
url stringlengths 58 61 | repository_url stringclasses 1
value | labels_url stringlengths 72 75 | comments_url stringlengths 67 70 | events_url stringlengths 65 68 | html_url stringlengths 48 51 | id int64 600M 3.43B | node_id stringlengths 18 24 | number int64 2 7.78k | title stringlengths 1 290 | user dict | labels listlengths 0 4 | state stringclasses 2
values | locked bool 1
class | assignee dict | assignees listlengths 0 4 | milestone dict | comments listlengths 0 30 | created_at stringdate 2020-04-14 18:18:51 2025-09-18 08:25:34 | updated_at stringdate 2020-04-29 09:23:05 2025-09-22 08:47:53 | closed_at stringlengths 20 20 ⌀ | author_association stringclasses 4
values | type null | active_lock_reason null | draft bool 0
classes | pull_request dict | body stringlengths 0 228k ⌀ | closed_by dict | reactions dict | timeline_url stringlengths 67 70 | performed_via_github_app null | state_reason stringclasses 4
values | sub_issues_summary dict | issue_dependencies_summary dict | is_pull_request bool 1
class |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/datasets/issues/5756 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5756/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5756/comments | https://api.github.com/repos/huggingface/datasets/issues/5756/events | https://github.com/huggingface/datasets/issues/5756 | 1,669,678,080 | I_kwDODunzps5jhUQA | 5,756 | Calling shuffle on a IterableDataset with streaming=True, gives "ValueError: cannot reshape array" | {
"avatar_url": "https://avatars.githubusercontent.com/u/21077341?v=4",
"events_url": "https://api.github.com/users/rohfle/events{/privacy}",
"followers_url": "https://api.github.com/users/rohfle/followers",
"following_url": "https://api.github.com/users/rohfle/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Hi! I've merged a PR on the Hub with a fix: https://huggingface.co/datasets/fashion_mnist/discussions/3",
"Thanks, this appears to have fixed the issue.\r\n\r\nI've created a PR for the same change in the mnist dataset: https://huggingface.co/datasets/mnist/discussions/3/files"
] | 2023-04-16T04:59:47Z | 2023-04-18T03:40:56Z | 2023-04-18T03:40:56Z | NONE | null | null | null | null | ### Describe the bug
When calling shuffle on a IterableDataset with streaming=True, I get the following error:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/administrator/Documents/Projects/huggingface/jax-diffusers-sprint-consistency-models/virtualenv/lib/python3.1... | {
"avatar_url": "https://avatars.githubusercontent.com/u/21077341?v=4",
"events_url": "https://api.github.com/users/rohfle/events{/privacy}",
"followers_url": "https://api.github.com/users/rohfle/followers",
"following_url": "https://api.github.com/users/rohfle/following{/other_user}",
"gists_url": "https://a... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5756/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5756/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5755 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5755/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5755/comments | https://api.github.com/repos/huggingface/datasets/issues/5755/events | https://github.com/huggingface/datasets/issues/5755 | 1,669,048,438 | I_kwDODunzps5je6h2 | 5,755 | ImportError: cannot import name 'DeprecatedEnum' from 'datasets.utils.deprecation_utils' | {
"avatar_url": "https://avatars.githubusercontent.com/u/1405491?v=4",
"events_url": "https://api.github.com/users/fivejjs/events{/privacy}",
"followers_url": "https://api.github.com/users/fivejjs/followers",
"following_url": "https://api.github.com/users/fivejjs/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"update the version. fix"
] | 2023-04-14T23:28:54Z | 2023-04-14T23:36:19Z | 2023-04-14T23:36:19Z | NONE | null | null | null | null | ### Describe the bug
The module moved to new place?
### Steps to reproduce the bug
in the import step,
```python
from datasets.utils.deprecation_utils import DeprecatedEnum
```
error:
```
ImportError: cannot import name 'DeprecatedEnum' from 'datasets.utils.deprecation_utils'
```
### Expected behavior... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1405491?v=4",
"events_url": "https://api.github.com/users/fivejjs/events{/privacy}",
"followers_url": "https://api.github.com/users/fivejjs/followers",
"following_url": "https://api.github.com/users/fivejjs/following{/other_user}",
"gists_url": "https:/... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5755/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5755/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5753 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5753/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5753/comments | https://api.github.com/repos/huggingface/datasets/issues/5753/events | https://github.com/huggingface/datasets/issues/5753 | 1,668,659,536 | I_kwDODunzps5jdblQ | 5,753 | [IterableDatasets] Add column followed by interleave datasets gives bogus outputs | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Problem with the code snippet! Using global vars and functions was not a good idea with iterable datasets!\r\n\r\nIf we update to:\r\n```python\r\nfrom datasets import load_dataset\r\n\r\noriginal_dataset = load_dataset(\"librispeech_asr\", \"clean\", split=\"validation\", streaming=True)\r\n\r\n# now add a new co... | 2023-04-14T17:32:31Z | 2025-07-04T05:22:53Z | 2023-04-14T17:36:37Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
If we add a new column to our iterable dataset using the hack described in #5752, when we then interleave datasets the new column is pinned to one value.
### Steps to reproduce the bug
What we're going to do here is:
1. Load an iterable dataset in streaming mode (`original_dataset`)
2. A... | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5753/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5753/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5752 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5752/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5752/comments | https://api.github.com/repos/huggingface/datasets/issues/5752/events | https://github.com/huggingface/datasets/issues/5752 | 1,668,574,209 | I_kwDODunzps5jdGwB | 5,752 | Streaming dataset looses `.feature` method after `.add_column` | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | null | [] | null | [
"I believe the issue resides in this line:\r\nhttps://github.com/huggingface/datasets/blob/7c3a9b057c476c40d157bd7a5d57f49066239df0/src/datasets/iterable_dataset.py#L1415\r\n\r\nIf we pass the **new** features of the dataset to the `.map` method we can return the features after adding a column, e.g.:\r\n```python\r... | 2023-04-14T16:39:50Z | 2024-01-18T10:15:20Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
After appending a new column to a streaming dataset using `.add_column`, we can no longer access the list of dataset features using the `.feature` method.
### Steps to reproduce the bug
```python
from datasets import load_dataset
original_dataset = load_dataset("librispeech_asr", "clean", sp... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5752/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5752/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5750 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5750/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5750/comments | https://api.github.com/repos/huggingface/datasets/issues/5750/events | https://github.com/huggingface/datasets/issues/5750 | 1,668,289,067 | I_kwDODunzps5jcBIr | 5,750 | Fail to create datasets from a generator when using Google Big Query | {
"avatar_url": "https://avatars.githubusercontent.com/u/895720?v=4",
"events_url": "https://api.github.com/users/ivanprado/events{/privacy}",
"followers_url": "https://api.github.com/users/ivanprado/followers",
"following_url": "https://api.github.com/users/ivanprado/following{/other_user}",
"gists_url": "ht... | [] | closed | false | null | [] | null | [
"`from_generator` expects a generator function, not a generator object, so this should work:\r\n```python\r\nfrom datasets import Dataset\r\nfrom google.cloud import bigquery\r\n\r\nclient = bigquery.Client()\r\n\r\ndef gen()\r\n # Perform a query.\r\n QUERY = (\r\n 'SELECT name FROM `bigquery-public-d... | 2023-04-14T13:50:59Z | 2023-04-17T12:20:43Z | 2023-04-17T12:20:43Z | NONE | null | null | null | null | ### Describe the bug
Creating a dataset from a generator using `Dataset.from_generator()` fails if the generator is the [Google Big Query Python client](https://cloud.google.com/python/docs/reference/bigquery/latest). The problem is that the Big Query client is not pickable. And the function `create_config_id` tries t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5750/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5750/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5749 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5749/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5749/comments | https://api.github.com/repos/huggingface/datasets/issues/5749/events | https://github.com/huggingface/datasets/issues/5749 | 1,668,016,321 | I_kwDODunzps5ja-jB | 5,749 | AttributeError: 'Version' object has no attribute 'match' | {
"avatar_url": "https://avatars.githubusercontent.com/u/54584290?v=4",
"events_url": "https://api.github.com/users/gulnaz-zh/events{/privacy}",
"followers_url": "https://api.github.com/users/gulnaz-zh/followers",
"following_url": "https://api.github.com/users/gulnaz-zh/following{/other_user}",
"gists_url": "... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"I got the same error, and the official website for visual genome is down. Did you solve this problem? ",
"I am in the same situation now :( ",
"Thanks for reporting, @gulnaz-zh.\r\n\r\nI am investigating it.",
"The host server is down: https://visualgenome.org/\r\n\r\nWe are contacting the dataset authors.",... | 2023-04-14T10:48:06Z | 2023-06-30T11:31:17Z | 2023-04-18T12:57:08Z | NONE | null | null | null | null | ### Describe the bug
When I run
from datasets import load_dataset
data = load_dataset("visual_genome", 'region_descriptions_v1.2.0')
AttributeError: 'Version' object has no attribute 'match'
### Steps to reproduce the bug
from datasets import load_dataset
data = load_dataset("visual_genome", 'region_descripti... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5749/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5749/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5744 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5744/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5744/comments | https://api.github.com/repos/huggingface/datasets/issues/5744/events | https://github.com/huggingface/datasets/issues/5744 | 1,667,076,620 | I_kwDODunzps5jXZIM | 5,744 | [BUG] With Pandas 2.0.0, `load_dataset` raises `TypeError: read_csv() got an unexpected keyword argument 'mangle_dupe_cols'` | {
"avatar_url": "https://avatars.githubusercontent.com/u/15572698?v=4",
"events_url": "https://api.github.com/users/keyboardAnt/events{/privacy}",
"followers_url": "https://api.github.com/users/keyboardAnt/followers",
"following_url": "https://api.github.com/users/keyboardAnt/following{/other_user}",
"gists_u... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @keyboardAnt.\r\n\r\nWe haven't noticed any crash in our CI tests. Could you please indicate specifically the `load_dataset` command that crashes in your side, so that we can reproduce it?",
"This has been fixed in `datasets` 2.11",
"I am still getting this bug with the latest pandas and ... | 2023-04-13T20:21:28Z | 2024-04-09T16:13:59Z | 2023-07-06T17:01:59Z | NONE | null | null | null | null | The `load_dataset` function with Pandas `1.5.3` has no issue (just a FutureWarning) but crashes with Pandas `2.0.0`.
For your convenience, I opened a draft Pull Request to fix it quickly: https://github.com/huggingface/datasets/pull/5745
---
* The FutureWarning mentioned above:
```
FutureWarning: the 'mangle_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5744/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5744/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5743 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5743/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5743/comments | https://api.github.com/repos/huggingface/datasets/issues/5743/events | https://github.com/huggingface/datasets/issues/5743 | 1,666,843,832 | I_kwDODunzps5jWgS4 | 5,743 | dataclass.py in virtual environment is overriding the stdlib module "dataclasses" | {
"avatar_url": "https://avatars.githubusercontent.com/u/71216295?v=4",
"events_url": "https://api.github.com/users/syedabdullahhassan/events{/privacy}",
"followers_url": "https://api.github.com/users/syedabdullahhassan/followers",
"following_url": "https://api.github.com/users/syedabdullahhassan/following{/oth... | [] | closed | false | null | [] | null | [
"We no longer depend on `dataclasses` (for almost a year), so I don't think our package is the problematic one. \r\n\r\nI think it makes more sense to raise this issue in the `dataclasses` repo: https://github.com/ericvsmith/dataclasses."
] | 2023-04-13T17:28:33Z | 2023-04-17T12:23:18Z | 2023-04-17T12:23:18Z | NONE | null | null | null | null | ### Describe the bug
"e:\Krish_naik\FSDSRegression\venv\Lib\dataclasses.py" is overriding the stdlib module "dataclasses"
### Steps to reproduce the bug
module issue
### Expected behavior
overriding the stdlib module "dataclasses"
### Environment info
VS code | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5743/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5743/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5739 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5739/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5739/comments | https://api.github.com/repos/huggingface/datasets/issues/5739/events | https://github.com/huggingface/datasets/issues/5739 | 1,663,762,901 | I_kwDODunzps5jKwHV | 5,739 | weird result during dataset split when data path starts with `/data` | {
"avatar_url": "https://avatars.githubusercontent.com/u/1772912?v=4",
"events_url": "https://api.github.com/users/airlsyn/events{/privacy}",
"followers_url": "https://api.github.com/users/airlsyn/followers",
"following_url": "https://api.github.com/users/airlsyn/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [
"Same problem.",
"hi! \r\nI think you can run python from `/data/train/raw/` directory and load dataset as `load_dataset(\"code_contests\")` to mitigate this issue as a workaround. \r\n@ericxsun Do you want to open a PR to fix the regex? As you already found the solution :) ",
"> hi! I think you can run python ... | 2023-04-12T04:51:35Z | 2023-04-21T14:20:59Z | null | NONE | null | null | null | null | ### Describe the bug
The regex defined here https://github.com/huggingface/datasets/blob/f2607935c4e45c70c44fcb698db0363ca7ba83d4/src/datasets/utils/py_utils.py#L158
will cause a weird result during dataset split when data path starts with `/data`
### Steps to reproduce the bug
1. clone dataset into local path
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5739/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5739/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5738 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5738/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5738/comments | https://api.github.com/repos/huggingface/datasets/issues/5738/events | https://github.com/huggingface/datasets/issues/5738 | 1,663,477,690 | I_kwDODunzps5jJqe6 | 5,738 | load_dataset("text","dataset.txt") loads the wrong dataset! | {
"avatar_url": "https://avatars.githubusercontent.com/u/41713505?v=4",
"events_url": "https://api.github.com/users/Tylersuard/events{/privacy}",
"followers_url": "https://api.github.com/users/Tylersuard/followers",
"following_url": "https://api.github.com/users/Tylersuard/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"You need to provide a text file as `data_files`, not as a configuration:\r\n\r\n```python\r\nmy_dataset = load_dataset(\"text\", data_files=\"TextFile.txt\")\r\n```\r\n\r\nOtherwise, since `data_files` is `None`, it picks up Colab's sample datasets from the `content` dir."
] | 2023-04-12T01:07:46Z | 2023-04-19T12:08:27Z | 2023-04-19T12:08:27Z | NONE | null | null | null | null | ### Describe the bug
I am trying to load my own custom text dataset using the load_dataset function. My dataset is a bunch of ordered text, think along the lines of shakespeare plays. However, after I load the dataset and I inspect it, the dataset is a table with a bunch of latitude and longitude values! What in th... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5738/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5738/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5737 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5737/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5737/comments | https://api.github.com/repos/huggingface/datasets/issues/5737/events | https://github.com/huggingface/datasets/issues/5737 | 1,662,919,811 | I_kwDODunzps5jHiSD | 5,737 | ClassLabel Error | {
"avatar_url": "https://avatars.githubusercontent.com/u/10896776?v=4",
"events_url": "https://api.github.com/users/mrcaelumn/events{/privacy}",
"followers_url": "https://api.github.com/users/mrcaelumn/followers",
"following_url": "https://api.github.com/users/mrcaelumn/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi, you can use the `cast_column` function to change the feature type from a `Value(int64)` to `ClassLabel`:\r\n\r\n```py\r\ndataset = dataset.cast_column(\"label\", ClassLabel(names=[\"label_1\", \"label_2\", \"label_3\"]))\r\nprint(dataset.features)\r\n{'text': Value(dtype='string', id=None),\r\n 'label': ClassL... | 2023-04-11T17:14:13Z | 2023-04-13T16:49:57Z | 2023-04-13T16:49:57Z | NONE | null | null | null | null | ### Describe the bug
I still getting the error "call() takes 1 positional argument but 2 were given" even after ensuring that the value being passed to the label object is a single value and that the ClassLabel object has been created with the correct number of label classes
### Steps to reproduce the bug
from... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5737/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5737/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5736 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5736/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5736/comments | https://api.github.com/repos/huggingface/datasets/issues/5736/events | https://github.com/huggingface/datasets/issues/5736 | 1,662,286,061 | I_kwDODunzps5jFHjt | 5,736 | FORCE_REDOWNLOAD raises "Directory not empty" exception on second run | {
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"events_url": "https://api.github.com/users/rcasero/events{/privacy}",
"followers_url": "https://api.github.com/users/rcasero/followers",
"following_url": "https://api.github.com/users/rcasero/following{/other_user}",
"gists_url": "https:/... | [] | open | false | null | [] | null | [
"Hi ! I couldn't reproduce your issue :/\r\n\r\nIt seems that `shutil.rmtree` failed. It is supposed to work even if the directory is not empty, but you still end up with `OSError: [Errno 39] Directory not empty:`. Can you make sure another process is not using this directory at the same time ?",
"I have the same... | 2023-04-11T11:29:15Z | 2023-11-30T07:16:58Z | null | NONE | null | null | null | null | ### Describe the bug
Running `load_dataset(..., download_mode=datasets.DownloadMode.FORCE_REDOWNLOAD)` twice raises a `Directory not empty` exception on the second run.
### Steps to reproduce the bug
I cannot test this on datasets v2.11.0 due to #5711, but this happens in v2.10.1.
1. Set up a script `my_dataset.p... | null | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5736/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5736/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5734 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5734/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5734/comments | https://api.github.com/repos/huggingface/datasets/issues/5734/events | https://github.com/huggingface/datasets/issues/5734 | 1,662,058,028 | I_kwDODunzps5jEP4s | 5,734 | Remove temporary pin of fsspec | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-04-11T09:04:17Z | 2023-04-11T11:04:52Z | 2023-04-11T11:04:52Z | MEMBER | null | null | null | null | Once root cause is found and fixed, remove the temporary pin introduced by:
- #5731 | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5734/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5734/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5732 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5732/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5732/comments | https://api.github.com/repos/huggingface/datasets/issues/5732/events | https://github.com/huggingface/datasets/issues/5732 | 1,662,020,571 | I_kwDODunzps5jEGvb | 5,732 | Enwik8 should support the standard split | {
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"events_url": "https://api.github.com/users/lucaslingle/events{/privacy}",
"followers_url": "https://api.github.com/users/lucaslingle/followers",
"following_url": "https://api.github.com/users/lucaslingle/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"events_url": "https://api.github.com/users/lucaslingle/events{/privacy}",
"followers_url": "https://api.github.com/users/lucaslingle/followers",
"following_url": "https://api.github.com/users/lucaslingle/following{/other_user}",
"gists_u... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"events_url": "https://api.github.com/users/lucaslingle/events{/privacy}",
"followers_url": "https://api.github.com/users/lucaslingle/followers",
"following_url": "https://api.github.com/users/lucaslingle/following{/other_user}"... | null | [
"#self-assign",
"The Enwik8 pipeline is not present in this codebase, and is hosted elsewhere. I have opened a PR [there](https://huggingface.co/datasets/enwik8/discussions/4) instead. "
] | 2023-04-11T08:38:53Z | 2023-04-11T09:28:17Z | 2023-04-11T09:28:16Z | NONE | null | null | null | null | ### Feature request
The HuggingFace Datasets library currently supports two BuilderConfigs for Enwik8. One config yields individual lines as examples, while the other config yields the entire dataset as a single example. Both support only a monolithic split: it is all grouped as "train".
The HuggingFace Datasets l... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10287371?v=4",
"events_url": "https://api.github.com/users/lucaslingle/events{/privacy}",
"followers_url": "https://api.github.com/users/lucaslingle/followers",
"following_url": "https://api.github.com/users/lucaslingle/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5732/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5732/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5730 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5730/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5730/comments | https://api.github.com/repos/huggingface/datasets/issues/5730/events | https://github.com/huggingface/datasets/issues/5730 | 1,662,007,926 | I_kwDODunzps5jEDp2 | 5,730 | CI is broken: ValueError: Name (mock) already in the registry and clobber is False | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-04-11T08:29:46Z | 2023-04-11T08:47:56Z | 2023-04-11T08:47:56Z | MEMBER | null | null | null | null | CI is broken for `test_py310`.
See: https://github.com/huggingface/datasets/actions/runs/4665326892/jobs/8258580948
```
=========================== short test summary info ============================
ERROR tests/test_builder.py::test_builder_with_filesystem_download_and_prepare - ValueError: Name (mock) already ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5730/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5730/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5728 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5728/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5728/comments | https://api.github.com/repos/huggingface/datasets/issues/5728/events | https://github.com/huggingface/datasets/issues/5728 | 1,661,925,932 | I_kwDODunzps5jDvos | 5,728 | The order of data split names is nondeterministic | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-04-11T07:31:25Z | 2023-04-26T15:05:13Z | 2023-04-26T15:05:13Z | MEMBER | null | null | null | null | After this CI error: https://github.com/huggingface/datasets/actions/runs/4639528358/jobs/8210492953?pr=5718
```
FAILED tests/test_data_files.py::test_get_data_files_patterns[data_file_per_split4] - AssertionError: assert ['random', 'train'] == ['train', 'random']
At index 0 diff: 'random' != 'train'
Full diff:... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5728/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5728/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5727 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5727/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5727/comments | https://api.github.com/repos/huggingface/datasets/issues/5727/events | https://github.com/huggingface/datasets/issues/5727 | 1,661,536,363 | I_kwDODunzps5jCQhr | 5,727 | load_dataset fails with FileNotFound error on Windows | {
"avatar_url": "https://avatars.githubusercontent.com/u/122648572?v=4",
"events_url": "https://api.github.com/users/joelkowalewski/events{/privacy}",
"followers_url": "https://api.github.com/users/joelkowalewski/followers",
"following_url": "https://api.github.com/users/joelkowalewski/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi! Can you please paste the entire error stack trace, not only the last few lines?",
"`----> 1 dataset = datasets.load_dataset(\"glue\", \"ax\")\r\n\r\nFile ~\\anaconda3\\envs\\huggingface\\Lib\\site-packages\\datasets\\load.py:1767, in load_dataset(path, name, data_dir, data_files, split, cache_dir, features, ... | 2023-04-10T23:21:12Z | 2023-07-21T14:08:20Z | 2023-07-21T14:08:19Z | NONE | null | null | null | null | ### Describe the bug
Although I can import and run the datasets library in a Colab environment, I cannot successfully load any data on my own machine (Windows 10) despite following the install steps:
(1) create conda environment
(2) activate environment
(3) install with: ``conda` install -c huggingface -c conda-... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5727/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5727/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5726 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5726/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5726/comments | https://api.github.com/repos/huggingface/datasets/issues/5726/events | https://github.com/huggingface/datasets/issues/5726 | 1,660,944,807 | I_kwDODunzps5jAAGn | 5,726 | Fallback JSON Dataset loading does not load all values when features specified manually | {
"avatar_url": "https://avatars.githubusercontent.com/u/3610788?v=4",
"events_url": "https://api.github.com/users/myluki2000/events{/privacy}",
"followers_url": "https://api.github.com/users/myluki2000/followers",
"following_url": "https://api.github.com/users/myluki2000/following{/other_user}",
"gists_url":... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @myluki2000.\r\n\r\nI am working on a fix."
] | 2023-04-10T15:22:14Z | 2023-04-21T06:35:28Z | 2023-04-21T06:35:28Z | NONE | null | null | null | null | ### Describe the bug
The fallback JSON dataset loader located here:
https://github.com/huggingface/datasets/blob/1c4ec00511868bd881e84a6f7e0333648d833b8e/src/datasets/packaged_modules/json/json.py#L130-L153
does not load the values of features correctly when features are specified manually and not all features... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5726/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5726/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5725 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5725/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5725/comments | https://api.github.com/repos/huggingface/datasets/issues/5725/events | https://github.com/huggingface/datasets/issues/5725 | 1,660,455,202 | I_kwDODunzps5i-Iki | 5,725 | How to limit the number of examples in dataset, for testing? | {
"avatar_url": "https://avatars.githubusercontent.com/u/845175?v=4",
"events_url": "https://api.github.com/users/ndvbd/events{/privacy}",
"followers_url": "https://api.github.com/users/ndvbd/followers",
"following_url": "https://api.github.com/users/ndvbd/following{/other_user}",
"gists_url": "https://api.gi... | [] | closed | false | null | [] | null | [
"Hi! You can use the `nrows` parameter for this:\r\n```python\r\ndata = load_dataset(\"json\", data_files=data_path, nrows=10)\r\n```",
"@mariosasko I get:\r\n\r\n`TypeError: __init__() got an unexpected keyword argument 'nrows'`",
"I misread the format in which the dataset is stored - the `nrows` parameter wo... | 2023-04-10T08:41:43Z | 2023-04-21T06:16:24Z | 2023-04-21T06:16:24Z | NONE | null | null | null | null | ### Describe the bug
I am using this command:
`data = load_dataset("json", data_files=data_path)`
However, I want to add a parameter, to limit the number of loaded examples to be 10, for development purposes, but can't find this simple parameter.
### Steps to reproduce the bug
In the description.
### Expected beh... | {
"avatar_url": "https://avatars.githubusercontent.com/u/845175?v=4",
"events_url": "https://api.github.com/users/ndvbd/events{/privacy}",
"followers_url": "https://api.github.com/users/ndvbd/followers",
"following_url": "https://api.github.com/users/ndvbd/following{/other_user}",
"gists_url": "https://api.gi... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5725/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5725/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5724 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5724/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5724/comments | https://api.github.com/repos/huggingface/datasets/issues/5724/events | https://github.com/huggingface/datasets/issues/5724 | 1,659,938,135 | I_kwDODunzps5i8KVX | 5,724 | Error after shuffling streaming IterableDatasets with downloaded dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/41177966?v=4",
"events_url": "https://api.github.com/users/szxiangjn/events{/privacy}",
"followers_url": "https://api.github.com/users/szxiangjn/followers",
"following_url": "https://api.github.com/users/szxiangjn/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Moving `\"en\"` to the end of the path instead of passing it as a config name should fix the error:\r\n```python\r\nimport datasets\r\ndataset = datasets.load_dataset('/path/to/your/data/dir/en', streaming=True, split='train')\r\ndataset = dataset.shuffle(buffer_size=10_000, seed=42)\r\nnext(iter(dataset))\r\n```\... | 2023-04-09T16:58:44Z | 2023-04-20T20:37:30Z | 2023-04-20T20:37:30Z | NONE | null | null | null | null | ### Describe the bug
I downloaded the C4 dataset, and used streaming IterableDatasets to read it. Everything went normal until I used `dataset = dataset.shuffle(seed=42, buffer_size=10_000)` to shuffle the dataset. Shuffled dataset will throw the following error when it is used by `next(iter(dataset))`:
```
File "/d... | {
"avatar_url": "https://avatars.githubusercontent.com/u/41177966?v=4",
"events_url": "https://api.github.com/users/szxiangjn/events{/privacy}",
"followers_url": "https://api.github.com/users/szxiangjn/followers",
"following_url": "https://api.github.com/users/szxiangjn/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5724/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5724/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5722 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5722/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5722/comments | https://api.github.com/repos/huggingface/datasets/issues/5722/events | https://github.com/huggingface/datasets/issues/5722 | 1,659,837,510 | I_kwDODunzps5i7xxG | 5,722 | Distributed Training Error on Customized Dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/16603773?v=4",
"events_url": "https://api.github.com/users/wlhgtc/events{/privacy}",
"followers_url": "https://api.github.com/users/wlhgtc/followers",
"following_url": "https://api.github.com/users/wlhgtc/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Hmm the error doesn't seem related to data loading.\r\n\r\nRegarding `split_dataset_by_node`: it's generally used to split an iterable dataset (e.g. when streaming) in pytorch DDP. It's not needed if you use a regular dataset since the pytorch DataLoader already assigns a subset of the dataset indices to each node... | 2023-04-09T11:04:59Z | 2023-07-24T14:50:46Z | 2023-07-24T14:50:46Z | NONE | null | null | null | null | Hi guys, recently I tried to use `datasets` to train a dual encoder.
I finish my own datasets according to the nice [tutorial](https://huggingface.co/docs/datasets/v2.11.0/en/dataset_script)
Here are my code:
```python
class RetrivalDataset(datasets.GeneratorBasedBuilder):
"""CrossEncoder dataset."""
B... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5722/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5722/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5721 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5721/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5721/comments | https://api.github.com/repos/huggingface/datasets/issues/5721/events | https://github.com/huggingface/datasets/issues/5721 | 1,659,680,682 | I_kwDODunzps5i7Leq | 5,721 | Calling datasets.load_dataset("text" ...) results in a wrong split. | {
"avatar_url": "https://avatars.githubusercontent.com/u/1841186?v=4",
"events_url": "https://api.github.com/users/cyrilzakka/events{/privacy}",
"followers_url": "https://api.github.com/users/cyrilzakka/followers",
"following_url": "https://api.github.com/users/cyrilzakka/following{/other_user}",
"gists_url":... | [] | open | false | null | [] | null | [] | 2023-04-08T23:55:12Z | 2023-04-08T23:55:12Z | null | NONE | null | null | null | null | ### Describe the bug
When creating a text dataset, the training split should have the bulk of the examples by default. Currently, testing does.
### Steps to reproduce the bug
I have a folder with 18K text files in it. Each text file essentially consists in a document or article scraped from online. Calling the follo... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5721/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5721/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5720 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5720/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5720/comments | https://api.github.com/repos/huggingface/datasets/issues/5720/events | https://github.com/huggingface/datasets/issues/5720 | 1,659,610,705 | I_kwDODunzps5i66ZR | 5,720 | Streaming IterableDatasets do not work with torch DataLoaders | {
"avatar_url": "https://avatars.githubusercontent.com/u/29244648?v=4",
"events_url": "https://api.github.com/users/jlehrer1/events{/privacy}",
"followers_url": "https://api.github.com/users/jlehrer1/followers",
"following_url": "https://api.github.com/users/jlehrer1/following{/other_user}",
"gists_url": "htt... | [] | open | false | null | [] | null | [
"Edit: This behavior is true even without `.take/.set`",
"I'm experiencing the same problem that @jlehrer1. I was able to reproduce it with a very small example:\r\n\r\n```py\r\nfrom datasets import Dataset, load_dataset, load_dataset_builder\r\nfrom torch.utils.data import DataLoader\r\n\r\n\r\ndef my_gen():\r\n... | 2023-04-08T18:45:48Z | 2025-03-19T14:06:47Z | null | NONE | null | null | null | null | ### Describe the bug
When using streaming datasets set up with train/val split using `.skip()` and `.take()`, the following error occurs when iterating over a torch dataloader:
```
File "/Users/julian/miniconda3/envs/sims/lib/python3.9/site-packages/torch/utils/data/dataloader.py", line 363, in __iter__
self.... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5720/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5720/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5719 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5719/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5719/comments | https://api.github.com/repos/huggingface/datasets/issues/5719/events | https://github.com/huggingface/datasets/issues/5719 | 1,659,203,222 | I_kwDODunzps5i5W6W | 5,719 | Array2D feature creates a list of list instead of a numpy array | {
"avatar_url": "https://avatars.githubusercontent.com/u/15215732?v=4",
"events_url": "https://api.github.com/users/offchan42/events{/privacy}",
"followers_url": "https://api.github.com/users/offchan42/followers",
"following_url": "https://api.github.com/users/offchan42/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou need to set the format to `np` before indexing the dataset to get NumPy arrays:\r\n```python\r\nfeatures = Features(dict(seq=Array2D((2,2), 'float32'))) \r\nds = Dataset.from_dict(dict(seq=[np.random.rand(2,2)]), features=features)\r\nds.set_format(\"np\")\r\na = ds[0]['seq']\r\n```\r\n\r\n> I th... | 2023-04-07T21:04:08Z | 2023-04-20T15:34:41Z | 2023-04-20T15:34:41Z | NONE | null | null | null | null | ### Describe the bug
I'm not sure if this is expected behavior or not. When I create a 2D array using `Array2D`, the data has list type instead of numpy array. I think it should not be the expected behavior especially when I feed a numpy array as input to the data creation function. Why is it converting my array int... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5719/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5719/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5717 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5717/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5717/comments | https://api.github.com/repos/huggingface/datasets/issues/5717/events | https://github.com/huggingface/datasets/issues/5717 | 1,658,729,866 | I_kwDODunzps5i3jWK | 5,717 | Errror when saving to disk a dataset of images | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Looks like as long as the number of shards makes a batch lower than 1000 images it works. In my training set I have 40K images. If I use `num_shards=40` (batch of 1000 images) I get the error, but if I update it to `num_shards=50` (batch of 800 images) it works.\r\n\r\nI will be happy to share my dataset privately... | 2023-04-07T11:59:17Z | 2025-07-13T08:27:47Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
Hello!
I have an issue when I try to save on disk my dataset of images. The error I get is:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/arrow_dataset.py", line 1442, in save_... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5717/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5717/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5716 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5716/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5716/comments | https://api.github.com/repos/huggingface/datasets/issues/5716/events | https://github.com/huggingface/datasets/issues/5716 | 1,658,613,092 | I_kwDODunzps5i3G1k | 5,716 | Handle empty audio | {
"avatar_url": "https://avatars.githubusercontent.com/u/38179632?v=4",
"events_url": "https://api.github.com/users/ben-8543/events{/privacy}",
"followers_url": "https://api.github.com/users/ben-8543/followers",
"following_url": "https://api.github.com/users/ben-8543/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! Can you share one of the problematic audio files with us?\r\n\r\nI tried to reproduce the error with the following code: \r\n```python\r\nimport soundfile as sf\r\nimport numpy as np\r\nfrom datasets import Audio\r\n\r\nsf.write(\"empty.wav\", np.array([]), 16000)\r\nAudio(sampling_rate=24000).decode_example(... | 2023-04-07T09:51:40Z | 2023-09-27T17:47:08Z | 2023-09-27T17:47:08Z | NONE | null | null | null | null | Some audio paths exist, but they are empty, and an error will be reported when reading the audio path.How to use the filter function to avoid the empty audio path?
when a audio is empty, when do resample , it will break:
`array, sampling_rate = sf.read(f) array = librosa.resample(array, orig_sr=sampling_rate, target_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5716/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5716/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5715 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5715/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5715/comments | https://api.github.com/repos/huggingface/datasets/issues/5715/events | https://github.com/huggingface/datasets/issues/5715 | 1,657,479,788 | I_kwDODunzps5iyyJs | 5,715 | Return Numpy Array (fixed length) Mode, in __get_item__, Instead of List | {
"avatar_url": "https://avatars.githubusercontent.com/u/34066771?v=4",
"events_url": "https://api.github.com/users/jungbaepark/events{/privacy}",
"followers_url": "https://api.github.com/users/jungbaepark/followers",
"following_url": "https://api.github.com/users/jungbaepark/following{/other_user}",
"gists_u... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou can use [`.set_format(\"np\")`](https://huggingface.co/docs/datasets/process#format) to get NumPy arrays (or Pytorch tensors with `.set_format(\"torch\")`) in `__getitem__`.\r\n\r\nAlso, have you been able to reproduce the linked PyTorch issue with a HF dataset?\r\n "
] | 2023-04-06T13:57:48Z | 2023-04-20T17:16:26Z | 2023-04-20T17:16:26Z | NONE | null | null | null | null | ### Feature request
There are old known issues, but they can be easily forgettable problems in multiprocessing with pytorch-dataloader:
Too high usage of RAM or shared-memory in pytorch when we set num workers > 1 and returning type of dataset or dataloader is "List" or "Dict".
https://github.com/pytorch/pytorch... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5715/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5715/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5713 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5713/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5713/comments | https://api.github.com/repos/huggingface/datasets/issues/5713/events | https://github.com/huggingface/datasets/issues/5713 | 1,657,141,251 | I_kwDODunzps5ixfgD | 5,713 | ArrowNotImplementedError when loading dataset from the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | closed | false | null | [] | null | [
"Hi Julien ! This sounds related to https://github.com/huggingface/datasets/issues/5695 - TL;DR: you need to have shards smaller than 2GB to avoid this issue\r\n\r\nThe number of rows per shard is computed using an estimated size of the full dataset, which can sometimes lead to shards bigger than `max_shard_size`. ... | 2023-04-06T10:27:22Z | 2023-04-06T13:06:22Z | 2023-04-06T13:06:21Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
Hello,
I have created a dataset by using the image loader. Once the dataset is created I try to download it and I get the error:
```
Traceback (most recent call last):
File "/home/jplu/miniconda3/envs/image-xp/lib/python3.10/site-packages/datasets/builder.py", line 1860, in _prepare_split_... | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5713/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5713/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5712 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5712/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5712/comments | https://api.github.com/repos/huggingface/datasets/issues/5712/events | https://github.com/huggingface/datasets/issues/5712 | 1,655,972,106 | I_kwDODunzps5itCEK | 5,712 | load_dataset in v2.11.0 raises "ValueError: seek of closed file" in np.load() | {
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"events_url": "https://api.github.com/users/rcasero/events{/privacy}",
"followers_url": "https://api.github.com/users/rcasero/followers",
"following_url": "https://api.github.com/users/rcasero/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | null | [] | null | [
"Closing since this is a duplicate of #5711",
"> Closing since this is a duplicate of #5711\r\n\r\nSorry @mariosasko , my internet went down went submitting the issue, and somehow it ended up creating a duplicate"
] | 2023-04-05T16:47:10Z | 2023-04-06T08:32:37Z | 2023-04-05T17:17:44Z | NONE | null | null | null | null | ### Describe the bug
Hi,
I have some `dataset_load()` code of a custom offline dataset that works with datasets v2.10.1.
```python
ds = datasets.load_dataset(path=dataset_dir,
name=configuration,
data_dir=dataset_dir,
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5712/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5712/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5711 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5711/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5711/comments | https://api.github.com/repos/huggingface/datasets/issues/5711/events | https://github.com/huggingface/datasets/issues/5711 | 1,655,971,647 | I_kwDODunzps5itB8_ | 5,711 | load_dataset in v2.11.0 raises "ValueError: seek of closed file" in np.load() | {
"avatar_url": "https://avatars.githubusercontent.com/u/1219084?v=4",
"events_url": "https://api.github.com/users/rcasero/events{/privacy}",
"followers_url": "https://api.github.com/users/rcasero/followers",
"following_url": "https://api.github.com/users/rcasero/following{/other_user}",
"gists_url": "https:/... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"It seems like https://github.com/huggingface/datasets/pull/5626 has introduced this error. \r\n\r\ncc @albertvillanova \r\n\r\nI think replacing:\r\nhttps://github.com/huggingface/datasets/blob/0803a006db1c395ac715662cc6079651f77c11ea/src/datasets/download/streaming_download_manager.py#L777-L778\r\nwith:\r\n```pyt... | 2023-04-05T16:46:49Z | 2023-04-07T09:16:59Z | 2023-04-07T09:16:59Z | NONE | null | null | null | null | ### Describe the bug
Hi,
I have some `dataset_load()` code of a custom offline dataset that works with datasets v2.10.1.
```python
ds = datasets.load_dataset(path=dataset_dir,
name=configuration,
data_dir=dataset_dir,
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5711/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5711/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5710 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5710/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5710/comments | https://api.github.com/repos/huggingface/datasets/issues/5710/events | https://github.com/huggingface/datasets/issues/5710 | 1,655,703,534 | I_kwDODunzps5isAfu | 5,710 | OSError: Memory mapping file failed: Cannot allocate memory | {
"avatar_url": "https://avatars.githubusercontent.com/u/53392976?v=4",
"events_url": "https://api.github.com/users/Saibo-creator/events{/privacy}",
"followers_url": "https://api.github.com/users/Saibo-creator/followers",
"following_url": "https://api.github.com/users/Saibo-creator/following{/other_user}",
"g... | [] | closed | false | null | [] | null | [
"Hi! This error means that PyArrow's internal [`mmap`](https://man7.org/linux/man-pages/man2/mmap.2.html) call failed to allocate memory, which can be tricky to debug. Since this error is more related to PyArrow than us, I think it's best to report this issue in their [repo](https://github.com/apache/arrow) (they a... | 2023-04-05T14:11:26Z | 2023-04-20T17:16:40Z | 2023-04-20T17:16:40Z | NONE | null | null | null | null | ### Describe the bug
Hello, I have a series of datasets each of 5 GB, 600 datasets in total. So together this makes 3TB.
When I trying to load all the 600 datasets into memory, I get the above error message.
Is this normal because I'm hitting the max size of memory mapping of the OS?
Thank you
```te... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5710/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5710/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5709 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5709/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5709/comments | https://api.github.com/repos/huggingface/datasets/issues/5709/events | https://github.com/huggingface/datasets/issues/5709 | 1,655,423,503 | I_kwDODunzps5iq8IP | 5,709 | Manually dataset info made not taken into account | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | [] | closed | false | null | [] | null | [
"hi @jplu ! Did I understand you correctly that you create the dataset, push it to the Hub with `.push_to_hub` and you see a `dataset_infos.json` file there, then you edit this file, load the dataset with `load_dataset` and you don't see any changes in `.info` attribute of a dataset object? \r\n\r\nThis is actually... | 2023-04-05T11:15:17Z | 2023-04-06T08:52:20Z | 2023-04-06T08:52:19Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
Hello,
I'm manually building an image dataset with the `from_dict` approach. I also build the features with the `cast_features` methods. Once the dataset is created I push it on the hub, and a default `dataset_infos.json` file seems to have been automatically added to the repo in same time. Hen... | {
"avatar_url": "https://avatars.githubusercontent.com/u/959590?v=4",
"events_url": "https://api.github.com/users/jplu/events{/privacy}",
"followers_url": "https://api.github.com/users/jplu/followers",
"following_url": "https://api.github.com/users/jplu/following{/other_user}",
"gists_url": "https://api.githu... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5709/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5709/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5708 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5708/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5708/comments | https://api.github.com/repos/huggingface/datasets/issues/5708/events | https://github.com/huggingface/datasets/issues/5708 | 1,655,023,642 | I_kwDODunzps5ipaga | 5,708 | Dataset sizes are in MiB instead of MB in dataset cards | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
},
{
"color": "E5583E",
"default": false,
"descrip... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Example of bulk edit: https://huggingface.co/datasets/aeslc/discussions/5",
"looks great! \r\n\r\nDo you encode the fact that you've already converted a dataset? (to not convert it twice) or do you base yourself on the info contained in `dataset_info`",
"I am only looping trough the dataset cards, assuming tha... | 2023-04-05T06:36:03Z | 2023-12-21T10:20:28Z | 2023-12-21T10:20:27Z | MEMBER | null | null | null | null | As @severo reported in an internal discussion (https://github.com/huggingface/moon-landing/issues/5929):
Now we show the dataset size:
- from the dataset card (in the side column)
- from the datasets-server (in the viewer)
But, even if the size is the same, we see a mismatch because the viewer shows MB, while t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5708/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5708/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5706 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5706/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5706/comments | https://api.github.com/repos/huggingface/datasets/issues/5706/events | https://github.com/huggingface/datasets/issues/5706 | 1,653,545,835 | I_kwDODunzps5ijxtr | 5,706 | Support categorical data types for Parquet | {
"avatar_url": "https://avatars.githubusercontent.com/u/1430243?v=4",
"events_url": "https://api.github.com/users/kklemon/events{/privacy}",
"followers_url": "https://api.github.com/users/kklemon/followers",
"following_url": "https://api.github.com/users/kklemon/following{/other_user}",
"gists_url": "https:/... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/22622299?v=4",
"events_url": "https://api.github.com/users/mhattingpete/events{/privacy}",
"followers_url": "https://api.github.com/users/mhattingpete/followers",
"following_url": "https://api.github.com/users/mhattingpete/following{/other_user}",
"gist... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/22622299?v=4",
"events_url": "https://api.github.com/users/mhattingpete/events{/privacy}",
"followers_url": "https://api.github.com/users/mhattingpete/followers",
"following_url": "https://api.github.com/users/mhattingpete/following{/other_use... | null | [
"Hi ! We could definitely a type that holds the categories and uses a DictionaryType storage. There's a ClassLabel type that is similar with a 'names' parameter (similar to a id2label in deep learning frameworks) that uses an integer array as storage.\r\n\r\nIt can be added in `features.py`. Here are some pointers:... | 2023-04-04T09:45:35Z | 2024-06-07T12:20:43Z | 2024-06-07T12:20:43Z | NONE | null | null | null | null | ### Feature request
Huggingface datasets does not seem to support categorical / dictionary data types for Parquet as of now. There seems to be a `TODO` in the code for this feature but no implementation yet. Below you can find sample code to reproduce the error that is currently thrown when attempting to read a Parq... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5706/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5706/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5705 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5705/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5705/comments | https://api.github.com/repos/huggingface/datasets/issues/5705/events | https://github.com/huggingface/datasets/issues/5705 | 1,653,500,383 | I_kwDODunzps5ijmnf | 5,705 | Getting next item from IterableDataset took forever. | {
"avatar_url": "https://avatars.githubusercontent.com/u/16588434?v=4",
"events_url": "https://api.github.com/users/HongtaoYang/events{/privacy}",
"followers_url": "https://api.github.com/users/HongtaoYang/followers",
"following_url": "https://api.github.com/users/HongtaoYang/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [
"Hi! It can take some time to iterate over Parquet files as big as yours, convert the samples to Python, and find the first one that matches a filter predicate before yielding it...",
"Thanks @mariosasko, I figured it was the filter operation. I'm closing this issue because it is not a bug, it is the expected beh... | 2023-04-04T09:16:17Z | 2023-04-05T23:35:41Z | 2023-04-05T23:35:41Z | NONE | null | null | null | null | ### Describe the bug
I have a large dataset, about 500GB. The format of the dataset is parquet.
I then load the dataset and try to get the first item
```python
def get_one_item():
dataset = load_dataset("path/to/datafiles", split="train", cache_dir=".", streaming=True)
dataset = dataset.filter(lambda... | {
"avatar_url": "https://avatars.githubusercontent.com/u/16588434?v=4",
"events_url": "https://api.github.com/users/HongtaoYang/events{/privacy}",
"followers_url": "https://api.github.com/users/HongtaoYang/followers",
"following_url": "https://api.github.com/users/HongtaoYang/following{/other_user}",
"gists_u... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5705/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5705/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5702 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5702/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5702/comments | https://api.github.com/repos/huggingface/datasets/issues/5702/events | https://github.com/huggingface/datasets/issues/5702 | 1,653,104,720 | I_kwDODunzps5iiGBQ | 5,702 | Is it possible or how to define a `datasets.Sequence` that could potentially be either a dict, a str, or None? | {
"avatar_url": "https://avatars.githubusercontent.com/u/10508116?v=4",
"events_url": "https://api.github.com/users/gitforziio/events{/privacy}",
"followers_url": "https://api.github.com/users/gitforziio/followers",
"following_url": "https://api.github.com/users/gitforziio/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi ! `datasets` uses Apache Arrow as backend to store the data, and it requires each column to have a fixed type. Therefore a column can't have a mix of dicts/lists/strings.\r\n\r\nThough it's possible to have one (nullable) field for each type:\r\n```python\r\nfeatures = Features({\r\n \"text_alone\": Value(\"... | 2023-04-04T03:20:43Z | 2023-04-05T14:15:18Z | 2023-04-05T14:15:17Z | NONE | null | null | null | null | ### Feature request
Hello! Apologies if my question sounds naive:
I was wondering if it’s possible, or how one would go about defining a 'datasets.Sequence' element in datasets.Features that could potentially be either a dict, a str, or None?
Specifically, I’d like to define a feature for a list that contains 18... | {
"avatar_url": "https://avatars.githubusercontent.com/u/10508116?v=4",
"events_url": "https://api.github.com/users/gitforziio/events{/privacy}",
"followers_url": "https://api.github.com/users/gitforziio/followers",
"following_url": "https://api.github.com/users/gitforziio/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5702/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5702/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5699 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5699/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5699/comments | https://api.github.com/repos/huggingface/datasets/issues/5699/events | https://github.com/huggingface/datasets/issues/5699 | 1,652,437,419 | I_kwDODunzps5ifjGr | 5,699 | Issue when wanting to split in memory a cached dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/47528215?v=4",
"events_url": "https://api.github.com/users/FrancoisNoyez/events{/privacy}",
"followers_url": "https://api.github.com/users/FrancoisNoyez/followers",
"following_url": "https://api.github.com/users/FrancoisNoyez/following{/other_user}",
"g... | [] | open | false | null | [] | null | [
"Hi ! Good catch, this is wrong indeed and thanks for opening a PR :)",
"Facing the same issue. Kindly fix this bug."
] | 2023-04-03T17:00:07Z | 2024-05-15T13:12:18Z | null | NONE | null | null | null | null | ### Describe the bug
**In the 'train_test_split' method of the Dataset class** (defined datasets/arrow_dataset.py), **if 'self.cache_files' is not empty**, then, **regarding the input parameters 'train_indices_cache_file_name' and 'test_indices_cache_file_name', if they are None**, we modify them to make them not No... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5699/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5699/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5698 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5698/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5698/comments | https://api.github.com/repos/huggingface/datasets/issues/5698/events | https://github.com/huggingface/datasets/issues/5698 | 1,652,183,611 | I_kwDODunzps5ielI7 | 5,698 | Add Qdrant as another search index | {
"avatar_url": "https://avatars.githubusercontent.com/u/2649301?v=4",
"events_url": "https://api.github.com/users/kacperlukawski/events{/privacy}",
"followers_url": "https://api.github.com/users/kacperlukawski/followers",
"following_url": "https://api.github.com/users/kacperlukawski/following{/other_user}",
... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"@mariosasko I'd appreciate your feedback on this. "
] | 2023-04-03T14:25:19Z | 2023-04-11T10:28:40Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
I'd suggest adding Qdrant (https://qdrant.tech) as another search index available, so users can directly build an index from a dataset. Currently, FAISS and ElasticSearch are only supported: https://huggingface.co/docs/datasets/faiss_es
### Motivation
ElasticSearch is a keyword-based search syst... | null | {
"+1": 6,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5698/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5698/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5696 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5696/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5696/comments | https://api.github.com/repos/huggingface/datasets/issues/5696/events | https://github.com/huggingface/datasets/issues/5696 | 1,651,707,008 | I_kwDODunzps5icwyA | 5,696 | Shuffle a sharded iterable dataset without seed can lead to duplicate data | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists... | null | [] | 2023-04-03T09:40:03Z | 2023-04-04T14:58:18Z | 2023-04-04T14:58:18Z | MEMBER | null | null | null | null | As reported in https://github.com/huggingface/datasets/issues/5360
If `seed=None` in `.shuffle()`, shuffled datasets don't use the same shuffling seed across nodes.
Because of that, the lists of shards is not shuffled the same way across nodes, and therefore some shards may be assigned to multiple nodes instead o... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5696/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5696/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5695 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5695/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5695/comments | https://api.github.com/repos/huggingface/datasets/issues/5695/events | https://github.com/huggingface/datasets/issues/5695 | 1,650,974,156 | I_kwDODunzps5iZ93M | 5,695 | Loading big dataset raises pyarrow.lib.ArrowNotImplementedError | {
"avatar_url": "https://avatars.githubusercontent.com/u/32778667?v=4",
"events_url": "https://api.github.com/users/amariucaitheodor/events{/privacy}",
"followers_url": "https://api.github.com/users/amariucaitheodor/followers",
"following_url": "https://api.github.com/users/amariucaitheodor/following{/other_use... | [] | closed | false | null | [] | null | [
"Hi ! It looks like an issue with PyArrow: https://issues.apache.org/jira/browse/ARROW-5030\r\n\r\nIt appears it can happen when you have parquet files with row groups larger than 2GB.\r\nI can see that your parquet files are around 10GB. It is usually advised to keep a value around the default value 500MB to avoid... | 2023-04-02T14:42:44Z | 2024-05-15T12:04:47Z | 2023-04-10T08:04:04Z | NONE | null | null | null | null | ### Describe the bug
Calling `datasets.load_dataset` to load the (publicly available) dataset `theodor1289/wit` fails with `pyarrow.lib.ArrowNotImplementedError`.
### Steps to reproduce the bug
Steps to reproduce this behavior:
1. `!pip install datasets`
2. `!huggingface-cli login`
3. This step will throw the e... | {
"avatar_url": "https://avatars.githubusercontent.com/u/32778667?v=4",
"events_url": "https://api.github.com/users/amariucaitheodor/events{/privacy}",
"followers_url": "https://api.github.com/users/amariucaitheodor/followers",
"following_url": "https://api.github.com/users/amariucaitheodor/following{/other_use... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 1,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5695/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5695/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5694 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5694/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5694/comments | https://api.github.com/repos/huggingface/datasets/issues/5694/events | https://github.com/huggingface/datasets/issues/5694 | 1,650,467,793 | I_kwDODunzps5iYCPR | 5,694 | Dataset configuration | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | [
{
"color": "c5def5",
"default": false,
"description": "Generic discussion on the library",
"id": 2067400324,
"name": "generic discussion",
"node_id": "MDU6TGFiZWwyMDY3NDAwMzI0",
"url": "https://api.github.com/repos/huggingface/datasets/labels/generic%20discussion"
}
] | open | false | null | [] | null | [
"Originally we also though about adding it to the YAML part of the README.md:\r\n\r\n```yaml\r\nbuilder_config:\r\n data_dir: data\r\n data_files:\r\n - split: train\r\n pattern: \"train-[0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9]*.*\"\r\n```\r\n\r\nHaving it in the README.md could make it easier to mod... | 2023-04-01T13:08:05Z | 2023-04-04T14:54:37Z | null | MEMBER | null | null | null | null | Following discussions from https://github.com/huggingface/datasets/pull/5331
We could have something like `config.json` to define the configuration of a dataset.
```json
{
"data_dir": "data"
"data_files": {
"train": "train-[0-9][0-9][0-9][0-9]-of-[0-9][0-9][0-9][0-9][0-9]*.*"
}
}
```
... | null | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5694/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5694/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5692 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5692/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5692/comments | https://api.github.com/repos/huggingface/datasets/issues/5692/events | https://github.com/huggingface/datasets/issues/5692 | 1,649,818,644 | I_kwDODunzps5iVjwU | 5,692 | pyarrow.lib.ArrowInvalid: Unable to merge: Field <field> has incompatible types | {
"avatar_url": "https://avatars.githubusercontent.com/u/32219669?v=4",
"events_url": "https://api.github.com/users/cyanic-selkie/events{/privacy}",
"followers_url": "https://api.github.com/users/cyanic-selkie/followers",
"following_url": "https://api.github.com/users/cyanic-selkie/following{/other_user}",
"g... | [] | open | false | null | [] | null | [
"Hi! The link pointing to the code that generated the dataset is broken. Can you please fix it to make debugging easier?",
"> Hi! The link pointing to the code that generated the dataset is broken. Can you please fix it to make debugging easier?\r\n\r\nSorry about that, it's fixed now.\r\n",
"@cyanic-selkie cou... | 2023-03-31T18:19:40Z | 2024-01-14T07:24:21Z | null | NONE | null | null | null | null | ### Describe the bug
When loading the dataset [wikianc-en](https://huggingface.co/datasets/cyanic-selkie/wikianc-en) which I created using [this](https://github.com/cyanic-selkie/wikianc) code, I get the following error:
```
Traceback (most recent call last):
File "/home/sven/code/rector/answer-detection/trai... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5692/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5692/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5690 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5690/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5690/comments | https://api.github.com/repos/huggingface/datasets/issues/5690/events | https://github.com/huggingface/datasets/issues/5690 | 1,649,289,883 | I_kwDODunzps5iTiqb | 5,690 | raise AttributeError(f"No {package_name} attribute {name}") AttributeError: No huggingface_hub attribute hf_api | {
"avatar_url": "https://avatars.githubusercontent.com/u/55964850?v=4",
"events_url": "https://api.github.com/users/wccccp/events{/privacy}",
"followers_url": "https://api.github.com/users/wccccp/followers",
"following_url": "https://api.github.com/users/wccccp/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Hi @wccccp, thanks for reporting. \r\nThat's weird since `huggingface_hub` _has_ a module called `hf_api` and you are using a recent version of it. \r\n\r\nWhich version of `datasets` are you using? And is it a bug that you experienced only recently? (cc @lhoestq can it be somehow related to the recent release of ... | 2023-03-31T08:22:22Z | 2023-07-21T14:21:57Z | 2023-07-21T14:21:57Z | NONE | null | null | null | null | ### Describe the bug
rta.sh
Traceback (most recent call last):
File "run.py", line 7, in <module>
import datasets
File "/home/appuser/miniconda3/envs/pt2/lib/python3.8/site-packages/datasets/__init__.py", line 37, in <module>
from .builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, Dat... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5690/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5690/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5688 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5688/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5688/comments | https://api.github.com/repos/huggingface/datasets/issues/5688/events | https://github.com/huggingface/datasets/issues/5688 | 1,648,463,504 | I_kwDODunzps5iQY6Q | 5,688 | Wikipedia download_and_prepare for GCS | {
"avatar_url": "https://avatars.githubusercontent.com/u/25522531?v=4",
"events_url": "https://api.github.com/users/adrianfagerland/events{/privacy}",
"followers_url": "https://api.github.com/users/adrianfagerland/followers",
"following_url": "https://api.github.com/users/adrianfagerland/following{/other_user}"... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Hi @adrianfagerland, thanks for reporting.\r\n\r\nPlease note that \"wikipedia\" is a special dataset, with an Apache Beam builder: https://beam.apache.org/\r\nYou can find more info about Beam datasets in our docs: https://huggingface.co/docs/datasets/beam\r\n\r\nIt was implemented to be run in parallel processin... | 2023-03-30T23:43:22Z | 2024-03-15T15:59:18Z | 2024-03-15T15:59:18Z | NONE | null | null | null | null | ### Describe the bug
I am unable to download the wikipedia dataset onto GCS.
When I run the script provided the memory firstly gets eaten up, then it crashes.
I tried running this on a VM with 128GB RAM and all I got was a two empty files: _data_builder.lock_, _data.incomplete/beam-temp-wikipedia-train-1ab2039a... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5688/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5688/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5687 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5687/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5687/comments | https://api.github.com/repos/huggingface/datasets/issues/5687/events | https://github.com/huggingface/datasets/issues/5687 | 1,647,009,018 | I_kwDODunzps5iK1z6 | 5,687 | Document to compress data files before uploading | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
}
] | closed | false | null | [] | null | [
"Great idea!\r\n\r\nShould we also take this opportunity to include some audio/image file formats? Currently, it still reads very text heavy. Something like:\r\n\r\n> We support many text, audio, and image data extensions such as `.zip`, `.rar`, `.mp3`, and `.jpg` among many others. For data extensions like `.csv`,... | 2023-03-30T06:41:07Z | 2023-04-19T07:25:59Z | 2023-04-19T07:25:59Z | MEMBER | null | null | null | null | In our docs to [Share a dataset to the Hub](https://huggingface.co/docs/datasets/upload_dataset), we tell users to upload directly their data files, like CSV, JSON, JSON-Lines, text,... However, these extensions are not tracked by Git LFS by default, as they are not in the `.giattributes` file. Therefore, if they are t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5687/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5687/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5685 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5685/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5685/comments | https://api.github.com/repos/huggingface/datasets/issues/5685/events | https://github.com/huggingface/datasets/issues/5685 | 1,646,048,667 | I_kwDODunzps5iHLWb | 5,685 | Broken Image render on the hub website | {
"avatar_url": "https://avatars.githubusercontent.com/u/15908060?v=4",
"events_url": "https://api.github.com/users/FrancescoSaverioZuppichini/events{/privacy}",
"followers_url": "https://api.github.com/users/FrancescoSaverioZuppichini/followers",
"following_url": "https://api.github.com/users/FrancescoSaverioZ... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nYou can fix the viewer by adding the `dataset_info` YAML field deleted in https://huggingface.co/datasets/Francesco/cell-towers/commit/b95b59ddd91ebe9c12920f0efe0ed415cd0d4298 back to the metadata section of the card. \r\n\r\nTo avoid this issue in the feature, you can use `huggingface_hub`'s [RepoCard... | 2023-03-29T15:25:30Z | 2023-03-30T07:54:25Z | 2023-03-30T07:54:25Z | NONE | null | null | null | null | ### Describe the bug
Hi :wave:
Not sure if this is the right place to ask, but I am trying to load a huge amount of datasets on the hub (:partying_face: ) but I am facing a little issue with the `image` type
",
"Closed in #5693 "
] | 2023-03-29T11:44:49Z | 2023-04-03T18:31:11Z | 2023-04-03T18:31:11Z | CONTRIBUTOR | null | null | null | null | Following [this](https://github.com/huggingface/datasets/issues/5650) issue I think we should add a note about the order of patterns that is used to find splits, see [my comment](https://github.com/huggingface/datasets/issues/5650#issuecomment-1488412527). Also we should reference this page in pages about packaged load... | {
"avatar_url": "https://avatars.githubusercontent.com/u/59462357?v=4",
"events_url": "https://api.github.com/users/stevhliu/events{/privacy}",
"followers_url": "https://api.github.com/users/stevhliu/followers",
"following_url": "https://api.github.com/users/stevhliu/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5681/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5681/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5679 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5679/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5679/comments | https://api.github.com/repos/huggingface/datasets/issues/5679/events | https://github.com/huggingface/datasets/issues/5679 | 1,645,184,622 | I_kwDODunzps5iD4Zu | 5,679 | Allow load_dataset to take a working dir for intermediate data | {
"avatar_url": "https://avatars.githubusercontent.com/u/38018689?v=4",
"events_url": "https://api.github.com/users/lu-wang-dl/events{/privacy}",
"followers_url": "https://api.github.com/users/lu-wang-dl/followers",
"following_url": "https://api.github.com/users/lu-wang-dl/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"Hi ! AFAIK a dataset must be present on a local disk to be able to efficiently memory map the datasets Arrow files. What makes you think that it is possible to load from a cloud storage and have good performance ?\r\n\r\nAnyway it's already possible to download_and_prepare a dataset as Arrow files in a cloud stora... | 2023-03-29T07:21:09Z | 2023-04-12T22:30:25Z | null | NONE | null | null | null | null | ### Feature request
As a user, I can set a working dir for intermediate data creation. The processed files will be moved to the cache dir, like
```
load_dataset(…, working_dir=”/temp/dir”, cache_dir=”/cloud_dir”).
```
### Motivation
This will help the use case for using datasets with cloud storage as cache. It wi... | null | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5679/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5679/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5678 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5678/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5678/comments | https://api.github.com/repos/huggingface/datasets/issues/5678/events | https://github.com/huggingface/datasets/issues/5678 | 1,645,018,359 | I_kwDODunzps5iDPz3 | 5,678 | Add support to create a Dataset from spark dataframe | {
"avatar_url": "https://avatars.githubusercontent.com/u/38018689?v=4",
"events_url": "https://api.github.com/users/lu-wang-dl/events{/privacy}",
"followers_url": "https://api.github.com/users/lu-wang-dl/followers",
"following_url": "https://api.github.com/users/lu-wang-dl/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"if i read spark Dataframe , got an error on multi-node Spark cluster.\r\nDid the Api (Dataset.from_spark) support Spark cluster, read dataframe and save_to_disk?\r\n\r\nError: \r\n_pickle.PicklingError: Could not serialize object: RuntimeError: It appears that you are attempting to reference SparkContext from a b... | 2023-03-29T04:36:28Z | 2024-08-27T14:43:19Z | 2023-07-21T14:15:38Z | NONE | null | null | null | null | ### Feature request
Add a new API `Dataset.from_spark` to create a Dataset from Spark DataFrame.
### Motivation
Spark is a distributed computing framework that can handle large datasets. By supporting loading Spark DataFrames directly into Hugging Face Datasets, we enable take the advantages of spark to processing t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 2,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 2,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5678/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5678/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5677 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5677/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5677/comments | https://api.github.com/repos/huggingface/datasets/issues/5677/events | https://github.com/huggingface/datasets/issues/5677 | 1,644,828,606 | I_kwDODunzps5iChe- | 5,677 | Dataset.map() crashes when any column contains more than 1000 empty dictionaries | {
"avatar_url": "https://avatars.githubusercontent.com/u/7139344?v=4",
"events_url": "https://api.github.com/users/mtoles/events{/privacy}",
"followers_url": "https://api.github.com/users/mtoles/followers",
"following_url": "https://api.github.com/users/mtoles/following{/other_user}",
"gists_url": "https://ap... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [] | 2023-03-29T00:01:31Z | 2023-07-07T14:01:14Z | 2023-07-07T14:01:14Z | NONE | null | null | null | null | ### Describe the bug
`Dataset.map()` crashes any time any column contains more than `writer_batch_size` (default 1000) empty dictionaries, regardless of whether the column is being operated on. The error does not occur if the dictionaries are non-empty.
### Steps to reproduce the bug
Example:
```
import datasets... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5677/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5677/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5675 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5675/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5675/comments | https://api.github.com/repos/huggingface/datasets/issues/5675/events | https://github.com/huggingface/datasets/issues/5675 | 1,641,763,478 | I_kwDODunzps5h21KW | 5,675 | Filter datasets by language code | {
"avatar_url": "https://avatars.githubusercontent.com/u/5658496?v=4",
"events_url": "https://api.github.com/users/named-entity/events{/privacy}",
"followers_url": "https://api.github.com/users/named-entity/followers",
"following_url": "https://api.github.com/users/named-entity/following{/other_user}",
"gists... | [] | closed | false | null | [] | null | [
"The dataset still can be found, if instead of using the search form you just enter the language code in the url, like https://huggingface.co/datasets?language=language:myv. \r\n\r\nBut of course having a more complete list of languages in the search form (or just a fallback to the language codes, if they are missi... | 2023-03-27T09:42:28Z | 2023-03-30T08:08:15Z | 2023-03-30T08:08:15Z | NONE | null | null | null | null | Hi! I use the language search field on https://huggingface.co/datasets
However, some of the datasets tagged by ISO language code are not accessible by this search form.
For example, [myv_ru_2022](https://huggingface.co/datasets/slone/myv_ru_2022) is has `myv` language tag but it is not included in Languages search fo... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 6,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 6,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5675/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5675/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5674 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5674/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5674/comments | https://api.github.com/repos/huggingface/datasets/issues/5674/events | https://github.com/huggingface/datasets/issues/5674 | 1,641,084,105 | I_kwDODunzps5h0PTJ | 5,674 | Stored XSS | {
"avatar_url": "https://avatars.githubusercontent.com/u/21213484?v=4",
"events_url": "https://api.github.com/users/Fadavvi/events{/privacy}",
"followers_url": "https://api.github.com/users/Fadavvi/followers",
"following_url": "https://api.github.com/users/Fadavvi/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Hi! You can contact `security@huggingface.co` to report this vulnerability."
] | 2023-03-26T20:55:58Z | 2024-04-30T22:56:41Z | 2023-03-27T21:01:55Z | NONE | null | null | null | null | x | {
"avatar_url": "https://avatars.githubusercontent.com/u/21213484?v=4",
"events_url": "https://api.github.com/users/Fadavvi/events{/privacy}",
"followers_url": "https://api.github.com/users/Fadavvi/followers",
"following_url": "https://api.github.com/users/Fadavvi/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5674/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5674/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5672 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5672/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5672/comments | https://api.github.com/repos/huggingface/datasets/issues/5672/events | https://github.com/huggingface/datasets/issues/5672 | 1,641,005,322 | I_kwDODunzps5hz8EK | 5,672 | Pushing dataset to hub crash | {
"avatar_url": "https://avatars.githubusercontent.com/u/14275989?v=4",
"events_url": "https://api.github.com/users/tzvc/events{/privacy}",
"followers_url": "https://api.github.com/users/tzvc/followers",
"following_url": "https://api.github.com/users/tzvc/following{/other_user}",
"gists_url": "https://api.git... | [] | closed | false | null | [] | null | [
"Hi ! It's been fixed by https://github.com/huggingface/datasets/pull/5598. We're doing a new release tomorrow with the fix and you'll be able to push your 100k images ;)\r\n\r\nBasically `push_to_hub` used to fail if the remote repository already exists and has a README.md without dataset_info in the YAML tags.\r\... | 2023-03-26T17:42:13Z | 2023-03-30T08:11:05Z | 2023-03-30T08:11:05Z | NONE | null | null | null | null | ### Describe the bug
Uploading a dataset with `push_to_hub()` fails without error description.
### Steps to reproduce the bug
Hey there,
I've built a image dataset of 100k images + text pair as described here https://huggingface.co/docs/datasets/image_dataset#imagefolder
Now I'm trying to push it to the hub b... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5672/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5672/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5671 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5671/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5671/comments | https://api.github.com/repos/huggingface/datasets/issues/5671/events | https://github.com/huggingface/datasets/issues/5671 | 1,640,840,012 | I_kwDODunzps5hzTtM | 5,671 | How to use `load_dataset('glue', 'cola')` | {
"avatar_url": "https://avatars.githubusercontent.com/u/40193664?v=4",
"events_url": "https://api.github.com/users/makinzm/events{/privacy}",
"followers_url": "https://api.github.com/users/makinzm/followers",
"following_url": "https://api.github.com/users/makinzm/following{/other_user}",
"gists_url": "https:... | [] | closed | false | null | [] | null | [
"Sounds like an issue with incompatible `transformers` dependencies versions.\r\n\r\nCan you try to update `transformers` ?\r\n\r\nEDIT: I checked the `transformers` dependencies and it seems like you need `tokenizers>=0.10.1,<0.11` with `transformers==4.5.1`\r\n\r\nEDIT2: this old version of `datasets` seems to im... | 2023-03-26T09:40:34Z | 2023-03-28T07:43:44Z | 2023-03-28T07:43:43Z | NONE | null | null | null | null | ### Describe the bug
I'm new to use HuggingFace datasets but I cannot use `load_dataset('glue', 'cola')`.
- I was stacked by the following problem:
```python
from datasets import load_dataset
cola_dataset = load_dataset('glue', 'cola')
------------------------------------------------------------------------... | {
"avatar_url": "https://avatars.githubusercontent.com/u/40193664?v=4",
"events_url": "https://api.github.com/users/makinzm/events{/privacy}",
"followers_url": "https://api.github.com/users/makinzm/followers",
"following_url": "https://api.github.com/users/makinzm/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5671/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5671/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5670 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5670/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5670/comments | https://api.github.com/repos/huggingface/datasets/issues/5670/events | https://github.com/huggingface/datasets/issues/5670 | 1,640,607,045 | I_kwDODunzps5hya1F | 5,670 | Unable to load multi class classification datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/19690506?v=4",
"events_url": "https://api.github.com/users/ysahil97/events{/privacy}",
"followers_url": "https://api.github.com/users/ysahil97/followers",
"following_url": "https://api.github.com/users/ysahil97/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi ! This sounds related to https://github.com/huggingface/datasets/issues/5406\r\n\r\nUpdating `datasets` fixes the issue ;)",
"Thanks @lhoestq!\r\n\r\nI'll close this issue now."
] | 2023-03-25T18:06:15Z | 2023-03-27T22:54:56Z | 2023-03-27T22:54:56Z | NONE | null | null | null | null | ### Describe the bug
I've been playing around with huggingface library, mostly with `datasets` and wanted to download the multi class classification datasets to fine tune BERT on this task. ([link](https://huggingface.co/docs/transformers/training#train-with-pytorch-trainer)).
While loading the dataset, I'm getting... | {
"avatar_url": "https://avatars.githubusercontent.com/u/19690506?v=4",
"events_url": "https://api.github.com/users/ysahil97/events{/privacy}",
"followers_url": "https://api.github.com/users/ysahil97/followers",
"following_url": "https://api.github.com/users/ysahil97/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5670/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5670/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5669 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5669/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5669/comments | https://api.github.com/repos/huggingface/datasets/issues/5669/events | https://github.com/huggingface/datasets/issues/5669 | 1,638,070,046 | I_kwDODunzps5hovce | 5,669 | Almost identical datasets, huge performance difference | {
"avatar_url": "https://avatars.githubusercontent.com/u/2437102?v=4",
"events_url": "https://api.github.com/users/eli-osherovich/events{/privacy}",
"followers_url": "https://api.github.com/users/eli-osherovich/followers",
"following_url": "https://api.github.com/users/eli-osherovich/following{/other_user}",
... | [] | open | false | null | [] | null | [
"Do I miss something here?",
"Hi! \r\n\r\nThe first dataset stores images as bytes (the \"image\" column type is `datasets.Image()`) and decodes them as `PIL.Image` objects and the second dataset stores them as variable-length lists (the \"image\" column type is `datasets.Sequence(...)`)), so I guess going from `... | 2023-03-23T18:20:20Z | 2023-04-09T18:56:23Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
I am struggling to understand (huge) performance difference between two datasets that are almost identical.
### Steps to reproduce the bug
# Fast (normal) dataset speed:
```python
import cv2
from datasets import load_dataset
from torch.utils.data import DataLoader
dataset = load_dataset(... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5669/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5669/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5666 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5666/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5666/comments | https://api.github.com/repos/huggingface/datasets/issues/5666/events | https://github.com/huggingface/datasets/issues/5666 | 1,637,675,062 | I_kwDODunzps5hnPA2 | 5,666 | Support tensorflow 2.12.0 in CI | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-03-23T14:37:51Z | 2023-03-23T16:14:54Z | 2023-03-23T16:14:54Z | MEMBER | null | null | null | null | Once we find out the root cause of:
- #5663
we should revert the temporary pin on tensorflow introduced by:
- #5664 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5666/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5666/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5665 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5665/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5665/comments | https://api.github.com/repos/huggingface/datasets/issues/5665/events | https://github.com/huggingface/datasets/issues/5665 | 1,637,193,648 | I_kwDODunzps5hlZew | 5,665 | Feature request: IterableDataset.push_to_hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"+1",
"+1",
"+1, should be possible now? :) https://huggingface.co/blog/xethub-joins-hf",
"Haha we're working hard to integrate Xet in the HF back-end, it will enable cool use cases :)\n\nAnyway about `IterableDataset.push_to_hub`, I'd be happy to to provide guidance and answer questions if anyone wants to st... | 2023-03-23T09:53:04Z | 2025-06-06T16:13:22Z | 2025-06-06T16:12:36Z | CONTRIBUTOR | null | null | null | null | ### Feature request
It'd be great to have a lazy push to hub, similar to the lazy loading we have with `IterableDataset`.
Suppose you'd like to filter [LAION](https://huggingface.co/datasets/laion/laion400m) based on certain conditions, but as LAION doesn't fit into your disk, you'd like to leverage streaming:
`... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 32,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 32,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5665/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5665/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5663 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5663/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5663/comments | https://api.github.com/repos/huggingface/datasets/issues/5663/events | https://github.com/huggingface/datasets/issues/5663 | 1,637,173,248 | I_kwDODunzps5hlUgA | 5,663 | CI is broken: ModuleNotFoundError: jax requires jaxlib to be installed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-03-23T09:39:43Z | 2023-03-23T10:09:55Z | 2023-03-23T10:09:55Z | MEMBER | null | null | null | null | CI test_py310 is broken: see https://github.com/huggingface/datasets/actions/runs/4498945505/jobs/7916194236?pr=5662
```
FAILED tests/test_arrow_dataset.py::BaseDatasetTest::test_map_jax_in_memory - ModuleNotFoundError: jax requires jaxlib to be installed. See https://github.com/google/jax#installation for installati... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5663/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5663/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5661 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5661/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5661/comments | https://api.github.com/repos/huggingface/datasets/issues/5661/events | https://github.com/huggingface/datasets/issues/5661 | 1,637,129,445 | I_kwDODunzps5hlJzl | 5,661 | CI is broken: Unnecessary `dict` comprehension | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [] | 2023-03-23T09:13:01Z | 2023-03-23T09:37:51Z | 2023-03-23T09:37:51Z | MEMBER | null | null | null | null | CI check_code_quality is broken:
```
src/datasets/arrow_dataset.py:3267:35: C416 [*] Unnecessary `dict` comprehension (rewrite using `dict()`)
Found 1 error.
``` | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5661/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5661/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5660 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5660/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5660/comments | https://api.github.com/repos/huggingface/datasets/issues/5660/events | https://github.com/huggingface/datasets/issues/5660 | 1,635,543,646 | I_kwDODunzps5hfGpe | 5,660 | integration with imbalanced-learn | {
"avatar_url": "https://avatars.githubusercontent.com/u/30216?v=4",
"events_url": "https://api.github.com/users/tansaku/events{/privacy}",
"followers_url": "https://api.github.com/users/tansaku/followers",
"following_url": "https://api.github.com/users/tansaku/following{/other_user}",
"gists_url": "https://a... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "ffffff",
"default": true... | closed | false | null | [] | null | [
"You can convert any dataset to pandas to be used with imbalanced-learn using `.to_pandas()`\r\n\r\nOtherwise if you want to keep a `Dataset` object and still use e.g. [make_imbalance](https://imbalanced-learn.org/stable/references/generated/imblearn.datasets.make_imbalance.html#imblearn.datasets.make_imbalance), y... | 2023-03-22T11:05:17Z | 2023-07-06T18:10:15Z | 2023-07-06T18:10:15Z | NONE | null | null | null | null | ### Feature request
Wouldn't it be great if the various class balancing operations from imbalanced-learn were available as part of datasets?
### Motivation
I'm trying to use imbalanced-learn to balance a dataset, but it's not clear how to get the two to interoperate - what would be great would be some examples. I'v... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5660/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5660/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5659 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5659/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5659/comments | https://api.github.com/repos/huggingface/datasets/issues/5659/events | https://github.com/huggingface/datasets/issues/5659 | 1,635,447,540 | I_kwDODunzps5hevL0 | 5,659 | [Audio] Soundfile/libsndfile requirements too stringent for decoding mp3 files | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"cc @polinaeterna @lhoestq ",
"@sanchit-gandhi can you please also post the logs of `pip install soundfile==0.12.1`? To check what wheel is being installed or if it's being built from source (I think it's the latter case). \r\nRequired `libsndfile` binary **should** be bundeled with `soundfile` wheel but I assume... | 2023-03-22T10:07:33Z | 2024-07-12T01:35:01Z | 2023-04-07T08:51:28Z | CONTRIBUTOR | null | null | null | null | ### Describe the bug
I'm encountering several issues trying to load mp3 audio files using `datasets` on a TPU v4.
The PR https://github.com/huggingface/datasets/pull/5573 updated the audio loading logic to rely solely on the `soundfile`/`libsndfile` libraries for loading audio samples, regardless of their file t... | {
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
... | {
"+1": 3,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 3,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5659/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5659/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5654 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5654/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5654/comments | https://api.github.com/repos/huggingface/datasets/issues/5654/events | https://github.com/huggingface/datasets/issues/5654 | 1,633,523,705 | I_kwDODunzps5hXZf5 | 5,654 | Offset overflow when executing Dataset.map | {
"avatar_url": "https://avatars.githubusercontent.com/u/118280608?v=4",
"events_url": "https://api.github.com/users/jan-pair/events{/privacy}",
"followers_url": "https://api.github.com/users/jan-pair/followers",
"following_url": "https://api.github.com/users/jan-pair/following{/other_user}",
"gists_url": "ht... | [] | open | false | null | [] | null | [
"Upd. the above code works if we replace `25` with `1`, but the result value at key \"hr\" is not a tensor but a list of lists of lists of uint8.\r\n\r\nAdding `train_data.set_format(\"torch\")` after map fixes this, but the original issue remains\r\n\r\n",
"As a workaround, one can replace\r\n`return {\"hr\": to... | 2023-03-21T09:33:27Z | 2023-03-21T10:32:07Z | null | NONE | null | null | null | null | ### Describe the bug
Hi, I'm trying to use `.map` method to cache multiple random crops from the image to speed up data processing during training, as the image size is too big.
The map function executes all iterations, and then returns the following error:
```bash
Traceback (most recent call last): ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5654/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5654/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5653 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5653/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5653/comments | https://api.github.com/repos/huggingface/datasets/issues/5653/events | https://github.com/huggingface/datasets/issues/5653 | 1,633,254,159 | I_kwDODunzps5hWXsP | 5,653 | Doc: save_to_disk, `num_proc` will affect `num_shards`, but it's not documented | {
"avatar_url": "https://avatars.githubusercontent.com/u/42400165?v=4",
"events_url": "https://api.github.com/users/RmZeta2718/events{/privacy}",
"followers_url": "https://api.github.com/users/RmZeta2718/followers",
"following_url": "https://api.github.com/users/RmZeta2718/following{/other_user}",
"gists_url"... | [
{
"color": "0075ca",
"default": true,
"description": "Improvements or additions to documentation",
"id": 1935892861,
"name": "documentation",
"node_id": "MDU6TGFiZWwxOTM1ODkyODYx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/documentation"
},
{
"color": "7057... | closed | false | null | [] | null | [
"I agree this should be documented"
] | 2023-03-21T05:25:35Z | 2023-03-24T16:36:23Z | 2023-03-24T16:36:23Z | NONE | null | null | null | null | ### Describe the bug
[`num_proc`](https://huggingface.co/docs/datasets/main/en/package_reference/main_classes#datasets.DatasetDict.save_to_disk.num_proc) will affect `num_shards`, but it's not documented
### Steps to reproduce the bug
Nothing to reproduce
### Expected behavior
[document of `num_shards`](https://... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5653/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5653/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5651 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5651/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5651/comments | https://api.github.com/repos/huggingface/datasets/issues/5651/events | https://github.com/huggingface/datasets/issues/5651 | 1,631,967,509 | I_kwDODunzps5hRdkV | 5,651 | expanduser in save_to_disk | {
"avatar_url": "https://avatars.githubusercontent.com/u/42400165?v=4",
"events_url": "https://api.github.com/users/RmZeta2718/events{/privacy}",
"followers_url": "https://api.github.com/users/RmZeta2718/followers",
"following_url": "https://api.github.com/users/RmZeta2718/following{/other_user}",
"gists_url"... | [
{
"color": "7057ff",
"default": true,
"description": "Good for newcomers",
"id": 1935892877,
"name": "good first issue",
"node_id": "MDU6TGFiZWwxOTM1ODkyODc3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/good%20first%20issue"
}
] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/35114142?v=4",
"events_url": "https://api.github.com/users/benjaminbrown038/events{/privacy}",
"followers_url": "https://api.github.com/users/benjaminbrown038/followers",
"following_url": "https://api.github.com/users/benjaminbrown038/following{/other_use... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/35114142?v=4",
"events_url": "https://api.github.com/users/benjaminbrown038/events{/privacy}",
"followers_url": "https://api.github.com/users/benjaminbrown038/followers",
"following_url": "https://api.github.com/users/benjaminbrown038/followin... | null | [
"`save_to_disk` should indeed expand `~`. Marking it as a \"good first issue\".",
"#self-assign\r\n\r\nFile path to code: \r\n\r\nhttps://github.com/huggingface/datasets/blob/2.13.0/src/datasets/arrow_dataset.py#L1364\r\n\r\n@RmZeta2718 I created a pull request for this issue. ",
"Hello, \r\nIt says `save_to_di... | 2023-03-20T12:02:18Z | 2023-10-27T14:04:37Z | 2023-10-27T14:04:37Z | NONE | null | null | null | null | ### Describe the bug
save_to_disk() does not expand `~`
1. `dataset = load_datasets("any dataset")`
2. `dataset.save_to_disk("~/data")`
3. a folder named "~" created in current folder
4. FileNotFoundError is raised, because the expanded path does not exist (`/home/<user>/data`)
related issue https://github.... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5651/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5651/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5650 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5650/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5650/comments | https://api.github.com/repos/huggingface/datasets/issues/5650/events | https://github.com/huggingface/datasets/issues/5650 | 1,630,336,919 | I_kwDODunzps5hLPeX | 5,650 | load_dataset can't work correct with my image data | {
"avatar_url": "https://avatars.githubusercontent.com/u/41611046?v=4",
"events_url": "https://api.github.com/users/WiNE-iNEFF/events{/privacy}",
"followers_url": "https://api.github.com/users/WiNE-iNEFF/followers",
"following_url": "https://api.github.com/users/WiNE-iNEFF/following{/other_user}",
"gists_url"... | [] | closed | false | null | [] | null | [
"Can you post a reproducible code snippet of what you tried to do?\r\n\r\n",
"> Can you post a reproducible code snippet of what you tried to do?\n> \n> \n\n```python\nfrom datasets import load_dataset\n\ndataset = load_dataset(\"my_folder_name\", split=\"train\")\n```",
"hi @WiNE-iNEFF ! can you please also te... | 2023-03-18T13:59:13Z | 2023-07-24T14:13:02Z | 2023-07-24T14:13:01Z | NONE | null | null | null | null | I have about 20000 images in my folder which divided into 4 folders with class names.
When i use load_dataset("my_folder_name", split="train") this function create dataset in which there are only 4 images, the remaining 19000 images were not added there. What is the problem and did not understand. Tried converting imag... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5650/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5650/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5649 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5649/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5649/comments | https://api.github.com/repos/huggingface/datasets/issues/5649/events | https://github.com/huggingface/datasets/issues/5649 | 1,630,173,460 | I_kwDODunzps5hKnkU | 5,649 | The index column created with .to_sql() is dependent on the batch_size when writing | {
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"events_url": "https://api.github.com/users/lsb/events{/privacy}",
"followers_url": "https://api.github.com/users/lsb/followers",
"following_url": "https://api.github.com/users/lsb/following{/other_user}",
"gists_url": "https://api.github.co... | [] | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/o... | null | [
"Thanks for reporting, @lsb. \r\n\r\nWe are investigating it.\r\n\r\nOn the other hand, please note that in the next `datasets` release, the index will not be created by default (see #5583). If you would like to have it, you will need to explicitly pass `index=True`. ",
"I think this is low enough priority for me... | 2023-03-18T05:25:17Z | 2023-06-17T07:01:57Z | 2023-06-17T07:01:57Z | NONE | null | null | null | null | ### Describe the bug
It seems like the "index" column is designed to be unique? The values are only unique per batch. The SQL index is not a unique index.
This can be a problem, for instance, when building a faiss index on a dataset and then trying to match up ids with a sql export.
### Steps to reproduce the ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/45281?v=4",
"events_url": "https://api.github.com/users/lsb/events{/privacy}",
"followers_url": "https://api.github.com/users/lsb/followers",
"following_url": "https://api.github.com/users/lsb/following{/other_user}",
"gists_url": "https://api.github.co... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5649/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5649/timeline | null | not_planned | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5648 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5648/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5648/comments | https://api.github.com/repos/huggingface/datasets/issues/5648/events | https://github.com/huggingface/datasets/issues/5648 | 1,629,253,719 | I_kwDODunzps5hHHBX | 5,648 | flatten_indices doesn't work with pandas format | {
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"events_url": "https://api.github.com/users/alialamiidrissi/events{/privacy}",
"followers_url": "https://api.github.com/users/alialamiidrissi/followers",
"following_url": "https://api.github.com/users/alialamiidrissi/following{/other_user}"... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | open | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
... | null | [
"Thanks for reporting! This can be fixed by setting the format to `arrow` in `flatten_indices` and restoring the original format after the flattening. I'm working on a PR that reduces the number of the `flatten_indices` calls in our codebase and makes `flatten_indices` a no-op when a dataset does not have an indice... | 2023-03-17T12:44:25Z | 2023-03-21T13:12:03Z | null | NONE | null | null | null | null | ### Describe the bug
Hi,
I noticed that `flatten_indices` throws an error when the batch format is `pandas`. This is probably due to the fact that flatten_indices uses map internally which doesn't accept dataframes as the transformation function output
### Steps to reproduce the bug
tabular_data = pd.DataFrame(np.r... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5648/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5648/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5647 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5647/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5647/comments | https://api.github.com/repos/huggingface/datasets/issues/5647/events | https://github.com/huggingface/datasets/issues/5647 | 1,628,225,544 | I_kwDODunzps5hDMAI | 5,647 | Make all print statements optional | {
"avatar_url": "https://avatars.githubusercontent.com/u/49101362?v=4",
"events_url": "https://api.github.com/users/gagan3012/events{/privacy}",
"followers_url": "https://api.github.com/users/gagan3012/followers",
"following_url": "https://api.github.com/users/gagan3012/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"related to #5444 ",
"We now log these messages instead of printing them (addressed in #6019), so I'm closing this issue."
] | 2023-03-16T20:30:07Z | 2023-07-21T14:20:25Z | 2023-07-21T14:20:24Z | NONE | null | null | null | null | ### Feature request
Make all print statements optional to speed up the development
### Motivation
Im loading multiple tiny datasets and all the print statements make the loading slower
### Your contribution
I can help contribute | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5647/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5647/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5645 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5645/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5645/comments | https://api.github.com/repos/huggingface/datasets/issues/5645/events | https://github.com/huggingface/datasets/issues/5645 | 1,627,108,278 | I_kwDODunzps5g-7O2 | 5,645 | Datasets map and select(range()) is giving dill error | {
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"events_url": "https://api.github.com/users/Tanya-11/events{/privacy}",
"followers_url": "https://api.github.com/users/Tanya-11/followers",
"following_url": "https://api.github.com/users/Tanya-11/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"It looks like an error that we observed once in https://github.com/huggingface/datasets/pull/5166\r\n\r\nCan you try to update `datasets` ?\r\n\r\n```\r\npip install -U datasets\r\n```\r\n\r\nif it doesn't work, can you make sure you don't have packages installed that may modify `dill`'s behavior, such as `apache-... | 2023-03-16T10:01:28Z | 2023-03-17T04:24:51Z | 2023-03-17T04:24:51Z | NONE | null | null | null | null | ### Describe the bug
I'm using Huggingface Datasets library to load the dataset in google colab
When I do,
> data = train_dataset.select(range(10))
or
> train_datasets = train_dataset.map(
> process_data_to_model_inputs,
> batched=True,
> batch_size=batch_size,
> remove_columns... | {
"avatar_url": "https://avatars.githubusercontent.com/u/90728105?v=4",
"events_url": "https://api.github.com/users/Tanya-11/events{/privacy}",
"followers_url": "https://api.github.com/users/Tanya-11/followers",
"following_url": "https://api.github.com/users/Tanya-11/following{/other_user}",
"gists_url": "htt... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5645/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5645/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5641 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5641/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5641/comments | https://api.github.com/repos/huggingface/datasets/issues/5641/events | https://github.com/huggingface/datasets/issues/5641 | 1,625,942,730 | I_kwDODunzps5g6erK | 5,641 | Features cannot be named "self" | {
"avatar_url": "https://avatars.githubusercontent.com/u/14365168?v=4",
"events_url": "https://api.github.com/users/alialamiidrissi/events{/privacy}",
"followers_url": "https://api.github.com/users/alialamiidrissi/followers",
"following_url": "https://api.github.com/users/alialamiidrissi/following{/other_user}"... | [] | closed | false | null | [] | null | [] | 2023-03-15T17:16:40Z | 2023-03-16T17:14:51Z | 2023-03-16T17:14:51Z | NONE | null | null | null | null | ### Describe the bug
Hi,
I noticed that we cannot create a HuggingFace dataset from Pandas DataFrame with a column named `self`.
The error seems to be coming from arguments validation in the `Features.from_dict` function.
### Steps to reproduce the bug
```python
import datasets
dummy_pandas = pd.DataFrame([0... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5641/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5641/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5639 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5639/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5639/comments | https://api.github.com/repos/huggingface/datasets/issues/5639/events | https://github.com/huggingface/datasets/issues/5639 | 1,625,737,098 | I_kwDODunzps5g5seK | 5,639 | Parquet file wrongly recognized as zip prevents loading a dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/22726840?v=4",
"events_url": "https://api.github.com/users/clefourrier/events{/privacy}",
"followers_url": "https://api.github.com/users/clefourrier/followers",
"following_url": "https://api.github.com/users/clefourrier/following{/other_user}",
"gists_u... | [] | closed | false | null | [] | null | [] | 2023-03-15T15:20:45Z | 2023-03-16T13:40:14Z | 2023-03-16T13:40:14Z | MEMBER | null | null | null | null | ### Describe the bug
When trying to `load_dataset_builder` for `HuggingFaceGECLM/StackExchange_Mar2023`, extraction fails, because parquet file [devops-00000-of-00001-22fe902fd8702892.parquet](https://huggingface.co/datasets/HuggingFaceGECLM/StackExchange_Mar2023/resolve/1f8c9a2ab6f7d0f9ae904b8b922e4384592ae1a5/data... | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5639/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5639/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5638 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5638/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5638/comments | https://api.github.com/repos/huggingface/datasets/issues/5638/events | https://github.com/huggingface/datasets/issues/5638 | 1,625,564,471 | I_kwDODunzps5g5CU3 | 5,638 | xPath to implement all operations for Path | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
" I think https://github.com/fsspec/universal_pathlib is the project you are looking for.\r\n\r\n`xPath` has the methods often used in dataset scripts, and `mkdir` is not one of them (`dl_manager`'s role is to \"interact\" with the file system, so using `mkdir` is discouraged).",
"Right is there a difference betw... | 2023-03-15T13:47:11Z | 2023-03-17T13:21:12Z | 2023-03-17T13:21:12Z | CONTRIBUTOR | null | null | null | null | ### Feature request
Current xPath implementation is a great extension of Path in order to work with remote objects. However some methods such as `mkdir` are not implemented correctly. It should instead rely on `fsspec` methods, instead of defaulting do `Path` methods which only work locally.
### Motivation
I'm using... | {
"avatar_url": "https://avatars.githubusercontent.com/u/24695242?v=4",
"events_url": "https://api.github.com/users/thomasw21/events{/privacy}",
"followers_url": "https://api.github.com/users/thomasw21/followers",
"following_url": "https://api.github.com/users/thomasw21/following{/other_user}",
"gists_url": "... | {
"+1": 1,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 1,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5638/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5638/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5637 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5637/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5637/comments | https://api.github.com/repos/huggingface/datasets/issues/5637/events | https://github.com/huggingface/datasets/issues/5637 | 1,625,295,691 | I_kwDODunzps5g4AtL | 5,637 | IterableDataset with_format does not support 'device' keyword for jax | {
"avatar_url": "https://avatars.githubusercontent.com/u/91322985?v=4",
"events_url": "https://api.github.com/users/Lime-Cakes/events{/privacy}",
"followers_url": "https://api.github.com/users/Lime-Cakes/followers",
"following_url": "https://api.github.com/users/Lime-Cakes/following{/other_user}",
"gists_url"... | [] | open | false | null | [] | null | [
"Hi! Yes, only `torch` is currently supported. Unlike `Dataset`, `IterableDataset` is not PyArrow-backed, so we cannot simply call `to_numpy` on the underlying subtables to format them numerically. Instead, we must manually convert examples to (numeric) arrays while preserving consistency with `Dataset`, which is n... | 2023-03-15T11:04:12Z | 2025-01-07T06:59:33Z | null | NONE | null | null | null | null | ### Describe the bug
As seen here: https://huggingface.co/docs/datasets/use_with_jax dataset.with_format() supports the keyword 'device', to put data on a specific device when loaded as jax. However, when called on an IterableDataset, I got the error `TypeError: with_format() got an unexpected keyword argument 'devi... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5637/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5637/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5634 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5634/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5634/comments | https://api.github.com/repos/huggingface/datasets/issues/5634/events | https://github.com/huggingface/datasets/issues/5634 | 1,622,424,174 | I_kwDODunzps5gtDpu | 5,634 | Not all progress bars are showing up when they should for downloading dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"events_url": "https://api.github.com/users/garlandz-db/events{/privacy}",
"followers_url": "https://api.github.com/users/garlandz-db/followers",
"following_url": "https://api.github.com/users/garlandz-db/following{/other_user}",
"gists_... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\nBy default, tqdm has `leave=True` to \"keep all traces of the progress bar upon the termination of iteration\". However, we use `leave=False` in some places (as of recently), which removes the bar once the iteration is over.\r\n\r\nI feel like our TQDM bars are noisy, so I think we should always set `l... | 2023-03-13T23:04:18Z | 2023-10-11T16:30:16Z | 2023-10-11T16:30:16Z | NONE | null | null | null | null | ### Describe the bug
During downloading the rotten tomatoes dataset, not all progress bars are displayed properly. This might be related to [this ticket](https://github.com/huggingface/datasets/issues/5117) as it raised the same concern but its not clear if the fix solves this issue too.
ipywidgets
<img width=... | {
"avatar_url": "https://avatars.githubusercontent.com/u/110427462?v=4",
"events_url": "https://api.github.com/users/garlandz-db/events{/privacy}",
"followers_url": "https://api.github.com/users/garlandz-db/followers",
"following_url": "https://api.github.com/users/garlandz-db/following{/other_user}",
"gists_... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5634/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5634/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5633 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5633/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5633/comments | https://api.github.com/repos/huggingface/datasets/issues/5633/events | https://github.com/huggingface/datasets/issues/5633 | 1,621,469,970 | I_kwDODunzps5gpasS | 5,633 | Cannot import datasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/11250555?v=4",
"events_url": "https://api.github.com/users/ruplet/events{/privacy}",
"followers_url": "https://api.github.com/users/ruplet/followers",
"following_url": "https://api.github.com/users/ruplet/following{/other_user}",
"gists_url": "https://a... | [] | closed | false | null | [] | null | [
"Okay, the issue was likely caused by mixing `conda` and `pip` usage - I forgot that I have already used `pip` in this environment previously and that it was 'spoiled' because of it. Creating another environment and installing `datasets` by pip with other packages from the `requirements.txt` file solved the problem... | 2023-03-13T13:14:44Z | 2023-03-13T17:54:19Z | 2023-03-13T17:54:19Z | NONE | null | null | null | null | ### Describe the bug
Hi,
I cannot even import the library :( I installed it by running:
```
$ conda install datasets
```
Then I realized I should maybe use the huggingface channel, because I encountered the error below, so I ran:
```
$ conda remove datasets
$ conda install -c huggingface datasets
```
Pl... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5633/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5633/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5632 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5632/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5632/comments | https://api.github.com/repos/huggingface/datasets/issues/5632/events | https://github.com/huggingface/datasets/issues/5632 | 1,621,177,391 | I_kwDODunzps5goTQv | 5,632 | Dataset cannot convert too large dictionnary | {
"avatar_url": "https://avatars.githubusercontent.com/u/108518627?v=4",
"events_url": "https://api.github.com/users/MaraLac/events{/privacy}",
"followers_url": "https://api.github.com/users/MaraLac/followers",
"following_url": "https://api.github.com/users/MaraLac/following{/other_user}",
"gists_url": "https... | [] | open | false | null | [] | null | [
"Answered on the forum:\r\n\r\n> To fix the overflow error, we need to merge [support LargeListArray in pyarrow by xwwwwww · Pull Request #4800 · huggingface/datasets · GitHub](https://github.com/huggingface/datasets/pull/4800), which adds support for the large lists. However, before merging it, we need to come up ... | 2023-03-13T10:14:40Z | 2023-03-16T15:28:57Z | null | NONE | null | null | null | null | ### Describe the bug
Hello everyone!
I tried to build a new dataset with the command "dict_valid = datasets.Dataset.from_dict({'input_values': values_array})".
However, I have a very large dataset (~400Go) and it seems that dataset cannot handle this.
Indeed, I can create the dataset until a certain size of m... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5632/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5632/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5631 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5631/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5631/comments | https://api.github.com/repos/huggingface/datasets/issues/5631/events | https://github.com/huggingface/datasets/issues/5631 | 1,620,442,854 | I_kwDODunzps5glf7m | 5,631 | Custom split names | {
"avatar_url": "https://avatars.githubusercontent.com/u/79091831?v=4",
"events_url": "https://api.github.com/users/ErfanMoosaviMonazzah/events{/privacy}",
"followers_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followers",
"following_url": "https://api.github.com/users/ErfanMoosaviMonazzah/followin... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | closed | false | null | [] | null | [
"Hi!\r\n\r\nYou can also use names other than \"train\", \"validation\" and \"test\". As an example, check the [script](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/blob/e095840f23f3dffc1056c078c2f9320dad9ca74d/common_voice_11_0.py#L139) of the Common Voice 11 dataset. "
] | 2023-03-12T17:21:43Z | 2023-03-24T14:13:00Z | 2023-03-24T14:13:00Z | NONE | null | null | null | null | ### Feature request
Hi,
I participated in multiple NLP tasks where there are more than just train, test, validation splits, there could be multiple validation sets or test sets. But it seems currently only those mentioned three splits supported. It would be nice to have the support for more splits on the hub. (curren... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5631/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5631/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5629 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5629/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5629/comments | https://api.github.com/repos/huggingface/datasets/issues/5629/events | https://github.com/huggingface/datasets/issues/5629 | 1,619,921,247 | I_kwDODunzps5gjglf | 5,629 | load_dataset gives "403" error when using Financial phrasebank | {
"avatar_url": "https://avatars.githubusercontent.com/u/67709789?v=4",
"events_url": "https://api.github.com/users/Jimchoo91/events{/privacy}",
"followers_url": "https://api.github.com/users/Jimchoo91/followers",
"following_url": "https://api.github.com/users/Jimchoo91/following{/other_user}",
"gists_url": "... | [] | open | false | null | [] | null | [
"Hi! You seem to be using an outdated version of `datasets` that downloads the older script version. To avoid the error, you can either pass `revision=\"main\"` to `load_dataset` (this can fail if a script uses newer features of the lib) or update your installation with `pip install -U datasets` (better solution)."... | 2023-03-11T07:46:39Z | 2023-03-13T18:27:26Z | null | NONE | null | null | null | null | When I try to load this dataset, I receive the following error:
ConnectionError: Couldn't reach https://www.researchgate.net/profile/Pekka_Malo/publication/251231364_FinancialPhraseBank-v10/data/0c96051eee4fb1d56e000000/FinancialPhraseBank-v10.zip (error 403)
Has this been seen before? Thanks. The website loads ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5629/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5629/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5627 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5627/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5627/comments | https://api.github.com/repos/huggingface/datasets/issues/5627/events | https://github.com/huggingface/datasets/issues/5627 | 1,619,336,609 | I_kwDODunzps5ghR2h | 5,627 | Unable to load AutoTrain-generated dataset from the hub | {
"avatar_url": "https://avatars.githubusercontent.com/u/8560151?v=4",
"events_url": "https://api.github.com/users/ijmiller2/events{/privacy}",
"followers_url": "https://api.github.com/users/ijmiller2/followers",
"following_url": "https://api.github.com/users/ijmiller2/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | [
"The AutoTrain format is not supported right now. I think it would require a dedicated dataset builder",
"Okay, good to know. Thanks for the reply. For now I will just have to\nmanage the split manually before training, because I can’t find any way of\npulling out file indices or file names from the autogenerated... | 2023-03-10T17:25:58Z | 2023-03-11T15:44:42Z | null | NONE | null | null | null | null | ### Describe the bug
DatasetGenerationError: An error occurred while generating the dataset -> ValueError: Couldn't cast ... because column names don't match
```
ValueError: Couldn't cast
_data_files: list<item: struct<filename: string>>
child 0, item: struct<filename: string>
child 0, filename: string
... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5627/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5627/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5625 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5625/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5625/comments | https://api.github.com/repos/huggingface/datasets/issues/5625/events | https://github.com/huggingface/datasets/issues/5625 | 1,618,971,855 | I_kwDODunzps5gf4zP | 5,625 | Allow "jsonl" data type signifier | {
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url":... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
}
] | open | false | null | [] | null | [
"You can use \"json\" instead. It doesn't work by extension names, but rather by dataset builder names, e.g. \"text\", \"imagefolder\", etc. I don't think the example in `transformers` is correct because of that",
"Yes, I understand the reasoning but this issue is to propose that the example in transformers (whil... | 2023-03-10T13:21:48Z | 2023-03-11T10:35:39Z | null | CONTRIBUTOR | null | null | null | null | ### Feature request
`load_dataset` currently does not accept `jsonl` as type but only `json`.
### Motivation
I was working with one of the `run_translation` scripts and used my own datasets (`.jsonl`) as train_dataset. But the default code did not work because
```
FileNotFoundError: Couldn't find a dataset scri... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5625/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5625/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5624 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5624/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5624/comments | https://api.github.com/repos/huggingface/datasets/issues/5624/events | https://github.com/huggingface/datasets/issues/5624 | 1,617,400,192 | I_kwDODunzps5gZ5GA | 5,624 | glue datasets returning -1 for test split | {
"avatar_url": "https://avatars.githubusercontent.com/u/8939967?v=4",
"events_url": "https://api.github.com/users/lithafnium/events{/privacy}",
"followers_url": "https://api.github.com/users/lithafnium/followers",
"following_url": "https://api.github.com/users/lithafnium/following{/other_user}",
"gists_url":... | [] | closed | false | null | [] | null | [
"Hi @lithafnium, thanks for reporting.\r\n\r\nPlease note that you can use the \"Community\" tab in the corresponding dataset page to start any discussion: https://huggingface.co/datasets/glue/discussions\r\n\r\nIndeed this issue was already raised there (https://huggingface.co/datasets/glue/discussions/5) and answ... | 2023-03-09T14:47:18Z | 2023-03-09T16:49:29Z | 2023-03-09T16:49:29Z | NONE | null | null | null | null | ### Describe the bug
Downloading any dataset from GLUE has -1 as class labels for test split. Train and validation have regular 0/1 class labels. This is also present in the dataset card online.
### Steps to reproduce the bug
```
dataset = load_dataset("glue", "sst2")
for d in dataset:
# prints out -1
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5624/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5624/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5618 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5618/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5618/comments | https://api.github.com/repos/huggingface/datasets/issues/5618/events | https://github.com/huggingface/datasets/issues/5618 | 1,612,977,934 | I_kwDODunzps5gJBcO | 5,618 | Unpin fsspec < 2023.3.0 once issue fixed | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [] | closed | false | null | [] | null | [] | 2023-03-07T08:41:51Z | 2023-03-07T13:39:03Z | 2023-03-07T13:39:03Z | MEMBER | null | null | null | null | Unpin `fsspec` upper version once root cause of our CI break is fixed.
See:
- #5614 | {
"avatar_url": "https://avatars.githubusercontent.com/u/42851186?v=4",
"events_url": "https://api.github.com/users/lhoestq/events{/privacy}",
"followers_url": "https://api.github.com/users/lhoestq/followers",
"following_url": "https://api.github.com/users/lhoestq/following{/other_user}",
"gists_url": "https:... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5618/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5618/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5616 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5616/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5616/comments | https://api.github.com/repos/huggingface/datasets/issues/5616/events | https://github.com/huggingface/datasets/issues/5616 | 1,612,932,508 | I_kwDODunzps5gI2Wc | 5,616 | CI is broken after fsspec-2023.3.0 release | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [] | 2023-03-07T08:06:39Z | 2023-03-07T08:37:29Z | 2023-03-07T08:37:29Z | MEMBER | null | null | null | null | As reported by @lhoestq, our CI is broken after `fsspec` 2023.3.0 release:
```
FAILED tests/test_filesystem.py::test_compression_filesystems[Bz2FileSystem] - AssertionError: assert [{'created': ...: False, ...}] == ['file.txt']
At index 0 diff: {'name': 'file.txt', 'size': 70, 'type': 'file', 'created': 1678175677... | {
"avatar_url": "https://avatars.githubusercontent.com/u/8515462?v=4",
"events_url": "https://api.github.com/users/albertvillanova/events{/privacy}",
"followers_url": "https://api.github.com/users/albertvillanova/followers",
"following_url": "https://api.github.com/users/albertvillanova/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5616/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5616/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5615 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5615/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5615/comments | https://api.github.com/repos/huggingface/datasets/issues/5615/events | https://github.com/huggingface/datasets/issues/5615 | 1,612,552,653 | I_kwDODunzps5gHZnN | 5,615 | IterableDataset.add_column is unable to accept another IterableDataset as a parameter. | {
"avatar_url": "https://avatars.githubusercontent.com/u/6466389?v=4",
"events_url": "https://api.github.com/users/zsaladin/events{/privacy}",
"followers_url": "https://api.github.com/users/zsaladin/followers",
"following_url": "https://api.github.com/users/zsaladin/following{/other_user}",
"gists_url": "http... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"Hi! You can use `concatenate_datasets([ids1, ids2], axis=1)` to do this."
] | 2023-03-07T01:52:00Z | 2023-03-09T15:24:05Z | 2023-03-09T15:23:54Z | NONE | null | null | null | null | ### Describe the bug
`IterableDataset.add_column` occurs an exception when passing another `IterableDataset` as a parameter.
The method seems to accept only eager evaluated values.
https://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/iterable_dataset.py#L1388-L1391
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5615/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5615/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5613 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5613/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5613/comments | https://api.github.com/repos/huggingface/datasets/issues/5613/events | https://github.com/huggingface/datasets/issues/5613 | 1,611,875,473 | I_kwDODunzps5gE0SR | 5,613 | Version mismatch with multiprocess and dill on Python 3.10 | {
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "h... | [] | open | false | null | [] | null | [
"Sorry, I just found https://github.com/apache/beam/issues/24458. It seems this issue is being worked on. ",
"Reopening, since I think the docs should inform the user of this problem. For example, [this page](https://huggingface.co/docs/datasets/installation) says \r\n> Datasets is tested on Python 3.7+.\r\n\r\nb... | 2023-03-06T17:14:41Z | 2024-04-05T20:13:52Z | null | NONE | null | null | null | null | ### Describe the bug
Grabbing the latest version of `datasets` and `apache-beam` with `poetry` using Python 3.10 gives a crash at runtime. The crash is
```
File "/Users/adpauls/sc/git/DSI-transformers/data/NQ/create_NQ_train_vali.py", line 1, in <module>
import datasets
File "/Users/adpauls/Library/Caches/... | {
"avatar_url": "https://avatars.githubusercontent.com/u/1243668?v=4",
"events_url": "https://api.github.com/users/adampauls/events{/privacy}",
"followers_url": "https://api.github.com/users/adampauls/followers",
"following_url": "https://api.github.com/users/adampauls/following{/other_user}",
"gists_url": "h... | {
"+1": 10,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 10,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5613/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5613/timeline | null | reopened | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5612 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5612/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5612/comments | https://api.github.com/repos/huggingface/datasets/issues/5612/events | https://github.com/huggingface/datasets/issues/5612 | 1,611,262,510 | I_kwDODunzps5gCeou | 5,612 | Arrow map type in parquet files unsupported | {
"avatar_url": "https://avatars.githubusercontent.com/u/26709476?v=4",
"events_url": "https://api.github.com/users/TevenLeScao/events{/privacy}",
"followers_url": "https://api.github.com/users/TevenLeScao/followers",
"following_url": "https://api.github.com/users/TevenLeScao/following{/other_user}",
"gists_u... | [] | open | false | null | [] | null | [
"I'm attaching a minimal reproducible example:\r\n```python\r\nfrom datasets import load_dataset\r\nimport pyarrow as pa\r\nimport pyarrow.parquet as pq\r\n\r\ntable_with_map = pa.Table.from_pydict(\r\n {\"a\": [1, 2], \"b\": [[(\"a\", 2)], [(\"b\", 4)]]},\r\n schema=pa.schema({\"a\": pa.int32(), \"b\": pa.ma... | 2023-03-06T12:03:24Z | 2024-03-15T18:56:12Z | null | CONTRIBUTOR | null | null | null | null | ### Describe the bug
When I try to load parquet files that were processed with Spark, I get the following issue:
`ValueError: Arrow type map<string, string ('warc_headers')> does not have a datasets dtype equivalent.`
Strangely, loading the dataset with `streaming=True` solves the issue.
### Steps to reproduce ... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 5,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 5,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5612/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5612/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5610 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5610/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5610/comments | https://api.github.com/repos/huggingface/datasets/issues/5610/events | https://github.com/huggingface/datasets/issues/5610 | 1,610,698,006 | I_kwDODunzps5gAU0W | 5,610 | use datasets streaming mode in trainer ddp mode cause memory leak | {
"avatar_url": "https://avatars.githubusercontent.com/u/15223544?v=4",
"events_url": "https://api.github.com/users/gromzhu/events{/privacy}",
"followers_url": "https://api.github.com/users/gromzhu/followers",
"following_url": "https://api.github.com/users/gromzhu/following{/other_user}",
"gists_url": "https:... | [] | open | false | null | [] | null | [
"Same problem, \r\ntransformers 4.28.1\r\ndatasets 2.12.0\r\n\r\nleak around 100Mb per 10 seconds when use dataloader_num_werker > 0 in training argumennts for transformer train, possile bug in transformers repo, but still not found solution :(\r\n",
"found an article described a problem, may be helpful for someb... | 2023-03-06T05:26:49Z | 2024-03-07T01:11:32Z | null | NONE | null | null | null | null | ### Describe the bug
use datasets streaming mode in trainer ddp mode cause memory leak
### Steps to reproduce the bug
import os
import time
import datetime
import sys
import numpy as np
import random
import torch
from torch.utils.data import Dataset, DataLoader, random_split, RandomSampler, Sequenti... | null | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5610/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5610/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5609 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5609/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5609/comments | https://api.github.com/repos/huggingface/datasets/issues/5609/events | https://github.com/huggingface/datasets/issues/5609 | 1,610,062,862 | I_kwDODunzps5f95wO | 5,609 | `load_from_disk` vs `load_dataset` performance. | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | open | false | null | [] | null | [
"Hi! We've recently made some improvements to `save_to_disk`/`list_to_disk` (100x faster in some scenarios), so it would help if you could install `datasets` directly from `main` (`pip install git+https://github.com/huggingface/datasets.git`) and re-run the \"benchmark\".",
"Great to hear! I'll give it a try when... | 2023-03-05T05:27:15Z | 2023-07-13T18:48:05Z | null | NONE | null | null | null | null | ### Describe the bug
I have downloaded `openwebtext` (~12GB) and filtered out a small amount of junk (it's still huge). Now, I would like to use this filtered version for future work. It seems I have two choices:
1. Use `load_dataset` each time, relying on the cache mechanism, and re-run my filtering.
2. `save_to_di... | null | {
"+1": 4,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 4,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5609/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5609/timeline | null | null | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5608 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5608/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5608/comments | https://api.github.com/repos/huggingface/datasets/issues/5608/events | https://github.com/huggingface/datasets/issues/5608 | 1,609,996,563 | I_kwDODunzps5f9pkT | 5,608 | audiofolder only creates dataset of 13 rows (files) when the data folder it's reading from has 20,000 mp3 files. | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | [] | closed | false | null | [] | null | [
"Hi!\r\n\r\n> naming convention of mp3 files\r\n\r\nYes, this could be the problem. MP3 files should end with `.mp3`/`.MP3` to be recognized as audio files.\r\n\r\nIf the file names are not the culprit, can you paste the audio folder's directory structure to help us reproduce the error (e.g., by running the `tree ... | 2023-03-05T00:14:45Z | 2023-03-12T00:02:57Z | 2023-03-12T00:02:57Z | NONE | null | null | null | null | ### Describe the bug
x = load_dataset("audiofolder", data_dir="x")
When running this, x is a dataset of 13 rows (files) when it should be 20,000 rows (files) as the data_dir "x" has 20,000 mp3 files. Does anyone know what could possibly cause this (naming convention of mp3 files, etc.)
### Steps to reproduce the b... | {
"avatar_url": "https://avatars.githubusercontent.com/u/107211437?v=4",
"events_url": "https://api.github.com/users/jcho19/events{/privacy}",
"followers_url": "https://api.github.com/users/jcho19/followers",
"following_url": "https://api.github.com/users/jcho19/following{/other_user}",
"gists_url": "https://... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5608/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5608/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5606 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5606/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5606/comments | https://api.github.com/repos/huggingface/datasets/issues/5606/events | https://github.com/huggingface/datasets/issues/5606 | 1,608,911,632 | I_kwDODunzps5f5gsQ | 5,606 | Add `Dataset.to_list` to the API | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | [
{
"color": "a2eeef",
"default": true,
"description": "New feature or request",
"id": 1935892871,
"name": "enhancement",
"node_id": "MDU6TGFiZWwxOTM1ODkyODcx",
"url": "https://api.github.com/repos/huggingface/datasets/labels/enhancement"
},
{
"color": "7057ff",
"default": true... | closed | false | {
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
"gists_url": "... | [
{
"avatar_url": "https://avatars.githubusercontent.com/u/50972773?v=4",
"events_url": "https://api.github.com/users/kyoto7250/events{/privacy}",
"followers_url": "https://api.github.com/users/kyoto7250/followers",
"following_url": "https://api.github.com/users/kyoto7250/following{/other_user}",
... | null | [
"Hello, I have an interest in this issue.\r\nIs the `Dataset.to_dict` you are describing correct in the code here?\r\n\r\nhttps://github.com/huggingface/datasets/blob/35b789e8f6826b6b5a6b48fcc2416c890a1f326a/src/datasets/arrow_dataset.py#L4633-L4667",
"Yes, this is where `Dataset.to_dict` is defined.",
"#self-a... | 2023-03-03T16:17:10Z | 2023-03-27T13:26:40Z | 2023-03-27T13:26:40Z | COLLABORATOR | null | null | null | null | Since there is `Dataset.from_list` in the API, we should also add `Dataset.to_list` to be consistent.
Regarding the implementation, we can re-use `Dataset.to_dict`'s code and replace the `to_pydict` calls with `to_pylist`. | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5606/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5606/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5604 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5604/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5604/comments | https://api.github.com/repos/huggingface/datasets/issues/5604/events | https://github.com/huggingface/datasets/issues/5604 | 1,608,304,775 | I_kwDODunzps5f3MiH | 5,604 | Problems with downloading The Pile | {
"avatar_url": "https://avatars.githubusercontent.com/u/11065386?v=4",
"events_url": "https://api.github.com/users/sentialx/events{/privacy}",
"followers_url": "https://api.github.com/users/sentialx/followers",
"following_url": "https://api.github.com/users/sentialx/following{/other_user}",
"gists_url": "htt... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n\r\nYou can specify `download_config=DownloadConfig(resume_download=True))` in `load_dataset` to resume the download when re-running the code after the timeout error:\r\n```python\r\nfrom datasets import load_dataset, DownloadConfig\r\ndataset = load_dataset('the_pile', split='train', cache_dir='F:\\da... | 2023-03-03T09:52:08Z | 2023-10-14T02:15:52Z | 2023-03-24T12:44:25Z | NONE | null | null | null | null | ### Describe the bug
The downloads in the screenshot seem to be interrupted after some time and the last download throws a "Read timed out" error.
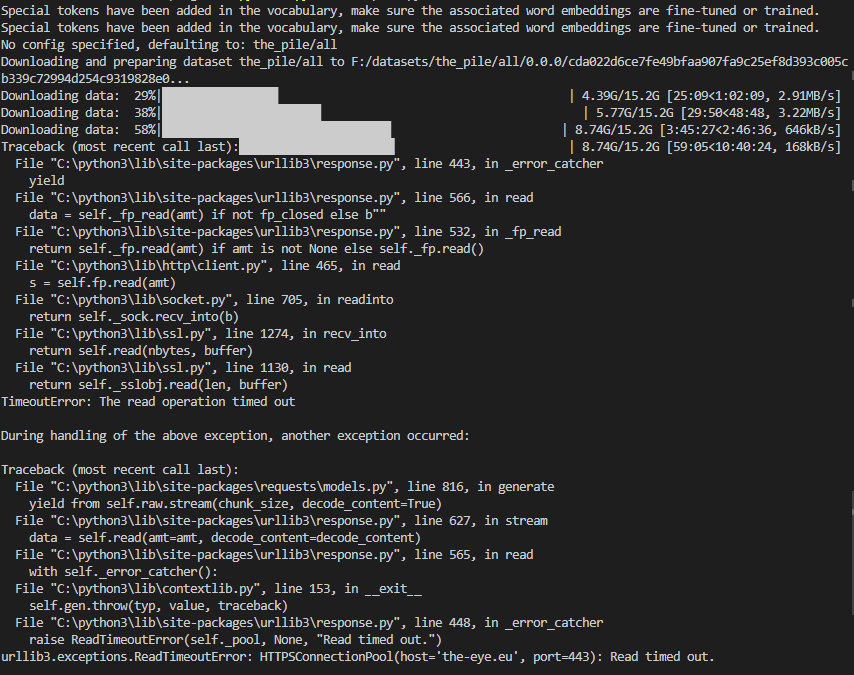
Here are the downloaded files:
`hg_user` but my repo cont... | 2023-03-02T12:08:39Z | 2023-03-14T16:55:35Z | 2023-03-14T16:55:34Z | NONE | null | null | null | null | ### Describe the bug
Get `Authorization error` when try to push data into hugginface datasets hub.
### Steps to reproduce the bug
I did all steps in the [tutorial](https://huggingface.co/docs/datasets/share),
1. `huggingface-cli login` with WRITE token
2. `git lfs install`
3. `git clone https://huggingfa... | {
"avatar_url": "https://avatars.githubusercontent.com/u/107404835?v=4",
"events_url": "https://api.github.com/users/OleksandrKorovii/events{/privacy}",
"followers_url": "https://api.github.com/users/OleksandrKorovii/followers",
"following_url": "https://api.github.com/users/OleksandrKorovii/following{/other_us... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5601/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5601/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5600 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5600/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5600/comments | https://api.github.com/repos/huggingface/datasets/issues/5600/events | https://github.com/huggingface/datasets/issues/5600 | 1,606,585,596 | I_kwDODunzps5fwoz8 | 5,600 | Dataloader getitem not working for DreamboothDatasets | {
"avatar_url": "https://avatars.githubusercontent.com/u/76955987?v=4",
"events_url": "https://api.github.com/users/salahiguiliz/events{/privacy}",
"followers_url": "https://api.github.com/users/salahiguiliz/followers",
"following_url": "https://api.github.com/users/salahiguiliz/following{/other_user}",
"gist... | [] | closed | false | null | [] | null | [
"Hi! \r\n\r\n> (see example of DreamboothDatasets)\r\n\r\n\r\nCould you please provide a link to it? If you are referring to the example in the `diffusers` repo, your issue is unrelated to `datasets` as that example uses `Dataset` from PyTorch to load data."
] | 2023-03-02T11:00:27Z | 2023-03-13T17:59:35Z | 2023-03-13T17:59:35Z | NONE | null | null | null | null | ### Describe the bug
Dataloader getitem is not working as before (see example of [DreamboothDatasets](https://github.com/huggingface/peft/blob/main/examples/lora_dreambooth/train_dreambooth.py#L451C14-L529))
moving Datasets to 2.8.0 solved the issue.
### Steps to reproduce the bug
1- using DreamBoothDataset ... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5600/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5600/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5597 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5597/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5597/comments | https://api.github.com/repos/huggingface/datasets/issues/5597/events | https://github.com/huggingface/datasets/issues/5597 | 1,604,928,721 | I_kwDODunzps5fqUTR | 5,597 | in-place dataset update | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | [
{
"color": "ffffff",
"default": true,
"description": "This will not be worked on",
"id": 1935892913,
"name": "wontfix",
"node_id": "MDU6TGFiZWwxOTM1ODkyOTEz",
"url": "https://api.github.com/repos/huggingface/datasets/labels/wontfix"
}
] | closed | false | null | [] | null | [
"We won't support in-place modifications since `datasets` is based on the Apache Arrow format which doesn't support in-place modifications.\r\n\r\nIn your case the old dataset is garbage collected pretty quickly so you won't have memory issues.\r\n\r\nNote that datasets loaded from disk (memory mapped) are not load... | 2023-03-01T12:58:18Z | 2023-03-02T13:30:41Z | 2023-03-02T03:47:00Z | NONE | null | null | null | null | ### Motivation
For the circumstance that I creat an empty `Dataset` and keep appending new rows into it, I found that it leads to creating a new dataset at each call. It looks quite memory-consuming. I just wonder if there is any more efficient way to do this.
```python
from datasets import Dataset
ds = Datas... | {
"avatar_url": "https://avatars.githubusercontent.com/u/3585459?v=4",
"events_url": "https://api.github.com/users/speedcell4/events{/privacy}",
"followers_url": "https://api.github.com/users/speedcell4/followers",
"following_url": "https://api.github.com/users/speedcell4/following{/other_user}",
"gists_url":... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5597/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5597/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5596 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5596/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5596/comments | https://api.github.com/repos/huggingface/datasets/issues/5596/events | https://github.com/huggingface/datasets/issues/5596 | 1,604,919,993 | I_kwDODunzps5fqSK5 | 5,596 | [TypeError: Couldn't cast array of type] Can only load a subset of the dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | [] | closed | false | null | [] | null | [
"Apparently some JSON objects have a `\"labels\"` field. Since this field is not present in every object, you must specify all the fields types in the README.md\r\n\r\nEDIT: actually specifying the feature types doesn’t solve the issue, it raises an error because “labels” is missing in the data",
"We've updated t... | 2023-03-01T12:53:08Z | 2023-12-05T03:22:00Z | 2023-03-02T11:12:11Z | NONE | null | null | null | null | ### Describe the bug
I'm trying to load this [dataset](https://huggingface.co/datasets/bigcode-data/the-stack-gh-issues) which consists of jsonl files and I get the following error:
```
casted_values = _c(array.values, feature[0])
File "/opt/conda/lib/python3.7/site-packages/datasets/table.py", line 1839, in wr... | {
"avatar_url": "https://avatars.githubusercontent.com/u/44069155?v=4",
"events_url": "https://api.github.com/users/loubnabnl/events{/privacy}",
"followers_url": "https://api.github.com/users/loubnabnl/followers",
"following_url": "https://api.github.com/users/loubnabnl/following{/other_user}",
"gists_url": "... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5596/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5596/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5594 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5594/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5594/comments | https://api.github.com/repos/huggingface/datasets/issues/5594/events | https://github.com/huggingface/datasets/issues/5594 | 1,603,980,995 | I_kwDODunzps5fms7D | 5,594 | Error while downloading the xtreme udpos dataset | {
"avatar_url": "https://avatars.githubusercontent.com/u/24687672?v=4",
"events_url": "https://api.github.com/users/simran-khanuja/events{/privacy}",
"followers_url": "https://api.github.com/users/simran-khanuja/followers",
"following_url": "https://api.github.com/users/simran-khanuja/following{/other_user}",
... | [] | closed | false | null | [] | null | [
"Hi! I cannot reproduce this error on my machine.\r\n\r\nThe raised error could mean that one of the downloaded files is corrupted. To verify this is not the case, you can run `load_dataset` as follows:\r\n```python\r\ntrain_dataset = load_dataset('xtreme', 'udpos.English', split=\"train\", cache_dir=args.cache_dir... | 2023-02-28T23:40:53Z | 2023-11-04T20:45:56Z | 2023-07-24T14:22:18Z | NONE | null | null | null | null | ### Describe the bug
Hi,
I am facing an error while downloading the xtreme udpos dataset using load_dataset. I have datasets 2.10.1 installed
```Downloading and preparing dataset xtreme/udpos.Arabic to /compute/tir-1-18/skhanuja/multilingual_ft/cache/data/xtreme/udpos.Arabic/1.0.0/29f5d57a48779f37ccb75cb8708d1... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5594/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5594/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5586 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5586/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5586/comments | https://api.github.com/repos/huggingface/datasets/issues/5586/events | https://github.com/huggingface/datasets/issues/5586 | 1,602,961,544 | I_kwDODunzps5fi0CI | 5,586 | .sort() is broken when used after .filter(), only in 2.10.0 | {
"avatar_url": "https://avatars.githubusercontent.com/u/57797966?v=4",
"events_url": "https://api.github.com/users/MattYoon/events{/privacy}",
"followers_url": "https://api.github.com/users/MattYoon/followers",
"following_url": "https://api.github.com/users/MattYoon/following{/other_user}",
"gists_url": "htt... | [
{
"color": "d73a4a",
"default": true,
"description": "Something isn't working",
"id": 1935892857,
"name": "bug",
"node_id": "MDU6TGFiZWwxOTM1ODkyODU3",
"url": "https://api.github.com/repos/huggingface/datasets/labels/bug"
}
] | closed | false | null | [] | null | [
"Thanks for reporting and thanks @mariosasko for fixing ! We just did a patch release `2.10.1` with the fix"
] | 2023-02-28T12:18:09Z | 2023-02-28T18:17:26Z | 2023-02-28T17:21:59Z | NONE | null | null | null | null | ### Describe the bug
Hi, thank you for your support!
It seems like the addition of multiple key sort (#5502) in 2.10.0 broke the `.sort()` method.
After filtering a dataset with `.filter()`, the `.sort()` seems to refer to the query_table index of the previous unfiltered dataset, resulting in an IndexError.
... | {
"avatar_url": "https://avatars.githubusercontent.com/u/47462742?v=4",
"events_url": "https://api.github.com/users/mariosasko/events{/privacy}",
"followers_url": "https://api.github.com/users/mariosasko/followers",
"following_url": "https://api.github.com/users/mariosasko/following{/other_user}",
"gists_url"... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5586/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5586/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
https://api.github.com/repos/huggingface/datasets/issues/5585 | https://api.github.com/repos/huggingface/datasets | https://api.github.com/repos/huggingface/datasets/issues/5585/labels{/name} | https://api.github.com/repos/huggingface/datasets/issues/5585/comments | https://api.github.com/repos/huggingface/datasets/issues/5585/events | https://github.com/huggingface/datasets/issues/5585 | 1,602,190,030 | I_kwDODunzps5ff3rO | 5,585 | Cache is not transportable | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | [] | closed | false | null | [] | null | [
"Hi ! No the cache is not transportable in general. It will work on a shared filesystem if you use the same python environment, but not across machines/os/environments.\r\n\r\nIn particular, reloading cached datasets does work, but reloading cached processed datasets (e.g. from `map`) may not work. This is because ... | 2023-02-28T00:53:06Z | 2023-02-28T21:26:52Z | 2023-02-28T21:26:52Z | NONE | null | null | null | null | ### Describe the bug
I would like to share cache between two machines (a Windows host machine and a WSL instance).
I run most my code in WSL. I have just run out of space in the virtual drive. Rather than expand the drive size, I plan to move to cache to the host Windows machine, thereby sharing the downloads.
I... | {
"avatar_url": "https://avatars.githubusercontent.com/u/4443482?v=4",
"events_url": "https://api.github.com/users/davidgilbertson/events{/privacy}",
"followers_url": "https://api.github.com/users/davidgilbertson/followers",
"following_url": "https://api.github.com/users/davidgilbertson/following{/other_user}",... | {
"+1": 0,
"-1": 0,
"confused": 0,
"eyes": 0,
"heart": 0,
"hooray": 0,
"laugh": 0,
"rocket": 0,
"total_count": 0,
"url": "https://api.github.com/repos/huggingface/datasets/issues/5585/reactions"
} | https://api.github.com/repos/huggingface/datasets/issues/5585/timeline | null | completed | {
"completed": 0,
"percent_completed": 0,
"total": 0
} | {
"blocked_by": 0,
"blocking": 0,
"total_blocked_by": 0,
"total_blocking": 0
} | false |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.