
Table results vs chart

Hi! Thanks for the great work. Curious for the 1.5B, the pass@1 numbers in the table seem inconsistent with the chart and results in the paper:
| Model | AIME24 | AIME25 | HMMT-24-25 | HLE-Math |
|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 26.8 (60.0) | 21.4 (36.7) | 14.2 (26.5) | 2.9 (5.0) |
| OpenMath-Nemotron-1.5B CoT | 61.6 (80.0) | 49.5 (66.7) | 39.9 (53.6) | 5.4 (5.4) |
| OpenMath-Nemotron-1.5B TIR | 52.0 (83.3) | 39.7 (70.0) | 37.2 (60.7) | 2.5 (6.2) |
| + Self GenSelect | 83.3 | 70.0 | 62.2 | 7.9 |
| + 32B GenSelect | 83.3 | 70.0 | 62.8 | 8.3 |
What are the details of the 61.6% and 80% results? The 43% pass@1 I'm eyeballing from the figure matches DeepScaleR closely, but 61.6% pass@1 would be absurdly impressive...
majority@64 = 58.2%: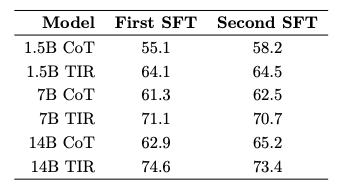
eyeballing pass@1 = ~41%, majority@64 = ~55% (first sft stage)
eyeballing pass@1 = ~43%, majority@64 = ~58%
Thank you very much for your time!

Hi @rawsh , thanks for your interest in our work! Please note that most of our results are presented on the comp-math-24-25 evaluation set that is a combination of 60 AIME problems and 196 HMMT problems from 2024 and 2025. Table 7 has a breakdown of those numbers into AIME24, AIME25 and HMMT sets. So the 61.6% and 80% are the results our 1.5B model gets on AIME24 with pass@1 and majority@64 correspondingly. While the other numbers you're referring to are on the combined set, which is generally harder and thus has lower scores.
Hope this clears it up and let us know if you have any more questions. Please also keep in mind that even though we run 64 generations, there is still a lot of variance and it's easy to see +=3% in AIME scores as those only have 30 problems.
@igitman Thank you for the explanation! Congrats on such strong models + pipeline!
I was able to replicate AIME24 with lighteval:
| Test Set | Average Accuracy@64 | Standard Error |
|---|---|---|
| AIME 2024 | 0.6099 | 0.0692 |
avg@16:
| Test Set | Average Accuracy@16 | Standard Error |
|---|---|---|
| AIME 2024 | 0.6521 | 0.0703 |
| AMC 22-23 | 0.8464 | 0.0318 |
| AMC 24 | 0.7319 | 0.0572 |