
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 3.43B | node_id stringlengths 18 24 | number int64 2 7.78k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at stringdate 2020-04-14 18:18:51 2025-09-18 08:25:34 | updated_at stringdate 2020-04-29 09:23:05 2025-09-22 08:47:53 | closed_at stringlengths 20 20 ⌀ | author_association stringclasses 4
values | type null | active_lock_reason null | draft bool 0
classes | pull_request dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 4
values | sub_issues_summary dict | issue_dependencies_summary dict | is_pull_request bool 1
class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5381 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5381/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5381/comments | https://api.github.com/repos/huggingface/datasets/issues/5381/events | https://github.com/huggingface/datasets/issues/5381 | 1,504,498,387 | I_kwDODunzps5ZrNLT | 5,381 | Wrong URL for the_pile dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/45738728?v=4",
"events_url": "https://api.github.com/users/LeoGrin/events{/privacy}",
"followers_url": "https://api.github.com/users/LeoGrin/followers",
"following_url": "https://api.github.com/users/LeoGrin/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi! This error can happen if there is a local file/folder with the same name as the requested dataset. And to avoid it, rename the local file/folder.\r\n\r\nSoon, it will be possible to explicitly request a Hub dataset as follows:https://github.com/huggingface/datasets/issues/5228#issuecomment-1313494020"
] | 2022-12-20T12:40:14Z | 2023-02-15T16:24:57Z | 2023-02-15T16:24:57Z | NONE | null | null | null | null | ### Describe the bug
When trying to load `the_pile` dataset from the library, I get a `FileNotFound` error.
### Steps to reproduce the bug
Steps to reproduce:
Run:
```
from datasets import load_dataset
dataset = load_dataset("the_pile")
```
I get the output:
"name": "FileNotFoundError",
"message... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5381/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5381/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5380 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5380/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5380/comments | https://api.github.com/repos/huggingface/datasets/issues/5380/events | https://github.com/huggingface/datasets/issues/5380 | 1,504,404,043 | I_kwDODunzps5Zq2JL | 5,380 | Improve dataset `.skip()` speed in streaming mode | {
"avatar_url": "https://avatars.githubusercontent.com/u/173537?v=4",
"events_url": "https://api.github.com/users/versae/events{/privacy}",
"followers_url": "https://api.github.com/users/versae/followers",
"following_url": "https://api.github.com/users/versae/following{/other_user}",
"gists_url": "https://api... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | open | false | null | [] | null | [
"Hi! I agree `skip` can be inefficient to use in the current state.\r\n\r\nTo make it fast, we could use \"statistics\" stored in Parquet metadata and read only the chunks needed to form a dataset. \r\n\r\nAnd thanks to the \"datasets-server\" project, which aims to store the Parquet versions of the Hub datasets (o... | 2022-12-20T11:25:23Z | 2023-03-08T10:47:12Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
Add extra information to the `dataset_infos.json` file to include the number of samples/examples in each shard, for example in a new field `num_examples` alongside `num_bytes`. The `.skip()` function could use this information to ignore the download of a shard when in streaming mode, which AFAICT... | null | {
"+1": 7,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 7,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5380/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5380/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5378 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5378/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5378/comments | https://api.github.com/repos/huggingface/datasets/issues/5378/events | https://github.com/huggingface/datasets/issues/5378 | 1,503,887,508 | I_kwDODunzps5Zo4CU | 5,378 | The dataset "the_pile", subset "enron_emails" , load_dataset() failure | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Thanks for reporting @shaoyuta. We are investigating it.\r\n\r\nWe are transferring the issue to \"the_pile\" Community tab on the Hub: https://huggingface.co/datasets/the_pile/discussions/4"
] | 2022-12-20T02:19:13Z | 2022-12-20T07:52:54Z | 2022-12-20T07:52:54Z | NONE | null | null | null | null | ### Describe the bug
When run
"datasets.load_dataset("the_pile","enron_emails")" failure

### Steps to reproduce the bug
Run below code in python cli:
>>> import datasets
>>> datasets.load_dataset(... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5378/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5378/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5374 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5374/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5374/comments | https://api.github.com/repos/huggingface/datasets/issues/5374/events | https://github.com/huggingface/datasets/issues/5374 | 1,501,872,945 | I_kwDODunzps5ZhMMx | 5,374 | Using too many threads results in: Got disconnected from remote data host. Retrying in 5sec | {
"avatar_url": "https://avatars.githubusercontent.com/u/62820084?v=4",
"events_url": "https://api.github.com/users/Muennighoff/events{/privacy}",
"followers_url": "https://api.github.com/users/Muennighoff/followers",
"following_url": "https://api.github.com/users/Muennighoff/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"The data files are hosted on HF at https://huggingface.co/datasets/allenai/c4/tree/main\r\n\r\nYou have 200 runs streaming the same files in parallel. So this is probably a Hub limitation. Maybe rate limiting ? cc @julien-c \r\n\r\nMaybe you can also try to reduce the number of HTTP requests by increasing the bloc... | 2022-12-18T11:38:58Z | 2023-07-24T15:23:07Z | 2023-07-24T15:23:07Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
`streaming_download_manager` seems to disconnect if too many runs access the same underlying dataset 🧐
The code works fine for me if I have ~100 runs in parallel, but disconnects once scaling to 200.
Possibly related:
- https://github.com/huggingface/datasets/pull/3100
- https://github.com/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5374/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5374/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5371 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5371/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5371/comments | https://api.github.com/repos/huggingface/datasets/issues/5371/events | https://github.com/huggingface/datasets/issues/5371 | 1,501,369,036 | I_kwDODunzps5ZfRLM | 5,371 | Add a robustness benchmark dataset for vision | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Ccing @nazneenrajani @lvwerra @osanseviero "
] | 2022-12-17T12:35:13Z | 2022-12-20T06:21:41Z | null | MEMBER | null | null | null | null | ### Name
ImageNet-C
### Paper
Benchmarking Neural Network Robustness to Common Corruptions and Perturbations
### Data
https://github.com/hendrycks/robustness
### Motivation
It's a known fact that vision models are brittle when they meet with slightly corrupted and perturbed data. This is also corre... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 2,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5371/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5371/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5363 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5363/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5363/comments | https://api.github.com/repos/huggingface/datasets/issues/5363/events | https://github.com/huggingface/datasets/issues/5363 | 1,498,171,317 | I_kwDODunzps5ZTEe1 | 5,363 | Dataset.from_generator() crashes on simple example | {
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"events_url": "https://api.github.com/users/villmow/events{/privacy}",
"followers_url": "https://api.github.com/users/villmow/followers",
"following_url": "https://api.github.com/users/villmow/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [] | 2022-12-15T10:21:28Z | 2022-12-15T11:51:33Z | 2022-12-15T11:51:33Z | NONE | null | null | null | null | null | {
"avatar_url": "https://avatars.githubusercontent.com/u/2743060?v=4",
"events_url": "https://api.github.com/users/villmow/events{/privacy}",
"followers_url": "https://api.github.com/users/villmow/followers",
"following_url": "https://api.github.com/users/villmow/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5363/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5363/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5362 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5362/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5362/comments | https://api.github.com/repos/huggingface/datasets/issues/5362/events | https://github.com/huggingface/datasets/issues/5362 | 1,497,643,744 | I_kwDODunzps5ZRDrg | 5,362 | Run 'GPT-J' failure due to download dataset fail (' ConnectionError: Couldn't reach http://eaidata.bmk.sh/data/enron_emails.jsonl.zst ' ) | {
"avatar_url": "https://avatars.githubusercontent.com/u/52023469?v=4",
"events_url": "https://api.github.com/users/shaoyuta/events{/privacy}",
"followers_url": "https://api.github.com/users/shaoyuta/followers",
"following_url": "https://api.github.com/users/shaoyuta/following{/other_user}",
"gists_url": "htt... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @shaoyuta.\r\n\r\nWe have checked and yes, apparently there is an issue with the server hosting the data of the \"enron_emails\" subset of \"the_pile\" dataset: http://eaidata.bmk.sh/data/enron_emails.jsonl.zst\r\nIt seems to be down: The connection has timed out.\r\n\r\nPlease note that at t... | 2022-12-15T01:23:03Z | 2022-12-15T07:45:54Z | 2022-12-15T07:45:53Z | NONE | null | null | null | null | ### Describe the bug
Run model "GPT-J" with dataset "the_pile" fail.
The fail out is as below:
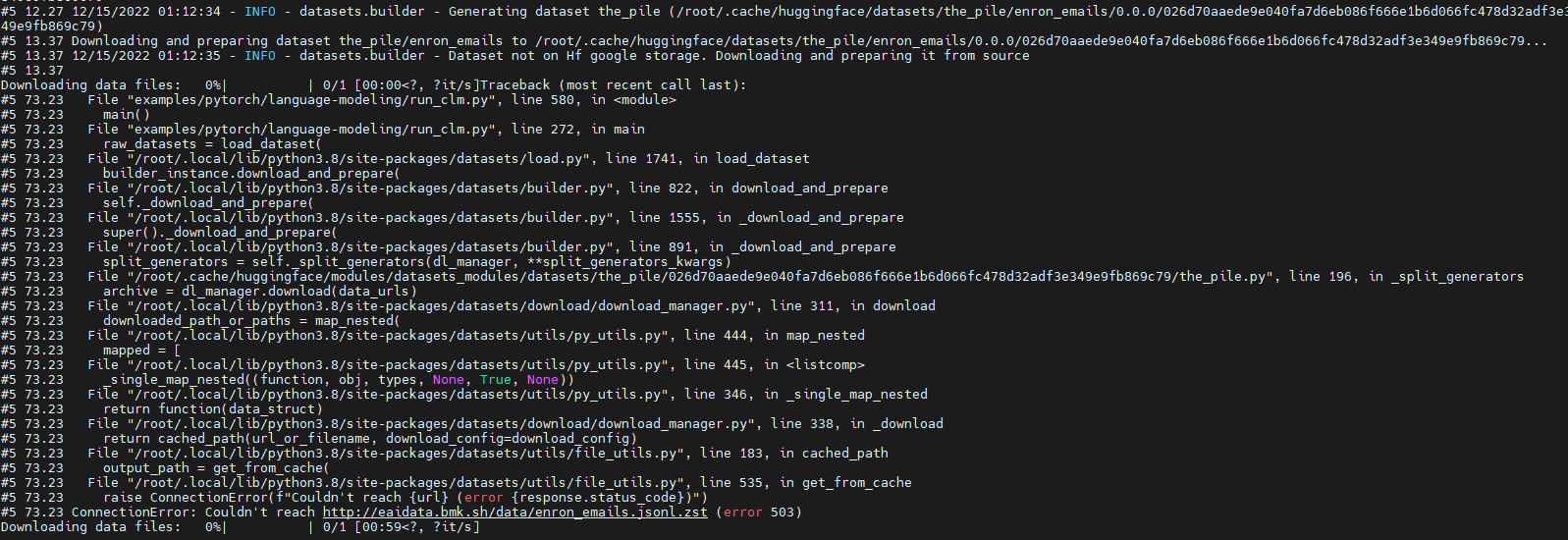
Looks like which is due to "http://eaidata.bmk.sh/data/enron_emails.jsonl.zst" unreachable .
### Steps to ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5362/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5362/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5361 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5361/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5361/comments | https://api.github.com/repos/huggingface/datasets/issues/5361/events | https://github.com/huggingface/datasets/issues/5361 | 1,497,153,889 | I_kwDODunzps5ZPMFh | 5,361 | How concatenate `Audio` elements using batch mapping | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"You can try something like this ?\r\n```python\r\ndef mapper_function(batch):\r\n return {\"concatenated_audio\": [np.concatenate([audio[\"array\"] for audio in batch[\"audio\"]])]}\r\n\r\ndataset = dataset.map(\r\n mapper_function,\r\n batched=True,\r\n batch_size=3,\r\n remove_columns=list(dataset.... | 2022-12-14T18:13:55Z | 2023-07-21T14:30:51Z | 2023-07-21T14:30:51Z | NONE | null | null | null | null | ### Describe the bug
I am trying to do concatenate audios in a dataset e.g. `google/fleurs`.
```python
print(dataset)
# Dataset({
# features: ['path', 'audio'],
# num_rows: 24
# })
def mapper_function(batch):
# to merge every 3 audio
# np.concatnate(audios[i: i+3]) for i in range(i, len(batc... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5361/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5361/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5360 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5360/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5360/comments | https://api.github.com/repos/huggingface/datasets/issues/5360/events | https://github.com/huggingface/datasets/issues/5360 | 1,496,947,177 | I_kwDODunzps5ZOZnp | 5,360 | IterableDataset returns duplicated data using PyTorch DDP | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"If you use huggingface trainer, you will find the trainer has wrapped a `IterableDatasetShard` to avoid duplication.\r\nSee:\r\nhttps://github.com/huggingface/transformers/blob/dfd818420dcbad68e05a502495cf666d338b2bfb/src/transformers/trainer.py#L835\r\n",
"If you want to support it by datasets natively, maybe w... | 2022-12-14T16:06:19Z | 2023-06-15T09:51:13Z | 2023-01-16T13:33:33Z | MEMBER | null | null | null | null | As mentioned in https://github.com/huggingface/datasets/issues/3423, when using PyTorch DDP the dataset ends up with duplicated data. We already check for the PyTorch `worker_info` for single node, but we should also check for `torch.distributed.get_world_size()` and `torch.distributed.get_rank()` | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5360/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5360/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5354 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5354/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5354/comments | https://api.github.com/repos/huggingface/datasets/issues/5354/events | https://github.com/huggingface/datasets/issues/5354 | 1,492,174,125 | I_kwDODunzps5Y8MUt | 5,354 | Consider using "Sequence" instead of "List" | {
"avatar_url": "https://avatars.githubusercontent.com/u/15568078?v=4",
"events_url": "https://api.github.com/users/tranhd95/events{/privacy}",
"followers_url": "https://api.github.com/users/tranhd95/followers",
"following_url": "https://api.github.com/users/tranhd95/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22453634?v=4",
"events_url": "https://api.github.com/users/avinashsai/events{/privacy}",
"followers_url": "https://api.github.com/users/avinashsai/followers",
"following_url": "https://api.github.com/users/avinashsai/following{/other_user}",
... | null | [
"Hi! Linking a comment to provide more info on the issue: https://stackoverflow.com/a/39458225. This means we should replace all (most of) the occurrences of `List` with `Sequence` in function signatures.\r\n\r\n@tranhd95 Would you be interested in submitting a PR?",
"Hi all! I tried to reproduce this issue and d... | 2022-12-12T15:39:45Z | 2025-06-21T13:56:58Z | null | NONE | null | null | null | null | ### Feature request
Hi, please consider using `Sequence` type annotation instead of `List` in function arguments such as in [`Dataset.from_parquet()`](https://github.com/huggingface/datasets/blob/main/src/datasets/arrow_dataset.py#L1088). It leads to type checking errors, see below.
**How to reproduce**
```py
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5354/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5354/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5353 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5353/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5353/comments | https://api.github.com/repos/huggingface/datasets/issues/5353/events | https://github.com/huggingface/datasets/issues/5353 | 1,491,880,500 | I_kwDODunzps5Y7Eo0 | 5,353 | Support remote file systems for `Audio` | {
"avatar_url": "https://avatars.githubusercontent.com/u/46894149?v=4",
"events_url": "https://api.github.com/users/OllieBroadhurst/events{/privacy}",
"followers_url": "https://api.github.com/users/OllieBroadhurst/followers",
"following_url": "https://api.github.com/users/OllieBroadhurst/following{/other_user}"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Just seen https://github.com/huggingface/datasets/issues/5281"
] | 2022-12-12T13:22:13Z | 2022-12-12T13:37:14Z | 2022-12-12T13:37:14Z | NONE | null | null | null | null | ### Feature request
Hi there!
It would be super cool if `Audio()`, and potentially other features, could read files from a remote file system.
### Motivation
Large amounts of data is often stored in buckets. `load_from_disk` is able to retrieve data from cloud storage but to my knowledge actually copies the datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/46894149?v=4",
"events_url": "https://api.github.com/users/OllieBroadhurst/events{/privacy}",
"followers_url": "https://api.github.com/users/OllieBroadhurst/followers",
"following_url": "https://api.github.com/users/OllieBroadhurst/following{/other_user}"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5353/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5353/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5352 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5352/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5352/comments | https://api.github.com/repos/huggingface/datasets/issues/5352/events | https://github.com/huggingface/datasets/issues/5352 | 1,490,796,414 | I_kwDODunzps5Y279- | 5,352 | __init__() got an unexpected keyword argument 'input_size' | {
"avatar_url": "https://avatars.githubusercontent.com/u/82662111?v=4",
"events_url": "https://api.github.com/users/J-shel/events{/privacy}",
"followers_url": "https://api.github.com/users/J-shel/followers",
"following_url": "https://api.github.com/users/J-shel/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"Hi @J-shel, thanks for reporting.\r\n\r\nI think the issue comes from your call to `load_dataset`. As first argument, you should pass:\r\n- either the name of your dataset (\"mrf\") if this is already published on the Hub\r\n- or the path to the loading script of your dataset (\"path/to/your/local/mrf.py\").",
"... | 2022-12-12T02:52:03Z | 2022-12-19T01:38:48Z | null | NONE | null | null | null | null | ### Describe the bug
I try to define a custom configuration with a input_size attribute following the instructions by "Specifying several dataset configurations" in https://huggingface.co/docs/datasets/v1.2.1/add_dataset.html
But when I load the dataset, I got an error "__init__() got an unexpected keyword argument... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5352/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5352/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5351 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5351/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5351/comments | https://api.github.com/repos/huggingface/datasets/issues/5351/events | https://github.com/huggingface/datasets/issues/5351 | 1,490,659,504 | I_kwDODunzps5Y2aiw | 5,351 | Do we need to implement `_prepare_split`? | {
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"events_url": "https://api.github.com/users/jmwoloso/events{/privacy}",
"followers_url": "https://api.github.com/users/jmwoloso/followers",
"following_url": "https://api.github.com/users/jmwoloso/following{/other_user}",
"gists_url": "http... | [] | closed | false | null | [] | null | [
"Hi! `DatasetBuilder` is a parent class for concrete builders: `GeneratorBasedBuilder`, `ArrowBasedBuilder` and `BeamBasedBuilder`. When writing a builder script, these classes are the ones you should inherit from. And since all of them implement `_prepare_split`, you only have to implement the three methods mentio... | 2022-12-12T01:38:54Z | 2022-12-20T18:20:57Z | 2022-12-12T16:48:56Z | NONE | null | null | null | null | ### Describe the bug
I'm not sure this is a bug or if it's just missing in the documentation, or i'm not doing something correctly, but I'm subclassing `DatasetBuilder` and getting the following error because on the `DatasetBuilder` class the `_prepare_split` method is abstract (as are the others we are required to im... | {
"avatar_url": "https://avatars.githubusercontent.com/u/7530947?v=4",
"events_url": "https://api.github.com/users/jmwoloso/events{/privacy}",
"followers_url": "https://api.github.com/users/jmwoloso/followers",
"following_url": "https://api.github.com/users/jmwoloso/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5351/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5351/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5348 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5348/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5348/comments | https://api.github.com/repos/huggingface/datasets/issues/5348/events | https://github.com/huggingface/datasets/issues/5348 | 1,486,975,626 | I_kwDODunzps5YoXKK | 5,348 | The data downloaded in the download folder of the cache does not respect `umask` | {
"avatar_url": "https://avatars.githubusercontent.com/u/55560583?v=4",
"events_url": "https://api.github.com/users/SaulLu/events{/privacy}",
"followers_url": "https://api.github.com/users/SaulLu/followers",
"following_url": "https://api.github.com/users/SaulLu/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"note, that `datasets` already did some of that umask fixing in the past and also at the hub - the recent work on the hub about the same: https://github.com/huggingface/huggingface_hub/pull/1220\r\n\r\nAlso I noticed that each file has a .json counterpart and the latter always has the correct perms:\r\n\r\n```\r\n-... | 2022-12-09T15:46:27Z | 2022-12-09T17:21:26Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
For a project on a cluster we are several users to share the same cache for the datasets library. And we have a problem with the permissions on the data downloaded in the cache.
Indeed, it seems that the data is downloaded by giving read and write permissions only to the user launching the com... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5348/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5348/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5346 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5346/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5346/comments | https://api.github.com/repos/huggingface/datasets/issues/5346/events | https://github.com/huggingface/datasets/issues/5346 | 1,486,884,983 | I_kwDODunzps5YoBB3 | 5,346 | [Quick poll] Give your opinion on the future of the Hugging Face Open Source ecosystem! | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"As the survey is finished, can we close this issue, @LysandreJik ?",
"Yes! I'll post a public summary on the forums shortly.",
"Is the summary available? I would be interested in reading your findings."
] | 2022-12-09T14:48:02Z | 2023-06-02T20:24:44Z | 2023-01-25T19:35:40Z | MEMBER | null | null | null | null | Thanks to all of you, Datasets is just about to pass 15k stars!
Since the last survey, a lot has happened: the [diffusers](https://github.com/huggingface/diffusers), [evaluate](https://github.com/huggingface/evaluate) and [skops](https://github.com/skops-dev/skops) libraries were born. `timm` joined the Hugging Face... | {
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 3,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5346/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5346/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5345 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5345/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5345/comments | https://api.github.com/repos/huggingface/datasets/issues/5345/events | https://github.com/huggingface/datasets/issues/5345 | 1,486,555,384 | I_kwDODunzps5Ymwj4 | 5,345 | Wrong dtype for array in audio features | {
"avatar_url": "https://avatars.githubusercontent.com/u/25608944?v=4",
"events_url": "https://api.github.com/users/qmeeus/events{/privacy}",
"followers_url": "https://api.github.com/users/qmeeus/followers",
"following_url": "https://api.github.com/users/qmeeus/following{/other_user}",
"gists_url": "https://a... | [] | open | false | null | [] | null | [
"After some more investigation, this is due to [this line of code](https://github.com/huggingface/datasets/blob/main/src/datasets/features/audio.py#L279). The function `sf.read(file)` should be updated to `sf.read(file, dtype=\"float32\")`\r\n\r\nIndeed, the default value in soundfile is `float64` ([see here](https... | 2022-12-09T11:05:11Z | 2023-02-10T14:39:28Z | null | NONE | null | null | null | null | ### Describe the bug
When concatenating/interleaving different datasets, I stumble into an error because the features can't be aligned. After some investigation, I understood that the audio arrays had different dtypes, namely `float32` and `float64`. Consequently, the datasets cannot be merged.
### Steps to repro... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5345/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5345/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5343 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5343/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5343/comments | https://api.github.com/repos/huggingface/datasets/issues/5343/events | https://github.com/huggingface/datasets/issues/5343 | 1,485,297,823 | I_kwDODunzps5Yh9if | 5,343 | T5 for Q&A produces truncated sentence | {
"avatar_url": "https://avatars.githubusercontent.com/u/13484072?v=4",
"events_url": "https://api.github.com/users/junyongyou/events{/privacy}",
"followers_url": "https://api.github.com/users/junyongyou/followers",
"following_url": "https://api.github.com/users/junyongyou/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [] | 2022-12-08T19:48:46Z | 2022-12-08T19:57:17Z | 2022-12-08T19:57:17Z | NONE | null | null | null | null | Dear all, I am fine-tuning T5 for Q&A task using the MedQuAD ([GitHub - abachaa/MedQuAD: Medical Question Answering Dataset of 47,457 QA pairs created from 12 NIH websites](https://github.com/abachaa/MedQuAD)) dataset. In the dataset, there are many long answers with thousands of words. I have used pytorch_lightning to... | {
"avatar_url": "https://avatars.githubusercontent.com/u/13484072?v=4",
"events_url": "https://api.github.com/users/junyongyou/events{/privacy}",
"followers_url": "https://api.github.com/users/junyongyou/followers",
"following_url": "https://api.github.com/users/junyongyou/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5343/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5343/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5342 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5342/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5342/comments | https://api.github.com/repos/huggingface/datasets/issues/5342/events | https://github.com/huggingface/datasets/issues/5342 | 1,485,244,178 | I_kwDODunzps5YhwcS | 5,342 | Emotion dataset cannot be downloaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/78887193?v=4",
"events_url": "https://api.github.com/users/cbarond/events{/privacy}",
"followers_url": "https://api.github.com/users/cbarond/followers",
"following_url": "https://api.github.com/users/cbarond/following{/other_user}",
"gists_url": "https:... | [
{
"color": "cfd3d7",
"default": true,
"description": "This issue or pull request already exists",
"id": 1935892865,
"name": "duplicate",
"node_id": "MDU6TGFiZWwxOTM1ODkyODY1",
"url": "https://api.github.com/repos/huggingface/datasets/labels/duplicate"
}
] | closed | false | null | [] | null | [
"Hi @cbarond there's already an open issue at https://github.com/dair-ai/emotion_dataset/issues/5, as the data seems to be missing now, so check that issue instead 👍🏻 ",
"Thanks @cbarond for reporting and @alvarobartt for pointing to the issue we opened in the author's repo.\r\n\r\nIndeed, this issue was first ... | 2022-12-08T19:07:09Z | 2023-02-23T19:13:19Z | 2022-12-09T10:46:11Z | NONE | null | null | null | null | ### Describe the bug
The emotion dataset gives a FileNotFoundError. The full error is: `FileNotFoundError: Couldn't find file at https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1`.
It was working yesterday (December 7, 2022), but stopped working today (December 8, 2022).
### Steps to reproduce the bug
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5342/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5342/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5338 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5338/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5338/comments | https://api.github.com/repos/huggingface/datasets/issues/5338/events | https://github.com/huggingface/datasets/issues/5338 | 1,482,646,151 | I_kwDODunzps5YX2KH | 5,338 | `map()` stops every 1000 steps | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Hi !\r\n\r\n> It starts using all the cores (I am not sure why because I did not pass num_proc)\r\n\r\nThe tokenizer uses Rust code that is multithreaded. And maybe the `feature_extractor` might run some things in parallel as well - but I'm not super familiar with its internals.\r\n\r\n> then progress bar stops at... | 2022-12-07T19:09:40Z | 2025-02-14T18:10:07Z | 2022-12-10T00:39:28Z | NONE | null | null | null | null | ### Describe the bug
I am passing the following `prepare_dataset` function to `Dataset.map` (code is inspired from [here](https://github.com/huggingface/community-events/blob/main/whisper-fine-tuning-event/run_speech_recognition_seq2seq_streaming.py#L454))
```python3
def prepare_dataset(batch):
# load and res... | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"g... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5338/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5338/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5337 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5337/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5337/comments | https://api.github.com/repos/huggingface/datasets/issues/5337/events | https://github.com/huggingface/datasets/issues/5337 | 1,481,692,156 | I_kwDODunzps5YUNP8 | 5,337 | Support webdataset format | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"I like the idea of having `webdataset` as an optional dependency to ensure our loader generates web datasets the same way as the main project.",
"Webdataset is the one of the most popular dataset formats for large scale computer vision tasks. Upvote for this issue. ",
"Any updates on this?",
"We haven't had ... | 2022-12-07T11:32:25Z | 2024-03-06T14:39:29Z | 2024-03-06T14:39:28Z | MEMBER | null | null | null | null | Webdataset is an efficient format for iterable datasets. It would be nice to support it in `datasets`, as discussed in https://github.com/rom1504/img2dataset/issues/234.
In particular it would be awesome to be able to load one using `load_dataset` in streaming mode (either from a local directory, or from a dataset o... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5337/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5337/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5332 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5332/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5332/comments | https://api.github.com/repos/huggingface/datasets/issues/5332/events | https://github.com/huggingface/datasets/issues/5332 | 1,476,513,072 | I_kwDODunzps5YAc0w | 5,332 | Passing numpy array to ClassLabel names causes ValueError | {
"avatar_url": "https://avatars.githubusercontent.com/u/1475568?v=4",
"events_url": "https://api.github.com/users/freddyheppell/events{/privacy}",
"followers_url": "https://api.github.com/users/freddyheppell/followers",
"following_url": "https://api.github.com/users/freddyheppell/following{/other_user}",
"gi... | [] | closed | false | null | [] | null | [
"Should `datasets` allow `ClassLabel` input parameter to be an `np.array` even though internally we need to cast it to a Python list? @lhoestq @mariosasko ",
"Hi! No, I don't think so. The `names` parameter is [annotated](https://github.com/huggingface/datasets/blob/582236640b9109988e5f7a16a8353696ffa09a16/src/d... | 2022-12-05T12:59:03Z | 2022-12-22T16:32:50Z | 2022-12-22T16:32:50Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
If a numpy array is passed to the names argument of ClassLabel, creating a dataset with those features causes an error.
### Steps to reproduce the bug
https://colab.research.google.com/drive/1cV_es1PWZiEuus17n-2C-w0KEoEZ68IX
TLDR:
If I define my classes as:
```
my_classes = np.array(['on... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5332/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5332/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5326 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5326/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5326/comments | https://api.github.com/repos/huggingface/datasets/issues/5326/events | https://github.com/huggingface/datasets/issues/5326 | 1,471,634,168 | I_kwDODunzps5Xt1r4 | 5,326 | No documentation for main branch is built | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-12-01T16:50:58Z | 2022-12-02T16:26:01Z | 2022-12-02T16:26:01Z | MEMBER | null | null | null | null | Since:
- #5250
- Commit: 703b84311f4ead83c7f79639f2dfa739295f0be6
the docs for main branch are no longer built.
The change introduced only triggers the docs building for releases. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5326/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5326/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5325 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5325/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5325/comments | https://api.github.com/repos/huggingface/datasets/issues/5325/events | https://github.com/huggingface/datasets/issues/5325 | 1,471,536,822 | I_kwDODunzps5Xtd62 | 5,325 | map(...batch_size=None) for IterableDataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/299380?v=4",
"events_url": "https://api.github.com/users/frankier/events{/privacy}",
"followers_url": "https://api.github.com/users/frankier/followers",
"following_url": "https://api.github.com/users/frankier/following{/other_user}",
"gists_url": "https... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}"... | null | [
"Hi! I agree it makes sense for `IterableDataset.map` to support the `batch_size=None` case. This should be super easy to fix.",
"@mariosasko as this is something simple maybe I can include it as part of https://github.com/huggingface/datasets/pull/5311? Let me know :+1:",
"#self-assign",
"Feel free to close ... | 2022-12-01T15:43:42Z | 2022-12-07T15:54:43Z | 2022-12-07T15:54:42Z | CONTRIBUTOR | null | null | null | null | ### Feature request
Dataset.map(...) allows batch_size to be None. It would be nice if IterableDataset did too.
### Motivation
Although it may seem a bit of a spurious request given that `IterableDataset` is meant for larger than memory datasets, but there are a couple of reasons why this might be nice.
One is th... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5325/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5325/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5324 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5324/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5324/comments | https://api.github.com/repos/huggingface/datasets/issues/5324/events | https://github.com/huggingface/datasets/issues/5324 | 1,471,524,512 | I_kwDODunzps5Xta6g | 5,324 | Fix docstrings and types in documentation that appears on the website | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | open | false | null | [] | null | [
"I agree we have a mess with docstrings...",
"Ok, I believe we've cleaned up most of the old syntax we were using for the user-facing docs! There are still a couple of `:obj:`'s and `:class:` floating around in the docstrings we don't expose that I'll track down :)",
"Hi @polinaeterna @albertvillanova @stevhliu... | 2022-12-01T15:34:53Z | 2024-01-23T16:21:54Z | null | CONTRIBUTOR | null | null | null | null | While I was working on https://github.com/huggingface/datasets/pull/5313 I've noticed that we have a mess in how we annotate types and format args and return values in the code. And some of it is displayed in the [Reference section](https://huggingface.co/docs/datasets/package_reference/builder_classes) of the document... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5324/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5324/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5323 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5323/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5323/comments | https://api.github.com/repos/huggingface/datasets/issues/5323/events | https://github.com/huggingface/datasets/issues/5323 | 1,471,518,803 | I_kwDODunzps5XtZhT | 5,323 | Duplicated Keys in Taskmaster-2 Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/52380283?v=4",
"events_url": "https://api.github.com/users/liaeh/events{/privacy}",
"followers_url": "https://api.github.com/users/liaeh/followers",
"following_url": "https://api.github.com/users/liaeh/following{/other_user}",
"gists_url": "https://api.... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @liaeh.\r\n\r\nWe are having a look at it. ",
"I have transferred the discussion to the Community tab of the dataset: https://huggingface.co/datasets/taskmaster2/discussions/1"
] | 2022-12-01T15:31:06Z | 2022-12-01T16:26:06Z | 2022-12-01T16:26:06Z | NONE | null | null | null | null | ### Describe the bug
Loading certain splits () of the taskmaster-2 dataset fails because of a DuplicatedKeysError. This occurs for the following domains: `'hotels', 'movies', 'music', 'sports'`. The domains `'flights', 'food-ordering', 'restaurant-search'` load fine.
Output:
### Steps to reproduce the bug
```
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5323/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5323/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5317 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5317/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5317/comments | https://api.github.com/repos/huggingface/datasets/issues/5317/events | https://github.com/huggingface/datasets/issues/5317 | 1,470,390,164 | I_kwDODunzps5XpF-U | 5,317 | `ImageFolder` performs poorly with large datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/1086393?v=4",
"events_url": "https://api.github.com/users/salieri/events{/privacy}",
"followers_url": "https://api.github.com/users/salieri/followers",
"following_url": "https://api.github.com/users/salieri/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [
"Hi ! ImageFolder is made for small scale datasets indeed. For large scale image datasets you better group your images in TAR archives or Arrow/Parquet files. This is true not just for ImageFolder loading performance, but also because having millions of files is not ideal for your filesystem or when moving the data... | 2022-12-01T00:04:21Z | 2022-12-01T21:49:26Z | null | NONE | null | null | null | null | ### Describe the bug
While testing image dataset creation, I'm seeing significant performance bottlenecks with imagefolders when scanning a directory structure with large number of images.
## Setup
* Nested directories (5 levels deep)
* 3M+ images
* 1 `metadata.jsonl` file
## Performance Degradation Point... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5317/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5317/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5316 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5316/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5316/comments | https://api.github.com/repos/huggingface/datasets/issues/5316/events | https://github.com/huggingface/datasets/issues/5316 | 1,470,115,681 | I_kwDODunzps5XoC9h | 5,316 | Bug in sample_by="paragraph" | {
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "h... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @adampauls.\r\n\r\nWe are having a look at it. "
] | 2022-11-30T19:24:13Z | 2022-12-01T15:19:02Z | 2022-12-01T15:19:02Z | NONE | null | null | null | null | ### Describe the bug
I think [this line](https://github.com/huggingface/datasets/blob/main/src/datasets/packaged_modules/text/text.py#L96) is wrong and should be `batch = f.read(self.config.chunksize)`. Otherwise it will never terminate because even when `f` is finished reading, `batch` will still be truthy from the l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5316/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5316/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5315 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5315/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5315/comments | https://api.github.com/repos/huggingface/datasets/issues/5315/events | https://github.com/huggingface/datasets/issues/5315 | 1,470,026,797 | I_kwDODunzps5XntQt | 5,315 | Adding new splits to a dataset script with existing old splits info in metadata's `dataset_info` fails | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_use... | null | [
"EDIT:\r\nI think in this case, the metadata files (either README or JSON) should not be read (i.e. `self.info.splits` should be None).\r\n\r\nOne idea: \r\n- I think ideally we should set this behavior when we pass `--save_info` to the CLI `test`\r\n- However, currently, the builder is unaware of this: `save_info`... | 2022-11-30T18:02:15Z | 2022-12-02T07:02:53Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
If you first create a custom dataset with a specific set of splits, generate metadata with `datasets-cli test ... --save_info`, then change your script to include more splits, it fails.
That's what happened in https://huggingface.co/datasets/mrdbourke/food_vision_199_classes/discussions/2#6385f... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5315/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5315/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5314 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5314/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5314/comments | https://api.github.com/repos/huggingface/datasets/issues/5314/events | https://github.com/huggingface/datasets/issues/5314 | 1,469,685,118 | I_kwDODunzps5XmZ1- | 5,314 | Datasets: classification_report() got an unexpected keyword argument 'suffix' | {
"avatar_url": "https://avatars.githubusercontent.com/u/42126634?v=4",
"events_url": "https://api.github.com/users/JonathanAlis/events{/privacy}",
"followers_url": "https://api.github.com/users/JonathanAlis/followers",
"following_url": "https://api.github.com/users/JonathanAlis/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"This seems similar to https://github.com/huggingface/datasets/issues/2512 Can you try to update seqeval ? ",
"@JonathanAlis also note that the metrics are deprecated in our `datasets` library.\r\n\r\nPlease, use the new library 🤗 Evaluate instead: https://huggingface.co/docs/evaluate"
] | 2022-11-30T14:01:03Z | 2023-07-21T14:40:31Z | 2023-07-21T14:40:31Z | NONE | null | null | null | null | https://github.com/huggingface/datasets/blob/main/metrics/seqeval/seqeval.py
> import datasets
predictions = [['O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
references = [['O', 'O', 'O', 'B-MISC', 'I-MISC', 'I-MISC', 'O'], ['B-PER', 'I-PER', 'O']]
seqeval = datasets.load_metri... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5314/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5314/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5306 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5306/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5306/comments | https://api.github.com/repos/huggingface/datasets/issues/5306/events | https://github.com/huggingface/datasets/issues/5306 | 1,465,968,639 | I_kwDODunzps5XYOf_ | 5,306 | Can't use custom feature description when loading a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Forgot to actually convert the feature dict to a Feature object. Closing."
] | 2022-11-28T07:55:44Z | 2022-11-28T08:11:45Z | 2022-11-28T08:11:44Z | MEMBER | null | null | null | null | ### Describe the bug
I have created a feature dictionary to describe my datasets' column types, to use when loading the dataset, following [the doc](https://huggingface.co/docs/datasets/main/en/about_dataset_features). It crashes at dataset load.
### Steps to reproduce the bug
```python
# Creating features
task_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5306/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5306/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5305 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5305/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5305/comments | https://api.github.com/repos/huggingface/datasets/issues/5305/events | https://github.com/huggingface/datasets/issues/5305 | 1,465,627,826 | I_kwDODunzps5XW7Sy | 5,305 | Dataset joelito/mc4_legal does not work with multiple files | {
"avatar_url": "https://avatars.githubusercontent.com/u/3775944?v=4",
"events_url": "https://api.github.com/users/JoelNiklaus/events{/privacy}",
"followers_url": "https://api.github.com/users/JoelNiklaus/followers",
"following_url": "https://api.github.com/users/JoelNiklaus/following{/other_user}",
"gists_ur... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting @JoelNiklaus.\r\n\r\nPlease note that since we moved all dataset loading scripts to the Hub, the issues and pull requests relative to specific datasets are directly handled on the Hub, in their Community tab. I'm transferring this issue there: https://huggingface.co/datasets/joelito/mc4_legal/... | 2022-11-28T00:16:16Z | 2022-11-28T07:22:42Z | 2022-11-28T07:22:42Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
The dataset https://huggingface.co/datasets/joelito/mc4_legal works for languages like bg with a single data file, but not for languages with multiple files like de. It shows zero rows for the de dataset.
joelniklaus@Joels-MacBook-Pro ~/N/P/C/L/p/m/mc4_legal (main) [1]> python test_mc4_legal.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5305/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5305/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5304 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5304/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5304/comments | https://api.github.com/repos/huggingface/datasets/issues/5304/events | https://github.com/huggingface/datasets/issues/5304 | 1,465,110,367 | I_kwDODunzps5XU89f | 5,304 | timit_asr doesn't load the test split. | {
"avatar_url": "https://avatars.githubusercontent.com/u/17842800?v=4",
"events_url": "https://api.github.com/users/seyong92/events{/privacy}",
"followers_url": "https://api.github.com/users/seyong92/followers",
"following_url": "https://api.github.com/users/seyong92/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"The [timit_asr.py](https://huggingface.co/datasets/timit_asr/blob/main/timit_asr.py) script iterates over the WAV files per split directory using this:\r\n```python\r\nwav_paths = sorted(Path(data_dir).glob(f\"**/{split}/**/*.wav\"))\r\nwav_paths = wav_paths if wav_paths else sorted(Path(data_dir).glob(f\"**/{spli... | 2022-11-26T10:18:22Z | 2023-02-10T16:33:21Z | 2023-02-10T16:33:21Z | NONE | null | null | null | null | ### Describe the bug
When I use the function ```timit = load_dataset('timit_asr', data_dir=data_dir)```, it only loads train split, not test split.
I tried to change the directory and filename to lower case to upper case for the test split, but it does not work at all.
```python
DatasetDict({
train: Datase... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5304/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5304/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5298 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5298/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5298/comments | https://api.github.com/repos/huggingface/datasets/issues/5298/events | https://github.com/huggingface/datasets/issues/5298 | 1,464,681,871 | I_kwDODunzps5XTUWP | 5,298 | Bug in xopen with Windows pathnames | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-11-25T15:21:32Z | 2022-11-29T08:21:25Z | 2022-11-29T08:21:25Z | MEMBER | null | null | null | null | Currently, `xopen` function has a bug with local Windows pathnames:
From its implementation:
```python
def xopen(file: str, mode="r", *args, **kwargs):
file = _as_posix(PurePath(file))
main_hop, *rest_hops = file.split("::")
if is_local_path(main_hop):
return open(file, mode, *args, **kwarg... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5298/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5298/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5296 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5296/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5296/comments | https://api.github.com/repos/huggingface/datasets/issues/5296/events | https://github.com/huggingface/datasets/issues/5296 | 1,464,553,580 | I_kwDODunzps5XS1Bs | 5,296 | Bug in xjoin with Windows pathnames | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-11-25T13:29:33Z | 2022-11-29T08:05:13Z | 2022-11-29T08:05:13Z | MEMBER | null | null | null | null | Currently, `xjoin` function has a bug with local Windows pathnames: instead of returning the OS-dependent join pathname, it always returns it in POSIX format.
```python
from datasets.download.streaming_download_manager import xjoin
path = xjoin("C:\\Users\\USERNAME", "filename.txt")
```
Join path should be:
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5296/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5296/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5295 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5295/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5295/comments | https://api.github.com/repos/huggingface/datasets/issues/5295/events | https://github.com/huggingface/datasets/issues/5295 | 1,464,006,743 | I_kwDODunzps5XQvhX | 5,295 | Extractions failed when .zip file located on read-only path (e.g., SageMaker FastFile mode) | {
"avatar_url": "https://avatars.githubusercontent.com/u/2340781?v=4",
"events_url": "https://api.github.com/users/verdimrc/events{/privacy}",
"followers_url": "https://api.github.com/users/verdimrc/followers",
"following_url": "https://api.github.com/users/verdimrc/following{/other_user}",
"gists_url": "http... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"Hi ! Thanks for reporting. Indeed the lock file should be placed in a directory with write permission (e.g. in the directory where the archive is extracted).",
"I opened https://github.com/huggingface/datasets/pull/5320 to fix this - it places the lock file in the cache directory instead of trying to put in next... | 2022-11-25T03:59:43Z | 2023-07-21T14:39:09Z | 2023-07-21T14:39:09Z | NONE | null | null | null | null | ### Describe the bug
Hi,
`load_dataset()` does not work .zip files located on a read-only directory. Looks like it's because Dataset creates a lock file in the [same directory](https://github.com/huggingface/datasets/blob/df4bdd365f2abb695f113cbf8856a925bc70901b/src/datasets/utils/extract.py) as the .zip file.
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5295/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5295/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5293 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5293/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5293/comments | https://api.github.com/repos/huggingface/datasets/issues/5293/events | https://github.com/huggingface/datasets/issues/5293 | 1,463,669,201 | I_kwDODunzps5XPdHR | 5,293 | Support streaming datasets with pathlib.Path.with_suffix | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2022-11-24T17:52:08Z | 2022-11-29T07:06:33Z | 2022-11-29T07:06:33Z | MEMBER | null | null | null | null | Extend support for streaming datasets that use `pathlib.Path.with_suffix`.
This feature will be useful e.g. for datasets containing text files and annotated files with the same name but different extension. | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5293/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5293/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5292 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5292/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5292/comments | https://api.github.com/repos/huggingface/datasets/issues/5292/events | https://github.com/huggingface/datasets/issues/5292 | 1,463,053,832 | I_kwDODunzps5XNG4I | 5,292 | Missing documentation build for versions 2.7.1 and 2.6.2 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"- Build docs for 2.6.2:\r\n - Commit: a6a5a1cf4cdf1e0be65168aed5a327f543001fe8\r\n - Build docs GH Action: https://github.com/huggingface/datasets/actions/runs/3539470622/jobs/5941404044\r\n- Build docs for 2.7.1:\r\n - Commit: 5ef1ab1cc06c2b7a574bf2df454cd9fcb071ccb2\r\n - Build docs GH Action: https://github... | 2022-11-24T09:42:10Z | 2022-11-24T10:10:02Z | 2022-11-24T10:10:02Z | MEMBER | null | null | null | null | After the patch releases [2.7.1](https://github.com/huggingface/datasets/releases/tag/2.7.1) and [2.6.2](https://github.com/huggingface/datasets/releases/tag/2.6.2), the online docs were not properly built (the build_documentation workflow was not triggered).
There was a fix by:
- #5291
However, both documentati... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5292/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5292/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5288 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5288/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5288/comments | https://api.github.com/repos/huggingface/datasets/issues/5288/events | https://github.com/huggingface/datasets/issues/5288 | 1,462,134,067 | I_kwDODunzps5XJmUz | 5,288 | Lossy json serialization - deserialization of dataset info | {
"avatar_url": "https://avatars.githubusercontent.com/u/57542204?v=4",
"events_url": "https://api.github.com/users/anuragprat1k/events{/privacy}",
"followers_url": "https://api.github.com/users/anuragprat1k/followers",
"following_url": "https://api.github.com/users/anuragprat1k/following{/other_user}",
"gist... | [] | open | false | null | [] | null | [
"Hi ! JSON is a lossy format indeed. If you want to keep the feature types or other metadata I'd encourage you to store them as well. For example you can use `dataset.info.write_to_directory` and `DatasetInfo.from_directory` to store the feature types, split info, description, license etc."
] | 2022-11-23T17:20:15Z | 2022-11-25T12:53:51Z | null | NONE | null | null | null | null | ### Describe the bug
Saving a dataset to disk as json (using `to_json`) and then loading it again (using `load_dataset`) results in features whose labels are not type-cast correctly. In the code snippet below, `features.label` should have a label of type `ClassLabel` but has type `Value` instead.
### Steps to re... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5288/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5288/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5286 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5286/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5286/comments | https://api.github.com/repos/huggingface/datasets/issues/5286/events | https://github.com/huggingface/datasets/issues/5286 | 1,461,908,087 | I_kwDODunzps5XIvJ3 | 5,286 | FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/enwiki/20220301/dumpstatus.json | {
"avatar_url": "https://avatars.githubusercontent.com/u/32490135?v=4",
"events_url": "https://api.github.com/users/roritol/events{/privacy}",
"followers_url": "https://api.github.com/users/roritol/followers",
"following_url": "https://api.github.com/users/roritol/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"I found a solution \r\n\r\nIf you specifically install datasets==1.18 and then run\r\n\r\nimport datasets\r\nwiki = datasets.load_dataset('wikipedia', '20200501.en')\r\nthen this should work (it worked for me.)",
"I have the same problem here but installing datasets==1.18 wont work for me\r\n",
"This works wit... | 2022-11-23T14:54:15Z | 2024-11-23T01:16:41Z | 2022-11-25T11:33:14Z | NONE | null | null | null | null | ### Describe the bug
I follow the steps provided on the website [https://huggingface.co/datasets/wikipedia](https://huggingface.co/datasets/wikipedia)
$ pip install apache_beam mwparserfromhell
>>> from datasets import load_dataset
>>> load_dataset("wikipedia", "20220301.en")
however this results in the follo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/32490135?v=4",
"events_url": "https://api.github.com/users/roritol/events{/privacy}",
"followers_url": "https://api.github.com/users/roritol/followers",
"following_url": "https://api.github.com/users/roritol/following{/other_user}",
"gists_url": "https:... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5286/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5286/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5284 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5284/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5284/comments | https://api.github.com/repos/huggingface/datasets/issues/5284/events | https://github.com/huggingface/datasets/issues/5284 | 1,461,519,733 | I_kwDODunzps5XHQV1 | 5,284 | Features of IterableDataset set to None by remove column | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "fef2c0",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}"... | null | [
"Related to https://github.com/huggingface/datasets/issues/5245",
"#self-assign",
"Thanks @lhoestq and @alvarobartt!\r\n\r\nThis would be extremely helpful to have working for the Whisper fine-tuning event - we're **only** training using streaming mode, so it'll be quite important to have this feature working t... | 2022-11-23T10:54:59Z | 2025-02-07T11:36:41Z | 2022-11-28T12:53:24Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
The `remove_column` method of the IterableDataset sets the dataset features to None.
### Steps to reproduce the bug
```python
from datasets import Audio, load_dataset
# load LS in streaming mode
dataset = load_dataset("librispeech_asr", "clean", split="validation", streaming=True)
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5284/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5284/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5281 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5281/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5281/comments | https://api.github.com/repos/huggingface/datasets/issues/5281/events | https://github.com/huggingface/datasets/issues/5281 | 1,459,930,271 | I_kwDODunzps5XBMSf | 5,281 | Support cloud storage in load_dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "BDE59C",
"default": fals... | open | false | null | [] | null | [
"Or for example an archive on GitHub releases! Before I added support for JXL (locally only, PR still pending) I was considering hosting my files on GitHub instead...",
"+1 to this. I would like to use 'audiofolder' with a data_dir that's on S3, for example. I don't want to upload my dataset to the Hub, but I wo... | 2022-11-22T14:00:10Z | 2024-11-15T15:03:41Z | null | MEMBER | null | null | null | null | Would be nice to be able to do
```python
data_files=["s3://..."] # or gs:// or any cloud storage path
storage_options = {...}
load_dataset(..., data_files=data_files, storage_options=storage_options)
```
The idea would be to use `fsspec` as in `download_and_prepare` and `save_to_disk`.
This has been reque... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 39,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 22,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 61,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5281/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5281/timeline | null | reopened | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5280 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5280/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5280/comments | https://api.github.com/repos/huggingface/datasets/issues/5280/events | https://github.com/huggingface/datasets/issues/5280 | 1,459,823,179 | I_kwDODunzps5XAyJL | 5,280 | Import error | {
"avatar_url": "https://avatars.githubusercontent.com/u/40760055?v=4",
"events_url": "https://api.github.com/users/feketedavid1012/events{/privacy}",
"followers_url": "https://api.github.com/users/feketedavid1012/followers",
"following_url": "https://api.github.com/users/feketedavid1012/following{/other_user}"... | [] | closed | false | null | [] | null | [
"Hi ! Can you \r\n```python\r\nimport platform\r\nprint(platform.python_version())\r\n```\r\nto see that it returns ?",
"Hi,\n\n3.8.13\n\nGet Outlook for Android<https://aka.ms/AAb9ysg>\n________________________________\nFrom: Quentin Lhoest ***@***.***>\nSent: Tuesday, November 22, 2022 2:37:02 PM\nTo: huggingfa... | 2022-11-22T12:56:43Z | 2022-12-15T19:57:40Z | 2022-12-15T19:57:40Z | NONE | null | null | null | null | https://github.com/huggingface/datasets/blob/cd3d8e637cfab62d352a3f4e5e60e96597b5f0e9/src/datasets/__init__.py#L28
Hy,
I have error at the above line. I have python version 3.8.13, the message says I need python>=3.7, which is True, but I think the if statement not working properly (or the message wrong) | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5280/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5280/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5278 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5278/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5278/comments | https://api.github.com/repos/huggingface/datasets/issues/5278/events | https://github.com/huggingface/datasets/issues/5278 | 1,459,574,490 | I_kwDODunzps5W_1ba | 5,278 | load_dataset does not read jsonl metadata file properly | {
"avatar_url": "https://avatars.githubusercontent.com/u/81414263?v=4",
"events_url": "https://api.github.com/users/065294847/events{/privacy}",
"followers_url": "https://api.github.com/users/065294847/followers",
"following_url": "https://api.github.com/users/065294847/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Can you try to remove \"drop_labels=false\" ? It may force the loader to infer the labels instead of reading the metadata",
"Hi, thanks for responding. I tried that, but it does not change anything.",
"Can you try updating `datasets` ? Metadata support was added in `datasets` 2.4",
"Probably the issue, will ... | 2022-11-22T10:24:46Z | 2023-02-14T14:48:16Z | 2022-11-23T11:38:35Z | NONE | null | null | null | null | ### Describe the bug
Hi, I'm following [this page](https://huggingface.co/docs/datasets/image_dataset) to create a dataset of images and captions via an image folder and a metadata.json file, but I can't seem to get the dataloader to recognize the "text" column. It just spits out "image" and "label" as features.
B... | {
"avatar_url": "https://avatars.githubusercontent.com/u/81414263?v=4",
"events_url": "https://api.github.com/users/065294847/events{/privacy}",
"followers_url": "https://api.github.com/users/065294847/followers",
"following_url": "https://api.github.com/users/065294847/following{/other_user}",
"gists_url": "... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5278/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5278/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5276 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5276/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5276/comments | https://api.github.com/repos/huggingface/datasets/issues/5276/events | https://github.com/huggingface/datasets/issues/5276 | 1,459,363,442 | I_kwDODunzps5W_B5y | 5,276 | Bug in downloading common_voice data and snall chunk of it to one's own hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/48530104?v=4",
"events_url": "https://api.github.com/users/capsabogdan/events{/privacy}",
"followers_url": "https://api.github.com/users/capsabogdan/followers",
"following_url": "https://api.github.com/users/capsabogdan/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Sounds like one of the file is not a valid one, can you make sure you uploaded valid mp3 files ?",
"Well I just sharded the original commonVoice dataset and pushed a small chunk of it in a private rep\n\nWhat did go wrong?\n\nHolen Sie sich Outlook für iOS<https://aka.ms/o0ukef>\n________________________________... | 2022-11-22T08:17:53Z | 2023-07-21T14:33:10Z | 2023-07-21T14:33:10Z | NONE | null | null | null | null | ### Describe the bug
I'm trying to load the common voice dataset. Currently there is no implementation to download just par tof the data, and I need just one part of it, without downloading the entire dataset
Help please?
 https://github.com/huggingface/moon-landing/pull/4609",
"FYI there are still 2k+ weekly users on `datasets` 2.6.1 which doesn't support the string label format for... | 2022-11-22T08:14:47Z | 2023-01-26T10:52:35Z | 2023-01-26T10:40:21Z | MEMBER | null | null | null | null | After an internal discussion (https://github.com/huggingface/moon-landing/issues/4563):
- YAML integer keys are not preserved server-side: they are transformed to strings
- See for example this Hub PR: https://huggingface.co/datasets/acronym_identification/discussions/1/files
- Original:
```yaml
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 1,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5275/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5275/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5274 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5274/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5274/comments | https://api.github.com/repos/huggingface/datasets/issues/5274/events | https://github.com/huggingface/datasets/issues/5274 | 1,458,646,455 | I_kwDODunzps5W8S23 | 5,274 | load_dataset possibly broken for gated datasets? | {
"avatar_url": "https://avatars.githubusercontent.com/u/20826878?v=4",
"events_url": "https://api.github.com/users/TristanThrush/events{/privacy}",
"followers_url": "https://api.github.com/users/TristanThrush/followers",
"following_url": "https://api.github.com/users/TristanThrush/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"@BradleyHsu",
"Btw, thanks very much for finding the hub rollback temporary fix and bringing the issue to our attention @KhoomeiK!",
"I see the same issue when calling `load_dataset('poloclub/diffusiondb', 'large_random_1k')` with `datasets==2.7.1` and `huggingface-hub=0.11.0`. No issue with `datasets=2.6.1` a... | 2022-11-21T21:59:53Z | 2023-05-27T00:06:14Z | 2022-11-28T02:50:42Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
When trying to download the [winoground dataset](https://huggingface.co/datasets/facebook/winoground), I get this error unless I roll back the version of huggingface-hub:
```
[/usr/local/lib/python3.7/dist-packages/huggingface_hub/utils/_validators.py](https://localhost:8080/#) in validate_rep... | {
"avatar_url": "https://avatars.githubusercontent.com/u/20826878?v=4",
"events_url": "https://api.github.com/users/TristanThrush/events{/privacy}",
"followers_url": "https://api.github.com/users/TristanThrush/followers",
"following_url": "https://api.github.com/users/TristanThrush/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5274/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5274/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5273 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5273/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5273/comments | https://api.github.com/repos/huggingface/datasets/issues/5273/events | https://github.com/huggingface/datasets/issues/5273 | 1,458,018,050 | I_kwDODunzps5W55cC | 5,273 | download_mode="force_redownload" does not refresh cached dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/28439912?v=4",
"events_url": "https://api.github.com/users/nomisto/events{/privacy}",
"followers_url": "https://api.github.com/users/nomisto/followers",
"following_url": "https://api.github.com/users/nomisto/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [] | 2022-11-21T14:12:43Z | 2022-11-21T14:13:03Z | null | NONE | null | null | null | null | ### Describe the bug
`load_datasets` does not refresh dataset when features are imported from external file, even with `download_mode="force_redownload"`. The bug is not limited to nested fields, however it is more likely to occur with nested fields.
### Steps to reproduce the bug
To reproduce the bug 3 files are ne... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5273/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5273/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5272 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5272/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5272/comments | https://api.github.com/repos/huggingface/datasets/issues/5272/events | https://github.com/huggingface/datasets/issues/5272 | 1,456,940,021 | I_kwDODunzps5W1yP1 | 5,272 | Use pyarrow Tensor dtype | {
"avatar_url": "https://avatars.githubusercontent.com/u/18228395?v=4",
"events_url": "https://api.github.com/users/franz101/events{/privacy}",
"followers_url": "https://api.github.com/users/franz101/followers",
"following_url": "https://api.github.com/users/franz101/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! We're using the Arrow format for the datasets, and PyArrow tensors are not part of the Arrow format AFAIK:\r\n\r\n> There is no direct support in the arrow columnar format to store Tensors as column values.\r\n\r\nsource: https://github.com/apache/arrow/issues/4802#issuecomment-508494694",
"@wesm @rok its b... | 2022-11-20T15:18:41Z | 2024-11-11T03:03:17Z | null | NONE | null | null | null | null | ### Feature request
I was going the discussion of converting tensors to lists.
Is there a way to leverage pyarrow's Tensors for nested arrays / embeddings?
For example:
```python
import pyarrow as pa
import numpy as np
x = np.array([[2, 2, 4], [4, 5, 100]], np.int32)
pa.Tensor.from_numpy(x, dim_names=["dim1... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5272/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5272/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5270 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5270/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5270/comments | https://api.github.com/repos/huggingface/datasets/issues/5270/events | https://github.com/huggingface/datasets/issues/5270 | 1,456,508,990 | I_kwDODunzps5W0JA- | 5,270 | When len(_URLS) > 16, download will hang | {
"avatar_url": "https://avatars.githubusercontent.com/u/32936898?v=4",
"events_url": "https://api.github.com/users/Freed-Wu/events{/privacy}",
"followers_url": "https://api.github.com/users/Freed-Wu/followers",
"following_url": "https://api.github.com/users/Freed-Wu/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [
"It can fix the bug temporarily.\r\n```python\r\nfrom datasets import DownloadConfig\r\nconfig = DownloadConfig(num_proc=8)\r\nIn [5]: dataset = load_dataset('Freed-Wu/kodak', split='test', download_config=config)\r\nDownloading and preparing dataset kodak/default to /home/wzy/.cache/huggingface/datasets/Freed-Wu__... | 2022-11-19T14:27:41Z | 2022-11-21T15:27:16Z | null | NONE | null | null | null | null | ### Describe the bug
```python
In [9]: dataset = load_dataset('Freed-Wu/kodak', split='test')
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2.53k/2.53k [00:00<00:00, 1.88MB/s]
[1... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5270/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5270/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5269 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5269/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5269/comments | https://api.github.com/repos/huggingface/datasets/issues/5269/events | https://github.com/huggingface/datasets/issues/5269 | 1,456,485,799 | I_kwDODunzps5W0DWn | 5,269 | Shell completions | {
"avatar_url": "https://avatars.githubusercontent.com/u/32936898?v=4",
"events_url": "https://api.github.com/users/Freed-Wu/events{/privacy}",
"followers_url": "https://api.github.com/users/Freed-Wu/followers",
"following_url": "https://api.github.com/users/Freed-Wu/following{/other_user}",
"gists_url": "htt... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"I don't think we need completion on the datasets-cli, since we're mainly developing huggingface-cli",
"I see."
] | 2022-11-19T13:48:59Z | 2022-11-21T15:06:15Z | 2022-11-21T15:06:14Z | NONE | null | null | null | null | ### Feature request
Like <https://github.com/huggingface/huggingface_hub/issues/1197>, datasets-cli maybe need it, too.
### Motivation
See above.
### Your contribution
Maybe. | {
"avatar_url": "https://avatars.githubusercontent.com/u/32936898?v=4",
"events_url": "https://api.github.com/users/Freed-Wu/events{/privacy}",
"followers_url": "https://api.github.com/users/Freed-Wu/followers",
"following_url": "https://api.github.com/users/Freed-Wu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5269/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5269/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5265 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5265/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5265/comments | https://api.github.com/repos/huggingface/datasets/issues/5265/events | https://github.com/huggingface/datasets/issues/5265 | 1,455,274,864 | I_kwDODunzps5Wvbtw | 5,265 | Get an IterableDataset from a map-style Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "fef2c0",
"default": fals... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"I think `stream` could be misleading since the data is not being streamed from remote endpoints (one could think that's the case when they see `load_dataset` followed by `stream`). Hence, I prefer the second option.\r\n\r\nPS: When we resolve https://github.com/huggingface/datasets/issues/4542, we could add `as_tf... | 2022-11-18T14:54:40Z | 2023-02-01T16:36:03Z | 2023-02-01T16:36:03Z | MEMBER | null | null | null | null | This is useful to leverage iterable datasets specific features like:
- fast approximate shuffling
- lazy map, filter etc.
Iterating over the resulting iterable dataset should be at least as fast at iterating over the map-style dataset.
Here are some ideas regarding the API:
```python
# 1.
# - consistency wi... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5265/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5265/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5264 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5264/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5264/comments | https://api.github.com/repos/huggingface/datasets/issues/5264/events | https://github.com/huggingface/datasets/issues/5264 | 1,455,252,906 | I_kwDODunzps5WvWWq | 5,264 | `datasets` can't read a Parquet file in Python 3.9.13 | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Could you share the full stack trace please ?\r\n\r\n\r\nCan you also try running this code ? It can be useful to determine if the issue comes from `datasets` or `fsspec` (streaming) or `pyarrow` (parquet reading):\r\n```python\r\nds = load_dataset(\"parquet\", data_files=a_parquet_file_url, use_auth_token=True)\r... | 2022-11-18T14:44:01Z | 2023-05-07T09:52:59Z | 2022-11-22T11:18:08Z | NONE | null | null | null | null | ### Describe the bug
I have an error when trying to load this [dataset](https://huggingface.co/datasets/bigcode/the-stack-dedup-pjj) (it's private but I can add you to the bigcode org). `datasets` can't read one of the parquet files in the Java subset
```python
from datasets import load_dataset
ds = load_data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5264/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5264/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5263 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5263/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5263/comments | https://api.github.com/repos/huggingface/datasets/issues/5263/events | https://github.com/huggingface/datasets/issues/5263 | 1,455,252,626 | I_kwDODunzps5WvWSS | 5,263 | Save a dataset in a determined number of shards | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2022-11-18T14:43:54Z | 2022-12-14T18:22:59Z | 2022-12-14T18:22:59Z | MEMBER | null | null | null | null | This is useful to distribute the shards to training nodes.
This can be implemented in `save_to_disk` and can also leverage multiprocessing to speed up the process | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5263/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5263/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5262 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5262/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5262/comments | https://api.github.com/repos/huggingface/datasets/issues/5262/events | https://github.com/huggingface/datasets/issues/5262 | 1,455,171,100 | I_kwDODunzps5WvCYc | 5,262 | AttributeError: 'Value' object has no attribute 'names' | {
"avatar_url": "https://avatars.githubusercontent.com/u/102913847?v=4",
"events_url": "https://api.github.com/users/emnaboughariou/events{/privacy}",
"followers_url": "https://api.github.com/users/emnaboughariou/followers",
"following_url": "https://api.github.com/users/emnaboughariou/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi ! It looks like your \"isDif\" column is a Sequence of Value(\"string\"), not a Sequence of ClassLabel.\r\n\r\nYou can convert your Value(\"string\") feature type to a ClassLabel feature type this way:\r\n```python\r\nfrom datasets import ClassLabel, Sequence\r\n\r\n# provide the label_names yourself\r\nlabel_n... | 2022-11-18T13:58:42Z | 2022-11-22T10:09:24Z | 2022-11-22T10:09:23Z | NONE | null | null | null | null | Hello
I'm trying to build a model for custom token classification
I already followed the token classification course on huggingface
while adapting the code to my work, this message occures :
'Value' object has no attribute 'names'
Here's my code:
`raw_datasets`
generates
DatasetDict({
train: Datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/102913847?v=4",
"events_url": "https://api.github.com/users/emnaboughariou/events{/privacy}",
"followers_url": "https://api.github.com/users/emnaboughariou/followers",
"following_url": "https://api.github.com/users/emnaboughariou/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5262/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5262/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5261 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5261/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5261/comments | https://api.github.com/repos/huggingface/datasets/issues/5261/events | https://github.com/huggingface/datasets/issues/5261 | 1,454,647,861 | I_kwDODunzps5WtCo1 | 5,261 | Add PubTables-1M | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url"... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | open | false | null | [] | null | [
"cc @albertvillanova the author would like to add this dataset to the hub: https://github.com/microsoft/table-transformer/issues/68#issuecomment-1319114621. Could you help him out?"
] | 2022-11-18T07:56:36Z | 2022-11-18T08:02:18Z | null | CONTRIBUTOR | null | null | null | null | ### Name
PubTables-1M
### Paper
https://openaccess.thecvf.com/content/CVPR2022/html/Smock_PubTables-1M_Towards_Comprehensive_Table_Extraction_From_Unstructured_Documents_CVPR_2022_paper.html
### Data
https://github.com/microsoft/table-transformer
### Motivation
Table Transformer is now available in 🤗 Transforme... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5261/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5261/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5260 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5260/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5260/comments | https://api.github.com/repos/huggingface/datasets/issues/5260/events | https://github.com/huggingface/datasets/issues/5260 | 1,453,921,697 | I_kwDODunzps5WqRWh | 5,260 | consumer-finance-complaints dataset not loading | {
"avatar_url": "https://avatars.githubusercontent.com/u/8098496?v=4",
"events_url": "https://api.github.com/users/adiprasad/events{/privacy}",
"followers_url": "https://api.github.com/users/adiprasad/followers",
"following_url": "https://api.github.com/users/adiprasad/following{/other_user}",
"gists_url": "h... | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @adiprasad.\r\n\r\nWe are having a look at it.",
"I have opened an issue in that dataset Community tab on the Hub: https://huggingface.co/datasets/consumer-finance-complaints/discussions/1\r\n\r\nPlease note that in the meantime, you can load the dataset by passing `ignore_verifications=Tru... | 2022-11-17T20:10:26Z | 2022-11-18T10:16:53Z | null | NONE | null | null | null | null | ### Describe the bug
Error during dataset loading
### Steps to reproduce the bug
```
>>> import datasets
>>> cf_raw = datasets.load_dataset("consumer-finance-complaints")
Downloading builder script: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5260/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5260/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5259 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5259/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5259/comments | https://api.github.com/repos/huggingface/datasets/issues/5259/events | https://github.com/huggingface/datasets/issues/5259 | 1,453,555,923 | I_kwDODunzps5Wo4DT | 5,259 | datasets 2.7 introduces sharding error | {
"avatar_url": "https://avatars.githubusercontent.com/u/3616964?v=4",
"events_url": "https://api.github.com/users/DCNemesis/events{/privacy}",
"followers_url": "https://api.github.com/users/DCNemesis/followers",
"following_url": "https://api.github.com/users/DCNemesis/following{/other_user}",
"gists_url": "h... | [] | closed | false | null | [] | null | [
"I notice a comment in the code says:\r\n`Having lists of different sizes makes sharding ambigious, raise an error in this case until we decide how to define sharding without ambiguity for users` \r\n \r\n ... which suggests this update was pushed knowing that it might break some things. But, it didn't seem to h... | 2022-11-17T15:36:52Z | 2022-12-24T01:44:02Z | 2022-11-18T12:52:05Z | NONE | null | null | null | null | ### Describe the bug
dataset fails to load with runtime error
`RuntimeError: Sharding is ambiguous for this dataset: we found several data sources lists of different lengths, and we don't know over which list we should parallelize:
- key audio_files has length 46
- key data has length 0
To fix this, check the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3616964?v=4",
"events_url": "https://api.github.com/users/DCNemesis/events{/privacy}",
"followers_url": "https://api.github.com/users/DCNemesis/followers",
"following_url": "https://api.github.com/users/DCNemesis/following{/other_user}",
"gists_url": "h... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5259/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5259/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5258 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5258/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5258/comments | https://api.github.com/repos/huggingface/datasets/issues/5258/events | https://github.com/huggingface/datasets/issues/5258 | 1,453,516,636 | I_kwDODunzps5Woudc | 5,258 | Restore order of split names in dataset_info for canonical datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0e8a16",
"default": false,
"description": "Contribution to a dataset script",
"id": 4564477500,
"name": "dataset contribution",
"node_id": "LA_kwDODunzps8AAAABEBBmPA",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20contribution"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"The bulk edit is running...\r\n\r\nSee for example: \r\n- A single config: https://huggingface.co/datasets/acronym_identification/discussions/2\r\n- Multiple configs: https://huggingface.co/datasets/babi_qa/discussions/1",
"TODO: Add \"dataset_info\" YAML metadata to:\r\n- [x] \"chr_en\" has no metadata JSON fil... | 2022-11-17T15:13:15Z | 2023-02-16T09:49:05Z | 2022-11-19T06:51:37Z | MEMBER | null | null | null | null | After a bulk edit of canonical datasets to create the YAML `dataset_info` metadata, the split names were accidentally sorted alphabetically. See for example:
- https://huggingface.co/datasets/bc2gm_corpus/commit/2384629484401ecf4bb77cd808816719c424e57c
Note that this order is the one appearing in the preview of the... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5258/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5258/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5255 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5255/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5255/comments | https://api.github.com/repos/huggingface/datasets/issues/5255/events | https://github.com/huggingface/datasets/issues/5255 | 1,452,631,517 | I_kwDODunzps5WlWXd | 5,255 | Add a Depth Estimation dataset - DIODE / NYUDepth / KITTI | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "e99695",
"default": false,
"description": "Requesting to add a new dataset",
"id": 2067376369,
"name": "dataset request",
"node_id": "MDU6TGFiZWwyMDY3Mzc2MzY5",
"url": "https://api.github.com/repos/huggingface/datasets/labels/dataset%20request"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Also cc @mariosasko and @lhoestq ",
"Cool ! Let us know if you have questions or if we can help :)\r\n\r\nI guess we'll also have to create the NYU CS Department on the Hub ?",
"> I guess we'll also have to create the NYU CS Department on the Hub ?\r\n\r\nYes, you're right! Let me add it to my profile first, a... | 2022-11-17T03:22:22Z | 2022-12-17T12:20:38Z | 2022-12-17T12:20:37Z | MEMBER | null | null | null | null | ### Name
NYUDepth
### Paper
http://cs.nyu.edu/~silberman/papers/indoor_seg_support.pdf
### Data
https://cs.nyu.edu/~silberman/datasets/nyu_depth_v2.html
### Motivation
Depth estimation is an important problem in computer vision. We have a couple of Depth Estimation models on Hub as well:
* [GLPN... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5255/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5255/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5251 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5251/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5251/comments | https://api.github.com/repos/huggingface/datasets/issues/5251/events | https://github.com/huggingface/datasets/issues/5251 | 1,451,761,321 | I_kwDODunzps5WiB6p | 5,251 | Docs are not generated after latest release | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | null | [] | null | [
"After a discussion with @mishig25:\r\n- He said that this action should be triggered if we call our release branch according to the regex `v*-release`, as transformers does\r\n- I said that our procedure is different: our release branch is *temporary* and it is deleted just after the release PR is merged to main\r... | 2022-11-16T14:59:31Z | 2022-11-22T16:27:50Z | 2022-11-22T16:27:50Z | MEMBER | null | null | null | null | After the latest `datasets` release version 0.7.0, the docs were not generated.
As we have changed the release procedure (so that now we do not push directly to main branch), maybe we should also change the corresponding GitHub action:
https://github.com/huggingface/datasets/blob/edf1902f954c5568daadebcd8754bdad4... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5251/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5251/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5249 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5249/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5249/comments | https://api.github.com/repos/huggingface/datasets/issues/5249/events | https://github.com/huggingface/datasets/issues/5249 | 1,451,692,247 | I_kwDODunzps5WhxDX | 5,249 | Protect the main branch from inadvertent direct pushes | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d4c5f9",
"default": false,
"description": "Maintenance tasks",
"id": 4296013012,
"name": "maintenance",
"node_id": "LA_kwDODunzps8AAAABAA_01A",
"url": "https://api.github.com/repos/huggingface/datasets/labels/maintenance"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"It seems all the tasks have been addressed, meaning this issue can be closed, no?"
] | 2022-11-16T14:19:03Z | 2023-12-21T10:28:27Z | 2023-12-21T10:28:26Z | MEMBER | null | null | null | null | We have decided to implement a protection mechanism in this repository, so that nobody (not even administrators) can inadvertently push accidentally directly to the main branch.
See context here:
- d7c942228b8dcf4de64b00a3053dce59b335f618
To do:
- [x] Protect main branch
- Settings > Branches > Branch protec... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5249/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5249/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5245 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5245/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5245/comments | https://api.github.com/repos/huggingface/datasets/issues/5245/events | https://github.com/huggingface/datasets/issues/5245 | 1,450,376,433 | I_kwDODunzps5Wcvzx | 5,245 | Unable to rename columns in streaming dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/9079808?v=4",
"events_url": "https://api.github.com/users/peregilk/events{/privacy}",
"followers_url": "https://api.github.com/users/peregilk/followers",
"following_url": "https://api.github.com/users/peregilk/following{/other_user}",
"gists_url": "http... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}"... | null | [
"Hi @peregilk this bug is directly related to https://github.com/huggingface/datasets/issues/3888, and still not fixed... But I'll try to have a look!",
"Thanks @alvarobartt. It is great if you are able to fix it, but when reading the explanation it seems like it is possible to work around it.\r\n\r\nWe also trie... | 2022-11-15T21:04:41Z | 2022-11-28T12:53:24Z | 2022-11-28T12:53:24Z | NONE | null | null | null | null | ### Describe the bug
Trying to rename column in a streaming datasets, destroys the features object.
### Steps to reproduce the bug
The following code illustrates the error:
```
from datasets import load_dataset
dataset = load_dataset('mc4', 'en', streaming=True, split='train')
dataset.info.features
# {'text':... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5245/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5245/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5244 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5244/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5244/comments | https://api.github.com/repos/huggingface/datasets/issues/5244/events | https://github.com/huggingface/datasets/issues/5244 | 1,450,019,225 | I_kwDODunzps5WbYmZ | 5,244 | Allow dataset streaming from private a private source when loading a dataset with a dataset loading script | {
"avatar_url": "https://avatars.githubusercontent.com/u/48770768?v=4",
"events_url": "https://api.github.com/users/bruno-hays/events{/privacy}",
"followers_url": "https://api.github.com/users/bruno-hays/followers",
"following_url": "https://api.github.com/users/bruno-hays/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! What kind of private source ? We're exploring adding support for cloud storage and URIs like s3://, gs:// etc. with authentication in the download manager",
"Hello! It's a google cloud storage, so gs://, but I'm using it with https.\r\nBeing able to provide a file system like [here](https://huggingface.co/d... | 2022-11-15T16:02:10Z | 2022-11-23T14:02:30Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
Add arguments to the function _get_authentication_headers_for_url_ like custom_endpoint and custom_token in order to add flexibility when downloading files from a private source.
It should also be possible to provide these arguments from the dataset loading script, maybe giving them to the dl_... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5244/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5244/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5243 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5243/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5243/comments | https://api.github.com/repos/huggingface/datasets/issues/5243/events | https://github.com/huggingface/datasets/issues/5243 | 1,449,523,962 | I_kwDODunzps5WZfr6 | 5,243 | Download only split data | {
"avatar_url": "https://avatars.githubusercontent.com/u/48530104?v=4",
"events_url": "https://api.github.com/users/capsabogdan/events{/privacy}",
"followers_url": "https://api.github.com/users/capsabogdan/followers",
"following_url": "https://api.github.com/users/capsabogdan/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi @capsabogdan! Unfortunately, it's hard to implement because quite often datasets data is being hosted in a single archive for all splits :( So we have to download the whole archive to split it into splits. This is the case for CommonVoice too. \r\n\r\nHowever, for cases when data is distributed in separate arch... | 2022-11-15T10:15:54Z | 2025-02-25T14:47:03Z | null | NONE | null | null | null | null | ### Feature request
Is it possible to download only the data that I am requesting and not the entire dataset? I run out of disk spaceas it seems to download the entire dataset, instead of only the part needed.
common_voice["test"] = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="test",
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5243/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5243/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5242 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5242/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5242/comments | https://api.github.com/repos/huggingface/datasets/issues/5242/events | https://github.com/huggingface/datasets/issues/5242 | 1,449,069,382 | I_kwDODunzps5WXwtG | 5,242 | Failed Data Processing upon upload with zip file full of images | {
"avatar_url": "https://avatars.githubusercontent.com/u/82735473?v=4",
"events_url": "https://api.github.com/users/scrambled2/events{/privacy}",
"followers_url": "https://api.github.com/users/scrambled2/followers",
"following_url": "https://api.github.com/users/scrambled2/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"cc @abhishekkrthakur @SBrandeis "
] | 2022-11-15T02:47:52Z | 2022-11-15T17:59:23Z | null | NONE | null | null | null | null | I went to autotrain and under image classification arrived where it was time to prepare my dataset. Screenshot below

I chose the method 2 option. I have a csv file with two columns. ~23,000 files.
I... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5242/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5242/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5232 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5232/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5232/comments | https://api.github.com/repos/huggingface/datasets/issues/5232/events | https://github.com/huggingface/datasets/issues/5232 | 1,446,294,165 | I_kwDODunzps5WNLKV | 5,232 | Incompatible dill versions in datasets 2.6.1 | {
"avatar_url": "https://avatars.githubusercontent.com/u/10574123?v=4",
"events_url": "https://api.github.com/users/vinaykakade/events{/privacy}",
"followers_url": "https://api.github.com/users/vinaykakade/followers",
"following_url": "https://api.github.com/users/vinaykakade/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Thanks for reporting, @vinaykakade.\r\n\r\nWe are discussing about making a release early this week.\r\n\r\nPlease note that in the meantime, in your specific case (as we also pointed out here: https://github.com/huggingface/datasets/issues/5162#issuecomment-1291720293), you can circumvent the issue by pinning `mu... | 2022-11-12T06:46:23Z | 2022-11-14T08:24:43Z | 2022-11-14T08:07:59Z | NONE | null | null | null | null | ### Describe the bug
datasets version 2.6.1 has a dependency on dill<0.3.6. This causes a conflict with dill>=0.3.6 used by multiprocess dependency in datasets 2.6.1
This issue is already fixed in https://github.com/huggingface/datasets/pull/5166/files, but not yet been released. Please release a new version of the... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5232/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5232/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5231 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5231/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5231/comments | https://api.github.com/repos/huggingface/datasets/issues/5231/events | https://github.com/huggingface/datasets/issues/5231 | 1,445,883,267 | I_kwDODunzps5WLm2D | 5,231 | Using `set_format(type='torch', columns=columns)` makes Array2D/3D columns stop formatting correctly | {
"avatar_url": "https://avatars.githubusercontent.com/u/99206017?v=4",
"events_url": "https://api.github.com/users/plamb-viso/events{/privacy}",
"followers_url": "https://api.github.com/users/plamb-viso/followers",
"following_url": "https://api.github.com/users/plamb-viso/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"In case others find this, the problem was not with set_format, but my usages of `to_pandas()` and `from_pandas()` which I was using during dataset splitting; somewhere in the chain of converting to and from pandas the `Array2D/Array3D` types get converted to series of `Sequence()` types"
] | 2022-11-11T18:54:36Z | 2022-11-11T20:42:29Z | 2022-11-11T18:59:50Z | NONE | null | null | null | null | I have a Dataset with two Features defined as follows:
```
'image': Array3D(dtype="int64", shape=(3, 224, 224)),
'bbox': Array2D(dtype="int64", shape=(512, 4)),
```
On said dataset, if I `dataset.set_format(type='torch')` and then use the dataset in a dataloader, these columns are correctly cast to Tensors of ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/99206017?v=4",
"events_url": "https://api.github.com/users/plamb-viso/events{/privacy}",
"followers_url": "https://api.github.com/users/plamb-viso/followers",
"following_url": "https://api.github.com/users/plamb-viso/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5231/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5231/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5230 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5230/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5230/comments | https://api.github.com/repos/huggingface/datasets/issues/5230/events | https://github.com/huggingface/datasets/issues/5230 | 1,445,507,580 | I_kwDODunzps5WKLH8 | 5,230 | dataclasses error when importing the library in python 3.11 | {
"avatar_url": "https://avatars.githubusercontent.com/u/76044840?v=4",
"events_url": "https://api.github.com/users/yonikremer/events{/privacy}",
"followers_url": "https://api.github.com/users/yonikremer/followers",
"following_url": "https://api.github.com/users/yonikremer/following{/other_user}",
"gists_url"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"I opened [this issue](https://github.com/python/cpython/issues/99401).\r\nPython's maintainers say that the issue is caused by [this change](https://docs.python.org/3.11/whatsnew/3.11.html#dataclasses).\r\nI believe adding a `__hash__` method to `datasets.utils.version.Version` should solve (at least partially) th... | 2022-11-11T13:53:49Z | 2023-05-25T04:37:05Z | 2022-11-14T15:27:37Z | NONE | null | null | null | null | ### Describe the bug
When I import datasets using python 3.11 the dataclasses standard library raises the following error:
`ValueError: mutable default <class 'datasets.utils.version.Version'> for field version is not allowed: use default_factory`
When I tried to import the library using the following jupyter note... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5230/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5230/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5229 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5229/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5229/comments | https://api.github.com/repos/huggingface/datasets/issues/5229/events | https://github.com/huggingface/datasets/issues/5229 | 1,445,121,028 | I_kwDODunzps5WIswE | 5,229 | Type error when calling `map` over dataset containing 0-d tensors | {
"avatar_url": "https://avatars.githubusercontent.com/u/7878215?v=4",
"events_url": "https://api.github.com/users/phipsgabler/events{/privacy}",
"followers_url": "https://api.github.com/users/phipsgabler/followers",
"following_url": "https://api.github.com/users/phipsgabler/following{/other_user}",
"gists_ur... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nWe could address this by calling `.item()` on such tensors to extract the value, but this would lose us the type, which could lead to storing the generated dataset in a suboptimal format. Considering this, I think the only proper fix would be implementing support for 0-D tensors on Apache Arrow's side ... | 2022-11-11T08:27:28Z | 2023-01-13T16:00:53Z | 2023-01-13T16:00:53Z | NONE | null | null | null | null | ### Describe the bug
0-dimensional tensors in a dataset lead to `TypeError: iteration over a 0-d array` when calling `map`. It is easy to generate such tensors by using `.with_format("...")` on the whole dataset.
### Steps to reproduce the bug
```
ds = datasets.Dataset.from_list([{"a": 1}, {"a": 1}]).with_fo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5229/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5229/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5228 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5228/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5228/comments | https://api.github.com/repos/huggingface/datasets/issues/5228/events | https://github.com/huggingface/datasets/issues/5228 | 1,444,763,105 | I_kwDODunzps5WHVXh | 5,228 | Loading a dataset from the hub fails if you happen to have a folder of the same name | {
"avatar_url": "https://avatars.githubusercontent.com/u/43149077?v=4",
"events_url": "https://api.github.com/users/dakinggg/events{/privacy}",
"followers_url": "https://api.github.com/users/dakinggg/followers",
"following_url": "https://api.github.com/users/dakinggg/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [
"`load_dataset` first checks for a local directory before checking for the Hub.\r\n\r\nTo make it explicit that it has to fetch the Hub, we could support the `hffs` syntax:\r\n```python\r\nload_dataset(\"hf://datasets/glue\")\r\n```\r\n\r\nwould that work for you ? Also cc @mariosasko who's leading the `hffs` proje... | 2022-11-11T00:51:54Z | 2023-05-03T23:23:04Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
I'm not 100% sure this should be considered a bug, but it was certainly annoying to figure out the cause of. And perhaps I am just missing a specific argument needed to avoid this conflict. Basically I had a situation where multiple workers were downloading different parts of the glue dataset and ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5228/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5228/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5227 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5227/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5227/comments | https://api.github.com/repos/huggingface/datasets/issues/5227/events | https://github.com/huggingface/datasets/issues/5227 | 1,444,620,094 | I_kwDODunzps5WGyc- | 5,227 | datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files | {
"avatar_url": "https://avatars.githubusercontent.com/u/102275116?v=4",
"events_url": "https://api.github.com/users/ScottM-wizard/events{/privacy}",
"followers_url": "https://api.github.com/users/ScottM-wizard/followers",
"following_url": "https://api.github.com/users/ScottM-wizard/following{/other_user}",
"... | [] | closed | false | null | [] | null | [
"Fixed. Please close.",
"how to fix?i need your help"
] | 2022-11-10T21:57:06Z | 2023-10-07T05:04:41Z | 2022-11-10T22:05:43Z | NONE | null | null | null | null | ### Describe the bug
From these lines:
from datasets import list_datasets, load_dataset
dataset = load_dataset("wikisql","binary")
I get error message:
datasets.data_files.EmptyDatasetError: The directory at wikisql doesn't contain any data files
And yet the 'wikisql' is reported to exist via the list_datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/102275116?v=4",
"events_url": "https://api.github.com/users/ScottM-wizard/events{/privacy}",
"followers_url": "https://api.github.com/users/ScottM-wizard/followers",
"following_url": "https://api.github.com/users/ScottM-wizard/following{/other_user}",
"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5227/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5227/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5226 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5226/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5226/comments | https://api.github.com/repos/huggingface/datasets/issues/5226/events | https://github.com/huggingface/datasets/issues/5226 | 1,444,385,148 | I_kwDODunzps5WF5F8 | 5,226 | Q: Memory release when removing the column? | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Hi ! Datasets are memory mapped from your disk, i.e. they're not loaded in RAM. This is possible thanks to the Arrow data format.\r\n\r\nTherefore the column you remove is not in RAM, so removing it doesn't cause the RAM to decrease.",
"Thanks for the explanation! @lhoestq \r\nI wonder since it is memory mapped,... | 2022-11-10T18:35:27Z | 2022-11-29T15:10:10Z | 2022-11-29T15:10:10Z | NONE | null | null | null | null | ### Describe the bug
How do I release memory when I use methods like `.remove_columns()` or `clear()` in notebooks?
```python
from datasets import load_dataset
common_voice = load_dataset("mozilla-foundation/common_voice_11_0", "ja", use_auth_token=True)
# check memory -> RAM Used (GB): 0.704 / Total (GB) 33.670... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5226/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5226/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5225 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5225/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5225/comments | https://api.github.com/repos/huggingface/datasets/issues/5225/events | https://github.com/huggingface/datasets/issues/5225 | 1,444,305,183 | I_kwDODunzps5WFlkf | 5,225 | Add video feature | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "008672",
"default": true... | open | false | null | [] | null | [
"@NielsRogge @rwightman may have additional requirements regarding this feature.\r\n\r\nWhen adding a new (decodable) type, the hardest part is choosing the right decoding library. What I mean by \"right\" here is that it has all the features we need and is easy to install (with GPU support?).\r\n\r\nSome candidate... | 2022-11-10T17:36:11Z | 2022-12-02T15:13:15Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
Add a `Video` feature to the library so folks can include videos in their datasets.
### Motivation
Being able to load Video data would be quite helpful. However, there are some challenges when it comes to videos:
1. Videos, unlike images, can end up being extremely large files
2. Often times ... | null | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5225/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5225/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5224 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5224/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5224/comments | https://api.github.com/repos/huggingface/datasets/issues/5224/events | https://github.com/huggingface/datasets/issues/5224 | 1,443,640,867 | I_kwDODunzps5WDDYj | 5,224 | Seems to freeze when loading audio dataset with wav files from local folder | {
"avatar_url": "https://avatars.githubusercontent.com/u/45894267?v=4",
"events_url": "https://api.github.com/users/uriii3/events{/privacy}",
"followers_url": "https://api.github.com/users/uriii3/followers",
"following_url": "https://api.github.com/users/uriii3/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"I just tried to do the same but changing the `.wav` files to `.mp3` files and that doesn't fix it.",
"I don't know if anyone will ever read this but I've tried to upload the same dataset with google colab and the output seems more clarifying. I didn't specify the train/test split so the dataset wasn't fully uplo... | 2022-11-10T10:29:31Z | 2023-04-25T09:54:05Z | 2022-11-22T11:24:19Z | NONE | null | null | null | null | ### Describe the bug
I'm following the instructions in [https://huggingface.co/docs/datasets/audio_load#audiofolder-with-metadata](url) to be able to load a dataset from a local folder.
I have everything into a folder, into a train folder and then the audios and csv. When I try to load the dataset and run from term... | {
"avatar_url": "https://avatars.githubusercontent.com/u/45894267?v=4",
"events_url": "https://api.github.com/users/uriii3/events{/privacy}",
"followers_url": "https://api.github.com/users/uriii3/followers",
"following_url": "https://api.github.com/users/uriii3/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5224/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5224/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5222 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5222/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5222/comments | https://api.github.com/repos/huggingface/datasets/issues/5222/events | https://github.com/huggingface/datasets/issues/5222 | 1,442,412,507 | I_kwDODunzps5V-Xfb | 5,222 | HuggingFace website is incorrectly reporting that my datasets are pickled | {
"avatar_url": "https://avatars.githubusercontent.com/u/10626398?v=4",
"events_url": "https://api.github.com/users/ProGamerGov/events{/privacy}",
"followers_url": "https://api.github.com/users/ProGamerGov/followers",
"following_url": "https://api.github.com/users/ProGamerGov/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"cc @McPatate maybe you know what's happening ?",
"Yes I think I know what is happening. We check in zips for pickles, and the UI must display the pickle jar when a scan has an associated list of imports, even when empty.\r\n~I'll fix ASAP !~",
"> I'll fix ASAP !\r\n\r\nActually I'd rather leave it like that f... | 2022-11-09T16:41:16Z | 2022-11-09T18:10:46Z | 2022-11-09T18:06:57Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
HuggingFace is incorrectly reporting that my datasets are pickled. They are not picked, they are simple ZIP files containing PNG images.
Hopefully this is the right location to report this bug.
### Steps to reproduce the bug
Inspect my dataset respository here: https://huggingface.co/datasets... | {
"avatar_url": "https://avatars.githubusercontent.com/u/9112841?v=4",
"events_url": "https://api.github.com/users/McPatate/events{/privacy}",
"followers_url": "https://api.github.com/users/McPatate/followers",
"following_url": "https://api.github.com/users/McPatate/following{/other_user}",
"gists_url": "http... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5222/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5222/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5221 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5221/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5221/comments | https://api.github.com/repos/huggingface/datasets/issues/5221/events | https://github.com/huggingface/datasets/issues/5221 | 1,442,309,094 | I_kwDODunzps5V9-Pm | 5,221 | Cannot push | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Did you run `huggingface-cli lfs-enable-largefiles` before committing or before adding ? Maybe you can try before adding\r\n\r\nAnyway I'd encourage you to split your data into several TAR archives if possible, this way the dataset can loaded faster using multiprocessing (by giving each process a subset of shards ... | 2022-11-09T15:32:05Z | 2022-11-10T18:11:21Z | 2022-11-10T18:11:11Z | NONE | null | null | null | null | ### Describe the bug
I am facing the issue when I try to push the tar.gz file around 11G to HUB.
```
(venv) ╭─laptop@laptop ~/PersonalProjects/data/ulaanbal_v0 ‹main●›
╰─$ du -sh *
4.0K README.md
13G data
516K test.jsonl
18M train.jsonl
4.0K ulaanbal_v0.py
11G ulaanbal_v0.tar.gz
452K validation.jsonl... | {
"avatar_url": "https://avatars.githubusercontent.com/u/43239645?v=4",
"events_url": "https://api.github.com/users/bayartsogt-ya/events{/privacy}",
"followers_url": "https://api.github.com/users/bayartsogt-ya/followers",
"following_url": "https://api.github.com/users/bayartsogt-ya/following{/other_user}",
"g... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5221/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5221/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5220 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5220/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5220/comments | https://api.github.com/repos/huggingface/datasets/issues/5220/events | https://github.com/huggingface/datasets/issues/5220 | 1,441,664,377 | I_kwDODunzps5V7g15 | 5,220 | Implicit type conversion of lists in to_pandas | {
"avatar_url": "https://avatars.githubusercontent.com/u/48946947?v=4",
"events_url": "https://api.github.com/users/sanderland/events{/privacy}",
"followers_url": "https://api.github.com/users/sanderland/followers",
"following_url": "https://api.github.com/users/sanderland/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"I think this behavior comes from PyArrow:\r\n```python\r\nimport pyarrow as pa\r\nt = pa.table({\"a\": [[0]]})\r\nt.to_pandas().a.values[0]\r\n# array([0])\r\n```\r\n\r\nI believe this has to do with zero-copy: you can get a pandas DataFrame without copying the buffers from arrow, and therefore end up with numpy a... | 2022-11-09T08:40:18Z | 2022-11-10T16:12:26Z | 2022-11-10T16:12:26Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
```
ds = Dataset.from_list([{'a':[1,2,3]}])
ds.to_pandas().a.values[0]
```
Results in `array([1, 2, 3])` -- a rather unexpected conversion of types which made downstream tools expecting lists not happy.
### Steps to reproduce the bug
See snippet
### Expected behavior
Keep the original typ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/48946947?v=4",
"events_url": "https://api.github.com/users/sanderland/events{/privacy}",
"followers_url": "https://api.github.com/users/sanderland/followers",
"following_url": "https://api.github.com/users/sanderland/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5220/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5220/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5219 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5219/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5219/comments | https://api.github.com/repos/huggingface/datasets/issues/5219/events | https://github.com/huggingface/datasets/issues/5219 | 1,441,255,910 | I_kwDODunzps5V59Hm | 5,219 | Delta Tables usage using Datasets Library | {
"avatar_url": "https://avatars.githubusercontent.com/u/23002137?v=4",
"events_url": "https://api.github.com/users/reichenbch/events{/privacy}",
"followers_url": "https://api.github.com/users/reichenbch/followers",
"following_url": "https://api.github.com/users/reichenbch/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! Interesting :) Can you provide concrete examples of cases where it can be useful ?",
"Few example blogs and posts that might help on this - \r\n\r\n1. https://hevodata.com/learn/databricks-delta-tables/\r\n2. https://docs.databricks.com/delta/index.html\r\n\r\nBasically, we are looking at utility of Dataset... | 2022-11-09T02:43:56Z | 2023-03-02T19:29:12Z | null | NONE | null | null | null | null | ### Feature request
Adding compatibility of Datasets library with Delta Format. Elevating the utilities of Datasets library from Machine Learning Scope to Data Engineering Scope as well.
### Motivation
We know datasets library can absorb csv, json, parquet, etc. file formats but it would be great if Datasets library... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5219/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5219/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5218 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5218/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5218/comments | https://api.github.com/repos/huggingface/datasets/issues/5218/events | https://github.com/huggingface/datasets/issues/5218 | 1,441,254,194 | I_kwDODunzps5V58sy | 5,218 | Delta Tables usage using Datasets Library | {
"avatar_url": "https://avatars.githubusercontent.com/u/103188035?v=4",
"events_url": "https://api.github.com/users/rcv-koo/events{/privacy}",
"followers_url": "https://api.github.com/users/rcv-koo/followers",
"following_url": "https://api.github.com/users/rcv-koo/following{/other_user}",
"gists_url": "https... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [] | 2022-11-09T02:42:18Z | 2022-11-09T02:42:36Z | 2022-11-09T02:42:36Z | NONE | null | null | null | null | ### Feature request
Adding compatibility of Datasets library with Delta Format. Elevating the utilities of Datasets library from Machine Learning Scope to Data Engineering Scope as well.
### Motivation
We know datasets library can absorb csv, json, parquet, etc. file formats but it would be great if Datasets library... | {
"avatar_url": "https://avatars.githubusercontent.com/u/103188035?v=4",
"events_url": "https://api.github.com/users/rcv-koo/events{/privacy}",
"followers_url": "https://api.github.com/users/rcv-koo/followers",
"following_url": "https://api.github.com/users/rcv-koo/following{/other_user}",
"gists_url": "https... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5218/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5218/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5216 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5216/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5216/comments | https://api.github.com/repos/huggingface/datasets/issues/5216/events | https://github.com/huggingface/datasets/issues/5216 | 1,441,041,947 | I_kwDODunzps5V5I4b | 5,216 | save_elasticsearch_index | {
"avatar_url": "https://avatars.githubusercontent.com/u/12739718?v=4",
"events_url": "https://api.github.com/users/amobash2/events{/privacy}",
"followers_url": "https://api.github.com/users/amobash2/followers",
"following_url": "https://api.github.com/users/amobash2/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [
"Hi ! I think there exist tools to dump and reload an index in your elastic search but I'm not super familiar with it.\r\n\r\nAnyway after reloading an index in elastic search you can call `ds.load_elasticsearch_index` which will connect the index to the dataset without re-indexing"
] | 2022-11-08T23:06:52Z | 2022-11-09T13:16:45Z | null | NONE | null | null | null | null | Hi,
I am new to Dataset and elasticsearch. I was wondering is there any equivalent approach to save elasticsearch index as of save_faiss_index locally for later use, to remove the need to re-index a dataset? | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5216/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5216/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5209 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5209/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5209/comments | https://api.github.com/repos/huggingface/datasets/issues/5209/events | https://github.com/huggingface/datasets/issues/5209 | 1,438,367,678 | I_kwDODunzps5Vu7-- | 5,209 | Implement ability to define splits in metadata section of dataset card | {
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"@merveenoyan Do you want different files to be splits or configurations?\r\n\r\nFrom [what you specified in `Readme.md`](https://huggingface.co/datasets/inria-soda/tabular-benchmark/commit/fb4575853772c62a20203bdd6cc0202f5db4ce4e) I hypothesize that you want to have 4 **configs** corresponding to directories: `\"c... | 2022-11-07T13:27:16Z | 2023-07-21T14:36:02Z | 2023-07-21T14:36:01Z | CONTRIBUTOR | null | null | null | null | ### Feature request
If you go here: https://huggingface.co/datasets/inria-soda/tabular-benchmark/tree/main you will see bunch of folders that has various CSV files. I’d like dataset viewer to show these files instead of only one dataset like it currently does. (and also people to be able to load them as splits inste... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 2,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5209/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5209/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5207 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5207/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5207/comments | https://api.github.com/repos/huggingface/datasets/issues/5207/events | https://github.com/huggingface/datasets/issues/5207 | 1,437,858,506 | I_kwDODunzps5Vs_rK | 5,207 | Connection error of the HuggingFace's dataset Hub due to SSLError with proxy | {
"avatar_url": "https://avatars.githubusercontent.com/u/82404?v=4",
"events_url": "https://api.github.com/users/leemgs/events{/privacy}",
"followers_url": "https://api.github.com/users/leemgs/followers",
"following_url": "https://api.github.com/users/leemgs/following{/other_user}",
"gists_url": "https://api.... | [] | open | false | null | [] | null | [
"Hi ! It looks like an issue with your python environment, can you make sure you're able to run GET requests to https://huggingface.co using `requests` in python ?",
"Thanks for your reply. Does this mean that I have to use the `do_dataset `function and the `requests `function to download the dataset from the com... | 2022-11-07T06:56:23Z | 2025-03-08T09:04:10Z | null | NONE | null | null | null | null | ### Describe the bug
It's weird. I could not normally connect the dataset Hub of HuggingFace due to a SSLError in my office.
Even when I try to connect using my company's proxy address (e.g., http_proxy and https_proxy),
I'm getting the SSLError issue. What should I do to download the datanet stored in Hugg... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5207/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5207/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5206 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5206/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5206/comments | https://api.github.com/repos/huggingface/datasets/issues/5206/events | https://github.com/huggingface/datasets/issues/5206 | 1,437,223,894 | I_kwDODunzps5VqkvW | 5,206 | Use logging instead of printing to console | {
"avatar_url": "https://avatars.githubusercontent.com/u/16692099?v=4",
"events_url": "https://api.github.com/users/bilelomrani1/events{/privacy}",
"followers_url": "https://api.github.com/users/bilelomrani1/followers",
"following_url": "https://api.github.com/users/bilelomrani1/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Actually upon closer inspection, it is documented in the code that this behavior is intentional, so I'll close this."
] | 2022-11-05T23:48:02Z | 2022-11-06T00:06:00Z | 2022-11-06T00:05:59Z | NONE | null | null | null | null | ### Describe the bug
Some logs ([here](https://github.com/huggingface/datasets/blob/4a6e1fe2735505efc7e3a3dbd3e1835da0702575/src/datasets/builder.py#L778), [here](https://github.com/huggingface/datasets/blob/4a6e1fe2735505efc7e3a3dbd3e1835da0702575/src/datasets/builder.py#L786), and [here](https://github.com/huggingfa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16692099?v=4",
"events_url": "https://api.github.com/users/bilelomrani1/events{/privacy}",
"followers_url": "https://api.github.com/users/bilelomrani1/followers",
"following_url": "https://api.github.com/users/bilelomrani1/following{/other_user}",
"gist... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5206/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5206/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5204 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5204/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5204/comments | https://api.github.com/repos/huggingface/datasets/issues/5204/events | https://github.com/huggingface/datasets/issues/5204 | 1,437,221,259 | I_kwDODunzps5VqkGL | 5,204 | `push_to_hub` not propagating `token` through `DownloadConfig` | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}",
"gists_u... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/36760800?v=4",
"events_url": "https://api.github.com/users/alvarobartt/events{/privacy}",
"followers_url": "https://api.github.com/users/alvarobartt/followers",
"following_url": "https://api.github.com/users/alvarobartt/following{/other_user}"... | null | [
"#self-assign",
"@lhoestq can you close this issue as part of the recent #5205 merge? Thanks 🤗 ",
"Thank you :)"
] | 2022-11-05T23:32:20Z | 2022-11-08T10:12:09Z | 2022-11-08T10:12:08Z | MEMBER | null | null | null | null | ### Describe the bug
When trying to upload a new 🤗 Dataset to the Hub via Python, and providing the `token` as a parameter to the `Dataset.push_to_hub` function, it just works for the first time, assuming that the dataset didn't exist before.
But when trying to run `Dataset.push_to_hub` again over the same dataset... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5204/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5204/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5202 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5202/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5202/comments | https://api.github.com/repos/huggingface/datasets/issues/5202/events | https://github.com/huggingface/datasets/issues/5202 | 1,435,886,090 | I_kwDODunzps5VleIK | 5,202 | CI fails after bulk edit of canonical datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Fixed by: https://huggingface.co/datasets/paws/discussions/1"
] | 2022-11-04T10:51:20Z | 2023-02-16T09:11:10Z | 2023-02-16T09:11:10Z | MEMBER | null | null | null | null | ```
______ test_get_dataset_config_info[paws-labeled_final-expected_splits2] _______
[gw0] linux -- Python 3.7.15 /opt/hostedtoolcache/Python/3.7.15/x64/bin/python
path = 'paws', config_name = 'labeled_final'
expected_splits = ['train', 'test', 'validation']
@pytest.mark.parametrize(
"path, config... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5202/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5202/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5200 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5200/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5200/comments | https://api.github.com/repos/huggingface/datasets/issues/5200/events | https://github.com/huggingface/datasets/issues/5200 | 1,435,831,559 | I_kwDODunzps5VlQ0H | 5,200 | Some links to canonical datasets in the docs are outdated | {
"avatar_url": "https://avatars.githubusercontent.com/u/16348744?v=4",
"events_url": "https://api.github.com/users/polinaeterna/events{/privacy}",
"followers_url": "https://api.github.com/users/polinaeterna/followers",
"following_url": "https://api.github.com/users/polinaeterna/following{/other_user}",
"gist... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"Thanks for catching this, I can go through the docs and replace the links to their corresponding datasets on the Hub!"
] | 2022-11-04T10:06:21Z | 2022-11-07T18:40:20Z | 2022-11-07T18:40:20Z | CONTRIBUTOR | null | null | null | null | As we don't have canonical datasets in the github repo anymore, some old links to them doesn't work. I don't know how many of them are there, I found link to SuperGlue here: https://huggingface.co/docs/datasets/dataset_script#multiple-configurations, probably there are more of them. These links should be replaced by li... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5200/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5200/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5193 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5193/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5193/comments | https://api.github.com/repos/huggingface/datasets/issues/5193/events | https://github.com/huggingface/datasets/issues/5193 | 1,433,883,780 | I_kwDODunzps5Vd1SE | 5,193 | "One or several metadata. were found, but not in the same directory or in a parent directory" | {
"avatar_url": "https://avatars.githubusercontent.com/u/20109584?v=4",
"events_url": "https://api.github.com/users/lambda-science/events{/privacy}",
"followers_url": "https://api.github.com/users/lambda-science/followers",
"following_url": "https://api.github.com/users/lambda-science/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Also unrelated but still: https://huggingface.co/docs/datasets/image_dataset#generate-the-dataset\r\n```If your loading script passed the test, you should now have a dataset_infos.json file in your dataset folder.```\r\nIt's not the case anymore as it's now in the readme.md, it was confusing to me",
"And here is... | 2022-11-02T22:46:25Z | 2022-11-03T13:39:16Z | 2022-11-03T13:35:44Z | NONE | null | null | null | null | ### Describe the bug
When loading my own dataset, on loading it I get an error.
Here is my dataset link: https://huggingface.co/datasets/corentinm7/MyoQuant-SDH-Data
And the error after loading with:
```python
from datasets import load_dataset
load_dataset("corentinm7/MyoQuant-SDH-Data")
```
```python
Downlo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/20109584?v=4",
"events_url": "https://api.github.com/users/lambda-science/events{/privacy}",
"followers_url": "https://api.github.com/users/lambda-science/followers",
"following_url": "https://api.github.com/users/lambda-science/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5193/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5193/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5190 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5190/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5190/comments | https://api.github.com/repos/huggingface/datasets/issues/5190/events | https://github.com/huggingface/datasets/issues/5190 | 1,433,014,626 | I_kwDODunzps5VahFi | 5,190 | `path` is `None` when downloading a custom audio dataset from the Hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/26859204?v=4",
"events_url": "https://api.github.com/users/lewtun/events{/privacy}",
"followers_url": "https://api.github.com/users/lewtun/followers",
"following_url": "https://api.github.com/users/lewtun/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Hi! Yes, this is expected behavior - we do this as a security measure to not leak local paths (this info would be useless on other users' machines anyways) and only push audio bytes. \r\n"
] | 2022-11-02T11:51:25Z | 2022-11-02T12:55:02Z | 2022-11-02T12:55:02Z | MEMBER | null | null | null | null | ### Describe the bug
I've created an [audio dataset](https://huggingface.co/datasets/lewtun/audio-test-push) using the `audiofolder` feature desribed in the [docs](https://huggingface.co/docs/datasets/audio_dataset#audiofolder) and then pushed it to the Hub.
Locally, I can see the `audio.path` feature is of the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5190/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5190/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5189 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5189/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5189/comments | https://api.github.com/repos/huggingface/datasets/issues/5189/events | https://github.com/huggingface/datasets/issues/5189 | 1,432,769,143 | I_kwDODunzps5VZlJ3 | 5,189 | Reduce friction in tabular dataset workflow by eliminating having splits when dataset is loaded | {
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [
"I have to admit I'm not a fan of this idea, as this would result in a non-consistent behavior between tabular and non-tabular datasets, which is confusing if done without the context you provided. Instead, we could consider returning a `Dataset` object rather than `DatasetDict` if there is only one split in the ge... | 2022-11-02T09:15:02Z | 2022-12-06T12:13:17Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
Sorry for cryptic name but I'd like to explain using code itself. When I want to load a specific dataset from a repository (for instance, this: https://huggingface.co/datasets/inria-soda/tabular-benchmark)
```python
from datasets import load_dataset
dataset = load_dataset("inria-soda/tabular-b... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5189/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5189/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5186 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5186/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5186/comments | https://api.github.com/repos/huggingface/datasets/issues/5186/events | https://github.com/huggingface/datasets/issues/5186 | 1,432,045,011 | I_kwDODunzps5VW0XT | 5,186 | Incorrect error message when Dataset.from_sql fails and sqlalchemy not installed | {
"avatar_url": "https://avatars.githubusercontent.com/u/32437151?v=4",
"events_url": "https://api.github.com/users/nateraw/events{/privacy}",
"followers_url": "https://api.github.com/users/nateraw/followers",
"following_url": "https://api.github.com/users/nateraw/following{/other_user}",
"gists_url": "https:... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Hi! The first `Dataset.from_sql` call also outputs the \"ImportError: Using URI string without sqlalchemy installed.\" message, but you also get \"During handling of the above exception another exception occurred: ...\" after which the ValueError is printed. I agree that this behavior makes it easy to miss the ori... | 2022-11-01T20:25:51Z | 2022-11-15T18:24:39Z | 2022-11-15T18:24:39Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
When calling `Dataset.from_sql` (in my case, with sqlite3), it fails with a message ```ValueError: Please pass `features` or at least one example when writing data``` when I don't have `sqlalchemy` installed.
### Steps to reproduce the bug
Make a new sqlite db with `sqlite3` and `pandas` from... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5186/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5186/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5185 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5185/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5185/comments | https://api.github.com/repos/huggingface/datasets/issues/5185/events | https://github.com/huggingface/datasets/issues/5185 | 1,432,021,611 | I_kwDODunzps5VWupr | 5,185 | Allow passing a subset of output features to Dataset.map | {
"avatar_url": "https://avatars.githubusercontent.com/u/48946947?v=4",
"events_url": "https://api.github.com/users/sanderland/events{/privacy}",
"followers_url": "https://api.github.com/users/sanderland/followers",
"following_url": "https://api.github.com/users/sanderland/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [] | 2022-11-01T20:07:20Z | 2022-11-01T20:07:34Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
Currently, map does one of two things to the features (if I'm not mistaken):
* when you do not pass features, types are assumed to be equal to the input if they can be cast, and inferred otherwise
* when you pass a full specification of features, output features are set to this
However, so... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5185/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5185/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5183 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5183/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5183/comments | https://api.github.com/repos/huggingface/datasets/issues/5183/events | https://github.com/huggingface/datasets/issues/5183 | 1,431,418,066 | I_kwDODunzps5VUbTS | 5,183 | Loading an external dataset in a format similar to conll2003 | {
"avatar_url": "https://avatars.githubusercontent.com/u/112555442?v=4",
"events_url": "https://api.github.com/users/Taghreed7878/events{/privacy}",
"followers_url": "https://api.github.com/users/Taghreed7878/followers",
"following_url": "https://api.github.com/users/Taghreed7878/following{/other_user}",
"gis... | [] | closed | false | null | [] | null | [] | 2022-11-01T13:18:29Z | 2022-11-02T11:57:50Z | 2022-11-02T11:57:50Z | NONE | null | null | null | null | I'm trying to load a custom dataset in a Dataset object, it's similar to conll2003 but with 2 columns only (word entity), I used the following script:
features = datasets.Features(
{"tokens": datasets.Sequence(datasets.Value("string")),
"ner_tags": datasets.Sequence(
datasets.featu... | {
"avatar_url": "https://avatars.githubusercontent.com/u/112555442?v=4",
"events_url": "https://api.github.com/users/Taghreed7878/events{/privacy}",
"followers_url": "https://api.github.com/users/Taghreed7878/followers",
"following_url": "https://api.github.com/users/Taghreed7878/following{/other_user}",
"gis... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5183/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5183/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5182 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5182/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5182/comments | https://api.github.com/repos/huggingface/datasets/issues/5182/events | https://github.com/huggingface/datasets/issues/5182 | 1,431,029,547 | I_kwDODunzps5VS8cr | 5,182 | Add notebook / other resource links to the task-specific data loading guides | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Yea this would be great! We would need an object detection tutorial notebook too if it doesn't already exist there. ",
"There is one: https://huggingface.co/docs/datasets/object_detection.\r\n\r\nI will start the work. "
] | 2022-11-01T07:57:26Z | 2022-11-03T01:49:57Z | 2022-11-03T01:49:57Z | MEMBER | null | null | null | null | Does it make sense to include links to notebooks / scripts that show how to use a dataset for training / fine-tuning a model?
For example, here in [https://huggingface.co/docs/datasets/image_classification] we could include a mention of https://github.com/huggingface/notebooks/blob/main/examples/image_classificatio... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5182/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5182/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5181 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5181/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5181/comments | https://api.github.com/repos/huggingface/datasets/issues/5181/events | https://github.com/huggingface/datasets/issues/5181 | 1,431,027,102 | I_kwDODunzps5VS72e | 5,181 | Add a guide for semantic segmentation | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
... | null | [
"Sure this sounds great! Would this be pure torchvision, albumentations, or something else?",
"I am considering `torchvision` and `albumentations`. Also [works with TensorFlow](https://github.com/deep-diver/segformer-tf-transformers/blob/main/notebooks/TFSegFormer_Finetune.ipynb). \r\n\r\nI am assigning the issue... | 2022-11-01T07:54:50Z | 2022-11-04T18:23:36Z | 2022-11-04T18:23:36Z | MEMBER | null | null | null | null | Currently, we have these guides for object detection and image classification:
* https://huggingface.co/docs/datasets/object_detection
* https://huggingface.co/docs/datasets/image_classification
I am proposing adding a similar guide for semantic segmentation.
I am happy to contribute a PR for it.
Cc: @os... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5181/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5181/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5180 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5180/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5180/comments | https://api.github.com/repos/huggingface/datasets/issues/5180/events | https://github.com/huggingface/datasets/issues/5180 | 1,431,012,438 | I_kwDODunzps5VS4RW | 5,180 | An example or recommendations for creating large image datasets? | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [
"The beam utilities allow to prepare a dataset as parquet in your cloud storage. From my perspective this CLI is not super easy to use, but we've been working on a new python API to prepare a dataset in your cloud storage:\r\n```python\r\nfrom datasets import load_dataset_builder\r\n\r\nbuilder = load_dataset_build... | 2022-11-01T07:38:38Z | 2022-11-02T10:17:11Z | null | MEMBER | null | null | null | null | I know that Apache Beam and `datasets` have [some connector utilities](https://huggingface.co/docs/datasets/beam). But it's a little unclear what we mean by "But if you want to run your own Beam pipeline with Dataflow, here is how:". What does that pipeline do?
As a user, I was wondering if we have this support for... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5180/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5180/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5179 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5179/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5179/comments | https://api.github.com/repos/huggingface/datasets/issues/5179/events | https://github.com/huggingface/datasets/issues/5179 | 1,430,826,100 | I_kwDODunzps5VSKx0 | 5,179 | `map()` fails midway due to format incompatibility | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Cc: @lhoestq ",
"You can end up with a list instead of a tensor if all the tensors inside the list can't be stacked together - can you make sure all your inputs are tensors with the same shape ?",
"Is there an easy way to ensure it?",
"You can make sure your `tokenize` function always return tensors of the s... | 2022-11-01T03:57:59Z | 2022-11-08T11:35:26Z | 2022-11-08T11:35:26Z | MEMBER | null | null | null | null | ### Describe the bug
I am using the `emotion` dataset from Hub for sequence classification. After training the model, I am using it to generate predictions for all the entries present in the `validation` split of the dataset.
```py
def get_test_accuracy(model):
def fn(batch):
inputs = {k:v.to(device... | {
"avatar_url": "https://avatars.githubusercontent.com/u/22957388?v=4",
"events_url": "https://api.github.com/users/sayakpaul/events{/privacy}",
"followers_url": "https://api.github.com/users/sayakpaul/followers",
"following_url": "https://api.github.com/users/sayakpaul/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5179/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5179/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5178 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5178/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5178/comments | https://api.github.com/repos/huggingface/datasets/issues/5178/events | https://github.com/huggingface/datasets/issues/5178 | 1,430,800,810 | I_kwDODunzps5VSEmq | 5,178 | Unable to download the Chinese `wikipedia`, the dumpstatus.json not found! | {
"avatar_url": "https://avatars.githubusercontent.com/u/37113676?v=4",
"events_url": "https://api.github.com/users/beyondguo/events{/privacy}",
"followers_url": "https://api.github.com/users/beyondguo/followers",
"following_url": "https://api.github.com/users/beyondguo/following{/other_user}",
"gists_url": "... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"In the dumps page of the wiki (https://dumps.wikimedia.org/zhwiki/), I found the following dumps:\r\n```\r\nIndex of /zhwiki/\r\n[../](https://dumps.wikimedia.org/)\r\n[20220701/](https://dumps.wikimedia.org/zhwiki/20220701/) 21-Aug-2022 01:48 -\r\n[202207... | 2022-11-01T03:17:55Z | 2022-11-02T08:27:15Z | 2022-11-02T08:24:29Z | NONE | null | null | null | null | ### Describe the bug
I tried:
`data = load_dataset('wikipedia', '20220301.zh', beam_runner='DirectRunner')`
and
`data = load_dataset("wikipedia", language="zh", date="20220301", beam_runner='DirectRunner')`
but both got:
`FileNotFoundError: Couldn't find file at https://dumps.wikimedia.org/zhwiki/20220301/dumpsta... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5178/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5178/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5176 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5176/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5176/comments | https://api.github.com/repos/huggingface/datasets/issues/5176/events | https://github.com/huggingface/datasets/issues/5176 | 1,430,214,539 | I_kwDODunzps5VP1eL | 5,176 | prepare dataset for cloud storage doesn't work | {
"avatar_url": "https://avatars.githubusercontent.com/u/27285078?v=4",
"events_url": "https://api.github.com/users/araonblake/events{/privacy}",
"followers_url": "https://api.github.com/users/araonblake/followers",
"following_url": "https://api.github.com/users/araonblake/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"It looks like an issue with `gcsfs`, are you able to instantiate a `GCSFileSystem` manually ?",
"closing since it was probably due to gcsfs"
] | 2022-10-31T17:28:57Z | 2023-03-28T09:11:46Z | 2023-03-28T09:11:45Z | NONE | null | null | null | null | ### Describe the bug
Following the [documentation](https://huggingface.co/docs/datasets/filesystems#load-and-save-your-datasets-using-your-cloud-storage-filesystem) and [this PR](https://github.com/huggingface/datasets/pull/4724), I was downloading and storing huggingface dataset to cloud storage.
```
from datasets ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5176/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5176/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5175 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5175/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5175/comments | https://api.github.com/repos/huggingface/datasets/issues/5175/events | https://github.com/huggingface/datasets/issues/5175 | 1,428,696,231 | I_kwDODunzps5VKCyn | 5,175 | Loading an external NER dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/112555442?v=4",
"events_url": "https://api.github.com/users/Taghreed7878/events{/privacy}",
"followers_url": "https://api.github.com/users/Taghreed7878/followers",
"following_url": "https://api.github.com/users/Taghreed7878/following{/other_user}",
"gis... | [] | closed | false | null | [] | null | [] | 2022-10-30T09:31:55Z | 2022-11-01T13:15:49Z | 2022-11-01T13:15:49Z | NONE | null | null | null | null | I need to use huggingface datasets to load a custom dataset similar to conll2003 but with more entities and each the files contain only two columns: word and ner tag.
I tried this code snnipet that I found here as an answer to a similar issue:
from datasets import Dataset
INPUT_COLUMNS = "ID Text NER".split()
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/112555442?v=4",
"events_url": "https://api.github.com/users/Taghreed7878/events{/privacy}",
"followers_url": "https://api.github.com/users/Taghreed7878/followers",
"following_url": "https://api.github.com/users/Taghreed7878/following{/other_user}",
"gis... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5175/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5175/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5172 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5172/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5172/comments | https://api.github.com/repos/huggingface/datasets/issues/5172/events | https://github.com/huggingface/datasets/issues/5172 | 1,425,523,114 | I_kwDODunzps5U98Gq | 5,172 | Inconsistency behavior between handling local file protocol and other FS protocols | {
"avatar_url": "https://avatars.githubusercontent.com/u/37735580?v=4",
"events_url": "https://api.github.com/users/leoleoasd/events{/privacy}",
"followers_url": "https://api.github.com/users/leoleoasd/followers",
"following_url": "https://api.github.com/users/leoleoasd/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [] | 2022-10-27T12:03:20Z | 2024-05-08T19:31:13Z | null | NONE | null | null | null | null | ### Describe the bug
These lines us used during load_from_disk:
```
if is_remote_filesystem(fs):
dest_dataset_dict_path = extract_path_from_uri(dataset_dict_path)
else:
fs = fsspec.filesystem("file")
dest_dataset_dict_path = dataset_dict_path
```
If a local FS is given, then it will the URL as th... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5172/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5172/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.