Datasets:


dataset_info:
- config_name: DINO
features:
- name: random_crop
dtype: bool
- name: epochs
dtype: int64
- name: seed
dtype: int64
- name: best_checkpoint_test_loss
dtype: float64
- name: model_idx
dtype: int64
- name: dataset_name
dtype: string
- name: best_checkpoint_test_accuracy
dtype: float64
- name: weight_decay
dtype: float64
- name: batch_size
dtype: int64
- name: base_model
dtype: string
- name: best_checkpoint_val_loss
dtype: float64
- name: dataset_chosen_targets
dtype: string
- name: best_checkpoint_train_accuracy
dtype: float64
- name: best_checkpoint_train_loss
dtype: float64
- name: max_train_steps
dtype: int64
- name: best_checkpoint_val_accuracy
dtype: float64
- name: lr_scheduler
dtype: string
- name: learning_rate
dtype: float64
- name: random_flip
dtype: bool
- name: split
dtype: string
- name: subset
dtype: string
- name: hf_model_id
dtype: string
- name: hf_model_url
dtype: string
splits:
- name: train
num_bytes: 556679
num_examples: 701
- name: val
num_bytes: 78880
num_examples: 100
- name: test
num_bytes: 159344
num_examples: 201
download_size: 253029
dataset_size: 794903
- config_name: MAE
features:
- name: random_crop
dtype: bool
- name: epochs
dtype: int64
- name: seed
dtype: int64
- name: best_checkpoint_test_loss
dtype: float64
- name: model_idx
dtype: int64
- name: dataset_name
dtype: string
- name: best_checkpoint_test_accuracy
dtype: float64
- name: weight_decay
dtype: float64
- name: batch_size
dtype: int64
- name: base_model
dtype: string
- name: best_checkpoint_val_loss
dtype: float64
- name: dataset_chosen_targets
dtype: string
- name: best_checkpoint_train_accuracy
dtype: float64
- name: best_checkpoint_train_loss
dtype: float64
- name: max_train_steps
dtype: int64
- name: best_checkpoint_val_accuracy
dtype: float64
- name: lr_scheduler
dtype: string
- name: learning_rate
dtype: float64
- name: random_flip
dtype: bool
- name: split
dtype: string
- name: subset
dtype: string
- name: hf_model_id
dtype: string
- name: hf_model_url
dtype: string
splits:
- name: train
num_bytes: 553950
num_examples: 701
- name: val
num_bytes: 79028
num_examples: 100
- name: test
num_bytes: 158815
num_examples: 201
download_size: 253409
dataset_size: 791793
- config_name: ResNet
features:
- name: random_crop
dtype: bool
- name: epochs
dtype: int64
- name: seed
dtype: int64
- name: best_checkpoint_test_loss
dtype: float64
- name: model_idx
dtype: int64
- name: dataset_name
dtype: string
- name: best_checkpoint_test_accuracy
dtype: float64
- name: weight_decay
dtype: float64
- name: batch_size
dtype: int64
- name: base_model
dtype: string
- name: best_checkpoint_val_loss
dtype: float64
- name: dataset_chosen_targets
dtype: string
- name: best_checkpoint_train_accuracy
dtype: float64
- name: best_checkpoint_train_loss
dtype: float64
- name: max_train_steps
dtype: int64
- name: best_checkpoint_val_accuracy
dtype: float64
- name: lr_scheduler
dtype: string
- name: learning_rate
dtype: float64
- name: random_flip
dtype: bool
- name: split
dtype: string
- name: subset
dtype: string
- name: hf_model_id
dtype: string
- name: hf_model_url
dtype: string
splits:
- name: train
num_bytes: 559861
num_examples: 701
- name: val
num_bytes: 79621
num_examples: 100
- name: test
num_bytes: 160334
num_examples: 201
download_size: 254554
dataset_size: 799816
- config_name: SD_1k
features:
- name: model_idx
dtype: int64
- name: imagenet_class_id
dtype: string
- name: imagenet_class_name
dtype: string
- name: split
dtype: string
- name: subset
dtype: string
- name: seed
dtype: int64
- name: learning_rate
dtype: float64
- name: max_train_steps
dtype: int64
- name: rank
dtype: int64
- name: pretrained_model_name_or_path
dtype: string
- name: n_training_samples
dtype: int64
- name: hf_model_id
dtype: string
- name: hf_model_url
dtype: string
- name: hf_model_path
dtype: string
splits:
- name: train
num_bytes: 906691
num_examples: 3500
- name: val
num_bytes: 64114
num_examples: 251
- name: test
num_bytes: 128377
num_examples: 499
- name: val_holdout
num_bytes: 67364
num_examples: 249
- name: test_holdout
num_bytes: 137229
num_examples: 501
download_size: 198659
dataset_size: 1303775
- config_name: SD_200
features:
- name: model_idx
dtype: int64
- name: imagenet_class_id
dtype: string
- name: imagenet_class_name
dtype: string
- name: split
dtype: string
- name: subset
dtype: string
- name: seed
dtype: int64
- name: learning_rate
dtype: float64
- name: max_train_steps
dtype: int64
- name: rank
dtype: int64
- name: pretrained_model_name_or_path
dtype: string
- name: n_training_samples
dtype: int64
- name: hf_model_id
dtype: string
- name: hf_model_url
dtype: string
- name: hf_model_path
dtype: string
splits:
- name: train
num_bytes: 924063
num_examples: 3500
- name: val
num_bytes: 65187
num_examples: 251
- name: test
num_bytes: 130863
num_examples: 499
- name: val_holdout
num_bytes: 68302
num_examples: 249
- name: test_holdout
num_bytes: 138450
num_examples: 501
download_size: 158079
dataset_size: 1326865
- config_name: SupViT
features:
- name: random_crop
dtype: bool
- name: epochs
dtype: int64
- name: seed
dtype: int64
- name: best_checkpoint_test_loss
dtype: float64
- name: model_idx
dtype: int64
- name: dataset_name
dtype: string
- name: best_checkpoint_test_accuracy
dtype: float64
- name: weight_decay
dtype: float64
- name: batch_size
dtype: int64
- name: base_model
dtype: string
- name: best_checkpoint_val_loss
dtype: float64
- name: dataset_chosen_targets
dtype: string
- name: best_checkpoint_train_accuracy
dtype: float64
- name: best_checkpoint_train_loss
dtype: float64
- name: max_train_steps
dtype: int64
- name: best_checkpoint_val_accuracy
dtype: float64
- name: lr_scheduler
dtype: string
- name: learning_rate
dtype: float64
- name: random_flip
dtype: bool
- name: split
dtype: string
- name: subset
dtype: string
- name: hf_model_id
dtype: string
- name: hf_model_url
dtype: string
splits:
- name: train
num_bytes: 562795
num_examples: 698
- name: val
num_bytes: 79433
num_examples: 99
- name: test
num_bytes: 161793
num_examples: 201
download_size: 248900
dataset_size: 804021
configs:
- config_name: DINO
data_files:
- split: train
path: DINO/train-*
- split: val
path: DINO/val-*
- split: test
path: DINO/test-*
- config_name: MAE
data_files:
- split: train
path: MAE/train-*
- split: val
path: MAE/val-*
- split: test
path: MAE/test-*
- config_name: ResNet
data_files:
- split: train
path: ResNet/train-*
- split: val
path: ResNet/val-*
- split: test
path: ResNet/test-*
- config_name: SD_1k
data_files:
- split: train
path: SD_1k/train-*
- split: val
path: SD_1k/val-*
- split: test
path: SD_1k/test-*
- split: val_holdout
path: SD_1k/val_holdout-*
- split: test_holdout
path: SD_1k/test_holdout-*
- config_name: SD_200
data_files:
- split: train
path: SD_200/train-*
- split: val
path: SD_200/val-*
- split: test
path: SD_200/test-*
- split: val_holdout
path: SD_200/val_holdout-*
- split: test_holdout
path: SD_200/test_holdout-*
- config_name: SupViT
data_files:
- split: train
path: SupViT/train-*
- split: val
path: SupViT/val-*
- split: test
path: SupViT/test-*
tags:
- probex
- model-j
- weight-space-learning
- model-zoo
- hyperparameters
- stable-diffusion
- vit
- resnet
size_categories:
- 10K<n<100K
Model-J Dataset
This dataset contains the hyperparameters, metadata, and Hugging Face links for all models in the Model-J dataset, introduced in:
Learning on Model Weights using Tree Experts (CVPR 2025) by Eliahu Horwitz*, Bar Cavia*, Jonathan Kahana*, Yedid Hoshen
🌐 Project | 📃 Paper | 💻 GitHub | 🤗 Models
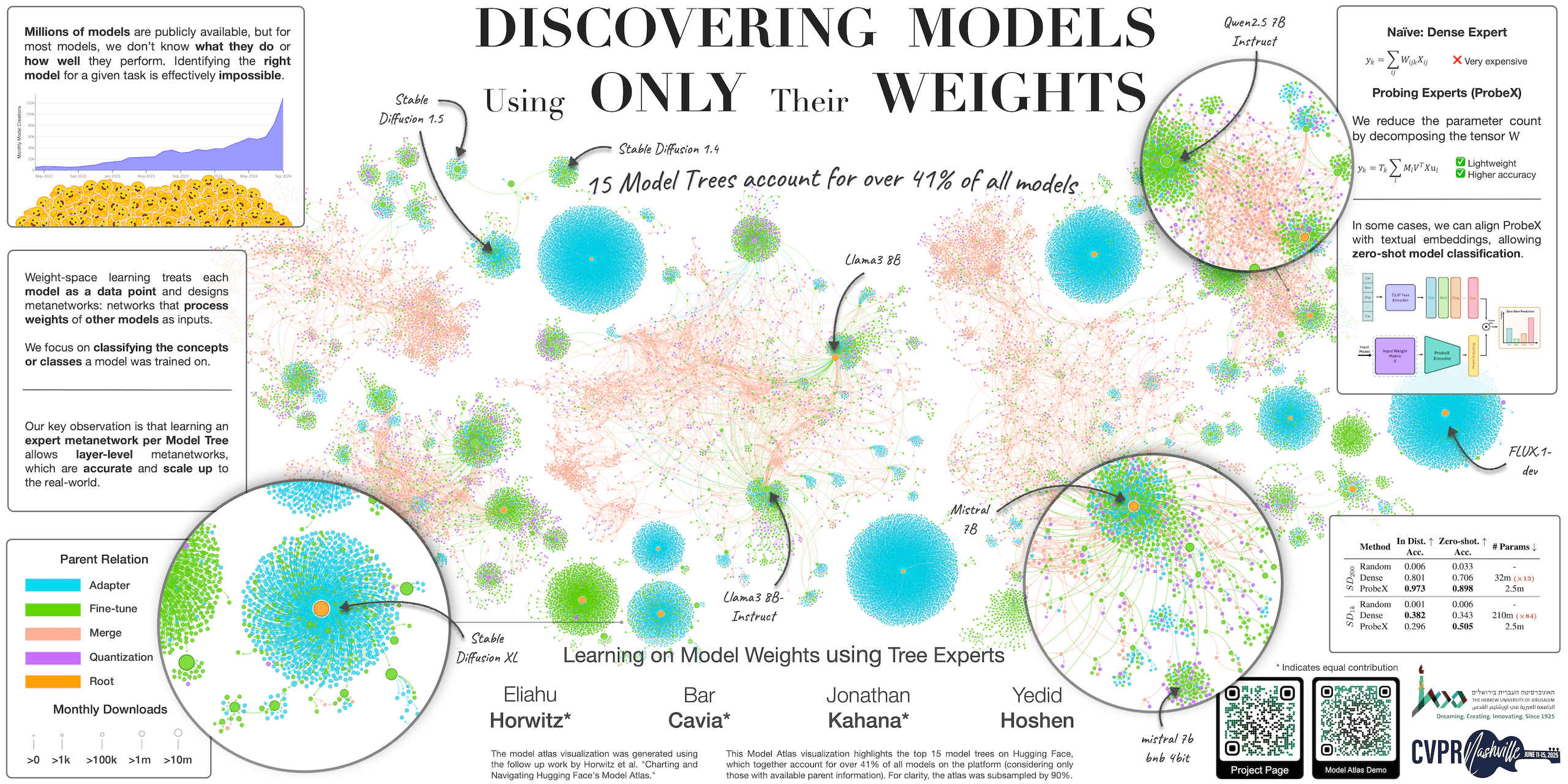
Overview
Model-J is a large-scale dataset of trained neural networks designed for research on learning from model weights. It contains 14,004 models spanning 6 subsets, each with train/val/test splits. Every row in this dataset provides the full training hyperparameters, performance metrics, and a direct link to the corresponding model weights on Hugging Face.
Subsets
Discriminative (one model per HF repo)
| Subset | Base Model | Train | Val | Test | Total |
|---|---|---|---|---|---|
| DINO | facebook/dino-vitb16 |
701 | 100 | 201 | 1,002 |
| MAE | facebook/vit-mae-base |
701 | 100 | 201 | 1,002 |
| SupViT | google/vit-base-patch16-224 |
698 | 99 | 201 | 998 |
| ResNet | microsoft/resnet-18 |
701 | 100 | 201 | 1,002 |
Each discriminative model is a full fine-tuned classifier hosted in its own Hugging Face repository. The hf_model_id and hf_model_url columns point directly to the model.
Generative (bundled LoRA models in a single HF repo)
| Subset | Train | Val | Test | Val Holdout | Test Holdout | Total |
|---|---|---|---|---|---|---|
| SD_200 | 3,500 | 251 | 499 | 249 | 501 | 5,000 |
| SD_1k | 3,500 | 251 | 499 | 249 | 501 | 5,000 |
Each generative model is a LoRA adapter. All models within a subset are bundled into a single Hugging Face repository (SD_1k, SD_200). The hf_model_path column provides the path to each model's weights within the repo. Each model's directory also contains its training images.
Citation
If you find this useful for your research, please use the following.
@InProceedings{Horwitz_2025_CVPR,
author = {Horwitz, Eliahu and Cavia, Bar and Kahana, Jonathan and Hoshen, Yedid},
title = {Learning on Model Weights using Tree Experts},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},
month = {June},
year = {2025},
pages = {20468-20478}
}