': 'sss', 'username': 'lox', 'email': '<EMAIL>'}, follow=True)
response = self.client.get('/singup')
| 3f90c0f4800ce73dfcda7b7ad22ffd8abb162d7c | [
"Python"
] | 3 | Python | VolkovCode/hw04_tests | af4b9f77aa5ac7f077288122ee46e60520010767 | 908b4d328ead618316c1ea66190443898712e480 |
refs/heads/master | <repo_name>khsk/Musou-ranbun<file_sep>/src/store.js
import Vue from 'vue';
import Vuex from 'vuex';
import _ from 'lodash';
Vue.use(Vuex);
const state = {
currentSentence: '',
count: 0,
sentences:[],
};
const mutations = {
setState(state, payload) {
console.log('mutation setState',payload);
const s = payload.state;
state.currentSentence = s.currentSentence;
state.count = s.count;
state.sentences = s.sentences;
},
increment (state) {
console.log('increment');
state.count++;
console.log(state.count);
},
setCount(state, payload) {
state.count = payload.count;
},
currentSentence(state, payload) {
state.currentSentence = payload.sentence;
},
sentences (state, payload) {
console.log('sentences');
console.log(payload.sentence);
state.sentences.push({
sentence : payload.sentence,
index : state.count - 1, // countは1始まりなので
count : state.count,
});
},
deleteSentence (state, payload) {
state.sentences = state.sentences.filter( (v, i) => {
return v.count != payload.count;
});
},
allDeleteSentence (state) {
state.sentences = [];
},
changeIndex(state, payload) {
if (payload.oldIndex == payload.newIndex) {
return;
}
const oldSentenceIndex = state.sentences.findIndex((element) => {
return element.index == payload.oldIndex;
});
state.sentences.forEach((sentence) => {
if (payload.oldIndex < payload.newIndex &&
payload.oldIndex <= sentence.index &&
sentence.index <= payload.newIndex) {
sentence.index -= 1;
} else if(
payload.newIndex <= sentence.index &&
sentence.index <= payload.oldIndex) {
sentence.index += 1;
}
});
state.sentences[oldSentenceIndex].index = payload.newIndex;
},
};
const actions = {
initState({commit}) {
commit('allDeleteSentence');
commit('setCount', {count:0});
commit('currentSentence', {sentence:''});
},
setState({commit}, payload) {
commit('setState', payload);
},
saveCurrentSentence ({commit}, sentence)
{
commit('currentSentence', {sentence});
},
addSentence ({commit}, sentence) {
commit('increment');
commit('sentences', {sentence});
},
deleteSentence ({commit}, payload) {
commit('deleteSentence', payload);
},
countUp ({commit}) {
commit('increment');
},
copyText ({getters}) {
let text = '';
getters.orderedSentences.forEach((sentence) => {
text += sentence.sentence + '\n';
});
document.addEventListener('copy', (e) => {
e.preventDefault();
e.clipboardData.setData('text/plain', text);
}, {once:true,});
document.execCommand('copy');
},
copyTextWithCreatedNumber ({getters}) {
let text = '';
getters.orderedSentences.forEach((sentence) => {
// ここString.padStartに変えるとCountにlodash不要に
text += sentence.sentence + ' ' + _.padStart(sentence.count, 3, '0') + '\n';
});
document.addEventListener('copy', (e) => {
e.preventDefault();
e.clipboardData.setData('text/plain', text);
}, {once:true,});
document.execCommand('copy');
},
};
const getters = {
allState(state) {
console.log('getter all state',state);
return state;
},
sentences (state) {state.sentences;},
maxCount (state) {
console.log('maxCount',state.count);
return state.count;
},
currentSentence(state) {
return state.currentSentence;
},
orderedSentences(state) {
console.log('orderedSentences',_.orderBy(state.sentences, 'index'));
return _.orderBy(state.sentences, 'index');
},
};
export default new Vuex.Store({
state,
mutations,
actions,
getters,
});
<file_sep>/構想.md
# 画面構成
* 単行入力画面
* 文章確認画面
* 文章編集画面?
* 文章出力画面?
# アクション
## 単行入力画面
* 文章確認画面移動ボタン
* input
## 文章確認画面
* 単行入力画面移動ボタン
* 全削除ボタン
* 行ごとに
* 編集ボタン
* 削除ボタン
* 出力ボタン?
# アプリ構成
* index(App?)
* ヘッダーコンポーネント
* ルートビュー
* 入力画面
* 編集画面
<file_sep>/README.md
# Musou-ranbun
Vue.jsとElectronを使用したTODO習作亜種アプリです。一行のセンテンスを積み上げ並び替える書き流しアプリ。
夢想乱文
# 概要
input textをlocalStorageに保存し、あとから並び替え・編集・削除・全体のコピーができるアプリです。
並び替えにはvuedraggableを使い、vueのコンポーネントを使いながらもマウスでのドラッグ操作で実現を目指しています。。
2017年5月ごろにVue.js、Vue-router、Vuexの使用感を探るために開発しました。
そのためコミット時期からみるとかなり古いコードです。
***
Qiitaへの投稿を予定していましたが、他の投稿予定記事ストックが減らず、一年以上死蔵しているため整理ついでに公開。
ドラッグ操作など、細かい所で処理を煮詰めきれていませんが、
* 投稿予定が決まらない
* コードが古くなりすぎている
なにより
**Vue,Vue-router,Vuex**による一連のデータの流れと実装方法の概略というメインテーマを完了できているため、
手を加える場合は改修よりこのコードを参考に新規組み直しを選択すると思います。
# 使用技術
* vue
* vue-material
* vue-router
* vuedraggable
* vuex
* vuex-router-sync
* electron
# きっかけ
習作のTODOアプリを作るにしても、なにか特徴をもたせたかったため。
文章を書いているとどうしても気になる前後の文章をできるだけ意識せず、好きなセンテンスを好きなだけ書き、
あとから各センテンスを並び替え・編集できる創作補助ツールのようなものを目指した。
| 9c0c5ad40061e4a9a1d77c3d95fa93efd5f19411 | [
"JavaScript",
"Markdown"
] | 3 | JavaScript | khsk/Musou-ranbun | 12dc2eae503a1b118041d8b341e920bb68fca232 | c32e718440c768f46a0c3b32b322203bf9f69c41 |
refs/heads/master | <file_sep>package main
import (
"github.com/helloshiki/ndb"
"log"
)
type Transaction = ndb.Transaction
type Response struct {
DBName string
TableName string
Code string
UID int
SavedVersion uint64
SavedStamp int64
}
func putTrx(trx *Transaction) {
select {
case ReqChan <- trx:
default:
log.Printf("reqChain is full")
}
}
func GetTrx() *Transaction {
return <-ReqChan
}
func PutResp(res *Response) {
select {
case RespChan <- res:
default:
log.Printf("respChain is full")
}
}
func getResp() *Response {
return <-RespChan
}
func Work() {
go func() {
for {
resp := getResp()
switch resp.Code {
case "OK":
updateSavedVersion(resp)
log.Printf("table %s's record %d, version %d done at %d", resp.TableName, resp.UID, resp.SavedVersion, resp.SavedStamp)
case "SKIP":
//log.Printf("table %s's record %d, version %d skipped at %d", resp.TableName, resp.ID, resp.SavedVersion, resp.SavedStamp)
}
}
}()
}
func GetData(trx *Transaction) (uint64, []byte) { //return latest version data
db := ndb.GetDB(trx.DBName)
table := db.GetTable(trx.TableName)
return table.GetRowBytes(trx.UID, trx.Version)
}
func updateSavedVersion(resp *Response) {
db := ndb.GetDB(resp.DBName)
table := db.GetTable(resp.TableName)
table.UpdateSavedVersion(resp.UID, resp.SavedVersion)
}
var ReqChan chan *Transaction
var RespChan chan *Response
func init() {
ndb.SetPutTx(putTrx)
ReqChan = make(chan *Transaction, 100*1024*1024)
RespChan = make(chan *Response, 100*1024*1024)
}
<file_sep>package models
import "encoding/json"
import (
"github.com/shopspring/decimal"
)
type User struct {
UID int
GID int
TCC decimal.Decimal
ETH decimal.Decimal
NASH decimal.Decimal
Desc string
Worker map[int]bool
I1 int
}
func (u *User) GetUID() int {
return u.UID
}
func (u *User) Index() map[string][]string {
return nil
}
func (u *User) Stat() map[string][]string {
return nil
}
func (u *User) Encode() []byte {
bs, _ := json.Marshal(u)
return bs
}
func (u *User) Category() string {
return "User"
}
<file_sep>package ndb
import (
"errors"
"sync"
"time"
)
const (
K = 1024
M = 1024 * K
G = 1024 * M
)
const (
ROWSIZE = M
PRIMARYKEY = "pk"
)
var (
DBErrDec = errors.New("dec fail")
DBErrSync = errors.New("not sync")
DBErrNotFound = errors.New("not found")
DBErrNotSupport = errors.New("not support")
DBErrDup = errors.New("duplicate")
)
type MetaInfo struct {
Version uint64
UpdateStamp time.Time
SavedVersion uint64
SavedStamp time.Time
}
type Stat struct {
StatKey map[string]interface{}
Count int
}
type Table struct {
dbName string
tableName string
rows []Row // map[idx] => row
idxIndexes map[int]int // map[uid] => idx
metas map[int]*MetaInfo // map[uid] => idx
indexes map[string][]int // map[indexKey] => [uid, uid, uid]
stats map[string][]*Stat //map[statName] => [statinfo, statinfo]
fieldStats map[string]map[string]int //map[statName] => map[statKey] => count
sorting map[string]bool // map[indexKey] => bool
sortlock *sync.Mutex // map[indexKey] => lock
statting bool
statlock *sync.Mutex
lock *sync.Mutex
allocChan chan int
}
type DB struct {
rwLock sync.RWMutex
dbName string
tables map[string]*Table
}
type Transaction struct {
DBName string
TableName string
Cmd string
UID int
Version uint64
}
var (
putTrx func(*Transaction)
)
<file_sep>package ndb
import (
"fmt"
"log"
)
func (db *DB) GetTable(tableName string) *Table {
return db.tables[tableName]
}
func (db *DB) mustGetTable(tableName string) *Table {
db.rwLock.RLock()
if _, ok := db.tables[tableName]; !ok {
panic(fmt.Errorf("table %s is not exsit", tableName))
}
db.rwLock.RUnlock()
return db.tables[tableName]
}
func (db *DB) CreateTable(row Row) {
tableName := getTableName(row)
log.Printf("tableName is %s", tableName)
db.rwLock.Lock()
defer db.rwLock.Unlock()
if tb := db.GetTable(tableName); tb != nil {
panic(fmt.Errorf("%s has been created", tableName))
}
db.tables[tableName] = newTable(db.dbName, tableName)
}
func (db *DB) Insert(row Row) error {
return db.insert(row, false)
}
func (db *DB) Load(row Row) error {
return db.insert(row, true)
}
func (db *DB) insert(row Row, isLoad bool) error {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.insert(row, isLoad)
}
//全覆盖更新
func (db *DB) Update(row Row) error {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.Update(row)
}
func (db *DB) UpdateFunc(row Row, cb func(row Row) bool) error {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.UpdateFunc(row, cb)
}
//更新某个列 cmd 支持REPLACE, INC, DESC, ZERO
func (db *DB) UpdateFiled(row Row, fieldName string, cmd string, value interface{}, strict bool) (string, string, error) {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.UpdateField(row, fieldName, cmd, value, strict)
}
func (db *DB) Get(row Row) Row {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.Get(row)
}
func (db *DB) GetByIndex(row Row, indexName string) []int {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.GetByIndex(row, indexName)
}
func (db *DB) GetStat(row Row, statName string, all bool) []*Stat {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
return table.GetStat(row, statName, all)
}
func (db *DB) Delete(row Row) {
tableName := getTableName(row)
table := db.mustGetTable(tableName)
table.Delete(row)
}
func newDB(dbName string) *DB {
return &DB{
dbName: dbName,
tables: make(map[string]*Table),
}
}
<file_sep>package ndb
type Row interface {
GetUID() int //主键
Index() map[string][]string //索引
Stat() map[string][]string //统计列
Encode() []byte
}
<file_sep>package controller
import (
"fmt"
"github.com/helloshiki/ndb"
"github.com/helloshiki/ndb/example/models"
"github.com/shopspring/decimal"
"log"
)
//用户转账
func Transfer(fromID int, toID int, asset string, amount decimal.Decimal) error {
from := &models.User{UID: fromID}
to := &models.User{UID: toID}
//先检查转账的两个账号是否存在
if ndb.Get(from) == nil || ndb.Get(to) == nil {
log.Printf("user %d or %d not found", fromID, toID)
return fmt.Errorf("user %d or %d not found", fromID, toID)
}
//先扣钱
if b, e, err := ndb.UpdateField(from, asset, "DEC", amount, true); err != nil {
log.Printf("user %d asset[%s] DESC failed", fromID, asset)
return err
} else {
log.Printf("id %d's %s change from %s to %s", fromID, asset, b, e)
}
//再发钱
if b, e, err := ndb.UpdateField(to, asset, "INC", amount, true); err != nil {
log.Printf("user %d asset[%s] INC failed", toID, asset)
return err
} else {
log.Printf("id %d's %s change from %s to %s", toID, asset, b, e)
}
return nil
}
<file_sep>package ndb
import (
"fmt"
"reflect"
)
const DefaultDBName = "default"
var (
DefaultDB *DB
dbMap = map[string]*DB{}
)
func init() {
DefaultDB = newDB(DefaultDBName)
dbMap[DefaultDBName] = DefaultDB
}
func GetDB(dbName string) *DB {
return dbMap[dbName]
}
func CreateTable(row Row) {
DefaultDB.CreateTable(row)
}
func Get(row Row) Row {
return DefaultDB.Get(row)
}
func MustGet(cond Row) Row {
row := DefaultDB.Get(cond)
if row == nil {
panic(fmt.Errorf("MustGet fail %+v", cond))
}
return row
}
func GetByIndex(row Row, indexName string) []int {
return DefaultDB.GetByIndex(row, indexName)
}
func MustFirst(cond Row, indexName string) Row {
ridArr := DefaultDB.GetByIndex(cond, indexName)
if len(ridArr) > 1 {
panic(fmt.Errorf("MustFirst %s fail. %d", indexName, len(ridArr)))
}
if len(ridArr) == 0 {
return nil
}
rid := ridArr[0]
val := reflect.ValueOf(cond).Elem()
val.FieldByName("Rid").Set(reflect.ValueOf(rid))
return MustGet(cond)
}
func GetStat(row Row, statName string, all bool) []*Stat {
return DefaultDB.GetStat(row, statName, all)
}
func Delete(row Row) {
DefaultDB.Delete(row)
}
func UpdateField(row Row, fieldName string, cmd string, value interface{}, strict bool) (string, string, error) {
return DefaultDB.UpdateFiled(row, fieldName, cmd, value, strict)
}
func MustUpdateField(cond Row, fieldName string, cmd string, value interface{}) {
_, _, err := UpdateField(cond, fieldName, cmd, value, false)
if err != nil {
panic(fmt.Errorf("MustUpdateField fail %+v %s %s %+v %s", cond, fieldName, cmd, value, err.Error()))
}
}
func Insert(row Row) error {
return DefaultDB.Insert(row)
}
func MustInsert(cond Row) {
if err := Insert(cond); err != nil {
panic(fmt.Errorf("MustInsert fail %+v %+v", cond, err))
}
}
func Load(row Row) error {
return DefaultDB.Load(row)
}
func MustLoad(cond Row) {
if err := Load(cond); err != nil {
panic(fmt.Errorf("MustLoad fail %+v %+v", cond, err))
}
}
func Update(row Row) error {
return DefaultDB.Update(row)
}
func MustUpdate(cond Row) {
if err := Update(cond); err != nil {
panic(fmt.Errorf("MustUpdate fail %+v %+v", cond, err))
}
}
func UpdateFunc(row Row, cb func(row Row) bool) error {
return DefaultDB.UpdateFunc(row, cb)
}
func MustUpdateFunc(cond Row, cb func(row Row) bool) {
if err := UpdateFunc(cond, cb); err != nil {
panic(fmt.Errorf("MustUpdateFunc fail %+v %+v", cond, err))
}
}
func GetTable(tableName string) *Table {
return DefaultDB.GetTable(tableName)
}
func SetPutTx(fn func(*Transaction)) {
putTrx = fn
}
<file_sep>package ndb
import (
"fmt"
"github.com/shopspring/decimal"
"log"
"reflect"
"sort"
"sync"
"time"
)
func getTableName(row Row) string {
val := reflect.ValueOf(row)
typ := reflect.Indirect(val).Type()
tableName := typ.Name()
if val.Kind() != reflect.Ptr {
panic(fmt.Errorf("cannot use non-ptr struct %s", tableName))
}
return tableName
}
func newTable(dbName, tableName string) *Table {
return &Table{
dbName: dbName,
tableName: tableName,
rows: make([]Row, 0),
idxIndexes: make(map[int]int),
metas: make(map[int]*MetaInfo),
indexes: make(map[string][]int),
stats: make(map[string][]*Stat),
fieldStats: make(map[string]map[string]int),
sorting: make(map[string]bool),
statting: false,
sortlock: &sync.Mutex{},
statlock: &sync.Mutex{},
lock: &sync.Mutex{},
allocChan: make(chan int, ROWSIZE),
}
}
func (tb *Table) nextIdx() int {
select {
case index := <-tb.allocChan:
return index
default:
allocSize := len(tb.rows)
toAppend := make([]Row, ROWSIZE/2)
tb.rows = append(tb.rows, toAppend...)
for i := 0; i < ROWSIZE/2; i++ {
tb.allocChan <- allocSize + i
}
return <-tb.allocChan
}
}
func (tb *Table) putIdx(idx int) {
select {
case tb.allocChan <- idx:
return
default:
log.Printf("table %s's chan is full", tb.tableName)
}
}
func (tb *Table) getIndexKey(row Row, indexName string) string {
if indexName == PRIMARYKEY {
return indexName
}
if indexs := row.Index(); indexs != nil {
if indexFields, ok := indexs[indexName]; ok {
indexKey := indexName
val := reflect.ValueOf(row)
sort.StringSlice(indexFields).Sort()
for i := 0; i < len(indexFields); i++ {
indexKey += fmt.Sprintf(":%v", reflect.Indirect(val).FieldByName(indexFields[i]))
}
return indexKey
}
}
return ""
}
func (tb *Table) getStatKey(row Row, statName string) (map[string]interface{}, string) {
if stats := row.Stat(); stats != nil {
if statFields, ok := stats[statName]; ok {
sort.StringSlice(statFields).Sort() //先排
val := reflect.ValueOf(row)
statKey := make(map[string]interface{})
statKeyStr := ""
for i := 0; i < len(statFields); i++ {
statKey[statFields[i]] = reflect.Indirect(val).FieldByName(statFields[i]).Interface()
statKeyStr += fmt.Sprintf(":%v", reflect.Indirect(val).FieldByName(statFields[i]))
}
return statKey, statKeyStr
}
}
return nil, ""
}
func (table *Table) sortIndex(index string) {
slock := table.sortlock
slock.Lock()
if table.sorting[index] {
slock.Unlock()
return
}
table.sorting[index] = true
slock.Unlock()
time.AfterFunc(3*time.Second, func() {
slock := table.sortlock
slock.Lock()
table.sorting[index] = false
slock.Unlock()
start := time.Now().Unix()
lock := table.lock
lock.Lock()
indexes := table.indexes
sort.IntSlice(indexes[index]).Sort()
length := len(indexes[index])
lock.Unlock()
end := time.Now().Unix()
log.Printf("sort index %s:%s %d records finished in %d second", table.tableName, index, length, end-start)
})
}
func (table *Table) sortStat(statName string) {
slock := table.statlock
slock.Lock()
if table.statting {
slock.Unlock()
return
}
table.statting = true
slock.Unlock()
time.AfterFunc(3*time.Second, func() {
slock := table.statlock
slock.Lock()
table.statting = false
slock.Unlock()
start := time.Now().Unix()
lock := table.lock
lock.Lock()
sort.SliceStable(table.stats[statName], func(i, j int) bool { return table.stats[statName][i].Count > table.stats[statName][j].Count })
lock.Unlock()
end := time.Now().Unix()
log.Printf("sort stat %s:%s %d records finished in %d second", table.tableName, statName, len(table.stats[statName]), end-start)
})
}
func (table *Table) insert(row Row, isLoad bool) error {
tableName := table.tableName
uid := row.GetUID()
lock := table.lock
lock.Lock()
defer lock.Unlock()
if rid, ok := table.idxIndexes[uid]; ok { //exist
log.Printf("record id[%d] is exist in table %s %d row", uid, tableName, rid)
return DBErrDup // fmt.Errorf("record %d is exist in %s", uid, tableName)
}
idx := table.nextIdx()
//创建meta
meta := &MetaInfo{Version: 1, UpdateStamp: time.Now(), SavedVersion: 0, SavedStamp: time.Now()}
////从数据库加载时load需传值,避免回写
if isLoad {
meta.SavedVersion = 1
}
table.metas[uid] = meta
table.rows[idx] = row
table.idxIndexes[uid] = idx
//发起持久化指令
table.putTx("INSERT", uid, meta.Version)
//putTrx(&Transaction{Cmd: "INSERT", DBName:table.dbName, TableName: tableName, ID: uid, Version: meta.Version})
//添加到主键列表
pk := PRIMARYKEY
table.indexes[pk] = append(table.indexes[pk], uid)
//列表排序
table.sortIndex(pk)
//log.Printf("insert record id[%d] in table %s's %d row", id, tableName, rid)
indexs := row.Index()
if indexs == nil {
return nil
}
//存在索引,创建索引
for indexName, indexFields := range indexs {
if len(indexFields) == 0 {
continue
}
indexKey := table.getIndexKey(row, indexName)
table.indexes[indexKey] = append(table.indexes[indexKey], uid)
//索引排序
table.sortIndex(indexKey)
}
stats := row.Stat()
if stats == nil {
return nil
}
//存在统计列,创建统计数据
for statName, statFields := range stats {
if len(statFields) == 0 {
continue
}
statKey, statKeyStr := table.getStatKey(row, statName)
//log.Printf("stat key of %s is %+v", statName, statKey)
if _, ok := table.fieldStats[statName]; !ok {
table.fieldStats[statName] = make(map[string]int)
}
if _, ok := table.fieldStats[statName][statKeyStr]; !ok { //创建新记录
table.fieldStats[statName][statKeyStr] = 1
table.stats[statName] = append(table.stats[statName], &Stat{statKey, 1})
} else {
table.fieldStats[statName][statKeyStr] += 1
for i := 0; i < len(table.stats[statName]); i++ {
if reflect.DeepEqual(table.stats[statName][i].StatKey, statKey) {
table.stats[statName][i].Count += 1
break
}
}
}
table.sortStat(statName)
}
return nil
}
//全覆盖更新
func (table *Table) Update(row Row) error {
tableName := table.tableName
uid := row.GetUID()
lock := table.lock
lock.Lock()
defer lock.Unlock()
if rid, ok := table.idxIndexes[uid]; ok {
table.rows[rid] = row
//更新meta
meta := table.metas[uid]
meta.Version += 1
meta.UpdateStamp = time.Now()
//发起持久化指令
table.putTx("UPDATE", uid, meta.Version)
} else {
log.Printf("record %d is not exist in table %s", uid, tableName)
return fmt.Errorf("record %d is not exist in table %s", uid, tableName)
}
return nil
}
func (table *Table) UpdateFunc(row Row, cb func(row Row) bool) error {
tableName := table.tableName
uid := row.GetUID()
lock := table.lock
lock.Lock()
defer lock.Unlock()
rid, ok := table.idxIndexes[uid]
if !ok {
log.Printf("record %d is not exist in table %s", uid, tableName)
return fmt.Errorf("record %d is not exist in table %s", uid, tableName)
}
if cb(table.rows[rid]) == false {
log.Printf("record %d in table %s callback failed", uid, tableName)
return fmt.Errorf("record %d in table %s callback failed", uid, tableName)
}
//更新meta
meta := table.metas[uid]
meta.Version += 1
meta.UpdateStamp = time.Now()
//发起持久化指令
table.putTx("UPDATE", uid, meta.Version)
return nil
}
//cmd支持REPLACE,INC,DEC,ZERO,某些特殊类型只支持REPLACE,strict是否严格模式,当严格模式时,当前行必须已被序列化, 成功时,返回该列更新前后的值
func (table *Table) UpdateField(row Row, fieldName string, cmd string, value interface{}, strict bool) (string, string, error) {
tableName := table.tableName
uid := row.GetUID()
lock := table.lock
lock.Lock()
defer lock.Unlock()
b := ""
e := ""
if strict { //严格模式,主要用在用户资产转账场景
if meta, ok := table.metas[uid]; !ok || (meta.Version != meta.SavedVersion &&
meta.UpdateStamp.After(meta.SavedStamp.Add(5*time.Second))) {
log.Printf("row %d in table[%s] strict check failed", uid, tableName)
return b, e, fmt.Errorf("row %d in table[%s] strict check failed", uid, tableName)
}
}
if rid, ok := table.idxIndexes[uid]; ok {
val := reflect.ValueOf(table.rows[rid]).Elem()
switch val.FieldByName(fieldName).Type().Kind() {
case reflect.Map, reflect.String, reflect.Struct: //直接替换的类型
if val.FieldByName(fieldName).Type().Name() == "Decimal" {
d1 := val.FieldByName(fieldName).Interface().(decimal.Decimal)
d2 := value.(decimal.Decimal)
b = d1.String()
switch cmd {
case "REPLACE":
val.FieldByName(fieldName).Set(reflect.ValueOf(value))
case "INC":
val.FieldByName(fieldName).Set(reflect.ValueOf(d1.Add(d2)))
case "DEC":
if d1.GreaterThanOrEqual(d2) {
val.FieldByName(fieldName).Set(reflect.ValueOf(d1.Sub(d2)))
} else {
return b, e, DBErrDec // fmt.Errorf("record %d %s not enough", uid, fieldName)
}
case "ZERO":
val.FieldByName(fieldName).Set(reflect.ValueOf(decimal.Zero))
default:
panic(fmt.Errorf("unsupport update cmd %s ", cmd))
}
e = val.FieldByName(fieldName).Interface().(decimal.Decimal).String()
} else { //REPLACE
b = fmt.Sprintf("%+v", val.FieldByName(fieldName))
val.FieldByName(fieldName).Set(reflect.ValueOf(value))
e = fmt.Sprintf("%+v", value)
}
case reflect.Int:
b = fmt.Sprintf("%+v", val.FieldByName(fieldName))
switch cmd {
case "REPLACE":
val.FieldByName(fieldName).SetInt(int64(value.(int)))
case "INC":
val.FieldByName(fieldName).SetInt(val.FieldByName(fieldName).Int() + int64(value.(int)))
case "DEC":
if val.FieldByName(fieldName).Int() >= int64(value.(int)) {
val.FieldByName(fieldName).SetInt(val.FieldByName(fieldName).Int() - int64(value.(int)))
} else {
return "", "", DBErrDec // fmt.Errorf("record %d %s not enough", uid, fieldName)
}
case "ZERO":
val.FieldByName(fieldName).SetInt(0)
default:
panic(fmt.Errorf("unsupport update cmd %s ", cmd))
}
e = fmt.Sprintf("%+v", val.FieldByName(fieldName))
default:
log.Printf("unsupport type is %+v in table[%s],field[%s]", val.FieldByName(fieldName).Type().Kind(), tableName, fieldName)
return "", "", DBErrNotSupport // fmt.Errorf("unsupport type is %+v in table[%s],field[%s]", val.FieldByName(fieldName).Type().Kind(), tableName, fieldName)
}
//更新meta
meta := table.metas[uid]
meta.Version += 1
meta.UpdateStamp = time.Now()
//发起持久化指令
table.putTx("UPDATE", uid, meta.Version)
} else {
log.Printf("record %d is not exist in table %s", uid, tableName)
return b, e, DBErrNotFound // fmt.Errorf("record %d is not exist in table %s", uid, tableName)
}
return b, e, nil
}
func (table *Table) putTx(cmd string, uid int, version uint64) {
putTrx(&Transaction{
Cmd: cmd,
DBName: table.dbName,
TableName: table.tableName,
UID: uid,
Version: version,
})
}
func (table *Table) Get(row Row) Row {
tableName := table.tableName
uid := row.GetUID()
lock := table.lock
lock.Lock()
defer lock.Unlock()
if rid, ok := table.idxIndexes[uid]; ok {
return table.rows[rid]
}
log.Printf("record %d is not exist in table %s", uid, tableName)
return nil
}
/*使用索引名查找, 相关索引列都要赋值*/
func (table *Table) GetByIndex(row Row, indexName string) []int {
indexKey := table.getIndexKey(row, indexName)
if indexKey == "" {
return nil
}
lock := table.lock
lock.Lock()
defer lock.Unlock()
return table.indexes[indexKey]
}
func (table *Table) GetStat(row Row, statName string, all bool) []*Stat {
lock := table.lock
lock.Lock()
defer lock.Unlock()
if !all { //查特定条件
if val, ok := table.fieldStats[statName]; ok {
statKey, statKeystr := table.getStatKey(row, statName)
if v, ok := val[statKeystr]; ok {
return []*Stat{&Stat{statKey, v}}
}
return []*Stat{&Stat{statKey, 0}}
}
}
//查全部
return table.stats[statName]
}
func (table *Table) Delete(row Row) {
uid := row.GetUID()
lock := table.lock
lock.Lock()
defer lock.Unlock()
idx, ok := table.idxIndexes[uid]
if !ok {
return
}
meta := table.metas[uid]
delete(table.idxIndexes, uid)
delete(table.metas, uid)
table.putIdx(idx)
//发起持久化指令
table.putTx("DELETE", uid, meta.Version)
//删除主键列表
pk := PRIMARYKEY
indexArr := table.indexes[pk]
arrLen := len(indexArr)
for i := 0; i < arrLen; i++ {
if indexArr[i] == uid {
indexArr[i] = indexArr[arrLen-1]
indexArr = indexArr[:arrLen-1]
break
}
}
table.indexes[pk] = indexArr
//列表排序
table.sortIndex(pk)
//log.Printf("delete recoed %d from %s", uid, table.tableName)
indexs := row.Index()
if indexs == nil {
return
}
//存在索引,删除索引
for indexName, indexFields := range indexs {
if len(indexFields) == 0 {
continue
}
indexKey := table.getIndexKey(row, indexName)
indexArr := table.indexes[indexKey]
arrLen := len(indexArr)
for i := 0; i < arrLen; i++ {
if indexArr[i] == uid {
indexArr[i] = indexArr[arrLen-1]
indexArr = indexArr[:arrLen-1]
break
}
}
table.indexes[indexKey] = indexArr
//索引排序
table.sortIndex(indexKey)
}
stats := row.Stat()
if stats == nil {
return
}
//存在统计列,删除统计数据
for statName, statFields := range stats {
if len(statFields) == 0 {
continue
}
statKey, statKeyStr := table.getStatKey(row, statName)
log.Printf("stat key of %s is %+v", statName, statKey)
if _, ok := table.fieldStats[statName]; !ok {
panic("what!!!")
}
if _, ok := table.fieldStats[statName][statKeyStr]; !ok {
panic("what!!!!!!")
} else {
table.fieldStats[statName][statKeyStr] -= 1
if table.fieldStats[statName][statKeyStr] < 0 {
panic("what!!!!!!!!!")
}
for i := 0; i < len(table.stats[statName]); i++ {
if reflect.DeepEqual(table.stats[statName][i].StatKey, statKey) {
table.stats[statName][i].Count -= 1
if table.stats[statName][i].Count < 0 {
panic("what!!!!!!!!!!!!!")
}
break
}
}
}
table.sortStat(statName)
}
}
func (table *Table) GetRowBytes(uid int, version uint64) (uint64, []byte) {
lock := table.lock
lock.Lock()
defer lock.Unlock()
meta, ok := table.metas[uid]
if !ok || meta.SavedVersion >= version { //记录已被删除或当前版本小于已保存版本
return 0, nil
}
idx := table.idxIndexes[uid]
obj := table.rows[idx]
ver := meta.Version
buf := obj.Encode()
return ver, buf
}
func (table *Table) UpdateSavedVersion(uid int, version uint64) {
lock := table.lock
lock.Lock()
defer lock.Unlock()
if meta, ok := table.metas[uid]; ok && meta.SavedVersion < version {
meta.SavedVersion = version
meta.SavedStamp = time.Now()
}
}
<file_sep>package main
import (
"flag"
"github.com/helloshiki/ndb"
"github.com/helloshiki/ndb/example/controller"
"github.com/helloshiki/ndb/example/models"
"github.com/shopspring/decimal"
"log"
"net/http"
_ "net/http/pprof"
"os"
"os/signal"
"runtime"
"runtime/pprof"
"time"
)
var (
CpuProfile = flag.String("cpu-profile", "", "write cpu profile to file")
HeapProfile = flag.String("heap-profile", "", "write heap profile to file")
)
func main() {
log.Printf("main")
runtime.GOMAXPROCS(runtime.NumCPU())
flag.Parse()
if *CpuProfile != "" {
file, err := os.Create(*CpuProfile)
if err != nil {
log.Panicln(err)
}
pprof.StartCPUProfile(file)
defer pprof.StopCPUProfile()
}
if *HeapProfile != "" {
file, err := os.Create(*HeapProfile)
if err != nil {
log.Panicln(err)
}
defer pprof.WriteHeapProfile(file)
}
go func() {
log.Println(http.ListenAndServe("localhost:6060", nil))
}()
//for test
sample()
sigChan := make(chan os.Signal, 1)
signal.Notify(sigChan, os.Interrupt)
log.Println(<-sigChan)
}
func sample() {
go Work()
//////////////////建表/////////////////////////////////////////
u1 := models.User{UID: 1, GID: 0, TCC: decimal.New(99, 2), ETH: decimal.New(199, 2), NASH: decimal.New(299, 2), Worker: map[int]bool{2: true}, I1: 1000}
ndb.CreateTable(&u1)
ndb.Insert(&u1)
ndb.Insert(&u1)
u2 := models.User{UID: 2, GID: 0, TCC: decimal.New(99, 2), ETH: decimal.New(199, 2), NASH: decimal.New(299, 2), Worker: map[int]bool{1: true}}
ndb.Insert(&u2)
m1 := models.TchMachine{}
ndb.CreateTable(&m1)
//////////////////建表/////////////////////////////////////////
///////////////////插入/////////////////////////////////////////
ucnt := 10
//插入ucnt个用户
for i := 0; i <= ucnt; i++ {
u := models.User{UID: i, GID: 0, TCC: decimal.New(99, 2), ETH: decimal.New(199, 2), NASH: decimal.New(299, 2), Worker: map[int]bool{1: true}}
ndb.Insert(&u)
}
mcnt := 1000000
start := time.Now().Unix()
//插入mcnt台矿机
for i := 0; i < mcnt; i++ {
m := models.TchMachine{ID: i, GID: 0, UID: i % ucnt}
//log.Printf("m:+%v", m)
ndb.Load(&m)
}
end := time.Now().Unix()
log.Printf("insert %d records in %d second", mcnt, end-start)
///////////////////插入/////////////////////////////////////////
///////////////////删除/////////////////////////////////////////
u10 := models.User{UID: 10}
ndb.Delete(&u10)
///////////////////删除/////////////////////////////////////////
///////////////////更新/////////////////////////////////////////
start = time.Now().Unix()
for i := 0; i < mcnt; i++ {
u := models.User{UID: i % 10}
ndb.UpdateField(&u, "TCC", "INC", decimal.New(123, -1), false)
}
end = time.Now().Unix()
log.Printf("update %d records in %d second", mcnt, end-start)
start = time.Now().Unix()
for i := 0; i < mcnt; i++ {
m := models.TchMachine{ID: i % 10, GID: 0, UID: i % ucnt}
ndb.Update(&m)
}
end = time.Now().Unix()
log.Printf("update %d records in %d second", mcnt, end-start)
///////////////////更新/////////////////////////////////////////
///////////////////转账/////////////////////////////////////////////
//ndb.UpdateFunc((controller.Transfer(nil, nil, nil)).(ndb.CallBack))
log.Printf("before transfer: user1: %+v, user2: %+v", ndb.Get(&u1), ndb.Get(&u2))
controller.Transfer(1, 2, "TCC", decimal.New(1, 1))
controller.Transfer(1, 2, "TCC", decimal.New(1, 100))
controller.Transfer(1, 2, "ETH", decimal.New(1, -1))
controller.Transfer(1, 2, "NASH", decimal.New(1, 2))
log.Printf("after transfer: user1: %+v, user2: %+v", ndb.Get(&u1), ndb.Get(&u2))
log.Printf("before u1 is %+v", u1)
if b, e, err := ndb.UpdateField(&u1, "Desc", "REPLACE", "ssss", false); err == nil {
log.Printf("DESC change from %s to %s", b, e)
} else {
log.Printf("err is %+v", err)
}
if b, e, err := ndb.UpdateField(&u1, "Worker", "REPLACE", map[int]bool{3: true}, false); err == nil {
log.Printf("Worker change from %s to %s", b, e)
} else {
log.Printf("err is %+v", err)
}
if b, e, err := ndb.UpdateField(&u1, "I1", "ZERO", 0, true); err == nil {
log.Printf("I1 change from %s to %s", b, e)
} else {
log.Printf("err is %+v", err)
}
if b, e, err := ndb.UpdateField(&u1, "I1", "REPLACE", 1000, true); err == nil {
log.Printf("I1 change from %s to %s", b, e)
} else {
log.Printf("err is %+v", err)
}
if b, e, err := ndb.UpdateField(&u1, "I1", "INC", 100, true); err == nil {
log.Printf("I1 change from %s to %s", b, e)
} else {
log.Printf("err is %+v", err)
}
if b, e, err := ndb.UpdateField(&u1, "I1", "DEC", 10, false); err == nil {
log.Printf("I1 change from %s to %s", b, e)
} else {
log.Printf("err is %+v", err)
}
log.Printf("after u1 is %+v", u1)
m := models.TchMachine{GID: 0, UID: 1}
arr := ndb.GetByIndex(&m, "guid")
log.Printf("GID:0 UID:1's TchMachine count is %d", len(arr))
arr = ndb.GetByIndex(&m, "pk")
log.Printf("TchMachine count is %d", len(arr))
time.Sleep(5 * time.Second)
stat := ndb.GetStat(&m, "guid", true)
for i := 0; i < len(stat); i++ {
log.Printf("TchMachine stat[%d] is %+v", i, stat[i])
}
stat = ndb.GetStat(&m, "guid", false)
for i := 0; i < len(stat); i++ {
log.Printf("TchMachine stat[%d] is %+v", i, stat[i])
}
///////////////////转账/////////////////////////////////////////////
}
<file_sep>package main
import (
//"encoding/json"
"log"
"time"
)
const (
WORKCNT = 1
)
func work() {
for i := 0; i < WORKCNT; i++ {
go func() {
ticker := time.NewTicker(3 * time.Second)
counter := 0
printedCounter := 0
for {
select {
case trx := <-ReqChan:
switch trx.Cmd {
case "INSERT", "UPDATE":
//log.Printf("insert/update record %s %d", trx.TableName, trx.ID)
lastest, buf := GetData(trx)
var resp *Response
if buf != nil {
//todo save to db
time.Sleep(100 * time.Millisecond) //模拟数据库插入耗时
counter++
resp = &Response{Code: "OK", DBName: trx.DBName, TableName: trx.TableName, UID: trx.UID, SavedVersion: lastest, SavedStamp: time.Now().Unix()}
} else {
resp = &Response{Code: "SKIP", DBName: trx.DBName, TableName: trx.TableName, UID: trx.UID, SavedVersion: trx.Version, SavedStamp: time.Now().Unix()}
}
PutResp(resp)
case "DELETE":
log.Printf("delete record %d", trx.UID)
resp := &Response{Code: "OK", DBName: trx.DBName, TableName: trx.TableName, UID: trx.UID, SavedVersion: trx.Version, SavedStamp: time.Now().Unix()}
PutResp(resp)
}
case <-ticker.C:
if counter != printedCounter {
log.Printf("=======update db %d times======", counter)
printedCounter = counter
}
}
}
}()
}
}
func init() {
work()
}
<file_sep>package models
import "encoding/json"
type TchMachine struct {
ID int
GID int
UID int
}
var (
indexes = map[string][]string{
"guid": {"GID", "UID"},
"gid": {"GID"},
"uid": {"UID"},
}
stats = map[string][]string{
"guid": {"GID", "UID"},
}
)
//索引列的值暂不支持修改,如需修改,可以先删除记录,再插入新记录
func (t *TchMachine) Index() map[string][]string {
return indexes
}
//索引列的值暂不支持修改,如需修改,可以先删除记录,再插入新记录
func (t *TchMachine) Stat() map[string][]string {
return stats
}
func (t *TchMachine) GetUID() int {
return t.ID
}
func (u *TchMachine) Encode() []byte {
bs, _ := json.Marshal(u)
return bs
}
func (u *TchMachine) Category() string {
return "TchMachine"
}
| 425a79f894c21378d439c53edc2bb05152b811d7 | [
"Go"
] | 11 | Go | helloshiki/ndb | 7dbed117fe1b5b0a2704f7d31d39e19786d8beda | 549de5654dbe990c981f37251e9e5059cc7fe709 |
refs/heads/main | <repo_name>kardespro/Nodejs-Soru-sor-Api<file_sep>/app.js
var express = require('express');
var app = express();
var fs = require("fs");
app.get('/api/soru/:soru', function (req, res) {
fs.readFile( __dirname + "/api/" + "sorular.json", 'utf8', function (err, data) {
var cevap = JSON.parse( data );
var soru = cevap["soru" + req.params.soru + "Cevap:" +cevap]
console.log("Started api");
res.end( JSON.stringify(user));
});
})
var server = app.listen(6060, function () {
var host = server.address().address
var port = server.address().port
console.log("Api Başlatıldı! SITEN:" +host)
})
<file_sep>/komut.js
//test komut
//API ICIN
const Discord = require("discord.js");
const get = require("request")
exports.run = async (client, message, args) => {
let soru = args.join(' ');
if(!soru) return message.reply('Soru Sor')
let krds = encodeURI(soru)
get(`https://api.kardespro.cf/api/soru/${krds}`, async function (err, resp, body) {
body = JSON.parse(body);
if(err) return message.channel.send('Api Ye Baglanilmadi!')
message.channel.send(body.Cevap)
})
}
exports.conf = {
enabled: true,
guildOnly: false,
aliases: ["sor"],
permLevel: 0
};
exports.help = {
name: "sor",
description: "bota soru sorarsınız",
usage: "sor"
};
<file_sep>/README.md
# Nodejs-Soru-sor-Api
Nodejs Soru Sor Api
| cde3d231f6033daa184b671eb83b205612fcd2dc | [
"JavaScript",
"Markdown"
] | 3 | JavaScript | kardespro/Nodejs-Soru-sor-Api | ff32612bc8ba0ec3386065face93858ad4be9059 | 19a99c1c330222012ab235aad185d962214ce52f |
refs/heads/master | <file_sep># 计算机组织与体系结构实习 Lab 4: Architecture Optimization For Specific Application
1700012751 麦景
[TOC]
## 使用x86 SIMD指令对应用程序进行优化并分析
> 1. 读入一幅YUV420格式的图像.
> 2. YUV420到ARGB8888转换(Alpha 分别取1~255,for(A=1;A<255;A=A+3),共85幅图像).
> 3. 根据A计算alpha混合后的RGB值(A*RGB/256),得到不同亮度的alpha混合.
>
> 4) 将alpha混合后的图像转换成YUV420格式,保存输出文件.
>
> 然后分别使用x86-64的基础ISA、MMX、SSE2、AVX编写图像处理基准程序,记录运行时间并进行简要分析.
### Usage
源码见https://github.com/magic3007/intel-simd.
运行方式如下:
```bash
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
make -j8
./demo --help
# Convert YUV420 file to RGB
# Usage: ./demo [OPTIONS]
#
#Options:
# -h,--help Print this help message and exit
# -f TEXT REQUIRED Input YUV420 file
# -s BOOLEAN Whether to dump the output
./demo -f ../testcases/dem1.yuv
```
通过设置命令行参数`-s`, 可以避免磁盘IO对运行时间的测量带来影响. 同时为了获得稳定的测量结果, 我们将令alpha遍历0 ~ 254, 进行255次如下的转换操作:
```c++
void do_work(Impl &impl, YUV420 *yuv_src, YUV420 *yuv_dst, RGB *rgb,
uint8_t alpha){
impl.YUV2RGB(yuv_src, rgb);
impl.AlphaBlend(rgb, alpha);
impl.RGB2YUV(rgb, yuv_dst);
}
```
### Simple ISA实现
每次调用`do_work`函数都会完成如下三项工作:
- YUV图像到RGB图像的转换
- 设置GRB图像透明度
- RGB图像到YUV图像的转换
转换方式我们使用了[wikipedia](https://en.wikipedia.org/wiki/YUV)上使用整数运算的方案, 核心函数如下. 向量化方案亦使用相同的转换方式.
```c++
void ImplSimple::YUV2RGB(YUV420 *yuv, RGB *rgb) {
assert(yuv->height_ == rgb->height_);
assert(yuv->width_ == rgb->width_);
auto y = yuv->y_;
auto u = yuv->u_;
auto v = yuv->v_;
auto r = rgb->r_;
auto g = rgb->g_;
auto b = rgb->b_;
for(size_t i = 0; i < yuv->size_; ++i){
int c = y[i] - 16;
int d = u[i] - 128;
int e = v[i] - 128;
r[i] = clamp((298 * c + 409 * e + 128) >> 8);
g[i] = clamp((298 * c - 100 * d - 208 * e + 128) >> 8);
b[i] = clamp((298 * c + 516 * d + 128) >> 8);
}
}
```
```c++
void ImplSimple::AlphaBlend(RGB *rgb, uint8_t alpha) {
auto r = rgb->r_;
auto g = rgb->g_;
auto b = rgb->b_;
for(size_t i = 0; i < rgb->size_; i++){
r[i] = (uint32_t)alpha * r[i] >> 8;
g[i] = (uint32_t)alpha * g[i] >> 8;
b[i] = (uint32_t)alpha * b[i] >> 8;
}
}
```
```c++
void ImplSimple::RGB2YUV(RGB *rgb, YUV420 *yuv) {
assert(yuv->height_ == rgb->height_);
assert(yuv->width_ == rgb->width_);
auto y = yuv->y_;
auto u = yuv->u_;
auto v = yuv->v_;
auto r = rgb->r_;
auto g = rgb->g_;
auto b = rgb->b_;
for(size_t i = 0; i < rgb->size_; i++){
int c = r[i];
int d = g[i];
int e = b[i];
y[i] = clamp(((66 * c + 129 * d + 25 * e + 128) >> 8) + 16);
u[i] = clamp(((-38 * c - 74 * d + 112 * e + 128) >> 8) + 128);
v[i] = clamp(((112 * c - 94 * d - 18 * e + 128) >> 8) + 128);
}
}
```
### Vectorization Scheme
Vectorization scheme亦使用相同的转换方式, 以YUV图像到RGB图像的转换为例, 我们通过template的方式可以得到关于vectorization scheme的通用计算方式, 我们对于各个vectorization scheme, 只需要实现加法, 减法, 乘法, 右移, 存取内存即可.
```c++
template <class SIMD>
void ImplSimd<SIMD>::YUV2RGB(YUV420 *yuv, RGB *rgb) {
assert(yuv->height_ == rgb->height_);
assert(yuv->width_ == rgb->width_);
assert(yuv->size_ % kStride == 0);
auto y = yuv->y_;
auto u = yuv->u_;
auto v = yuv->v_;
auto r = rgb->r_;
auto g = rgb->g_;
auto b = rgb->b_;
for(size_t i = 0; i < yuv->size_; i += kStride){
Vector c = sub(load(y+i), cn(16));
Vector d = sub(load(u+i), cn(128));
Vector e = sub(load(v+i), cn(128));
/*
r[i] = clamp((298 * c + 409 * e + 128) >> 8);
g[i] = clamp((298 * c - 100 * d - 208 * e + 128) >> 8);
b[i] = clamp((298 * c + 516 * d + 128) >> 8);
*/
store(rli(add(add(mul(cn(298),c),mul(cn(409),e)),cn(128)), 8), r + i);
store(rli(add(sub(sub(mul(cn(298),c),mul(cn(100),d)),mul(cn(208),e)), cn(128)), 8), g + i);
store(rli(add(add(mul(cn(298),c),mul(cn(516),d)),cn(128)), 8), b + i);
SIMD::Empty();
}
}
```
我们可以通过[Intel Intrinsic 接口](https://software.intel.com/sites/landingpage/IntrinsicsGuide/)非常方便地实现该功能, 此project用到的部分接口如下:
| | MMX | SSE2 | AVX |
| -------------- | ------------------------ | ------------------------ | ------------------------ |
| header file | `#include <emmintrin.h>` | `#include <emmintrin.h>` | `#include <immintrin.h>` |
| 清零 | `_mm_setzero_si64` | `_mm_setzero_si128` | `_mm256_setzero_si256` |
| 设置常数 | `_mm_set1_pi16` | `_mm_set1_epi16` | `_mm256_set1_epi16` |
| 16位加法 | `_mm_add_pi16` | `_mm_add_epi16` | `_mm256_add_epi16` |
| 16位减法 | `_mm_sub_pi16` | `_mm_sub_epi16` | `_mm256_sub_epi16` |
| 16位乘法(低位) | `_mm_mullo_pi16` | `_mm_mullo_epi16` | `_mm256_mullo_epi16` |
| 16位算术右移 | `_mm_srai_pi16` | `_mm_srai_epi16` | `_mm256_srai_epi16` |
| 解包 | `_mm_unpacklo_pi8` | `_mm_unpacklo_epi8` | |
| 打包 | `_mm_packs_pi16` | `_mm_packs_epi16` | `_mm256_packs_epi16` |
| 读内存 | | `_mm_loadl_epi64` | |
| 写内存 | | `_mm_storel_epi64` | |
| 转换为整数 | `_m_to_int` | | |
### 实验结果与分析
以下实验数据在_WSL Ubuntu 18.04_下测量4次得到, 处理器为_Intel(R) Core(TM) i7-7700HQ CPU @ 2.80GHz_, 编译器为_g++ (Ubuntu 7.5.0-3ubuntu1~18.04) 7.5.0_.

在向量化方案中, 我们使用16位整数进行运行, 得到上图中的理想加速比, 即红色虚线; 以及我们真实结果得到的加速比, 即紫色实线. 通过分析我们可以得到如下结论
- MMX相比于simple ISA有约1.8倍的提升, 但远小于4倍的理想加速比, 我认为是MMX与SSE2和AVX不同, 缺乏直接存取内存的intrinsic接口.
- SSE2相比于simple ISA有约5.6倍的提升,与理想加速比比较接近, 并且相比于MMX, 其真实加速比曲线与理想加速比曲线基本平行.
- AVX与SSE2加速比基本相当, 我认为这与本代码的实现方式相关. 实际上, 在本测试平台上, AVX不支持部分特定形式的存取intrinsic接口, 且部分intrinsic接口在本测试平台上并不存在, 因此在AVX的存取寄存器实现中我们本代码使用了部分SSE2的存取intrinsic接口, 故这部分成为了事实上的bottleneck.
## 设计自定义扩展指令对SIMD应用优化并分析
> 1. 设计若干32位宽的扩展指令
> - 支持8个宽度为256位的SIMD指令专用寄存器
> - 支持8/16/32位pack、unpack计算
> - 支持加/减/乘法
> - 支持饱和计算
> - 支持必要的数据传输指令
> 2. 可参考RISCV指令设计格式SIMD指令扩展编码,可自行设计汇编助记符。在文档里要写明自己设计指令的编码,助记符,以及指令语义。
8个宽度为256位的SIMD指令专用寄存器分别标号为`v0` - `v7`.
汇编助记符分为三个部分, 以`_v_adds_pi16`为例进行解释:
- `v` 表示SIMD拓展指令.
- `add`表示加法运算, 类似地, 可以定义运算`sub`, `mul`, `pack`, `unpack`, `load`, `store`, `setzero`, `set1`, `rli`等. 打包和解包的含义除此以外, 我们还可以定义后缀
- `s` 表示饱和运算, 故例子的`addus`表示无符号饱和加法
- `lo`和`hi`分别表示低位和高位. 如`_v_mullo_pi16`表示16位有符号数乘法, 结果保存低位.
- 对于`load`和`store`, 可支持非对齐地址
- `pi16` 中的`pi` 表示有符号, `16`表示16位整数, 除此以外, 我们可以进一步推广到8位和32位整数及其有无符号运算(`pu`)
而对于三元操作`op $reg0, $reg1, $reg2`, 其操作数顺序作如下规定: `$reg0`是目标数, 且 `$reg0 = $reg1 op $reg2`.
一些汇编助记符的例子如下, 其他可以类似推广得到:
| Assembly Language | Remark |
| ------------------------------------- | ------------------------------------------------------------ |
| `_v_adds_pu32 $reg0, $reg1, $reg2` | 32位无符号整数饱和加法 |
| `_v_mullo_pu16 $reg0, $reg1, $reg2` | 16位无符号整数乘法, 且结果保留低位 |
| `_v_packs_pu8 $reg0, $reg1, $reg2` | 8位无符号整数饱和打包 |
| `_v_unpacklo_pi8 $reg0, $reg1, $reg2` | 将`$reg1`和`$reg2`的低位部分以8位为单位进行解包 |
| `_v_load_pi32 $reg0, $rs1` | 将寄存器`$rs1`指向的内存以32位有符号整数为单位加载入SIMD指令专用寄存器, |
| `_v_store_pi32 $reg0, $rs1` | 将SIMD指令专用寄存器以32位有符号整数为单位加写回寄存器`$rs1`指向的内存 |
| `_v_set1_pi32 $reg0, imm` | 将`$reg0`以32位有符号整数为单位设置成立即数`imm` |
| `_v_setzero $reg0` | 将`$reg0`清零 |
参考RISC-V的"P" Standard Extension, 我们可以如下设计指令编码:
类似于RISC-V 32I, 我们可以R型指令(寄存器之间的运算, 如`_v_adds_pu32 $reg0, $reg1, $reg2`),S型指令(存取内存指令, 如`_v_load_pi32 $reg0, $rs1`)和I型指令(如`_v_set1_pi32 $reg0, imm`).
指令长度编码与RISC-V的规定相同, 由于这里使用32位指令, 即使用下图的第二行:

对于R型指令
| Field | funct9 | vrs2 | i/u | sta | vrs1 | width | funct2 | vrd | opcode |
| --------- | -------- | ------------- | ---------- | -------------- | ------------- | ---------- | -------- | ---------- | ------ |
| Bit Range | 31-23 | 22-20 | 19 | 18 | 17-15 | 14-12 | 11-10 | 9-7 | 6-0 |
| Remark | 功能指示 | 源向量寄存器2 | 是否有符号 | 是否为饱和运算 | 源向量寄存器1 | 操作数宽度 | 功能指示 | 目标寄存器 | 操作码 |
- 我们可以指定任意与RISC-V RV32I不冲突的opcode作为指示SIMD的拓展指令.
- 操作数宽度的设置与RISC-V "P" standard extension相同

对于S型指令
| Field | funct10 | rs1 | width | funct2 | vrd | opcode |
| --------- | -------- | --------- | ---------- | -------- | -------------- | ------ |
| Bit Range | 31-20 | 19-15 | 14-12 | 11-10 | 9-7 | 6-0 |
| Remark | 功能指示 | 源寄存器1 | 操作数宽度 | 功能指示 | 目标向量寄存器 | 操作码 |
对于I型指令
| Field | imm[11:0] | funct11 | width | funct2 | vrd | opcode |
| --------- | --------- | -------- | ---------- | -------- | -------------- | ------ |
| Bit Range | 31-20 | 19-15 | 14-12 | 11-10 | 9-7 | 6-0 |
| Remark | 立即数 | 功能指示 | 操作数宽度 | 功能指示 | 目标向量寄存器 | 操作码 |
> 3. 采用设计的SIMD扩展指令,重新编写lab4中的图像计算核心函数,并在文档中给出该核心函数的相应代码.
C++版本的图像计算核心代码如下, SIMD指令专用寄存器位数为256, 操作数宽度为16, 下图中的`kStride`为256/16=16.
```c++
auto y = yuv->y_;
auto u = yuv->u_;
auto v = yuv->v_;
auto r = rgb->r_;
auto g = rgb->g_;
auto b = rgb->b_;
for(int i = 0; i < yuv->size_; i += kStride){
Vector c = load(r+i);
Vector d = load(g+i);
Vector e = load(b+i);
/*
y[i] = clamp(((66 * c + 129 * d + 25 * e + 128) >> 8) + 16);
u[i] = clamp(((-38 * c - 74 * d + 112 * e + 128) >> 8) + 128);
v[i] = clamp(((112 * c - 94 * d - 18 * e + 128) >> 8) + 128);
*/
store(add(rli(add(add(add(mul(cn(66),c), mul(cn(129), d)), mul(cn(25), e)), cn(128)),8), cn(16)), y+i);
store(add(rli(add(sub(sub(mul(cn(112),e), mul(cn(38), c)), mul(cn(74), d)), cn(128)),8), cn(128)), u+i);
store(add(rli(add(sub(sub(mul(cn(112),c), mul(cn(94), d)), mul(cn(18), e)), cn(128)),8), cn(128)), v+i);
}
```
翻译得到的汇编代码如下
```assembly
# auto y = yuv->y_
# auto u = yuv->u_
# auto v = yuv->v_
# auto r = rgb->r_
# auto g = rgb->g_
# auto b = rgb->b_
# 假设通用寄存器$a1-$a6已经分别存放着数组y, u, v, r, g, b的首地址; $a7 已经存放着 yuv->size_
# kStride为16, 由编译时决定
xor $t1, $t1, $t1 # i = 0
loop:
_v_setzero $v7
# Vector c = load(r+i)
addiw $t2, $a4, $t1
_v_load_pi128 $v0, $t2
_v_unpacklo_pi8 $v0, $v0, $v7
# Vector d = load(g+i)
addiw $t2, $a5, $t1
_v_load_pi128 $v1, $t2
_v_unpacklo_pi8 $v1, $v1, $v7
# Vector e = load(b+i)
addiw $t2, $a6, $t1
_v_load_pi128 $v2, $t2
_v_unpacklo_pi8 $v2, $v2, $v7
# =========================================================
# store(add(rli(add(add(add(mul(cn(66),c), mul(cn(129), d)), mul(cn(25), e)), cn(128)),8), cn(16)), y+i)
# =========================================================
# mul(cn(66),c)
_v_set1_pi16 $v7, 66
_v_mullo_pi16 $v3, $v0, $v7
# mul(cn(129), d)
_v_set1_pi16 $v7, 129
_v_mullo_pi16 $v4, $v1, $v7
# mul(cn(25), e)
_v_set1_pi16 $v7, 25
_v_mullo_pi16 $v5, $v2, $v7
# add(add(add(mul(cn(66),c), mul(cn(129), d)), mul(cn(25), e)),cn(128))
_v_add_pi16 $v3, $v3, $v4
_v_add_pi16 $v3, $v3, $v5
_v_set1_pi16 $v7, 128
_v_add_pi16 $v3, $v3, $v7
# rli(add(add(add(mul(cn(66),c), mul(cn(129), d)), mul(cn(25), e)), cn(128)),8)
_v_rli_pi16 $v3, $v3, 8
# add(rli(add(add(add(mul(cn(66),c), mul(cn(129), d)), mul(cn(25), e)), cn(128)),8), cn(16))
_v_set1_pi16 $v7, 16
_v_add_pi16 $v3, $v3, $v7
# store
_v_setzero $v7
_v_packs_pi16 $v3, $v3, $v7
_v_store_pi128 $v3, $v3, $a1
# =========================================================
# store(add(rli(add(sub(sub(mul(cn(112),e), mul(cn(38), c)), mul(cn(74), d)), cn(128)),8), cn(128)), u+i)
# =========================================================
# mul(cn(38),c)
_v_set1_pi16 $v7, 38
_v_mullo_pi16 $v3, $v0, $v7
# mul(cn(74), d)
_v_set1_pi16 $v7, 129
_v_mullo_pi16 $v4, $v1, $v7
# mul(cn(112), e)
_v_set1_pi16 $v7, 25
_v_mullo_pi16 $v5, $v2, $v7
# add(sub(sub(mul(cn(112),e), mul(cn(38), c)), mul(cn(74), d)), cn(128))
_v_sub_pi16 $v5, $v5, $v4
_v_sub_pi16 $v5, $v5, $v3
_v_set1_pi16 $v7, 128
_v_add_pi16 $v3, $v5, $v7
# rli
_v_rli_pi16 $v3, $v3, 8
# add
_v_set1_pi16 $v7, 128
_v_add_pi16 $v3, $v3, $v7
# store
_v_setzero $v7
_v_packs_pi16 $v3, $v3, $v7
_v_store_pi128 $v3, $v3, $a2
# =========================================================
# store(add(rli(add(sub(sub(mul(cn(112),c), mul(cn(94), d)), mul(cn(18), e)), cn(128)),8), cn(128)), v+i)
# =========================================================
# mul(cn(112),c)
_v_set1_pi16 $v7, 112
_v_mullo_pi16 $v3, $v0, $v7
# mul(cn(94), d)
_v_set1_pi16 $v7, 94
_v_mullo_pi16 $v4, $v1, $v7
# mul(cn(18), e)
_v_set1_pi16 $v7, 18
_v_mullo_pi16 $v5, $v2, $v7
# add(sub(sub(mul(cn(112),c), mul(cn(94), d)), mul(cn(18), e)), cn(128))
_v_sub_pi16 $v3, $v3, $v4
_v_sub_pi16 $v3, $v3, $v5
_v_set1_pi16 $v7, 128
_v_add_pi16 $v3, $v3, $v7
# rli
_v_rli_pi16 $v3, $v3, 8
# add
_v_set1_pi16 $v7, 128
_v_add_pi16 $v3, $v3, $v7
# store
_v_setzero $v7
_v_packs_pi16 $v3, $v3, $v7
_v_store_pi128 $v3, $v3, $a3
bge $t1, $a7, L2
addiw $t1, $t1, 16
j loop
L2: nop
```
> 4. 定性分析采用自己设计的SIMD扩展指令后可以获得最大指令减少数(相对于未使用SIMD指令),以及可以获得的潜在性能提升.
使用SIMD扩展指令集优化的代码每次能处理16个像素, 因此理想的情况下处理速度会变成普通版本的16倍,图像处理核心部分的动态指令数会变为原来的16分之一附近.<file_sep>#include <cstdlib>
#include <cstdio>
#include <cstdint>
#include <sys/time.h>
void usage(int argc, char const *argv[]){
fprintf(stderr,
"C Benchmark: Ackermann Function.\n"
"Usage:\n"
" %s <m> <n>\n"
"Description:\n"
" Calculate the Ackermann Function ack(m,n).\n",
argv[0]
);
}
int ackermann(int m, int n){
if (m == 0) return n+1;
if (n == 0) return ackermann( m - 1, 1 );
return ackermann( m - 1, ackermann( m, n - 1 ) );
}
int main(int argc, const char** argv) {
if(argc != 3){
usage(argc, argv);
exit(EXIT_FAILURE);
}
int m = atoi(argv[1]);
int n = atoi(argv[2]);
struct timeval start, end;
gettimeofday(&start, nullptr);
printf("%d\n", ackermann(m, n));
gettimeofday(&end, nullptr);
uint64_t delta = (end.tv_sec * 1000000 + end.tv_usec)
- (start.tv_sec * 1000000 + start.tv_usec);
fprintf(stderr, "Elasped Time: %lu ms.\n",delta / 1000);
return 0;
}<file_sep># 计算机组织与体系结构实习 Lab 2: RISV-Simulator
1700012751 麦景
[TOC]
*<mark>Note</mark>: 本次lab的完整源代码和部分文档托管在[此](https://github.com/magic3007/RISCV-Simulator), 为避免重复, 其中README.md的内容会被引用作为本报告的一部分.*
## 实验(开发)环境
以下toolchains配置均在操作系统Ubuntu18.04下进行. 在本次lab中, 我们使用了`SiFive` 提供的[prebuilt RISC-V GCC toolchain](https://www.sifive.com/boards), 同时我们需要如下的编译指示:
- `-Wa,-march=rv64im`: compulsorily compile the source file into RV64I executable file
- `-static`: statically linking
- `-Wl,--no-relax`: To start running from `main`, we have to forbid the compiler to leverage the global pointer to optimize
由于这个prebuilt的toolchain中的库函数含有16-bit的压缩后的指令, 因此我们的simulator从函数`main`开始执行, 更多关于交叉编译RISC-V二进制文件的使用方法见[此](https://github.com/magic3007/RISCV-Simulator/blob/master/README.md#how-to-compile-your-customized-c-source-codes-into-risc-v-executable-file).
## 设计概述
本次lab实现的simulator用Go语言实现, 且同时支持模拟*RV64I*指令集和*RV64M*指令集. 此simulator支持两种模式: single-instruction mode和pipeline mode, 分别对应于lab要求中的功能模拟和性能模拟. 此simulator主要具有两大sparkle points
- 利用数据驱动编程的思想, 各指令的特性可自由配置, 相关的配置信息在表[src/action_table.csv](./https://github.com/magic3007/RISCV-Simulator/blob/master/src/action_table.csv)中, 这里总结出可配置特性及其给表格中对应的列, 相关列的含义将在下面的section中给出.
| 配置特性 | 相关列 |
| ------------------------------------------- | ---------------------------------------------------- |
| 指令类型的识别与解析 | `Type`, `Opcode`, `Funct3` `Funct7` `BitConstraint` |
| 指令显示格式 | `DisplayFormat` |
| 指令行为(single-instruction mode) | `Action1` `Action2` |
| 指令跳转识别信号(pipeline mode) | `IsBranch` `IsIndirectJump` |
| 执行阶段行为(pipeline mode) | `ALUFunction` |
| 访存阶段行为(pipeline mode) | `MemoryAccessFunction` |
| PC相关的计算行为(pipeline mode) | `ValCFunction` `PositiveOptionPC` `NegativeOptionPC` |
| 执行结果和访存结果目标寄存器(pipeline mode) | `dstE` `dstM` |
| 执行结果寄存器选择来源(pipeline mode) | `M_valE_Source` |
| 执行阶段时延 | `EStagePeriod` |
| 访存阶段时延 | `MStagePeriod` |
- 提供了类似`gdb` 的交互模式, 便于调试, 查看寄存器和内存信息.
## 具体设计和实现
### 存储接口
simulator的存储接口主要包括两部分, 分别是寄存器和内存, 分别被封装在`package register`和`package memory`内部. `package memory`主要是对64位虚拟内存空间进行管理.
### 可执行文件的读取和装载
可执行文件的读取主要利用了Go语言标准库提供的包[debug/elf](https://golang.org/pkg/debug/elf/). 在运行simulator时, 可通过命令行参数`-v`选择是否显示ELF File Header的信息:
```bash
$ ./bin/sim -f testcases/add.out -v=1
FileHeader
Class : ELFCLASS64
Data : ELFDATA2LSB
Version : EV_CURRENT
OSABI : ELFOSABI_NONE
ABIVersion : 0
ByteOrder : LittleEndian
Type : ET_EXEC
Machine : EM_RISCV
Entry : 0x00000000000100cc
Sections : [0xc0000ee000 0xc0000ee080 0xc0000ee100 0xc0000ee180 0xc0000ee200 0xc0000ee280 0xc0000ee300 0xc0000ee380 0xc0000ee400 0xc0000ee480 0xc0000ee500 0xc0000ee580 0xc0000ee600 0xc0000ee680 0xc0000ee700 0xc0000ee780 0xc0000ee800 0xc0000ee880 0xc0000ee900]
Progs : [0xc0000ba1e0 0xc0000ba240]
closer : 0xc0000b8018
gnuNeed : []
gnuVersym : []
===========================================
Porgram 0:
ProgHeader
Type : PT_LOAD
Flags : PF_X+PF_R
Off : 0x0000000000000000
Vaddr : 0x0000000000010000
Paddr : 0x0000000000010000
Filesz : 0x000000000000056e
Memsz : 0x000000000000056e
Align : 0x0000000000001000
ReaderAt : 0xc000098360
sr : &{0xc0000b8018 0 0 1390}
===========================================
Porgram 1:
ProgHeader
Type : PT_LOAD
Flags : PF_W+PF_R
Off : 0x0000000000000570
Vaddr : 0x0000000000011570
Paddr : 0x0000000000011570
Filesz : 0x00000000000007a8
Memsz : 0x00000000000007e0
Align : 0x0000000000001000
ReaderAt : 0xc000098390
sr : &{0xc0000b8018 1392 1392 3352}
```
ELF 文件中的program, section和segment的区别和联系如下:
> program, section & segment in ELF File
program table: optional in linking view
section table: optional in execution view

因此对于可执行文件, 我们只需要关注program, 把各program加载到对应的内存位置即可.
### 初始化
程序正式运行前的初始化主要包括如下部分:
- 栈空间的分配和栈顶指针的初始化
由于栈的位置和大小并不由ELF文件自身规定, 我们采用OS中常用的`0x7ffffffff000`作为栈顶`STACK_TOP`, 同时默认分配`STACK_SIZE`为4M的栈空间.
- 程序entry的设置
由于prebuilt的toolchain中的库函数含有16-bit的压缩指令, 因此我们的simulator从函数`main`开始执行
### 指令语义的解析
正如前面所说, 指令语义的解析主要是通过[src/action_table.csv](./https://github.com/magic3007/RISCV-Simulator/blob/master/src/action_table.csv)中的配置进行的, 其中与指令语义解析相关的列有 `Type`, `Opcode`, `Funct3`, `Funct7` 和 `BitConstraint`.

其中的`Type` 与 [The RISC-V Instruction Set Manual](https://content.riscv.org/wp-content/uploads/2017/05/riscv-spec-v2.2.pdf) 中对指令分类相同:

`Opcode`, `Funct3`, `Funct7` 则分别代表各个类型指令对应的部分的限制. 除此以外, 部分指令如`SLLI`, `SRLI` 和 `SRAI` 等, 会对其他部分有限制, 我们通过`BitConstraint`限制.

通过如上的方式识别指令类型后, 我们就可以很方便地提取出各指令中的`rd`, `rs1`, `rs2` `imm`等部分, 从而完成指令语义的解析.
指令对应的操作我们也可以在[src/action_table.csv](./https://github.com/magic3007/RISCV-Simulator/blob/master/src/action_table.csv)中进行配置, 在single-instruction mode中与此相关的是列是`Action1`和`Action2`. 在pipeline mode中的操作配置见下面的section.

除此以外, 我们为了模拟`gdb`, 还可以对各指令的Display Format进行配置. Assembly Language的显示格式主要有以下五种:
| Display Format | Example |
| -------------- | ------------------- |
| DSS | `add rd, rs1, rs2` |
| DIS | `lb rd, imm(rs1)` |
| DSI | `xori rd, rs1, imm` |
| SIS | `sb rs2, imm(rs1)` |
| DI | `auipc rd, imm` |
同样地, 我们在[src/action_table.csv](./https://github.com/magic3007/RISCV-Simulator/blob/master/src/action_table.csv)中进行配置, 从而可以非常方便地输出易于解读的汇编指令, 显示效果见下面的section.
### 控制信号的处理
控制信号主要用在pipeline mode下. 此simulator运行五级流水线,其设计如下:

在真实的数字电路设计中, 上图中的红色框的部分的具体行为会根据识别出来的指令类型而决定, 但是此次工作比较繁琐. 但是在模拟的过程中, 其实对于红色框的具体行为我们可以自己配置, 从代码结构上看, 即为通过传递函数指针的方式实现, 这样我们同样可以在[src/action_table.csv](./https://github.com/magic3007/RISCV-Simulator/blob/master/src/action_table.csv)中配置流水线指令的行为, 从而减少控制信号带来的繁琐负担.

同时, 一般来说在执行阶段的除法和访存阶段的时延一般较大, 在此流水线中设计中, 我们可以在[src/pipeline/config.go](https://github.com/magic3007/RISCV-Simulator/blob/master/src/pipeline/config.go)中配置流水线的步近周期, 在[src/action_table.csv](./https://github.com/magic3007/RISCV-Simulator/blob/master/src/action_table.csv)也可以配置执行阶段和访存阶段的时延, 从而非常方便地为接下来对Cache的模拟提供了接口.

### 性能计数相关模块的处理
性能计数比较方便, 只需要在程序特定的位置使用计数器即可. 目前提供的性能计数指标主要为下面的[section](#功能测试和性能评测)服务.
### 调试接口
由于本simulator本身就提供类似于`gdb`的交互模式, 故调试接口是天然的. 在调试模式下, 该simulator支持如下类似于`gdb`的操作:
- `c`: Continue running until the program comes to the end
- `reg`: Display register information
- `info`: Display the address of this symbol defined in ELF file
- `si`: In single-instruction mode, the function of this operations is the same as that of `gdb`, namely running a single machine instruction. However, in pipeline mode, it means running a single pipeline stage.
- ` x/<length><format> [address]`: Display the memory contents at a given address using the specified format.
- `status`(only in pipeline mode): Display the status of each pipeline register.
*<mark>Note</mark>: Operation `si` has different function in single-instruction mode and pipeline mode. We will explain why we have such design in the following section.*
下面是分别single-instruction mode和pipeline mode的调试过程的截图, 查看调试过程的动图见[此](https://github.com/magic3007/RISCV-Simulator/blob/master/README.md#single-instruction-mode).


## 功能测试和性能评测
- 在Data Hazard中, 只有类似于如下的情况才会需要停顿, 其他情况可以通过data forward解决.
```assembly
lw $t1, 20($t0)
or $t2, $t1, $s5
```
- 在Control Hazard中, 对于基于寄存器的非直接跳转, 我们需要通过插入bubble; 对于条件跳转, 这里默认采取了always taken的转移预测策略.
- 在此评测中, 为了统一标准, 我们把把单个Step的周期(即`Cycle Per Step`=30)调得足够大, 使得访存和执行阶段都可以在一个Step内完成.
| | Cycle Per Step | number of Steps | number of Cycles | number of Valid Instructions | CPI | SPI(Step Per Inst.) | Jump Prediction Success Rate | number of Indirect Jump | Stall for Data Hazard |
| --------------- | -------------- | ---------- | ----------- | ----------------------- | -------- | -------------------- | ---------------------------- | ------------------ | --------------------- |
| add | 30 | 292 | 8760 | 232 | 37.75862 | 1.25862 | 83.33333% | 1 | 52 |
| mul-div | 30 | 317 | 9510 | 257 | 37.00389 | 1.23346 | 83.33333% | 1 | 52 |
| n! | 30 | 342 | 10260 | 268 | 38.28358 | 1.27612 | 90.00000% | 21 | 28 |
| qsort | 30 | 24506 | 735180 | 19184 | 38.32256 | 1.27742 | 51.53639% | 159 | 3204 |
| simple-function | 30 | 307 | 9210 | 243 | 37.90123 | 1.26337 | 83.33333% | 3 | 52 |
结果分析:
- 当前假设加法和乘除法都能在一个Step完成的配置下, `add` , `mul-div`和 `simple-function` 三者的数据相差不大, 甚至`Stall for Data Hazard`, `Jump Prediction Success Rate`完全相同, 通过观察他们三者的代码发现符合预期, 而`simple-function`相比于`add` 和`mul-div`, `# of Indirect Jump` 要多2, 这分别来源于单次函数调用及其返回, 也符合预期
- `n!`中`Jump Prediction Success Rate`为90%, 观察程序, 我们需要计算10的阶乘, 而程序的核心部分如下
```c
int cal_n(int i)
{
if(i==1)
return i;
else
return i*cal_n(i-1);
}
```
进一步, 观察汇编程序, 其条件跳转指令为
```assembly
101ac: 00f71663 bne a4,a5,101b8 <cal_n+0x30>
```
故如果采用always taken的策略, `Jump Prediction Success Rate`确实是90%, 符合预期.
- `qsort`的`Jump Prediction Success Rate`仅有51.53639%,并且其间接跳转次数和data hazard造成的stall也较多, 整体来看CPI最高.
## Summary
总的来说, 该模拟器提供了如下的功能特性:
- 提供了类似于`gdb`的交互模式, 支持单指令模拟和流水线模拟.
- 利用数据驱动编程的思想, 指令可自由配置, 这为拓展新的指令集提供了方便手段.
- 在流水线模式下, 流水线的步近周期, 指令执行周期等均可自由配置, 同时为接下来对存储的访问延时预留了接口.
更多关于此simulator的使用方式见[此](https://github.com/magic3007/RISCV-Simulator).😜<file_sep>#!/usr/bin/env bash
loops=(1000000 10000000 100000000)
opts=(-O0 -O2 -O3)
src_proc=./src/whetstone.c
bin_proc=./bin/whetdc
num_repeats=3
LOG_FILE=log2.txt
for opt in ${opts[@]}; do
gcc $opt $src_proc -o $bin_proc $opt -lm
for loop in ${loops[*]}; do
echo $opt $loop ":" | tee -a $LOG_FILE
for ((i=1; i<=$num_repeats; i ++)) do
$bin_proc $loop | tee -a $LOG_FILE
done
done
done<file_sep>#include <cstdlib>
#include <cstdio>
#include <cstdint>
#include <sys/time.h>
void usage(int argc, char const *argv[]){
fprintf(stderr,
"C Benchmark: General Matrix Multiplication(GEMM).\n"
"Usage:\n"
" %s <N> <K> <M>\n"
"Description:\n"
" Calculate the multiplication of Matrix A_{NxK} and Matrix B_{KxM}.\n",
argv[0]
);
}
template<class T>
void gemm(void *A_, void *B_, void *C_, int N, int K, int M){
T (*A)[K] = (T (*)[K])A_;
T (*B)[M] = (T (*)[M])B_;
T (*C)[M] = (T (*)[M])C_;
for(int i = 0; i < N; i++)
for(int k = 0; k < K; k++)
for(int j = 0; j < M; j++)
C[i][j] += A[i][k] * B[k][j];
}
int main(int argc, char const *argv[]){
if(argc != 4){
usage(argc, argv);
exit(EXIT_FAILURE);
}
int N = atoi(argv[1]);
int K = atoi(argv[2]);
int M = atoi(argv[3]);
using ElementType = float;
void *A = malloc(sizeof(ElementType) * N * K);
void *B = malloc(sizeof(ElementType) * K * M);
void *C = calloc(N * M, sizeof(ElementType));
struct timeval start, end;
gettimeofday(&start, nullptr);
gemm<ElementType>(A, B, C, N, K, M);
gettimeofday(&end, nullptr);
uint64_t delta = (end.tv_sec * 1000000 + end.tv_usec)
- (start.tv_sec * 1000000 + start.tv_usec);
fprintf(stderr, "Elasped Time: %lu ms.\n",delta / 1000);
free(A);
free(B);
free(C);
return 0;
}
<file_sep>import java.util.*;
public class gemm{
public static void multiply(float[][] A, float[][] B, float[][] C,
int N, int K, int M){
for(int i = 0; i < N; i++){
for(int k = 0; k < K; k++){
for(int j = 0; j < M; j++){
C[i][j] += A[i][k] * B[k][j];
}
}
}
}
public static void main(String[] args) {
if (args.length != 3) {
System.err.println("Lack of Parameters!");
System.exit(-1);
}
int N = Integer.parseInt(args[0]);
int K = Integer.parseInt(args[1]);
int M = Integer.parseInt(args[2]);
float [][] A = new float[N][K];
float [][] B = new float[K][M];
float [][] C = new float[N][M];
for(int i = 0; i < N; i++)
for(int j = 0; j < M; j++)
C[i][j] = 0;
long startTimestemp = System.currentTimeMillis();
multiply(A, B, C, N, K, M);
long endTimestemp = System.currentTimeMillis();
System.out.println("Elapsed time: " + (endTimestemp - startTimestemp) + " ms.");
}
}<file_sep># 计算机组织与体系结构实习 Lab 3: Cache Simulator
1700012751 麦景
[TOC]
_Note: 代码和使用方法见 https://github.com/magic3007/RISCV-Simulator._
## 单级Cache模拟
> 保持associativity为8, 在不同的Cache Size(32KB ~ 32MB)的条件下, Miss Rate随Block Size(32B, 64B, 128B, 256B, 512B, 1024B, 2048B, 4096B)的变化趋势如下.

<img src="./lab3_report.assets/1589297600636.png" alt="1589297600636" style="zoom:110%;" />
分析:
- Cache Size不变时, 随着Block Size变大, Miss Rate变小
- 在相同Block Size的条件下, Cache Size越大, Miss Rate越小
- 在Block Size在64B ~ 256B的时候, Miss Rate随Cache Size变大下降较快, 256B后下降速度减弱
- 同时这两条曲线有一些微妙的差别. trace1的各条曲线在左侧聚合, trace2的各条曲线在右边聚合. 这原因是trace2的空间局部性更差, 当Block Size较小时, Cache Size上升带来的Miss Rate下降程度越大.
> 保持Block Size为256B, 在不同的Cache Size(32KB ~ 32MB)的条件下, Miss Rate随associativity(1,2,4,8,16)的变化趋势如下.


分析:
- 对于trace1和trace2, 随着associativity增加, 总体上Miss Rate均下降, 但是当associativity超过2之后Miss Rate下降趋势不明显
- 当associativity不变, 随着cache size增大, miss Rate下降. 但是这两个trace有各自特点
- 对trace1来说, cache size在32KB ~ 256KB时miss Rate下降不明显; 在512KB ~ 32MB之间miss rate下降迅速, 并且在cache size为32MB的时候, 基本达到了下限.
- 对trace2来说, 其miss rate大致分布为三个部分
- cache size为32KB ~ 384KB时, miss rate大致都在0.3 ~ 0.36
- cache size为1MB ~ 32MB时, miss rate基本相同, 且达到下界0.17附近
- cache size为512KB-986KB时, miss rate处于前两者之间, 且曲线基本重合, 即在256KB ~ 1MB之间miss rate存在一个较大的gap; 同时此时Miss Rate随associativity的变化较为反常, 随着associativity增加, Miss Rate上升.
> 在如下配置进行测试, Write Through 和 Write Back、 Write Allocate 和 No-write Allocate 的总访问延时如下(数据分别见[policy.trace1.csv](./policy.trace1.csv)和[policy.trace2.csv](./policy.trace2.csv))
| configuration | |
| ------------------------------- | ----- |
| cache hit latency (cycle) | 1 |
| main memory hit latency (cycle) | 10 |
| Block Size | 256B |
| Associativity | 8 |
| Cache Size | 512KB |
_trace1_:
| WriteUpPolicy | WriteDownPolicy | Miss Rate | AMAT |
| ------------- | ----------------- | --------- | ----- |
| Write Back | Write Allocate | 0.308 | 4.542 |
| Write Back | No-write Allocate | 0.6497 | 7.497 |
| Write Through | Write Allocate | 0.308 | 7.576 |
| Write Through | No-write Allocate | 0.6497 | 7.52 |
_trace2_:
| WriteUpPolicy | WriteDownPolicy | Miss Rate | AMAT |
| ------------- | ----------------- | --------- | -------- |
| Write Back | Write Allocate | 0.256427 | 4.745616 |
| Write Back | No-write Allocate | 0.61565 | 7.156497 |
| Write Through | Write Allocate | 0.256427 | 7.036349 |
| Write Through | No-write Allocate | 0.61565 | 7.156497 |
分析:
- 对于trace1和trace2, 均为采取Write Back+Write Allocate的组合AMAT和Miss Rate最小
- 在单级缓存中, 采取Write Allocate策略比采取No-write Allocate策略Miss Rate更小
## 与lab2中的CPU模拟器联调完成模拟
与Lab2中的流水线模拟器联调,运行测试程序。该测试中cache和Main Memory的配置如下, 并且假设执行阶段可以一个步进周期内完成, 同时由于程序代码本身比较小, 这里仅考虑Data Cache.
| Level | Capacity | Associativity | Line Size(Bytes) | WriteUp Policy | WriteBack Policy | Hit Latency |
| ----------- | -------- | ------------- | ---------------- | -------------- | ---------------- | ----------- |
| L1 | 32KB | 8 | 64 | write back | write allocate | 1 |
| L2 | 256KB | 8 | 64 | write back | write allocate | 8 |
| LLC | 8MB | 8 | 64 | write back | write allocate | 20 |
| Main Mamory | 1GB | - | - | - | - | 40 |
不使用cache, cpu直接访问main memory其结果如下:
| | number of Cycles | number of Valid Instructions | CPI | Jump Prediction Success Rate | number of Indirect Jump | Stall for Data Hazard |
| --------------- | ----------- | ----------------------- | -------- | ---------------------------- | ------------------ | --------------------- |
| add | 2359 | 232 | 10.16810 | 83.33333% | 1 | 52 |
| mul-div | 2384 | 257 | 9.27626 | 83.33333% | 1 | 52 |
| n! | 2331 | 268 | 8.69776 | 90.00000% | 21 | 28 |
| qsort | 270635 | 19184 | 14.10733 | 51.53639% | 159 | 3204 |
| simple-function | 2452 | 243 | 10.09054 | 83.33333% | 3 | 52 |
使用如上配置的cache的结果如下:
| | number of Cycles | number of Valid Instructions | CPI | L1 Miss Rate | AMAT |
| --------------- | ----------- | ----------------------- | -------- | ---------------------------- | --------------------- |
| add | 455 | 232 | 1.96121 | 0.011931 | 1.811280 |
| mul-div | 480 | 257 | 1.86770 | 0.011638 | 1.791367 |
| n! | 583 | 268 | 2.17537 | 0.012155 | 1.826535 |
| qsort | 44079 | 19184 | 2.29770 | 0.000782 | 1.053147 |
| simple-function | 484 | 243 | 1.99177 | 0.011638 | 1.791367 |
我们可以看到, 由于这几个程序访问的数据内存范围较小, 有较好的空间局部性和时间局部性, 极大地减少了CPI.
## 高速缓存管理策略优化
在如下默认配置下, _cacti6.5_的模拟结果为(假设CPU主频为2.0GHz, 即1 cpu cycle=0.5ns):
| | WriteUp Policy | WriteBack Policy | Technology size (nm) | Capacity | Associativity | Block Size(Bytes) | Hit Latency(ns) | Cycle |
| ----------------- | -------------- | ----------------- | -------------------- | -------- | ------------- | ----------------- | --------------- | ----- |
| L1 Cache | write back | write allocate | 32 | 32KB | 8 | 64 | 0.468579 | 1 |
| L2 Cache | write back | write allocate | 32 | 256KB | 8 | 64 | 0.673308 | 2 |
| LCC Cache | write back | write allocate | 32 | 8MB | 8 | 64 | 1.66275 | 4 |
| Main Memory(DRAM) | - | - | 68 | 1GB | 1 | 64 | 12.8821 | 26 |
在该默认配置下, 用模拟器运行trace2017中的两个trace结果如下:
| | 01-mcf-gem5-xcg | 02-stream-gem5-xaa |
| ---------------- | --------------- | ------------------ |
| L1 Miss Rate | 0.200455 | 0.113404 |
| L2 Miss Rate | 0.396293 | 0.755171 |
| L3 Miss Rate | 0.303580 | 0.799801 |
| AMAT (cpu cycle) | 2.751130 | 4.815993 |
> 请填写最终确定的优化方案,并陈述理由。对于涉及到的算法,需要详细描述算法设计和实现思路,并给出优缺点分析。
- LFU(Least Frequently Used): 与LRU类似, 但是每次选择访问频率最小的数据被淘汰
- pros: 高效, 对热点内容效果较好
- cons: 算法复杂, 用硬件实现比较困难
- cache prefetching: 当预测到将连续访问连续内存地址的时候, 预先后面的内容
- pros: 能利用预测信息减少访存时间, 其中instruction prefetching尤为常用.
- cons: 预测错误会增大开销
在该优化配置下, 用模拟器运行trace2017中的两个trace结果如下:
| | 01-mcf-gem5-xcg | 02-stream-gem5-xaa |
| ------------ | --------------- | ------------------ |
| L1 Miss Rate | 0.181500 | 0.113404 |
| L2 Miss Rate | 0.347836 | 0.755253 |
| L3 Miss Rate | 0.444222 | 0.887442 |
| AMAT (ns) | 2.542618 | 4.759982 |
可以看到, 这两个trace的AMAT均有大幅下降.
<file_sep>#!/usr/bin/env bash
if [[ "$1" == "quick_sort" || "$1" == "gemm" || "$1" == "ackermann" ]]; then
mkdir build
cd build
cmake ..
make -j$(nproc) $1
echo ./bin/"$@"
./bin/"$@"
else
echo "Usage: $0 <gemm|quick_sort|ackermann> <...params>"
echo " $0 gemm <N> <K> <M>"
echo " $0 quick_sort <N>"
echo " $0 ackermann <m> <n>"
fi<file_sep># Computer Architecture Engineering of PKU
Implementation for the lesson Computer Architecture Engineering(2020 Spring, advised by Prof. <NAME>) in Peking University. 🎈🎏
In this lesson, we have to complete four labs:
1. [Profile technology](./lab1/lab1_report.md)
2. [RISCV Simulator](./lab2/lab2_report.md)
3. [Cache Simulator](./lab3/lab3_report.md)
4. [Architecture Optimization For Specific Application](./lab4/lab4_report.md)<file_sep># ===== helper functions =======
function(add_executable_config TARGETNAME)
target_compile_options(${TARGETNAME} PRIVATE
-Wall -Wextra -pedantic -Werror
-Wno-unused-variable
-Wno-unused-parameter
-Wno-empty-body
-Wno-sign-compare
-Wno-missing-field-initializers
-Wno-unused-function
-Wno-unused-private-field
-Wno-vla
-O2
)
set_target_properties(${TARGETNAME} PROPERTIES RUNTIME_OUTPUT_DIRECTORY
"${PROJECT_BINARY_DIR}/bin")
endfunction()
add_executable(gemm gemm.cpp)
add_executable_config(gemm)
add_executable(quick_sort quick_sort.cpp)
add_executable_config(quick_sort)
add_executable(ackermann ackermann.cpp)
add_executable_config(ackermann)<file_sep>#!/usr/bin/env bash
loops=(1000000 10000000 100000000)
programs=(./bin/whetdc)
num_repeats=1
LOG_FILE=log.txt
for prog in ${programs[@]}; do
for loop in ${loops[*]}; do
echo $prog $loop ":" | tee -a $LOG_FILE
for ((i=1; i<=$num_repeats; i ++)) do
$prog $loop | tee -a $LOG_FILE
done
dones
done<file_sep>#!/usr/bin/env bash
loops=(1000000 10000000 100000000 1000000000)
bin_proc=./icc_whetstone
num_repeats=3
LOG_FILE=log_icc.txt
for loop in ${loops[*]}; do
echo "icc -O3" $loop ":" | tee -a $LOG_FILE
for ((i=1; i<=$num_repeats; i ++)) do
$bin_proc $loop | tee -a $LOG_FILE
done
done
<file_sep>import java.util.*;
public class ackermann {
static int ack(int m, int n) {
if (m == 0) return n + 1;
if (n == 0) return ack(m - 1, 1);
return ack(m -1, ack(m, n -1));
}
public static void main(String[] args) {
if (args.length != 2) {
System.err.println("Lack of Parameters!");
System.exit(-1);
}
int m = Integer.parseInt(args[0]);
int n = Integer.parseInt(args[1]);
long startTimestemp = System.currentTimeMillis();
System.out.println(ack(m, n));
long endTimestemp = System.currentTimeMillis();
System.out.println("Elapsed time: " + (endTimestemp - startTimestemp) + " ms.");
}
}<file_sep># 计算机组织与体系结构实习Lab 1: 处理器性能评测
麦景
1700012751
------
* [计算机组织与体系结构实习Lab 1: 处理器性能评测](#计算机组织与体系结构实习lab-1-处理器
性能评测)
* [评测程序](#评测程序)
* [文献阅读](#文献阅读)
* [相对性能指标](#相对性能指标)
* [Profile实例](#profile实例)
* [whetstone](#whetstone)
* [dhrystone](#dhrystone)
* [编程语言对性能的影响](#编程语言对性能的影响)
* [性能评测](#性能评测)
* [工作背景和评测目标](#工作背景和评测目标)
* [评测环境](#评测环境)
* [评测步骤及要求 & 评测结果及简要分析](#评测步骤及要求--评测结果及简要分析)
* [Dhrystone](#dhrystone-1)
* [whetstone](#whetstone-1)
* [SPEC CPU2000](#spec-cpu2000)
* [Summary](#summary)
------
## 评测程序
> 1. 我们针对系统评测的不同角度会采用不同的评测程序. 在目前已有的评测程序中, 为下列评测目标找到某些合适的评测程序(列出即可).
| 评测目标 | 评测程序 | 评测目标 | 评测程序 |
| ------------------ | ----------------------------------------- | ------------------ | ------------------------------ |
| CPU整点性能 | CINT2017 | CPU浮点性能 | CFP2017 |
| 计算机事务处理能力 | TPC-E, PCMark | 嵌入式系统计算能力 | EEMBC, CoreMark |
| 2D处理能力 | GFXBench2D | 3D处理能力 | SPECapc, GFXBench3D |
| 并行计算性能 | SPECrate, ACCEL, MPI2007, OMP2012 | 系统响应速度 | SiSoftwareSandra |
| 编译优化能力 | OOPACK, Bench++, Haney | 操作系统性能 | Perfmon |
| 多媒体处理能力 | VLC Benchmark | IO处理能力 | IO500, TPC-C, TPC-W, SPECsfs97 |
| 浏览器性能 | [BrowserBench](https://browserbench.org/) | 网络传输速率 | netperf |
| Java运行环境性能 | SPECJVM | 邮件服务性能 | SPECmail |
| 文件服务器性能 | SPECSFS | Web服务器性能 | SPECWeb |
| 服务器功耗和性能 | SPCEpower_sjj2008, TPC-Energy | | |
> *Conception: **SPECRatio***(<u>use geometric means</u>)
>
> Using the geometric mean ensures two important properties:
>
> 1. the geometric mean of ratios = the ratio of the geometric means
> 2. The choice of the reference computer is irrelevant.
>
> 
*Credit to:*
- *Computer Architecture: A Quantitative Approach*, Chapter 1.8 & Appendix D
- [The Standard Performance Evaluation Corporation (SPEC)](http://spec.org/)
- [Transaction-processing Concil(TPC)](http://www.tpc.org)
- [Unified cross-platform 3D graphics benchmark database](https://gfxbench.com/)
## 文献阅读
阅读文献(*<NAME>, An Overview of Common Benchmarks, IEEE Computer, December 1990.*), 并回答下面的问题.
### 相对性能指标
> 1. 简述用于性能评测的MIPS指标之含义,以及它是如何被计算的.
MIPS字面意思是 millions of instructions per second, 但是随着CISC的出现逐渐失去了意义. 现在重新定义"VAX MIPS", 度量性能与VAX 11/780之间的比值. 运行评测程序需要控制的变量有编程语言, 编译器, 评测角度等.
### Profile实例
> 2. 使用Linux下的剖视工具(例如`gprof`)对`dhrystone`和`whetstone`进行剖视,参考论文Table 1形式给出数据,你的结果和该论文是否一致,为什么?
#### whetstone
由于`gprof`采样频率过低(采样周期为0.01s), 无法记录单次执行时间少于0.01s的函数. 我们采用`vtune`进行profile. 假设`amplxe-cl`已在路径当中:
```shell
$ cd whetstone
$ make debug
$ amplxe-cl -V
$ amplxe-cl -collect hotspots ./debug/whetdc 300000
$ amplxe-cl -report hotspots -format=csv > whetstone_300000.csv
```
整理后的statistics如下:
| 行标签 | 求和项:CPU Time | Percent | | |
| ----------------------- | --------------- | ------- | ----------------- | ------ |
| main | 5.030017 | 33.99% | | |
| P3 | 1.599985 | 10.81% | | |
| P0 | 0.529996 | 3.58% | | |
| PA | 0.599998 | 4.05% | User Code | 52.43% |
| Trigonometric functions | 2.979982 | 20.14% | | |
| Other math functions | 4.040002 | 27.30% | Library functions | 47.43% |
| Others | 0.020002 | 0.14% | | |
| 总计 | 14.799982 | 100.00% | | |
完整数据见[此](./whetstone/whetstone_300000.xlsx). 其与论文中Table 1给的数据不太一致, 在具体结果上能细微差别, 比如P0(Indexing)时间占比远小于论文中的数据, 可能的原因是Cache的大小不同.
#### dhrystone
课程给的`dhrystone`版本过老, 会发生`times`重复定义的情况, 参考[Errors while compiling dhrystone in unix](https://stackoverflow.com/questions/9948508/errors-while-compiling-dhrystone-in-unix)对代码进行修改. 我们使用`prof`来进行profile(假设已安装`prof`).
Usage: 对`makefile`进行修改后, 方便进行profile:
```shell
$ cd whetstone
$ make clean
$ make prof-cc_dry2
$ make prof-cc_dry2reg
$ make prof-gcc_dry2
$ make prof-gcc_dry2reg
```
profile结果如下, `number of runs`均为100000000:
`cc_dry2`

`cc_dry2reg`

`gcc_dry2`

`gcc_dry2reg`

这个结果与论文中Table 3的结论不太一致. 在这次实验中的hotspots是library function`strcmp`, 但在论文中仅仅占用不足10%. 同时, 我们也看到了不同编译器和寄存器分配策略也会对profile结果造成影响.
### 编程语言对性能的影响
> 3. 论文中讨论了处理器之外可能对性能造成影响的因素,请分别使用两种不同的语言(例如C和Java)使用同一算法实现快速排序、矩阵乘法、求Ackermann函数,验证文中的观点。(请保留你的程序,我们在后面可能还会用到它).
除了处理器之外, 论文讨论了可能对性能造成影响的因素有:
- 编程语言
- 编译器
- 运行库
- cache的大小
不同编译语言, 在函数调用序列, 指针语法和字符串语法等方面的不同会导致性能的差异.
C语言写的代码在目录[CBenchmark](./CBenchmark)下, 进入该目录运行`prof.sh`即可, 编译优化选项为`-O2`.
```bash
> cd CBenchmark
> ./prof.sh
Usage: ./prof.sh <gemm|quick_sort|ackermann> <...params>
./prof.sh gemm <N> <K> <M>
./prof.sh quick_sort <N>
./prof.sh ackermann <m> <n>
```
Java语言写的代码在目录[JavaBenchmark](./JavaBenchmark)中. 测试使用Java 11.
```bash
> java -version
openjdk version "11.0.6" 2020-01-14 LTS
OpenJDK Runtime Environment 18.9 (build 11.0.6+10-LTS)
OpenJDK 64-Bit Server VM 18.9 (build 11.0.6+10-LTS, mixed mode, sharing
```
在相同[评测环境](#评测环境)下两者评测结果如下.
| | C(Elasped Time/ms) | Java(Elasped Time/ms) | Ratio |
| :-------------------------: | ------------------ | --------------------- | ----------- |
| gemm(N=1000, K=1000,M=1000) | 1186 | 1379 | 1.162731872 |
| quick_sort(N=100000000) | 30142 | 33677 | 1.117278216 |
| ackermann(m=4, n=1) | 19973 | 26376 | 1.320582787 |
*Tips: 运行Java程序发生栈溢出情况时可以通过添加编译选项`-Xss<stack size>` 调整栈大小, 如`-Xss1M`, 同理也可以用`-Xmx<heap size>`调整堆大小.*
我们看到, 一般情况下, C语言的程序比相同实现的Java程序要快. 这说明了编译语言和编译优化对评测程序性能的重要影响.
## 性能评测
基于某个给定的计算机系统平台,使用`dhrystone`、`whetstone`、`SPEC CPU2000`开展评测、分析、研究并给出报告.
### 工作背景和评测目标
轻量应用服务器(Simple Application Server)是可快速搭建且易于管理的轻量级云服务器, 其提供基于单台服务器的应用部署,安全管理,运维监控等服务, 与阿里云ECS云服务器相比, 其可用于快速搭建个人网站, 云端学习环境, 电商建设, 社区论坛等.
在本次实验中, 我们将评测阿里云轻量应用服务器的处理器性能.
### 评测环境
| **项目** | **详细指标和参数** |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
| 处理器型号及相关参数(频率、架构、缓存等) `cat /proc/cpuinfo` | model name : Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz<br />cache size : 33792 KB |
| 内存 `free -h` | 2G |
| 外存 `df -h` | 40G |
| 操作系统及其版本 `lsb_release -a` | LSB Version: :core-4.1-amd64:core-4.1-noarch<br/>Distributor ID: CentOS<br/>Description: CentOS Linux release 7.7.1908 (Core)<br/>Release: 7.7.1908<br/>Codename: Core |
| 编译器版本 (及编译参数) `gcc -v` | gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-39)<br /><br />Configured with: ../configure --prefix=/usr --mandir=/usr/share/man --infodir=/usr/share/info --with-bugurl=http://bugzilla.redhat.com/bugzilla --enable-bootstrap --enable-shared --enable-threads=posix --enable-checking=release --with-system-zlib --enable-__cxa_atexit --disable-libunwind-exceptions --enable-gnu-unique-object --enable-linker-build-id --with-linker-hash-style=gnu --enable-languages=c,c++,objc,obj-c++,java,fortran,ada,go,lto --enable-plugin --enable-initfini-array --disable-libgcj --with-isl=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/isl-install --with-cloog=/builddir/build/BUILD/gcc-4.8.5-20150702/obj-x86_64-redhat-linux/cloog-install --enable-gnu-indirect-function --with-tune=generic --with-arch_32=x86-64 --build=x86_64-redhat-linux<br/>Thread model: posix |
| 库函数及其版本 | Glibc 2.17 |
### 评测步骤及要求 & 评测结果及简要分析
如无特殊说明, 以下单个测试点重复三次并采用几何平均值.
#### Dhrystone
> 1. 在linux下基于dhrystone-2.1所提供的Makefile编译dhrystone.
[如上所述](#dhrystone)进行修改即可编译通过.
> 2. 分别采用$10^8$、$3\times 10^8$、$5\times 10^8$、$7\times 10^8$、$9\times 10^8$为输入次数,运行编译生成的两个程序,记录、处理相关数据并做出解释。
完整数据记录见[dhrystone_statistic.xlsx](./dhrystone_statistic.xlsx), 进入目录[dhrystone-2.1](./dhrystone-2.1), 编译完成后运行脚本[dhrystone_profile.sh](./dhrystone-2.1/dhrystone_profile.sh)即可. 单个测试点重复三次, 采用几何平均值. 整理后的数据如下.
| | `gcc_dry2` | `gcc_dry2reg` | Ratio |
| ------ | ---------- | ------------- | ----- |
| 10^8 | 13889210.85 | 14007816 | 1.008539372 |
| 3*10^8 | 13731956.07 | 14341841.31 | 1.044413573 |
| 5*10^8 | 13863504.27 | 13769938.94 | 0.993250961 |
| 7*10^8 | 13908838.08 | 14193107.31 | 1.020438029 |
| 9*10^8 | 13923625.55 | 13890154.73 | 0.997596113 |
实验结果说明, 在当前编译器和机器配置下, `gcc_dry2`和`gcc_dry2rag`两者速度差别并不大, 可能是现代处理器的L1 Cache的读写速度相比于以前有了较大的提升.
> 3. 对dhrystone代码做少量修改,使其运行结果不变但“性能”提升.
观察`rhry.h`, `dhry_1.c`he `dhry_2.c`我们可以得知, 实际上程序有较多的死代码, 如图实际上在`drhy_1.c`中, 第176-179行是不会执行的.但是由于为了防止编译优化, 程序采用了独立编译后链接的方式(即第173行的`Func_1`是定义在另一个文件`dhry_2.c`中的), 因此这段这段代码不会被忽略, 其存在的作用是防止对第154行的固定地址, 固定字符的`strcpy`进行编译优化.

<u>我们仅仅把第177行的`strcpy`屏蔽</u>, 并进行测试, 得到的结果如下(固定循环次数为3*10^8), 我们发现仅仅屏蔽一行根本不会执行的代码会把速度就能把速度提高了1.13倍.
| | `gcc_dry2reg` | optimized `gcc_dry2reg` | Ratio |
| ---------- | ------------- | ----------------------- | -------- |
| Epoch 1 | 17857142 | 20134228 | |
| Epoch 2 | 17857142 | 20270270 | |
| Epoch 3 | 17804154 | 20134228 | |
| 几何平均值 | 17839461.8 | 20179473.6 | 1.131171 |
> 4. 采用dhrystone进行评测有哪些可改进的地方?对其做出修改、评测和说明
首先, dhrystone中用于测试的proc函数过于简单, 不能很好体现实际工作中的计算机的工作负载. 由于dhrystone使用独立编译后链接的方式, 从上一题的数据我们可以看到, 仅仅屏蔽一个不会执行的函数就可以提高速度, 依赖于编译器优化能力. 而且实际上用于测试的proc计算量并不大, 更多是在考量分支预测和编译编译优化, 不能很好体现CPU的实际运行性能.
#### whetstone
> 1. 在linux下使用编译器分别采用-O0、-O2、-O3选项对whetstone程序进行编译并执行,记录评测结果.
> 2. 分别采用10^6, 10^7, 10^8, 10^9为输入次数,运行编译生成的可执行程序,记录、处理相关数据并做出解释.
> 3. 进一步改进whetstone程序性能(例如新的编译选项),用实验结果回答.
由于gcc对Intel CPU的特性优化不足, 我们选用Intel提供的编译器`icc`进行编译, 同时开启`-O3` 编译优化. `icc`版本如下:
```
Intel(R) C Intel(R) 64 Compiler for applications running on Intel(R) 64, Version 192.168.127.12 Build 20190206
Copyright (C) 1985-2019 Intel Corporation. All rights reserved.
```
| time(s), MIPS | 10^6 | 10^7 | 10^8 | 10^9 |
| ------------- | :----------------: | :----------------: | :----------------: | :----------------: |
| gcc -O0 | 53.33126(1875.094) | 522.9637(1912.167) | 5267.992(1898.23) | 52854.6(1891.964) |
| gcc -O2 | 29.32957(3409.532) | 220.3313(4538.625) | 2182.98(4580.857) | 21940.94(4557.808) |
| gcc -O3 | 28.32944(3529.886) | 204.5841(4887.949) | 2140.017(4672.848) | 21115.69(4735.806) |
| icc -O3 | <5s | 22.66172(44127.3) | 225.6662(44378.77) | 2302.992(43421.74) |
我们看到循环次数为10^6时MIPS较低, 可能是缓存为未预热的原因. 同时我们可以看到不同编译优化级别和编译器对程序的运行速度有很大的影响, 使用针对Intel CPU进行优化的编译器`icc`可以获得10倍以上的速度提升, 这说明我们在进行profiling的时候必须需要指明编译器和编译选项.
#### SPEC CPU2000
> 1. 完成SPEC CPU2000的安装.
> 2. 修改自己的config文件,分别用低强度优化(例如O2)和高强度优化(例如O3)完成完整的SPEC CPU2000的评测,提交评测报告文件.
由于该版本发布时所在编译平台与目前的编译平台相差较大, 需要做如下的改动.
- 文件 `benchsspec/CINT2000/252.eon/src/ggRaster.cc` 需要include `string.h`
- 对gcc和g++添加如下编译选项
```
CC = gcc -DHAS_ERRLIST -DSPEC_STDCPP -m32
CXX = g++ -DHAS_ERRLIST -DSPEC_STDCPP -fpermissive -m32
```
- 对178.galgel添加编译选项 `-ffixed-form`
```
178.galgel=default=default=default:
notes0051= 178.galgel: FC = gfortran -ffixed-form
FC = gfortran -ffixed-form
F77 = gfortran -ffixed-form
```
`source shrc`后, 分别运行` runspec -c linux-x86-gcc.cfg -T all -n 3 int fp` 得到高强度优化结果. 添加选项`-e gcc33-low-opt `可以进行低强度优化. profile结果如下, 完整文件见[SPECCPU2000_result.tar.gz](./SPECCPU2000_result.tar.gz).
**CINT2000(gcc33-low-opt)**

**CINT2000(gcc33-high-opt)**

**CFP2000(gcc33-low-opt)**

**CFP2000(gcc33-high-opt)**

### Summary
在这次实验中, 我们看到不同的编译器, 不同的编译选项, 不同的优化算法等都会对评测结果产生影响, 一个好的benchmark应该是编译依赖较小的, 而且由于不同编译平台的特性, 部分程序不一定能通过其他编译器的编译. 故在发布benchmark的时候, 应该指明编译器的版本和选项.
同时, 在计算机体系结构领域, 为了得到一个标准机器无关的性能指标, 我们通常使用相对指标, 同时采用几何平均数得到比较准确的结果.<file_sep>#include <cstdlib>
#include <cstdio>
#include <cstdint>
#include <sys/time.h>
#include <utility>
void usage(int argc, char const *argv[]){
fprintf(stderr,
"C Benchmark: Quick Sort.\n"
"Usage:\n"
" %s <N>\n"
"Description:\n"
" Sort an array with N elements in an ascending order.\n",
argv[0]
);
}
void quickSort(int *a, int l, int r){
if(l>=r) return;
int i = l, j = r, mid = a[(l+r)>>1];
while(i<=j){
while(a[i] < mid) i++;
while(mid < a[j]) j--;
if(i<=j) std::swap(a[i],a[j]), i++, j--;
}
if(l < j)quickSort(a, l, j);
if(i < r)quickSort(a, i, r);
}
int main(int argc, const char** argv) {
if(argc != 2){
usage(argc, argv);
exit(EXIT_FAILURE);
}
int N = atoi(argv[1]);
int *arr = (int*)malloc(sizeof(int) * N);
srand(0);
for(int i = 0; i < N; i++)
arr[i] = rand();
struct timeval start, end;
gettimeofday(&start, nullptr);
quickSort(arr, 0, N-1);
gettimeofday(&end, nullptr);
uint64_t delta = (end.tv_sec * 1000000 + end.tv_usec)
- (start.tv_sec * 1000000 + start.tv_usec);
fprintf(stderr, "Elasped Time: %lu ms.\n",delta / 1000);
free(arr);
return 0;
}<file_sep>#!/usr/bin/env bash
loops=(100000000 300000000 500000000 700000000 900000000)
programs=(./gcc_dry2 ./gcc_dry2reg)
num_repeats=3
LOG_FILE=log.txt
for prog in ${programs[@]}; do
for loop in ${loops[*]}; do
echo $prog $loop ":" | tee -a $LOG_FILE
for ((i=1; i<=$num_repeats; i ++)) do
echo " Epoch " $i ":" $(echo $loop | $prog | grep "Dhrystones per Second:" | tr -cd "[0-9.]") | tee -a $LOG_FILE
done
done
done<file_sep>cmake_minimum_required(VERSION 3.5)
project(CBenchmark)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_VERBOSE_MAKEFILE off)
set(CMAKE_EXPORT_COMPILE_COMMANDS off)
message(STATUS "PROJECT_SOURCE_DIR: ${PROJECT_SOURCE_DIR}")
message(STATUS "PROJECT_BINARY_DIR: ${PROJECT_BINARY_DIR}")
add_subdirectory(src) | 71abc3ab299feaaca99ca91c600194b080db8f43 | [
"CMake",
"Markdown",
"Java",
"C++",
"Shell"
] | 17 | Markdown | magic3007/Computer-Architecture-Engineering-of-PKU | 42c2be7fe7d0a6141c3e221b13a491f6cec47b2c | 692b7ddc693dfcfe9fbd231df58dae2ec9171462 |
refs/heads/main | <file_sep>import cv2
import numpy as np
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
def Recog(img_color):
img_hsv = cv2.cvtColor(img_color, cv2.COLOR_BGR2HSV)
lower_red = np.array([0, 120, 40])
upper_red = np.array([20, 255, 255])
mask0 = cv2.inRange(img_hsv, lower_red, upper_red)
lower_red = np.array([160, 120, 40])
upper_red = np.array([180, 255, 255])
mask1 = cv2.inRange(img_hsv, lower_red, upper_red)
red_mask = mask0 + mask1
lower_blue = np.array([100, 50, 50])
upper_blue = np.array([140, 255, 255])
blue_mask = cv2.inRange(img_hsv, lower_blue, upper_blue)
red_hsv = img_hsv.copy()
blue_hsv = img_hsv.copy()
red_count = len(red_hsv[np.where(red_mask != 0)])
blue_count = len(blue_hsv[np.where(blue_mask != 0)])
if red_count > blue_count:
color = "red"
red_hsv[np.where(red_mask != 0)] = 0
red_hsv[np.where(red_mask == 0)] = 255
else:
color = "blue"
blue_hsv[np.where(blue_mask != 0)] = 0
blue_hsv[np.where(blue_mask == 0)] = 255
print(color)
return color
def color_img(img, push_color):
if push_color == "red":
lower = (0 - 10, 60, 60)
upper = (0 + 10, 255, 255)
# elif push_color == "green":
# lower = (60 - 10, 100, 100)
# upper = (60 + 10, 255, 255)
#
# elif push_color == "yellow":
# lower = (30 - 10, 100, 100)
# upper = (30 + 10, 255, 255)
elif push_color == "blue":
lower = (120 - 20, 60, 60)
upper = (120 + 20, 255, 255)
img_color = img
img_hsv = cv2.cvtColor(img_color, cv2.COLOR_BGR2HSV)
img_mask = cv2.inRange(img_hsv, lower, upper)
img_result = cv2.bitwise_and(img_color, img_color, mask=img_mask)
return img_result
while(True):
ret, frame = cap.read() # Read 결과와 frame
if(ret) :
color = Recog(frame)
img_color = color_img(frame, color)
copy = img_color.copy()
gray = cv2.cvtColor(img_color, cv2.COLOR_BGR2GRAY)
binary = cv2.threshold(gray, 127, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY)[1]
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
cv2.drawContours(frame, [cnt], 0, (255, 0, 0), 3) # blue
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
filepath = ['./result/']
if (area > 10000 and area < 20000) and (w/h > 0.8 and w/h < 1.2):
cv2.rectangle(frame, (x, y), (x + w, y + h), (36, 255, 12), 2)
filepath.append(str(area))
filepath.append('.jpg')
filepath = ''.join(filepath)
crop_img = frame[y:y + h, x:x + w]
cv2.imwrite(filepath, crop_img)
cv2.imshow('result', frame) # 컬러 화면 출력
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
# img_color = cv.imread('alphabet.jpg')
# img_gray = cv.cvtColor(img_color, cv.COLOR_BGR2GRAY)
# ret, img_binary = cv.threshold(img_gray, 127, 255, 0)
# contours, hierarchy = cv.findContours(img_binary, cv.RETR_LIST, cv.CHAIN_APPROX_SIMPLE)
#
# for cnt in contours:
# cv.drawContours(img_color, [cnt], 0, (255, 0, 0), 3) # blue
#
# area = cv.contourArea(cnt)
# print(area)
#
# x, y, w, h = cv.boundingRect(cnt)
#
# filepath=['./']
#
# if area > 5000 :
# cv.rectangle(img_color, (x, y), (x +w, y+h), (36, 255, 12), 2)
# filepath.append(str(area))
# filepath.append('.jpg')
# filepath = ''.join(filepath)
#
# crop_img = img_color[y:y+h, x:x+w]
#
# cv.imwrite(filepath, crop_img)
#
#
# cv.imshow("result", img_color)
#
# cv.waitKey(0)<file_sep># 2021ESWContest_Robot_2001
## _✨SY WannaB ✨_
| Member | Assigned Tasks |
| ------ | ------ |
| <NAME> | Project Manager , Robot Motion Control, Algorithm Design |
| <NAME> | Image Processing Programming, Build Environment |
| <NAME> | Image Processing Programming, Serial Communications |
| <NAME> | Programming Assistance, Text Recognition |
| <NAME> | Programming Assistance, Color Recognition |
<b> Fighting!!! We can do !!!! </b>
<file_sep>import cv2
import numpy as np
import pytesseract
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
def Recog(img_color):
img_crop = cv2.resize(img_color, (64, 64))
#cv2.imshow('crop', img_crop) # 화면 확인용
img_hsv = cv2.cvtColor(img_crop, cv2.COLOR_BGR2HSV)
lower_red = np.array([0, 120, 40])
upper_red = np.array([20, 255, 255])
mask0 = cv2.inRange(img_hsv, lower_red, upper_red)
lower_red = np.array([160, 120, 40])
upper_red = np.array([180, 255, 255])
mask1 = cv2.inRange(img_hsv, lower_red, upper_red)
red_mask = mask0 + mask1
lower_blue = np.array([100, 50, 50])
upper_blue = np.array([140, 255, 255])
blue_mask = cv2.inRange(img_hsv, lower_blue, upper_blue)
red_hsv = img_hsv.copy()
blue_hsv = img_hsv.copy()
red_count = len(red_hsv[np.where(red_mask != 0)])
blue_count = len(blue_hsv[np.where(blue_mask != 0)])
if red_count > blue_count:
color = "red"
red_hsv[np.where(red_mask != 0)] = 0
red_hsv[np.where(red_mask == 0)] = 255
else:
color = "blue"
blue_hsv[np.where(blue_mask != 0)] = 0
blue_hsv[np.where(blue_mask == 0)] = 255
print(color)
return color
def color_img(img, push_color):
if push_color == "red":
lower = (0 - 10, 60, 60)
upper = (0 + 10, 255, 255)
elif push_color == "blue":
lower = (120 - 20, 60, 60)
upper = (120 + 20, 255, 255)
img_color = img
img_hsv = cv2.cvtColor(img_color, cv2.COLOR_BGR2HSV)
img_mask = cv2.inRange(img_hsv, lower, upper)
img_result = cv2.bitwise_and(img_color, img_color, mask=img_mask)
#cv2.imshow('mask', img_result) # 화면 확인용
return img_result
def textRecog(textimage):
textimage = cv2.resize(textimage, (64, 64))
textimage = cv2.cvtColor(textimage, cv2.COLOR_BGR2GRAY)
result = np.zeros((64, 128), np.uint8) + 255
result[:, :64] = textimage
result[:, 64:128] = textimage
cv2.imshow("canny", result)
cv2.waitKey(1)
text_image = pytesseract.image_to_string(result)
text_image.replace(" ", "")
text_image.rstrip()
text_image = text_image[0:2]
if text_image == "AA":
text = "A"
elif text_image == "BB":
text = "B"
elif text_image == "CC":
text = "C"
elif text_image == "DD":
text = "D"
else:
text = "error"
if text == "error":
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
textimage = cv2.dilate(textimage, kernel)
result = np.zeros((64, 128), np.uint8) + 255
result[:, :64] = textimage
result[:, 64:128] = textimage
cv2.imshow("canny", result)
cv2.waitKey(1)
text_image = pytesseract.image_to_string(result, lang='eng')
text_image.replace(" ", "")
text_image.rstrip()
text_image = text_image[0:2]
if text_image == "AA":
text = "A"
elif text_image == "BB":
text = "B"
elif text_image == "CC":
text = "C"
elif text_image == "DD":
text = "D"
else:
text = "error"
if text == "error":
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
textimage = cv2.erode(textimage, kernel)
result = np.zeros((64, 128), np.uint8) + 255
result[:, :64] = textimage
result[:, 64:128] = textimage
cv2.imshow("canny", result)
cv2.waitKey(1)
text_image = pytesseract.image_to_string(result, lang='eng')
text_image.replace(" ", "")
text_image.rstrip()
text_image = text_image[0:2]
if text_image == "AA":
text = "A"
elif text_image == "BB":
text = "B"
elif text_image == "CC":
text = "C"
elif text_image == "DD":
text = "D"
else:
text = "error"
return text
while(True):
ret, frame = cap.read()
if(ret) :
color = Recog(frame)
img_color = color_img(frame, color)
copy = img_color.copy()
gray = cv2.cvtColor(img_color, cv2.COLOR_BGR2GRAY)
binary = cv2.threshold(gray, 127, 255, cv2.THRESH_OTSU + cv2.THRESH_BINARY)[1]
contours, hierarchy = cv2.findContours(binary, cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
for cnt in contours:
cv2.drawContours(frame, [cnt], 0, (255, 255, 0), 3)
area = cv2.contourArea(cnt)
x, y, w, h = cv2.boundingRect(cnt)
#filepath = ['./result/']
if (area > 10000 and area < 20000) and (w/h > 0.8 and w/h < 1.2):
cv2.rectangle(frame, (x, y), (x + w, y + h), (36, 255, 12), 2)
# filepath.append(str(area))
# filepath.append('.jpg')
# filepath = ''.join(filepath)
crop_img = frame[y:y + h, x:x + w]
cv2.imshow('crop_alphabet', crop_img)
text = textRecog(crop_img)
print(text)
# cv2.imwrite(filepath, crop_img)
cv2.imshow('result', frame) # 컬러 화면 출력
if cv2.waitKey(1) == ord('q'):
break
cap.release()
cv2.destroyAllWindows() | 8b824f1cec9f1c44ce50f431ead0bce9d9f4c894 | [
"Markdown",
"Python"
] | 3 | Python | stellakim1012/2021ESWContest_Robot_2001 | a7302c20d399823c9d2ae8333a47b8ff6168749b | 779c339124f572c8f7ab7ced7ffdf8d70c027b4b |
refs/heads/master | <repo_name>myjupyter/HW1<file_sep>/final.c
//Составить программу построчной обработки текста. Суть обработки - отбор строк,
//содержащих одинаковое количество открывающих и закрывающих круглых скобок.
//Программа считывает входные данные со стандартного ввода, и печатает результат
//в стандартный вывод. Процедура отбора нужных строк должна быть оформлена в
//виде отдельной функции, которой на вход подается массив строк (который
//необходимо обработать), количество переданных строк, а также указатель на
//переменную, в которой необходимо разместить результат - массив отобранных
//строк. В качестве возвращаемого значения функция должна возвращать количество
//строк, содержащихся в результирующем массиве. Программа должна уметь
//обрабатывать ошибки - такие как неверные входные данные(отсутствие входных
//строк) или ошибки выделения памяти и т.п. В случае возникновения ошибки нужно
//выводить об этом сообщение "[error]" и завершать выполнение программы.
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
// Функция для освобождения памяти для двумерного массива
// Принимает указатель на массив указателей и размер массива
void freeArray(char **stringArray, int sizeOfStringArray) {
if (stringArray != NULL) {
for (int i = 0; i < sizeOfStringArray; i++)
free(stringArray[i]);
free(stringArray);
}
}
// В случае недостатка памяти генерируется "исключение".
// Память, которая выделялась ранее, освобождается, выводится сообщение
// "[error]" в стандартный поток вывода, программа завершается успешно Если
// память не была выделена вообще, но исключение сработало, помещаем в char* str
// NULL, в size - 0
// Возвращает 0
int genMemoryError(char **str, int size) {
freeArray(str, size);
printf("[error]");
return -1;
}
// Функция обработки строк.
// Принимает константный указатель на обрабатываемый массив строк, пустой указатель на новый
// массив указателей, куда поместится результат обработки, размер
// обрабатываемого массива. Возвращает размер уже заполненного нового массива.
int processString(char * const *stringArray, char ***newStringArray,
int sizeOfStringArray) {
int counter = 0, sizeOfNewStringArray = 0;
char const *iterator = NULL;
(*newStringArray) = (char **)calloc(sizeOfStringArray, sizeof(char *));
if ((*newStringArray) == NULL) {
freeArray((char **)stringArray, sizeOfStringArray);
return genMemoryError(NULL, 0);
}
for (int i = 0; i < sizeOfStringArray; i++, counter = 0) {
iterator = stringArray[i];
for (; *iterator != '\0' && counter >= 0; iterator++) {
if (*iterator == '(')
counter++;
if (*iterator == ')')
counter--;
}
if (*iterator == '\0' && counter == 0) {
(*newStringArray)[sizeOfNewStringArray++] = strdup(stringArray[i]);
if ((*newStringArray)[sizeOfNewStringArray - 1] == NULL) {
freeArray((char **)stringArray, sizeOfStringArray);
return genMemoryError(*newStringArray, sizeOfNewStringArray - 1);
}
}
}
return sizeOfNewStringArray;
}
// Функция перевыделения памяти в случае, если capacity и size совпадают
// Принимает указатель на массив указателей и старый capacity массива
int reallocArray(char ***ptr, int* oldSize) {
char **handler = (char **)realloc((*ptr), (*oldSize + (*oldSize)/2) * sizeof(char *));
if (!handler) {
return genMemoryError((*ptr), *oldSize);
}
*oldSize = *oldSize + (*oldSize)/2;
(*ptr) = handler;
return 0;
}
// Функция для чтения строк и страндартного ввода.
// Принимает пустой указатель.
// Возвращает количество считанных строк
int readFromStdInput(char ***stringArray) {
int capacity = 16;
char *buffer = NULL;
int sizeOfStringArray = 0;
if (scanf(" %m[^\n]", &buffer) == -1) {
printf("[error]");
return -1;
}
(*stringArray) = (char **)calloc(capacity, sizeof(char *));
if ((*stringArray) == NULL)
return genMemoryError(NULL, 0);
while (1) {
if (sizeOfStringArray == capacity)
if(reallocArray(&(*stringArray), &capacity) == -1) {
return -1;
}
(*stringArray)[sizeOfStringArray++] = strdup(buffer);
if ((*stringArray)[sizeOfStringArray - 1] == NULL)
return genMemoryError((*stringArray), sizeOfStringArray - 1);
free(buffer);
buffer = NULL;
if (scanf(" %m[^\n]", &buffer) == -1) {
break;
}
}
return sizeOfStringArray;
}
// Функция для вывода строк в стандартный вывод
// Пинимает указатель на массива указателей и размер массива
void printStringArray(char **stringArray, int sizeOfStringArray) {
if (stringArray != NULL) {
for (int i = 0; i < sizeOfStringArray; i++) {
printf("%s\n", stringArray[i]);
}
}
}
int main(void) {
char **stringArray = NULL;
char **newStringArray = NULL;
int sizeOfStringArray = readFromStdInput(&stringArray);
if(sizeOfStringArray == -1)
return 0;
int sizeOfNewStringArray = processString(stringArray,
&newStringArray, sizeOfStringArray);
if(sizeOfNewStringArray == -1)
return 0;
printStringArray(newStringArray, sizeOfNewStringArray);
freeArray(stringArray, sizeOfStringArray);
freeArray(newStringArray, sizeOfNewStringArray);
return 0;
}
<file_sep>/makefile
all:
gcc -ggdb -Wall final.c -o prog -Werror=int-to-pointer-cast
| 0ab4894192c4c92d94e2527cf4fd5a1b3fcf631a | [
"C",
"Makefile"
] | 2 | C | myjupyter/HW1 | 5fefc6a6608989adc04bed5845199f05da9ec705 | 28ae9f4a61ad74f4d5076250b83ccdb92b7e57ef |
refs/heads/master | <repo_name>hydroflame/go-semaphore<file_sep>/README.md
# go-semaphore
Provides simple, dynamic, semaphores for golang
I hope the documentation is to the point and helpful.
It is licensed under the MIT/X11 license, a copy is provided for your convenience.<file_sep>/semaphore.go
package semaphore
import (
"runtime"
"sync"
)
const maxSize int = 2147483647
const minSize int = 1
// The Semaphore follows the standard semaphore pattern, but can be expanded
// and contracted.
type Semaphore interface {
Take(int)
Give(int)
}
// semaphore is the main struct used. It is not created directly, as some
// values will need to be initialized and their nil value is not helpful.
type semaphore struct {
take chan *need
give chan int
counterMutex sync.Mutex
counter int
kill chan struct{}
}
type need struct {
n int
wg sync.WaitGroup
}
// NewSemaphore create a semaphore pool of the appropriate size.
// Please use this function instead of trying to initialize
// a semaphore directly.
func NewSemaphore() Semaphore {
sema := &semaphore{
take: make(chan *need),
}
go sema.manageNeeds()
return sema
}
func (s *semaphore) manageNeeds() {
for {
select {
case n := <-s.take:
holdon:
s.counterMutex.Lock()
if n.n > s.counter {
s.counterMutex.Unlock()
runtime.Gosched()
goto holdon
}
s.counter -= n.n
s.counterMutex.Unlock()
n.wg.Done()
case <-s.kill:
return
}
}
}
// Take allows you to take a resource from the semaphore pool.
//
// (Use one before taking an action.)
func (s *semaphore) Take(n int) {
want := need{
n: n,
}
want.wg.Add(1)
s.take <- &want
want.wg.Wait()
}
// Give allows you to give back a number resource from the semaphore pool.
func (s *semaphore) Give(n int) {
s.counterMutex.Lock()
s.counter += n
s.counterMutex.Unlock()
}
<file_sep>/semaphore_test.go
package semaphore
import (
"sync"
"testing"
"time"
)
func TestSemaphore(t *testing.T) {
sem := NewSemaphore()
sem.Give(4)
sem.Take(4)
var wg0, wg1 sync.WaitGroup
wg0.Add(1)
wg1.Add(1)
go func() {
wg1.Wait()
sem.Take(2)
wg0.Done()
}()
wg1.Done()
time.Sleep(2 * time.Second)
sem.Give(2)
wg0.Wait()
}
| 459c2d33e4a35a2ba12710fca44cfcf47e10bdad | [
"Markdown",
"Go"
] | 3 | Markdown | hydroflame/go-semaphore | 5445b01957ca81fad928cd35ee4096f97a65b69d | ebc9edd4bbe6a780002eb90ff6f0a615c8e9cb8c |
refs/heads/master | <file_sep><?php
class Usuario{
public $id;
private $Habilitado;
public $Mail;
public function getID(){
return $this->id;
}
public function getMail(){
return $this->Mail;
}
public function setMail($newMail){
$this->Mail = $newMail;
}
//funciones para la base de datos:
public static function obtenerTodos($pdo){
$params = array();
$statement = $pdo->prepare('
SELECT *
FROM Usuario
WHERE Habilitado = 1
');
$statement->execute($params);
$statement->setFetchMode(PDO::FETCH_CLASS, 'Usuario');
return $statement->fetchAll(); // fetch trae uno solo. fetchAll trae todos los registros.
}//obtenerTodos
public static function ObtenerPorId($id, $pdo){
$params = array(':ID' => $id);
$statement = $pdo->prepare('
SELECT *
FROM Usuario
WHERE id = :ID
AND Habilitado = 1
LIMIT 0,1');
$statement->execute($params);
$statement->setFetchMode(PDO::FETCH_CLASS, 'Usuario');
return $statement->fetch();
}//obtenerPorId
public static function ObtenerPorMail($mail, $pdo){
$params = array(':MAIL' => $mail);
$statement = $pdo->prepare('
SELECT *
FROM Usuario
WHERE Mail = :MAIL
AND Habilitado = 1
LIMIT 0,1');
$statement->execute($params);
$statement->setFetchMode(PDO::FETCH_CLASS, 'Usuario');
return $statement->fetch();
}
public static function CrearUsuario($mail, $pdo){
$params = array(':Mail' => $mail, ':Habilitado' => true);
$statement = $pdo -> prepare('
INSERT INTO Usuario
(Mail, Habilitado)
VALUES (:Mail, :Habilitado)');
$statement->execute($params);
$statement->setFetchMode(PDO::FETCH_CLASS, 'Usuario');
return $statement->fetch();
}//crearUsuario
public static function Login($mail, $pdo){
$params = array(':Mail' => $mail);
$statement = $pdo->prepare('
SELECT *
FROM Usuario
WHERE Mail = :Mail
AND Habilitado = 1
LIMIT 0,1');
$statement->execute($params);
$statement->setFetchMode(PDO::FETCH_CLASS, 'Usuario');
return $statement->fetch();
}//Login
}//usuario
?><file_sep><?php
class UsuarioController{
public static function ObtenerTodos($pdo){
$listaUsuarios = Usuario::ObtenerTodos($pdo);
return $listaUsuarios;
}//obtenerTodos
public static function ObtenerPorId($id, $pdo){
$usuario = Usuario::ObtenerPorId($id, $pdo);
return $usuario;
}//obtenerPorId
public static function ObtenerPorMail($mail, $pdo){
$usuario = Usuario::ObtenerPorMail($mail, $pdo);
return $usuario;
}
public static function Login($mail, $pdo){
$usuario = Usuario::Login($mail, $pdo);
return $usuario;
}//Login
}
?><file_sep>
<?php
//All database connection variables
/*
define('DB_USER', "root"); // db user
define('DB_PASSWORD', ""); // db password (mention your db password here)
define('DB_DATABASE', "appnimal"); // database name
define('DB_SERVER', "localhost"); // db server
*/
class Db_Config{
public $server = "localhost";
public $database = "appnimal";
public $password = "";
public $username = "root";
}
?>
<file_sep><?php
class DB_CONNECT extends PDO{
protected $transactionCounter = 0;
public function beginTransaction() {
if(!$this::$transactionCounter++) {
return parent::beginTransaction();
}
$this->exec('SAVEPOINT trans'.$this->transactionCounter);
return $this->transactionCounter >= 0;
}//beginTransaction
public function commit() {
if(!--$this->transactionCounter) {
return parent::commit();
}
return $this->transactionCounter >= 0;
}//commit
public function rollBack() {
if (!--$this->transactionCounter) {
$this->exec('ROLLBACK TO trans'.$this->transactionCounter + 1);
return true;
}
return parent::rollback();
}//rollBack
}//db_connect
/*
class DB_CONNECT{
function connect(){
// import database connection variables
require 'db_config.php';
// Connecting to mysql database
$con = mysql_connect(DB_SERVER, DB_USER, DB_PASSWORD) or die(mysql_error());
// Selecing database
$db = mysql_select_db(DB_DATABASE) or die(mysql_error()) or die(mysql_error());
}
function close() {
// closing db connection
mysql_close();
}
}
*/
?><file_sep><?php
require 'Slim-2.6.2/Slim/Slim.php';
require 'db_connect.php';
require 'db_config.php';
require 'script/objects/Usuario.php';
require 'script/controllers/UsuarioController.php';
// Permite el acceso desde otros dominios (CORS) - INICIO
if (isset($_SERVER['HTTP_ORIGIN'])) {
header("Access-Control-Allow-Origin: {$_SERVER['HTTP_ORIGIN']}");
header('Access-Control-Allow-Credentials: true');
header('Access-Control-Max-Age: 86400');
}
if ($_SERVER['REQUEST_METHOD'] == 'OPTIONS') {
if (isset($_SERVER['HTTP_ACCESS_CONTROL_REQUEST_METHOD']))
header("Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS");
if (isset($_SERVER['HTTP_ACCESS_CONTROL_REQUEST_HEADERS']))
header("Access-Control-Allow-Headers: {$_SERVER['HTTP_ACCESS_CONTROL_REQUEST_HEADERS']}");
}
// Permite el acceso desde otros dominios (CORS) - FIN
date_default_timezone_set('America/Argentina/Buenos_Aires');
\Slim\Slim::registerAutoloader();
$app = new \Slim\Slim();
$db_config = new Db_config();
$pdo = new db_connect("mysql:host=" . $db_config->server . ";dbname=" . $db_config->database, $db_config->username, $db_config->password);
$app->get('/usuario', function () use ($app, $pdo){
try{
$listaUsuario = UsuarioController::ObtenerTodos($pdo);
echo json_encode($listaUsuario);
}
catch (Exception $ex){
$app->response->setStatus(500);
echo $ex->getMessage();
}
});//usuario
$app->get('/usuario/mail/:mail', function($mail) use ($app, $pdo){
try{
// $datosRecibidos = json_decode($app->request->get('Mail'));
$usuario = UsuarioController::ObtenerPorMail($mail, $pdo);
echo json_encode(array($usuario));
}catch(Exception $ex){
$app->response->setStatus(500);
echo $ex->getMessage();
}
});//usuario->mail
$app->get('/usuario/:id', function($id) use ($app, $pdo){
try{
$usuario = UsuarioController::ObtenerPorId($id, $pdo);
echo json_encode(array($usuario));
}catch(Exception $ex){
$app->response->setStatus(500);
echo $ex->getMessage();
}
});//usuario->id
$app->get('/usuario/login', function() use ($app, $pdo) {
try{
$usuario = null;
$respuesta = false;
$datosRecibidos = json_decode($app->request->getBody());
$usuario = UsuarioController::Login($datosRecibidos->Mail, $pdo);
if ($usuario == null){
$respuesta = false;
}else{
$respuesta = true;
}
echo json_encode(array("Validado" => $respuesta, "Usuario" => $usuario));
}
catch (Exception $ex){
$app->response->setStatus(500);
echo $ex->getMessage();
}
});//Login
$app->run(); //corre los resultados
?> | a091d154d79723c0a59e9e0a9c57a3f916ecc1fa | [
"PHP"
] | 5 | PHP | francoAlonso/Appnimal_PHP | da14cbf57edea191a6d7cfc9e1e433fe2e09f1d3 | eaffdd279a3d7813e7baec820f1c687d34cfb133 |
refs/heads/master | <file_sep>import styled from 'styled-components'
import Background from '../../../assets/background.jpg'
export const Container = styled.div`
@import url('https://fonts.googleapis.com/css?family=Roboto:400,700&display=swap');
height: 100vh;
background: url(${Background}) no-repeat;
background-size: cover;
color: #fff;
display: flex;
flex-direction: column;
justify-content: center;
align-items: center;
font-family: Roboto, Arial, Helvetica, sans-serif;
${props => props.drop === true ? `height: 80vh;` : `height: 100vh;`}
div {
font-size: 50px;
}
`<file_sep>import React, { Component } from 'react';
import Navbar from '../../components/Navbar'
import { Container } from './styles';
export default function Sobre() {
return (
<>
<Navbar />
<Container>
Sobre
</Container>
</>
)
}
| 04c312cf986e518e746850368a5c35af749c76cf | [
"JavaScript"
] | 2 | JavaScript | Lokecross/ReactJS-tests | 8db9783c8a7c815bbc118cdf9c75b574d50503d3 | 32c7c8b46bae69c7eeb6a37ff6988f5cc011e43e |
refs/heads/master | <file_sep># Midify-Android
This is the Android component of Midify
<file_sep>package sg.edu.nus.midify.main.login;
import android.os.Bundle;
import android.support.v4.app.Fragment;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import com.facebook.widget.LoginButton;
import java.util.Arrays;
import java.util.List;
import sg.edu.nus.midify.R;
public class LoginFragment extends Fragment {
public static final String LOGIN_TAG = "LOGIN";
private static final List<String> PERMISSIONS = Arrays.asList(
"email",
"public_profile",
"user_friends"
);
private LoginButton fbLoginButton;
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
View view = inflater.inflate(R.layout.fragment_login, container, false);
fbLoginButton = (LoginButton) view.findViewById(R.id.login_button);
fbLoginButton.setReadPermissions(PERMISSIONS);
return view;
}
}
<file_sep>package sg.edu.nus.midify.midi;
import android.content.Context;
import android.graphics.Color;
import android.media.MediaPlayer;
import android.net.Uri;
import android.support.v7.widget.RecyclerView;
import android.util.Log;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.ImageView;
import android.widget.Toast;
import com.afollestad.materialdialogs.MaterialDialog;
import com.melnykov.fab.FloatingActionButton;
import org.apache.commons.io.IOUtils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.Date;
import java.util.Formatter;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import retrofit.Callback;
import retrofit.RetrofitError;
import retrofit.client.Response;
import retrofit.mime.TypedByteArray;
import sg.edu.nus.POJOs.MidiPOJO;
import sg.edu.nus.helper.Constant;
import sg.edu.nus.helper.http.ConnectionHelper;
import sg.edu.nus.helper.http.DownloadImageTask;
import sg.edu.nus.helper.http.MidifyRestClient;
import sg.edu.nus.helper.persistence.PersistenceHelper;
import sg.edu.nus.midify.R;
public class MidiListAdapter extends RecyclerView.Adapter<MidiViewHolder> implements MidiViewHolder.ViewHolderOnClick, DownloadImageTask.DownloadImageTaskDelegate {
// List of MIDIs to be displayed
private List<MidiPOJO> midiList;
private boolean isLocalUser;
private List<MidiPOJO> localMidis;
private Map<String, MidiPOJO> localOwnMidis;
private Map<String, MidiPOJO> localRefMidis;
// Delegate for MidiListAdapter
private MidiListDelegate delegate;
// Media Player
private MediaPlayer mediaPlayer;
private String previousFilePath;
private String previousFileId;
public MidiListAdapter(MidiListDelegate delegate, boolean isLocalUser, List<MidiPOJO> localMidis) {
this.delegate = delegate;
this.midiList = new ArrayList<>();
this.isLocalUser = isLocalUser;
this.localMidis = localMidis;
updateLocalMidisMap();
}
private void updateLocalMidisMap() {
this.localOwnMidis = new HashMap<>();
this.localRefMidis = new HashMap<>();
for (MidiPOJO midi : localMidis) {
if (midi.isRef()) {
localRefMidis.put(midi.getRefId(), midi);
} else {
localOwnMidis.put(midi.getFileId(), midi);
}
}
}
@Override
public MidiViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View itemView = LayoutInflater
.from(parent.getContext())
.inflate(R.layout.item_midi, parent, false);
return new MidiViewHolder(itemView, this, delegate.getContext());
}
@Override
public void onBindViewHolder(MidiViewHolder holder, int position) {
if (position >= midiList.size()) {
return;
}
MidiPOJO midi = midiList.get(position);
holder.setPosition(position);
holder.getMidiNameTextView().setText(midi.getFileName());
holder.getDurationTextView().setText(getDurationStringFormat(midi.getDuration()));
holder.getEditedTimeTextView().setText(getEditedTimeStringFormat(midi.getEditedTime()));
updateForkButton(position, holder);
if (ConnectionHelper.checkNetworkConnection()) {
String profilePictureURL = ConnectionHelper.getFacebookProfilePictureURL(midi.getOwnerId());
ConnectionHelper.downloadImage(holder.getProfilePictureView(), profilePictureURL, this);
}
}
private void updateForkButton(int position, MidiViewHolder holder) {
if (isLocalUser) {
holder.updateForkButton(MidiViewHolder.FORK_BUTTON_HIDDEN_STATE);
} else {
MidiPOJO currentMidi = midiList.get(position);
if (localRefMidis.containsKey(currentMidi.getFileId())
|| localRefMidis.containsKey(currentMidi.getRefId())) {
holder.updateForkButton(MidiViewHolder.FORK_BUTTON_FORKED_STATE);
} else if (localOwnMidis.containsKey(currentMidi.getRefId())) {
holder.updateForkButton(MidiViewHolder.FORK_BUTTON_HIDDEN_STATE);
} else {
holder.updateForkButton(MidiViewHolder.FORK_BUTTON_UNFORKED_STATE);
}
}
}
private String getDurationStringFormat(long seconds) {
long minute = seconds / 60;
long remainderSeconds = seconds - minute * 60;
return String.format("%02d:%02d", minute, remainderSeconds);
}
private String getEditedTimeStringFormat(Date date) {
SimpleDateFormat dateFormat = new SimpleDateFormat("dd MMM, yyyy");
return "Last edited on " + dateFormat.format(date);
}
@Override
public int getItemCount() {
return midiList.size();
}
public void refreshMidiList(List<MidiPOJO> newList) {
Collections.sort(newList, new Comparator<MidiPOJO>() {
@Override
public int compare(MidiPOJO lhs, MidiPOJO rhs) {
return -1 * lhs.getEditedTime().compareTo(rhs.getEditedTime());
}
});
this.midiList.clear();
this.midiList.addAll(newList);
notifyDataSetChanged();
}
@Override
public void onPlayButtonClick(View v, int position, MidiItemDelegate itemDelegate) {
MidiPOJO midi = midiList.get(position);
if (!midi.isOnlyRemote()) {
playLocalMidi(midi.getLocalFilePath(), itemDelegate);
} else {
// Download the midi (This case is mainly for fork feature)
playRemoteMidi(midi.getFileId(), itemDelegate);
}
}
private void playLocalMidi(String filePath, final MidiItemDelegate itemDelegate) {
itemDelegate.updatePlayIcon();
File midiFile = new File(filePath);
if (!midiFile.exists()) {
Log.e(Constant.MEDIA_TAG, "MIDI file cannot be found for playback");
return;
}
if (mediaPlayer == null || (previousFilePath != null && !previousFilePath.equals(filePath))) {
if (mediaPlayer != null) {
mediaPlayer.release();
}
mediaPlayer = MediaPlayer.create(delegate.getContext(), Uri.fromFile(midiFile));
previousFilePath = filePath;
mediaPlayer.start();
mediaPlayer.setOnCompletionListener(new MediaPlayer.OnCompletionListener() {
@Override
public void onCompletion(MediaPlayer mp) {
mp.pause();
mp.seekTo(0);
}
});
mediaPlayer.setOnSeekCompleteListener(new MediaPlayer.OnSeekCompleteListener() {
@Override
public void onSeekComplete(MediaPlayer mp) {
itemDelegate.updatePlayIcon();
}
});
} else {
if (mediaPlayer.isPlaying()) {
mediaPlayer.pause();
} else {
mediaPlayer.start();
}
}
}
private void playRemoteMidi(final String fileId, final MidiItemDelegate itemDelegate) {
itemDelegate.updatePlayIcon();
if (mediaPlayer == null || (previousFileId != null && !previousFileId.equals(fileId))) {
if (mediaPlayer != null) {
mediaPlayer.release();
}
previousFileId = fileId;
final MaterialDialog progressDialog = new MaterialDialog.Builder(delegate.getContext())
.title(R.string.dialog_remote_progress_title)
.content(R.string.dialog_remote_progress_content)
.cancelable(false)
.progress(true, 0)
.show();
MidifyRestClient.instance().downloadMidi(fileId, new Callback<Response>() {
@Override
public void success(Response response, Response response2) {
byte[] data = ((TypedByteArray) response.getBody()).getBytes();
String localFilePath = PersistenceHelper.saveMidiData(Constant.DEFAULT_TEMP_REMOTE_MIDI_NAME, data);
if (localFilePath == null) {
return;
}
File midiFile = new File(localFilePath);
if (!midiFile.exists()) {
Log.e(Constant.MEDIA_TAG, "MIDI file cannot be found for playback");
return;
}
mediaPlayer = MediaPlayer.create(delegate.getContext(), Uri.fromFile(midiFile));
mediaPlayer.start();
mediaPlayer.setOnCompletionListener(new MediaPlayer.OnCompletionListener() {
@Override
public void onCompletion(MediaPlayer mp) {
mp.pause();
mp.seekTo(0);
}
});
mediaPlayer.setOnSeekCompleteListener(new MediaPlayer.OnSeekCompleteListener() {
@Override
public void onSeekComplete(MediaPlayer mp) {
itemDelegate.updatePlayIcon();
}
});
progressDialog.dismiss();
}
@Override
public void failure(RetrofitError error) {
progressDialog.dismiss();
Log.e(Constant.REQUEST_TAG, "Reuqest Failed for URL: " + error.getUrl());
}
});
} else {
if (mediaPlayer.isPlaying()) {
mediaPlayer.pause();
} else {
mediaPlayer.start();
}
}
}
@Override
public int onForkButtonClick(View v, final int position, int forkState) {
MidiPOJO midi = midiList.get(position);
if (forkState == MidiViewHolder.FORK_BUTTON_HIDDEN_STATE) {
Toast.makeText(delegate.getContext(), "Cannot fork a track in hidden state", Toast.LENGTH_SHORT).show();
} else if (forkState == MidiViewHolder.FORK_BUTTON_FORKED_STATE) {
Toast.makeText(delegate.getContext(), "Cannot fork an already forked track", Toast.LENGTH_SHORT).show();
} else {
if (ConnectionHelper.checkNetworkConnection()) {
final MaterialDialog progressDialog = new MaterialDialog.Builder(delegate.getContext())
.title(R.string.dialog_fork_progress_title)
.content(R.string.dialog_fork_progress_content_1)
.cancelable(false)
.progress(true, 0)
.show();
Map<String, String> params = new HashMap<>();
params.put(Constant.REQUEST_PARAM_FILE_ID, midi.getFileId());
MidifyRestClient.instance().forkMidi(MidiPOJO.createBodyRequest(params), new Callback<MidiPOJO>() {
@Override
public void success(MidiPOJO midiPOJO, Response response) {
final MidiPOJO newMidi = midiPOJO;
localMidis.add(newMidi);
PersistenceHelper.saveMidiList(delegate.getContext(), localMidis);
progressDialog.setContent(delegate.getContext().getString(R.string.dialog_fork_progress_content_2));
MidifyRestClient.instance().downloadMidi(newMidi.getFileId(), new Callback<Response>() {
@Override
public void success(Response response, Response response2) {
byte[] data = ((TypedByteArray) response.getBody()).getBytes();
String localFilePath = PersistenceHelper.saveMidiData(newMidi.getFileName()
+ System.currentTimeMillis() / 1000, data);
newMidi.setLocalFilePath(localFilePath);
PersistenceHelper.saveMidiList(delegate.getContext(), localMidis);
updateLocalMidisMap();
notifyItemChanged(position);
progressDialog.dismiss();
}
@Override
public void failure(RetrofitError error) {
Log.e(Constant.REQUEST_TAG, "Reuqest Failed for URL: " + error.getUrl());
progressDialog.dismiss();
}
});
}
@Override
public void failure(RetrofitError error) {
Log.e(Constant.REQUEST_TAG, "Reuqest Failed for URL: " + error.getUrl());
progressDialog.dismiss();
}
});
} else {
Toast.makeText(delegate.getContext(), "No network connection", Toast.LENGTH_SHORT).show();
}
}
return 0;
}
@Override
public void handle(ImageView imageView) {
imageView.setColorFilter(Color.argb(100, 0, 0, 0));
}
public static interface MidiListDelegate {
public Context getContext();
}
}
<file_sep>package sg.edu.nus.helper;
import android.content.Context;
import android.view.View;
import android.view.animation.Animation;
import android.view.animation.AnimationUtils;
import android.view.animation.RotateAnimation;
import sg.edu.nus.midify.R;
/**
* Created by Youn on 16/4/15
*/
public class AnimationHelper {
public static void rotateInfinitely(Context context, View v) {
Animation rotation = AnimationUtils.loadAnimation(context, R.anim.rotate);
rotation.setFillEnabled(true);
rotation.setFillAfter(true);
v.startAnimation(rotation);
}
}
<file_sep>package sg.edu.nus.helper.persistence;
import android.content.Context;
import android.content.SharedPreferences;
import android.graphics.Bitmap;
import android.util.Log;
import com.google.gson.Gson;
import com.google.gson.reflect.TypeToken;
import org.apache.commons.io.IOUtils;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.lang.reflect.Type;
import java.nio.channels.FileChannel;
import java.util.ArrayList;
import java.util.List;
import sg.edu.nus.POJOs.MidiPOJO;
import sg.edu.nus.helper.Constant;
public class PersistenceHelper {
// Retrieve the list of local Midis
public static List<MidiPOJO> getMidiList(Context context) {
SharedPreferences midiPreferences = context.getSharedPreferences(Constant.MIDI_PREFS_NAME,
Context.MODE_PRIVATE);
String serializedDataFromPreferences = midiPreferences.getString(Constant.MIDI_PREFS_KEY, null);
if (serializedDataFromPreferences == null) {
return new ArrayList<MidiPOJO>();
}
Type midiListType = new TypeToken<List<MidiPOJO>>(){}.getType();
List<MidiPOJO> midiList = new Gson().fromJson(serializedDataFromPreferences, midiListType);
if (midiList == null) {
throw new NullPointerException("The persistence data is not in correct format");
}
return midiList;
}
// Save the given list of Midis
public static void saveMidiList(Context context, List<MidiPOJO> midiList) {
SharedPreferences midiPreferences = context.getSharedPreferences(Constant.MIDI_PREFS_NAME,
Context.MODE_PRIVATE);
String json = new Gson().toJson(midiList);
midiPreferences.edit().putString(Constant.MIDI_PREFS_KEY, json).apply();
}
// Get the stored Facebook USER ID
public static String getFacebookUserId(Context context) {
SharedPreferences facebookPreferences = context.getSharedPreferences(Constant.FACEBOOK_PREFS_NAME,
Context.MODE_PRIVATE);
String facebookUserId = facebookPreferences.getString(Constant.FACEBOOK_PREFS_USER_ID, null);
if (facebookUserId == null) {
throw new NullPointerException("Facebook User ID does not exist");
}
return facebookUserId;
}
// Save the given Facebook USER ID
public static void saveFacebookUserId(Context context, String facebookUserId) {
SharedPreferences facebookPreferences = context.getSharedPreferences(Constant.FACEBOOK_PREFS_NAME,
Context.MODE_PRIVATE);
facebookPreferences.edit().putString(Constant.FACEBOOK_PREFS_USER_ID, facebookUserId).apply();
}
// Get the stored Facebook USER NAME
public static String getFacebookUserName(Context context) {
SharedPreferences facebookPreferences = context.getSharedPreferences(Constant.FACEBOOK_PREFS_NAME,
Context.MODE_PRIVATE);
String facebookUserId = facebookPreferences.getString(Constant.FACEBOOK_PREFS_USER_NAME, null);
if (facebookUserId == null) {
throw new NullPointerException("Facebook User Name does not exist");
}
return facebookUserId;
}
// Save the given Facebook USER NAME
public static void saveFacebookUserName(Context context, String facebookUserName) {
SharedPreferences facebookPreferences = context.getSharedPreferences(Constant.FACEBOOK_PREFS_NAME,
Context.MODE_PRIVATE);
facebookPreferences.edit().putString(Constant.FACEBOOK_PREFS_USER_NAME, facebookUserName).apply();
}
// Get the stored Facebook Access Token
public static String getFacebookToken(Context context) {
SharedPreferences facebookPreferences = context.getSharedPreferences(Constant.FACEBOOK_PREFS_NAME,
Context.MODE_PRIVATE);
return facebookPreferences.getString(Constant.FACEBOOK_PREFS_TOKEN, null);
}
// Save the given Facebook Access Token
public static void saveFacebookToken(Context context, String facebookToken) {
SharedPreferences facebookPreferences = context.getSharedPreferences(Constant.FACEBOOK_PREFS_NAME,
Context.MODE_PRIVATE);
facebookPreferences.edit().putString(Constant.FACEBOOK_PREFS_TOKEN, facebookToken).apply();
}
// Save the given image locally
public static void saveImage(String imageName, Bitmap finalBitmap) {
String filePath = Constant.BASE_FILE_DIR + imageName + ".jpg";
File file = new File (filePath);
if (file.exists()) {
file.delete ();
}
try {
FileOutputStream out = new FileOutputStream(file);
finalBitmap.compress(Bitmap.CompressFormat.JPEG, 90, out);
out.flush();
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
// Copy a local file
public static void copy(File src, File dst) throws IOException {
FileInputStream inStream = new FileInputStream(src);
FileOutputStream outStream = new FileOutputStream(dst);
FileChannel inChannel = inStream.getChannel();
FileChannel outChannel = outStream.getChannel();
inChannel.transferTo(0, inChannel.size(), outChannel);
inStream.close();
outStream.close();
}
public static String saveMidiData(String fileName, byte[] data) {
String localFilePath = Constant.BASE_FILE_DIR + fileName + ".mid";
File localMidifFile = new File(localFilePath);
try {
if (!localMidifFile.exists()) {
if (!localMidifFile.createNewFile()) {
throw new IOException();
}
}
FileOutputStream outputStream = new FileOutputStream(localMidifFile);
IOUtils.write(data, outputStream);
outputStream.close();
return localFilePath;
} catch (IOException e) {
Log.e(Constant.RECORD_TAG, "Error in storing midi file locally");
}
return null;
}
}
<file_sep>package sg.edu.nus.midify.main.user;
import android.content.Context;
import android.content.Intent;
import android.graphics.Bitmap;
import android.net.Uri;
import android.support.v7.widget.RecyclerView;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import java.io.File;
import java.util.ArrayList;
import java.util.List;
import sg.edu.nus.POJOs.UserPOJO;
import sg.edu.nus.helper.Constant;
import sg.edu.nus.helper.http.ConnectionHelper;
import sg.edu.nus.helper.persistence.PersistenceHelper;
import sg.edu.nus.midify.R;
import sg.edu.nus.midify.midi.MidiActivity;
public class UserListAdapter extends RecyclerView.Adapter<UserViewHolder> implements UserViewHolder.ViewHolderOnClick {
private List<UserPOJO> userList;
private Context context;
public UserListAdapter(Context context) {
this.context = context;
this.userList = new ArrayList<>();
}
public void addDefaultUser() {
String userId = PersistenceHelper.getFacebookUserId(context);
String userName = PersistenceHelper.getFacebookUserName(context);
this.userList.add(UserPOJO.createUserWithoutToken(userId, userName));
}
@Override
public UserViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
View itemView = LayoutInflater
.from(parent.getContext())
.inflate(R.layout.item_user, parent, false);
return new UserViewHolder(itemView, this);
}
@Override
public void onBindViewHolder(UserViewHolder holder, int position) {
if (position >= userList.size()) {
return;
}
UserPOJO user = userList.get(position);
holder.setUserId(user.getUserId());
holder.setUserName(user.getName());
holder.getProfileNameView().setText(user.getName());
if (ConnectionHelper.checkNetworkConnection()) {
String profilePictureURL = ConnectionHelper.getSmallFacebookProfilePictureURL(user.getUserId());
ConnectionHelper.downloadImage(holder.getProfilePictureView(), profilePictureURL);
} else if (position == 0) {
File localProfilePicture = new File(Constant.DEFAULT_PROFILE_PICTURE_PATH);
if (localProfilePicture.exists()) {
holder.getProfilePictureView().setImageURI(Uri.fromFile(localProfilePicture));
}
}
}
@Override
public int getItemCount() {
return userList.size();
}
public void refreshUserList(List<UserPOJO> newList) {
this.userList.clear();
addDefaultUser();
this.userList.addAll(newList);
notifyDataSetChanged();
}
@Override
public void onViewHolderClick(View v, String userId, String userName, Bitmap imageBitmap) {
Intent midiIntent = new Intent(context, MidiActivity.class);
midiIntent.putExtra(Constant.INTENT_PARAM_USER_ID, userId);
midiIntent.putExtra(Constant.INTENT_PARAM_USER_NAME, userName);
midiIntent.putExtra(Constant.INTENT_PARAM_USER_PROFILE_PICTURE, imageBitmap);
context.startActivity(midiIntent);
}
}
<file_sep>apply plugin: 'com.android.application'
android {
compileSdkVersion 22
buildToolsVersion '21.1.2'
defaultConfig {
applicationId "sg.edu.nus.midify"
minSdkVersion 17
targetSdkVersion 22
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
proguardFiles getDefaultProguardFile('proguard-android.txt'), 'proguard-rules.pro'
}
}
}
dependencies {
compile fileTree(dir: 'libs', include: ['*.jar'])
/* Support Libraries */
compile 'com.android.support:support-v4:22.0.0'
compile 'com.android.support:appcompat-v7:22.0.0'
compile 'com.android.support:cardview-v7:22.0.0'
compile 'com.android.support:recyclerview-v7:22.0.0'
compile 'org.apache.commons:commons-io:1.3.2'
/* Iconify */
compile 'com.joanzapata.android:android-iconify:1.0.9'
/* Circular Image View */
compile 'com.pkmmte.view:circularimageview:1.1'
/* Floating Action Button */
compile 'com.melnykov:floatingactionbutton:1.3.0'
/* HTTP REQUEST */
compile 'com.squareup.retrofit:retrofit:1.9.0'
compile 'com.squareup.okhttp:okhttp:2.3.0'
compile 'com.google.code.gson:gson:2.3.1'
/* FACEBOOK SDK */
compile 'com.facebook.android:facebook-android-sdk:3.23.1'
/* Material Dialogs */
compile 'com.afollestad:material-dialogs:0.7.0.0'
}
<file_sep>package sg.edu.nus.midify.midi;
import android.content.Context;
import android.graphics.Color;
import android.media.MediaPlayer;
import android.support.v7.widget.RecyclerView;
import android.view.View;
import android.widget.ImageView;
import android.widget.TextView;
import com.joanzapata.android.iconify.IconDrawable;
import com.joanzapata.android.iconify.Iconify;
import com.melnykov.fab.FloatingActionButton;
import sg.edu.nus.midify.R;
public class MidiViewHolder extends RecyclerView.ViewHolder implements View.OnClickListener, MidiItemDelegate {
public static final int FORK_BUTTON_HIDDEN_STATE = 0;
public static final int FORK_BUTTON_UNFORKED_STATE = 1;
public static final int FORK_BUTTON_FORKED_STATE = 2;
private int position;
private int currentForkState;
private boolean isPaused;
// UI Controls
private ImageView profilePictureView;
private TextView midiNameTextView;
private TextView durationTextView;
private TextView editedTimeTextView;
private FloatingActionButton playButton;
private FloatingActionButton forkButton;
private Context context;
// Delegate
private ViewHolderOnClick delegate;
public MidiViewHolder(View itemView, ViewHolderOnClick delegate, Context context) {
super(itemView);
this.delegate = delegate;
this.context = context;
this.isPaused = true;
this.currentForkState = FORK_BUTTON_HIDDEN_STATE;
// Assign UI Controls
profilePictureView = (ImageView) itemView.findViewById(R.id.profile_picture);
midiNameTextView = (TextView) itemView.findViewById(R.id.midi_name);
durationTextView = (TextView) itemView.findViewById(R.id.midi_duration);
editedTimeTextView = (TextView) itemView.findViewById(R.id.midi_created_time);
playButton = (FloatingActionButton) itemView.findViewById(R.id.play_button);
updatePlayIcon();
playButton.setShadow(true);
playButton.setOnClickListener(this);
forkButton = (FloatingActionButton) itemView.findViewById(R.id.fork_button);
forkButton.setOnClickListener(this);
}
public void updateForkButton(int state) {
currentForkState = state;
if (state == FORK_BUTTON_HIDDEN_STATE) {
forkButton.setVisibility(View.GONE);
} else if (state == FORK_BUTTON_FORKED_STATE) {
IconDrawable icon;
icon = new IconDrawable(context, Iconify.IconValue.fa_check);
icon.color(Color.WHITE);
icon.sizeDp(24);
forkButton.setImageDrawable(icon);
forkButton.setColorNormalResId(R.color.ForkedColorNormal);
forkButton.setColorPressedResId(R.color.ForkedColorPressed);
forkButton.setColorRippleResId(R.color.ForkedColorRipple);
} else if (state == FORK_BUTTON_UNFORKED_STATE) {
IconDrawable icon;
icon = new IconDrawable(context, Iconify.IconValue.fa_code_fork);
icon.color(Color.WHITE);
icon.sizeDp(24);
forkButton.setImageDrawable(icon);
forkButton.setColorNormalResId(R.color.UnforkedColorNormal);
forkButton.setColorPressedResId(R.color.UnforkedColorPressed);
forkButton.setColorRippleResId(R.color.UnforkedColorRipple);
}
}
@Override
public void updatePlayIcon() {
IconDrawable icon;
if (isPaused) {
icon = new IconDrawable(context, Iconify.IconValue.fa_play);
} else {
icon = new IconDrawable(context, Iconify.IconValue.fa_pause);
}
isPaused = !isPaused;
icon.color(Color.WHITE);
icon.sizeDp(24);
playButton.setImageDrawable(icon);
}
public void setPosition(int position) {
this.position = position;
}
public ImageView getProfilePictureView() {
return this.profilePictureView;
}
public TextView getMidiNameTextView() {
return this.midiNameTextView;
}
public TextView getDurationTextView() {
return this.durationTextView;
}
public TextView getEditedTimeTextView() {
return this.editedTimeTextView;
}
public FloatingActionButton getPlayButton() {
return this.playButton;
}
public FloatingActionButton getForkButton() {
return this.forkButton;
}
@Override
public void onClick(View v) {
if (v.getId() == R.id.play_button) {
onPlayClick(v);
} else if (v.getId() == R.id.fork_button) {
onForkClick(v);
}
}
private void onPlayClick(View v) {
delegate.onPlayButtonClick(v, this.position, this);
}
private void onForkClick(View v) {
delegate.onForkButtonClick(v, this.position, this.currentForkState);
}
public static interface ViewHolderOnClick {
// Delegate handle when 'Play' button is tapped
public void onPlayButtonClick(View v, int position, MidiItemDelegate itemDelegate);
// Delegate handle when 'Fork' button is tapped
public int onForkButtonClick(View v, int position, int forkState);
}
}
<file_sep>package sg.edu.nus.POJOs;
public class ActivityPOJO {
private static final int JOIN_ACTIVITY_TYPE = 0;
private static final int CREATE_ACTIVITY_TYPE = 1;
private static final int FORK_ACTIVITY_TYPE = 2;
private static final int PUBLIC_ACTIVITY_TYPE = 3;
private static final int FOLLOW_ACTIVITY_TYPE = 4;
private int activityType;
private UserPOJO giver;
private UserPOJO receiver;
private MidiPOJO midiFile;
public int getActivityType() {
return this.activityType;
}
public UserPOJO getGiver() {
return this.giver;
}
public UserPOJO getReceiver() {
return this.receiver;
}
public MidiPOJO getMidiFile() {
return this.midiFile;
}
public void setActivityType(int activityType) {
this.activityType = activityType;
}
public void setGiver(UserPOJO user) {
this.giver = user;
}
public void setReceiver(UserPOJO user) {
this.receiver = user;
}
public void setMidiFile(MidiPOJO midi) {
this.midiFile = midi;
}
}
<file_sep>package sg.edu.nus.helper.http;
import com.google.gson.Gson;
import com.google.gson.GsonBuilder;
import java.io.File;
import java.io.IOException;
import java.util.List;
import retrofit.Callback;
import retrofit.RequestInterceptor;
import retrofit.RestAdapter;
import retrofit.client.Response;
import retrofit.converter.GsonConverter;
import retrofit.http.Query;
import retrofit.mime.TypedFile;
import sg.edu.nus.POJOs.MidiPOJO;
import sg.edu.nus.POJOs.UserPOJO;
public class MidifyRestClient {
private static final String DATE_FORMAT = "yyyy-MM-dd'T'HH:mm:ss.SSS'Z'";
private static final String IP = "192.168.0.102";
private static final String PORT = "9000";
private static final String BASE_URL = "http://" + IP + ":" + PORT + "/api";
// Singleton Instance
private static MidifyRestClient instance;
// Access Token
private String accessToken;
// Retrofit API Interface
private MidifyService midifyApi;
// INITIALIZE INSTANCE OF REST CLIENT
public static void initialize() {
if (instance == null) {
instance = new MidifyRestClient();
}
// Create the interface
RequestInterceptor requestInterceptor = new RequestInterceptor() {
@Override
public void intercept(RequestFacade request) {
instance.checkAccessToken();
request.addHeader("Authorization", instance.accessToken);
}
};
Gson gson = new GsonBuilder().setDateFormat(DATE_FORMAT).create();
RestAdapter restAdapter = new RestAdapter.Builder()
.setConverter(new GsonConverter(gson))
.setLogLevel(RestAdapter.LogLevel.BASIC)
.setEndpoint(BASE_URL)
.setRequestInterceptor(requestInterceptor)
.build();
instance.midifyApi = restAdapter.create(MidifyService.class);
}
// RETRIVE FRIENDS ACTION
public void getFriends(Callback<List<UserPOJO>> callback) {
midifyApi.retrieveFriends(callback);
}
// RETRIEVE MIDIS FOR USER
public void getMidisForUser(String userId, Callback<List<MidiPOJO>> callback) {
midifyApi.retrieveMidiForUser(userId, callback);
}
// FORK ACTION
public void forkMidi(MidiPOJO requestParams, Callback<MidiPOJO> callback) {
midifyApi.forkMidi(requestParams, callback);
}
// CONVERT ACTION
public void convertMidi(String filePath, String title, boolean isPublic, long duration,
Callback<MidiPOJO> callback) throws IOException {
File file = new File(filePath);
if (!file.exists()) {
throw new IOException("File does not exist");
}
TypedFile uploadFile = new TypedFile("application/octet-stream", file);
midifyApi.convertMidi(uploadFile, title, isPublic, duration, callback);
}
public void downloadMidi(String fileId, Callback<Response> callback) {
midifyApi.downloadMidi(fileId, callback);
}
// AUTHENTICATE ACTION
public void authenticate(String accessToken, String userId, Callback<UserPOJO> callback) {
UserPOJO user = UserPOJO.createUserWithoutName(accessToken, userId);
midifyApi.authenticate(user, callback);
}
public static MidifyRestClient instance() {
return instance;
}
/* TOKEN HELPER FUNCTIONS */
public void setAccessToken(String token) {
this.accessToken = token;
}
public void checkAccessToken() {
if (this.accessToken == null) {
throw new NullPointerException("The access token is null");
}
}
}
| 7eaeed29cfb77c546e99e3168ed1bf785a8a8adb | [
"Markdown",
"Java",
"Gradle"
] | 10 | Markdown | imouto1994/Midify-Android | 34e10d1f0864854632f1ddec6fbb2019fb0931a0 | 7748f2458ced045266567e88f788d8ab2ecd0d3b |
refs/heads/master | <repo_name>rmohamme/Connect-4<file_sep>/MainActivity.java
package com.example.ritzbitz.connect4;
import android.os.Bundle;
import android.support.design.widget.FloatingActionButton;
import android.support.design.widget.Snackbar;
import android.support.v7.app.AppCompatActivity;
import android.support.v7.widget.Toolbar;
import android.view.View;
import android.widget.Button;
public class MainActivity extends AppCompatActivity {
Connect4View view;
Connect4Game game;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
//TODO: INITIALIZE ALL THE BUTTONS AND ADD THEM TO THE ARRAY, THEN DISABLE THEM IN VIEW
//buttons on row 0
Button b00 = (Button) findViewById(R.id.button00);
Button b01 = (Button) findViewById(R.id.button01);
Button b02 = (Button) findViewById(R.id.button02);
Button b03 = (Button) findViewById(R.id.button03);
Button b04 = (Button) findViewById(R.id.button04);
Button b05 = (Button) findViewById(R.id.button05);
Button b06 = (Button) findViewById(R.id.button06);
//buttons on row 1
Button b10 = (Button) findViewById(R.id.button10);
Button b11 = (Button) findViewById(R.id.button11);
Button b12 = (Button) findViewById(R.id.button12);
Button b13 = (Button) findViewById(R.id.button13);
Button b14 = (Button) findViewById(R.id.button14);
Button b15 = (Button) findViewById(R.id.button15);
Button b16 = (Button) findViewById(R.id.button16);
//buttons on row 2
Button b20 = (Button) findViewById(R.id.button20);
Button b21 = (Button) findViewById(R.id.button21);
Button b22 = (Button) findViewById(R.id.button22);
Button b23 = (Button) findViewById(R.id.button23);
Button b24 = (Button) findViewById(R.id.button24);
Button b25 = (Button) findViewById(R.id.button25);
Button b26 = (Button) findViewById(R.id.button26);
//buttons on row 3
Button b30 = (Button) findViewById(R.id.button30);
Button b31 = (Button) findViewById(R.id.button31);
Button b32 = (Button) findViewById(R.id.button32);
Button b33 = (Button) findViewById(R.id.button33);
Button b34 = (Button) findViewById(R.id.button34);
Button b35 = (Button) findViewById(R.id.button35);
Button b36 = (Button) findViewById(R.id.button36);
//buttons on row 4
Button b40 = (Button) findViewById(R.id.button40);
Button b41 = (Button) findViewById(R.id.button41);
Button b42 = (Button) findViewById(R.id.button42);
Button b43 = (Button) findViewById(R.id.button43);
Button b44 = (Button) findViewById(R.id.button44);
Button b45 = (Button) findViewById(R.id.button45);
Button b46 = (Button) findViewById(R.id.button46);
//buttons on row 5
Button b50 = (Button) findViewById(R.id.button50);
Button b51 = (Button) findViewById(R.id.button51);
Button b52 = (Button) findViewById(R.id.button52);
Button b53 = (Button) findViewById(R.id.button53);
Button b54 = (Button) findViewById(R.id.button54);
Button b55 = (Button) findViewById(R.id.button55);
Button b56 = (Button) findViewById(R.id.button56);
//buttons on row 6
Button b60 = (Button) findViewById(R.id.button60);
Button b61 = (Button) findViewById(R.id.button61);
Button b62 = (Button) findViewById(R.id.button62);
Button b63 = (Button) findViewById(R.id.button63);
Button b64 = (Button) findViewById(R.id.button64);
Button b65 = (Button) findViewById(R.id.button65);
Button b66 = (Button) findViewById(R.id.button66);
Button newGame = (Button) findViewById(R.id.newGame);
//could be a point of error
Button[][] buttons = {{b00, b01, b02, b03, b04, b05, b06},
{b10, b11, b12, b13, b14, b15, b16},
{b20, b21, b22, b23, b24, b25, b26},
{b30, b31, b32, b33, b34, b35, b36},
{b40, b41, b42, b43, b44, b45, b46},
{b50, b51, b52, b53, b54, b55, b56},
{b60, b61, b62, b63, b64, b65, b66}};
view = new Connect4View(buttons, newGame);
game = new Connect4Game(view);
}
// Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
// setSupportActionBar(toolbar);
//
// FloatingActionButton fab = (FloatingActionButton) findViewById(R.id.fab);
// fab.setOnClickListener(new View.OnClickListener() {
// @Override
// public void onClick(View view) {
// Snackbar.make(view, "Replace with your own action", Snackbar.LENGTH_LONG)
// .setAction("Action", null).show();
// }
// });
// }
public void buttonClicked(View v) {
switch (v.getId()) {
case R.id.button60:
game.updateGameBoard(0);
break;
case R.id.button61:
game.updateGameBoard(1);
break;
case R.id.button62:
game.updateGameBoard(2);
break;
case R.id.button63:
game.updateGameBoard(3);
break;
case R.id.button64:
game.updateGameBoard(4);
break;
case R.id.button65:
game.updateGameBoard(5);
break;
case R.id.button66:
game.updateGameBoard(6);
break;
case R.id.newGame:
game.newGame();
break;
default:
break;
}
}
}
| 0b05f901ac942c9617fc33f366d1b7340d1b8889 | [
"Java"
] | 1 | Java | rmohamme/Connect-4 | 4cf73e453ebac099251a7a7971b92a57683447fd | 129ac30daad8c9f7e96dfb75fc3a6ae919c982e5 |
refs/heads/master | <file_sep>Sentinel backend documentation
# The Goal
This project aims to simplify scripting sentinel class offensive by creating a class that translates attack choices into an Achaea command, freeing the user from having to worry about command syntax and order.
# Important warning for people who aren't familiar with Lua inheritance
**ONLY USE `sent_att` WHEN INVOKING THE `new` METHOD, SUCH AS `att = sent_att:new()`**
All other methods should be invoked using the instance (`att` in the example above), not the template `sent_att`
# The Template
- The template for sentinel attacks is `sent_att`. This table contains all sorts of methods, dictionaries, and other fields you may need to construct an attack.
- New instances are created using the `sent_att:new()` method
- Generally balanceful actions are selected using `sent_att:act(<action name>, <array of additional arguments>)`
- any previously selected actions that's incompatible with the current action are automatically overriden
- <action name> is generally the name of the ability
- second argument can be omitted if there are not additional arguments
- Example 1: `sent_att:act("skullbash")`
- Example 2: `sent_att:act("doublestrike", {"curare", "left leg"})
- `sent_att:summon(<animal>)` can be used in place of `sent_att:act("summon",{<animal>})`. You are welcome.
- Basilisk gaze/glare attacks are unified under `sent_att:act("eye",<affliction>)`
- Order of additional arguments is generally <direction>, <venom>, <limb>
- Balanceless actions can be added using `sent_att:no_bal(<balanceless command>)`
- some special balanceless commands have their own methods, like `sent_att:enr(<animal>)`, `sent_att:morph(<animal>)`, `sent_att:stand()`, `sent_att:parry()`
- Actual construction and sending of commands is done via `sent_att:commit()` method
## Documentation todo:
- script example
- structure of sent_att
- more detailed explanation of methods<file_sep>local unpack = unpack or table.unpack
sent_att = {}
sent_att.__index = sent_att
sent_att.settings = {}
--bal_move
--eq_move
--eq_special
--no_bal = {}
sent_att.settings.stand = false
sent_att.settings.lightpipes = false
sent_att.settings.pipes = {}
-- target
sent_att.settings.target_limb = "nothing"
-- dir
-- bal_list = {}
-- bal_str
sent_att.settings.sep = "|||"
sent_att.settings.my_spear = my_spear or "spear"
sent_att.settings.my_axe = my_axe or "handaxe"
sent_att.refs = {}
sent_att.refs.basilisk_eye = {
confusion = "gaze",
paralysis = "gaze",
stupidity = "glare",
impatience = "glare",
}
sent_att.refs.ents = {
butterfly = true,
raven = true,
fox = true,
badger = true,
lemming = true,
wolf = true,
}
sent_att.refs.bal_moves = {
axe = true,
aim = true,
trip = true,
grab = true,
rive = true,
thrust = true,
spin = true,
brace = true,
rivestrike = true,
ensnare = true,
lacerate = true,
scythe = true,
rattle = true,
truss = true,
skullbash = true,
gouge = true,
impale = true,
drag = true,
wrench = true,
doublestrike = true,
extirpate = true,
ambush = true,
burrow = true,
dig = true,
dismember = true,
fitness = true,
fly = true,
leap = true,
maul = true,
might = true,
pound = true,
shred = true,
snap = true,
stampede = true,
trumpet = true,
yank = true,
tumble = true,
}
sent_att.refs.eq_moves = {
eye = true,
freeze = true,
melody = true,
negate = true,
petrify = true,
shield = true,
web = true,
}
sent_att.refs.eq_moves_sp = {
howl = true,
contemplate = true,
summon = true,
}
function sent_att:new()
local new_att = {}
setmetatable(new_att,self)
new_att.settings = {}
setmetatable(new_att.settings, {__index = self.settings})
new_att.settings.no_bal = {}
return new_att
end
function sent_att:target(name)
self.settings.target = name
return self.settings.target
end
function sent_att:axe(venom, limb)
local bal_list = {}
if limb and limb ~= self.settings.target_limb then
table.insert(bal_list, string.format("target %s", limb))
end
if venom then
table.insert(bal_list, string.format("wipe %s", self.settings.my_axe))
table.insert(bal_list, string.format("envenom %s with %s", self.settings.my_axe, venom))
end
table.insert(bal_list,string.format("throw %s at %s", self.settings.my_axe, self.settings.target))
self.bal_str = table.concat(bal_list, self.settings.sep)
return self.bal_str
end
function sent_att:aim(dir, venom, limb)
local bal_list = {}
if not dir then
error("Need a direction for LoS - sent_att:aim")
return
end
if limb and limb ~= self.settings.target_limb then
table.insert(bal_list, string.format("target %s", limb))
end
if venom then
table.insert(bal_list, string.format("wipe %s", self.settings.my_axe))
table.insert(bal_list, string.format("envenom %s with %s", self.settings.my_axe, venom))
end
table.insert(bal_list, string.format("throw %s %s at %s", self.settings.my_axe, dir, self.settings.target))
self.bal_str = table.concat(bal_list, self.settings.sep)
return self.bal_str
end
function sent_att:trip(side)
if side ~= "left" and side ~= "right" then
error("sent_att:trip requires left or right as argument")
return
end
self.bal_str = string.format("trip %s %s", self.settings.target, side)
return self.bal_str
end
function sent_att:grab(dir)
if type(dir) ~= "string" then
error("sent_att:grab needs a direction")
end
self.bal_str = string.format("bthrow axe at %s %s", self.settings.target, dir)
return self.bal_str
end
function sent_att:rive()
self.bal_str = string.format("rive %s", self.settings.target)
return self.bal_str
end
function sent_att:thrust(venom, limb)
local bal_list = {}
table.insert(bal_list, string.format("thrust %s", self.settings.target))
if venom then
table.insert(bal_list, venom)
end
if limb and limb~="nothing" then
table.insert(bal_list, limb)
end
self.bal_str = table.concat(bal_list, " ")
return self.bal_str
end
function sent_att:spin(ven1, ven2, ven3)
local bal_list = {}
table.insert(bal_list, string.format("wipe %s", self.settings.my_spear))
table.insert(bal_list, string.format("envenom %s with %s", self.settings.my_spear, ven1))
table.insert(bal_list, string.format("envenom %s with %s", self.settings.my_spear, ven2))
table.insert(bal_list, string.format("envenom %s with %s", self.settings.my_spear, ven3))
table.insert(bal_list, "spin spear")
self.bal_str = table.concat(bal_list, self.settings.my_spearsep)
return self.bal_str
end
function sent_att:brace()
self.bal_str = "brace spear"
return self.bal_str
end
function sent_att:rivestrike(venom, limb)
local bal_list = {}
table.insert(bal_list, string.format("rivestrike %s", self.settings.target))
if limb and limb~="nothing" then
table.insert(bal_list, limb)
end
if venom then
table.insert(bal_list, venom)
end
self.bal_str = table.concat(bal_list, " ")
return self.bal_str
end
function sent_att:ensnare()
self.bal_str = string.format("ensnare %s", self.settings.target)
return self.bal_str
end
function sent_att:lacerate(venom, limb)
local bal_list = {}
table.insert(bal_list, string.format("lacerate %s", self.settings.target))
if limb and limb~="nothing" then
table.insert(bal_list, limb)
end
if venom then
table.insert(bal_list, venom)
end
self.bal_str = table.concat(bal_list, " ")
return self.bal_str
end
function sent_att:scythe()
self.bal_str = string.format("scythe %s", self.settings.target)
return self.bal_str
end
function sent_att:rattle ()
self.bal_str = string.format("rattle %s", self.settings.target)
return self.bal_str
end
function sent_att:truss()
local bal_list = {}
table.insert(bal_list, "outr rope")
table.insert(bal_list, string.format("truss %s", self.settings.target))
self.bal_str = table.concat(bal_list, self.settings.sep)
return self.bal_str
end
function sent_att:skullbash()
self.bal_str = string.format("skullbash %s", self.settings.target)
return self.bal_str
end
function sent_att:gouge(venom, limb)
local bal_list = {}
table.insert(bal_list, string.format("gouge %s", self.settings.target))
if limb and limb~="nothing" then
table.insert(bal_list, limb)
end
if venom then
table.insert(bal_list, venom)
end
self.bal_str = table.concat(bal_list, " ")
return self.bal_str
end
function sent_att:impale()
self.bal_str = string.format("impale %s", self.settings.target)
return self.bal_str
end
function sent_att:drag(dir)
self.bal_str = string.format("drag %s", dir)
return self.bal_str
end
function sent_att:wrench()
self.bal_str = "wrench"
return self.bal_str
end
function sent_att:doublestrike(venom, limb)
local bal_list = {}
table.insert(bal_list, string.format("doublestrike %s", self.settings.target))
if limb and limb~="nothing" then
table.insert(bal_list, limb)
end
if venom then
table.insert(bal_list, venom)
end
self.bal_str = table.concat(bal_list, " ")
return self.bal_str
end
function sent_att:extirpate()
self.bal_str = string.format("extirpate %s", self.settings.target)
return self.bal_str
end
function sent_att:eye(aff)
if not self.refs.basilisk_eye[aff] then
error("Affliction not available through a basilisk eye power")
return
end
self.eq_str = string.format("%s %s %s", self.refs.basilisk_eye[aff], self.settings.target, aff)
return self.eq_str
end
function sent_att:ambush()
self.bal_str = string.format("ambush %s", self.settings.target)
return self.bal_str
end
function sent_att:burrow(dir)
dir = dir or "below"
self.bal_str = string.format("burrow %s", dir)
return self.bal_str
end
function sent_att:dig()
self.bal_str = "dig"
return self.bal_str
end
function sent_att:dismember()
self.bal_str = string.format("dismember %s", self.settings.target)
return self.bal_str
end
function sent_att:fitness()
self.bal_str = "fitness"
return self.bal_str
end
function sent_att:fly()
self.bal_str = "fly"
return self.bal_str
end
function sent_att:howl()
self.eq_str = string.format("howl %s", self.settings.target)
return self.eq_str
end
function sent_att:freeze(ground)
if not ground then
self.eq_str = string.format("freeze %s", self.settings.target)
else
self.eq_str = "freeze ground"
end
return self.eq_str
end
function sent_att:leap(dir)
self.bal_str = string.format("leap %s", dir)
return self.bal_str
end
function sent_att:maul(limb)
local bal_list = {}
table.insert(bal_list, string.format("maul %s", self.settings.target))
if limb and limb~="nothing" then
table.insert(bal_list, limb)
end
self.bal_str = table.concat(bal_list, " ")
return self.bal_str
end
function sent_att:melody()
self.eq_str = "sing melody"
return self.eq_str
end
function sent_att:might()
self.bal_str = "might"
return self.bal_str
end
function sent_att:negate()
self.eq_str = string.format("negate %s", self.settings.target)
return self.eq_str
end
function sent_att:petrify()
self.eq_str = string.format("petrify %s", self.settings.target)
return self.eq_str
end
function sent_att:pound()
self.bal_str = string.format("pound %s", self.settings.target)
return self.bal_str
end
function sent_att:shred()
self.bal_str = string.format("shred %s", self.settings.target)
return self.bal_str
end
function sent_att:snap()
self.bal_str = string.format("snap %s", self.settings.target)
return self.bal_str
end
function sent_att:stampede()
self.bal_str = string.format("stampede %s", self.settings.target)
return self.bal_str
end
function sent_att:trumpet()
self.bal_str = string.format("trumpet %s", self.settings.target)
return self.bal_str
end
function sent_att:yank()
self.bal_str = string.format("yank %s", self.settings.target)
return self.bal_str
end
function sent_att:summon(animal)
self.eq_str = string.format("summon %s", animal)
self.eq_special = "summon"
self.eq_special_args = {animal}
return self.eq_str
end
function sent_att:tumble(dir)
if not dir then
error("sent_att:tumble need a valid direction!")
return
end
self.bal_str = string.format("tumble %s", dir)
return self.bal_str
end
function sent_att:shield()
self.eq_str = "touch shield"
return self.eq_str
end
function sent_att:contemplate()
self.eq_str = string.format("contemplate %s", self.settings.target)
return self.eq_str
end
function sent_att:web()
self.eq_str = string.format("touch web %s", self.settings.target)
return self.eq_str
end
function sent_att:morph(animal)
if type(animal) ~= "string" then
error("sent_att:morph needs a valid animal argument")
return
end
self.to_morph = animal
end
function sent_att:enr(ent)
if not ent then
self.settings.enrage = nil
else
if not self.refs.ents[ent] then
error(tostring(ent).." is not a valid animal to enrage!")
return
else
self.settings.enrage = ent
end
end
return self.settings.enrage
end
function sent_att:diss(ent)
if not ent then
self.settings.dismiss = nil
else
if not self.refs.ents[ent] then
error(tostring(ent).." is not a valid animal to enrage!")
return
else
self.settings.dismiss = ent
end
end
return self.settings.dismiss
end
function sent_att:parry(limb)
if type(limb) ~= "string" then
error("sent_att:parry needs a limb specified")
return
end
self.to_parry = limb
end
function sent_att:act(move, args)
if self.refs.bal_moves[move] then
self.bal_move = move
self.bal_args = args
self.eq_move = false
elseif self.refs.eq_moves[move] then
self.bal_move = false
self.eq_move = move
self.eq_args = args
self.eq_special = false
elseif self.refs.eq_moves_sp[move] then
self.eq_move = false
self.eq_special = move
self.eq_special_args = args
end
end
function sent_att:no_bal(move)
table.insert(self.settings.no_bal, move)
end
function sent_att:stand(negate, args)
if not negate then
self.settings.stand = true
else
self.settings.stand = false
end
end
function sent_att:setpipes(pipelist)
if type(pipelist) ~= "table" or #pipelist == 0 then
error("pipe list needs to be an array of pipe ids")
return
end
self.settings.pipes = pipelist
return self.settings.pipes
end
function sent_att:lightpipes(negate)
if not negate then
self.settings.lightpipes = true
else
self.settings.lightpipes = false
end
end
function sent_att:commit()
local do_first = {}
if self.to_morph then
table.insert(do_first, string.format("morph %s", self.to_morph))
end
if self.settings.stand then
table.insert(do_first, "stand")
end
if self.settings.lightpipes and #self.settings.pipes > 0 then
for _,v in ipairs(self.settings.pipes) do
table.insert(do_first, string.format("light %s", v))
end
end
if self.to_parry then
table.insert(do_first, string.format("parry %s", self.to_parry))
end
local actions = {}
local actions_free = {}
if #do_first > 0 then
table.insert(actions_free, table.concat(do_first,self.settings.sep))
end
if #self.settings.no_bal > 0 then
table.insert(actions_free, table.concat(self.settings.no_bal, self.settings.sep))
end
if #actions_free > 0 then
table.insert(actions, table.concat(actions_free, self.settings.sep))
end
if self.settings.enrage then
table.insert(actions, string.format("enrage %s %s", self.settings.enrage, self.settings.target))
end
if self.settings.dismiss and self.bal_move~="impale" and self.bal_move~="wrench" and not self.eq_move and (not self.eq_special or self.eq_special=="summon") then
table.insert(actions, string.format("dismiss %s", self.settings.dismiss))
end
-- cecho("<red:green>stopped")
if self.bal_move then
if self.bal_args then
table.insert(actions, self[self.bal_move](self, unpack(self.bal_args)))
else
-- print(self[self.bal_move](self))
table.insert(actions, self[self.bal_move](self))
end
end
if self.eq_move then
if self.eq_args then
table.insert(actions, self[self.eq_move](self, unpack(self.eq_args)))
else
table.insert(actions, self[self.eq_move](self))
end
end
if self.eq_special then
if self.eq_special_args then
table.insert(actions, self[self.eq_special](self,unpack(self.eq_special_args)))
else
table.insert(actions, self[self.eq_special](self))
end
end
if self.bal_special then
if self.bal_special_args then
table.insert(actions, self[self.bal_special](self, unpack(self.bal_special_args)))
else
table.insert(actions, self[self.bal_special](self))
end
end
local attack_str = table.concat(actions, self.settings.sep)
if string.upper(attack_str)==attack_queued then
return
end
send("queue addclear eqbal "..table.concat(actions, self.settings.sep))
--display(actions)
return table.concat(actions, self.settings.sep)
end | 1d6116da5c79851d7a3736f4706c1595df652ef9 | [
"Markdown",
"Lua"
] | 2 | Markdown | RollanzMushing/Achaea_sentinel_backend | e845cff042a1562b051402851a21158c4af3d1c7 | 229b1e5aebeac379031b7e39fc8c46c923aca5da |
refs/heads/master | <repo_name>linares/third-party-experiments<file_sep>/apps/landing/views.py
# Create your views here.
from django.http import HttpResponse, HttpResponseForbidden
import oauth2 as oauth
from django.shortcuts import redirect
from django.template import Context, loader
import twitter
import settings
from django.template.context import RequestContext
def home(request):
if request.user.is_authenticated():
timeline = getStatusesForRequest(request)
t = loader.get_template('main/main_page.html')
c = RequestContext(request, {
'timeline' : timeline
})
return HttpResponse(t.render(c))
else :
return redirect('/landing')
def getTwitterApiForRequest(request):
uprofile = request.user.get_profile()
api = twitter.Api(consumer_key=settings.TWITTER_CONSUMER_KEY,
consumer_secret=settings.TWITTER_CONSUMER_SECRET,
access_token_key=uprofile.twitter_access_token,
access_token_secret=uprofile.twitter_access_token_secret)
return api
def getStatusesForRequest(request, max_id=None):
api = getTwitterApiForRequest(request)
print max_id
timeline = []
if max_id == None :
statuses = api.GetHomeTimeline(count=75)
else :
statuses = api.GetHomeTimeline(count=50, max_id=max_id)
for status in statuses:
timeline.append({
'created_at' : status.created_at,
'text' : status.text,
'user' : {
'name' : status.user.screen_name,
'profile_image_url' : status.user.profile_image_url
}
})
setLastStatusId(request, statuses)
return timeline
def setLastStatusId(request, statuses):
request.session['last_status_id'] = statuses[len(statuses)-1].id
def getLastStatusId(request):
return request.session['last_status_id']
def signin(request):
if request.user.is_authenticated():
return redirect('/')
else :
t = loader.get_template('landing/landing_page.html')
c = Context({
})
return HttpResponse(t.render(c))
def page(request, page_id):
if request.user.is_authenticated():
timeline = getStatusesForRequest(request, getLastStatusId(request))
t = loader.get_template('main/main_page.html')
c = RequestContext(request, {
'timeline' : timeline
})
return HttpResponse(t.render(c))
else:
return HttpResponseForbidden()
<file_sep>/apps/landing/api/handlers.py
#from django.conf import settings
#from django.http import HttpResponseForbidden, Http404
#from piston.handler import BaseHandler
#from piston.utils import rc, FormValidationError
#import datetime
#
#
#class InfiniteScrollHandler(BaseHandler):
#
# def read(self, request, page_id=1):
#
# if not request.user.is_authenticated():
# return HttpResponseForbidden()
# elif not page_id:
# return Http404()
# else:
#
#
#
#
#
#
#
#
#
# <file_sep>/apps/thirdparty/views.py
from django.http import HttpResponse
from django.contrib.auth.models import User
from django.contrib.auth import authenticate, login
from django.shortcuts import redirect
import settings
from urlparse import parse_qs
import twitter
import oauth2 as oauth
from models import UserProfile
import settings
def home(request):
return HttpResponse("Signed IN Home")
def oauth_req(request):
consumer = oauth.Consumer(key=settings.TWITTER_CONSUMER_KEY, secret=settings.TWITTER_CONSUMER_SECRET)
request_token_url = settings.TWITTER_OAUTH_REQUEST_TOKEN_URL
client = oauth.Client(consumer)
resp, content = client.request(request_token_url, "GET")
request.session['request_token'] = parse_qs(content)['oauth_token'][0]
request.session['request_token_secret'] = parse_qs(content)['oauth_token_secret'][0]
return redirect(settings.TWITTER_OAUTH_PERMS_REDIRECT_URL + parse_qs(content)['oauth_token'][0])
def twitter_signed_in(request):
print request
consumer = oauth.Consumer(key=settings.TWITTER_CONSUMER_KEY, secret=settings.TWITTER_CONSUMER_SECRET)
access_token_url = settings.TWITTER_OAUTH_REQUEST_TOKEN_EXCHANGE
print request.GET['oauth_verifier']
token = oauth.Token(request.session['request_token'], request.session['request_token_secret'])
client = oauth.Client(consumer, token)
resp, content = client.request(access_token_url, "POST", body='oauth_verifier=%s' % request.GET['oauth_verifier'])
print content
access_token = parse_qs(content)['oauth_token'][0]
access_token_secret = parse_qs(content)['oauth_token_secret'][0]
user_id = parse_qs(content)['user_id'][0]
screen_name = parse_qs(content)['screen_name'][0]
api = twitter.Api(consumer_key=settings.TWITTER_CONSUMER_KEY,
consumer_secret=settings.TWITTER_CONSUMER_SECRET,
access_token_key=access_token,
access_token_secret=access_token_secret)
twitter_user = api.GetUser(user_id)
try:
user = User.objects.get(username__exact=screen_name)
except User.DoesNotExist:
user = None
if user == None :
#we've got a new user
user = User.objects.create_user(username=screen_name, email='<EMAIL>', password=<PASSWORD>)
user.save()
print 'first time user'
#now update the profile for this user with twitter information
twitter_profile = user.get_profile()
twitter_profile.set_twitter_info(twitter_user, access_token, access_token_secret)
twitter_profile.save()
print 'updated user\'s twitter profile'
#now authenticate the user and log them in
user = authenticate(username=user)
print user
login(request, user)
print 'user should now be authenticated and logged in'
return redirect(settings.ROOT_URL)<file_sep>/apps/landing/urls.py
from django.conf import settings
from django.conf.urls.defaults import patterns, include, url
import os
urlpatterns = patterns('',
url(r'pages/(?P<page_id>[^/]+).html', 'marissa.apps.landing.views.page', name='page'),
)
<file_sep>/urls.py
from django.conf.urls.defaults import patterns, include, url
from apps.landing import urls
urlpatterns = patterns('',
url(r'^$', 'marissa.apps.landing.views.home', name='home'),
url(r'^twitter_signed_in$', 'marissa.apps.thirdparty.views.twitter_signed_in', name='home'),
url(r'^landing$', 'marissa.apps.landing.views.signin', name='home'),
url(r'^landing', include(urls)),
url(r'^oauth$', 'marissa.apps.thirdparty.views.oauth_req')
)
<file_sep>/models.py
from django.db import models
from django.db.models.signals import post_save
# Create your models here.
from django.contrib.auth.models import User
class UserProfile(models.Model):
# This field is required.
user = models.OneToOneField(User)
#twitter identity
twitter_id = models.CharField(max_length=200, null=False, blank=False)
twitter_screen_name = models.CharField(max_length=200, null=False, blank=False)
twitter_profile_img =models.CharField(max_length=200, null=False, blank=False)
def create_user_profile(sender, instance, created, **kwargs):
if created:
UserProfile.objects.create(user=instance)
post_save.connect(create_user_profile, sender=User)<file_sep>/apps/landing/tests.py
"""
This file demonstrates writing tests using the unittest module. These will pass
when you run "manage.py test".
Replace this with more appropriate tests for your application.
"""
from django.test import TestCase
import twitter
class SimpleTest(TestCase):
def test_basic_addition(self):
"""
Tests that 1 + 1 always equals 2.
"""
api=twitter.Api(consumer_key='ZU6XVnclcgHpQjdqK8zUw',consumer_secret='<KEY>', access_token_key='<KEY>', access_token_secret='<KEY>')
timeline = api.GetUserTimeline(count=50, include_entities=True)
print timeline
<file_sep>/apps/landing/api/urls.py
#from django.conf.urls.defaults import *
#from piston.resource import Resource
#
#infinite_scroll_handler = Resource(InfiniteScrollHandler)
#
#urlpatterns = patterns('',
#
## url(r'^page/(?P<page_id>[^/]+)/?$', infinite_scroll_handler), # GET /pages/N
#)<file_sep>/requirements.txt
django==1.3
mysql-python
python-memcached # Python-memcached bindings
south==0.7.5 # SQL schema migration
fabric # Command line tools
django-countries
boto==2.3.0 # AWS utils
django-ses==0.4.1 # Django AWS SES plugin
django-piston # Django API framework
django-debug-toolbar # Debug toolbar
raven==0.7 # Error logging framework
django-sentry==1.13.5 # Error logging framework (django-plugin)
#pytz # Recommended python timezone lib
django-storages # Django storage engine for S3
xlrd # Extract data from excel spreadsheets
python-dateutil==1.5 # Extended date utilities
twilio # Sends SMS messages
urbanairship # Mobile push notifications
celery==2.5.1 # Python queue framework
django-celery==2.5.1 # Allows django to run as a message broker
kombu==2.1.3 # Also required as part of django-celery
suds # SOAP library
django-picklefield # Custom django field for pickled objects
django-extensions==0.8 # Additional django utils
oauth
python-twitter<file_sep>/apps/landing/templates/landing/landing_page.html
{% extends "base.html" %}
{% block extrahead %}
<script src="http://platform.twitter.com/anywhere.js?id=ZU6XVnclcgHpQjdqK8zUw&v=1" type="text/javascript"></script>
{% endblock %}
{% block content %}
<div data-role="page" id="home">
<div data-role="content" style="padding: 0;">
{% if not user.authenticated %}
<button type="button" id="signin-btn">Sign In with Twitter</button>
<script>
$('#signin-btn').click(function() {
window.location.replace('/oauth');
});
</script>
{% else %}
{% endif %}
{% block inner_content %}{% endblock %}
</div>
</div>
{% endblock %}
<file_sep>/apps/thirdparty/models.py
from django.contrib.auth.models import User
from django.db.models.signals import post_save
from django.db import models
import datetime
import twitter
class UserProfile(models.Model):
# This field is required.
user = models.OneToOneField(User)
#twitter identity
twitter_id = models.CharField(max_length=200, null=False, blank=False, unique=True)
twitter_screen_name = models.CharField(max_length=200, null=False, blank=False, unique=True)
twitter_profile_img = models.CharField(max_length=200, null=False, blank=False)
twitter_access_token = models.CharField(max_length=200, null=False, blank=False, default='')
twitter_access_token_secret = models.CharField(max_length=200, null=False, blank=False, default='')
def get_twitter_id(self):
return self.twitter_id
def get_twitter_screen_name(self):
return self.twitter_screen_name
def get_twitter_profile_img(self):
return self.twitter_profile_img
def get_twitter_access_token(self):
return self.twitter_access_token
def get_twitter_access_token_secret(self):
return self.twitter_access_token_secret
def set_twitter_access_token_secret(self, value):
self.twitter_access_token_secret = value
def set_twitter_id(self, value):
self.twitter_id = value
def set_twitter_screen_name(self, value):
self.twitter_screen_name = value
def set_twitter_profile_img(self, value):
self.twitter_profile_img = value
def set_twitter_access_token(self, value):
self.twitter_access_token = value
def del_twitter_id(self):
del self.twitter_id
def del_twitter_screen_name(self):
del self.twitter_screen_name
def del_twitter_profile_img(self):
del self.twitter_profile_img
def del_twitter_access_token(self):
del self.twitter_access_token
def del_twitter_access_token_secret(self):
del self.twitter_access_token_secret
def set_twitter_info(self, twitter_user, access_token_key, access_token_secret):
self.twitter_id = twitter_user.GetId()
self.twitter_screen_name = twitter_user.GetScreenName()
self.twitter_profile_img = twitter_user.GetProfileImageUrl()
self.twitter_access_token = access_token_key
self.twitter_access_token_secret = access_token_secret
class Tweet(models.Model):
#twitter identity
tweet_id = models.CharField(max_length=200, null=False, blank=False, unique=True)
twitter_screen_name = models.CharField(max_length=200, null=False, blank=False, unique=True)
twitter_profile_img = models.CharField(max_length=200, null=False, blank=False)
def create_user_profile(sender, instance, created, **kwargs):
if created:
UserProfile.objects.create(user=instance)
post_save.connect(create_user_profile, sender=User)
<file_sep>/fabfile.py
from fabric.api import *
from fabric.contrib.console import confirm
import fabric.operations
import time
# Global env settings
env.git_repo = "<EMAIL>:brelig/infoscout.git"
def dev():
""" staging dev server settings """
env.hosts = ['<EMAIL>']
env.source_root = '/var/www/dev'
env.project_root = env.source_root + '/infoscout/pricescout'
env.activate = 'source /var/www/dev/infoscout/pricescout/ve/bin/activate'
env.deploy_user = 'staging'
env.settings_module = 'infoscout.pricescout.envsettings.dev'
env.apache_conf = 'infoscout-dev'
env.celeryd_conf = env.project_root + '/celeryd/config_dev'
def staging():
""" staging dev server settings """
env.hosts = ['<EMAIL>']
env.source_root = '/var/www/staging'
env.project_root = env.source_root + '/infoscout/pricescout'
env.activate = 'source /var/www/staging/infoscout/pricescout/ve/bin/activate'
env.deploy_user = 'staging'
env.branch = 'shoparoo2'
env.settings_module = 'infoscout.pricescout.envsettings.staging'
env.celeryd_conf = env.project_root + '/celeryd/config_staging'
env.apache_conf = 'infoscout-staging'
env.other_apache_confs = [(env.source_root+'/infoscout/shoparoo', 'shoparoo-staging'),
(env.source_root+'/infoscout/receipthog','receipthog-staging')
]
def prod():
""" prod dev server settings """
env.hosts = ['prod@172.16.58.3', 'prod@172.16.31.10']
env.source_root = '/var/www/prod'
env.project_root = env.source_root + '/infoscout/pricescout'
env.activate = 'source /var/www/prod/infoscout/pricescout/ve/bin/activate'
env.deploy_user = 'prod'
env.settings_module = 'infoscout.pricescout.envsettings.prod'
env.apache_conf = 'infoscout-prod'
def prod_api():
prod()
env.hosts = ['prod@172.16.58.3']
def prod_upload():
prod()
env.celeryd_conf = env.project_root + '/celeryd/config_prod'
env.hosts = ['prod@172.16.31.10']
# Apps under south migration
south_apps = ('dynsettings',
'mobileauth',
'pricescoutapp',
'rdl',
'mturk',
'gameengine',
'sentry',
'djcelery')
def deploy(codeonly=False, syncdb=True, staticfiles=True):
""" Deploys to prod/staging environment """
git_pull()
if not codeonly:
set_permissions()
pip_install_req()
validate()
if staticfiles:
collect_static()
if syncdb:
remote_syncdb()
sync_dynsettings()
# set them again, required for new logs files
set_permissions()
# Restart celery
if hasattr(env, 'celeryd_conf'):
celeryd('restart')
apache("restart")
#def prod_deploy():
# """
# jbrelig: Did not work well. Needs some work
# """
#
# prod()
#
# # First roll out to prod_api
# with settings(hosts=['prod@172.16.58.3'], ):
## prod_api()
# deploy()
#
# # Now roll out prod_upload
# # Don't include the remote_syncdb
# # and collect_static. Do that on the prod_api box
# with settings(hosts=['prod@172.16.31.10']):
## prod_upload()
# git_pull()
# set_permissions()
# pip_install_req()
# validate()
# set_permissions()
# celeryd('restart')
# apache('restart')
def tag():
""" Tags code to version number """
local('git fetch --tags')
print("Showing latest tags for reference")
local('git tag | tail -5')
refspec = prompt('Tag name [in format x.x.x]? ')
local('git tag -a %(ref)s -m "Tagging version %(ref)s in fabfile"' % {
'ref': refspec})
local('git push --tags')
def virtualenv(command):
""" Wrap call in virtualenv """
with cd(env.project_root):
return sudo(env.activate + '&&' + command, user=env.deploy_user)
def collect_static():
""" Collects static files for prod deploys """
managepy("collectstatic --noinput")
def pip_install_req():
with cd(env.project_root):
virtualenv('pip install -r requirements.txt')
def remote_syncdb():
""" Sync db remotely. """
managepy("syncdb")
managepy("migrate")
def _remote_syncdb_app(app):
managepy("migrate "+app)
def local_syncdb():
for app in south_apps:
_local_syncdb_app(app)
def _local_syncdb_app(app):
""" Sync db locally (creates schemamigration files) """
with settings(warn_only=True):
result = local("python manage.py schemamigration " + app + " --auto")
if result.failed:
pass
# abort("Aborting at user request.")
local('python manage.py migrate ' + app)
def git_pull():
local('git fetch --tags')
local('git tag | tail -5')
tag = fabric.operations.prompt("Tag to deploy? (blank for HEAD)")
# If no tag provided, reset to branch
if not tag:
branch = fabric.operations.prompt("Branch to deploy? (blank for master)") or 'master'
tag = "remotes/origin/%s" % branch
tag_name = local('git rev-parse %s' % tag, capture=True).strip()
else:
tag_name = tag
with cd(env.source_root):
run('git fetch --tags')
run("git clean -f")
run("git fetch")
run("git reset --hard %s" % tag)
# Write tag number to tag file
run("echo %s > %s/tag" % (tag_name, env.project_root))
def validate():
""" Validate nothing is broke """
managepy("validate")
def set_permissions():
with cd(env.project_root):
sudo("chgrp www-data logs -R")
sudo("chmod 775 logs -R")
sudo("chmod 775 media")
sudo("chmod 775 celeryd")
def sync_dynsettings():
""" Sync dyn settings in database """
managepy("syncsettings")
def setup_instance():
"""
Installs base libraries on empty ec2 ubuntu environment.
We ideally should NOT have to run this again as
we have a snapshot of the ubuntu instance on AWS all loaded
and ready to go
"""
sudo("apt-get install git")
sudo("apt-get install htop")
sudo("apt-get install apache2 libapache2-mod-wsgi")
sudo("a2enmod mod-wsgi")
sudo("apt-get install mysql-client python2.7-mysqldb")
sudo("apt-get install memcached")
sudo("apt-get install python-pip python-virtualenv python-dev build-essential")
sudo("apt-get install python-imaging")
sudo("apt-get install libxslt-dev libxml2-dev")
# Uninstall some pacakges not using (or we dont want at OS)
sudo("apt-get uninstall boto")
# setup tesseract 3.0
setup_tesseract()
# setup open cv
setup_opencv()
# Removes 'indexes' on default apache vhost (security)
sudo("perl -pi -e 's/Indexes//g' /etc/apache2/sites-available/default")
apache("reload")
def setup_tesseract():
"""
Have to install tesseract 3.00 from source. Used steps from here:
http://dudczak.info/dry/index.php/2011/01/tesseract-3-0-installation-on-ubuntu-10-10-server/
"""
sudo ("apt-get install build-essential autoconf")
sudo ("apt-get install libpng12-dev libjpeg62-dev libtiff4-dev zlib1g-dev")
sudo ("apt-get install libleptonica-dev")
# Install leptonica from source (ignore, installed via aptitude above)
# sudo ("mkdir /home/prod/leptonica")
# with cd("/home/prod/leptonica"):
# sudo("wget http://www.leptonica.org/source/leptonica-1.68.tar.gz")
# sudo("tar -zxvf leptonlib-1.68.tar.gz")
# with cd("/home/prod/leptonlib-1.68"):
# sudo ("./configure")
# sudo ("make")
# sudo ("checkinstall")
# sudo ("ldconfig")
# Install tesseract from source
sudo ("mkdir /home/ubuntu/tesseract")
with cd("/home/ubuntu/tesseract"):
sudo ("wget http://tesseract-ocr.googlecode.com/files/tesseract-3.00.tar.gz")
sudo ("tar -zxvf tesseract-3.00.tar.gz")
with cd("/home/ubuntu/tesseract/tesseract-3.00"):
sudo ("./runautoconf")
sudo ("./configure")
sudo ("make")
sudo ("make install")
sudo ("ldconfig")
# Install tesseract english language files
with cd("/usr/local/share/tessdata"):
sudo ("wget http://tesseract-ocr.googlecode.com/files/eng.traineddata.gz")
sudo ("gunzip eng.traineddata.gz")
def setup_opencv():
"""
Installs OpenCV with python bindings
Documented on readme file here:
https://github.com/brelig/infoscout/tree/master/infoscout/apps/rdl/bannerdetect
"""
sudo ("apt-get install build-essential libgtk2.0-dev libjpeg62-dev libtiff4-dev libjasper-dev libopenexr-dev cmake python-dev")
sudo ("apt-get install python-numpy libtbb-dev libeigen2-dev yasm libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev")
sudo ("apt-get install libvorbis-dev libxvidcore-dev cmake-gui")
sudo ("mkdir /home/ubuntu/opencv")
with cd("/home/ubuntu/opencv"):
sudo ("wget http://sourceforge.net/projects/opencvlibrary/files/opencv-unix/2.3.1/OpenCV-2.3.1a.tar.bz2/download -O OpenCV-2.3.1a.tar.bz2")
sudo ("tar -xvf OpenCV-2.3.1a.tar.bz2")
with cd("/home/ubuntu/opencv/OpenCV-2.3.1"):
sudo ("mkdir release")
with cd ("/home/ubuntu/opencv/OpenCV-2.3.1/release"):
sudo ("cmake -D WITH_TBB=ON -D BUILD_NEW_PYTHON_SUPPORT=ON -D WITH_V4L=OFF -D INSTALL_C_EXAMPLES=ON -D INSTALL_PYTHON_EXAMPLES=ON -D BUILD_EXAMPLES=ON ..")
sudo ("make")
sudo ("make install")
def setup_environment():
"""
Setups a new environment. Creates dir, clones git repo,
installs virtualenv, etc.
"""
# Copy SSH keypair for GitHub from root to deploy_user .ssh dir
# NOTE: SSH keypair must already be in root dir. They should be
with settings(warn_only=True):
sudo("cp /root/.ssh/id_rsa* /home/%s/.ssh/." % env.deploy_user)
sudo("chown -R %s:%s /home/%s/.ssh" % (env.deploy_user, env.deploy_user, env.deploy_user))
# Create directory
sudo("mkdir -p " + env.source_root)
sudo("chown -R %s:%s %s" % (env.deploy_user, 'www-data', env.source_root))
with cd(env.source_root):
branch = env.branch if hasattr(env,'branch') else 'master'
run("git clone -b %s %s ." % (branch, env.git_repo))
sudo("chown -R %s:%s %s" % (env.deploy_user, 'www-data', env.source_root))
# Install virtualenv and install pip reqs
with cd(env.project_root):
run("virtualenv ve")
pip_install_req()
# Link apache vhost
setup_apache_vhost(env.project_root, env.apache_conf)
# Setup other apache vhosts
if hasattr(env,'other_apache_confs'):
for path, apache_conf in env.other_apache_confs:
setup_apache_vhost(path, apache_conf)
def setup_apache_vhost(path, apache_conf):
""" Creates sym link and activates apache conf """
with settings(warn_only=True):
sudo("rm /etc/apache2/sites-available/%s" % apache_conf)
sudo("ln -s %s/apache/conf/%s /etc/apache2/sites-available/%s" % (path, apache_conf, apache_conf))
sudo("a2ensite %s" % apache_conf)
apache("reload")
#def server_install():
# """
# Deprecated... see setup_environment above
# """
# sudo('yum install -y git-core')
# sudo('yum install -y httpd')
# sudo('yum install -y httpd-devel')
# sudo('yum install -y make')
# sudo('yum install -y gcc')
# sudo('yum install -y python-devel')
# sudo('yum install -y mysql')
# sudo('yum install -y mysql-server')
# sudo('yum install -y mysql-devel')
# sudo('chgrp -R mysql /var/lib/mysql')
# sudo('chmod -R 770 /var/lib/mysql')
# install_mod_wsgi()
# install_python_deps()
#
#
#def install_mod_wsgi():
# sudo('wget http://modwsgi.googlecode.com/files/mod_wsgi-3.3.tar.gz;tar -xzvf mod_wsgi-3.3.tar.gz;cd mod_wsgi-3.3; ./configure ; make ; make install;')
#
#
#def install_python_deps():
# sudo('easy_install pip')
# sudo('easy_install virtualenv')
def init_datamaster_db():
""" Creates datamaster tables """
managepy("syncdb --database=datamaster")
managepy('migrate datamaster --database="datamaster"')
def migrate_datamaster_db():
managepy("migrate datamaster --database=datmaster")
def seedmasterdata(dataset="all"):
""" Sync datamaster in database """
managepy("seedmasterdata %s" % dataset)
def seedbannerimages():
""" Pull in banner images in database """
managepy("seedbannerimages")
apache('restart')
def synconionconfig():
""" Pulls in config from s3. NOT using atm """
managepy("synconionconfig")
def managepy(cmd):
""" Run generic manage.py command """
virtualenv("python manage.py %s --settings=%s" % (cmd, env.settings_module))
def last_commit():
""" Simply outpus the last GIT commit deployed """
with cd(env.project_root):
run('git log -1 --format="%H%n%aD"')
def apache(cmd):
sudo("/etc/init.d/apache2 " + cmd)
def memcache(cmd):
sudo("/etc/init.d/memcached " + cmd)
def celeryd(cmd):
""" Runs celeryd command. Example fab dev celeryd:start """
sudo("%s/celeryd/celeryd %s %s" % (env.project_root, cmd, env.celeryd_conf))
def datadump(dumpmethod,local_file):
"""
Runs datadump on specificed server and
downloads generated file to current directory
"""
# Run command, the last line is the filename (slightly hacky)
file_path = virtualenv('python manage.py datadump %s --settings=%s' % (dumpmethod, env.settings_module))
file_path = file_path.strip()
# Right now just saves to log dir (might be better spot?)
print "Download dump file to %s" % local_file
# Download file
get(file_path, local_file)
# Delete remote file
sudo("rm %s" % file_path) | e3574077942e8472675ad64ab4ba753346040d8f | [
"Python",
"Text",
"HTML"
] | 12 | Python | linares/third-party-experiments | a17ba9f5fa53f8873e3516d1e359070a77ab9902 | 2fd09f40ece1a483733b2052e7fcc42b85bca327 |
refs/heads/master | <file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$userId = $_SESSION['adminID'];
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<!-- Mobile Specific Meta -->
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Favicon-->
<link rel="shortcut icon" href="img/fav.png">
<!-- Author Meta -->
<meta name="author" content="colorlib">
<!-- Meta Description -->
<meta name="description" content="">
<!-- Meta Keyword -->
<meta name="keywords" content="">
<!-- meta character set -->
<meta charset="UTF-8">
<!-- Site Title -->
<title>Disaster Prevention</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>LOGO</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="../dashboard/dashboard.php">Dashboard</a></li>
<li><a href="../videos/video.php">Videos</a></li>
<li><a href="../students/student.php">Students</a></li>
<li><a href="../reports/report.php">Reports</a></li>
<li><a href="../logs/log.php">Activity Logs</a></li>
<li class="menu-has-children"><a href="">Account</a>
<ul>
<li><a href="#" data-toggle="modal" data-target="#editProfileModal" onclick="changeID(<?php echo $userId; ?>, 'edit_prof')">Update Info</a></li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeID(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionAdmin.php">Logout</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<!-- start banner Area -->
<!-- Start top-category-widget Area -->
<section class="relative about-banner" id="home">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
</div>
</div>
</div>
</section>
<!-- End banner Area -->
<section class="top-category-widget-area pt-100 pb-90">
<div class="container">
<h1>Dashboard</h1>
<hr>
<br>
<div class="row">
<div class="col-lg-4">
<div class="single-cat-widget">
<div class="content relative">
<div class="overlay overlay-bg"></div>
<a href="../videos/video.php" style="color: inherit; text-decoration: inherit; ">
<div class="thumb">
<img class="content-image img-fluid d-block mx-auto" src="../../img/animated_video3.jpg" alt="">
</div>
<div class="content-details">
<h4 class="content-title mx-auto text-uppercase">Animated Video</h4>
<span></span>
<p>Upload and Manage videos and exams</p>
</div>
</a>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="single-cat-widget">
<div class="content relative">
<div class="overlay overlay-bg"></div>
<a href="../students/student.php" style="color: inherit; text-decoration: inherit; ">
<div class="thumb">
<img class="content-image img-fluid d-block mx-auto" src="../../img/student3.jpg" alt="">
</div>
<div class="content-details">
<h4 class="content-title mx-auto text-uppercase">Student Info</h4>
<span></span>
<p>View student scores and details</p>
</div>
</a>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="single-cat-widget">
<div class="content relative">
<div class="overlay overlay-bg"></div>
<a href="../reports/report.php" style="color: inherit; text-decoration: inherit; ">
<div class="thumb">
<img class="content-image img-fluid d-block mx-auto" src="../../img/report2.jpg" alt="">
</div>
<div class="content-details">
<h4 class="content-title mx-auto text-uppercase">Chart and Reports</h4>
<span></span>
<p>View and Print multiple reports</p>
</div>
</a>
</div>
</div>
</div>
<div class="col-lg-4">
<div class="single-cat-widget">
<div class="content relative">
<div class="overlay overlay-bg"></div>
<a href="../logs/log.php" style="color: inherit; text-decoration: inherit; ">
<div class="thumb">
<img class="content-image img-fluid d-block mx-auto" src="../../img/report.jpg" alt="">
</div>
<div class="content-details">
<h4 class="content-title mx-auto text-uppercase">Activity Logs</h4>
<span></span>
<p>Track account activities</p>
</div>
</a>
</div>
</div>
</div>
</div>
</div>
</section>
<br>
<br><br>
<div class="modal animated zoomIn" id="editProfileModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Profile</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editProfile">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area">
<div class="container">
</div>
</footer>
<!-- End top-category-widget Area -->
<!-- End footer Area -->
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script type="text/javascript">
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = '../students/changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit_prof')
{
document.getElementById("editProfile").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
</script><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$name = $_POST['nameTxt'];
$description = $_POST['descriptionTxt'];
$fileDir = "../../video/".$_FILES['videoFile']['name'];
$thumbnail = "../../video/thumbnail/".$_FILES['thumbnailFile']['name'];
$video_size = $_FILES['videoFile']['size'];
$thumbnail_size = $_FILES['thumbnailFile']['size'];
$video_tmp = $_FILES['videoFile']['tmp_name'];
$thumbnail_tmp = $_FILES['thumbnailFile']['tmp_name'];
if(!is_dir("../../video/")) {
mkdir("../../video/");
}
if(!is_dir("../../video/thumbnail/")) {
mkdir("../../video/thumbnail/");
}
if($video_size > 2097152 || $thumbnail_size > 2097152) {
$errors[]='File size must be excately 2 MB';
}
if(empty($errors)==true) {
move_uploaded_file($video_tmp,$fileDir);
move_uploaded_file($thumbnail_tmp,$thumbnail);
echo "alert(success)";
echo $sql = "INSERT INTO video(name,description,fileDir,thumbnail) VALUES('$name','$description','$fileDir','$thumbnail')";
$result = mysqli_query($con, $sql);
}else{
print_r($errors);
}
header("Location:video.php");
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$userId = $_SESSION['adminID'];
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<!-- Mobile Specific Meta -->
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Favicon-->
<link rel="shortcut icon" href="img/fav.png">
<!-- Author Meta -->
<meta name="author" content="colorlib">
<!-- Meta Description -->
<meta name="description" content="">
<!-- Meta Keyword -->
<meta name="keywords" content="">
<!-- meta character set -->
<meta charset="UTF-8">
<!-- Site Title -->
<title>Disaster Prevention</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
<link rel="stylesheet" href="../../css/animate.css">
<link rel="stylesheet" href="https://www.w3schools.com/w3css/4/w3.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>LOGO</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="../dashboard/dashboard.php">Dashboard</a></li>
<li><a href="../videos/video.php">Videos</a></li>
<li><a href="../students/student.php">Students</a></li>
<li><a href="../reports/report.php">Reports</a></li>
<li><a href="../logs/log.php">Activity Logs</a></li>
<li class="menu-has-children"><a href=#>Account</a>
<ul>
<li><a href="#" data-toggle="modal" data-target="#editProfileModal" onclick="changeID(<?php echo $userId; ?>, 'edit_prof')">Update Info</a></li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeID(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionAdmin.php">Logout</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<!-- start banner Area -->
<!-- End banner Area -->
<!-- Start top-category-widget Area -->
<section class="relative about-banner" id="home">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
</div>
</div>
</div>
</section>
<!-- Start top-category-widget Area -->
<section class="popular-destination-area section-gap pt-5 pb-0">
<div class="container">
<div class="row">
<div class="col-lg-6">
<h1 class="mb-10">Student Information</h1>
</div>
<div class="col-lg-6">
<a href="#" class="genric-btn info circle" style="float:right" data-toggle="modal" data-target="#addStudentModal" >
<i class="fa fa-print" aria-hidden="true"></i> Print
</a>
<a href="#" class="genric-btn info circle" style="float:right; margin-right: 20px;" data-toggle="modal" data-target="#addStudentModal" >ADD STUDENT</a>
</div>
</div>
<hr>
</div>
</section>
<section class="destinations-area section-gap pt-0">
<div class="container">
<div class="row">
<div class="col-lg-12">
<table width=100% class="table table-bordered" style="background-color: white">
<thead>
<tr>
<th width=5% >ID</th>
<th width=20%>Student No.</th>
<th width=30%>Name</th>
<th width=35%>Email</th>
<th width=10%>Actions</th>
</tr>
</thead>
<tbody>
<?php
$sql = "Select *from user where status=1";
$result = mysqli_query($con, $sql);
while($row = mysqli_fetch_array($result)){
?>
<tr>
<td><?php echo $row['id']; ?></td>
<td><?php echo $row['studNo']; ?></td>
<td><?php echo $row['name']; ?></td>
<td><?php echo $row['email']; ?></td>
<td class="center">
<a class="btn btn-info" href="#" data-toggle="modal" data-target="#editStudentModal" onclick="changeID(<?php echo $row['id']; ?>, 'edit')">
<i class="fa fa-edit" aria-hidden="true"></i>
</a>
<a class="btn btn-danger" href="#" data-toggle="modal" data-target="#deleteStudentModal" onclick="changeID(<?php echo $row['id']; ?>, 'delete')">
<i class="fa fa-trash" aria-hidden="true"></i>
</a>
</td>
</tr>
<?php
}
?>
</tbody>
</table>
<br><br><br><br><br><br><br><br><br><br><br><br><br><br><br>
</div>
</div>
</div>
</section>
<div class="modal animated zoomIn" id="addStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="addStudent.php" method=post id="">
<div class="modal-header">
<h3 style="text-align:center">Add Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<form class="form-wrap" action="addStudent.php" method="post">
<input type="text" required class="form-control" name="studNoTxt" placeholder="Student No." onfocus="this.placeholder = ''" onblur="this.placeholder = 'Student No. '"><br>
<input type="text" required class="form-control" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
<input type="email" required class="form-control" name="emailTxt" placeholder="Email Address " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Email Address '"><br>
<input type="text" required class="form-control" name="usernameTxt" placeholder="Username " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Password '"><br>
<input type="password" required class="form-control" name="passwordTxt" placeholder="<PASSWORD> " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Password '"><br><br>
<button type="submit" name="registerSubmit" class="genric-btn info text-uppercase form-control">Save</button>
</form>
</div>
</form>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="editStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editStudentForm">
<form class="form-horizontal" action="editStudent.php" method=post >
<input type="text" required class="form-control" name="studNoTxt" placeholder="Student No." onfocus="this.placeholder = ''" onblur="this.placeholder = 'Student No. '"><br>
<input type="text" required class="form-control" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
<input type="email" required class="form-control" name="emailTxt" placeholder="Email Address " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Email Address '"><br>
<input type="text" required class="form-control" name="usernameTxt" placeholder="Username " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Username '"><br>
<input type="<PASSWORD>" required class="form-control" name="passwordTxt" placeholder="Password " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Password '"><br>
<button type="submit" name="registerSubmit" class="genric-btn info text-uppercase form-control">Save</button>
</form>
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="deleteStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="deleteStudent.php" method=post id="deleteStudentForm">
<div class="modal-header">
<h3 style="text-align:center">Delete Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<p>Are you sure you want to delete this student</p>
<br>
<button type="submit" class="btn btn-primary" style="width:45%" name="residentSubmit">Yes</button>
<button class="btn btn-default" data-dismiss="modal" style="width:45%; float: right">Cancel</button>
</div>
</form>
</div>
</div>
</div>
<br><br>
<div class="modal animated zoomIn" id="editProfileModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Profile</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editProfile">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area">
<div class="container">
</div>
</footer>
<!-- End top-category-widget Area -->
<!-- End footer Area -->
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
<script type="text/javascript">
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = 'changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit')
{
document.getElementById("editStudentForm").innerHTML = xhr.responseText;
}
else if(type==='delete')
{
document.getElementById("deleteStudentForm").action = "deleteStudent.php?id="+xhr.responseText+"";
}
else if(type==='edit_prof')
{
document.getElementById("editProfile").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
// ajax stop
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
</script>
</body>
</html>
<file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$id = $_GET['id'];
$sql = "DELETE FROM user where id='$id'";
echo $sql = "Update video Set status=0 where id = $id";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Deleted a video.');
echo "<script>alert('Delete Successful');
window.location.href = 'video.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'video.php' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$userId = $_SESSION['adminID'];
$date = date("Y-m-d H:i:s");
$scheduleID = 0;
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<!-- Mobile Specific Meta -->
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Favicon-->
<link rel="shortcut icon" href="img/fav.png">
<!-- Author Meta -->
<meta name="author" content="colorlib">
<!-- Meta Description -->
<meta name="description" content="">
<!-- Meta Keyword -->
<meta name="keywords" content="">
<!-- meta character set -->
<meta charset="UTF-8">
<!-- Site Title -->
<title>Disaster Prevention</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>LOGO</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="../dashboard/dashboard.php">Dashboard</a></li>
<li><a href="../videos/video.php">Videos</a></li>
<li><a href="../students/student.php">Students</a></li>
<li><a href="../reports/report.php">Reports</a></li>
<li><a href="../logs/log.php">Activity Logs</a></li>
<li class="menu-has-children"><a href=#>Account</a>
<ul>
<li><a href="#" data-toggle="modal" data-target="#editProfileModal" onclick="changeIDprofile(<?php echo $userId; ?>, 'edit_prof')">Update Info</a></li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeIDprofile(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionAdmin.php">Logout</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<!-- start banner Area -->
<section class="relative about-banner" id="home">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
</div>
</div>
</div>
</section>
<!-- End banner Area -->
<!-- Start top-category-widget Area -->
<!-- Start top-category-widget Area -->
<section class="popular-destination-area section-gap pt-5 pb-0">
<div class="container">
<div class="row">
<div class="col-lg-6">
<h1>Animated videos</h1>
</div>
<div class="col-lg-6">
<?php /*
$sqlSched = "SELECT *from schedule
WHERE '$date' BETWEEN startDate AND endDate AND status = 1";
$resultSched = mysqli_query($con, $sqlSched);
if(mysqli_fetch_row($resultSched)>0)
{
<a href="#" class="genric-btn info circle" style="float:right; margin-right: 20px;" data-toggle="modal" data-target="#updateScheduleModal" >Update Schedule</a>
}
else
{
<a href="#" class="genric-btn info circle" style="float:right; margin-right: 20px;" data-toggle="modal" data-target="#setScheduleModal" >Set Schedule</a>
}
*/
?>
<a href="#" class="genric-btn info circle" style="float:right; margin-right: 20px;" data-toggle="modal" data-target="#uploadModal" >Upload Video</a>
</div>
</div>
<hr>
</div>
</section>
<section class="destinations-area section-gap pt-0">
<div class="container">
<div class="row">
<?php
$sql = "Select A.*, B.id AS 'sV', C.id as sID
from video A
INNER JOIN schedule_video B ON A.id = B.videoID
INNER JOIN schedule C ON B.scheduleID = C.id
WHERE '$date' BETWEEN C.startDate AND C.endDate AND A.status = 1";
$result = mysqli_query($con, $sql);
while($row = mysqli_fetch_array($result)){
$scheduleID = $row['sID'];
?>
<div class="col-lg-4">
<div class="single-destinations video-box">
<div class="thumb relative">
<div class="overlay overlay-bg"></div>
<img style="width: 50%; height: 50%" class="content-image img-fluid d-block mx-auto" src="<?php echo $row['thumbnail']; ?>" alt="">
</div>
<div class="details">
<h4 style="font-weight: bold; text-align:center"><?php echo $row['name']; ?></h4>
<p>
<?php echo $row['description']; ?>
</p>
<ul class="package-list">
<li class="d-flex justify-content-between align-items-center">
<span>Passed</span>
<span>0</span>
</li>
<li class="d-flex justify-content-between align-items-center">
<span>Failed</span>
<span>0</span>
</li>
<li class="d-flex justify-content-between align-items-center">
<span>Questions</span>
<span>3</span>
</li>
<li class="d-flex justify-content-between align-items-center">
<a href="updateVideo.php?videoID=<?php echo $row['id']; ?>" class="genric-btn info circle" style="float:right; margin-right: 20px; width:100%" >Update</a>
</li>
<li class="d-flex justify-content-between align-items-center">
<a href="#" class="genric-btn danger circle" style="float:right; margin-right: 20px; width:100%" data-toggle="modal" data-target="#deleteVideoModal" onclick="changeID(<?php echo $row['id']; ?>, 'delete')" >Delete</a>
</li>
</ul>
</div>
</div>
</div>
<?php
}
?>
</div>
</div>
</section>
<div class="modal animated zoomIn" id="uploadModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="addVideo.php" method=post id="uploadForm" enctype = "multipart/form-data">
<div class="modal-header">
<h3 style="text-align:center">Upload Video</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<input type="text" class="form-control" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
<textarea class="form-control" name="descriptionTxt" placeholder="Description" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Description'" required></textarea>
<br>Thumbnail
<input type="file" class="form-control" name="thumbnailFile">
<br>
Video
<input type="file" class="form-control" name="videoFile">
<br>
<button type="submit" class="btn btn-primary" style="width:100%" name="residentSubmit">Save</button>
</div>
</form>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="setScheduleModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class=row>
<div class="col-lg-12">
<form class="form-horizontal" action="setSchedule.php" method=post id="uploadForm" enctype = "multipart/form-data">
<div class="modal-header">
<h3 style="text-align:center">Set Schedule</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
Start Date
<input type="datetime-local" class="form-control" name="startDateTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
End Date
<input type="datetime-local" class="form-control" name="endDateTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
<button type="submit" class="btn btn-primary" style="width:100%" name="residentSubmit">Save</button>
</div>
</form>
</div>
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="updateScheduleModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class=row>
<div class="col-lg-12">
<form class="form-horizontal" action="setSchedule.php" method=post id="uploadForm" enctype = "multipart/form-data">
<div class="modal-header">
<h3 style="text-align:center">Update Schedule</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
Start Date
<input type="datetime-local" class="form-control" name="startDateTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
End Date
<input type="datetime-local" class="form-control" name="endDateTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '"><br>
<button type="submit" class="btn btn-primary" style="width:100%" name="residentSubmit">Save</button>
</div>
</form>
</div>
</div>
<div class="row">
<div class="col-lg-12">
<h4 style="border-bottom:1px solid #e6e6e6"><b>Current Videos</b></h4>
<br>
</div>
<?php
$sql2 = "SELECT B.* from schedule_video A
INNER JOIN video B ON A.videoID = B.id
where A.scheduleID = $scheduleID";
$result2 = mysqli_query($con, $sql2);
if(mysqli_fetch_row($result2)>0)
{
while($row2 = mysqli_fetch_array($result2))
{
?>
<div class="col-lg-12">
<button class="genric-btn danger-border radius" style=" margin: 3px auto; float:left;">
<i class="fa fa-plus fa-fw"></i>
<?php
echo $row2['name'];
?>
</button>
</div>
<?php
}
}
else
{
?>
<div class="col-lg-12">
<?php
echo "none";
?>
</div>
<?php
}
?>
</div>
<div class="row">
<div class="col-lg-12">
<br>
<h4 style="border-bottom:1px solid #e6e6e6"><b>Available Videos</b></h4>
<br>
</div>
<?php
$sql3 = "SELECT *from video
where id NOT IN (Select videoID from schedule_video where scheduleID = $scheduleID)";
$result3 = mysqli_query($con, $sql3);
while($row3 = mysqli_fetch_array($result3))
{
?>
<div class="col-lg-12">
<button class="genric-btn success-border radius" style="margin-bottom: 3px; margin-left: 10px; padding-top: 1px; padding-bottom:1px; float:left;">
<i class="fa fa-plus fa-fw"></i>
<?php
echo $row3['name'];
?>
</button>
</div>
<?php
}
?>
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="deleteVideoModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="deleteVideo.php" method=post id="deleteVideoForm">
<div class="modal-header">
<h3 style="text-align:center">Delete Video</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<p>Are you sure you want to delete this video</p>
<br>
<button type="submit" class="btn btn-primary" style="width:45%" name="residentSubmit">Yes</button>
<button class="btn btn-default" data-dismiss="modal" style="width:45%; float: right">Cancel</button>
</div>
</form>
</div>
</div>
</div>
<br><br>
<div class="modal animated zoomIn" id="editProfileModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Profile</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editProfile">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area">
<div class="container">
</div>
</footer>
<!-- End top-category-widget Area -->
<!-- End footer Area -->
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
<script type="text/javascript">
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = 'changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit')
{
document.getElementById("editStudentForm").innerHTML = xhr.responseText;
}
else if(type==='delete')
{
document.getElementById("deleteVideoForm").action = "deleteVideo.php?id="+xhr.responseText+"";
}
}
xhr.send();
// ajax stop
return false;
}
function changeIDprofile(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = '../students/changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit_prof')
{
document.getElementById("editProfile").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
// ajax stop
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
</script>
</body>
</html><file_sep>-- phpMyAdmin SQL Dump
-- version 4.7.4
-- https://www.phpmyadmin.net/
--
-- Host: 127.0.0.1
-- Generation Time: Mar 09, 2019 at 04:15 AM
-- Server version: 10.1.28-MariaDB
-- PHP Version: 7.1.10
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Database: `disasterdb`
--
-- --------------------------------------------------------
--
-- Table structure for table `admin`
--
CREATE TABLE `admin` (
`id` int(11) NOT NULL,
`username` varchar(50) NOT NULL,
`password` varchar(50) NOT NULL,
`name` varchar(100) NOT NULL,
`email` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `admin`
--
INSERT INTO `admin` (`id`, `username`, `password`, `name`, `email`, `dateCreated`, `status`) VALUES
(1, 'admin', '<PASSWORD>', 'admin', 'admin', '2019-02-28 01:56:01', 1);
-- --------------------------------------------------------
--
-- Table structure for table `evaluation`
--
CREATE TABLE `evaluation` (
`id` int(11) NOT NULL,
`videoID` int(11) NOT NULL,
`question` text NOT NULL,
`answer` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `evaluation`
--
INSERT INTO `evaluation` (`id`, `videoID`, `question`, `answer`, `dateCreated`, `status`) VALUES
(1, 1, 'question 1', 'answer', '2019-03-05 00:00:00', 1),
(2, 1, 'question 2', 'answer', '2019-03-05 00:00:00', 1),
(3, 1, 'question 3', 'answer', '2019-03-05 00:00:00', 1),
(4, 1, 'wow', '', '2019-03-09 10:22:32', 0);
-- --------------------------------------------------------
--
-- Table structure for table `evaluation_choices`
--
CREATE TABLE `evaluation_choices` (
`id` int(11) NOT NULL,
`evaluationID` int(11) NOT NULL,
`choice` varchar(150) NOT NULL,
`isCorrect` int(1) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `evaluation_choices`
--
INSERT INTO `evaluation_choices` (`id`, `evaluationID`, `choice`, `isCorrect`, `dateCreated`, `status`) VALUES
(1, 1, 'choice 1', 1, '2019-03-05 00:00:00', 1),
(2, 1, 'choice 2', 0, '2019-03-05 00:00:00', 1),
(3, 1, 'choice 3', 0, '2019-03-05 00:00:00', 1),
(4, 2, 'choice 1', 0, '2019-03-05 00:00:00', 1),
(5, 2, 'choice 2', 1, '2019-03-05 00:00:00', 1),
(6, 2, 'choice 3', 0, '2019-03-05 00:00:00', 1),
(7, 3, 'choice 1', 1, '2019-03-05 00:00:00', 1),
(8, 3, 'choice 2', 0, '2019-03-05 00:00:00', 1),
(9, 3, 'choice 3', 0, '2019-03-05 00:00:00', 1),
(10, 3, 'yeah', 0, '2019-03-09 10:31:54', 0);
-- --------------------------------------------------------
--
-- Table structure for table `logs`
--
CREATE TABLE `logs` (
`id` int(11) NOT NULL,
`userID` int(11) NOT NULL,
`userType` varchar(15) NOT NULL,
`description` text NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `logs`
--
INSERT INTO `logs` (`id`, `userID`, `userType`, `description`, `dateCreated`, `status`) VALUES
(1, 1, 'admin', 'Logged in', '2019-03-06 17:12:25', 1),
(2, 1, 'admin', 'Added new question', '2019-03-06 17:13:39', 1),
(3, 1, 'admin', 'Added new question', '2019-03-06 17:13:52', 1),
(4, 1, 'admin', 'Deleted a student.', '2019-03-06 17:14:38', 1),
(5, 1, 'admin', 'Logged out', '2019-03-06 17:15:07', 1),
(6, 2, 'user', 'Logged in', '2019-03-06 17:15:14', 1),
(7, 2, 'user', 'Logged out', '2019-03-06 17:16:53', 1),
(8, 2, 'user', 'Logged in', '2019-03-06 17:23:58', 1),
(9, 2, 'user', 'Logged out', '2019-03-06 17:24:07', 1),
(10, 1, 'admin', 'Logged in', '2019-03-06 17:24:09', 1),
(11, 1, 'admin', 'Deleted a video.', '2019-03-06 17:24:50', 1),
(12, 1, 'admin', 'Logged out', '2019-03-06 17:25:14', 1),
(13, 2, 'user', 'Logged in', '2019-03-06 17:25:21', 1),
(14, 1, 'admin', 'Logged in', '2019-03-08 20:53:07', 1),
(15, 1, 'user', 'Change Admin Password', '2019-03-08 21:22:06', 1),
(16, 1, 'admin', 'Logged out', '2019-03-08 21:22:14', 1),
(17, 1, 'admin', 'Logged in', '2019-03-08 21:22:33', 1),
(18, 1, 'admin', 'Logged in', '2019-03-09 09:38:53', 1),
(19, 1, 'admin', 'Added new question', '2019-03-09 10:22:32', 1),
(20, 1, 'admin', 'Added new question', '2019-03-09 10:31:54', 1),
(21, 1, 'admin', 'Deleted a option from a question.', '2019-03-09 10:33:44', 1);
-- --------------------------------------------------------
--
-- Table structure for table `schedule`
--
CREATE TABLE `schedule` (
`id` int(11) NOT NULL,
`startDate` datetime NOT NULL,
`endDate` datetime NOT NULL,
`videoID` int(11) NOT NULL,
`dateCreated` datetime NOT NULL,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Table structure for table `user`
--
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`studNo` varchar(50) NOT NULL,
`username` varchar(50) NOT NULL,
`password` varchar(50) NOT NULL,
`name` varchar(100) NOT NULL,
`email` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user`
--
INSERT INTO `user` (`id`, `studNo`, `username`, `password`, `name`, `email`, `dateCreated`, `status`) VALUES
(1, 'S2019123456', 'test123', 'cc03e747a6afbbcbf8be7668acfebee5', 'John Doe', '<EMAIL>', '2019-02-28 10:56:24', 0),
(2, '1', 'a', '0cc175b9c0f1b6a831c399e269772661', 'a', 'a', '2019-03-04 10:32:06', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user_certificates`
--
CREATE TABLE `user_certificates` (
`id` int(11) NOT NULL,
`userID` int(11) NOT NULL,
`videoID` int(11) NOT NULL,
`year` int(11) NOT NULL,
`isWatch` int(11) NOT NULL,
`scoreStatus` int(11) DEFAULT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user_certificates`
--
INSERT INTO `user_certificates` (`id`, `userID`, `videoID`, `year`, `isWatch`, `scoreStatus`, `dateCreated`, `status`) VALUES
(6, 2, 1, 2019, 1, 2, '2019-03-05 20:50:25', 1),
(7, 0, 1, 2019, 1, NULL, '2019-03-05 23:17:11', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user_certificates_detail`
--
CREATE TABLE `user_certificates_detail` (
`id` int(11) NOT NULL,
`userCertID` int(11) NOT NULL,
`score` int(11) NOT NULL,
`dateCreated` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user_certificates_detail`
--
INSERT INTO `user_certificates_detail` (`id`, `userCertID`, `score`, `dateCreated`) VALUES
(1, 6, 2, '2019-03-05 20:57:41'),
(2, 6, 2, '2019-03-05 20:58:27'),
(3, 6, 1, '2019-03-05 20:58:27');
-- --------------------------------------------------------
--
-- Table structure for table `video`
--
CREATE TABLE `video` (
`id` int(11) NOT NULL,
`name` varchar(100) NOT NULL,
`description` text NOT NULL,
`fileDir` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1',
`thumbnail` varchar(500) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `video`
--
INSERT INTO `video` (`id`, `name`, `description`, `fileDir`, `dateCreated`, `status`, `thumbnail`) VALUES
(1, 'Fire Disaster Preparedness', ' \r\n \r\n \r\n Fire is one of the most common disasters. Fire causes more deaths than any other type of disaster. But fire doesn\'t have to be deadly if you have early warning from a smoke detector and everyone in your family and friends knows how to escape calmly. Watch the video for more information. ', '../../video/sandglass-300x420.swf', '2019-03-05 00:00:00', 1, '../../video/thumbnail/fire.gif'),
(7, 'test', 'test123', '../../video/sandglass-300x420.swf', '2019-03-06 13:31:17', 0, '../../video/thumbnail/1.png'),
(8, '', ' \r\n ', '../../video/sandglass-300x420.swf', '2019-03-06 14:37:43', 0, '../../video/thumbnail/scary-face-519x390.jpg');
--
-- Indexes for dumped tables
--
--
-- Indexes for table `admin`
--
ALTER TABLE `admin`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `evaluation`
--
ALTER TABLE `evaluation`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `evaluation_choices`
--
ALTER TABLE `evaluation_choices`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `logs`
--
ALTER TABLE `logs`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `schedule`
--
ALTER TABLE `schedule`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user`
--
ALTER TABLE `user`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user_certificates`
--
ALTER TABLE `user_certificates`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user_certificates_detail`
--
ALTER TABLE `user_certificates_detail`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `video`
--
ALTER TABLE `video`
ADD PRIMARY KEY (`id`);
--
-- AUTO_INCREMENT for dumped tables
--
--
-- AUTO_INCREMENT for table `admin`
--
ALTER TABLE `admin`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=2;
--
-- AUTO_INCREMENT for table `evaluation`
--
ALTER TABLE `evaluation`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=5;
--
-- AUTO_INCREMENT for table `evaluation_choices`
--
ALTER TABLE `evaluation_choices`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=11;
--
-- AUTO_INCREMENT for table `logs`
--
ALTER TABLE `logs`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=22;
--
-- AUTO_INCREMENT for table `schedule`
--
ALTER TABLE `schedule`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
--
-- AUTO_INCREMENT for table `user`
--
ALTER TABLE `user`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
--
-- AUTO_INCREMENT for table `user_certificates`
--
ALTER TABLE `user_certificates`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=8;
--
-- AUTO_INCREMENT for table `user_certificates_detail`
--
ALTER TABLE `user_certificates_detail`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=4;
--
-- AUTO_INCREMENT for table `video`
--
ALTER TABLE `video`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=9;
COMMIT;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$video_id = $_GET['videoID'];
//check if record exist
$editQuestionID=0;
if(isset($_GET['editQuestionID']))
{
$editQuestionID = $_GET['editQuestionID'];
}
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="author" content="colorlib">
<meta name="description" content="">
<meta name="keywords" content="">
<meta charset="UTF-8">
<title>Video Details</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>Logo</h3>
</div>
<nav id="nav-menu-container">
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="../dashboard/dashboard.php">Dashboard</a></li>
<li><a href="../videos/video.php">Videos</a></li>
<li><a href="../students/student.php">Students</a></li>
<li><a href="../reports/report.php">Reports</a></li>
<li><a href="../logs/log.php">Activity Logs</a></li>
<li class="menu-has-children"><a href=#>Account</a>
<ul>
<li><a href="../updateInfo/updateinfo.php">Update Info</a></li>
<li><a href="../changePassword/changePassword.php">Change Password</a></li>
<li><a href="../logoutSessionAdmin.php">Logout</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<section class="about-banner relative">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
<h1 class="text-white">
</h1>
</div>
</div>
</div>
</section>
<?php
$sql1 = "Select * from video where id='$video_id'";
$result1 = mysqli_query($con, $sql1);
if(mysqli_num_rows($result1)>0)
{
while($row1 = mysqli_fetch_array($result1)){
$path = $row1['fileDir'];
$video_title =$row1['name'];
$desc = $row1['description'];
}
}
?>
<section class="destinations-area pt-20">
<?php
if(isset($_GET['editVideo']))
{
?>
<form action="updateVideoDetails.php?id=<?php echo $video_id; ?>" method=post enctype = "multipart/form-data">
<h1 class="pb-10 d-flex justify-content-center"><b> </b></h1>
<div class="container">
<input type="text" class="form-control" style="width:100%" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '" value= "<?php echo $video_title;?>">
<br><div class="row">
<div class="map-wrap" style="width:100%; height: 445px; box-shadow: 0px 10px 30px 0px rgba(60, 64, 143, 0.3);">
<embed style="width:100%; height: 400px; play="true" loop="false" menu="true" src="<?php echo $path; ?>">
<b>Video File</b>
<input type="file" name="videoFile" >
<input type="hidden" name="videoFile_tmp" value = "<?php echo $path; ?>" >
<b>
Thumbnail
</b>
<input type="file" name="thumbnailFile" >
<input type="hidden" name="thumbnailFile_tmp" value = "<?php echo $path; ?>" >
<br><br>
</div>
</div>
<div class="row">
<div class="col-lg-2">
</div>
<div class="pb-20 pt-20 col-lg-8">
<textarea class="form-control" rows=7 name="descriptionTxt" placeholder="Description" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Description'" required>
<?php echo $desc; ?>
</textarea>
</div>
</div>
</div><div class="container">
<a href="updateVIdeo.php?videoID=<?php echo $video_id; ?>" ><button class="primary-btn text-uppercase text-center" style="float:right; background-color:gray;">CANCEL</button>
<button id="btn_submit" name="save_video" class="primary-btn text-uppercase text-center" style="float:right; margin-right: 10px">SAVE VIDEO</button>
</div>
</form>
<?php
}
else
{
?>
<h1 class="pb-10 d-flex justify-content-center">
<b> <?php echo $video_title;?></b>
</h1>
<div class="container">
<div class="row">
<div class="map-wrap" style="width:100%; height: 445px; box-shadow: 0px 10px 30px 0px rgba(60, 64, 143, 0.3);">
<embed style="width:100%; height: 400px; play="true" loop="false" menu="true" src="<?php echo $path?>">
</div>
</div>
<div class="row d-flex justify-content-center">
<div class=" pb-20 col-lg-8 text-center">
<p class="pt-20 font-weight-bold"><?php echo $desc; ?></p>
</div>
</div>
<div class="row">
<div class="col-lg-12">
<a href="updateVideo.php?videoID=<?php echo $video_id; ?>&editVideo=true" class="genric-btn info radius" style="float:right; background-color: #f8b600" >UPDATE VIDEO DETIALS</a>
</div>
</div>
</div>
<?php
}
?>
</section>
<br><br><br>
<hr>
<section class="price-area pt-20 pb-20">
<div class="container">
<h1 style="text-align:center">Exam</h1>
<a href="#" class="genric-btn info radius" style="float:right;" data-toggle="modal" data-target="#addQuestionModal" >Add Question</a>
</div>
<br>
<br><br>
<form class="form-wrap" action="updateQuestion.php?videoID=<?php echo $video_id; ?>&questionID=<?php echo $editQuestionID; ?>" method="POST">
<div class="container" style="width:90%; box-shadow: 0px 10px 10px 0px rgba(60, 64, 143, 0.3);">
<div class="row d-flex justify-content-center">
<div class="menu-content col-lg-8">
</div>
</div>
<div class="row">
<?php
$sql2 = "SELECT A.id, A.question
FROM evaluation A
INNER JOIN video B ON A.videoID = B.id
WHERE A.videoID ='$video_id' and A.status = 1";
$result2 = mysqli_query($con, $sql2);
if(mysqli_num_rows($result2)>0)
{
while($row2 = mysqli_fetch_array($result2)){
$evalId = $row2['id'];
?>
<div class="col-lg-12">
<?php
if($editQuestionID == $evalId)
{
?>
<?php
}
else
{
?>
<button type="button" style="float:right; margin:5px; padding:0" class="close" data-toggle="modal" data-target="#deleteQuestionModal" onclick="deleteQuestionID(<?php echo $row2['id']; ?>)"><i class="fa fa-times" aria-hidden="true"></i></button>
<i style="float:right; margin:10px; padding:0; font-size: 1.5em" class="fa fa-edit close" aria-hidden="true" onclick="editQuestionID(<?php echo $row2['id']; ?>)" > </i>
<?php
}
?>
<div class="single-price pt-5 pb-0" style=" <?php if($editQuestionID == $evalId) echo "background-color:white"; ?>">
<h4 class="text-uppercase">
<?php
if($editQuestionID == $evalId)
{
?>
<input type="text" class="form-control" name="questionTxt" value="<?php echo $row2['question']?>">
<?php
}
else
{
echo $row2['question'];
}
?>
</h4>
<ul class="price-list">
<?php
$sql3 = "SELECT B.id, B.choice, B.isCorrect
FROM evaluation A
INNER JOIN evaluation_choices B ON A.id = B.evaluationID
WHERE A.id = '$evalId' and B.status = 1";
$result3 = mysqli_query($con, $sql3);
$choiceCounter=0;
if(mysqli_num_rows($result3)>0)
{
while($row3 = mysqli_fetch_array($result3))
{
if($editQuestionID == $evalId)
{
?>
<li class="d-flex align-items-center">
<div class="primary-radio">
<input type="radio" name="choiceAnswer" id="default-radio_<?php echo $choiceCounter; ?>" value="<?php echo $row3['id']; ?>" <?php if($row3['isCorrect'] == 1) echo "checked"; ?> style="float:left; ">
<label for="default-radio_<?php echo $choiceCounter; ?>" ></label>
</div>
<label class="text-uppercase" >
<input type="hidden" class="form-control" name="choiceID_<?php echo $choiceCounter; ?>" value="<?php echo $row3['id'] ?>">
<input type="text" class="form-control" name="choiceTxt_<?php echo $choiceCounter; ?>" value="<?php echo $row3['choice'] ?>">
</label>
</li>
<?php
}
else
{
?>
<li class="d-flex justify-content-between align-items-center">
<p>
<label class="text-uppercase">
<?php echo $row3['choice'] ?>
</label>
<button type="button" style=" margin-left:10px;" class="btn btn-danger" data-toggle="modal" data-target="#deleteChoiceModal" onclick="deleteChoiceID(<?php echo $row3['id'];?>)"><i class="fa fa-trash" aria-hidden="true"></i></button>
<?php
if($row3['isCorrect'] == 1)
{
echo "<i>Answer</i>";
}
?>
</p>
</li>
<?php
}
$choiceCounter++;
}
?>
<input type="hidden" class="form-control" name="choiceCounter" value="<?php echo $choiceCounter; ?>">
<?php
}
?>
</ul>
<?php if($editQuestionID == $evalId)
{
?>
<button id="btn_submit" name="save_video" class="primary-btn text-uppercase text-center" style="float:right; background-color:gray;">CANCEL</button>
<button id="btn_submit" name="save_video" class="primary-btn text-uppercase text-center" style="float:right; margin-right: 10px;">SAVE</button>
<?php
}
else
{
?>
<a href="#" class="genric-btn success radius" style="float:left;" data-toggle="modal" data-target="#addChoiceModal" onclick="choicesIDChange(<?php echo $row2['id']; ?>)" >Add Choices</a>
<?php
}
?>
<br><br><hr>
</div>
</div>
<?php
}
}
?>
</div>
</div>
<br>
<div class="container">
</div><br><br>
</form>
</section>
<div class="modal animated zoomIn" id="addQuestionModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="addQuestion.php?videoID=<?php echo $video_id; ?>" method=post>
<div class="modal-header">
<h3 style="text-align:center">Add Question</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<textarea class="form-control" name="questionTxt" placeholder="Question" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Question'" required></textarea>
<br>
<button type="submit" class="btn btn-primary" style="width:100%" name="residentSubmit">Save</button>
</div>
</form>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="addChoiceModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="addChoice.php" method=post id=addChoiceForm >
<div class="modal-header">
<h3 style="text-align:center">Add Choices</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<input type=text class="form-control" name="choiceTxt" placeholder="Choices" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Choices'" required>
<br>
<button type="submit" class="btn btn-primary" style="width:100%" name="residentSubmit">Save</button>
</div>
</form>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="deleteQuestionModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="deleteQuestion.php" method=post id="deleteQuestionForm">
<div class="modal-header">
<h3 style="text-align:center">Delete Question</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<p>Are you sure you want to delete this question?</p>
<br>
<button type="submit" class="btn btn-primary" style="width:45%" name="residentSubmit">Yes</button>
<button class="btn btn-default" data-dismiss="modal" style="width:45%; float: right">Cancel</button>
</div>
</form>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="deleteChoiceModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<form class="form-horizontal" action="deleteChoice.php" method=post id="deleteChoiceForm">
<div class="modal-header">
<h3 style="text-align:center">Delete Choice</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body">
<p>Are you sure you want to delete this choice?</p>
<br>
<button type="submit" class="btn btn-primary" style="width:45%" name="residentSubmit">Yes</button>
<button class="btn btn-default" data-dismiss="modal" style="width:45%; float: right">Cancel</button>
</div>
</form>
</div>
</div>
</div>
<footer class="footer-area section-gap pt-20"></footer>
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script>
$('#btn_view_exam').click(function(){
$('#exam_collapse').slideToggle('slow');
});
function choicesIDChange(id)
{
document.getElementById("addChoiceForm").action = "addChoice.php?videoID=<?php echo $video_id; ?>&questionID="+id;
}
function deleteQuestionID(id)
{
document.getElementById("deleteQuestionForm").action = "deleteQuestion.php?videoID=<?php echo $video_id; ?>&questionID="+id;
}
function deleteChoiceID(id)
{
document.getElementById("deleteChoiceForm").action = "deleteChoice.php?videoID=<?php echo $video_id; ?>&choiceID="+id;
}
function editQuestionID(id)
{
window.location.href = 'updateVideo.php?videoID=<?php echo $video_id; ?>&editQuestionID='+id;
}
</script><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$id = $_GET['id'];
$name = $_POST['nameTxt'];
$description = $_POST['descriptionTxt'];
$fileDir = "../../video/".$_FILES['videoFile']['name'];
$fileDir_tmp = $_POST['videoFile_tmp'];
$thumbnail = "../../video/thumbnail/".$_FILES['thumbnailFile']['name'];
$video_size = $_FILES['videoFile']['size'];
$thumbnail_size = $_FILES['thumbnailFile']['size'];
$video_tmp = $_FILES['videoFile']['tmp_name'];
$thumbnail_tmp = $_FILES['thumbnailFile']['tmp_name'];
if(!is_dir("../../video/")) {
mkdir("../../video/");
}
if(!is_dir("../../video/thumbnail/")) {
mkdir("../../video/thumbnail/");
}
if($video_size > 2097152 || $thumbnail_size > 2097152) {
$errors[]='File size must be excately 2 MB';
}
if(empty($errors)==true) {
if( $_FILES['videoFile']['name'] != "")
{
move_uploaded_file($video_tmp,$fileDir);
if($fileDir_tmp != $fileDir)
{
unlink($fileDir_tmp);
}
}
else{
$fileDir = $fileDir_tmp;
}
if( $_FILES['thumbnailFile']['name'] != "")
{
move_uploaded_file($thumbnail_tmp,$thumbnail);
if($thumbnail_tmp != $thumbnail)
{
unlink($thumbnail_tmp);
}
}
else{
$thumbnail = $thumbnail_tmp;
}
echo "alert(success)";
echo $sql = "Update video set name='$name' , description= \"".$description."\", fileDir = '$fileDir', thumbnail='$thumbnail' where id = $id";
$result = mysqli_query($con, $sql);
}else{
print_r($errors);
}
header("Location:updateVideo.php?videoID=$id");
?><file_sep><?php
function addLogs($id,$userType,$description)
{
$sql = "INSERT INTO logs(userID,userType,description) VALUES($userID,'userType','$description')";
$result = mysqli_query($con, $sql);
}
?><file_sep>-- phpMyAdmin SQL Dump
-- version 4.7.4
-- https://www.phpmyadmin.net/
--
-- Host: 127.0.0.1
-- Generation Time: Mar 14, 2019 at 06:21 AM
-- Server version: 10.1.28-MariaDB
-- PHP Version: 7.1.10
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET AUTOCOMMIT = 0;
START TRANSACTION;
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Database: `disasterdb`
--
-- --------------------------------------------------------
--
-- Table structure for table `admin`
--
CREATE TABLE `admin` (
`id` int(11) NOT NULL,
`username` varchar(50) NOT NULL,
`password` varchar(50) NOT NULL,
`name` varchar(100) NOT NULL,
`email` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `admin`
--
INSERT INTO `admin` (`id`, `username`, `password`, `name`, `email`, `dateCreated`, `status`) VALUES
(1, 'admin', '<PASSWORD>', 'admin', 'admin', '2019-02-28 01:56:01', 1);
-- --------------------------------------------------------
--
-- Table structure for table `evaluation`
--
CREATE TABLE `evaluation` (
`id` int(11) NOT NULL,
`videoID` int(11) NOT NULL,
`question` text NOT NULL,
`answer` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `evaluation`
--
INSERT INTO `evaluation` (`id`, `videoID`, `question`, `answer`, `dateCreated`, `status`) VALUES
(1, 1, 'question 1', 'answer', '2019-03-05 00:00:00', 1),
(2, 1, 'question 2', 'answer', '2019-03-05 00:00:00', 1),
(3, 1, 'question 3', 'answer', '2019-03-05 00:00:00', 1);
-- --------------------------------------------------------
--
-- Table structure for table `evaluation_choices`
--
CREATE TABLE `evaluation_choices` (
`id` int(11) NOT NULL,
`evaluationID` int(11) NOT NULL,
`choice` varchar(150) NOT NULL,
`isCorrect` int(1) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `evaluation_choices`
--
INSERT INTO `evaluation_choices` (`id`, `evaluationID`, `choice`, `isCorrect`, `dateCreated`, `status`) VALUES
(1, 1, 'choice 1', 0, '2019-03-05 00:00:00', 1),
(2, 1, 'choice 2', 1, '2019-03-05 00:00:00', 1),
(3, 1, 'choice 3', 0, '2019-03-05 00:00:00', 1),
(4, 2, 'choice 1', 0, '2019-03-05 00:00:00', 1),
(5, 2, 'choice 2', 0, '2019-03-05 00:00:00', 1),
(6, 2, 'choice 3', 1, '2019-03-05 00:00:00', 1),
(7, 3, 'choice 1', 1, '2019-03-05 00:00:00', 1),
(8, 3, 'choice 2', 0, '2019-03-05 00:00:00', 1),
(9, 3, 'choice 3', 0, '2019-03-05 00:00:00', 1),
(10, 3, 'yeah', 0, '2019-03-09 10:31:54', 0),
(11, 3, 'wew', 0, '2019-03-09 12:27:15', 0);
-- --------------------------------------------------------
--
-- Table structure for table `logs`
--
CREATE TABLE `logs` (
`id` int(11) NOT NULL,
`userID` int(11) NOT NULL,
`userType` varchar(15) NOT NULL,
`description` text NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `logs`
--
INSERT INTO `logs` (`id`, `userID`, `userType`, `description`, `dateCreated`, `status`) VALUES
(1, 1, 'user', 'Change Admin Password', '2019-03-14 13:20:35', 1),
(2, 1, 'user', 'Change Admin Password', '2019-03-14 13:20:57', 1);
-- --------------------------------------------------------
--
-- Table structure for table `schedule`
--
CREATE TABLE `schedule` (
`id` int(11) NOT NULL,
`startDate` datetime NOT NULL,
`endDate` datetime NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `schedule`
--
INSERT INTO `schedule` (`id`, `startDate`, `endDate`, `dateCreated`, `status`) VALUES
(7, '2019-01-01 00:00:00', '2019-12-31 23:59:00', '2019-03-14 13:11:59', 1);
-- --------------------------------------------------------
--
-- Table structure for table `schedule_video`
--
CREATE TABLE `schedule_video` (
`id` int(11) NOT NULL,
`scheduleID` int(11) NOT NULL,
`videoID` int(11) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `schedule_video`
--
INSERT INTO `schedule_video` (`id`, `scheduleID`, `videoID`, `dateCreated`, `status`) VALUES
(3, 7, 1, '2019-03-14 13:14:43', 1),
(4, 7, 7, '2019-03-14 13:14:43', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user`
--
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`studNo` varchar(50) NOT NULL,
`username` varchar(50) NOT NULL,
`password` varchar(50) NOT NULL,
`name` varchar(100) NOT NULL,
`email` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user`
--
INSERT INTO `user` (`id`, `studNo`, `username`, `password`, `name`, `email`, `dateCreated`, `status`) VALUES
(1, 'S2019123456', 'test123', '<PASSWORD>', 'John Doe', '<EMAIL>', '2019-02-28 10:56:24', 0),
(2, '1', 'a', '0<PASSWORD>', 'a', 'a', '2019-03-04 10:32:06', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user_certificates`
--
CREATE TABLE `user_certificates` (
`id` int(11) NOT NULL,
`userID` int(11) NOT NULL,
`schedule_videoID` int(11) NOT NULL,
`year` int(11) NOT NULL,
`isWatch` int(11) NOT NULL,
`scoreStatus` int(11) DEFAULT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user_certificates`
--
INSERT INTO `user_certificates` (`id`, `userID`, `schedule_videoID`, `year`, `isWatch`, `scoreStatus`, `dateCreated`, `status`) VALUES
(12, 2, 3, 2019, 1, 67, '2019-03-09 07:48:42', 1),
(13, 2, 4, 2019, 1, NULL, '2019-03-09 08:38:55', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user_certificates_detail`
--
CREATE TABLE `user_certificates_detail` (
`id` int(11) NOT NULL,
`userCertID` int(11) NOT NULL,
`score` int(11) NOT NULL,
`dateCreated` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user_certificates_detail`
--
INSERT INTO `user_certificates_detail` (`id`, `userCertID`, `score`, `dateCreated`) VALUES
(26, 12, 67, '2019-03-09 07:48:52'),
(27, 12, 0, '2019-03-09 08:38:40'),
(28, 13, 0, '2019-03-09 08:38:58');
-- --------------------------------------------------------
--
-- Table structure for table `video`
--
CREATE TABLE `video` (
`id` int(11) NOT NULL,
`name` varchar(100) NOT NULL,
`description` text NOT NULL,
`fileDir` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL DEFAULT '1',
`thumbnail` varchar(500) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `video`
--
INSERT INTO `video` (`id`, `name`, `description`, `fileDir`, `dateCreated`, `status`, `thumbnail`) VALUES
(1, 'Fire Disaster Preparedness', 'Fire is one of the most common disasters. Fire causes more deaths than any other type of disaster. But fire doesn\'t have to be deadly if you have early warning from a smoke detector and everyone in your family and friends knows how to escape calmly. Watch the video for more information. ', '../../video/sandglass-300x420.swf', '2019-03-05 00:00:00', 1, '../../video/thumbnail/1.png'),
(7, 'test', 'test123', '../../video/sandglass-300x420.swf', '2019-03-06 13:31:17', 1, '../../video/thumbnail/1.png');
--
-- Indexes for dumped tables
--
--
-- Indexes for table `admin`
--
ALTER TABLE `admin`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `evaluation`
--
ALTER TABLE `evaluation`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `evaluation_choices`
--
ALTER TABLE `evaluation_choices`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `logs`
--
ALTER TABLE `logs`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `schedule`
--
ALTER TABLE `schedule`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `schedule_video`
--
ALTER TABLE `schedule_video`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user`
--
ALTER TABLE `user`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user_certificates`
--
ALTER TABLE `user_certificates`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user_certificates_detail`
--
ALTER TABLE `user_certificates_detail`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `video`
--
ALTER TABLE `video`
ADD PRIMARY KEY (`id`);
--
-- AUTO_INCREMENT for dumped tables
--
--
-- AUTO_INCREMENT for table `admin`
--
ALTER TABLE `admin`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=2;
--
-- AUTO_INCREMENT for table `evaluation`
--
ALTER TABLE `evaluation`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=5;
--
-- AUTO_INCREMENT for table `evaluation_choices`
--
ALTER TABLE `evaluation_choices`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=12;
--
-- AUTO_INCREMENT for table `logs`
--
ALTER TABLE `logs`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
--
-- AUTO_INCREMENT for table `schedule`
--
ALTER TABLE `schedule`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=8;
--
-- AUTO_INCREMENT for table `schedule_video`
--
ALTER TABLE `schedule_video`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=5;
--
-- AUTO_INCREMENT for table `user`
--
ALTER TABLE `user`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
--
-- AUTO_INCREMENT for table `user_certificates`
--
ALTER TABLE `user_certificates`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=14;
--
-- AUTO_INCREMENT for table `user_certificates_detail`
--
ALTER TABLE `user_certificates_detail`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=29;
--
-- AUTO_INCREMENT for table `video`
--
ALTER TABLE `video`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=9;
COMMIT;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$id = $_GET['questionID'];
$videoID = $_GET['videoID'];
$choice = $_POST['choiceTxt'];
$sql = "INSERT INTO evaluation_choices(evaluationID,choice) VALUES($id,'$choice')";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Added new question');
echo "<script>alert('Successful');
window.location.href = 'updateVideo.php?videoID=$videoID' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'updateVideo.php?videoID=$videoID' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$date = date("Y-m-d H:i:s");
$sql = "Select * from user where id='$userId'";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
$name = $row['username'];
}
}
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="author" content="colorlib">
<meta name="description" content="">
<meta name="keywords" content="">
<meta charset="UTF-8">
<title>User View</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
<div class="row align-items-center">
<div class="col-lg-6 col-sm-6 col-6 header-top-left">
</div>
<div class="col-lg-6 col-sm-6 col-6 header-top-right">
<ul>
<li><a href="#">Welcome <?php echo strtoupper($name); ?></a></li>
</ul>
</div>
</div>
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>Logo</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="index.php">Dashboard</a></li>
<li><a href="user_videos.php">Videos</a></li>
<li><a href="evaluation.php">Evaluation History</a></li>
<li class="menu-has-children"><a href="#">Account Settings</a>
<ul>
<li>
<a href="#" data-toggle="modal" data-target="#editStudentModal" onclick="changeID(<?php echo $userId; ?>, 'edit')">Modify Account Details</a>
</li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeID(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionUser.php">Log out</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<section class="about-banner relative">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
<h1 class="text-white">
</h1>
</div>
</div>
</div>
</section>
<section class="destinations-area pt-20 pb-20">
<h1 class="pb-10 d-flex justify-content-center"><b> Video List</b></h1>
<div class="container">
<div class="row">
<?php
/*$sql1 = "Select A.*, COUNT(B.id) AS 'vidcount'
from video A
INNER JOIN evaluation B ON A.id = B.videoID
GROUP BY A.id";*/
$sql1 = "Select A.*, B.id AS 'sV'
from video A
INNER JOIN schedule_video B ON A.id = B.videoID
INNER JOIN schedule C ON B.scheduleID = C.id
WHERE '$date' BETWEEN C.startDate AND C.endDate AND A.status = 1";
$result1 = mysqli_query($con, $sql1);
if(mysqli_num_rows($result1)>0)
{
while($row = mysqli_fetch_array($result1)){
$vidID = $row['id'];
/*$sql2 = "SELECT A.id, B.scoreStatus
FROM user A
LEFT JOIN user_certificates B ON B.userID = A.id
LEFT JOIN evaluation C ON C.videoID = B.videoID
LEFT JOIN video D ON B.videoID = D.id
WHERE A.id = '$userId'";*/
$sql2 = "SELECT A.id, B.scoreStatus, D.startDate, D.endDate, C.scheduleID
FROM user A
LEFT JOIN user_certificates B ON B.userID = A.id
LEFT JOIN schedule_video C ON B.schedule_videoID = C.id
LEFT JOIN schedule D ON C.scheduleID = D.id
WHERE A.id = '$userId' AND C.videoID = '$vidID' AND '$date' BETWEEN D.startDate AND D.endDate";
$result2 = mysqli_query($con, $sql2);
if(mysqli_num_rows($result2)>0)
{
while($row2 = mysqli_fetch_array($result2)){
$scoreStatus = $row2['scoreStatus'];
}
}
else{
$scoreStatus = '';
}
?>
<div class="col-lg-4">
<div class="single-destinations video-box" style="box-shadow: 0px 10px 30px 0px rgba(60, 64, 143, 0.8);">
<div class="thumb relative">
<div class="overlay overlay-bg"></div>
<img style="width: 50%; height: 50%" class="content-image img-fluid d-block mx-auto" src="<?php echo $row['thumbnail']; ?>" alt="">
</div>
<div class="details">
<h4 class="d-flex justify-content-center">
<span><b><?php echo $row['name']; ?></b></span>
<div class="star"></div>
</h4>
<p class="justify-content-center">
<?php echo $row['description']; ?>
</p>
<ul class="package-list">
<li class="d-flex justify-content-between align-items-center">
<span><b>Watch Video</b></span>
<a href="watch_video.php?videoID=<?php echo $row['id']?>&&sV=<?php echo $row['sV']?>" class="genric-btn info circle small">WATCH</a>
</li>
<li class="d-flex justify-content-between align-items-center">
<span><b>Take the Exam</b></span>
<?php
if($scoreStatus == null || $scoreStatus == ""){
?>
<a href="watch_video.php?videoID=<?php echo $row['id']?>&&sV=<?php echo $row['sV']?>" class="genric-btn info circle small">GO TO EXAM</a>
<?php
}else{
if($scoreStatus >= 50){
$statusScore = "PASSED";
$color = "green";
}else{
$statusScore = "FAILED";
$color = "red";
}
?>
<span style="color: <?php echo $color; ?>; font-weight: bold;"><?php echo $statusScore; ?> </span> | <a href="watch_video.php?videoID=<?php echo $row['id']?>&&sV=<?php echo $row['sV']?>" class="genric-btn success circle small">RE-TAKE</a>
<?php
}
?>
</li>
</ul>
</div>
</div>
</div>
<?php
}
}
?>
</div>
</div>
</section>
<div class="modal animated zoomIn" id="editStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editStudentForm">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area section-gap"></footer>
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script type="text/javascript">
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = 'changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit')
{
document.getElementById("editStudentForm").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
// ajax stop
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
/*function checkPassFunction(){
alert("test");
var pass = $("input[name=txtPass]").val();
var pass1 = $("input[name=txtConfirmPass]").val();
}*/
</script><file_sep><?php
session_start();
$id=$_GET['id'];
if(isset($_GET['id']))
{
$_SESSION['userID'] = $id;
header('Location:dashboard/index.php');
}
else
{
header('Location:../login.php');
}
?><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$sql = "Select * from user where id='$userId'";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
$name = $row['username'];
}
}
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="author" content="colorlib">
<meta name="description" content="">
<meta name="keywords" content="">
<meta charset="UTF-8">
<title>User View</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
<div class="row align-items-center">
<div class="col-lg-6 col-sm-6 col-6 header-top-left">
</div>
<div class="col-lg-6 col-sm-6 col-6 header-top-right">
<ul>
<li><a href="#">Welcome <?php echo strtoupper($name); ?></a></li>
</ul>
</div>
</div>
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>Logo</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="index.php">Dashboard</a></li>
<li><a href="user_videos.php">Videos</a></li>
<li><a href="evaluation.php">Evaluation History</a></li>
<!--<li class="menu-has-children"><a href="">Pages</a>
<ul>
<li><a href="#">Elements</a></li>
<li class="menu-has-children"><a href="">Level 2 </a>
<ul>
<li><a href="#">Item One</a></li>
<li><a href="#">Item Two</a></li>
</ul>
</li>
</ul>
</li>-->
<li class="menu-has-children"><a href="#">Account Settings</a>
<ul>
<li>
<a href="#" data-toggle="modal" data-target="#editStudentModal" onclick="changeID(<?php echo $userId; ?>, 'edit')">Modify Account Details</a>
</li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeID(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionUser.php">Log out</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<section class="about-banner relative">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
<h1 class="text-white">
</h1>
</div>
</div>
</div>
</section>
<section class="home-about-area pt-20" style="background: white">
<div class="container-fluid">
<div class="row align-items-center justify-content-end">
<div class="col-lg-6 col-md-12 home-about-left">
<h1>
Did not find your Package? <br>
Feel free to ask us. <br>
We‘ll make it for you
</h1>
<p>
inappropriate behavior is often laughed off as “boys will be boys,” women face higher conduct standards especially in the workplace. That’s why it’s crucial that, as women, our behavior on the job is beyond reproach. inappropriate behavior is often laughed.
</p>
<a href="user_videos.php" class="primary-btn text-uppercase">Proceed to Videos</a>
</div>
<div class="col-lg-6 col-md-12 home-about-right no-padding">
<img class="img-fluid" src="../../img/disaster4.jpg" alt="">
</div>
</div>
</div>
</section>
<div class="modal animated zoomIn" id="editStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editStudentForm">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area section-gap"></footer>
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script type="text/javascript">
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = 'changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit')
{
document.getElementById("editStudentForm").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
// ajax stop
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
</script><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$pass = md5($_POST['txtPass']);
$confirmPass = md5($_POST['txtConfirmPass']);
if($pass == $confirmPass){
echo $sql = "Update user SET password = <PASSWORD>' WHERE id = '$userId' ";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$userId, 'user', 'Change Student Password');
echo "<script>alert('Password updated successfully');
window.location.href = 'index.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'index.php' </script>";
}
}else{
echo "<script>alert('ERROR! PASSWORD DID NOT MATCH');
window.location.href = 'index.php' </script>";
}
?><file_sep><?php
session_start();
$id=$_GET['id'];
if(isset($_GET['id']))
{
$_SESSION['adminID'] = $id;
header('Location:dashboard/dashboard.php');
}
else
{
header('Location:../login.php');
}
?><file_sep><?php
session_start();
include "../connect.php";
echo $adminID = $_SESSION['adminID'];
addLogs($con,$adminID, 'admin', 'Logged out');
unset($_SESSION['adminID']);
header('location:../login.php');
?><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
?>
<a href="../logoutSessionUser.php">LOGOUT</a><file_sep><?php
$host="localhost";
$user="root";
$password="";
$con=mysqli_connect($host,$user,$password,"<PASSWORD>");
function addLogs($con,$id,$userType,$description)
{
$sql = "INSERT INTO logs(userID,userType,description) VALUES($id,'$userType','$description')";
$result = mysqli_query($con, $sql);
}
?><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$id = $_GET['id'];
$studNo = $_POST['studNoTxt'];
$name = $_POST['nameTxt'];
$email = $_POST['emailTxt'];
$username=$_POST['usernameTxt'];
echo $sql = "Update user SET studNo = '$studNo', name = '$name', email = '$email', username = '$username' WHERE id = '$userId' ";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$userId, 'user', 'Updated Student Information');
echo "<script>alert('Update Successful');
window.location.href = 'index.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'index.php' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$scoreCounter = 0;
$qa = 0;
$sV = $_POST['txtSched'];
if(isset($_POST['exam_submit'])){
foreach($_POST['choice_q'] as $question => $answer){
echo "Question Num: ". $question." User Answer: ".$answer." ";
$sql = "Select B.id, A.videoID from evaluation A
INNER JOIN evaluation_choices B ON A.id = B.evaluationID
where A.id='$question' AND B.isCorrect = 1";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
echo "Right Answer:" .$row['id']. "<br>";
$videoId = $row['videoID'];
$qa++;
if($row['id']== $answer){
$scoreCounter++;
}
}
}
}
//echo "Score is: ".$scoreCounter;
$check = "Select * from user_certificates where userID='$userId' AND schedule_videoID = '$sV'";
$result1 = mysqli_query($con, $check);
if(mysqli_num_rows($result1)>0)
{
while($row1 = mysqli_fetch_array($result1)){
$user_cert_ID = $row1['id'];
$currentScore = $row1['scoreStatus'];
}
$date = date("Y-m-d H:i:s");
$final_score = ($scoreCounter / $qa) * 100;
$score_final = number_format($final_score, 2, '.', '');
$user_sql = "INSERT INTO user_certificates_detail (userCertID, score, dateCreated)
VALUES('$user_cert_ID','$score_final', '$date')";
if(mysqli_query($con, $user_sql)){
//echo "Records inserted successfully.";
addLogs($con,$userId, 'user', 'Take exam on videoID '. $videoId);
} else{
echo "ERROR: Could not able to execute $user_sql. " . mysqli_error($con);
}
}
if($final_score > $currentScore || $currentScore = ""){
$score_final = number_format($final_score, 2, '.', '');
echo $user_sql1 = "UPDATE user_certificates
SET scoreStatus = $score_final
WHERE userId = '$userId' AND schedule_videoID = '$sV'";
if(mysqli_query($con, $user_sql1)){
echo "Records updated successfully.";
} else{
echo "ERROR: Could not able to execute $user_sql. " . mysqli_error($con);
}
}
header('Location:user_videos.php');
}
?><file_sep><?php
session_start();
include "../connect.php";
echo $userID = $_SESSION['userID'];
addLogs($con,$userID, 'user', 'Logged out');
unset($_SESSION['userID']);
header('location:../login.php');
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$videoID = $_GET['videoID'];
$choiceID = $_GET['choiceID'];
//$sql = "DELETE FROM user where id='$id'";
$sql = "Update evaluation_choices Set status=0 where id = $choiceID";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Deleted a option from a question.');
echo "<script>alert('Delete Successful');
window.location.href = 'updateVideo.php?videoID=".$videoID."' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'updateVideo.php?videoID=".$videoID."' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$id = $_GET['id'];
$studNo = $_POST['studNoTxt'];
$name = $_POST['nameTxt'];
$email = $_POST['emailTxt'];
$username=$_POST['usernameTxt'];
$password = md5($_POST['passwordTxt']);
$sql = "Update user SET studNo = '$studNo', name = '$name', email = '$email', username = '$username', password = <PASSWORD>' where id = $id ";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Updated Student Information');
echo "<script>alert('Update Successful');
window.location.href = 'student.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'student.php' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$userId = $_SESSION['adminID'];
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<!-- Mobile Specific Meta -->
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Favicon-->
<link rel="shortcut icon" href="img/fav.png">
<!-- Author Meta -->
<meta name="author" content="colorlib">
<!-- Meta Description -->
<meta name="description" content="">
<!-- Meta Keyword -->
<meta name="keywords" content="">
<!-- meta character set -->
<meta charset="UTF-8">
<!-- Site Title -->
<title>Disaster Prevention</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>LOGO</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="../dashboard/dashboard.php">Dashboard</a></li>
<li><a href="../videos/video.php">Videos</a></li>
<li><a href="../students/student.php">Students</a></li>
<li><a href="../reports/report.php">Reports</a></li>
<li><a href="../logs/log.php">Activity Logs</a></li>
<li class="menu-has-children"><a href=#>Account</a>
<ul>
<li><a href="#" data-toggle="modal" data-target="#editProfileModal" onclick="changeIDprofile(<?php echo $userId; ?>, 'edit_prof')">Update Info</a></li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeIDprofile(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionAdmin.php">Logout</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<!-- start banner Area -->
<section class="relative about-banner" id="home">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
</div>
</div>
</div>
</section>
<!-- End banner Area -->
<!-- Start top-category-widget Area -->
<!-- Start top-category-widget Area -->
<section class="popular-destination-area section-gap pt-5 pb-0">
<div class="container">
<div class="row">
<div class="col-lg-6">
<h1>Activity Logs</h1>
</div>
</div>
<hr>
</div>
</section>
<section class="destinations-area section-gap pt-0">
<div class="container">
<div class="row">
<div class="col-lg-12">
<table width=100% class="table table-bordered" style="background-color: white">
<thead>
<tr>
<th width=5% >ID</th>
<th width=30%>NAME</th>
<th width=50%>DESCRIPTION</th>
<th width=15%>TIME</th>
</tr>
</thead>
<tbody>
<?php
$sql = "SELECT *,
(CASE
WHEN (A.userType = 'admin')
THEN
(SELECT Z.name FROM admin Z WHERE Z.id = A.userID)
ELSE
(SELECT Z.name FROM user Z WHERE Z.id = A.userID)
END
)As 'name'
FROM `logs` A";
$result = mysqli_query($con, $sql);
while($row = mysqli_fetch_array($result)){
?>
<tr>
<td><?php echo $row['id']; ?></td>
<td><?php echo $row['name']; ?></td>
<td><?php echo $row['description']; ?></td>
<td><center><?php echo date('m/d/Y',strtotime($row['dateCreated']))."<br>".date('h:i:s a',strtotime($row['dateCreated']));?></center></td>
</tr>
<?php
}
?>
</tbody>
</table>
</div>
</div>
</div>
</section>
<br><br>
<div class="modal animated zoomIn" id="editProfileModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Profile</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editProfile">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area">
<div class="container">
</div>
</footer>
<!-- End top-category-widget Area -->
<!-- End footer Area -->
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script type="text/javascript">
function changeIDprofile(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = '../students/changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit_prof')
{
document.getElementById("editProfile").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
</script><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$query = '';
$year = '';
if(isset($_GET['year']))
{
$year = $_GET['year'];
$query = "SELECT B.score, D.name, B.dateCreated
FROM user_certificates A
INNER JOIN user_certificates_detail B ON A.id = B.userCertID
INNER JOIN schedule_video C ON A.schedule_videoID = C.id
INNER JOIN video D ON C.videoID = D.id
INNER JOIN schedule E ON C.scheduleID = E.id
WHERE A.userID = '$userId' AND YEAR(E.startDate) = '$year' AND YEAR(E.endDate) = '$year'";
//$query = "AND YEAR(E.startDate) = '$year' AND YEAR(E.endDate) = '$year'";
}
else{
$query= "SELECT B.score, D.name, B.dateCreated
FROM user_certificates A
INNER JOIN user_certificates_detail B ON A.id = B.userCertID
INNER JOIN schedule_video C ON A.schedule_videoID = C.id
INNER JOIN video D ON C.videoID = D.id
INNER JOIN schedule E ON C.scheduleID = E.id
WHERE A.userID = '$userId'";
}
$sql = "Select * from user where id='$userId'";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
$name = $row['username'];
}
}
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="author" content="colorlib">
<meta name="description" content="">
<meta name="keywords" content="">
<meta charset="UTF-8">
<title>User View</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
<div class="row align-items-center">
<div class="col-lg-6 col-sm-6 col-6 header-top-left">
</div>
<div class="col-lg-6 col-sm-6 col-6 header-top-right">
<ul>
<li><a href="#">Welcome <?php echo strtoupper($name); ?></a></li>
</ul>
</div>
</div>
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>Logo</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="index.php">Dashboard</a></li>
<li><a href="user_videos.php">Videos</a></li>
<li><a href="evaluation.php">Evaluation History</a></li>
<li class="menu-has-children"><a href="#">Account Settings</a>
<ul>
<li>
<a href="#" data-toggle="modal" data-target="#editStudentModal" onclick="changeID(<?php echo $userId; ?>, 'edit')">Modify Account Details</a>
</li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeID(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionUser.php">Log out</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<section class="about-banner relative">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
<h1 class="text-white">
</h1>
</div>
</div>
</div>
</section>
<section class="price-area pt-20">
<div class="container">
<div class="row d-flex justify-content-center">
<div class="menu-content pb-70 col-lg-8">
<div class="title text-center">
<h1 class="mb-10">History of taken exam</h1>
<select class="form-control" id="select_year" onchange="changeYear()">
<?php
$sql_year = "SELECT YEAR(A.startDate) AS 'year'
FROM schedule A
GROUP BY YEAR(A.startDate)";
$result_year = mysqli_query($con, $sql_year);
if(mysqli_num_rows($result_year)>0)
{
while($row_year = mysqli_fetch_array($result_year)){
?>
<option value="<?php echo $row_year['year']; ?>"><?php echo $row_year['year']; ?></option>
<?php
}
}
?>
</select>
</div>
</div>
</div>
<div class="row">
<?php
/*$sql2 = "SELECT B.score, C.name, B.dateCreated,
(SELECT COUNT(id) FROM evaluation WHERE videoID = A.videoID) AS 'question_count'
FROM user_certificates A
INNER JOIN user_certificates_detail B ON A.id = B.userCertID
INNER JOIN video C ON A.videoID = C.id
WHERE A.userID = '$userId'";*/
$sql2 = $query;
$result2 = mysqli_query($con, $sql2);
if(mysqli_num_rows($result2)>0)
{
while($row2 = mysqli_fetch_array($result2)){
$score = $row2['score'];
$title = $row2['name'];
$taken = $row2['dateCreated'];
if($score > 50){
$color = "text-success";
$status = "PASSED";
}else{
$color = "text-danger";
$status = "FAILED";
}
?>
<div class="col-lg-4">
<div class="single-price">
<h4 class="<?php echo $color; ?>" style="font-size: 30px"><?php echo $status; ?></h4>
<ul class="price-list">
<li class="d-flex justify-content-between align-items-center">
<span class="font-weight-bold">Video</span>
<span><?php echo $title; ?></span>
</li>
<li class="d-flex justify-content-between align-items-center">
<span class="font-weight-bold">Score</span>
<span><?php echo $score; ?>%</span>
</li>
<li class="d-flex justify-content-between align-items-center">
<span class="font-weight-bold">Date Taken</span>
<span><?php echo $taken; ?></span>
</li>
</ul>
</div>
</div>
<?php
}
}
?>
</div>
</div>
</section>
<div class="modal animated zoomIn" id="editStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editStudentForm">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area section-gap pt-20"></footer>
<!-- End price Area -->
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script type="text/javascript">
$( document ).ready(function() {
d = document.getElementById("select_year").value;
<?php
if($year == ''){
echo "window.location = 'evaluation.php?year='+d;";
}
?>
});
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = 'changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit')
{
document.getElementById("editStudentForm").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
// ajax stop
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
function changeYear(){
d = document.getElementById("select_year").value;
window.location = 'evaluation.php?year='+d;
}
</script><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$studNo = $_POST['studNoTxt'];
$name = $_POST['nameTxt'];
$email = $_POST['emailTxt'];
$username=$_POST['usernameTxt'];
$password = md5($_POST['passwordTxt']);
$sql = "INSERT INTO user(studNo,name,email,username,password,status) VALUES('$studNo','$name','$email','$username','$password',1)";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Added new Student');
echo "<script>alert('Register Successful');
window.location.href = 'student.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'student.php' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionUser.php";
$userId = $_SESSION['userID'];
$video_id = $_GET['videoID'];
$sV = $_GET['sV'];
$sql = "Select * from user where id='$userId'";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
$name = $row['username'];
}
}
//check if record exist
$check = "Select * from user_certificates where userID='$userId' AND schedule_videoID = '$sV'";
$result1 = mysqli_query($con, $check);
if(mysqli_num_rows($result1)>0)
{
//echo "DATA EXIST";
}
else{
$date = date("Y-m-d H:i:s");
$user_sql = "INSERT INTO user_certificates (userID, schedule_videoID, year, isWatch, scoreStatus, dateCreated, status)
VALUES('$userId', '$sV', '2019', 1, NULL, '$date', 1)";
if(mysqli_query($con, $user_sql)){
//echo "Records inserted successfully.";
addLogs($con,$userId, 'user', 'Watched VideoID of '. $video_id);
} else{
echo "ERROR: Could not able to execute $user_sql. " . mysqli_error($con);
}
}
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<meta name="author" content="colorlib">
<meta name="description" content="">
<meta name="keywords" content="">
<meta charset="UTF-8">
<title>User View</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="../../css/linearicons.css">
<link rel="stylesheet" href="../../css/font-awesome.min.css">
<link rel="stylesheet" href="../../css/bootstrap.css">
<link rel="stylesheet" href="../../css/magnific-popup.css">
<link rel="stylesheet" href="../../css/jquery-ui.css">
<link rel="stylesheet" href="../../css/nice-select.css">
<link rel="stylesheet" href="../../css/animate.min.css">
<link rel="stylesheet" href="../../css/owl.carousel.css">
<link rel="stylesheet" href="../../css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
<div class="container">
<div class="row align-items-center">
<div class="col-lg-6 col-sm-6 col-6 header-top-left">
</div>
<div class="col-lg-6 col-sm-6 col-6 header-top-right">
<ul>
<li><a href="#">Welcome <?php echo strtoupper($name); ?></a></li>
</ul>
</div>
</div>
</div>
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>Logo</h3>
</div>
<nav id="nav-menu-container">
<ul class="nav-menu">
<li><a href="index.php">Dashboard</a></li>
<li><a href="user_videos.php">Videos</a></li>
<li><a href="evaluation.php">Evaluation History</a></li>
<li class="menu-has-children"><a href="#">Account Settings</a>
<ul>
<li>
<a href="#" data-toggle="modal" data-target="#editStudentModal" onclick="changeID(<?php echo $userId; ?>, 'edit')">Modify Account Details</a>
</li>
<li><a href="#" data-toggle="modal" data-target="#changePasswordModal" onclick="changeID(<?php echo $userId; ?>, 'changePass')">Change Password</a></li>
<li><a href="../logoutSessionUser.php">Log out</a></li>
</ul>
</li>
</ul>
</nav><!-- #nav-menu-container -->
</div>
</div>
</header><!-- #header -->
<section class="about-banner relative">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row d-flex align-items-center justify-content-center">
<div class="about-content col-lg-12">
<h1 class="text-white">
</h1>
</div>
</div>
</div>
</section>
<?php
$sql1 = "Select * from video where id='$video_id'";
$result1 = mysqli_query($con, $sql1);
if(mysqli_num_rows($result1)>0)
{
while($row1 = mysqli_fetch_array($result1)){
$path = $row1['fileDir'];
$video_title =$row1['name'];
$desc = $row1['description'];
}
}
?>
<section class="destinations-area pt-20">
<h1 class="pb-10 d-flex justify-content-center"><b> <?php echo $video_title;?></b></h1>
<div class="container">
<div class="row">
<div class="map-wrap" style="width:100%; height: 445px; box-shadow: 0px 10px 30px 0px rgba(60, 64, 143, 0.3);">
<embed style="width:100%; height: 400px; play="true" loop="false" menu="true" src="<?php echo $path?>">
</div>
</div>
<div class="row d-flex justify-content-center">
<div class=" pb-20 col-lg-8 text-center">
<p class="pt-20 font-weight-bold"><?php echo $desc; ?></p>
</div>
</div>
<div class="row d-flex justify-content-center">
<button id="btn_view_exam" class="primary-btn text-uppercase text-center">TAKE THE EXAM</button>
</div>
</div>
</section>
<section id="exam_collapse" class="price-area pt-20 pb-20">
<form class="form-wrap" action="checkUserAnswer.php" method="POST">
<input type="hidden" value="<?php echo $sV; ?>" name="txtSched">
<div class="container" style="width:100%; box-shadow: 0px 10px 30px 0px rgba(60, 64, 143, 0.3);">
<div class="row d-flex justify-content-center">
<div class="menu-content col-lg-8">
</div>
</div>
<div class="row">
<?php
$sql2 = "SELECT A.id, A.question
FROM evaluation A
INNER JOIN video B ON A.videoID = B.id
WHERE A.videoID ='$video_id'
AND A.status=1 AND B.status = 1
ORDER BY RAND()";
$result2 = mysqli_query($con, $sql2);
if(mysqli_num_rows($result2)>0)
{
while($row2 = mysqli_fetch_array($result2)){
$evalId = $row2['id'];
?>
<div class="col-lg-12">
<div class="single-price">
<h4 class="text-uppercase"><?php echo $row2['question']?></h4>
<ul class="price-list">
<?php
$sql3 = "SELECT B.id, B.choice
FROM evaluation A
INNER JOIN evaluation_choices B ON A.id = B.evaluationID
WHERE A.id = '$evalId' AND A.status=1 AND B.status = 1
ORDER BY RAND()";
$result3 = mysqli_query($con, $sql3);
if(mysqli_num_rows($result3)>0)
{
while($row3 = mysqli_fetch_array($result3)){
?>
<li class="d-flex justify-content-between align-items-center">
<label class="text-uppercase">
<input style="height: 16px; width: 16px" type="radio" name="choice_q[<?php echo $evalId ?>]" value="<?php echo $row3['id'] ?>"> <?php echo $row3['choice'] ?>
</label>
</li>
<?php
}
}
?>
</ul>
</div>
</div>
<?php
}
}
?>
</div>
<div class="row d-flex justify-content-center">
<button id="btn_submit" name="exam_submit" class="primary-btn text-uppercase text-center">SUBMIT</button>
</div>
</div>
</form>
</section>
<div class="modal animated zoomIn" id="editStudentModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Edit Student</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="editStudentForm">
</div>
</div>
</div>
</div>
<div class="modal animated zoomIn" id="changePasswordModal">
<div class="modal-dialog" role="document">
<div class="modal-content">
<div class="modal-header">
<h3 style="text-align:center">Change Password</h3>
<button type="button" class="close" data-dismiss="modal">×</button>
</div>
<div class="modal-body" id="changePassForm">
</div>
</div>
</div>
</div>
<footer class="footer-area section-gap pt-20"></footer>
<script src="../../js/vendor/jquery-2.2.4.min.js"></script>
<script src="../../js/popper.min.js"></script>
<script src="../../js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=AIzaSyBhOdIF3Y9382fqJYt5I_sswSrEw5eihAA"></script>
<script src="../../js/jquery-ui.js"></script>
<script src="../../js/easing.min.js"></script>
<script src="../../js/hoverIntent.js"></script>
<script src="../../js/superfish.min.js"></script>
<script src="../../js/jquery.ajaxchimp.min.js"></script>
<script src="../../js/jquery.magnific-popup.min.js"></script>
<script src="../../js/jquery.nice-select.min.js"></script>
<script src="../../js/owl.carousel.min.js"></script>
<script src="../../js/mail-script.js"></script>
<script src="../../js/main.js"></script>
</body>
</html>
<script type="text/javascript">
$('#btn_view_exam').click(function(){
$('#exam_collapse').slideToggle('slow');
});
</script>
<script type="text/javascript">
function changeID(newID,type){
var xhr;
if (window.XMLHttpRequest) xhr = new XMLHttpRequest(); // all browsers
else xhr = new ActiveXObject("Microsoft.XMLHTTP"); // for IE
var url = 'changeID.php?id='+newID+'&actiontype='+type;
xhr.open('GET', url, false);
xhr.onreadystatechange = function () {
if(type==='edit')
{
document.getElementById("editStudentForm").innerHTML = xhr.responseText;
}
else if(type==='changePass')
{
document.getElementById("changePassForm").innerHTML = xhr.responseText;
}
}
xhr.send();
// ajax stop
return false;
}
function validateForm() {
var pass = document.forms["changePassForm"]["txtPass"].value;
var pass1 = document.forms["changePassForm"]["txtConfirmPass"].value;
if (pass != pass1) {
alert("Password did not match");
return false;
}
}
/*function checkPassFunction(){
alert("test");
var pass = $("input[name=txtPass]").val();
var pass1 = $("input[name=txtConfirmPass]").val();
}*/
</script><file_sep><?php
include "../../connect.php";
$id = $_GET['id'];
$type =$_GET['actiontype'];
if($type=="delete"){
echo $id;
}
else if($type =="edit")
{
$sql = "Select *from user where id='$id'";
$result = mysqli_query($con, $sql);
$row = mysqli_fetch_array($result);
?>
<form class="form-horizontal" action="editStudent.php?id=<?php echo $id; ?>" method=post >
<input type="text" required class="form-control" name="studNoTxt" placeholder="Student No." onfocus="this.placeholder = ''" onblur="this.placeholder = 'Student No. '" value="<?php echo $row['studNo']; ?>"><br>
<input type="text" required class="form-control" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '" value="<?php echo $row['name']; ?>"><br>
<input type="email" required class="form-control" name="emailTxt" placeholder="Email Address " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Email Address '" value="<?php echo $row['email']; ?>"><br>
<input type="text" required class="form-control" name="usernameTxt" placeholder="Username " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Username '" value="<?php echo $row['username']; ?>"><br>
<input type="password" required class="form-control" name="passwordTxt" placeholder="<PASSWORD> " onfocus="this.placeholder = ''" onblur="this.placeholder = '<PASSWORD> '"><br>
<button type="submit" name="registerSubmit" class="genric-btn info text-uppercase form-control">Save</button>
</form>
<?php
}
else if($type =="edit_prof")
{
$sql = "Select * from admin where id='$id'";
$result = mysqli_query($con, $sql);
$row = mysqli_fetch_array($result);
?>
<form class="form-horizontal" action="../updateInfo/updateinfo.php?id=<?php echo $id; ?>" method=post >
<input type="text" required class="form-control" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '" value="<?php echo $row['name']; ?>"><br>
<input type="email" required class="form-control" name="emailTxt" placeholder="Email Address " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Email Address '" value="<?php echo $row['email']; ?>"><br>
<input type="text" required class="form-control" name="usernameTxt" placeholder="Username " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Username '" value="<?php echo $row['username']; ?>"><br>
<button type="submit" name="registerSubmit" class="genric-btn info text-uppercase form-control">Save</button>
</form>
<?php
}
else if($type =="changePass"){
$sql = "Select * from admin where id='$id'";
$result = mysqli_query($con, $sql);
$row = mysqli_fetch_array($result);
?>
<form class="form-horizontal" action="../changePassword/changePassword.php?id=<?php echo $id; ?>" method=post name="changePassForm" onsubmit="return validateForm()">
<input type="password" required class="form-control" id="txtPass" name="txtPass" placeholder="<PASSWORD>" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Password '" value="<?php echo $row['password']; ?>"><br>
<input type="password" required class="form-control" id="txtConfirmPass" name="txtConfirmPass" placeholder="Confirm Password" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Confirm Password '" value=""><br>
<button type="submit" name="changePassSubmit" class="genric-btn info text-uppercase form-control" >SAVE</button>
</form>
<?php
}
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$videoID = $_GET['videoID'];
$questionID = $_GET['questionID'];
//$sql = "DELETE FROM user where id='$id'";
$sql = "Update evaluation Set status=0 where id = $questionID";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Deleted a question.');
echo "<script>alert('Delete Successful');
window.location.href = 'updateVideo.php?videoID=".$videoID."' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'updateVideo.php?videoID=".$videoID."' </script>";
}
?><file_sep> <?php
include "connect.php";
if(isset($_POST['loginSubmit']))
{
$username=$_POST['usernameTxt'];
$password = md5($_POST['passwordTxt']);
$sql = "Select *from admin where username='$username' AND password='$<PASSWORD>'";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
addLogs($con,$row['id'], 'admin', 'Logged in');
header("Location:admin/loginSessionAdmin.php?id=".$row['id']);
}
}
else
{
$sql = "Select *from user where username='$username' AND password='$<PASSWORD>'";
$result = mysqli_query($con, $sql);
if(mysqli_num_rows($result)>0)
{
while($row = mysqli_fetch_array($result)){
addLogs($con,$row['id'], 'user', 'Logged in');
header("Location:user/loginSessionUser.php?id=".$row['id']);
}
}
else{
echo "<script>alert('Incorrect username or password');
window.location.href = 'login.php' </script>";
}
}
}
else if(isset($_POST['registerSubmit']))
{
$studNo = $_POST['studNoTxt'];
$name = $_POST['nameTxt'];
$email = $_POST['emailTxt'];
$username=$_POST['usernameTxt'];
$password = md5($_POST['passwordTxt']);
$sql = "INSERT INTO user(studNo,name,email,username,password,status) VALUES('$studNo','$name','$email','$username','$password',1)";
$result = mysqli_query($con, $sql);
if($result)
{
"<script>alert('Register Successful');
window.location.href = 'login.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'login.php' </script>";
}
}
?>
<!DOCTYPE html>
<html lang="zxx" class="no-js">
<head>
<!-- Mobile Specific Meta -->
<meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no">
<!-- Favicon-->
<link rel="shortcut icon" href="img/fav.png">
<!-- Author Meta -->
<meta name="author" content="colorlib">
<!-- Meta Description -->
<meta name="description" content="">
<!-- Meta Keyword -->
<meta name="keywords" content="">
<!-- meta character set -->
<meta charset="UTF-8">
<!-- Site Title -->
<title>Disaster Prevention</title>
<link href="https://fonts.googleapis.com/css?family=Poppins:100,200,400,300,500,600,700" rel="stylesheet">
<!--
CSS
============================================= -->
<link rel="stylesheet" href="css/linearicons.css">
<link rel="stylesheet" href="css/font-awesome.min.css">
<link rel="stylesheet" href="css/bootstrap.css">
<link rel="stylesheet" href="css/magnific-popup.css">
<link rel="stylesheet" href="css/jquery-ui.css">
<link rel="stylesheet" href="css/nice-select.css">
<link rel="stylesheet" href="css/animate.min.css">
<link rel="stylesheet" href="css/owl.carousel.css">
<link rel="stylesheet" href="css/main.css">
</head>
<body>
<header id="header">
<div class="header-top">
</div>
<div class="container main-menu">
<div class="row align-items-center justify-content-between d-flex">
<div id="logo">
<h3>Logo</h3>
</div>
</div>
</div>
</header><!-- #header -->
<!-- start banner Area -->
<section class="banner-area relative">
<div class="overlay overlay-bg"></div>
<div class="container">
<div class="row fullscreen align-items-center justify-content-between">
<div class="col-lg-6 col-md-6 banner-left">
<h6 class="text-white">Be ready, Be prepared </h6>
<h1 class="text-white">Disaster Prevention</h1>
<p class="text-white">
" There's no harm in hoping for the best as long as you're prepared for the worst. " — <NAME>
</p>
<a href="#" class="primary-btn text-uppercase">Learn More</a>
</div>
<div class="col-lg-4 col-md-6 banner-right">
<ul class="nav nav-tabs" id="myTab" role="tablist">
<li class="nav-item">
<a class="nav-link active" id="flight-tab" data-toggle="tab" href="#login" role="tab" aria-controls="login" aria-selected="true">Login</a>
</li>
<li class="nav-item">
<a class="nav-link" id="hotel-tab" data-toggle="tab" href="#register" role="tab" aria-controls="register" aria-selected="false">Register</a>
</li>
</ul>
<div class="tab-content" id="myTabContent">
<div class="tab-pane fade show active" id="login" role="tabpanel" aria-labelledby="login-tab">
<form class="form-wrap" name="loginForm" action="login.php" method="post">
<input type="text" required class="form-control" name="usernameTxt" placeholder="Username" onfocus="this.placeholder = ''" onblur="this.placeholder = 'Username '">
<input type="password" required class="form-control" name="passwordTxt" placeholder="<PASSWORD> " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Password '">
<button type="submit" name="loginSubmit" class="primary-btn text-uppercase" >Login</button>
</form>
</div>
<div class="tab-pane fade" id="register" role="tabpanel" aria-labelledby="register-tab">
<form class="form-wrap" action="login.php" method="post">
<input type="text" required class="form-control" name="studNoTxt" placeholder="Student No. " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Student No. '">
<input type="text" required class="form-control" name="nameTxt" placeholder="Name " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Name '">
<input type="email" required class="form-control" name="emailTxt" placeholder="Email Address " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Email Address '">
<input type="text" required class="form-control" name="usernameTxt" placeholder="Username " onfocus="this.placeholder = ''" onblur="this.placeholder = 'Username '">
<input type="<PASSWORD>" class="form-control" name="passwordTxt" placeholder="<PASSWORD> " onfocus="this.placeholder = ''" onblur="this.placeholder = '<PASSWORD> '">
<button type="submit" name="registerSubmit" class="primary-btn text-uppercase" >Register</button>
</form>
</div>
</div>
</div>
</div>
</div>
</section>
<!-- End banner Area -->
<!-- End footer Area -->
<footer class="footer-area">
<div class="container">
</div>
</footer>
<script src="js/vendor/jquery-2.2.4.min.js"></script>
<script src="js/popper.min.js"></script>
<script src="js/vendor/bootstrap.min.js"></script>
<script src="https://maps.googleapis.com/maps/api/js?key=<KEY>sswSrEw5eihAA"></script>
<script src="js/jquery-ui.js"></script>
<script src="js/easing.min.js"></script>
<script src="js/hoverIntent.js"></script>
<script src="js/superfish.min.js"></script>
<script src="js/jquery.ajaxchimp.min.js"></script>
<script src="js/jquery.magnific-popup.min.js"></script>
<script src="js/jquery.nice-select.min.js"></script>
<script src="js/owl.carousel.min.js"></script>
<script src="js/mail-script.js"></script>
<script src="js/main.js"></script>
</body>
</html>
<script type="text/javascript">
</script><file_sep>-- phpMyAdmin SQL Dump
-- version 4.5.1
-- http://www.phpmyadmin.net
--
-- Host: 127.0.0.1
-- Generation Time: Mar 05, 2019 at 10:26 PM
-- Server version: 10.1.13-MariaDB
-- PHP Version: 5.6.23
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Database: `disasterdb`
--
-- --------------------------------------------------------
--
-- Table structure for table `admin`
--
CREATE TABLE `admin` (
`id` int(11) NOT NULL,
`username` varchar(50) NOT NULL,
`password` varchar(50) NOT NULL,
`name` varchar(100) NOT NULL,
`email` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `admin`
--
INSERT INTO `admin` (`id`, `username`, `password`, `name`, `email`, `dateCreated`, `status`) VALUES
(1, 'admin', '<PASSWORD>', 'admin', 'admin', '2019-02-28 01:56:01', 1);
-- --------------------------------------------------------
--
-- Table structure for table `evaluation`
--
CREATE TABLE `evaluation` (
`id` int(11) NOT NULL,
`videoID` int(11) NOT NULL,
`question` text NOT NULL,
`answer` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `evaluation`
--
INSERT INTO `evaluation` (`id`, `videoID`, `question`, `answer`, `dateCreated`, `status`) VALUES
(1, 1, 'question 1', 'answer', '2019-03-05 00:00:00', 1),
(2, 1, 'question 2', 'answer', '2019-03-05 00:00:00', 1),
(3, 1, 'question 3', 'answer', '2019-03-05 00:00:00', 1);
-- --------------------------------------------------------
--
-- Table structure for table `evaluation_choices`
--
CREATE TABLE `evaluation_choices` (
`id` int(11) NOT NULL,
`evaluationID` int(11) NOT NULL,
`choice` varchar(150) NOT NULL,
`isCorrect` bit(1) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `evaluation_choices`
--
INSERT INTO `evaluation_choices` (`id`, `evaluationID`, `choice`, `isCorrect`, `dateCreated`, `status`) VALUES
(1, 1, 'choice 1', b'0', '2019-03-05 00:00:00', 1),
(2, 1, 'choice 2', b'1', '2019-03-05 00:00:00', 1),
(3, 1, 'choice 3', b'0', '2019-03-05 00:00:00', 1),
(4, 2, 'choice 1', b'0', '2019-03-05 00:00:00', 1),
(5, 2, 'choice 2', b'0', '2019-03-05 00:00:00', 1),
(6, 2, 'choice 3', b'1', '2019-03-05 00:00:00', 1),
(7, 3, 'choice 1', b'1', '2019-03-05 00:00:00', 1),
(8, 3, 'choice 2', b'0', '2019-03-05 00:00:00', 1),
(9, 3, 'choice 3', b'0', '2019-03-05 00:00:00', 1);
-- --------------------------------------------------------
--
-- Table structure for table `schedule`
--
CREATE TABLE `schedule` (
`id` int(11) NOT NULL,
`startDate` datetime NOT NULL,
`endDate` datetime NOT NULL,
`videoID` int(11) NOT NULL,
`dateCreated` datetime NOT NULL,
`status` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Table structure for table `user`
--
CREATE TABLE `user` (
`id` int(11) NOT NULL,
`studNo` varchar(50) NOT NULL,
`username` varchar(50) NOT NULL,
`password` varchar(50) NOT NULL,
`name` varchar(100) NOT NULL,
`email` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user`
--
INSERT INTO `user` (`id`, `studNo`, `username`, `password`, `name`, `email`, `dateCreated`, `status`) VALUES
(1, 'S2019123456', 'test123', 'cc03e747a6afbbcbf8be7668acfebee5', '<NAME>', '<EMAIL>', '2019-02-28 10:56:24', 1),
(2, '1', 'a', '0cc175b9c0f1b6a831c399e269772661', 'a', 'a', '2019-03-04 10:32:06', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user_certificates`
--
CREATE TABLE `user_certificates` (
`id` int(11) NOT NULL,
`userID` int(11) NOT NULL,
`videoID` int(11) NOT NULL,
`year` int(11) NOT NULL,
`isWatch` int(11) NOT NULL,
`scoreStatus` int(11) DEFAULT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user_certificates`
--
INSERT INTO `user_certificates` (`id`, `userID`, `videoID`, `year`, `isWatch`, `scoreStatus`, `dateCreated`, `status`) VALUES
(6, 2, 1, 2019, 1, 2, '2019-03-05 20:50:25', 1);
-- --------------------------------------------------------
--
-- Table structure for table `user_certificates_detail`
--
CREATE TABLE `user_certificates_detail` (
`id` int(11) NOT NULL,
`userCertID` int(11) NOT NULL,
`score` int(11) NOT NULL,
`dateCreated` datetime NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `user_certificates_detail`
--
INSERT INTO `user_certificates_detail` (`id`, `userCertID`, `score`, `dateCreated`) VALUES
(1, 6, 2, '2019-03-05 20:57:41'),
(2, 6, 2, '2019-03-05 20:58:27'),
(3, 6, 1, '2019-03-05 20:58:27');
-- --------------------------------------------------------
--
-- Table structure for table `video`
--
CREATE TABLE `video` (
`id` int(11) NOT NULL,
`name` varchar(100) NOT NULL,
`description` text NOT NULL,
`fileDir` varchar(150) NOT NULL,
`dateCreated` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
`status` int(11) NOT NULL,
`thumbnail` varchar(500) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Dumping data for table `video`
--
INSERT INTO `video` (`id`, `name`, `description`, `fileDir`, `dateCreated`, `status`, `thumbnail`) VALUES
(1, 'Fire Disaster Preparedness', 'Fire is one of the most common disasters. Fire causes more deaths than any other type of disaster. But fire doesn''t have to be deadly if you have early warning from a smoke detector and everyone in your family and friends knows how to escape calmly. Watch the video for more information.', 'video/fire.swf', '2019-03-05 00:00:00', 1, 'video/thumb/fire.gif');
--
-- Indexes for dumped tables
--
--
-- Indexes for table `admin`
--
ALTER TABLE `admin`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `evaluation`
--
ALTER TABLE `evaluation`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `evaluation_choices`
--
ALTER TABLE `evaluation_choices`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `schedule`
--
ALTER TABLE `schedule`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user`
--
ALTER TABLE `user`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user_certificates`
--
ALTER TABLE `user_certificates`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `user_certificates_detail`
--
ALTER TABLE `user_certificates_detail`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `video`
--
ALTER TABLE `video`
ADD PRIMARY KEY (`id`);
--
-- AUTO_INCREMENT for dumped tables
--
--
-- AUTO_INCREMENT for table `admin`
--
ALTER TABLE `admin`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=2;
--
-- AUTO_INCREMENT for table `evaluation`
--
ALTER TABLE `evaluation`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=4;
--
-- AUTO_INCREMENT for table `evaluation_choices`
--
ALTER TABLE `evaluation_choices`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=10;
--
-- AUTO_INCREMENT for table `schedule`
--
ALTER TABLE `schedule`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
--
-- AUTO_INCREMENT for table `user`
--
ALTER TABLE `user`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
--
-- AUTO_INCREMENT for table `user_certificates`
--
ALTER TABLE `user_certificates`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=7;
--
-- AUTO_INCREMENT for table `user_certificates_detail`
--
ALTER TABLE `user_certificates_detail`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=4;
--
-- AUTO_INCREMENT for table `video`
--
ALTER TABLE `video`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=7;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$videoID = $_GET['videoID'];
$questionID = $_GET['questionID'];
$questionTxt = $_POST['questionTxt'];
$choiceCounter = $_POST['choiceCounter'];
$choiceAnswer = $_POST['choiceAnswer'];
$sql = "Update evaluation SET question = '$questionTxt' where id = $questionID ";
$result = mysqli_query($con, $sql);
for($i=0; $i<$choiceCounter; $i++)
{
$choiceID = $_POST['choiceID_'.$i];
$choiceTxt = $_POST['choiceTxt_'.$i];
if($choiceAnswer == $choiceID)
{
$sql = "Update evaluation_choices SET choice= '$choiceTxt', isCorrect=1 where id = $choiceID ";
}
else
{
$sql = "Update evaluation_choices SET choice= '$choiceTxt', isCorrect=0 where id = $choiceID ";
}
$result = mysqli_query($con, $sql);
}
if($result)
{
addLogs($con,$adminID, 'admin', 'Updated Student Information');
echo "<script>alert('Update Successful');
window.location.href = 'updateVideo.php?videoID=$videoID' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'updateVideo.php?videoID=$videoID' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$startDate = $_POST['startDateTxt'];
$endDate = $_POST['endDateTxt'];
$sql = "INSERT INTO schedule (startDate,endDate) VALUES('$startDate','$endDate')";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$adminID, 'admin', 'Added new schedule');
echo "<script>alert('Successful');
window.location.href = 'video.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = 'video.php' </script>";
}
?><file_sep><?php
include "../../connect.php";
include "../sessionAdmin.php";
$userId = $_SESSION['adminID'];
$id = $_GET['id'];
$name = $_POST['nameTxt'];
$email = $_POST['emailTxt'];
$username=$_POST['usernameTxt'];
echo $sql = "Update admin SET name = '$name', email = '$email', username = '$username' WHERE id = '$userId' ";
$result = mysqli_query($con, $sql);
if($result)
{
addLogs($con,$userId, 'user', 'Updated Student Information');
echo "<script>alert('Update Successful');
window.location.href = '../dashboard/dashboard.php' </script>";
}
else
{
echo "<script>alert('error');
window.location.href = '../dashboard/dashboard.php' </script>";
}
?> | c84913e77e7879338bcc97ba518f6296e65aef60 | [
"SQL",
"PHP"
] | 35 | PHP | cathpot05/disaster | edf99560229f8e04b0453d3ce3b17c141f961b43 | 95cba2ade0e4e468c82395e5f5bb022a5b64b00c |
refs/heads/master | <repo_name>KevinMakau/CS120B_Lab11<file_sep>/turnin/Kmaka003_Lab11_part1_main.c
/* Author: kmaka003
* Partner(s) Name:
* Lab Section:
* Assignment: Lab # Exercise #
* Exercise Description: [optional - include for your own benefit]
*
* I acknowledge all content contained herein, excluding template or example
* code, is my own original work.
*/
#include <avr/io.h>
#ifdef _SIMULATE_
#include "simAVRHeader.h"
#include <avr/interrupt.h>
#endif
////////////////////////////////////////////////////////////////////////////////
//Functionality - Sets bit on a PORTx
//Parameter: Takes in a uChar for a PORTx, the pin number and the binary value
//Returns: The new value of the PORTx
unsigned char SetBit(unsigned char pin, unsigned char number, unsigned char bin_value)
{
return (bin_value ? pin | (0x01 << number) : pin & ~(0x01 << number));
}
////////////////////////////////////////////////////////////////////////////////
//Functionality - Gets bit from a PINx
//Parameter: Takes in a uChar for a PINx and the pin number
//Returns: The value of the PINx
unsigned char GetBit(unsigned char port, unsigned char number)
{
return ( port & (0x01 << number) );
}
volatile unsigned char TimerFlag = 0; // TimerISR() sets this to 1. C programmer should clear to 0.
// Internal variables for mapping AVR's ISR to our cleaner TimerISR model.
unsigned long _avr_timer_M = 1; // Start count from here, down to 0. Default 1ms
unsigned long _avr_timer_cntcurr = 0; // Current internal count of 1ms ticks
// Set TimerISR() to tick every M ms
void TimerSet(unsigned long M) {
_avr_timer_M = M;
_avr_timer_cntcurr = _avr_timer_M;
}
void TimerOn() {
// AVR timer/counter controller register TCCR1
TCCR1B = 0x0B; // bit3 = 1: CTC mode (clear timer on compare)
// bit2bit1bit0=011: prescaler /64
// 00001011: 0x0B
// SO, 8 MHz clock or 8,000,000 /64 = 125,000 ticks/s
// Thus, TCNT1 register will count at 125,000 ticks/s
// AVR output compare register OCR1A.
OCR1A = 125; // Timer interrupt will be generated when TCNT1==OCR1A
// We want a 1 ms tick. 0.001 s * 125,000 ticks/s = 125
// So when TCNT1 register equals 125,
// 1 ms has passed. Thus, we compare to 125.
// AVR timer interrupt mask register
TIMSK1 = 0x02; // bit1: OCIE1A -- enables compare match interrupt
//Initialize avr counter
TCNT1 = 0;
// TimerISR will be called every _avr_timer_cntcurr milliseconds
_avr_timer_cntcurr = _avr_timer_M;
//Enable global interrupts
SREG |= 0x80; // 0x80: 1000000
}
void TimerOff() {
TCCR1B = 0x00; // bit3bit2bit1bit0=0000: timer off
}
void TimerISR() {
TimerFlag = 1;
}
// In our approach, the C programmer does not touch this ISR, but rather TimerISR()
ISR(TIMER1_COMPA_vect)
{
// CPU automatically calls when TCNT0 == OCR0 (every 1 ms per TimerOn settings)
_avr_timer_cntcurr--; // Count down to 0 rather than up to TOP
if (_avr_timer_cntcurr == 0) { // results in a more efficient compare
TimerISR(); // Call the ISR that the user uses
_avr_timer_cntcurr = _avr_timer_M;
}
}
// Permission to copy is granted provided that this header remains intact.
// This software is provided with no warranties.
////////////////////////////////////////////////////////////////////////////////
////////////////////////////////////////////////////////////////////////////////
//Functionality - finds the greatest common divisor of two values
//Parameter: Two long int's to find their GCD
//Returns: GCD else 0
unsigned long int findGCD(unsigned long int a, unsigned long int b)
{
unsigned long int c;
while(1){
c = a % b;
if( c == 0 ) { return b; }
a = b;
b = c;
}
return 0;
}
////////////////////////////////////////////////////////////////////////////////
//Struct for Tasks represent a running process in our simple real-time operating system
typedef struct _task{
// Tasks should have members that include: state, period,
//a measurement of elapsed time, and a function pointer.
signed char state; //Task's current state
unsigned long period; //Task period
unsigned long elapsedTime; //Time elapsed since last task tick
int (*TickFct)(int); //Task tick function
} task;
// Permission to copy is granted provided that this header remains intact.
// This software is provided with no warranties.
////////////////////////////////////////////////////////////////////////////////
// Returns '\0' if no key pressed, else returns char '1', '2', ... '9', 'A', ...
// If multiple keys pressed, returns leftmost-topmost one
// Keypad must be connected to port C
// Keypad arrangement
// Px4 Px5 Px6 Px7
// col 1 2 3 4
// row ______________
//Px0 1 | 1 | 2 | 3 | A
//Px1 2 | 4 | 5 | 6 | B
//Px2 3 | 7 | 8 | 9 | C
//Px3 4 | * | 0 | # | D
// Keypad Setup Values
#define KEYPADPORT PORTC
#define KEYPADPIN PINC
#define ROW1 0
#define ROW2 1
#define ROW3 2
#define ROW4 3
#define COL1 4
#define COL2 5
#define COL3 6
#define COL4 7
unsigned char GetKeypadKey() {
// Check keys in col 1
KEYPADPORT = SetBit(0xFF,COL1,0); // Set Px4 to 0; others 1
asm("nop"); // add a delay to allow PORTx to stabilize before checking
if ( GetBit(~KEYPADPIN,ROW1) ) { return '1'; }
if ( GetBit(~KEYPADPIN,ROW2) ) { return '4'; }
if ( GetBit(~KEYPADPIN,ROW3) ) { return '7'; }
if ( GetBit(~KEYPADPIN,ROW4) ) { return '*'; }
// Check keys in col 2
KEYPADPORT = SetBit(0xFF,COL2,0); // Set Px5 to 0; others 1
asm("nop"); // add a delay to allow PORTx to stabilize before checking
if ( GetBit(~KEYPADPIN,ROW1) ) { return '2'; }
if ( GetBit(~KEYPADPIN,ROW2) ) { return '5'; }
if ( GetBit(~KEYPADPIN,ROW3) ) { return '8'; }
if ( GetBit(~KEYPADPIN,ROW4) ) { return '0'; }
// Check keys in col 3
KEYPADPORT = SetBit(0xFF,COL3,0); // Set Px6 to 0; others 1
asm("nop"); // add a delay to allow PORTx to stabilize before checking
if ( GetBit(~KEYPADPIN,ROW1) ) { return '3'; }
if ( GetBit(~KEYPADPIN,ROW2) ) { return '6'; }
if ( GetBit(~KEYPADPIN,ROW3) ) { return '9'; }
if ( GetBit(~KEYPADPIN,ROW4) ) { return '#'; }
// Check keys in col 4
KEYPADPORT = SetBit(0xFF,COL4,0); // Set Px7 to 0; others 1
asm("nop"); // add a delay to allow PORTx to stabilize before checking
if (GetBit(~KEYPADPIN,ROW1) ) { return 'A'; }
if (GetBit(~KEYPADPIN,ROW2) ) { return 'B'; }
if (GetBit(~KEYPADPIN,ROW3) ) { return 'C'; }
if (GetBit(~KEYPADPIN,ROW4) ) { return 'D'; }
return '\0';
}
unsigned char currLetter = '\0';
int KeypadSM_Tick (int);
int main(void) {
/* Insert DDR and PORT initializations */
DDRA = 0x00; PORTA = 0x00;
DDRB = 0xFF; PORTB = 0xFF;
/* Insert your solution below */
unsigned int i = 0;
static task KeypadSM;
task tasks[] = {KeypadSM};
unsigned char numTasks = 1;
//Keypad Task
KeypadSM.state = 0;
KeypadSM.period = 100;
KeypadSM.elapsedTime = KeypadSM.period;
KeypadSM.TickFct = &KeypadSM_Tick;
i++;
unsigned long GCD = tasks[0].period;
for (i = 1; 1 < numTasks; i++){
GCD = findGCD(GCD, tasks[i].period);
}
TimerSet(GCD);
TimerOn();
while (1) {
for (i = 0;i < numTasks; ++i) {
if (tasks[i].elapsedTime >= tasks[i].period) {
tasks[i].state = tasks[i].TickFct(tasks[i].state);
tasks[i].elapsedTime = 0;
}
tasks[i].elapsedTime += GCD;
}
while(!TimerFlag)
TimerFlag = 0;
}
return 1;
}
int KeypadSM_Tick (int state){
unsigned char currLetterTmp = GetKeypadKey();
if (currLetterTmp == '\0'){
currLetter = currLetter;
}
else{
currLetter = currLetterTmp;
}
return 0;
}
| 7c1fe4e058d5eb884108612eb65c3201a4fb8f96 | [
"C"
] | 1 | C | KevinMakau/CS120B_Lab11 | cb56fc849ed71759d3356a821abe08933b8ff5b7 | 6bd375876dab856f75e1dfa7a9938878a2c45e07 |
refs/heads/master | <file_sep>const got = require('got');
const parseString = require('xml2js').parseString;
const args = require('commander');
const fs = require('fs');
const blessed = require('blessed');
const contrib = require('blessed-contrib');
const randomColor = require('randomcolor');
let screen = blessed.screen();
let grid = new contrib.grid({rows: 12, cols: 12, screen: screen});
let line = grid.set(0, 0, 6, 12, contrib.line, {
xPadding: 5,
label: "GPU temp",
showLegend: true,
legend: {width: 20}
});
let log = grid.set(6, 0, 6, 12, blessed.log, {mouse:true});
let graph_data = [];
args
.version("0.1.0")
.option("-s, --server [ip]", "Server IP address")
.option("-p, --port [port]", "Server port", 82)
.option("-u, --username [username]", "RemoteServer username", "MSIAfterburner")
.option("-p, --password [<PASSWORD>]", "RemoteServer password", "<PASSWORD>")
.option("-t, --time [ms]", "Update time interval [ms]", "100")
.option("-l, --log [file]", "Log to [file]")
.option("-v, --verbose", "Show textual output")
.parse(process.argv);
if (!args.server) {
console.log("-s or --server [ip] is required!");
args.help();
}
var auth = 'Basic ' + new Buffer(args.username + ':' + args.password).toString('base64');
setInterval(fetch, args.time);
screen.key(['escape', 'q', 'C-c'], function(ch, key) {
return process.exit(0);
});
screen.render();
function genRandColor() {
let c = randomColor();
while (graph_data.find(e => e.style.line == c)) {
c = randomColor();
}
return c;
}
function fetch() {
got(`http://${args.server}:${args.port}/mahm`, { headers: {"Authorization": auth} }).then(response => {
parseString(response.body, function(err, result) {
display(result);
});
}).catch(error => {
console.log(error);
});
}
function display(result) {
if (args.verbose) {
console.log(JSON.stringify(result.HardwareMonitor.HardwareMonitorEntries[0].HardwareMonitorEntry));
} else {
for (var entry of result.HardwareMonitor.HardwareMonitorEntries[0].HardwareMonitorEntry) {
log.log(entry);
if (!graph_data.find((e) => e.title == entry.localizedSrcName[0])) {
var series = {
title: entry.localizedSrcName[0],
x: [],
y: [],
};
graph_data.push(series);
}
var i = graph_data.findIndex((e) => e.title == entry.localizedSrcName[0]);
if (graph_data[i].y.length > 10)
graph_data[i].y.shift();
if (graph_data[i].x.length > 10)
graph_data[i].x.shift();
graph_data[i].y.push(Number(entry.data[0]));
let last_x = graph_data[i].x.length > 0 ? graph_data[i].x[0] : 0;
graph_data[i].x.push(last_x + 1);
line.setData(graph_data);
screen.render();
//console.log(graph_data);
}
}
}<file_sep>const got = require('got');
const parseString = require('xml2js').parseString;
const term = require('terminal-kit').terminal;
const args = require('commander');
const fs = require('fs');
args
.version("0.1.0")
.option("-s, --server [ip]", "Server IP address")
.option("-p, --port [port]", "Server port", 82)
.option("-u, --username [username]", "RemoteServer username", "MSIAfterburner")
.option("-p, --password [password]", "RemoteServer password", "<PASSWORD>")
.option("-t, --time [ms]", "Update time interval [ms]", "100")
.option("-l, --log [file]", "Log to [file]")
.option("-v, --verbose", "Show textual output")
.parse(process.argv);
if (!args.server) {
console.log("-s or --server [ip] is required!");
args.help();
}
var auth = 'Basic ' + new Buffer(args.username + ':' + args.password).toString('base64');
setInterval(fetch, args.time);
function fetch() {
got(`http://${args.server}:${args.port}/mahm`, { headers: {"Authorization": auth} }).then(response => {
parseString(response.body, function(err, result) {
display(result);
if (args.log) {
log(result);
}
});
}).catch(error => {
console.log(error.response.body);
});
}
function display(result) {
if (args.verbose) {
console.log(JSON.stringify(result.HardwareMonitor.HardwareMonitorEntries[0].HardwareMonitorEntry));
} else {
term.clear();
for (var entry of result.HardwareMonitor.HardwareMonitorEntries[0].HardwareMonitorEntry) {
term.red.bold(entry.localizedSrcName[0]);
term.green(" (%f %s)\t", Math.round(entry.data[0] * 100) / 100, entry.localizedSrcUnits[0])
term.column(35);
term.bar(Number(entry.data[0]) / Number(entry.maxLimit[0]), {innerSize: 40, barStyle: term.green});
term.nextLine();
}
}
}
function log(result) {
fs.appendFile(args.log, JSON.stringify(result.HardwareMonitor.HardwareMonitorEntries[0].HardwareMonitorEntry));
}
<file_sep>## miningtemp
### Installation
`npm install`
### Usage
`node index.js -s [ip] [options]`
Options:
-V, --version output the version number
-s, --server [ip] Server IP address
-p, --port [port] Server port (default: 82)
-u, --username [username] RemoteServer username (default: MSIAfterburner)
-p, --password [password] RemoteServer password (default: <PASSWORD>)
-t, --time [ms] Update time interval [ms] (default: 100)
-l, --log [file] Log to [file]
-v, --verbose Show textual output
-h, --help output usage information
| 22ee460cf59fb6cebdb99ab23340d6f8cdf22a05 | [
"JavaScript",
"Markdown"
] | 3 | JavaScript | ccc-techzone/mimon | bfa1670eb5d3c49b7715be5d5ccfeb33c2481700 | 07049a5dcf7769534f4fd1e0af06f3f4409c7630 |
refs/heads/master | <file_sep>package edu.dlsu.mobidev.labrandomrestaurant;
import android.os.Parcel;
import android.os.Parcelable;
/**
* Created by courtneyngo on 10/15/16.
*/
public class Restaurant implements Parcelable{
public static final String RESTAURANT = "restaurant";
public static final String NAME = "name";
public static final String WEIGHT = "weight";
private String name;
private int weight;
private int listPosition;
public Restaurant(){}
public Restaurant(String name, int weight) {
this.name = name;
this.weight = weight;
}
public Restaurant(String name, int weight, int listPosition) {
this.name = name;
this.weight = weight;
this.listPosition = listPosition;
}
protected Restaurant(Parcel in) {
name = in.readString();
weight = in.readInt();
listPosition = in.readInt();
}
public static final Creator<Restaurant> CREATOR = new Creator<Restaurant>() {
@Override
public Restaurant createFromParcel(Parcel in) {
return new Restaurant(in);
}
@Override
public Restaurant[] newArray(int size) {
return new Restaurant[size];
}
};
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getWeight() {
return weight;
}
public void setWeight(int weight) {
this.weight = weight;
}
@Override
public int describeContents() {
return 0;
}
@Override
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(name);
dest.writeInt(weight);
dest.writeInt(listPosition);
}
public int getListPosition() {
return listPosition;
}
public void setListPosition(int listPosition) {
this.listPosition = listPosition;
}
}
<file_sep>package edu.dlsu.mobidev.labrandomrestaurant;
import android.content.Intent;
import android.os.Bundle;
import android.support.design.widget.Snackbar;
import android.support.v7.app.AppCompatActivity;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
public class AddRestaurantActivity extends AppCompatActivity {
EditText etName, etWeight;
Button buttonDone;
Restaurant restaurant;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_add_restaurant);
etName = (EditText) findViewById(R.id.et_name);
etWeight = (EditText) findViewById(R.id.et_weight);
buttonDone = (Button) findViewById(R.id.button_done);
restaurant = new Restaurant();
if(getIntent().hasExtra(Restaurant.RESTAURANT) ){
setTitle("Edit a restaurant");
restaurant = getIntent().getParcelableExtra(Restaurant.RESTAURANT);
etName.setText(restaurant.getName());
etWeight.setText(String.valueOf(restaurant.getWeight()));
}
buttonDone.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Intent resultIntent = new Intent();
String name = etName.getText().toString();
int weight = Integer.parseInt(etWeight.getText().toString());
if(!name.trim().isEmpty() && weight > 0){
restaurant.setName(name);
restaurant.setWeight(weight);
resultIntent.putExtra(Restaurant.RESTAURANT, restaurant);
setResult(RESULT_OK, resultIntent);
finish();
}else{
Snackbar.make(buttonDone, "Please enter a restaurant name and a valid positive weight.", Snackbar.LENGTH_SHORT).show();
}
}
});
}
}
<file_sep>package edu.dlsu.mobidev.labrandomrestaurant;
import android.content.Intent;
import android.support.design.widget.Snackbar;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.view.View;
import android.widget.Button;
import android.widget.EditText;
public class EditRestaurant extends AppCompatActivity {
EditText etName, etWeight;
Button buttonDone;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_edit_restaurant);
etName = (EditText) findViewById(R.id.et_name);
etWeight = (EditText) findViewById(R.id.et_weight);
buttonDone = (Button) findViewById(R.id.button_done);
buttonDone.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
Intent resultIntent = new Intent();
String name = etName.getText().toString();
int weight = Integer.parseInt(etWeight.getText().toString());
if(!name.trim().isEmpty() && weight > 0){
resultIntent.putExtra(Restaurant.NAME, etName.getText().toString());
resultIntent.putExtra(Restaurant.WEIGHT, etWeight.getText().toString());
setResult(RESULT_OK, resultIntent);
}else{
Snackbar.make(buttonDone, "Please enter a restaurant name and a valid positive weight.", Snackbar.LENGTH_SHORT).show();
}
}
});
}
}
<file_sep>package edu.dlsu.mobidev.labrandomrestaurant;
import android.support.v7.widget.RecyclerView;
import android.view.View;
import android.view.ViewGroup;
import java.util.ArrayList;
/**
* Created by courtneyngo on 10/15/16.
*/
public class RestaurantAdapterSkeleton extends RecyclerView.Adapter<RestaurantAdapterSkeleton.RestaurantViewHolder>{
ArrayList<Restaurant> restaurantList;
private OnItemClickLister onItemClickLister;
public RestaurantAdapterSkeleton(ArrayList<Restaurant> restaurantList){
this.restaurantList = restaurantList;
}
@Override
public RestaurantViewHolder onCreateViewHolder(ViewGroup parent, int viewType) {
// TODO
return null;
}
@Override
public void onBindViewHolder(RestaurantViewHolder holder, int position) {
Restaurant restaurant = restaurantList.get(position);
restaurant.setListPosition(position);
// TODO update the display
/*
// This code will "tag" a value to the container
// The value, restaurant at this position, can be used later when the item is clicked
holder.container.setTag(restaurant);
// if an item is clicked, we update the listener in MainActivity of the event
holder.container.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
// Here, we retrieve the "tag" we set earlier, which will return the Restaurant object
Restaurant restaurant = (Restaurant) v.getTag();
// and we flag the listener (MainActivity's implementation) that an item has been clicked
onItemClickLister.onItemClick(restaurant);
}
});
*/
}
@Override
public int getItemCount() {
return restaurantList.size();
}
public void addRestaurant(Restaurant restaurant){
restaurantList.add(restaurant);
// notifyItemChanged will add a new item on the list, avoiding to update the whole list
notifyItemInserted(restaurantList.size()-1);
}
// DO NOT CHANGE
// Call this method if you want to edit a restaurant
public void editRestaurant(Restaurant restaurant){
restaurantList.set(restaurant.getListPosition(), restaurant);
// notifyItemChanged will update the item on that position, not the whole list
notifyItemChanged(restaurant.getListPosition());
}
public ArrayList<Restaurant> getRestaurantList(){
return restaurantList;
}
public class RestaurantViewHolder extends RecyclerView.ViewHolder{
View container; // assign this to ViewGroup (Relative or Linear) of the list item
// TODO
public RestaurantViewHolder(View itemView){
super(itemView);
// TODO
}
}
public interface OnItemClickLister{
public void onItemClick(Restaurant restaurant);
}
public void setOnItemClickLister(OnItemClickLister onItemClickLister) {
this.onItemClickLister = onItemClickLister;
}
}
| c5d4e6a6cb283bda545a97f7888546c9986c071c | [
"Java"
] | 4 | Java | itsoverhere/LabRandomRestaurant | aa620c6e1d94461977487b467190d92e3a9af760 | 436fdba631696d139674da05eecb102a4ec533d7 |
refs/heads/master | <file_sep>/*
* EEPROMConfig.cpp
*
* Created on: Dec 6, 2017
* Author: <NAME>
*/
#include <EEPROM.h>
#include <EEPROMConfig.h>
#define DEBUG(...) { if (debugPrint) debugPrint->println(__VA_ARGS__); }
EEPROMConfig::EEPROMConfig(BaseConfigItem &root) :
debugPrint(0),
root(root),
size(0),
checksum(0)
{
int start = sizeof(int); // Leave room for checksum
int i=0;
int maxSize = root.init(start);
checksum = root.getChecksum(0);
size = maxSize-2;
}
void EEPROMConfig::init() {
// Init from defaults if what is being stored has changed
unsigned int storedChecksum = 0;
EEPROM.get(0, storedChecksum);
if (storedChecksum != checksum) {
DEBUG("checksum: ")
DEBUG(checksum)
DEBUG("stored checksum: ")
DEBUG(storedChecksum)
DEBUG("Initializing EEPROM")
root.put();
EEPROM.put(0, checksum);
commit();
}
}
bool EEPROMConfig::commit() {
DEBUG("Committing")
return EEPROM.commit();
}
<file_sep># ESPConfig
At a high level this provides a polymorphic set of classes called ConfigItems. They contain a name, a value and a size and can be used wherever a native type would be expected. In addition there is a CompositeConfigItem that is a collection of other config items.
The class EEPROMConfig is initialized with a single config item (remember, they can be composite). It creates a checksum of the passed config item from the names, sizes and positions of all the config items it contains. It compares it with a checksum from the EEPROM and if they are different, it will initialize the EEPROM with the passed item. It modifies all the passed items with an offset that is used when writing their values to EEPROM.
Config items are responsible for writing their own values to EEPROM. e.g.:
## Example
```c++
ByteConfigItem anItem("an_item", 6);
EEPROMConfig config(anItem);
anItem = 20;
anItem.put();
// For ESPxxxx
config.commit();
```
<file_sep>/*
* ConfigItem.h
*
* Created on: Dec 6, 2017
* Author: Paul
*/
#ifndef LIBRARIES_CONFIGS_CONFIGITEM_H_
#define LIBRARIES_CONFIGS_CONFIGITEM_H_
#include "Arduino.h"
#include <EEPROM.h>
#ifndef DEBUG
#define DEBUG(...) {}
#endif
struct BaseConfigItem {
BaseConfigItem(const char *name, int maxSize) :
name(name),
maxSize(maxSize),
start(-1)
{}
virtual ~BaseConfigItem() {}
virtual int init(int start) { this->start = start; return start + maxSize; }
virtual unsigned int getChecksum(int index) {
unsigned int checksum = 0;
for (int i=0; name[i] != 0; i++) {
checksum += name[i] ^ index;
}
return checksum;
}
virtual BaseConfigItem* get(const char *name) {
if (strcmp(name, this->name) == 0) {
return this;
}
return 0;
}
virtual void fromString(const String &s) = 0;
virtual void put() const = 0;
virtual BaseConfigItem& get() = 0;
virtual String toJSON(bool bare = false) const = 0;
virtual void debug(Print *debugPrint) const = 0;
const char *name;
byte maxSize;
int start;
};
template<typename T>
struct ConfigItem : public BaseConfigItem {
ConfigItem(const char *name, const byte maxSize, const T value)
: BaseConfigItem(name, maxSize), value(value)
{}
T value;
virtual void put() const { EEPROM.put(start, value); }
virtual BaseConfigItem& get() { EEPROM.get(start, value); return *this; }
virtual void debug(Print *debugPrint) const;
operator T () const { return value; }
};
struct BooleanConfigItem : public ConfigItem<bool> {
BooleanConfigItem(const char *name, const bool value)
: ConfigItem(name, sizeof(bool), value)
{}
virtual void fromString(const String &s) { value = s.equalsIgnoreCase("true") ? 1 : 0; }
virtual String toJSON(bool bare = false) const { return value ? "true" : "false"; }
BooleanConfigItem& operator=(const bool val) { value = val; return *this; }
};
struct ByteConfigItem : public ConfigItem<byte> {
ByteConfigItem(const char *name, const byte value)
: ConfigItem(name, sizeof(byte), value)
{}
virtual void fromString(const String &s) { value = s.toInt(); }
virtual String toJSON(bool bare = false) const { return String(value); }
ByteConfigItem& operator=(const byte val) { value = val; return *this; }
};
struct IntConfigItem : public ConfigItem<int> {
IntConfigItem(const char *name, const int value)
: ConfigItem(name, sizeof(int), value)
{}
virtual void fromString(const String &s) { value = s.toInt(); }
virtual String toJSON(bool bare = false) const { return String(value); }
IntConfigItem& operator=(const int val) { value = val; return *this; }
};
struct StringConfigItem : public ConfigItem<String> {
StringConfigItem(const char *name, const byte maxSize, const String &value)
: ConfigItem(name, maxSize, value)
{}
virtual void fromString(const String &s) { value = s; }
virtual String toJSON(bool bare = false) const;
virtual void put() const;
virtual BaseConfigItem& get();
StringConfigItem& operator=(const String &val) { value = val; return *this; }
};
/**
* TODO: parse JSON to populate all items!
*/
struct CompositeConfigItem : public BaseConfigItem {
CompositeConfigItem(const char *name, const byte maxSize, BaseConfigItem** value)
: BaseConfigItem(name, maxSize), value(value)
{}
BaseConfigItem** value; // an array of pointers to BaseConfigItems
virtual int init(int start);
virtual BaseConfigItem* get(const char *name);
virtual unsigned int getChecksum(int index);
virtual void fromString(const String &s) { }
virtual String toJSON(bool bare = false) const;
virtual void put() const;
virtual BaseConfigItem& get();
CompositeConfigItem& operator=(BaseConfigItem** val) { value = val; return *this; }
virtual void debug(Print *debugPrint) const;
};
#endif /* LIBRARIES_CONFIGS_CONFIGITEM_H_ */
<file_sep>/*
* EEPROMConfig.h
*
* Created on: Dec 6, 2017
* Author: Paul
*/
#ifndef LIBRARIES_CONFIGS_EEPROMCONFIG_H_
#define LIBRARIES_CONFIGS_EEPROMCONFIG_H_
#include "Arduino.h"
#include <ConfigItem.h>
class EEPROMConfig {
public:
EEPROMConfig(BaseConfigItem &root);
void init();
void setDebugPrint(Print *debugPrint) {
this->debugPrint = debugPrint;
int marker = 0;
EEPROM.get(0, marker);
debugPrint->println("");
debugPrint->println(size);
debugPrint->println(marker);
}
bool commit();
private:
Print *debugPrint;
BaseConfigItem &root;
int size;
unsigned int checksum;
};
#endif /* LIBRARIES_CONFIGS_EEPROMCONFIG_H_ */
<file_sep>/*
* Configcpp
*
* Created on: Dec 6, 2017
* Author: Paul
*/
#include <ConfigItem.h>
#ifdef notdef
#include <sstream>
#include <iomanip>
String escape_json(const std::string &s) {
std::ostringstream o;
o << "\"";
for (auto c = s.cbegin(); c != s.cend(); c++) {
switch (*c) {
case '"': o << "\\\""; break;
case '\\': o << "\\\\"; break;
case '\b': o << "\\b"; break;
case '\f': o << "\\f"; break;
case '\n': o << "\\n"; break;
case '\r': o << "\\r"; break;
case '\t': o << "\\t"; break;
default:
if ('\x00' <= *c && *c <= '\x1f') {
o << "\\u"
<< std::hex << std::setw(4) << std::setfill('0') << (int)*c;
} else {
o << *c;
}
}
}
o << "\"";
return o.str().c_str();
}
#else
String escape_json(const String &s) {
String ret("\"");
ret.reserve(s.length() + 10);
const char *start = s.c_str();
const char *end = start + strlen(s.c_str());
for (const char *c = start; c != end; c++) {
switch (*c) {
case '"': ret += "\\\""; break;
case '\\': ret += "\\\\"; break;
case '\b': ret += "\\b"; break;
case '\f': ret += "\\f"; break;
case '\n': ret += "\\n"; break;
case '\r': ret += "\\r"; break;
case '\t': ret += "\\t"; break;
default:
if ('\x00' <= *c && *c <= '\x1f') {
char buf[10];
sprintf(buf, "\\u%04x", (int)*c);
ret += buf;
} else {
ret += *c;
}
}
}
ret += "\"";
return ret;
}
#endif
template <class T>
void ConfigItem<T>::debug(Print *debugPrint) const {
if (debugPrint != 0) {
debugPrint->print(name);
debugPrint->print(":");
debugPrint->print(value);
debugPrint->print(" (");
debugPrint->print(maxSize);
debugPrint->println(")");
}
}
template void ConfigItem<byte>::debug(Print *debugPrint) const;
template void ConfigItem<bool>::debug(Print *debugPrint) const;
template void ConfigItem<int>::debug(Print *debugPrint) const;
template void ConfigItem<String>::debug(Print *debugPrint) const;
void StringConfigItem::put() const {
int end = start + maxSize;
for (int i = start; i < end; i++) {
if (i - start < value.length()) {
EEPROM.write(i, value[i - start]);
} else {
EEPROM.write(i, 0);
break;
}
}
}
BaseConfigItem& StringConfigItem::get() {
value = String();
value.reserve(maxSize+1);
int end = start + maxSize;
for (int i = start; i < end; i++) {
byte readByte = EEPROM.read(i);
if (readByte > 0 && readByte < 128) {
value += char(readByte);
} else {
break;
}
}
return *this;
}
String StringConfigItem::toJSON(bool bare) const
{
return escape_json(value);
}
void CompositeConfigItem::debug(Print *debugPrint) const {
if (debugPrint != 0) {
debugPrint->print(name);
debugPrint->print(": {");
char *sep = "";
for (int i=0; value[i] != 0; i++) {
debugPrint->print(sep);
value[i]->debug(debugPrint);
sep = ",";
}
debugPrint->print("}");
}
}
String CompositeConfigItem::toJSON(bool bare) const {
String json;
json.reserve(200);
if (!bare) {
json.concat("{");
}
char *sep = "";
for (int i=0; value[i] != 0; i++) {
json.concat(sep);
json.concat("\"");
json.concat(value[i]->name);
json.concat("\"");
json.concat(":");
json.concat(value[i]->toJSON());
sep = ",";
}
if (!bare) {
json.concat("}");
}
return json;
}
void CompositeConfigItem::put() const {
for (int i=0; value[i] != 0; i++) {
value[i]->put();
}
}
BaseConfigItem& CompositeConfigItem::get() {
for (int i=0; value[i] != 0; i++) {
value[i]->get();
}
return *this;
}
int CompositeConfigItem::init(int start) {
this->start = start;
for (int i=0; value[i] != 0; i++) {
start = value[i]->init(start);
}
this->maxSize = start - this->start;
return start;
}
BaseConfigItem* CompositeConfigItem::get(const char *name) {
if (strcmp(name, this->name) == 0) {
return this;
}
for (int i=0; value[i] != 0; i++) {
BaseConfigItem *itemP = value[i]->get(name);
if (itemP != 0) {
return itemP;
}
}
return 0;
}
unsigned int CompositeConfigItem::getChecksum(int index) {
unsigned int checksum = BaseConfigItem::getChecksum(index);
for (int i=0; value[i] != 0; i++) {
checksum += value[i]->getChecksum(index + i) ^ index;
}
return checksum;
}
| 05811de51371987547dfb670046e1953b5be5bd6 | [
"Markdown",
"C++"
] | 5 | C++ | judge2005/ESPConfig | 459a64d1612adc95ae6cc5ea96b07fa7337f317a | fdd2ccb726d7ce349af88efed37aae1a8d21aa1f |
refs/heads/master | <repo_name>397-f20/Team-Green<file_sep>/App.js
// package dependencies
import React, { useState, useEffect } from 'react';
import { Platform, StyleSheet, Text, View , KeyboardAvoidingView} from 'react-native';
import { NavigationContainer } from '@react-navigation/native';
import { createBottomTabNavigator } from '@react-navigation/bottom-tabs';
import { createStackNavigator } from '@react-navigation/stack';
import { MaterialCommunityIcons, AntDesign, FontAwesome } from '@expo/vector-icons';
import {firebase} from './config/firebase';
import { ContextProvider } from './src/UserContext';
// components
import Profile from './src/Profile/Profile.js';
import Social from './src/Social/Social.js';
import Timer from './src/Timer/Timer.js';
import Login from './src/Login/Login';
import Friends from './src/Friends/Friends';
// import FriendMessages from './src/FriendMessages/FriendMessages';
const Tab = createBottomTabNavigator();
const Stack = createStackNavigator();
const SocialStack = createStackNavigator();
const App = () => {
const [context, setContext] = useState({userData: null, userUID: null});
return (
<KeyboardAvoidingView style={{flex: 1}} behavior={Platform.OS == "ios" ? "padding" : "height"}>
<ContextProvider>
<MainNavigator />
</ContextProvider>
</KeyboardAvoidingView>
)
}
const MainNavigator = () => {
return (
<NavigationContainer>
<Stack.Navigator initialRouteName='Login' headerMode="none">
<Stack.Screen name='Login' component={Login}/>
<Stack.Screen name='Home' component={Home}/>
</Stack.Navigator>
</NavigationContainer>
);
}
// const SocialNavigator = () => {
// return (
// <SocialStack.Navigator initialRouteName='SocialTab' headerMode="none">
// <SocialStack.Screen name='SocialTab' component={Social} />
// <SocialStack.Screen name="FriendMessages" component={FriendMessages} />
// </SocialStack.Navigator>
// );
// }
const Home = () => {
return (
<Tab.Navigator
initialRouteName="Timer"
tabBarOptions={{activeTintColor: "black", inactiveTintColor: '#2a2a72', style: {backgroundColor: '#00a4e4', borderTopColor: '#00a4e4', color: 'white'}}}
screenOptions={({ route }) => ({
tabBarIcon: ({ focused }) => {
let iconName;
if (route.name === 'Tank') {
iconName = focused
? <MaterialCommunityIcons name="fishbowl" size={24} color="black" />
: <MaterialCommunityIcons name="fishbowl-outline" size={24} color="#2a2a72" />;
} else if (route.name === 'Timer') {
iconName = focused
? <AntDesign name="clockcircle" size={24} color="black" />
: <AntDesign name="clockcircleo" size={24} color="#2a2a72" />;
} else if (route.name === 'Profile') {
iconName = focused
? <FontAwesome name="user" size={24} color="black" />
: <AntDesign name="user" size={24} color="#2a2a72" />
} else if (route.name === 'Social') {
iconName = focused
? <MaterialCommunityIcons name="account-group" size={24} color="black" />
: <MaterialCommunityIcons name="account-group-outline" size={24} color="#2a2a72" />
}
return iconName;
},
})}
>
<Tab.Screen name="Timer" component={Timer} />
<Tab.Screen name="Tank" component={Social} />
<Tab.Screen name="Social" component={Friends} />
<Tab.Screen name="Profile" component={Profile} />
</Tab.Navigator>
);
}
export default App;
<file_sep>/src/Timer/ProgressBar.js
import React, { useState, useEffect, useContext } from 'react';
import { Text, View, StyleSheet, TouchableOpacity } from 'react-native';
import IntervalBlock from './IntervalBlock';
import INTERVALS from '../../config/intervals'; // constant intervals
const ProgressBar = ({intervalProgress, inProgress}) => {
const dynamicStyles = {
fontWeight: '600',
color: (INTERVALS[intervalProgress].type === 'study') ? 'white' : 'black'
}
const viewStyles = {
backgroundColor: (INTERVALS[intervalProgress].type === 'study') ? 'blue' : 'orange',
justifyContent: 'center',
alignItems: 'center',
paddingVertical: 3,
paddingHorizontal: 8,
borderRadius: 4
}
const getText = () => {
if (inProgress) {
if (INTERVALS[intervalProgress].type === 'study') return 'Currently: studying';
else return 'Currently: taking break';
}
if (INTERVALS[intervalProgress].type === 'study') return 'Next up: study';
else return 'Next up: break'
}
return (
<View style={{alignSelf: 'center'}}>
<View style={styles.intervalBar}>{INTERVALS.map((interval, index) => (
<IntervalBlock key={index} data={interval} isFilled={intervalProgress > index}/>
))}
</View>
<View style={{...viewStyles, opacity: 0.7}}>
<Text style={{ ...dynamicStyles}}>You've completed {Math.ceil(intervalProgress / 2)} cycle(s). {getText()}</Text>
</View>
</View>
)
}
const styles = StyleSheet.create({
intervalBar: {
flexDirection: 'row',
alignItems: 'center',
justifyContent: 'space-between',
marginVertical: 10,
}
})
export default ProgressBar;
<file_sep>/cypress/integration/App.spec.js
import { firebase } from '../../config/firebase';
import 'firebase/auth';
describe ('Test App', () => {
// manually trigger firebase logout to ensure clean startup of app
before(() => {
firebase.auth().signOut();
})
it ('launches', () => {
cy.visit('/');
});
it('logs in', () => {
cy.visit('/');
cy.wait(3000)
const email = "<EMAIL>";
const password = "<PASSWORD>";
cy.get('input').eq(0).type(email).should('have.value', email);
cy.get('input').eq(1).type(password).should('have.value', password);
cy.contains("Sign in").click()
cy.wait(3000);
cy.contains("Timer").click()
cy.contains("Start").click()
cy.contains("Pause")
})
it('when-then: when user naviagte to Tank tab, see a friend list and navigate to fishtank of friend', () => {
cy.visit('/');
cy.wait(3000);
cy.contains("Tank").click();
cy.contains("(You)").click();
cy.contains("Atul").click();
});
});<file_sep>/src/Login/Validation.js
export const Validation = (_displayName, _password, _confirmPassword, setErrorMessage) => {
//NEED TO ADD SIGN IN VALIDATION
if (_password.length < 6) {
setErrorMessage('Error: password must be at least 6 characters');
return false;
}
if (_password !== _confirmPassword) {
setErrorMessage('Error: password fields do not match')
return false;
}
if (_displayName === '') {
setErrorMessage('Error: please enter a display name')
return false;
}
return true;
}<file_sep>/src/FriendMessages/Message.js
import React from 'react';
import { View, Text, StyleSheet} from 'react-native';
import { useUserContext } from '../UserContext';
const Message = ({msg, type}) => {
const { userData } = useUserContext();
return(
<View style={styles.container}>
<View>
<View style={{
height: '100%',
width: 3,
position: 'absolute',
top: 0,
left: -10,
borderRadius: 10,
backgroundColor: msg.from === userData.name ? 'rgb(0, 164, 228)' : 'rgb(150, 150, 150)'}} />
<View style={styles.metaData}>
<Text style={{marginRight: 20, fontSize: 12, fontWeight: '700', color: 'gray'}}>{msg.from}</Text>
<Text style={{fontWeight: '600', fontSize: 12, color: 'rgb(0, 164, 228)'}}>{msg.timestamp}</Text>
</View>
<Text style={styles.text}>{msg.message}</Text>
</View>
</View>
)
}
const styles = StyleSheet.create({
container: {
flex: 1,
justifyContent: 'center',
flexDirection: 'column',
alignItems: 'flex-start',
marginLeft: 20,
marginBottom: 10
},
leftBar: {
height: '100%',
width: 3,
backgroundColor: 'rgb(0, 164, 228)',
position: 'absolute',
top: 0,
left: -10,
borderRadius: 10
},
metaData: {
flexDirection: 'row',
justifyContent: 'flex-start',
alignItems: 'center'
},
text: {
fontSize: 18,
color: 'black'
}
})
export default Message;
<file_sep>/config/firebase.js
import * as firebase from 'firebase';
import "firebase/database";
const firebaseConfig = {
apiKey: "<KEY>",
authDomain: "tempo-873ec.firebaseapp.com",
databaseURL: "https://tempo-873ec.firebaseio.com",
projectId: "tempo-873ec",
storageBucket: "tempo-873ec.appspot.com",
messagingSenderId: "397266004128",
appId: "1:397266004128:web:03868b2510d5b88e6a01c5"
};
firebase.initializeApp(firebaseConfig);
export { firebase };<file_sep>/src/FishTank/FishArray.js
export const fishArray = {
0: {
name: require('../../assets/deadfish.png'),
ratio: .54
},
1: {
name: require('../../assets/koifish.png'),
ratio: 1.32
},
2: {
name: require('../../assets/redfish.png'),
ratio: 1
},
3: {
name: require('../../assets/fatfish.png'),
ratio: .64
},
4: {
name: require('../../assets/pufferfish.png'),
ratio: 1
},
5: {
name: require('../../assets/magikarp.png'),
ratio: 1
},
}
export const fishArrayLength = () => {
return Object.keys(fishArray).length;
}<file_sep>/config/intervals.js
/*
Constants file for the timer intervals
Follows 8 cycles of study --> break --> study ...
*/
const INTERVALS = [
{
length: 25,
type: 'study'
},
{
length: 5,
type: 'break'
},
{
length: 25,
type: 'study'
},
{
length: 5,
type: 'break'
},
{
length: 25,
type: 'study'
},
{
length: 5,
type: 'break'
},
{
length: 25,
type: 'study'
},
{
length: 20,
type: 'break'
}
]
export default INTERVALS;<file_sep>/__tests__/Timer.test.js
import React from 'react';
import {fireEvent, render, act } from '@testing-library/react-native';
import {expect, it} from '@jest/globals';
import Timer from '../src/Timer/Timer.js';
import { lessThan } from 'react-native-reanimated';
jest.useFakeTimers();
describe('Timer', () => {
it('Timer counts down correctly', () => {
async() => {
const timer = render(<Timer />)
const start = timer.queryByText('Start')
fireEvent.press(start);
for (let i = 10; i > 1; i--) {
let renderedTime = '00:' + i.toString();
if (i < 10) {
renderedTime = '00:0' + i.toString();
}
let timeIsThere = timer.queryByText(renderedTime);
expect(timeIsThere).toBeTruthy();
act(() => jest.runOnlyPendingTimers());
}
}
})
it('Timer displays time correctly', () => {
async() =>{
const timer = render(<Timer />)
const start = timer.queryByText('Start');
expect(start).toBeTruthy();
}
})
it('should restart timer on restart', () => {
async () => {
const timer = render(<Timer />)
const start = timer.queryByText('Start')
const restart = timer.queryByText('Restart')
fireEvent.press(start);
act(() => jest.runOnlyPendingTimers());
let ranTime = '00:10';
let timeIsThere = timer.queryByText(ranTime);
expect(timeIsThere).toBeTruthy();
fireEvent.press(restart)
let startTime = '25:00';
let startTimeThere = timer.queryByText(startTime);
expect(startTimeThere).toBeTruthy();
}
})
});<file_sep>/__tests__/Login.test.js
import {expect} from '@jest/globals';
import { Validation } from '../src/Login/Validation';
describe('Login', () => {
test('successfully validates displayName', () => {
expect(Validation('', 'hello!', 'hello!', (value) => {})).toBe(false);
expect(Validation('<NAME>', 'hello!', 'hello!', (value) => {})).toBe(true);
})
test('validates password with confirm password', () => {
expect(Validation('<NAME>', 'hello!', 'hello!', (value) => {})).toBe(true);
expect(Validation('<NAME>', 'hello!', 'hello!j', (value) => {})).toBe(false);
})
})
<file_sep>/src/FishTank/Background.js
// package dependencies
import React from 'react';
import { View, StyleSheet, Dimensions } from 'react-native';
import { LinearGradient } from 'expo-linear-gradient';
// components
import BubbleWrapper from './BubbleWrapper.js';
import FishWrapper from './FishWrapper.js';
// dimensions
const SCREEN_WIDTH = Dimensions.get('screen').width;
const SCREEN_HEIGHT = Dimensions.get('screen').height;
const Background = ( props ) => {
return (
<View style={styles.container}>
<LinearGradient
// Background Linear Gradient
colors={['#eaeaea', '#00a4e4']}
style={styles.gradient}
start={[0, .1]}
end={[.2, .9]}
/>
<FishWrapper SCREEN_WIDTH={SCREEN_WIDTH} SCREEN_HEIGHT={SCREEN_HEIGHT} fishObjects={props.fishObjects} />
<BubbleWrapper />
</View>
);
}
const styles = StyleSheet.create({
container: {
position: 'absolute',
top: 0,
backgroundColor: 'lightblue',
width: SCREEN_WIDTH,
height: SCREEN_HEIGHT
},
gradient:{
position: 'absolute',
left: 0,
top: 0,
height: SCREEN_HEIGHT,
width: SCREEN_WIDTH
}
})
export default Background;<file_sep>/src/Social/Dropdown.js
import React, {useState} from 'react';
import { View, TouchableOpacity, Text, StyleSheet, Dimensions, ScrollView } from 'react-native';
const Dropdown = ({ friendsList, loggedIn, changeUser, currentlySelected }) => {
const [showDropdown, setShowDropdown] = useState(false);
const internalChangeUser = (uid) => {
setShowDropdown(false);
changeUser(uid);
}
return (
<View >
<TouchableOpacity style={styles.currentSelection} activeOpacity={1} onPress={() => setShowDropdown(!showDropdown)}>
<Text style={styles.currentSelectionText}>{currentlySelected.name} {currentlySelected.id === loggedIn ? "(You)" : ""}</Text>
<Text style={styles.currentSelectionTextCarat}>⌄</Text>
</TouchableOpacity>
{showDropdown &&
<ScrollView
contentContainerStyle={styles.scrollView}
>
{
Object.values(friendsList).map((friend) => (
<SingleOption user={friend} key={friend.friendUID} changeUser={internalChangeUser} loggedIn={loggedIn} />
))
}
</ScrollView>}
</View>
)
}
const SingleOption = ({ user, changeUser, loggedIn }) => {
return (
<TouchableOpacity onPress={() => changeUser(user.friendUID)}>
<View style={styles.singleOption}>
<Text>{user.friendName} {user.friendUID === loggedIn ? "(You)" : ""}</Text>
</View>
</TouchableOpacity>
)
}
const styles = StyleSheet.create({
container: {
position: 'absolute',
shadowColor: "#000000",
shadowOffset: {
width: 0,
height: 4,
},
shadowOpacity: 0.3,
shadowRadius: 4,
elevation: 5
},
currentSelection: {
flexDirection: 'row',
marginTop: 150,
width: Dimensions.get('screen').width * 0.4,
height: 30,
backgroundColor: 'rgba(0, 0, 0, 0.1)',
marginLeft: 50,
borderRadius: 25,
justifyContent: 'space-between',
alignItems: 'center'
},
currentSelectionText: {
paddingHorizontal: 20,
color: 'black',
fontWeight: '500'
},
currentSelectionTextCarat: {
paddingHorizontal: 20,
fontSize: 25,
bottom: 6
},
scrollView: {
backgroundColor: 'rgba(0, 0, 0, 0.1)',
marginLeft: 50,
marginTop: 20,
borderRadius: 25,
paddingVertical: 10,
paddingHorizontal: 20,
width: Dimensions.get('screen').width * 0.4
},
singleOption: {
borderBottomColor: 'rgba(0, 0, 0, 0.2)',
borderBottomWidth: 1,
paddingVertical: 10
}
})
export default Dropdown;<file_sep>/__tests__/FishObtained.test.js
/*
Background Component Testing
Unit tests for the fish obtained functionality
*/
import React from 'react';
import { create } from 'react-test-renderer';
import ShallowRenderer from 'react-test-renderer/shallow';
import {fireEvent, render, act } from '@testing-library/react-native'; // using react native testing library
import { firebase } from '../config/firebase';
import Timer from '../src/Timer/Timer';
import Social from '../src/Social/Social';
import Background from '../src/FishTank/Background';
const shallow = new ShallowRenderer(); // shallow rendering for components
const testUser = 'a'; // user to test on
/*
NOTE:
All tests use Jest fake timers
Using Jest mock functions to control passing of time
*/
describe('Fish Obtained', () => {
it('should render Background', () => {
render(<Background numFish={{idx: 0, size: 1}}/>);
});
it('should render Social', () => {
render(<Social/>);
})
it('should add fish at end of timer', () => {
let fakeFishCount = {"hello": {idx: 0, size: 1}}; // mock firebase fish count
const incrementFish = () => fakeFishCount["goodbye"] = {idx:1, size:2}; // mock function for when timer ends
// const social = render(<Social/>)
// const initialBackground = social.props.children[0];
// expect(initialBackground.props.fishObjects).toEqual({});
const loadedBackground = shallow.render(<Background fishObjects={fakeFishCount}/>);
expect(loadedBackground.props.children[1].props.fishObjects).toEqual(fakeFishCount);
incrementFish();
const reloadedBackground = shallow.render(<Background fishObjects={fakeFishCount}/>);
expect(reloadedBackground.props.children[1].props.fishObjects).toEqual(fakeFishCount);
})
});<file_sep>/src/Profile/UserSummary.js
import React from 'react';
import {View, Text, StyleSheet} from 'react-native';
const UserSummary = ({userData}) => {
return (
<View style={styles.container}>
<Text style={styles.text}>
Congratulations! You have studied {Object.values(userData.history).length} days in total!
</Text>
<Text style={styles.text}>
Total Fish: {userData.fish}
</Text>
</View>
);
};
const styles = StyleSheet.create({
container: {
flex: 1
},
text:{
paddingVertical: 10
}
});
export default UserSummary;
<file_sep>/src/Profile/ProfileHeader.js
import React from 'react';
import {View, Text, Image, StyleSheet} from 'react-native';
const ProfileHeader = ({title, img}) => {
return (
<View style={styles.header}>
<Text style={styles.text}>{title}</Text>
<Image style={styles.img} source={img}/>
</View>
);
};
ProfileHeader.defaultProps = {
title: '<NAME>',
img: "https://randomuser.me/api/portraits/men/1.jpg"
};
const styles = StyleSheet.create({
header: {
height: 100,
padding: 15,
alignSelf: "stretch",
backgroundColor: 'darkblue',
flexDirection: "row",
justifyContent: "space-between",
marginTop: 25
},
text: {
color: 'white',
fontSize: 23,
paddingVertical: 20
},
img:{
width: 75,
height: 75,
borderRadius: 75/2,
alignSelf: "center",
}
});
export default ProfileHeader;<file_sep>/src/FishTank/Fish.js
import React, { useState, useEffect} from 'react';
import { Image, Animated, StyleSheet } from 'react-native';
import { fishArray } from './FishArray.js';
const Fish = ( props ) => {
const [fishAnimated, setFishAnimated] = useState(new Animated.Value(0));
const animationDuration = 250000 * props.random + 75000;
const chosenIndex = props.fishType;
const [name, setName] = useState(fishArray[chosenIndex].name)
const [ratio, setRatio] = useState(fishArray[chosenIndex].ratio)
const [initialTop, setInitialTop] = useState(Math.floor(Math.random() * (props.SCREEN_HEIGHT - 100)) + 50)
const [initialLeft, setInitialLeft] = useState(Math.floor(Math.random() * (props.SCREEN_WIDTH -100)) + 50)
const [size, setSize] = useState(props.sizeRandom);
const runFishAnimation = () => {
Animated.loop(
Animated.sequence([
Animated.timing(fishAnimated, {
toValue: 100,
useNativeDriver: true,
duration: animationDuration,
}),
Animated.timing(fishAnimated, {
toValue: 0,
useNativeDriver: true,
duration: animationDuration,
})
])
).start();
}
// TO DO
const getTranslateX = () => {
const difference = (props.SCREEN_WIDTH - initialLeft);
const moveRight = ((props.SCREEN_WIDTH - 50) - initialLeft);
const moveLeft = (25 - initialLeft);
if (difference > props.SCREEN_WIDTH / 2) {
return [0, moveRight - 10, moveRight, moveRight - 10, moveLeft + 10, moveLeft, moveLeft + 10, moveRight - 10, moveRight, moveRight - 10, 10, 0];
} else {
return [0, moveLeft + 10, moveLeft, moveLeft + 10, moveRight - 10, moveRight, moveRight - 10, moveLeft + 10, moveLeft, moveLeft + 10, -10, 0];
}
}
// TO DO
const getTranslateY = () => {
const difference = props.SCREEN_HEIGHT - initialTop;
if (difference > props.SCREEN_HEIGHT / 2) {
return [0, 5, 15, 35, 75, 135, 195, 235, 255, 265, 270, 265, 255, 235, 195, 135, 75, 35, 15, 5, 0]
} else {
return [0, -5, -15, -35, -75, -135, -195, -235, -255, -265, -270, -265, -255, -235, -195, -135, -75, -35, -15, -5, 0]
}
}
useEffect(() => {
runFishAnimation();
}, [])
const fishAnimation = {
transform: [
{
translateY: fishAnimated.interpolate({
inputRange: [0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100],
outputRange: getTranslateY()
})
},
{
translateX: fishAnimated.interpolate({
inputRange: [0, 22.5, 25, 27.5, 47.5, 50, 52.5, 72.5, 75, 77.5, 97.5, 100],
outputRange: getTranslateX()
})
}
]
}
return (
<Animated.View style={[fishAnimation, styles.fish, {top: initialTop, left: initialLeft}]}>
<Image source={name} style={{width: size, height: size * ratio}} ></Image>
</Animated.View>
)
}
const styles = StyleSheet.create({
fish: {
position: 'absolute'
}
})
export default Fish;<file_sep>/src/Logout/Logout.js
/*
Logout Button Component
**Note**
This button is currently fixed on each tab screen so that it's accessible.
This design is temporary and can be changed for the screens.
*/
import React from 'react';
import { StyleSheet, Text, View, TouchableOpacity } from 'react-native';
import { firebase } from '../../config/firebase'
import { useNavigation } from '@react-navigation/native';
import 'firebase/auth';
import { useUserContext } from '../UserContext';
const Logout = () => {
const { userUidCallback } = useUserContext();
const navigation = useNavigation(); // get navigation object
// Signs user out with firebase
// Redirects to login page if successful
const logout = () => {
userUidCallback(null);
firebase.auth().signOut()
.then(function() {
navigation.navigate('Login');
})
.catch(function(err) {
alert(err.message);
})
}
return (
<TouchableOpacity style={styles.buttonPosition} onPress={logout} activeOpacity={1}>
<View style={styles.button}>
<Text style={styles.text}>Log out</Text>
</View>
</TouchableOpacity>
)
}
const styles = StyleSheet.create({
button: {
height: 30,
width: '50%',
borderRadius: 12,
backgroundColor: '"#00a4e4"',
justifyContent: 'center',
alignItems: 'center'
},
text: {
fontSize: 20,
color: '#FFF'
},
buttonPosition: {
position: 'absolute',
right: 10,
top: 45
}
})
export default Logout;
<file_sep>/src/FishTank/FishWrapper.js
// package dependencies
import React, { useState, useEffect } from 'react';
import { View } from 'react-native';
// components
import Fish from './Fish.js';
const FishWrapper = ( props ) => {
const [renderedFish, setRenderedFish] = useState(props.fishObjects)
useEffect(() => {
setRenderedFish([])
setRenderedFish(props.fishObjects);
}, [props.fishObjects])
return (
<View>
{(renderedFish && renderedFish != []) ? Object.keys(renderedFish).map((fish) => (
<Fish SCREEN_WIDTH={props.SCREEN_WIDTH} SCREEN_HEIGHT={props.SCREEN_HEIGHT} key={fish} random={Math.random()} sizeRandom={renderedFish[fish].size} fishType={renderedFish[fish].idx} />
)) : null}
</View>
)
}
export default FishWrapper;<file_sep>/README.md
# Tempo
<NAME>
A beautiful app to encourage studying.
# Firebase
Added Firebase project called Tempo for this app.
> #### Firebase Project: **https://console.firebase.google.com/u/1/project/tempo-873ec/overview**
> #### Hosted URL: **https://tempo-873ec.web.app/**
## Setup
When first pulling the firebase repo, run:
> `yarn install`
This will ensure all necessary packages are installed in your local repo.
> **Note**
>
> Firebase has been setup to deploy to a folder called **web-build**. This can be changed in the **firebase.json** by editing **`"public": ...`**
## Usage
You simply need to import the **firebase** object in the file. The firebase object is in ***config/firebase.js***
> `import { firebase } from 'config/firebase';`
You can now use all the firebase functions from that object, i.e. for **Real Time Database**:
> `const db = firebase.database().ref(); `
## Deploy to Hosting
Added scripts to the package.json to simplify deployment:
### Build and Deploy
> `yarn run deploy`
This will run `yarn run build` and then `firebase deploy`.
### Build Only
> `yarn run build`
This will run `expo build:web`. You can then run `firebase deploy` to deploy the project.
## Test Data
The Real Time Database currently has some test data for users.
To make it easier to see what the data is, there is a json copy of it in ***test_data/users.json***.
<file_sep>/src/Social/Social.js
// package dependencies
import React, { useState, useEffect } from 'react';
import { View, StyleSheet} from 'react-native';
import { firebase } from '../../config/firebase'
import 'firebase/auth';
// components
import Background from '../FishTank/Background.js';
import Dropdown from './Dropdown.js';
import { useUserContext } from '../UserContext';
const Social = ({route}) => {
const initialShow = route && route.params && route.params.initialShow ? route.params.initialShow : null;
const { userData } = useUserContext();
const [displayedUser, setDisplayedUser] = useState(userData);
// user = {id}
const changeUser = (uid) => {
// change displayed user --> uid -> call to firebase -- > set displayed user from firebase response
firebase.database().ref('users/' + uid).on('value', snap => {
if (snap.val()) {
setDisplayedUser(snap.val());
}
});
}
useEffect(() => {
if (initialShow) changeUser(initialShow)
}, [initialShow])
return (
<View style={styles.container}>
<Background fishObjects={displayedUser.fishObjects} />
<Dropdown friendsList={userData.friends} loggedIn={userData.id} changeUser={changeUser} currentlySelected={displayedUser} />
</View>
);
}
const styles = StyleSheet.create({
container: {
flex: 1,
},
modal:{
width: 25,
height: 25
},
dropdown: {
top: 500
}
});
export default Social; | 7a3edff9219e20db40e354190fff3aa10977d0d1 | [
"JavaScript",
"Markdown"
] | 20 | JavaScript | 397-f20/Team-Green | 097828fdf86593876219e3b3f926c9cba4c25a02 | c255dfdb44daddcc97e58067b3e51eddd4446fa4 |
refs/heads/master | <file_sep>var App = function () {
var loadSound = $('#load_sound')[0];
var ambientSound = $("#ambient_sound")[0];
var pressSound = $("#press_sound")[0];
var acceptSound = $("#accept_sound")[0];
var weaponSound = $(".weapon_sound");
var service = "/telcel-ironman/servicio/";
loadSound.muted = true;
ambientSound.muted = true;
var scale = 1;
var fx = $("#fx_wrapper");
var gameW = $("#game_wrapper");
var doc = $("#wrapper");
var imgWidth = 798;
var imgHeight = 402;
var pattern = $("#pattern");
var mask = $("#mask");
var UI = $("#UI");
var scoreW = $("#score_wrapper");
var paper = Raphael(0, 0, imgWidth, imgHeight);
var svg = $("svg");
var overlay = $("#overlay");
var leftControls = $("#left_controls");
var bottomControls = $("#bottom_controls");
var rightControls = $("#right_controls");
var adjuster = new Adjuster({
d: doc,
g:gameW,
fx:fx,
p: pattern,
m: mask,
ui: UI,
o: overlay
}, paper, svg, imgWidth, imgHeight, true);
var intro = new Array;
var nextVideo = new Array();
var userId = 0;
var weaponId;
var map = new IronMap("map_canvas");
var weaponCount = {};
var answer = {};
var currentQuestion;
var tuit;
var trivia;
var video;
var frameNum = 0;
var newPlayer = true;
var km = 0;
var imgLoader = new ImageLoader();
var player = new ScenePlayer(10, paper);
var game = new Game(gameW);
/******* Interaction Handlers *******/
function interactionHandler(e) {
_gaq.push(['_trackEvent', 'Click', e.target.value, 'App event']);
pressSound.play();
switch (e.target.value) {
case "play":
hideOverlay();
acceptSound.play();
break;
case "share":
scrleft = (screen.width / 2) - (400 /2); //centres horizontal
scrtop = ((screen.height / 2) - (200 /2)) - 40; //centres vertical
mywindow = window.open("https://www.facebook.com/sharer/sharer.php?u=http://ironman4glte.com/", "mywindow", "location=1,status=1,scrollbars=1, width=400,height=200,left="+scrleft+",top="+scrtop);
break;
case "help":
showOverlay(e.target.value);
break;
case "ranking":
showOverlay(e.target.value);
break;
case "go3":
if(game.getToken()){
showOverlay("advertGame");
}else{
showOverlay("advertAcumulables");
}
var timeOut = setTimeout(function() {
hideOverlay();
mask.fadeOut();
scoreW.fadeIn();
UI.fadeOut(function(){
game.start();
});
},2000);
break;
case "attack":
weaponId = $(e.target).index();
if(weaponCount[weaponId] > 0){
showOverlay(e.target.value);
$("#attack_tuit").children().hide();
$('#attack_tuit').children().eq(weaponId).show();
$("#attack_ranking ul li").removeClass("active");
}else{
showOverlay("advertWeapon");
}
break;
case "destroy":
if (userId) {
acceptSound.play();
$.ajax({
type: "POST",
dataType: "json",
url: service+"index.php/call/realizar_disparo/",
data: {
arma: weaponId+1,
objetivo: userId.id
},
success: function (e) {
var temp = weaponSound.eq(weaponId);
temp[0].play();
hideOverlay();
$(userId).removeClass("active");
weaponCount[weaponId] = weaponCount[weaponId]-1;
if(weaponCount[weaponId] == 0){
$('#weapon_block #weapon_indicator').children().eq(weaponId).attr("disabled","disabled")
}
$('#weapon_block #weapon_count').children().eq(weaponId).html(weaponCount[weaponId]);
}
});
}
break;
default:
$(e.target).parent().children().removeClass("active");
$(e.target).addClass("active");
if (e.target.id != 0) {
userId = e.target;
};
}
}
/******* Set Init Data ********/
function setInitData(e) {
if(e.data.token){
game.setToken(e.data.token);
}else{
game.setToken(false);
}
if(e.data.score){
$("#advertScore_wrapper span").html(e.data.score+"km");
showOverlay("advertScore");
}
km = e.data.info.kilometrosRecorridos;
$("#km_counter").html(km+" Km");
if(km > 0){
newPlayer = false;
}else{
newPlayer = true;
}
$("#avatar_block img").attr("src",e.data.profile_image_url);
$("#avatar_block span").html(e.data.info.idTwitter);
weaponCount[0] = e.data.arma1;
weaponCount[1] = e.data.arma2;
weaponCount[2] = e.data.arma3;
$('#weapon_block #weapon_count').children().eq(0).html(weaponCount[0]);
$('#weapon_block #weapon_count').children().eq(1).html(weaponCount[1]);
$('#weapon_block #weapon_count').children().eq(2).html(weaponCount[2]);
$("#ranking_wrapper ul").html("");
for (x in e.data.ranking)
{
$("#ranking_wrapper ul").append('<li id="'+e.data.ranking[x].idUsuario+'">'+e.data.ranking[x].idTwitter+'</li>');
}
if(e.data.coordenada){
map.addMarker(e.data.coordenada.latitud, e.data.coordenada.longitud);
}
if(trivia){
video = e.data.siguienteVideo;
frameNum = e.data.frames;
imgLoader.load(frameNum,frameNum,video+"/"+video+"_",function(e){
nextVideo = e.imageArray;
});
}
$("#ranking_block ul").html("");
$("#attack_ranking ul").html("");
var temp = e.data.rankingProximo.anteriores;
var xj = 1;
for (x in temp){
$("#ranking_block ul").append('<li id="' + temp[x].idUsuario + '"><span>'+temp[x].posicion+'</span>'+ temp[x].idTwitter+ '</li>');
if( xj > 2){
$("#attack_ranking ul").append('<li value="user" class="interaction" id="' + temp[x].idUsuario + '">'+ temp[x].idTwitter+ '</li>');
}
xj++;
}
$("#ranking_block ul").append('<li class="me" ><span>'+ e.data.info.posicion+'</span>'+ e.data.info.idTwitter+ '</li>');
temp = e.data.rankingProximo.siguientes;
xj = 0 ;
for (x in temp){
$("#ranking_block ul").append('<li id="' + temp[x].idUsuario + '"><span>'+temp[x].posicion+'</span>'+ temp[x].idTwitter+ '</li>');
if(xj < 2){
$("#attack_ranking ul").append('<li value="user" class="interaction" id="' + temp[x].idUsuario + '">'+ temp[x].idTwitter+ '</li>');
xj++;
}
}
$("#go_content").html(tuit);
$(".interaction").off("click", interactionHandler);
$(".interaction").on("click", interactionHandler);
}
/********* Overlay functions *********/
function showOverlay(key) {
if(!key){
$("#loader").addClass("active_wrap").show();
}else{
$("#" + key + "_wrapper").append('<button id="close" class="close" ></button>');
$("#" + key + "_wrapper").addClass("active_wrap").show();
$(".close").on("click",function(){ hideOverlay() });
$("#prompt_wrapper").show();
}
overlay.fadeIn();
}
function hideOverlay(c) {
overlay.fadeOut(function () {
$(".active_wrap").hide().removeClass("active_wrap");
if($(".active_wrap").children(".close")){
$(".active_wrap").children(".close").remove();
$(".close").off();
}
if (c) {
c();
}
});
};
/********** Intro image load *********/
function init(){
$("#preload").remove();
imgLoader.load(50, 50, "game/game", function (e) {
intro = e.imageArray;
$.ajax({
dataType: "json",
url: service+"index.php/call/carga_inicial2/",
success: function (e) {
if (e.success) {
setInitData(e);
hideOverlay(function () {
fx.fadeIn();
leftControls.animate({
left: 0
});
bottomControls.animate({
bottom: 0
});
rightControls.animate({
right: 0
}, function () {
if(newPlayer){
showOverlay("help");
}
});
});
loadSound.pause();
ambientSound.play();
player.play(intro, true);
} else {
self.location="index.html";
}
}
});
});
}
/******** Events *******/
gameW.on("onFinish", function(e){
if(e.CXV){
var CXV = e.CXV;
$.ajax({
type: "POST",
dataType: "json",
data:{CXV:CXV},
url: service+"index.php/call/reload",
success: function (e) {
if(e.data){
setInitData(e);
}
}
});
}
scoreW.fadeOut();
mask.fadeIn();
UI.fadeIn(function(){
});
});
$(document).keyup(function (e) {
if (e.keyCode == 27) {
hideOverlay();
}
});
$(window).load(function(){
init();
});
document.ontouchmove = function (e) {
e.preventDefault();
};
$(".attack").tooltip();
};<file_sep>var IronMap = function(id) {
var markersArray = [];
var lat;
var long;
var styles = [ {
featureType : 'landscape',
elementType : 'all',
stylers : [ {
hue : '#224f60'
}, {
saturation : 28
}, {
lightness : -71
}, {
visibility : 'on'
} ]
}, {
featureType : 'landscape.man_made',
elementType : 'all',
stylers : [ {
hue : '#207391'
}, {
saturation : 50
}, {
lightness : -61
}, {
visibility : 'on'
} ]
}, {
featureType : 'road',
elementType : 'all',
stylers : [ {
hue : '#80d2f0'
}, {
saturation : -21
}, {
lightness : 23
}, {
visibility : 'on'
} ]
}, {
featureType : 'poi.park',
elementType : 'all',
stylers : [ {
hue : '#1a647f'
}, {
saturation : 40
}, {
lightness : -62
}, {
visibility : 'on'
} ]
}, {
featureType : 'road.highway',
elementType : 'all',
stylers : [ {
hue : '#28d1ef'
}, {
saturation : -14
}, {
lightness : -15
}, {
visibility : 'on'
} ]
}, {
featureType : 'poi.school',
elementType : 'all',
stylers : [ {
hue : '#8ee6f6'
}, {
saturation : 72
}, {
lightness : -8
}, {
visibility : 'on'
} ]
}, {
featureType : 'road.local',
elementType : 'all',
stylers : [ {
hue : '#8ee6f6'
}, {
saturation : -15
}, {
lightness : -24
}, {
visibility : 'on'
} ]
}, {
featureType : 'water',
elementType : 'all',
stylers : [ {
hue : '#81d2e6'
}, {
saturation : 40
}, {
lightness : -7
}, {
visibility : 'on'
} ]
} ];
var options = {
mapTypeControlOptions : {
mapTypeIds : [ 'Styled' ]
},
center : new google.maps.LatLng(19.438019159516003, -99.13311233520506),
zoom : 2,
mapTypeControl : false,
navigationControl : false,
streetViewControl : false,
navigationControlOptions : {
style : google.maps.NavigationControlStyle.SMALL
},
mapTypeId : 'Styled'
};
var div = document.getElementById(id);
var map = new google.maps.Map(div, options);
var styledMapType = new google.maps.StyledMapType(styles, {
name : 'Styled'
});
map.mapTypes.set('Styled', styledMapType);
this.addMarker = function(_lat,_long) {
lat = _lat;
long = _long
clearOverlays();
var markerPos = new google.maps.LatLng(lat, long);
marker = new google.maps.Marker({
position : markerPos,
map : map
});
map.setCenter(markerPos);
markersArray.push(marker);
var flightPlanCoordinates = [
new google.maps.LatLng(19.438019159516003, -99.13311233520506),
new google.maps.LatLng(lat, long),
];
var flightPath = new google.maps.Polyline({
path: flightPlanCoordinates,
strokeColor: '#FF0000',
strokeOpacity: 1.0,
strokeWeight: 2
});
flightPath.setMap(map);
};
function clearOverlays() {
for ( var i = 0; i < markersArray.length; i++) {
markersArray[i].setMap(null);
}
markersArray = [];
}
};
<file_sep>var SpaceShip = function(_holder) {
var holder = _holder;
var shipType1 = "statics/img/nave_1.gif";
var shipType2 = "statics/img/nave_2.gif";
var shipType3 = "statics/img/nave_3.gif";
var xplotionImg = "statics/img/explosion_gif_once.gif";
var shipType;
var laser1Sound = $('#laser1_sound')[0];
var explotionSound = $("#explotion_sound")[0];
var scoreSound = $("#score_sound")[0];
var prev;
var grades;
var spaceShipW = 400;
function getGrades(){
var rand = Math.floor(Math.random()*4) + 1;
if(prev == rand){
rand = Math.floor(Math.random()*4) + 1;
}
prev = rand;
switch (rand) {
case 1:
grades = {
top:0-spaceShipW,
left: Math.floor((Math.random()*document.documentElement.clientWidth)+1),
width:spaceShipW
}
break;
case 2:
grades = {
top:Math.floor((Math.random()*document.documentElement.clientHeight)+1)-spaceShipW/2,
left:document.documentElement.clientWidth,
width:spaceShipW
}
break;
case 3:
grades = {
top:document.documentElement.clientHeight,
left:Math.floor((Math.random()*document.documentElement.clientWidth)+1)-spaceShipW/2,
width:spaceShipW
}
break;
case 4:
grades = {
top: Math.floor((Math.random()*document.documentElement.clientHeight)+1)-spaceShipW/2,
left:0-spaceShipW,
width:spaceShipW
}
break;
default:
break;
}
return grades;
}
function uniqueid(){
// always start with a letter (for DOM friendlyness)
var idstr=String.fromCharCode(Math.floor((Math.random()*25)+65));
do {
// between numbers and characters (48 is 0 and 90 is Z (42-48 = 90)
var ascicode=Math.floor((Math.random()*42)+48);
if (ascicode<58 || ascicode>64){
// exclude all chars between : (58) and @ (64)
idstr+=String.fromCharCode(ascicode);
}
} while (idstr.length<10);
return (idstr);
}
this.create = function(){
shipType = Math.floor((Math.random()*3)+1);
var ship = $('<div/>');
ship.css({
position:"absolute",
width:10,
left:((document.documentElement.clientWidth/2)-25)+Math.floor((Math.random()*50)+(Math.random())*0),
top:((document.documentElement.clientHeight/2)-25)+Math.floor((Math.random()*50)+(Math.random())*0)
});
ship.append("<img draggable='false' width='100%' src="+eval("shipType"+shipType)+" />");
ship.attr("title",shipType);
ship.fadeIn("slow");
holder.append(ship);
ship.animate(getGrades(), 2500, "linear", function(e){
ship.remove();
});
ship.on("click",function(e){
ship.append("<img draggable='false' style='position:absolute; top:0; left:0; z-index:10;' width='100%' src='"+xplotionImg+"?="+uniqueid()+"' />");
explotionSound.pause();
// laser1Sound.play();
holder.trigger({
type:"onDestroy",
c:$(e.currentTarget).attr("title")
});
explotionSound.play();
ship.stop();
// ship.fadeOut();
var timeOut = setTimeout(function() {
ship.remove();
scoreSound.play();
},1000);
});
};
}<file_sep>var App = function () {
document.ontouchmove = function (e) {
e.preventDefault();
};
var scale = 1;
var doc = $("#wrapper");
var imgWidth = 798;
var imgHeight = 402;
var pattern = $("#pattern");
var mask = $("#mask");
var UI = $("#UI");
var paper = Raphael(0, 0, imgWidth, imgHeight);
var svg = $("svg");
var overlay = $("#overlay");
var leftControls = $("#left_controls");
var bottomControls = $("#bottom_controls");
var rightControls = $("#right_controls");
var adjuster = new Adjuster({
d: doc,
p: pattern,
m: mask,
ui: UI,
o: overlay
}, paper, svg, imgWidth, imgHeight, true);
var intro = new Array;
var nextVideo = new Array();
var userId = 0;
var weaponId;
var map = new IronMap("map_canvas");
var weaponCount = {};
var tuit;
var video;
var imgLoader = new ImageLoader();
var player = new ScenePlayer(10, paper);
/******** Events *******/
$(document).keyup(function (e) {
if (e.keyCode == 27) {
hideOverlay();
} // esc
});
function interactionHandler(e) {
//console.log(e.target.title);
switch (e.target.title) {
case "play":
hideOverlay();
break;
case "help":
showOverlay(e.target.title);
break;
case "go":
if(tuit){
showOverlay(e.target.title);
}
break;
case "send":
$.ajax({
dataType: "json",
url: "/telcel-ironman/servicio/index.php/call/avanzar",
success: function (e) {
if(e.success){
player.play(nextVideo, function(){
player.play(intro, true);
});
setInitData(e);
hideOverlay();
}else{
tuit=false;
}
}
});
break;
case "attack":
weaponId = $(e.target).index();
if(weaponCount[weaponId] > 0){
showOverlay(e.target.title);
$("#attack_tuit").children().hide();
$('#attack_tuit').children().eq(weaponId).show();
}
break;
case "user":
$(e.target).parent().children().removeClass("active");
$(e.target).addClass("active");
if (e.target.id != 0) {
userId = e.target;
};
break;
case "destroy":
if (userId) {
$.ajax({
type: "POST",
dataType: "json",
url: "http://qa1.clarusdigital.com/telcel-ironman/servicio/index.php/call/realizar_disparo/",
data: {
arma: weaponId+1,
objetivo: userId.id
},
success: function (e) {
//console.log(e);
hideOverlay();
$(userId).removeClass("active");
weaponCount[weaponId] = weaponCount[weaponId]-1;
$('#armor_block #armor_count').children().eq(weaponId).html(weaponCount[weaponId]);
}
});
}
break;
}
}
/******* Set Init Data ********/
function setInitData(e) {
//console.log(e.data.info);
$("#avatar_block img").attr("src", "https://api.twitter.com/1/users/profile_image?screen_name=" + e.data.info.idTwitter + "&size=bigger");
$("#avatar_block span").html(e.data.info.idTwitter);
var temp = e.data.rankingProximo.siguientes;
if(temp[1]){
$("#ranking_block ul").append('<li id="' + temp[0].idUsuario + '">' + temp[0].nombre + '</li>');
$("#ranking_block ul").append('<li id="' + temp[1].idUsuario + '">' + temp[1].nombre + '</li>');
}
temp = e.data.rankingProximo.anteriores;
if(temp[1]){
$("#ranking_block ul").append('<li id="' + temp[0].idUsuario + '">' + temp[0].nombre + '</li>');
$("#ranking_block ul").append('<li id="' + temp[1].idUsuario + '">' + temp[1].nombre + '</li>');
}
$('#armor_block #armor_count').children().eq(0).html(e.data.arma1);
$('#armor_block #armor_count').children().eq(1).html(e.data.arma2);
$('#armor_block #armor_count').children().eq(2).html(e.data.arma3);
weaponCount[0] = e.data.arma1;
weaponCount[1] = e.data.arma2;
weaponCount[2] = e.data.arma3;
if(e.data.siguienteTweet){
//console.log("tenemos otro tiro");
tuit = e.data.siguienteTweet;
video = "periferico1";
imgLoader.load(150,150,video+"/"+video+"_",function(e){
nextVideo = e.imageArray;
});
}
$("#go_content").html(tuit);
$("#attack_ranking ul").html($("#ranking_block ul").html());
$("#attack_ranking ul li").addClass("interaction");
$("#attack_ranking ul li").attr("title", "user");
$(".interaction").on("click", interactionHandler);
}
/********* Overlay functions *********/
function showOverlay(key) {
$("#" + key + "_wrapper").addClass("active_wrap").show();
overlay.fadeIn();
}
function hideOverlay(c) {
overlay.fadeOut(function () {
if (c) {
c();
}
$(".active_wrap").hide().removeClass("active_wrap");
});
};
/********** Intro image load *********/
imgLoader.load(20, 20, "loop2/loop2_", function (e) {
intro = e.imageArray;
//console.log(intro);
player.play(intro, true);
});
};<file_sep>var App = function () {
window.scrollTo(0, 1);
var service = "/telcel-ironman/servicio/";
var imgWidth = 480;
var imgHeight = 300;
var paper = Raphael(0, 0, imgWidth, imgHeight);
var svg = $("svg");
var pattern = $("#pattern");
var overlay = $("#overlay");
var UI = $("#UI");
var xx = $("#advertPortrait");
var doc = $("body");
var weaponCount = {};
var answer = {};
var currentQuestion;
var tuit;
var trivia;
var video;
var frameNum = 0;
var adjuster = new Adjuster({
b:doc,
p: pattern,
o:overlay,
u:UI
}, paper, svg, imgWidth, imgHeight, true);
var imgLoader = new ImageLoader();
var player = new ScenePlayer(10, paper);
document.ontouchmove = function (e) {
e.preventDefault();
};
$(window).on("load",function(){
init();
optionalData();
window.scrollTo(0, 1);
});
function setInitData(e) {
km = e.data.info.kilometrosRecorridos;
$("#km_counter").html(km+" Km");
$("#avatar_block img").attr("src", "https://api.twitter.com/1/users/profile_image?screen_name=" + e.data.info.idTwitter+ "&size=bigger");
$("#avatar_block span").html(e.data.info.idTwitter);
weaponCount[0] = e.data.arma1;
weaponCount[1] = e.data.arma2;
weaponCount[2] = e.data.arma3;
// $('#weapon_block #weapon_indicator').children().eq(0).addClass("l"+weaponCount[0]+"w")
// $('#weapon_block #weapon_indicator').children().eq(1).addClass("l"+weaponCount[1]+"w")
// $('#weapon_block #weapon_indicator').children().eq(2).addClass("l"+weaponCount[2]+"w")
// $('#weapon_block #weapon_count').children().eq(0).html(weaponCount[0]);
// $('#weapon_block #weapon_count').children().eq(1).html(weaponCount[1]);
// $('#weapon_block #weapon_count').children().eq(2).html(weaponCount[2]);
if(trivia){
video = e.data.siguienteVideo;
frameNum = e.data.frames;
imgLoader.load(frameNum,frameNum,video+"_m/"+video+"_",function(e){
nextVideo = e.imageArray;
});
}
$("#ranking_block ul").html("");
$("#attack_ranking ul").html("");
var temp = e.data.rankingProximo.anteriores;
var xj = 1;
for (x in temp){
$("#ranking_block ul").append('<li id="' + temp[x].idUsuario + '"><span>'+temp[x].posicion+'</span>'+ temp[x].idTwitter+ '</li>');
if( xj > 2){
$("#attack_ranking ul").append('<li value="user" class="interaction" id="' + temp[x].idUsuario + '">'+ temp[x].idTwitter+ '</li>');
}
xj++;
}
$("#ranking_block ul").append('<li class="me" ><span>'+ e.data.info.posicion+'</span>'+ e.data.info.idTwitter+ '</li>');
temp = e.data.rankingProximo.siguientes;
xj = 0 ;
for (x in temp){
$("#ranking_block ul").append('<li id="' + temp[x].idUsuario + '"><span>'+temp[x].posicion+'</span>'+ temp[x].idTwitter+ '</li>');
if(xj < 2){
$("#attack_ranking ul").append('<li value="user" class="interaction" id="' + temp[x].idUsuario + '">'+ temp[x].idTwitter+ '</li>');
xj++;
}
}
// $("#attack_ranking ul").html($("#ranking_block ul").html());
//
// $("#attack_ranking ul li").addClass("interaction");
// $("#attack_ranking ul li").attr("title", "user");
//
$(".interaction").off("click", interactionHandler);
$(".interaction").on("click", interactionHandler);
}
function optionalData(){
$.ajax({
type: "POST",
dataType: "json",
url: service+"index.php/call/obtener_pregunta",
success: function (e) {
if(e.success){
var preguntas = e.data;
if(preguntas){
trivia = true;
for (x in preguntas){
// console.log(e.data[x]);
var p = '<div class="question_wrapper"><p id="'+preguntas[x].idPregunta+'">'+preguntas[x].pregunta+'</p></div>';
var respuestas = preguntas[x].respuestas;
var r ="";
for (y in respuestas){
// console.log(respuestas[y]);
r += '<li id="'+respuestas[y].idRespuesta+'">'+respuestas[y].respuesta+'</li>';
//$("#answer_wrapper ul").append('<li id="'+respuestas[y].idRespuesta+'">'+respuestas[y].respuesta+'</li>');
}
$("#trivia_content").append('<div class="question_row">'+p+'<div class="answer_wrapper"><ul>'+r+'</ul></div></div>');
}
currentQuestion = 0;
$('#trivia_content').children().eq(currentQuestion).show();
$(".answer_wrapper ul li").on("click",function(e){
$(".answer_wrapper ul li").removeClass("active");
$(e.target).addClass("active");
console.log($(e.target).index());
answer["respuesta"+(currentQuestion+1)] = e.target.id;
});
$("#nextBtn").on("click",function(){
if(answer["respuesta"+(currentQuestion+1)]){
if(currentQuestion <2){
currentQuestion++;
$('.question_row').hide();
$('#trivia_content').children().eq(currentQuestion).show();
}else{
console.log(answer);
hideOverlay();
trivia = false;
$.ajax({
type: "POST",
data:answer,
dataType: "json",
url: service+"index.php/call/responder_trivia",
success: function (e) {
console.log(e);
if(e.success){
trivia = false;
var score = e.data.respuesta1 + e.data.respuesta2 + e.data.respuesta3;
$("#advertAnswer_wrapper").addClass("correct"+score);
setInitData(e);
player.play(nextVideo, function(){
player.play(intro, true);
showOverlay("advertAnswer");
});
}
}
});
}
}
});
}
}
}
});
}
function init(){
imgLoader.load(20, 20, "loop2/loop2_", function (e) {
intro = e.imageArray;
$.ajax({
dataType: "json",
url: service+"index.php/call/carga_inicial2/",
success: function (e) {
if (e.success) {
setInitData(e);
hideOverlay(function () {
$("#avatar_block").animate({
left: 0
});
$("#menu_block").animate({
bottom: 0
});
$("#header").animate({
top: 0
}, .2,"linear", function () {
});
});
player.play(intro, true);
} else {
self.location="index.html";
}
}
});
});
}
function showOverlay(key) {
if(!key){
$("#loader").addClass("active_wrap").show();
}else{
$("#" + key + "_wrapper").append('<button id="close" class="close" ></button>');
$("#" + key + "_wrapper").addClass("active_wrap").show();
$(".close").on("click",function(){ hideOverlay() });
$("#prompt_wrapper").show();
}
overlay.show();
overlay.animate({
opacity: 1
});
}
function hideOverlay(c) {
overlay.anim({
opacity: 0
}, .2, 'linear', function(){
overlay.hide();
$(".active_wrap").hide().removeClass("active_wrap");
if($(".active_wrap").children(".close")){
$(".active_wrap").children(".close").remove();
$(".close").off();
}
if (c) {
c();
}
});
};
/******* Interaction Handlers *******/
function interactionHandler(e) {
_gaq.push(['_trackEvent', 'Click', e.target.value, 'App event']);
// pressSound.play();
switch (e.target.value) {
case "go2":
if(trivia){
if(imgLoader.getStatus()){
showOverlay();
imgLoader.addEvent(function(e){
nextVideo = e.imageArray;
hideOverlay(function(){
showOverlay("trivia");
});
});
}else{
showOverlay("trivia");
}
}else{
showOverlay("advertTrivia");
}
break;
case "send":
// acceptSound.play();
$.ajax({
dataType: "json",
url: service+"index.php/call/avanzar",
success: function (e) {
if(e.success){
setInitData(e);
hideOverlay();
}else{
hideOverlay();
setInitData(e);
}
player.play(nextVideo, function(){
player.play(intro, true);
});
}
});
break;
case "attack":
weaponId = $(e.target).index();
if(weaponCount[weaponId] > 0){
showOverlay(e.target.value);
$("#attack_tuit").children().hide();
$('#attack_tuit').children().eq(weaponId).show();
$("#attack_ranking ul li").removeClass("active");
}else{
showOverlay("advertWeapon");
}
break;
case "destroy":
if (userId) {
$.ajax({
type: "POST",
dataType: "json",
url: service+"index.php/call/realizar_disparo/",
data: {
arma: weaponId+1,
objetivo: userId.id
},
success: function (e) {
// var temp = weaponSound.eq(weaponId);
// temp[0].play();
hideOverlay();
$(userId).removeClass("active");
weaponCount[weaponId] = weaponCount[weaponId]-1;
if(weaponCount[weaponId] == 0){
$('#weapon_block #weapon_indicator').children().eq(weaponId).attr("disabled","disabled")
}
$('#weapon_block #weapon_count').children().eq(weaponId).html(weaponCount[weaponId]);
}
});
}
break;
default:
$(e.target).parent().children().removeClass("active");
$(e.target).addClass("active");
if (e.target.id != 0) {
userId = e.target;
};
}
}
window.addEventListener("resize", function() {
window.scrollTo(0, 1);
adjuster.temp();
}, false);
adjuster.temp();
};<file_sep>/**
*
*/
var Adjuster = function(_elements, paper, svg, imgWidth, imgHeight, ex) {
var elements = _elements;
if (ex) {
var p = paper;
var s = svg;
var w = imgWidth;
var h = imgHeight;
}
function ajust() {
for (x in elements) {
elements[x].width(window.innerWidth);
elements[x].height(window.innerHeight);
}
if (ex) {
ratio1 = w / h;
ratio2 = window.innerWidth / window.innerHeight;
if (ratio1 < ratio2) {
scale = innerWidth / w;
} else {
scale = innerHeight / h;
}
p.setSize(w * scale, h * scale);
s.css({
left : -(w * scale - innerWidth) / 2,
top : -(h * scale - innerHeight) / 2
});
}
}
window.onresize = function() {
ajust();
};
ajust();
};<file_sep>//normalizes all the members of an array
//by the member indicated by index parameter
var _multiply1_array_ = [0, 0, 0, 0];
function normalize(array, index)
{
k = array[index];
for (var i = 0; i < array.length; i++)
array[i] = array[i] / k;
//return array;
}
//rounds array elements
function roundArray(array)
{
for (var i=0; i < array.length; i++)
array[i] = Math.round(array[i]);
}
function Matrix(matrix)
{
if (matrix==null)
{
this.identity = new Array (
new Array(1, 0, 0, 0),
new Array(0, 1, 0, 0),
new Array(0, 0, 1, 0),
new Array(0, 0, 0, 1))
this.matrix = this.identity;
}
else
this.matrix = matrix;
//returns a 4x4 array
this.getMatrix = function()
{
return this.matrix
}
this.setTranslation = function(translation)
{
if (translation.length!=3)
alert("expected array length: 3");
else
{
this.matrix[0][3] = translation[0];
this.matrix[1][3] = translation[1];
this.matrix[2][3] = translation[2];
}
}
//sets perspective viewpoint matrix
this.setPerspective = function(distance)
{
this.matrix[3][2] = 1/distance;
}
this.setScale = function(scale)
{
if (scale.length!=3)
alert("expected array length: 3");
else
{
this.matrix[0][0] = scale[0]
this.matrix[1][1] = scale[1]
this.matrix[2][2] = scale[2]
}
}
//from axis angle rotation array sets rotation matrix
this.setRotation = function(rotation)
{
if (rotation.length!=4)
alert("expected array length: 4");
else
{
var r0 = Math.cos(rotation[3])
var r1 = Math.sin(rotation[3])
var r2 = 1 - r0
var r3 = rotation[0]
var r4 = rotation[1]
var r5 = rotation[2]
this.matrix[0][0] = r2 * r3 * r3 + r0
this.matrix[0][1] = r2 * r3 * r4 - r1 * r5
this.matrix[0][2] = r2 * r3 * r5 + r1 * r4
this.matrix[1][0] = r2 * r3 * r4 + r1 * r5
this.matrix[1][1] = r2 * r4 * r4 + r0
this.matrix[1][2] = r2 * r4 * r5 - r1 * r3
this.matrix[2][0] = r2 * r3 * r5 - r1 * r4
this.matrix[2][1] = r2 * r4 * r5 + r1 * r3
this.matrix[2][2] = r2 * r5 * r5 + r0
}
}
//Multiples this 4x4 order matrix to 1x4 matrix
this.multiply1 = function(array)
{
if (array.length != 4)
alert("expected array length: 4");
else
{
cols = this.matrix[0].length;
for(var i = 0; i < 4; i++)
_multiply1_array_[i] = 0;
for (var i=0; i< this.matrix.length; i++)
for (var j=0; j< array.length; j++)
_multiply1_array_[i] += this.matrix[i][j]* array[j];
}
for(var i = 0; i < 4; i++)
array[i] = _multiply1_array_[i];
}
//Multiples only 4x4 Matrix objects
this.multiply4 = function(matrix_a, matrix_b)
{
//clean
for (var i=0; i<4; i++)
for (var j=0; j<4; j++)
for (var k=0; k<4; k++)
{
this.matrix[i][j] = 0;
}
for (var i=0; i<4; i++)
for (var j=0; j<4; j++)
for (var k=0; k<4; k++)
{
this.matrix[i][j] += matrix_a.getMatrix()[i][k]* matrix_b.getMatrix()[k][j];
}
}
this.toString = function()
{
for (var i=0; i <this.matrix.length; i++)
{
for (var j=0; j < this.matrix[i].length; j++)
document.write(this.matrix[i][j] + ", ");
document.write("<br>")
}
}
}<file_sep>var ScenePlayer = function(fr, paper) {
var paper = paper;
var timer;
var frameRate = 1000 / fr;
var frame = 0;
var imageArray = new Array();
var generic;
var onEndScene;
var c = paper
.image("statics/img/null.jpg", 0, 0, paper.width, paper.height);
this.play = function(images, _loop) {
stopTimer();
if (_loop) {
generic = _loop;
}
imageArray = images;
initTimer();
};
this.stop = function() {
stopTimer();
};
this.addEvent = function(c) {
onEndScene = c;
};
function initTimer() {
timer = setInterval(drawImages, frameRate);
}
function drawImages() {
var randomnumber = Math.floor(Math.random() * (20 - 17 + 1)) + 17;
$("#vel_counter").html(randomnumber + " Mb/s");
// paper.image(imageArray[frame], 0, 0, paper.width, paper.height);
c.attr({
src : imageArray[frame],
width : paper.width,
height : paper.height
});
frame++;
if (typeof generic != "boolean") {
imageArray[frame - 1] = null;
}
if (frame == imageArray.length) {
if (typeof generic == "boolean") {
frame = 0;
} else {
generic();
}
}
}
function stopTimer() {
clearInterval(timer);
frame = 1;
}
};<file_sep>var ImageLoader = function() {
var tempArray = new Array();
var imageBuffer;
var nameSpace;
var limit = 0;
var block = 10;
var currentImage = 0;
var path = "statics/img/renders/";
var ext = ".jpg";
var counter = 0;
var onCompleteEvent;
var busy = false;
//////console.log("create Image Loader");
this.addEvent = function(c) {
onCompleteEvent = c;
};
this.load = function(i, l, n, c) {
onCompleteEvent = c;
imageBuffer = i;
limit = l;
nameSpace = n;
////console.log("loading");
loadBlock();
busy = true;
};
this.getStatus = function() {
return busy;
};
function loadBlock() {
for ( var x = 1; x <= block; x++) {
var image = new Image();
image.onload = function() { // always fires the event.
counter++;
if (counter == block) {
if (currentImage == limit) {
onCompleteEvent({
name : nameSpace,
imageArray : tempArray
});
counter = 0;
tempArray = new Array();
currentImage = 0;
block = 10;
busy = false;
} else {
counter = 0;
loadBlock();
}
}
};
image.src = path + nameSpace + currentImage + ext;
tempArray[currentImage] = image.src;
currentImage++;
}
}
;
}; | 07cccdebd619d74e4209fca5398136b547b32395 | [
"JavaScript"
] | 9 | JavaScript | vinci1618/IronMan | 604eaa0fde4d440af8d0af5b31075dad2a81d572 | 9276991291e7b729d03dd4960b4154e866a28b63 |
refs/heads/master | <repo_name>Ximpia/django-elasticsearch<file_sep>/django_elasticsearch/management/__init__.py
__author__ = 'jorgealegre'
<file_sep>/django_elasticsearch/mapping.py
# python
import logging
# pyes
from pyes import mappings
from abc import ABCMeta, abstractmethod
import sys
from . import DjangoElasticEngineException
from django.utils.translation import ugettext_lazy as _
# django
# djes
from . import ENGINE
import fields
__author__ = 'jorgealegre'
logger = logging.getLogger(__name__)
def model_to_mapping(model, connection, index_name, **kwargs):
"""
This receives a model and generates the mapping
:return:
"""
meta = model._meta
logger.debug(u'meta: {} fields: {}'.format(meta, meta.fields + meta.many_to_many))
mapping = fields.DocumentObjectField(
name=kwargs.get('name', model._meta.db_table),
connection=connection,
index_name=index_name,
)
if '_routing' in kwargs:
mapping['_routing'] = kwargs['_routing']
for field in meta.fields + meta.many_to_many:
field_type = type(field).__name__
if hasattr(sys.modules[ENGINE + '.mapping'], '{}Mapping'.format(field_type)):
# django model field type
field_mapping = getattr(sys.modules[ENGINE + '.mapping'], '{}Mapping'
.format(field_type)).get(field)
if field_mapping:
mapping.add_property(field_mapping)
elif hasattr(mappings, field_type):
# ElasticSearch fields from pyes
mapping.add_property(field)
else:
raise DjangoElasticEngineException(_(u'Field type {} not supported'.format(field_type)))
logger.info(u'model_to_mapping :: model: {} index_name: {}'.format(
model._meta.db_table,
index_name
))
return mapping
class FieldMapping(object):
__metaclass__ = ABCMeta
@classmethod
@abstractmethod
def get(cls, field):
"""
Generate mapping for Field
:param Field field: Django model field
:return: Elastic mapping for field
:rtype mappings.IntegerField
"""
pass
class AutoFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
Mapping for AutoField
:param field:
:param kwargs:
:return:
"""
return fields.StringField(name=field.name,
store=True,
index='not_analyzed')
class IntegerFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
Generate mapping for IntegerField
:param Field field: Django model field
:return: Elastic mapping for field
:rtype mappings.IntegerField
"""
return mappings.IntegerField(name=field.name,
**kwargs)
class PositiveSmallIntegerFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
Generate mapping for PositiveSmallInteger
:param field:
:param kwargs:
:return:
"""
return mappings.IntegerField(name=field.name,
**kwargs)
class SmallIntegerFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
return mappings.IntegerField(name=field.name,
**kwargs)
class PositiveIntegerFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
return mappings.IntegerField(name=field.name,
**kwargs)
class PositionFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
return mappings.GeoPointField(name=field.name,
**kwargs)
class FloatFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
return mappings.FloatField(name=field.name,
**kwargs)
class DecimalFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
return mappings.DoubleField(name=field.name,
**kwargs)
class BooleanFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
return mappings.BooleanField(name=field.name,
**kwargs)
class NullBooleanFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
pass
class CharFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
Mapping for CharField
:param field:
:return:
"""
return mappings.MultiField(name=field.name,
fields={field.name: fields.StringField(name=field.name,
index="analyzed",
term_vector="with_positions_offsets"),
"raw": fields.StringField(name="raw",
index="not_analyzed")}
)
class TextFieldMapping(FieldMapping):
@classmethod
def get(cls, field, analyzer='snowball', **kwargs):
"""
:param field:
:return:
"""
return fields.StringField(name=field.name,
analyzer=analyzer,
**kwargs)
class DateTimeFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
:param field:
:return:
"""
return mappings.DateField(name=field.name,
format='%Y-%m-%dT%H:%M:%S',
**kwargs)
class DateFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
:param field:
:return:
"""
return mappings.DateField(name=field.name,
format='%Y-%m-%d',
**kwargs)
class DictFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
:param field:
:return:
"""
return mappings.ObjectField(name=field.name,
**kwargs)
class SetFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
:param field:
:return:
"""
return mappings.ObjectField(name=field.name,
**kwargs)
class ListFieldMapping(FieldMapping):
@classmethod
def get(cls, field, **kwargs):
"""
:param field:
:return:
"""
return mappings.ObjectField(name=field.name,
**kwargs)
<file_sep>/django_elasticsearch/creation.py
# python
import logging
# django
from djangotoolbox.db.base import NonrelDatabaseCreation
# pyes
from pyes.exceptions import NotFoundException
# djes
from mapping import model_to_mapping
TEST_DATABASE_PREFIX = 'test_'
__author__ = 'jorgealegre'
logger = logging.getLogger(__name__)
class DatabaseCreation(NonrelDatabaseCreation):
data_types = {
'DateTimeField': 'date',
'DateField': 'date',
'TimeField': 'time',
'FloatField': 'float',
'EmailField': 'string',
'URLField': 'string',
'BooleanField': 'bool',
'NullBooleanField': 'bool',
'CharField': 'string',
'CommaSeparatedIntegerField': 'string',
'IPAddressField': 'ip',
'SlugField': 'string',
'FileField': 'string',
'FilePathField': 'string',
'TextField': 'string',
'XMLField': 'string',
'IntegerField': 'integer',
'SmallIntegerField': 'integer',
'PositiveIntegerField': 'integer',
'PositiveSmallIntegerField': 'integer',
'BigIntegerField': 'long',
'GenericAutoField': 'string',
'StringForeignKey': 'string',
'AutoField': 'string',
'RelatedAutoField': 'string',
'OneToOneField': 'string',
'DecimalField': 'decimal',
'AbstractIterableField': 'nested',
'ListField': 'nested',
'SetField': 'nested',
'DictField': 'object',
'EmbeddedModelField': 'object',
}
def sql_indexes_for_field(self, model, f, style):
return []
def index_fields_group(self, model, group, style):
return []
def sql_indexes_for_model(self, model, style):
print 'sql_indexes_for_model....'
return []
def sql_create_model(self, model, style, known_models=set()):
"""
Create mapping for model
:param model
:param style
:param known_models
:rtype list, dict
"""
logger.debug(u'sql_create_model....')
logger.debug(u'index: {}'.format(model._meta.db_table))
self.connection.put_mapping(model._meta.db_table, model_to_mapping(model).as_dict())
return [], {}
def create_test_db(self, verbosity=1, autoclobber=False):
"""
"""
from django.core.management import call_command
test_database_name = self._get_test_db_name()
self.connection.settings_dict['NAME'] = test_database_name
if verbosity >= 1:
print("Creating test database for alias '{}'".format(self.connection.alias))
try:
self._drop_database(test_database_name)
except NotFoundException:
pass
self.connection.indices.create_index(test_database_name)
self.connection.cluster.cluster_health(wait_for_status='green')
call_command('migrate',
verbosity=max(verbosity - 1, 0),
interactive=False,
database=self.connection.alias,
load_initial_data=False)
def destroy_test_db(self, old_database_name, verbosity=1):
"""
Destroy a test database, prompting the user for confirmation if the
database already exists. Returns the name of the test database created.
"""
if verbosity >= 1:
print "Destroying test database '%s'..." % self.connection.alias
test_database_name = self.connection.settings_dict['NAME']
self._drop_database(test_database_name)
self.connection.settings_dict['NAME'] = old_database_name
def _drop_database(self, database_name):
try:
self.connection.indices.delete_index(database_name)
except NotFoundException:
pass
self.connection.cluster.cluster_health(wait_for_status='green')
def sql_destroy_model(self, model, references_to_delete, style):
print model
<file_sep>/django_elasticsearch/management/commands/migrate.py
# python
import logging
# django
from django.conf import settings
from django.db import connections, DEFAULT_DB_ALIAS
from django.core.management.base import BaseCommand
# pyes
from pyes.exceptions import IndexAlreadyExistsException, ElasticSearchException
# django_elasticsearch
from django_elasticsearch.mapping import model_to_mapping
from django_elasticsearch.models import get_settings_by_meta
from django_elasticsearch import ENGINE, OPERATION_CREATE_INDEX
__author__ = 'jorgealegre'
logger = logging.getLogger(__name__)
class Command(BaseCommand):
def handle(self, *args, **options):
engine = settings.DATABASES.get(DEFAULT_DB_ALIAS, {}).get('ENGINE', '')
global_index_name = settings.DATABASES.get(DEFAULT_DB_ALIAS, {}).get('NAME', '')
options = settings.DATABASES.get(DEFAULT_DB_ALIAS, {}).get('OPTIONS', {})
connection = connections[DEFAULT_DB_ALIAS]
es_connection = connection.connection
# Call regular migrate if engine is different from ours
if engine != ENGINE:
return super(Command, self).handle(**options)
else:
# project global index
has_alias = connection.ops.has_alias(global_index_name)
if not has_alias:
try:
index_name_final, alias = connection.ops.create_index(global_index_name, options,
skip_register=True)
self.stdout.write(u'index "{}" created with physical name "{}"'.format(alias, index_name_final))
connection.ops.build_django_engine_structure()
# register create index for global
connection.ops.register_index_operation(index_name_final, OPERATION_CREATE_INDEX,
connection.ops.build_es_settings_from_django(options))
except IndexAlreadyExistsException:
pass
except ElasticSearchException:
import traceback
logger.error(traceback.format_exc())
logger.debug(u'models: {}'.format(connection.introspection.models))
for app_name, app_models in connection.introspection.models.iteritems():
for model in app_models:
mapping = model_to_mapping(model, es_connection, global_index_name)
try:
mapping.save()
self.stdout.write(u'Mapping for model {}.{} updated'.format(app_name, model.__name__))
except Exception as e:
import traceback
logger.error(traceback.format_exc())
self.stderr.write(u'Could not update mapping, rebuilding global index...')
connection.ops.rebuild_index(global_index_name)
mapping.save()
if not hasattr(model._meta, 'indices'):
continue
for model_index in model._meta.indices:
model_index_name = model_index.keys()[0]
index_name = u'{}__{}'.format(model._meta.db_table, model_index_name)
logger.debug(u'model index name: {}'.format(index_name))
index_data = model_index[model_index_name]
logger.debug(u'index_data: {}'.format(index_data))
try:
index_physical, alias = connection.ops.create_index(index_name,
get_settings_by_meta(index_data))
self.stdout.write(u'index "{}" created with physical name "{}"'.format(alias,
index_physical))
except IndexAlreadyExistsException:
pass
mapping = model_to_mapping(model, es_connection, index_name)
try:
mapping.save()
self.stdout.write(u'Mapping for model {}.{} updated'
.format(app_name, index_name))
except Exception as e:
self.stderr.write(u'Could not update mapping, rebuilding index "{}" ...'
.format(index_name))
connection.ops.rebuild_index(index_name)
mapping.save()
<file_sep>/django_elasticsearch/compiler.py
import logging
import json
from django.db.models.sql.compiler import SQLCompiler as BaseSQLCompiler
from django.db.utils import DatabaseError
from djangotoolbox.db.basecompiler import NonrelQuery, NonrelCompiler, \
NonrelInsertCompiler, NonrelUpdateCompiler, NonrelDeleteCompiler
from django.db.models.fields import AutoField
import datetime
import django
from django.conf import settings
from django.db.models.fields import NOT_PROVIDED
from django.db.models.query import QuerySet
from django.db.models.sql import aggregates as sqlaggregates
from django.db.models.sql.constants import MULTI, SINGLE
from django.db.models.sql.where import AND, OR
from django.db.utils import DatabaseError, IntegrityError
from django.utils.tree import Node
from django.db import connections
try:
from django.db.models.sql.where import SubqueryConstraint
except ImportError:
SubqueryConstraint = None
try:
from django.db.models.sql.datastructures import EmptyResultSet
except ImportError:
class EmptyResultSet(Exception):
pass
if django.VERSION >= (1, 5):
from django.db.models.constants import LOOKUP_SEP
else:
from django.db.models.sql.constants import LOOKUP_SEP
if django.VERSION >= (1, 6):
def get_selected_fields(query):
if query.select:
return [info.field for info in (query.select +
query.related_select_cols)]
else:
return query.model._meta.fields
else:
def get_selected_fields(query):
if query.select_fields:
return (query.select_fields + query.related_select_fields)
else:
return query.model._meta.fields
from django_elasticsearch import WRITE_QUEUE
__author__ = 'jorgealegre'
logger = logging.getLogger(__name__)
class DBQuery(NonrelQuery):
def __init__(self, compiler, fields):
super(DBQuery, self).__init__(compiler, fields)
def fetch(self, low_mark=0, high_mark=None):
"""
Returns an iterator over some part of query results.
"""
raise NotImplementedError
def count(self, limit=None):
"""
Returns the number of objects that would be returned, if
this query was executed, up to `limit`.
"""
raise NotImplementedError
def delete(self):
"""
Called by NonrelDeleteCompiler after it builds a delete query.
"""
raise NotImplementedError
def order_by(self, ordering):
"""
Reorders query results or execution order. Called by
NonrelCompilers during query building.
:param ordering: A list with (field, ascending) tuples or a
boolean -- use natural ordering, if any, when
the argument is True and its reverse otherwise
"""
raise NotImplementedError
def add_filter(self, field, lookup_type, negated, value):
"""
Adds a single constraint to the query. Called by add_filters for
each constraint leaf in the WHERE tree built by Django.
:param field: Lookup field (instance of Field); field.column
should be used for database keys
:param lookup_type: Lookup name (e.g. "startswith")
:param negated: Is the leaf negated
:param value: Lookup argument, such as a value to compare with;
already prepared for the database
"""
raise NotImplementedError
def add_filters(self, filters):
"""
Converts a constraint tree (sql.where.WhereNode) created by
Django's SQL query machinery to nonrel style filters, calling
add_filter for each constraint.
This assumes the database doesn't support alternatives of
constraints, you should override this method if it does.
TODO: Simulate both conjunctions and alternatives in general
let GAE override conjunctions not to split them into
multiple queries.
"""
if filters.negated:
self._negated = not self._negated
if not self._negated and filters.connector != AND:
raise DatabaseError("Only AND filters are supported.")
# Remove unneeded children from the tree.
children = self._get_children(filters.children)
if self._negated and filters.connector != OR and len(children) > 1:
raise DatabaseError("When negating a whole filter subgroup "
"(e.g. a Q object) the subgroup filters must "
"be connected via OR, so the non-relational "
"backend can convert them like this: "
"'not (a OR b) => (not a) AND (not b)'.")
# Recursively call the method for internal tree nodes, add a
# filter for each leaf.
for child in children:
if isinstance(child, Node):
self.add_filters(child)
continue
field, lookup_type, value = self._decode_child(child)
self.add_filter(field, lookup_type, self._negated, value)
if filters.negated:
self._negated = not self._negated
# ----------------------------------------------
# Internal API for reuse by subclasses
# ----------------------------------------------
def _decode_child(self, child):
"""
Produces arguments suitable for add_filter from a WHERE tree
leaf (a tuple).
"""
# TODO: Call get_db_prep_lookup directly, constraint.process
# doesn't do much more.
constraint, lookup_type, annotation, value = child
packed, value = constraint.process(lookup_type, value, self.connection)
alias, column, db_type = packed
field = constraint.field
opts = self.query.model._meta
if alias and alias != opts.db_table:
raise DatabaseError("This database doesn't support JOINs "
"and multi-table inheritance.")
# For parent.child_set queries the field held by the constraint
# is the parent's primary key, while the field the filter
# should consider is the child's foreign key field.
if column != field.column:
if not field.primary_key:
raise DatabaseError("This database doesn't support filtering "
"on non-primary key ForeignKey fields.")
field = (f for f in opts.fields if f.column == column).next()
assert field.rel is not None
value = self._normalize_lookup_value(
lookup_type, value, field, annotation)
return field, lookup_type, value
def _normalize_lookup_value(self, lookup_type, value, field, annotation):
"""
Undoes preparations done by `Field.get_db_prep_lookup` not
suitable for nonrel back-ends and passes the lookup argument
through nonrel's `value_for_db`.
TODO: Blank `Field.get_db_prep_lookup` and remove this method.
"""
# Undo Field.get_db_prep_lookup putting most values in a list
# (a subclass may override this, so check if it's a list) and
# losing the (True / False) argument to the "isnull" lookup.
if lookup_type not in ('in', 'range', 'year') and \
isinstance(value, (tuple, list)):
if len(value) > 1:
raise DatabaseError("Filter lookup type was %s; expected the "
"filter argument not to be a list. Only "
"'in'-filters can be used with lists." %
lookup_type)
elif lookup_type == 'isnull':
value = annotation
else:
value = value[0]
# Remove percents added by Field.get_db_prep_lookup (useful
# if one were to use the value in a LIKE expression).
if lookup_type in ('startswith', 'istartswith'):
value = value[:-1]
elif lookup_type in ('endswith', 'iendswith'):
value = value[1:]
elif lookup_type in ('contains', 'icontains'):
value = value[1:-1]
# Prepare the value for a database using the nonrel framework.
return self.ops.value_for_db(value, field, lookup_type)
def _get_children(self, children):
"""
Filters out nodes of the given contraint tree not needed for
nonrel queries; checks that given constraints are supported.
"""
result = []
for child in children:
if SubqueryConstraint is not None \
and isinstance(child, SubqueryConstraint):
raise DatabaseError("Subqueries are not supported.")
if isinstance(child, tuple):
constraint, lookup_type, _, value = child
# When doing a lookup using a QuerySet Django would use
# a subquery, but this won't work for nonrel.
# TODO: Add a supports_subqueries feature and let
# Django evaluate subqueries instead of passing
# them as SQL strings (QueryWrappers) to
# filtering.
if isinstance(value, QuerySet):
raise DatabaseError("Subqueries are not supported.")
# Remove leafs that were automatically added by
# sql.Query.add_filter to handle negations of outer
# joins.
if lookup_type == 'isnull' and constraint.field is None:
continue
result.append(child)
return result
def _matches_filters(self, entity, filters):
"""
Checks if an entity returned by the database satisfies
constraints in a WHERE tree (in-memory filtering).
"""
# Filters without rules match everything.
if not filters.children:
return True
result = filters.connector == AND
for child in filters.children:
# Recursively check a subtree,
if isinstance(child, Node):
submatch = self._matches_filters(entity, child)
# Check constraint leaf, emulating a database condition.
else:
field, lookup_type, lookup_value = self._decode_child(child)
entity_value = entity[field.column]
if entity_value is None:
if isinstance(lookup_value, (datetime.datetime, datetime.date,
datetime.time)):
submatch = lookup_type in ('lt', 'lte')
elif lookup_type in (
'startswith', 'contains', 'endswith', 'iexact',
'istartswith', 'icontains', 'iendswith'):
submatch = False
else:
submatch = EMULATED_OPS[lookup_type](
entity_value, lookup_value)
else:
submatch = EMULATED_OPS[lookup_type](
entity_value, lookup_value)
if filters.connector == OR and submatch:
result = True
break
elif filters.connector == AND and not submatch:
result = False
break
if filters.negated:
return not result
return result
def _order_in_memory(self, lhs, rhs):
for field, ascending in self.compiler._get_ordering():
column = field.column
result = cmp(lhs.get(column), rhs.get(column))
if result != 0:
return result if ascending else -result
return 0
class SQLCompiler(NonrelCompiler):
"""
A simple query: no joins, no distinct, etc.
"""
query_class = DBQuery
def results_iter(self):
"""
Returns an iterator over the results from executing query given
to this compiler. Called by QuerySet methods.
"""
fields = self.get_fields()
try:
results = self.build_query(fields).fetch(
self.query.low_mark, self.query.high_mark)
except EmptyResultSet:
results = []
for entity in results:
yield self._make_result(entity, fields)
def has_results(self):
return self.get_count(check_exists=True)
def execute_sql(self, result_type=MULTI):
"""
Handles SQL-like aggregate queries. This class only emulates COUNT
by using abstract NonrelQuery.count method.
"""
aggregates = self.query.aggregate_select.values()
# Simulate a count().
if aggregates:
assert len(aggregates) == 1
aggregate = aggregates[0]
assert isinstance(aggregate, sqlaggregates.Count)
opts = self.query.get_meta()
if aggregate.col != '*' and \
aggregate.col != (opts.db_table, opts.pk.column):
raise DatabaseError("This database backend only supports "
"count() queries on the primary key.")
count = self.get_count()
if result_type is SINGLE:
return [count]
elif result_type is MULTI:
return [[count]]
raise NotImplementedError("The database backend only supports "
"count() queries.")
# ----------------------------------------------
# Additional NonrelCompiler API
# ----------------------------------------------
def _make_result(self, entity, fields):
"""
Decodes values for the given fields from the database entity.
The entity is assumed to be a dict using field database column
names as keys. Decodes values using `value_from_db` as well as
the standard `convert_values`.
"""
result = []
for field in fields:
value = entity.get(field.column, NOT_PROVIDED)
if value is NOT_PROVIDED:
value = field.get_default()
else:
value = self.ops.value_from_db(value, field)
value = self.query.convert_values(value, field,
self.connection)
if value is None and not field.null:
raise IntegrityError("Non-nullable field %s can't be None!" %
field.name)
result.append(value)
return result
def check_query(self):
"""
Checks if the current query is supported by the database.
In general, we expect queries requiring JOINs (many-to-many
relations, abstract model bases, or model spanning filtering),
using DISTINCT (through `QuerySet.distinct()`, which is not
required in most situations) or using the SQL-specific
`QuerySet.extra()` to not work with nonrel back-ends.
"""
if hasattr(self.query, 'is_empty') and self.query.is_empty():
raise EmptyResultSet()
if (len([a for a in self.query.alias_map if
self.query.alias_refcount[a]]) > 1 or
self.query.distinct or self.query.extra or self.query.having):
raise DatabaseError("This query is not supported by the database.")
def get_count(self, check_exists=False):
"""
Counts objects matching the current filters / constraints.
:param check_exists: Only check if any object matches
"""
if check_exists:
high_mark = 1
else:
high_mark = self.query.high_mark
try:
return self.build_query().count(high_mark)
except EmptyResultSet:
return 0
def build_query(self, fields=None):
"""
Checks if the underlying SQL query is supported and prepares
a NonrelQuery to be executed on the database.
"""
self.check_query()
if fields is None:
fields = self.get_fields()
query = self.query_class(self, fields)
query.add_filters(self.query.where)
query.order_by(self._get_ordering())
# This at least satisfies the most basic unit tests.
if connections[self.using].use_debug_cursor or (connections[self.using].use_debug_cursor is None and
settings.DEBUG):
self.connection.queries.append({'sql': repr(query)})
return query
def get_fields(self):
"""
Returns fields which should get loaded from the back-end by the
current query.
"""
# We only set this up here because related_select_fields isn't
# populated until execute_sql() has been called.
fields = get_selected_fields(self.query)
# If the field was deferred, exclude it from being passed
# into `resolve_columns` because it wasn't selected.
only_load = self.deferred_to_columns()
if only_load:
db_table = self.query.model._meta.db_table
only_load = dict((k, v) for k, v in only_load.items()
if v or k == db_table)
if len(only_load.keys()) > 1:
raise DatabaseError("Multi-table inheritance is not "
"supported by non-relational DBs %s." %
repr(only_load))
fields = [f for f in fields if db_table in only_load and
f.column in only_load[db_table]]
query_model = self.query.model
if query_model._meta.proxy:
query_model = query_model._meta.proxy_for_model
for field in fields:
if field.model._meta != query_model._meta:
raise DatabaseError("Multi-table inheritance is not "
"supported by non-relational DBs.")
return fields
def _get_ordering(self):
"""
Returns a list of (field, ascending) tuples that the query
results should be ordered by. If there is no field ordering
defined returns just the standard_ordering (a boolean, needed
for MongoDB "$natural" ordering).
"""
opts = self.query.get_meta()
if not self.query.default_ordering:
ordering = self.query.order_by
else:
ordering = self.query.order_by or opts.ordering
if not ordering:
return self.query.standard_ordering
field_ordering = []
for order in ordering:
if LOOKUP_SEP in order:
raise DatabaseError("Ordering can't span tables on "
"non-relational backends (%s)." % order)
if order == '?':
raise DatabaseError("Randomized ordering isn't supported by "
"the backend.")
ascending = not order.startswith('-')
if not self.query.standard_ordering:
ascending = not ascending
name = order.lstrip('+-')
if name == 'pk':
name = opts.pk.name
field_ordering.append((opts.get_field(name), ascending))
return field_ordering
class SQLInsertCompiler(SQLCompiler):
def __init__(self, *args, **kwargs):
super(SQLInsertCompiler, self).__init__(*args, **kwargs)
self.opts = self.query.get_meta()
def _get_pk(self, data):
"""
Get primary key
How is possible we have pk in doc???
:param data:
:return:
"""
pk_column = self.opts.pk.column
pk = None
if pk_column in data:
pk = data[pk_column]
return pk
def _get_internal_data(self):
"""
Get internal data for insert operation
:return:
"""
# TODO: make one query to ES for internal data for model and default indices
from mapping import model_to_mapping
data = {
'indices': {
'default': [
{}
],
'model': {
'main': [
{}
],
'index': [
{}
]
},
},
'is_blocked': False,
}
# model = self.opts.db_table
# default_indices = self.connection.default_indices
# index_data = self.opts.indices[0]
# indices = ["{}__{}".format(self.opts.db_table, index_data.keys()[0])]
# also save mapping in case needs to
indices = data['indices']['default'] + \
data['indices']['model']['main'] + \
data['indices']['model']['index']
for index_data in indices:
if index_data['has_mapping'] is False:
try:
mapping = model_to_mapping(self.opts.db_table,
self.connection.connection,
index_data['index'])
mapping.save()
except Exception:
pass
return data
def _send_queue(self, bulk_data):
"""
Send data to queue, adding to bulk
:param bulk_data: bulk data to write to queue
:return:
"""
import base64
bulk_data_encoded = base64.encodestring(bulk_data)
queue_bulk_data = json.dumps({
u'create': {
u'_index': self.connection.default_indices[0],
u'_type': WRITE_QUEUE,
}
}) + '\n' + json.dumps({'data': bulk_data_encoded}) + '\n'
self.connection.connection.bulker.add(queue_bulk_data)
def execute_sql(self, return_id=False):
"""
Execute insert statement
Insert data into ElasticSearch using bulk inserts.
:param bool return_id:
:return: primary key saved in case we have return_id True.
"""
import time
assert not (return_id and len(self.query.objs) != 1)
# query internal index to get indices, like 'alias': [index1, index2]
# alias would be the default indices, model table name
internal_data = self._get_internal_data()
while internal_data['is_blocked']:
time.sleep(0.2)
internal_data = self._get_internal_data()
pk_field = self.opts.pk
for obj in self.query.objs:
field_values = {}
for field in self.query.fields:
field, field_kind, db_type = self.ops.convert_as(field)
# check field_kind if is related field or many to many
if field_kind in ['ForeignKey', 'GenericRelation', 'GenericForeignKey']:
# we need the model associated with field
logger.debug(u'SQLInsertCompiler.execute_sql :: field_kind: {} field: {} rel: {}'.format(
field_kind,
field.name,
field.rel.to
))
value = self.ops.to_dict(field.rel.to)
logger.debug(u'SQLInsertCompiler.execute_sql :: object :: value: {}'.format(value))
else:
value = field.get_db_prep_save(
getattr(obj, field.attname) if self.query.raw else field.pre_save(obj, obj._state.adding),
connection=self.connection
)
if value is None and not field.null and not field.primary_key:
raise IntegrityError(u"You can't set {} (a non-nullable field) to None!".format(field.name))
logger.debug(u'SQLInsertCompiler.execute_sql :: before value_for_db :: field: {} '
u'value: {}'.format(field, value))
value = self.ops.value_for_db(value, field)
logger.debug(u'SQLInsertCompiler.execute_sql :: after value_for_db :: value: {}'.format(value))
field_values[field.column] = value
if not hasattr(self.opts, 'disable_default_index') or \
(hasattr(self.opts, 'disable_default_index') and self.opts.disable_default_index is False):
# default index
logger.debug(u'SQLInsertCompiler.execute_sql :: default index')
for index_data in internal_data['indices']['default']:
bulk_data = json.dumps({
u'create': {
u'_index': index,
u'_type': self.opts.db_table,
u'_id': self._get_pk(field_values),
}
}) + '\n' + json.dumps(field_values) + '\n'
logger.debug(u'SQLInsertCompiler.execute_sql :: default index index: {}'.format(
index
))
logger.debug(u'SQLInsertCompiler.execute_sql :: bulk obj: {}'.format(bulk_data))
if index_data['rebuild_mode'] == 'building':
self._send_queue(bulk_data)
else:
self.connection.connection.bulker.add(bulk_data)
if hasattr(self.opts, 'indices') and self.opts.indices:
# custom general index
logger.debug(u'SQLInsertCompiler.execute_sql :: disable default index')
index_data = self.opts.indices[0]
for index in internal_data['indices']['model']['main']:
index_conf = {
u'create': {
u'_index': index,
u'_type': self.opts.db_table,
u'_id': self._get_pk(field_values),
}
}
if 'routing' in index_data:
index_conf.update({
u'_routing': index_data['routing']
})
bulk_data = json.dumps(index_conf) + '\n' + \
json.dumps(field_values) + '\n'
logger.debug(u'SQLInsertCompiler.execute_sql :: bulk obj: {}'.format(bulk_data))
if index_data['rebuild_mode'] == 'building':
self._send_queue(bulk_data)
else:
self.connection.connection.bulker.add(bulk_data)
# model indices
if hasattr(self.opts, 'indices') and len(self.opts.indices) > 1:
for index_data in internal_data['indices']['model']['index']:
logger.debug(u'SQLInsertCompiler.execute_sql :: index: {}'.format(index_data.keys()[0]))
index = "{}__{}".format(self.opts.db_table, index_data.keys()[0])
index_conf = {
u'index': {
u'_index': index,
u'_type': self.opts.db_table,
u'_id': self._get_pk(field_values),
}
}
if 'routing' in index_data:
index_conf.update({
u'_routing': index_data['routing']
})
bulk_data = json.dumps(index_conf) + '\n' + \
json.dumps(field_values) + '\n'
logger.debug(u'SQLInsertCompiler.execute_sql :: bulk obj: {}'.format(bulk_data))
if index_data['rebuild_mode'] == 'building':
self._send_queue(bulk_data)
else:
self.connection.connection.bulker.add(bulk_data)
# Writes real inserts into indices as well as dumps into queue (write_queue)
res = self.connection.connection.bulker.flush_bulk(forced=True)
# Pass the key value through normal database de-conversion.
logger.debug(u'SQLInsertCompiler.execute_sql :: response: {} type: {}'.format(res, type(res)))
if return_id is False:
return
# keys = res['items']['create']['_id']
keys = map(lambda x: x['create']['_id'] if 'create' in x else x['index']['_id'], res['items'])
logger.debug(u'SQLInsertCompiler.execute_sql :: response keys: {}'.format(keys))
# curl -XGET 'http://localhost:9200/djes_test/djes_examplemodelmeta/_search?q=*:*&pretty'
# from djes.models import ExampleModel, ExampleModelMeta
# ExampleModelMeta.objects.create(name_people='I am the real thing', has_address=True, number_votes=756)
return self.ops.convert_values(self.ops.value_from_db(keys[0], pk_field), pk_field)
class SQLUpdateCompiler(SQLCompiler):
def execute_sql(self, return_id=False):
pass
class SQLDeleteCompiler(NonrelDeleteCompiler, SQLCompiler):
def execute_sql(self, return_id=False):
pass
<file_sep>/README.md
# django-elasticsearch
<file_sep>/django_elasticsearch/base.py
# python
from itertools import chain
import logging
import traceback
import pprint
from datetime import datetime
import json
import pickle
# django
from django.db.backends import connection_created
from django.db import connections, router, transaction, models as dj_models, DEFAULT_DB_ALIAS
from django.utils.datastructures import SortedDict
from django.conf import settings
from django.utils.translation import ugettext as _
from django.utils.functional import Promise
from django.utils.safestring import EscapeString, EscapeUnicode, SafeString, \
SafeUnicode
from django.db.models.fields.related import ManyToManyField
# djangotoolbox
from djangotoolbox.db.base import (
NonrelDatabaseClient,
NonrelDatabaseFeatures,
NonrelDatabaseIntrospection,
NonrelDatabaseOperations,
NonrelDatabaseValidation,
NonrelDatabaseWrapper,
)
# pyes
from pyes import ES
from pyes.exceptions import IndexAlreadyExistsException, IndexMissingException, ElasticSearchException
from pyes.query import Search, QueryStringQuery
import pyes.mappings
from pyes.helpers import SettingsBuilder
# djes
from creation import DatabaseCreation
from schema import DatabaseSchemaEditor
from . import ENGINE, NUMBER_OF_REPLICAS, NUMBER_OF_SHARDS, INTERNAL_INDEX, \
OPERATION_CREATE_INDEX, OPERATION_DELETE_INDEX, OPERATION_UPDATE_MAPPING
from mapping import model_to_mapping
import exceptions
logger = logging.getLogger(__name__)
__author__ = 'jorgealegre'
class DatabaseFeatures(NonrelDatabaseFeatures):
string_based_auto_field = True
class DatabaseOperations(NonrelDatabaseOperations):
compiler_module = 'django_elasticsearch.compiler'
SCROLL_TIME = '10m'
ADD_BULK_SIZE = 1000
def value_for_db(self, value, field, lookup=None):
"""
Does type-conversions needed before storing a value in the
the database or using it as a filter parameter.
This is a convience wrapper that only precomputes field's kind
and a db_type for the field (or the primary key of the related
model for ForeignKeys etc.) and knows that arguments to the
`isnull` lookup (`True` or `False`) should not be converted,
while some other lookups take a list of arguments.
In the end, it calls `_value_for_db` to do the real work; you
should typically extend that method, but only call this one.
:param value: A value to be passed to the database driver
:param field: A field the value comes from
:param lookup: None if the value is being prepared for storage;
lookup type name, when its going to be used as a
filter argument
"""
field, field_kind, db_type = self._convert_as(field, lookup)
# Argument to the "isnull" lookup is just a boolean, while some
# other lookups take a list of values.
if lookup == 'isnull':
return value
elif lookup in ('in', 'range', 'year'):
return [self._value_for_db(subvalue, field,
field_kind, db_type, lookup)
for subvalue in value]
else:
return self._value_for_db(value, field,
field_kind, db_type, lookup)
def _value_for_db(self, value, field, field_kind, db_type, lookup):
"""
Converts a standard Python value to a type that can be stored
or processed by the database driver.
This implementation only converts elements of iterables passed
by collection fields, evaluates Django's lazy objects and
marked strings and handles embedded models.
Currently, we assume that dict keys and column, model, module
names (strings) of embedded models require no conversion.
We need to know the field for two reasons:
-- to allow back-ends having separate key spaces for different
tables to create keys refering to the right table (which can
be the field model's table or the table of the model of the
instance a ForeignKey or other relation field points to).
-- to know the field of values passed by typed collection
fields and to use the proper fields when deconverting values
stored for typed embedding field.
Avoid using the field in any other way than by inspecting its
properties, it may not hold any value or hold a value other
than the one you're asked to convert.
You may want to call this method before doing other back-end
specific conversions.
:param value: A value to be passed to the database driver
:param field: A field having the same properties as the field
the value comes from; instead of related fields
you'll get the related model primary key, as the
value usually needs to be converted using its
properties
:param field_kind: Equal to field.get_internal_type()
:param db_type: Same as creation.db_type(field)
:param lookup: None if the value is being prepared for storage;
lookup type name, when its going to be used as a
filter argument
"""
# Back-ends may want to store empty lists or dicts as None.
if value is None:
return None
# Force evaluation of lazy objects (e.g. lazy translation
# strings).
# Some back-ends pass values directly to the database driver,
# which may fail if it relies on type inspection and gets a
# functional proxy.
# This code relies on unicode cast in django.utils.functional
# just evaluating the wrapped function and doing nothing more.
# TODO: This has been partially fixed in vanilla with:
# https://code.djangoproject.com/changeset/17698, however
# still fails for proxies in lookups; reconsider in 1.4.
# Also research cases of database operations not done
# through the sql.Query.
if isinstance(value, Promise):
value = unicode(value)
# Django wraps strings marked as safe or needed escaping,
# convert them to just strings for type-inspecting back-ends.
if isinstance(value, (SafeString, EscapeString)):
value = str(value)
elif isinstance(value, (SafeUnicode, EscapeUnicode)):
value = unicode(value)
# Convert elements of collection fields.
# We would need to test set and list collections. DictField should do OK with ObjectField
if field_kind in ('ListField', 'SetField', 'DictField',):
value = self._value_for_db_collection(value, field,
field_kind, db_type, lookup)
if field_kind in ['DateTimeField', 'TimeField']:
value = value.strftime("%Y-%m-%dT%H:%M:%S")
if field_kind == 'DateField':
value = value.strftime("%Y-%m-%d")
return value
def to_dict(self, instance):
opts = instance._meta
data = {}
# for f in opts.concrete_fields + opts.many_to_many:
for f in opts.concrete_fields:
"""if isinstance(f, ManyToManyField):
if instance.pk is None:
data[f.name] = []
else:
data[f.name] = list(f.value_from_object(instance).values_list('pk', flat=True))
else:"""
data[f.name] = f.value_from_object(instance)
return data
def _value_for_db_model(self, value, field, field_kind, db_type, lookup):
"""
Converts a field => value mapping received from an
EmbeddedModelField the format chosen for the field storage.
The embedded instance fields' values are also converted /
deconverted using value_for/from_db, so any back-end
conversions will be applied.
Returns (field.column, value) pairs, possibly augmented with
model info (to be able to deconvert the embedded instance for
untyped fields) encoded according to the db_type chosen.
If "dict" db_type is given a Python dict is returned.
If "list db_type is chosen a list with columns and values
interleaved will be returned. Note that just a single level of
the list is flattened, so it still may be nested -- when the
embedded instance holds other embedded models or collections).
Using "bytes" or "string" pickles the mapping using pickle
protocol 0 or 2 respectively.
If an unknown db_type is used a generator yielding (column,
value) pairs with values converted will be returned.
TODO: How should EmbeddedModelField lookups work?
"""
# value would by id or list of ids for many relationships
if lookup:
# raise NotImplementedError("Needs specification.")
return value
# Convert using proper instance field's info, change keys from
# fields to columns.
# TODO/XXX: Arguments order due to Python 2.5 compatibility.
value = (
(subfield.column, self._value_for_db(
subvalue, lookup=lookup, *self._convert_as(subfield, lookup)))
for subfield, subvalue in value.iteritems())
# Cast to a dict, interleave columns with values on a list,
# serialize, or return a generator.
if db_type == 'dict':
value = dict(value)
elif db_type == 'list':
value = list(item for pair in value for item in pair)
elif db_type == 'bytes':
value = pickle.dumps(dict(value), protocol=2)
elif db_type == 'string':
value = pickle.dumps(dict(value))
return value
def sql_flush(self, style, tables, sequences, allow_cascade=False):
for table in tables:
self.connection.indices.delete_mapping(self.connection.db_name, table)
return []
def _convert_as(self, field, lookup=None):
"""
Computes parameters that should be used for preparing the field
for the database or deconverting a database value for it.
"""
# We need to compute db_type using the original field to allow
# GAE to use different storage for primary and foreign keys.
db_type = self.connection.creation.db_type(field)
if field.rel is not None:
field = field.rel.get_related_field()
field_kind = field.get_internal_type()
# Values for standard month / day queries are integers.
if (field_kind in ('DateField', 'DateTimeField') and
lookup in ('month', 'day')):
db_type = 'integer'
return field, field_kind, db_type
def convert_as(self, field, lookup=None):
"""
Get field data
:param field:
:param lookup:
:return:
"""
return self._convert_as(field, lookup)
def check_aggregate_support(self, aggregate):
"""
This function is meant to raise exception if backend does
not support aggregation.
"""
pass
def create_index(self, index_name, options=None, has_alias=True, model=None,
skip_register=False, index_settings=None):
"""
Creates index with options as settings
index_name should contain time created:
myindex-mm-dd-yyyyTHH:MM:SS with alias myindex
:param index_name:
:param options:
:return:
:raises IndexAlreadyExistsException when can't create index.
"""
# "logstash-%{+YYYY.MM.dd}"
import random
alias = index_name if has_alias is True else None
index_name = u'{}-{}_{}'.format(
index_name,
datetime.now().strftime("%Y.%m.%d"),
random.randint(1, 999)
)
es_connection = self.connection.connection
if index_settings is None and options is not None:
index_settings = {
'analysis': options.get('ANALYSIS', {}),
'number_of_replicas': options.get('NUMBER_OF_REPLICAS', NUMBER_OF_REPLICAS),
'number_of_shards': options.get('NUMBER_OF_SHARDS', NUMBER_OF_SHARDS),
}
es_connection.indices.create_index(index_name, settings=index_settings)
# alias
if has_alias:
es_connection.indices.add_alias(alias, index_name)
if not skip_register:
self.register_index_operation(index_name, OPERATION_CREATE_INDEX, index_settings, model=model)
if has_alias:
logger.info(u'index "{}" aliased "{}" created'.format(index_name, alias))
else:
logger.info(u'index "{}" created'.format(index_name))
return index_name, alias
def has_alias(self, alias):
"""
Check if alias exists
:param alias:
:return:
"""
es_connection = self.connection.connection
try:
indices = es_connection.indices.get_alias(alias)
except IndexMissingException:
return False
if indices:
return True
return False
def delete_index(self, index_name, skip_register=False):
"""
Deletes index
:param index_name: Index name
:return:
"""
es_connection = self.connection.connection
es_connection.indices.delete_index(index_name)
# save index creation data
if not skip_register:
es_connection.index({
'operation': OPERATION_DELETE_INDEX,
'alias': index_name,
'created_on': datetime.now().strftime("%Y-%m-%dT%H:%M:%S"),
'updated_on': datetime.now().strftime("%Y-%m-%dT%H:%M:%S"),
}, INTERNAL_INDEX, 'indices')
logger.info(u'index "{}" deleted'.format(index_name))
def register_index_operation(self, index_name, operation, index_settings, model=None):
"""
Register index operation
:param index_name:
:param operation:
:return:
"""
es_connection = self.connection.connection
es_connection.index({
'operation': operation,
'index_name': index_name,
'alias': index_name,
'model': model or '',
'settings': index_settings,
'created_on': datetime.now().strftime("%Y-%m-%dT%H:%M:%S"),
'updated_on': datetime.now().strftime("%Y-%m-%dT%H:%M:%S"),
}, INTERNAL_INDEX, 'indices')
logger.info(u'register_index_operation :: operation: {} index: {}'.format(
operation,
index_name,
))
def register_mapping_update(self, index_name, mapping, mapping_old=''):
"""
Register mapping update, writing sent mapping, current mapping at ES, and ES
processed mapping after sent (returned by ES)
:param index_name:
:param mapping:
:return:
"""
import base64
mapping_dict = mapping
if not isinstance(mapping, dict):
mapping_dict = mapping.as_dict()
es_connection = self.connection.connection
# TODO get last sequence, add by one and have format
# '{0:05d}'.format(2)
path = u'/{}/_mapping/{}/'.format(mapping.index_name, mapping.name)
# logger.debug(u'register_mapping_update :: path: {}'.format(path))
result = es_connection._send_request('GET', path)
# logger.debug(u'register_mapping_update :: result: {}'.format(result))
mapping_server = result[result.keys()[0]]['mappings']
if isinstance(mapping_old, dict):
mapping_old = base64.encodestring(json.dumps(mapping_dict))
es_connection.index({
'operation': OPERATION_UPDATE_MAPPING,
'doc_type': mapping.name,
'index_name': mapping.index_name,
'sequence': '99999',
'mapping': base64.encodestring(json.dumps(mapping_dict)),
'mapping_old': mapping_old,
'mapping_server': base64.encodestring(json.dumps(mapping_server)),
'created_on': datetime.now().strftime("%Y-%m-%dT%H:%M:%S"),
'updated_on': datetime.now().strftime("%Y-%m-%dT%H:%M:%S"),
}, INTERNAL_INDEX, 'mapping_migration')
logger.info(u'register_mapping_update :: index: {} doc_type: {}'.format(
index_name,
mapping.name,
))
def get_mappings(self, index_name, doc_type):
"""
Get mappings for index and doc_type in dict form
:param index_name:
:param doc_type:
:return: dictionary with mapping on ElasticSearch
"""
es_connection = self.connection.connection
path = u'/{}/_mapping/{}/'.format(index_name, doc_type)
result = es_connection._send_request('GET', path)
try:
mapping_dict = result[result.keys()[0]]['mappings']
except IndexError:
mapping_dict = {}
return mapping_dict
def rebuild_index(self, alias):
"""
Rebuilds index in the background
1. Rebuild global index: Rebuilds whole database with all models
2. Model rebuild: Rebuilds only model main store data and associated indexes
Sync with Rebuilt Indices
=========================
1. Starts rebuild index, we mark index at internal db with rebuild_mode: building
2. Add inserts and updated from time rebuild index starts to queue
3. End rebuild, mark rebuild_mode: syncing. This will block other save requests from a little while
4. Rebuild process gets requests from queue, mark indices as synced (no more data sent to queue).
At this time saving operations would save into new index.
After done, makes changes for alias to new index, delete old index. Mark index rebuild_mode: none.
5. Saving operations would go to new index
:param alias: Index alias
:return:
"""
es_connection = self.connection.connection
options = settings.DATABASES.get(DEFAULT_DB_ALIAS, {}).get('OPTIONS', {})
# 1. create alt index
logger.debug(u'rebuild_index :: alias: {}'.format(alias))
index_data = self.create_index(alias, options, has_alias=False)
index_name_physical = index_data[0]
# 2. Inspect all models: create mappings for alt index: mapping.save()
if alias in map(lambda x: x['NAME'], settings.DATABASES.values()):
# global index
for app_name, app_models in self.connection.introspection.models.iteritems():
for model in app_models:
mapping = model_to_mapping(model, es_connection, index_name_physical)
mapping.save()
else:
# get model by index
# {model}__{model_index_name}
if '__' not in alias:
raise exceptions.RebuildIndexException(_(u'Invalid model index format "{}"'.format(alias)))
alias_fields = alias.split('__')
for app_name, app_models in self.connection.introspection.models.iteritems():
for model in app_models:
if model._meta.db_table == alias_fields[0]:
mapping = model_to_mapping(alias_fields[0], es_connection, index_name_physical)
mapping.save()
logger.debug(u'rebuild_index :: Updated mappings!!')
# 2. export/import data to new index
# bulk operations
results = es_connection.search(Search(QueryStringQuery('*:*')),
indices=es_connection.indices.get_alias(alias),
scroll=self.SCROLL_TIME)
scroll_id = results.scroller_id
es_connection.bulk_size = self.ADD_BULK_SIZE
bulk = es_connection.create_bulker()
while results:
logger.debug(u'rebuild_index :: results: {}'.format(results))
for result in results:
# add to bulk for index
# content = json.dumps(result.get_meta()) + '\n'
meta = result.get_meta()
content = '{ "index" : { "_index" : "{index_name}", "_type" : "{doc_type}", ' \
'"_id" : "{id}" } }\n'\
.format(index_name_physical,
meta['type'],
meta['id'])
content += json.dumps(result) + '\n'
# make bulk add to new index "index_name_physical"
bulk.add(content)
results = es_connection.search_scroll(scroll_id, scroll=self.SCROLL_TIME)
bulk.flush_bulk()
# 3. assign alias to new index
indices = es_connection.indices.get_alias(alias)
es_connection.indices.change_aliases([
('remove', indices[0], alias, {}),
('add', index_name_physical, alias, {}),
])
# 4. delete old index
self.delete_index(indices[0])
def build_es_settings_from_django(self, options):
"""
Build ElasticSearch settings from django options in DATABASES setting
:param options:
:return:
"""
es_settings = {}
es_settings.update({
'number_of_replicas': options.get('NUMBER_OF_REPLICAS', 1),
'number_of_shards': options.get('NUMBER_OF_SHARDS', 5),
})
if 'ANALYSIS' in options and options['ANALYSIS'].keys():
es_settings['analysis'] = options.get('ANALYSIS', '')
return es_settings
def build_django_engine_structure(self):
"""
Build and save .django_engine mappings for document types
:return:
"""
from django_elasticsearch.fields import DocumentObjectField, DateField, StringField, ObjectField, \
IntegerField
es_connection = self.connection.connection
# create .django_engine index
try:
# build settings
# attach mappings to settings
options = {
'number_of_replicas': 1,
'number_of_shards': 1,
}
# index_settings = SettingsBuilder(options, mappings)
self.create_index(INTERNAL_INDEX, options=options, skip_register=True)
# indices
mapping_indices = DocumentObjectField(
name='indices',
connection=self.connection,
index_name=INTERNAL_INDEX,
properties={
'operation': StringField(index='not_analyzed'),
'index_name': StringField(index='not_analyzed'),
'alias': StringField(index='not_analyzed'),
'model': StringField(index='not_analyzed'),
'settings': ObjectField(),
'created_on': DateField(),
'updated_on': DateField(),
})
result = es_connection.indices.put_mapping(doc_type='indices',
mapping=mapping_indices,
indices=INTERNAL_INDEX)
logger.info(u'{} result: {}'.format('.django_engine/indices',
pprint.PrettyPrinter(indent=4).pformat(result)))
# mapping_migration
mapping_migration = DocumentObjectField(
name='mapping_migration',
connection=self.connection,
index_name=INTERNAL_INDEX,
properties={
'operation': StringField(index='not_analyzed'),
'doc_type': StringField(index='not_analyzed'),
'index_name': StringField(index='not_analyzed'),
'sequence': IntegerField(),
'mapping': StringField(index='not_analyzed'),
'mapping_server': StringField(index='not_analyzed'),
'mapping_old': StringField(index='not_analyzed'),
'created_on': DateField(),
'updated_on': DateField(),
})
result = es_connection.indices.put_mapping(doc_type='mapping_migration',
mapping=mapping_migration,
indices=INTERNAL_INDEX)
logger.info(u'{} result: {}'.format('.django_engine/mapping_migration',
pprint.PrettyPrinter(indent=4).pformat(result)))
# register index operation
self.register_index_operation(INTERNAL_INDEX, OPERATION_CREATE_INDEX, options)
# register mapping update
self.register_mapping_update(INTERNAL_INDEX, mapping_indices)
self.register_mapping_update(INTERNAL_INDEX, mapping_migration)
except (IndexAlreadyExistsException, ElasticSearchException):
traceback.print_exc()
logger.info(u'Could not create index')
class DatabaseClient(NonrelDatabaseClient):
pass
class DatabaseValidation(NonrelDatabaseValidation):
pass
class DatabaseIntrospection(NonrelDatabaseIntrospection):
def __init__(self, *args, **kwargs):
super(NonrelDatabaseIntrospection, self).__init__(*args, **kwargs)
self._models = {}
self._models_discovered = False
self._mappings = {}
def _discover_models(self):
"""
Discover django models and set into _models class attribute
"""
# db = options.get('database')
db = DEFAULT_DB_ALIAS
tables = self.table_names()
all_models = [
(app.__name__.split('.')[-2],
[m for m in dj_models.get_models(app, include_auto_created=True)
if router.allow_syncdb(db, m)])
for app in dj_models.get_apps()
]
logger.debug(u'all_models: {}'.format(all_models))
def model_installed(model):
opts = model._meta
converter = self.table_name_converter
return not ((converter(opts.db_table) in tables) or
(opts.auto_created and converter(opts.auto_created._meta.db_table) in tables))
manifest = SortedDict(
(app_name, list(filter(model_installed, model_list)))
for app_name, model_list in all_models
)
for app_name, model_list in manifest.items():
logger.debug(u'app_name: {} model_list: {}'.format(app_name, model_list))
app_models = []
for model in model_list:
app_models.append(model)
self._models[app_name] = app_models
@property
def models(self):
if not self._models_discovered:
self._discover_models()
self._models_discovered = True
return self._models
@property
def mappings(self):
return self._mappings
def django_table_names(self, only_existing=False):
"""
Returns a list of all table names that have associated cqlengine models
and are present in settings.INSTALLED_APPS.
"""
all_models = list(chain.from_iterable(self.cql_models.values()))
tables = [model.column_family_name(include_keyspace=False)
for model in all_models]
return tables
def table_names(self, cursor=None):
"""
Returns all table names
"""
# TODO: get content types from indices
return []
def get_table_list(self, cursor):
return self.table_names()
def get_table_description(self, *_):
"""
Get model mapping
"""
return ""
class DatabaseWrapper(NonrelDatabaseWrapper):
vendor = 'elasticsearch'
def __init__(self, *args, **kwargs):
super(DatabaseWrapper, self).__init__(*args, **kwargs)
# Set up the associated backend objects
self.features = DatabaseFeatures(self)
self.ops = DatabaseOperations(self)
self.client = DatabaseClient(self)
self.creation = DatabaseCreation(self)
self.validation = DatabaseValidation(self)
self.introspection = DatabaseIntrospection(self)
self.commit_on_exit = False
self.connected = False
self.autocommit = True
self.es_url = '{}:{}'.format(self.settings_dict['HOST'], self.settings_dict['PORT'])
self.default_indices = []
del self.connection
def connect(self):
import pprint
logger.debug(u'connect... es_url: {} options: {}'.format(self.es_url,
pprint.PrettyPrinter(indent=4)
.pformat(self.settings_dict)))
if not self.connected or self.connection is None:
self.connection = ES(self.es_url,
default_indices=[self.settings_dict['NAME']],
bulk_size=1000)
connection_created.send(sender=self.__class__, connection=self)
self.connected = True
self.default_indices = [self.settings_dict['NAME']]
def __getattr__(self, attr):
if attr == "connection":
assert not self.connected
self.connect()
return getattr(self, attr)
raise AttributeError(attr)
def reconnect(self):
if self.connected:
del self.connection
self.connected = False
self.connect()
def _commit(self):
pass
def _rollback(self):
pass
def close(self):
pass
def schema_editor(self, *args, **kwargs):
"""
Returns a new instance of this backend's SchemaEditor (Django>=1.7)
"""
return DatabaseSchemaEditor(self, *args, **kwargs)
<file_sep>/requirements.txt
-e git+https://github.com/django-nonrel/django.git@0<PASSWORD>9<PASSWORD>9<PASSWORD>#egg=django
djangotoolbox==1.6.2
pyes==0.99.5
six==1.9.0
urllib3==1.10
<file_sep>/django_elasticsearch/__init__.py
import inspect
import django
# from django.db import connections, router, transaction, models, DEFAULT_DB_ALIAS
# from django.db import models as dj_models, router
from django.db import connections, router, transaction, models as dj_models, DEFAULT_DB_ALIAS
import django.db.models.options as options
from django.utils.datastructures import SortedDict
__author__ = 'jorgealegre'
options.DEFAULT_NAMES = options.DEFAULT_NAMES + ('indices',
'disable_default_index')
ENGINE = 'django_elasticsearch'
NUMBER_OF_REPLICAS = 1
NUMBER_OF_SHARDS = 5
INTERNAL_INDEX = '.django_engine'
OPERATION_DELETE_INDEX = 'delete_index'
OPERATION_CREATE_INDEX = 'create_index'
OPERATION_UPDATE_MAPPING = 'update_mapping'
WRITE_QUEUE = 'write_queue'
def get_installed_apps():
"""
Return list of all installed apps
"""
if django.VERSION >= (1, 7):
from django.apps import apps
return apps.get_apps()
else:
from django.db import models
return models.get_apps()
class DjangoElasticEngineException(Exception):
pass
<file_sep>/django_elasticsearch/management/commands/get_mappings.py
# python
import logging
import pprint
from optparse import make_option
import sys
# django
from django.db import connections, DEFAULT_DB_ALIAS
from django.core.management.base import BaseCommand
__author__ = 'jorgealegre'
logger = logging.getLogger(__name__)
class Command(BaseCommand):
args = ''
help = 'Get mappings for index and doc type'
can_import_settings = True
option_list = BaseCommand.option_list + (
make_option('--index',
action='store',
dest='index',
default='',
help='Index name'),
make_option('--doc_type',
action='store',
dest='doc_type',
default='',
help='Doc type'),
)
def handle(self, *args, **options):
connection = connections[DEFAULT_DB_ALIAS]
index_name = options.get('index', '')
doc_type = options.get('doc_type', '')
if index_name == '':
self.stderr.write(u'index must be informed.')
sys.exit(1)
mappings = connection.ops.get_mappings(index_name, doc_type)
self.stdout.write(pprint.PrettyPrinter(indent=4).pformat(mappings))
<file_sep>/django_elasticsearch/exceptions.py
__author__ = 'jorgealegre'
class RebuildIndexException(Exception):
pass
<file_sep>/django_elasticsearch/schema.py
import logging
try:
from django.db.backends.schema import BaseDatabaseSchemaEditor
except ImportError:
BaseDatabaseSchemaEditor = object
logger = logging.getLogger(__name__)
__author__ = 'jorgealegre'
class DatabaseSchemaEditor(BaseDatabaseSchemaEditor):
def create_model(self, model):
logger.debug(u'DatabaseSchemaEditor :: create_model...')
pass
def delete_model(self, model):
logger.debug(u'DatabaseSchemaEditor :: delete_model...')
pass
<file_sep>/django_elasticsearch/manager.py
from django.db import connections
from django.db.models.manager import Manager as DJManager
from django.db.models.fields import FieldDoesNotExist
from pyes.queryset import QuerySet
from pyes.models import ElasticSearchModel
__author__ = 'jorgealegre'
'''class Manager(DJManager):
def __init__(self, manager_func=None):
super(Manager, self).__init__()
self._manager_func = manager_func
self._collection = None
def contribute_to_class(self, model, name):
# TODO: Use weakref because of possible memory leak / circular reference.
self.model = model
# setattr(model, name, ManagerDescriptor(self))
if model._meta.abstract or (self._inherited and not self.model._meta.proxy):
model._meta.abstract_managers.append((self.creation_counter, name,
self))
else:
model._meta.concrete_managers.append((self.creation_counter, name,
self))
def __get__(self, instance, owner):
"""Descriptor for instantiating a new QuerySet object when
Document.objects is accessed.
"""
self.model = owner #We need to set the model to get the db
if instance is not None:
# Document class being used rather than a document object
return self
if self._collection is None:
self._collection = connections[self.db].db_connection[owner._meta.db_table]
# owner is the document that contains the QuerySetManager
queryset = QuerySet(owner, self._collection)
if self._manager_func:
if self._manager_func.func_code.co_argcount == 1:
queryset = self._manager_func(queryset)
else:
queryset = self._manager_func(owner, queryset)
return queryset'''
class IndexManager(DJManager):
def __init__(self):
super(IndexManager, self).__init__()
def get_queryset(self):
# 1. get connection
# 2. instantiate es.QuerySet
MyModel = type('MyModel', (ElasticSearchModel,), {})
connection = connections[self.db].db_connection
return QuerySet(MyModel, index=index, type=doc_type, es_url=connection.es_url, es_kwargs=es_kwargs))
class ESMeta(object):
pass
def add_es_manager(sender, **kwargs):
"""
Fix autofield
"""
from django.conf import settings
cls = sender
database = settings.DATABASES[cls.objects.db]
if 'elasticsearch' in database['ENGINE']:
if cls._meta.abstract:
return
if getattr(cls, 'objects', None) is None:
# Create the default manager, if needed.
try:
cls._meta.get_field('objects')
raise ValueError("Model %s must specify a custom Manager, because it has a field named "
"'index'" % cls.__name__)
except FieldDoesNotExist:
pass
setattr(cls, 'objects', IndexManager())
<file_sep>/django_elasticsearch/fields.py
# python
import logging
# django
from collections import OrderedDict
from django.db import connections, DEFAULT_DB_ALIAS
# pyes
from pyes import mappings
from pyes.mappings import get_field
from pyes.models import DotDict, SortedDict
__author__ = 'jorgealegre'
logger = logging.getLogger(__name__)
class StringField(mappings.StringField):
def __init__(self, *args, **kwargs):
super(StringField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(StringField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class DateField(mappings.DateField):
def __init__(self, *args, **kwargs):
super(DateField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(DateField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class BooleanField(mappings.BooleanField):
def __init__(self, *args, **kwargs):
super(BooleanField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(BooleanField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class DoubleField(mappings.DoubleField):
def __init__(self, *args, **kwargs):
super(DoubleField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(DoubleField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class FloatField(mappings.FloatField):
def __init__(self, *args, **kwargs):
super(FloatField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(FloatField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class IntegerField(mappings.IntegerField):
def __init__(self, *args, **kwargs):
super(IntegerField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(IntegerField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class LongField(mappings.LongField):
def __init__(self, *args, **kwargs):
super(LongField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(LongField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class MultiField(mappings.MultiField):
def __init__(self, *args, **kwargs):
super(MultiField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(MultiField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class NestedObject(mappings.NestedObject):
def __init__(self, *args, **kwargs):
super(NestedObject, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(NestedObject, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class ShortField(mappings.ShortField):
def __init__(self, *args, **kwargs):
super(ShortField, self).__init__(*args, **kwargs)
def as_dict(self):
map_ = super(ShortField, self).as_dict()
if self.index is False and self.tokenize is False:
map_['index'] = 'no'
elif self.index is True and self.tokenize is False:
map_['index'] = 'not_analyzed'
elif self.index is True and self.tokenize is True:
map_['index'] = 'analyzed'
return map_
class ObjectField(mappings.ObjectField):
def __init__(self, name=None, path=None, properties=None,
dynamic=None, enabled=None, include_in_all=None, dynamic_templates=None,
include_in_parent=None, include_in_root=None,
connection=None, index_name=None):
self.name = name
self.type = "object"
self.path = path
self.properties = properties
self.include_in_all = include_in_all
self.dynamic = dynamic
self.dynamic_templates = dynamic_templates or []
self.enabled = enabled
self.include_in_all = include_in_all
self.include_in_parent = include_in_parent
self.include_in_root = include_in_root
self.connection = connection
self.index_name = index_name
if properties:
# name -> Field
map_ = {}
for item in properties:
logger.debug(u'type: {}'.format(type(properties[item])))
if isinstance(properties[item], dict):
logger.debug(u'Will get field from dictionary')
map_[item] = get_field(item, properties[item])
else:
instance = properties[item]
instance.name = item
map_[item] = instance
self.properties = OrderedDict(sorted([(name, data) for name, data in map_.items()]))
else:
self.properties = {}
def as_dict(self):
map_ = super(ObjectField, self).as_dict()
if 'type' in map_:
del map_['type']
return map_
class DocumentObjectField(ObjectField):
def __init__(self, _all=None, _boost=None, _id=None,
_index=None, _source=None, _type=None, _routing=None, _ttl=None,
_parent=None, _timestamp=None, _analyzer=None, _size=None, date_detection=None,
numeric_detection=None, dynamic_date_formats=None, _meta=None, *args, **kwargs):
super(DocumentObjectField, self).__init__(*args, **kwargs)
self._timestamp = _timestamp
self._all = _all
self._boost = _boost
self._id = _id
self._index = _index
self._source = _source
self._routing = _routing
self._ttl = _ttl
self._analyzer = _analyzer
self._size = _size
self._type = _type
if self._type is None:
self._type = {"store": "yes"}
self._parent = _parent
self.date_detection = date_detection
self.numeric_detection = numeric_detection
self.dynamic_date_formats = dynamic_date_formats
self._meta = DotDict(_meta or {})
def get_meta(self, subtype=None):
"""
Return the meta data.
"""
if subtype:
return DotDict(self._meta.get(subtype, {}))
return self._meta
def enable_compression(self, threshold="5kb"):
self._source.update({"compress": True, "compression_threshold": threshold})
def as_dict(self):
result = super(DocumentObjectField, self).as_dict()
result['_type'] = self._type
if self._all is not None:
result['_all'] = self._all
if self._source is not None:
result['_source'] = self._source
if self._boost is not None:
result['_boost'] = self._boost
if self._routing is not None:
result['_routing'] = self._routing
if self._ttl is not None:
result['_ttl'] = self._ttl
if self._id is not None:
result['_id'] = self._id
if self._timestamp is not None:
result['_timestamp'] = self._timestamp
if self._index is not None:
result['_index'] = self._index
if self._parent is not None:
result['_parent'] = self._parent
if self._analyzer is not None:
result['_analyzer'] = self._analyzer
if self._size is not None:
result['_size'] = self._size
if self.date_detection is not None:
result['date_detection'] = self.date_detection
if self.numeric_detection is not None:
result['numeric_detection'] = self.numeric_detection
if self.dynamic_date_formats is not None:
result['dynamic_date_formats'] = self.dynamic_date_formats
if 'type' in result:
del result['type']
return result
def save(self):
"""
Save mapping, registering into .django_engine internal index
:return:
"""
if self.connection is None:
raise RuntimeError(u"No connection available")
try:
connection = connections[DEFAULT_DB_ALIAS]
es_connection = self.connection
mappings_old = connection.ops.get_mappings(self.index_name, self.name)
es_connection.indices.put_mapping(doc_type=self.name,
mapping=self,
indices=self.index_name)
connection.ops.register_mapping_update(self.index_name, self, mappings_old)
except Exception:
# reindex
# MergeMappingException
# 1. create alt index
# 2. export/import data to new index
# 3. assign alias to new index
# 4. delete old index
# TODO: Implement model reindex
import traceback
logger.error(traceback.format_exc())
logger.info(u'Could not update mappings for doc_type:"{}"'.format(self.name))
def __repr__(self):
return "<DocumentObjectField:%s>" % self.name
def get_code(self, num=1):
data = SortedDict(self.as_dict())
data.pop("properties", [])
var_name ="doc_%s"%self.name
code= [var_name+" = "+self.__class__.__name__+"(name=%r, "%self.name+", ".join(["%s=%r"%(k,v) for k,v in list(data.items())])+")"]
for name, field in list(self.properties.items()):
num+=1
vname, vcode = field.get_code(num)
code.append(vcode)
code.append("%s.add_property(%s)"%(var_name, vname))
<file_sep>/django_elasticsearch/models.py
# python
import logging
# django
from django.db import models
from django.utils.translation import ugettext_lazy as _
from django.contrib.auth.models import User
__author__ = 'jorgealegre'
DATE_CHUNKS_PER_DAY = 'per_day'
DATE_CHUNKS_PER_MONTH = 'per_month'
DATE_CHUNKS_CHOICE = (
(DATE_CHUNKS_PER_DAY, _(u'Per Day')),
(DATE_CHUNKS_PER_MONTH, _(u'Per Month')),
)
logger = logging.getLogger(__name__)
def get_settings_by_meta(meta_index):
return {
'number_of_replicas': meta_index['number_of_replicas'],
'number_of_shards': meta_index['number_of_shards'],
}
class BaseModel(models.Model):
"""
ES index name:
$appname-$modelname-$modelindex-$datecreated
alias:
$appname-$modelname-$modelindex
Some cases we would want model forced into a model index, disallow from db default index
created_by:
{
'id': id,
'value': username,
}
"""
created_on = models.DateTimeField(auto_now_add=True)
updated_on = models.DateTimeField(auto_now=True)
# created_by = models.ForeignKey(User, null=True, blank=True)
# updated_by = models.ForeignKey(User, null=True, blank=True)
class Meta:
abstract = True
indices = [
{
'by_user': {
'routing_field': 'user.id',
'number_of_replicas': 1,
'number_of_shards': 5,
},
}
]
| f9b37903a732a7999af69d7d6cbab8a4e3941d09 | [
"Markdown",
"Python",
"Text"
] | 15 | Python | Ximpia/django-elasticsearch | 60250183be48d3b1df901be79ab474c28fa2d63c | a52d2a7f1220613ce6f3ac1756a32f3d88c81e0a |
refs/heads/master | <file_sep>package com.example.passwordgenerator
import android.os.Build
import androidx.appcompat.app.AppCompatActivity
import android.os.Bundle
import androidx.annotation.RequiresApi
import kotlinx.android.synthetic.main.activity_main.*
import java.lang.StringBuilder
import kotlin.random.Random
@Suppress("UNUSED_CHANGED_VALUE")
class MainActivity : AppCompatActivity() {
@ExperimentalStdlibApi
@RequiresApi(Build.VERSION_CODES.N)
private fun stringGenerator(): String {
var upperCaseChars = "QWERTYUIOPLKJHGFDSAZXCVBNM"
var lowerCaseChars = "qwertyuioplkjhgfdsazxcvbnm"
var numChars = "0123456789"
var specialChars = "!@#$%^&*()"
var maxLenght = 10
var allowedChars = "$upperCaseChars $lowerCaseChars $numChars $specialChars"
var random = Random
var randomPass = StringBuilder(maxLenght)
randomPass.append(allowedChars.toCharArray(random.nextInt(allowedChars.length -1)))
var i = randomPass.length
repeat(maxLenght.rangeTo(other = i++).count()) {
}
return randomPass.toString()
}
@ExperimentalStdlibApi
@RequiresApi(Build.VERSION_CODES.N)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_main)
rvButton.setOnClickListener {
var pass = stringGenerator()
textView1.text = pass
}
}
}
| b65fb06349fc14459d86e97526bebda836322c8b | [
"Kotlin"
] | 1 | Kotlin | albert-yakubov/PasswordGenerator | ab56cc6a0df787928de1c27de7c946fc3e83a87f | 24ea6ea885e44ecf46cf68dae1a3bc8049e2b0d3 |
refs/heads/master | <file_sep>const initialState = {
books: [],
booksLoader: true,
movie: '',
errorBooksLoaded: false
}
export default (state = initialState, action) => {
switch(action.type) {
case 'LOADED_BOOKS':
return {
...state,
books: action.payload,
booksLoader: false,
errorBooksLoaded: false
}
case 'SEARCH_CHANGE':
return {
...state,
movie: action.payload,
booksLoader: true,
errorBooksLoaded: false
}
case 'MOVIES_FETCHED':
console.log(action.payload)
return {
...state,
books: action.payload,
booksLoader: false,
errorBooksLoaded: false
}
case 'MOVIES_FAILED':
return {
...state,
booksLoader: false,
errorBooksLoaded: true
}
default:
return state;
}
}<file_sep>import React from 'react';
import AuthForm from './auth';
import RegForm from './reg';
import './form.scss';
class FormContainer extends React.Component {
render() {
const { register, author, authorSubmit, registerSubmit, state, toggleForm } = this.props;
if(state.reg) {
return (
<div className="bg-form">
<RegForm registerSubmit={registerSubmit} _toggleForm={toggleForm} register={register} />
</div>
);
}
return (
<div className="bg-form">
<AuthForm authorSubmit={authorSubmit} _toggleForm={toggleForm} author={author} />
</div>
);
}
}
export default FormContainer;<file_sep>const initialState = {
user: {
name: '',
password: '',
authUser: false
}
}
export default (state = initialState, action) => {
switch(action.type) {
case 'ADD_USER':
return {
...state,
user: {
login: action.payload.login,
authUser: true,
password: action.payload.password
}
}
case 'USER_LOGOUT':
action.payload.push('/');
return {
...state,
user: {
login: '',
password: ''
}
}
default:
return state;
}
}<file_sep>import React from 'react';
import Spinner from '../../spinner';
const defaultVideo = {
id: {
videoId: 'feRFJkFHhrU'
},
snippet: {
description: "Какой плейлист для современного, уставшего человека самый нужный, чтобы можно было с удовольствием все...",
liveBroadcastContent: "none",
publishedAt: "2018-07-22T17:30:17.000Z",
title: "Нежный Шум Моря и Звук Волны, Морской Прибой, Море 3 Часа Для Сна"
}
}
const VideoDetail = ({video = defaultVideo}) => {
if(!video) {
video = defaultVideo;
}
const videoSrc = `https://www.youtube.com/embed/${video.id.videoId}`;
return(
<div>
<div className="ui embed">
<iframe src={videoSrc} />
</div>
<div className="ui segment">
<h4 className="ui header">{video.snippet.title}</h4>
<p>{video.snippet.description}</p>
</div>
</div>
);
}
export default VideoDetail;<file_sep>
import youtube from '../components/apis/youtube';
const getMovies = (text) => async (dispatch) => {
function onSuccess(success) {
dispatch({ type: 'MOVIES_FETCHED', payload: success })
return success
}
function onError(error) {
dispatch({ type: 'MOVIES_FAILED', error })
return error
}
try {
const URL = `https://api.tvmaze.com/search/shows?q=${text}`
const res = await fetch(URL, {
method: 'GET'
})
const success = await res.json()
const data = success.map(item => item.show);
return onSuccess(data)
} catch (error) {
return onError(error)
}
}
const searchChanged = (text) => {
return {
type: 'SEARCH_CHANGE',
payload: text
}
}
const loadedBooks = (books) => {
return {
type: 'LOADED_BOOKS',
payload: books
};
}
const userAuthor = (user) => {
return {
type: 'ADD_USER',
payload: user
};
}
const userLogout = (navigator) => {
return {
type: 'USER_LOGOUT',
payload: navigator
}
}
const loadedVideos = (text) => async (dispatch) => {
function onSuccess(success) {
dispatch({ type: 'LOADED_VIDEOS', payload: success })
return success
}
function onError(error) {
dispatch({ type: 'LOADED_VIDEOS_FAILED', error })
return error
}
try {
const response = await youtube.get('/search', {
params: {
q: text
}
})
console.log(response.data.items)
return onSuccess(response.data.items)
} catch (error) {
return onError(error)
}
}
const changeSearchVideos = (text) => {
return {
type: 'SEARCH_VIDEOS',
payload: text
}
}
const selectedVideo = (video) => {
return {
type: 'SELECTED_VIDEO',
payload: video
}
}
const loadedMusics = (musics) => {
return {
type: 'LOADED_MUSICS',
payload: musics
};
}
const loadedImages = (images) => {
return {
type: 'LOADED_IMAGES',
payload: images
};
}
export {
loadedVideos,
loadedBooks,
loadedMusics,
userAuthor,
userLogout,
getMovies,
searchChanged,
changeSearchVideos,
selectedVideo,
loadedImages
};<file_sep>export * from './audio';
export * from './video';
export * from './images';
export * from './books';<file_sep>import React from 'react';
export default ({onSearchChange, value}) => {
return(
<div className="ui icon input">
<input onChange={onSearchChange} value={value} key="editor1" type="text" placeholder="Search..." />
<i className="inverted circular search link icon"></i>
</div>
)
}<file_sep>import * as firebase from 'firebase';
const config = {
apiKey: "<KEY>",
authDomain: "global-project-d6644.firebaseapp.com",
databaseURL: "https://global-project-d6644.firebaseio.com",
projectId: "global-project-d6644",
storageBucket: "global-project-d6644.appspot.com",
messagingSenderId: "524645160819"
};
firebase.initializeApp(config);
const firebaseDB = firebase.database();
export {
firebaseDB
}
// firebaseDB.ref('users').orderByChild('lastname').limitToFirst(4).once('value')
// .then(snapshop => {
// const users = [];
// snapshop.forEach((childSnapshot) => {
// users.push({
// id: childSnapshot.key,
// ...childSnapshot.val()
// })
// });
// console.log(users)
// })
// .catch((err) => {
// console.log(err)
// })
// firebaseDB.ref('users').push({
// name: 'Nikita',
// lastname: 'Rumonov'
// });
// ---------------------- support
// ref(name(users)).push([...array])
// ref(name/id-user(- Le2SZIJ5HKbuUPmBjec )).once('value') or update or delete
// .then(snapshot => {
// console.log(snapshot);
// })
// -----------------
// remove(delete)
// ref(name).remove().then... or ref(name/name2).remove()
// or ref(name).set(null)
// update data
// ref(name).set(newValue)
// or ref(name).update(newUpdate)
// get data
// ref().once('value')
// .then((response) => {
// console.log(response.val());
// })
// .ref(name).once('value')
// .then(res => {
// console.log(res.val())
// })
// при изменении и для получения данных
// ref(name).on('value', (snapshot) => {
// console.log(snapshot.val())
// })
// on('child_added') or on('child_deleted')
// .ref('users').limitToFirst(1) limited users get
// изменит name на text
// ref(name).orderByChild(name).equalTo(text)<file_sep>import React from 'react';
const styles = {
position: 'absolute',
left: 0 + 'px',
right: 0 + 'px',
top: 0 + 'px',
bottom: 0 + 'px'
};
const Spinner = () => {
return (
<div className="ui segment" style={styles}>
<div className="ui active inverted dimmer">
<div className="ui text loader">Загрузка</div>
</div>
<p></p>
</div>
);
}
export default Spinner;<file_sep>import React from 'react';
import './modal.scss';
export default ({data, closeModal}) => {
const { image, name, rating, summary, language,
premiered, officialSite, network = {} } = data;
const img = (image === undefined || image === null) ? 'https://fcrmedia.ie/wp-content/themes/fcr/assets/images/default.jpg' : `https${image.medium.slice(4)}`;
const { country } = network ? network : {name: 'Неизвестно'};
const { average } = rating ? rating : '0';
const paragArray = [
{
text: 'Язык',
value: language || 'Неизвестно'
},
{
text: 'Премьера',
value: premiered || 'Неизвестно'
},
{
text: 'Официальный сайт',
value: officialSite || 'Неизвестно'
},
{
text: 'Страна',
value: country ? country.name || 'Неизвестно' : 'Неизвестно'
}
];
return(
<div className="modal-container" onClick={closeModal}>
<div className="modal">
<div className="d-flex block-content">
<div className="content-image">
<img src={img} />
</div>
<div className="content-books">
<h4>{name || 'Неизвестно'}</h4>
<div className="statistic">Рейтинг: <span>{average || '0'}</span></div>
{
paragArray.map(({text, value}, i) => {
return <div key={i} className="statistic">{text}: <span>{value}</span></div>
})
}
</div>
</div>
<h4 className="media-title d-none text-center">{name || 'Неизвестно'}</h4>
<p className="ui segment text-information">{summary || 'Not text'}</p>
</div>
</div>
)
}<file_sep>import React, { Component } from "react";
import { connect } from 'react-redux';
import { Route, Switch } from 'react-router-dom';
import { userAuthor, userLogout, loadedBooks, searchChanged,
getMovies, changeSearchVideos, loadedVideos, selectedVideo } from '../../actions';
import FormContainer from '../auth_reg-form';
import VideosPage from '../pages/videos';
import BooksPage from '../pages/books';
import { firebaseDB } from '../../firebase';
import { withRouter } from 'react-router-dom';
import '../../styles/App.scss';
class App extends Component {
state = {
reg: false
}
registerValues = {
login: '',
password: ''
}
authorValues = {
login: '',
password: ''
}
onTermSubmit = (e) => {
const input = e.target;
this.props.changeSearchVideos(input.value);
// this.props.loadedVideos(input.value);
}
onSubmitVideos = (e) => {
e.preventDefault();
this.props.loadedVideos(this.props.searchVideos);
}
onVideoSelect = (video) => {
this.props.selectedVideo(video);
}
register = (input) => {
if(input.classList.contains('login')) {
const value = input.value;
this.registerValues.login = value;
} else if(input.classList.contains('password')) {
const value = input.value;
this.registerValues.password = value;
}
}
author = (input) => {
if(input.classList.contains('login')) {
const value = input.value;
this.authorValues.login = value;
} else if(input.classList.contains('password')) {
const value = input.value;
this.authorValues.password = value;
}
}
authorSubmit = (e) => {
e.preventDefault();
if(this.authorValues.login !== '' && this.authorValues.password !== '') {
const { userAuthor } = this.props;
firebaseDB.ref('users').once('value')
.then((response) => {
const data = response.val();
let users = [];
for(let i in data) {
let obj = {login: data[i].login, password: data[i].password};
users.push(obj);
}
const user = users.find(item => (item.login === this.authorValues.login && item.password === this.authorValues.password));
if(user) {
userAuthor(user);
this.props.history.push('/video');
}
else alert('Не верный логин или пароль');
})
.catch(err => console.log(err))
}
}
registerSubmit = (e) => {
e.preventDefault();
if(this.registerValues.login !== '' && this.registerValues.password !== '') {
const { userAuthor } = this.props;
firebaseDB.ref('users').once('value')
.then((response) => {
const data = response.val();
let users = [];
for(let i in data) {
let obj = {login: data[i].login, password: data[i].password};
users.push(obj);
}
const user = users.find(item => (item.login === this.registerValues.login));
if(!user) {
const { userAuthor } = this.props;
firebaseDB.ref('users').push({
login: this.registerValues.login,
password: <PASSWORD>
})
.then(() => {
userAuthor({
login: this.registerValues.login,
password: this.register<PASSWORD>
});
this.props.history.push('/video');
})
.catch(err => {
console.log(err);
})
}
else alert('Такой user уже занят');
})
.catch(err => console.log(err))
}
}
toggleForm = (status) => {
this.setState({reg: status});
}
onSearchChange = (e) => {
const input = e.target
this.props.searchChanged(input.value)
this.props.getMovies(input.value)
}
render() {
const { authUser } = this.props.user;
const { userLogout, books, booksLoader, loadedBooks,
movies, videos, videosLoading, loadedVideos, selectVideo,
errorVideosLoading, errorBooksLoaded } = this.props;
return (
<Switch>
<Route
exact
path="/"
component={() => <FormContainer toggleForm={this.toggleForm} state={this.state} authorSubmit={this.authorSubmit}
registerSubmit={this.registerSubmit} author={this.author} register={this.register} />}
/>
<Route
path="/video"
render={() => <VideosPage loadedVideos={loadedVideos} errorVideosLoading={errorVideosLoading} onSubmitVideos={this.onSubmitVideos} selectVideo={selectVideo} videosLoading={videosLoading}
videos={videos} onTermSubmit={this.onTermSubmit} navigator={this.props.history}
userLogout={userLogout} authUser={authUser} onVideoSelect={this.onVideoSelect} />}
/>
<Route
path="/books"
render={() => <BooksPage errorBooksLoaded={errorBooksLoaded} value={movies} onSearchChange={this.onSearchChange} loadedBooks={loadedBooks}
books={books} booksLoader={booksLoader} navigator={this.props.history} userLogout={userLogout} authUser={authUser} />}
/>
</Switch>
);
}
}
const mapStateToProps = (state) => {
return {
user: state.user.user,
books: state.books.books,
booksLoader: state.books.booksLoader,
errorBooksLoaded: state.books.errorBooksLoaded,
movies: state.books.movie,
videos: state.videos.videos,
videosLoading: state.videos.videosLoading,
errorVideosLoading: state.videos.errorVideosLoading,
searchVideos: state.videos.searchVideos,
selectVideo: state.videos.selectVideo
}
};
const mapDispatchToProps = {
userAuthor,
userLogout,
searchChanged,
getMovies,
loadedVideos,
changeSearchVideos,
selectedVideo,
loadedBooks
};
export default connect(mapStateToProps, mapDispatchToProps)(withRouter(App));<file_sep>import React from 'react';
import Header from '../../header-component';
import Spinner from '../../spinner';
import BookCard from './book-card';
import SearcBar from '../../search-component';
import ErrorMessage from '../../error-message';
import ModalInfo from '../../moda-info';
import './book.scss';
const url = 'https://api.tvmaze.com/search/shows?q=';
const defaultUrl = 'stargate';
class BooksPage extends React.Component {
state = {
displayModal: false,
dataModal: {}
}
componentDidMount = () => {
fetch(url+defaultUrl)
.then(response => {
return response.json();
})
.then(res => {
const data = res.map(item => item.show);
this.props.loadedBooks(data);
})
.catch(err => {
console.log(err)
});
}
openModal = (data) => {
this.setState({displayModal: true, dataModal: data});
}
closeModal = (e) => {
console.log('click')
if(e.target.classList.contains('modal-container')) {
this.setState({displayModal: false});
}
}
render() {
const { authUser, userLogout, navigator, books,
errorBooksLoaded, booksLoader, onSearchChange, value } = this.props;
console.log(books)
if(authUser) {
return(
<div>
<Header navigator={navigator} userLogout={userLogout} />
<div className="search-books-block">
<div className="container container-search-bar">
<div>
<SearcBar onSearchChange={onSearchChange} value={value} />
</div>
</div>
</div>
<section className="books-sections container-books">
{
errorBooksLoaded ? <ErrorMessage service="Сервисе книг" /> :
booksLoader ? <Spinner /> :
<div className="ui link cards">
{
books.map((book, i) => {
return(
<BookCard openModal={this.openModal} {...book} key={book.id} />
)
})
}
</div>
}
</section>
{
this.state.displayModal ? <ModalInfo data={this.state.dataModal} closeModal={this.closeModal} /> : null
}
</div>
);
}
return(
<div className="not-user">Вы ещё не найдены...</div>
);
}
}
export default BooksPage;
<file_sep>import React from 'react';
import './videos.scss';
export default ({video, onVideoSelect}) => {
const image = video.snippet.thumbnails.medium.url ? video.snippet.thumbnails.medium.url : 'https://doc.louisiana.gov/assets/camaleon_cms/image-not-found-4a963b95bf081c3ea02923dceaeb3f8085e1a654fc54840aac61a57a60903fef.png'
return(
<div onClick={() => onVideoSelect(video)} className="video-item item">
<img className="ui image" src={image} />
<div className="content">
<div className="header">{video.snippet.title}</div>
</div>
</div>
)
}<file_sep>import React from 'react';
import Header from '../../header-component';
import Spinner from '../../spinner';
import SearchVideo from '../../search-videos';
import VideoCard from './video-card';
import VideoDetail from './videoDetail';
import ErrorMessage from '../../error-message';
import './videos.scss';
class VideosPage extends React.Component {
componentDidMount() {
this.props.loadedVideos('море');
}
render() {
const { authUser, userLogout, navigator, onTermSubmit,
videos = [], videosLoading, onVideoSelect, selectVideo, errorVideosLoading, onSubmitVideos } = this.props;
if(authUser) {
return(
<div>
<Header navigator={navigator} userLogout={userLogout} />
<div className="search-books-block">
<div className="container container-search-bar">
<div>
<form onSubmit={onSubmitVideos}>
<SearchVideo onTermSubmit={onTermSubmit} />
</form>
</div>
</div>
</div>
<div className="section-videos-container">
{
errorVideosLoading ? <ErrorMessage service="Youtube" /> :
videosLoading ?
<div onClick={onSubmitVideos} className="ui segment message-loading">
<h4 className="header ui">Нажмите Enter чтобы начать поиск</h4>
<p>Но можешь нажать на это сообщение</p>
</div>
:
<section className="videos-section books-sections container-books">
<div className="video-detail-container">
<VideoDetail video={selectVideo} />
</div>
<div className="ui list">
{videos.map((video, i) => <VideoCard key={i} video={video} onVideoSelect={onVideoSelect} />)}
</div>
</section>
}
</div>
</div>
);
}
return(
<div className="not-user">Вы ещё не найдены...</div>
);
}
}
export default VideosPage;
<file_sep>const initialState = {
videos: [],
searchVideos: '',
videosLoading: true,
selectVideo: null,
errorVideosLoading: false
}
export default (state = initialState, action) => {
switch(action.type) {
case 'LOADED_VIDEOS':
return {
...state,
videos: action.payload,
videosLoading: false,
errorVideosLoading: false
}
case 'SEARCH_VIDEOS':
return {
...state,
searchVideos: action.payload,
errorVideosLoading: false,
videosLoading: true
}
case 'SELECTED_VIDEO':
return {
...state,
selectVideo: action.payload,
errorVideosLoading: false
}
case 'LOADED_VIDEOS_FAILED':
return {
...state,
videosLoading: false,
errorVideosLoading: true
}
default:
return state;
}
}<file_sep>import React from 'react';
export default ({onTermSubmit}) => {
return(
<div className="ui icon input">
<input onChange={onTermSubmit} key="editor2" type="text" placeholder="Search..." />
<i className="inverted circular search link icon"></i>
</div>
)
}<file_sep>import React from 'react';
import Button from '@material-ui/core/Button';
const styles = {
submit: {
color: 'white',
backgroundColor: '#2196f3',
float: 'right',
marginTop: '20px'
},
register: {
float: 'right',
marginRight: '10px',
marginTop: '20px'
}
}
const AuthForm = ({_toggleForm, author, authorSubmit}) => {
return (
<div className="form-block">
<h1 className="text-center italic">Вход</h1>
<form>
<div className="form-group">
<i className="fas fa-user"></i>
<input className="login" onChange={(e) => author(e.target)} placeholder="Логин" required/>
</div>
<div className="form-group">
<i className="fas fa-lock"></i>
<input className="password" onChange={(e) => author(e.target)} placeholder="Пароль" required/>
</div>
<Button onClick={authorSubmit} type="submit" style={styles.submit} variant="contained" size="medium" color="primary">
<span style={{color: 'white', fontSize: '12px'}}>Войти</span>
</Button>
<Button onClick={() => _toggleForm(true)} style={styles.register} variant="contained" size="medium" color="default">
<span style={{fontSize: '12px'}}>Регистрация</span>
</Button>
</form>
</div>
);
}
export default AuthForm;<file_sep>import React from 'react';
import './error.scss';
const style = {
width: '350px',
marginLeft: '20px',
marginTop: '20px',
display: 'inline-block'
};
const ErrorIndicator = () => {
return (
<div className="error-container">
<img src="https://cdn.dribbble.com/users/1078347/screenshots/2799566/oops.png" alt="error image"/>
<h1>Произошла ошибка! Просим прощения</h1>
<h2>Мы разберёмся с этой проблемой, просим зайдите позже.</h2>
</div>
);
};
export default ErrorIndicator;
<file_sep>
import { combineReducers } from 'redux';
import user from './user';
import books from './books';
import videos from './videos';
export default combineReducers({
user,
books,
videos
});
| 440433974a0a070cfca3de82e03472036e12cdd7 | [
"JavaScript"
] | 19 | JavaScript | ArcherSpins/users_application_web_version | 2e9ba0a3784120d325a5b2c49f2bf8de9a249993 | 8e82798a56695c8629e003bf41e9936694571056 |
refs/heads/master | <file_sep>const groupAdultsByAgeRange = (people) => {
return people.filter((person)=>{
return person.age >= 18
}).reduce((acc, val)=>{
if (val.age <= 20){
return {
...acc,
'20 and younger': (
acc.hasOwnProperty('20 and younger')
? acc['20 and younger'].concat(val)
: [val]
)
}
}else if (val.age <= 30){
return {
...acc,
'21-30': (
acc.hasOwnProperty('21-30')
? acc['21-30'].concat(val)
: [val]
)
}
}else if (val.age <= 40) {
return {
...acc,
'31-40': (
acc.hasOwnProperty('31-40')
? acc['31-40'].concat(val)
: [val]
)
}
}else if (val.age <= 50) {
return {
...acc,
'41-50': (
acc.hasOwnProperty('41-50')
? acc['41-50'].concat(val)
: [val]
)
}
}else{
return {
...acc,
'51 and older': (
acc.hasOwnProperty('51 and older')
? acc['51 and older'].concat(val)
: [val]
)
}
}
},{})
}
module.exports = { groupAdultsByAgeRange }
| b0fbacf8b1a672e3abe7a69e65177006ce4482af | [
"JavaScript"
] | 1 | JavaScript | weichichou/week2_homework | 47fbf5e151817bc323e647809248c75a71147fd8 | 64a6673dd6e59b3607313bc97d9e898b32b402c6 |
refs/heads/master | <file_sep># Quiz Game
# Author:
# Date: Dec. 4 /2020
quiz_score = 0
# Question 1
q1 = int(input("1 - 1"))
if q1 == 0:
print("You are correct.")
quiz_score += 1
elif q1 != 0:
print("You are incorrect the answer is 0.")
quiz_score = 0
# Question 2
q2 = int(input("2 - 1"))
if q2 == 1:
print("You are correct.")
quiz_score += 1
elif q2 != 1:
print("You are incorrect the answer is 1.")
quiz_score = 0
# Question 3
q3 = int(input("3 - 1"))
if q3 == 2:
print("You are correct.")
quiz_score += 1
elif q3 != 2:
print("You are incorrect the answer is 2.")
quiz_score = 0
# Question 4
q4 = int(input("4 - 1"))
if q4 == 3:
print("You are correct.")
quiz_score += 1
elif q4 != 3:
print("You are incorrect the answer is 3.")
quiz_score = 0
# Question 5
q5 = int(input("5 - 1"))
if q5 == 4:
print("You are correct.")
quiz_score += 1
elif q5 != 4:
print("You are incorrect the answer is 4.")
quiz_score = 0
# print out the score
print(f"you got {quiz_score} out of 5.")
<file_sep># mapit.py - open a browser and search for a place
import webbrowser, sys
if len(sys.argv) > 1:
arguments = " ".join(sys.argv[1:])
print(arguments)
if len(sys.argv) > 1:
address= " ".join(sys.argv[1:])
prefix = "https://www.google.ca/maps/place/"
webbrowser.open(prefix + address)
# TODO: Get the address form the clipbroad.
| 44a3f3509b1fc4f1f0d75f9f9c21a1446be4f2b9 | [
"Python"
] | 2 | Python | XD7X728/programming-2-a1 | 267d8b5d2f2eb7af00697f6a83c6b38ea1ffcc4e | 346389d5e4b23dcd67ca15cde2becfb096f89f9a |
refs/heads/master | <repo_name>Kamsaw/System-Publikacji<file_sep>/src/main/java/org/zut/dao/WydanieDAO.java
package org.zut.dao;
import java.util.List;
import javax.sql.DataSource;
import org.springframework.dao.DataAccessException;
import org.springframework.dao.EmptyResultDataAccessException;
import org.springframework.jdbc.core.BeanPropertyRowMapper;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.zut.model.Wydanie;
public class WydanieDAO {
private DataSourceTransactionManager transactionManager;
private JdbcTemplate jdbcTemplate;
public void setTransactionManager(DataSourceTransactionManager transactionManager) {
this.transactionManager = transactionManager;
DataSource dataSource = transactionManager.getDataSource();
jdbcTemplate = new JdbcTemplate(dataSource);
}
public List<Wydanie> getAllWydanie(){
List<Wydanie> wydania = null;
String sql = "SELECT * FROM wydanie";
try {
wydania = jdbcTemplate.query(sql, new BeanPropertyRowMapper<Wydanie>(Wydanie.class));
} catch (DataAccessException e) {
e.printStackTrace();
}
return wydania;
};
public Wydanie getWydanie(Integer id){
Wydanie wydanie;
String sql = "SELECT * FROM wydanie WHERE id=?";
try {
wydanie = (Wydanie) jdbcTemplate.queryForObject(sql, new Object[] { id }, new BeanPropertyRowMapper<Wydanie>(Wydanie.class));
} catch (EmptyResultDataAccessException e) {
wydanie = new Wydanie();
}
return wydanie;
};
public void deleteWydanie(Integer id) {
String sql = "DELETE FROM wydanie WHERE id=?";
jdbcTemplate.update(sql, new Object[] { id });
}
public void insertWydanie(Wydanie wydanie) {
String sql = "INSERT INTO wydanie (`czasopismo_id`,`numer`, `opublikowane`) VALUES (?,?,?)";
jdbcTemplate.update(sql, new Object[] { wydanie.getCzasopismoId(), wydanie.getNumer(), wydanie.getOpublikowane()});
}
public void updateWydanie(Wydanie wydanie) {
String sql = "UPDATE wydanie set `czasopismo_id` = ?, `numer` = ?, `opublikowane`=? where id = ?";
jdbcTemplate.update(sql, new Object[] { wydanie.getCzasopismoId(), wydanie.getNumer(), wydanie.getOpublikowane(),
wydanie.getId()});
}
public List<Wydanie> getWydanieByCzasopismoId(Integer czasopismo_id, Boolean all) {
List<Wydanie> wydania = null;
String sql = "SELECT * FROM wydanie WHERE czasopismo_id=? " + (!all?" AND opublikowane = 1":"");
try {
wydania = jdbcTemplate.query(sql, new Object[] { czasopismo_id }, new BeanPropertyRowMapper<Wydanie>(Wydanie.class));
} catch (DataAccessException e) {
e.printStackTrace();
}
return wydania;
}
}<file_sep>/target/m2e-wtp/web-resources/META-INF/maven/org.zut/springsww/pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.zut</groupId>
<artifactId>springsww</artifactId>
<packaging>war</packaging>
<version>1.0-SNAPSHOT</version>
<name>springsww</name>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java-version>1.6</java-version>
<org.springframework-version>3.1.1.RELEASE</org.springframework-version>
<org.aspectj-version>1.6.10</org.aspectj-version>
<org.slf4j-version>1.6.6</org.slf4j-version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- Spring MVC support -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-webmvc</artifactId>
<version>4.1.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
<version>4.1.4.RELEASE</version>
</dependency>
<!-- Tag libs support for view layer -->
<dependency>
<groupId>taglibs</groupId>
<artifactId>standard</artifactId>
<version>1.1.2</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>javax.servlet-api</artifactId>
<version>3.1.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>jstl</groupId>
<artifactId>jstl</artifactId>
<version>1.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.9</version>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>3.0.7.RELEASE</version>
</dependency>
</dependencies>
<build>
<finalName>springsww</finalName>
</build>
</project>
<file_sep>/src/main/java/org/zut/controller/SiteController.java
package org.zut.controller;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RequestParam;
import org.zut.model.Wydanie;
import org.zut.service.CzasopismoService;
import org.zut.service.WydanieService;
import org.zut.service.ArtykulService;
@Controller
public class SiteController {
private CzasopismoService czasopismoService;
private WydanieService wydanieService;
private ArtykulService artykulService;
private ApplicationContext context;
@RequestMapping(value = "/", method = RequestMethod.GET)
public String siteCzasopisma(Model model) {
context = new ClassPathXmlApplicationContext("content-module.xml");
czasopismoService = (CzasopismoService) context.getBean("czasopismoService");
model.addAttribute("czasopisma", czasopismoService.getAllCzasopismo());
return "siteCzasopisma";
}
@RequestMapping(value = "/lista-wydan", method = RequestMethod.GET)
public String siteWydania(Model model, @RequestParam("czasopismo_id") Integer czasopismo_id) {
context = new ClassPathXmlApplicationContext("content-module.xml");
czasopismoService = (CzasopismoService) context.getBean("czasopismoService");
model.addAttribute("czasopismo", czasopismoService.getCzasopismo(czasopismo_id));
wydanieService = (WydanieService) context.getBean("wydanieService");
model.addAttribute("wydania", wydanieService.getWydanieByCzasopismoId(czasopismo_id, false));
return "siteWydania";
}
@RequestMapping(value = "/lista-artykulow", method = RequestMethod.GET)
public String siteArtykuly(Model model, @RequestParam("wydanie_id") Integer wydanie_id) {
context = new ClassPathXmlApplicationContext("content-module.xml");
wydanieService = (WydanieService) context.getBean("wydanieService");
Wydanie wydanie = wydanieService.getWydanie(wydanie_id);
model.addAttribute("wydanie", wydanie);
czasopismoService = (CzasopismoService) context.getBean("czasopismoService");
model.addAttribute("czasopismo", czasopismoService.getCzasopismo(wydanie.getCzasopismoId()));
artykulService = (ArtykulService) context.getBean("artykulService");
model.addAttribute("artykuly", artykulService.getArtykulByWydanieId(wydanie_id, false));
return "siteArtykuly";
}
}
<file_sep>/README.md
# System Publikacji
System napisany w Springu, pozwalający na publikowanie numerów wydań i artykułów czasopism.
Pozwalający również na zarządzanie użytkownikami z dwoma rolami: Autora i Redaktora.
### Uruchamianie
1. Importujemy bazę danych z src\main\resources\springsww.sql
2. Konfiguracja [Tomcat](https://tomcat.apache.org/tomcat-7.0-doc/jndi-datasource-examples-howto.html):
conf\tomcat-users.xml
```sh
<?xml version="1.0" encoding="UTF-8"?>
<tomcat-users>
<role rolename="manager-gui"/>
<user username="admin" password="<PASSWORD>" roles="manager-gui"/>
</tomcat-users>
```
conf\context.xml w <Context>
```sh
<Resource name="jdbc/SpringSWW" auth="Container" type="javax.sql.DataSource"
URIEncoding="UTF-8"
maxActive="100" maxIdle="30" maxWait="10000"
username="root" password="<PASSWORD>" driverClassName="com.mysql.jdbc.Driver"
connectionProperties="useUnicode=yes;characterEncoding=utf8;"
url="jdbc:mysql://localhost:3306/springsww"/>
```
3. Import projektu w Spring Tool Suite: File->Import->Maven->Existing Maven Projects
4. Aktualizacja bibliotek: (prawym myszki na projekt) Maven->Update Project...
5. Uruchamiamy na Tomcat: Run As -> Run on Server -> Tomcat
6. Standardowy adres: [http://localhost:8080/springsww/](http://localhost:8080/springsww/)
### Screenshots

<hr>

<hr>

<file_sep>/src/main/resources/springsww.sql
-- phpMyAdmin SQL Dump
-- version 4.5.1
-- http://www.phpmyadmin.net
--
-- Host: 127.0.0.1
-- Czas generowania: 20 Gru 2015, 20:13
-- Wersja serwera: 10.1.8-MariaDB
-- Wersja PHP: 5.6.14
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Baza danych: `springsww`
--
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `artykul`
--
CREATE TABLE `artykul` (
`id` int(11) NOT NULL,
`uzytkownik_id` int(11) NOT NULL,
`wydanie_id` int(11) NOT NULL,
`tytul` varchar(255) NOT NULL,
`plik` varchar(255) NOT NULL,
`zatwierdzony` int(1) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Zrzut danych tabeli `artykul`
--
INSERT INTO `artykul` (`id`, `uzytkownik_id`, `wydanie_id`, `tytul`, `plik`, `zatwierdzony`) VALUES
(5, 4, 4, 'Człowiek', 'plik.pdf', 1),
(6, 4, 4, 'Samochód', 'plik2.pdf', 1),
(7, 4, 4, 'Piesek', 'plik3.pdf', 1),
(8, 4, 5, 'Piesek', 'asxdas.pdf', 1),
(9, 4, 5, 'Rolnik', 'asdas.pdf', 1),
(10, 4, 5, 'Komputer', 'asdfasd.pdf', 1),
(11, 4, 7, 'Klucz', 'wert.pdf', 1),
(12, 4, 7, 'Klawiatura', 'asdfsd.pdf', 1),
(13, 4, 8, 'Kartka', 'asads.pdf', 1),
(14, 4, 8, 'Kot', 'asf.pdf', 1),
(15, 4, 9, 'Gracz', 'efasd.pdf', 1),
(16, 4, 10, 'Taśma', 'asdas.pdf', 1),
(17, 4, 10, 'Nożyczki ', '564.pdf', 1),
(18, 4, 11, 'Nic', 'asdas.pdf', 1),
(19, 4, 11, 'Coś', 'fasdf.pdf', 1),
(20, 4, 12, 'Tapeta', 'a21.pdf', 1),
(21, 4, 12, 'Głośnik', '1231df.pdf', 1),
(22, 4, 13, 'Prosto', 'asd52.pdf', 1),
(23, 4, 13, 'Nie', 'asd.pdf', 1),
(24, 4, 13, 'Tak', 'asdfa.pdf', 1),
(25, 4, 13, 'Niet', 'asda5s.pdf', 1),
(26, 4, 14, 'Wszyscy', '15.pdf', 1),
(27, 4, 14, 'Może', '32sd.pdf', 1),
(28, 4, 14, 'Zawsze', '211.pdf', 1),
(29, 4, 15, 'Pierwszy', 'sad01.pdf', 1),
(30, 4, 15, 'Trzeci', 'sadf1.pdf', 1),
(31, 4, 15, 'Dwunasty', 'asdfa12.pdf', 1);
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `czasopismo`
--
CREATE TABLE `czasopismo` (
`id` int(11) NOT NULL,
`issn` varchar(255) CHARACTER SET latin1 NOT NULL,
`nazwa` varchar(255) CHARACTER SET latin1 NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Zrzut danych tabeli `czasopismo`
--
INSERT INTO `czasopismo` (`id`, `issn`, `nazwa`) VALUES
(3, '1354-215E', 'Problemy Ekonomiczne'),
(4, '5641-192X', 'Problemy Turystyczne'),
(5, '9874-160P', 'Problemy Informatyczne'),
(6, '1181-651C', 'Historia Uniwersytetu');
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `uzytkownik`
--
CREATE TABLE `uzytkownik` (
`id` int(11) NOT NULL,
`imie` varchar(255) CHARACTER SET latin1 NOT NULL,
`nazwisko` varchar(255) CHARACTER SET latin1 NOT NULL,
`email` varchar(255) CHARACTER SET latin1 NOT NULL,
`haslo` varchar(255) CHARACTER SET latin1 NOT NULL,
`rola` int(2) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Zrzut danych tabeli `uzytkownik`
--
INSERT INTO `uzytkownik` (`id`, `imie`, `nazwisko`, `email`, `haslo`, `rola`) VALUES
(3, 'Kamil', 'Sawicki', '<EMAIL>', 'ksawicki', 2),
(4, 'Jan', 'Kowalski', '<EMAIL>', 'jkowalski', 1),
(5, 'Andrzej', 'Andrzejowicz', 'aandrzejowicz', 'aandrzejowicz', 0);
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `wydanie`
--
CREATE TABLE `wydanie` (
`id` int(11) NOT NULL,
`czasopismo_id` int(11) NOT NULL,
`numer` varchar(255) CHARACTER SET latin1 NOT NULL,
`opublikowane` int(1) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
--
-- Zrzut danych tabeli `wydanie`
--
INSERT INTO `wydanie` (`id`, `czasopismo_id`, `numer`, `opublikowane`) VALUES
(4, 3, '2015/05/11/1141', 1),
(5, 3, '2016/10/11/51611', 1),
(6, 3, '2015/12/11/1236', 0),
(7, 4, '2015/01/10/456', 1),
(8, 4, '2015/02/10/1156', 1),
(9, 4, '2015/08/11/3212', 0),
(10, 5, '2015/05/11/4564', 1),
(11, 5, '2014/10/11/51611', 1),
(12, 5, '2013/10/11/81611', 1),
(13, 6, '2011/05/11/5464', 1),
(14, 6, '2012/05/11/45121', 1),
(15, 6, '2013/05/11/1231', 1);
--
-- Indeksy dla zrzutów tabel
--
--
-- Indexes for table `artykul`
--
ALTER TABLE `artykul`
ADD PRIMARY KEY (`id`),
ADD KEY `uzytkownik_id` (`uzytkownik_id`),
ADD KEY `wydanie_id` (`wydanie_id`);
--
-- Indexes for table `czasopismo`
--
ALTER TABLE `czasopismo`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `uzytkownik`
--
ALTER TABLE `uzytkownik`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `email` (`email`);
--
-- Indexes for table `wydanie`
--
ALTER TABLE `wydanie`
ADD PRIMARY KEY (`id`),
ADD KEY `czasopismo_id` (`czasopismo_id`);
--
-- AUTO_INCREMENT for dumped tables
--
--
-- AUTO_INCREMENT dla tabeli `artykul`
--
ALTER TABLE `artykul`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=32;
--
-- AUTO_INCREMENT dla tabeli `czasopismo`
--
ALTER TABLE `czasopismo`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=7;
--
-- AUTO_INCREMENT dla tabeli `uzytkownik`
--
ALTER TABLE `uzytkownik`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=7;
--
-- AUTO_INCREMENT dla tabeli `wydanie`
--
ALTER TABLE `wydanie`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=16;
--
-- Ograniczenia dla zrzutów tabel
--
--
-- Ograniczenia dla tabeli `artykul`
--
ALTER TABLE `artykul`
ADD CONSTRAINT `artykul_ibfk_1` FOREIGN KEY (`wydanie_id`) REFERENCES `wydanie` (`id`) ON DELETE CASCADE ON UPDATE CASCADE,
ADD CONSTRAINT `artykul_ibfk_2` FOREIGN KEY (`uzytkownik_id`) REFERENCES `uzytkownik` (`id`) ON DELETE CASCADE ON UPDATE CASCADE;
--
-- Ograniczenia dla tabeli `wydanie`
--
ALTER TABLE `wydanie`
ADD CONSTRAINT `wydanie_ibfk_1` FOREIGN KEY (`czasopismo_id`) REFERENCES `czasopismo` (`id`) ON DELETE CASCADE ON UPDATE CASCADE;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep>/src/main/java/org/zut/model/Artykul.java
package org.zut.model;
public class Artykul{
private Integer id;
private Integer uzytkownik_id;
private Uzytkownik uzytkownik;
private Integer wydanie_id;
private String tytul;
private String plik;
private Integer zatwierdzony;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public Integer getUzytkownikId() {
return uzytkownik_id;
}
public void setUzytkownikId(Integer uzytkownik_id) {
this.uzytkownik_id = uzytkownik_id;
}
public Integer getWydanieId() {
return wydanie_id;
}
public void setWydanieId(Integer wydanie_id) {
this.wydanie_id = wydanie_id;
}
public String getTytul() {
return tytul;
}
public void setTytul(String tytul) {
this.tytul = tytul;
}
public String getPlik() {
return plik;
}
public void setPlik(String plik) {
this.plik = plik;
}
public Integer getZatwierdzony() {
return zatwierdzony;
}
public void setZatwierdzony(Integer zatwierdzony) {
this.zatwierdzony = zatwierdzony;
}
public Uzytkownik getUzytkownik() {
return uzytkownik;
}
public void setUzytkownik(Uzytkownik uzytkownik) {
this.uzytkownik = uzytkownik;
}
}<file_sep>/target/springsww/WEB-INF/classes/springsww.sql
-- phpMyAdmin SQL Dump
-- version 4.5.1
-- http://www.phpmyadmin.net
--
-- Host: 127.0.0.1
-- Czas generowania: 13 Gru 2015, 23:26
-- Wersja serwera: 10.1.8-MariaDB
-- Wersja PHP: 5.6.14
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Baza danych: `springsww`
--
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `artykul`
--
CREATE TABLE `artykul` (
`id` int(11) NOT NULL,
`uzytkownik_id` int(11) NOT NULL,
`wydanie_id` int(11) NOT NULL,
`tytul` varchar(255) NOT NULL,
`plik` varchar(255) NOT NULL,
`zatwierdzony` int(1) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `czasopismo`
--
CREATE TABLE `czasopismo` (
`id` int(11) NOT NULL,
`issn` varchar(255) NOT NULL,
`nazwa` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Zrzut danych tabeli `czasopismo`
--
INSERT INTO `czasopismo` (`id`, `issn`, `nazwa`) VALUES
(2, 'wetqe11', 'wrqwera11');
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `uzytkownik`
--
CREATE TABLE `uzytkownik` (
`id` int(11) NOT NULL,
`imie` varchar(255) NOT NULL,
`nazwisko` varchar(255) NOT NULL,
`email` varchar(255) NOT NULL,
`haslo` varchar(255) NOT NULL,
`rola` int(2) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Zrzut danych tabeli `uzytkownik`
--
INSERT INTO `uzytkownik` (`id`, `imie`, `nazwisko`, `email`, `haslo`, `rola`) VALUES
(3, 'aaa', 'bbb', '1', '1', 0),
(5, 'srth', 'tey', 'erty', 'ertyer', 0),
(6, 'asdfg', 'sgsdf', 'gsdf', 'gsdfgsdf', 0),
(22, 'adsf', 'asdfasd', 'fasdfasd', 'fasd', 1);
-- --------------------------------------------------------
--
-- Struktura tabeli dla tabeli `wydanie`
--
CREATE TABLE `wydanie` (
`id` int(11) NOT NULL,
`czasopismo_id` int(11) NOT NULL,
`numer` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
--
-- Zrzut danych tabeli `wydanie`
--
INSERT INTO `wydanie` (`id`, `czasopismo_id`, `numer`) VALUES
(1, 2, 'yurtyu'),
(2, 2, 'ertyert');
--
-- Indeksy dla zrzutów tabel
--
--
-- Indexes for table `artykul`
--
ALTER TABLE `artykul`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `czasopismo`
--
ALTER TABLE `czasopismo`
ADD PRIMARY KEY (`id`);
--
-- Indexes for table `uzytkownik`
--
ALTER TABLE `uzytkownik`
ADD PRIMARY KEY (`id`),
ADD UNIQUE KEY `email` (`email`);
--
-- Indexes for table `wydanie`
--
ALTER TABLE `wydanie`
ADD PRIMARY KEY (`id`);
--
-- AUTO_INCREMENT for dumped tables
--
--
-- AUTO_INCREMENT dla tabeli `artykul`
--
ALTER TABLE `artykul`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT;
--
-- AUTO_INCREMENT dla tabeli `czasopismo`
--
ALTER TABLE `czasopismo`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
--
-- AUTO_INCREMENT dla tabeli `uzytkownik`
--
ALTER TABLE `uzytkownik`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=23;
--
-- AUTO_INCREMENT dla tabeli `wydanie`
--
ALTER TABLE `wydanie`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=3;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep>/src/main/java/org/zut/service/ArtykulService.java
package org.zut.service;
import java.util.List;
import org.springframework.stereotype.Service;
import org.zut.dao.ArtykulDAO;
import org.zut.model.Artykul;
@Service
public class ArtykulService {
private ArtykulDAO artykulDAO;
public void setArtykulDAO(ArtykulDAO artykulDAO) {
this.artykulDAO = artykulDAO;
}
public List<Artykul> getAllArtykul() {
return artykulDAO.getAllArtykul();
}
public Artykul getArtykul(Integer id) {
return artykulDAO.getArtykul(id);
}
public void deleteArtykul(Integer id) {
artykulDAO.deleteArtykul(id);
}
public void insertArtykul(Artykul artykul) {
artykulDAO.insertArtykul(artykul);
}
public void updateArtykul(Artykul artykul) {
artykulDAO.updateArtykul(artykul);
}
public List<Artykul> getArtykulByWydanieId(Integer wydanie_id, Boolean all) {
return artykulDAO.getArtykulByWydanieId(wydanie_id, all);
}
}
| 38c7a56352f71cd114b0843463b97659e71bfe5c | [
"Markdown",
"Java",
"Maven POM",
"SQL"
] | 8 | Java | Kamsaw/System-Publikacji | 1145b107d6d03b7f0b2b2fa6cd8794a5cd2ab15d | a661f1543c49f677298c089a34f83781a506e8ed |
refs/heads/main | <file_sep>using System.Collections.Generic;
using System.Threading.Tasks;
namespace Core.Interfaces
{
public interface IGenericRepository<T> where T : class
{
//Task<IReadOnlyList<T>> GetAllAsync();
Task<IReadOnlyList<T>> GetAll();
Task<T> GetByIdAsync(int id);
Task<T> CreateAsync(T TEntity);
Task<IReadOnlyList<T>> CreateRangeAsync(IReadOnlyList<T> TEntity);
Task<T> UpdateAsync(int id, T TEntity);
Task DeleteAsync(int id);
}
}
<file_sep>using Core.Entities.Identity;
using Microsoft.AspNetCore.Identity;
using System.Linq;
using System.Threading.Tasks;
namespace Infrastructure.Identity
{
public class AppIdentittyDbContextSeed
{
public static async Task SeedUserAsync(UserManager<AppUser> userManager)
{
if (!userManager.Users.Any())
{
var user = new AppUser
{
DisplayName = "Bob",
Email = "<EMAIL>",
UserName = "<EMAIL>",
Address = new Address
{
FirstName = "Bob",
LastName = "Bobity",
Street = "G.T. Road",
City = "Chandpur",
State = "BD",
ZipCode = "20102012"
}
};
await userManager.CreateAsync(user, "Pa$$w0rd");
}
}
}
}
<file_sep>using Core.Interfaces;
using System.Threading.Tasks;
namespace Infrastructure.Data
{
public class Uom : IUom
{
public StoreContext _context { get; }
public Uom(StoreContext context)
{
_context = context;
}
public IProductRepository productRepository => new ProductRepository(_context);
public IProductBrandRepository productBrandRepository => new ProductBrandRepository(_context);
public IProductTypeRepository productTypeRepository => new ProductTypeRepository(_context);
public async Task<int> completedTask()
{
return await _context.SaveChangesAsync();
}
}
}
<file_sep>using System.Threading.Tasks;
namespace Core.Interfaces
{
public interface IUom
{
IProductRepository productRepository { get; }
IProductBrandRepository productBrandRepository { get; }
IProductTypeRepository productTypeRepository { get; }
Task<int> completedTask();
}
}
<file_sep>using AutoMapper;
using Core.Entities;
using Core.Interfaces;
using Microsoft.AspNetCore.Authorization;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using ProductAPI.DTOs;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace ProductAPI.Controllers
{
public class ProductController : BaseApiController
{
private readonly IUom _uom;
private readonly IMapper _mapper;
public ProductController(IUom uom, IMapper mapper)
{
_uom = uom;
_mapper = mapper;
}
[HttpPost]
public async Task<ActionResult<ProductDto>> CreateProduct(ProductDto product)
{
var productEntity = new Product
{
Name = product.Name,
Price = product.Price,
Description = product.Description,
ProductUrl = product.ProductUrl,
ProductBrandId = product.ProductBrandId,
ProductTypeId = product.ProductTypeId
};
await _uom.productRepository.CreateAsync(productEntity);
await _uom.completedTask();
return product;
}
[HttpPut]
public async Task<ActionResult<ProductDto>> UpdateProduct(int id, ProductDto product)
{
var productEntity = new Product
{
Name = product.Name,
Price = product.Price,
Description = product.Description,
ProductUrl = product.ProductUrl,
ProductBrandId = product.ProductBrandId,
ProductTypeId = product.ProductTypeId
};
await _uom.productRepository.UpdateAsync(id, productEntity);
await _uom.completedTask();
return product;
}
[HttpDelete]
public async Task<ActionResult<int>> DeleteProduct(int id)
{
await _uom.productRepository.DeleteAsync(id);
var deleteComplete = await _uom.completedTask();
return deleteComplete;
}
[HttpGet]
[ProducesResponseType(typeof(ProductDto), StatusCodes.Status200OK)]
[ProducesResponseType(StatusCodes.Status404NotFound)]
[Authorize]
public async Task<ActionResult<IReadOnlyList<ProductDto>>> GetProducts()
{
var products = await _uom.productRepository.GetAll();
var productToReturn = _mapper.Map<IReadOnlyList<Product>, IReadOnlyList<ProductDto>>(products);
return Ok(productToReturn);
}
[HttpGet("{id}")]
[ProducesResponseType(typeof(ProductDto), StatusCodes.Status200OK)]
[ProducesResponseType(StatusCodes.Status404NotFound)]
public async Task<ActionResult<ProductDto>> GetProducts(int id)
{
var product = await _uom.productRepository.GetByIdAsync(id);
return Ok(_mapper.Map<Product,ProductDto>(product));
}
[HttpPost("brand")]
public async Task<ActionResult<ProductBrand>> CreateBrand(ProductBrand brand)
{
var brands = await _uom.productBrandRepository.CreateAsync(brand);
await _uom.completedTask();
return brands;
}
[HttpPost("brands")]
public async Task<ActionResult<IReadOnlyList< ProductBrand>>> CreateBrand(IReadOnlyList<ProductBrand> brand)
{
var brands = await _uom.productBrandRepository.CreateRangeAsync(brand);
await _uom.completedTask();
return Ok(brands);
}
[HttpGet("brands")]
public async Task<ActionResult<IReadOnlyList<ProductBrand>>> GetProductBrands()
{
var brands = await _uom.productBrandRepository.GetAll();
return Ok(brands);
}
[HttpPost("type")]
public async Task<ActionResult<ProductType>> CreateProductType(ProductType productType)
{
var productTypeCreated = await _uom.productTypeRepository.CreateAsync(productType);
await _uom.completedTask();
return Ok(productTypeCreated);
}
[HttpPost("types")]
public async Task<ActionResult<IReadOnlyList<ProductType>>> CreateProductType(IReadOnlyList<ProductType> productTypes)
{
var productTypesCreated = await _uom.productTypeRepository.CreateRangeAsync(productTypes);
await _uom.completedTask();
return Ok(productTypesCreated);
}
[HttpGet("types")]
public async Task<ActionResult<IReadOnlyList<ProductType>>> GetProductTypes()
{
var types = await _uom.productTypeRepository.GetAll();
return Ok(types);
}
}
}
<file_sep>using Core.Entities;
using Core.Interfaces;
using Microsoft.EntityFrameworkCore;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace Infrastructure.Data
{
public class ProductBrandRepository : IProductBrandRepository
{
private readonly StoreContext _context;
public ProductBrandRepository(StoreContext context)
{
_context = context;
}
public async Task<ProductBrand> CreateAsync(ProductBrand TEntity)
{
var result = await _context.ProductBrands.AddAsync(TEntity);
return result.Entity;
}
public async Task<IReadOnlyList<ProductBrand>> CreateRangeAsync(IReadOnlyList<ProductBrand> TEntity)
{
await _context.ProductBrands.AddRangeAsync(TEntity);
return TEntity;
}
public Task DeleteAsync(int id)
{
throw new System.NotImplementedException();
}
public async Task<IReadOnlyList<ProductBrand>> GetAll()
{
var brands = await _context.ProductBrands.ToListAsync();
return brands;
}
public Task<ProductBrand> GetByIdAsync(int id)
{
throw new System.NotImplementedException();
}
public Task<ProductBrand> UpdateAsync(int id, ProductBrand TEntity)
{
throw new System.NotImplementedException();
}
}
}
<file_sep>using Core.Entities;
namespace Core.Interfaces
{
public interface IProductTypeRepository : IGenericRepository<ProductType>
{
}
}
<file_sep>using Core.Entities;
using Core.Interfaces;
using Microsoft.EntityFrameworkCore;
using System.Collections.Generic;
using System.Threading.Tasks;
namespace Infrastructure.Data
{
public class ProductRepository : IProductRepository
{
private readonly StoreContext _context;
public ProductRepository(StoreContext context)
{
_context = context;
}
public async Task<Product> CreateAsync(Product TEntity)
{
var result = await _context.Products.AddAsync(TEntity);
return result.Entity;
}
public async Task<IReadOnlyList<Product>> CreateRangeAsync(IReadOnlyList<Product> TEntity)
{
await _context.Products.AddRangeAsync(TEntity);
return TEntity;
}
public Task DeleteAsync(int id)
{
var entityToDelete = GetByIdAsync(id);
_context.Remove(entityToDelete);
return Task.CompletedTask;
}
public async Task<IReadOnlyList<Product>> GetAll()
{
var products = await _context.Products
.Include(x => x.ProductBrand)
.Include(x => x.ProductType)
.ToListAsync();
return products;
}
public async Task<Product> GetByIdAsync(int id)
{
var product = await _context.Products
.Include(x=>x.ProductBrand)
.Include(x=>x.ProductType)
.FirstOrDefaultAsync(x => x.Id == id);
return product;
}
public async Task<Product> UpdateAsync(int id, Product TEntity)
{
var product = await _context.Products
.FirstOrDefaultAsync(x => x.Id == id);
if (product != null)
{
product.Name = TEntity.Name;
product.Price = TEntity.Price;
product.ProductUrl = TEntity.ProductUrl;
product.ProductBrandId = TEntity.ProductBrandId;
product.ProductTypeId = TEntity.ProductTypeId;
}
return product;
}
}
}
<file_sep>using Core.Entities;
using Core.Interfaces;
using Microsoft.EntityFrameworkCore;
using System;
using System.Collections.Generic;
using System.Text;
using System.Threading.Tasks;
namespace Infrastructure.Data
{
public class ProductTypeRepository : IProductTypeRepository
{
private readonly StoreContext _context;
public ProductTypeRepository(StoreContext context)
{
_context = context;
}
public async Task<ProductType> CreateAsync(ProductType TEntity)
{
var result = await _context.ProductTypes.AddAsync(TEntity);
return result.Entity;
}
public async Task<IReadOnlyList<ProductType>> CreateRangeAsync(IReadOnlyList<ProductType> TEntity)
{
await _context.ProductTypes.AddRangeAsync(TEntity);
return TEntity;
}
public Task DeleteAsync(int id)
{
throw new NotImplementedException();
}
public async Task<IReadOnlyList<ProductType>> GetAll()
{
var types = await _context.ProductTypes.ToListAsync();
return types;
}
public Task<ProductType> GetByIdAsync(int id)
{
throw new NotImplementedException();
}
public Task<ProductType> UpdateAsync(int id, ProductType TEntity)
{
throw new NotImplementedException();
}
}
}
<file_sep>using Infrastructure.Data;
using Infrastructure.Identity;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.EntityFrameworkCore;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using ProductAPI.Extensions;
using ProductAPI.Mapper;
using ProductAPI.MiddleWare;
namespace ProductAPI
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
var connectionString = Configuration.GetConnectionString("OrclConnection");
services.AddControllers();
services.AddDbContext<StoreContext>(options => options
.UseOracle(connectionString, x => x.UseOracleSQLCompatibility("11")));
services.AddDbContext<AppIdentityDbContext>(options =>
{
options.UseOracle(connectionString, x => x.UseOracleSQLCompatibility("11"));
});
services.AddApplicationServices();
services.AddIdentityServices(Configuration);
services.AddSwaggerServices();
services.AddAutoMapper(typeof(MapProfiles));
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
//if (env.IsDevelopment())
//{
// app.UseDeveloperExceptionPage();
//}
app.UseMiddleware<ExceptionMiddleWare>();
app.UseStatusCodePagesWithReExecute("/errors/{0}");
app.UseHttpsRedirection();
app.UseRouting();
app.UseAuthentication();
app.UseAuthorization();
app.UseSwaggerDoc();
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
}
}
<file_sep>using AutoMapper;
using Core.Entities;
using Core.Entities.Identity;
using ProductAPI.DTOs;
namespace ProductAPI.Mapper
{
public class MapProfiles : Profile
{
public MapProfiles()
{
CreateMap<Product, ProductDto>()
.ForMember(d => d.ProductBrand, o => o.MapFrom(s => s.ProductBrand.Name))
.ForMember(d => d.ProductType, o => o.MapFrom(s => s.ProductType.Name))
.ForMember(d => d.ProductUrl, o => o.MapFrom<ProductUrlResolver>());
CreateMap<Address, AddressDto>().ReverseMap();
}
}
}
<file_sep>using Core.Entities;
using Microsoft.EntityFrameworkCore;
using Microsoft.EntityFrameworkCore.Metadata.Builders;
namespace Infrastructure.Config
{
public class ProductBrandConfiguration : IEntityTypeConfiguration<ProductBrand>
{
public void Configure(EntityTypeBuilder<ProductBrand> builder)
{
builder.Property(p => p.Name).IsRequired().HasMaxLength(200);
}
}
}
<file_sep>using Core.Entities;
using Microsoft.EntityFrameworkCore;
using System;
using System.Collections.Generic;
using System.Reflection;
using System.Text;
using System.Threading.Tasks;
namespace Infrastructure.Data
{
public class StoreContext : DbContext
{
public StoreContext(DbContextOptions<StoreContext> options)
: base(options)
{
}
public DbSet<Product> Products { get; set; }
public DbSet<ProductType> ProductTypes { get; set; }
public DbSet<ProductBrand> ProductBrands { get; set; }
protected override void OnModelCreating(ModelBuilder builder)
{
base.OnModelCreating(builder);
builder.ApplyConfigurationsFromAssembly(Assembly.GetExecutingAssembly());
}
public Task MigrateAsync()
{
throw new NotImplementedException();
}
}
}
<file_sep>using Core.Entities;
namespace Core.Interfaces
{
public interface IProductRepository : IGenericRepository<Product>
{
}
}
| 215ad9d1c798d24ba9c3d08d002f1b4f31a48751 | [
"C#"
] | 14 | C# | baitul10/WebAPI | 9789ef9fd9cbf7343e6e607bf255851bcf30f99d | 30881aa5ad4a8461fc74e9a7e6de69eaf76fcced |
refs/heads/master | <file_sep>package cyq.com.myapplication;
import android.animation.Animator;
import android.animation.AnimatorListenerAdapter;
import android.os.Bundle;
import android.support.design.widget.FloatingActionButton;
import android.support.design.widget.Snackbar;
import android.support.v7.app.AppCompatActivity;
import android.support.v7.widget.Toolbar;
import android.view.View;
/**
* 淡入淡出动画
*/
public class CrossfadeActivity extends AppCompatActivity {
private View mContentView;
private View mLoadingView;
private int animTime = 2000;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_crossfade);
Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
setSupportActionBar(toolbar);
FloatingActionButton fab = (FloatingActionButton) findViewById(R.id.fab);
fab.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Snackbar.make(view, "这是一个淡入淡出视图", Snackbar.LENGTH_LONG)
.setAction("try again", new View.OnClickListener() {
@Override
public void onClick(View v) {
mLoadingView.setVisibility(View.VISIBLE);
mLoadingView.setAlpha(1f);
crossfade();
}
}).show();
}
});
mContentView = findViewById(R.id.content);
mLoadingView = findViewById(R.id.loading_spinner);
mContentView.setVisibility(View.GONE);
crossfade();
}
/**
* 淡入淡出动画
*/
private void crossfade(){
//1.内容view设置为可见,但是完全透明。
mContentView.setAlpha(0);
mContentView.setVisibility(View.VISIBLE);
//2.内容view设置百分之百不透明,并clear所有的动画监听。
mContentView.animate().alpha(1f).setDuration(animTime).setListener(null);
//3.进度条view设置为完全透明,并在动画结束时设置view.gone
mLoadingView.animate().alpha(0f).setDuration(animTime).setListener(new AnimatorListenerAdapter() {
@Override
public void onAnimationEnd(Animator animation) {
mLoadingView.setVisibility(View.GONE);
}
});
}
}
<file_sep>package cyq.com.myapplication;
import android.graphics.drawable.Animatable;
import android.graphics.drawable.AnimatedVectorDrawable;
import android.graphics.drawable.Drawable;
import android.os.Handler;
import android.os.Message;
import android.support.v7.app.AppCompatActivity;
import android.os.Bundle;
import android.view.View;
import android.widget.ImageView;
/**
* https://shapeshifter.design/ 这是一个生成svg图片的工具
* 这个类实现了svg动画
*/
public class AnimaterVectorDrawableActivity extends AppCompatActivity {
private ImageView imageView,anmator_img;
private Drawable drawable,smile;
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_animater_vector_drawable);
imageView = findViewById(R.id.imageView);
anmator_img = findViewById(R.id.animate_img);
/**
* 三角形旋转动画
*/
imageView.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
drawable = imageView.getBackground();
if (drawable instanceof Animatable){
((Animatable) drawable).start();
}
}
});
anmator_img.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View v) {
smile = anmator_img.getBackground();
if (smile instanceof Animatable){
handler.post(runnable);
}
}
});
}
Runnable runnable = new Runnable() {
@Override
public void run() {
((Animatable) smile).start();
handler.postDelayed(this,2000);
}
};
Handler handler = new Handler(){
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
}
};
@Override
protected void onDestroy() {
super.onDestroy();
if(smile!=null){
((Animatable) smile).stop();
}
}
}
<file_sep>package cyq.com.myapplication;
import android.animation.Animator;
import android.animation.ObjectAnimator;
import android.animation.ValueAnimator;
import android.content.Intent;
import android.os.Bundle;
import android.support.design.widget.FloatingActionButton;
import android.support.design.widget.Snackbar;
import android.support.v7.app.AppCompatActivity;
import android.support.v7.widget.Toolbar;
import android.view.View;
import android.view.Menu;
import android.view.MenuItem;
import android.view.animation.AccelerateInterpolator;
import android.view.animation.AnimationSet;
import android.view.animation.AnimationUtils;
import android.widget.ImageView;
import android.widget.TextView;
import android.widget.Toast;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map;
public class MainActivity extends AppCompatActivity {
ImageView imageView;
List l = new ArrayList();
List l2 = new LinkedList();
Map m = new HashMap();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Toolbar toolbar = (Toolbar) findViewById(R.id.toolbar);
setSupportActionBar(toolbar);
FloatingActionButton fab = (FloatingActionButton) findViewById(R.id.fab);
fab.setOnClickListener(new View.OnClickListener() {
@Override
public void onClick(View view) {
Snackbar.make(view, "Replace with your own action", Snackbar.LENGTH_LONG)
.setAction("开始", new View.OnClickListener() {
@Override
public void onClick(View view) {
va.start();
}
}).show();
}
});
TextView textView = findViewById(R.id.textview);
textView.setText("valueAnimator");
imageView = findViewById(R.id.img);
valueAnimator();
}
private ValueAnimator va;
private void valueAnimator(){
va = ValueAnimator.ofFloat(0,1720);
va.setDuration(1000);
va.setInterpolator(new AccelerateInterpolator());
va.setRepeatCount(1);
va.setRepeatMode(ValueAnimator.REVERSE);
va.addUpdateListener(new ValueAnimator.AnimatorUpdateListener() {
@Override
public void onAnimationUpdate(ValueAnimator valueAnimator) {
float s = (float) valueAnimator.getAnimatedValue();
// textView.setText(s+"");
// imageView.setRotation(s);
// textView.setTranslationX(s);
imageView.setTranslationY(s);
// textView.setTranslationZ(s);
}
});
va.start();
}
@Override
public boolean onCreateOptionsMenu(Menu menu) {
// Inflate the menu; this adds items to the action bar if it is present.
getMenuInflater().inflate(R.menu.menu_main, menu);
return true;
}
@Override
public boolean onOptionsItemSelected(MenuItem item) {
// Handle action bar item clicks here. The action bar will
// automatically handle clicks on the Home/Up button, so long
// as you specify a parent activity in AndroidManifest.xml.
int id = item.getItemId();
//noinspection SimplifiableIfStatement
if (id == R.id.toleft) {
ObjectAnimator.ofFloat(imageView,"translationX",900,0).setDuration(2000).start();
return true;
}else if (id == R.id.toright){
ObjectAnimator.ofFloat(imageView,"translationX",0,900).setDuration(2000).start();
}else if (id == R.id.crossfade){
Intent intent = new Intent(this,CrossfadeActivity.class);
startActivity(intent);
}else if(id == R.id.cardflip){
Intent intent = new Intent(this,CardFlipActivity.class);
startActivity(intent);
}else if(id == R.id.animatorvector){
Intent intent = new Intent(this,AnimaterVectorDrawableActivity.class);
startActivity(intent);
}
return super.onOptionsItemSelected(item);
}
}
| 7ae7c9f8d25801ad90ba8802a79d46734cab2e4e | [
"Java"
] | 3 | Java | cyq123/MyApplication | 8b819692e950951cb9578baec0359c68eab15274 | f69765ecc9e1a0f71d0f9310217d879412916772 |
refs/heads/main | <repo_name>algofairness/info-access-clusters<file_sep>/C++ code/run.sh
g++ main.cpp -o main -std=c++11
./main
<file_sep>/gscholar/histogram.py
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import sys
from scipy import stats
import matplotlib.cm as cm
def main():
probfile = sys.argv[1]
file = open(probfile, "r")
nodes = file.readlines()
all_data = []
for index, line in enumerate(nodes):
line = line.split(",")
#print("the length of the line is ", len(line))
for prob in line:
all_data.append(float(prob))
file.close()
plt.hist(all_data)
plt.xlabel("value at p_ij")
plt.ylabel("count")
plt.yscale('log', nonposy='clip')
plt.title("Composition of probabilities in information access vectors")
#plt.autoscale(enable=True, axis='both', tight=None)
plt.savefig("probability_composition.png", bbox_inches='tight')
plt.close()
return
if __name__ == "__main__":
main()
<file_sep>/build_generic_network.py
import csv
import sys
import networkx as nx
import main_pipelines as mp
import pickle
from networkx.readwrite import json_graph
import json
def populate_network(graph, input_csv_filename):
'''
Helper function that gets a generic edgelist at INPUT_CSV_FILENAME as an input in the format from, to
and populates the graph graph with defined edges (and thus nodes), directed or undirected depending on the graph type.
:param graph: networkx object to populate; nodes differentiable by node_id, given when scraping data.
:return: None.
'''
with open(input_csv_filename, 'r') as csv_file:
read_csv = csv.reader(csv_file, delimiter=',')
next(read_csv)
for row in read_csv:
graph.add_edge(int(row[0]), int(row[1]))
return
def convert_to_nx_graph(graph):
temp_graph = nx.Graph()
temp_graph.add_nodes_from(list(graph.nodes(data=True)))
for edge in graph.edges:
temp_graph.add_edge(edge[0], edge[1])
return temp_graph
def largest_connected_component_transform(G):
'''
Since convert_to_nx_graph() converts using the exact same naming and attributes of the nodes,
preserving their consistency, we are allowed to get the largest component of the main graph
using the largest component of the converted graph.
:param G: graph to be
:return:
'''
print("Length of G before largest_connected_component(): {}; type of G: {}".format(len(G), type(G)))
if nx.is_directed(G):
print("is_directed(G) = True; get nx.strongly_connected_components(G)")
largest_cc = max(nx.strongly_connected_components(G), key=len)
else:
print("is_directed(G) = False; get nx.connected_components(G)")
largest_cc = max(nx.connected_components(G), key=len)
G = G.subgraph(largest_cc).copy()
print("Length of G after largest_connected_component(): {}; type of G: {}".format(len(G), type(G)))
return G
def test_plot_attribute_bar():
# Set K = 3 and IDENTIFIER_STRING = "test" in main_pipelines.py.
G = nx.Graph()
G.add_nodes_from(
[(0, {'cluster': 0, 'value': 'A'}), (1, {'cluster': 0, 'value': 'B'}), (2, {'cluster': 0, 'value': 'A'}),
(3, {'cluster': 0, 'value': 'A'}), (4, {'cluster': 1, 'value': 'B'}), (5, {'cluster': 1, 'value': 'B'}),
(6, {'cluster': 1, 'value': 'B'}), (7, {'cluster': 2, 'value': 'A'}), (8, {'cluster': 2, 'value': 'B'}),
(9, {'cluster': 2, 'value': 'C'}), (10, {'cluster': 2, 'value': 'A'}), (11, {'cluster': 2, 'value': 'B'}),
(12, {'cluster': 2, 'value': 'C'})])
mp.plot_all_attributes(G, "some_clustering_method", "test_vectors_ialphavalue_simulationvalue.txt", "value")
def test_case_1_largest_connected_component():
print("Test Case 1 for largest_connected_component():")
G = nx.MultiDiGraph()
true_type = type(G)
G.add_edges_from([(0, 1), (0, 2), (0, 3), (1, 0), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3), (2, 4), (4, 4), (5, 5)])
G.add_node(6)
G = largest_connected_component_transform(G)
edges = [(0, 1), (0, 2), (0, 3), (1, 0), (1, 2), (1, 3), (2, 0), (2, 1), (2, 2), (2, 3), (2, 4), (4, 4)]
try:
if type(G) != true_type:
print("Test Case 2 Failed (code 0): test_largest_connected_component\n")
return
counter = 0
for edge in G.edges:
if edge[0] != edges[counter][0] or edge[1] != edges[counter][1]:
print("Test Case 2 Failed (code 1): test_largest_connected_component\n")
return
counter += 1
print("Test Case 2 Passed: test_largest_connected_component\n")
return
except:
print("Test Case 2 Failed (code 2): test_largest_connected_component\n")
return
def test_case_2_largest_connected_component():
print("Test Case 2 for largest_connected_component():")
G = nx.MultiDiGraph()
true_type = type(G)
G.add_edges_from(
[('0', '1'), ('0', '4'), ('1', '0'), ('4', '0'), ('4', '1'), ('5', '5')])
G.add_node('2')
G = largest_connected_component_transform(G)
edges = [('0', '1'), ('0', '4'), ('1', '0'), ('4', '0'), ('4', '1')]
try:
if type(G) != true_type:
print("Test Case 2 Failed (code 0): test_largest_connected_component\n")
return
counter = 0
for edge in G.edges:
if edge[0] != edges[counter][0] or edge[1] != edges[counter][1]:
print("Test Case 2 Failed (code 1): test_largest_connected_component\n")
return
counter += 1
print("Test Case 2 Passed: test_largest_connected_component\n")
return
except:
print("Test Case 2 Failed (code 2): test_largest_connected_component\n")
return
def test_largest_connected_component():
test_case_1_largest_connected_component()
test_case_2_largest_connected_component()
def graph_to_json(graph, output_path):
data = json_graph.node_link_data(graph)
with open(output_path, 'w') as json_file:
json.dump(data, json_file, ensure_ascii=False)
return
def json_to_graph(input_path):
with open(input_path, 'r') as json_file:
data = json.load(json_file)
graph = json_graph.node_link_graph(data)
return graph
# def set_attributes(graph):
# '''
# Helper function that gets a generic csv file of nodes with attributes and populates the graph's nodes by their node_id
# at NODE_ID with their attributes.
# :param graph: networkx object to populate; nodes differentiable by node_id, given when scraping data.
# :return: None.
# '''
# all_nodes_attributes = {}
# with open(ATTRIBUTE_CSV_FILE, 'r') as attribute_file:
# read_attribute_file = csv.reader(attribute_file)
# next(read_attribute_file)
# for row in read_attribute_file:
# attr_dict = {}
# for i in range(len(FIELDNAMES)):
# attr_dict[FIELDNAMES[i]] = row[i]
# all_nodes_attributes[int(row[NODE_ID])] = attr_dict
# nx.set_node_attributes(graph, all_nodes_attributes)
# return
if __name__ == "__main__":
# test_largest_connected_component()
G = nx.MultiDiGraph()
G = largest_connected_component_transform(G)
print([edge for edge in G.edges])
<file_sep>/cliques_test.py
"""Pipeline for building the triangular cliques graph."""
import main_pipelines as mp
import networkx as nx
import matplotlib.pyplot as plt
import pickle
from random import seed
from random import random
from scipy.stats import bernoulli
import build_generic_network as bgn
import community as community_louvain
import matplotlib.cm as cm
INPUT_PICKLED_GRAPH = "output_files/exp_small-alpha-randcl/randcl_pickle"
def main():
G = random_cliques_graph()
print("Length of G: {}".format(len(G)))
produce_edgelist(G, "randcl")
return
def cliques_graph():
# Construct:
G = nx.Graph()
for i in range(21):
G.add_node(i)
for i in range(6):
for j in range(i + 1, 7):
G.add_edge(i, j)
for i in range(7, 13):
for j in range(i + 1, 14):
G.add_edge(i, j)
for i in range(14, 20):
for j in range(i + 1, 21):
G.add_edge(i, j)
G.add_edge(6, 13)
G.add_edge(13, 20)
# Display:
fig = plt.figure()
nx.draw_spring(G, with_labels=True)
plt.show()
plt.close()
# Pickle:
with open("output_files/cliques_pickle", 'wb') as pickle_file:
pickle.dump(G, pickle_file)
return G
def random_cliques_graph():
# Construct:
G = nx.Graph()
for i in range(300):
G.add_node(i)
intra_random_states = [0, 1, 2]
for k in range(len(intra_random_states)):
base = k * 100
trials = bernoulli.rvs(0.5, size=4950, random_state=intra_random_states[k])
index = 0
for i in range(base, base + 99):
for j in range(i + 1, base + 100):
if trials[index]:
G.add_edge(i, j)
index += 1
num_of_intra_edges = len(G.edges)
print("Expectation(|intra-community edges|) = ~7425:", num_of_intra_edges)
inter_random_states = [3, 4, 5]
for k in range(len(inter_random_states) - 1):
for m in range(k + 1, len(inter_random_states)):
source_base = k * 100
target_base = m * 100
trials = bernoulli.rvs(0.005, size=10000, random_state=inter_random_states[k])
index = 0
for i in range(source_base, source_base + 100):
for j in range(target_base, target_base + 100):
if trials[index]:
G.add_edge(i, j)
index += 1
num_of_inter_edges = len(G.edges) - num_of_intra_edges
print("Expectation(|inter-community edges|) = ~150:", num_of_inter_edges)
# Take the largest connected component:
G = bgn.largest_connected_component_transform(G)
# Display:
fig = plt.figure()
nx.draw_spring(G, with_labels=True)
plt.show()
plt.close()
# Pickle:
with open("output_files/randcl_pickle", 'wb') as pickle_file:
pickle.dump(G, pickle_file)
return G
def produce_edgelist(G, keyword):
with open("output_files/{}_edgelist.txt".format(keyword), 'w') as txt_file:
num_of_nodes = len(G.nodes)
directed = 0
txt_file.write("{}\t{}\n".format(num_of_nodes, directed))
for edge in G.edges:
txt_file.write("{}\t{}\n".format(edge[0], edge[1]))
return
def equality_test():
output = []
with open("output_files/exp_small-alpha-randcl/randcl_K3_composition_map.csv", mode='r') as file:
next(file)
for row in file:
row = row.split(",")
new_row = [row[0]]
print(row[0], row[1])
# error = 0
# cluster_nodes = {i - 1: set(row[i]) for i in range(1, 4)}
# print(cluster_nodes)
# for i in range(1, 4):
# for node in range((i-1) * 100, i * 100)):
# if node not in cluster_nodes[i-1]:
# error
if __name__ == "__main__":
main()
<file_sep>/helper_pipelines/choose_p.sh
#############################################################################################
# This pipeline is the same as run.sh except that it clusters and runs analysis based only
# on the largest connected component of the dblp network (which contains 2190 nodes).
#############################################################################################
# for i in 1 2 3
# do
# echo "hi $i times"
# done
#
for i in 5 10 15 20 25 30 35 40 45 50
do
python3 clustering_pipeline.py before_vectors_seed_cc $i
cd C++\ code/
g++ main.cpp -o main -std=c++11
echo "../data/dblp/cc_pagerank_seed_edgelist.txt" "../data/dblp/pagerank_vectors_cc_$i.txt" $1 $2 "n"| ./main
cd ..
python3 clustering_pipeline.py find_p_after_vectors $i >> data/dblp/pagerank_p_ari.txt
done
<file_sep>/gscholar/louvain/louvain.py
import community as community_louvain
import matplotlib.cm as cm
import matplotlib.pyplot as plt
import networkx as nx
import sys
def main():
filename = sys.argv[1]
print(filename)
file = open("../datasets/" + filename + ".txt", "r")
lines = file.readlines()
graph = nx.Graph()
counter = 0
for line in lines:
if counter != 0:
s = int(line.split(None, 2)[0])
t = int(line.split(None, 2)[1])
graph.add_node(s)
graph.add_node(t)
if not graph.has_edge(s, t):
graph.add_edge(s, t)
#graph.add_edge(t, s) # for spectral use undirected
counter +=1
file.close()
n = graph.number_of_nodes()
print(graph.number_of_nodes())
# compute the best partition
#dblp = 6.94, twitch = 5, strong-house = 1.03, gscholar = 11
partition = community_louvain.best_partition(graph, resolution=5, randomize=None, random_state=None)
zero = 0
one = 0
outfilename = filename + "_louvain.txt"
outfile = open(outfilename, "w")
for key in partition.keys():
outfile.write(str(key) + "\t" + str(partition[key]) + "\n")
if partition[key] >= 2:
print("error")
if partition[key] == 1:
one += 1
if partition[key] == 0:
zero += 1
#print(partition[key])
outfile.close()
print(zero)
print(one)
'''
print(partition)
for key in partition.keys():
print(key)
print(partition[key])
'''
'''
# draw the graph
pos = nx.spring_layout(graph)
# color the nodes according to their partition
cmap = cm.get_cmap('viridis', max(partition.values()) + 1)
nx.draw_networkx_nodes(graph, pos, partition.keys(), node_size=40,
cmap=cmap, node_color=list(partition.values()))
nx.draw_networkx_edges(graph, pos, alpha=0.5)
plt.savefig(filename + ".png")
#plt.show()
'''
main()
<file_sep>/example_hyperparameter_tuning/cc_dblp.py
"""DBLP-specific wrappers for mp.count_cc() and experimentation pipeline."""
import main_pipelines as mp
# Main variable input:
METHOD = "spectral"
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.INPUT_PICKLED_GRAPH = "output_files/main_files/{}_pickle".format(mp.IDENTIFIER_STRING)
mp.K = 2
mp.LABELING_FILE = "output_files/main_files/{}_K{}_labeling_file_{}.csv".format(mp.IDENTIFIER_STRING, mp.K, METHOD)
mp.ALPHA_VALUES = [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
mp.count_cc_wrapper()
return
if __name__ == '__main__':
main()
#####
# cc cluster_sizes match new graphs sizes
# cc cluster_sizes match democrat and le_score cluster_sizes
# cc_cs = mp.cc_cluster_sizes("output_files/strong-house_K2_cc_iac.csv")
# new_cs = mp.cs_by_search_unnamed("output_files/name_edited_strong-house_K2_output_strings_le_score.txt", ALPHA_VALUES)
#
#####
<file_sep>/main.py
import main_pipelines as mp
import ctypes
from pathlib import Path
import subprocess
import sys
import os
import argparse
import configparser
import json
import shutil
import vector_analysis
import data_rep
#ConfigParser support https://docs.python.org/3/library/configparser.html#supported-ini-file-structure
parser = argparse.ArgumentParser(description='get path to the config file.')
parser.add_argument('filepath', help='path to the config file, including filename')
args = parser.parse_args()
configFile=args.filepath #get configFile
#configFile="PATH TO CONFIGFILE" #uncomment this line to overwrite configFile
config = configparser.ConfigParser() #make config object
config.read(configFile) #read configFile
#GLOBAL CONFIG VARIABLES (ENSURE THIS MATCHES CONFIGFILE NAMES/FORMAT)
#[GENERAL]
experimentName = config['GENERAL']['experimentName']
generateVectors = config['GENERAL']['generateVectors']
runAnalysis = config['GENERAL']['runAnalysis']
runDataRep = config['GENERAL']['runDataRep']
runHoldout = config['GENERAL']['runHoldout']
genHoldVectors = config['GENERAL']['genHoldVectors']
simAllSeeds = config['GENERAL']['simAllSeeds']
repititions = config['GENERAL']['repititions']
alpha1list = config['GENERAL']['alpha1list'] #must be changed to list of floats
alpha1listFlt = [float(item) for item in alpha1list.split(',')] #usable list of floats
alpha2list = config['GENERAL']['alpha2list'] #must be changed to list of floats
alpha2listFlt = [float(item) for item in alpha2list.split(',')] #usable list of floats
#[FILES]
inEdgesFile = config['FILES']['inEdgesFile']
inNodesFile = config['FILES']['inNodesFile']
inHoldEdgesFile = config['FILES']['inHoldEdgesFile']
inHoldNodesFile = config['FILES']['inHoldNodesFile']
outputDir = config['FILES']['outputDir']
outVectorDir = config['FILES']['outVectorDir']
outHoldVecDir = config['FILES']['outHoldVecDir']
inVectorDir = config['FILES']['inVectorDir']
inHoldVecDir = config['FILES']['inHoldVecDir']
outAnalysisDir = config['FILES']['outAnalysisDir']
outHoldAnalysisDir = config['FILES']['outHoldAnalysisDir']
inAnalysisDir = config['FILES']['inAnalysisDir']
inHoldAnalysisDir = config['FILES']['inHoldAnalysisDir']
#[ANALYSIS]
vsDummy = config['ANALYSIS']['vsDummy']
usePCA = config['ANALYSIS']['usePCA']
useZachKNN = config['ANALYSIS']['useZachKNN']
useKNN = config['ANALYSIS']['useKNN']
useSVR = config['ANALYSIS']['useSVR']
useRandomForest = config['ANALYSIS']['useRandomForest']
knnNeighbors = config['ANALYSIS']['knnNeighbors']
knnRepititions = config['ANALYSIS']['knnRepititions']
pcaComponents = config['ANALYSIS']['pcaComponents']
def main():
directories = make_directory(0) #make directories for this specific experiment, always input 0
expDir = directories[0] #parent directory for this experiment
expAnalysisDir = directories[1] #experiment analysis subfolder
expVectorDir = directories[2] #experiment vector subfolder
#if running holdout, made two more subfolders
if runHoldout=='yes':
expHoldAnalysisDir = directories[3] #holdout analysis subfolder
expHoldVectorDir = directories[4] #holdout vector subfolder
print("Created experiment directory... Paths are:")
print(" Experiment directory:", expDir, "\n Vector directory:", expVectorDir, "\n Analysis directory:", expAnalysisDir)
if runHoldout=='yes':
#run_holdout_analysis(expHoldVectorDir, expHoldAnalysisDir, inHoldNodesFile)
run_holdout_pipeline(directories)
return
if generateVectors=="yes":
print("starting simulation... vector files going to", expVectorDir)
run_simulation(expVectorDir)
print("simulation was run - vector files are in", expVectorDir)
if runAnalysis=='yes':
print("running analysis... files going to", expAnalysisDir)
run_analysis(expVectorDir, expAnalysisDir, inNodesFile)
if runDataRep=='yes':
print("representing data from", expAnalysisDir, "... files going to", expAnalysisDir)
run_datarep(expAnalysisDir, expAnalysisDir)
if runAnalysis=='no':
if runDataRep=='yes':
print("representing data from", inAnalysisDir, "... files going to", expAnalysisDir)
run_datarep(inAnalysisDir, expAnalysisDir)
return
#makes the directory structure with a copy of the configFile in it
#makes/returns 3 directories/paths. the vector path changes based on generateVectors
def make_directory(versionNum):
dirname = experimentName + "_v" + str(versionNum)
dirPath = outputDir + dirname + "/"
if os.path.isdir(dirPath): #if directory exsists...
return make_directory(versionNum+1) #...recursively check for the next version
else:
os.mkdir(dirPath) #make the experiment directory
configCopy = dirPath + experimentName + "ConfigRecord.ini"
shutil.copyfile(configFile, configCopy) #copy config file to experiment folder
#make analysis directories
if runHoldout == 'yes':
holdAnalysisPath = dirPath+outHoldAnalysisDir
os.mkdir(holdAnalysisPath)
analysisPath = dirPath+outAnalysisDir
os.mkdir(analysisPath)
#make vector directories
if generateVectors=='yes':
if genHoldVectors=='yes':
holdVectorPath = dirPath+outHoldVecDir
os.mkdir(holdVectorPath)
if genHoldVectors=='no':
holdVectorPath = dirPath+inHoldVecDir
os.mkdir(holdVectorPath)
vectorPath = dirPath+outVectorDir
os.mkdir(vectorPath)
if generateVectors=='no':
if genHoldVectors=='yes':
holdVectorPath = dirPath+outHoldVecDir
os.mkdir(holdVectorPath)
if genHoldVectors=='no':
holdVectorPath = dirPath+inHoldVecDir
vectorPath = inVectorDir
#return paths
if runHoldout == 'yes':
return dirPath, analysisPath, vectorPath, holdAnalysisPath, holdVectorPath
if runHoldout == 'no':
return dirPath, analysisPath, vectorPath
def run_simulation(vectorDir):
for a1 in alpha1listFlt:
for a2 in alpha2listFlt:
#run normal simulation (always happens)
outVectorFile = vectorDir+"vectors"+experimentName+"_"+str(a1)+"_"+str(a2)+"_.txt"
subprocess.Popen(["./C++ code/main", inEdgesFile, outVectorFile,
str(a1), str(a2), repititions, simAllSeeds, inNodesFile]).wait() #run C++ code
return 1
#runs the entire holdout experiment pipeline and outputs an alaysis file
def run_holdout_pipeline(directories):
#build experiemnt directory
expDir = directories[0]
expAnalysisDir = directories[1]
expVectorDir = directories[2] #this will change if generateVectors=='no'
expHoldAnalysisDir = directories[3]
expHoldVectorDir = directories[4]
completeAnalysisFile = expDir+"completeAnalysis"+experimentName+".txt"
components = int(pcaComponents)
#create the output file, write its header
with open(completeAnalysisFile, 'a') as f:
header = "a1,a2,mseRegDummy,stdRegDummy,mseHoldDummy,"
header += "mseRegKNN,stdRegKNN,mseHoldKNN,"
header += "mseRegSVR,stdRegSVR,mseHoldSVR,"
header += "mseRegRF,stdRegRF,mseHoldRF\n"
f.write(header)
#run the information cascade simulation by calling main.cc in C++/code
for a1 in alpha1listFlt:
for a2 in alpha2listFlt:
#run normal simulation
outVectorFile = expVectorDir+"vectors"+experimentName+"_"+str(a1)+"_"+str(a2)+"_.txt"
subprocess.Popen(["./C++ code/main", inEdgesFile, outVectorFile,
str(a1), str(a2), repititions, simAllSeeds, inNodesFile]).wait() #run C++ code
#run holdout simulation
outHoldVectorFile = expHoldVectorDir+"holdoutVectors"+experimentName+"_"+str(a1)+"_"+str(a2)+"_.txt"
subprocess.Popen(["./C++ code/main", inHoldEdgesFile, outHoldVectorFile,
str(a1), str(a2), repititions, simAllSeeds, inHoldNodesFile]).wait() #run C++ code
#run analysis on the created vectors
#REG DUMMY
regAnalysisDummy = expAnalysisDir+"regAnalysisDummy.txt"
header="alpha1,alpha2,mean,vectorFile\n"
make_analysis_file(regAnalysisDummy, header)
regDummy=vector_analysis.runDummy(inNodesFile, outVectorFile, regAnalysisDummy, a1, a2)
#HOLD DUMMY
holdAnalysisDummy = expAnalysisDir+"holdAnalysisDummy.txt"
header="alpha1,alpha2,mean,vectorFile\n"
make_analysis_file(holdAnalysisDummy, header)
holdDummy=vector_analysis.holdoutDummy(inNodesFile, outVectorFile, inHoldNodesFile,
outHoldVectorFile, holdAnalysisDummy, a1, a2, components)
#if useKNN == 'yes':
#regular KNN
analysisFile = expAnalysisDir+"analysisKNN.txt"
header="alpha1,alpha2,mse,vectorFile\n"
make_analysis_file(analysisFile, header)
regKNN=vector_analysis.KNN(inNodesFile, outVectorFile, analysisFile, a1,
a2, int(knnNeighbors), int(knnRepititions))
#holdout KNN
holdAnalysisFile = expHoldAnalysisDir+"analysisHoldoutKNN.txt"
header="alpha1,alpha2,accuracy,vectorFile\n"
make_analysis_file(holdAnalysisFile, header)
holdKNN=vector_analysis.holdoutKNN(inNodesFile, outVectorFile, inHoldNodesFile,
outHoldVectorFile, holdAnalysisFile, a1, a2, int(knnNeighbors), components)
#if useSVR == 'yes':
#normal SVR
analysisFile = expAnalysisDir+"analysisSVR.txt"
header="alpha1,alpha2,mean,std,vectorFile\n" #come back
make_analysis_file(analysisFile, header)
regSVR=vector_analysis.runSVR(inNodesFile, outVectorFile, analysisFile, a1, a2)
#holdout SVR
holdAnalysisFile = expHoldAnalysisDir+"analysisHoldoutSVR.txt"
header="alpha1,alpha2,accuracy,vectorFile\n"
make_analysis_file(holdAnalysisFile, header)
holdSVR=vector_analysis.holdoutSVR(inNodesFile, outVectorFile, inHoldNodesFile,
outHoldVectorFile, holdAnalysisFile, a1, a2, components)
#if useRandomForest == 'yes':
#normal RF
analysisFile = expAnalysisDir+"analysisRandomForest.txt"
header="alpha1,alpha2,mean,std,vectorFile\n" #come back
make_analysis_file(analysisFile, header)
regRF=vector_analysis.randomForest(inNodesFile, outVectorFile, analysisFile, a1, a2)
#holdout RF
holdAnalysisFile = expHoldAnalysisDir+"analysisHoldoutRandomForest.txt"
header="alpha1,alpha2,accuracy,vectorFile\n"
make_analysis_file(holdAnalysisFile, header)
holdRF=vector_analysis.holdoutRandomForest(inNodesFile, outVectorFile, inHoldNodesFile,
outHoldVectorFile, holdAnalysisFile, a1, a2, components)
with open(completeAnalysisFile, 'a') as f:
out = str(a1) + ',' + str(a2) + ','
out += str(round(regDummy[0],3))+','+str(round(regDummy[1],3))+','+ str(round(holdDummy,3))+','
out += str(round(regKNN[0],3))+','+str(round(regKNN[1],3))+','+ str(round(holdKNN,3))+ ','
out += str(round(regSVR[0],3))+','+str(round(regSVR[1],3))+','+ str(round(holdSVR,3))+ ','
out += str(round(regRF[0],3))+','+str(round(regRF[1],3))+','+ str(round(holdRF,3))+'\n'
f.write(out)
#write to file
return 1
def run_analysis(vectorDir, analysisDir, nodefile):
if vsDummy == 'yes':
print("Running Dummy analysis...")
analysisFile = analysisDir+"analysisDummy.txt"
header="alpha1,alpha2,mean,std,vectorFile\n" #come back
make_analysis_file(analysisFile, header)
for file in os.scandir(vectorDir):
if file.is_file() and file.name.endswith('.txt'):
alphas=get_alphas_from_filepath(file.path)
vector_analysis.runDummy(nodefile, file.path, analysisFile, alphas[0], alphas[1])
#copy and change below three lines when adding new analysis
if usePCA == 'yes':
print("Running PCA analysis...")
analysisFile = analysisDir+"analysisPCA.txt"
header="alpha1,alpha2,correlation,p-value,vectorFile\n"
make_analysis_file(analysisFile, header)
#go through vectorDir, run analysis on each vector file
for file in os.scandir(vectorDir):
if file.is_file() and file.name.endswith('.txt'):
alphas=get_alphas_from_filepath(file.path)
#change below line when adding new analysis
vector_analysis.pearson_analysis(nodefile, file.path,
analysisFile, alphas[0], alphas[1])
if useZachKNN == 'yes':
print("Running zachKNN analysis...")
analysisFile = analysisDir+"analysiszachKNN.txt"
header="alpha1,alpha2,accuracy,vectorFile\n"
make_analysis_file(analysisFile, header)
for file in os.scandir(vectorDir):
if file.is_file() and file.name.endswith('.txt'):
alphas=get_alphas_from_filepath(file.path)
vector_analysis.zachKNN(nodefile, file.path, analysisFile, alphas[0],
alphas[1], int(knnNeighbors), int(knnRepititions))
if useKNN == 'yes':
analysisFile = analysisDir+"analysisKNN.txt"
header="alpha1,alpha2,accuracy,std,vectorFile\n"
make_analysis_file(analysisFile, header)
for file in os.scandir(vectorDir):
if file.is_file() and file.name.endswith('.txt'):
alphas=get_alphas_from_filepath(file.path)
vector_analysis.KNN(nodefile, file.path, analysisFile, alphas[0],
alphas[1], int(knnNeighbors), int(knnRepititions))
if useRandomForest == 'yes':
print("Running Random Forest analysis...")
analysisFile = analysisDir+"analysisRandomForest.txt"
header="alpha1,alpha2,mean,std,vectorFile\n" #come back
make_analysis_file(analysisFile, header)
for file in os.scandir(vectorDir):
if file.is_file() and file.name.endswith('.txt'):
alphas=get_alphas_from_filepath(file.path)
vector_analysis.randomForest(nodefile, file.path, analysisFile, alphas[0], alphas[1])
if useSVR == 'yes':
print("Running SVR analysis...")
analysisFile = analysisDir+"analysisSVR.txt"
header="alpha1,alpha2,mean,std,vectorFile\n" #come back
make_analysis_file(analysisFile, header)
for file in os.scandir(vectorDir):
if file.is_file() and file.name.endswith('.txt'):
alphas=get_alphas_from_filepath(file.path)
vector_analysis.runSVR(nodefile, file.path, analysisFile, alphas[0], alphas[1])
return 1
def make_analysis_file(analysisFile, header):
with open(analysisFile, 'a') as f: #make analysis file header
out = "EXPERIMENT: " + experimentName + "\n"
out += header
f.write(out)
return 1
def run_datarep(inAnalysisDir, outAnalysisDir):
if usePCA == 'yes':
inAnalysisFile= inAnalysisDir+"analysisPCA.txt"
outHeatmapFile= outAnalysisDir+"heatmapPCA.png"
data_rep.pcaHeatmap(inAnalysisFile, outHeatmapFile)
if vsDummy == 'yes':
boop = 'bop' #do nothing
if useZachKNN == 'yes':
inAnalysisFile= inAnalysisDir+"analysiszachKNN.txt"
outHeatmapFile= outAnalysisDir+"heatmapzachKNN.png"
data_rep.zachKNNHeatmap(inAnalysisFile, outHeatmapFile)
if vsDummy == 'yes':
analysisName = 'ZachKNN'
inDummyFile= inAnalysisDir+"analysisDummy.txt"
outVsDummyFile= outAnalysisDir+"heatmapZachKNNvsDummy.png"
data_rep.vsDummyHeatmap(analysisName, inAnalysisFile, inDummyFile, outVsDummyFile)
if useKNN == 'yes':
inAnalysisFile= inAnalysisDir+"analysisKNN.txt"
outHeatmapFile= outAnalysisDir+"heatmapKNN.png"
data_rep.KNNHeatmap(inAnalysisFile, outHeatmapFile)
if vsDummy == 'yes':
analysisName = 'KNN'
inDummyFile= inAnalysisDir+"analysisDummy.txt"
outVsDummyFile= outAnalysisDir+"heatmapKNNvsDummy.png"
data_rep.vsDummyHeatmap(analysisName, inAnalysisFile, inDummyFile, outVsDummyFile)
if useRandomForest == 'yes':
inAnalysisFile= inAnalysisDir+"analysisRandomForest.txt"
outHeatmapFile= outAnalysisDir+"heatmapRandomForest.png"
data_rep.randomForestHeatmap(inAnalysisFile, outHeatmapFile)
if vsDummy == 'yes':
analysisName = 'RandomForest'
inDummyFile= inAnalysisDir+"analysisDummy.txt"
outVsDummyFile= outAnalysisDir+"heatmapRandomForestvsDummy.png"
data_rep.vsDummyHeatmap(analysisName, inAnalysisFile, inDummyFile, outVsDummyFile)
if useSVR == 'yes':
inAnalysisFile= inAnalysisDir+"analysisSVR.txt"
outHeatmapFile= outAnalysisDir+"heatmapSVR.png"
data_rep.SVRHeatmap(inAnalysisFile, outHeatmapFile)
if vsDummy == 'yes':
analysisName = 'SVR'
inDummyFile= inAnalysisDir+"analysisDummy.txt"
outVsDummyFile= outAnalysisDir+"heatmapSVRvsDummy.png"
data_rep.vsDummyHeatmap(analysisName, inAnalysisFile, inDummyFile, outVsDummyFile)
if vsDummy == 'yes':
inAnalysisFile= inAnalysisDir+"analysisDummy.txt"
outHeatmapFile= outAnalysisDir+"heatmapDummy.png"
data_rep.dummyHeatmap(inAnalysisFile, outHeatmapFile)
return
def get_alphas_from_filepath(filepath):
pathlist=filepath.split('_')
alpha1 = pathlist[-3]
alpha2 = pathlist[-2]
return alpha1, alpha2
if __name__=="__main__":
main()
<file_sep>/cluster_consistency/cluster_graphing.py
import matplotlib.pyplot as plt
import numpy as np
import seaborn
import csv
import sys
import statistics
import numpy
import pylab as pl
from matplotlib import collections as mc
import random
# The noise variable controls the displacement of new lines from the cluster center line so that
# large clusters are visibly larger. This number is set in an ad hoc way based on the dataset
# size so that clusters aren't so large they run into each other and aren't so small the size
# isn't visible.
NOISE = 0.0001
TICKSIZE = 15
FONTSIZE = 20
TITLESIZE = 30
plt.rcdefaults()
def plot_line_segments(line_segments_lol):
lc = mc.LineCollection(line_segments_lol, alpha=0.01)
fig, ax = pl.subplots()
ax.add_collection(lc)
ax.autoscale()
ax.margins(0.1)
plt.show()
def get_clustid_position(clustid, count):
# return clustid + (count - 1) * NOISE * ((-1) ** count)
#return clustid
return random.normalvariate(clustid, 0.1)
def get_alpha_position(alpha, count):
return random.normalvariate(alpha, 0.005)
# return alpha + (count - 1) * NOISE * ((-1) ** count)
# return alpha
def read_cluster_alpha_file(filename):
"""
Given a CSV file where rows are points, columns are alpha values, and entries are cluster
labels.
Returns two dictionaries of dictionaries:
- alpha -> cluster label -> list of ids in the cluster
- pointid -> alpha -> cluster label
CSV input example:
id,0.1,0.2,0.3
1,0,0,0
2,0,0,0
3,0,0,0
4,1,1,1
5,1,1,1
"""
all_lines = []
alpha_clustlabel_dict = {}
pointid_alpha_clust_dict = {}
with open (filename) as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
pointid = ''
line_segments = []
for alpha, clust in row.items():
if pointid == '':
pointid = clust
continue
alpha = float(alpha)
clust = int(clust)
if not alpha in alpha_clustlabel_dict:
alpha_clustlabel_dict[alpha] = {}
if not clust in alpha_clustlabel_dict[alpha]:
alpha_clustlabel_dict[alpha][clust] = []
alpha_clustlabel_dict[alpha][clust].append(pointid)
if not pointid in pointid_alpha_clust_dict:
pointid_alpha_clust_dict[pointid] = {}
pointid_alpha_clust_dict[pointid][alpha] = clust
return alpha_clustlabel_dict, pointid_alpha_clust_dict
def read_externalinfo_file(filename, headerid):
with open (filename) as csvfile:
externalinfo = {}
reader = csv.DictReader(csvfile)
for row in reader:
idval = ''
for header, value in row.items():
if header == headerid:
idval = value
externalinfo[idval] = {}
else:
externalinfo[idval][header] = value
return externalinfo
def graph_alpha_v_clustid(pointid_alpha_clust_dict):
"""
Input: a dictionary mapping from pointid -> alpha -> cluster id
This function displays a graph where the x-axis is alpha, the y-axis is the cluster
label, and each line is a point.
"""
alpha_clust_count = {}
all_lines = []
for pointid in pointid_alpha_clust_dict:
line_segments = []
for alpha in pointid_alpha_clust_dict[pointid]:
clustlabel = pointid_alpha_clust_dict[pointid][alpha]
if not alpha in alpha_clust_count:
alpha_clust_count[alpha] = {}
if not clustlabel in alpha_clust_count[alpha]:
alpha_clust_count[alpha][clustlabel] = 0
alpha_clust_count[alpha][clustlabel] += 1
# x = get_alpha_position(alpha, alpha_clust_count[alpha][clustlabel])
# y = get_clustid_position(clustlabel, alpha_clust_count[alpha][clustlabel])
x, y = numpy.random.multivariate_normal([alpha, clustlabel],
[[0.001, 0],[0,0.005]])
line_segments.append([x, y])
all_lines.append(line_segments)
plot_line_segments(all_lines)
def string_to_list(stringlist):
stringlist = stringlist[1:-1]
parts = stringlist.split(",")
num_parts = [ int(x) for x in parts ]
return num_parts
def graph_alpha_v_externalinfo(alpha_clustlabel_dict, pointid_alpha_clust_dict, externalinfo):
all_lines = []
for pointid in pointid_alpha_clust_dict:
line_segments = []
for alpha in pointid_alpha_clust_dict[pointid]:
clustlabel = pointid_alpha_clust_dict[pointid][alpha]
cluster = alpha_clustlabel_dict[alpha][clustlabel]
cluster = [ int(x) for x in cluster ]
x = random.normalvariate(alpha, 0.005)
citationcount_avg = statistics.mean(cluster)
y = random.normalvariate(citationcount_avg, 50)
line_segments.append([x, y])
all_lines.append(line_segments)
plot_line_segments(all_lines)
## TODO
# then make one graphing function that does graphs with y-axis meaning the cluster position
# and another that reads in additional data mapping from id to actual information and groups
# cluster by real data position.
def save_plot(xtitle, ytitle, figtitle, filename, plot):
"""
This function isn't currently used, but a modified version of it could be useful for saving
the generated image to file.
"""
xlabel = plt.xlabel(xtitle, fontsize = FONTSIZE)
ylabel = plt.ylabel(ytitle, fontsize = FONTSIZE)
title = plt.title(figtitle, fontsize = TITLESIZE)
plt.xticks(fontsize = TICKSIZE)
plt.yticks(fontsize = TICKSIZE)
box = plot.get_position()
plot.set_position([box.x0, box.y0, box.width * 0.85, box.height]) # resize position
# Put a legend to the right side
legend = plot.legend(loc='lower center', bbox_to_anchor=(1.7, 0.5), ncol=1,
prop={'size': FONTSIZE})
bb = (ylabel, ylabel, title, legend)
plot.figure.savefig(filename, bbox_extra_artists = bb, bbox_inches = 'tight')
print("plot saved to:" + filename)
plt.clf()
plt.close()
# MAIN: assumes the labeling file is given as input on the command line, e.g.:
# python3 cluster_graphing.py test_labels.csv
alpha_clustlabel_dict, pointid_alpha_clust_dict = read_cluster_alpha_file(sys.argv[1])
# externalinfo = read_externalinfo_file(sys.argv[2], 'network_id')
# graph_alpha_v_externalinfo(alpha_clustlabel_dict, pointid_alpha_clust_dict, externalinfo)
graph_alpha_v_clustid(pointid_alpha_clust_dict)
<file_sep>/plot_clustering_consistency.py
#!/usr/bin/env python
import sklearn.metrics as sm
import pandas as pd
import numpy as np
import sys
import pylab
def compute_clustering_similarity_map(clusterings):
n = clusterings.shape[1]
result = np.zeros((n,n))
for i in range(n):
for j in range(n):
result[i, j] = sm.adjusted_rand_score(clusterings[:,i], clusterings[:,j])
return result
if __name__ == '__main__':
df = pd.read_csv(sys.argv[1])
df = df.iloc[:,1:]
d = compute_clustering_similarity_map(np.array(df))
pylab.matshow(d)
pylab.colorbar()
pylab.show()
<file_sep>/C++ code Orig/main.cpp
// Information spreads from source nodes (seeds), over the network (IC model)
// Writes out information access vectors for each node to a file
//configuration - libraries it include
//generate make file
//#include <iostream> //#include <string> //#include <fstream> //#include <vector>
#include <iostream> // std::cout
#include <fstream>
#include <stdio.h>
#include <string.h>
//#include <bits/stdc++.h>
#include "graph.cpp"
#include "gen_vectors.h"
#include "simulation.h"
#include "print.h"
using namespace std;
Graph readGraph(string);
vector<int> getSeeds(string);
int main(int argc, char* argv[]) {
// bool google_scholar_dataset = false;
clock_t tStart = clock();
//
// // Setting up variables
// string large = "n";
// string outFileName = "dblp_correct_vectors.txt";
// string fileName = "../data/dblp/dblp_correct_c_style.txt";
//
// if (google_scholar_dataset)
// {
// string fileName = "../data/data/google_scholar_c_style.txt";
// string outFileName = "google_scholar_vectors.txt";
// string large = "y";
//
// } else {
// Reads file's Name
string fileName = argv[1];
// Determines where vectors will be saved
string outFileName = argv[2];
// Determines whether vectors will be written out column-wise
// cout << "Is this a large network? y/n ";
// cin >> large;
// }
// Loads data in the graph
Graph netGraph = readGraph(fileName);
//netGraph.printGraph();
vector<int> seeds = getSeeds(fileName);
//Set Simulation Variables
// cout << "Enter variables: \nrep (1000), maxK (100), gap (5), minAlpha (0.1), maxAlpha (0.5)\n";
// Probability of propagation (through edges)
float alpha = stof(argv[3]);
// Number of repetitions for simulation:
int rep = stoi(argv[4]);
// Use all seeds? y or n
string useAllSeeds = argv[5];
// Use multiple sources for spreading the same info (MIT)
string multiSource = argv[6];
if(multiSource=="y") {
simulation(seeds, alpha, rep, netGraph);
printProbs(netGraph, alpha, rep, outFileName);
return 0;
}
if (useAllSeeds=="y") {
generate_vectors(alpha, rep, netGraph, outFileName);
} else {
generate_vectors_select_seeds(alpha, rep, netGraph, outFileName, seeds);
}
// generate_vectors(alpha, rep, netGraph, outFileName);
// simulation(seeds, alpha, rep, netGraph);
// printProbs(netGraph, alpha, rep, outFileName);
// add a function to write out probabilities
cout << "Time: " << (float)(clock() - tStart)/CLOCKS_PER_SEC << endl;
return 0;
}
// Reads the network from file
// Format: Number of nodes - Direction of Graph ... Source - Destination
Graph readGraph(string file) {
ifstream input;
input.open(file);
int numV;
input >> numV; // Number of Nodes
cout << "Number of Nodes: " << numV << endl;
Graph netGraph(numV);
bool dir;
input >> dir; // 0: Undirected, 1: Directed
string from, to;
bool isSeed = false;
while (input >> from >> to) {
if (from == "s") {
isSeed = true;
} else if (not isSeed) {
netGraph.addEdge(stoi(from), stoi(to), dir);
}
}
input.close();
return netGraph;
}
vector<int> getSeeds(string file) {
ifstream input;
input.open(file);
vector<int> seeds;
string line;
string s = "s";
bool isSeed = false;
while (input >> line)
{
if (isSeed) {
int seed = stoi(line);
seeds.push_back(seed);
}
else if (line.at(0) == s.at(0)) {
isSeed = true;
// cout << "line 158";
// char * pch;
// int n = line.length();
// line = line.substr(1, n);
// cout << line;
// char charArray[n];
// strcpy(charArray, line.c_str());
// pch = strtok (charArray,"\t");
// while (pch != NULL) {
// int seed;
// try {
// seed = stoi(pch);
// } catch (...){
// cout << pch;
// cout << "Your data file is not in the correct format. See the example and try again.";
// }
// seeds.push_back(seed);
// pch = strtok (NULL, "\t");
// }
}
}
input.close();
return seeds;
}
<file_sep>/C++ code/print.h
//Print on file
#ifndef print_h
#define print_h
#include <stdio.h>
// Help accessing array values from https://www.geeksforgeeks.org/pass-2d-array-parameter-c/
void writeVectorsSeedSubset(string outName, int rep, int n, float *vectors, vector<int> seeds) {
ofstream outMin (outName);
int num_seeds = seeds.size();
for (int k = 0; k < num_seeds; k++) {
outMin << seeds.at(k) << ",";
}
outMin << endl;
for (int i = 0; i < n; i++) {
// outMin << i << ",";
for (int j = 0; j < num_seeds; j++) {
float output = float(*((vectors+i*num_seeds) + j))/rep;
outMin << output << ",";
}
outMin << endl;
}
outMin.close();
}
void writeVectors(string outName, int rep, int n, float *vectors) {
ofstream outMin (outName);
for (int i = 0; i < n; i++) {
// outMin << i << ",";
for (int j = 0; j < n; j++) {
float output = float(*((vectors+i*n) + j))/rep;
outMin << output << ",";
}
outMin << endl;
}
outMin.close();
}
void printProbs(Graph& netGraph, float alpha, int rep, string fileName) {
// string fileName = "../Exp/Results/" + algName + "_" + to_string(k) + "_" + to_string(int(alpha*10)) + ".txt";
ofstream outMin (fileName);
for(int i = 0; i < netGraph.n; i++)
outMin << float(i) << "\t"<< float(netGraph.prob[i])/rep << endl;
outMin.close();
}
// void printProbs(Graph& netGraph, string algName, int k, float alpha, int rep) {
// string fileName = "../Exp/Results/" + algName + "_" + to_string(k) + "_" + to_string(int(alpha*10)) + ".txt";
// ofstream outMin (fileName);
// for(int i = 0; i < netGraph.n; i++)
// outMin << float(netGraph.prob[i])/rep << endl;
// outMin.close();
// }
void writeOnFile(vector<float> results, string algName, float alpha, int k, int gap) {
string fileName = "../Exp/Results/All_" + algName + "_" + to_string(int(alpha*10)) + "_min.txt";
ofstream outMin (fileName);
for(int i = 0; i <= k; i += gap)
outMin << i << ": " << results[i/gap] << endl;
outMin.close();
}
void writeWeighted(Graph& netGraph, string name, int alpha, int round, int rep, bool isWeighted) {
int numV = netGraph.n;
string fileName = "../Exp/Weight/" + name + "/" + to_string(alpha);
if(isWeighted)
fileName += "_weight";
else
fileName += "_simple";
ofstream outPut (fileName + to_string(round) + ".txt");
vector<bool> seen(numV, 0);
int cand = 0;
float maxim;
for(int i = 0; i < numV; i++) {
maxim = 0;
for(int j = 0; j < numV; j++) {
if(seen[j]) continue;
if(netGraph.weight[j] > maxim) {
cand = j;
maxim = netGraph.weight[j];
}
}
seen[cand] = true;
outPut << (float) netGraph.prob[cand] / rep << "\t" << netGraph.weight[cand] << endl;
}
outPut.close();
}
void writeAve(Graph& netGraph, string name, int alpha, int redo, int rep) {
int minPerc = netGraph.n;
int ninPer = 0, eighPer = 0, sevPer = 0, sixPer = 0, fivPer = 0;
int ninDiff = 0, eighDiff = 0, sevDiff = 0, sixDiff = 0, fivDiff = 0;
int numV = netGraph.n;
string fileName = "../Exp/Weight/" + name + "_" + to_string(alpha);
ofstream outPut (fileName + ".txt");
outPut << "For all top " << float(minPerc * 100 / numV) << "% the probability increased\n";
outPut << "For top 90% probability increased for " << ninPer * 100 / (redo * numV / 10) << "% \n";
outPut << "With average of: " << float(ninDiff) / (redo * rep * numV / 10) << endl;
outPut << "For top 80% probability increased for " << eighPer * 100 / (redo * numV * 2 / 10) << "% \n";
outPut << "With average of: " << float(eighDiff) / (redo * rep * numV * 2 / 10) << endl;
outPut << "For top 70% probability increased for " << sevPer * 100 / (redo * numV * 3 / 10) << "% \n";
outPut << "With average of: " << float(sevDiff) / (redo * rep * numV * 3 / 10) << endl;
outPut << "For top 60% probability increased for " << sixPer * 100 / (redo * numV * 4 / 10) << "% \n";
outPut << "With average of: " << float(sixDiff) / (redo * rep * numV * 4 / 10) << endl;
outPut << "For top 50% probability increased for " << fivPer * 100 / (redo * numV * 5 / 10) << "% \n";
outPut << "With average of: " << float(fivDiff) / (redo * rep * numV * 5 / 10) << endl;
outPut.close();
}
void computeWeight(Graph& netGraph, vector<int> simp, vector<int> weight, int round, int eps) {
int numV = netGraph.n;
int diff;
int minPerc = netGraph.n;
int ninPer = 0, eighPer = 0, sevPer = 0, sixPer = 0, fivPer = 0;
int ninDiff = 0, eighDiff = 0, sevDiff = 0, sixDiff = 0, fivDiff = 0;
vector<bool> seen(numV, 0);
int cand = 0, ctr = 0;
float maxim;
for(int i = 0; i < numV; i++) {
maxim = 0;
for(int j = 0; j < numV; j++) {
if(seen[j]) continue;
if(netGraph.weight[j] > maxim) {
cand = j;
maxim = netGraph.weight[j];
}
}
seen[cand] = true;
diff = weight[cand] - simp[cand];
if(diff < 0)
minPerc = min(minPerc, ctr);
if(ctr < numV / 10) {
ninDiff += diff;
if(diff >= -eps)
ninPer++;
}
if(ctr < numV * 2 / 10) {
eighDiff += diff;
if(diff >= -eps)
eighPer++;
}
if(ctr < numV * 3 / 10) {
sevDiff += diff;
if(diff >= -eps)
sevPer++;
}
if(ctr < numV * 4 / 10) {
sixDiff += diff;
if(diff >= -eps)
sixPer++;
}
if(ctr < numV * 5 / 10) {
fivDiff += diff;
if(diff >= -eps)
fivPer++;
}else return;
ctr++;
}
}
#endif /* print_h */
<file_sep>/report_file_object_class.py
class ReportFileObject:
def __init__(self, report_file_path):
"""Initializes the class instance using the report file path."""
# Makes the path t the report file the object's attribute for easy accessing: we don't have to pass the path
# to the print method every time we'd like to print a string.
self.report_file_path = report_file_path
return
def print(self, string):
"""Writes a string both to the terminal and the report file."""
# Prints the string in the terminal.
print(string)
# Opens the report file in the updating mode.
with open(self.report_file_path, 'a') as file:
# Writes the string to the report file.
file.write(string)
return
<file_sep>/example_hyperparameter_tuning/cp_dblp.py
"""DBLP-specific wrappers for mp.core_periphery() and experimentation pipeline."""
import main_pipelines as mp
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.INPUT_PICKLED_GRAPH = "output_files/main_files/{}_pickle".format(mp.IDENTIFIER_STRING)
mp.K = 2
# mp.CP_THRESHOLD = -1
mp.LABELING_FILE = "output_files/main_files/{}_K2_labeling_file_cp.csv".format(mp.IDENTIFIER_STRING)
mp.EXPERIMENT = "cp"
# mp.core_periphery()
mp.statistical_analyses()
return
if __name__ == '__main__':
main()
<file_sep>/C++ code Orig/run.sh
g++ ./main.cpp -o main -std=c++11
#./main
echo 'Please enter the path to input file'
read input
echo 'Please enter the path to output file'
read output
echo 'Please enter the alpha value?'
read alpha
value=${alpha#*.}
echo 'Please enter the number of repetitions?'
read nr
echo "Run multi source simulation (MIT): y or n?"
read multi
echo "Run simulations for all seeds: y or n?"
read response
./main $input $output $alpha $nr $response $multi
#./main "../output_files/dblp_edgelist_MIT.txt" "../output_files/dblp_probs_MIT/dblp_vectors_i${value}_${nr}.txt" $alpha $nr $response $multi
#./main "../output_files/dblp_edgelist.txt" "../output_files/dblp_vectors/dblp_vectors_i${value}_${nr}.txt" $alpha $nr $response
<file_sep>/build_dblp_datasets.py
import networkx as nx
import pandas as pd
import csv
import build_generic_network as bgn
import os
YEARS_OF_JOB = [2000, 2001, 2002, 2003, 2004, 2005, 2021]
NODES_PATH = "dblp_data/faculty_data.xlsx"
PUBLICATIONS_PATH = "dblp_data/processed_publications.csv"
NODE_ATTRIBUTES_TO_PROCESS = ['name', 'gender', 'year_of_job', 'dblp_id', "gs_id", "followup_title",
"followup_location", "followup_department"]
NODE_ATTRIBUTES_TO_PRODUCE = ['node', 'dblp_id', 'gender', 'phd', 'phd_rank', 'job_rank']
NON_UNIQUE_AUTH_PATH = "dblp_data/non_unique_auth.txt"
def read_nodelist():
# Uses NODES_PATH, NODE_ATTRIBUTES_TO_PROCESS
node_dict = {}
df_faculty = pd.read_excel(NODES_PATH, "faculty")
for index, row in df_faculty.iterrows():
node = preprocess_id(row['dblp_id'])
if node == -1:
continue
node_dict[node] = {}
node_dict[node]["excel_index"] = index
for attribute in NODE_ATTRIBUTES_TO_PROCESS:
node_dict[node][attribute] = row[attribute]
node_dict[node]["phd"] = row["location_phd"]
node_dict[node]["job"] = row["location_job"]
node_dict[node]["phd_rank"] = university_to_rank(node_dict[node]["phd"])
node_dict[node]["job_rank"] = university_to_rank(node_dict[node]["job"])
# with open(NODES_PATH, 'r') as file:
# first = 1
# for line in file:
# if first:
# first -= 1
# continue
# if line[-1] == "\n":
# line = line[:-1]
# line = line.split("; ")
#
# node = pre_process_dblp_id(line[2])
# node_dict[node] = {}
#
# for i in range(len(NODE_ATTRIBUTES_TO_PROCESS)):
# node_dict[node][NODE_ATTRIBUTES_TO_PROCESS[i]] = line[i]
print("len(node_dict) =", len(node_dict))
return node_dict
def preprocess_id(name):
try:
output = name.split(":")
except:
return -1
if output == ["#NAME?"] or output == ["#ERROR!"]:
return -1
if len(output) > 2:
raise ValueError("len(output) > 2")
if len(output) == 1:
raise ValueError("len(output) == 1")
output[0], output[1] = output[1], output[0]
output = "".join(output)
function_output = []
for i in output:
if i.isalpha() or i.isnumeric():
function_output.append(i)
function_output = "".join(function_output)
return function_output
def university_to_rank(university):
'''
Takes in the name of a university and returns its rank
(according to the ranking system described in https://advances.sciencemag.org/content/1/1/e1400005)
'''
with open("dblp_data/faculty_data - schools.csv") as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
if row[0] == university:
return float(row[2])
return -1
def populate_with_nodes(graph, node_dict):
for node in node_dict:
graph.add_node(node)
nx.set_node_attributes(graph, node_dict)
find_non_unique_auth(graph)
print("Before removal of non-unique auth: len(graph.nodes)=", len(graph.nodes))
remove_non_unique_auth(graph)
print("After removal of non-unique auth: len(graph.nodes)=", len(graph.nodes))
return graph
def find_non_unique_auth(graph):
"""
Finds those authors in the xml file whose raw names are mapped to the same string after preprocessing.
:param graph: nx.Graph
:return: None
"""
if not os.path.isfile(NON_UNIQUE_AUTH_PATH):
with open(NON_UNIQUE_AUTH_PATH, 'w') as file_to_write:
all_proc_authors = set()
all_raw_authors = set()
non_unique_authors = set()
with open(PUBLICATIONS_PATH, 'r') as file_to_read:
csv_reader = csv.reader(file_to_read, delimiter=',')
starting = 1
for row in csv_reader:
if starting:
starting -= 1
continue
publication_type, year, num_of_auth, author, title = parse_publication(row)
if num_of_auth > 1:
for a in author:
p_name = preprocess_name(a)
# Checking of pigeonholing:
if p_name in all_proc_authors and a not in all_raw_authors:
non_unique_authors.add(p_name)
all_proc_authors.add(p_name)
all_raw_authors.add(a)
print("len(all_proc_authors) =", len(all_proc_authors))
unique_authors = all_proc_authors - non_unique_authors
authors_of_interest = set(graph.nodes.keys())
print("Check: {} and {}".format(len(graph), len(authors_of_interest)))
# Pruning our authors of interest from the faculty data
# by removing the non-unique authors found in their set:
for a in authors_of_interest:
# Finds non-unique authors of interest:
if a not in unique_authors:
file_to_write.write(a + "\n")
return
def remove_non_unique_auth(graph):
with open(NON_UNIQUE_AUTH_PATH, 'r') as file:
for node in file:
if node[-1] == "\n":
node = node[:-1]
graph.remove_node(node)
return
def populate_with_edges(graph, year_of_job):
# Uses PUBLICATIONS_PATH
# inclusive of yoj-1
with open(PUBLICATIONS_PATH, 'r') as file:
csv_reader = csv.reader(file, delimiter=',')
start = 1
for row in csv_reader:
if start:
start -= 1
continue
publication_type, year, num_of_auth, author, title = parse_publication(row)
# Exclude the publications with no year specified or two years specified
# (as was in one single-author publication, manually validated against dblp as having two years):
if year is None:
continue
if year < year_of_job and num_of_auth > 1:
for i in range(len(author) - 1):
for j in range(i + 1, len(author)):
author_i = preprocess_name(author[i])
author_j = preprocess_name(author[j])
if graph.has_node(author_i) and graph.has_node(author_j):
graph.add_edge(author_i, author_j)
print("populate_with_edges len(graph) =", len(graph))
return graph
def preprocess_name(name):
function_output = []
for i in name:
if i.isalpha() or i.isnumeric():
function_output.append(i)
function_output = "".join(function_output)
# name_segments = name.split(" ")
# reordered_name_segments = [name_segments[-1]]
# reordered_name_segments.extend(name_segments[:-1])
#
# print(reordered_name_segments)
# name_list = []
# for segment in reordered_name_segments:
# sub_string = []
# for i in segment:
# if i.isalpha():
# sub_string.append(i)
# else:
# sub_string.append("=")
# name_list.append("".join(sub_string))
#
# finalized_substrings = []
# for i in range(len(name_list)):
# if i < 2:
# if i == 0:
# finalized_substrings.append(name_list[i] + ":")
# else:
# finalized_substrings.append(name_list[i])
# else:
# if i == 2:
# finalized_substrings.append("_" + name_list[i])
# else:
# finalized_substrings.append(name_list[i])
# print(finalized_substrings)
# print("".join(finalized_substrings))
return function_output
def parse_publication(row):
publication_type = row[0]
try:
year = int(row[1][1:-1])
except:
year = None
try:
num_of_auth = int(row[2])
except:
raise ValueError("error")
author = row[3][1:-1].replace("'", "").split(", ")
title = row[4][2:-2]
return publication_type, year, num_of_auth, author, title
def make_edgelist(graph, output_name):
if graph.is_multigraph():
raise TypeError("Graph has parallel edges")
if graph.is_directed():
directed = 1
else:
directed = 0
with open(output_name, 'w') as txt_file:
num_of_nodes = len(graph.nodes)
txt_file.write("{}\t{}\n".format(num_of_nodes, directed))
for edge in graph.edges:
txt_file.write("{}\t{}\n".format(edge[0], edge[1]))
return
def make_nodelist(graph, output_name, attribute_list):
# Requires attribute_list to have "node" at index 0.
with open(output_name, 'w') as txt_file:
header_string = "; ".join(attribute_list)
txt_file.write(header_string + "\n")
for node in range(len(graph.nodes)):
row = [node]
for a in attribute_list[1:]:
row.append(graph.nodes[node][a])
str_row = [str(i) for i in row]
line_string = "; ".join(str_row)
txt_file.write(line_string + "\n")
return
def convert_graphs_to_json():
for year in YEARS_OF_JOB:
graph = nx.Graph()
edgelist_name = "../information-access-clustering/dblp_data/datasets_by_yoj/dblp_yoj_{}_edgelist.txt".format(year)
nodelist_name = "../information-access-clustering/dblp_data/datasets_by_yoj/dblp_yoj_{}_nodelist.txt".format(year)
# Populate graph with edges:
with open(edgelist_name, 'r') as edges_file:
first_line = True
for line in edges_file:
if first_line:
first_line = False
continue
if line[-1] == "\n":
line = line[:-1]
line = [int(i) for i in line.split("\t")]
graph.add_edge(line[0], line[1])
# Assign the attributes to the nodes:
node_to_attr = {}
with open(nodelist_name, 'r') as nodes_file:
first_line = True
for line in nodes_file:
if first_line:
first_line = False
fields = line[:-1].split("; ")
continue
if line[-1] == "\n":
line = line[:-1]
line = line.split("; ")
row = []
for i in range(len(line)):
if i == 0:
row.append(int(line[i]))
else:
try:
row.append(float(line[i]))
except:
row.append(line[i])
node = row[0]
node_to_attr[node] = {}
for i in range(1, len(fields)):
node_to_attr[node][fields[i]] = row[i]
nx.set_node_attributes(graph, node_to_attr)
print("Graph: {} nodes, {} edges".format(len(graph.nodes), len(graph.edges)))
# Jsonify the networkx object:
output_path = "../information-access-clustering/dblp_data/datasets_by_yoj/dblp_yoj_{}.json".format(year)
bgn.graph_to_json(graph, output_path)
return
def main():
if os.path.isfile(NON_UNIQUE_AUTH_PATH):
raise ValueError("File already exists at NON_UNIQUE_AUTH_PATH")
for year_of_job in YEARS_OF_JOB:
graph = nx.Graph()
edgelist_name = "dblp_data/datasets_by_yoj/dblp_yoj_{}_edgelist.txt".format(year_of_job)
nodelist_name = "dblp_data/datasets_by_yoj/dblp_yoj_{}_nodelist.txt".format(year_of_job)
node_dict = read_nodelist()
graph = populate_with_nodes(graph, node_dict)
graph = populate_with_edges(graph, year_of_job)
graph = bgn.largest_connected_component_transform(graph)
graph = nx.convert_node_labels_to_integers(graph, ordering="sorted")
make_edgelist(graph, edgelist_name)
attribute_list = NODE_ATTRIBUTES_TO_PRODUCE
keys = {key for key in graph.nodes[0]}
for a in attribute_list:
try:
keys.remove(a)
except:
continue
for key in keys:
attribute_list.append(key)
make_nodelist(graph, nodelist_name, attribute_list)
print("Dataset created for year_of_job = {} with {} nodes and {} edges\n".format(year_of_job, len(graph.nodes), len(graph.edges)))
convert_graphs_to_json()
return
if __name__ == '__main__':
main()
<file_sep>/C++ code/main.cpp
// Information spreads from source nodes (seeds), over the network (IC model)
// Writes out information access vectors for each node to a file
//configuration - libraries it include
//generate make file
//#include <iostream> //#include <string> //#include <fstream> //#include <vector>
#include <iostream> // std::cout
#include <fstream>
#include <sstream>
#include <stdio.h>
#include <string.h>
#include <map>
#include <string>
//#include <bits/stdc++.h>
#include "graph.cpp"
#include "gen_vectors.h"
#include "simulation.h"
#include "print.h"
using namespace std;
Graph readGraph(string);
vector<int> getSeeds(string);
void selectHeuristic(int, int, float, int, int, int, Graph);
void algDescription();
bool makeNodeMap(map<string, string> &argMap, string);
map<string, string> nodeMap;
int main(int argc, char* argv[]) {
clock_t tStart = clock();
//command line argument implementation from http://www.cplusplus.com/articles/DEN36Up4/
//argv[1] = srcEdges - edgelist data file
//argv[2] = dstVectorFile file to write vectors to
//argv[3] = alpha1 - probability of transmission between nodes in different phd programs
//argv[4] = alpha2 - probability of transmission between nodes in same phd programs
//argv[5] = repNumber - number of simulation repititions
//argv[6] = simSeeds - whether to simulate all nodes as seeds
//argv[7] = srcNodes - nodelist data file
// Loads data in the graph
string edgeFile = argv[1];
// cout << edgeFile;
string nodeFile = argv[7];
// Determines where vectors will be saved
//string outName;
//cout << "Enter file path to save vectors: ";
//cin >> outName;
string outFileName = argv[2];
// Determines whether vectors will be written out column-wise
// cout << "Is this a large network? y/n ";
// cin >> large;
// }
//
// cout << edgeFile;
//map<string, string> nodeMap;
bool rc = makeNodeMap(nodeMap, nodeFile);
cout << "makeNodeMap returned: " << rc << "\n";
// test map looks good...
//cout << "0" << "/" << nodeMap["0"] << "\n";
//cout << "3" << "/" << nodeMap["3"] << "\n";
//cout << "node 2==5 (want no):" << (nodeMap["2"]==nodeMap["5"]);
//cout << "node 2==6 (want yes):" << (nodeMap["2"]==nodeMap["6"]);
Graph netGraph = readGraph(edgeFile);
//netGraph.printGraph(nodeMap);
vector<int> seeds = getSeeds(edgeFile);
// string centerOption = "deg"; //Chooses the center
//cout << "Central close (cent), Max degree (deg), Min max dist (dist): ");
//cin >> option;
// int initSeed = pickCenter(netGraph, centerOption);
// cout << "Center: " << initSeed << endl;
//algDescription();
// int alg; // Reads alg's Name
// cout << "Enter alg's id: ";
// cin >> alg;
//Set Simulation Variables
// cout << "Enter variables: \nrep (1000), maxK (100), gap (5), alpha1 (0.1), maxAlpha1 (0.5)\n";
//int rep, maxK, gap;
//string probStr;
//cout << "alpha:";
//cin >> probStr;
//string repStr;
//cout << "Number of repetitions for simulation:";
//cin >> repStr;
int rep = stoi(argv[5]);
int maxK;
int gap;
maxK = 100, gap = 10;
//float alpha1, maxAlpha1;
// float alpha1 = 0.1, maxAlpha1 = 0.1;
//cin >> rep >> maxK >> gap >> redo >> alpha1 >> maxAlpha1;
bool weightExp = false;//true;
float alpha1 = stof(argv[3]);
float maxAlpha1 = alpha1;
float alpha2 = stof(argv[4]);
float maxAlpha2 = alpha2;
string useAllSeeds = argv[6];
//cout << "Use all seeds? y or n";
//cin >> useAllSeeds;
clock_t tAlph;
for(float alpha_1 = alpha1, alpha_2 = alpha2;
alpha_1 <= maxAlpha1 && alpha_2 <= maxAlpha2;
alpha_1 += 0.1, alpha_2 += 0.1) {
cout << "\n-----alpha_1 = " << alpha_1 << "----alpha_2 = " << alpha_2 <<"-----\n";
tAlph = clock();
if (useAllSeeds=="yes") {
generate_vectors(alpha_1, alpha2, rep, netGraph, nodeMap, outFileName);
} else {
generate_vectors_select_seeds(alpha_1, alpha_2, rep, netGraph, nodeMap, outFileName, seeds);
}
// generate_vectors(alpha, rep, netGraph, outFileName);
// simulation(seeds, alpha, rep, netGraph);
// printProbs(netGraph, alpha, rep, outFileName);
// add a function to write out probabilities
cout << "Time: " << (float)(clock() - tAlph)/CLOCKS_PER_SEC << endl;
}
cout << "Time: " << (float)(clock() - tStart)/CLOCKS_PER_SEC << endl;
return 0;
}
// Reads the network from file
// Format: Number of nodes - Direction of Graph ... Source - Destination
Graph readGraph(string file) {
ifstream input;
input.open(file);
int numV;
input >> numV; // Number of Nodes
cout << "Number of Nodes: " << numV << endl;
Graph netGraph(numV);
bool dir;
input >> dir; // 0: Undirected, 1: Directed
string from, to;
bool isSeed = false;
while (input >> from >> to) {
if (from == "s") {
isSeed = true;
} else if (not isSeed) {
string fromPhd = nodeMap[from];
string toPhd = nodeMap[to];
netGraph.addEdge(stoi(from), stoi(to), fromPhd, toPhd, dir);
}
}
input.close();
return netGraph;
}
//reads nodeFile to add phd values to a map from nodeID-> phd
bool makeNodeMap(map<string, string> &argMap, string file)
{
ifstream inFile(file);
if (not inFile.is_open()) return false;
string line;
while (getline(inFile, line))
{
// stream variable for parsing the line from the file
istringstream ss(line);
// using string for nodeId for now, but should be changed to int
string nodeId;
string phd;
string skip;
// read node, then skip dplp_id and gender, then read phd
getline(ss, nodeId, ';');
getline(ss, skip, ';'); // skip dplp_id
getline(ss, skip, ';'); // skip gender
getline(ss, phd, ';');
//cout << "\"" << nodeId << "\"";
//cout << ", \"" << phd << "\"";
// add line data to map
argMap[nodeId] = phd;
//cout << "\n";
}
return true;
}
vector<int> getSeeds(string file) {
ifstream input;
input.open(file);
vector<int> seeds;
string line;
string s = "s";
bool isSeed = false;
while (input >> line)
{
if (isSeed) {
int seed = stoi(line);
seeds.push_back(seed);
}
else if (line.at(0) == s.at(0)) {
isSeed = true;
// cout << "line 158";
// char * pch;
// int n = line.length();
// line = line.substr(1, n);
// cout << line;
// char charArray[n];
// strcpy(charArray, line.c_str());
// pch = strtok (charArray,"\t");
// while (pch != NULL) {
// int seed;
// try {
// seed = stoi(pch);
// } catch (...){
// cout << pch;
// cout << "Your data file is not in the correct format. See the example and try again.";
// }
// seeds.push_back(seed);
// pch = strtok (NULL, "\t");
// }
}
}
input.close();
return seeds;
}
//
// void selectHeuristic(int algID, int init, float alpha, int rep, int k, int gap, Graph graph) {
// vector<float> results;
//
// switch(algID) {
// case 1:
// results = random(init, alpha, rep, k, gap, graph);
// writeOnFile(results, "random", alpha, k, gap);
// break;
// case 2:
// results = max_deg(init, alpha, rep, k, gap, graph);
// writeOnFile(results, "maxdeg", alpha, k, gap);
// break;
// case 3:
// results = min_deg(init, alpha, rep, k, gap, graph);
// writeOnFile(results, "mindeg", alpha, k, gap);
// break;
// case 4:
// results = k_gonz(init, alpha, rep, k, gap, graph);
// writeOnFile(results, "gonzalez", alpha, k, gap);
// break;
// case 5:
// results = naiveMyopic(init, alpha, rep, k, gap, graph);
// writeOnFile(results, "naivemyopic", alpha, k, gap);
// break;
// case 6:
// results = myopic(init, alpha, rep, k, gap, graph);
// writeOnFile(results, "myopic", alpha, k, gap);
// break;
// case 7:
// results = naiveGreedy_Reach(init, alpha, rep, k, gap, graph, true);
// writeOnFile(results, "naivegreedy", alpha, k, gap);
// break;
// case 8:
// results = greedy_Reach(init, alpha, rep, k, gap, graph, true);
// writeOnFile(results, "greedy", alpha, k, gap);
// break;
// case 9:
// results = naiveGreedy_Reach(init, alpha, rep, k, gap, graph, false);
// writeOnFile(results, "naivereach", alpha, k, gap);
// break;
// case 10:
// results = greedy_Reach(init, alpha, rep, k, gap, graph, false);
// writeOnFile(results, "reach", alpha, k, gap);
// }
// }
//
// void algDescription() {
// cout << "--- \nEnter 1 for 'Random':\n Randomly chooses k nodes" << endl;
// cout << "Enter 2 for 'Max Degree':\n Picks k nodes with maximum degrees" << endl;
// cout << "Enter 3 for 'Min Degree':\n Picks k nodes with minimum degrees" << endl;
// cout << "Enter 4 for 'Gonzalez':\n Each time pich the furthest node from sources -- repeat" << endl;
// cout << "Enter 5 for 'Naive Myopic':\n Runs Simulation -- Picks k min probable nodes" << endl;
// cout << "Enter 6 for 'Myopic':\n Runs Simulation -- Picks the min probable node -- repeat" << endl;
// cout << "Enter 7 for 'Naive Greedy':\n Runs Simulation -- Picks the k nodes that increases min probability the most" << endl;
// cout << "Enter 8 for 'Greedy':\n Runs Simulation -- Picks the node that increases min probability the most -- repeat" << endl;
// cout << "Enter 9 for 'Naive Reach':\n Runs Simulation -- Picks the k nodes that increases average probability the most" << endl;
// cout << "Enter 10 for 'Reach':\n Runs Simulation -- Picks the node that increases average probability the most -- repeat" << endl;
// }
<file_sep>/helper_pipelines/run.sh
#############################################################################################
# This pipeline first runs Python code to generate a network based off the dblp
# format. It pickles the network and also writes it out in the correct format to be
# fed into the C++ code. The C++ code then generates vectors based off the network file
# generated by the before_vectors python pipeline. The after_vectors python pipeline
# then reads in the vectors and unpickles the network created in before_vectors in order to
# ensure the node indices match up. It then performs clustering and cluster analysis using
# the unpickled network and the vectors.
#############################################################################################
python3 clustering_pipeline.py before_vectors
cd C++\ code/
g++ main.cpp -o main -std=c++11
echo "../data/dblp/edgelist.txt" "../data/dblp/vectors.txt" $1 $2 "y"| ./main
cd ..
python3 clustering_pipeline.py after_vectors
<file_sep>/clustering.py
import networkx
class Clustering:
EPSILON = 0.001 # Weight to use on matching graph instead of 0.
def __init__(self, alpha, clustering_lol):
self.alpha = alpha
self.clustering = clustering_lol
self.k = len(self.clustering)
self.labeling = [ i for i in range(0, self.k) ]
def set_labeling(self, label_list):
self.labeling = label_list
def get_labeling(self):
return self.labeling
def get_dict_id_labels(self):
id_labels = {}
for cluster, label in zip(self.clustering, self.labeling):
for point in cluster:
id_labels[point] = label
return id_labels
def node_label(cat, num):
return str(cat) + "." + str(num)
def get_index(node_label):
return int(node_label.split(".")[-1])
def get_intersection_weight(clustlist1, clustlist2):
intersection = set(clustlist1).intersection(clustlist2)
weight = len(intersection)
return weight
def get_percent_weight(clustlist1, clustlist2):
print(" clust1 size:" + str(len(clustlist1)) + " clust2 size:" + str(len(clustlist2)))
intersection = set(clustlist1).intersection(clustlist2)
weight = len(intersection)
print(" intersection size:" + str(weight))
if weight == 0:
return 0
percent = weight / len(clustlist1)
print(" percent:" + str(percent))
return percent
def make_bipartite_graph(clustering1, clustering2):
k = clustering1.k
assert(k == clustering2.k)
graph = networkx.Graph()
for i in range(0, k):
n1 = Clustering.node_label(1, i)
graph.add_node(n1, bipartite=0)
for i in range(0, k):
n2 = Clustering.node_label(2, i)
graph.add_node(n2, bipartite=1)
for i in range(0, k):
for j in range(0, k):
clust1 = clustering1.clustering[i]
clust2 = clustering2.clustering[j]
n1 = Clustering.node_label(1, i)
n2 = Clustering.node_label(2, j)
weight = Clustering.get_intersection_weight(clust1, clust2)
print("n1:" + n1 + " n2:" + n2 + " weight:" + str(weight))
if weight == 0:
weight = Clustering.EPSILON
graph.add_edge(n1, n2, weight = weight)
return graph
def matching_to_dict(matching_dict_tuples):
matching = {}
for start, end in matching_dict_tuples:
matching[start] = end
matching[end] = start
return matching
def set_labeling_maxmatching(clustering_start, clustering_end):
k = clustering_start.k
graph = Clustering.make_bipartite_graph(clustering_start, clustering_end)
# matching = networkx.bipartite.maximum_matching(graph)
matching_tuples = networkx.algorithms.max_weight_matching(
graph, maxcardinality=False, weight='weight')
matching = Clustering.matching_to_dict(matching_tuples)
print(matching)
startlabeling = clustering_start.get_labeling()
print("start labels:" + str(startlabeling))
endlabeling = []
for i in range(0, k):
startnode = Clustering.node_label(1, i)
nodematch = matching[startnode]
j = Clustering.get_index(nodematch)
startlabel = startlabeling[j]
endlabeling.append(startlabel)
clustering_end.set_labeling(endlabeling)
# c1 = Clustering(0.5, [[1,2],[2,3],[1,3]])
# c2 = Clustering(0.5, [[1,2],[1,3],[2,3]])
# Clustering.set_labeling_maxmatching(c1, c2)
<file_sep>/helper_pipelines/graph_examples.py
import utils
import numpy as np
import networkx as nx
from copy import *
import matplotlib.pyplot as plt
import random
def depth_two_star(n):
# n is the number of nodes in the first layer out
G = nx.OrderedGraph() # Allows multiple edges, to use as proxy for closeness in future
# center
G.add_node(0, cluster=None, color=None, activated=False)
# first layer of spokes
for node in range(n):
G.add_node(node, cluster=None, color=None, activated=False)
G.add_edge(0, node) # These graphs are undirected, so only need to add edge one way
# second layer of spokes
count = n
prev_nodes = deepcopy(G.nodes)
for node in prev_nodes:
if node != 0:
G.add_node(count, cluster=None, color=None, activated=False)
G.add_edge(node, count)
count += 1
return G
def independent_cascade(graph, seeds, alpha, rounds):
activated = seeds
for i in seeds:
graph.node[i]["activated"] = True
graph_after_each_round = [deepcopy(graph)]
for round in range(rounds):
new_active = []
for k in activated:
for neighbor in graph.neighbors(k):
num = random.random()
if num <= alpha and not graph.node[neighbor]["activated"]:
graph.node[neighbor]["activated"] = True
new_active.append(neighbor)
activated = new_active
print(activated)
graph_after_each_round.append(deepcopy(graph))
return graph_after_each_round
def color(graph):
node_to_color = []
for node in graph.nodes:
if graph.node[node]["activated"]:
node_to_color.append("#1d9bf0")
else:
node_to_color.append("#afb5c9")
return node_to_color
def main():
graph = depth_two_star(10)
graphs = independent_cascade(graph, [0], 0.4, 3)
# pos = nx.spring_layout(graph)
for graph in graphs:
color_map = color(graph)
print(graph)
# Figure out how to keep order of the nodes consistent in drawing
nx.draw_kamada_kawai(graph, with_labels=True, node_color=color_map)
# nx.draw(graph, with_labels=True)
plt.draw()
plt.show()
if __name__ == "__main__":
main()
<file_sep>/data_rep.py
#implementation from https://www.python-graph-gallery.com/heatmap/ and
#https://www.kite.com/python/docs/seaborn.heatmap
#https://blog.quantinsti.com/creating-heatmap-using-python-seaborn/
#https://towardsdatascience.com/heatmap-basics-with-pythons-seaborn-fb92ea280a6c
import seaborn
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#datafile = "output_files/analysis/analysis1-5.txt"
#outfile = "output_files/analysis/heatmap1-5.png"
def main():
#heatmap(datafile, outfile)
return 1
#TO DO: make one heatmap file and just pass in analysis name
def pcaHeatmap(datafile, outfile):
df = pd.read_csv(datafile, header=1, usecols=[0,1,2,3])
shapedDF = df.pivot(index='alpha2', columns='alpha1', values='correlation')
print(shapedDF)
fig, ax = plt.subplots(figsize=(11, 9))
# plot heatmap
seaborn.heatmap(shapedDF, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = 'PCA Rank Correlations\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
return
def zachKNNHeatmap(datafile, outfile):
df = pd.read_csv(datafile, header=1, usecols=[0,1,2])
shapedDF = df.pivot(index='alpha2', columns='alpha1', values='accuracy')
print(shapedDF)
fig, ax = plt.subplots(figsize=(11, 9))
# plot heatmap
seaborn.heatmap(shapedDF, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = 'Zach KNN Average Accuracy\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
return
def KNNHeatmap(datafile, outfile):
df = pd.read_csv(datafile, header=1, usecols=[0,1,2])
shapedDF = df.pivot(index='alpha2', columns='alpha1', values='accuracy')
print(shapedDF)
fig, ax = plt.subplots(figsize=(11, 9))
# plot heatmap
seaborn.heatmap(shapedDF, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = 'KNN Average Mean Squared Error\nAcross K Folds\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
return
def randomForestHeatmap(datafile, outfile):
df = pd.read_csv(datafile, header=1, usecols=[0,1,2,3])
shapedDF = df.pivot(index='alpha2', columns='alpha1', values='mean')
print(shapedDF)
fig, ax = plt.subplots(figsize=(11, 9))
# plot heatmap
seaborn.heatmap(shapedDF, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = 'Random Forests Average Mean Squared Error\nAcross K Folds\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
return
def SVRHeatmap(datafile, outfile):
df = pd.read_csv(datafile, header=1, usecols=[0,1,2,3])
shapedDF = df.pivot(index='alpha2', columns='alpha1', values='mean')
print(shapedDF)
fig, ax = plt.subplots(figsize=(11, 9))
# plot heatmap
seaborn.heatmap(shapedDF, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = 'SVR Average Mean Squared Error Across K Folds\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
return
def dummyHeatmap(datafile, outfile):
df = pd.read_csv(datafile, header=1, usecols=[0,1,2,3])
shapedDF = df.pivot(index='alpha2', columns='alpha1', values='mean')
print(shapedDF)
fig, ax = plt.subplots(figsize=(11, 9))
# plot heatmap
seaborn.heatmap(shapedDF, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = 'Dummy Average Mean Squared Error Across K Folds\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
return
def vsDummyHeatmap(analysisName, realfile, dummyfile, outfile):
real_df = pd.read_csv(realfile, header=1, usecols=[0,1,2])
dummy_df = pd.read_csv(dummyfile, header=1, usecols=[0,1,2])
if analysisName == 'PCA':
return
if (analysisName == 'ZachKNN') or (analysisName == 'KNN'):
real_df['accuracy'] = dummy_df['mean']/real_df['accuracy']
shaped_result = real_df.pivot(index='alpha2', columns='alpha1', values='accuracy')
print(shaped_result)
fig, ax = plt.subplots(figsize=(11, 9))
seaborn.heatmap(shaped_result, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = analysisName+' Average Mean Squared Error \nDivided by Dummy Mean Squared Error\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
if (analysisName == 'RandomForest') or (analysisName == 'SVR'):
real_df['mean'] = dummy_df['mean']/real_df['mean']
shaped_result = real_df.pivot(index='alpha2', columns='alpha1', values='mean')
print(shaped_result)
fig, ax = plt.subplots(figsize=(11, 9))
seaborn.heatmap(shaped_result, cmap="Blues", linewidth=0.3,
cbar_kws={"shrink": .8}).invert_yaxis()
title = analysisName+' Average Mean Squared Error \nDivided by Dummy Mean Squared Error\n'.upper()
plt.title(title, loc='left')
plt.savefig(outfile)
else:
print("unable to make vsDummy heatmap for", analysisName)
return
main()
<file_sep>/cluster_consistency/cluster_labeling.py
import csv
import pandas as pd
import random
import sys
from clustering import Clustering
def string_to_list(stringlist):
stringlist = stringlist[1:-1]
print(stringlist)
parts = stringlist.split(",")
print(parts)
num_parts = [ int(x) for x in parts ]
return num_parts
def read_clustering_file(filename):
"""
Given a CSV file where rows are alpha values and entries are cluster lists this returns
a list of alpha values and a list of lists of clustering objects.
CSV input example:
alpha,c1,c2
0.1,"[1,2,3]","[4,5]"
0.2,"[4,5]","[1,2,3]"
0.3,"[1,2,3]","[4,5]"
"""
alpha_clustering_lol = []
with open (filename) as csvfile:
reader = csv.DictReader(csvfile)
cluster_names = []
alphas = []
for row in reader:
alpha = ''
alpha_clusters = []
for clustname, clustlist in row.items():
if alpha == '':
alpha = clustlist
else:
clustlist = string_to_list(clustlist)
alpha_clusters.append(clustlist)
clustering = Clustering(alpha, alpha_clusters)
alphas.append(alpha)
alpha_clustering_lol.append(clustering)
return alphas, alpha_clustering_lol
def clustering_to_labeling(alpha_clustering_lol):
last = None
for clustering in alpha_clustering_lol:
if last == None:
last = clustering
else:
print("---------")
Clustering.set_labeling_maxmatching(last, clustering)
last = clustering
def write_clustering_labels_to_file(alphas, alpha_clustering_lol, filename):
id_alpha_label_dod = {}
for alpha, clustering in zip(alphas, alpha_clustering_lol):
dict_id_labels = clustering.get_dict_id_labels()
for pointid in dict_id_labels:
if not pointid in id_alpha_label_dod:
id_alpha_label_dod[pointid] = {'id': pointid}
id_alpha_label_dod[pointid][alpha] = dict_id_labels[pointid]
f = open(filename, "w")
with open(filename, 'w') as csvfile:
colnames = ['id'] + alphas
writer = csv.DictWriter(csvfile, fieldnames = colnames)
writer.writeheader()
for pointid in id_alpha_label_dod:
writer.writerow(id_alpha_label_dod[pointid])
def main(clustering_file, labeling_file):
# MAIN: takes as input a clustering file and outputs a labeling file
print(clustering_file)
alphas, alpha_clustering_lol = read_clustering_file(clustering_file)
clustering_to_labeling(alpha_clustering_lol)
write_clustering_labels_to_file(alphas, alpha_clustering_lol, labeling_file)
return
<file_sep>/helper_pipelines/eigengap_calculator.py
import scipy
from scipy.sparse import csgraph
# from scipy.sparse.linalg import eigsh
from numpy import linalg as LA
from networkx import *
import matplotlib.pyplot as plt
import numpy as np
'''
Code from: https://github.com/ciortanmadalina/high_noise_clustering/blob/master/spectral_clustering.ipynb
'''
def eigenDecomposition(A, plot=True, topK=5):
"""
:param A: Affinity matrix
:param plot: plots the sorted eigen values for visual inspection
:return A tuple containing:
- the optimal number of clusters by eigengap heuristic
- all eigen values
- all eigen vectors
This method performs the eigen decomposition on a given affinity matrix,
following the steps recommended in the paper:
1. Construct the normalized affinity matrix: L = D−1/2ADˆ −1/2.
2. Find the eigenvalues and their associated eigen vectors
3. Identify the maximum gap which corresponds to the number of clusters
by eigengap heuristic
References:
https://papers.nips.cc/paper/2619-self-tuning-spectral-clustering.pdf
http://www.kyb.mpg.de/fileadmin/user_upload/files/publications/attachments/Luxburg07_tutorial_4488%5b0%5d.pdf
"""
L = csgraph.laplacian(A, normed=True)
n_components = A.shape[0]
# LM parameter : Eigenvalues with largest magnitude (eigs, eigsh), that is, largest eigenvalues in
# the euclidean norm of complex numbers.
# eigenvalues, eigenvectors = eigsh(L, k=n_components, which="LM", sigma=1.0, maxiter=5000)
eigenvalues, eigenvectors = LA.eig(L)
if plot:
plt.title('Largest eigen values of input matrix')
plt.scatter(np.arange(len(eigenvalues)), eigenvalues)
plt.grid()
# Identify the optimal number of clusters as the index corresponding
# to the larger gap between eigen values
index_largest_gap = np.argsort(np.diff(eigenvalues))[::-1][:topK]
nb_clusters = index_largest_gap + 1
return nb_clusters, eigenvalues, eigenvectors
def choose_spectral_k(graph):
node_list = list(graph.nodes())
adj_matrix = nx.to_numpy_matrix(graph,
nodelist=node_list) # Converts graph to an adj matrix with adj_matrix[i][j] represents weight between node i,j.
affinity_matrix = adj_matrix
k, _, _ = eigenDecomposition(affinity_matrix)
print(f'Optimal number of clusters {k}')
plt.show()
<file_sep>/README.md
# Running experiments
The code in C++ code/, main.py, vector_analysis.py, and data_rep.py runs an
independent cascade simulation to generate vectors, runs analysis on those vectors,
and represents the results visually.
Run the code:
- to run an experiment, type the following:
python3 main.py config_files/testing.ini
where testing.ini is the config file corresponding to your experiment
Directory Structure:
- Make sure you have an output directory whose path matches the one in the config
file variable [FILES][outputDir]. This is where your results will go
- For organizational purposes you should have two directories above this repository
named "data" and "results". These should hold any needed input data (such as the files
referenced in config variables [FILES][inEdgesFile], [FILES][inNodesFile], [FILES][inHoldEdgesFile],
[FILES][inHoldNodesFile], [FILES][inAnalysisDir])
- When writing paths to directories in the config file, always include the slash
at the end of the path to a directory (i.e, use .../Foo/Bar/ NOT .../Foo/Bar)
Config Files:
- find config files in the config_files folder
- see EXAMPLE.ini for a guide of how to use config files
- generally try to have a unique [GENERAL][experimentName] for each file
- NOTE: config files from previous experiments will not always work when run again.
this is because as the pipeline grown, I add things to the config file. So always
check the format of the most recent config file (EXAMPLE.ini) before running
When adding an analysis method, make sure to add:
- variable to config file
- global variable to main
- clause to main.run_analysis()
- analysis function in vector_analysis.py
- clause to main.run_datarep()
# information-access-clustering info
This repository consists of code that runs the full Information Access Clustering pipeline:
1. Reconstructing graphs and edgelists for independent cascade simulations.
2. Performing simulations that generate vector files, given alpha values.
3. Tuning the hyperparameter K, the number of clusters for information access clustering, through Gap Statistic, Silhouette Analysis, and Elbow Method.
4. Running the Information Access Clustering and relevant statistical analyses.
5. Clustering the graph with existing methods for deeper analysis.
# Execution Files
1. run.sh: bash script for running "build_*" scripts, simulations, and after_vectors pipeline.
2. run_k.sh: for finding the K hyperparameter.
Please edit the bash scripts with the specific methods you'd like to run, as well as the relevant hyperparameters
the methods use in main_pipelines (specified inside).
# References to the Used Code Bases:
Tuning K:
- [Gap Statistic](https://anaconda.org/milesgranger/gap-statistic/notebook)
- [Silhouette Analysis](https://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_silhouette_analysis.html)
- [Elbow Method](https://towardsdatascience.com/k-means-clustering-with-scikit-learn-6b47a369a83c)
Clustering:
- [Spectral Clustering](https://scikit-learn.org/stable/modules/generated/sklearn.cluster.SpectralClustering.html)
- [Fluid Communities](https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.community.asyn_fluid.asyn_fluidc.html#networkx.algorithms.community.asyn_fluid.asyn_fluidc)
- [Role2Vec](https://github.com/benedekrozemberczki/karateclub)
- [Louvain](https://github.com/taynaud/python-louvain)
- [Core/Periphery](https://github.com/skojaku/core-periphery-detection/blob/7d924402caa935e0c2e66fca40457d81afa618a5/cpnet/Rombach.py)
Hypothesis Testing:
- [Kolmogorov-Smirnov](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.ks_2samp.html)
- [Kruskal-Wallis](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.kruskal.html)
- [Fisher Exact](https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.fisher_exact.html)
Additional Methods:
- [Connected Components](https://networkx.org/documentation/stable/reference/algorithms/component.html)
- [Adjusted Rand Index](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.adjusted_rand_score.html)
# information access regression info
When running regression experiments make sure to add the heatmap function in data_rep.py
TO DO:
- make one heatmap function and just pass in analysis name
<file_sep>/helper_pipelines/read_coauthorship.py
# import utils
import numpy as np
import networkx as nx
import json
import time
from progress.bar import Bar
import csv
def create_star_matrix(n, directed):
X = []
first_row = [0]
for node in range(n - 1):
first_row.append(1)
X.append(first_row)
for node in range(n - 1):
node_row = [1]
for neighbor in range(n - 1):
node_row.append(0)
X.append(node_row)
return np.array(X)
def make_networkx(c_style_filename):
file = open(c_style_filename, "r")
lines = file.readlines()
first_line = lines[0].split("\t")
if (first_line[1] == "0"):
G = nx.MultiGraph() # Allows multiple edges, to use as proxy for closeness in future
else:
G = nx.MultiDiGraph()
for line in lines:
line = line.split("\t")
node = int(line[0])
neighbor = int(line[1])
G.add_node(node, cluster=None, color=None)
G.add_node(neighbor, cluster=None, color=None)
G.add_edge(node, neighbor)
return G
def make_network_with_citations(coauthorship_filename, citations_filename):
file = open(coauthorship_filename, "r")
coauthor_lines = file.readlines()
g = nx.Graph()
name_to_citations, gender_to_citations, phd_to_citations, name_to_phd_rank = get_citations(citations_filename)
# print(gender_to_citations)
person_to_index = {}
index = 0
for index2, line in enumerate(coauthor_lines):
cpy = line.split(",")
if cpy[0][-1] == "\n":
cpy[0] = cpy[0][:-1]
if cpy[0] not in person_to_index:
person_to_index[cpy[0]] = index
index += 1
counter = 0
for line in coauthor_lines:
counter += 1
line = line.split(",")
if line[-1][-1] == "\n":
line[-1] = line[-1][:-1]
node = person_to_index[line[0]]
# citations = name_to_citations[eliminate_middle_inits(line[0])]
if line[0][2:] in name_to_citations:
citations = name_to_citations[line[0][2:]]
gender = gender_to_citations[line[0][2:]]
phd = phd_to_citations[line[0][2:]]
phd_rank = name_to_phd_rank[line[0][2:]]
else:
citations = -1
gender = 'not found'
# print('not found')
g.add_node(node, cluster=None, color=None, citation_count=citations, dblp_id=line[0], gender=gender, phd=phd,
phd_rank=phd_rank)
for neighbor in line[1:]:
neighbor_index = person_to_index[neighbor]
# neighbor_citations = name_to_citations[eliminate_middle_inits(neighbor)]
if neighbor[2:] in name_to_citations:
neighbor_citations = name_to_citations[neighbor[2:]]
neighbor_gender = gender_to_citations[neighbor[2:]]
neighbor_phd = phd_to_citations[neighbor[2:]]
neighbor_phd_rank = name_to_phd_rank[neighbor[2:]]
else:
neighbor_citations = -1
neighbor_gender = 'not found'
# print ("not found")
neighbor_phd = "not found"
g.add_node(neighbor_index, cluster=None, color=None, citation_count=neighbor_citations, dblp_id=neighbor,
gender=neighbor_gender, phd=neighbor_phd, phd_rank=neighbor_phd_rank)
g.add_edge(node, neighbor_index)
return g
def eliminate_middle_inits(name):
new_name = name
for index, char in enumerate(name[:-1]):
if char == ".":
new_name = name[:index - 2] + name[index + 1:]
return new_name
def university_to_rank(university):
'''
Takes in the name of a university and returns its rank
(according to the ranking system described in https://advances.sciencemag.org/content/1/1/e1400005)
'''
with open("data/dblp/faculty_data - schools.csv") as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
if row[0] == university[1:]:
return float(row[2])
return -1
def get_citations(filename):
'''
Takes in file output by gs_scrape. Returns dictionaries mapping dblp ids to
metadata about scholars.
'''
dict = {} # citation count dictionary
gender_dict = {}
phd_dict = {}
phd_rank_dict = {}
job_rank_dict = {}
with open(filename) as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
line_count = 0
for row in csv_reader:
dblp_id = row[-3][1:] # Cuts off space at start of id
dict[dblp_id] = int(row[-1])
gender_dict[dblp_id] = row[1]
phd_dict[dblp_id] = row[2]
phd_rank_dict[dblp_id] = university_to_rank(row[2])
job_rank_dict[dblp_id] = university_to_rank(row[3])
return dict, gender_dict, phd_dict, phd_rank_dict, job_rank_dict
def read_data(filename):
# Reads data in from adjancency list text file to adjancency list dict
file = open(filename, "r")
authors = file.readlines()
graph_for_igraph = []
logical_graph = {}
for line in authors:
line = line[:-1]
line = line.split(",")
author = line[0]
logical_graph[author] = []
for j in line[1:]:
logical_graph[author].append(j)
graph_for_igraph.append({'from': author, 'to': j})
person_to_index = {}
for index, node in enumerate(logical_graph):
person_to_index[node] = index
graph = {}
for node in logical_graph:
graph[person_to_index[node]] = []
for neighbor in logical_graph[node]:
graph[person_to_index[node]].append(person_to_index[neighbor])
return graph, graph_for_igraph
def write_graph_as_edges(graph, filename):
# Writes adjancency list graph to filename
file = open(filename, "w")
n = len(graph)
file.write(str(n) + "\t" + str(1) + "\n")
person_to_index = {}
for index, node in enumerate(graph):
person_to_index[node] = index
for index, node in enumerate(graph):
for neighbor in graph[node]:
file.write(str(index) + "\t" + str(person_to_index[neighbor]) + "\n")
file.close()
# def write_graph_with_seeds(graph, filename, seeds):
# # Writes adjancency list graph to filename
# print(seeds)
# file = open(filename, "w")
# n = len(graph)
# file.write(str(n) + "\t" + str(1) + "\n")
# person_to_index = {}
# for index, node in enumerate(graph):
# person_to_index[node] = index
# print(enumerate(graph))
# for index, node in enumerate(graph):
# for neighbor in graph[node]:
# file.write(str(index) + "\t" + str(person_to_index[neighbor]) + "\n")
# file.write("s\t")
# for seed in seeds:
# file.write(str(person_to_index[graph.node[seed]])+"\t")
# file.close()
# help from https://stackoverflow.com/questions/4454298/prepend-a-line-to-an-existing-file-in-python
def write_graph(graph, seeds, filename, include_seeds):
'''
Writes out graph into a file formatted as an edgelist so that it can be read into
the C++ code to create vectors.
seeds should be a list of the node ids for any seed nodes if include_seeds= True
filename is the file to write the edgelist to
include_seeds should be False if the vectors are going to be created using all
the nodes as seeds, and True if the vectors will only use a subset of nodes as seeds.
'''
nx.write_edgelist(graph, filename, data=False)
insert_str = str(graph.number_of_nodes()) + "\t 0"
f = open(filename, 'r');
s = f.read();
f.close()
l = s.splitlines();
l.insert(0, insert_str);
s = '\n'.join(l)
f = open(filename, 'w');
f.write(s + "\n");
f.close();
if (include_seeds):
with open(filename, "a") as f:
f.write("s\t")
for seed in seeds:
f.write(str(seed) + "\t")
def create_star():
# Creates a 20-pointed star graph
graph = {}
points = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20]
graph = {point: [0] for point in points}
graph[0] = points
print(graph)
return graph
def create_networkx_star(n, directed):
# n is number of nodes in the star
if (not directed):
G = nx.MultiGraph() # Allows multiple edges, to use as proxy for closeness in future
else:
G = nx.MultiDiGraph()
G.add_node(0, cluster=None, color=None)
for node in range(n - 1):
G.add_node(node, cluster=None, color=None)
G.add_edge(0, node)
G.add_edge(node, 0)
return G
def read_in_vectors(filename):
'''
Takes in a filepath with probability vectors and returns a dict of prob vectors
'''
file = open(filename, "r")
nodes = file.readlines()
vectors = {}
for index, line in enumerate(nodes):
line = line.split(",")
# print("the length of the line is ", len(line))
node = index
vectors[node] = []
for prob in line[:-1]:
# print(prob)
vectors[node].append(float(prob))
return vectors
def read_in_seed_vectors(filename):
'''
Takes in a filepath with probability vectors and returns a dict of prob vectors
'''
file = open(filename, "r")
nodes = file.readlines()
vectors = {}
for index, line in enumerate(nodes):
if index != 0: # deals with first line that lists seeds
line = line.split(",")
# print("the length of the line is ", len(line))
node = index
vectors[node] = []
for prob in line[:-1]:
# print(prob)
vectors[node].append(float(prob))
return vectors
def create_hardcoded_stars(alpha, n):
# n is number of spokes, (it does not include the center)
vectors = []
center_vector = [1]
for i in range(n):
center_vector.append(alpha)
vectors.append(center_vector)
for i in range(n):
ith_vector = [alpha]
for j in range(n):
if (i == j):
ith_vector.append(1)
else:
ith_vector.append(alpha ** 2)
vectors.append(ith_vector)
return np.array(vectors)
# def create_mini_gs_graph(id, levels_out):
# # This function converts the google scholar file to a file that can be run through c code
# start_time = time.time()
# graph = {id:[]}
# paper_to_authors = {}
# with open(in_filename, 'r') as fobj:
# lines = fobj.readlines()
# for line in lines:
# if line == "\n":
# pass
# line = line.encode().decode('utf-8-sig')
# data = json.loads(line)
# print (type(data))
# print ("processing" + data['name'] + " in first for loop after" + str(time.time() - start_time) + "seconds")
# for paper in data['paper']:
# if paper['paper_id'] in paper_to_authors:
# paper_to_authors[paper['paper_id']].append(data['google_id'])
# else:
# paper_to_authors[paper['paper_id']] = [data['google_id']]
#
# # Attempt to clear up some memory
# del lines
# del line
# del data
#
# for paper in paper_to_authors:
# print ("processing " + paper + "in second for loop after" + str(time.time() - start_time) + "seconds")
# in_network = False
# for author in paper_to_authors[paper]:
# if author in graph:
# in_network = True
# if in_network:
# for author in paper_to_authors[paper]:
# if author in graph:
# graph[author] += paper_to_authors[paper]
# else:
# graph[author] = paper_to_authors[paper]
# # print(graph[author])
# # coauthors = []
# # for paper in datum['paper']:
# # for author in paper['author_list']:
# # coauthors += ''
# # graph[datum['google_id']] = coauthors
# return graph
def gs_to_c_style(in_filename, out_filename):
# This function converts the google scholar file to a file that can be run through c code
start_time = time.time()
graph = {}
paper_to_authors = {}
author_to_index = {}
index = -1
with open(in_filename, 'r') as fobj:
lines = fobj.readlines()
n = len(lines)
for line in lines:
if line == "\n":
pass
line = line.encode().decode('utf-8-sig')
data = json.loads(line)
print(type(data))
print("processing" + data['name'] + " in first for loop after" + str(time.time() - start_time) + "seconds")
index += 1
for paper in data['paper']:
if paper['title'] in paper_to_authors:
paper_to_authors[paper['title']].append(index)
else:
paper_to_authors[paper['title']] = [index]
# Attempt to clear up some memory
del lines
del line
del data
# write out to file
file = open(out_filename, "w")
bar = Bar('Processing')
file.write(str(n) + "\t1\n")
count = 0
for paper in paper_to_authors:
print("processing paper" + str(count) + "in second for loop after" + str(time.time() - start_time) + "seconds")
count += 1
for author in paper_to_authors[paper]:
for author2 in paper_to_authors[paper]:
bar.next()
if author != author2:
file.write(str(author) + "\t" + str(author2) + "\n")
file.close()
bar.finish()
# file = open(filename, "w")
# n = len(graph)
# file.write(str(n) + "\t" + str(1) + "\n")
# person_to_index = {}
# for index, node in enumerate(graph):
# person_to_index[node] = index
# for index, node in enumerate(graph):
# for neighbor in graph[node]:
# file.write(str(index) + "\t" + str(person_to_index[neighbor]) + "\n")
# file.close()
# def gs_to_c_style(in_filename, out_filename):
# # This function converts the google scholar file to a file that can be run through c code
# start_time = time.time()
# graph = {}
# paper_to_authors = {}
# with open(in_filename, 'r') as fobj:
# lines = fobj.readlines()
# for line in lines:
# if line == "\n":
# pass
# line = line.encode().decode('utf-8-sig')
# data = json.loads(line)
# print (type(data))
# print ("processing" + data['name'] + " in first for loop after" + str(time.time() - start_time) + "seconds")
# for paper in data['paper']:
# if paper['paper_id'] in paper_to_authors:
# paper_to_authors[paper['paper_id']].append(data['google_id'])
# else:
# paper_to_authors[paper['paper_id']] = [data['google_id']]
#
# # Attempt to clear up some memory
# del lines
# del line
# del data
#
# for paper in paper_to_authors:
# print ("processing in second for loop after" + str(time.time() - start_time) + "seconds")
# for author in paper_to_authors[paper]:
# if author in graph:
# graph[author] += paper_to_authors[paper]
# else:
# graph[author] = paper_to_authors[paper]
# # print(graph[author])
# # coauthors = []
# # for paper in datum['paper']:
# # for author in paper['author_list']:
# # coauthors += ''
# # graph[datum['google_id']] = coauthors
# print(graph)
# write_graph_as_edges(graph, out_filename)
#
def writeout_clusters(graph, filename):
with open(filename, "w") as f:
for node_int in range(len(graph.nodes)):
f.write(str(node_int) + ", " + str(graph.nodes[node_int]["cluster"]) + "\n")
def make_full_network_with_citations(coauthorship_filename, citations_filename):
file = open(coauthorship_filename, "r")
coauthor_lines = file.readlines()
g = nx.Graph()
name_to_citations, gender_to_citations = get_citations(citations_filename)
# person_to_index = {}
# index = 0
# for index2, line in enumerate(coauthor_lines):
# cpy = line.split(",")
# if cpy[0][-1] == "\n":
# cpy[0] = cpy[0][:-1]
# if cpy[0] not in person_to_index:
# index += 1
# person_to_index[cpy[0]] = index
counter = 0
for line in coauthor_lines:
counter += 1
line = line.split(",")
if line[-1][-1] == "\n":
line[-1] = line[-1][:-1]
node = line[0]
# citations = name_to_citations[eliminate_middle_inits(line[0])]
if line[0][2:] in name_to_citations:
citations = name_to_citations[line[0][2:]]
else:
citations = -1
g.add_node(node)
for neighbor in line[1:]:
neighbor_index = neighbor
# neighbor_citations = name_to_citations[eliminate_middle_inits(neighbor)]
if line[0][2:] in name_to_citations:
neighbor_citations = name_to_citations[line[0][2:]]
else:
neighbor_citations = -1
g.add_node(neighbor_index)
g.add_edge(node, neighbor_index)
return g
def make_network_with_ids(coauthorship_filename, citations_filename):
'''
Creates a networkx network based on format of dblp files. Includes node attributes
based on faculty_data:
cluster=None, color=None, citation_count, dblp_id, gender, phd (school name), phd_rank (rank of school)
Coauthorship_filename should indicate a file in adjacency list format, where each
node is a dblp id.
Citations_filename should indicate a file that lists each dblp id followed by its
number of citations.
'''
file = open(coauthorship_filename, "r")
coauthor_lines = file.readlines() # each line is a list of coauthors for one author
g = nx.Graph() # undirected, no parallel edges
# get all metadata for nodes:
name_to_citations, gender_to_citations, phd_to_citations, name_to_phd_rank, name_to_job_rank = get_citations(
citations_filename)
# add all nodes and edges to graph:
for line in coauthor_lines:
line = line.split(",")
if line[-1][-1] == "\n": # eliminates trailing newline
line[-1] = line[-1][:-1]
node = line[0]
if line[0][2:] in name_to_citations: # [2:] fixes disparity with "a/" e.g. in dblp ids
citations = name_to_citations[line[0][2:]]
gender = gender_to_citations[line[0][2:]]
phd = phd_to_citations[line[0][2:]]
phd_rank = name_to_phd_rank[line[0][2:]]
job_rank = name_to_job_rank[line[0][2:]]
else:
citations = -1
gender = 'not found'
phd = "not found"
phd_rank = -1
job_rank = -1
g.add_node(node, cluster=None, color=None, citation_count=citations, dblp_id=line[0], gender=gender, phd=phd,
phd_rank=phd_rank, job_rank=job_rank)
for neighbor in line[1:]:
neighbor_index = neighbor
if neighbor[2:] in name_to_citations:
neighbor_citations = name_to_citations[neighbor[2:]]
neighbor_gender = gender_to_citations[neighbor[2:]]
neighbor_phd = phd_to_citations[neighbor[2:]]
neighbor_phd_rank = name_to_phd_rank[neighbor[2:]]
neighbor_job_rank = name_to_job_rank[neighbor[2:]]
else:
neighbor_citations = -1
neighbor_gender = "not found"
neighbor_phd = "not found"
neighbor_phd_rank = -1
neighbor_job_rank = -1
g.add_node(neighbor_index, cluster=None, color=None, citation_count=neighbor_citations, dblp_id=neighbor,
gender=neighbor_gender, phd=neighbor_phd, phd_rank=neighbor_phd_rank, job_rank=neighbor_job_rank)
g.add_edge(node, neighbor_index)
return g
if __name__ == "__main__":
# gs_to_c_style('data/google_scholar.txt', 'data/google_scholar_c_style.txt')
# graph, igraphy_graph = read_data("data/dblp/coauthorship_one_hop_out.txt")
# igraph_ex = utils.make_graph(igraphy_graph)
# utils.display_graph(igraph_ex, "first_20_coauthorship.png")
# write_graph_as_edges(graph, "data//dblp/coauthorship_one_hop_c_style.txt")
graph = make_full_network_with_citations("data/dblp/coauthorship_correct.txt", "data/dblp/dblp_id_citations")
graph = nx.convert_node_labels_to_integers(graph)
print(graph.number_of_nodes())
nx.write_edgelist(graph, "data/dblp/dblp_correct.edgelist",
data=False) # need to write out indices rather than ids (double check c code to confirm)
<file_sep>/example_hyperparameter_tuning/role2vec_dblp.py
"""DBLP-specific wrappers for mp.role2vec_pipeline() pipeline."""
import main_pipelines as mp
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.INPUT_PICKLED_GRAPH = "output_files/main_files/{}_pickle".format(mp.IDENTIFIER_STRING)
mp.K = 2
mp.LABELING_FILE = "output_files/main_files/{}_K{}_labeling_file_role2vec.csv".format(mp.IDENTIFIER_STRING, mp.K)
mp.EXPERIMENT = "role2vec"
mp.role2vec_pipeline()
# mp.statistical_analyses()
return
if __name__ == "__main__":
main()
<file_sep>/results/Exp1-4FULLanalysis/Exp1-4KNNConfigRecord.ini
;DO NOT USE FOLLOWING CHARACTERS IN KEYNAMES: ?{}|&~![()^"
;experimentName: name of the experiment
;generateVectors: yes-run simulation no- dont run sim, use input vector files
[GENERAL]
experimentName = Exp1-4KNN
generateVectors = no
runAnalysis = yes
runDataRep = yes
simAllSeeds = yes
repititions = 10000
alphaList = 0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95
[FILES]
inEdgesFile = input/real_input/dblp_yoj_2000_edgelist.txt
inNodesFile = input/real_input/dblp_yoj_2000_nodelist.txt
outputDir = output_files/
outVectorDir = vectors/
inVectorDir = /home/dataquacs/zachbroadman/results/Exp1-4/vectors/
outAnalysisDir = analysis/
inAnalysisDir = /home/dataquacs/zachbroadman/results/Exp1-4/exp1-4results/
[ANALYSIS]
;methods [SVR, randomForest, KNN, PCA]
usePCA = yes
useZachKNN = yes
useKNN = yes
useSVR = yes
useRandomForest = yes
knnNeighbors = 3
knnRepititions = 10
<file_sep>/results/Exp1-4KNNK15_v0/Exp1-4KNNK15ConfigRecord.ini
;DO NOT USE FOLLOWING CHARACTERS IN KEYNAMES: ?{}|&~![()^"
;experimentName: name of the experiment
;generateVectors: yes-run simulation no- dont run sim, use input vector files
[GENERAL]
experimentName = Exp1-4KNNK15
generateVectors = no
runAnalysis = yes
runDataRep = yes
runHoldout = no
genHoldVectors = no
simAllSeeds = yes
repititions = 10000
alphaList = 0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95
alpha1list = 0.05
alpha2list = 0.1
[FILES]
inEdgesFile = input/real_input/dblp_yoj_2000_edgelist.txt
inNodesFile = input/real_input/dblp_yoj_2000_nodelist.txt
inHoldEdgesFile = input/real_input/holdout/dblp_yoj_2001_edgelist.txt
inHoldNodesFile = input/real_input/holdout/dblp_yoj_2001_nodelist.txt
outputDir = output_files/
outHoldVecDir = holdoutVectors/
outVectorDir = vectors/
inVectorDir = /home/dataquacs/zachbroadman/results/Exp1-4/vectors/
inHoldVecDir = EMPTYPATH
outAnalysisDir = analysis/
outHoldAnalysisDir = holdoutAnalysis/
inAnalysisDir = /home/dataquacs/zachbroadman/results/Exp1-4/exp1-4results/
inHoldAnalysisDir = EMPTYPATH
[ANALYSIS]
;methods [SVR, randomForest, KNN, PCA]
vsDummy = no
usePCA = no
useZachKNN = no
useKNN = yes
useSVR = no
useRandomForest = no
knnNeighbors = 15
knnRepititions = 10
pcaComponents = 500
<file_sep>/example_hyperparameter_tuning/fluidcr_ari_and_sa_dblp.py
"""DBLP-specific wrappers for mp.iac_vs_x_ari() for fluidcr and experimentation pipeline."""
import main_pipelines as mp
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.INPUT_PICKLED_GRAPH = "output_files/main_files/{}_pickle".format(mp.IDENTIFIER_STRING)
mp.K = 2
mp.IAC_LABELING_FILE = "output_files/main_files/{}_K{}_labeling_file_iac.csv".format(mp.IDENTIFIER_STRING, mp.K)
main_labeling_file = "output_files/fluidcr/dblp_K2_labeling_file_fluidcr.csv"
mp.preprocess_fluidcr(main_labeling_file)
for seed in mp.SEEDS:
mp.LABELING_FILE = "output_files/fluidcr/{}_labeling_files_fluidcr/{}_K{}_labeling_file_fluidcrs{}.csv".format(
mp.IDENTIFIER_STRING, mp.IDENTIFIER_STRING, mp.K, seed)
mp.EXPERIMENT = "fluidcrs{}".format(seed)
mp.ALPHA_VALUES = [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
mp.iac_vs_x_ari()
mp.statistical_analyses()
return
if __name__ == '__main__':
main()
<file_sep>/config_files/experiment1-4.ini
;DO NOT USE FOLLOWING CHARACTERS IN KEYNAMES: ?{}|&~![()^"
[GENERAL]
;name of the experiment - will be used to generate directory stucture
experimentName = Exp1-4
;generateVectors (yes/no) if no, must provide path to input vectors in inVectorDir
generateVectors = yes
;runAnalysis (yes/no)
runAnalysis = no
;runDataRep (yes/no) optional, if yes run data visualization methods
runDataRep = no
;runholdout (yes/no) if yes, run the entire holdout pipeline (including analysis)
runHoldout = no
;genHoldVectors (yes/no) if yes, run IC simulation for holdout data
; if no, provide inHoldVecDir
genHoldVectors = no
;simAllSeeds (yes/no) if yes, run simulation for all seeds
simAllSeeds = yes
;repititions (int) number of times to run the IC simulation
repititions = 10000
;alpha1list (comma-separated alpha1 float values)
; example: 0.1,0.2,0.35,0.5
alpha1list = 0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95
;alpha1list (comma-separated alpha1 float values; same format as alpha1list)
alpha2list = 0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95
[FILES]
;inEdgesFile (path to input edgelist)
inEdgesFile = ../data/dblp_jobrankprediction/dblp_yoj_2000_edgelist.txt
;inNodesFile (path to input nodelist)
inNodesFile = ../data/dblp_jobrankprediction/dblp_yoj_2000_nodelist.txt
;inHoldEdgesFile (path to input edgelist of holdout data)
inHoldEdgesFile = ../data/dblp_jobrankprediction/holdout/dblp_yoj_2001_edgelist.txt
;inHoldNodesFile (path to input nodelist of holdout data)
inHoldNodesFile = ../data/dblp_jobrankprediction/holdout/dblp_yoj_2001_nodelist.txt
;outputDir (output directory) used to build directory structure and output files
outputDir = output_files/
;outVectorDir (vector output directory) this is build as a subdirectory of outputDir
outVectorDir = vectors/
;outHoldVectorDir (holdout vector output directory) this is build as a subdirectory of outputDir
outHoldVecDir = holdoutVectors/
;inVectorDir (input vector directory) path to the directory of input vectors
; the analysis will be run on every file in the directory
; make sure the namestyle is: vectors<experimentName>_<alpha1>_<alpha2>_.txt
inVectorDir = EMPTYPATH
;inHoldVecDir (input holdout vector direction) same conventions as inVectorDir
inHoldVecDir = EMPTYPATH
;outAnalysisDir (path to analysis output directory) build as a subdirectory of outputDir
outAnalysisDir = analysis/
;outHoldAnalysisDir (path to holdout analysis output directory) build as a subdirectory of outputDir
outHoldAnalysisDir = holdoutAnalysis/
;inAnalysisDir (path to analysis input) use this if you're ONLY running datarep
inAnalysisDir = EMPTYPATH
;inHoldAnalysisDir (path to holdout analysis input) use this if you're ONLY running datarep
inHoldAnalysisDir = EMPTYPATH
[ANALYSIS]
;methods [SVR, randomForest, KNN, PCA]
;vsDummy (yes/no) if yes: compare each analysis to Dummy regressor
vsDummy = no
;usePCA (yes/no) if yes, run pearson coefficient analysis
usePCA = no
;useZachKNN (yes/no) if yes, run zach KNN analysis
useZachKNN = no
;useKNN (yes/no) if yes, run KNN analysis
useKNN = yes
;useSVR (yes/no) if yes, run SVR analysis
useSVR = no
;useRandomForest (yes/no) if yes, run Random Forest analysis
useRandomForest = no
;knnNeighbors (int) neighbors for use in KNN
knnNeighbors = 15
;knnRepititions (int) number of repititions for use only in zachKNN
knnRepititions = 10
;pcaComponents (int) number of components for use in PCA
pcaComponents = 500
<file_sep>/main_pipelines.py
"""
Main experimental pipelines.
"""
import matplotlib
import report_file_object_class as rfo
import networkx as nx
import matplotlib.pyplot as plt
import seaborn as sns
import pickle
import sys
import math
import os
import csv
import copy
import build_cosponsorship as cosponsorship
import build_dblp as dblp
import build_twitch_network as twitch
from sklearn.cluster import KMeans, SpectralClustering
from scipy import stats
from helper_pipelines import read_coauthorship as read
from helper_pipelines import clustering_pipeline as cp
from helper_pipelines import eigengap_calculator as eigen
import pyreadr
import pandas as pd
import build_generic_network as bgn
import statistics
from sklearn.metrics import pairwise_distances
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.cm as cm
from cluster_consistency import cluster_labeling
from karateclub import Role2Vec
from collections import OrderedDict
import cpnet
import numpy as np
# ==== IDENTIFIER: ==== #
# Unique identifier string for each data set.
# Must be either one word (eg. "twitch") or several words using a hyphen
# (eg. "strong-house"). Do NOT use "_" (underscore).
IDENTIFIER_STRING = "twitch"
# ==== PARAMETERS FOR TUNING K = NUMBER OF CLUSTERS: ==== #
MIN_CLUSTERS = 1
MAX_CLUSTERS = 16
N_REFS = 4
# ==== PIPELINE AFTER_VECTORS PARAMETERS: ==== #
K = -1 # Hyperparameter k.
ATTRIBUTE = "" # Node attribute, about which to create distribution or bar graphs.
INPUT_PICKLED_GRAPH = "" # Path to a pickled graph with nodes and relevant attributes.
VECTOR_FILE_INVARIANT = "" # Invariant for the vector txt files for different alpha values.
REPORT_FILE_PATH = "" # File to which write the results of the clustering experiment.
REPORT_FILE = rfo.ReportFileObject(REPORT_FILE_PATH) # Instance of the report file (for convenience in writing to it).
# Alpha values for other data sets:
ALPHA_VALUES = [] # Must match the alpha values used for creating the vector files.
PLOT_PDF = 1 # Whether the attribute is for plotting a PDF or not; if 1, plot_attribute_distributions() will be run;
# if 0, plot_attribute_bar().
PDF_LOG = 0 # If PLOT_PDF = 1, when drawing a PDF, should we take log(attribute)?
LOG_BASE = 10 # If PDF_LOG = 1, what is the base for log used in creating a PDF.
# (Optional) parameter for dataset_pdf(), which plots the PDF of the entire dataset.
DATASET_LOG = 1 # If 0, input numbers for PDF are raw; if 1, log of LOG_BASE is taken of them.
# (Optional) Colors used for the graphs.
COLOR_PALETTE = ["#FFC107", "#1E88E5", "#2ECE54", "#EC09D7", "#DDEC4E", "#D81B50", "#CCD85D", "#3701FA", "#D39CA7", "#27EA9F", "#5D5613", "#DC6464"]
BAR_GRAPH_COLOR_PALETTE = ["#BA65A4", "#1A4D68"]
# ==== PARAMETERS FOR CLUSTERING METHODS BEYOND INFORMATION ACCESS AND SPECTRAL: ==== #
IAC_LABELING_FILE = ""
LABELING_FILE = ""
EXPERIMENT = ""
# Repeated fluid communities clustering pipeline hyperparameters:
SEEDS = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] # Seeds used for random number generation states.
# For core-periphery:
CP_THRESHOLD = 0.5 # Threshold for turning continuous "coreness" measure for each node into binary core/periphery data.
def main():
# General experimentation pipeline:
# 1. Pipelines "build_*" to build a relevant graph pickle and edgelist for simulations: in main_pipelines.
# 2. Simulations to generate vector files for each of the alpha values: with run.sh.
# 3. Gap, Silhouette, and/or Elbow methods to find K: in main_pipelines.
# 4. Pipeline "after_vectors" to run clustering Information Access and Spectral Clustering methods
# and generate plots: in main_pipelines.
# 5. Run "repeated_fluidc", "role2vec_pipeline", or "core_periphery" clustering methods and
# use additional methods for deeper analysis.
# ========== #
# 1. Pipelines "build_*":
if sys.argv[1] == "build_twitch":
twitch.main()
elif sys.argv[1] == "build_cosponsorship":
cosponsorship.main()
elif sys.argv[1] == "build_dblp":
dblp.main()
# 2. Files for simulations can be found in output_files directory.
# 3. Methods for finding K.
elif sys.argv[1] == "granger_gap_statistic":
granger_gap_statistic_wrapper()
elif sys.argv[1] == "silhouette_analysis":
silhouette_analysis_wrapper()
elif sys.argv[1] == "elbow_method":
elbow_method_wrapper()
# 4. Pipeline after_vectors for information access and spectral clustering and plotting the relevant graphs.
elif sys.argv[1] == "after_vectors":
pipeline_after_vectors()
# 5. Other clustering methods:
elif sys.argv[1] == "repeated_fluidc":
repeated_fluidc()
elif sys.argv[1] == "fluid_communities":
fluid_communities()
elif sys.argv[1] == "role2vec_pipeline":
role2vec_pipeline()
elif sys.argv[1] == "core_periphery":
core_periphery()
# Additional methods for analysis:
# Outputs the adjusted rand index scores between clusterings of information access and some other method.
elif sys.argv[1] == "iac_vs_x_ari":
iac_vs_x_ari()
# Computes the mean of adjusted rand index scores across repeated fluid communities clusterings for each alpha value.
elif sys.argv[1] == "mean_ari":
mean_ari()
# Runs the Fisher Exact test on the clusters; hardcoded with K=2.
elif sys.argv[1] == "fisher_exact":
fisher_exact()
# Counts the number of connected components in each cluster, given a clustering in a labeling file.
elif sys.argv[1] == "count_cc":
count_cc_wrapper()
# Given some clustering in the LABELING_FILE, runs statistical analyses for one of DBLP, Co-sponsorship, and Twitch
# based on its default attributes and settings.
elif sys.argv[1] == "statistical_analyses":
statistical_analyses()
# Plot the PDF of the entire dataset.
elif sys.argv[1] == "dataset_pdf":
dataset_pdf()
# Calculate the adjusted rand index between two clusterings
elif sys.argv[1] == "calc_ari":
calculate_ari()
# Creates a .csv file that maps each node to its KMeans cluster (reproducible with random_state=1).
elif sys.argv[1] == "clustering_map":
clustering_map()
# Creates a .csv file that maps cluster compositions to clusters.
elif sys.argv[1] == "composition_map":
composition_map()
# Computes the composition of probabilities in the information access vector files.
elif sys.argv[1] == "probability_composition":
probability_composition()
# Generates profiles of nodes in .csv (to be used along with edgelist to reconstruct graphs).
elif sys.argv[1] == "generate_profiles":
generate_profiles()
return
# "granger_gap_statistic"
def granger_gap_statistic_wrapper():
"""Wrapper for granger_gap_statistic. Output will be displayed in terminal."""
for alpha_value in ALPHA_VALUES:
print("\n{}: Gap Statistic for {}".format(IDENTIFIER_STRING, alpha_value))
X = read.read_in_vectors(VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:]))
X = [X[i] for i in X]
X = np.array(X)
gap_statistic_output = granger_gap_statistic(X, alpha_value)
print("Optimal number of clusters is {} among {}".format(gap_statistic_output[0], gap_statistic_output[1]))
return
# Granger Gap Statistic code adapted from https://anaconda.org/milesgranger/gap-statistic/notebook
def granger_gap_statistic(data, alpha_value):
"""
Notes from the source:
Calculates KMeans optimal K using Gap Statistic from Tibshirani, Walther, Hastie
Params:
data: ndarry of shape (n_samples, n_features)
nrefs: number of sample reference datasets to create
maxClusters: Maximum number of clusters to test for
Returns: (gaps, optimalK)
"""
gaps = np.zeros((len(range(1, MAX_CLUSTERS)),))
resultsdf = pd.DataFrame({'clusterCount': [], 'gap': []})
for gap_index, k in enumerate(range(1, MAX_CLUSTERS)):
# Holder for reference dispersion results
refDisps = np.zeros(N_REFS)
# For n references, generate random sample and perform kmeans getting resulting dispersion of each loop
for i in range(N_REFS):
# Create new random reference set
randomReference = np.random.random_sample(size=data.shape)
# Fit to it
km = KMeans(k)
km.fit(randomReference)
refDisp = km.inertia_
refDisps[i] = refDisp
# Fit cluster to original data and create dispersion
km = KMeans(k)
km.fit(data)
origDisp = km.inertia_
# Calculate gap statistic
gap = np.log(np.mean(refDisps)) - np.log(origDisp)
# Assign this loop's gap statistic to gaps
gaps[gap_index] = gap
resultsdf = resultsdf.append({'clusterCount': k, 'gap': gap}, ignore_index=True)
x_data = [i for i in range(1, MAX_CLUSTERS)]
y_data = [gaps[i - 1] for i in x_data]
plt.scatter(x_data, y_data)
plt.plot(x_data, y_data)
plt.xticks(x_data)
plt.title("Value of K vs. Gap Statistic\nNumber of references used: {}".format(N_REFS))
plt.xlabel("Value of K")
plt.ylabel("Gap Statistic")
plt.savefig("output_files/{}_gap_alpha_{}.png".format(IDENTIFIER_STRING, alpha_value), bbox_inches='tight')
plt.close()
return (gaps.argmax() + 1,
resultsdf) # Plus 1 because index of 0 means 1 cluster is optimal, index 2 = 3 clusters are optimal
# "silhouette_analysis"
def silhouette_analysis_wrapper():
"""Wrapper for silhouette_analysis. Output will be displayed in terminal."""
for alpha_value in ALPHA_VALUES:
print("\n{}: Silhouette Analysis for {}".format(IDENTIFIER_STRING, alpha_value))
X = read.read_in_vectors(VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:]))
X = [X[i] for i in X]
X = np.array(X)
silhouette_analysis(X, alpha_value)
return
# Silhouette Analysis code adapted from https://scikit-learn.org/stable/auto_examples/cluster/plot_kmeans_silhouette_analysis.html
def silhouette_analysis(X, alpha_value):
"""
Main function for silhouette_analysis.
:param X: array of information access vectors.
:param alpha_value: alpha value.
:return: None.
"""
for n_clusters in range(2, MAX_CLUSTERS):
# Create a subplot with 1 row and 2 columns
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
# The 1st subplot is the silhouette plot
# The silhouette coefficient can range from -1, 1 but in this example all
# lie within [-0.1, 1]
ax1.set_xlim([-0.1, 1])
# The (n_clusters+1)*10 is for inserting blank space between silhouette
# plots of individual clusters, to demarcate them clearly.
ax1.set_ylim([0, len(X) + (n_clusters + 1) * 10])
# Initialize the clusterer with n_clusters value and a random generator
# seed of 10 for reproducibility.
clusterer = KMeans(n_clusters=n_clusters, random_state=10)
cluster_labels = clusterer.fit_predict(X)
# The silhouette_score gives the average value for all the samples.
# This gives a perspective into the density and separation of the formed
# clusters
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters,
"The average silhouette_score is :", silhouette_avg)
# Compute the silhouette scores for each sample
sample_silhouette_values = silhouette_samples(X, cluster_labels)
y_lower = 10
for i in range(n_clusters):
# Aggregate the silhouette scores for samples belonging to
# cluster i, and sort them
ith_cluster_silhouette_values = \
sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i) / n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper),
0, ith_cluster_silhouette_values,
facecolor=color, edgecolor=color, alpha=0.7)
# Label the silhouette plots with their cluster numbers at the middle
ax1.text(-0.05, y_lower + 0.5 * size_cluster_i, str(i))
# Compute the new y_lower for next plot
y_lower = y_upper + 10 # 10 for the 0 samples
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
# The vertical line for average silhouette score of all the values
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([]) # Clear the yaxis labels / ticks
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
# 2nd Plot showing the actual clusters formed
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1], marker='.', s=30, lw=0, alpha=0.7,
c=colors, edgecolor='k')
# Labeling the clusters
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='o',
c="white", alpha=1, s=200, edgecolor='k')
for i, c in enumerate(centers):
ax2.scatter(c[0], c[1], marker='$%d$' % i, alpha=1,
s=50, edgecolor='k')
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.savefig(
"output_files/{}_sil_alpha_{}_cluster_{}.png".format(IDENTIFIER_STRING, str(alpha_value)[2:], n_clusters))
plt.close(fig)
return
# "elbow_method"
def elbow_method_wrapper():
"""Wrapper for elbow_method. Output will be displayed in terminal."""
print("running!")
for alpha_value in ALPHA_VALUES:
print("\n{}: Elbow Method for {}".format(IDENTIFIER_STRING, alpha_value))
vector_file_path = VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:])
vectors = read.read_in_vectors(vector_file_path)
elbow_method(vector_file_path, vectors, MIN_CLUSTERS, MAX_CLUSTERS)
return
# Elbow_method code adapted from https://towardsdatascience.com/k-means-clustering-with-scikit-learn-6b47a369a83c
def elbow_method(vector_file, vectors, min_k, max_k):
"""
Creates elbow graphs for choosing k (number of clusters) for the clustering methods.
:param vector_file: vector file path.
:param vectors: dict of information access vectors by nodes.
:param min_k: minimum number of clusters to calculate distortion for.
:param max_k: maximum number of clusters to calculate distortion for.
:return: None.
"""
X = np.array(list(vectors.values()))
distortions = []
for i in range(min_k, max_k):
print("On k value " + str(i))
kmeans = KMeans(n_clusters=i, random_state=1).fit(X)
distortions.append(kmeans.inertia_)
print(kmeans.inertia_)
# plot
print(distortions)
plt.plot(range(min_k, max_k), distortions, marker='o')
plt.xticks(range(min_k, max_k))
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
vector_file_name = vector_file[:-4].split("_")
plt.title("Information Access Clustering Elbow Plot (alpha = 0.{})".format(vector_file_name[-2][1:]))
plt.savefig("output_files/{}_elbow_{}_{}.png".format(IDENTIFIER_STRING, vector_file_name[-2], vector_file_name[-1]),
bbox_inches='tight')
plt.close()
return
# "after_vectors"
def pipeline_after_vectors():
"""Driver function for the after_vectors pipeline.
Runs information access and spectral clustering methods
and the relevant statistical analysis for the given ATTRIBUTE."""
# Loads the input pickled graph into a local variable graph.
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
# Begins Information Access Clustering.
# Prints the passed string in the terminal and writes it to the report file.
REPORT_FILE.print("\n================INFORMATION ACCESS==================")
labeling_file = "output_files/{}_K{}_labeling_file_iac.csv".format(IDENTIFIER_STRING, K)
if not os.path.isfile(labeling_file):
# composition_map executes information access clustering and saves a composition_map file.
clustering_file = composition_map()
# cluster_labeling uses that file to create a matrix of relabeled clusters.
cluster_labeling.main(clustering_file, labeling_file)
cluster_dict = read_in_clusters(labeling_file)
# For each alpha value, performs the information access clustering and plots the results.
for alpha_value in ALPHA_VALUES:
graph = assign_clusters(graph, cluster_dict, alpha_value)
vector_file_path = VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:])
REPORT_FILE.print("\n+++++{}+++++\n".format(vector_file_path))
plot_all_attributes(graph, "information_access", vector_file_path=vector_file_path, alpha_value=alpha_value)
# Begins Spectral Clustering.
REPORT_FILE.print("\n================SPECTRAL==================")
spectral_labeling_file = "output_files/{}_K{}_labeling_file_spectral.csv".format(IDENTIFIER_STRING, K)
if not os.path.isfile(spectral_labeling_file):
spectral_clustering_file = spectral_composition()
cluster_labeling_spectral(spectral_clustering_file, spectral_labeling_file)
spectral_cluster_dict = read_in_generic(spectral_labeling_file)
graph = assign_generic_clusters(graph, spectral_cluster_dict)
plot_all_attributes(graph, "spectral")
return
# "composition_map" (placed here for Top-Down Design)
def composition_map():
"""
Creates a file that shows the composition (by nodes) of the information access clusters.
:return: a str path to the output file.
"""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
output_filename = "output_files/{}_K{}_composition_map.csv".format(IDENTIFIER_STRING, K)
with open(output_filename, 'a') as file:
fieldnames = ["Alpha_Values"]
fieldnames.extend(["Cluster {}".format(k) for k in range(K)])
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for alpha_value in ALPHA_VALUES:
print("Composition map for alpha = {}".format(alpha_value))
vector_file_path = VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:])
vectors = read.read_in_vectors(vector_file_path)
# Clusters the nodes: the vertices have a "cluster" attribute with a number of the cluster to which they were
# assigned. If the loop has performed the loop one, updates the "cluster" values for the same graph based
# on the clustering from the new vector file corresponding to the current alpha value.
graph = information_access_clustering(vectors, K, graph)
clusters_total = {i: [] for i in range(K)}
for node_int in range(len(graph.nodes)):
j = graph.nodes[node_int]["cluster"]
clusters_total[j].append(node_int)
row = [alpha_value]
row.extend(clusters_total[k] for k in range(K))
user_obj_writer.writerow(row)
return output_filename
def information_access_clustering(vectors, k, graph):
"""
Runs Information Access Clustering on the graph.
:param vectors: dict of information access vectors by nodes.
:param k: number of clusters to enforce.
:param graph: networkx graph.
:return: networkx graph, having nodes with a populated "cluster" attribute.
"""
X = np.array(list(vectors.values()))
labels = KMeans(n_clusters=k, random_state=1).fit_predict(X)
for node in graph.nodes:
graph.nodes[node]["cluster"] = labels[node]
# Although the graph itself is mutated by the function above,
# returns a graph pointer for consistency.
return graph
def read_in_clusters(cluster_label_file):
"""
Reads a labeling file into format: {node: {alpha: cluster, alpha: cluster…}…}}
:param cluster_label_file: path to the lableing file.
:return: clustering dict.
"""
cluster_dict = {}
with open(cluster_label_file, "r") as f:
lines = csv.reader(f)
first = True
for row in lines:
if first:
alpha_values = [float(alpha_value) for alpha_value in row[1:]]
first = False
else:
node = int(row[0])
cluster_dict[node] = {}
for index in range(1, len(row)):
alpha = alpha_values[index - 1]
cluster_dict[node][alpha] = int(row[index])
return cluster_dict
def assign_clusters(graph, cluster_dict, alpha):
"""
From the clustering dict, assigns the cluster label to each node in graph.
:param graph: networkx graph.
:param cluster_dict: clustering dict created by read_in_clusters.
:param alpha: alpha value.
:return: networkx graph, having nodes with a populated "cluster" attribute.
"""
for node in graph.nodes:
cluster = int(cluster_dict[node][alpha])
graph.nodes[node]["cluster"] = cluster
return graph
def plot_all_attributes(graph, cluster_method, vector_file_path=None, alpha_value=None):
"""
Decides which graphs to plot based on whether the ATTRIBUTE is continuous or discrete.
If continuous, Kolmogorov-Smirnov and Kruskal–Wallis tests are also performed.
:param graph: networkx graph.
:param cluster_method: cluster method label (e.g. "iac", "spectral", "role2vec", etc.).
:param vector_file_path: path to vector files (vector file invariant) if "iac".
:param alpha_value: alpha value if "iac".
:return: None.
"""
if PLOT_PDF:
plot_attribute_distributions(graph, cluster_method, vector_file_path=vector_file_path, alpha_value=alpha_value, k_clusters=K)
else:
plot_attribute_bar(graph, cluster_method, vector_file_path=vector_file_path, alpha_value=alpha_value, k_clusters=K)
return
def plot_attribute_distributions(graph, cluster_method, vector_file_path=None, alpha_value=None,
identifier_string=IDENTIFIER_STRING, k_clusters=K, attribute=ATTRIBUTE,
pdf_log=PDF_LOG, log_base=LOG_BASE, color_palette=COLOR_PALETTE,
report_file=REPORT_FILE):
"""
Plots the distribution of the continuous ATTRIBUTE for nodes in each cluster.
:param graph: networkx graph.
:param cluster_method: cluster method label (e.g. "iac", "spectral", "role2vec", etc.).
:param vector_file_path: path to vector files (vector file invariant) if "iac".
:param alpha_value: alpha value if "iac".
:param identifier_string: dataset identifier string (e.g. "dblp", "twitch", etc.)
:param k_clusters: number of clusters to enforce.
:param attribute: attribute to use for plotting the distribution.
:param pdf_log: whether to take the log of the attribute value (boolean: True or False).
:param log_base: if True, the log base.
:param color_palette: color palette to be used for plotting the graphs.
:param report_file: report file object to document the statistical test results (Kolmogorov-Smirnov and Kruskal–Wallis).
:return: None.
"""
if k_clusters < 2:
raise ValueError("k_clusters must be more than 1")
clusters_total = {cluster: [] for cluster in range(k_clusters)}
no_attribute_dict = {cluster: 0.0 for cluster in range(k_clusters)}
# Processes the data -- nodes' available attribute values -- to be used for the analyses.
for node in graph.nodes:
cluster = graph.nodes[node]["cluster"]
# A node can either have the ATTRIBUTE or not: node["attribute"] or node.
# If has ATTRIBUTE, it either has a value for ATTRIBUTE or not: node["attribute"] = value or node["attribute"].
# If it has a value, the value can be either a str type or an int/float type.
# If it's str type, the string can be a word or a str of a number.
# All of these are handled by the "try" section,
# assuming that the attribute value that is unavailable is represented by None.
try:
value = float(graph.nodes[node][attribute])
if pdf_log:
clusters_total[cluster].append(math.log(value, log_base))
else:
clusters_total[cluster].append(value)
except:
no_attribute_dict[cluster] += 1
# Computes and writes cluster sizes, clusters' portions from the total,
# and the percentages of available nodes in them.
summarize_clusters(clusters_total, no_attribute_dict, k_clusters, attribute, report_file)
plt.figure(figsize=(12, 10))
color_counter = 0
for cluster in clusters_total:
input = [i for i in clusters_total[cluster]]
for i in input:
if i < 0:
print(i)
# print(input)
try:
sns.distplot(input, hist=False, kde=True,
kde_kws = {'linewidth': 3},
label=str(cluster), norm_hist=True, color=color_palette[color_counter])
except:
pass
color_counter += 1
# Runs and writes the results of Pairwise Kolmogorov-Smirnov and Kruskal-Wallis tests."""
kolmogorov_smirnov_test(clusters_total, k_clusters, report_file)
kruskal_wallis_test(clusters_total, k_clusters, report_file)
# Settings for x and y ranges for different experiments
# if attribute == "views":
# plt.xlim(-100000, 200000)
# plt.xlim(-100000, 500000)
# plt.xlim(-1000000, 2000000)
# if attribute == "followers_count":
# plt.xlim(-100000, 200000)
# plt.xlim(-50000, 100000)
# if attribute == "average_favorite_count":
# plt.xlim(-1000, 2000)
# plt.xlim(-550, 1000)
# if attribute == "average_retweet_count":
# plt.xlim(-500, 2000)
# plt.xlim(-400, 1000)
# if attribute == "world_system":
# plt.ylim(0, 1.5)
plt.legend()
# Depending on whether we're taking log of the values, writes the corresponding x-axis label.
if pdf_log:
plt.xlabel("log({}) with base {}".format(attribute, log_base))
else:
plt.xlabel(attribute)
# Writes the y-axis label.
plt.ylabel("PDF")
# Depending on the clustering method, writes the corresponding title and saves the plot with a unique name.
if cluster_method == "information_access":
vector_file_name_tokens = vector_file_path[:-4].split("_")
print(vector_file_name_tokens)
if pdf_log:
plt.title("Density at log({}) for different clusters (alpha = {})".format(attribute, alpha_value))
else:
plt.title("Density at {} for different clusters (alpha = {})".format(attribute, alpha_value))
plt.savefig("output_files/{}_PDF_K{}_{}_{}_{}_vs_{}.png".format(identifier_string, k_clusters,
vector_file_name_tokens[-2],
vector_file_name_tokens[-1], attribute,
cluster_method), bbox_inches='tight')
else:
if pdf_log:
plt.title("Density at log({}) for different clusters".format(attribute))
else:
plt.title("Density at {} for different clusters".format(attribute))
plt.savefig(
"output_files/{}_PDF_K{}_{}_vs_{}.png".format(identifier_string, k_clusters, attribute, cluster_method),
bbox_inches='tight')
plt.close()
return
def summarize_clusters(clusters_total, no_attribute_dict, k_clusters, attribute, report_file):
"""
Computes and writes cluster sizes, clusters' portions from the total,
and the percentages of available nodes in them.
:param clusters_total: dict {cluster: [attr_value1, attr_value2, ...]}.
:param no_attribute_dict: dict {cluster: num of nodes with no attribute value}.
:param k_clusters: number of clusters to enforce.
:param attribute: node attribute at hand.
:param report_file: report file object to document the summary.
:return: None.
"""
# Computes and writes the cluster sizes.
cluster_sizes = {cluster: len(clusters_total[cluster]) for cluster in range(k_clusters)}
report_file.print("\nCluster sizes:" + str(cluster_sizes))
# Finds the total number of nodes that have available attribute values.
total_num_of_nodes = 0
for cluster in cluster_sizes:
total_num_of_nodes += cluster_sizes[cluster]
portions = {}
# For each cluster, writes its portion from the total and the percent of available nodes in it.
for cluster in cluster_sizes:
# Finds and writes the portion of the cluster from the total.
portion = cluster_sizes[cluster] / total_num_of_nodes
portions[cluster] = portion
report_file.print("\n" + "Portion of {} from the total: {}".format(cluster, portion))
# Finds and writes the percent available nodes in the cluster.
available_percent = cluster_sizes[cluster] / (cluster_sizes[cluster] + no_attribute_dict[cluster])
report_file.print("\n" + f"Percent with {attribute} available in cluster {cluster}: {available_percent}")
# Run chi2 test to see whether there is a relationship between cluster and having ATTRIBUTE data:
num_with_data = np.array(list(cluster_sizes.values()))
num_without_data = np.array(list(no_attribute_dict.values()))
r_c_table = np.array((num_with_data, num_without_data))
try:
g, p, dof, expctd = stats.chi2_contingency(r_c_table)
report_file.print(
"\n" + f"pvalue from chi2 two-way test of significant relationship between cluster and having {attribute} data: {p}")
except ValueError as e:
report_file.print(str(e))
return
def kolmogorov_smirnov_test(clusters_total, k_clusters, report_file):
"""
Runs and writes the results of Pairwise Kolmogorov-Smirnov test.
:param clusters_total: dict {cluster: [attr_value1, attr_value2, ...]}.
:param k_clusters: number of clusters to enforce.
:param report_file: report file object to document the result.
:return: None.
"""
for i in range(k_clusters):
current_num = k_clusters - 1 - i
for j in range(current_num):
report_file.print("\n{} to {}".format(j, current_num))
test_output = stats.ks_2samp(clusters_total[j], clusters_total[current_num])
report_file.print("\n" + str(test_output))
return
def kruskal_wallis_test(clusters_total, k_clusters, report_file):
"""
Runs and writes the results of Kruskal-Wallis test.
:param clusters_total: dict {cluster: [attr_value1, attr_value2, ...]}.
:param k_clusters: number of clusters to enforce.
:param report_file: report file object to document the result.
:return: None.
"""
arg_list = [clusters_total[i] for i in range(k_clusters)]
report_file.print("\nkruskal-wallis, {}-clusters:\n".format(k_clusters))
test_output = stats.kruskal(*arg_list)
report_file.print(str(test_output) + "\n")
return
def plot_attribute_bar(graph, cluster_method, vector_file_path=None, alpha_value=None,
identifier_string=IDENTIFIER_STRING, k_clusters=K, attribute=ATTRIBUTE,
color_palette=BAR_GRAPH_COLOR_PALETTE, report_file=REPORT_FILE):
"""
Plots a bar graph of the cluster composition for the discrete ATTRIBUTE.
:param graph: networkx graph.
:param cluster_method: cluster method label (e.g. "iac", "spectral", "role2vec", etc.).
:param vector_file_path: path to vector files (vector file invariant) if "iac".
:param alpha_value: alpha value if "iac".
:param identifier_string: dataset identifier string (e.g. "dblp", "twitch", etc.)
:param k_clusters: number of clusters to enforce.
:param attribute: attribute to use for plotting the distribution.
:param color_palette: color palette to be used for plotting the graphs.
:param report_file: report file object to document the statistical test results (Kolmogorov-Smirnov and Kruskal–Wallis).
:return: None.
"""
# Holder for categorical values of the attribute: when we take a set of it,
# we can determine the nodes' values without hard-coding them.
nodes = []
clusters_total = {cluster: [] for cluster in range(k_clusters)}
no_attribute_dict = {cluster: 0.0 for cluster in range(k_clusters)}
for node in graph.nodes:
node_cluster = graph.nodes[node]["cluster"]
try:
if graph.nodes[node][attribute] is not None:
# Since the data type is categorical, there is no need to convert to int or float or take log.
value = graph.nodes[node][attribute]
# Relabels the binary attribute to the attribute name itself for interpretability.
if value == 0 or value == "0" or value == "False" or value is False:
value = "not {}".format(attribute)
elif value == 1 or value == "1" or value == "True" or value is True:
value = attribute
clusters_total[node_cluster].append(value)
nodes.append(value)
except:
no_attribute_dict[node_cluster] += 1
continue
report_file.print(str([("Cluster {}".format(i), len(clusters_total[i])) for i in clusters_total]))
total_size = len(nodes)
if total_size == 0:
raise ValueError("Zero nodes")
set_of_attr_values = set(nodes)
list_of_attr_values = sorted(set_of_attr_values)
x_values = [i for i in range(k_clusters)]
attr_sections = {}
for attr_value in list_of_attr_values:
y_values = [clusters_total[a_cluster].count(attr_value)/len(clusters_total[a_cluster]) for a_cluster in x_values]
attr_sections[attr_value] = y_values
print(y_values)
offset = [0 for i in x_values]
for_legend_values = []
for_legend_labels = []
color_counter = 0
for attr_value in list_of_attr_values:
bar_container_object = plt.bar(x_values, attr_sections[attr_value], bottom=offset,
color=color_palette[color_counter])
for_legend_values.append(bar_container_object[0])
for_legend_labels.append(attr_value)
offset = np.add(offset, attr_sections[attr_value]).tolist()
color_counter += 1
plt.xlabel('Clusters')
plt.xticks(x_values)
plt.ylabel('Probability')
plt.legend(for_legend_values, for_legend_labels)
if cluster_method == "information_access":
vector_file_name_tokens = vector_file_path[:-4].split("_")
print(vector_file_name_tokens)
plt.title('Frequency of {} across\n{} clusters\n(alpha = {})'.format(attribute, cluster_method, alpha_value))
plt.savefig("output_files/{}_BG_K{}_{}_{}_{}_vs_{}.png".format(identifier_string, k_clusters,
vector_file_name_tokens[-2],
vector_file_name_tokens[-1], attribute,
cluster_method),
bbox_inches='tight')
else:
plt.title('Frequency of {} across\n{} clusters'.format(attribute, cluster_method))
plt.savefig(
"output_files/{}_BG_K{}_{}_vs_{}.png".format(identifier_string, k_clusters, attribute, cluster_method),
bbox_inches='tight')
plt.close()
return
def spectral_composition():
"""
Creates a file that shows the composition (by nodes) of the spectral clusters.
:return: a str path to the output file.
"""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
output_filename = "output_files/{}_K{}_composition_map_spectral.csv".format(IDENTIFIER_STRING, K)
with open(output_filename, 'a') as file:
fieldnames = ["Cluster {}".format(k) for k in range(K)]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
print("Composition map for spectral")
graph = spectral_clustering(graph)
clusters_total = {i: [] for i in range(K)}
for node_int in range(len(graph.nodes)):
j = graph.nodes[node_int]["cluster"]
clusters_total[j].append(node_int)
row = [clusters_total[k] for k in range(K)]
user_obj_writer.writerow(row)
return output_filename
def spectral_clustering(graph):
"""
Runs Spectral Clustering on the graph.
:param graph: networkx graph.
:return: networkx graph, having nodes with a populated "cluster" attribute.
"""
if nx.is_directed(graph):
# nx.Graph is used to make sure the adjacency matrix is symmetric, for that's what spectral clustering accepts.
temp_graph = nx.Graph()
for edge in graph.edges:
temp_graph.add_edge(edge[0], edge[1])
# Extracts only the necessary attribute values to reduce the space complexity.
# Hence, it doesn't call largest_connected_component_transform().
attributes_dict = {}
for node in graph.nodes:
try:
attributes_dict[node] = {ATTRIBUTE: graph.nodes[node][ATTRIBUTE]}
except:
continue
nx.set_node_attributes(temp_graph, attributes_dict)
graph = temp_graph
# Adapted from https://stackoverflow.com/questions/23684746/spectral-clustering-using-scikit-learn-on-graph-generated-through-networkx
node_list = list(graph.nodes())
# Converts graph to an adj matrix with adj_matrix[i][j] represents weight between node i,j.
adj_matrix = nx.to_numpy_matrix(graph, nodelist=node_list)
labels = SpectralClustering(affinity = 'precomputed', assign_labels="discretize",random_state=0,n_clusters=K).fit_predict(adj_matrix)
for node in node_list:
graph.nodes[node]["cluster"] = labels[node]
return graph
def cluster_labeling_spectral(spectral_clustering_file, spectral_labeling_file):
"""
Creates a labeling file for spectral clustering.
:param spectral_clustering_file: path to the clustering file from spectral_composition.
:param spectral_labeling_file: path to the output labeling file.
:return: None.
"""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
cluster_dict = {}
with open(spectral_clustering_file, "r") as f:
lines = csv.reader(f)
first = True
for row in lines:
if first:
first = False
else:
for cluster in range(K):
nodes = row[cluster][1:-1].split(", ")
for node in nodes:
cluster_dict[int(node)] = cluster
with open(spectral_labeling_file, 'a') as file:
fieldnames = ["id", "cluster"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for node_int in range(len(graph.nodes)):
row = [node_int, cluster_dict[node_int]]
user_obj_writer.writerow(row)
return
def read_in_generic(labeling_file):
"""
Reads clusters into format: {node: cluster}.
:param labeling_file: labeling file with two columns: node and cluster.
:return: dict {node: cluster}.
"""
cluster_dict = {}
with open(labeling_file, "r") as f:
lines = csv.reader(f)
first = True
for row in lines:
if first:
first = False
else:
cluster_dict[int(row[0])] = int(row[1])
return cluster_dict
def assign_generic_clusters(graph, cluster_dict):
"""
Given a graph, assigns cluster labels to nodes from cluster_dict.
:param graph: networkx graph.
:param cluster_dict: dict {node: cluster}.
:return: networkx graph, having nodes with a populated "cluster" attribute.
"""
for node in graph.nodes:
cluster = int(cluster_dict[node])
graph.nodes[node]["cluster"] = cluster
return graph
# "repeated_fluidc"
def repeated_fluidc():
"""
Runs a repeats fluid communities clustering and determines mean and standard deviation
of the number of connected components in each resulting cluster.
:return: mean and standard deviation.
"""
# Access pickled graph:
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
# Computing labelings:
seed_to_labeling = {}
for seed in SEEDS:
labeling_dict = fluid_communities(save_labeling=False, seed=seed)
seed_to_labeling[seed] = labeling_dict
# Documenting:
clustering_file = "output_files/{}_K{}_composition_map_fluidcr.csv".format(IDENTIFIER_STRING, K)
with open(clustering_file, 'w') as file:
# Header:
fieldnames = ["Seed_Values"]
fieldnames.extend(["Cluster {}".format(k) for k in range(K)])
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for seed in SEEDS:
print("Composition map for seed value = {}".format(seed))
clusters = {i: [] for i in range(K)}
for node in range(len(G)):
cluster = seed_to_labeling[seed][node]
clusters[cluster].append(node)
row = [seed]
row.extend(clusters[i] for i in range(K))
user_obj_writer.writerow(row)
# Relabeling for cluster consistency:
labeling_file = "output_files/{}_K{}_labeling_file_fluidcr.csv".format(IDENTIFIER_STRING, K)
cluster_labeling.main(clustering_file, labeling_file)
# Computation:
# Form: {node: {seed: cluster, seed: cluster…}…}}
cluster_dict = read_in_clusters(labeling_file)
seed_to_counts = {}
seed_to_sizes = {}
for seed in SEEDS:
cluster_dict_by_seed = {node: cluster_dict[node][seed] for node in range(len(G))}
count_dict, cluster_sizes = count_cc(cluster_dict_by_seed)
print("Connected component counts:", count_dict)
seed_to_counts[seed] = count_dict
seed_to_sizes[seed] = cluster_sizes
cluster_to_values = {i: [seed_to_counts[seed][i] for seed in SEEDS] for i in range(K)}
means = {i: statistics.mean(cluster_to_values[i]) for i in range(K)}
stdevs = {i: statistics.stdev(cluster_to_values[i]) for i in range(K)}
# Documenting:
output_filename = "output_files/{}_K{}_fluidcr.txt".format(IDENTIFIER_STRING, K)
with open(output_filename, mode='w') as file:
file.write("Means: {}\n".format(means))
file.write("Standard Deviations: {}".format(stdevs))
print("Means: {}".format(means))
print("Standard Deviations: {}".format(stdevs))
cc_output_filename = "output_files/{}_K{}_cc_fluidcr.csv".format(IDENTIFIER_STRING, K)
with open(cc_output_filename, mode="w") as file:
fieldnames = ["seed", "cluster_sizes", "connected_components"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for seed in SEEDS:
row = [seed, seed_to_sizes[seed], seed_to_counts[seed]]
user_obj_writer.writerow(row)
return means, stdevs
# "fluid_communities"
def fluid_communities(save_labeling=True, seed=1):
"""
Single fluid communities clustering pipeline.
:param save_labeling: whether to save the resulting labeling file or not.
:param seed: int random number generation state.
:return: dict {node: cluster}.
"""
# Access pickled graph:
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
# Make G undirected to be accepted by asyn_fluidc:
if nx.is_directed(G):
G = bgn.convert_to_nx_graph(G)
# Cluster by asyn_fluidc:
# Reference: https://networkx.org/documentation/stable/reference/algorithms/generated/networkx.algorithms.community.asyn_fluid.asyn_fluidc.html#networkx.algorithms.community.asyn_fluid.asyn_fluidc
clusters = nx.algorithms.community.asyn_fluid.asyn_fluidc(G, k=K, seed=seed)
# Node-to-cluster dictionary:
node_to_cluster = {}
cluster_num = 0
for cluster in clusters:
for node in cluster:
node_to_cluster[node] = cluster_num
cluster_num += 1
# Save cluster labels:
if save_labeling:
with open(LABELING_FILE, 'w') as file:
# Header:
fieldnames = ["node", "asyn_fluidc_cluster_S{}".format(seed)]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for node in range(len(G)):
row = [node, node_to_cluster[node]]
user_obj_writer.writerow(row)
print("Completed fluid communities clustering with K = {} and S = {}".format(K, seed))
return node_to_cluster
# "role2vec_pipeline"
def role2vec_pipeline():
"""Pipeline for role2vec clustering, enforcing K."""
print("role2vec: ", INPUT_PICKLED_GRAPH, IDENTIFIER_STRING)
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
if nx.is_directed(G):
G = bgn.convert_to_nx_graph(G)
# Reference: https://github.com/benedekrozemberczki/karateclub
role2vec = Role2Vec()
role2vec.fit(G)
# Ordered by nodes: [0, 1, 2, ...]
embedding = role2vec.get_embedding()
output_filename = "output_files/role2vec_{}_vectors.csv".format(IDENTIFIER_STRING)
with open(output_filename, mode="w") as output_file:
user_obj_writer = csv.writer(output_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for row in embedding:
user_obj_writer.writerow(row)
# Assumption: ordered by nodes as in the data:
clustering = KMeans(n_clusters=K, random_state=1).fit_predict(embedding)
clustering_to_labeling_file(G, clustering)
print("Completed role2vec clustering with K = {}".format(K))
return
def clustering_to_labeling_file(G, clustering):
"""
Given a clustering dictionary, creates a labeling file.
:param G: networkx graph.
:param clustering: dict {node: cluster}.
:return: None.
"""
labeling_filename = "output_files/{}_K{}_labeling_file_role2vec.csv".format(IDENTIFIER_STRING, K)
with open(labeling_filename, 'w') as file:
# Header:
fieldnames = ["node", "role2vec_cluster"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for i in range(len(G)):
row = [i, clustering[i]]
user_obj_writer.writerow(row)
return
# "core_periphery"
def core_periphery():
"""Pipeline for core-periphery clustering, using the CP_THRESHOLD."""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
# Reference: https://github.com/skojaku/core-periphery-detection/blob/7d924402caa935e0c2e66fca40457d81afa618a5/cpnet/Rombach.py
rb = cpnet.Rombach()
rb.detect(G)
pair_id = rb.get_pair_id()
coreness = rb.get_coreness()
save_cp(pair_id, coreness)
clustering = make_cp_clustering(coreness)
# Hardcoded K=2, since binary by threshold:
filename = "output_files/main_files/{}_K2_labeling_file_cp.csv"
with open(filename.format(IDENTIFIER_STRING), mode="w") as file:
# Header:
fieldnames = ["node", "coreness_binary_{}".format(CP_THRESHOLD)]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for i in range(len(G)):
row = [i, clustering[i]]
user_obj_writer.writerow(row)
return
def save_cp(pair_id, coreness):
"""
Given pair_id and coreness core_periphery, plots the distribution of coreness and prints the number of
core-periphery groups in terminal.
:param pair_id: {node: core-periphery group number} from core_periphery.
:param coreness: {node: coreness value} from core_periphery.
:return: None.
"""
num_of_groups = len(set(list(pair_id.values())))
input = list(coreness.values())
sns.distplot(input, hist=False, kde=True,
kde_kws={'linewidth': 3},
label="dataset", norm_hist=True, color=COLOR_PALETTE[0])
plt.xlabel("coreness")
plt.ylabel("PDF")
plt.title("Density at coreness for {}".format(IDENTIFIER_STRING))
plt.savefig("output_files/{}_cp_coreness.png".format(IDENTIFIER_STRING), bbox_inches='tight')
plt.close()
print("{} num_of_groups = {}".format(IDENTIFIER_STRING, num_of_groups))
return
def make_cp_clustering(coreness):
"""
Using the CP_THRESHOLD, turns the continuous coreness into a binary 0/1 clustering.
:param coreness: {node: coreness value} from core_periphery.
:return: dict {node: cluster from {0, 1}}
"""
print("Using core-periphery threshold = {}".format(CP_THRESHOLD))
clustering = {}
for node in coreness:
if coreness[node] <= CP_THRESHOLD:
clustering[node] = 0
else:
clustering[node] = 1
return clustering
# "iac_vs_x_ari"
def iac_vs_x_ari():
"""Computes and saves the adjusted rand index (ari) scores between information access (IAC_LABELING_FILE)
and some other (LABELING_FILE) clusterings."""
# {alpha: ari}
ari_dict = {}
# {alpha: OrderedDict({node: cluster})}
iac_clustering = ordered_read_in_iac()
# OrderedDict({node: cluster})
x_clustering = ordered_read_in_x()
for alpha in ALPHA_VALUES:
ari_dict[alpha] = cp.return_adj_rand_index(iac_clustering[alpha], x_clustering)
save_ari(ari_dict)
return
def ordered_read_in_iac():
"""
Reads in the information access clustering labeling file into a clustering dictionary, using IAC_LABELING_FILE.
:return: ordered dict {alpha: OrderedDict({node: cluster})}.
"""
initial_clustering = read_in_clusters(IAC_LABELING_FILE)
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
clustering = {alpha: OrderedDict() for alpha in ALPHA_VALUES}
for node in range(len(G)):
for alpha in ALPHA_VALUES:
clustering[alpha][node] = initial_clustering[node][alpha]
return clustering
def ordered_read_in_x():
"""
Reads in the other clustering labeling file into a clustering dictionary, using LABELING_FILE.
:return: ordered dict {alpha: OrderedDict({node: cluster})}.
"""
initial_clustering = read_in_generic(LABELING_FILE)
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
clustering = OrderedDict()
for node in range(len(G)):
clustering[node] = initial_clustering[node]
return clustering
def save_ari(ari_dict):
"""
Saves the given dictionary of ari scores into a .csv file.
:param ari_dict: dict {alpha: ari score}.
:return: None.
"""
x_token = LABELING_FILE.split("_")[-1].replace(".csv", "")
filename = "output_files/{}_K{}_ari_iac_vs_{}.csv".format(IDENTIFIER_STRING, K, x_token)
with open(filename, mode="w") as file:
# Header:
fieldnames = ["alpha", "ari_score"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for alpha in ALPHA_VALUES:
row = [alpha, ari_dict[alpha]]
user_obj_writer.writerow(row)
print("Saved ari scores for aic vs. {}".format(x_token))
return
# "mean_ari"
def mean_ari():
"""Computes and documents the mean of adjusted rand index (ari) scores across repeated fluid communities
clusterings for each alpha value."""
ari_filename_invariant = "output_files/fluidcr_ari_sa/fluidcr_{}_ari_sa/fluidcrs{}/{}_K{}_ari_iac_vs_fluidcrs{}.csv".format(IDENTIFIER_STRING, "{}", IDENTIFIER_STRING, K, "{}")
# {seed: {alpha: ari}}
data = access_ari(ari_filename_invariant)
# {alpha: mean}
alpha_to_mean = calculate_means(data)
document_means(alpha_to_mean)
return
def access_ari(ari_filename_invariant):
"""
Reads in ari files across fluid community seeds into a dictionary.
:param ari_filename_invariant: invariant str path to the fluid community ari file.
:return: dict {seed: {alpha: ari}}.
"""
# {seed: {alpha: ari}}
data = {}
for seed in SEEDS:
data[seed] = {}
ari_filename = ari_filename_invariant.format(seed, seed)
with open(ari_filename, mode="r") as file:
next(file)
for row in file:
if row[-1] == "\n":
row = row[:-1]
row = row.split(",")
alpha = float(row[0])
ari = float(row[1])
data[seed][alpha] = ari
return data
def calculate_means(data):
"""
Calculates the mean ari across fluid community seeds for each alpha value.
:param data: dict {seed: {alpha: ari}}.
:return: dict {alpha: mean ari score}.
"""
# {alpha: [ari_seed_1, ari_seed_2, ...]}
alpha_to_ari_scores = {alpha: [] for alpha in ALPHA_VALUES}
for alpha in ALPHA_VALUES:
for seed in data:
alpha_to_ari_scores[alpha].append(data[seed][alpha])
# {alpha: mean}
alpha_to_mean = {alpha: statistics.mean(alpha_to_ari_scores[alpha]) for alpha in ALPHA_VALUES}
return alpha_to_mean
def document_means(alpha_to_mean):
"""
Documents the means of ari values into a .csv file.
:param alpha_to_mean: dict {alpha: mean ari score}.
:return: None.
"""
filename = "output_files/{}_K{}_mean_of_ari_scores.csv"
with open(filename.format(IDENTIFIER_STRING, K), mode="w") as file:
# Header:
fieldnames = ["alpha", "mean_of_ari_scores"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for alpha in ALPHA_VALUES:
row = [alpha, alpha_to_mean[alpha]]
user_obj_writer.writerow(row)
return
# "fisher_exact"
def fisher_exact():
"""Pipeline for running the Fisher Exact test."""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
with open("output_files/{}_{}_fisher_exact.csv".format(IDENTIFIER_STRING, ATTRIBUTE), 'a') as file:
fieldnames = ["alpha_value", "p_value", "contingency_table"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
labeling_file = "output_files/{}_K{}_labeling_file_iac.csv".format(IDENTIFIER_STRING, 2)
if not os.path.isfile(labeling_file):
raise FileNotFoundError("labeling_file not found")
cluster_dict = read_in_clusters(labeling_file)
for alpha_value in ALPHA_VALUES:
print("Fisher Exact for alpha = {}".format(alpha_value))
graph = assign_clusters(graph, cluster_dict, alpha_value)
fisher_exact_helper(graph, alpha_value, user_obj_writer)
spectral_labeling_file = "output_files/{}_K{}_labeling_file_spectral.csv".format(IDENTIFIER_STRING, K)
if not os.path.isfile(spectral_labeling_file):
raise FileNotFoundError("spectral_labeling_file not found")
spectral_cluster_dict = read_in_generic(spectral_labeling_file)
graph = assign_generic_clusters(graph, spectral_cluster_dict)
fisher_exact_helper(graph, "spectral", user_obj_writer)
return
def fisher_exact_helper(graph, label, user_obj_writer, attribute=ATTRIBUTE):
"""
Helper method for the Fisher Exact test.
:param graph: networkx graph.
:param label: label to be used to identify the p-value in the .csv file (e.g. alpha value or "spectral").
:param user_obj_writer: .csv writer.
:param attribute: attribute to run the test against.
:return: None.
"""
if attribute == "gender":
contingency_table = {"M": [0, 0], "F": [0, 0]}
else:
contingency_table = {attribute: [0, 0], "not-" + attribute: [0, 0]}
for node_int in range(len(graph.nodes)):
attr_value = graph.nodes[node_int][attribute]
if attr_value == "True" or attr_value is True or attr_value == 1 or attr_value == "1":
attr_value = attribute
elif attr_value == "False" or attr_value is False or attr_value == 0 or attr_value == "0":
attr_value = "not-" + attribute
cluster = graph.nodes[node_int]["cluster"]
contingency_table[attr_value][cluster] += 1
odds_ratio, p_value = stats.fisher_exact([contingency_table[i] for i in contingency_table])
row = [label, p_value, contingency_table]
user_obj_writer.writerow(row)
return
# "count_cc"
def count_cc_wrapper():
"""Wrapper for counting the number of connected components in each cluster,
given the clustering in the LABELING_FILE."""
mode_token = LABELING_FILE.split("_")[-1].split(".")[0]
if mode_token == "iac":
with open("output_files/{}_K{}_cc_{}.csv".format(IDENTIFIER_STRING, K, mode_token), mode="w") as file:
# Fieldnames and writer:
fieldnames = ["alpha", "cluster_sizes", "connected_components"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Counting connected components for each alpha value:
all_alpha_labeling_dict = read_in_clusters(LABELING_FILE)
for alpha_value in ALPHA_VALUES:
print("\nFor alpha = {}".format(alpha_value))
labeling_dict = {int(node): int(all_alpha_labeling_dict[node][alpha_value]) for node in
all_alpha_labeling_dict}
count_dict, cluster_sizes = count_cc(labeling_dict)
print("Connected components: {}".format(count_dict))
# Documenting:
row = [alpha_value, cluster_sizes, count_dict]
user_obj_writer.writerow(row)
else:
with open("output_files/{}_K{}_cc_{}.csv".format(IDENTIFIER_STRING, K, mode_token), mode="w") as file:
# Fieldnames and writer:
fieldnames = ["clustering_method", "cluster_sizes", "connected_components"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Counting connected components:
labeling_dict = read_in_generic(LABELING_FILE)
count_dict, cluster_sizes = count_cc(labeling_dict)
print("Connected components: {}".format(count_dict))
# Documenting:
row = [mode_token, cluster_sizes, count_dict]
user_obj_writer.writerow(row)
return
def count_cc(labeling_dict):
"""
Counts the number of connected components in each cluster, given the clustering in the LABELING_FILE.
:param G: graph, from which to take induced subgraphs.
:param labeling_dict: dict {node: cluster}.
:param k_clusters: a priori number of clusters used in the LABELING_FILE.
:return: dict {cluster: number of connected components in its induced subgraph}.
"""
# Access pickled graph, if G is not specified by argument:
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
# Iterable of nodes per each cluster as a basis of induced subgraph:
clusters = {i: [] for i in range(K)}
for node in range(len(G)):
clusters[labeling_dict[node]].append(node)
cluster_sizes = {i: len(clusters[i]) for i in range(len(clusters))}
print("Cluster sizes: {}".format(cluster_sizes))
# Counts the number of connected components in each induced subgraph:
count_dict = {}
for i in range(K):
# Induced subgraph by cluster:
temp_graph = G.subgraph(clusters[i])
# quick_display(temp_graph)
# Make temp_graph undirected to be accepted by number_connected_components:
if nx.is_directed(temp_graph):
temp_graph = bgn.convert_to_nx_graph(temp_graph)
# Number of connected components:
num_of_cc = nx.number_connected_components(temp_graph)
count_dict[i] = num_of_cc
return count_dict, cluster_sizes
# "statistical_analyses"
def statistical_analyses():
"""Given some clustering in the LABELING_FILE, runs statistical analyses for one of DBLP, Co-sponsorship, and Twitch
based on its default attributes and settings."""
cluster_dict = read_in_generic(LABELING_FILE)
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
for node in G.nodes:
G.nodes[node]["cluster"] = cluster_dict[node]
x_token = LABELING_FILE.split("_")[-1].replace(".csv", "")
# Invariant for report file:
report_file_path = "output_files/{}_K{}_{}_output_strings_{}.txt".format(IDENTIFIER_STRING, K, x_token, "{}")
if IDENTIFIER_STRING == "dblp":
# Distribution for "citation_count":
attr_report_file = rfo.ReportFileObject(report_file_path.format("citation_count"))
plot_attribute_distributions(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K,
attribute="citation_count",
pdf_log=0, report_file=attr_report_file)
# Distribution for "phd_rank":
attr_report_file = rfo.ReportFileObject(report_file_path.format("phd_rank"))
plot_attribute_distributions(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K,
attribute="phd_rank",
pdf_log=0, report_file=attr_report_file)
# Distribution for "job_rank":
attr_report_file = rfo.ReportFileObject(report_file_path.format("job_rank"))
plot_attribute_distributions(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K,
attribute="job_rank",
pdf_log=0, report_file=attr_report_file)
# Bar graph for "gender":
attr_report_file = rfo.ReportFileObject(report_file_path.format("gender"))
plot_attribute_bar(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K, attribute="gender",
report_file=attr_report_file)
fisher_exact_modularized(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, attribute="gender")
elif IDENTIFIER_STRING == "strong-house":
# Distribution for "le_score":
attr_report_file = rfo.ReportFileObject(report_file_path.format("le_score"))
plot_attribute_distributions(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K,
attribute="le_score",
pdf_log=0, report_file=attr_report_file)
# Bar graph for "democrat":
attr_report_file = rfo.ReportFileObject(report_file_path.format("democrat"))
plot_attribute_bar(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K, attribute="democrat",
report_file=attr_report_file)
fisher_exact_modularized(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, attribute="democrat")
elif IDENTIFIER_STRING == "twitch":
# Distribution for "views":
attr_report_file = rfo.ReportFileObject(report_file_path.format("views"))
plot_attribute_distributions(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K,
attribute="views",
pdf_log=1, report_file=attr_report_file)
# Bar graph for "partner":
attr_report_file = rfo.ReportFileObject(report_file_path.format("partner"))
plot_attribute_bar(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, k_clusters=K, attribute="partner",
report_file=attr_report_file)
fisher_exact_modularized(G, EXPERIMENT, identifier_string=IDENTIFIER_STRING, attribute="partner")
return
# "dataset_pdf"
def dataset_pdf():
"""Plots the PDF of the entire dataset for ATTRIBUTE."""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
if (IDENTIFIER_STRING == "dblp"):
graph = fix_dblp(graph)
nodes = []
if DATASET_LOG:
for node in graph.nodes:
try:
nodes.append(math.log(float(graph.nodes[node][ATTRIBUTE]), LOG_BASE))
except:
continue
else:
for node in graph.nodes:
try:
nodes.append(float(graph.nodes[node][ATTRIBUTE]))
except:
continue
print("Attribute available for {} nodes (percentage: {}):".format(len(nodes), len(nodes) / len(graph)), nodes)
sns.distplot(nodes, hist=False, kde=True,
kde_kws={'linewidth': 3},
label='dataset', norm_hist=True)
if DATASET_LOG:
plt.xlabel("log({}) with base {}".format(ATTRIBUTE, LOG_BASE))
else:
plt.xlabel(ATTRIBUTE)
plt.ylabel("PDF")
if DATASET_LOG:
plt.title("Density at log({}) with base {} for different clusters".format(ATTRIBUTE, LOG_BASE))
plt.savefig("output_files/{}_PDF_full_log_{}.png".format(IDENTIFIER_STRING, ATTRIBUTE), bbox_inches='tight')
else:
plt.title("Density at {} for different clusters".format(ATTRIBUTE))
plt.savefig("output_files/{}_PDF_full_{}.png".format(IDENTIFIER_STRING, ATTRIBUTE), bbox_inches='tight')
plt.clf()
return
def fix_dblp(graph):
"""
Changes the attribute value -1 to None for consistency.
:param graph: networkx graph.
:return: networkx graph with modified attribute values for nodes.
"""
for node in graph.nodes:
if graph.nodes[node][ATTRIBUTE] == -1:
graph.nodes[node][ATTRIBUTE] = None
return graph
# "calc_ari"
def calculate_ari():
"""Previous calculate adjusted rand index method: please instead use the new iac_vs_x_ari method."""
create_ari_files()
spectral_clusters = cp.read_in_clusters("output_files/{}_K{}_spectral_ari.csv".format(IDENTIFIER_STRING, K))
for alpha_value in ALPHA_VALUES:
cluster_file = "output_files/{}_K{}_{}_information_access_ari.csv".format(IDENTIFIER_STRING, K,
str(alpha_value)[2:])
info_clusters = cp.read_in_clusters(cluster_file)
print(f"alpha: {alpha_value}")
cp.adj_rand_index(info_clusters, spectral_clusters)
return
def create_ari_files():
"""Helper method for calculate_ari."""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
labeling_file = "output_files/{}_K{}_labeling_file_iac.csv".format(IDENTIFIER_STRING, 2)
if not os.path.isfile(labeling_file):
raise FileNotFoundError("labeling_file not found")
cluster_dict = read_in_clusters(labeling_file)
for alpha_value in ALPHA_VALUES:
print("create_ari_files for alpha = {}".format(alpha_value))
graph = assign_clusters(graph, cluster_dict, alpha_value)
# save csv of node to cluster to later run ari
node_to_cluster_filename = "output_files/{}_K{}_{}_information_access_ari.csv".format(IDENTIFIER_STRING, K,
str(alpha_value)[2:])
read.writeout_clusters(graph, node_to_cluster_filename)
print("create_ari_files for spectral")
spectral_labeling_file = "output_files/{}_K{}_labeling_file_spectral.csv".format(IDENTIFIER_STRING, K)
if not os.path.isfile(spectral_labeling_file):
raise FileNotFoundError("spectral_labeling_file not found")
spectral_cluster_dict = read_in_generic(spectral_labeling_file)
graph = assign_generic_clusters(graph, spectral_cluster_dict)
# save csv of node to cluster to later run ari
node_to_cluster_filename = "output_files/{}_K{}_spectral_ari.csv".format(IDENTIFIER_STRING, K)
read.writeout_clusters(graph, node_to_cluster_filename)
return
# "clustering_map"
def clustering_map():
"""Creates a .csv file that maps each node to its KMeans cluster (reproducible with random_state=1)."""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
graph = pickle.load(file)
fieldnames = ["node_int"]
fieldnames.extend(["cluster at alpha = {}".format(alpha_value) for alpha_value in ALPHA_VALUES])
rows = [[node_int] for node_int in range(len(graph))]
for alpha_value in ALPHA_VALUES:
print("Clustering map for alpha = {}".format(alpha_value))
vector_file_path = VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:])
vectors = read.read_in_vectors(vector_file_path)
graph = information_access_clustering(vectors, K, graph)
# Can iterate over range(len(graph.nodes)) because the nodes are numbered from 0 to len(graph.nodes).
# Will iterate over range(len(graph.nodes)) because it makes the ultimate file ordered.
for node_int in range(len(graph.nodes)):
rows[node_int].append(graph.nodes[node_int]["cluster"])
with open("output_files/{}_K{}_cluster_map.csv".format(IDENTIFIER_STRING, K), 'a') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for row in rows:
user_obj_writer.writerow(row)
return
# "probability_composition"
def probability_composition():
"""Computes the composition of probabilities in the information access vector files."""
print("Building the composition table")
histogram_values = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
holder_dict = {alpha_value: {(i / 10): 0 for i in range(1, 10)} for alpha_value in ALPHA_VALUES}
smaller_values = {alpha_value: 0 for alpha_value in ALPHA_VALUES}
all_data = {alpha_value: [] for alpha_value in ALPHA_VALUES}
for alpha_value in ALPHA_VALUES:
print("Table component for alpha = {}".format(alpha_value))
vector_file_path = VECTOR_FILE_INVARIANT.format(str(alpha_value)[2:])
vectors = read.read_in_vectors(vector_file_path)
for row in vectors:
for i in vectors[row]:
all_data[alpha_value].append(i)
if i < 0.1:
smaller_values[alpha_value] += 1
else:
for j in range(len(histogram_values)):
hist_comp_value_i = len(histogram_values) - 1 - j
if i >= histogram_values[hist_comp_value_i]:
holder_dict[alpha_value][histogram_values[hist_comp_value_i]] += 1
break
histogram_table = [["alpha", "< 0.1", ">= 0.1 && < 0.2", ">= 0.2 && < 0.3", ">= 0.3 && < 0.4", ">= 0.4 && < 0.5",
">= 0.5 && < 0.6", ">= 0.6 && < 0.7", ">= 0.7 && < 0.8", ">= 0.8 && < 0.9", ">= 0.9"]]
for alpha_value in ALPHA_VALUES:
histogram_table.append([alpha_value, smaller_values[alpha_value]])
histogram_table[-1].extend([holder_dict[alpha_value][i] for i in histogram_values])
with open("output_files/{}_probability_composition.csv".format(IDENTIFIER_STRING), 'a') as file:
writer = csv.DictWriter(file, fieldnames=histogram_table[0])
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
for i in range(1, len(histogram_table)):
user_obj_writer.writerow(histogram_table[i])
for alpha_value in ALPHA_VALUES:
print("Building the histogram for alpha = {}".format(alpha_value))
plt.hist(all_data[alpha_value])
plt.xlim(xmin=0, xmax=1)
plt.xlabel("value at p_ij")
plt.ylabel("count")
plt.title("Composition of probabilities in information access vectors (alpha = {})".format(alpha_value))
plt.savefig("output_files/{}_{}_probability_composition.png".format(IDENTIFIER_STRING, str(alpha_value)[2:]),
bbox_inches='tight')
plt.close()
return
# "generate_profiles"
def generate_profiles(G=None):
"""Generates profiles of nodes in .csv (to be used along with edgelist to reconstruct graphs)."""
# Access graph through pickle, if G is not passed as an argument:
if G == None:
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
# Catch fieldnames except for that which includes "cluster":
fieldnames = ["node"]
for fieldname in G.nodes[0]:
if "cluster" in fieldname:
continue
fieldnames.append(fieldname)
with open("output_files/{}_profiles.csv".format(IDENTIFIER_STRING), 'w') as file:
# Header:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows (iterates of range(len(G)), which corresponds to "node" ids used in edgelist):
for node in range(len(G)):
row = [node]
row.extend([G.nodes[node][attribute] for attribute in fieldnames[1:]])
user_obj_writer.writerow(row)
return
# Methods used by external scripts:
def fisher_exact_modularized(G, clustering_method, identifier_string=IDENTIFIER_STRING, attribute=ATTRIBUTE,
input_pickled_graph=INPUT_PICKLED_GRAPH):
"""Modularized Fisher Exact test."""
# Access graph through pickle, if G is not passed as an argument:
# if G == None:
# with open(input_pickled_graph, "rb") as file:
# G = pickle.load(file)
# Fisher Exact:
with open("output_files/{}_{}_fisher_exact.csv".format(identifier_string, attribute), 'a') as file:
if os.stat("output_files/{}_{}_fisher_exact.csv".format(identifier_string, attribute)).st_size == 0:
fieldnames = ["clustering", "p_value", "contingency_table"]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# try:
# cluster_ex = G.nodes[0]["cluster"]
# except:
# cluster_dict = read_in_generic(labeling_file)
# G = assign_generic_clusters(G, cluster_dict)
fisher_exact_helper(G, clustering_method, user_obj_writer, attribute=attribute)
return
def add_centrality(graph):
"""Adds attributes representing network structure importance metrics to the nodes of graph."""
deg_centrality = nx.degree_centrality(graph)
# between_centrality = nx.betweenness_centrality(graph)
pagerank = nx.pagerank_numpy(graph)
for node in deg_centrality:
graph.nodes[node]["degree_centrality"] = deg_centrality[node]
# graph.nodes[node]["betweeness_centrality"] = between_centrality[node]
graph.nodes[node]["pagerank"] = pagerank[node]
def quick_display_wrapper_K2(G, labeling_dict):
"""Wrapper for quick_display() with K=2 clusters."""
# Assigning colors based on binary variable:
color_map = {i: COLOR_PALETTE[0] if labeling_dict[i] == 1 else COLOR_PALETTE[1] for i in labeling_dict}
# Displaying the colored graph:
quick_display(G, color_map=color_map)
return
def quick_display(G, nodelist=None, color_map=None):
"""
Quick plotting of the graph.
:param G: graph.
:param color_map: must be of form {node: color}.
:return: None.
"""
fig = plt.figure()
# If nodelist not specified, nodelist = sorted nodes iterable:
if nodelist == None:
nodelist = [i for i in range(len(G))]
# If one color specified:
if color_map == None:
nx.draw_spring(G, with_labels=True)
# If one color: color_map == "r":
elif len(color_map) == 1:
nx.draw_spring(G, node_color=color_map, with_labels=True)
# If individual mapping:
else:
node_color = [color_map[i] for i in nodelist]
nx.draw_spring(G, nodelist=nodelist, node_color=node_color, with_labels=True)
plt.show()
plt.close()
return
def cc_cluster_sizes(filename):
"""Reads in a file for cluster sizes."""
alpha_to_cs = {}
with open(filename, mode="r") as file:
next(file)
for row in file:
if row[-1] == "\n":
row = row[:-1]
row = row.split('"')
if row[0][-1] == ",":
alpha = float(row[0][:-1])
else:
alpha = float(row[0])
cs = row[1]
alpha_to_cs[alpha] = str_to_dict(cs)
return alpha_to_cs
def str_to_dict(string):
"""Input example: "{0: 214, 1: 224}"."""
output_dict = {}
pairs = string[1:-1].split(", ")
for i in pairs:
elements = i.split(": ")
output_dict[int(elements[0])] = int(elements[1])
return output_dict
def cs_by_search_unnamed(filename, alpha_values):
"""Reads in a file for cluster sizes."""
alpha_to_cs = {}
index = 0
with open(filename, mode="r") as file:
for row in file:
if "Cluster sizes:" in row:
if row[-1] == "\n":
row = row[:-1]
cs = row.replace("Cluster sizes:", "")
alpha_to_cs[alpha_values[index]] = str_to_dict(cs)
index += 1
return alpha_to_cs
def cs_by_binary_output(filename):
"""Reads in a file for cluster sizes."""
alpha_to_cs = {}
with open(filename, mode="r") as file:
for row in file:
if row[0] == "+":
alpha = float(row.split("_")[-2].replace("i", "0."))
alpha_to_cs[alpha] = {}
elif row[0] == "[":
if row[-1] == "\n":
row = row[:-1]
row = row[2:-2].split("), (")
for pair in row:
pair = pair.split(", ")
pair[0] = pair[0][1:-1].replace("Cluster ", "")
cluster = int(pair[0])
size = int(pair[1])
alpha_to_cs[alpha][cluster] = size
return alpha_to_cs
def cs_by_continuous_output(filename):
"""Reads in a file for cluster sizes."""
alpha_to_cs = {}
with open(filename, mode="r") as file:
for row in file:
if "================SPECTRAL==================" in row:
break
elif row[0] == "+":
alpha = float(row.split("_")[-2].replace("i", "0."))
elif "Cluster sizes:" in row:
if row[-1] == "\n":
row = row[:-1]
cs = row.replace("Cluster sizes:", "")
alpha_to_cs[alpha] = str_to_dict(cs)
return alpha_to_cs
def louvain_preprocess():
"""Preprocesses a .txt clustering file from Louvain method."""
filename = "output_files/{}_louvain.txt".format(IDENTIFIER_STRING)
with open(filename, mode="r") as input_file:
with open(LABELING_FILE, mode="w") as output_file:
# Header:
fieldnames = ["node", "louvain_cluster"]
writer = csv.DictWriter(output_file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(output_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for row in input_file:
if row[-1] == "\n":
row = row[:-1]
row = row.split("\t")
print(row)
new_row = [int(row[0]), int(row[1])]
user_obj_writer.writerow(new_row)
return
def preprocess_fluidcr(main_labeling_file):
"""Preprocesses a repeated fluid communities clustering file."""
with open(INPUT_PICKLED_GRAPH, "rb") as file:
G = pickle.load(file)
# Form: {node: {seed: cluster, seed: cluster…}…}}
cluster_dict = read_in_clusters(main_labeling_file)
for seed in SEEDS:
cluster_dict_by_seed = {node: cluster_dict[node][seed] for node in range(len(G))}
filename = "output_files/fluidcr/{}_labeling_files_fluidcr/{}_K{}_labeling_file_fluidcrs{}.csv".format(
IDENTIFIER_STRING, IDENTIFIER_STRING, K, seed)
with open(filename, mode="w") as file:
# Header:
fieldnames = ["node", "fluidcrs{}".format(seed)]
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Rows:
for i in range(len(G)):
row = [i, cluster_dict_by_seed[i]]
user_obj_writer.writerow(row)
return
if __name__ == "__main__":
main()
<file_sep>/gscholar/elbow_method.py
import networkx as nx
import matplotlib.pyplot as plt
import numpy as np
import sys
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.cm as cm
# Parameters for finding K:
MIN_CLUSTERS = 1
MAX_CLUSTERS = 11
N_REFS = 4
# Elbow_method code by <NAME>, adapted from https://towardsdatascience.com/k-means-clustering-with-scikit-learn-6b47a369a83c.
def main():
'''reads the vectors'''
filename = sys.argv[1]
file = open(filename, "r")
nodes = file.readlines()
vectors = {}
for index, line in enumerate(nodes):
line = line.split(",")
# print("the length of the line is ", len(line))
node = index
vectors[node] = []
for prob in line:
vectors[node].append(float(prob))
"""Make elbow graph to choose k hyper-parameter for the clustering methods."""
X = np.array(list(vectors.values()))
distortions = []
for i in range(MIN_CLUSTERS, MAX_CLUSTERS):
print("On k value " + str(i))
kmeans = KMeans(n_clusters=i, random_state=1).fit(X)
distortions.append(kmeans.inertia_)
print(kmeans.inertia_)
# plot
print(distortions)
plt.plot(range(MIN_CLUSTERS, MAX_CLUSTERS), distortions, marker='o')
plt.xticks(range(MIN_CLUSTERS, MAX_CLUSTERS))
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
#vector_file_name = vector_file[:-4].split("_")
plt.title("Elbow Method")#"Information Access Clustering Elbow Plot (alpha = 0.{})").format(vector_file_name[-2][1:]))
plt.tight_layout()
plt.savefig("elbow_method")
plt.close()
return
if __name__ == "__main__":
main()
<file_sep>/gscholar/spectral.py
import networkx as nx
import numpy as np
import sys
import math
from sklearn.cluster import SpectralClustering
#from sklearn.metrics import adjusted_rand_score
#from sklearn.metrics import pairwise_distances
# Range of K:
MIN_CLUSTERS = 2
MAX_CLUSTERS = 5
def main():
filename = sys.argv[1]
outfilename = sys.argv[2]
clusternames = sys.argv[3]
print("reading the graph...")
file = open(filename, "r")
lines = file.readlines()
graph = nx.Graph()
counter = 0
for line in lines:
if counter != 0:
s = int(line.split(None, 2)[0])
t = int(line.split(None, 2)[1])
graph.add_node(s)
graph.add_node(t)
graph.add_edge(s, t)
graph.add_edge(t, s) # for spectral use undirected
counter +=1
file.close()
print(graph.number_of_nodes())
n = graph.number_of_nodes()
node_list = list(graph.nodes())
# Converts graph to an adj matrix with adj_matrix[i][j] = weight between node i,j.
#adj_matrix = nx.to_numpy_matrix(graph, nodelist=node_list, dtype=np.int32)
adj_matrix = nx.to_scipy_sparse_matrix(graph, nodelist=node_list, dtype=np.int8)
graph.clear()
outfile = open(outfilename, "w")
for k in range(MIN_CLUSTERS, MAX_CLUSTERS+1):
outfile.write("for " + str(k) + " clusters:\n")
print("spectral # of clusters: " + str(k))
labels = SpectralClustering(affinity = 'precomputed', assign_labels="discretize",random_state=0,n_clusters=k).fit_predict(adj_matrix)
#n_components = 10 * log(n) * k
file = open(clusternames[:-4] + "_" + str(k) + ".txt", "w")
for i in range(0, n):
file.write(str(i) + "\t" + str(labels[i]) + "\n")
file.close();
buckets = [0] * k
for i in range(0, n):
buckets[labels[i]] += 1
for i in range(0, k):
outfile.write("%" + str(int(round(buckets[i] * 100 / n))) + " ")
outfile.write("\n")
outfile.close()
return
if __name__ == "__main__":
main()
<file_sep>/run.sh
#!/usr/bin/env bash
echo "Hello, $(whoami)!"
# Structure:
# 1. Runs the before_vectors pipeline for world_trade dataset to create a pickled networkx
# object and an edgelist in the format compatible for running the simulations.
# 2. Compiles the C++ code.
# 3. Asks for experiment data for purposes of specified naming
# and passing it further as arguments.
# 4. Runs the simulations and creates a vectors file for Information Access Clustering.
# 5. Runs the after_vectors pipeline based on the pickled graph and vectors file:
# clustering methods and cluster analysis.
# Note:
# The controllers of the after_vectors pipeline must be customized (for now)
# in main_pipelines.py for each vector file (with a specific alpha value) and attribute.
#python3 main_pipelines.py before_vectors_world_trade #was commented
#g++ C++\ code/main.cpp -o C++\ code/main -std=c++11 #was commented
echo 'Please enter the alpha value?'
read alpha
value=${alpha#*.}
echo 'Please enter the number of repetitions?'
read nr
echo "Run simulations for all seeds: y or n?"
read response
echo "output_files/star_edgelist.txt" "output_files/star_vectors_i${value}_${nr}.txt" $alpha $nr $response| ./C++\ code/main
#python3 main_pipelines.py after_vectors #was commented
<file_sep>/input/data_cosponsorship/README.txt
Co-sponsorship Network Data
The co-sponsorship network is built from two separate files: (1) govtrack_cosponsor_data_114_congress.csv for nodes and edges, as well as additional node attributes, and (2) CELHouse93to115.xlsx (in the parent directory) for such node attributes as "democrat" and "legislative effectiveness score", used in the experiments.
Citation
1. Co-sponsorship Network Data from GovTrack: http://jhfowler.ucsd.edu/cosponsorship.htm
<NAME>. Connecting the Congress: A Study of Cosponsorship Networks. In Political Analysis 14 (4): 456-487, 2006.
<NAME>. Legislative Cosponsorship Networks in the U.S. House and Senate. In Social Networks 28 (4): 454-465, 2006.
2. House of Representatives: Legislative Effectiveness Data from 93rd-110th Congress (1973-2008): https://thelawmakers.org/data-download
<NAME> and <NAME>. Legislative Effectiveness in the United States Congress: The Lawmakers. Cambridge University Press, 2014.<file_sep>/C++ code Orig/README.txt
To use:
Make sure your data is in the format show in seed_dataset_example.txt, and described here:
The first line should be the number of nodes in your network, followed by either
0 or 1 to indicate whether the network is directed. (0 for undirected, 1 for directed)
The following lines should be an edgelist, with each line representing an edge between two nodes.
If the network is directed, it should be in the format:
from to
If you are running the simulation with a subset of the nodes as seeds, then at the end of the file there should be a line starting with "s" that lists the seed nodes,
separated by tabs. All separators within lines in the whole file should be tabs.
Once your data is in the correct format, run run.sh. You will be prompted to put in
the path to your data file, the path where you want the output saved, the probability
of information spreading between any two connected nodes (if you don't know, 0.1 is a pretty standard
estimate) and the number of times you want the simulation repeated (if the network isn't too
big 10,000 is a good number, but obviously you can decide to lower it or raise it depending on a
speed/accuracy tradeoff).
If you are using a subset of the nodes as seeds, then the first row of the output will list the seeds. The following rows will be vectors.
Each row is the vector for that row number's node. Each column represents a seed,
so that the item at row i column j is the probability that node i receives information
from seed j (according to the seed ordering in row 0).
<file_sep>/dblp_test.py
import csv
import build_dblp_datatsets
FILE_INPUT = "dblp_data/processed_publications.csv"
PUBLICATIONS_PATH = "dblp_data/processed_publications.csv"
def coauthorship_test():
publications = {}
publications["1"] = {"type": "inproceedings", "year": 2018, "number_of_authors": 5,
"author": ["<NAME>.", "<NAME>", "<NAME>", "<NAME>",
"<NAME>"],
"title": "Detection of Glottal Activity Errors in Production of Stop Consonants in Children with Cleft Lip and Palate."}
publications["2"] = {
"type": "article", "year": 2017, "number_of_authors": 4,
"author": ["<NAME>", "<NAME>", "<NAME>", "<NAME>"],
"title": "Influence of charging behaviour given charging infrastructure specification: A case study of Singapore."}
publications["3"] = {
"type": "inproceedings", "year": 2020, "number_of_authors": 6,
"author": ["<NAME>", "<NAME>", "<NAME>", "<NAME>", "<NAME> 0083", "<NAME>"],
"title": "Working Pose and Layout Optimization of surgical robot."}
publications["4"] = {"type": "inproceedings", "year": 2011, "number_of_authors": 5, "author": ["<NAME>.",
"<NAME>",
"<NAME>",
"<NAME>.",
"<NAME>."],
"title": "Prediction of first lactation 305-day milk yield based on weekly test day records using artificial neural networks in Sahiwal Cattle."}
publications["5"] = {
"type": "article", "year": 2020, "number_of_authors": 2, "author": ["<NAME>", "<NAME>."],
"title": "An availability predictive trust factor-based semi-Markov mechanism for effective cluster head selection in wireless sensor networks."}
publications["6"] = {
"type": "article", "year": 1973, "number_of_authors": 1, "author": ["<NAME>"],
"title": "Military Aviation and Air Traffic Control System Planning."}
publications["7"] = {"type": "inproceedings",
"year": 2018,
"number_of_authors": 2,
"author": ["<NAME>",
"<NAME>"],
"title": "Heuristic Based Learning of Parameters for Dictionaries in Sparse Representations."}
publications["8"] = {
"type": "article", "year": 2011, "number_of_authors": 4,
"author": ['<NAME>.', '<NAME>', '<NAME>.', '<NAME>.'],
"title": "MapReduce Based Information Retrieval Algorithms for Efficient Ranking of Webpages."}
publications["9"] = {
"type": "inproceedings", "year": 2020, "number_of_authors": 5,
"author": ["<NAME>.", "<NAME>.", "<NAME>.", "<NAME>", "<NAME>."],
"title": "Performance Evaluation of Various Beamforming Techniques for Phased Array Antennas."}
publications["10"] = {
"type": "article", "year": 2020, "number_of_authors": 2, "author": ["<NAME>", "<NAME>."],
"title": "Automatic multiple human tracking using an adaptive hybrid GMM based detection in a crowd."}
# Checking for correct reading and uniqueness:
with open(FILE_INPUT, "r") as file:
csv_reader = csv.reader(file, delimiter=',')
rows = set()
for row in csv_reader:
if len(row) > 5:
raise ValueError("More than 5 columns")
test_results = {p: None for p in publications}
with open(FILE_INPUT, "r") as file:
csv_reader = csv.reader(file, delimiter=',')
start = 1
for row in csv_reader:
if start:
start -= 1
continue
publication_type = row[0]
try:
year = int(row[1][1:-1])
except:
year = None
try:
num_of_auth = int(row[2])
except:
raise ValueError("error")
author = row[3][1:-1].replace("'", "").split(", ")
title = row[4][2:-2]
# print([publication_type, year, num_of_auth, author, title])
for p in publications:
if publications[p]["title"] == title and publications[p]["year"] == year and publications[p][
"number_of_authors"] == num_of_auth and publications[p]["author"] == author and publications[p][
"type"] == publication_type:
test_results[p] = "Correct"
print(test_results)
return
def compare_oct_dblp_with_2021_dblp():
auth_2021 = set()
with open("dblp_data/datasets_by_yoj/dblp_yoj_2021_nodelist.txt", 'r') as file:
for line in file:
auth_2021.add(line.split("; ")[1])
# print(auth_2021)
auth_oct = set()
with open("dblp_data/drive-download-20210412T150103Z-001/dblp_nodes_oct_2020.txt", 'r') as file:
for line in file:
auth_oct.add(line.split("; ")[2][2:])
# print(auth_oct)
auth_oct.remove('lp_id')
# print("auth_2021 - auth_oct", len(auth_2021 - auth_oct), auth_2021 - auth_oct)
print("\nauth_oct - auth_2021", len(auth_oct - auth_2021), auth_oct - auth_2021)
# print(auth_2021.intersection(auth_oct))
non_unique_set = set()
with open("dblp_data/non_unique_auth.txt", 'r') as file:
for line in file:
if line[-1] == "\n":
line = line[:-1]
non_unique_set.add(line)
difference = auth_oct - auth_2021
preprocessed_dif = set()
for node in difference:
name = build_dblp_datatsets.preprocess_id(node)
preprocessed_dif.add(name)
print(len(preprocessed_dif - non_unique_set), preprocessed_dif - non_unique_set)
return
def test_uniqueness_of_hiring():
all_raw_authors = set()
with open(PUBLICATIONS_PATH, 'r') as file:
csv_reader = csv.reader(file, delimiter=',')
starting = 1
for row in csv_reader:
if starting:
starting -= 1
print(row)
continue
publication_type, year, num_of_auth, author, title = parse_publication(row)
if num_of_auth > 1:
for a in author:
all_raw_authors.add(a)
print("len(all_raw_authors) =", len(all_raw_authors))
return
if __name__ == '__main__':
# coauthorship_test()
compare_oct_dblp_with_2021_dblp()
<file_sep>/plot_dendrogram.py
#!/usr/bin/env python
# https://stackoverflow.com/questions/2455761/reordering-matrix-elements-to-reflect-column-and-row-clustering-in-naiive-python
import numpy as np
import pylab
import scipy.cluster.hierarchy as sch
import pandas as pd
import sys
def load_df(name):
df = pd.read_csv(name, header=None)
df = df.drop(columns=445)
return df
def get_distance_matrix(x):
D = np.zeros(x.shape)
for i in range(len(x)):
for j in range(len(x)):
D[i,j] = sum((x[i,:] - x[j,:]) ** 2) ** 0.5
return D
def clique_p(n, v):
r = np.zeros((n, n))
r[:,:] = v
for i in range(n):
r[i,i] = 1.0
return r
def plot_dendro(x):
D = get_distance_matrix(x)
# Compute and plot dendrogram.
fig = pylab.figure()
axdendro = fig.add_axes([0.09,0.1,0.2,0.8])
Y = sch.linkage(x, method='centroid')
Z = sch.dendrogram(Y, orientation='right')
axdendro.set_xticks([])
axdendro.set_yticks([])
# Plot distance matrix.
axmatrix = fig.add_axes([0.3,0.1,0.6,0.8])
index = Z['leaves']
D = D[index,:]
D = D[:,index]
im = axmatrix.matshow(D, aspect='auto', origin='lower')
axmatrix.set_xticks([])
axmatrix.set_yticks([])
# Plot colorbar.
axcolor = fig.add_axes([0.91,0.1,0.02,0.8])
pylab.colorbar(im, cax=axcolor)
# Display and save figure.
fig.show()
fig.savefig('dendrogram.png')
if __name__ == '__main__':
if len(sys.argv) < 2:
print("Usage:\n\t%s csv-file" % sys.argv[0])
sys.exit(1)
plot_dendro(np.array(load_df(sys.argv[1])))
<file_sep>/config_files/experiment1-4FULLanalysis.ini
;DO NOT USE FOLLOWING CHARACTERS IN KEYNAMES: ?{}|&~![()^"
;experimentName: name of the experiment
;generateVectors: yes-run simulation no- dont run sim, use input vector files
[GENERAL]
experimentName = Exp1-4KNN
generateVectors = no
runAnalysis = yes
runDataRep = yes
runHoldout = no
genHoldVectors = no
simAllSeeds = yes
repititions = 10000
alpha1list = 0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95
alpha2list = 0.05,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.95
[FILES]
inEdgesFile = ../data/dblp_jobrankprediction/dblp_yoj_2000_edgelist.txt
inNodesFile = ../data/dblp_jobrankprediction/dblp_yoj_2000_nodelist.txt
inHoldEdgesFile = EMPTYPATH
inHoldNodesFile = EMPTYPATH
outputDir = output_files/
outVectorDir = vectors/
outHoldVecDir = EMPTYPATH
inVectorDir = ../results/dblp_job_rank_prediction/Exp1-4/exp1-4vectors/
inHoldVecDir = EMPTYPATH
outAnalysisDir = analysis/
inAnalysisDir = ../results/dblp_job_rank_prediction/Exp1-4/exp1-4results/
inHoldAnalysisDir = EMPTYPATH
[ANALYSIS]
;methods [SVR, randomForest, KNN, PCA]
vsDummy = no
usePCA = no
useZachKNN = no
useKNN = no
useSVR = yes
useRandomForest = no
knnNeighbors = 3
knnRepititions = 10
pcaComponents = 500
<file_sep>/gscholar/StrongComponent.py
import sys
graph = {}
in_comp = {}
# Format: the file should contain list of edges:
# each edge in one line - node ids separated by space
def main():
filename = sys.argv[1]
load_graph(filename)
comp = lscc()
out_put(filename, comp)
# Load the "Directed" graph
def load_graph(file):
nodes = 0
edges = 0
f = open(file, "r")
for line in f:
edges += 1
s = int(line.split(None, 2)[0])
t = int(line.split(None, 2)[1])
if s not in graph:
graph[s] = [t]
nodes += 1
else:
if t not in graph[s]:
graph[s].append(t)
if t not in graph:
graph[t] = []
nodes += 1
print("number of nodes: " + str(nodes) + " number of edges: " + str(edges))
f.close()
# Outputs the largest strongly connected component
def out_put(filename, largest):
out = open(filename[:-4] + "_lscc.txt", "w")
index = {}
nodes = 0
for node in graph:
if in_comp[node] == largest:
index[node] = nodes
nodes += 1
edges = 0
for node in graph:
if in_comp[node] == largest:
for neighbor in graph[node]:
if in_comp[neighbor] == largest:
edges += 1
out.write(str(index[node]) + "\t" + str(index[neighbor]) + "\n")
print("number of nodes: " + str(nodes) + " number of edges: " + str(edges))
out.close()
# Labels the nodes by their strongly connected components' id
# Returns the id of the largest component
def lscc():
maxim = 0
largest = 0
visit = {}
root = {}
index = {}
node_id = 0
comp = 0
path = []
for key in graph:
in_comp[key] = 0
visit[key] = False
#For every Spanning Tree:
for key in graph:
if not visit[key]:
stack = [key]
#Start
while stack:
#print(node_id+1)
#print(stack)
top_s = stack.pop()
if in_comp[top_s] != 0:
continue
stack.append(top_s)
if not visit[top_s]:
node_id += 1
index[top_s] = node_id
visit[top_s] = True
root[top_s] = node_id
path.append(top_s)
if len(path) == 0:
print(top_s)
count = 0
for neighbor in graph[top_s]:
if visit[neighbor]:
continue
stack.append(neighbor)
count += 1
#Next Step
if count != 0:
continue
#print("now: ", top_s)
stack.pop()
for neighbor in graph[top_s]:
if in_comp[neighbor] != 0:
continue
root[top_s] = min(root[top_s], root[neighbor])
#print(root)
#print("check", top_s, index[top_s])
if root[top_s] != index[top_s]:
continue
#print("pass")
count = 0
comp += 1
while path:
vertex = path.pop()
count += 1
in_comp[vertex] = comp
if vertex == top_s:
break
if maxim < count:
maxim = count
largest = comp
if maxim > len(graph) / 2:
return largest
#print("root", root)
#print("index", index)
#print("incomp", in_comp)
print("Largest component id: ", largest)
return largest
if __name__ == "__main__":
main()
<file_sep>/dblp_parsing.py
import os
import csv
DATA_FILEPATH = "dblp_data/faculty_data - faculty.csv"
PUBLICATION_ITEM_CATEGORIES = {"article", "inproceedings", "proceedings", "book", "incollection", "phdthesis",
"mastersthesis", "www"}
DBLP_XML_FILEPATH = "dblp_data/dblp-2021-04-01.xml"
CSV_OUTPUT_FILEPATH = "dblp_data/processed_publications.csv"
def main():
# year_to_num = year_to_prof()
# print(year_to_num)
parse_xml_for_publications()
return
def year_to_prof(printing=0):
"""Counts {year: num of people with year_of_job of that year}.
Uses: DATA_FILEPATH.
:return: {year: num of people with year_of_job of that year}
"""
with open(DATA_FILEPATH, 'r') as file:
next(file).split(",")
year_to_num = {}
for row in file:
row = row.split(",")
year = -1
for item in row:
try:
year = int(item)
except ValueError:
pass
if year not in year_to_num:
year_to_num[year] = 0
year_to_num[year] += 1
total = 0
for year in sorted(year_to_num):
if printing:
print("{}: {}".format(year, year_to_num[year]))
total += year_to_num[year]
print("year_to_prof: total = {} professors".format(total))
return year_to_num
def parse_xml_for_publications():
"""Parses the DBLP xml file and processes each publication (for memory efficiency).
Uses: DATA_FILEPATH, DBLP_XML_FILEPATH, PUBLICATION_ITEM_CATEGORIES, CSV_OUTPUT_FILEPATH.
:return: None
"""
if os.path.isfile(CSV_OUTPUT_FILEPATH):
raise ValueError("File at CSV_OUTPUT_FILEPATH already exists: please delete the file to start parsing")
with open(DBLP_XML_FILEPATH, 'r') as file:
# Start with the first line of the file:
line = next(file)
print("Start: {}".format(line))
# Non-publication item beginning with "<" (should be 3 words and "" or "\n"):
non_publication_items = []
# Search for "<[publication_item]":
while True:
if "<" not in line:
try:
line = next(file)
continue
except StopIteration:
print("Finished parsing the file")
print("non_publication_items = {}".format(non_publication_items))
return
else:
# Cases of location:
# (i) "...<[publication_item] ...>"
# (ii) "<[publication_item] ...>"
index_of_arrow = line.find("<")
# line = "<[publication_item] ...>"
line = line[index_of_arrow:]
# Check if it's a valid publication item:
publication_item = line[1:].split(" ")[0]
if publication_item not in PUBLICATION_ITEM_CATEGORIES:
non_publication_items.append(publication_item)
line = line[len(publication_item) + 1:]
continue
publication = []
# Once found and legal, add to publication all strings from "[publication_item] ..."
# to "</publication_item>"
closing_string = "</{}>".format(publication_item)
while closing_string not in line:
publication.append(line)
line = next(file)
begin_index = line.find(closing_string)
end_index = begin_index + len(closing_string)
publication.append(line[:end_index])
# Process the publication:
process_publication(publication)
# Update line to what's right after "</publication_item>", even if it's "":
line = line[end_index:]
return
def process_publication(publication):
"""
Helper function that processes the publication.
Uses: CSV_OUTPUT_FILEPATH, PUBLICATION_ITEM_CATEGORIES.
:param publication: a list of strings.
:return: None
"""
if not os.path.isfile(CSV_OUTPUT_FILEPATH):
with open(CSV_OUTPUT_FILEPATH, 'w') as output_file:
fieldnames = ["type", "year", "number_of_authors", "author", "title"]
writer = csv.DictWriter(output_file, fieldnames=fieldnames)
writer.writeheader()
with open(CSV_OUTPUT_FILEPATH, 'a') as output_file:
user_obj_writer = csv.writer(output_file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
# Induce year:
years = []
for line in publication:
while "<year>" in line:
i_begin = line.find("<year>") + len("<year>")
i_end = line.find("</year>")
year = int(line[i_begin:i_end])
line = line[i_end + len("</year>"):]
years.append(year)
if len(years) == 0:
year = None
else:
year = years
# Induce title:
titles = []
for line in publication:
while "<title>" in line:
i_begin = line.find("<title>") + len("<title>")
i_end = line.find("</title>")
title = line[i_begin:i_end]
line = line[i_end + len("</title>"):]
titles.append(title)
if len(titles) == 0:
title = None
else:
title = titles
# Induce type:
publication_type = publication[-1][2:-1]
if publication_type not in PUBLICATION_ITEM_CATEGORIES:
raise ValueError("Processed publication type is not in PUBLICATION_ITEM_CATEGORIES")
# Induce the number of authors:
num_of_auth = 0
for line in publication:
num_of_auth += line.count("<author")
if num_of_auth == 0:
author = None
else:
# Induce author:
authors = []
for line in publication:
while "<author" in line:
i_begin = line.find("<author") + len("<author")
i_end = line.find("</author>")
author = line[i_begin:i_end]
author = author.split(">")[1]
authors.append(author)
line = line[i_end + len("</author>"):]
author = authors
if len(author) != num_of_auth:
raise ValueError("len(author) = {}, while num_of_auth = {}".format(len(author), num_of_auth))
row = [publication_type, year, num_of_auth, author, title]
user_obj_writer.writerow(row)
return
if __name__ == '__main__':
main()
<file_sep>/C++ code/simulation.h
// Simulate the spread of information over network
// Also outputs the results
#ifndef simulation_h
#define simulation_h
// #include <vector> //#include <time.h> //#include "graph.cpp"
// #include "computation.h"
#include <iostream>
#include <fstream>
#include <math.h>
#include <queue>
#include <stdio.h>
#include <string.h>
using namespace std;
void print_result(vector<int>&, int, int, Graph, int*);
struct simRes {
int node;
float minPr;
float minWeight;
int minGroup;
int nodeW;
float minPrW;
float minWeightW;
int minGroupW;
int rep;
float avePr;
};
simRes simulation(vector<int>& seeds, float alpha1, float alpha2, int rep, Graph graph, map<string, string> map) {
//srand(static_cast<unsigned int>(time(NULL)));
random_device rand_dev;
mt19937 generator(rand_dev());
uniform_int_distribution<int> distr(0, INT_MAX);
const int numV = graph.n;
int k = int(seeds.size());
for(int i = 0; i < numV; i++)
graph.prob[i] = 0;
for(int i = 0; i < k; i++)
graph.prob[seeds[i]] = rep;
bool* isOn = new bool [numV];
//vector<bool> isOn = ...
//make sure to delete when done
queue<int> onNodes, empty; // Infected nodes this round, declaration of container class
/*int* hitTime = new int [numV]{}; // Hit time of nodes for each round
int rounds, lastNode;*/
AdjListNode* iter = nullptr;
// Run simulation for each repetition
for(int simRound = 0; simRound < rep; simRound++) {
memset(isOn, 0, numV);
//set seed nodes to be ON
for(int i = 0; i < k; i++)
isOn[seeds[i]] = true;
for(int i = 0; i < k; i++)
onNodes.push(seeds[i]);
/*rounds = 1;
lastNode = onNodes.back();*/
// Runs until no new node gets infected
while(!onNodes.empty()) {
//iterator?
//what is a container?
int curOnNode = onNodes.front();
iter = graph.neighbors[curOnNode].head;// Neighbors of them
while(iter) {
float alphaVal;
if(isOn[iter->id]) { iter = iter->next; continue; }
if (map[to_string(curOnNode)]==iter->phd) {alphaVal = alpha2;}
//add more else if statements here for more infection rates
else {alphaVal = alpha1;}
//cout << "alphaVal is: " << to_string(alphaVal) << "\n\n";
//INT_MAX is max int
//float is called a cast; it forces the type of distr(generator)
// to be a float. Static_cast is a better way to cast in C++
if((float) distr(generator) / INT_MAX <= alphaVal) {
isOn[iter->id] = true;
graph.prob[iter->id] += 1;
onNodes.push(iter->id);
/*hitTime[iter->id] += rounds;*/
}
iter = iter->next;
}
/*if(onNodes.front() == lastNode) {
lastNode = onNodes.back();
rounds++;
}*/
onNodes.pop();
}
// Release memory
swap(onNodes, empty);
}
int minim = 0;
for(int v = 0; v < numV; v++)
if(graph.prob[minim] > graph.prob[v])
minim = v;
int minimW = 0;
for(int v = 0; v < numV; v++)
if(float(graph.prob[minimW])/pow(graph.weight[minimW],2) > float(graph.prob[v])/pow(graph.weight[v],2))
minimW = v;
// In case "Average" is needed
float ave = 0;
for(int v = 0; v < numV; v++)
ave += float(graph.prob[v] / rep);
ave /= numV;
float minP = float(graph.prob[minim]) / rep;
float minW = graph.weight[minim];
int minG = graph.group[minim];
float minWP = float(graph.prob[minimW]) / rep;
float minWW = graph.weight[minimW];
int minWG = graph.group[minimW];
simRes result = {minim, minP, minW, minG, minimW, minWP, minWW, minWG, rep, ave};
delete[] isOn;
delete[] iter;
swap(onNodes, empty);
/*delete[] hitTime;*/
return result;
}
#endif /* simulation_h */
<file_sep>/example_hyperparameter_tuning/ari_mean_dblp.py
"""Pipeline to count the mean adjusted rand index score for fluid communities clusterings against IAC."""
import main_pipelines as mp
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.K = 2
mp.ALPHA_VALUES = [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
mp.mean_ari()
return
if __name__ == '__main__':
main()
<file_sep>/C++ code Orig/graph.cpp
//Network Data Structure
#include <iostream>
#include <random>
#include <climits>
using namespace std;
// Adjacency List Node
struct AdjListNode {
int id;
struct AdjListNode* next;
};
// Adjacency List
struct AdjList {
struct AdjListNode *head;
};
// Class Graph
class Graph {
public:
int n;
int *degree, *in_degree;
int *prob, *group;
struct AdjList* neighbors;
float* weight;
//int* thresh;
Graph(int n) {
this->n = n;
degree = new int [n];
in_degree = new int [n];
prob = new int [n];
weight = new float [n];
group = new int [n];
//thresh = new int [n];
neighbors = new AdjList [n];
for (int i = 0; i < n; ++i) {
neighbors[i].head = NULL;
degree[i] = in_degree[i] = prob[i] = 0;
weight[i] = 1;
group[i] = 1; //thresh[i] = 1;
}
}
void setRand() {
//srand(static_cast<unsigned int>(time(NULL)));
random_device rand_dev;
mt19937 generator(rand_dev());
uniform_int_distribution<int> distrW(0, INT_MAX);
uniform_int_distribution<int> distrG(0, 1);
for (int i = 0; i < n; ++i) {
weight[i] = (float) distrW(generator)/INT_MAX;
group[i] = distrG(generator);
uniform_int_distribution<int> distrT(0, in_degree[i]);
//thresh[i] = (int) distrT(generator); // Thresh = 0 or d_i?
}
}
AdjListNode* newAdjListNode(int id) {
AdjListNode* newNode = new AdjListNode;
newNode->id = id;
newNode->next = NULL;
return newNode;
}
void addEdge(int src, int dest, bool dir) {
degree[src]++;
in_degree[dest]++;
AdjListNode* newNode = newAdjListNode(dest);
newNode->next = neighbors[src].head;
neighbors[src].head = newNode;
if(dir) { return; }
degree[dest]++;
newNode = newAdjListNode(src);
newNode->next = neighbors[dest].head;
neighbors[dest].head = newNode;
}
void printGraph() {
for (int v = 0; v < n; ++v) {
AdjListNode* iter = neighbors[v].head;
cout<<"Vertex " << v << ":";
while (iter) {
cout << " " << iter->id;
iter = iter->next;
}
cout << endl;
}
}
};
<file_sep>/helper_pipelines/clustering_pipeline.py
# libraries
# import igraph
import random
import numpy as np
from sklearn.cluster import KMeans, SpectralClustering
from sklearn.metrics import adjusted_rand_score
import itertools
# from igraph import RainbowPalette
from copy import deepcopy
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
import networkx as nx
import time
from scipy import stats
import seaborn as sns
import pickle
from collections import OrderedDict
import sys
import os
# my own code
from helper_pipelines import choose_seeds
from helper_pipelines import read_coauthorship as read
from helper_pipelines.choose_seeds import *
from helper_pipelines.eigengap_calculator import *
# These are the parameters. Should make them readable from command line arguments.
K = 3
ALPHA = 0.4
STAR = False
N = 21
FILEPATH = 'data/dblp/coauthorship_c_style.txt'
REP = 100
PATHFORIMAGE = 'networkx_coauthorship_k3.png'
VECTOR_PATH = 'data/dblp/coauthorship_vectors.txt'
plt.rcParams.update({'font.size': 18})
def cluster_stats(x, estimator, clusters, node_to_cluster):
print("Cluster stats:")
print("Size:", cluster_size(node_to_cluster, clusters))
print("Radii:", cluster_radius(x, estimator, clusters))
print("Distribution of distance from center across clusters:", distribution_of_dist_from_center())
print("Betweeness centrality across clusters:", betweeness_centrality())
def cluster_size(node_to_cluster, clusters):
size = {cluster: 0 for cluster in clusters}
for node in node_to_cluster:
size[node_to_cluster[node]] += 1
return size
def distribution_of_dist_from_center():
return "NOT YET IMPLEMENTED"
def betweeness_centrality():
return "NOT YET IMPLEMENTED"
def cluster_radius(x, estimator, y):
# help from https://datascience.stackexchange.com/questions/32753/find-cluster-diameter-and-associated-cluster-points-with-kmeans-clustering-scik/32776
y_kmeans = estimator.predict(x)
# empty dictionaries
clusters_centroids = dict()
clusters_radii = dict()
'''looping over clusters and calculate Euclidian distance of
each point within that cluster from its centroid and
pick the maximum which is the radius of that cluster'''
for cluster in list(set(y)):
clusters_centroids[cluster] = list(zip(estimator.cluster_centers_[:, 0], estimator.cluster_centers_[:, 1]))[
cluster]
clusters_radii[cluster] = max([np.linalg.norm(np.subtract(i, clusters_centroids[cluster])) for i in
zip(x[y_kmeans == cluster, 0], x[y_kmeans == cluster, 1])])
# print (clusters_radii)
# Visualising the clusters and cluster circles
# fig, ax = plt.subplots(1,figsize=(7,5))
#
# plt.scatter(x[y_kmeans == 0, 0], x[y_kmeans == 0, 1], s = 100, c = 'red', label = 'Iris-setosa')
# art = mpatches.Circle(clusters_centroids[0],clusters_radii[0], edgecolor='r',fill=False)
# ax.add_patch(art)
#
# plt.scatter(x[y_kmeans == 1, 0], x[y_kmeans == 1, 1], s = 100, c = 'blue', label = 'Iris-versicolour')
# art = mpatches.Circle(clusters_centroids[1],clusters_radii[1], edgecolor='b',fill=False)
# ax.add_patch(art)
#
# plt.scatter(x[y_kmeans == 2, 0], x[y_kmeans == 2, 1], s = 100, c = 'green', label = 'Iris-virginica')
# art = mpatches.Circle(clusters_centroids[2],clusters_radii[2], edgecolor='g',fill=False)
# ax.add_patch(art)
#
# #Plotting the centroids of the clusters
# plt.scatter(estimator.cluster_centers_[:, 0], estimator.cluster_centers_[:,1], s = 100, c = 'yellow', label = 'Centroids')
#
# plt.legend()
# plt.tight_layout()
# plt.savefig('data/dblp/kmeans.jpg',dpi=300)
return clusters_radii
def cluster(vectors, k, graph, cluster):
X = np.array(list(vectors.values()))
# X = read.create_hardcoded_stars(0.5,20)
labels = KMeans(n_clusters=k, random_state=1).fit_predict(X)
# print(kmeans.labels_) # This seems to be correct
# print (kmeans.cluster_centers_)
# print (graph.number_of_nodes())
for node in graph.nodes:
graph.nodes[node]["cluster"] = labels[node]
node_to_cluster = {}
# nodes = list(graph.keys())
# nodes.sort()
# print(graph)
for node in graph:
node_to_cluster[node] = labels[node]
# # vectors[node].reshape(1, -1)
# # print(node, vectors[node])
# vector = np.array(vectors[node]).reshape(1, -1)
# cluster_label = kmeans.predict(vector)[0]
# node_to_cluster[node] = cluster_label
# cluster_stats(X, kmeans, kmeans.labels_, node_to_cluster)
return node_to_cluster
def spectral_cluster_star(X, k, graph):
sc = SpectralClustering(n_clusters=k, random_state=1, affinity='precomputed').fit(X)
print(sc.labels_)
for node in graph.nodes:
graph.node[node]["cluster"] = sc.labels_[node]
node_to_cluster = {}
# nodes = list(graph.keys())
# nodes.sort()
# print(graph)
for node in graph:
node_to_cluster[node] = sc.labels_[node - 1]
return node_to_cluster
def spectral_cluster(k, graph):
'''
runs spectral clustering on graph and saves the cluster index in the cluster attribute of each node
'''
# help from https://stackoverflow.com/questions/23684746/spectral-clustering-using-scikit-learn-on-graph-generated-through-networkx
node_list = list(graph.nodes())
adj_matrix = nx.to_numpy_matrix(graph,
nodelist=node_list) # Converts graph to an adj matrix with adj_matrix[i][j] represents weight between node i,j.
labels = SpectralClustering(affinity='precomputed', assign_labels="discretize", random_state=0,
n_clusters=k).fit_predict(adj_matrix)
print(labels)
for node in node_list:
graph.nodes[node]["cluster"] = labels[node]
node_to_cluster = {}
# nodes = list(graph.keys())
# nodes.sort()
# print(graph)
for node in node_list:
node_to_cluster[node] = labels[node]
return node_to_cluster
# def color_nodes(k, g, clusters, filename):
# # Color the nodes according to their cluster, then plot
#
# pal = RainbowPalette(n=k)
#
# color_dict = {}
# for index, cluster_label in enumerate(clusters.values()):
# if cluster_label not in color_dict:
# color_dict[cluster_label] = pal[int(cluster_label)]
#
# g.vs['label'] = list(range(g.vcount()))
# out = igraph.plot(g,layout=g.layout('kk'), vertex_color = [color_dict[cluster] for cluster in g.vs["cluster"]])
# out.save(filename)
#
# def make_graph(graph, cluster):
# # all_ids = sorted(list(set(itertools.chain.from_iterable((e['from'],e['to']) for e in entries))))
# # raw_id_to_id = {raw:v for v,raw in enumerate(all_ids)}
#
# g = igraph.Graph(len(graph.keys()))
# # print(graph.keys())
# g.vs["my_id"] = list(graph.keys())
# # print(g.vs.find(name="2"))
#
# for node in graph:
# # print(node)
# this_v = g.vs.find(my_id=node)
# this_v["cluster"] = cluster[node]
# for neighbor in graph[node]:
# that_v = g.vs.find(my_id=neighbor)
# that_v["cluster"] = cluster[neighbor]
# g.add_edge(this_v, that_v)
#
# return g
def networkx_color(graph, k):
pal = RainbowPalette(n=k)
color_map = []
for node in graph:
print(graph.node[node]["cluster"])
graph.node[node]["color"] = pal[int(graph.node[node]["cluster"])]
print(graph.node[node]["color"])
color_map.append(pal[int(graph.node[node]["cluster"])])
return color_map
# code adapted from https://towardsdatascience.com/k-means-clustering-with-scikit-learn-6b47a369a83c
def elbow_method(vectors, min_k, max_k, step):
'''
Make elbow graph to choose k value
'''
X = np.array(list(vectors.values()))
distortions = []
for i in range(min_k, max_k):
print("On k value " + str(i))
kmeans = KMeans(n_clusters=i, random_state=1).fit(X)
distortions.append(kmeans.inertia_)
print(kmeans.inertia_)
# plot
print(distortions)
plt.plot(range(min_k, max_k), distortions, marker='o')
plt.xticks(range(min_k, max_k))
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.title("Information Access Clustering Elbow Plot")
plt.show()
# def spectral_elbow_method(graph, min_k, max_k, step):
# '''
# Make elbow graph to choose k value for spectral clustering
# '''
# node_list = list(graph.nodes())
# adj_matrix = nx.to_numpy_matrix(graph, nodelist=node_list) #Converts graph to an adj matrix with adj_matrix[i][j] represents weight between node i,j.
#
# distortions = []
# for i in range(min_k, max_k):
# print("On k value " + str(i))
# labels = SpectralClustering(affinity = 'precomputed', assign_labels="discretize",random_state=0,n_clusters=k).fit(adj_matrix)
# distortions.append(kmeans.inertia_)
# print (kmeans.inertia_)
#
# # plot
# print(distortions)
# plt.plot(range(min_k, max_k), distortions, marker='o')
# plt.xticks(range(min_k, max_k))
# plt.xlabel('Number of clusters')
# plt.ylabel('Distortion')
# plt.title("Information Access Clustering Elbow Plot")
# plt.show()
def visualize(graph, clusters):
color_map = networkx_color(graph, K)
print(clusters)
print(time.time() - start)
# make visualization of graph colored by clustering
g = make_graph(graph, clusters)
color_nodes(K, g, clusters, PATHFORIMAGE)
pos = nx.spring_layout(graph)
nx.draw(graph, with_labels=True, node_color=color_map)
plt.draw()
plt.show()
def plot_citations(g):
nodes = list(g.nodes(data=True))
clusters_total = {cluster: 0 for cluster in range(K)}
clusters_count = {cluster: 0 for cluster in range(K)}
cluster_total_count = {cluster: 0 for cluster in range(K)}
no_cites = 0
for node in nodes:
data = node[1]
citations = data["citation_count"]
cluster = data["cluster"]
cluster_total_count[cluster] += 1
if citations >= 0:
clusters_total[cluster] += citations
clusters_count[cluster] += 1
else:
no_cites += 1
citation_averages = []
for cluster in clusters_total:
if clusters_count[cluster] == 0:
print("cluster " + str(cluster) + " had no members")
citation_averages.append(0)
else:
citation_averages.append(clusters_total[cluster] / clusters_count[cluster])
print(f"There are {no_cites} people without citation records")
print(clusters_count)
print(cluster_total_count)
print(citation_averages)
plt.plot(citation_averages)
plt.show()
def plot_attribute_distributions(g, attribute, cluster_method):
'''
Plots the distribution of some numerical node attribute for nodes in each cluster.
'''
print("\nStarting analysis of " + attribute)
fig = plt.figure(figsize=(12, 10))
nodes = list(g.nodes(data=True))
clusters_total = {cluster: [] for cluster in range(K)}
no_cites = 0
no_cites_dict = {cluster: 0.0 for cluster in range(K)}
cluster_size = {cluster: 0.0 for cluster in range(K)}
for node in nodes:
data = node[1]
# print(data)
value = data[attribute]
cluster = data["cluster"]
cluster_size[cluster] += 1
try: # negative value implies the value was not found
clusters_total[cluster].append(float(value))
except:
no_cites += 1
no_cites_dict[cluster] += 1
print(cluster_size)
citation_averages = []
for cluster in clusters_total:
input = [int(i) for i in clusters_total[cluster]]
# clusters_total[cluster].sort()
# plt.hist(clusters_total[cluster], bins = int(2450/5))
print(f"total nodes in cluster {cluster}: {cluster_size[cluster]}")
percent = no_cites_dict[cluster] / cluster_size[cluster]
print(f"percent with {attribute} in cluster {cluster}: {1 - percent}")
sns.distplot(input, hist=False, kde=True,
kde_kws={'linewidth': 3},
label=str(cluster))
# with open("output_files/output_strings.txt", 'a') as file:
# file.write("\n0 to 2")
# file.write(str(stats.ks_2samp(clusters_total[0], clusters_total[2])))
# file.write("1 to 2")
# file.write(str(stats.ks_2samp(clusters_total[1], clusters_total[2])))
# file.write("0 to 1")
# file.write(str(stats.ks_2samp(clusters_total[0], clusters_total[1])))
print(len(clusters_total[0]), clusters_total[0])
print(len(clusters_total[1]), clusters_total[1])
print(len(clusters_total[2]), clusters_total[2])
print("\n0 to 2")
print(stats.ks_2samp(clusters_total[0], clusters_total[2]))
print("1 to 2")
print(stats.ks_2samp(clusters_total[1], clusters_total[2]))
print("0 to 1")
print(stats.ks_2samp(clusters_total[0], clusters_total[1]))
# with open("output_files/output_strings.txt", 'a') as file:
# file.write("\nkruskal-wallis, 3-clusters:\n")
# file.write(stats.kruskal(clusters_total[0], clusters_total[1], clusters_total[2]))
print("\nkruskal-wallis, 3-clusters:")
print(stats.kruskal(clusters_total[0], clusters_total[1], clusters_total[2]))
if (K == 12):
print("kruskal-wallis, 12-clusters:")
print(
stats.kruskal(clusters_total[0], clusters_total[1], clusters_total[2], clusters_total[3], clusters_total[4],
clusters_total[5], clusters_total[6], clusters_total[7], clusters_total[8], clusters_total[9],
clusters_total[10], clusters_total[11]))
print(attribute + str(len(nodes) - no_cites))
plt.xlim(-50000, 100000)
# plt.ylim(0, 5000)
plt.xlabel(attribute)
plt.ylabel("PDF")
plt.title("Density at " + attribute + " for different clusters")
# plt.show()
plt.savefig("../output_files/" + attribute + " vs. " + cluster_method + ".png", bbox_inches='tight')
def plot_attribute_bar(graph, attribute, cluster_method):
fig = plt.figure()
ax = plt.subplot()
nodes = list(graph.nodes(data=True))
cluster_to_attrib = {cluster: [] for cluster in range(K)}
for node in nodes:
data = node[1]
# print(node)
attrib = data[attribute]
if attrib != "not found":
cluster = data["cluster"]
cluster_to_attrib[cluster].append(attrib)
# width = 0.35
# fig, ax = plt.subplots()
for cluster in cluster_to_attrib:
# need list of x axis and height of y axis
cluster_size = len(cluster_to_attrib[cluster])
attrib_lst = cluster_to_attrib[cluster]
freqs = {i: attrib_lst.count(i) / cluster_size for i in set(attrib_lst)}
print(freqs)
ax.bar(list(freqs.keys()), list(freqs.values()), label=cluster, alpha=0.2, linewidth=1)
plt.title("Frequency of " + attribute + " across information access clusters")
plt.xlabel(attribute)
plt.ylabel("portion of cluster")
ax.legend()
plt.savefig("../output_files/plots/" + attribute + " vs. " + cluster_method + ".png")
plt.clf()
def connected_components(graph):
size_comps = [len(c) for c in sorted(nx.connected_components(graph), key=len, reverse=False)]
print(size_comps)
def add_centrality(graph):
'''
Adds attributes representing network structure importance metrics to the nodes of graph.
'''
deg_centrality = nx.degree_centrality(graph)
# between_centrality = nx.betweenness_centrality(graph)
pagerank = nx.pagerank_numpy(graph)
for node in deg_centrality:
graph.nodes[node]["degree_centrality"] = deg_centrality[node]
# graph.nodes[node]["betweeness_centrality"] = between_centrality[node]
graph.nodes[node]["pagerank"] = pagerank[node]
def read_in_clusters(filename):
'''
Reads in clusters from the cluster csv files.
'''
cluster_dict = OrderedDict()
with open(filename, "r") as f:
lines = f.readlines()
for line in lines:
line = line[:-1]
line = line.split(",")
# print(line)
cluster_dict[line[0]] = int(line[1])
return cluster_dict
def adj_rand_index(dict1, dict2):
'''
Calculates the adjusted rand index between two clusterings.
'''
# print(graph1.nodes())
# spec_graph_clusters = nx.get_node_attributes(graph1,'cluster')
# info_access_graph = nx.get_node_attributes(graph2,'cluster')
if (list(dict1.keys()) == list(dict2.keys())):
vals = list(dict1.values())
# print(dict2.keys())
print(adjusted_rand_score(list(dict1.values()),
list(dict2.values()))) # check these actually align in the same order
else:
print("Order of two dicts is wrong")
def return_adj_rand_index(dict1, dict2):
'''
Calculates AND returns the adjusted rand index between two clusterings.
'''
# Check if the orders are the same:
if (list(dict1.keys()) == list(dict2.keys())):
ari = adjusted_rand_score(list(dict1.values()), list(dict2.values()))
return ari
else:
raise ValueError("Orders are not the same")
def plot_all_attributes(graph, cluster_method):
'''
Plots distributions of various attributes over nodes in each cluster.
'''
plot_attribute_distributions(graph, "followers_count", cluster_method)
# plot_attribute_bar(graph, "gender", cluster_method)
# plot_attribute_distributions(graph, "phd_rank", cluster_method)
# plot_attribute_distributions(graph, "degree_centrality", cluster_method)
# plot_attribute_distributions(graph, "betweeness_centrality", cluster_method)
# plot_attribute_distributions(graph, "pagerank", cluster_method)
# plot_attribute_distributions(graph, "job_rank", cluster_method)
def dblp_citations_pipeline(cluster_method):
if cluster_method == "info_access":
graph = read.make_network_with_citations("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
add_centrality(graph)
# print(nx.number_connected_components(graph))
# print(graph.number_of_nodes())
# connected_components(graph)
vectors = read.read_in_vectors("data/dblp/old_coauthorship_vectors_48.txt") # need to make vectors
clusters = cluster(vectors, K, graph)
plot_citations(graph)
plot_all_attributes(graph, "information access")
# plot_attribute_bar(graph, "gender")
# with open("data/dblp/info_access_graph_46_pickle", "ab") as f:
# pickle.dump(graph, f)
# read.writeout_clusters(graph, "data/dblp/info_access_46_clusters.csv")
elif cluster_method == "spectral":
graph = read.make_network_with_citations("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
add_centrality(graph)
clusters = spectral_cluster(K, graph)
plot_citations(graph)
# plot_all_attributes(graph, "spectral")
# with open("data/dblp/spectral_graph_46_pickle", "ab") as f:
# pickle.dump(graph, f)
# read.writeout_clusters(graph, "data/dblp/spectral_clusters_46.csv")
else:
spectral_dict = read_in_clusters("data/dblp/spectral_clusters_46.csv")
info_access_dict = read_in_clusters("data/dblp/info_access_46_clusters.csv")
adj_rand_index(spectral_dict, info_access_dict)
# def seed_pipeline(p):
# graph = read.make_network_with_citations("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
# # add_centrality(graph)
# seeds = random_seeds(graph, p)
# read.write_graph(graph, seeds, "data/dblp/random_seed_edgelist.txt", True)
def plot_p(filename):
with open(filename, "r") as f:
aris = f.readlines()
ari_vals = []
for ari in aris:
if ari != "\n":
ari_vals.append(float(ari))
fig = plt.figure(figsize=(12, 10))
x_vals = [5, 10, 15, 20, 25, 30, 35, 40, 45, 50]
plt.plot(x_vals, ari_vals)
plt.xlabel("p")
plt.ylabel("Adjusted Random Index")
plt.title("ARI vs. p")
# plt.show()
plt.savefig("data/dblp/plots/ari_p.png", bbox_inches='tight')
# def main():
# start = time.time()
# if STAR:
# graph = read.create_networkx_star(N, True)
# else:
# graph = read.make_networkx(FILEPATH)
#
# # Read in vectors
# vectors = read.read_in_vectors(VECTOR_PATH)
#
# # cluster vectors using kmeans
# clusters = cluster(vectors, K, graph)
#
# # print (clusters)
def pipeline_before_vectors_cc():
'''
Runs the first half of the basic pipeline on only the largest connected component,
until vectors need to be generated in C++
'''
graph = read.make_network_with_ids("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
largest_cc = max(nx.connected_components(graph), key=len)
graph = graph.subgraph(largest_cc).copy()
add_centrality(graph)
graph = nx.convert_node_labels_to_integers(graph) # replaces dblp id label with integer label. First label is 0.
with open("data/dblp/cc_network_pickle", "wb") as f:
pickle.dump(graph, f)
read.write_graph(graph, [], "data/dblp/cc_edgelist.txt", False)
def pipeline_after_vectors_cc(vector_file):
'''
Runs the second half of the basic pipeline on only the largest connected component,
after vectors have been generated in C++
'''
with open("data/dblp/cc_network_pickle", "rb") as f:
graph = pickle.load(f)
vectors = read.read_in_vectors(vector_file)
clusters = cluster(vectors, K, graph)
# read.writeout_clusters(graph, "data/dblp/cc_95_clusters.csv")
plot_all_attributes(graph, "information access")
clusters = spectral_cluster(K, graph)
# read.writeout_clusters(graph, "data/dblp/spectral_3_clusters.csv")
plot_all_attributes(graph, "spectral")
def pipeline_before_vectors():
'''
Runs the first half of the basic pipeline, until vectors need to be generated in C++
'''
graph = read.make_network_with_ids("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
add_centrality(graph)
graph = nx.convert_node_labels_to_integers(graph) # replaces dblp id label with integer label. First label is 0.
with open("data/dblp/network_pickle", "wb") as f:
pickle.dump(graph, f)
read.write_graph(graph, [], "data/dblp/edgelist.txt", False)
def pipeline_after_vectors(vector_file):
'''
Runs the second half of the basic pipeline, after vectors have been generated in C++
'''
# os.chdir('..')
# print(os.getcwd())
# os.chdir('output_files')
print(os.getcwd())
with open("../output_files/pickled_graph_quantifiers_added", "rb") as f:
graph = pickle.load(f)
vectors = read.read_in_vectors(vector_file)
print("\n================INFORMATION ACCESS==================")
cluster_method = "iac"
clusters = cluster(vectors, K, graph, cluster_method)
plot_all_attributes(graph, "information access")
print("\n================SPECTRAL==================")
cluster_method = "spectral"
clusters = spectral_cluster(K, graph)
plot_all_attributes(graph, "spectral")
def cc_info_access_elbow_pipeline(vector_file):
with open("output_files/pickled_graph", "rb") as f:
graph = pickle.load(f)
# choose_spectral_k(graph)
vectors = read.read_in_vectors(vector_file)
elbow_method(vectors, 1, 10, 1)
def seed_before_vector_pipeline(seed_strategy, p):
'''
Runs the first half of the basic pipeline on only the largest connected component,
until vectors need to be generated in C++. Provides list of seeds to create vectors with.
'''
graph = read.make_network_with_ids("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
largest_cc = max(nx.connected_components(graph), key=len)
graph = graph.subgraph(largest_cc).copy()
add_centrality(graph)
graph = nx.convert_node_labels_to_integers(graph) # replaces dblp id label with integer label. First label is 0.
with open("data/dblp/cc_network_pickle", "wb") as f:
pickle.dump(graph, f)
seeds = []
if seed_strategy == "random":
seeds = random_seeds(graph, p)
elif seed_strategy == "between":
seeds = centrality_seeds(graph, p, "betweeness_centrality")
elif seed_strategy == "degree":
seeds = centrality_seeds(graph, p, "degree_centrality")
elif seed_strategy == "pagerank":
seeds = centrality_seeds(graph, p, "pagerank")
read.write_graph(graph, seeds, f"data/dblp/cc_{seed_strategy}_seed_edgelist.txt", True)
def seed_after_vectors_cc(vector_file):
'''
Runs the second half of the basic pipeline on only the largest connected component,
after vectors with a particular subset of seeds have been generated in C++
'''
with open("data/dblp/cc_network_pickle", "rb") as f:
graph = pickle.load(f)
vectors = read.read_in_seed_vectors(vector_file)
clusters = cluster(vectors, 3, graph)
plot_all_attributes(graph, "information access")
clusters = spectral_cluster(3, graph)
plot_all_attributes(graph, "spectral")
def seed_compare_cc(vector_file, p):
with open("data/dblp/cc_network_pickle", "rb") as f:
graph = pickle.load(f)
vectors = read.read_in_seed_vectors(vector_file)
clusters = cluster(vectors, 3, graph)
read.writeout_clusters(graph, f"data/dblp/seed_clusters_{p}.csv")
seed_clusters = read_in_clusters(f"data/dblp/seed_clusters_{p}.csv")
full_clusters = read_in_clusters("data/dblp/cc_4_clusters.csv")
adj_rand_index(seed_clusters, full_clusters)
def compare_clusters():
info_access_clusters = read_in_clusters("data/dblp/cc_95_clusters.csv")
spectral_clusters = read_in_clusters("data/dblp/spectral_12_clusters.csv")
adj_rand_index(info_access_clusters, spectral_clusters)
if __name__ == "__main__":
'''
Any "before" pipeline should be run before the C++ code. It will build a networkx graph
based off of the dblp data, pickle the graph, and write out an edgelist of the graph correctly
formatted to be used as input to the C++ code.
Any "after" pipeline should be run once you have generated vectors using the C++ code.
It will unpickle the networkx graph and then run some kind of clustering and analysis,
depending on which after pipeline it is.
Any "cc" pipeline is run only on the largest fully connected component of the dblp network
'''
with open("data/dblp/dblp_id_citations", "rb") as f:
graph = pickle.load(f)
for node in graph.nodes:
print(graph.nodes[node])
print(type(graph.nodes[node]["citation_count"]))
print("\n\n\n\n\n\n\n\n")
if (sys.argv[1] == "before_vectors"):
# This is the stanard before pipeline for the full dblp network with full seeds
pipeline_before_vectors()
elif (sys.argv[1] == "before_vectors_cc"):
# This is the same as the previous but only with the largest fully connected component
pipeline_before_vectors_cc()
elif (sys.argv[1] == "after_vectors"):
# This is the standard after pipeline for the full dblp network with full seeds.
# It does both info access and spectral clustering, and saves plots comparing each clustering
# to each of the data features.
pipeline_after_vectors("../output_files/cc_vectors.txt")
elif (sys.argv[1] == "after_vectors_cc"):
# This does the same as above but only on the largest fully connected component.
pipeline_after_vectors_cc("data/dblp/cc_vectorspoint4.txt")
elif (sys.argv[1] == "cc_info_elbow"):
# This creates an elbow plot for info access clustering on the largest connected component only
# (Change the vector file path to generate an elbow plot based off a different alpha value)
cc_info_access_elbow_pipeline("data/dblp/cc_vectorspoint05.txt")
elif (sys.argv[1] == "before_vectors_seed_cc"):
# This runs the first half of the pipeline on the largest fully connected component.
# It also chooses the top p (which you can input through sys.argv[2]) seeds according
# to the metric given in the first argument, and includes them in the edgelist file
# so that p-dimensional vectors can be generated with the C++ code.
seed_before_vector_pipeline("degree", int(sys.argv[2]))
elif (sys.argv[1] == "after_vectors_seed_cc"):
# This is the after pipeline that goes with the previous before pipeline. It runs info
# access clustering and spectral clustering on the network using the p-dimensional vectors
# and creates analysis plots.
seed_after_vectors_cc("data/dblp/cc_degree_seed_vectors.txt")
elif (sys.argv[1] == "find_p_after_vectors"):
# This pipeline is for creating a plot to compare the p-dimensional vector clustering
# to the n-dimensional vector clustering across different p values.
seed_compare_cc("data/dblp/cc_degree_seed_vectors.txt", int(sys.argv[2]))
print("\n")
elif (sys.argv[1] == "compare_clusters"):
# This pipeline compares spectral clustering to info access clustering using the adjusted
# rand index.
compare_clusters()
else:
print("Invalid option")
# plot_p("data/dblp/pagerank_p_ari.txt")
# dblp_citations_pipeline("info_access") # Change filename
# seed_pipeline(6)
# spectral_dict = read_in_clusters("data/dblp/spectral_clusters_46.csv")
# info_access_dict = read_in_clusters("data/dblp/info_access_46_clusters.csv")
# adj_rand_index(spectral_dict, info_access_dict)
# graph = read.make_networkx(FILEPATH)
# print(graph.size(), graph.number_of_nodes())
# graph = read.make_network_with_citations("data/dblp/coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
# read.write_graph(graph, [], "data/dblp/c_style_48.txt", False)
# vectors = read.read_in_vectors("data/dblp/vectors_48.txt")
# clusters = cluster(vectors, 3, graph)
# read.writeout_clusters(graph, "data/dblp/info_access_clusters_48.csv")
<file_sep>/helper_pipelines/README.md
# information-access-clustering
Execution files:
run.sh:
This file will run the full pipeline to generate analysis plots for the full dblp network (including islands). To run:
./run.sh ALPHA REPS
I recommend using reps >= 10,000 to get good results. I've also been using alpha around 0.4, though the clusters are fairly consistent across different alpha values.
cc_run.sh
This file does the exact same thing as run.sh, except on only the largest fully connected component of the dblp network.
choose_p.sh
This file runs clustering on the fully connected component of the dblp network with only the top pagerank seeds. It generates a file of adjusted rand indices between the p-dimensional vector clusterings and the full vector clusterings.
seed_subset_run.sh:
This file runs the full clustering pipeline for the largest fully connected component of the dblp network with a subset of the nodes as seeds for the vectors. It is currently set up to run clustering with the seeds that have the top degree centralities.
Other:
There are several other pipelines that you can run that don't have execution files. I would recommend starting with clustering_pipeline.py and looking at the bottom of the file. There are many different options that can be entered from the command line to run different pipelines. There are comments in the file describing what each does.
<file_sep>/build_twitch_network.py
import csv
import networkx as nx
import pickle
import sys
import build_generic_network as bgn
ATTRIBUTE_CSV_FILE = "data_twitch/ENGB/musae_ENGB_target.csv"
FIELDNAMES = ["id", "days", "mature", "views", "partner", "new_id"]
CSV_EDGELIST_FILENAME = "data_twitch/ENGB/musae_ENGB_edges.csv"
def main():
twitch()
return
def twitch():
G = nx.Graph()
all_nodes_attributes = {}
with open(ATTRIBUTE_CSV_FILE, 'r') as attribute_file:
read_attribute_file = csv.reader(attribute_file)
next(read_attribute_file)
for row in read_attribute_file:
G.add_node(row[-1])
attr_dict = {}
for i in range(len(FIELDNAMES)):
attr_dict[FIELDNAMES[i]] = row[i]
all_nodes_attributes[row[-1]] = attr_dict
nx.set_node_attributes(G, all_nodes_attributes)
with open(CSV_EDGELIST_FILENAME, 'r') as csv_file:
read_csv = csv.reader(csv_file, delimiter=',')
next(read_csv)
for row in read_csv:
G.add_edge(row[0], row[1])
G = bgn.largest_connected_component_transform(G)
G = nx.convert_node_labels_to_integers(G, ordering="sorted")
with open("output_files/twitch_pickle", 'wb') as pickle_file:
pickle.dump(G, pickle_file)
with open("output_files/twitch_edgelist.txt", 'w') as txt_file:
num_of_nodes = len(G.nodes)
directed = 0
txt_file.write("{}\t{}\n".format(num_of_nodes, directed))
for edge in G.edges:
txt_file.write("{}\t{}\n".format(edge[0], edge[1]))
if __name__ == "__main__":
main()
<file_sep>/helper_pipelines/seed_subset_run.sh
#############################################################################################
# This pipeline is the same as run.sh except that it clusters and runs analysis based only
# on the largest connected component of the dblp network (which contains 2190 nodes) and
# only based on a select set of seed nodes.
#############################################################################################
python3 clustering_pipeline.py before_vectors_seed_cc 35
cd C++\ code/
g++ main.cpp -o main -std=c++11
echo "../data/dblp/cc_degree_seed_edgelist.txt" "../data/dblp/cc_degree_seed_vectors.txt" $1 $2 "n"| ./main
cd ..
python3 clustering_pipeline.py after_vectors_seed_cc
python3 clustering_pipeline.py find_p_after_vectors 35
<file_sep>/gscholar/info_access.py
import networkx as nx
import numpy as np
import sys
from sklearn.cluster import KMeans
# Parameters for finding K:
MIN_CLUSTERS = 2
MAX_CLUSTERS = 11
def main():
vector_file_path = sys.argv[1]
outfilename = sys.argv[2]
clusternames = sys.argv[3]
print("reading vectors...")
file = open(vector_file_path, "r")
nodes = file.readlines()
vectors = {}
for index, line in enumerate(nodes):
line = line.split(",")
node = index
vectors[node] = []
count = 0
#print("the length of the line is ", len(line))
for prob in line:
vectors[node].append(float(prob))
n = index + 1
X = np.array(list(vectors.values()))
outfile = open(outfilename, "w")
for k in range(MIN_CLUSTERS, MAX_CLUSTERS, 1):
outfile.write("for " + str(k) + " clusters:\n")
print("info access # of clusters: " + str(k))
labels = KMeans(n_clusters=k, random_state=1).fit_predict(X)
file = open(clusternames[:-4] + "_" + str(k) + ".txt", "w")
for id in range(0, n):
file.write(str(id) + "\t" + str(labels[id]) + "\n")
file.close();
buckets = [0] * k
for i in range(0, n):
buckets[labels[i]] += 1
for i in range(0, k):
outfile.write("%" + str(int(round(buckets[i] * 100 / n))) + " ")
outfile.write("\n")
outfile.close()
return
if __name__ == "__main__":
main()
<file_sep>/helper_pipelines/choose_seeds.py
import random
import networkx as nx
def random_seeds(graph, p):
n = graph.number_of_nodes()
seeds = random.sample(range(1, n + 1), p)
return seeds
def centrality_seeds(graph, p, centrality_type):
nodes = sorted(graph.nodes(data=True), key=lambda x: x[1][centrality_type], reverse=True)
seeds = []
for i in range(p):
seeds.append(nodes[i][0])
return seeds
# def connected_component_seeds(graph):
# largest_cc = max(nx.connected_components(graph), key=len)
# s = graph.subgraph(largest_cc).copy()
# return s.nodes(data=False)
<file_sep>/gscholar/cite_plot.py
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as np
import sys
from scipy import stats
import matplotlib.cm as cm
from decimal import Decimal
# Parameters for finding K:
MIN_CLUSTERS = 1
MAX_CLUSTERS = 10
N_REFS = 4
# (Optional) Colors used for the graphs.
COLOR_PALETTE = ["#FFC107", "#1E88E5", "#2ECE54", "#EC09D7", "#DDEC4E", "#D81B50", "#CCD85D", "#3701FA", "#D39CA7", "#27EA9F", "#5D5613", "#DC6464"]
def main():
citefile = sys.argv[1]
clusterfile = sys.argv[2]
K = int(sys.argv[3])
citations = []
file = open(citefile, "r")
for line in file:
s = int(line.split(None, 2)[0])
t = int(line.split(None, 2)[1])
citations.append(t)
file.close()
n = 0
clusters = []
file = open(clusterfile, "r")
for line in file:
s = int(line.split(None, 2)[0])
t = int(line.split(None, 2)[1])
clusters.append(t)
n += 1
file.close()
clusters_total = {cluster: [] for cluster in range(K)}
for i in range(0, n):
cluster = clusters[i]
value = float(citations[i])
clusters_total[cluster].append(value)
print((len(clusters_total[0]) + len(clusters_total[1])) / float(n))
#print(clusters_total[0])
#print(clusters_total[1])
#test_output = stats.kruskal(clusters_total[0][-93506:], clusters_total[1][-92134:])
#stat, pval = stats.kruskal(clusters_total[0], clusters_total[1])
#print('p-value =','{:.20e}'.format(Decimal(pval)))
#print(pval)
#print(str(test_output) + "\n")
plt.figure(figsize=(12, 10))
color_counter = 0
#for cluster in clusters_total:
for cluster in clusters_total:
sns.distplot(clusters_total[cluster], hist = False, kde = True, hist_kws = {'linewidth': 3}, label = str(cluster), norm_hist = True, color=COLOR_PALETTE[color_counter])
color_counter += 1
# Runs and writes the results of Pairwise Kolmogorov-Smirnov and Kruskal-Wallis tests."""
#kolmogorov_smirnov_test(clusters_total, K)
kruskal_wallis_test(clusters_total, K)
plt.xlabel("citations")
plt.ylabel("PDF")
plt.title("Cluster Citation Density")
plt.autoscale(enable=True, axis='both', tight=None)
plt.savefig("Cluster_Citation_Density" + str(K), bbox_inches='tight')
def kruskal_wallis_test(clusters_total, K):
"""Runs and writes the results of Kruskal-Wallis test."""
arg_list = [clusters_total[i] for i in range(K)]
print("\nkruskal-wallis, {}-clusters:\n".format(K))
#print(*arg_list)
#print(arg_list)
test_output = stats.kruskal(*arg_list)
stat, pval = stats.kruskal(*arg_list)
print('p-value =','{:.20e}'.format(Decimal(pval)))
print(str(test_output) + "\n")
return
def kolmogorov_smirnov_test(clusters_total, K):
"""Runs and writes the results of Pairwise Kolmogorov-Smirnov test."""
for i in range(K):
current_num = K - 1 - i
for j in range(current_num):
print("\n{} to {}".format(j, current_num))
test_output = stats.ks_2samp(clusters_total[j], clusters_total[current_num])
print("\n" + str(test_output))
return
if __name__ == "__main__":
main()
<file_sep>/example_hyperparameter_tuning/fluidcr_dblp.py
"""DBLP-specific wrappers for mp.repeated_fluidc() pipeline."""
import main_pipelines as mp
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.INPUT_PICKLED_GRAPH = "output_files/main_files/{}_pickle".format(mp.IDENTIFIER_STRING)
mp.K = 2
mp.LABELING_FILE = "output_files/main_files/{}_K{}_labeling_file_fluidc.csv".format(mp.IDENTIFIER_STRING, mp.K)
mp.EXPERIMENT = "fluidc"
mp.repeated_fluidc()
return
if __name__ == "__main__":
main()
<file_sep>/helper_pipelines/utils.py
from operator import mul, sub
from fractions import Fraction
from functools import reduce
import itertools
import matplotlib.pyplot as plt
import pickle
from scipy.stats import spearmanr
import os
import igraph
# Creates a picture of a graph using igraph's plotting facility
def display_graph(g, filename, layout='kk'):
g.vs['label'] = list(range(g.vcount()))
out = igraph.plot(g, layout=g.layout(layout))
out.save(filename)
def make_entries(graph_dict):
entries = []
for i in graph_dict:
for k in graph_dict[i]:
entries.append({'from': i, 'to': k})
return entries
# Input: entries is a list of dicts, representing an edge: requires
# {'from':id1,'to':id2}. the ids are unique integers, not
# necessarily consecutive
# Returns a igraph.Graph
def make_graph(entries):
all_ids = sorted(list(set(itertools.chain.from_iterable((e['from'], e['to']) for e in entries))))
raw_id_to_id = {raw: v for v, raw in enumerate(all_ids)}
g = igraph.Graph(len(all_ids))
for e in entries:
v1, v2 = raw_id_to_id[e['from']], raw_id_to_id[e['to']]
if not (g.are_connected(v1, v2) or v1 == v2):
g.add_edge(v1, v2)
h = g.induced_subgraph([i for i in range(g.vcount()) if g.degree(i) != 0])
return h
def add_path(g, m, ind1, ind2=None):
if m <= 0: return g
first_new_vert = g.vcount()
if ind2 == None:
p = igraph.Graph(m)
p.add_edges([(i, i + 1) for i in range(m - 1)])
g = g + p
g.add_edge(ind1, first_new_vert)
elif m == 1:
g.add_edge(ind1, ind2)
else:
p = igraph.Graph(m - 1)
p.add_edges([(i, i + 1) for i in range(m - 2)])
g = g + p
g.add_edge(ind1, first_new_vert)
g.add_edge(g.vcount() - 1, ind2)
return g
# enumerates all partions of the integer n
# each output list is length of the partition, not n
def partitions(n):
a = [0 for i in range(n + 1)]
k = 1
y = n - 1
while k != 0:
x = a[k - 1] + 1
k -= 1
while 2 * x <= y:
a[k] = x
y -= x
k += 1
l = k + 1
while x <= y:
a[k] = x
a[l] = y
yield a[:k + 2]
x += 1
y -= 1
a[k] = x + y
y = x + y - 1
yield a[:k + 1]
# enumerates all possibilities for n labeled boxes, r unlabeled balls
# length of each tuple is always n
def unlabeled_balls_labeled_boxes(n, r):
for c in itertools.combinations_with_replacement(range(n), r):
t = [0 for _ in range(n)]
for i in c:
t[i] += 1
yield tuple(t)
# returns generator of all pairs of vertices (as indices)
# that are not edges in the input graph (not including self loops)
def non_edges(graph):
numVerts = graph.vcount()
if graph.is_directed():
return ((i, j) for (i, j) in itertools.product(range(numVerts), repeat=2)
if i != j and not graph.are_connected(i, j))
else:
return ((i, j) for (i, j) in itertools.combinations(range(numVerts), 2)
if not graph.are_connected(i, j))
# defaults to strongly connected
# note vertex ids change from input graph
def get_largest_component(graph, mode='STRONG'):
comps = graph.components(mode)
return comps.giant()
# Does the Spearman correlation test between xs and ys
def spearman(xs, ys, return_pvalue=True):
# make sure they're the same length and have no None's
mlength = min(len(xs), len(ys))
xs, ys = xs[:mlength], ys[:mlength]
xs = [xs[i] for i in range(len(xs)) if xs[i] != None and ys[i] != None]
ys = [ys[i] for i in range(len(ys)) if xs[i] != None and ys[i] != None]
coeff, pval = spearmanr(xs, ys)
if return_pvalue:
return coeff, pval
else:
return coeff
# returns n choose k
def choose(n, k):
if n < 0:
n = 0
if k < 0:
k = 0
if k == 1:
return int(n)
if k == 2:
return int((n * (n - 1)) // 2)
return int(reduce(mul, (Fraction(n - i, i + 1) for i in range(k)), 1))
def list_to_str(l):
s = ''
for i in l:
s += str(i)
return s
def memoize(f):
cache = {}
def memoizedFunction(*args):
if args not in cache:
cache[args] = f(*args)
return cache[args]
memoizedFunction.cache = cache
return memoizedFunction
# Plots a time series
def plot(time_series, plot_label=None, xlabel='n', ylabel='Probability', plot_type='-', show=True):
if plot_type == None:
plot_type = '-'
line, = plt.plot(range(1, len(time_series) + 1), time_series, plot_type, linewidth=1, markersize=8)
# adds label from plot_label
if plot_label != None:
line.set_label(plot_label)
x1, x2, y1, y2 = plt.axis()
plt.axis([x1, len(time_series) + 1, y1, y2])
plt.ylabel(ylabel)
plt.xlabel(xlabel)
if plot_label != None:
plt.legend()
if show:
plt.show()
else:
return plt
# Plots more than one time series
def plots(time_series, plot_labels=[], xlabel='n', ylabel='probability', plot_types=[], show=True):
if len(plot_types) == 0:
plot_types = ['-'] * len(time_series)
# plots lines
lines = []
for seq, plot_type in zip(time_series, plot_types):
line, = plt.plot(range(1, len(seq) + 1), seq, plot_type, linewidth=1) # , markersize=8)
lines.append(line)
# adds labels from plot_labels
for line, label in zip(lines, plot_labels):
line.set_label(label)
x1, x2, y1, y2 = plt.axis()
plt.axis([x1, max(len(seq) for seq in time_series) + 1, y1, y2])
plt.ylabel(ylabel)
plt.xlabel(xlabel)
if len(plot_labels) > 0:
plt.legend(loc='center right')
if show:
plt.show()
else:
return plt
def plots_fancy(xs, time_series, time_series_stds=None, plot_labels=[], xlabel='k', ylabel='probability', plot_types=[],
logy=False, show=True):
if len(plot_types) == 0:
plot_types = ['-'] * len(time_series)
# plots lines
lines = []
if time_series_stds is None:
for seq, plot_type in zip(time_series, plot_types):
line, = plt.plot(xs, seq, plot_type, linewidth=3) # , markersize=8)
lines.append(line)
else:
for seq, stds, plot_type in zip(time_series, time_series_stds, plot_types):
line, = plt.plot(xs, seq, plot_type, linewidth=3) # , markersize=8)
plt.errorbar(xs, seq, yerr=stds, color=line.get_color(), fmt='none') # , markersize=8)
lines.append(line)
if logy:
plt.yscale('log')
# adds labels from plot_labels
for line, label in zip(lines, plot_labels):
line.set_label(label)
x1, x2, y1, y2 = plt.axis()
# plt.axis([x1, max(len(seq) for seq in time_series)+1, y1, y2])
plt.ylabel(ylabel)
plt.xlabel(xlabel)
if len(plot_labels) > 0:
plt.legend(loc='upper left', bbox_to_anchor=(1.05, 1.02))
# ax = plt.gca()
# ax.legend().draggable()
if show:
plt.show()
else:
return plt
# prettyprint a matrix
def mprint(m):
for r in m:
print(r)
# writes obj to file given by filename
def writeObj(obj, filename):
with open(filename, 'wb') as outfile:
pickle.dump(obj, outfile)
print("Pickled %s object" % filename)
# reads object and returns it from file
# given by filename
def readObj(filename):
obj = pickle.load(open(filename, 'rb'))
print("%s loaded." % filename)
return obj
# shortcut to load specific data sets
def load(name):
name_to_loc = {'prac': 'prac/prac.p',
'irvine': 'Data_Sets/irvine/irvine.p',
'email-arenas': 'Data_Sets/email_arenas/email-arenas.p',
'email-EU': 'Data_Sets/email_EU/email-EU.p',
'enron': 'Data_Sets/enron/enron_graph.p',
'fb': 'Data_Sets/fb/fb.p',
'arxiv-5': 'Data_Sets/arxiv_5/arxiv-5.p',
'arxiv-4': 'Data_Sets/arxiv_4/arxiv-4.p',
'arxiv-3': 'Data_Sets/arxiv_3/arxiv-3.p',
'arxiv-2': 'Data_Sets/arxiv_2/arxiv-2.p',
# 'hypertext':'hypertext09/hypertext09.p',
# 'hypertext09':'hypertext09/hypertext09.p',
'arxiv': 'Data_Sets/arxiv_grqc/arxiv_grqc.p',
'arxiv_grqc': 'Data_Sets/arxiv_grqc/arxiv_grqc.p'}
if name not in name_to_loc:
print("Can't find %s" % name)
return readObj(name_to_loc[name])
# loads Ashkan's saved probabilities into a python object
# one file location for each algorithm
def load_probs(file_locs=['All_K_Probs_TIM_5', 'All_K_Probs_Greedy_5', 'All_K_Probs_Naive_5']):
repeats = 20
k_incr, max_k = 5, 100
ks = [1] + [k for k in range(k_incr, max_k + 1, k_incr)]
all_probs = [[[[] for _ in range(repeats)] for _ in ks] for _ in file_locs]
for alg_i, file_loc in enumerate(file_locs):
for k_i, k in enumerate(ks):
for r in range(repeats):
fname = '../Charts/%s/%iNumb_%iprob.txt' % (file_loc, k, r)
if not os.path.isfile(fname):
fname = '../Charts/%s/%iNumb_%i_prob.txt' % (file_loc, k, r)
with open(fname, 'r') as f:
probs = [float(line.rstrip('\n')) for line in f]
all_probs[alg_i][k_i][r] = probs
return all_probs
<file_sep>/vector_analysis.py
'''
Runs the analysis on vector file
'''
import numpy as np
from numpy import mean
from numpy import std
import time
import configparser
import math
from sklearn.decomposition import PCA
from sklearn.neighbors import KNeighborsRegressor
from sklearn.neighbors import RadiusNeighborsRegressor
from sklearn.dummy import DummyRegressor
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import RepeatedKFold
from sklearn.ensemble import RandomForestRegressor
from scipy import stats
from io import StringIO
def main():
#pearson_analysis(nodelist, infile)
#knn(srcNodes, dstVectorFile, dstAnalysisFile, 0.5, 0.5, 3, 25)
return True
#takes as input a numpy matrix, then performs PCA analysis on it
#info on analysis: https://scikit-learn.org/stable/modules/generated/sklearn.decomposition.PCA.html
def pca_analysis(file):
X = np.loadtxt(file, delimiter=',')
print("Matrix: \n", X, "\n")
pca2 = PCA(n_components=1)
pca2.fit(X)
write_pca("PCA2", pca2, outfile)
return True
def zachKNN(nodefile, vecfile, analysisfile, a1, a2, neighbors, reps):
acc_list=[]
for i in range(reps):
#split data
data = split_data(nodefile, vecfile)
Xtrain = data[0]
ytrain = data[1]
Xtest = data[2]
ytest = data[3]
#train classifier
neigh = KNeighborsRegressor(n_neighbors=neighbors)
neigh.fit(Xtrain, ytrain)
#check classifier accuracy
accuracy = test_classifier(neigh, Xtest, ytest)
acc_list.append(accuracy)
result = sum(acc_list)/len(acc_list)
with open(analysisfile, 'a') as f:
out = str(a1) + "," + str(a2) + "," #alpha1 and alpha2
out += str(result) + ","#avg classifier accuracy
out += vecfile + "\n" # vector files
f.write(out)
print(a1,a2)
print("file:", vecfile, "--> accuracy:", result)
return 1
def KNN(nodefile, vecfile, analysisfile, a1, a2, neighbors, reps):
print("Running KNN analysis...")
cleanVecFile = clean_vectors(vecfile)
Xvectors = np.loadtxt(cleanVecFile, delimiter=',')
ranksLst = np.loadtxt(nodefile, delimiter='; ', skiprows=1, usecols=4)
yranks = np.array(ranksLst)
#make estimator/model
neigh = KNeighborsRegressor(n_neighbors=neighbors)
#train classifier using k-fold cross validation
scores = cross_val_score(neigh, Xvectors, yranks, scoring="neg_root_mean_squared_error")
with open(analysisfile, 'a') as f:
out = str(a1) + "," + str(a2) + "," #alpha1 and alpha2
out += str(mean(scores)) + "," + str(std(scores)) + ","#avg classifier accuracy
out += vecfile + "\n" # vector files
f.write(out)
print("[a1, a2] = [", a1, ", ", a2, "]: average accuracy=", mean(scores), " std=", std(scores))
return mean(scores), std(scores)
def holdoutKNN(nodefile, vecfile, holdnodefile, holdvecfile, analysisfile, a1, a2, neighbors, components):
print("Running KNN Holdout Analysis...")
X_train, y_train = make_data(nodefile, vecfile)
X_test, y_test = make_data(holdnodefile, holdvecfile)
# intialize pca and knn,dummy regression models
# from https://towardsdatascience.com/principal-component-analysis-for-dimensionality-reduction-115a3d157bad
pca = PCA(n_components=components)
knn = KNeighborsRegressor(n_neighbors=neighbors)
# fit and transform data
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.fit_transform(X_test)
#fit to models
knn.fit(X_train_pca, y_train)
#make predictions on test data
knn_pred = knn.predict(X_test_pca)
#get scores
knn_score = mean_squared_error(y_test, knn_pred, squared=False)
print("knn score: ", knn_score)
return knn_score
def randomForest(nodefile, vecfile, analysisfile, a1, a2):
# evaluate random forest ensemble for regression
# define dataset
start = time.time() #beginning time
X, y = make_data(nodefile, vecfile)
# define the model
model = RandomForestRegressor()
# evaluate the model
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
#scoring was originally 'neg_mean_absolute_error'
n_scores = cross_val_score(model, X, y, scoring='neg_root_mean_squared_error', cv=cv, n_jobs=-1, error_score='raise')
# report performance
end = time.time() #end time
with open(analysisfile, 'a') as f:
out = str(a1) + "," + str(a2) + ","
out += str(mean(n_scores)) + "," + str(std(n_scores)) + ","
out += vecfile + "\n"
f.write(out)
print('a1, a2 =', a1, ',', a2, ' MSE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)), "time: ", end-start)
return mean(n_scores), std(n_scores)
def holdoutRandomForest(nodefile, vecfile, holdnodefile, holdvecfile, analysisfile, a1, a2, components):
print("Running Random Forest Holdout Analysis...")
X_train, y_train = make_data(nodefile, vecfile)
X_test, y_test = make_data(holdnodefile, holdvecfile)
#initialize pca and random forest regressor
pca = PCA(n_components=components)
rf = RandomForestRegressor()
# fit and transform data
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.fit_transform(X_test)
#fit to models
rf.fit(X_train_pca, y_train)
#make predictions on test data
rf_pred = rf.predict(X_test_pca)
#get scores
rf_score = mean_squared_error(y_test, rf_pred, squared=False)
print("random forest score: ", rf_score)
return rf_score
def runSVR(nodefile, vecfile, analysisfile, a1, a2):
X, y = make_data(nodefile, vecfile)
start = time.time() #beginning time
regressor = SVR(kernel = 'rbf')
n_scores = cross_val_score(regressor, X, y, scoring='neg_root_mean_squared_error')
end = time.time()
with open(analysisfile, 'a') as f:
out = str(a1) + "," + str(a2) + ","
out += str(mean(n_scores)) + "," + str(std(n_scores)) + ","
out += vecfile + "\n"
f.write(out)
print('a1, a2 =', a1, ',', a2, ' MSE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)), "time: ", end-start)
return mean(n_scores), std(n_scores)
def holdoutSVR(nodefile, vecfile, holdnodefile, holdvecfile, analysisfile, a1, a2, components):
print("Running SVR Holdout Analysis...")
X_train, y_train = make_data(nodefile, vecfile)
X_test, y_test = make_data(holdnodefile, holdvecfile)
# intialize pca and svr,dummy regression models
# from https://towardsdatascience.com/principal-component-analysis-for-dimensionality-reduction-115a3d157bad
pca = PCA(n_components=components)
svr = SVR(kernel = 'rbf')
# fit and transform data
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.fit_transform(X_test)
#fit to models
svr.fit(X_train_pca, y_train)
#make predictions on test data
svr_pred = svr.predict(X_test_pca)
#get scores
svr_score = mean_squared_error(y_test, svr_pred, squared=False)
print("svr score: ", svr_score)
return svr_score
def runDummy(nodefile, vecfile, analysisfile, a1, a2):
start = time.time() #beginning time
X, y = make_data(nodefile, vecfile)
dummy_regr = DummyRegressor(strategy="median")
n_scores = cross_val_score(dummy_regr, X, y, scoring='neg_root_mean_squared_error')
with open(analysisfile, 'a') as f:
out = str(a1) + "," + str(a2) + ","
out += str(mean(n_scores)) + "," + str(std(n_scores)) + ","
out += vecfile + "\n"
f.write(out)
end = time.time()
print('MSE: %.3f (%.3f)' % (mean(n_scores), std(n_scores)), "time: ", end-start)
return mean(n_scores), std(n_scores)
def holdoutDummy(nodefile, vecfile, holdnodefile, holdvecfile, analysisfile, a1, a2, components):
print("Running Dummy Holdout Analysis...")
X_train, y_train = make_data(nodefile, vecfile)
X_test, y_test = make_data(holdnodefile, holdvecfile)
# intialize pca and knn,dummy regression models
# from https://towardsdatascience.com/principal-component-analysis-for-dimensionality-reduction-115a3d157bad
pca = PCA(n_components=components)
dummy = DummyRegressor(strategy="median")
# fit and transform data
X_train_pca = pca.fit_transform(X_train)
X_test_pca = pca.fit_transform(X_test)
#fit to models
dummy.fit(X_train_pca, y_train)
#make predictions on test data
dummy_pred = dummy.predict(X_test_pca)
#get scores
dummy_score = mean_squared_error(y_test, dummy_pred, squared=False)
print("dummy score: ", dummy_score)
return dummy_score
def make_data(nodefile, vecfile):
cleanVecFile = clean_vectors(vecfile)
Xvectors = np.loadtxt(cleanVecFile, delimiter=',')
ranksLst = np.loadtxt(nodefile, delimiter='; ', skiprows=1, usecols=4)
yranks = np.array(ranksLst)
return Xvectors, yranks
#returns a tuple of (Xtrain, ytrain, Xtest, ytest)
def split_data(nodefile, vecfile):
cleanVecFile = clean_vectors(vecfile)
Xvectors = np.loadtxt(cleanVecFile, delimiter=',')
ranksLst = np.loadtxt(nodefile, delimiter='; ', skiprows=1, usecols=4)
yranks = np.array(ranksLst)
#partition process from https://stackoverflow.com/questions/3674409/how-to-split-partition-a-dataset-into-training-and-test-datasets-for-e-g-cros
indices = np.random.permutation(Xvectors.shape[0])
training_idx, test_idx = indices[:80], indices[80:]
Xtrain, Xtest = Xvectors[training_idx,:], Xvectors[test_idx,:]
ytrain, ytest = yranks[training_idx], yranks[test_idx]
return Xtrain, ytrain, Xtest, ytest
def test_classifier(classifier, Xtest, ytest):
acc_hits=0
predictions = classifier.predict(Xtest)
valueRange = np.ptp(ytest)
errorRad = 0.1*valueRange
for i in range(predictions.shape[0]):
if math.dist([predictions[i]], [ytest[i]]) <= errorRad:
acc_hits+=1
#accuracy for k
accuracy=acc_hits/Xtest.shape[0]
return accuracy
#info on analysis: https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.spearmanr.html
def pearson_analysis(nodefile, vecfile, analysisfile, a1, a2):
ranksLst = np.loadtxt(nodefile, delimiter='; ', skiprows=1, usecols=4)
ranksLst.sort()
ranksArr = np.array(ranksLst)
#run pca
cleanVecFile = clean_vectors(vecfile)
vectors = np.loadtxt(cleanVecFile, delimiter=',')
pca2 = PCA(n_components=1)
pca2.fit(vectors)
#get components from PCA
components = np.reshape(pca2.components_, (pca2.components_.size,))
#build a list of tuples (rank, componentVal)
rankscomps=[]
for i in range(ranksLst.size):
rankscomps.append([ranksLst[i], components[i]])
#sort rankscomps by component values
rankscomps.sort(key=lambda t: t[1])
#get a list of the ranks sorted by component values
sortedRanksLst = extract_ith_tuple(rankscomps, 0)
#make into array to run pearson
sortedRanksArr = np.array(sortedRanksLst)
#run the pearson analysis
result = stats.pearsonr(ranksArr, sortedRanksArr)#this compares ranks to ranks sorted by components
#result = stats.pearsonr(ranksArr, components) #this compares ranks to components
#print results to file (file should be unique to experiment)
with open(analysisfile, 'a') as f:
out = str(a1) + "," + str(a2) + "," #alpha1 and alpha2
out += str(result[0]) + "," + str(result[1]) + "," #correlation coef and p-value
out += vecfile + "\n" # vector files
f.write(out)
print(out)
return result
def extract_ith_tuple(list, i):
out = []
for tuple in list:
out.append(tuple[i])
return out
#reads in the vector file and removes trailing commas from each line
#returns a StringIO object, which behaves like a file
def clean_vectors(filename):
out = ""
with open(filename, 'r') as f:
line = f.readline()
while line:
out += line.strip(",\n") + "\n"
line = f.readline()
return StringIO(out)
def clean_vector_file(filename):
with open(filename, 'r+') as f:
line = f.readline()
while line:
if line[-1] == ",":
line.strip(",\n") + "\n"
line = f.readline()
else:
line = f.readline()
def write_pca(name, pca, filename):
with open(filename, 'a') as f:
out = "------------------------- " + name + " -------------------------\n"
out += "n_components_:\n" + str(pca.n_components_) + "\n"
out += "components_:\n" + str(pca.components_.shape) + "\n" + str(pca.components_) + "\n"
out += "explained_variance_:\n" + str(pca.explained_variance_) + "\n"
out += "explained_variance_ratio_:\n" + str(pca.explained_variance_ratio_) + "\n"
out += "\n\n"
f.write(out)
return True
if __name__ == '__main__':
main()
<file_sep>/run_k.sh
#!/usr/bin/env bash
echo "Hello, $(whoami)!"
# Runs the elbow method for K-Means Clustering based on the VECTOR_FILE (vectors produced
# by the C++ code) corresponding to a specific alpha value. One should run the simulations
# and change the filename in the constant to generate the plot for different
# alpha hyperparameters.
python3 k_methods_star.py
#python3 main_pipelines.py elbow_method
<file_sep>/build_dblp.py
import numpy as np
import networkx as nx
import json
import csv
import pickle
def university_to_rank(university):
'''
Takes in the name of a university and returns its rank
(according to the ranking system described in https://advances.sciencemag.org/content/1/1/e1400005)
'''
with open("/Users/Zach/Documents/*THESIS/Code/dblp_data - schools.csv") as csv_file:
csv_reader = csv.reader(csv_file, delimiter=',')
for row in csv_reader:
if row[0] == university:
return float(row[2])
print(university)
return None
# def get_citations(filename):
# '''
# Takes in file output by gs_scrape. Returns dictionaries mapping dblp ids to
# metadata about scholars.
# '''
# dict = {} # citation count dictionary
# gender_dict = {}
# phd_dict = {}
# phd_rank_dict = {}
# job_rank_dict = {}
# with open(filename) as csv_file:
# csv_reader = csv.reader(csv_file, delimiter=',')
# line_count = 0
# for row in csv_reader:
# dblp_id = row[-3][1:] # Cuts off space at start of id
# if int(row[-1]) != -1:
# dict[dblp_id] = int(row[-1])
# else:
# dict[dblp_id] = None
# gender_dict[dblp_id] = row[1]
# phd_dict[dblp_id] = row[2]
# phd_rank_dict[dblp_id] = university_to_rank(row[2])
# job_rank_dict[dblp_id] = university_to_rank(row[3])
# return dict, gender_dict, phd_dict, phd_rank_dict, job_rank_dict
# for line in reader(file):
def get_citations(filename):
'''
Takes in file output by gs_scrape. Returns dictionaries mapping dblp ids to
metadata about scholars.
'''
dict = {} # citation count dictionary
with open(filename) as csv_file:
for row in csv.reader(csv_file):
dblp_id = row[-3][1:] # Cuts off space at start of id
if int(row[-1]) != -1:
dict[dblp_id] = int(row[-1])
else:
dict[dblp_id] = None
return dict
def get_all_metadata(faculty_data_file):
'''
Takes in faculty data file. Returns dictionaries mapping dblp ids to
metadata about scholars.
'''
gender_dict = {}
phd_dict = {}
job_dict = {}
phd_rank_dict = {}
job_rank_dict = {}
with open(faculty_data_file) as csv_file:
for row in csv.reader(csv_file):
dblp_id = row[5]
gender_dict[dblp_id] = row[1]
phd_dict[dblp_id] = row[2]
job_dict[dblp_id] = row[3]
phd_rank_dict[dblp_id] = university_to_rank(row[2])
job_rank_dict[dblp_id] = university_to_rank(row[3])
return gender_dict, phd_dict, job_dict, phd_rank_dict, job_rank_dict
def make_network_with_ids(coauthorship_filename, citations_filename):
'''
Creates a networkx network based on format of dblp files. Includes node attributes
based on faculty_data:
cluster=None, color=None, citation_count, dblp_id, gender, phd (school name), phd_rank (rank of school)
Coauthorship_filename should indicate a file in adjacency list format, where each
node is a dblp id.
Citations_filename should indicate a file that lists each dblp id followed by its
number of citations.
'''
file = open(coauthorship_filename, "r")
coauthor_lines = file.readlines() # each line is a list of coauthors for one author
g = nx.Graph() # undirected, no parallel edges
# get all metadata for nodes:
gender_to_citations, phd_to_citations, name_to_job, name_to_phd_rank, name_to_job_rank = get_all_metadata("data/dblp/faculty_data - faculty.csv")
name_to_citations = get_citations(citations_filename)
# add all nodes and edges to graph:
for line in coauthor_lines:
line = line.split(",")
if line[-1][-1] == "\n": # eliminates trailing newline
line[-1] = line[-1][:-1]
node = line[0]
if line[0][2:] in name_to_citations: # [2:] fixes disparity with "a/" e.g. in dblp ids
citations = name_to_citations[line[0][2:]]
gender = gender_to_citations[line[0][2:]]
phd = phd_to_citations[line[0][2:]]
job = name_to_job[line[0][2:]]
phd_rank = name_to_phd_rank[line[0][2:]]
job_rank = name_to_job_rank[line[0][2:]]
else:
print(line[0][2:])
citations = None
gender = None
phd = None
phd_rank = None
job_rank = None
g.add_node(node, cluster=None, color=None, citation_count = citations, dblp_id = line[0], gender = gender, phd = phd, job = job, phd_rank = phd_rank, job_rank=job_rank)
for neighbor in line[1:]:
neighbor_index = neighbor
if neighbor[2:] in name_to_citations:
neighbor_citations = name_to_citations[neighbor[2:]]
neighbor_gender = gender_to_citations[neighbor[2:]]
neighbor_phd = phd_to_citations[neighbor[2:]]
neighbor_job = name_to_job[neighbor[2:]]
neighbor_phd_rank = name_to_phd_rank[neighbor[2:]]
neighbor_job_rank = name_to_job_rank[neighbor[2:]]
else:
print(neighbor[2:])
neighbor_citations = None
neighbor_gender = None
neighbor_phd = None
neighbor_phd_rank = None
neighbor_job_rank = None
g.add_node(neighbor_index, cluster=None, color=None, citation_count = neighbor_citations, dblp_id = neighbor, gender=neighbor_gender, phd=neighbor_phd, job = neighbor_job, phd_rank = neighbor_phd_rank, job_rank=neighbor_job_rank)
g.add_edge(node, neighbor_index)
return g
def add_centrality(graph):
'''
Adds attributes representing network structure importance metrics to the nodes of graph.
'''
deg_centrality = nx.degree_centrality(graph)
between_centrality = nx.betweenness_centrality(graph)
pagerank = nx.pagerank_numpy(graph)
for node in deg_centrality:
graph.nodes[node]["degree_centrality"] = deg_centrality[node]
graph.nodes[node]["betweeness_centrality"] = between_centrality[node]
graph.nodes[node]["pagerank"] = pagerank[node]
def write_graph(graph, seeds, filename, include_seeds):
'''
Writes out graph into a file formatted as an edgelist so that it can be read into
the C++ code to create vectors.
seeds should be a list of the node ids for any seed nodes if include_seeds= True
filename is the file to write the edgelist to
include_seeds should be False if the vectors are going to be created using all
the nodes as seeds, and True if the vectors will only use a subset of nodes as seeds.
'''
nx.write_edgelist(graph, filename, data=False)
insert_str = str(graph.number_of_nodes()) + "\t 0"
f = open(filename, 'r'); s = f.read(); f.close()
l = s.splitlines(); l.insert(0, insert_str); s = '\n'.join(l)
f = open(filename, 'w'); f.write(s + "\n"); f.close();
if (include_seeds):
with open(filename, "a") as f:
f.write("s\t")
for seed in seeds:
f.write(str(seed) + "\t")
def main():
'''
Runs the first half of the basic pipeline on only the largest connected component,
until vectors need to be generated in C++
'''
graph = make_network_with_ids("data/dblp/october_coauthorship_dblp_ids.txt", "data/dblp/dblp_id_citations")
print(f"number of nodes in whole graph: {graph.number_of_nodes()}")
print(f"number of edges in whole graph: {graph.number_of_edges()}")
largest_cc = max(nx.connected_components(graph), key=len)
graph = graph.subgraph(largest_cc).copy()
print(f"number of nodes in sub graph: {graph.number_of_nodes()}")
print(f"number of edges in sub graph: {graph.number_of_edges()}")
add_centrality(graph)
graph = nx.convert_node_labels_to_integers(graph) # replaces dblp id label with integer label. First label is 0.
with open("output_files/dblp_pickle", "wb") as f:
pickle.dump(graph, f)
write_graph(graph, [], "output_files/dblp_edgelist.txt", False)
if __name__ == '__main__':
main()
<file_sep>/config_files/holdout2002.ini
;DO NOT USE FOLLOWING CHARACTERS IN KEYNAMES: ?{}|&~![()^"
;experimentName: name of the experiment
;generateVectors: yes-run simulation no- dont run sim, use input vector files
[GENERAL]
experimentName = holdout2002
generateVectors = yes
runAnalysis = yes
runDataRep = no
runHoldout = yes
genHoldVectors = yes
simAllSeeds = yes
repititions = 10000
alphaList = 0.1,0.2
alpha1list = 0.2
alpha2list = 0.8
[FILES]
inEdgesFile = ../data/dblp_jobrankprediction/dblp_yoj_2000_edgelist.txt
inNodesFile = ../data/dblp_jobrankprediction/dblp_yoj_2000_nodelist.txt
inHoldEdgesFile = ../data/dblp_jobrankprediction/holdout/dblp_yoj_2002_edgelist.txt
inHoldNodesFile = ../data/dblp_jobrankprediction/holdout/dblp_yoj_2002_nodelist.txt
outputDir = output_files/
outVectorDir = vectors/
outHoldVecDir = holdoutVectors/
inVectorDir = EMPTYPATH
inHoldVecDir = EMPTYPATH
outAnalysisDir = analysis/
outHoldAnalysisDir = holdoutAnalysis/
inAnalysisDir = ../results/dblp_job_rank_prediction/SVRfullPL1000_v0/analysis/
inHoldAnalysisDir = EMPTYPATH
[ANALYSIS]
;methods [SVR, randomForest, KNN, PCA]
vsDummy = no
usePCA = no
useZachKNN = no
useKNN = yes
useSVR = yes
useRandomForest = yes
knnNeighbors = 3
knnRepititions = 10
pcaComponents = 500
<file_sep>/C++ code/gen_vectors.h
#include "simulation.h"
#include "print.h"
#include <stdio.h>
using namespace std;
// function to create and write information access vectors using all nodes as seeds
void generate_vectors(float alpha1, float alpha2, int rep, Graph& graph, map<string, string> map, string outName)
{
int n = graph.n;
cout << to_string(n);
// int *ary = new int[sizeX*sizeY];
float *vectors = new float[n*n];
// float **vectors = new float[n][n];
for (int i = 0; i < n; i++) {
vector<int> seeds;
seeds.push_back(i); //Add ith node of graph, whose id should just be i
// cout << "Line 15" << endl;
simulation(seeds, alpha1, alpha2, rep, graph, map);
// cout << graph.prob[i] << endl; //prob[i] is the probability of i at this point
for (int j = 0; j < n; j++) {
// cout << graph.prob[j] << endl;
vectors[j*n + i] = graph.prob[j]; //For some reason causes seg fault after 3417 iterations
// cout << to_string(j) + "\n";
// vectors[j][i] = graph.prob[j]; //THIS IS THE PROBLEMATIC LINE
}
// cout << "line 28";
}
// now write vectors to file
// writeVectors(outName, rep, graph.n, vectors);
cout << "About to start writing vectors to file" << endl;
writeVectors(outName, rep, graph.n, (float *)vectors);
}
void generate_large_vectors(float alpha1, float alpha2, int rep, Graph& graph, map<string, string> map, string outName)
{
// Write out information access vectors for a large dataset
cout << "In large vector generator" << endl;
int n = graph.n;
ofstream outMin (outName);
for (int i = 0; i < n; i++) {
cout << "seed is " << to_string(i) << endl;
vector<int> seeds;
seeds.push_back(i); //Add ith node of graph, whose id should just be i
simulation(seeds, alpha1, alpha2, rep, graph, map);
//write probabilities to file
for (int j = 0; j < n; j++) {
outMin << graph.prob[j]/rep << ",";
}
outMin << endl;
}
outMin.close();
}
void generate_vectors_select_seeds(float alpha1, float alpha2, int rep, Graph& graph, map<string, string> map, string outName, vector<int>& all_seeds)
{
int n = graph.n;
cout << to_string(n);
// int *ary = new int[sizeX*sizeY];
int num_seeds = all_seeds.size();
float *vectors = new float[n*num_seeds];
for (int i = 0; i < num_seeds; i++) {
// cout << "Line 12" << endl;
vector<int> seeds;
seeds.push_back(all_seeds.at(i)); //Add ith node of graph, whose id should just be i
// cout << "Line 15" << endl;
simulation(seeds, alpha1, alpha2, rep, graph, map);
// cout << graph.prob[1] << endl; //prob[i] is the probability of i at this point
for (int j = 0; j < n; j++) {
// cout << graph.prob[j] << endl;
vectors[j*num_seeds + i] = graph.prob[j];
// cout << to_string(j) + "\n";
// vectors[j][i] = graph.prob[j]; //THIS IS THE PROBLEMATIC LINE
}
}
// now write vectors to file
writeVectorsSeedSubset(outName, rep, graph.n, (float *)vectors, all_seeds);
}
<file_sep>/build_cosponsorship.py
import csv
import networkx as nx
import pickle
import sys
import build_generic_network as bgn
import pandas as pd
import os
import matplotlib.pyplot as plt
CONGRESS = "114"
DATA_FILE = "data_cosponsorship/govtrack_cosponsor_data_{}_congress.csv".format(CONGRESS)
FIELDNAMES = ["bills_sponsored", "bills_originally_cosponsored", "name", "thomas_id", "bioguide_id", "state",
"district"]
FILES = ["govtrack-stats-2016-senate-cosponsored",
"govtrack-stats-2016-senate-bills-introduced",
"govtrack-stats-2016-senate-bills-reported-(Bills Out of Committee)",
"govtrack-stats-2016-senate-committee-positions",
"govtrack-stats-2016-senate-cosponsors",
"govtrack-stats-2016-senate-transparency-bills",
"govtrack-stats-2016-senate-ideology",
"govtrack-stats-2016-senate-cosponsored-other-party-(Joining Bipartisan Bills)",
"govtrack-stats-2016-senate-bills-enacted-ti",
"govtrack-stats-2016-senate-leadership",
"govtrack-stats-2016-senate-missed-votes",
"govtrack-stats-2016-senate-bills-with-committee-leaders",
"govtrack-stats-2016-senate-bills-with-companion-(Working with the Other Chamber)",
"govtrack-stats-2016-senate-bills-with-cosponsors-both-parties-count-(Writing Bipartisan Bills)"]
MAIN_PICKLE = "output_files/strong-house_pickle"
# Attributes except for le_score
ATTRIBUTES = {"democrat": "1 = Democrat"}
def main():
strong_cosponsorship()
return
def weak_nested_edges(G, bill_nodes_list):
# if len(bill_nodes_list) == 0:
# raise ValueError("Change of set while empty: 'ONE NODE: FALSE FALSE'")
for u in range(len(bill_nodes_list) - 1):
for v in range((u + 1), len(bill_nodes_list)):
G.add_edge(bill_nodes_list[u], bill_nodes_list[v])
return
def strong_nested_edges(G, sponsor_list, orig_cosp_list, first_push):
if first_push:
return
if len(sponsor_list) < 1 and len(orig_cosp_list) > 0:
raise ValueError(
"bill with zero sponsors but non-zero original cosponsor(s): sponsors {}; original cosponsors {}".format(
sponsor_list, orig_cosp_list))
if len(sponsor_list) < 1:
raise ValueError("zero sponsors: sponsor {}; original cosponsor(s) {}".format(sponsor_list, orig_cosp_list))
if len(sponsor_list) > 1:
raise ValueError(
"more than one sponsor: sponsors {}; original cosponsor(s) {}".format(sponsor_list, orig_cosp_list))
sponsor = sponsor_list[0]
for i in orig_cosp_list:
G.add_edge(sponsor, i)
return
def strong_cosponsorship():
G = nx.DiGraph()
all_nodes_attributes = {}
with open(DATA_FILE, 'r') as data_file:
read_data_file = csv.reader(data_file)
all_nodes = set()
# Declaring for convention:
current_row = next(read_data_file)
orig_cosp_list = []
sponsor_list = []
fieldnames_length = len(FIELDNAMES)
first_push = True
for row in read_data_file:
previous_row = current_row
current_row = row
if current_row[0] != previous_row[0]:
strong_nested_edges(G, sponsor_list, orig_cosp_list, first_push)
first_push = False
sponsor_list = []
orig_cosp_list = []
if current_row[6] == "TRUE" or current_row[7] == "TRUE":
if current_row[6] == "TRUE" and current_row[7] == "TRUE":
raise ValueError("legislator is both a sponsor and an original cosponsor")
if current_row[1] not in all_nodes:
G.add_node(current_row[1])
all_nodes_attributes[current_row[1]] = {FIELDNAMES[attribute_num]: current_row[attribute_num - 1]
for attribute_num
in range(2, fieldnames_length)}
all_nodes_attributes[current_row[1]][FIELDNAMES[0]] = []
all_nodes_attributes[current_row[1]][FIELDNAMES[1]] = []
all_nodes.add(current_row[1])
# Means the node is a sponsor:
if current_row[6] == "TRUE":
all_nodes_attributes[current_row[1]][FIELDNAMES[0]].append([current_row[0]])
sponsor_list.append(current_row[1])
# Means the node is an original cosponsor:
if current_row[7] == "TRUE":
all_nodes_attributes[current_row[1]][FIELDNAMES[1]].append([current_row[0]])
orig_cosp_list.append(current_row[1])
strong_nested_edges(G, sponsor_list, orig_cosp_list, first_push)
nx.set_node_attributes(G, all_nodes_attributes)
G = bgn.largest_connected_component_transform(G)
G = nx.convert_node_labels_to_integers(G, ordering="sorted")
legislative_effectiveness_score(G)
for attribute in ATTRIBUTES:
set_attribute(G, attribute)
with open(MAIN_PICKLE, 'wb') as pickle_file:
pickle.dump(G, pickle_file)
with open("output_files/strong-house_edgelist.txt", 'w') as txt_file:
num_of_nodes = len(G.nodes)
directed = 1
txt_file.write("{}\t{}\n".format(num_of_nodes, directed))
for edge in G.edges:
txt_file.write("{}\t{}\n".format(edge[0], edge[1]))
return
def weak_cosponsorship():
G = nx.Graph()
all_nodes_attributes = {}
with open(DATA_FILE, 'r') as data_file:
read_data_file = csv.reader(data_file)
all_nodes = set()
# Declaring for convention:
current_row = next(read_data_file)
bill_nodes_list = []
fieldnames_length = len(FIELDNAMES)
for row in read_data_file:
previous_row = current_row
current_row = row
if current_row[0] != previous_row[0]:
weak_nested_edges(G, bill_nodes_list)
bill_nodes_list = []
if current_row[6] == "TRUE" or current_row[7] == "TRUE":
if current_row[1] not in all_nodes:
G.add_node(current_row[1])
all_nodes_attributes[current_row[1]] = {FIELDNAMES[attribute_num]: current_row[attribute_num] for attribute_num
in range(1, fieldnames_length)}
all_nodes_attributes[current_row[1]][FIELDNAMES[0]] = [current_row[0]]
all_nodes.add(current_row[1])
else:
all_nodes_attributes[current_row[1]][FIELDNAMES[0]].append(current_row[0])
bill_nodes_list.append(current_row[1])
weak_nested_edges(G, bill_nodes_list)
nx.set_node_attributes(G, all_nodes_attributes)
print("Length of G:", len(G))
G = bgn.largest_connected_component_transform(G)
G = nx.convert_node_labels_to_integers(G, ordering="sorted")
# nx.draw_circular(G, with_labels=True)
# plt.show()
with open(MAIN_PICKLE, 'wb') as pickle_file:
pickle.dump(G, pickle_file)
with open("output_files/cosponsorship_edgelist.txt", 'w') as txt_file:
num_of_nodes = len(G.nodes)
directed = 0
txt_file.write("{}\t{}\n".format(num_of_nodes, directed))
for edge in G.edges:
txt_file.write("{}\t{}\n".format(edge[0], edge[1]))
return
def legislative_effectiveness_score(graph):
print("graph length =", len(graph))
for node in graph.nodes:
graph.nodes[node]["edited_name"] = " ".join(graph.nodes[node]["name"].split(" ")[:2])
bioguide_id_node_dict = {graph.nodes[node]['bioguide_id']: node for node in graph.nodes}
print("bioguide_id_node_dict length =", len(bioguide_id_node_dict))
edited_name_id_node_dict = {graph.nodes[node]['edited_name']: node for node in graph.nodes}
print("name_id_node_dict length =", len(edited_name_id_node_dict))
# test_add_att_rep(graph, bioguide_id_node_dict)
if not os.path.isfile("CELHouse93to115.csv"):
df = pd.read_excel(r"CELHouse93to115.xlsx")
df.to_csv("CELHouse93to115.csv")
with open("CELHouse93to115.csv", 'r') as data_file:
read_data_file = csv.reader(data_file)
name_score_dict = {}
fieldnames_row = next(read_data_file)
for item in range(len(fieldnames_row)):
if fieldnames_row[item] == "Legislator name, as given in THOMAS":
name_column = item
print("name_column =", name_column)
elif fieldnames_row[item] == "Congress number":
congress_number_column = item
print("congress_number_column =", congress_number_column)
elif fieldnames_row[item] == "Legislative Effectiveness Score (1-5-10)":
le_score_column = item
print("le_score_column =", le_score_column)
for row in read_data_file:
if row[congress_number_column] != CONGRESS:
continue
# Checked: 100 members; LEScores match with the table.
name_score_dict[" ".join(row[name_column].split(" ")[:2])] = row[le_score_column]
# print(name_score_dict)
if name_score_dict["<NAME>"] == 2.075010777:
print("True")
found_counter = 0
not_found_for_list = []
for member_name in edited_name_id_node_dict:
if member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>,":
dataset_name = "<NAME>"
elif member_name == "<NAME>,":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>.":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>,":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>.":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>.":
dataset_name = "<NAME>"
else:
dataset_name = member_name
try:
le_score = name_score_dict[dataset_name]
graph.nodes[edited_name_id_node_dict[member_name]]["le_score"] = le_score
found_counter += 1
except:
not_found_for_list.append((member_name, edited_name_id_node_dict[member_name]))
print("Legislative Effectiveness score found for {}; not found for {}".format(found_counter, not_found_for_list))
return
def set_attribute(graph, attribute):
print("graph length =", len(graph))
for node in graph.nodes:
graph.nodes[node]["edited_name"] = " ".join(graph.nodes[node]["name"].split(" ")[:2])
bioguide_id_node_dict = {graph.nodes[node]['bioguide_id']: node for node in graph.nodes}
print("bioguide_id_node_dict length =", len(bioguide_id_node_dict))
edited_name_id_node_dict = {graph.nodes[node]['edited_name']: node for node in graph.nodes}
print("name_id_node_dict length =", len(edited_name_id_node_dict))
# test_add_att_rep(graph, bioguide_id_node_dict)
if not os.path.isfile("CELHouse93to115.csv"):
df = pd.read_excel(r"CELHouse93to115.xlsx")
df.to_csv("CELHouse93to115.csv")
with open("CELHouse93to115.csv", 'r') as data_file:
read_data_file = csv.reader(data_file)
name_attr_dict = {}
fieldnames_row = next(read_data_file)
for item in range(len(fieldnames_row)):
if fieldnames_row[item] == "Legislator name, as given in THOMAS":
name_column = item
print("name_column =", name_column)
elif fieldnames_row[item] == "Congress number":
congress_number_column = item
print("congress_number_column =", congress_number_column)
elif fieldnames_row[item] == ATTRIBUTES[attribute]:
attribute_column = item
print("{}_column =".format(attribute), attribute_column)
for row in read_data_file:
if row[congress_number_column] != CONGRESS:
continue
# Checked: 100 members; LEScores match with the table.
name_attr_dict[" ".join(row[name_column].split(" ")[:2])] = row[attribute_column]
# print(name_score_dict)
found_counter = 0
not_found_for_list = []
for member_name in edited_name_id_node_dict:
if member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>,":
dataset_name = "<NAME>"
elif member_name == "<NAME>,":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>.":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>,":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>.":
dataset_name = "<NAME>"
elif member_name == "<NAME>":
dataset_name = "<NAME>"
elif member_name == "<NAME>.":
dataset_name = "<NAME>"
else:
dataset_name = member_name
try:
attribute_value = name_attr_dict[dataset_name]
graph.nodes[edited_name_id_node_dict[member_name]][attribute] = attribute_value
found_counter += 1
except:
not_found_for_list.append((member_name, edited_name_id_node_dict[member_name]))
print("{} found for {}; not found for {}".format(attribute, found_counter, not_found_for_list))
return
def test_add_att_sen(graph, bioguide_id_node_dict):
test_cases = [("T000476", "Tillis"),
("M000303", "McCain"),
("I000024", "Inhofe"),
("M001111", "Murray"),
("B000575", "Blunt")]
counter = 0
for test_case in test_cases:
counter += 1
node_num = bioguide_id_node_dict[test_case[0]]
if graph.nodes[node_num]["name"].split(", ")[0] == test_case[1]:
print("Test Case {}: Successful".format(counter))
else:
print("Test Case {}: Successful".format(counter))
def csv_nodes(G):
fieldnames = ["name", "bioguide_id", "state", "district", "democrat", "le_score"]
with open("output_files/cosponsorship_graph_nodes.csv", 'a') as file:
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
user_obj_writer = csv.writer(file, delimiter=',', quotechar='"', quoting=csv.QUOTE_NONNUMERIC)
counter = 0
not_found = []
for node in G.nodes:
try:
row = [G.nodes[node][i] for i in fieldnames]
user_obj_writer.writerow(row)
counter += 1
except:
not_found.append(G.nodes[node][fieldnames[0]])
print("counter =", counter)
print("not_found =", not_found)
return
def analyze_the_graph(G):
temp_graph = nx.Graph()
for edge in G.edges:
temp_graph.add_edge(edge[0], edge[1])
smallest_cc = min(nx.connected_components(temp_graph), key=len)
other_graph = G.subgraph(smallest_cc).copy()
cc = nx.strongly_connected_components(other_graph)
print([len(i) for i in cc])
return
if __name__ == "__main__":
main()
<file_sep>/example_hyperparameter_tuning/ari_dblp.py
"""DBLP-specific wrappers for mp.iac_vs_x_ari() and experimentation pipeline."""
import main_pipelines as mp
# Main variable input:
METHOD = "cp"
def main():
mp.IDENTIFIER_STRING = "dblp"
mp.INPUT_PICKLED_GRAPH = "output_files/main_files/{}_pickle".format(mp.IDENTIFIER_STRING)
mp.K = 2
mp.IAC_LABELING_FILE = "output_files/main_files/{}_K{}_labeling_file_iac.csv".format(mp.IDENTIFIER_STRING, mp.K)
mp.LABELING_FILE = "output_files/main_files/{}_K{}_labeling_file_{}.csv".format(mp.IDENTIFIER_STRING, mp.K, METHOD)
mp.ALPHA_VALUES = [0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 0.95]
mp.iac_vs_x_ari()
return
if __name__ == '__main__':
main()
<file_sep>/build_star.py
import networkx as nx
import pickle
import main_pipelines as mp
def main():
G = nx.Graph()
for i in range(1, 21):
G.add_edge(0, i)
mp.quick_display(G)
with open("output_files/star_pickle", 'wb') as pickle_file:
pickle.dump(G, pickle_file)
with open("output_files/star_edgelist.txt", 'w') as txt_file:
num_of_nodes = len(G.nodes)
directed = 0
txt_file.write("{}\t{}\n".format(num_of_nodes, directed))
for edge in G.edges:
txt_file.write("{}\t{}\n".format(edge[0], edge[1]))
return
if __name__ == '__main__':
main()
| da7941942fb95b9682f8805ab726bf21e36df6d1 | [
"Markdown",
"INI",
"Python",
"Text",
"C",
"C++",
"Shell"
] | 61 | Shell | algofairness/info-access-clusters | 282c4d0c654030d4c199b5c93970666ec36aca56 | 441d456f3581e4d6fe279dc4284784b768239efb |
refs/heads/master | <file_sep>use opendatasheets;
ALTER TABLE `alert_all_changes`
MODIFY `BOM_PATH` LONGTEXT; <file_sep>
DELIMITER $$
DROP PROCEDURE IF EXISTS `GET_ITEM_PATH` $$
CREATE PROCEDURE `GET_ITEM_PATH`(IN _list LONGTEXT, out _item_path LONGTEXT)
BEGIN
DECLARE _next LONGTEXT DEFAULT NULL;
DECLARE _nextlen LONGTEXT DEFAULT NULL;
DECLARE _value LONGTEXT DEFAULT NULL;
DECLARE _temp_item_path LONGTEXT DEFAULT '';
DECLARE _temp_value LONGTEXT DEFAULT '';
iterator:
LOOP
-- exit the loop if the list seems empty or was null;
-- this extra caution is necessary to avoid an endless loop in the proc.
IF LENGTH(TRIM(_list)) = 0 OR _list IS NULL THEN
LEAVE iterator;
END IF;
-- capture the next value from the list
SET _next = SUBSTRING_INDEX(_list,',',1);
-- save the length of the captured value; we will need to remove this
-- many characters + 1 from the beginning of the string
-- before the next iteration
SET _nextlen = LENGTH(_next);
-- trim the value of leading and trailing spaces, in case of sloppy CSV strings
SET _value = TRIM(_next);
-- select name by bom_id
select name into _temp_value from bom where id = _value;
-- CONCTENATE ITEM WITH PREVIOUS ONE
IF LENGTH(_temp_item_path) > 0 THEN
SET _temp_item_path = CONCAT(_temp_item_path, " > ", _temp_value);
ELSE
SET _temp_item_path = _temp_value;
END IF;
-- rewrite the original string using the `INSERT()` string function,
-- args are original string, start position, how many characters to remove,
-- and what to "insert" in their place (in this case, we "insert"
-- an empty string, which removes _nextlen + 1 characters)
SET _list = INSERT(_list,1,_nextlen + 1,'');
END LOOP;
SET _item_path = _temp_item_path;
END $$<file_sep>use opendatasheets;
DROP FUNCTION IF EXISTS GET_BOM_PATH;
DELIMITER $$
CREATE FUNCTION GET_BOM_PATH(com_id_in integer(100), site_id_in integer(100), uploaded_mpn_in VARCHAR(255), uploaded_supplier_in VARCHAR(255), man_id_in integer(11))
RETURNS LONGTEXT
DETERMINISTIC
BEGIN
DECLARE concatenated_path LONGTEXT;
IF com_id_in < 1 AND (uploaded_mpn_in is NULL OR uploaded_mpn_in = '') AND (uploaded_supplier_in is NULL OR uploaded_supplier_in = '')
AND uploaded_mpn_in < 1
THEN
RETURN NULL;
END IF;
CALL CREATE_BOM_PATH_LIST(com_id_in, site_id_in, uploaded_mpn_in , uploaded_supplier_in, man_id_in, @bom_path_list);
select @bom_path_list into concatenated_path;
RETURN concatenated_path;
END
$$
DELIMITER ;<file_sep>use opendatasheets;
DROP PROCEDURE IF EXISTS ALERT_BUILD_GIDEP_CHANGES;
CREATE PROCEDURE `ALERT_BUILD_GIDEP_CHANGES`()
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
DECLARE msg TEXT;
DECLARE code CHAR(5) DEFAULT '00000';
GET DIAGNOSTICS CONDITION 1
msg = MESSAGE_TEXT, code = RETURNED_SQLSTATE;
select msg,code;
END;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, GIDEP_ABSTRACT, GIDEP_DDATE, GIDEP_CEDATE, GIDEP_DOC_NUM, GIDEP_CAGE, GIDEP_DOC_TYPE_ID,
GIDEP_SUMMERY_ID, GIDEP_PDF_ID, PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
br.ROW_NUMBER,
br.BOM_ID,
albmp.uploaded_man_id,
albmp.matched_man_id,
br.UPLOADED_SUPPLIER,
algidepchanges.SE_SUPPLIER_NAME,
br.latest_mpn,
CASE WHEN algidepchanges.COMMERCIAL_PART_NUMBER IS NULL THEN algidepchanges.NAN_MPN ELSE algidepchanges.COMMERCIAL_PART_NUMBER END,
br.UPLOADED_CPN,
br.PART_CATEGORY,
algidepchanges.CHANGE_DATE,
algidepchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
algidepchanges.ABSTRACT,
algidepchanges.DDATE,
algidepchanges.CEDATE,
algidepchanges.DOC_NUM,
algidepchanges.CAGE,
algidepchanges.DOC_TYPE_ID,
algidepchanges.GIDEP_SUMMERY_ID,
algidepchanges.PDF_ID,
algidepchanges.PATCH_ID,
GET_BOM_PATH( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 0 AND als.IS_DELETED = 0
INNER JOIN bom_result br
ON br.BOM_ID = alsi.ITEM_ID AND br.status_flag = 0
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = br.com_id AND albmp.uploaded_man_id = br.man_id AND albmp.uploaded_mpn = br.NAN_MPN
INNER JOIN alert_gidep_changes algidepchanges
ON albmp.feature_id = 7
AND albmp.matched_com_id = algidepchanges.COM_ID
AND albmp.matched_man_id = algidepchanges.MAN_ID
AND albmp.matched_mpn = algidepchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, GIDEP_ABSTRACT, GIDEP_DDATE, GIDEP_CEDATE, GIDEP_DOC_NUM, GIDEP_CAGE, GIDEP_DOC_TYPE_ID,
GIDEP_SUMMERY_ID, GIDEP_PDF_ID, PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
br.ROW_NUMBER,
br.BOM_ID,
albmp.uploaded_man_id,
albmp.matched_man_id,
br.UPLOADED_SUPPLIER,
algidepchanges.SE_SUPPLIER_NAME,
br.latest_mpn,
CASE WHEN algidepchanges.COMMERCIAL_PART_NUMBER IS NULL THEN algidepchanges.NAN_MPN ELSE algidepchanges.COMMERCIAL_PART_NUMBER END,
br.UPLOADED_CPN,
br.PART_CATEGORY,
algidepchanges.CHANGE_DATE,
algidepchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
algidepchanges.ABSTRACT,
algidepchanges.DDATE,
algidepchanges.CEDATE,
algidepchanges.DOC_NUM,
algidepchanges.CAGE,
algidepchanges.DOC_TYPE_ID,
algidepchanges.GIDEP_SUMMERY_ID,
algidepchanges.PDF_ID,
algidepchanges.PATCH_ID,
GET_BOM_PATH( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 1 AND als.IS_DELETED = 0
INNER JOIN alert_boms_per_project bomsPerProject
ON bomsPerProject.project_id = alsi.ITEM_ID
INNER JOIN bom_result br
ON br.BOM_ID = bomsPerProject.BOM_ID AND br.status_flag = 0
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = br.com_id AND albmp.uploaded_man_id = br.man_id AND albmp.uploaded_mpn = br.NAN_MPN
INNER JOIN alert_gidep_changes algidepchanges
ON albmp.feature_id = 7
AND albmp.matched_com_id = algidepchanges.COM_ID
AND albmp.matched_man_id = algidepchanges.MAN_ID
AND albmp.matched_mpn = algidepchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, GIDEP_ABSTRACT, GIDEP_DDATE, GIDEP_CEDATE, GIDEP_DOC_NUM, GIDEP_CAGE, GIDEP_DOC_TYPE_ID,
GIDEP_SUMMERY_ID, GIDEP_PDF_ID, PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
null,
null,
albmp.uploaded_man_id,
albmp.matched_man_id,
alpd.man_name,
algidepchanges.SE_SUPPLIER_NAME,
alpd.mpn,
CASE WHEN algidepchanges.COMMERCIAL_PART_NUMBER IS NULL THEN algidepchanges.NAN_MPN ELSE algidepchanges.COMMERCIAL_PART_NUMBER END,
null,
null,
algidepchanges.CHANGE_DATE,
algidepchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
algidepchanges.ABSTRACT,
algidepchanges.DDATE,
algidepchanges.CEDATE,
algidepchanges.DOC_NUM,
algidepchanges.CAGE,
algidepchanges.DOC_TYPE_ID,
algidepchanges.GIDEP_SUMMERY_ID,
algidepchanges.PDF_ID,
algidepchanges.PATCH_ID,
GET_BOM_PATH( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 3 AND als.IS_DELETED = 0
INNER join alert_part_detail alpd
ON alpd.com_id = alsi.ITEM_ID
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = alsi.ITEM_ID AND albmp.uploaded_man_id = alpd.man_id AND albmp.uploaded_mpn = alpd.NAN_MPN
INNER JOIN alert_gidep_changes algidepchanges
ON albmp.feature_id = 7
AND albmp.matched_com_id = algidepchanges.COM_ID
AND albmp.matched_man_id = algidepchanges.MAN_ID
AND albmp.matched_mpn = algidepchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, GIDEP_ABSTRACT, GIDEP_DDATE, GIDEP_CEDATE, GIDEP_DOC_NUM, GIDEP_CAGE, GIDEP_DOC_TYPE_ID
,GIDEP_SUMMERY_ID, GIDEP_PDF_ID, PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
acl.ROW_NUM,
acl.acl_id,
albmp.uploaded_man_id,
albmp.matched_man_id,
acl.SUPPLIER,
algidepchanges.SE_SUPPLIER_NAME,
acl.latest_mpn,
CASE WHEN algidepchanges.COMMERCIAL_PART_NUMBER IS NULL THEN algidepchanges.NAN_MPN ELSE algidepchanges.COMMERCIAL_PART_NUMBER END,
acl.CPN,
acl.PART_CATEGORY,
algidepchanges.CHANGE_DATE,
algidepchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
algidepchanges.ABSTRACT,
algidepchanges.DDATE,
algidepchanges.CEDATE,
algidepchanges.DOC_NUM,
algidepchanges.CAGE,
algidepchanges.DOC_TYPE_ID,
algidepchanges.GIDEP_SUMMERY_ID,
algidepchanges.PDF_ID,
algidepchanges.PATCH_ID,
GET_BOM_PATH( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( algidepchanges.COM_ID, als.site_id, br.latest_mpn,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 2 AND als.IS_DELETED = 0
INNER JOIN acl_data acl
ON acl.acl_id = alsi.ITEM_ID
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = acl.com_id AND albmp.uploaded_man_id = acl.man_id AND albmp.uploaded_mpn = acl.NAN_MPN
INNER JOIN alert_gidep_changes algidepchanges
ON albmp.feature_id = 7
AND albmp.matched_com_id = algidepchanges.COM_ID
AND albmp.matched_man_id = algidepchanges.MAN_ID
AND albmp.matched_mpn = algidepchanges.NAN_MPN;
END;
<file_sep>use opendatasheets;
DROP PROCEDURE IF EXISTS ALERT_BUILD_PCN_CHANGES;
CREATE PROCEDURE `ALERT_BUILD_PCN_CHANGES`()
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
DECLARE msg TEXT;
DECLARE code CHAR(5) DEFAULT '00000';
GET DIAGNOSTICS CONDITION 1
msg = MESSAGE_TEXT, code = RETURNED_SQLSTATE;
select msg,code;
END;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, PCN_ID, PCN_URL, PCN_NO, PCN_NOTIFICATION_DATE, PCN_EFFECTIVE_DATE, PCN_LAST_TIME_BUY_DATE,
PCN_LAST_SHIP_DATE, PCN_DESCRIPTION_OF_CHANGE, PCN_SOURCE, PCN_LC_STATE, PCN_TYPE_OF_CHANGE,PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
br.ROW_NUMBER,
br.BOM_ID,
albmp.uploaded_man_id,
albmp.matched_man_id,
br.UPLOADED_SUPPLIER,
alpcnchanges.man_name,
br.latest_mpn,
CASE WHEN alpcnchanges.COMMERCIAL_PART_NUMBER IS NULL THEN alpcnchanges.NAN_MPN ELSE alpcnchanges.COMMERCIAL_PART_NUMBER END,
br.UPLOADED_CPN,
br.PART_CATEGORY,
alpcnchanges.CHANGE_DATE,
alpcnchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
alpcnchanges.PCN_ID,
alpcnchanges.PCN_URL,
alpcnchanges.PCN_NO,
alpcnchanges.NOTIFICATION_DATE,
alpcnchanges.EFFECTIVE_DATE,
alpcnchanges.LAST_TIME_BUY_DATE,
alpcnchanges.LAST_SHIP_DATE,
alpcnchanges.DESCRIPTION_OF_CHANGE,
alpcnchanges.PCN_SOURCE,
alpcnchanges.LC_STATE,
alpcnchanges.TYPE_OF_CHANGE,
alpcnchanges.PATCH_ID,
GET_BOM_PATH( alpcnchanges.COM_ID, als.site_id ,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( alpcnchanges.COM_ID, als.site_id,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 0 AND als.IS_DELETED = 0
INNER JOIN bom_result br
ON br.BOM_ID = alsi.ITEM_ID AND br.status_flag = 0
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = br.com_id AND albmp.uploaded_man_id = br.man_id AND albmp.uploaded_mpn = br.NAN_MPN
INNER JOIN alert_pcn_changes alpcnchanges
ON albmp.feature_id = 1
AND albmp.matched_com_id = alpcnchanges.COM_ID
AND albmp.matched_man_id = alpcnchanges.MAN_ID
AND albmp.matched_mpn = alpcnchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID, UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN,
MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID, UPLOADED_COM_ID, MATCH_TYPE, PCN_ID, PCN_URL,
PCN_NO, PCN_NOTIFICATION_DATE, PCN_EFFECTIVE_DATE, PCN_LAST_TIME_BUY_DATE, PCN_LAST_SHIP_DATE, PCN_DESCRIPTION_OF_CHANGE,
PCN_SOURCE, PCN_LC_STATE, PCN_TYPE_OF_CHANGE,PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
br.ROW_NUMBER,
br.BOM_ID,
albmp.uploaded_man_id,
albmp.matched_man_id,
br.UPLOADED_SUPPLIER,
alpcnchanges.man_name,
br.latest_mpn,
CASE WHEN alpcnchanges.COMMERCIAL_PART_NUMBER IS NULL THEN alpcnchanges.NAN_MPN ELSE alpcnchanges.COMMERCIAL_PART_NUMBER END,
br.UPLOADED_CPN,
br.PART_CATEGORY,
alpcnchanges.CHANGE_DATE,
alpcnchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
alpcnchanges.PCN_ID,
alpcnchanges.PCN_URL,
alpcnchanges.PCN_NO,
alpcnchanges.NOTIFICATION_DATE,
alpcnchanges.EFFECTIVE_DATE,
alpcnchanges.LAST_TIME_BUY_DATE,
alpcnchanges.LAST_SHIP_DATE,
alpcnchanges.DESCRIPTION_OF_CHANGE,
alpcnchanges.PCN_SOURCE,
alpcnchanges.LC_STATE,
alpcnchanges.TYPE_OF_CHANGE,
alpcnchanges.PATCH_ID,
GET_BOM_PATH( alpcnchanges.COM_ID, als.site_id ,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( alpcnchanges.COM_ID, als.site_id,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 1 AND als.IS_DELETED = 0
INNER JOIN alert_boms_per_project bomsPerProject
ON bomsPerProject.project_id = alsi.ITEM_ID
INNER JOIN bom_result br
ON br.BOM_ID = bomsPerProject.BOM_ID AND br.status_flag = 0
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = br.com_id AND albmp.uploaded_man_id = br.man_id AND albmp.uploaded_mpn = br.NAN_MPN
INNER JOIN alert_pcn_changes alpcnchanges
ON albmp.feature_id = 1
AND albmp.matched_com_id = alpcnchanges.COM_ID
AND albmp.matched_man_id = alpcnchanges.MAN_ID
AND albmp.matched_mpn = alpcnchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, PCN_ID, PCN_URL, PCN_NO, PCN_NOTIFICATION_DATE, PCN_EFFECTIVE_DATE, PCN_LAST_TIME_BUY_DATE,
PCN_LAST_SHIP_DATE, PCN_DESCRIPTION_OF_CHANGE, PCN_SOURCE, PCN_LC_STATE, PCN_TYPE_OF_CHANGE,PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
null,
null,
albmp.uploaded_man_id,
albmp.matched_man_id,
alpd.man_name,
alpcnchanges.man_name,
alpd.mpn,
CASE WHEN alpcnchanges.COMMERCIAL_PART_NUMBER IS NULL THEN alpcnchanges.NAN_MPN ELSE alpcnchanges.COMMERCIAL_PART_NUMBER END,
null,
null,
alpcnchanges.CHANGE_DATE,
alpcnchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
alpcnchanges.PCN_ID,
alpcnchanges.PCN_URL,
alpcnchanges.PCN_NO,
alpcnchanges.NOTIFICATION_DATE,
alpcnchanges.EFFECTIVE_DATE,
alpcnchanges.LAST_TIME_BUY_DATE,
alpcnchanges.LAST_SHIP_DATE,
alpcnchanges.DESCRIPTION_OF_CHANGE,
alpcnchanges.PCN_SOURCE,
alpcnchanges.LC_STATE,
alpcnchanges.TYPE_OF_CHANGE,
alpcnchanges.PATCH_ID,
GET_BOM_PATH( alpcnchanges.COM_ID, als.site_id ,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( alpcnchanges.COM_ID, als.site_id,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 3 AND als.IS_DELETED = 0
INNER join alert_part_detail alpd
ON alpd.com_id = alsi.ITEM_ID
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = alsi.ITEM_ID AND albmp.uploaded_man_id = alpd.man_id AND albmp.uploaded_mpn = alpd.NAN_MPN
INNER JOIN alert_pcn_changes alpcnchanges
ON albmp.feature_id = 1
AND albmp.matched_com_id = alpcnchanges.COM_ID
AND albmp.matched_man_id = alpcnchanges.MAN_ID
AND albmp.matched_mpn = alpcnchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID, UPLOADED_MAN_NAME,
MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID, UPLOADED_COM_ID,
MATCH_TYPE, PCN_ID, PCN_URL, PCN_NO, PCN_NOTIFICATION_DATE, PCN_EFFECTIVE_DATE, PCN_LAST_TIME_BUY_DATE, PCN_LAST_SHIP_DATE,
PCN_DESCRIPTION_OF_CHANGE, PCN_SOURCE, PCN_LC_STATE, PCN_TYPE_OF_CHANGE,PATCH_ID, BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
acl.ROW_NUM,
acl.acl_id,
albmp.uploaded_man_id,
albmp.matched_man_id,
acl.SUPPLIER,
alpcnchanges.man_name,
acl.latest_mpn,
CASE WHEN alpcnchanges.COMMERCIAL_PART_NUMBER IS NULL THEN alpcnchanges.NAN_MPN ELSE alpcnchanges.COMMERCIAL_PART_NUMBER END,
acl.CPN,
acl.PART_CATEGORY,
alpcnchanges.CHANGE_DATE,
alpcnchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
alpcnchanges.PCN_ID,
alpcnchanges.PCN_URL,
alpcnchanges.PCN_NO,
alpcnchanges.NOTIFICATION_DATE,
alpcnchanges.EFFECTIVE_DATE,
alpcnchanges.LAST_TIME_BUY_DATE,
alpcnchanges.LAST_SHIP_DATE,
alpcnchanges.DESCRIPTION_OF_CHANGE,
alpcnchanges.PCN_SOURCE,
alpcnchanges.LC_STATE,
alpcnchanges.TYPE_OF_CHANGE,
alpcnchanges.PATCH_ID,
GET_BOM_PATH( alpcnchanges.COM_ID, als.site_id ,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( alpcnchanges.COM_ID, als.site_id,br.latest_mpn, br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 2 AND als.IS_DELETED = 0
INNER JOIN acl_data acl
ON acl.acl_id = alsi.ITEM_ID
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = acl.com_id AND albmp.uploaded_man_id = acl.man_id AND albmp.uploaded_mpn = acl.NAN_MPN
INNER JOIN alert_pcn_changes alpcnchanges
ON albmp.feature_id = 1
AND albmp.matched_com_id = alpcnchanges.COM_ID
AND albmp.matched_man_id = alpcnchanges.MAN_ID
AND albmp.matched_mpn = alpcnchanges.NAN_MPN;
END;
<file_sep>USE opendatasheets;
DROP PROCEDURE IF EXISTS CREATE_BOM_PATH_LIST;
DELIMITER $$
CREATE PROCEDURE CREATE_BOM_PATH_LIST(IN com_id_in INTEGER(100),
IN site_id_in INTEGER(100),
uploaded_mpn_in VARCHAR(255),
uploaded_supplier_in VARCHAR(255),
man_id_in INTEGER(11),
OUT bom_path_list LONGTEXT)
BEGIN
DECLARE finished INTEGER DEFAULT 0;
DECLARE bom_id_temp INTEGER DEFAULT 0;
DECLARE bom_path LONGTEXT DEFAULT "";
DECLARE current_bom_name LONGTEXT DEFAULT "";
DECLARE result LONGTEXT DEFAULT "";
DECLARE item_path_temp LONGTEXT DEFAULT "";
DECLARE name_temp LONGTEXT DEFAULT "";
DECLARE com_id_temp INTEGER DEFAULT 0;
DECLARE cur_bom_id CURSOR FOR SELECT bom_id, com_id FROM tmp_view_bom;
-- declare NOT FOUND handler
DECLARE CONTINUE HANDLER FOR NOT FOUND
SET finished = 1;
IF com_id_in > 0
THEN
SET @v =
concat(
'CREATE OR REPLACE VIEW tmp_view_bom as SELECT distinct br.bom_id, br.com_id FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.com_id =',
com_id_in,
' AND br.site_id =',
site_id_in,
'
AND b.status_flag = 0
AND br.status_flag = 0');
PREPARE stm FROM @v;
EXECUTE stm;
DEALLOCATE PREPARE stm;
ELSEIF uploaded_mpn_in IS NOT NULL
AND uploaded_mpn_in != ''
AND uploaded_supplier_in IS NOT NULL
AND uploaded_supplier_in != ''
THEN
SET @v =
concat(
'CREATE OR REPLACE VIEW tmp_view_bom as SELECT distinct br.bom_id, br.com_id FROM bom_result br, bom b
WHERE br.bom_id = b.id AND br.uploaded_mpn =',
uploaded_mpn_in,
' AND br.uploaded_supplier =',
uploaded_supplier_in,
' AND br.site_id = ',
site_id_in,
' AND b.status_flag = 0
AND br.status_flag = 0');
PREPARE stm FROM @v;
EXECUTE stm;
DEALLOCATE PREPARE stm;
ELSEIF uploaded_mpn_in IS NOT NULL
AND uploaded_mpn_in != ''
AND man_id_in > 0
THEN
SET @v =
concat(
'CREATE OR REPLACE VIEW tmp_view_bom as SELECT distinct br.bom_id, br.com_id FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.uploaded_mpn =',
uploaded_mpn_in,
' AND br.man_id =',
man_id_in,
' AND br.site_id = site_id_in
AND b.status_flag = 0
AND br.status_flag = 0');
PREPARE stm FROM @v;
EXECUTE stm;
DEALLOCATE PREPARE stm;
ELSEIF uploaded_mpn_in IS NOT NULL AND uploaded_mpn_in != ''
THEN
SET @v =
concat(
'CREATE OR REPLACE VIEW tmp_view_bom as SELECT distinct br.bom_id, br.com_id FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.uploaded_mpn = ',
uploaded_mpn_in,
' AND br.site_id =',
site_id_in,
'AND b.status_flag = 0
AND br.status_flag = 0');
PREPARE stm FROM @v;
EXECUTE stm;
DEALLOCATE PREPARE stm;
END IF;
OPEN cur_bom_id;
getBomPath:
LOOP
FETCH cur_bom_id INTO bom_id_temp, com_id_temp;
IF finished = 1
THEN
LEAVE getBomPath;
END IF;
SELECT item_path
INTO item_path_temp
FROM bom
WHERE id = bom_id_temp;
SELECT name
INTO name_temp
FROM bom
WHERE id = bom_id_temp;
IF item_path_temp IS NULL OR LENGTH(item_path_temp) = 0
THEN
SET @concatenated_name = name_temp;
ELSE
CALL GET_ITEM_PATH(item_path_temp, @_item_path);
IF LENGTH(@_item_path) > 0
THEN
SET @concatenated_name = CONCAT(@_item_path, " > ", name_temp);
ELSE
SET @concatenated_name = name_temp;
END IF;
END IF;
IF LENGTH(result) > 0
THEN
SET result = CONCAT(result, " , ", @concatenated_name);
ELSE
SET result = @concatenated_name;
END IF;
END LOOP getBomPath;
CLOSE cur_bom_id;
SET bom_path_list = result;
END
$$
DELIMITER ;
<file_sep>
USE opendatasheets;
DROP FUNCTION IF EXISTS GET_BOM_COUNT;
DELIMITER $$
CREATE FUNCTION GET_BOM_COUNT(com_id_in INTEGER(100),
site_id_in INTEGER(100),
uploaded_mpn_in VARCHAR(255),
uploaded_supplier_in VARCHAR(255),
man_id_in INTEGER(11))
RETURNS INTEGER(100)
DETERMINISTIC
BEGIN
DECLARE count_bom_id INTEGER(100) DEFAULT 0;
IF com_id_in > 0
THEN
SELECT count(DISTINCT br.bom_id, br.com_id)
INTO count_bom_id
FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.com_id = com_id_in
AND br.site_id = site_id_in
AND b.status_flag = 0
AND br.status_flag = 0;
ELSEIF uploaded_mpn_in IS NOT NULL
AND uploaded_mpn_in != ''
AND uploaded_supplier_in IS NOT NULL
AND uploaded_supplier_in != ''
THEN
SELECT count(DISTINCT br.bom_id, br.com_id)
INTO count_bom_id
FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.uploaded_mpn = uploaded_mpn_in
AND br.uploaded_supplier = uploaded_supplier_in
AND br.site_id = site_id_in
AND b.status_flag = 0
AND br.status_flag = 0;
ELSEIF uploaded_mpn_in IS NOT NULL
AND uploaded_mpn_in != ''
AND man_id_in > 0
THEN
SELECT count(DISTINCT br.bom_id, br.com_id)
INTO count_bom_id
FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.uploaded_mpn = uploaded_mpn_in
AND br.man_id = man_id_in
AND br.site_id = site_id_in
AND b.status_flag = 0
AND br.status_flag = 0;
ELSEIF uploaded_mpn_in IS NOT NULL AND uploaded_mpn_in != ''
THEN
SELECT count(DISTINCT br.bom_id, br.com_id)
INTO count_bom_id
FROM bom_result br, bom b
WHERE br.bom_id = b.id
AND br.uploaded_mpn = uploaded_mpn_in
AND br.site_id = site_id_in
AND b.status_flag = 0
AND br.status_flag = 0;
END IF;
RETURN count_bom_id;
END
$$
DELIMITER ;
<file_sep>use opendatasheets;
DROP PROCEDURE IF EXISTS ALERT_BUILD_DML_CHANGES;
CREATE PROCEDURE `ALERT_BUILD_DML_CHANGES`()
BEGIN
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
DECLARE msg TEXT;
DECLARE code CHAR(5) DEFAULT '00000';
GET DIAGNOSTICS CONDITION 1
msg = MESSAGE_TEXT, code = RETURNED_SQLSTATE;
select msg,code;
END;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID, UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID, UPLOADED_COM_ID, MATCH_TYPE, DML_COL_1, DML_COL_2, DML_COL_3, DML_COL_4, DML_COL_5, DML_COL_6, DML_COL_7, DML_COL_8, DML_COL_9, DML_COL_10, DML_OLD_VALUE, DML_NEW_VALUE, PATCH_ID
,BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
br.ROW_NUMBER,
br.BOM_ID,
albmp.uploaded_man_id,
albmp.matched_man_id,
br.UPLOADED_SUPPLIER,
aldmlchanges.man_name,
br.latest_mpn,
CASE WHEN aldmlchanges.COMMERCIAL_PART_NUMBER IS NULL THEN aldmlchanges.NAN_MPN ELSE aldmlchanges.COMMERCIAL_PART_NUMBER END,
br.UPLOADED_CPN,
br.PART_CATEGORY,
aldmlchanges.CHANGE_DATE,
aldmlchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
aldmlchanges.COL_1,
aldmlchanges.COL_2,
aldmlchanges.COL_3,
aldmlchanges.COL_4,
aldmlchanges.COL_5,
aldmlchanges.COL_6,
aldmlchanges.COL_7,
aldmlchanges.COL_8,
aldmlchanges.COL_9,
aldmlchanges.COL_10,
aldmlchanges.OLD_VALUE,
aldmlchanges.NEW_VALUE,
aldmlchanges.PATCH_ID,
GET_BOM_PATH( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 0 AND als.IS_DELETED = 0
INNER JOIN bom_result br
ON br.BOM_ID = alsi.ITEM_ID AND br.status_flag = 0
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = br.com_id AND albmp.uploaded_man_id = br.man_id AND albmp.uploaded_mpn = br.NAN_MPN
INNER JOIN alert_dml_changes aldmlchanges
ON albmp.feature_id = aldmlchanges.feature_id
AND albmp.matched_com_id = aldmlchanges.COM_ID
AND albmp.matched_man_id = aldmlchanges.MAN_ID
AND albmp.matched_mpn = aldmlchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, DML_COL_1, DML_COL_2, DML_COL_3, DML_COL_4, DML_COL_5, DML_COL_6, DML_COL_7, DML_COL_8,
DML_COL_9, DML_COL_10, DML_OLD_VALUE, DML_NEW_VALUE, PATCH_ID ,BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
br.ROW_NUMBER,
br.BOM_ID,
albmp.uploaded_man_id,
albmp.matched_man_id,
br.UPLOADED_SUPPLIER,
aldmlchanges.man_name,
br.latest_mpn,
CASE WHEN aldmlchanges.COMMERCIAL_PART_NUMBER IS NULL THEN aldmlchanges.NAN_MPN ELSE aldmlchanges.COMMERCIAL_PART_NUMBER END,
br.UPLOADED_CPN,
br.PART_CATEGORY,
aldmlchanges.CHANGE_DATE,
aldmlchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
aldmlchanges.COL_1,
aldmlchanges.COL_2,
aldmlchanges.COL_3,
aldmlchanges.COL_4,
aldmlchanges.COL_5,
aldmlchanges.COL_6,
aldmlchanges.COL_7,
aldmlchanges.COL_8,
aldmlchanges.COL_9,
aldmlchanges.COL_10,
aldmlchanges.OLD_VALUE,
aldmlchanges.NEW_VALUE,
aldmlchanges.PATCH_ID,
GET_BOM_PATH( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 1 AND als.IS_DELETED = 0
INNER JOIN alert_boms_per_project bomsPerProject
ON bomsPerProject.project_id = alsi.ITEM_ID
INNER JOIN bom_result br
ON br.BOM_ID = bomsPerProject.BOM_ID AND br.status_flag = 0
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = br.com_id AND albmp.uploaded_man_id = br.man_id AND albmp.uploaded_mpn = br.NAN_MPN
INNER JOIN alert_dml_changes aldmlchanges
ON albmp.feature_id = aldmlchanges.feature_id
AND albmp.matched_com_id = aldmlchanges.COM_ID
AND albmp.matched_man_id = aldmlchanges.MAN_ID
AND albmp.matched_mpn = aldmlchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, DML_COL_1, DML_COL_2, DML_COL_3, DML_COL_4, DML_COL_5, DML_COL_6, DML_COL_7, DML_COL_8,
DML_COL_9, DML_COL_10, DML_OLD_VALUE, DML_NEW_VALUE, PATCH_ID,BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
null,
null,
albmp.uploaded_man_id,
albmp.matched_man_id,
alpd.man_name,
aldmlchanges.man_name,
alpd.mpn,
CASE WHEN aldmlchanges.COMMERCIAL_PART_NUMBER IS NULL THEN aldmlchanges.NAN_MPN ELSE aldmlchanges.COMMERCIAL_PART_NUMBER END,
null,
null,
aldmlchanges.CHANGE_DATE,
aldmlchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
aldmlchanges.COL_1,
aldmlchanges.COL_2,
aldmlchanges.COL_3,
aldmlchanges.COL_4,
aldmlchanges.COL_5,
aldmlchanges.COL_6,
aldmlchanges.COL_7,
aldmlchanges.COL_8,
aldmlchanges.COL_9,
aldmlchanges.COL_10,
aldmlchanges.OLD_VALUE,
aldmlchanges.NEW_VALUE,
aldmlchanges.PATCH_ID,
GET_BOM_PATH( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 3 AND als.IS_DELETED = 0
INNER join alert_part_detail alpd
ON alpd.com_id = alsi.ITEM_ID
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = alsi.ITEM_ID AND albmp.uploaded_man_id = alpd.man_id AND albmp.uploaded_mpn = alpd.NAN_MPN
INNER JOIN alert_dml_changes aldmlchanges
ON albmp.feature_id = aldmlchanges.feature_id
AND albmp.matched_com_id = aldmlchanges.COM_ID
AND albmp.matched_man_id = aldmlchanges.MAN_ID
AND albmp.matched_mpn = aldmlchanges.NAN_MPN;
insert into alert_all_changes(SETTING_ID, SCOPE_ID, FEATURE_ID, ROW_NUMBER, BOM_ID, UPLOADED_MAN_ID, MATCHED_MAN_ID,
UPLOADED_MAN_NAME, MATCHED_MAN_NAME, UPLOADED_MPN, MATCHED_MPN, UPLOADED_CPN, PART_CATEGORY, CHANGE_DATE, MATCHED_COM_ID,
UPLOADED_COM_ID, MATCH_TYPE, DML_COL_1, DML_COL_2, DML_COL_3, DML_COL_4, DML_COL_5, DML_COL_6, DML_COL_7, DML_COL_8,
DML_COL_9, DML_COL_10, DML_OLD_VALUE, DML_NEW_VALUE, PATCH_ID,BOM_PATH,NO_OF_AFFECTED_BOM_OPTIONS)
SELECT als.ALERT_SETTING_ID,
als.alert_scope_id,
albmp.feature_id,
acl.ROW_NUM,
acl.acl_id,
albmp.uploaded_man_id,
albmp.matched_man_id,
acl.SUPPLIER,
aldmlchanges.man_name,
acl.latest_mpn,
CASE WHEN aldmlchanges.COMMERCIAL_PART_NUMBER IS NULL THEN aldmlchanges.NAN_MPN ELSE aldmlchanges.COMMERCIAL_PART_NUMBER END,
acl.CPN,
acl.PART_CATEGORY,
aldmlchanges.CHANGE_DATE,
aldmlchanges.COM_ID,
albmp.uploaded_com_id,
albmp.match_type,
aldmlchanges.COL_1,
aldmlchanges.COL_2,
aldmlchanges.COL_3,
aldmlchanges.COL_4,
aldmlchanges.COL_5,
aldmlchanges.COL_6,
aldmlchanges.COL_7,
aldmlchanges.COL_8,
aldmlchanges.COL_9,
aldmlchanges.COL_10,
aldmlchanges.OLD_VALUE,
aldmlchanges.NEW_VALUE,
aldmlchanges.PATCH_ID,
GET_BOM_PATH( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id),
GET_BOM_COUNT( aldmlchanges.COM_ID, als.site_id, br.latest_mpn ,br.UPLOADED_SUPPLIER,albmp.matched_man_id)
FROM alert_setting als
INNER JOIN alert_setting_items alsi
ON als.ALERT_SETTING_ID = alsi.ALERT_SETTING_ID AND als.ALERT_SCOPE_ID = 2 AND als.IS_DELETED = 0
INNER JOIN acl_data acl
ON acl.acl_id = alsi.ITEM_ID
INNER JOIN alert_best_match_part albmp
ON albmp.uploaded_com_id = acl.com_id AND albmp.uploaded_man_id = acl.man_id AND albmp.uploaded_mpn = acl.NAN_MPN
INNER JOIN alert_dml_changes aldmlchanges
ON albmp.feature_id = aldmlchanges.feature_id
AND albmp.matched_com_id = aldmlchanges.COM_ID
AND albmp.matched_man_id = aldmlchanges.MAN_ID
AND albmp.matched_mpn = aldmlchanges.NAN_MPN;
END;
| 5e8c79191044342947e28f13fbd17c7a85bc2ebb | [
"SQL"
] | 8 | SQL | mohamadsalahdarwish/bom_path_count | 1d84343a802eb55a0be16ca3a4babfb8625ad5ed | 72539419d764e4ed4f3b43868e6462bb603a6381 |
refs/heads/master | <file_sep><?php
$connect = mysqli_connect('localhost','root','','fabricrent');
if(!$connect){
echo mysqli_error($connect);
}
?><file_sep><?php
$username=$_POST['user'];
$password=$_POST['pass'];
$username= stripcslashes($username);
$password= stripcslashes($password);
$username= mysql_real_escape_string($username);
$password= mysql_real_escape_string($password);
$password = md5($password);
mysql_connect("localhost","root","");
mysql_select_db("fabricrent");
$result = mysql_query("select * from users where username='$username' and password='$<PASSWORD>'")
or die("failed to query database".mysql_error());
$row = mysql_fetch_array($result);
if($row['username'] == $username && $row['password'] == $password){
session_start();
$_SESSION['user'] = $username;
header("Location:./admin/index.php");
}
else{
echo "Login failed!";
}
?><file_sep><?php
include ('./connection.php');
$username = $_POST['username'];
$password = $_POST['<PASSWORD>'];
$phone = $_POST['phone'];
$email = $_POST['email'];
$pass = md5($password);
$sql = "INSERT INTO users(username, password, phn, email) VALUES('$username','$pass','$phone','$email')";
$query = mysqli_query($connect, $sql);
if(!$query){
echo "Failed to register! Please try again";
}else{
echo "alert('Your account is created. Kindly login to continue!')";
header("Location: ./log.php");
}
?> | 6264cc68d7212b557ee70d8182ee288b38f68ed1 | [
"PHP"
] | 3 | PHP | Aishu1996/FabricRent | ba47aa6c40a272de738dd4c721f3b123ec1ba3b6 | ffe1ea964be61c9e5585fdf07f48b7b57d10bbe7 |
refs/heads/master | <file_sep>//<debug>
Ext.Loader.setPath({
'Ext': 'sdk/src',
'Ext.ux': 'libs/ux'
});
//</debug>
Ext.application({
name: 'PinchZoomImage',
requires: [
'Ext.MessageBox'
],
views: ['Main'],
icon: {
57: 'resources/icons/Icon.png',
72: 'resources/icons/Icon~ipad.png',
114: 'resources/icons/Icon@2x.png',
144: 'resources/icons/Icon~ipad@2x.png'
},
phoneStartupScreen: 'resources/loading/Homescreen.jpg',
tabletStartupScreen: 'resources/loading/Homescreen~ipad.jpg',
launch: function() {
Ext.fly('appLoadingIndicator').destroy();
Ext.Viewport.add(Ext.create('PinchZoomImage.view.Main'));
// redraw image when orientation is changed.
Ext.getDom('ext-viewport').addEventListener('orientationchange', function() {
var pinchzooms = Ext.ComponentQuery.query('pinchzoomimage');
for (var i=0;i<pinchzooms.length;i++) {
pinchzooms[i].redraw();
}
});
},
onUpdated: function() {
Ext.Msg.confirm(
"Application Update",
"This application has just successfully been updated to the latest version. Reload now?",
function() {
window.location.reload();
}
);
}
});
| 602c83ddbf543834d6469d6b67754c23c622a8e0 | [
"JavaScript"
] | 1 | JavaScript | deanchou/ppinchzoom | 6cadbf41fbc772efdbdfdc765b1829be4c43bf55 | b6225fe9a4d0639ac6927a92a2726fd800808648 |
refs/heads/master | <repo_name>DilanLivera/yelpcamp<file_sep>/routes/campgrounds.js
const express = require("express"),
router = express.Router(),
Campground = require("../models/campground"),
expressSanitizer = require("express-sanitizer"),
middlewear = require("../middlewear"),
NodeGeocoder = require('node-geocoder');
// set up node geocoder
let options = {
provider: 'google',
httpAdapter: 'https',
apiKey: process.env.GEOCODER_API_KEY,
formatter: null
};
let geocoder = NodeGeocoder(options);
router.use(expressSanitizer());
//INDEX - show all campgrounds
router.get("/", (req, res) => {
//get all the campgrounds from the database
Campground.find({}, (err, allCampgrounds) => {
if(err) {
console.log("Oops, something went wrong!!!");
console.log(err);
} else {
//show all the campgrounds
res.render("campgrounds/index", {campgrounds: allCampgrounds, page: 'campgrounds'});
}
});
});
//CREATE - add new campground to DB
router.post("/", middlewear.isLoggedIn, (req, res) => {
//get name, image url and description form and add campgrounds and sanitize
const name = req.sanitize(req.body.name),
imageURL = req.sanitize(req.body.image),
cost = req.sanitize(req.body.cost),
description = req.sanitize(req.body.description),
oldLocation = req.sanitize(req.body.location),
author = {
id: req.user._id,
username: req.user.username
};
//get the geocode for the user input location
geocoder.geocode(oldLocation, function (err, data) {
if (err || !data.length) {
req.flash('error', 'Invalid address');
return res.redirect('back');
}
let lat = data[0].latitude,
lng = data[0].longitude,
location = data[0].formattedAddress;
let newCampground = { name: name, image: imageURL, cost: cost, description: description, author: author, location: location, lat: lat, lng: lng };
//add new campground to the database
Campground.create(newCampground, (err, returnedCampground) => {
if(err){
req.flash("error", "Oops, Something went wrong while creating the campground.");
res.redirect("back");
} else {
//show all the campgrounds
req.flash("sucess", "Campground added successfully.");
res.redirect("/campgrounds");
}
});
});
});
//NEW - show form to create new campground
router.get("/new", middlewear.isLoggedIn, (req, res) => {
res.render("campgrounds/new");
});
//SHOW - shows more info about one campground
router.get("/:id", (req, res) => {
//find the campground with provided id
Campground.findById(req.params.id).populate("comments").exec((err, foundCampground) => {
if(err){
req.flash("error", "Oops, soemething went wrong while getting the campground");
res.redirect("back");
} else {
//render show template with that campground
res.render("campgrounds/show", { campground: foundCampground });
}
});
});
//EDIT - show form to edit campground after checking the authorization of the user
router.get("/:id/edit",middlewear.checkCampgroundOwnership, (req, res) => {
//find the campground
Campground.findById(req.params.id, (err, foundCampground) => {
if(err){
req.flash("error", "Oops, something went wrong while getting the campground");
res.redirect("back");
} else {
//show the edit campground page
res.render("campgrounds/edit", { campground: foundCampground });
}
});
});
//UPDATE - update the campground from edit form
router.put("/:id", middlewear.checkCampgroundOwnership, (req, res) => {
//sanitize the campground
req.body.campground.name = req.sanitize(req.body.campground.name);
req.body.campground.image = req.sanitize(req.body.campground.image);
req.body.campground.cost = req.sanitize(req.body.campground.cost);
req.body.campground.description = req.sanitize(req.body.campground.description);
let oldLocation = req.sanitize(req.body.campground.location);
//geo code the user input location
geocoder.geocode(oldLocation, function (err, data) {
if (err || !data.length) {
req.flash('error', 'Invalid address');
return res.redirect('back');
}
req.body.campground.lat = data[0].latitude;
req.body.campground.lng = data[0].longitude;
req.body.campground.location = data[0].formattedAddress;
//find the campground from the collection and update
Campground.findByIdAndUpdate(req.params.id, req.body.campground, (err, updatedCampground) => {
if(err){
req.flash("error", "Oops, something went wrong while updating the campground");
res.redirect("/campgrounds");
} else {
req.flash("success", "Campground updated successfully");
res.redirect(`/campgrounds/${updatedCampground._id}`);
}
});
});
});
//DESTROY - delete a campground
router.delete("/:id", middlewear.checkCampgroundOwnership, (req, res) => {
//find the campground and delete
Campground.findByIdAndRemove(req.params.id, (err) => {
if(err){
req.flash("error", "Oops, something went wrong while deleting the campground");
res.redirect("back");
} else {
req.flash("success", "Campground deleted successfully");
res.redirect("/campgrounds");
}
});
});
module.exports = router;<file_sep>/sampleData.js
let campgrounds = [
{
name: "Morgan Conservation Park",
image: "https://images.unsplash.com/photo-1525811902-f2342640856e?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1051&q=80",
description: "There are so many places to camp along the River Murray, and each one provides a different aspect to this waterway. Morgan Conservation Park is no exception. Located around 150km from Adelaide, this Park run by National Parks SA is a great place for a weekend away without having to travel too far.",
Address: "Morgan-Cadell Rd, Morgan SA 5320"
},
{
name: "Western KI Caravan Park",
image: "https://images.unsplash.com/photo-1508873696983-2dfd5898f08b?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80",
description: "We do not normally camp at caravan parks as we like to experience more isolated and private locations, but we had a need for hot showers and to do some much needed washing of clothes. We investigated the camping locations in the Western part of the Island, and decided that this caravan park would best suit our needs – all the above facilities plus easy and close access to Flinders Chase National Park (just under 10 mins drive away)."
},
{
name: "The Grampians - Mount Stapylton",
image: "https://images.unsplash.com/photo-1506535995048-638aa1b62b77?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80",
description: "Mt Stapylton campground is the campground closest to Horsham, and located within the beautiful Northern Grampians. After spending time near Halls Gap, this area was noticeably drier, and the surroundings less lush."
},
{
name: "EnginePoint",
image: "https://images.unsplash.com/photo-1527707240828-f7ca7d3c46a9?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80",
description: "<p>Engine Point offers 4 sites overlooking beautiful waters of Boston Bay.</p> <p>The camping area is located at one end of a long beautiful beach, which you come across on one of the many walks that can be done in the NP. Access can be done with a 2WD, but is meant to be 4WD.</p>"
},
{
name: "Innes-National Prk",
image: "https://images.unsplash.com/photo-1478131143081-80f7f84ca84d?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80",
description: "<p>Innes NP is around 3.5 hours from Adelaide (via Minlaton, Warooka and Marion Bay).</p> <p>As this is a coastal park, beautiful scenery and beaches can be found – rugged coastlines with beaches with some big waves, so small children need very close supervision around the water, as at some beaches the undertow is very strong. Ethel Beach is stunning, with orange sand and pounding waves. There is a shipwreck on the beach, but all that remains is some jagged pieces of the boat, and hard to work out what it once was!. In the right light conditions, photographers will enjoy this beach.</p>"
},
{
name: "<NAME>",
image: "https://images.unsplash.com/photo-1519095614420-850b5671ac7f?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1350&q=80",
description: ""
},
{
name: "Hillocks Drive Butlers Beach",
image: "https://images.unsplash.com/photo-1444210971048-6130cf0c46cf?ixlib=rb-1.2.1&auto=format&fit=crop&w=1352&q=80",
description: ""
},
{
name: "<NAME>",
image: "https://images.unsplash.com/photo-1508768516474-73606cb84ce2?ixlib=rb-1.2.1&auto=format&fit=crop&w=1399&q=80",
description: ""
},
{
name: "<NAME>",
image: "https://images.unsplash.com/photo-1464207687429-7505649dae38?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1952&q=80",
description: ""
},
{
name: "<NAME>",
image: "https://images.unsplash.com/photo-1455763916899-e8b50eca9967?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1350&q=80",
description: ""
}
];
<file_sep>/seeds.js
const mongoose = require("mongoose"),
Campground = require("./models/campground"),
Comment = require("./models/comment");
function seedDB(){
let data = [
{
name: "Morgan Conservation Park",
image: "https://images.unsplash.com/photo-1525811902-f2342640856e?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1051&q=80",
description: "There are so many places to camp along the River Murray, and each one provides a different aspect to this waterway. Morgan Conservation Park is no exception. Located around 150km from Adelaide, this Park run by National Parks SA is a great place for a weekend away without having to travel too far."
},
{
name: "Western KI Caravan Park",
image: "https://images.unsplash.com/photo-1508873696983-2dfd5898f08b?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80",
description: "We do not normally camp at caravan parks as we like to experience more isolated and private locations, but we had a need for hot showers and to do some much needed washing of clothes. We investigated the camping locations in the Western part of the Island, and decided that this caravan park would best suit our needs – all the above facilities plus easy and close access to Flinders Chase National Park (just under 10 mins drive away)."
},
{
name: "The Grampians - Mount Stapylton",
image: "https://images.unsplash.com/photo-1506535995048-638aa1b62b77?ixlib=rb-1.2.1&ixid=eyJhcHBfaWQiOjEyMDd9&auto=format&fit=crop&w=1050&q=80",
description: "Mt Stapylton campground is the campground closest to Horsham, and located within the beautiful Northern Grampians. After spending time near Halls Gap, this area was noticeably drier, and the surroundings less lush."
}
]
//remove all the campgrounds
Campground.remove({}, (err) => {
if(err){
console.log("Oops, something went wrong!!!");
console.log(err);
} else {
console.log("All campgrounds are removed.");
//add campgrounds
/* data.forEach((seedCampground) => {
Campground.create(seedCampground, (err, campground) => {
if(err){
console.log("Oops, something went wrong!!!");
console.log(err);
} else {
console.log("Campground added.");
//create a comment and add to the campground
Comment.create(
{
text: "This place is great, but I wish there was internet.",
author: "Homer"
},(err, comment) => {
if(err){
console.log("Oops, something went wrong.");
console.log(err);
} else {
campground.comments.push(comment);
campground.save();
console.log("Creates new comment.")
}
}
);
}
});
});*/
}
});
}
module.exports = seedDB; | ae5d945175b92fa22320b41a39d4217ff42f5489 | [
"JavaScript"
] | 3 | JavaScript | DilanLivera/yelpcamp | 8f3c836286c8e8e7e361982b6d6898db6c6d230c | 7ff34b5fbdd7ae0211e917898cc4efd533450290 |
refs/heads/master | <file_sep>window.onload = function(){
var images = document.querySelectorAll('#slider .images img');
var i = 0;
document.getElementById('btn-prev').onclick = function(){
images[i].className = '';
i--;
if(i<0){
i = images.length - 1;
}
images[i].className = 'active';
}
document.getElementById('btn-next').onclick = function(){
images[i].className = '';
i++;
if(i>= images.length){
i = 0;
}
images[i].className = 'active';
}
}
$('#my-tabs li a').click(function (e) {
e.preventDefault();
$(this).tab('show');
})
$('#my-tabs a[href="#life"]').tab('show') // селектор по имени
$('#my-tabs a:first').tab('show') // выбор первой вкладки
$('#my-tabs a:last').tab('show') // последняя вкладка
$('#my-tabs li:eq(2) a').tab('show') // выбор вкладки по номеру | 3d390553b06d7148c2dc05a2bad82c46c6c38e32 | [
"JavaScript"
] | 1 | JavaScript | IvanPopovych/example | 0b5de71d5fdc2eb364a351820bc0332dd6d0374e | e57ec84d39d53efb0cfe19acfaa66b20f9d0272f |
refs/heads/master | <file_sep>**Vehicle Detection Project**
Here is the writeup for SDC-P5.
The goals / steps of this project are the following:
* Perform a Histogram of Oriented Gradients (HOG) feature extraction on a labeled training set of images and train a classifier Linear SVM classifier
* Apply a color transform and append binned color features, as well as histograms of color, to HOG feature vector.
* Normalize features and randomize a selection for training and testing.
* Using sliding-window technique and trained classifier to search for vehicles in images.
* Run pipeline on a video stream and create a heat map of recurring detections frame by frame to reject outliers and follow detected vehicles.
* Estimate a bounding box for vehicles detected.
[//]: # (Image References)
[image1]: ./examples/car_not_car.png
[image2]: ./examples/HOG_example.jpg
[image3]: ./output_images/sliding_windows.jpg
[image4]: ./output_images/sliding_window.jpg
[image5]: ./output_images/bboxes_and_heat.png
[image6]: ./output_images/labels_map.png
[image7]: ./output_images/output_bboxes.png
[video1]: ./project_video.mp4
## [Rubric](https://review.udacity.com/#!/rubrics/513/view) Points
### Here I will consider the rubric points individually and describe how I addressed each point in my implementation.
### Histogram of Oriented Gradients (HOG)
#### 1. Extract HOG features from the training images
The code for this step is contained in lines 45 through 57 of the file called `classification.py`).
I started by reading in all the `vehicle` and `non-vehicle` images. Here is an example of one of each of the `vehicle` and `non-vehicle` classes:
![alt text][image1]
I then explored different color spaces and different `skimage.hog()` parameters (`orientations`, `pixels_per_cell`, and `cells_per_block`). I grabbed random images from each of the two classes and displayed them to get a feel for what the `skimage.hog()` output looks like.
Here is an example using the `YCrCb` color space and HOG parameters of `orientations=8`, `pixels_per_cell=(8, 8)` and `cells_per_block=(2, 2)`:
![alt text][image2]
#### 2. Settled on final choice of HOG parameters
I tried various combinations of parameters and here was the final one that gave best performance. `color_space=YCrCb`, `orientations=9`, `cell_per_block=2`, `pixels_per_cell=(8,8)`, and use 3 channels.
#### 3. Trained a classifier using selected HOG features and color features
I trained a linear SVM using `sklearn.svm.LinearSVC` with default parameters. The train datas contains 17760 samples and the features length was 8460. The Linear svc gave accuray 98.99% on test set. I had aslo experimented the svm with rbf kernel, it take extremely long time to train and reached accuracy 99.45%. Though it had higher accuracy I didn't use it for detection because it also take extramely long time for predict.
### Sliding Window Search
The code for this step is contained in lines 76 through 105 of the file called `detection.py`.
I slided the widow on image from left to right and from up to bottom. Empircally, the step size may be 1/4 of window size thus each two adjucent windows may have 3/4 overlap area. For each patch of window, svm classication was runned on it to judge whether a car was located in it. If we had high confidence that there was a car in it which has high svm prediction score, we will mark this area with a bounding box indicate that a car located in it. After one pass through sliding window search, we end up with multiple bounding boxes, some of which may overlap. Finally, we merge the overlap bounding box into bigger one. The resulted bounding boxes were the location of cars that we want to find. That was the overall process.
To improve performance of the process, I did not slide over the entire images because the cars only appear in half bottom part of the image. Also as known that we extracted HOG features for each window, we can merge this operations into extracting the whole area of HOG features once and slide windows on HOG feature map instead of original image. Accordingly, we had to tranform the window size and step in pixel metrics into HOG features metrics.
To better detect difference sizes of cars in the images, we need to slide window on more than one scale of the images. The scale was bigger than 1. Size 1 is the original image size, the bigger scale indicate that the slide window may cover bigger area. Thus small scale is better at caputure small cars and big scale is better at caputure the big one.
I decided to search window positions at two scales(1, 1.5) all over the image and came up with this
![alt text][image3]
Ultimately I searched on two scales using YCrCb 3-channel HOG features plus spatially binned color and histograms of color in the feature vector, which provided a nice result. Here are some example images:
![alt text][image4]
---
### Video Implementation
Here's a [link to my video result](./project_video_output.mp4)
I recorded the positions of positive detections in each frame of the video. From the positive detections I created a heatmap and then thresholded that map to identify vehicle positions. I then used `scipy.ndimage.measurements.label()` to identify individual blobs in the heatmap. I then assumed each blob corresponded to a vehicle. I constructed bounding boxes to cover the area of each blob detected.
Here's an example result showing the heatmap from a series of frames of video, the result of `scipy.ndimage.measurements.label()` and the bounding boxes then overlaid on the last frame of video:
Here are six frames and their corresponding heatmaps:
![alt text][image5]
Here is the output of `scipy.ndimage.measurements.label()` on the integrated heatmap from all six frames:
![alt text][image6]
Here the resulting bounding boxes are drawn onto the last frame in the series:
![alt text][image7]
---
### Discussion
Here I'll talk about the approach I took, what techniques I used, what worked and why, where the pipeline might fail and how I might improve it if I were going to pursue this project further.
At the begining of training classifier, although I had exaughted the combination of extract feature params, the accuracy of classifier could not reach above 99%. Finally, I found that the mistake come from I set the range of the color histogram bin size to be always between 1 and 255. After removed this restriction the accuracy reached 99%.
I had spended tons of time tuning the detection parameters including `heat_threshold`, `score_threshold`, and `scale`. I found it was really hard for me to make it work well. The biggest problem was that the svm classicfication can not generalize well to video frames. Sometime it may detect so many false positive such that even though I apply the heatmap and threshold predict socre it will not work well. Increased the predict score can reduce the false positives, but the cars also got lost. Maybe I should spend more time to improve the svm classifier.
Another problem may be low performance of pipline. The pipeline need to take 1 second to process 1 image! That was not practical for realtime detection.<file_sep>import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import pickle
import glob
import cv2
from utils import *
from scipy.ndimage.measurements import label
from moviepy.editor import VideoFileClip
def add_heat(heatmap, bbox_list):
# Iterate through list of bboxes
for box in bbox_list:
# Add += 1 for all pixels inside each bbox
# Assuming each "box" takes the form ((x1, y1), (x2, y2))
heatmap[box[0][1]:box[1][1], box[0][0]:box[1][0]] += 1
# Return updated heatmap
return heatmap# Iterate through list of bboxes
def apply_threshold(heatmap, threshold):
# Zero out pixels below the threshold
heatmap[heatmap <= threshold] = 0
# Return thresholded map
return heatmap
def draw_labeled_bboxes(img, labels):
# Iterate through all detected cars
for car_number in range(1, labels[1]+1):
# Find pixels with each car_number label value
nonzero = (labels[0] == car_number).nonzero()
# Identify x and y values of those pixels
nonzeroy = np.array(nonzero[0])
nonzerox = np.array(nonzero[1])
# Define a bounding box based on min/max x and y
bbox = ((np.min(nonzerox), np.min(nonzeroy)), (np.max(nonzerox), np.max(nonzeroy)))
# Draw the box on the image
cv2.rectangle(img, bbox[0], bbox[1], (0,0,255), 6)
# Return the image
return img
# Define a single function that can extract features using hog sub-sampling and make predictions
def find_cars_bboxes(img, ystart, ystop, scale, svc, X_scaler, orient, pix_per_cell, cell_per_block, spatial_size, hist_bins):
# Scale to 0 between 1 to keep the same as training data
img = img.astype(np.float32)/255
img_tosearch = img[ystart:ystop,:,:]
ctrans_tosearch = convert_color(img_tosearch, color_space='YCrCb')
if scale != 1:
imshape = ctrans_tosearch.shape
ctrans_tosearch = cv2.resize(ctrans_tosearch, (np.int(imshape[1]/scale), np.int(imshape[0]/scale)))
ch1 = ctrans_tosearch[:,:,0]
ch2 = ctrans_tosearch[:,:,1]
ch3 = ctrans_tosearch[:,:,2]
# Define blocks and steps as above
nxblocks = (ch1.shape[1] // pix_per_cell) - cell_per_block + 1
nyblocks = (ch1.shape[0] // pix_per_cell) - cell_per_block + 1
nfeat_per_block = orient*cell_per_block**2
# 64 was the orginal sampling rate, with 8 cells and 8 pix per cell
window = 64
nblocks_per_window = (window // pix_per_cell) - cell_per_block + 1
cells_per_step = 2 # Instead of overlap, define how many cells to step
nxsteps = (nxblocks - nblocks_per_window) // cells_per_step + 1
nysteps = (nyblocks - nblocks_per_window) // cells_per_step + 1
# Compute individual channel HOG features for the entire image
hog1 = get_hog_features(ch1, orient, pix_per_cell, cell_per_block, feature_vec=False)
hog2 = get_hog_features(ch2, orient, pix_per_cell, cell_per_block, feature_vec=False)
hog3 = get_hog_features(ch3, orient, pix_per_cell, cell_per_block, feature_vec=False)
box_list = []
for xb in range(nxsteps):
for yb in range(nysteps):
ypos = yb*cells_per_step
xpos = xb*cells_per_step
# Extract HOG for this patch
hog_feat1 = hog1[ypos:ypos+nblocks_per_window, xpos:xpos+nblocks_per_window].ravel()
hog_feat2 = hog2[ypos:ypos+nblocks_per_window, xpos:xpos+nblocks_per_window].ravel()
hog_feat3 = hog3[ypos:ypos+nblocks_per_window, xpos:xpos+nblocks_per_window].ravel()
hog_features = np.hstack((hog_feat1, hog_feat2, hog_feat3))
xleft = xpos*pix_per_cell
ytop = ypos*pix_per_cell
# Extract the image patch
subimg = cv2.resize(ctrans_tosearch[ytop:ytop+window, xleft:xleft+window], (64,64))
# Get color features
spatial_features = bin_spatial(subimg, size=spatial_size)
hist_features = color_hist(subimg, nbins=hist_bins)
# Scale features and make a prediction
test_features = X_scaler.transform(np.hstack((spatial_features, hist_features, hog_features)).reshape(1, -1))
test_prediction = svc.predict(test_features)
scores = svc.decision_function(test_features)
if test_prediction == 1 and scores[0] > score_threshold :
xbox_left = np.int(xleft*scale)
ytop_draw = np.int(ytop*scale)
win_draw = np.int(window*scale)
box_list.append(((xbox_left, ytop_draw+ystart),(xbox_left+win_draw,ytop_draw+win_draw+ystart)))
return box_list
# load a pe-trained svc model from a serialized (pickle) file
dist_pickle = pickle.load(open("svc_pickle.p", "rb" ))
# get attributes of our svc object
svc = dist_pickle["svc"]
X_scaler = dist_pickle["scaler"]
orient = dist_pickle["orient"]
pix_per_cell = dist_pickle["pix_per_cell"]
cell_per_block = dist_pickle["cell_per_block"]
spatial_size = dist_pickle["spatial_size"]
hist_bins = dist_pickle["hist_bins"]
ystart = 400
ystop = 656
scales = [1, 1.5]
heat_threshold = 2
score_threshold = 1
heats = []
heat_avg_count = 20
debug = True
def get_average_heat(heat):
global heats
heats.append(np.copy(heat))
if len(heats) > heat_avg_count:
heats = heats[-heat_avg_count:]
return np.average(heats, axis=0)
def heatmap_img(heat):
return cv2.applyColorMap(heat/np.max(heat)*255, cv2.COLORMAP_JET)
def pipeline(img):
box_list = []
for scale in scales:
boxes = find_cars_bboxes(img, ystart, ystop, scale, svc, X_scaler, orient, pix_per_cell, cell_per_block, spatial_size, hist_bins)
box_list += boxes
heat = np.zeros_like(img[:,:,0]).astype(np.float)
# Add heat to each box in box list
heat = add_heat(heat,box_list)
if debug:
# Contruct Heat map for display
heatmap_img = heat/np.max(heat)*255
heatmap_img = cv2.merge((heatmap_img, heatmap_img, heatmap_img))
heatmap_img = cv2.applyColorMap(heatmap_img, cv2.COLORMAP_JET)
heatmap_shape = (int(heatmap_img.shape[0]/3), int(heatmap_img.shape[1]/3))
heatmap_img = cv2.resize(heatmap_img, (heatmap_shape[1], heatmap_shape[0]))
# Apply average smooth
heat = get_average_heat(heat)
# Apply threshold to help remove false positives
heat = apply_threshold(heat, heat_threshold)
# Visualize the heatmap when displaying
heat = np.clip(heat, 0, 255)
# Find final boxes from heatmap using label function
labels = label(heat)
label_bbx_img = draw_labeled_bboxes(img, labels)
if debug:
# Add debug image
ori_box_img = cv2.resize(draw_boxes(img, box_list), (heatmap_shape[1], heatmap_shape[0]))
label_bbx_img[0:heatmap_shape[0], heatmap_shape[1]:heatmap_shape[1]*2, :] = ori_box_img
label_bbx_img[0:heatmap_shape[0], 0:heatmap_shape[1], :] = heatmap_img
return label_bbx_img
def main():
# Process the video stream using the provided pipline
easy_output = 'project_video_output.mp4'
clip1 = VideoFileClip('project_video.mp4')
easy_clip = clip1.fl_image(pipeline)
easy_clip.write_videofile(easy_output, audio=False)
def test():
fig = plt.figure(figsize=(10,10))
images = glob.glob('test_images/*.jpg')
length = len(images)
for i, file in enumerate(images):
img = mpimg.imread(file)
box_list = []
for scale in scales:
boxes = find_cars_bboxes(img, ystart, ystop, scale, svc, X_scaler, orient, pix_per_cell, cell_per_block, spatial_size, hist_bins)
box_list += boxes
heat = np.zeros_like(img[:,:,0]).astype(np.float)
# Add heat to each box in box list
heat = add_heat(heat,box_list)
heatmap_img = heat/np.max(heat)*255
heatmap_img = cv2.merge((heatmap_img, heatmap_img, heatmap_img))
heatmap_img = cv2.applyColorMap(heatmap_img, cv2.COLORMAP_JET)
heatmap_shape = (int(heatmap_img.shape[0]/3), int(heatmap_img.shape[1]/3))
heatmap_img = cv2.resize(heatmap_img, (heatmap_shape[1], heatmap_shape[0]))
# Apply threshold to help remove false positives
heat = apply_threshold(heat, heat_threshold)
# Visualize the heatmap when displaying
heatmap = np.clip(heat, 0, 255)
# Find final boxes from heatmap using label function
labels = label(heatmap)
label_bbx_img = draw_labeled_bboxes(img, labels)
label_bbx_origin_img = draw_boxes(img,box_list)
label_bbx_img_test = np.copy(label_bbx_img)
label_bbx_img_test[0:heatmap_shape[0], 0:heatmap_shape[1], :] = heatmap_img
fig.add_subplot(length, 2, i*2+1)
plt.imshow(label_bbx_origin_img)
fig.add_subplot(length, 2, i*2+2)
plt.imshow(label_bbx_img_test)
plt.show()
if __name__ == "__main__":
main()
#1test()
<file_sep>import matplotlib.image as mpimg
import matplotlib.pyplot as plt
import numpy as np
import cv2
import glob
import time
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
from skimage.feature import hog
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn import svm
from utils import *
import pickle
# Divide up into cars and notcars
images = glob.glob('train_data/**/*.png', recursive=True)
cars = []
notcars = []
for image in images:
if 'non-vehicles' in image:
notcars.append(image)
else:
cars.append(image)
print("number of cars", len(cars))
print("number of notcars", len(notcars))
### TODO: Tweak these parameters and see how the results change.
color_space = 'YCrCb' # Can be RGB, HSV, LUV, HLS, YUV, YCrCb
orient = 9
cell_per_block = 2
pix_per_cell = 8
hog_channel = "ALL" # Can be 0, 1, 2, or "ALL"
spatial_size = (32, 32)
hist_bins = 32
spatial_feat = 1
hist_feat = 1
hog_feat = 1
t=time.time()
car_features = extract_features(cars, color_space=color_space,
spatial_size=spatial_size, hist_bins=hist_bins,
orient=orient, pix_per_cell=pix_per_cell,
cell_per_block=cell_per_block,
hog_channel=hog_channel, spatial_feat=spatial_feat,
hist_feat=hist_feat, hog_feat=hog_feat)
notcar_features = extract_features(notcars, color_space=color_space,
spatial_size=spatial_size, hist_bins=hist_bins,
orient=orient, pix_per_cell=pix_per_cell,
cell_per_block=cell_per_block,
hog_channel=hog_channel, spatial_feat=spatial_feat,
hist_feat=hist_feat, hog_feat=hog_feat)
t2 = time.time()
print(round(t2-t, 2), 'Seconds to extract HOG features...')
# Create an array stack of feature vectors
X = np.vstack((car_features, notcar_features)).astype(np.float64)
# Define the labels vector
y = np.hstack((np.ones(len(car_features)), np.zeros(len(notcar_features))))
print("shape of X", X.shape)
print("shape of y", y.shape)
# Split up data into randomized training and test sets
rand_state = np.random.randint(0, 100)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.1, random_state=rand_state)
print("shape of train data", X_train.shape)
print("shape of test data", X_train.shape)
# Fit a per-column scaler
X_scaler = StandardScaler().fit(X_train)
# Apply the scaler to X
X_train = X_scaler.transform(X_train)
X_test = X_scaler.transform(X_test)
print('Using:',orient,'orientations',pix_per_cell,
'pixels per cell and', cell_per_block,'cells per block')
# Use a linear SVC
#svc = LinearSVC(C=10)
# Check the training time for the SVC
svc = LinearSVC()
t=time.time()
svc.fit(X_train, y_train)
#parameters = {'C':[1, 10]}
#svc = GridSearchCV(svc, parameters)
#svc.fit(X_train, y_train)
t2 = time.time()
print(round(t2-t, 2), 'Seconds to train SVC...')
# Check the score of the SVC
print('Test Accuracy of SVC = ', round(svc.score(X_test, y_test), 4))
# Check the prediction time for a single sample
t=time.time()
n_predict = 10
print('My SVC predicts: ', svc.predict(X_test[0:n_predict]))
print('For these',n_predict, 'labels: ', y_test[0:n_predict])
t2 = time.time()
print(round(t2-t, 5), 'Seconds to predict', n_predict,'labels with SVC')
print(svc.decision_function(X_test[0:n_predict]))
# Save svc model and parameters
save_data = {
"svc": svc,
"scaler": X_scaler,
"orient": orient,
"pix_per_cell": pix_per_cell,
"cell_per_block": cell_per_block,
"spatial_size": spatial_size,
"hist_bins": hist_bins,
}
pickle.dump(save_data, open("svc_pickle.p", "wb"))
| 52dd7ce95998492facdb3950a10ad55c06254498 | [
"Markdown",
"Python"
] | 3 | Markdown | dgdn/carnd-vehicle-detection | 780b067c06af0942ad8fa6dd6fbec8d0b344f4ce | 74676af5922b501d3723431649da634bc2cb54d9 |
refs/heads/master | <file_sep>import React, { Component } from 'react';
import {
Platform,
StyleSheet,
Text,
View
} from 'react-native';
import LanguageSelect from './app/components/LanguageSelect/LanguageSelect';
import TranslateOutput from './app/components/TranslateOutput/TranslateOutput';
import TranslateInput from './app/components/TranslateInput/TranslateInput';
export default class App extends Component<{}> {
constructor(){
super();
this.state = {
TranslateText: '',
language: 'ru' //default language must be set according to yandex api
}
}
selectLanguage(lang) {
this.setState({language: lang}, () => {
console.log(lang);
});
}
translateText(text) {
//query the api to translate word
fetch('https://translate.yandex.net/api/v1.5/tr.json/translate?key=<KEY>&lang='+this.state.language+'&text='+text).then((response) => {
let res = JSON.parse(response._bodyText);
this.setState({translatedText: res.text[0]});
});
}
render() {
return (
<View style={styles.container}>
<LanguageSelect language={this.state.language} onSelect={this.selectLanguage.bind(this)}/>
<TranslateInput onSubmit={this.translateText.bind(this)} />
<TranslateOutput translation={this.state.translatedText} />
</View>
);
}
}
const styles = StyleSheet.create({
});
<file_sep><h1>weTranslate</h1>
<p>This application lets the user translate words entered in English to other languages</p>
<h2>Technologies Used: </h2>
<ul>
<li>React Native</li>
<li>Yandex API</li>
</ul>
<file_sep>import { AppRegistry } from 'react-native';
import App from './App';
import LanguageSelect from './app/components/LanguageSelect/LanguageSelect';
import TranslateOutput from './app/components/TranslateOutput/TranslateOutput';
import TranslateInput from './app/components/TranslateInput/TranslateInput';
AppRegistry.registerComponent('LanguageSelect', () => LanguageSelect);
AppRegistry.registerComponent('TranslateOutput', () => TranslateOutput);
AppRegistry.registerComponent('TranslateInput', () => TranslateInput);
AppRegistry.registerComponent('weTranslate', () => App);
<file_sep>rootProject.name = 'weTranslate'
include ':app'
<file_sep>import React, { Component } from 'react';
import {
Platform,
StyleSheet,
Text,
View,
TextInput,
TouchableHighlight
} from 'react-native';
export default class TranslateInput extends Component<{}> {
constructor(){
super();
this.state = {
translateString: ''
}
}
render() {
return (
<View style={styles.container}>
<Text style={styles.description}>
Translate A Word
</Text>
<View style={styles.row}>
<TextInput
underlineColorAndroid='transparent'
style = {styles.translateInput}
onChangeText = {(value) => this.setState({translateString: value})}
placeholder="Enter a word..."
/>
<TouchableHighlight
style={styles.button}
onPress={() => {this.props.onSubmit(this.state.translateString)}}
underlaycolor='#99d9f4'
>
<Text style={styles.buttonText}> Go</Text>
</TouchableHighlight>
</View>
</View>
);
}
}
const styles = StyleSheet.create({
description: {
marginBottom: 20,
fontSize: 18,
textAlign: 'center',
color: '#656865'
},
container: {
padding: 30,
marginTop: 65,
alignItems: 'center'
},
row: {
flexDirection: 'row',
alignItems: 'center',
alignSelf: 'stretch'
},
button: {
height: 36,
flex: 1,
flexDirection: 'row',
backgroundColor: '#48bbec',
borderColor: '#48bbec',
borderWidth: 1,
borderRadius: 8,
alignSelf: 'stretch',
justifyContent: 'center'
},
buttonText: {
fontSize: 18,
color: 'white',
alignSelf: 'center'
},
translateInput: {
height: 36,
padding: 4,
marginRight: 5,
flex: 4,
fontSize: 18,
borderColor: '#48bbec',
borderRadius: 8,
color: '#48bbec',
borderWidth: 1
}
});
| 70b2dcaa4e3ba92bd15efd4d1ed12f5b8cbd598c | [
"JavaScript",
"Markdown",
"Gradle"
] | 5 | JavaScript | AnandSundar/ReactNative-weTranslate | 56b7434904bc593c11f88d5fdeaebdb535fb8946 | eb925947650cf68da2e56c16231b1a0d43ed7ad3 |
refs/heads/main | <file_sep>import sys
import boto3
from botocore.exceptions import ClientError
import time
client_LB_NV = boto3.client('elb', region_name='us-east-1')
def delete_load_balancer(client, nome):
client.delete_load_balancer(LoadBalancerName=nome)
time.sleep(15)
print("Load balancer terminado")
def create_load_balancer(client, nome, security_id):
res = client.create_load_balancer(
LoadBalancerName=nome,
Listeners=[
{
'Protocol': 'HTTP',
'LoadBalancerPort': 80,
'InstancePort': 8080
}
],
AvailabilityZones=[
'us-east-1a',
'us-east-1b',
'us-east-1c',
'us-east-1d',
'us-east-1e',
'us-east-1f',
],
SecurityGroups=[security_id],
Tags=[
{'Key': 'Name', 'Value': 'LoadBOrm'},
]
)
print("LoadBalancer Criado")
with open("loadBalancer_DNS.txt", "w") as file:
file.write(res['DNSName'])
<file_sep>import sys
import boto3
from botocore.exceptions import ClientError
client_Inst_NV = boto3.client('ec2', region_name='us-east-1')
def delete_security_group(client, sGroupName):
response = client.describe_security_groups()
for group in response['SecurityGroups']:
if group['GroupName'] == sGroupName:
client.delete_security_group(GroupName=sGroupName)
def create_security_group(client, sGroupName):
response = client.describe_vpcs()
vpc_id = response.get('Vpcs', [{}])[0].get('VpcId', '')
try:
response = client.create_security_group(GroupName=sGroupName,
Description='Security Group',
VpcId=vpc_id)
security_group_id = response['GroupId']
print('Security Group Created %s in vpc %s.' %
(security_group_id, vpc_id))
data = client.authorize_security_group_ingress(
GroupId=security_group_id,
IpPermissions=[
{'IpProtocol': 'tcp',
'FromPort': 80,
'ToPort': 80,
'IpRanges': [{'CidrIp': '0.0.0.0/0'}]},
{'IpProtocol': 'tcp',
'FromPort': 22,
'ToPort': 22,
'IpRanges': [{'CidrIp': '0.0.0.0/0'}]},
{'IpProtocol': 'tcp',
'FromPort': 8080,
'ToPort': 8080,
'IpRanges': [{'CidrIp': '0.0.0.0/0'}]},
{'IpProtocol': 'tcp',
'FromPort': 5432,
'ToPort': 5432,
'IpRanges': [{'CidrIp': '0.0.0.0/0'}]}
])
return security_group_id
except ClientError as e:
print(e)
<file_sep>import sys
import boto3
from botocore.exceptions import ClientError
from create_security_group import *
client_Inst_NV = boto3.client('ec2', region_name='us-east-1')
resource_NV = boto3.resource('ec2', region_name='us-east-1')
client_Inst_Oh = boto3.client('ec2', region_name='us-east-2')
resource_Oh = boto3.resource('ec2', region_name='us-east-2')
waiterInicialize_NV = client_Inst_NV.get_waiter('instance_status_ok')
waiterInicialize_Oh = client_Inst_Oh.get_waiter('instance_status_ok')
def get_ip(client, nome):
ip = client.describe_instances(
Filters=[
{
'Name': 'tag:Name',
'Values': [nome]
},
{
'Name': 'instance-state-name',
'Values': ['running']
}
])
inst_ip = ip['Reservations'][0]['Instances'][0]['PublicIpAddress']
return(inst_ip)
# Deleta uma instancia caso exista
def get_instance_id(client, nome):
instance_id = client.describe_instances(
Filters=[
{
'Name': 'tag:Name',
'Values': [nome]
},
{
'Name': 'instance-state-name',
'Values': ['running']
}
])
inst_id = instance_id['Reservations'][0]['Instances'][0]['InstanceId']
return(inst_id)
def delete_instances(client, nome):
instance_id = client.describe_instances(
Filters=[
{
'Name': 'tag:Name',
'Values': [nome]
}
]
)
ids = []
for reservation in (instance_id["Reservations"]):
for instance in reservation["Instances"]:
ids.append(instance["InstanceId"])
try:
client.terminate_instances(InstanceIds=ids)
client.get_waiter('instance_terminated').wait(InstanceIds=ids)
print('Instancia:', nome, ' terminada')
except ClientError as e:
print(e)
# Cria a instancia de Ohio
def create_instance_Oh(security_id):
userData_Oh = """#!/bin/sh
cd home/ubuntu
sudo apt update
git clone https://github.com/JoaoVictorRodrigues/Projeto_Cloud.git
cd Projeto_Cloud
chmod +x config_db.sh
./config_db.sh
"""
# create a new EC2 instance
try:
instance = resource_Oh.create_instances(
ImageId='ami-0dd9f0e7df0f0a138',
MinCount=1,
MaxCount=1,
InstanceType='t2.micro',
SecurityGroupIds=[security_id],
KeyName='Pub_JoaoR_2',
TagSpecifications=[
{
'ResourceType': 'instance',
'Tags': [
{
'Key': 'Name',
'Value': 'Ohio_DB',
},
],
},
],
UserData=userData_Oh
)
client_Inst_Oh.get_waiter('instance_status_ok').wait(
InstanceIds=[instance[0].id])
print("Ohio_DB criado e rodando")
except ClientError as e:
print(e)
# Cria a instancia de North Virginia
def create_instance_NV(security_id, inst_ip):
userData_Nv = """#!/bin/sh
cd home/ubuntu
sudo apt update
git clone https://github.com/JoaoVictorRodrigues/tasks.git
sudo sed -i 's/node1/{0}/' /home/ubuntu/tasks/portfolio/settings.py
cd tasks
./install.sh
cd ..
sudo reboot
""".format(inst_ip)
try:
instance = resource_NV.create_instances(
ImageId='ami-0885b1f6bd170450c',
MinCount=1,
MaxCount=1,
InstanceType='t2.micro',
SecurityGroupIds=[security_id],
KeyName='Pub-JoaoR',
TagSpecifications=[
{
'ResourceType': 'instance',
'Tags': [
{
'Key': 'Name',
'Value': 'NorthV_ORM',
},
],
},
],
UserData=userData_Nv
)
client_Inst_NV.get_waiter('instance_status_ok').wait(
InstanceIds=[instance[0].id])
print("NorthV_ORM criado e rodando")
except ClientError as e:
print(e)
def delete_image(nome):
try:
image_id = client_Inst_NV.describe_images(
Filters=[
{
'Name': 'name',
'Values': [nome]
}
]
)
if len(image_id['Images']) > 0:
inst_id = image_id['Images'][0]['ImageId']
client_Inst_NV.deregister_image(ImageId=inst_id)
except ClientError as e:
print(e)
def create_AMI_ORM(instance_id, nome):
ami = client_Inst_NV.create_image(
InstanceId=instance_id, NoReboot=True, Name=nome)
client_Inst_NV.get_waiter('image_available').wait(
ImageIds=[ami["ImageId"]])
print("Imagem criada")
return ami['ImageId']
<file_sep># Projeto_Cloud
Configure suas credenciais através do AWS configure
```
aws configure
```
Após a configuração rode o script projeto.py
```
python3 projeto.py
```
Espere o processo terminar, logo após é possivel testar a conexão e fazer requisições através do arquivo run.py
Abaixo estão os comandos a serem utilizados
- get: Mostra todas as notas
- add: Adiciona uma nova nota com um titulo e uma descrição
- delete: Deleta todas as notas
```
python3 run.py get
python3 run.py add titulo descricao
python3 run.py delete
```
<file_sep>import sys
import boto3
from botocore.exceptions import ClientError
from create_security_group import *
from create_load_balancer import *
from create_auto_caling import *
from create_instance import *
import time
#Deleta antes de criar para não haver conflito
delete_auto_scaling(client_AS_NV,'AutoScaling')
delete_AS_launch(client_AS_NV,'LaunchAS')
delete_instances(client_Inst_Oh, 'Ohio_DB')
delete_instances(client_Inst_NV, 'NorthV_ORM')
delete_load_balancer(client_LB_NV,'LoadBalancer')
time.sleep(60)
delete_security_group(client_Inst_Oh, "SgOhio")
delete_security_group(client_Inst_NV, "SgNorth")
#Criação
Ohio = create_security_group(client_Inst_Oh, "SgOhio")
North = create_security_group(client_Inst_NV, "SgNorth")
create_instance_Oh(Ohio)
inst_ip = get_ip(client_Inst_Oh,'Ohio_DB')
create_instance_NV(North,inst_ip)
inst_id = get_instance_id(client_Inst_NV,'NorthV_ORM')
delete_image('ORM')
ami = create_AMI_ORM(inst_id,'ORM')
delete_instances(client_Inst_NV, 'NorthV_ORM')
create_load_balancer(client_LB_NV,'LoadBalancer',North)
create_AS_launch(client_AS_NV,'LaunchAS',ami,North)
create_auto_scalling(client_AS_NV, 'AutoScaling','LaunchAS')<file_sep>import sys
import boto3
from botocore.exceptions import ClientError
import time
client_AS_NV = boto3.client('autoscaling')
def delete_AS_launch(client, nome):
launch_name = client.describe_launch_configurations(
LaunchConfigurationNames=[nome])
try:
if len(launch_name['LaunchConfigurations']):
client.delete_launch_configuration(LaunchConfigurationName=nome)
#client.get_waiter('launch_deleted').wait(LaunchConfigurationName=nome)
print("Launch terminado")
except ClientError as e:
print(e)
def create_AS_launch(client, nome, image, security_id):
client.create_launch_configuration(
LaunchConfigurationName=nome,
ImageId=image,
KeyName='Pub-JoaoR',
SecurityGroups=[security_id],
InstanceType='t2.micro'
)
print("Launch Criado")
def delete_auto_scaling(client, nome):
as_name = client.describe_auto_scaling_groups(AutoScalingGroupNames=[nome])
for name in as_name["AutoScalingGroups"]:
if name['AutoScalingGroupName'] == nome:
client.delete_auto_scaling_group(
AutoScalingGroupName=nome, ForceDelete=True)
def create_auto_scalling(client, nome, launch_name):
client.create_auto_scaling_group(
AutoScalingGroupName=nome,
LaunchConfigurationName=launch_name,
MinSize=2,
MaxSize=5,
DesiredCapacity=2,
AvailabilityZones=[
'us-east-1a',
'us-east-1b',
'us-east-1c',
'us-east-1d',
'us-east-1e',
'us-east-1f',
],
LoadBalancerNames=['LoadBalancer'],
CapacityRebalance=True
)
print("Auto Scaling Criado")
| ca0e03659a2d31c88499f81e6af307359be0ad58 | [
"Markdown",
"Python"
] | 6 | Python | JoaoVictorRodrigues/Projeto_Cloud | 60af3dba986088d922e2c5f681439dbeea89127e | e1f9f7234b469642cfa28b2ffc4491742fe82f7f |
refs/heads/master | <file_sep>using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Runtime.Api;
using Microsoft.ML.Runtime.Data;
namespace BeerML.MultiClassClassification
{
public class DrinkData
{
[Column(ordinal: "0")]
public string FullName;
[Column(ordinal: "1")]
public string Type;
[Column(ordinal: "2")]
public string Country;
}
public class DrinkPrediction
{
[ColumnName("PredictedLabel")]
public string Type;
[ColumnName("Score")]
public float[] Scores;
}
public class MultiClassClassificationDemo
{
public static void Run()
{
// Define context
var mlContext = new MLContext(seed: 0);
// Define data file format
TextLoader textLoader = mlContext.Data.TextReader(new TextLoader.Arguments()
{
Separator = ",",
HasHeader = true,
Column = new[]
{
new TextLoader.Column("FullName", DataKind.Text, 0),
new TextLoader.Column("Type", DataKind.Text, 1),
new TextLoader.Column("Country", DataKind.Text, 2)
}
});
// Load training data
var trainingDataView = textLoader.Read("2_MultiClassClassification/problem2_train.csv");
// Define features
var dataProcessPipeline =
mlContext.Transforms.Conversion.MapValueToKey("Type", "Label")
.Append(mlContext.Transforms.Text.FeaturizeText("FullName", "FullNameFeaturized"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Country", "CountryEncoded"))
.Append(mlContext.Transforms.Concatenate("Features", "FullNameFeaturized", "CountryEncoded"));
// Use Multiclass classification
var trainer = mlContext.MulticlassClassification.Trainers.StochasticDualCoordinateAscent(DefaultColumnNames.Label, DefaultColumnNames.Features);
var trainingPipeline = dataProcessPipeline
.Append(trainer)
.Append(mlContext.Transforms.Conversion.MapKeyToValue("PredictedLabel"));
// Train the model based on training data
var watch = Stopwatch.StartNew();
var trainedModel = trainingPipeline.Fit(trainingDataView);
watch.Stop();
Console.WriteLine($"Trained the model in: {watch.ElapsedMilliseconds / 1000} seconds.");
// Use model for predictions
IEnumerable<DrinkData> drinks = new[]
{
new DrinkData { FullName = "<NAME>" },
new DrinkData { FullName = "<NAME>"},
new DrinkData { FullName = "<NAME>"},
new DrinkData { FullName = "<NAME>"},
new DrinkData { FullName = "Château de Lavison"},
new DrinkData { FullName = "<NAME>"},
new DrinkData { FullName = "Glengoyne 25 Years"},
new DrinkData { FullName = "Oremus Late Harvest Tokaji Cuvée"},
new DrinkData { FullName = "<NAME>"},
new DrinkData { FullName = "<NAME>secco Extra Dry"}
};
var predFunction = trainedModel.MakePredictionFunction<DrinkData, DrinkPrediction>(mlContext);
foreach (var drink in drinks)
{
var prediction = predFunction.Predict(drink);
Console.WriteLine($"{drink.FullName} is {prediction.Type}");
}
// Evaluate the model
var testDataView = textLoader.Read("2_MultiClassClassification/problem2_validate.csv");
var predictions = trainedModel.Transform(testDataView);
var metrics = mlContext.MulticlassClassification.Evaluate(predictions);
Console.WriteLine($"Accuracy: {metrics.AccuracyMicro:P2}");
}
}
}
<file_sep># beer-ml
ML.NET playground
This demo project uses Systembolaget database to perform 4 types of Machine Learning using ML.NET framework:
- Binary Classification
- Multi-Class Classification
- Regression
- Clustering
<file_sep>using Microsoft.ML;
using Microsoft.ML.Runtime.Api;
using Microsoft.ML.Runtime.Data;
using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.IO;
using System.Linq;
namespace BeerML.Regression
{
public class PriceData
{
[Column(ordinal: "3")]
public int Year;
[Column(ordinal: "4")]
public int Month;
[Column(ordinal: "5")]
public int Day;
[Column(ordinal: "7")]
public float Consumption;
[Column(ordinal: "6")]
public int Weekday;
[Column(ordinal: "8")]
public float Temperature;
}
public class PricePrediction
{
[ColumnName("Score")]
public float Consumption;
}
public class RegressionDemo
{
public static void Run()
{
// Define context
var mlContext = new MLContext(seed: 0);
// Define data file format
TextLoader textLoader = mlContext.Data.TextReader(new TextLoader.Arguments()
{
Separator = ",",
HasHeader = true,
Column = new[]
{
new TextLoader.Column("Year", DataKind.I4, 3),
new TextLoader.Column("Month", DataKind.I4, 4),
new TextLoader.Column("Day", DataKind.I4, 5),
new TextLoader.Column("Consumption", DataKind.R4, 7),
new TextLoader.Column("Weekday", DataKind.I4, 6),
new TextLoader.Column("Temperature", DataKind.R4, 8)
}
});
// Load training data
var trainingDataView = textLoader.Read("3_Regression/consumption_training.csv");
var dataProcessPipeline = mlContext.Transforms.CopyColumns("Consumption", "Label")
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Year", "YearEncoded"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Month", "MonthEncoded"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Day", "DayEncoded"))
.Append(mlContext.Transforms.Categorical.OneHotEncoding("Temperature", "TemperatureEncoded"))
.Append(mlContext.Transforms.Concatenate("Features", "YearEncoded", "MonthEncoded", "DayEncoded", "TemperatureEncoded")); // "CompaniesEncoded", "InstallationsEncoded"));
// Use Poisson Regressionn
var trainer = mlContext.Regression.Trainers.PoissonRegression(labelColumn: "Label", featureColumn: "Features");
var trainingPipeline = dataProcessPipeline.Append(trainer);
// Train the model based on training data
var watch = Stopwatch.StartNew();
var trainedModel = trainingPipeline.Fit(trainingDataView);
watch.Stop();
Console.WriteLine($"Trained the model in: {watch.ElapsedMilliseconds / 1000} seconds.");
var predFunction = trainedModel.MakePredictionFunction<PriceData, PricePrediction>(mlContext);
//read evaluation data from csv - consumption_result.csv
var file = System.IO.File.ReadAllLines("3_Regression/consumption_result.csv");
List<PriceData> prices = new List<PriceData>();
var query = from line in file
let data = line.Split(',')
orderby data[0], data[1]
select new
{
Mother = data[0],
Daughter = data[1],
PodId = data[2],
Year = data[3],
Month = data[4],
Day = data[5],
Weekday = data[6],
Consumption = data[7],
Temperature = data[8]
};
var dataOnly = query.Skip(1);
foreach (var s in dataOnly)
{
var price = new PriceData()
{
Year = Int32.Parse(s.Year),
Month = Int32.Parse(s.Month),
Day = Int32.Parse(s.Day),
Weekday = Int32.Parse(s.Weekday),
Temperature = float.Parse(s.Temperature)
};
prices.Add(price);
}
using (var w = new StreamWriter("3_Regression/forecast.csv"))
{
foreach (var p in prices)
{
var prediction = predFunction.Predict(p);
Console.WriteLine($"{p.Year}-{p.Month}-{p.Day} is {prediction.Consumption}");
var line = string.Format("{0},{1},{2},{3},{4}", p.Year, p.Month, p.Day, p.Weekday, prediction.Consumption);
w.WriteLine(line);
}
w.Flush();
}
}
}
}
<file_sep>using System;
using System.Collections.Generic;
using System.Diagnostics;
using System.Linq;
using Microsoft.ML;
using Microsoft.ML.Runtime.Api;
using Microsoft.ML.Runtime.Data;
namespace BeerML.BinaryClassification
{
public class BeerOrWineData
{
[Column(ordinal: "0")]
public string FullName;
[Column(ordinal: "1")]
public bool Beer;
}
public class BeerOrWinePrediction
{
[ColumnName("PredictedLabel")]
public bool Beer;
public float Probability { get; set; }
public float Score { get; set; }
}
public class BinaryClassificationDemo
{
public static void Run()
{
// Define context
var mlContext = new MLContext(seed: 0);
// Define data file format
TextLoader textLoader = mlContext.Data.TextReader(new TextLoader.Arguments()
{
Separator = ",",
HasHeader = true,
Column = new[]
{
new TextLoader.Column("FullName", DataKind.Text, 0),
new TextLoader.Column("Beer", DataKind.Bool, 1)
}
});
// Load training data
var trainingDataView = textLoader.Read("1_BinaryClassification/problem1_train.csv");
// Define features
var dataProcessPipeline = mlContext.Transforms.Text.FeaturizeText("FullName", "Features");
// Use Binary classification
var trainer = mlContext.BinaryClassification.Trainers.StochasticDualCoordinateAscent(labelColumn: "Beer", featureColumn: "Features");
var trainingPipeline = dataProcessPipeline.Append(trainer);
// Train the model based on training data
var watch = Stopwatch.StartNew();
var trainedModel = trainingPipeline.Fit(trainingDataView);
watch.Stop();
Console.WriteLine($"Trained the model in: {watch.ElapsedMilliseconds / 1000} seconds.");
// Use model for predictions
List<BeerOrWineData> drinks = new List<BeerOrWineData>
{
new BeerOrWineData { FullName = "<NAME>" },
new BeerOrWineData { FullName = "<NAME>"},
new BeerOrWineData { FullName = "<NAME>"},
new BeerOrWineData { FullName = "<NAME>"},
new BeerOrWineData { FullName = "<NAME>"},
new BeerOrWineData { FullName = "<NAME>"}
};
var predFunction = trainedModel.MakePredictionFunction<BeerOrWineData, BeerOrWinePrediction>(mlContext);
foreach (var drink in drinks)
{
var prediction = predFunction.Predict(drink);
Console.WriteLine($"{drink.FullName} is {prediction.Beer}");
}
// Evaluate the model
var testDataView = textLoader.Read("1_BinaryClassification/problem1_validate.csv");
var predictions = trainedModel.Transform(testDataView);
var metrics = mlContext.BinaryClassification.Evaluate(predictions, "Beer", "Score");
Console.WriteLine($"Accuracy: {metrics.Accuracy:P2}");
// Cross validation
var fullDataView = textLoader.Read("1_BinaryClassification/problem1.csv");
var cvResults = mlContext.BinaryClassification.CrossValidate(fullDataView, trainingPipeline, numFolds: 5, labelColumn: "Beer");
Console.WriteLine($"Avg Accuracy is: {cvResults.Select(r => r.metrics.Accuracy).Average():P2}");
}
}
}
| c2e5e29f6e85aeed311bcebbfef5a7558c65fa45 | [
"Markdown",
"C#"
] | 4 | C# | sanjaybhagia/ml-test | dae08d5ddfafa4865b21b0acbd69ebe51573151e | 4f09298ed26d1bd25328e375a200f64312c3fa6e |
refs/heads/master | <repo_name>fenixPrague/fenixPrague.github.io<file_sep>/README.md
# fenixPrague.github.io<file_sep>/scripts/map.js
function initMap() {
var element = document.getElementById('map');
var location = {lat: 50.082178, lng: 14.425751};
var options = {
zoom: 15,
center: location,
gestureHandling: 'greedy'
}
var map = new google.maps.Map(element, options);
var marker = new google.maps.Marker({
position: location,
map: map
});
var content = "<h3><p>Vodičkova 791/41</p><p>Praha-Nové Město 110 00</p><p>Czech Republic</p></h3>";
var infoWindow = new google.maps.InfoWindow({
content: content
});
marker.addListener('click', function() {
infoWindow.open(map, marker);
map.setZoom(17);
map.setCenter(marker.getPosition());
});
}
initMap(); | 3045f9e55abf3f7e1082926fb871dff739e480f4 | [
"Markdown",
"JavaScript"
] | 2 | Markdown | fenixPrague/fenixPrague.github.io | 310e116b47d279e3b50ab4c8492327726b01ec40 | 40ce335216748327d3f2f21a1a8cf7f2ce58eb8e |
refs/heads/master | <repo_name>larserikfinholt/tavlaapp<file_sep>/www/js/settings-user.controller.js
angular.module('tavla')
.controller('UserSettingsController', function ($stateParams, TavlaService, CalendarService, $state, user) {
console.log("UserSettingsController", $stateParams);
var vm = this;
var isEditMode = !!user;
vm.calendars = CalendarService.calendars;
vm.save = function () {
TavlaService.addOrUpdateUser(vm.user).then(function (d) {
TavlaService.login().then(function (d) {
//$state.transitionTo("app.settings", $stateParams, {
// reload: true,
// inherit: false,
// notify: true
//});
$state.go("app.settings", { 'status': 'San Diego' }, { reload: true });
});
});
}
function init() {
if (isEditMode) {
vm.user = user;
vm.title = "Edit user";
} else {
vm.title = "Add new user";
vm.user = {};
}
}
init();
});<file_sep>/www/templates/settings-user.html
<ion-view view-title="Settings">
<div class="bar bar-header bar-light">
<h1 class="title">{{vm.title}}</h1>
</div>
<ion-content>
<div class="list list-inset">
<label class="item item-input item-stacked-label">
<span class="input-label">First Name</span>
<input type="text" placeholder="Enter name" ng-model="vm.user.name">
</label>
<label class="item item-select item-stacked-label">
<span class="input-label">Calendar</span>
<select ng-model="vm.user.calendars" ng-options="c.name as c.name for c in vm.calendars"></select>
</label>
<div class="item">
{{vm.user.userId?'Has added Facebook or google login':'Not connected with Tavla'}}
</div>
<div class="item item-checkbox">
<label class="checkbox">
<input type="checkbox" ng-model="vm.user.isAdmin">
</label>
Is administrator
</div>
<div class="item ">
<button class="button button-assertive" ng-click="vm.save()">
Save
</button>
</div>
</div>
<pre>{{vm|json}}</pre>
</ion-content>
</ion-view><file_sep>/www/js/register.controller.js
angular.module('tavla')
.controller('RegisterController', function ($state, TavlaService, CalendarService, mode) {
var vm = this;
vm.mode = mode;
vm.toCreate = {
action: 'RegisterNewFamily',
users: [
{
userName:'name1',
calendar: ''
}
]
};
vm.calendars = [];
vm.setMode = function (m) {
if (m === 'register') {
console.log("Go state: newfamily", $state);
$state.go('newfamily');
} else {
console.log("Go state: join", $state);
$state.go('join');
}
};
vm.register = function () {
console.log("Register...", vm.toCreate);
TavlaService.register(vm.toCreate).then(function(d) {
$state.go('app.home');
});
};
vm.addUser=function() {
vm.toCreate.users.push({ userName: null, calendar: null });
};
vm.removeUser=function(user) {
var indx = vm.toCreate.users.indexOf(user);
vm.toCreate.users.splice(indx, 1);
}
vm.restart = function () {
console.log("restrting and logging out...");
TavlaService.logout().then(function (x) {
$state.go('login');
console.log("Reloading....");
window.cookies.clear(function () {
console.log('Cookies cleared!');
});
window.location.reload();
});
};
vm.init=function() {
CalendarService.getAllCalendars().then(function (c)
{
vm.calendars = c.map(function (d) { return d.name; });
});
}
vm.init();
});<file_sep>/www/js/settings-main.controller.ts
/// <reference path="../../typings/tsd.d.ts"/>
interface Window { cookies: any; }
module tavla {
export class SettingsMainController {
public static $inject=['$state', 'TavlaService'];
constructor(private $state:any, private tavlaService:any){
}
usersClick(){
this.$state.go('app.settings-main-users');
}
tasksClick(){
this.$state.go('app.settings-main-tasks');
}
logout(){
this.tavlaService.logout().then(x=>{
this.$state.go('login');
console.log("Reloading....");
window.cookies.clear(function() {
console.log('Cookies cleared!');
});
window.location.reload();
})
}
}
}
angular.module('tavla').controller('SettingsMainController',tavla.SettingsMainController);<file_sep>/www/js/regular.controller.js
angular.module('tavla')
.controller('RegularController', function ($state, $scope, $ionicModal, settings, TavlaService) {
var vm = this;
vm.tavlaService = TavlaService;
vm.weekdays = moment.weekdays();
vm.edit = function (user) {
console.log("State", $state);
//$state.go("app.settingsuser", { user: user });
}
vm.init = function () {
console.log("Starting regularcontroller", settings);
if (TavlaService.tavlaSetting.regularEvents.data && TavlaService.tavlaSetting.regularEvents.data.length == 7) {
console.log("got regular data before");
}
else {
var arr = [];
for (var i = 0; i < 7; i++) {
arr.push({ dayNo: i, events: [] });
}
TavlaService.tavlaSetting.regularEvents.data = arr;
}
}
vm.init();
vm.edit=function(event) {
vm.currentEvent = event;
$scope.modal.show();
vm.currentDay = null;
}
vm.add=function(day) {
vm.currentDay = day;
vm.currentEvent = {
user: null,
title: null,
hour: 12,
minutes: 0
};
$scope.modal.show();
}
vm.save=function() {
if (vm.currentDay) {
// Is a new event
console.log("Added event");
TavlaService.tavlaSetting.regularEvents.data[vm.currentDay.dayNo].events.push(vm.currentEvent);
}
TavlaService.saveSettingWithName('regularEvents').then(function(r) {
console.log("Saved", r);
$scope.modal.hide();
});
}
$ionicModal.fromTemplateUrl('templates/popup-regular.html', {
scope: $scope
}).then(function (modal) {
$scope.modal = modal;
});
});<file_sep>/typings/tsd.d.ts
/// <reference path="lodash/lodash.d.ts" />
/// <reference path="angularjs/angular.d.ts" />
/// <reference path="moment/moment.d.ts" />
/// <reference path="ionic/ionic.d.ts" />
/// <reference path="angular-ui-router/angular-ui-router.d.ts" />
<file_sep>/www/js/tavla.service.js
/* global WindowsAzure */
/// <reference path="../../typings/tsd.d.ts"/>
angular.module('tavla')
.factory('TavlaService', function ($q, $http, Mocks, $ionicPlatform) {
var root = 'https://tavlaapi.azure-mobile.net/';
var client = WindowsAzure.MobileServiceClient(root, 'jFWBtWeZsRaerKJzkCVCzkwgmdKBhI46');
if (window.tinyHippos != undefined || !window.cordova) {
root = "http://localhost:17588";
console.log("Using localhost");
client = new WindowsAzure.MobileServiceClient(root, 'jFWBtWeZsRaerKJzkCVCzkwgmdKBhI46');
}
var service = {
updates: 0,
isSettingsLoaded: false,
saved: null,
doneIts: null,
tavlaSetting: {},
shoppingList: null,
weather: [],
errors: [],
authenticate: function (provider) {
var dfd = $q.defer();
if (window.tinyHippos != undefined ) {
dfd.resolve('ripple');
} else {
console.log("DEVICE------");
$ionicPlatform.ready(function () {
client = new WindowsAzure.MobileServiceClient(root, 'jFWBtWeZsRaerKJzkCVCzkwgmdKBhI46');
if (ionic.Platform.isWebView()) {
console.log("Prevent sleep - starting insomnia...");
window.plugins.insomnia.keepAwake();
}
console.log("Calling authenticate with google...");
client.login(provider).done(function (d) {
console.log("Login success", provider, d);
dfd.resolve({ isLoggedIn: true, user: d.userId });
}, function (e) {
console.warn("Noe gikk feil i google pålogging", e);
dfd.resolve({ isLoggedIn: false, error: e });
});
});
}
return dfd.promise;
},
login: function () {
var self = this;
var dfd = $q.defer();
console.log("Calling start...");
client.invokeApi('start', {
body: null,
method: "get",
headers: {
'Content-Type': 'application/json'
}
}).done(function (d) {
self.updates++;
console.info("Completed Start call - main setting loaded", d.result, self.updates);
self.isSettingsLoaded = true;
self.saved = d.result;
dfd.resolve(d);
}, function (e) {
console.warn("Noe gikk feil i pålogging", e);
dfd.resolve({ isLoggedIn: false, error: e });
});
return dfd.promise;
},
loadDoneItSummary:function(){
var self = this;
var dfd = $q.defer();
console.log("Loading doneit summary...");
client.invokeApi('summary', {
body: null,
method: "get",
headers: {
'Content-Type': 'application/json'
}
}).done(function (d) {
console.info("Loaded doneit summary", d.result);
self.summary = d.result;
dfd.resolve(d);
}, function (e) {
console.warn("Noe gikk feil i lasting av summary", e);
dfd.resolve({ isLoggedIn: false, error: e });
});
return dfd.promise;
},
register: function (model) {
var self = this;
var dfd = $q.defer();
console.log("Calling register...");
client.invokeApi('start', {
body: model,
method: "post"
}).done(function (d) {
console.log("Ferdig registrert på!");
console.log("Logged in", d.result);
self.isSettingsLoaded = true;
self.saved = d.result;
dfd.resolve({ saved: true, result: d.result });
}, function (d) {
console.warn("Fikk ikke registrert", d);
dfd.resolve({ error: d });
});
return dfd.promise;
},
test: function () {
console.log("Calling from TavlaService");
var dfd = $q.defer();
var todoItemTable = client.getTable('todoitem');
todoItemTable.read().done(function (d) {
dfd.resolve(d);
}, function (e) {
console.log("Error getting items", e);
dfd.resolve({ error: e });
});
return dfd.promise;
},
logout: function () {
console.log("LOGOUT!!!!!!!!!!!!!!!!!!!!!!!!!!!!!");
window.localStorage['hasLoggedInBefore'] = 'no';
var dfd = $q.defer();
client.logout();
dfd.resolve({ isLoggedIn: false, logout: new Date() });
return dfd.promise;
},
getSettings: function () {
var self = this;
var dfd = $q.defer();
if (self.isSettingsLoaded) {
dfd.resolve(self.saved);
} else {
console.log('calling getSettings...');
self.saved = Mocks.settings;
self.isSettingsLoaded = true;
dfd.resolve(self.saved);
}
return dfd.promise;
},
addOrUpdateUser: function (user) {
var dfd = $q.defer();
console.log("Calling add user...");
client.invokeApi('User/addOrUpdateUser', {
body: user,
method: "post"
}).done(function (d) {
console.log("Added/saved", d.result);
dfd.resolve({ saved: true, result: d });
}, function (d) {
console.warn("Fikk ikke registrert", d);
dfd.resolve({ error: d });
});
return dfd.promise;
},
loadAllDoneIts: function () {
var self = this;
var dfd = $q.defer();
if (self.doneIts === null) {
console.log("Loading doneIt's...");
var doneItTable = client.getTable('doneIt');
doneItTable.read().then(function (d) {
//console.log("Loaded doneits, but waiting on TavlaSettings", d);
var settingsTable = client.getTable('TavlaSetting');
console.log("Loading settings...");
settingsTable.read().then(function (ts) {
self.parseTavlaSetting(ts);
self.doneIts = d;
self.refreshAlerts();
self.loadAllListItems().then(function () {
console.info("Loaded TavlsSettings, DoneIts and ListItems");
dfd.resolve({ saved: true, result: d });
});
});
});
} else {
dfd.resolve(self.doneIts);
}
return dfd.promise;
},
getPointsForUser: function (user) {
return this.getPointsForUserFromSummary(user);
// Old method
var self = this;
// Get last payment
var usersDoneIts = _.where(self.doneIts, { user: user.name });
var clears = _.where(usersDoneIts, { type: 999 });
var startFrom = moment("2015-1-1");
if (clears.length > 0) {
// find the newest
var sortedClears = _.sortBy(clears, 'dateTime').reverse();
startFrom = moment(sortedClears[0].dateTime);
}
// Get doneits for user after clear date
var currentDoneits = _.filter(usersDoneIts, function (d) {
return startFrom.isBefore(d.dateTime);
});
console.log("Calculating from", { user: user, allDonits: self.doneIts, usersDoneIts: usersDoneIts, clears: clears, startFrom: startFrom, currentDoneIts: currentDoneits });
// Sum doneIts points
var points = 0;
_.each(currentDoneits, function (s) {
// get points for type
var task = _.find(self.tavlaSetting.tasks, function (t) { return t.data.taskTypeId === s.type; });
if (task) {
points = points + task.data.points;
} else {
if (s.type === 1) {
points = points + 10;
}
if (s.type != 1) {
console.warn("Unable to find task for doneIt", s);
}
}
});
return points;
},
getPointsForUserFromSummary: function (user) {
var self = this;
// Get last payment
var summary = _.where(self.summary, { name: user.name });
console.log("Calculating from summary", { summary:summary });
// Sum doneIts points
var points = 0;
_.each(summary, function (s) {
// get points for type
var task = _.find(self.tavlaSetting.tasks, function (t) { return t.data.taskTypeId === s.type; });
if (task) {
points = points + (task.data.points*s.total);
} else {
if (s.type === 1) {
points = points + 10;
}
if (s.type != 1) {
console.warn("Unable to find task for doneIt", s);
}
}
});
return points;
},
refreshAlerts: function () {
var self = this;
_.each(self.saved.members, function (user) {
user.alerts = [];
// Only tasks where user has an alert set up
var taskWithAlertForUser = _.where(self.tavlaSetting.tasks, function (t) {
if (t.data.warningDays) {
var u = _.find(t.data.users, { id: user.id });
if (u) return true;
}
return false;
});
if (taskWithAlertForUser.length > 0) {
// Only users doneit
var usersDoneIts = _.where(self.doneIts, { user: user.name });
_.each(taskWithAlertForUser, function (t) {
// Assume sorted list
var last = _.findLast(usersDoneIts, { type: t.data.taskTypeId });
if (last && t.data.warningDays && t.data.warningDays > 0) {
var maxDate = moment(last.dateTime).add(t.data.warningDays, 'days');
//console.log('compare', { task:t, max: maxDate.format("dddd, DD.MM HH:mm"), last:moment(last.dateTime).format("dddd, DD.MM HH:mm") });
if (maxDate.isBefore()) {
user.alerts.push({
name: t.data.name,
last: moment(last.dateTime),
warningDays: t.data.warningDays
});
}
}
});
// Hack for Buster
if (true) {
// Assume sorted list
var last = _.findLast(usersDoneIts, { type: 1 });
if (last) {
var maxDate = moment(last.dateTime).add(2, 'days');
//console.log('compare', { task:t, max: maxDate.format("dddd, DD.MM HH:mm"), last:moment(last.dateTime).format("dddd, DD.MM HH:mm") });
if (maxDate.isBefore()) {
user.alerts.push({
name: 'Buster',
last: moment(last.dateTime),
warningDays: 2
});
}
}
}
}
//console.log("Alerts for user calculated", user.alerts);
});
console.log("Alerts refreshed. Using", { members: self.saved.members, tasks: self.tavlaSetting.tasks, doneIts: self.doneIts });
},
parseTavlaSetting: function (ts) {
var self = this;
// console.log("parsing", ts);
//var t = ts[0].type;
var tasks = _.where(ts, { type: 'task' });
_.each(tasks, function (t) {
t.data = t.jsonStringifiedData ? JSON.parse(t.jsonStringifiedData) : null;
});
self.tavlaSetting = {
regularEvents: {
id: ts[0].id,
data: ts[0].jsonStringifiedData ? JSON.parse(ts[0].jsonStringifiedData) : null
},
diverse: {
id: ts[1].id,
data: ts[1].jsonStringifiedData ? JSON.parse(ts[1].jsonStringifiedData) : {
yrPath: 'http://www.yr.no/sted/Norge/Telemark/Skien/Gulset/varsel.xml'
}
},
tasks: tasks,
};
console.log("Got TavlaSettings", self.tavlaSetting);
},
saveSettingWithName: function (name) {
var self = this;
var dfd = $q.defer();
var settingTable = client.getTable('TavlaSetting');
switch (name) {
case 'regularEvents':
var s = self.tavlaSetting.regularEvents;
var toSave = {
id: s.id,
Type: 'regularEvents',
JsonStringifiedData: JSON.stringify(s.data)
};
settingTable.update(toSave).then(function (d) {
console.log("Saved setting", toSave, d);
dfd.resolve(d);
});
break;
case 'diverse':
var div = self.tavlaSetting.diverse;
var toSaveDiv = {
id: div.id,
Type: 'diverse',
JsonStringifiedData: JSON.stringify(div.data)
};
settingTable.update(toSaveDiv).then(function (d) {
console.log("Saved setting", toSaveDiv, d);
dfd.resolve(d);
});
break;
default:
console.warn("Cannot saveSettingWithName", name);
}
return dfd.promise;
},
saveTask: function (task) {
var dfd = $q.defer();
var settingTable = client.getTable('TavlaSetting');
if (task.type != "task") {
console.warn("Not a real task - cant save", task);
return;
}
task.JsonStringifiedData = JSON.stringify(task.data);
if (task.id == null) {
settingTable.insert(task).then(function (d) {
console.log("Created task setting", task, d);
dfd.resolve(d);
}, function (err) {
alert("Error: " + err);
});
} else {
settingTable.update(task).then(function (d) {
console.log("Saved task setting", task, d);
dfd.resolve(d);
});
}
return dfd.promise;
},
registerDoneIt: function (user, type) {
var dfd = $q.defer();
console.log("Calling add doneit...");
var doneItTable = client.getTable('doneIt');
doneItTable.insert({ familyMemberId: user.id, type: type }).then(function (d) {
console.log("Added doneit", d);
//self.doneIts.push(d);
dfd.resolve(d);
});
return dfd.promise;
},
loadAllListItems: function () {
var self = this;
var dfd = $q.defer();
if (self.shoppingList === null) {
console.log("Loading listItems's...");
var listItemTable = client.getTable('listItem');
listItemTable.read().then(function (d) {
//console.log("Loaded doneits, but waiting on TavlaSettings", d);
console.log("Loaded listItems", d);
self.shoppingList = d;
dfd.resolve(d);
});
} else {
dfd.resolve(self.shoppingList);
}
return dfd.promise;
},
addListItem: function (listId, data) {
var dfd = $q.defer();
console.log("Calling add addListItem...");
var listItemTable = client.getTable('listItem');
listItemTable.insert({ type: listId, data: data }).then(function (d) {
console.log("Added listItem", d);
dfd.resolve(d);
});
return dfd.promise;
},
removeListItem: function (item) {
var dfd = $q.defer();
console.log("Calling removeListItem...",item);
var listItemTable = client.getTable('listItem');
listItemTable.del({ id: item.id }).then(function () {
console.log("deleted listItem", item);
dfd.resolve(item.id);
});
return dfd.promise;
},
refresh: function () {
var self = this;
var dfd = $q.defer();
console.log("Doing a TavlaService refresh....");
self.isSettingsLoaded = true;
self.login().then(function () {
self.doneIts = null;
self.shoppingList = null;
self.loadAllDoneIts().then(function () {
dfd.resolve();
self.getWeatherForecast().then(function () {
self.loadDoneItSummary().then(function () {
console.info("refresh complete");
})
});;
});
});
return dfd.promise;
},
getWeatherForecast: function () {
var self = this;
var path = self.tavlaSetting.diverse.data.yrPath;
console.log("Loading weather for", path);
var dfd = $q.defer();
client.invokeApi('weather', {
body: null,
method: "get",
parameters: {
yrPath: path
},
headers: {
'Content-Type': 'application/json'
}
}).done(function (d) {
//console.log("Got weather", d.result);
//var formatStr = 'D/M ddd HH:MM';
var dayNo = 0;
var days = [];
for (var i = 0; i < d.result.length; i++) {
var toFind = moment().startOf('day').add(12, 'hour').add(dayNo, 'days');
var current = moment(d.result[i].dateFrom, "YYYY-MM-DD HH:mm");
//console.log('looking for ' + toFind.format(formatStr) + " --- current: " + current.format(formatStr));
if (current.isAfter(toFind)) {
days.push(d.result[i]);
//console.log("found:", moment(d.result[i].dateFrom, "YYYY-MM-DD HH:mm").format(formatStr));
dayNo++;
}
}
self.weather = days;
console.info("Final TavlaService model", self);
dfd.resolve(d);
});
return dfd.promise;
},
recognizeSpeech: function () {
var dfd = $q.defer();
var maxMatches = 1;
var promptString = "Snakk nå"; // optional
var language = "nb-NO"; // optional
if (window.tinyHippos != undefined || !window.cordova) {
dfd.resolve({ item: { title: 'melk' } });
} else {
window.plugins.speechrecognizer.startRecognize(function (result) {
console.log("Fikk svar", result);
if (result && result.length === 1) {
dfd.resolve({
item: {
title: result[0]
}
});
}
}, function (errorMessage) {
console.log("Error message: " + errorMessage);
dfd.resolve({
item: {
title: errorMessage
}
});
}, maxMatches, promptString, language);
}
return dfd.promise;
},
getSupportedLanguages: function () {
window.plugins.speechrecognizer.getSupportedLanguages(function (languages) {
// display the json array
console.log("Languages:", languages);
}, function (error) {
alert("Could not retrieve the supported languages : " + error);
});
},
};
return service;
}).filter('todaysOfType', function () {
// function to invoke by Angular each time
// Angular passes in the `items` which is our Array
return function (items, type, stop) {
// Create a new Array
//console.log("kjører todaysOfType...........");
var filtered = [];
// loop through existing Array
if (items) {
for (var i = 0; i < items.length; i++) {
var item = items[i];
// check if the individual Array element begins with `a` or not
if (item.type === type && moment(item.dateTime).isSame(moment(), 'day')) {
// push it into the Array if it does!
filtered.push(item);
}
}
}
// boom, return the Array after iteration's complete
return filtered;
};
}).filter('hoursOld', function () {
// function to invoke by Angular each time
// Angular passes in the `items` which is our Array
return function (items, hours, stop) {
// Create a new Array
var filtered = [];
//console.log("kjører hoursOld...........");
// loop through existing Array
if (items) {
for (var i = 0; i < items.length; i++) {
var item = items[i];
// check if the individual Array element begins with `a` or not
if (moment(item.dateTime).add(hours, 'hours').isAfter()) {
// push it into the Array if it does!
filtered.push(item);
}
}
}
// boom, return the Array after iteration's complete
return filtered;
};
}).filter('taskEnabledForUser', function () {
// function to invoke by Angular each time
// Angular passes in the `items` which is our Array
return function (items, user, stop) {
// Create a new Array
var filtered = [];
if (items && user && user.id) {
//console.log("kjører taskEnabledForUser...........");
// loop through existing Array
for (var i = 0; i < items.length; i++) {
var item = items[i];
// check if the individual Array element begins with `a` or not
if (item.data.isEnabled) {
var enabledUser = _.findWhere(item.data.users, { enabled: true, id: user.id });
// push it into the Array if it does!
if (enabledUser) {
filtered.push(item);
}
}
}
}
// boom, return the Array after iteration's complete
return filtered;
};
}).filter('latestForUser', function () {
// function to invoke by Angular each time
// Angular passes in the `items` which is our Array
return function (items, user, stop) {
// Create a new Array
var filtered = [];
if (items && user && user.name) {
//console.log("kjører latestForUser...........");
// loop through existing Array
for (var i = 0; i < items.length; i++) {
var item = items[i];
// check if the individual Array element begins with `a` or not
if (moment(item.dateTime).add(7, 'days').isAfter() && item.user == user.name) {
// push it into the Array if it does!
filtered.push(item);
}
}
// boom, return the Array after iteration's complete
filtered.reverse();
}
return filtered;
};
})
.directive('tavlaWeather', function () {
return {
restrict: 'E',
scope: {
model: '='
},
template: '<div class="weather"><span>{{model.temperature}}</span><img ng-src="http://symbol.yr.no/grafikk/sym/b38/{{model.symbolNumber}}.png" alt="symbol"></div>'
};
});
<file_sep>/www/js/app.js
// Ionic Starter App
// angular.module is a global place for creating, registering and retrieving Angular modules
// 'starter' is the name of this angular module example (also set in a <body> attribute in index.html)
// the 2nd parameter is an array of 'requires'
// 'starter.controllers' is found in controllers.js
angular.module('tavla', ['ionic'])
.run(function ($ionicPlatform) {
//moment.locale('nb-no');
$ionicPlatform.ready(function () {
// Hide the accessory bar by default (remove this to show the accessory bar above the keyboard
// for form inputs)
if (window.cordova && window.cordova.plugins && window.cordova.plugins.Keyboard) {
cordova.plugins.Keyboard.hideKeyboardAccessoryBar(true);
}
if (window.StatusBar) {
// org.apache.cordova.statusbar required
StatusBar.styleDefault();
}
console.info("Device ready, starting!!!!!!!!!", window.plugins);
});
})
.config(function ($compileProvider, $stateProvider, $urlRouterProvider) {
$compileProvider.aHrefSanitizationWhitelist(/^\s*(https?|ftp|mailto|file|ghttps?|ms-appx|x-wmapp0):/);
// // Use $compileProvider.urlSanitizationWhitelist(...) for Angular 1.2
$compileProvider.imgSrcSanitizationWhitelist(/^\s*(https?|ftp|file|ms-appx|x-wmapp0):|data:image\//);
$stateProvider
.state('login', {
url: "/login",
templateUrl: "templates/login.html",
controller: "LoginController as vm"
})
.state('register', {
url: '/login/register',
templateUrl: "templates/register.html",
controller: "RegisterController as vm",
resolve: {
mode: function () { return 'select'; }
}
})
.state('newfamily', {
url: '/login/newfamily',
templateUrl: "templates/register.newfamily.html",
controller: "RegisterController as vm",
resolve: {
mode: function () { return 'newfamily'; }
}
})
.state('join', {
url: '/login/join',
templateUrl: "templates/register.join.html",
controller: "RegisterJoinController as vm",
resolve: {
mode: function () { return 'join'; }
}
})
.state('app', {
url: "/app",
abstract: true,
templateUrl: "templates/menu.html",
controller: 'AppController as main'
})
.state('app.home', {
url: "/home",
views: {
'menuContent': {
templateUrl: "templates/home.html",
controller: "HomeController as vm"
}
},
resolve: {
calendarItems: function (CalendarService, doneIts) {
return CalendarService.getItems();
},
doneIts: function(TavlaService) {
return TavlaService.loadAllDoneIts();
}
}
})
.state('app.calendar', {
url: "/calendar",
views: {
'menuContent': {
templateUrl: "templates/calendar.html",
controller: "CalendarController as vm"
}
}
})
.state('app.settings-main', {
url: "/settings/main",
views: {
'menuContent': {
templateUrl: "templates/settings.html",
controller: 'SettingsMainController as vm'
}
},
resolve: {
settings: function (TavlaService) {
return TavlaService.getSettings();
}
}
})
.state('app.settings-main-users', {
url: "/settings/main/users",
views: {
'menuContent': {
templateUrl: "templates/settings-main-users.html",
controller: 'SettingsMainUsersController as vm'
}
},
resolve: {
settings: function (TavlaService) {
return TavlaService.getSettings();
}
}
})
.state('app.settings-main-tasks', {
url: "/settings/main/tasks",
views: {
'menuContent': {
templateUrl: "templates/settings-main-tasks.html",
controller: 'SettingsMainTasksController as vm'
}
},
resolve: {
settings: function (TavlaService) {
return TavlaService.getSettings();
}
}
}).state('app.regular', {
url: "/regular",
views: {
'menuContent': {
templateUrl: "templates/regular.html",
controller: 'RegularController as vm'
}
},
resolve: {
settings: function (TavlaService) {
return TavlaService.getSettings();
}
}
})
.state('app.settingsuser', {
url: "/settingsuser",
views: {
'menuContent': {
templateUrl: "templates/settings-user.html",
controller: 'UserSettingsController as vm',
}
},
params: {
user:null
},
resolve: {
user: function ($stateParams) {
return $stateParams.user;
}
}
}).state('app.settingstasks', {
url: "/settingstasks",
views: {
'menuContent': {
templateUrl: "templates/settings-tasks.html",
controller: 'TasksSettingsController as vm',
}
},
params: {
task:null
},
resolve: {
task: function ($stateParams) {
return $stateParams.task;
}
}
});
//.state('app.single', {
// url: "/playlists/:playlistId",
// views: {
// 'menuContent': {
// templateUrl: "templates/playlist.html",
// controller: 'PlaylistCtrl'
// }
// }
//});
// if none of the above states are matched, use this as the fallback
$urlRouterProvider.otherwise('/login');
})
.constant('AzureMobileServiceClient',
{
API_URL: "https://tavla-service.azure-mobile.net/",
API_KEY: '<KEY>'
})
.constant('Mocks', {
calendars: [
{ id: '1', name: '<EMAIL>' },
{ id: '2', name: '<EMAIL>' },
{ id: '3', name: '<EMAIL>' },
{ id: '4', name: '<EMAIL>' }
],
calendarItems: [
{ calendar_id: '1', eventLocation: "", title: "TEST1 title", allDay: 0, dtstart: new Date(new Date().getTime() + 2 * 60 * 60 * 1000).getTime(), dtend: 1426183200000 }, // moment().add(0,'days').add(2, 'hours') },
{ calendar_id: '2', eventLocation: "Camillas", title: "TEST2 title", allDay: 0, dtstart: new Date(new Date().getTime() + 3 * 60 * 60 * 1000).getTime() },//moment().add(0, 'days').add(3, 'hours') },
{ calendar_id: '1', eventLocation: "", title: "TEST3 title", allDay: 0, dtstart: new Date(new Date().getTime() + 2 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(2, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TEST4 title", allDay: 0, dtstart: new Date(new Date().getTime() + 1 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '1', eventLocation: "", title: "TESTx title", allDay: 0, dtstart: new Date(new Date().getTime() + 14 * 24 * 60 * 60 * 1000).getTime() }, //moment().add(1, 'days') },
{ calendar_id: '3', eventLocation: "Markus", title: "TEST5 title", allDay: 0, dtstart: new Date(new Date().getTime() + 1 * 24 * 60 * 60 * 1000).getTime() } //moment().add(1, 'days') },
],
settings: {
family: {
"id": "784eda9d-9e09-48a5-bf5e-e307d48a35b9",
"name": "Finholt",
"secret": "123"
},
members: [
{
"id": "2d9db721-eefb-4d7f-ade8-c2480b811f04",
"name": "Markus",
"familyId": "784eda9d-9e09-48a5-bf5e-e307d48a35b9"
},
{
"id": "4a7a0a3f-afda-48f1-b418-e6cc3a9fd21c",
"name": "Camilla",
"calendars": "",
"familyId": "784eda9d-9e09-48a5-bf5e-e307d48a35b9"
},
{
"id": "5f00d18e-a5c9-49da-91dc-6f309b452f7c",
"userId": "NOUSER",
"name": "<NAME>",
"calendars": "<EMAIL>",
"familyId": "784eda9d-9e09-48a5-bf5e-e307d48a35b9",
"isAdmin": true
}
],
"registerState": "completed",
"currentUserId": "NOUSER"
}
});
<file_sep>/www/js/settings-main-tasks.controller.js
angular.module('tavla')
.controller('SettingsMainTasksController', function ($state, settings, TavlaService) {
var vm = this;
vm.tavlaService = TavlaService;
vm.editTask = function (task) {
console.log("State", $state);
$state.go("app.settingstasks", { task: task });
}
vm.init=function() {
console.log("Starting SettingsMainTasksController", settings);
}
vm.init();
}); <file_sep>/www/js/typescript-test.ts
/// <reference path="../../typings/tsd.d.ts"/>
class jalla {
constructor(asd) {
console.log("Created");
ionic.Platform.isAndroid();
}
}<file_sep>/www/js/settings.controller.js
angular.module('tavla')
.controller('SettingsController', function ($state, settings, TavlaService) {
var vm = this;
vm.tavlaService = TavlaService;
vm.edit=function(user) {
console.log("State", $state);
$state.go("app.settingsuser", { user: user });
}
vm.editTask = function (task) {
console.log("State", $state);
$state.go("app.settingstasks", { task: task });
}
vm.init=function() {
console.log("Starting settingscontroller", settings);
}
vm.init();
}); <file_sep>/www/js/register-join.controller.js
angular.module('tavla')
.controller('RegisterJoinController', function ($state, TavlaService, CalendarService, mode) {
var vm = this;
vm.d = null;
vm.state = 'verify';
vm.members = [];
vm.tryRegister = function (nameToJoin) {
var model = {
action: 'JoinFamily',
familyName: vm.joinFamilyName,
secret: vm.joinFamilyPassword,
nameToJoin: nameToJoin,
users: []
};
console.log("Join...", model);
TavlaService.register(model).then(function (d) {
vm.d = d;
console.log("Register result", d);
if (d.result && d.result.currentUser) {
console.log("Successfully joined! - Restarintng...........");
$state.go('login');
window.location.reload();
} else {
if (d.result) {
vm.members = d.result.map(function (m) {
return {
name: m.name,
registered: !!m.userId
};
});
vm.state = 'selectPerson';
} else {
vm.err = d.message || 'Unable to find family with that name and password';
}
}
//
});
}
vm.init=function() {
}
vm.init();
});<file_sep>/www/js/typescript-test.js
/// <reference path="../../typings/tsd.d.ts"/>
var jalla = (function () {
function jalla(asd) {
console.log("Created");
ionic.Platform.isAndroid();
}
return jalla;
})();
<file_sep>/www/js/settings-main.controller.js
var tavla;
(function (tavla) {
var SettingsMainController = (function () {
function SettingsMainController($state, tavlaService) {
this.$state = $state;
this.tavlaService = tavlaService;
}
SettingsMainController.$inject = [
'$state',
'TavlaService'
];
SettingsMainController.prototype.usersClick = function () {
this.$state.go('app.settings-main-users');
};
SettingsMainController.prototype.tasksClick = function () {
this.$state.go('app.settings-main-tasks');
};
SettingsMainController.prototype.logout = function () {
var _this = this;
this.tavlaService.logout().then(function (x) {
_this.$state.go('login');
console.log("Reloading....");
window.cookies.clear(function () {
console.log('Cookies cleared!');
});
window.location.reload();
});
};
return SettingsMainController;
})();
tavla.SettingsMainController = SettingsMainController;
})(tavla || (tavla = {}));
angular.module('tavla').controller('SettingsMainController', tavla.SettingsMainController);
<file_sep>/www/js/calendar.controller.js
angular.module('tavla')
.controller('CalendarController', function (TavlaService, CalendarService) {
var vm = this;
vm.tavlaService = TavlaService;
vm.calendarService = CalendarService;
vm.reload=function() {
CalendarService.reload();
};
vm.logout=function() {
window.localStorage['hasLoggedInBefore'] = 'no';
};
});<file_sep>/www/js/settings-tasks.controller.js
angular.module('tavla')
.controller('TasksSettingsController', function ($stateParams, TavlaService, $state, task) {
var vm = this;
var isEditMode = !!task;
console.log("TasksSettingsController", $stateParams, { isEditMode: isEditMode, task: task });
vm.tavlaService = TavlaService;
vm.save = function () {
TavlaService.saveTask(vm.task).then(function (d) {
console.log("Task saved", d);
TavlaService.refresh().then(function (e) {
//$state.transitionTo("app.settings", $stateParams, {
// reload: true,
// inherit: false,
// notify: true
//});
$state.go("app.settings", { 'status': 'San Diego' }, { reload: true });
});
});
}
function init() {
// get next taskId availible
var nextTaskTypeId = 100;
if (vm.tavlaService.tavlaSetting.tasks.length > 0) {
var max = Math.max.apply(null, vm.tavlaService.tavlaSetting.tasks.map(function (t) {
return t.data.taskTypeId;
}));
if (_.isNumber(max) && max>99) {
nextTaskTypeId = max + 1;
} else {
alert("Error i taskTypeId", max);
}
}
if (isEditMode) {
vm.task = task;
vm.title = "Edit task setting";
} else {
vm.title = "Add new task";
vm.task = {
id: null,
type:'task',
data: {
users: [
],
isEnabled: true,
name: '',
points: 50,
taskTypeId: nextTaskTypeId
}
};
}
// add entry for all users if not present
for (var idx in vm.tavlaService.saved.members) {
var user = vm.tavlaService.saved.members[idx];
var u = _.findWhere(vm.task.data.users, { id: user.id });
if (!u) {
vm.task.data.users.push({ id: user.id, name: user.name, enabled: false });
}
}
console.log("Ready to fill in data into new task", vm.task);
}
init();
});<file_sep>/www/js/calendar.service.js
angular.module('tavla')
.factory('CalendarService', function ($q, TavlaService, Mocks) {
console.log("Creating CalendarService....");
var isDevice = navigator.userAgent.match(/(iPhone|iPod|iPad|Android|BlackBerry|IEMobile)/);
function fillInUserAndCalendarInfo(data, days) {
console.log("fillInUserAndCalendarInfo", data);
// empty array with days ready to be filled out
var arr = [];
for (var i = 0; i < days; i++) {
arr.push({
date: moment().startOf('day').add(i, 'days'),
items: []
});
}
// Get regular Events
var nextDays = [];
nextDays.push(moment().day());
nextDays.push(moment().add(1, 'day').day());
nextDays.push(moment().add(2, 'day').day());
console.log("About to add regularEvents", { regularEvents: TavlaService.tavlaSetting.regularEvents, nextDays: nextDays });
if (TavlaService.tavlaSetting.regularEvents && TavlaService.tavlaSetting.regularEvents.data ) {
for (var k = 0; k < nextDays.length; k++) {
var events = TavlaService.tavlaSetting.regularEvents.data[nextDays[k]].events;
for (var j = 0; j < events.length; j++) {
arr[k].items.push( {
title: events[j].title,
user: events[j].user,
dtstart: moment().startOf('day').add(k, 'days').add(events[j].hour, 'hours').add(events[j].minutes, 'minutes').toDate()
}
);
}
}
} else {
console.log("No regularEvents", TavlaService.tavlaSetting);
}
_.each(arr, function (day) {
// check if is configured
var correctDay = _.filter(data.calendarItems, function (item) {
return day.date.isSame(item.dtstart, 'day');
});
// add username
var withUserInfo = correctDay.map(function (d) {
// find calendar
d.calendar = _.find(data.calendars, { id: d.calendar_id });
if (!d.calendar) {
console.warn("Fant ikke kalendar for item", d);
}
if (d.calendar) {
d.user = _.find(data.settings.members, { calendars: d.calendar.name });
if (!d.user) {
//console.warn("Fant ikke bruker for kalender item", d);
}
}
return d;
});
// add to return array
_.each(withUserInfo, function (w) {
// only add if userinfo is present
if (w.user) {
day.items.push(w);
}
});
});
console.log("Result", { fromCalendar: arr });
return arr;
}
var service = {
calendars: [],
days: [],
isLoaded: false,
allEvents:[],
getAllCalendars: function () {
var self = this;
var dfd = $q.defer();
if (self.isLoaded) {
dfd.resolve(self.calendars);
} else {
console.log('calling getAllCalendars...');
ionic.Platform.ready(function () {
console.log("Device ready", isDevice);
//console.log("Device ready", plugins);
if (!isDevice) {
console.log('FAKE!!!');
self.calendars = Mocks.calendars;
dfd.resolve(self.calendars);
} else {
window.plugins.calendar.listCalendars(function (d) {
console.log('Got list of calendars', d);
self.calendars = d;
//TavlaService.getSupportedLanguages();
dfd.resolve(self.calendars);
}, function (e) {
console.log("Error", e);
});
}
});
}
return dfd.promise;
},
getItems: function (settings) {
var self = this;
var dfd = $q.defer();
if (self.isLoaded) {
dfd.resolve(self.items);
} else {
console.log("calling getCalendars...");
this.getAllCalendars().then(function (cals) {
// merge with settings
//console.log('mergining', cals, settings);
var start = new Date();
var end = new Date(2015, 6, 1);
if (!isDevice) {
self.days = fillInUserAndCalendarInfo({
calendarItems: Mocks.calendarItems,
calendars: self.calendars,
settings: TavlaService.saved
}, 30);
self.isLoaded = true;
dfd.resolve(self.days);
} else {
console.log("calling listEventsInRange from plugin...");
window.plugins.calendar.listEventsInRange(start, end, (function (d) {
// merge with settings
console.log('Got list of calendars items', JSON.stringify(d));
self.allEvents = d;
self.days = fillInUserAndCalendarInfo( {
calendarItems: d,
calendars: self.calendars,
settings: TavlaService.saved
}, 30);
self.isLoaded = true;
dfd.resolve(self.days);
}), function (e) {
console.warn("Could not get list of cal items", e);
dfd.reject(e);
});
}
});
}
return dfd.promise;
},
refresh: function () {
var self = this;
var dfd = $q.defer();
console.log("Doing a CalendarService refresh....");
self.isLoaded = false;
self.getItems().then(function () {
dfd.resolve();
});
return dfd.promise;
},
}
return service;
}).filter('dayRange', function () {
// function to invoke by Angular each time
// Angular passes in the `items` which is our Array
return function (items, start, stop) {
// Create a new Array
var filtered = [];
var startDate = moment().startOf('day').add(start, 'days');
var stopDate = moment().startOf('day').add(stop, 'days');
var range = moment().range(startDate, stopDate );
// loop through existing Array
for (var i = 0; i < items.length; i++) {
var item = items[i];
// check if the individual Array element begins with `a` or not
if (range.contains(item.date)) {
// push it into the Array if it does!
filtered.push(item);
}
}
// boom, return the Array after iteration's complete
return filtered;
};
}).filter('upcommingEvents', function () {
// function to invoke by Angular each time
// Angular passes in the `items` which is our Array
return function (items, start, stop) {
// Create a new Array
var filtered = [];
var startDate = moment().startOf('day').add(start, 'days');
var stopDate = moment().startOf('day').add(stop, 'days');
var range = moment().range(startDate, stopDate);
// loop through existing Array
for (var i = 0; i < items.length; i++) {
var item = items[i];
// check if the individual Array element begins with `a` or not
if (range.contains(item.date)) {
// push it into the Array if it does!
filtered= filtered.concat(item.items);
}
}
// boom, return the Array after iteration's complete
return filtered;
};
});<file_sep>/www/js/home.controller.js
angular.module('tavla')
.controller('HomeController', function (TavlaService, calendarItems, CalendarService, $ionicModal, $scope, $interval, $ionicLoading) {
var vm = this;
vm.points = 1;
vm.updates = TavlaService.updates;
vm.days = calendarItems;
vm.settings = TavlaService.saved;
vm.tavlaService = TavlaService;
vm.calendarService = CalendarService;
vm.buster = function (u) {
vm.user = u || vm.user;
console.log("Buster");
vm.taskClick({data: { taskTypeId: 1 } });
};
vm.taskClick = function (task) {
vm.loading = true;
$scope.modal.hide();
$scope.modalAlert.hide();
TavlaService.registerDoneIt(vm.user, task.data.taskTypeId).then(function(d) {
TavlaService.doneIts.push(d);
TavlaService.refreshAlerts();
vm.loading = false;
});
console.log("TaskClick", task, vm.user);
vm.user = null;
};
//vm.calculatePoints=function() {
// TavlaService.doneIts
//}
vm.getTaskNameForType = function (doneIt) {
if (doneIt.type === 1) {
return "Buster";
}
if (doneIt.type === 999) {
return "Nullstilling";
}
var t = _.find(vm.tavlaService.tavlaSetting.tasks, function(a){ return a.data.taskTypeId===doneIt.type; });
if (t) {
return t.data.name;
} else {
return "Unknown task";
}
};
vm.showUserDialog = function (user) {
vm.user = user;
vm.points = TavlaService.getPointsForUser(user);
$scope.modal.show();
};
vm.alertClick = function (type) {
$scope.modalAlert.show();
};
vm.showShopping = function () {
$scope.modalShopping.show();
};
vm.addShopping = function () {
vm.tavlaService.recognizeSpeech().then(function (a) {
if (a.item.title && a.item.title != 0) {
vm.addShoppingListItem(a.item.title);
} else {
$ionicLoading.show({
template: 'Sorry, could you please repeat...',
duration: 1500
});
}
});
};
vm.addShoppingListItem = function (item) {
var toAdd = {};
toAdd.data = item;
console.log("Addding", toAdd);
vm.saving = true;
vm.tavlaService.addListItem(0, item).then(function (d) {
vm.tavlaService.shoppingList.push(d);
console.log("Added", d, vm.tavlaService.shoppingList);
vm.saving = false;
});
//vm.tavlaService.saveSettingWithName('diverse').then(function (r) {
// //$ionicLoading.show({
// // template: 'Added: ' + item,
// // duration: 1500
// //});
// console.log("Saved", r);
// vm.saving = false;
//});
};
vm.shoppingListRemoveItem = function (item) {
vm.tavlaService.removeListItem(item).then(function(id){
_.remove(vm.tavlaService.shoppingList, {id:id});
});
};
vm.refresh = function () {
TavlaService.refresh().then(function () {
CalendarService.refresh().then(function () {
console.log("Refresh complete");
$scope.$broadcast('scroll.refreshComplete');
});
});
};
function init() {
vm.tavlaService.getWeatherForecast().then(function () {
vm.tavlaService.loadDoneItSummary();
});
}
$ionicModal.fromTemplateUrl('templates/popup-user.html', {
scope: $scope
}).then(function (modal) {
$scope.modal = modal;
});
$ionicModal.fromTemplateUrl('templates/popup-alerts.html', {
scope: $scope
}).then(function (modal) {
$scope.modalAlert = modal;
});
$ionicModal.fromTemplateUrl('templates/popup-shopping.html', {
scope: $scope
}).then(function (modal) {
$scope.modalShopping = modal;
});
$interval(function () {
console.log("reload calndars");
CalendarService.refresh();
}, 30 * 60 * 1000);
init();
}); | 1e4064027302574b08748b852fcab9a2a4124570 | [
"JavaScript",
"TypeScript",
"HTML"
] | 18 | JavaScript | larserikfinholt/tavlaapp | 0e38396ca0ac9cc772b8c9e0a9a736fc8d7887c4 | 749fe060d8fd801cbca94c70828e3ab0b13a833b |
refs/heads/master | <repo_name>smarandi/test-app<file_sep>/app/component/Home/Stories/StoryReducer.js
// import { SplashActionTypes } from './SplashActions';
import { StoryActionTypes } from './StoryActions';
const initialState = {
data: [],
subscription: 'TRIAL',
};
const storyReducer = (state = initialState, action) => {
switch (action.type) {
case StoryActionTypes.LOAD_DATA:
return { ...state, data: action.payload };
case StoryActionTypes.LOAD_SUBSCRIPTION_STATUS:
return { ...state, subscription: action.payload };
default:
return state;
}
};
export default storyReducer;
<file_sep>/app/styles/Quiz/Quiz.js
import COLORS from '../Common/Colors';
const style = {
sliderItem: {
// backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
width: '85%',
height: '85%',
justifyContent: 'center',
alignContent: 'center',
borderRadius: 10,
marginTop: '10%',
shadowColor: '#615f61',
shadowOffset: { width: 0, height: 2 },
shadowOpacity: 0.75,
elevation: 1,
},
sliderItemHeader: {
flex: 1,
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
borderTopLeftRadius: 10,
borderTopRightRadius: 10,
flexDirection: 'row',
justifyContent: 'space-around',
alignItems: 'flex-end',
paddingBottom: 5,
},
scoreContainer: {
flex: 3,
justifyContent: 'center',
alignItems: 'center',
},
countContainer: {
flex: 3,
justifyContent: 'center',
alignItems: 'center',
},
highlightedText: {
fontSize: 24,
color: COLORS.MAGENTA_SHADE,
},
infoText: {
fontSize: 12,
color: COLORS.WHITE,
alignSelf: 'center',
},
courseLogoContainer: {
flex: 4,
justifyContent: 'flex-end',
alignItems: 'center',
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
},
logo: {
height: 55,
width: 75,
borderRadius: 5,
},
courseTitle: {
fontSize: 16,
color: COLORS.WHITE,
fontWeight: '500',
alignSelf: 'center',
textAlign: 'center',
},
highlightedQuizIndexContainer: {
flexDirection: 'row',
justifyContent: 'center',
alignItems: 'flex-end',
},
quizCountText: {
fontSize: 16,
color: COLORS.WHITE,
},
backgroundImage: {
position: 'absolute',
// flex: 1,
//
width: '100%',
height: '100%',
borderRadius: 10,
borderTopLeftRadius: 0,
borderTopRightRadius: 0,
backgroundColor: 'transparent',
},
menuContainer: {
flex: 3,
borderBottomLeftRadius: 10,
borderBottomRightRadius: 10,
},
touchableStyle: {
ios: {
width: 33,
height: 33,
borderRadius: 15,
backgroundColor: '#c0c0c0',
position: 'absolute',
top: '11%',
left: '11%',
},
android: {
width: 33,
height: 33,
borderRadius: 15,
backgroundColor: '#c0c0c0',
position: 'absolute',
top: '11%',
left: '15.5%',
},
},
};
export default style;
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
<file_sep>/app/component/More/Help.js
/* eslint-disable react/no-array-index-key */
import React, { Component } from 'react';
import { Text, View, Image } from 'react-native';
import COLORS from '../../styles/Common/Colors';
import HelpStyles from '../../styles/More/Help';
import Phone from '../../assets/img/more/phone-help.png';
import Mail from '../../assets/img/more/mail.png';
class Help extends Component {
static navigationOptions = {
title: 'Help & Feedback',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
render() {
return (
<View style={HelpStyles.container}>
<View style={{ flex: 2 }}>
<View style={HelpStyles.phoneNumberContainer}>
<Text style={HelpStyles.phoneInfoText}>For any queries, please call us at</Text>
<View>
<View style={HelpStyles.phoneCallToAction}>
<Image
source={Phone}
style={HelpStyles.phoneIcon}
resizeMode="contain"
/>
<Text style={HelpStyles.phoneText}>+91 9975165183</Text>
</View>
</View>
</View>
<View style={HelpStyles.emailContainer} >
<Text style={HelpStyles.phoneInfoText}>or mail us at</Text>
<View>
<View style={HelpStyles.emailCallToAction}>
<Image
source={Mail}
style={HelpStyles.phoneIcon}
resizeMode="contain"
/>
<View>
<Text style={HelpStyles.emailText}><EMAIL></Text>
<Text style={HelpStyles.emailText}><EMAIL></Text>
</View>
</View>
</View>
</View>
</View>
<View style={HelpStyles.linkContainer}>
<Text style={HelpStyles.linkText}>Link to our website</Text>
<View style={HelpStyles.button}>
<Text style={HelpStyles.buttonText}>www.inspirescareer.com</Text>
</View>
</View>
<View style={{ flex: 1 }} />
</View>
);
}
}
export default Help;
<file_sep>/app/component/More/Parent.js
/* eslint-disable react/no-unescaped-entities */
import React, { Component } from 'react';
import { Text, View, Image, TouchableOpacity } from 'react-native';
import COLORS from '../../styles/Common/Colors';
import ParentStyles from '../../styles/More/Parent';
import ParentHeaderIcon from '../../assets/img/more/parent-app.png';
import ParentBackground from '../../assets/img/more/parent-app-background.png';
class Parent extends Component {
static navigationOptions = {
title: 'Parent App',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
render() {
return (
<View style={{ flex: 1 }}>
<View style={ParentStyles.headerSection}>
<Image
source={ParentBackground}
style={ParentStyles.backgroundImage}
resizeMode="contain"
/>
<View style={ParentStyles.headerIconContainer}>
<Image
source={ParentHeaderIcon}
style={ParentStyles.headerIcon}
resizeMode="contain"
/>
<Text style={ParentStyles.textInfo}>
Know more about your kid's interests
</Text>
</View>
</View>
<View style={ParentStyles.instructionContainer}>
<Text style={ParentStyles.instructionHeader}>Follow these steps to login in to Parent App</Text>
<Text style={ParentStyles.bullet}>1. Enter the registered mobile number.</Text>
<Text style={ParentStyles.info}>+91 9988899888</Text>
<Text style={ParentStyles.bullet}>2. Enter the below mention parent code.</Text>
<Text style={ParentStyles.info}>WA3DS4</Text>
</View>
<View style={ParentStyles.buttonContainer}>
<TouchableOpacity style={ParentStyles.button}>
<Text style={ParentStyles.buttonText}>Get Parent App</Text>
</TouchableOpacity>
</View>
</View>
);
}
}
export default Parent;
//
// <Text>
// Hello Parent
// </Text>
<file_sep>/app/Store.js
import { applyMiddleware, createStore } from 'redux';
import { createLogger } from 'redux-logger';
import thunk from 'redux-thunk';
import promise from 'redux-promise-middleware';
import reducer from './Reducers';
const loggerMiddleware = createLogger({ predicate: () => ({ logger: console, diff: true }) });
const middleware = [promise(), thunk, loggerMiddleware];
export default createStore(reducer, applyMiddleware(...middleware));
<file_sep>/app/styles/More/Parent.js
import COLORS from '../Common/Colors';
/* Actual Scorecard Styles */
const style = {
headerSection: {
flex: 2,
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
justifyContent: 'center',
alignItems: 'center',
},
headerIconContainer: {
flex: 1,
position: 'absolute',
justifyContent: 'center',
alignItems: 'center',
},
textInfo: {
paddingTop: '2%',
color: COLORS.WHITE,
fontSize: 16,
},
backgroundImage: {
width: '100%',
height: '100%',
},
headerIcon: {
width: 150,
height: 150,
},
instructionContainer: {
flex: 2,
justifyContent: 'space-around',
paddingLeft: '5%',
paddingTop: '2%',
backgroundColor: COLORS.WHITE,
},
instructionHeader: {
color: COLORS.BACKGROUND_COLOR_SECONDARY,
fontSize: 16,
fontWeight: '400',
},
bullet: {
color: COLORS.BACKGROUND_COLOR_PRIMARY,
fontSize: 16,
fontWeight: '200',
},
info: {
fontSize: 20,
fontWeight: '400',
paddingLeft: '5%',
},
buttonContainer: {
flex: 1,
backgroundColor: COLORS.WHITE,
justifyContent: 'center',
alignItems: 'center',
},
button: {
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
width: '50%',
padding: 10,
borderRadius: 5,
},
buttonText: {
color: COLORS.WHITE,
fontSize: 24,
fontWeight: '500',
},
};
export default style;
//
// borderColor: 'purple',
// borderWidth: 1,
// borderStyle: 'solid',
<file_sep>/app/component/Quiz/QuizAnalysis.js
import React, { Component } from 'react';
import { Text, View, Dimensions, StyleSheet, Image, TouchableOpacity, ScrollView } from 'react-native';
import COLORS from '../../styles/Common/Colors';
import Search from '../../assets/img/quiz/search.png';
import QuizAnalysisStyles from '../../styles/Quiz/QuizAnalysis';
import quizAnalysis from './SampleQuestionsResults.json';
import { ALPHABET_TO_INDEX } from '../../scripts/Quiz/Enums';
const { width } = Dimensions.get('window');
class QuizAnalysis extends Component {
static navigationOptions = {
title: 'Quiz Analysis',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
renderQuizItem = (item, index) => (
<View key={index}>
<View style={{ flexDirection: 'row', paddingBottom: '5%' }}>
<Text style={{ fontSize: 18, fontWeight: '300' }}>{index + 1}. </Text>
<Text style={{ fontSize: 18, fontWeight: '300' }}>{item.question}</Text>
</View>
<Text style={{
fontSize: 16, fontWeight: '500', paddingLeft: '5%', paddingBottom: '5%',
}}
>
Ans. {item.answerIndex} ({item.options[ALPHABET_TO_INDEX[item.answerIndex]]})
</Text>
{(
item.answerIndex !== item.selectedAnswerIndex ?
<Text
style={{
fontSize: 16,
fontWeight: '300',
paddingLeft: '5%',
paddingBottom: '5%',
color: COLORS.MAGENTA_SHADE,
}}
>
Your Ans. {item.selectedAnswerIndex} ({item.options[ALPHABET_TO_INDEX[item.selectedAnswerIndex]]})
</Text>
: <Text />
)}
</View>
);
render() {
return (
<ScrollView>
<View style={{ justifyContent: 'center', alignItems: 'center' }}>
<View style={QuizAnalysisStyles.headerContainer} >
<View >
<View style={{ flexDirection: 'row', justifyContent: 'center', alignItems: 'center' }}>
<Text style={{ fontSize: 24, color: COLORS.MAGENTA_SHADE }}>7</Text>
<Text style={{ fontSize: 12, color: COLORS.WHITE }}>/10</Text>
</View>
<Text style={{ fontSize: 14, paddingTop: 5, color: COLORS.WHITE }}>Score</Text>
</View>
<View style={{ justifyContent: 'center', alignItems: 'center' }}>
<View style={{
backgroundColor: COLORS.YELLOW_SHADE,
width: 60,
height: 60,
justifyContent: 'center',
alignItems: 'center',
borderRadius: 30,
}}
>
<Text style={{ fontSize: 28, color: COLORS.WHITE, backgroundColor: 'transparent' }}>5</Text>
</View>
<Text style={{ fontSize: 16, paddingTop: 5, color: COLORS.WHITE }}>Quiz No</Text>
</View>
<View style={{ justifyContent: 'center', alignItems: 'center' }}>
<View style={{ flexDirection: 'row', justifyContent: 'center', alignItems: 'center' }}>
<Text style={{ fontSize: 24, color: COLORS.MAGENTA_SHADE }}>100</Text>
<Text style={{ fontSize: 12, color: COLORS.WHITE }}> sec</Text>
</View>
<Text style={{ fontSize: 14, paddingTop: 5, color: COLORS.WHITE }}>Time</Text>
</View>
</View>
</View>
<View style={{ padding: '10%' }}>
{quizAnalysis.map((quizItem, index) => this.renderQuizItem(quizItem, index))}
</View>
</ScrollView>
);
}
}
export default QuizAnalysis;
<file_sep>/app/component/Onboarding/Onboard.js
import React, { Component } from 'react';
import { Text, View, Image } from 'react-native';
import Styles from '../../styles/Common/Onboard';
import background from '../../assets/img/onboardingbackground.png';
import firstImage from '../../assets/img/onboarding-1.png';
/* TODO: Implement Carousel */
class Onboard extends Component {
/**
* Header and Header Mode set to null & none to remove
* the top header from a screen/View
* @type {{header: null, headerMode: string}}
*/
static navigationOptions = {
header: null,
headerMode: 'none',
};
componentDidMount() {
}
render() {
return (
<View style={Styles.container}>
<Image source={background} style={Styles.background} resizeMode="contain" />
<View style={Styles.overlayContainer}>
<Image source={firstImage} style={Styles.overlayContent} resizeMode="contain" />
</View>
<Text style={Styles.onBoardingText}>Understanding Yourself</Text>
</View>
);
}
}
export default Onboard;
<file_sep>/app/component/Quiz/QuizMenuBackground.js
import React, { Component } from 'react';
import { Text, View } from 'react-native';
import QuizMenuStyles from '../../styles/Quiz/QuizMenuBackground';
import COLORS from '../../styles/Common/Colors';
class QuizMenu extends Component {
componentDidMount() {
}
render() {
return (
<View style={QuizMenuStyles.menuItemsContainer}>
<View style={QuizMenuStyles.rowTop}>
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREEN_SHADE }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
</View>
<View style={QuizMenuStyles.rowMiddle}>
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
</View>
<View style={QuizMenuStyles.rowBottom}>
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
<View style={{ ...QuizMenuStyles.column, backgroundColor: COLORS.GREY }} />
</View>
</View>
);
}
}
export default QuizMenu;
<file_sep>/app/styles/Auth/Register.js
import COLORS from '../Common/Colors';
const textInputFontSize = 16;
const style = {
overlayContainer: {
display: 'flex',
flex: 1,
position: 'absolute',
},
mobileViewContainer: {
ios: {
// width: 350,
backgroundColor: COLORS.BACKGROUND_COLOR_SHADE,
borderRadius: 15,
padding: 25,
},
android: {
// width: 350,
backgroundColor: COLORS.BACKGROUND_COLOR_SHADE,
borderRadius: 15,
padding: 25,
},
},
fullWidthTextInput: {
ios: {
fontSize: textInputFontSize,
borderWidth: 1,
borderTopColor: 'transparent',
borderLeftColor: 'transparent',
borderRightColor: 'transparent',
borderBottomColor: 'grey',
width: '100%',
paddingTop: 15,
},
android: {
fontSize: textInputFontSize,
width: '100%',
},
},
classAndSchoolContainer: {
flexWrap: 'nowrap',
flexDirection: 'row',
justifyContent: 'space-around',
},
classDropdownContainer: {
width: '30%',
},
schoolInputContainer: {
width: '60%',
marginLeft: 10,
marginTop: 15,
},
cityDropdown: {
width: '40%',
},
areaDropdown: {
width: '55%',
},
schoolInputText: {
ios: {
fontSize: textInputFontSize,
borderWidth: 1,
borderTopColor: 'transparent',
borderLeftColor: 'transparent',
borderRightColor: 'transparent',
borderBottomColor: 'grey',
marginTop: '5%',
},
android: {
fontSize: textInputFontSize,
marginTop: '-6%',
},
},
emailAndMobileContainer: {
paddingTop: 10,
},
buttonContainer: {
marginTop: '10%',
width: 180,
alignItems: 'center',
backgroundColor: COLORS.YELLOW_SHADE,
borderRadius: 15,
borderWidth: 1,
borderColor: COLORS.BLACK,
},
buttonText: {
fontSize: 20,
padding: 5,
color: COLORS.BLACK,
},
loginTextContainer: {
alignItems: 'center',
},
loginText: {
fontSize: 16,
paddingTop: 10,
color: COLORS.WHITE,
},
termsAndConditionsText: {
color: COLORS.WHITE,
},
};
export default style;
<file_sep>/app/component/Home/Video/VideoReducer.js
// import { SplashActionTypes } from './SplashActions';
import { VideoActionTypes } from './VideoActions';
const initialState = {
course: {},
};
const videoReducer = (state = initialState, action) => {
switch (action.type) {
case VideoActionTypes.LOAD_DATA:
return { ...state, course: action.payload };
default:
return state;
}
};
export default videoReducer;
<file_sep>/app/component/Explore/ExploreReducer.js
// import { SplashActionTypes } from './SplashActions';
import { ExploreActionTypes } from './ExploreActions';
const initialState = {
data: [],
plan: 'PAID', /* TODO: SET DEFAULT TO TRIAL */
};
const exploreReducer = (state = initialState, action) => {
switch (action.type) {
case ExploreActionTypes.LOAD_DATA:
return { ...state, data: action.payload };
case ExploreActionTypes.LOAD_SUBSCRIPTION_STATUS:
return { ...state, plan: action.payload.plan };
default:
return state;
}
};
export default exploreReducer;
<file_sep>/app/component/ScoreCard/ScoreCardNavigation.js
import { StackNavigator } from 'react-navigation';
import ScoreCard from './ScoreCard';
import Search from './Search';
const Routes = {
Search: { screen: Search },
ScoreCard: { screen: ScoreCard },
};
export default StackNavigator(Routes);
<file_sep>/app/styles/ScoreCard/ScoreCard.js
import COLORS from '../Common/Colors';
const style = {
icon: {
width: 28,
height: 13,
},
parent: {
backgroundColor: COLORS.WHITE,
},
searchSection: {
width: '100%',
height: '25%',
justifyContent: 'center',
alignItems: 'center',
},
resultSection: {
width: '100%',
height: '75%',
},
searchInputContainer: {
width: '90%',
height: '35%',
borderStyle: 'solid',
borderWidth: 1,
borderColor: COLORS.BACKGROUND_COLOR_SECONDARY,
borderRadius: 10,
flexDirection: 'row',
},
textInputContainer: {
width: '90%',
justifyContent: 'center',
alignItems: 'flex-start',
paddingLeft: 15,
},
textInput: {
ios: {
fontSize: 18,
width: '100%',
},
android: {
fontSize: 18,
width: '100%',
},
},
searchIconContainer: {
justifyContent: 'center',
width: '10%',
},
searchIcon: {
width: 25,
height: 25,
},
resultItemContainer: {
flexDirection: 'row',
justifyContent: 'flex-start',
alignItems: 'center',
marginLeft: '5%',
},
resultIcon: {
width: 100,
height: 100,
},
resultTextContainer: {
marginLeft: '5%',
},
resultText: {
fontSize: 22,
fontWeight: '200',
},
};
export default style;
//
// borderColor: 'purple',
// borderWidth: 1,
// borderStyle: 'solid',
<file_sep>/app/component/Authentication/MobileNumber.js
import React, { Component } from 'react';
import PropTypes from 'prop-types';
import { Text, View, TextInput, TouchableOpacity, Image, Platform } from 'react-native';
import { isEmpty, isLength, isMobilePhone, isNumeric } from 'validator';
import Styles from '../../styles/Auth/MobileNumber';
import AuthStyles from '../../styles/Auth/Auth';
import background from '../../assets/img/onboardingbackground.png';
import { generate } from '../../services/Auth';
const mobileNumberInputStyle = Platform.select(Styles.textInput);
class MobileNumber extends Component {
/**
* Header and Header Mode set to null & none to remove
* the top header from a screen/View
* @type {{header: null, headerMode: string}}
*/
static navigationOptions = {
header: null,
headerMode: 'none',
};
static propTypes = {
navigation: PropTypes.object.isRequired,
};
state = {
text: '',
};
handleTextInputChange = text => this.setState({ text })
handleSuccess = (res) => {
/* TODO: Handle Different Status Codes other than 200 */
switch (res.status) {
case 101:
this.props.navigation.navigate('Register');
break;
default:
this.props.navigation.navigate('OTP', { phone: this.state.text });
}
};
handleLoginClick = () => {
const formData = new FormData();
formData.append('phone_number', this.state.text);
generate(formData)
.then(res => this.handleSuccess(res))
.catch(() => {}); // this.props.navigation.navigate('Register'));
/* TODO: Appropriately Handle This Catch on Application Level */
};
render() {
return (
<View style={AuthStyles.container}>
<Image source={background} style={AuthStyles.background} resizeMode="contain" />
<View style={Styles.overlayContainer}>
<View style={Styles.mobileViewContainer}>
<Text style={Styles.mobileViewLabel}> Enter the registered</Text>
<Text style={Styles.mobileViewLabel}> mobile number.</Text>
<TextInput
maxLength={10}
value={this.state.text}
keyboardType="numeric"
style={mobileNumberInputStyle}
onChangeText={text => this.handleTextInputChange(text)}
/>
<TouchableOpacity
onPress={() => this.handleLoginClick()}
>
<View style={Styles.buttonContainer}>
<Text style={Styles.buttonText}>Continue</Text>
</View>
</TouchableOpacity>
</View>
<Text style={Styles.registrationText}>Not Registered?
<Text
accessible
onPress={() => this.props.navigation.navigate('Register')}
> Register Here.
</Text>
</Text>
</View>
</View>
);
}
}
export default MobileNumber;
<file_sep>/app/styles/Explore/Stories.js
import COLORS from '../Common/Colors';
const style = {
scrollablePicker: {
height: '25%',
backgroundColor: COLORS.WHITE,
// borderColor: 'red',
// borderWidth: 1,
// borderStyle: 'solid',
},
storyHeaderContainer: {
height: '100%',
},
clickableImageStyle: {
width: '100%',
height: '100%',
},
bottomViewContainer: {
position: 'absolute',
flex: 1,
flexDirection: 'row',
padding: 20,
alignItems: 'flex-end',
height: '95%',
},
titleContainer: {
width: '70%',
backgroundColor: 'transparent',
},
titleText: {
fontSize: 20,
color: COLORS.WHITE,
},
dateContainer: {
width: '30%',
backgroundColor: 'transparent',
},
dateText: {
fontSize: 14,
color: COLORS.WHITE,
},
quoteText: {
backgroundColor: 'transparent',
fontSize: 16,
color: COLORS.WHITE,
textAlign: 'center',
},
quoteContainer: {
position: 'absolute',
flex: 1,
flexDirection: 'row',
padding: 20,
paddingLeft: '55%',
alignItems: 'flex-end',
height: '50%',
width: '100%',
justifyContent: 'flex-end',
},
storyPickerImageStyle: {
ios: {
width: 100,
height: 100,
paddingLeft: 10,
paddingRight: 10,
borderRadius: 50,
},
android: {
width: 80,
height: 80,
paddingLeft: 10,
paddingRight: 10,
borderRadius: 50,
},
},
storyPickerImageNotSelected: {
width: 75,
height: 75,
opacity: 0.5,
borderRadius: 40,
},
scrollListContainer: {
// borderColor: 'red',
// borderStyle: 'solid',
// borderWidth: 1,
flexDirection: 'row',
justifyContent: 'center',
alignItems: 'center',
paddingTop: '5%',
paddingBottom: '5%',
},
touchableNav: {
position: 'absolute',
flex: 1,
width: '100%',
height: '100%',
backgroundColor: 'transparent',
},
};
export default style;
// borderColor: 'red',
// borderStyle: 'solid',
// borderWidth: 1,<file_sep>/app/component/Quiz/QuestionAnswer.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, Image, TouchableOpacity, Platform, ScrollView } from 'react-native';
import Modal from 'react-native-modal';
// import Toast from 'react-native-simple-toast';
import COLORS from '../../styles/Common/Colors';
import { INDEX_TO_ALPHABET } from '../../scripts/Quiz/Enums';
import QuestionAnswerStyles from '../../styles/Quiz/QuestionAnswer';
import Background from '../../assets/img/quiz/background.png';
import BadScore from '../../assets/img/quiz/bad-score.png';
import ExcellentScore from '../../assets/img/quiz/excellent-score.png';
import GoodScore from '../../assets/img/quiz/good-score.png';
import Questions from './SampleQuestions.json';
import Video from '../Home/Video/Video';
import { QuizActions } from './QuizActions';
import { validateAnswer } from '../../services/Quiz';
// const question = {
// question_id: 'abc123',
// question_no: '1',
// question: 'Lorem ipsum dolor sit amet, consectetur adipiscing elit?',
// options: ['Lorem', 'ipsum', 'dolor', 'sit'],
// answer: 'Lorem',
// };
@connect(store => ({ auth: store.auth, quiz: store.quiz }))
class QuestionAnswer extends Component {
static navigationOptions = {
title: 'Quizzes',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
static propTypes={
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
quiz: PropTypes.object.isRequired,
};
state = {
progress: 10,
// quizEnded: false,
// startModalOpen: true,
// showTimer: true,
};
decreaseTime = () => {
if (this.state.progress !== 0) {
this.setState({ progress: this.state.progress - 1 });
}
};
getWidth = timerValue => (100 - ((10 - timerValue) * 10));
evaluateAnswer = (selectedAnswerIndex, optionId) => {
console.log('Entering Evaluate Answer');
/* TODO: ADD Authentication Things */
this.props.dispatch(QuizActions.stopTimer());
this.props.dispatch(QuizActions.hideTimer());
const { uuid: quizId, questions } = this.props.quiz.quizObject;
const { currentQuestionIndex } = this.props.quiz.quizState;
const questionId = questions[currentQuestionIndex].uuid;
const { courseId } = this.props.navigation.state.params;
const timeTakenToAnswer = this.state.progress;
const quizResponseObject = {
quiz_id: quizId,
question_id: questionId,
course_uuid: courseId,
answer_id: [optionId],
};
console.log('Params', this.props.navigation.state.params);
console.log('Time ', timeTakenToAnswer);
console.log('Response ', quizResponseObject);
validateAnswer(quizResponseObject)
.then(data => console.log('I am a success', data))
.catch(err =>);
};
handleActionClick = () => {
this.props.dispatch(QuizActions.endQuiz());
this.props.navigation.navigate('QuizAnalysis');
};
handleStartActionClick = () => {
this.props.dispatch(QuizActions.startQuiz());
};
// this.setState({ quizEnded: false });
// this.setState({ startModalOpen: false });
// {
// this.setState({ startModalOpen: false });
// setTimeout(() => this.decreaseTime(), 1000);
// };
renderOptions = (option, index) => (
<TouchableOpacity
key={index}
style={QuestionAnswerStyles.singleOptionContainer}
onPress={() => this.evaluateAnswer(index, option.uuid)}
>
<Text style={QuestionAnswerStyles.optionText}>
{INDEX_TO_ALPHABET[index]}. {option.choice}
</Text>
</TouchableOpacity>
);
renderInterface = (question, currentQuestionIndex) => {
const { question: query, options } = question;
return (
<View>
<View style={QuestionAnswerStyles.sliderAndTimerContainer}>
{
// this.props.quiz.showTimer &&
(
<View style={QuestionAnswerStyles.timerContainer}>
<Text style={QuestionAnswerStyles.timerText}>{this.state.progress} sec</Text>
</View>
)
}
{
// this.props.quiz.showTimer &&
(
<View style={QuestionAnswerStyles.sliderContainer}>
<View style={QuestionAnswerStyles.sliderExternal}>
<View style={{
width: `${this.getWidth(this.state.progress)}%`,
height: '100%',
backgroundColor: COLORS.MAGENTA_SHADE,
borderRadius: 15,
}}
/>
</View>
</View>
)
}
<Text style={{ fontSize: 18 }}>
{currentQuestionIndex + 1}/ {this.props.quiz.quizObject.questions.length || 0}
</Text>
</View>
<View style={{ flex: 4 }}>
<View style={QuestionAnswerStyles.questionContainer}>
<Text style={QuestionAnswerStyles.questionNumber}>
{currentQuestionIndex + 1}.
</Text>
<View style={QuestionAnswerStyles.questionTextContainer}>
<Text style={QuestionAnswerStyles.questionText}>
{query}
</Text>
</View>
</View>
<View style={QuestionAnswerStyles.optionsContainer}>
{options.map((option, index) => this.renderOptions(option, index))}
</View>
</View>
</View>
);
};
render() {
// console.log('Props', this.props.navigation.state.params);
const { questions } = this.props.quiz.quizObject;
const { currentQuestionIndex } = this.props.quiz.quizState;
if (this.props.quiz.startTimer) {
setTimeout(() => this.decreaseTime(), 1000);
}
console.log(this.props.quiz.quizEnded);
return (this.props.quiz && questions.length === 0 ?
<Text>Getting Questions</Text> :
<ScrollView style={QuestionAnswerStyles.mainContainer}>
{this.renderInterface(questions[currentQuestionIndex], currentQuestionIndex)}
<Modal isVisible={this.props.quiz.quizEnded}>
<View style={QuestionAnswerStyles.modalContainer}>
<View style={QuestionAnswerStyles.modal}>
<Image
style={{ width: '100%', height: '90%' }}
source={Background}
resizeMode="contain"
/>
<View style={QuestionAnswerStyles.modalInfoContainer}>
<Text style={{ fontSize: 18, color: COLORS.WHITE }}>Good going Nithin!</Text>
<Image
source={GoodScore}
style={{ width: 150, height: 150 }}
/>
<Text style={{ fontSize: 16, color: COLORS.WHITE }}>You Scored</Text>
<View style={{ flexDirection: 'row', justifyContent: 'center', alignItems: 'center' }}>
<Text style={{ fontSize: 24, color: COLORS.MAGENTA_SHADE }}>7</Text>
<Text style={{ fontSize: 20, color: COLORS.WHITE }}>/10</Text>
</View>
</View>
<TouchableOpacity style={Platform.select(QuestionAnswerStyles.modalCta)} onPress={() => this.handleActionClick()}>
<Text style={QuestionAnswerStyles.modalCtaText}>Analysis</Text>
</TouchableOpacity>
</View>
</View>
</Modal>
<Modal isVisible={this.props.quiz.startModalOpen}>
<View style={QuestionAnswerStyles.modalContainer}>
<View style={QuestionAnswerStyles.modal}>
<Image
style={{ width: '100%', height: '90%' }}
source={Background}
resizeMode="contain"
/>
<View style={QuestionAnswerStyles.modalInfoContainer}>
<View style={QuestionAnswerStyles.modalStartQuizInfoLabelContainer}>
<Text style={QuestionAnswerStyles.quizCountText}>5</Text>
<Text style={{ fontSize: 16, color: COLORS.WHITE }}>Quiz No.</Text>
</View>
<View style={QuestionAnswerStyles.modalStartStatsInfoContainer}>
<View style={QuestionAnswerStyles.modalStartTimerContainer}>
<Text style={{ fontSize: 24, color: COLORS.MAGENTA_SHADE }}>10</Text>
<Text style={{ fontSize: 12 }}>Questions</Text>
</View>
<View style={QuestionAnswerStyles.modalStartTimerContainer}>
<Text style={{ fontSize: 24, color: COLORS.MAGENTA_SHADE }}>100 s</Text>
<Text style={{ fontSize: 12 }}>Time</Text>
</View>
</View>
</View>
<TouchableOpacity
style={Platform.select(QuestionAnswerStyles.modalCta)}
onPress={() => this.handleStartActionClick()}
>
<Text style={QuestionAnswerStyles.startModalCtaText}>START</Text>
</TouchableOpacity>
</View>
</View>
</Modal>
</ScrollView>
);
}
}
export default QuestionAnswer;
<file_sep>/app/component/ScoreCard/CallToAction.js
/* eslint-disable react/no-unescaped-entities */
import React, { Component } from 'react';
import { Text, View, Dimensions } from 'react-native';
import Carousel from 'react-native-snap-carousel';
import COLORS from '../../styles/Common/Colors';
import CallToActionStyles from '../../styles/ScoreCard/CallToAction';
const { width } = Dimensions.get('window');
const entries = [2, 3, 4];
class Projects extends Component {
static navigationOptions = {
title: 'Projects',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
renderItem = ({ item, index }) => (
<View
index={index}
style={{
width, justifyContent: 'center', alignItems: 'center',
}}
>
<View style={CallToActionStyles.itemContainer}>
<Text style={CallToActionStyles.ctaActionText}>Read the article</Text>
<Text style={CallToActionStyles.ctaContentText}>"Introduction to Color Theory" to get more insigts on visual design</Text>
</View>
</View>
);
render() {
return (
<View style={CallToActionStyles.parentView}>
<View style={CallToActionStyles.carouselContainer}>
<Carousel
ref={(c) => { this._carousel = c; }}
data={entries}
renderItem={this.renderItem}
sliderWidth={width}
itemWidth={width}
/>
</View>
</View>
);
}
}
export default Projects;
<file_sep>/app/component/Home/Video/VideoActions.js
const VideoActionTypes = {
LOAD_DATA: 'VIDEO/LOAD_DATA',
};
const VideoActions = {
loadInfo: payload => ({ type: VideoActionTypes.LOAD_DATA, payload }),
loadCourseInfo: payload => (dispatch) => {
const { data } = payload;
dispatch(VideoActions.loadInfo(data[0]));
},
};
export {
VideoActionTypes,
VideoActions,
};
<file_sep>/app/component/ScoreCard/ScoreCardReducer.js
// import { SplashActionTypes } from './SplashActions';
import { ScoreCardActionTypes } from './ScoreCardActions';
const initialState = {
data: [],
totalTimeSpent: 0,
};
const scoreCardReducer = (state = initialState, action) => {
switch (action.type) {
case ScoreCardActionTypes.LOAD_DATA:
return { ...state, data: action.payload };
case ScoreCardActionTypes.LOAD_TIME_SPENT:
return { ...state, totalTimeSpent: action.payload };
default:
return state;
}
};
export default scoreCardReducer;
<file_sep>/app/component/Home/Stories/StoryNavigation.js
import { StackNavigator } from 'react-navigation';
import Stories from './Stories';
import StoryDetails from '../Common/SecondView';
const Routes = {
Stories: { screen: Stories },
StoryDetails: { screen: StoryDetails },
};
export default StackNavigator(Routes);
<file_sep>/app/component/Authentication/AuthActions.js
const AuthActionTypes = {
STORE_AUTH_TOKEN: 'AUTH/STORE_AUTH_TOKEN',
STORE_USER_ID: 'AUTH/STORE_USER_ID',
STORE_USER_NAME: 'AUTH/STORE_USER_NAME',
STORE_USER_PLAN: 'AUTH/STORE_USER_PLAN',
};
const AuthActions = {
storeAuthToken: payload => ({ type: AuthActionTypes.STORE_AUTH_TOKEN, payload }),
storeUserId: payload => ({ type: AuthActionTypes.STORE_USER_ID, payload }),
storeUserName: payload => ({ type: AuthActionTypes.STORE_USER_NAME, payload }),
storeUserPlan: payload => ({ type: AuthActionTypes.STORE_USER_PLAN, payload }),
storeAuthenticationCredentials: payload => (dispatch) => {
const {
auth_token, user_id, username, plan,
} = payload;
dispatch(AuthActions.storeAuthToken(auth_token));
dispatch(AuthActions.storeUserId(user_id));
dispatch(AuthActions.storeUserName(username));
dispatch(AuthActions.storeUserPlan(plan));
},
};
export {
AuthActionTypes,
AuthActions,
};
<file_sep>/app/component/More/MoreNavigation.js
import { StackNavigator } from 'react-navigation';
import More from './More';
import Policy from './Policy';
import Help from './Help';
import Parent from './Parent';
const Routes = {
More: { screen: More },
Help: { screen: Help },
Parent: { screen: Parent },
Policy: { screen: Policy },
};
export default StackNavigator(Routes);
<file_sep>/app/component/Authentication/OTP.js
/* eslint-disable no-underscore-dangle */
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, TextInput, TouchableOpacity, Platform, Image } from 'react-native';
import styles from '../../styles/Auth/OTP';
import AuthStyles from '../../styles/Auth/Auth';
import background from '../../assets/img/onboardingbackground.png';
import { login } from '../../services/Auth';
import { AuthActions } from './AuthActions';
const mobileNumberInputStyle = Platform.select(styles.textInput);
@connect(store => ({ auth: store.auth }))
class OTP extends Component {
/**
* Header and Header Mode set to null & none to remove
* the top header from a screen/View
* @type {{header: null, headerMode: string}}
*/
static navigationOptions = {
header: null,
headerMode: 'none',
};
static propTypes = {
navigation: PropTypes.object.isRequired,
auth: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
};
state = {
firstDigit: '',
secondDigit: '',
thirdDigit: '',
fourthDigit: '',
};
handleSuccess = ({ status, data }) => {
const {
auth_token, user_id, username, plan,
} = data;
/* TODO: Handle Different Status Codes other than 200 */
switch (status) {
case 200:
this.props.dispatch(AuthActions.storeAuthenticationCredentials({
auth_token, user_id, username, plan,
}));
this.props.navigation.navigate('Home');
break;
default:
this.props.navigation.navigate('MobileNumber');
}
};
handleLoginClick = () => {
const {
firstDigit, secondDigit, thirdDigit, fourthDigit,
} = this.state;
const otp = `${firstDigit}${secondDigit}${thirdDigit}${fourthDigit}`;
const { phone } = this.props.navigation.state.params;
const formData = new FormData();
formData.append('phone_number', phone);
formData.append('otp', otp);
login(formData).then(data => this.handleSuccess(data)).catch(() => {});
};
render() {
const {
firstDigit, secondDigit, thirdDigit, fourthDigit,
} = this.state;
return (
<View style={AuthStyles.container}>
<Image source={background} style={AuthStyles.background} resizeMode="contain" />
<View style={styles.overlayContainer}>
<View style={styles.mobileViewContainer}>
<Text style={styles.mobileViewLabel}> Enter the code sent to the registered</Text>
<Text style={styles.mobileViewLabel}> mobile number.
<Text style={styles.changeNumber} accessible onPress={() => this.props.navigation.goBack()}> Change Number</Text>
</Text>
{/* <Text style={styles.resendCode}> Resend Code</Text> */}
<View style={styles.inputContainer}>
<TextInput
keyboardType="numeric"
maxLength={1}
value={firstDigit}
style={mobileNumberInputStyle}
onChangeText={text => this.setState({ firstDigit: text })}
/>
<TextInput
keyboardType="numeric"
maxLength={1}
value={secondDigit}
style={mobileNumberInputStyle}
onChangeText={text => this.setState({ secondDigit: text })}
/>
<TextInput
keyboardType="numeric"
maxLength={1}
value={thirdDigit}
style={mobileNumberInputStyle}
onChangeText={text => this.setState({ thirdDigit: text })}
/>
<TextInput
keyboardType="numeric"
maxLength={1}
value={fourthDigit}
style={mobileNumberInputStyle}
onChangeText={text => this.setState({ fourthDigit: text })}
/>
</View>
<TouchableOpacity
onPress={() => this.handleLoginClick()}
>
<View style={styles.buttonContainer}>
<Text style={styles.buttonText}>Login</Text>
</View>
</TouchableOpacity>
</View>
</View>
</View>
);
}
}
export default OTP;
<file_sep>/app/styles/Auth/MobileNumber.js
import COLORS from '../Common/Colors';
const style = {
overlayContainer: {
display: 'flex',
flex: 1,
position: 'absolute',
justifyContent: 'center',
alignItems: 'center',
},
mobileViewContainer: {
width: 325,
height: 275,
backgroundColor: COLORS.BACKGROUND_COLOR_SHADE,
borderRadius: 15,
justifyContent: 'center',
alignItems: 'center',
},
mobileViewLabel: {
fontSize: 20,
},
textInput: {
ios: {
fontSize: 20,
paddingTop: 25,
borderWidth: 1,
borderTopColor: 'transparent',
borderLeftColor: 'transparent',
borderRightColor: 'transparent',
borderBottomColor: 'grey',
width: '70%',
},
android: {
fontSize: 20,
paddingTop: 25,
width: '70%',
textAlign: 'center',
},
},
buttonContainer: {
marginTop: 45,
width: 180,
alignItems: 'center',
backgroundColor: COLORS.YELLOW_SHADE,
borderRadius: 15,
borderWidth: 1,
borderColor: 'black',
},
buttonText: {
fontSize: 20,
padding: 5,
color: COLORS.BLACK,
},
registrationText: {
fontSize: 16,
paddingTop: 10,
color: COLORS.WHITE,
},
};
export default style;
<file_sep>/app/component/Explore/ExploreWrapper.js
import React, { Component } from 'react';
import { Image, StyleSheet } from 'react-native';
import AppNavigationStyles from '../../styles/Explore/Explore';
import exploreImage from '../../assets/img/explore/explore.png';
import ExploreNavigation from './ExploreNavigation';
const styles = StyleSheet.create(AppNavigationStyles);
class ExploreScreen extends Component {
static navigationOptions = {
header: null,
headerMode: 'none',
tabBarLabel: 'Explore',
tabBarIcon: ({ tintColor }) => (<Image source={exploreImage} style={[styles.icon, { tintColor }]} />
),
};
render() {
return (<ExploreNavigation />);
}
}
export default ExploreScreen;
<file_sep>/app/scripts/Enums.js
const BASE_URL = {
URL: 'http://172.16.17.32',
};
const METHOD = {
POST: 'post',
GET: 'get',
};
export { BASE_URL, METHOD };
<file_sep>/app/styles/Quiz/QuizMenuTopOverlay.js
import COLORS from '../Common/Colors';
const style = {
menuItemsContainer: {
flex: 1,
position: 'absolute',
width: '100%',
height: '100%',
// zIndex: 2,
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
},
column: {
flex: 1,
backgroundColor: 'transparent',
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
},
cell1: {
flex: 1,
backgroundColor: 'transparent',
},
rowTop: {
flex: 3,
flexDirection: 'row',
backgroundColor: 'transparent',
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
},
rowMiddle: {
flex: 3,
flexDirection: 'row',
backgroundColor: 'transparent',
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
},
rowBottom: {
flex: 4,
flexDirection: 'row',
backgroundColor: 'transparent',
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
},
touchableStyle: {
ios: {
width: 33,
height: 33,
borderRadius: 15,
// backgroundColor: '#c0c0c0',
position: 'absolute',
top: '35%',
left: '25%',
alignItems: 'center',
justifyContent: 'center',
},
android: {
width: 33,
height: 33,
borderRadius: 15,
// backgroundColor: '#c0c0c0',
position: 'absolute',
top: '32%',
left: '42%',
alignItems: 'center',
justifyContent: 'center',
},
},
touchable: {
flex: 1,
},
};
export default style;
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
<file_sep>/app/component/Authentication/AuthReducer.js
// import { SplashActionTypes } from './SplashActions';
import { AuthActionTypes } from './AuthActions';
const initialState = {
token: '1d866253385f7497dd2def1a5c0adf58314788f79e014f658ce6f61e749f8b7e',
id: 'a7a24e90f734d9204c1a9be60e138bba439ff4101efa2957dc10eed067cda3b4',
username: '',
plan: '',
};
const splashReducer = (state = initialState, action) => {
switch (action.type) {
case AuthActionTypes.STORE_AUTH_TOKEN:
return { ...state, token: action.payload };
case AuthActionTypes.STORE_USER_ID:
return { ...state, id: action.payload };
case AuthActionTypes.STORE_USER_NAME:
return { ...state, username: action.payload };
case AuthActionTypes.STORE_USER_PLAN:
return { ...state, plan: action.payload };
default:
return state;
}
};
export default splashReducer;
<file_sep>/app/component/Home/Blogs/Blogs.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, Dimensions, StyleSheet, Image } from 'react-native';
import Carousel from 'react-native-snap-carousel';
import { getAllBlogs } from '../../../services/Explore';
import COLORS from '../../../styles/Common/Colors';
import DEMO_IMAGE from '../../../assets/img/home/blogs/color-graph.png';
import DEMO_IMAGE_2 from '../../../assets/img/home/blogs/type.png';
import BlogStyles from '../../../styles/Explore/Blog';
import { BlogActions } from './BlogActions';
const { width } = Dimensions.get('window');
const styles = StyleSheet.create(BlogStyles);
const entries = [2, 3, 4, 5, 6, 7];
const date = '2nd Nov 2017';
const description = 'Lorem ipsum dolor sit amet, consectetur adipiscing elit. ' +
'Vivamus tristique tortor sit amet nunc lobortis, facilisis accumsan turpis suscipit. ' +
'Curabitur id eleifend ipsum.';
@connect(store => ({ auth: store.auth, blog: store.blog }))
class Blogs extends Component {
static navigationOptions = {
title: 'Blogs',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
static propTypes = {
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
blog: PropTypes.object.isRequired,
};
componentDidMount() {
const { token, id } = this.props.auth;
const { uuid } = this.props.navigation.state.params;
const formData = new FormData();
formData.append('course_uuid', uuid);
getAllBlogs(token, id, formData)
.then(data => this.props.dispatch(BlogActions.loadCourseInfo(data)));
}
renderItem = ({ item, index }) => {
const { blog_info, blog_name: title, image_link: link } = item;
return (
<View
index={index}
style={{
width,
height: '100%',
justifyContent: 'center',
alignItems: 'center',
}}
>
<View style={styles.sliderItem}>
<View style={styles.sliderImageContainer}>
<Image
style={styles.sliderImage}
source={{ uri: link }}
resizeMode="cover"
/>
</View>
</View>
</View>
);
};
render() {
const { data } = this.props.blog;
return (data.length === 0 ? (<Text>Loading...</Text>) :
(
<View>
<View style={styles.carouselContainer}>
<Carousel
ref={(c) => { this._carousel = c; }}
data={data}
renderItem={this.renderItem}
sliderWidth={width}
itemWidth={width}
/>
</View>
<View style={styles.titleContainer}>
<Text style={styles.chapter}>Chapter 4/10</Text>
<Text style={styles.title}>Basic Color Harmonies Used in Design</Text>
<View style={{ justifyContent: 'center', alignItems: 'center' }}>
<Image
style={{ width: 150, height: 150 }}
source={DEMO_IMAGE_2}
resizeMode="contain"
/>
<Text style={styles.chapter}>Read</Text>
</View>
</View>
</View>
)
);
}
}
export default Blogs;
//
// <View style={{}}>
// <Image
// style={{}}
// source={DEMO_IMAGE}
// resizeMode="cover"
// />
// <Text style={styles.chapter}>Read</Text>
// </View>;
//
// <View style={styles.sliderTextContentContainer}>
// <View style={styles.headerContainer}>
// <View style={styles.titleContainer}>
// <Text style={styles.title}>{title}</Text>
// </View>
// <View style={styles.dateContainer}>
// <Text style={styles.date}>{date}</Text>
// </View>
// </View>
// <View style={styles.descriptionContainer}>
// <Text style={styles.description}>{description}</Text>
// </View>
// <TouchableOpacity style={styles.readMoreContainer}>
// <Text style={styles.readMoreText}>Read More</Text>
// </TouchableOpacity>
// </View>
<file_sep>/app/component/Home/Common/SecondView.js
import React, { Component } from 'react';
import PropTypes from 'prop-types';
import { Text, View, StyleSheet, Image, ScrollView } from 'react-native';
import COLORS from '../../../styles/Common/Colors';
import StoryStyles from '../../../styles/Explore/StoryDetails';
// const date = '2nd Nov 2017';
const styles = StyleSheet.create(StoryStyles);
class StoryDetails extends Component {
static navigationOptions = ({ navigation }) => ({
// header: null,
// headerMode: 'none',
title: `${navigation.state.params.header} - ${navigation.state.params.course}`,
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE, fontSize: 16 },
});
static propTypes = {
navigation: PropTypes.object.isRequired,
};
render() {
const { url, title, details, date } = this.props.navigation.state.params;
return (
<View>
<View style={styles.imageView}>
<View>
<Image
accessible
source={{ uri: url }}
style={styles.clickableImageStyle}
resizeMode="cover"
/>
</View>
</View>
<View style={styles.textView}>
<View style={styles.titleAndDateContainer}>
<View style={styles.titleContainer}>
<Text style={styles.titleText}>{title}</Text>
</View>
<View style={styles.dateContainer}>
<Text style={styles.date}>{date}</Text>
</View>
</View>
<View style={styles.storyContainer}>
<ScrollView>
<Text style={styles.story}>{details}</Text>
</ScrollView>
</View>
</View>
</View>
);
}
}
export default StoryDetails;
// import DemoImage from '../../../assets/img/home/stories/story-demo-2.png';
// const title = 'What really matters in the world of design';
// const story = 'Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus tristique tortor sit amet nunc lobortis, ' +
// 'facilisis accumsan turpis suscipit. Curabitur id eleifend ipsum. Aenean et tortor sollicitudin, ' +
// 'dignissim odio quis, lobortis nisi. Praesent nec auctor turpis. Donec ac tincidunt est. Integer suscipit ' +
// 'luctus luctus. Vestibulum eleifend purus id ipsum rutrum interdum. Duis porta mauris ipsum, vehicula rutrum ' +
// 'urna placerat ut. Etiam a odio elit. Cras scelerisque auctor massa, et rutrum mi pretium id. ' +
// 'Aenean sit amet nibh pretium, lobortis nisl ac, tristique mi. Nullam blandit cursus felis a elementum. ' +
// 'Vestibulum eget mollis eros, et accumsan tellus. Pellentesque habitant morbi tristique senectus et netus et' +
// ' malesuada fames ac turpis egestas. Suspendisse viverra magna justo, convallis porttitor erat auctor vitae.' +
// 'Nulla bibendum consectetur nisi, congue varius leo ultrices vel. Vestibulum consectetur facilisis erat ' +
// 'vitae efficitur. Morbi nec sollicitudin ante. Donec purus lorem, tempor in vehicula vel, viverra at nisi. ' +
// 'Etiam tincidunt sem lectus, in rutrum augue dignissim ornare. Class aptent taciti sociosqu ad litora ' +
// 'torquent per conubia nostra, per inceptos himenaeos. Phasellus elementum suscipit est luctus ultricies. ' +
// 'Curabitur facilisis ante eget erat convallis, sed suscipit lacus laoreet. Praesent sollicitudin viverra ' +
// 'orci id porta. Vivamus malesuada lacinia faucibus. Duis lacinia fermentum fermentum. Sed in varius magna. ' +
// 'Fusce pharetra elementum est sit amet bibendum. Etiam lectus tortor, vulputate ut fermentum at, pharetra at ' +
// 'ex. Donec vehicula elit scelerisque lorem scelerisque, ac auctor lacus tincidunt. Fusce fringilla ' +
// 'suscipit orci eu pharetra. Donec vestibulum massa hendrerit varius tempor.';
<file_sep>/app/styles/More/Help.js
import COLORS from '../Common/Colors';
const style = {
title: {
fontSize: 20,
fontWeight: '400',
padding: '5%',
},
paragraph: {
fontSize: 18,
fontWeight: '300',
padding: '5%',
textAlign: 'justify',
},
container: {
flex: 1,
backgroundColor: COLORS.WHITE,
},
linkContainer: {
flex: 1,
backgroundColor: COLORS.BACKGROUND_COLOR_SHADE,
justifyContent: 'space-around',
alignItems: 'center',
},
linkText: {
fontSize: 18,
},
button: {
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
padding: 10,
borderRadius: 5,
},
buttonText: {
fontSize: 20,
color: COLORS.WHITE,
},
phoneNumberContainer: {
flex: 1,
justifyContent: 'center',
alignItems: 'center',
},
emailContainer: {
flex: 1,
justifyContent: 'center',
alignItems: 'center',
},
phoneCallToAction: {
flexDirection: 'row',
borderWidth: 1,
borderStyle: 'solid',
borderColor: COLORS.BACKGROUND_COLOR_PRIMARY,
justifyContent: 'space-around',
alignItems: 'center',
padding: 10,
width: 250,
borderRadius: 5,
},
phoneIcon: {
width: 35,
height: 35,
},
phoneText: {
fontSize: 22,
fontWeight: '300',
},
phoneInfoText: {
fontSize: 18,
fontWeight: '300',
padding: 10,
},
emailCallToAction: {
flexDirection: 'row',
borderWidth: 1,
borderStyle: 'solid',
borderColor: COLORS.BACKGROUND_COLOR_PRIMARY,
justifyContent: 'space-around',
alignItems: 'center',
padding: 10,
width: 300,
borderRadius: 5,
},
emailText: {
fontSize: 16,
fontWeight: '300',
},
};
export default style;
<file_sep>/app/component/ScoreCard/ScoreCardActions.js
const ScoreCardActionTypes = {
LOAD_DATA: 'ScoreCard/LOAD_DATA',
LOAD_TIME_SPENT: 'ScoreCard/LOAD_TIME_SPENT',
};
const ScoreCardActions = {
loadInfo: payload => ({ type: ScoreCardActionTypes.LOAD_DATA, payload }),
loadCourseInfo: payload => (dispatch) => {
const { data } = payload;
// const courseData = data.slice(0, data.length - 1);
dispatch(ScoreCardActions.loadInfo(data));
},
loadTotalTimeSpent: payload => ({ type: ScoreCardActionTypes.LOAD_TIME_SPENT, payload }),
};
export {
ScoreCardActionTypes,
ScoreCardActions,
};
<file_sep>/app/styles/Explore/Blog.js
import COLORS from '../Common/Colors';
const style = {
icon: {
width: 28,
height: 13,
},
carouselContainer: {
// justifyContent: 'center',
// alignItems: 'center',
// paddingTop: 0,
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
height: '55%',
},
sliderItem: {
backgroundColor: 'white',
shadowColor: '#615f61',
shadowOffset: { width: 0, height: 2 },
shadowOpacity: 0.75,
elevation: 1,
// width: '60%',
// height: '90%',
justifyContent: 'center',
alignContent: 'center',
borderRadius: 10,
},
sliderImageContainer: {
justifyContent: 'center',
alignItems: 'center',
width: 200,
height: 200,
padding: 10,
},
sliderImage: {
width: '100%',
height: '100%',
borderRadius: 10,
},
chapter: {
fontSize: 16,
// color: COLORS.WHITE,
fontWeight: '400',
},
title: {
fontSize: 20,
// color: COLORS.WHITE,
fontWeight: '400',
},
titleContainer: {
justifyContent: 'center',
alignItems: 'center',
},
};
export default style;
//
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
//
// sliderTextContentContainer: {
// width: '100%',
// height: '60%',
// padding: 15,
// },
// headerContainer: {
// flexDirection: 'row',
// },
// titleContainer: {
// width: '70%',
// },
// dateContainer: {
// width: '30%',
// justifyContent: 'flex-end',
// alignItems: 'flex-end',
// },
// date: {
// fontSize: 12,
// color: COLORS.WHITE,
// },
// descriptionContainer: {
// paddingTop: 15,
// paddingBottom: 15,
// },
// description: {
// fontSize: 18,
// color: COLORS.WHITE,
// textAlign: 'justify',
// height: '70%',
// },
// readMoreText: {
// color: COLORS.WHITE,
// },
// readMoreContainer: {
// justifyContent: 'flex-end',
// alignItems: 'center',
// },
<file_sep>/app/styles/Quiz/QuizAnalysis.js
import COLORS from '../Common/Colors';
const style = {
headerContainer: {
marginTop: 20,
width: '80%',
height: 125,
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
borderRadius: 10,
flexDirection: 'row',
justifyContent: 'space-between',
padding: 20,
alignItems: 'flex-end',
},
};
export default style;
//
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
<file_sep>/app/component/Explore/Explore.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, StyleSheet, Image, TouchableOpacity, Dimensions } from 'react-native';
import { Container, DeckSwiper } from 'native-base';
import COLORS from '../../styles/Common/Colors';
import HomeStyles from '../../styles/Explore/Home';
import LOGO from '../../assets/img/home/graphics-design/course-logo.png';
import VIDEO_ICON from '../../assets/img/home/graphics-design/video.png';
import BLOG from '../../assets/img/home/graphics-design/blogs.png';
import STORIES from '../../assets/img/home/graphics-design/stories.png';
import PROJECTS from '../../assets/img/home/graphics-design/projects.png';
import { getAllCourse } from '../../services/Explore';
import { ExploreActions } from './ExploreActions';
const styles = StyleSheet.create(HomeStyles);
const height = Dimensions.get('window').height - 150;
@connect(store => ({ auth: store.auth, explore: store.explore }))
class Home extends Component {
static propTypes = {
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
explore: PropTypes.object.isRequired,
};
static navigationOptions = {
title: 'Home',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE, alignSelf: 'flex-start' },
};
componentDidMount() {
const { token, id } = this.props.auth;
getAllCourse(token, id)
.then(data => this.props.dispatch(ExploreActions.loadData(data)))
.catch(err => console.log(err));
}
renderItem = (item) => {
const { course_name: course, uuid } = item;
return (
<View style={{ ...HomeStyles.container, height }}>
<View style={styles.courseCard}>
<View style={styles.columnLeft}>
<View style={styles.courseLogoContainer}>
{/* <View style={styles.courseLogoIconContainer}> */}
<Image
style={styles.courseIcon}
source={LOGO}
resizeMode="contain"
/>
{/* </View> */}
<Text style={styles.label}>{course}</Text>
</View>
<View style={styles.courseVideoContainer}>
<TouchableOpacity
style={styles.videoIconContainer}
onPress={() => this.props.navigation.navigate('Video', { uuid, plan: this.props.explore.plan })}
>
<Image
style={styles.videoIcon}
source={VIDEO_ICON}
resizeMode="contain"
/>
</TouchableOpacity>
<Text style={styles.label}>Video</Text>
</View>
<View style={styles.seeJourney}>
<TouchableOpacity
style={styles.seeJourneyContainer}
onPress={() => this.props.navigation.navigate('Journey', { uuid })}
>
<Text style={styles.seeJourneyLabel}>
See Journey
</Text>
</TouchableOpacity>
</View>
</View>
<View style={styles.columnRight}>
<View style={styles.courseActivity}>
<TouchableOpacity
style={styles.courseActivityIconContainer}
onPress={() => this.props.navigation.navigate('Story', { uuid, plan: this.props.explore.plan, course })}
>
<Image
source={STORIES}
style={styles.courseActivityIcon}
resizeMode="contain"
/>
</TouchableOpacity>
<Text style={styles.label}>Stories</Text>
</View>
<View style={styles.courseActivity}>
<TouchableOpacity
style={styles.courseActivityIconContainer}
onPress={() => this.props.navigation.navigate('Projects', { uuid, plan: this.props.explore.plan, course })}
>
<Image
source={PROJECTS}
style={styles.courseActivityIcon}
resizeMode="contain"
/>
</TouchableOpacity>
<Text style={styles.label}>Projects</Text>
</View>
<View style={styles.courseActivity}>
<TouchableOpacity
style={styles.courseActivityIconContainer}
onPress={() => this.props.navigation.navigate('Blog', { uuid, plan: this.props.explore.plan, course })}
>
<Image
source={BLOG}
style={styles.courseActivityIcon}
resizeMode="contain"
/>
</TouchableOpacity>
<Text style={styles.label}>Blog</Text>
</View>
</View>
</View>
</View>);
};
render() {
const { data } = this.props.explore;
return (data.length > 0 ?
(
<View style={{ flex: 1 }}>
<Container>
<DeckSwiper
dataSource={data}
renderItem={this.renderItem}
/>
</Container>
</View>
)
:
<Text>Loading</Text>);
}
}
export default Home;
<file_sep>/app/component/Quiz/QuizNavigation.js
import { StackNavigator } from 'react-navigation';
import Quiz from './Quiz';
import QuizAnalysis from './QuizAnalysis';
import QuestionAnswer from './QuestionAnswer';
const Routes = {
Quiz: { screen: Quiz },
QuizAnalysis: { screen: QuizAnalysis },
QuestionAnswer: { screen: QuestionAnswer },
};
export default StackNavigator(Routes);
<file_sep>/app/component/AppNavigation.js
/* eslint-disable react/no-multi-comp */
// import React, { Component } from 'react';
// import { Text, View, Button, StyleSheet, Image } from 'react-native';
// import Quiz from './Quiz/Quiz';
import { TabNavigator } from 'react-navigation';
import Explore from './Explore/ExploreWrapper';
import ScoreCard from './ScoreCard/ScoreCardWrapper';
import More from './More/MoreWrapper';
import Quiz from './Quiz/QuizWrapper';
import COLORS from '../styles/Common/Colors';
const Routes = {
Explore: { screen: Explore },
Quiz: { screen: Quiz },
ScoreCard: { screen: ScoreCard },
More: { screen: More },
};
const NavigationOptions = {
tabBarPosition: 'bottom',
animationEnabled: true,
swipeEnabled: false,
mode: 'modal',
tabBarOptions: {
activeTintColor: COLORS.BACKGROUND_COLOR_SECONDARY,
inactiveTintColor: COLORS.BACKGROUND_COLOR_SHADE,
showIcon: true,
labelStyle: { fontSize: 12 },
tabStyle: { width: 100 },
upperCaseLabel: false,
allowFontScaling: false,
style: {
backgroundColor: COLORS.WHITE,
},
},
};
export default TabNavigator(Routes, NavigationOptions);
<file_sep>/app/component/Home/Stories/Stories.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, Image, ScrollView, TouchableOpacity, Platform } from 'react-native';
import moment from 'moment';
import { getAllStory } from '../../../services/Explore';
import COLORS from '../../../styles/Common/Colors';
import StoryStyles from '../../../styles/Explore/Stories';
import { StoryActions } from './StoryActions';
@connect(store => ({ auth: store.auth, story: store.story }))
class Stories extends Component {
static navigationOptions = {
// header: null,
// headerMode: 'none',
title: 'Stories',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
static propTypes = {
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
story: PropTypes.object.isRequired,
};
state = {
selectedIndex: 0,
};
componentDidMount() {
const { token, id } = this.props.auth;
const { uuid } = this.props.navigation.state.params;
const formData = new FormData();
formData.append('course_uuid', uuid);
getAllStory(token, id, formData)
.then(data => this.props.dispatch(StoryActions.loadCourseInfo(data)));
}
selectThisItem = index => this.setState({ selectedIndex: index });
renderItem = (item, index) => {
const { image_link: image } = item;
return (
<TouchableOpacity
key={index}
onPress={() => this.selectThisItem(index)}
style={{
paddingLeft: 10,
paddingRight: 10,
alignItems: 'center',
justifyContent: 'center',
}}
>
<Image
source={{ uri: image }}
style={
index === this.state.selectedIndex ?
Platform.select(StoryStyles.storyPickerImageStyle) :
StoryStyles.storyPickerImageNotSelected
}
resizeMode="contain"
/>
</TouchableOpacity>
);
};
render() {
const { selectedIndex } = this.state;
const { course } = this.props.navigation.state.params;
return (this.props.story.data.length === 0 ?
<Text>Loading...</Text> :
<View style={{ flex: 1 }}>
<ScrollView horizontal style={{ flex: 2 }}>
<View style={StoryStyles.scrollListContainer}>
{this.props.story.data.map((item, index) => this.renderItem(item, index))}
</View>
</ScrollView>
<View style={{ flex: 3 }}>
<View style={StoryStyles.storyHeaderContainer}>
<View>
<Image
accessible
source={{ uri: this.props.story.data[this.state.selectedIndex].image_link }}
style={StoryStyles.clickableImageStyle}
resizeMode="cover"
/>
</View>
</View>
<View style={StoryStyles.quoteContainer}>
<Text style={StoryStyles.quoteText}>
{this.props.story.data[selectedIndex].story_details || null}
</Text>
</View>
<View style={StoryStyles.bottomViewContainer}>
<View style={StoryStyles.titleContainer}>
<Text style={StoryStyles.titleText}>
{this.props.story.data[selectedIndex].story_name}
</Text>
</View>
</View>
<TouchableOpacity
style={StoryStyles.touchableNav}
onPress={() => this.props.navigation.navigate(
'Detail',
{
header: 'Stories',
course,
url: this.props.story.data[this.state.selectedIndex].image_link,
title: this.props.story.data[selectedIndex].story_name,
details: this.props.story.data[selectedIndex].story_details,
date: moment().format('DD-MM-YYYY'),
},
)}
/>
</View>
</View>
);
}
}
export default Stories;
<file_sep>/app/styles/ScoreCard/Header.js
import COLORS from '../Common/Colors';
/* Actual Scorecard Styles */
const style = {
sectionHeader: {
height: 200,
flexDirection: 'row',
},
quizPlayedSection: {
width: '30%',
justifyContent: 'flex-end',
marginBottom: '10%',
alignItems: 'center',
},
logoSection: {
width: '40%',
justifyContent: 'center',
alignItems: 'center',
},
hoursSpentSection: {
width: '30%',
justifyContent: 'flex-end',
marginBottom: '10%',
},
backgroundImageContainer: {
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
position: 'absolute',
opacity: 1,
},
backgroundImage: {
width: 150,
height: 100,
borderRadius: 10,
},
logoText: {
paddingTop: '5%',
fontSize: 22,
color: COLORS.WHITE,
backgroundColor: 'transparent',
},
hoursSpentSectionOneContainer: {
flexDirection: 'row',
justifyContent: 'center',
alignItems: 'flex-end',
},
hoursSpentNumeric: {
fontSize: 30,
backgroundColor: 'transparent',
color: COLORS.YELLOW_SHADE,
},
hoursSpentUnit: {
fontSize: 18,
backgroundColor: 'transparent',
color: COLORS.YELLOW_SHADE,
},
hourSpentLabel: {
fontSize: 14,
backgroundColor: 'transparent',
color: COLORS.WHITE,
fontWeight: '400',
},
quizPlayedSectionOneContainer: {
flexDirection: 'row',
justifyContent: 'center',
alignItems: 'flex-end',
},
quizPlayedNumeric: {
fontSize: 30,
backgroundColor: 'transparent',
color: COLORS.YELLOW_SHADE,
},
quizPlayedUnit: {
fontSize: 18,
backgroundColor: 'transparent',
color: COLORS.YELLOW_SHADE,
},
quizPlayedLabel: {
fontSize: 14,
backgroundColor: 'transparent',
color: COLORS.WHITE,
fontWeight: '400',
},
};
export default style;
//
// borderColor: 'purple',
// borderWidth: 1,
// borderStyle: 'solid',
<file_sep>/app/scripts/Http.js
/* eslint-disable no-underscore-dangle */
const raiseStatus = (response) => {
console.log('Raw Response', response);
if (response.status === 200) {
return JSON.parse(response._bodyText);
}
/* TODO: Add remaining handlers */
throw new Error({ message: 'Fetch Failed', status: response.status });
};
export default raiseStatus;
<file_sep>/app/component/Home/Blogs/BlogReducer.js
// import { SplashActionTypes } from './SplashActions';
import { BlogActionTypes } from './BlogActions';
const initialState = {
data: [],
};
const blogReducer = (state = initialState, action) => {
switch (action.type) {
case BlogActionTypes.LOAD_DATA:
return { ...state, data: action.payload };
default:
return state;
}
};
export default blogReducer;
<file_sep>/app/component/ScoreCard/Search.js
import React, { Component } from 'react';
import PropTypes from 'prop-types';
import { Text, View, TextInput, Image, Platform, ScrollView, TouchableOpacity } from 'react-native';
import SearchStyles from '../../styles/ScoreCard/ScoreCard';
import COLORS from '../../styles/Common/Colors';
import SearchIcon from '../../assets/img/score-card/search.png';
/* Temporary Imports */
import Architecture from '../../assets/img/score-card/architecture.png';
import GraphicDesign from '../../assets/img/score-card/graphic-design.png';
import Pilot from '../../assets/img/score-card/pilot.png';
const baseUrl = '../../assets/img/score-card/';
const courses = [
{ icon: Architecture, title: 'Architecture' },
{ icon: GraphicDesign, title: 'Graphic Design' },
{ icon: Pilot, title: 'Pilot' },
{ icon: Architecture, title: 'Software Engineer' },
{ icon: GraphicDesign, title: 'Chartered Accountant' },
{ icon: Pilot, title: 'Aeronautical Engineer' },
{ icon: Architecture, title: 'Marine Biologist' },
{ icon: GraphicDesign, title: 'Geologist' },
{ icon: Pilot, title: 'Astronaut' },
{ icon: Architecture, title: 'Cartoonist' },
{ icon: GraphicDesign, title: 'Game Developer' },
{ icon: Pilot, title: 'Nuclear Scientist' },
];
class Search extends Component {
static navigationOptions = {
title: 'Score Card',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
static propTypes = {
navigation: PropTypes.object.isRequired,
};
render() {
return (
<View style={SearchStyles.parent}>
<View style={SearchStyles.searchSection}>
<View style={SearchStyles.searchInputContainer}>
<View style={SearchStyles.textInputContainer}>
<TextInput
placeholder="Search a career"
style={Platform.select(SearchStyles.textInput)}
autoCorrect={false}
underlineColorAndroid="transparent"
/>
</View>
<View style={SearchStyles.searchIconContainer}>
<Image
source={SearchIcon}
style={SearchStyles.searchIcon}
resizeMode="contain"
/>
</View>
</View>
</View>
<View style={SearchStyles.resultSection}>
<ScrollView>
{
courses.map(result => (
<TouchableOpacity
style={SearchStyles.resultItemContainer}
key={result.title}
onPress={() => this.props.navigation.navigate('ScoreCard')}
>
<View>
<Image
source={result.icon}
style={SearchStyles.resultIcon}
/>
</View>
<View style={SearchStyles.resultTextContainer}>
<Text style={SearchStyles.resultText}>{result.title}</Text>
</View>
</TouchableOpacity>
))
}
</ScrollView>
</View>
</View>
);
}
}
export default Search;
<file_sep>/app/component/Quiz/Quiz.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, Dimensions, Image } from 'react-native';
// import { Button, Icon, Fab } from 'native-base';
import Carousel from 'react-native-snap-carousel';
import { getQuizStatus } from '../../services/Quiz';
import COLORS from '../../styles/Common/Colors';
import CourseLogo from '../../assets/img/quiz/course-logo.png';
import QuizMenuBackground from '../../assets/img/quiz/quiz-background-1.png';
import QuizStyles from '../../styles/Quiz/Quiz';
import { QuizActions } from './QuizActions';
import QuizMenuBackgroundLayout from './QuizMenuBackground';
import QuizMenuTopOverlay from './QuizMenuTopOverlay';
const { width } = Dimensions.get('window');
@connect(store => ({ auth: store.auth, quiz: store.quiz, explore: store.explore }))
class Quiz extends Component {
static navigationOptions = {
title: 'Quizzes',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
static propTypes = {
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
quiz: PropTypes.object.isRequired,
explore: PropTypes.object.isRequired,
};
componentDidMount() {
const { token, id } = this.props.auth;
// const { uuid } = this.props.navigation.state.params;
const formData = new FormData();
formData.append('course_uuid', 'cede100d9c76');
getQuizStatus(token, id, formData)
.then(data => this.props.dispatch(QuizActions.loadCourseInfo(data)));
}
componentWillReceiveProps(nextProps) {
if (nextProps && (this.props.quiz.currentIndex !== nextProps.quiz.currentIndex)) {
const { token, id } = this.props.auth;
const { data: courses } = this.props.explore;
const { currentIndex } = nextProps.quiz;
const course_uuid = courses[currentIndex].uuid;
const formData = new FormData();
// formData.append('course_uuid', course_uuid);
formData.append('course_uuid', 'cede100d9c76');
getQuizStatus(token, id, formData)
.then(data => this.props.dispatch(QuizActions.loadCourseInfo(data)));
}
}
startQuiz = (quizIndex) => {
const { token, id } = this.props.auth;
const { data: courses } = this.props.explore;
const { currentIndex, quizObject } = this.props.quiz;
const courseUUID = courses[currentIndex].uuid;
const formData = new FormData();
// formData.append('course_uuid', courseUUID);
formData.append('course_uuid', 'cede100d9c76'); // Remove hardcoded stuff
formData.append('uuid', quizIndex.uuid);
getQuizStatus(token, id, formData)
.then((data) => {
this.props.dispatch(QuizActions.loadQuizQuestions(data));
this.props.navigation.navigate('QuestionAnswer', { courseId: 'cede100d9c76' }); // Remove hardcoded
})
.catch(() => { /* Handle Catch */ });
};
renderItem = ({ item, index }) => (
<View style={{
width,
height: '100%',
justifyContent: 'flex-start',
alignItems: 'center',
backgroundColor: COLORS.WHITE,
}}
>
<View style={QuizStyles.sliderItem}>
<View style={QuizStyles.sliderItemHeader}>
<View style={QuizStyles.scoreContainer}>
<Text style={QuizStyles.highlightedText}>7</Text>
<Text style={QuizStyles.infoText}>Average Score</Text>
</View>
<View style={QuizStyles.courseLogoContainer}>
<Image
source={CourseLogo}
style={QuizStyles.logo}
/>
<Text style={QuizStyles.courseTitle}>{item.course_name.slice(0, 20)}</Text>
</View>
<View style={QuizStyles.countContainer}>
<View style={QuizStyles.highlightedQuizIndexContainer}>
<Text style={QuizStyles.highlightedText}>4</Text>
<Text style={QuizStyles.quizCountText}> /10</Text>
</View>
<Text style={QuizStyles.infoText}>Quizzes Played</Text>
</View>
</View>
<View style={QuizStyles.menuContainer}>
<QuizMenuBackgroundLayout />
<Image
source={QuizMenuBackground}
style={QuizStyles.backgroundImage}
resizeMode="cover"
/>
<QuizMenuTopOverlay
touchableActionHandler={this.startQuiz}
quizList={this.props.quiz.data}
/>
</View>
</View>
</View>
);
handleScroll = () => {
if (this.props.quiz.currentIndex !== this.carousel.currentIndex) {
this.props.dispatch(QuizActions.updateCurrentIndex(this.carousel.currentIndex));
}
};
render() {
const { data: courses } = this.props.explore;
const { data: quizData } = this.props.quiz;
return (courses.length === 0 ?
(<Text>Loading...</Text>) :
(
<View style={{ backgroundColor: COLORS.WHITE }}>
<Carousel
ref={(c) => { this.carousel = c; }}
data={courses}
renderItem={this.renderItem}
sliderWidth={width}
itemWidth={width}
onScroll={() => this.handleScroll()}
/>
</View>
)
);
}
}
export default Quiz;
// state = {
// isModalVisible: false,
// fabActive: false,
// };
// showModal = () => this.setState({ isModalVisible: true });
//
// hideModal = () => this.setState({ isModalVisible: false });
//
// handleFabClick = () =>
// this.setState({ fabActive: !this.state.fabActive, isModalVisible: true });
//
// <Carousel
// ref={(c) => { this._carousel = c; }}
// data={entries}
// renderItem={this.renderItem}
// sliderWidth={width}
// itemWidth={itemWidth}
// />
//
// renderItem = ({ item, index }) => (
// <View
// index={index}
// style={{
// width: itemWidth,
// paddingHorizontal: horizontalMargin,
// height: '100%',
// justifyContent: 'center',
// alignItems: 'center',
// borderStyle: 'solid',
// borderColor: 'red',
// borderWidth: 1,
// }}
// >
// <View style={{ styles.sliderItem}}>
// <View style={styles.sliderImageContainer}>
// <Image
// style={styles.sliderImage}
// source={DEMO_IMAGE}
// resizeMode="cover"
// />
// </View>
// <View style={styles.sliderTextContentContainer}>
// <View style={styles.headerContainer}>
// <View style={styles.titleContainer}>
// <Text style={styles.title}>{title}</Text>
// </View>
// <View style={styles.dateContainer}>
// <Text style={styles.date}>{date}</Text>
// </View>
// </View>
// <View style={styles.descriptionContainer}>
// <Text style={styles.description}>{description}</Text>
// </View>
// <TouchableOpacity style={styles.readMoreContainer}>
// <Text style={styles.readMoreText}>Read More</Text>
// </TouchableOpacity>
// </View>
// </View>
// </View>
// );
//
// <View style={{ flex: 1 }}>
// <TouchableOpacity onPress={this.showModal}>
// <Text>Show Modal</Text>
// </TouchableOpacity>
// <Modal isVisible={this.state.isModalVisible}>
// <View style={{ flex: 1 }}>
// <Text>Hello!</Text>
// <TouchableOpacity onPress={this.hideModal}>
// <Text>Hide Modal</Text>
// </TouchableOpacity>
// </View>
// </Modal>
// </View>
//
// <Icon name="search" />
// <Button style={{ backgroundColor: '#34A34F' }}>
// <Icon name="logo-whatsapp" />
// </Button>
// <Button style={{ backgroundColor: '#3B5998' }}>
// <Icon name="logo-facebook" />
// </Button>
// <Button disabled style={{ backgroundColor: '#DD5144' }}>
// <Icon name="mail" />
// </Button>
//
// <Fab
// active={this.state.fabActive}
// direction="up"
// style={{ backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY }}
// position="bottomRight"
// onPress={() => this.handleFabClick()}
// >
// <Icon name="search" />
// </Fab>
// <Modal isVisible={this.state.isModalVisible}>
// <View style={{ flex: 1 }}>
// <Text>Hello!</Text>
// <TouchableOpacity onPress={this.hideModal}>
// <Text>Hide Modal</Text>
// </TouchableOpacity>
// </View>
// </Modal>
<file_sep>/app/component/Home/Journey/Journey.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, Image, ScrollView, Platform, TouchableOpacity, Dimensions } from 'react-native';
import { getJourney } from '../../../services/Explore';
import COLORS from '../../../styles/Common/Colors';
import JourneyStyles from '../../../styles/Explore/Journey';
import Background from '../../../assets/img/journey/journey-background.png';
import Assessment from '../../../assets/img/journey/assesments.png';
import Professionals from '../../../assets/img/journey/professionals.png';
import Launch from '../../../assets/img/journey/launch.png';
import Stories from '../../../assets/img/journey/stories.png';
import Blog from '../../../assets/img/journey/blogs.png';
import Projects from '../../../assets/img/journey/projects.png';
const { height } = Dimensions.get('window');
// const styles = StyleSheet.create(JourneyStyles);
@connect(store => ({ auth: store.auth }))
class Journey extends Component {
static navigationOptions = {
title: 'Journey',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
state = {
storiesRead: 0,
projectsCompleted: 0,
blogsRead: 0,
totalStories: 0,
totalProjects: 0,
totalBlogs: 10,
};
static propTypes = {
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
};
componentDidMount() {
const { token, id } = this.props.auth;
const { uuid } = this.props.navigation.state.params;
const formData = new FormData();
formData.append('course_uuid', uuid);
getJourney(token, id, formData)
.then(response => this.updateJourneyData(response.data));
}
updateJourneyData = (data) => {
const {
stories_attempted: storiesRead,
projects_attempted: projectsCompleted,
blogs_attempted: blogsRead,
total_stories: totalStories,
total_projects: totalProjects,
total_blogs: totalBlogs,
} = data;
this.setState({
storiesRead, projectsCompleted, blogsRead, totalStories, totalProjects, totalBlogs,
});
};
render() {
const {
storiesRead, projectsCompleted, blogsRead, totalStories, totalProjects, totalBlogs,
} = this.state;
return (
<View>
<ScrollView>
<View>
<Image
style={Platform.select(JourneyStyles.background)}
source={Background}
resizeMode="contain"
/>
<View style={JourneyStyles.infoOverlay}>
<View style={JourneyStyles.sectionOne}>
<View>
<Image
source={Assessment}
style={{ width: 150, height: 150 }}
resizeMode="contain"
/>
</View>
<View style={JourneyStyles.sectionAssessmentInfo}>
<View style={JourneyStyles.sectionNumberLabelContainer}>
<Text style={JourneyStyles.sectionLabel}>1</Text>
</View>
<TouchableOpacity style={JourneyStyles.sectionLabelContainer}>
<Text style={JourneyStyles.sectionLabel}>Assesments </Text>
</TouchableOpacity>
</View>
</View>
<View style={JourneyStyles.sectionTwo}>
<View style={JourneyStyles.sectionTwoParent}>
<View style={JourneyStyles.sectionTwoItemContainer}>
<View>
<View style={JourneyStyles.sectionTwoImageContainer}>
<Image
source={Stories}
style={JourneyStyles.sectionTwoImage}
resizeMode="contain"
/>
</View>
<Text style={JourneyStyles.sectionTwoLabel}>Stories</Text>
<Text style={JourneyStyles.sectionTwoLabel}>{storiesRead}/{totalStories}</Text>
</View>
<View>
<View style={JourneyStyles.sectionTwoImageContainer}>
<Image
source={Projects}
style={JourneyStyles.sectionTwoImage}
resizeMode="contain"
/>
</View>
<Text style={JourneyStyles.sectionTwoLabel}>Projects</Text>
<Text style={JourneyStyles.sectionTwoLabel}>{projectsCompleted}/{totalProjects}</Text>
</View>
<View>
<View style={JourneyStyles.sectionTwoImageContainer}>
<Image
source={Blog}
style={JourneyStyles.sectionTwoImage}
resizeMode="contain"
/>
</View>
<Text style={JourneyStyles.sectionTwoLabel}>Blogs</Text>
<Text style={JourneyStyles.sectionTwoLabel}>{blogsRead}/{totalBlogs}</Text>
</View>
</View>
<View style={JourneyStyles.sectionTwoNumericLabel}>
<Text style={JourneyStyles.sectionLabel}>2</Text>
</View>
</View>
</View>
<View style={JourneyStyles.sectionThree}>
<View style={JourneyStyles.sectionJourneyProfessionalsImageContainer}>
<Image
source={Professionals}
style={Platform.select(JourneyStyles.sectionProfessionalsImage)}
resizeMode="contain"
/>
</View>
<View style={JourneyStyles.sectionProfessionals}>
<View style={JourneyStyles.sectionNumberLabelContainer}>
<Text style={JourneyStyles.sectionLabel}>3</Text>
</View>
<TouchableOpacity style={JourneyStyles.sectionLabelContainer}>
<Text style={JourneyStyles.sectionLabel}>Meet Real Life Professionals</Text>
</TouchableOpacity>
</View>
</View>
<View style={JourneyStyles.sectionFour}>
<View style={JourneyStyles.sectionJourneyLaunchImageContainer}>
<Image
source={Launch}
style={JourneyStyles.sectionLaunchImage}
resizeMode="contain"
/>
</View>
<View style={JourneyStyles.sectionLaunch}>
<TouchableOpacity style={JourneyStyles.sectionLaunchLabelContainer}>
<Text style={JourneyStyles.sectionLabel}>
Experience through junior internship & gain social skills
</Text>
</TouchableOpacity>
<View style={JourneyStyles.sectionLaunchNumberLabelContainer}>
<Text style={JourneyStyles.sectionLabel}>4</Text>
</View>
</View>
</View>
</View>
</View>
</ScrollView>
</View>
);
}
}
export default Journey;
<file_sep>/app/styles/Explore/StoryDetails.js
import COLORS from '../Common/Colors';
const style = {
imageView: {
height: '40%',
},
textView: {
height: '60%',
backgroundColor: COLORS.WHITE,
padding: 20,
},
clickableImageStyle: {
width: '100%',
height: 400,
},
dateContainer: {
width: '25%',
justifyContent: 'flex-end',
},
date: {
fontSize: 10,
},
titleText: {
fontSize: 16,
},
titleContainer: {
width: '75%',
paddingRight: 5,
},
titleAndDateContainer: {
flexDirection: 'row',
},
storyContainer: {
flex: 1,
paddingTop: 20,
// borderWidth: 1,
// borderStyle: 'solid',
// borderColor: 'red',
},
story: {
textAlign: 'justify',
},
};
export default style;
<file_sep>/app/services/Explore.js
/**
* global fetch
*/
import { BASE_URL, METHOD } from '../scripts/Enums';
import raiseStatus from '../scripts/Http';
// const auth = 'c3<PASSWORD>a9f<PASSWORD>31ca021ad3<PASSWORD>38773f3913ffab57c5<PASSWORD>35f<PASSWORD>';
// const user_id = 'f10b7fce14a9ce5d4c89843ff21d4668a1d0b398a31461cfeb8c656f4d3e9ec3';
const auth = '<PASSWORD>';
const user_id = 'a7a24e90f734d9204c1a9be60e138bba439ff4101efa2957dc10eed067cda3b4';
const getAllCourse = (token, id) =>
fetch(`${BASE_URL.URL}/app2/course/getcourseforuser`, {
headers: {
// auth_token: token,
// user_id: id,
auth_token: auth,
user_id,
},
method: METHOD.POST,
body: JSON.stringify({ uuid: '' }),
}).then(raiseStatus);
const getCourse = (token, id, uuid) =>
fetch(`${BASE_URL.URL}/app2/course/getcourseforuser`, {
headers: {
// auth_token: token,
// user_id: id,
auth_token: auth,
user_id,
},
method: METHOD.POST,
body: uuid,
}).then(raiseStatus);
const getAllStory = (token, id, uuid) =>
fetch(`${BASE_URL.URL}/app2/story/getstoryforuser`, {
headers: {
// auth_token: token,
// user_id: id,
auth_token: auth,
user_id,
},
method: METHOD.POST,
body: uuid,
}).then(raiseStatus);
const getAllProjects = (token, id, uuid) =>
fetch(`${BASE_URL.URL}/app2/project/getprojectforuser`, {
headers: {
// auth_token: token,
// user_id: id,
auth_token: auth,
user_id,
},
method: METHOD.POST,
body: uuid,
}).then(raiseStatus);
const getAllBlogs = (token, id, uuid) =>
fetch(`${BASE_URL.URL}/app2/blog/getblogforuser`, {
headers: {
// auth_token: token,
// user_id: id,
auth_token: auth,
user_id,
},
method: METHOD.POST,
body: uuid,
}).then(raiseStatus);
const getJourney = (token, id, uuid) =>
fetch(`${BASE_URL.URL}/app2/useractivitydata/journey`, {
headers: {
// auth_token: token,
// user_id: id,
auth_token: auth,
user_id,
},
method: METHOD.POST,
body: uuid,
}).then(raiseStatus);
export {
getAllCourse,
getCourse,
getAllStory,
getAllProjects,
getAllBlogs,
getJourney,
};
<file_sep>/app/component/Quiz/QuizActions.js
const QuizActionTypes = {
LOAD_DATA: 'Quiz/LOAD_DATA',
UPDATE_CURRENT_INDEX: 'Quiz/UPDATE_CURRENT_INDEX',
LOAD_QUESTIONS: 'Quiz/LOAD_QUESTIONS',
START_QUIZ: 'Quiz/START_QUIZ',
START_TIMER: 'QUIZ/START_TIMER',
STOP_TIMER: 'Quiz/STOP_TIMER',
END_QUIZ: 'Quiz/END_QUIZ',
HIDE_TIMER: 'Quiz/HIDE_TIMER',
};
const QuizActions = {
updateCurrentIndex: payload => ({ type: QuizActionTypes.UPDATE_CURRENT_INDEX, payload }),
loadInfo: payload => ({ type: QuizActionTypes.LOAD_DATA, payload }),
startQuiz: () => ({ type: QuizActionTypes.START_QUIZ }),
endQuiz: () => ({ type: QuizActionTypes.END_QUIZ }),
startTimer: () => ({ type: QuizActionTypes.START_TIMER }),
stopTimer: () => ({ type: QuizActionTypes.STOP_TIMER }),
hideTimer: () => ({ type: QuizActionTypes.HIDE_TIMER }),
loadQuestions: payload => ({ type: QuizActionTypes.LOAD_QUESTIONS, payload }),
loadCourseInfo: payload => (dispatch) => {
const { data } = payload;
const quizInfo = data.slice(0, data.length - 1);
console.log('Quiz Data', quizInfo);
dispatch(QuizActions.loadInfo(quizInfo));
},
loadQuizQuestions: payload => (dispatch) => {
const { data } = payload;
const quizObject = data.slice(0, data.length - 1);
// TODO: Don't forget to enable this
// dispatch(QuizActions.loadQuestions(quizObject));
},
};
export {
QuizActionTypes,
QuizActions,
};
<file_sep>/app/services/Auth.js
/**
* global fetch
*/
import { BASE_URL, METHOD } from '../scripts/Enums';
import raiseStatus from '../scripts/Http';
const register = formBody =>
fetch(`${BASE_URL.URL}/app2/auth/signup`, {
method: 'post',
body: formBody,
}).then(raiseStatus);
const generate = phone => fetch(`${BASE_URL.URL}/app2/auth/generate`, {
method: METHOD.POST,
body: phone,
}).then(raiseStatus);
const login = auth =>
fetch(`${BASE_URL.URL}/app2/auth/login`, {
method: METHOD.POST,
body: auth,
}).then(raiseStatus);
export { register, generate, login };
<file_sep>/app/component/Quiz/QuizReducer.js
// import { SplashActionTypes } from './SplashActions';
import { QuizActionTypes } from './QuizActions';
const initialState = {
data: [],
courses: [],
currentIndex: 0,
startTimer: false,
quizEnded: false,
startModalOpen: true,
showTimer: true,
progress: 10,
quizState: {
currentQuestionIndex: 0,
},
quizObject:
{
uuid: '92984c62885c',
quiz_name: 'quiz 1',
questions: [
{
uuid: '2cade43a6bb5',
question: 'who is <NAME> ?',
option_type: 'mutiple',
marks: 10,
options: [
{
uuid: '116879b9565a',
choice: 'scientist',
},
{
uuid: 'd559137c9cd8',
choice: 'player',
},
],
},
{
uuid: '373e51c52a73',
question: 'who is creator of c++ ?',
option_type: 'single',
marks: 12,
options: [
{
uuid: 'e109b5b09ea3',
choice: 'Bjarne Stroustrup',
},
{
uuid: 'a3c172282e11',
choice: 'sachin tendulkar',
},
],
},
],
},
};
const quizReducer = (state = initialState, action) => {
switch (action.type) {
case QuizActionTypes.LOAD_DATA:
return { ...state, data: action.payload };
case QuizActionTypes.UPDATE_CURRENT_INDEX:
return { ...state, currentIndex: action.payload };
case QuizActionTypes.LOAD_QUESTIONS:
return { ...state, questions: action.payload };
case QuizActionTypes.START_QUIZ:
return { ...state, startTimer: true, startModalOpen: false };
case QuizActionTypes.START_TIMER:
return { ...state, showTimer: true };
case QuizActionTypes.STOP_TIMER:
return { ...state, startTimer: false };
case QuizActionTypes.END_QUIZ:
return { ...state, quizEnded: true };
case QuizActionTypes.HIDE_TIMER:
return { ...state, showTimer: false };
default:
return state;
}
};
export default quizReducer;
<file_sep>/app/component/Explore/ExploreNavigation.js
import { StackNavigator } from 'react-navigation';
import Home from './Explore';
// import StoryNavigation from './StoryNavigation';
// import Story from '../Home/Stories/Stories';
import Blog from '../Home/Blogs/Blogs';
import Video from '../Home/Video/Video';
import Journey from '../Home/Journey/Journey';
import Projects from '../Home/Projects/Projects';
import Story from '../Home/Stories/Stories';
import DetailView from '../Home/Common/SecondView';
const Routes = {
Home: { screen: Home },
Journey: { screen: Journey },
Story: { screen: Story },
Projects: { screen: Projects },
Blog: { screen: Blog },
Video: { screen: Video },
Detail: { screen: DetailView },
};
export default StackNavigator(Routes);
<file_sep>/app/component/More/Policy.js
/* eslint-disable react/no-array-index-key */
import React, { Component } from 'react';
import { Text, ScrollView } from 'react-native';
import COLORS from '../../styles/Common/Colors';
import PolicyStyles from '../../styles/More/Policy';
const policy = [
'Lorem ipsum dolor sit amet, consectetur adipiscing elit. ' +
'Cras malesuada eget tellus eu rhoncus. Mauris id congue massa. ' +
'Nullam volutpat nunc sed ornare vestibulum. ' +
'Pellentesque habitant morbi tristique senectus et netus et malesuada fames ac turpis egestas. ',
'Aenean vulputate vitae tortor nec fringilla. ' +
'Suspendisse vitae consectetur ipsum, vel molestie ipsum. Maecenas sed sem mi. ' +
'Suspendisse eu semper dui. Suspendisse consequat molestie sodales. Nulla tempus malesuada orci ac dictum. ' +
'Nulla semper ipsum bibendum, suscipit lorem nec, faucibus purus.',
];
class Policy extends Component {
static navigationOptions = {
title: 'Policy',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
render() {
return (
<ScrollView style={PolicyStyles.container} >
<Text style={PolicyStyles.title}>Privacy Policy</Text>
{
policy.map((paragraph, index) =>
<Text key={index} style={PolicyStyles.paragraph}>{paragraph}</Text>)
}
</ScrollView>
);
}
}
export default Policy;
<file_sep>/app/component/Authentication/AuthNavigation.js
import { StackNavigator } from 'react-navigation';
import MobileNumber from './MobileNumber';
import OTP from './OTP';
import Register from './Register';
import Home from '../AppNavigation';
const Routes = {
Home: { screen: Home },
MobileNumber: { screen: MobileNumber },
OTP: { screen: OTP },
Register: { screen: Register },
};
const NavigationOptions = {
header: null,
headerMode: 'none',
};
export default StackNavigator(Routes, NavigationOptions);
//
// class AuthNavigation extends Component {
// /**
// * Header and Header Mode set to null & none to remove
// * the top header from a screen/View
// * @type {{header: null, headerMode: string}}
// */
// static navigationOptions = {
// };
//
// render() {
// return (
// <View style={Styles.container}>
// <Image source={background} style={Styles.background} resizeMode="contain" />
// <MobileNumber />
// </View>
// );
// }
// }
//
// export default AuthNavigation;
// StackNavigator({
// MobileNumber: { screen: MobileNumber },
// OTP: { screen: OTP },
// Register: { screen: Register },
// });
//
// <Register />
// <OTP />
// import React, { Component } from 'react';
// import { View, Image } from 'react-native';
// // import { StackNavigator } from 'react-navigation';
// import Styles from '../../styles/Auth/Auth';
// import background from '../../assets/img/onboardingbackground.png';
<file_sep>/app/component/Home/Stories/StoryActions.js
const StoryActionTypes = {
LOAD_DATA: 'Story/LOAD_DATA',
LOAD_SUBSCRIPTION_STATUS: 'Story/LOAD_SUBSCRIPTION_STATUS',
};
const StoryActions = {
loadInfo: payload => ({ type: StoryActionTypes.LOAD_DATA, payload }),
loadSubscriptionStatus: payload => ({ type: StoryActionTypes.LOAD_SUBSCRIPTION_STATUS, payload }),
loadCourseInfo: payload => (dispatch) => {
const { data } = payload;
const subscriptionStatus = data[data.length - 1];
const courseData = data.slice(0, data.length - 1);
dispatch(StoryActions.loadInfo(courseData));
dispatch(StoryActions.loadSubscriptionStatus(subscriptionStatus));
},
};
export {
StoryActionTypes,
StoryActions,
};
<file_sep>/app/styles/ScoreCard/CallToAction.js
import COLORS from '../Common/Colors';
const style = {
parentView: {
backgroundColor: COLORS.WHITE,
},
carouselContainer: {
justifyContent: 'center',
alignItems: 'center',
height: 200,
},
itemContainer: {
backgroundColor: COLORS.YELLOW_SHADE,
width: '50%',
height: '85%',
justifyContent: 'space-around',
alignItems: 'center',
borderRadius: 10,
padding: 10,
shadowColor: '#615f61',
shadowOffset: { width: 0, height: 2 },
shadowOpacity: 0.75,
elevation: 1,
},
ctaActionText: {
textAlign: 'center',
fontSize: 12,
fontWeight: '200',
},
ctaContentText: {
textAlign: 'center',
},
};
export default style;
//
// borderColor: 'purple',
// borderWidth: 1,
// borderStyle: 'solid',
<file_sep>/app/component/Home/Stories/StoryWrapper.js
import React, { Component } from 'react';
import StoryNavigation from './StoryNavigation';
import COLORS from '../../../styles/Common/Colors';
class StoryWrapper extends Component {
static navigationOptions = {
title: 'Stories',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE, textAlign: 'left' },
// header: null,
// headerMode: 'none',
};
render() {
return (<StoryNavigation />);
}
}
export default StoryWrapper;
<file_sep>/app/component/Home/Video/Video.js
import React, { Component } from 'react';
import { connect } from 'react-redux';
import PropTypes from 'prop-types';
import { Text, View, StyleSheet } from 'react-native';
import YouTube from 'react-native-youtube';
import COLORS from '../../../styles/Common/Colors';
import VideoStyles from '../../../styles/Explore/Video';
import { getCourse } from '../../../services/Explore';
import { VideoActions } from './VideoActions';
const styles = StyleSheet.create(VideoStyles);
const REPLACEABLE_YOUTUBE_LINK_PART = 'https://www.youtube.com/watch?v=';
/**
* TODO: handle Video length info in frontend
* TODO: Add api key for android */
@connect(store => ({ auth: store.auth, video: store.video }))
class Video extends Component {
static navigationOptions = {
title: 'Video',
headerStyle: { backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY },
headerTitleStyle: { color: COLORS.WHITE },
};
static propTypes = {
navigation: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
auth: PropTypes.object.isRequired,
video: PropTypes.object.isRequired,
};
componentDidMount() {
const { token, id } = this.props.auth;
const { uuid } = this.props.navigation.state.params;
const formData = new FormData();
formData.append('uuid', uuid);
getCourse(token, id, formData)
.then(data => this.props.dispatch(VideoActions.loadCourseInfo(data)));
}
getView = (course) => {
const { course_details: details, course_name: title, video_link: link } = course;
const videoId = link.replace(REPLACEABLE_YOUTUBE_LINK_PART, '');
return (
<View>
<View>
<YouTube
videoId={videoId}
style={{ alignSelf: 'stretch', height: 300 }}
/>
</View>
<View style={{
justifyContent: 'space-between',
flexDirection: 'row',
padding: 10,
}}
>
<View>
<Text style={styles.videoLabel}>{title}</Text>
</View>
<View>
<Text style={styles.videoLabel}>2:05 min</Text>
</View>
</View>
<View style={{ padding: 10, flex: 1 }}>
<Text style={styles.videoDescription}>{details}</Text>
</View>
</View>
);
};
render() {
const { course } = this.props.video;
return (Object.keys(course).length > 0 ? this.getView(course) : (<Text>Loading...</Text>));
}
}
export default Video;
<file_sep>/app/styles/Explore/Explore.js
import COLORS from '../Common/Colors';
const style = {
icon: {
width: 28,
height: 13,
},
};
export default style;
<file_sep>/app/component/Splash/Splash.js
import React, { Component } from 'react';
import PropTypes from 'prop-types';
import { connect } from 'react-redux';
import { View, StyleSheet, Image } from 'react-native';
import { StackNavigator } from 'react-navigation';
import { SplashActions } from './SplashActions';
import Onboard from '../Onboarding/Onboard';
import Auth from '../Authentication/AuthNavigation';
import Home from '../AppNavigation';
import Styles from '../../styles/Common/Splash';
import logo from '../../assets/img/logo.png';
@connect(store => ({ splash: store.splash }))
class Splash extends Component {
/**
* Header and Header Mode set to null & none to remove
* the top header from a screen/View
* @type {{header: null, headerMode: string}}
*/
static navigationOptions = {
header: null,
headerMode: 'none',
};
static propTypes = {
splash: PropTypes.object.isRequired,
dispatch: PropTypes.func.isRequired,
navigation: PropTypes.object.isRequired,
};
/**
* Fired the load reducer (is used for logging application activity)
*/
componentDidMount() {
this.props.dispatch(SplashActions.load());
setTimeout(() => this.props.navigation.navigate('Auth'), 1000);
}
render() {
return (
<View style={styles.container}>
<Image
style={Styles.logo}
source={logo}
resizeMode="contain"
/>
</View>
);
}
}
const styles = StyleSheet.create(Styles);
/**
* This is base splash screen that
* can be seen with inspire logo.
* It is wrapped in a stack navigator
*/
export default StackNavigator({
Splash: { screen: Splash },
Onboard: { screen: Onboard },
Auth: { screen: Auth },
Home: { screen: Home },
});
<file_sep>/app/Reducers.js
import { combineReducers } from 'redux';
import splash from './component/Splash/SplashReducer';
import auth from './component/Authentication/AuthReducer';
import explore from './component/Explore/ExploreReducer';
import video from './component/Home/Video/VideoReducer';
import story from './component/Home/Stories/StoryReducer';
import project from './component/Home/Projects/ProjectReducer';
import blog from './component/Home/Blogs/BlogReducer';
import scoreCard from './component/ScoreCard/ScoreCardReducer';
import quiz from './component/Quiz/QuizReducer';
export default combineReducers({
splash,
auth,
explore,
video,
story,
project,
blog,
scoreCard,
quiz,
});
<file_sep>/app/styles/Explore/Journey.js
import COLORS from '../Common/Colors';
const style = {
icon: {
width: 28,
height: 13,
},
background: {
ios: {
flex: 1,
width: '100%',
marginTop: '-56%',
marginBottom: '-56%',
top: 0,
left: 0,
},
android: {
flex: 1,
width: '100%',
// marginTop: '-35%',
// marginBottom: '-35%',
marginTop: '-65%',
marginBottom: '-65%',
},
},
infoOverlay: {
position: 'absolute',
// borderColor: 'red',
// borderStyle: 'solid',
// borderWidth: 1,
width: '100%',
height: '100%',
},
sectionOne: {
// borderColor: 'black',
// borderStyle: 'solid',
// borderWidth: 1,
width: '100%',
height: '25%',
alignItems: 'center',
justifyContent: 'center',
},
sectionTwo: {
// borderColor: 'green',
// borderStyle: 'solid',
// borderWidth: 1,
width: '100%',
height: '25%',
},
sectionThree: {
// borderColor: 'purple',
// borderStyle: 'solid',
// borderWidth: 1,
width: '100%',
height: '25%',
},
sectionFour: {
// borderColor: 'yellow',
// borderStyle: 'solid',
// borderWidth: 1,
width: '100%',
height: '25%',
},
sectionNumberLabelContainer: {
backgroundColor: COLORS.MAGENTA_SHADE,
borderRadius: 5,
borderWidth: 1,
borderStyle: 'solid',
borderColor: 'black',
width: 20,
height: 20,
justifyContent: 'center',
alignItems: 'center',
marginTop: 5,
},
sectionLabel: {
color: COLORS.WHITE,
textAlign: 'center',
},
sectionAssessmentInfo: {
flexDirection: 'row',
justifyContent: 'center',
alignContent: 'center',
marginLeft: '-8%',
},
sectionLabelContainer: {
backgroundColor: COLORS.BACKGROUND_COLOR_SECONDARY,
borderRadius: 5,
width: 135,
height: 40,
justifyContent: 'center',
alignItems: 'center',
},
sectionTwoParent: {
justifyContent: 'center',
alignItems: 'center',
flexDirection: 'row',
},
sectionTwoItemContainer: {
backgroundColor: COLORS.BACKGROUND_COLOR_SECONDARY,
flexDirection: 'row',
padding: 15,
borderRadius: 5,
width: 200,
marginTop: '17%',
marginLeft: '-10%',
justifyContent: 'space-around',
alignItems: 'center',
},
sectionTwoImageContainer: {
width: 50,
height: 50,
backgroundColor: 'white',
alignItems: 'center',
justifyContent: 'center',
borderRadius: 5,
},
sectionTwoImage: {
width: 35,
height: 35,
},
sectionTwoLabel: {
fontSize: 12,
fontWeight: '300',
textAlign: 'center',
color: COLORS.WHITE,
},
sectionTwoNumericLabel: {
backgroundColor: COLORS.MAGENTA_SHADE,
borderRadius: 5,
borderWidth: 1,
borderStyle: 'solid',
borderColor: 'black',
width: 20,
height: 20,
justifyContent: 'center',
alignItems: 'center',
marginTop: '15%',
},
sectionProfessionals: {
flexDirection: 'row',
justifyContent: 'flex-end',
// alignContent: 'flex-end',
marginRight: '13%',
},
sectionProfessionalsImage: {
ios: {
width: 125,
height: 125,
marginTop: '-15%',
marginRight: '15%',
},
android: {
width: 100,
height: 100,
marginTop: '-5%',
marginRight: '15%',
},
},
sectionJourneyProfessionalsImageContainer: {
// borderColor: 'purple',
// borderStyle: 'solid',
// borderWidth: 1,
// justifyContent: 'flex-end',
alignItems: 'flex-end',
},
sectionJourneyLaunchImageContainer: {
// borderColor: 'purple',
// borderStyle: 'solid',
// borderWidth: 1,
alignItems: 'center',
},
sectionLaunchImage: {
width: 175,
height: 175,
marginLeft: '-15%',
},
sectionLaunch: {
flexDirection: 'row',
justifyContent: 'center',
marginLeft: '-8%',
},
sectionLaunchLabelContainer: {
backgroundColor: COLORS.BACKGROUND_COLOR_SECONDARY,
borderRadius: 5,
width: 135,
height: 80,
justifyContent: 'center',
alignItems: 'center',
},
sectionLaunchNumberLabelContainer: {
backgroundColor: COLORS.MAGENTA_SHADE,
borderRadius: 5,
borderWidth: 1,
borderStyle: 'solid',
borderColor: 'black',
width: 20,
height: 20,
justifyContent: 'center',
alignItems: 'center',
marginTop: '8%',
},
};
export default style;
// {
// borderColor: 'red',
// borderStyle: 'solid',
// borderWidth: 1,
// }
<file_sep>/app/component/ScoreCard/Articles.js
import React, { Component } from 'react';
import PropTypes from 'prop-types';
import { Image, View, Text } from 'react-native';
import { Container, DeckSwiper, Card, CardItem, Body } from 'native-base';
import ArticleStyles from '../../styles/ScoreCard/Articles';
class Articles extends Component {
static propTypes = {
articlesRead: PropTypes.number.isRequired,
totalArticles: PropTypes.number.isRequired,
totalTimeSpent: PropTypes.number.isRequired,
articleList: PropTypes.array.isRequired,
};
renderItem = (article) => {
const {
blog_name: title,
image_link: link,
modified_date: date,
} = article;
return (
<Card style={{ elevation: 3 }}>
<CardItem>
<Body>
<View style={ArticleStyles.cardStyle}>
<View style={ArticleStyles.cardIconAndTitleContainer}>
<View style={ArticleStyles.cardIconContainer}>
<Image
source={{ uri: link }}
style={ArticleStyles.articleIcon}
resizeMode="cover"
/>
</View>
<View style={ArticleStyles.cardTitleContainer}>
<Text style={ArticleStyles.cardTitle}>
{title}
</Text>
</View>
</View>
<View style={ArticleStyles.cardBottomContainer}>
<View>
<Text style={ArticleStyles.cardBottomText}>{date}</Text>
</View>
<View>
<Text style={ArticleStyles.cardBottomText}>0 min</Text>
</View>
<View style={ArticleStyles.blogTypeContainer}>
<Text style={ArticleStyles.cardBottomText}>Knowledge</Text>
</View>
</View>
</View>
</Body>
</CardItem>
</Card>
);
};
render() {
const {
articlesRead, totalArticles, totalTimeSpent, articleList,
} = this.props;
return (
<View style={ArticleStyles.articleParent}>
<View style={ArticleStyles.textSection}>
<View>
<Text style={ArticleStyles.articleHeadText}>
Articles Read ({articlesRead}/{totalArticles})
</Text>
</View>
<View>
<Text style={ArticleStyles.articleHeadText}>
{totalTimeSpent} min
</Text>
</View>
</View>
<View style={ArticleStyles.swipeDeckContainer}>
<Container>
<DeckSwiper
dataSource={articleList}
renderItem={this.renderItem}
/>
</Container>
</View>
</View>
);
}
}
export default Articles;
<file_sep>/app/styles/ScoreCard/Articles.js
import COLORS from '../Common/Colors';
/* Actual Scorecard Styles */
const style = {
articleParent: {
height: 250,
backgroundColor: COLORS.WHITE,
},
textSection: {
flexDirection: 'row',
justifyContent: 'space-between',
paddingTop: '2%',
},
articleHeadText: {
fontSize: 20,
fontWeight: '400',
},
swipeDeckContainer: {
padding: '5%',
height: 200,
},
cardStyle: {
width: '100%',
height: '100%',
},
articleIcon: {
width: 80,
height: 80,
},
cardIconAndTitleContainer: {
flexDirection: 'row',
alignItems: 'center',
justifyContent: 'space-around',
},
cardIconContainer: {
width: '30%',
},
cardTitleContainer: {
width: '70%',
},
cardTitle: {
fontSize: 18,
},
cardBottomContainer: {
flexDirection: 'row',
alignItems: 'center',
justifyContent: 'space-around',
paddingTop: '5%',
},
cardBottomText: {
fontSize: 16,
},
blogTypeContainer: {
borderWidth: 1,
borderColor: COLORS.BACKGROUND_COLOR_SHADE,
borderStyle: 'dashed',
borderRadius: 15,
padding: 5,
},
};
export default style;
// borderWidth: 1,
// borderColor: 'purple',
// borderStyle: 'solid',
<file_sep>/app/styles/Explore/Home.js
import COLORS from '../Common/Colors';
const style = {
container: {
// flex: 1,
justifyContent: 'center',
alignItems: 'center',
height: '100%',
},
courseCard: {
backgroundColor: COLORS.BACKGROUND_COLOR_PRIMARY,
width: '85%',
height: '75%',
alignItems: 'center',
borderRadius: 10,
flexDirection: 'row',
shadowColor: '#615f61',
shadowOffset: { width: 0, height: 2 },
shadowOpacity: 0.75,
elevation: 1,
},
columnLeft: {
flex: 6,
height: '100%',
// flexDirection: 'row',
justifyContent: 'space-around',
alignItems: 'center',
},
columnRight: {
flex: 4,
height: '90%',
justifyContent: 'space-between',
},
courseLogoContainer: {
justifyContent: 'center',
alignItems: 'center',
top: 0,
},
courseLogoIconContainer: {
borderRadius: 15,
width: 135,
height: 135,
},
courseIcon: {
width: 135,
height: 135,
borderRadius: 15,
},
label: {
color: COLORS.WHITE,
backgroundColor: 'transparent',
},
courseVideoContainer: {
justifyContent: 'center',
alignItems: 'center',
},
videoIconContainer: {
borderRadius: 5,
borderWidth: 1,
borderStyle: 'solid',
borderColor: COLORS.BACKGROUND_COLOR_SECONDARY,
width: 125,
height: 75,
justifyContent: 'center',
alignItems: 'center',
},
seeJourneyContainer: {
backgroundColor: COLORS.YELLOW_SHADE,
width: 125,
height: 35,
justifyContent: 'center',
alignItems: 'center',
borderRadius: 5,
},
seeJourneyLabel: {
color: COLORS.BLACK,
fontSize: 16,
fontWeight: '300',
},
courseActivity: {
alignItems: 'center',
justifyContent: 'center',
},
courseActivityIconContainer: {
backgroundColor: COLORS.BACKGROUND_COLOR_SHADE,
padding: 10,
borderRadius: 5,
},
courseActivityIcon: {
width: 65,
height: 65,
},
videoIcon: {
width: 75,
height: 25,
},
seeJourney: {
justifyContent: 'center',
alignItems: 'center',
// flex: 4,
},
};
export default style;
//
// borderStyle: 'solid',
// borderWidth: 1,
// borderColor: 'yellow',
//
// borderStyle: 'solid',
// borderWidth: 1,
// borderColor: 'red',
<file_sep>/app/component/Authentication/Register.js
import React, { Component } from 'react';
import PropTypes from 'prop-types';
import { Text, View, TextInput, TouchableOpacity, Platform, Image, ScrollView } from 'react-native';
import { Dropdown } from 'react-native-material-dropdown';
import styles from '../../styles/Auth/Register';
import AuthStyles from '../../styles/Auth/Auth';
import background from '../../assets/img/onboardingbackground.png';
import { register } from '../../services/Auth';
// const mobileNumberInputStyle = Platform.select(styles.textInput);
// const fullWidthTextInput = Platform.select(styles.fullWidthTextInput);
class Register extends Component {
/**
* Header and Header Mode set to null & none to remove
* the top header from a screen/View
* @type {{header: null, headerMode: string}}
*/
static navigationOptions = {
header: null,
headerMode: 'none',
};
static classes= [
{ value: 'VIII' },
{ value: 'IX' },
{ value: 'X' },
{ value: 'XI' },
{ value: 'XII' },
];
static cities=[
{ value: 'Mumbai' },
{ value: 'Bengaluru' },
{ value: 'Chennai' },
{ value: 'Delhi' },
{ value: 'Pune' },
];
static area = [];
state={
firstName: '',
lastName: '',
school: '',
userName: '',
emailId: '',
mobileNumber: '',
selectedClass: 'X',
selectedCity: '',
selectedArea: '',
};
static propTypes = {
navigation: PropTypes.object.isRequired,
};
handleSubmit = () => {
const {
selectedClass, selectedCity, selectedArea, firstName, lastName, school, emailId, mobileNumber, userName,
} = this.state;
const formData = new FormData();
formData.append('first_name', firstName);
formData.append('last_name', lastName);
formData.append('username', userName);
formData.append('email_id', emailId);
formData.append('phone_number', mobileNumber);
formData.append('school', school);
formData.append('class', selectedClass);
formData.append('city', selectedCity);
formData.append('area', selectedArea);
/* TODO: Handle Different Status Codes other than 200 */
register(formData)
.then(response => (response.status === 200 ? this.props.navigation.navigate('MobileNumber') : '')
.catch());
// this.props.navigation.navigate('MobileNumber');
};
render() {
const {
selectedClass, selectedCity, selectedArea, firstName, lastName, school, emailId, mobileNumber, userName,
} = this.state;
return (
<ScrollView>
<View style={AuthStyles.container}>
<Image source={background} style={AuthStyles.background} resizeMode="contain" />
<ScrollView style={styles.overlayContainer}>
<View style={Platform.select(styles.mobileViewContainer)}>
<View>
<Text>Firstname</Text>
<TextInput
value={firstName}
onChangeText={text => this.setState({ firstName: text })}
style={Platform.select(styles.fullWidthTextInput)}
/>
</View>
<View>
<Text style={{ paddingTop: 10 }}>Lastname</Text>
<TextInput
value={lastName}
onChangeText={text => this.setState({ lastName: text })}
style={Platform.select(styles.fullWidthTextInput)}
/>
</View>
<View>
<Text style={{ paddingTop: 10 }}>Username</Text>
<TextInput
value={userName}
onChangeText={text => this.setState({ userName: text })}
style={Platform.select(styles.fullWidthTextInput)}
/>
</View>
<View style={styles.classAndSchoolContainer}>
<View style={styles.classDropdownContainer}>
<Dropdown
label="Class"
data={Register.classes}
baseColor="rgba(0,0,0,1)"
value={selectedClass}
/>
</View>
<View style={styles.schoolInputContainer}>
<Text>School</Text>
<TextInput
value={school}
onChangeText={text => this.setState({ school: text })}
style={Platform.select(styles.schoolInputText)}
/>
</View>
</View>
<View style={styles.emailAndMobileContainer}>
<Text>Email ID</Text>
<TextInput
value={emailId}
onChangeText={text => this.setState({ emailId: text })}
style={Platform.select(styles.fullWidthTextInput)}
/>
</View>
<View style={styles.emailAndMobileContainer}>
<Text>Mobile Number</Text>
<TextInput
value={mobileNumber}
onChangeText={text => this.setState({ mobileNumber: text })}
style={Platform.select(styles.fullWidthTextInput)}
/>
</View>
<View style={styles.classAndSchoolContainer}>
<View style={styles.cityDropdown}>
<Dropdown
label="City"
data={Register.cities}
baseColor="rgba(0,0,0,1)"
value={selectedCity}
/>
</View>
<View style={styles.areaDropdown}>
<Dropdown
label="Area"
data={Register.area}
baseColor="rgba(0,0,0,1)"
value={selectedArea}
/>
</View>
</View>
<View style={{
width: '100%',
justifyContent: 'center',
alignItems: 'center',
}}
>
<TouchableOpacity
onPress={() => this.handleSubmit()}
>
<View style={styles.buttonContainer}>
<Text style={styles.buttonText}>Continue</Text>
</View>
</TouchableOpacity>
</View>
</View>
<View style={styles.loginTextContainer}>
<Text style={styles.loginText}>Already Registered?
<Text accessible onPress={() => this.props.navigation.goBack()}> Login Here.</Text>
</Text>
{/* <Text style={styles.termsAndConditionsText}>By registering you agree to our */}
{/* <Text accessible onPress={() => console.log('I am pressed')}> Terms and Privacy Policy.</Text> */}
{/* </Text> */}
</View>
</ScrollView>
</View>
</ScrollView>
);
}
}
export default Register;
/* Add Terms and Condition */
<file_sep>/app/styles/More/More.js
import COLORS from '../Common/Colors';
const style = {
icon: {
width: 28,
height: 13,
},
campaignContainer: {
height: '42%',
backgroundColor: COLORS.WHITE,
shadowColor: '#615f61',
shadowOffset: { width: 0, height: 2 },
shadowOpacity: 0.75,
elevation: 1,
},
socialMediaContainer: {
paddingTop: '2%',
paddingLeft: '2%',
marginTop: '2%',
height: '18%',
backgroundColor: COLORS.WHITE,
shadowColor: '#615f61',
shadowOffset: { width: 1, height: 1 },
shadowOpacity: 0.50,
elevation: 1,
},
settingsContainer: {
marginTop: '2%',
height: '18%',
backgroundColor: COLORS.WHITE,
shadowColor: '#615f61',
shadowOffset: { width: 1, height: 1 },
shadowOpacity: 0.50,
elevation: 1,
// borderColor: 'blue',
// borderWidth: 1,
// borderStyle: 'solid',
},
aboutContainer: {
marginTop: '2%',
height: '17.5%',
backgroundColor: COLORS.WHITE,
// borderColor: 'yellow',
// borderWidth: 1,
// borderStyle: 'solid',
},
campaignContainerTitle: {
paddingTop: '5%',
paddingLeft: '5%',
fontSize: 18,
},
campaignCarouselSection: {
paddingTop: '2%',
paddingLeft: '5%',
justifyContent: 'center',
alignItems: 'center',
},
campaignCarouselContainer: {
borderRadius: 10,
width: 200,
height: 125,
shadowColor: '#615f61',
shadowOffset: { width: 1, height: 1 },
shadowOpacity: 0.50,
elevation: 1,
},
campaignImage: {
width: 200,
height: 125,
},
campaignTitle: {
ios: {
fontSize: 18,
textAlign: 'center',
fontWeight: '300',
},
android: {
fontSize: 16,
textAlign: 'center',
fontWeight: '300',
},
},
campaignTitleContainer: {
margin: '1%',
width: 200,
},
socialMediaText: {
fontSize: 16,
padding: '2%',
},
socialMediaIconContainer: {
flexDirection: 'row',
width: '50%',
justifyContent: 'space-around',
paddingLeft: '1%',
},
socialMediaIcons: {
width: 40,
height: 40,
},
actionIcons: {
width: 25,
height: 25,
},
actionIconChevron: {
width: 15,
height: 15,
},
actionButtonStyle: {
flexDirection: 'row',
width: '100%',
justifyContent: 'space-between',
alignItems: 'center',
borderBottomColor: 'grey',
borderBottomWidth: 1,
height: '50%',
},
actionButtonLeftLabelContainer: {
flexDirection: 'row',
alignItems: 'center',
},
};
export default style;
// borderColor: 'pink',
// borderWidth: 1,
// borderStyle: 'solid',
//
// borderColor: 'green',
// borderWidth: 1,
// borderStyle: 'solid',
| 9e69479f90727bf9a585b64231f40eeb81b6d35e | [
"JavaScript"
] | 66 | JavaScript | smarandi/test-app | 493bed7f6a3c7f68b15cdc6e1bbda6f0866240b2 | 8de6a2dcfca0d4db50084a1d1ea878ad6ea9605d |
refs/heads/master | <file_sep># -*- coding: utf-8 -*-
from underthesea import word_tokenize
from abc import ABC
import codecs
import numpy as np
from gensim.models import Word2Vec
from gensim.models import FastText
import re
from scipy.stats import entropy
#khao báo danh sách
words=[] ## Danh sach rong = [] để chứa các từ: chiều
WordTokens = []
StopWordsInput = [] ## Danh sách stopword trong van bản
ListSentence = [] ## Danh sách chưa các câu (Documnent
class WordSegment(ABC):
def parseword(self):
pass #
class ViWordSegment(WordSegment):
# overriding abstract method
def parseword(self):
StopWordList = ReadStopWordList("stopwordsVi.txt")
for word in word_tokenize(Text):
NewWord = word.replace('.', '').replace(',', '').strip()
WordTokens.append(NewWord)
if not (NewWord in words) and NewWord != '':
if not (NewWord in StopWordList):
words.append(NewWord.lower())
else:
StopWordsInput.append(NewWord)
def ReadStopWordList(fName):
fo = codecs.open(fName, encoding='utf-8', mode='r')
strContain = fo.read()
fo.close()
return strContain.split('\r\n')
def transform_row(row):
# Xóa số dòng ở đầu câu
row = re.sub(r"^[0-9\.]+", "", row)
# Xóa dấu chấm, phẩy, hỏi ở cuối câu
row = re.sub(r"[\.,\?]+$", "", row)
# Xóa tất cả dấu chấm, phẩy, chấm phẩy, chấm thang, ... trong câu
row = row.replace(",", " ").replace(".", " ") \
.replace(";", " ").replace("“", " ") \
.replace(":", " ").replace("”", " ") \
.replace('"', " ").replace("'", " ") \
.replace("!", " ").replace("?", " ")
row = row.strip()
return row
# Bat dau thực hiện chương trình
# khai bao dữ liệu để test
# corpus = ["tôi yêu công việc lập trình.",
# "Tiếng Anh với tôi cũng rất căng.",
# "Python là 1 ngôn ngữ lập trình",
# "Tôi rất thích bóng đá",
# "tôi ghét ở một mình"]
# corpus = [
# "Đã bấy lâu nay bác tới nhà",
# "Trẻ thời đi vắng, chợ thời xa",
# "Ao sâu nước cả, khôn chài cá",
# "Vườn rộng rào thưa, khó đuổi gà",
# "Cải chửa ra cây, cà mới nụ",
# "Bầu vừa rụng rốn, mướp đương hoa",
# "Đầu trò tiếp khách, trầu không có",
# "Bác đến chơi đây ta với ta",
# ]
# corpus = [
# 'Một màu xanh xanh chấm thêm vàng vàng',
# 'Một màu xanh chấm thêm vàng cánh đồng hoang vu',
# 'Một màu nâu nâu một màu tím tím',
# 'Màu nâu tím mắt em tôi ôi đẹp dịu dàng',
# 'Một màu xanh lam chấm thêm màu chàm',
# 'Thời chinh chiến đã xa rồi sắc màu tôi',
# 'Một màu đen đen một màu trắng trắng',
# 'Chiều hoang vắng chiếc xe tang đi vội vàng'
# ]
# corpus = [
# 'Machine Learning và AI trong thời gian qua đã đạt được các thành tựu vô cùng đáng kinh ngạc',
# 'Blockchain - từ công nghệ tiền ảo đến ứng dụng tương lai',
# 'Tác hại kinh hoàng của game online với giới trẻ hiện nay',
# 'Mâu thuẫn khi chơi game và nam sinh giết hại bạn của mình cho bõ tức',
# 'Trí tuệ nhân tạo OpenAI chính thức đánh bại 5 game thủ chuyên nghiệp giỏi nhất thế giới'
#
# ]
# đọc file
corpus = []
with open('tuyen_ngon_doc_lap.txt', 'r', encoding='utf8') as file:
for sentences in file:
corpus.append(transform_row(sentences))
for sentences in corpus:
W = None
Text = sentences
ListSentence.append(Text)
W = ViWordSegment()
W.parseword()
words = list(set(words))
words.sort()
X = np.zeros([len(words), len(words)])
for sentences in corpus:
# tương tu cũng loai bo stopword tung cau
tokens = []
for word in word_tokenize(sentences):
NewWord = word.replace('.', '').replace(',', '').strip()
if NewWord != '':
if not (NewWord in StopWordsInput):
tokens.append(NewWord.lower())
data = []
for sentences in corpus:
tokens = []
for word in word_tokenize(sentences):
NewWord = word.replace('.', '').replace(',', '').strip()
if NewWord != '':
if not (NewWord in StopWordsInput):
tokens.append(NewWord.lower())
data.append(tokens)
print('tập data:',data)
modelW2V_Gensim = Word2Vec(data,
size=100,
min_count=2, # số lần xuất hiện thấp nhất của mỗi từ vựng
window=4, # khai báo kích thước windows size
sg=1, # sg = 1 sử dụng mô hình skip-grams - sg=0 -> sử dụng CBOW
workers=1
)
modelW2V_Gensim.init_sims(replace=True)
# # Saving the model for later use. Can be loaded using Word2Vec.load()
model_name = "300features_40minwords_10context"
modelW2V_Gensim.save(model_name)
print('Tìm top-10 từ tương đồng với từ: [độc lập]')
for index, word_tuple in enumerate(modelW2V_Gensim.wv.most_similar("độc lập")):
print('%s.%s\t\t%s\t%s' % (index, word_tuple[0], word_tuple[1],word_tuple))
| 5b46e58b76d7a4e6dad962469783ef7ae659fcbd | [
"Python"
] | 1 | Python | thinnv/BaiTapWord2Vec | 4fc46eb2620ae4763aa19c6b48b9b95288d37c96 | 18dd5dbf39df85a15bc64fc331cd7667b5319e1e |
refs/heads/master | <repo_name>draconian00/angular_heroes<file_sep>/src/app/dashboard.component.ts
import { Component, OnInit } from '@angular/core';
import { Hero } from './hero';
import { HeroService } from './hero.service';
@Component({
selector: 'my-dashboard',
templateUrl: './dashboard.component.html',
styleUrls: ['./dashboard.component.css']
})
export class DashboardComponent implements OnInit {
heroes: Hero[] = [];
constructor(private heroService: HeroService) { }
ngOnInit(): void {
this.heroService.getTest()
.then(data => console.log(data));
this.heroService.getHeroes()
.then((data_arr) => {
let temp_arr = data_arr;
let currentIndex, tempValue, randomIndex;
currentIndex = temp_arr.length;
while (0 !== currentIndex && currentIndex === undefined) {
// Pick a remaining element
randomIndex = Math.floor(Math.random() * currentIndex);
currentIndex -= 1;
// and swap it whit the current element;
tempValue = temp_arr[currentIndex];
temp_arr[currentIndex] = temp_arr[randomIndex];
temp_arr[randomIndex] = tempValue;
}
this.heroes = temp_arr.slice(1,5);
});
}
} | ac612991f17669c5204d27c198dec5435536997f | [
"TypeScript"
] | 1 | TypeScript | draconian00/angular_heroes | 34e8b1637a40f0442e817f6d0531d5b1ed9d3ae2 | ae16951c6a91e2cf5380c39cbfa595b01b8efe62 |
refs/heads/master | <repo_name>dakyboy/WordsWithRoom<file_sep>/app/src/main/java/com/dakiiii/wordswithroom/WordRoomDatabase.java
package com.dakiiii.wordswithroom;
import android.content.Context;
import android.os.AsyncTask;
import android.util.Log;
import androidx.annotation.NonNull;
import androidx.room.Database;
import androidx.room.Room;
import androidx.room.RoomDatabase;
import androidx.sqlite.db.SupportSQLiteDatabase;
@Database(entities = {Word.class}, exportSchema = false, version = 1)
public abstract class WordRoomDatabase extends RoomDatabase {
public static final String TAG_ROOM_DB = "Room DB: ";
public abstract WordDao eWordDao();
private static WordRoomDatabase sWordRoomDatabase;
public static WordRoomDatabase getInstance(final Context context) {
if (sWordRoomDatabase == null) {
Log.d(TAG_ROOM_DB, "Room db Null");
synchronized (WordRoomDatabase.class) {
if (sWordRoomDatabase == null) {
sWordRoomDatabase = Room.databaseBuilder(context.getApplicationContext()
, WordRoomDatabase.class, "word_database")
.fallbackToDestructiveMigration()
.addCallback(sCallback)
.build();
}
}
}
Log.d(TAG_ROOM_DB, sWordRoomDatabase.toString());
return sWordRoomDatabase;
}
private static RoomDatabase.Callback sCallback = new Callback() {
@Override
public void onOpen(@NonNull SupportSQLiteDatabase db) {
super.onOpen(db);
new PopulateDbAsync(sWordRoomDatabase).execute();
}
};
private static class PopulateDbAsync extends AsyncTask<Void, Void, Void> {
private final WordDao eWordDao;
String[] words = {"Lemon haze", "Gorilla glue", "Logs"};
PopulateDbAsync(WordRoomDatabase database) {
eWordDao = database.eWordDao();
}
@Override
protected Void doInBackground(Void... voids) {
if (eWordDao.getAnyWord().length < 1) {
for (int a = 1; a <= words.length - 1; a++) {
Word word = new Word(words[a]);
eWordDao.insert(word);
}
}
return null;
}
}
}
<file_sep>/settings.gradle
rootProject.name='Words With Room'
include ':app'
<file_sep>/app/src/main/java/com/dakiiii/wordswithroom/WordRepository.java
package com.dakiiii.wordswithroom;
import android.app.Application;
import android.os.AsyncTask;
import androidx.lifecycle.LiveData;
import java.util.List;
public class WordRepository {
private WordDao eWordDao;
private LiveData<List<Word>> eAllWords;
public WordRepository(Application application) {
WordRoomDatabase wordRoomDatabase = WordRoomDatabase.getInstance(application);
eWordDao = wordRoomDatabase.eWordDao();
eAllWords = eWordDao.getAllWords();
}
public void insert(Word word) {
new insertAsyncTask(eWordDao).execute(word);
}
public LiveData<List<Word>> getAllWords() {
return eAllWords;
}
public void deleteAll() {
new deleteAllWordsAsyncTask(eWordDao).execute();
}
public void deleteWord(Word word) {
new deleteWordAsyncTask(eWordDao).execute(word);
}
// Insert word Async Task
private static class insertAsyncTask extends AsyncTask<Word, Void, Void> {
private WordDao eAsyncWordDao;
insertAsyncTask(WordDao wordDao) {
eAsyncWordDao = wordDao;
}
@Override
protected Void doInBackground(Word... words) {
eAsyncWordDao.insert(words[0]);
return null;
}
}
// clear db Async Task
private static class deleteAllWordsAsyncTask extends AsyncTask<Void, Void, Void> {
private WordDao eAsyncTaskWordDao;
deleteAllWordsAsyncTask(WordDao wordDao) {
eAsyncTaskWordDao = wordDao;
}
@Override
protected Void doInBackground(Void... voids) {
eAsyncTaskWordDao.deleteAll();
return null;
}
}
// delete word Async tAsk
private static class deleteWordAsyncTask extends AsyncTask<Word, Void, Void> {
private WordDao eDeleteWordDao;
deleteWordAsyncTask(WordDao wordDao) {
eDeleteWordDao = wordDao;
}
@Override
protected Void doInBackground(Word... words) {
eDeleteWordDao.deleteWord(words[0]);
return null;
}
}
}
<file_sep>/README.md
# WordsWithRoom
Android fundamentals 10.1 codelab. Migrated from AppCompat to newer Androidx libraries
<file_sep>/app/src/main/java/com/dakiiii/wordswithroom/WordViewModel.java
package com.dakiiii.wordswithroom;
import android.app.Application;
import androidx.lifecycle.AndroidViewModel;
import androidx.lifecycle.LiveData;
import java.util.List;
public class WordViewModel extends AndroidViewModel {
private WordRepository eWordRepository;
private LiveData<List<Word>> eAllWords;
public WordViewModel(Application application) {
super(application);
eWordRepository = new WordRepository(application);
eAllWords = eWordRepository.getAllWords();
}
LiveData<List<Word>> getAllWords() {
return eAllWords;
}
public void insert(Word word) {
eWordRepository.insert(word);
}
public void deleteAll(){
eWordRepository.deleteAll();
}
public void deleteWord(Word word) {
eWordRepository.deleteWord(word);
}
}
| 16940bdb9945b10b6f0f7b9e28ac5c0d58553cb6 | [
"Markdown",
"Java",
"Gradle"
] | 5 | Java | dakyboy/WordsWithRoom | b55be3df959b5c404ef9b2bf36942b7dd058b096 | 129604ddb2536322cf66dd4244f7f42dd282c410 |
refs/heads/master | <file_sep>import React, { Component } from 'react';
import { Row, Card, Col } from 'react-materialize';
import {connect} from 'react-redux';
import {standardizeAddress} from './actions';
import {push} from 'react-router-redux';
class Form extends Component {
constructor(props) {
super(props);
this.state = {address: {
Address1:'',
Address2:'',
City:'',
State:'',
Zip5:''
}
};
}
handleChange(event) {
let updatedAddress=this.state.address;
updatedAddress[event.target.id]= event.target.value;
this.setState({address:updatedAddress});
}
standardize(event) {
event.preventDefault();
const promise=this.props.dispatch(
standardizeAddress(this.state.address)
);
promise.then(function(data){
if(data.type==="STANDARDIZE_SUCCESS"){
this.props.dispatch(push('/address'))
}else{
this.props.dispatch(push('/error'))
}
}.bind(this));
}
render() {
return (
<div>
<Row>
<Col className="offset-l3 offset-m3" l={6} m={6} s={12}>
<Card className='light-blue darken-1' textClassName='white-text' title='Enter Address to Standardize & Verify' key="1">
<input type="text"
placeholder="Address Line 1"
id="Address1"
className="validate" required="" aria-required="true"
value={this.state.address.Address1}
onChange={this.handleChange.bind(this)}
/>
<input type="text"
placeholder="Address Line 2"
id="Address2"
value={this.state.address.Address2}
onChange={this.handleChange.bind(this)}
/>
<input type="text"
placeholder="City"
id="City"
className="validate"
required=""
aria-required="true"
onChange={this.handleChange.bind(this)}
value={this.state.address.City}/>
<input type="text"
placeholder="State"
id="State"
className="validate"
required=""
aria-required="true"
onChange={this.handleChange.bind(this)}
value={this.state.address.State}/>
<input type="text"
placeholder="Postal Code"
id="Zip5"
className="validate"
required=""
aria-required="true"
onChange={this.handleChange.bind(this)}
value={this.state.address.Zip5}/>
</Card>
</Col>
</Row>
<Row>
<a href="#" className="waves-effect waves-light btn-large light-blue darken-1" onClick={this.standardize.bind(this)}>
<i className="material-icons left">location_on</i> Standardize
</a>
</Row>
</div>
);
}
}
var Container = connect()(Form);
export default Container;<file_sep>import React, { Component } from 'react';
import { Card, Col } from 'react-materialize';
import {connect} from 'react-redux';
class Map extends Component {
render() {
let mapAddr='';
if(this.props.address.Address1){
mapAddr=this.props.address.Address1.replace(/\s+/g, '+');
mapAddr=mapAddr+'+'+this.props.address.City.replace(/\s+/g, '+');
mapAddr=mapAddr+'+'+this.props.address.State.replace(/\s+/g, '+');
mapAddr=mapAddr+'+'+this.props.address.Zip5.replace(/\s+/g, '+');
}
const srcUrl="https://www.google.com/maps/embed/v1/place?key=<KEY>&q="+mapAddr;
return (
<Col l={6} m={6} s={12}>
<Card className='light-blue darken-1' textClassName='white-text' title='Map' key="4">
<div className="mapContainer">
<iframe
src={srcUrl}>
</iframe>
</div>
</Card>
</Col>
)
}
}
const mapStateToProps = (state, ownProps) => {
return {address:state.addressReducer}
}
const Container = connect(mapStateToProps)(Map);
export default Container;<file_sep># StandardLy
Thinkful Full Stack Web Developer Bootcamp React App Project
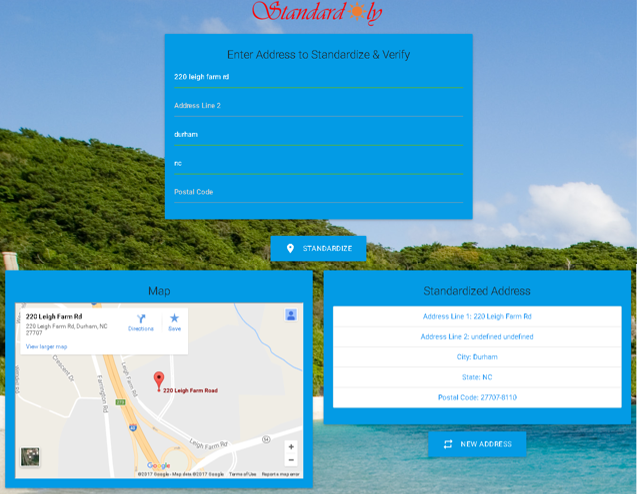
## Overview
Standardly is a web based client to standardize US addresses using Smarty Streets API. The app utilizes React ecosystem libraries and components along with Redux for state management
##Use Case
Why is this app useful? Everytime you send mail for personal or business reasons, if ever in doubt about the address, give StandardLy a shot. It will provide you receipient address in USPS standard along with location on Map for added confidence.
##UX
The initial wireframes can be seen below:
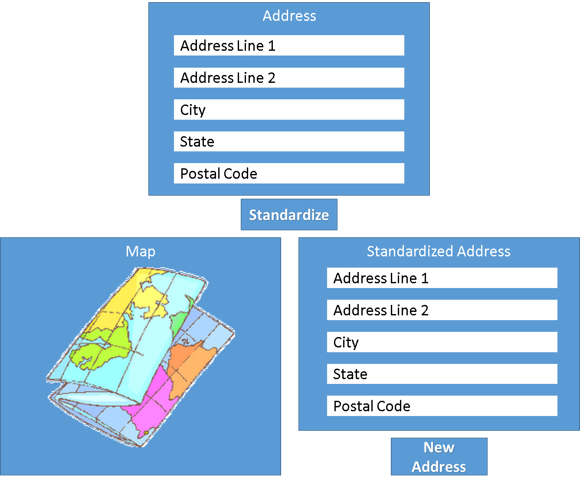
StandardLy is a responsive web application designed around concepts of Google's Materialize design. The app heavily relies on MaterializeCSS to render consistent user interface on various devices alogn with some custom styling as well. The app is designed with simplicity and effciency in mind. StandardLy is a single page app with just one click result without any complexities.
##Working Prototype
You can access a working prototype of the app here: https://niketarachhadia.github.io/av
##Technical
* The app is based on create-react-app starter kit. It utilized Redux, Redux-Routes, Isomorphic Fetch, React-Materialize
* StandardLy App utilizes Smarty Streets API to lookup, verify and standardize addresses. State management is handeled by Redux reducers while business logic and services layer is provided by Action creators.Navigation and conditional rendering is handeled by Redux-Routes. Calls to Smarty Streets APIs are made using Isomorphic Fetch.
##Development Roadmap
This is v1.0 of the app, but future enhancements are expected to include:
* Database of USPS addresses, NCOA, Census and other datasets for address lookup and standardization
* Server side APIs to make the App self containing without external dependencies
* Business and places lookup
<file_sep>import React, { Component } from 'react';
import './App.css';
import Form from './form';
const divStyle = {
};
class App extends Component {
render() {
return (
<div className="App" id="top">
<div>
<img className="responsive-img" src={'./standards.png'} alt="Logo" />
</div>
<Form/>
{this.props.children}
</div>
);
}
}
export default App;
<file_sep>import React, { Component } from 'react';
import {Row} from 'react-materialize';
import Map from './map';
import Address from './address';
class Results extends Component {
render() {
return (
<div id="results">
<Row>
<Map/>
<Address/>
</Row>
</div>
);
}
}
export default Results;<file_sep>import React from 'react';
import ReactDOM from 'react-dom';
import App from './App';
import Results from './results';
import Error from './error';
import {Provider} from 'react-redux';
import store from './store';
import { syncHistoryWithStore} from 'react-router-redux';
import { Router, Route, hashHistory } from 'react-router';
const history = syncHistoryWithStore(hashHistory, store)
var routes = (
<Provider store={store}>
<Router history={history}>
<Route path="/" component={App}>
<Route path="/address" component={Results} />
<Route path="/error" component={Error} />
</Route>
</Router>
</Provider>
);
ReactDOM.render(routes, document.getElementById('root'));
| 02d37c0ada0ca276b6163873db28359526229ccf | [
"JavaScript",
"Markdown"
] | 6 | JavaScript | niketarachhadia/av | 4f520ba6a188e0b9877404156a8ebcab5fb937f2 | c3fd9b05727e3b314ac33e7d980c7fce94868698 |
refs/heads/master | <repo_name>BruchesLena/Python<file_sep>/Vectorising.java
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
public class Vectorising {
/**
* @param args
*/
public static void main(String[] args) throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException{
// TODO Auto-generated method stub
writeInFile(format(parseFile("D:/Machine Learning/SentAnalysis/bank_train_2016.xml")), "D:/Machine Learning/SentAnalysis/Vectors.txt", false);
}
public static List<String> parseFile(String path)throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
List<String> twits = new ArrayList<String>();
List<String> buffered = new ArrayList<String>();
List<String> twitsWithEval = new ArrayList<String>();
DocumentBuilderFactory f = DocumentBuilderFactory.newInstance();
f.setValidating(false);
DocumentBuilder builder = f.newDocumentBuilder();
File file = new File(path);
Document doc = builder.parse(new InputSource(new InputStreamReader(new FileInputStream(file), "UTF-8")));
NodeList nodeList = doc.getElementsByTagName("column");
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (Node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
if (element.getAttribute("name").equals("id") |
element.getAttribute("name").equals("text") |
element.getAttribute("name").equals("sberbank") |
element.getAttribute("name").equals("vtb") |
element.getAttribute("name").equals("gazprom") |
element.getAttribute("name").equals("alfabank") |
element.getAttribute("name").equals("bankmoskvy") |
element.getAttribute("name").equals("raiffeisen") |
element.getAttribute("name").equals("uralsib") |
element.getAttribute("name").equals("rshb")) {
if (!element.getTextContent().equals("NULL")) {
twits.add(element.getTextContent());
}
}
}
}
for (int i = 1; i < twits.size(); i++) {
if (twits.get(i).equals("0") |
twits.get(i).equals("1") |
twits.get(i).equals("-1")) {
String current = " " + twits.get(i-2) + " " + twits.get(i-1).length() + " " + isPunctuationMark(twits.get(i-1)) + " " + twits.get(i);
buffered.add(current);
}
}
for (String str : buffered) {
if (!str.startsWith("0") &&
!str.startsWith("1") &&
!str.startsWith("-1")) {
twitsWithEval.add(str);
}
}
return twitsWithEval;
}
public static void writeInFile(List<String> data, String path, boolean b) throws IOException {
FileWriter writer = new FileWriter(path, b);
for (String s : data) {
writer.write(s + "\n");
writer.flush();
}
}
public static List<String> format (List<String> processed) {
List<String> result = new ArrayList<String>();
for (String str : processed) {
if (str.startsWith(" 1") |
str.startsWith(" 2") |
str.startsWith(" 3") |
str.startsWith(" 4") |
str.startsWith(" 5") |
str.startsWith(" 6") |
str.startsWith(" 7") |
str.startsWith(" 8") |
str.startsWith(" 9"))
result.add(str);
}
return result;
}
public static Integer isPunctuationMark(String twit) {
if (twit.endsWith("!")) {
return 1;
}
return 0;
}
}
<file_sep>/Statistics/src/statistics/CombinedTest.java
package statistics;
import static org.junit.Assert.*;
import java.util.HashSet;
import org.junit.Test;
import com.onpositive.semantic.wordnet.Grammem.PartOfSpeech;
import junit.framework.TestCase;
public class CombinedTest extends TestCase {
@Test
public void test01() throws Exception { //"красная" не имеет конфликтов
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("красная поляна", "красная");
assertTrue(result.contains(PartOfSpeech.ADJF));
}
@Test
public void test02() throws Exception { //"по" не имеет конфликтов
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("вахта по северному", "по");
//System.out.println(result);
}
@Test
public void test03() throws Exception { //"на" [МЕЖД] имеет два коэффициента
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("катастрофе на сочинской", "на");
System.out.println(result);
}
@Test
public void test04() throws Exception { //"которую" не имеет конфликтов
//"попали" конфликт между словами одной части речи (ГЛ)
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("в которую попали", "которую");
System.out.println(result);
}
@Test
public void test05() throws Exception { //сумма коэффициентов не равна 1
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("выяснения её причин", "её");
System.out.println(result);
}
@Test
public void test06() throws Exception { //"и" [МЕЖД] имеет три коэффициента
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("причин и последствий", "и");
System.out.println(result);
}
@Test
public void test07() throws Exception { //сумма коэффициентов не равна 1
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach(", что ещё", "что");
System.out.println(result);
}
@Test
public void test08() throws Exception { // коэффициенты: 0 и пустой ArrayList
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("что ещё в", "ещё");
System.out.println(result);
}
@Test
public void test09() throws Exception { //"после" [СУЩ] имеет три коэффициента
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach(". после начала", "после");
System.out.println(result);
}
@Test
public void test10() throws Exception { //коэффициенты: 0 и пустой ArrayList
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("ремонта все отвалы", "все");
System.out.println(result);
}
@Test
public void test11() throws Exception { //"на" [МЕЖД] имеет три коэффициента
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("поступать на незаконную", "на");
System.out.println(result);
}
@Test
public void test12() throws Exception { // сумма коэффициентов не равна 1
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("свалку в верховьях", "в");
System.out.println(result);
}
@Test
public void test13() throws Exception { //сумма коэффиицентов не равна 1
HashSet<PartOfSpeech> result = TestingWithPOS.chooseWithCombinedApproach("7 или 8", "или");
System.out.println(result);
}
}
<file_sep>/LinRegression.py
import numpy as np
import sklearn.linear_model as lm
#df = np.loadtxt("D:\Regression\data_set.txt", delimiter = ' ')
#print df
x_data = np.loadtxt("D:\Regression\input.txt", delimiter = ' ')
y_data = np.loadtxt("D:\Regression\output.txt")
<<<<<<< HEAD
test_data = np.loadtxt("D:/Regression/test_input.txt", delimiter = ' ')
#print test_data
skm = lm.LogisticRegression(solver='lbfgs')
skm.fit(x_data, y_data)
f = open('D:/Regression/our_output.txt', 'w')
for array in test_data:
prediction = skm.predict(array)
for element in prediction:
#print element
f.write(str(element) + '\n')
f.close()
=======
skm = lm.LogisticRegression(solver='lbfgs')
skm.fit(x_data, y_data)
prediction = skm.predict([3, 0])
print "Prediction"
print prediction
>>>>>>> branch 'master' of https://github.com/BruchesLena/Python.git
<file_sep>/Statistics/syntax/SynCorpora.java
package syntax;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FilenameFilter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
public class SynCorpora {
public static void main(String[] args) throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
List<Sentence> corpora = loadCorpora("D:/syntagrus in UTF");
}
public static List<Sentence> loadCorpora(String path) throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
List<Sentence> corpora = new ArrayList<>();
File folder = new File(path);
List<File> folderFiles = getXmlFiles(folder);
int ww = 0;
for (int i = 0; i < folderFiles.size(); i++) {
DocumentBuilderFactory f = DocumentBuilderFactory.newInstance();
f.setValidating(false);
DocumentBuilder builder = f.newDocumentBuilder();
Document doc = builder.parse(new InputSource(new InputStreamReader(new FileInputStream(folderFiles.get(i)),"UTF-8")));
NodeList nodeList = doc.getElementsByTagName("S");
for (int j = 0; j < nodeList.getLength(); j++) {
Sentence sentence = new Sentence();
Node node = nodeList.item(j);
sentence.id = getSentenceID(node);
NodeList words = getWords(node);
List<WordForm> wordForms = new ArrayList<>();
for (int w = 0; w < words.getLength(); w++) {
Node word = words.item(w);
wordForms.add(setWordForm(word));
}
sentence.words = wordForms;
ww += wordForms.size();
corpora.add(sentence);
}
}
System.out.println("Sentences " + corpora.size());
System.out.println("Words " + ww);
return corpora;
}
public static NodeList getWords(Node node) {
if (node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
return element.getElementsByTagName("W");
}
return null;
}
public static int getSentenceID(Node node) {
if (node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
return Integer.parseInt(element.getAttribute("ID"));
}
return 0;
}
public static WordForm setWordForm(Node node) {
WordForm wordForm = new WordForm();
wordForm.word = node.getTextContent();
if (node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
String dom = element.getAttribute("DOM");
if (dom.equals("_root")) {
wordForm.dom = 0;
}
else {
wordForm.dom = Integer.parseInt(element.getAttribute("DOM"));
}
wordForm.features = element.getAttribute("FEAT");
wordForm.id = Integer.parseInt(element.getAttribute("ID"));
wordForm.lemma = element.getAttribute("LEMMA");
wordForm.link = element.getAttribute("LINK");
}
return wordForm;
}
private static List<File> getXmlFiles(File folder) {
List<File> folderFiles = new ArrayList<File>();
File[] files = folder.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
boolean isTxt = name.endsWith(".tgt");
return isTxt;
}
});
if (files != null) {
folderFiles.addAll(Arrays.asList(files));
}
File[] folders = folder.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
boolean isFolder = dir.isDirectory();
return isFolder;
}
});
if (folders != null) {
for (int f = 0; f < folders.length; f++) {
File newFile = folders[f];
List<File> filesList = getXmlFiles(newFile);
folderFiles.addAll(filesList);
}
}
return folderFiles;
}
}
<file_sep>/Statistics/src/statistics/TestSubstitution.java
package statistics;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import com.onpositive.semantic.wordnet.AbstractWordNet;
import com.onpositive.semantic.wordnet.GrammarRelation;
import com.onpositive.semantic.wordnet.TextElement;
import com.onpositive.semantic.wordnet.WordNetProvider;
public class TestSubstitution {
public static void main(String[] args) {
// TODO Auto-generated method stub
String test = "их";
System.out.println(new FullSubstitution(getLastLetters(test), getSubstitution(test)).toString());
String test1 = "двигаем";
Substitution testSub = new Substitution(0, "");
System.out.println("subToWord " + subToWord(test1, testSub));
}
public static List<Substitution> getSubstitution(String word) {
List<Substitution> substitutions = new ArrayList<>();
HashSet<String> basicForms = new HashSet<>();
int end = 0;
String flex = null;
AbstractWordNet instance = WordNetProvider.getInstance();
GrammarRelation[] possibleGrammarForms = instance.getPossibleGrammarForms(word);
if (possibleGrammarForms == null) {
return null;
}
for (GrammarRelation g : possibleGrammarForms) {
TextElement textElement = g.getWord();
String basicForm = textElement.getBasicForm();
basicForms.add(basicForm);
}
for (String baseForm : basicForms) {
outer: for (int w = 0; w < word.length(); w++) {
for (int b = 0; b < baseForm.length(); b++) {
if (word.charAt(w) != baseForm.charAt(b)) {
end = word.length() - w;
flex = baseForm.substring(b);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (b == baseForm.length()-1 && w < word.length()-1) {
end = word.length() - b -1;
flex = "";
substitutions.add(new Substitution(end, flex));
break outer;
}
if (w == word.length() - 1 && b < baseForm.length()-1) {
end = 0;
flex = baseForm.substring(b+1);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (word.charAt(w) == baseForm.charAt(b)) {
if (w == word.length()-1 && b == baseForm.length()-1) {
substitutions.add(new Substitution(0, ""));
break outer;
}
w++;
continue;
}
}
}
}
return substitutions;
}
public static String getLastLetters(String word) {
if (word.length() >= 3) {
return word.substring(word.length() - 3);
}
if (word.length() < 3) {
return word;
}
return null;
}
public static String subToWord(String word, Substitution sub) {
String newWord = word.substring(0, word.length() - sub.letters);
newWord = newWord + sub.ending;
return newWord;
}
}
<file_sep>/Statistics/src/statistics/FullSubWithPOS.java
package statistics;
import java.io.Serializable;
public class FullSubWithPOS implements Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
public FullSubstitution fullSubstitution;
public String partOfSpeech;
public double probability;
public FullSubWithPOS(FullSubstitution fullSubstitution, String partOfSpeech) {
this.fullSubstitution = fullSubstitution;
this.partOfSpeech = partOfSpeech;
}
public String toString() {
return fullSubstitution.toString() + " - " + partOfSpeech + " (" + probability + ")";
}
}
<file_sep>/untitled0.py
# -*- coding: utf-8 -*-
"""
Created on Thu May 05 22:25:45 2016
@author: User
"""
"""
mnist_loader
~~~~~~~~~~~~
A library to load the MNIST image data. For details of the data
structures that are returned, see the doc strings for ``load_data``
and ``load_data_wrapper``. In practice, ``load_data_wrapper`` is the
function usually called by our neural network code.
"""
#### Libraries
# Standard library
import cPickle
import gzip
import random
# Third-party libraries
import numpy as np
def load_data():
"""Return the MNIST data as a tuple containing the training data,
the validation data, and the test data.
The ``training_data`` is returned as a tuple with two entries.
The first entry contains the actual training images. This is a
numpy ndarray with 50,000 entries. Each entry is, in turn, a
numpy ndarray with 784 values, representing the 28 * 28 = 784
pixels in a single MNIST image.
The second entry in the ``training_data`` tuple is a numpy ndarray
containing 50,000 entries. Those entries are just the digit
values (0...9) for the corresponding images contained in the first
entry of the tuple.
The ``validation_data`` and ``test_data`` are similar, except
each contains only 10,000 images.
This is a nice data format, but for use in neural networks it's
helpful to modify the format of the ``training_data`` a little.
That's done in the wrapper function ``load_data_wrapper()``, see
below.
"""
f = gzip.open("C:\Users\User\Documents\Python Scripts\mnist_pkl.gz", 'rb')
training_data, validation_data, test_data = cPickle.load(f)
f.close()
return (training_data, validation_data, test_data)
def load_data_wrapper():
"""Return a tuple containing ``(training_data, validation_data,
test_data)``. Based on ``load_data``, but the format is more
convenient for use in our implementation of neural networks.
In particular, ``training_data`` is a list containing 50,000
2-tuples ``(x, y)``. ``x`` is a 784-dimensional numpy.ndarray
containing the input image. ``y`` is a 10-dimensional
numpy.ndarray representing the unit vector corresponding to the
correct digit for ``x``.
``validation_data`` and ``test_data`` are lists containing 10,000
2-tuples ``(x, y)``. In each case, ``x`` is a 784-dimensional
numpy.ndarry containing the input image, and ``y`` is the
corresponding classification, i.e., the digit values (integers)
corresponding to ``x``.
Obviously, this means we're using slightly different formats for
the training data and the validation / test data. These formats
turn out to be the most convenient for use in our neural network
code."""
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (list(training_data), list(validation_data), list(test_data))
def vectorized_result(j):
"""Return a 10-dimensional unit vector with a 1.0 in the jth
position and zeroes elsewhere. This is used to convert a digit
(0...9) into a corresponding desired output from the neural
network."""
e = np.zeros((10, 1))
e[j] = 1.0
return e
class Network(object):
def __init__(self, sizes):
"""
The list ``sizes`` contains the number of neurons in the respective layers of the network.
For example, if the list was [2, 3, 1] then it would be a three-layer network, with the first layer containing
2 neurons, the second layer 3 neurons, and the third layer 1 neuron. Индекс маасива - номер слоя.
The biases and weights for the network are initialized randomly, using a Gaussian distribution with mean 0,
and variance 1.
Например: size = [2, 3, 1]
* [np.random.randn(y, 1) for y in sizes[1:]]
np.random.randn() - Return a sample (or samples) from the “standard normal” distribution.
(y, 1) for y in sizes[1:] - [(3, 1), (1, 1)]
(3 нейрона) (1 нейрон)
=> [array([[ 1.07525546],
[ 0.57338746], array([[-0.71175361]])]
[-0.73410565]]),
* [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
list(zip(size[:-1], size[1:])) => [(2, 3), (3, 1)]
[1 (2 нейрона) - 2 (3 нейрона)] [2 (3 нейрона) - 3 (1 нейрон)]
[array([[-1.05200768, 0.14314311],
[ 0.52989804, -1.18860133], array([[-0.6810671 , -1.08362344, 0.72229427]])]
[-1.89307825, -0.7838967 ]]),
"""
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x) for x, y in zip(sizes[:-1], sizes[1:])]
def __sigmoid(self, z):
"""
The sigmoid function Одна из возможных функций активации.
Переменная Z.
aji - input activation (j-слой, i-номер нейрона);
THETAj - матрица весов от слоя j к слою j+1;
Пример: a12 = g(THETA1_10 * X0 + THETA1_11 * X1 + ...); + bias
Z2 = THET1 * a1
a2 = g(Z2)
То есть, мы берем веса от предыдущего слоя к текущему * активацию нейронов предыдущего слоя;
Z3 = THET2 * a2 Получаем активацию нейронов текущего слоя;
a3 = g(Z3)
сигмоида - g(...)
"""
return 1.0 / (1.0 + np.exp(-z))
def sigmoid_prime(self, z):
"""
Derivative of the sigmoid function. Производная от целевой функции. В данном случае от сигмоиды.
Необходима для алгоритма обратного распространения ошибки.
"""
return self.sigmoid(z) * (1 - self.sigmoid(z))
def feedforward(self, a):
"""
Return the output of the network if ``a`` is input.
Алгоритм прямого распространения.
Аргумент: результат активации предыдущего слоя нейронной сети.
Результат
b w
[array([[-0.14877072], [array([[-0.04895646, -0.23310937], array([[ 1.35913542,
[-0.48624419], array([[-0.97742067]])] [ 0.0458885 , -1.66712799], -1.2862489,
[ 1.14379203]]), [-1.3024894 , 0.35921608]]), -1.26460679]])]
zip(b, w) - соединяем по индексу подмассивы.
[[-0.04895646, -0.23310937], [[a11], [[-0.14877072]
[ 0.0458885 , -1.66712799], * [a12], + [-0.48624419] = а2
[-1.3024894 , 0.35921608]] [a13]] [ 1.14379203]]
[[ 1.35913542, * [[a21], [a22], [a23]] + [[-0.97742067]] = a3
-1.2862489,
-1.26460679]]
"""
for bias, weight in zip(self.biases, self.weights):
a = self.sigmoid(np.dot(weight, a) + bias)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data):
"""
Для тренировки нейронной сети с помощью using mini-batch Stochastic Gradient Descent.
training_data - [(x, y), (x, y)]
test_data - если есть, то после каждой эпохи происходит оценка.
eta - шаг обучения (the learning rate);
"""
if test_data:
n_test = len(test_data)
n = len(training_data)
for j in range(epochs):
# В каждой эпохе:
# перемешивание training_data
# random.shuffle(training_data)
# разбивка training_data на партии: диапазон от 0 до количества объектов в training_data c заданным шагом;
# range(0, 20, 5) => [0, 5, 10, 15]
mini_batches = [training_data[k:k+mini_batch_size] for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
# для каждой партии обновление весов и bias;
self.update_mini_batch(mini_batch, eta)
# оценка результата, если есть тестовые данные;
if test_data:
print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), n_test))
else:
print("Epoch {0} complete".format(j))
def update_mini_batch(self, mini_batch, eta):
"""
Обновляем веса и значения bias с помощью алгоритма градиентного спуска для каждого пакета тренировочных данных.
"""
# инициализируем новые массивы весов и bias - копии старых, но 0 вместо значений;
new_bias = [np.zeros(b.shape) for b in self.biases]
new_weights = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
# Для каждого (x, y) вызывается алгоритм обратного распространения ошибки.
# Результат разница между новыми и старыми весами и bias.
delta_new_bias, delta_new_weights = self.backprop(x, y)
# На каждом шаге мы обновялем веса и bias суммируя текущие для очередной пары (x, y) и ранее записанные
# в массивы new_bias, new_weights; Для формулы градиентного спуска.
new_bias = [nb + dnb for nb, dnb in zip(new_bias, delta_new_bias)]
new_weights = [nw + dnw for nw, dnw in zip(new_weights, delta_new_weights)]
# Gradient descent:
# старый вес - (шаг обучения / колич. эл. в пакете) * новый вес
self.weights = [w - (eta / len(mini_batch)) * nw for w, nw in zip(self.weights, new_weights)]
self.biases = [b - (eta / len(mini_batch)) * nb for b, nb in zip(self.biases, new_bias)]
def backprop(self, x, y):
"""
Return a tuple ``(nabla_b, nabla_w)`` representing the
gradient for the cost function C_x. ``nabla_b`` and
``nabla_w`` are layer-by-layer lists of numpy arrays, similar
to ``self.biases`` and ``self.weights``."""
# инициализируем новые массивы весов и bias - копии старых, но 0 вместо значений;
new_bias = [np.zeros(b.shape) for b in self.biases]
new_weights = [np.zeros(w.shape) for w in self.weights]
############################ Feedforward algorithm. ##############################
# Z2 = THET1 * a1
# a2 = g(Z2)
# W X b
# [[-0.04895646, -0.23310937], [[-0.14877072]
# [0.0458885, -1.66712799], * X + [-0.48624419]
# [-1.3024894, 0.35921608]] [1.14379203]]
# [[1.35913542, * а1 + [[-0.97742067]]
# - 1.2862489,
# -1.26460679]]
activation = x
# list to store all the activations (а), layer by layer.
activations = [x]
# list to store all the z vectors, layer by layer.
zs = list()
# Сначала activation = input.
# Потом переменная activation переопределяется после каждой пары W, b.
# То есть, для каждого x из (x, y) будет последовательность activations = [x, a1, a2, a3, ..., an]
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation) + b
zs.append(z)
activation = self.sigmoid(z)
activations.append(activation)
############################ Backward pass algorithm. ##############################
# Помним, что дельта для последнего слоя и для остальных считается по-разному.
# Считаем дельту для последнего слоя: a (последнего слоя) - y (из (x, y)) * производ. сигмоиды от z (посл. сл.)
delta = self.cost_derivative(activations[-1], y) * self.sigmoid_prime(zs[-1])
# Обновляем bias для последнего слоя.
new_bias[-1] = delta
# Обновляем веса для последнего слоя: дельта * а (предпоследнего слоя).Т
new_weights[-1] = np.dot(delta, activations[-2].transpose())
# Расчитываем дельту для каждого слоя кроме последнего. Идем с конца.
for l in range(2, self.num_layers):
# если слой 2, то берем z с индексом -2.
z = zs[-l]
# считаем производную сигмоиды от z.
sp = self.sigmoid_prime(z)
# дельта = (веса предыдущего слоя (идем с конца, т.е. -2 + 1 = -1)).Т * дельту предыдущего слоя (сначала это
# последний слой, потом на каждом цикле переназначаем переменную delta) * производную сигмоиды от z.
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
# в массиве записываем bias для слоя;
new_bias[-l] = delta
# в массиве записываем новые веса для слоя; дельта * activations последующего
new_weights[-l] = np.dot(delta, activations[-l - 1].transpose())
return (new_bias, new_weights)
def evaluate(self, test_data):
"""Return the number of test inputs for which the neural network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever neuron in the final layer has the highest activation.
"""
# Финальный прогон на последних весах и bias.
test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
"""Return the vector of partial derivatives \partial C_x \partial a for the output activations."""
return (output_activations-y)
<file_sep>/Statistics/src/statistics/FullSubstitution.java
package statistics;
import java.io.Serializable;
import java.util.List;
public class FullSubstitution implements Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
public String lastLetters;
public List<Substitution> substitutions;
public FullSubstitution(String lastLetters, List<Substitution> substitutions) {
this.lastLetters = lastLetters;
this.substitutions = substitutions;
}
public String toString() {
if (substitutions == null) {
return null;
}
if (isPunctuationMark(lastLetters)) {
return "Punct";
}
else if (isNumber(lastLetters)) {
return "Number";
}
else {
return lastLetters + substitutions.toString();
}
}
public static boolean isPunctuationMark(String word) {
String[] marks = {".", ",", "?", "!", "\"", ":", ";", "-", "(", ")"};
for (String mark : marks) {
if (word.contains(mark)) {
return true;
}
}
return false;
}
public static boolean isNumber(String word) {
String[] numbers = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9", "-ом"};
for (String number : numbers) {
if (word.contains(number)) {
return true;
}
}
return false;
}
}
<file_sep>/Statistics/src/statistics/TestingWithPOS.java
package statistics;
import java.io.File;
import java.io.FileInputStream;
import java.io.FilenameFilter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import com.onpositive.semantic.wordnet.Grammem.PartOfSpeech;
import com.onpositive.text.analisys.tests.util.TestingUtil;
import com.onpositive.text.analysis.CombinedMorphologicParser;
import com.onpositive.text.analysis.IToken;
import com.onpositive.text.analysis.lexic.WordFormToken;
import com.onpositive.text.analysis.syntax.SyntaxToken;
import com.onpositive.text.analysis.utils.AdditionalMetadataHandler;
public class TestingWithPOS {
public static void main(String[] args) throws IOException, SAXException, ParserConfigurationException {
// TODO Auto-generated method stub
HashMap<Entry, Integer> statistics = ReadingPOSStatistics.readStatistics();
Set<Entry> entries = statistics.keySet();
List<String> processed = new ArrayList<>();
List<String> coefficients = new ArrayList<>();
int right = 0;
int ambig = 0;
int proc = 0;
int noStat = 0;
int rightUnknown = 0;
int ambigUnknown = 0;
int Unknown = 0;
int noAmbig = 0;
double combined = 1;
double stat = 1;
File folder = new File("D:/Лена/NoAmbig");
List<File> folderFiles = getXmlFiles(folder);
for (int k = 0; k < 5; k++) {
combined = combined - 0.05;
stat = 1;
for (int l = 0; l < 5; l++) {
stat = stat - 0.05;
right = 0;
proc = 0;
// }
// }
for (int i = 2502; i < 2503; i++) { //изменить значения i на файлы, на которых проводится тестирование
System.out.println(i);
DocumentBuilderFactory f = DocumentBuilderFactory.newInstance();
f.setValidating(false);
DocumentBuilder builder = f.newDocumentBuilder();
Document doc = builder.parse(new InputSource(new InputStreamReader(new FileInputStream(folderFiles.get(i)),"UTF-8")));
NodeList nodeList = doc.getElementsByTagName("token");
for (int j = 0; j < nodeList.getLength(); j++) {
Node node = nodeList.item(j);
if (Statistics.getSubstitution(Statistics.getTextFromToken(node)) == null) {
if (Statistics.isNumber(Statistics.getTextFromToken(node)) | Statistics.isPunctuationMark(Statistics.getTextFromToken(node))) {
continue;
}
//else {
//processed.add(getTextFromToken(node) + " [Unknown]");
//continue;
//}
}
//для незнакомых слов
if (!Analysis.inDictionary(Statistics.getTextFromToken(node)) && !Statistics.isNumber(Statistics.getTextFromToken(node)) && !Statistics.isPunctuationMark(Statistics.getTextFromToken(node))) {
proc++;
Unknown++;
HashMap<Entry, Integer> statForUnknown = StatisticsReader.readStatistics();
Set<Entry> entriesForUnknown = statForUnknown.keySet();
String rightPOS = POSStatistics.getPOSFromToken(node);
String lemma = Statistics.getLemmaFromToken(node);
String letters = Statistics.getLastLetters(Statistics.getTextFromToken(node));
List<Entry> current = new ArrayList<>();
List<LemmaChoice> lemmas = new ArrayList<>();
for (Entry entry : entriesForUnknown) {
if (entry.homonym.lastLetters.equals(letters)) {
current.add(entry);
}
}
if (current.size() == 0) {
continue;
}
getContextsForUnknownWords(nodeList, j, current, lemmas);
if (lemmas.size() == 0) {
continue;
}
else {
lemmas = Analysis.countLemmas(lemmas);
LemmaChoice rightLemma = Testing.chooseLemma(lemmas);
HashMap<FullSubWithPOS, Integer> statForGuessing = ReadingStatForGuessing.readStatistics();
Set<FullSubWithPOS> fullSubsWithPOS = statForGuessing.keySet();
String pos = "";
for (FullSubWithPOS fs : fullSubsWithPOS) {
if (fs.fullSubstitution.lastLetters.equals(Statistics.getLastLetters(Statistics.subToWord(Statistics.getTextFromToken(nodeList.item(j)), rightLemma.lemma)))) {
pos = fs.partOfSpeech;
}
}
if (Statistics.subToWord(Statistics.getTextFromToken(nodeList.item(j)), rightLemma.lemma).equals(lemma) && rightPOS.equals(pos)) {
rightUnknown++;
if (j > 0 && j < nodeList.getLength()-1) {
processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + Statistics.getTextFromToken(node) + " [ ? " + lemma + " " + pos + "]" + Statistics.getTextFromToken(nodeList.item(j+1)));
}
else {
processed.add(Statistics.getTextFromToken(node) + " [ ? " + lemma + " " + pos + "]");
}
}
else {
ambigUnknown++;
if (j > 0 && j < nodeList.getLength()-1) {
processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + Statistics.getTextFromToken(node) + " [ ? " + Statistics.subToWord(Statistics.getTextFromToken(nodeList.item(j)), rightLemma.lemma) + " " + pos + "]; Right: " + lemma + " " + rightPOS + " " + Statistics.getTextFromToken(nodeList.item(j+1)));
}
else {
processed.add(Statistics.getTextFromToken(node) + " [ ? " + Statistics.subToWord(Statistics.getTextFromToken(nodeList.item(j)), rightLemma.lemma) + " " + pos + "]; Right: " + lemma + " " + rightPOS);
}
}
}
}
// для слов с омонимией
if (Statistics.getPartsOfSpeech(Statistics.getTextFromToken(node))!=null && Statistics.getPartsOfSpeech(Statistics.getTextFromToken(node)).size()>1) {
HashSet<PartOfSpeech> partsOfSpeech = Statistics.getPartsOfSpeech(Statistics.getTextFromToken(node));
if (partsOfSpeech.contains(PartOfSpeech.VERB) && partsOfSpeech.contains(PartOfSpeech.INFN)) {
continue;
}
HashSet<PartOfSpeech> posWithCombApproach = chooseWithCombinedApproach(nodeList, j);
String rightPOS = POSStatistics.getPOSFromToken(node);
List<Entry> current = new ArrayList<>();
List<POSChoice> parts = new ArrayList<>();
proc++;
for (Entry e : entries) {
if (e.getPartsOfSpeech().toString().equals(Statistics.getPartsOfSpeech(Statistics.getTextFromToken(node)).toString())) {
current.add(e);
}
}
// if (current.isEmpty()) {
// noStat++;
// processed.add(Statistics.getTextFromToken(node) + " [No statistics/before]");
// continue;
// }
getContextsForWordsInDict(nodeList, j, current, parts);
// if (parts.size() == 0) {
// noStat++;
// processed.add(Statistics.getTextFromToken(node) + " [No statistics/after]");
// continue;
// }
// else {
parts = countLemmas(parts);
POSChoice rightpart = chooseLemma(parts);
HashSet<PartOfSpeech> result = new HashSet<>();
if (rightpart == null) {
result = getResultPOSWithCoef(posWithCombApproach, null, combined, stat);
}
else {
result = getResultPOSWithCoef(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech), combined, stat);
}
if (result.contains(toPartOfSpeech(rightPOS))) {
if (result.size() == 1) {
right++;
noAmbig++;
if (j > 0 && j < nodeList.getLength()-1 && rightpart!=null) {
processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + " " + Statistics.getTextFromToken(node) + " [" + result.toString() + " (" + visualizeChoice(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech)) + ")] " + Statistics.getTextFromToken(nodeList.item(j+1)));
}
else if (rightpart!=null) {
processed.add(Statistics.getTextFromToken(node) + " [" + result.toString() + " (" + visualizeChoice(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech)) + ")]");
}
}
if (result.size() > 1) {
right++;
if (j > 0 && j < nodeList.getLength()-1 && rightpart!=null) {
processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + " " + Statistics.getTextFromToken(node) + " [" + result.toString() + " (" + visualizeChoice(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech)) + ")] " + Statistics.getTextFromToken(nodeList.item(j+1)));
}
else if (rightpart!=null) {
processed.add(Statistics.getTextFromToken(node) + " [" + result.toString() + " (" + visualizeChoice(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech)) + ")]");
}
}
}
else {
ambig++;
if (j > 0 && j < nodeList.getLength()-1 && rightpart!=null) {
processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + " " + Statistics.getTextFromToken(node) + " [" + result.toString() + " (" + visualizeChoice(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech)) + ")]; Right: " + rightPOS + " " + Statistics.getTextFromToken(nodeList.item(j+1)));
}
else if (rightpart!=null) {
processed.add(Statistics.getTextFromToken(node) + " [" + result.toString() + " (" + visualizeChoice(posWithCombApproach, toPartOfSpeech(rightpart.partOfSpeech)) + ")]; Right: " + rightPOS);
}
}
// if (rightpart.partOfSpeech.equals(rightPOS)) {
// right++;
// if (j > 0 && j < nodeList.getLength()-1) {
// processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + " " + Statistics.getTextFromToken(node) + " [" + rightpart.partOfSpeech + " " + rightpart.coefficient + "]" + " " + Statistics.getTextFromToken(nodeList.item(j+1)));
// }
// else {
// processed.add(Statistics.getTextFromToken(node) + " [" + rightpart.partOfSpeech + " " + rightpart.coefficient + "]");
// }
// }
// else {
// ambig++;
// if (j > 0 && j < nodeList.getLength()-1) {
// processed.add(Statistics.getTextFromToken(nodeList.item(j-1)) + " " + Statistics.getTextFromToken(node) + " [" + rightpart.partOfSpeech + " " + rightpart.coefficient + "]; Right: " + rightPOS + " " + Statistics.getTextFromToken(nodeList.item(j+1)));
// }
// else {
// processed.add(Statistics.getTextFromToken(node) + " [" + rightpart.partOfSpeech + " " + rightpart.coefficient + "]; Right: " + rightPOS);
// }
// }
//}
}
}
coefficients.add(addResults(combined, stat, right));
}
}
}
// System.out.println("processed: " + proc);
// System.out.println("right: " + right);
// System.out.println("wrong: " + ambig);
// System.out.println("noAmbig: " + noAmbig);
// System.out.println("unknown: " + Unknown);
// System.out.println("rightUnknown: " + rightUnknown);
// System.out.println("ambigUnknown: " + ambigUnknown);
// System.out.println("noStat: " + noStat);
Analysis.writeInFile(coefficients, "D:/Лена/Statistics/Coef.txt", false);
}
public static void getContextsForWordsInDict(NodeList nodeList, int j,
List<Entry> current, List<POSChoice> parts) {
if (j > 0) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j-1))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j-1))));
for (Entry ent : current) {
if (ent.contextElement.fullSubstition.toString().equals(context.toString()) && ent.contextElement.position.equals("-1")) {
parts.add(new POSChoice(ent.partOfSpeech, ent.probability*1.00));
break;
}
}
}
if (j > 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j-2))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j-2))));
for (Entry ent : current) {
if (ent.contextElement.fullSubstition.toString().equals(context.toString()) && ent.contextElement.position.equals("-2")) {
parts.add(new POSChoice(ent.partOfSpeech, ent.probability*0.93));
break;
}
}
}
if (j < nodeList.getLength() - 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j+1))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j+1))));
for (Entry ent : current) {
if (ent.contextElement.fullSubstition.toString().equals(context.toString()) && ent.contextElement.position.equals("+1")) {
parts.add(new POSChoice(ent.partOfSpeech, ent.probability*0.97));
break;
}
}
}
if (j < nodeList.getLength() - 2) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j+2))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j+2))));
for (Entry ent : current) {
if (ent.contextElement.fullSubstition.toString().equals(context.toString()) && ent.contextElement.position.equals("+2")) {
parts.add(new POSChoice(ent.partOfSpeech, ent.probability*0.88));
break;
}
}
}
}
public static void getContextsForUnknownWords(NodeList nodeList, int j,
List<Entry> current, List<LemmaChoice> lemmas) {
if (j > 0) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j-1))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j-1))));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*1.00));
}
}
}
if (j > 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j-2))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j-2))));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.93));
}
}
}
if (j < nodeList.getLength() - 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j+1))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j+1))));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.97));
}
}
}
if (j < nodeList.getLength() - 2) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(Statistics.getTextFromToken(nodeList.item(j+2))), Statistics.getSubstitution(Statistics.getTextFromToken(nodeList.item(j+2))));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.88));
}
}
}
}
public static List<POSChoice> countLemmas(List<POSChoice> parts) {
if (parts.size() == 0) {
return null;
}
List<POSChoice> processed = new ArrayList<>();
for (POSChoice part : parts) {
if (processed.size() == 0) {
processed.add(part);
}
else {
for (int i = 0; i < processed.size(); i++) {
if (i == processed.size()-1 && !processed.get(i).partOfSpeech.equals(part.partOfSpeech)) {
processed.add(part);
break;
}
if (processed.get(i).partOfSpeech.equals(part.partOfSpeech)) {
processed.get(i).coefficient = processed.get(i).coefficient + part.coefficient;
break;
}
}
}
}
return processed;
}
public static POSChoice chooseLemma(List<POSChoice> processed) {
if (processed == null) {
return null;
}
double cur = 0;
for (POSChoice part : processed) {
if (part.coefficient > cur) {
cur = part.coefficient;
}
}
for (POSChoice part : processed) {
if (part.coefficient == cur) {
return part;
}
}
return null;
}
private static List<File> getXmlFiles(File folder) {
List<File> folderFiles = new ArrayList<File>();
File[] files = folder.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
boolean isTxt = name.endsWith(".xml");
return isTxt;
}
});
if (files != null) {
folderFiles.addAll(Arrays.asList(files));
}
File[] folders = folder.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
boolean isFolder = dir.isDirectory();
return isFolder;
}
});
if (folders != null) {
for (int f = 0; f < folders.length; f++) {
File newFile = folders[f];
List<File> filesList = getXmlFiles(newFile);
folderFiles.addAll(filesList);
}
}
return folderFiles;
}
public static PartOfSpeech toPartOfSpeech(String pos) {
if (pos.equals("ADJF")) {
return PartOfSpeech.ADJF;
}
if (pos.equals("ADJS")) {
return PartOfSpeech.ADJS;
}
if (pos.equals("ADVB")) {
return PartOfSpeech.ADVB;
}
if (pos.equals("COMP")) {
return PartOfSpeech.COMP;
}
if (pos.equals("CONJ")) {
return PartOfSpeech.CONJ;
}
if (pos.equals("GRND")) {
return PartOfSpeech.GRND;
}
if (pos.equals("INFN")) {
return PartOfSpeech.INFN;
}
if (pos.equals("INTJ")) {
return PartOfSpeech.INTJ;
}
if (pos.equals("NOUN")) {
return PartOfSpeech.NOUN;
}
if (pos.equals("NPRO")) {
return PartOfSpeech.NPRO;
}
if (pos.equals("NUMR")) {
return PartOfSpeech.NUMR;
}
if (pos.equals("PRCL")) {
return PartOfSpeech.PRCL;
}
if (pos.equals("PRED")) {
return PartOfSpeech.PRED;
}
if (pos.equals("PREP")) {
return PartOfSpeech.PREP;
}
if (pos.equals("PRTF")) {
return PartOfSpeech.PRTF;
}
if (pos.equals("PRTS")) {
return PartOfSpeech.PRTS;
}
if (pos.equals("VERB")) {
return PartOfSpeech.VERB;
}
return null;
}
public static HashSet<PartOfSpeech> chooseWithCombinedApproach(NodeList nodeList, int j) {
if (j > 0 && j < nodeList.getLength()-1) {
String textFromToken = Statistics.getTextFromToken(nodeList.item(j));
String str = Statistics.getTextFromToken(nodeList.item(j-1)) + " " + textFromToken + " " + Statistics.getTextFromToken(nodeList.item(j+1));
return chooseWithCombinedApproach(
str, textFromToken);
}
return new HashSet<PartOfSpeech>();
}
public static HashSet<PartOfSpeech> chooseWithCombinedApproach(
String str, String textFromToken) {
HashSet<PartOfSpeech> partsOfSpeech = new HashSet<>();
List<IToken> wordFormTokens = TestingUtil.getWordFormTokens(str);
AdditionalMetadataHandler.setStoreMetadata(true);
CombinedMorphologicParser cmp = new CombinedMorphologicParser();
List<IToken> processed = cmp.process(wordFormTokens);
for (IToken proc : processed) {
if (!proc.hasCorrelation() || proc.getCorrelation() > 0.05) {
String shortStringValue = proc.getShortStringValue().trim();
if (proc.getShortStringValue().trim().equals(textFromToken)) {
if (proc instanceof SyntaxToken) {
SyntaxToken ch = (SyntaxToken) proc;
partsOfSpeech.add(ch.getPartOfSpeech());
}
}
}
}
return partsOfSpeech;
}
// public static HashMap<PartOfSpeech, Double> normalizeCoefficients(List<IToken> processed) {
// HashMap<PartOfSpeech, Double> probabilities = new HashMap<>();
// double general = 0;
// for (IToken token : processed) {
// general += token.getCorrelation();
// }
// }
//
public static HashSet<PartOfSpeech> getResultPOS(HashSet<PartOfSpeech> posWithCombined, PartOfSpeech posWithStat) {
HashSet<PartOfSpeech> result = new HashSet<>();
if (posWithStat == null) {
result.addAll(posWithCombined);
return result;
}
if (posWithCombined.contains(posWithStat)) {
result.add(posWithStat);
}
else {
result.addAll(posWithCombined);
result.add(posWithStat);
}
return result;
}
public static HashSet<PartOfSpeech> getResultPOSWithCoef(HashSet<PartOfSpeech> posWithCombined, PartOfSpeech posWithStat, double combined, double stat) {
HashSet<PartOfSpeech> result = new HashSet<>();
HashMap<PartOfSpeech, Double> counting = new HashMap<>();
counting.put(posWithStat, stat);
for (PartOfSpeech pos : posWithCombined) {
if (counting.containsKey(pos)) {
double value = counting.get(pos) + combined;
counting.put(pos, value);
}
else {
counting.put(pos, combined);
}
}
double current = 0;
for (PartOfSpeech pos : counting.keySet()) {
if (counting.get(pos) > current) {
current = counting.get(pos);
}
}
for (PartOfSpeech pos : counting.keySet()) {
if (counting.get(pos) == current) {
result.add(pos);
}
}
return result;
}
public static String addResults(double combined, double stat, int right) {
return combined + " " + stat + " " + right;
}
public static String visualizeChoice(HashSet<PartOfSpeech> posWithCombined, PartOfSpeech posWithStat) {
if (posWithStat == null) {
return "Combined Approach: " + posWithCombined.toString() + " Statistics: No Statistics";
}
return "Combined Approach: " + posWithCombined.toString() + " Statistics: " + posWithStat;
}
}
<file_sep>/Statistics/src/statistics/Entry.java
package statistics;
import java.io.Serializable;
import java.util.HashSet;
import java.util.Set;
import java.util.stream.Collectors;
import com.onpositive.semantic.wordnet.Grammem;
import com.onpositive.semantic.wordnet.Grammem.PartOfSpeech;
public class Entry implements Serializable {
/**
*
*/
private static final long serialVersionUID = 1L;
public FullSubstitution homonym;
public ContextElement contextElement;
public Substitution lemma;
public float probability;
public String partOfSpeech;
public Set<String> partsOfSpeech;
public Entry(FullSubstitution homonym, ContextElement contextElement, Substitution lemma) {
this.homonym = homonym;
this.contextElement = contextElement;
this.lemma = lemma;
}
public Entry(ContextElement prev, HashSet<PartOfSpeech> partsOfSpeech, String partOfSpeech2) {
this.contextElement = prev;
this.partOfSpeech = partOfSpeech2;
this.partsOfSpeech = partsOfSpeech.stream().map(p -> p.id).collect(Collectors.toSet());
}
public String toString() {
if (homonym!=null && lemma!=null) {
return homonym.toString() + " | " + contextElement.toString() + " | " + lemma.toString() + " | " + partOfSpeech + " | " + probability;
}
else {
return contextElement.toString() + " | " + partsOfSpeech.toString() + " | " + partOfSpeech + " | " + probability;
}
}
public Set<PartOfSpeech> getPartsOfSpeech() {
return partsOfSpeech.stream().map(str -> (PartOfSpeech) Grammem.get(str)).collect(Collectors.toSet());
}
}
<file_sep>/Statistics/src/statistics/AnalysisWithPOS.java
package statistics;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Set;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.SAXException;
import com.onpositive.text.analisys.tests.util.TestingUtil;
import com.onpositive.text.analysis.IToken;
import com.onpositive.text.analysis.utils.MorphologicUtils;
public class AnalysisWithPOS {
public static void main(String[] args) throws IOException, SAXException, ParserConfigurationException {
// TODO Auto-generated method stub
List<String> results = new ArrayList<>();
File f = new File("D:/Лена/Statistics/Text.txt");
String text = "";
final int length = (int) f.length();
if (length != 0) {
char[] cbuf = new char[length];
InputStreamReader isr = new InputStreamReader(new FileInputStream(f), "UTF-8");
final int read = isr.read(cbuf);
text = new String (cbuf, 0, read);
isr.close();
}
List<String> processed = analyze(text);
Testing.writeInFile(processed, "D:/Лена/Statistics/Results.txt", false);
}
public static List<String> analyze(String text) throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
List<String> wordForms = new ArrayList<>();
List<IToken> sentences = TestingUtil.getSentences(text);
for (IToken sentence : sentences) {
List<IToken> words = sentence.getChildren();
List<IToken> chain = MorphologicUtils.getWithNoConflicts(words);
for (IToken token : chain) {
if (token.getShortStringValue().endsWith(" ")) {
wordForms.add(token.getShortStringValue().substring(0, token.getShortStringValue().length()-1));
}
else {
wordForms.add(token.getShortStringValue());
}
}
}
List<String> processed = new ArrayList<>();
for (int i = 0; i < wordForms.size(); i++) {
List<LemmaChoice> lemmas = new ArrayList<>();
if (!Analysis.inDictionary(wordForms.get(i)) && !Statistics.isNumber(wordForms.get(i)) && !Statistics.isPunctuationMark(wordForms.get(i)) && !wordForms.get(i).equals("") && !wordForms.get(i).equals("\r")) {
Set<Entry> entriesForUnknown = StatisticsReader.readStatistics().keySet();
String letters = Statistics.getLastLetters(wordForms.get(i));
List<Entry> current = new ArrayList<>();
for (Entry entry : entriesForUnknown) {
if (entry.homonym.lastLetters.equals(letters)) {
current.add(entry);
}
}
if (current.size() == 0) {
processed.add(wordForms.get(i) + " [No statictics before]");
continue;
}
if (i > 0) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-1)), Statistics.getSubstitution(wordForms.get(i-1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*1.00));
}
}
}
if (i > 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-2)), Statistics.getSubstitution(wordForms.get(i-2)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.93));
}
}
}
if (i < wordForms.size() - 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+1)), Statistics.getSubstitution(wordForms.get(i+1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.97));
}
}
}
if (i < wordForms.size() - 2) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+2)), Statistics.getSubstitution(wordForms.get(i+2)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.88));
}
}
}
if (lemmas.size() == 0) {
continue;
}
else {
lemmas = Analysis.countLemmas(lemmas);
List<LemmaChoice> rightLemmas = Analysis.chooseLemma(lemmas);
HashMap<FullSubWithPOS, Integer> statForGuessing = ReadingStatForGuessing.readStatistics();
Set<FullSubWithPOS> fullSubsWithPOS = statForGuessing.keySet();
String pos = "";
for (LemmaChoice rightLemma : rightLemmas) {
for (FullSubWithPOS fs : fullSubsWithPOS) {
if (fs.fullSubstitution.lastLetters.equals(Statistics.getLastLetters(Statistics.subToWord(wordForms.get(i), rightLemma.lemma)))) {
pos = fs.partOfSpeech;
}
}
processed.add(i + wordForms.get(i) + " [ ? " + Statistics.subToWord(wordForms.get(i), rightLemma.lemma) + " " + pos + " (" + rightLemma.coefficient + ")]");
}
continue;
}
}
if (Analysis.getBasicForms(wordForms.get(i)) == null) {
continue;
}
if (Analysis.getBasicForms(wordForms.get(i)).size() == 1) {
processed.add(wordForms.get(i) + " [" + Analysis.getBasicForms(wordForms.get(i)) + "]");
continue;
}
if (Analysis.getBasicForms(wordForms.get(i)).size() > 1) {
Set<Entry> entries = ReadingPOSStatistics.readStatistics().keySet();
List<Substitution> substitutions = Statistics.getSubstitution(wordForms.get(i));
List<Entry> current = new ArrayList<>();
for (Entry entry : entries) {
if (entry.homonym!=null && entry.homonym.substitutions.toString().equals(substitutions.toString())) {
current.add(entry);
}
}
if (current.size() == 0) {
processed.add(wordForms.get(i) + " [No statictics before]");
continue;
}
if (i > 0) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-1)), Statistics.getSubstitution(wordForms.get(i-1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*1.00));
}
}
}
if (i > 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-2)), Statistics.getSubstitution(wordForms.get(i-2)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.93));
}
}
}
if (i < wordForms.size() - 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+1)), Statistics.getSubstitution(wordForms.get(i+1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.97));
}
}
}
if (i < wordForms.size() - 2) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+2)), Statistics.getSubstitution(wordForms.get(i+2)));;
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.88));
}
}
}
if (lemmas.size() == 0) {
processed.add(wordForms.get(i) + " [No statictics after]");
continue;
}
else {
lemmas = Analysis.countLemmas(lemmas);
List<LemmaChoice> rightLemmas = Analysis.chooseLemma(lemmas);
for (LemmaChoice rightLemma : rightLemmas) {
processed.add(i + wordForms.get(i) + " [" + Statistics.subToWord(wordForms.get(i), rightLemma.lemma) + " (" + rightLemma.coefficient + ")]");
}
}
}
}
return processed;
}
}
<file_sep>/Statistics/src/statistics/POSChoice.java
package statistics;
public class POSChoice {
public String partOfSpeech;
public double coefficient;
public POSChoice(String partOfSpeech, double coefficient) {
this.partOfSpeech = partOfSpeech;
this.coefficient = coefficient;
}
}
<file_sep>/Statistics/src/statistics/Statistics.java
package statistics;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FilenameFilter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import com.onpositive.semantic.wordnet.AbstractWordNet;
import com.onpositive.semantic.wordnet.GrammarRelation;
import com.onpositive.semantic.wordnet.MeaningElement;
import com.onpositive.semantic.wordnet.TextElement;
import com.onpositive.semantic.wordnet.WordNetProvider;
import com.onpositive.semantic.wordnet.Grammem.PartOfSpeech;
public class Statistics {
public static void main(String[] args) throws ParserConfigurationException, UnsupportedEncodingException, FileNotFoundException, SAXException, IOException {
// TODO Auto-generated method stub
HashMap<Entry, Integer> statistics = getStatistics();
}
public static List<Substitution> getSubstitution(String word) {
List<Substitution> substitutions = new ArrayList<>();
HashSet<String> basicForms = new HashSet<>();
int end = 0;
String flex = null;
AbstractWordNet instance = WordNetProvider.getInstance();
GrammarRelation[] possibleGrammarForms = instance.getPossibleGrammarForms(word);
if (possibleGrammarForms == null) {
return null;
}
for (GrammarRelation g : possibleGrammarForms) {
TextElement textElement = g.getWord();
String basicForm = textElement.getBasicForm();
basicForms.add(basicForm);
}
for (String baseForm : basicForms) {
outer: for (int w = 0; w < word.length(); w++) {
for (int b = 0; b < baseForm.length(); b++) {
if (word.charAt(w) != baseForm.charAt(b)) {
end = word.length() - w;
flex = baseForm.substring(b);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (b == baseForm.length()-1 && w < word.length()-1) {
end = word.length() - b -1;
flex = "";
substitutions.add(new Substitution(end, flex));
break outer;
}
if (w == word.length() - 1 && b < baseForm.length()-1) {
end = 0;
flex = baseForm.substring(b+1);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (word.charAt(w) == baseForm.charAt(b)) {
if (w == word.length()-1 && b == baseForm.length()-1) {
substitutions.add(new Substitution(0, ""));
break outer;
}
w++;
continue;
}
}
}
}
return substitutions;
}
public static Entry getEntry(String previousWord, String homonym, String lemma) {
ContextElement prev = new ContextElement(new FullSubstitution(getLastLetters(previousWord.toLowerCase()), getSubstitution(previousWord.toLowerCase())));
FullSubstitution hom = new FullSubstitution(getLastLetters(homonym.toLowerCase()), getSubstitution(homonym.toLowerCase()));
FullSubstitution lem = getLemma(homonym.toLowerCase(), lemma.toLowerCase());
Entry entry = new Entry(hom, prev, lem.substitutions.get(0));
return entry;
}
public static HashSet<PartOfSpeech> getPartsOfSpeech(String word) {
AbstractWordNet instance = WordNetProvider.getInstance();
GrammarRelation[] possibleGrammarForms = instance.getPossibleGrammarForms(word.toLowerCase());
HashSet<PartOfSpeech> partsOfSpeech = new HashSet<>();
if (possibleGrammarForms == null) {
return null;
}
for (GrammarRelation gr : possibleGrammarForms) {
TextElement textElement = gr.getWord();
MeaningElement[] concepts = textElement.getConcepts();
for (MeaningElement m : concepts) {
PartOfSpeech partOfSpeech = m.getPartOfSpeech();
if (partOfSpeech != null) {
partsOfSpeech.add(partOfSpeech);
}
}
}
return partsOfSpeech;
}
public static FullSubstitution getLemma(String word, String lemma) {
List<Substitution> substitutions = new ArrayList<>();
int end = 0;
String flex = null;
outer: for (int w = 0; w < word.length(); w++) {
for (int b = 0; b < lemma.length(); b++) {
if (word.charAt(w) != lemma.charAt(b)) {
end = word.length() - w;
flex = lemma.substring(b);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (b == lemma.length()-1 && w < word.length()-1) {
end = word.length() - b -1;
flex = "";
substitutions.add(new Substitution(end, flex));
break outer;
}
if (w == word.length() - 1 && b < lemma.length()-1) {
end = 0;
flex = lemma.substring(b+1);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (word.charAt(w) == lemma.charAt(b)) {
if (w == word.length()-1 && b == lemma.length()-1) {
substitutions.add(new Substitution(0, ""));
break outer;
}
w++;
continue;
}
}
}
return new FullSubstitution(getLastLetters(lemma), substitutions);
}
public static String getLastLetters(String word) {
if (word.length() >= 3) {
return word.substring(word.length() - 3);
}
if (word.length() < 3) {
return word;
}
return null;
}
public static boolean isPunctuationMark(String word) {
String[] marks = {".", ",", "?", "!", "\"", ":", ";", "-", "(", ")"};
for (String mark : marks) {
if (mark.equalsIgnoreCase(word)) {
return true;
}
}
return false;
}
public static boolean isNumber(String word) {
String[] numbers = {"0", "1", "2", "3", "4", "5", "6", "7", "8", "9"};
for (String number : numbers) {
if (word.contains(number)) {
return true;
}
}
return false;
}
public static HashMap<Entry, Integer> formHashMap(List<Entry> statistics) {
HashMap<Entry, Integer> dictionary = new HashMap<Entry, Integer>();
for (Entry entry : statistics) {
Set<Entry> entries = dictionary.keySet();
if (entries.size() == 0) {
dictionary.put(entry, 1);
continue;
}
Object[] ents = entries.toArray();
for (int i = 0; i < ents.length; i++) {
if (i == ents.length - 1 && !ents[i].toString().equals(entry.toString())) {
dictionary.put(entry, 1);
}
else if (!ents[i].toString().equals(entry.toString())) {
continue;
}
else {
int value = dictionary.get(ents[i]);
value = value + 1;
dictionary.replace((Entry) ents[i], dictionary.get(ents[i]), value);
//dictionary.put((Entry) ents[i], value);
break;
}
}
}
return dictionary;
}
public static HashMap<FullSubstitution, Integer> getHomonymNumber(HashMap<Entry, Integer> dictionary) {
HashMap<FullSubstitution, Integer> homonyms = new HashMap<FullSubstitution, Integer>();
Set<Entry> entriesInDict = dictionary.keySet();
for (Entry entryInDict : entriesInDict) {
FullSubstitution homonym = entryInDict.homonym;
if (homonyms.size() == 0) {
homonyms.put(homonym, dictionary.get(entryInDict));
continue;
}
Object[] homs = homonyms.keySet().toArray();
for (int i = 0; i < homs.length; i++) {
if (i == homs.length - 1 && !homs[i].toString().equals(homonym.toString())) {
homonyms.put(homonym, dictionary.get(entryInDict));
}
else if (!homs[i].toString().equals(homonym.toString())) {
continue;
}
else {
int value = dictionary.get(entryInDict);
value = value + homonyms.get(homs[i]);
homonyms.put((FullSubstitution) homs[i], value); //переделать на replace
break;
}
}
}
return homonyms;
}
public static HashMap<Bigram, Integer> countBigrams(HashMap<Entry, Integer> dictionary) {
HashMap<Bigram, Integer> bigrams = new HashMap<Bigram, Integer>();
Set<Entry> entriesInDict = dictionary.keySet();
for (Entry entry : entriesInDict) {
Bigram bigram = new Bigram(entry.homonym, entry.contextElement);
if (bigrams.size() == 0) {
bigrams.put(bigram, dictionary.get(entry));
continue;
}
Object[] keyBigrams = bigrams.keySet().toArray();
for (int i = 0; i < keyBigrams.length; i++) {
if (i == keyBigrams.length - 1 && !keyBigrams[i].toString().equals(bigram.toString())) {
bigrams.put(bigram, dictionary.get(entry));
}
else if (!keyBigrams[i].toString().equals(bigram.toString())) {
continue;
}
else {
int value = dictionary.get(entry);
value = value + bigrams.get(keyBigrams[i]);
bigrams.put((Bigram)keyBigrams[i], value); //переделать на replace
break;
}
}
}
return bigrams;
}
public static HashMap<Entry, Integer> countProbability(HashMap<Entry, Integer> dictionary, HashMap<Bigram, Integer> bigrams) {
Set<Entry> entriesInDict = dictionary.keySet();
Set<Bigram> keyBigrams = bigrams.keySet();
for (Entry entry : entriesInDict) {
for (Bigram bigram : keyBigrams) {
// if (!entry.contextElement.toString().equals(bigram.contextElement.toString()) | !entry.homonym.toString().equals(bigram.homonym.toString())) {
// continue;
// }
ContextElement entryCE = entry.contextElement;
ContextElement bigramCE = bigram.contextElement;
FullSubstitution entryH = entry.homonym;
FullSubstitution bigramH = bigram.homonym;
if (entry.contextElement.equals(bigram.contextElement) && entry.homonym.equals(bigram.homonym)) {
//if (entry.contextElement.toString().equals(bigram.contextElement.toString()) && entry.homonym.toString().equals(bigram.homonym.toString())) {
entry.probability = (float) ((dictionary.get(entry)*1.0) / (bigrams.get(bigram)*1.0));
int getEntry = dictionary.get(entry);
int getBigram = bigrams.get(bigram);
if (entry.probability > 1) {
System.out.println((dictionary.get(entry)*1.0) + "/" + (bigrams.get(bigram)*1.0));
}
}
}
}
return dictionary;
}
public static List<String> visualizeProbability(HashMap<Entry, Integer> dictionary, HashMap<Bigram, Integer> bigrams) {
List<String> visualizing = new ArrayList<>();
Set<Entry> entriesInDict = dictionary.keySet();
Set<Bigram> bigram = bigrams.keySet();
for (Entry entryInDict : entriesInDict) {
FullSubstitution homonym = entryInDict.homonym;
ContextElement contextElement = entryInDict.contextElement;
for (Bigram b : bigram) {
if (b.contextElement.toString().equals(contextElement.toString()) && b.homonym.toString().equals(homonym.toString())) {
visualizing.add(entryInDict.toString() + " (" + dictionary.get(entryInDict) + " / " + bigrams.get(b) + ")");
}
}
}
return visualizing;
}
public static String subToWord(String word, Substitution sub) {
String newWord = word.substring(0, word.length() - sub.letters);
newWord = newWord + sub.ending;
return newWord;
}
public static HashMap<Entry, Integer> getStatistics() throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
List<Entry> dictionary = new ArrayList<>();
File folder = new File("D:/Лена/NoAmbig");
List<File> folderFiles = getXmlFiles(folder);
for (int j = 0; j < 500; j++) { //значения для тренировки
DocumentBuilderFactory f = DocumentBuilderFactory.newInstance();
f.setValidating(false);
DocumentBuilder builder = f.newDocumentBuilder();
Document doc = builder.parse(new InputSource(new InputStreamReader(new FileInputStream(folderFiles.get(j)),"UTF-8")));
NodeList nodeList = doc.getElementsByTagName("token");
System.out.println("nodeList.getLength = " + nodeList.getLength());
for (int i = 0; i < nodeList.getLength(); i++) {
Node node = nodeList.item(i);
if (node != null) {
if (getSubstitution(getTextFromToken(node))!=null && getSubstitution(getTextFromToken(node)).size() > 1) {
String lemma = getLemmaFromToken(node);
if (i > 1) {
Node prevNode = nodeList.item(i-1);
if (prevNode != null) {
if (getSubstitution(getTextFromToken(prevNode)) == null) {
continue;
}
if (getPartsOfSpeech(getTextFromToken(prevNode)) != null | isPunctuationMark(getTextFromToken(prevNode)) | isNumber(getTextFromToken(prevNode))) {
Entry entry = getEntry(getTextFromToken(prevNode), getTextFromToken(node), lemma);
entry.contextElement.position = "-1";
dictionary.add(entry);
}
}
}
if (i > 2) {
Node node2 = nodeList.item(i-2);
if (node2 != null) {
if (getSubstitution(getTextFromToken(node2)) == null) {
continue;
}
if (getPartsOfSpeech(getTextFromToken(node2)) != null | isPunctuationMark(getTextFromToken(node2)) | isNumber(getTextFromToken(node2))) {
Entry entry = getEntry(getTextFromToken(node2), getTextFromToken(node), lemma);
entry.contextElement.position = "-2";
dictionary.add(entry);
}
}
}
if (i < nodeList.getLength()) {
Node node2 = nodeList.item(i+1);
if (node2 != null) {
if (getSubstitution(getTextFromToken(node2)) == null) {
continue;
}
if (getPartsOfSpeech(getTextFromToken(node2)) != null | isPunctuationMark(getTextFromToken(node2)) | isNumber(getTextFromToken(node2))) {
Entry entry = getEntry(getTextFromToken(node2), getTextFromToken(node), lemma);
entry.contextElement.position = "+1";
dictionary.add(entry);
}
}
}
if (i < nodeList.getLength() - 2) {
Node node2 = nodeList.item(i+2);
if (node2 != null) {
if (getSubstitution(getTextFromToken(node2)) == null) {
continue;
}
if (getPartsOfSpeech(getTextFromToken(node2)) != null | isPunctuationMark(getTextFromToken(node2)) | isNumber(getTextFromToken(node2))) {
Entry entry = getEntry(getTextFromToken(node2), getTextFromToken(node), lemma);
entry.contextElement.position = "+2";
dictionary.add(entry);
}
}
}
}
}
}
}
System.out.println("dictionary.size = " + dictionary.size());
HashMap<Entry, Integer> dict = formHashMap(dictionary);
System.out.println("form HashMap");
HashMap<Bigram, Integer> bigrams = countBigrams(dict);
System.out.println("count bigrams");
dict = countProbability(dict, bigrams);
System.out.println("count probability");
return dict;
}
public static String getLemmaFromToken(Node node) {
if (node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
Element tfr = (Element) element.getFirstChild();
Element v = (Element) tfr.getFirstChild();
Element l = (Element) v.getFirstChild();
return l.getAttribute("t");
}
return null;
}
public static String getTextFromToken(Node node) {
if (node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
return element.getAttribute("text").toLowerCase();
}
return null;
}
public static String getPOSFromToken(Node node) {
if (node.ELEMENT_NODE == node.getNodeType()) {
Element element = (Element) node;
Element tfr = (Element) element.getFirstChild();
Element v = (Element) tfr.getFirstChild();
Element l = (Element) v.getFirstChild();
Element g = (Element) l.getFirstChild();
return g.getAttribute("v");
}
return null;
}
private static List<File> getXmlFiles(File folder) {
List<File> folderFiles = new ArrayList<File>();
File[] files = folder.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
boolean isTxt = name.endsWith(".xml");
return isTxt;
}
});
if (files != null) {
folderFiles.addAll(Arrays.asList(files));
}
File[] folders = folder.listFiles(new FilenameFilter() {
@Override
public boolean accept(File dir, String name) {
// TODO Auto-generated method stub
boolean isFolder = dir.isDirectory();
return isFolder;
}
});
if (folders != null) {
for (int f = 0; f < folders.length; f++) {
File newFile = folders[f];
List<File> filesList = getXmlFiles(newFile);
folderFiles.addAll(filesList);
}
}
return folderFiles;
}
}
<file_sep>/Statistics/src/statistics/Bigram.java
package statistics;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import com.onpositive.semantic.wordnet.Grammem.PartOfSpeech;
public class Bigram {
public FullSubstitution homonym;
public ContextElement contextElement;
public Set<PartOfSpeech> partsOfSpeech;
public Bigram(FullSubstitution homonym, ContextElement contextElement) {
this.homonym = homonym;
this.contextElement = contextElement;
}
public Bigram(Set<PartOfSpeech> partsOfSpeech, ContextElement contextElement2) {
// TODO Auto-generated constructor stub
this.partsOfSpeech = partsOfSpeech;
this.contextElement = contextElement2;
}
public String toString() {
if (homonym!=null) {
return homonym.toString() + " " + contextElement.toString();
}
else {
return contextElement.toString() + " " + partsOfSpeech.toString();
}
}
public String POSInEngToString() {
List<String> pos = new ArrayList<>();
for (PartOfSpeech p : partsOfSpeech) {
pos.add(p.id);
}
return pos.toString();
}
}
<file_sep>/Statistics/src/statistics/TestEntry.java
package statistics;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import com.onpositive.semantic.wordnet.AbstractWordNet;
import com.onpositive.semantic.wordnet.GrammarRelation;
import com.onpositive.semantic.wordnet.TextElement;
import com.onpositive.semantic.wordnet.WordNetProvider;
public class TestEntry {
public static void main(String[] args) {
// TODO Auto-generated method stub
Entry test = getEntry("мы", "меняем", "меняю");
System.out.println(test.toString());
}
public static Entry getEntry(String previousWord, String homonym, String lemma) {
ContextElement prev = new ContextElement(new FullSubstitution(getLastLetters(previousWord), getSubstitution(previousWord)));
FullSubstitution hom = new FullSubstitution(getLastLetters(homonym), getSubstitution(homonym));
FullSubstitution lem = getLemma(homonym, lemma);
Entry entry = new Entry(hom, prev, lem.substitutions.get(0));
return entry;
}
public static FullSubstitution getLemma(String word, String lemma) {
List<Substitution> substitutions = new ArrayList<>();
int end = 0;
String flex = null;
outer: for (int w = 0; w < word.length(); w++) {
for (int b = 0; b < lemma.length(); b++) {
if (word.charAt(w) != lemma.charAt(b)) {
end = word.length() - w;
flex = lemma.substring(b);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (b == lemma.length()-1 && w < word.length()-1) {
end = word.length() - b -1;
flex = "";
substitutions.add(new Substitution(end, flex));
break outer;
}
if (w == word.length() - 1 && b < lemma.length()-1) {
end = 0;
flex = lemma.substring(b+1);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (word.charAt(w) == lemma.charAt(b)) {
if (w == word.length()-1 && b == lemma.length()-1) {
substitutions.add(new Substitution(0, ""));
break outer;
}
w++;
continue;
}
}
}
return new FullSubstitution(getLastLetters(lemma), substitutions);
}
public static List<Substitution> getSubstitution(String word) {
List<Substitution> substitutions = new ArrayList<>();
HashSet<String> basicForms = new HashSet<>();
int end = 0;
String flex = null;
AbstractWordNet instance = WordNetProvider.getInstance();
GrammarRelation[] possibleGrammarForms = instance.getPossibleGrammarForms(word);
if (possibleGrammarForms == null) {
return null;
}
for (GrammarRelation g : possibleGrammarForms) {
TextElement textElement = g.getWord();
String basicForm = textElement.getBasicForm();
basicForms.add(basicForm);
}
for (String baseForm : basicForms) {
outer: for (int w = 0; w < word.length(); w++) {
for (int b = 0; b < baseForm.length(); b++) {
if (b == baseForm.length()-1 && w < word.length()-1 && word.charAt(w) == baseForm.charAt(b)) {
end = word.length() - b -1;
flex = "";
substitutions.add(new Substitution(end, flex));
break outer;
}
if (w == word.length() - 1 && b < baseForm.length()-1) {
end = 0;
flex = baseForm.substring(b+1);
substitutions.add(new Substitution(end, flex));
break outer;
}
if (word.charAt(w) == baseForm.charAt(b)) {
if (w == word.length()-1 && b == baseForm.length()-1) {
substitutions.add(new Substitution(0, ""));
break outer;
}
w++;
continue;
}
if (word.charAt(w) != baseForm.charAt(b)) {
end = word.length() - w;
flex = baseForm.substring(b);
substitutions.add(new Substitution(end, flex));
break outer;
}
}
}
}
return substitutions;
}
public static String getLastLetters(String word) {
if (word.length() >= 3) {
return word.substring(word.length() - 3);
}
if (word.length() < 3) {
return word;
}
return null;
}
public static boolean isPunctuationMark(String word) {
String[] marks = {".", ",", "?", "!", "\"", ":", ";", "-", "(", ")"};
for (String mark : marks) {
if (mark.equalsIgnoreCase(word)) {
return true;
}
}
return false;
}
public static List<String> visualizeProbability(HashMap<Entry, Float> dictionary, HashMap<Bigram, Float> bigrams) {
List<String> visualizing = new ArrayList<>();
Set<Entry> entriesInDict = dictionary.keySet();
Object[] homs = bigrams.keySet().toArray();
for (Entry entryInDict : entriesInDict) {
FullSubstitution homonym = entryInDict.homonym;
for (int i = 0; i < homs.length; i++) {
if (homs[i].toString().equals(homonym.toString())) {
visualizing.add(entryInDict.toString() + " (" + dictionary.get(entryInDict) + " / " + bigrams.get(homs[i]) + ")");
}
}
}
return visualizing;
}
}
<file_sep>/Statistics/src/statistics/Analysis.java
package statistics;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import javax.xml.parsers.ParserConfigurationException;
import org.xml.sax.SAXException;
import com.onpositive.semantic.wordnet.AbstractWordNet;
import com.onpositive.semantic.wordnet.GrammarRelation;
import com.onpositive.semantic.wordnet.TextElement;
import com.onpositive.semantic.wordnet.WordNetProvider;
import com.onpositive.text.analisys.tests.util.TestingUtil;
import com.onpositive.text.analysis.IToken;
import com.onpositive.text.analysis.lexic.PrimitiveTokenizer;
import com.onpositive.text.analysis.lexic.WordFormParser;
import com.onpositive.text.analysis.utils.MorphologicUtils;
public class Analysis {
public static void main(String[] args) throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
// TODO Auto-generated method stub
HashMap<Entry, Integer> dictionary = StatisticsReader.readStatistics();
Set<Entry> entries = dictionary.keySet();
List<String> results = new ArrayList<>();
File f = new File("D:/Лена/Statistics/Text.txt");
String text = "";
final int length = (int) f.length();
if (length != 0) {
char[] cbuf = new char[length];
InputStreamReader isr = new InputStreamReader(new FileInputStream(f), "UTF-8");
final int read = isr.read(cbuf);
text = new String (cbuf, 0, read);
isr.close();
}
List<IToken> sentences = TestingUtil.getSentences(text);
for (IToken sentence : sentences) {
List<String> wordForms = new ArrayList<>();
List<IToken> words = sentence.getChildren();
List<IToken> chain = MorphologicUtils.getWithNoConflicts(words);
for (IToken token : chain) {
if (token.getShortStringValue().endsWith(" ")) {
wordForms.add(token.getShortStringValue().substring(0, token.getShortStringValue().length()-1));
}
else {
wordForms.add(token.getShortStringValue());
}
}
List<String> processed = analyze(wordForms, entries);
results.addAll(processed);
}
writeInFile(results, "D:/Лена/Statistics/Results.txt", false);
}
public static List<IToken> tokens(String line) {
final List<IToken> tokenize = new PrimitiveTokenizer().tokenize(line);
final WordFormParser wordFormParser = new WordFormParser(
WordNetProvider.getInstance());
wordFormParser.setIgnoreCombinations(true);
final List<IToken> process = wordFormParser.process(tokenize);
return process;
}
public static HashSet<String> getBasicForms(String wordForm) {
HashSet<String> basicForms = new HashSet<>();
AbstractWordNet instance = WordNetProvider.getInstance();
GrammarRelation[] possibleGrammarForms = instance.getPossibleGrammarForms(wordForm);
if (possibleGrammarForms == null) {
return null;
}
for (GrammarRelation g : possibleGrammarForms) {
TextElement textElement = g.getWord();
String basicForm = textElement.getBasicForm();
basicForms.add(basicForm);
}
return basicForms;
}
public static List<String> analyze(List<String> wordForms, Set<Entry> entries) throws UnsupportedEncodingException, FileNotFoundException, SAXException, IOException, ParserConfigurationException {
List<String> processed = new ArrayList<>();
for (int i = 0; i < wordForms.size(); i++) {
List<LemmaChoice> lemmas = new ArrayList<>();
if (!inDictionary(wordForms.get(i)) && !Statistics.isNumber(wordForms.get(i)) && !Statistics.isPunctuationMark(wordForms.get(i)) && !wordForms.get(i).equals("") && !wordForms.get(i).equals("\r")) {
String letters = Statistics.getLastLetters(wordForms.get(i));
List<Entry> current = new ArrayList<>();
for (Entry entry : entries) {
if (entry.homonym.lastLetters.equals(letters)) {
current.add(entry);
}
}
if (current.size() == 0) {
processed.add(wordForms.get(i) + " [No statictics before]");
continue;
}
if (i > 0) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-1)), Statistics.getSubstitution(wordForms.get(i-1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*1.00));
}
}
}
if (i > 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-2)), Statistics.getSubstitution(wordForms.get(i-2)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.93));
}
}
}
if (i < wordForms.size() - 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+1)), Statistics.getSubstitution(wordForms.get(i+1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.97));
}
}
}
if (i < wordForms.size() - 2) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+2)), Statistics.getSubstitution(wordForms.get(i+2)));;
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.88));
}
}
}
if (lemmas.size() == 0) {
continue;
}
else {
lemmas = Analysis.countLemmas(lemmas);
List<LemmaChoice> rightLemmas = Analysis.chooseLemma(lemmas);
for (LemmaChoice rightLemma : rightLemmas) {
processed.add(i + wordForms.get(i) + " [ ? " + Statistics.subToWord(wordForms.get(i), rightLemma.lemma) + " (" + rightLemma.coefficient + ")]");
}
continue;
}
}
if (getBasicForms(wordForms.get(i)) == null) {
continue;
}
if (getBasicForms(wordForms.get(i)).size() == 1) {
processed.add(wordForms.get(i) + " [" + getBasicForms(wordForms.get(i)) + "]");
continue;
}
if (getBasicForms(wordForms.get(i)).size() > 1) {
List<Substitution> substitutions = Statistics.getSubstitution(wordForms.get(i));
List<Entry> current = new ArrayList<>();
for (Entry entry : entries) {
if (entry.homonym.substitutions.toString().equals(substitutions.toString())) {
current.add(entry);
}
}
if (current.size() == 0) {
processed.add(wordForms.get(i) + " [No statictics before]");
continue;
}
if (i > 0) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-1)), Statistics.getSubstitution(wordForms.get(i-1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*1.00));
}
}
}
if (i > 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i-2)), Statistics.getSubstitution(wordForms.get(i-2)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("-2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.93));
}
}
}
if (i < wordForms.size() - 1) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+1)), Statistics.getSubstitution(wordForms.get(i+1)));
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+1")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.97));
}
}
}
if (i < wordForms.size() - 2) {
FullSubstitution context = new FullSubstitution(Statistics.getLastLetters(wordForms.get(i+2)), Statistics.getSubstitution(wordForms.get(i+2)));;
for (int e = 0; e < current.size(); e++) {
if (current.get(e).contextElement.fullSubstition.toString().equals(context.toString()) && current.get(e).contextElement.position.equals("+2")) {
lemmas.add(new LemmaChoice(current.get(e).lemma, current.get(e).probability*0.88));
}
}
}
if (lemmas.size() == 0) {
processed.add(wordForms.get(i) + " [No statictics after]");
continue;
}
else {
lemmas = countLemmas(lemmas);
List<LemmaChoice> rightLemmas = chooseLemma(lemmas);
for (LemmaChoice rightLemma : rightLemmas) {
processed.add(i + wordForms.get(i) + " [" + Statistics.subToWord(wordForms.get(i), rightLemma.lemma) + " (" + rightLemma.coefficient + ")]");
}
}
}
}
return processed;
}
public static List<LemmaChoice> countLemmas(List<LemmaChoice> lemmas) {
List<LemmaChoice> processed = new ArrayList<>();
for (LemmaChoice lemma : lemmas) {
if (processed.size() == 0) {
processed.add(lemma);
}
else {
for (LemmaChoice lpro : processed) {
if (lpro.lemma.toString().equals(lemma.lemma.toString())) {
lpro.coefficient = lpro.coefficient + lemma.coefficient;
}
}
}
}
return processed;
}
public static List<LemmaChoice> chooseLemma(List<LemmaChoice> processed) {
List<LemmaChoice> rightLemmas = new ArrayList<>();
double cur = 0;
for (LemmaChoice lemma : processed) {
if (lemma.coefficient > cur) {
cur = lemma.coefficient;
}
}
for (LemmaChoice lemma : processed) {
if (lemma.coefficient == cur) {
rightLemmas.add(lemma);
}
}
return rightLemmas;
}
public static boolean inDictionary(String word) {
AbstractWordNet instance = WordNetProvider.getInstance();
GrammarRelation[] possibleGrammarForms = instance.getPossibleGrammarForms(word);
if (possibleGrammarForms == null) {
return false;
}
return true;
}
public static void writeInFile(List<String> data, String path, boolean b) throws IOException {
try (FileWriter writer = new FileWriter(path, b)) {
for (String s : data) {
writer.write(s + "\n");
writer.flush();
}
}
}
}
<file_sep>/newNetwork.py
import numpy as np
import cPickle
import gzip
import random
f = gzip.open("C:\Users\User\Documents\Python Scripts\mnist_pkl.gz", 'rb')
training_data, validation_data, test_data = cPickle.load(f)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e
#training_inputs = [np.reshape(x, (784, 1)) for x in training_data[0]]
#training_results = [vectorized_result(y) for y in training_data[1]]
#training_data = zip(training_inputs, training_results)
#validation_inputs = [np.reshape(x, (784, 1)) for x in validation_data[0]]
#validation_data = zip(validation_inputs, validation_data[1])
#test_inputs = [np.reshape(x, (784, 1)) for x in test_data[0]]
#test_data = zip(test_inputs, test_data[1])
def __sigmoid(self, z):
return 1.0 / (1.0 + np.exp(-z))
def sigmoid_prime(self, z):
return self.sigmoid(z)*(1 - self.sigmoid(z))
class network:
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes [1:]]
self.weights = [np.random.randn(x, y) for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
for bias, weight in zip(self.biases, self.weights):
a = self.sigmoid(np.dot(weight, a) + bias)
def backprop(self, x):
new_bias = [np.zeros(b.shape) for b in self.biases]
new_weights = [np.zeros(w.shape) for w in self.weights]
activation = x
activations = [x]
zs = list()
for b, w in zip(new_bias, new_weights):
z = np.dot(activation, w) + b
zs.append(z)
activation = self.sigmoid(z)
activations.append(activation)
delta = self.cost_derivative(activations[-1], x) * self.sigmoid_prime(zs[-1])
new_bias[-1] = delta
new_weights[-1] = np.dot(delta, activations[-2].transpose())
for l in range(2, self.num_layers):
z = zs[-l]
sp = self.sigmoid_prime(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
new_bias[-l] = delta
new_weights[-l] = np.dot(delta, activations[-l - 1].transpose())
return (new_bias, new_weights)
def update_mini_batch(self, mini_batch, eta):
new_bias = [np.zeros(b.shape) for b in self.biases]
new_weights = [np.zeros(w.shape) for w in self.weights]
for x in mini_batch:
delta_new_bias, delta_new_weights = self.backprop(x)
new_bias = [nb + dnb for nb, dnb in zip(new_bias, delta_new_bias)]
new_weights = [nw + dnw for nw, dnw in zip(new_weights, delta_new_weights)]
self.weights = [w - (eta / len(mini_batch)) * nw for w, nw in zip(self.weights, new_weights)]
self.biases = [b - (eta / len(mini_batch)) * nb for b, nb in zip(self.biases, new_bias)]
def SGD(self, training_data, epochs, mini_batch_size, eta, test_data = None):
for j in range(epochs):
mini_batches = [training_data[k:k+mini_batch_size] for k in range(0, len(training_data), mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print("Epoch {0}: {1} / {2}".format(j, self.evaluate(test_data), len(test_data)))
else:
print("Epoch {0} complete".format(j))
def evaluate(self, test_data):
test_results = [(np.argmax(self.feedforward(x)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
return (output_activations-y)
nn = network([784, 100, 10])
nn.SGD(training_data, 25, 10, 0.1, test_data) | 836298cafbc8b461b61d38224beaaf394c3bb712 | [
"Java",
"Python"
] | 17 | Java | BruchesLena/Python | 6457d55f9f1cbb9392710ecd0ba8e26a9355f08f | b60d18fbb6d7d2320c39febcff70d229662d8a1e |
refs/heads/master | <repo_name>vijayvardhan94/MLinR<file_sep>/Linear_Regression_MTcars.r
?cars
head(cars)
#scatter plot is drawn to visulaize any linear relationship between the explanatory and the response variable.
#This is a scatter plot along with the smoothing line
scatter.smooth(x=cars$speed, y=cars$dist, main="Dist ~ Speed") # scatterplot
#Boxplots are mainly used to check for outliers.
par(mfrow=c(1, 2)) # divide graph area in 2 columns
boxplot(cars$speed, main="Speed", sub=paste("Outlier rows: ", boxplot.stats(cars$speed)$out)) # box plot for 'speed'
boxplot(cars$dist, main="Distance", sub=paste("Outlier rows: ", boxplot.stats(cars$dist)$out)) # box plot for 'distance'
#Density plot – Check if the response variable is close to normality
par(mfrow=c(1, 2)) # divide graph area in 2 columns
plot(density(cars$speed), main="Density Plot: Speed", ylab="Frequency", sub=paste("Skewness:", round(e1071::skewness(cars$speed), 2))) # density plot for 'speed'
polygon(density(cars$speed), col="red")
plot(density(cars$dist), main="Density Plot: Distance", ylab="Frequency", sub=paste("Skewness:", round(e1071::skewness(cars$dist), 2))) # density plot for 'dist'
polygon(density(cars$dist), col="red")
cor(cars$speed, cars$dist)
#Building a linear model. So far we have checked for outliers using box plot, and also checked for linearity using scatter plots and the smoothing line.
#We also checked the corelation using the cor function
linearMod <- lm(dist ~ speed, data=cars) # build linear regression model on full data
print(linearMod)
summary(linearMod)
#dist = −17.579 + 3.932∗speed
#now that we have built a linear model its important to see how the model will perform with a new set of data.
# Create Training and Test data -
set.seed(100) # setting seed to reproduce results of random sampling
trainingRowIndex <- sample(1:nrow(cars), 0.8*nrow(cars)) # row indices for training data
trainingData <- cars[trainingRowIndex, ] # model training data
testData <- cars[-trainingRowIndex, ] # test data
lmMod <- lm(dist ~ speed, data=trainingData) # build the model
distPred <- predict(lmMod, testData) # predict distance
summary (lmMod)
actuals_preds <- data.frame(cbind(actuals=testData$dist, predicteds=distPred)) # make actuals_predicteds dataframe.
correlation_accuracy <- cor(actuals_preds) # 82.7%
head(actuals_preds)<file_sep>/Linear_Regression_Womendataset.r
#dataset contains 15 observations with 2 variables
?women
View(women)
#scatter plot is drawn to visulaize any linear relationship between the explanatory and the response variable.
#This is a scatter plot along with the smoothing line
scatter.smooth(x=women$weight, y=women$height, main="Weight ~ Height") # scatterplot
#Boxplots are mainly used to check for outliers.
par(mfrow=c(1, 2)) # divide graph area in 2 columns
boxplot(women$weight, main="Weight", sub=paste("Outlier rows: ", boxplot.stats(women$weight)$out)) # box plot for 'speed'
boxplot(women$height, main="Height", sub=paste("Outlier rows: ", boxplot.stats(women$height)$out)) # box plot for 'distance'
#checking for croelation between the response and the explanatory variables
cor(women$weight, women$height)
#Building a linear model. So far we have checked for outliers using box plot, and also checked for linearity using scatter plots and the smoothing line.
#We also checked the corelation using the cor function
linearMod <- lm(height ~ weight, data=women) # build linear regression model on full data
print(linearMod)
summary(linearMod)
#height = 25.723456 + 0.287249∗weight
## Create Training and Test data -
set.seed(100) # setting seed to reproduce results of random sampling
trainingRowIndex <- sample(1:nrow(women), 0.8*nrow(women)) # row indices for training data
trainingData <- women[trainingRowIndex, ] # model training data
testData <- women[-trainingRowIndex, ]
lmMod <- lm(height ~ weight, data=trainingData) # build the model
distPred <- predict(lmMod, testData) # predict height
summary (lmMod)
actuals_preds <- data.frame(cbind(actuals=testData$height, predicteds=heightPred)) # make actuals_predicteds dataframe.
correlation_accuracy <- cor(actuals_preds)
correlation_accuracy
#head(actuals_preds)
#View(actuals_preds)<file_sep>/README.md
# ML using R
| 1055b3ccab1115c810088b8c3805194820a54942 | [
"Markdown",
"R"
] | 3 | R | vijayvardhan94/MLinR | 49cf7cfccdfeec96e451c2f07aab02df36c1ebac | 9dcca8e8f7f908ffab51bf66635a2594549ea2f2 |
refs/heads/master | <repo_name>Build-Week-30Before30/BackEnd<file_sep>/database/seeds/2_list_comments.js
exports.seed = knex => {
return knex('list_comments').del()
// .then(() => {
// // Inserts seed entries
// return knex('list_comments').insert({
// list_id: 1,
// user_id: 1,
// content: 'Comment contents'
// });
// });
};
<file_sep>/tests/lists.test.js
const session = require('supertest-session');
const database = require('../database');
const server = require('../server');
const knexCleaner = require('knex-cleaner');
let request;
beforeEach(async () => {
request = session(server);
await knexCleaner.clean(database, {
mode: 'truncate',
restartIdentity: true,
});
});
describe('lists', () => {
beforeEach(async () => {
await request
.post('/api/auth/register')
.send({ username: 'test', password: '<PASSWORD>' });
await request
.post('/api/auth/login')
.auth('test', 'test');
});
test('400 when trying to create list without all fields', async () => {
const response = await request
.post('/api/lists');
expect(response.status).toBe(400);
});
test('201 when creating a list with all fields', async () => {
const response = await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
expect(response.status).toBe(201);
});
test('200 when getting all lists', async () => {
const response = await request
.get('/api/lists');
expect(response.status).toBe(200);
});
test('404 when getting an unknown list', async () => {
const response = await request
.get('/api/lists/1');
expect(response.status).toBe(404);
});
test('204 when deleting a list', async () => {
await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
const response = await request
.delete('/api/lists/1');
expect(response.status).toBe(204);
});
test('201 when creating a comment with all fields', async () => {
await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
await request
.post('/api/lists/1/comments')
.send({ content: 'Content' });
const response = await request
.post('/api/lists/1/comments')
.send({ content: 'Content' });
expect(response.status).toBe(201);
});
test('204 when deleting a comment', async () => {
await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
await request
.post('/api/lists/1/comments')
.send({ content: 'Content' });
const response = await request
.delete('/api/lists/comments/1');
expect(response.status).toBe(204);
});
test('400 when creating an item without all fields', async () => {
await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
const response = await request
.post('/api/lists/1/items');
expect(response.status).toBe(400);
});
test('201 when creating an item with all fields', async () => {
await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
const response = await request
.post('/api/lists/1/items')
.send({ name: 'Name', description: 'Description' });
expect(response.status).toBe(201);
});
test('204 when deleting an item', async () => {
await request
.post('/api/lists')
.send({ name: 'Name', description: 'Description' });
await request
.post('/api/lists/1/items')
.send({ name: 'Name', description: 'Description' });
const response = await request
.delete('/api/lists/items/1')
expect(response.status).toBe(204);
});
});<file_sep>/database/migrations/20191018200104_list_items.js
exports.up = knex => {
return knex.schema.createTable('list_items', table => {
table.increments();
table.integer('list_id').notNullable();
table.string('name', 255).notNullable();
table.text('description');
table.boolean('completed').notNullable().defaultTo(0);
table.date('deadline');
table.foreign('list_id').references('id').inTable('lists').onDelete('CASCADE');
});
};
exports.down = knex => {
return knex.schema.dropTable('list_items');
};<file_sep>/database/migrations/20191022130330_list_comments.js
exports.up = knex => {
return knex.schema.createTable('list_comments', table => {
table.increments();
table.timestamps(false, true);
table.integer('list_id').notNullable();
table.integer('user_id').notNullable();
table.text('content').notNullable();
table.foreign('list_id').references('id').inTable('lists').onDelete('CASCADE');
table.foreign('user_id').references('id').inTable('users').onDelete('CASCADE');
});
};
exports.down = knex => {
return knex.schema.dropTable('list_comments');
};<file_sep>/tests/auth.test.js
const request = require('supertest');
const database = require('../database');
const server = require('../server');
const knexCleaner = require('knex-cleaner');
beforeEach(async () => {
await knexCleaner.clean(database, {
mode: 'truncate',
restartIdentity: true,
});
});
describe('auth', () => {
test('successful registration responds with 201', async () => {
const response = await request(server)
.post('/api/auth/register')
.send({ username: 'test', password: '<PASSWORD>' });
expect(response.status).toBe(201);
});
test('successful registration responds with id and username', async () => {
const response = await request(server)
.post('/api/auth/register')
.send({ username: 'test', password: '<PASSWORD>' });
expect(response.body.id).toBe(1);
expect(response.body.username).toBe('test');
});
test('registration with duplicate name responds with 409', async () => {
await request(server)
.post('/api/auth/register')
.send({ username: 'test', password: '<PASSWORD>' });
const response = await request(server)
.post('/api/auth/register')
.send({ username: 'test', password: '<PASSWORD>' });
expect(response.status).toBe(409);
});
test('logging in with unknown user responds with 404', async () => {
const response = await request(server)
.post('/api/auth/login')
.auth('test', 'test');
expect(response.status).toBe(404);
});
test('logging in with bad password responds with 401', async () => {
await request(server)
.post('/api/auth/register')
.send({ username: 'test', password: '<PASSWORD>' });
const response = await request(server)
.post('/api/auth/login')
.auth('test', 'badpassword');
expect(response.status).toBe(401);
});
});<file_sep>/middleware/auth/basic.js
module.exports = (req, res, next) => {
const authorization = req.headers.authorization;
if (!authorization || !authorization.startsWith('Basic ')) {
return res.status(401).json({ message: 'You must be logged in to access this resource.' });
};
const [username, password] = Buffer.from(authorization.slice(6), 'base64').toString('ascii').split(':');
if (!username || !password) {
return res.status(400).json({ message: 'Malformed credentials.' });
};
req.auth = { username, password };
next();
};<file_sep>/routes/lists.js
const router = require('express').Router();
const sessionAuth = require('../middleware/auth/session');
const database = require('../database');
router.post('/', [sessionAuth], (req, res) => {
const { name, description, deadline, is_private } = req.body;
if (!name || !description) {
return res.status(400).json({ message: 'You must provide a name and description.' });
};
database('lists')
.returning('id')
.insert({ name, description, deadline, is_private, user_id: req.session.user.id })
.then(data => {
const [id] = data;
database('lists')
.join('users', 'users.id', 'lists.user_id')
.select('lists.*', 'users.username as created_by')
.where('lists.id', id)
.first()
.then(list => res.status(201).send(list))
.catch(error => res.status(500).send(error));
})
.catch(error => res.status(500).send(error));
});
router.get('/', [sessionAuth], (req, res) => {
database('lists')
.join('users', 'users.id', 'lists.user_id')
.select('lists.*', 'users.username as created_by')
.then(lists => res.send(lists))
.catch(error => res.status(500).send(error));
});
router.get('/:id', [sessionAuth], (req, res) => {
database('lists')
.join('users', 'users.id', 'lists.user_id')
.select('lists.*', 'users.username as created_by')
.where('lists.id', req.params.id)
.first()
.then(list => {
if (!list) {
return res.status(404).json({ message: 'The specified list could not be found.' });
};
database('list_comments')
.join('users', 'users.id', 'list_comments.user_id')
.select('list_comments.id',
'users.id as user_id',
'list_comments.content',
'users.username as created_by',
'list_comments.created_at',
'list_comments.updated_at')
.where({ list_id: list.id })
.then(comments => {
list.comments = comments;
database('list_items')
.where({ list_id: list.id })
.then(items => {
list.items = items;
res.send(list);
})
.catch(error => res.status(500).send(error));
})
.catch(error => res.status(500).send(error));
})
.catch(error => res.status(500).send(error));
});
router.put('/:id', [sessionAuth], (req, res) => {
database('lists')
.update({ name, description, deadline, is_private } = req.body, 'id')
.where({ id: req.params.id })
.then(data => {
const [id] = data;
if (!id) {
return res.status(404).json({ message: 'The specified list could not be found.' });
};
database('lists')
.join('users', 'users.id', 'lists.user_id')
.select('lists.*', 'users.username as created_by')
.where('lists.id', id)
.first()
.then(list => res.status(201).send(list))
.catch(error => res.status(500).send(error));
})
.catch(error => res.status(500).send(error));
});
router.delete('/:id', [sessionAuth], (req, res) => {
database('lists')
.where({ id: req.params.id })
.del()
.then(rows => {
if (!rows) {
return res.status(404).json({ message: 'The specified list could not be found.' });
};
res.sendStatus(204);
})
.catch(error => res.status(500).send(error));
});
router.post('/:id/comments', [sessionAuth], (req, res) => {
if (!req.body.content) {
return res.status(400).json({ message: 'You must specify the content for the comment.' });
};
database('lists')
.where({ id: req.params.id })
.first()
.then(list => {
if (!list) {
return res.status(404).json({ message: 'The specified list could not be found.' });
};
database('list_comments')
.returning('*')
.insert({ list_id: list.id, user_id: req.session.user.id, content: req.body.content })
.then(comment => {
res.status(201).send(comment);
})
.catch(error => res.status(500).send(error));
})
.catch(error => res.status(500).send(error));
});
router.delete('/comments/:commentId', [sessionAuth], (req, res) => {
database('list_comments')
.where({ id: req.params.commentId })
.del()
.then(rows => {
if (!rows) {
return res.status(404).json({ message: 'The specified comment could not be found.' });
};
res.sendStatus(204);
})
.catch(error => res.status(500).send(error));
});
router.post('/:id/items', [sessionAuth], (req, res) => {
if (!req.body.name || !req.body.description) {
return res.status(400).json({ message: 'You must provide a name and description.' });
};
database('lists')
.where('lists.id', req.params.id)
.first()
.then(list => {
if (!list) {
return res.status(404).json({ message: 'The specified list could not be found.' });
};
database('list_items')
.returning('*')
.insert({ list_id: list.id, name: req.body.name, description: req.body.description, deadline: req.body.deadline })
.then(item => res.status(201).send(item[0]))
.catch(error => res.status(500).send(error));
})
.catch(error => res.status(500).send(error));
});
router.delete('/items/:itemId', [sessionAuth], (req, res) => {
database('list_items')
.where({ id: req.params.itemId })
.del()
.then(rows => {
if (!rows) {
return res.status(404).json({ message: 'The specified item could not be found.' });
};
res.sendStatus(204);
})
.catch(error => res.status(500).send(error));
});
router.put('/items/:itemId', [sessionAuth], (req, res) => {
database('list_items')
.update({ name, description, deadline, completed } = req.body, '*')
.where({ id: req.params.itemId })
.then(data => {
if (!data) {
return res.status(404).json({ message: 'The specified item could not be found.' });
};
res.send(data);
})
.catch(error => res.status(500).send(error));
});
module.exports = router;<file_sep>/database/seeds/1_lists.js
exports.seed = knex => {
return knex('lists').del()
// .then(() => {
// // Inserts seed entries
// return knex('lists').insert({
// name: 'List name',
// description: 'List description',
// user_id: 1,
// });
// });
};
<file_sep>/middleware/auth/session.js
const database = require('../../database');
module.exports = (req, res, next) => {
req.headers['Access-Control-Allow-Origin'] = req.headers.referer;
if (!req.session || !req.session.user) {
return res.status(401).json({ message: 'You must be logged in to access this resource.' });
};
database('users')
.where({ id: req.session.user.id })
.first()
.then(user => {
req.session.user = user;
next();
})
.catch(error => res.status(500).send(error));
}; | 8346e11e5970f9f719e08324a38ffe4225c61dbb | [
"JavaScript"
] | 9 | JavaScript | Build-Week-30Before30/BackEnd | 17e4e9aae8e5b2f85f9909f16d916788854b99db | 79612a882c117545b799939f964c40e38b2cb6c6 |
refs/heads/master | <file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.pdftjeneste;
import org.springframework.stereotype.Service;
import no.nav.boot.conditionals.ConditionalOnK8s;
import no.nav.foreldrepenger.mottak.innsending.pdf.modell.DokumentBestilling;
@Service
@ConditionalOnK8s
public class PdfGeneratorTjeneste implements PdfGenerator {
private final PdfGeneratorConnection connection;
public PdfGeneratorTjeneste(PdfGeneratorConnection connection) {
this.connection = connection;
}
@Override
public byte[] generate(DokumentBestilling dokument) {
return connection.genererPdf(dokument);
}
@Override
public String toString() {
return getClass().getSimpleName() + "[connection=" + connection +"]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
import static com.fasterxml.jackson.annotation.JsonTypeInfo.As.PROPERTY;
import static com.fasterxml.jackson.annotation.JsonTypeInfo.Id.NAME;
import com.fasterxml.jackson.annotation.JsonSubTypes;
import com.fasterxml.jackson.annotation.JsonTypeInfo;
import com.fasterxml.jackson.databind.PropertyNamingStrategies;
import com.fasterxml.jackson.databind.annotation.JsonNaming;
@JsonNaming(PropertyNamingStrategies.LowerCaseStrategy.class)
@JsonTypeInfo(use = NAME, include = PROPERTY, property = "type")
@JsonSubTypes({
@JsonSubTypes.Type(value = TemaBlokk.class, name = "TEMA"),
@JsonSubTypes.Type(value = FeltBlokk.class, name = "FELT"),
@JsonSubTypes.Type(value = GruppeBlokk.class, name = "GRUPPE"),
@JsonSubTypes.Type(value = TabellRad.class, name = "TABELLRAD"),
@JsonSubTypes.Type(value = FritekstBlokk.class, name = "FRITEKST"),
@JsonSubTypes.Type(value = ListeBlokk.class, name = "LISTE")
})
public abstract class Blokk {
}
<file_sep>FROM ghcr.io/navikt/fp-baseimages/java:17-appdynamics
LABEL org.opencontainers.image.source=https://github.com/navikt/fpsoknad-mottak
ENV APP_NAME=fpsoknad-mottak
ENV APPD_ENABLED=true
ENV APPDYNAMICS_CONTROLLER_HOST_NAME=appdynamics.adeo.no
ENV APPDYNAMICS_CONTROLLER_PORT=443
ENV APPDYNAMICS_CONTROLLER_SSL_ENABLED=true
COPY target/*.jar app.jar
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
public enum PersonType {
UKJENT, UTENLANDSK, NORSK
}
<file_sep>package no.nav.foreldrepenger.mottak.config;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.MessageSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.support.ResourceBundleMessageSource;
@Configuration
public class MottakConfiguration {
public static final String LANDKODER = "landkoder";
public static final String KVITTERINGSTEKSTER = "kvitteringstekster";
@Bean
@Qualifier(LANDKODER)
public MessageSource landkoderSource() {
var messageSource = new ResourceBundleMessageSource();
messageSource.setBasename(LANDKODER);
return messageSource;
}
@Bean
@Qualifier(KVITTERINGSTEKSTER)
public MessageSource kvitteringsteksterSource() {
var messageSource = new ResourceBundleMessageSource();
messageSource.setBasename(KVITTERINGSTEKSTER);
return messageSource;
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import org.springframework.http.HttpStatusCode;
// FEIL HARDT! Innsending av søknad feilet!
public class InnsendingFeiletFpFordelException extends RuntimeException {
public InnsendingFeiletFpFordelException(Throwable throwable) {
super(throwable);
}
public InnsendingFeiletFpFordelException(String message) {
super(message);
}
public InnsendingFeiletFpFordelException(HttpStatusCode httpStatus, String message) {
super(String.format("[%s] %s", httpStatus.value(), message));
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.dto;
import static no.nav.foreldrepenger.common.util.StreamUtil.safeStream;
import static no.nav.foreldrepenger.common.util.TimeUtil.nowWithinPeriod;
import java.time.LocalDate;
import java.util.List;
import java.util.Objects;
import java.util.Optional;
import no.nav.foreldrepenger.common.domain.felles.ProsentAndel;
public record ArbeidsforholdDTO(ArbeidsgiverDTO arbeidsgiver,
AnsettelsesperiodeDTO ansettelsesperiode,
List<ArbeidsavtaleDTO> arbeidsavtaler) {
public ProsentAndel gjeldendeStillingsprosent() {
return safeStream(arbeidsavtaler)
.filter(this::erGjeldende)
.map(ArbeidsavtaleDTO::stillingsprosent)
.filter(Objects::nonNull)
.findFirst()
.orElse(null);
}
private boolean erGjeldende(ArbeidsavtaleDTO arbeidsavtaleDTO) {
var fom = arbeidsavtaleDTO.gyldighetsperiode().fom();
if (fom.isAfter(LocalDate.now())) {
return true;
}
var tom = Optional.ofNullable(arbeidsavtaleDTO.gyldighetsperiode().tom())
.orElse(LocalDate.now());
return nowWithinPeriod(fom, tom);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.util;
import static no.nav.foreldrepenger.common.util.StringUtil.taint;
import java.net.URI;
import org.springframework.http.HttpHeaders;
import org.springframework.web.util.UriComponentsBuilder;
public final class URIUtil {
private URIUtil() {
}
public static URI uri(String base, String path) {
return uri(URI.create(base), path);
}
public static URI uri(URI base, String path) {
return uri(base, path, null);
}
public static URI uri(URI base, String path, HttpHeaders queryParams) {
return builder(base, path, queryParams)
.build()
.toUri();
}
public static UriComponentsBuilder builder(URI base, String path, HttpHeaders queryParams) {
return UriComponentsBuilder
.fromUri(base)
.pathSegment(path)
.queryParams(queryParams);
}
public static HttpHeaders queryParams(String key, String value) {
var httpHeaders = headers();
httpHeaders.add(key, taint(value));
return httpHeaders;
}
public static HttpHeaders queryParams(String key, String value, String key1, String value1) {
var httpHeaders = headers();
httpHeaders.add(key, taint(value));
httpHeaders.add(key1, taint(value1));
return httpHeaders;
}
public static HttpHeaders headers() {
return new HttpHeaders();
}
public static URI uri(URI base, HttpHeaders queryParams) {
return uri(base, null, queryParams);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.dkif;
import com.fasterxml.jackson.annotation.JsonProperty;
import no.nav.foreldrepenger.common.oppslag.dkif.Målform;
public record Kontaktinformasjon(@JsonProperty("spraak") Målform målform) {
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.GetMapping;
import no.nav.foreldrepenger.common.domain.AktørId;
import no.nav.foreldrepenger.common.domain.Fødselsnummer;
import no.nav.foreldrepenger.common.domain.felles.Person;
import no.nav.foreldrepenger.common.util.TokenUtil;
import no.nav.foreldrepenger.mottak.http.ProtectedRestController;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.ArbeidsInfo;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.EnkeltArbeidsforhold;
import no.nav.foreldrepenger.mottak.oppslag.pdl.PDLConnection;
@ProtectedRestController(OppslagController.OPPSLAG_PATH)
public class OppslagController {
public static final Logger LOG = LoggerFactory.getLogger(OppslagController.class);
public static final String OPPSLAG_PATH = "/oppslag";
private final PDLConnection pdl;
private final ArbeidsInfo arbeidsforhold;
private final TokenUtil tokenUtil;
public OppslagController(PDLConnection pdl, ArbeidsInfo arbeidsforhold, TokenUtil tokenUtil) {
this.pdl = pdl;
this.arbeidsforhold = arbeidsforhold;
this.tokenUtil = tokenUtil;
}
@GetMapping("/aktoer")
public AktørId aktør() {
return pdl.aktørId(fnr());
}
@GetMapping("/person")
public Person person() {
return pdl.hentPerson(fnr());
}
@GetMapping("/person/arbeidsforhold")
public List<EnkeltArbeidsforhold> arbeidsforhold() {
return arbeidsforhold.hentArbeidsforhold();
}
private Fødselsnummer fnr() {
return tokenUtil.autentisertBrukerOrElseThrowException();
}
@Override
public String toString() {
return getClass().getSimpleName() + " [pdl=" + pdl + ", tokenUtil=" + tokenUtil + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.dto;
import static org.assertj.core.api.Assertions.assertThat;
import org.junit.jupiter.api.Test;
class OrganisasjonsNavnDTOTest {
@Test
void test1() {
var navn = new OrganisasjonsNavnDTO.NavnDTO("sammensatt", "navnelinje1", "navnelinje2", "navnelinje3", "navnelinje4", "navnelinje5");
var organisasjonsNavnDTO = new OrganisasjonsNavnDTO(navn);
assertThat(organisasjonsNavnDTO.tilOrganisasjonsnavn())
.isEqualTo("navnelinje1, navnelinje2, navnelinje3, navnelinje4, navnelinje5");
}
@Test
void test2() {
var navn = new OrganisasjonsNavnDTO.NavnDTO("sammensatt", "navnelinje1", "navnelinje2", null, "", null);
var organisasjonsNavnDTO = new OrganisasjonsNavnDTO(navn);
assertThat(organisasjonsNavnDTO.tilOrganisasjonsnavn())
.isEqualTo("navnelinje1, navnelinje2");
}
@Test
void test3() {
var navn = new OrganisasjonsNavnDTO.NavnDTO("sammensatt", null, null, "navnelinje3", null, null);
var organisasjonsNavnDTO = new OrganisasjonsNavnDTO(navn);
assertThat(organisasjonsNavnDTO.tilOrganisasjonsnavn())
.isEqualTo("navnelinje3");
}
@Test
void test4() {
var navn = new OrganisasjonsNavnDTO.NavnDTO(null,null, null, null, null, null);
var organisasjonsNavnDTO = new OrganisasjonsNavnDTO(navn);
assertThat(organisasjonsNavnDTO.tilOrganisasjonsnavn())
.isNotNull()
.isEmpty();
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import static no.nav.foreldrepenger.common.domain.felles.InnsendingsType.LASTET_OPP;
import static no.nav.foreldrepenger.common.domain.felles.TestUtils.engangssøknad;
import static no.nav.foreldrepenger.common.domain.felles.TestUtils.person;
import static no.nav.foreldrepenger.common.domain.felles.TestUtils.termin;
import static no.nav.foreldrepenger.common.domain.felles.TestUtils.valgfrittVedlegg;
import static no.nav.foreldrepenger.common.innsending.SøknadType.ENDRING_FORELDREPENGER;
import static no.nav.foreldrepenger.common.innsending.SøknadType.INITIELL_ENGANGSSTØNAD;
import static no.nav.foreldrepenger.common.innsending.SøknadType.INITIELL_FORELDREPENGER;
import static no.nav.foreldrepenger.common.innsending.SøknadType.INITIELL_SVANGERSKAPSPENGER;
import static no.nav.foreldrepenger.common.innsending.mappers.Mappables.DELEGERENDE;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.VEDLEGG1;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.VEDLEGG2;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.VEDLEGG3;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.endringssøknad;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.foreldrepengesøknad;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.svp;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertNotNull;
import static org.junit.jupiter.api.Assertions.assertNull;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.ArgumentMatchers.any;
import static org.mockito.Mockito.when;
import java.time.LocalDate;
import java.util.List;
import java.util.Optional;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.junit.jupiter.MockitoExtension;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.mock.mockito.MockBean;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import no.nav.foreldrepenger.common.domain.AktørId;
import no.nav.foreldrepenger.common.domain.Saksnummer;
import no.nav.foreldrepenger.common.domain.felles.Ettersending;
import no.nav.foreldrepenger.common.domain.felles.EttersendingsType;
import no.nav.foreldrepenger.common.domain.felles.ProsentAndel;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
import no.nav.foreldrepenger.common.innsending.mappers.AktørIdTilFnrConverter;
import no.nav.foreldrepenger.common.innsending.mappers.DomainMapper;
import no.nav.foreldrepenger.common.innsending.mappers.V1SvangerskapspengerDomainMapper;
import no.nav.foreldrepenger.common.innsending.mappers.V3EngangsstønadDomainMapper;
import no.nav.foreldrepenger.common.innsending.mappers.V3ForeldrepengerDomainMapper;
import no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils;
import no.nav.foreldrepenger.mottak.config.JacksonConfiguration;
import no.nav.foreldrepenger.mottak.innsending.mappers.DelegerendeDomainMapper;
import no.nav.foreldrepenger.mottak.innsending.pdf.MappablePdfGenerator;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.ArbeidsforholdTjeneste;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.EnkeltArbeidsforhold;
import no.nav.foreldrepenger.mottak.util.JacksonWrapper;
@ExtendWith(MockitoExtension.class)
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = {
JacksonConfiguration.class,
JacksonWrapper.class,
MetdataGenerator.class,
KonvoluttGenerator.class,
DelegerendeDomainMapper.class,
V3ForeldrepengerDomainMapper.class,
V3EngangsstønadDomainMapper.class,
V1SvangerskapspengerDomainMapper.class
})
class TestFPFordelSerialization {
private static final AktørId AKTØRID = new AktørId("1111111111");
private static final List<EnkeltArbeidsforhold> ARB_FORHOLD = arbeidsforhold();
@MockBean
private AktørIdTilFnrConverter aktørIdTilFnrConverter;
@MockBean
@Qualifier(DELEGERENDE)
private MappablePdfGenerator mappablePdfGenerator;
@MockBean
private ArbeidsforholdTjeneste arbeidsforhold;
@Autowired
private KonvoluttGenerator konvoluttGenerator;
@Autowired
@Qualifier(DELEGERENDE)
private DomainMapper domainMapper;
@BeforeEach
void before() {
when(arbeidsforhold.hentArbeidsforhold()).thenReturn(ARB_FORHOLD);
when(mappablePdfGenerator.generer(any(), any(), any())).thenReturn(new byte[0]);
when(aktørIdTilFnrConverter.konverter(any())).thenReturn(new AktørId("1234"));
}
@Test
void testESXMLKonverteringOK() {
var engangstønad = engangssøknad(false, termin(), VEDLEGG3);
assertNotNull(domainMapper.tilXML(engangstønad, AKTØRID, SøknadEgenskap.of(INITIELL_ENGANGSSTØNAD)));
}
@Test
void testSVPXMLKonverteringOK() {
var svp = svp();
assertNotNull(domainMapper.tilXML(svp, AKTØRID, SøknadEgenskap.of(INITIELL_SVANGERSKAPSPENGER)));
}
@Test
void testFPXMLKonverteringOK() {
var foreldrepengesøknad = foreldrepengesøknad();
assertNotNull(domainMapper.tilXML(foreldrepengesøknad, AKTØRID, SøknadEgenskap.of(INITIELL_FORELDREPENGER)));
}
@Test
void testFPEndringXMLKonverteringOK() {
var endringssøknad = endringssøknad(VEDLEGG2);
assertNotNull(domainMapper.tilXML(endringssøknad, AKTØRID, SøknadEgenskap.of(ENDRING_FORELDREPENGER)));
}
@Test
void testKonvolutt() {
var søknad = foreldrepengesøknad( false, valgfrittVedlegg(ForeldrepengerTestUtils.ID142, LASTET_OPP));
var innsendingPersonInfo = new InnsendingPersonInfo(person().navn(), person().aktørId(), person().fnr());
var konvolutt = konvoluttGenerator.generer(søknad, SøknadEgenskap.of(INITIELL_FORELDREPENGER), innsendingPersonInfo);
assertNotNull(konvolutt.getMetadata());
assertEquals(1, konvolutt.getVedlegg().size());
assertEquals(søknad, konvolutt.getInnsending());
assertNotNull(konvolutt.XMLHovedDokument());
assertNotNull(konvolutt.PDFHovedDokument());
assertTrue(konvolutt.erInitiellForeldrepenger());
}
@Test
void testKonvoluttEndring() {
var es = endringssøknad(ForeldrepengerTestUtils.VEDLEGG1, VEDLEGG2);
var innsendingPersonInfo = new InnsendingPersonInfo(person().navn(), person().aktørId(), person().fnr());
var konvolutt = konvoluttGenerator.generer(es, SøknadEgenskap.of(ENDRING_FORELDREPENGER), innsendingPersonInfo);
assertNotNull(konvolutt.getMetadata());
assertNotNull(konvolutt.XMLHovedDokument());
assertNotNull(konvolutt.PDFHovedDokument());
assertEquals(es, konvolutt.getInnsending());
assertEquals(2, konvolutt.getVedlegg().size());
assertTrue(konvolutt.erEndring());
}
@Test
void testKonvoluttEttersending() {
var es = new Ettersending(new Saksnummer("42"), EttersendingsType.FORELDREPENGER, List.of(VEDLEGG1, VEDLEGG2), null);
var konvolutt = konvoluttGenerator.generer(es, SøknadEgenskap.ETTERSENDING_FORELDREPENGER, person().aktørId());
assertNotNull(konvolutt.getMetadata());
assertEquals(2, konvolutt.getVedlegg().size());
assertNull(konvolutt.XMLHovedDokument());
assertNull(konvolutt.PDFHovedDokument());
assertEquals(es, konvolutt.getInnsending());
assertTrue(konvolutt.erEttersending());
}
private static List<EnkeltArbeidsforhold> arbeidsforhold() {
return List.of(EnkeltArbeidsforhold.builder()
.arbeidsgiverId("1234")
.from(LocalDate.now().minusDays(200))
.to(Optional.of(LocalDate.now()))
.stillingsprosent(ProsentAndel.valueOf(90))
.arbeidsgiverNavn("El Bedrifto").build());
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf;
import static no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesÅrsak.ARBEID;
import static no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesÅrsak.LOVBESTEMT_FERIE;
import static no.nav.foreldrepenger.common.util.StreamUtil.safeStream;
import static no.nav.foreldrepenger.mottak.innsending.pdf.PdfOutlineItem.INFOSKRIV_OUTLINE;
import static org.apache.pdfbox.pdmodel.common.PDRectangle.A4;
import java.io.IOException;
import java.time.LocalDate;
import java.time.ZoneId;
import java.time.format.DateTimeFormatter;
import java.time.format.FormatStyle;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Locale;
import java.util.Optional;
import org.apache.pdfbox.pdmodel.PDPage;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
import no.nav.foreldrepenger.common.domain.Søknad;
import no.nav.foreldrepenger.common.domain.felles.ProsentAndel;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Foreldrepenger;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.GradertUttaksPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.LukketPeriodeMedVedlegg;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesPeriode;
import no.nav.foreldrepenger.mottak.innsending.foreldrepenger.InnsendingPersonInfo;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.EnkeltArbeidsforhold;
@Component
public class InfoskrivRenderer {
public static final Logger LOG = LoggerFactory.getLogger(InfoskrivRenderer.class);
private final PdfElementRenderer renderer;
private final SøknadTextFormatter textFormatter;
private static final String NAV_URL = "nav.no/inntektsmelding";
private static final float STARTY = PdfElementRenderer.calculateStartY();
public InfoskrivRenderer(PdfElementRenderer renderer, SøknadTextFormatter textFormatter) {
this.renderer = renderer;
this.textFormatter = textFormatter;
}
FontAwareCos renderInfoskriv(List<EnkeltArbeidsforhold> arbeidsforhold,
Søknad søknad,
FontAwareCos cosOriginal,
FontAwarePdfDocument doc,
InnsendingPersonInfo person) throws IOException {
if (søknad.getFørsteInntektsmeldingDag() == null) {
LOG.warn("Ingen førsteInntektsmeldingDag i søknad, dropper infoskriv til bruker.");
return cosOriginal;
}
var fulltNavn = person.navn().navn();
var formattertFornavn = formattertFornavn(fulltNavn);
var datoInntektsmelding = søknad.getFørsteInntektsmeldingDag();
var ytelse = (Foreldrepenger) søknad.getYtelse();
var cos = førstesideInfoskriv(doc, cosOriginal);
var y = STARTY;
y = header(doc, cos, y);
y -= addBlankLine();
y -= renderer.addLeftHeading(txt("infoskriv.header", fristTekstFra(datoInntektsmelding)), cos, y);
y -= addTinyBlankLine();
if (!erSperreFristPassert(datoInntektsmelding)) {
y -= renderer.addLineOfRegularText(txt("infoskriv.paragraf1", fulltNavn, fristTekstFra(datoInntektsmelding)), cos, y);
} else {
y -= renderer.addLineOfRegularText(txt("infoskriv.paragraf1.passert", fulltNavn), cos, y);
}
y -= addTinyBlankLine();
y -= renderer.addLineOfRegularText(txt("infoskriv.paragraf2", formattertFornavn, NAV_URL), cos, y);
y -= addTinyBlankLine();
y -= renderer.addLineOfRegularText(txt("infoskriv.paragraf3", formattertFornavn), cos, y);
y -= addTinyBlankLine();
y -= addBlankLine();
y -= renderer.addLeftHeading(txt("infoskriv.opplysningerfrasøknad", fulltNavn), cos, y);
y -= addTinyBlankLine();
List<String> opplysninger = new ArrayList<>();
opplysninger.add(txt("infoskriv.arbeidstaker", person.fnr().value()));
opplysninger.add(txt("infoskriv.ytelse"));
opplysninger.add(txt("infoskriv.startdato", formattertDato(søknad.getFørsteUttaksdag())));
y -= renderer.addLinesOfRegularText(opplysninger, cos, y);
y -= addBlankLine();
var perioder = sorted(ytelse.fordeling().perioder());
var ferieArbeidsperioder = ferieOgArbeid(perioder);
if (!ferieArbeidsperioder.isEmpty()) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderFerieArbeidsperioder(ferieArbeidsperioder, scratchcos, STARTY);
var behov = STARTY - x;
if (behov < y) {
scratchcos.close();
y = renderFerieArbeidsperioder(ferieArbeidsperioder, cos, y);
} else {
cos = førstesideInfoskriv(doc, cos, scratch1, scratchcos);
y = STARTY - behov;
}
}
var gradertePerioder = tilGradertePerioder(perioder);
if (!gradertePerioder.isEmpty()) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderGradertePerioder(gradertePerioder, arbeidsforhold, scratchcos, STARTY);
var behov = STARTY - x;
if (behov < y) {
scratchcos.close();
renderGradertePerioder(gradertePerioder, arbeidsforhold, cos, y);
} else {
cos = førstesideInfoskriv(doc, cos, scratch1, scratchcos);
}
}
return cos;
}
private float renderGradertePerioder(List<GradertUttaksPeriode> gradertePerioder,
List<EnkeltArbeidsforhold> arbeidsforhold,
FontAwareCos cos,
float y) throws IOException {
y -= renderer.addLineOfRegularText(txt("svp.kombinertarbeid"), cos, y);
y -= addTinyBlankLine();
for (var periode : gradertePerioder) {
y -= renderer.addLineOfRegularText(txt("fom", formattertDato(periode.getFom())), cos, y);
y -= renderer.addLineOfRegularText(txt("tom", formattertDato(periode.getTom())), cos, y);
if (periode.getVirksomhetsnummer() != null) {
y -= renderer.addLinesOfRegularText(arbeidsgivere(arbeidsforhold, periode.getVirksomhetsnummer()), cos, y);
}
y -= renderer.addLineOfRegularText(txt("arbeidstidprosent", prosentFra(periode.getArbeidstidProsent())), cos, y);
y -= addTinyBlankLine();
}
return y;
}
private List<String> arbeidsgivere(List<EnkeltArbeidsforhold> arbeidsforhold, List<String> virksomhetsnummer) {
return safeStream(arbeidsforhold).filter(a -> virksomhetsnummer.contains(a.arbeidsgiverId()))
.map(EnkeltArbeidsforhold::arbeidsgiverNavn)
.map(s -> txt("arbeidsgiver", s))
.toList();
}
private float renderFerieArbeidsperioder(List<UtsettelsesPeriode> ferieArbeidsperioder, FontAwareCos cos, float y) throws IOException {
y -= renderer.addLineOfRegularText(txt("svp.utsettelse"), cos, y);
y -= addTinyBlankLine();
for (var periode : ferieArbeidsperioder) {
y -= renderer.addLineOfRegularText(txt("fom", formattertDato(periode.getFom())), cos, y);
y -= renderer.addLineOfRegularText(txt("tom", formattertDato(periode.getTom())), cos, y);
y -= renderer.addLineOfRegularText(txt("utsettelsesårsak", textFormatter.capitalize(periode.getÅrsak().name())), cos, y);
y -= addTinyBlankLine();
}
y -= addBlankLine();
return y;
}
private float header(FontAwarePdfDocument doc, FontAwareCos cos, float y) throws IOException {
y -= renderer.addLogo(doc, cos, y);
return y;
}
private static String formattertDato(LocalDate date) {
return date.format(
DateTimeFormatter.ofLocalizedDate(FormatStyle.LONG).withLocale(Locale.forLanguageTag("nb")).withZone(ZoneId.systemDefault()));
}
private static PDPage newPage() {
return new PDPage(A4);
}
private String txt(String key, Object... values) {
return textFormatter.fromMessageSource(key, values);
}
private static float addTinyBlankLine() {
return 10;
}
private static float addBlankLine() {
return 20;
}
private static String prosentFra(ProsentAndel prosent) {
return Optional.ofNullable(prosent).map(ProsentAndel::prosent).map(p -> p.intValue() + " %").orElse("Ukjent");
}
private static String fristTekstFra(LocalDate datoInntektsmelding) {
return erSperreFristPassert(datoInntektsmelding) ? "" : " etter " + formattertDato(datoInntektsmelding);
}
private static boolean erSperreFristPassert(LocalDate fristDato) {
return fristDato.isBefore(LocalDate.now().plusDays(1));
}
private List<GradertUttaksPeriode> tilGradertePerioder(List<LukketPeriodeMedVedlegg> perioder) {
return perioder.stream()
.filter(p -> p instanceof GradertUttaksPeriode)
.map(GradertUttaksPeriode.class::cast)
.filter(GradertUttaksPeriode::isErArbeidstaker)
.toList();
}
private List<UtsettelsesPeriode> ferieOgArbeid(List<LukketPeriodeMedVedlegg> periode) {
return periode.stream().filter(InfoskrivRenderer::isFerieOrArbeid).map(UtsettelsesPeriode.class::cast).toList();
}
private static boolean isFerieOrArbeid(LukketPeriodeMedVedlegg periode) {
if (periode instanceof UtsettelsesPeriode utsettelsesPeriode) {
var årsak = utsettelsesPeriode.getÅrsak();
return årsak.equals(LOVBESTEMT_FERIE) || årsak.equals(ARBEID);
}
return false;
}
private static List<LukketPeriodeMedVedlegg> sorted(List<LukketPeriodeMedVedlegg> perioder) {
perioder.sort(Comparator.comparing(LukketPeriodeMedVedlegg::getFom));
return perioder;
}
private static FontAwareCos førstesideInfoskriv(FontAwarePdfDocument doc,
FontAwareCos cos,
PDPage scratch,
FontAwareCos scratchcos) throws IOException {
cos.close();
doc.addPage(scratch);
cos = scratchcos;
return cos;
}
private FontAwareCos førstesideInfoskriv(FontAwarePdfDocument doc, FontAwareCos cos) throws IOException {
cos.close();
var newPage = newPage();
doc.addPage(newPage);
renderer.addOutlineItem(doc, newPage, INFOSKRIV_OUTLINE);
return new FontAwareCos(doc, newPage);
}
static String formattertFornavn(String name) {
return Optional.ofNullable(name)
.map(String::toLowerCase)
.map(n -> n.substring(0, n.indexOf(" ")))
.map(n -> Character.toUpperCase(n.charAt(0)) + n.substring(1))
.orElse("");
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.dkif;
import static io.netty.handler.codec.http.HttpResponseStatus.BAD_GATEWAY;
import static org.assertj.core.api.Assertions.assertThat;
import java.io.IOException;
import java.net.URI;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import org.springframework.web.reactive.function.client.WebClient;
import no.nav.foreldrepenger.common.oppslag.dkif.Målform;
import okhttp3.mockwebserver.MockResponse;
import okhttp3.mockwebserver.MockWebServer;
@ExtendWith(SpringExtension.class)
class DigdirKrrProxyConnectionTest {
private static MockWebServer mockWebServer;
private static DigdirKrrProxyConnection digdirKrrProxyConnection;
@BeforeAll
static void setUp() throws IOException {
mockWebServer = new MockWebServer();
mockWebServer.start();
var baseUrl = String.format("http://localhost:%s", mockWebServer.getPort());
var webClient = WebClient.create();
var digdirKrrProxyConfig = new DigdirKrrProxyConfig(URI.create(baseUrl), "rest/v1/person");
digdirKrrProxyConnection = new DigdirKrrProxyConnection(webClient, digdirKrrProxyConfig);
}
@AfterAll
static void tearDown() throws IOException {
mockWebServer.shutdown();
}
@Test
void happycase() {
var body = """
{
"personident": "string",
"aktiv": true,
"kanVarsles": true,
"reservert": true,
"spraak": "NB",
"epostadresse": "string",
"epostadresseOppdatert": "2022-03-15T13:10:01.920Z",
"mobiltelefonnummer": "string",
"mobiltelefonnummerOppdatert": "2022-03-15T13:10:01.920Z",
"sikkerDigitalPostkasse": {
"adresse": "string",
"leverandoerAdresse": "string",
"leverandoerSertifikat": "string"
}
}
""";
mockWebServer.enqueue(new MockResponse()
.setBody(body)
.addHeader("Content-Type", "application/json"));
var målform = digdirKrrProxyConnection.målform();
assertThat(målform).isEqualTo(Målform.NB);
}
@Test
void defaultMålformBrukesVedTomBody() {
mockWebServer.enqueue(new MockResponse()
.addHeader("Content-Type", "application/json"));
var målform = digdirKrrProxyConnection.målform();
assertThat(målform).isEqualTo(Målform.NB);
}
@Test
void skalBrukeDefaultMålformVed4xxFeil() {
mockWebServer.enqueue(new MockResponse()
.setResponseCode(404)
.addHeader("Content-Type", "application/json"));
var målform = digdirKrrProxyConnection.målform();
assertThat(målform).isEqualTo(Målform.NB);
}
@Test
void sjekkerAtRetryMekanismenFungere() {
mockWebServer.enqueue(new MockResponse()
.setResponseCode(BAD_GATEWAY.code()));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(BAD_GATEWAY.code()));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(BAD_GATEWAY.code()));
mockWebServer.enqueue(new MockResponse()
.setBody("""
{"spraak": "NB"}
""")
.addHeader("Content-Type", "application/json"));
var målform = digdirKrrProxyConnection.målform();
assertThat(målform).isEqualTo(Målform.NB);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.util;
import static java.lang.management.ManagementFactory.getRuntimeMXBean;
import static java.time.Instant.ofEpochMilli;
import static no.nav.boot.conditionals.Cluster.NAIS_CLUSTER_NAME;
import static no.nav.boot.conditionals.Cluster.NAIS_IMAGE_NAME;
import static no.nav.boot.conditionals.Cluster.NAIS_NAMESPACE_NAME;
import java.time.ZoneId;
import java.util.Map;
import org.springframework.boot.actuate.info.Info.Builder;
import org.springframework.boot.actuate.info.InfoContributor;
import org.springframework.core.env.Environment;
import org.springframework.stereotype.Component;
@Component
public class ExtraInfoContributor implements InfoContributor {
private final Environment env;
public ExtraInfoContributor(Environment env) {
this.env = env;
}
@Override
public void contribute(Builder builder) {
builder.withDetail("Cluster information", Map.of(
"Java version", env.getProperty("java.version"),
"Startup time", ofEpochMilli(getRuntimeMXBean().getStartTime()).atZone(ZoneId.systemDefault()).toLocalDateTime(),
"Cluster name", env.getProperty(NAIS_CLUSTER_NAME),
"Namespace name", env.getProperty(NAIS_NAMESPACE_NAME),
"Image name", env.getProperty(NAIS_IMAGE_NAME)));
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold;
import static java.time.format.DateTimeFormatter.ISO_LOCAL_DATE;
import java.net.URI;
import java.time.LocalDate;
import java.time.Period;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.context.properties.bind.DefaultValue;
import org.springframework.web.util.UriBuilder;
@ConfigurationProperties(prefix = "arbeidsforhold")
public class ArbeidsforholdConfig {
private static final String DEFAULT_BASE_URI = "https://aareg-services.intern.nav.no/api";
private static final String V1_ARBEIDSTAKER_ARBEIDSFORHOLD = "/v1/arbeidstaker/arbeidsforhold";
private static final String TREÅR = "3y";
private static final String FOM_NAVN = "ansettelsesperiodeFom";
private static final String SPORINGSINFORMASJON_NAVN = "sporingsinformasjon";
private static final String HISTORIKK_NAVN = "historikk";
private static final boolean ER_HISTORIKK_AKTIVE = false;
private final Period tidTilbake;
private final String arbeidsforholdPath;
private final boolean sporingsinformasjon;
private final URI baseUri;
public ArbeidsforholdConfig(@DefaultValue(DEFAULT_BASE_URI) URI baseUri,
@DefaultValue(V1_ARBEIDSTAKER_ARBEIDSFORHOLD) String arbeidsforholdPath,
@DefaultValue(TREÅR) Period tidTilbake,
@DefaultValue("true") boolean sporingsinformasjon) {
this.baseUri = baseUri;
this.tidTilbake = tidTilbake;
this.arbeidsforholdPath = arbeidsforholdPath;
this.sporingsinformasjon = sporingsinformasjon;
}
public String getArbeidsforholdPath() {
return arbeidsforholdPath;
}
public boolean isSporingsinformasjon() {
return sporingsinformasjon;
}
public Period getTidTilbake() {
return tidTilbake;
}
URI getArbeidsforholdURI(UriBuilder b, LocalDate fom) {
return b.path(getArbeidsforholdPath())
.queryParam(HISTORIKK_NAVN, ER_HISTORIKK_AKTIVE)
.queryParam(SPORINGSINFORMASJON_NAVN, isSporingsinformasjon())
.queryParam(FOM_NAVN, fom.format(ISO_LOCAL_DATE))
.build();
}
@Override
public String toString() {
return "ArbeidsforholdConfig{" +
"arbeidsforholdPath='" + arbeidsforholdPath + '\'' +
", sporingsinformasjon=" + sporingsinformasjon +
", tidTilbake=" + tidTilbake +
"} " + super.toString();
}
public URI getBaseUri() {
return baseUri;
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending;
import static org.assertj.core.api.Assertions.assertThat;
import static org.assertj.core.api.Assertions.assertThatCode;
import static org.assertj.core.api.Assertions.assertThatThrownBy;
import java.time.LocalDate;
import java.util.List;
import org.junit.jupiter.api.Test;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.Adopsjon;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.StønadskontoType;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UttaksPeriode;
import no.nav.foreldrepenger.common.error.UnexpectedInputException;
class SøknadValidatorTest {
@Test
void overlapp_1() {
var p1 = getUttaksPeriode(LocalDate.now(), LocalDate.now().plusWeeks(1));
var p2 = getUttaksPeriode(p1.getTom(), p1.getTom().plusWeeks(1));
assertThat(SøknadValidator.finnesOverlapp(List.of(p1, p2))).isTrue();
}
@Test
void overlapp_2() {
var p1 = getUttaksPeriode(LocalDate.now(), LocalDate.now().plusWeeks(1));
var p2 = getUttaksPeriode(p1.getTom().plusDays(1), p1.getTom().plusWeeks(1));
var p3 = getUttaksPeriode(p2.getTom().plusDays(1), p2.getTom().plusWeeks(1));
assertThat(SøknadValidator.finnesOverlapp(List.of(p1, p2, p3))).isFalse();
}
@Test
void overlapp_3() {
var p1 = getUttaksPeriode(LocalDate.now(), LocalDate.now().plusWeeks(1));
var p2 = getUttaksPeriode(p1.getTom().plusDays(1), p1.getTom().plusWeeks(1));
var p3 = getUttaksPeriode(p2.getTom().minusDays(2), p2.getTom().plusWeeks(1));
assertThat(SøknadValidator.finnesOverlapp(List.of(p1, p2, p3))).isTrue();
}
@Test
void adopsjon_ulik_antall_barn_og_fødselsdatoer_skal_gi_feil() {
var adopsjon = new Adopsjon(2, null, false, false, List.of(), LocalDate.now(), List.of(LocalDate.now()));
assertThatThrownBy(() -> SøknadValidator.validerAdopsjon(adopsjon)).isInstanceOf(UnexpectedInputException.class);
}
@Test
void adopsjon_fødselsdatoer_null_skal_ikke_gi_exception() {
var adopsjon = new Adopsjon(2, null, false, false, List.of(), LocalDate.now(), null);
assertThatCode(() -> SøknadValidator.validerAdopsjon(adopsjon)).doesNotThrowAnyException();
}
@Test
void adopsjon_likt_antall_barn_og_fødselsdatoer_skal_ikke_gi_feil() {
var adopsjon = new Adopsjon(2, null, false, false, List.of(), LocalDate.now(), List.of(LocalDate.now(), LocalDate.now().minusYears(1)));
assertThatCode(() -> SøknadValidator.validerAdopsjon(adopsjon)).doesNotThrowAnyException();
}
private static UttaksPeriode getUttaksPeriode(LocalDate fom, LocalDate tom) {
return new UttaksPeriode(fom, tom, List.of(), StønadskontoType.FELLESPERIODE, false, null, false, null, false);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
record PDLSivilstand(PDLSivilstand.Type type) {
public enum Type {
UOPPGITT,
UGIFT,
GIFT,
ENKE_ELLER_ENKEMANN,
SKILT,
SEPARERT,
REGISTRERT_PARTNER,
SEPARERT_PARTNER,
SKILT_PARTNER,
GJENLEVENDE_PARTNER,
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import static no.nav.foreldrepenger.common.util.CounterRegistry.FEILET_KVITTERINGER;
import static no.nav.foreldrepenger.common.util.CounterRegistry.FORDELT_KVITTERING;
import static no.nav.foreldrepenger.common.util.CounterRegistry.FP_SENDFEIL;
import static no.nav.foreldrepenger.common.util.CounterRegistry.GITTOPP_KVITTERING;
import static no.nav.foreldrepenger.common.util.CounterRegistry.MANUELL_KVITTERING;
import static no.nav.foreldrepenger.mottak.http.WebClientConfiguration.FPFORDEL;
import static org.springframework.http.HttpHeaders.LOCATION;
import static org.springframework.http.MediaType.APPLICATION_JSON;
import static org.springframework.http.MediaType.MULTIPART_MIXED;
import java.net.URI;
import java.time.Duration;
import java.util.Optional;
import org.jetbrains.annotations.Nullable;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.http.ResponseEntity;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.client.WebClient;
import no.nav.foreldrepenger.common.innsending.SøknadType;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.FPSakFordeltKvittering;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.FordelKvittering;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.GosysKvittering;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.PendingKvittering;
import no.nav.foreldrepenger.mottak.http.Retry;
import reactor.core.publisher.Mono;
@Component
public class FordelConnection {
private static final Logger LOG = LoggerFactory.getLogger(FordelConnection.class);
private final WebClient webClient;
private final FordelConfig cfg;
protected FordelConnection(@Qualifier(FPFORDEL) WebClient webClient, FordelConfig cfg) {
this.webClient = webClient;
this.cfg = cfg;
}
public FordelResultat send(Konvolutt konvolutt) {
try {
LOG.info("Sender {} til {}", name(konvolutt.getType()), name());
var kvittering = sendSøknad(konvolutt);
LOG.info("Sendte {} til {}, fikk kvittering {}", name(konvolutt.getType()), name(), kvittering);
return kvittering;
} catch (UventetPollingStatusFpFordelException e) {
throw e;
} catch (Exception e) {
LOG.info("Feil ved sending av {}", konvolutt.getMetadata());
FP_SENDFEIL.increment();
throw e;
}
}
@Retry
private FordelResultat sendSøknad(Konvolutt konvolutt) {
var leveranseRespons = webClient.post()
.uri(cfg.fordelEndpoint())
.contentType(MULTIPART_MIXED)
.bodyValue(konvolutt.getPayload())
.accept(APPLICATION_JSON)
.retrieve()
.toEntity(FordelKvittering.class)
.doOnRequest(va -> konvolutt.getType().count()) // Skal kjøres hver gang, uavhengig om OK elelr feilet respons!
.onErrorResume(e -> Mono.error(new InnsendingFeiletFpFordelException(e)))
.defaultIfEmpty(ResponseEntity.noContent().build())
.block();
return handleRespons(leveranseRespons);
}
/**
* RESPONS FRA INNSENDING ENDEPUNKT I FPFORDEL
* 200 -> forsendelse fordelt til GOSYS
* 202 -> sendt inn, men ikke fordelt enda. Følge redirect 'location' som redirecter til '/status'-endepunktet
* 303 -> fordelt i FPSAK
* ANNET -> Feiltilstand. Vi kan ikke garantere at vi har mottatt noe. Feil hardt.
*/
private FordelResultat handleRespons(ResponseEntity<FordelKvittering> leveranseRespons) {
if (leveranseRespons == null || leveranseRespons.getBody() == null) {
FEILET_KVITTERINGER.increment();
var httpStatus = leveranseRespons != null ? leveranseRespons.getStatusCode() : null;
throw new InnsendingFeiletFpFordelException(httpStatus, "Tom respons fra fpfordel. Må sjekkes opp");
}
var body = leveranseRespons.getBody();
if (body instanceof FPSakFordeltKvittering kvittering) {
return håndterFpsakFordeltKvittering(kvittering);
}
if (body instanceof PendingKvittering kvittering) {
return håndterPendingKvittering(locationFra(leveranseRespons), kvittering);
}
if (body instanceof GosysKvittering kvittering) {
return håndterGosysKvittering(kvittering);
}
FEILET_KVITTERINGER.increment();
throw new InnsendingFeiletFpFordelException(leveranseRespons.getStatusCode() + " Uventet format på kvitteringen mottatt ved innsending av dokument!");
}
private static FordelResultat håndterFpsakFordeltKvittering(FPSakFordeltKvittering kvittering) {
LOG.info("Forsendelse mottatt og fordelt til FPSAK");
FORDELT_KVITTERING.increment();
return new FordelResultat(kvittering.getJournalpostId(), kvittering.getSaksnummer());
}
private static FordelResultat håndterGosysKvittering(GosysKvittering kvittering) {
LOG.info("Søknaden er sendt til manuell behandling i Gosys, journalId er {}", kvittering.getJournalpostId());
MANUELL_KVITTERING.increment();
return new FordelResultat(kvittering.getJournalpostId(), null);
}
private FordelResultat håndterPendingKvittering(URI pollURI, PendingKvittering pendingKvittering) {
LOG.info("Søknaden er mottatt, men enda ikke fordelt til FPSAK eller GOSYS. Starter polling på status..");
for (var i = 1; i <= cfg.maxPollingForsøk(); i++) {
LOG.info("Poller {} for {}. gang av {}", pollURI, i, cfg.maxPollingForsøk());
var kvittering = status(pollURI, pendingKvittering.getPollInterval());
if (kvittering == null || kvittering.getBody() == null) {
FEILET_KVITTERINGER.increment();
var httpStatus = kvittering != null ? kvittering.getStatusCode() : null;
throw new UventetPollingStatusFpFordelException(httpStatus, "Tom respons fra fpfordel ved polling på status.");
}
var fordelResultat = oversett(kvittering, i);
if (fordelResultat != null) {
return fordelResultat;
}
}
LOG.info("Pollet FPFordel {} ganger, uten å få svar, gir opp", cfg.maxPollingForsøk());
GITTOPP_KVITTERING.increment();
throw new UventetPollingStatusFpFordelException("Forsendelser er mottatt, men ikke fordel. ");
}
@Nullable
private static FordelResultat oversett(ResponseEntity<FordelKvittering> response, int forsøk) {
var body = response.getBody();
if (body instanceof FPSakFordeltKvittering kvittering) {
return håndterFpsakFordeltKvittering(kvittering);
}
else if (body instanceof GosysKvittering kvittering) {
return håndterGosysKvittering(kvittering);
} else if (body instanceof PendingKvittering) {
LOG.info("Fikk pending kvittering på {}. forsøk", forsøk);
return null;
} else {
FEILET_KVITTERINGER.increment();
throw new UventetPollingStatusFpFordelException(response.getStatusCode(), "Uventet kvitteringer etter leveranse av søknad, gir opp");
}
}
@Retry
private ResponseEntity<FordelKvittering> status(URI pollingURL, Duration delay) {
return webClient.get()
.uri(pollingURL)
.accept(APPLICATION_JSON)
.retrieve()
.toEntity(FordelKvittering.class)
.delayElement(delay)
.onErrorResume(e -> {
FEILET_KVITTERINGER.increment();
return Mono.error(new UventetPollingStatusFpFordelException(e));
})
.block();
}
private static URI locationFra(ResponseEntity<FordelKvittering> respons) {
return Optional.ofNullable(respons.getHeaders().getFirst(LOCATION))
.map(URI::create)
.orElseThrow(() -> new UventetPollingStatusFpFordelException("Respons innehold ingen location header for å sjekke på status!"));
}
private static String name() {
return "fpfordel";
}
private static String name(SøknadType type) {
return type.name().toLowerCase();
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
import static no.nav.foreldrepenger.common.util.StringUtil.mask;
import java.util.List;
import java.util.Objects;
import java.util.Set;
import com.fasterxml.jackson.annotation.JsonProperty;
class PDLSøker {
private final Set<PDLNavn> navn;
@JsonProperty("kjoenn")
private final Set<PDLKjønn> kjønn;
@JsonProperty("foedsel")
private final Set<PDLFødsel> fødselsdato;
private final Set<PDLForelderBarnRelasjon> forelderBarnRelasjon;
@JsonProperty("doedfoedtBarn")
private final List<PDLDødfødtBarn> dødfødtBarn;
private final Set<PDLSivilstand> sivilstand;
private String id;
public PDLSøker(Set<PDLNavn> navn,
Set<PDLKjønn> kjønn,
Set<PDLFødsel> fødselsdato,
Set<PDLForelderBarnRelasjon> forelderBarnRelasjon,
List<PDLDødfødtBarn> dødfødtBarn,
Set<PDLSivilstand> sivilstand) {
this.navn = navn;
this.kjønn = kjønn;
this.fødselsdato = fødselsdato;
this.forelderBarnRelasjon = forelderBarnRelasjon;
this.dødfødtBarn = dødfødtBarn;
this.sivilstand = sivilstand;
}
public Set<PDLNavn> getNavn() {
return navn;
}
public Set<PDLKjønn> getKjønn() {
return kjønn;
}
public Set<PDLFødsel> getFødselsdato() {
return fødselsdato;
}
public Set<PDLForelderBarnRelasjon> getForelderBarnRelasjon() {
return forelderBarnRelasjon;
}
public List<PDLDødfødtBarn> getDødfødtBarn() {
return dødfødtBarn;
}
public Set<PDLSivilstand> getSivilstand() {
return sivilstand;
}
public String getId() {
return id;
}
PDLSøker withId(String id) {
this.id = id;
return this;
}
@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null || getClass() != o.getClass()) {
return false;
}
var pdlSøker = (PDLSøker) o;
return Objects.equals(navn, pdlSøker.navn) && Objects.equals(kjønn, pdlSøker.kjønn) && Objects.equals(fødselsdato, pdlSøker.fødselsdato)
&& Objects.equals(forelderBarnRelasjon, pdlSøker.forelderBarnRelasjon) && Objects.equals(dødfødtBarn, pdlSøker.dødfødtBarn)
&& Objects.equals(id, pdlSøker.id) && Objects.equals(sivilstand, pdlSøker.sivilstand);
}
@Override
public int hashCode() {
return Objects.hash(navn, kjønn, fødselsdato, forelderBarnRelasjon, dødfødtBarn, id, sivilstand);
}
@Override
public String toString() {
return "PDLSøker{" + "navn=" + navn + ", kjønn=" + kjønn + ", fødselsdato=" + fødselsdato
+ ", forelderBarnRelasjon=" + forelderBarnRelasjon + ", dødfødtBarn=" + dødfødtBarn + ", sivilstand=" + sivilstand + ", id='" + mask(id) + '\''
+ '}';
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.mappers;
import no.nav.foreldrepenger.common.domain.AktørId;
import no.nav.foreldrepenger.common.domain.Søknad;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Endringssøknad;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
import no.nav.foreldrepenger.common.innsending.mappers.DomainMapper;
import no.nav.foreldrepenger.common.innsending.mappers.MapperEgenskaper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import java.util.List;
import static java.util.Arrays.asList;
import static no.nav.foreldrepenger.common.innsending.mappers.Mappables.DELEGERENDE;
import static no.nav.foreldrepenger.common.innsending.mappers.Mappables.egenskaperFor;
import static no.nav.foreldrepenger.common.innsending.mappers.Mappables.mapperFor;
@Component
@Qualifier(DELEGERENDE)
public class DelegerendeDomainMapper implements DomainMapper {
private final List<DomainMapper> mappers;
private final MapperEgenskaper mapperEgenskaper;
public DelegerendeDomainMapper(DomainMapper... mappers) {
this(asList(mappers));
}
@Autowired
public DelegerendeDomainMapper(List<DomainMapper> mappers) {
this.mappers = mappers;
this.mapperEgenskaper = egenskaperFor(mappers);
}
@Override
public MapperEgenskaper mapperEgenskaper() {
return mapperEgenskaper;
}
@Override
public String tilXML(Søknad søknad, AktørId søker, SøknadEgenskap egenskap) {
return mapperFor(mappers, egenskap).tilXML(søknad, søker, egenskap);
}
@Override
public String tilXML(Endringssøknad endringssøknad, AktørId søker, SøknadEgenskap egenskap) {
return mapperFor(mappers, egenskap).tilXML(endringssøknad, søker, egenskap);
}
@Override
public String toString() {
return getClass().getSimpleName() + " [mappers=" + mappers + ", mapperEgenskaper=" + mapperEgenskaper + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import no.nav.foreldrepenger.common.domain.Saksnummer;
record FordelResultat(String journalId, Saksnummer saksnummer) {
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
import java.util.List;
import java.util.Objects;
import com.fasterxml.jackson.annotation.JsonCreator;
import com.fasterxml.jackson.databind.PropertyNamingStrategies;
import com.fasterxml.jackson.databind.annotation.JsonNaming;
@JsonNaming(PropertyNamingStrategies.LowerCaseStrategy.class)
public class ListeBlokk extends Blokk {
private final String tittel;
private final List<String> punkter;
@JsonCreator
public ListeBlokk(String tittel, List<String> punkter) {
this.tittel = tittel;
this.punkter = punkter;
}
public ListeBlokk(String tittel, String... punkter) {
this(tittel, List.of(punkter));
}
public String getTittel() {
return tittel;
}
public List<String> getPunkter() {
return punkter;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
var that = (ListeBlokk) o;
return Objects.equals(tittel, that.tittel) && Objects.equals(punkter, that.punkter);
}
@Override
public int hashCode() {
return Objects.hash(tittel, punkter);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf;
import static java.util.Comparator.comparing;
import static no.nav.foreldrepenger.common.innsending.mappers.MapperEgenskaper.FORELDREPENGER;
import static no.nav.foreldrepenger.mottak.innsending.pdf.PdfOutlineItem.FORELDREPENGER_OUTLINE;
import static no.nav.foreldrepenger.mottak.innsending.pdf.PdfThrowableFunction.uncheck;
import static no.nav.foreldrepenger.mottak.util.CollectionUtil.tryOrEmpty;
import static org.apache.pdfbox.pdmodel.common.PDRectangle.A4;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.time.LocalDate;
import java.util.List;
import java.util.function.Function;
import org.apache.pdfbox.pdmodel.PDPage;
import org.springframework.stereotype.Component;
import no.nav.foreldrepenger.common.domain.Søknad;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Endringssøknad;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Foreldrepenger;
import no.nav.foreldrepenger.common.error.UnexpectedInputException;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
import no.nav.foreldrepenger.common.innsending.mappers.MapperEgenskaper;
import no.nav.foreldrepenger.mottak.innsending.foreldrepenger.InnsendingPersonInfo;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.ArbeidsInfo;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.EnkeltArbeidsforhold;
@Component
public class ForeldrepengerPdfGenerator implements MappablePdfGenerator {
private static final float INITIAL_Y = PdfElementRenderer.calculateStartY();
private final ArbeidsInfo arbeidsInfo;
private final ForeldrepengeInfoRenderer fpRenderer;
private final InfoskrivRenderer infoskrivRenderer;
public ForeldrepengerPdfGenerator(ArbeidsInfo arbeidsInfo,
ForeldrepengeInfoRenderer fpRenderer,
InfoskrivRenderer infoskrivRenderer) {
this.arbeidsInfo = arbeidsInfo;
this.fpRenderer = fpRenderer;
this.infoskrivRenderer = infoskrivRenderer;
}
@Override
public MapperEgenskaper mapperEgenskaper() {
return FORELDREPENGER;
}
@Override
public byte[] generer(Søknad søknad, SøknadEgenskap egenskap, InnsendingPersonInfo person) {
return switch (egenskap.getType()) {
case INITIELL_FORELDREPENGER -> generer(søknad, person);
case ENDRING_FORELDREPENGER -> generer((Endringssøknad) søknad, person);
default -> throw new UnexpectedInputException("Ukjent type " + egenskap.getType() + " for søknad, kan ikke lage PDF");
};
}
private byte[] generer(Søknad søknad, InnsendingPersonInfo person) {
var stønad = (Foreldrepenger) søknad.getYtelse();
try (var doc = new FontAwarePdfDocument(); var baos = new ByteArrayOutputStream()) {
var page = new PDPage(A4);
doc.addPage(page);
fpRenderer.addOutlineItem(doc, page, FORELDREPENGER_OUTLINE);
var cos = new FontAwareCos(doc, page);
Function<CosyPair, Float> headerFn = uncheck(p -> fpRenderer.header(doc, p.cos(), false, p.y(), person));
float y = headerFn.apply(new CosyPair(cos, INITIAL_Y));
var docParam = new DocParam(doc, headerFn);
var cosy = new CosyPair(cos, y);
if (stønad.relasjonTilBarn() != null) {
Function<CosyPair, Float> relasjonTilBarnFn = uncheck(p -> fpRenderer.relasjonTilBarn(stønad.relasjonTilBarn(),
søknad.getVedlegg(), p.cos, p.y));
cosy = render(docParam, relasjonTilBarnFn, cosy);
}
var annenForelder = stønad.annenForelder();
if (annenForelder != null) {
Function<CosyPair, Float> annenForelderFn = uncheck(p -> fpRenderer.annenForelder(annenForelder, stønad.fordeling().erAnnenForelderInformert(),
stønad.rettigheter(), p.cos, p.y));
cosy = render(docParam, annenForelderFn, cosy);
}
if (søknad.getTilleggsopplysninger() != null && !søknad.getTilleggsopplysninger().isBlank()) {
Function<CosyPair, Float> tilleggsopplysningerFn = uncheck(p -> fpRenderer.renderTilleggsopplysninger(søknad.getTilleggsopplysninger(), p.cos, p.y));
cosy = render(docParam, tilleggsopplysningerFn, cosy);
}
var opptjening = stønad.opptjening();
var arbeidsforhold = aktiveArbeidsforhold(stønad.relasjonTilBarn().relasjonsDato());
if (opptjening != null) {
Function<CosyPair, Float> arbeidsforholdOpptjFn = uncheck(p -> fpRenderer.arbeidsforholdOpptjening(arbeidsforhold, p.cos, p.y));
cosy = render(docParam, arbeidsforholdOpptjFn, cosy);
if (!opptjening.utenlandskArbeidsforhold().isEmpty()) {
Function<CosyPair, Float> utenlandsArbeidsforholdFn = uncheck(p -> fpRenderer.utenlandskeArbeidsforholdOpptjening(
opptjening.utenlandskArbeidsforhold(),
søknad.getVedlegg(), p.cos, p.y));
cosy = render(docParam, utenlandsArbeidsforholdFn, cosy);
}
if (!opptjening.annenOpptjening().isEmpty()) {
Function<CosyPair, Float> annenOpptjeningFn = uncheck(p -> fpRenderer.annenOpptjening(opptjening.annenOpptjening(),
søknad.getVedlegg(), p.cos, p.y));
cosy = render(docParam, annenOpptjeningFn, cosy);
}
if (!opptjening.egenNæring().isEmpty()) {
Function<CosyPair, Float> egenNæringFn = uncheck(p ->
fpRenderer.egneNæringerOpptjening(opptjening.egenNæring(), p.cos, p.y));
cosy = render(docParam, egenNæringFn, cosy);
}
if (opptjening.frilans() != null) {
Function<CosyPair, Float> frilansFn = uncheck(p ->
fpRenderer.frilansOpptjening(opptjening.frilans(), p.cos, p.y));
cosy = render(docParam, frilansFn, cosy);
}
if (stønad.medlemsskap() != null) {
Function<CosyPair, Float> medlemskapFn = uncheck(p ->
fpRenderer.medlemsskap(stønad.medlemsskap(), stønad.relasjonTilBarn(), p.cos, p.y));
cosy = render(docParam, medlemskapFn, cosy);
}
if (stønad.fordeling() != null) {
var forCos = fpRenderer.fordeling(doc, søknad.getSøker().søknadsRolle(), stønad,
søknad.getVedlegg(), false, cosy.cos(), cosy.y(), person);
cosy = new CosyPair(forCos, -1);
}
if (!arbeidsforhold.isEmpty()) {
cosy = new CosyPair(infoskrivRenderer.renderInfoskriv(arbeidsforhold, søknad, cosy.cos(), doc, person), -1);
}
}
cosy.cos().close();
doc.save(baos);
return baos.toByteArray();
} catch (Exception e) {
throw new UnexpectedInputException("Kunne ikke lage PDF", e);
}
}
private byte[] generer(Endringssøknad søknad, InnsendingPersonInfo person) {
var ytelse = (Foreldrepenger) søknad.getYtelse();
try (var doc = new FontAwarePdfDocument(); var baos = new ByteArrayOutputStream()) {
var page = new PDPage(A4);
doc.addPage(page);
Function<CosyPair, Float> headerFn = uncheck(p -> fpRenderer.header(doc, p.cos(), true, p.y(), person));
var docParam = new DocParam(doc, headerFn);
var cosy = new CosyPair(new FontAwareCos(doc, page), INITIAL_Y);
cosy = new CosyPair(cosy.cos(), headerFn.apply(cosy));
if (ytelse.relasjonTilBarn() != null) {
Function<CosyPair, Float> relasjonTilBarnFn = uncheck(p -> fpRenderer.relasjonTilBarn(ytelse.relasjonTilBarn(),
søknad.getVedlegg(), p.cos, p.y));
cosy = render(docParam, relasjonTilBarnFn, cosy);
}
var annenForelder = ytelse.annenForelder();
if (annenForelder != null) {
Function<CosyPair, Float> annenForelderFn = uncheck(p -> fpRenderer.annenForelder(annenForelder, ytelse.fordeling().erAnnenForelderInformert(),
ytelse.rettigheter(), p.cos, p.y));
cosy = render(docParam, annenForelderFn, cosy);
}
var tilleggsopplysninger = søknad.getTilleggsopplysninger();
if (tilleggsopplysninger != null && !tilleggsopplysninger.isBlank()) {
Function<CosyPair, Float> tilleggsopplysningerFn = uncheck(p -> fpRenderer.renderTilleggsopplysninger(søknad.getTilleggsopplysninger(), p.cos, p.y));
cosy = render(docParam, tilleggsopplysningerFn, cosy);
}
if (ytelse.fordeling() != null) {
var fordelCos = fpRenderer.fordeling(doc, søknad.getSøker().søknadsRolle(), ytelse,
søknad.getVedlegg(), true, cosy.cos(), cosy.y(), person);
cosy = new CosyPair(fordelCos, -1);
}
cosy.cos().close();
doc.save(baos);
return baos.toByteArray();
} catch (Exception e) {
throw new UnexpectedInputException("Kunne ikke lage PDF", e);
}
}
private List<EnkeltArbeidsforhold> aktiveArbeidsforhold(LocalDate relasjonsdato) {
return tryOrEmpty(arbeidsInfo::hentArbeidsforhold).stream()
.filter(a -> a.to().isEmpty() || a.to().get().isAfter(relasjonsdato))
.sorted(comparing(EnkeltArbeidsforhold::from))
.toList();
}
private static CosyPair render(DocParam param, Function<CosyPair, Float> renderFunction, CosyPair cosy) throws IOException {
var scratchPage = new PDPage(A4);
var scratchCos = new FontAwareCos(param.doc(), scratchPage);
var initialYAfterHeader = param.headerFn().apply(new CosyPair(scratchCos, INITIAL_Y));
var scratchCosy = new CosyPair(scratchCos, initialYAfterHeader);
var scratchY = renderFunction.apply(scratchCosy);
var fitsAvailableYSpace = initialYAfterHeader - scratchY <= cosy.y();
if (fitsAvailableYSpace) {
// innholdet passer på eksisterende side, da skriver vi til den
scratchCos.close();
return new CosyPair(cosy.cos(), renderFunction.apply(cosy));
} else {
cosy.cos().close();
param.doc().addPage(scratchPage);
return new CosyPair(scratchCos, scratchY);
}
}
private record CosyPair(FontAwareCos cos, float y) { }
private record DocParam(FontAwarePdfDocument doc, Function<CosyPair, Float> headerFn) { }
}
<file_sep>ytelse.relasjontilbarn.antall=Ugyldig antall barn [${validatedValue}], må være flere enn 0
ytelse.relasjontilbarn.adopsjon.fødselssdato.fortid=Fødselsdato for adoptert barn [${validatedValue}] kan ikke være en framtidig dato
ytelse.relasjontilbarn.adopsjon.fødselssdato.notnull=Fødselsdato må være satt
ytelse.aktørid.notnull=Aktørid må være satt
ytelse.søknadsrolle.notnull=Søknadsrolle må være satt
ytelse.relasjontilbarn.framtidig.termindato.fortid=Termindato [${validatedValue}] må være satt og kan ikke være lenger tilbake i tid enn {weeks} uker
ytelse.relasjontilbarn.framtidig.terminbekreftelse.fortid=Terminbekreftelsesdato [${validatedValue}] må være satt og kan ikke være en framtidig dato
ytelse.relasjontilbarn.fødsel.fødselsdato=Fødselsdato for barn [${validatedValue}] kan ikke være en en framtidig dato
ytelse.relasjontilbarn.fødsel.fødselsdato.match=Antall barn og antall fødselsdatoer må matche
ytelse.medlemsskap.periode.ugyldig=Perioden {validatedValue} er ugyldig
prosent.ugyldig=Prosentandel må være mellom 0 og 100, var {validatedValue}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold;
import java.util.List;
import no.nav.foreldrepenger.common.domain.Orgnummer;
public interface ArbeidsInfo {
List<EnkeltArbeidsforhold> hentArbeidsforhold();
String orgnavn(Orgnummer orgnr);
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import java.time.LocalDateTime;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import no.nav.foreldrepenger.common.domain.Kvittering;
import no.nav.foreldrepenger.common.domain.Søknad;
import no.nav.foreldrepenger.common.domain.felles.Ettersending;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Endringssøknad;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
import no.nav.foreldrepenger.mottak.innsending.SøknadSender;
import no.nav.foreldrepenger.mottak.innsending.pdf.InfoskrivPdfEkstraktor;
@Service
public class FordelSøknadSender implements SøknadSender {
private static final Logger LOG = LoggerFactory.getLogger(FordelSøknadSender.class);
private final FordelConnection connection;
private final KonvoluttGenerator generator;
private final InfoskrivPdfEkstraktor ekstraktor;
private final InnsendingHendelseProdusent hendelser;
public FordelSøknadSender(FordelConnection connection,
KonvoluttGenerator generator,
InfoskrivPdfEkstraktor ekstraktor,
InnsendingHendelseProdusent hendelseProdusent) {
this.connection = connection;
this.generator = generator;
this.ekstraktor = ekstraktor;
this.hendelser = hendelseProdusent;
}
@Override
public Kvittering søk(Søknad søknad, SøknadEgenskap egenskap, InnsendingPersonInfo person) {
return send(generator.generer(søknad, egenskap, person), person);
}
@Override
public Kvittering endreSøknad(Endringssøknad endring, SøknadEgenskap egenskap, InnsendingPersonInfo person) {
return send(generator.generer(endring, egenskap, person), person);
}
@Override
public Kvittering ettersend(Ettersending ettersending, SøknadEgenskap egenskap, InnsendingPersonInfo person) {
return send(generator.generer(ettersending, egenskap, person.aktørId()), ettersending.dialogId(), person);
}
Kvittering send(Konvolutt konvolutt, InnsendingPersonInfo person) {
return send(konvolutt, null, person);
}
private Kvittering send(Konvolutt konvolutt, String dialogId, InnsendingPersonInfo person) {
var pdfHovedDokument = konvolutt.PDFHovedDokument();
var infoskrivPdf = konvolutt.erInitiellForeldrepenger() ? infoskrivPdf(pdfHovedDokument) : null;
var mottattDato = LocalDateTime.now();
FordelResultat fordelKvittering;
try {
fordelKvittering = connection.send(konvolutt);
} catch (UventetPollingStatusFpFordelException e) {
LOG.info("Uventet kvittering ved polling på status for innsendt dokument fra fpfordel. Returnerer kvittering uten saksnummer", e);
fordelKvittering = new FordelResultat(null, null);
}
publiserHendelse(konvolutt, dialogId, fordelKvittering, person);
return new Kvittering(mottattDato, fordelKvittering.saksnummer(), pdfHovedDokument, infoskrivPdf);
}
private void publiserHendelse(Konvolutt konvolutt, String dialogId, FordelResultat kvittering, InnsendingPersonInfo person) {
try {
hendelser.publiser(kvittering, dialogId, konvolutt, person);
} catch (Exception e) {
LOG.warn("Kunne ikke publisere hendelse", e);
}
}
private byte[] infoskrivPdf(byte[] pdf) {
return ekstraktor.infoskriv(pdf);
}
@Override
public String toString() {
return getClass().getSimpleName() + " [connection=" + connection + ", generator=" + generator
+ ", ekstraktor=" + ekstraktor + ", hendelseProdusent=" + hendelser + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.pdftjeneste;
import static no.nav.foreldrepenger.mottak.http.WebClientConfiguration.PDF_GENERATOR;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.client.WebClient;
import no.nav.foreldrepenger.mottak.http.Retry;
import no.nav.foreldrepenger.mottak.innsending.pdf.modell.DokumentBestilling;
import reactor.core.publisher.Mono;
@Component
public class PdfGeneratorConnection {
private static final Logger LOG = LoggerFactory.getLogger(PdfGeneratorConnection.class);
private final WebClient webClient;
private final PdfGeneratorConfig cfg;
public PdfGeneratorConnection(@Qualifier(PDF_GENERATOR) WebClient client, PdfGeneratorConfig cfg) {
this.webClient = client;
this.cfg = cfg;
}
@Retry
byte[] genererPdf(DokumentBestilling dto) {
if (cfg.isEnabled()) {
return webClient.post()
.uri(cfg.pdfUri())
.body(Mono.just(dto), DokumentBestilling.class)
.retrieve()
.bodyToMono(byte[].class)
.block();
}
LOG.info("PdfGenerator er ikke aktivert");
return new byte[0];
}
@Override
public String toString() {
return getClass().getSimpleName() + "[config=" + cfg + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold;
import no.nav.foreldrepenger.common.domain.felles.ProsentAndel;
import java.time.LocalDate;
import java.util.Optional;
import static no.nav.foreldrepenger.common.util.StringUtil.mask;
public record EnkeltArbeidsforhold(String arbeidsgiverId,
String arbeidsgiverIdType,
LocalDate from,
Optional<LocalDate> to,
ProsentAndel stillingsprosent,
String arbeidsgiverNavn) {
@Override
public String toString() {
return "EnkeltArbeidsforhold{" +
"arbeidsgiverId='" + mask(arbeidsgiverId) + '\'' +
", arbeidsgiverIdType='" + arbeidsgiverIdType + '\'' +
", from=" + from +
", to=" + to +
", stillingsprosent=" + stillingsprosent +
", arbeidsgiverNavn='" + mask(arbeidsgiverNavn) + '\'' +
'}';
}
public static Builder builder() {
return new Builder();
}
public static class Builder {
private String arbeidsgiverId;
private String arbeidsgiverIdType;
private LocalDate from;
private Optional<LocalDate> to;
private ProsentAndel stillingsprosent;
private String arbeidsgiverNavn;
Builder() {
}
public Builder arbeidsgiverId(String arbeidsgiverId) {
this.arbeidsgiverId = arbeidsgiverId;
return this;
}
public Builder arbeidsgiverIdType(String arbeidsgiverIdType) {
this.arbeidsgiverIdType = arbeidsgiverIdType;
return this;
}
public Builder from(LocalDate from) {
this.from = from;
return this;
}
public Builder to(Optional<LocalDate> to) {
this.to = to;
return this;
}
public Builder stillingsprosent(ProsentAndel stillingsprosent) {
this.stillingsprosent = stillingsprosent;
return this;
}
public Builder arbeidsgiverNavn(String arbeidsgiverNavn) {
this.arbeidsgiverNavn = arbeidsgiverNavn;
return this;
}
public EnkeltArbeidsforhold build() {
return new EnkeltArbeidsforhold(this.arbeidsgiverId, this.arbeidsgiverIdType, this.from,
this.to, this.stillingsprosent, this.arbeidsgiverNavn);
}
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.dto;
import no.nav.foreldrepenger.common.domain.felles.ProsentAndel;
public record ArbeidsavtaleDTO(Periode gyldighetsperiode, ProsentAndel stillingsprosent) {
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import org.springframework.stereotype.Component;
import no.nav.foreldrepenger.mottak.util.JacksonWrapper;
@Component
public class MetdataGenerator {
private final JacksonWrapper mapper;
public MetdataGenerator(JacksonWrapper mapper) {
this.mapper = mapper;
}
public String generer(FordelMetadata metadata) {
return mapper.writeValueAsString(metadata);
}
@Override
public String toString() {
return getClass().getSimpleName() + " [mapper=" + mapper + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.ETTERSENDING_ENGANGSSTØNAD;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.ETTERSENDING_FORELDREPENGER;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.ETTERSENDING_SVANGERSKAPSPENGER;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.INITIELL_ENGANGSSTØNAD;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.INITIELL_FORELDREPENGER;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.INITIELL_SVANGERSKAPSPENGER;
import static no.nav.foreldrepenger.common.innsending.SøknadEgenskap.UKJENT;
import no.nav.foreldrepenger.common.domain.Søknad;
import no.nav.foreldrepenger.common.domain.engangsstønad.Engangsstønad;
import no.nav.foreldrepenger.common.domain.felles.Ettersending;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Foreldrepenger;
import no.nav.foreldrepenger.common.domain.svangerskapspenger.Svangerskapspenger;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
final class Inspektør {
private Inspektør() {
}
static SøknadEgenskap inspiser(Søknad søknad) {
var ytelse = søknad.getYtelse();
if (ytelse instanceof Foreldrepenger) {
return INITIELL_FORELDREPENGER;
}
if (ytelse instanceof Engangsstønad) {
return INITIELL_ENGANGSSTØNAD;
}
if (ytelse instanceof Svangerskapspenger) {
return INITIELL_SVANGERSKAPSPENGER;
}
return UKJENT;
}
static SøknadEgenskap inspiser(Ettersending ettersending) {
return switch (ettersending.type()) {
case FORELDREPENGER -> ETTERSENDING_FORELDREPENGER;
case ENGANGSSTØNAD -> ETTERSENDING_ENGANGSSTØNAD;
case SVANGERSKAPSPENGER -> ETTERSENDING_SVANGERSKAPSPENGER;
};
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.dto;
import com.fasterxml.jackson.annotation.JsonProperty;
public enum ArbeidsgiverType {
@JsonProperty("Organisasjon")
ORGANISASJON,
@JsonProperty("Person")
PERSON
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf;
import static java.util.Arrays.asList;
import static no.nav.foreldrepenger.common.domain.BrukerRolle.MEDMOR;
import static no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.StønadskontoType.FEDREKVOTE;
import static no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesÅrsak.LOVBESTEMT_FERIE;
import static no.nav.foreldrepenger.common.util.LangUtil.toBoolean;
import static no.nav.foreldrepenger.common.util.StreamUtil.distinct;
import static org.apache.pdfbox.pdmodel.common.PDRectangle.A4;
import java.io.IOException;
import java.time.LocalDate;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.util.ArrayList;
import java.util.Comparator;
import java.util.List;
import java.util.Optional;
import org.apache.pdfbox.pdmodel.PDPage;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import no.nav.foreldrepenger.common.domain.BrukerRolle;
import no.nav.foreldrepenger.common.domain.felles.Vedlegg;
import no.nav.foreldrepenger.common.domain.felles.annenforelder.AnnenForelder;
import no.nav.foreldrepenger.common.domain.felles.annenforelder.NorskForelder;
import no.nav.foreldrepenger.common.domain.felles.annenforelder.UkjentForelder;
import no.nav.foreldrepenger.common.domain.felles.annenforelder.UtenlandskForelder;
import no.nav.foreldrepenger.common.domain.felles.medlemskap.Medlemsskap;
import no.nav.foreldrepenger.common.domain.felles.opptjening.AnnenOpptjening;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.Adopsjon;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.FremtidigFødsel;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.Fødsel;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.Omsorgsovertakelse;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.RelasjonTilBarn;
import no.nav.foreldrepenger.common.domain.felles.ÅpenPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Foreldrepenger;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Rettigheter;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.GradertUttaksPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.LukketPeriodeMedVedlegg;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.MorsAktivitet;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.OppholdsPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.OverføringsPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.StønadskontoType;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UttaksPeriode;
import no.nav.foreldrepenger.mottak.innsending.foreldrepenger.InnsendingPersonInfo;
@Component
public class ForeldrepengeInfoRenderer extends FellesSøknadInfoRenderer {
private static final String UTTAKSPERIODETYPE = "uttaksperiodetype";
private static final String FØDSELSDATO = "fødselsdato";
private static final String DOKUMENTASJON = "dokumentasjon";
private static final String DAGER = "dager";
private static final String ALENESORG_KEY = "aleneomsorg";
private static final DateTimeFormatter FMT = DateTimeFormatter.ofPattern("dd.MM.yyyy HH:mm");
private static final float STARTY = PdfElementRenderer.calculateStartY();
private static final int INDENT = 20;
private final PdfElementRenderer renderer;
private final SøknadTextFormatter textFormatter;
public ForeldrepengeInfoRenderer(PdfElementRenderer renderer, SøknadTextFormatter textFormatter) {
super(renderer, textFormatter);
this.renderer = renderer;
this.textFormatter = textFormatter;
}
public float header(FontAwarePdfDocument doc, FontAwareCos cos, boolean endring, float y, InnsendingPersonInfo person)
throws IOException {
y -= renderer.addLogo(doc, cos, y);
y -= renderer.addCenteredHeading(
endring ? txt("endringsøknad_fp")
: txt("søknad_fp"),
cos, y);
y -= renderer.addCenteredRegular(
textFormatter.fromMessageSource("mottatt", FMT.format(LocalDateTime.now())), cos, y);
y -= renderer.addCenteredRegulars(søker(person), cos, y);
y -= renderer.addDividerLine(cos, y);
return y;
}
public float annenForelder(AnnenForelder annenForelder, Boolean erAnnenForlderInformert,
Rettigheter rettigheter, FontAwareCos cos, float y) throws IOException {
y -= renderer.addLeftHeading(txt("omannenforelder"), cos, y);
if (annenForelder instanceof NorskForelder norskForelder) {
y -= renderer.addLinesOfRegularText(INDENT, norskForelder(norskForelder), cos, y);
if (rettigheter.harAleneOmsorgForBarnet() != null) {
y -= renderer.addLineOfRegularText(INDENT,
txt(ALENESORG_KEY, jaNei(rettigheter.harAleneOmsorgForBarnet())), cos, y);
}
} else if (annenForelder instanceof UtenlandskForelder utenlandskForelder) {
y -= renderer.addLinesOfRegularText(INDENT, utenlandskForelder(utenlandskForelder), cos, y);
if (rettigheter.harAleneOmsorgForBarnet() != null) {
y -= renderer.addLineOfRegularText(INDENT,
txt(ALENESORG_KEY, jaNei(rettigheter.harAleneOmsorgForBarnet())), cos, y);
}
} else {
y -= renderer.addLineOfRegularText(INDENT, "Jeg kan ikke oppgi navnet til den andre forelderen", cos, y);
}
if (!(annenForelder instanceof UkjentForelder)) {
y -= renderer.addLineOfRegularText(INDENT, txt("harrett", jaNei(rettigheter.harAnnenForelderRett())), cos, y);
y = annenForelderOppholdtSegIEøs(rettigheter, cos, y);
y = annenForelderTilsvarendeRettEøs(rettigheter, cos, y);
y = morUfør(rettigheter, cos, y);
if (erAnnenForlderInformert != null) {
y -= renderer.addLineOfRegularText(INDENT, txt("informert", jaNei(erAnnenForlderInformert)), cos, y);
}
}
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private float annenForelderOppholdtSegIEøs(Rettigheter rettigheter, FontAwareCos cos, float y) throws IOException {
if (rettigheter.harAnnenForelderOppholdtSegIEØS() != null) {
y -= renderer.addLineOfRegularText(INDENT, txt("annenForelderOppholdtSegIEos",
jaNei(rettigheter.harAnnenForelderOppholdtSegIEØS())), cos, y);
}
return y;
}
private float annenForelderTilsvarendeRettEøs(Rettigheter rettigheter, FontAwareCos cos, float y) throws IOException {
if (rettigheter.harAnnenForelderTilsvarendeRettEØS() != null) {
y -= renderer.addLineOfRegularText(INDENT, txt("annenforelderTilsvarendeEosRett",
jaNei(rettigheter.harAnnenForelderTilsvarendeRettEØS())), cos, y);
}
return y;
}
private float morUfør(Rettigheter rettigheter, FontAwareCos cos, float y) throws IOException {
if (rettigheter.harMorUføretrygd() != null) {
y -= renderer.addLineOfRegularText(INDENT, txt("harmorufor", jaNei(rettigheter.harMorUføretrygd())), cos,
y);
}
return y;
}
float annenOpptjening(List<AnnenOpptjening> annenOpptjening, List<Vedlegg> vedlegg, FontAwareCos cos, float y)
throws IOException {
if (CollectionUtils.isEmpty(annenOpptjening)) {
return y;
}
y -= renderer.addLeftHeading(txt("annenopptjening"), cos, y);
for (var annen : annenOpptjening) {
y -= renderer.addLinesOfRegularText(INDENT, annen(annen), cos, y);
y = renderVedlegg(vedlegg, annen.vedlegg(), "vedleggannenopptjening", cos, y);
y -= PdfElementRenderer.BLANK_LINE;
}
return y;
}
public List<String> annen(AnnenOpptjening annen) {
var attributter = new ArrayList<String>();
attributter.add(txt("type", cap(annen.type().name())));
addIfSet(attributter, annen.periode());
return attributter;
}
private static PDPage newPage() {
return new PDPage(A4);
}
private void addIfTrue(List<String> attributter, String key, boolean value) {
if (value) {
attributter.add(txt(key, jaNei(value)));
}
}
public float medlemsskap(Medlemsskap medlemsskap, RelasjonTilBarn relasjonTilBarn,
FontAwareCos cos, float y) throws IOException {
y -= renderer.addLeftHeading(txt("medlemsskap"), cos, y);
var tidligereOpphold = medlemsskap.tidligereUtenlandsopphold();
var framtidigeOpphold = medlemsskap.framtidigUtenlandsopphold();
var land = textFormatter.countryName(medlemsskap.landVedDato(relasjonTilBarn.relasjonsDato()));
if (relasjonTilBarn instanceof FremtidigFødsel) {
y -= renderer.addLineOfRegularText(INDENT,
txt("terminføderi", land, pluralize(relasjonTilBarn.getAntallBarn())), cos, y);
}
if (relasjonTilBarn instanceof Fødsel) {
y -= renderer.addLineOfRegularText(INDENT,
txt("fødtei", land, pluralize(relasjonTilBarn.getAntallBarn())), cos, y);
}
if (relasjonTilBarn instanceof Adopsjon) {
if (((Adopsjon) relasjonTilBarn).getOmsorgsovertakelsesdato().isBefore(LocalDate.now())) {
y -= renderer.addLineOfRegularText(INDENT, txt("adopsjonomsorgovertok", land), cos, y);
} else {
y -= renderer.addLineOfRegularText(INDENT, txt("adopsjonomsorgovertar", land), cos, y);
}
}
if (relasjonTilBarn instanceof Omsorgsovertakelse) {
if (((Omsorgsovertakelse) relasjonTilBarn).getOmsorgsovertakelsesdato().isBefore(LocalDate.now())) {
y -= renderer.addLineOfRegularText(INDENT, txt("adopsjonomsorgovertok", land), cos, y);
} else {
y -= renderer.addLineOfRegularText(INDENT, txt("adopsjonomsorgovertar", land), cos, y);
}
}
y -= renderer.addLineOfRegularText(INDENT, txt("siste12") +
(medlemsskap.isBoddINorge() ? " Norge" : ":"), cos, y);
if (!tidligereOpphold.isEmpty()) {
y -= renderer.addBulletList(INDENT, textFormatter.utenlandsOpphold(tidligereOpphold),
cos, y);
}
y -= renderer.addLineOfRegularText(INDENT, txt("neste12") +
(medlemsskap.isNorgeNeste12() ? " Norge" : ":"), cos, y);
if (!framtidigeOpphold.isEmpty()) {
y -= renderer.addBulletList(INDENT, textFormatter.utenlandsOpphold(framtidigeOpphold),
cos,
y);
}
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private static String pluralize(int antallBarn) {
return antallBarn > 1 ? "a" : "et";
}
public float omBarn(RelasjonTilBarn relasjon, FontAwareCos cos, float y)
throws IOException {
y -= renderer.addLeftHeading(txt("barn"), cos, y);
y -= renderer.addLinesOfRegularText(INDENT, barn(relasjon), cos, y);
y -= renderer.addLineOfRegularText(INDENT, txt("antallbarn", relasjon.getAntallBarn()), cos, y);
return y;
}
public FontAwareCos fordeling(FontAwarePdfDocument doc, BrukerRolle rolle, Foreldrepenger stønad,
List<Vedlegg> vedlegg, boolean erEndring, FontAwareCos cos, float y, InnsendingPersonInfo person)
throws IOException {
var fordeling = stønad.fordeling();
var dekningsgrad = stønad.dekningsgrad();
var antallBarn = stønad.relasjonTilBarn().getAntallBarn();
y -= renderer.addLeftHeading(txt("perioder"), cos, y);
if (dekningsgrad != null) {
y -= renderer.addLineOfRegularText(txt("dekningsgrad", dekningsgrad.kode()), cos, y);
}
var headerSize = 190F;
for (var periode : sorted(fordeling.perioder())) {
if (periode.getClass().equals(UttaksPeriode.class)) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderUttaksPeriode((UttaksPeriode) periode, rolle, vedlegg, antallBarn,
scratchcos, STARTY - 190);
var behov = STARTY - 190 - x;
if (behov < y) {
scratchcos.close();
y = renderUttaksPeriode((UttaksPeriode) periode, rolle, vedlegg, antallBarn, cos,
y);
} else {
cos = nySide(doc, cos, scratch1, scratchcos, erEndring, person);
y = STARTY - (headerSize + behov);
}
} else if (periode instanceof GradertUttaksPeriode) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderGradertPeriode((GradertUttaksPeriode) periode, rolle, vedlegg, antallBarn,
scratchcos,
STARTY - 190);
var behov = STARTY - 190 - x;
if (behov < y) {
scratchcos.close();
y = renderGradertPeriode((GradertUttaksPeriode) periode, rolle, vedlegg, antallBarn, cos,
y);
} else {
cos = nySide(doc, cos, scratch1, scratchcos, erEndring, person);
y = STARTY - (headerSize + behov);
}
} else if (periode instanceof OppholdsPeriode) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderOppholdsPeriode((OppholdsPeriode) periode, vedlegg, scratchcos,
STARTY - 190);
var behov = STARTY - 190 - x;
if (behov < y) {
scratchcos.close();
y = renderOppholdsPeriode((OppholdsPeriode) periode, vedlegg, cos, y);
} else {
cos = nySide(doc, cos, scratch1, scratchcos, erEndring, person);
y = STARTY - (headerSize + behov);
}
} else if (periode instanceof UtsettelsesPeriode) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderUtsettelsesPeriode((UtsettelsesPeriode) periode, vedlegg,
scratchcos, STARTY - 190);
var behov = STARTY - 190 - x;
if (behov < y) {
scratchcos.close();
y = renderUtsettelsesPeriode((UtsettelsesPeriode) periode, vedlegg,
cos,
y);
} else {
cos = nySide(doc, cos, scratch1, scratchcos, erEndring, person);
y = STARTY - (headerSize + behov);
}
} else if (periode instanceof OverføringsPeriode) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = renderOverføringsPeriode((OverføringsPeriode) periode, rolle, vedlegg,
scratchcos, STARTY - 190);
var behov = STARTY - 190 - x;
if (behov < y) {
scratchcos.close();
y = renderOverføringsPeriode((OverføringsPeriode) periode, rolle, vedlegg,
cos,
y);
} else {
cos = nySide(doc, cos, scratch1, scratchcos, erEndring, person);
y = STARTY - (headerSize + behov);
}
}
}
if (fordeling.ønskerJustertUttakVedFødsel() != null) {
var scratch1 = newPage();
var scratchcos = new FontAwareCos(doc, scratch1);
var x = STARTY - 190;
x -= renderer.addLineOfRegularText(txt("fp.justeruttak",
jaNei(toBoolean(fordeling.ønskerJustertUttakVedFødsel())), pluralize(antallBarn)), scratchcos, STARTY - 190);
var behov = STARTY - 190 - x;
if (behov < y) {
scratchcos.close();
y = renderer.addLineOfRegularText(txt("fp.justeruttak",
jaNei(toBoolean(fordeling.ønskerJustertUttakVedFødsel())), pluralize(antallBarn)), cos, y);
} else {
cos = nySide(doc, cos, scratch1, scratchcos, erEndring, person);
y = STARTY - (headerSize + behov);
}
}
return cos;
}
public float renderTilleggsopplysninger(String tilleggsopplysninger, FontAwareCos cos, float y)
throws IOException {
y -= renderer.addLeftHeading(txt("tilleggsopplysninger"), cos, y);
y -= renderer.addLineOfRegularText(INDENT, tilleggsopplysninger, cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private FontAwareCos nySide(FontAwarePdfDocument doc, FontAwareCos cos, PDPage scratch,
FontAwareCos scratchcos, boolean erEndring, InnsendingPersonInfo person) throws IOException {
cos.close();
header(doc, scratchcos, erEndring, STARTY, person);
doc.addPage(scratch);
cos = scratchcos;
return cos;
}
public float renderOverføringsPeriode(OverføringsPeriode overføring, BrukerRolle rolle, List<Vedlegg> vedlegg,
FontAwareCos cos, float y) throws IOException {
y -= renderer.addBulletPoint(txt("overføring"), cos, y);
y -= renderer.addLinesOfRegularText(INDENT, uttaksData(overføring, rolle), cos, y);
y = renderVedlegg(vedlegg, overføring.getVedlegg(), DOKUMENTASJON, cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private List<String> uttaksData(OverføringsPeriode overføring, BrukerRolle rolle) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "fom", overføring.getFom());
addIfSet(attributter, "tom", overføring.getTom());
addIfSet(attributter, DAGER, String.valueOf(overføring.dager()));
attributter.add(txt(UTTAKSPERIODETYPE, kontoTypeForRolle(overføring.getUttaksperiodeType(), rolle)));
attributter.add(txt("overføringsårsak", cap(overføring.getÅrsak().name())));
return attributter;
}
public float renderUtsettelsesPeriode(UtsettelsesPeriode utsettelse, List<Vedlegg> vedlegg,
FontAwareCos cos, float y) throws IOException {
y -= renderer.addBulletPoint(txt("utsettelse"), cos, y);
y -= renderer.addLinesOfRegularText(INDENT, uttaksData(utsettelse), cos, y);
y = renderVedlegg(vedlegg, utsettelse.getVedlegg(), DOKUMENTASJON, cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private List<String> uttaksData(UtsettelsesPeriode utsettelse) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "fom", utsettelse.getFom());
addIfSet(attributter, "tom", utsettelse.getTom());
addIfSet(attributter, DAGER, String.valueOf(utsettelse.dager()));
if (utsettelse.getÅrsak().getKey() != null) {
attributter.add(txt("utsettelsesårsak", txt(utsettelse.getÅrsak().getKey())));
} else {
attributter.add(txt("utsettelsesårsak", cap(utsettelse.getÅrsak().name())));
}
// attributter.add(txt("utsettelsesårsak", cap(utsettelse.getÅrsak().name())));
addIfSet(attributter, utsettelse.getMorsAktivitetsType());
if (!utsettelse.getÅrsak().equals(LOVBESTEMT_FERIE)) {
attributter.add(txt("erarbeidstaker", jaNei(utsettelse.isErArbeidstaker())));
}
return attributter;
}
public float renderOppholdsPeriode(OppholdsPeriode opphold, List<Vedlegg> vedlegg,
FontAwareCos cos, float y) throws IOException {
y -= renderer.addBulletPoint(txt("opphold"), cos, y);
y -= renderer.addLinesOfRegularText(INDENT, uttaksData(opphold), cos, y);
y = renderVedlegg(vedlegg, opphold.getVedlegg(), DOKUMENTASJON, cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private List<String> uttaksData(OppholdsPeriode opphold) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "fom", opphold.getFom());
addIfSet(attributter, "tom", opphold.getTom());
addIfSet(attributter, DAGER, String.valueOf(opphold.dager()));
if (opphold.getÅrsak().getKey() != null) {
attributter.add(txt("oppholdsårsak", txt(opphold.getÅrsak().getKey())));
} else {
attributter.add(txt("oppholdsårsak", cap(opphold.getÅrsak().name())));
}
return attributter;
}
public float renderUttaksPeriode(UttaksPeriode uttak, BrukerRolle rolle, List<Vedlegg> vedlegg, int antallBarn,
FontAwareCos cos, float y)
throws IOException {
y -= renderer.addBulletPoint(txt("uttak"), cos, y);
y -= renderer.addLinesOfRegularText(INDENT, uttaksData(uttak, antallBarn, rolle), cos, y);
y = renderVedlegg(vedlegg, uttak.getVedlegg(), DOKUMENTASJON, cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
public float renderGradertPeriode(GradertUttaksPeriode gradert, BrukerRolle rolle, List<Vedlegg> vedlegg,
int antallBarn,
FontAwareCos cos, float y)
throws IOException {
y -= renderer.addBulletPoint(txt("gradertuttak"), cos, y);
y -= renderer.addLinesOfRegularText(INDENT, uttaksData(gradert, antallBarn, rolle), cos, y);
y = renderVedlegg(vedlegg, gradert.getVedlegg(), DOKUMENTASJON, cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private List<String> uttaksData(GradertUttaksPeriode gradert, int antallBarn, BrukerRolle rolle) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "fom", gradert.getFom());
addIfSet(attributter, "tom", gradert.getTom());
addIfSet(attributter, DAGER, String.valueOf(gradert.dager()));
attributter.add(txt(UTTAKSPERIODETYPE, kontoTypeForRolle(gradert.getUttaksperiodeType(), rolle)));
addIfSet(attributter, "fp.justeresvedfødsel", gradert.getJusteresVedFødsel());
addListIfSet(attributter, ARBEIDSGIVER, gradert.getVirksomhetsnummer());
attributter.add(txt("skalgraderes", jaNei(gradert.isArbeidsForholdSomskalGraderes())));
attributter.add(txt("erarbeidstaker", jaNei(gradert.isErArbeidstaker())));
addIfSet(attributter, "erfrilans", gradert.getFrilans());
addIfSet(attributter, "erselvstendig", gradert.getSelvstendig());
addIfSet(attributter, gradert.getMorsAktivitetsType());
if (antallBarn > 1) {
attributter.add(txt("ønskerflerbarnsdager", jaNei(gradert.isØnskerFlerbarnsdager())));
}
attributter.add(txt("gradertprosent", prosentFra(gradert.getArbeidstidProsent())));
attributter.add(txt("ønskersamtidiguttak", jaNei(gradert.isØnskerSamtidigUttak())));
addIfSet(attributter, gradert.isØnskerSamtidigUttak(), "samtidiguttakprosent",
String.valueOf(prosentFra(gradert.getSamtidigUttakProsent())));
return attributter;
}
private void addIfSet(List<String> attributter, String key, Boolean value) {
if (value != null) {
attributter.add(txt(key, jaNei(value.booleanValue())));
}
}
private List<String> uttaksData(UttaksPeriode uttak, int antallBarn, BrukerRolle rolle) {
var attributter = new ArrayList<String>();
addIfSet(attributter, "fom", uttak.getFom());
addIfSet(attributter, "tom", uttak.getTom());
addIfSet(attributter, DAGER, String.valueOf(uttak.dager()));
attributter.add(txt(UTTAKSPERIODETYPE, kontoTypeForRolle(uttak.getUttaksperiodeType(), rolle)));
addIfSet(attributter, "fp.justeresvedfødsel", uttak.getJusteresVedFødsel());
addIfSet(attributter, uttak.getMorsAktivitetsType());
if (antallBarn > 1) {
attributter.add(txt("ønskerflerbarnsdager", jaNei(uttak.isØnskerFlerbarnsdager())));
}
attributter.add(txt("ønskersamtidiguttak", jaNei(uttak.isØnskerSamtidigUttak())));
addIfSet(attributter, uttak.isØnskerSamtidigUttak(), "samtidiguttakprosent",
String.valueOf(prosentFra(uttak.getSamtidigUttakProsent())));
return attributter;
}
private String kontoTypeForRolle(StønadskontoType type, BrukerRolle rolle) {
if (MEDMOR.equals(rolle) && FEDREKVOTE.equals(type)) {
return txt("uttakfedrekvotemedmor");
}
return cap(type.name());
}
private static List<LukketPeriodeMedVedlegg> sorted(List<LukketPeriodeMedVedlegg> perioder) {
perioder.sort(Comparator.comparing(LukketPeriodeMedVedlegg::getFom));
return perioder;
}
private void addIfSet(List<String> attributter, MorsAktivitet morsAktivitetsType) {
if (morsAktivitetsType != null) {
if (morsAktivitetsType.getKey() != null) {
attributter.add(txt("morsaktivitet", txt(morsAktivitetsType.getKey())));
} else {
attributter.add(txt("morsaktivitet", cap(morsAktivitetsType.name())));
}
}
}
public float relasjonTilBarn(RelasjonTilBarn relasjon, List<Vedlegg> vedlegg, FontAwareCos cos,
float y)
throws IOException {
y -= PdfElementRenderer.BLANK_LINE;
y = omBarn(relasjon, cos, y);
y = renderVedlegg(vedlegg, relasjon.getVedlegg(), "vedleggrelasjondok", cos, y);
y -= PdfElementRenderer.BLANK_LINE;
return y;
}
private List<String> søker(InnsendingPersonInfo person) {
return asList(
textFormatter.navn(person.navn()),
textFormatter.fromMessageSource("fødselsnummerinline", person.fnr().value()));
}
private List<String> utenlandskForelder(UtenlandskForelder utenlandsForelder) {
List<String> attributter = new ArrayList<>();
attributter.add(Optional.ofNullable(utenlandsForelder.navn())
.map(n -> txt("navninline", n))
.orElse("Ukjent"));
attributter.add(txt("nasjonalitetinline",
textFormatter.countryName(utenlandsForelder.land(),
utenlandsForelder.land().getName())));
addIfSet(attributter, "utenlandskid", utenlandsForelder.id());
return attributter;
}
private List<String> norskForelder(NorskForelder norskForelder) {
return asList(
Optional.ofNullable(norskForelder.navn())
.map(n -> txt("navninline", n))
.orElse("Ukjent"),
txt("fnr", norskForelder.fnr().value()));
}
private void addListIfSet(List<String> attributter, String key, List<String> values) {
if (CollectionUtils.isEmpty(values)) {
return;
}
addIfSet(attributter, key, String.join(",", values));
}
private void addIfSet(List<String> attributter, boolean value, String key, String otherValue) {
if (value) {
attributter.add(txt(key, otherValue));
}
}
private void addIfSet(List<String> attributter, String key, List<LocalDate> datoer) {
if (!CollectionUtils.isEmpty(datoer)) {
attributter.add(txt(key, textFormatter.datoer(datoer)));
}
}
private void addIfSet(List<String> attributter, ÅpenPeriode periode) {
if (periode != null) {
addIfSet(attributter, "fom", periode.fom());
addIfSet(attributter, "tom", periode.tom());
}
}
private String jaNei(Boolean value) {
return jaNei(toBoolean(value));
}
private List<String> barn(RelasjonTilBarn relasjonTilBarn) {
if (relasjonTilBarn instanceof Fødsel) {
return fødsel((Fødsel) relasjonTilBarn);
}
if (relasjonTilBarn instanceof Adopsjon) {
return adopsjon((Adopsjon) relasjonTilBarn);
}
if (relasjonTilBarn instanceof FremtidigFødsel) {
return termin((FremtidigFødsel) relasjonTilBarn);
}
if (relasjonTilBarn instanceof Omsorgsovertakelse) {
return omsorgsovertakelse((Omsorgsovertakelse) relasjonTilBarn);
}
throw new IllegalArgumentException(relasjonTilBarn.getClass().getSimpleName() + " ikke støttet");
}
private List<String> termin(FremtidigFødsel termin) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "fødselmedtermin", termin.getTerminDato());
addIfSet(attributter, "utstedtdato", termin.getUtstedtDato());
return attributter;
}
private List<String> adopsjon(Adopsjon adopsjon) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "adopsjonsdato", adopsjon.getOmsorgsovertakelsesdato());
addIfSet(attributter, "ankomstdato", adopsjon.getAnkomstDato());
addIfSet(attributter, FØDSELSDATO, adopsjon.getFødselsdato());
addIfTrue(attributter, "ektefellesbarn", adopsjon.isEktefellesBarn());
return attributter;
}
private List<String> fødsel(Fødsel fødsel) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, FØDSELSDATO, distinct(fødsel.getFødselsdato()));
addIfSet(attributter, "termindato", fødsel.getTermindato());
return attributter;
}
private List<String> omsorgsovertakelse(Omsorgsovertakelse overtakelse) {
List<String> attributter = new ArrayList<>();
addIfSet(attributter, "omsorgsovertakelsesdato", overtakelse.getOmsorgsovertakelsesdato());
addIfSet(attributter, FØDSELSDATO, overtakelse.getFødselsdato());
return attributter;
}
@Override
public String toString() {
return getClass().getSimpleName() + " [renderer=" + renderer + ", textFormatter=" + textFormatter + "]";
}
public void addOutlineItem(FontAwarePdfDocument doc, PDPage page, PdfOutlineItem title) {
renderer.addOutlineItem(doc, page, title);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf;
import static no.nav.foreldrepenger.mottak.innsending.pdf.PdfOutlineItem.INFOSKRIV_OUTLINE;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import org.apache.pdfbox.multipdf.PageExtractor;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.interactive.documentnavigation.destination.PDPageDestination;
import org.apache.pdfbox.pdmodel.interactive.documentnavigation.outline.PDOutlineNode;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Component;
@Component
public class InfoskrivPdfEkstraktor {
public static final Logger LOG = LoggerFactory.getLogger(InfoskrivPdfEkstraktor.class);
public byte[] infoskriv(byte[] pdf) {
try (var doc = PDDocument.load(pdf)) {
var outline = doc.getDocumentCatalog().getDocumentOutline();
var node = outline.getFirstChild();
var startpageExtraction = infoskrivStartpage(node);
if (startpageExtraction > -1) {
return extractPagesFrom(doc, startpageExtraction);
}
} catch (IOException e) {
LOG.warn("Feil ved ekstrahering fra søknadspdf, dropper infoskriv", e);
}
return null;
}
private static byte[] extractPagesFrom(PDDocument doc, int page) throws IOException {
var pe = new PageExtractor(doc);
pe.setStartPage(page);
try (var infodoc = pe.extract()) {
var baos = new ByteArrayOutputStream();
infodoc.save(baos);
infodoc.close();
return baos.toByteArray();
}
}
private static int infoskrivStartpage(PDOutlineNode bm) {
try {
for (var node : bm.children()) {
if (node.getTitle().equals(INFOSKRIV_OUTLINE.getTitle())) {
var destination = (PDPageDestination) node.getDestination();
return destination.retrievePageNumber() + 1;
}
}
} catch (IOException swallow) {
LOG.warn("Feil ved leting etter PDPageDestination på noden, defaulter til ingen treff");
}
return -1;
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
import java.util.Set;
import static no.nav.foreldrepenger.common.util.StringUtil.mask;
record PDLWrappedNavn(Set<PDLNavn> navn) {
}
record PDLNavn(String fornavn, String mellomnavn, String etternavn) {
@Override
public String toString() {
return "PDLNavn{" +
"fornavn='" + fornavn + '\'' +
", mellomnavn='" + mellomnavn + '\'' +
", etternavn='" + mask(etternavn) + '\'' +
'}';
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
import static no.nav.foreldrepenger.common.util.StringUtil.mask;
record PDLIdentInformasjon(String ident, PDLIdentInformasjon.PDLIdentGruppe gruppe, boolean historikk) {
enum PDLIdentGruppe {
AKTORID,
FOLKEREGISTERIDENT,
NPID
}
@Override
public String toString() {
return "PDLIdentInformasjon{" +
"ident='" + mask(ident) + '\'' +
", gruppe=" + gruppe +
", historikk=" + historikk +
'}';
}
}
<file_sep>package no.nav.foreldrepenger.mottak.http;
import org.springframework.retry.annotation.Backoff;
import org.springframework.retry.annotation.Retryable;
import org.springframework.web.reactive.function.client.WebClientResponseException;
import java.lang.annotation.Target;
import static java.lang.annotation.ElementType.METHOD;
import static java.lang.annotation.ElementType.TYPE;
@Target({ TYPE, METHOD })
@Retryable(
exclude = {
WebClientResponseException.NotFound.class,
WebClientResponseException.UnsupportedMediaType.class,
WebClientResponseException.UnprocessableEntity.class,
WebClientResponseException.BadRequest.class,
WebClientResponseException.Forbidden.class,
WebClientResponseException.Unauthorized.class
},
maxAttemptsExpression = "#{${rest.retry.attempts:3}}",
backoff = @Backoff(delayExpression = "#{${rest.retry.delay:500}}")
)
public @interface Retry {
}
<file_sep>package no.nav.foreldrepenger.mottak.http.filters;
import static no.nav.foreldrepenger.common.util.Constants.NAV_CALL_ID;
import static no.nav.foreldrepenger.common.util.Constants.NAV_CONSUMER_ID;
import static no.nav.foreldrepenger.common.util.MDCUtil.toMDC;
import java.io.IOException;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.GenericFilterBean;
import jakarta.servlet.FilterChain;
import jakarta.servlet.ServletException;
import jakarta.servlet.ServletRequest;
import jakarta.servlet.ServletResponse;
import jakarta.servlet.http.HttpServletRequest;
import no.nav.foreldrepenger.common.util.CallIdGenerator;
/**
* Brukes ved innkommende requester for å sette MDC fra headere
* - callid
*/
@Component
public class HeadersToMDCFilterBean extends GenericFilterBean {
private static final Logger LOG = LoggerFactory.getLogger(HeadersToMDCFilterBean.class);
private final CallIdGenerator generator = new CallIdGenerator();
private final String applicationName;
public HeadersToMDCFilterBean(@Value("${spring.application.name:fpsoknad-mottak}") String applicationName) {
this.applicationName = applicationName;
}
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
putValues((HttpServletRequest) request);
chain.doFilter(request, response);
}
private void putValues(HttpServletRequest request) {
try {
toMDC(NAV_CONSUMER_ID, request.getHeader(NAV_CONSUMER_ID), applicationName);
toMDC(NAV_CALL_ID, request.getHeader(NAV_CALL_ID), generator.create());
} catch (Exception e) {
LOG.warn("Noe gikk galt ved setting av MDC-verdier for request {}, MDC-verdier er inkomplette", request.getRequestURI(), e);
}
}
@Override
public String toString() {
return getClass().getSimpleName() + " [generator=" + generator + ", applicationName=" + applicationName + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
record PDLAdresseBeskyttelse(PDLAdresseBeskyttelse.PDLAdresseGradering gradering) {
static enum PDLAdresseGradering {
STRENGT_FORTROLIG_UTLAND,
STRENGT_FORTROLIG,
FORTROLIG,
UGRADERT
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.dto;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public record OrganisasjonsNavnDTO(NavnDTO navn) {
public String tilOrganisasjonsnavn() {
return Stream.of(navn.navnelinje1(), navn.navnelinje2(), navn.navnelinje3(), navn.navnelinje4(), navn.navnelinje5())
.filter(s -> s != null && !s.isEmpty())
.collect(Collectors.joining(", "));
}
public record NavnDTO(String sammensattnavn, String navnelinje1, String navnelinje2, String navnelinje3, String navnelinje4, String navnelinje5) {
}
}
<file_sep>AD=Andorra
AE=De Forente Arabiske Emirater
AF=Afghanistan
AG=Antigua og Barbuda
AI=Anguilla
AL=Albania
AM=Armenia
AO=Angola
AR=Argentina
AS=Amerikansk Samoa
AT=Østerrike
AU=Australia
AW=Aruba
AX=Åland
AZ=Aserbajdsjan
BA=Bosnia-Hercegovina
BB=Barbados
BD=Bangladesh
BE=Belgia
BF=Burkina Faso
BG=Bulgaria
BH=Bahrain
BI=Burundi
BJ=Benin
BL=Saint Barthelemy
BM=Bermuda
BN=Brunei Darussalam
BO=Bolivia
BQ=Bonaire, Saint Eustatius og Saba
BR=Brasil
BS=Bahamas
BT=Bhutan
BW=Botswana
BY=Hviterussland
BZ=Belize
CA=Canada
CC=Kokosøyene (Keelingøyene)
CD=Kongo
CF=Sentralafrikanske Republikk
CG=Kongo, Brazzaville
CH=Sveits
CI=Elfenbenskysten
CK=Cookøyene
CL=Chile
CM=Kamerun
CN=Kina
CO=Colombia
CR=Costa Rica
CU=Cuba
CV=Kapp Verde
CW=Curacao
CX=Christmasøya
CY=Kypros
CZ=Tsjekkia
DE=Tyskland
DJ=Djibouti
DK=Danmark
DM=Dominica
DO=Den Dominikanske Republikk
DZ=Algerie
EC=Ecuador
EE=Estland
EG=Egypt
EH=Vest-Sahara
ER=Eritrea
ES=Spania
ET=Etiopia
FI=Finland
FJ=Fiji
FK=Falklandsøyene (Malvinas)
FM=Mikronesiaføderasjonen
FO=Færøyene
FR=Frankrike
GA=Gabon
GB=Storbritannia
GD=Grenada
GE=Georgia
GF=Fransk Guyana
GG=Guernsey
GH=Ghana
GI=Gibraltar
GL=Grønland
GM=Gambia
GN=Guinea
GP=Guadeloupe
GQ=Ekvatorial-Guinea
GR=Hellas
GS=Sør-Georgia/Søndre Sandwichøyene
GT=Guatemala
GU=Guam
GW=Guinea-Bissau
GY=Guyana
HK=Hong Kong
HM=Heard- og McDonaldøyene
HN=Honduras
HR=Kroatia
HT=Haiti
HU=Ungarn
ID=Indonesia
IE=Irland
IL=Israel
IM=Isle of Man
IN=India
IO=Det Britiske terr. i Indiahavet
IQ=Irak
IR=Iran
IS=Island
IT=Italia
JE=Jersey
JM=Jamaica
JO=Jordan
JP=Japan
KE=Kenya
KG=Kirgisistan
KH=Kambodsja
KI=Kiribati
KM=Komorene
KN=Saint Kitts og Nevis
KP=Nord-Korea
KR=Sør-Korea
KW=Kuwait
KY=Caymanøyene
KZ=Kasakhstan
LA=Laos
LB=Libanon
LC=Saint Lucia
LI=Liechtenstein
LK=Sri Lanka
LR=Liberia
LS=Lesotho
LT=Litauen
LU=Luxemburg
LV=Latvia
LY=Libya
MA=Marokko
MC=Monaco
MD=Moldova
ME=Montenegro
MF=Saint Martin, FR
MG=Madagaskar
MH=Marshalløyene
MK=Makedonia
ML=Mali
MM=Myanmar/Burma
MN=Mongolia
MO=Macao
MP=Nordre Marianene
MQ=Martinique
MR=Mauritania
MS=Montserrat
MT=Malta
MU=Mauritius
MV=Maldivene
MW=Malawi
MX=Mexico
MY=Malaysia
MZ=Mosambik
NA=Namibia
NC=Ny Caledonia
NE=Niger
NF=Norfolkøya
NG=Nigeria
NI=Nicaragua
NL=Nederland
NO=Norge
NP=Nepal
NR=Nauru
NU=Niue
NZ=New Zealand
OM=Oman
PA=Panama
PE=Peru
PF=Fransk Polynesia
PG=Papua Ny-Guinea
PH=Filippinene
PK=Pakistan
PL=Polen
PM=Saint Pierre og Miquelon
PN=Pitcairn
PR=Puerto Rico
PS=Palestina
PT=Portugal
PW=Palau
PY=Paraguay
QA=Qatar
RE=Reunion
RO=Romania
RS=Serbia
RU=Russland
RW=Rwanda
SA=Saudi-Arabia
SB=Salomonøyene
SC=Seychellene
SD=Sudan
SE=Sverige
SG=Singapore
SH=Sankt Helena
SI=Slovenia
SK=Slovakia
SL=Sierra Leone
SM=San Marino
SN=Senegal
SO=Somalia
SR=Surinam
SS=Sør-Sudan
ST=Sao Tome og Principe
SV=El Salvador
SX=Sint Marteen (Nederlandsk del)
SY=Syria
SZ=Swaziland
TC=Turks og Caicosøyene
TD=Tsjad
TF=Franske Sørlige Territorier
TG=Togo
TH=Thailand
TJ=Tadsjikistan
TK=Tokelau
TL=Øst-Timor
TM=Turkmenistan
TN=Tunisia
TO=Tonga
TR=Tyrkia
TT=Trinidad og Tobago
TV=Tuvalu
TW=Taiwan
TZ=Tanzania
UA=Ukraina
UG=Uganda
UM=USA mindre utenforliggende øyer
US=USA
UY=Uruguay
UZ=Usbekistan
VA=Vatikanstaten
VC=Saint Vincent og Grenadine
VE=Venezuela
VG=Jomfruøyene, Britisk
VI=Jomfruøyene, US
VN=Vietnam
VU=Vanuatu
WF=Wallis og Futuna
WS=Samoa
XB=Kanariøyene
XC=Ceuta og Melilla
XK=Kosovo
YE=Jemen
YT=Mayotte
ZA=Sør-Afrika
ZM=Zambia
ZW=Zimbabwe
<file_sep>package no.nav.foreldrepenger.mottak.innsending;
import java.util.List;
import java.util.Objects;
import no.nav.foreldrepenger.common.domain.Søknad;
import no.nav.foreldrepenger.common.domain.Ytelse;
import no.nav.foreldrepenger.common.domain.engangsstønad.Engangsstønad;
import no.nav.foreldrepenger.common.domain.felles.relasjontilbarn.Adopsjon;
import no.nav.foreldrepenger.common.domain.foreldrepenger.Foreldrepenger;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.LukketPeriodeMedVedlegg;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesPeriode;
import no.nav.foreldrepenger.common.domain.foreldrepenger.fordeling.UtsettelsesÅrsak;
import no.nav.foreldrepenger.common.error.UnexpectedInputException;
final class SøknadValidator {
private SøknadValidator() {
// Skal ikke instansieres
}
static void validerFørstegangssøknad(Søknad søknad) {
var ytelse = søknad.getYtelse();
validerSøknad(ytelse);
if (ytelse instanceof Foreldrepenger foreldrepenger) {
if (foreldrepenger.relasjonTilBarn() instanceof Adopsjon adopsjon) {
validerAdopsjon(adopsjon);
}
var perioder = foreldrepenger.fordeling().perioder();
//Allerede validert på minst en periode
if (perioder.stream().allMatch(SøknadValidator::erFriUtsettelse)) {
throw new UnexpectedInputException(
"Søknad må inneholde minst en søknadsperiode som ikke er fri utsettelse");
}
} else if (ytelse instanceof Engangsstønad engangsstønad && engangsstønad.relasjonTilBarn() instanceof Adopsjon adopsjon) {
validerAdopsjon(adopsjon);
}
}
static void validerAdopsjon(Adopsjon adopsjon) {
//caser i endringssøknad der ikke fødselsdatoer stemmer med antall barn. Feks hvis ett barn er mer enn 3 år
if (adopsjon.getFødselsdato() != null && adopsjon.getFødselsdato().size() != adopsjon.getAntallBarn()) {
throw new UnexpectedInputException("Ved adopsjon må antall barn match antall fødselsdatoer oppgitt!");
}
}
static void validerSøknad(Ytelse ytelse) {
if (ytelse instanceof Foreldrepenger foreldrepenger) {
var perioder = foreldrepenger.fordeling().perioder();
if (perioder.isEmpty()) {
throw new UnexpectedInputException("Søknad må inneholde minst en søknadsperiode");
}
if (finnesOverlapp(perioder)) {
throw new UnexpectedInputException("Søknad inneholder overlappende søknadsperioder");
}
}
}
private static boolean erFriUtsettelse(LukketPeriodeMedVedlegg p) {
return p instanceof UtsettelsesPeriode utsettelsesPeriode && Objects.equals(utsettelsesPeriode.getÅrsak(),
UtsettelsesÅrsak.FRI);
}
static boolean finnesOverlapp(List<LukketPeriodeMedVedlegg> perioder) {
for (var i = 0; i < perioder.size() - 1; i++) {
for (var j = i + 1; j < perioder.size(); j++) {
if (overlapper(perioder.get(i), perioder.get(j))) {
return true;
}
}
}
return false;
}
private static boolean overlapper(LukketPeriodeMedVedlegg periode1, LukketPeriodeMedVedlegg periode2) {
var fomBeforeOrEqual = periode1.getFom().isBefore(periode2.getTom()) || periode1.getFom().isEqual(periode2.getTom());
var tomAfterOrEqual = periode1.getTom().isAfter(periode2.getFom()) || periode1.getTom().isEqual(periode2.getFom());
return fomBeforeOrEqual && tomAfterOrEqual;
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
import com.fasterxml.jackson.databind.PropertyNamingStrategies;
import com.fasterxml.jackson.databind.annotation.JsonNaming;
@JsonNaming(PropertyNamingStrategies.LowerCaseStrategy.class)
public record MottattDato(String beskrivelse, String datoTid) {
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import no.nav.foreldrepenger.common.domain.AktørId;
import no.nav.foreldrepenger.common.domain.Fødselsnummer;
import no.nav.foreldrepenger.common.domain.Navn;
public record InnsendingPersonInfo(Navn navn, AktørId aktørId, Fødselsnummer fnr) {
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.pdftjeneste;
import static org.assertj.core.api.Assertions.assertThat;
import java.io.IOException;
import java.net.URI;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.springframework.web.reactive.function.client.WebClient;
import no.nav.foreldrepenger.mottak.innsending.pdf.modell.DokumentBestilling;
import okhttp3.mockwebserver.MockResponse;
import okhttp3.mockwebserver.MockWebServer;
class PdfGeneratorConnectionTest {
private static MockWebServer mockWebServer;
private static PdfGeneratorConnection pdfGeneratorConnection;
@BeforeAll
static void setUp() throws IOException {
mockWebServer = new MockWebServer();
mockWebServer.start();
var baseUrl = String.format("http://localhost:%s", mockWebServer.getPort());
var webClient = WebClient.create();
var pdfGeneratorConfig = new PdfGeneratorConfig(URI.create(baseUrl), "/api/v1/genpdf/soknad-v2/soknad", true);
pdfGeneratorConnection = new PdfGeneratorConnection(webClient, pdfGeneratorConfig);
}
@AfterAll
static void tearDown() throws IOException {
mockWebServer.shutdown();
}
@Test
void verifiserAtKlientKlarerÅReturnereByteArray() {
var ettEllerAnnet = """
This license is copied below, and is also available with a FAQ at:
http://scripts.sil.org/OFL
-----------------------------------------------------------
SIL OPEN FONT LICENSE Version 1.1 - 26 February 2007
-----------------------------------------------------------
PREAMBLE
""";
mockWebServer.enqueue(new MockResponse()
.setBody(ettEllerAnnet)
.addHeader("Content-Type", "application/json"));
var result = pdfGeneratorConnection.genererPdf(new DokumentBestilling("test", null, null, null));
assertThat(result).isEqualTo(ettEllerAnnet.getBytes());
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.foreldrepenger;
import static no.nav.foreldrepenger.common.domain.felles.InnsendingsType.LASTET_OPP;
import static no.nav.foreldrepenger.common.domain.felles.TestUtils.person;
import static no.nav.foreldrepenger.common.domain.felles.TestUtils.valgfrittVedlegg;
import static no.nav.foreldrepenger.common.innsending.SøknadType.INITIELL_FORELDREPENGER;
import static no.nav.foreldrepenger.common.innsending.mappers.Mappables.DELEGERENDE;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.foreldrepengesøknad;
import static org.assertj.core.api.Assertions.assertThat;
import static org.assertj.core.api.Assertions.assertThatThrownBy;
import static org.mockito.ArgumentMatchers.any;
import static org.mockito.Mockito.when;
import static org.springframework.http.HttpHeaders.CONTENT_TYPE;
import static org.springframework.http.HttpHeaders.LOCATION;
import java.io.IOException;
import java.net.URI;
import java.time.Duration;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.junit.jupiter.MockitoExtension;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.mock.mockito.MockBean;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import org.springframework.web.reactive.function.client.WebClient;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import no.nav.foreldrepenger.common.domain.AktørId;
import no.nav.foreldrepenger.common.domain.Saksnummer;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.FPSakFordeltKvittering;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.FordelKvittering;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.GosysKvittering;
import no.nav.foreldrepenger.common.innsending.foreldrepenger.PendingKvittering;
import no.nav.foreldrepenger.common.innsending.mappers.AktørIdTilFnrConverter;
import no.nav.foreldrepenger.common.innsending.mappers.V1SvangerskapspengerDomainMapper;
import no.nav.foreldrepenger.common.innsending.mappers.V3EngangsstønadDomainMapper;
import no.nav.foreldrepenger.common.innsending.mappers.V3ForeldrepengerDomainMapper;
import no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils;
import no.nav.foreldrepenger.mottak.config.JacksonConfiguration;
import no.nav.foreldrepenger.mottak.innsending.mappers.DelegerendeDomainMapper;
import no.nav.foreldrepenger.mottak.innsending.pdf.MappablePdfGenerator;
import no.nav.foreldrepenger.mottak.util.JacksonWrapper;
import okhttp3.mockwebserver.MockResponse;
import okhttp3.mockwebserver.MockWebServer;
@ExtendWith(MockitoExtension.class)
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = {
JacksonConfiguration.class,
JacksonWrapper.class,
MetdataGenerator.class,
KonvoluttGenerator.class,
DelegerendeDomainMapper.class,
V3ForeldrepengerDomainMapper.class,
V3EngangsstønadDomainMapper.class,
V1SvangerskapspengerDomainMapper.class
})
class FordelConnectionTest {
private static final String JOURNALPOSTID = "123456789";
private static final Saksnummer SAKSNUMMER = new Saksnummer("11122233344");
private static String baseUrl;
@MockBean
private AktørIdTilFnrConverter aktørIdTilFnrConverter;
@MockBean
@Qualifier(DELEGERENDE)
private MappablePdfGenerator mappablePdfGenerator;
@Autowired
private ObjectMapper objectMapper;
@Autowired
private KonvoluttGenerator konvoluttGenerator;
private Konvolutt defaultRequestKonvolutt;
private static MockWebServer mockWebServer;
private static FordelConnection fordelConnection;
@BeforeAll
static void setUp() throws IOException {
mockWebServer = new MockWebServer();
mockWebServer.start();
baseUrl = String.format("http://localhost:%s", mockWebServer.getPort());
var webClient = WebClient.create();
var fordelConfig = new FordelConfig(URI.create(baseUrl), "/innsending", 3);
fordelConnection = new FordelConnection(webClient, fordelConfig);
}
@BeforeEach
void before() {
when(mappablePdfGenerator.generer(any(), any(), any())).thenReturn(new byte[0]);
when(aktørIdTilFnrConverter.konverter(any())).thenReturn(new AktørId("1234"));
defaultRequestKonvolutt = lagDefaultKonvolutt();
}
/*
* Mottar første en OK 200 med en gosys kvittering
* Da er innsendingen mottatt og fordelt
*/
@Test
void happyCaseGosysFordelingFirstTry() throws JsonProcessingException {
// Arrange
var gosysKvittering = new GosysKvittering(JOURNALPOSTID);
mockWebServer.enqueue(new MockResponse()
.setResponseCode(200)
.setBody(tilBody(gosysKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
// Act
var resultat = fordelConnection.send(defaultRequestKonvolutt);
// Assert
assertThat(resultat.journalId()).isEqualTo(gosysKvittering.getJournalpostId());
assertThat(resultat.saksnummer()).isNull();
}
/*
* Mottar første en SEE_OTHER 303 forventer vi en FpsakKvittering
* og da innsendingen er mottatt og fordelt
*/
@Test
void happyCaseFpsakFordelingFirstTry() throws JsonProcessingException {
// Arrange
var fpSakFordeltKvittering = new FPSakFordeltKvittering(JOURNALPOSTID, SAKSNUMMER);
mockWebServer.enqueue(new MockResponse()
.setResponseCode(303)
.setBody(tilBody(fpSakFordeltKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
// Act
var resultat = fordelConnection.send(defaultRequestKonvolutt);
// Assert
assertThat(resultat.journalId()).isEqualTo(fpSakFordeltKvittering.getJournalpostId());
assertThat(resultat.saksnummer()).isEqualTo(fpSakFordeltKvittering.getSaksnummer());
}
/*
* Mottar første en ACCEPTED 202 pending kvittering (mottatt, men ikke fordelt)
* Følger redirekt 303 med kvittering om at innsendinger er fordelt til fpsak
* Da er vi ferdig og returnerer resultat tilbake til bruker
*/
@Test
void forsendelseMottattMenIkkeFordeltFPSAKOrdnesOppIVedPollingFørstegang() throws JsonProcessingException {
// Arrange
var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(202)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json")
.addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
var fpSakFordeltKvittering = new FPSakFordeltKvittering(JOURNALPOSTID, SAKSNUMMER);
mockWebServer.enqueue(new MockResponse()
.setResponseCode(303)
.setBody(tilBody(fpSakFordeltKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
// Act
var resultat = fordelConnection.send(defaultRequestKonvolutt);
// Assert
assertThat(resultat.journalId()).isEqualTo(fpSakFordeltKvittering.getJournalpostId());
assertThat(resultat.saksnummer()).isEqualTo(fpSakFordeltKvittering.getSaksnummer());
}
/*
* Mottar første en ACCEPTED 202 pending kvittering (mottatt, men ikke fordelt)
* Følger OK 200 med kvittering om at innsendinger er fordelt til gosys
* Da er vi ferdig og returnerer resultat tilbake til bruker
*/
@Test
void forsendelseMottattMenIkkeFordeltGosysPollerStatusEnGangOK() throws JsonProcessingException {
// Arrange
var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(202)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json")
.addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
var gosysKvittering = new GosysKvittering(JOURNALPOSTID);
mockWebServer.enqueue(new MockResponse()
.setResponseCode(200)
.setBody(tilBody(gosysKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
// Act
var resultat = fordelConnection.send(defaultRequestKonvolutt);
// Assert
assertThat(resultat.journalId()).isEqualTo(gosysKvittering.getJournalpostId());
assertThat(resultat.saksnummer()).isNull();
}
/*
* Mottar første en ACCEPTED 202 pending kvittering (mottatt, men ikke fordelt)
* Følger redirekt 303 med kvittering om at innsendinger er fordelt til fpsak
* Da er vi ferdig og returnerer resultat tilbake til bruker
*/
@Test
void forsendelseMottattMenIkkeFordeltFPSAKOrdnesOppIVedPollingAndreGang() throws JsonProcessingException {
// Arrange
// Fra innsendingsendepuntket
var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(202)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json")
.addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
// Fra statusendepunktet
// 1) PENDING
// 2) FORDELT I FPSAK
mockWebServer.enqueue(new MockResponse()
.setResponseCode(200)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
var fpSakFordeltKvittering = new FPSakFordeltKvittering(JOURNALPOSTID, SAKSNUMMER);
mockWebServer.enqueue(new MockResponse()
.setResponseCode(303)
.setBody(tilBody(fpSakFordeltKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
// Act
var resultat = fordelConnection.send(defaultRequestKonvolutt);
// Assert
assertThat(resultat.journalId()).isEqualTo(fpSakFordeltKvittering.getJournalpostId());
assertThat(resultat.saksnummer()).isEqualTo(fpSakFordeltKvittering.getSaksnummer());
}
/*
* Mottar første en ACCEPTED 202 pending kvittering (mottatt, men ikke fordelt)
* Poller men får OK 200 med pending kvittering
* Poller men får OK 200 med pending kvittering
* Poller men får OK 200 med pending kvittering
* Feiler og returnerer UventetFpFordelResponseException siden innsendingen ikke er ikke fordelt
*/
@Test
void pollingOverMaxForsøkSkalHiveException() throws JsonProcessingException {
// Arrange
// Fra innsendingsendepuntket
var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(202)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json")
.addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
// Fra statusendepunktet
// 1) PENDING
// 2) PENDING
// 3) PENDING
mockWebServer.enqueue(new MockResponse()
.setResponseCode(200)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(200)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(200)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
// Act
assertThatThrownBy(() -> fordelConnection.send(defaultRequestKonvolutt))
.isInstanceOf(UventetPollingStatusFpFordelException.class);
}
@Test
void pendingKvitteringUtenLocationHeaderSkalHiveUventetFpFordelResponseException() throws JsonProcessingException {
// Arrange
// Fra innsendingsendepuntket
var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(202)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json"));
//.addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
// Act
assertThatThrownBy(() -> fordelConnection.send(defaultRequestKonvolutt))
.isInstanceOf(UventetPollingStatusFpFordelException.class);
}
@Test
void forsendelseInneholderUkjentOKStatusFeilerHardt() {
// Arrange
mockWebServer.enqueue(new MockResponse()
.setResponseCode(204)
.addHeader(CONTENT_TYPE, "application/json"));
// Act
assertThatThrownBy(() -> fordelConnection.send(defaultRequestKonvolutt))
.isInstanceOf(InnsendingFeiletFpFordelException.class);
}
// @Test
// void forsendelseInneholderUkjent5xxStatusFeilerHardt() {
// // Arrange
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
//
//
// // Act
// assertThatThrownBy(() -> fordelConnection.send(defaultRequestKonvolutt))
// .isInstanceOf(InnsendingFeiletFpFordelException.class);
// }
//
// /*
// * Mottar første en ACCEPTED 202 pending kvittering (mottatt, men ikke fordelt)
// * Følger redirekt 303 med kvittering om at innsendinger er fordelt til fpsak
// * Da er vi ferdig og returnerer resultat tilbake til bruker
// */
// @Test
// void verifiserAtViHiverUventetFpFordelResponseExceptionVed5xxFeilUnderPolling() throws JsonProcessingException {
// // Arrange - Fra innsendingsendepuntket
// var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(202)
// .setBody(tilBody(pendingKvittering))
// .addHeader(CONTENT_TYPE, "application/json")
// .addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
//
// // Fra statusendepunktet (retry 2 ganger på 5xx feil, og siste faller ut til UventetFpFordelResponseException)
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(500)
// .addHeader(CONTENT_TYPE, "application/json"));
//
// // Act
// assertThatThrownBy(() -> fordelConnection.send(defaultRequestKonvolutt))
// .isInstanceOf(UventetPollingStatusFpFordelException.class);
// }
@Test
void verifiserAtViHiverUventetFpFordelResponseExceptionVedNoContentUnderPolling() throws JsonProcessingException {
// Arrange - Fra innsendingsendepuntket
var pendingKvittering = new PendingKvittering(Duration.ofMillis(100));
mockWebServer.enqueue(new MockResponse()
.setResponseCode(202)
.setBody(tilBody(pendingKvittering))
.addHeader(CONTENT_TYPE, "application/json")
.addHeader(LOCATION, baseUrl + "/api/forsendelse/status?forsendelseId=123456789"));
// Fra statusendepunktet
mockWebServer.enqueue(new MockResponse()
.setResponseCode(204)
.addHeader(CONTENT_TYPE, "application/json"));
// Act
assertThatThrownBy(() -> fordelConnection.send(defaultRequestKonvolutt))
.isInstanceOf(UventetPollingStatusFpFordelException.class);
}
private Konvolutt lagDefaultKonvolutt() {
var søknad = foreldrepengesøknad( false, valgfrittVedlegg(ForeldrepengerTestUtils.ID142, LASTET_OPP));
return konvoluttGenerator.generer(søknad, SøknadEgenskap.of(INITIELL_FORELDREPENGER), new InnsendingPersonInfo(person().navn(), person().aktørId(), person().fnr()));
}
private String tilBody(FordelKvittering kvittering) throws JsonProcessingException {
return objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(kvittering);
}
@AfterAll
static void tearDown() throws IOException {
mockWebServer.shutdown();
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.pdftjeneste;
import java.util.Random;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.stereotype.Service;
import no.nav.foreldrepenger.mottak.innsending.pdf.modell.DokumentBestilling;
@Service
@ConditionalOnMissingBean(PdfGeneratorTjeneste.class)
public class PdfGeneratorStub implements PdfGenerator {
private static final Random RANDOM = new Random();
@Override
public byte[] generate(DokumentBestilling dokument) {
var result = new byte[1];
RANDOM.nextBytes(result);
return result;
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
import java.time.LocalDate;
import com.fasterxml.jackson.annotation.JsonProperty;
record PDLFødsel(@JsonProperty("foedselsdato") LocalDate fødselsdato) {
}<file_sep><?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.1.3</version>
<relativePath/>
</parent>
<modelVersion>4.0.0</modelVersion>
<groupId>no.nav.foreldrepenger</groupId>
<artifactId>fpsoknad-mottak</artifactId>
<version>0-SNAPSHOT</version>
<licenses>
<license>
<name>MIT License</name>
<url>https://opensource.org/licenses/MIT</url>
</license>
</licenses>
<properties>
<java.version>17</java.version>
<maven.compiler.source>${java.version}</maven.compiler.source>
<maven.compiler.target>${java.version}</maven.compiler.target>
<maven.build.timestamp.format>yyyy-MM-dd HH:mm</maven.build.timestamp.format>
<timestamp>${maven.build.timestamp}</timestamp>
<sonar.moduleKey>${project.artifactId}</sonar.moduleKey>
<sonar.projectKey>navikt_fpsoknad-mottak</sonar.projectKey>
<sonar.organization>navikt</sonar.organization>
<sonar.host.url>https://sonarcloud.io</sonar.host.url>
<boot-conditionals.version>5.0.9</boot-conditionals.version>
<token-support.version>3.0.10</token-support.version>
<fpsoknad-felles.version>2.5.0</fpsoknad-felles.version>
<jacoco.version>0.8.10</jacoco.version>
<pdfbox.version>2.0.29</pdfbox.version>
<nv-i18n.version>1.29</nv-i18n.version>
<reflections.version>0.10.2</reflections.version>
<logstash-logback-encoder.version>7.4</logstash-logback-encoder.version>
<springdoc.version>2.2.0</springdoc.version>
<spring.vault.version>4.0.1</spring.vault.version>
<spring.graphql.version>2.0.1</spring.graphql.version>
</properties>
<scm>
<connection>scm:git:https://github.com/navikt/fpsoknad-mottak.git</connection>
<developerConnection>scm:git:https://github.com/navikt/fpsoknad-mottak.git
</developerConnection>
<tag>HEAD</tag>
</scm>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<fork>true</fork>
<compilerArgs>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.code=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.comp=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.file=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.main=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.model=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.parser=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.processing=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.tree=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.util=ALL-UNNAMED</arg>
<arg>-J--add-opens=jdk.compiler/com.sun.tools.javac.jvm=ALL-UNNAMED</arg>
</compilerArgs>
<parameters>true</parameters>
<source>${java.version}</source>
<target>${java.version}</target>
<release>${java.version}</release>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>build-info</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.jacoco</groupId>
<artifactId>jacoco-maven-plugin</artifactId>
<version>${jacoco.version}</version>
<executions>
<execution>
<goals>
<goal>prepare-agent</goal>
</goals>
</execution>
<execution>
<id>report</id>
<phase>verify</phase>
<goals>
<goal>report-aggregate</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-vault-dependencies</artifactId>
<version>${spring.vault.version}</version>
<scope>import</scope>
<type>pom</type>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.reactivestreams</groupId>
<artifactId>reactive-streams</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-configuration-processor</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-common</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>org.springdoc</groupId>
<artifactId>springdoc-openapi-starter-webmvc-ui</artifactId>
<version>${springdoc.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-vault-config</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.graphql-java-kickstart</groupId>
<artifactId>graphql-webclient-spring-boot-starter</artifactId>
<version>${spring.graphql.version}</version>
</dependency>
<!-- Retry -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-aspects</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.retry</groupId>
<artifactId>spring-retry</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjrt</artifactId>
</dependency>
<dependency>
<groupId>org.aspectj</groupId>
<artifactId>aspectjweaver</artifactId>
</dependency>
<dependency>
<groupId>com.neovisionaries</groupId>
<artifactId>nv-i18n</artifactId>
<version>${nv-i18n.version}</version>
</dependency>
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>${logstash-logback-encoder.version}</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>${pdfbox.version}</version>
</dependency>
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>xmpbox</artifactId>
<version>${pdfbox.version}</version>
</dependency>
<!-- Interne avhengigheter -->
<dependency>
<groupId>no.nav.foreldrepenger</groupId>
<artifactId>fpsoknad-felles</artifactId>
<version>${fpsoknad-felles.version}</version>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
</dependency>
<dependency>
<groupId>no.nav.boot</groupId>
<artifactId>boot-conditionals</artifactId>
<version>${boot-conditionals.version}</version>
</dependency>
<dependency>
<groupId>no.nav.security</groupId>
<artifactId>token-validation-spring</artifactId>
<version>${token-support.version}</version>
</dependency>
<dependency>
<groupId>no.nav.security</groupId>
<artifactId>token-client-spring</artifactId>
<version>${token-support.version}</version>
</dependency>
<!-- Test avhengigheter -->
<dependency>
<groupId>no.nav.foreldrepenger</groupId>
<artifactId>fpsoknad-felles</artifactId>
<version>${fpsoknad-felles.version}</version>
<type>test-jar</type>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.reflections</groupId>
<artifactId>reflections</artifactId>
<version>${reflections.version}</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>mockwebserver</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.mockito</groupId>
<artifactId>mockito-junit-jupiter</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<distributionManagement>
<repository>
<id>fpsoknad-mottak</id>
<name>Github navikt Maven Packages</name>
<url>https://maven.pkg.github.com/navikt/fpsoknad-mottak</url>
</repository>
</distributionManagement>
</project>
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.pdftjeneste;
import no.nav.foreldrepenger.mottak.innsending.pdf.modell.DokumentBestilling;
public interface PdfGenerator {
byte[] generate(DokumentBestilling dokument);
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
import java.util.List;
import java.util.Objects;
public class TabellRad extends Blokk {
private final String venstreTekst;
private final String høyreTekst;
private final List<? extends Blokk> underBlokker;
public TabellRad(String venstreTekst, String høyreTekst, List<? extends Blokk> underBlokker) {
this.venstreTekst = venstreTekst;
this.høyreTekst = høyreTekst;
this.underBlokker = underBlokker;
}
public String getVenstreTekst() {
return venstreTekst;
}
public String getHøyreTekst() {
return høyreTekst;
}
public List<? extends Blokk> getUnderBlokker() {
return underBlokker;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
var tabellRad = (TabellRad) o;
return Objects.equals(venstreTekst, tabellRad.venstreTekst) && Objects.equals(høyreTekst, tabellRad.høyreTekst) && Objects.equals(underBlokker, tabellRad.underBlokker);
}
@Override
public int hashCode() {
return Objects.hash(venstreTekst, høyreTekst, underBlokker);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
import java.util.Objects;
public class FeltBlokk extends Blokk {
private String felt;
private String verdi;
public FeltBlokk(String felt, String verdi) {
this.felt = felt;
this.verdi = verdi;
}
public static FeltBlokk felt(String felt, String verdi) {
return new FeltBlokk(felt, verdi);
}
public String getFelt() {
return felt;
}
public String getVerdi() {
return verdi;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
var feltBlokk = (FeltBlokk) o;
return Objects.equals(felt, feltBlokk.felt) && Objects.equals(verdi, feltBlokk.verdi);
}
@Override
public int hashCode() {
return Objects.hash(felt, verdi);
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
import static org.assertj.core.api.Assertions.assertThat;
import java.io.IOException;
import java.net.URI;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import org.springframework.web.reactive.function.client.WebClient;
import no.nav.foreldrepenger.common.domain.felles.Bankkonto;
import no.nav.foreldrepenger.mottak.oppslag.kontonummer.KontoregisterConfig;
import no.nav.foreldrepenger.mottak.oppslag.kontonummer.KontoregisterConnection;
import okhttp3.mockwebserver.MockResponse;
import okhttp3.mockwebserver.MockWebServer;
@ExtendWith(SpringExtension.class)
class KontonummerHentTest {
private static MockWebServer mockWebServer;
private static PDLConnection pdlConnection;
@BeforeAll
static void setUp() throws IOException {
mockWebServer = new MockWebServer();
mockWebServer.start();
var baseUrl = String.format("http://localhost:%s", mockWebServer.getPort());
var webClient = WebClient.create();
var kontoregisterConfig = new KontoregisterConfig(URI.create(baseUrl));
var kontoregisterConnection = new KontoregisterConnection(webClient, kontoregisterConfig);
pdlConnection = new PDLConnection(null, null, null, null, kontoregisterConnection, null);
}
@AfterAll
static void tearDown() throws IOException {
mockWebServer.shutdown();
}
@Test
void happycase() {
mockWebServer.enqueue(new MockResponse()
.setBody(happyCaseBodyFraNyttEndepunkt())
.addHeader("Content-Type", "application/json"));
var bankkonto = pdlConnection.kontonr();
assertThat(bankkonto.kontonummer()).isEqualTo("8361347234732292");
assertThat(bankkonto.banknavn()).isEqualTo("DNB");
}
@Test
void oppslagFeilerVerifiserAtFailSafe() {
mockWebServer.enqueue(new MockResponse().setResponseCode(400));
var bankkonto = pdlConnection.kontonr();
assertThat(bankkonto).isEqualTo(Bankkonto.UKJENT);
}
private String happyCaseBodyFraNyttEndepunkt() {
return """
{
"kontonummer": "8361347234732292",
"utenlandskKontoInfo": {
"banknavn": "DNB",
"bankkode": "CC123456789",
"bankLandkode": "SE",
"valutakode": "SEK",
"swiftBicKode": "SHEDNO22",
"bankadresse1": "string",
"bankadresse2": "string",
"bankadresse3": "string"
}
}
""";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold;
import static java.time.LocalDate.now;
import static no.nav.foreldrepenger.mottak.http.WebClientConfiguration.ARBEIDSFORHOLD;
import static org.springframework.http.MediaType.APPLICATION_JSON;
import java.time.LocalDate;
import java.util.List;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.client.WebClient;
import org.springframework.web.reactive.function.client.WebClientResponseException;
import no.nav.foreldrepenger.mottak.http.Retry;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.dto.ArbeidsforholdDTO;
import reactor.core.publisher.Mono;
@Component
public class ArbeidsforholdConnection {
private static final Logger LOG = LoggerFactory.getLogger(ArbeidsforholdConnection.class);
private final WebClient webClient;
private final ArbeidsforholdConfig cfg;
public ArbeidsforholdConnection(@Qualifier(ARBEIDSFORHOLD) WebClient client, ArbeidsforholdConfig cfg) {
this.webClient = client;
this.cfg = cfg;
}
List<ArbeidsforholdDTO> hentArbeidsforhold() {
return hentArbeidsforhold(now().minus(cfg.getTidTilbake()));
}
@Retry
private List<ArbeidsforholdDTO> hentArbeidsforhold(LocalDate fom) {
LOG.info("Henter arbeidsforhold for perioden fra {}", fom);
var arbeidsforhold = webClient.get()
.uri(b -> cfg.getArbeidsforholdURI(b, fom))
.accept(APPLICATION_JSON)
.retrieve()
.bodyToFlux(ArbeidsforholdDTO.class)
.onErrorResume(e -> e instanceof WebClientResponseException.NotFound notFound && notFound.getResponseBodyAsString().contains("Fant ikke forespurt(e) ressurs(er)"),
error -> {
LOG.info("Personen har ikke arbeidsforhold i Aareg");
return Mono.empty();
})
.collectList()
.blockOptional()
.orElse(List.of());
LOG.info("Hentet {} arbeidsforhold for perioden fra {}", arbeidsforhold.size(), fom);
return arbeidsforhold;
}
@Override
public String toString() {
return getClass().getSimpleName() + "[cfg=" + cfg + ", webClient=" + webClient + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.pdl;
import java.time.LocalDate;
import com.fasterxml.jackson.annotation.JsonProperty;
record PDLDødsfall(@JsonProperty("doedsdato") LocalDate dødsdato) {
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold;
import static org.assertj.core.api.Assertions.assertThat;
import java.io.IOException;
import java.net.URI;
import org.junit.jupiter.api.AfterAll;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.springframework.boot.test.mock.mockito.MockBean;
import org.springframework.test.context.junit.jupiter.SpringExtension;
import org.springframework.web.reactive.function.client.WebClient;
import no.nav.foreldrepenger.mottak.oppslag.pdl.PDLConnection;
import okhttp3.mockwebserver.MockResponse;
import okhttp3.mockwebserver.MockWebServer;
@ExtendWith(SpringExtension.class)
class OrganisasjonConnectionTest {
private static MockWebServer mockWebServer;
@MockBean
private PDLConnection pdlConnection;
private OrganisasjonConnection organisasjonConnection;
@BeforeAll
static void setUp() throws IOException {
mockWebServer = new MockWebServer();
mockWebServer.start(63631);
}
@BeforeEach
void setupConnection() {
var baseUrl = String.format("http://localhost:%s", mockWebServer.getPort());
var webClient = WebClient.builder().baseUrl(baseUrl).build();
var organisasjonConfig = new OrganisasjonConfig(URI.create(baseUrl), "/v1/organisasjon/{orgnr}");
organisasjonConnection = new OrganisasjonConnection(webClient, pdlConnection, organisasjonConfig);
}
@AfterAll
static void tearDown() throws IOException {
mockWebServer.shutdown();
}
@Test
void returnererNavnSomErSammensettningenAvNavnelinjerSeparertMedKomma() {
var body = """
{
"navn": {
"navnelinje1": "Sauefabrikk AS",
"navnelinje2": "navnelinje2",
"navnelinje3": "navnelinje3"
}
}
""";
mockWebServer.enqueue(new MockResponse()
.setBody(body)
.addHeader("Content-Type", "application/json"));
var navn = organisasjonConnection.navn("999999999");
assertThat(navn).isEqualTo("Sauefabrikk AS, navnelinje2, navnelinje3");
}
@Test
void ingenBodyReturnererOrgnummerSomNavn() {
mockWebServer.enqueue(new MockResponse()
.addHeader("Content-Type", "application/json"));
var navn = organisasjonConnection.navn("999999999");
assertThat(navn).isEqualTo("999999999");
}
@Test
void tomBodyReturnererOrgnummerSomNavn() {
var body = """
{}
""";
mockWebServer.enqueue(new MockResponse()
.setBody(body)
.addHeader("Content-Type", "application/json"));
var navn = organisasjonConnection.navn("999999999");
assertThat(navn).isEqualTo("999999999");
}
@Test
void skalBrukeOrgnummerSomDefaultVed4xxFeil() {
mockWebServer.enqueue(new MockResponse()
.setResponseCode(404)
.addHeader("Content-Type", "application/json"));
var navn = organisasjonConnection.navn("999999999");
assertThat(navn).isEqualTo("999999999");
}
// @Test
// void skalBrukeOrgnummerSomDefaultVed5xxFeil() {
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(INTERNAL_SERVER_ERROR.code()));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(INTERNAL_SERVER_ERROR.code()));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(INTERNAL_SERVER_ERROR.code()));
// mockWebServer.enqueue(new MockResponse()
// .setResponseCode(INTERNAL_SERVER_ERROR.code()));
//
// var navn = organisasjonConnection.navn("999999999");
// assertThat(navn).isEqualTo("999999999");
// }
}
<file_sep>package no.nav.foreldrepenger.mottak.oppslag.kontonummer.dto;
public record Konto(String kontonummer, UtenlandskKontoInfo utenlandskKontoInfo) {
public static final Konto UKJENT = new Konto(null, null);
}
<file_sep>package no.nav.foreldrepenger.mottak.innsyn;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import jakarta.validation.Valid;
import no.nav.foreldrepenger.common.domain.Orgnummer;
import no.nav.foreldrepenger.mottak.http.ProtectedRestController;
import no.nav.foreldrepenger.mottak.oppslag.arbeidsforhold.ArbeidsInfo;
@Deprecated // Brukes av fpinfo-historikk til å lage infoskriv om AGs IM
@ProtectedRestController(InnsynController.PATH)
public class InnsynController {
public static final String PATH = "/innsyn";
private final ArbeidsInfo arbeidsforhold;
public InnsynController(ArbeidsInfo arbeidsforhold) {
this.arbeidsforhold = arbeidsforhold;
}
@GetMapping("/orgnavn")
public String orgnavn(@Valid @RequestParam(name = "orgnr") Orgnummer orgnr) {
return arbeidsforhold.orgnavn(orgnr);
}
@Override
public String toString() {
return getClass().getSimpleName() + " [arbeidsforhold=" + arbeidsforhold + "]";
}
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf.modell;
public record DokumentPerson(String id,
String typeId,
String navn,
PersonType type,
String bosattLand,
String nasjonalitet) {
public static final DokumentPerson UKJENT = new DokumentPerson(null, null, null, PersonType.UKJENT, null, null);
}
<file_sep>package no.nav.foreldrepenger.mottak.innsending.pdf;
import static java.util.stream.Collectors.joining;
import static no.nav.foreldrepenger.common.util.StreamUtil.safeStream;
import static no.nav.foreldrepenger.mottak.config.MottakConfiguration.KVITTERINGSTEKSTER;
import static no.nav.foreldrepenger.mottak.config.MottakConfiguration.LANDKODER;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
import java.util.Collections;
import java.util.List;
import java.util.Locale;
import java.util.Optional;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.MessageSource;
import org.springframework.context.support.ResourceBundleMessageSource;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import com.neovisionaries.i18n.CountryCode;
import no.nav.foreldrepenger.common.domain.Navn;
import no.nav.foreldrepenger.common.domain.felles.medlemskap.Utenlandsopphold;
import no.nav.foreldrepenger.common.domain.felles.ÅpenPeriode;
@Component
public class SøknadTextFormatter {
private static final DateTimeFormatter DATE_FMT = DateTimeFormatter.ofPattern("dd.MM.uuuu");
private final MessageSource landkoder;
private final MessageSource kvitteringstekster;
private final Locale locale;
@Autowired
public SøknadTextFormatter(@Qualifier(LANDKODER) MessageSource landkoder,
@Qualifier(KVITTERINGSTEKSTER) MessageSource kvitteringstekster) {
this(landkoder, kvitteringstekster, CountryCode.NO.toLocale());
}
private SøknadTextFormatter(MessageSource landkoder, MessageSource kvitteringstekster, Locale locale) {
this.landkoder = landkoder;
this.kvitteringstekster = kvitteringstekster;
this.locale = locale;
}
public String countryName(CountryCode code, Object... values) {
return countryName(code.getAlpha2(), values);
}
private String countryName(String isoCode, Object... values) {
return Optional.ofNullable(getMessage(isoCode, landkoder, values)).orElse(isoCode);
}
public String fromMessageSource(String key, Object... values) {
return getMessage(key, kvitteringstekster, values);
}
public String navn(String navn) {
return fromMessageSource("navninline", navn);
}
public String navn(Navn navn) {
var sammensattnavn = sammensattNavn(navn);
return sammensattnavn.isEmpty() ? "" : fromMessageSource("navninline", sammensattnavn);
}
public String sammensattNavn(Navn navn) {
if (navn == null) {
return null;
}
return sammensattNavn(navn.fornavn(), navn.mellomnavn(), navn.etternavn());
}
private String sammensattNavn(String fornavn, String mellomnavn, String etternavn) {
return Stream.of(fornavn, mellomnavn, etternavn)
.filter(s -> s != null && !s.isEmpty())
.collect(Collectors.joining(" "));
}
public String dato(LocalDate localDate) {
return Optional.ofNullable(localDate)
.map(s -> s.format(DATE_FMT))
.orElse("");
}
public String datoer(List<LocalDate> datoer) {
return safeStream(datoer)
.map(this::dato)
.collect(joining(", "));
}
public String yesNo(boolean b) {
return b ? "Ja" : "Nei";
}
public String periode(ÅpenPeriode periode) {
var sb = new StringBuilder("fra og med " + dato(periode.fom()));
if (periode.tom() != null) {
sb.append(" til og med ").append(dato(periode.tom()));
}
return sb.toString();
}
public String enkelPeriode(ÅpenPeriode periode) {
var sb = new StringBuilder(dato(periode.fom()));
if (periode.tom() != null) {
sb.append(" - ").append(dato(periode.tom()));
}
return sb.toString();
}
public String capitalize(String orig) {
var lowerWithSpace = orig.replace("_", " ").toLowerCase();
return lowerWithSpace.substring(0, 1).toUpperCase() + lowerWithSpace.substring(1);
}
public List<String> utenlandsOpphold(List<Utenlandsopphold> opphold) {
if (CollectionUtils.isEmpty(opphold)) {
return Collections.singletonList(countryName(CountryCode.NO));
}
return safeStream(opphold)
.map(this::formatOpphold)
.toList();
}
private String formatOpphold(Utenlandsopphold opphold) {
return countryName(opphold.land(), opphold.land().getName())
+ ": "
+ dato(opphold.fom()) + " - "
+ dato(opphold.tom());
}
private String getMessage(String key, MessageSource messages, Object... values) {
return getMessage(key, null, messages, values);
}
private String getMessage(String key, String defaultValue, MessageSource messages, Object... values) {
((ResourceBundleMessageSource) messages).setDefaultEncoding("utf-8");
return messages.getMessage(key, values, defaultValue, locale);
}
public List<UtenlandsoppholdFormatert> utenlandsPerioder(List<Utenlandsopphold> opphold) {
if (CollectionUtils.isEmpty(opphold)) {
return Collections.singletonList(new UtenlandsoppholdFormatert(countryName(CountryCode.NO), null));
}
return safeStream(opphold)
.map(o -> new UtenlandsoppholdFormatert(countryName(o.land(), o.land().getName()), dato(o.fom(), o.tom())))
.collect(Collectors.toList());
}
private String dato(LocalDate fom, LocalDate tom) {
return dato(fom) + " – " + dato(tom);
}
@Override
public String toString() {
return getClass().getSimpleName() + " [landkoder=" + landkoder + ", kvitteringstekster=" + kvitteringstekster
+ ", locale=" + locale + "]";
}
}
<file_sep>[](https://github.com/navikt/fpsoknad-mottak/actions/workflows/build.yml)
[](https://sonarcloud.io/dashboard?id=navikt_fpsoknad-mottak)
[](https://sonarcloud.io/dashboard?id=navikt_fpsoknad-mottak)
[](https://sonarcloud.io/dashboard?id=navikt_fpsoknad-mottak)
[](https://sonarcloud.io/dashboard?id=navikt_fpsoknad-mottak)
[](https://sonarcloud.io/dashboard?id=navikt_fpsoknad-mottak)
fpsoknad-mottak
================
Mottar søknader om svangerskapspenger, foreldrepenger og engangsstønad fra frontend og sender dem videre inn i NAV for behandling.
### For å kjøre lokalt:
Sett ekstraparameter `-parameters` til javac (I IntelliJ: Settings > Build, Execution, Deployment > Compiler > Java Compiler > Additional command line parameters).
Dette for at man skal slippe å annotere alle constructor-parametre med @JsonProperty("xyz").
Start no.nav.foreldrepenger.mottak.MottakApplicationLocal.
### For å kjøre i et internt testmiljø med registre tilgjengelig:
Få tak i en Java truststore med gyldige sertifikater for aktuelt miljø.
`java -jar fpsoknad-mottak-<version>.jar -Djavax.net.ssl.trustStore=/path/til/truststore -Djavax.net.ssl.trustStorePassword=........`
---
# Henvendelser
Spørsmål kan rettes til:
* <EMAIL>
## For NAV-ansatte
Interne henvendelser kan sendes via Slack i kanalen #teamforeldrepenger.
<file_sep>package no.nav.foreldrepenger.mottak.innsending;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.foreldrepengesøknad;
import static no.nav.foreldrepenger.common.util.ForeldrepengerTestUtils.svp;
import static org.assertj.core.api.Assertions.assertThat;
import org.junit.jupiter.api.Test;
import no.nav.foreldrepenger.common.innsending.SøknadEgenskap;
class InspektørTest {
@Test
void verifiserAtSVPMatcherMedRiktigSøknadEgenskap() {
assertThat(Inspektør.inspiser(svp())).isEqualTo(SøknadEgenskap.INITIELL_SVANGERSKAPSPENGER);
}
@Test
void verifiserAtFPSøknadMatcherMedRiktigSøknadEgenskap() {
assertThat(Inspektør.inspiser(foreldrepengesøknad(false))).isEqualTo(SøknadEgenskap.INITIELL_FORELDREPENGER);
}
}
<file_sep>adopsjonektefellesbarn=Adopsjon av ektefelles barn: {0}
adopsjonomsorgovertar=Jeg var på omsorgsovertagelsestidspunktet i {0}
adopsjonomsorgovertok=Jeg kommer på omsorgsovertagelsestidspunktet til å være i {0}
adopsjonsdato=Adopsjonsdato: {0}
aktør=Aktør: {0}
aleneomsorg=Aleneomsorg: {0}
ankomstdato=Ankomstdato: {0}
annenopptjening=Andre inntektskilder
annenforelderukjent=Annen forelder er ukjent
antallbarn=Antall barn: {0}
arbeidsforhold=Arbeidsforhold
arbeidsgiver=Arbeidsgiver: {0}
arbeidsgiverIkkeFunnet=Arbeidsgiver med organisasjonsnummer: {0}
arbeidstidprosent=Arbeidstid i prosent: {0}
barn=Opplysninger om barnet eller barna
dager=Antall dager: {0}
dekningsgrad={0} prosent foreldrepenger (dekningsgrad)
dokumentasjon=Vedlegg
egennæring=Egen næringsvirksomhet
egennæringavsluttet=Jeg startet egen næring {0} og sluttet {1}
egennæringbeskrivelseendring=Beskrivelse av endring: {0}
egennæringbruttoinntekt=Næringsinntekt omregnet til årsinntekt før skatt: {0}
egennæringendringsdato=Endringsdato: {0}
egennæringoppstartsdato=Virksomheten ble startet: {0}
egennæringpågår=Jeg startet egen næring {0} og har fortsatt virksomheten
egennæringtyper=Virksomhetstype{0}: {1}
ektefellesbarn=Adopsjon av ektefelles barn: {0}
endringsøknad_fp=Søknad om endring av foreldrepenger
erarbeidstaker=Skal jobbe som arbeidstaker: {0}
erfrilans=Skal jobbe som frilanser: {0}
erselvstendig=Skal jobbe som selvstendig næringsdrivende: {0}
fnr=Fødselsnummer: {0}
fom=Fra og med: {0}
fosterhjem=Inntekt som fosterforelder: {0}
fp.justeruttak=Jeg ønsker at perioden som starter på termin blir endret til å starte fra fødselsdato når barn{1} blir født: {0}
fp.justeresvedfødsel=Justeres ved fødsel: {0}
framtidigeopphold=Framtidige opphold
frilans=Frilansoppdrag
frilansavsluttet=Jeg startet som frilanser {0}, men har nå sluttet som frilanser
frilanspågår=Jeg startet som frilanser {0} og jobber fortsatt som dette
fødselmedtermin=Fødsel med termin {0}
fødselsdato=Fødselsdato: {0}
fødselsdatony= med fødselsdato {0}
fødselsnummerinline=Fødselsnummer: {0}
fødselsnummer=Fødselsnummer
fødtei=Jeg var i {0} da barn{1} ble født
gjelder=Søknaden gjelder {0} barn
gjelderfødselsdato=Søknaden gjelder {0} barn med fødselsdato {1}.
gjeldertermindato=Søknaden gjelder {0} barn med termindato {1}.
gradertprosent=Jeg skal jobbe {0} prosent
gradertuttak=Kombinere foreldrepenger med arbeid
harrett=Har den andre forelderen rett til foreldrepenger: {0}
harmorufor=Har mor uføretrygd: {0}
annenforelderTilsvarendeEosRett=Har den andre forelderen arbeidet eller mottatt pengestøtte i et EØS-land i minst seks av de siste ti månedene før barnet ble født: {0}
annenForelderOppholdtSegIEos=Har den andre forelderen oppholdt seg fast i et annet EØS-land enn Norge ett år før barnet ble født: {0}
ikkeoppgitt=Ikke oppgitt
infoominntekt=Informasjon om inntekt
informert=Er den andre forelderen informert om søknaden: {0}
infoskriv.arbeidstaker=Arbeidstaker som inntektsmeldingen gjelder: {0}
infoskriv.header=NAV trenger inntektsmelding så snart som mulig{0}
infoskriv.opplysningerfrasøknad={0} har gitt disse opplysningene til NAV
infoskriv.paragraf1={0} har søkt NAV om foreldrepenger. Som arbeidsgiver må du sende digital inntektsmelding \
til NAV så snart som mulig{1}.
infoskriv.paragraf1.passert={0} har søkt NAV om foreldrepenger. Som arbeidsgiver må du sende digital inntektsmelding \
til NAV så snart som mulig. Hvis du allerede har sendt inn inntektsmelding i tråd med informasjonen \
under kan du se bort fra denne meldingen.
infoskriv.paragraf2=NAV kan ikke behandle søknaden før vi har fått inntektsmeldingen til {0}. Hvis du utsetter \
å sende inntektsmeldingen blir utbetalingen fra NAV forsinket. Du kan sende inntektsmeldingen fra \
deres eget lønns- og personalsystem eller fra altinn.no. Du kan lese mer om inntektsmelding på {1}.
infoskriv.paragraf3=I inntektsmeldingen skal du legge inn inntekten til {0} og fylle inn samme startdato {0} \
har skrevet i søknaden sin. Under ser du hva {0} har oppgitt i søknaden sin om foreldrepenger. Hvis dato \
ikke stemmer med det som er avtalt mellom dere, må du avklare dette med {0} før du sender inntektsmeldingen. \
Hvis dato som er oppgitt i søknaden er feil, må {0} sende en ny søknad til NAV med riktig dato.
infoskriv.startdato=Startdato for foreldrepengeperioden: {0}
infoskriv.ytelse=Ytelsen som inntektsmeldingen gjelder: Foreldrepenger
land=Land: {0}
medlemsskap=Informasjon om utenlandsopphold
morsaktivitet=Mors aktivitet i perioden: {0}
morsaktivitet.sykdom=For syk til å ta seg av barnet
morsaktivitet.kvalprog=Kvalifiseringsprogram
morsaktivitet.introprog=Introduksjonsprogram
morsaktivitet.samtidig=Samtidig uttak
mottatt=Mottatt: {0}
mottattid=Sendt til NAV
nasjonalitetinline=Nasjonalitet: {0}
nasjonalitet=Nasjonalitet
nasjonalitet.norsk=Norsk
navninline=Navn: {0}
navn=Navn
neste12=De neste 12 månedene skal jeg bo i
nystartetvirksomhet=Nyoppstartet virksomhet: {0}
nyligyrkesaktiv=Blitt yrkesaktiv i løpet av de tre siste ferdigliknede årene: {0}
nyoppstartet=Nyoppstartet som frilanser: {0}
nærrelasjon=Nær relasjon: {0}
ombarn=Informasjon om barnet
omannenforelder=Informasjon om annen forelder
omsorgiperiodene=Omsorg i periodene:
omsorgsovertagelsebeskrivelse=Beskrivelse: {0}
omsorgsovertakelsesdato=Omsorgsovertakelsesdato: {0}
omsorgsovertakelsesårsak=Årsak: {0}
oppdrag:Oppdrag for nær venn eller familie
opphold=Opphold
oppholdsårsak=Oppholdsårsak: {0}
orgnummer=Organisasjonsnummer: {0}
overføring=Overføring
overføringsårsak=Overføringsårsak: {0}
periode.opphold.uttakfellesannen=Den andre forelderen skal ta ut fellesperiode
periode.opphold.uttakkvoteannen=Den andre forelderen skal ta ut egen kvote
perioder=Perioden med foreldrepenger
periode.utsettelse.hv=Øvelse eller tjeneste i Heimevernet
periode.utsettelse.nav=NAV tiltak som utgjør 100 % arbeid
registrertiland=Registrert i {0}
regnskapsfører=Regnskapsfører: {0}, nær relasjon: {1}
regnskapsførertelefon=Regnskapsfører: {0}, telefon {1}, nær relasjon: {2}
rettigheter=Rettigheter
samtidiguttakprosent=Samtidig uttak i prosent: {0}
siste12=De siste 12 månedene har jeg bodd i
skalgraderes=Skal kombinere foreldrepenger med arbeid: {0}
stillingsprosent=Stillingsprosent: {0} prosent
svp.behovfra=Jeg har behov for tilrettelegging fra {0}.
svp.frilans=Frilans
svp.gradering=Med tilrettelegging kan jeg jobbe {0} prosent.
svp.heltilrettelegging=Arbeidsgiver kan tilrettelegge arbeidet fra {0}.
svp.delvistilrettelegging=Arbeidsgiver kan delvis tilrettelegge arbeidet fra
svp.privatarbeidsgiver=Privat arbeidsgiver
svp.risikofaktorer=Risikofaktorer: {0}
svp.kombinertarbeid=Kombinere foreldrepenger med delvis arbeid:
svp.utsettelse=Utsettelse av foreldrepenger på grunn av lovbestemt ferie eller arbeid på heltid:
svp.selvstendig=Selvstendig næringsvirksomhet
svp.sluttearbeid=Jeg kan ikke jobbe i min stilling og arbeidsgiver kan ikke tilrettelegge fra {0}.
svp.stillingsprosent=Jeg kan jobbe i {0} prosent stilling.
svp.søknad=Søknad om svangerskapspenger
svp.omfødsel=Gjelder barn født {0}, med termin {1}.
svp.termindato=Termindato er {0}.
svp.tilretteleggingfra=Arbeidsgiver kan tilrettelegge fra {0}.
svp.tiltak=Tiltak: {0}
svp.vedlegg.tilrettelegging=Skjema for tilrettelegging og omplassering ved graviditet
søknad_engang=Søknad om engangsstønad
søknad_fp=Søknad om foreldrepenger
søkeradopsjonalene=Søker adopsjon alene: {0}
termindato=Termindato: {0}
termindatotekst=Med termindato den {0}
termindatotekstny=, med termindato den {0}
terminbekreftelsedatert=Det er vedlagt en terminbekreftelse som er datert den {0}.
terminføderi:Jeg kommer til å være i {0} når barn{1} blir født
tidligereopphold=Tidligere opphold
tilknytning=Tilknytning til Norge
tilleggsopplysninger=Tilleggsopplysninger
tilrettelegging=Tilretteleggingsbehov
tilretteleggingsForhold=Arbeidsforhold med tilretteleggingsbehov
tom=Til og med: {0}
type=Type: {0}
utenlandskarbeid=Utenlandske arbeidsforhold
utenlandskid=Fødselsnummer eller D-nummer: {0}
utsettelse=Utsettelse
utsettelsesårsak=Årsak til utsettelse: {0}
utstedtdato=Bekreftelse utstedt: {0}
uttak=Uttak
uttakfedrekvotemedmor=Medmorkvote
uttaksperiodetype=Del av foreldrepengene: {0}
varigendring=Varig endring i virksomheten eller arbeidssituasjonen min de siste fire årene: {0}
vedlegg1=Vedlegg:
vedlegg2={0} ({1})
vedlegg=Vedlegg: {0} ({1})
vedleggannenopptjening=Dokumentasjon av andre inntektskilder
vedleggrelasjondok=Dokumentasjon av relasjon til barn
vedleggutenlandskarbeid=Dokumentasjon av utenlandsk arbeidsforhold
virksomhetsland=Landet virksomheten er registrert i: {0}
virksomhetsnavn=Navn på virksomheten: {0}
virksomhetsnummer=Virksomhetsnummer: {0}
ønskerflerbarnsdager=Ønsker uttak av flerbarnsdager: {0}
ønskersamtidiguttak=Ønsker samtidig uttak: {0}
| 1a07dd2237bdaef37245dc8900c9ab51c865f3e3 | [
"Markdown",
"Maven POM",
"INI",
"Java",
"Dockerfile"
] | 64 | Java | navikt/fpsoknad-mottak | e9a1019da2ed9bb73443b9fbc0e0106a92962f7a | 700416e75dbe49be561b64717681524182aaeda4 |
refs/heads/master | <file_sep>using System;
using System.Collections.Generic;
using System.ComponentModel;
using System.Data;
using System.Drawing;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows.Forms;
using WindowsFormsApplication1;
namespace WindowsFormsApplication1
{
public partial class Form1 : Form
{
//Using global variable for counting list of objects in the list box.
public double salesTaxedItemPrice = 0;
public double finalPriceBeforeTax = 0;
public double importedItemTotal = 0;
public double saleTaxExemptedItemTotal = 0;
List<string> importItem = new List<string>();
List<double> importItemPrice = new List<double>();
List<string> taxExemptedItem = new List<string>();
List<double> taxExemptedItemPrice = new List<double>();
List<string> salesTaxItem = new List<string>();
List<double> salesTaxItemPrice = new List<double>();
public string importedItem = string.Empty;
public Form1()
{
InitializeComponent();
}
/// <summary>
/// This method will calculate the total without any taxes.
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void addButton_Click(object sender, EventArgs e)
{
double price = 0;
price = double.Parse(priceTextbox.Text);
itemListbox.Items.Add(itemTextbox.Text);
priceListbox.Items.Add(price);
//// It will check if anything is checked in the checkbox list.
//// If it does then it will add total to different variables.
//// It will store name of item and price into the collection (global variable), for later use.
if(taxExemptedItemCheckbox.Checked== true)
{
taxExemptedItem.Add(itemTextbox.Text);
taxExemptedItemPrice.Add(price);
saleTaxExemptedItemTotal = saleTaxExemptedItemTotal + price;
}
else if(ImportedCheckbox.Checked == true)
{
importItem.Add(itemTextbox.Text);
importItemPrice.Add(price);
importedItemTotal = importedItemTotal + price;
}
else
{
salesTaxItem.Add(itemTextbox.Text);
salesTaxItemPrice.Add(price);
salesTaxedItemPrice = salesTaxedItemPrice + price;
}
finalPriceBeforeTax = salesTaxedItemPrice + importedItemTotal;
itemTextbox.Clear();
priceTextbox.Clear();
Console.WriteLine("Sales tax exempted item total price: " + saleTaxExemptedItemTotal);
Console.WriteLine("Import item total price: " + importedItemTotal);
Console.WriteLine("Total price for taxed item: " + salesTaxedItemPrice);
}
private void totalButton_Click(object sender, EventArgs e)
{
TaxCalculator calculator = new TaxCalculator();
foreach (string item in taxExemptedItem)
{
receiptListbox.Items.Add(item);
}
foreach (double price in taxExemptedItemPrice)
{
receiptPriceListbox.Items.Add(price);
}
foreach (string item in importItem)
{
receiptListbox.Items.Add("Imported " + item);
}
foreach (double importPrice in importItemPrice)
{
receiptPriceListbox.Items.Add(calculator.ImportTaxCalculator(importPrice));
}
foreach (string item in salesTaxItem)
{
receiptListbox.Items.Add(item);
}
foreach (double price in salesTaxItemPrice)
{
receiptPriceListbox.Items.Add(price);
}
double salesTax = finalPriceBeforeTax * 0.1;
double salesTaxConvert = Math.Round((Double)salesTax, 2);
Console.WriteLine("Sales tax: " + salesTaxConvert);
receiptListbox.Items.Add("Sales tax: ");
receiptPriceListbox.Items.Add(salesTaxConvert);
double totalAmount = salesTaxConvert + finalPriceBeforeTax + saleTaxExemptedItemTotal;
double totalAmountConvert = Math.Round((Double)totalAmount, 2);
Console.WriteLine("Total : " + totalAmountConvert);
receiptListbox.Items.Add("Total : ");
receiptPriceListbox.Items.Add(totalAmountConvert);
}
/// <summary>
/// Clears the values.
/// </summary>
/// <param name="sender"></param>
/// <param name="e"></param>
private void clearButton_Click(object sender, EventArgs e)
{
salesTaxedItemPrice = 0;
finalPriceBeforeTax = 0;
importedItemTotal = 0;
saleTaxExemptedItemTotal = 0;
itemTextbox.Clear();
priceTextbox.Clear();
itemListbox.Items.Clear();
priceListbox.Items.Clear();
receiptListbox.Items.Clear();
receiptPriceListbox.Items.Clear();
}
}
}
<file_sep>using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace WindowsFormsApplication1
{
class TaxCalculator
{
/// <summary>
/// This will calculate sales tax.
/// </summary>
/// <param name="totalAmount"></param>
/// <returns>
/// This will return final price include sales tax
/// </returns>
public double SalesTaxCalculator(double totalAmount, string item)
{
double salesTax = 0;
double priceWithSalesTax = 0;
try
{
salesTax = totalAmount * 0.1;
priceWithSalesTax = totalAmount + salesTax;
}
catch (Exception ex)
{
Console.Write(ex.Message);
}
return priceWithSalesTax;
}
/// <summary>
/// This method will calculate sales tax exempted price.
/// </summary>
/// <param name="totalAmount"></param>
/// <param name="salesTaxExempted"></param>
/// <param name="item"></param>
/// <returns> This will return total amount with sales tax exempted price.</returns>
public double SalesTaxExemption(double totalAmount, bool salesTaxExempted, string item)
{
try
{
if (salesTaxExempted != true)
{
SalesTaxCalculator(totalAmount, item);
}
return totalAmount;
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
return totalAmount;
}
/// <summary>
/// This will calculate import tax.
/// </summary>
/// <param name="totalAmount"></param>
/// <returns>This will return total price with import tax.</returns>
public double ImportTaxCalculator(double totalAmount)
{
double imporTax = 0;
double priceWithImportTax = 0;
try
{
imporTax = totalAmount * 0.05;
priceWithImportTax = imporTax + totalAmount;
return priceWithImportTax;
}
catch(Exception ex)
{
Console.WriteLine(ex.Message);
}
return priceWithImportTax;
}
}
}
| 707837b6d511bea4db0ce8b7717b84ad243974eb | [
"C#"
] | 2 | C# | khchoi89/GitHub | d5076a420b7c4b784b1842d1284c420aa313ac4b | 245ad3e62a25250f771377ed41c3b29c3072ecde |
refs/heads/master | <file_sep>#include "MSI_protocol.h"
#include "../sim/mreq.h"
#include "../sim/sim.h"
#include "../sim/hash_table.h"
extern Simulator *Sim;
/*************************
* Constructor/Destructor.
*************************/
MSI_protocol::MSI_protocol (Hash_table *my_table, Hash_entry *my_entry)
: Protocol (my_table, my_entry)
{
// Initialize lines to not have the data yet!
this->state = MSI_CACHE_I;
}
MSI_protocol::~MSI_protocol ()
{
}
void MSI_protocol::dump (void)
{
const char *block_states[7] = {"X","I","IS","IM", "S", "M", "SM"};
fprintf (stderr, "MSI_protocol - state: %s\n", block_states[state]);
}
void MSI_protocol::process_cache_request (Mreq *request)
{
switch (state) {
case MSI_CACHE_I: do_cache_I(request); break;
case MSI_CACHE_IS: do_cache_IS(request); break;
case MSI_CACHE_IM: do_cache_IM(request); break;
case MSI_CACHE_S: do_cache_S(request); break;
case MSI_CACHE_M: do_cache_M(request); break;
case MSI_CACHE_SM: do_cache_SM(request); break;
default:
fatal_error ("Invalid Cache State for MSI Protocol\n");
}
}
void MSI_protocol::process_snoop_request (Mreq *request)
{
switch (state) {
case MSI_CACHE_I: do_snoop_I(request); break;
case MSI_CACHE_IS: do_snoop_IS(request); break;
case MSI_CACHE_IM: do_snoop_IM(request); break;
case MSI_CACHE_S: do_snoop_S(request); break;
case MSI_CACHE_M: do_snoop_M(request); break;
case MSI_CACHE_SM: do_snoop_SM(request); break;
default:
fatal_error ("Invalid Cache State for MSI Protocol\n");
}
}
inline void MSI_protocol::do_cache_I (Mreq *request)
{
switch (request->msg) {
// If we get a request from the processor we need to get the data
case LOAD:
/* Line up the GETS in the Bus' queue */
send_GETS(request->addr);
/* The IS state means that we have sent the GET message and we are now waiting
on DATA */
state = MSI_CACHE_IS;
/* This is a cache miss */
Sim->cache_misses++;
break;
case STORE:
/* Line up the GETM in the Bus' queue */
send_GETM(request->addr);
/* The IM state means that we have sent the GET message and we are now waiting
* on DATA
*/
state = MSI_CACHE_IM;
/* This is a cache miss */
Sim->cache_misses++;
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: I state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_cache_IS (Mreq *request){
switch (request->msg) {
/* If the block is in the IS state that means it sent out a GET message
* and is waiting on DATA. Therefore the processor should be waiting
* on a pending request. Therefore we should not be getting any requests from
* the processor.
*/
case LOAD:
case STORE:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error("Should only have one outstanding request per processor!");
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: IS state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_cache_IM (Mreq *request){
switch (request->msg) {
/* If the block is in the IM state that means it sent out a GET message
* and is waiting on DATA. Therefore the processor should be waiting
* on a pending request. Therefore we should not be getting any requests from
* the processor.
*/
case LOAD:
case STORE:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error("Should only have one outstanding request per processor!");
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: IM state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_cache_S (Mreq *request)
{
switch (request->msg) {
/* The S state means we have the data but can NOT modify it
A read request can be satisfied immediately.
A write request requires a GETM
*/
case LOAD:
// There was no need to send anything on the bus on a READ hit.
send_DATA_to_proc(request->addr);
break;
case STORE:
/* Line up the GETM in the Bus' queue */
send_GETM(request->addr);
state = MSI_CACHE_SM;
// Note: this is a WRITE hit
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: S state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_cache_M (Mreq *request)
{
switch (request->msg) {
/* The M state means we have the data and we can modify it. Therefore any request
* from the processor (read or write) can be immediately satisfied.
*/
case LOAD:
case STORE:
// Note: There was no need to send anything on the bus on a hit.
send_DATA_to_proc(request->addr);
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: M state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_cache_SM (Mreq *request){
switch (request->msg) {
/* If the block is in the SM state that means it sent out a GET message
* and is waiting on DATA. Therefore the processor should be waiting
* on a pending request. Therefore we should not be getting any requests from
* the processor.
*/
case LOAD:
case STORE:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error("Should only have one outstanding request per processor!");
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: S state shouldn't see this message\n");
}
}
/* Should be DONE */
inline void MSI_protocol::do_snoop_I (Mreq *request)
{
switch (request->msg) {
case GETS:
case GETM:
case DATA:
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: I state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_snoop_IS (Mreq *request){
switch (request->msg) {
case GETS:
case GETM:
break;
case DATA:
/** IS state meant that the block had sent the GETS and was waiting on DATA.
* Now that Data is received we can send the DATA to the processor and finish
* the transition to S. */
send_DATA_to_proc(request->addr);
state = MSI_CACHE_S;
if (get_shared_line())
{
// Nothing to do for IS->S in MSI protocol (i think...)
// more to do when MESI
}
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: IS state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_snoop_IM (Mreq *request){
switch (request->msg) {
case GETS:
// Should not see a GETS since t is waiting for data to transition to M
//request->print_msg (my_table->moduleID, "ERROR");
//fatal_error ("Client: GETS seen while in IM\n");
case GETM:
/** While in IM we will see our own GETM on the bus. We should just
* ignore it and wait for DATA to show up.
*/
break;
case DATA:
/** IM state meant that the block had sent the GETM and was waiting on DATA.
* Now that Data is received we can send the DATA to the processor and finish
* the transition to M.
*/
send_DATA_to_proc(request->addr);
state = MSI_CACHE_M;
if (get_shared_line())
{
// Nothing to do for IM->M in MSI protocol
}
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: IM state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_snoop_S (Mreq *request)
{
switch (request->msg) {
case GETS: // stay in S
break;
case GETM: // invalidate
state = MSI_CACHE_I;
break;
case DATA: // shouldn't get data here
fatal_error ("Should not see data for this line! I have the line!");
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: S state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_snoop_M (Mreq *request)
{
switch (request->msg) {
case GETS:
// send data out
set_shared_line();
send_DATA_on_bus(request->addr,request->src_mid);
// go to state S
state = MSI_CACHE_S;
break;
case GETM:
/**
* Another cache wants the data so we send it to them and transition to
* Invalid since they will be transitioning to M. When we send the DATA
* it will go on the bus the next cycle and the memory will see it and cancel
* its lookup for the DATA.
*/
set_shared_line();
send_DATA_on_bus(request->addr,request->src_mid);
state = MSI_CACHE_I;
break;
case DATA:
fatal_error ("Should not see data for this line! I have the line!");
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: M state shouldn't see this message\n");
}
}
inline void MSI_protocol::do_snoop_SM (Mreq *request){
switch (request->msg) {
case GETS:
break;
case GETM:
state = MSI_CACHE_IM;
Sim->cache_misses++;
break;
case DATA:
/** SM state meant that the block had sent the GETM and was waiting on DATA.
* Now that Data is received we can send the DATA to the processor and finish
* the transition to M.
*/
send_DATA_to_proc(request->addr);
state = MSI_CACHE_M;
if (get_shared_line())
{
// Nothing to do for SM->M in MSI protocol
}
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: SM state shouldn't see this message\n");
}
}
<file_sep>#include "MESI_protocol.h"
#include "../sim/mreq.h"
#include "../sim/sim.h"
#include "../sim/hash_table.h"
extern Simulator *Sim;
/*************************
* Constructor/Destructor.
*************************/
MESI_protocol::MESI_protocol (Hash_table *my_table, Hash_entry *my_entry)
: Protocol (my_table, my_entry)
{
this->state = MESI_CACHE_I;
}
MESI_protocol::~MESI_protocol ()
{
}
void MESI_protocol::dump (void)
{
const char *block_states[8] = {"X", "I", "ISE", "IM", "S", "SM", "E", "M"};
fprintf (stderr, "MESI_protocol - state: %s\n", block_states[state]);
}
void MESI_protocol::process_cache_request (Mreq *request)
{
switch (state) {
case MESI_CACHE_I: do_cache_I(request); break;
case MESI_CACHE_ISE: do_cache_ISE(request); break;
case MESI_CACHE_IM: do_cache_IM(request); break;
case MESI_CACHE_S: do_cache_S(request); break;
case MESI_CACHE_SM: do_cache_SM(request); break;
case MESI_CACHE_E: do_cache_E(request); break;
case MESI_CACHE_M: do_cache_M(request); break;
default:
fatal_error ("Invalid Cache State for MESI Protocol\n");
}
}
void MESI_protocol::process_snoop_request (Mreq *request)
{
switch (state) {
case MESI_CACHE_I: do_snoop_I(request); break;
case MESI_CACHE_ISE: do_snoop_ISE(request); break;
case MESI_CACHE_IM: do_snoop_IM(request); break;
case MESI_CACHE_S: do_snoop_S(request); break;
case MESI_CACHE_SM: do_snoop_SM(request); break;
case MESI_CACHE_E: do_snoop_E(request); break;
case MESI_CACHE_M: do_snoop_M(request); break;
default:
fatal_error ("Invalid Cache State for MESI Protocol\n");
}
}
inline void MESI_protocol::do_cache_I (Mreq *request)
{
switch (request->msg) {
case LOAD:
send_GETS(request->addr);
state = MESI_CACHE_ISE;
Sim->cache_misses++;
break;
case STORE:
send_GETM(request->addr);
state = MESI_CACHE_IM;
Sim->cache_misses++;
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: I state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_cache_ISE (Mreq *request){
switch (request->msg) {
case LOAD:
case STORE:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error("Should only have one outstanding request per processor!");
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: ISE state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_cache_IM (Mreq *request){
switch (request->msg) {
case LOAD:
case STORE:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error("Should only have one outstanding request per processor!");
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: IM state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_cache_S (Mreq *request)
{
switch (request->msg) {
case LOAD:
// There was no need to send anything on the bus on a READ hit.
send_DATA_to_proc(request->addr);
break;
case STORE:
/* Line up the GETM in the Bus' queue */
send_GETM(request->addr);
state = MESI_CACHE_SM;
// Note: this is a WRITE hit
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: S state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_cache_SM (Mreq *request){
switch (request->msg) {
case LOAD:
case STORE:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error("Should only have one outstanding request per processor!");
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: SM state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_cache_E (Mreq *request)
{
switch (request->msg) {
case LOAD:
// read hit
send_DATA_to_proc(request->addr);
break;
case STORE:
// write hit, but state updates to M
state = MESI_CACHE_M;
send_DATA_to_proc(request->addr);
Sim->silent_upgrades++;
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: E state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_cache_M (Mreq *request)
{
switch (request->msg) {
case LOAD:
case STORE:
// Note: There was no need to send anything on the bus on a hit.
send_DATA_to_proc(request->addr);
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: M state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_I (Mreq *request)
{
switch (request->msg) {
case GETS:
case GETM:
case DATA:
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: I state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_ISE (Mreq *request){
switch (request->msg) {
case GETS:
case GETM: break;
case DATA:
if (get_shared_line() == true) state = MESI_CACHE_S;
else state = MESI_CACHE_E;
send_DATA_to_proc(request->addr);
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: ISE state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_IM (Mreq *request){
switch (request->msg) {
case GETS:
case GETM: break;
case DATA:
state = MESI_CACHE_M;
send_DATA_to_proc(request->addr);
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: IM state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_S (Mreq *request)
{
switch (request->msg) {
case GETS: // stay in S
set_shared_line();
break;
case GETM: // invalidate
state = MESI_CACHE_I;
break;
case DATA: // shouldn't get data here
fatal_error ("Should not see data for this line! I have the line!");
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: S state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_SM (Mreq *request){
switch (request->msg) {
case GETS:
set_shared_line();
break;
case GETM:
state = MESI_CACHE_IM;
Sim->cache_misses++;
break;
case DATA:
send_DATA_to_proc(request->addr);
state = MESI_CACHE_M;
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: SM state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_E (Mreq *request)
{
switch (request->msg) {
case GETS:
state = MESI_CACHE_S;
set_shared_line();
send_DATA_on_bus(request->addr,request->src_mid);
break;
case GETM:
state = MESI_CACHE_I;
set_shared_line();
send_DATA_on_bus(request->addr,request->src_mid);
break;
case DATA:
fatal_error ("Should not see data for this line! I have the line!");
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: E state shouldn't see this message\n");
}
}
inline void MESI_protocol::do_snoop_M (Mreq *request)
{
switch (request->msg) {
case GETS:
state = MESI_CACHE_S;
set_shared_line();
send_DATA_on_bus(request->addr,request->src_mid);
// go to state S
break;
case GETM:
state = MESI_CACHE_I;
set_shared_line();
send_DATA_on_bus(request->addr,request->src_mid);
break;
case DATA:
fatal_error ("Should not see data for this line! I have the line!");
break;
default:
request->print_msg (my_table->moduleID, "ERROR");
fatal_error ("Client: M state shouldn't see this message\n");
}
}
| 2433dd5343b638805a41cb37d1ca42889e6819bc | [
"C++"
] | 2 | C++ | asaltiel72/cs4290-proj3 | 3ffb4dcfe7d781ea94dbffd84a632d12e449922b | 5169fd97c61ad23d967e9e63d9152eaa85e99246 |
refs/heads/master | <file_sep>
Examples of use
''''''''''''''
- `Heterogeneity of marginal effects <https://github.com/thierrymoudiki/teller/blob/master/teller/demo/thierrymoudiki_011119_boston_housing.ipynb>`_
- `Significance of marginal effects <https://github.com/thierrymoudiki/teller/blob/master/teller/demo/thierrymoudiki_081119_boston_housing.ipynb>`_
- `Model comparison <https://github.com/thierrymoudiki/teller/blob/master/teller/demo/thierrymoudiki_151119_boston_housing.ipynb>`_
- `Classification <https://github.com/thierrymoudiki/teller/blob/master/teller/demo/thierrymoudiki_041219_breast_cancer_classif.ipynb>`_
- `Interactions <https://github.com/thierrymoudiki/teller/blob/master/teller/demo/thierrymoudiki_041219_boston_housing_interactions.ipynb>`_<file_sep>import numpy as np
from .memoize import memoize
from .progress_bar import Progbar
from joblib import Parallel, delayed
from tqdm import tqdm
from .numerical_gradient import numerical_gradient
from scipy.stats import t
from scipy.special import expit
def get_code_pval(pval):
assert (pval >= 0) & (pval <= 1), "must have pval >= 0 & pval <= 1"
if (pval >= 0) & (pval < 0.001):
return "***"
if (pval >= 0.001) & (pval < 0.01):
return "**"
if (pval >= 0.01) & (pval < 0.05):
return "*"
if (pval >= 0.05) & (pval < 0.1):
return "."
if pval >= 0.1:
return "-"
@memoize
def numerical_gradient_jackknife(
f, X, normalize=False, level=95, h=None, n_jobs=None
):
n, p = X.shape
mean_grads = []
if n_jobs is None:
print("\n")
print("Calculating the effects...")
pbar = Progbar(n)
for i in range(n):
X_i = np.delete(X, i, 0)
grad_i = numerical_gradient(f, X_i, normalize, verbose=0)
mean_grads.append(np.mean(grad_i, axis=0))
pbar.update(i)
pbar.update(n)
print("\n")
mean_grads = np.asarray(mean_grads)
mean_est = np.mean(mean_grads, axis=0)
se_est = np.clip(
((n - 1) * np.var(mean_grads, axis=0)) ** 0.5,
a_min=np.finfo(float).eps,
a_max=None,
)
t_est = mean_est / se_est
qt = t.ppf(1 - (1 - level / 100) * 0.5, n - 1)
p_values = 2 * t.sf(x=np.abs(t_est), df=n - 1)
# cat("Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1", "\n")
signif_codes = [get_code_pval(elt) for elt in p_values]
return (
mean_est,
se_est,
mean_est + qt * se_est,
mean_est - qt * se_est,
p_values,
signif_codes,
)
# if n_jobs is not None:
def gradient_column(i):
X_i = np.delete(X, i, 0)
grad_i = numerical_gradient(f, X_i, normalize, verbose=0)
mean_grads.append(np.mean(grad_i, axis=0))
print("\n")
print("Calculating the effects...")
Parallel(n_jobs=n_jobs, prefer="threads")(
delayed(gradient_column)(m) for m in tqdm(range(n))
)
print("\n")
mean_grads = np.asarray(mean_grads)
mean_est = np.mean(mean_grads, axis=0)
se_est = np.clip(
((n - 1) * np.var(mean_grads, axis=0)) ** 0.5,
a_min=np.finfo(float).eps,
a_max=None,
)
t_est = mean_est / se_est
qt = t.ppf(1 - (1 - level / 100) * 0.5, n - 1)
p_values = 2 * t.sf(x=np.abs(t_est), df=n - 1)
# cat("Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1", "\n")
signif_codes = [get_code_pval(elt) for elt in p_values]
return (
mean_est,
se_est,
mean_est + qt * se_est,
mean_est - qt * se_est,
p_values,
signif_codes,
)
<file_sep>from setuptools import setup, find_packages
from codecs import open
from os import path
__version__ = '0.6.2'
with open("README.md", "r") as fh:
long_description = fh.read()
# get the dependencies and installs
here = path.abspath(path.dirname(__file__))
with open(path.join(here, 'requirements.txt'), encoding='utf-8') as f:
all_reqs = f.read().split('\n')
install_requires = [x.strip() for x in all_reqs if 'git+' not in x]
setup(
name='the-teller',
version=__version__,
description='teller, explainable machine learning',
long_description='Model-agnostic Machine Learning explainability',
url='https://github.com/thierrymoudiki/teller',
alias='the-teller',
download_url='https://github.com/thierrymoudiki/teller/tarball/' + __version__,
license='BSD',
classifiers=[
'Development Status :: 3 - Alpha',
'Intended Audience :: Developers',
'Programming Language :: Python :: 3',
],
keywords='',
packages=find_packages(exclude=['docs', 'tests*']),
include_package_data=True,
author='<NAME>',
install_requires=["numpy >= 1.13.0", "pandas >= 0.25.1",
"scipy >= 0.19.0", "scikit-learn >= 0.18.0",
"joblib >= 0.13.2"].append(install_requires),
author_email='<EMAIL>'
)
<file_sep>from .deepcopy import deepcopy
from .memoize import memoize
from .misc import diff_list, merge_two_dicts, flatten, is_factor, tuple_insert
from .numerical_gradient import numerical_gradient, numerical_interactions
from .numerical_gradient_jackknife import (
numerical_gradient_jackknife,
get_code_pval,
)
from .numerical_gradient_gaussian import numerical_gradient_gaussian
from .numerical_interactions_jackknife import numerical_interactions_jackknife
from .numerical_interactions_gaussian import numerical_interactions_gaussian
from .progress_bar import Progbar
from .scoring import score_regression, score_classification
from .t_test import t_test
from .var_test import var_test
__all__ = [
"deepcopy",
"memoize",
"diff_list",
"merge_two_dicts",
"flatten",
"is_factor",
"tuple_insert",
"numerical_gradient",
"numerical_interactions",
"numerical_gradient_jackknife",
"numerical_interactions_jackknife",
"numerical_gradient_gaussian",
"numerical_interactions_gaussian",
"get_code_pval",
"Progbar",
"score_regression",
"score_classification",
"t_test",
"var_test",
]
<file_sep>**WARNING:** This repository is no longer updated, and is now transferred under [Techtonique
/
teller](https://github.com/Techtonique/teller)

<hr>
 [](https://github.com/thierrymoudiki/teller/blob/master/LICENSE) [](https://pepy.tech/project/the-teller) [](https://the-teller.readthedocs.io/en/latest/?badge=latest)
There is an increasing need for __transparency__ and __fairness__ in Machine Learning (ML) models predictions. Consider for example a banker who has to explain to a client why his/her loan application is rejected, or a health professional who must explain what constitutes his/her diagnosis. Some ML models are indeed very accurate, but are considered hard to explain, relatively to popular linear models.
__Source of figure__: James, Gareth, et al. An introduction to statistical learning. Vol. 112. New York: springer, 2013.

We do not want to sacrifice this high accuracy to explainability. Hence: __ML explainability__. There are a lot of ML explainability tools out there, _in the wild_ (don't take my word for it).
The `teller` is a __model-agnostic tool for ML explainability__ - agnostic, as long as this model possesses methods `fit` and `predict`. The `teller`'s philosophy is to rely on [Taylor series](https://en.wikipedia.org/wiki/Taylor_series) to explain ML models predictions: a little increase in model's explanatory variables + a little decrease, and we can obtain approximate sensitivities of its predictions to changes in these explanatory variables.
## Installation
- From Pypi, stable version:
```bash
pip install the-teller
```
- From Github, for the development version:
```bash
pip install git+https://github.com/thierrymoudiki/teller.git
```
## Package description
These notebooks will be some good introductions:
- [Heterogeneity of marginal effects](/teller/demo/thierrymoudiki_011119_boston_housing.ipynb)
- [Significance of marginal effects](/teller/demo/thierrymoudiki_081119_boston_housing.ipynb)
- [Model comparison](/teller/demo/thierrymoudiki_151119_boston_housing.ipynb)
- [Classification](/teller/demo/thierrymoudiki_041219_breast_cancer_classif.ipynb)
- [Interactions](/teller/demo/thierrymoudiki_041219_boston_housing_interactions.ipynb)
## Contributing
Your contributions are welcome, and valuable. Please, make sure to __read__ the [Code of Conduct](CONTRIBUTING.md) first.
If you're not comfortable with Git/Version Control yet, please use [this form](https://forms.gle/Y18xaEHL78Fvci7r8).
In Pull Requests, let's strive to use [`black`](https://black.readthedocs.io/en/stable/) for formatting:
```bash
pip install black
black --line-length=80 file_submitted_for_pr.py
```
## API Documentation
[https://the-teller.readthedocs.io/en/latest/?badge=latest](https://the-teller.readthedocs.io/en/latest/?badge=latest)
## Dependencies
- Numpy
- Pandas
- Scipy
- scikit-learn
## Citation
```
@misc{moudiki2019teller,
author={<NAME>.},
title={\code{teller}, {M}odel-agnostic {M}achine {L}earning explainability},
howpublished={\url{https://github.com/thierrymoudiki/teller}},
note={BSD 3-Clause Clear License. Version 0.x.x.},
year={2019--2020}
}
```
## References
- Press, <NAME>., <NAME>., <NAME>., & <NAME>. (1992). Numerical recipes in C (Vol. 2). Cambridge: Cambridge university press.
- <NAME>, <NAME>, <NAME>, et al. SciPy: Open Source Scientific Tools for Python, 2001-, http://www.scipy.org/ [Online; accessed 2019-01-04]
- Scikit-learn: Machine Learning in Python, Pedregosa et al., JMLR 12, pp. 2825-2830, 2011.
## License
[BSD 3-Clause](LICENSE) © <NAME>, 2019.
<file_sep># version 0.5.0
- Add functionality for explaining interactions
# version 0.4.0
- Add functionality for explaining classifiers decisions
# version 0.3.0
- Add functionality for comparing (and explain) models
# version 0.2.0
- Improve interface for `fit`
- Add (Jackknife) Student tests for marginal effects
# version 0.1.0
- Initial version<file_sep>import numpy as np
from os import chdir
wd="/Users/moudiki/Documents/Python_Packages/teller"
#
chdir(wd)
import teller as tr
import pandas as pd
from sklearn import datasets
import numpy as np
from sklearn import datasets
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
# import data
boston = datasets.load_boston()
X = np.delete(boston.data, 11, 1)
y = boston.target
col_names = np.append(np.delete(boston.feature_names, 11), 'MEDV')
# split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=123)
print(X_train.shape)
print(X_test.shape)
# fit a linear regression model
regr = RandomForestRegressor(n_estimators=1000, random_state=123)
regr.fit(X_train, y_train)
# creating the explainer
expr = tr.Explainer(obj=regr)
# print(expr.get_params())
# heterogeneity of effects -----
# fitting the explainer
expr.fit(X_test, y_test, X_names=col_names[:-1],
y_name=col_names[-1], method="avg")
print(expr.summary())
# confidence int. and tests on effects -----
expr.fit(X_test, y_test, X_names=col_names[:-1],
y_name=col_names[-1], method="ci")
print(expr.summary())
# interactions -----
varx = "RAD"
expr.fit(X_test, y_test, X_names=col_names[:-1],
y_name=col_names[-1],
col_inters = varx, method="inters")
print(expr.summary())
varx = "RM"
expr.fit(X_test, y_test, X_names=col_names[:-1],
y_name=col_names[-1],
col_inters = varx, method="inters")
print(expr.summary())
<file_sep>import numpy as np
from .deepcopy import deepcopy
from .memoize import memoize
from .progress_bar import Progbar
from joblib import Parallel, delayed
from tqdm import tqdm
from numpy.linalg import norm
from sklearn.preprocessing import MinMaxScaler
@memoize
def numerical_gradient(f, X, normalize=False, h=None, n_jobs=None, verbose=1):
n, p = X.shape
grad = np.zeros_like(X)
zero = 1e-4
if n_jobs is None:
# naive version -----
if h is not None:
double_h = 2 * h
if verbose == 1:
print("\n")
print("Calculating the effects...")
pbar = Progbar(p)
for ix in range(p):
value_x = deepcopy(X[:, ix])
X[:, ix] = value_x + h
fx_plus = f(X)
X[:, ix] = value_x - h
fx_minus = f(X)
X[:, ix] = value_x # restore (!)
grad[:, ix] = (fx_plus - fx_minus) / double_h
pbar.update(ix)
if verbose == 1:
pbar.update(p)
print("\n")
if normalize == True:
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_grad = scaler.fit_transform(grad)
return scaled_grad / scaled_grad.sum(axis=1)[:, None]
return grad
# if h is None: -----
eps_factor = zero ** (1 / 3)
if verbose == 1:
print("\n")
print("Calculating the effects...")
pbar = Progbar(p)
for ix in range(p):
value_x = deepcopy(X[:, ix])
cond = np.abs(value_x) > zero
h = eps_factor * value_x * cond + zero * np.logical_not(cond)
X[:, ix] = value_x + h
fx_plus = f(X)
X[:, ix] = value_x - h
fx_minus = f(X)
X[:, ix] = value_x # restore (!)
grad[:, ix] = (fx_plus - fx_minus) / (2 * h)
if verbose == 1:
pbar.update(ix)
if verbose == 1:
pbar.update(p)
print("\n")
if normalize == True:
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_grad = scaler.fit_transform(grad)
return scaled_grad / scaled_grad.sum(axis=1)[:, None]
return grad
# if n_jobs is not None:
eps_factor = zero ** (1 / 3)
def gradient_column(ix):
value_x = deepcopy(X[:, ix])
cond = np.abs(value_x) > zero
h = eps_factor * value_x * cond + zero * np.logical_not(cond)
X[:, ix] = value_x + h
fx_plus = f(X)
X[:, ix] = value_x - h
fx_minus = f(X)
X[:, ix] = value_x # restore (!)
grad[:, ix] = (fx_plus - fx_minus) / (2 * h)
if verbose == 1:
print("\n")
print("Calculating the effects...")
Parallel(n_jobs=n_jobs, prefer="threads")(
delayed(gradient_column)(m) for m in tqdm(range(p))
)
print("\n")
if normalize == True:
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_grad = scaler.fit_transform(grad)
return scaled_grad / scaled_grad.sum(axis=1)[:, None]
return grad
Parallel(n_jobs=n_jobs, prefer="threads")(
delayed(gradient_column)(m) for m in range(p)
)
if normalize == True:
scaler = MinMaxScaler(feature_range=(-1, 1))
scaled_grad = scaler.fit_transform(grad)
return scaled_grad / scaled_grad.sum(axis=1)[:, None]
return grad
@memoize
def numerical_interactions(f, X, ix1, ix2, h=None, k=None):
n, p = X.shape
# naive version -----
if h is not None:
assert k is not None, "`k` must be provided along with `h`"
value_x1 = deepcopy(X[:, ix1])
value_x2 = deepcopy(X[:, ix2])
X[:, ix1] = value_x1 + h
X[:, ix2] = value_x2 + k
fx_11 = f(X)
X[:, ix1] = value_x1 + h
X[:, ix2] = value_x2 - k
fx_12 = f(X)
X[:, ix1] = value_x1 - h
X[:, ix2] = value_x2 + k
fx_21 = f(X)
X[:, ix1] = value_x1 - h
X[:, ix2] = value_x2 - k
fx_22 = f(X)
X[:, ix1] = value_x1 # restore (!)
X[:, ix2] = value_x2 # restore (!)
inters = ((fx_11 - fx_12) - (fx_21 - fx_22)) / (4 * (h * k))
return inters
# if h is None: -----
zero = np.finfo(float).eps
eps_factor = zero ** (1 / 4)
value_x1 = deepcopy(X[:, ix1])
value_x2 = deepcopy(X[:, ix2])
cond1 = np.abs(value_x1) > zero
cond2 = np.abs(value_x2) > zero
h1 = eps_factor * value_x1 * cond1 + 1e-4 * np.logical_not(cond1)
h2 = eps_factor * value_x2 * cond2 + 1e-4 * np.logical_not(cond2)
X[:, ix1] = value_x1 + h1
X[:, ix2] = value_x2 + h2
fx_11 = f(X)
X[:, ix1] = value_x1 + h1
X[:, ix2] = value_x2 - h2
fx_12 = f(X)
X[:, ix1] = value_x1 - h1
X[:, ix2] = value_x2 + h2
fx_21 = f(X)
X[:, ix1] = value_x1 - h1
X[:, ix2] = value_x2 - h2
fx_22 = f(X)
X[:, ix1] = value_x1 # restore (!)
X[:, ix2] = value_x2 # restore (!)
return ((fx_11 - fx_12) - (fx_21 - fx_22)) / (4 * h1 * h2)
<file_sep>.. _ref-base-model:
Explainer
''''''''''''''''''''
Explainer
---------------------------------
.. automodule:: teller.explainer.explainer
:members:
:undoc-members:
<file_sep>import numpy as np
import pandas as pd
from sklearn.base import BaseEstimator
from ..utils import (
is_factor,
numerical_gradient,
numerical_gradient_jackknife,
numerical_gradient_gaussian,
numerical_interactions,
numerical_interactions_jackknife,
numerical_interactions_gaussian,
Progbar,
score_regression,
score_classification,
)
class Explainer(BaseEstimator):
"""Class Explainer for: effects of features on the response.
Parameters
----------
obj: object
fitted object containing methods `fit` and `predict`
n_jobs: int
number of jobs for parallel computing
y_class: int
class whose probability has to be explained (for classification only)
normalize: boolean
whether the features must be normalized or not (changes the effects)
"""
def __init__(self, obj, n_jobs=None, y_class=0, normalize=False):
self.obj = obj
self.n_jobs = n_jobs
self.y_mean_ = None
self.effects_ = None
self.residuals_ = None
self.r_squared_ = None
self.adj_r_squared_ = None
self.effects_ = None
self.ci_ = None
self.ci_inters_ = {}
self.type_fit = None
self.y_class = y_class # classification only
self.normalize = normalize
self.type_ci = None
def fit(
self,
X,
y,
X_names,
y_name,
method="avg",
type_ci="jackknife",
scoring=None,
level=95,
col_inters=None,
):
"""Fit the explainer's attribute `obj` to training data (X, y).
Parameters
----------
X: {array-like}, shape = [n_samples, n_features]
Training vectors, where n_samples is the number
of samples and n_features is the number of features.
y: {array-like}, shape = [n_samples, ]
Target values.
X_names: {array-like}, shape = [n_features, ]
Column names (strings) for training vectors.
y_names: str
Column name (string) for vector of target values.
method: str
Type of summary requested for effects. Either `avg`
(for average effects), `inters` (for interactions)
or `ci` (for effects including confidence intervals
around them).
type_ci: str
Type of resampling for `method == 'ci'` (confidence
intervals around effects). Either `jackknife`
bootsrapping or `gaussian` (gaussian white noise with
standard deviation equal to `0.01` applied to the
features).
scoring: str
measure of errors must be in ("explained_variance",
"neg_mean_absolute_error", "neg_mean_squared_error",
"neg_mean_squared_log_error", "neg_median_absolute_error",
"r2", "rmse") (default: "rmse")
level: int
Level of confidence required for `method == 'ci'` (in %)
col_inters: str
Name of column for computing interactions
Returns
-------
self: object
"""
assert method in (
"avg",
"ci",
"inters",
), "must have: `method` in ('avg', 'ci', 'inters')"
n, p = X.shape
self.X_names = X_names
self.y_name = y_name
self.level = level
self.scoring = scoring
self.method = method
self.type_ci = type_ci
if is_factor(y): # classification ---
self.n_classes = len(np.unique(y))
assert (
self.y_class <= self.n_classes
), "self.y_class must be <= number of classes"
assert hasattr(
self.obj, "predict_proba"
), "`self.obj` must be a classifier and have a method `predict_proba`"
self.type_fit = "classification"
self.score_ = score_classification(self.obj, X, y, scoring=scoring)
if scoring is None:
self.scoring = "accuracy"
def predict_proba(x):
return self.obj.predict_proba(x)[:, self.y_class]
y_hat = predict_proba(X)
# heterogeneity of effects
if method == "avg":
self.grad = numerical_gradient(
predict_proba,
X,
normalize=self.normalize,
n_jobs=self.n_jobs,
)
# confidence intervals
if method == "ci":
if type_ci=="jackknife":
self.ci_ = numerical_gradient_jackknife(
predict_proba,
X,
normalize=self.normalize,
n_jobs=self.n_jobs,
level=level,
)
if type_ci=="gaussian":
self.ci_ = numerical_gradient_gaussian(
predict_proba,
X,
normalize=self.normalize,
n_jobs=self.n_jobs,
level=level,
)
# interactions
if method == "inters":
assert col_inters is not None, "`col_inters` must be provided"
self.col_inters = col_inters
ix1 = np.where(X_names == col_inters)[0][0]
pbar = Progbar(p)
if type_ci=="jackknife":
for ix2 in range(p):
self.ci_inters_.update(
{
X_names[ix2]: numerical_interactions_jackknife(
f=predict_proba,
X=X,
ix1=ix1,
ix2=ix2,
verbose=0,
)
}
)
pbar.update(ix2)
if type_ci=="gaussian":
for ix2 in range(p):
self.ci_inters_.update(
{
X_names[ix2]: numerical_interactions_gaussian(
f=predict_proba,
X=X,
ix1=ix1,
ix2=ix2,
verbose=0,
)
}
)
pbar.update(ix2)
pbar.update(p)
print("\n")
else: # is_factor(y) == False # regression ---
self.type_fit = "regression"
self.score_ = score_regression(self.obj, X, y, scoring=scoring)
if scoring is None:
self.scoring = "rmse"
y_hat = self.obj.predict(X)
# heterogeneity of effects
if method == "avg":
self.grad = numerical_gradient(
self.obj.predict,
X,
normalize=self.normalize,
n_jobs=self.n_jobs,
)
# confidence intervals
if method == "ci":
if type_ci=="jackknife":
self.ci_ = numerical_gradient_jackknife(
self.obj.predict,
X,
normalize=self.normalize,
n_jobs=self.n_jobs,
level=level,
)
if type_ci=="gaussian":
self.ci_ = numerical_gradient_gaussian(
self.obj.predict,
X,
normalize=self.normalize,
n_jobs=self.n_jobs,
level=level,
)
# interactions
if method == "inters":
assert col_inters is not None, "`col_inters` must be provided"
self.col_inters = col_inters
ix1 = np.where(X_names == col_inters)[0][0]
pbar = Progbar(p)
if type_ci=="jackknife":
for ix2 in range(p):
self.ci_inters_.update(
{
X_names[ix2]: numerical_interactions_jackknife(
f=self.obj.predict,
X=X,
ix1=ix1,
ix2=ix2,
verbose=0,
)
}
)
if type_ci=="gaussian":
for ix2 in range(p):
self.ci_inters_.update(
{
X_names[ix2]: numerical_interactions_gaussian(
f=self.obj.predict,
X=X,
ix1=ix1,
ix2=ix2,
verbose=0,
)
}
)
pbar.update(ix2)
pbar.update(p)
print("\n")
self.y_mean_ = np.mean(y)
ss_tot = np.sum((y - self.y_mean_) ** 2)
ss_reg = np.sum((y_hat - self.y_mean_) ** 2)
ss_res = np.sum((y - y_hat) ** 2)
self.residuals_ = y - y_hat
self.r_squared_ = 1 - ss_res / ss_tot
self.adj_r_squared_ = 1 - (1 - self.r_squared_) * (n - 1) / (
n - p - 1
)
# classification and regression ---
if method == "avg":
res_df = pd.DataFrame(data=self.grad, columns=X_names)
res_df_mean = res_df.mean()
res_df_std = res_df.std()
res_df_min = res_df.min()
res_df_max = res_df.max()
data = pd.concat(
[res_df_mean, res_df_std, res_df_min, res_df_max], axis=1
)
df_effects = pd.DataFrame(
data=data.values,
columns=["mean", "std", "min", "max"],
index=X_names,
)
# heterogeneity of effects
self.effects_ = df_effects.sort_values(by=["mean"], ascending=False)
return self
def summary(self):
"""Summary of effects.
Returns
-------
Prints the summary of effects.
"""
assert (
(self.ci_ is not None)
| (self.effects_ is not None)
| (self.ci_inters_ is not None)
), "object not fitted, fit the object first"
if (self.ci_ is not None) & (self.method == "ci"):
# (mean_est, se_est,
# mean_est + qt*se_est, mean_est - qt*se_est,
# p_values, signif_codes)
df_mean = pd.Series(data=self.ci_[0], index=self.X_names)
df_se = pd.Series(data=self.ci_[1], index=self.X_names)
df_ubound = pd.Series(data=self.ci_[2], index=self.X_names)
df_lbound = pd.Series(data=self.ci_[3], index=self.X_names)
df_pvalue = pd.Series(data=self.ci_[4], index=self.X_names)
df_signif = pd.Series(data=self.ci_[5], index=self.X_names)
data = pd.concat(
[df_mean, df_se, df_lbound, df_ubound, df_pvalue, df_signif],
axis=1,
)
self.ci_summary_ = pd.DataFrame(
data=data.values,
columns=[
"Estimate",
"Std. Error",
str(self.level) + "% lbound",
str(self.level) + "% ubound",
"Pr(>|t|)",
"",
],
index=self.X_names,
).sort_values(by=["Estimate"], ascending=False)
print("\n")
print(f"Score ({self.scoring}): \n {np.round(self.score_, 3)}")
if self.type_fit == "regression":
print("\n")
print("Residuals: ")
self.residuals_dist_ = pd.DataFrame(
pd.Series(
data=np.quantile(
self.residuals_, q=[0, 0.25, 0.5, 0.75, 1]
),
index=["Min", "1Q", "Median", "3Q", "Max"],
)
).transpose()
print(self.residuals_dist_.to_string(index=False))
print("\n")
if self.type_ci=="jackknife":
print("Tests on marginal effects (Jackknife): ")
if self.type_ci=="gaussian":
print("Tests on marginal effects (Gaussian noise): ")
with pd.option_context(
"display.max_rows", None, "display.max_columns", None
):
print(self.ci_summary_)
print("\n")
print(
"Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘-’ 1"
)
if self.type_fit == "regression":
print("\n")
print(
f"Multiple R-squared: {np.round(self.r_squared_, 3)}, Adjusted R-squared: {np.round(self.adj_r_squared_, 3)}"
)
if (self.effects_ is not None) & (self.method == "avg"):
print("\n")
print("Heterogeneity of marginal effects: ")
with pd.option_context(
"display.max_rows", None, "display.max_columns", None
):
print(self.effects_)
print("\n")
if (self.ci_inters_ is not None) & (self.method == "inters"):
print("\n")
print("Interactions with " + self.col_inters + ": ")
with pd.option_context(
"display.max_rows", None, "display.max_columns", None
):
print(
pd.DataFrame(
self.ci_inters_,
index=[
"Estimate",
"Std. Error",
str(95) + "% lbound",
str(95) + "% ubound",
"Pr(>|t|)",
"",
],
).transpose()
)
<file_sep>teller.utils package
====================
Submodules
----------
teller.utils.deepcopy module
----------------------------
.. automodule:: teller.utils.deepcopy
:members:
:undoc-members:
:show-inheritance:
teller.utils.memoize module
---------------------------
.. automodule:: teller.utils.memoize
:members:
:undoc-members:
:show-inheritance:
teller.utils.misc module
------------------------
.. automodule:: teller.utils.misc
:members:
:undoc-members:
:show-inheritance:
teller.utils.numerical\_gradient module
---------------------------------------
.. automodule:: teller.utils.numerical_gradient
:members:
:undoc-members:
:show-inheritance:
teller.utils.numerical\_gradient\_gaussian module
-------------------------------------------------
.. automodule:: teller.utils.numerical_gradient_gaussian
:members:
:undoc-members:
:show-inheritance:
teller.utils.numerical\_gradient\_jackknife module
--------------------------------------------------
.. automodule:: teller.utils.numerical_gradient_jackknife
:members:
:undoc-members:
:show-inheritance:
teller.utils.numerical\_interactions\_gaussian module
-----------------------------------------------------
.. automodule:: teller.utils.numerical_interactions_gaussian
:members:
:undoc-members:
:show-inheritance:
teller.utils.numerical\_interactions\_jackknife module
------------------------------------------------------
.. automodule:: teller.utils.numerical_interactions_jackknife
:members:
:undoc-members:
:show-inheritance:
teller.utils.progress\_bar module
---------------------------------
.. automodule:: teller.utils.progress_bar
:members:
:undoc-members:
:show-inheritance:
teller.utils.scoring module
---------------------------
.. automodule:: teller.utils.scoring
:members:
:undoc-members:
:show-inheritance:
teller.utils.t\_test module
---------------------------
.. automodule:: teller.utils.t_test
:members:
:undoc-members:
:show-inheritance:
teller.utils.var\_test module
-----------------------------
.. automodule:: teller.utils.var_test
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: teller.utils
:members:
:undoc-members:
:show-inheritance:
<file_sep>"""Paired t-test"""
import numpy as np
import math
from scipy.stats import t
def t_test(x, y, alternative="less", var_equal=False, mu=0, conf_level=0.95):
assert alternative in (
"two.sided",
"less",
"greater",
), "must have: `alternative` in ('two.sided', 'less', 'greater')"
nx = len(x)
ny = len(y)
mx = np.mean(x)
vx = nx * np.var(x) / (nx - 1)
my = np.mean(y)
vy = ny * np.var(y) / (ny - 1)
estimate = {"mean of x": mx, "mean of y": my}
if var_equal:
df = nx + ny - 2
v = 0
if nx > 1:
v = v + (nx - 1) * vx
if ny > 1:
v = v + (ny - 1) * vy
v = v / df
stderr = math.sqrt(v * (1 / nx + 1 / ny))
else:
stderrx = math.sqrt(vx / nx)
stderry = math.sqrt(vy / ny)
stderr = math.sqrt(stderrx ** 2 + stderry ** 2)
df = stderr ** 4 / (stderrx ** 4 / (nx - 1) + stderry ** 4 / (ny - 1))
if stderr < 10 * np.finfo(float).eps * max(math.fabs(mx), math.fabs(my)):
raise ValueError("data are essentially constant")
tstat = (mx - my - mu) / stderr
if alternative == "less":
pval = t.cdf(tstat, df)
cint = np.array([-np.inf, tstat + t.ppf(conf_level, df)])
elif alternative == "greater":
pval = 1 - t.cdf(tstat, df)
cint = np.array([tstat - t.ppf(conf_level, df), np.inf])
else:
pval = 2 * t.cdf(-math.fabs(tstat), df)
alpha = 1 - conf_level
cint = t.ppf(1 - alpha / 2, df)
cint = tstat + np.array([-cint, cint])
cint = mu + cint * stderr
return {
"statistic": tstat,
"parameter": df,
"p.value": pval,
"f.int": cint,
"estimate": estimate,
"null.value": mu,
"alternative": alternative,
}
<file_sep>
Citation
''''''''''
.. code-block:: console
@misc{moudiki2019teller,
author={<NAME>.},
title={\code{teller}, {M}odel-agnostic {M}achine {L}earning explainability},
howpublished={\url{https://github.com/thierrymoudiki/teller}},
note={BSD 3-Clause Clear License. Version 0.x.x.},
year={2019--2020}
}<file_sep>from .explainer import Comparator
from .explainer import Explainer
__all__ = ["Comparator", "Explainer"]
<file_sep>"""Variance ratio test"""
# Authors: <NAME>
#
# License: BSD 3
import numpy as np
from scipy.stats import f
# inspired from R's var.test
def var_test(x, y, ratio=1, alternative="less", level=95):
level = level / 100
assert alternative in (
"twosided",
"less",
"greater",
), "must have `alternative` in ('twosided', 'less', 'greater')"
dfx = len(x) - 1
dfy = len(y) - 1
assert dfx >= 1, "not enough observations for `x`"
assert dfy >= 1, "not enough observations for `y`"
varx = np.var(x)
vary = np.var(y)
estimate = varx / vary
statistic = estimate / ratio
parameter = [dfx, dfy]
pval = f.cdf(statistic, dfx, dfy)
if alternative == "twosided":
pval = 2 * min(pval, 1 - pval)
beta = (1 - level) / 2
cint = [
estimate / f.ppf(1 - beta, dfx, dfy),
estimate / f.ppf(beta, dfx, dfy),
]
if alternative == "greater":
pval = 1 - pval
cint = [estimate / f.ppf(level, dfx, dfy), np.infty]
if alternative == "less":
cint = [0, estimate / f.ppf(1 - level, dfx, dfy)]
return {
"statistic": statistic,
"parameter": parameter,
"p_value": pval,
"conf_int": cint,
"estimate": estimate,
"null_value": ratio,
"alternative": alternative,
}
<file_sep>import numpy as np
from os import chdir
#wd="/Users/moudiki/Documents/Python_Packages/teller"
#
#chdir(wd)
import teller as tr
import pandas as pd
from sklearn import datasets, linear_model
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
# import data
boston = datasets.load_boston()
X = np.delete(boston.data, 11, 1)
y = boston.target
col_names = np.append(np.delete(boston.feature_names, 11), 'MEDV')
# split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=123)
print(X_train.shape)
print(X_test.shape)
# fit a linear regression model
regr = linear_model.LinearRegression()
regr.fit(X_train, y_train)
print(col_names)
print(regr.coef_)
# creating the explainer
expr = tr.Explainer(obj=regr)
# print(expr.get_params())
# fitting the explainer
expr.fit(X_test, y_test, X_names=col_names[:-1], y_name=col_names[-1])
# heterogeneity of effects
print(expr.summary())<file_sep>joblib >= 0.13.2
numpy >= 1.13.0
pandas >= 0.25.1
scikit-learn >= 0.18.0
scipy >= 0.19.0
tqdm >= 4.28.1
.
<file_sep>.. _ref-homepage:
The teller's documentation
=========================================
.. image:: https://img.shields.io/pypi/v/the-teller
:target: https://pypi.org/project/the-teller/
:alt: Latest PyPI version
.. image:: https://img.shields.io/pypi/l/teller
:target: https://github.com/thierrymoudiki/teller/blob/master/LICENSE
:alt: PyPI - License
.. image:: https://pepy.tech/badge/the-teller
:target: https://pepy.tech/project/the-teller
:alt: Number of PyPI downloads
The `teller`'s **source code** is `available on GitHub <https://github.com/thierrymoudiki/teller>`_. You can read blog posts about `teller` `here <https://thierrymoudiki.github.io/blog/#ExplainableML>`_, and for current references, consult section :ref:`ref-references`.
.. toctree::
:maxdepth: 1
:caption: Quickstart
Quickstart/Installation
Quickstart/Examples of use
.. toctree::
:maxdepth: 1
:caption: API Documentation
APIDocumentation/Explainer
APIDocumentation/Comparator
.. toctree::
:maxdepth: 1
:caption: Contributing
Contributing/Guidelines
Contributing/Testing
.. toctree::
:maxdepth: 1
:caption: Citing teller
Citation
.. toctree::
:maxdepth: 1
:caption: License
License
Indices and tables
==================
* :ref:`genindex`
* :ref:`modindex`
<file_sep>import math
import pandas as pd
import teller as tr
import numpy as np
from sklearn import datasets
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer, load_wine, load_iris, make_classification
breast_cancer = load_breast_cancer()
Z = breast_cancer.data
t = breast_cancer.target
np.random.seed(123)
X_train, X_test, y_train, y_test = train_test_split(Z, t, test_size=0.2)
print(X_train.shape)
print(X_test.shape)
clf1 = ExtraTreesClassifier(n_estimators=250,
max_features=int(math.sqrt(X_train.shape[1])),
random_state=24869)
clf1.fit(X_train, y_train)
# creating the explainer
expr1 = tr.Explainer(obj=clf1, y_class=1, normalize=False)
# fitting the explainer (for heterogeneity of effects only)
expr1.fit(X_test, y_test, X_names=breast_cancer.feature_names,
y_name="diagnosis", method="avg")
# summary of results for the model
print(expr1.summary())
# confidence intervals and tests on marginal effects (Jackknife)
expr1.fit(X_test, y_test, X_names=breast_cancer.feature_names,
y_name="diagnosis", method="ci")
# summary of results for the model
print(expr1.summary())
<file_sep>import pickle
def deepcopy(x):
return pickle.loads(pickle.dumps(x, -1))
<file_sep>
Installation
''''''''''
`teller` is currently available for Python.
For Python
----------
**Stable version** From Pypi:
.. code-block:: console
pip install the-teller
**Development version** From GitHub. For this to work, you'll first need to have `Git installed <https://git-scm.com/book/en/v2/Getting-Started-Installing-Git>`_ :
.. code-block:: console
pip install git+https://github.com/thierrymoudiki/teller.git
Next section presents some **examples of use of the teller** in Python.<file_sep>"""Scoring functions"""
# Authors: <NAME>
#
# License: BSD 3
import numpy as np
import sklearn.metrics as skm
def score_regression(obj, X, y, scoring=None, **kwargs):
""" Score the model on test set covariates X and response y. """
preds = obj.predict(X)
if type(preds) == tuple: # if there are std. devs in the predictions
preds = preds[0]
if scoring is None:
scoring = "neg_mean_squared_error"
# check inputs
assert scoring in (
"explained_variance",
"neg_mean_absolute_error",
"neg_mean_squared_error",
"neg_mean_squared_log_error",
"neg_median_absolute_error",
"r2",
"rmse",
), "'scoring' should be in ('explained_variance', 'neg_mean_absolute_error', \
'neg_mean_squared_error', 'neg_mean_squared_log_error', \
'neg_median_absolute_error', 'r2', 'rmse')"
def f_rmse(x):
return np.sqrt(skm.mean_squared_error(x))
scoring_options = {
"explained_variance": skm.explained_variance_score,
"neg_mean_absolute_error": skm.mean_absolute_error,
"neg_mean_squared_error": skm.mean_squared_error,
"neg_mean_squared_log_error": skm.mean_squared_log_error,
"neg_median_absolute_error": skm.median_absolute_error,
"r2": skm.r2_score,
"rmse": f_rmse,
}
return scoring_options[scoring](y, preds, **kwargs)
def score_classification(obj, X, y, scoring=None, **kwargs):
""" Score the model on test set covariates X and response y. """
preds = obj.predict(X)
if scoring is None:
scoring = "accuracy"
# check inputs
assert scoring in (
"accuracy",
"average_precision",
"brier_score_loss",
"f1",
"f1_micro",
"f1_macro",
"f1_weighted",
"f1_samples",
"neg_log_loss",
"precision",
"recall",
"roc_auc",
), "'scoring' should be in ('accuracy', 'average_precision', \
'brier_score_loss', 'f1', 'f1_micro', \
'f1_macro', 'f1_weighted', 'f1_samples', \
'neg_log_loss', 'precision', 'recall', \
'roc_auc')"
scoring_options = {
"accuracy": skm.accuracy_score,
"average_precision": skm.average_precision_score,
"brier_score_loss": skm.brier_score_loss,
"f1": skm.f1_score,
"f1_micro": skm.f1_score,
"f1_macro": skm.f1_score,
"f1_weighted": skm.f1_score,
"f1_samples": skm.f1_score,
"neg_log_loss": skm.log_loss,
"precision": skm.precision_score,
"recall": skm.recall_score,
"roc_auc": skm.roc_auc_score,
}
return scoring_options[scoring](y, preds, **kwargs)
<file_sep>teller.explainer package
========================
Submodules
----------
teller.explainer.comparator module
----------------------------------
.. automodule:: teller.explainer.comparator
:members:
:undoc-members:
:show-inheritance:
teller.explainer.explainer module
---------------------------------
.. automodule:: teller.explainer.explainer
:members:
:undoc-members:
:show-inheritance:
Module contents
---------------
.. automodule:: teller.explainer
:members:
:undoc-members:
:show-inheritance:
<file_sep>.. _ref-classification-models:
Comparator
''''''''''''''''''''
Comparator module
----------------------------------
.. automodule:: teller.explainer.comparator
:members:
:undoc-members:
<file_sep>import numpy as np
from .memoize import memoize
from .progress_bar import Progbar
from joblib import Parallel, delayed
from tqdm import tqdm
from .numerical_gradient import numerical_interactions
from scipy.stats import t
from scipy.stats import norm
def get_code_pval(pval):
assert (pval >= 0) & (pval <= 1), "must have pval >= 0 & pval <= 1"
if (pval >= 0) & (pval < 0.001):
return "***"
if (pval >= 0.001) & (pval < 0.01):
return "**"
if (pval >= 0.01) & (pval < 0.05):
return "*"
if (pval >= 0.05) & (pval < 0.1):
return "."
if pval >= 0.1:
return "-"
@memoize
def numerical_interactions_gaussian(
f, X, ix1, ix2, level=95, h=None, n_jobs=None, verbose=1
):
n, p = X.shape
mean_grads = []
rv = norm()
if n_jobs is None:
if verbose == 1:
print("\n")
print("Calculating the effects...")
pbar = Progbar(n)
for i in range(n):
np.random.seed(i)
X_i = X + rv.rvs()*0.01
inters_i = numerical_interactions(f, X_i, ix1, ix2)
mean_grads.append(np.mean(inters_i))
if verbose == 1:
pbar.update(i)
if verbose == 1:
pbar.update(n)
print("\n")
mean_grads = np.asarray(mean_grads)
mean_est = np.mean(mean_grads)
se_est = np.clip(
((n - 1) * np.var(mean_grads)) ** 0.5,
a_min=np.finfo(float).eps,
a_max=None,
)
t_est = mean_est / se_est
qt = t.ppf(1 - (1 - level / 100) * 0.5, n - 1)
p_value = 2 * t.sf(x=np.abs(t_est), df=n - 1)
# cat("Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1", "\n")
signif_code = get_code_pval(p_value)
return (
mean_est,
se_est,
mean_est + qt * se_est,
mean_est - qt * se_est,
p_value,
signif_code,
)
# if n_jobs is not None:
def interactions_column(i):
np.random.seed(i)
X_i = X + rv.rvs()*0.01
inters_i = numerical_interactions(f, X_i, ix1, ix2)
mean_grads.append(np.mean(inters_i))
print("\n")
print("Calculating the effects...")
Parallel(n_jobs=n_jobs, prefer="threads")(
delayed(interactions_column)(m) for m in tqdm(range(n))
)
print("\n")
mean_grads = np.asarray(mean_grads)
mean_est = np.mean(mean_grads)
se_est = np.clip(
((n - 1) * np.var(mean_grads)) ** 0.5,
a_min=np.finfo(float).eps,
a_max=None,
)
t_est = mean_est / se_est
qt = t.ppf(1 - (1 - level / 100) * 0.5, n - 1)
p_values = 2 * t.sf(x=np.abs(t_est), df=n - 1)
# cat("Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1", "\n")
signif_codes = [get_code_pval(elt) for elt in p_values]
return (
mean_est,
se_est,
mean_est + qt * se_est,
mean_est - qt * se_est,
p_values,
signif_codes,
)
<file_sep>import numpy as np
import pandas as pd
from scipy import stats
from sklearn.base import BaseEstimator
from ..utils import (
deepcopy,
get_code_pval,
is_factor,
memoize,
numerical_gradient,
numerical_gradient_jackknife,
numerical_gradient_gaussian,
score_regression,
score_classification,
t_test,
var_test,
)
class Comparator(BaseEstimator):
"""class Comparator.
Parameters
----------
obj1: object
fitted object containing methods `fit` and `predict`
obj2: object
fitted object containing methods `fit` and `predict`
"""
# construct the object -----
def __init__(self, obj1, obj2):
self.obj1 = obj1
self.obj2 = obj2
# summary of the object -----
def summary(self):
"""Summary of effects.
Returns
-------
Prints the summary of effects.
"""
assert (self.obj1.residuals_ is not None) & (
self.obj2.residuals_ is not None
), "provided objects must be fitted first"
assert (
self.obj1.scoring == self.obj2.scoring
), "scoring metrics must match for both objects"
print("\n")
print(f"Scores ({self.obj1.scoring}): ")
print(f"Object1: {np.round(self.obj1.score_, 3)}")
print(f"Object2: {np.round(self.obj2.score_, 3)}")
print("\n")
print("R-squared: ")
print("Object1: ")
print(
f"Multiple: {np.round(self.obj1.r_squared_, 3)}, Adjusted: {np.round(self.obj1.adj_r_squared_, 3)}"
)
print("Object2: ")
print(
f"Multiple: {np.round(self.obj2.r_squared_, 3)}, Adjusted: {np.round(self.obj2.adj_r_squared_, 3)}"
)
print("\n")
print("Residuals: ")
print("Object1: ")
print(self.obj1.residuals_dist_.to_string(index=False))
print("Object2: ")
print(self.obj2.residuals_dist_.to_string(index=False))
print("\n")
print("Paired t-test (H0: mean(resids1) > mean(resids2) at 5%): ")
t_test_obj = t_test(self.obj1.residuals_, self.obj2.residuals_)
print(f"statistic: {np.round(t_test_obj['statistic'], 5)}")
print(f"p.value: {np.round(t_test_obj['p.value'], 5)}")
print(
f"conf. int: [{t_test_obj['f.int'][0]}, {np.round(t_test_obj['f.int'][1], 5)}]"
)
print(f"mean of x: {np.round(t_test_obj['estimate']['mean of x'], 5)}")
print(f"mean of y: {np.round(t_test_obj['estimate']['mean of y'], 5)}")
print(f"alternative: {t_test_obj['alternative']}")
if self.obj1.ci_summary_ is not None:
df1_summary = self.obj1.ci_summary_[
["Estimate", "Std. Error", ""]
].sort_index(axis=0)
df2_summary = self.obj2.ci_summary_[
["Estimate", "Std. Error", ""]
].sort_index(axis=0)
df_summary = pd.DataFrame(
data=pd.concat([df1_summary, df2_summary], axis=1).values,
columns=[
"Estimate1",
"Std. Error1",
"Signif.",
"Estimate2",
"Std. Error2",
"Signif.",
],
index=df1_summary.index,
)
print("\n")
print("Marginal effects: ")
print(df_summary)
print("\n")
print("Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘-’ 1")
| e1dc6127b4b9a809aedcccbef8dc5f13e0b03b76 | [
"Markdown",
"Python",
"Text",
"reStructuredText"
] | 26 | reStructuredText | thierrymoudiki/teller | 97b5170be61c0ccefd7e0c637fc00e816a66ef1f | 2cd174fdbcdbec9b05cf6028be91ec802eb306b7 |
refs/heads/master | <repo_name>AravindSK1/ChiPy_event<file_sep>/chitube/dbPopulate.py
import pandas as pd
df = pd.read_csv("/Users/aravindsenthilkumar/Downloads/USvideos.csv")
print(df)
| 0a9e9e97344ea4b5102bc3cee7fd410626ef419f | [
"Python"
] | 1 | Python | AravindSK1/ChiPy_event | a8c1e79c1a1f76921cc512a666a37363b5b594ad | 1ab9697d949e88781addc169a74a42be5722dc13 |
refs/heads/main | <file_sep>import { HttpClient } from '@angular/common/http';
import { Injectable } from '@angular/core';
import { Observable, Subject } from 'rxjs';
import { AuthenticationService } from './authentication.service';
@Injectable({
providedIn: 'root'
})
export class QueuemanagementService {
constructor(private http : HttpClient,private authenticationService:AuthenticationService) { }
GetQueueDetailSub = new Subject<any>();
GetQueueDetailSub$ = this.GetQueueDetailSub.asObservable()
getQue(): Observable<Response> {
return this.http.get<any>("https://localhost:44352/api/QueueManagement")
}
QueueDetails(item:any){
this.GetQueueDetailSub.next(item)
}
deleteItem(id:any): Observable<any>{
console.log(id)
return this.http.delete('https://localhost:44352/api/QueueManagement/' + Number(id))
}
updateItem(id:any,NewQueueTime:any): Observable<any>{
console.log(id)
return this.http.patch('https://localhost:44352/api/QueueManagement',
{
"QueueId" : id,
"NewQueueTime": NewQueueTime
})
}
userId:any
addItem(QueueTime:any): Observable<any>{
this.authenticationService.userSubject.subscribe(
result => {
this.userId = result.userId
}
)
return this.http.put('https://localhost:44352/api/QueueManagement',
{
"UserId" : this.userId,
"QueueTime": QueueTime
})
}
getArryOfTime(){
let arryOfTime = []
for(let i = 10; i <= 22;i++){
arryOfTime.push(i + ':00')
arryOfTime.push(i + ':15')
arryOfTime.push(i + ':30')
arryOfTime.push(i + ':45')
}
return arryOfTime
}
}
<file_sep>import { Component, OnInit } from '@angular/core';
import { QueuemanagementService } from 'src/app/shared/queuemanagement.service';
@Component({
selector: 'app-queue-list-screen',
templateUrl: './queue-list-screen.component.html',
styleUrls: ['./queue-list-screen.component.css']
})
export class QueueListScreenComponent implements OnInit {
constructor(private queuemanagement:QueuemanagementService) { }
isLoeaded = false
que:any
disending = false
NewQueueTime:any
displayNonePopUp = false
arryOfTime:any
newhourAndMinutesTime:any
ngOnInit(): void {
this.queuemanagement.getQue().subscribe(
result => {
this.isLoeaded = true
this.que = result
this.que.sort((a:any, b:any) => (a.name > b.name) ? 1 : -1)
}
)
this.arryOfTime = this.queuemanagement.getArryOfTime()
}
onClickHour(e:any){
this.newhourAndMinutesTime = e.target.value
}
onClickItem(item:any){
this.queuemanagement.QueueDetails(item)
}
onSortArray(fieald:any){
if(fieald == 'queueTime'){
this.que.sort((a:any, b:any) => this.disending ? (new Date(a.queueTime) > new Date(b.queueTime)) ? 1 : -1 : (new Date(a.queueTime) > new Date(b.queueTime)) ? -1 : 1 )
}
else {
this.que.sort((a:any, b:any) => this.disending ? (a.name > b.name) ? 1 : -1 : (a.name > b.name) ? -1 : 1 )
}
this.disending = !this.disending
}
onAddItem(){
this.queuemanagement.addItem(this.NewQueueTime + 'T' + this.newhourAndMinutesTime).subscribe(
result => {
this.displayNonePopUp = false
window.location.reload()
}
)
}
}
<file_sep>import { TestBed } from '@angular/core/testing';
import { QueuemanagementService } from './queuemanagement.service';
describe('QueuemanagementService', () => {
let service: QueuemanagementService;
beforeEach(() => {
TestBed.configureTestingModule({});
service = TestBed.inject(QueuemanagementService);
});
it('should be created', () => {
expect(service).toBeTruthy();
});
});
<file_sep>import { Component, OnInit } from '@angular/core';
import { AuthenticationService } from 'src/app/shared/authentication.service';
@Component({
selector: 'app-header',
templateUrl: './header.component.html',
styleUrls: ['./header.component.css']
})
export class HeaderComponent implements OnInit {
constructor(private authenticationService: AuthenticationService) { }
logedIn = true
ngOnInit(): void {
this.authenticationService.userSubject.subscribe(
result => {
console.log(result)
if(result == null || Object.keys(result).length === 0){
this.logedIn = false
}else{
this.logedIn = true
}
console.log(typeof({}))
}
)
}
logOut(){
this.authenticationService.logout()
}
}
<file_sep>import { Component, OnInit } from '@angular/core';
import { FormControl, FormGroup, Validators } from '@angular/forms';
import { Router } from '@angular/router';
import { AuthenticationService } from 'src/app/shared/authentication.service';
@Component({
selector: 'app-login-screen',
templateUrl: './login-screen.component.html',
styleUrls: ['./login-screen.component.css']
})
export class LoginScreenComponent implements OnInit {
constructor(private authenticationService: AuthenticationService,private router:Router) { }
isLoeaded = true
loginForm = new FormGroup({
username : new FormControl('', [Validators.required,Validators.email]),
password: new FormControl('',[Validators.required])
})
res = true
ngOnInit(): void {
}
onFormSubmit(){
if(this.loginForm.invalid)
return
this.isLoeaded = false
this.authenticationService.logIn(this.loginForm.value).subscribe(
result => {
this.router.navigate(['queues-list'])
this.isLoeaded = true
},error => {
this.res = false
this.isLoeaded = true
}
)
}
get username() { return this.loginForm.get('username') }
get password() { return this.loginForm.get('password') }
}
<file_sep>import { Injectable } from "@angular/core";
import { HttpInterceptor, HttpHandler, HttpRequest, HttpEvent } from "@angular/common/http";
import { BehaviorSubject, Observable } from 'rxjs';
import { AuthenticationService } from "./authentication.service";
@Injectable()
export class Interceptor implements HttpInterceptor {
constructor (private authenticationService: AuthenticationService) {}
token:any
intercept(request: HttpRequest<any>, next: HttpHandler): Observable<HttpEvent<any>> {
this.authenticationService.userSubject.subscribe(
result => {
this.token = result.token
}
)
const customReq = request.clone({
setHeaders: {
'Authorization' : `Bearer ${this.token}`
}
});
return next.handle(customReq);
}
}<file_sep>import { NgModule } from '@angular/core';
import { RouterModule, Routes } from '@angular/router';
import { LoginScreenComponent } from './componennts/login-screen/login-screen.component';
import { QueueListScreenComponent } from './componennts/queue-list-screen/queue-list-screen.component';
import { SignupScreenComponent } from './componennts/signup-screen/signup-screen.component';
import { CheckAuthGuard } from './guards/check-auth.guard';
const routes: Routes = [
{ path : '', redirectTo: 'login-page', pathMatch: 'full' },
{ path: 'login-page', component: LoginScreenComponent },
{ path: 'signup-page', component: SignupScreenComponent},
{ path: 'queues-list', component: QueueListScreenComponent,canActivate:[CheckAuthGuard]}
];
@NgModule({
imports: [RouterModule.forRoot(routes)],
exports: [RouterModule]
})
export class AppRoutingModule { }
<file_sep>import { Route } from '@angular/compiler/src/core';
import { Component, OnInit } from '@angular/core';
import { ActivatedRoute, Router } from '@angular/router';
import { AuthenticationService } from 'src/app/shared/authentication.service';
import { QueuemanagementService } from 'src/app/shared/queuemanagement.service';
@Component({
selector: 'app-queue-detail-screen',
templateUrl: './queue-detail-screen.component.html',
styleUrls: ['./queue-detail-screen.component.css']
})
export class QueueDetailScreenComponent implements OnInit {
displayNonePopUp = false
QueueDetail:any
NewQueueTime:any
user:any
isUpdateSituation = false
newhourAndMinutesTime:any
arryOfTime:any
constructor(private queuemanagement:QueuemanagementService,private router:Router,private authenticationService: AuthenticationService) { }
ngOnInit(): void {
this.arryOfTime = this.queuemanagement.getArryOfTime()
this.authenticationService.userSubject.subscribe(
result => {
this.user = result
}
)
this.queuemanagement.GetQueueDetailSub$.subscribe(
result => {
this.displayNonePopUp = true
this.QueueDetail = result
}
)
}
onClickHour(e:any){
this.newhourAndMinutesTime = e.target.value
}
onDeleteItem(){
this.queuemanagement.deleteItem(this.QueueDetail.id).subscribe(
result => {
this.displayNonePopUp = false
window.location.reload()
}
)
}
onUpdateItem(){
this.queuemanagement.updateItem(this.QueueDetail.id,this.NewQueueTime + 'T' + this.newhourAndMinutesTime).subscribe(
result => {
this.displayNonePopUp = false
window.location.reload()
}
)
}
}
<file_sep>import { HttpClient, HttpErrorResponse } from '@angular/common/http';
import { Injectable } from '@angular/core';
import { Router } from '@angular/router';
import { BehaviorSubject, Observable } from 'rxjs';
import { catchError, map, retry} from 'rxjs/operators';
import { User } from '../models/User';
@Injectable({
providedIn: 'root'
})
export class AuthenticationService {
public userSubject: BehaviorSubject<any>
public user?: Observable<any>
private handleErro(errorResponse:HttpErrorResponse){
if(errorResponse.error instanceof ErrorEvent){
console.error('client side error',errorResponse.error.message)
} else {
console.error('server side error',errorResponse)
}
return Observable.throw(errorResponse.status);
}
constructor(private http : HttpClient,private router:Router) {
this.userSubject = new BehaviorSubject<User>(JSON.parse(localStorage.getItem('user') || '{}'));
}
logIn(loginForm:any): Observable<Response> {
return this.http.post<any>("https://localhost:44352/api/Authentication",{
"UserName" : loginForm.username,
"Password": <PASSWORD>
}).pipe(
map(user => {
localStorage.setItem('user', JSON.stringify(user.result));
this.userSubject.next(user.result);
return user
}),
catchError(this.handleErro))
}
logout() {
localStorage.removeItem('user');
this.userSubject.next(null);
this.router.navigate(['']);
window.location.reload()
}
signUp(loginForm:any): Observable<Response> {
console.log(loginForm)
return this.http.put<any>("https://localhost:44352/api/Authentication",{
"Name":loginForm.name,
"UserName": loginForm.email,
"Password": <PASSWORD>
}).pipe(
map(user => {
return user
}),
catchError(this.handleErro))
}
}
| 23a20be5256fb1bbccb65c421ca20132a64356ef | [
"TypeScript"
] | 9 | TypeScript | aharonReiss/DogBarberShopClient | 806551ac7928fdf307ef8f62623d0ba542eb28a6 | 7a7318a3e1dcdcbf8f6711e5a4de888d44c982bf |
refs/heads/master | <file_sep>import time
import os
import torch
import logging as logger
def load_model(model, model_file, depth_input=False, is_restore=False):
t_start = time.time()
if isinstance(model_file, str):
if not os.path.exists(model_file):
logger.warning("Model file:%s does not exist!"%model_file)
return
state_dict = torch.load(model_file, map_location=torch.device('cpu'))
if 'model' in state_dict.keys():
state_dict = state_dict['model']
else:
state_dict = model_file
t_ioend = time.time()
if is_restore:
new_state_dict = OrderedDict()
for k, v in state_dict.items():
name = 'module.' + k
new_state_dict[name] = v
state_dict = new_state_dict
if depth_input:
mean_w = state_dict['conv1.weight'].mean(dim=1, keepdim=True)
state_dict['conv1.weight'] = mean_w
model.load_state_dict(state_dict, strict=False)
ckpt_keys = set(state_dict.keys())
own_keys = set(model.state_dict().keys())
missing_keys = own_keys - ckpt_keys
unexpected_keys = ckpt_keys - own_keys
if len(missing_keys) > 0:
logger.warning('Model keys:{}, state dict: {}, missing key(s) in state_dict: {}'.format(len(own_keys), len(ckpt_keys),
', '.join('{}'.format(k) for k in missing_keys)
))
if len(unexpected_keys) > 0:
logger.warning('Unexpected key(s) in state_dict: {}'.format(
', '.join('{}'.format(k) for k in unexpected_keys)
))
del state_dict
t_end = time.time()
logger.info("Load model, Time usage:\n\tIO: {}, initialize parameters: {}".format(t_ioend - t_start, t_end - t_ioend))
return model
<file_sep>import torch
import random
class DataPrefetcher(object):
def __init__(self, loader, cnt=3):
self.list = []
self.pre_idx = 0
self.idx = 0
self.cnt = cnt ###len(loader.dataset.train_scales)
self.arr = list(range(self.cnt))
self.loader = iter(loader)
self.stream = torch.cuda.Stream()
self.preload()
def preload(self):
try:
if len(self.list) == 0 or len(self.list) >= self.cnt:
self.idx = 0
self.pre_idx = 0
self.list = []
random.shuffle(self.arr)
self.next_input, self.next_depth, self.next_target, self.next_gate = next(self.loader)
except StopIteration:
self.next_input = None
self.next_depth = None
self.next_target = None
self.next_gate = None
return
with torch.cuda.stream(self.stream):
idx = self.arr[self.pre_idx]
self.next_input[idx] = self.next_input[idx].cuda(non_blocking=True)
self.next_depth[idx] = self.next_depth[idx].cuda(non_blocking=True)
self.next_target[idx] = self.next_target[idx].cuda(non_blocking=True)
self.next_gate[idx] = self.next_gate[idx].cuda(non_blocking=True)
self.idx = idx
self.pre_idx += 1
self.list.append(idx)
def next(self):
torch.cuda.current_stream().wait_stream(self.stream)
if self.next_input is None:
return None, None, None, None
input = self.next_input[self.idx]
depth = self.next_depth[self.idx]
target = self.next_target[self.idx]
gate = self.next_gate[self.idx]
self.preload()
return input, depth, target, gate
<file_sep>import cv2
import os
import os.path as osp
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import pickle
datasets = ['NLPR', 'NJUD']
#datasets = ['NLPR', 'NJUD', 'LFSD', 'RGBD135', 'SSD100', 'STEREO797', 'DUT', 'SIP']
def cal_score(img, gt, beta=0.3):
img = np.float32(img)
gt = np.float32(gt)
gt *= 1/255.0
img *= 1/255.0
gt[gt >= 0.5] =1.
gt[gt < 0.5] = 0.
img[img >= 0.5] = 1.
img[img < 0.5] = 0.
over = (img*gt).sum()
union = ((img+gt)>=1).sum()
sum_gt = gt.sum()
iou = over / (1e-7 + union);
cover = over / (1e-7 + sum_gt);
f_beta = (1.+beta) * iou * cover / (1e-7 + iou + beta*cover)
return iou, cover, f_beta
S = [0] * len(datasets)
for dataset in datasets:
path = osp.join('train', dataset)
#path = osp.join('test', dataset)
imgs = [line.rstrip() for line in open(osp.join(path, "test.txt"))]
scores = {}
sum_s = 0
for f in tqdm(imgs):
depth = cv2.imread(osp.join(path, "ostu_depth", f+".jpg"), 0)
if depth is None:
print("depth is None, check:", dataset)
assert depth is not None
try:
gt = cv2.imread(osp.join(path, "mask", f+".png"), 0) # gt->mask
except:
gt = cv2.imread(osp.join(path, "mask", f+".jpg"), 0)
if gt is None:
print("gt:{} is None!".format(os.path.join(path, "mask", f)))
assert gt is not None
iou, cover, f_beta = cal_score(depth, gt, 0.3)
#print("name:", f, " iou:", iou, " cover:", cover, " f_beta:", f_beta)
scores[f] = {"iou":iou, "cover":cover, "f_beta":f_beta}
sum_s += f_beta
"""
plt.subplot(121)
plt.imshow(depth, cmap="gray")
plt.subplot(122)
plt.imshow(gt, cmap="gray")
plt.show()
"""
sum_s /= len(imgs)
idx = datasets.index(dataset)
S[idx] = sum_s
print("Dataset:", dataset, "Mean f:", S[idx])
with open(osp.join("train", dataset+"_score.pkl"), "wb") as fout:
pickle.dump(scores, fout)
<file_sep>#!/usr/bin/python3
#coding=utf-8
import os
import os.path as osp
import cv2
import torch
import numpy as np
try:
from . import transform
except:
import transform
from torch.utils.data import Dataset, DataLoader
import pickle
class Config(object):
def __init__(self, **kwargs):
self.kwargs = kwargs
print('\nParameters...')
for k, v in self.kwargs.items():
print('%-10s: %s'%(k, v))
"""
if 'LFSD' in self.kwargs['datapath']:
self.mean = np.array([[[128.67, 117.24, 107.97]]])
self.std = np.array([[[66.14, 58.32, 56.37]]])
elif 'NJUD' in self.kwargs['datapath']:
self.mean = np.array([[[104.89, 101.66, 92.15]]])
self.std = np.array([[[55.89, 53.03, 53.95]]])
elif 'NLPR' in self.kwargs['datapath']:
self.mean = np.array([[[126.74, 123.91, 123.04]]])
self.std = np.array([[[52.91, 52.31, 50.61]]])
elif 'STEREO797' in self.kwargs['datapath']:
self.mean = np.array([[[113.17, 110.05, 98.60]]])
self.std = np.array([[[58.60, 55.89, 58.32]]])
"""
#else:
#raise ValueError
"""
self.mean = np.array([[[0.485, 0.456, 0.406]]])*255.0
self.std = np.array([[[0.229, 0.224, 0.225]]])*255.0
"""
self.mean = np.array([[[128.67, 117.24, 107.97]]])
self.std = np.array([[[66.14, 58.32, 56.37]]])
self.d_mean = 116.09
self.d_std = 56.61
def __getattr__(self, name):
if name in self.kwargs:
return self.kwargs[name]
else:
return None
class RGBDData(Dataset):
def __init__(self, cfg):
# NJUD: depth:*.jpg, gt:*.png, rgb:*.jpg
# NLPR: depth:*.jpg, gt:*.jpg, rgb:*.jpg
self.samples = []
self.mode = cfg.mode
if cfg.mode == "train":
with open(osp.join(cfg.datapath, "NLPR_score.pkl"), "rb") as fin:
nlpr_data = pickle.load(fin)
with open(osp.join(cfg.datapath, "NJUD_score.pkl"), "rb") as fin:
njud_data = pickle.load(fin)
with open(osp.join(cfg.datapath, "NLPR", cfg.mode+'.txt'), 'r') as lines:
for line in lines:
line = line.strip()
image_name = osp.join(cfg.datapath, "NLPR/rgb", line+".jpg")
depth_name = osp.join(cfg.datapath, "NLPR/depth", line+".jpg")
ostu_rgb_name = osp.join(cfg.datapath, "NLPR/ostu_rgb", line+".jpg")
mask_name = osp.join(cfg.datapath, "NLPR/gt", line+".jpg")
#self.samples.append([image_name, ostu_rgb_name, mask_name])
key = nlpr_data[line]['f_beta']
self.samples.append([key, image_name, depth_name, mask_name])
with open(osp.join(cfg.datapath, "NJUD", cfg.mode+'.txt'), 'r') as lines:
for line in lines:
line = line.strip()
image_name = osp.join(cfg.datapath, "NJUD/rgb", line+".jpg")
depth_name = osp.join(cfg.datapath, "NJUD/depth", line+".jpg")
ostu_rgb_name = osp.join(cfg.datapath, "NJUD/ostu_rgb", line+".jpg")
mask_name = osp.join(cfg.datapath, "NJUD/gt", line+".png")
#self.samples.append([image_name, ostu_rgb_name, mask_name])
key = njud_data[line]['f_beta']
self.samples.append([key, image_name, depth_name, mask_name])
"""
with open(osp.join(cfg.datapath, "train.txt"), "r") as fin:
for line in fin:
line = line.strip()
image_name = osp.join(cfg.datapath, "input_train", line+".jpg")
depth_name = osp.join(cfg.datapath, "depth_train", line+".png")
mask_name = osp.join(cfg.datapath, "gt_train", line+".png")
self.samples.append([image_name, depth_name, mask_name])
"""
print("train mode: len(samples):%s"%(len(self.samples)))
else:
#LFSD,NJUD,NLPR,STEREO797
#image, depth: *.jpg, mask:*.png
def read_test(name):
samples = []
with open(osp.join(cfg.datapath, "test.txt"), "r") as lines:
for line in lines:
line = line.strip()
image_name = osp.join(cfg.datapath, "image", line+".jpg")
depth_name = osp.join(cfg.datapath, "depth", line+".jpg")
ostu_rgb_name = osp.join(cfg.datapath, "ostu_rgb", line+".jpg")
mask_name = osp.join(cfg.datapath, "mask", line+".png")
samples.append([line, image_name, depth_name, mask_name])
return samples
db_name = cfg.datapath.rstrip().split("/")[-1]
self.samples = read_test(db_name)
print("test mode name:%s, len(samples):%s"%(db_name, len(self.samples)))
if cfg.mode == 'train':
if cfg.train_scales is None:
cfg.train_scales = [224, 256, 320]
print("Train_scales:", cfg.train_scales)
self.transform = transform.Compose(
transform.MultiResize(cfg.train_scales),
transform.MultiRandomHorizontalFlip(),
transform.MultiNormalize(),
transform.MultiToTensor()
)
elif cfg.mode == 'test':
self.transform = transform.Compose(
transform.Resize((256, 256)),
transform.Normalize(mean=cfg.mean, std=cfg.std, d_mean=cfg.d_mean, d_std=cfg.d_std),
transform.ToTensor(depth_gray=True))
else:
raise ValueError
def __getitem__(self, idx):
key, image_name, depth_name, mask_name = self.samples[idx]
image = cv2.imread(image_name).astype(np.float32)[:,:,::-1]
depth = cv2.imread(depth_name).astype(np.float32)[:,:, ::-1]
mask = cv2.imread(mask_name).astype(np.float32)[:,:,::-1]
H, W, C = mask.shape
image, depth, mask = self.transform(image, depth, mask)
if self.mode == "train":
gate_gt = torch.zeros(1)
gate_gt[0] = key
return image, depth, mask, gate_gt
else:
mask_name = mask_name.split("/")[-1]
return image, depth, mask, (H,W), mask_name
def __len__(self):
return len(self.samples)
""" for train loader """
def train_collate_fn(batch):
images, depths, masks, gate_gt = zip(*batch)
l = len(images[0])
images_t, depths_t, masks_t = {}, {}, {}
gates_t = {}
gate_gt = torch.stack(gate_gt)
for i in range(l):
images_t[i] = []
depths_t[i] = []
masks_t[i] = []
gates_t[i] = gate_gt
for i in range(len(images)):
for j in range(l):
images_t[j].append(images[i][j])
depths_t[j].append(depths[i][j])
masks_t[j].append(masks[i][j])
for i in range(l):
images_t[i] = torch.stack(images_t[i])
depths_t[i] = torch.stack(depths_t[i])
masks_t[i] = torch.stack(masks_t[i])
return images_t, depths_t, masks_t, gates_t
if __name__=='__main__':
import time
def plot_3x3(images, depths, masks):
l = len(images)
for j in range(min(l, 3)):
image, depth, mask = images[j], depths[j], masks[j]
image = image.permute(1,2,0).numpy()*255.0
depth = depth.permute(1,2,0).numpy()*255.0
mask = mask.permute(1,2,0).numpy()*255.0
H, W, _ = image.shape
mask = mask.squeeze()
depth = depth.squeeze()
plt.subplot(331 + 3*j)
plt.imshow(np.uint8(image))
plt.subplot(332 + 3*j)
plt.imshow(np.uint8(depth), cmap='gray')
plt.subplot(333 + 3*j)
plt.imshow(np.uint8(mask), cmap='gray')
from data_prefetcher import *
import matplotlib.pyplot as plt
plt.ion()
cfg = Config(mode='train', datapath='../data/RGBD_sal/train')
data = RGBDData(cfg)
loader = DataLoader(data, batch_size=32, shuffle=True, num_workers=0, drop_last=True, collate_fn=train_collate_fn)
#images, depths, masks, gate = next(iter(loader))
#import pdb; pdb.set_trace()
for i in range(3):
prefetcher = DataPrefetcher(loader)
rgb, depth, mask, gt = prefetcher.next()
while rgb is not None:
print("shape:", rgb.shape, " is_cuda:", rgb.is_cuda)
rgb, depth, mask = rgb.cpu(), depth.cpu(), mask.cpu()
plot_3x3([rgb[0], rgb[1], rgb[2]], [depth[0], depth[1], depth[2]], [mask[0], mask[1], mask[2]])
input()
#time.sleep(0.1)
rgb, depth, mask, gt = prefetcher.next()
#for i, (images, depths, masks, gate) in enumerate(loader):
# k = 0
# plot_3x3([images[0][k], images[1][k], images[2][k]], [depths[0][k], depths[1][k], depths[2][k]], [masks[0][k], masks[1][k], masks[2][k]])
# input()
#for i in range(100):
# images, depths, masks, gt = data[i]
# plot_3x3(images, depths, masks)
# input()
<file_sep># DPANet:Depth Potentiality-Aware Gated Attention Network for RGB-D Salient Object Detection [(paper)](https://ieeexplore.ieee.org/document/9247470) [(project)](https://rmcong.github.io/proj_DPANet.html) [(talk)](https://www.bilibili.com/video/BV1Ry4y1m7WL)
This repo. is an official implementation of the *DPANet* , which has been published on the journal *IEEE Transactions on Image Processing, 2021*.
The main pipeline is shown as the following,

And some visualization results are listed


## Dependencies
```
>= Pytorch 1.0.0
OpenCV-Python
[optional] matlab
```
## Preparation
- download the official pretrained model of ResNet-50/ResNet-34/ResNet-18 implemented in Pytorch if you want to train the network again.
- download or put the RGB-D saliency benchmark datasets ([Google drive](https://drive.google.com/file/d/19pvXom9vs7cS4L1y-bZI8YDtSg7r4LT0/view?usp=sharing)) in the folder of `data` for training or test.
- [optional] generate the pseudo label (provided for `NJUD` and `NLPR`) using the scripts `gen.m` and `cal_score.py`.
## Training
```
python3 train.py --tag res50 --save_path res50_res
```
make sure that the GPU memory is enough (the original training is conducted on 8 NVIDIA RTX2080Ti cards with the batch size of 32).
## Test
```
python3 test.py --tag res50 --gpu 0 --model res50_res/model-30
```
We provide the trained model file ([Google drive](https://drive.google.com/file/d/1bXERDgTKfzkZfXKs8z5vj1QNM3zL-QTL/view?usp=sharing)), and run this command to check its integrity:
```
md5sum model-res50-epoch30.pt
```
you will obtain the code `b666d297e0237035f6e48f80711ca927`.
Please use the matlab code to evaluate the MAE, F-measure, or other metrics rather than using the `accuracy` defined in the `test.py`.
The saliency maps are also available ([Google drive](https://drive.google.com/file/d/1sIqEKDCi_rSY4t1THPlBSyAd05F2ve_Q/view?usp=sharing)).
## Evaluation
We provide the evaluation code in the folder "eval_code" for fair comparisons. You may need to revise the `algorithms` , `prepath`, and `maskpath` defined in the `main.m`. The saliency maps of the competitors (official maps or obtained by running the official code) are provided ([Google drive](https://drive.google.com/file/d/1SEhDaiIVJJccv7dIlpk_rp0KZhWab8ie/view?usp=sharing)).
## Citation
Please cite the `DPANet` in your publications if it helps your research:
```
@article{DPANet,
title={{DPANet}: Depth potentiality-aware gated attention network for {RGB-D} salient object detection},
author={<NAME> and <NAME> and <NAME> and <NAME>},
journal={IEEE Transactions on Image Processing},
year={2021},
publisher={IEEE}
}
```
<file_sep>#!/usr/bin/python3
#coding=utf-8
import os
import sys
#sys.path.insert(0, '../')
sys.dont_write_bytecode = True
import cv2
import numpy as np
import matplotlib.pyplot as plt
plt.ion()
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
#from tensorboardX import SummaryWriter
from lib import dataset
from network import Segment
import time
import logging as logger
import argparse
from tqdm import tqdm
DATASETS = ['./data/RGBD_sal/test/DUT',
'./data/RGBD_sal/test/RGBD135',
'./data/RGBD_sal/test/SSD100',
'./data/RGBD_sal/test/LFSD',
'./data/RGBD_sal/test/SIP',
'./data/RGBD_sal/test/NJUD', './data/RGBD_sal/test/NLPR', './data/RGBD_sal/test/STEREO797']
class Test(object):
def __init__(self, conf, Dataset, datapath, Network):
## dataset
#self.cfg = Dataset.Config(datapath='../data/SOD', snapshot='./out/model-30', mode='test')
self.datapath = datapath.split("/")[-1]
print("Testing on %s"%self.datapath)
self.cfg = Dataset.Config(datapath = datapath, snapshot=conf.model, mode='test')
self.tag = conf.tag
self.data = Dataset.RGBDData(self.cfg)
self.loader = DataLoader(self.data, batch_size=1, shuffle=True, num_workers=0)
## network
self.net = Network(backbone='resnet50', cfg=self.cfg, norm_layer=nn.BatchNorm2d)
self.net.train(False)
self.net.cuda()
self.net.eval()
def accuracy(self):
with torch.no_grad():
mae, fscore, cnt, number = 0, 0, 0, 256
mean_pr, mean_re, threshod = 0, 0, np.linspace(0, 1, number, endpoint=False)
cost_time = 0
for image, d, mask, (H,W), name in self.loader:
image, d, mask = image.cuda().float(), d.cuda().float(), mask.cuda().float()
start_time = time.time()
out, gate = self.net(image, d)
pred = torch.sigmoid(out)
torch.cuda.synchronize()
end_time = time.time()
cost_time += end_time - start_time
## MAE
#pred = F.interpolate(pred, size=(H,W), mode='bilinear')
#mask = F.interpolate(mask, size=(H,W), mode='bilinear')
cnt += 1
mae += (pred-mask).abs().mean()
## F-Score
precision = torch.zeros(number)
recall = torch.zeros(number)
for i in range(number):
temp = (pred >= threshod[i]).float()
precision[i] = (temp*mask).sum()/(temp.sum()+1e-12)
recall[i] = (temp*mask).sum()/(mask.sum()+1e-12)
mean_pr += precision
mean_re += recall
fscore = mean_pr*mean_re*(1+0.3)/(0.3*mean_pr+mean_re+1e-12)
if cnt % 20 == 0:
fps = image.shape[0] / (end_time - start_time)
print('MAE=%.6f, F-score=%.6f, fps=%.4f'%(mae/cnt, fscore.max()/cnt, fps))
fps = len(self.loader.dataset) / cost_time
msg = '%s MAE=%.6f, F-score=%.6f, len(imgs)=%s, fps=%.4f'%(self.datapath, mae/cnt, fscore.max()/cnt, len(self.loader.dataset), fps)
print(msg)
logger.info(msg)
def show(self):
with torch.no_grad():
for image, d, mask, (H, W), maskpath in self.loader:
image, d, mask = image.cuda().float(), d.cuda().float(), mask.cuda().float()
out, out2_1, _, _, _, out2_2, _, _, _, gate = self.net(image, d)
pred = torch.sigmoid(out)
out2_1 = torch.sigmoid(out2_1)
out2_2 = torch.sigmoid(out2_2)
plt.subplot(231)
plt.title("image")
image = image[0].permute(1,2,0).cpu().numpy()*255
plt.imshow(np.uint8(image))
plt.subplot(232)
plt.title("gt")
mask = mask[0, 0].cpu().numpy()
plt.imshow(mask, cmap='gray')
plt.subplot(233)
plt.title("pred-final")
tmp = pred[0, 0].cpu().numpy()
plt.imshow(tmp, cmap='gray')
plt.subplot(234)
plt.title("pred-out1")
out2_1 = out2_1[0].permute(1,2,0).cpu().squeeze().numpy()*255
plt.imshow(np.uint8(out2_1), cmap='gray')
plt.subplot(235)
plt.title("pred-out2")
out2_2 = out2_2[0].permute(1,2,0).cpu().squeeze().numpy()*255
plt.imshow(np.uint8(out2_2), cmap='gray')
plt.show()
input()
def save(self):
with torch.no_grad():
for image, d, mask, (H, W), name in tqdm(self.loader):
image, d = image.cuda().float(), d.cuda().float()
out, gate = self.net(image, d)
out = F.interpolate(out, size=(H,W), mode='bilinear')
pred = (torch.sigmoid(out[0,0])*255).cpu().numpy()
head = './rgbd_pred/{}/'.format(self.tag) + self.cfg.datapath.split('/')[-1]
if not os.path.exists(head):
os.makedirs(head)
cv2.imwrite(head+'/'+name[0],np.uint8(pred))
if __name__=='__main__':
conf = argparse.ArgumentParser(description="train model")
conf.add_argument("--tag", type=str)
conf.add_argument("--gpu", type=int, default=0)
conf.add_argument("--model", type=str)
args = conf.parse_args()
logger.basicConfig(level=logger.INFO, format='%(levelname)s %(asctime)s %(filename)s: %(lineno)d] %(message)s', datefmt='%Y-%m-%d %H:%M:%S', \
filename="test_%s.log"%(args.tag), filemode="w")
logger.info("Configuration:{}".format(args))
os.environ['CUDA_VISIBLE_DEVICES'] = str(args.gpu)
for e in DATASETS:
t =Test(args, dataset, e, Segment)
t.accuracy() # this is not accurate due to the resize operation, please use the matlab code to eval the performance
# t.show()
t.save()
<file_sep>#!/usr/bin/python3
#coding=utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
from resnet import resnet18, resnet34, resnet50
from lib.utils import load_model
class SA(nn.Module):
def __init__(self, in_channel, norm_layer=nn.BatchNorm2d):
super(SA, self).__init__()
self.conv1 = nn.Conv2d(in_channel, 256, kernel_size=3, stride=1, padding=1)
self.bn1 = norm_layer(256)
self.conv2 = nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1)
def forward(self, x):
out1 = F.relu(self.bn1(self.conv1(x)), inplace=True) #256
out2 = self.conv2(out1)
w, b = out2[:, :256, :, :], out2[:, 256:, :, :]
return F.relu(w * out1 + b, inplace=True)
""" fusion two level features """
class FAM(nn.Module):
def __init__(self, in_channel_left, in_channel_down, norm_layer=nn.BatchNorm2d):
super(FAM, self).__init__()
self.conv_d1 = nn.Conv2d(in_channel_down, 256, kernel_size=3, stride=1, padding=1)
self.conv_l = nn.Conv2d(in_channel_left, 256, kernel_size=3, stride=1, padding=1)
self.conv3 = nn.Conv2d(256*2, 256, kernel_size=3, stride=1, padding=1)
self.bn3 = norm_layer(256)
def forward(self, left, down):
down_mask = self.conv_d1(down)
left_mask = self.conv_l(left)
if down.size()[2:] != left.size()[2:]:
down_ = F.interpolate(down, size=left.size()[2:], mode='bilinear')
z1 = F.relu(left_mask * down_, inplace=True)
else:
z1 = F.relu(left_mask * down, inplace=True)
if down_mask.size()[2:] != left.size()[2:]:
down_mask = F.interpolate(down_mask, size=left.size()[2:], mode='bilinear')
z2 = F.relu(down_mask * left, inplace=True)
out = torch.cat((z1, z2), dim=1)
return F.relu(self.bn3(self.conv3(out)), inplace=True)
class CrossAttention(nn.Module):
def __init__(self, in_channel=256, ratio=8):
super(CrossAttention, self).__init__()
self.conv_query = nn.Conv2d(in_channel, in_channel//ratio, kernel_size=1)
self.conv_key = nn.Conv2d(in_channel, in_channel//ratio, kernel_size=1)
self.conv_value = nn.Conv2d(in_channel, in_channel, kernel_size=1)
def forward(self, rgb, depth):
bz, c, h, w = rgb.shape
depth_q = self.conv_query(depth).view(bz, -1, h*w).permute(0, 2, 1)
depth_k = self.conv_key(depth).view(bz, -1, h*w)
mask = torch.bmm(depth_q, depth_k) #bz, hw, hw
mask = torch.softmax(mask, dim=-1)
rgb_v = self.conv_value(rgb).view(bz, c, -1)
feat = torch.bmm(rgb_v, mask.permute(0,2,1)) # bz, c, hw
feat = feat.view(bz, c, h, w)
return feat
class CMAT(nn.Module):
def __init__(self, in_channel, CA=True, ratio=8):
super(CMAT, self).__init__()
self.CA = CA
self.sa1 = SA(in_channel)
self.sa2 = SA(in_channel)
if self.CA:
self.att1 = CrossAttention(256, ratio=ratio)
self.att2 = CrossAttention(256, ratio=ratio)
else:
print("Warning: not use CrossAttention!")
self.conv2 = nn.Conv2d(256, 256, 3, 1, 1)
self.conv3 = nn.Conv2d(256, 256, 3, 1, 1)
def forward(self, rgb, depth, beta, gamma, gate):
rgb = self.sa1(rgb)
depth = self.sa2(depth)
if self.CA:
feat_1 = self.att1(rgb, depth)
feat_2 = self.att2(depth, rgb)
else:
w1 = self.conv2(rgb)
w2 = self.conv3(depth)
feat_1 = F.relu(w2*rgb, inplace=True)
feat_2 = F.relu(w1*depth, inplace=True)
out1 = rgb + gate * beta * feat_1
out2 = depth + (1.0-gate) * gamma * feat_2
return out1, out2
class Fusion(nn.Module):
def __init__(self, in_channel, norm_layer=nn.BatchNorm2d):
super(Fusion, self).__init__()
self.conv0 = nn.Conv2d(in_channel*2, 256, 3, 1, 1)
self.bn0 = norm_layer(256)
def forward(self, x1, x2, alpha, beta):
out1 = alpha * x1 + beta*(1.0 - alpha) * x2
out2 = x1 * x2
out = torch.cat((out1, out2), dim=1)
out = F.relu(self.bn0(self.conv0(out)), inplace=True)
return out
class Segment(nn.Module):
def __init__(self, backbone='resnet18', norm_layer=nn.BatchNorm2d, cfg=None, aux_layers=True):
super(Segment, self).__init__()
self.cfg = cfg
self.aux_layers = aux_layers
if backbone == 'resnet18':
channels = [64, 128, 256, 512]
self.backbone_rgb = resnet18(in_channel=3, norm_layer=norm_layer)
self.backbone_d = resnet18(in_channel=1, norm_layer=norm_layer)
backbone_rgb = load_model(self.backbone_rgb, 'model_zoo/resnet18-5c106cde.pth')
backbone_d = load_model(self.backbone_d, 'model_zoo/resnet18-5c106cde.pth', depth_input=True)
elif backbone == 'resnet34':
channels = [64, 128, 256, 512] # resnet34
self.backbone_rgb = resnet34(in_channel=3, norm_layer=norm_layer)
self.backbone_d = resnet34(in_channel=1, norm_layer=norm_layer)
backbone_rgb = load_model(self.backbone_rgb, 'model_zoo/resnet34-333f7ec4.pth')
backbone_d = load_model(self.backbone_rgb, 'model_zoo/resnet34-333f7ec4.pth', depth_input=True)
elif backbone == 'resnet50':
channels = [256, 512, 1024, 2048]
self.backbone_rgb = resnet50(in_channel=3, norm_layer=norm_layer)
self.backbone_d = resnet50(in_channel=1, norm_layer=norm_layer)
backbone_rgb = load_model(self.backbone_rgb, 'model_zoo/resnet50-19c8e357.pth')
backbone_d = load_model(self.backbone_rgb, 'model_zoo/resnet50-19c8e357.pth', depth_input=True)
else:
raise Exception("backbone:%s does not support!"%backbone)
if backbone_rgb is None:
print("Warning: the model_zoo of {} does no exist!".format(backbone))
else:
self.backbone_rgb = backbone_rgb
self.backbone_d = backbone_d
# fusion modules
self.cmat5 = CMAT(channels[3], True, ratio=8)
self.cmat4 = CMAT(channels[2], True, ratio=8)
self.cmat3 = CMAT(channels[1], True, ratio=8)
self.cmat2 = CMAT(channels[0], True, ratio=8)
# low-level & high-level
self.fam54_1 = FAM(256, 256)
self.fam43_1 = FAM(256, 256)
self.fam32_1 = FAM(256, 256)
self.fam54_2 = FAM(256, 256)
self.fam43_2 = FAM(256, 256)
self.fam32_2 = FAM(256, 256)
# fusion, TBD
self.fusion = Fusion(256)
if self.aux_layers:
self.linear5_1 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear4_1 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear3_1 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear2_1 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear5_2 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear4_2 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear3_2 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear2_2 = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.linear_out = nn.Conv2d(256, 1, kernel_size=3, stride=1, padding=1)
self.gap1 = nn.AdaptiveAvgPool2d(1)
self.gap2 = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channels[-1]*2, 512),
##nn.Dropout(p=0.3),
nn.ReLU(True),
nn.Linear(512, 256+1),
nn.Sigmoid(),
)
self.initialize()
def forward(self, rgb, depth):
raw_size = rgb.size()[2:]
bz = rgb.shape[0]
enc2_1, enc3_1, enc4_1, enc5_1 = self.backbone_rgb(rgb)
enc2_2, enc3_2, enc4_2, enc5_2 = self.backbone_d(depth)
rgb_gap = self.gap1(enc5_1)
rgb_gap = rgb_gap.view(bz, -1)
depth_gap = self.gap2(enc5_2)
depth_gap = depth_gap.view(bz, -1)
feat = torch.cat((rgb_gap, depth_gap), dim=1)
feat = self.fc(feat)
gate = feat[:, -1].view(bz, 1, 1, 1)
alpha = feat[:, :256]
alpha = alpha.view(bz, 256, 1, 1)
out5_1, out5_2 = self.cmat5(enc5_1, enc5_2, 1, 1, gate)
de4_1, de4_2 = self.cmat4(enc4_1, enc4_2, 1, 1, gate)
de3_1, de3_2 = self.cmat3(enc3_1, enc3_2, 1, 1, gate)
de2_1, de2_2 = self.cmat2(enc2_1, enc2_2, 1, 1, gate)
out4_1 = self.fam54_1(de4_1, out5_1)
out3_1 = self.fam43_1(de3_1, out4_1)
out2_1 = self.fam32_1(de2_1, out3_1)
out4_2 = self.fam54_2(de4_2, out5_2)
out3_2 = self.fam43_2(de3_2, out4_2)
out2_2 = self.fam32_2(de2_2, out3_2)
# final fusion
out = self.fusion(out2_1, out2_2, alpha, gate)
out = F.interpolate(self.linear_out(out), size=raw_size, mode='bilinear', )
# aux_layer
if self.training and self.aux_layers:
out5_1 = F.interpolate(self.linear5_1(out5_1), size=raw_size, mode='bilinear')
out4_1 = F.interpolate(self.linear4_1(out4_1), size=raw_size, mode='bilinear')
out3_1 = F.interpolate(self.linear3_1(out3_1), size=raw_size, mode='bilinear')
out2_1 = F.interpolate(self.linear2_1(out2_1), size=raw_size, mode='bilinear')
out5_2 = F.interpolate(self.linear5_2(out5_2), size=raw_size, mode='bilinear')
out4_2 = F.interpolate(self.linear4_2(out4_2), size=raw_size, mode='bilinear')
out3_2 = F.interpolate(self.linear3_2(out3_2), size=raw_size, mode='bilinear')
out2_2 = F.interpolate(self.linear2_2(out2_2), size=raw_size, mode='bilinear')
return out, out2_1, out3_1, out4_1, out5_1, out2_2, out3_2, out4_2, out5_2, gate.view(bz, -1)
else:
return [out, gate.view(bz, -1)]
def initialize(self):
if self.cfg and self.cfg.snapshot:
print("loading state dict:%s ..."%(self.cfg.snapshot))
self.load_state_dict(torch.load(self.cfg.snapshot))
else:
pass
<file_sep>import cv2
import matplotlib.pyplot as plt
from transform import *
#func1 = Resize(256, 256)
#func = RandomResizedCrop(224, scale=(0.4, 1.0), ratio=(3./5, 5./3))
func1 = Resize(256)
func = RandomCrop(224, 224)
transform = Compose(
MultiResize([256, 320, 352]),
MultiNormalize(),
RandomHorizontalFlip(),
MultiToTensor())
for j in range(30):
keys = []
with open("../data/RGBD_sal/train/NJUD/train.txt", "r") as fin:
for line in fin:
line = line.rstrip()
keys.append(line)
for i in range(1, 10+1):
img = cv2.imread("../data/RGBD_sal/train/NJUD/rgb/%s.jpg"%keys[i]).astype(np.float32)
mask = cv2.imread("../data/RGBD_sal/train/NJUD/gt/%s.png"%keys[i]).astype(np.float32)
depth = cv2.imread("../data/RGBD_sal/train/NJUD/depth/%s.jpg"%keys[i]).astype(np.float32)
img, depth, mask = func1(img, depth, mask)
out, depth_1, mask_1 = func(img, depth, mask)
imgs, depths, masks = transform(img, depth, mask)
import pdb; pdb.set_trace()
plt.subplot(231)
plt.title("image")
plt.imshow(img[:, :, ::-1])
plt.subplot(232)
plt.title("depth")
plt.imshow(depth, cmap='gray')
plt.subplot(233)
plt.title("gt")
plt.imshow(mask, cmap='gray')
plt.subplot(234)
plt.imshow(out[:, :, ::-1])
plt.subplot(235)
plt.imshow(depth_1, cmap='gray')
plt.subplot(236)
plt.imshow(mask_1, cmap='gray')
plt.show()
<file_sep>#!/usr/bin/python3
#coding=utf-8
import cv2
import torch
import numpy as np
import random
import math
import collections
import warnings
def _is_pil_image(img):
if accimage is not None:
return isinstance(img, (Image.Image, accimage.Image))
else:
return isinstance(img, Image.Image)
def _is_tensor_image(img):
return torch.is_tensor(img) and img.ndimension() == 3
def _is_numpy_image(img):
return isinstance(img, np.ndarray) and (img.ndim in {2, 3})
class Compose(object):
def __init__(self, *ops):
self.ops = ops
def __call__(self, image, depth, mask):
for op in self.ops:
image, depth, mask = op(image, depth, mask)
return image, depth, mask
class Normalize(object):
def __init__(self, mean, std, d_mean=None, d_std=None):
self.mean = mean
self.std = std
self.d_mean = d_mean
self.d_std = d_std
if self.d_mean is None:
print("Warning: no d_mean supplied in Normalize!")
self.d_mean = np.mean(self.mean)
self.d_std = np.mean(self.std)
def __call__(self, image, depth, mask):
#image = (image - self.mean)/self.std
mask /= 255.0
#depth = (depth - self.d_mean) / self.d_std
image /= 255.0
depth /= 255.0
return image, depth, mask
class Resize(object):
def __init__(self, size):
if isinstance(size, int):
self.size = size
self.W = self.size
self.H = self.size
self.keep_ratio = True
else:
H, W = size
self.H = H
self.W = W
self.keep_ratio = False
def __call__(self, image, depth, mask):
if not self.keep_ratio:
image = self.resize(image, self.H, self.W)
depth = self.resize(depth, self.H, self.W)
mask = self.resize(mask, self.H, self.W)
else:
h, w, _ = image.shape
#if (h >= w and w == self.size) or (h <= w and h == self.size):
# return image, depth, mask
if w < h:
ow = self.size
oh = int(self.size*h/w)
image = self.resize(image, oh, ow)
depth = self.resize(depth, oh, ow)
mask = self.resize(mask, oh, ow)
else:
oh = self.size
ow = int(self.size*w/h)
image = self.resize(image, oh, ow)
depth = self.resize(depth, oh, ow)
mask = self.resize(mask , oh, ow)
h, w, _ = image.shape
if h > 400:
print("image.shape:{}".format(image.shape))
image = self.resize(image, 400, self.size)
depth = self.resize(depth, 400, self.size)
mask = self.resize(mask , 400, self.size)
elif w > 400:
print("image.shape:{}".format(image.shape))
image = self.resize(image, self.size, 400)
depth = self.resize(depth, self.size, 400)
mask = self.resize(mask , self.size, 400)
return image, depth, mask
def resize(self, img, h, w):
return cv2.resize(img, dsize=(w, h), interpolation=cv2.INTER_CUBIC)
class MultiResize(object):
def __init__(self, size_list):
assert isinstance(size_list, list)
self.size_list = size_list
def __call__(self, image, depth, mask):
images, depths, masks = [], [], []
for size in self.size_list:
image = self.resize(image, size, size)
depth = self.resize(depth, size, size)
mask = self.resize(mask , size, size)
images.append(image)
depths.append(depth)
masks.append(mask)
return images, depths, masks
def resize(self, img, h, w):
return cv2.resize(img, dsize=(w, h), interpolation=cv2.INTER_CUBIC)
class MultiNormalize(object):
def __call__(self, images, depths, masks):
for i in range(len(images)):
images[i] /= 255.0
depths[i] /= 255.0
masks[i] /= 255.0
return images, depths, masks
class MultiToTensor(object):
def __call__(self, images, depths, masks):
images_t, depths_t, masks_t = [], [], []
for i in range(len(images)):
image = torch.from_numpy(images[i])
image = image.permute(2, 0, 1)
mask = torch.from_numpy(masks[i])
mask = mask.permute(2, 0, 1).mean(dim=0, keepdim=True)
depth = torch.from_numpy(depths[i])
depth = depth.permute(2, 0, 1).mean(dim=0, keepdim=True)
images_t.append(image)
depths_t.append(depth)
masks_t.append(mask)
return images_t, depths_t, masks_t
class RandomCrop(object):
def __init__(self, H, W):
self.H = H
self.W = W
def __call__(self, image, depth, mask):
H,W,_ = image.shape
xmin = np.random.randint(W-self.W+1)
ymin = np.random.randint(H-self.H+1)
image = image[ymin:ymin+self.H, xmin:xmin+self.W, :]
mask = mask[ymin:ymin+self.H, xmin:xmin+self.W, :]
depth = depth[ymin:ymin+self.H, xmin:xmin+self.W]
return image, depth, mask
def random_hflip(image, depth, mask):
if np.random.randint(2)==1:
image = image[:,::-1,:].copy()
mask = mask[:,::-1,:].copy()
depth = depth[:, ::-1, :].copy()
return image, depth, mask
class RandomHorizontalFlip(object):
def __call__(self, image,depth, mask):
return random_hflip(image, depth, mask)
class MultiRandomHorizontalFlip(object):
def __call__(self, images, depths, masks):
len_ = len(images)
for i in range(len_):
images[i], depths[i], masks[i] = random_hflip(images[i], depths[i], masks[i])
return images, depths, masks
class ToTensor(object):
def __init__(self, depth_gray=True):
self.depth_gray = depth_gray
def __call__(self, image, depth, mask):
image = np.ascontiguousarray(image)
image = torch.from_numpy(image)
image = image.permute(2, 0, 1)
mask = np.ascontiguousarray(mask)
mask = torch.from_numpy(mask)
mask = mask.permute(2, 0, 1)
depth = np.ascontiguousarray(depth)
depth = torch.from_numpy(depth)
depth = depth.permute(2, 0, 1)
if self.depth_gray == True:
return image, depth.mean(dim=0, keepdim=True), mask.mean(dim=0, keepdim=True)
else:
return image, depth, mask.mean(dim=0, keepdim=True)
class RandomMask(object):
def __init__(self):
self.thresh = 1
def out_saliency(self, x1, y1, x2, y2, gt):
return gt[y1:y2, x1:x2].sum() == 0
def __call__(self, image, depth, gt):
if True: #random.random() > 0.5:
#mask = np.random.binomial(1, 0.95, (14,14))
#mask = cv2.resize(mask, dsize=image.shape[:-1], interpolation=cv2.INTER_NEAREST)[:,:,np.newaxis]
#return mask*image
""" https://github.com/kkanshul/Hide-and-Seek/blob/master/hide_patch.py """
s = image.shape
ht = s[0]
wd = s[1]
# possible grid size, 0 means no hiding
grid_sizes=[0,16,32,44,56]
# hiding probability
hide_prob = 0.5
# randomly choose one grid size
grid_size= grid_sizes[random.randint(0,len(grid_sizes)-1)]
# hide the patches
if(grid_size > 0):
for x in range(0,wd,grid_size):
for y in range(0,ht,grid_size):
x_end = min(wd, x+grid_size)
y_end = min(ht, y+grid_size)
if (random.random() <= hide_prob) and self.out_saliency(x, y, x_end, y_end, gt):
image[y:y_end,x:x_end,:]=0
depth[y:y_end, x:x_end, :] = 0
return image, depth, gt
else:
return image, depth, gt
def resize(img, size, interpolation=cv2.INTER_CUBIC):
if not _is_numpy_image(img):
raise TypeError('img should be numpy image. Got {}'.format(type(img)))
if not (isinstance(size, int) or (isinstance(size, collections.Iterable) and len(size) == 2)):
raise TypeError('Got inappropriate size arg: {}'.format(size))
w, h, = size
if isinstance(size, int):
if (w <= h and w == size) or (h <= w and h == size):
return img
if w < h:
ow = size
oh = int(size * h / w)
output = cv2.resize(img, dsize=(ow, oh), interpolation=interpolation)
else:
oh = size
ow = int(size * w / h)
output = cv2.resize(img, dsize=(ow, oh), interpolation=interpolation)
else:
output = cv2.resize(img, dsize=size[::-1], interpolation=interpolation)
return output
#if img.shape[2]==1:
# return(output[:,:,np.newaxis])
#else:
# return(output)
def crop(img, i, j, h, w):
if not _is_numpy_image(img):
raise TypeError('img should be numpy image. Got {}'.format(type(img)))
if len(img.shape) == 3:
return img[i:i+h, j:j+w, :]
else:
return img[i:i+h, j:j+w]
def resized_crop(img, i, j, h, w, size, interpolation=cv2.INTER_CUBIC):
assert _is_numpy_image(img), 'img should be numpy image'
img = crop(img, i, j, h, w)
img = resize(img, size, interpolation=interpolation)
return img
class RandomResizedCrop(object):
"""Crop the given numpy ndarray to random size and aspect ratio.
A crop of random size (default: of 0.08 to 1.0) of the original size and a random
aspect ratio (default: of 3/4 to 4/3) of the original aspect ratio is made. This crop
is finally resized to given size.
This is popularly used to train the Inception networks.
Args:
size: expected output size of each edge
scale: range of size of the origin size cropped
ratio: range of aspect ratio of the origin aspect ratio cropped
interpolation: Default: cv2.INTER_CUBIC
"""
def __init__(self, size, scale=(0.08, 1.0), ratio=(3. / 4., 4. / 3.), interpolation=cv2.INTER_CUBIC):
self.size = (size, size)
self.interpolation = interpolation
self.scale = scale
self.ratio = ratio
@staticmethod
def get_params(img, scale, ratio):
"""Get parameters for ``crop`` for a random sized crop.
Args:
img (numpy ndarray): Image to be cropped.
scale (tuple): range of size of the origin size cropped
ratio (tuple): range of aspect ratio of the origin aspect ratio cropped
Returns:
tuple: params (i, j, h, w) to be passed to ``crop`` for a random
sized crop.
"""
for attempt in range(10):
area = img.shape[0] * img.shape[1]
target_area = random.uniform(*scale) * area
aspect_ratio = random.uniform(*ratio)
w = int(round(math.sqrt(target_area * aspect_ratio)))
h = int(round(math.sqrt(target_area / aspect_ratio)))
if random.random() < 0.5:
w, h = h, w
if w <= img.shape[1] and h <= img.shape[0]:
i = random.randint(0, img.shape[0] - h)
j = random.randint(0, img.shape[1] - w)
return i, j, h, w
# Fallback
w = min(img.shape[0], img.shape[1])
i = (img.shape[0] - w) // 2
j = (img.shape[1] - w) // 2
return i, j, w, w
def __call__(self, img, depth, mask):
"""
Args:
img (numpy ndarray): Image to be cropped and resized.
Returns:
numpy ndarray: Randomly cropped and resized image.
"""
i, j, h, w = self.get_params(img, self.scale, self.ratio)
img_1 = resized_crop(img, i, j, h, w, self.size, self.interpolation)
depth_1 = resized_crop(depth, i, j, h, w, self.size, self.interpolation)
mask_1 = resized_crop(mask, i, j, h, w, self.size, self.interpolation)
return img_1, depth_1, mask_1
def __repr__(self):
interpolate_str = _pil_interpolation_to_str[self.interpolation]
format_string = self.__class__.__name__ + '(size={0}'.format(self.size)
format_string += ', scale={0}'.format(tuple(round(s, 4) for s in self.scale))
format_string += ', ratio={0}'.format(tuple(round(r, 4) for r in self.ratio))
format_string += ', interpolation={0})'.format(interpolate_str)
return format_string
| abf3245dd30dd8fc1e725f2ea1baa6506d7742e9 | [
"Markdown",
"Python"
] | 9 | Python | JosephChenHub/DPANet | 803a876afbb94474e1cb5ac258bc357fd762a418 | de3c5fd72cff4a2e736ed2b078840785d9a2f5d7 |
refs/heads/master | <file_sep># sql-connection
sql connection
<file_sep>var express = require('express');
var app = express();
var sql = require("mssql");
var bodyparser = require('body-parser');
app.listen(process.env.PORT || 1234);
app.use(bodyparser.json())
var db;
// config for your database
var config = {
'user': 'sa',
'password': '<PASSWORD>$$',
'server': '172.16.17.32\\SQLEXPRESS',
'database': 'CFMSNLSCFDATA'
};
sql.connect(config, function (err) {
if(err){
console.log("connection error "+err);
}else{
console.log("connection established");
console.log("sql "+sql);
db=sql;
console.log("db "+db);
module.exports = db;
}
});
app.all('/*', function(req, res, next) {
// CORS headers
res.header("Access-Control-Allow-Origin", "*"); // restrict it to the required domain
res.header('Access-Control-Allow-Methods', 'GET,PUT,POST,DELETE,OPTIONS');
// Set custom headers for CORS
res.header('Access-Control-Allow-Headers', 'Content-type,Accept,X-Access-Token,X-Key');
if (req.method == 'OPTIONS') {
res.status(200).end();
} else {
next();
}
});
/* var server = app.listen(5000, function () {
console.log('Server is running..');
// config for your database
var config = {
'user': 'sa',
'password': '<PASSWORD>$$',
'server': '192.168.0.5\\SQLEXPRESS',
'database': 'CFMSNLSCFDATA'
};
//console.log("config "+config);
sql.connect(config, function (err) {
if (err){
console.log("ervvv "+err);
}else{
console.log("connection etalished");
var request = new sql.Request();
// query to the database and get the records
request.query('select grp_name_vc from tblmastchitgroup', function (err, recordset) {
if (err) console.log("er "+err);
console.log("vv "+recordset);
// send records as a response
//res.send(recordset);
});
}
});
}); */
app.get('/get',function(req,res){
console.log("db=== "+db);
var request = new db.Request();
console.log("bsdc "+request);
// query to the database and get the records
request.query('select grp_name_vc from tblmastchitgroup', function (err, recordset) {
if (err) console.log("er "+err);
//console.log("vv "+recordset);
// send records as a response
res.send(recordset);
});
});
app.post('/login',function(req,res){
var username=req.body.username;
var password=<PASSWORD>;
console.log("us "+username);
console.log("sd "+password);
var request = new db.Request();
//var request=new db.Request()
request.input('user_id_vc', sql.VarChar(20), username);
request.query('select mob_password_vc from tbl_users where user_id_vc =@user_id_vc').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
if(recordset==null || recordset.lenth ==0){
res.send({"message":"Invalid username","status":202});
}
if(recordset[0].mob_password_vc===password){
res.send({"message":"successfully valid user","status":200});
}else{
res.send({"message":"Invalid password","status":201});
}
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getUsers',function(req,res){
var request = new db.Request();
request.query('select * from tbl_users').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getBranches',function(req,res){
var request=new db.Request();
request.query('select brn_id_vc from tblmastbranch').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getGroups/:branch',function(req,res){
var request=new db.Request();
console.log("branch "+req.params.branch);
request.input('brn_id_vc', sql.VarChar(20), req.params.branch);
request.query('select grp_name_vc from tblmastchitgroup where brn_id_vc=@brn_id_vc').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getSubscribers/:branch/:group',function(req,res){
var request=new db.Request();
console.log("branch "+req.params.branch);
request.input('brn_id_vc', sql.VarChar(20), req.params.branch);
request.input('grp_name_vc', sql.VarChar(20), req.params.group);
request.query('select subr_no_i from tblmastsubscriber where brn_id_vc=@brn_id_vc AND grp_name_vc=@grp_name_vc').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getSubscriber/:branch/:group/:sub',function(req,res){
var request=new db.Request();
request.input('brn_id_vc', sql.VarChar(20), req.params.branch);
request.input('grp_name_vc', sql.VarChar(20), req.params.group);
request.input('subr_no_i', sql.Int(20), req.params.sub);
request.query('select * from tblmastsubscriber where brn_id_vc=@brn_id_vc AND grp_name_vc=@grp_name_vc AND subr_no_i=@subr_no_i').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getsub/:id',function(req,res){
var request=new db.Request();
request.input('subr_no_i', sql.Int(20), req.params.id);
request.query('select * from tblmastsubscriber where subr_no_i=@subr_no_i').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.get('/getsubscribers',function(req,res){
var request=new db.Request();
//request.input('subr_no_i', sql.Int(20), req.params.id);
request.query('select brn_id_vc ,grp_name_vc ,isnull(subr_no_i,0) as subr_no_i ,isnull(subr_name_vc,0) as subr_name_vc,isnull(subr_mobile_vc,subr_phno_vc) as subr_mobile_vc from tblmastsubscriber').then(function(recordset) {
//console.log("pass "+recordset[0].mob_password_vc);
res.json(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.post('/getinstallments',function(req,res){
var request=new db.Request();
request.input('brn_id_vc', sql.VarChar(20), req.body.selectedbranch);
request.input('grp_name_vc', sql.VarChar(20), req.body.selectedgroup);
request.input('subr_no_i', sql.Int(20), req.body.selectedsub);
request.query('select max(adj_end_inst_i) as adj_end_inst_i from tbltrnreceipts where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND subr_no_i =@subr_no_i').then(function(recordset) {
console.log("kjn "+recordset[0].adj_end_inst_i);
request.input('auc_no_i', sql.Int(20), recordset[0].adj_end_inst_i);
request.query('select convert(varchar(10), auc_date_d,103) as auc_date_d,auc_no_i,auc_intamount_n from tbltrnauctions where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND auc_no_i>@auc_no_i').then(function(record){
//res.send(record);
request.query('select isnull(sum(isnull(auc_intamount_n,0)),0) as auc_intamount_n from tbltrnauctions where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND auc_no_i>@auc_no_i').then(function(count){
//res.send(record);
res.json({"data":record,"count":count});
}).catch(function(err){
console.log("er "+err);
});
}).catch(function(err){
console.log("er "+err);
});
//res.send(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
});
app.post('/getinstallments1',function(req,res){
var request=new db.Request();
request.input('brn_id_vc', sql.VarChar(20), req.body.selectedbranch);
request.input('grp_name_vc', sql.VarChar(20), req.body.selectedgroup);
request.input('subr_no_i', sql.Int(20), req.body.selectedsub);
request.query('select max(adj_end_inst_i) as adj_end_inst_i from tbltrnreceipts where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND subr_no_i =@subr_no_i').then(function(recordset) {
console.log("auc "+recordset[0].adj_end_inst_i);
request.input('auc_no_i', sql.Int(20), recordset[0].adj_end_inst_i);
request.query('select count(*) from tbltrnauctions where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND subr_no_i =@subr_no_i').then(function(recordset1) {
console.log("kjn "+recordset1[0]);
request.input('auc_no_i', sql.Int(20), recordset[0].adj_end_inst_i);
if(recordset1==0){
request.query('select convert(varchar(10),auc_duedate_d,103) as auc_duedate_d,auc_no_i,convert(int,auc_intamount_n) as auc_intamount_n ,penalty from npspenalty where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND auc_no_i >@auc_no_i').then(function(record) {
//res.json(re);
request.query('select isnull(sum(isnull(auc_intamount_n,0)),0) as auc_intamount_n from tbltrnauctions where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND auc_no_i>@auc_no_i').then(function(amount){
request.query('select isnull(dbo.subrpaidamount (@brn_id_vc,@grp_name_vc,@subr_no_i),0) as subrcramount').then(function(credit){
var penalityamount=0;
record.forEach(function(re){
penalityamount=penalityamount+re.penalty;
});
res.json({"data":record,"count":amount,"creditamount":credit,"penalityamount":penalityamount});
}).catch(function(err){
console.log("err "+err);
});
}).catch(function(err){
console.log("scsk "+err);
});
}).catch(function(err){
console.log("err"+err);
});
}else{
request.query('select convert(varchar(10),auc_duedate_d,103) as auc_duedate_d,auc_no_i,convert(int,auc_intamount_n) as auc_intamount_n ,penalty from pspenalty where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND auc_no_i >@auc_no_i').then(function(record) {
//console.log("jj");
//res.json(re);
request.query('select isnull(sum(isnull(auc_intamount_n,0)),0) as auc_intamount_n from tbltrnauctions where brn_id_vc =@brn_id_vc AND grp_name_vc =@grp_name_vc AND auc_no_i>@auc_no_i').then(function(amount){
//res.json({"data":record,"count":amount});
request.query('select isnull(dbo.subrpaidamount (@brn_id_vc,@grp_name_vc,@subr_no_i),0) as subrcramount').then(function(credit){
var penalityamount=0;
record.forEach(function(re){
penalityamount=penalityamount+re.penalty;
});
res.json({"data":record,"count":amount,"creditamount":credit,"penalityamount":penalityamount});
}).catch(function(err){
console.log("err "+err);
});
}).catch(function(err){
console.log("scsk "+err);
});
}).catch(function(err){
console.log("err"+err);
});
}
//res.send(recordset);
}).catch(function(err) {
console.log("fetching err "+err);
});
}).catch(function(err){
console.log("hbj "+err);
});
});
app.get('/search/:text',function(req,res){
var request=new db.Request();
console.log('dcds '+req.params.text);
request.input('text', sql.VarChar(20), req.params.text);
var value=req.params.text;
var query="select brn_id_vc ,grp_name_vc ,isnull(subr_no_i,0) as subr_no_i ,isnull(subr_name_vc,0) as subr_name_vc,isnull(subr_mobile_vc,subr_phno_vc) as subr_mobile_vc from tblmastsubscriber where (subr_mobile_vc LIKE '%"+req.params.text+"%' OR subr_name_vc LIKE '%"+req.params.text+"%' OR subr_phno_vc LIKE '%"+req.params.text+"%')";
request.query(query).then(function(re){
res.send(re);
}).catch(function(err){
console.log("err "+err);
});
});
app.post('/pay',function(req,res){
var request=new db.Request();
var d = new Date();
var n = d.toLocaleString();
console.log("err "+req.body.amount);
//console.log('dcds '+req.params.text);
request.input('brn_id_vc', sql.VarChar(20), req.body.branch);
request.input('grp_name_vc', sql.VarChar(20), req.body.group);
request.input('subr_no_i', sql.Int(20), req.body.sub);
request.input('rec_date_d',sql.Date,n);
request.input('ent_date_d',sql.Date,n);
request.input('rec_amount_n',sql.Numeric,req.body.amount);
//var value=req.params.text;
request.query('select (isnull(max(isnull(rec_number_n,0)),0) + 1) as rec_number_n from tblmobiledata').then(function(primary){
console.log("sc "+primary[0].rec_number_n)
request.input('rec_number_n',sql.Numeric,primary[0].rec_number_n);
var query='insert into tblmobiledata (brn_id_vc ,grp_name_vc ,subr_no_i ,subr_part_i ,rec_date_d ,ent_date_d ,rec_amount_n ,rec_otheramount_n,coll_id_n,rec_number_n) values (@brn_id_vc,@grp_name_vc,@subr_no_i,0,@rec_date_d,@ent_date_d,@rec_amount_n,0,1,@rec_number_n)';
request.query(query).then(function(re){
console.log("statusCode: ", res.statusCode);
if(res.statusCode='200'){
res.json({"message":"Payment is success","status":200});
}else{
res.json({"message":"Payment failed","status":202});
}
res.send(re);
}).catch(function(err){
console.log("errn "+err);
});
}).catch(function(err){
console.log("errk "+err);
});
});
app.get('/getpayments',function(req,res){
var request=new db.Request();
request.query('select * from tblmobiledata').then(function(re){
res.send(re);
}).catch(function(err){
console.log("err "+err);
});
}); | 9d8e02925b760688239b9966157900aa632bf6cd | [
"Markdown",
"JavaScript"
] | 2 | Markdown | ChaitanyaMM/sql-connection | 4472145e6ae9694200a4e0568ef83305e6ccac10 | 7669790ba336b2e6e2f833fb2e9202eaa07be286 |
refs/heads/master | <file_sep>require 'rails_helper'
RSpec.feature 'Sign Out', :type => :feature do
scenario 'user signs out successfully' do
user = FactoryGirl.create(:user)
sign_in(user.email, user.password)
expect(current_path).to eq(root_path)
click_link 'Sign Out'
expect has_link?('Sign In')
end
end<file_sep>require 'rails_helper'
RSpec.describe Entry, type: :model do
it { should belong_to(:user) }
it { should have_many(:comments) }
# Tests the search class method of Entry class.
describe '#search' do
before do
@entry1 = FactoryGirl.create(:entry, title: "Greece is awesome")
@entry2 = FactoryGirl.create(:entry, title: "Checkout my trip to New York!")
end
# Tests that if no entries match the search, no entries will be returned
it 'does not return any entries if none match' do
search = Entry.search('America')
expect(search.count).to eq(0)
end
# Tests that if an entry does match the search, it returns ONLY the entry
it 'returns entries that match search terms' do
search = Entry.search('Greece')
expect(search).to include(@entry1)
expect(search).to_not include(@entry2)
end
end
end<file_sep>class Entry < ApplicationRecord
belongs_to :user
has_many :comments
scope :of_followed_users, -> (following_users) { where user_id: following_users }
# Finds entry where search term matches title
def self.search(search)
where("title ILIKE ?", "%#{search}%")
end
end
<file_sep>class UsersController < ApplicationController
before_action :set_user, only: [:show, :following, :followers, :journal, :places]
# Displays all users
def index
@users = User.all
end
# Displays a user's profile page
def show
@places = @user.places.order("created_at asc")
end
# displays a page of users that the given user is following
def following
@following = @user.following
end
# displays a page of users that are following a given user
def followers
@followers = @user.followers
end
# returns all of a user's journal entries
def journal
@entries = @user.entries.order("created_at desc")
end
private
# Finds the specific user from the id sent through params
def set_user
@user = User.find(params[:id])
end
end
<file_sep>#Venture
Users have accounts with log in/out sign up capability. - Devise, OmniAuth
Users follow other members, places
Users have followers
has many posts
has many places
has one journal
has many entries through journal
Place (board)
Place has many posts
Post
belongs to User
belongs to Place
Keyword
name:string
??
## Database
Journal
user_id:integer
- on second thought, I'm not sure journal needs to be its own model. Maybe to have followers, but for now users can only follow people.
-Entry
-journal_id:integer
Entry
user_id:integer
title:string
content:text
User
profile_picture: ? (use paperclip)
first_name:string
last_name:string
email:string
Followings
user_id:integer
follower_id:integer
Connection? (May use to join users)
Place
name:string
date created:datetime
created_by:integer
Post
name:string
image: ? (use paperclip)
user_id:integer
description:text
link:string
## Style
Each profile page lists all Places(boards)
Interactive Map at the top of each page that has pins in places traveled and different pins for places planning to travel
## Tips
from stack overflow for dealing with followers based on twitter:
rails generate model Person name:string
rails generate model Followings person_id:integer follower_id:integer blocked:boolean
class Person < ActiveRecord::Base
has_many :followers, :class_name => 'Followings', :foreign_key => 'person_id'
has_many :following, :class_name => 'Followings', :foreign_key => 'follower_id'
end
class Followings < ActiveRecord::Base
belongs_to :person
belongs_to :follower, :class_name => 'Person'
end
## Game Plan
Initially just set up the application with the journal functionality. Users can add journal posts.
They can follow people and see their journal posts.
User's own journal posts can be displayed on their own profile page.
Profile page has a settings feature that can edit profile information.
Add later: When a journal is created, it is associated with a specific location.
Add later: photo posts
<file_sep>class Post < ApplicationRecord
belongs_to :place
has_attached_file :post_photo, default_url: ':style/no-image.png', styles: { medium: "236x300#" }
validates_attachment_content_type :post_photo, content_type: /\Aimage\/.*\z/
# Returns the user who owns the place and therefore the post
def post_user
place = self.place
place.user
end
# Finds post where search term matches description or link
def self.search(search)
where("description ILIKE ? OR link ILIKE ?", "%#{search}%", "%#{search}%")
end
end
<file_sep>class RelationshipsController < ApplicationController
# follows a user by finding the given user and passing
# its id to the follow method for current user.
def follow_user
@user = User.find(params[:id])
if current_user.follow(@user.id)
redirect_to '/'
end
end
# unfollows a user by finding the given user and passing
# its id to the unfollow method for current user.
def unfollow_user
@user = User.find(params[:id])
if current_user.unfollow(@user.id)
redirect_to '/'
end
end
end
<file_sep>class User < ApplicationRecord
# Include default devise modules. Others available are:
# :confirmable, :lockable, :timeoutable and :omniauthable
devise :database_authenticatable, :registerable,
:recoverable, :rememberable, :trackable, :validatable
devise :omniauthable, :omniauth_providers => [:facebook]
has_many :entries, dependent: :destroy
has_many :follower_relationships, foreign_key: :following_id, class_name: 'FollowRelationship'
has_many :followers, through: :follower_relationships, source: :follower
has_many :following_relationships, foreign_key: :follower_id, class_name: 'FollowRelationship'
has_many :following, through: :following_relationships, source: :following
has_many :comments, dependent: :destroy
has_many :places
has_many :posts, :through => :places
has_attached_file :profile_picture,
:default_url => ':style/default.png',
:styles => { :small => "45x45#", :thumb => "80x80#", :medium => "140x140#"}
validates_attachment_content_type :profile_picture, content_type: /\Aimage\/.*\z/
# Follows a user by setting the following_id to the given user
# and the follower_id to the id of this User object
def follow(user_id)
following_relationships.create(following_id: user_id, follower_id: self.id)
end
# Unfollows a user by destroying the relationship
def unfollow(user_id)
following_relationships.find_by(following_id: user_id).destroy
end
# Determines whether or not the given user is being followed by
# this User object. Returns true or false
def following?(user_id)
user = User.find_by(id: user_id)
self.following.include?(user) ? true : false
end
# Determines whether or not the given user is a follower of
# this User object. Returns true or false
def followers?(user_id)
user = User.find_by(id: user_id)
self.followers.include?(user) ? true : false
end
# Returns a users full name by adding the first and last names
def full_name
full_name = self.first_name + " " + self.last_name
end
# Finds user where search term matches first_name, last_name, or email
def self.search(search)
where("first_name ILIKE ? OR last_name ILIKE ? OR email ILIKE ?", "%#{search}%", "%#{search}%", "%#{search}%")
end
# Gets information from facebook
def self.from_omniauth(auth)
where(provider: auth.provider, uid: auth.uid).first_or_create do |user|
user.provider = auth.provider
user.uid = auth.uid
user.first_name = auth.info.first_name
user.last_name = auth.info.last_name
user.email = auth.info.email
user.password = <PASSWORD>[0,20]
end
end
end
<file_sep>require 'rails_helper'
RSpec.describe FollowRelationship, type: :model do
it {should belong_to(:follower) }
it { should belong_to(:following) }
end<file_sep>require 'rails_helper'
# Tests the basic associations of the user model.
RSpec.describe Post, type: :model do
before do
@post1 = FactoryGirl.create(:post)
@post2 = FactoryGirl.create(:post)
end
it { should belong_to(:place) }
# Tests the post_user method of the Post model.
describe ".post_user" do
# Tests that the post_user method returns the users who has the post
# through the place
it "returns the user who owns the place that owns the post" do
@place = @post1.place
@user = @place.user
expect(@post1.post_user).to be(@user)
end
end
# Tests the search method of the Post model.
describe "#search" do
before(:each) do
@post1.update(description: "Awesome Greece!", link: 'www.greece-is-awesome.com')
@post2.update(description: "Awesome Statue of Liberty", link: "www.liberty.com")
end
# Tests that if no posts match the search, no posts will be returned
it 'does not return any posts if none match' do
search = Post.search('America')
expect(search.count).to eq(0)
end
# Tests that if a post does match the search, it returns ONLY the posts that match
it "returns posts that match search terms and none that don't" do
search = Post.search('Greece')
expect(search).to include(@post1)
expect(search).to_not include(@post2)
end
# Tests that if multiple posts match the search, they are all returned
it 'can return multiple posts if they match' do
search = Post.search('awesome')
expect(search).to include(@post1)
expect(search).to include(@post2)
end
# Tests that the search terms are compared to link
it 'returns post if link matches the search terms' do
search = Post.search('greece-is-awesome')
expect(search).to include(@post1)
end
# Tests that search terms are compared to description
it 'returns post if description matches the search terms' do
search = Post.search('statue')
expect(search).to include(@post2)
end
end
end<file_sep>class PlacesController < ApplicationController
before_action :set_place, only: [:show, :edit, :update, :destroy]
before_action :owned_place, only: [:edit, :update, :destroy]
# list all of a user's places
def index
if current_user && Place.of_followed_users(current_user.following).length > 0
@places = Place.of_followed_users(current_user.following).order('created_at DESC')
else
@places = Place.all
end
end
# show a specific place
def show
end
# renders form to create new place
def new
@place = Place.new
end
# creates a new place
def create
@place = Place.new(user_id: current_user.id)
@place.update(place_params)
if @place.save
redirect_to place_path(@place)
else
redirect_to controller: 'places', action: 'new'
end
end
# renders form to edit place
def edit
end
# updates place
def update
if @place.update(place_params)
redirect_to place_path(@place)
else
redirect_to controller: 'places', action: 'edit'
end
end
# deletes a place
def destroy
@place.destroy
redirect_to places_path
end
private
# Finds the specific place
def set_place
@place = Place.find_by(id: params[:id])
end
# strong params for place
def place_params
params.require(:place).permit(:name)
end
# checks if a user owns a place to ensure that a user can't edit
# other user's entries
def owned_place
unless current_user == @place.user
flash[:alert] = "That place doesn't belong to you!"
redirect_to root_path
end
end
end
<file_sep>Rails.application.routes.draw do
devise_for :users, :controllers => { :omniauth_callbacks => "user/omniauth_callbacks", registrations: 'registrations' }
root 'places#index'
resources :entries do
resources :comments
end
resources :users
resources :places do
resources :posts
end
get '/users/:id/follow_user', to: 'relationships#follow_user', as: :follow_user
get '/users/:id/unfollow_user', to: 'relationships#unfollow_user', as: :unfollow_user
get '/users/:id/following', to: 'users#following', as: :following
get '/users/:id/followers', to: 'users#followers', as: :followers
get '/users/:id/journal', to: 'users#journal', as: :journal
get '/search', to: 'search#search', as: :search
# For details on the DSL available within this file, see http://guides.rubyonrails.org/routing.html
end
<file_sep>require 'rails_helper'
RSpec.feature 'User profile page', :type => :feature do
let(:user) { FactoryGirl.create(:user) }
before(:each) { visit user_path(user) }
scenario 'has link to journal' do
click_link 'Journal'
expect(current_path).to eq(journal_path(user))
end
scenario 'has link to places' do
click_link 'Places'
expect(current_path).to eq(user_path(user))
end
scenario "displays that user has no places if none exist" do
expect has_content?("no places")
end
scenario "lists user's places" do
place = FactoryGirl.create(:place, user: user)
expect has_content?(place.name)
end
scenario 'links to followers' do
expect has_link? followers_path(user)
end
scenario 'links to following' do
expect has_link? following_path(user)
end
context 'logged in' do
before do
sign_in(user.email, user.password)
visit user_path(user)
end
context 'own page' do
scenario 'has link to edit profile' do
click_link 'Edit Profile'
expect(current_path).to eq(edit_user_registration_path)
end
scenario 'has link to create new place' do
expect has_link? new_place_path
end
context 'places' do
scenario 'can create a new place' do
click_on 'new-place'
fill_in 'Name', with: 'Greece'
click_on 'Create Place'
expect(user.places.count).to eq(1)
end
scenario 'clicking place shows posts' do
pending
place = FactoryGirl.create(:place, name: 'America')
visit user_path(user)
click_on place_path(place)
expect has_content? 'America'
end
end
scenario 'can create a new journal entry' do
click_on 'Journal'
click_on 'New Journal Entry'
fill_in 'Title', with: 'This is a cool title!'
fill_in 'Content', with: 'and some pretty cool content to match my title!'
click_on 'Create Entry'
expect(user.entries.count).to eq(1)
end
end
context "other user's page" do
let(:user_2) { FactoryGirl.create(:user) }
before { visit user_path(user_2) }
scenario 'has link to follow user if not following' do
expect has_link? 'Follow'
end
scenario 'does not have unfollow link if user is not following' do
click_link 'Follow'
visit user_path(user_2)
click_link 'Unfollow' # making sure unfollow is clicked at least once
expect has_no_link? 'Unfollow'
end
scenario 'has link to unfollow user if already following' do
click_link 'Follow'
expect has_link? 'Unfollow'
end
scenario 'does not have follow link if user is already following' do
click_link 'Follow'
expect has_no_link? 'Follow'
end
scenario 'does not have link to add new place' do
expect has_no_link? new_place_path
end
end
end
context 'not logged in' do
scenario 'does not have follow link' do
expect has_no_link? 'Follow'
end
scenario 'does not have unfollow link' do
expect has_no_link? 'Unfollow'
end
scenario 'does not have link to add new place' do
expect has_no_link? new_place_path
end
end
end<file_sep>class PostsController < ApplicationController
before_action :set_post, only: [:show, :edit, :update, :destroy]
before_action :set_place
before_action :owned_post, only: [:edit, :update, :destroy]
# list all posts
def index
@posts = @place.posts.order("created_at desc")
end
# show a specific post
def show
end
# renders form to create new post
def new
@post = Post.new
end
# creates a new post
def create
@post = Post.new(place_id: @place.id)
@post.update(post_params)
if @post.save
redirect_to place_post_path(@place, @post)
else
redirect_to controller: 'posts', action: 'new'
end
end
# renders form to edit post
def edit
end
# updates post
def update
if @post.update(post_params)
redirect_to place_post_path(@place, @post)
else
redirect_to controller: 'posts', action: 'edit'
end
end
# deletes a post
def destroy
@post.destroy
redirect_to root_path
end
private
def set_post
@post = Post.find(params[:id])
end
def set_place
@place = Place.find(params[:place_id])
end
def post_params
params.require(:post).permit(:link, :description, :post_photo)
end
def owned_post
unless current_user == @post.post_user
flash[:alert] = "That post doesn't belong to you!"
redirect_to root_path
end
end
end
<file_sep>class CommentsController < ApplicationController
before_action :set_entry
def create
@comment = @entry.comments.build(comment_params)
@comment.user_id = current_user.id
if @comment.save
redirect_to :back
else
redirect_to entry_path(@entry)
end
end
def destroy
@entry.comments.find(params[:id]).destroy
redirect_to entry_path(@entry)
end
private
def comment_params
params.require(:comment).permit(:content)
end
def set_entry
@entry = Entry.find(params[:entry_id])
end
end
<file_sep>require 'rails_helper'
RSpec.feature 'Edit User', :type => :feature do
context 'not signed in with facebook' do
scenario 'edits the current user' do
user = FactoryGirl.create(:user, first_name: 'James')
sign_in(user.email, user.password)
click_on 'Profile'
click_on 'Edit Profile'
fill_in 'First name', with: 'John'
fill_in 'Current password', with: <PASSWORD>
click_on 'Update'
expect(User.first.first_name).to eq("John")
end
end
context 'signed in with facebook' do
scenario 'edits current user' do
user = FactoryGirl.create(:facebook_user)
sign_in(user.email, user.password)
click_on 'Profile'
click_on 'Edit Profile'
fill_in 'First name', with: 'John'
click_on 'Update'
expect(User.first.first_name).to eq("John")
end
end
end<file_sep>require 'faker'
FactoryGirl.define do
factory :place do
name { Faker::Lorem.words }
association :user
end
end<file_sep>require 'faker'
FactoryGirl.define do
factory :user do
first_name { Faker::Name.first_name }
last_name { Faker::Name.last_name }
email { Faker::Internet.email }
password { Faker::<PASSWORD>.password(8) }
factory :facebook_user do
provider { Faker::Omniauth.facebook[:provider] }
uid { Faker::Omniauth.facebook[:uid] }
first_name { Faker::Omniauth.facebook[:info][:first_name] }
last_name { Faker::Omniauth.facebook[:info][:last_name] }
email { Faker::Omniauth.facebook[:info][:email] }
password '<PASSWORD>'
end
end
end<file_sep>require 'faker'
FactoryGirl.define do
factory :post do
link { Faker::Internet.url }
description { Faker::Lorem.sentence }
association :place
end
end<file_sep>require 'rails_helper'
RSpec.feature 'Sign In', :type => :feature do
scenario 'cannot sign in if not registered' do
sign_in('<EMAIL>', '<PASSWORD>')
expect(current_path).to eq(new_user_session_path)
end
scenario 'can sign in if registered' do
user = FactoryGirl.create(:user)
sign_in(user.email, user.password)
expect(current_path).to eq(root_path)
end
context 'with facebook' do
scenario 'can sign in with facebook' do
user = FactoryGirl.create(:facebook_user)
sign_in(user.email, user.password)
expect(current_path).to eq(root_path)
end
end
end<file_sep>class SearchController < ApplicationController
def search
@users = User.search(params[:search]).order("created_at DESC")
@places = Place.search(params[:search]).order("created_at DESC")
@posts = Post.search(params[:search]).order("created_at DESC")
@entries = Entry.search(params[:search]).order("created_at DESC")
end
end<file_sep>class Place < ApplicationRecord
has_many :posts
belongs_to :user
scope :of_followed_users, -> (following_users) { where user_id: following_users }
# Finds place where search term matches name
def self.search(search)
where("name ILIKE ?", "%#{search}%")
end
end
<file_sep>class CreateFollowRelationships < ActiveRecord::Migration[5.0]
def change
create_table :follow_relationships do |t|
t.integer :following_id, :null => false
t.integer :follower_id, :null => false
t.timestamps
end
end
end
<file_sep># Venture
Venture is a social travel app that allows users to share images and journal entries associated with locations.
<file_sep>module ApplicationHelper
# Converts a date to 'Month day, year' for example 'February 23, 2017'
def to_date(date)
date.strftime("%B %e, %Y")
end
# returns the number of followers a user has. For example '86 followers'
def display_followers(user_id)
user = User.find_by(id: user_id)
num = user.followers.length
return "#{num} followers"
end
# returns the number of users that one is following. For example '103 following'
def display_following(user_id)
user = User.find_by(id: user_id)
num = user.following.length
return "#{num} following"
end
end
<file_sep>require 'rails_helper'
# Tests the basic associations of the user model.
RSpec.describe User, type: :model do
before(:each) do
@user1 = FactoryGirl.create(:user)
@user2 = FactoryGirl.create(:user)
end
it { should have_many(:entries) }
it { should have_many(:places) }
it { should have_many(:follower_relationships) }
it { should have_many(:following_relationships) }
# Tests the full_name method of user
describe ".full_name" do
it 'should return user first_name and last_name' do
expect(@user1.full_name).to eq("#{@user1.first_name} " + "#{@user1.last_name}")
end
end
context 'user1 follows user2' do
before(:each) { @user1.follow(@user2.id) }
# Tests the follow method of the User model.
describe ".follow" do
# Tests that when one user follows another, the user.following
# array contains the followed user
it "follows a user" do
expect(@user1.following).to include(@user2)
end
# Tests that when one user follows another, the followed
# user.follower array contains the following user
it "makes self a follower of the followed user" do
expect(@user2.followers).to include(@user1)
end
end
# Tests the unfollow method of the User model.
describe ".unfollow" do
before(:each) { @user1.unfollow(@user2.id) }
# Tests that when one user unfollows another, the user.following
# array no longer contains the unfollowed user
it "unfollows a user" do
expect(@user1.following).to_not include(@user2)
end
# Tests that when one user unfollows another, the followed
# user.follower array no longer contains the unfollowing user
it "removes self as a follower of the followed user" do
expect(@user2.followers).to_not include(@user1)
end
end
# Tests the following? method of the User model.
describe ".following?" do
# Tests that when one user follows another, the following?
# method returns true if user.following contains the followed user
it "returns true if a user is following the given user" do
expect(@user1).to be_following(@user2.id)
end
end
# Tests the followers? method of the User model.
describe ".followers?" do
# Tests that when one user follows another, the followers?
# method returns true if user.followers contains the following user
it "returns true if a user is following the given user" do
expect(@user2).to be_followers(@user1.id)
end
end
end
# Tests the search class method of User class.
describe '#search' do
before(:each) do
@user1.update(first_name: "Rory", last_name: 'Gilmore', email: '<EMAIL>')
@user2.update(first_name: "Logan", last_name: "Huntzberger", email: '<EMAIL>')
end
# Tests that if no users match the search, no users will be returned
it 'does not return any users if none match' do
search = User.search('Alice')
expect(search.count).to eq(0)
end
# Tests that if a user does match the search, it returns ONLY the users that match
it "returns users that match search terms and none that don't" do
search = User.search('Rory')
expect(search).to include(@user1)
expect(search).to_not include(@user2)
end
# Tests that if multiple users match the search, they are all returned
it 'can return multiple users if they match' do
search = User.search('a')
expect(search).to include(@user1)
expect(search).to include(@user2)
end
# Tests that the search terms are compared to first name
it 'returns user if first name matches the search terms' do
search = User.search('Rory')
expect(search).to include(@user1)
end
# Tests that search terms are compared to last name
it 'returns user if last name matches the search terms' do
search = User.search('Gilmore')
expect(search).to include(@user1)
end
# Tests that search terms are compared to email
it 'returns user if email matches the search terms' do
search = User.search('<EMAIL>')
expect(search).to include(@user2)
end
end
end<file_sep>require 'rails_helper'
RSpec.feature 'Sign Up', :type => :feature do
scenario 'can sign up successfully' do
visit new_user_registration_path
sign_up_with('Rory', 'Gilmore', '<EMAIL>', '<PASSWORD>', '<PASSWORD>')
expect has_link? "Sign Out"
end
end<file_sep>class EntriesController < ApplicationController
before_action :set_entry, only: [:show, :edit, :update, :destroy]
before_action :owned_entry, only: [:edit, :update, :destroy]
# list all entries
def index
if current_user && Entry.of_followed_users(current_user.following).length > 0
@entries = Entry.of_followed_users(current_user.following).order('created_at DESC')
else
@entries = Entry.all
end
end
# show a specific entry
def show
end
# renders form to create new entry
def new
@entry = Entry.new
end
# creates a new entry
def create
@entry = Entry.new(user_id: current_user.id)
@entry.update(entry_params)
if @entry.save
redirect_to entry_path(@entry)
else
redirect_to controller: 'entries', action: 'new'
end
end
# renders form to edit entry
def edit
end
# updates entry
def update
if @entry.update(entry_params)
redirect_to entry_path(@entry)
else
redirect_to controller: 'entries', action: 'edit'
end
end
# deletes an entry
def destroy
@entry.destroy
redirect_to entries_path
end
private
# Finds the specific entry
def set_entry
@entry = Entry.find_by(id: params[:id])
end
# strong params for entry
def entry_params
params.require(:entry).permit(:title, :content)
end
# checks if a user owns an entry to ensure that a user can't edit
# other user's entries
def owned_entry
unless current_user == @entry.user
flash[:alert] = "That entry doesn't belong to you!"
redirect_to root_path
end
end
end
<file_sep># This file should contain all the record creation needed to seed the database with its default values.
# The data can then be loaded with the rails db:seed command (or created alongside the database with db:setup).
#
# Examples:
#
# movies = Movie.create([{ name: 'Star Wars' }, { name: 'Lord of the Rings' }])
# Character.create(name: 'Luke', movie: movies.first)
Entry.create(user_id: 1, title: "Hello World!", content: "Hello hello hello!!")
Entry.create(user_id: 1, title: "This is a super cool title!", content: "And this is some even cooler content!")
Entry.create(user_id: 2, title: "Hi! This is a title", content: "Hello! Do you like my content?")
Entry.create(user_id: 3, title: "Title!", content: "Content!")<file_sep>require 'rails_helper'
# Tests the basic associations of the place model.
RSpec.describe Place, type: :model do
it { should belong_to(:user) }
it { should have_many(:posts) }
# Tests the search class method of Place class.
describe '#search' do
before do
@place1 = FactoryGirl.create(:place, name: "Greece")
@place2 = FactoryGirl.create(:place, name: "New York")
end
# Tests that if no places match the search, no places will be returned
it 'does not return any places if none match' do
search = Place.search('America')
expect(search.count).to eq(0)
end
# Tests that if a place does match the search, it returns ONLY the place
it 'returns only places that match search terms' do
search = Place.search('Greece')
expect(search).to include(@place1)
expect(search).to_not include(@place2)
end
end
end | f43dab4648b97adb7b520c61b2a78d1cd4527290 | [
"Markdown",
"Ruby"
] | 30 | Ruby | msosborne3/venture | f5e1e7e3276cfdb62269949bd5f3879a5279bdb5 | 7d23ee7c6fbe03990c6b5229af328068672510a3 |
refs/heads/master | <repo_name>dschuermann/gait-based-device-pairing<file_sep>/android/settings.gradle
include ':app', ':bwatch', ':bdevice'
<file_sep>/android/app/src/main/java/com/example/bandana/SensorListener.java
/*
* Copyright (C) IBR, TU Braunschweig & Ambient Intelligence, Aalto University
* All Rights Reserved
* Written by <NAME>, <NAME>, <NAME>
*/
package com.example.bandana;
import android.content.Context;
import android.content.Intent;
import android.hardware.Sensor;
import android.hardware.SensorEvent;
import android.hardware.SensorEventListener;
import android.hardware.SensorManager;
import android.os.Handler;
import android.os.HandlerThread;
import android.util.Log;
import org.greenrobot.eventbus.EventBus;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
public class SensorListener implements SensorEventListener {
Context context;
int duration;
private SensorManager sensorManager;
private Sensor sensorMag;
private Sensor sensorGravity;
private Sensor sensorAcc;
private Sensor sensorGyr;
int curSampleCount = 0;
long beginTime = -1;
private float[] gravityValues = null;
private float[] magneticValues = null;
private float[] gyroValues = null;
File rotatedFile;
File rawFile;
FileOutputStream rotatedStream;
FileOutputStream rawStream;
OutputStreamWriter rotatedWriter;
OutputStreamWriter rawWriter;
public SensorListener(Context context, int duration) {
this.context = context;
this.duration = duration;
}
public void listen() {
sensorManager = (SensorManager) context.getSystemService(Context.SENSOR_SERVICE);
sensorMag = sensorManager.getDefaultSensor(Sensor.TYPE_MAGNETIC_FIELD);
sensorGravity = sensorManager.getDefaultSensor(Sensor.TYPE_GRAVITY);
sensorAcc = sensorManager.getDefaultSensor(Sensor.TYPE_ACCELEROMETER);
sensorGyr = sensorManager.getDefaultSensor(Sensor.TYPE_GYROSCOPE);
HandlerThread mSensorThread = new HandlerThread("Listener Thread");
mSensorThread.start();
Handler mSensorHandler = new Handler(mSensorThread.getLooper());
rotatedFile = new File(context.getFilesDir(), "rotatedData");
rawFile = new File(context.getFilesDir(), "sensorData");
try {
rotatedFile.createNewFile();
rawFile.createNewFile();
rotatedStream = context.openFileOutput("rotatedData", Context.MODE_PRIVATE);
rotatedWriter = new OutputStreamWriter(rotatedStream);
rawStream = context.openFileOutput("sensorData", Context.MODE_PRIVATE);
rawWriter = new OutputStreamWriter(rawStream);
} catch (IOException e) {
Log.e("Exception", "File write failed: ", e);
}
beginTime = System.currentTimeMillis();
sensorManager.registerListener(this, sensorMag, 20000, mSensorHandler);
sensorManager.registerListener(this, sensorGravity, 20000, mSensorHandler);
sensorManager.registerListener(this, sensorAcc, 20000, mSensorHandler);
sensorManager.registerListener(this, sensorGyr, 20000, mSensorHandler);
}
public void onSensorChanged(SensorEvent event) {
if ((gravityValues != null) && (magneticValues != null) && (gyroValues != null)
&& (event.sensor.getType() == Sensor.TYPE_ACCELEROMETER)) {
long time = System.currentTimeMillis();
if (time >= beginTime + duration * 1000) {
stopSensor();
} else {
if (curSampleCount % 3000 == 0) {
// intent.putExtra("NotificationText",Integer.toString(curSampleCount / 50) + "/ " + duration);
EventBus.getDefault().post(new MessageEvent(MessageEvent.ProtocolState.WALKING, null));
}
float[] deviceRelativeAcceleration = new float[4];
deviceRelativeAcceleration[0] = event.values[0];
deviceRelativeAcceleration[1] = event.values[1];
deviceRelativeAcceleration[2] = event.values[2];
deviceRelativeAcceleration[3] = 0;
/* Change the device relative acceleration values to earth relative values
X axis -> East
Y axis -> North Pole
Z axis -> Sky
*/
float[] R = new float[16];
float[] I = new float[16];
float[] earthAcc = new float[16];
SensorManager.getRotationMatrix(R, I, gravityValues, magneticValues);
float[] inv = new float[16];
android.opengl.Matrix.invertM(inv, 0, R, 0);
android.opengl.Matrix.multiplyMV(earthAcc, 0, inv, 0, deviceRelativeAcceleration, 0);
// Log.d(Constants.TAG, "earthAcc[2] " + earthAcc[2]);
try {
rotatedWriter.append(time + ",");
rotatedWriter.append(earthAcc[2] + "\n");
rawWriter.append(time + ",");
rawWriter.append(deviceRelativeAcceleration[0] + "," + deviceRelativeAcceleration[1] + "," + deviceRelativeAcceleration[2] + ",");
rawWriter.append(gyroValues[0] + "," + gyroValues[1] + "," + gyroValues[2] + "\n");
} catch (IOException e) {
e.printStackTrace();
}
curSampleCount++;
}
} else if (event.sensor.getType() == Sensor.TYPE_GRAVITY) {
gravityValues = event.values;
} else if (event.sensor.getType() == Sensor.TYPE_MAGNETIC_FIELD) {
magneticValues = event.values;
} else if (event.sensor.getType() == Sensor.TYPE_GYROSCOPE) {
gyroValues = event.values;
}
}
private void stopSensor() {
sensorManager.unregisterListener(this);
try {
rotatedWriter.close();
rotatedStream.flush();
rotatedStream.close();
rawWriter.close();
rawStream.flush();
rawStream.close();
} catch (IOException e) {
e.printStackTrace();
}
final Intent intent = new Intent(Constants.ACTION_SENSOR_COMPLETED);
context.sendBroadcast(intent);
}
@Override
public void onAccuracyChanged(Sensor sensor, int accuracy) {
}
}
<file_sep>/android/app/src/main/java/com/example/bandana/BluetoothManager.java
/*
* Copyright (C) IBR, TU Braunschweig & Ambient Intelligence, Aalto University
* All Rights Reserved
* Written by <NAME>, <NAME>, <NAME>
*/
package com.example.bandana;
import android.bluetooth.BluetoothAdapter;
import android.bluetooth.BluetoothDevice;
import android.bluetooth.BluetoothServerSocket;
import android.bluetooth.BluetoothSocket;
import android.content.BroadcastReceiver;
import android.content.Context;
import android.content.Intent;
import android.content.IntentFilter;
import android.os.Handler;
import android.os.HandlerThread;
import android.util.Log;
import org.greenrobot.eventbus.EventBus;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.nio.ByteBuffer;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.Set;
import java.util.UUID;
/**
* This class is causing crashes and needs to be fixed. Sometimes the socket is closed before the reliability/fingerprint
* exchange. It may be because Threads/Sockets are not closed properly.
*/
public class BluetoothManager {
Context context;
private BluetoothAdapter adapter;
private AcceptThread acceptThread;
private List<ConnectThread> connectThreads;
private ArrayList<BluetoothDevice> deviceList;
private int failedConnectionCount;
private static final UUID MY_UUID_INSECURE = UUID.fromString("8ce255c0-200a-11e0-ac64-0800200c9a66");
private BluetoothSocket connectedSocket; // Successfully connected socket
private boolean isConnected;
boolean isServer;
private boolean registered;
private final BroadcastReceiver mReceiver1;
public void close() {
if (acceptThread != null) {
acceptThread.cancel();
}
if (connectThreads.size() > 0) {
for (ConnectThread ct : connectThreads) {
ct = null;
}
}
if (connectedSocket != null) {
try {
connectedSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
connectedSocket = null;
}
isConnected = false;
registered = false;
//just to make sure
if (registered) {
context.unregisterReceiver(mReceiver1);
registered = false;
}
}
public BluetoothManager(Context context) {
this.context = context;
adapter = BluetoothAdapter.getDefaultAdapter();
connectThreads = Collections.synchronizedList(new ArrayList<ConnectThread>());
deviceList = new ArrayList<>();
failedConnectionCount = 0;
connectedSocket = null;
isConnected = false;
isServer = false;
/** Discovers devices around and puts them into the device list */
mReceiver1 = new BroadcastReceiver() {
public void onReceive(Context context, Intent intent) {
String action = intent.getAction(); //may need to chain this to a recognizing function
if (BluetoothDevice.ACTION_FOUND.equals(action)) {
/** Get the BluetoothDevice object from the Intent */
BluetoothDevice device = intent.getParcelableExtra(BluetoothDevice.EXTRA_DEVICE);
//Log.d("BluetoothService",device.getName());
deviceList.add(device);
}
/** Start discovery process again until a connection is found */
else if (BluetoothAdapter.ACTION_DISCOVERY_FINISHED.equals(action)) {
if (deviceList.size() == 0) {
adapter.startDiscovery();
} else {
sendConnectionRequest(deviceList);
}
}
/** first look for paired devices..speed up the process */
else if (Constants.ACTION_PAIRED_FOUND.equals(action)) {
if (deviceList.size() > 0) {
sendConnectionRequest(deviceList);
}
}
}
};
}
public void startConnection() {
// final Intent intent = new Intent(Constants.ACTION_UPDATE_NOTIFICATION);
//// intent.putExtra("NotificationText", "Looking for devices");
// intent.putExtra(Constants.EXTRA_PROTOCOL_STATE, MainService.ProtocolState.BLUETOOTH_DISCOVER);
// intent.setFlags(Intent.FLAG_RECEIVER_FOREGROUND);
// context.sendBroadcast(intent);
EventBus.getDefault().post(new MessageEvent(MessageEvent.ProtocolState.BLUETOOTH_DISCOVER, null));
/** Start a separate thread to listen for connection requests */
acceptThread = new AcceptThread();
acceptThread.start();
IntentFilter filter = new IntentFilter(BluetoothDevice.ACTION_FOUND);
filter.addAction(BluetoothAdapter.ACTION_DISCOVERY_FINISHED);
filter.addAction(Constants.ACTION_PAIRED_FOUND);
HandlerThread receiverThread = new HandlerThread("Receiver thread");
receiverThread.start();
Handler receiverHandler = new Handler(receiverThread.getLooper());
Set<BluetoothDevice> bondedDevices = adapter.getBondedDevices();
if (adapter.isDiscovering()) {
adapter.cancelDiscovery();
}
/** Start discovering the devices around */
if (bondedDevices.size() > 0) {
for (BluetoothDevice bd : bondedDevices) {
deviceList.add(bd);
Log.d("PAIRED", "device added ");
}
}
adapter.startDiscovery();
if (!registered) {
context.registerReceiver(mReceiver1, filter, null, receiverHandler);
registered = true;
if (bondedDevices.size() > 0) {
final Intent pintent = new Intent(Constants.ACTION_PAIRED_FOUND);
context.sendBroadcast(pintent);
}
}
}
/**
* Server thread, listens for connection requests
*/
private class AcceptThread extends Thread {
private final BluetoothServerSocket mmServerSocket;
public AcceptThread() {
BluetoothServerSocket tmp = null;
try {
/** MY_UUID is the app's UUID string, also used by the client code */
tmp = adapter.listenUsingInsecureRfcommWithServiceRecord("Bandana", MY_UUID_INSECURE);
} catch (IOException e) {
e.printStackTrace();
}
mmServerSocket = tmp;
}
public synchronized void run() {
BluetoothSocket socket = null;
/** Keep listening until exception occurs or a socket is returned */
while (!isInterrupted()) {
try {
socket = mmServerSocket.accept();
} catch (IOException e) {
e.printStackTrace();
break;
}
if (socket != null && !isConnected) {
/** A connection was accepted. Send an intent to main activity to start sensor reading */
connectedSocket = socket;
isServer = true;
connect();
break;
}
}
}
public void cancel() {
try {
mmServerSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* Client thread, sends connection request to discovered devices
*/
private class ConnectThread extends Thread {
private BluetoothSocket mmSocket;
private BluetoothDevice mmDevice;
public ConnectThread(BluetoothDevice device) {
mmDevice = device;
}
public synchronized void run() {
BluetoothSocket tmp = null;
try {
tmp = mmDevice.createInsecureRfcommSocketToServiceRecord(MY_UUID_INSECURE);
} catch (IOException e) {
e.printStackTrace();
}
mmSocket = tmp;
try {
mmSocket.connect();
/** Connection successful, get the socket and output stream to send reliability */
if (!isConnected) {
connectedSocket = mmSocket;
connect();
}
} catch (IOException e) {
failedConnectionCount++;
if (failedConnectionCount == connectThreads.size()) {
failedConnectionCount = 0;
connectThreads.clear();
deviceList.clear();
adapter.startDiscovery();
}
return;
}
}
public void cancel() {
try {
mmSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
/**
* When the discovery is completed, sends a connection request to each of the devices in the device list
*/
private void sendConnectionRequest(ArrayList<BluetoothDevice> deviceList) {
for (BluetoothDevice device : deviceList) {
ConnectThread connectThread = new ConnectThread(device);
connectThread.start();
connectThreads.add(connectThread);
}
}
/**
* Called when the device is successfully connected
*/
private void connect() {
/** Send an intent to main activity to start sensor reading */
final Intent intent = new Intent(Constants.ACTION_CONNECTED);
context.sendBroadcast(intent);
isConnected = true;
acceptThread.interrupt();
//acceptThread.cancel();
adapter.cancelDiscovery();
if (registered) {
context.unregisterReceiver(mReceiver1);
registered = false;
}
}
/**
* Read the reliability array sent by the connected device
*/
public ArrayList<Double> getReliability() {
ArrayList<Double> reliability = new ArrayList<>();
InputStream inStream = null;
try {
inStream = connectedSocket.getInputStream();
} catch (IOException e) {
e.printStackTrace();
}
byte[] mmBuffer = new byte[8];
/** Reads reliability values until the value -1.0 is read */
while (true) {
try {
inStream.read(mmBuffer);
double relValue = ByteBuffer.wrap(mmBuffer).getDouble();
if (relValue == -1.0)
break;
reliability.add(relValue);
} catch (IOException e) {
e.printStackTrace();
break;
}
}
return reliability;
}
/**
* Send the reliability array to the connected device
*/
public void sendReliability(ArrayList<Double> reliability) {
OutputStream outStream = null;
try {
outStream = connectedSocket.getOutputStream();
} catch (IOException e) {
e.printStackTrace();
}
try {
for (double relValue : reliability) {
outStream.write(ByteBuffer.allocate(8).putDouble(relValue).array());
}
outStream.write(ByteBuffer.allocate(8).putDouble(-1.0).array());
} catch (IOException e) {
e.printStackTrace();
}
}
/**
* Read the fingerprint array sent by the connected device
*/
public ArrayList<Integer> getFingerprint() {
ArrayList<Integer> fingerprint = new ArrayList<>();
InputStream inStream = null;
try {
inStream = connectedSocket.getInputStream();
} catch (IOException e) {
e.printStackTrace();
}
byte[] mmBuffer = new byte[4];
/** Reads fingerprint values until the value -1.0 is read */
while (true) {
try {
inStream.read(mmBuffer);
int fpBit = ByteBuffer.wrap(mmBuffer).getInt();
if (fpBit == -1.0)
break;
fingerprint.add(fpBit);
} catch (IOException e) {
e.printStackTrace();
break;
}
}
return fingerprint;
}
/**
* Send the fingerprint array to the connected device
*/
public void sendFingerprint(ArrayList<Integer> fingerprint) {
OutputStream outStream = null;
try {
outStream = connectedSocket.getOutputStream();
} catch (IOException e) {
e.printStackTrace();
}
try {
for (int fpBit : fingerprint) {
outStream.write(ByteBuffer.allocate(4).putInt(fpBit).array());
}
outStream.write(ByteBuffer.allocate(4).putInt(-1).array());
} catch (IOException e) {
e.printStackTrace();
}
}
}
<file_sep>/android/app/src/main/java/com/example/bandana/GaitCycleDetection.java
/*
* Copyright (C) IBR, TU Braunschweig & Ambient Intelligence, Aalto University
* All Rights Reserved
* Written by <NAME>, <NAME>, <NAME>
*/
package com.example.bandana;
import android.util.Log;
import java.util.ArrayList;
import java.lang.*;
import org.jtransforms.fft.DoubleFFT_1D;
public class GaitCycleDetection {
ArrayList<Double> filteredData; // Rotated and filtered data
int numberOfGaitCycles, rightShiftHalfGaitCycles;
int gaitResampleRate;
boolean shortCycleExists = false; // true if a cycle with less than 40 samples is found
public GaitCycleDetection(ArrayList<Double> filteredData, int numberOfGaitCycles, int gaitResampleRate, int rightShiftHalfGaitCycles){
this.filteredData = new ArrayList<>(filteredData);
this.numberOfGaitCycles = numberOfGaitCycles;
this.gaitResampleRate = gaitResampleRate;
this.rightShiftHalfGaitCycles = rightShiftHalfGaitCycles;
}
/** Finds the gait cycles in the given signal and returns a list of gait cycles */
public ArrayList<ArrayList<Double>> detectCycles(){
ArrayList<ArrayList<Double>> relativeMaxima = new ArrayList<>(getAutocorrelationMaxima());
ArrayList<Double> corrDistances = new ArrayList<>(getAutoCorrelationDistances(relativeMaxima));
ArrayList<Integer> minimaIndices = new ArrayList<>(filterDataMinima(corrDistances));
ArrayList<ArrayList<Double>> halfCycles = new ArrayList<>(split(minimaIndices));
ArrayList<ArrayList<Double>> cycles = new ArrayList<>();
for(int i = 0; i < halfCycles.size(); i+=2){
if( i + 1 < halfCycles.size()){
ArrayList<Double> cycle = new ArrayList<Double>();
cycle.addAll(halfCycles.get(i));
cycle.addAll(halfCycles.get(i + 1));
cycles.add(cycle);
}
}
ArrayList<ArrayList<Double>> cyclesResample = new ArrayList<ArrayList<Double>>();
for(int i = 0; i < cycles.size(); i++){
cyclesResample.add(resample(cycles.get(i), gaitResampleRate));
}
return cyclesResample;
}
/** Returns a combined array of the local minima values and indices */
private ArrayList<ArrayList<Double>> getAutocorrelationMaxima(){
ArrayList<Double> autoCorrelation = new ArrayList<>(getAutoCorrelation());
ArrayList<Integer> relativeMaximaIndices = getRelativeMaxima(autoCorrelation, 15);
ArrayList<Double> relativeMaximaValues = new ArrayList<>();
for(int i = 0; i < relativeMaximaIndices.size(); i++){
relativeMaximaValues.add(autoCorrelation.get(relativeMaximaIndices.get(i)));
}
ArrayList<ArrayList<Double>> relativeMaxima = new ArrayList<>();
for(int i = 0; i < relativeMaximaIndices.size(); i++){
ArrayList<Double> tuple = new ArrayList<>();
Integer obj = new Integer(relativeMaximaIndices.get(i));
tuple.add(obj.doubleValue());
tuple.add(relativeMaximaValues.get(i));
relativeMaxima.add(tuple);
}
return relativeMaxima;
}
/** Implementation of auto-correlation algorithm */
private ArrayList<Double> getAutoCorrelation(){
ArrayList<Double> autoCorrelation = new ArrayList<>(filteredData);
int size = filteredData.size();
double mean = getMean(filteredData);
double variance = getVariance(filteredData);
for(int i = 0; i < size; i++){
autoCorrelation.set(i, autoCorrelation.get(i) - mean);
}
autoCorrelation = getCorrelation(autoCorrelation);
for(int i = 0; i < size; i++){
autoCorrelation.set(i, autoCorrelation.get(i)/ ((size-i)*variance));
}
return autoCorrelation;
}
/** Computes and returns the correlation of the input signal */
private ArrayList<Double> getCorrelation(ArrayList<Double> input){
ArrayList<Double> result = new ArrayList<Double>();
double sum;
for (int i=0;i<input.size();i++) {
sum=0;
for (int j=0;j<input.size()-i;j++) {
sum+=input.get(j)*input.get(j+i);
}
result.add(sum);
}
return result;
}
/** Finds and returns the indices of the local maxima within a duration of 30 samples */
private ArrayList<Integer> getRelativeMaxima(ArrayList<Double> input, int order){
ArrayList<Integer> result = new ArrayList<Integer>();
int size = input.size();
for(int i = 0; i < size; i++){
boolean isMaxima = true;
int plus = order;
int minus = order;
if(i < order){
minus = i;
}
else if( size - i - 1 < order){
plus = size - i - 1;
}
for(int j = 1; j <= plus; j++){
if(input.get(i) < input.get(i + j)){
isMaxima = false;
break;
}
}
for(int j = 1; j <= minus; j++){
if(input.get(i) < input.get(i - j)){
isMaxima = false;
break;
}
}
if(isMaxima){
result.add(i);
}
}
return result;
}
/** Finds and returns the distances between every local maxima in the input */
private ArrayList<Double> getAutoCorrelationDistances(ArrayList<ArrayList<Double>> input){
ArrayList<Double> output = new ArrayList<Double>();
for(int i = 0; i < input.size() - 1; i++){
output.add(input.get(i+1).get(0) - input.get(i).get(0));
}
return output;
}
/** Finds and returns the indices of local minima with similar distances */
private ArrayList<Integer> filterDataMinima(ArrayList<Double> input){
int meanDistance = (int) Math.ceil(getMean(input));
int radius = 10;
int minRange = 0;
int maxRange = meanDistance;
int upTo;
ArrayList<Integer> minimaIndices = new ArrayList<>();
if(numberOfGaitCycles == 0){
upTo = Integer.MAX_VALUE;
}
else{
upTo = numberOfGaitCycles * 2 + 1 + 1 + rightShiftHalfGaitCycles;
}
for(int i = 0; i < upTo; i++){
if(minRange >= filteredData.size()){
break;
}
ArrayList<Double> rangeRaw;
if(maxRange >= filteredData.size()){
maxRange = filteredData.size();
rangeRaw = new ArrayList<>(filteredData.subList(minRange, maxRange));
}
else{
rangeRaw = new ArrayList<>(filteredData.subList(minRange, maxRange + 1));
}
int minimumIndex = getMinimum(rangeRaw) + minRange;
minimaIndices.add(minimumIndex);
minRange = minimumIndex + meanDistance - radius;
maxRange = minimumIndex + meanDistance + radius;
rangeRaw.clear();
}
minimaIndices.remove(0);
minimaIndices = new ArrayList<>(minimaIndices.subList(rightShiftHalfGaitCycles, minimaIndices.size()));
return minimaIndices;
}
/** Splits the input data according to the local minima indices */
private ArrayList<ArrayList<Double>> split(ArrayList<Integer> input){
ArrayList<ArrayList<Double>> output = new ArrayList<ArrayList<Double>>();
for(int i = 0; i < input.size() - 1; i++){
output.add(new ArrayList<>(filteredData.subList(input.get(i), input.get(i + 1))));
}
return output;
}
/** Upsample method to complete cycles with less than 40 samples to 40 Hz */
private ArrayList<Double> upsample(ArrayList<Double> input, double newRate){
int inputLength = input.size();
double oldRate = inputLength;
int size = (int)(newRate/oldRate * inputLength);
ArrayList<Double> output = new ArrayList<Double>();
double dx = 1./oldRate;
double dX = 1./newRate;
output.add(input.get(0));
double k = 0;
for (int i = 1; i < size - 1; i++) {
double X = i * dX;
int p = (int)(X/dx);
int q = p + 1;
k = (input.get(q) - input.get(p))/dx;
double x = p * dx;
output.add(i, input.get(p) + (X - x) * k);
}
output.add(size - 1, input.get(inputLength - 1) + ((size - 1) *dX - (inputLength -1)*dx) *k);
return output;
}
/** Resamples cycles to 40 Hz */
private ArrayList<Double> resample(ArrayList<Double> theInput, int resampleRate){
ArrayList<Double> resample = new ArrayList<Double>();
ArrayList<Double> input = new ArrayList<>(theInput);
Log.d(Constants.TAG, "resample theInput.size(): " + theInput.size());
if(input.size() < 40){
Log.d(Constants.TAG, "upsample cycle with " + input.size());
shortCycleExists = true;
input = upsample(input, 40);
}
DoubleFFT_1D fftDo = new DoubleFFT_1D(input.size());
double[] fft = new double[input.size() * 2];
for(int i = 0; i < input.size(); i++){
fft[i] = input.get(i);
}
fftDo.realForwardFull(fft);
int newSize = Math.min(input.size(),resampleRate );
double[] resampleDouble = new double[newSize*2];
int firstHalf = (newSize+1)/2;
int secondHalf = newSize - firstHalf;
for(int i = 0; i < firstHalf * 2; i++){
resampleDouble[i] = fft[i];
}
for(int i = (firstHalf * 2), j = fft.length - (secondHalf * 2); (i < (newSize * 2) && j < fft.length); i++, j++){
resampleDouble[i] = fft[j];
}
fftDo = new DoubleFFT_1D(newSize);
fftDo.complexInverse(resampleDouble, true);
for(int i = 0; i < resampleDouble.length; i+=2){
resample.add(resampleDouble[i] * (float)resampleRate / (float) input.size());
}
return resample;
}
/** Returns the index of the minimum value in the input*/
private int getMinimum(ArrayList<Double> input){
int minIndex = 0;
for(int i = 1; i < input.size(); i++){
if(input.get(i) < input.get(minIndex)){
minIndex = i;
}
}
return minIndex;
}
/** Returns the mean value of the input */
private double getMean(ArrayList<Double> input)
{
double sum = 0.0;
for(double a : input)
sum += a;
return sum/input.size();
}
/** Returns the variance of the input */
private double getVariance(ArrayList<Double> input)
{
double mean = getMean(input);
double temp = 0;
for(double a :input)
temp += (a-mean)*(a-mean);
return temp/input.size();
}
}
| 5b25c34b06b9fc2a0a7921edfc350831318191b2 | [
"Java",
"Gradle"
] | 4 | Gradle | dschuermann/gait-based-device-pairing | ace1fe13aba755732ee1ed6f1afbe4b63d2937d6 | 31ad65648927b4676c25eb0ea90b3f6ec4fd4f63 |
refs/heads/master | <repo_name>guoyuan4191/saleManage<file_sep>/app01/views.py
from django.shortcuts import render,HttpResponse,redirect
from utils.code import check_code
from django.contrib import auth
# Create your views here.
def code(request):
img,random_code = check_code()
request.session['random_code'] = random_code
# 在内存中读写bytes
from io import BytesIO
stream = BytesIO()
img.save(stream,'png')
return HttpResponse(stream.getvalue())
def login(request):
if request.method == 'GET':
return render(request,'login.html')
user = request.POST.get('user')
pwd = request.POST.get('pwd')
code = request.POST.get('code')
if code.upper() != request.session['random_code'].upper():
return render(request,'login.html',{'msg':'验证码错误'})
user = auth.authenticate(username=user,password=pwd)
if user:
auth.login(request,user)
return redirect('/index/')
return render(request, 'login.html', {'msg': '用户名或密码错误'})
<file_sep>/app01/models.py
from django.db import models
# Create your models here.
class SaleInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
age = models.IntegerField()
email = models.EmailField()
company = models.CharField(max_length=64)
def __str__(self):
return self.name
| 8104737433039f73c2865dd1c3589b9d9cb0925f | [
"Python"
] | 2 | Python | guoyuan4191/saleManage | 68acd9bfe2a581c4fb9d9bed92258c910691ba94 | 66a322e95671fb24e95a0a91471d8be95e2e1d53 |
refs/heads/master | <repo_name>rafi179/crud-php-mvc<file_sep>/php-mvc/app/core/Flasher.php
<?php
// class Flasher
class Flasher{
// fungsi set Flash message
public static function setFlasher($pesan, $aksi, $tipe){
$_SESSION['flash'] = [
'pesan' => $pesan,
'aksi' => $aksi,
'tipe' => $tipe
];
}
// fungsi memanggil flash message
public static function flash(){
if (isset($_SESSION['flash'])){
echo '<div class="alert alert-' . $_SESSION['flash']['tipe'] . ' alert-dismissible fade show" role="alert">Data Mahasiswa
<strong>' . $_SESSION['flash']['pesan'] . '</strong> ' . $_SESSION['flash']['aksi']. '.
<button type="button" class="close" data-dismiss="alert" aria-label="Close">
<span aria-hidden="true">×</span>
</button>
</div>';
unset($_SESSION['flash']);
}
}
// flash message sweetalert
public static function getSweetFlash(){
if(isset($_SESSION['flash'])){
$aksi = $_SESSION['flash']['aksi'];
$tipe = $_SESSION['flash']['tipe'];
$pesan = $_SESSION['flash']['pesan'];
$sweetalert = "<script>
Swal.fire({
title: '$pesan',
text: 'Data mahasiswa berhasil $aksi',
icon: '$tipe',
confirmButtonColor: '#007BFF'
});
</script>";
echo $sweetalert;
unset($_SESSION['flash']);
}
}
}<file_sep>/php-mvc/app/models/Mahasiswa_model.php
<?php
// membuat kelas modal untuk mahasiswa
class Mahasiswa_model{
// properti database
private $tabel = 'table_mahasiswa';
private $db;
// constructor
public function __construct(){
// membuat object database
$this->db = new Database();
}
// fungsi mengabil semua data di database
public function getAllMahasiswa(){
// melakukan prepare query
$this->db->query('SELECT * FROM '. $this->tabel);
// eksekusi query dan mengambil semua data mahasiswa
return $this->db->resultAll();
}
// fungsi mengabil satu data di database
public function getMahasiswaById($id){
// melakukan prepare query
$this->db->query('SELECT * FROM '. $this->tabel.' WHERE id=:id');
// melakukan binding value id
$this->db->bind('id', $id);
// eksekusi query dan mengambil satu data mahasiswa
return $this->db->single();
}
// fungsi tambah data mahasiswa
public function addMahasiswa($data){
$this->db->query("INSERT INTO $this->tabel VALUES ('' , :nim, :nama, :email, :jurusan)");
$this->db->bind('nim', $data['nim']);
$this->db->bind('nama', $data['nama']);
$this->db->bind('email', $data['email']);
$this->db->bind('jurusan', $data['jurusan']);
$this->db->execute();
return $this->db->rowCount();
}
// fungsi hapus data Mahasiswa
public function deleteMahasiswa($id){
$this->db->query("DELETE FROM $this->tabel WHERE id=:id");
$this->db->bind('id', $id);
$this->db->execute();
return $this->db->rowCount();
}
// fungsi Update data mahasiswa
public function updateMahasiswa($id, $data){
$this->db->query("UPDATE $this->tabel SET nim=:nim, nama=:nama, email=:email, jurusan=:jurusan WHERE id=:id");
$this->db->bind('id', $id);
$this->db->bind('nim', $data['nim']);
$this->db->bind('nama', $data['nama']);
$this->db->bind('email', $data['email']);
$this->db->bind('jurusan', $data['jurusan']);
$this->db->execute();
return $this->db->rowCount();
}
// fungsi mengabil satu data di database
public function cariMahasiswa($keyword){
// melakukan prepare query
$this->db->query("SELECT * FROM $this->tabel WHERE nama LIKE :keyword");
// melakukan binding value id
$this->db->bind('keyword', "%$keyword%");
// eksekusi query dan mengambil satu data mahasiswa
return $this->db->resultAll();
}
}<file_sep>/php-mvc/app/views/about/index.php
<div class="container">
<div class="jumbotron">
<h1 class="display-4">About Me</h1>
<p class="lead">Hallo, nama saya <?= $data['nama'] ?>, umur saya <?= $data['umur'] ?> tahun, saya seorang <?= $data['pekerjaan'] ?></p>
<hr class="my-4">
<a class="btn btn-primary btn-lg" href="<?= BASEURL; ?>/about/page" role="button">Learn more</a>
</div>
</div>
<file_sep>/php-mvc/app/controllers/About.php
<?php
// membuat kelas About yang extends ke kelas Controller
class About extends Controller{
// index
public function index($nama = '<NAME>', $pekerjaan = 'Mahasiswa', $umur = 21){
$data['nama'] = $nama;
$data['pekerjaan'] = $pekerjaan;
$data['umur'] = $umur;
$data['judul'] = 'About';
$this->view('layouts/header', $data);
$this->view('about/index', $data);
$this->view('layouts/footer');
}
// page
public function page()
{
$data['judul'] = 'Pages';
$this->view('layouts/header', $data);
$this->view('about/page', $data);
$this->view('layouts/footer');
}
}<file_sep>/database/php_mvc.sql
-- phpMyAdmin SQL Dump
-- version 5.0.4
-- https://www.phpmyadmin.net/
--
-- Host: 127.0.0.1
-- Generation Time: Jul 03, 2021 at 10:39 AM
-- Server version: 10.4.17-MariaDB
-- PHP Version: 7.4.14
SET SQL_MODE = "NO_AUTO_VALUE_ON_ZERO";
START TRANSACTION;
SET time_zone = "+00:00";
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8mb4 */;
--
-- Database: `php_mvc`
--
-- --------------------------------------------------------
--
-- Table structure for table `table_mahasiswa`
--
CREATE TABLE `table_mahasiswa` (
`id` int(11) NOT NULL,
`nim` int(11) NOT NULL,
`nama` varchar(50) NOT NULL,
`email` varchar(255) NOT NULL,
`jurusan` varchar(255) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
--
-- Dumping data for table `table_mahasiswa`
--
INSERT INTO `table_mahasiswa` (`id`, `nim`, `nama`, `email`, `jurusan`) VALUES
(2, 19050210, '<NAME>', '<EMAIL>', 'Teknik Mesin'),
(6, 19020302, '<NAME>', '<EMAIL>', 'Teknik Elektronika'),
(8, 19040100, '<NAME>', '<EMAIL>', 'Teknik Komputer'),
(9, 19040179, '<NAME>', '<EMAIL>', 'Teknik Komputer');
--
-- Indexes for dumped tables
--
--
-- Indexes for table `table_mahasiswa`
--
ALTER TABLE `table_mahasiswa`
ADD PRIMARY KEY (`id`);
--
-- AUTO_INCREMENT for dumped tables
--
--
-- AUTO_INCREMENT for table `table_mahasiswa`
--
ALTER TABLE `table_mahasiswa`
MODIFY `id` int(11) NOT NULL AUTO_INCREMENT, AUTO_INCREMENT=10;
COMMIT;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
<file_sep>/php-mvc/public/js/script.js
$(function(){
// tombol Tambah
$('.tombolTambah').on('click', function(){
$('#judulModal').html('Tambah Data Mahasiswa');
$('.modal-footer button[type=submit]').html('Tambah Data');
// mengkosongkan isi input di modal Tambah data
$('#nama').val('');
$('#nim').val('');
$('#email').val('');
$('#jurusan').val('Pilih Jurusan');
});
// tombol Ubah
$('.tombolUbah').on('click', function(){
$('#judulModal').html('Ubah Data Mahasiswa');
$('.modal-footer button[type=submit]').html('Ubah Data');
// mengambil isi href kemudian ganti isi attribut action di form
const href = $(this).attr('href');
$('.modal-content form').attr('action', href)
// mengambil id lewat attribut data-id
const id = $(this).data('id');
// melakukan request data lewat ajax
$.ajax({
url: 'http://localhost:8080/php-mvc/public/mahasiswa/getEdit',
data: {id : id},
method: 'post',
dataType: 'json',
success: function(data){
// menampilkan data ke input ubah data
$('#nama').val(data.nama);
$('#nim').val(data.nim);
$('#email').val(data.email);
$('#jurusan').val(data.jurusan);
}
});
});
// tombol Hapus
$('.tombolHapus').on('click', function(e){
// mematikan href jika ingin menggunakan sweetalert
e.preventDefault();
// mengambil nilai attrubut href
const href = $(this).attr('href');
// sweetalert confirm
Swal.fire({
title: 'Apakah anda yakin?',
text: "Data Mahasiswa akan dihapus",
type: 'warning',
showCancelButton: true,
confirmButtonColor: '#3085d6',
cancelButtonColor: '#d33',
confirmButtonText: 'Hapus data!'
}).then((result) => {
if (result.value) {
// pindah ke halaman delete jika di konfirmasi
document.location.href = href;
}
});
});
});<file_sep>/php-mvc/app/models/User_model.php
<?php
// membuat kelas model untuk user
class User_model{
private $user = '<NAME>';
public function getUser(){
return $this->user;
}
}<file_sep>/php-mvc/app/config/config.php
<?php
// membuat konstanta Base url
define('BASEURL', 'http://localhost:8080/php-mvc/public');
// kontanta Database
define('DB_HOST', 'localhost');
define('DB_NAME', 'php_mvc');
define('DB_USER', 'root');
define('DB_PASS', '');<file_sep>/php-mvc/app/controllers/Mahasiswa.php
<?php
// membuat controller untuk mahasiswa
class Mahasiswa extends Controller{
// index
public function index(){
$data['judul'] = 'Daftar Mahasiswa';
$data['mhs'] = $this->model('Mahasiswa_model')->getAllMahasiswa();
$this->view('layouts/header', $data);
$this->view('mahasiswa/index', $data);
$this->view('layouts/footer');
}
// detail mahasiswa
public function detail($id){
$data['judul'] = 'Detail Mahasiswa';
$data['mhs'] = $this->model('Mahasiswa_model')->getMahasiswaById($id);
$this->view('layouts/header', $data);
$this->view('mahasiswa/detail', $data);
$this->view('layouts/footer');
}
// tambah data mahasiswa
public function tambah(){
if($this->model('Mahasiswa_model')->addMahasiswa($_POST) > 0){
header('Location: ' . BASEURL . '/mahasiswa');
Flasher::setFlasher('Berhasil', 'ditambahkan', 'success');
exit;
}else{
header('Location: ' . BASEURL . '/mahasiswa');
Flasher::setFlasher('Gagal', 'ditambahkan', 'danger');
exit;
}
}
// Hapus data mahasiswa
public function hapus($id){
if($this->model('Mahasiswa_model')->deleteMahasiswa($id) > 0){
header('Location: ' . BASEURL . '/mahasiswa');
Flasher::setFlasher('Berhasil', 'dihapus', 'success');
exit;
}else{
header('Location: ' . BASEURL . '/mahasiswa');
Flasher::setFlasher('Gagal', 'dihapus', 'danger');
exit;
}
}
// Ubah Data mahasiswa
public function ubah($id){
if($this->model('Mahasiswa_model')->updateMahasiswa($id, $_POST) > 0){
header('Location: ' . BASEURL . '/mahasiswa');
Flasher::setFlasher('Berhasil', 'diubah', 'success');
exit;
}else{
header('Location: ' . BASEURL . '/mahasiswa');
Flasher::setFlasher('Gagal', 'diubah', 'danger');
exit;
}
}
// mengambil satu data mahasiswa dengan tipe data json
public function getEdit(){
echo json_encode($this->model('Mahasiswa_model')->getMahasiswaById($_POST['id']));
}
// fungsi cari data mahasiswa
public function cari(){
$data['judul'] = 'Daftar Mahasiswa';
$data['mhs'] = $this->model('Mahasiswa_model')->cariMahasiswa($_POST['keyword']);
$this->view('layouts/header', $data);
$this->view('mahasiswa/index', $data);
$this->view('layouts/footer');
}
} | a9a612aa9f88d955cf559ad447adef6b055f103d | [
"JavaScript",
"SQL",
"PHP"
] | 9 | PHP | rafi179/crud-php-mvc | 34efda6f1ae675c7c9ffae6959c9247b7ab7ba28 | 8f0126aedd4c26c84df6d5a6c66f65b91d01054c |
refs/heads/master | <file_sep>import joblib
import sklearn
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import librosa, librosa.display
import numpy as np
import matplotlib.pyplot as plt
def load_file(file_path):
test_features = []
signal, sr = librosa.load(file_path, sr = 22050)
n_fft = 2048
n_mfcc = 13
hop_length = 512
num_segments = 3
SAMPLE_RATE = 22050
DURATION = 10 # measured in seconds.
SAMPLES_PER_TRACK = SAMPLE_RATE * DURATION
num_samples_per_segment = int(SAMPLES_PER_TRACK / num_segments)
for s in range(num_segments):
start_sample = num_samples_per_segment * s # if s= 0 -> then start_sample = 0
finish_sample = start_sample + num_samples_per_segment
# features
rolloff = librosa.feature.spectral_rolloff(y=signal[start_sample: finish_sample], sr=sr, roll_percent=0.1)
pitches, magnitudes = librosa.piptrack(y=signal[start_sample: finish_sample], sr=sr)
mfcc = librosa.feature.mfcc(signal[start_sample: finish_sample],
sr =sr,
n_fft = n_fft,
n_mfcc = n_mfcc,
hop_length = hop_length
)
chroma_cq = librosa.feature.chroma_cqt(y=signal[start_sample: finish_sample], sr=sr)
# Combining all the features
features = np.concatenate((pitches, rolloff, mfcc, chroma_cq), axis = 0)
test_features.append(features)
test_feat = np.array(test_features)
model_features = test_feat.reshape(test_feat.shape[0], (test_feat.shape[1]*test_feat.shape[2]))
return model_features
# def predict(cough_fp, saved_model_fp):
# loaded_model = joblib.load(saved_model_fp)
# cough_features = load_file(cough_fp)
# result = loaded_model.predict_proba(cough_features)
# print("Results are : ", result)
# class_neg = []
# class_pos = []
# l = 0
# for i in result:
# j = np.argmax(i)
# k = result[l][j]
# if j == 0:
# class_neg.append(k)
# else:
# class_pos.append(k)
# l += 1
# print("class neg: ", class_neg)
# print("class pos: ", class_pos)
# if not class_neg:
# print("covid positive")
# prob_pos = np.mean(class_pos)
# print("prob posit: ", prob_pos)
# # return prob_neg
# elif not class_pos:
# print("covid negative")
# prob_neg = np.mean(class_neg)
# print("prob neg: ", prob_neg)
# # return prob_pos
# else:
# prob_neg = np.mean(class_neg)
# # print(m)
# prob_pos = np.mean(class_pos)
# if prob_neg > prob_pos:
# print("covid neg")
# return "Covid Negatve :" + str(prob_neg)
# else:
# print("covid pos")
# return "Covid Positive" + str(prob_pos)
# ignoring negative and returning 0
# def predict(cough_fp, saved_model_fp):
# loaded_model = joblib.load(saved_model_fp)
# cough_features = load_file(cough_fp)
# result = loaded_model.predict_proba(cough_features)
# print("Results are : ", result)
# class_neg = []
# class_pos = []
# l = 0
# for i in result:
# j = np.argmax(i)
# k = result[l][j]
# if j == 0:
# class_neg.append(k)
# else:
# class_pos.append(k)
# l += 1
# print("class neg: ", class_neg)
# print("class pos: ", class_pos)
# if not class_neg:
# print("covid positive")
# prob_pos = np.mean(class_pos)
# print("prob posit: ", prob_pos)
# # return "Covid positive: " + str(prob_pos)
# return prob_pos * 100
# elif not class_pos:
# # print("covid negative")
# # prob_neg = np.mean(class_neg)
# # print("prob neg: ", prob_neg)
# # return "Covid negative: "+ str(prob_neg)
# return 0
# else:
# prob_neg = np.mean(class_neg)
# # print(m)
# prob_pos = np.mean(class_pos)
# if prob_neg > prob_pos:
# # print("covid neg")
# # return "Covid Negatve :" + str(prob_neg)
# return 0
# else:
# print("covid pos")
# # return "Covid Positive :" + str(prob_pos)
# return prob_pos * 100
# returning prob of the class having max vote count
def predict(cough_fp, saved_model_fp):
loaded_model = joblib.load(saved_model_fp)
cough_features = load_file(cough_fp)
result = loaded_model.predict_proba(cough_features)
print("Results are : ", result)
class_neg = []
class_pos = []
l = 0
for i in result:
j = np.argmax(i)
k = result[l][j]
if j == 0:
class_pos.append(k)
else:
class_neg.append(k)
l += 1
print("class neg: ", class_neg)
print("class pos: ", class_pos)
if not class_neg:
print("covid positive")
prob_pos = np.mean(class_pos)
print("prob posit: ", prob_pos)
# return "Covid positive: " + str(prob_pos)
return prob_pos
elif not class_pos:
# print("covid negative")
# prob_neg = np.mean(class_neg)
# print("prob neg: ", prob_neg)
# return "Covid negative: "+ str(prob_neg)
return 0
else:
prob_neg = np.mean(class_neg)
prob_pos = np.mean(class_pos)
if len(class_neg) > len(class_pos):
return 0
# if prob_neg > prob_pos:
# print("covid neg")
# return "Covid Negatve :" + str(prob_neg)
# return 0
else:
return prob_pos<file_sep>let currentStep = 0;
// onload show first step
showStep(currentStep);
// on next button click
document.getElementById('next').addEventListener('click', function () {
// Validating the form
if (validateForm(currentStep)) {
// incrementing the step
currentStep += 1;
// showing the incremented step;
showStep(currentStep);
}
});
// on prev button click
document.getElementById('previous').addEventListener('click', function () {
// decrementing the step
currentStep -= 1;
// showing decremented step
showStep(currentStep);
});
function showStep(step) {
// display button
// checking whether the current step is valid or not
if (step === 0 || step === 1) {
document.getElementById('previous').style.display = 'none'
document.getElementById('next').style.display = 'inline';
document.getElementById('submit').style.display = 'none';
} else if (step === document.getElementsByClassName('step').length - 1) {
document.getElementById('previous').style.display = 'inline'
document.getElementById('next').style.display = 'none';
document.getElementById('submit').style.display = 'inline';
} else {
document.getElementById('previous').style.display = 'inline'
document.getElementById('next').style.display = 'inline';
document.getElementById('submit').style.display = 'none';
}
// displaying question counter
document.querySelector('#step-counter h1').textContent = step + 1;
currentStep = step;
document.querySelectorAll('.step').forEach((item, index) => {
// display step
if (index !== step) {
item.style.display = 'none';
} else {
item.style.display = 'block';
}
});
}
// for form validation
function validateForm(step) {
let subForm = document.querySelectorAll('.step')[step];
let flag = true;
// for radio button input (consent form) validation
if (subForm.querySelector('input[type=radio]') != null) {
if (subForm.querySelector("input[type=radio]").checked !== true) {
alert("Please, agree with the terms.");
flag = false;
}
}
// for all input['number'] and select tags
subForm.querySelectorAll("input[type=number], select").forEach((item) => {
// console.log(item);
if (item.value === '' || item.value <= 0) {
item.classList.add('is-invalid');
flag = false;
} else {
item.classList.remove('is-invalid');
item.classList.add('is-valid');
}
});
// for all input['checkbox']
if (subForm.querySelector('input[type=checkbox]') != null) {
let check = false;
subForm.querySelectorAll('input[type=checkbox]').forEach((item, index) => {
// Can't skip the process -- show alert if user tries to do so
if (item.checked === true)
check = true;
});
if (!check) {
alert("Please check atleast one value.");
flag = false;
}
}
return flag;
}
// Adding event listener for fetching result
document.querySelector('#submit').addEventListener('click', fetchResult);
async function fetchResult(e) {
e.preventDefault();
if (currentStep === document.getElementsByClassName('step').length - 1 && validateForm(currentStep)) {
/////// loader added
$('#loader_1').show();
$('#loader_1').html('Wait.. <img src="static/app_assets/images/loader.gif" />')
///////
var messgae_print = $('#message_print').val();
var rizwan = document.getElementById('mydatas');
let fd = new FormData(rizwan);
let cough_audio, breath_audio;
if (document.querySelector('#cough-audio') != null) {
cough_audio = await fetch(document.querySelector('#cough-audio').src).then(
r => r.blob()
);
} else {
alert("Please record cough, its mandatory!");
$('#loader_1').hide(); //loader added here
return;
}
if (document.querySelector('#breath-audio') != null) {
breath_audio = await fetch(document.querySelector('#breath-audio').src).then(
r => r.blob()
);
} else {
alert("Please record breath, its mandatory!");
$('#loader_1').hide(); //loader added here
return;
}
fd.append("cough_data", cough_audio, "coughFile.wav");
fd.append("breath_data", breath_audio, "breathFile.wav");
$.ajax({
type: "POST",
url: 'https://predict.reliefme.org/data',
// url: 'http://127.0.0.1:5000/data',
data: fd, // Data sent to server, a set of key/value pairs (i.e. form fields and values)
contentType: false, // The content type used when sending data to the server.
cache: false, // To unable request pages to be cached
processData: false,
success: function (result) {
Swal.fire({
html: "<div style='margin-bottom: 10px;'> <img src='static/app_assets/images/logo-black.png' width='300'> </div>" +
"<h4>Your Statistical symptoms show probability of Corona : </h4>" +
"<h4>Your cough patterns show probability of Corona : </h4>" +
"<h4>Your breath patterns show probability of Corona : </h4>" +
"<h3 class='font-weight-bold text-success' align = 'center'><u>Final Result</u></h3>" +
"<h4 class='font-weight-bold'> </h4>",
onBeforeOpen: () => {
const content = Swal.getContent()
if (content) {
const b = content.querySelectorAll('h4')
if (b) {
let {prediction, cough_result, breath_result, msg} = result;
b[0].textContent += prediction + " %";
b[1].textContent += cough_result+ " %";
b[2].textContent += breath_result+ " %";
b[3].textContent = msg;
}
}
}
// showCancelButton: true,
// confirmButtonColor: '#3085d6',
// cancelButtonColor: '#d33',
// confirmButtonText: 'Download!',
// className: 'window'
// // text: result
// }).then((result) => {
// if (result.value) {
// // window.scrollTo(0, 0);
// var image;
// html2canvas(document.querySelector(".window"), {width: 2000, height: 2000}).then(function (canvas) {
// image = canvas.toDataURL("", "image/png", 0.9);
// // console.log(image);
// let link = document.createElement('a');
// link.href = image
// link.download = "ReliefMe-report.png"
// link.click();
// URL.revokeObjectURL(link.href);
// }).catch(err => console.log(err));
// }
});
////////// loader added
$('#loader_1').hide();
/////////////
}
});
}
}<file_sep>// Some global variables
let coughHasRecorded = false;
let breathHasRecorded = false;<file_sep>//webkitURL is deprecated but nevertheless
URL = window.URL || window.webkitURL;
var gumStream; //stream from getUserMedia()
var rec; //Recorder.js object
var input; //MediaStreamAudioSourceNode we'll be recording
// shim for AudioContext when it's not avb.
var AudioContext = window.AudioContext || window.webkitAudioContext;
var audioContext //audio context to help us record
var recordButton = document.getElementById("recordButton");
let timer;
//add events to those 2 buttons
recordButton.addEventListener("click", startRecording);
function startRecording() {
document.getElementById('bulb').style.display = 'inline-block';
document.querySelector('#recordBreathButton').disabled = true;
console.log("recordButton clicked");
timer = setTimeout(stopRecording, 11800);
/*
Simple constraints object, for more advanced audio features see
https://addpipe.com/blog/audio-constraints-getusermedia/
*/
var constraints = {
audio: true,
video: false
}
/*
Disable the record button until we get a success or fail from getUserMedia()
*/
recordButton.disabled = true;
/*
We're using the standard promise based getUserMedia()
https://developer.mozilla.org/en-US/docs/Web/API/MediaDevices/getUserMedia
*/
navigator.mediaDevices.getUserMedia(constraints).then(function (stream) {
console.log("getUserMedia() success, stream created, initializing Recorder.js ...");
/*
create an audio context after getUserMedia is called
sampleRate might change after getUserMedia is called, like it does on macOS when recording through AirPods
the sampleRate defaults to the one set in your OS for your playback device
*/
audioContext = new AudioContext();
/* assign to gumStream for later use */
gumStream = stream;
/* use the stream */
input = audioContext.createMediaStreamSource(stream);
/*
Create the Recorder object and configure to record mono sound (1 channel)
Recording 2 channels will double the file size
*/
rec = new Recorder(input, {
numChannels: 1
})
//start the recording process
rec.record()
console.log("Recording started");
}).catch(function (err) {
//enable the record button if getUserMedia() fails
document.querySelector('#recordBreathButton').disabled = breathHasRecorded ? true : false;
recordButton.disabled = false;
});
}
function stopRecording() {
document.getElementById('bulb').style.display = 'none';
document.querySelector('#recordBreathButton').disabled = breathHasRecorded ? true : false;
clearTimeout(timer);
//disable the stop button, enable the record too allow for new recordings
//tell the recorder to stop the recording
rec.stop();
//stop microphone access
gumStream.getAudioTracks()[0].stop();
//create the wav blob and pass it on to createDownloadLink
rec.exportWAV(createDownloadLink);
}
function createDownloadLink(blob) {
var url = URL.createObjectURL(blob);
var au = document.createElement('audio');
var li = document.createElement('li');
//add controls to the <audio> element
au.controls = true;
au.src = url;
au.id = "cough-audio";
//add the new audio element to li
li.appendChild(au);
// ! setting recorded state
coughHasRecorded = true;
//add the li element to the ol
recordingsList.appendChild(li);
recordButton.disabled = true;
document.querySelector('#del-cough').style.display = 'inline-block';
}
// Adding delete cough event on button click
document.querySelector('#del-cough').addEventListener('click', () => {
let li = document.querySelector('#recordingsList li');
// ! setting recorded state
coughHasRecorded = false;
li.remove();
recordButton.disabled = false;
document.querySelector('#del-cough').style.display = 'none';
});<file_sep>//webkitURL is deprecated but nevertheless
URL = window.URL || window.webkitURL;
var bgumStream; //stream from getUserMedia()
var brec; //Recorder.js object
var binput; //MediaStreamAudioSourceNode we'll be recording
// shim for AudioContext when it's not avb.
var bAudioContext = window.AudioContext || window.webkitAudioContext;
var baudioContext //audio context to help us record
var brecordButton = document.getElementById("recordBreathButton");
let breath_timer;
//add events to those 2 buttons
brecordButton.addEventListener("click", startBreathRecording);
function startBreathRecording() {
document.getElementById('bulb_breath').style.display = 'inline-block';
document.querySelector('#recordButton').disabled = true;
// console.log("recordButton clicked");
breath_timer = setTimeout(stopBreathRecording, 11800);
var constraints = {
audio: true,
video: false
}
brecordButton.disabled = true;
navigator.mediaDevices.getUserMedia(constraints).then(function (stream) {
console.log("getUserMedia() success, stream created, initializing Recorder.js ...");
/*
create an audio context after getUserMedia is called
sampleRate might change after getUserMedia is called, like it does on macOS when recording through AirPods
the sampleRate defaults to the one set in your OS for your playback device
*/
baudioContext = new AudioContext();
/* assign to bgumStream for later use */
bgumStream = stream;
/* use the stream */
binput = baudioContext.createMediaStreamSource(stream);
/*
Create the Recorder object and configure to record mono sound (1 channel)
Recording 2 channels will double the file size
*/
brec = new Recorder(binput, {
numChannels: 1
})
//start the recording process
brec.record()
console.log("Recording started");
}).catch(function (err) {
//enable the record button if getUserMedia() fails
brecordButton.disabled = false;
document.querySelector('#recordButton').disabled = coughHasRecorded ? true : false;
});
}
function stopBreathRecording() {
// Setting some states and values
document.getElementById('bulb_breath').style.display = 'none';
document.querySelector('#recordButton').disabled = coughHasRecorded ? true : false;
clearTimeout(breath_timer);
//tell the recorder to stop the recording
brec.stop();
//stop microphone access
bgumStream.getAudioTracks()[0].stop();
//create the wav blob and pass it on to createDownloadLink
brec.exportWAV(createBreathDownloadLink);
}
function createBreathDownloadLink(blob) {
var url = URL.createObjectURL(blob);
var au = document.createElement('audio');
var li = document.createElement('li');
//add controls to the <audio> element
au.controls = true;
au.src = url;
au.id = "breath-audio";
//add the new audio element to li
li.appendChild(au);
// ! setting recorded state
breathHasRecorded = true;
//add the li element to the ol
recordingsBreathList.appendChild(li);
brecordButton.disabled = true;
document.querySelector('#del-breath').style.display = 'inline-block';
}
// Adding delete cough event on button click
document.querySelector('#del-breath').addEventListener('click', () => {
let li = document.querySelector('#recordingsBreathList li');
// ! setting recorded state
breathHasRecorded = false;
li.remove();
brecordButton.disabled = false;
document.querySelector('#del-breath').style.display = 'none';
});<file_sep>click==7.0
itsdangerous==1.1.0
Flask==1.1.2
Flask-Cors==3.0.8
google-auth==1.16.0
google-auth-oauthlib==0.4.1
google-pasta==0.2.0
grpcio==1.29.0
h5py==2.10.0
idna==2.9
imbalanced-learn==0.6.2
imblearn==0.0
ipython==7.14.0
ipython-genutils==0.2.0
ipywidgets==7.5.1
isort==4.3.21
itsdangerous==1.1.0
jedi==0.17.0
Jinja2==2.11.2
joblib==0.15.1
jsonschema==3.2.0
librosa==0.7.2
Markdown==3.2.2
matplotlib==3.2.1
numba==0.48.0
numpy==1.18.4
oauthlib==3.1.0
packaging==20.4
pandas==1.0.3
pickleshare==0.7.5
protobuf==3.12.2
requests==2.23.0
requests-oauthlib==1.3.0
resampy==0.2.2
scikit-learn==0.22.1
scipy==1.4.1
seaborn==0.10.1
sklearn==0.0
terminado==0.8.3
urllib3==1.25.9
wcwidth==0.1.9
webencodings==0.5.1
Werkzeug==1.0.1
wrapt==1.12.1
SoundFile==0.10.3.post1
MarkupSafe==1.1.1
colorama==0.4.3
ip2geotools==0.1.5
uuid==1.30
pymongo==3.10.1
<file_sep>from flask import Flask, render_template, url_for, request, jsonify, make_response, flash, redirect
from sklearn.externals import joblib
import librosa
import requests
import uuid
import json
import cough as CP
import text_api
import breath as bm
import os
from ip2geotools.databases.noncommercial import DbIpCity
from urllib.request import urlopen
from pymongo import MongoClient
import pandas as pd
import numpy as np
from werkzeug.utils import secure_filename
application = Flask(__name__)
client = MongoClient("localhost", 27017)
db = client.SentencesDatabase
users = db["Users"]
# UPLOAD_FOLDER = './uploads'
# ALLOWED_EXTENSIONS = {'mp3', 'wav'}
# application.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
#def allowed_file(filename):
# return '.' in filename and \
# filename.rsplit('.', 1)[1].lower() in ALLOWED_EXTENSIONS
@application.route('/', methods=['GET', 'POST'])
def index():
dicti = data()
return render_template('app.html',predic=dicti)
@application.route('/data', methods=['GET', 'POST'])
def data():
if request.method == 'POST':
try:
age = request.form.get('age')
gender = request.form.get('gender')
smoker = request.form.get('smoker')
symptoms = request.form.getlist('reported_symptoms')
medical_history = request.form.getlist('medical_history')
symptoms = ",".join(symptoms) + ","
medical_history = ",".join(medical_history) + ","
# hasham = request.files
hasham = request.files.get("cough_data")
breath = request.files.get("breath_data")
location = request.form.get("user_locations")
# Textual model
response = {"age": [int(age)], "gender": [gender],
"smoker": [smoker], "patient_reported_symptoms": [symptoms],
"medical_history": [medical_history]
}
if location == "furqan":
# location = f"{loc_response.country}, {loc_response.region}, {loc_response.city}"
location = "Empty"
df1 = pd.DataFrame(response)
prediction = round(text_api.predict(df1, "./model81.pkl"), 2)
# pp = os.getcwd()
hash = uuid.uuid4().hex
cough_path = "./uploads/cough/hasham"
breath_path = "./uploads/breath/breath"
with open(cough_path + hash + ".wav", 'wb') as ft:
ft.write(hasham.read())
with open(breath_path + hash + ".wav", 'wb') as ft:
ft.write(breath.read())
# return symptoms
# return jsonify(hasham.read())
# check if the post request has the file part
# if 'file' not in request.files:
# flash('No file part')
# return redirect(request.url)
# file = request.files['file']
# # if user does not select file, browser also
# # submit an empty part without filename
# if file.filename == '':
# flash('No selected file')
# return redirect(request.url)
# if file and allowed_file(file.filename):
# filename = secure_filename(file.filename)
# file.save(os.path.join(app.config['UPLOAD_FOLDER'], filename))
####### Predictions
cough_result = CP.predict(cough_path+ hash + ".wav", './cough_model.pkl')
breath_result = bm.predict(breath_path+ hash + ".wav", './breath_model.pkl')
cough_result = round(cough_result, 2)
breath_result = round(breath_result, 2)
####### DB insertion
users.insert_one({
"age": age,
"gender" : gender,
"smoker" : smoker,
"symptoms": symptoms,
"medical_history": medical_history,
"cough_path": cough_path+ hash + ".wav",
"breath_path": breath_path+ hash + ".wav",
"statistical_result": prediction,
"cough_results": cough_result,
"breath_results": breath_result,
"location": location
})
msg = ""
######## Conditions
if prediction == 0 and cough_result == 0 and breath_result == 0:
msg = "Hooray! You are safe. You are Covid free!!!"
elif prediction == 0 and cough_result > 0 and breath_result > 0:
msg = "We are worried! You need to visit doctor.!!!"
elif prediction > 0 and cough_result > 0 and breath_result > 0:
msg = "Your health condition seems Serious. You need to visit doctor!!!"
elif prediction > 0 and cough_result == 0 and breath_result == 0:
msg = "Hooray! You are safe. You are Covid free, Just take rest and eat healthy..!!!"
elif prediction > 0 and cough_result == 0 and breath_result > 0:
msg = "There are very mild Symptoms, Don't worry, we suggest you to Isolate yourself and eat healthy Food!!!"
elif prediction > 0 and cough_result > 0 and breath_result == 0:
msg = "There are mild Symptoms of Corona, we suggest you to Isolate yourself and eat healthy Food!!!"
elif prediction == 0 and cough_result > 0 and breath_result == 0:
msg = "There are very mild Symptoms of Corona, Don't worry, we suggest you to Isolate yourself and eat healthy Food!!!"
elif prediction == 0 and cough_result == 0 and breath_result > 0:
msg = "There are extremely low symptoms, Don't worry, Stay at Home and eat healthy Food!!!"
############
return jsonify({
"prediction": round((prediction * 100), 2),
"cough_result": round((cough_result * 100), 2),
"breath_result": round((breath_result * 100), 2),
"msg": msg
})
except:
return "Please check if the values are entered correctly"
# if __name__ == "__main__":
# application.run(debug=True)
# if __name__ == '__main__':
# application.run(host='0.0.0.0', port=80)
<file_sep>var userLocation = (function() {
return {
init: function() {
this.getLocation();
},
getLocation: function() {
var self = this;
navigator.geolocation.getCurrentPosition(self.geocodeLocation, self.printError);
},
geocodeLocation: function(loc) {
var self = userLocation;
self.position = {
lat: loc.coords.latitude,
long: loc.coords.longitude
}
self.geocoder = new google.maps.Geocoder();
var currentLocation = new google.maps.LatLng(self.position.lat, self.position.long);
self.geocoder.geocode({
'latLng': currentLocation
}, function(results, status) {
if (status == google.maps.GeocoderStatus.OK) {
self.address = results[2].formatted_address;
self.printLocation();
}
// else if(status == google.maps.GeocoderStatus.REQUEST_DENIED){
// var location2 = "furqan";
// $('#user_locations').val(location2);
// }
// else if(status == google.maps.GeocoderStatus.ZERO_RESULTS){
// var location2 = "furqan";
// $('#user_locations').val(location2);
// }
// else if(status == google.maps.GeocoderStatus.INVALID_REQUEST){
// var location2 = "furqan";
// $('#user_locations').val(location2);
// }
// else if(status == google.maps.GeocoderStatus.UNKNOWN_ERROR){
// var location2 = "furqan";
// $('#user_locations').val(location2);
// }
});
},
printLocation: function() {
var self = userLocation;
$('#user_locations').val(self.address);
},
printError: function() {
// alert("Please Allow Location for Better performance");
var location2 = "furqan";
$('#user_locations').val(location2);
// alert(self_address);
// $('#geo_city').val(geo_city);
// $('.searchTextField12').val(self_address);
// navigator.geolocation.getCurrentPosition(function(position) {
// yourFunction(position.coords.latitude, position.coords.longitude);
// });
// Geolocation();
// $('#searchTextField_rent_a_car_salman').val('No location found');
}
};
}());
$(document).ready(function() {
userLocation.init();
});<file_sep>import joblib
import sklearn
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
import librosa, librosa.display
import numpy as np
import matplotlib.pyplot as plt
############ Without Silence #############
def load_file(file_path):
test_features = []
signal, sr = librosa.load(file_path, sr = 22050)
n_fft = 2048
n_mfcc = 13
hop_length = 512
num_segments = 1
SAMPLE_RATE = 22050
DURATION = 4 # measured in seconds.
SAMPLES_PER_TRACK = SAMPLE_RATE * DURATION
num_samples_per_segment = int(SAMPLES_PER_TRACK / num_segments)
for s in range(num_segments):
start_sample = num_samples_per_segment * s # if s= 0 -> then start_sample = 0
finish_sample = start_sample + num_samples_per_segment
# features
zc = librosa.feature.chroma_stft(y=signal[start_sample: finish_sample],
sr=sr,n_chroma=12, n_fft=4096)
mfcc = librosa.feature.mfcc(signal[start_sample: finish_sample],
sr =sr,
n_fft = 2048,
n_mfcc = 13,
hop_length = 512
)
chroma_cq = librosa.feature.chroma_cqt(y=signal[start_sample: finish_sample], sr=sr)
pitches, magnitudes = librosa.piptrack(y=signal[start_sample: finish_sample], sr=sr)
rolloff = librosa.feature.spectral_rolloff(y=signal[start_sample: finish_sample], sr=sr, roll_percent=0.1)
# Combining all the features
features = np.concatenate((zc, mfcc, chroma_cq, pitches, rolloff), axis = 0)
test_features.append(features)
test_feat = np.array(test_features)
model_features = test_feat.reshape(test_feat.shape[0], (test_feat.shape[1]*test_feat.shape[2]))
return model_features
def predict(cough_fp, saved_model_fp):
loaded_model = joblib.load(saved_model_fp)
breath_features = load_file(cough_fp)
y_pred = loaded_model.predict_proba(breath_features)
k = np.argmax(y_pred)
if k == 1:
return y_pred[0][1]
elif k == 0:
return 0
| 84c95b03e12626e75eaa0a19f719811417c27b00 | [
"JavaScript",
"Python",
"Text"
] | 9 | Python | ReliefMe/Cough_python | eebd7ddfb8407abef12c4427de30547fdb1ba52a | 511b7556303b789c2daf724fc69ac7dfb9308dc8 |
refs/heads/master | <file_sep>import sys, os
from Bio import SeqIO
from Bio.Alphabet import IUPAC, Gapped
from Bio.Align import MultipleSeqAlignment
from Bio.Phylo.PAML import baseml,yn00,codeml
from Bio.SeqRecord import SeqRecord
inputfile=sys.argv[1]
treefile=sys.argv[2]
outputfile=sys.argv[3]
filehandler=open(inputfile)
align = MultipleSeqAlignment([], Gapped(IUPAC.unambiguous_dna, "-"))
msa = "MSA.phy"
phylip=open(msa, 'w')
for record in SeqIO.parse(filehandler, 'fasta'):
id=record.id
sequence=str(record.seq)
align.add_sequence(id, sequence)
phylip.write(align.format('phylip-sequential'))
phylip.close()
cml=codeml.Codeml(alignment="MSA.phy", tree=treefile, out_file = outputfile)
cml.set_options(seqtype=1) # set this option bases on codon or aminoacid, values accepted 1,2 or 3
cml.set_options(model=3)
cml.set_options(NSsites="3")
cml.set_options(ncatG="3")
cml.run()
<file_sep>## README
### How to run HYPHYMP to get dN and dS value at each codon/amino acid
1) In the command line, type HYPHYMP and hit enter. Note: HYPHYMP needs to be installed
2) Choose option 1 (Selection Analyses)
3) Choose option 3 [SLAC]
4) Choose option 1 ([**Universal**] Universal code.)
5) Provide full path to the sequence alignment file
6) Provide full path to the tree from sequence alignment
7) Choose option 1 ([**All**] )
8) Select the number of samples used to assess ancestral reconstruction uncertainty, default is 100
The results are printed on the terminal. These can be copied and save in a file.
<file_sep>import sys, os
from Bio import SeqIO
from Bio.Alphabet import IUPAC, Gapped
from Bio.Align import MultipleSeqAlignment
from Bio.Phylo.PAML import baseml,yn00
from Bio.SeqRecord import SeqRecord
inputfile=sys.argv[1]
filehandler=open(inputfile)
align = MultipleSeqAlignment([], Gapped(IUPAC.unambiguous_dna, "-"))
msa = "MSA.phy"
phylip=open(msa, 'w')
for record in SeqIO.parse(filehandler, 'fasta'):
id=record.id
sequence=str(record.seq)
align.add_sequence(id, sequence)
phylip.write(align.format('phylip-sequential'))
phylip.close()
yn=yn00.Yn00()
yn.alignment=msa
yn.out_file=sys.argv[2]
yn.run(verbose=True)
<file_sep>## 29 March 2019
Biopython Script for getting dN/dS completed
## 11 April 2019
Used HYPHYMP to get dN dS at each codon positions
| c1ad811f1bb25997b56776c2f43cb7b4ff1d7e15 | [
"Markdown",
"Python"
] | 4 | Python | TeamMacLean/msa_to_dnds | d75f4b2c6983afb3cc40188e4baee8cdbb2fc6f4 | 20854d31769975548d3581807200313dcae7e3c8 |
refs/heads/master | <repo_name>davydworzak/Django_repo_practice<file_sep>/apps/movies/views.py
from django.shortcuts import render, redirect
# Create your views here.
def index(request):
if request.method=="GET":
return render(request, 'movies/index.html')
elif request.method=="POST":
if request.POST['add'] == 'movie':
Movie.objects.create(title=request.POST['title'])
return redirect('/')
elif request.POST['add'] == 'actor':
Actor.objects.create(first_name=request.POST['first_name'],last_name=request.POST['last_name'])
return redirect('/')<file_sep>/apps/movies/templates/movies/index.html
<!DOCTYPE html>
<html lang="en">
<body>
<head>
<meta charset="utf-8">
<title>Movies</title>
</head>
<form action='' method='POST'>
{% csrf_token %}
<input type="hidden" name="add" value="movie">
Movie Title: <input type="text" name="title"/>
<input type="submit" value="Submit" />
</form>
<form action='' method='POST'>
{% csrf_token %}
<input type="hidden" name="add" value="actor">
First Name: <input type="text" name="first_name"/>
Last Name: <input type="text" name="last_name"/>
<input type="submit" value="Submit" />
</form>
<h1>List of Movies</h1>
<h1>List of Actors</h1>
</body>
</html><file_sep>/apps/movies/models.py
from __future__ import unicode_literals
from django.db import models
class Movie(models.Model):
title=models.CharField(max_length=100)
created_at = models.DateTimeField(auto_now_add = True)
class Actor(models.Model):
first_name=models.CharField(max_length=100)
last_name=models.CharField(max_length=100)
created_at = models.DateTimeField(auto_now_add = True)
| 0036340f8a62c02a05e76076fc8f9b428f69caa4 | [
"Python",
"HTML"
] | 3 | Python | davydworzak/Django_repo_practice | ff6888a2a0d604311bc1de98650404056c350ea9 | c2896a55f6c7ebf4f0ad39945e34ef01682fc278 |
refs/heads/master | <file_sep>/* Copyright 2011 <NAME>
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
* File: Class.cpp
* Author: tjoppen
*
* Created on February 14, 2010, 4:20 PM
*/
#include "Class.h"
#include <sstream>
#include <stdexcept>
#include <iostream>
using namespace std;
extern bool verbose;
extern bool generateDefaultCtor;
extern bool generateRequiredCtor;
extern bool generateRequiredAndVectorsCtor;
extern bool generateAllCtor;
const string variablePostfix = "_james";
const string nodeWithPostfix = "node" + variablePostfix;
const string tempWithPostfix = "temp" + variablePostfix;
const string convertedWithPostfix = "converted" + variablePostfix;
const string ssWithPostfix = "ss" + variablePostfix;
Class::Class(FullName name, ClassType type) : name(name), type(type),
isDocument(false), base(NULL) {
}
Class::Class(FullName name, ClassType type, FullName baseType) : name(name),
type(type), isDocument(false), baseType(baseType), base(NULL) {
}
Class::~Class() {
}
bool Class::isSimple() const {
return type == SIMPLE_TYPE;
}
bool Class::isBuiltIn() const {
return false;
}
bool Class::hasBase() const {
return baseType.second.length() > 0;
}
void Class::addConstructor(const Constructor& constructor) {
//first make sure an identical constructor doesn't already exist
for(list<Constructor>::const_iterator it = constructors.begin(); it != constructors.end(); it++)
if(it->hasSameSignature(constructor))
return;
constructors.push_back(constructor);
}
void Class::doPostResolveInit() {
//figure out which constructors we need
if(generateDefaultCtor) addConstructor(Constructor(this));
if(generateRequiredCtor) addConstructor(Constructor(this, false, false));
if(generateRequiredAndVectorsCtor) addConstructor(Constructor(this, true, false));
if(generateAllCtor) addConstructor(Constructor(this, true, true));
if(constructors.size() == 0)
throw runtime_error("No constructors in class " + getClassname());
//make sure members classes add us as their friend
for(std::list<Member>::iterator it = members.begin(); it != members.end(); it++) {
//there's no need to befriend ourselves
if(it->cl && it->cl != this)
it->cl->friends.insert(getClassname());
}
}
std::list<Class::Member>::iterator Class::findMember(std::string name) {
for(std::list<Member>::iterator it = members.begin(); it != members.end(); it++)
if(it->name == name)
return it;
return members.end();
}
void Class::addMember(Member memberInfo) {
if(findMember(memberInfo.name) != members.end())
throw runtime_error("Member " + memberInfo.name + " defined more than once in " + this->name.second);
if(verbose) cerr << this->name.second << " got " << memberInfo.type.first << ":" << memberInfo.type.second << " " << memberInfo.name << ". Occurance: ";
if(memberInfo.maxOccurs == UNBOUNDED) {
if(verbose) cerr << "at least " << memberInfo.minOccurs;
} else if(memberInfo.minOccurs == memberInfo.maxOccurs) {
if(verbose) cerr << "exactly " << memberInfo.minOccurs;
} else {
if(verbose) cerr << "between " << memberInfo.minOccurs << "-" << memberInfo.maxOccurs;
}
if(verbose) cerr << endl;
members.push_back(memberInfo);
}
/**
* Default implementation of generateAppender()
*/
string Class::generateAppender() const {
ostringstream oss;
if(base) {
if(base->isSimple()) {
//simpleContent
oss << base->generateElementSetter("content", nodeWithPostfix, "\t") << endl;
} else {
//call base appender
oss << "\t" << base->getClassname() << "::appendChildren(" << nodeWithPostfix << ");" << endl;
}
}
for(std::list<Member>::const_iterator it = members.begin(); it != members.end(); it++) {
if (!it->cl)
continue;
string name = it->name;
string setterName = it->name;
string nodeName = name + "Node";
if(it != members.begin())
oss << endl;
if(it->isArray()) {
string itName = "it" + variablePostfix;
setterName = "(*" + itName + ")";
oss << "\tfor(std::vector<" << it->cl->getClassname() << ">::const_iterator " << itName << " = " << name << ".begin(); " << itName << " != " << name << ".end(); " << itName << "++)" << endl;
} else if(it->isOptional()) {
//insert a non-null check
setterName += ".get()";
oss << "\tif(" << name << ".isSet())" << endl;
}
oss << "\t{" << endl;
if(it->isAttribute) {
//attribute
oss << "\t\tXercesString " << tempWithPostfix << "(\"" << name << "\");" << endl;
oss << "\t\tDOMAttr *" << nodeName << " = " << nodeWithPostfix << "->getOwnerDocument()->createAttribute(" << tempWithPostfix << ");" << endl;
oss << it->cl->generateAttributeSetter(setterName, nodeName, "\t\t") << endl;
oss << "\t\t" << nodeWithPostfix << "->setAttributeNode(" << nodeName << ");" << endl;
} else {
//element
oss << "\t\tXercesString " << tempWithPostfix << "(\"" << name << "\");" << endl;
oss << "\t\tDOMElement *" << nodeName << " = " << nodeWithPostfix << "->getOwnerDocument()->createElement(" << tempWithPostfix << ");" << endl;
oss << it->cl->generateElementSetter(setterName, nodeName, "\t\t") << endl;
oss << "\t\t" << nodeWithPostfix << "->appendChild(" << nodeName << ");" << endl;
}
oss << "\t}" << endl;
}
return oss.str();
}
string Class::generateElementSetter(string memberName, string nodeName, string tabs) const {
if(isSimple() && base)
return base->generateElementSetter(memberName, nodeName, tabs);
return tabs + memberName + ".appendChildren(" + nodeName + ");";
}
string Class::generateAttributeSetter(string memberName, string attributeName, string tabs) const {
if(isSimple() && base)
return base->generateAttributeSetter(memberName, attributeName, tabs);
throw runtime_error("Tried to generateAttributeSetter() for a non-simple Class");
}
string Class::generateParser() const {
ostringstream oss;
string childName = "child" + variablePostfix;
string nameName = "name" + variablePostfix;
if(base) {
if(base->isSimple()) {
//simpleContent
oss << base->generateMemberSetter("content", nodeWithPostfix, "\t") << endl;
} else {
oss << "\t" << base->getClassname() << "::parseNode(" << nodeWithPostfix << ");" << endl;
}
oss << endl;
}
oss << "\tfor(DOMNode *" << childName << " = " << nodeWithPostfix << "->getFirstChild(); " << childName << "; " << childName << " = " << childName << "->getNextSibling()) {" << endl;
oss << "\t\tif(!" << childName << "->getLocalName())" << endl;
oss << "\t\t\tcontinue;" << endl;
oss << endl;
oss << "\t\tXercesString " << nameName << "(" << childName << "->getLocalName());" << endl;
oss << endl;
//TODO: replace this with a map<pair<string, DOMNode::ElementType>, void(*)(DOMNode*)> thing?
//in other words, lookin up parsing function pointers in a map should be faster then all these string comparisons
bool first = true;
for(std::list<Member>::const_iterator it = members.begin(); it != members.end(); it++) {
if (!it->cl)
continue;
if(!it->isAttribute) {
if(first)
first = false;
else
oss << endl;
oss << "\t\tif(" << nameName << " == \"" << it->name << "\" && " << childName << "->getNodeType() == DOMNode::ELEMENT_NODE) {" << endl;
string memberName = it->name;
if(!it->isRequired()) {
memberName += tempWithPostfix;
oss << "\t\t\t" << it->cl->getClassname() << " " << memberName << ";" << endl;
}
string childElementName = "childElement" + variablePostfix;
oss << "\t\t\tDOMElement *" << childElementName << " = dynamic_cast<DOMElement*>(" << childName << ");" << endl;
oss << it->cl->generateMemberSetter(memberName, childElementName, "\t\t\t");
if(it->isArray()) {
oss << "\t\t\t" << it->name << ".push_back(" << memberName << ");" << endl;
} else if(it->isOptional()) {
oss << "\t\t\t" << it->name << " = " << memberName << ";" << endl;
}
oss << "\t\t}" << endl;
}
}
oss << "\t}" << endl;
//attributes
for(std::list<Member>::const_iterator it = members.begin(); it != members.end(); it++) {
if (!it->cl)
continue;
if(it->isAttribute) {
string attributeNodeName = "attributeNode" + variablePostfix;
oss << "\t{" << endl;
oss << "\t\tXercesString " << tempWithPostfix << "(\"" << it->name << "\");" << endl;
oss << "\t\tif(" << nodeWithPostfix << "->hasAttribute(" << tempWithPostfix << ")) {" << endl;
oss << "\t\t\tDOMAttr *" << attributeNodeName << " = " << nodeWithPostfix << "->getAttributeNode(" << tempWithPostfix << ");" << endl;
string attributeName = it->name;
if(it->isOptional()) {
attributeName += "Temp";
oss << "\t\t\t" << it->cl->getClassname() << " " << attributeName << ";" << endl;
}
oss << it->cl->generateAttributeParser(attributeName, attributeNodeName, "\t\t\t") << endl;
if(it->isOptional()) {
oss << "\t\t\t" << it->name << " = " << attributeName << ";" << endl;
}
oss << "\t\t}" << endl << "\t}" << endl;
}
}
return oss.str();
}
string Class::generateMemberSetter(string memberName, string nodeName, string tabs) const {
if(isSimple() && base)
return base->generateMemberSetter(memberName, nodeName, tabs);
ostringstream oss;
oss << tabs << memberName << ".parseNode(" << nodeName << ");" << endl;
return oss.str();
}
string Class::generateAttributeParser(string memberName, string attributeName, string tabs) const {
if(isSimple() && base)
return base->generateAttributeParser(memberName, attributeName, tabs);
throw runtime_error("Tried to generateAttributeParser() for a non-simple Class");
}
string Class::getClassname() const {
return name.second;
}
string Class::getBaseHeader() const {
if(base->isSimple())
return base->getBaseHeader();
return "\"" + base->getClassname() + ".h\"";
}
bool Class::hasHeader() const {
return true;
}
void Class::writeImplementation(ostream& os) const {
ClassName className = name.second;
os << "#include <sstream>" << endl;
os << "#include <xercesc/dom/DOMDocument.hpp>" << endl;
os << "#include <xercesc/dom/DOMElement.hpp>" << endl;
os << "#include <xercesc/dom/DOMAttr.hpp>" << endl;
os << "#include <libjames/XercesString.h>" << endl;
os << "#include \"" << className << ".h\"" << endl;
//no implementation needed for simple types
if(isSimple())
return;
os << endl;
os << "using namespace std;" << endl;
os << "using namespace xercesc;" << endl;
os << "using namespace james;" << endl;
os << endl;
if (needsProtectedDefaultConstructor()) {
if(base && !base->isSimple())
os << className << "::" << className << "() : " << base->getClassname() << "() {}" << endl;
else
os << className << "::" << className << "() {}" << endl;
os << endl;
}
//constructors
for(list<Constructor>::const_iterator it = constructors.begin(); it != constructors.end(); it++) {
it->writeBody(os);
os << endl;
}
//method implementations
//unmarshalling constructors
if(base && !base->isSimple())
os << className << "::" << className << "(std::istream& is) : " << base->getClassname() << "() {" << endl;
else
os << className << "::" << className << "(std::istream& is) {" << endl;
os << "\tis >> *this;" << endl;
os << "}" << endl;
os << endl;
//factory method
os << className << " " << className << "::fromString(const std::string& str) {" << endl;
os << "\tistringstream iss(str);" << endl;
os << "\treturn " << className << "(iss);" << endl;
os << "}" << endl;
os << endl;
//string cast operator
os << className << "::operator std::string () const {" << endl;
os << "\tostringstream oss;" << endl;
os << "\toss << *this;" << endl;
os << "\treturn oss.str();" << endl;
os << "}" << endl;
os << endl;
//getName()
os << "std::string " << className << "::getName() const {" << endl;
os << "\treturn \"" << className << "\";" << endl;
os << "}" << endl;
os << endl;
//getNamespace()
os << "std::string " << className << "::getNamespace() const {" << endl;
os << "\treturn \"" << name.first << "\";" << endl;
os << "}" << endl;
os << endl;
os << "void " << className << "::appendChildren(xercesc::DOMElement *" << nodeWithPostfix << ") const {" << endl;
os << generateAppender();
os << "}" << endl << endl;
os << "void " << className << "::parseNode(xercesc::DOMElement *" << nodeWithPostfix << ") {" << endl;
os << generateParser() << endl;
os << "}" << endl << endl;
os << "std::ostream& operator<< (std::ostream& os, const " << className << "& obj) {" << endl;
os << "\treturn james::marshal(os, obj, static_cast<void (james::XMLObject::*)(xercesc::DOMElement*) const>(&" << className << "::appendChildren), obj.getName(), obj.getNamespace());" << endl;
os << "}" << endl << endl;
os << "std::istream& operator>> (std::istream& is, " << className << "& obj) {" << endl;
os << "\treturn james::unmarshal(is, obj, static_cast<void (james::XMLObject::*)(xercesc::DOMElement*)>(&" << className << "::parseNode), obj.getName());" << endl;
os << "}" << endl << endl;
}
set<string> Class::getIncludedClasses() const {
set<string> classesToInclude;
//return classes of any simple non-builtin elements and any required non-simple elements
for(list<Member>::const_iterator it = members.begin(); it != members.end(); it++)
if (it->cl && ((!it->cl->isBuiltIn() && it->cl->isSimple()) || (it->isRequired() && !it->cl->isSimple())))
classesToInclude.insert(it->cl->getClassname());
return classesToInclude;
}
set<string> Class::getPrototypeClasses() const {
set<string> classesToInclude = getIncludedClasses();
set<string> classesToPrototype;
//return the classes of any non-simple non-required elements
for(list<Member>::const_iterator it = members.begin(); it != members.end(); it++)
if(it->cl && classesToInclude.find(it->cl->getClassname()) == classesToInclude.end() && !it->cl->isSimple() && !it->isRequired())
classesToPrototype.insert(it->cl->getClassname());
return classesToPrototype;
}
void Class::writeHeader(ostream& os) const {
ClassName className = name.second;
os << "#ifndef _" << className << "_H" << endl;
os << "#define _" << className << "_H" << endl;
os << "#include <vector>" << endl;
if(isDocument)
os << "#include <istream>" << endl;
os << "#include <xercesc/util/XercesDefs.hpp>" << endl;
os << "XERCES_CPP_NAMESPACE_BEGIN class DOMElement; XERCES_CPP_NAMESPACE_END" << endl;
os << "#include <libjames/HexBinary.h>" << endl;
os << "#include <libjames/optional.h>" << endl;
os << "// Fix issue with identifiers named 'major' or 'minor'" << endl;
os << "// See https://bugzilla.redhat.com/show_bug.cgi?id=130601" << endl;
os << "#undef major" << endl;
os << "#undef minor" << endl;
//simple types only need a typedef
if(isSimple()) {
os << "typedef " << base->getClassname() << " " << name.second << ";" << endl;
} else {
if(base && base->hasHeader())
os << "#include " << getBaseHeader() << endl;
if(!base || base->isSimple())
os << "#include <libjames/XMLObject.h>" << endl;
if(isDocument)
os << "#include <libjames/XMLDocument.h>" << endl;
//include member classes that we can't prototype
set<string> classesToInclude = getIncludedClasses();
for(set<string>::const_iterator it = classesToInclude.begin(); it != classesToInclude.end(); it++)
os << "#include \"" << *it << ".h\"" << endl;
os << endl;
set<string> classesToPrototype = getPrototypeClasses();
//member class prototypes, but only for classes that we haven't already included
for(set<string>::const_iterator it = classesToPrototype.begin(); it != classesToPrototype.end(); it++)
os << "class " << *it << ";" << endl;
if(classesToPrototype.size() > 0)
os << endl;
if(isDocument)
os << "class " << className << " : public " << base->getClassname() << ", public james::XMLDocument";
else if(base && !base->isSimple())
os << "class " << className << " : public " << base->getClassname();
else
os << "class " << className << " : public james::XMLObject";
os << " {" << endl;
if (needsProtectedDefaultConstructor()) {
os << "protected:" << endl;
os << "\t" << className << "();" << endl;
os << endl;
if(friends.size()) {
//add friends
for(set<string>::const_iterator it = friends.begin(); it != friends.end(); it++)
os << "\tfriend class " << *it << ";" << endl;
os << endl;
}
}
os << "public:" << endl;
//constructors
for(list<Constructor>::const_iterator it = constructors.begin(); it != constructors.end(); it++) {
os << "\t";
it->writePrototype(os, true);
os << endl;
}
//prototypes
//add constructor for unmarshalling this document from an istream of string
os << "\t" << className << "(std::istream& is);" << endl;
os << endl;
//factory method for unmarshalling std::string
//we can't use a constructor since that would conflict with the required
//element constructor for a type that only has one string element
os << "\tstatic " << className << " fromString(const std::string& str);" << endl;
os << endl;
//string cast operator
os << "\toperator std::string () const;" << endl;
//getName()
os << "\tstd::string getName() const;" << endl;
//getNamespace()
os << "\tstd::string getNamespace() const;" << endl;
os << "\tvoid appendChildren(xercesc::DOMElement *node) const;" << endl;
os << "\tvoid parseNode(xercesc::DOMElement *node);" << endl;
os << endl;
//simpleContent
if(base && base->isSimple())
os << "\t" << base->getClassname() << " content;" << endl;
//members
for(list<Member>::const_iterator it = members.begin(); it != members.end(); it++) {
os << "\t";
//elements of unknown types are shown commented out
if (!it->cl)
os << "//";
if(it->isOptional())
os << "james::optional<";
else if(it->isArray())
os << "std::vector<";
if (it->cl)
os << it->cl->getClassname();
else
os << it->type.second;
if(it->isOptional() || it->isArray())
os << " >";
os << " " << it->name << ";";
if (!it->cl)
os << "\t//" << it->type.first << ":" << it->type.second << " is undefined";
os << endl;
}
os << "};" << endl;
os << endl;
os << "std::ostream& operator<< (std::ostream& os, const " << className << "& obj);" << endl;
os << "std::istream& operator>> (std::istream& is, " << className << "& obj);" << endl;
os << endl;
//include classes that we prototyped earlier
for(set<string>::const_iterator it = classesToPrototype.begin(); it != classesToPrototype.end(); it++)
os << "#include \"" << *it << ".h\"" << endl;
if(classesToPrototype.size() > 0)
os << endl;
}
os << "#endif //_" << className << "_H" << endl;
}
bool Class::shouldUseConstReferences() const {
return true;
}
bool Class::needsProtectedDefaultConstructor() const {
for (std::list<Constructor>::const_iterator it = constructors.begin(); it != constructors.end(); it++)
if (it->isDefaultConstructor())
return false;
return true;
}
bool Class::Member::isArray() const {
return maxOccurs > 1 || maxOccurs == UNBOUNDED;
}
bool Class::Member::isOptional() const {
return minOccurs == 0 && maxOccurs == 1;
}
bool Class::Member::isRequired() const {
return !isArray() && !isOptional();
}
std::list<Class::Member> Class::getElements(bool includeBase, bool vectors, bool optionals) const {
std::list<Member> ret;
if(includeBase && base)
ret = base->getElements(true, vectors, optionals);
//regard the contents of a complexType with simpleContents as a required
//element named "content" since we already have that as an element
//check isBuiltIn() else we end up adding "content" more than once
if(base && base->isSimple() && base->isBuiltIn()) {
Member contentMember;
contentMember.name = "content";
contentMember.cl = base;
contentMember.minOccurs = contentMember.maxOccurs = 1;
ret.push_back(contentMember);
}
for(std::list<Member>::const_iterator it = members.begin(); it != members.end(); it++)
if(it->isRequired() || (it->isArray() && vectors) || (it->isOptional() && optionals))
ret.push_back(*it);
return ret;
}
Class::Constructor::Constructor(Class *cl) : cl(cl) {
}
Class::Constructor::Constructor(Class *cl, bool vectors, bool optionals) :
cl(cl) {
if(cl->base)
baseArgs = cl->base->getElements(true, vectors, optionals);
ourArgs = cl->getElements(false, vectors, optionals);
}
list<Class::Member> Class::Constructor::getAllArguments() const {
list<Class::Member> ret = baseArgs;
ret.insert(ret.end(), ourArgs.begin(), ourArgs.end());
return ret;
}
bool Class::Constructor::hasSameSignature(const Constructor& other) const {
list<Member> a = getAllArguments();
list<Member> b = other.getAllArguments();
if(a.size() != b.size())
return false;
list<Member>::iterator ita = a.begin(), itb = b.begin();
//return false if the arguments in any position are of different types or
//if one is an array but the other isn't
for(; ita != a.end(); ita++, itb++)
if(ita->cl && (ita->cl->getClassname() != itb->cl->getClassname() || ita->isArray() != itb->isArray()))
return false;
return true;
}
bool Class::Constructor::isDefaultConstructor() const {
return baseArgs.size() + ourArgs.size() == 0;
}
void Class::Constructor::writePrototype(ostream &os, bool withSemicolon) const {
list<Member> all = getAllArguments();
os << cl->getClassname() << "(";
for(list<Member>::const_iterator it = all.begin(); it != all.end(); it++) {
if (!it->cl)
continue;
if(it != all.begin())
os << ", ";
if(it->isArray())
os << "const std::vector<";
else if(it->cl->shouldUseConstReferences())
os << "const ";
os << it->cl->getClassname();
if(it->isArray())
os << " >&";
else if(it->cl->shouldUseConstReferences())
os << "&";
os << " " << it->name;
}
os << ")";
if(withSemicolon)
os << ";";
}
void Class::Constructor::writeBody(ostream &os) const {
list<Member> all = getAllArguments();
os << cl->getClassname() << "::";
writePrototype(os, false);
if(all.size() > 0 || (cl->base && !cl->base->isSimple()))
os << " :" << endl << "\t";
bool hasParens = false;
if(cl->base && !cl->base->isSimple()) {
//pass the base class' elements
os << cl->base->getClassname() << "(";
bool first = true;
for(list<Member>::const_iterator it = baseArgs.begin(); it != baseArgs.end(); it++) {
if (!it->cl)
continue;
if (first)
first = false;
else
os << ", ";
os << it->name;
}
os << ")";
hasParens = true;
}
bool first = true;
for(list<Member>::const_iterator it = ourArgs.begin(); it != ourArgs.end(); it++) {
if (!it->cl)
continue;
if (first && !hasParens)
first = false;
else if(hasParens || !first)
os << ", ";
os << it->name << "(" << it->name << ")";
}
os << " {" << endl << "}" << endl;
}
<file_sep># This file is in the public domain.
all:
mkdir -p generated
james generated example.xsd
g++ example.cpp generated/*.cpp -ljames -lxerces-c -o example
<file_sep># This file is in the public domain.
add_library(libjames
Exceptions.cpp
HexBinary.cpp
XercesString.cpp
XMLObject.cpp
)
set_target_properties(libjames PROPERTIES OUTPUT_NAME james)
install(TARGETS libjames DESTINATION lib)
install(FILES
Exceptions.h
HexBinary.h
version.h
XercesString.h
XMLDocument.h
XMLObject.h
optional.h
DESTINATION include/libjames
)
<file_sep>// This file is in the public domain.
#include <iostream>
#include <xercesc/util/PlatformUtils.hpp>
#include "generated/PersonDocument.h"
#include "generated/PersonListDocument.h"
int main() {
//initialize Xerces-C++
xercesc::XMLPlatformUtils::Initialize();
//unmarshal personIn from stdin
PersonDocument personIn(std::cin);
//create a list containing personIn and some other person
PersonListDocument list;
list.person.push_back(personIn);
list.person.push_back(PersonType("Some Otherguy", "Somewhere 999", 1985));
//finally, marshal the list to stdout
std::cout << list;
//terminate Xerces-C++
xercesc::XMLPlatformUtils::Terminate();
return 0;
}
<file_sep>/* Copyright 2011 <NAME>
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
* File: BuiltInClasses.cpp
* Author: tjoppen
*
* Created on February 14, 2010, 6:48 PM
*/
#include <stdexcept>
#include <sstream>
#include "BuiltInClasses.h"
#include "main.h"
using namespace std;
BuiltInClass::BuiltInClass(string name) : Class(FullName(XSL, name), Class::SIMPLE_TYPE) {
}
BuiltInClass::~BuiltInClass() {
}
bool BuiltInClass::isBuiltIn() const {
return true;
}
string BuiltInClass::generateAppender() const {
throw runtime_error("generateAppender() called in BuiltInClass");
}
string BuiltInClass::generateElementSetter(string memberName, string nodeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tstring " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << " << memberName << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << nodeName << "->setTextContent(XercesString(" << convertedWithPostfix << "));" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string BuiltInClass::generateAttributeSetter(string memberName, string attributeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tstring " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << " << memberName << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << attributeName << "->setValue(XercesString(" << convertedWithPostfix << "));" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string BuiltInClass::generateParser() const {
throw runtime_error("generateParser() called in BuiltInClass");
}
string BuiltInClass::generateMemberSetter(string memberName, string nodeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << XercesString(" << nodeName << "->getTextContent());" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << memberName << ";" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string BuiltInClass::generateAttributeParser(string memberName, string attributeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << XercesString(" << attributeName << "->getValue());" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << memberName << ";" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
/**
* ByteClass stuff
*/
string ByteClass::generateElementSetter(string memberName, string nodeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tstring " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << (int)" << memberName << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << convertedWithPostfix << ";" << endl;
oss << tabs << nodeName << "->setTextContent(XercesString(" << convertedWithPostfix << "));" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string ByteClass::generateAttributeSetter(string memberName, string attributeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tstring " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << (int)" << memberName << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << attributeName << "->setValue(XercesString(" << convertedWithPostfix << "));" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string ByteClass::generateMemberSetter(string memberName, string nodeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tint " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << XercesString(" << nodeName << "->getTextContent());" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << memberName << " = " << tempWithPostfix << ";" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string ByteClass::generateAttributeParser(string memberName, string attributeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tint " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << XercesString(" << attributeName << "->getValue());" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << memberName << " = " << tempWithPostfix << ";" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
/**
* UnsignedByteClass stuff
*/
string UnsignedByteClass::generateElementSetter(string memberName, string nodeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tstring " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << (unsigned int)" << memberName << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << nodeName << "->setTextContent(XercesString(" << convertedWithPostfix << "));" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string UnsignedByteClass::generateAttributeSetter(string memberName, string attributeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tstring " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << (unsigned int)" << memberName << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << convertedWithPostfix << ";" << endl;
oss << tabs << "\t" << attributeName << "->setValue(XercesString(" << convertedWithPostfix << "));" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string UnsignedByteClass::generateMemberSetter(string memberName, string nodeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tunsigned int " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << XercesString(" << nodeName << "->getTextContent());" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << memberName << " = " << tempWithPostfix << ";" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
string UnsignedByteClass::generateAttributeParser(string memberName, string attributeName, string tabs) const {
ostringstream oss;
oss << tabs << "{" << endl;
oss << tabs << "\tstringstream " << ssWithPostfix << ";" << endl;
oss << tabs << "\tunsigned int " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << ssWithPostfix << " << XercesString(" << attributeName << "->getValue());" << endl;
oss << tabs << "\t" << ssWithPostfix << " >> " << tempWithPostfix << ";" << endl;
oss << tabs << "\t" << memberName << " = " << tempWithPostfix << ";" << endl;
oss << tabs << "}" << endl;
return oss.str();
}
<file_sep>/* Copyright 2011 <NAME>
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
* File: BuiltInClasses.h
* Author: tjoppen
*
* Created on February 14, 2010, 6:48 PM
*/
#ifndef _BUILTINCLASSES_H
#define _BUILTINCLASSES_H
#include "Class.h"
class BuiltInClass : public Class {
public:
BuiltInClass(std::string name);
virtual ~BuiltInClass();
bool isBuiltIn() const;
std::string generateAppender() const;
virtual std::string generateElementSetter(std::string memberName, std::string nodeName, std::string tabs) const;
virtual std::string generateAttributeSetter(std::string memberName, std::string attributeName, std::string tabs) const;
std::string generateParser() const;
virtual std::string generateMemberSetter(std::string memberName, std::string nodeName, std::string tabs) const;
virtual std::string generateAttributeParser(std::string memberName, std::string attributeName, std::string tabs) const;
};
#define GENERATE_BUILTIN(name, xslName, classname)\
class name : public BuiltInClass {\
public:\
name() : BuiltInClass(xslName) {}\
name(std::string xslOverride) : BuiltInClass(xslOverride) {}\
std::string getClassname() const {return classname;}
//for types that lack/don't need a header, like int, float etc.
#define HEADERLESS bool hasHeader() const { return false; }
//same as GENERATE_BUILTIN, except header-less and shouldUseConstReferences() is made to return false
#define GENERATE_BUILTIN_NONCONST(name, xslName, classname)\
GENERATE_BUILTIN(name, xslName, classname)\
HEADERLESS\
bool shouldUseConstReferences() const {return false;}
#define GENERATE_BUILTIN_ALIAS(name, base, override)\
class name : public base {\
public:\
name() : base(override) {}
GENERATE_BUILTIN_NONCONST(ByteClass, "byte", "char")
virtual std::string generateElementSetter(std::string memberName, std::string nodeName, std::string tabs) const;
virtual std::string generateAttributeSetter(std::string memberName, std::string attributeName, std::string tabs) const;
virtual std::string generateMemberSetter(std::string memberName, std::string nodeName, std::string tabs) const;
virtual std::string generateAttributeParser(std::string memberName, std::string attributeName, std::string tabs) const;
};
GENERATE_BUILTIN_NONCONST(UnsignedByteClass, "unsignedByte", "unsigned char")
virtual std::string generateElementSetter(std::string memberName, std::string nodeName, std::string tabs) const;
virtual std::string generateAttributeSetter(std::string memberName, std::string attributeName, std::string tabs) const;
virtual std::string generateMemberSetter(std::string memberName, std::string nodeName, std::string tabs) const;
virtual std::string generateAttributeParser(std::string memberName, std::string attributeName, std::string tabs) const;
};
GENERATE_BUILTIN_NONCONST(ShortClass, "short", "short")};
GENERATE_BUILTIN_NONCONST(UnsignedShortClass, "unsignedShort", "unsigned short")};
GENERATE_BUILTIN_NONCONST(IntClass, "int", "int")};
GENERATE_BUILTIN_NONCONST(UnsignedIntClass, "unsignedInt", "unsigned int")};
GENERATE_BUILTIN_NONCONST(LongClass, "long", "long long")};
GENERATE_BUILTIN_NONCONST(UnsignedLongClass, "unsignedLong", "unsigned long long")};
GENERATE_BUILTIN(StringClass, "string", "std::string")
std::string getBaseHeader() const {
return "<string>";
}
std::string generateElementSetter(std::string memberName, std::string nodeName, std::string tabs) const {
return tabs + "{ XercesString " + tempWithPostfix + "(" + memberName + "); " + nodeName + "->setTextContent(" + tempWithPostfix + "); }";
}
std::string generateAttributeSetter(std::string memberName, std::string attributeName, std::string tabs) const {
return tabs + "{ XercesString " + tempWithPostfix + "(" + memberName + "); " + attributeName + "->setValue(" + tempWithPostfix + "); }";
}
std::string generateMemberSetter(std::string memberName, std::string nodeName, std::string tabs) const {
return tabs + memberName + " = XercesString(" + nodeName + "->getTextContent());";
}
std::string generateAttributeParser(std::string memberName, std::string attributeName, std::string tabs) const {
return tabs + memberName + " = XercesString(" + attributeName + "->getValue());";
}
};
GENERATE_BUILTIN_NONCONST(FloatClass, "float", "float")};
GENERATE_BUILTIN_NONCONST(DoubleClass, "double", "double")};
GENERATE_BUILTIN_NONCONST(BooleanClass, "boolean", "bool")
std::string generateElementSetter(std::string memberName, std::string nodeName, std::string tabs) const {
return tabs + "{ XercesString " + tempWithPostfix + "(" + memberName + " ? \"true\" : \"false\"); " + nodeName + "->setTextContent(" + tempWithPostfix + "); }";
}
std::string generateAttributeSetter(std::string memberName, std::string attributeName, std::string tabs) const {
return tabs + "{ XercesString " + tempWithPostfix + "(" + memberName + " ? \"true\" : \"false\"); " + attributeName + "->setValue(" + tempWithPostfix + "); }";
}
std::string generateMemberSetter(std::string memberName, std::string nodeName, std::string tabs) const {
std::ostringstream oss;
oss << tabs << "{" << std::endl;
oss << tabs << "//TODO: Strip string prior to this?" << std::endl;
oss << tabs << "XercesString " << tempWithPostfix << "(" << nodeName << "->getTextContent());" << std::endl;
oss << tabs << memberName << " = " << tempWithPostfix << " == \"true\" || " << tempWithPostfix << " == \"1\";" << std::endl;
oss << tabs << "}" << std::endl;
return oss.str();
}
std::string generateAttributeParser(std::string memberName, std::string attributeName, std::string tabs) const {
std::ostringstream oss;
oss << tabs << "{" << std::endl;
oss << tabs << "//TODO: Strip string prior to this?" << std::endl;
oss << tabs << "XercesString " << tempWithPostfix << "(" << attributeName << "->getValue());" << std::endl;
oss << tabs << memberName << " = " << tempWithPostfix << " == \"true\" || " << tempWithPostfix << " == \"1\";" << std::endl;
oss << tabs << "}" << std::endl;
return oss.str();
}
};
GENERATE_BUILTIN(HexBinaryClass, "hexBinary", "james::HexBinary") HEADERLESS};
//aliases
GENERATE_BUILTIN_ALIAS(IntegerClass, IntClass, "integer")};
GENERATE_BUILTIN_ALIAS(AnyURIClass, StringClass, "anyURI")};
GENERATE_BUILTIN_ALIAS(TimeClass, StringClass, "time")};
GENERATE_BUILTIN_ALIAS(DateClass, StringClass, "date")};
GENERATE_BUILTIN_ALIAS(DateTimeClass, StringClass, "dateTime")};
GENERATE_BUILTIN_ALIAS(LanguageClass, StringClass, "language")};
#endif /* _BUILTINCLASSES_H */
| 46f1240fd13eec238345cac2e070cb2310eca3f5 | [
"CMake",
"Makefile",
"C++"
] | 6 | C++ | alexbonjardini/james | 9a7be3a89048069ec06d2f08d2fe79be1999e16c | 2d6ead77606f388b07a5ab46f63aabc2057d0b10 |
refs/heads/develop | <file_sep>#!/usr/bin/env node
// ---------------------------------------------------------------------------------------------------------------------
// This script is intended to execute all unit tests in the Chrome Browser.
// ---------------------------------------------------------------------------------------------------------------------
/* eslint-env node, es6 */
require('shelljs/global');
var chalk = require('chalk'),
path = require('path'),
KARMA_CONFIG_PATH = path.join(__dirname, '..', 'test', 'karma.conf');
module.exports = function (exit) {
console.info(chalk.yellow.bold('Running unit tests within browser...'));
var KarmaServer = require('karma').Server;
(new KarmaServer({ // eslint-disable no-new
cmd: 'start',
configFile: KARMA_CONFIG_PATH
}, exit)).start();
};
// ensure we run this script exports if this is a direct stdin.tty run
!module.parent && module.exports(exit);
<file_sep>var expect = require('chai').expect,
LJSON = require('../../');
describe('json.stringify', function () {
it('should stringify a simple', function () {
expect(LJSON.stringify({
'one-key': true
})).to.eql('{"one-key":true}');
});
describe('async variant', function () {
it('should stringify a simple object', function (done) {
LJSON.async.stringify({
'one-key': true
}, function (err, json) {
if (err) { return done(err); }
expect(json).to.eql('{"one-key":true}');
done();
});
});
});
});
<file_sep>var expect = require('chai').expect,
bomb = require('../../lib/bomb'),
TEST_STRING = 'string',
testInput = {
number: 12,
utf8: 'string',
utf16: String.fromCharCode(0xFEFF) + 'string',
utf32: '뮿string',
utf16BigEndian: 'þÿstring',
utf16LittleEndian: 'ÿþstring'
};
describe('lib/bomb', function () {
describe('trim', function () {
// edge cases
describe('edge case', function () {
it('returns an unchanged value for undefined / no input', function () {
expect(bomb.trim()).to.equal(undefined);
});
it('returns and unchanged value for non string input', function () {
expect(bomb.trim(testInput.number)).to.equal(testInput.number);
});
});
// regular string input
it('returns an unchanged value for regular string input', function () {
expect(bomb.trim(TEST_STRING)).to.equal(TEST_STRING);
});
// BOM compliant string input tests
describe('BOM removal', function () {
it.skip('correctly removes UTF-16 BOM', function () { // @todo: unskip after a utf16 BOM has been found
expect(bomb.trim(testInput.utf16)).to.equal(TEST_STRING);
});
it('correctly removes UTF-32 BOM', function () {
expect(bomb.trim(testInput.utf32)).to.equal(TEST_STRING);
});
it('correctly removes big endian UTF-16 BOM', function () {
expect(bomb.trim(testInput.utf16BigEndian)).to.equal(TEST_STRING);
});
it('correctly removes little endian UTF-16 BOM', function () {
expect(bomb.trim(testInput.utf16LittleEndian)).to.equal(TEST_STRING);
});
it('correctly removes UTF-8 BOM', function () {
expect(bomb.trim(testInput.utf8)).to.equal(TEST_STRING);
});
});
});
});
<file_sep>var bomb = {
/**
* @private
* @type {Object}
*/
code: { // @todo: could be shifted to outside the bomb object
FEFF: 0xFEFF,
BBBF: 0xBBBF,
FE: 0xFE,
FF: 0xFF,
EF: 0xEF,
BB: 0xBB,
BF: 0xBF
},
/**
* Checks whether string has BOM
*
* @param {String} str An input string that is tested for the presence of BOM
*
* @returns {Number} If greater than 0, implies that a BOM of returned length was found. Else, zero is returned.
*/
indexOfBOM: function (str) {
if (typeof str !== 'string') {
return 0;
}
// @todo: compress logic below
// remove UTF-16 and UTF-32 BOM (https://en.wikipedia.org/wiki/Byte_order_mark#UTF-8)
if ((str.charCodeAt(0) === bomb.code.FEFF) || (str.charCodeAt(0) === bomb.code.BBBF)) {
return 1;
}
// big endian UTF-16 BOM
if ((str.charCodeAt(0) === bomb.code.FE) && (str.charCodeAt(1) === bomb.code.FF)) {
return 2;
}
// little endian UTF-16 BOM
if ((str.charCodeAt(0) === bomb.code.FF) && (str.charCodeAt(1) === bomb.code.FE)) {
return 2;
}
// UTF-8 BOM
if ((str.charCodeAt(0) === bomb.code.EF) && (str.charCodeAt(1) === bomb.code.BB) &&
(str.charCodeAt(2) === bomb.code.BF)) {
return 3;
}
return 0;
},
/**
* Trim BOM from a string
*
* @param {String} str An input string that is tested for the presence of BOM
* @returns {String} The input string stripped of any BOM, if found. If the input is not a string, it is returned as
* is.
*/
trim: function (str) {
var pos = bomb.indexOfBOM(str);
return pos ? str.slice(pos) : str;
}
};
module.exports = bomb;
<file_sep># liquid-json
Implementation of `JSON` which ignores BOM and shows more detailed error messages on parse failures.
## usage
```terminal
$ npm install liquid-json --save;
```
```javascript
var LJSON = require('liquid-json');
LJSON.parse('{ "hello": "world" }');
LJSON.stringify({ hello: 'world' });
```
`LJSON.parse` accepts `reviver` function as second parameter and `LJSON.stringify` accepts standard JSON parameters.
All errors raised from this module has error name as `JSONError`.
### asynchronous flavour
```javascript
var LJSON = require('liquid-json').async;
LJSON.parse('{ "hello": "world" }', function (err, obj) {
console.log(obj); // logs the object
});
LJSON.stringify({ hello: 'world' }, function (err, text) {
console.log(text); // logs '{"hello":"world"}'
});
```
## attributions
- https://github.com/rlidwka/jju
- https://github.com/ariya/esprima
| ca995658c2d3884ebf5d4f1284fed65fe48a38e1 | [
"JavaScript",
"Markdown"
] | 5 | JavaScript | postmanlabs/liquid-json | 57c62137ac1294550e75439fbdbf92b15c82a4f9 | f78e019eeed0ee1f69801904f6bb89ea24aece6c |
refs/heads/master | <repo_name>rafasilverio/insertionsort<file_sep>/README.md
insertionsort
=============
Exemplo simples de um insertionSort utilizando C
<file_sep>/insertionSort.c
#include <stdlib.h>
#include <stdio.h>
/**Exemplo de ordenação usando insertionSort*/
int main(){
int i, j, chave;
int v[5] = {1, 22, 5, 10, 5};
/**O insertionSort "separa" uma chave do vetor e compara com as demais posições,
caso ache o local devido da chave ele abre um espaço com o while e a insere no
local adequado*/
for(i = 1; i < 5; i++){
chave = v[i]; /*chave*/
j = i-1;
while((j > 0) && (v[j] > chave)){ /*loop que "abre" o espaço para a chave*/
v[j+1] = v[j];
j--;
}
v[j+1] = chave;
}
/*Loop para o print da sequancia*/
for(i = 0; i < 5; i++)
printf("%d, ", v[i]);
printf("\n");
return 0;
}
| 7a71b74ea7434f11a33e0a44520bdedf419e5317 | [
"Markdown",
"C"
] | 2 | Markdown | rafasilverio/insertionsort | 58ba3dc2bb421e83db3272bbc8a767fa7339bc03 | 9881966cedbb05c1b0ef7cb32a8f812207c32572 |
refs/heads/master | <file_sep>#include <stdio.h>
#include <syscall.h>
int
main (int argc, char **argv)
{
int i;
/*
char* buffer="Hello word!\n";
int res=write (1, buffer, 12);
printf("Value is '%i'\n",res);
buffer="Goodbye world!\n";
write (1, buffer, 15);
*/
printf("There are '%i' arguements\n",argc);
if(argc!=0) {
for (i = 1; i < argc; i++)
printf("%s ", argv[i]);
printf("\n");
}
return EXIT_SUCCESS;
}
<file_sep>#include "userprog/syscall.h"
#include <stdio.h>
#include <syscall-nr.h>
#include "threads/synch.h"
#include "threads/interrupt.h"
#include "threads/thread.h"
#include "threads/vaddr.h"
#include "threads/init.h"
#include "userprog/pagedir.h"
#include "../syscall-nr.h"
bool isValidAddress(void* addr){
if (addr != NULL && is_user_vaddr (addr))
{
return (pagedir_get_page (thread_current()->pagedir, addr) != NULL);
}
return false;
}
struct file_node {
struct file* aFile;
int fd;
struct list_elem node;
tid_t owner;
};
void exitWithError(){
thread_current()->exit_status=-1;
thread_exit();
}
void checkForBadArgs(struct intr_frame *f,int numArgs){
for(int i=0; i<=numArgs; ++i) {
if (!is_user_vaddr(f->esp + (4 * i)) && isValidAddress(f->esp + (4 * i))) {
// printf("BAD ARGS DETECTED\n");
exitWithError();
}
}
}
struct file_node* get_file_node(int fd){
struct list* f_list=&thread_current()->fileList;
struct list_elem* e;
struct file_node* F;
for (e = list_begin(f_list); e != list_end(f_list); e = list_next(f_list)) {
//printf("Closed\n");
struct file_node* F= list_entry(e,struct file_node, node);
//printf("FD IS %i FFD is %i\n",fd,F->fd);
if (fd==F->fd) {
return F;
//break;
}
}
return NULL;
}
static void syscall_handler(struct intr_frame *);
void
syscall_init(void) {
intr_register_int(0x30, 3, INTR_ON, syscall_handler, "syscall");
lock_init(&file_lock);
}
/*Placeholder system call, can be used for debug*/
void placeHolderSyscall(struct intr_frame *f){
printf("SYSTEM CALL IS NOT IMPLEMENTED YET!!!!!!!!!!!!!\n");
//#f->eax=10;
}
void haltSyscall(struct intr_frame *f) {
shutdown ();
}
void exitSyscall(struct intr_frame *f){
checkForBadArgs(f,1);
int value = get_user(f->esp + 4);
if(is_user_vaddr(f->esp + 4)) {
//printf("VALUE IS %i\n", value);
thread_current()->exit_status = value;
thread_exit();
}else{
exitWithError();
}
}
void execSyscall(struct intr_frame *f){
checkForBadArgs(f,1);
unsigned long buffer_address = get_user(f->esp + 7);
buffer_address = buffer_address * 256 + get_user(f->esp + 6);
buffer_address = buffer_address * 256 + get_user(f->esp + 5);
buffer_address = buffer_address * 256 + get_user(f->esp + 4);
if(!is_user_vaddr(buffer_address)){
exitWithError();
}
if(!isValidAddress((void*)buffer_address)){
exitWithError();
}
//printf((char*)buffer_address);
///printf("eee\n");
f->eax=process_execute(buffer_address);
}
void waitSyscall(struct intr_frame *f){
checkForBadArgs(f,1);
tid_t id=get_user(f->esp + 4);
f->eax=process_wait(id);
}
void createsyscall(struct intr_frame *f)
{
checkForBadArgs(f,2);
unsigned long buffer_address = get_user(f->esp + 7);
buffer_address = buffer_address * 256 + get_user(f->esp + 6);
buffer_address = buffer_address * 256 + get_user(f->esp + 5);
buffer_address = buffer_address * 256 + get_user(f->esp + 4);
if(!isValidAddress((void*)buffer_address)){
exitWithError();
}
if(buffer_address==0){
//printf("NULL FILENAME\n");
exitWithError();
//return;
}else {
unsigned long initial_size = get_user(f->esp + 11);
initial_size = initial_size * 256 + get_user(f->esp + 10);
initial_size = initial_size * 256 + get_user(f->esp + 9);
initial_size = initial_size * 256 + get_user(f->esp + 8);
lock_acquire(&file_lock);
bool success = filesys_create(buffer_address, initial_size);
lock_release(&file_lock);
f->eax = (int) success;
//printf("CREATED\n");
//return;
}
}
void open(struct intr_frame *f)
{
checkForBadArgs(f,1);
unsigned long buffer_address = get_user(f->esp + 7);
buffer_address = buffer_address * 256 + get_user(f->esp + 6);
buffer_address = buffer_address * 256 + get_user(f->esp + 5);
buffer_address = buffer_address * 256 + get_user(f->esp + 4);
//char file[128];
if(!isValidAddress((void*)buffer_address)){
exitWithError();
}
char* file=(char*)buffer_address;
if(file[0]=='\0') {
//printf("NULL INPUIT\n");
f->eax=-1;
return;
}
struct file_node* a_node = (struct file_node*)malloc(sizeof(struct file_node));
if(!a_node){
f->eax=-1;
return;
}
lock_acquire(&file_lock);
struct file *afile = filesys_open(file);
if(!afile)
{
//printf("BAD FILE\n");
f->eax=-1;
lock_release(&file_lock);
return;
}
a_node->aFile = afile;
a_node->fd = thread_current()->fd;
a_node->owner=thread_current()->tid;
thread_current()->fd++;
list_push_back(&thread_current()->fileList, &a_node->node);
lock_release(&file_lock);
//return a_node->fd;
f->eax=a_node->fd;
}
void closeSyscall(struct intr_frame *f) {
checkForBadArgs(f,1);
int fd = get_user(f->esp + 4);
if (fd < 2) {
f->eax = -1;
return;
}
lock_acquire(&file_lock);
struct list_elem *e;
struct list *f_list = &thread_current()->fileList;
if (fd != -1) {
struct file_node *F = get_file_node(fd);
if(F!=NULL) {
file_close(F->aFile);
list_remove(&F->node);
free(F);
}
} else {
for (e = list_begin(f_list); e != list_end(f_list); e = list_next(f_list)) {
struct file_node *F = list_entry(e,
struct file_node, node);
file_close(F->aFile);
list_remove(&F->node);
free(F);
}
}
//printf("Closed\n");
lock_release(&file_lock);
}
void readSyscall(struct intr_frame *f)
{
//printf("vvv\n");
//int readSyscall(int fd, void* buffer, unsigned size)
checkForBadArgs(f,3);
int fd = get_user(f->esp + 4);
unsigned size = get_user(f->esp + 15);
size =size*256+ get_user(f->esp + 14);
size =size*256+ get_user(f->esp + 13);
size =size*256+ get_user(f->esp + 12);
//printf("Reading size %i\n",size);
//printf("Buffer start address: '%p'\n", start_of_buffer);
unsigned long buffer_address = get_user(f->esp + 11);
buffer_address = buffer_address * 256 + get_user(f->esp + 10);
buffer_address = buffer_address * 256 + get_user(f->esp + 9);
buffer_address = buffer_address * 256 + get_user(f->esp + 8);
void* buffer=(void*)buffer_address;
if(!is_user_vaddr(buffer)){
printf("Invalid address!\n");
exitWithError();
}
//printf("aaa\n");
//if(buffer[0]=='\0'){
// exitWithError();
//}
//printf("aaa\n");
//putbuf((char*)buffer,11);
if(fd<2){
f->eax=-1;
return;
}
if(fd>thread_current()->fd){
f->eax=-1;
return;
}
if(fd == 0)
{
int j = 0;
uint8_t* locBuffer = (uint8_t*) buffer;
for(j = 0; j < size; ++j)
{
locBuffer[j] = input_getc();
}
f->eax=size;
return;
}
lock_acquire(&file_lock);
struct file_node *F=get_file_node(fd);
struct aFile *aFile = F->aFile;
if(!aFile)
{
lock_release(&file_lock);
printf("BADD FILE\n");
f->eax=-1;
return;
}
//printf("Got file\n");
int num_bytes = file_read(aFile, buffer, size);
//printf("READ FILE\n");
lock_release(&file_lock);
f->eax=num_bytes;
return;
}
void writeSyscall(struct intr_frame *f) {
//Getting arguements from stack
checkForBadArgs(f,3);
// printf("aaa\n");
int fd = get_user(f->esp + 4);
//unsigned size = get_user(f->esp + 12);
unsigned size = get_user(f->esp + 15);
size =size*256+ get_user(f->esp + 14);
size =size*256+ get_user(f->esp + 13);
size =size*256+ get_user(f->esp + 12);
//printf("Buffer start address: '%p'\n", start_of_buffer);
unsigned long buffer_address = get_user(f->esp + 11);
buffer_address = buffer_address * 256 + get_user(f->esp + 10);
buffer_address = buffer_address * 256 + get_user(f->esp + 9);
buffer_address = buffer_address * 256 + get_user(f->esp + 8);
void* buffer=(void*)buffer_address;
if((!is_user_vaddr(buffer))||!is_user_vaddr(buffer+size)){
exitWithError();
}
if((fd<=0)||fd>thread_current()->fd){
//f->eax=-1;
//return;
exitWithError();
}
if (fd == 1) {
// printf("aeeee\n");
putbuf(buffer_address, size);
f->eax=size;
return;
}
//printf("FD=%i\n",fd);
if(fd<1||fd>thread_current()->fd){
//Checks for invalid fd's
//printf("FAIL\n");
exitWithError();
}
lock_acquire(&file_lock);
struct file_node *F=get_file_node(fd);
ASSERT(F->fd==fd);
struct file *aFile = F->aFile;
if(!aFile)
{
lock_release(&file_lock);
printf("BADD FILE\n");
f->eax=-1;
return;
}
//writing to the file itself
int num_bytes = file_write (aFile, buffer,size);
//After we write to the file we release the lock and
//Setup our interupt frame to return to the user
lock_release(&file_lock);
f->eax=num_bytes;
return;
}
//void seeksyscall(int fd, unsigned position)
void seeksyscall(struct intr_frame *f)
{
checkForBadArgs(f,2);
int fd=get_user(f->esp + 4);
unsigned position = get_user(f->esp + 11);
position =position*256+ get_user(f->esp + 10);
position =position*256+ get_user(f->esp + 9);
position =position*256+ get_user(f->esp + 8);
lock_acquire(&file_lock);
struct list_elem *e;
struct file_node *F;
e = list_begin(&thread_current()->fileList);
while( F->fd != fd || e != list_end(&thread_current()->fileList) ) {
F = list_entry(e, struct file_node, node);
e = list_next(e);
}
struct file *aFile = F->aFile;
if(!aFile)
{
lock_release(&file_lock);
//f->eax=-1;
return;
}
file_seek(aFile, position);
lock_release(&file_lock);
}
//bool removesyscall(const char* file)
bool removesyscall(struct intr_frame *f)
{
checkForBadArgs(f,1);
unsigned long buffer_address = get_user(f->esp + 7);
buffer_address = buffer_address * 256 + get_user(f->esp + 6);
buffer_address = buffer_address * 256 + get_user(f->esp + 5);
buffer_address = buffer_address * 256 + get_user(f->esp + 4);
//char file[128];
char* file=(char*)buffer_address;
lock_acquire(&file_lock);
bool check = filesys_remove(file);
lock_release(&file_lock);
return check;
}
//int filesizesyscall(int fd)
void filesizesyscall(struct intr_frame *f)
{
int fd=get_user(f->esp+4);
lock_acquire(&file_lock);
struct file_node *F=get_file_node(fd);
struct file *aFile = F->aFile;
if(!aFile)
{
lock_release(&file_lock);
f->eax=-1;
return;
}
int size = file_length(aFile);
lock_release(&file_lock);
f->eax=size;
return;
}
void mmap(struct intr_frame *f){
thread_current()->mapid++;
f->eax=(thread_current()->mapid);
return;
}
static void
syscall_handler(struct intr_frame *f) {
/*SYSCALL LIST*/
int (*p[14]) (void* sp);
p[SYS_HALT]=haltSyscall;
p[SYS_EXIT]=exitSyscall;
p[SYS_EXEC]=execSyscall;
p[SYS_WAIT]=waitSyscall;
p[SYS_CREATE]=createsyscall;//Create
p[SYS_REMOVE]=removesyscall;//Remove
p[SYS_OPEN]=open;//Open
p[SYS_FILESIZE]=filesizesyscall;//Filesize
p[SYS_READ]=readSyscall;//Read
p[SYS_WRITE]=writeSyscall; //Write
p[SYS_SEEK]=seeksyscall;//seek
p[SYS_TELL]=placeHolderSyscall;//tell
p[SYS_CLOSE]=closeSyscall;//close
p[SYS_MMAP]= mmap;
p[SYS_MUNMAP]=placeHolderSyscall;
void *stack_pointer = f->esp;
//printf("Address is '%p'\n", stack_pointer);
// printf("PHYS_BASE is '%p'\n", PHYS_BASE);
if (is_user_vaddr(stack_pointer)&&isValidAddress(stack_pointer)&&(PHYS_BASE>stack_pointer)) {
int index=get_user(stack_pointer);
//printf("RUNNING SYSCALL %i\n",index);
if(index<0 || index>12){
thread_current()->exit_status=-1;
thread_exit();
}
p[index](f);
//printf("done\n");
return;
}
thread_exit();
}
<file_sep>#include "vm/page.h"
#include <string.h>
#include <stdbool.h>
#include "filesys/file.h"
#include "threads/interrupt.h"
#include "threads/malloc.h"
#include "threads/palloc.h"
#include "threads/thread.h"
#include "threads/vaddr.h"
#include "userprog/pagedir.h"
#include "userprog/syscall.h"
//check_expected ([<<'EOF']);
//alternate install page that is no differnt from the one in process.c
//Its here because its 3:50 am as I type this
bool
install_page1(void *upage, void *kpage, bool writable) {
struct thread *t = thread_current();
// Verify that there's not already a page at that virtual
// address, then map our page there.
return (pagedir_get_page(t->pagedir, upage) == NULL
&& pagedir_set_page(t->pagedir, upage, kpage, writable));
}
bool extend_stack(void* user_vaddr){
if(!user_vaddr){
printf("BAD USER ADDRESS!\n");
return false;
}
//printf("input address is %p\n",user_vaddr);
//ASSERT(user_vaddr==pg_round_down(user_vaddr));
if ( (size_t) (PHYS_BASE - pg_round_down(user_vaddr)) > (1 << 23)) {
//printf("DKJADHKJAAD\n");
return false;
}
//printf("DEBUG: EXTENDING STACK\n");
//We start by creating our new page table entry
struct sup_page_table_entry *new_stack_page=malloc(sizeof(struct sup_page_table_entry));
//printf("New address is %p\n",new_stack_page);
if(!new_stack_page){
return false;
}
//Since we are creating a new page, we want its address to be at the bottom
//of page relitive to the user virtural address
//printf("Page allocated\n");
ASSERT(new_stack_page);
new_stack_page->user_vaddr=pg_round_down(user_vaddr);
//printf("Created page with address %p\n",pg_round_down(user_vaddr));
new_stack_page->is_loaded=true;
new_stack_page->is_writable=true;
new_stack_page->is_pinned=true;
//We create a frame that our page is gonna map too
void* new_frame=fAlloc(PAL_USER,new_stack_page);
//and check its validity
if(!new_frame){
free(new_stack_page);
printf("DEBUG: FRAME FAILED TO ALLOCATE!!!!\n");
return false;
}
//printf("installing page at adddress %p\n",user_vaddr);
if(!install_page1(new_stack_page->user_vaddr,new_frame,true)){
free(new_stack_page);
fFree(new_frame);
printf("DEBUG: INSTALL PAGE FAILED!!!\n");
return false;
}
//printf("page installed\n");
if(intr_context()){
new_stack_page->is_pinned= false;
}
//printf("final insert\n");
list_push_back(&thread_current()->page_list,&new_stack_page->elem);
//printf("done\n");
return true;
}
//All this function does is walk through the threads page list and returns the page with
//the same address as our rounded down user_vaddr
struct sup_page_table_entry* get_pte_from_user(void* user_vaddr){
struct list_elem *e;
enum intr_level old_level;
//printf("DEBUG: Checking %p with\n",pg_round_down(user_vaddr));
old_level = intr_disable ();
for (e = list_begin(&thread_current()->page_list); e != list_end(&thread_current()->page_list); e = list_next(e)) {
struct sup_page_table_entry* cur_page=list_entry(e,struct sup_page_table_entry,elem);
//printf("DEBUG: Checking %p with list with %p\n",pg_round_down(user_vaddr),cur_page->user_vaddr);
if(cur_page->user_vaddr==pg_round_down(user_vaddr)){
intr_set_level (old_level);
return cur_page;
}
}
intr_set_level (old_level);
//printf("Failed to find\n");
return NULL;
}
void setFile(struct sup_page_table_entry* page,struct file* file,int32_t offset,uint8_t * upage, uint32_t file_read_bytes,uint32_t file_zero_bytes,bool writable){
page->user_vaddr=upage;
page->file=file;
page->file_offset=offset;
page->file_read_bytes=file_read_bytes;
page->file_zero_bytes=file_zero_bytes;
page->is_loaded=false;
page->is_pinned=false;
}
bool pt_add_file(struct file* file,int32_t offset,uint8_t * upage,uint32_t file_read_bytes,uint32_t file_zero_bytes,bool writible,size_t debug){
//printf("DEBUG: %p is set to lazily load a file when accesed\n",upage);
struct sup_page_table_entry *new_page=malloc(sizeof(struct sup_page_table_entry));
if(!new_page) {
printf("BOGAS\n");
return false;
}
//printf("DEBUG: ADDING UPAGE %p \n",pg_round_down(upage));
//printf("ID %p\n",debug);
ASSERT(upage==pg_round_down(upage));
//setFile(new_page,file,offset,upage,file_read_bytes,file_zero_bytes,writible);
new_page->debugID=debug;
new_page->user_vaddr=upage;
new_page->file=file;
new_page->file_offset=offset;
new_page->file_read_bytes=file_read_bytes;
new_page->file_zero_bytes=file_zero_bytes;
new_page->is_loaded=false;
new_page->is_pinned=false;
new_page->file_offset=offset;
//printf("page parameters set!\n");
new_page->is_writable=writible;
new_page->for_file=true;
new_page->is_loaded=false;
new_page->is_pinned=false;
//printf("NEW UPAGE IS %p\n",new_page->user_vaddr);
//file_load(new_page);
list_push_back (&thread_current()->page_list, &new_page->elem);
//printf("ADDED FILE!\n");
return true;
}
bool pt_add_mmap(struct file* file,int32_t offset,uint8_t * upage,uint32_t file_read_bytes,uint32_t file_zero_bytes, bool writable){
struct sup_page_table_entry *new_page=malloc(sizeof(struct sup_page_table_entry));
if(!new_page) {
return false;
}
//printf("DEBUG: ADDING UPAGE %p \n",pg_round_down(upage));
//printf("ID %p\n",debug);
ASSERT(upage==pg_round_down(upage));
//setFile(new_page,file,offset,upage,file_read_bytes,file_zero_bytes,writible);
new_page->debugID=0;
new_page->user_vaddr=upage;
new_page->file=file;
new_page->file_offset=offset;
new_page->file_read_bytes=file_read_bytes;
new_page->file_zero_bytes=file_zero_bytes;
new_page->is_loaded=false;
new_page->is_pinned=false;
new_page->file_offset=offset;
//printf("page parameters set!\n");
new_page->is_writable=writable;
new_page->for_mmap=true;
new_page->is_loaded=false;
new_page->is_pinned=false;
//printf("NEW UPAGE IS %p\n",new_page->user_vaddr);
//file_load(new_page);
list_push_back (&thread_current()->page_list, &new_page->elem);
//printf("ADDED FILE!\n");
return true;
}
bool page_load(struct sup_page_table_entry* pt){
pt->is_pinned=true;
if(pt->is_loaded){
//printf("DEBUG: %p is already loaded\n");
return true;
}
//printf("LOADING\n");
if(pt->for_file){
return file_load(pt);
}
if(pt->for_swap){
printf("Swap\n");
return NULL;
}
if(pt->for_mmap){
printf("mmap\n");
return NULL;
}
//printf("NOT LOADED\n");
return false;
}
bool mmap_load(struct sup_page_table_entry* pt){
}
bool swap_load(struct sup_page_table_entry* pt){
}
bool file_load(struct sup_page_table_entry* pt){
//printf("ID IS %i\n",pt->debugID);
enum palloc_flags flags=PAL_USER;
if(pt->file_read_bytes==0){
//printf("SETTING TO ZERO\n");
flags |= PAL_ZERO;
}
uint8_t *file_frame=NULL;
file_frame=fAlloc(pt,flags);
//printf("DEBUG: %p is now getting a frame at %p mapped to it\n",pt->user_vaddr,file_frame);
if(file_frame==NULL){
//printf("BOGAS\n");
return false;
}
if(pt->file_read_bytes) {
//printf("Has bytes\n");
lock_acquire(&file_lock);
file_seek(pt->file, pt->file_offset);
if (file_read(pt->file, file_frame,pt->file_read_bytes) != (int) pt->file_read_bytes) {
lock_release(&file_lock);
fFree(file_frame);
printf("File read error\n");
file_seek(pt->file, 0);
return false;
}
lock_release(&file_lock);
//printf("Loaded setting memory\n");
memset(file_frame + pt->file_read_bytes, 0, pt->file_zero_bytes);
//printf("Memory set!\n");
}
// printf("installing page!\n");
if(!install_page1(pt->user_vaddr,file_frame,pt->is_writable)){
fFree(file_frame);
//printf("DEBUG: Failed to install page\n");
return false;
}
pt->is_loaded=true;
//printf("DEBUG: %p has been successfuly loaded!\n",pt->user_vaddr);
return true;
}
<file_sep>//
// Created by pintos on 5/12/18.
//
#ifndef PINTOS_SWAP_H
#define PINTOS_SWAP_H
#include "threads/synch.h"
#include "threads/vaddr.h"
#include "devices/block.h"
#include <list.h>
#endif //PINTOS_SWAP_H
<file_sep>#ifndef VM_FRAME_H
#define VM_FRAME_H
#include "threads/palloc.h"
#include "threads/synch.h"
#include "vm/page.h"
#include <stdbool.h>
#include <stdint.h>
#include <list.h>
struct list global_frame_table;
struct lock global_frame_lock;
struct lock global_evictor_lock;
struct frame_entry {
void* base_address;
struct thread* owner;
struct list_elem elem;
struct sup_page_table_entry* supplementry_PT;
void* frame;
};
void *try_evict(struct frame_entry* victim,enum palloc_flags flag);
void initialize_frame_table(void);
void* fAlloc(struct sup_page_table_entry* curPage,enum palloc_flags flag);//Allocates a new locked frame
void fFree(struct frame_entry* curFrame);//Frees the frame
#endif /* vm/frame.h */<file_sep>#include "vm/frame.h"
#include "filesys/file.h"
#include "threads/malloc.h"
#include "threads/palloc.h"
#include "threads/synch.h"
#include "threads/thread.h"
#include "userprog/pagedir.h"
#include "userprog/syscall.h"
#include "threads/vaddr.h"
#include "vm/page.h"
void initialize_frame_table(void){
list_init(&global_frame_table);
lock_init(&global_frame_lock);
}
//This function will only work if the global frame lock has been aquired by its caller
void * try_evict(struct frame_entry* victim,enum palloc_flags flag){
//struct sup_page_table_entry* page_table=victim->supplementry_PT;
//printf("victim is %p\n",victim);
//printf("victim PT %p\n",victim->supplementry_PT);
if(!victim->supplementry_PT->is_pinned) {
printf("IS NOT PINNED\n");
struct thread *t = victim->owner;
if(pagedir_is_accessed(t->pagedir,victim->supplementry_PT->user_vaddr)){
//Since we are evicting the frame, we want to make sure that it appears
//to not have been accessed
pagedir_set_accessed(t->pagedir, victim->supplementry_PT->user_vaddr, false);
printf("set accesed\n");
return NULL;
}
//If its dirty then we can swap it out or write it to its memory mapped file
if(pagedir_is_dirty(t->pagedir,victim->supplementry_PT->user_vaddr)||victim->supplementry_PT->for_swap){
if(victim->supplementry_PT->for_mmap){
printf("MMUP\n");
//We write our victims frame to the file
lock_acquire(&file_lock);
file_write_at(victim->supplementry_PT->file,victim->frame,victim->supplementry_PT->file_read_bytes,victim->supplementry_PT->file_offset);
lock_release(&file_lock);
}else{
printf("SWAP\n");
//If its a swap frame then we can swap it out
//TODO implement swap_page_out
PANIC("OH NO I DONT KNOW HOW TO SWAP YET PLEASE HALP ME!!!!");
}
}
//printf("Finalizing eviction\n");
victim->supplementry_PT->is_loaded=false;
list_remove(&victim->elem);
pagedir_clear_page(t->pagedir,victim->supplementry_PT->user_vaddr);
//printf("Victim is %p\n",victim->frame);
palloc_free_page(victim->frame);
free(victim);
/*
struct frame_entry* fresh_frame=palloc_get_page(flag);
if(!fresh_frame){
PANIC("You filled up the swap space. You monster.");
}else {
printf("Successfuly evicited\n");
}*/
printf("Successfuly evicited\n");
return palloc_get_page(flag);
}
// printf("entered loop\n");
return NULL;
}
void* fAlloc(struct sup_page_table_entry* curPage,enum palloc_flags flag){
if(!(flag & PAL_USER)) {
printf("NOT FOR KERNAL\n");
return NULL;
}
//printf("PAGE VADDR IS %p\n",curPage->user_vaddr);
void* new_frame=palloc_get_page(flag);
while(!new_frame){
lock_acquire(&global_frame_lock);
struct list_elem *e=list_begin(&global_frame_table);
struct frame_entry * evicted_victim=NULL;
while(true) {
struct frame_entry *victim = list_entry(e,struct frame_entry,elem);
if(victim){
if(victim->owner) {
evicted_victim = try_evict(victim, flag);
}
}
//printf("ROTATED\n");
//printf("%p is the victims address and %p is its pages address\n",victim,victim->supplementry_PT->user_vaddr);
//printf("OK\n");
//We try to evict the current victim
//If we successfuly evicited our victim then we set our
//newframe to it and leave the loop
if(evicted_victim&&evicted_victim!=NULL){
//printf("Got a valid frame! %p\n",evicted_victim);
//printf("Rounded is! %p\n",pg_round_down(evicted_victim));
new_frame=evicted_victim;
//printf("Eviction successful\n");
//new_frame=palloc_get_page(flag);
lock_release(&global_frame_lock);
break;
}
//if we hit the end of the list
//then we just go back to the start and repeat
//printf("NEXT\n");
e=list_next(e);
if(e==list_end(&global_frame_table)){
e=list_begin(&global_frame_table);
}
}
}
//printf("Got a valid frame! %p\n",new_frame);
//Now that we have a new frame we gotta add it to our frame table
lock_acquire(&global_frame_lock);
struct frame_entry* frame_to_add=malloc(sizeof(struct frame_entry));
frame_to_add->frame=new_frame;
frame_to_add->supplementry_PT=curPage;
frame_to_add->owner=thread_current();
//printf("Frame created for thread %s with frame address of %p\n", thread_current()->name,new_frame);
//printf("Adding to list\n");
list_push_back(&global_frame_table,&frame_to_add->elem);
//printf("Added!\n");
lock_release(&global_frame_lock);
//printf("frame address is %i\n",frame_to_add->user_vaddr);
//printf("%p is the new file frames spt\n",frame_to_add->supplementry_PT);
return new_frame;
}
void fFree(struct frame_entry* curFrame){
struct list_elem* e;
lock_acquire(&global_frame_lock);
//We just walk through our global frame table
//and if we find a frame_entry which has the same frame as curFrame
//we remove and free it
for (e = list_begin(&global_frame_table); e != list_end(&global_frame_table); e = list_next(e)) {
struct frame_entry* frame_to_remove=list_entry(e,struct frame_entry,elem);
if(frame_to_remove->frame=curFrame){
list_remove(e);
free(frame_to_remove);
palloc_free_page(curFrame);
break;
}
}
lock_release(&global_frame_lock);
}
<file_sep>//
// Created by pintos on 5/12/18.
//
#ifndef PINTOS_PAGE_H
#define PINTOS_PAGE_H
#include <list.h>
struct sup_page_table_entry{
uint32_t* user_vaddr;
bool for_swap;
bool for_mmap;
bool for_file;
bool is_loaded;
bool is_pinned;
bool is_writable;
size_t swap_id;
struct list_elem elem;
size_t debugID;
struct file* file;
size_t file_offset;
size_t file_read_bytes;
size_t file_zero_bytes;
};
bool install_page1(void *upage, void *kpage, bool writable);
bool extend_stack(void* user_vaddr);
struct sup_page_table_entry* get_pte_from_user(void* user_vaddr);
bool page_load(struct sup_page_table_entry* pt);
bool mmap_load(struct sup_page_table_entry* pt);
bool swap_load(struct sup_page_table_entry* pt);
bool file_load(struct sup_page_table_entry* pt);
bool pt_add_file(struct file* file,int32_t offset,uint8_t * upage,uint32_t file_read_bytes,uint32_t file_zero_bytes,bool writible,size_t debug);
bool pt_add_mmap(struct file* file,int32_t offset,uint8_t * upage,uint32_t file_read_bytes,uint32_t file_zero_bytes, bool writeable);
#endif //PINTOS_PAGE_H
<file_sep>#ifndef USERPROG_PROCESS_H
#define USERPROG_PROCESS_H
#include "threads/thread.h"
#include "threads/synch.h"
#include "vm/frame.h"
#include "vm/page.h"
tid_t process_execute (const char *file_name);
struct thread* find_by_tid(tid_t tid,struct thread* cur);
int process_wait (tid_t);
void process_exit (void);
void process_activate (void);
struct arguments {
struct thread *parent;
char *args;
bool success;
struct semaphore child_spawn_lock; /*Prevents the parent from running until the child has compleatly started or failed to start*/
};
/*Created on the fly in process_wait()
*
* */
struct childStatus{
struct semaphore blocker;
int exit_code;
};
#endif /* userprog/process.h */
<file_sep>#!/bin/bash
# PINTOS-P2: USERPROG -- ITEMIZED PASS/FAIL TESTING SCRIPT (for use with QEMU)
# By: Brian, Matthew, and Michael -- UCDenver CSCI 3453, Spring 2018
# NOTE: To allow execution of this script, run the following command:
# chmod +x ./pintos-*-tests.sh
main ()
{
echo -e "PINTOS-P2: USERPROG -- ITEMIZED PASS/FAIL TESTING SCRIPT\n"
echo -e "NOTE: This script must be run from your Pintos 'src/userprog/' directory.\n"
echo -e "This script will build Pintos, and if successful, will use QEMU"
echo -e "to execute the tests that are not commented out in this script.\n"
read -p "Press the [ENTER] key to continue, or [CTRL]+[C] to abort testing."
echo -e "\n BUILDING PINTOS: \n"
make all
BUILD_SUCCESS=!$?
if (( $BUILD_SUCCESS )); then
cd build
# Run all the following tests that are not commented out:
test-args-none
# test-args-single
# test-args-multiple
# test-args-many
# test-args-dbl-space
# test-sc-bad-sp
# test-sc-bad-arg
# test-sc-boundary
# test-sc-boundary-2
# test-sc-boundary-3
# test-halt
# test-exit
# test-create-normal
# test-create-empty
# test-create-null
# test-create-bad-ptr
# test-create-long
# test-create-exists
# test-create-bound
# test-open-normal
# test-open-missing
# test-open-boundary
# test-open-empty
# test-open-null
# test-open-bad-ptr
# test-open-twice
# test-close-normal
# test-close-twice
# test-close-stdin
# test-close-stdout
# test-close-bad-fd
# test-read-normal
# test-read-bad-ptr
# test-read-boundary
# test-read-zero
# test-read-stdout
# test-read-bad-fd
# test-write-normal
# test-write-bad-ptr
# test-write-boundary
# test-write-zero
# test-write-stdin
# test-write-bad-fd
# test-exec-once
# test-exec-arg
# test-exec-bound
# test-exec-bound-2
# test-exec-bound
# test-exec-multiple
# test-exec-missing
# test-exec-bad-ptr
# test-wait-simple
# test-wait-twice
# test-wait-killed
# test-wait-bad-pid
# test-multi-recurse
# test-multi-child-fd
# test-rox-simple
# test-rox-child
# test-rox-multichild
# test-bad-read
# test-bad-write
# test-bad-read2
# test-bad-write2
# test-bad-jump
# test-bad-jump2
# test-multi-oom
# test-lg-create
# test-lg-full
# test-lg-random
# test-lg-seq-block
# test-lg-seq-random
# test-sm-create
# test-sm-full
# test-sm-random
# test-sm-seq-block
# test-sm-seq-random
# test-syn-read
# test-syn-remove
# test-syn-write
echo -e "\n SCRIPT EXECUTION TERMINATED SUCCESSFULLY. \n"
else
echo -e "\n ERROR: FAILED TO BUILD PINTOS. NO TESTS WERE RUN. \n"
fi
}
test-args-none()
{
echo -e "\n RUNNING TEST: args-none \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/args-none -a args-none -- -q -f run args-none < /dev/null 2> tests/userprog/args-none.errors |tee tests/userprog/args-none.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/args-none.ck tests/userprog/args-none tests/userprog/args-none.result
}
test-args-single()
{
echo -e "\n RUNNING TEST: args-single \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/args-single -a args-single -- -q -f run 'args-single onearg' < /dev/null 2> tests/userprog/args-single.errors |tee tests/userprog/args-single.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/args-single.ck tests/userprog/args-single tests/userprog/args-single.result
}
test-args-multiple()
{
echo -e "\n RUNNING TEST: args-multiple \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/args-multiple -a args-multiple -- -q -f run 'args-multiple some arguments for you!' < /dev/null 2> tests/userprog/args-multiple.errors |tee tests/userprog/args-multiple.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/args-multiple.ck tests/userprog/args-multiple tests/userprog/args-multiple.result
}
test-args-many()
{
echo -e "\n RUNNING TEST: args-many \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/args-many -a args-many -- -q -f run 'args-many a b c d e f g h i j k l m n o p q r s t u v' < /dev/null 2> tests/userprog/args-many.errors |tee tests/userprog/args-many.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/args-many.ck tests/userprog/args-many tests/userprog/args-many.result
}
test-args-dbl-space()
{
echo -e "\n RUNNING TEST: args-dbl-space \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/args-dbl-space -a args-dbl-space -- -q -f run 'args-dbl-space two spaces!' < /dev/null 2> tests/userprog/args-dbl-space.errors |tee tests/userprog/args-dbl-space.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/args-dbl-space.ck tests/userprog/args-dbl-space tests/userprog/args-dbl-space.result
}
test-sc-bad-sp()
{
echo -e "\n RUNNING TEST: sc-bad-sp \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/sc-bad-sp -a sc-bad-sp -- -q -f run sc-bad-sp < /dev/null 2> tests/userprog/sc-bad-sp.errors |tee tests/userprog/sc-bad-sp.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/sc-bad-sp.ck tests/userprog/sc-bad-sp tests/userprog/sc-bad-sp.result
}
test-sc-bad-arg()
{
echo -e "\n RUNNING TEST: sc-bad-arg \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/sc-bad-arg -a sc-bad-arg -- -q -f run sc-bad-arg < /dev/null 2> tests/userprog/sc-bad-arg.errors |tee tests/userprog/sc-bad-arg.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/sc-bad-arg.ck tests/userprog/sc-bad-arg tests/userprog/sc-bad-arg.result
}
test-sc-boundary()
{
echo -e "\n RUNNING TEST: sc-boundary \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/sc-boundary -a sc-boundary -- -q -f run sc-boundary < /dev/null 2> tests/userprog/sc-boundary.errors |tee tests/userprog/sc-boundary.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/sc-boundary.ck tests/userprog/sc-boundary tests/userprog/sc-boundary.result
}
test-sc-boundary-2()
{
echo -e "\n RUNNING TEST: sc-boundary-2 \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/sc-boundary-2 -a sc-boundary-2 -- -q -f run sc-boundary-2 < /dev/null 2> tests/userprog/sc-boundary-2.errors |tee tests/userprog/sc-boundary-2.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/sc-boundary-2.ck tests/userprog/sc-boundary-2 tests/userprog/sc-boundary-2.result
}
test-sc-boundary-3()
{
echo -e "\n RUNNING TEST: sc-boundary-3 \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/sc-boundary-3 -a sc-boundary-3 -- -q -f run sc-boundary-3 < /dev/null 2> tests/userprog/sc-boundary-3.errors |tee tests/userprog/sc-boundary-3.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/sc-boundary-3.ck tests/userprog/sc-boundary-3 tests/userprog/sc-boundary-3.result
}
test-halt()
{
echo -e "\n RUNNING TEST: halt \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/halt -a halt -- -q -f run halt < /dev/null 2> tests/userprog/halt.errors |tee tests/userprog/halt.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/halt.ck tests/userprog/halt tests/userprog/halt.result
}
test-exit()
{
echo -e "\n RUNNING TEST: exit \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exit -a exit -- -q -f run exit < /dev/null 2> tests/userprog/exit.errors |tee tests/userprog/exit.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exit.ck tests/userprog/exit tests/userprog/exit.result
}
test-create-normal()
{
echo -e "\n RUNNING TEST: create-normal \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-normal -a create-normal -- -q -f run create-normal < /dev/null 2> tests/userprog/create-normal.errors |tee tests/userprog/create-normal.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-normal.ck tests/userprog/create-normal tests/userprog/create-normal.result
}
test-create-empty()
{
echo -e "\n RUNNING TEST: create-empty \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-empty -a create-empty -- -q -f run create-empty < /dev/null 2> tests/userprog/create-empty.errors |tee tests/userprog/create-empty.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-empty.ck tests/userprog/create-empty tests/userprog/create-empty.result
}
test-create-null()
{
echo -e "\n RUNNING TEST: create-null \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-null -a create-null -- -q -f run create-null < /dev/null 2> tests/userprog/create-null.errors |tee tests/userprog/create-null.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-null.ck tests/userprog/create-null tests/userprog/create-null.result
}
test-create-bad-ptr()
{
echo -e "\n RUNNING TEST: create-bad-ptr \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-bad-ptr -a create-bad-ptr -- -q -f run create-bad-ptr < /dev/null 2> tests/userprog/create-bad-ptr.errors |tee tests/userprog/create-bad-ptr.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-bad-ptr.ck tests/userprog/create-bad-ptr tests/userprog/create-bad-ptr.result
}
test-create-long()
{
echo -e "\n RUNNING TEST: create-long \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-long -a create-long -- -q -f run create-long < /dev/null 2> tests/userprog/create-long.errors |tee tests/userprog/create-long.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-long.ck tests/userprog/create-long tests/userprog/create-long.result
}
test-create-exists()
{
echo -e "\n RUNNING TEST: create-exists \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-exists -a create-exists -- -q -f run create-exists < /dev/null 2> tests/userprog/create-exists.errors |tee tests/userprog/create-exists.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-exists.ck tests/userprog/create-exists tests/userprog/create-exists.result
}
test-create-bound()
{
echo -e "\n RUNNING TEST: create-bound \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/create-bound -a create-bound -- -q -f run create-bound < /dev/null 2> tests/userprog/create-bound.errors |tee tests/userprog/create-bound.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/create-bound.ck tests/userprog/create-bound tests/userprog/create-bound.result
}
test-open-normal()
{
echo -e "\n RUNNING TEST: open-normal \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-normal -a open-normal -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run open-normal < /dev/null 2> tests/userprog/open-normal.errors |tee tests/userprog/open-normal.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-normal.ck tests/userprog/open-normal tests/userprog/open-normal.result
}
test-open-missing()
{
echo -e "\n RUNNING TEST: open-missing \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-missing -a open-missing -- -q -f run open-missing < /dev/null 2> tests/userprog/open-missing.errors |tee tests/userprog/open-missing.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-missing.ck tests/userprog/open-missing tests/userprog/open-missing.result
}
test-open-boundary()
{
echo -e "\n RUNNING TEST: open-boundary \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-boundary -a open-boundary -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run open-boundary < /dev/null 2> tests/userprog/open-boundary.errors |tee tests/userprog/open-boundary.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-boundary.ck tests/userprog/open-boundary tests/userprog/open-boundary.result
}
test-open-empty()
{
echo -e "\n RUNNING TEST: open-empty \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-empty -a open-empty -- -q -f run open-empty < /dev/null 2> tests/userprog/open-empty.errors |tee tests/userprog/open-empty.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-empty.ck tests/userprog/open-empty tests/userprog/open-empty.result
}
test-open-null()
{
echo -e "\n RUNNING TEST: open-null \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-null -a open-null -- -q -f run open-null < /dev/null 2> tests/userprog/open-null.errors |tee tests/userprog/open-null.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-null.ck tests/userprog/open-null tests/userprog/open-null.result
}
test-open-bad-ptr()
{
echo -e "\n RUNNING TEST: open-bad-ptr \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-bad-ptr -a open-bad-ptr -- -q -f run open-bad-ptr < /dev/null 2> tests/userprog/open-bad-ptr.errors |tee tests/userprog/open-bad-ptr.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-bad-ptr.ck tests/userprog/open-bad-ptr tests/userprog/open-bad-ptr.result
}
test-open-twice()
{
echo -e "\n RUNNING TEST: open-twice \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/open-twice -a open-twice -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run open-twice < /dev/null 2> tests/userprog/open-twice.errors |tee tests/userprog/open-twice.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/open-twice.ck tests/userprog/open-twice tests/userprog/open-twice.result
}
test-close-normal()
{
echo -e "\n RUNNING TEST: close-normal \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/close-normal -a close-normal -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run close-normal < /dev/null 2> tests/userprog/close-normal.errors |tee tests/userprog/close-normal.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/close-normal.ck tests/userprog/close-normal tests/userprog/close-normal.result
}
test-close-twice()
{
echo -e "\n RUNNING TEST: close-twice \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/close-twice -a close-twice -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run close-twice < /dev/null 2> tests/userprog/close-twice.errors |tee tests/userprog/close-twice.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/close-twice.ck tests/userprog/close-twice tests/userprog/close-twice.result
}
test-close-stdin()
{
echo -e "\n RUNNING TEST: close-stdin \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/close-stdin -a close-stdin -- -q -f run close-stdin < /dev/null 2> tests/userprog/close-stdin.errors |tee tests/userprog/close-stdin.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/close-stdin.ck tests/userprog/close-stdin tests/userprog/close-stdin.result
}
test-close-stdout()
{
echo -e "\n RUNNING TEST: close-stdout \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/close-stdout -a close-stdout -- -q -f run close-stdout < /dev/null 2> tests/userprog/close-stdout.errors |tee tests/userprog/close-stdout.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/close-stdout.ck tests/userprog/close-stdout tests/userprog/close-stdout.result
}
test-close-bad-fd()
{
echo -e "\n RUNNING TEST: close-bad-fd \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/close-bad-fd -a close-bad-fd -- -q -f run close-bad-fd < /dev/null 2> tests/userprog/close-bad-fd.errors |tee tests/userprog/close-bad-fd.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/close-bad-fd.ck tests/userprog/close-bad-fd tests/userprog/close-bad-fd.result
}
test-read-normal()
{
echo -e "\n RUNNING TEST: read-normal \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/read-normal -a read-normal -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run read-normal < /dev/null 2> tests/userprog/read-normal.errors |tee tests/userprog/read-normal.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/read-normal.ck tests/userprog/read-normal tests/userprog/read-normal.result
}
test-read-bad-ptr()
{
echo -e "\n RUNNING TEST: read-bad-ptr \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/read-bad-ptr -a read-bad-ptr -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run read-bad-ptr < /dev/null 2> tests/userprog/read-bad-ptr.errors |tee tests/userprog/read-bad-ptr.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/read-bad-ptr.ck tests/userprog/read-bad-ptr tests/userprog/read-bad-ptr.result
}
test-read-boundary()
{
echo -e "\n RUNNING TEST: read-boundary \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/read-boundary -a read-boundary -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run read-boundary < /dev/null 2> tests/userprog/read-boundary.errors |tee tests/userprog/read-boundary.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/read-boundary.ck tests/userprog/read-boundary tests/userprog/read-boundary.result
}
test-read-zero()
{
echo -e "\n RUNNING TEST: read-zero \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/read-zero -a read-zero -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run read-zero < /dev/null 2> tests/userprog/read-zero.errors |tee tests/userprog/read-zero.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/read-zero.ck tests/userprog/read-zero tests/userprog/read-zero.result
}
test-read-stdout()
{
echo -e "\n RUNNING TEST: read-stdout \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/read-stdout -a read-stdout -- -q -f run read-stdout < /dev/null 2> tests/userprog/read-stdout.errors |tee tests/userprog/read-stdout.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/read-stdout.ck tests/userprog/read-stdout tests/userprog/read-stdout.result
}
test-read-bad-fd()
{
echo -e "\n RUNNING TEST: read-bad-fd \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/read-bad-fd -a read-bad-fd -- -q -f run read-bad-fd < /dev/null 2> tests/userprog/read-bad-fd.errors |tee tests/userprog/read-bad-fd.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/read-bad-fd.ck tests/userprog/read-bad-fd tests/userprog/read-bad-fd.result
}
test-write-normal()
{
echo -e "\n RUNNING TEST: write-normal \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/write-normal -a write-normal -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run write-normal < /dev/null 2> tests/userprog/write-normal.errors |tee tests/userprog/write-normal.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/write-normal.ck tests/userprog/write-normal tests/userprog/write-normal.result
}
test-write-bad-ptr()
{
echo -e "\n RUNNING TEST: write-bad-ptr \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/write-bad-ptr -a write-bad-ptr -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run write-bad-ptr < /dev/null 2> tests/userprog/write-bad-ptr.errors |tee tests/userprog/write-bad-ptr.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/write-bad-ptr.ck tests/userprog/write-bad-ptr tests/userprog/write-bad-ptr.result
}
test-write-boundary()
{
echo -e "\n RUNNING TEST: write-boundary \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/write-boundary -a write-boundary -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run write-boundary < /dev/null 2> tests/userprog/write-boundary.errors |tee tests/userprog/write-boundary.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/write-boundary.ck tests/userprog/write-boundary tests/userprog/write-boundary.result
}
test-write-zero()
{
echo -e "\n RUNNING TEST: write-zero \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/write-zero -a write-zero -p ../../tests/userprog/sample.txt -a sample.txt -- -q -f run write-zero < /dev/null 2> tests/userprog/write-zero.errors |tee tests/userprog/write-zero.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/write-zero.ck tests/userprog/write-zero tests/userprog/write-zero.result
}
test-write-stdin()
{
echo -e "\n RUNNING TEST: write-stdin \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/write-stdin -a write-stdin -- -q -f run write-stdin < /dev/null 2> tests/userprog/write-stdin.errors |tee tests/userprog/write-stdin.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/write-stdin.ck tests/userprog/write-stdin tests/userprog/write-stdin.result
}
test-write-bad-fd()
{
echo -e "\n RUNNING TEST: write-bad-fd \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/write-bad-fd -a write-bad-fd -- -q -f run write-bad-fd < /dev/null 2> tests/userprog/write-bad-fd.errors |tee tests/userprog/write-bad-fd.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/write-bad-fd.ck tests/userprog/write-bad-fd tests/userprog/write-bad-fd.result
}
test-exec-once()
{
echo -e "\n RUNNING TEST: exec-once \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-once -a exec-once -p tests/userprog/child-simple -a child-simple -- -q -f run exec-once < /dev/null 2> tests/userprog/exec-once.errors |tee tests/userprog/exec-once.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-once.ck tests/userprog/exec-once tests/userprog/exec-once.result
}
test-exec-arg()
{
echo -e "\n RUNNING TEST: exec-arg \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-arg -a exec-arg -p tests/userprog/child-args -a child-args -- -q -f run exec-arg < /dev/null 2> tests/userprog/exec-arg.errors |tee tests/userprog/exec-arg.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-arg.ck tests/userprog/exec-arg tests/userprog/exec-arg.result
}
test-exec-bound()
{
echo -e "\n RUNNING TEST: exec-bound \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-bound -a exec-bound -p tests/userprog/child-args -a child-args -- -q -f run exec-bound < /dev/null 2> tests/userprog/exec-bound.errors |tee tests/userprog/exec-bound.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-bound.ck tests/userprog/exec-bound tests/userprog/exec-bound.result
}
test-exec-bound-2()
{
echo -e "\n RUNNING TEST: exec-bound-2 \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-bound-2 -a exec-bound-2 -- -q -f run exec-bound-2 < /dev/null 2> tests/userprog/exec-bound-2.errors |tee tests/userprog/exec-bound-2.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-bound-2.ck tests/userprog/exec-bound-2 tests/userprog/exec-bound-2.result
}
test-exec-bound()
{
echo -e "\n RUNNING TEST: exec-bound \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-bound-3 -a exec-bound-3 -- -q -f run exec-bound-3 < /dev/null 2> tests/userprog/exec-bound-3.errors |tee tests/userprog/exec-bound-3.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-bound-3.ck tests/userprog/exec-bound-3 tests/userprog/exec-bound-3.result
}
test-exec-multiple()
{
echo -e "\n RUNNING TEST: exec-multiple \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-multiple -a exec-multiple -p tests/userprog/child-simple -a child-simple -- -q -f run exec-multiple < /dev/null 2> tests/userprog/exec-multiple.errors |tee tests/userprog/exec-multiple.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-multiple.ck tests/userprog/exec-multiple tests/userprog/exec-multiple.result
}
test-exec-missing()
{
echo -e "\n RUNNING TEST: exec-missing \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-missing -a exec-missing -- -q -f run exec-missing < /dev/null 2> tests/userprog/exec-missing.errors |tee tests/userprog/exec-missing.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-missing.ck tests/userprog/exec-missing tests/userprog/exec-missing.result
}
test-exec-bad-ptr()
{
echo -e "\n RUNNING TEST: exec-bad-ptr \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/exec-bad-ptr -a exec-bad-ptr -- -q -f run exec-bad-ptr < /dev/null 2> tests/userprog/exec-bad-ptr.errors |tee tests/userprog/exec-bad-ptr.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/exec-bad-ptr.ck tests/userprog/exec-bad-ptr tests/userprog/exec-bad-ptr.result
}
test-wait-simple()
{
echo -e "\n RUNNING TEST: wait-simple \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/wait-simple -a wait-simple -p tests/userprog/child-simple -a child-simple -- -q -f run wait-simple < /dev/null 2> tests/userprog/wait-simple.errors |tee tests/userprog/wait-simple.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/wait-simple.ck tests/userprog/wait-simple tests/userprog/wait-simple.result
}
test-wait-twice()
{
echo -e "\n RUNNING TEST: wait-twice \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/wait-twice -a wait-twice -p tests/userprog/child-simple -a child-simple -- -q -f run wait-twice < /dev/null 2> tests/userprog/wait-twice.errors |tee tests/userprog/wait-twice.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/wait-twice.ck tests/userprog/wait-twice tests/userprog/wait-twice.result
}
test-wait-killed()
{
echo -e "\n RUNNING TEST: wait-killed \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/wait-killed -a wait-killed -p tests/userprog/child-bad -a child-bad -- -q -f run wait-killed < /dev/null 2> tests/userprog/wait-killed.errors |tee tests/userprog/wait-killed.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/wait-killed.ck tests/userprog/wait-killed tests/userprog/wait-killed.result
}
test-wait-bad-pid()
{
echo -e "\n RUNNING TEST: wait-bad-pid \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/wait-bad-pid -a wait-bad-pid -- -q -f run wait-bad-pid < /dev/null 2> tests/userprog/wait-bad-pid.errors |tee tests/userprog/wait-bad-pid.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/wait-bad-pid.ck tests/userprog/wait-bad-pid tests/userprog/wait-bad-pid.result
}
test-multi-recurse()
{
echo -e "\n RUNNING TEST: multi-recurse \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/multi-recurse -a multi-recurse -- -q -f run 'multi-recurse 15' < /dev/null 2> tests/userprog/multi-recurse.errors |tee tests/userprog/multi-recurse.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/multi-recurse.ck tests/userprog/multi-recurse tests/userprog/multi-recurse.result
}
test-multi-child-fd()
{
echo -e "\n RUNNING TEST: multi-child-fd \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/multi-child-fd -a multi-child-fd -p ../../tests/userprog/sample.txt -a sample.txt -p tests/userprog/child-close -a child-close -- -q -f run multi-child-fd < /dev/null 2> tests/userprog/multi-child-fd.errors |tee tests/userprog/multi-child-fd.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/multi-child-fd.ck tests/userprog/multi-child-fd tests/userprog/multi-child-fd.result
}
test-rox-simple()
{
echo -e "\n RUNNING TEST: rox-simple \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/rox-simple -a rox-simple -- -q -f run rox-simple < /dev/null 2> tests/userprog/rox-simple.errors |tee tests/userprog/rox-simple.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/rox-simple.ck tests/userprog/rox-simple tests/userprog/rox-simple.result
}
test-rox-child()
{
echo -e "\n RUNNING TEST: rox-child \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/rox-child -a rox-child -p tests/userprog/child-rox -a child-rox -- -q -f run rox-child < /dev/null 2> tests/userprog/rox-child.errors |tee tests/userprog/rox-child.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/rox-child.ck tests/userprog/rox-child tests/userprog/rox-child.result
}
test-rox-multichild()
{
echo -e "\n RUNNING TEST: rox-multichild \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/rox-multichild -a rox-multichild -p tests/userprog/child-rox -a child-rox -- -q -f run rox-multichild < /dev/null 2> tests/userprog/rox-multichild.errors |tee tests/userprog/rox-multichild.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/rox-multichild.ck tests/userprog/rox-multichild tests/userprog/rox-multichild.result
}
test-bad-read()
{
echo -e "\n RUNNING TEST: bad-read \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/bad-read -a bad-read -- -q -f run bad-read < /dev/null 2> tests/userprog/bad-read.errors |tee tests/userprog/bad-read.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/bad-read.ck tests/userprog/bad-read tests/userprog/bad-read.result
}
test-bad-write()
{
echo -e "\n RUNNING TEST: bad-write \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/bad-write -a bad-write -- -q -f run bad-write < /dev/null 2> tests/userprog/bad-write.errors |tee tests/userprog/bad-write.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/bad-write.ck tests/userprog/bad-write tests/userprog/bad-write.result
}
test-bad-read2()
{
echo -e "\n RUNNING TEST: bad-read2 \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/bad-read2 -a bad-read2 -- -q -f run bad-read2 < /dev/null 2> tests/userprog/bad-read2.errors |tee tests/userprog/bad-read2.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/bad-read2.ck tests/userprog/bad-read2 tests/userprog/bad-read2.result
}
test-bad-write2()
{
echo -e "\n RUNNING TEST: bad-write2 \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/bad-write2 -a bad-write2 -- -q -f run bad-write2 < /dev/null 2> tests/userprog/bad-write2.errors |tee tests/userprog/bad-write2.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/bad-write2.ck tests/userprog/bad-write2 tests/userprog/bad-write2.result
}
test-bad-jump()
{
echo -e "\n RUNNING TEST: bad-jump \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/bad-jump -a bad-jump -- -q -f run bad-jump < /dev/null 2> tests/userprog/bad-jump.errors |tee tests/userprog/bad-jump.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/bad-jump.ck tests/userprog/bad-jump tests/userprog/bad-jump.result
}
test-bad-jump2()
{
echo -e "\n RUNNING TEST: bad-jump2 \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/userprog/bad-jump2 -a bad-jump2 -- -q -f run bad-jump2 < /dev/null 2> tests/userprog/bad-jump2.errors |tee tests/userprog/bad-jump2.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/bad-jump2.ck tests/userprog/bad-jump2 tests/userprog/bad-jump2.result
}
test-multi-oom()
{
echo -e "\n RUNNING TEST: multi-oom \n"
pintos -v -k -T 360 --qemu --filesys-size=2 -p tests/userprog/no-vm/multi-oom -a multi-oom -- -q -f run multi-oom < /dev/null 2> tests/userprog/no-vm/multi-oom.errors |tee tests/userprog/no-vm/multi-oom.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/userprog/no-vm/multi-oom.ck tests/userprog/no-vm/multi-oom tests/userprog/no-vm/multi-oom.result
}
test-lg-create()
{
echo -e "\n RUNNING TEST: lg-create \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/lg-create -a lg-create -- -q -f run lg-create < /dev/null 2> tests/filesys/base/lg-create.errors |tee tests/filesys/base/lg-create.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/lg-create.ck tests/filesys/base/lg-create tests/filesys/base/lg-create.result
}
test-lg-full()
{
echo -e "\n RUNNING TEST: lg-full \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/lg-full -a lg-full -- -q -f run lg-full < /dev/null 2> tests/filesys/base/lg-full.errors |tee tests/filesys/base/lg-full.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/lg-full.ck tests/filesys/base/lg-full tests/filesys/base/lg-full.result
}
test-lg-random()
{
echo -e "\n RUNNING TEST: lg-random \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/lg-random -a lg-random -- -q -f run lg-random < /dev/null 2> tests/filesys/base/lg-random.errors |tee tests/filesys/base/lg-random.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/lg-random.ck tests/filesys/base/lg-random tests/filesys/base/lg-random.result
}
test-lg-seq-block()
{
echo -e "\n RUNNING TEST: lg-seq-block \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/lg-seq-block -a lg-seq-block -- -q -f run lg-seq-block < /dev/null 2> tests/filesys/base/lg-seq-block.errors |tee tests/filesys/base/lg-seq-block.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/lg-seq-block.ck tests/filesys/base/lg-seq-block tests/filesys/base/lg-seq-block.result
}
test-lg-seq-random()
{
echo -e "\n RUNNING TEST: lg-seq-random \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/lg-seq-random -a lg-seq-random -- -q -f run lg-seq-random < /dev/null 2> tests/filesys/base/lg-seq-random.errors |tee tests/filesys/base/lg-seq-random.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/lg-seq-random.ck tests/filesys/base/lg-seq-random tests/filesys/base/lg-seq-random.result
}
test-sm-create()
{
echo -e "\n RUNNING TEST: sm-create \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/sm-create -a sm-create -- -q -f run sm-create < /dev/null 2> tests/filesys/base/sm-create.errors |tee tests/filesys/base/sm-create.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/sm-create.ck tests/filesys/base/sm-create tests/filesys/base/sm-create.result
}
test-sm-full()
{
echo -e "\n RUNNING TEST: sm-full \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/sm-full -a sm-full -- -q -f run sm-full < /dev/null 2> tests/filesys/base/sm-full.errors |tee tests/filesys/base/sm-full.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/sm-full.ck tests/filesys/base/sm-full tests/filesys/base/sm-full.result
}
test-sm-random()
{
echo -e "\n RUNNING TEST: sm-random \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/sm-random -a sm-random -- -q -f run sm-random < /dev/null 2> tests/filesys/base/sm-random.errors |tee tests/filesys/base/sm-random.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/sm-random.ck tests/filesys/base/sm-random tests/filesys/base/sm-random.result
}
test-sm-seq-block()
{
echo -e "\n RUNNING TEST: sm-seq-block \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/sm-seq-block -a sm-seq-block -- -q -f run sm-seq-block < /dev/null 2> tests/filesys/base/sm-seq-block.errors |tee tests/filesys/base/sm-seq-block.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/sm-seq-block.ck tests/filesys/base/sm-seq-block tests/filesys/base/sm-seq-block.result
}
test-sm-seq-random()
{
echo -e "\n RUNNING TEST: sm-seq-random \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/sm-seq-random -a sm-seq-random -- -q -f run sm-seq-random < /dev/null 2> tests/filesys/base/sm-seq-random.errors |tee tests/filesys/base/sm-seq-random.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/sm-seq-random.ck tests/filesys/base/sm-seq-random tests/filesys/base/sm-seq-random.result
}
test-syn-read()
{
echo -e "\n RUNNING TEST: syn-read \n"
pintos -v -k -T 300 --qemu --filesys-size=2 -p tests/filesys/base/syn-read -a syn-read -p tests/filesys/base/child-syn-read -a child-syn-read -- -q -f run syn-read < /dev/null 2> tests/filesys/base/syn-read.errors |tee tests/filesys/base/syn-read.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/syn-read.ck tests/filesys/base/syn-read tests/filesys/base/syn-read.result
}
test-syn-remove()
{
echo -e "\n RUNNING TEST: syn-remove \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/syn-remove -a syn-remove -- -q -f run syn-remove < /dev/null 2> tests/filesys/base/syn-remove.errors |tee tests/filesys/base/syn-remove.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/syn-remove.ck tests/filesys/base/syn-remove tests/filesys/base/syn-remove.result
}
test-syn-write()
{
echo -e "\n RUNNING TEST: syn-write \n"
pintos -v -k -T 60 --qemu --filesys-size=2 -p tests/filesys/base/syn-write -a syn-write -p tests/filesys/base/child-syn-wrt -a child-syn-wrt -- -q -f run syn-write < /dev/null 2> tests/filesys/base/syn-write.errors |tee tests/filesys/base/syn-write.output
echo -e "\n RESULT: \n"
perl -I../.. ../../tests/filesys/base/syn-write.ck tests/filesys/base/syn-write tests/filesys/base/syn-write.result
}
main "$@"
<file_sep>#include "userprog/process.h"
#include <debug.h>
#include <inttypes.h>
#include <round.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "userprog/gdt.h"
#include "userprog/pagedir.h"
#include "userprog/tss.h"
#include "userprog/syscall.h"
#include "filesys/directory.h"
#include "filesys/file.h"
#include "filesys/filesys.h"
#include "threads/flags.h"
#include "threads/init.h"
#include "threads/interrupt.h"
#include "threads/palloc.h"
#include "threads/thread.h"
#include "threads/vaddr.h"
#include "vm/frame.h"
#include "vm/page.h"
static thread_func start_process NO_RETURN;
static bool load(const char *cmdline, void (**eip)(void), void **esp);
/* Starts a new thread running a user program loaded from
FILENAME. The new thread may be scheduled (and may even exit)
before process_execute() returns. Returns the new process's
thread id, or TID_ERROR if the thread cannot be created. */
tid_t
process_execute(const char *file_name) {
if (strlen(file_name) >= 128) {
return TID_ERROR;
}
char fn_copy[128];
//char* fn_args;
char program_name[128];
tid_t tid;
/* Make a copy of FILE_NAME.
Otherwise there's a race between the caller and load(). */
//fn_args=palloc_get_page(0);
if (fn_copy == NULL)
return TID_ERROR;
strlcpy(fn_copy, file_name, 128);
//printf("Input is '%s'\n", fn_copy);
struct thread* cur=thread_current();
int argc = 0;
char *cur_arguement;
char *token;
char *str1;
int j = 0;
//This first loop checks the number of arguements
//so we can push argc to the stack
str1 = fn_copy;
token = strtok_r(str1, " ", &cur_arguement);
strlcpy(program_name, token, 128);
strlcpy(fn_copy, file_name, 128);//Strtok messes up fn_copy from file_name
//Everything here is static, even the stuff that gets passed to the child
//To ensure we dont die before them we use a semaphore to block the parent
//to give the child time to setup
struct arguments cc;
struct arguments *cur_args = &cc;
cur_args->parent = thread_current();
cur_args->args = fn_copy;
sema_init(&cur_args->child_spawn_lock,0);
cur_args->success=false;
/* Create a new thread to execute PROGRAM_NAME.
* For whatever reason it did not like passing the arguements struct in to start_process
* via thread_create so I just decided to pass in the entire string and reparse it later*/
tid = thread_create(program_name, PRI_DEFAULT, start_process, cur_args);
if (tid == TID_ERROR) {
//palloc_free_page(fn_copy);
//palloc_free_page(program_name);
tid=-1;
}else {
sema_down(&cur_args->child_spawn_lock);
// printf("Woke up\n");
if(cur_args->success==false){
tid=-1;
//printf("BOGAS\n");
}
//free(cur_args->args);
//free(cur_args);
//printf("Exited sema down\n");
}
//palloc_free_page (argv);
return tid;
}
/* A thread function that loads a user process and starts it
running. */
static void
start_process(void *in_args) {
//printf("ENTERED START_PROCESS!\n");
struct arguments *args_struct = (struct arguments *) in_args;
struct intr_frame if_;
bool success;
/* Initialize interrupt frame and load executable. */
memset(&if_, 0, sizeof if_);
if_.gs = if_.fs = if_.es = if_.ds = if_.ss = SEL_UDSEG;
if_.cs = SEL_UCSEG;
if_.eflags = FLAG_IF | FLAG_MBS;
list_init(&thread_current()->page_list);
success = load(args_struct->args, &if_.eip, &if_.esp);
//palloc_free_page(args_struct->args);//We clear out the textual arguements to save spac
args_struct->args=NULL;
/* If load failed, quit. */
if (!success) {
//printf("no-such-file");
thread_current()->exit_status=-1;
//printf("Unlocking parent\n");
args_struct->success=false;
sema_up(&args_struct->child_spawn_lock);
// printf("Unlocked\n");
thread_current()->failed_to_spawn=true;
thread_exit();
}
//We initialize the current threads parent and synronazation varibles
args_struct->success=true;
//setup_parent(args_struct->parent);
struct thread *cur = thread_current();
cur->parent = args_struct->parent;
//printf("Pushing child with id %i\n",cur->tid);
list_push_back(&cur->parent->children, &cur->child_elem);
//We add ourselves to the parents children list
//And unblock the parent
sema_up(&args_struct->child_spawn_lock);
thread_yield();//Once we are ready to switch to user mode we let the parent finish and cleanup first.
/* Start the user process by simulating a return from an
interrupt, implemented by intr_exit (in
threads/intr-stubs.S). Because intr_exit takes all of its
arguments on the stack in the form of a `struct intr_frame',
we just point the stack pointer (%esp) to our stack frame
and jump to it. */
asm volatile ("movl %0, %%esp; jmp intr_exit" : : "g" (&if_) : "memory");
NOT_REACHED();
}
/* HELPERS FOR SYNCRONAZATION OF PROCESSES*/
//Used to search a children list by thread id.
struct thread *find_by_tid(tid_t tid,struct thread* cur) {
struct thread* child=NULL;
struct list *children = &cur->children;
if (!list_empty(children)) {
struct list_elem *e;
//printf("ENTERED SEARCH\n");
for (e = list_begin(children); e != list_end(&cur->children); e = list_next(e)) {
//printf("ENTERED SEARCH1\n");
child = list_entry(e,struct thread, child_elem);
//printf("Comparing child id: %i to input %i\n",child->tid,tid);
if (child->tid == tid) {
//printf("GOT IT\n");
break;
}
}
}//else{
//printf("LIST EMPTY\n");
//}
//printf("Returning\n");
return child;
}
/* Waits for thread TID to die and returns its exit status. If
it was terminated by the kernel (i.e. killed due to an
exception), returns -1. If TID is invalid or if it was not a
child of the calling process, or if process_wait() has already
been successfully called for the given TID, returns -1
immediately, without waiting.
This function will be implemented in problem 2-2. For now, it
does nothing. */
int
process_wait(tid_t child_tid) {
//printf("ENTERED WAIT\n");
struct thread* cur=thread_current();
struct thread* child=find_by_tid(child_tid,cur);
int exit_code=0;
if (child != NULL) {
cur->p_waiting_on=child_tid;
/*
* The childStatus struct contains a semaphore which we use to block the parent.
* When the child dies, it calls sema_up() on the semaphore.
*
*/
struct childStatus* child_life=(struct childStatus*) malloc(sizeof(struct childStatus));
sema_init(&child_life->blocker,0);
child->p_waiter=child_life;
sema_down(&child_life->blocker);
exit_code=child_life->exit_code;
free(child_life);
}else{
return -1;//If the ID dosent exist in the threads children list we return -1
}
return exit_code;
}
/* Free the current process's resources. */
void
process_exit(void) {
struct thread *cur = thread_current();
uint32_t *pd;
enum intr_level old_level;
old_level = intr_disable ();
if (cur->exe != NULL) {
//printf("UNLOCKIGN EXE\n");
file_allow_write(cur->exe);
file_close(cur->exe);
cur->exe = NULL;
}
//printf("Is it even working???\n");
if(!cur->failed_to_spawn) {
printf("%s: exit(%d)\n", cur->name, cur->exit_status);
enum intr_level old_level;
//printf("afhkjahfjkafa\n");
if (lock_held_by_current_thread(&file_lock)) {
//printf("RELEASING FILE LOCK\n");
lock_release(&file_lock);
}
/* Destroy the current process's page directory and switch back
to the kernel-only page directory. */
lock_acquire(&file_lock);
lock_release(&file_lock);
if (lock_held_by_current_thread(&global_frame_lock)) {
//printf("RELEASING FRAME LOCK\n");
lock_release(&global_frame_lock);
}
if(!list_empty(&cur->page_list)){
while(!list_empty(&cur->page_list)){
struct list_elem* e=list_pop_front(&cur->page_list);
struct sup_page_table_entry *page_to_kill = list_entry(e,struct sup_page_table_entry,elem);
if(page_to_kill) {
//printf("Killing page with address of %p\n", page_to_kill->user_vaddr);;
if (page_to_kill->is_loaded) {
fFree(pagedir_get_page(cur->pagedir, page_to_kill->user_vaddr));
pagedir_clear_page(cur->pagedir, page_to_kill->user_vaddr);
}
}
free(page_to_kill);
}
}
//printf("Done\n");
struct thread *t;
if (&cur->parent) {
//printf("Thread has parrent\n");
struct thread *parent = &cur->parent;
if (!list_empty(&cur->parent->children)) {
list_remove(&cur->child_elem);
}
if (cur->p_waiter != NULL) {
cur->p_waiter->exit_code = cur->exit_status;
sema_up(&cur->p_waiter->blocker);
}
}
if (!list_empty(&cur->children)) {
//printf("ENTERED SEARCH1\n");
struct list_elem *e;
struct thread *child = NULL;
for (e = list_begin(&cur->children); e != list_end(&cur->children); e = list_next(e)) {
//printf("ENTERED SEARCH1\n");
child = list_entry(e,
struct thread, child_elem);
child->parent = NULL;
}
}
pd = cur->pagedir;
if (pd != NULL) {
/* Correct ordering here is crucial. We must set
cur->pagedir to NULL before switching page directories,
so that a timer interrupt can't switch back to the
process page directory. We must activate the base page
directory before destroying the process's page
directory, or our active page directory will be one
that's been freed (and cleared). */
cur->pagedir = NULL;
pagedir_activate(NULL);
pagedir_destroy(pd);
}
}
intr_set_level (old_level);
//printf("returning\n");
/*We remove ourselves from our parents children list, and wake up the parent
*if they are waiting on us we wake them up
*/
}
/* Sets up the CPU for running user code in the current
thread.
This function is called on every context switch. */
void
process_activate(void) {
struct thread *t = thread_current();
/* Activate thread's page tables. */
pagedir_activate(t->pagedir);
/* Set thread's kernel stack for use in processing
interrupts. */
tss_update();
}
/* We load ELF binaries. The following definitions are taken
from the ELF specification, [ELF1], more-or-less verbatim. */
/* ELF types. See [ELF1] 1-2. */
typedef uint32_t Elf32_Word, Elf32_Addr, Elf32_Off;
typedef uint16_t Elf32_Half;
/* For use with ELF types in printf(). */
#define PE32Wx PRIx32 /* Print Elf32_Word in hexadecimal. */
#define PE32Ax PRIx32 /* Print Elf32_Addr in hexadecimal. */
#define PE32Ox PRIx32 /* Print Elf32_Off in hexadecimal. */
#define PE32Hx PRIx16 /* Print Elf32_Half in hexadecimal. */
/* Executable header. See [ELF1] 1-4 to 1-8.
This appears at the very beginning of an ELF binary. */
struct Elf32_Ehdr {
unsigned char e_ident[16];
Elf32_Half e_type;
Elf32_Half e_machine;
Elf32_Word e_version;
Elf32_Addr e_entry;
Elf32_Off e_phoff;
Elf32_Off e_shoff;
Elf32_Word e_flags;
Elf32_Half e_ehsize;
Elf32_Half e_phentsize;
Elf32_Half e_phnum;
Elf32_Half e_shentsize;
Elf32_Half e_shnum;
Elf32_Half e_shstrndx;
};
/* Program header. See [ELF1] 2-2 to 2-4.
There are e_phnum of these, starting at file offset e_phoff
(see [ELF1] 1-6). */
struct Elf32_Phdr {
Elf32_Word p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
Elf32_Word p_filesz;
Elf32_Word p_memsz;
Elf32_Word p_flags;
Elf32_Word p_align;
};
/* Values for p_type. See [ELF1] 2-3. */
#define PT_NULL 0 /* Ignore. */
#define PT_LOAD 1 /* Loadable segment. */
#define PT_DYNAMIC 2 /* Dynamic linking info. */
#define PT_INTERP 3 /* Name of dynamic loader. */
#define PT_NOTE 4 /* Auxiliary info. */
#define PT_SHLIB 5 /* Reserved. */
#define PT_PHDR 6 /* Program header table. */
#define PT_STACK 0x6474e551 /* Stack segment. */
/* Flags for p_flags. See [ELF3] 2-3 and 2-4. */
#define PF_X 1 /* Executable. */
#define PF_W 2 /* Writable. */
#define PF_R 4 /* Readable. */
static bool setup_stack(void **esp, int argc, char **argv);
static bool validate_segment(const struct Elf32_Phdr *, struct file *);
static bool load_segment(struct file *file, off_t ofs, uint8_t *upage,
uint32_t read_bytes, uint32_t zero_bytes,
bool writable);
/* Loads an ELF executable from FILE_NAME into the current thread.
Stores the executable's entry point into *EIP
and its initial stack pointer into *ESP.
Returns true if successful, false otherwise. */
bool
load(const char *cmdline, void (**eip)(void), void **esp) {
//printf("aaa\n");
char **argv = palloc_get_page(0);
int argc = 0;
char *scratch_space;
char *token;
char *str1;
int j = 0;
bool fail=false;
//This first loop checks the number of arguements
//so we can push argc to the stack
for (j = 0, str1 = cmdline;; j++, str1 = NULL) {
token = strtok_r(str1, " ", &scratch_space);
if (token == NULL) {
argc = j;
break;
}
argv[j] = token;
}
//printf("loading\n");
struct thread *t = thread_current();
struct Elf32_Ehdr ehdr;
struct file *file = NULL;
off_t file_ofs;
bool success = false;
int i;
/* Allocate and activate page directory. */
t->pagedir = pagedir_create();
if (t->pagedir == NULL)
goto done;
list_init(&t->page_list);
process_activate();
/* Open executable file. */
file = filesys_open(argv[0]);
if (file == NULL) {
printf("load: %s: open failed\n", argv[0]);
return false;
goto done;
}
file_deny_write(file);
/* Read and verify executable header. */
if (file_read(file, &ehdr, sizeof ehdr) != sizeof ehdr
|| memcmp(ehdr.e_ident, "\177ELF\1\1\1", 7)
|| ehdr.e_type != 2
|| ehdr.e_machine != 3
|| ehdr.e_version != 1
|| ehdr.e_phentsize != sizeof(struct Elf32_Phdr)
|| ehdr.e_phnum > 1024) {
printf("load: %s: error loading executable\n", argv[0]);
file_allow_write(file);
return false;
goto done;
}
/* Read program headers. */
file_ofs = ehdr.e_phoff;
for (i = 0; i < ehdr.e_phnum; i++) {
struct Elf32_Phdr phdr;
if (file_ofs < 0 || file_ofs > file_length(file))
goto done;
file_seek(file, file_ofs);
if (file_read(file, &phdr, sizeof phdr) != sizeof phdr)
goto done;
file_ofs += sizeof phdr;
switch (phdr.p_type) {
case PT_NULL:
case PT_NOTE:
case PT_PHDR:
case PT_STACK:
default:
/* Ignore this segment. */
break;
case PT_DYNAMIC:
case PT_INTERP:
case PT_SHLIB:
goto done;
case PT_LOAD:
if (validate_segment(&phdr, file)) {
bool writable = (phdr.p_flags & PF_W) != 0;
uint32_t file_page = phdr.p_offset & ~PGMASK;
uint32_t mem_page = phdr.p_vaddr & ~PGMASK;
uint32_t page_offset = phdr.p_vaddr & PGMASK;
uint32_t read_bytes, zero_bytes;
if (phdr.p_filesz > 0) {
/* Normal segment.
Read initial part from disk and zero the rest. */
read_bytes = page_offset + phdr.p_filesz;
zero_bytes = (ROUND_UP(page_offset + phdr.p_memsz, PGSIZE)
- read_bytes);
} else {
/* Entirely zero.
Don't read anything from disk. */
read_bytes = 0;
zero_bytes = ROUND_UP(page_offset + phdr.p_memsz, PGSIZE);
}
if (!load_segment(file, file_page, (void *) mem_page,
read_bytes, zero_bytes, writable))
goto done;
} else
goto done;
break;
}
}
/* Set up stack. */
if (!setup_stack(esp, argc, argv))
goto done;
/* Start address. */
*eip = (void (*)(void)) ehdr.e_entry;
success = true;
done:
/*
if(fail){
file_allow_write(file);
thread_current()->exit_status=-1;
return false;
}*/
//palloc_free_page(argv);
thread_current()->exe=file;
/* We arrive here whether the load is successful or not. */
return success;
}
/* load() helpers. */
static bool install_page(void *upage, void *kpage, bool writable);
//void push(void* kpage,uint8_t* ofs,void*buffer,size_t size);
/* Checks whether PHDR describes a valid, loadable segment in
FILE and returns true if so, false otherwise. */
static bool
validate_segment(const struct Elf32_Phdr *phdr, struct file *file) {
/* p_offset and p_vaddr must have the same page offset. */
if ((phdr->p_offset & PGMASK) != (phdr->p_vaddr & PGMASK))
return false;
/* p_offset must point within FILE. */
if (phdr->p_offset > (Elf32_Off) file_length(file))
return false;
/* p_memsz must be at least as big as p_filesz. */
if (phdr->p_memsz < phdr->p_filesz)
return false;
/* The segment must not be empty. */
if (phdr->p_memsz == 0)
return false;
/* The virtual memory region must both start and end within the
user address space range. */
if (!is_user_vaddr((void *) phdr->p_vaddr))
return false;
if (!is_user_vaddr((void *) (phdr->p_vaddr + phdr->p_memsz)))
return false;
/* The region cannot "wrap around" across the kernel virtual
address space. */
if (phdr->p_vaddr + phdr->p_memsz < phdr->p_vaddr)
return false;
/* Disallow mapping page 0.
Not only is it a bad idea to map page 0, but if we allowed
it then user code that passed a null pointer to system calls
could quite likely panic the kernel by way of null pointer
assertions in memcpy(), etc. */
if (phdr->p_vaddr < PGSIZE)
return false;
/* It's okay. */
return true;
}
/* Loads a segment starting at offset OFS in FILE at address
UPAGE. In total, READ_BYTES + ZERO_BYTES bytes of virtual
memory are initialized, as follows:
- READ_BYTES bytes at UPAGE must be read from FILE
starting at offset OFS.
- ZERO_BYTES bytes at UPAGE + READ_BYTES must be zeroed.
The pages initialized by this function must be writable by the
user process if WRITABLE is true, read-only otherwise.
Return true if successful, false if a memory allocation error
or disk read error occurs. */
static bool
load_segment(struct file *file, off_t ofs, uint8_t *upage,
uint32_t read_bytes, uint32_t zero_bytes, bool writable) {
ASSERT((read_bytes + zero_bytes) % PGSIZE == 0);
ASSERT(pg_ofs(upage) == 0);
ASSERT(ofs % PGSIZE == 0);
//file_seek(file, ofs);
while (read_bytes > 0 || zero_bytes > 0) {
/* Calculate how to fill this page.
We will read PAGE_READ_BYTES bytes from FILE
and zero the final PAGE_ZERO_BYTES bytes. */
size_t page_read_bytes = read_bytes < PGSIZE ? read_bytes : PGSIZE;
size_t page_zero_bytes = PGSIZE - page_read_bytes;
//uint8_t *kpage = palloc_get_page(PAL_USER);
//printf("Address of upage is %p with read address at %p and zero address at %p\n",upage,upage+ page_read_bytes,upage+ page_zero_bytes);
/*
struct sup_page_table_entry *new_page=malloc(sizeof(struct sup_page_table_entry));
if(!new_page) {
printf("BOGAS\n");
return false;
}
if(!writable){
printf("REEEEE\n");
}
ASSERT(upage==pg_round_down(upage));
//setFile(new_page,file,offset,upage,file_read_bytes,file_zero_bytes,writible);
new_page->debugID=list_size (&thread_current()->page_list);
new_page->user_vaddr=upage;
new_page->file=file;
new_page->file_offset=ofs;
new_page->file_read_bytes=page_read_bytes;
new_page->file_zero_bytes=page_zero_bytes;
new_page->is_loaded=false;
new_page->is_pinned=false;
new_page->file_offset=ofs;
//printf("page parameters set!\n");
new_page->for_file=true;
new_page->is_writable=writable;
new_page->is_loaded=true;
new_page->is_pinned=false;
uint8_t *file_frame=fAlloc(new_page,PAL_USER);
if (file_read(file, file_frame, page_read_bytes) != (int) page_read_bytes) {
fFree(file_frame);
free(new_page);
printf("FILE READ ERROR\n");
return false;
}
list_push_back (&thread_current()->page_list, &new_page->elem);
if(!install_page1(new_page->user_vaddr,file_frame,new_page->is_writable)){
fFree(file_frame);
printf("Failed to install page\n");
return false;
}
printf("Created page\n");
/* Get a page of memory.
uint8_t *kpage = palloc_get_page(PAL_USER);
//uint8_t *kpage=fAlloc(PAL_USER,upage);
if (kpage == NULL) {
printf("NULL KPAGE\n");
return false;
}
if (file_read(file, kpage, page_read_bytes) != (int) page_read_bytes) {
palloc_free_page(kpage);
printf("FILE READ ERROR\n");
return false;
}
memset(kpage + page_read_bytes, 0, page_zero_bytes);
if (!install_page(upage, kpage, writable)) {
printf("ASSHOLE\n");
palloc_free_page(kpage);
return false;
}
*/
if (!pt_add_file(file, ofs, upage, page_read_bytes, page_zero_bytes, writable,list_size (&thread_current()->page_list))) {
printf("ASSHOLE!\n");
return false;
}
//printf("FSIZE IS %i\n",list_size (&thread_current()->page_list));
//printf("SEGMENT LOADED\n");
/* Advance. */
read_bytes -= page_read_bytes;
zero_bytes -= page_zero_bytes;
ofs += page_read_bytes;
upage += PGSIZE;
}
return true;
}
/*decrements *esp by size(moving to the next part in the stack)
* and then copys the contents of buffer into esp
*/
/*
void push(void **esp, void *buffer, size_t size) {
//printf("Before\n");
char temp_buffer[size];
//hex_dump(kpage+*ofs-size,kpage+*ofs-size,size, true);
//hex_dump((unsigned int)(ofs-size),kpage,size, true);
//printf("Old esp is '%p'\n",kpage+*ofs);
*esp -= size;
//printf("new esp is '%p'\n",kpage+*ofs);
//printf("Pushing '%s' with size '%i' to address '%p'\n",buffer,size,kpage+*ofs);
memcpy(*esp, buffer, size);
//hex_dump(kpage+*ofs,kpage+*ofs,size, true);
//*(kpage+*ofs)=5;
}*/
void push(void *kpage, unsigned int *ofs, void *buffer, size_t size) {
//printf("Before\n");
char temp_buffer[size];
//hex_dump(kpage+*ofs-size,kpage+*ofs-size,size, true);
//hex_dump((unsigned int)(ofs-size),kpage,size, true);
//printf("Old esp is '%p'\n",kpage+*ofs);
*ofs -= size;
//printf("new esp is '%p'\n",kpage+*ofs);
//printf("Pushing '%s' with size '%i' to address '%p'\n",buffer,size,kpage+*ofs);
memcpy(kpage + *ofs, buffer, size);
//hex_dump(kpage+*ofs,kpage+*ofs,size, true);
//*(kpage+*ofs)=5;
}
/* Create a minimal stack by mapping a zeroed page at the top of
user virtual memory. */
static bool
setup_stack(void **esp, int argc, char **argv) {
char buffer[2048];
//printf("Setting up stack\n");
/*OLD METHOD THAT USED INSTALL PAGE
uint8_t *kpage;
uint8_t *upage;
bool success = false;
uint32_t addresses[argc + 1];//When pushing arguements we save their addresses;
kpage = palloc_get_page(PAL_USER | PAL_ZERO);
if (kpage != NULL) {
upage = ((uint8_t *) PHYS_BASE) - PGSIZE;
success = install_page1(upage, kpage, true);
//success=fAlloc()
if (success) {
*esp = PHYS_BASE;
//*esp = PHYS_BASE - 12;
} else {
palloc_free_page(kpage);
return;
}
}
*/
//printf("Extending stack\n");
//printf("STACK ADDRESS IS %p\n",((uint8_t *) PHYS_BASE) - PGSIZE);
uint8_t * upage = ((uint8_t *) PHYS_BASE) - PGSIZE;
bool success = extend_stack(upage);
//printf("Done\n");
uint8_t * kpage=pg_round_down(((uint8_t *) PHYS_BASE) - PGSIZE);
//uint8_t * kpage=PHYS_BASE;
if(!success){
return false;
}
*esp = PHYS_BASE;
uint32_t addresses[argc + 1];//When pushing arguements we save their addresses;
//*/
unsigned int ofs = PGSIZE;
// - sizeof(uint8_t);
//Now that we have our stack setup we gotta push our values to it
//size_t offset = 0;
for (int i = 0; i < argc; ++i) {
size_t arg_size = strlen(argv[i]) + 1;
//Inner loop used for counting the size of each arguement
//We push our addresses
//printf("Pushing argument '%s'\n",argv[i]);
push(kpage, &ofs, argv[i], arg_size);
//push(esp, argv[i], arg_size);
addresses[i] = (unsigned int) (*esp) - ((unsigned int) PGSIZE - (unsigned int) (ofs));
//addresses[i]=*esp-(unsigned int)PGSIZE-(unsigned int)(ofs);
//printf("Done pushing\n");
//hex_dump(kpage-PGSIZE,buffer,PGSIZE, true);
//offset -= size_rounded;//We move our offset to the next position on the stack
}
//char test=0;
/*Now that we have the contents of our arguements pushed in the stack, and their addresses on the
* stack saved, we can word aligh the stack pointer*/
//*esp=(void*)ROUND_DOWN((unsigned long)*esp,4);
unsigned int i = ((unsigned int) (ofs)) % 4;
ofs -= i;
/*Now that we are aligned we can start pushing pointers to argv
*We start with a null terminator for the entire argv
*/
uint32_t null = 0;/*
* Yes I know passing in a refrence to an int and de refrencing it in the function
* Seems like extra work but it saves the time of having to make another push() function
*/
push(kpage, &ofs, &null, sizeof(uint32_t));
//push(esp, &null, sizeof(uint32_t));
/*We then go in reverse order and push the addresses of each argv, rounding down each time*/
for (int i = argc - 1; i >= 0; --i) {
uint32_t cur_address = addresses[i];
push(kpage, &ofs, &cur_address, sizeof(uint32_t));
//push(esp,&cur_address, sizeof(uint32_t));
}
/*We push the address of our new array on the stack in this case it is the last value of esp*/
uint32_t start_of_argv = (unsigned int) (*esp) - ((unsigned int) PGSIZE - (unsigned int) (ofs));
//*esp=(void*)ROUND_DOWN((unsigned long)*esp,4);
//push(esp,&start_of_argv, 1);
push(kpage, &ofs, &start_of_argv, sizeof(uint32_t));
//push(esp, &start_of_argv, sizeof(uint32_t));
/*we then push argc*/
push(kpage, &ofs, &argc, sizeof(uint32_t));
//push(esp, &argc, sizeof(uint32_t));
//ofs -= sizeof(void *);
/*and finaly our return address*/
uint32_t zero = 0;
push(kpage, &ofs, &zero, sizeof(uint32_t));
//push(esp, &zero, sizeof(uint32_t));
//We change *esp back to its origional value
//*esp=oldesp;
//and then subtract our offset.
unsigned int ofs2 = (unsigned int) PGSIZE - (unsigned int) (ofs);
*esp = (unsigned int) (*esp) - ofs2;
//*esp = (unsigned int) (*esp) - ofs;
//printf("Final ESP is %p\n",*esp);
//hex_dump((uintptr_t)*esp, *esp,200,true);
return success;
}
/* Adds a mapping from user virtual address UPAGE to kernel
virtual address KPAGE to the page table.
If WRITABLE is true, the user process may modify the page;
otherwise, it is read-only.
UPAGE must not already be mapped.
KPAGE should probably be a page obtained from the user pool
with palloc_get_page().
Returns true on success, false if UPAGE is already mapped or
if memory allocation fails. */
static bool
install_page(void *upage, void *kpage, bool writable) {
struct thread *t = thread_current();
// Verify that there's not already a page at that virtual
// address, then map our page there.
return (pagedir_get_page(t->pagedir, upage) == NULL
&& pagedir_set_page(t->pagedir, upage, kpage, writable));
}
<file_sep>#ifndef USERPROG_SYSCALL_H
#define USERPROG_SYSCALL_H
struct lock file_lock;
void syscall_init (void);
#endif /* userprog/syscall.h */
| a95c59f54a73b671eb6aad481b6047542fd8baa5 | [
"C",
"Shell"
] | 11 | C | ucd-os-burgundy-s18/pintos3 | c97d07b47bd8c5a1a6921aaf812b2c9758f90d65 | 0c8c34749d56269fed70d156601884bfbe9af542 |
refs/heads/master | <repo_name>alapinsk/whois_parser<file_sep>/whois.py
import re
import sys
import argparse
import csv
from patterns import WHOISPATTERNS, get_error, get_provider
rx_get_domain_date_rest = re.compile(r"^(.+?)\n(.+?)\n+((?:.+\n)+)", re.MULTILINE)
pattern_dict = WHOISPATTERNS['fields']
rx_list = [(field, re.compile('(' + pattern + r")\.*(:|])+[^\S\n]*(?P<val>.+?)\n", re.DOTALL))
for (field, pattern) in pattern_dict.items()]
def search_rest_pattern(rest, rx):
m = rx.search(rest, re.IGNORECASE)
if m:
return m.group('val')
else:
return ''
def generate_dict(path, sep):
f = open(path, 'r', encoding="utf8")
text = f.read()
for match in rx_get_domain_date_rest.finditer(text):
res_dict = {}
domain, date, rest = match.groups()
domain = domain.strip()
rest = rest.replace(sep, '')
error = get_error(rest)
res_dict['domain'] = domain
res_dict['date'] = date
res_dict['error'] = error
for field, rx in rx_list:
if error != '':
res = ''
else:
res = search_rest_pattern(rest, rx)
res_dict[field] = res
if error != '':
provider = ''
else:
provider = get_provider(rest)
res_dict['provider'] = provider
res_dict['rest'] = rest
yield res_dict
f.close()
def main(path_in, path_out):
sep = ','
g = generate_dict(path_in, sep)
header = True
with open(path_out, 'w', encoding="utf8", newline='') as f:
writer = csv.writer(f, quoting=csv.QUOTE_ALL)
for d in g:
if header:
keys = d.keys()
writer.writerow(keys)
header = False
values = d.values()
writer.writerow(values)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-i', '--input', default='Data/results_all.tsv')
parser.add_argument('-o', '--output', default='output.csv')
args = parser.parse_args()
main(args.input, args.output)
<file_sep>/patterns.py
WHOISPATTERNS = {
'fields': {
'name': r'name|person|registrar',
'country': r'country',
'city': r'city',
'created': r'created|Created|Created Date|Created On|Created on|Creation Date|Creation Date \(dd/mm/yyyy\)|Registration Date|Registered On|Registered on|Registered|Registered Date|registration|registered|requested on|record activated'
}
}
def get_error(rest):
if 'No whois information found.' in rest:
error = 'NA'
elif 'no entries found' in rest:
error = 'NA'
elif 'No entries found for the selected source(s).' in rest:
error = 'NA'
elif 'Status: connect' in rest:
error = 'SC'
elif 'connection attempt failed' in rest:
error = 'SF'
elif 'no data of the requested type was found' in rest:
error = 'NO'
elif 'host has failed to respond' in rest:
error = 'HF'
elif 'Lookup refused.' in rest:
error = 'LR'
elif 'excessive access' in rest:
error = 'EA'
elif 'limit exceeded' in rest:
error = 'EA'
elif 'many simulataneous connections' in rest:
error = 'EA'
elif 'You have exceeded this limit' in rest:
error = 'EA'
elif 'You have exceeded the query limit' in rest:
error = 'EA'
elif 'blacklisted' in rest:
error = 'EA'
elif 'Invalid pattern' in rest:
error = 'IP'
elif 'No such host is known.' in rest:
error = 'UH'
elif 'Failure to abide' in rest:
error = 'FA'
elif 'NOT FOUND' in rest:
error = 'NF'
elif len(rest) < 120:
error = 'NA'
else:
error = ''
return error
def get_provider(rest):
if 'icann' in rest:
provider = 'icann'
elif 'ICANN' in rest:
provider = 'icann'
elif 'nominet' in rest:
provider = 'nominet'
elif 'nic.it' in rest:
provider = 'nic.it'
elif 'SIDN' in rest:
provider = 'SIDN'
elif 'eurid' in rest:
provider = 'eurid'
elif 'dns.pl' in rest:
provider = 'dns.pl'
elif 'godaddy' in rest:
provider = 'godaddy'
elif '% Rights to the data above are restricted by copyright.' in rest:
provider = 'ripencc'
elif 'nic.it' in rest:
provider = 'nicit'
elif 'ripe.net' in rest:
provider = 'ripenet'
elif '[Domain]' in rest:
provider = 'brackets'
elif 'DOMREG' in rest:
provider = 'domreg'
elif 'domain.hu' in rest:
provider = 'domain.hu'
elif 'FRNIC' in rest:
provider = 'frnic'
elif 'DNS Belgium' in rest:
provider = 'dnsbelgium'
elif 'networksolutions' in rest:
provider = 'networksolutions'
elif 'rotld.ro' in rest:
provider = 'rotld.ro'
elif 'DK Hostmaster' in rest:
provider = 'dkhostmaster'
elif 'cxDA' in rest:
provider = 'cxDA'
elif 'Afilias' in rest:
provider = 'afilias'
elif 'norid.no' in rest:
provider = 'norid.no'
elif 'wildwestdomains' in rest:
provider = 'wildwestdomains'
elif 'registry.si' in rest:
provider = 'registry.si'
elif 'RESTENA' in rest:
provider = 'RESTENA'
elif 'internet.ee' in rest:
provider = 'internet.ee'
elif 'NIC Chile' in rest:
provider = 'nicchile'
elif 'cointernet.co' in rest:
provider = 'cointernet.co'
elif 'registro.br' in rest:
provider = 'registro.br'
elif 'whois.sk-nic.sk' in rest:
provider = 'whois.sk-nic.sk'
elif 'RIPN' in rest:
provider = 'ripn'
elif 'dnc.org' in rest:
provider = 'dnc.org'
elif 'PT.whois-servers.net' in rest:
provider = 'PT.whois-servers.net'
else:
provider = ''
return provider
| c8885917337b1e49282bd973e68f2d0b05ba3af8 | [
"Python"
] | 2 | Python | alapinsk/whois_parser | c664c76640fa4f9e5e67a1f3062b0354893c8f74 | a1adbc1260f2467573f1476351070b33aaa14f88 |
refs/heads/master | <repo_name>codemagician45/gandi_deploy<file_sep>/app.py
import pymysql
from flask import Flask, url_for
app = Flask(__name__)
conn = pymysql.connect(host='localhost', user='root',
passwd='', db='ticket_sell', autocommit=True, unix_socket='/srv/run/mysqld/mysqld.sock')
@app.route('/')
def index():
cursor = conn.cursor()
try:
query = "INSERT INTO tickets (ticket_number, ticket_status) VALUES ('105', 0)"
cursor.execute(query)
conn.commit()
cursor.close()
except:
conn.rollback()
cursor.close()
cursor = conn.cursor()
query1 = "SELECT * FROM tickets WHERE ticket_status=0"
cursor.execute(query1)
tickets = cursor.fetchall()
data = []
for ticket in tickets:
ticket_number = {
'ticket_number': ticket[1]
}
data.append(ticket_number)
cursor.close()
return {'status': 'success', 'data': data}, 200
if __name__ == "__main__":
app.run(host='localhost', debug=True)
<file_sep>/wsgi.py
from app import app as application
if __name__ == 'app':
application.run()
| 13662a585cc06d2362785f811f81eaac1387e682 | [
"Python"
] | 2 | Python | codemagician45/gandi_deploy | 668399faf67aa9ad5a4d44005d444508ca057922 | 73459d25dd4e9db37952eb84760464abedde3de0 |
refs/heads/master | <file_sep>// TrashBOT - Events
// VERSION: 3.06
// AUTHOR: TiCubius <<EMAIL>>
const APIjs = require("./API.js")
const API = new APIjs()
module.exports = class Events {
/**
* Retrives the highest Role a Twitch User has, according to the userstate Object
*
* @param {object} userstate
* @returns {string} role
*/
static getTwitchHighestRole(userstate) {
let role = "Viewer"
if (userstate.subscriber) {role = "Subscriber"}
if (userstate.mod) {role = "Moderator"}
return role
}
/**
* Triggered when a Twitch Message has been sent to the Twitch Channel
*
* @param {string} channel
* @param {object} userstate
* @param {string} message
* @param {boolean} self
*/
static onTwitchMessage(channel, userstate, message, self) {
let viewer_data = {
"id": userstate["user-id"],
"username": userstate["display-name"] || userstate["username"],
"role": Events.getTwitchHighestRole(userstate)
}
let message_data = {
"viewer_id": userstate["user-id"],
"channel": channel,
"content": message
}
API.fetchViewer("Twitch", viewer_data.id).then((viewer) => {
// THE USER HAS CHANGED USERNAME, UPDATE THE DATABASE
if (viewer_data.username != viewer.username) {
// We don't wanna change the Role of the user, only its username
// If it became a Sub or a Follower, it should have been modfied
// If it became a Streamer or a Moderator, we should have changed it manually
viewer_data.role = viewer.role
API.updateViewer("Twitch", viewer_data).then((viewer_updated) => {
// Event creation is automated on the Backend
// API.createEvent("Twitch", event_data).then((event) => {}).catch((error) => {
// console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
// })
}).catch((error) => {
console.log(" - " + "TrashMates API: UPDATE VIEWER FAILED".red)
})
}
API.createMessage("Twitch", message_data).then((message) => {
console.log(" - " + (message_data.viewer_id).cyan + ": " + message_data.content)
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE MESSAGE FAILED".red)
console.log(" - " + (message_data.viewer_id).red + ": " + message_data.content)
})
}).catch((error) => {
API.createViewer("Twitch", viewer_data).then((viewer) => {
API.createMessage("Twitch", message_data).then((message) => {
console.log(" - " + (message_data.viewer_id).green + ": " + message_data.content)
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE MESSAGE FAILED".red)
console.log(" - " + (message_data.viewer_id).yellow + ": " + message_data.content)
})
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (message_data.viewer_id).red + ": " + message_data.content)
})
})
}
/**
* Triggered when a Twitch User has followed the Twitch Channel
*
* @param {JSON} follower
*/
static onTwitchFollows(follower) {
let viewer_data = {
"id": follower.id,
"username": follower.display_name,
"role": "Follower"
}
let event_data = {
"viewer_id": follower.id,
"type": "VIEWER_FOLLOWED",
"content": follower.display_name + " has followed the channel"
}
API.fetchViewer("Twitch", viewer_data.id).then((viewer) => {
API.createEvent("Twitch", event_data).then((created_event) => {}).catch((errors) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
})
if (viewer.role == "Viewer") {
API.updateViewer("Twitch", viewer_data).then((updated_viewer) => {
console.log(" - " + (viewer_data.id).green + " has followed the channel")
}).catch((errors) => {
console.log(" - " + "TrashMates API: UPDATE VIEWER FAILED".red)
console.log(" - " + (viewer_data.id).red + " has followed the channel")
})
}
}).catch((errors) => {
API.createViewer("Twitch", viewer_data).then((created_viewer) => {
API.createEvent("Twitch", event_data).then((create_event) => {
console.log(" - " + (viewer_data.id).green + " has followed the channel")
}).catch((errors) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).yellow + " has followed the channel")
})
}).catch((errors) => {
console.log(" - " + (viewer_data.id).red + " has followed the channel")
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
})
})
}
/**
* Triggered when a Twitch User has subscribed to the Twitch Channel
*
* @param {string} channel
* @param {string} username
* @param {string} method
* @param {string} message
* @param {object} userstate
*/
static onTwitchSubscription(channel, username, method, message, userstate) {
let viewer_data = {
"id": userstate["user-id"],
"username": userstate["display-name"] || userstate["username"],
// When subbing, the user is still a 'viewer'.
// We wanna change his role only if he's a viewer, not if he's a sub or moderator
"role": Events.getTwitchHighestRole(userstate) == "Viewer" ? "Subscriber" : Events.getTwitchHighestRole(userstate)
}
let event_data = {
"viewer_id": userstate["user-id"],
"type": "VIEWER_SUBSCRIBED",
"content": username + " is now subscribed to the channel!"
}
if (message) {event_data.content += " [" + message + "]"}
API.fetchViewer("Twitch", viewer_data.id).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
})
API.updateViewer("Twitch", viewer_data).then((viewer) => {
console.log(" - " + (viewer_data.id).green + " has subscribed to the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: UPDATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).red + " has subscribed to the channel!")
})
}).catch((error) => {
API.createViewer("Twitch", viewer_data).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " has subscribed to the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).yellow + " has subscribed to the channel!")
})
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (viewer_data.id).red + " has subscribed to the channel!")
})
})
}
/**
* Triggered when a Twitch User has cheered to the Twitch Channel
* @param {string} channel
* @param {object} userstate
* @param {string} message
*/
static onTwitchCheer(channel, userstate, message) {
let viewer_data = {
"id": userstate["user-id"],
"username": userstate["display-name"] || userstate["username"],
"role": Events.getTwitchHighestRole(userstate)
}
let event_data = {
"viewer_id": userstate["user-id"],
"type": "VIEWER_CHEERED",
"content": `${viewer_data.username} cheered ${userstate.bits} to the channel!`
}
if (message) {event_data.content += " [" + message + "]"}
API.fetchViewer("Twitch", viewer_data.id).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " has cheered to the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
})
}).catch((error) => {
API.createViewer("Twitch", viewer_data).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " has cheered to the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).yellow + " has cheered to the channel!")
})
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (viewer_data.id).red + " has cheered to the channel!")
})
})
}
/**
* Triggered when a Twitch User has hosted the Twitch Channel
* @param {string} channel
* @param {string} username
* @param {Number} viewers
* @param {boolean} autohost
*/
static onTwitchHosted(channel, username, viewers, autohost) {
API.fetchViewerFromTwitchByUsername(username).then((user) => {
let viewer_data = {
"id": user.id,
"username": user.display_name || user.login,
"role": 'Viewer'
}
let event_data = {
"viewer_id": user.id,
"type": "VIEWER_HOSTING",
"content": `${viewer_data.username} has hosted the channel for ${viewers} viewers!`
}
if (autohost) {event_data.content += " [AUTOHOST]"}
API.fetchViewer("Twitch", viewer_data.id).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " has hosted the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
})
}).catch((error) => {
API.createViewer("Twitch", viewer_data).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " has hosted the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).yellow + " has hosted the channel!")
})
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (viewer_data.id).red + " has hosted the channel!")
})
})
}).catch((error) => {
console.log(error)
console.log(" - " + "Twitch API: FETCH VIEWER FAILED".red)
})
}
/**
* Triggered when a Twitch User was banned from the Twitch Channel
* @param {string} channel
* @param {object} username
* @param {reason} reason
*/
static onTwitchBan(channel, username, reason) {
API.fetchViewerFromTwitchByUsername(username).then((user) => {
let viewer_data = {
"id": user.id,
"username": user.display_name || user.login,
"role": 'Viewer'
}
let event_data = {
"viewer_id": user.id,
"type": "VIEWER_BANNED",
"content": `${viewer_data.username} was banned from the channel!`
}
if (reason) {event_data.content += " [" + reason + "]"}
API.fetchViewer("Twitch", viewer_data.id).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " was banned from the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
})
}).catch((error) => {
API.createViewer("Twitch", viewer_data).then((viewer) => {
API.createEvent("Twitch", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + " was banned from the channel!")
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).yellow + " was banned from the channel!")
})
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (viewer_data.id).red + " was banned from the channel!")
})
})
}).catch((error) => {
console.log(error)
console.log(" - " + "Twitch API: FETCH VIEWER FAILED".red)
})
}
/**
* Triggered when a Twitch Stream is launched
*
* @param {JSON} stream
* @param {JSON} settings
* @param {Discord} Discord
*/
static onTwitchStream(stream, settings, Discord) {
let date = new Date(stream.started_at).toISOString().replace(/T/, ' ').replace(/\..+/, '')
// RNG is used to bypass Discord's image caching
let random = Math.floor(Math.random()*1000000)
settings.discord.embed.footer.text = "EN LIVE DEPUIS " + date
settings.discord.embed.fields[0].value = stream.title
settings.discord.embed.fields[1].value = stream.game.name
settings.discord.embed.image.url = `https://static-cdn.jtvnw.net/previews-ttv/live_user_${settings.api.twitch.username.toLowerCase()}-1280x720.jpg?${random}`
let embed = settings.discord.embed
// Send a Discord Message containing all the informations
// Note: Most of the Stream informations is
// displayed thanks to Discord Embeds
Discord.guilds
.get(settings.discord.server_id).channels
.find("name", settings.discord.channel_name)
.send("@everyone", { embed })
.then()
.catch((errors) => console.error(errors))
}
/**
* Triggered when a Discord Member has been sent to a Discord Channel
*
* @param {Message} message
*/
static onDiscordMessage(message) {
let viewer_data = {
"id": message.author.id,
"username": message.author.username,
"discriminator": message.author.discriminator,
"role": message.member.highestRole.name
}
let message_data = {
"id": message.id,
"viewer_id": message.author.id,
"channel": message.channel.name,
"content": message.cleanContent
}
if (message.attachments) {
message.attachments.forEach((attachement) => {
message_data.content += "\n" + attachement.url
})
}
API.fetchViewer("Discord", viewer_data.id).then((viewer) => {
API.createMessage("Discord", message_data).then((message) => {
console.log(" - " + (message_data.viewer_id).cyan + ": " + message_data.content)
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE MESSAGE FAILED".red)
console.log(" - " + (message_data.viewer_id).red + ": " + message_data.content)
})
}).catch((error) => {
API.createViewer("Discord", viewer_data).then((viewer) => {
API.createMessage("Discord", message_data).then((message) => {
console.log(" - " + (message_data.viewer_id).green + ": " + message_data.content)
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE MESSAGE FAILED".red)
console.log(" - " + (message_data.viewer_id).red + ": " + message_data.content)
})
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (message_data.viewer_id).red + ": " + message_data.content)
})
})
}
/**
* Triggered when a Discord Member has join the Discord Server
*
* @param {GuildMember} member
*/
static onDiscordMemberAdd(member) {
let viewer_data = {
"id": member.user.id,
"username": member.user.username,
"discriminator": member.user.discriminator,
"role": member.highestRole.name
}
let event_data = {
"viewer_id": member.user.id,
"type": "MEMBER_JOINED",
"content": member.user.username + "#" + member.user.discriminator + " has joined the server"
}
API.fetchViewer("Discord", viewer_data.id).then((viewer) => {
API.createEvent("Discord", event_data).then((event) => {
console.log(" - " + (viewer_data.id).green + ": " + event_data.content)
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
console.log(" - " + (viewer_data.id).red + ": " + event_data.content)
})
}).catch((error) => {
API.createViewer("Discord", viewer_data).then((viewer) => {
// EVENT IS AUTOMATIC
}).catch((error) => {
console.log(" - " + "TrashMates API: CREATE VIEWER FAILED".red)
console.log(" - " + (viewer_data.id).red + ": " + event_data.content)
})
})
}
/**
* Triggered when a Discord Member has been updated
*
* @param {GuildMember} oldMember
* @param {GuildMember} newMember
*/
static onDiscordMemberUpdate(oldMember, newMember) {
let viewer_data = {
"id": newMember.user.id,
"username": newMember.displayName,
"discriminator": newMember.user.discriminator,
"role": newMember.highestRole.name
}
let event_data = {
"viewer_id": newMember.user.id,
"type": "MEMBER_UPDATED",
"content": false
}
// Some changes aren't THAT important...
if ((oldMember.user.username != newMember.user.username) || (oldMember.user.discriminator != newMember.user.discriminator)) {
event_data.content = newMember.user.username + "#" + newMember.user.discriminator + " has changed username (from " + oldMember.user.username + "#" + oldMember.user.discriminator + ")"
}
if (oldMember.displayName != newMember.displayName) {
event_data.content = newMember.user.username + "#" + newMember.user.discriminator + " has changed display name (from " + oldMember.displayName + " to " + newMember.displayName + ")"
}
if (oldMember.highestRole.name != newMember.highestRole.name) {
event_data.content = newMember.user.username + "#" + newMember.user.discriminator + " became " + newMember.highestRole.name + " (from " + oldMember.highestRole.name + ")"
}
if (event_data.content) {
API.updateViewer("Discord", viewer_data).then((viewer_updated) => {
// Event creation is automated on the Backend
// API.createEvent("Discord", event_data).then((event) => {}).catch((error) => {
// console.log(" - " + "TrashMates API: CREATE EVENT FAILED".red)
// })
}).catch((error) => {
console.log(" - " + "TrashMates API: UPDATE VIEWER FAILED".red)
})
}
}
/**
* Triggered when a Discord Member leaves the Discord Server
*
* @param {GuildMember} member
*/
static onDiscordMemberRemove(member) {
let viewer_data = {
"id": member.user.id,
"username": member.user.username,
"discriminator": member.user.discriminator,
"role": "leavers"
}
let event_data = {
"viewer_id": member.user.id,
"type": "MEMBER_REMOVED",
"content": member.user.username + "#" + member.user.discriminator + " has left the server"
}
API.updateViewer("Discord", viewer_data).then((viewer_updated) => {
API.createEvent("Discord", event_data).then(() => {
console.log(" - " + (viewer_data.id).green + ": " + event_data.content)
}).catch((errors) => {
console.log(" - " + "TrashMates API: CREATE EVENT FAILED")
console.log(" - " + (viewer_data.id).yellow + ": " + event_data.content)
})
}).catch((errors) => {
console.log(" - " + "TrashMates API: UPDATE VIEWER FAILED")
console.log(" - " + (viewer_data.id).red + ": " + event_data.content)
})
}
}
<file_sep>// TrashBOT - TrashMatesAPI
// VERSION: 3.00
// AUTHOR: TiCubius <<EMAIL>>
const fs = require("fs")
const request = require("request")
const settings = JSON.parse(fs.readFileSync("app/config.json"))
// FIX: SSLv3 HANDSHAKE FAILURE
const tls = require('tls')
tls.DEFAULT_ECDH_CURVE = 'auto'
module.exports = class API {
constructor() {
this.trashmates = {}
this.trashmates.url = settings.api.trashmates.url
this.trashmates.token = settings.api.trashmates.token
this.twitch = {}
this.twitch.userid = settings.api.twitch.userid
this.twitch.url = settings.api.twitch.url
this.twitch.key = settings.api.twitch.key
this.followers = []
}
/**
* POST - Adds a new Event
*
* @param {string} type Discord|Twitch
* @param {JSON} event {userid, type, content}
* @returns {Promise}
*/
createEvent(type, event) {
return new Promise((resolve, reject) => {
request.post(this.trashmates.url + type.toLowerCase() + "/events/", {method: "POST", headers: {"token": this.trashmates.token}, form: event}, (errors, response, body) => {
if (errors || response.statusCode != 201) {
reject({"errors": "TrashMates API: " + type + " Event creation failed"})
} else {
resolve(JSON.parse(body))
}
})
})
}
/**
* POST - Adds a new Message
*
* @param {string} type Discord|Twitch
* @param {JSON} message {userid, channel, content, [id]}
* @returns {Promise}
*/
createMessage(type, message) {
return new Promise((resolve, reject) => {
request(this.trashmates.url + type.toLowerCase() + "/messages", {method: "POST", headers: {"token": this.trashmates.token}, form: message}, (errors, response, body) => {
if (errors || response.statusCode != 201) {
reject({"errors": "TrashMates API: " + type + " Message creation failed"})
} else {
resolve(JSON.parse(body))
}
})
})
}
/**
* POST - Adds a new Viewer
*
* @param {string} type Discord|Twitch
* @param {JSON} viewer {userid, username, role, [discriminator]}
* @returns {Promise}
*/
createViewer(type, viewer) {
return new Promise((resolve, reject) => {
request(this.trashmates.url + type.toLowerCase() + "/viewers", {method: "POST", headers: {"token": this.trashmates.token}, form: viewer}, (errors, response, body) => {
if (errors || response.statusCode != 201) {
reject({"errors": "TrashMates API: " + type + " Viewer creation failed"})
} else {
let event_data = {
"userid": viewer.userid,
"type": "VIEWER_CREATED",
"content": viewer.username + " was created"
}
if (type == "Discord") {
event_data.type = "MEMBER_JOINED"
event_data.content = viewer.username + "#" + viewer.discriminator + " has joined the server"
}
this.createEvent(type, event_data).then((event) => {
resolve(JSON.parse(body))
}).catch((error) => {
resolve(JSON.parse(body))
})
}
})
})
}
/**
* GET - Retrives the Viewer
*
* @param {string} type Discord|Twitch
* @param {Number} viewerid
* @returns {Promise}
*/
fetchViewer(type, viewerid) {
return new Promise((resolve, reject) => {
request(this.trashmates.url + type.toLowerCase() + "/viewers/" + viewerid, {method: "GET", headers: {"token": this.trashmates.token}}, (errors, response, body) => {
if (errors || response.statusCode != 200 || JSON.parse(body).hasOwnProperty("errors")) {
reject({"errors": "TrashMates API: " + type + " Viewer retrieving failed"})
} else {
resolve(JSON.parse(body))
}
})
})
}
/**
* PATCH - Updates the Viewer
*
* @param {string} type Discord|Twitch
* @param {JSON} viewer {username, role, [discriminator]}
* @returns {Promise}
*/
updateViewer(type, viewer) {
viewer["_method"] = "patch"
return new Promise((resolve, reject) => {
request(this.trashmates.url + type.toLowerCase() + "/viewers/" + viewer.id, {method: "POST", headers: {"token": this.trashmates.token}, form: viewer}, (errors, response, body) => {
if (errors || response.statusCode != 200) {
reject({"errors": "TrashMates API: " + type + " Viewer updating failed"})
} else {
resolve(JSON.parse(body))
}
})
})
}
/**
* GET - FEtch the user's data from Twitch, thanks to his username
* @param {string} username
*/
fetchViewerFromTwitchByUsername(username) {
return new Promise((resolve, reject) => {
let generated_url = this.twitch.url + "users/?login=" + username
// We make a GET request to the Twitch API if the generated url
// looks like https://twitch.tv/helix/users/?login=XXX
if (generated_url != this.twitch.url + "users/") {
request(generated_url, {method: "GET", headers: {"Client-ID": this.twitch.key}}, (errors, response, body) => {
if (errors || response.statusCode != 200) {
reject({"errros": "Twitch API: Fetch User's data failed"})
} else {
resolve(JSON.parse(body).data[0])
}
})
}
})
}
/**
* GET - Fetch the 100 latest followers ID, from the Twitch API
*/
fetchLatestFollowersID() {
return new Promise((resolve, reject) => {
request(this.twitch.url + "users/follows?first=100&to_id=" + this.twitch.userid, {method: "GET", headers: {"Client-ID": this.twitch.key}}, (errors, response, body) => {
if (errors || response.statusCode != 200) {
reject({"errors": "Twitch API: Fetch Latest Followers ID failed"})
} else {
resolve(JSON.parse(body).data)
}
})
})
}
/**
* GET - Fetch the 100 latest followers informations, from the Twitch API
*/
fetchLatestFollowers() {
return new Promise((resolve, reject) => {
this.fetchLatestFollowersID().then((followers) => {
let url = this.twitch.url + "users/?id="
followers.forEach((follower) => {
if (this.followers.indexOf(follower.from_id) < 0) {
this.followers.push(follower.from_id)
url += follower.from_id + "&id="
}
})
// We make a GET request to the Twitch API if the generated url
// looks like https://twitch.tv/helix/users/?id=XXX,&id=
// (and we remove the last 4 chars)
let generated_url = url.slice(0, -4)
if (generated_url != this.twitch.url + "users/") {
request(generated_url, {method: "GET", headers: {"Client-ID": this.twitch.key}}, (errors, response, body) => {
if (errors || response.statusCode != 200) {
reject({"errros": "Twitch API: Fetch Latest Followers failed"})
} else {
resolve(JSON.parse(body).data)
}
})
}
}).catch((errors) => {
console.log(" - " + "ERROR WHILE FETCHING LATEST FOLLOWERS ID".red)
})
})
}
/**
* GET - Fetch the Stream data for the Twitch User, from the Twitch API
*/
fetchStream() {
return new Promise((resolve, reject) => {
request(this.twitch.url + "streams?user_id=" + this.twitch.userid, {method: "GET", headers: {"Client-ID": this.twitch.key}}, (errors, response, body) => {
if (errors || response.statusCode != 200) {
reject({"errors": "Twitch API: Fetch Stream failed"})
} else {
let json = JSON.parse(body).data
if (json.length > 0)
{
json = json[0]
this.fetchGame(json.game_id).then((game) => {
json.game = game[0]
resolve(json)
}).catch((errors) => {
reject({"errors": "Twitch API: Fetch Stream failed"})
})
} else {
resolve([])
}
}
})
})
}
/**
* GET - Fetch tha Game daa for the Twitch Game ID, from the Twitch API
*
* @param {int|string} gameid
*/
fetchGame(gameid) {
return new Promise((resolve, reject) => {
request(this.twitch.url + "games?id=" + gameid, {method: "GET", headers: {"Client-ID": this.twitch.key}}, (errors, response, body) => {
if (errors || response.statusCode != 200) {
reject({"errors": "Twitch API: Fetch Game failed"})
} else {
resolve(JSON.parse(body).data)
}
})
})
}
}
| a9fdd09a7febd49569f4cde0947d1bfb8e7618ee | [
"JavaScript"
] | 2 | JavaScript | TrashMates/TrashBOT | c889e3b31a88f76684ef105bd9a980e1cbf84e6e | daad07919396e0d48434acb1e0fb746901ffb282 |
refs/heads/master | <repo_name>muriloxk/estudo-design-patterns-csharp<file_sep>/StatePattern.Exercicio/Domain/Regras.cs
using System;
namespace StatePattern.Exercicio.Domain
{
public class Conta
{
public Conta(string titular, double saldo)
{
Titular = titular;
Saldo = saldo;
Estado = new Positiva();
}
public string Titular { get; internal set; }
public double Saldo { get; internal set; }
internal IEstadoConta Estado { get; set; }
public void Depositar(double quantia)
{
Estado.Depositar(this, quantia);
}
public void Sacar(double quantia)
{
Estado.Sacar(this, quantia);
if (Saldo < 0 && Estado.GetType() != typeof(Negativa))
Estado = new Negativa(Titular);
}
}
internal interface IEstadoConta
{
void Depositar(Conta conta, double quantia);
void Sacar(Conta conta, double quantia);
}
internal class Negativa : IEstadoConta
{
public Negativa(string titular)
{
Console.WriteLine($"A conta do {titular} foi negativada");
}
public void Sacar(Conta conta, double quantia)
{
throw new Exception("Você não pode realizar saque, a conta esta negativa");
}
public void Depositar(Conta conta, double quantia)
{
var valor = quantia * 0.95;
conta.Saldo += valor;
Console.WriteLine($"Saldo após o depósito da quantia de {valor}: {conta.Saldo}");
}
}
internal class Positiva : IEstadoConta
{
public void Sacar(Conta conta, double quantia)
{
conta.Saldo -= quantia;
Console.WriteLine($"Saldo após o saque : {conta.Saldo}");
}
public void Depositar(Conta conta, double quantia)
{
var valor = quantia * 0.98;
conta.Saldo += valor;
Console.WriteLine($"Saldo após o depósito da quantia de {valor}: {conta.Saldo}");
}
}
}
<file_sep>/StrategyPattern.Exemplo2/PatoDaCabecaVermelha.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class PatoDaCabecaVermelha : Pato
{
public override void Aparecer()
{
Console.WriteLine("Apareceu o pato da cabeça vermelha");
}
}
}
<file_sep>/ChainOfResponsability.Exercicio/IResposta.cs
namespace ChainOfResponsability.Exercicio
{
public interface IResposta
{
string GerarResposta(Requisicao requisicao);
}
}
<file_sep>/Visitor.Exemplo/Program.cs
using System;
namespace Visitor.Exemplo
{
class Program
{
static void Main(string[] args)
{
var expressao = new Soma(new Numero(5), new Numero(2));
var expressao2 = new Soma(expressao, new Numero(5));
Console.WriteLine($"Expressão 2: {expressao2.Avalia()}");
var expressao3 = new Subtracao(expressao2, new Numero(200));
Console.WriteLine($"Expressão 3: {expressao3.Avalia()}");
var impressora = new Impressora();
impressora.Visita(expressao2);
impressora.Visita(expressao3);
Console.ReadKey();
}
}
public interface IVisitor
{
void Visita(IExpressao expressao);
void VisitaSoma(Soma expressao);
void VisitaSubtracao(Subtracao expressao);
void VisitaMultiplicacao(Multiplicacao expressao);
void VisitaDivisao(Divisao expressao);
void VisitaRaizQuadrada(RaizQuadrada expressao);
void VisitaNumero(Numero expressao);
}
public class ImpressoraAlternativa : IVisitor
{
public void Visita(IExpressao expressao)
{
expressao.Aceita(this);
}
public void VisitaDivisao(Divisao expressao)
{
Console.Write("(");
Console.Write(" / ");
expressao.Esquerda.Aceita(this);
Console.Write(" ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaMultiplicacao(Multiplicacao expressao)
{
Console.Write("(");
Console.Write(" * ");
expressao.Esquerda.Aceita(this);
Console.Write(" ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaNumero(Numero expressao)
{
Console.Write(expressao.Valor);
}
public void VisitaRaizQuadrada(RaizQuadrada expressao)
{
Console.Write(" ^ ");
expressao.Aceita(this);
}
public void VisitaSoma(Soma expressao)
{
Console.Write("(");
Console.Write(" + ");
expressao.Esquerda.Aceita(this);
Console.Write(" ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaSubtracao(Subtracao expressao)
{
Console.Write("(");
Console.Write(" - ");
expressao.Esquerda.Aceita(this);
Console.Write(" ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
}
public class Impressora : IVisitor
{
public void Visita(IExpressao expressao)
{
expressao.Aceita(this);
}
public void VisitaSoma(Soma expressao)
{
Console.Write("(");
expressao.Esquerda.Aceita(this);
Console.Write(" + ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaDivisao(Divisao expressao)
{
Console.Write("(");
expressao.Esquerda.Aceita(this);
Console.Write(" / ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaMultiplicacao(Multiplicacao expressao)
{
Console.Write("(");
expressao.Esquerda.Aceita(this);
Console.Write(" * ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaRaizQuadrada(RaizQuadrada expressao)
{
Console.Write("(");
Console.Write(" ^ ");
expressao.Aceita(this);
Console.Write(")");
}
public void VisitaSubtracao(Subtracao expressao)
{
Console.Write("(");
expressao.Esquerda.Aceita(this);
Console.Write(" - ");
expressao.Direita.Aceita(this);
Console.Write(")");
}
public void VisitaNumero(Numero expressao)
{
Console.Write(expressao.Valor);
}
}
public interface IExpressao
{
int Avalia();
void Aceita(IVisitor visitor);
}
public class Numero : IExpressao
{
public int Valor { get; private set; }
public Numero(int numero)
{
Valor = numero;
}
public int Avalia()
{
return Valor;
}
public void Aceita(IVisitor visitor)
{
visitor.VisitaNumero(this);
}
}
public class Subtracao : IExpressao
{
public IExpressao Esquerda { get; private set; }
public IExpressao Direita { get; private set; }
public Subtracao(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 - resultadoExpressao2;
}
public void Aceita(IVisitor visitor)
{
visitor.VisitaSubtracao(this);
}
}
public class Soma : IExpressao
{
public IExpressao Esquerda { get; private set; }
public IExpressao Direita { get; private set; }
public Soma(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 + resultadoExpressao2;
}
public void Aceita(IVisitor visitor)
{
visitor.VisitaSoma(this);
}
}
public class Multiplicacao : IExpressao
{
public IExpressao Esquerda { get; private set; }
public IExpressao Direita { get; private set; }
public Multiplicacao(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 * resultadoExpressao2;
}
public void Aceita(IVisitor visitor)
{
visitor.VisitaMultiplicacao(this);
}
}
public class Divisao : IExpressao
{
public IExpressao Esquerda { get; private set; }
public IExpressao Direita { get; private set; }
public Divisao(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 / resultadoExpressao2;
}
public void Aceita(IVisitor visitor)
{
visitor.VisitaDivisao(this);
}
}
public class RaizQuadrada : IExpressao
{
public int Numero { get; private set; }
public RaizQuadrada(IExpressao numero)
{
Numero = numero.Avalia();
}
public int Avalia()
{
return (int)Math.Sqrt(Numero);
}
public void Aceita(IVisitor visitor)
{
visitor.VisitaRaizQuadrada(this);
}
}
}
<file_sep>/ChainOfResponsability.Exemplo/DescontoAcimaDeQuinhetos.cs
using System;
namespace ChainOfResponsability.Exemplo
{
public class DescontoAcimaDeQuinhetos : IDesconto
{
public IDesconto Proximo { get; set; }
public double Calcular(Orcamento orcamento)
{
if (orcamento.Valor > 500.0)
return orcamento.Valor * 0.07;
return Proximo.Calcular(orcamento);
}
}
}
<file_sep>/FacadeWithSingleton/Program.cs
using System;
namespace FacadeWithSingleton
{
class Program
{
static void Main(string[] args)
{
var empresaFacade = EmpresaSingleton.Instancia;
var cliente = new Cliente("Murilo");
empresaFacade.SalvarCliente(cliente);
empresaFacade.LancarFatura(cliente, new Cobranca());
empresaFacade.Cobrar(cliente);
Console.ReadKey();
}
}
public class Cliente
{
public Cliente(string nome)
{
Nome = nome;
}
public override string ToString()
{
return Nome;
}
public string Nome { get; private set; }
}
public class ClienteDAO
{
public void Salvar(Cliente cliente)
{
Console.WriteLine("Salvou o cliente {0}", cliente);
}
}
public class Cobranca
{
public void Cobrar(Cliente cliente)
{
Console.WriteLine("Cobrou o cliente");
}
}
public class Fatura
{
public void LancarFatura(Cliente cliente, Cobranca cobranca)
{
Console.WriteLine("Lançou a fatura braba no {0}", cliente);
}
}
public class EmpresaFacade
{
public void LancarFatura(Cliente cliente, Cobranca cobranca)
{
new Fatura().LancarFatura(cliente, cobranca);
}
public void Cobrar(Cliente cliente)
{
new Cobranca().Cobrar(cliente);
}
public void SalvarCliente(Cliente cliente)
{
new ClienteDAO().Salvar(cliente);
}
}
public class EmpresaSingleton
{
private static EmpresaFacade _instancia;
public static EmpresaFacade Instancia {
get
{
if (_instancia == null)
_instancia = new EmpresaFacade();
return _instancia;
}
private set { }
}
private EmpresaSingleton(){ }
}
}
<file_sep>/FacadeWithSingleton/Cliente.cs
namespace FacadeWithSingleton
{
public class Cliente
{
}
}<file_sep>/ChainOfResponsability.Exemplo2/PagamentoBancoChain.cs
namespace ChainOfResponsability.Exemplo2
{
public abstract class PagamentoBancoChain
{
private PagamentoBancoChain _proximo;
public PagamentoBancoChain Proximo
{
get
{
return _proximo;
}
set
{
if (_proximo == null)
{
_proximo = value;
return;
}
_proximo.Proximo = value;
}
}
protected EBanco Banco { get; set; }
public PagamentoBancoChain(EBanco banco)
{
Banco = banco;
}
public void EfetuarPagamento(Debito debito)
{
if (debito.Banco == Banco)
{
Pagar(debito);
return;
}
Proximo?.EfetuarPagamento(debito);
}
protected abstract void Pagar(Debito debito);
}
}
<file_sep>/StrategyPattern.Exemplo2/PatoDasMontanhas.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class PatoDasMontanhas : Pato
{
public override void Aparecer()
{
Console.Write("Apareceu o pato das montanhas");
}
}
}
<file_sep>/Flyweight.Exercicio/Program.cs
using System;
using System.Collections.Generic;
namespace Flyweight.Exercicio
{
class Program
{
static void Main(string[] args)
{
var notas = new NotasMusicas();
IList<INotaMusical> musica = new List<INotaMusical>()
{
notas.BuscarNota("Re"),
notas.BuscarNota("Mi"),
notas.BuscarNota("Fa"),
notas.BuscarNota("So"),
notas.BuscarNota("La"),
};
var piano = new Piano();
piano.TocarMusica(musica);
Console.ReadKey();
}
}
public interface INotaMusical
{
int Frequencia { get; }
}
public class Fa : INotaMusical
{
public int Frequencia => 262;
}
public class Re : INotaMusical
{
public int Frequencia => 120;
}
public class Do : INotaMusical
{
public int Frequencia => 200;
}
public class Mi : INotaMusical
{
public int Frequencia => 35;
}
public class So : INotaMusical
{
public int Frequencia => 100;
}
public class La : INotaMusical
{
public int Frequencia => 100;
}
public class NotasMusicas
{
private IDictionary<string, INotaMusical> Notas
= new Dictionary<string, INotaMusical>()
{
{ "Re", new Re() },
{ "Mi", new Mi() },
{ "Fa", new Fa() },
{ "Do", new Do() },
{ "So", new So() },
{ "La", new La() }
};
public INotaMusical BuscarNota(string nota)
{
return Notas[nota];
}
}
public class Piano
{
public void TocarMusica(IList<INotaMusical> notas)
{
foreach(var nota in notas)
{
Console.Beep(nota.Frequencia, 300);
}
}
}
}
<file_sep>/ChainOfResponsability.Exercicio/Program.cs
using System;
namespace ChainOfResponsability.Exercicio
{
class Program
{
static void Main(string[] args)
{
var requisicao = new Requisicao(EFormato.PORCENTO);
var servidor = new CriarReposta();
Console.WriteLine($"Resposta do servidor: {servidor.GerarResposta(requisicao)}");
Console.ReadKey();
}
}
}
<file_sep>/StrategyPattern.Exemplo2/Program.cs
namespace StrategyPattern.Exemplo2
{
class Program
{
static void Main(string[] args)
{
// Aqui deixa o código mais reusavel para outras classes
// sem precisar de muitas ligações de herança e quando tiver que ter alterações
// não teremos grandes danos;
// EXEMPLO BASEADO NO LIVRO HEAD FIRST : DESIGN PATTERNS
var patoDaCabecaVermelha = new PatoDaCabecaVermelha();
patoDaCabecaVermelha.ComportamentoDeFalar = new QuackAlto();
patoDaCabecaVermelha.ComportamentoDeVoar = new VoarComFoguete();
patoDaCabecaVermelha.Aparecer();
patoDaCabecaVermelha.Falar();
patoDaCabecaVermelha.Voar();
var patoDasMontanhas = new PatoDasMontanhas();
patoDasMontanhas.ComportamentoDeFalar = new Quack();
patoDasMontanhas.ComportamentoDeVoar = new VoarComAsas();
patoDasMontanhas.Aparecer();
patoDasMontanhas.Falar();
patoDasMontanhas.Voar();
var patoDoSitio = new PatoDoSitio();
patoDoSitio.ComportamentoDeVoar = new NaoVoar();
patoDoSitio.ComportamentoDeFalar = new Quack();
patoDoSitio.Aparecer();
patoDoSitio.Falar();
patoDoSitio.Voar();
}
}
}
<file_sep>/StrategyPattern.Exemplo2/Quack.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class Quack : IComportamentoDeFalar
{
public void Falar()
{
Console.WriteLine("Quack!");
}
}
}
<file_sep>/ChainOfResponsability.Exemplo2/PagamentoItau.cs
using System;
namespace ChainOfResponsability.Exemplo2
{
public class PagamentoItau : PagamentoBancoChain
{
public PagamentoItau() : base(EBanco.Itau)
{
}
protected override void Pagar(Debito debito)
{
Console.WriteLine("Pagamento realizado via Itau");
}
}
}
<file_sep>/StrategyPattern.Exemplo2/VoarComFoguete.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class VoarComFoguete : IComportamentoDeVoar
{
public void Voar()
{
Console.WriteLine("Voando com um foguete");
}
}
}
<file_sep>/ChainOfResponsability.Exemplo2/Conta.cs
namespace ChainOfResponsability.Exemplo2
{
public class Debito
{
public Debito(EBanco banco, double valor)
{
Banco = banco;
Valor = valor;
}
public EBanco Banco { get; set; }
public double Valor { get; set; }
}
}<file_sep>/Memento.Exemplo2/Program.cs
using System;
using System.Collections.Generic;
namespace Memento.Exemplo2
{
class Program
{
static void Main(string[] args)
{
var contrato = new Contrato(DateTime.Now, "Cliente 1", TipoContrato.Novo);
contrato.ExibirFaseContrato();
contrato.Avanca();
contrato.ExibirFaseContrato();
contrato.Avanca();
contrato.ExibirFaseContrato();
contrato.Avanca();
contrato.ExibirFaseContrato();
contrato.Voltar();
contrato.ExibirFaseContrato();
contrato.Voltar();
contrato.ExibirFaseContrato();
Console.ReadKey();
}
}
public enum TipoContrato
{
Novo,
EmAndamento,
Acertado,
Concluido,
}
public class Contrato
{
public DateTime Data { get; private set; }
public string Cliente { get; private set; }
public TipoContrato Tipo { get; private set; }
private HistoricoContrato Historico { get; set; }
public Contrato(DateTime data, string cliente, TipoContrato tipo)
{
Data = data;
Cliente = cliente;
Tipo = tipo;
Historico = new HistoricoContrato();
}
public void Avanca()
{
if (Tipo == TipoContrato.Novo)
{
Historico.AdicionarUmEstadoDoContrato(new ContratoMemento(new Contrato(this.Data, this.Cliente, this.Tipo)));
Tipo = TipoContrato.EmAndamento;
}
else if (Tipo == TipoContrato.EmAndamento)
{
Historico.AdicionarUmEstadoDoContrato(new ContratoMemento(new Contrato(this.Data, this.Cliente, this.Tipo)));
Tipo = TipoContrato.Acertado;
}
else if (Tipo == TipoContrato.Acertado)
{
Historico.AdicionarUmEstadoDoContrato(new ContratoMemento(new Contrato(this.Data, this.Cliente, this.Tipo)));
Tipo = TipoContrato.Concluido;
}
}
public void Voltar()
{
Tipo = Historico.RetornarUltimoEstadoDoContrato().Contrato.Tipo;
}
public void ExibirFaseContrato()
{
Console.WriteLine(Tipo);
}
}
public class ContratoMemento
{
public Contrato Contrato { get; private set; }
public ContratoMemento(Contrato contratoMemento)
{
Contrato = contratoMemento;
}
}
public class HistoricoContrato
{
private List<ContratoMemento> ContratosMemento { get; set; }
public HistoricoContrato()
{
ContratosMemento = new List<ContratoMemento>();
}
public void AdicionarUmEstadoDoContrato(ContratoMemento contrato)
{
ContratosMemento.Add(contrato);
}
public ContratoMemento RetornarUltimoEstadoDoContrato()
{
if (ContratosMemento.Count <= 0)
return null;
var estadoContrato = ContratosMemento[ContratosMemento.Count - 1];
ContratosMemento.Remove(estadoContrato);
return estadoContrato;
}
}
}
<file_sep>/StrategyPattern.Exercicio2/Program.cs
using System;
namespace StrategyPattern.Exercicio2
{
class Program
{
static void Main(string[] args)
{
var conta = new Conta(600);
var realizadorInvestimento = new RealizadoraDeInvestimento();
var conservador = realizadorInvestimento.RealizarInvestimento(conta, new Conservador());
var moderado = realizadorInvestimento.RealizarInvestimento(conta, new Moderado());
var arrojado = realizadorInvestimento.RealizarInvestimento(conta, new Arrojado());
Console.WriteLine($"Conservador: {conservador}");
Console.WriteLine($"Moderado: {moderado}");
Console.WriteLine($"Arrojado: {arrojado}");
Console.ReadKey();
}
}
public interface Investimento
{
double Calcular(Conta conta);
}
public class Conta
{
public Conta(double saldo)
{
Saldo = saldo;
}
public double Saldo { get; set; }
}
public class Conservador : Investimento
{
const double RETORNO_INVESTIMENTO = 0.75;
public double Calcular(Conta conta)
{
return (conta.Saldo * 0.008) * RETORNO_INVESTIMENTO;
}
}
public class Moderado : Investimento
{
const double RETORNO_INVESTIMENTO = 0.75;
public double Calcular(Conta conta)
{
var risco = new Random().Next(2);
if (risco == 0)
{
return (conta.Saldo * 0.025) * RETORNO_INVESTIMENTO;
}
return (conta.Saldo * 0.0075) * RETORNO_INVESTIMENTO;
}
}
public class Arrojado : Investimento
{
const double RETORNO_INVESTIMENTO = 0.75;
public double Calcular(Conta conta)
{
var risco = new Random().Next(101);
if (risco >= 0 && risco <= 20)
return (conta.Saldo * 0.05) * RETORNO_INVESTIMENTO;
if (risco >= 20 && risco <= 30)
return (conta.Saldo * 0.03) * RETORNO_INVESTIMENTO;
return (conta.Saldo * 0.006) * RETORNO_INVESTIMENTO;
}
}
public class RealizadoraDeInvestimento
{
public double RealizarInvestimento(Conta conta, Investimento investimento)
{
return investimento.Calcular(conta);
}
}
}
<file_sep>/Decorator.Exemplo/Program.cs
using System;
using System.Collections.Generic;
using System.Collections.ObjectModel;
using System.Linq;
namespace Decorator.Exemplo
{
class Program
{
static void Main(string[] args)
{
var orcamento = new Orcamento();
orcamento.AdicionarItem("Lápis", 5);
orcamento.AdicionarItem("Pincel", 15);
var calcularIcmsComIss = new ICMS(new ISS());
Console.WriteLine(calcularIcmsComIss.Calcular(orcamento));
var calcularIcmsComIMA = new ICMS(new IMA());
Console.WriteLine(calcularIcmsComIMA.Calcular(orcamento));
Console.ReadKey();
}
}
public class Orcamento
{
private Dictionary<string, double> itens;
public double Valor
{
get
{
return itens.Sum(x => x.Value);
}
private set { }
}
public ReadOnlyDictionary<string, double> Itens
{
get
{
return new ReadOnlyDictionary<string, double>(itens);
}
private set { }
}
public void AdicionarItem(string descricao, double valor)
{
itens.Add(descricao, valor);
}
public Orcamento()
{
itens = new Dictionary<string, double>();
}
}
public abstract class Imposto
{
protected Imposto(Imposto proximo)
{
Proximo = proximo;
}
protected Imposto()
{
Proximo = null;
}
protected Imposto Proximo { get; private set; }
protected double CalculoDoProximo(Orcamento orcamento)
{
if (Proximo == null)
return 0;
return Proximo.Calcular(orcamento);
}
public abstract double Calcular(Orcamento orcamento);
}
public class ICMS : Imposto
{
public ICMS(Imposto proximo) : base(proximo) { }
public ICMS() : base() { }
public override double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.07 + CalculoDoProximo(orcamento);
}
}
public class ISS : Imposto
{
public ISS(Imposto proximo) : base (proximo) { }
public ISS() : base () { }
public override double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.05 + CalculoDoProximo(orcamento);
}
}
public class IMA : Imposto
{
public IMA(Imposto proximo) : base(proximo) { }
public IMA() : base () { }
public override double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.2 + CalculoDoProximo(orcamento);
}
}
public class ICPP : Imposto
{
public ICPP(Imposto proximo) : base(proximo) { }
public ICPP() : base() { }
public override double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.2 + CalculoDoProximo(orcamento);
}
}
public class IKCV : Imposto
{
public IKCV(Imposto proximo) : base(proximo) { }
public IKCV() : base() { }
public override double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.2 + CalculoDoProximo(orcamento);
}
}
}
<file_sep>/ChainOfResponsability.Exercicio/CriarReposta.cs
using System;
namespace ChainOfResponsability.Exercicio
{
public class CriarReposta
{
public string GerarResposta(Requisicao requisicao)
{
var respostaJson = new RespostaJSON();
var respostaPorcento = new RespostaPorcento(respostaJson);
var respostaCsv = new RespostaCSV(respostaPorcento);
var respostaXml = new RespostaXML(respostaCsv);
return respostaXml.GerarResposta(requisicao);
}
}
}
<file_sep>/Command.Exemplo/Program.cs
using System;
using System.Collections.Generic;
namespace Command.Exemplo
{
class Program
{
static void Main(string[] args)
{
var filaDeProcessos = new FilaDeTrabalho();
var pedido1 = new Pedido("Murilo", 500);
filaDeProcessos.Adicionar(new PagarPedido(pedido1));
filaDeProcessos.Adicionar(new FinalizaPedido(pedido1));
var pedido2 = new Pedido("José", 500);
filaDeProcessos.Adicionar(new PagarPedido(pedido2));
filaDeProcessos.Adicionar(new FinalizaPedido(pedido2));
filaDeProcessos.ExecutarComandos();
Console.ReadKey();
}
}
public interface ICommand
{
void Executa();
}
public class FilaDeTrabalho
{
private IList<ICommand> ListaDeComandos { get; set; }
public FilaDeTrabalho()
{
ListaDeComandos = new List<ICommand>();
}
public void Adicionar(ICommand command)
{
ListaDeComandos.Add(command);
}
public void ExecutarComandos()
{
foreach (ICommand command in ListaDeComandos)
command.Executa();
}
}
public class PagarPedido : ICommand
{
public Pedido Pedido { get; private set; }
public PagarPedido(Pedido pedido)
{
Pedido = pedido;
}
public void Executa()
{
Pedido.Paga();
}
}
public class FinalizaPedido : ICommand
{
public Pedido Pedido { get; private set; }
public FinalizaPedido(Pedido pedido)
{
Pedido = pedido;
}
public void Executa()
{
Pedido.Finaliza();
}
}
public class Pedido
{
public String Cliente { get; private set; }
public double Valor { get; private set; }
public Status Status { get; private set; }
public DateTime DataFinalizacao { get; private set; }
public Pedido(String cliente, double valor)
{
Cliente = cliente;
Valor = valor;
Status = Status.Novo;
}
public void Paga()
{
Status = Status.Pago;
Console.WriteLine($"Pagando pedido do {Cliente}");
}
public void Finaliza()
{
DataFinalizacao = DateTime.Now;
Status = Status.Entregue;
Console.WriteLine($"Finalizando pedido do {Cliente}");
}
}
public enum Status
{
Novo,
Processado,
Pago,
ItemSeparado,
Entregue
}
}
<file_sep>/ChainOfResponsability.Exemplo/DescontoPorMaisDeCincoItens.cs
using System;
namespace ChainOfResponsability.Exemplo
{
public class DescontoPorMaisDeCincoItens : IDesconto
{
public IDesconto Proximo { get; set; }
public double Calcular(Orcamento orcamento)
{
if (orcamento.Itens.Count > 5)
return orcamento.Valor * 0.1;
return Proximo.Calcular(orcamento);
}
}
}
<file_sep>/ChainOfResponsability.Exemplo/SemDesconto.cs
using System;
namespace ChainOfResponsability.Exemplo
{
public class SemDesconto : IDesconto
{
public IDesconto Proximo { get; set; }
public double Calcular(Orcamento orcamento)
{
return 0;
}
}
}
<file_sep>/Bridge.Exemplo/Program.cs
using System;
using System.Text;
namespace Bridge.Exemplo
{
class Program
{
static void Main(string[] args)
{
var mensagemAdmEmail = new MensagemParaOAdministrador("Murilo", new EnviaPorEmail());
mensagemAdmEmail.Envia();
var mensagemAdmSms = new MensagemParaOAdministrador("Murilo", new EnviaPorSMS());
mensagemAdmSms.Envia();
var mensagemClienteEmail = new MensagemParaOCliente("José", new EnviaPorEmail());
mensagemClienteEmail.Envia();
var mensagemClienteSMS = new MensagemParaOCliente("José", new EnviaPorSMS());
mensagemClienteSMS.Envia();
Console.ReadKey();
}
}
public interface IEnvia
{
void Envia(IMensagem mensagem);
}
public interface IMensagem
{
IEnvia Enviador { get; }
void Envia();
string FormatarMensagem();
}
public class EnviaPorEmail : IEnvia
{
public void Envia(IMensagem mensagem)
{
var mensagemParaEnviar = new StringBuilder();
mensagemParaEnviar.AppendLine("Enviando mensagem por e-mail");
mensagemParaEnviar.AppendLine(mensagem.FormatarMensagem());
Console.WriteLine(mensagemParaEnviar.ToString());
}
}
public class EnviaPorSMS : IEnvia
{
public void Envia(IMensagem mensagem)
{
var mensagemParaEnviar = new StringBuilder();
mensagemParaEnviar.AppendLine("Enviando mensagem por SMS");
mensagemParaEnviar.AppendLine(mensagem.FormatarMensagem());
Console.WriteLine(mensagemParaEnviar.ToString());
}
}
public class MensagemParaOCliente : IMensagem
{
private string Nome;
public IEnvia Enviador { get; private set; }
public MensagemParaOCliente(string nome, IEnvia enviador)
{
Nome = nome;
Enviador = enviador;
}
public void Envia()
{
Enviador.Envia(this);
}
public string FormatarMensagem()
{
return $"Mensagem para o cliente { Nome }";
}
}
public class MensagemParaOAdministrador : IMensagem
{
private string Nome;
public IEnvia Enviador { get; private set; }
public MensagemParaOAdministrador(string nome, IEnvia enviador)
{
Nome = nome;
Enviador = enviador;
}
public void Envia()
{
Enviador.Envia(this);
}
public string FormatarMensagem()
{
return $"Mensagem para o administrador { Nome }";
}
}
}
<file_sep>/StrategyPattern/Program.cs
using System;
namespace StrategyPattern
{
public class Program
{
static void Main(string[] args)
{
var orcamento = new Orcamento(500);
var calculadoraImpostos = new CalculadoraImpostos();
var ICMS = calculadoraImpostos.Calcular(orcamento, new ICMS());
var ISS = calculadoraImpostos.Calcular(orcamento, new ISS());
var ICCC = calculadoraImpostos.Calcular(orcamento, new ICCC());
Console.WriteLine(ICMS);
Console.WriteLine(ISS);
Console.WriteLine(ICCC);
Console.ReadKey();
}
}
public class Orcamento
{
public Orcamento(double valor)
{
Valor = valor;
}
public double Valor { get; set; }
}
public class CalculadoraImpostos
{
public Double Calcular(Orcamento orcamento, Imposto imposto)
{
return imposto.Calcular(orcamento);
}
}
public interface Imposto
{
double Calcular(Orcamento orcamento);
}
public class ICMS : Imposto
{
public double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.05;
}
}
public class ICCC : Imposto
{
public double Calcular(Orcamento orcamento)
{
if (orcamento.Valor < 1000)
return orcamento.Valor * 0.05;
if (orcamento.Valor >= 1000 && orcamento.Valor <= 3000)
return orcamento.Valor * 0.07;
return orcamento.Valor * 0.08 + 30;
}
}
public class ISS : Imposto
{
public double Calcular(Orcamento orcamento)
{
return orcamento.Valor * 0.06 + 50;
}
}
}
<file_sep>/AbstractFactory/Herbivoro.cs
namespace AbstractFactory
{
public class Herbivoro
{
}
}<file_sep>/ChainOfResponsability.Exercicio/Requisicao.cs
using System;
namespace ChainOfResponsability.Exercicio
{
public class Requisicao
{
public EFormato Formato { get; private set; }
public Requisicao(EFormato formato)
{
Formato = formato;
}
}
public enum EFormato
{
XML,
CSV,
PORCENTO
}
}
<file_sep>/StrategyPattern.Exemplo2/IComportamentoDeVoar.cs
namespace StrategyPattern.Exemplo2
{
public interface IComportamentoDeVoar
{
public void Voar();
}
}
<file_sep>/ChainOfResponsability.Exercicio/RespostaXML.cs
namespace ChainOfResponsability.Exercicio
{
public class RespostaXML : IResposta
{
public RespostaXML(IResposta proxima)
{
Proxima = proxima;
}
public IResposta Proxima { get; private set; }
public string GerarResposta(Requisicao requisicao)
{
if (requisicao.Formato == EFormato.XML)
return "Reposta em formato XML";
return Proxima.GerarResposta(requisicao);
}
}
}
<file_sep>/README.md
# estudo-design-patterns-c-sharp
Estudo de SOLID e design patterns utilizando C# com conteudos
do curso da Alura (C# SOLID, C# Design Patterns I, C# Design Patterns II), livros GOF e Use Cabeça - Design Patterns C#
<file_sep>/BulderPattern.Exemplo/Program.cs
using System;
using System.Collections.Generic;
namespace BulderPattern.Exemplo
{
class Program
{
static void Main(string[] args)
{
NotaFiscal nf = new NotaFiscalBuilder().ParaEmpresa("Caelum")
.ComCnpj("123.456.789/0001-10")
.Com(new ItemDaNota("item 1", 100.0))
.Com(new ItemDaNota("item 2", 200.0))
.Com(new ItemDaNota("item 3", 300.0))
.ComObservacoes("entregar nf pessoalmente")
.Constroi();
}
}
// Utilizamos aqui o builder pattern com fluent interface;
class NotaFiscalBuilder
{
public String RazaoSocial { get; private set; }
public String Cnpj { get; private set; }
public double ValorTotal { get; private set; }
public double Impostos { get; private set; }
public String Observacoes { get; private set; }
private IList<ItemDaNota> todosItens = new List<ItemDaNota>();
private DateTime? _date = null;
public DateTime Data
{
get
{
if (_date == null)
return DateTime.Now;
return _date.Value;
}
private set {
_date = value;
}
}
public NotaFiscalBuilder ParaEmpresa(String razaoSocial)
{
RazaoSocial = razaoSocial;
return this; // retorno eu mesmo, o próprio builder, para que o cliente continue utilizando
}
public NotaFiscalBuilder ComCnpj(String cnpj)
{
Cnpj = cnpj;
return this;
}
public NotaFiscalBuilder Com(ItemDaNota item)
{
todosItens.Add(item);
ValorTotal += item.Valor;
Impostos += item.Valor * 0.05;
return this;
}
public NotaFiscalBuilder ComObservacoes(String observacoes)
{
Observacoes = observacoes;
return this;
}
public NotaFiscalBuilder NaData(DateTime date)
{
Data = date;
return this;
}
public NotaFiscal Constroi()
{
return new NotaFiscal(RazaoSocial, Cnpj, Data, ValorTotal, Impostos, todosItens, Observacoes);
}
}
public class NotaFiscal
{
private String RazaoSocial { get; set; }
private String Cnpj { get; set; }
private DateTime DataDeEmissao { get; set; }
private double ValorBruto { get; set; }
private double Impostos { get; set; }
private IList<ItemDaNota> Itens { get; set; }
private String Observacoes { get; set; }
public NotaFiscal(String razaoSocial,
String cnpj,
DateTime dataDeEmissao,
double valorBruto,
double impostos,
IList<ItemDaNota> itens,
String observacoes)
{
this.RazaoSocial = razaoSocial;
this.Cnpj = cnpj;
this.DataDeEmissao = dataDeEmissao;
this.ValorBruto = valorBruto;
this.Impostos = impostos;
this.Itens = itens;
this.Observacoes = observacoes;
}
}
//Só pra praticar o conceito, item da nota era uma classe simples de se c
public class ItemDaNotaBuilder
{
public string Descricao { get; private set; }
public double Valor { get; private set; }
public ItemDaNotaBuilder ComDecricao(string descricao)
{
this.Descricao = descricao;
return this;
}
public ItemDaNotaBuilder ComValor(double valor)
{
this.Valor = valor;
return this;
}
public ItemDaNota Constroi()
{
return new ItemDaNota(Descricao, Valor);
}
}
public class ItemDaNota
{
public ItemDaNota(string descricao, double valor)
{
Descricao = descricao;
Valor = valor;
}
public string Descricao { get; set; }
public double Valor { get; set; }
}
}
<file_sep>/StrategyPattern.Exemplo2/IComportamentoDeFalar.cs
namespace StrategyPattern.Exemplo2
{
public interface IComportamentoDeFalar
{
public void Falar();
}
}
<file_sep>/StatePattern.Exemplo/Program.cs
using System;
using System.Collections.Generic;
using System.Collections.ObjectModel;
using System.Linq;
namespace StatePattern.Exemplo
{
class Program
{
static void Main(string[] args)
{
var orcamento = new Orcamento();
orcamento.AdicionarItem("Canetas", 1_000);
orcamento.Aprovar();
orcamento.RealizarDesconto();
Console.WriteLine(orcamento.Liquido);
orcamento.Finalizar();
Console.WriteLine(orcamento.Liquido);
orcamento.Reprovar();
Console.ReadKey();
}
}
public abstract class EstadoOrcamento
{
protected Orcamento Orcamento { get; private set; }
protected EstadoOrcamento(Orcamento orcamento)
{
Orcamento = orcamento;
}
public abstract void Aprovar();
public abstract void Reprovar();
public abstract void Finalizar();
public abstract void RealizarDesconto();
}
public class EmAprovacao : EstadoOrcamento
{
public EmAprovacao(Orcamento orcamento) : base(orcamento) { }
public override void Aprovar()
{
Orcamento.MudarEstado(new Aprovado(Orcamento));
Console.WriteLine("Orcamento aprovado");
}
public override void Reprovar()
{
Orcamento.MudarEstado(new Reprovado(Orcamento));
Console.WriteLine("Orcamento reprovado");
}
public override void Finalizar()
{
Orcamento.MudarEstado(new Finalizado(Orcamento));
Console.WriteLine("Orcamento finalizado");
}
public override void RealizarDesconto()
{
Orcamento.Desconto = Orcamento.Valor * 0.05;
}
}
public class Aprovado : EstadoOrcamento
{
public Aprovado(Orcamento orcamento) : base(orcamento) { }
public override void Aprovar()
{
throw new Exception("O orçamento já está aprovado");
}
public override void Reprovar()
{
throw new Exception("O orçamento já está aprovado");
}
public override void Finalizar()
{
Orcamento.MudarEstado(new Finalizado(Orcamento));
Console.WriteLine("Orcamento finalizado");
}
public override void RealizarDesconto()
{
Orcamento.Desconto = Orcamento.Valor * 0.07;
}
}
public class Reprovado : EstadoOrcamento
{
public Reprovado(Orcamento orcamento) : base(orcamento) { }
public override void Aprovar()
{
throw new Exception("O orçamento já está reprovado");
}
public override void Reprovar()
{
throw new Exception("O orçamento já está reprovado");
}
public override void Finalizar()
{
Orcamento.MudarEstado(new Finalizado(Orcamento));
Console.WriteLine("Orcamento finalizado");
}
public override void RealizarDesconto()
{
throw new Exception("O orçamento já está reprovado");
}
}
public class Finalizado : EstadoOrcamento
{
public Finalizado(Orcamento orcamento) : base(orcamento) { }
public override void Aprovar()
{
throw new Exception("O orçamento já está finalizado");
}
public override void Reprovar()
{
throw new Exception("O orçamento já está finalizado");
}
public override void Finalizar()
{
throw new Exception("O orçamento já está finalizado");
}
public override void RealizarDesconto()
{
throw new Exception("O orçamento já está finalizado");
}
}
public class Orcamento
{
private EstadoOrcamento Estado { get; set; }
private Dictionary<string, double> itens;
private double _desconto;
public double Desconto
{
get
{
return _desconto;
}
set
{
if (_desconto > 0)
throw new Exception("O orçamento já sofreu desconto");
_desconto = value;
}
}
public double Liquido
{
get
{
return Valor - Desconto;
}
private set { }
}
public Orcamento()
{
itens = new Dictionary<string, double>();
MudarEstado(new EmAprovacao(this));
}
public void Aprovar()
{
Estado.Aprovar();
}
public void Reprovar()
{
Estado.Reprovar();
}
public void Finalizar()
{
Estado.Finalizar();
}
public double Valor
{
get
{
return itens.Sum(x => x.Value);
}
set { }
}
public ReadOnlyDictionary<string, double> Itens
{
get
{
return new ReadOnlyDictionary<string, double>(itens);
}
private set { }
}
public void RealizarDesconto()
{
Estado.RealizarDesconto();
}
public void AdicionarItem(string descricao, double valor)
{
itens.Add(descricao, valor);
}
public void MudarEstado(EstadoOrcamento estado)
{
Estado = estado;
}
}
}
<file_sep>/Memento.Exemplo/Program.cs
using System;
using System.Collections.Generic;
namespace Memento.Exemplo
{
class Program
{
static void Main(string[] args)
{
Texto texto = new Texto();
texto.EscreverTexto("Primeira linha do texto\n");
texto.EscreverTexto("Segunda linha do texto\n");
texto.EscreverTexto("Terceira linha do texto\n");
Console.WriteLine(texto);
texto.DesfazerEscrita();
Console.WriteLine(texto);
texto.DesfazerEscrita();
Console.WriteLine(texto);
texto.DesfazerEscrita();
Console.WriteLine(texto);
texto.DesfazerEscrita();
Console.WriteLine(texto);
Console.ReadKey();
}
}
public class TextoMemento
{
public string EstadoTexto { get; protected set; }
public TextoMemento(string texto)
{
EstadoTexto = texto;
}
}
public class HistoricoTexto
{
protected List<TextoMemento> Estados { get; set; }
public HistoricoTexto()
{
Estados = new List<TextoMemento>();
}
public void Adicionar(TextoMemento textoMemento)
{
Estados.Add(textoMemento);
}
public TextoMemento GetUltimoEstadoSalvo()
{
if (Estados.Count <= 0)
return new TextoMemento("");
TextoMemento estadoSalvo = Estados[Estados.Count - 1];
Estados.Remove(estadoSalvo);
return estadoSalvo;
}
}
public class Texto
{
protected string TextoAtual { get; set; }
private HistoricoTexto Historico { get; set; }
public Texto()
{
Historico = new HistoricoTexto();
TextoAtual = "";
}
public void EscreverTexto(string novoTexto)
{
Historico.Adicionar(new TextoMemento(TextoAtual));
TextoAtual += novoTexto;
}
public void DesfazerEscrita()
{
TextoAtual = Historico.GetUltimoEstadoSalvo().EstadoTexto;
}
public override string ToString()
{
return TextoAtual;
}
}
}
<file_sep>/Singleton.Exemplo/Program.cs
using System;
using System.Collections.Generic;
namespace Singleton.Exemplo
{
class Program
{
static void Main(string[] args)
{
var instancia1 = LoadBalancer.GetLoadBalancer();
var instancia2 = LoadBalancer.GetLoadBalancer();
var instancia3 = LoadBalancer.GetLoadBalancer();
Console.WriteLine(Object.ReferenceEquals(instancia1, instancia2));
Console.WriteLine(Object.ReferenceEquals(instancia2, instancia3));
Console.ReadKey();
}
}
public class Server
{
public string Name { get; set; }
public string IP { get; set; }
}
public sealed class LoadBalancer
{
private static readonly LoadBalancer Instance = new LoadBalancer();
private List<Server> _servers;
private LoadBalancer()
{
_servers = new List<Server>()
{
new Server { Name = "ServerI", IP = "172.16.58.3" },
new Server { Name = "ServerII", IP = "172.16.58.3" },
new Server { Name = "ServerIII", IP = "192.168.127.12" },
new Server { Name = "ServerIV", IP = "172.16.17.32" },
new Server { Name = "ServerII", IP = "172.16.17.32" },
};
}
public static LoadBalancer GetLoadBalancer()
{
return Instance;
}
}
}
<file_sep>/ChainOfResponsability.Exemplo/CalculadoraDeDescontos.cs
using System;
namespace ChainOfResponsability.Exemplo
{
public class CalculadoraDeDescontos
{
public double Calcular(Orcamento orcamento)
{
var descontoAcimaDeQuinhetos = new DescontoAcimaDeQuinhetos();
var descontoAcimaDeCincoItems = new DescontoPorMaisDeCincoItens();
var descontoVendaCasada = new DescontoPorVendaCasada();
var semDesconto = new SemDesconto();
descontoAcimaDeCincoItems.Proximo = descontoVendaCasada;
descontoVendaCasada.Proximo = descontoAcimaDeQuinhetos;
descontoAcimaDeQuinhetos.Proximo = semDesconto;
return descontoAcimaDeQuinhetos.Calcular(orcamento);
}
}
}
<file_sep>/ChainOfResponsability.Exemplo/Program.cs
using System;
namespace ChainOfResponsability.Exemplo
{
class Program
{
static void Main(string[] args)
{
var calculadoraDeDescontos = new CalculadoraDeDescontos();
var orcamento = new Orcamento();
orcamento.AdicionarItem("Produto A", 100);
orcamento.AdicionarItem("Produto B", 100);
orcamento.AdicionarItem("Produto C", 100);
orcamento.AdicionarItem("Produto D", 100);
orcamento.AdicionarItem("Produto E", 100);
orcamento.AdicionarItem("Produto F", 100);
orcamento.AdicionarItem("Produto G", 100);
orcamento.AdicionarItem("Produto H", 100);
orcamento.AdicionarItem("Produto I", 100);
orcamento.AdicionarItem("Produto J", 100);
var desconto = calculadoraDeDescontos.Calcular(orcamento);
Console.WriteLine(desconto);
Console.ReadKey();
}
}
}
<file_sep>/ChainOfResponsability.Exercicio/RespostaJSON.cs
namespace ChainOfResponsability.Exercicio
{
public class RespostaJSON : IResposta
{
public string GerarResposta(Requisicao requisicao)
{
return "Resposta em JSON por padrão caso não encontre um formato";
}
}
}
<file_sep>/Interpreter.Exemplo/Program.cs
using System;
namespace Interpreter.Exemplo
{
class Program
{
static void Main(string[] args)
{
var expressao = new Soma(new Numero(5), new Numero(2));
var expressao2 = new Soma(expressao, new Numero(5));
Console.WriteLine($"Expressão 2: {expressao2.Avalia()}" );
var expressao3 = new Subtracao(expressao2, new Numero(200));
Console.WriteLine($"Expressão 3: {expressao3.Avalia()}");
Console.ReadKey();
}
}
public interface IExpressao
{
int Avalia();
}
public class Numero : IExpressao
{
private int Valor { get; set; }
public Numero(int numero)
{
Valor = numero;
}
public int Avalia()
{
return Valor;
}
}
public class Subtracao
{
private IExpressao Esquerda { get; set; }
private IExpressao Direita { get; set; }
public Subtracao(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 - resultadoExpressao2;
}
}
public class Soma : IExpressao
{
private IExpressao Esquerda { get; set; }
private IExpressao Direita { get; set; }
public Soma(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 + resultadoExpressao2;
}
}
public class Multiplicacao : IExpressao
{
private IExpressao Esquerda { get; set; }
private IExpressao Direita { get; set; }
public Multiplicacao(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 * resultadoExpressao2;
}
}
public class Divisao : IExpressao
{
private IExpressao Esquerda { get; set; }
private IExpressao Direita { get; set; }
public Divisao(IExpressao esquerda, IExpressao direita)
{
Esquerda = esquerda;
Direita = direita;
}
public int Avalia()
{
var resultadoExpressao1 = Esquerda.Avalia();
var resultadoExpressao2 = Direita.Avalia();
return resultadoExpressao1 / resultadoExpressao2;
}
}
public class RaizQuadrada : IExpressao
{
private int Numero { get; set; }
public RaizQuadrada(IExpressao numero)
{
Numero = numero.Avalia();
}
public int Avalia()
{
return (int)Math.Sqrt(Numero);
}
}
}
<file_sep>/ObserverPattern.Exemplo/Program.cs
using System;
using System.Collections.Generic;
namespace ObserverPattern.Exemplo
{
class Program
{
static void Main(string[] args)
{
NotaFiscal nf = new NotaFiscalBuilder().ParaEmpresa("Caelum")
.ComCnpj("123.456.789/0001-10")
.Com(new ItemDaNota("item 1", 100.0))
.Com(new ItemDaNota("item 2", 200.0))
.Com(new ItemDaNota("item 3", 300.0))
.ComObservacoes("entregar nf pessoalmente")
.Constroi();
}
}
// Utilizamos aqui o builder pattern com fluent interface;
class NotaFiscalBuilder
{
public String RazaoSocial { get; private set; }
public String Cnpj { get; private set; }
public double ValorTotal { get; private set; }
public double Impostos { get; private set; }
public String Observacoes { get; private set; }
private List<INotificaNotaFical> Notificacoes { get; set; }
private IList<ItemDaNota> todosItens = new List<ItemDaNota>();
public NotaFiscalBuilder()
{
Notificacoes = new List<INotificaNotaFical>();
}
private DateTime? _date = null;
public DateTime Data
{
get
{
if (_date == null)
return DateTime.Now;
return _date.Value;
}
private set
{
_date = value;
}
}
public NotaFiscalBuilder ParaEmpresa(String razaoSocial)
{
RazaoSocial = razaoSocial;
return this; // retorno eu mesmo, o próprio builder, para que o cliente continue utilizando
}
public NotaFiscalBuilder ComCnpj(String cnpj)
{
Cnpj = cnpj;
return this;
}
public NotaFiscalBuilder Com(ItemDaNota item)
{
todosItens.Add(item);
ValorTotal += item.Valor;
Impostos += item.Valor * 0.05;
return this;
}
public NotaFiscalBuilder ComObservacoes(String observacoes)
{
Observacoes = observacoes;
return this;
}
public NotaFiscalBuilder NaData(DateTime date)
{
Data = date;
return this;
}
public NotaFiscal Constroi()
{
var nota = new NotaFiscal(RazaoSocial, Cnpj, Data, ValorTotal, Impostos, todosItens, Observacoes);
GerarNotificacoes(nota);
return nota;
}
public void Adicionar(INotificaNotaFical notificacao)
{
Notificacoes.Add(notificacao);
}
private void GerarNotificacoes(NotaFiscal nota)
{
foreach(var notificacao in Notificacoes)
{
notificacao.Notificar(nota);
}
}
}
public class NotaFiscal
{
private String RazaoSocial { get; set; }
private String Cnpj { get; set; }
private DateTime DataDeEmissao { get; set; }
private double ValorBruto { get; set; }
private double Impostos { get; set; }
private IList<ItemDaNota> Itens { get; set; }
private String Observacoes { get; set; }
public NotaFiscal(String razaoSocial,
String cnpj,
DateTime dataDeEmissao,
double valorBruto,
double impostos,
IList<ItemDaNota> itens,
String observacoes)
{
RazaoSocial = razaoSocial;
Cnpj = cnpj;
DataDeEmissao = dataDeEmissao;
ValorBruto = valorBruto;
Impostos = impostos;
Itens = itens;
Observacoes = observacoes;
}
}
//Só pra praticar o conceito, item da nota era uma classe simples de se c
public class ItemDaNotaBuilder
{
public string Descricao { get; private set; }
public double Valor { get; private set; }
public ItemDaNotaBuilder ComDecricao(string descricao)
{
Descricao = descricao;
return this;
}
public ItemDaNotaBuilder ComValor(double valor)
{
Valor = valor;
return this;
}
public ItemDaNota Constroi()
{
return new ItemDaNota(Descricao, Valor);
}
}
public class ItemDaNota
{
public ItemDaNota(string descricao, double valor)
{
Descricao = descricao;
Valor = valor;
}
public string Descricao { get; set; }
public double Valor { get; set; }
}
public interface INotificaNotaFical
{
public void Notificar(NotaFiscal nota);
}
public class NotificaNotaFiscalPorEmail : INotificaNotaFical
{
public void Notificar(NotaFiscal nota)
{
Console.WriteLine("Notifica nota fiscal por email");
}
}
public class NotificaNotaFiscalParaOBanco : INotificaNotaFical
{
public void Notificar(NotaFiscal nota)
{
Console.WriteLine("Salva nota fiscal no banco");
}
}
}
<file_sep>/StrategyPattern.Exemplo2/PatoDoSitio.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class PatoDoSitio : Pato
{
public override void Aparecer()
{
Console.Write("Apareceu o pato do sitio");
}
}
}
<file_sep>/ChainOfResponsability.Exemplo/Orcamento.cs
using System;
using System.Collections.Generic;
using System.Collections.ObjectModel;
using System.Linq;
namespace ChainOfResponsability.Exemplo
{
public class Orcamento
{
private Dictionary<string, double> itens;
public double Valor
{
get
{
return itens.Sum(x => x.Value);
}
private set { }
}
public ReadOnlyDictionary<string, double> Itens
{
get
{
return new ReadOnlyDictionary<string, double>(itens);
}
private set { }
}
public void AdicionarItem(string descricao, double valor)
{
itens.Add(descricao, valor);
}
public Orcamento()
{
itens = new Dictionary<string, double>();
}
}
}
<file_sep>/StrategyPattern.Exemplo2/Mudo.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class Mudo : IComportamentoDeFalar
{
public void Falar()
{
Console.WriteLine("...");
}
}
}
<file_sep>/Factory.Exemplo/ConfiguracoesArquivo.cs
namespace Factory.Exemplo
{
internal class ConfiguracoesArquivo
{
public ConfiguracoesArquivo()
{
}
public string GetStringConnection()
{
return "";
}
}
}<file_sep>/ChainOfResponsability.Exercicio/RespostaCSV.cs
namespace ChainOfResponsability.Exercicio
{
public class RespostaCSV : IResposta
{
public RespostaCSV(IResposta proxima)
{
Proxima = proxima;
}
public IResposta Proxima { get; private set; }
public string GerarResposta(Requisicao requisicao)
{
if (requisicao.Formato == EFormato.CSV)
return "Reposta em formato CSV";
return Proxima.GerarResposta(requisicao);
}
}
}
<file_sep>/ChainOfResponsability.Exercicio/RespostaPorcento.cs
namespace ChainOfResponsability.Exercicio
{
public class RespostaPorcento : IResposta
{
public RespostaPorcento(IResposta proxima)
{
Proxima = proxima;
}
public IResposta Proxima { get; private set; }
public string GerarResposta(Requisicao requisicao)
{
if (requisicao.Formato == EFormato.PORCENTO)
return "Reposta em formato separado por porcento";
return Proxima?.GerarResposta(requisicao);
}
}
}
<file_sep>/StrategyPattern.Exemplo2/Pato.cs
using System;
namespace StrategyPattern.Exemplo2
{
public abstract class Pato
{
public IComportamentoDeVoar ComportamentoDeVoar { private get; set; }
public IComportamentoDeFalar ComportamentoDeFalar { private get; set; }
public void Falar()
{
ComportamentoDeFalar.Falar();
}
public void Voar()
{
ComportamentoDeVoar.Voar();
}
public void Nadar()
{
Console.WriteLine("Modo de nadar básico");
}
public virtual void Aparecer()
{
Console.WriteLine("O pato apareceu");
}
}
}
<file_sep>/Adapter.Exemplo/Program.cs
using System;
namespace Adapter.Exemplo
{
public class Program
{
static void Main(string[] args)
{
var tomadaDe3 = new TomadaDeTresPinos();
var adaptador = new AdapterTomada(tomadaDe3);
adaptador.LigarTomadaDeDoisPinos();
TomadaDeDoisPinos t2 = new AdapterTomada(tomadaDe3);
t2.LigarTomadaDeDoisPinos();
Console.ReadKey();
}
}
public class TomadaDeDoisPinos
{
public virtual void LigarTomadaDeDoisPinos()
{
Console.WriteLine("Ligado na tomada de dois pinos");
}
}
public class TomadaDeTresPinos
{
public void LigarTomadaDeTresPinos()
{
Console.WriteLine("Ligar na tomada de três pinos");
}
}
public class AdapterTomada : TomadaDeDoisPinos
{
private TomadaDeTresPinos TomadaDeTresPinos { get; set; }
public AdapterTomada(TomadaDeTresPinos tomadaDeTresPinos)
{
TomadaDeTresPinos = tomadaDeTresPinos;
}
public override void LigarTomadaDeDoisPinos()
{
TomadaDeTresPinos.LigarTomadaDeTresPinos();
}
}
}
<file_sep>/AbstractFactory/Program.cs
using System;
namespace AbstractFactory
{
class Program
{
static void Main(string[] args)
{
ContinenteFactory africa = new AfricaFactory();
MundoAnimal mundoAnimal = new MundoAnimal(africa);
mundoAnimal.ExecutarCadeiaAlimentar();
ContinenteFactory america = new AmericaFactory();
MundoAnimal mundoAnimalDaAmerica = new MundoAnimal(america);
mundoAnimalDaAmerica.ExecutarCadeiaAlimentar();
Console.ReadKey();
}
}
public abstract class ContinenteFactory
{
public abstract Herbivoro CriarHerbivoro();
public abstract Carnivoro CriarCarnivoro();
}
public class AfricaFactory : ContinenteFactory
{
public override Carnivoro CriarCarnivoro()
{
return new Leao();
}
public override Herbivoro CriarHerbivoro()
{
return new Coelho();
}
}
public class AmericaFactory : ContinenteFactory
{
public override Carnivoro CriarCarnivoro()
{
return new Lobo();
}
public override Herbivoro CriarHerbivoro()
{
return new Bisao();
}
}
public class Coelho : Herbivoro { }
public class Leao : Carnivoro
{
public override void Comer(Herbivoro herbivoro)
{
Console.WriteLine($"Leão come { herbivoro.GetType().Name }");
}
}
public class Bisao : Herbivoro { }
public class Lobo : Carnivoro
{
public override void Comer(Herbivoro herbivoro)
{
Console.WriteLine($"Lobo come { herbivoro.GetType().Name }");
}
}
// Client
public class MundoAnimal
{
private Herbivoro _herbivoro;
private Carnivoro _carnivoro;
public MundoAnimal(ContinenteFactory factory)
{
_carnivoro = factory.CriarCarnivoro();
_herbivoro = factory.CriarHerbivoro();
}
public void ExecutarCadeiaAlimentar()
{
_carnivoro.Comer(_herbivoro);
}
}
}
<file_sep>/ChainOfResponsability.Exemplo2/Program.cs
using System;
namespace ChainOfResponsability.Exemplo2
{
public class Program
{
// Aqui utilizamos o template method para realizar a corrente.
static void Main(string[] args)
{
var debitoParaPagarNoNuBank = new Debito(EBanco.NuBank, 500);
var debitoParaPagarNoItau = new Debito(EBanco.Itau, 300);
var debitoParaPagarNoBradesco = new Debito(EBanco.Bradesco, 500);
var realizarPagamento = new RealizarPagamento();
realizarPagamento.EfetuarPagamento(debitoParaPagarNoItau);
realizarPagamento.EfetuarPagamento(debitoParaPagarNoNuBank);
realizarPagamento.EfetuarPagamento(debitoParaPagarNoBradesco);
Console.ReadKey();
}
}
}
<file_sep>/Decorator/Program.cs
using System;
using System.Collections.Generic;
using System.Linq;
namespace Decorator
{
class Program
{
static void Main(string[] args)
{
var listaContas = new List<Conta>()
{
new Conta(90, DateTime.Now.AddYears(-1)),
new Conta(150, DateTime.Now.AddYears(-1)),
new Conta(150, DateTime.Now.AddYears(-1)),
new Conta(500_100, DateTime.Now.AddYears(-1)),
new Conta(500_100, DateTime.Now),
};
var filtros = new FiltroContaSaldoMaiorQueQuinhetosMil(new FiltroContaSaldoMenorQueCem(new FiltroContasComAberturaNoMesCorrente()));
var contasFiltradas = filtros.Filtra(listaContas);
ImprimirContasFiltradas(contasFiltradas);
Console.ReadKey();
}
private static void ImprimirContasFiltradas(IList<Conta> contasFiltradas)
{
var contador = 0;
foreach (var conta in contasFiltradas)
{
Console.WriteLine($"{contador}. {conta}");
contador += 1;
}
}
}
public class Conta
{
public Conta(double saldo,
DateTime dataAbertura)
{
Saldo = saldo;
DataAbertura = dataAbertura;
}
public double Saldo { get; set; }
public DateTime DataAbertura { get; set; }
public override string ToString()
{
return $"[ {Saldo}, {DataAbertura.ToString("dd/MM/yyyy")} ]";
}
}
public abstract class Filtro
{
protected Filtro Proximo { get; set; }
protected IList<Conta> ContasFiltradas { get; set; }
protected Filtro(Filtro proximo)
{
Proximo = proximo;
ContasFiltradas = new List<Conta>();
}
protected Filtro()
{
Proximo = null;
ContasFiltradas = new List<Conta>();
}
public IList<Conta> Filtra(IList<Conta> contas)
{
foreach (var conta in contas)
{
if (CondicaoFiltro(conta))
ContasFiltradas.Add(conta);
}
return ContasFiltradas.Concat(ProximoFiltro(contas).Where(p => !ContasFiltradas.Contains(p))).ToList();
}
protected abstract bool CondicaoFiltro(Conta conta);
protected IList<Conta> ProximoFiltro(IList<Conta> contas)
{
if (Proximo == null)
return new List<Conta>();
return Proximo.Filtra(contas);
}
}
public class FiltroContaSaldoMenorQueCem : Filtro
{
public FiltroContaSaldoMenorQueCem(Filtro proximo ) : base(proximo) { }
public FiltroContaSaldoMenorQueCem() : base() { }
protected override bool CondicaoFiltro(Conta conta)
{
return conta.Saldo < 100;
}
}
public class FiltroContaSaldoMaiorQueQuinhetosMil : Filtro
{
public FiltroContaSaldoMaiorQueQuinhetosMil(Filtro proximo) : base(proximo) { }
public FiltroContaSaldoMaiorQueQuinhetosMil() : base() { }
protected override bool CondicaoFiltro(Conta conta)
{
return conta.Saldo > 500_000;
}
}
public class FiltroContasComAberturaNoMesCorrente : Filtro
{
public FiltroContasComAberturaNoMesCorrente(Filtro proximo) : base(proximo) { }
public FiltroContasComAberturaNoMesCorrente() : base() { }
protected override bool CondicaoFiltro(Conta conta)
{
return conta.DataAbertura.Month == DateTime.Now.Month
&& conta.DataAbertura.Year == DateTime.Now.Year;
}
}
}
<file_sep>/ChainOfResponsability.Exemplo2/PagamentoBradesco.cs
using System;
namespace ChainOfResponsability.Exemplo2
{
public class PagamentoBradesco : PagamentoBancoChain
{
public PagamentoBradesco() : base(EBanco.Bradesco)
{
}
protected override void Pagar(Debito debito)
{
Console.WriteLine("Pagamento realizado via Bradesco");
}
}
}
<file_sep>/StrategyPattern.Exemplo2/NaoVoar.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class NaoVoar : IComportamentoDeVoar
{
public void Voar()
{
Console.WriteLine("Não consegue voar");
}
}
}
<file_sep>/Factory.Exemplo/Program.cs
using System;
using System.Data;
namespace Factory.Exemplo
{
class Program
{
static void Main(String[] args)
{
IDbConnection conexao = new FactoryConnection().GetConnection();
IDbCommand comando = conexao.CreateCommand();
comando.CommandText = "select * from tabela";
Console.ReadKey();
}
}
public class FactoryConnection
{
//Classes SqlConnection e ConfiguracoesArquivo são hipotéticas;
public IDbConnection GetConnection()
{
IDbConnection conexao = new SqlConnection();
conexao.ConnectionString = new ConfiguracoesArquivo().GetStringConnection();
conexao.Open();
return conexao;
}
}
}
<file_sep>/StatePattern.Exercicio/Program.cs
using System;
using StatePattern.Exercicio.Domain;
namespace StatePattern.Exercicio
{
class Program
{
static void Main(string[] args)
{
try
{
var conta = new Conta("Murilo", 500);
conta.Depositar(500);
conta.Sacar(1500);
conta.Sacar(100);
conta.Depositar(150000);
return;
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
}
Console.ReadKey();
}
}
}
<file_sep>/TemplateMethod.Exercicio/Program.cs
using System;
using System.Collections.Generic;
using System.Collections.ObjectModel;
namespace TemplateMethod.Exercicio
{
class Program
{
static void Main(string[] args)
{
var bancoItau = new Banco("Itau", "Av. Paulista, São Paulo - SP", "(55) 88888-8888", "<EMAIL>");
bancoItau.AdicionarConta(new Conta("Murilo", "131", "1312-1", 10000000));
bancoItau.AdicionarConta(new Conta("José", "131", "1312-1", 10000));
bancoItau.AdicionarConta(new Conta("Maria", "131", "1312-1", 5000000000000));
var relatorioSimples = new RelatorioSimples();
var relatorioComplexo = new RelatorioComplexo();
Console.WriteLine("Relatorio simples: ");
relatorioSimples.GerarRelatorio(bancoItau);
Console.WriteLine("");
Console.WriteLine("");
Console.WriteLine("Relatorio Complexo: ");
relatorioComplexo.GerarRelatorio(bancoItau);
Console.ReadKey();
}
}
public class Banco
{
public Banco(string nome, string endereco, string telefone, string email)
{
Nome = nome;
Endereco = endereco;
Telefone = telefone;
Email = email;
_contas = new List<Conta>();
}
public string Nome { get; set; }
public string Endereco { get; set; }
public string Telefone { get; set; }
public string Email { get; set; }
private List<Conta> _contas;
public ReadOnlyCollection<Conta> Contas
{
get
{
return new ReadOnlyCollection<Conta>(_contas);
}
private set { }
}
public void AdicionarConta(Conta conta)
{
_contas.Add(conta);
}
}
public class Conta
{
public Conta(string titular, string agencia, string numeroConta, double saldo)
{
Titular = titular;
Agencia = agencia;
NumeroConta = numeroConta;
Saldo = saldo;
}
public string Titular { get; set; }
public string Agencia { get; set; }
public string NumeroConta { get; set; }
public double Saldo { get; set; }
}
public interface IRelatorio
{
void GerarRelatorio(Banco banco);
}
public abstract class Relatorio : IRelatorio
{
public void GerarRelatorio(Banco banco)
{
ImprimirCabecalho(banco);
Console.WriteLine("********************");
ImprimirContas(banco);
Console.WriteLine("********************");
ImprimirRodape(banco);
}
protected abstract void ImprimirCabecalho(Banco banco);
protected abstract void ImprimirContas(Banco banco);
protected abstract void ImprimirRodape(Banco banco);
}
public class RelatorioComplexo : Relatorio
{
protected override void ImprimirCabecalho(Banco banco)
{
Console.WriteLine(banco.Nome);
Console.WriteLine($"Endereço: {banco.Endereco}");
Console.WriteLine($"Telefone: {banco.Telefone}");
}
protected override void ImprimirContas(Banco banco)
{
foreach(Conta conta in banco.Contas)
{
Console.WriteLine();
Console.WriteLine("[ ");
Console.WriteLine($" Titular: {conta.Titular};");
Console.WriteLine($" Agência: {conta.Agencia};");
Console.WriteLine($" Numero da conta: {conta.NumeroConta};");
Console.WriteLine($" Saldo: {conta.Saldo.ToString("C")};");
Console.Write("]");
Console.WriteLine();
}
}
protected override void ImprimirRodape(Banco banco)
{
Console.WriteLine(banco.Email);
Console.WriteLine(DateTime.Now.ToString("dd/MM/yyyy"));
}
}
public class RelatorioSimples : Relatorio
{
protected override void ImprimirCabecalho(Banco banco)
{
Console.WriteLine($"{banco.Nome} - {banco.Telefone}");
}
protected override void ImprimirContas(Banco banco)
{
foreach (Conta conta in banco.Contas)
{
Console.WriteLine($"[Titular: {conta.Titular}, Saldo: {conta.Saldo.ToString("C")}]");
}
}
protected override void ImprimirRodape(Banco banco)
{
ImprimirCabecalho(banco);
}
}
}
<file_sep>/StrategyPattern.Exemplo2/QuackAlto.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class QuackAlto : IComportamentoDeFalar
{
public void Falar()
{
Console.WriteLine("Quack alto!");
}
}
}
<file_sep>/ChainOfResponsability.Exemplo2/EBanco.cs
namespace ChainOfResponsability.Exemplo2
{
public enum EBanco
{
Itau,
NuBank,
Bradesco,
}
}
<file_sep>/ChainOfResponsability.Exemplo/DescontoPorVendaCasada.cs
using System;
namespace ChainOfResponsability.Exemplo
{
public class DescontoPorVendaCasada : IDesconto
{
public IDesconto Proximo { get; set; }
public double Calcular(Orcamento orcamento)
{
if (Existe("Caneta", orcamento) && Existe("Lapis", orcamento))
return orcamento.Valor * 0.05;
return Proximo.Calcular(orcamento);
}
private bool Existe(String nomeDoItem, Orcamento orcamento)
{
foreach (var item in orcamento.Itens)
{
if (item.Key.ToUpper().Equals(nomeDoItem.ToUpper()))
return true;
}
return false;
}
}
}
<file_sep>/StrategyPattern.Exemplo2/VoarComAsas.cs
using System;
namespace StrategyPattern.Exemplo2
{
public class VoarComAsas : IComportamentoDeVoar
{
public void Voar()
{
Console.WriteLine("Voando com asas");
}
}
}
<file_sep>/ChainOfResponsability.Exemplo2/RealizarPagamento.cs
namespace ChainOfResponsability.Exemplo2
{
public class RealizarPagamento
{
public void EfetuarPagamento(Debito debito)
{
var meiosDePagamento = new PagamentoNuBank();
meiosDePagamento.Proximo = new PagamentoItau();
meiosDePagamento.Proximo = new PagamentoBradesco();
meiosDePagamento.EfetuarPagamento(debito);
}
}
}
<file_sep>/TemplateMethod.Exemplo/Program.cs
using System;
using System.Collections.Generic;
using System.Linq;
namespace TemplateMethod.Exemplo
{
class Program
{
static void Main(string[] args)
{
var orcamento = new Orcamento(500,
new List<Item>()
{
new Item(100, "Borracha"),
new Item(200, "Lapis"),
new Item(300, "Caderno"),
new Item(500, "Estoujo"),
new Item(500, "Estoujo")
}
);
Console.WriteLine($"Calculo do imposto IKCV: { new IKCV().Calcula(orcamento) }");
Console.WriteLine($"Calculo do imposto ICPP: { new ICPP().Calcula(orcamento) }");
Console.WriteLine($"Calculo do imposto ICPP: { new IHIT().Calcula(orcamento) }");
Console.ReadKey();
}
}
public class Orcamento
{
public Orcamento(double valor, List<Item> itens)
{
Valor = valor;
Itens = itens;
}
public double Valor { get; set; }
public List<Item> Itens { get; set; }
}
public class Item
{
public Item(double valor, string descricao)
{
Valor = valor;
Descricao = descricao;
}
public double Valor { get; set; }
public string Descricao { get; set; }
}
public interface Imposto
{
public double Calcula(Orcamento orcamento);
}
public abstract class TemplateDeImpostoCondicional : Imposto
{
public double Calcula(Orcamento orcamento)
{
if (DeveUsarMaximaTaxacao(orcamento))
{
return MaximaTaxacao(orcamento);
}
return MinimaTaxacao(orcamento);
}
protected abstract bool DeveUsarMaximaTaxacao(Orcamento orcamento);
protected abstract double MaximaTaxacao(Orcamento orcamento);
protected abstract double MinimaTaxacao(Orcamento orcamento);
}
public class IKCV : TemplateDeImpostoCondicional
{
protected override bool DeveUsarMaximaTaxacao(Orcamento orcamento)
{
return orcamento.Valor > 500 && TemItemMaiorQue100ReaisNo(orcamento);
}
private bool TemItemMaiorQue100ReaisNo(Orcamento orcamento)
{
foreach (var item in orcamento.Itens)
{
if (item.Valor > 100)
return true;
}
return false;
}
protected override double MaximaTaxacao(Orcamento orcamento)
{
return orcamento.Valor * 0.10;
}
protected override double MinimaTaxacao(Orcamento orcamento)
{
return orcamento.Valor * 0.06;
}
}
public class ICPP : TemplateDeImpostoCondicional
{
protected override bool DeveUsarMaximaTaxacao(Orcamento orcamento)
{
return orcamento.Valor >= 500;
}
protected override double MaximaTaxacao(Orcamento orcamento)
{
return orcamento.Valor * 0.07;
}
protected override double MinimaTaxacao(Orcamento orcamento)
{
return orcamento.Valor * 0.05;
}
}
public class IHIT : TemplateDeImpostoCondicional
{
protected override bool DeveUsarMaximaTaxacao(Orcamento orcamento)
{
return possuiDoisItensComOmesmoNome(orcamento.Itens);
}
private bool possuiDoisItensComOmesmoNome(List<Item> itens)
{
var repetidos = itens.GroupBy(p => p.Descricao).Where(g => g.Count() > 1).ToList();
return repetidos.Count() > 0;
}
protected override double MaximaTaxacao(Orcamento orcamento)
{
return orcamento.Valor * 0.07;
}
protected override double MinimaTaxacao(Orcamento orcamento)
{
return orcamento.Valor * 0.05;
}
}
}
<file_sep>/AbstractFactory/Carnivoro.cs
namespace AbstractFactory
{
public abstract class Carnivoro
{
public abstract void Comer(Herbivoro herbivoro);
}
}<file_sep>/ChainOfResponsability.Exemplo2/PagamentoNuBank.cs
using System;
namespace ChainOfResponsability.Exemplo2
{
public class PagamentoNuBank : PagamentoBancoChain
{
public PagamentoNuBank() : base(EBanco.NuBank)
{
}
protected override void Pagar(Debito debito)
{
Console.WriteLine("Pagamento realizado via NuBank");
}
}
}
| f9d7879ddae7553d372fa4461915131e7c6a1bf9 | [
"Markdown",
"C#"
] | 64 | C# | muriloxk/estudo-design-patterns-csharp | 452b39686dfd42aa3acd60e078485a80222e863a | 2c673238953a061e4ff4f7a876a47d0493f1f534 |
refs/heads/master | <repo_name>castab/My-Bootstrap4-Website<file_sep>/gulpfile.js
const { src, dest, series, watch } = require('gulp')
const htmlclean = require('gulp-htmlclean')
const newer = require('gulp-newer')
const replace = require('gulp-html-replace')
const concat = require('gulp-concat')
const cleancss = require('gulp-clean-css')
const uglifycss = require('gulp-uglifycss')
const uglify = require ('gulp-uglify')
const imagemin = require('gulp-imagemin')
const deporder = require('gulp-deporder')
const stripdebug = require('gulp-strip-debug')
const browserSync = require('browser-sync')
const folder = {
src: 'src/',
build: 'build/'
}
function servebuild() {
browserSync.init({
server: {
baseDir: './'
},
startPath: 'build/'
})
watch('build/**/*').on('change', browserSync.reload)
}
function json(cb) {
src(folder.src + 'data/**/*')
.pipe(dest(folder.build + 'data/'))
cb()
}
function fonts(cb) {
src('./node_modules/@fortawesome/fontawesome-free/webfonts/**/*')
.pipe(dest(folder.build + 'webfonts/'))
cb()
}
function images(cb) {
src(folder.src + 'images/**/*')
.pipe(newer(folder.build + 'images/'))
.pipe(imagemin({ optimizationlevel: 5 }))
.pipe(dest(folder.build + 'images/'))
cb()
}
function css(cb) {
src([
'./node_modules/bootstrap/dist/css/bootstrap.css',
'./node_modules/@fortawesome/fontawesome-free/css/all.css',
folder.src + 'css/**/*'
])
.pipe(concat('main.css'))
.pipe(cleancss())
.pipe(uglifycss())
.pipe(dest(folder.build + 'css/'))
cb()
}
function html(cb) {
src(folder.src + '*.html')
.pipe(newer(folder.build))
.pipe(replace({
'js': './js/main.js',
'css': './css/main.css'
}))
.pipe(htmlclean())
.pipe(dest(folder.build))
cb()
}
function js(cb) {
src([
'./node_modules/jquery/dist/jquery.js',
'./node_modules/angular/angular.js',
'./node_modules/angular-animate/angular-animate.js',
'./node_modules/angular-route/angular-route.js',
'./node_modules/bootstrap/dist/js/bootstrap.bundle.js',
'./node_modules/lodash/lodash.js',
folder.src + 'js/**/*'
])
.pipe(deporder())
.pipe(concat('main.js'))
.pipe(stripdebug())
.pipe(uglify())
.pipe(dest(folder.build + 'js/'))
cb()
}
exports.build = series(images, html, css, js, json, fonts)
exports.servebuild = servebuild<file_sep>/gulpfile-old.js
// Gulp.js configuration
'use strict';
var
// modules
gulp = require('gulp'),
newer = require('gulp-newer'),
imagemin = require('gulp-imagemin'),
browserSync = require('browser-sync'),
htmlclean = require('gulp-htmlclean'),
concat = require('gulp-concat'),
deporder = require('gulp-deporder'),
stripdebug = require('gulp-strip-debug'),
uglify = require('gulp-uglify'),
reload = browserSync.reload,
replace = require('gulp-html-replace'),
uglifycss = require('gulp-uglifycss'),
cleancss = require('gulp-clean-css')
// folders
folder = {
src: 'src/',
build: 'build/'
}
;
// image processing
gulp.task('images', function() {
var out = folder.build + 'images/';
return gulp.src(folder.src + 'images/**/*')
.pipe(newer(out))
.pipe(imagemin({ optimizationLevel: 5 }))
.pipe(gulp.dest(out));
});
// Static server
gulp.task('serve-dev', function() {
browserSync.init({
server: {
baseDir: "./"
},
startPath: "src/"
});
gulp.watch("src/**/*").on("change", reload);
});
gulp.task('serve-build', function() {
browserSync.init({
server: {
baseDir: "./"
},
startPath: "build/"
});
gulp.watch("build/**/*").on("change", reload);
});
// HTML processing
gulp.task('html', gulp.series('images', function() {
var out = folder.build;
var page = gulp.src(folder.src + '*.html')
.pipe(newer(out));
page = page.pipe(replace({
'js': './js/main.js',
'css': './css/main.css'
}))
page = page.pipe(htmlclean());
return page.pipe(gulp.dest(out));
}));
// JSON processing
gulp.task('json', function() {
var json = gulp.src(folder.src + 'data/**/*');
return json.pipe(gulp.dest(folder.build + 'data/'));
});
// Fontawesome fonts copy
gulp.task('fonts', function() {
var fonts = gulp.src('./node_modules/@fortawesome/fontawesome-free/webfonts/**/*');
return fonts.pipe(gulp.dest(folder.build + 'webfonts/'));
})
// JavaScript processing
gulp.task('js', function() {
var jsbuild = gulp.src([
'./node_modules/jquery/dist/jquery.js',
'./node_modules/angular/angular.js',
'./node_modules/angular-animate/angular-animate.js',
'./node_modules/angular-route/angular-route.js',
'./node_modules/bootstrap/dist/js/bootstrap.bundle.js',
'./node_modules/lodash/lodash.js',
folder.src + 'js/**/*'
])
.pipe(deporder())
.pipe(concat('main.js'));
jsbuild = jsbuild
.pipe(stripdebug())
.pipe(uglify());
return jsbuild.pipe(gulp.dest(folder.build + 'js/'));
});
// CSS processing
gulp.task('css', gulp.series('images', function() {
var cssbuild = gulp.src([
'./node_modules/bootstrap/dist/css/bootstrap.css',
'./node_modules/@fortawesome/fontawesome-free/css/all.css',
folder.src + 'css/**/*'
]);
cssbuild = cssbuild.pipe(concat('main.css')).pipe(cleancss()).pipe(uglifycss());
return cssbuild.pipe(gulp.dest(folder.build + 'css/'));
}));
gulp.task('build', gulp.series(['html', 'css', 'js', 'json', 'fonts']));<file_sep>/README.md
# My Bootstrap 4 Website
Main Challenge: Write as little HTML as possible.
Now viewable on my [website](https://www.supernet.tech)! | e7861de8017f14ffffdde4e5ff79bef280a88275 | [
"JavaScript",
"Markdown"
] | 3 | JavaScript | castab/My-Bootstrap4-Website | eb872b53fa484c9564f5657bf55f066cf4289b25 | fd604dd7bb2d234ce1d52ae8bd7c669b97324f1d |
refs/heads/master | <file_sep>import styled from "styled-components";
const Heading = styled.h5`
text-align: center;
transform: rotateX(180deg);
`;
export default Heading;
<file_sep>import styled from "styled-components";
const Image = styled.img`
content: url("${props => props.src}")
height: 120px;
width: 120px;
border-radius: 50%;
cursor: pointer;
&:hover {
height: auto;
width: auto;
max-height: 100%;
max-width: 100%;
}
`;
export default Image;
<file_sep># Recruitment task
[](https://github.com/prettier/prettier) 
This repository contains a recruitment task that consisted of creating a front-end application to display images fetched from a remote, mock API. See a [**LIVE DEMO**](https://zie8m.github.io/op-e-recruitment/).

## Features
* Built with [ReactJS](https://reactjs.org/), [styled-components](https://www.styled-components.com/) and [Semantic UI React](https://react.semantic-ui.com/).
* Basic unit testing implemented using [Jest](https://jestjs.io/)
* Consistent code standards and quality
* Friendly, straight-forward UI that responds to user interactions instantly
* Works on mobile devices - the app is responsive
* The project was built on top of [create-react-app](https://github.com/facebook/create-react-app). Installation, development process and building ready bundles is simple and doesn't require much effort.
### Installation and usage
To run the project on your local machine use:
* ```git clone https://github.com/zie8m/op-e-recruitment.git```
* ```cd op-e-recruitment```
* ```npm install``` - make sure you have Node and NPM installed on your local machine beforehand
Commands you can use with the project:
* ```npm start``` - run development server with hot reloading
* ```npm test``` - run unit tests
* ```npm run build``` - create a production-ready build
* ```npm deploy``` - build and deploy the bundle to GitHub Pages
<file_sep>import React, { Fragment } from "react";
import { Responsive, Grid } from "semantic-ui-react";
const Layout = ({ children }) => (
<Fragment>
<Responsive maxWidth={799}>
<Grid columns={1} divided>
{children}
</Grid>
</Responsive>
<Responsive minWidth={800}>
<Grid columns={2} divided>
{children}
</Grid>
</Responsive>
</Fragment>
);
export default Layout;
<file_sep>import getChunks from "./getChunks";
describe("getChunks utility:", () => {
it("return proper amount of chunks", () => {
let testArr = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12];
let expectedArr = [[1, 2, 3, 4, 5, 6], [7, 8, 9, 10, 11, 12]];
expect(getChunks(testArr, 6)).toEqual(expectedArr);
});
it("should work with objects", () => {
let testArr = [{ id: 1 }, { id: 2 }, { id: 3 }, { id: 4 }];
let expectedArr = [[{ id: 1 }, { id: 2 }], [{ id: 3 }, { id: 4 }]];
expect(getChunks(testArr, 2)).toEqual(expectedArr);
});
it("should use the default parameter - 12", () => {
let testArr = [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24
];
let expectedArr = [
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12],
[13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24]
];
expect(getChunks(testArr)).toEqual(expectedArr);
});
it("should work properly if the complete length of an array is smaller than the specified chunk", () => {
let testArr = [1, 2, 3, 4, 5, 6];
let expectedArr = [[1, 2, 3, 4, 5, 6]];
expect(getChunks(testArr, 7)).toEqual(expectedArr);
});
});
<file_sep>import React from "react";
import ImageWrapper from "./ImageWrapper";
import Image from "./Image";
const Display = props => {
return (
<ImageWrapper>
<Image src={props.src} />
</ImageWrapper>
);
};
export default Display;
| eba1c52f73571527a6c1853c5f2704405b4f0ad4 | [
"JavaScript",
"Markdown"
] | 6 | JavaScript | zie8m/op-e-recruitment | 93715a8bcf0a44b5e609a1b7088a57d9bc761172 | b8852bbdef3139eeba84123e1ffcf58163f7649f |
refs/heads/master | <file_sep>#!/bin/python3
# This USB HID description for basic keyboard is from Linux kernel documentation.
# https://www.kernel.org/doc/Documentation/usb/gadget_hid.txt
HID_DESCRIPTION = [
0x05, 0x01,
0x09, 0x06,
0xa1, 0x01,
0x05, 0x07,
0x19, 0xe0,
0x29, 0xe7,
0x15, 0x00,
0x25, 0x01,
0x75, 0x01,
0x95, 0x08,
0x81, 0x02,
0x95, 0x01,
0x75, 0x08,
0x81, 0x03,
0x95, 0x05,
0x75, 0x01,
0x05, 0x08,
0x19, 0x01,
0x29, 0x05,
0x91, 0x02,
0x95, 0x01,
0x75, 0x03,
0x91, 0x03,
0x95, 0x06,
0x75, 0x08,
0x15, 0x00,
0x25, 0x65,
0x05, 0x07,
0x19, 0x00,
0x29, 0x65,
0x81, 0x00,
0xc0
]
HID_DESCRIPTION_BYTES = bytes(HID_DESCRIPTION)
FILE_NAME = "report_desc"
with open(FILE_NAME, "wb") as file:
file.write(HID_DESCRIPTION_BYTES)
print("writing to " + FILE_NAME + " ok")
<file_sep>#!/bin/python3
import evdev
import pyudev
from threading import Event
from queue import Queue
# keyboard detection
context = pyudev.Context()
monitor = pyudev.Monitor.from_netlink(context)
devinput = "/dev/input/"
event_location = ""
device_list = []
monitor.filter_by('input')
print("kissa")
def log_event(action, device):
if 'ID_INPUT_KEYBOARD' in device:
try:
event_location = device.device_node
print('{0} - {1}'.format(action, event_location))
if event_location[0:(len(devinput))] == devinput:
print('{0} : {1}'.format(event_location[0:(len(devinput))], devinput))
if action == "add":
device_list.append(event_location)
else:
try:
device_list.remove(event_location)
except ValueError:
pass
print(device_list)
except TypeError:
pass
observer = pyudev.MonitorObserver(monitor, log_event)
observer.start()
# keyboard detection
while True:
pass
def returnKeyboards():
return [evdev.InputDevice(fn) for fn in evdev.list_devices()]
class FindDevices():
def __init__(self, device_queue: Queue, exit_event: Event):
device_queue.put_nowait(returnKeyboards)
# if len(sys.argv) < 2:
# print("give evdev device file path as argument")
# exit(-1)
#
#Initialize input event reading.
#input_device = evdev.InputDevice(sys.argv[1])
#print(input_device)
#
#
<file_sep>
import {Renderer} from "./renderer";
import { Keyboard } from "./keyboard";
let renderer: Renderer, keyboard: Keyboard;
main();
function main() {
const canvas = document.getElementById("glCanvas") as HTMLCanvasElement;
const gl = canvas.getContext("webgl");
if (gl === null) {
console.error("webgl not supported");
return;
}
renderer = Renderer.create(gl);
if (renderer === null) {
return;
}
keyboard = new Keyboard();
renderer.draw(keyboard);
const loadButton = document.getElementById("loadButton");
loadButton.addEventListener("click", loadHeatmap, false);
}
function loadHeatmap(event: MouseEvent): any {
if (renderer === null) {
return;
}
let httpRequest = new XMLHttpRequest();
httpRequest.onreadystatechange = parseHeatmapJSON;
httpRequest.open("GET", "heatmap.api");
httpRequest.send();
}
function parseHeatmapJSON(this: XMLHttpRequest, e: Event) {
if (this.readyState === XMLHttpRequest.DONE) {
if (this.status === 200) {
const heatmap = JSON.parse(this.responseText);
keyboard.updateHeatmap(heatmap);
renderer.draw(keyboard);
} else {
console.error("HTTP GET error");
}
}
}<file_sep>import evdev
settings = {
"profileName": "Profile-0",
"profileID": 0,
"keyData": [
{
"displayName": "Esc",
"evdevName": "KEY_ESC",
"EvdevID": 1,
"mappedEvdevName": "KEY_ESC",
"mappedEvdevID": 1
},
{
"displayName": "F1",
"evdevName": "KEY_F1",
"EvdevID": 59,
"mappedEvdevName": "KEY_F1",
"mappedEvdevID": 59
},
{
"displayName": "F2",
"evdevName": "KEY_F2",
"EvdevID": 60,
"mappedEvdevName": "KEY_F2",
"mappedEvdevID": 60
},
{
"displayName": "F3",
"evdevName": "KEY_F3",
"EvdevID": 61,
"mappedEvdevName": "KEY_F3",
"mappedEvdevID": 61
},
{
"displayName": "F4",
"evdevName": "KEY_F4",
"EvdevID": 62,
"mappedEvdevName": "KEY_F4",
"mappedEvdevID": 62
},
{
"displayName": "F5",
"evdevName": "KEY_F5",
"EvdevID": 63,
"mappedEvdevName": "KEY_F5",
"mappedEvdevID": 63
},
{
"displayName": "F6",
"evdevName": "KEY_F6",
"EvdevID": 64,
"mappedEvdevName": "KEY_F6",
"mappedEvdevID": 64
},
{
"displayName": "F7",
"evdevName": "KEY_F7",
"EvdevID": 65,
"mappedEvdevName": "KEY_F7",
"mappedEvdevID": 65
},
{
"displayName": "F8",
"evdevName": "KEY_F8",
"EvdevID": 66,
"mappedEvdevName": "KEY_F8",
"mappedEvdevID": 66
},
{
"displayName": "F9",
"evdevName": "KEY_F9",
"EvdevID": 67,
"mappedEvdevName": "KEY_F9",
"mappedEvdevID": 67
},
{
"displayName": "F10",
"evdevName": "KEY_F10",
"EvdevID": 68,
"mappedEvdevName": "KEY_F10",
"mappedEvdevID": 68
},
{
"displayName": "F11",
"evdevName": "KEY_F11",
"EvdevID": 87,
"mappedEvdevName": "KEY_F11",
"mappedEvdevID": 87
},
{
"displayName": "F12",
"evdevName": "KEY_F12",
"EvdevID": 88,
"mappedEvdevName": "KEY_F12",
"mappedEvdevID": 88
},
{
"displayName": "Print",
"evdevName": "KEY_PRINT",
"EvdevID": 210,
"mappedEvdevName": "KEY_PRINT",
"mappedEvdevID": 210
},
{
"displayName": "ScrollLock",
"evdevName": "KEY_SCROLLLOCK",
"EvdevID": 70,
"mappedEvdevName": "KEY_SCROLLLOCK",
"mappedEvdevID": 70
},
{
"displayName": "Pause",
"evdevName": "KEY_PAUSE",
"EvdevID": 119,
"mappedEvdevName": "KEY_PAUSE",
"mappedEvdevID": 119
},
{
"displayName": "§",
"evdevName": "KEY_GRAVE",
"EvdevID": 41,
"mappedEvdevName": "KEY_GRAVE",
"mappedEvdevID": 41
},
{
"displayName": "1",
"evdevName": "KEY_1",
"EvdevID": 2,
"mappedEvdevName": "KEY_1",
"mappedEvdevID": 2
},
{
"displayName": "2",
"evdevName": "KEY_2",
"EvdevID": 3,
"mappedEvdevName": "KEY_2",
"mappedEvdevID": 3
},
{
"displayName": "3",
"evdevName": "KEY_3",
"EvdevID": 4,
"mappedEvdevName": "KEY_3",
"mappedEvdevID": 4
},
{
"displayName": "4",
"evdevName": "KEY_4",
"EvdevID": 5,
"mappedEvdevName": "KEY_4",
"mappedEvdevID": 5
},
{
"displayName": "5",
"evdevName": "KEY_5",
"EvdevID": 6,
"mappedEvdevName": "KEY_5",
"mappedEvdevID": 6
},
{
"displayName": "6",
"evdevName": "KEY_6",
"EvdevID": 7,
"mappedEvdevName": "KEY_6",
"mappedEvdevID": 7
},
{
"displayName": "7",
"evdevName": "KEY_7",
"EvdevID": 8,
"mappedEvdevName": "KEY_7",
"mappedEvdevID": 8
},
{
"displayName": "8",
"evdevName": "KEY_8",
"EvdevID": 9,
"mappedEvdevName": "KEY_8",
"mappedEvdevID": 9
},
{
"displayName": "9",
"evdevName": "KEY_9",
"EvdevID": 10,
"mappedEvdevName": "KEY_9",
"mappedEvdevID": 10
},
{
"displayName": "0",
"evdevName": "KEY_0",
"EvdevID": 11,
"mappedEvdevName": "KEY_0",
"mappedEvdevID": 11
},
{
"displayName": "+",
"evdevName": "KEY_MINUS",
"EvdevID": 12,
"mappedEvdevName": "KEY_MINUS",
"mappedEvdevID": 12
},
{
"displayName": "´",
"evdevName": "KEY_EQUAL",
"EvdevID": 13,
"mappedEvdevName": "KEY_EQUAL",
"mappedEvdevID": 13
},
{
"displayName": "<=",
"evdevName": "KEY_BACKSPACE",
"EvdevID": 14,
"mappedEvdevName": "KEY_BACKSPACE",
"mappedEvdevID": 14
},
{
"displayName": "Insert",
"evdevName": "KEY_INSERT",
"EvdevID": 110,
"mappedEvdevName": "KEY_INSERT",
"mappedEvdevID": 110
},
{
"displayName": "Home",
"evdevName": "KEY_HOME",
"EvdevID": 102,
"mappedEvdevName": "KEY_HOME",
"mappedEvdevID": 102
},
{
"displayName": "PageUp",
"evdevName": "KEY_PAGEUP",
"EvdevID": 104,
"mappedEvdevName": "KEY_PAGEUP",
"mappedEvdevID": 104
},
{
"displayName": "NumLock",
"evdevName": "KEY_NUMLOCK",
"EvdevID": 69,
"mappedEvdevName": "KEY_NUMLOCK",
"mappedEvdevID": 69
},
{
"displayName": "/",
"evdevName": "KEY_KPSLASH",
"EvdevID": 98,
"mappedEvdevName": "KEY_KPSLASH",
"mappedEvdevID": 98
},
{
"displayName": "*",
"evdevName": "KEY_KPASTERISK",
"EvdevID": 55,
"mappedEvdevName": "KEY_KPASTERISK",
"mappedEvdevID": 55
},
{
"displayName": "kp-",
"evdevName": "KEY_KPMINUS",
"EvdevID": 74,
"mappedEvdevName": "KEY_KPMINUS",
"mappedEvdevID": 74
},
{
"displayName": "Tab",
"evdevName": "KEY_TAB",
"EvdevID": 15,
"mappedEvdevName": "KEY_TAB",
"mappedEvdevID": 15
},
{
"displayName": "q",
"evdevName": "KEY_Q",
"EvdevID": 16,
"mappedEvdevName": "KEY_Q",
"mappedEvdevID": 16
},
{
"displayName": "w",
"evdevName": "KEY_W",
"EvdevID": 17,
"mappedEvdevName": "KEY_W",
"mappedEvdevID": 17
},
{
"displayName": "e",
"evdevName": "KEY_E",
"EvdevID": 18,
"mappedEvdevName": "KEY_E",
"mappedEvdevID": 18
},
{
"displayName": "r",
"evdevName": "KEY_R",
"EvdevID": 19,
"mappedEvdevName": "KEY_R",
"mappedEvdevID": 19
},
{
"displayName": "t",
"evdevName": "KEY_T",
"EvdevID": 20,
"mappedEvdevName": "KEY_T",
"mappedEvdevID": 20
},
{
"displayName": "y",
"evdevName": "KEY_Y",
"EvdevID": 21,
"mappedEvdevName": "asffasf",
"mappedEvdevID": 21
},
{
"displayName": "u",
"evdevName": "KEY_U",
"EvdevID": 22,
"mappedEvdevName": "KEY_U",
"mappedEvdevID": 22
},
{
"displayName": "i",
"evdevName": "KEY_I",
"EvdevID": 23,
"mappedEvdevName": "KEY_I",
"mappedEvdevID": 23
},
{
"displayName": "o",
"evdevName": "KEY_O",
"EvdevID": 24,
"mappedEvdevName": "KEY_O",
"mappedEvdevID": 24
},
{
"displayName": "p",
"evdevName": "KEY_P",
"EvdevID": 25,
"mappedEvdevName": "KEY_P",
"mappedEvdevID": 25
},
{
"displayName": "å",
"evdevName": "KEY_LEFTBRACE",
"EvdevID": 26,
"mappedEvdevName": "KEY_LEFTBRACE",
"mappedEvdevID": 26
},
{
"displayName": "^",
"evdevName": "KEY_RIGHTBRACE",
"EvdevID": 27,
"mappedEvdevName": "KEY_RIGHTBRACE",
"mappedEvdevID": 27
},
{
"displayName": "Enter",
"evdevName": "KEY_ENTER",
"EvdevID": 28,
"mappedEvdevName": "KEY_ENTER",
"mappedEvdevID": 28
},
{
"displayName": "Del",
"evdevName": "KEY_DELETE",
"EvdevID": 111,
"mappedEvdevName": "KEY_DELETE",
"mappedEvdevID": 111
},
{
"displayName": "End",
"evdevName": "KEY_END",
"EvdevID": 107,
"mappedEvdevName": "KEY_END",
"mappedEvdevID": 107
},
{
"displayName": "PageDown",
"evdevName": "KEY_PAGEDOWN",
"EvdevID": 109,
"mappedEvdevName": "KEY_PAGEDOWN",
"mappedEvdevID": 109
},
{
"displayName": "kp7",
"evdevName": "KEY_KP7",
"EvdevID": 71,
"mappedEvdevName": "KEY_KP7",
"mappedEvdevID": 71
},
{
"displayName": "kp8",
"evdevName": "KEY_KP8",
"EvdevID": 72,
"mappedEvdevName": "KEY_KP8",
"mappedEvdevID": 72
},
{
"displayName": "kp9",
"evdevName": "KEY_KP9",
"EvdevID": 73,
"mappedEvdevName": "KEY_KP9",
"mappedEvdevID": 73
},
{
"displayName": "kp+",
"evdevName": "KEY_KPPLUS",
"EvdevID": 78,
"mappedEvdevName": "KEY_KPPLUS",
"mappedEvdevID": 78
},
{
"displayName": "CapsLock",
"evdevName": "KEY_CAPSLOCK",
"EvdevID": 58,
"mappedEvdevName": "KEY_CAPSLOCK",
"mappedEvdevID": 58
},
{
"displayName": "a",
"evdevName": "KEY_A",
"EvdevID": 30,
"mappedEvdevName": "KEY_A",
"mappedEvdevID": 30
},
{
"displayName": "s",
"evdevName": "KEY_S",
"EvdevID": 31,
"mappedEvdevName": "KEY_S",
"mappedEvdevID": 31
},
{
"displayName": "d",
"evdevName": "KEY_D",
"EvdevID": 32,
"mappedEvdevName": "KEY_D",
"mappedEvdevID": 32
},
{
"displayName": "f",
"evdevName": "KEY_F",
"EvdevID": 33,
"mappedEvdevName": "KEY_F",
"mappedEvdevID": 33
},
{
"displayName": "g",
"evdevName": "KEY_G",
"EvdevID": 34,
"mappedEvdevName": "KEY_G",
"mappedEvdevID": 34
},
{
"displayName": "h",
"evdevName": "KEY_H",
"EvdevID": 35,
"mappedEvdevName": "KEY_H",
"mappedEvdevID": 35
},
{
"displayName": "j",
"evdevName": "KEY_J",
"EvdevID": 36,
"mappedEvdevName": "KEY_J",
"mappedEvdevID": 36
},
{
"displayName": "k",
"evdevName": "KEY_K",
"EvdevID": 37,
"mappedEvdevName": "KEY_K",
"mappedEvdevID": 37
},
{
"displayName": "l",
"evdevName": "KEY_L",
"EvdevID": 38,
"mappedEvdevName": "KEY_L",
"mappedEvdevID": 38
},
{
"displayName": "ö",
"evdevName": "KEY_SEMICOLON",
"EvdevID": 39,
"mappedEvdevName": "KEY_SEMICOLON",
"mappedEvdevID": 39
},
{
"displayName": "ä",
"evdevName": "KEY_APOSTROPHE",
"EvdevID": 40,
"mappedEvdevName": "KEY_APOSTROPHE",
"mappedEvdevID": 40
},
{
"displayName": "'",
"evdevName": "KEY_BACKSLASH",
"EvdevID": 43,
"mappedEvdevName": "KEY_BACKSLASH",
"mappedEvdevID": 43
},
{
"displayName": "kp4",
"evdevName": "KEY_KP4",
"EvdevID": 75,
"mappedEvdevName": "KEY_KP4",
"mappedEvdevID": 75
},
{
"displayName": "kp5",
"evdevName": "KEY_KP5",
"EvdevID": 76,
"mappedEvdevName": "KEY_KP5",
"mappedEvdevID": 76
},
{
"displayName": "kp6",
"evdevName": "KEY_KP6",
"EvdevID": 77,
"mappedEvdevName": "KEY_KP6",
"mappedEvdevID": 77
},
{
"displayName": "LeftShift",
"evdevName": "KEY_LEFTSHIFT",
"EvdevID": 42,
"mappedEvdevName": "KEY_LEFTSHIFT",
"mappedEvdevID": 42
},
{
"displayName": "<",
"evdevName": "KEY_102ND",
"EvdevID": 86,
"mappedEvdevName": "KEY_102ND",
"mappedEvdevID": 86
},
{
"displayName": "z",
"evdevName": "KEY_Z",
"EvdevID": 44,
"mappedEvdevName": "KEY_Z",
"mappedEvdevID": 44
},
{
"displayName": "x",
"evdevName": "KEY_X",
"EvdevID": 45,
"mappedEvdevName": "KEY_X",
"mappedEvdevID": 45
},
{
"displayName": "c",
"evdevName": "KEY_C",
"EvdevID": 46,
"mappedEvdevName": "KEY_C",
"mappedEvdevID": 46
},
{
"displayName": "v",
"evdevName": "KEY_V",
"EvdevID": 47,
"mappedEvdevName": "KEY_V",
"mappedEvdevID": 47
},
{
"displayName": "b",
"evdevName": "KEY_B",
"EvdevID": 48,
"mappedEvdevName": "KEY_B",
"mappedEvdevID": 48
},
{
"displayName": "n",
"evdevName": "KEY_N",
"EvdevID": 49,
"mappedEvdevName": "KEY_N",
"mappedEvdevID": 49
},
{
"displayName": "m",
"evdevName": "KEY_M",
"EvdevID": 50,
"mappedEvdevName": "KEY_M",
"mappedEvdevID": 50
},
{
"displayName": ",",
"evdevName": "KEY_COMMA",
"EvdevID": 51,
"mappedEvdevName": "KEY_COMMA",
"mappedEvdevID": 51
},
{
"displayName": ".",
"evdevName": "KEY_DOT",
"EvdevID": 52,
"mappedEvdevName": "KEY_DOT",
"mappedEvdevID": 52
},
{
"displayName": "-",
"evdevName": "KEY_SLASH",
"EvdevID": 53,
"mappedEvdevName": "KEY_SLASH",
"mappedEvdevID": 53
},
{
"displayName": "Shift",
"evdevName": "KEY_RIGHTSHIFT",
"EvdevID": 54,
"mappedEvdevName": "KEY_RIGHTSHIFT",
"mappedEvdevID": 54
},
{
"displayName": "Up",
"evdevName": "KEY_UP",
"EvdevID": 103,
"mappedEvdevName": "KEY_UP",
"mappedEvdevID": 103
},
{
"displayName": "kp1",
"evdevName": "KEY_KP1",
"EvdevID": 79,
"mappedEvdevName": "KEY_KP1",
"mappedEvdevID": 79
},
{
"displayName": "kp2",
"evdevName": "KEY_KP2",
"EvdevID": 80,
"mappedEvdevName": "KEY_KP2",
"mappedEvdevID": 80
},
{
"displayName": "kp3",
"evdevName": "KEY_KP3",
"EvdevID": 81,
"mappedEvdevName": "KEY_KP3",
"mappedEvdevID": 81
},
{
"displayName": "kpEnter",
"evdevName": "KEY_KPENTER",
"EvdevID": 96,
"mappedEvdevName": "KEY_KPENTER",
"mappedEvdevID": 96
},
{
"displayName": "LeftCtrl",
"evdevName": "KEY_LEFTCTRL",
"EvdevID": 29,
"mappedEvdevName": "KEY_LEFTCTRL",
"mappedEvdevID": 29
},
{
"displayName": "Win",
"evdevName": "KEY_LEFTMETA",
"EvdevID": 125,
"mappedEvdevName": "KEY_LEFTMETA",
"mappedEvdevID": 125
},
{
"displayName": "Alt",
"evdevName": "KEY_LEFTALT",
"EvdevID": 56,
"mappedEvdevName": "KEY_LEFTALT",
"mappedEvdevID": 56
},
{
"displayName": "Space",
"evdevName": "KEY_SPACE",
"EvdevID": 57,
"mappedEvdevName": "KEY_SPACE",
"mappedEvdevID": 57
},
{
"displayName": "Alt",
"evdevName": "KEY_RIGHTALT",
"EvdevID": 100,
"mappedEvdevName": "KEY_RIGHTALT",
"mappedEvdevID": 100
},
{
"displayName": "Win",
"evdevName": "KEY_RIGHTMETA",
"EvdevID": 126,
"mappedEvdevName": "KEY_RIGHTMETA",
"mappedEvdevID": 126
},
{
"displayName": "Menu",
"evdevName": "KEY_MENU",
"EvdevID": 139,
"mappedEvdevName": "KEY_MENU",
"mappedEvdevID": 139
},
{
"displayName": "Ctrl",
"evdevName": "KEY_RIGHTCTRL",
"EvdevID": 97,
"mappedEvdevName": "KEY_RIGHTCTRL",
"mappedEvdevID": 97
},
{
"displayName": "Left",
"evdevName": "KEY_LEFT",
"EvdevID": 105,
"mappedEvdevName": "KEY_LEFT",
"mappedEvdevID": 105
},
{
"displayName": "Down",
"evdevName": "KEY_DOWN",
"EvdevID": 108,
"mappedEvdevName": "KEY_DOWN",
"mappedEvdevID": 108
},
{
"displayName": "Right",
"evdevName": "KEY_RIGHT",
"EvdevID": 106,
"mappedEvdevName": "KEY_RIGHT",
"mappedEvdevID": 106
},
{
"displayName": "kp0",
"evdevName": "KEY_KP0",
"EvdevID": 82,
"mappedEvdevName": "KEY_KP0",
"mappedEvdevID": 82
},
{
"displayName": "kp,",
"evdevName": "KEY_KPDOT",
"EvdevID": 83,
"mappedEvdevName": "KEY_KPDOT",
"mappedEvdevID": 83
}
]
}<file_sep>from http.server import HTTPServer, BaseHTTPRequestHandler
from queue import Queue
from threading import Thread, Event
import json
# Import Tuple type which is used in optional function type annotations.
from typing import Tuple
import keyprofile
class WebServerManager():
"""Creates new web server thread."""
def __init__(self):
self.exit_event = Event()
web_server_settings = ("", 8080)
self.settings_queue = Queue()
self.web_server_thread = Thread(group=None, target=WebServer, args=(web_server_settings, self.settings_queue, self.exit_event))
self.web_server_thread.start()
def close(self):
"""Close web server. This method will block until web server is closed."""
self.exit_event.set()
self.web_server_thread.join()
def get_settings_queue(self) -> Queue:
return self.settings_queue
# Class WebServer inherits HTTPServer class which is from Python standard library.
# https://docs.python.org/3/library/http.server.html
# Also, note that HTTPServer inherits TCPServer.
# https://docs.python.org/3/library/socketserver.html#socketserver.TCPServer
class WebServer(HTTPServer):
# Type annotations of this constructor are optional.
def __init__(self, address_and_port: Tuple [str, int], settings_queue: Queue, exit_event: Event) -> None:
# Run constructor from HTTPServer first. Note the RequestHandler class.
super().__init__(address_and_port, RequestHandler)
# Some object attributes specific to this class. You can modify
# them from RequestHandler's methods.
self.settings_queue = settings_queue
# Check exit event every 0.5 seconds if there is no new TCP connections.
self.timeout = 0.5
# TODO: Load saved profiles/settings from file
# if file is not found default to keyprofile.settings
self.settings = [{}]
# keyprofile.setting
# Main thread is waiting for profiles/settings so lets send them.
self.settings_queue.put_nowait(self.settings)
print("web server running")
while True:
# This method will timeout because exit_event must be checked enough often
# to shutdown cleanly.
self.handle_request()
if exit_event.is_set():
# There was exit event, lets close the web server.
break
self.server_close()
# Save profiles/settings.
with open('data.txt', 'w') as outfile:
json.dump(self.settings, outfile)
print("web server exited")
# Python standard library HTTPServer works with request handler system, so lets
# make our own request handler.
class RequestHandler(BaseHTTPRequestHandler):
# By default the HTTP version is 1.0.
def do_GET(self) -> None:
"""Handler for HTTP GET requests."""
# Print some information about the HTTP request.
#print("HTTP GET Request, path: " + self.path)
#print("client_address: " + str(self.client_address))
#print("request_version: " + self.request_version)
#print("headers: " + str(self.headers))
if self.path == "/json.api":
message = json.dumps(self.server.settings)
message_bytes = message.encode()
self.send_utf8_bytes(message_bytes, "text/json")
elif self.path == "/heatmap.api":
f = open("heatmap_stats.txt", 'r')
heatmap_info = f.read()
message_bytes = heatmap_info.encode()
self.send_utf8_bytes(message_bytes, "text/json")
elif self.path == "/":
self.send_utf8_file("../frontend/control.html", "text/html")
elif self.path == "/styles.css":
self.send_utf8_file("../frontend/styles.css", "text/css")
elif self.path == "/script.js":
self.send_utf8_file("../frontend/script.js", "application/javascript")
else:
message_bytes = b"<html><body><h1>Hello world</h1></body></html>"
self.send_utf8_bytes(message_bytes, "text/html")
def do_POST(self) -> None:
"""Handler for HTTP POST requests."""
#print("HTTP POST Request, path: " + self.path)
#print("client_address: " + str(self.client_address))
#print("request_version: " + self.request_version)
#print("headers: " + str(self.headers))
content_length = self.headers.get("Content-Length", 0)
response = self.rfile.read(int(content_length))
self.server.settings = json.loads(response.decode("utf-8"))
# Send new settings to main thread.
self.server.settings_queue.put_nowait(self.server.settings)
self.send_response(200)
self.end_headers()
def send_utf8_file(self, file_name: str, mime_type: str) -> None:
"""Mime type is string like 'text/json'"""
file = open(file_name, mode='rb')
file_as_bytes = file.read()
file.close()
self.send_utf8_bytes(file_as_bytes, mime_type)
def send_utf8_bytes(self, message_bytes: bytes, mime_type: str) -> None:
"""Mime type is string like 'text/json'"""
# 200 is HTTP status code for successfull request.
self.send_response(200)
self.send_header("Content-Encoding", "UTF-8")
self.send_header("Content-Type", mime_type + "; charset=utf-8")
self.end_headers()
# Write HTTP message body which is the HTML web page.
self.wfile.write(message_bytes)
self.wfile.flush()
<file_sep># Projektikurssi17
Keyboard remapper executed with a raspberry pi 3B and a rapsberry pi zero w. Raspberry pi 3B is where a keyboard will be connected. Pi hears what the user types on the keyboard and can execute macros and alter the input given. Then the data is sent to zero w wirelessly expecting that the zero is on and plugged to a pc or other device that can understand usb keyboards. The zero w appears as a keyboard to the pc and routes the key inputs in hid format to the pc. The setting in raspberry pi can be altered through wifi by first connecting to the raspberry pi's wifi and then altering the settings from the front end webpage (connect to ip address and port that I cant remeber now). The project is ready and working. Demonstration and additional documentation on the project working might be added somewhere in the future. The use of two raspberry pi's was necessary because one of them has usb host port that can read a keyboard and other has usb slave that can act as a keyboard. They were also accessible to us for the project.
<file_sep># Preview:
http://htmlpreview.github.io/?https://github.com/miikka-h/Projektikurssi17/blob/master/frontend/control.html
<file_sep>#!/bin/python3
import os
import sys
import socket
import time
import io
# http://www.usb.org/developers/hidpage/Hut1_12v2.pdf
# See chapter 10 for keycodes.
# The following HID Report structure is for example keyboard from Linux kernel documentation
# https://www.kernel.org/doc/Documentation/usb/gadget_hid.txt
# byte 1: modifier key bit flags from LeftContror to Right GUI (0xE0 to 0xE7)
# byte 2: some byte, not used (exists because of BIOS keyboard support?)
# byte 3-8: keycode values from 0-101
FILE_NAME = "/dev/hidg0"
HID_REPORT_SIZE_BYTES = 8
# Functions
def try_to_connect(socket_object: socket.SocketType, server_address: str, port_number: int) -> bool:
try:
socket_object.connect((server_address, port_number))
except OSError as error:
print("error: " + error.strerror)
return False
return True
def connection_retry_loop(socket_object: socket.SocketType, server_address: str, port_number: int) -> None:
while True:
if try_to_connect(socket_object, server_address, port_number):
print("connected to the server")
break
else:
print("trying to reconnect to the server in 5 seconds")
time.sleep(5.0)
def reset_keys(file: io.BufferedWriter) -> None:
file.write(bytes(HID_REPORT_SIZE_BYTES))
file.flush()
def main() -> None:
# Check arguments
if len(sys.argv) <= 2:
print("give server address and server port number as arguments")
exit(-1)
# Open file.
if not os.path.exists(FILE_NAME):
print(FILE_NAME + " does not exist")
exit(-1)
file = open(FILE_NAME, "ab")
# Create socket.
socket_object = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = sys.argv[1]
port_number = int(sys.argv[2])
try:
print("trying to connect to the server")
connection_retry_loop(socket_object, server_address, port_number)
while True:
data = socket_object.recv(HID_REPORT_SIZE_BYTES)
byte_count = len(data)
if byte_count == 0:
print("server disconnected")
print("trying to reconnect")
reset_keys(file)
socket_object.close()
socket_object = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
connection_retry_loop(socket_object, server_address, port_number)
elif byte_count != HID_REPORT_SIZE_BYTES:
print("error: USB HID report size " + str(byte_count) + " bytes is unsupported")
socket_object.close()
reset_keys(file)
file.close()
exit(-1)
else:
# No errors
file.write(data)
file.flush()
except OSError as error:
print("error: " + error.strerror)
try:
reset_keys(file)
except OSError as error:
print("couldn't reset keyboard keys")
print("error: " + error.strerror)
file.close()
socket_object.close()
except KeyboardInterrupt:
reset_keys(file)
file.close()
socket_object.close()
# Start main function
if __name__ == "__main__":
main()
<file_sep>#!/bin/python3
from queue import Queue, Empty
from threading import Thread, Event
from collections import OrderedDict
import socket
import time
from typing import List
import pyudev
import evdev
from evdev import ecodes
from web_server import WebServerManager
from hid_report import HidReport
class HidDataSocket():
"""
TCP Socket for sending USB HID report data.
Call `create_socket()` method before using other methods.
"""
def __init__(self) -> None:
self.server_socket = None # type: socket.SocketType
self.connection_socket = None # type: socket.SocketType
self.address = None
def create_socket(self) -> bool:
"""Returns False if there is socket creation error."""
try:
self.server_socket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
self.server_socket.setsockopt(
socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.server_socket.bind(("", 25001))
self.server_socket.listen(0)
return True
except OSError as error:
print("error: " + error.strerror)
return False
def close(self) -> None:
"""Close all sockets."""
if self.connection_socket is not None:
self.connection_socket.close()
if self.server_socket is not None:
self.server_socket.close()
def wait_connection(self) -> None:
"""Close previous connection to client if it exists and wait for new connection."""
if self.connection_socket is not None:
self.connection_socket.close()
print("waiting for client")
(self.connection_socket, self.address) = self.server_socket.accept()
print("client from " + str(self.address) + " connected")
def send_hid_report_if_there_is_new_changes(self, hid_report: HidReport) -> bool:
"""Returns False if client disconnected."""
if not hid_report.update_report():
return True
try:
self.connection_socket.sendall(hid_report.report)
return True
except OSError as error:
print("error: " + error.strerror)
print("client " + str(self.address) + " disconnected")
return False
def mapProfiles(settings):
profileMap = {}
i = 0
print(settings)
while i < len(settings):
if "profileID" in settings[i]:
index = settings[i]["profileID"]
profileMap[index] = i
i = i + 1
return profileMap
def cutfrom(key: int, elements: OrderedDict):
"""Expects that the key is in the elements list and
remove all elements after and including that position."""
while (key in elements):
elements.popitem(last=True)
class KeyRemapper:
"""Map one key to multiple keys."""
def __init__(self, settings) -> None:
"""Argument `settings` is profile JSON dictionary."""
if not ("keyData" in settings[0]):
settings = [{"keyData": {}}]
self.settings = settings
self.profileMap = mapProfiles(
self.settings) # Profile ID mapped to index in the list
self.current_profile = (-1, 0)
self.old_profiles = OrderedDict([self.current_profile])
# New settings retunrs the first mod
def set_new_settings(self, settings) -> None:
"""Argument `settings` is profile JSON dictionary."""
if not ("keyData" in settings[0]):
settings = [{'keyData': {}}]
self.settings = settings
self.profileMap = mapProfiles(
self.settings) # Profile ID mapped to index in the list
self.current_profile = (-1, 0)
self.old_profiles = OrderedDict([self.current_profile])
def remap_key(self, key_event) -> List[List[int]]:
"""
Currently is specialized in handling the profile changes.
REMAPS one key to multiple keys.
Key id values are evdev id numbers.
Returns list containing lists of keys. List of keys
represents keys that are included in one USB hid report.
"""
evdevId = key_event.code
empty_nothing = []
empty_key = []
empty_key.append(empty_nothing) # type: List[List[int]]
if key_event.value == 0: # key up
if evdevId in self.old_profiles:
print("returned from a mode")
cutfrom(evdevId, self.old_profiles)
self.current_profile = self.old_profiles.popitem(last=True)
self.old_profiles[
self.current_profile[0]] = self.current_profile[1]
return (empty_key, True)
if str(evdevId) in self.settings[self.current_profile[1]]["keyData"]:
try:
keyMapping = self.settings[
self.current_profile[1]]["keyData"][str(evdevId)]
except KeyError:
print("Key has no special effect")
key = []
key.append(evdevId)
mapped_key = []
mapped_key.append(key) # type: List[List[int]]
return (mapped_key, False)
if "mappedEvdevID" in keyMapping:
return (keyMapping["mappedEvdevID"], False)
key = [evdevId]
mapped_key = []
mapped_key.append(key) # type: List[List[int]]
return (mapped_key, False)
elif key_event.value == 1: # key down
if evdevId in self.old_profiles:
return (empty_key, False)
# print("kissa" + str(evdevId))
# print(self.settings)
# print(self.current_profile)
# print(self.settings[self.current_profile[1]])
# fst = (self.settings[self.current_profile[1]])
# print(fst['keyData'])
if str(evdevId) in self.settings[self.current_profile[1]]["keyData"]:
# try:
keyMapping = self.settings[
self.current_profile[1]]["keyData"][str(evdevId)]
# except KeyError:
# print("Key has no special effect")
# key = []
# key.append(evdevId)
# mapped_key = []
# mapped_key.append(key) # type: List[List[int]]
# return (mapped_key, False)
if "profiles" in keyMapping:
if evdevId not in self.old_profiles:
self.current_profile = (evdevId, self.profileMap[
keyMapping["profiles"][0]])
self.old_profiles[
self.current_profile[0]] = self.current_profile[1]
print(self.old_profiles)
return (empty_key, True)
if "mappedEvdevID" in keyMapping:
return (keyMapping["mappedEvdevID"], False)
else:
pass
# print("kissa")
# print(self.settings[self.current_profile[1]]["keyData"])
# print("1")
# print(self.settings)
# print("2")
# print(self.settings[self.current_profile[1]])
# print("3")
# print(evdevId)
print(key_event.value)
key = []
key.append(evdevId)
mapped_key = []
mapped_key.append(key) # type: List[List[int]]
return(mapped_key, False)
# If full_profile_history goes trough any staying changes the currently
# pressed buttons have to be all risen except for the profile change
# buttons that were pressed before the lastly modified mode change
# button in the history
# If profile is toggled the full history has to be erased
# "clean" means doing the previous
# list_of_hid_reports = [] # type: List[List[int]]
# empty_hid = [] # type: List[int]
# tells which keys have to be risen in the next operation.
# clean = False
# try:
# print(self.current_profile)
# mapdata = self.settings[self.current_profile][
# "keyData"][str(key_event.code)]
#
# if "mappedEvdevID" in mapdata:
# list_of_hid_reports = mapdata["mappedEvdevID"]
#
# if "profiles" in mapdata:
# list_of_hid_reports.append(empty_hid)
#
# TODO follow keyboard limitations. Uper limit to the list of
# currently_pressed_profiles needed?
#
# Profiles start from 1 apparently and lists usually start from 0
# key_down = 1
# if key_event.value == 1:
# self.currently_pressed_profiles.append(list_of_hid_reports)
# if "profiles" in mapdata:
# if mapdata["toggle"]:
# self.currently_pressed_profiles = []
# self.current_profile = self.profileMap[
# mapdata["profiles"][0]]
# clean all buttons
# clean = True # doesn't include mod buttons
# self.full_profile_history = [
# self.profileMap[mapdata["profiles"][0]]]
#
# else:
# self.full_profile_history.append(self.current_profile)
# print(self.settings)
# print(self.profileMap)
# self.current_profile = self.profileMap[
# mapdata["profiles"][0]]
#
# clean but no mods should be cleaned
# clean = True # doesn't include mod buttons
#
# key_up = 0
# else: # if key_event.value == 0:
# self.currently_pressed_profiles.remove(list_of_hid_reports)
#
# if "profiles" in mapdata:
# profile = self.profileMap[mapdata["profiles"][0]]
# if profile in self.full_profile_history:
# KeyRemapper.cutfrom(profile, self.full_profile_history)
# clean = True
# if len(self.full_profile_history) > 0:
# self.current_profile = self.full_profile_history[
# len(self.full_profile_history) - 1]
# else:
# self.full_profile_history = []
# self.current_profile = 0
# except KeyError as error:
# empty_hid.append(key_event.code)
# list_of_hid_reports.append(empty_hid)
# TODO debug and make this all work
# TODO we need the ability to send button up command for all
# buttons that have to be risen in mode change.
# the key press to add, and a value whether every previous key press
# should be cleaned
class KeyboardManager:
"""Read input from all availlable keyboards.
Starts a new thread to monitor device events from Linux udev system.
This allows adding and removing keyboards at runtime without constantly
polling udev for new device events.
Call `close()` to close device monitoring thread.
"""
def __init__(self) -> None:
self.context = pyudev.Context()
self.device_list = [] # type: List[evdev.InputDevice]
for keyboard in self.context.list_devices(subsystem="input", ID_INPUT_KEYBOARD=1):
if keyboard.device_node != None:
keyboard = evdev.InputDevice(keyboard.device_node)
print("Keyboard '" + keyboard.name + "' added")
self.device_list.append(keyboard)
monitor = pyudev.Monitor.from_netlink(self.context)
monitor.filter_by("input")
self.exit_event = Event()
self.event_queue = Queue() # type: Queue
self.device_monitor_thread = Thread(
group=None, target=monitor_device_events, args=(self.exit_event, self.event_queue, monitor))
self.device_monitor_thread.start()
self.key_event_buffer = [] # type: List[evdev.InputEvent]
self.clear_keys = False
def close(self) -> None:
"""Send exit event to device monitoring thread. Waits until thread is closed."""
self.exit_event.set()
self.device_monitor_thread.join()
def get_key_events(self) -> List[evdev.InputEvent]:
"""
Returns list of evdev keyboard events from all currently connected keyboards.
If clearing current key events is requested, returns empty list.
"""
self.key_event_buffer.clear()
for keyboard in self.device_list:
while True:
try:
evdev_event = keyboard.read_one()
if evdev_event is None:
break
elif evdev_event.type == ecodes.EV_KEY and not self.clear_keys:
self.key_event_buffer.append(evdev_event)
except OSError:
break
self.clear_keys = False
return self.key_event_buffer
def request_clear_key_events(self) -> None:
"""
Request clearing key event buffers. Clearing key events will
happen at next `get_key_events()` method call.
"""
self.clear_keys = True
def check_device_events(self) -> None:
"""
Check if there new device events from device monitoring thread.
Updates keyboard list if there is new events.
"""
while True:
try:
(event, device_node) = self.event_queue.get(block=False)
if event == KEYBOARD_ADDED:
keyboard = evdev.InputDevice(device_node)
print("Keyboard '" + keyboard.name + "' added")
self.device_list.append(keyboard)
elif event == KEYBOARD_REMOVED:
removed_device = None
for evdev_device in self.device_list:
if evdev_device.fn == device_node:
removed_device = evdev_device
break
if removed_device != None:
print("Keyboard '" + removed_device.name + "' removed")
self.device_list.remove(removed_device)
removed_device.close()
except Empty:
break
KEYBOARD_ADDED = 0
KEYBOARD_REMOVED = 1
def monitor_device_events(exit_event: Event, event_queue: Queue, monitor: pyudev.Monitor):
"""
A new thread should be created to run this function.
"""
while True:
device = monitor.poll(timeout=0.5)
if device != None:
if not ('ID_INPUT_KEYBOARD' in device.properties and device.device_node != None):
continue
if device.action == "add":
event_queue.put_nowait((KEYBOARD_ADDED, device.device_node))
elif device.action == "remove":
event_queue.put_nowait((KEYBOARD_REMOVED, device.device_node))
if exit_event.is_set():
break
def main():
try:
# Lets load all necessary components and form connections.
keyboard_manager = KeyboardManager()
web_server_manager = WebServerManager()
hid_data_socket = HidDataSocket()
if not hid_data_socket.create_socket():
print("error: Could not create socket for HidDataSocket.")
web_server_manager.close()
hid_data_socket.close()
exit(-1)
hid_data_socket.wait_connection()
# Create evdev keycode to USB HID report converter.
hid_report = HidReport()
# Actual server logic loop.
run(web_server_manager, hid_data_socket, hid_report, keyboard_manager)
except KeyboardInterrupt:
# handle ctrl-c
web_server_manager.close()
hid_data_socket.close()
keyboard_manager.close()
exit(0)
def run(web_server_manager: WebServerManager, hid_data_socket: HidDataSocket, hid_report: HidReport, keyboard_manager: KeyboardManager) -> None:
keypresses = ""
keyspressed = 0
clean = False
print("waiting for settings from web server thread")
key_remapper = KeyRemapper(web_server_manager.get_settings_queue().get())
print("received settings from web server thread")
keyboard_manager.request_clear_key_events()
while True:
time.sleep(0.001)
keyboard_manager.check_device_events()
try:
new_settings = web_server_manager.get_settings_queue().get(
block=False)
key_remapper.set_new_settings(new_settings)
except Empty:
pass
for event in keyboard_manager.get_key_events():
if event.value == 1:
web_server_manager.get_heatmap_queue().put_nowait(event.code)
heatmap_key = str(event)[
str(event).find("code") + 5:str(event).find("code") + 7]
# print(event)
# profile handling
tuple_data = key_remapper.remap_key(event)
print(tuple_data)
new_keys_list = tuple_data[0]
clean = tuple_data[1]
# profile handling
if len(new_keys_list) == 1:
key_list = new_keys_list[0]
# key_down = 1
if event.value == 1:
for k in key_list:
hid_report.add_key(k)
keypresses += heatmap_key + "|"
# print(keypresses)
keyspressed += 1
if keyspressed == 10:
f = open('heatmap_data.txt', 'w')
f.write(keypresses)
f.close()
heatmap()
keyspressed = 0
# key_up = 0
elif event.value == 0:
for k in key_list:
hid_report.remove_key(k)
else:
if event.value == 1:
for report in new_keys_list:
key_list = report
# print(key_list)
for k in key_list:
hid_report.add_key(k)
keypresses += heatmap_key + "|"
keyspressed += 1
if keyspressed == 10:
f = open('heatmap_data.txt', 'w')
f.write(keypresses)
f.close()
heatmap()
keyspressed = 0
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
for k in key_list:
hid_report.remove_key(k)
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
# break
# pass
# TODO: Handle more complicated key remaps.
if clean:
hid_report.clear()
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
# break
f.close()
def send_and_reset_if_client_disconnected(hid_data_socket: HidDataSocket, hid_report: HidReport, keyboard_manager: KeyboardManager) -> None:
if not hid_data_socket.send_hid_report_if_there_is_new_changes(hid_report):
hid_data_socket.wait_connection()
keyboard_manager.request_clear_key_events()
hid_report.clear()
def heatmap() -> None:
heatmap_stats = {}
with open("heatmap_stats.txt", 'r') as statfile:
help_dict = statfile.read().strip('{').strip('}').split(',')
for entry in help_dict:
(key, val) = entry.rstrip("\n").split(':')
heatmap_stats[int(key)] = int(val)
statfile.close()
# print(heatmap_stats)
hmdata = open("heatmap_data.txt", 'r')
statfile = open("heatmap_stats.txt", 'w')
key_presses = hmdata.read().split('|')
hmdata.close()
# print(key_presses)
for kpress in key_presses:
if kpress is not "":
heatmap_stats[int(kpress)] = heatmap_stats[int((kpress).rstrip())]
heatmap_stats[int(kpress)] += 1
# print(heatmap_stats[int(kpress)])
# print(heatmap_stats)
if heatmap_stats is not "":
statfile.write(str(heatmap_stats))
statfile.close()
if __name__ == "__main__":
main()
print("main thread exitted")
<file_sep>
# Keyboard server for Raspberry Pi 3
TCP server socket ports:
* `25001` USB HID report data
* `8080` Web frontend for configuration
## Setup
1. Install Python 3 and some python packages.
```
sudo apt-get install python3 python3-pip
```
```
pip3 install --upgrade pip
```
```
pip3 install --user evdev pyudev
```
If your Python 3 version is 3.4 or older, also install `typing` python package.
```
pip3 install --user typing
```
2. If you don't want to run server as root, check that your Linux user account belongs to group `input`.
(Needed for `/dev/input/event`)
```
groups your_user_name
```
To add user to a group, run this.
```
sudo usermod -a -G input your_user_name
```
3. Setup WLAN access point. [https://www.raspberrypi.org/documentation/configuration/wireless/access-point.md](https://www.raspberrypi.org/documentation/configuration/wireless/access-point.md)
4. Run
```
python3 main.py /dev/input/event_device_you_want_to_listen
```<file_sep>
import {glMatrix, mat4, vec3, vec4} from "gl-matrix";
import {loadProgram} from "./utils";
const VERTEX_SHADER_SOURCE = `
attribute vec3 coordinate;
uniform mat4 modelMatrix;
uniform mat4 viewMatrix;
uniform mat4 projectionMatrix;
void main() {
gl_Position = projectionMatrix * viewMatrix * modelMatrix * vec4(coordinate, 1.0);
}
`;
const FRAGMENT_SHADER_SOURCE = `
precision mediump float;
uniform vec3 color;
void main() {
gl_FragColor = vec4(color, 1.0);
}
`;
// Side face at z = 1.0
const CUBE_FACE_VERTICES = [
// Triangle 1
-1.0, 1.0, 1.0,
1.0, -1.0, 1.0,
-1.0, -1.0, 1.0,
// Triangle 2
-1.0, 1.0, 1.0,
1.0, 1.0, 1.0,
1.0, -1.0, 1.0,
];
function cubeFaceTransform(matrix: mat4): number[] {
let vec = vec4.create();
let bufferVec = vec4.create();
let newVertices = [];
for (let i = 0; i < CUBE_FACE_VERTICES.length; i+= 3) {
vec4.set(vec, CUBE_FACE_VERTICES[i], CUBE_FACE_VERTICES[i+1], CUBE_FACE_VERTICES[i+2], 1.0);
vec4.transformMat4(bufferVec, vec, matrix);
newVertices.push(bufferVec[0], bufferVec[1], bufferVec[2]);
}
return newVertices;
}
function pushAll(from: number[], to: number[]) {
for (let x of from) {
to.push(x);
}
}
/**
* Return all faces except top face.
*/
function createCubeSideVertices(): number[] {
let vertices: number[] = [];
let matrix = mat4.create();
pushAll(CUBE_FACE_VERTICES, vertices);
mat4.fromYRotation(matrix, Math.PI/2.0);
pushAll(cubeFaceTransform(matrix), vertices);
mat4.fromYRotation(matrix, Math.PI);
pushAll(cubeFaceTransform(matrix), vertices);
mat4.fromYRotation(matrix, Math.PI * 1.5);
pushAll(cubeFaceTransform(matrix), vertices);
mat4.fromXRotation(matrix, Math.PI/2.0);
pushAll(cubeFaceTransform(matrix), vertices);
return vertices;
}
const CUBE_SIDE_VERTICES = createCubeSideVertices();
function createCubeTopFace(): number[] {
let vertices: number[] = [];
let matrix = mat4.create();
mat4.fromXRotation(matrix, -Math.PI/2.0);
pushAll(cubeFaceTransform(matrix), vertices);
return vertices;
}
const CUBE_TOP_VERTICES = createCubeTopFace();
export class Cube {
public modelMatrix: mat4;
public topFaceColor: vec3;
public sideFaceColor: vec3;
constructor() {
this.modelMatrix = mat4.create();
this.topFaceColor = vec3.create();
vec3.set(this.topFaceColor, 0.5, 0.5, 0.5);
this.sideFaceColor = vec3.create();
vec3.set(this.sideFaceColor, 0.3, 0.3, 0.3);
}
}
export class CubeRenderer {
private vertices: WebGLBuffer;
private topVertices: WebGLBuffer;
constructor(gl: WebGLRenderingContext, private program: CubeProgram) {
this.vertices = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, this.vertices);
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(CUBE_SIDE_VERTICES), gl.STATIC_DRAW);
this.topVertices = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, this.topVertices);
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(CUBE_TOP_VERTICES), gl.STATIC_DRAW);
}
render(gl: WebGLRenderingContext, cube: Cube, viewMatrix: mat4, projectionMatrix: mat4) {
// Draw cube side faces.
gl.bindBuffer(gl.ARRAY_BUFFER, this.vertices);
gl.vertexAttribPointer(this.program.vertexAttribute, 3, gl.FLOAT, false, 0, 0);
gl.enableVertexAttribArray(this.program.vertexAttribute);
gl.useProgram(this.program.program);
gl.uniformMatrix4fv(this.program.viewMatrixUniform, false, viewMatrix);
gl.uniformMatrix4fv(this.program.modelMatrixUniform, false, cube.modelMatrix);
gl.uniformMatrix4fv(this.program.projectionMatrixUniform, false, projectionMatrix);
gl.uniform3fv(this.program.colorUniform, cube.sideFaceColor);
gl.drawArrays(gl.TRIANGLES, 0, CUBE_SIDE_VERTICES.length/3.0);
// Draw cube top face.
gl.bindBuffer(gl.ARRAY_BUFFER, this.topVertices);
gl.vertexAttribPointer(this.program.vertexAttribute, 3, gl.FLOAT, false, 0, 0);
gl.enableVertexAttribArray(this.program.vertexAttribute);
gl.useProgram(this.program.program);
gl.uniformMatrix4fv(this.program.viewMatrixUniform, false, viewMatrix);
gl.uniformMatrix4fv(this.program.modelMatrixUniform, false, cube.modelMatrix);
gl.uniformMatrix4fv(this.program.projectionMatrixUniform, false, projectionMatrix);
gl.uniform3fv(this.program.colorUniform, cube.topFaceColor);
gl.drawArrays(gl.TRIANGLES, 0, CUBE_TOP_VERTICES.length/3.0);
}
}
export class CubeProgram {
public vertexAttribute: number;
public modelMatrixUniform: WebGLUniformLocation;
public viewMatrixUniform: WebGLUniformLocation;
public projectionMatrixUniform: WebGLUniformLocation;
public colorUniform: WebGLUniformLocation;
constructor(gl: WebGLRenderingContext, public program: WebGLProgram) {
this.vertexAttribute = gl.getAttribLocation(program, "coordinate");
this.modelMatrixUniform = gl.getUniformLocation(program, "modelMatrix");
this.viewMatrixUniform = gl.getUniformLocation(program, "viewMatrix");
this.projectionMatrixUniform = gl.getUniformLocation(program, "projectionMatrix");
this.colorUniform = gl.getUniformLocation(program, "color");
}
/**
* Create TriangleProgram. Returns null if creation fails.
* @param gl
*/
static create(gl: WebGLRenderingContext): CubeProgram {
const program = loadProgram(gl, VERTEX_SHADER_SOURCE, FRAGMENT_SHADER_SOURCE);
if (program === null) {
return null;
}
return new CubeProgram(gl, program);
}
}<file_sep>
import {glMatrix, mat4, vec3} from "gl-matrix";
import {loadProgram} from "./utils";
const VERTEX_SHADER_SOURCE = `
attribute vec3 coordinate;
attribute vec3 color;
varying vec3 fragmentColor;
uniform mat4 modelMatrix;
uniform mat4 viewMatrix;
uniform mat4 projectionMatrix;
void main() {
fragmentColor = color;
gl_Position = projectionMatrix * viewMatrix * modelMatrix * vec4(coordinate, 1.0);
}
`;
const FRAGMENT_SHADER_SOURCE = `
precision mediump float;
varying vec3 fragmentColor;
void main() {
gl_FragColor = vec4(fragmentColor, 1.0);
}
`;
const TRIANGLE_VERTICES = [
-1.0, 1.0, 0.0,
1.0, -1.0, 0.0,
-1.0, -1.0, 0.0,
];
const TRIANGLE_VERTEX_COLORS = [
1.0, 0.0, 0.0,
0.0, 1.0, 0.0,
0.0, 0.0, 1.0,
];
export class Triangle {
public modelMatrix: mat4;
constructor() {
this.modelMatrix = mat4.create();
}
}
export class TriangleRenderer {
private triangleVertexAttributeData: WebGLBuffer;
private triangleColorData: WebGLBuffer;
constructor(gl: WebGLRenderingContext, private program: TriangleProgram) {
this.triangleVertexAttributeData = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, this.triangleVertexAttributeData);
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(TRIANGLE_VERTICES), gl.STATIC_DRAW);
this.triangleColorData = gl.createBuffer();
gl.bindBuffer(gl.ARRAY_BUFFER, this.triangleColorData);
gl.bufferData(gl.ARRAY_BUFFER, new Float32Array(TRIANGLE_VERTEX_COLORS), gl.STATIC_DRAW);
}
render(gl: WebGLRenderingContext, triangle: Triangle, viewMatrix: mat4, projectionMatrix: mat4) {
gl.bindBuffer(gl.ARRAY_BUFFER, this.triangleVertexAttributeData);
gl.vertexAttribPointer(this.program.vertexAttribute, 3, gl.FLOAT, false, 0, 0);
gl.enableVertexAttribArray(this.program.vertexAttribute);
gl.bindBuffer(gl.ARRAY_BUFFER, this.triangleColorData);
gl.vertexAttribPointer(this.program.colorAttribute, 3, gl.FLOAT, false, 0, 0);
gl.enableVertexAttribArray(this.program.colorAttribute);
gl.useProgram(this.program.program);
gl.uniformMatrix4fv(this.program.viewMatrixUniform, false, viewMatrix);
gl.uniformMatrix4fv(this.program.modelMatrixUniform, false, triangle.modelMatrix);
gl.uniformMatrix4fv(this.program.projectionMatrixUniform, false, projectionMatrix);
gl.drawArrays(gl.TRIANGLES, 0, 3);
}
}
export class TriangleProgram {
public vertexAttribute: number;
public colorAttribute: number;
public modelMatrixUniform: WebGLUniformLocation;
public viewMatrixUniform: WebGLUniformLocation;
public projectionMatrixUniform: WebGLUniformLocation;
constructor(gl: WebGLRenderingContext, public program: WebGLProgram) {
this.vertexAttribute = gl.getAttribLocation(program, "coordinate");
this.colorAttribute = gl.getAttribLocation(program, "color");
this.modelMatrixUniform = gl.getUniformLocation(program, "modelMatrix");
this.viewMatrixUniform = gl.getUniformLocation(program, "viewMatrix");
this.projectionMatrixUniform = gl.getUniformLocation(program, "projectionMatrix");
}
/**
* Create TriangleProgram. Returns null if creation fails.
* @param gl
*/
static create(gl: WebGLRenderingContext): TriangleProgram {
const program = loadProgram(gl, VERTEX_SHADER_SOURCE, FRAGMENT_SHADER_SOURCE);
if (program === null) {
return null;
}
return new TriangleProgram(gl, program);
}
}<file_sep>#!/bin/python3
import sys
import socket
import time
HID_REPORT_SIZE_BYTES = 8
# Functions
def try_to_connect(socket_object: socket.SocketType, server_address: str, port_number: int) -> bool:
try:
socket_object.connect((server_address, port_number))
except OSError as error:
print("error: " + error.strerror)
return False
return True
def connection_retry_loop(socket_object: socket.SocketType, server_address: str, port_number: int) -> None:
while True:
if try_to_connect(socket_object, server_address, port_number):
print("connected to the server")
break
else:
print("trying to reconnect to the server in 5 seconds")
time.sleep(0.5)
def main() -> None:
if len(sys.argv) <= 2:
print("give server address and server port number as arguments")
exit(-1)
socket_object = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server_address = sys.argv[1]
port_number = int(sys.argv[2])
f = open('heatmap_data.txt', 'w')
try:
print("trying to connect to the server")
connection_retry_loop(socket_object, server_address, port_number)
while True:
data = socket_object.recv(HID_REPORT_SIZE_BYTES)
byte_count = len(data)
# Lets do some error handling.
if byte_count == 0:
print("server disconnected ")
print("trying to reconnect")
socket_object.close()
socket_object = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
connection_retry_loop(
socket_object, server_address, port_number)
elif byte_count != HID_REPORT_SIZE_BYTES:
print("error: USB HID report size " +
str(byte_count) + " bytes is unsupported")
socket_object.close()
exit(-1)
else:
# No errors
if data[0] == 0:
print("data: ", end='')
else:
print("data: {0:0=#10b} ".format(data[0]), end='')
print("| ", end='')
for i in range(2, 8):
if data[i] == 0:
print(" ", end='')
else:
print("{0:0=#4x} ".format(data[i]), end='')
f.write("{0:0=#4x} ".format(data[i]))
print("|")
except OSError as error:
print("error: " + error.strerror)
socket_object.close()
except KeyboardInterrupt:
socket_object.close()
f.close()
# Start main function
if __name__ == "__main__":
main()
<file_sep>
/**
* Creates WebGL program. Returns null if program creation failed.
* @param gl
* @param vertexShaderSource
* @param fragmentShaderSource
*/
export function loadProgram(gl: WebGLRenderingContext, vertexShaderSource: string, fragmentShaderSource: string): WebGLProgram {
const vertexShader = loadShader(gl, gl.VERTEX_SHADER, vertexShaderSource);
if (vertexShader === null) {
return null;
}
const fragmentShader = loadShader(gl, gl.FRAGMENT_SHADER, fragmentShaderSource);
if (fragmentShader === null) {
gl.deleteShader(vertexShader);
return null;
}
const program = gl.createProgram();
gl.attachShader(program, vertexShader);
gl.attachShader(program, fragmentShader);
gl.linkProgram(program);
gl.deleteShader(vertexShader);
gl.deleteShader(fragmentShader);
if (!gl.getProgramParameter(program, gl.LINK_STATUS)) {
const errorMessage = gl.getProgramInfoLog(program);
console.error(`Program linking error: ${errorMessage}`);
gl.deleteProgram(program);
return null;
}
return program;
}
/**
* Creates WebGL shader. Returns null if shader creation failed.
* @param gl
* @param shaderType
* @param sourceCode
*/
export function loadShader(gl: WebGLRenderingContext, shaderType: number, sourceCode: string): WebGLShader {
const shader = gl.createShader(shaderType);
gl.shaderSource(shader, sourceCode);
gl.compileShader(shader);
if (!gl.getShaderParameter(shader, gl.COMPILE_STATUS)) {
const errorMessage = gl.getShaderInfoLog(shader);
console.error(`Shader compile error: ${errorMessage}`);
gl.deleteShader(shader);
return null;
}
return shader;
}
<file_sep>import evdev
class HasKeyboard:
def __init__(self):
print("")
def evaluator():
devices = [evdev.InputDevice(fn) for fn in evdev.list_devices()]
for device in devices:
#capabilityMap = device.capabilities(True, False)
print(device.name + " " + device.fn)
HasKeyboard.evaluator()
class Reader:
def __init__(self, device):
self.device = device
#device = evdev.InputDevice('/dev/input/event3')
#print(device)
def reader(self):
for event in self.device.read_loop():
if event.type == evdev.ecodes.EV_KEY:
print(evdev.categorize(event))
<file_sep># Zero-client
This directory contains
* Bash-shell script that starts Raspberry Pi Zero USB keyboard gadget and zero-client.py
* Script options: `--enable-usb-ethernet-gadget`
* Default server address and port for zero-client.py are `192.168.0.1` and `25001`
* Zero-client Python 3 application that writes USB HID report data from TCP socket to a file at `/dev/hidg0`.
* Server address and port are required arguments.
* If connection to server is lost, Zero-client will try to reconnect at every 5 seconds.
Note that Zero-client is designed to only work on Raspberry Pi Zero or Zero W.
# Setup
1. Configure WLAN, [https://www.raspberrypi.org/documentation/configuration/wireless/wireless-cli.md](https://www.raspberrypi.org/documentation/configuration/wireless/wireless-cli.md), If you run Zero-client on Raspberry Pi Zero there
is no WLAN chip included on the board, so you probably have use Raspberry Pi Zero as USB ethernet gadget to get connection to the server.
2. Copy `zero-client.py`, `copy-usb-hid-description.py`, `start.sh` to the root of the filesystem `/`.
3. Add line `bash -eu /start.sh &` to `rc.local` before `exit` command. This will make
Zero-client to automatically start at boot. See also: [https://www.raspberrypi.org/documentation/linux/usage/rc-local.md](https://www.raspberrypi.org/documentation/linux/usage/rc-local.md)
4. Add line `dtoverlay=dwc2` to end of `/boot/config.txt`.
5. Reboot Raspberry Pi.
6. Connect Raspberry Pi to some computer with USB cable.
<file_sep>
#!/bin/bash -eu
# Bash options:
# "-e" - exit the script if some command fails.
# "-u" - exit the script if uninitialized variable is used.
# TODO: Check that script is running as root.
# Kernel module configuration is based on tutorial in the Linux kernel documentation.
# https://www.kernel.org/doc/Documentation/usb/gadget_configfs.txt
cd /
export CONFIGFS_HOME="/configfs_dir"
if [[ ! -d "$CONFIGFS_HOME" ]] ; then
mkdir "$CONFIGFS_HOME"
fi
modprobe libcomposite
mount none $CONFIGFS_HOME -t configfs
mkdir $CONFIGFS_HOME/usb_gadget/g1
cd $CONFIGFS_HOME/usb_gadget/g1
echo 0x5 > idVendor
echo 0x5 > idProduct
mkdir strings/0x409
echo 12345 > strings/0x409/serialnumber
echo "some_manufacturer" > strings/0x409/manufacturer
echo "USB multi-device" > strings/0x409/product
# Create configuration
mkdir configs/c.1
mkdir configs/c.1/strings/0x409
echo test_configuration > configs/c.1/strings/0x409/configuration
# Setup hid usb function, with keyboard settings
mkdir functions/hid.usb0
# report_lenght depends from USB HID Description
echo 8 > functions/hid.usb0/report_length
echo 1 > functions/hid.usb0/protocol
echo 0 > functions/hid.usb0/subclass
cd functions/hid.usb0
# TODO: Copy hid description bytes from this script or set python script
# file path to variable.
python3 /copy-usb-hid-description.py
cd ../..
ln -s functions/hid.usb0 configs/c.1
if [[ "$#" = "1" && "$1" = "--enable-usb-ethernet-gadget" ]] ; then
# Setup ethernet usb function
mkdir functions/ecm.usb0
# Set MAC addresses because otherwise they would be random
echo 16:c4:b2:24:c0:03 > functions/ecm.usb0/dev_addr
echo fa:4d:9e:fa:5a:d6 > functions/ecm.usb0/host_addr
ln -s functions/ecm.usb0 configs/c.1
fi
# Start usb gadget mode
echo 20980000.usb > UDC
# Start Raspberry Pi Zero keyboard client.
cd /
python3 zero-client.py "192.168.0.1" "25001"<file_sep>from http.server import HTTPServer, BaseHTTPRequestHandler
from queue import Queue, Empty
from threading import Thread, Event
import json
import os
import copy
# Import Tuple type which is used in optional function type annotations.
from typing import Tuple
import keyprofile
class WebServerManager():
"""Creates new web server thread."""
def __init__(self):
self.exit_event = Event()
web_server_settings = ("", 8080)
self.settings_queue = Queue()
self.heatmap_queue = Queue()
self.current_profile_queue = Queue()
self.web_server_thread = Thread(group=None, target=WebServer, args=(
web_server_settings, self.settings_queue, self.heatmap_queue, self.current_profile_queue, self.exit_event))
self.web_server_thread.start()
def close(self):
"""Close web server. This method will block until web server is closed."""
self.exit_event.set()
self.web_server_thread.join()
def get_settings_queue(self) -> Queue:
return self.settings_queue
def get_heatmap_queue(self) -> Queue:
return self.heatmap_queue
def get_profile_queue(self) -> Queue:
return self.current_profile_queue
class Heatmap:
def __init__(self):
self.heatmap_data = {}
self.tempHeatmap_data = {}
def add_keypress(self, evdev_id: int) -> None:
key = str(evdev_id)
try:
self.heatmap_data[key] = self.heatmap_data[key] + 1
except KeyError:
self.heatmap_data[key] = 1
try:
self.tempHeatmap_data[key] = self.tempHeatmap_data[key] + 1
except KeyError:
self.tempHeatmap_data[key] = 1
def get_heatmap_data(self):
return self.heatmap_data
def json_string(self) -> str:
return json.dumps(self.heatmap_data)
def set_heatmap_data(self, heatmap_data) -> None:
self.heatmap_data = heatmap_data
def get_tempHeatmap_data(self):
return self.tempHeatmap_data
def json_tempString(self) -> str:
return json.dumps(self.tempHeatmap_data)
def set_tempHeatmap_data(self, tempHeatmap_data) -> None:
self.tempHeatmap_data = tempHeatmap_data
def reset_tempHeatmap_data(self) -> None:
self.tempHeatmap_data = {}
HEATMAP_FILE_NAME = 'heatmap_stats.txt'
#TEMPHEATMAT_FILE_NAME = 'temp_heatmap_stats.txt'
PROFILE_DATA_FILE_NAME = 'data.txt'
CURRENT_PROFILE_FILE_NAME = 'curprofile.txt'
# Class WebServer inherits HTTPServer class which is from Python standard library.
# https://docs.python.org/3/library/http.server.html
# Also, note that HTTPServer inherits TCPServer.
# https://docs.python.org/3/library/socketserver.html#socketserver.TCPServer
class WebServer(HTTPServer):
# Type annotations of this constructor are optional.
def __init__(self, address_and_port: Tuple[str, int], settings_queue: Queue, heatmap_queue: Queue, current_profile_queue: Queue, exit_event: Event) -> None:
# Run constructor from HTTPServer first. Note the RequestHandler class.
super().__init__(address_and_port, RequestHandler)
# Some object attributes specific to this class. You can modify
# them from RequestHandler's methods.
self.settings_queue = settings_queue
self.current_profile_queue = current_profile_queue
# Check exit event every 0.5 seconds if there is no new TCP
# connections.
self.timeout = 0.5
# Initialize profiles
self.settings = [{}]
if os.path.exists(PROFILE_DATA_FILE_NAME):
with open(PROFILE_DATA_FILE_NAME, 'r') as profiles_file:
file_contents = profiles_file.read()
self.settings = json.loads(file_contents)
self.current_profile = 1
if os.path.exists(CURRENT_PROFILE_FILE_NAME):
with open(CURRENT_PROFILE_FILE_NAME, 'r') as curprofile_file:
file_contents = curprofile_file.read()
self.current_profile = json.loads(file_contents)
# Initialize heatmap
self.heatmap = Heatmap()
if os.path.exists(HEATMAP_FILE_NAME):
with open(HEATMAP_FILE_NAME, 'r') as heatmap_file:
file_contents = heatmap_file.read()
heatmap_data = json.loads(file_contents)
self.heatmap.set_heatmap_data(heatmap_data)
# Main thread is waiting for profiles/settings so lets send them.
parse_mappedEvdevID_and_send_settings(
self.settings, self.settings_queue)
set_current_profile(self.current_profile, self.current_profile_queue)
print("web server running")
while True:
# This method will timeout because exit_event must be checked enough often
# to shutdown cleanly.
self.handle_request()
if exit_event.is_set():
# There was exit event, lets close the web server.
break
try:
while True:
evdev_id = heatmap_queue.get(block=False)
self.heatmap.add_keypress(evdev_id)
except Empty:
pass
try:
while True:
self.current_profile = current_profile_queue.get(block=False)
print("kissa istuu puussa " + str(self.current_profile))
except Empty:
pass
self.server_close()
# Save profiles/settings.
with open(PROFILE_DATA_FILE_NAME, 'w') as outfile:
json.dump(self.settings, outfile)
# Save heatmap.
with open(HEATMAP_FILE_NAME, 'w') as outfile:
outfile.write(self.heatmap.json_string())
# Save information about current profile.
with open(CURRENT_PROFILE_FILE_NAME, 'w') as outfile:
json.dump(self.current_profile, outfile)
print("web server exited")
# Python standard library HTTPServer works with request handler system, so lets
# make our own request handler.
class RequestHandler(BaseHTTPRequestHandler):
# By default the HTTP version is 1.0.
def do_GET(self) -> None:
"""Handler for HTTP GET requests."""
# Print some information about the HTTP request.
# print("HTTP GET Request, path: " + self.path)
# print("client_address: " + str(self.client_address))
# print("request_version: " + self.request_version)
# print("headers: " + str(self.headers))
# get key-binding settings in json form
if self.path == "/json.api":
message = json.dumps(self.server.settings)
message_bytes = message.encode()
self.send_utf8_bytes(message_bytes, "text/json")
# get heatmap statistics in json form
elif self.path == "/heatmap.api":
text = self.server.heatmap.json_string()
message_bytes = text.encode()
self.send_utf8_bytes(message_bytes, "text/json")
elif self.path == "/resetHeatmap.api":
self.server.heatmap.reset_tempHeatmap_data()
text = self.server.heatmap.json_tempString()
message_bytes = text.encode()
self.send_utf8_bytes(message_bytes, "text/json")
elif self.path == "/tempHeatmap.api":
text = self.server.heatmap.json_tempString()
message_bytes = text.encode()
self.send_utf8_bytes(message_bytes, "text/json")
elif self.path == "/curprofile.api":
text = str(self.server.current_profile)
message_bytes = text.encode()
self.send_utf8_bytes(message_bytes, "text/json")
elif self.path == "/":
self.send_utf8_file("../frontend/control.html", "text/html")
elif self.path == "/webgl-keyboard":
self.send_utf8_file(
"../webgl-keyboard/dist/index.html", "text/html")
elif self.path == "/styles.css":
self.send_utf8_file("../frontend/styles.css", "text/css")
elif self.path == "/script.js":
self.send_utf8_file("../frontend/script.js",
"application/javascript")
elif self.path == "/bundle.js":
self.send_utf8_file(
"../webgl-keyboard/dist/bundle.js", "application/javascript")
else:
message_bytes = b"<html><body><h1>Hello world</h1></body></html>"
self.send_utf8_bytes(message_bytes, "text/html")
def do_POST(self) -> None:
"""Handler for HTTP POST requests."""
# print("HTTP POST Request, path: " + self.path)
# print("client_address: " + str(self.client_address))
# print("request_version: " + self.request_version)
# print("headers: " + str(self.headers))
content_length = self.headers.get("Content-Length", 0)
response = self.rfile.read(int(content_length))
self.server.settings = json.loads(response.decode("utf-8"))
parse_mappedEvdevID_and_send_settings(
self.server.settings, self.server.settings_queue)
print("abcdefghijklmn")
# # prepare the loaded settings data for usage with hid data.
#
# print(self.server.settings)
# for profile in self.server.settings:
# # try:
# for key in profile["keyData"]:
# list_of_hid_reports = [] # type: List[List[int]]
# single_hid = [] # type: List[int]
# if "mappedEvdevID" in profile["keyData"][key]:
# key_reports_strings = profile["keyData"][key][
# "mappedEvdevID"].split("|")
# for i in key_reports_strings:
# single_hid = [int(x) for x in i.split(":")]
# list_of_hid_reports.append(single_hid)
# profile["keyData"][key]["mappedEvdevID"] = list_of_hid_reports
# # if "profile" in key:
# # except KeyError as error:
# print(self.server.settings)
#
# # Send new settings to main thread.
# self.server.settings_queue.put_nowait(self.server.settings)
self.send_response(200)
self.end_headers()
def send_utf8_file(self, file_name: str, mime_type: str) -> None:
"""Mime type is string like 'text/json'"""
file = open(file_name, mode='rb')
file_as_bytes = file.read()
file.close()
self.send_utf8_bytes(file_as_bytes, mime_type)
def send_utf8_bytes(self, message_bytes: bytes, mime_type: str) -> None:
"""Mime type is string like 'text/json'"""
# 200 is HTTP status code for successfull request.
self.send_response(200)
self.send_header("Content-Encoding", "UTF-8")
self.send_header("Content-Type", mime_type + "; charset=utf-8")
self.end_headers()
# Write HTTP message body which is the HTML web page.
self.wfile.write(message_bytes)
self.wfile.flush()
def set_current_profile(current_profile, current_profile_queue):
current_profile_queue.put_nowait(current_profile)
def parse_mappedEvdevID_and_send_settings(profile_list, settings_queue):
"""
Parse key "mappedEvdevID" value "1:2:3|4:5:6" to
[[1,2,3], [4,5,6]]
"""
# Server must have original settings because it saves
# the settings to a file, so lets make a copy
new_settings = copy.deepcopy(profile_list)
for profile in new_settings:
if "keyData" not in profile:
continue
for evdev_id_key in profile["keyData"]:
key_object = profile["keyData"][evdev_id_key]
if "mappedEvdevID" not in key_object:
continue
hid_report_list = []
hid_report_list_string = key_object["mappedEvdevID"]
if hid_report_list_string == "undefined":
key_object["mappedEvdevID"] = hid_report_list
continue
delay_list = []
for key_string in hid_report_list_string.split("|"):
if key_string[:1] == "$":
if len(key_string) > 1:
delay_number_string = key_string[1:]
delay_number = float(delay_number_string)
delay_list.pop()
delay_list.append(delay_number)
continue
evdev_id_list = [int(x) for x in key_string.split(":")]
hid_report_list.append(evdev_id_list)
delay_list.append(0.1)
key_object["mappedEvdevID"] = hid_report_list
key_object["delay_list"] = delay_list
# Send new settings to main thread.
settings_queue.put_nowait(new_settings)
<file_sep>from evdev import ecodes
import evdev
# http://www.usb.org/developers/hidpage/Hut1_12v2.pdf
# See chapter 10 for keycodes.
EVDEV_TO_HID_MAP = {
ecodes.KEY_A: 0x04,
ecodes.KEY_B: 0x05,
ecodes.KEY_C: 0x06,
ecodes.KEY_D: 0x07,
ecodes.KEY_E: 0x08,
ecodes.KEY_F: 0x09,
ecodes.KEY_G: 0x0A,
ecodes.KEY_H: 0x0B,
ecodes.KEY_I: 0x0C,
ecodes.KEY_J: 0x0D,
ecodes.KEY_K: 0x0E,
ecodes.KEY_L: 0x0F,
ecodes.KEY_M: 0x10,
ecodes.KEY_N: 0x11,
ecodes.KEY_O: 0x12,
ecodes.KEY_P: 0x13,
ecodes.KEY_Q: 0x14,
ecodes.KEY_R: 0x15,
ecodes.KEY_S: 0x16,
ecodes.KEY_T: 0x17,
ecodes.KEY_U: 0x18,
ecodes.KEY_V: 0x19,
ecodes.KEY_W: 0x1A,
ecodes.KEY_X: 0x1B,
ecodes.KEY_Y: 0x1C,
ecodes.KEY_Z: 0x1D,
ecodes.KEY_1: 0x1E,
ecodes.KEY_2: 0x1F,
ecodes.KEY_3: 0x20,
ecodes.KEY_4: 0x21,
ecodes.KEY_5: 0x22,
ecodes.KEY_6: 0x23,
ecodes.KEY_7: 0x24,
ecodes.KEY_8: 0x25,
ecodes.KEY_9: 0x26,
ecodes.KEY_0: 0x27,
ecodes.KEY_ENTER: 0x28,
ecodes.KEY_ESC: 0x29,
ecodes.KEY_BACKSPACE: 0x2A,
ecodes.KEY_TAB: 0x2B,
ecodes.KEY_SPACE: 0x2C,
ecodes.KEY_MINUS: 0x2D,
ecodes.KEY_EQUAL: 0x2E,
ecodes.KEY_LEFTBRACE: 0x2F,
ecodes.KEY_RIGHTBRACE: 0x30,
ecodes.KEY_BACKSLASH: 0x31,
# Some key here, internet said it would be "HAS<PASSWORD>", but didn't find it from ecodes.
ecodes.KEY_SEMICOLON: 0x33,
ecodes.KEY_APOSTROPHE: 0x34,
ecodes.KEY_GRAVE: 0x35,
ecodes.KEY_COMMA: 0x36,
ecodes.KEY_DOT: 0x37,
ecodes.KEY_SLASH: 0x38,
ecodes.KEY_CAPSLOCK: 0x39,
ecodes.KEY_F1: 0x3A,
ecodes.KEY_F2: 0x3B,
ecodes.KEY_F3: 0x3C,
ecodes.KEY_F4: 0x3D,
ecodes.KEY_F5: 0x3E,
ecodes.KEY_F6: 0x3F,
ecodes.KEY_F7: 0x40,
ecodes.KEY_F8: 0x41,
ecodes.KEY_F9: 0x42,
ecodes.KEY_F10: 0x43,
ecodes.KEY_F11: 0x44,
ecodes.KEY_F12: 0x45,
ecodes.KEY_PRINT: 0x46,
ecodes.KEY_SCROLLLOCK: 0x47,
ecodes.KEY_PAUSE: 0x48,
ecodes.KEY_INSERT: 0x49,
ecodes.KEY_HOME: 0x4A,
ecodes.KEY_PAGEUP: 0x4B,
ecodes.KEY_DELETE: 0x4C,
ecodes.KEY_END: 0x4D,
ecodes.KEY_PAGEDOWN: 0x4E,
ecodes.KEY_RIGHT: 0x4F,
ecodes.KEY_LEFT: 0x50,
ecodes.KEY_DOWN: 0x51,
ecodes.KEY_UP: 0x52,
ecodes.KEY_NUMLOCK: 0x53,
ecodes.KEY_KPSLASH: 0x54,
ecodes.KEY_KPASTERISK: 0x55,
ecodes.KEY_KPMINUS: 0x56,
ecodes.KEY_KPPLUS: 0x57,
ecodes.KEY_KPENTER: 0x58,
ecodes.KEY_KP1: 0x59,
ecodes.KEY_KP2: 0x5A,
ecodes.KEY_KP3: 0x5B,
ecodes.KEY_KP4: 0x5C,
ecodes.KEY_KP5: 0x5D,
ecodes.KEY_KP6: 0x5E,
ecodes.KEY_KP7: 0x5F,
ecodes.KEY_KP8: 0x60,
ecodes.KEY_KP9: 0x61,
ecodes.KEY_KP0: 0x62,
ecodes.KEY_KPDOT: 0x63,
ecodes.KEY_102ND: 0x64,
ecodes.KEY_COMPOSE: 0x65,
ecodes.KEY_POWER: 0x66,
ecodes.KEY_KPEQUAL: 0x67,
ecodes.KEY_LEFTCTRL: 0xE0,
ecodes.KEY_LEFTSHIFT: 0xE1,
ecodes.KEY_LEFTALT: 0xE2,
ecodes.KEY_LEFTMETA: 0xE3,
ecodes.KEY_RIGHTCTRL: 0xE4,
ecodes.KEY_RIGHTSHIFT: 0xE5,
ecodes.KEY_RIGHTALT: 0xE6,
ecodes.KEY_RIGHTMETA: 0xE7
# TODO find out how to refer to the rest of the keys
}
MODIFIER_KEY_BITMASKS = {
ecodes.KEY_LEFTCTRL: 0b00000001,
ecodes.KEY_LEFTSHIFT: 0b00000010,
ecodes.KEY_LEFTALT: 0b00000100,
ecodes.KEY_LEFTMETA: 0b00001000,
ecodes.KEY_RIGHTCTRL: 0b00010000,
ecodes.KEY_RIGHTSHIFT: 0b00100000,
ecodes.KEY_RIGHTALT: 0b01000000,
ecodes.KEY_RIGHTMETA: 0b10000000,
}
class HidReport:
"""
Convert evdev keyboard key ids to USB HID keyboard report.
Attribute `self.report` contains USB HID keyboard report data.
Run method `update_report()` before accessing HID report data
to make sure that HID report data is up to date.
"""
def __init__(self) -> None:
self.clear()
def clear(self) -> None:
"""Clears all keys from HID report."""
self.keycodes = {}
self.report = bytearray(8)
self.report_update = False
def add_key(self, evdev_key: int) -> None:
"""
Add evdev key to HID report.
"""
try:
bitmask = MODIFIER_KEY_BITMASKS[evdev_key]
self.report[0] = self.report[0] | bitmask
self.report_update = True
return
except KeyError:
pass
if len(self.keycodes) >= 6:
return
try:
self.keycodes[evdev_key] = EVDEV_TO_HID_MAP[evdev_key]
self.report_update = True
except KeyError:
print("unknown key: " + str(evdev_key))
def remove_key(self, evdev_key: int) -> None:
"""
Remove evdev key from HID report.
"""
try:
bitmask = MODIFIER_KEY_BITMASKS[evdev_key]
self.report[0] = self.report[0] & (~bitmask)
self.report_update = True
return
except KeyError:
pass
try:
del self.keycodes[evdev_key]
self.report_update = True
except KeyError:
print("unknown key: " + str(evdev_key))
def update_report(self) -> bool:
"""
Update HID report data buffer if some keys were added or removed earlier.
Returns True if buffer was updated.
"""
if not self.report_update:
return False
else:
self.report_update = False
# Update hid report keycodes.
i = 2
for _, item in self.keycodes.items():
self.report[i] = item
i += 1
# Set rest of the hid report keycodes to zero.
for j in range(i, 8):
self.report[j] = 0x00
return True
<file_sep># Test-client
Prints USB HID reports sent by the server to the console.
# Running
```
python3 test-client.py server_address server_port_number
```<file_sep># WebGL keyboard
WebGL 3D-keyboard prototype for displaying keyboard heatmaps.
Programmed with TypeScript. Uses glMath matrix and vector library.
This project uses [webpack](https://webpack.js.org/) as building
system.
Building tested with Node.js 8.
# Building and running
1. Install Node.js. To get latest Node.js
LTS version easily on Linux
install Node.js with [nvm (Node Version Manager)](https://github.com/creationix/nvm).
2. Install project dependencies with `npm install`.
3. Build project with `npm run build`. npm will download required
dependencies automatically.
4. Open `dist/index.html` in your web browser.
# Development
You can start webpack development web server with `npm run start`.<file_sep>import { Cube } from "./cube";
import { Triangle } from "./triangle";
import { mat4, vec3 } from "gl-matrix";
const DEFAULT_KEY_SCALE = 0.10;
class Key {
public cube: Cube;
constructor(x: number, z: number, xScale: number, zScale: number) {
this.cube = new Cube();
mat4.fromScaling(this.cube.modelMatrix, [xScale, DEFAULT_KEY_SCALE, zScale]);
mat4.translate(this.cube.modelMatrix, this.cube.modelMatrix, [x, 5.0, z]);
}
setColor(r: number, b: number, g: number) {
vec3.set(this.cube.topFaceColor, r, g, b);
}
static transformAndScaleX(x: number, z: number, xScale: number): Key {
return new Key(x, z, xScale, DEFAULT_KEY_SCALE);
}
static transform(x: number, z: number): Key {
return new Key(x, z, DEFAULT_KEY_SCALE, DEFAULT_KEY_SCALE);
}
}
const END_COLOR = [1.0, 0.0, 0.0];
const START_COLOR = [0.0, 1.0, 0.0];
export class Keyboard {
public cube: Cube;
public triangle: Triangle;
public keyboardCase: Cube;
public keys: Map<number, Key>;
constructor() {
this.cube = new Cube();
mat4.fromTranslation(this.cube.modelMatrix, [2,0,-10]);
this.triangle = new Triangle();
mat4.fromTranslation(this.triangle.modelMatrix, [0,0,-10])
this.keyboardCase = new Cube();
mat4.fromScaling(this.keyboardCase.modelMatrix, [4, 0.20, 2]);
vec3.set(this.keyboardCase.topFaceColor, 0, 0.2, 0.5);
this.keys = new Map();
// Id values match Linux kernel input event codes, from file input-event-codes.h
// Escape
this.generateKeyRow(1, 1, -34, -10);
this.generateKeyRow(2, 13, -31, -4);
this.generateKeyRow(16, 27, -29, 0);
this.generateKeyRow(30, 41, -27, 4);
this.generateKeyRow(43, 53, -28, 8);
// Function keys
this.generateKeyRow(59, 62, -28, -10);
this.generateKeyRow(63, 66, -15, -10);
this.generateKeyRow(67, 70, -2, -10);
// Left shift
this.generateKeyRowWithKeyScaling(42,42, -27, 8, 0.115, 0);
// Left alt
this.generateKeyRowWithKeyScaling(56,56, -19, 12, 0.115, 0);
// Space
this.generateKeyRowWithKeyScaling(57,57, -1.6, 12, 0.75, 0);
}
private generateKeyRow(idFrom: number, idTo: number, startX: number, startZ: number) {
for (let i = idFrom, x = startX; i <= idTo; i++, x += 3) {
const key = Key.transform(x, startZ);
this.keys.set(i, key);
}
}
private generateKeyRowWithKeyScaling(idFrom: number, idTo: number, startX: number, startZ: number, xScale: number, xStep: number) {
for (let i = idFrom, x = startX; i <= idTo; i++, x += xStep) {
const key = Key.transformAndScaleX(x, startZ, xScale);
this.keys.set(i, key);
}
}
updateHeatmap(heatmap: any) {
for (const [keyId, key] of this.keys) {
const keypressCount = heatmap[keyId];
if (keypressCount >= 1) {
const value = Math.min(15, keypressCount - 1) / 15;
const color1 = vec3.create();
const color2 = vec3.create();
vec3.scale(color1, END_COLOR, value);
vec3.scale(color2, START_COLOR, 1.0 - value);
vec3.add(color1, color1, color2);
key.setColor(color1[0], color1[1], color1[2]);
}
}
}
}<file_sep>
import {glMatrix, mat4, vec3} from "gl-matrix";
import {TriangleRenderer, TriangleProgram} from "./triangle"
import {CubeProgram, CubeRenderer} from "./cube"
import {Keyboard} from "./keyboard";
export class Renderer {
private projectionMatrix: mat4;
private viewMatrix: mat4;
private triangleRenderer: TriangleRenderer;
private cubeRenderer: CubeRenderer;
constructor(private gl: WebGLRenderingContext, triangleProgram: TriangleProgram, cubeProgram: CubeProgram) {
this.projectionMatrix = mat4.create();
mat4.perspective(this.projectionMatrix, 45 * Math.PI / 180, gl.canvas.width/gl.canvas.height, 0.1, 100);
this.viewMatrix = mat4.create();
mat4.lookAt(this.viewMatrix, [0,5,5], [0,0,0], [0,1,0]);
this.triangleRenderer = new TriangleRenderer(gl, triangleProgram);
this.cubeRenderer = new CubeRenderer(gl, cubeProgram);
gl.clearColor(0, 0, 0, 1);
gl.enable(gl.DEPTH_TEST);
}
/**
* Create WebGL renderer. Returns null if creation failed.
* @param gl
*/
static create(gl: WebGLRenderingContext): Renderer {
const triangleProgram = TriangleProgram.create(gl);
if (triangleProgram === null) {
return null;
}
const cubeProgram = CubeProgram.create(gl);
if (cubeProgram === null) {
return null;
}
return new Renderer(gl, triangleProgram, cubeProgram);
}
draw(keyboard: Keyboard) {
const gl = this.gl;
gl.clear(gl.COLOR_BUFFER_BIT | gl.DEPTH_BUFFER_BIT);
this.cubeRenderer.render(gl, keyboard.cube, this.viewMatrix, this.projectionMatrix);
this.triangleRenderer.render(gl, keyboard.triangle, this.viewMatrix, this.projectionMatrix);
this.cubeRenderer.render(gl, keyboard.keyboardCase, this.viewMatrix, this.projectionMatrix);
for (let x of keyboard.keys) {
this.cubeRenderer.render(gl, x[1].cube, this.viewMatrix, this.projectionMatrix);
}
}
}<file_sep>#!/bin/python3
from queue import Queue, Empty
from threading import Thread, Event
from collections import OrderedDict
import socket
import time
from typing import List
import sys
import pyudev
import evdev
from evdev import ecodes
from web_server import WebServerManager
from hid_report import HidReport
class HidDataSocket():
"""
TCP Socket for sending USB HID report data.
Call `create_socket()` method before using other methods.
"""
def __init__(self) -> None:
self.server_socket = None # type: socket.SocketType
self.connection_socket = None # type: socket.SocketType
self.address = None
def create_socket(self) -> bool:
"""Returns False if there is socket creation error."""
try:
self.server_socket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
self.server_socket.setsockopt(
socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.server_socket.bind(("", 25001))
self.server_socket.listen(0)
return True
except OSError as error:
print("error: " + error.strerror)
return False
def close(self) -> None:
"""Close all sockets."""
if self.connection_socket is not None:
self.connection_socket.close()
if self.server_socket is not None:
self.server_socket.close()
def wait_connection(self) -> None:
"""Close previous connection to client if it exists and wait for new connection."""
if self.connection_socket is not None:
self.connection_socket.close()
print("waiting for client")
(self.connection_socket, self.address) = self.server_socket.accept()
print("client from " + str(self.address) + " connected")
def send_hid_report_if_there_is_new_changes(self, hid_report: HidReport) -> bool:
"""Returns False if client disconnected."""
if not hid_report.update_report():
return True
try:
self.connection_socket.sendall(hid_report.report)
return True
except OSError as error:
print("error: " + error.strerror)
print("client " + str(self.address) + " disconnected")
return False
class KeyboardManager:
"""Read input from all availlable keyboards.
Starts a new thread to monitor device events from Linux udev system.
This allows adding and removing keyboards at runtime without constantly
polling udev for new device events.
Call `close()` to close device monitoring thread.
"""
def __init__(self) -> None:
self.context = pyudev.Context()
self.device_list = [] # type: List[evdev.InputDevice]
for keyboard in self.context.list_devices(subsystem="input", ID_INPUT_KEYBOARD=1):
if keyboard.device_node != None:
keyboard = evdev.InputDevice(keyboard.device_node)
print("Keyboard '" + keyboard.name + "' added")
if len(sys.argv) > 1 and sys.argv[1] == "--grab-keyboards":
try:
keyboard.grab()
except IOError:
print("cant't grab keyboard " + keyboard.name)
self.device_list.append(keyboard)
monitor = pyudev.Monitor.from_netlink(self.context)
monitor.filter_by("input")
self.exit_event = Event()
self.event_queue = Queue() # type: Queue
self.device_monitor_thread = Thread(
group=None, target=monitor_device_events, args=(self.exit_event, self.event_queue, monitor))
self.device_monitor_thread.start()
self.key_event_buffer = [] # type: List[evdev.InputEvent]
self.clear_keys = False
def close(self) -> None:
"""Send exit event to device monitoring thread. Waits until thread is closed."""
for keyboard in self.device_list:
try:
keyboard.ungrab()
except IOError:
pass
self.exit_event.set()
self.device_monitor_thread.join()
def get_key_events(self) -> List[evdev.InputEvent]:
"""
Returns list of evdev keyboard events from all currently connected keyboards.
If clearing current key events is requested, returns empty list.
"""
self.key_event_buffer.clear()
for keyboard in self.device_list:
while True:
try:
evdev_event = keyboard.read_one()
if evdev_event is None:
break
elif evdev_event.type == ecodes.EV_KEY and not self.clear_keys:
self.key_event_buffer.append(evdev_event)
except OSError:
break
self.clear_keys = False
return self.key_event_buffer
def request_clear_key_events(self) -> None:
"""
Request clearing key event buffers. Clearing key events will
happen at next `get_key_events()` method call.
"""
self.clear_keys = True
def check_device_events(self) -> None:
"""
Check if there new device events from device monitoring thread.
Updates keyboard list if there is new events.
"""
while True:
try:
(event, device_node) = self.event_queue.get(block=False)
if event == KEYBOARD_ADDED:
keyboard = evdev.InputDevice(device_node)
print("Keyboard '" + keyboard.name + "' added")
self.device_list.append(keyboard)
elif event == KEYBOARD_REMOVED:
removed_device = None
for evdev_device in self.device_list:
if evdev_device.fn == device_node:
removed_device = evdev_device
break
if removed_device != None:
print("Keyboard '" + removed_device.name + "' removed")
self.device_list.remove(removed_device)
removed_device.close()
except Empty:
break
def mapProfiles(settings):
"""Profile ID mapped to index in the list in an OrderedDict"""
profileMap = OrderedDict()
i = 0
print(settings)
while i < len(settings):
if "profileID" in settings[i]:
index = settings[i]["profileID"]
profileMap[index] = i
i = i + 1
return profileMap
def cutfrom(key: int, elements: OrderedDict):
"""Expects that the key is in the elements list and
remove all elements after and including that position."""
while (key in elements):
print(key)
elements.popitem(last=True)
class KeyRemapper:
"""Map one key to multiple keys."""
def __init__(self, settings) -> None:
"""Argument `settings` is profile JSON dictionary."""
if not ("keyData" in settings[0]):
settings = [{"keyData": {}}]
self.settings = settings
self.profileMap = mapProfiles(
self.settings) # Profile ID mapped to index in the list
# current_profile[0] = evdevId that was used to choose this profile if exists
# current_profile[1]= list location of the profile in settings
self.current_profile = (
-1, 0)
self.old_profiles = OrderedDict([self.current_profile])
self.forget = []
# New settings retunrs the first mod
def set_new_settings(self, settings, web_server_manager) -> None:
"""Argument `settings` is profile JSON dictionary."""
if not ("keyData" in settings[0]):
settings = [{'keyData': {}}]
self.settings = settings
self.profileMap = mapProfiles(
self.settings) # Profile ID mapped to index in the list
first = self.profileMap.popitem(last=False)
print("profileMap and first index(ID) from there => " +
str(self.profileMap) + str(first))
self.profileMap[first[0]] = first[1]
# current_profile[0] = evdevId that was used to choose this profile if exists
# current_profile[1]= list location of the profile in settings
self.current_profile = (
-1, 0) # TODO send current mode for the front end.
self.old_profiles = OrderedDict([self.current_profile])
web_server_manager.get_profile_queue().put_nowait(
[first[0]])
print("Lähetettiin seuraava profiili:")
print(self.current_profile[1])
self.forget = []
def remap_key(self, key_event, web_server_manager) -> List[List[int]]:
"""
REMAPS one key to multiple keys.
also specialized in handling the profile changes.
Key id values are evdev id numbers.
Returns a Tuple(List[List[int]], Bool)
containing the output evdevID inside a list structure(List[List[int]]) and
Bool wether to tell to remove all keys marked as pressed effectively rising them.
"""
evdevId = key_event.code
empty_nothing = []
empty_key = []
empty_key.append(empty_nothing) # type: List[List[int]]
# ----------------------------key up
if key_event.value == 0:
# key is lifted up so it nolonger needs to be inored
if evdevId in self.forget:
self.forget.remove(evdevId)
return (empty_key, False)
# return from swapped profiles
if evdevId in self.old_profiles:
print("returned from a mode")
cutfrom(evdevId, self.old_profiles)
self.current_profile = self.old_profiles.popitem(
last=True) # TODO send current mode for the front end. Maybe unnecessary if.
if "profileID" in self.settings[self.current_profile[1]]:
profileID = self.settings[self.current_profile[1]
]["profileID"]
web_server_manager.get_profile_queue().put_nowait(profileID)
self.old_profiles[
self.current_profile[0]] = self.current_profile[1]
return (empty_key, True)
# Do we actually have settings for this button
if str(evdevId) in self.settings[self.current_profile[1]]["keyData"]:
# the current "action" or "setting"
keyMapping = self.settings[
self.current_profile[1]]["keyData"][str(evdevId)]
if "mappedEvdevID" in keyMapping:
return (keyMapping["mappedEvdevID"], False)
key = [evdevId]
mapped_key = []
mapped_key.append(key) # type: List[List[int]]
return (mapped_key, False)
# -----------------------key down
elif key_event.value == 1:
# Ignore old down pressed profile switch buttons
if evdevId in self.old_profiles:
return (empty_key, False)
# Ignore keys set to forget. Necessary in context of toggle switch
# hotkey combinations.
if evdevId in self.forget:
return (empty_key, False)
# Do we actually have settings for this button
# self.current_profile[0] => evdevID self.current_profile[1] => indeksi
# self.current_profile[1] => profiili ID ?
print("kissa ei ole puussa" + str(self.current_profile))
if str(evdevId) in self.settings[self.current_profile[1]]["keyData"]:
# the current "action" or "setting"
keyMapping = self.settings[
self.current_profile[1]]["keyData"][str(evdevId)]
if "profiles" in keyMapping:
# if evdevId not in self.old_profiles:
# Toggle to different profile
if keyMapping["toggle"]:
for button in self.old_profiles:
if not button == -1:
self.forget.append(button)
self.current_profile = (
-1, self.profileMap[keyMapping["profiles"][0]])
# TODO send current mode for the front end. if Might not be needed.
if "profileID" in self.settings[self.current_profile[1]]:
profileID = self.settings[self.current_profile[1]
]["profileID"]
web_server_manager.get_profile_queue().put_nowait(profileID)
print(self.current_profile)
self.old_profiles = OrderedDict([self.current_profile])
return (empty_key, True)
# Temporary switch while button pressed
self.current_profile = (
evdevId, self.profileMap[keyMapping["profiles"][0]])
# TODO send current mode for the front end.
if "profileID" in self.settings[self.current_profile[1]]:
profileID = self.settings[self.current_profile[1]
]["profileID"]
web_server_manager.get_profile_queue().put_nowait(profileID)
web_server_manager.get_profile_queue().put_nowait(
self.current_profile[1])
self.old_profiles[
self.current_profile[0]] = self.current_profile[1]
print(self.old_profiles)
return (empty_key, True)
if "mappedEvdevID" in keyMapping:
return (keyMapping["mappedEvdevID"], False)
print(key_event.value)
key = []
key.append(evdevId)
mapped_key = []
mapped_key.append(key) # type: List[List[int]]
return(mapped_key, False)
def remap_key_delays_list(self, evdevID):
delayList = []
print(evdevID)
if str(evdevID) in self.settings[self.current_profile[1]]["keyData"]:
print(self.settings[self.current_profile[1]]["keyData"])
if "delay_list" in self.settings[self.current_profile[1]]["keyData"][str(evdevID)]:
print(self.settings[self.current_profile[1]]
["keyData"][str(evdevID)])
delayList = self.settings[self.current_profile[1]
]["keyData"][str(evdevID)]["delay_list"]
print(delayList)
return delayList
KEYBOARD_ADDED = 0
KEYBOARD_REMOVED = 1
def monitor_device_events(exit_event: Event, event_queue: Queue, monitor: pyudev.Monitor):
"""
A new thread should be created to run this function.
"""
while True:
device = monitor.poll(timeout=0.5)
if device != None:
if not ('ID_INPUT_KEYBOARD' in device.properties and device.device_node != None):
continue
if device.action == "add":
event_queue.put_nowait((KEYBOARD_ADDED, device.device_node))
elif device.action == "remove":
event_queue.put_nowait((KEYBOARD_REMOVED, device.device_node))
if exit_event.is_set():
break
def main():
try:
# Lets load all necessary components and form connections.
keyboard_manager = KeyboardManager()
web_server_manager = WebServerManager()
hid_data_socket = HidDataSocket()
if not hid_data_socket.create_socket():
print("error: Could not create socket for HidDataSocket.")
web_server_manager.close()
hid_data_socket.close()
exit(-1)
hid_data_socket.wait_connection()
# Create evdev keycode to USB HID report converter.
hid_report = HidReport()
# Actual server logic loop.
run(web_server_manager, hid_data_socket, hid_report, keyboard_manager)
except KeyboardInterrupt:
# handle ctrl-c
web_server_manager.close()
hid_data_socket.close()
keyboard_manager.close()
exit(0)
def run(web_server_manager: WebServerManager, hid_data_socket: HidDataSocket, hid_report: HidReport, keyboard_manager: KeyboardManager) -> None:
print("waiting for settings from web server thread")
key_remapper = KeyRemapper(web_server_manager.get_settings_queue().get())
print("received settings from web server thread")
clean = False
keyboard_manager.request_clear_key_events()
while True:
time.sleep(0.001)
keyboard_manager.check_device_events()
try:
new_settings = web_server_manager.get_settings_queue().get(
block=False)
key_remapper.set_new_settings(new_settings, web_server_manager)
except Empty:
pass
for event in keyboard_manager.get_key_events():
if event.value == 1:
web_server_manager.get_heatmap_queue().put_nowait(event.code)
# if key_remapper.change_profile(event.code):
# continue
# profile handling
tuple_data = key_remapper.remap_key(event, web_server_manager)
print(tuple_data)
new_keys_list = tuple_data[0]
clean = tuple_data[1]
# profile handling
if len(new_keys_list) == 1:
key_list = new_keys_list[0]
# key_down = 1
if event.value == 1:
for k in key_list:
hid_report.add_key(k)
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
# key_up = 0
elif event.value == 0:
for k in key_list:
hid_report.remove_key(k)
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
else:
if event.value == 1:
delays_list = key_remapper.remap_key_delays_list(
event.code)
for i in range(0, len(new_keys_list)):
key_list = new_keys_list[i]
for k in key_list:
hid_report.add_key(k)
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
for k in key_list:
hid_report.remove_key(k)
send_and_reset_if_client_disconnected(
hid_data_socket, hid_report, keyboard_manager)
if i < len(delays_list):
time.sleep(delays_list[i])
if clean:
hid_report.clear()
def send_and_reset_if_client_disconnected(hid_data_socket: HidDataSocket, hid_report: HidReport, keyboard_manager: KeyboardManager) -> None:
if not hid_data_socket.send_hid_report_if_there_is_new_changes(hid_report):
hid_data_socket.wait_connection()
keyboard_manager.request_clear_key_events()
hid_report.clear()
if __name__ == "__main__":
main()
print("main thread exitted")
| 9ccc0cb9d62345e11d56f0062ea9d5db7b348020 | [
"Markdown",
"Python",
"TypeScript",
"Shell"
] | 24 | Python | miikka-h/Projektikurssi17 | 87155b059de1a58ac010284c642f8dace19c8170 | 4c1dc68a016f1a34aa8a9cf8ff29d8c31343c48a |
refs/heads/master | <repo_name>lgdamefans/virus_simulator<file_sep>/covid_simulator/motion.py
'''
file that contains all function related to population mobility
and related computations
'''
import numpy as np
def update_positions(population):
'''update positions of all people
Uses heading and speed to update all positions for
the next time step
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
'''
#update positions
#x
population[:,1] = population[:,1] + (population[:,3] * population[:,5])
#y
population[:,2] = population[:,2] + (population [:,4] * population[:,5])
return population
def out_of_bounds(population, xbounds, ybounds):
'''checks which people are about to go out of bounds and corrects
Function that updates headings of individuals that are about to
go outside of the world boundaries.
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
xbounds, ybounds : list or tuple
contains the lower and upper bounds of the world [min, max]
'''
#update headings and positions where out of bounds
#update x heading
#determine number of elements that need to be updated 使要出边界的点转向
shp = population[:,3][(population[:,1] <= xbounds[:,0]) &
(population[:,3] < 0)].shape
population[:,3][(population[:,1] <= xbounds[:,0]) &
(population[:,3] < 0)] = np.clip(np.random.normal(loc = 0.5,
scale = 0.5/3,
size = shp),
a_min = 0.05, a_max = 1)
shp = population[:,3][(population[:,1] >= xbounds[:,1]) &
(population[:,3] > 0)].shape
population[:,3][(population[:,1] >= xbounds[:,1]) &
(population[:,3] > 0)] = np.clip(-np.random.normal(loc = 0.5,
scale = 0.5/3,
size = shp),
a_min = -1, a_max = -0.05)
#update y heading
shp = population[:,4][(population[:,2] <= ybounds[:,0]) &
(population[:,4] < 0)].shape
population[:,4][(population[:,2] <= ybounds[:,0]) &
(population[:,4] < 0)] = np.clip(np.random.normal(loc = 0.5,
scale = 0.5/3,
size = shp),
a_min = 0.05, a_max = 1)
shp = population[:,4][(population[:,2] >= ybounds[:,1]) &
(population[:,4] > 0)].shape
population[:,4][(population[:,2] >= ybounds[:,1]) &
(population[:,4] > 0)] = np.clip(-np.random.normal(loc = 0.5,
scale = 0.5/3,
size = shp),
a_min = -1, a_max = -0.05)
return population
def update_randoms(population, pop_size, speed=0.01, heading_update_chance=0.02,
speed_update_chance=0.02, heading_multiplication=1,
speed_multiplication=1):
'''updates random states such as heading and speed
Function that randomized the headings and speeds for population members
with settable odds.
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
pop_size : int
the size of the population
heading_update_chance : float
the odds of updating the heading of each member, each time step
speed_update_chance : float
the oodds of updating the speed of each member, each time step
heading_multiplication : int or float
factor to multiply heading with (default headings are between -1 and 1)
speed_multiplication : int or float
factor to multiply speed with (default speeds are between 0.0001 and 0.05
speed : int or float
mean speed of population members, speeds will be taken from gaussian distribution
with mean 'speed' and sd 'speed / 3'
'''
#randomly update heading ~N(0,1)
#x
update = np.random.random(size=(pop_size,))
shp = update[update <= heading_update_chance].shape
population[:,3][update <= heading_update_chance] = np.random.normal(loc = 0,
scale = 1/3,
size = shp) * heading_multiplication
#y
update = np.random.random(size=(pop_size,))
shp = update[update <= heading_update_chance].shape
population[:,4][update <= heading_update_chance] = np.random.normal(loc = 0,
scale = 1/3,
size = shp) * heading_multiplication
#randomize speeds
update = np.random.random(size=(pop_size,))
shp = update[update <= heading_update_chance].shape
population[:,5][update <= heading_update_chance] = np.random.normal(loc = speed,
scale = speed / 3,
size = shp) * speed_multiplication
#max speed
population[:,5] = np.clip(population[:,5], a_min=0.0001, a_max=0.05)
return population
def get_motion_parameters(xmin, ymin, xmax, ymax):
'''gets destination center and wander ranges
Function that returns geometric parameters of the destination
that the population members have set.
Keyword arguments:
------------------
xmin, ymin, xmax, ymax : int or float
lower and upper bounds of the destination area set.
'''
x_center = xmin + ((xmax - xmin) / 2)
y_center = ymin + ((ymax - ymin) / 2)
x_wander = (xmax - xmin) / 2
y_wander = (ymax - ymin) / 2
return x_center, y_center, x_wander, y_wander
<file_sep>/README.md
# virus_simulator
本仿真程序是通过模拟在一定区域内随机行走的人群,来模拟新冠病毒在人群中传播的。
所有人群的个体都有四种状态:健康,感染,免疫,死亡。
在不同的防疫措施下,人们的移动不一样,在没有进行封锁的情况下,人们的移动方向和距离是完全随机且服从高斯分布的,在封锁的情况下,大部分的行动被限制,但仍有少部分人保持移动,这代表了一些从事不可或缺工作的人。
封锁从人数第一次达到临界开始,一直持续到疫情结束。
感染的模式也有两种,在人群中感染人数偏少的时候,以感染人为中心的一片区域为感染区,在感染区中的健康人有小概率被感染,而在感染人数超过半数时,一个健康人被感染的概率取决于周边患病人的个数。而死亡和痊愈,全部取决于概率。对于死亡,不同的年龄有着不同的死亡率,这也符合新冠病毒对高龄人死亡率较高的事实,而得到治疗的患者致死率将为原来的一半。
同时,还引入了经济因素,根据参考文献,这里设置了三种主要经济成分,一部分来自于人,主要取决于健康人的个数,而一部分为商业,将商业分为了两部分,一部分会受到封锁的冲击而逐渐关闭,另一部分为一些必需品如饮食等,还有一部分为政府收入,来自于另外两个所缴纳的税金。
根据不同的防疫措施,我进行了实验,以下分别为什么都不做,封锁,封锁+洗手+戴口罩的结果
Do no work:
total timesteps taken: 3384
total dead: 94
total recovered: 1815
total unaffected: 81
deathrate 94/2000 = 4.7%

Lockdown:
total timesteps taken: 4335
total dead: 55
total recovered: 1568
total unaffected: 377
deathrate = 2.75%

Lockdown(wash hands+wear masks)
total timesteps taken: 4413
total dead: 24
total recovered: 1306
total unaffected: 670
deathrate = 1.2%

此外,针对不同的人群密度,我也进行了一次实验,用来考察人群聚集度对病毒传播的影响,分别考察在高密度、中密度、低密度情况下疫情的传播状况
High density(population = 5000)
total timesteps taken: 1806
total dead: 398
total recovered: 4568
total unaffected: 34
deathrate = 7.96%

Mid density(population = 2000)
total timesteps taken: 3384
total dead: 94
total recovered: 1815
total unaffected: 81
deathrate 94/2000 = 4.7%

Low density
total timesteps taken: 1071
total dead: 0
total recovered: 10
total unaffected: 990

Reference: https://github.com/paulvangentcom/python_corona_simulation
<file_sep>/covid_simulator/path_planning.py
'''
contains methods related to goal-directed traveling behaviour
and path planning
'''
import numpy as np
from motion import get_motion_parameters, update_randoms
def go_to_location(patient, destination, location_bounds, dest_no=1):
'''sends patient to defined location
Function that takes a patient an destination, and sets the location
as active for that patient.
Keyword arguments
-----------------
patient : 1d array
1d array of the patient data, is a row from population matrix
destination : 1d array
1d array of the destination data, is a row from destination matrix
location_bounds : list or tuple
defines bounds for the location the patient will be roam in when sent
there. format: [xmin, ymin, xmax, ymax]
dest_no : int
the location number, used as index for destinations array if multiple possible
destinations are defined`.
TODO: vectorize
'''
x_center, y_center, x_wander, y_wander = get_motion_parameters(location_bounds[0],
location_bounds[1],
location_bounds[2],
location_bounds[3])
patient[13] = x_wander
patient[14] = y_wander
destination[(dest_no - 1) * 2] = x_center
destination[((dest_no - 1) * 2) + 1] = y_center
patient[11] = dest_no #set destination active
return patient, destination
def set_destination(population, destinations):
'''sets destination of population
Sets the destination of population if destination marker is not 0.
Updates headings and speeds as well.
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
destinations : ndarray
the array containing all destinations information
'''
#how many destinations are active
active_dests = np.unique(population[:,11][population[:,11] != 0])
#set destination
for d in active_dests:
dest_x = destinations[:,int((d - 1) * 2)]
dest_y = destinations[:,int(((d - 1) * 2) + 1)]
#compute new headings
head_x = dest_x - population[:,1]
head_y = dest_y - population[:,2]
#head_x = head_x / np.sqrt(head_x)
#head_y = head_y / np.sqrt(head_y)
#reinsert headings into population of those not at destination yet
population[:,3][(population[:,11] == d) &
(population[:,12] == 0)] = head_x[(population[:,11] == d) &
(population[:,12] == 0)]
population[:,4][(population[:,11] == d) &
(population[:,12] == 0)] = head_y[(population[:,11] == d) &
(population[:,12] == 0)]
#set speed to 0.01
population[:,5][(population[:,11] == d) &
(population[:,12] == 0)] = 0.02
return population
def check_at_destination(population, destinations, wander_factor=1.5, speed = 0.01):
'''check who is at their destination already
Takes subset of population with active destination and
tests who is at the required coordinates. Updates at destination
column for people at destination.
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
destinations : ndarray
the array containing all destinations information
wander_factor : int or float
defines how far outside of 'wander range' the destination reached
is triggered
'''
#how many destinations are active
active_dests = np.unique(population[:,11][(population[:,11] != 0)])
#see who is at destination
for d in active_dests:
dest_x = destinations[:,int((d - 1) * 2)]
dest_y = destinations[:,int(((d - 1) * 2) + 1)]
#see who arrived at destination and filter out who already was there
at_dest = population[(np.abs(population[:,1] - dest_x) < (population[:,13] * wander_factor)) &
(np.abs(population[:,2] - dest_y) < (population[:,14] * wander_factor)) &
(population[:,12] == 0)]
if len(at_dest) > 0:
#mark those as arrived
at_dest[:,12] = 1
#insert random headings and speeds for those at destination
at_dest = update_randoms(at_dest, pop_size = len(at_dest), speed = speed,
heading_update_chance = 1, speed_update_chance = 1)
#at_dest[:,5] = 0.001
#reinsert into population
population[(np.abs(population[:,1] - dest_x) < (population[:,13] * wander_factor)) &
(np.abs(population[:,2] - dest_y) < (population[:,14] * wander_factor)) &
(population[:,12] == 0)] = at_dest
return population
def keep_at_destination(population, destinations, wander_factor=1):
'''keeps those who have arrived, within wander range
Function that keeps those who have been marked as arrived at their
destination within their respective wander ranges
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
destinations : ndarray
the array containing all destinations information
wander_factor : int or float
defines how far outside of 'wander range' the destination reached
is triggered
'''
#how many destinations are active
active_dests = np.unique(population[:,11][(population[:,11] != 0) &
(population[:,12] == 1)])
for d in active_dests:
dest_x = destinations[:,int((d - 1) * 2)][(population[:,12] == 1) &
(population[:,11] == d)]
dest_y = destinations[:,int(((d - 1) * 2) + 1)][(population[:,12] == 1) &
(population[:,11] == d)]
#see who is marked as arrived
arrived = population[(population[:,12] == 1) &
(population[:,11] == d)]
ids = np.int32(arrived[:,0]) # find unique IDs of arrived persons
#check if there are those out of bounds
#replace x oob
#where x larger than destination + wander, AND heading wrong way, set heading negative
shp = arrived[:,3][arrived[:,1] > (dest_x + (arrived[:,13] * wander_factor))].shape
arrived[:,3][arrived[:,1] > (dest_x + (arrived[:,13] * wander_factor))] = -np.random.normal(loc = 0.5,
scale = 0.5 / 3,
size = shp)
#where x smaller than destination - wander, set heading positive
shp = arrived[:,3][arrived[:,1] < (dest_x - (arrived[:,13] * wander_factor))].shape
arrived[:,3][arrived[:,1] < (dest_x - (arrived[:,13] * wander_factor))] = np.random.normal(loc = 0.5,
scale = 0.5 / 3,
size = shp)
#where y larger than destination + wander, set heading negative
shp = arrived[:,4][arrived[:,2] > (dest_y + (arrived[:,14] * wander_factor))].shape
arrived[:,4][arrived[:,2] > (dest_y + (arrived[:,14] * wander_factor))] = -np.random.normal(loc = 0.5,
scale = 0.5 / 3,
size = shp)
#where y smaller than destination - wander, set heading positive
shp = arrived[:,4][arrived[:,2] < (dest_y - (arrived[:,14] * wander_factor))].shape
arrived[:,4][arrived[:,2] < (dest_y - (arrived[:,14] * wander_factor))] = np.random.normal(loc = 0.5,
scale = 0.5 / 3,
size = shp)
#slow speed
arrived[:,5] = np.random.normal(loc = 0.005,
scale = 0.005 / 3,
size = arrived[:,5].shape)
#reinsert into population
population[(population[:,12] == 1) &
(population[:,11] == d)] = arrived
return population
def reset_destinations(population, ids=[]):
'''clears destination markers
Function that clears all active destination markers from the population
Keyword arguments
-----------------
population : ndarray
the array containing all the population information
ids : ndarray or list
array containing the id's of the population members that need their
destinations reset
'''
if len(ids) == 0:
#if ids empty, reset everyone
population[:,11] = 0
else:
pass
#else, reset id's
pass<file_sep>/covid_simulator/environment.py
'''
file that contains all functions to define destinations in the
environment of the simulated world.
'''
import numpy as np
def build_hospital(xmin, xmax, ymin, ymax, plt, addcross=True):
'''builds hospital
Defines hospital and returns wall coordinates for
the hospital, as well as coordinates for a red cross
above it
Keyword arguments
-----------------
xmin : int or float
lower boundary on the x axis
xmax : int or float
upper boundary on the x axis
ymin : int or float
lower boundary on the y axis
ymax : int or float
upper boundary on the y axis
plt : matplotlib.pyplot object
the plot object to which to append the hospital drawing
if None, coordinates are returned
Returns
-------
None
'''
#plot walls
plt.plot([xmin, xmin], [ymin, ymax], color = 'black')
plt.plot([xmax, xmax], [ymin, ymax], color = 'black')
plt.plot([xmin, xmax], [ymin, ymin], color = 'black')
plt.plot([xmin, xmax], [ymax, ymax], color = 'black')
#plot red cross
if addcross:
xmiddle = xmin + ((xmax - xmin) / 2)
height = np.min([0.3, (ymax - ymin) / 5])
plt.plot([xmiddle, xmiddle], [ymax, ymax + height], color='red',
linewidth = 3)
plt.plot([xmiddle - (height / 2), xmiddle + (height / 2)],
[ymax + (height / 2), ymax + (height / 2)], color='red',
linewidth = 3)<file_sep>/covid_simulator/simulation.py
import os
import sys
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from config import Configuration, config_error
from economic import economical_change
from environment import build_hospital
from infection import find_nearby, infect, recover_or_die, compute_mortality,\
healthcare_infection_correction
from motion import update_positions, out_of_bounds, update_randoms,\
get_motion_parameters
from path_planning import go_to_location, set_destination, check_at_destination,\
keep_at_destination, reset_destinations
from population import initialize_population, initialize_destination_matrix,\
set_destination_bounds, save_data, save_population, Population_trackers
from visualiser import build_fig, draw_tstep, set_style, plot_sir
#set seed for reproducibility
#np.random.seed(100)
class Simulation():
#TODO: if lockdown or otherwise stopped: destination -1 means no motion
def __init__(self, *args, **kwargs):
#load default config data
self.Config = Configuration(*args, **kwargs)
self.frame = 0
#initialize default population
self.population_init()
self.pop_tracker = Population_trackers()
#initalise destinations vector
self.destinations = initialize_destination_matrix(self.Config.pop_size, 1)
def reinitialise(self):
'''reset the simulation'''
self.frame = 0
self.population_init()
self.pop_tracker = Population_trackers()
self.destinations = initialize_destination_matrix(self.Config.pop_size, 1)
def population_init(self):
'''(re-)initializes population'''
self.population = initialize_population(self.Config, self.Config.mean_age,
self.Config.max_age, self.Config.xbounds,
self.Config.ybounds)
def tstep(self):
'''
takes a time step in the simulation
'''
if self.frame == 0 and self.Config.visualise:
#initialize figure
self.fig, self.spec, self.ax1, self.ax2 , self.ax3 = build_fig(self.Config)
#check destinations if active
#define motion vectors if destinations active and not everybody is at destination
active_dests = len(self.population[self.population[:,11] != 0]) # look op this only once
if active_dests > 0 and len(self.population[self.population[:,12] == 0]) > 0:
self.population = set_destination(self.population, self.destinations)
self.population = check_at_destination(self.population, self.destinations,
wander_factor = self.Config.wander_factor_dest,
speed = self.Config.speed)
if active_dests > 0 and len(self.population[self.population[:,12] == 1]) > 0:
#keep them at destination 到达dest 以一定范围wander
self.population = keep_at_destination(self.population, self.destinations,
self.Config.wander_factor)
#out of bounds 要把wander的方向朝向修改 防止wander超出边界
#define bounds arrays, excluding those who are marked as having a custom destination
if len(self.population[:,11] == 0) > 0:
_xbounds = np.array([[self.Config.xbounds[0] + 0.02, self.Config.xbounds[1] - 0.02]] * len(self.population[self.population[:,11] == 0]))
_ybounds = np.array([[self.Config.ybounds[0] + 0.02, self.Config.ybounds[1] - 0.02]] * len(self.population[self.population[:,11] == 0]))
self.population[self.population[:,11] == 0] = out_of_bounds(self.population[self.population[:,11] == 0],
_xbounds, _ybounds)
#set randoms 最大感染数 只要到达过最大感染数就持续lockdown
if self.Config.lockdown:
if len(self.pop_tracker.infectious) == 0:
mx = 0
else:
mx = np.max(self.pop_tracker.infectious)
if len(self.population[self.population[:,6] == 1]) >= len(self.population) * self.Config.lockdown_percentage or\
mx >= (len(self.population) * self.Config.lockdown_percentage):
#reduce speed of all members of society 使最大速度为0.001
self.population[:,5] = np.clip(self.population[:,5], a_min = None, a_max = 0.001)
#set speeds of complying people to 0 遵循lockdown的速度 为0
self.population[:,5][self.Config.lockdown_vector == 0] = 0
else:
#update randoms
self.population = update_randoms(self.population, self.Config.pop_size, self.Config.speed)
else:
#update randoms
self.population = update_randoms(self.population, self.Config.pop_size, self.Config.speed)
#for dead ones: set speed and heading to 0
self.population[:,3:5][self.population[:,6] == 3] = 0
#update positions
self.population = update_positions(self.population)
#find new infections
self.population, self.destinations = infect(self.population, self.Config, self.frame,
send_to_location = self.Config.self_isolate,
location_bounds = self.Config.isolation_bounds,
destinations = self.destinations,
location_no = 1,
location_odds = self.Config.self_isolate_proportion)
#recover and die
self.population = recover_or_die(self.population, self.frame, self.Config)
#send cured back to population if self isolation active
#perhaps put in recover or die class
#send cured back to population
self.population[:,11][self.population[:,6] == 2] = 0
#compute gdp
peoplegdp, businessgdp, governgdp, totalgdp = economical_change(self.population, self.Config)
#update population statistics
self.pop_tracker.update_counts(self.population, peoplegdp, businessgdp, governgdp, totalgdp)
#visualise
if self.Config.visualise:
draw_tstep(self.Config, self.population, self.pop_tracker, self.frame,
self.fig, self.spec, self.ax1, self.ax2,self.ax3)
#report stuff to console
sys.stdout.write('\r')
sys.stdout.write('%i: healthy: %i, infected: %i, immune: %i, in treatment: %i, \
dead: %i, of total: %i' %(self.frame, self.pop_tracker.susceptible[-1], self.pop_tracker.infectious[-1],
self.pop_tracker.recovered[-1], len(self.population[self.population[:,10] == 1]),
self.pop_tracker.fatalities[-1], self.Config.pop_size))
#save popdata if required
if self.Config.save_pop and (self.frame % self.Config.save_pop_freq) == 0:
save_population(self.population, self.frame, self.Config.save_pop_folder)
#run callback
self.callback()
#update frame
self.frame += 1
def callback(self):
'''placeholder function that can be overwritten.
By ovewriting this method any custom behaviour can be implemented.
The method is called after every simulation timestep.
'''
#0号病人
if self.frame == 50:
print('\ninfecting patient zero')
self.population[0][6] = 1
self.population[0][8] = 50
self.population[0][10] = 1
def run(self):
'''run simulation'''
i = 0
while i < self.Config.simulation_steps:
try:
self.tstep()
except KeyboardInterrupt:
print('\nCTRL-C caught, exiting')
sys.exit(1)
#check whether to end if no infecious persons remain.
#check if self.frame is above some threshold to prevent early breaking when simulation
#starts initially with no infections.
if self.Config.endif_no_infections and self.frame >= 500:
if len(self.population[(self.population[:,6] == 1) |
(self.population[:,6] == 4)]) == 0:
i = self.Config.simulation_steps
if self.Config.save_data:
save_data(self.population, self.pop_tracker)
#report outcomes
print('\n-----stopping-----\n')
print('total timesteps taken: %i' %self.frame)
print('total dead: %i' %len(self.population[self.population[:,6] == 3]))
print('total recovered: %i' %len(self.population[self.population[:,6] == 2]))
print('total infected: %i' %len(self.population[self.population[:,6] == 1]))
print('total infectious: %i' %len(self.population[(self.population[:,6] == 1) |
(self.population[:,6] == 4)]))
print('total unaffected: %i' %len(self.population[self.population[:,6] == 0]))
def plot_sir(self, size=(6,3), include_fatalities=False,
title='S-I-R plot of simulation'):
plot_sir(self.Config, self.pop_tracker, size, include_fatalities,
title)
if __name__ == '__main__':
#initialize
sim = Simulation()
#set number of simulation steps
sim.Config.simulation_steps = 20000
#set color mode
sim.Config.plot_style = 'default' #can also be dark
#set colorblind mode if needed
#sim.Config.colorblind_mode = True
#set colorblind type (default deuteranopia)
#sim.Config.colorblind_type = 'deuteranopia'
#set reduced interaction
#sim.Config.set_reduced_interaction()
#sim.population_init()
#set lockdown scenario
#sim.Config.set_lockdown(lockdown_percentage = 0.1, lockdown_compliance = 0.95)
#set self-isolation scenario
#sim.Config.set_self_isolation(self_isolate_proportion = 0.9,
# isolation_bounds = [0.02, 0.02, 0.09, 0.98],
# traveling_infects=False)
#sim.population_init() #reinitialize population to enforce new roaming bounds
#run, hold CTRL+C in terminal to end scenario early
sim.run()<file_sep>/covid_simulator/economic.py
def economical_change(population,Config):
'''
five economical factor are considered : People Houses Business Govern Healthcare
Parameters
----------
population
Config
Returns
-------
'''
personalgdp = 2500.0
employmentrate = 1;
basicbsgdp = 15000000.0
infection_rate = len(population[population[:,6] == 1])/len(population)
# as the infection rate rise, the business is shuting down
phealnum = len(population[population[:,6] == 0])
pimmune = len(population[population[:,6] == 2])
peoplegdp = (phealnum+pimmune) * personalgdp*(0.5+0.5*(1-infection_rate))
if infection_rate < Config.lockdown_percentage:
businessgdp = basicbsgdp*(0.6*(1-infection_rate/Config.lockdown_percentage)+0.4)
else:
businessgdp = basicbsgdp*0.4
governgdp = 0.15*peoplegdp + 0.25 * businessgdp
totalgdp = peoplegdp + governgdp + businessgdp
return peoplegdp,businessgdp,governgdp,totalgdp
<file_sep>/covid_simulator/config.py
'''
file that contains all configuration related methods and classes
'''
import numpy as np
class config_error(Exception):
pass
class Configuration():
def __init__(self, *args, **kwargs):
#simulation variables
self.verbose = kwargs.get('verbose', True) #whether to print infections, recoveries and fatalities to the terminal
self.simulation_steps = kwargs.get('simulation_steps', 10000) #total simulation steps performed
self.tstep = kwargs.get('tstep', 0) #current simulation timestep
self.save_data = kwargs.get('save_data', False) #whether to dump data at end of simulation
self.save_pop = kwargs.get('save_pop', False) #whether to save population matrix every 'save_pop_freq' timesteps
self.save_pop_freq = kwargs.get('save_pop_freq', 10) #population data will be saved every 'n' timesteps. Default: 10
self.save_pop_folder = kwargs.get('save_pop_folder', 'pop_data/') #folder to write population timestep data to
self.endif_no_infections = kwargs.get('endif_no_infections', True) #whether to stop simulation if no infections remain
self.world_size = kwargs.get('world_size', [2, 2]) #x and y sizes of the world
#scenario flags
self.traveling_infects = kwargs.get('traveling_infects', False)
self.self_isolate = kwargs.get('self_isolate', False)
self.lockdown = kwargs.get('lockdown', False)
self.lockdown_percentage = kwargs.get('lockdown_percentage', 0.999) #after this proportion is infected, lock-down begins
self.lockdown_compliance = kwargs.get('lockdown_compliance', 0.95) #fraction of the population that will obey the lockdown
#visualisation variables
self.visualise = kwargs.get('visualise', True) #whether to visualise the simulation
self.plot_mode = kwargs.get('plot_mode', 'sir') #default or sir
#size of the simulated world in coordinates
self.x_plot = kwargs.get('x_plot', [0, self.world_size[0]])
self.y_plot = kwargs.get('y_plot', [0, self.world_size[1]])
self.save_plot = kwargs.get('save_plot', True)
self.plot_path = kwargs.get('plot_path', 'render/') #folder where plots are saved to
self.plot_style = kwargs.get('plot_style', 'default') #can be default, dark, ...
self.colorblind_mode = kwargs.get('colorblind_mode', False)
#if colorblind is enabled, set type of colorblindness
#available: deuteranopia, protanopia, tritanopia. defauld=deuteranopia
self.colorblind_type = kwargs.get('colorblind_type', 'deuteranopia')
#world variables, defines where population can and cannot roam
self.xbounds = kwargs.get('xbounds', [self.x_plot[0] + 0.02, self.x_plot[1] - 0.02])
self.ybounds = kwargs.get('ybounds', [self.y_plot[0] + 0.02, self.y_plot[1] - 0.02])
#population variables
self.pop_size = kwargs.get('pop_size', 1000)
self.mean_age = kwargs.get('mean_age', 45)
self.max_age = kwargs.get('max_age', 105)
self.age_dependent_risk = kwargs.get('age_dependent_risk', True) #whether risk increases with age
self.risk_age = kwargs.get('risk_age', 55) #age where mortality risk starts increasing
self.critical_age = kwargs.get('critical_age', 75) #age at and beyond which mortality risk reaches maximum
self.critical_mortality_chance = kwargs.get('critical_mortality_chance', 0.1) #maximum mortality risk for older age
self.risk_increase = kwargs.get('risk_increase', 'quadratic') #whether risk between risk and critical age increases 'linear' or 'quadratic'
#movement variables
#mean_speed = 0.01 # the mean speed (defined as heading * speed)
#std_speed = 0.01 / 3 #the standard deviation of the speed parameter
#the proportion of the population that practices social distancing, simulated
#by them standing still
self.proportion_distancing = kwargs.get('proportion_distancing', 0)
self.speed = kwargs.get('speed', 0.01) #average speed of population
#when people have an active destination, the wander range defines the area
#surrounding the destination they will wander upon arriving
self.wander_range = kwargs.get('wander_range', 0.05)
self.wander_factor = kwargs.get('wander_factor', 1)
self.wander_factor_dest = kwargs.get('wander_factor_dest', 1.5) #area around destination
#infection variables
self.infection_range = kwargs.get('infection_range', 0.01) #range surrounding sick patient that infections can take place
self.infection_chance = kwargs.get('infection_chance', 0.023) #chance that an infection spreads to nearby healthy people each tick
self.recovery_duration = kwargs.get('recovery_duration', (200, 500)) #how many ticks it may take to recover from the illness
self.mortality_chance = kwargs.get('mortality_chance', 0.02) #global baseline chance of dying from the disease
#healthcare variables
self.healthcare_capacity = kwargs.get('healthcare_capacity', 300) #capacity of the healthcare system
self.treatment_factor = kwargs.get('treatment_factor', 0.5) #when in treatment, affect risk by this factor
self.no_treatment_factor = kwargs.get('no_treatment_factor', 3) #risk increase factor to use if healthcare system is full
#risk parameters
self.treatment_dependent_risk = kwargs.get('treatment_dependent_risk', True) #whether risk is affected by treatment
#self isolation variables
self.self_isolate_proportion = kwargs.get('self_isolate_proportion', 0.6)
self.isolation_bounds = kwargs.get('isolation_bounds', [0.02, 0.02, 0.1, 0.98])
#lockdown variables
self.lockdown_percentage = kwargs.get('lockdown_percentage', 0.05)
self.lockdown_vector = kwargs.get('lockdown_vector', [])
def get_palette(self):
'''returns appropriate color palette
Uses config.plot_style to determine which palette to pick,
and changes palette to colorblind mode (config.colorblind_mode)
and colorblind type (config.colorblind_type) if required.
Palette colors are based on
https://venngage.com/blog/color-blind-friendly-palette/
'''
#palette colors are: [healthy, infected, immune, dead]
palettes = {'regular': {'default': ['gray', 'red', 'green', 'black'],
'dark': ['#404040', '#ff0000', '#00ff00', '#000000']},
'deuteranopia': {'default': ['gray', '#a50f15', '#08519c', 'black'],
'dark': ['#404040', '#fcae91', '#6baed6', '#000000']},
'protanopia': {'default': ['gray', '#a50f15', '08519c', 'black'],
'dark': ['#404040', '#fcae91', '#6baed6', '#000000']},
'tritanopia': {'default': ['gray', '#a50f15', '08519c', 'black'],
'dark': ['#404040', '#fcae91', '#6baed6', '#000000']}
}
if self.colorblind_mode:
return palettes[self.colorblind_type.lower()][self.plot_style]
else:
return palettes['regular'][self.plot_style]
def get(self, key):
'''gets key value from config'''
try:
return self.__dict__[key]
except:
raise config_error('key %s not present in config' %key)
def set(self, key, value):
'''sets key value in config'''
self.__dict__[key] = value
def read_from_file(self, path):
'''reads config from filename'''
#TODO: implement
pass
def set_lockdown(self, lockdown_percentage=0.1, lockdown_compliance=0.9):
'''sets lockdown to active'''
self.lockdown = True
#fraction of the population that will obey the lockdown
self.lockdown_percentage = lockdown_percentage
self.lockdown_vector = np.zeros((self.pop_size,))
#lockdown vector is 1 for those not complying
self.lockdown_vector[np.random.uniform(size=(self.pop_size,)) >= lockdown_compliance] = 1
def set_self_isolation(self, self_isolate_proportion=0.9,
isolation_bounds = [0.02, 0.02, 0.09, 0.98],
traveling_infects=False):
'''sets self-isolation scenario to active'''
self.self_isolate = True
self.isolation_bounds = isolation_bounds
self.self_isolate_proportion = self_isolate_proportion
#set roaming bounds to outside isolated area
self.xbounds = [0.1, 1.1]
self.ybounds = [0.02, 0.98]
#update plot bounds everything is shown
self.x_plot = [0, 1.1]
self.y_plot = [0, 1]
#update whether traveling agents also infect
self.traveling_infects = traveling_infects
def set_reduced_interaction(self, speed = 0.001):
'''sets reduced interaction scenario to active'''
self.speed = speed
def set_demo(self, destinations, population):
#make C
#first leg
destinations[:,0][0:100] = 0.05
destinations[:,1][0:100] = 0.7
population[:,13][0:100] = 0.01
population[:,14][0:100] = 0.05
#Top
destinations[:,0][100:200] = 0.1
destinations[:,1][100:200] = 0.75
population[:,13][100:200] = 0.05
population[:,14][100:200] = 0.01
#Bottom
destinations[:,0][200:300] = 0.1
destinations[:,1][200:300] = 0.65
population[:,13][200:300] = 0.05
population[:,14][200:300] = 0.01
#make O
#first leg
destinations[:,0][300:400] = 0.2
destinations[:,1][300:400] = 0.7
population[:,13][300:400] = 0.01
population[:,14][300:400] = 0.05
#Top
destinations[:,0][400:500] = 0.25
destinations[:,1][400:500] = 0.75
population[:,13][400:500] = 0.05
population[:,14][400:500] = 0.01
#Bottom
destinations[:,0][500:600] = 0.25
destinations[:,1][500:600] = 0.65
population[:,13][500:600] = 0.05
population[:,14][500:600] = 0.01
#second leg
destinations[:,0][600:700] = 0.3
destinations[:,1][600:700] = 0.7
population[:,13][600:700] = 0.01
population[:,14][600:700] = 0.05
#make V
#First leg
destinations[:,0][700:800] = 0.35
destinations[:,1][700:800] = 0.7
population[:,13][700:800] = 0.01
population[:,14][700:800] = 0.05
#Bottom
destinations[:,0][800:900] = 0.4
destinations[:,1][800:900] = 0.65
population[:,13][800:900] = 0.05
population[:,14][800:900] = 0.01
#second leg
destinations[:,0][900:1000] = 0.45
destinations[:,1][900:1000] = 0.7
population[:,13][900:1000] = 0.01
population[:,14][900:1000] = 0.05
#Make I
#leg
destinations[:,0][1000:1100] = 0.5
destinations[:,1][1000:1100] = 0.7
population[:,13][1000:1100] = 0.01
population[:,14][1000:1100] = 0.05
#I dot
destinations[:,0][1100:1200] = 0.5
destinations[:,1][1100:1200] = 0.8
population[:,13][1100:1200] = 0.01
population[:,14][1100:1200] = 0.01
#make D
#first leg
destinations[:,0][1200:1300] = 0.55
destinations[:,1][1200:1300] = 0.67
population[:,13][1200:1300] = 0.01
population[:,14][1200:1300] = 0.03
#Top
destinations[:,0][1300:1400] = 0.6
destinations[:,1][1300:1400] = 0.75
population[:,13][1300:1400] = 0.05
population[:,14][1300:1400] = 0.01
#Bottom
destinations[:,0][1400:1500] = 0.6
destinations[:,1][1400:1500] = 0.65
population[:,13][1400:1500] = 0.05
population[:,14][1400:1500] = 0.01
#second leg
destinations[:,0][1500:1600] = 0.65
destinations[:,1][1500:1600] = 0.7
population[:,13][1500:1600] = 0.01
population[:,14][1500:1600] = 0.05
#dash
destinations[:,0][1600:1700] = 0.725
destinations[:,1][1600:1700] = 0.7
population[:,13][1600:1700] = 0.03
population[:,14][1600:1700] = 0.01
#Make 1
destinations[:,0][1700:1800] = 0.8
destinations[:,1][1700:1800] = 0.7
population[:,13][1700:1800] = 0.01
population[:,14][1700:1800] = 0.05
#Make 9
#right leg
destinations[:,0][1800:1900] = 0.91
destinations[:,1][1800:1900] = 0.675
population[:,13][1800:1900] = 0.01
population[:,14][1800:1900] = 0.08
#roof
destinations[:,0][1900:2000] = 0.88
destinations[:,1][1900:2000] = 0.75
population[:,13][1900:2000] = 0.035
population[:,14][1900:2000] = 0.01
#middle
destinations[:,0][2000:2100] = 0.88
destinations[:,1][2000:2100] = 0.7
population[:,13][2000:2100] = 0.035
population[:,14][2000:2100] = 0.01
#left vertical leg
destinations[:,0][2100:2200] = 0.86
destinations[:,1][2100:2200] = 0.72
population[:,13][2100:2200] = 0.01
population[:,14][2100:2200] = 0.01
###################
##### ROW TWO #####
###################
#S
#first leg
destinations[:,0][2200:2300] = 0.115
destinations[:,1][2200:2300] = 0.5
population[:,13][2200:2300] = 0.01
population[:,14][2200:2300] = 0.03
#Top
destinations[:,0][2300:2400] = 0.15
destinations[:,1][2300:2400] = 0.55
population[:,13][2300:2400] = 0.05
population[:,14][2300:2400] = 0.01
#second leg
destinations[:,0][2400:2500] = 0.2
destinations[:,1][2400:2500] = 0.45
population[:,13][2400:2500] = 0.01
population[:,14][2400:2500] = 0.03
#middle
destinations[:,0][2500:2600] = 0.15
destinations[:,1][2500:2600] = 0.48
population[:,13][2500:2600] = 0.05
population[:,14][2500:2600] = 0.01
#bottom
destinations[:,0][2600:2700] = 0.15
destinations[:,1][2600:2700] = 0.41
population[:,13][2600:2700] = 0.05
population[:,14][2600:2700] = 0.01
#Make I
#leg
destinations[:,0][2700:2800] = 0.25
destinations[:,1][2700:2800] = 0.45
population[:,13][2700:2800] = 0.01
population[:,14][2700:2800] = 0.05
#I dot
destinations[:,0][2800:2900] = 0.25
destinations[:,1][2800:2900] = 0.55
population[:,13][2800:2900] = 0.01
population[:,14][2800:2900] = 0.01
#M
#Top
destinations[:,0][2900:3000] = 0.37
destinations[:,1][2900:3000] = 0.5
population[:,13][2900:3000] = 0.07
population[:,14][2900:3000] = 0.01
#Left leg
destinations[:,0][3000:3100] = 0.31
destinations[:,1][3000:3100] = 0.45
population[:,13][3000:3100] = 0.01
population[:,14][3000:3100] = 0.05
#Middle leg
destinations[:,0][3100:3200] = 0.37
destinations[:,1][3100:3200] = 0.45
population[:,13][3100:3200] = 0.01
population[:,14][3100:3200] = 0.05
#Right leg
destinations[:,0][3200:3300] = 0.43
destinations[:,1][3200:3300] = 0.45
population[:,13][3200:3300] = 0.01
population[:,14][3200:3300] = 0.05
#set all destinations active
population[:,11] = 1
| bbcc02b3f013b873f871d6e26a6740cf12a6464f | [
"Markdown",
"Python"
] | 7 | Python | lgdamefans/virus_simulator | 0afc329fde8d98434867a0bcda86fd3b8c973f27 | e015145957f84e33fc332321709291142ac4c150 |
refs/heads/master | <repo_name>JoseRamirezAyala/GPIOandSocketIO<file_sep>/projectp2_62453/bin/server.js
var io = require('socket.io')();
var PythonShell = require('python-shell');
var Stopwatch = require('timer-stopwatch');
var TimeFormat = require('hh-mm-ss')
var t1, t2, t3, t4, t5, t6, t7, t8 = {}
var m1, m2, m3, m4, m5, m6, m7, m8 = 0;
var opt =
{
scriptPath: __dirname + "/scripts/",
args: []
}
io.sockets.on('connection', (socket) => {
console.log("nuevo Cliente conectado con id: " + socket.id);
socket.on('prender', (data) => {
opt.args = [];
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
switch (data.id) {
case 0:
t1 = new Stopwatch(Number(data.time));
t1.start();
t1.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t1.onTime(function (ms) {
m1 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 1:
t2 = new Stopwatch(Number(data.time));
t2.start();
t2.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t2.onTime(function (ms) {
m2 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 2:
t3 = new Stopwatch(Number(data.time));
t3.start();
t3.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t3.onTime(function (ms) {
m3 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 3:
t4 = new Stopwatch(Number(data.time));
t4.start();
t4.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t4.onTime(function (ms) {
m4 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 4:
t5 = new Stopwatch(Number(data.time));
t5.start();
t5.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t5.onTime(function (ms) {
m5 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 5:
t6 = new Stopwatch(Number(data.time));
t6.start();
t6.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t6.onTime(function (ms) {
m6 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 6:
t7 = new Stopwatch(Number(data.time));
t7.start();
t7.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t7.onTime(function (ms) {
m7 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
case 7:
t8 = new Stopwatch(Number(data.time));
t8.start();
t8.onDone(function () {
io.sockets.emit('termino', data.id);
opt.args = [];
id = data.id
data.state = false
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
});
t8.onTime(function (ms) {
m8 = ms.ms;
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(ms.ms) });
});
break;
}
});
socket.on('stop', (data) => {
opt.args = [];
opt.args.push(JSON.stringify(data));
PythonShell.run("leds.py", opt, (err, res) => {
opt.args = []
if (err) {
throw err;
}
else {
console.log(res[0])
}
});
switch (data.id) {
case 0:
t1.stop();
break;
case 1:
t2.stop();
break;
case 2:
t3.stop();
break;
case 3:
t4.stop();
break;
case 4:
t5.stop();
break;
case 5:
t6.stop();
break;
case 6:
t7.stop();
break;
case 7:
t8.stop();
break;
}
io.sockets.emit('restante', { id: data.id, time: TimeFormat.fromMs(0) });
io.sockets.emit('termino', data.id);
});
socket.on('pause', (data) => {
switch (data.id) {
case 0:
t1.stop();
break;
case 1:
t2.stop();
break;
case 2:
t3.stop();
break;
case 3:
t4.stop();
break;
case 4:
t5.stop();
break;
case 5:
t6.stop();
break;
case 6:
t7.stop();
break;
case 7:
t8.stop();
break;
}
});
socket.on('resume', (data) => {
switch (data.id) {
case 0:
t1.reset(m1);
t1.start();
break;
case 1:
t2.reset(m2);
t2.start();
break;
case 2:
t3.reset(m3);
t3.start();
break;
case 3:
t4.reset(m4);
t4.start();
break;
case 4:
t5.reset(m5);
t5.start();
break;
case 5:
t6.reset(m6);
t6.start();
break;
case 6:
t7.reset(m7);
t7.start();
break;
case 7:
t8.reset(m8);
t8.start();
break;
}
});
});
module.exports = io;
<file_sep>/projectp2_62453/public/js/client.js
var socket = io('http://192.168.55.55:3000');
var min1 = document.getElementById("min1");
var sec1 = document.getElementById("sec1");
var img1 = document.getElementById("img1");
var lbl1 = document.getElementById("lbl1");
var min2 = document.getElementById("min2");
var sec2 = document.getElementById("sec2");
var img2 = document.getElementById("img2");
var lbl2 = document.getElementById("lbl2");
var min3 = document.getElementById("min3");
var sec3 = document.getElementById("sec3");
var img3 = document.getElementById("img3");
var lbl3 = document.getElementById("lbl3");
var min4 = document.getElementById("min4");
var sec4 = document.getElementById("sec4");
var img4 = document.getElementById("img4");
var lbl4 = document.getElementById("lbl4");
var min5 = document.getElementById("min5");
var sec5 = document.getElementById("sec5");
var img5 = document.getElementById("img5");
var lbl5 = document.getElementById("lbl5");
var min6 = document.getElementById("min6");
var sec6 = document.getElementById("sec6");
var img6 = document.getElementById("img6");
var lbl6 = document.getElementById("lbl6");
var min7 = document.getElementById("min7");
var sec7 = document.getElementById("sec7");
var img7 = document.getElementById("img7");
var lbl7 = document.getElementById("lbl7");
var min8 = document.getElementById("min8");
var sec8 = document.getElementById("sec8");
var img8 = document.getElementById("img8");
var lbl8 = document.getElementById("lbl8");
var c1, c2, c3, c4, c5, c6, c7, c8 = false;
// Function
function miliseconds(min, sec) {
if (sec != 0 && min == 0)
return ((min * 60 + sec) * 1000);
else if (sec != 0 && min != 0)
return (((min + sec) - (40 * min)) * 1000);
else
return ((min * 60 + sec) * 10);
}
function timeFormat(time) {
if (time < 0)
time = time * -1
if (time < 10)
return "0" + time
else
return time
}
var turn_led = (param) => {
var led_obj = {
id: param,
time: "",
state: true
}
switch (param) {
case 0:
if (!c1) {
c1 = true;
if (parseInt(min1.value) == 0 && parseInt(sec1.value) == 0) {
alert("Asigna numero para de encender");
} else {
img1.src = "./images/on.png"
led_obj.time = timeFormat(min1.value) + ":" + timeFormat(sec1.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 1:
if (!c2) {
c2 = true;
if (parseInt(min2.value) == 0 && parseInt(sec2.value) == 0) {
alert("Asigna numero para de encender");
} else {
img2.src = "./images/on.png"
led_obj.time = timeFormat(min2.value) + ":" + timeFormat(sec2.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 2:
if (c3) {
c3 = true;
if (parseInt(min3.value) == 0 && parseInt(sec3.value) == 0) {
alert("Asigna numero para de encender");
} else {
img3.src = "./images/on.png"
led_obj.time = timeFormat(min3.value) + ":" + timeFormat(sec3.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 3:
if (!c4) {
c4 = true;
if (parseInt(min4.value) == 0 && parseInt(sec4.value) == 0) {
alert("Asigna numero para de encender");
} else {
img4.src = "./images/on.png"
led_obj.time = timeFormat(min4.value) + ":" + timeFormat(sec4.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 4:
if (!c5) {
c5 = true;
if (parseInt(min5.value) == 0 && parseInt(sec5.value) == 0) {
alert("Asigna numero para de encender");
} else {
img5.src = "./images/on.png"
led_obj.time = timeFormat(min5.value) + ":" + timeFormat(sec5.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 5:
if (!c6) {
c6 = true
if (parseInt(min6.value) == 0 && parseInt(sec6.value) == 0) {
alert("Asigna numero para de encender");
} else {
img6.src = "./images/on.png"
led_obj.time = timeFormat(min6.value) + ":" + timeFormat(sec6.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 6:
if (!c7) {
c7 = true;
if (parseInt(min7.value) == 0 && parseInt(sec7.value) == 0) {
alert("Asigna numero para de encender");
} else {
img7.src = "./images/on.png"
led_obj.time = timeFormat(min7.value) + ":" + timeFormat(sec7.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
case 7:
if (!c8) {
c8 = true
if (parseInt(min8.value) == 0 && parseInt(sec8.value) == 0) {
alert("Asigna numero para de encender");
}
else {
img8.src = "./images/on.png"
led_obj.time = timeFormat(min8.value) + ":" + timeFormat(sec8.value)
var timeParts = led_obj.time.split(":");
led_obj.time = miliseconds(timeParts[0], timeParts[1]);
socket.emit('prender', led_obj);
}
}
break;
default:
break;
}
}
var stop = (param) => {
var led_obj = {
id: param,
state: false
}
switch (param) {
case 0:
sec1.value, min1.value = 0
lbl1.innerHTML = "00:00:00";
c1 = false;
break;
case 1:
sec2.value, min2.value = 0
lbl2.innerHTML = "00:00:00";
c2 = false;
break;
case 2:
sec3.value, min3.value = 0
lbl3.innerHTML = "00:00:00";
c3 = false;
break;
case 3:
sec4.value, min4.value = 0
lbl4.innerHTML = "00:00:00";
c4 = false;
break;
case 4:
sec5.value, min5.value = 0
lbl5.innerHTML = "00:00:00";
c5 = false;
break;
case 5:
sec6.value, min6.value = 0
lbl6.innerHTML = "00:00:00";
c6 = false;
break;
case 6:
sec7.value, min7.value = 0
lbl7.innerHTML = "00:00:00";
c7 = false;
break;
case 7:
sec8.value, min8.value = 0
lbl8.innerHTML = "00:00:00";
c8 = false;
break;
}
socket.emit('stop', led_obj);
}
var pause = (param) => {
var led_obj = {
id: param,
state: false
}
switch (param) {
case 0:
sec1.value, min1.value = 0
lbl1.innerHTML = "00:00:00";
break;
case 1:
sec2.value, min2.value = 0
lbl2.innerHTML = "00:00:00";
break;
case 2:
sec3.value, min3.value = 0
lbl3.innerHTML = "00:00:00";
break;
case 3:
sec4.value, min4.value = 0
lbl4.innerHTML = "00:00:00";
break;
case 4:
sec5.value, min5.value = 0
lbl5.innerHTML = "00:00:00";
break;
case 5:
sec6.value, min6.value = 0
break;
case 6:
sec7.value, min7.value = 0
break;
case 7:
sec8.value, min8.value = 0
break;
}
socket.emit('pause', led_obj);
}
var resume = (param) => {
var led_obj = {
id: param,
state: false
}
socket.emit('resume', led_obj);
}
socket.on('restante', (data) => {
switch (data.id) {
case 0:
img1.src = "./images/on.png";
lbl1.innerHTML = data.time;
c1 = true;
break;
case 1:
img2.src = "./images/on.png";
lbl2.innerHTML = data.time;
c2 = true;
cbreak;
case 2:
img3.src = "./images/on.png";
lbl3.innerHTML = data.time;
c3 = true;
break;
case 3:
img4.src = "./images/on.png";
lbl4.innerHTML = data.time;
c4 = true;
break;
case 4:
img5.src = "./images/on.png";
lbl5.innerHTML = data.time;
c5 = true;
break;
case 5:
img6.src = "./images/on.png";
lbl6.innerHTML = data.time;
c6 = true;
break;
case 6:
img7.src = "./images/on.png";
lbl7.innerHTML = data.time;
c7 = true;
break;
case 7:
img8.src = "./images/on.png";
lbl8.innerHTML = data.time;
c8 = true;
break;
}
});
socket.on('termino', (data) => {
switch (data) {
case 0:
img1.src = "./images/off.png";
c1 = false;
break;
case 1:
img2.src = "./images/off.png";
c2 = false;
break;
case 2:
img3.src = "./images/off.png";
c3 = false;
break;
case 3:
img4.src = "./images/off.png";
c4 = false;
break;
case 4:
img5.src = "./images/off.png";
c5 = false;
break;
case 5:
img6.src = "./images/off.png";
c6 = false;
break;
case 6:
img7.src = "./images/off.png";
c7 = false;
break;
case 7:
img8.src = "./images/off.png";
c8 = false;
break;
}
});
<file_sep>/projectp2_62453/bin/scripts/leds.py
import sys
import json
import RPi.GPIO as GPIO
import time
GPIO.setwarnings(False)
outs = [37,35,33,31,29,40,38,36]
GPIO.setmode(GPIO.BOARD)
GPIO.setup(outs,GPIO.OUT)
leds = sys.argv
leds.remove(leds[0])
leds = json.loads(leds[0])
if leds["state"] == True:
GPIO.output(outs[leds["id"]],1)
print(1)
else:
GPIO.output(outs[leds["id"]],0)
print(0) | 8280d06728b918173a7af37f6e45798a49a249a9 | [
"JavaScript",
"Python"
] | 3 | JavaScript | JoseRamirezAyala/GPIOandSocketIO | bc3a49563065db846f4fbb8c4168d739eaf3c2d8 | c2ce584dee1aa9fa9e3cabe3df8ed6863148e88f |
refs/heads/master | <repo_name>masahiro331/gbiew<file_sep>/go.mod
module github.com/masahiro331/biff
go 1.13
require (
github.com/eihigh/goban v0.0.0-20190801102221-2682b1cd4874
github.com/jroimartin/gocui v0.4.0
github.com/nsf/termbox-go v0.0.0-20200418040025-38ba6e5628f1
)
<file_sep>/main.go
package main
import (
"fmt"
"log"
"os"
"github.com/nsf/termbox-go"
)
type FileInfo struct {
f *os.File
offset int64
}
const (
coldef = termbox.ColorDefault
LineSize = 69
LineByteSize = 16
)
func drawFullView(f *FileInfo, offset int) {
_, h := termbox.Size()
h = h - 2
viewSize := h * LineByteSize
if offset == 0 {
f.f.Seek(0, 0)
f.offset = 0
}
if offset == -1 {
fi, err := f.f.Stat()
if err != nil {
log.Fatal(err)
}
f.f.Seek(-int64(viewSize), 2)
f.offset = fi.Size() - int64(viewSize)
}
buf := make([]byte, viewSize)
_, err := f.f.Read(buf)
if err != nil {
log.Fatal(err)
}
termbox.Clear(coldef, coldef)
for y := 0; y < h; y++ {
for x, r := range lineStr(buf[LineByteSize*y:LineByteSize*(y+1)], uint64(f.offset)) {
termbox.SetCell(x, y, r, coldef, coldef)
}
f.offset = f.offset + LineByteSize
}
termbox.Flush()
}
func drawResetView(f *FileInfo) {
_, h := termbox.Size()
h = h - 2
viewSize := h * LineByteSize
buf := make([]byte, viewSize)
_, err := f.f.Read(buf)
if err != nil {
log.Fatal(err)
}
termbox.Clear(coldef, coldef)
for y := 0; y < h; y++ {
f.offset = f.offset + LineByteSize
for x, r := range lineStr(buf[LineByteSize*y:LineByteSize*(y+1)], uint64(f.offset)) {
termbox.SetCell(x, y, r, coldef, coldef)
}
}
termbox.Flush()
}
func drawDownView(f *FileInfo, offset int, forward bool) error {
_, h := termbox.Size()
h = h - 2
viewSize := h * LineByteSize
if forward {
offset = viewSize
}
_, err := f.f.Seek(int64(-viewSize+offset), 1)
if err != nil {
return err
}
buf := make([]byte, viewSize)
_, err = f.f.Read(buf)
if err != nil {
return err
}
f.offset = f.offset - int64(viewSize-offset)
termbox.Clear(coldef, coldef)
for y := 0; y < h; y++ {
f.offset = f.offset + LineByteSize
for x, r := range lineStr(buf[LineByteSize*y:LineByteSize*(y+1)], uint64(f.offset)) {
termbox.SetCell(x, y, r, coldef, coldef)
}
}
termbox.Flush()
return nil
}
func drawUpView(f *FileInfo, offset int, back bool) error {
_, h := termbox.Size()
h = h - 2
viewSize := h * LineByteSize
if back {
offset = viewSize
}
_, err := f.f.Seek(int64(-viewSize-offset), 1)
if err != nil {
return err
}
buf := make([]byte, viewSize)
_, err = f.f.Read(buf)
if err != nil {
return err
}
f.offset = f.offset - int64(viewSize+offset)
termbox.Clear(coldef, coldef)
for y := 0; y < h; y++ {
f.offset = f.offset + LineByteSize
for x, r := range lineStr(buf[LineByteSize*y:LineByteSize*(y+1)], uint64(f.offset)) {
termbox.SetCell(x, y, r, coldef, coldef)
}
}
termbox.Flush()
return nil
}
func main() {
if len(os.Args) < 2 {
log.Fatal("invalid arguments")
}
f, err := os.Open(os.Args[1])
if err != nil {
log.Fatal(err)
}
mainLoop(&FileInfo{
f: f,
offset: 0,
})
}
func mainLoop(f *FileInfo) {
var put_g bool
if err := termbox.Init(); err != nil {
log.Fatal(err)
}
defer termbox.Close()
drawFullView(f, 0)
MAINLOOP:
for {
switch ev := termbox.PollEvent(); ev.Type {
case termbox.EventKey:
switch ev.Key {
case termbox.KeyEsc, termbox.KeyCtrlC:
break MAINLOOP
case termbox.KeyCtrlF:
err := drawDownView(f, LineByteSize, true)
if err != nil {
break
}
case termbox.KeyCtrlB:
err := drawUpView(f, LineByteSize, true)
if err != nil {
break
}
}
switch ev.Ch {
case 'j':
err := drawDownView(f, LineByteSize, false)
if err != nil {
break
}
case 'k':
err := drawUpView(f, LineByteSize, false)
if err != nil {
break
}
case 'g':
if put_g {
drawFullView(f, 0)
put_g = false
} else {
put_g = true
}
case 'G':
drawFullView(f, -1)
// Command
case ':':
// Search
case '/':
drawFullView(f, -1)
}
}
}
}
func drawCommand(f *FileInfo, offset int) {
}
func drawSearch(f *FileInfo, offset int) {
}
func lineStr(buf []byte, offset uint64) []rune {
var binaryStr string
for i, b := range buf {
if i%2 == 0 {
binaryStr = binaryStr + " "
}
binaryStr = binaryStr + fmt.Sprintf("%02x", b)
}
return []rune(fmt.Sprintf("%08x: %s %s", offset, binaryStr, formatBinaryString(buf)))
}
func formatBinaryString(buf []byte) (str string) {
for _, b := range buf {
if b > 0x20 && b < 0x7f {
str = str + string(b)
} else {
str = str + "."
}
}
return
}
| 2034148d023a892b28d38ff25264029071260021 | [
"Go",
"Go Module"
] | 2 | Go Module | masahiro331/gbiew | a4d36aa42083afc9fb8c8bbd64c339e7182658fb | 7d7c05c7eea04a739cc2c222d111a5c1a7a543cf |
refs/heads/master | <repo_name>jbeguna04/image-parsing<file_sep>/src/utilities/index.js
const childProcess = require('child_process')
const brain = require('brain.js')
const cheerio = require('cheerio')
const fastGlob = require('fast-glob')
const fs = require('fs')
const javascriptBarcodeReader = require('javascript-barcode-reader')
const os = require('os')
// const javascriptBarcodeReader = require('../../../Javascript-Barcode-Reader/src')
/**
* Create worker process equal to cpu cores
*
* @returns {Array} array of child process forks
*/
async function createWorkerProcesses(imagesCount) {
const WORKERS = []
let NO_OF_CORES = await new Promise(resolve => {
switch (os.platform()) {
case 'win32':
childProcess.exec('wmic CPU Get NumberOfCores', {}, (err, out) => {
resolve(
parseInt(
out
.replace(/\r/g, '')
.split('\n')[1]
.trim(),
10
)
)
})
break
case 'darwin':
case 'linux':
childProcess.exec('getconf _NPROCESSORS_ONLN', {}, (err, out) => {
resolve(parseInt(out, 10))
})
break
case 'freebsd':
case 'openbsd':
childProcess.exec('getconf NPROCESSORS_ONLN', {}, (err, out) => {
resolve(parseInt(out, 10))
})
break
case 'sunos':
childProcess.exec(
'kstat cpu_info|grep core_id|sort -u|wc -l',
{},
(err, out) => {
resolve(parseInt(out, 10))
}
)
break
default:
resolve()
break
}
})
NO_OF_CORES = Math.min(NO_OF_CORES || os.cpus().length / 2, imagesCount)
// If available ram is less than 500MB, use only two worker processes
if ((os.totalmem() - os.freemem()) / (1024 * 1024 * 1024) < 0.5) {
NO_OF_CORES = 2
}
for (let i = 0; i < NO_OF_CORES; i += 1) {
WORKERS.push(childProcess.fork(`${__dirname}/processTaskWorker.js`))
}
return WORKERS
}
/**
* Extracts position & dimensions of objects from SVG design File
* @param {String} designFilePath Path to the svg design file
* @returns {Object} JSON object
*/
async function getDesignData(path) {
const designData = {
questions: {},
}
const ROLL_NO_PATTERN = new RegExp(/rollnobarcode/gi)
const QUESTION_PATTERN = new RegExp(/(q[1-9][0-9]?[ad])\b/gi)
const $ = cheerio.load(fs.readFileSync(path, 'utf8'))
const svgViewBox = $('svg')[0].attribs.viewBox.split(' ')
designData.width = Math.ceil(svgViewBox[2] - svgViewBox[0])
designData.height = Math.ceil(svgViewBox[3] - svgViewBox[1])
let gotRollNo = false
let x
let y
let rx
let ry
let width
let height
const groups = $('g')
for (let i = 0; i < groups.length; i += 1) {
const group = groups[i]
const title = $(group)
.find('title')
.first()
.html()
.trim()
.toLowerCase()
const isQuestionGroup = QUESTION_PATTERN.test(title)
const isRollNoGroup =
isQuestionGroup || gotRollNo ? false : ROLL_NO_PATTERN.test(title)
if (isQuestionGroup || isRollNoGroup) {
const transform = $(group)
.attr('transform')
.replace(/(translate)|\(|\)/gi, '')
.split(',')
.map(val => parseInt(val, 10))
const rect = $(group)
.find('rect')
.first()
const left = parseInt(rect.attr('x'), 10)
const top = parseInt(rect.attr('y'), 10)
rx = parseInt(rect.attr('rx') || 0, 10)
ry = parseInt(rect.attr('ry') || 0, 10)
x = left - rx + transform[0]
y = top - ry + transform[1]
width = parseInt(rect.attr('width'), 10) + rx
height = parseInt(rect.attr('height'), 10) + ry
}
if (isQuestionGroup) {
const optionTitle = title.slice(-1)
const questionNumber = title.slice(0, -1)
if (!designData.questions[questionNumber]) {
designData.questions[questionNumber] = {}
}
if (optionTitle === 'a') {
designData.questions[questionNumber].x1 = x
designData.questions[questionNumber].y1 = y
} else {
designData.questions[questionNumber].x2 = x + width
designData.questions[questionNumber].y2 = y + height
}
}
if (isRollNoGroup) {
designData.rollNo = { x1: x, y1: y, x2: x + width, y2: y + height }
gotRollNo = true
}
}
return designData
}
/**
* Return a list of valid image format files from the provided path
* @param {String} path Path to sarch for images
* @param {Array.<String>} format Array of extensions of valid image formats
* @returns {Array.<String>} List of file paths
*/
function getImagePaths(path) {
const format = [
'png',
'jpg',
'jpeg',
'jpe',
// 'jfif',
'gif',
'tif',
'tiff',
'bmp',
// 'dib',
]
return fastGlob(`${path}/*.{${format.join(',')}}`, {
onlyFiles: true,
})
}
/**
* Returns a trained neural network function
* @returns {Function} Neural network function
*/
function getNeuralNet() {
const net = new brain.NeuralNetwork()
return net.fromJSON(
JSON.parse(fs.readFileSync(`${__dirname}/../../training-data/data.json`))
)
}
/**
*
* @param {Object} designData A JSON Object containing information about the position, width, height of elements in svg design file (available from utiltities/getDesignData)
* @param {String} path Path of scanned image file
* @param {Object=} resultsData Path to csv file for training data
* @param {Number=} rollNo Roll no of the current scanned image
*
* @returns {Object} {title: {String}, data: {buffer}}
*/
async function getQuestionsData(designData, img, resultsData, rollNo) {
const isTestData = resultsData && rollNo
return new Promise((resolveCol, rejectCol) => {
img.resize(designData.width).max()
const promises = []
// extract all questions portions
Object.keys(designData.questions).forEach(title => {
const p = new Promise(resolve => {
const q = designData.questions[title]
img
.extract({
left: q.x1,
top: q.y1,
width: q.x2 - q.x1,
height: q.y2 - q.y1,
})
// .toFile(`${__dirname}\\tmp\\${title}.png`, err => {
// if (err) console.log(err)
// })
.toColourspace('b-w')
.threshold()
.toBuffer({ resolveWithObject: true })
.then(res => {
const data = res.data.map(val => (val === 0 ? 1 : 0))
if (isTestData) {
// for training data
if (resultsData[rollNo] && resultsData[rollNo][title] !== '*') {
const o = {}
o[resultsData[rollNo][title]] = 1
resolve({ input: data, output: o })
} else {
resolve(false)
}
} else {
// for processing data
resolve({ title, data })
}
})
})
promises.push(p)
})
Promise.all(promises)
.then(res => {
resolveCol(res)
})
.catch(err => {
rejectCol(err)
})
})
}
/**
*
* @param {Object} designData A JSON Object containing information about the position, width, height of elements in svg design file (available from utiltities/getDesignData)
* @param {String} path Path of scanned image file
* @returns {String} Roll Number
*/
async function getRollNoFromImage(designData, img) {
const metadata = await img.metadata()
const rollNoPos = designData.rollNo
const ratio = metadata.width / designData.width
const width = Math.ceil((rollNoPos.x2 - rollNoPos.x1) * ratio)
const height = Math.ceil((rollNoPos.y2 - rollNoPos.y1) * ratio)
const { data } = await img
.extract({
left: Math.floor(rollNoPos.x1 * ratio),
top: Math.floor(rollNoPos.y1 * ratio),
width,
height,
})
.toBuffer({ resolveWithObject: true })
// add missing channel
const newData = []
for (let i = 0; i < data.length; i += 3) {
newData.push(data[i])
newData.push(data[i + 1])
newData.push(data[i + 2])
newData.push(255)
}
return javascriptBarcodeReader(
{ data: newData, width, height },
{ barcode: 'code-39' }
)
}
/**
*
* @param {String} path CSV file path
* @returns {Object} JSON Object
*/
async function readCsvToJson(path) {
const resultData = {}
const resultFile = fs.readFileSync(path, 'utf8')
const rows = resultFile.split('\n')
const headerValues = rows[0]
.split(',')
.map(word => word.replace(/(\s)|(\.)|(-)|(_)/gi, '').toLowerCase())
const rollNoIndex =
headerValues.indexOf('rollno') ||
headerValues.indexOf('rollnumber') ||
headerValues.indexOf('roll#')
for (let i = 1; i < rows.length; i += 1) {
const values = rows[i].split(',').map(word => word.toLowerCase())
const obj = {}
for (let j = 0; j < values.length; j += 1) {
obj[headerValues[j]] = values[j]
}
resultData[values[rollNoIndex]] = obj
}
return resultData
}
/**
*
* @param {String} path JSON file path
* @returns {Object} CSV String
*/
function readJsonToCsv(obj) {
let header = ''
let csv = ''
const keys = Object.keys(obj)
// Prepare header row
Object.keys(obj[keys[0]]).forEach(prop => {
header += `${prop[0].toUpperCase() + prop.substr(1)},`
})
header += 'RollNo'
// prepare data rows
keys.forEach(key => {
Object.keys(obj[key]).forEach(prop => {
csv += `${obj[key][prop]},`
})
csv += key
csv += '\n'
})
return `${header}\n${csv}`
}
module.exports = {
createWorkerProcesses,
getDesignData,
getImagePaths,
getNeuralNet,
getRollNoFromImage,
readCsvToJson,
readJsonToCsv,
getQuestionsData,
}
<file_sep>/src/renderer/router/index.js
import Vue from 'vue'
import Router from 'vue-router'
Vue.use(Router)
export default new Router({
routes: [
{
path: '/',
redirect: '/home',
},
{
path: '/home',
meta: {
title: 'Home',
icon: 'fa-home',
},
component: require('@/components/Home').default,
},
{
path: '/generate',
meta: {
title: 'Generate',
icon: 'fa-file-alt',
},
component: require('@/components/Generate').default,
children: [
{
path: 'choose-design', // design
meta: {
title: 'Design',
icon: 'fa-object-group',
},
component: require('@/components/Generate/Design').default,
},
{
path: 'choose-data',
meta: {
title: 'Data',
icon: 'fa-database',
},
component: require('@/components/Generate/Data').default,
},
{
path: 'choose-options',
meta: {
title: 'Options',
icon: 'fa-qrcode',
},
component: require('@/components/Generate/options').default,
},
{
path: 'start-generate',
meta: {
title: 'Generate',
icon: 'fa-play',
},
component: require('@/components/Generate/Progress').default,
},
],
},
{
path: '/process',
meta: {
title: 'Process',
icon: 'fa-play',
},
component: require('@/components/Process').default,
children: [
{
path: 'choose-design',
meta: {
title: 'Design',
icon: 'fa-object-group',
},
component: require('@/components/Process/Design').default,
},
{
path: 'choose-data',
meta: {
title: 'Data',
icon: 'fa-database',
},
component: require('@/components/Process/Data').default,
},
{
path: 'choose-options',
meta: {
title: 'Options',
icon: 'fa-qrcode',
},
component: require('@/components/Process/options').default,
},
{
path: 'start-process',
meta: {
title: 'Process',
icon: 'fa-play',
},
component: require('@/components/Process/Progress').default,
},
],
},
{
path: '/train',
meta: {
title: 'Train',
icon: 'fa-vials',
},
component: require('@/components/Train').default,
},
{
path: '/about',
meta: {
title: 'About',
icon: 'fa-info-circle',
},
component: require('@/components/About').default,
},
{
path: '*',
redirect: '/',
},
],
})
<file_sep>/src/utilities/process.js
/**
* Import utilty functions
*/
const { processTask } = require('./processTaskWorker')
const {
createWorkerProcesses,
getDesignData,
getImagePaths,
} = require('./index')
/**
* Start processing scanned image files to get result
*
* @param {String} designFilePath design file path
* @param {String} imagesDirectory scanned images directory
* @param {String} neuralNetFilePath neuralNet file path
* @param {String} outputPath output path
* @param {Boolean} useWorkers Enable parrallel processing
*
* @returns null
*/
async function process(
designFilePath,
imagesDirectory,
outputPath,
useWorkers
) {
console.time('PREPARE-DATA')
const imagePaths = await getImagePaths(imagesDirectory)
const designData = await getDesignData(designFilePath)
console.timeEnd('PREPARE-DATA')
if (!useWorkers) {
console.time('PROCESS-DATA-USING-SINGLE-THREAD')
processTask(designData, imagePaths).then(res => {
console.timeEnd('PROCESS-DATA-USING-SINGLE-THREAD')
console.log(res)
})
} else {
const TOTAL_IMAGES = imagePaths.length
const WORKER_PROCESSES = await createWorkerProcesses(TOTAL_IMAGES)
const TOTAL_PROCESS = WORKER_PROCESSES.length
const STEP = Math.floor(TOTAL_IMAGES / TOTAL_PROCESS)
for (let i = 0; i < TOTAL_PROCESS; i += 1) {
const startIndex = i * STEP
const endIndex = i === TOTAL_PROCESS - 1 ? TOTAL_IMAGES : (i + 1) * STEP
const worker = WORKER_PROCESSES[i]
console.time(`PROCESS-DATA-USING-THREAD-${i}`)
worker.send({
designData,
imagePaths: imagePaths.slice(startIndex, endIndex),
})
worker.on('message', res => {
console.timeEnd(`PROCESS-DATA-USING-THREAD-${i}`)
console.log(res)
})
}
}
}
module.exports = {
process,
}
<file_sep>/src/utilities/test.js
const processModule = require('./process')
const trainModule = require('./train')
if (process.env.TEST_TYPE === 'process') {
processModule.process(
'D:\\Current\\image-parsing\\sample-data\\design\\AnswerSheet-1.svg',
'D:\\Current\\image-parsing\\sample-data\\image\\Processed',
'D:\\Current\\image-parsing\\sample-data\\result',
true
)
} else if (process.env.TEST_TYPE === 'train') {
trainModule.train(
'D:\\Current\\image-parsing\\sample-data\\design\\AnswerSheet-1.svg',
'D:\\Current\\image-parsing\\sample-data\\image\\Processed',
'D:\\Current\\image-parsing\\sample-data\\result\\AnswerSheet_Data.csv',
'D:\\Current\\image-parsing\\training-data\\data.json'
)
}
<file_sep>/src/utilities/processTaskWorker.js
const sharp = require('sharp')
/**
* Import utilty functions
*/
const {
getRollNoFromImage,
getQuestionsData,
getNeuralNet,
} = require('./index')
const neuralNet = getNeuralNet()
/**
*
* @param {Object} designData A JSON Object containing information about the position, width, height of elements in svg design file (available from utiltities/getDesignData)
* @param {Array.<String>} imagePaths List of scanned images paths
*
* @returns {Object} Compiled result JSON
*/
async function processTask(designData, imagePaths) {
const promises = []
for (let i = 0; i < imagePaths.length; i += 1) {
const imagePath = imagePaths[i]
const sharpImage = sharp(imagePath).raw() // TODO: Preprocess image
const sharpImageClone = sharpImage.clone()
const promise = new Promise(resolve => {
Promise.all([
getRollNoFromImage(designData, sharpImage),
getQuestionsData(designData, sharpImageClone),
]).then(res => {
const [rollNo, questionsData] = res
const questionsCount = questionsData.length
const resultsJson = {}
if (!resultsJson[rollNo]) resultsJson[rollNo] = {}
for (let j = questionsCount - 1; j >= 0; j -= 1) {
const q = questionsData[j]
const pre = neuralNet.run(q.data)
let resultArray = []
Object.keys(pre).forEach((key, index) => {
resultArray[index] = {
key,
val: pre[key],
}
})
resultArray.sort((a, b) => b.val - a.val)
const topKeyValue = resultArray[0]
if (topKeyValue.val >= 0.95 && topKeyValue.key === '?') {
resultsJson[rollNo][q.title] = topKeyValue.key
} else {
resultArray = resultArray.filter(item => item.key !== '?')
if (
topKeyValue.val < 0.4 ||
topKeyValue.val - resultArray[1].val < 0.2
) {
resultsJson[rollNo][q.title] = '*'
} else {
resultsJson[rollNo][q.title] = topKeyValue.key
}
}
}
resolve(resultsJson)
})
})
promises.push(promise)
}
// eslint-disable-next-line
return Promise.all(promises)
.then(res => {
if (process && process.send) {
process.send(res)
process.exit(0)
}
return res
})
.catch(err => {
console.log(err)
process.exit(1)
})
}
process.on('message', m => {
processTask(m.designData, m.imagePaths)
})
module.exports = {
processTask,
}
| 669cf3547305a9aada0ff790be5cb2438b574ebd | [
"JavaScript"
] | 5 | JavaScript | jbeguna04/image-parsing | 2f27f82462b8def3064ff39e3fdac1c249e185ca | 4b4631fde9ae42b4eea9f9f313eaad12cec8276a |
refs/heads/main | <repo_name>chinice/myFirstDotnetProject<file_sep>/MyLearning/Utils/ErrorHandlerMiddleware.cs
using System;
using System.Collections.Generic;
using System.Net;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Http;
using Newtonsoft.Json;
namespace MyLearning.Utils
{
public class ErrorHandlerMiddleware
{
private readonly RequestDelegate _next;
public ErrorHandlerMiddleware(RequestDelegate next)
{
_next = next;
}
public async Task Invoke(HttpContext context)
{
try
{
await _next(context);
} catch (Exception ex)
{
if ( ex.InnerException != null )
{
// LogWriter.LogWrite(ex.InnerException.Message);
// LogWriter.LogWrite(ex.StackTrace);
}
// LogWriter.LogWrite(ex.Message);
// LogWriter.LogWrite(ex.StackTrace);
await HandleErrorAsync(context, ex);
}
}
private static Task HandleErrorAsync(HttpContext context, Exception exception)
{
switch(exception)
{
case AppException e:
// custom application error
context.Response.StatusCode = (int)HttpStatusCode.BadRequest;
break;
case KeyNotFoundException e:
// not found error
context.Response.StatusCode = (int)HttpStatusCode.NotFound;
break;
default:
// unhandled error
context.Response.StatusCode = (int)HttpStatusCode.InternalServerError;
break;
}
var response = new { Status = false, Message = exception.Message, Data = new { } };
var payload = JsonConvert.SerializeObject(response);
context.Response.ContentType = "application/json";
return context.Response.WriteAsync(payload);
}
}
}<file_sep>/MyLearning/Data/MyLearningDbContext.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.EntityFrameworkCore;
using MyLearning.Models;
public class MyLearningDbContext : DbContext
{
public MyLearningDbContext (DbContextOptions<MyLearningDbContext> options)
: base(options)
{
}
public DbSet<Product> Product { get; set; }
public DbSet<User> User { get; set; }
}
<file_sep>/MyLearning/Dtos/UserCreateDto.cs
using System;
using System.ComponentModel.DataAnnotations;
namespace MyLearning.Dtos
{
public class UserCreateDto
{
[Required(ErrorMessage = "Username is required")]
[MinLength(5, ErrorMessage = "Username cannot be less than 5 characters")]
public string UserName { get; set; }
[Required(ErrorMessage = "Password is required")]
[MinLength(8, ErrorMessage = "Password must be at least 8 characters")]
public string Password { get; set; }
[Required(ErrorMessage = "Name is required")]
//[RegularExpression(@"^[A-Z]")]
public string Name { get; set; }
[Required(ErrorMessage = "Phone is required")]
public string Phone { get; set; }
[Required(ErrorMessage = "Address is required")]
public string Address { get; set; }
}
}
<file_sep>/MyLearning/Models/User.cs
using System;
using System.Collections.Generic;
using Newtonsoft.Json;
namespace MyLearning.Models
{
public class User
{
public int Id { get; set; }
public string UserName { get; set; }
[JsonIgnore]
public string Password { get; set; }
public string Name { get; set; }
public string Phone { get; set; }
public string Address { get; set; }
public int Status { get; set; } = 1;
public string Salt { get; set; }
public DateTime CreatedAt { get; set; }
public DateTime UpdatedAt { get; set; } = DateTime.Now;
public ICollection<Product> Products { get; set; }
}
}
<file_sep>/MyLearning/Services/IProductRepository.cs
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
using MyLearning.Models;
namespace MyLearning.Services
{
public interface IProductRepository
{
public Task<Product> AddProduct(Product product);
public Task<ICollection<Product>> GetAllProducts();
public Task<Product> GetProductById(int id);
public Task<bool> UpdateProduct(Product product);
public Task<bool> DeleteProduct(Product product);
public Task<bool> CheckProductExist(int id);
}
}
<file_sep>/MyLearning/Services/UserRepository.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.EntityFrameworkCore;
using MyLearning.Models;
using MyLearning.Utils;
namespace MyLearning.Services
{
public class UserRepository: IUserRepository
{
private readonly MyLearningDbContext _myLearningDbContext;
public UserRepository(MyLearningDbContext myLearningDbContext)
{
_myLearningDbContext = myLearningDbContext;
}
public async Task<User> AddUser(User user)
{
await _myLearningDbContext.User.AddAsync(user);
await new DbUtil().SaveChanges(_myLearningDbContext);
return user;
}
public async Task<bool> DeleteUser(User user)
{
_myLearningDbContext.User.Remove(user);
var result = await new DbUtil().SaveChanges(_myLearningDbContext);
return result;
}
public async Task<ICollection<User>> GetAllUsers()
{
var users = await _myLearningDbContext.User.OrderByDescending(u => u.Name).ToListAsync();
return users;
}
public async Task<User> GetUser(int id)
{
var user = await _myLearningDbContext.User.Where( u => u.Id == id ).FirstOrDefaultAsync();
return user;
}
public async Task<bool> UpdateUser(User user)
{
_myLearningDbContext.User.Update(user);
var result = await new DbUtil().SaveChanges(_myLearningDbContext);
return result;
}
public async Task<bool> CheckUserExist(int id)
{
var userExist = await _myLearningDbContext.User.AnyAsync(u => u.Id == id);
return userExist;
}
public async Task<bool> CheckUserExistByUserName(string username)
{
var userExist = await _myLearningDbContext.User.AnyAsync(u => u.UserName == username);
return userExist;
}
}
}
<file_sep>/MyLearning/Services/AuthRepository.cs
using System.Threading.Tasks;
using Microsoft.EntityFrameworkCore;
using MyLearning.Models;
using MyLearning.Utils;
namespace MyLearning.Services
{
public class AuthRepository: IAuthRepository
{
private readonly MyLearningDbContext _myLearningDbContext;
public AuthRepository(MyLearningDbContext myLearningDbContext)
{
_myLearningDbContext = myLearningDbContext;
}
public async Task<User> Authenticate(string userName, string password)
{
var user = await _myLearningDbContext.User.SingleOrDefaultAsync(u => u.UserName == userName && u.Password == password);
return user;
}
public async Task<User> Register(User user)
{
await _myLearningDbContext.User.AddAsync(user);
await new DbUtil().SaveChanges(_myLearningDbContext);
return user;
}
public async Task<bool> PasswordUpdate(User user)
{
_myLearningDbContext.User.Update(user);
var result = await new DbUtil().SaveChanges(_myLearningDbContext);
return result;
}
}
}<file_sep>/MyLearning/Services/IAuthRepository.cs
using System.Threading.Tasks;
using MyLearning.Models;
namespace MyLearning.Services
{
public interface IAuthRepository
{
public Task<User> Authenticate(string userName, string password);
public Task<User> Register(User user);
public Task<bool> PasswordUpdate(User user);
}
}<file_sep>/MyLearning/Services/ProductRepository.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.EntityFrameworkCore;
using MyLearning.Models;
using MyLearning.Utils;
namespace MyLearning.Services
{
public class ProductRepository: IProductRepository
{
private readonly MyLearningDbContext _myLearningDbContext;
public ProductRepository(MyLearningDbContext myLearningDbContext)
{
_myLearningDbContext = myLearningDbContext;
}
public async Task<Product> AddProduct(Product product)
{
await _myLearningDbContext.Product.AddAsync(product);
await new DbUtil().SaveChanges(_myLearningDbContext);
return product;
}
public async Task<bool> DeleteProduct(Product product)
{
_myLearningDbContext.Product.Remove(product);
var result = await new DbUtil().SaveChanges(_myLearningDbContext);
return result;
}
public async Task<ICollection<Product>> GetAllProducts()
{
var products = await _myLearningDbContext.Product.OrderByDescending(p => p.ProductName).ToListAsync();
return products;
}
public async Task<Product> GetProductById(int id)
{
var product = await _myLearningDbContext.Product.Where(p => p.Id == id).FirstOrDefaultAsync();
return product;
}
public async Task<bool> UpdateProduct(Product product)
{
_myLearningDbContext.Product.Update(product);
var result = await new DbUtil().SaveChanges(_myLearningDbContext);
return result;
}
public async Task<bool> CheckProductExist(int id)
{
var userExist = await _myLearningDbContext.Product.AnyAsync(p => p.Id == id);
return userExist;
}
}
}
<file_sep>/MyLearning/Dtos/ProductCreateDto.cs
using System;
using System.ComponentModel.DataAnnotations;
namespace MyLearning.Dtos
{
public class ProductCreateDto
{
[Required(ErrorMessage = "Product name is required")]
public string ProductName { get; set; }
[Required(ErrorMessage = "Product description is required")]
public string ProductDescription { get; set; }
[Required(ErrorMessage = "Product amount is required")]
public decimal ProductAmount { get; set; }
[Required(ErrorMessage = "Quantity is required")]
public int Quantity { get; set; } = 0;
}
}
<file_sep>/MyLearning/Startup.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Builder;
using Microsoft.AspNetCore.Hosting;
using Microsoft.AspNetCore.HttpsPolicy;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Configuration;
using Microsoft.Extensions.DependencyInjection;
using Microsoft.Extensions.Hosting;
using Microsoft.Extensions.Logging;
using Microsoft.EntityFrameworkCore;
using MyLearning.Services;
using Microsoft.AspNetCore.Http.Features;
using Microsoft.OpenApi.Models;
using System.Reflection;
using System.IO;
using System.Text;
using Microsoft.AspNetCore.Authentication.JwtBearer;
using Microsoft.AspNetCore.Http;
using Microsoft.IdentityModel.Tokens;
using MyLearning.Utils;
using Newtonsoft.Json;
namespace MyLearning
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Configuration = configuration;
}
public IConfiguration Configuration { get; }
// This method gets called by the runtime. Use this method to add services to the container.
public void ConfigureServices(IServiceCollection services)
{
services.AddCors(c =>
{
c.AddPolicy("AllowOrigin", options => options
.SetIsOriginAllowed(_ => true)
.AllowAnyOrigin()
.AllowAnyHeader()
.AllowAnyMethod());
//.WithOrigins("http://localhost:52403", "http://localhost:4200"));
});
services.AddResponseCompression();
services.AddControllers().AddNewtonsoftJson(
opt =>
{
opt.SerializerSettings.ReferenceLoopHandling = Newtonsoft.Json.ReferenceLoopHandling.Ignore;
});
// configure strongly typed settings
var appSettingsSection = Configuration.GetSection("AppSettings");
services.Configure<AppSettings>(appSettingsSection);
services.AddDbContext<MyLearningDbContext>(options =>
options.UseSqlServer(Configuration.GetConnectionString("MyLearningDbContext")));
services.AddScoped<IUserRepository, UserRepository>();
services.AddScoped<IProductRepository, ProductRepository>();
services.AddScoped<IAuthRepository, AuthRepository>();
// configures services for multipartbodylength
services.Configure<FormOptions>(o =>
{
o.ValueLengthLimit = int.MaxValue;
o.MultipartBodyLengthLimit = int.MaxValue;
o.MemoryBufferThreshold = int.MaxValue;
});
// formats model state error message to custom message
services.Configure<ApiBehaviorOptions>(options =>
{
options.InvalidModelStateResponseFactory = actionContext =>
{
var errors = actionContext.ModelState.Where(
e => e.Value.Errors.Count > 0
).Select(e => new
{
Error = e.Value.Errors.First().ErrorMessage,
}).ToArray();
return new BadRequestObjectResult(new
{
Status = false,
Message = errors,
Data = new { }
});
};
});
// get appsettings instance
var appSettings = appSettingsSection.Get<AppSettings>();
// get secret key
var secretKey = Encoding.UTF8.GetBytes(appSettings.SecretKey);
// configure authentication
services.AddAuthentication(option =>
{
option.DefaultAuthenticateScheme = JwtBearerDefaults.AuthenticationScheme;
option.DefaultChallengeScheme = JwtBearerDefaults.AuthenticationScheme;
}).AddJwtBearer(options => {
options.SaveToken = true;
options.RequireHttpsMetadata = false;
options.Events = new JwtBearerEvents
{
OnTokenValidated = context =>
{
// TODO:: Validate user by token
var userRepo = context.HttpContext.RequestServices.GetRequiredService<IUserRepository>();
var userId = int.Parse(context.Principal.Identity.Name);
var user = userRepo.GetUser(userId);
if ( user == null )
{
context.Fail(new Exception("Unauthorized"));
}
return Task.CompletedTask;
},
OnAuthenticationFailed = context =>
{
var message = "";
if (context.Exception is SecurityTokenValidationException)
{
message = "Invalid token";
} else if (context.Exception is SecurityTokenInvalidIssuerException)
{
message = "Invalid Issuer";
} else if ( context.Exception.GetType() == typeof(SecurityTokenExpiredException))
{
message = "Token Expired";
} else if (context.Exception is SecurityTokenInvalidAudienceException)
{
message = "Invalid Audience";
}
context.Response.WriteAsync(JsonConvert.SerializeObject(
new {
Status = false,
Message = message,
Data = new {}
}, Formatting.Indented));
return Task.FromResult<object>(0);
}
};
options.TokenValidationParameters = new TokenValidationParameters
{
ValidateIssuer = false,
ValidateAudience = false,
ValidateLifetime = false,
ValidateIssuerSigningKey = true,
// ValidIssuer = Configuration["AppSettings:Issuer"], // commented because ValidateIssuer is false
// ValidAudience = Configuration["AppSettings:Issuer"], // commented because ValidateAudience is false
IssuerSigningKey = new SymmetricSecurityKey(secretKey),
// set clockskew to zero so tokens expire exactly at specified time
ClockSkew = TimeSpan.Zero
};
});
// Register the Swagger generator, defining 1 or more Swagger documents
services.AddSwaggerGen(c => {
c.SwaggerDoc("v1", new OpenApiInfo
{
Version = "v1",
Title = "My Learning API",
Description = "An ASP.NET Core Web API for Chinice" +
" App extending the functionality of Ebusiness. The project was done in asp.net core 3.1",
TermsOfService = new Uri("http://www.elixirprimehouse.com/"),
Contact = new OpenApiContact
{
Name = "<NAME>",
Email = "<EMAIL>",
Url = new Uri("http://www.elixirprimehouse.com/"),
},
License = new OpenApiLicense
{
Name = "Elixir Prime House",
Url = new Uri("http://www.elixirprimehouse.com/"),
}
});
c.AddSecurityDefinition("Bearer", new OpenApiSecurityScheme
{
In = ParameterLocation.Header,
Description = "JWT Authorization header using the Bearer scheme (Example: 'Bearer 12345abcdef')",
Name = "Authorization",
Type = SecuritySchemeType.ApiKey,
Scheme = "Bearer"
});
c.AddSecurityRequirement(new OpenApiSecurityRequirement {
{
new OpenApiSecurityScheme
{
Reference = new OpenApiReference
{
Type = ReferenceType.SecurityScheme,
Id = "Bearer"
},
Scheme = "oauth2",
Name = "Bearer",
In = ParameterLocation.Header
},
new string[] { }
}
});
// Set the comments path for the Swagger JSON and UI.
var xmlFile = $"{Assembly.GetExecutingAssembly().GetName().Name}.xml";
var xmlPath = Path.Combine(AppContext.BaseDirectory, xmlFile);
c.IncludeXmlComments(xmlPath);
});
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IWebHostEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
app.UseResponseCompression();
// Enable middleware to serve generated Swagger as a JSON endpoint.
app.UseSwagger();
// Enable middleware to serve swagger-ui (HTML, JS, CSS, etc.),
// specifying the Swagger JSON endpoint.
app.UseSwaggerUI(c =>
{
c.SwaggerEndpoint("v1/swagger.json", "Elixir Prime House");
});
app.UseHttpsRedirection();
app.UseMiddleware<ErrorHandlerMiddleware>();
app.UseAuthentication();
app.UseRouting();
app.UseAuthorization();
app.UseCors("AllowOrigin");
app.UseEndpoints(endpoints =>
{
endpoints.MapControllers();
});
}
}
}
<file_sep>/MyLearning/Controllers/UserController.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Authentication.JwtBearer;
using Microsoft.AspNetCore.Authorization;
using Microsoft.AspNetCore.Cors;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using MyLearning.Dtos;
using MyLearning.Services;
using MyLearning.Utils;
namespace MyLearning.Controllers
{
[Route("api/[controller]")]
[ApiController]
[Produces("application/json")]
[EnableCors("AllowOrigin")]
[Microsoft.AspNetCore.Authorization.Authorize(AuthenticationSchemes = JwtBearerDefaults.AuthenticationScheme)]
public class UserController : ControllerBase
{
private readonly IUserRepository _userRepository;
public UserController(IUserRepository userRepository)
{
_userRepository = userRepository;
}
/// <summary>
/// Get all users
/// </summary>
/// <returns>Users retrieved successfully</returns>
/// <returns code="200">Users retrieved successfully</returns>
[AllowAnonymous]
[HttpGet]
[ProducesResponseType(StatusCodes.Status200OK, Type = typeof(ResponseMessage))]
public async Task<IActionResult> Get()
{
var users = await _userRepository.GetAllUsers();
return Ok(new {
Status = true,
Message = "Users retrieved successfully",
Data = users
});
}
/// <summary>
/// Get specific user by ID
/// </summary>
/// <param name="id"></param>
/// <returns>User retrieved successfully</returns>
/// <returns code="200">User retrieved successfully</returns>
/// <returns code="422">The user does not exist</returns>
[HttpGet("{id}", Name = "Get")]
[ProducesResponseType(StatusCodes.Status200OK, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status422UnprocessableEntity, Type = typeof(ResponseMessage))]
public async Task<IActionResult> Get(int id)
{
var user = await _userRepository.GetUser(id);
if(user == null)
{
return StatusCode(422, new
{
Status = false,
Message = "The user does not exist",
Data = new { }
});
}
else
{
return Ok(new
{
Status = true,
Message = "User retrieved successfully",
Data = user
});
}
}
/// <summary>
/// Create a new user
/// </summary>
/// <param name="userCreateDto"></param>
/// <returns>User successfully created</returns>
/// <returns code="201">User successfully created</returns>
/// <returns code="400">Model state error</returns>
/// <returns code="422">The username already exist</returns>
/// <returns code="500">Internal Server Error</returns>
[HttpPost]
[ProducesResponseType(StatusCodes.Status201Created, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status400BadRequest, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status422UnprocessableEntity, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status500InternalServerError, Type = typeof(ResponseMessage))]
public async Task<IActionResult> Post([FromBody] UserCreateDto userCreateDto)
{
if(!ModelState.IsValid)
{
return BadRequest(new {
Status = false,
Message = ModelState,
Data = new { }
});
}
//check if user exist
var userExist = await _userRepository.CheckUserExistByUserName(userCreateDto.UserName);
if(userExist)
{
return StatusCode(422, new
{
Status = false,
Message = "The username already exist",
Data = new { }
});
}
//Hash password
string password = HashUtil.HashString(userCreateDto.Password, "SHA1");
var user = await _userRepository.AddUser(new Models.User
{
UserName = userCreateDto.UserName,
Password = <PASSWORD>,
Name = userCreateDto.Name,
Phone = userCreateDto.Phone,
Address = userCreateDto.Address,
CreatedAt = DateTime.Now
});
if(user.Id > 0)
{
return StatusCode(201, new {
Status = true,
Message = "User successfully created",
Data = user
});
}
else
{
return StatusCode(500, new
{
Status = false,
Message = "Internal server error",
Data = new { }
});
}
}
/// <summary>
/// Update a user
/// </summary>
/// <param name="userCreateDto"></param>
/// <param name="id"></param>
/// <returns>User was successfully updated</returns>
/// <returns code="201">User was successfully updated</returns>
/// <returns code="422">User does not exist</returns>
/// <returns code="500">Internal Server Error</returns>
[HttpPut("{id}")]
[ProducesResponseType(StatusCodes.Status201Created, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status422UnprocessableEntity, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status500InternalServerError, Type = typeof(ResponseMessage))]
public async Task<IActionResult> Put([FromBody] UserCreateDto userCreateDto, int id)
{
var user = await _userRepository.GetUser(id);
if(user == null)
{
return StatusCode(422, new
{
Status = false,
Message = "The user does not exist",
Data = new { }
});
}
user.UserName = userCreateDto.UserName;
user.Name = userCreateDto.Name;
user.Phone = userCreateDto.Phone;
user.Address = userCreateDto.Address;
var result = await _userRepository.UpdateUser(user);
if(result)
{
return StatusCode(201, new
{
Status = true,
Message = "User successfully updated",
Data = user
});
}
else
{
return StatusCode(500, new
{
Status = false,
Message = "Internal server error",
Data = new { }
});
}
}
/// <summary>
/// Delete a user
/// </summary>
/// <param name="id"></param>
/// <returns>User was successfully deleted</returns>
/// <returns code="200">User was successfully deleted</returns>
/// <returns code="422">The user does not exist</returns>
/// <returns code="500">Internal Server Error</returns>
[HttpDelete("{id}")]
[ProducesResponseType(StatusCodes.Status201Created, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status422UnprocessableEntity, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status500InternalServerError, Type = typeof(ResponseMessage))]
public async Task<IActionResult> Delete(int id)
{
var user = await _userRepository.GetUser(id);
if (user == null)
{
return StatusCode(422, new
{
Status = false,
Message = "The user does not exist",
Data = new { }
});
}
var result = await _userRepository.DeleteUser(user);
if(result)
{
return StatusCode(200, new
{
Status = true,
Message = "User successfully deleted",
Data = new { }
});
}
else
{
return StatusCode(500, new
{
Status = false,
Message = "Internal server error",
Data = new { }
});
}
}
}
}
<file_sep>/MyLearning/Utils/HashUtil.cs
using System;
using System.Security.Cryptography;
using System.Text;
namespace MyLearning.Utils
{
public static class HashUtil
{
public static void HashPassword(string password, out byte[] passwordHash, out byte[] passwordSalt)
{
using (var hmac = new System.Security.Cryptography.HMACSHA512())
{
passwordSalt = hmac.Key;
passwordHash = hmac.ComputeHash(System.Text.Encoding.UTF8.GetBytes(password));
}
}
public static bool VerifyPasswordHash(string password, byte[] storedHash, byte[] storedSalt)
{
using (var hmac = new System.Security.Cryptography.HMACSHA512(storedSalt))
{
var computedHash = hmac.ComputeHash(System.Text.Encoding.UTF8.GetBytes(password));
for (int i = 0; i < computedHash.Length; i++)
{
if (computedHash[i] != storedHash[i]) return false;
}
}
return true;
}
public static string HashString(string inputString, string hashName)
{
HashAlgorithm algorithm = HashAlgorithm.Create(hashName);
if (algorithm == null)
{
throw new ArgumentException("Unrecognized hash name", "hashName");
}
byte[] hash = algorithm.ComputeHash(Encoding.UTF8.GetBytes(inputString));
return Convert.ToBase64String(hash);
}
}
}<file_sep>/MyLearning/Services/IUserRepository.cs
using System;
using System.Collections.Generic;
using System.Threading.Tasks;
using MyLearning.Models;
namespace MyLearning.Services
{
public interface IUserRepository
{
public Task<User> AddUser(User user);
public Task<bool> UpdateUser(User user);
public Task<User> GetUser(int id);
public Task<ICollection<User>> GetAllUsers();
public Task<bool> DeleteUser(User user);
public Task<bool> CheckUserExist(int id);
public Task<bool> CheckUserExistByUserName(string username);
}
}
<file_sep>/MyLearning/Controllers/AuthController.cs
using System;
using System.Collections.Generic;
using System.IdentityModel.Tokens.Jwt;
using System.Linq;
using System.Security.Claims;
using System.Text;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Options;
using Microsoft.IdentityModel.Tokens;
using MyLearning.Dtos;
using MyLearning.Services;
using MyLearning.Utils;
namespace MyLearning.Controllers
{
[Route("api/[controller]")]
[ApiController]
public class AuthController : ControllerBase
{
private readonly IAuthRepository _authRepository;
private readonly AppSettings _appSettings;
public AuthController(IAuthRepository authRepository, IOptions<AppSettings> options)
{
_authRepository = authRepository;
_appSettings = options.Value;
}
[HttpPost("login")]
public async Task<IActionResult> Login([FromBody] LoginDto loginDto)
{
if (!ModelState.IsValid)
{
return StatusCode(400, new
{
Status = false,
Message = ModelState,
Data = new { }
});
}
string hashPassword = HashUtil.HashString(loginDto.Password, "SHA1");
var user = await _authRepository.Authenticate(loginDto.Username, hashPassword);
var tokenHandler = new JwtSecurityTokenHandler();
var key = Encoding.ASCII.GetBytes(_appSettings.SecretKey);
var tokenDescriptor = new SecurityTokenDescriptor
{
Subject = new ClaimsIdentity(new Claim[]
{
new Claim(ClaimTypes.Name, user.Id.ToString())
}),
Expires = DateTime.UtcNow.AddSeconds(int.Parse(_appSettings.TokenExpiry)),
SigningCredentials = new SigningCredentials(new SymmetricSecurityKey(key), SecurityAlgorithms.HmacSha256Signature)
};
var token = tokenHandler.CreateToken(tokenDescriptor);
var tokenString = tokenHandler.WriteToken(token);
if (user == null)
{
return Unauthorized(new
{
Status = false,
Message = "Invalid credential",
Data = new { }
});
}
else
{
return Ok(new
{
Status = true,
Message = "Login Successful",
Data = new
{
Name = user.Name,
Phone = user.Phone,
Token = tokenString
}
});
}
}
}
}<file_sep>/MyLearning/Controllers/ProductController.cs
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.AspNetCore.Cors;
using Microsoft.AspNetCore.Http;
using Microsoft.AspNetCore.Mvc;
using Microsoft.EntityFrameworkCore;
using MyLearning.Dtos;
using MyLearning.Models;
using MyLearning.Services;
namespace MyLearning.Data
{
[Route("api/[controller]")]
[ApiController]
[Produces("application/json")]
[EnableCors("AllowOrigin")]
public class ProductController : ControllerBase
{
private readonly IProductRepository _productRepository;
public ProductController(IProductRepository productRepository)
{
_productRepository = productRepository;
}
/// <summary>
/// Get all products
/// </summary>
/// <returns>Products retrieved successfully</returns>
/// <returns code="200">Products retrieved successfully</returns>
[HttpGet]
[ProducesResponseType(StatusCodes.Status200OK, Type = typeof(ResponseMessage))]
public async Task<IActionResult> GetProduct()
{
var products = await _productRepository.GetAllProducts();
return Ok(new
{
Status = true,
Message = "Products retrieved successfully",
Data = products
});
}
/// <summary>
/// Get specific product by ID
/// </summary>
/// <param name="id"></param>
/// <returns>Product retrieved successfully</returns>
/// <returns code="200">Product retrieved successfully</returns>
/// <returns code="422">The product was not found</returns>
[HttpGet("{id}")]
public async Task<IActionResult> GetProduct(int id)
{
var product = await _productRepository.GetProductById(id);
if (product == null)
{
return StatusCode(422, new
{
Status = false,
Message = "The product was not found",
Data = new { }
});
}
return Ok(new
{
Status = true,
Message = "Product retrieved successfully",
Data = product
});
}
/// <summary>
/// Update a product
/// </summary>
/// <param name="productCreateDto"></param>
/// <param name="id"></param>
/// <returns>Product was successfully updated</returns>
/// <returns code="201">Product was successfully updated</returns>
/// <returns code="422">The product was not found</returns>
/// <returns code="500">Internal Server Error</returns>
[HttpPut("{id}")]
[ProducesResponseType(StatusCodes.Status201Created, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status422UnprocessableEntity, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status500InternalServerError, Type = typeof(ResponseMessage))]
public async Task<IActionResult> PutProduct([FromBody] ProductCreateDto productCreateDto, int id)
{
var product = await _productRepository.GetProductById(id);
if (product == null)
{
return StatusCode(422, new
{
Status = false,
Message = "The product was not found",
Data = new { }
});
}
product.ProductName = productCreateDto.ProductName;
product.ProductDescription = productCreateDto.ProductDescription;
product.ProductAmount = productCreateDto.ProductAmount;
product.Quantity = productCreateDto.Quantity;
var result = await _productRepository.UpdateProduct(product);
if (result)
{
return StatusCode(201, new
{
Status = true,
Message = "Product successfully updated",
Data = product
});
}
else
{
return StatusCode(500, new
{
Status = false,
Message = "Internal server error",
Data = new { }
});
}
}
/// <summary>
/// Create a new product
/// </summary>
/// <param name="productCreateDto"></param>
/// <returns>Product successfully created</returns>
/// <returns code="201">Product successfully created</returns>
/// <returns code="400">Model state error</returns>
/// <returns code="500">Internal Server Error</returns>
[HttpPost]
[ProducesResponseType(StatusCodes.Status201Created, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status400BadRequest, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status500InternalServerError, Type = typeof(ResponseMessage))]
public async Task<IActionResult> PostProduct([FromBody] ProductCreateDto productCreateDto)
{
if (!ModelState.IsValid)
{
return BadRequest(new
{
Status = false,
Message = ModelState,
Data = new { }
});
}
var product = await _productRepository.AddProduct(new Models.Product
{
ProductName = productCreateDto.ProductName,
ProductDescription = productCreateDto.ProductDescription,
ProductAmount = productCreateDto.ProductAmount,
Quantity = productCreateDto.Quantity,
CreatedAt = DateTime.Now
});
if (product.Id > 0)
{
return StatusCode(201, new
{
Status = true,
Message = "Product successfully created",
Data = product
});
}
else
{
return StatusCode(500, new
{
Status = false,
Message = "Internal server error",
Data = new { }
});
}
}
/// <summary>
/// Delete a product
/// </summary>
/// <param name="id"></param>
/// <returns>Product was successfully deleted</returns>
/// <returns code="200">Product was successfully deleted</returns>
/// <returns code="422">Product not found</returns>
/// <returns code="500">Internal Server Error</returns>
[HttpDelete("{id}")]
[ProducesResponseType(StatusCodes.Status201Created, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status422UnprocessableEntity, Type = typeof(ResponseMessage))]
[ProducesResponseType(StatusCodes.Status500InternalServerError, Type = typeof(ResponseMessage))]
public async Task<IActionResult> DeleteProduct(int id)
{
var product = await _productRepository.GetProductById(id);
if(product == null)
{
return StatusCode(422, new
{
Status = false,
Message = "Product not found",
Data = new { }
});
}
var result = await _productRepository.DeleteProduct(product);
if (result)
{
return StatusCode(200, new
{
Status = true,
Message = "Product successfully deleted",
Data = new { }
});
}
else
{
return StatusCode(500, new
{
Status = false,
Message = "Internal server error",
Data = new { }
});
}
}
}
}
<file_sep>/MyLearning/Models/Product.cs
using System;
using System.ComponentModel.DataAnnotations;
namespace MyLearning.Models
{
public class Product
{
public Product()
{
}
public int Id { get; set; }
[MaxLength(160)]
public string ProductName { get; set; }
public string ProductDescription { get; set; }
public decimal ProductAmount { get; set; }
public int Quantity { get; set; } = 0;
public int Status { get; set; } = 1;
public DateTime CreatedAt { get; set; }
public DateTime UpdatedAt { get; set; } = DateTime.Now;
public User User { get; set; }
}
}
<file_sep>/MyLearning/Utils/DbUtil.cs
using System.Threading.Tasks;
namespace MyLearning.Utils
{
public class DbUtil
{
public async Task<bool> SaveChanges(MyLearningDbContext myLearningDbContext)
{
var isSaved = await myLearningDbContext.SaveChangesAsync();
if (isSaved == 1)
{
return true;
}
else
{
return false;
}
}
}
} | 8c2d1f5f70211f0d9976c1dc537da8c3d5e6b151 | [
"C#"
] | 18 | C# | chinice/myFirstDotnetProject | e0a57b349db12cb1ea94138685abf1b305ac7a42 | 377667987fbb863363bf1e69c7c227bc30cd6e4d |
refs/heads/master | <repo_name>MarcMcIntosh/fibonacci<file_sep>/src/formula.js
function formula(number) {
const n = (number|0);
if (number < 2) { return n }
const SQRT_5 = Math.sqrt(5);
const PHI = (1 + SQRT_5) / 2;
// const ans = PHI ** n / (PHI + 2);
const x = PHI ** n;
const y = (1 - PHI) ** n;
const ans = (x - y) / SQRT_5;
return Math.round(ans);
}
module.exports = formula;
<file_sep>/test/memo.js
const assert = require('assert');
const jsc = require('jsverify');
const memo = require('../src/memo');
const matrix = require('../src/matrix');
describe('memo vs matrix', function() {
this.timeout(0);
const tests = Array.from({ length: 100 }, (d, i) => i);
tests.forEach((n) => {
it(`memo(${n}) === matrix(${n})`, () => {
assert.equal(memo(n), matrix(n));
});
});
jsc.property('matrix(n) === recursive(n) with unit8', jsc.uint8, n => memo(n) === matrix(n));
});
<file_sep>/src/matrix.js
function matrix(number) {
const n = number|0;
if (number < 2) { return n; }
const mtx = [0, 1];
for(let i = 0; i < n - 1; i += 1) {
const [ a, b ] = mtx;
mtx[0] = b;
mtx[1] = a + b;
}
return mtx[1];
}
module.exports = matrix;
<file_sep>/src/memo.js
function fibonacci(number, memo = {}) {
const n = number|0;
if (memo[n]) return memo[n];
if (n < 2) return n;
memo[n] = fibonacci(n - 1, memo) + fibonacci(n - 2, memo);
return memo[n];
}
module.exports = fibonacci
<file_sep>/src/recursive.js
function recursive(number) {
const n = number|0;
if (number < 2) { return n; }
return recursive(n - 1) + recursive(n - 2);
};
module.exports = recursive;
<file_sep>/test/formual.js
const assert = require('assert');
// const jsc = require('jsverify');
const matrix = require('../src/matrix');
const formula = require('../src/formula');
xdescribe('formula', function() {
this.timeout(0);
// jsc.property('matrix(n) === recursive(n) Range 0 to 30', jsc.number(0, 30), n => matrix(n) === recursive(n));
const tests = Array.from({ length: 100 }, (d, i) => i);
tests.forEach((n) => {
it(`formual(${n}) === matrix(${n})`, () => {
assert.equal(formula(n), matrix(n));
});
});
});
<file_sep>/README.md
# fibonacci
property based testing the fibonacci sequence
<file_sep>/test/matrix.js
const assert = require('assert');
// const jsc = require('jsverify');
const recursive = require('../src/recursive');
const matrix = require('../src/matrix');
describe('matrix', function() {
this.timeout(0);
// jsc.property('matrix(n) === recursive(n) Range 0 to 30', jsc.number(0, 30), n => matrix(n) === recursive(n));
const tests = Array.from({ length: 40 }, (d, i) => i);
tests.forEach((n) => {
it(`matrix(${n}) === recursive(${n})`, () => {
assert.equal(matrix(n), recursive(n));
});
});
});
| 1e4ccd5494e867dc851f0d8d17f23cf123c17764 | [
"JavaScript",
"Markdown"
] | 8 | JavaScript | MarcMcIntosh/fibonacci | 45e9d2f242efdc249dc67787a29e28311b496b99 | c0fc37ab85361d4d244e616412dadf95457c6304 |
refs/heads/main | <file_sep>const express = require('express')
const bodyParser = require('body-parser');
const cors = require('cors');
const MongoClient = require('mongodb').MongoClient;
const uri = "mongodb+srv://arabian:<EMAIL>/burjAlArab?retryWrites=true&w=majority";
const app = express()
app.use(cors());
app.use(bodyParser.json());
app.use(bodyParser.urlencoded({ extended: false }));
app.get('/', function (req, res) {
res.send('hello world')
})
const client = new MongoClient(uri, { useNewUrlParser: true, useUnifiedTopology: true });
client.connect((err) => {
const bookings = client.db("burjAlArab").collection("bookings");
console.log('db connection successfully');
//1st thing to do to connect with client
app.post('/addBooking', (req, res) => {
const newBooking = req.body;
console.log(newBooking);
bookings.insertOne(newBooking)
.then(result => {
// res.send(result.insertedCount > 0);
console.log(result);
})
})
});
app.listen(5000)<file_sep># burj-al-arab-backend-server-
# burj-al-arab-backend-server
# burj-al-arab-server
# burj-al-arab-server
| 50afc6fbee36a8072ca25cf6fbd205684c14c97b | [
"JavaScript",
"Markdown"
] | 2 | JavaScript | Tanviras/burj-al-arab-server | 7c8f7a2febc1a2a8d51cae900a9ccb1d19469f9a | 72784a1a44406f81a8817e0e13ea38767bee5047 |
refs/heads/master | <repo_name>Arteaga2k/ios_topics<file_sep>/PlayAudio/PlayAudio/ViewController.swift
//
// ViewController.swift
// PlayAudio
//
// Created by <NAME> on 6/1/16.
import UIKit
import AVFoundation
class ViewController: UIViewController {
let centeredButton = UIButton()
var audioPlayer:AVAudioPlayer!
func addButton() {
centeredButton.setTitle("Play", for: UIControlState())
centeredButton.setTitleColor(UIColor.blue, for: UIControlState())
centeredButton.translatesAutoresizingMaskIntoConstraints = false
centeredButton.addTarget(self, action: #selector(ViewController.playAudio(_:)), for: .touchUpInside)
self.view.addSubview(centeredButton)
centeredButton.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
centeredButton.centerYAnchor.constraint(equalTo: view.centerYAnchor).isActive = true
}
func playAudio(_ sender: UIButton!) {
playWordAudio("robot02")
}
func playWordAudio(_ aWord:String) {
/*
Audio files came from here:
http://www.metanetsoftware.com/blog/2016/tools-for-gamemaking-music-loops
*/
let audioUrl = URL(fileURLWithPath: Bundle.main.path(forResource: aWord, ofType: "mp3")!)
try! AVAudioSession.sharedInstance().setCategory(AVAudioSessionCategoryPlayback, with: [])
try! AVAudioSession.sharedInstance().setActive(true)
do {
try self.audioPlayer = AVAudioPlayer(contentsOf:audioUrl)
self.audioPlayer.prepareToPlay()
self.audioPlayer.play()
} catch {
print("ERROR: Play sound: \(error)")
}
// } else {
// print("Sound file not found: \(aWord)")
// }
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
addButton()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/TransitionWithView/TransitionWithView/ViewController.swift
//
// ViewController.swift
// TransitionWithView
//
// Created by <NAME> on 4/28/15.
// Copyright (c) 2015 h4labs. All rights reserved.
//
import UIKit
class ViewController: UIViewController {
/*
Need to use a container as described here:
http://stackoverflow.com/questions/29923061/trying-to-curl-up-curl-down-with-two-views-using-autolayout-in-swift?noredirect=1#comment47975892_29923061
http://stackoverflow.com/questions/9524048/how-to-flip-an-individual-uiview-without-flipping-the-parent-view
*/
var container:UIView! // Place cardFront/cardBack in this container
var cardFront:UIView!
var cardBack:UIView!
func centerViewXY(_ parent: UIView, child: UIView) {
let constX = NSLayoutConstraint(item: child, attribute: NSLayoutAttribute.centerX, relatedBy: NSLayoutRelation.equal, toItem: parent, attribute: NSLayoutAttribute.centerX, multiplier: 1, constant: 0)
parent.addConstraint(constX)
let constY = NSLayoutConstraint(item: child, attribute: NSLayoutAttribute.centerY, relatedBy: NSLayoutRelation.equal, toItem: parent, attribute: NSLayoutAttribute.centerY, multiplier: 1, constant: 0)
parent.addConstraint(constY)
}
func addStandardConstraints(_ view:UIView, constraint:String, viewDictionary:Dictionary<String,AnyObject>, metrics:Dictionary<String, Int>) {
view.addConstraints(NSLayoutConstraint.constraints(withVisualFormat: constraint, options: [], metrics: metrics, views: viewDictionary))
}
func curlUp() {
let transitionOptions = UIViewAnimationOptions.transitionCurlUp
UIView.transition(from: cardFront,
to: cardBack,
duration: 5.0,
options: transitionOptions,
completion: { _ in
let transitionOptions = UIViewAnimationOptions.transitionCurlDown
UIView.transition(from: self.cardBack,
to: self.cardFront,
duration: 5.0,
options: transitionOptions,
completion: { _ in
//
})
})
}
func buildView() {
let height = 100
let width = 100
container = UIView()
container.translatesAutoresizingMaskIntoConstraints = false
container.backgroundColor = UIColor.black
self.view.addSubview(container)
cardBack = UIView(frame: CGRect(x: 0, y: 0, width: CGFloat(width), height: CGFloat(height)))
cardBack.backgroundColor = UIColor.red
container.addSubview(cardBack)
cardFront = UIView(frame: CGRect(x: 0, y: 0, width: CGFloat(width), height: CGFloat(height)))
cardFront.backgroundColor = UIColor.green
container.addSubview(cardFront)
let viewDictionary:Dictionary<String,UIView> = ["container": container]
let metrics:Dictionary<String,Int> = ["width": width, "height": height]
let h0Constraint = "H:[container(==width)]"
let v0Constraint = "V:[container(==height)]"
addStandardConstraints(self.view, constraint: h0Constraint, viewDictionary: viewDictionary, metrics: metrics)
addStandardConstraints(self.view, constraint: v0Constraint, viewDictionary: viewDictionary, metrics: metrics)
centerViewXY(self.view, child: container)
Timer.scheduledTimer(timeInterval: 2, target: self, selector: #selector(ViewController.curlUp), userInfo: nil, repeats: false)
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
self.view.backgroundColor = UIColor.purple
buildView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/GradientView/GradientView/ViewController.swift
//
// ViewController.swift
// GradientView
//
// Created by <NAME> on 9/4/16.
//
import UIKit
class ViewController: UIViewController {
func buildView() {
let v = GradientView(frame: self.view.bounds)
self.view.addSubview(v)
}
override func viewDidLoad() {
super.viewDidLoad()
buildView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/ButtonsInStackView/ButtonsInStackView/ViewController.swift
//
// ViewController.swift
// ButtonsInStackView
//
// Created by <NAME> on 5/31/16.
//
import UIKit
class ViewController: UIViewController {
let button1 = UIButton()
let button2 = UIButton()
let button3 = UIButton()
let button4 = UIButton()
let label = UILabel()
func buttonAction(_ button: UIButton) {
let tag = button.tag
label.text = "\(tag)"
}
func customizeButtons() {
// Button 1
button1.setTitle("cornerRadius = 10", for: UIControlState())
button1.backgroundColor = UIColor.blue
button1.layer.cornerRadius = 10
button1.setTitleColor(UIColor.orange, for: UIControlState())
button1.addTarget(self, action: #selector(buttonAction), for: .touchUpInside)
// Button 2
button2.setTitle("Border", for: UIControlState())
button2.backgroundColor = UIColor.gray
button2.layer.borderWidth = 3
button2.layer.borderColor = UIColor.black.cgColor
button2.addTarget(self, action: #selector(buttonAction), for: .touchUpInside)
// Button 3
button3.backgroundColor = UIColor.gray
button3.setTitle("Custom Font", for: UIControlState())
button3.addTarget(self, action: #selector(buttonAction), for: .touchUpInside)
let fontSize:CGFloat = 20
let aFontName = "American Typewriter"
if let aFont:UIFont = UIFont(name: aFontName, size: fontSize) {
button3.titleLabel?.font = aFont
}
// Button 4
button4.backgroundColor = UIColor.gray
button4.setTitle("Image", for: UIControlState())
button4.addTarget(self, action: #selector(buttonAction), for: .touchUpInside)
let imageName = "star"
if let image = UIImage(named: imageName) {
button4.setImage(image, for: UIControlState())
}
}
func createLabel() {
let fontSize:CGFloat = 24
label.translatesAutoresizingMaskIntoConstraints = false
label.font = UIFont.systemFont(ofSize: fontSize)
label.text = "0"
view.addSubview(label)
}
override func viewDidLoad() {
super.viewDidLoad()
let allButtons = [button1, button2, button3, button4]
var i = 1
allButtons.forEach {
$0.translatesAutoresizingMaskIntoConstraints = false
$0.tag = i
i += 1
self.view.addSubview($0)
}
customizeButtons()
createLabel()
let stackView = UIStackView(arrangedSubviews: allButtons)
stackView.translatesAutoresizingMaskIntoConstraints = false
stackView.axis = .vertical
stackView.alignment = .fill
stackView.spacing = 10 // Space between buttons
view.addSubview(stackView)
let margins = view.layoutMarginsGuide
// Center vertically, iOS9 style
// stackView.centerXAnchor.constraintEqualToAnchor(view.centerXAnchor).active = true
stackView.centerYAnchor.constraint(equalTo: view.centerYAnchor).isActive = true
stackView.leadingAnchor.constraint(equalTo: margins.leadingAnchor, constant: 20).isActive = true
stackView.trailingAnchor.constraint(equalTo: margins.trailingAnchor, constant: -20).isActive = true
// Label
label.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
label.topAnchor.constraint(equalTo: topLayoutGuide.bottomAnchor, constant: 50.0).isActive = true
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/LineDrawingAnimation/LineDrawingAnimation/ViewController.swift
//
// ViewController.swift
// LineDrawingAnimation
//
// Created by <NAME> on 5/26/16.
//
import UIKit
class ViewController: UIViewController {
func addLine(_ x0: CGFloat, y0: CGFloat, x1: CGFloat, y1: CGFloat) {
let layer = CAShapeLayer()
let startPoint = CGPoint(x: x0, y: y0)
let endPoint = CGPoint(x: x1, y: y1)
let path = UIBezierPath()
path.move(to: startPoint)
path.addLine(to: endPoint)
layer.path = path.cgPath
layer.strokeColor = UIColor.red.cgColor
layer.lineWidth = 2
view.layer.addSublayer(layer)
let drawAnimation = CABasicAnimation(keyPath: "strokeEnd")
drawAnimation.repeatCount = 1.0
drawAnimation.fromValue = 0
drawAnimation.toValue = 1
drawAnimation.duration = 3.0
drawAnimation.timingFunction = CAMediaTimingFunction(name: kCAMediaTimingFunctionLinear)
layer.add(drawAnimation, forKey: "drawLineAnimation")
}
override func viewDidLoad() {
super.viewDidLoad()
addLine(20, y0: 20, x1: 250, y1: 500)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/ShapeLayer/ShapeLayer/ViewController.swift
//
// ViewController.swift
// ShapeLayer
//
// Created by <NAME> on 3/19/16.
//
import UIKit
class ViewController: UIViewController {
func toRadians(_ degrees:CGFloat) -> CGFloat {
return degrees * CGFloat(M_PI)/180
}
func addLine(_ x0: CGFloat, y0: CGFloat, x1: CGFloat, y1: CGFloat) {
let layer = CAShapeLayer()
let startPoint = CGPoint(x: x0, y: y0)
let endPoint = CGPoint(x: x1, y: y1)
let path = UIBezierPath()
path.move(to: startPoint)
path.addLine(to: endPoint)
layer.path = path.cgPath
// layer.fillColor = UIColor.blueColor().CGColor
layer.strokeColor = UIColor.red.cgColor
layer.lineWidth = 2
view.layer.addSublayer(layer)
}
// Set cornerRadius=1 to make normal rectangle
func addRect(_ x: CGFloat, y: CGFloat, width: CGFloat, height: CGFloat) {
let layer = CAShapeLayer()
layer.path = UIBezierPath(roundedRect: CGRect(x: 164, y: 164, width: 160, height: 160), cornerRadius: 1).cgPath
layer.fillColor = UIColor.blue.cgColor
layer.strokeColor = UIColor.black.cgColor
layer.lineWidth = 2
view.layer.addSublayer(layer)
}
func addRoundedRect(_ x: CGFloat, y: CGFloat, width: CGFloat, height: CGFloat) {
let layer = CAShapeLayer()
let cornerRadius:CGFloat = 10
layer.path = UIBezierPath(roundedRect: CGRect(x: 64, y: 64, width: 160, height: 160), cornerRadius: cornerRadius).cgPath
layer.fillColor = UIColor.red.cgColor
view.layer.addSublayer(layer)
}
/*
We draw it this way if we need to animate drawing the circle
*/
func addCircleWithArc(){
let layer = CAShapeLayer()
let radius:CGFloat = 50
let center = CGPoint(x: 100, y: 500)
let startAngle:CGFloat = 1
let endAngle:CGFloat = 360
let clockwise = true
layer.path = UIBezierPath(arcCenter: center,
radius: radius,
startAngle: toRadians(startAngle),
endAngle:toRadians(endAngle),
clockwise: clockwise).cgPath
layer.fillColor = UIColor.blue.cgColor
layer.strokeColor = UIColor.red.cgColor
layer.lineWidth = 2
view.layer.addSublayer(layer)
}
func addCircle(_ x: CGFloat, y: CGFloat, radius: CGFloat){
let layer = CAShapeLayer()
let path = UIBezierPath(ovalIn: CGRect(x: x, y: y, width: radius, height: radius))
layer.fillColor = UIColor.orange.cgColor
layer.path = path.cgPath
view.layer.addSublayer(layer)
}
func addEllipse(_ x: CGFloat, y: CGFloat, width: CGFloat, height: CGFloat) {
let layer = CAShapeLayer()
let path = UIBezierPath(ovalIn: CGRect(x: x, y: y, width: height, height: width))
layer.path = path.cgPath
view.layer.addSublayer(layer)
}
func addTriangle(_ x: CGFloat, y: CGFloat, width: CGFloat, height: CGFloat){
let center = CGPoint(x: width/2 + x, y: y)
let bottomLeft = CGPoint(x: x, y: height + y)
let bottomRight = CGPoint(x: width + x, y: height + y)
let layer = CAShapeLayer()
let path = UIBezierPath()
path.move(to: center)
path.addLine(to: bottomLeft)
path.addLine(to: bottomRight)
path.close()
layer.path = path.cgPath
view.layer.addSublayer(layer)
}
override func viewDidLoad() {
super.viewDidLoad()
addLine(20, y0: 20, x1: 25, y1: 500)
addRect(164, y: 164, width: 160, height: 160)
addRoundedRect(64, y: 64, width: 160, height: 160)
addCircleWithArc()
addCircle(90, y:260, radius:40)
addEllipse(290, y:360, width: 80, height: 40)
addTriangle(40, y: 400, width: 40, height: 40)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/AppRotation/AppRotation/ViewController.swift
//
// ViewController.swift
// AppRotation
//
// Created by <NAME> on 9/3/16.
//
import UIKit
class ViewController: UIViewController {
let widthLabel = UILabel()
let heightLabel = UILabel()
let stackView = UIStackView()
func buildView() {
[widthLabel, heightLabel, stackView].forEach({
$0.translatesAutoresizingMaskIntoConstraints = false
})
stackView.addArrangedSubview(widthLabel)
stackView.addArrangedSubview(heightLabel)
stackView.axis = .horizontal
stackView.distribution = .equalSpacing
widthLabel.text = "0"
heightLabel.text = "Rotate screen"
self.view.addSubview(stackView)
}
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view, typically from a nib.
buildView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
extension ViewController {
override func viewWillTransition(to size: CGSize, with coordinator: UIViewControllerTransitionCoordinator) {
super.viewWillTransition(to: size, with: coordinator)
print("\(self) \(#function)")
// let transitionToWide = size.width > size.height
let w = size.width
let h = size.height
print("\nToSize: \(w), \(h)\n")
if self.view.backgroundColor == UIColor.red {
self.view.backgroundColor = UIColor.green
} else {
self.view.backgroundColor = UIColor.red
}
}
}
<file_sep>/TableViewWithCustomCell/TableViewWithCustomCell/SimpleTableViewController.swift
//
// SimpleTableViewController.swift
// SimpleTableViewController
//
// Created by <NAME> on 3/8/16.
// Copyright © 2016 h4labs. All rights reserved.
//
import UIKit
class SimpleTableViewController: UITableViewController {
let rowData = ["one", "two", "three"]
let CellIdentifier = "Cell"
override func viewDidLoad() {
self.tableView.rowHeight = 80
self.tableView.register(UINib(nibName: "CustomTableViewCell", bundle: nil), forCellReuseIdentifier: CellIdentifier)
}
}
// Data source delegate
extension SimpleTableViewController {
// We can skip overriding this function and it will default to 1
override func numberOfSections(in tableView: UITableView) -> Int {
// Return the number of sections.
return 1
}
override func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return rowData.count
}
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell:CustomTableViewCell = tableView.dequeueReusableCell(withIdentifier: CellIdentifier, for: indexPath) as! CustomTableViewCell
// Configure the cell...
cell.label1?.text = rowData[(indexPath as NSIndexPath).row]
cell.label2?.text = "\((indexPath as NSIndexPath).row + 1)"
let imageName:String = "fr_icon"
if let image = UIImage(named: imageName) {
cell.imageView1.image = image
}
return cell
}
//: Optional Header title
override func tableView(_ tableView: UITableView, titleForHeaderInSection section: Int) -> String? {
return "Header"
}
}
<file_sep>/AlertControllers/AlertControllers/ViewController.swift
//
// ViewController.swift
// AlertControllers
//
// Created by <NAME> on 6/1/16.
//
import UIKit
class ViewController: UIViewController {
let button1 = UIButton()
let label1 = UILabel()
func addLabel() {
view.addSubview(label1)
label1.translatesAutoresizingMaskIntoConstraints = false
label1.text = "Click the Alert button"
label1.textColor = UIColor.gray
label1.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
label1.centerYAnchor.constraint(equalTo: view.centerYAnchor, constant: 40).isActive = true
}
func addButton() {
view.addSubview(button1)
button1.translatesAutoresizingMaskIntoConstraints = false
button1.setTitle("Alert", for: UIControlState())
button1.addTarget(self, action: #selector(ViewController.showGameOverAlert(_:)), for: .touchUpInside)
button1.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
button1.centerYAnchor.constraint(equalTo: view.centerYAnchor, constant: -40).isActive = true
}
func showGameOverAlert(_ button: UIButton) {
let alertController = UIAlertController(title: "Game Over", message: "Play again?", preferredStyle: .alert)
// Using closure handler
let action1 = UIAlertAction(title: "Yes", style: .default) { (action) -> Void in
self.label1.text = "Starting new game."
}
// Calling function handler
let action2 = UIAlertAction(title: "No", style: .default, handler: noHandler(_:))
alertController.addAction(action1)
alertController.addAction(action2)
self.present(alertController, animated: true, completion: nil)
}
func noHandler(_ action: UIAlertAction) {
label1.text = "That's all folks!"
}
override func viewDidLoad() {
super.viewDidLoad()
view.backgroundColor = UIColor.purple
addButton()
addLabel()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/TapGesture/TapGesture/ViewController.swift
//
// ViewController.swift
// TapGesture
//
// Created by <NAME> on 3/15/16.
//
import UIKit
class ViewController: UIViewController {
let view1 = UIView()
func addTapView() {
let height = 100
let width = 100
view1.translatesAutoresizingMaskIntoConstraints = false
view1.backgroundColor = UIColor.cyan
self.view.addSubview(view1)
let viewDictionary:Dictionary<String,UIView> = ["view1": view1]
let metrics:Dictionary<String,Int> = ["width": width, "height": height]
let h0Constraint = "H:[view1(==width)]"
let v0Constraint = "V:[view1(==height)]"
[h0Constraint, v0Constraint].forEach {
let constraint = NSLayoutConstraint.constraints(withVisualFormat: $0, options: [], metrics: metrics, views: viewDictionary)
NSLayoutConstraint.activate(constraint)
}
// Center, iOS9 style
view1.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
view1.centerYAnchor.constraint(equalTo: view.centerYAnchor).isActive = true
}
func handleSingleTap(_ recognizer:UITapGestureRecognizer) {
let aColor = view1.backgroundColor
if aColor == UIColor.cyan {
view1.backgroundColor = UIColor.gray
} else {
view1.backgroundColor = UIColor.cyan
}
}
func addTapGesture() {
let singleTap =
UITapGestureRecognizer(target: self, action: #selector(handleSingleTap(_:)))
self.view1.addGestureRecognizer(singleTap)
}
override func viewDidLoad() {
super.viewDidLoad()
addTapView()
addTapGesture()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/GradientView/GradientView/GradientView.swift
//
// GradientView.swift
// GradientView
//
// Created by <NAME> on 9/4/16.
//
import UIKit
class GradientView: UIView {
override init(frame: CGRect) {
super.init(frame: frame)
//self.backgroundColor = UIColor.purple // Also, set solid color in init()
let layer = CAGradientLayer()
layer.colors = [UIColor.red.cgColor, UIColor.blue.cgColor, UIColor.green.cgColor]
layer.frame = self.bounds // full view
self.layer.addSublayer(layer)
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
}
<file_sep>/CenteredAutoLayoutButton/CenteredAutoLayoutButton/ViewController.swift
//
// ViewController.swift
// CenteredAutoLayoutButton
//
// Created by <NAME> on 8/14/14.
// Copyright (c) 2014 h4labs. All rights reserved.
//
import UIKit
class ViewController: UIViewController {
var centeredButton: UIButton!
func addButton() {
centeredButton = UIButton()
centeredButton.setTitle("Am I centered?", for: UIControlState())
centeredButton.setTitleColor(UIColor.blue, for: UIControlState())
centeredButton.translatesAutoresizingMaskIntoConstraints = false
centeredButton.addTarget(self, action: #selector(ViewController.pressed(_:)), for: .touchUpInside)
self.view.addSubview(centeredButton)
let viewDictionary:[String:AnyObject] = ["centeredButton": centeredButton]
let horizontal:[NSLayoutConstraint]! = NSLayoutConstraint.constraints(withVisualFormat: "H:|-50-[centeredButton]-50-|", options: NSLayoutFormatOptions(rawValue: 0), metrics: nil, views: viewDictionary)
let vertical:[NSLayoutConstraint]! = NSLayoutConstraint.constraints(withVisualFormat: "V:|-100-[centeredButton]-100-|", options: NSLayoutFormatOptions(rawValue: 0), metrics: nil, views: viewDictionary)
self.view.addConstraints(horizontal)
self.view.addConstraints(vertical)
}
func pressed(_ sender: UIButton!) {
let title = "Awesome"
let message = "You did it"
let alert = UIAlertController(title: title,
message:message,
preferredStyle: .alert)
let action = UIAlertAction(title: "Take Action 1?", style: .default, handler:nil)
alert.addAction(action)
let action2 = UIAlertAction(title: "Take Action 2?", style: .default, handler:nil)
alert.addAction(action2)
self.present(alert, animated: true, completion: nil)
}
override func viewDidLoad() {
super.viewDidLoad()
addButton()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/TransitionWithView/README.md
TransitionWithView
==================
https://h4labs.wordpress.com/2015/04/29/curling-a-uiview-updown-with-swift/

<file_sep>/CollectionViewWithCustomCell/CollectionViewWithCustomCell/CustomCollectionViewCell.swift
//
// CustomCollectionViewCell.swift
// CollectionViewWithCustomCell
//
// Created by <NAME> on 5/26/16.
// Copyright © 2016 <NAME>. All rights reserved.
//
import UIKit
class CustomCollectionViewCell: UICollectionViewCell {
@IBOutlet weak var imageView: UIImageView!
// @IBOutlet var imageView:UIImageView!
@IBOutlet weak var wordLabel:UILabel!
override func awakeFromNib() {
super.awakeFromNib()
// Initialization code
}
override init(frame: CGRect) {
super.init(frame:frame)
}
required init?(coder aDecoder: NSCoder) {
super.init(coder: aDecoder)
}
}
<file_sep>/CircleDrawingAnimation/CircleDrawingAnimation/ViewController.swift
//
// ViewController.swift
// CircleDrawingAnimation
//
// Created by <NAME> on 5/26/16.
//
import UIKit
class ViewController: UIViewController {
func toRadians(_ degrees:CGFloat) -> CGFloat {
return degrees * CGFloat(M_PI)/180
}
func addAnimatedCircleWithArc(){
let layer = CAShapeLayer()
let radius:CGFloat = 50
let center = CGPoint(x: 100, y: 350)
let startAngle:CGFloat = toRadians(0)
let endAngle:CGFloat = toRadians(360)
let clockwise = true
layer.path = UIBezierPath(arcCenter: center,
radius: radius,
startAngle: startAngle,
endAngle: endAngle,
clockwise: clockwise).cgPath
layer.fillColor = UIColor.clear.cgColor
layer.strokeColor = UIColor.red.cgColor
layer.lineWidth = 1
view.layer.addSublayer(layer)
let drawAnimation = CABasicAnimation(keyPath: "strokeEnd")
drawAnimation.repeatCount = 1.0
drawAnimation.fromValue = 0
drawAnimation.toValue = 1
drawAnimation.duration = 5.0
drawAnimation.timingFunction = CAMediaTimingFunction(name: kCAMediaTimingFunctionLinear)
layer.add(drawAnimation, forKey: "drawCircleAnimation")
}
override func viewDidLoad() {
super.viewDidLoad()
addAnimatedCircleWithArc()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/StackViewsInStackViews/StackViewsInStackViews/ViewController.swift
//
// ViewController.swift
// StackViewsInStackViews
//
// Created by <NAME> on 8/31/16.
//
import UIKit
class ViewController: UIViewController {
let mainStackView = UIStackView()
let buttonStackView = UIStackView()
let largeBox = UIView()
let smallBox = UIView()
func isPortrait() -> Bool {
return self.view.bounds.width < self.view.bounds.height
}
func addButtons() {
//: Left Button
let leftButton = UIButton()
leftButton.translatesAutoresizingMaskIntoConstraints = false
leftButton.setTitle("Left", for: .normal)
//: Right Button
let rightButton = UIButton()
rightButton.translatesAutoresizingMaskIntoConstraints = false
rightButton.setTitle("Right", for: .normal)
buttonStackView.addArrangedSubview(leftButton)
buttonStackView.addArrangedSubview(rightButton)
buttonStackView.backgroundColor = UIColor.lightGray
buttonStackView.axis = .horizontal
buttonStackView.spacing = 10
}
/*
https://forums.developer.apple.com/thread/12937
*/
override func viewWillTransition(to size: CGSize, with coordinator: UIViewControllerTransitionCoordinator) {
let isPortraitMode = isPortrait()
print("\n\nisPortrait=\(isPortraitMode)\n\n")
super.viewWillTransition(to: size, with: coordinator)
}
func buildView() {
addButtons()
[largeBox, smallBox, mainStackView, buttonStackView].forEach({
$0.translatesAutoresizingMaskIntoConstraints = false
})
// Add everything to stackview then constrain
mainStackView.addArrangedSubview(largeBox)
mainStackView.addArrangedSubview(smallBox)
mainStackView.addArrangedSubview(buttonStackView)
largeBox.backgroundColor = UIColor.red
largeBox.layer.borderWidth = 5
let width = min(self.view.bounds.width, self.view.bounds.height) - 40
largeBox.widthAnchor.constraint(equalToConstant: width).isActive = true
largeBox.heightAnchor.constraint(equalToConstant: width).isActive = true
// largeBox.heightAnchor.constraint(equalTo: mainStackView.heightAnchor, multiplier: 0.6).isActive = true
// largeBox.heightAnchor.constraint(equalToConstant: 200).isActive = true
smallBox.backgroundColor = UIColor.blue
smallBox.widthAnchor.constraint(equalToConstant: width).isActive = true
// smallBox.heightAnchor.constraint(equalToConstant: 50).isActive = true
smallBox.heightAnchor.constraint(equalTo: mainStackView.heightAnchor, multiplier: 0.1).isActive = true
mainStackView.axis = .vertical
mainStackView.spacing = 10
mainStackView.alignment = .center
mainStackView.backgroundColor = UIColor.black
self.view.addSubview(mainStackView)
// mainStackView.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
// mainStackView.centerYAnchor.constraint(equalTo: view.centerYAnchor).isActive = true
let margins = self.view.layoutMarginsGuide
mainStackView.leadingAnchor.constraint(equalTo: margins.leadingAnchor).isActive = true
mainStackView.trailingAnchor.constraint(equalTo: margins.trailingAnchor).isActive = true
mainStackView.topAnchor.constraint(equalTo: topLayoutGuide.bottomAnchor).isActive = true
mainStackView.bottomAnchor.constraint(equalTo: bottomLayoutGuide.topAnchor).isActive = true
}
override func viewDidLoad() {
super.viewDidLoad()
view.backgroundColor = UIColor.purple
buildView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/TransitionWithViewAndLabels/README.md
TransitionWithView Containing Centered UILabel
===

<file_sep>/CollectionViewWithCustomCell/CollectionViewWithCustomCell/ViewController.swift
//
// ViewController.swift
// CollectionViewBasic
//
// Created by <NAME> on 5/24/16.
//
import UIKit
class ViewController: UIViewController {
var collectionViewController:BasicCollectionViewController!
func addCollectionView() {
let viewDictionary:[String:AnyObject] = [
"collectionView": collectionViewController.view,
"topLayoutGuide": topLayoutGuide,
]
collectionViewController.view.translatesAutoresizingMaskIntoConstraints = false
self.view.addSubview(collectionViewController.view)
let metrics:[String:AnyObject] = [:]
let h0Constraint = "H:|-[collectionView]-|"
let v0Constraint = "V:[topLayoutGuide]-[collectionView]-|"
[h0Constraint, v0Constraint].forEach {
let constraint = NSLayoutConstraint.constraints(withVisualFormat: $0, options: [], metrics: metrics, views: viewDictionary)
NSLayoutConstraint.activate(constraint)
}
}
override func viewDidLoad() {
super.viewDidLoad()
self.view.backgroundColor = UIColor.purple
let flowLayout=UICollectionViewFlowLayout()
flowLayout.itemSize = CGSize(width: 100, height: 100)
flowLayout.minimumInteritemSpacing = 2
flowLayout.minimumLineSpacing = 5
flowLayout.scrollDirection = .vertical
// Must create with a FlowLayout if we create UICollectionViewController programatically
collectionViewController = BasicCollectionViewController(collectionViewLayout: flowLayout)
addCollectionView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/CenteredAutoLayoutButton/README.md
Centered Button with Autolayout
===============================
Create button programmatically (i.e. no storyboards) and added it with Autolayout.
<file_sep>/screenshots.sh
#!/bin/sh -x
convert ./screenshot.png -resize 50% screenshot-small.png; # Smaller screenshot
convert ./screenshot.png -resize 20% screenshot-toc.png; # Table of Contents screenshot
echo "git add screenshot*"
<file_sep>/TableViewWithSections/TableViewWithSections/SimpleTableViewController.swift
//
// SimpleTableViewController.swift
// SimpleTableViewController
//
// Created by <NAME> on 3/8/16.
//
/*
a: ace, ant, apple
b: banana, bird,
c: cat, corn, cow
d: deer, dog, duck
e: elephant, elk, elm
f: fowl, fruit
g: goat
m: milk, maple
a b c
// don't presort test data
let words = ["apple", "ace", "ant",
"banana", "bird",
"cat", "corn", "cow",
"deer", "dog", "duck",
"elephant", "elk", "elm",
"fowl", "fruit",
"goat",
"milk", "maple"]
*/
import UIKit
class SimpleTableViewController: UITableViewController {
var sectionIndex:[String] = []
var indexDictionary:[String:[String]] = [:]
let CellIdentifier = "Cell"
// don't presort test data
let words = ["maple", "apple", "ace", "ant",
"banana", "bird",
"cat", "corn", "cow",
"deer", "dog", "duck",
"elk", "elephant", "elm",
"fowl", "fruit",
"goat",
"milk"]
func generateIndex(_ wordList:[String]) -> ([String], [String:[String]]) {
var indexDictionary:[String:[String]] = [:]
for word in wordList {
let startIndex = word.startIndex
let firstLetter = "\(word[startIndex])" // Character to String
if let _ = indexDictionary[firstLetter] {
//var letterWordList:[String] = indexDictionary[firstLetter]!
//letterWordList.append(word)
indexDictionary[firstLetter]?.append(word)
} else {
let letterWordList = [word]
indexDictionary[firstLetter] = letterWordList
}
// print(firstLetter)
}
// print(indexDictionary)
let keyArray = Array(indexDictionary.keys).sorted() // sort
// print(keyArray)
for (key, _) in indexDictionary {
indexDictionary[key] = indexDictionary[key]?.sorted()
//print("\(key), \(value)")
}
// print("Results")
// print(indexDictionary)
// sort each array in the dictionary
return (keyArray, indexDictionary)
}
override func viewDidLoad() {
(sectionIndex, indexDictionary) = generateIndex(words)
self.tableView.register(UITableViewCell.self, forCellReuseIdentifier:CellIdentifier)
}
}
// Data source delegate
extension SimpleTableViewController {
override func numberOfSections(in tableView: UITableView) -> Int {
// Return the number of sections.
return sectionIndex.count
}
override func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
let letter = sectionIndex[section]
let anArray = indexDictionary[letter]
return anArray!.count
}
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let text:String
let cell = tableView.dequeueReusableCell(withIdentifier: CellIdentifier, for: indexPath)
let letter = sectionIndex[(indexPath as NSIndexPath).section]
if let anArray = indexDictionary[letter] {
text = anArray[(indexPath as NSIndexPath).row]
} else {
text = ""
}
// Configure the cell...
cell.textLabel?.text = text
return cell
}
override func tableView(_ tableView: UITableView, titleForHeaderInSection section: Int) -> String? {
return sectionIndex[section].uppercased()
}
}
<file_sep>/CustomUIView/CustomUIView/ViewController.swift
//
// ViewController.swift
// CustomUIView
//
// Created by <NAME> on 6/2/16.
//
import UIKit
class ViewController: UIViewController {
let customView = CustomView()
func addCustomView() {
customView.translatesAutoresizingMaskIntoConstraints = false
self.view.addSubview(customView)
customView.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
customView.centerYAnchor.constraint(equalTo: view.centerYAnchor).isActive = true
let width:CGFloat = 300 // Change me
customView.widthAnchor.constraint(equalToConstant: width).isActive = true
customView.heightAnchor.constraint(equalToConstant: width).isActive = true
// customView.backgroundColor = .purpleColor()
}
override func viewDidLoad() {
super.viewDidLoad()
addCustomView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/SimpleTableView/SimpleTableView/SimpleTableViewController.swift
//
// SimpleTableViewController.swift
// SimpleTableViewController
//
// Created by <NAME> on 3/8/16.
// Copyright © 2016 h4labs. All rights reserved.
//
import UIKit
class SimpleTableViewController: UITableViewController {
let rowData = ["one", "two", "three"]
let CellIdentifier = "Cell"
override func viewDidLoad() {
self.tableView.register(UITableViewCell.self, forCellReuseIdentifier:CellIdentifier)
}
}
// Data source delegate
extension SimpleTableViewController {
// We can skip overriding this function and it will default to 1
override func numberOfSections(in tableView: UITableView) -> Int {
// Return the number of sections.
return 1
}
override func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
return rowData.count
}
override func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let cell = tableView.dequeueReusableCell(withIdentifier: CellIdentifier, for: indexPath)
// Configure the cell...
cell.textLabel?.text = rowData[(indexPath as NSIndexPath).row]
return cell
}
//: Optional Header title
override func tableView(_ tableView: UITableView, titleForHeaderInSection section: Int) -> String? {
return "Header"
}
}
<file_sep>/ButtonCenteredWithAnchors/ButtonCenteredWithAnchors/ViewController.swift
//
// ViewController.swift
// CenteredAutoLayoutButton
//
// Created by <NAME> on 8/14/14.
//
import UIKit
class ViewController: UIViewController {
var centeredButton = UIButton()
func addButton() {
centeredButton.setTitle("Am I centered?", for: UIControlState())
centeredButton.setTitleColor(UIColor.blue, for: UIControlState())
centeredButton.translatesAutoresizingMaskIntoConstraints = false
centeredButton.addTarget(self, action: #selector(ViewController.pressed(_:)), for: .touchUpInside)
self.view.addSubview(centeredButton)
centeredButton.centerXAnchor.constraint(equalTo: view.centerXAnchor).isActive = true
centeredButton.centerYAnchor.constraint(equalTo: view.centerYAnchor, constant: -40).isActive = true
}
func pressed(_ sender: UIButton!) {
let title = "Awesome"
let message = "You did it"
let alert = UIAlertController(title: title,
message:message,
preferredStyle: .alert)
let action = UIAlertAction(title: "Take Action 1?", style: .default, handler:nil)
alert.addAction(action)
let action2 = UIAlertAction(title: "Take Action 2?", style: .default, handler:nil)
alert.addAction(action2)
self.present(alert, animated: true, completion: nil)
}
override func viewDidLoad() {
super.viewDidLoad()
addButton()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
<file_sep>/CustomUIView/CustomUIView/CustomView.swift
//
// CustomView.swift
// CustomUIView
//
// Created by <NAME> on 6/2/16.
//
import UIKit
class CustomView: UIView {
override init(frame: CGRect) {
super.init(frame: frame)
self.backgroundColor = UIColor.orange
}
required init?(coder aDecoder: NSCoder) {
fatalError("init(coder:) has not been implemented")
}
func addTriangle(_ x: CGFloat, y: CGFloat, width: CGFloat, height: CGFloat){
let center = CGPoint(x: width/2 + x, y: y)
let bottomLeft = CGPoint(x: x, y: height + y)
let bottomRight = CGPoint(x: width + x, y: height + y)
let layer = CAShapeLayer()
let path = UIBezierPath()
path.move(to: center)
path.addLine(to: bottomLeft)
path.addLine(to: bottomRight)
path.close()
layer.path = path.cgPath
self.layer.addSublayer(layer)
}
func addCircle(_ x: CGFloat, y: CGFloat, radius: CGFloat, color:UIColor){
let layer = CAShapeLayer()
let path = UIBezierPath(ovalIn: CGRect(x: x, y: y, width: radius, height: radius))
layer.fillColor = color.cgColor
layer.path = path.cgPath
self.layer.addSublayer(layer)
}
// Set cornerRadius=1 to make normal rectangle
func addRect(_ x: CGFloat, y: CGFloat, width: CGFloat, height: CGFloat) {
let layer = CAShapeLayer()
layer.path = UIBezierPath(roundedRect: CGRect(x: 10, y: 10, width: 160, height: 160), cornerRadius: 1).cgPath
layer.fillColor = UIColor.blue.cgColor
layer.strokeColor = UIColor.black.cgColor
layer.lineWidth = 2
self.layer.addSublayer(layer)
}
func toRadians(_ degrees:CGFloat) -> CGFloat {
return degrees * CGFloat(M_PI)/180
}
func addArc(_ radius:CGFloat, center:CGPoint){
let layer = CAShapeLayer()
let startAngle:CGFloat = 0
let endAngle:CGFloat = 180
let clockwise = true
layer.path = UIBezierPath(arcCenter: center,
radius: radius,
startAngle: toRadians(startAngle),
endAngle:toRadians(endAngle),
clockwise: clockwise).cgPath
layer.fillColor = UIColor.white.cgColor
layer.strokeColor = UIColor.gray.cgColor
layer.lineWidth = 2
self.layer.addSublayer(layer)
}
override func draw(_ rect: CGRect) {
let width = self.frame.width
let eyeRadius = width * 40/200
// Drawing code
addCircle(0, y:0, radius:width, color: UIColor.gray)
addCircle(width*0.25, y:width*0.15, radius:eyeRadius, color: UIColor.black)
addCircle(width*0.6, y:width*0.15, radius:eyeRadius, color: UIColor.black)
addTriangle(width/2 - eyeRadius/2, y: width/2 - eyeRadius/2, width: eyeRadius, height: eyeRadius)
let mouthRadius:CGFloat = width/4
let mounthCenter = CGPoint(x: width/2, y: width*0.65)
addArc(mouthRadius, center: mounthCenter)
}
}
<file_sep>/CollectionViewDelegate/CollectionViewDelegate/BasicViewController.swift
//
// BasicViewController.swift
// CollectionViewDelegate
//
// Created by <NAME> on 5/26/16.
//
import UIKit
class BasicCollectionViewController: UIViewController, UICollectionViewDataSource, UICollectionViewDelegate {
var collectionView:UICollectionView!
private let reuseIdentifier = "Cell"
// required init?(coder aDecoder: NSCoder) {
// fatalError("NSCoding not supported")
// // super.init(coder: aDecoder)
// }
override func viewDidLoad() {
super.viewDidLoad()
self.view.backgroundColor = UIColor.gray
let flowLayout=UICollectionViewFlowLayout()
flowLayout.minimumInteritemSpacing = 2
flowLayout.minimumLineSpacing = 2
collectionView = UICollectionView(frame: CGRect.zero, collectionViewLayout: flowLayout)
collectionView.dataSource = self
collectionView.delegate = self
collectionView.translatesAutoresizingMaskIntoConstraints = false
self.view.addSubview(collectionView)
let viewDictionary:[String:AnyObject] = [
"collectionView": collectionView,
"topLayoutGuide": topLayoutGuide,
]
let metrics:[String:AnyObject] = [:]
["H:|-0-[collectionView]-0-|",
"V:|[topLayoutGuide]-[collectionView]-|"].forEach {
let constraint = NSLayoutConstraint.constraints(withVisualFormat: $0, options: [], metrics: metrics, views: viewDictionary)
NSLayoutConstraint.activate(constraint)
}
collectionView.backgroundColor = UIColor.gray
// Register cell classes
self.collectionView.register(UICollectionViewCell.self, forCellWithReuseIdentifier: reuseIdentifier)
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
// MARK: UICollectionViewDataSource
extension BasicCollectionViewController {
@objc(numberOfSectionsInCollectionView:) func numberOfSections(in collectionView: UICollectionView) -> Int {
return 1
}
func collectionView(_ collectionView: UICollectionView, numberOfItemsInSection section: Int) -> Int {
return 10
}
}
// MARK: UICollectionViewDelegate
extension BasicCollectionViewController {
@objc(collectionView:cellForItemAtIndexPath:) func collectionView(_ collectionView: UICollectionView, cellForItemAt indexPath: IndexPath) -> UICollectionViewCell {
let cell = collectionView.dequeueReusableCell(withReuseIdentifier: reuseIdentifier, for: indexPath)
// Configure the cell
let aColor = (indexPath as NSIndexPath).row % 2 == 0 ? UIColor.orange : UIColor.green
cell.backgroundColor = aColor
return cell
}
}
<file_sep>/TableViewWithIndex/TableViewWithIndex/ViewController.swift
//
// ViewController.swift
// TableViewWithIndex
//
// Created by <NAME> on 3/9/16.
//
import UIKit
class ViewController: UIViewController {
let tableViewController = SimpleTableViewController()
func addTableView() {
let viewDictionary:[String:AnyObject] = [
"tableView": tableViewController.tableView,
"topLayoutGuide": topLayoutGuide,
]
tableViewController.tableView.translatesAutoresizingMaskIntoConstraints = false
self.view.addSubview(tableViewController.tableView)
let metrics:[String:AnyObject] = [:]
let h0Constraint = "H:|-[tableView]-|"
let v0Constraint = "V:[topLayoutGuide]-[tableView]-|"
[h0Constraint, v0Constraint].forEach {
let constraint = NSLayoutConstraint.constraints(withVisualFormat: $0, options: [], metrics: metrics, views: viewDictionary)
NSLayoutConstraint.activate(constraint)
}
}
override func viewDidLoad() {
super.viewDidLoad()
addTableView()
}
override func didReceiveMemoryWarning() {
super.didReceiveMemoryWarning()
// Dispose of any resources that can be recreated.
}
}
| 28db77f17e0477b9ca64ec2f7c6b8b18babe9e35 | [
"Swift",
"Markdown",
"Shell"
] | 27 | Swift | Arteaga2k/ios_topics | 182a00493eae374f3038a34a8a3ed66c03683852 | 235d44db451f14bc1ecb1b1352b56061d9bfae0e |
refs/heads/master | <file_sep>package com.jnj.honeur.security;
import org.pac4j.core.authorization.generator.AuthorizationGenerator;
import org.pac4j.core.context.WebContext;
import org.pac4j.core.profile.CommonProfile;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Collection;
/**
* Adds roles and permissions to the CasProfile
*
* @author <NAME>
*/
public class CasAuthorizationGenerator<P extends CommonProfile> implements AuthorizationGenerator<P> {
private static final Logger LOG = LoggerFactory.getLogger(CasAuthorizationGenerator.class);
private static final String DEFAULT_REMEMBER_ME_ATTRIBUTE_NAME = "longTermAuthenticationRequestTokenUsed";
private static final String ROLE_ATTRIBUTE_NAME = "role";
private static final String PERMISSION_ATTRIBUTE_NAME = "permission";
private static final String ID_ATTRIBUTE_NAME = "id";
public P generate(final WebContext context, final P profile) {
processRememberMe(profile);
processRoles(profile);
processPermissions(profile);
processId(profile);
return profile;
}
private void processRememberMe(final P profile) {
String rememberMeValue = (String) profile.getAttribute(DEFAULT_REMEMBER_ME_ATTRIBUTE_NAME);
boolean isRemembered = rememberMeValue != null && Boolean.parseBoolean(rememberMeValue);
profile.setRemembered(isRemembered);
}
private void processRoles(final P profile) {
Object roleObj = profile.getAttribute(ROLE_ATTRIBUTE_NAME);
if( roleObj instanceof Collection) {
profile.addRoles((Collection<String>)roleObj);
} else if (roleObj instanceof String){
profile.addRole((String)roleObj);
} else {
LOG.warn("No roles found in CasProfile!");
}
}
private void processPermissions(final P profile) {
Object permissionObj = profile.getAttribute(PERMISSION_ATTRIBUTE_NAME);
if(permissionObj instanceof Collection) {
profile.addPermissions((Collection<String>)permissionObj);
} else if(permissionObj instanceof String){
profile.addPermission((String) permissionObj);
} else {
LOG.warn("No permissions found in CasProfile!");
}
}
private void processId(final P profile) {
Object idObject = profile.getAttribute(ID_ATTRIBUTE_NAME);
if(idObject instanceof String){
profile.addAuthenticationAttribute(ID_ATTRIBUTE_NAME, idObject);
return;
}
LOG.warn("No id found in CasProfile!");
}
}
<file_sep>package com.jnj.honeur.security;
import org.junit.Before;
import org.junit.Test;
import org.pac4j.cas.profile.CasProfile;
import org.pac4j.core.profile.CommonProfile;
import java.util.ArrayList;
import java.util.List;
import static org.junit.Assert.*;
public class CasAuthorizationGeneratorTest {
private static final String ROLE_ADMIN = "ROLE_ADMIN";
private static final String ROLE_USER = "ROLE_USER";
private CasProfile casProfile;
@Before
public void setup() {
List<String> roles = new ArrayList<>();
roles.add(ROLE_ADMIN);
roles.add(ROLE_USER);
List<String> permissions = new ArrayList<>();
permissions.add("user:get");
permissions.add("role:get");
permissions.add("permission:get");
casProfile = new CasProfile();
casProfile.addAttribute("role", roles);
casProfile.addAttribute("permission", permissions);
}
@Test
public void generateEmpty() {
CasProfile emptyCasProfile = new CasProfile();
CommonProfile profile = new CasAuthorizationGenerator<>().generate(null, emptyCasProfile);
assertFalse(profile.isRemembered());
assertTrue(profile.getRoles().isEmpty());
assertTrue(profile.getPermissions().isEmpty());
assertSame(emptyCasProfile, profile);
}
@Test
public void generateRolesAndPermissions() {
assertFalse(casProfile.isRemembered());
assertTrue(casProfile.getRoles().isEmpty());
assertTrue(casProfile.getPermissions().isEmpty());
CommonProfile profile = new CasAuthorizationGenerator<>().generate(null, casProfile);
assertSame(casProfile, profile);
assertFalse(profile.isRemembered());
assertNotNull(profile.getRoles());
assertEquals(2, profile.getRoles().size());
assertTrue(profile.getRoles().contains(ROLE_ADMIN));
assertTrue(profile.getRoles().contains(ROLE_USER));
assertNotNull(profile.getPermissions());
assertEquals(3, profile.getPermissions().size());
assertTrue(profile.getPermissions().contains("user:get"));
assertTrue(profile.getPermissions().contains("role:get"));
assertTrue(profile.getPermissions().contains("permission:get"));
}
@Test
public void generateRememberMeMissing() {
CommonProfile profile = new CasAuthorizationGenerator<>().generate(null, casProfile);
assertFalse(profile.isRemembered());
}
@Test
public void generateRememberMeFalse() {
casProfile.addAttribute("longTermAuthenticationRequestTokenUsed", "false");
CommonProfile profile = new CasAuthorizationGenerator<>().generate(null, casProfile);
assertFalse(profile.isRemembered());
}
@Test
public void generateRememberMeTrue() {
casProfile.addAttribute("longTermAuthenticationRequestTokenUsed", "true");
CommonProfile profile = new CasAuthorizationGenerator<>().generate(null, casProfile);
assertTrue(profile.isRemembered());
}
}<file_sep>package com.jnj.honeur.security;
import org.apache.shiro.subject.Subject;
import java.security.Principal;
public class SecurityUtils2 {
public static String getSubjectName(final Subject subject) {
if(subject == null) {
return null;
}
if (subject.getPrincipal() != null) {
Principal principal = (Principal)subject.getPrincipal();
return principal.getName();
}
return null;
}
}
| 3e533a6f73010dc8410b1f1bd49a6d64e5fbef27 | [
"Java"
] | 3 | Java | petermoorthamer/HONEUR-Security | f94930192ff03a857d0dc31a7c1638562f8d20d1 | 59e1c2ea71f4febd81185b4151983fc6e63d82ac |
refs/heads/main | <repo_name>RamBourn/Voyage<file_sep>/src/view/WarView.java
package view;
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.FlowLayout;
import java.awt.GridLayout;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JRadioButton;
import javax.swing.JTextField;
import controller.WarController;
import model.War;
public class WarView extends JFrame{
private War w;
private WarController wc;
private JLabel attack;
private JLabel defend;
private JTextField []cPay;
private JButton ok;
private JLabel []ends;
private JRadioButton []atackAssist;
private JRadioButton []defendAssist;
public WarView(War w){
this.w=w;
wc=new WarController(w, this);
JPanel warCountry=new JPanel();
warCountry.setLayout(new FlowLayout());
ImageIcon[] image=new ImageIcon[4];
for(int j=0;j<4;j++){
image[j]=new ImageIcon("src/source/picture/"+(j+1)+".jpg");
}
attack=new JLabel(image[w.getAttack()]);
defend=new JLabel(image[w.getDefend()]);
attack.setPreferredSize(new Dimension(300, 250));
defend.setPreferredSize(new Dimension(300,250));
warCountry.add(attack);
JLabel X=new JLabel("X");
warCountry.add(X);
warCountry.add(defend);
warCountry.setPreferredSize(new Dimension(800,250));
JPanel spend=new JPanel();
spend.setLayout(new GridLayout(5,4));
JLabel []coun=new JLabel[4];
atackAssist=new JRadioButton[4];
defendAssist=new JRadioButton[4];
cPay=new JTextField[4];
for(int i=0;i<w.getGame().getCountry().length;i++){
coun[i]=new JLabel(w.getGame().getCountry()[i].getName());
cPay[i]=new JTextField("0");
atackAssist[i]=new JRadioButton("攻击方");
defendAssist[i]=new JRadioButton("防守方");
spend.add(coun[i]);
if(i!=w.getAttack())
spend.add(atackAssist[i]);
else
spend.add(new JLabel());
if(i!=w.getDefend())
spend.add(defendAssist[i]);
else
spend.add(new JLabel());
spend.add(cPay[i]);
}
spend.add(new JLabel());
ok=new JButton("确认");
ok.addActionListener(wc);
spend.add(ok);
spend.setPreferredSize(new Dimension(800,500));
JPanel result=new JPanel();
ends=new JLabel[3];
for(int i=0;i<3;i++){
ends[i]=new JLabel("第"+(i+1)+"回合");
result.add(ends[i]);
}
result.setLayout(new GridLayout(3,1));
result.setPreferredSize(new Dimension(800,300));
this.setLayout(new BorderLayout());
this.add(warCountry,BorderLayout.NORTH);
this.add(spend,BorderLayout.CENTER);
this.add(result,BorderLayout.SOUTH);
this.setBounds(300,100,800,900);
this.setVisible(true);
}
public boolean atOrde(int i){
return this.defendAssist[i].isSelected();
}
public int getCost(int i) {
return Integer.parseInt(this.cPay[i].getText());
}
public void end() {
this.dispose();;// TODO Auto-generated method stub
this.w.getGame().fresh();
}
public void setends(int j,int i){
this.ends[j].setText("第"+(j+1)+"回合:"+w.getGame().getCountry()[i].getName());
}
}
<file_sep>/src/model/War.java
package model;
import view.WarView;
public class War {
private Game g;
private int win;
private int mode;
int at;
int de;
private int choose;
public War(Game g,int mode,int choose,int at,int de){
this.g=g;
this.at=at;
this.de=de;
this.choose=choose;
this.mode=mode;
this.win=0;
openFireCost(at);
new WarView(this);
}
//开战消耗
public void openFireCost(int attack){
g.getCountry()[attack].changeMoney((int)(0.1*g.getCountry()[attack].getMoney()));
}
//战后赔偿
public void win(){
if(win>0)
this.getCompensate( true);
else
this.getCompensate( false);
}
//一场战役
public int aBattle(int attackPay,int attackAssist,int defendPay,int defendAssist){
if(1==mode)
if(attackPay+attackAssist>defendPay*1+defendAssist){
win++;
return at;
}
if(2==mode)
if(attackPay+attackAssist>defendPay*1.5+defendAssist){
win++;
return at;
}
if(3==mode)
if(attackPay+attackAssist>defendPay*2+defendAssist){
win++;
return at;
}
win--;
return de;
}
public void aWarCost(int []cost){
for(int i=0;i<this.g.getCountry().length;i++)
this.g.getCountry()[i].changeMoney(-cost[i]);
}
//获取赔偿
public void getCompensate(boolean w){
//低烈度
if(1==mode){
//获取探险家
if(1==choose&&true==w&&g.getCountry()[de].getsNumber()>=1){
g.getCountry()[at].addSeafarer(true);
g.getCountry()[de].addSeafarer(false);
}
//获取商人
if(2==choose&&true==w&&g.getCountry()[de].getmNumber()>=1){
g.getCountry()[at].addMerchant(true);
g.getCountry()[de].addMerchant(false);
}
//获取殖民者
if(3==choose&&true==w&&g.getCountry()[de].getcNumber()>=1){
g.getCountry()[at].addColonist(true);
g.getCountry()[de].addColonist(false);
}
//获取已知港口
if(4==choose&&true==w){
Port []po=g.getCountry()[de].getHasPort();
for(int i=0;i<po.length;i++){
if(po[i]!=null)
g.getCountry()[at].setHasPort(i, po[i]);
}
}
}
else{
//失败赔偿一半金钱
int money=g.getCountry()[at].getMoney();
g.getCountry()[at].changeMoney(-(int)(0.5*money));
g.getCountry()[de].changeMoney((int)(0.5*money));
}
if(2==mode){
//获取所有殖民地
if(1==choose&&true==w){
int []colonyPort=g.getCountry()[de].getColonyPort();
for(int i=0;i<colonyPort.length;i++){
g.getCountry()[at].colonySuccess(i);
g.getCountry()[de].loseColonyPort(i);
g.getPort()[i].setColonyCountry(g.getCountry()[at]);
}
}
//获取一半的探险家,商人,殖民者
if(2==choose&&true==w){
if(g.getCountry()[de].getsNumber()>=1){
g.getCountry()[at].addSeafarer(true);
g.getCountry()[de].addSeafarer(false);
}
if(g.getCountry()[de].getmNumber()>=1){
g.getCountry()[at].addMerchant(true);
g.getCountry()[de].addMerchant(false);
}
if(g.getCountry()[de].getcNumber()>=1){
g.getCountry()[at].addColonist(true);
g.getCountry()[de].addColonist(false);
}
}
}
else{
//失败赔偿90%金钱
int money=g.getCountry()[at].getMoney();
g.getCountry()[at].changeMoney(-(int)(0.9*money));
g.getCountry()[de].changeMoney((int)(0.9*money));
}
if(3==mode)
if(true==w){
//获取对方所有资源
g.getCountry()[at].changeMoney(g.getCountry()[de].getMoney());
for(int i=0;i<g.getCountry()[de].getsNumber();i++)
g.getCountry()[at].addSeafarer(true);
for(int i=0;i<g.getCountry()[de].getmNumber();i++)
g.getCountry()[at].addMerchant(true);
for(int i=0;i<g.getCountry()[de].getcNumber();i++)
g.getCountry()[at].addColonist(true);
int []colonyPort=g.getCountry()[de].getColonyPort();
for(int i=0;i<colonyPort.length;i++){
g.getCountry()[at].colonySuccess(i);
g.getCountry()[de].loseColonyPort(i);
g.getPort()[i].setColonyCountry(g.getCountry()[at]);
}
}
else{
//失败亦然
int temp=this.at;
this.at=this.de;
this.de=this.at;
this.getCompensate(true);
}
}
public Game getGame(){
return this.g;
}
public int getAttack(){
return at;
}
public int getDefend(){
return de;
}
}
<file_sep>/src/model/Country.java
package model;
public class Country {
private String name;
private int money;
private int seafarerNumber;
private int aSeafarerCost;
private int merchantNumber;
private int aMerchantCost;
private int colonistNumber;
private int aColonistCost;
private int colonyspped;
private Port []hasp;
private int []tradep;
private int []colonyDoing;
private int []colonyp;
public Country(String name,int money,int sNumber,int sCost,int mNumber,
int mCost,int cn,int cnCost,int colonySpeed){
this.name=name;
this.money=money;
this.seafarerNumber=sNumber;
this.aSeafarerCost=sCost;
this.merchantNumber=mNumber;
this.aMerchantCost=mCost;
this.colonistNumber=cn;
this.aColonistCost=cnCost;
this.colonyspped=colonySpeed;
this.hasp=new Port[6];
this.tradep=new int[6];
this.colonyp=new int[6];
this.colonyDoing=new int[6];
for(int i=0;i<this.colonyDoing.length;i++)
{
this.colonyDoing[i]=0;
this.tradep[i]=0;
this.colonyp[i]=0;
}
}
public void setHasPort(int i,Port p){
this.money-=this.aSeafarerCost;
this.hasp[i]=p;
}
public void setTradePort(int i){
this.money-=this.aMerchantCost;
this.tradep[i]++;
}
public void setColonyDoingPort(int i){
this.colonyDoing[i]++;
this.colonistNumber--;
}
public String getName() {
return this.name;
// TODO Auto-generated method stub
}
public int getsNumber(){
return this.seafarerNumber;
}
public int getsCost(){
return this.aSeafarerCost;
}
public int getmNumber(){
return this.merchantNumber;
}
public int getmCost(){
return this.aMerchantCost;
}
public int getcNumber(){
return this.colonistNumber;
}
public int getcCost(){
return this.aColonistCost;
}
public Port[]getHasPort(){
return this.hasp;
}
public String getHasPortNames(){
String name="";
for(int i=0;i<this.hasp.length;i++)
if(hasp[i]!=null)
name=name+hasp[i].getName();
return name;
}
public String getColonyDoingPortName(){
String name="";
for(int i=0;i<this.hasp.length;i++)
if(this.colonyDoing[i]!=0)
name=name+","+hasp[i].getName();
return name;
}
public String getColonyPortName(){
String name="";
for(int i=0;i<this.hasp.length;i++)
if(this.colonyp[i]!=0)
name=name+hasp[i].getName();
return name;
}
public int[]getTradePort(){
return this.tradep;
}
public int[]getColonyPort(){
return this.colonyp;
}
public int getMoney() {
return this.money;
}
public int getAcolonistCost() {
return this.aColonistCost;
}
public int getCononySpped() {
return this.colonyspped;
}
public void changeMoney(int add) {
this.money+=add;
}
/**
* add函数:战争胜利后获得战利品
* @param i
*/
public void addColonist(boolean i){
if(true==i)
this.colonistNumber++;
else
this.colonistNumber--;
}
public void addMerchant(boolean i){
if(true==i)
this.merchantNumber++;
else
this.merchantNumber--;
}
public void addSeafarer(boolean i){
if(true==i)
this.seafarerNumber++;
else
this.seafarerNumber--;
}
/**
* 国家日常开销
*/
public void dailyExpense(){
this.money-=20;
}
/**
* 商人回归
*/
public void resetMerchant() {
this.tradep=new int[6];
}
/**
* 殖民者胜利回家
* @param name
*/
public void colonistHome(String name) {
int i=0;
while(i<this.hasp.length){
if(this.hasp[i].getName().equals(name))
break;
}
this.colonistNumber+=this.colonyDoing[i];
this.colonyDoing[i]=0;
this.colonySuccess(i);
}
/**
* 殖民胜利
* @param i
*/
public void colonySuccess(int i){
this.colonyp[i]=1;
}
/**
* 殖民中端
* @param i
*/
public void colonistHome(int i) {
this.colonistNumber+=this.colonyDoing[i];
this.colonyDoing[i]=0;
}
/**
* 战败失去殖民地
* @param i
*/
public void loseColonyPort(int i) {
this.colonyp[i]=0;
}
//获取大臣总数
public int getall() {
return this.colonistNumber+this.merchantNumber+this.seafarerNumber;
}
}<file_sep>/src/view/ChooseView2.java
package view;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.Dimension;
import java.awt.GridLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.MouseEvent;
import java.awt.event.MouseListener;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JRadioButton;
import javax.swing.JTextField;
import model.Country;
import model.Game;
/**
* 派出商人殖民者,需所有人探险家回归之后
* @author hp
*
*/
public class ChooseView2 extends JFrame {
private Country c;
private int next;
private JPanel cinfo;
private JPanel sets;
private JPanel show;
private Game g;
private JLabel []m;
private JLabel []c1;
private JLabel wht;
private JRadioButton []p;
private JButton ok;
private JPanel right;
private int mode;
private int number;
private int count;
public ChooseView2(Country cn,int next1,Game g1,int count){
this.c=cn;
this.next=next1;
this.g=g1;
c.resetMerchant();
mode=1;
number=0;
this.count=count;
this.setLayout(new BorderLayout());
cinfo=new JPanel();
show=new JPanel();
sets=new JPanel();
cinfo.setPreferredSize(new Dimension(300,800));
right=new JPanel();
right.setPreferredSize(new Dimension(500,800));
right.setLayout(new BorderLayout(0,0));
this.add(cinfo,BorderLayout.WEST);
this.add(right,BorderLayout.EAST);
this.setcinfo();
this.setfirst("第一个商人");
this.setshow();
sets.setPreferredSize(new Dimension(500,380));
show.setPreferredSize(new Dimension(500,400));
this.setVisible(true);
this.setBounds(300, 100, 1000, 800);
}
public void setcinfo(){
cinfo.setLayout(new GridLayout(6,2));
cinfo.add(new JLabel(c.getName()));
cinfo.add(new JLabel("金钱:"+String.valueOf(c.getMoney())),new ImageIcon("src/source/picture/start.jpg"));
cinfo.add(new JLabel("探险家数目:"+c.getsNumber()),new ImageIcon("src/source/picture/start.jpg"));
cinfo.add(new JLabel("探险家花费:"+String.valueOf(c.getsCost())));
cinfo.add(new JLabel("商人数目:"+String.valueOf(c.getmNumber())));
cinfo.add(new JLabel("商人花费"+String.valueOf(c.getmCost())));
cinfo.add(new JLabel("殖民者数目"+String.valueOf(c.getcNumber())));
cinfo.add(new JLabel("殖民者花费"+String.valueOf(c.getcCost())));
cinfo.add(new JLabel("殖民速度:"+""+c.getCononySpped()));
String []p=c.getHasPortNames().split(",");
JLabel []port=new JLabel[p.length];
JPanel hasp=new JPanel();
hasp.setLayout(new GridLayout((p.length+3)/2,2));
hasp.add(new JLabel("已发现港口"));
hasp.add(new JLabel(":"));
for(int i=0;i<p.length;i++){
port[i]=new JLabel(p[i]);
hasp.add(port[i]);
}
cinfo.add(new JLabel(""+c.getCononySpped()));
cinfo.add(new JLabel("正在殖民:"+c.getColonyDoingPortName()));
cinfo.add(new JLabel("已殖民:"+c.getColonyPortName()));
}
public void setsets(String name){
wht.setText(name);
}
public void setfirst(String name){
wht=new JLabel(name);
p=new JRadioButton[6];
JPanel choose=new JPanel();
for(int i=0;i<6;i++){
p[i]=new JRadioButton(g.getPort()[i].getName());
choose.add(p[i]);
}
choose.setLayout(new GridLayout(3,2));
ok=new JButton("确认");
ok.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent e){
int judge=judge();
if(judge!=-1)
setone(mode,number,g.getPort()[judge].getName());
if(1==mode){
if((++number)<c.getmNumber()){
setsets("第"+(number+1)+"个商人");
g.sendMerchant(c, judge);
}
else{
number=0;
mode++;
setsets("第"+1+"个殖民者");
}
}
else
if(2==mode)
{
if((++number)<c.getcNumber()){
setsets("第"+(number)+"个殖民者");
g.sendColonist(c, judge);
}
else{
quit();
}
}
}
});
sets.setLayout(new BorderLayout(0,10));
wht.setPreferredSize(new Dimension(500,50));
choose.setPreferredSize(new Dimension(500,270));
ok.setPreferredSize(new Dimension(500,30));
sets.add(wht,BorderLayout.NORTH);
sets.add(choose,BorderLayout.CENTER);
sets.add(ok,BorderLayout.SOUTH);
right.add(sets,BorderLayout.NORTH);
}
public int judge(){
int j;
for( j=0;j<this.g.getPort().length;j++)
if(p[j].isSelected())
return j;
return -1;
}
public void setshow(){
int all=c.getall();
show.setLayout(new GridLayout(all,2));
m=new JLabel[c.getmNumber()];
c1=new JLabel[c.getcNumber()];
for(int i=0;i<c.getmNumber();i++){
m[i]=new JLabel("第"+(i+1)+"个商人");
show.add(m[i]);
}
for(int i=0;i<c.getcNumber();i++){
c1[i]=new JLabel("第"+(i+1)+"个殖民者");
show.add(c1[i]);
}
right.add(show,BorderLayout.SOUTH);
}
public void setone(int i,int j,String name){
if(1==i){
m[j].setText("第"+(j+1)+"个商人"+name);
}
if(2==i){
c1[j].setText("第"+(j+1)+"个殖民者"+name);
}
}
public void quit(){
next++;
if(next>=4)
next=0;
if(count<4)
new ChooseView2(g.getCountry()[next], next, g,mode);
else
g.continuing();
this.dispose();
}
}
<file_sep>/src/view/CountryView.java
package view;
import java.awt.BorderLayout;
import java.awt.Container;
import java.awt.Dimension;
import java.awt.GridLayout;
import java.awt.LayoutManager;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import model.Country;
import model.Game;
public class CountryView extends JPanel{
private Game g;
private JPanel []coun;
public CountryView(){
this.setLayout(new GridLayout(1,4));
coun=new JPanel[4];
coun[0]=new JPanel();
coun[0].setPreferredSize(new Dimension(400,300));
}
}
<file_sep>/README.md
# Voyage
A Voyage game with GUI
<file_sep>/src/view/ChooseView1.java
package view;
import java.awt.BorderLayout;
import java.awt.Dimension;
import java.awt.FlowLayout;
import java.awt.GridLayout;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import java.awt.event.MouseEvent;
import java.awt.event.MouseListener;
import javax.swing.ImageIcon;
import javax.swing.JButton;
import javax.swing.JFrame;
import javax.swing.JLabel;
import javax.swing.JPanel;
import javax.swing.JRadioButton;
import javax.swing.JTextField;
import model.Country;
import model.Game;
public class ChooseView1 extends JFrame {
private Country c;
private int next;
private JPanel cinfo;
private JPanel sets;
private JPanel show;
private Game g;
private JLabel []s;
private JLabel wht;
private JRadioButton east;
private JRadioButton west;
private JButton ok;
private JButton skip;
private JPanel right;
private int number;
private int count;
/**
* 派出探险家
* @param cn
* @param next1
* @param g1
* @param count
*/
public ChooseView1(Country cn,int next1,Game g1,int count){
this.c=cn;
this.next=next1;
this.g=g1;
c.resetMerchant();
this.count=count;
number=0;
this.setLayout(new BorderLayout());
cinfo=new JPanel();
show=new JPanel();
sets=new JPanel();
cinfo.setPreferredSize(new Dimension(300,800));
right=new JPanel();
right.setPreferredSize(new Dimension(500,800));
right.setLayout(new BorderLayout(0,0));
this.add(cinfo,BorderLayout.WEST);
this.add(right,BorderLayout.EAST);
this.setcinfo();
this.setfirst("第一个探险家");
this.setshow();
sets.setPreferredSize(new Dimension(500,300));
show.setPreferredSize(new Dimension(500,400));
ImageIcon picture1=new ImageIcon("src/source/picture/game.jpg");
this.setVisible(true);
this.setBounds(300, 100, 1000, 800);
}
public void setcinfo(){
cinfo.setLayout(new GridLayout(6,2));
cinfo.add(new JLabel(c.getName()));
cinfo.add(new JLabel("金钱:"+String.valueOf(c.getMoney())),new ImageIcon("src/source/picture/start.jpg"));
cinfo.add(new JLabel("探险家数目:"+c.getsNumber()),new ImageIcon("src/source/picture/start.jpg"));
cinfo.add(new JLabel("探险家花费:"+String.valueOf(c.getsCost())));
cinfo.add(new JLabel("商人数目:"+String.valueOf(c.getmNumber())));
cinfo.add(new JLabel("商人花费"+String.valueOf(c.getmCost())));
cinfo.add(new JLabel("殖民者数目"+String.valueOf(c.getcNumber())));
cinfo.add(new JLabel("殖民者花费"+String.valueOf(c.getcCost())));
cinfo.add(new JLabel("殖民速度:"+""+c.getCononySpped()));
String []p=c.getHasPortNames().split(",");
JLabel []port=new JLabel[p.length];
JPanel hasp=new JPanel();
hasp.setLayout(new GridLayout((p.length+3)/2,2));
hasp.add(new JLabel("已发现港口"));
hasp.add(new JLabel(":"));
for(int i=0;i<p.length;i++){
port[i]=new JLabel(p[i]);
hasp.add(port[i]);
}
cinfo.add(new JLabel(""+c.getCononySpped()));
cinfo.add(new JLabel("正在殖民:"+c.getColonyDoingPortName()));
cinfo.add(new JLabel("已殖民:"+c.getColonyPortName()));
}
public void setsets(String name){
wht.setText(name);
}
public void setfirst(String name){
wht=new JLabel(name);
east=new JRadioButton("东");
west=new JRadioButton("西");
skip=new JButton("跳过");
ok=new JButton("确认");
ok.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent e){
String judge=judge();
setone(number,judge());
if((++number)<c.getsNumber()){
setsets("第"+(number+1)+"个探险家:");
g.sendSeafarer(judge(), c);
return;
}
else{
quit();
}
}
});
sets.setLayout(new BorderLayout(0,10));
wht.setPreferredSize(new Dimension(500,100));
west.setPreferredSize(new Dimension(200,50));
east.setPreferredSize(new Dimension(200,50));
JPanel center=new JPanel();
center.add(east);
center.add(west);
center.setLayout(new FlowLayout());
center.setPreferredSize(new Dimension(500,50));
ok.setPreferredSize(new Dimension(500,30));
sets.add(wht,BorderLayout.NORTH);
sets.add(center,BorderLayout.CENTER);
sets.add(ok,BorderLayout.SOUTH);
right.add(sets,BorderLayout.NORTH);
}
public String judge(){
String judge="无";
if(east.isSelected())
judge="东";
if(west.isSelected())
judge="西";
return judge;
}
public void setshow(){
show.setLayout(new GridLayout(c.getsNumber(),1));
s=new JLabel[c.getsNumber()];
for(int i=0;i<c.getsNumber();i++){
s[i]=new JLabel("第"+(i+1)+"个探险家:");
show.add(s[i]);
}
right.add(show,BorderLayout.SOUTH);
}
public void setone(int j,String name){
s[j].setText("第"+(j+1)+"个探险家:"+name);
}
public void quit(){
count++;
next++;
if(next>=4)
next=0;
if(count<4)
new ChooseView1(g.getCountry()[next],next, g,count);
else{
this.g.fresh();
new ChooseView2(g.getCountry()[0],0, g,0);
}
this.dispose();
}
}
| 963755736645ef061586a051001775c392102aa1 | [
"Markdown",
"Java"
] | 7 | Java | RamBourn/Voyage | 1e2f2c3373dd0eea332ddd7e651da6203b2e0fb0 | 22dcf96932b62474ba7fe3763b4650a54221be60 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.