| --- |
| license: bsd-3-clause |
| library_name: braindecode |
| pipeline_tag: feature-extraction |
| tags: |
| - eeg |
| - biosignal |
| - pytorch |
| - neuroscience |
| - braindecode |
| - foundation-model |
| - convolutional |
| --- |
| |
| # Labram |
|
|
| Labram from Jiang, W B et al (2024) [Jiang2024]. |
|
|
| > **Architecture-only repository.** Documents the |
| > `braindecode.models.Labram` class. **No pretrained weights are |
| > distributed here.** Instantiate the model and train it on your own |
| > data. |
|
|
| ## Quick start |
|
|
| ```bash |
| pip install braindecode |
| ``` |
|
|
| ```python |
| from braindecode.models import Labram |
| |
| model = Labram( |
| n_chans=22, |
| sfreq=200, |
| input_window_seconds=4.0, |
| n_outputs=2, |
| ) |
| ``` |
|
|
| The signal-shape arguments above are illustrative defaults — adjust to |
| match your recording. |
|
|
| ## Documentation |
| - Full API reference: <https://braindecode.org/stable/generated/braindecode.models.Labram.html> |
| - Interactive browser (live instantiation, parameter counts): |
| <https://huggingface.co/spaces/braindecode/model-explorer> |
| - Source on GitHub: <https://github.com/braindecode/braindecode/blob/master/braindecode/models/labram.py#L196> |
|
|
|
|
| ## Architecture |
|
|
| 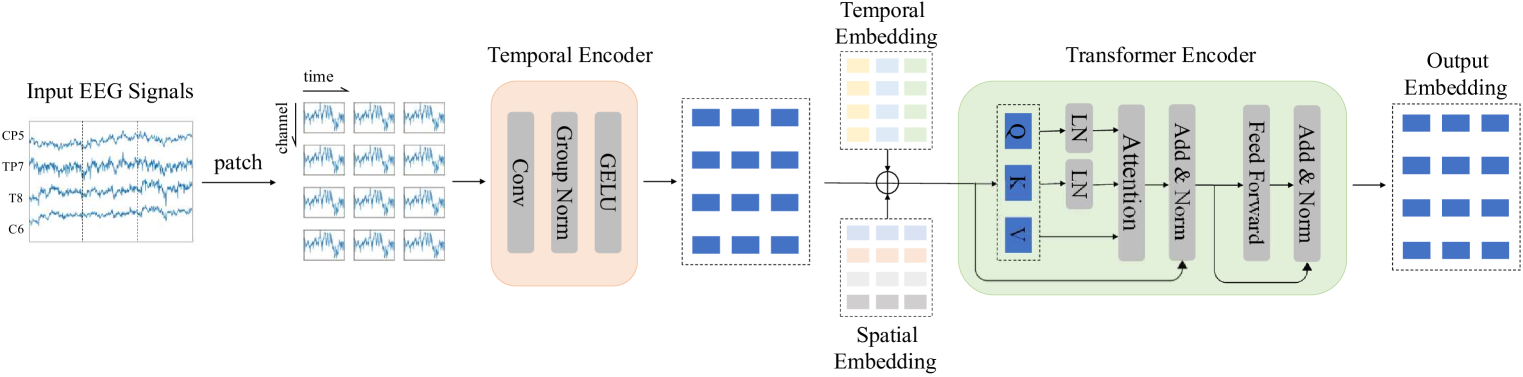 |
|
|
|
|
| ## Parameters |
|
|
| | Parameter | Type | Description | |
| |---|---|---| |
| | `patch_size` | int | The size of the patch to be used in the patch embedding. | |
| | `learned_patcher` | bool | Whether to use a learned patch embedding (via a convolutional layer) or a fixed patch embedding (via rearrangement). | |
| | `embed_dim` | int | The dimension of the embedding. | |
| | `conv_in_channels` | int | The number of convolutional input channels. | |
| | `conv_out_channels` | int | The number of convolutional output channels. | |
| | `num_layers` | int (default=12) | The number of attention layers of the model. | |
| | `num_heads` | int (default=10) | The number of attention heads. | |
| | `mlp_ratio` | float (default=4.0) | The expansion ratio of the mlp layer | |
| | `qkv_bias` | bool (default=False) | If True, add a learnable bias to the query, key, and value tensors. | |
| | `qk_norm` | Pytorch Normalize layer (default=nn.LayerNorm) | If not None, apply LayerNorm to the query and key tensors. Default is nn.LayerNorm for better weight transfer from original LaBraM. Set to None to disable Q,K normalization. | |
| | `qk_scale` | float (default=None) | If not None, use this value as the scale factor. If None, use head_dim**-0.5, where head_dim = dim // num_heads. | |
| | `drop_prob` | float (default=0.0) | Dropout rate for the attention weights. | |
| | `attn_drop_prob` | float (default=0.0) | Dropout rate for the attention weights. | |
| | `drop_path_prob` | float (default=0.0) | Dropout rate for the attention weights used on DropPath. | |
| | `norm_layer` | Pytorch Normalize layer (default=nn.LayerNorm) | The normalization layer to be used. | |
| | `init_values` | float (default=0.1) | If not None, use this value to initialize the gamma_1 and gamma_2 parameters for residual scaling. Default is 0.1 for better weight transfer from original LaBraM. Set to None to disable. | |
| | `use_abs_pos_emb` | bool (default=True) | If True, use absolute position embedding. | |
| | `use_mean_pooling` | bool (default=True) | If True, use mean pooling. | |
| | `init_scale` | float (default=0.001) | The initial scale to be used in the parameters of the model. | |
| | `neural_tokenizer` | bool (default=True) | The model can be used in two modes: Neural Tokenizer or Neural Decoder. | |
| | `attn_head_dim` | bool (default=None) | The head dimension to be used in the attention layer, to be used only during pre-training. | |
| | `activation: nn.Module, default=nn.GELU` | — | Activation function class to apply. Should be a PyTorch activation module class like `nn.ReLU` or `nn.ELU`. Default is `nn.GELU`. | |
| |
| |
| ## References |
| |
| 1. Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024, May. Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. The Twelfth International Conference on Learning Representations, ICLR. |
| 2. Wei-Bang Jiang, Li-Ming Zhao, Bao-Liang Lu. 2024. Labram Large Brain Model for Learning Generic Representations with Tremendous EEG Data in BCI. GitHub https://github.com/935963004/LaBraM (accessed 2024-03-02) |
| 3. Zhiliang Peng, Li Dong, Hangbo Bao, Qixiang Ye, Furu Wei. 2024. BEiT v2: Masked Image Modeling with Vector-Quantized Visual Tokenizers. arXiv:2208.06366 [cs.CV] |
| |
| |
| ## Citation |
| |
| Cite the original architecture paper (see *References* above) and braindecode: |
| |
| ```bibtex |
| @article{aristimunha2025braindecode, |
| title = {Braindecode: a deep learning library for raw electrophysiological data}, |
| author = {Aristimunha, Bruno and others}, |
| journal = {Zenodo}, |
| year = {2025}, |
| doi = {10.5281/zenodo.17699192}, |
| } |
| ``` |
| |
| ## License |
| |
| BSD-3-Clause for the model code (matching braindecode). |
| Pretraining-derived weights, if you fine-tune from a checkpoint, |
| inherit the licence of that checkpoint and its training corpus. |
| |

