
text stringlengths 256 16.4k |
|---|
What is the difference between logistic and logit regression? I understand that they are similar (or even the same thing) but could someone explain the difference(s) between these two? Is one about odds?
The logit is a link function / a transformation of a parameter. It is the logarithm of the odds. If we call the parameter $\pi$, it is defined as follows:
$$ {\rm logit}(\pi) = \log\bigg(\frac{\pi}{1-\pi}\bigg) $$ The logistic function is the inverse of the logit. If we have a value, $x$, the logistic is: $$ {\rm logistic}(x) = \frac{e^x}{1+e^x} $$ Thus (using matrix notation where $\boldsymbol X$ is an $N\times p$ matrix and $\boldsymbol\beta$ is a $p\times 1$ vector), logit regression is: $$ \log\bigg(\frac{\pi}{1-\pi}\bigg) = \boldsymbol{X\beta} $$ and logistic regression is: $$ \pi = \frac{e^\boldsymbol{X\beta}}{1+e^\boldsymbol{X\beta}} $$ For more information about these topics, it may help you to read my answer here: Difference between logit and probit models.
The odds of an event is the probability of the event divided by the probability of the event not occurring. Exponentiating the logit will give the odds. Likewise, you can get the odds by taking the output of the logistic and dividing it by 1 minus the logistic. That is:
$$ {\rm odds} = \exp({\rm logit}(\pi)) = \frac{{\rm logistic}(x)}{1-{\rm logistic}(x)} $$ For more on probabilities and odds, and how logistic regression is related to them, it may help you to read my answer here: Interpretation of simple predictions to odds ratios in logistic regression. |
Today is the first in our series of blogs that will focus on different problem-solving strategies in mathematics. The strategy that we’ll look at now is simple enough at its core: if you’re stuck on a problem that involves unknowns or variables, try substituting, or “plugging”, some numbers into those letters! What numbers you plug in, what you’re plugging into, and how this helps you find the solution varies from problem to problem.
This strategy is especially useful on standardized tests that involve multiple-choice questions, like the SAT. Substituting specific numbers into unknowns or variables can not only give you the ideas you need to eliminate a few wrong answers, but can often steer you to the right answer right away!
Some SAT questions seem to demand that you solve complicated equations, like this one:
Question: What values of \(x\) satisfy the following equation?
$$\sqrt{5x+24}=x+2$$
A. 5 and \(-\)4
B. \(-\)5
C. 4
D. 5
There is a procedure to solve this equation: square both sides, simplify until you get a quadratic equation, factor that quadratic, find the possible solutions, and eliminate extraneous solutions. But what if you’re running out of time, and need an answer,
fast? Well, given that there are answer choices here, do NOT solve the equation! Rather, just plug in your answer choices to see which ones satisfy that equation. Then you’ll have the solution at your fingertips, while avoiding unnecessary work.
Here, it’s helpful to remember that the square root function is
never negative. So, if you plug in \(-\)4 or \(-\)5 for x, you see that the square root is equal to a negative number, which can’t happen. So that immediately eliminates answer choices A and B. Now try x \(=\) 4: \(\sqrt{44}\) is definitely not equal to 6, so C is eliminated as the answer. That leaves D as the only possible option, but check it to be sure: plugging in x \(=\) 5 gives us \(\sqrt{49}=7\), correct! So the correct answer is D.
We found the answer not by tediously solving the equation step-by-step, but by taking advantage of the potential answer choices available to us!
Sometimes the multiple-choice answers may look fairly complicated. Then you won’t be able to plug the answer choices into anything, but you may be able to plug into the answer choices themselves! To see what we’re talking about, let’s try another problem.
Question: A population of bacteria doubles in size every 3 hours. If the initial population is 500, which of the following functions gives the population after \(t\) hours?
A. \(500\times 2^{3t}\)
B. \(500\times 2^{\frac{t}{3}}\)
C. \(500 + 2^{3t}\)
D. \(3\times 500^{\frac{t}{2}}\)
Well, if you know your exponential models, you’ll be able to figure this out. But suppose you blank out on the test? Then what? Plugging in comes to the rescue!
The initial population is 500; that means that when the experiment starts, at time
t \(=\) 0, we have 500 bacteria. So, if we plug in t \(=\) 0 into the correct answer above, we should get 500 back. Of course we don’t know what the correct answer is yet, so we try all of them! When plugging in t \(=\) 0 to choices A and B, we get 500, which means that A and B are possible answers. Answer choice C simplifies to 501, and D simplifies to 3, not what we’re looking for, so we can eliminate them immediately.
So which of A and B is correct? Keep using the given information. The bacteria double every 3 hours, so at time
t \(=\) 3, we should have 2 \(\times\) 500 \(=\) 1000 bacteria. Plug in t \(=\) 3 to answer choices A and B; we’re looking for the expression that simplifies to 1000. Choice A fails (check it… it’s way too big!), and only B works out. The answer is B!
The moral here is that when we happen to forget higher level math (how to create exponential functions that model a given physical situation), we might be able to succeed by remembering some more basic math (evaluating functions), and by using our answer choices to our advantage.
Not all SAT questions are multiple choice. But even open-ended questions can be solved by some judicious substitutions. Try this next one.
Question: The following equation is true for all values of \(x\). Find the value of \(a\).
$$\frac{3x^2+2x-5}{x-a}=3x+23+\frac{156}{x-a}$$
This one seems pretty tough. You might begin by multiplying both sides by \(x-a\) to clear those fractions, and then see what happens. Doing that isn’t all that terrible, but students tend to be put off by ugly expressions like this. Is there another way to do this that might be a little easier, or at least make us feel like we’re in more comfortable territory?
Well, reread the question: this is true for
all values of x. So, any value you plug in for x will give you a true expression. What’s your favorite value of x? Our favorite value is 0, because substituting 0 will often simplify things greatly! Let’s do just that:
$$\frac{3\times 0^2+2\times 0-5}{0-a}=3\times 0+23+\frac{156}{0-a}$$
$$\rightarrow \frac{5}{a}=23+\frac{156}{-a}$$Oh wow, now we can just solve for
a! Start by multiplying both sides by a.
$$5=23a-156$$
$$\rightarrow 23a=161$$
$$\rightarrow a=7$$There was still a little bit of work to do after we plugged in 0, but that was simple algebra compared to what we might have been facing otherwise.
Of course, this technique may not be helpful for every problem. But when you have a few variables or unknowns bugging you in a problem, try plugging in some simple numbers. You might be able to eliminate wrong answers, or reduce the problem to something more manageable, and friendlier!
Find this post interesting? Follow the blog using the link at the top of the page to get notified when new posts appear!
Want awesome tips and a mini-challenge, all designed to help you build vital problem-solving and critical thinking skills in your child? Click here to sign up for our monthly newsletter! |
We consider a smooth manifold $M$ of dimension $d$, a $C^{\infty}$ function $f:M\rightarrow \mathbb{R}$ and $p\in M$. Two charts in a neighborhood $Z$ of $p$: $\phi:U\subset \mathbb{R}^d\rightarrow Z,\phi(u)=p,\psi:V\subset \mathbb{R}^d\rightarrow Z,\psi(v)=p$ are s.t. the transition map $\tau=\phi^{-1}\circ \psi$ is a diffeomorphism. Note that $f$ is smooth iff $g=f\circ \phi$ or $g\circ\tau$ are smooth. Remark that $D(g\circ\tau)_v=Dg_u\circ D\tau_v$ and $Dg_u=0$ is equivalent to $D(g\circ \tau)_v=0$; in the previous case, one says that $p$ is a critical point of $f$.
Proposition 1. The signature of the Hessian of $f$ can be defined in $p\in M$ when $p$ is a critical point of $f$.
Proof. $D^2(g\circ\tau)_v(h,k)=D^2g_u(D\tau_v(h),D\tau_v(k))+Dg_u(D^2\tau_v(h,k))$. Since $Dg_u=0$, $D^2(g\circ\tau)_v(h,k)=D^2g_u(D\tau_v(h),D\tau_v(k))$. Let $K$ be the symmetric matrix associated to $D^2g_u$ and $P$ be the invertible matrix of the linear isomorphism $D\tau_v$; then the symmetric matrix associated to $D^2(g\circ\tau)_v$ is $P^TKP$. Clearly $K$ and $P^TKP$ have same signature and we are done.
Note that, in general, the Hessian of $f$ depends on the chosen chart!! In particular, its eigenvalues vary with the chosen chart.
According to Morse theory,
(*) We can choose a transition map $\tau$ s.t. $D\tau_v$ diagonalizes $K$, that is s.t. $P$ is orthogonal and $P^TKP=diag(\lambda_1\cdots,\lambda_q,\lambda_{q+1},\cdots,\lambda_d)$ where $\lambda_i<0$ for $i\leq q$ and otherwise, $\lambda_i\geq 0$.
Recall that $D\tau_v$ is an isomorphism between two representations of $TM_p$ and that $D^2(g\circ\tau)_v$ is a symmetric bilinear form defined on a representation of $TM_p$.
EDIT. I write the details of the second part. An element $h\in TM_p$ admits, as representative, a smooth curve $\gamma$ s.t. $\gamma(0)=p$; modulo the chart $\phi$, $h$ is identified to the unique vector $(\phi^{-1}\circ \gamma)'(0)\in\mathbb{R}^d$.
Proposition 2. The maximal dimension of the subspaces of the tangent space $TM_p$ of $M$ at $p$, on which $D^2g_v$ is negative definite, is $q$. This result does not depend on the chosen chart.
Proof. According to (*), the maximum is $\geq q$. Now, let $E$ be a subspace of $TM_p$ of dimension $r$ on which $D^2g_v$ is negative definite. There is a transition map $\tau$ associated to the decomposition $E\oplus E^{\perp}$; then $P^TKP$ is in the form $diag(X_r,Y_{n-r})$ where $X_r$ is symmetric $<0$. Note that $X_r$ has $r$ negative eigenvalues and, consequently, $r\leq q$. |
QML Tutorial¶
This tutorial is a general introduction to kernel-ridge regression with QML.
Theory¶
Regression model of some property, \(y\), for some system, \(\widetilde{\mathbf{X}}\) - this could correspond to e.g. the atomization energy of a molecule:
\(y\left(\widetilde{\mathbf{X}} \right) = \sum_i \alpha_i \ K\left( \widetilde{\mathbf{X}}, \mathbf{X}_i\right)\)
E.g. Using Gaussian kernel function with Frobenius norm:
\(K_{ij} = K\left( \mathbf{X}_i, \mathbf{X}_j\right) = \exp\left( -\frac{\| \mathbf{X}_i - \mathbf{X}_j\|_2^2}{2\sigma^2}\right)\)
Regression coefficients are obtained through kernel matrix inversion and multiplication with reference labels
\(\boldsymbol{\alpha} = (\mathbf{K} + \lambda \mathbf{I})^{-1} \mathbf{y}\) Tutorial exercises¶
git clone https://github.com/qmlcode/tutorial.git
Additionally, the repository contains Python3 scripts with the solutions to each exercise.
Exercise 1: Representations¶
In this exercise we use qml~to generate the Coulomb matrix and Bag of bonds (BoB) representations. [3]In QML data can be parsed via the
Compound class, which stores data and generates representations in Numpy’s ndarray format.If you run the code below, you will read in the file
qm7/0001.xyz (a methane molecule) and generate a coulomb matrix representation (sorted by row-norm) and a BoB representation.
import qml# Create the compound object mol from the file qm7/0001.xyz which happens to be methanemol = qml.Compound(xyz="qm7/0001.xyz")# Generate and print a coulomb matrix for compound with 5 atomsmol.generate_coulomb_matrix(size=5, sorting="row-norm")print(mol.representation)# Generate and print BoB bags for compound containing C and Hmol.generate_bob(asize={"C":2, "H":5})print(mol.representation)
The representations are simply stored as 1D-vectors.Note the keyword
size which is the largest number of atoms in a molecule occurring in test or training set.Additionally, the coulomb matrix can take a sorting scheme as keyword, and the BoB representations requires the specifications of how many atoms of a certain type to make room for in the representations.
Lastly, you can print the following properties which is read from the XYZ file:
# Print other properties stored in the objectprint(mol.coordinates)print(mol.atomtypes)print(mol.nuclear_charges)print(mol.name)print(mol.unit_cell)
Exercise 2: Kernels¶
In this exercise we generate a Gaussian kernel matrix, \(\mathbf{K}\), using the representations, \(\mathbf{X}\), which are generated similarly to the example in the previous exercise:
\(K_{ij} = \exp\left( -\frac{\| \mathbf{X}_i - \mathbf{X}_j\|_2^2}{2\sigma^2}\right)\)
QML supplies functions to generate the most basic kernels (E.g. Gaussian, Laplacian). In the exercise below, we calculate a Gaussian kernel for the QM7 dataset.In order to save time you can import the entire QM7 dataset as
Compound objects from the file
tutorial_data.py found in the tutorial GitHub repository.
# Import QM7, already parsed to QMLfrom tutorial_data import compoundsfrom qml.kernels import gaussian_kernel# For every compound generate a coulomb matrix or BoBfor mol in compounds: mol.generate_coulomb_matrix(size=23, sorting="row-norm") # mol.generate_bob(size=23, asize={"O":3, "C":7, "N":3, "H":16, "S":1})# Make a big 2D array with all the representationsX = np.array([mol.representation for mol in compounds])# Print all representationsprint(X)# Run on only a subset of the first 100 (for speed)X = X[:100]# Define the kernel widthsigma = 1000.0# K is also a Numpy arrayK = gaussian_kernel(X, X, sigma)# Print the kernelprint K
Exercise 3: Regression¶
With the kernel matrix and representations sorted out in the previous two exercise, we can now solve the \(\boldsymbol{\alpha}\) regression coefficients:
\(\boldsymbol{\alpha} = (\mathbf{K} + \lambda \mathbf{I})^{-1} \mathbf{y}\label{eq:inv}\)
One of the most efficient ways of solving this equation is using a Cholesky-decomposition.QML includes a function named
cho_solve() to do this via the math module
qml.math.In this step it is convenient to only use a subset of the full dataset as training data (see below).The following builds on the code from the previous step.To save time, you can import the PBE0/def2-TZVP atomization energies for the QM7 dataset from the file
tutorial_data.py.This has been sorted to match the ordering of the representations generated in the previous exercise.Extend your code from the previous step with the code below:
from qml.math import cho_solvefrom tutorial_data import energy_pbe0# Assign 1000 first molecules to the training setX_training = X[:1000]Y_training = energy_pbe0[:1000]sigma = 4000.0K = gaussian_kernel(X_training, X_training, sigma)print(K)# Add a small lambda to the diagonal of the kernel matrixK[np.diag_indices_from(K)] += 1e-8# Use the built-in Cholesky-decomposition to solvealpha = cho_solve(K, Y_training)print(alpha)
Exercise 4: Prediction¶
With the \(\boldsymbol{\alpha}\) regression coefficients from the previous step, we have (successfully) trained the machine, and we are now ready to do predictions for other compounds. This is done using the following equation:
\(y\left(\widetilde{\mathbf{X}} \right) = \sum_i \alpha_i \ K\left( \widetilde{\mathbf{X}}, \mathbf{X}_i\right)\)
In this step we further divide the dataset into a training and a test set. Try using the last 1000 entries as test set.
# Assign 1000 last molecules to the test setX_test = X[-1000:]Y_test = energy_pbe0[-1000:]# calculate a kernel matrix between test and training data, using the same sigmaKs = gaussian_kernel(X_test, X_training, sigma)# Make the predictionsY_predicted = np.dot(Ks, alpha)# Calculate mean-absolute-error (MAE):print np.mean(np.abs(Y_predicted - Y_test))
Exercise 5: Learning curves¶
Repeat the prediction from Exercise 2.4 with training set sizes of 1000, 2000, and 4000 molecules. Note the MAE for every training size. Plot a learning curve of the MAE versus the training set size. Generate a learning curve for the Gaussian and Laplacian kernels, as well using the coulomb matrix and bag-of-bonds representations. Which combination gives the best learning curve? Note you will have to adjust the kernel width (sigma) underway.
Exercise 6: Delta learning¶
A powerful technique in machine learning is the delta learning approach. Instead of predicting the PBE0/def2-TZVP atomization energies, we shall try to predict the difference between DFTB3 (a semi-empirical quantum method) and PBE0 atomization energies.Instead of importing the
energy_pbe0 data, you can import the
energy_delta and use this instead
from tutorial_data import energy_deltaY_training = energy_delta[:1000]Y_test = energy_delta[-1000:]
Finally re-draw one of the learning curves from the previous exercise, and note how the prediction improves. |
I'm currently studying Particle Physics and HEP and this acronym is omnipresent. I know it means
next-to-leading-order but, what is exactly the physical meaning of LO and NLO?
You say you know about Feynman diagrams, at least at tree level. So you might have seen loop diagrams, i.e. diagrams that contain a loop of internal lines (see e.g. https://en.wikipedia.org/wiki/One-loop_Feynman_diagram).
Now, the whole point of Feynman diagrams is to expand the phyisical quantity we are interested in as a power series, $$\sigma= a_0 + \alpha\cdot a_1 + \alpha^2 \cdot a_2 +\dotsm$$ For this to make sense, the expansion parameter $\alpha$, which usually is (related to) some coupling constant, needs to be small -- for example, in QED, $\alpha\approx 1/137$. Then, the higher-order terms, i.e. those with higher powers of $\alpha$, are suppressed, and the lower-order terms dominate (note that I'm glossing over quite a number of issues here to get the basic picture across).
In other words, the lowest-power of $\alpha$ with a nonzero term $a_i$ gives the most important contribution, called
leading order, and the other ones are higher-order. In particular, the next one is the next-to-leading order (NLO), contribution and so on (for example, this paper computes NNNNLO contributions: https://arxiv.org/abs/hep-ph/0610143).
This notation is used in other fields as well: Whenever you have a approximation scheme with a most important term and successively smaller corrections, it makes sense to speak of leading-order, NLO etc. |
Convergence of Limsup and Liminf Theorem
Let $\sequence {x_n}$ be a sequence in $\R$.
Let the limit superior of $\sequence {x_n}$ be $\overline l$.
Let the limit inferior of $\sequence {x_n}$ be $\underline l$.
Proof Sufficient Condition
First, suppose that $\overline l = \underline l = l$.
Let $\epsilon > 0$.
$\exists N_1: \forall n > N_1: x_n < l + \epsilon$
Similarly:
$\exists N_2: \forall n > N_2: x_n > l - \epsilon$
So take $N = \max \set {N_1, N_2}$.
If $n > N$, both the above inequalities hold at the same time.
So $l - \epsilon < x_n < l + \epsilon$ and so by Negative of Absolute Value:
$\size {x_n - l} < \epsilon$
Thus $x_n \to l$ as $n \to \infty$.
$\Box$
Necessary Condition
Then by Limit of Subsequence equals Limit of Real Sequence, all subsequences have a limit of $l$ and the result follows.
$\blacksquare$
Sources 1962: Bert Mendelson: Introduction to Topology... (previous) ... (next): $\S 2.5$: Limits: Exercise $5$ 1977: K.G. Binmore: Mathematical Analysis: A Straightforward Approach... (previous) ... (next): $\S 5$: Subsequences: Exercise $\S 5.15 \ (5)$ 2005: René L. Schilling: Measures, Integrals and Martingales... (previous) ... (next): $\S 8$ |
The Markov chain $(Xn; n\geq)$ has state-space $S = (0, 1, 2, . . .)$, with
$p_{i,0} = \frac{1}{4}$ and $p_{i,i+1} = \frac{3}{4}$ $\forall i \geq 0$, so that the transition matrix is
P =$\begin{pmatrix} \frac{1}{4} & \frac{3}{4} & 0 & 0 & ...\\\ \frac{1}{4} & 0 & \frac{3}{4} & 0 & ... \\\ \frac{1}{4} & 0 & 0 & \frac{3}{4} &... \\\ \vdots & \vdots&\vdots&\vdots& \ddots \end{pmatrix}$
Find the irreducible classes of intercommunicating states. For each class, state:
(a) whether it is
transient, positive recurrent or null recurrent(hint - think about the distribution of the return times - say to state 0 - in this case. From there, you can work out whether the states have a finite or infinite expected return time. Can you work out what sort of states you have here?)
(b) its
periodicity.
I have tried to approach the first part with a state space diagram and have found that only state 0 and 1 intercommunicate and that the rest of the states do not. But, it is possible to return to every state at some point (say we got to 3, we can then go to state 4, then state 0, 1, 2 and end up at 3 again. So would I put {0,1,2,3,4, ...} into one class?
I guess I am also not 100% sure about how to classify the states. |
Examples of solving linear discrete dynamical systems
The solution to a linear discrete dynamical system is an exponential because in each time step, we multiply by a fixed number. It is easy to see what number we multiply in each time step when the dynamical system is in function iteration form. When the dynamical system is given in difference form, we must first transform the dynamical system into function iteration form. These examples illustrate the process.
Example 1
A example of the simplest form is \begin{align*} z_{n+1} &= 0.5 z_n\\ z_0 &= 1024. \end{align*} The dynamical system is given function iteration form and everything is in terms of numbers. Solve the dynamical system and use it to compute $z_{10}$.
Solution: By solution, we mean a formula for $z_n$ just in terms of the initial condition and the time index $n$. In each time step, we multiply by 0.5. To go from time step zero to time step $n$, we must multiply by 0.5 a total of $t$ times. The solution is therefore
\begin{align*}
z_n = (0.5)^n z_0 = (0.5)^n1024
\end{align*}
Using the formula, it is simple to calculate $z_{10}$. It is $z_{10} = (0.5)^{10}1024 =1.$ Example 2
We can make the example slightly more complicated by using a parameter, let's call it $R$, as the number we must multiply by each time step. We'll also use $t$ rather than $n$ for the time step and let the initial condition be another parameter, let's use $d$. Choosing $p$ for the state variable, the dynamical system is \begin{align*} p_{t+1} &= Rp_t\\ p_0 &= d. \end{align*} Solve the dynamical system.
Solution: The system really isn't much harder than the previous. Our solution must be a formula for $p_t$ just in terms of the initial condition and the time index $t$. The solution will also contain the parameters $R$ and $d$ rather than just numbers like the previous example. The main point for the solution is that it can contain the value of the state variable only at the initial time point $t=0$.
Starting with $p_0=d$ at $t=0$, to get $p_t$, we must multiply by $R$ a total of $t$ times. The solution is $$p_t = R^t d.$$
Example 3
Let's mix things up a little bit by writing the dynamical system in difference form. Using $z_n$ as the state variable and keeping every else in terms of numbers, we'll examine the linear discrete dynamical system \begin{align*} z_{n+1} - z_n &= -0.5 z_n\\ z_0 &= 1024. \end{align*} Solve the dynamical system and use it to compute $z_{10}$.
Solution:In this example, the change in $z$ at each time step is half of the value of $z$, but with a negative sign. We subtract off half of $z$ at each time step, but it isn't clear how to write a formula that gives the result of subtracting off half $z$ for a total of $n$ times in a row. The reason the answer isn't so obvious is because the dynamical system is written in difference form, with the change is $z$ on the left side of the equation. If we rewrite the dynamical system in function iteration form by solving the evolution rule for $z_{n+1}$, then it will be clearer how to proceed.
To convert the evolution rule $z_{n+1} - z_n = -0.5 z_n$ to function iteration form, we solve for $z_{n+1}$ by adding $z_{n}$ to both sides of the equation. \begin{align*} z_{n+1} - z_n +z_n &= -0.5 z_n + z_n\\ z_{n+1} &= 0.5 z_n. \end{align*} Now $z_{n+1}$ is written as a function of $z_n$, i.e., $z_{n+1}=f(z_n)$ for the function $f(z)=0.5 z_n$. We must apply the function “multiply by 0.5” at each time step.
Combining the evolution rule with the initial condition, the dynamical system in function iteration form is \begin{align*} z_{n+1} &= 0.5 z_n\\ z_0 &= 1024. \end{align*} The dynamical system is identical to the one from the first example. The solution is that we must apply the function “multiply by 0.5” to $z_0$ a total of $n$ times to reach $z_n$: \begin{align*} z_n = (0.5)^n z_0 = (0.5)^n1024 \end{align*} After 10 time steps, $z_{10} = (0.5)^{10}1024 =1.$
Example 4
Let's try an example in difference form but with parameters. \begin{align*} p_{t+1} - p_t &= rp_t\\ p_0 &= d. \end{align*} Now, starting with the initial condition $d$, we add $rp_t$ at each time step, where $r$ and $d$ are parameters. Solve the dynamical system.
Solution: The system is given in difference form. To solve the dynamical system, we must rewrite it in function iteration form. We add $p_{t}$ to both sides of the evolution rule.
\begin{align*}
p_{t+1} - p_t + p_t &= rp_t + p_t\\
p_{t+1} &= (r+1)p_t.
\end{align*}
Combining this new form of the evolution rule with the initial condition, we can write the dynamical system in function iteration form as
\begin{align*}
p_{t+1} &= (r+1)p_t\\
p_0 &= d.
\end{align*}
At each time step we apply the function $p_{t+1} = f(p_t)$, where $f(p)=(r+1)p$. In other words, we apply the function “multiply by $r+1$.” To go from $p_0$ to $p_t$, we must apply this function $t$ times, or multiply by $r+1$ for a total of $t$ times. This is the same thing as multiplying by $(r+1)^t$. The solution is
$$p_t = (r+1)^t p_0.$$
Using the the initial condition, $p_0=d$, we could also write the solution as
$$p_t = (r+1)^t d.$$
This example is only slightly different from example 2. In fact, if we wanted to make it look exactly like example 2, we could define a new parameter $R$ by setting $R=r+1$. If we were to replace $r+1$ by the symbol $R$, then the dynamical system would be \begin{align*} p_{t+1} &= Rp_t\\ p_0 &= d. \end{align*} with solution $$p_t = R^t d.$$ That looks a little simpler. But in either case, the solution is pretty simple. We just multiply the initial condition $d$ by the number $r+1$, which we could also define as $R$, a total of $t$ times to get to $p_t$.
Example 5
Let's continue the moose example of the discrete dynamical system introduction. In that example, a moose population grew by 8% each year, starting with an initial population size of 1000 moose. If we let the state variable $m_t$ be the number of moose in a population in year $t$, then we can write the dynamical system as \begin{align*} m_{t+1}-m_t &= 0.08 m_t\\ m_0 &= 1000. \end{align*} Solve this dynamical system. Use the solution to calculate the moose population size every ten years up to year 50.
Solution: The dynamical system is written in difference form, as we derived the model thinking about the change in the moose population size. To rewrite it in function iteration form, we add $m_t$ to both sides to the evolution rule, obtaining
\begin{align*}
m_{t+1} &= 1.08 m_t\\
m_0 &= 1000.
\end{align*}
Since we start with a population size of 1000, and in each time step, we multiply the 1.08, the solution to the dynamical system is
$$m_t = 1000 \cdot (1.08)^t.$$
From this solution, we calculate the population size every 10 years.
\begin{align*}
m_{10} &= 1000 (1.08)^{10} \approx 2158.92\\
m_{20} &= 1000 (1.08)^{20} \approx 4660.96\\
m_{30} &= 1000 (1.08)^{30} \approx 10062.66\\
m_{40} &= 1000 (1.08)^{40} \approx 21724.52\\
m_{50} &= 1000 (1.08)^{50} \approx 46901.61
\end{align*} |
Because this is a diatomic molecule, there are no group orbitals. Put another way, the group orbitals
are the molecular orbitals. Knowing the nitrogen atomic orbitals (AOs) and their irreducible representation (irrep) labels is enough.
Since we'll work in the $D_{\mathrm{2h}}$ point group, we need its character table:
$$\begin{array}{c|cccccccc|cc} \hlineD_\mathrm{2h} & E & C_2(z) & C_2(y) & C_2(x) & i & \sigma(xy) & \sigma(xz) & \sigma(yz) & & \\ \hline\mathrm{A_g} & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & & x^2,y^2,z^2 \\\mathrm{B_{1g}} & 1 & 1 & -1 & -1 & 1 & 1 & -1 & -1 & R_z & xy \\\mathrm{B_{2g}} & 1 & -1 & 1 & -1 & 1 & -1 & 1 & -1 & R_y & xz \\\mathrm{B_{3g}} & 1 & -1 & -1 & 1 & 1 & -1 & -1 & 1 & R_x & yz \\\mathrm{A_u} & 1 & 1 & 1 & 1 & -1 & -1 & -1 & -1 & & \\\mathrm{B_{1u}} & 1 & 1 & -1 & -1 & -1 & -1 & 1 & 1 & z & \\\mathrm{B_{2u}} & 1 & -1 & 1 & -1 & -1 & 1 & -1 & 1 & y & \\\mathrm{B_{3u}} & 1 & -1 & -1 & 1 & -1 & 1 & 1 & -1 & x & \\ \hline\end{array}$$
Using the nitrogen atom's electron configuration $\ce{1s^{2} 2s^{2} 2p^{3}}$ as our minimal basis, no d-orbitals will be present, so we can assign irreps to each AO right away, in part because we assume the principal rotation axis (the one of highest order) is aligned along the z-axis:
$$\begin{array}{cccc}\hline\mathrm{s} & \mathrm{p}_x & \mathrm{p}_y & \mathrm{p}_z \\\hline\mathrm{A_{g}} & \mathrm{B_{3u}} & \mathrm{B_{2u}} & \mathrm{B_{1u}} \\\hline\end{array}$$
Then, proceed by starting to form the standard MO diagram for a diatomic, but add the irrep labels to each AO:
Note that I haven't spaced the energy levels properly; the $\ce{1s}$ should be much lower than it is relative to the $\ce{2s}$. More on this later. Regardless, because this is a homodiatomic, all AOs will mix at each energy level, even the core $\ce{1s}$ AOs. Then, attempt to form the MOs:
This is probably wrong, but it's a starting point. Again, energy levels will be discussed later. Finally, add symmetry labels to each MO, remembering that
MO symmetry is derived from AO symmetry, numbering is consecutive within each irrep, not with respect to the set of all MOs, and lowercase is used to signify that these are MOs; uppercase is for the irreps themselves.
This is our final MO diagram for $\ce{N2}$. To form the diagram for $\ce{N2^+}$, remove an electron from $\mathrm{4a_g}$. This ignores orbital relaxation effects, but for the purposes of working this out on paper, it should be fine.
Now for the matter of relative and absolute energy levels. It is probably possible to get the correct relative ordering of the MO energy levels. Here, I assume that since AO mixes with an identical partner on the other atom, the splitting for $\ce{1s}$ would be the same as $\ce{2s},~\ce{2p_z}$, etc. Since I drew the $\ce{1s}$ too high, the $\mathrm{3a_g}$ is almost certainly too high, and perhaps should even go below what is labeled as $\mathrm{2a_g}$. The way to confirm this, and the only way to get absolute energy levels, is to perform a quantum chemical calculation. Since we've used a minimal basis for the drawing, we'll stick a minimal basis in the calculation. Here is a Psi4 input file:
molecule {
N 0.0 0.0 0.0
N 0.0 0.0 1.0975
}
set {
basis sto-3g
scf_type direct
df_scf_guess false
cubeprop_orbitals [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
}
e, wfn = energy('hf', return_wfn=True)
cubeprop(wfn)
and from its output:
Orbital Energies (a.u.)
-----------------------
Doubly Occupied:
1Ag -15.518067 1B1u -15.516124 2Ag -1.442840
2B1u -0.722491 1B2u -0.573123 1B3u -0.573123
3Ag -0.539495
Virtual:
1B2g 0.281319 1B3g 0.281319 3B1u 1.123476
It looks like I might have messed up the diagram, because the ordering isn't what's expected (why isn't $\mathrm{B_{1u}}$ degenerate with the other two p-orbitals?), and the virtual degenerate p-orbitals have gerade symmetry. Time to plot!
In my haste, I forgot an important point. When you make the MOs from AOs, you're making two linear combinations:
\begin{align}\psi_{s} &= \frac{1}{\sqrt{2}} (\chi_{l} + \chi_{r}) \\\psi_{a} &= \frac{1}{\sqrt{2}} (\chi_{l} - \chi_{r}),\end{align}
which means that an antisymmetric combination of two s orbitals will look like a $\mathrm{p}_z$ orbital. This doesn't fully explain everything, but is a good starting point. The lesson up to now is that while drawing the diagrams by hand is a useful exercise, it is not enough to do only that when the goal is to perform a correlated
ab initio electronic structure calculation. |
Quantitative Modeling for Algorithmic Traders – Primer Quantitative Modeling techniques enable traders to mathematically identify, what makes data “tick” – no pun intended 🙂 .
They rely heavily on the following core attributes of any sample data under study:
Expectation– The mean or average value of the sample Variance– The observed spread of the sample Standard Deviation– The observed deviation from the sample’s mean Covariance– The linear association of two data samples Correlation– Solves the dimensionality problem in Covariance Why a dedicated primer on Quantitative Modeling?
Understanding how to use the five core attributes listed above in practice, will enable you to:
Construct diversified DARWIN portfolios using Darwinex’ proprietary Analytical Toolkit. Conduct mean-variance analysisfor validating your DARWIN portfolio’s composition. Build a solid foundation for implementing more sophisticated quantitative modeling techniques. Potentially improve the robustnessof trading strategies deployed across multiple assets.
Hence, a post dedicated to defining these core attributes, with practical examples in R (statistical computing language) should hopefully serve as good reference material to accompany existing and future posts.
Why R? It facilitates the analysis of large price datasets in short periods of time. Calculations that would otherwise require multiple lines of code in other languages, can be done much faster as R has a mature base of libraries for many quantitative finance applications. It’s free to download here.
* Sample data ( EUR/USD and GBP/USD End-of-Day Adjusted Close Price) used in this post was obtained from Yahoo, where it is freely available to the public.
Before progressing any further, we need to download EUR/USD and GBP/USD sample data from Yahoo Finance (time period: January 01 to March 31, 2017)
In R, this can be achieved with the following code:
library(quantmod)
getSymbols("EUR=X",src="yahoo",from="2017-01-01", to="2017-03-31")
getSymbols("GBP=X",src="yahoo",from="2017-01-01", to="2017-03-31")
Note: “EUR=X” and “GBP=X” provided by Yahoo are in terms of US Dollars, i.e. the data represents USD/EUR and USD/GBP respectively. Hence, we will need to convert base currencies first.
To achieve this, we will first extract the
Adjusted Close Price from each dataset, convert base currency and merge both into a new data frame for use later:
eurAdj = unclass(`EUR=X`$`EUR=X.Adjusted`)
# Convert to EUR/USD
eurAdj = 1/eurAdj
gbpAdj <- unclass(`GBP=X`$`GBP=X.Adjusted`)
# Convert to GBP/USD
gbpAdj <- 1/gbpAdj
# Extract EUR dates for plotting later.
eurDates = index(`EUR=X`)
# Create merged data frame.
eurgbp_merged <- data.frame(eurAdj,gbpAdj)
Finally, we merge the prices and dates to form one single dataframe, for use in the remainder of this post:
eurgbp_merged = data.frame(eurDates, eurgbp_merged)
colnames(eurgbp_merged) = c("Dates", "EURUSD", "GBPUSD")
The mean is its average value. μ of a price series μof a price series
It is calculated by adding all elements of the series, then dividing this sum by the total number of elements in the series.
Mathematically, the mean
μ of a price series P, where elements p ∈ P, with n number of elements in P, is expressed as: \(μ = E(p) = \frac{1}{n} ∑ (p_1 + p_2 + p_3 + … + p_n)\)
In R, the
mean of a sample can be calculated using the mean() function.
For example, to calculate the mean price observed in our sample of EUR/USD data, ranging from January 01 to March 31, 2017, we execute the following code to arrive at mean 1.065407:
mean(eurgbp_merged$EURUSD)
[1] 1.065407
Using the
plotly library in R, here’s the mean overlayed graphically on this EUR/USD sample:
library(plotly)
plot_ly(name="EUR/USD Price", x = eurgbp_merged$Dates, y = as.numeric(eurgbp_merged$EURUSD), type="scatter", mode="lines") %>%
add_trace(name="EUR/USD Mean", y=(as.numeric(mean(eurgbp_merged$EURUSD))), mode="lines")
The variance of a price series is simply the mean or expectation, of the square of (how much price deviates from the mean). σ² σ²
It characterises the range of movement around the mean, or “spread” of the price series.
Mathematically, the
variance σ² of a price series P, with elements p ∈ P, and mean μ, is expressed as: \(σ²(p) = E[(p – μ)²]\) Standard Deviation is simply the square root of variance, expressed as σ: \(σ = \sqrt{σ²(p)} = \sqrt{E[(p – μ)²]}\)
In R, the
standard deviation of a sample can be calculated using the sd() function.
For example, to calculate the standard deviation observed in our sample of EUR/USD data, ranging from January 01 to March 31, 2017, we execute the following code to arrive at s.d. 0.00996836:
sd(eurgbp_merged$EURUSD)
[1] 0.00996836
Using the
plotly library in R again, we can overlay a single (or more) positive and negative standard deviation from the mean, as follows:
plot_ly(name="EUR/USD Price", x = eurgbp_merged$Dates, y = as.numeric(eurgbp_merged$EURUSD), type="scatter", mode="lines") %>%
add_trace(name="+1 S.D.", y=(as.numeric(mean(eurgbp_merged$EURUSD))+sd(eurgbp_merged$EURUSD)), mode="lines", line=list(dash="dot")) %>%
add_trace(name="-1 S.D.", y=(as.numeric(mean(eurgbp_merged$EURUSD))-sd(eurgbp_merged$EURUSD)), mode="lines", line=list(dash="dot")) %>%
add_trace(name="EUR/USD Mean", y=(as.numeric(mean(eurgbp_merged$EURUSD))), mode="lines")
The sample covariance of two price series, in this case EUR/USD and GBP/USD, each with its respective sample mean, describes their linear association, i.e. how they move together in time.
Let’s denote EUR/USD by variable ‘
e’ and GBP/USD by variable ‘ g‘.
These price series will then have respective sample means of \(\overline{e}\) and \(\overline{g}\) respectively.
Mathematically, their
sample covariance, Cov(e, g), where both have n number of data points \((e_i, g_i)\), can be expressed as: \(Cov(e,g) = \frac{1}{n-1}\sum_{i=1}^{n}(e_i – \overline{e})(g_i – \overline{g})\)
In R,
sample covariance can be calculated easily using the cov() function.
Before we calculate covariance, let’s first use the
plotly library to draw a scatter plot of EUR/USD and GBP/USD.
To visualize linear association, we will also perform a
linear regression on the two price series, followed by drawing this as a line of best fit on the scatter plot.
This can be achieved in R using the following code:
# Perform linear regression on EUR/USD and GBP/USD
fit <- lm(EURUSD ~ GBPUSD, data=eurgbp_merged)
# Draw scatter plot with line of best fit
plot_ly(name="Scatter Plot", data=eurgbp_merged, y=~EURUSD, x=~GBPUSD, type="scatter", mode="markers") %>%
add_trace(name="Linear Regression", data=eurgbp_merged, x=~GBPUSD, y=fitted(fit), mode="lines")
Based on this plot, EUR/USD and GBP/USD have a positive linear association.
To
calculate the sample covariance of EUR/USD and GBP/USD between January 01 and March 31, 2017, we execute the following code to arrive at covariance 7.629787e-05:
cov(eurgbp_merged$EURUSD, eurgbp_merged$GBPUSD)
[1] 7.629787e-05
Problem: Being dimensional in nature, calculating just Covariance makes it difficult to compare price series with significantly different variances. Solution: Calculate Correlation, which is Covariance normalized by the standard deviations of each price series, hence making it dimensionless and a more interpretable ratio of linear association between two price series.
Mathematically, Correlation ρ(e,g) of EUR/USD and GBP/USD, where \(σ_e\) and \(σ_g\) are their respective standard deviations, can be expressed as:
\(ρ(e,g) = \frac{Cov(e,g)}{σ_e σ_g} = \frac{\frac{1}{n-1}\sum_{i=1}^{n}(e_i – \overline{e})(g_i – \overline{g})}{σ_e σ_g}\) Correlation = +1 indicates EXACT positive association. Correlation = -1 indicates EXACT negative association. Correlation = 0 indicates NO linear association.
In R,
correlation can be calculated easily using the cor() function.
For example, to calculate the correlation between EUR/USD and GBP/USD, from January 01 to March 31, 2017, we execute the following code to arrive at 0.5169411:
cor(eurgbp_merged$EURUSD, eurgbp_merged$GBPUSD)
[1] 0.5169411
0.5169411 implies reasonable positive correlation between EUR/USD and GBP/USD, which is what we visualized earlier with our scatter plot and line of best fit.
In future blog posts, we will examine how to construct diversified DARWIN Portfolios using the information above in practice.
Trade safe,
The Darwinex Team
—
Additional Resource: Learn more about DARWIN Portfolio Risk (VIDEO) * please activate CC mode to view subtitles. Do you have what it takes? – Join the Darwinex Trader Movement! |
I'm currently reading some papers about Markov chain lumping and I'm failing to see the difference between a Markov chain and a plain directed weighted graph.
For example in the article Optimal state-space lumping in Markov chains they provide the following definition of a CTMC (continuous time Markov chain):
We consider a finite CTMC $(\mathcal{S}, Q)$ with state space $\mathcal{S} = \{x_1, x_2, \ldots, x_n\}$ by a transition rate matrix $Q: \mathcal{S} \times \mathcal{S} \to \mathbb{R}^+$.
They don't mention the Markov property at all, and, in fact, if the weight on the edges represents a probability I believe the Markov property trivially holds since the probability depends only on the current state of the chain and not the path that lead to it.
In an other article On Relational Properties of Lumpability Markov chains are defined similarly:
A Markov chain $M$ will be represented as a triplet $(S, P, \pi)$ where $S$ is the finite set of states of $M$, $P$ the transition probability matrix indicating the probability of getting from one state to another, and $\pi$ is the initial probability distribution representing the likelyhood for the system to start in a certain state.
Again, no mention of past or future or independence.
There's a third paper Simple O(m logn) Time Markov Chain Lumping where they not only never state that the weights on the edges are probabilities, but they even say:
In many applications, the values $W(s, s')$ are non-negative. We do not make this assumption, however, because there are also applications where $W(s, s)$ is deliberately chosen as $-W(s, S \setminus \{s\})$, making it usually negative.
Moreover, it's stated that lumping should be a way to reduce the number of states while maintaining the Markov property (by aggregating "equivalent" state into a bigger state). Yet, to me, it looks like it's simply summing probabilities and it shouldn't even guarantee that the resulting peobabilities of the transitions to/from the aggregated states are in the range $[0,1]$. What does the lumping actually preserve then?
So, there are two possibilities that I see:
I didn't understand what a Markov chain is, or The use of the term Markov chain in those papers is bogus
Could someone clarify the situation?
It really looks like there are different communities using that term and they mean widely different things. From these 3 articles that I'm considering it looks like the Markov property is either trivial or useless, while looking at a different kind of papers it looks fundamental. |
Countable models of PA fall into two categories: the standard one $(\omega, S)$ and the nonstandard ones (all the rest). The only way I've seen to construct a nonstandard model is through taking an ultraproduct or, equivalently, using the compactness theorem. My question is wether or not these are all the models there are? There are continuum many ultrafilters and continuum many nonstandard, countable models, but I don't know if there's a surjective correspondence.
An ultrapower will never yield a countable nonstandard model of PA --- either you will recover the standard model or the result will be uncountable.
As far as the construction of a model is concerned, due to Tennenbaum's theorem (see http://en.wikipedia.org/wiki/Tennenbaum's_theorem) you will never see a recursive nonstandard model of PA. Hence, in some sense, you will never construct a countable model of PA other than the standard model.
On the other hand, if you consider the Henkin construction to be constructive enough for you, then by running his construction relative to the theory in ${\mathcal L}(+,\times,0,1,c,<)$ consisting of PA together with all the assertions $c > n$ for each $n \in {\mathbb N}$, then you would obtain a nonstandard model of PA.
It could be mentioned perhaps that Skolem's non-standard model of arithmetic (1933-1934) is countable and is a kind of a "definable" version of the ultraproduct construction. Namely, Skolem only uses definable sequences in his construction. The advantage of his model is that it is constructed without using the axiom of choice. |
According to my revision guide baryon and mesons always interact via the strong interaction.
Does this hold for baryon-baryon interactions? meson-meson?
Thanks
Physics Stack Exchange is a question and answer site for active researchers, academics and students of physics. It only takes a minute to sign up.Sign up to join this community
Quarks, the constituents of hadrons/mesons, interact via the strong, weak and electromagnetic force. So hadrons/mesons do interact via all this forces, too. Even if the total net-carge is zero. Take for instance the neutron, which has zero electric charge. Still it has a magnetic moment which gives rise to electromagnetic interactions. It can also decay via a weak process, which is commonly known as beta-radiation.
Charged hadrons, and neutral hadrons with nonzero magnetic moment, interact electromagnetically. A spinless, neutral hadron would not couple to the electromagnetic field at tree level, but the most obvious example of such a particle is the $\pi^0$, which
decays electromagnetically to two photons.
All particles with flavor participate in the weak interaction. You mostly hear about this in terms of decays, because for ordinary interaction energies the weak interaction is too feeble to contribute much to the dynamics. You can consider the weak interaction between strongly- or electromagnetically-interacting particles as a Yukawa-type force, $$ V \propto \frac{e^{-r/r_0}}{r}, $$ where the length scale is set by the mass of the weak boson, $r_0 \approx (\hbar c) / (m_Wc^2)$.
However, the weak interaction has a different set of symmetries than the strong and electromagnetic forces. Specifically, the weak interaction is broken under parity transformations, while the strong and E&M transitions are not. You can therefore peer down into the short-distance physics of low-energy interactions by looking for parity-violating observables. The most common method is to look for an asymmetry in a scalar quantity, like reaction rate, that depends on the angle between a spin and a momentum, $\vec\sigma\cdot\vec p$.
The purely hardronic weak interaction (by which I mean, without any leptonic decays involved) is a hard thing to suss out theoretically, because the strong force is both (a) strong, and (b) complicated. In many-body systems, you may have opposite-parity excited states which happen to be nearly degenerate in energy and are mixed by the weak interaction. The largest known enhancement of this type, to my knowledge, occurs in some of the excited states probed by neutron capture on lanthanum: there is a correlation between the incoming neutron's spin $\vec\sigma_\text{n}$ and the outgoing photon's direction $\vec k_\gamma$ that turns out to be a 10% asymmetry. But lanthanum is an enormously complicated nucleus. In neutron capture on hydrogen the same asymmetry is about ten parts per billion.
So, while hadrons
always interact via the strong interaction, theycertainly do not only interact via the strong interaction. |
In the above example, how is it that $f^{-1}((1,3)) = (2,3]$ ? Here is my understanding, kindly correct the misconceptions. The inverse for $(2,4]$ is not defined. The inverse is as below. $$f^{-1}(y)=\begin{cases} y+1 & \text { if } y \le 2\\ 2y-5 & \text{ if } y \gt 4\\ \end{cases}$$ So, if I have to find out for example, $f^{-1}(2\frac{1}{2})$, how do I do it? When does $f^{-1}(y)$ give me $3$ (to justify the $3$ in $(2,3]$ ) ?
The inverse image $f^{-1}(S)$ refers to the set $$\{x \in \Bbb{R} : f(x) \in S\}$$ This would mean that $$f^{-1}(\{2\frac{1}{2}\}) = \emptyset$$ We also have, $$f^{-1}(1, 3) = \{x \in S : 1 < f(x) < 3\},$$ which is true precisely for $2 < x \le 3$. There's no requirement that there be some $x$ such that $f(x) = 2.5$; just so long as it's less than $3$.
If $x>3$ we have that $f(x) = \frac{1}{2}(x+5) > \frac{1}{2} \cdot 8 = 4$ and so $f(x) \notin (1,3)$.
If $2< x \le 3$ we have that $f(x)=x-1 \in (1,2] \subseteq (1,3)$ and
If $x \le 2$, $f(x)=x-1 \le 1$,so $f(x) \notin (1,3)$
Hence $f^{-1}((1,3) = \{x: f(x) \in (1,3) \} = (2,3]$, as we covered all options for $x$.
Inverse image is not "image under a (non-existent) inverse function". For example: if $f: \mathbb{R} \to \mathbb{R}$ is the function that is constant with value $2$, then $f^{-1}(\{2\}) = \mathbb{R}$ and $f^{-1}(\{1\}) = \emptyset$. We are talking about inverse images of sets, not of points. |
It looks like you're new here. If you want to get involved, click one of these buttons!
Show that the map \(\Phi\) from the Introduction, which was roughly given by ‘Is • connected to ∗?’ is a monotone map from the preorder shown in Eq. (1.2) to \( \mathbb{B}.\)
If we apply the map "is \(\bullet\) connected to \(\star\)" to the diagram on the left we obtain the following diagram:
All the paths above are valid since they exist in the Boolean poset (as indicated by the colors in the diagram below); hence the map \(\phi\) is a monotone map.
If we apply the map "is \\(\bullet\\) connected to \\(\star\\)" to the diagram on the left we obtain the following diagram:
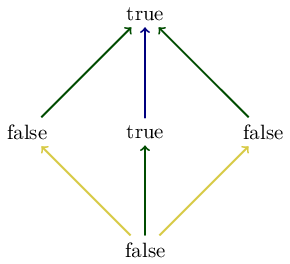
All the paths above are valid since they exist in the Boolean poset (as indicated by the colors in the diagram below); hence the map \\(\phi\\) is a monotone map.
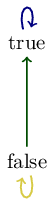
Since \(\mathrm{false} \le a\) for all \(a \in \mathbb{B}\) and \(\mathrm{true} \le \mathrm{true}\), it is sufficient to check that if \(a \le a'\) and \(f(a) = \mathrm{true}\), then \(f(a') = \mathrm{true}\). Because \(a\) is finer than \(a'\), every part in \(a\) is a subset of a part in \(b\). Therefore, since \(\bullet\) and \(\ast\) are in the same part in \(a\), they will also be in the same part in \(a'\). Hence, \(f(a') = \mathrm{true}\).
Since \\(\mathrm{false} \le a\\) for all \\(a \in \mathbb{B}\\) and \\(\mathrm{true} \le \mathrm{true}\\), it is sufficient to check that if \\(a \le a'\\) and \\(f(a) = \mathrm{true}\\), then \\(f(a') = \mathrm{true}\\). Because \\(a\\) is finer than \\(a'\\), every part in \\(a\\) is a subset of a part in \\(b\\). Therefore, since \\(\bullet\\) and \\(\ast\\) are in the same part in \\(a\\), they will also be in the same part in \\(a'\\). Hence, \\(f(a') = \mathrm{true}\\).
We want to show that x≤y implies Φ(x)≤ Φ(y). If x≤y, that means that if • and ∗ are connected in x then they are connected in y. So • and ∗ are either connected in both x and y, disconnected in x and y, or disconnected in x and connected in y. Then (Φ(x), Φ(y)) is either (true, true), (false, false), or (false, true). In all cases Φ(x)≤Φ(y). |
It looks like you're new here. If you want to get involved, click one of these buttons!
In this chapter we learned about left and right adjoints, and about joins and meets. At first they seemed like two rather different pairs of concepts. But then we learned some deep relationships between them. Briefly:
Left adjoints preserve joins, and monotone functions that preserve enough joins are left adjoints.
Right adjoints preserve meets, and monotone functions that preserve enough meets are right adjoints.
Today we'll conclude our discussion of Chapter 1 with two more bombshells:
Joins
are left adjoints, and meets are right adjoints.
Left adjoints are right adjoints seen upside-down, and joins are meets seen upside-down.
This is a good example of how category theory works. You learn a bunch of concepts, but then you learn more and more facts relating them, which unify your understanding... until finally all these concepts collapse down like the core of a giant star, releasing a supernova of insight that transforms how you see the world!
Let me start by reviewing what we've already seen. To keep things simple let me state these facts just for posets, not the more general preorders. Everything can be generalized to preorders.
In Lecture 6 we saw that given a left adjoint \( f : A \to B\), we can compute its right adjoint using joins:
$$ g(b) = \bigvee \{a \in A : \; f(a) \le b \} . $$ Similarly, given a right adjoint \( g : B \to A \) between posets, we can compute its left adjoint using meets:
$$ f(a) = \bigwedge \{b \in B : \; a \le g(b) \} . $$ In Lecture 16 we saw that left adjoints preserve all joins, while right adjoints preserve all meets.
Then came the big surprise: if \( A \) has all joins and a monotone function \( f : A \to B \) preserves all joins, then \( f \) is a left adjoint! But if you examine the proof, you'l see we don't really need \( A \) to have
all joins: it's enough that all the joins in this formula exist:
$$ g(b) = \bigvee \{a \in A : \; f(a) \le b \} . $$Similarly, if \(B\) has all meets and a monotone function \(g : B \to A \) preserves all meets, then \( f \) is a right adjoint! But again, we don't need \( B \) to have
all meets: it's enough that all the meets in this formula exist:
$$ f(a) = \bigwedge \{b \in B : \; a \le g(b) \} . $$ Now for the first of today's bombshells: joins are left adjoints and meets are right adjoints. I'll state this for binary joins and meets, but it generalizes.
Suppose \(A\) is a poset with all binary joins. Then we get a function
$$ \vee : A \times A \to A $$ sending any pair \( (a,a') \in A\) to the join \(a \vee a'\). But we can make \(A \times A\) into a poset as follows:
$$ (a,b) \le (a',b') \textrm{ if and only if } a \le a' \textrm{ and } b \le b' .$$ Then \( \vee : A \times A \to A\) becomes a monotone map, since you can check that
$$ a \le a' \textrm{ and } b \le b' \textrm{ implies } a \vee b \le a' \vee b'. $$And you can show that \( \vee : A \times A \to A \) is the left adjoint of another monotone function, the
diagonal
$$ \Delta : A \to A \times A $$sending any \(a \in A\) to the pair \( (a,a) \). This diagonal function is also called
duplication, since it duplicates any element of \(A\).
Why is \( \vee \) the left adjoint of \( \Delta \)? If you unravel what this means using all the definitions, it amounts to this fact:
$$ a \vee a' \le b \textrm{ if and only if } a \le b \textrm{ and } a' \le b . $$ Note that we're applying \( \vee \) to \( (a,a') \) in the expression at left here, and applying \( \Delta \) to \( b \) in the expression at the right. So, this fact says that \( \vee \) the left adjoint of \( \Delta \).
Puzzle 45. Prove that \( a \le a' \) and \( b \le b' \) imply \( a \vee b \le a' \vee b' \). Also prove that \( a \vee a' \le b \) if and only if \( a \le b \) and \( a' \le b \).
A similar argument shows that meets are really right adjoints! If \( A \) is a poset with all binary meets, we get a monotone function
$$ \wedge : A \times A \to A $$that's the
right adjoint of \( \Delta \). This is just a clever way of saying
$$ a \le b \textrm{ and } a \le b' \textrm{ if and only if } a \le b \wedge b' $$ which is also easy to check.
Puzzle 46. State and prove similar facts for joins and meets of any number of elements in a poset - possibly an infinite number.
All this is very beautiful, but you'll notice that all facts come in pairs: one for left adjoints and one for right adjoints. We can squeeze out this redundancy by noticing that every preorder has an "opposite", where "greater than" and "less than" trade places! It's like a mirror world where up is down, big is small, true is false, and so on.
Definition. Given a preorder \( (A , \le) \) there is a preorder called its opposite, \( (A, \ge) \). Here we define \( \ge \) by
$$ a \ge a' \textrm{ if and only if } a' \le a $$ for all \( a, a' \in A \). We call the opposite preorder\( A^{\textrm{op}} \) for short.
I can't believe I've gone this far without ever mentioning \( \ge \). Now we finally have really good reason.
Puzzle 47. Show that the opposite of a preorder really is a preorder, and the opposite of a poset is a poset. Puzzle 48. Show that the opposite of the opposite of \( A \) is \( A \) again. Puzzle 49. Show that the join of any subset of \( A \), if it exists, is the meet of that subset in \( A^{\textrm{op}} \). Puzzle 50. Show that any monotone function \(f : A \to B \) gives a monotone function \( f : A^{\textrm{op}} \to B^{\textrm{op}} \): the same function, but preserving \( \ge \) rather than \( \le \). Puzzle 51. Show that \(f : A \to B \) is the left adjoint of \(g : B \to A \) if and only if \(f : A^{\textrm{op}} \to B^{\textrm{op}} \) is the right adjoint of \( g: B^{\textrm{op}} \to A^{\textrm{ op }}\).
So, we've taken our whole course so far and "folded it in half", reducing every fact about meets to a fact about joins, and every fact about right adjoints to a fact about left adjoints... or vice versa! This idea, so important in category theory, is called
duality. In its simplest form, it says that things come on opposite pairs, and there's a symmetry that switches these opposite pairs. Taken to its extreme, it says that everything is built out of the interplay between opposite pairs.
Once you start looking you can find duality everywhere, from ancient Chinese philosophy:
to modern computers:
But duality has been studied very deeply in category theory: I'm just skimming the surface here. In particular, we haven't gotten into the connection between adjoints and duality!
This is the end of my lectures on Chapter 1. There's more in this chapter that we didn't cover, so now it's time for us to go through all the exercises. |
X
Search Filters
Format
Subjects
Language
Publication Date
Click on a bar to filter by decade
Slide to change publication date range
Physics of Particles and Nuclei Letters, ISSN 1547-4771, 12/2018, Volume 15, Issue 7, pp. 720 - 723
Journal Article
2. Study of the process e + e − → π + π − π 0 η in the c.m. energy range 1394–2005 MeV with the CMD-3 detector
Physics Letters, Section B: Nuclear, Elementary Particle and High-Energy Physics, ISSN 0370-2693, 10/2017, Volume 773, pp. 150 - 158
Journal Article
3. Study of the process e+e−→K+K− in the center-of-mass energy range 1010–1060 MeV with the CMD-3 detector
Physics Letters B, ISSN 0370-2693, 04/2018, Volume 779, pp. 64 - 71
The process has been studied using events from a data sample corresponding to an integrated luminosity of 5.7 pb collected with the CMD-3 detector in the...
VEPP-2M COLLIDER | PHI | ANNIHILATION | ASTRONOMY & ASTROPHYSICS | PHYSICS, NUCLEAR | RADIATIVE-CORRECTIONS | CROSS-SECTION | PION | PAIR | PHYSICS, PARTICLES & FIELDS | Physics - High Energy Physics - Experiment | Physics | High Energy Physics - Experiment
VEPP-2M COLLIDER | PHI | ANNIHILATION | ASTRONOMY & ASTROPHYSICS | PHYSICS, NUCLEAR | RADIATIVE-CORRECTIONS | CROSS-SECTION | PION | PAIR | PHYSICS, PARTICLES & FIELDS | Physics - High Energy Physics - Experiment | Physics | High Energy Physics - Experiment
Journal Article
EPJ Web of Conferences, ISSN 2100-014X, 2019, Volume 212, p. 7002
Journal Article
5. An amplitude analysis of the process e+e-→ 4π in the center-of-mass energy range 900–2000 MeV with the CMD3 detector at the VEPP-2000 e+e- collider
EPJ Web of Conferences, ISSN 2100-014X, 2019, Volume 212, p. 3008
Journal Article
EPJ Web of Conferences, ISSN 2100-014X, 2019, Volume 212, p. 4008
The cross section of the process e+ e−→ KS KL π0 has been studied with the CMD-3 detector at the VEPP-2000 electron-positron collider in the center-of-mass...
Cross sections
Cross sections
Journal Article
EPJ Web of Conferences, ISSN 2100-014X, 2019, Volume 212, p. 4001
Regular data taking with the CMD-3 at the electron-positron collider VEPP-2000 is under way since 2010. The collected data sample corresponds to about 200...
Luminosity
Luminosity
Journal Article
8. Measurement of the hadronic cross sections with the CMD-3 and SND detectors at the VEPP-2000 collider
EPJ Web of Conferences, ISSN 2101-6275, 08/2018, Volume 182, p. 2068
Conference Proceeding
Physics Letters B, ISSN 0370-2693, 06/2013, Volume 723, Issue 1-3, pp. 82 - 89
Journal Article
EPJ Web of Conferences, ISSN 2101-6275, 11/2016, Volume 130, p. 01014
Conference Proceeding
Physics letters B, ISSN 0370-2693, 09/2014, Volume 740, pp. 273 - 277
A search for the process $\epem\to \eta^\prime(958)$ in the $\pipi\eta\to\pipi\gamma\gamma$ final state has been performed with the CMD-3 detector at the...
Physics - High Energy Physics - Experiment | High Energy Physics | High Energy Physics - Experiment | Nuclear and High Energy Physics | Nuclear Experiment | Experiment | Physics
Physics - High Energy Physics - Experiment | High Energy Physics | High Energy Physics - Experiment | Nuclear and High Energy Physics | Nuclear Experiment | Experiment | Physics
Journal Article
12. Measurement of the e+e−→K+K−π+π− cross section with the CMD-3 detector at the VEPP-2000 collider
Physics Letters B, ISSN 0370-2693, 05/2016, Volume 756, Issue C, pp. 153 - 160
Journal Article
13. Study of the process e+e− → 3(π+π−)π0 in the c.m. energy range 1.6–2.0 GeV with the CMD-3 detector
Physics Letters B, ISSN 0370-2693, 05/2019, Volume 792, pp. 419 - 423
The cross section of the process has been measured for the first time using a data sample of 56.7 pb collected with the CMD-3 detector at the VEPP-2000...
Journal Article
Physics Letters, Section B: Nuclear, Elementary Particle and High-Energy Physics, ISSN 0370-2693, 01/2015, Volume 740, pp. 273 - 277
A search for the process e e →Λ (958) in the π π Λ→π π γγ final state has been performed with the CMD-3 detector at the VEPP-2000 e e collider. Using an...
Journal Article
Physics of Particles and Nuclei Letters, ISSN 1547-4771, 12/2018, Volume 15, Issue 7, pp. 749 - 753
Journal Article
16. Study of the process e+e−→π+π−π+π− in the c.m. energy range 920–1060 MeV with the CMD-3 detector
Physics Letters B, ISSN 0370-2693, 05/2017, Volume 768, Issue C, pp. 345 - 350
Journal Article
17. Investigation of the processes e + e − → 2 (π+π−π0) and e + e − → 3 (π+π−) with the aid of the CMD-3 detector
Physics of Atomic Nuclei, ISSN 1063-7788, 5/2015, Volume 78, Issue 3, pp. 353 - 357
The cross sections for the processes e + e − → 2(π+π−π0) and e + e − → 3(π+π−) at c.m. energies in the range of 1.5–2 GeV were measured with the aid of the...
Physics | Particle and Nuclear Physics | CROSS SECTIONS | PHYSICS OF ELEMENTARY PARTICLES AND FIELDS | GEV RANGE | POSITRON BEAMS | ELECTRONS | VEPP-2 | ELECTRON BEAMS | PIONS MINUS | PIONS PLUS | POSITRONS | COLLIDING BEAMS | PIONS NEUTRAL
Physics | Particle and Nuclear Physics | CROSS SECTIONS | PHYSICS OF ELEMENTARY PARTICLES AND FIELDS | GEV RANGE | POSITRON BEAMS | ELECTRONS | VEPP-2 | ELECTRON BEAMS | PIONS MINUS | PIONS PLUS | POSITRONS | COLLIDING BEAMS | PIONS NEUTRAL
Journal Article
JETP Letters, ISSN 0021-3640, 9/2015, Volume 102, Issue 5, pp. 266 - 270
The sensitivity of the VEPP-2000 e + e − collider in the search for the rare decay η → e + e − has been studied. The inverse reaction e + e − → η is proposed...
Solid State Physics | Quantum Information Technology, Spintronics | Atomic, Molecular, Optical and Plasma Physics | Biophysics and Biological Physics | Physics | Particle and Nuclear Physics
Solid State Physics | Quantum Information Technology, Spintronics | Atomic, Molecular, Optical and Plasma Physics | Biophysics and Biological Physics | Physics | Particle and Nuclear Physics
Journal Article
19. Measurement of the e(+)e(-) -> K+K-pi(+)pi(-) cross section with the CMD-3 detector at the VEPP-2000 collider
PHYSICS LETTERS B, ISSN 0370-2693, 05/2016, Volume 756, pp. 153 - 160
Journal Article
Physics of Particles and Nuclei Letters, ISSN 1547-4771, 9/2014, Volume 11, Issue 5, pp. 651 - 655
Journal Article |
This may be a silly question, and so I apologize in advance. But it stems from a reading of section 2 (page 5) of the physics paper, "Counting chiral primaries in N=1 d=4 superconformal field theories".
My
question is: What does the representation of $U(1)$ labeled as $\frac{1}{2}$ indicate?
My question is a group-theory question, and is as such a math question, but for those unfamiliar with the context, here is some background.
The superconformal group for $\mathcal{N} = 1$ supersymmetry in $d = 4$ spacetime dimensions is $SU(2,2|1)$. We focus our attention on a particular subgroup of $SU(2,2|1)$, called the maximal bosonic subgroup: $SU(2,2) \times U(1)_R$. The $U(1)_R$ is known as an R-symmetry group in physics. The generators of supersymmetry (the ''supercharges'') $Q$ and $Q^\dagger$ belong to representations $4_1$ and $\bar{4}_{-1}$ of $SU(2,2) \times U(1)_R$. The subscript denotes the $U(1)_R$ representation ($1$ is the fundamental, $-1$ is the anti-fundamental) and the $4$ and $\bar{4}$ are $SU(2,2)$ representations. So, so far we are labeling everything in terms of irreps of the maximal bosonic subgroup. The conformal group in $d = 4$ spacetime dimensions is $SO(4,2)$, which has a covering group $SU(2,2)$. We want to study a quantum field theory not in 4-dimensional Minkowski ("flat") space but on the space $\mathbb{R} \times S^3$. So one is interested in the Killing spinors of this space, and the isometries. Based on (4) and (5), we restrict our attention to the subgroup $U(1) \times SO(4)$ of the conformal group, which is the isometry group of $\mathbb{R} \times S^3$. The idea then is to decompose the generators in terms of representations of the isometry group $SU(2)_l \times SU(2)_r \times U(1)$ and the R-symmetry $U(1)_R$. Here we've used the fact that $\mathbb{so(4)} = \mathbb{su}(2)_l \times \mathbb{su}(2)_r$.
The claim is
$$4_1 \longrightarrow (2,1)_{\frac{1}{2},1} \oplus (1,2)_{-\frac{1}{2},1}$$ $$\bar{4}_{-1} \longrightarrow (2,1)_{-\frac{1}{2},-1} \oplus (1,2)_{\frac{1}{2},-1}$$
There are now
two $U(1)$ subscripts: the first is for the $U(1)$ which is part of the isometry group, and the second is for the $U(1)_R$ which is the R-symmetry group. Note that the $U(1)_R$ subscript is the same on each term on the right hand side and carries over from the left.
The question posed above pertains to the
first subscript in the above decomposition, i.e. the representation of the $U(1)$ which is part of the isometry group of the manifold.
I know that an element in $U(1)$ is represented by $e^{i\theta}$ and moreover, $U(1)$ is isomorphic to $SO(2)$. The latter made me think of the irreducible spinor representation of $SO(2)$, but that too is a real 1-dimensional representation (2d Dirac spinor with 2 complex components, but the Majorana-Weyl condition brings it down to 1 real component).
Also, if $U(1)$ is parametrized by $\left(\begin{array}{cc}\cos n\theta & \sin n\theta\\-\sin n\theta & \cos n\theta\end{array}\right)$, does $\frac{1}{2}$ simply mean that $n = 1/2$ in this representation, so that effectively, its a half rotation? |
In the comments section to Willie Wong's answer, the following Dirichlet series came up: the Riemann $\zeta$-function, Dirichlet $L$-functions, and Ramanujan's series $\sum_{n \geq 1}\tau(n) n^{-s}$, where $\tau(n)$ is the coefficient of $q^n$ in $\Delta(q) = q\prod_{n=1}^{\infty} (1-q^n)^{24}$.
First note that the $\zeta$-function is a special case of a Dirichlet $L$-function (it is the $L$-function of the trivial character).
Now what is it that Dirichlet $L$-functions and Ramanujan's series have in common? Well, they are all automorphic $L$-functions.
An automorphic form (for the group $\mathrm{GL}_n$ over $\mathbb Q$; there are generalizations where $\mathbb Q$ is replaced by an arbitrary number field $F$ and $\mathrm{GL}_n$ is replaced by an arbitrary reductive group, but to simplify the explanations, I will focus just on the simplest level of generality here) is a function on the product $\mathrm{GL}_n(\mathbb R)\times \mathrm{GL}_n(\mathbb Z/N\mathbb Z)$ for some integer $N \geq 1$ whichis
invariant under the natural (diagonal) action of $\mathrm{GL}_n(\mathbb Z)$;
grows moderately at infinity with respect to the $\mathrm{GL}_n(\mathbb R)$-coordinates;
satisfies a suitable differential equation in the $\mathrm{GL}_n(\mathbb R)$-coordinates.
Rather than explaining the generalities in more detail (they can be found in many places), I think it's better to illustrate them:
E.g. Dirichlet characters arise in the case $n = 1$: they are defined as functionson $(\mathbb Z/N\mathbb Z)^{\times} =: \mathrm{GL}_1(\mathbb Z/N\mathbb Z)$,and so we can make them into functions on $\mathrm{GL}_1(\mathbb R)\times
\mathrm{GL}_1(\mathbb Z/N\mathbb Z)$ by defining them to be trivial on the$\mathbb R^{\times}$-coordinate.
E.g. If $f(\tau)$ is a holomorphic modular form of weight $k$ and level one (where $\tau$ is an upper half-plane variable as usual), we can make $f$ into a function on$\mathrm{GL}_2(\mathbb R)$ by first identifying this matrix group with the collection of bases of $\mathbb R^2$, then identifying $\mathbb R^2$ with $\mathbb C$,and then defining, for any $\mathbb R$-basis $\omega_1,\omega_2$ of $\mathbb C$,$f(\omega_1,\omega_2) := \omega_2^{-k} f(\omega_1/\omega_2)$. (This presumesthat $\omega_1/\omega_2$ is in the upper half-plane rather than the lower,for simplicity.) Thus we get a function of the required kind (with $N = 1$).
The usual modularity condition becomes invariance under $\mathbb GL_2(\mathbb Z)$. The moderate growth condition becomes the condition that the Fourier expansion of $f$ involves only non-negative powers of $e^{2 \pi i \tau}$. The differential equation is the Cauchy--Riemann equation expressing holomorphy of $f$.
Higher level modular forms will involve values of $N$ that are $> 1$.
E.g. Maass forms are similar to the preceding example, except that now thedifferential equation expresses that a Maass form is an eigenvector of the Laplacian.
For any fixed $n$ and fixed $N$, we have Hecke operators acting on the spaceof automorphic forms, labelled by primes $p$ not dividing $N$, and so we canconsider Hecke eigenforms. In the case of Dirichlet characters, the fact that they are
characters of $(\mathbb Z/N\mathbb Z)^{\times}$ (rather than just arbitrary functions) can be reinterpreted as saying that they are Hecke eigenforms.
Of course, Ramanujan's $\Delta$ is well-known to be a Hecke eigenform of weight $12$ and level $1$.
Given an automorphic Hecke eigenform we can use the Hecke eigenvalues to makean Euler product Dirichlet series, which will give Dirichlet $L$-functionsfor Dirichlet characters, and Ramanujan's Dirichlet series for $\Delta$.(In the Dirichlet character case, if a prime $p$ divides the conductor $N$, we just have a trivial factor in the Euler product for that prime; when $n > 1$,and $N > 1$, it is a bit more of a battle to figure out what Euler factorsto put in at the primes dividing $p$, but it can be done.)
Actually, it is better to restrict to
cuspidal automorphic Hecke eigenforms.Cuspidal is a vacuous condition when $n = 1$ (i.e. in that case we agree to calleverything cuspidal), and when $n > 1$ we replace "moderate growth at infinity" by "rapid decay at infinity", suitably interpreted. I'll assume that all my eigenforms are cuspidalform now on. (E.g. $\Delta$ is cuspidal.)
In this way we get a natural class of $L$-functions which have:
meromorphic continuation to the whole complex plane, which is in factholomorphic with the sole exception of Riemann's $\zeta$.
Functional equation with completely understood $\Gamma$-factors. E.g. for aweight $k$ modular form of level one, if the $p$th Hecke eigenvalue is $a_p$,then the $L$-function is $\prod_p (1 - a_p p^{-s} + p^{k - 1 - 2s})^{-1},$ and the functional equation relates $s$ and $k - s$. For $\Delta,$ I've already noted that $k = 12$. (In general the functional equation relates the $L$-series of an automorphic eigenform with $L$-series of its "complex conjugate" suitably understood, just as in the case of Dirichlet characters that are not necessarily real valued.)
Conjecturally, they should all satisfy the analogue of RH, i.e. all non-trivial zeroes should lie on the critical line, in the centre of the critical strip.
Note incidentally that it is easy to change the apparent form of the functional equation. E.g. if we make a change of variable $s \mapsto s + 11/2$ in Ramanujan's series, then the functional equation will become $s \mapsto 1 -s$rather than $s \mapsto 12 -s $, and the critical line will be $\Re s = 1/2$, just as in the $\zeta$-function case.
All cuspidal automorphic $L$-functions can be renormalized in a similar way, so that the symmetry of the functional equation is $s \mapsto 1 -s$. This is called
unitary normalization, and is common in the automorphic forms literature.
Up to rescaling, there are only countably many automorphic eigenforms altogether (just because if we fix the level $N$ and (appropriately generalized version of) the weight the space of automorphic forms is finite dimensional) and so altogether we are talking about a very special class of just countably many Dirichlet series, but these seem to be the ones that naturally generalize $\zeta(s)$.
By the way, this general point of view is due to Langlands, and forms a part of the general Langlands program.
Another point of view was given by Selberg, which focuses more on capturing the analytic properties necessary for getting good properties of a Dirichlet series, rather than beginning from a conceptual construction (as in the automorphic point of view). Namely, he introduced the Selberg class of Dirichlet series. Note that part of his axioms are an Euler product, analytic continuation, and functional equation.
My sense is, though, that people expect the Selberg class of Dirichlet series to more-or-less coincide with the class of automorphic $L$-functions, so I think it is just two points of view on the same question: Langlands is showing how to
construct "good" Dirichlet series, and Selberg is writing down the properties a "good" Dirichlet series should satisfy. It turns out that "good" Dirichlet series are so special, though, that however you try to pick them out, you seem to end up with the same very special collection, namely the automorphic ones. |
I'm working on a homework assignment where my professor would like us to create a true regression model, simulate a sample of data and he's going to attempt to find our true regression model using some of the techniques we have learned in class. We likewise will have to do the same with a dataset he's given us.
He says that he's been able to produce a pretty accurate model for all past attempts to try and trick him. There have been some students that create some insane model but he arguably was able to produce a simpler model that was just sufficient.
How can I go about developing a tricky model for him to find? I don't want to be super cheap by doing 4 quadratic terms, 3 observations, and massive variance? How can I produce a seemingly innocuous dataset that has a tough little model underneath it?
He simply has 3 Rules to follow:
Your dataset must have one "Y" variable and 20 "X" variables labeled as "Y", "X1", ..., "X20".
Your response variable $Y$ must come from a linear regression model that satisfies:
$$ Y_i^\prime = \beta_0 + \beta_1 X_{i1}^\prime + \ldots + \beta_{p-1}X_{i,p-1}^\prime + \epsilon_i $$ where $\epsilon_i \sim N(0,\sigma^2)$ and $p \leq 21$.
All $X$-variables that were used to create $Y$ are contained in your dataset.
It should be noted, not all 20 X variables need to be in your real model
I was thinking of using something like the Fama-French 3 Factor Model and having him start with the stock data (SPX and AAPL) and have to transform those variables to the continuously compounded returns in order to obsfucate it a little more. But that leaves me with missing values in the first observation and it's time series (which we haven't discussed in class yet).
Unsure if this is the proper place to post something like this. I felt like it could generate some good discussion.
Edit: I'm also not asking for "pre-built" models in particular. I'm more curious about topics/tools in Statistics that would enable somebody to go about this. |
Korn inequality
An inequality concerning the derivatives of vector functions $f:\mathbb R^n\to \mathbb R^n$. Assuming that $f$ is continuosly differentiable, we denote by $Df$ the Jacobian matrix of its differential and by $D^s f$ its symmetric part, namely the matrix with entries \[ \frac{1}{2} \left(\frac{\partial f_j}{\partial x_i} + \frac{\partial f_i}{\partial x_j}\right)\, . \] Denoting by $|Df|$ and $|D^s f|$ the corresponding Hilbert-Schmidt norms, the original inequality of Korn (see [K2]) states that, if $f\in C^1_c (\mathbb R^n)$, then \[ \int |Df|^2 \leq 2 \int |D^s f|^2\, . \] In fact, when $f$ is $C^2$ a simple integration by parts yields the identity \[ \int |D^s f|^2 = \frac{1}{2} \int |D f|^2 + \frac{1}{2} \int ({\rm div}\, f)^2 \] from which Korn's inequality is obvious. A standard approximation procedure yields then the general statement: in fact for the same reason the inequality holds for functions in the Sobolev class $H^1_0$. The Korn's inequality can also be concluded easily using the Fourier Transform.
The inequality has been subsequently generalized to
$f\in W^{1,2} (\Omega)$, under the assumption that $\Omega$ is bounded and $\partial \Omega$ sufficiently regular (Lipschitz is sufficient); $f\in W^{1,p}_0 (\mathbb R^n)$ and $f\in W^{1,p} (\Omega)$ (again under the assumption that $\Omega$ is bounded and the boundary sufficiently regular) for $p\in ]1, \infty[$, in which case the inequality takes the form
\[ \|Du\|_{L^p} \leq C \|D^s u\|_{L^p}\, , \] where the constant $C$ depends, additionally, upon $p$.
The latter generalization uses the Calderon-Zygmund estimates for singular integral operators, see for instance [C]. The cases $p = 1, \infty$ of the inequality are false, as implied by a more general theorem of Ornstein about the failure of $L^1$ estimates for general singular integral operators, see [O]. For a modern proof the reader might consult [CFM].
References
[C] P. G. Ciarlet, "On Korn's inequality", Chinese Ann. Math., Ser B 31 (2010), pp. 607-618. [C2] P. G. Ciarlet, "Mathematical Elasticity", Vol. I : Three-Dimensional Elasticity, Series “Studies in Mathematics and its Applications”, North-Holland, Amsterdam, 1988. [CFM] S. Conti, D. Faraco, F. Maggi, "A new approach to counterexamples to $L^1$ estimates: Korn’s inequality, geometric rigidity, and regularity for gradients of separately convex functions", Arch. Rat. Mech. Anal. 175, (2005), pp. 287-300. [K] A. Korn, "Solution general du probleme d'equilibre dans la theorie de l'elasticite", Annales de la Faculte de Sciences de Toulouse, 10, (1908), pp. 705-724 [K2] A. Korn, "Ueber einige Ungleichungen, welche in der Theorie der elastischen und elektrischen Schwingungen eine Rolle spielen", Bulletin internationale de l'Academie de Sciences de Cracovie, 9, (1909), pp. 705-724 [O] D. Ornstein, "A non-inequality for differential operators in the $L^1$ norm", Arch. Rational Mech. Anal., 11, (1962), pp. 40–49 [F] G. Fichera, "Existence theorems in elasticity theory", Handbuch der Physik, VIa/2, Springer (1972) pp. 347–389 How to Cite This Entry:
Korn inequality.
Encyclopedia of Mathematics.URL: http://www.encyclopediaofmath.org/index.php?title=Korn_inequality&oldid=30665 |
FBA Flux Balance Analysis
FBA has been shown to be a very useful technique for analysis of metabolic capabilities of cellular systems. FBA involves carrying out a steady state analysis, using the stoichiometric matrix for the system in question. The system is assumed to be optimised with respect to functions such as maximisation of biomass production or minimisation of nutrient utilisation, following which it is solved to obtain a steady state flux distribution. This flux distribution is then used to interpret the metabolic capabilities of the system. The dynamic mass balance of the metabolic system is described using the stoichiometric matrix, relating the flux rates of enzymatic reactions, [math]\mathbf{v}_{n\times 1}[/math] to time derivatives of metabolite concentrations, [math]\mathbf{x}_{m\times 1}[/math] as
[math] \frac{d\mathbf{x}}{dt} = \mathbf{S}\,\mathbf{v} [/math]
[math] \mathbf{v}=[v_1 \ v_2 \ ... \ v_{n}\ b_1\ b_2\ ...\ b_{n_{ext}} ]^T [/math]
where [math]v_i[/math] signifies the internal fluxes, [math] b_i[/math] represents the exchange fluxes in the system and [math] n_{ext}[/math] is the number of external metabolites in the system. At steady state,
[math] \frac{d\mathbf{x}}{dt} = \mathbf{S}\,\mathbf{v} = 0 [/math]
Therefore, the required flux distribution belongs to the null space of [math] \mathbf{S}[/math] . Since [math] m \lt n[/math] , the system is under-determined and may be solved for [math] \mathbf{v}[/math] fixing an optimisation criterion, following which, the system translates into a linear programming problem:
[math] \min_{\mathbf{v}}\ \mathbf{c}^T\mathbf{v} \qquad \textrm{s. t.} \quad \mathbf{S}\,\mathbf{v}=0 [/math]
where [math]c[/math] represents the objective function composition, in terms of the fluxes. Further, we can constrain:
[math] 0 \lt v_i \lt \infty [/math]
[math] -\infty \lt b_i \lt \infty [/math]
which necessitates all internal irreversible reactions to have a flux in the positive direction and allows exchange fluxes to be in either direction. Practically, a finite upper bound can be imposed, so that the problem does not become unbounded. This upper bound may also be decided based on the knowledge of cellular physiology.
Perturbations
FBA also has the capabilities to address effect of gene deletions and other types of perturbations on the system. Gene deletion studies can be performed by constraining the reaction flux(es) corresponding to the gene(s) (and therefore, of their corresponding proteins(s)), to zero. Effects of inhibitors of particular proteins can also be studied in a similar way, by constraining the upper bounds of their fluxes to any defined fraction of the normal flux, corresponding to the extents of inhibition.
References Bonarius HPJ, Schmid G, Tramper J (1997) Flux analysis of underdetermined metabolic networks: The quest for the missing constraints. Trends Biotech 15: 308–314. Forster J, Famili I, Fu P, Palsson BO, Nielsen J (2003) Genome-scale reconstruction of the Saccharomyces cerevisiaemetabolic network. Genome Res 13: 244–253. Edwards JS, Palsson BO (2000) The Escherichia coliMG1655 in silico metabolic genotype: Its definition, characteristics, and capabilities. Proc Natl Acad Sci U S A 97: 5528–5533. Edwards JS, Covert M, Palsson BO (2002) Metabolic modelling of microbes: The flux-balance approach. Environ Microbiol 4: 133–133. Kauffman KJ, Prakash P, Edwards JS (2003) Advances in flux balance analysis. Curr Opin Biotech 14: 491–496. Alvarez-Vasquez F, Sims K, Cowart L, Okamoto Y, Voit E, et al. (2005) Simulation and validation of modelled sphingolipid metabolism in Saccharomyces cerevisiae. Nature 433: 425–430. Edwards JS, Ibarra RU, Palsson BO (2001) In silicopredictions of Escherichia coli metabolic capabilities are consistent with experimental data. Nat Biotechnol 19: 125–130. Raman K, Rajagopalan P, Chandra N (2005) Flux Balance Analysis of Mycolic Acid Pathway: Targets for Anti-Tubercular Drugs. PLoS Comput Biol 1(5): e46 |
The Annals of Statistics Ann. Statist. Volume 12, Number 3 (1984), 1100-1105. A Characterization Theorem for Externally Bayesian Groups Abstract
A contribution is made to the problem of combining the subjective probability density functions $f_1, \cdots, f_n$ of $n$ individuals for some parameter $\theta$. More precisely, the situation is addressed which occurs when the members of a group share a common likelihood for some data and want to ensure that combining their posterior distributions for $\theta$ will yield the same result obtained by applying Bayes' rule to the aggregated prior distribution. Under certain regularity conditions to be discussed below, the logarithmic opinion pool $\prod^n_{i=1} f^{w_i}_i \big/ \int \prod^n_{i=1} f^{w_i}_i d\mu$ with $w_i \geq 0$ and $\sum^n_{i=1} w_i = 1$ is shown to be the only pooling formula which satisfies this criterion of group rationality.
Article information Source Ann. Statist., Volume 12, Number 3 (1984), 1100-1105. Dates First available in Project Euclid: 12 April 2007 Permanent link to this document https://projecteuclid.org/euclid.aos/1176346726 Digital Object Identifier doi:10.1214/aos/1176346726 Mathematical Reviews number (MathSciNet) MR751297 Zentralblatt MATH identifier 0541.62003 JSTOR links.jstor.org Citation
Genest, Christian. A Characterization Theorem for Externally Bayesian Groups. Ann. Statist. 12 (1984), no. 3, 1100--1105. doi:10.1214/aos/1176346726. https://projecteuclid.org/euclid.aos/1176346726 |
Taiwanese Journal of Mathematics Taiwanese J. Math. Volume 16, Number 4 (2012), 1531-1555. HYBRID METHOD FOR DESIGNING EXPLICIT HIERARCHICAL FIXED POINT APPROACH TO MONOTONE VARIATIONAL INEQUALITIES Abstract
Let $C$ be a nonempty closed convex subset of a real Hilbert space $H$. Assume that $F: C \to H$ is a $\kappa$-Lipschitzian and $\eta$-strongly monotone operator with constants $\kappa,\eta \gt 0$, $f: C \to H$ is $L$-Lipschitzian with constant $L \geq 0$ and $T,V: C \to C$ are nonexpansive mappings with ${\rm Fix}(T) \neq \emptyset$. Let $0 \lt \mu \lt 2 \eta/\kappa^2$ and $0 \leq \gamma L \lt \tau$, where $\tau = 1 - \sqrt{1-\mu(2\eta-\mu\kappa^2)}$. Consider the hierarchical monotone variational inequality problem (in short, HMVIP):
VI (a): finding $z^* \in {\rm Fix}(T)$ such that $\langle(I-V)z^*, z-z^*\rangle \geq 0$, $\forall z \in {\rm Fix}(T)$;
VI (b): finding $x^* \in S$ such that $\langle(\mu F - \gamma f) x^*, x-x^*\rangle \geq 0$, $\forall z \in S$.
Here $S$ denotes the nonempty solution set of the VI (a). This paper combines hybrid steepest-descent method, viscosity method and projection method to design an explicit algorithm, that can be used to find the unique solution of the HMVIP. Strong convergence of the algorithm is proved under very mild conditions. Applications in hierarchical minimization problems are also included.
Article information Source Taiwanese J. Math., Volume 16, Number 4 (2012), 1531-1555. Dates First available in Project Euclid: 18 July 2017 Permanent link to this document https://projecteuclid.org/euclid.twjm/1500406747 Digital Object Identifier doi:10.11650/twjm/1500406747 Mathematical Reviews number (MathSciNet) MR2951151 Zentralblatt MATH identifier 1262.49011 Subjects Primary: 49J40: Variational methods including variational inequalities [See also 47J20] 47H10: Fixed-point theorems [See also 37C25, 54H25, 55M20, 58C30] 47J25: Iterative procedures [See also 65J15] Citation
Ceng, Lu-Chuan; Lin, Yen-Cherng; Petruşel, Adrian. HYBRID METHOD FOR DESIGNING EXPLICIT HIERARCHICAL FIXED POINT APPROACH TO MONOTONE VARIATIONAL INEQUALITIES. Taiwanese J. Math. 16 (2012), no. 4, 1531--1555. doi:10.11650/twjm/1500406747. https://projecteuclid.org/euclid.twjm/1500406747 |
Search
Now showing items 1-1 of 1
Production of charged pions, kaons and protons at large transverse momenta in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(Elsevier, 2014-09)
Transverse momentum spectra of $\pi^{\pm}, K^{\pm}$ and $p(\bar{p})$ up to $p_T$ = 20 GeV/c at mid-rapidity, |y| $\le$ 0.8, in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV have been measured using the ALICE detector ... |
Beside the wonderful examples above, there should also be counterexamples, where visually intuitive demonstrations are actually wrong. (e.g. missing square puzzle)
Do you know the other examples?
Mathematics Stack Exchange is a question and answer site for people studying math at any level and professionals in related fields. It only takes a minute to sign up.Sign up to join this community
Beside the wonderful examples above, there should also be counterexamples, where visually intuitive demonstrations are actually wrong. (e.g. missing square puzzle)
Do you know the other examples?
The never ending chocolate bar!
If only I knew of this as a child..
The trick here is that the left piece that is three bars wide grows at the bottom when it slides up. In reality, what would happen is that there would be a gap at the right between the three-bar piece and the cut. This gap is is three bars wide and one-third of a bar tall, explaining how we ended up with an "extra" piece.
Side by side comparison:
Notice how the base of the three-wide bar grows. Here's what it would look like in reality$^1$:
1: Picture source https://www.youtube.com/watch?v=Zx7vUP6f3GM
A bit surprised this hasn't been posted yet. Taken from this page:
Visualization can be misleading when working with alternating series. A classical example is \begin{align*} \ln 2=&\frac11-\frac12+\frac13-\frac14+\;\frac15-\;\frac16\;+\ldots,\\ \frac{\ln 2}{2}=&\frac12-\frac14+\frac16-\frac18+\frac1{10}-\frac1{12}+\ldots \end{align*} Adding the two series, one finds \begin{align*}\frac32\ln 2=&\left(\frac11+\frac13+\frac15+\ldots\right)-2\left(\frac14+\frac18+\frac1{12}+\ldots\right)=\\ =&\frac11-\frac12+\frac13-\frac14+\;\frac15-\;\frac16\;+\ldots=\\ =&\ln2. \end{align*}
Here's how to trick students new to calculus (applicable only if they don't have graphing calculators, at that time):
$0$. Ask them to find inverse of $x+\sin(x)$, which they will unable to. Then,
$1$. Ask them to draw graph of $x+\sin(x)$.
$2$. Ask them to draw graph of $x-\sin(x)$
$3$. Ask them to draw $y=x$ on both graphs.
Here's what they will do :
$4$. Ask them, "What do you conclude?". They will say that they are inverses of each other. And then get
very confused.
Construct a rectangle $ABCD$. Now identify a point $E$ such that $CD = CE$ and the angle $\angle DCE$ is a non-zero angle. Take the perpendicular bisector of $AD$, crossing at $F$, and the perpendicular bisector of $AE$, crossing at $G$. Label where the two perpendicular bisectors intersect as $H$ and join this point to $A$, $B$, $C$, $D$, and $E$.
Now, $AH=DH$ because $FH$ is a perpendicular bisector; similarly $BH = CH$. $AH=EH$ because $GH$ is a perpendicular bisector, so $DH = EH$. And by construction $BA = CD = CE$. So the triangles $ABH$, $DCH$ and $ECH$ are congruent, and so the angles $\angle ABH$, $\angle DCH$ and $\angle ECH$ are equal.
But if the angles $\angle DCH$ and $\angle ECH$ are equal then the angle $\angle DCE$ must be zero, which is a contradiction.
Proof : Let $O$ be the intersection of the bisector $[BC]$ and the bisector of $\widehat{BAC}$. Then $OB=OC$ and $\widehat{BAO}=\widehat{CAO}$. So the triangles $BOA$ and $COA$ are the same and $BA=CA$.
Another example :
From "Pastiches, paradoxes, sophismes, etc." and solution page 23 : http://www.scribd.com/JJacquelin/documents
A copy of the solution is added below. The translation of the comment is :
Explanation : The points A, B and P are not on a straight line ( the Area of the triangle ABP is 0.5 ) The graphical highlight is magnified only on the left side of the figure.
I think this could be the goats puzzle (Monty Hall problem) which is nicely visually represented with simple doors.
Three doors, behind 2 are goats, behind 1 is a prize.
You choose a door to open to try and get the prize, but before you open it, one of the other doors is opened to reveal a goat. You then have the option of changing your mind. Should you change your decision?
From looking at the diagram above, you know for a fact that you have a 1/3rd chance of guessing correctly.
Next, a door with a goat in is opened:
A cursory glance suggests that your odds have improved from 1/3rd to a 50/50 chance of getting it right. But the truth is different...
By calculating all possibilities we see that if you change, you have a higher chance of winning.
The easiest way to think about it for me is, if you choose the car first, switching is guaranteed to be a goat. If you choose a goat first, switching is guaranteed to be a car. You're more likely to choose a goat first because there are more goats, so you should always switch.
A favorite of mine was always the following:
\begin{align*} \require{cancel}\frac{64}{16} = \frac{\cancel{6}4}{1\cancel{6}} = 4 \end{align*}
I particularly like this one because of how simple it is and how it gets the right answer, though for the wrong reasons of course.
A recent example I found which is credited to Martin Gardner and is similar to some of the others posted here but perhaps with a slightly different reason for being wrong, as the diagonal cut really is straight.
I found the image at a blog belonging to Greg Ross.
Spoilers
The triangles being cut out are not isosceles as you might think but really have base $1$ and height $1.1$ (as they are clearly similar to the larger triangles). This means that the resulting rectangle is really $11\times 9.9$ and not the reported $11\times 10$.
Squaring the circle with Kochanski's Approximation
1
One of my favorites:
\begin{align} x&=y\\ x^2&=xy\\ x^2-y^2&=xy-y^2\\ \frac{(x^2-y^2)}{(x-y)}&=\frac{(xy-y^2)}{(x-y)}\\ x+y&=y\\ \end{align}
Therefore, $1+1=1$
The error here is in dividing by x-y
That $\sum_{n=1}^\infty n = -\frac{1}{12}$. http://www.numberphile.com/videos/analytical_continuation1.html
The way it is presented in the clip is completely incorrect, and could spark a great discussion as to why.
Some students may notice the hand-waving 'let's intuitively accept $1 -1 +1 -1 ... = 0.5$.
If we accept this assumption (and the operations on divergent sums that are usually not allowed) we can get to the result.
A discussion that the seemingly nonsense result directly follows a nonsense assumption is useful. This can reinforce why it's important to distinguish between convergent and divergent series. This can be done within the framework of convergent series.
A deeper discussion can consider the implications of allowing such a definition for divergent sequences - ie Ramanujan summation - and can lead to a discussion on whether such a definition is useful given it leads to seemingly nonsense results. I find this is interesting to open up the ideas that mathematics is not set in stone and can link to the history of irrational and imaginary numbers (which historically have been considered less-than-rigorous or interesting-but-not-useful).
\begin{equation} \log6=\log(1+2+3)=\log 1+\log 2+\log 3 \end{equation}
Here is one I saw on a whiteboard as a kid... \begin{align*} 1=\sqrt{1}=\sqrt{-1\times-1}=\sqrt{-1}\times\sqrt{-1}=\sqrt{-1}^2=-1 \end{align*}
I might be a bit late to the party, but here is one which my maths teacher has shown to me, which I find to be a very nice example why one shouldn't solve an equation by looking at the hand-drawn plots, or even computer-generated ones.
Consider the following equation: $$\left(\frac{1}{16}\right)^x=\log_{\frac{1}{16}}x$$
At least where I live, it is taught in school how the exponential and logarithmic plots look like when base is between $0$ and $1$, so a student should be able to draw a plot which would look like this:
Easy, right? Clearly there is just one solution, lying at the intersection of the graphs with the $x=y$ line (the dashed one; note the plots are each other's reflections in that line).
Well, this is clear at least until you try some simple values of $x$. Namely, plugging in $x=\frac{1}{2}$ or $\frac{1}{4}$ gives you two more solutions! So what's going on?
In fact, I have intentionally put in an incorrect plots (you get the picture above if you replace $16$ by $3$). The real plot looks like this:
You might disagree, but to be it still seems like it's a plot with just one intersection point. But, in fact, the part where the two plots meet has all three points of intersection. Zooming in on the interval with all the solutions lets one
barely see what's going on:
The oscillations are truly minuscule there. Here is the plot of the
difference of the two functions on this interval:
Note the scale of the $y$ axis: the differences are on the order of $10^{-3}$. Good luck drawing that by hand!
To get a better idea of what's going on with the plots, here they are with $16$ replaced by $50$:
Here is a measure theoretic one. By 'Picture', if we take a cover of $A:=[0,1]∩\mathbb{Q}$ by open intervals, we have an interval around every rational and so we also cover $[0,1]$; the Lebesgue measure of [0,1] is 1, so the measure of $A$ is 1. As a sanity check, the complement of this cover in $[0,1]$ can't contain any intervals, so its measure is surely negligible.
This is of course wrong, as the set of all rationals has Lebesgue measure $0$, and sets with no intervals need not have measure 0: see the fat Cantor set. In addition, if you fix the 'diagonal enumeration' of the rationals and take $\varepsilon$ small enough, the complement of the cover in $[0,1]$ contains $2^{ℵ_0}$ irrationals. I recently learned this from this MSE post.
There are two examples on Wikipedia:Missing_square_puzzle Sam Loyd's paradoxical dissection, and Mitsunobu Matsuyama's "Paradox". But I cannot think of something that is not a dissection.
This is my favorite.
\begin{align}-20 &= -20\\ 16 - 16 - 20 &= 25 - 25 - 20\\ 16 - 36 &= 25 - 45\\ 16 - 36 + \frac{81}{4} &= 25 - 45 + \frac{81}{4}\\ \left(4 - \frac{9}{2}\right)^2 &= \left(5 - \frac{9}{2}\right)^2\\ 4 - \frac{9}{2} &= 5 - \frac{9}{2}\\ 4 &= 5 \end{align}
You can generalize it to get any $a=b$ that you'd like this way:
\begin{align}-ab&=-ab\\ a^2 - a^2 - ab &= b^2 - b^2 - ab\\ a^2 - a(a + b) &= b^2 -b(a+b)\\ a^2 - a(a + b) + \frac{a + b}{2} &= b^2 -b(a+b) + \frac{a + b}{2}\\ \left(a - \frac{a+b}{2}\right)^2 &= \left(b - \frac{a+b}{2}\right)^2\\ a - \frac{a+b}{2} &= b - \frac{a+b}{2}\\ a &= b\\ \end{align}
It's beautiful because visually the "error" is obvious in the line $\left(4 - \frac{9}{2}\right)^2 = \left(5 - \frac{9}{2}\right)^2$, leading the observer to investigate the reverse FOIL process from the step before, even though this line is valid. I think part of the problem also stems from the fact that grade school / high school math education for the average person teaches there's only one "right" way to work problems and you always simplify, so most people are already confused by the un-simplifying process leading up to this point.
I've found that the number of people who can find the error unaided is something less than 1 in 4. Disappointingly, I've had several people tell me the problem stems from the fact that I started with negative numbers. :-(
Solution
When working with variables, people often remember that $c^2 = d^2 \implies c = \pm d$, but forget that when working with concrete values because the tendency to simplify everything leads them to turn squares of negatives into squares of positives before applying the square root. The number of people that I've shown this to who can find the error is a small sample size, but I've found some people can carefully evaluate each line and find the error, and then can't explain it even after they've correctly evaluated $\left(-\frac{1}{2}\right)^2=\left(\frac{1}{2}\right)^2$.
To give a contrarian interpretation of the question I will chime in with Goldbach's comet which counts the number of ways an integer can be expressed as the sum of two primes:
It is mathematically "wrong" because there is no proof that this function doesn't equal zero infitely often, and it is visually deceptive because it appears to be unbounded with its lower bound increasing at a linear rate.
This is essentially the same as the chocolate-puzzle. It's easier to see, however, that the total square shrinks.
This is a fake visual proof that a sphere has Euclidean geometry. Strangely enough, in a 3 dimensional hyperbolic space, the amount of curve a sphere will have approaches a nonzero amount and if you have an infinitely large object with exactly the amount of a curve a sphere approaches as its size approaches infinity, it will have Euclidean geometry and appear sort of the way that image appears.
I don't know about you but to me, it looks like the hexagons are stretched horizontally. If you also see it that way and you trust your eyes, then you could take that as a visual proof that $\tan\frac{7}{4} < 60^\circ$. If that's how you saw it, then it's an optical illusion because the hexagons are really stretched vertically. Unlike some optical illusions of images that appear different than they are but are still mathematically possible, this is an optical illusion of a mathematically impossible image. The math shows that $\tan^{-1} 60^\circ = \sqrt{3}$ and $\sqrt{3} < \frac{7}{4}$ because $7^2 = 49$ but $3 \times 4^2$ = 48. It's just like it's mathematically impossible for something to not be moving when it is moving but it's theoretically possible for your eyes to stop sending movement signals to your brain and have you not see movement in something that is moving which would look creepy for those who have not experienced it because your brain could still tell by a more complex method than signals from the eyes that it actually is moving.
To draw a hexagonal grid over a square grid more accurately, only the math and not your eye signals can be trusted to help you do it accurately. The math shows that the continued fraction of $\sqrt{3}$ is [1; 1, 2, 1, 2, 1, 2, 1 ... which is less than $\frac{7}{4}$, not more.
I do not think this really qualify as "visually intuitive", but it is definitely funny
They do such a great job at dramatizing these kind of situations. Who cannot remember of an instance in which he has been either a "Billy" or a "Pa' and Ma'"? Maybe more "Pa' and Ma'" instances on my part...;)
Thank you for your interest in this question. Because it has attracted low-quality or spam answers that had to be removed, posting an answer now requires 10 reputation on this site (the association bonus does not count).
Would you like to answer one of these unanswered questions instead? |
My best guess is that the series $$ \sum_{i=1}^n i(n-(i-1)) $$ becomes $$ 2 \Bigg[ n + 2(n-1) + ... + \frac{n}{2} \bigg(n-\bigg(\frac{n}{2}-1\bigg)\Bigg)\Bigg] $$ So the highest term is $n^2$ and there are $n$ terms. Does that mean its $O(n^3)$? That seems high. Intuitively, it seems like it should be closer to $O(n^2)$ but I can't find a way to bring it down mathematically.
We can lower bound the sum roughly by $$ \sum_{i=1}^n i(n+1-i) \geq \sum_{i=n/3}^{2n/3} (n/3)^2 \geq (n/3)^3. $$ This shows that it is $\Omega(n^3)$. Since each summand is at most $n^2$, the sum is also $O(n^3)$.
We can also compute the sum explicitly: $$ \sum_{i=1}^n i(n+1-i) = (n+1) \sum_{i=1}^n i - \sum_{i=1}^n i^2 = (n+1) \frac{(n+1)n}{2} - \frac{n(n+1)(2n+1)}{6} = \frac{n(n+1)(n+2)}{6}. $$ This expression equals the binomial coefficient $\binom{n+2}{3}$, and we can prove this bijectively. The binomial coefficient counts triples $(a,b,c)$ of elements satisfying $0 \leq a < b < c \leq n+1$. Notice that $1 \leq b \leq n$, and this corresponds to summation over $i$. Given $b$, we have $b$ choices for $a$ and $n+1-b$ choices for $c$.
$$\begin{align*} T(n)&=1n + 2(n-1) + 3(n-2) + ... + (n-1)2 + n\\ &=n(1+2+...+n)-(1+2+3+...+n)\\ &=(n-1)(1+2+3+...+n)\\ &=\Theta(n^3) \end{align*}$$
From ryan's comment, the summation, when you distribute $i$ and split it into more summations comes to $$\sum_{i=1}^n i(n-(i-1)) = \sum_{i=1}^n (i*n) + \sum_{i=1}^n (-(i^2)-i)$$ which is roughly $\frac{1}{2}n^3 - \frac{1}{3}n^3$ so the asymptotic bound is, in fact $O(n^3)$ |
Someone pointed out this puzzle in Kahneman's
Thinking, Fast and Slow. I paraphrase.
A game rewards participants based on how long it takes to obtain the first heads in a toss of a fair coin. If the first toss results in heads, then the player gets reward $r(1) = \$2$. If the first heads appears only in the second toss, then the player gets $r(2) = \$4$. And $r(3) = \$8$ if the first heads appears on the third toss, and so on. How highly can one price the ticket before this game stops making sense for a player?
It seems to me that the solution depends on what I choose for the random variable. If I choose the payoff as the random variable $X_P$, then the expected reward is the expected payoff, i.e. $E[\mathsf{reward}] = E[X_P] = \Sigma_{i=1}^{\infty} (\frac{1}{2})^i \times r(i) = \frac{1}{2}\times\$2 + \frac{1}{4}\times\$4 + \ldots = \infty$. This is the approach discussed in the book.
However, if I choose as random variable $X_N$ the number of tosses it takes to obtain the first heads, then my expected reward is the reward associated with the expectation $E[X_N]$ of the number of tosses leading up to and including the first heads, i.e. $E[\mathsf{reward}] = r(E[X_N]) = r(2) = \$4$ [cf. this].
While the first analysis suggests that a player ought to play the game no matter the cost of ticket, the second analysis pegs the ticket price strictly below $\$4$ for the game to be attractive for a player.
Is my alternative analysis correct? If yes, then how do I decide which is the correct approach to such puzzles? |
Let $X_n$ be independent Poisson random variables with $E[X_i] = \mu_i$, and let $Y_n = X_1+...+X_n$. I want to show that if $\sum_n \mu_n = \infty $ then $Y_n/E[Y_n] \rightarrow 1$ almost surly.
What I do know is that if $X_1,...$ are independent, and $E\left[X^4\right] < \infty$, then $Y_n/n \rightarrow E[X]$ a.s.* So What I tried is to center the random variables: let $C_n := X_n-\mu_n$. The $C$'s are independent, $E[C_n^4]< \infty, E[C_n] = 0$, which means: $\frac{C_1 +...+C_n}{n} \rightarrow 0$ a.s., or $\frac{\sum X_i - \sum \mu_i}{n} \rightarrow 0$ a.s. which, I think, completes the proof.
However I am not sure why the requirement $\sum_n \mu_n = \infty $ is necessary, so I suspect this proof is incorrect. Is it?
Edit: This argument is incorrect since the theorem requires $E[C^4]$ to be uniformly bounded, not just bounded. Any ideas? |
Difference between revisions of "Main Page"
(→Proof strategies)
m
Line 1: Line 1:
== The Problem ==
== The Problem ==
−
Let <math>[3]^n</math> be the set of all length <math>n</math> strings over the alphabet <math>1, 2, 3</math>. A ''combinatorial line'' is a set of three points in <math>[3]^n</math>, formed by taking a string with one or more wildcards <math>
+
Let <math>[3]^n</math> be the set of all length <math>n</math> strings over the alphabet <math>1, 2, 3</math>. A ''combinatorial line'' is a set of three points in <math>[3]^n</math>, formed by taking a string with one or more wildcards <math></math> in it, e.g., <math>\ldots</math>, and replacing those wildcards by <math>1, 2</math> and <math>3</math>, respectively. In the example given, the resulting combinatorial line is: <math>\{ 11211113\ldots, 11221223\ldots, 11231333\ldots \}</math>. A subset of <math>[3]^n</math> is said to be ''line-free'' if it contains no lines. Let <math>c_n</math> be the size of the largest line-free subset of <math>[3]^n</math>.
'''<math>k=3</math> Density Hales-Jewett (DHJ(3)) theorem:''' <math>\lim_{n \rightarrow \infty} c_n/3^n = 0</math>
'''<math>k=3</math> Density Hales-Jewett (DHJ(3)) theorem:''' <math>\lim_{n \rightarrow \infty} c_n/3^n = 0</math>
Revision as of 09:22, 14 February 2009 The Problem
Let [math][3]^n[/math] be the set of all length [math]n[/math] strings over the alphabet [math]1, 2, 3[/math]. A
combinatorial line is a set of three points in [math][3]^n[/math], formed by taking a string with one or more wildcards [math]\ast[/math] in it, e.g., [math]112\!\ast\!\!1\!\ast\!\ast3\ldots[/math], and replacing those wildcards by [math]1, 2[/math] and [math]3[/math], respectively. In the example given, the resulting combinatorial line is: [math]\{ 11211113\ldots, 11221223\ldots, 11231333\ldots \}[/math]. A subset of [math][3]^n[/math] is said to be line-free if it contains no lines. Let [math]c_n[/math] be the size of the largest line-free subset of [math][3]^n[/math]. [math]k=3[/math] Density Hales-Jewett (DHJ(3)) theorem: [math]\lim_{n \rightarrow \infty} c_n/3^n = 0[/math]
The original proof of DHJ(3) used arguments from ergodic theory. The basic problem to be considered by the Polymath project is to explore a particular combinatorial approach to DHJ, suggested by Tim Gowers.
Useful background materials
Some background to the project can be found here. General discussion on massively collaborative "polymath" projects can be found here. A cheatsheet for editing the wiki may be found here. Finally, here is the general Wiki user's guide
Threads (1-199) A combinatorial approach to density Hales-Jewett (inactive) (200-299) Upper and lower bounds for the density Hales-Jewett problem (inactive) (300-399) The triangle-removal approach (inactive) (400-499) Quasirandomness and obstructions to uniformity (inactive) (500-599) Possible proof strategies (active) (600-699) A reading seminar on density Hales-Jewett (active) (700-799) Bounds for the first few density Hales-Jewett numbers, and related quantities (active)
There is also a chance that we will be able to improve the known bounds on Moser's cube problem.
Here are some unsolved problems arising from the above threads.
Here is a tidy problem page.
Proof strategies
It is natural to look for strategies based on one of the following:
Szemerédi's original proof of Szemerédi's theorem. Szemerédi's combinatorial proof of Roth's theorem. Ajtai-Szemerédi's proof of the corners theorem. The density increment method. The triangle removal lemma. Ergodic-inspired methods. The Furstenberg-Katznelson argument. Bibliography
Density Hales-Jewett
H. Furstenberg, Y. Katznelson, “A density version of the Hales-Jewett theorem for k=3“, Graph Theory and Combinatorics (Cambridge, 1988). Discrete Math. 75 (1989), no. 1-3, 227–241. H. Furstenberg, Y. Katznelson, “A density version of the Hales-Jewett theorem“, J. Anal. Math. 57 (1991), 64–119. R. McCutcheon, “The conclusion of the proof of the density Hales-Jewett theorem for k=3“, unpublished.
Behrend-type constructions
M. Elkin, "An Improved Construction of Progression-Free Sets ", preprint. B. Green, J. Wolf, "A note on Elkin's improvement of Behrend's construction", preprint. K. O'Bryant, "Sets of integers that do not contain long arithmetic progressions", preprint.
Triangles and corners
M. Ajtai, E. Szemerédi, Sets of lattice points that form no squares, Stud. Sci. Math. Hungar. 9 (1974), 9--11 (1975). MR369299 I. Ruzsa, E. Szemerédi, Triple systems with no six points carrying three triangles. Combinatorics (Proc. Fifth Hungarian Colloq., Keszthely, 1976), Vol. II, pp. 939--945, Colloq. Math. Soc. János Bolyai, 18, North-Holland, Amsterdam-New York, 1978. MR519318 J. Solymosi, A note on a question of Erdős and Graham, Combin. Probab. Comput. 13 (2004), no. 2, 263--267. MR 2047239 |
Trying to solve a problem I ended up working on a polynomial of degree $n-1$ in $t$, $p(t)=\sum_{k=0}^{n-1} a_k t^k$, whose coefficients are given by
$a_k=\sum_{i=1}^n\cfrac{\beta_i^k}{\prod_{j=1\\j\neq i}^n (\beta_j-\beta_i)}$
Here, $\beta_i$ are $n$ distinct positive and ordered real numbers, so that $0<\beta_1<\beta_2<\cdots<\beta_n$. What can I say about the coefficients $a_k$? I made some attempts and I think that
$a_k=\begin{cases}0 &k=0,\dots,n-2\\z\neq0 &k=n-1\end{cases}$
but I don't know if this is true, how to prove it and what $z$ would be. Do any of you know a solution or a reference for this problem? Thanks |
The shapeUsing this, we can make a guess for how the cube might be folded:Once that fold is done, the shape looks more like this:A drawing of the finished product:And an animation of the whole process:
This seems to work:Below, I printed out the shape, and cut off the excess. The white parts are for glueing; if everything works out as planned, all of them will be covered by the coloured bits around the black squares.Joy, it all worked! Here's the final cube, with some white "intentionally" showing through between the pieces, highlighting the borders:...
If folded as shown below, it can be closed along the matching letters, to form a 12 sided polyhedron with six quadrilateral faces and two sets of three isosceles triangular faces. The quads are arranged in two triplets that join to form two right corners (as found in a cube), and the triangles 'join' the two groups of quads together. The shape has 120 degree ...
If you had some sort of super paper that defied all laws of physics, and was $0.05 \text{mm}$ thick, then folding it a hundred times would give a thickness of:$0.05 \times 2^{100} \text{mm}$$\approx 6.34\times10^{28} \text{mm}$Note that the observable universe has a width of around:$8.8\times10^{29} \text{mm}$Using the paper folding formula $W = \pi t \...
First, we need to figure what is the minimum amount of superconductor that we'll lose when making the cut. Optimally, we can cut the large cube net into two smaller cube nets without any waste at all. Let's start by trying to find such a cube net:The blue and yellow parts are pretty simple cube wraps, so after the cut, we can easily make the required two ...
This is the solution I intended, though I've accepted Penguino's Florian F's since it has the smallest number of folds.Dashed lines are mountain folds, and dotted lines are valley folds.Perhaps I'll make a 3D representation later, but the special thing about the resulting shape is that it can be made by cutting a cube into two halves as below, rotating ...
Consider what happens by doing $2$ folds, one in each direction.So after $2k$ foldsFor this to be a cube we need:So the number of folds we need isIn reality, this will only work if you cut the paper in half and stack the pieces, instead of folding the paper. I have ignored the amount of paper connecting the different layers of the folded cube, which ...
This is a classic. Any zig-zag pattern will do e.g. (sorry for the bad drawing):To get the cut, first we have to concertina fold like this, leaving a bit on each end which we make sure not to cut under any circumstances (this can be achieved by folding the bits it out of the way of any cuts that will harm it:Then we need to fold the thin rectangle like ...
There is no largest area, but the area can be made as close as wanted to 75.Let's imagine our rectangle. It has diagonal $AC$, centre $O$; let's say $AB$ is the longest side and $H$ is the middle of $AB$.The rectangle will be folded along a line $p$, which is perpendicular to $AC$ at point $O$. $p$ also crosses $AB$ at some point $M$.It is easy to note ... |
To understand the formula:
1) draw a Cartesian coordinates with a unit circle (centred at origin with a radius of 1).
2) draw a vector pointing towards 2-oclock (so we have $\theta = 30$, this is arbitrary but I prefer this 30 degree angle as I tend to confuse the sin and cos on a 45 degree angle) with a length of 1, so this vector ($\vec{V}$) ends on the unit circle.
3) The key point to remember is that we are converting the
unit vectors of the Cartesian system ($\hat{i}$ and $\hat{j}$) to those of the polar system ($\hat{r}$ and $\hat{\theta}$). Unit vector by definition is length 1.
4) To get to the radial unit vector $\hat{r}$: move $1\times cos(\theta)$ units along the x direction ($cos(\theta) \hat{i}$), then move $1\times sin(\theta)$ units along the y direction ($sin(\theta) \hat{j}$). That is the 1st equation: $\hat{r} = cos(\theta) \hat{i} + sin(\theta) \hat{j}$. Note that this how vector additions work. Draw it out on your paper and you will figure it out immediately.
5) Now to get the tangential unit vector ($\hat{\theta}$): that is, by definition, right-angle to $\hat{r}$, with a length of 1. So you will know that all you need to do is switch the positions of $cos(\theta)$ and $sin(\theta)$ in your 1st equation, and add a minus sign to one of them (so the dot product of these 2 resultant vectors is 0, equivalent to perpendicular). As we define anti-clock wise as the positive direction, the minus sign goes to the $\hat{i}$ direction. So here it is the 2nd equation: $\hat{\theta} = -sin(\theta) \hat{i} + cos(\theta) \hat{j}$.
6) If you dislike the step (5) way. Draw that $\hat{\theta}$ out on your unit circle: starting from origin, pointing towards 11-oclock (right angle to $\hat{r}$) and ending on the unit circle (length=1). To get to that end point by moving only along x- and y- directions, first move $-1\times sin(\theta)$ units on x-, then $1\times cos(\theta)$ units on y-. You get the same formula.
To reverse the conversion: from polar to Cartesian, you could simply do some pure algebra on the 2 equations we just derived, or use geometry to "move to" the target point you wish to derive. |
Mohammad Shoeb
Articles written in Pramana – Journal of Physics
Volume 37 Issue 5 November 1991 pp 419-424
A one parameter, semi-empirical formula for Λ-binding energy of heavy hypernuclei in the inverse powers of core mass number (
c) has been developed in the framework of the folding model. Unlike similar calculations reported by other authors (Deloff 1971; Daskaloyannis Λ data of Λ 28Si, Λ 40Ca, Λ 51V and Λ 39Y. Using the original Λ-nucleus potential, the Λ of ground and the experimentally known excited states of these hypernuclei have also been calculated by solving numerically the two-body Schrödinger equation. The agreement with the experimental data is satisfactory.
Volume 51 Issue 3-4 September 1998 pp 421-432 Research Articles
Variational Monte Carlo calculations of the ground state separation energies
Λ of the Λ 9Be have been made for an Urbana-type central space-exchange Λ Λ 9Be is analysed as a partially nine-body problem in the Λ — 2α model. The reduction of Λ due to the space-exchange Λ Λ 9Be a much more limited study gives ≅ 1.3 MeV. These values are much larger than that for ‘soft’ Λ
Volume 68 Issue 6 June 2007 pp 943-958 Research Articles
The $\Lambda \Lambda$ binding energy ($B_{\Lambda \Lambda}$) of the s- and p-shell hypernuclei are calculated variationally in the cluster model and multidimensional integrations are performed using Monte Carlo. A variety of phenomenological 𝛬-core potentials consistent with the 𝛬-core energies and a wide range of simulated s-state $\Lambda \Lambda$ potentials are taken as input. The $B_{\Lambda \Lambda}$ of $_{\Lambda \Lambda}^{6}$He is explained and $_{\Lambda \Lambda}^{5}$He and $_{\Lambda \Lambda}^{5}$H are predicted to be particle stable in the $\Lambda \Lambda$-core model. The results for s-shell hypernuclei are in excellent agreement with those of non-VMC calculations. The $_{\Lambda\Lambda}^{10}$Be in $\Lambda \Lambda \alpha \alpha$ model is overbound for combinations of $\Lambda \Lambda$ and $\Lambda \alpha$ potentials. A phenomenological dispersive three-body force, $V_{\Lambda \alpha \alpha}$, consistent with the $B_{\Lambda}$ of $_{\Lambda}^{9}$Be in the $\Lambda \alpha \alpha$ model underbinds $_{\Lambda \Lambda}^{10}$Be. The incremental $\Delta B_{\Lambda \Lambda}$ values for the s- and p-shell cannot be reconciled, consistent with the finding of earlier analyses.
Current Issue
Volume 93 | Issue 5 November 2019
Click here for Editorial Note on CAP Mode |
Your statement 'For example, Na+ bonds with OH− and Cl− bonds with H+ when NaOH is dissolved in H2O' is not correct if the ions are in solution.
In an ionic solid each ion is surrounded by other ions of the same charge and those of opposite charge, in NaCl each Na$^+$ ion is surrounded by 6 Cl$^-$ and
vice versa. The interaction between the ions is essentially Coulomb in nature with energy that varies with distance $r$ as $E \sim 1/r$. This is a long range interaction and so choosing a 'victim' ion this can interact with all its many neighbours, not just nearest neighbours, thus many interactions have to be summed up. The sum is called a Madeling Sum and the cohesive energy produced is written in the simple form $E\sim se^2/r_0$ where $s$ is the Madelung sum (-1.748 for NaCl), $r_0$ the closest separation of any two ions and $e$ the electronic charge. However the ions could just approach one another and the ionic solid could just collapse. Why does this not happen? What prevents this is the Coulomb repulsion between electrons (and between nuclei) as any two ions (or atoms) approach one another and the Pauli Exclusion principle. This ensures that only two electrons can fill an energy level and so energy is needed to promote an electron from one energy level into an unfilled one on the other atom as they approach. Both these effects are repulsive in nature and vary as $\sim 1/r^{12}$ so are very short range.
Having established that there is a binding energy holding a solid together when an ionic solid is added to a polar solvent we expect it to dissolve and free ions to be produced. Overall if this is to happen the free energy change $\Delta G$ must be negative. This is composed of two parts the enthalpy change (potential energy) $\Delta H$ and the entropy change $\Delta S$ as $\Delta G = \Delta H -T\Delta S$, where $T$ is the temperature. If the free energy is to be negative then there are four possibilities depending on the
sign of the change $\Delta H$ and $\Delta S$. The one situation that cannot occur if the solid is to dissolve is $\Delta H \gt 0, \; \Delta S \lt 0$ as this always makes $\Delta G$ positive. It will always dissolve if $\Delta H \lt 0, \; \Delta S \gt 0$ as $\Delta G $ is negative. The other cases depend on particular values.
We expect that $\Delta H$ will be positive on dissolution as the crystalline solid exists and it will take energy to make it dissolve. (This will cool the solution if heat is not supplied to keep the temperature constant). As there is a larger volume for the ions to occupy in solution than in the solid the entropy
change is expected to be positive. Simply having more places to occupy will increase the entropy. However, the solid does not have zero entropy, the ions can move albeit by a small amount about their equilibrium positions in the crystal and waves of vibrational motion called phonons exist and so there is already certain amount of entropy. This is lost on dissolution and has to be exceeded if the entropy change is to be positive. Also it is necessary to consider the entropy change in the solvent. As the ions are charged, in a polar solvent the dipoles are attracted to the charge, and partially order around the it. This leads to a decrease in entropy of the solvent as there are ions plus an 'atmosphere' of a few solvent molecules around each one. All these terms need to be considered, but as, say, NaCl does dissolve then the entropy change must be positive.
When the ion is dissolved, why do pairs of ions not form? This is because the solvent is polar and when the dielectric constant of the solvent is considered the energy varies as $E\sim 1/(\epsilon r)$ where $\epsilon$ is the dielectric constant, for water this 78 and 37 for acetonitrile, but for an ionic crystal it is only about 2, similar to that for non-polar hexane. This large dielectric constant means that the interaction of one ion to another is $\epsilon$ times smaller compared to that at the same distance in the crystal or in a non-polar solvent. In other words, in a polar solvent the ions are effectively independent. The interaction is small and comparable to the thermal motion jostling the molecules and so the number of times they form pairs is vanishingly small. This means that the solution will conduct electricity. |
I am studying Linear Discriminant Analysis (LDA). According to the formula for LDA, we are supposed to get the inverse of within group covariance. However, if $p\gg n$ (i.e., the dimension is much larger than the number of samples), what should I do?
One possibility is to regularize your estimate of the covariance matrix. See Regularization parameter to generate inverse covariance matrix.
Regularization uses assumed prior-information to turn the covariance inversion into a well-posed problem (this is also mentioned in the wikipedia article)
In practice, you can use a shrinkage estimator of the covariance matrix, such that:
$$\Sigma \rightarrow (\lambda-1)\Sigma+\lambda I_m$$
Where $\lambda$ is a hyperparameter that must be set in advance (and possibly optimized). |
So is $\Theta$ undefined for insertion sort?
This question contains a category error. It's like saying, "I know that Donald Trump has a height of at least 5 and at most 7. So are numbers undefined for Donald Trump?
$\Theta$ is notation for expressing the growth rate of mathematical functions. "Insertion sort" is not a mathematical function, so if you want to talk about $\Theta$ and insertion sort in the same sentence, you need to say what property of insertion sort you're measuring with a mathematical function that you wish to describe with $\Theta$.
We measure the resource usage of algorithms in terms of the length of the input, which is usually denoted $n$. You've proposed a function which is the number of execution steps of insertion sort on some input. However, this is a function of the input itself, not of its length. Some inputs of length $n$ will take roughly $n$ steps to sort (I'm using "roughly" to hide constant factors), and some inputs of length $n$ will take roughly $n^2$ steps. So you can't write this as a function of $n$ at all – the number of steps required isn't just a function of the length of the input but, rather, it's a function of the whole input. Because the thing you're trying to measure isn't a function of the length of the input, you can't directly measure it using $\Theta$ at all.
So we need to come up with a function that does just depend on the length of the input. Two natural functions are the best-case and worst-case number of execution steps. We know that, for an input of length $n$, the best case is that insertion sort finds that the input is already sorted, and in this case, it takes a linear number of steps. No more, no less, so we're entitled to say that the best-case running time of the algorithm is $\Theta(n)$. Similarly, we're entitled to say that the worst-case running time is $\Theta(n^2)$.
If the best and worst case was (asymptotically) the same (up to constant factors), then the running time would actually just be a function of the
length of the input, so it would make sense to say that the running time was, e.g., $\Theta(n\log n)$. However, unless the running time really is a function of $n$, this is an abuse of notation. In the case or insertion sort, where the best and worst case running times are different, we can abuse notation a little harder and say the running time is $\Omega(n)$ and $O(n^2)$. This says that, for any (sufficiently large) input, the running time will be somewhere between $n$ and $n^2$ steps (up to constant factors) but, again, there is no actual function of $n$ that is "the running time." It would be more formal to say that the running time $T(x)$ for an input $x$ satisfies $c|x|\leq T(x)\leq c'|x|^2$ for large enough $|x|$ and some constants $c$ and $c'$. |
In general, the intensity of an electric field is given by $$ I = \frac{c\epsilon_0}{2}E_0^2 $$ where $E_0$ is the peak amplitude of the electric field. Let's say we have an electric field $$ E(t) = E_0 \sin(\omega t). $$ Without having any other potential, the electric field is connected to its corresponding vector potential $A(t)$ via $$ E(t) = -\frac{1}{c}\dot{A}(t). $$ If we compute the vector potential by above electric field, we get $$ A(t) = -c\int_0^t\,dt'\,E(t') = E_0\frac{c}{\omega}\cos(\omega t). $$ We could compute the intensity for a given vector potential via $$ I=\frac{c\epsilon_0}{2}E_0^2=\frac{c\epsilon_0}{2}\frac{A_0^2}{c^2}=\frac{\epsilon_0}{2c}A_0^2 $$ $\textbf{but}$ I wonder how to define the peak amplitude $A_0$ since $\cos(\omega t)/\omega > 1$ is possible. A choice would of course be $$ A_0 := E_0\frac{c}{\omega} $$ but that's not very general since the time-dependent function could be anything. What I mean in general is that, if an intensity is given, the time-dependent parts $f(t)$ and $F(t)=\int_0^t\,dt'\,f(t')$ in $$ E(t)=E_0 f(t)~~~, ~~~ A(t) = A_0 F(t) = -c E_0 F(t) $$ should only be in [-1,1] or not? One could also think of using $\text{max}_t A(t)$, resp. $\text{max}_t E(t)$ to compute the intensity but that's not how I have seen it in several computer codes (which is the main reason I ask this).
One could also think of using [...] $\text{max}_t E(t)$ to compute the intensity
That's the definition of peak intensity. Anything else is OK if it can be derived from it, and incorrect if it differs from what can be derived from that.
That includes using $\text{max}_t A(t)$, unless you're in some restricted situation (say, a monochromatic beam, or some similarly minor variation) where it coincides with what you can get from $\text{max}_t E(t)$.
but that's not how I have seen it in several computer codes (which is the main reason I ask this).
If those codes are considering only restricted situations in which their alternative approaches coincide with the correct results, then they're doing it right. If they're using alternative approaches that do not coincide with what can be derived with the correct definition, then they're doing it wrong.
Since you do not give any precise details about what you
did see in those codes, and what the underlying assumptions are about the configurations that they're built to handle, there is nothing more we can say at present. |
Definition:Order Isomorphism Contents Definition
Let $\left({S, \preceq_1}\right)$ and $\left({T, \preceq_2}\right)$ be ordered sets.
Let $\phi: S \to T$ be a bijection such that:
Then $\phi$ is an
order isomorphism.
Let $\left({S, \preceq_1}\right)$ and $\left({T, \preceq_2}\right)$ be ordered sets.
Then $\phi$ is an order isomorphism. That is, $\phi$ is an order isomorphism if and only if: $(1): \quad \phi$ is surjective $(2): \quad \forall x, y \in S: x \preceq_1 y \iff \phi \left({x}\right) \preceq_2 \phi \left({y}\right)$ Two ordered sets $\left({S, \preceq_1}\right)$ and $\left({T, \preceq_2}\right)$ are (order) isomorphic if there exists such an order isomorphism between them.
$\left({S, \preceq_1}\right)$ is described as
(order) isomorphic to (or with) $\left({T, \preceq_2}\right)$, and vice versa.
This may be written $\left({S, \preceq_1}\right) \cong \left({T, \preceq_2}\right)$.
Where no confusion is possible, it may be abbreviated to $S \cong T$.
When $\left({S, \preceq_1}\right)$ and $\left({T, \preceq_2}\right)$ are well-ordered sets, the condition on the order preservation can be relaxed:
Let $\left({S, \preceq_1}\right)$ and $\left({T, \preceq_2}\right)$ be well-ordered sets. $\forall x, y \in S: x \mathop {\preceq_1} y \implies \phi \left({x}\right) \mathop {\preceq_2} \phi \left({y}\right)$ Then $\phi$ is an order isomorphism. Also see Equivalence of Definitions of Order Isomorphism Definition:Relation Isomorphism, from which it can be seen that order isomorphism is a special case. Inverse of Increasing Bijection need not be Increasing Results about order isomorphismscan be found here.
The word
isomorphism derives from the Greek morphe ( ) meaning μορφή formor structure, with the prefix iso-meaning equal.
Thus
isomorphism means equal structure. Sources |
Hydrogen iodide is a colourless gas that will decompose into colourless hydrogen gas and purple iodine gas according to the following endothermic reaction.
$$\ce{2 HI (g) <=> H2 (g) + I2 (g)}$$
A $\pu{1.0 L}$ glass container was filled with $\pu{0.60 mol}$ of hydrogen iodide gas. When equilibrium was established, there were $\pu{0.25 mol}$ of iodine gas present in the container. Calculate the equilibrium constant for this reaction. $$ \begin{array}{|c|c|c|c|}\hline &\ce{HI}&\ce{H2}&\ce{I2}\\\hline \text{Initial}&0.60&0&0\\\hline \text{Used/made}&0.50&0.25&0.25\\\hline \text{Equilibrium}&0.10&0.25&0.25\\\hline \end{array} $$ $$K=\frac{[\ce{H2}][\ce{I2}]}{[\ce{HI}]^2}=\frac{0.25\times0.25}{0.10^2}=6.25$$
This is what I understand:
Product always goes on the top, reactant on bottom Balancing coefficients eg $\ce{2HI}$ become powers $\ce{-> HI^2}$ Initially, 0.6 moles of hydrogen iodide gas was placed, then at equilibrium 0.25 moles of iodine gas. If there was 0.25 moles of iodine gas, there has to be 0.25 moles of hydrogen gas aswell thus the top part of the fraction becomes $0.25 \times 0.25$ I have no idea where the 0.1 moles come from …
I don't want to 'understand' these as much as I just want to be able to do them. |
Given tensor product of rank-2 Pauli matrices $\sigma^a$. Each $\sigma^a$ is related to the generator of SU(2) Lie algebra.
We know they satisfy
$$[\sigma^a, \sigma^b ] = 2 i \epsilon^{abc} \sigma^c$$
Do you know any equality/identity to simplify: $$ [\sigma^a \otimes \sigma^c, \sigma^b \otimes \sigma^d] = ? $$ also $$ [\sigma^a \otimes \sigma^c \otimes \sigma^e, \sigma^b \otimes \sigma^d \otimes \sigma^f] = ? $$ $$ [\sigma^a \otimes \sigma^c \otimes \sigma^e \otimes \sigma^g, \sigma^b \otimes \sigma^d \otimes \sigma^f \otimes \sigma^h] = ? $$ so that the final answers have no commutators?
Commutator is defined by default as $$ [A,B]:=AB-BA $$ |
The calculation is described in detail in the Wikipedia article on recombination.
If you consider the ionisation of hydrogen as a reaction:
$$ p + e \rightarrow H + \gamma $$
Then you can write down an expression for the equilibrium constant as a function of temperature using the Saha equation:
$$ \frac{n_pn_e}{n_H} = \left( \frac{m_ek_BT}{2\pi\hbar^2} \right)^{3/2} \exp \left( \frac{-E_I}{k_BT} \right) $$
If you take 50% ionisation you can work out the corresponding temperature and it turns out to be about 4,000K. So now it's just a matter of relating the temperature of the universe to the time after the Big Bang. Once we're past the various phase transitions that happened in the first few instants after the Big Bang the temperature is inversely proportional to the scale factor. Sadly there isn't a simple equation to give the scale factor as a function of time, however it's a straightforward numerical calculation, and the result is that the temperature was 4,000K about 380,000 years after the Big Bang.
That's how the figure of 380,000 years is calculated. |
Split Monomorphism is Monic Theorem
Let $\mathbf C$ be a metacategory.
Let $f: C \to D$ be a split monomorphism.
Then $f: C \rightarrowtail D$ is monic. Proof
Let $g: D \to C$ be a morphism such that:
$g \circ f = \operatorname{id}_C$
which is guaranteed to exist by definition of split monomorphism.
Suppose that $x, y: B \to C$ are morphisms such that: $f \circ x = f \circ y$
Then necessarily also:
$g \circ f \circ x = g \circ f \circ y$
and hence, since $g \circ f = \operatorname{id}_C$, it follows that:
$\operatorname{id}_C \circ x = \operatorname{id}_C \circ y$
which yields the result by the definition of identity morphism.
The situation is illustrated by the following commutative diagram: $\begin{xy} <-4em,0em>*+{B} = "B", <0em,0em> *+{C} = "C", <4em,0em> *+{D} = "D", <4em,-4em>*+{C} = "C2", "B"+/r.5em/+/^.25em/;"C"+/l.5em/+/^.25em/ **@{-} ?>*@{>} ?*!/_.6em/{x}, "B"+/r.5em/+/_.25em/;"C"+/l.5em/+/_.25em/ **@{-} ?>*@{>} ?*!/^.6em/{y}, "C";"D" **@{-} ?>*@{>} ?*!/_.6em/{f}, "C";"C2" **@{-} ?>*@{>} ?*!/^.6em/{\operatorname{id}_C}, "D";"C2" **@{-} ?>*@{>} ?*!/_.6em/{g}, \end{xy}$
$\blacksquare$ |
I have a couple questions regarding the proof of Proposition $3$ (see page $10-11$ of arxiv.org/abs/math/0102039) in Bezrukavnikov's paper "Quasi-exceptional sets and equivariant coherent sheaves on the nilpotent cone" . For simplicity, assume $G$ is simply connected, simple algebraic group (so that $G$ is its own universal cover). Also, $\alpha$ is a simple root, let $P_{\alpha}$ be the associated minimal parabolic and $u_a$ its unipotent radical; $G/B, G/P_{\alpha}$ are the flag variety and a partial flag variety with projection map $p_{\alpha}: G/B \rightarrow G/P_{\alpha}$; $\lambda, \lambda' \in \Lambda$ lie in the weight lattice and satisfy $s_{\alpha}(\lambda) = \lambda - n \alpha, s_{\alpha}(\lambda') = \lambda' - (n-1) \alpha$; and $O_{G/B}(\lambda')$ for instance is the line bundle associated to $\lambda'$. Set $\tilde{\mathcal{N}} = G \times_B \mathfrak{u}$ to be the Springer resolution ($u$ is unipotent radical, as usual).
Question $1$: Set $V_{\lambda'} = p_{\alpha}^* p_{\alpha *} O_{G/B}(\lambda')$.
On the first paragraph of pg $11$ it is claimed that there is a $G$-invariant filtration on $V_{\lambda'}$ with the quotients being $\mathcal{O}_{G/B}(\lambda'-i \alpha)$ for $0 \leq i \leq n-1$; why is this?
Question $2$: Set $\tilde{\mathcal{N}_{\alpha}} = G \times_B u_a$ (I am under the impression this is the same as what Roman defines on pg 11; if not, please correct me). How is the following exact sequence obtained (equation $23$ in the paper)? $0 \rightarrow O_{N'}(\alpha) \rightarrow O_{N'} \rightarrow O_{N'_{\alpha}} \rightarrow 0$
[In the above equation, I have used a ' to replace the tilde, since I cannot get Latex to work.]
Question $3$: Consider the natural projection $\pi': \tilde{\mathcal{N}_{\alpha}} \rightarrow T^{*}(G/P_\alpha)$.
The fibers are clearly projective lines. If $p': \tilde{\mathcal{N}_{\alpha}} \rightarrow G/B$ is the projection, in the last line of the proof (just before Prop $4$), it seems to be claimed that $p'^*(V_{\lambda'}(\lambda - \lambda'-\alpha))$ is isomorphic to a direct sum of copies of $\mathcal{O}_{\mathbb{P}^1}(-1)$ when restricted to any fibre of $\pi'$. Why is this?
EDIT: In all of the above, I had to simplify many of the Latex formulas to make them work (e.g. replace tilde by '). I think everything should be readable now, at the cost of bad notation. |
First of all, let me state the obvious:
After we got that out of the way we can focus on why. Phosphorus is awesome.
There are many different modifications of phosphorus in nature. With increasing thermodynamic stability they are $$\ce{P_{white} -> P_{red} -> P_{violet} -> P_{black}}.$$
Apart from this there are many low molecular different allotropes, like $\ce{P4 (white)}$, $\ce{P6}$, $\ce{P8}$, $\ce{P10}$, $\ce{P12}$. And because that is not enough, there are chain like polymeric allotropes, too.
Apart from this it is possible to formulate many different cations and anions, that are derived from the above molecular structures. Just to name a few, there are $\ce{P3+, P5+, P7+, P9+}$ mainly observed in gaseous phase an $\ce{P^{3-},P2^{4-}, P3^{5-}, P4^{2-}, P7-,...,}$ usually in combination with alkali metals. Most amazingly it may form anionic polymer strains of the general form $\ce{[P7-]_{\infty}, [P15-]_{\infty}}$.
But now for the most important part, phosphorus has stable oxidation states in compounds, ranging from $\mathrm{-III}$ to $\mathrm{+V}$. Here are a few examples:$$\ce{\overset{-III}{P}H3,\ \overset{-II}{P_2}H4,\ [\overset{-I}{P}H]_{n},\ \overset{\mathrm{\pm0}}{P4},\ H3\overset{\mathrm{+I}}{P}O2,\ H4\overset{\mathrm{+II}}{P2}O4,\ H3\overset{\mathrm{+III}}{P}O3,\ H2\overset{\mathrm{+IV}}{P2}O6,\ H3\overset{\mathrm{+V}}{P}O4}$$While dealing with these compounds it is usually completely unnecessary to describe bonding with hybrid orbitals.
In case of phosphane $\ce{PH3}$ it would be wrong. Assuming $\ce{{}^{sp^3}P}$ one would expect $\angle(\ce{H-P-H})\approx109^\circ$, while it is found to be $\angle(\ce{H-P-H})=93.5^\circ$, which is almost the same angle as the $\ce{p}$ orbitals are having towards each other.
In general your assumption is correct, that it is possible to form only three covalent bonds to reach a stable configuration. And that will most likely be the case when phosphorus forms compounds with more electropositive elements.
Now dealing with oxygen, means dealing with a much more electronegative element, i.e. $\ce{En(O)}\approx3.4$, $\ce{En(P)}\approx2.2$. That also means that bonds are much more polarised towards the oxygen.
Analysing the phosphate anion $\ce{PO4^{3-}}$ it is crucial to recognise its symmetry, which is tetrahedral $T_\mathrm{d}$. In this arrangement it is perfectly safe (but not at all necessary) to describe phosphorus as $\ce{sp^3}$ hybridised.
A Natural Bond Orbital analysis (BP86/def2-TZVPP) reveals that there are 4 equal $\ce{P-O}~\sigma$ single bonds and each oxygen has three lone pairs. The contribution of the $\ce{d}$ orbitals to bonding is well below $1\%$ and can be interpreted as numerical noise (use as polarisation functions) of the DFT method.\begin{array}{rlrr}\hline & &\mathrm{\%P (hyb)} &\mathrm{\%O (hyb)}\\\hline3\times&\ce{Bd(O-P)} & 24 (\ce{sp^3}) & 76 (\mathrm{sp^{2.3}})\\ &\ce{Lp(O)} & & 100 (\mathrm{sp^{0.4}})\\2\times&\ce{Lp(O)} & & 100 (\ce{p})\\\hline\end{array}
This is consistent with the partial charges, i.e. $q(\ce{P})=2.2$, $q(\ce{O})=-1.3$. Therefore a more accurate Lewis formula is with charge separation.
The corresponding NBO reflect the bonding picture one would expect given all details from above. It should be noted, that natural bond orbitals are a linear combination of the canonical orbitals and do not have a physical meaningful energy eigenvalue. The two top rows represent the $\ce{p}$ lone pair orbitals of oxygen, the third row represents the $\ce{sp^{0\!.4}}$ lone pair orbitals, the fourth row gives the $\sigma$ bonding orbitals. (The last row is the orientation of the molecule, core orbitals are not displayed.)
The corresponding canonical orbitals which have a physical meaningful eigenvalue are delocalised over the whole molecule, hence they are not providing a simple understandable bonding picture. While NBO fail to respect the symmetry point group, canonical orbitals are constructed to obey this principle. (Here shown from highest energy, top, to lowest energy, bottom, core orbitals not displayed.) |
The Setup
Let Greek indices be summed over $0,1,\dots, d$ and Latin indices over $1,2,\dots, d$. Consider a vector potential $A_\mu$ on $\mathbb R^{d,1}$ defined to gauge transform as$$ A_\mu\to A_\mu'=A_\mu+\partial_\mu\theta$$for some real-valued function $\theta$ on $\mathbb R^{d,1}$. The usual claim about Coulomb gauge fixing is that the condition$$ \partial^i A_i = 0$$serves to fix the gauge in the sense that $\partial^iA_i' = 0$ only if $\theta = 0$. The usual argument for this (as far as I am aware) is that $\partial^i A'_i =\partial^iA_i + \partial^i\partial_i\theta$, so the Coulomb gauge conditions on $A_\mu$ and $A_\mu'$ give $\partial^i\partial_i\theta=0$, but the only sufficiently smooth,
normalizable (Lesbegue-integrable?) solution to this (Laplace's) equation on $\mathbb R^d$ is $\theta(t,\vec x)=0$ for all $\vec x\in\mathbb R^d$. My Question
What, if any, is the physical justification for the smoothness and normalizability constraints on the gauge function $\theta$?
EDIT 01/26/2013Motivated by some of the comments, I'd like to add the following question: are there physically interesting examples in which the gauge function $\theta$ fails to be smooth and/or normalizable? References with more details would be appreciated. Lubos mentioned that perhaps monopoles or solitons could be involved in such cases; I'd like to know more!
Cheers! |
GTU Civil Engineering (Semester 3)
Fluid Mechanics May 2014
Fluid Mechanics
May 2014
Total marks: --
Total time: --
Total time: --
INSTRUCTIONS
(1) Assume appropriate data and state your reasons (2) Marks are given to the right of every question (3) Draw neat diagrams wherever necessary
(1) Assume appropriate data and state your reasons
(2) Marks are given to the right of every question
(3) Draw neat diagrams wherever necessary
1 (a) Define and explain following fluid properties.
(1) Surface tension (2) Dynamic viscosity (3) Capillarity
(1) Surface tension
(2) Dynamic viscosity
(3) Capillarity
7 M
1 (b) What is the use of manometer? Prove that intensity of pressure at any point in a fluid at rest has same magnitude in all directions.
7 M
2 (a) State Bernoulli's equation for compressible flow. Derive Bernoulli's equation for adiabatic process.
7 M
2 (b) A circular plate 3.5 m diameter is immersed in water in such a way that its greatest and least depth below free surface is 4 m and 1.5 m respectively. Determine the total pressure on one face of the plate and position of the center of pressure
7 M
2 (c) Define force of buoyancy and meta-centre. Discuss the conditions of equilibrium for floating and sub-merged bodies with neat sketches.
7 M
3 (a) i) A stream function in a two dimensional flow is ψ = 4xy. Calculate the velocity at the point (4, 3). Find the corresponding velocity potential ϕ.
4 M
3 (a) ii) State Bernoulli's equation for steady incompressible fluid flow. What assumptions are made in its derivation?
3 M
3 (b) What is venturimeter? Derive an expression for discharge through a Venturimeter.
7 M
3 (c) i) Define the terms : Stream line , Equipotential line , Flownet
3 M
3 (c) ii) What is pitot tube? How velocity at any point is determined by pitot tube?
4 M
3 (d) A horizontal venturimeter with inlet diameter 30 cm and throat diameter 10 cm is used to measure the flow of oil of specific gravity 0.8. The discharge of oil through venturimeter is 50 liters/s. Find the reading of the oil-mercury differential manometer. Take C
d= 0.98.
7 M
4 (a) A horizontal pipe of diameter 450 mm is suddenly contracted to a diameter of 250 mm. The pressure intensities in larger and smaller pipe are given as 14.5 N/cm
2and 12.5 N/cm 2respectively. If C c= 0.62. Find loss of head due to contraction and discharge of water.
7 M
4 (b) i) What do you understand by pipes in series and pipes in parallel?
4 M
4 (b) ii) Define: Co-efficient of velocity, Co-efficient of discharge, Vena-contracta.
3 M
5 (a) Derive an expression for discharge through fully submerged and partially submerged orifice.
7 M
5 (b) Water is flowing in a rectangular channel of 1.5 m wide and 0.75 m deep. Find discharge over a rectangular weir of crest length 65 cm, if head of water over the crest of weir is 25 cm and water flow over the weir. Take C
d= 0.62. Take approach velocity into consideration.
7 M
5 (c) i) What is orifice and mouthpiece? What is its use?
2 M
5 (c) ii) A circular tank of diameter 3 m contains water up to height of 4 m. The tank is provided with an orifice of diameter 0.4 m at the bottom. Find time taken by water to fall from 4.0 m to 1.0 m and for completely emptying the tank. Take C
d= 0.98.
5 M
5 (d) Prove that the discharge through a triangular notch or weir is
\[Q=\dfrac{8}{15}\times C_{d}\times \dfrac{\theta}{2}\times \sqrt{2g}H^{5}/2\]
\[Q=\dfrac{8}{15}\times C_{d}\times \dfrac{\theta}{2}\times \sqrt{2g}H^{5}/2\]
7 M
More question papers from Fluid Mechanics |
Difference between revisions of "Timeline of prime gap bounds"
Line 1,043: Line 1,043:
| [http://math.mit.edu/~drew/schinzel_3473955908_80550202480.txt 80,550,202,480]* [m=5] ([http://terrytao.wordpress.com/2014/05/17/polymath-8b-xi-finishing-up-the-paper/#comment-366807 Sutherland])
| [http://math.mit.edu/~drew/schinzel_3473955908_80550202480.txt 80,550,202,480]* [m=5] ([http://terrytao.wordpress.com/2014/05/17/polymath-8b-xi-finishing-up-the-paper/#comment-366807 Sutherland])
| Verification of several previous bounds
| Verification of several previous bounds
+ + + + +
|}
|}
Revision as of 10:07, 23 June 2014
Date [math]\varpi[/math] or [math](\varpi,\delta)[/math] [math]k_0[/math] [math]H[/math] Comments Aug 10 2005 6 [EH] 16 [EH] ([Goldston-Pintz-Yildirim]) First bounded prime gap result (conditional on Elliott-Halberstam) May 14 2013 1/1,168 (Zhang) 3,500,000 (Zhang) 70,000,000 (Zhang) All subsequent work (until the work of Maynard) is based on Zhang's breakthrough paper. May 21 63,374,611 (Lewko) Optimises Zhang's condition [math]\pi(H)-\pi(k_0) \gt k_0[/math]; can be reduced by 1 by parity considerations May 28 59,874,594 (Trudgian) Uses [math](p_{m+1},\ldots,p_{m+k_0})[/math] with [math]p_{m+1} \gt k_0[/math] May 30 59,470,640 (Morrison)
58,885,998? (Tao)
59,093,364 (Morrison)
57,554,086 (Morrison)
Uses [math](p_{m+1},\ldots,p_{m+k_0})[/math] and then [math](\pm 1, \pm p_{m+1}, \ldots, \pm p_{m+k_0/2-1})[/math] following [HR1973], [HR1973b], [R1974] and optimises in m May 31 2,947,442 (Morrison)
2,618,607 (Morrison)
48,112,378 (Morrison)
42,543,038 (Morrison)
42,342,946 (Morrison)
Optimizes Zhang's condition [math]\omega\gt0[/math], and then uses an improved bound on [math]\delta_2[/math] Jun 1 42,342,924 (Tao) Tiny improvement using the parity of [math]k_0[/math] Jun 2 866,605 (Morrison) 13,008,612 (Morrison) Uses a further improvement on the quantity [math]\Sigma_2[/math] in Zhang's analysis (replacing the previous bounds on [math]\delta_2[/math]) Jun 3 1/1,040? (v08ltu) 341,640 (Morrison) 4,982,086 (Morrison)
4,802,222 (Morrison)
Uses a different method to establish [math]DHL[k_0,2][/math] that removes most of the inefficiency from Zhang's method. Jun 4 1/224?? (v08ltu)
1/240?? (v08ltu)
4,801,744 (Sutherland)
4,788,240 (Sutherland)
Uses asymmetric version of the Hensley-Richards tuples Jun 5 34,429? (Paldi/v08ltu) 4,725,021 (Elsholtz)
4,717,560 (Sutherland)
397,110? (Sutherland)
4,656,298 (Sutherland)
389,922 (Sutherland)
388,310 (Sutherland)
388,284 (Castryck)
388,248 (Sutherland)
387,982 (Castryck)
387,974 (Castryck)
[math]k_0[/math] bound uses the optimal Bessel function cutoff. Originally only provisional due to neglect of the kappa error, but then it was confirmed that the kappa error was within the allowed tolerance.
[math]H[/math] bound obtained by a hybrid Schinzel/greedy (or "greedy-greedy") sieve
Jun 6 387,960 (Angelveit)
387,904 (Angeltveit)
Improved [math]H[/math]-bounds based on experimentation with different residue classes and different intervals, and randomized tie-breaking in the greedy sieve. Jun 7
26,024? (vo8ltu)
387,534 (pedant-Sutherland)
Many of the results ended up being retracted due to a number of issues found in the most recent preprint of Pintz. Jun 8 286,224 (Sutherland)
285,752 (pedant-Sutherland)
values of [math]\varpi,\delta,k_0[/math] now confirmed; most tuples available on dropbox. New bounds on [math]H[/math] obtained via iterated merging using a randomized greedy sieve. Jun 9 181,000*? (Pintz) 2,530,338*? (Pintz) New bounds on [math]H[/math] obtained by interleaving iterated merging with local optimizations. Jun 10 23,283? (Harcos/v08ltu) 285,210 (Sutherland) More efficient control of the [math]\kappa[/math] error using the fact that numbers with no small prime factor are usually coprime Jun 11 252,804 (Sutherland) More refined local "adjustment" optimizations, as detailed here.
An issue with the [math]k_0[/math] computation has been discovered, but is in the process of being repaired.
Jun 12 22,951 (Tao/v08ltu)
22,949 (Harcos)
249,180 (Castryck) Improved bound on [math]k_0[/math] avoids the technical issue in previous computations. Jun 13 Jun 14 248,898 (Sutherland) Jun 15 [math]348\varpi+68\delta \lt 1[/math]? (Tao) 6,330? (v08ltu)
6,329? (Harcos)
6,329 (v08ltu)
60,830? (Sutherland) Taking more advantage of the [math]\alpha[/math] convolution in the Type III sums Jun 16 [math]348\varpi+68\delta \lt 1[/math] (v08ltu) 60,760* (Sutherland) Attempting to make the Weyl differencing more efficient; unfortunately, it did not work Jun 18 5,937? (Pintz/Tao/v08ltu)
5,672? (v08ltu)
5,459? (v08ltu)
5,454? (v08ltu)
5,453? (v08ltu)
60,740 (xfxie)
58,866? (Sun)
53,898? (Sun)
53,842? (Sun)
A new truncated sieve of Pintz virtually eliminates the influence of [math]\delta[/math] Jun 19 5,455? (v08ltu)
5,453? (v08ltu)
5,452? (v08ltu)
53,774? (Sun)
53,672*? (Sun)
Some typos in [math]\kappa_3[/math] estimation had placed the 5,454 and 5,453 values of [math]k_0[/math] into doubt; however other refinements have counteracted this Jun 20 [math]178\varpi + 52\delta \lt 1[/math]? (Tao)
[math]148\varpi + 33\delta \lt 1[/math]? (Tao)
Replaced "completion of sums + Weil bounds" in estimation of incomplete Kloosterman-type sums by "Fourier transform + Weyl differencing + Weil bounds", taking advantage of factorability of moduli Jun 21 [math]148\varpi + 33\delta \lt 1[/math] (v08ltu) 1,470 (v08ltu)
1,467 (v08ltu)
12,042 (Engelsma) Systematic tables of tuples of small length have been set up here and here (update: As of June 27 these tables have been merged and uploaded to an online database of current bounds on [math]H(k)[/math] for [math]k[/math] up to 5000). Jun 22 Slight improvement in the [math]\tilde \theta[/math] parameter in the Pintz sieve; unfortunately, it does not seem to currently give an actual improvement to the optimal value of [math]k_0[/math] Jun 23 1,466 (Paldi/Harcos) 12,006 (Engelsma) An improved monotonicity formula for [math]G_{k_0-1,\tilde \theta}[/math] reduces [math]\kappa_3[/math] somewhat Jun 24 [math](134 + \tfrac{2}{3}) \varpi + 28\delta \le 1[/math]? (v08ltu)
[math]140\varpi + 32 \delta \lt 1[/math]? (Tao)
1,268? (v08ltu) 10,206? (Engelsma) A theoretical gain from rebalancing the exponents in the Type I exponential sum estimates Jun 25 [math]116\varpi+30\delta\lt1[/math]? (Fouvry-Kowalski-Michel-Nelson/Tao) 1,346? (Hannes)
1,007? (Hannes)
10,876? (Engelsma) Optimistic projections arise from combining the Graham-Ringrose numerology with the announced Fouvry-Kowalski-Michel-Nelson results on d_3 distribution Jun 26 [math]116\varpi + 25.5 \delta \lt 1[/math]? (Nielsen)
[math](112 + \tfrac{4}{7}) \varpi + (27 + \tfrac{6}{7}) \delta \lt 1[/math]? (Tao)
962? (Hannes) 7,470? (Engelsma) Beginning to flesh out various "levels" of Type I, Type II, and Type III estimates, see this page, in particular optimising van der Corput in the Type I sums. Integrated tuples page now online. Jun 27 [math]108\varpi + 30 \delta \lt 1[/math]? (Tao) 902? (Hannes) 6,966? (Engelsma) Improved the Type III estimates by averaging in [math]\alpha[/math]; also some slight improvements to the Type II sums. Tuples page is now accepting submissions. Jul 1 [math](93 + \frac{1}{3}) \varpi + (26 + \frac{2}{3}) \delta \lt 1[/math]? (Tao)
873? (Hannes)
Refactored the final Cauchy-Schwarz in the Type I sums to rebalance the off-diagonal and diagonal contributions Jul 5 [math] (93 + \frac{1}{3}) \varpi + (26 + \frac{2}{3}) \delta \lt 1[/math] (Tao)
Weakened the assumption of [math]x^\delta[/math]-smoothness of the original moduli to that of double [math]x^\delta[/math]-dense divisibility
Jul 10 7/600? (Tao) An in principle refinement of the van der Corput estimate based on exploiting additional averaging Jul 19 [math](85 + \frac{5}{7})\varpi + (25 + \frac{5}{7}) \delta \lt 1[/math]? (Tao) A more detailed computation of the Jul 10 refinement Jul 20 Jul 5 computations now confirmed Jul 27 633 (Tao)
632 (Harcos)
4,686 (Engelsma) Jul 30 [math]168\varpi + 48\delta \lt 1[/math]# (Tao) 1,788# (Tao) 14,994# (Sutherland) Bound obtained without using Deligne's theorems. Aug 17 1,783# (xfxie) 14,950# (Sutherland) Oct 3 13/1080?? (Nelson/Michel/Tao) 604?? (Tao) 4,428?? (Engelsma) Found an additional variable to apply van der Corput to Oct 11 [math]83\frac{1}{13}\varpi + 25\frac{5}{13} \delta \lt 1[/math]? (Tao) 603? (xfxie) 4,422?(Engelsma)
12 [EH] (Maynard)
Worked out the dependence on [math]\delta[/math] in the Oct 3 calculation Oct 21 All sections of the paper relating to the bounds obtained on Jul 27 and Aug 17 have been proofread at least twice Oct 23 700#? (Maynard) Announced at a talk in Oberwolfach Oct 24 110#? (Maynard) 628#? (Clark-Jarvis) With this value of [math]k_0[/math], the value of [math]H[/math] given is best possible (and similarly for smaller values of [math]k_0[/math]) Nov 19 105# (Maynard)
5 [EH] (Maynard)
600# (Maynard/Clark-Jarvis) One also gets three primes in intervals of length 600 if one assumes Elliott-Halberstam Nov 20 Optimizing the numerology in Maynard's large k analysis; unfortunately there was an error in the variance calculation Nov 21 68?? (Maynard)
582#*? (Nielsen])
59,451 [m=2]#? (Nielsen])
42,392 [m=2]? (Nielsen)
356?? (Clark-Jarvis) Optimistically inserting the Polymath8a distribution estimate into Maynard's low k calculations, ignoring the role of delta Nov 22 388*? (xfxie)
448#*? (Nielsen)
43,134 [m=2]#? (Nielsen)
698,288 [m=2]#? (Sutherland) Uses the m=2 values of k_0 from Nov 21 Nov 23 493,528 [m=2]#? Sutherland Nov 24 484,234 [m=2]? (Sutherland) Nov 25 385#*? (xfxie) 484,176 [m=2]? (Sutherland) Using the exponential moment method to control errors Nov 26 102# (Nielsen) 493,426 [m=2]#? (Sutherland) Optimising the original Maynard variational problem Nov 27 484,162 [m=2]? (Sutherland) Nov 28 484,136 [m=2]? (Sutherland Dec 4 64#? (Nielsen) 330#? (Clark-Jarvis) Searching over a wider range of polynomials than in Maynard's paper Dec 6 493,408 [m=2]#? (Sutherland) Dec 19 59#? (Nielsen)
10,000,000? [m=3] (Tao)
1,700,000? [m=3] (Tao)
38,000? [m=2] (Tao)
300#? (Clark-Jarvis)
182,087,080? [m=3] (Sutherland)
179,933,380? [m=3] (Sutherland)
More efficient memory management allows for an increase in the degree of the polynomials used; the m=2,3 results use an explicit version of the [math]M_k \geq \frac{k}{k-1} \log k - O(1)[/math] lower bound. Dec 20
55#? (Nielsen)
36,000? [m=2] (xfxie)
175,225,874? [m=3] (Sutherland)
27,398,976? [m=3] (Sutherland)
Dec 21 1,640,042? [m=3] (Sutherland) 429,798? [m=2] (Sutherland) Optimising the explicit lower bound [math]M_k \geq \log k-O(1)[/math] Dec 22 1,628,944? [m=3] (Castryck)
75,000,000? [m=4] (Castryck)
3,400,000,000? [m=5] (Castryck)
5,511 [EH] [m=3] (Sutherland)
2,114,964#? [m=3] (Sutherland)
309,954? [EH] [m=5] (Sutherland)
395,154? [m=2] (Sutherland)
1,523,781,850? [m=4] (Sutherland)
82,575,303,678? [m=5] (Sutherland)
A numerical precision issue was discovered in the earlier m=4 calculations Dec 23 41,589? [EH] [m=4] (Sutherland) 24,462,774? [m=3] (Sutherland)
1,512,832,950? [m=4] (Sutherland)
2,186,561,568#? [m=4] (Sutherland)
131,161,149,090#? [m=5] (Sutherland)
Dec 24 474,320? [EH] [m=4] (Sutherland)
1,497,901,734? [m=4] (Sutherland)
Dec 28 474,296? [EH] [m=4] (Sutherland) Jan 2 2014 474,290? [EH] [m=4] (Sutherland) Jan 6 54# (Nielsen) 270# (Clark-Jarvis) Jan 8 4 [GEH] (Nielsen) 8 [GEH] (Nielsen) Using a "gracefully degrading" lower bound for the numerator of the optimisation problem. Calculations confirmed here. Jan 9 474,266 [EH] [m=4] (Sutherland) Jan 28 395,106? [m=2] (Sutherland) Jan 29 3 [GEH] (Nielsen) 6 [GEH] (Nielsen) A new idea of Maynard exploits GEH to allow for cutoff functions whose support extends beyond the unit cube Feb 9 Jan 29 results confirmed here Feb 17 53?# (Nielsen) 264?# (Clark-Jarvis) Managed to get the epsilon trick to be computationally feasible for medium k Feb 22 51?# (Nielsen) 252?# (Clark-Jarvis) More efficient matrix computation allows for higher degrees to be used Mar 4 Jan 6 computations confirmed Apr 14 50?# (Nielsen) 246?# (Clark-Jarvis) A 2-week computer calculation! Apr 17 35,410 [m=2]* (xfxie) 398,646? [m=2]* (Sutherland)
25,816,462? [m=3]* (Sutherland)
1,541,858,666? [m=4]* (Sutherland)
84,449,123,072? [m=5]* (Sutherland)
Redoing the m=2,3,4,5 computations using the confirmed MPZ estimates rather than the unconfirmed ones Apr 18 398,244? [m=2]* (Sutherland)
1,541,183,756? [m=4]* (Sutherland)
84,449,103,908? [m=5]* (Sutherland)
Apr 28 398,130 [m=2]* (Sutherland)
1,526,698,470? [m=4]* (Sutherland)
83,833,839,882? [m=5]* (Sutherland)
May 1 81,973,172,502? [m=5] (Sutherland)
2,165,674,446#? [m=4] (Sutherland)
130,235,143,908#? [m=5] (Sutherland)
faster admissibility testing May 3 1,460,493,420? [m=4] (Sutherland)
80,088,836,006? [m=5] (Sutherland)
1,488,227,220?* [m=4] (Sutherland)
81,912,638,914?* [m=5] (Sutherland)
2,111,605,786?# [m=4] (Sutherland)
127,277,395,046?# [m=5] (Sutherland)
Fast admissibility testing for Hensley-Richards tuples May 3 3,393,468,735? [m=5] (de Grey)
2,113,163?# [m=3] (de Grey)
105,754,479?# [m=4] (de Grey)
5,274,206,963?# [m=5] (de Grey)
Improved hillclimbing; also confirmation of previous k values May 4 79,929,339,154? [m=5] (Sutherland)
2,111,597,632?# [m=4] (Sutherland)
126,630,432,986?# [m=5] (Sutherland)
May 5 32,285,928?# [m=3] (Sutherland) May 9 1,460,485,532? [m=4] (Sutherland)
79,929,332,990? [m=5] (Sutherland)
1,488,222,198?* [m=4] (Sutherland)
81,912,604,302?* [m=5] (Sutherland)
2,111,417,340?# [m=4] (Sutherland)
126,630,386,774?# [m=5] (Sutherland)
Fast admissibility testing for Hensley-Richards sequences May 14 1,440,495,268? [m=4] (Sutherland)
78,807,316,822 [m=5] (Sutherland)
1,467,584,468?* [m=4] (Sutherland)
80,761,835,464?* [m=5] (Sutherland)
2,082,729,956?# [m=4] (Sutherland)
124,840,189,042?# [m=5] (Sutherland)
Fast admissibility testing for Schinzel sequences May 18 1,435,011,318? [m=4] (Sutherland)
1,462,568,450?* [m=4] (Sutherland)
2,075,186,584?# [m=4] (Sutherland)
Faster modified Schinzel sieve testing May 23 1,424,944,070? [m=4] (Sutherland)
1,452,348,402?* [m=4] (Sutherland)
Fast restricted greedy sieving May 28 52? [m=2] [GEH] (de Grey)
51? [m=2] [GEH] (de Grey)
254? [m=2] [GEH] (Clark-Jarvis)
252? [m=2] [GEH] (Clark-Jarvis)
New bounds for [math]M_{k,1/(k-1)}[/math] May 30 1,404,556,152? [m=4] (Sutherland) Heuristically determined shift for the shifted greedy sieve June 8 80,550,202,480* [m=5] (Sutherland) Verification of several previous bounds June 23 78,602,310,160? [m=5] (Sutherland) Legend: ? - unconfirmed or conditional ?? - theoretical limit of an analysis, rather than a claimed record * - is majorized by an earlier but independent result # - bound does not rely on Deligne's theorems [EH] - bound is conditional the Elliott-Halberstam conjecture [GEH] - bound is conditional the generalized Elliott-Halberstam conjecture [m=N] - bound on intervals containing N+1 consecutive primes, rather than two strikethrough - values relied on a computation that has now been retracted
See also the article on
Finding narrow admissible tuples for benchmark values of [math]H[/math] for various key values of [math]k_0[/math]. |
Dynamical system definition
A dynamical system is a system whose state evolves with time over a state space according to a fixed rule.
For an introduction into the concepts behind a dynamical system, see the idea of a dynamical system.
Formal definition of dynamical system
A dynamical system is formally defined as a state space $X$, a set of times $T$, and a rule $R$ that specifies how the state evolves with time. The rule $R$ is a function whose domain is $X \times T$ (confused?) and whose codomain is $X$, i.e., $R : X \times T \to X$ (confused?). The rule function $R$ means that the $R$ takes two inputs, $R=R(\vc{x},t)$, where $\vc{x} \in X$ (confused?) is the initial state (at time $t=0$, for example) and $t \in T$ is a future time. In other words, $R(\vc{x},t)$ gives the state at time $t$ given that the initial state was $\vc{x}$. |
How large an interval with given tolerance for a Taylor polynomial?
This page treats a simple example of the first kind of questionmentioned on a previous page:‘Given a Taylor polynomialapproximation to a function, expanded at some given point, and given arequired tolerance,
on how large an interval around the given pointdoes the Taylor polynomial achieve that tolerance?’
The specific example we'll get to here is
‘For what range of$x\ge 25$ does $5+{1\over 10}(x-25)$ approximate $\sqrt{x}$ towithin $.001$?’
Again, with the degree-one Taylor polynomial andcorresponding remainder term, for reasonable functions $f$ we have$$f(x)=f(x_o)+f'(x_o)(x-x_o)+{f''(c)\over 2!}(x-x_o)^2$$for some $c$ between $x_o$ and $x$. The
remainder term is$$\hbox{remainder term }= {f''(c)\over 2!}(x-x_o)^2$$The notation $2!$ means ‘$2$-factorial’, which is just $2$, but whichwe write to be ‘forward compatible’ with other things later. Again: no, we do not know what $c$ is, except that it is between $x_o$and $x$. But this is entirely reasonable, since if we really knew itexactly then we'd be able to evaluate $f(x)$ exactly and we areevidently presuming that this isn't possible (or we wouldn't be doingall this!). That is, we have limited information about what $c$is, which we could view as the limitation on how precisely we can knowthe value $f(x)$.
To give an example of how to use this limited information, consider $f(x)=\sqrt{x}$ (yet again!). Taking $x_o=25$, we have \begin{align*} \sqrt{x}&=f(x)=f(x_o)+f'(x_o)(x-x_o)+{f''(c)\over 2!}(x-x_o)^2\\ &=\sqrt{25}+{1\over 2} { 1 \over \sqrt{25 }}(x-25)- {1\over 2!}{1\over 4}{ 1 \over (c)^{3/2 }}(x-25)^2\\ &=5+{1\over 10}(x-25)-{1\over 8}{ 1 \over c^{3/2 }}(x-25)^2 \end{align*} where all we know about $c$ is that it is between $25$ and $x$. What can we expect to get from this?
Well, we have to make a choice or two to get started: let's supposethat $x\ge 25$ (rather than smaller). Then we can write$$25\le c\le x$$From this, because the three-halves-power function is
increasing, we have$$25^{3/2}\le c^{3/2}\le x^{3/2}$$Taking inverses (with positive numbers) reverses the inequalities: wehave$$25^{-3/2}\ge c^{-3/2}\ge x^{-3/2}$$So, in the worst-case scenario, the value of $c^{-3/2}$ is atmost $25^{-3/2}=1/125$.
And we can rearrange the equation:$$\sqrt{x}-[5+{1\over 10}(x-25)]=-{1\over 8}{ 1 \over c^{3/2 }}(x-25)^2$$Taking absolute values
in order to talk about error, this is$$\left|\sqrt{x}-[5+{1\over 10}(x-25)]\right|=\left|{1\over 8}{ 1 \over c^{3/2 }}(x-25)^2\right|$$Now let's use our estimate $|{ 1 \over c^{3/2 }}|\le 1/125$ to write$$\left|\sqrt{x}-[5+{1\over 10}(x-25)]\right|\le\left|{1\over 8}{1\over 125}(x-25)^2\right|$$
OK, having done this simplification,
now we can answer questionslike For what range of $x\ge 25$ does $5+{1\over 10}(x-25)$approximate $\sqrt{x}$ to within $.001$? We cannot hope to tell exactly, but only to give a range of values of $x$ for which we canbe sure based upon our estimate. So the question becomes: solvethe inequality$$\left|{1\over 8}{1\over 125}(x-25)^2\right|\le .001$$(with $x\ge 25$). Multiplying out by the denominator of $8\cdot 125$gives (by coincidence?)$$|x-25|^2\le 1$$so the solution is $25\le x\le 26$.
So we can conclude that $\sqrt{x}$ is approximated to within $.001$ for all $x$ in the range $25\le x\le 26$. This is a worthwhile kind of thing to be able to find out.
Exercises For what range of values of $x$ is $x-{ x^3 \over 6 }$ within $0.01$ of $\sin x$? Only consider $-1\leq x\leq 1$. For what range ofvalues of $x$ inside this intervalis the polynomial $1+x+x^2/2$ within $.01$ of $e^x$? On how large an interval around $0$ is $1-x$ within $0.01$ of $1/(1+x)$? On how large an interval around $100$ is $10+{ x-100 \over 20 }$ within $0.01$ of $\sqrt{x}$? |
As @PaulDuBois commented, the above answer (@hjhjhj57) is incorrect for obtuse angles.
In fact, we can classify the outside of the triangle in
three regions:
1) $\alpha\geq 0$ and $\beta<0$, in which case $P$ is closest to either $AB$ or $AC$,
2) $\beta\geq 0$ and $\gamma<0$, in which case $P$ is closest to either $AB$ or $BC$,
3) $\gamma\geq 0$ and $\alpha<0$, in which case $P$ is closest to either $AC$ or $BC$.
The three regions are equivalent under substitution of variables and I will work out case 1:
If $\gamma<0$, and $(P-A)(B-A)>0$, $i.e.$ the projection of $P$ onto $AB$ where vector multiplication is the dot product, then $P$ is closest to $AB$ (verify that this can only be the case if $A$ is obtuse). Then\begin{eqnarray} \beta' &=& \text{min}(1, \frac{(P-A)(B-A)}{(B-A)(B-A)} ) \\ \gamma' &=& 0\end{eqnarray}
Otherwise $P$ is closest to $AC$ with\begin{eqnarray} \beta' &=& 0 \\ \gamma' &=& \text{min}(1, \text{max}(0, \frac{(P-A)(C-A)}{(C-A)(C-A)} ) )\end{eqnarray}
And lastly\begin{eqnarray} \alpha' &=& 1 - \beta' - \gamma' \\ P' &=& \alpha'A + \beta'B + \gamma'C\end{eqnarray} |
Good question! The proof given in Mohri's book indeed assumes continuity of the distribution, but this can be avoided with a finer definition of the $r_i$'s. Such a correction appears in these lecture notes who cite this paper.
Recall that you want the rectangles to be small enough, such that if $R_S$ intersects all of them, then $R\setminus R_s$ is small enough. Simultaneously, you want the rectangles to have large enough mass such that with high probability you do not miss a rectangle (here you use a simple bound on a geometric random variable as stated in the second point).
Suppose $R=[a,b]\times [c,d]$, and let us focus on $r_1$, the subrectangle having $[a,b]$ as an edge (if we are able to satisfy the above constraints for $r_1$, you can apply a similar construction for the rest of the rectangles). Define $r_1=[a,b]\times[c,c+h]$, where:
$h=\inf\big\{h'\big|\Pr\left[[a,b]\times[c,c+h']\right]\ge \frac{\epsilon}{4}\big\}$.
Note that $\Pr[r_1]\ge\frac{\epsilon}{4}$. To see why, let us assume that $\Pr[R]\ge\epsilon$ (otherwise we are done) and let $[a,b]\times[c,c+h']$ be some rectangle with mass $\ge \epsilon/4$. Now define the sequence of events$x_i=[a,b]\times[c,c+h+2^{-i}\Delta]$, where $\Delta=h'-h$, and identify the rectangle $x_i$ with the event that a point drawn from our distribution lies inside the rectangle. Now we have:
$\Pr\left[r_1\right]=\Pr\left[\bigcap\limits_{n=1}^\infty x_n\right]=\Pr\left[\lim\limits_{n\rightarrow\infty}x_n\right]=\lim\limits_{n\rightarrow\infty}\Pr[x_n]\ge \frac{\epsilon}{4}$.
To see why the last inequality holds note that the series converges, since it is decreasing and lower bounded by $\frac{\epsilon}{4}$ (by our choice of $h$). See this question for a discussion on the probability of limit events. This shows that you are covered on the second point, and can upper bound the probability that at least one of the rectangles is missed.
It remains to show what we should do in the case that $r_i\cap R_s\neq\emptyset$ for all $i$. We can no longer immediately claim that $\Pr\left[\bigcup\limits_{i}r_i\right]\le\epsilon$, but a more sensitive approach would do the trick. Let us define $r_i'$ to be the interior of the rectangle $r_i$ along with its corresponding edge from $R$. Note that if $R_S\cap r_i\neq\emptyset$ then $R\setminus R_S\subseteq\bigcup\limits_{i}r_i'$ (geometric argument). We can now conclude the proof by showing that $\Pr[r_i']\le\epsilon/4$. You can prove this by a similar approach, define a sequence of events converging to $r_1'$, and use the fact the the probability for each event in the sequence is upper bounded by $\epsilon/4$. |
It looks like you're new here. If you want to get involved, click one of these buttons!
In this chapter we learned about left and right adjoints, and about joins and meets. At first they seemed like two rather different pairs of concepts. But then we learned some deep relationships between them. Briefly:
Left adjoints preserve joins, and monotone functions that preserve enough joins are left adjoints.
Right adjoints preserve meets, and monotone functions that preserve enough meets are right adjoints.
Today we'll conclude our discussion of Chapter 1 with two more bombshells:
Joins
are left adjoints, and meets are right adjoints.
Left adjoints are right adjoints seen upside-down, and joins are meets seen upside-down.
This is a good example of how category theory works. You learn a bunch of concepts, but then you learn more and more facts relating them, which unify your understanding... until finally all these concepts collapse down like the core of a giant star, releasing a supernova of insight that transforms how you see the world!
Let me start by reviewing what we've already seen. To keep things simple let me state these facts just for posets, not the more general preorders. Everything can be generalized to preorders.
In Lecture 6 we saw that given a left adjoint \( f : A \to B\), we can compute its right adjoint using joins:
$$ g(b) = \bigvee \{a \in A : \; f(a) \le b \} . $$ Similarly, given a right adjoint \( g : B \to A \) between posets, we can compute its left adjoint using meets:
$$ f(a) = \bigwedge \{b \in B : \; a \le g(b) \} . $$ In Lecture 16 we saw that left adjoints preserve all joins, while right adjoints preserve all meets.
Then came the big surprise: if \( A \) has all joins and a monotone function \( f : A \to B \) preserves all joins, then \( f \) is a left adjoint! But if you examine the proof, you'l see we don't really need \( A \) to have
all joins: it's enough that all the joins in this formula exist:
$$ g(b) = \bigvee \{a \in A : \; f(a) \le b \} . $$Similarly, if \(B\) has all meets and a monotone function \(g : B \to A \) preserves all meets, then \( f \) is a right adjoint! But again, we don't need \( B \) to have
all meets: it's enough that all the meets in this formula exist:
$$ f(a) = \bigwedge \{b \in B : \; a \le g(b) \} . $$ Now for the first of today's bombshells: joins are left adjoints and meets are right adjoints. I'll state this for binary joins and meets, but it generalizes.
Suppose \(A\) is a poset with all binary joins. Then we get a function
$$ \vee : A \times A \to A $$ sending any pair \( (a,a') \in A\) to the join \(a \vee a'\). But we can make \(A \times A\) into a poset as follows:
$$ (a,b) \le (a',b') \textrm{ if and only if } a \le a' \textrm{ and } b \le b' .$$ Then \( \vee : A \times A \to A\) becomes a monotone map, since you can check that
$$ a \le a' \textrm{ and } b \le b' \textrm{ implies } a \vee b \le a' \vee b'. $$And you can show that \( \vee : A \times A \to A \) is the left adjoint of another monotone function, the
diagonal
$$ \Delta : A \to A \times A $$sending any \(a \in A\) to the pair \( (a,a) \). This diagonal function is also called
duplication, since it duplicates any element of \(A\).
Why is \( \vee \) the left adjoint of \( \Delta \)? If you unravel what this means using all the definitions, it amounts to this fact:
$$ a \vee a' \le b \textrm{ if and only if } a \le b \textrm{ and } a' \le b . $$ Note that we're applying \( \vee \) to \( (a,a') \) in the expression at left here, and applying \( \Delta \) to \( b \) in the expression at the right. So, this fact says that \( \vee \) the left adjoint of \( \Delta \).
Puzzle 45. Prove that \( a \le a' \) and \( b \le b' \) imply \( a \vee b \le a' \vee b' \). Also prove that \( a \vee a' \le b \) if and only if \( a \le b \) and \( a' \le b \).
A similar argument shows that meets are really right adjoints! If \( A \) is a poset with all binary meets, we get a monotone function
$$ \wedge : A \times A \to A $$that's the
right adjoint of \( \Delta \). This is just a clever way of saying
$$ a \le b \textrm{ and } a \le b' \textrm{ if and only if } a \le b \wedge b' $$ which is also easy to check.
Puzzle 46. State and prove similar facts for joins and meets of any number of elements in a poset - possibly an infinite number.
All this is very beautiful, but you'll notice that all facts come in pairs: one for left adjoints and one for right adjoints. We can squeeze out this redundancy by noticing that every preorder has an "opposite", where "greater than" and "less than" trade places! It's like a mirror world where up is down, big is small, true is false, and so on.
Definition. Given a preorder \( (A , \le) \) there is a preorder called its opposite, \( (A, \ge) \). Here we define \( \ge \) by
$$ a \ge a' \textrm{ if and only if } a' \le a $$ for all \( a, a' \in A \). We call the opposite preorder\( A^{\textrm{op}} \) for short.
I can't believe I've gone this far without ever mentioning \( \ge \). Now we finally have really good reason.
Puzzle 47. Show that the opposite of a preorder really is a preorder, and the opposite of a poset is a poset. Puzzle 48. Show that the opposite of the opposite of \( A \) is \( A \) again. Puzzle 49. Show that the join of any subset of \( A \), if it exists, is the meet of that subset in \( A^{\textrm{op}} \). Puzzle 50. Show that any monotone function \(f : A \to B \) gives a monotone function \( f : A^{\textrm{op}} \to B^{\textrm{op}} \): the same function, but preserving \( \ge \) rather than \( \le \). Puzzle 51. Show that \(f : A \to B \) is the left adjoint of \(g : B \to A \) if and only if \(f : A^{\textrm{op}} \to B^{\textrm{op}} \) is the right adjoint of \( g: B^{\textrm{op}} \to A^{\textrm{ op }}\).
So, we've taken our whole course so far and "folded it in half", reducing every fact about meets to a fact about joins, and every fact about right adjoints to a fact about left adjoints... or vice versa! This idea, so important in category theory, is called
duality. In its simplest form, it says that things come on opposite pairs, and there's a symmetry that switches these opposite pairs. Taken to its extreme, it says that everything is built out of the interplay between opposite pairs.
Once you start looking you can find duality everywhere, from ancient Chinese philosophy:
to modern computers:
But duality has been studied very deeply in category theory: I'm just skimming the surface here. In particular, we haven't gotten into the connection between adjoints and duality!
This is the end of my lectures on Chapter 1. There's more in this chapter that we didn't cover, so now it's time for us to go through all the exercises. |
When computing special bordism groups, I often need to determine existence of (singular) smooth $4$-manifolds with fixed fundamental group and certain properties like the spin behaviour (i.e. being totally non-spin, spin or almost spin - sometimes they are denoted as odd or even manifolds).
Usually I'm able to prove existence of such manifolds "algebraically", i.e. after studying the edge homomorphism of certain Atyiah-Hirzebruch spectral sequences and then infer the existence (or not) if such manifolds. This method as a drawback though: if I'm not able to compute the stable page of the AHSS I can't proceed. This is the reason why I'm interested in study a new, more topological, approach to this problem.
Let me be more clear with an example: Let $$\xi:= \eta_w \oplus Bp \colon K(D_{2n};1)\times BSpin\to BSO$$ be a stable bundle, where $D_{2n}$ is the Dihedral group with $n=0 \pmod{4}$ and $\eta_w$ is a vector bundle such that $w_1(\eta_w)=0$ and $w_2(\eta_w)=w \in H^2(D_{2n};\mathbb{Z}_2)$. The Bordism group $$\Omega_4(\xi)$$ contains as elements almost spin orientable $4$-manifolds with fundamental group $D_{2n}$ and such that $c^*(w)=w_2(M)$ where $c \colon M\to K(D_{2n};1)$ is the classifying map of the universal cover (this is a fancy way to say that $M$ has normal $1$-type $\xi$). You can think of it as a special $B$-bordism group.
An application of the AHSS for computing the bordism group $\Omega_4(\xi)$ gives that the signature and the edge homomorphism induce an isomorphism: $$\mathfrak{sg}\oplus \mathfrak{e} \colon \Omega_4(\xi)\cong 8\cdot \mathbb{Z} \oplus E_{4,0}^{\infty}$$ $$ M \mapsto (\mathfrak{sg}(M), c_*[M])$$
I know that $E_{4,0}^{\infty}=0$ or $\mathbb{Z}/2$ (I'm unable to determine what is $d_3 \colon E_{4,0}^3\cong \mathbb{Z}/2 \to E_{1,2}^3\cong \mathbb{Z}/2$)
In order to see which case can occur, I would like to establish existence (or not) of a closed $4$ manifold $M$, with the following properties:
It's orientable It's an element of $\Omega_4(\xi)$ (i.e. has normal $1$-type $\xi$) The element $c_*[M]$ in $H_4(D_{2n};\mathbb{Z})$ is non zero
I think surgery theory might be a way to deal with this problem, but since I've never studied it, I need some guidance in understanding HOW surgery could help me and WHERE can I learn the tools I need.
In the comments I was linked this paper. I have started reading it, but I'd like to know which chapter should I focus on: a quick search of "dihedral" and a glance at the index don't seem to show where surgery is used in a way I might be interested in. After a more careful read, it seems that lots of the results require properties on $\pi_1$ that I clearly don't have: torsion-free, virtually $\mathbb{Z}^n$, $PD_r$-group... Moreover the section about stable classification (the reason why I'm computing such bordism groups) doesn't tell us much, withouth proving anything. It's possible that due to my inexperience in this field, I'm unable to find the right chapters, but if someone could point me out where I should focus it would be very helpful.
PS: If needed I can add more explanations about the background of the problem I tried to describe here. I tried to keep explanations at minimum in order to avoid lengthy and boring questions. Let me know if something need more explanation. |
Refine Document Type Master's Thesis (5) (remove) Keywords Faculty / Organisational entity Fachbereich Mathematik (5) (remove)
Mathematische Modellierung eines Segways mit Umsetzung in der Schule als interdisziplinäre Projektarbeit (2016)
Das Ziel dieser Arbeit besteht darin, aufzuzeigen, wie eine mathematische Modellierung, verbunden mit Simulations- und Ansteuerungsaspekten eines Segways im Mathematikunterricht der gymnasialen Oberstufe als interdisziplinäres Projekt umgesetzt werden kann. Dabei werden sowohl Chancen, im Sinne von erreichbaren mathematischen Kompetenzen, als auch Schwierigkeiten eines solchen Projektes mit einer interdisziplinären Umsetzung geschildert.
Buses not arriving on time and then arriving all at once - this phenomenon is known from busy bus routes and is called bus bunching. This thesis combines the well studied but so far separate areas of bus-bunching prediction and dynamic holding strategies, which allow to modulate buses’ dwell times at stops to eliminate bus bunching. We look at real data of the Dublin Bus route 46A and present a headway-based predictive-control framework considering all components like data acquisition, prediction and control strategies. We formulate time headways as time series and compare several prediction methods for those. Furthermore we present an analytical model of an artificial bus route and discuss stability properties and dynamic holding strategies using both data available at the time and predicted headway data. In a numerical simulation we illustrate the advantages of the presented predictive-control framework compared to the classical approaches which only use directly available data.
Optimal control of partial differential equations is an important task in applied mathematics where it is used in order to optimize, for example, industrial or medical processes. In this thesis we investigate an optimal control problem with tracking type cost functional for the Cattaneo equation with distributed control, that is, \(\tau y_{tt} + y_t - \Delta y = u\). Our focus is on the theoretical and numerical analysis of the limit process \(\tau \to 0\) where we prove the convergence of solutions of the Cattaneo equation to solutions of the heat equation. We start by deriving both the Cattaneo and the classical heat equation as well as introducing our notation and some functional analytic background. Afterwards, we prove the well-posedness of the Cattaneo equation for homogeneous Dirichlet boundary conditions, that is, we show the existence and uniqueness of a weak solution together with its continuous dependence on the data. We need this in the following, where we investigate the optimal control problem for the Cattaneo equation: We show the existence and uniqueness of a global minimizer for an optimal control problem with tracking type cost functional and the Cattaneo equation as a constraint. Subsequently, we do an asymptotic analysis for \(\tau \to 0\) for both the forward equation and the aforementioned optimal control problem and show that the solutions of these problems for the Cattaneo equation converge strongly to the ones for the heat equation. Finally, we investigate these problems numerically, where we examine the different behaviour of the models and also consider the limit \(\tau \to 0\), suggesting a linear convergence rate.
In the present master’s thesis we investigate the connection between derivations and homogeneities of complete analytic algebras. We prove a theorem, which describes a specific set of generators for the module of derivations of an analytic algebra, which map the maximal ideal of R into itself. It turns out, that this set has a structure similar to a Cartan subalgebra and contains information regarding multi-homogeneity. In order to prove this theorem, we extend the notion of grading by Scheja and Wiebe to projective systems and state the connection between multi-gradings and pairwise commuting diagonalizable derivations. We prove a theorem similar to Cartan’s Conjugacy Theorem in the setup of infinite-dimensional Lie algebras, which arise as projective limits of finite-dimensional Lie algebras. Using this result, we can show that the structure of the aforementioned set of generators is an intrinsic property of the analytic algebra. At the end we state an algorithm, which is theoretically able to compute the maximal multi-homogeneity of a complete analytic algebra.
Cutting-edge cancer therapy involves producing individualized medicine for many patients at the same time. Within this process, most steps can be completed for a certain number of patients simultaneously. Using these resources efficiently may significantly reduce waiting times for the patients and is therefore crucial for saving human lives. However, this involves solving a complex scheduling problem, which can mathematically be modeled as a proportionate flow shop of batching machines (PFB). In this thesis we investigate exact and approximate algorithms for tackling many variants of this problem. Related mathematical models have been studied before in the context of semiconductor manufacturing. |
The
P-value approach involves determining "likely" or "unlikely" by determining the probability — assuming the null hypothesis were true — of observing a more extreme test statistic in the direction of the alternative hypothesis than the one observed. If the P-value is small, say less than (or equal to) \(\alpha\), then it is "unlikely." And, if the P-value is large, say more than \(\alpha\), then it is "likely."
If the
P-value is less than (or equal to) \(\alpha\), then the null hypothesis is rejected in favor of the alternative hypothesis. And, if the P-value is greater than \(\alpha\), then the null hypothesis is not rejected.
Specifically, the four steps involved in using the
P-value approach to conducting any hypothesis test are: Specify the null and alternative hypotheses. Using the sample data and assuming the null hypothesis is true, calculate the value of the test statistic. Again, to conduct the hypothesis test for the population mean μ, we use the t-statistic \(t^*=\frac{\bar{x}-\mu}{s/\sqrt{n}}\) which follows a t-distribution with n- 1 degrees of freedom. Using the known distribution of the test statistic, calculate the P -value: "If the null hypothesis is true, what is the probability that we'd observe a more extreme test statistic in the direction of the alternative hypothesis than we did?" (Note how this question is equivalent to the question answered in criminal trials: "If the defendant is innocent, what is the chance that we'd observe such extreme criminal evidence?") Set the significance level, \(\alpha\), the probability of making a Type I error to be small — 0.01, 0.05, or 0.10. Compare the P-value to \(\alpha\). If the P-value is less than (or equal to) \(\alpha\), reject the null hypothesis in favor of the alternative hypothesis. If the P-value is greater than \(\alpha\), do not reject the null hypothesis. Example S.3.2.1 Mean GPA Section
In our example concerning the mean grade point average, suppose that our random sample of
n = 15 students majoring in mathematics yields a test statistic t* equaling 2.5. Since n = 15, our test statistic t* has n - 1 = 14 degrees of freedom. Also, suppose we set our significance level α at 0.05, so that we have only a 5% chance of making a Type I error. Right Tailed
The
P-value for conducting the right-tailed test H 0 : μ = 3 versus H A : μ > 3 is the probability that we would observe a test statistic greater than t* = 2.5 if the population mean \(\mu\) really were 3. Recall that probability equals the area under the probability curve. The P-value is therefore the area under a t = n - 1 t 14curve and to the rightof the test statistic t* = 2.5. It can be shown using statistical software that the P-value is 0.0127. The graph depicts this visually.
The
P-value, 0.0127, tells us it is "unlikely" that we would observe such an extreme test statistic t* in the direction of H A if the null hypothesis were true. Therefore, our initial assumption that the null hypothesis is true must be incorrect. That is, since the P-value, 0.0127, is less than \(\alpha\) = 0.05, we reject the null hypothesis H 0 : μ = 3 in favor of the alternative hypothesis H A : μ > 3.
Note that we would not reject
H 0 : μ = 3 in favor of H A : μ > 3 if we lowered our willingness to make a Type I error to \(\alpha\) = 0.01 instead, as the P-value, 0.0127, is then greater than \(\alpha\) = 0.01. Left Tailed
In our example concerning the mean grade point average, suppose that our random sample of
n = 15 students majoring in mathematics yields a test statistic t* instead equaling -2.5. The P-value for conducting the left-tailed test H 0 : μ = 3 versus H A : μ < 3 is the probability that we would observe a test statistic less than t* = -2.5 if the population mean μ really were 3. The P-value is therefore the area under a t = n - 1 t 14curve and to the leftof the test statistic t* = -2.5. It can be shown using statistical software that the P-value is 0.0127. The graph depicts this visually.
The
P-value, 0.0127, tells us it is "unlikely" that we would observe such an extreme test statistic t* in the direction of H A if the null hypothesis were true. Therefore, our initial assumption that the null hypothesis is true must be incorrect. That is, since the P-value, 0.0127, is less than α = 0.05, we reject the null hypothesis H 0 : μ = 3 in favor of the alternative hypothesis H A : μ < 3.
Note that we would not reject
H 0 : μ = 3 in favor of H A : μ < 3 if we lowered our willingness to make a Type I error to α = 0.01 instead, as the P-value, 0.0127, is then greater than \(\alpha\) = 0.01. Two Tailed
In our example concerning the mean grade point average, suppose again that our random sample of
n = 15 students majoring in mathematics yields a test statistic t* instead equaling -2.5. The P-value for conducting the two-tailed test H 0 : μ = 3 versus H A : μ ≠ 3 is the probability that we would observe a test statistic less than -2.5 or greater than 2.5 if the population mean μ really were 3. That is, the two-tailed test requires taking into account the possibility that the test statistic could fall into either tail (and hence the name "two-tailed" test). The P-value is therefore the area under a t = n - 1 t 14curve to the leftof -2.5 and to the rightof the 2.5. It can be shown using statistical software that the P-value is 0.0127 + 0.0127, or 0.0254. The graph depicts this visually.
Note that the
P-value for a two-tailed test is always two times the P-value for either of the one-tailed tests. The P-value, 0.0254, tells us it is "unlikely" that we would observe such an extreme test statistic t* in the direction of H A if the null hypothesis were true. Therefore, our initial assumption that the null hypothesis is true must be incorrect. That is, since the P-value, 0.0254, is less than α = 0.05, we reject the null hypothesis H 0 : μ = 3 in favor of the alternative hypothesis H A : μ ≠ 3.
Note that we would not reject
H 0 : μ = 3 in favor of H A : μ ≠ 3 if we lowered our willingness to make a Type I error to α = 0.01 instead, as the P-value, 0.0254, is then greater than \(\alpha\) = 0.01.
Now that we have reviewed the critical value and
P-value approach procedures for each of three possible hypotheses, let's look at three new examples — one of a right-tailed test, one of a left-tailed test, and one of a two-tailed test.
The good news is that, whenever possible, we will take advantage of the test statistics and
P-values reported in statistical software, such as Minitab, to conduct our hypothesis tests in this course. |
I see three questions.
Question 1: Why do we care about $Set$ when we define functors $C\to Somebase$?
$Set$ is a very special category:
$Set$ is the terminal object of the category of Grothendieck topoi and geometric morphisms $Set$ is the free cocompletion of the one-object category. $Set$ is a "canonical choice" for a category whose terminal object is a generator, and where you can embody the set of natural numbers. the mystics claim that in $Set$ every epimorphism has a right inverse.
Question 2: why we do it for other categories as well?
A presheaf is a functor $F : C\to Set$; if $C=1$ this is a "static" set, but as soon as $C$ is bigger the set $Fc$ varies concordantly with the variability of structure in $C$. If you join this with the fact that, in a very precise sense, $F$ is a "space" ${\cal E}(F)$ lying over $C$, you get that it is a nice idea to study families of sets parametrized by a category.
Another analogy that I like very much is that presheaves describe actions of a category $C$ on sets, one set for each object of $C$, and consistently with morphisms of $C$ (what is a presheaf on a monoid? What is a functor $G \to Vect_k$ if $G$ is a group? In both cases $G$ is a one-object category).
In both these pictures it is a very natural request that the images of $c\in C$ under $F$, or equivalently the fibers of $\Pi : {\cal E}(F) \to C$ over $c$, are structured sets. Hence the need for presheaves of abelian groups, rings, $R$-modules, topological spaces, categories: in which way I can represent variable structured sets? In which ways I can make a category act on structured sets?
This intertwines with another important point, that also adresses your third question: in the internal language of a category of functors $[C,Set]$ you have the ability to speak about structured objects: you can say what a monoid, a group, a ring, a module, a poset... is in $[C,Set]$, by asking that certain maps (representing operations) make certain diagrams (representing properties of those operations) commute. The theory of internal structures is something we investigate since Lawvere's thesis (Functorial semantics), and his work, as well as the huge literature in topos theory, sheds a light on the precise meaning of the following items:
"Structures are categories", in the sense that there exists a category $Th(Grp)$ such that suitable functors $Th(Grp)\to Set$ correspond precisely to groups as naively defined to you day 1 of your first algebra course. The same things happens, in the very same way, for every other algebraic structure, at least those who satisfy a certain technical property (the category of the functors $Th(\Omega)\to Set$ is monadic over $Set$. The category $Th(\Omega)$ contains the archetypical shape that any $\Omega$ structure shall have; it is called a "theory". A functor $Th(Grp)\to Set$, i.e.a group, is a model for that theory. But models can exist in every context expressive enough to embody them. So, as sets correspond to the category $[1,Set]$, it is a natural question what structures internally to more general $[C,Set]$ are (and perhaps one day to even more general finitely-complete categories $K$). In a stunning turn of events, now, (say) an abelian group, i.e. a functor $Th(AbGrp)\to [C,Set]$ is precisely a functor $C\to Set$ such that each $Fc$ is an abelian group, i.e. the "models" for the "theory" of abelian groups internally to $[C,Set]$ are precisely the functors $C\to Set$ taking values in the subcategory of models for the theory of abelian groups in $Set$. If we call $Mod_{Th(\Omega)}( K)$ the $\Omega$-structures internal to the category $K$ we can "shift" the $Mod(-)$ correspondence in and out $[C,Set]$:$$Mod_{Th(AbGrp)}([C,Set]) \cong [C, Mod_{Th(AbGrp)}(Set)]$$This seemingly trivial statement fills me with wonder every time I see it.
So, somehow, once you are able to classify models for $\Omega$-structures in $Set =[1,Set]$, you are automatically able to classify models in every other $[C,Set]$. So sets, in this respect, play a central rôle!
This brings me to your last question, maybe the most intriguing one of the list.
Question 3: Why it seems that sheaves contain interesting information?
Long story short: because they do.
The internalization paradigm sketched above shows that "small" mathematicians could live in a single big, finitely complete category $K$, without even worrying about the presence of models for their theories outside it.
Thus, if you admit them to be big enough (i.e. if you leave the somewhat unsatisfying picture that "all categories are small"), each category works as a universe in which you can speak mathematical language ("speak the language of mathematics" is synonym, since model theory, with "studying models for the theory of $\Omega$-structures" as long as $\Omega$ runs over all possible theories). Small mathematicians are born in $K$, so they only see $K$-models for $Th(\Omega)$. (some small mathematicians even have problems accepting that what they're used to call "abstract groups", are instead
models for an even-more-abstract theory of groups).
As an aside and flamy comment, (i) the fact that until your mathematics is small, you can ignore the existence of large objects, and (ii) the difficulty to exit $K$, explains at least to a certain extent the resistance to categorical thinking.
To remedy the apparently arrogant tone of this last remark, let me stress that "small" has no pejorative meaning whatsoever, in the same sense a small category is not less legitimate to exist.
So
categories are universes in which you can interpret theories, and if you look from high enough there is plenty of other objects having the same properties of $Set$, and you shouldn't be afraid to move there (or rather, you shouldn't insist on living in $Set$: maybe your destiny is to conquer the category of sheaves on $S^n$, or the category of functions whose codomain is $\mathbb N$).
This apparently philosophical discussion opens instead a rather profound point: each category $K$ has a semantics, suited to interpret theories in $K$.
To be more precise, then, categories are
places, in each of which we can interpret different kinds of logics (if you like categorical thinking, you better familiarize with the idea that there is plenty of different logic s, in the same way -and with the same continuous spectrum of nuances in flavour and aroma- that there is plenty of different coffee beans; also, more than often the debate about the best coffee leads to the same war of religion the debate about the best logic does).
As you can see on the nLab page about internal logic
s, what determines the particular shape of semantics that you can interpret in $K$ is no more, no less than the nice categorical properties of $K$ (does it have finite co/limits? Does it have a nice factorization system? Does it have a subobject classifier? Is the poset $Sub(A)$ of subobjects of $A$ a lattice, is it modular, distributive, complemented...? -evidently this last question is about the internal logic of the category: propositions "are" the set, or rather the type, of "elements" for which the proposition is "true").
Categories of sheaves are nice objects in this respect because they have almost all these properties: subobjects can be joined, united, complemented; finite co/limits, and even infinite ones, exist. Subobjects are realized by maps to a "classifying" object $\Omega$, whose "elements" are truth values of propositions; each slice category $Sh(C)/P$ has the same properties and the functors $Sh(C)/P \leftrightarrows Sh(C)/Q$ induced by maps $P\to Q$ are "nice" (they preserve this structure).
A category of sheaves is then a good choice for the $K$ in which you want to live, simply because it is expressive enough to do
a lot of mathematics.
What I'm leaving outside of this comment, since I've alrady ridiculed myself in front of people who actually work with topoi and know this topic better than I do, is the following:
mention accessible and locally presentable categories. Categories of sheaves are locally presentable elementary topoi. These are very nice categories that albeit being large can be described by a set (sometimes a group is infinite, but can be generated by a finite set; sometimes a category is a proper class, but there is a set of objects generating it). Work "on a relative base": sets are no more special than another topos, they're only easier to handle. Most of topos theory works the same way if you fix a "base" topos once and for all, say $\cal S$, and study the 2-category of "topoi over $\cal S$". Since a topos is a generalized space, it turns out that this procedure is no different from studying the category of space-maps over a prescribed base $X$ as opposed to the category of all maps with variable codomain. $Set$ being the terminal object of $\bf Topoi$, ${\bf Topoi}/Set$ is merely $\bf Topoi$. |
Let $H = \triangle + V(x) : \mathbb{R}^2 \rightarrow \mathbb{R}^2$. I am interested in domain decomposition for an eigenproblem involving $H$.
The lowest 1000 eigenfunctions of $H$, $ \psi_i $, can be partitioned using a region, $\Omega \subset \mathbb{R}^2$, such that each $\psi_i$ localizes either inside of $\Omega$ or outside of $\Omega$. $\Omega$ is not a subspace of $\mathbb{R}^2$ as it may be an oddly shaped region.
Label the inner eigenfunctions $\psi_i^{in}$ and the outer ones $\psi_i^{out}$. There's only about 10 $\psi_i^{in}$s. Given $\Omega$, my goal is to efficiently compute the $\psi_i^{in}$.
One way to find the $\psi_i^{in}$ would be to discretize, compute all 1000 $\psi_i$s, and then partition. This is what I do now (5-point stencil for $\triangle$ on a $10^3 \times 10^3$ grid). The problem is that this requires diagonalizing over a 1000 dimensional space in order to get 10 eigenvectors. It seems like there would be a cheaper way to compute the $\psi_i^{in}$.
Edit: I reposted to https://scicomp.stackexchange.com/questions/1396/efficiently-computing-a-few-localized-eigenvectors#comment2200_1396 and hopefully clarified the problem statement. Edit I think I can solve this if I can at least figure a way to solve\begin{equation}\max \psi^T H \psi \text{ subject to } P\psi = \psi \text{ and } \psi^T \psi = 1\end{equation}where $P$ is projection onto the space of functions localized over $\Omega$. My guess is that this will end up looking like power iterations with a projection step built in between matrix applies. If this is doable then something like inverse iteration should be doable which will give me what I want. |
Diese Seite ist aus Gründen der Barrierefreiheit optimiert für aktuelle Browser. Sollten Sie einen älteren Browser verwenden, kann es zu Einschränkungen der Darstellung und Benutzbarkeit der Website kommen!
Collisionless reconnection: Magnetic field line interaction
Treumann, R. A., W. Baumjohann, and W. D. Gonzalez (2012),
Collisionless reconnection: Magnetic field line interaction, Annales Geophysicae, 30, 1515-1528, doi:10.5194/angeo-30-1515-2012, 14 journal pages, 7 Figures. Abstract Magnetic field lines are quantum objects carrying one quantum $\Phi_0=2\pi\hbar/e$ of magnetic flux and have finite radius $\lambda_m$. Here we argue that they possess a very specific dynamical interaction. Parallel field lines reject each other. When confined to a certain area they form two-dimensional lattices of hexagonal structure. We estimate the filling factor of such an area. Antiparallel field lines, on the other hand, attract each other. We identify the physical mechanism as being due to the action of the gauge potential field which we determine quantum mechanically for two parallel and two antiparallel field lines. The distortion of the quantum electrodynamic vacuum causes a cloud of virtual pairs. We calculate the virtual pair production rate from quantum electrodynamics and estimate the virtual pair cloud density, pair current and Lorentz force density acting on the field lines via the pair cloud. These properties of field line dynamics become important in collisionless reconnection, consistently explaining why and how reconnection can spontaneously set on in the field-free centre of a current sheet below the electron-inertial scale. Further information BibTeX
@article{id1748,
author = {R. A. Treumann and W. Baumjohann and W. D. Gonzalez},
journal = {Annales Geophysicae},
month = {oct},
note = {14 journal pages, 7 Figures},
pages = {1515-1528},
title = {{Collisionless reconnection: Magnetic field line interaction}},
volume = {30},
year = {2012},
url = {www.ann-geophys.net/30/1515/2012/},
doi = {10.5194/angeo-30-1515-2012},
} EndNote
%0 Journal Article
%A Treumann, R. A.
%A Baumjohann, W.
%A Gonzalez, W. D.
%D 2012
%V 30
%J Annales Geophysicae
%P 1515-1528
%Z 14 journal pages, 7 Figures
%T Collisionless reconnection: Magnetic field line interaction
%U www.ann-geophys.net/30/1515/2012/
%8 oct
Printed 15. Oct 2019 03:53 |
The
Minkowski distance is a metric in a normed vector space which can be considered as a generalization of both the Euclidean distance and the Manhattan distance. Definition [ edit ]
The Minkowski distance of order
p between two points X = ( x 1 , x 2 , … , x n ) and Y = ( y 1 , y 2 , … , y n ) ∈ R n {\displaystyle X=(x_{1},x_{2},\ldots ,x_{n}){\text{ and }}Y=(y_{1},y_{2},\ldots ,y_{n})\in \mathbb {R} ^{n}}
is defined as:
D ( X , Y ) = ( ∑ i = 1 n | x i − y i | p ) 1 / p {\displaystyle D\left(X,Y\right)=\left(\sum _{i=1}^{n}|x_{i}-y_{i}|^{p}\right)^{1/p}}
For
, the Minkowski distance is a p ≥ 1 {\displaystyle p\geq 1} metric as a result of the Minkowski inequality. When , the distance between (0,0) and (1,1) is p < 1 {\displaystyle p<1} , but the point (0,1) is at a distance 1 from both of these points. Since this violates the 2 1 / p > 2 {\displaystyle 2^{1/p}>2} triangle inequality, for it is not a metric. However, a metric can be obtained for these values by simply removing the exponent of p < 1 {\displaystyle p<1} . The resulting metric is also an 1 / p {\displaystyle 1/p} F-norm.
Minkowski distance is typically used with
p being 1 or 2, which correspond to the Manhattan distance and the Euclidean distance, respectively. In the limiting case of p reaching infinity, we obtain the Chebyshev distance: lim p → ∞ ( ∑ i = 1 n | x i − y i | p ) 1 p = max i = 1 n | x i − y i | . {\displaystyle \lim _{p\to \infty }{\left(\sum _{i=1}^{n}|x_{i}-y_{i}|^{p}\right)^{\frac {1}{p}}}=\max _{i=1}^{n}|x_{i}-y_{i}|.\,}
Similarly, for
p reaching negative infinity, we have: lim p → − ∞ ( ∑ i = 1 n | x i − y i | p ) 1 p = min i = 1 n | x i − y i | . {\displaystyle \lim _{p\to -\infty }{\left(\sum _{i=1}^{n}|x_{i}-y_{i}|^{p}\right)^{\frac {1}{p}}}=\min _{i=1}^{n}|x_{i}-y_{i}|.\,}
The Minkowski distance can also be viewed as a multiple of the
power mean of the component-wise differences between P and Q.
The following figure shows unit circles (the set of all points that are at the unit distance from the centre) with various values of
p: See also [ edit ] External links [ edit ] Simple IEEE 754 implementation in C++
NPM JavaScript Package/Module |
In Peskin's book (an introduction to QFT), Page 655, the axial vector current is defined as follows, \begin{eqnarray*} j^{\mu5} & = & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}\exp\bigg(-ie\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg)\psi(x-\frac{\epsilon}{2})\bigg\}. \tag{19.22} \end{eqnarray*}
Then he obtained $\partial_{\mu}j^{\mu5}$ as follows, \begin{eqnarray*} \partial_{\mu}j^{\mu5} & = & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{[\partial_{\mu}\bar{\psi}(x+\frac{\epsilon}{2})]\gamma^{\mu}\gamma^{5}\exp\bigg(-ie\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg)\psi(x-\frac{\epsilon}{2})\\ & & +\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}\exp\bigg(-ie\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg)[\partial_{\mu}\psi(x-\frac{\epsilon}{2})]\\ & & +\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}[-ie\epsilon^{\nu}\partial_{\color{Red}{\mu}}A_{\color{Red}{\nu}}(x)]\psi(x-\frac{\epsilon}{2})\bigg\}. \tag{19.24} \end{eqnarray*}
I know the last line of above formula (19.24) comes from \begin{eqnarray*} \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}\bigg[\partial_{\mu}\exp\bigg(-ie\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg)\bigg]\psi(x-\frac{\epsilon}{2})\bigg\}. \end{eqnarray*}
But when I carefully calculate it, I find \begin{eqnarray*} & & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}\bigg[\partial_{\mu}\exp\bigg(-ie\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg)\bigg]\psi(x-\frac{\epsilon}{2})\bigg\}\\ & = & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}\exp\bigg(-ie\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg)\\ & & \times(-ie)\partial_{\mu}\bigg[\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg]\psi(x-\frac{\epsilon}{2})\bigg\}\\ & = & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}(-ie)\partial_{\mu}\bigg[\int_{x-\epsilon/2}^{x+\epsilon/2}dz\cdot A(z)\bigg]\psi(x-\frac{\epsilon}{2})\bigg\}\\ & = & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}(-ie)[A_{\mu}(x+\frac{\epsilon}{2})-A_{\mu}(x-\frac{\epsilon}{2})]\psi(x-\frac{\epsilon}{2})\bigg\}\\ & = & \text{symm }\lim_{\epsilon\rightarrow0}\bigg\{\bar{\psi}(x+\frac{\epsilon}{2})\gamma^{\mu}\gamma^{5}[-ie\epsilon^{\nu}\partial_{\color{Red}{\nu}}A_{\color{Red}{\mu}}(x)]\psi(x-\frac{\epsilon}{2})\bigg\}. \end{eqnarray*}
The factor $\epsilon^{\nu}\partial_{\color{Red}{\nu}}A_{\color{Red}{\mu}}(x)$ in the last line of my calculation is different from the factor $\epsilon^{\nu}\partial_{\color{Red}{\mu}}A_{\color{Red}{\nu}}(x)$ in the last line of Peskin's calculation. So my question is: How this difference comes from? |
Like for $\pi$, we have an algorithm/infinite series that can give us the first 50 decimal places in about 3 terms. So if I wasn't to calculate like $ln(25551879...)$ (a really huge integer, most likely a prime), upto 100 decimal places, what will be the algorithm I should use or is used worldwide and how efficient is it? I know that the Taylor series is rather slow in its work, so any other algorithm in which this is computed?
Say you need an absolute tolerance of $2^{-m}$ for the answer.
Given a number of the form $x=a \cdot 2^n$, $a \in (1/2,1]$, write $\ln(x)=\ln(a)+n\ln(2)$.
Now compute $\ln(a)$ by taking $m$ terms of the Maclaurin series of $\ln(1+x)$ with $x=a-1$, and compute $\ln(2)$ as $-\ln(1/2)$ by taking $m \lceil \log_2(n) \rceil$ terms of the Maclaurin series of $\ln(1+x)$ with $x=-1/2$.
This way is a little bit fussy in terms of working with decimal numbers vs. binary numbers, but it has the advantage that the $\ln(a)$ term converges at worst like $2^{-m}$ rather than like $(9/10)^m$ like the analogous approach with decimal does. It has the downside that you have to precompute $\ln(2)$ to better accuracy since $n$ will be larger, but that doesn't matter that much because it's not a "live" problem (provided you enforce some cap on the size of the input and the size of its reciprocal).
This is generally not how people implement library functions in programming languages like C. See, for example, e_log.c at http://www.netlib.org/fdlibm/. This begins with an argument reduction similar to the one I suggested above (where the lower bound and the upper bound for $a$ differ by a factor of $2$), then converts the problem to $\ln(1+x)=\ln(1+y)-\ln(1-y)$ where $y=\frac{x}{2+x}$. This conversion leads to some series acceleration, since the series for the difference has only odd powers, and since $|y|<|x|$. (You could proceed with a Taylor series approach from here. If you did, it would use around $m/4$ terms, due to the aforementioned cancellations and the fact that $y$ is in the ballpark of $x/2$, taking into account that argument reduction has already been done.)
They then use a minimax polynomial to approximate $\frac{\ln(1+y)-\ln(1-y)-2y}{y}$. This kind of approach is what I usually see when I check source code for fast implementations of standard library functions. The coefficients of this minimax polynomial were probably relatively expensive to calculate, but again that's not a "live" problem so its speed doesn't really matter all that much.
This is essentially a more in depth discussion on the efficiency and accuracy of various methods.
Reducing the argument so that it is near $1$:
Fundamentally, most of the answers aim for the same goal: reduce the arguments to small values and use the Taylor expansion for $\ln(x)$. Thus far we've seen 3 approaches:
1) Factor out a power of 2 and use $\ln(a\cdot2^n)=\ln(a)+n\ln(2)$.
2) Factor out a power of 10 and use $\ln(a\cdot10^n)=\ln(a)+n\ln(10)$.
3) Reduce by square rooting using $\ln(x)=2\ln(\sqrt x)$.
We can note that square rooting the argument repeatedly reduces the argument much faster than the other methods, which divide the argument by a constant repeatedly, since $\sqrt x\ll x/10<x/2$ for large $x$. Realistically, if your input doesn't have more than, say, 1000 digits, then you only have to square root about 10 times at worst. However, this comes at the cost of having to perform more computations to find the square root itself, which are not easy. On the other hand though, performing the divisions is extremely easy. Due to the nature of how we write/store numbers, all the divisions can be computed at once by simply moving the decimal point. We can then easily truncate to whatever accuracy is desired. With the square rooting, the error is harder to manage, and since the log gets multiplied by 2 every time, the absolute error gets multiplied by 2 as well.
Of course, the choice of writing the argument as a multiple of a power of 2 or a power of 10 depends on whether or not this is being done by a computer or by a human. You will likely prefer to work in base 10.
There is also the additional question of what our range of $a$ should be. Since we want this to be as close to 1 as possible, we can do some algebra and see. For powers of 2, we want $a\in(a_0,2a_0]$ such that $2a_0-1=1-a_0$. Solving this gives $a\in[\frac23,\frac43]$. For powers of 10, we want $a\in[\frac2{11},\frac{20}{11}]$.
Using series expansions:
From here we
could use the standard Taylor expansion for the natural logarithm:
$$\ln(a)=\sum_{k=1}^\infty\frac{(-1)^{k+1}}k(a-1)^k=(a-1)-\frac{(a-1)^2}2+\frac{(a-1)^3}3-\frac{(a-1)^4}4+\mathcal O(a-1)^5$$
however this does not converge as fast as one could manage by performing a Taylor expansion closer to $a$. The above is given by using the integral definition of the natural logarithm and Taylor expanding the integrand at $1$:
$$\ln(a)=\int_1^a\frac{\mathrm dt}t=\sum_{k=0}^\infty(-1)^k\int_1^a(t-1)^k~\mathrm dt$$
But we can improve on this by expanding in the middle of $1$ and $a$:
\begin{align}\ln(a)=\int_1^a\frac{\mathrm dt}t&=\sum_{k=0}^\infty(-1)^k\left(\frac2{a+1}\right)^{k+1}\int_1^a\left(t-\frac{a+1}2\right)^k~\mathrm dt\\&=\sum_{k=0}^\infty\frac{(-1)^k}{k+1}\left(\frac{a-1}{a+1}\right)^{k+1}\left(1-(-1)^{k+1}\right)\\&=\sum_{k=0}^\infty\frac2{2k+1}\left(\frac{a-1}{a+1}\right)^{2k+1}\end{align}
For $a$ near $1$, the above has a rough error of $\mathcal O((a-1)/2)^{2n+1}$ when using $n$ terms. An algebraic derivation of the above is provided by Wikipedia but doesn't really show off just how fast this one converges. Since we're twice as close to the farthest bound on the integral, we gain an additional binary digit of accuracy per term. But since half of the terms vanish, this means we can basically compute twice as many digits per term! This is the method mentioned by Ian's answer.
Here is a rough Ruby program computing the logarithm using series.
Using root-finding methods:
While the series methods are really nice and converge decently fast, Wikipedia provides two more methods for even higher precision evaluation. The first is provided by Eric Towers and it involves computation of the logarithm via exponential functions. Of course, since the computation is cheap and the accuracy is not effected so much, I would recommend reducing the argument so that it is once again close to $1$. This will mean that $y$ as defined below will be close to $0$, allowing for faster computation of the exponential. This also means we can simply use $y_0=0$ as our initial guess.
$$y=\ln(x)\Rightarrow x=\exp(y)\Rightarrow x-\exp(y)=0$$
The calculation of the exponential functions can be performed using the Maclaurin expansion:
$$\operatorname{exmp1}(y)=\exp(y)-1=\sum_{n=1}^\infty\frac{y^n}{n!}=y+\frac{y^2}2+\mathcal O(y^3)$$
Since $y$ is near $0$, there is large floating point error in computing $\exp(y)$, which has a dominant term of $1$, so we use $\operatorname{expm1}(y)$ to circumvent this.
One may also note that since $\Delta y_n\to0$, it is easier to compute $\exp(\Delta y_n)$ than $\exp(y_{n+1})$ directly, and use $\exp(y_{n+1})=\exp(\Delta y_n)\exp(y_n)=\exp(y_n)+\exp(y_n)\operatorname{expm1}(\Delta y_n)$. This reduces the main exponentiation down to the first step, which is trivial since $\exp(0)=1$.
Let $y_0=0$ and $\operatorname{expy}_0=1$.
For Newton's method, let $\displaystyle\Delta y_0=x\operatorname{expy}_0-1$ and:
\begin{cases}\Delta y_n=x\operatorname{expy}_n-1,\\\operatorname{expy}_{n+1}=\operatorname{expy}_n+\operatorname{expy}_n\operatorname{expm1}(-\Delta y_n),\\y_{n+1}=y_n+\Delta y_n\end{cases}
For Halley's method, let $\displaystyle\Delta y_0=2\cdot\frac{x-\operatorname{expy}_0}{x+\operatorname{expy}_0}$ and:
\begin{cases}\displaystyle\Delta y_n=2\cdot\frac{x-\operatorname{expy}_n}{x+\operatorname{expy}_n},\\\operatorname{expy}_{n+1}=\operatorname{expy}_n+\operatorname{expy}_n\operatorname{expm1}(\Delta y_n),\\y_{n+1}=y_n+\Delta y_n\end{cases}
Using the agm:
The arithmetic-geometric mean is a powerful tool which can be used here to quickly compute the logarithm as well as $\pi$ and certain integrals. It is defined as:
$$a_0=a,b_0=b\\a_{n+1}=\frac{a_n+b_n}2,b_{n+1}=\sqrt{a_nb_n}\\M(a,b)=\lim_{n\to\infty}a_n=\lim_{n\to\infty}b_n$$
According to Wikipedia, this is so fast and cheap to compute that this can be used to compute the exponential function using logarithms faster than series approximating the exponential function! To achieve $p$ bits of accuracy, take an $m$ so that $s=x2^m$ is greater than $2^{p/2}$. We may then compute the natural logarithm as:
$$\ln(x)=\lim_{m\to\infty}\frac{\pi x2^{m-2}}{2M(x2^{m-2},1)}-m\ln(2)$$
which is essentially a restatement of the convergence rate of $M(1,t)$ as $t\to\infty$. For this method, reducing the argument isn't even necessary. We may in fact apply this directly to large arguments!
There are some drawbacks to this method, however. The computation requires us to compute some square roots on large floats, but this can be handled with a specially defined float classes and the respective functions.
Alternatively, of course, one could simply reduce the argument down to avoid large floats like before.
Here is a rough Ruby program computing the logarithm using the arithmetic-geometric mean.
I don't know what the fastest way is, but here's one reasonably efficient approach:
You can divide numbers with Newton-Raphson; Once you know how to do that, you can also take square roots with Newton-Raphson; You can use $\ln x=2\ln\sqrt{x}$ as often as you need to get the logarithm's argument close to $1$ before using the Maclaurin series of $\ln(1+x)$; If you need logarithms in another base, use $\log_ax=\frac{\ln x}{\ln a}$.
Halley's method is iterative and its convergence is cubic. Applied here, we would invert to use the exponential (which happily is its own derivative): $$ y_{n+1} = y_n+2 \cdot \frac{x- \mathrm{e}^{y_n}}{x + \mathrm{e}^{y_n}} \text{.} $$ For instance, with $x = 25551879$ and $y_0 = 2$ (i.e., not close), the iterates (all computed with 15-ish digit intermediates) are $2$, $4.$, $5.99999$, $7.99993$, $9.99946$, $11.996$, $13.9708$, $15.7959$, $16.9122$, $17.056$, $17.0562$. My point is not that 15 digits is enough, but that the method reached the shown precision in only ten steps.
You might ask, how do I get those exponentials? Use the power series. That converges quickly for any argument you are likely to see. As a rule of thumb, start with twice as many terms as your argument, so for $\mathrm{e}^{17.0562}$, start with $34$ terms in this Taylor series. This gives $2.5549{\dots}\times 10^{7}$ with error $2355.61{\dots}$. Then increase the number of terms in the exponentials by (in this case) $34$ as long as your estimate for $y_{n+1}$ still changes within your target precision. When that stops happening, take that as your final $y_{n+1}$ and repeat the process of extending the exponential series until your $y_{n+2}$ stabilizes. Continue until you get two $y$s in a row that agree to your target precision (plus enough extra unchanging bits that at least one of them is a zero so that you know which way to round the last bit in your reported answer).
Well$$ \ln(25551879) = \ln(0.25551879 \times 10^{8}) $$ $$= \ln(0.25551879) + \ln(10^8) $$ $$= 8 \times \ln(10) + \ln(0.25551879) $$
Since $\ln(10)$ is a constant that can be precomputed to a huge number of decimal places we only need a method that converges quickly for values less than $1.0$. I don't know if Taylor is good enough on that restricted range or if there is some other better method.
This addresses the issue you raised about the argument being a large number. As to generating lots of digits, there are a lot of good answers on this previous question.
The Taylor series is "slow" for radius close to $1$ (since it's centered on $x=1$, radius $1$ corresponds to $x=0$ and $x=2$), and doesn't work for radius greater than or equal to $1$. Pretty much any Taylor series will be fast for small radii. The log Taylor series has decreasing coefficients and it is alternating, so its error term can be given an upper bound of $x^n$. So if you have a radius less than $x^k$, then you'll be getting at least $k$ digits of accuracy for every term.
$25551879$ is well outside the radius of $1$, so a direct application of the Taylor series won't work. You'll have to write it in terms of some $x$ that is close to $1$. You could write it as $10^8 * 0.255$, then find its logarithm as $\ln(10^8) + \ln(0.255) = 8\ln(10)+\ln(1-0.745)$, and then use a precomputed value for $\ln(10)$ and the Taylor series for $\ln(1-0.745)$, but $0.745$ is a large radius, so you can get faster convergence by writing it in another form. For instance, if you've precomputed $\ln(2)$, then you can write it as $10^7*2*1.2775$, and now your radius is only $0.2775$. |
Current browse context:
astro-ph.CO
Change to browse by: Bookmark(what is this?) Astrophysics > Cosmology and Nongalactic Astrophysics Title: Constraining sterile neutrino cosmologies with strong gravitational lensing observations at redshift z~0.2
(Submitted on 4 Jan 2018 (v1), last revised 9 Oct 2018 (this version, v2))
Abstract: We use the observed amount of subhaloes and line-of-sight dark matter haloes in a sample of 11 gravitational lens systems from the Sloan Lens ACS Survey to constrain the free-streaming properties of the dark matter particles. In particular, we combine the detection of a small-mass dark matter halo by Vegetti et al. 2010 with the non-detections by Vegetti et al. 2014 and compare the derived subhalo and halo mass functions with expectations from cold dark matter (CDM) and resonantly produced sterile neutrino models. We constrain the half-mode mass, i.e. the mass scale at which the linear matter power spectrum is reduced by 50 per cent relatively to the CDM model, to be $\log M_{\rm{hm}} \left[M_\odot\right] < 12.0$ (equivalent thermal relic mass $m_{\rm th} > 0.3$ keV) at the 2$\sigma$ level. This excludes sterile neutrino models with neutrino masses $m_{\rm s} < 0.8$ keV at any value of $L_{\rm 6}$. Our constraints are weaker than currently provided by the number of Milky Way satellites, observations of the 3.5 keV X-ray line, and the Lyman $\alpha$ forest. However, they are more robust than the former as they are less affected by baryonic processes. Moreover, unlike the latter, they are not affected by assumptions on the thermal histories for the intergalactic medium. Gravitational lens systems with higher data quality and higher source and lens redshift are required to obtain tighter constraints. Submission historyFrom: Simona Vegetti [view email] [v1]Thu, 4 Jan 2018 19:00:10 GMT (8903kb) [v2]Tue, 9 Oct 2018 11:37:29 GMT (364kb,D) |
Archive:
Subtopics:
Comments disabled
Mon, 23 Jul 2018
The paper “Verification of Identities” (1997) of Rajagopalan and Schulman discusses fast ways to test whether a binary operation on a finite set is associative. In general, there is no method that is faster than the naïve algorithm of simply checking whether $$a\ast(b\ast c) = (a\ast b)\ast c$$ for all triples !!\langle a, b, c\rangle!!. This is because:
(Page 3.)
But R&S do not give an example. I now have a very nice example, and I think the process that led me to it is a good example of Lower Mathematics at work.
Let's say that an operation !!\ast!! is “good” if it is associative except in exactly one case. We want to find a “good” operation. My first idea was that if we could find a primitive good operation on a set of 3 elements, we could probably extend it to give a good operation on a larger set. Say the set is !!\{a_0, a_1, a_2, b_0, b_1, \ldots, b_{n-4}\}!!. We just need to define the extended operation so that if either of the operands is !!b_i!!, it is associative, and if both operands are !!a_i!! then it is the same as the primitive good operation we already found. The former part is easy: just make it constant, say !!x\ast y = b_0!! except when !!x,y\in\{a_0, a_1, a_2\}!!.
So now all we need to do is find a single good primitive operation, and I did not expend any thought on this at all. There are only !!3^9=19683!! binary operations, and we could quite easily write a program to check them all. In fact, we can do better: generate a binary operation at random and check it. If it's not the primitive good operation we want, just throw it away and try again. This could take longer to run than the exhaustive search, if there happen to be very few good operations and if the program is unlucky, but the program is easier to write, and the run time will be utterly insignificant either way.
I wrote the program, which instantly produced:
$$ \begin{array}{c|ccc} \ast & 0 & 1 & 2 \\ \hline 0 & 0 & 0 & 0 \\ 1 & 0 & 1 & 0 \\ 2 & 0 & 1 & 2 \end{array} $$
This is associative except for the case !!1\ast(2\ast 1) \ne (1\ast 2)\ast 1!!. This solves the problem. But confirming that this is a good operation requires manually checking 27 cases, or a perhaps not-immediately-obvious case analysis.
But on a later run of the program, I got lucky and it found a simpler operation, which I can explain without a table:
Now we don't have to check 27 cases. The operation is simpler, so the proof is too: We know !!b\ast c\ne 1!!, so !!a\ast(b\ast c) !! must be !!0!!. And the only way !!(a \ast b)\ast c \ne 0!! can occur is when !!a\ast b=2!! and !!c=1!!, so !!a=2, b=1, c=1!!.
Now we can even dispense with the construction that extended the operation from !!3!! to !!n!! elements, because the description of the extended operation is the same. We wanted to extend it to be constant whenever !!a!! or !!b!! was larger than !!2!!, and that's what the description already says!
So that reduces the whole thing to about two sentences, which explain the example and why it works. But when reduced in that way, you see how the example works but not how you might go about finding it. I think the interesting part is to see how to get there, and quite a lot of mathematical education tends to over-emphasize analysis (“how can we show this is a good operation?”) at the expense of synthesis (“how can we find a good operation?”).
The exhaustive search would probably have produced the simple operation early on in its run, so there is something to be said for that approach too. |
Consider $Q$ a interval in $R$. Number all the rationals in this interval. Then for rational $q_i$ consider interval $[q_j-\epsilon /2^{j+2} ,q_j+\epsilon/2^{j+2}]$. Now the whole interval lies inside the union of these intervals, sum of whose volumes is $ < \epsilon $.
Why I am getting this contradiction? I know (with proof) that an interval does not have measure 0. What is wrong with the above argument? I only know the concept of zero measure from analysis.
Consider $Q$ a interval in $R$. Number all the rationals in this interval. Then for rational $q_i$ consider interval $[q_j-\epsilon /2^{j+2} ,q_j+\epsilon/2^{j+2}]$. Now the whole interval lies inside the union of these intervals, sum of whose volumes is $ < \epsilon $.
The gap in the proof is that you do not know that the interval $[a,b]$ lies in the union of these balls. In fact, if $\epsilon < b-a,$ you have shown that there are points in $[a,b]$ which are not in any of the balls.
You've given a proof by contradiction that the union of the balls contains the interval. As a simpler example of this sort of phenomenon, consider the set $Q=[1,2]$ and the union $U$ of open balls around rationals $q∈[1,2]$with radius $|q-\sqrt 2|$. $U$ doesn't have the point $\sqrt 2 \in Q$.
If the above does not convince you, one can directly prove that this set has other points: First consider the variant with open balls around each $q_i$, $$B_i := B_i(\epsilon) := (q_i - \epsilon2^{-i-2}, q_i +\epsilon2^{-j-2})$$ As each $B_i$ is open, the complement $C_i=Q\setminus B_i$ is closed. For $\epsilon \ll 1$, they are not empty. Moreover, $$ D_i := Q \setminus \left (\bigcup_{j=1}^i B_j\right) = \bigcap_{j=1}^i C_j$$ is a sequence of nested, non-empty, closed, and bounded sets. By Cantor's Intersection Theorem, the set $\bigcap_{j=1}^\infty C_i$ is not empty, and thus $\bigcup_{j=1}^\infty B_i$ does not contain all of $Q$.
If you insist on using closed balls, you can use some $\epsilon'<\epsilon$; then notice that $\overline{B_i(\epsilon')} \subset B_i(\epsilon)$, so by the above, their union does not contain all of $Q$.
Further, the above works for every subset of $Q$ of measure more than $\epsilon$. |
6.2 - Binary Logistic Regression with a Single Categorical Predictor
Key Concepts Objectives Overview Binary logistic regression estimates the probability that a characteristic is present (e.g. estimate probability of "success") given the values of explanatory variables, in this case a single categorical variable ; π = Pr ( Y = 1| X = x). Suppose a physician is interested in estimating the proportion of diabetic persons in a population. Naturally she knows that all sections of the population do not have equal probability of ‘success’, i.e. being diabetic. Older population, population with hypertension, individuals with diabetes incidence in family are more likely to have diabetes. Consider the predictor variable X to be any of the risk factor that might contribute to the disease. Probability of success will depend on levels of the risk factor. Variables: Let Ybe a binary response variable X= ( X 1, X 2, ..., X) be a set of explanatory variables which can be discrete, continuous, or a combination. k xis the observed value of the explanatory variables for observation i i. In this section of the notes, we focus on a single variable X. Y i = 1 if the trait is present in observation (person, unit, etc...) i Y= 0 if the trait is NOT present in observation i i Model:
\[\pi_i=Pr(Y_i=1|X_i=x_i)=\dfrac{\text{exp}(\beta_0+\beta_1 x_i)}{1+\text{exp}(\beta_0+\beta_1 x_i)}\]
or,
\[\begin{align}
\text{logit}(\pi_i)&=\text{log}\left(\dfrac{\pi_i}{1-\pi_i}\right)\\ &= \beta_0+\beta_1 x_i\\ &= \beta_0+\beta_1 x_{i1} + \ldots + \beta_k x_{ik}\\ \end{align}\] Assumptions: The data Y 1, Y 2, ..., Yare independently distributed, i.e., cases are independent. n Distribution of Yis i Bin( n, π i ), i.e., binary logistic regression model assumes binomial distribution of the response. The dependent variable does NOT need to be normally distributed, but it typically assumes a distribution from an exponential family (e.g. binomial, Poisson, multinomial, normal,...) i Does NOT assume a linear relationship between the dependent variable and the independent variables, but it does assume linear relationship between the logit of the response and the explanatory variables; logit(π) = β 0+ β X. Independent (explanatory) variables can be even the power terms or some other nonlinear transformations of the original independent variables. The homogeneity of variance does NOT need to be satisfied. In fact, it is not even possible in many cases given the model structure. Errors need to be independent but NOT normally distributed. It uses maximum likelihood estimation (MLE) rather than ordinary least squares (OLS) to estimate the parameters, and thus relies on large-sample approximations. Goodness-of-fit measures rely on sufficiently large samples, where a heuristic rule is that not more than 20% of the expected cells counts are less than 5. Model Fit: Overall goodness-of-fit statistics of the model; we will consider: Pearson chi-square statistic, X 2 Deviance, G 2and Likelihood ratio test and statistic, Δ G 2 Hosmer-Lemeshow test and statistic Pearson chi-square statistic, Residual analysis: Pearson, deviance, adjusted residuals, etc... Overdispersion Parameter Estimation:
The
maximum likelihood estimator (MLE) for (β 0, β 1) is obtained by finding \((\hat{\beta}_0,\hat{\beta}_1)\) that maximizes:
\(L(\beta_0,\beta_1)=\prod\limits_{i=1}^N \pi_i^{y_i}(1-\pi_i)^{n_i-y_i}=\prod\limits_{i=1}^N \dfrac{\text{exp}\{y_i(\beta_0+\beta_1 x_i)\}}{1+\text{exp}(\beta_0+\beta_1 x_i)}\)
In general, there are no closed-form solutions, so the ML estimates are obtained by using iterative algorithms such as
Newton-Raphson (NR), or Iteratively re-weighted least squares (IRWLS). In Agresti (2013), see section 4.6.1 for GLMs, and for logistic regression, see sections 5.5.4-5.5.5.
Brief overview of Newton-Raphson (NR). Suppose we want to maximize a loglikelihood $l(\theta)$ with respect to a parameter $\theta=(\theta_1,\ldots,\theta_p)^T$. At each step of NR, the current estimate $\theta^{(t)}$ is updated as
\[
Applying NR to logistic regression. For the logit model with $p-1$ predictors $X$, $\beta=(\beta_0, \beta_1, \ldots, \beta_{p-1})$, the likelihood is
\begin{eqnarray}
so the loglikelihood is $
The first derivative of $x_i^T\beta$ with respect to $\beta_j$ is $x_{ij}$, thus
The second derivatives used in computing the standard errors of the parameter estimates, $\hat{\beta}$, are
\begin{eqnarray} \frac{\partial^2 l}{\partial\beta_j\partial\beta_k}
For reasons including numerical stability and speed, it is generally advisable to avoid computing matrix inverses directly. Thus in many implementations, clever methods are used to obtain the required information without directly constructing the inverse, or even the Hessian.
Interpretation of Parameter Estimates: exp(β 0) = the odds that the characteristic is present in an observation iwhen X= 0, i.e., at baseline. i exp(β 1) = for every unit increase in X , the odds that the characteristic is present is multiplied by i1 exp(β 1). This is similar to simple linear regression but instead of additive change it is a multiplicative change in rate. This is an estimated odds ratio.
\(\dfrac{\text{exp}(\beta_0+\beta_1(x_{i1}+1))}{\text{exp}(\beta_0+\beta_1 x_{i1})}=\text{exp}(\beta_1)\)
In general, the logistic model stipulates that the effect of a covariate on the chance of "success" is linear on the log-odds scale, or multiplicative on the odds scale.
If β > 0, then j exp(β ) > 1, and the odds increase. j If β < 0,then j exp(β ) < 1, and the odds decrease. j Inference for Logistic Regression: Confidence Intervals for parameters Hypothesis testing Distribution of probability estimates _________________________ Example - Student Smoking
The table below classifies 5375 high school students according to the smoking behavior of the student (
Z) and the smoking behavior of the student's parents ( Y ). We saw this example in Lesson 3 (Measuring Associations in I × J tables, smokeindep.sas and smokeindep.R).
How many parents smoke? Student smokes? Yes (Z = 1) No (Z = 2) Both (Y = 1)
400
1380
One (Y = 2)
416
1823
Neither (Y = 3)
188
1168
The test for independence yields
X 2 = 37.6 and G 2 = 38.4 with 2 df ( p-values are essentially zero), so Y and Z are related. It is natural to think of Z as a response and Y as a predictor in this example. We might be interested in exploring the dependency of student's smoking behavior on neither parent smoking versus at least one parent smoking. Thus we can combine or collapse the first two rows of our 3 × 2 table and look at a new 2 × 2 table:
Student smokes Student does not smoke 1–2 parents smoke
816
3203
Neither parent smokes
188
1168
For the chi-square test of independence, this table has
X 2 = 27.7, G 2 = 29.1, p-value ≈ 0, and = 1.58. Therefore, we estimate that a student is 58% more likely, on the odds scale, to smoke if he or she has at least one smoking parent than none.
But what if:
we want to model the "risk" of student smoking as a function of parents' smoking behavior. we want to describe the differences between student smokers and nonsmokers as a function of parents smoking behavior via descriptive discriminate analyses. we want to predict probabilitiesthat individuals fall into two categories of the binary response as a function of some explanatory variables, e.g. what is the probability that a student is a smoker given that neither of his/her parents smokes. we want to predictthat a student is a smoker given that neither of his/her parents smokes, i.e. probabilitiesthat individuals fall into two categories of the binary response as a function of some explanatory variables, we want to classifynew students into "smoking" or "nonsmoking" group depending on parents smoking behavior. we want to develop a social network model, adjust for "bias", analyze choice data, etc...
These are just some of the possibilities of logistic regression, which cannot be handled within a framework of goodness-of-fit only.
Consider the simplest case:
Ybinary response, and i Xbinary explanatory variable i link to 2 × 2 tables and chi-square test of independence
Arrange the data in our running example like this,
y i n i 1–2 parents smoke
816
4019
Neither parent smokes
188
1356
where
y i is the number of children who smoke, nis the number of children for a given level of parents' smoking behaviour, and π i i= P( y= 1| i x) is the probability of a randomly chosen student i ismoking given parents' smoking status. Here itakes values 1 and 2. Thus, we claim that all students who have at least one parent smoking will have the same probability of "success", and all student who have neither parent smoking will have the same probability of "success", though for the two groups success probabilities will be different. Then the response variable Yhas a binomial distribution:
\(y_i \sim Bin(n_i,\pi_i)\)
E xplanatory variable X is a dummy variable such that
X= 0 if neither parent smokes, i X= 1 if at least one parent smokes. i
Understanding the use of dummy variables is important in logistic regression.
A
dummy variable which is also known as an indicator variable, is a variable that can take two values only, typically the values 0 or 1 to indicate the absence or presence of a characteristic like in our smoking example.
Then the logistic regression model can be expressed as:
\(\text{logit}(\pi_i)=\text{log}\dfrac{\pi_i}{1-\pi_i}=\beta_0+\beta_1 X_i\) (1) or
\(\pi_i=\dfrac{\text{exp}(\beta_0+\beta_1 x_i)}{1+\text{exp}(\beta_0+\beta_1 x_i)}\) (2)
and it says that log-odds of a randomly chosen student smoking is β
0 for "smoking parents" = neither, and β 0 + β 1 for "smoking parents" = at least one parent is smoking. |
I'm struggling to understand a question I've been given. The question asks: Let $\psi$ be a boolean formula in $n$ variables. There are $2^n$ different combinations of assigning values to the variables. Consider the problem of deciding whether (strictly) more than $2^{n−1}$ of these assignments satisfy the formula $\psi$. We will call the language that corresponds to this decision problem, $L$.
From this I can tell that if $x_1, x_2, ..., x_n$ are the $n$ variables which can be either true or false. I understand why there would be $2^n$ different assignings for the formula, as each variable can be assigned 1 of 2 values. But then what is $\psi$ exactly, is it an assignment such as $\psi$=($x_1 \lor x_2 \lor ... x_n$). But then the later part of the question doesn't make any sense. Can someone please explain in more detail what it means by "deciding whether (strictly) more than $2^{n−1}$ of these assignments satisfy the formula $\psi$"?
The question is then to show that there exists a turing machine $M$ and polynomials $T$ and $p$, with the following properties:
• For every input $x$, $M$ terminates after at most $T(|x|)$ steps.
• If $x\in L$, then $Pr_{t∈\small\{0,1\small\}^{p(|x|)}}$[$M$ accepts $<x, t>$] $>$ 1/2.
• If $x\notin L$, then $Pr_{t∈\small\{0,1\small\}^{p(|x|)}}$[$M$ rejects $<x, t>$] $≥$ 1/2
Where $Pr_{t∈\{0,1\}^{p(|x|)}}$[$M$ accepts $<x, t>$] means the probability, for a give $t$ from the set $\{0,1\}^{P(|x|)}$, that M accepts the input $<x,t>$ is greater than 1/2. This is similar to the definition of bounded error probabilistic polynomial time(BPP), except that the definition for BPP have both equalities as $≥$, so I'm guessing I need to show that the language L is in BPP. But how would I even start the proof to show that he language is indeed in BPP. Also the definition of a language in BPP is not identical to what is mentioned in the question, so maybe there's a different approach to answering the question. Also, I don't need to explicitly find the polynomials $p$ and $T$, but instead argue that they exist.
Any help to assist me with the question would be much appreciated |
I am having some trouble with the following:
Let $(X_1,\mathcal{F}_1,\mu_1,T_1)$ be a measure preserving dynamical system with $T_1:X_1\to X_1$ is ergodic.
Suppose $(X_2,\mathcal{F}_2,\mu_2,T_2)$ is another dynamical system and there exists some surjective function $\pi: X_2\to X_1$ such that $\pi\circ T_2=T_1\circ \pi$ and $\mu_1=\pi_\star\mu_2$ (i.e. the pushforward measure).
Can we deduce ergodicity of $T_2$ from that of $T_1$?
Remark: I can show invariance, I am only interested in ergodicity! |
It looks like you're new here. If you want to get involved, click one of these buttons!
Last time we studied meets and joins of partitions. We observed an interesting difference between the two.
Suppose we have partitions \(P\) and \(Q\) of a set \(X\). To figure out if two elements \(x , x' \in X\) are in the same part of the meet \(P \wedge Q\), it's enough to know if they're the same part of \(P\) and the same part of \(Q\), since
$$ x \sim_{P \wedge Q} x' \textrm{ if and only if } x \sim_P x' \textrm{ and } x \sim_Q x'. $$ Here \(x \sim_P x'\) means that \(x\) and \(x'\) are in the same part of \(P\), and so on.
However, this does
not work for the join!
$$ \textbf{THIS IS FALSE: } \; x \sim_{P \vee Q} x' \textrm{ if and only if } x \sim_P x' \textrm{ or } x \sim_Q x' . $$ To understand this better, the key is to think about the "inclusion"
$$ i : \{x,x'\} \to X , $$ that is, the function sending \(x\) and \(x'\) to themselves thought of as elements of \(X\). We'll soon see that any partition \(P\) of \(X\) can be "pulled back" to a partition \(i^{\ast}(P)\) on the little set \( \{x,x'\} \). And we'll see that our observation can be restated as follows:
$$ i^{\ast}(P \wedge Q) = i^{\ast}(P) \wedge i^{\ast}(Q) $$ but
$$ \textbf{THIS IS FALSE: } \; i^{\ast}(P \vee Q) = i^{\ast}(P) \vee i^{\ast}(Q) . $$ This is just a slicker way of saying the exact same thing. But it will turn out to be more illuminating!
So how do we "pull back" a partition?
Suppose we have any function \(f : X \to Y\). Given any partition \(P\) of \(Y\), we can "pull it back" along \(f\) and get a partition of \(X\) which we call \(f^{\ast}(P)\). Here's an example from the book:
For any part \(S\) of \(P\) we can form the set of all elements of \(X\) that map to \(S\). This set is just the
preimage of \(S\) under \(f\), which we met in Lecture 9. We called it
$$ f^{\ast}(S) = \{x \in X: \; f(x) \in S \}. $$ As long as this set is nonempty, we include it our partition \(f^{\ast}(P)\).
So beware: we are now using the symbol \(f^{\ast}\) in two ways: for the preimage of a subset and for the pullback of a partition. But these two ways fit together quite nicely, so it'll be okay.
Summarizing:
Definition. Given a function \(f : X \to Y\) and a partition \(P\) of \(Y\), define the pullback of \(P\) along \(f\) to be this partition of \(X\):
$$ f^{\ast}(P) = \{ f^{\ast}(S) : \; S \in P \text{ and } f^{\ast}(S) \ne \emptyset \} . $$
Puzzle 40. Show that \( f^{\ast}(P) \) really is a partition using the fact that \(P\) is. It's fun to prove this using properties of the preimage map \( f^{\ast} : P(Y) \to P(X) \).
It's easy to tell if two elements of \(X\) are in the same part of \(f^{\ast}(P)\): just map them to \(Y\) and see if they land in the same part of \(P\). In other words,
$$ x\sim_{f^{\ast}(P)} x' \textrm{ if and only if } f(x) \sim_P f(x') $$ Now for the main point:
Proposition. Given a function \(f : X \to Y\) and partitions \(P\) and \(Q\) of \(Y\), we always have
$$ f^{\ast}(P \wedge Q) = f^{\ast}(P) \wedge f^{\ast}(Q) $$ but sometimes we have
$$ f^{\ast}(P \vee Q) \ne f^{\ast}(P) \vee f^{\ast}(Q) . $$
Proof. To prove that
$$ f^{\ast}(P \wedge Q) = f^{\ast}(P) \wedge f^{\ast}(Q) $$ it's enough to prove that they give the same equivalence relation on \(X\). That is, it's enough to show
$$ x \sim_{f^{\ast}(P \wedge Q)} x' \textrm{ if and only if } x \sim_{ f^{\ast}(P) \wedge f^{\ast}(Q) } x'. $$ This looks scary but we just follow our nose. First we rewrite the right-hand side using our observation about the meet of partitions:
$$ x \sim_{f^{\ast}(P \wedge Q)} x' \textrm{ if and only if } x \sim_{ f^{\ast}(P)} x' \textrm{ and } x\sim_{f^{\ast}(Q) } x'. $$ Then we rewrite everything using what we just saw about the pullback:
$$ f(x) \sim_{P \wedge Q} f(x') \textrm{ if and only if } f(x) \sim_P f(x') \textrm{ and } f(x) \sim_Q f(x'). $$ And this is true, by our observation about the meet of partitions! So, we're really just stating that observation in a new language.
To prove that sometimes
$$ f^{\ast}(P \vee Q) \ne f^{\ast}(P) \vee f^{\ast}(Q) , $$ we just need one example. So, take \(P\) and \(Q\) to be these two partitions:
They are partitions of the set
$$ Y = \{11, 12, 13, 21, 22, 23 \}. $$ Take \(X = \{11,22\} \) and let \(i : X \to Y \) be the inclusion of \(X\) into \(Y\), meaning that
$$ i(11) = 11, \quad i(22) = 22 . $$ Then compute everything! \(11\) and \(22\) are in different parts of \(i^{\ast}(P)\):
$$ i^{\ast}(P) = \{ \{11\}, \{22\} \} . $$ They're also in different parts of \(i^{\ast}(Q)\):
$$ i^{\ast}(Q) = \{ \{11\}, \{22\} \} .$$ Thus, we have
$$ i^{\ast}(P) \vee i^{\ast}(Q) = \{ \{11\}, \{22\} \} . $$ On the other hand, the join \(P \vee Q \) has just two parts:
$$ P \vee Q = \{\{11,12,13,22,23\},\{21\}\} . $$ If you don't see why, figure out the finest partition that's coarser than \(P\) and \(Q\) - that's \(P \vee Q \). Since \(11\) and \(22\) are in the same parts here, the pullback \(i^{\ast} (P \vee Q) \) has just one part:
$$ i^{\ast}(P \vee Q) = \{ \{11, 22 \} \} . $$ So, we have
$$ i^{\ast}(P \vee Q) \ne i^{\ast}(P) \vee i^{\ast}(Q) $$ as desired. \( \quad \blacksquare \)
Now for the real punchline. The example we just saw was the same as our example of a "generative effect" in Lecture 12. So, we have a new way of thinking about generative effects:
the pullback of partitions preserves meets, but it may not preserve joins!
This is an interesting feature of the logic of partitions. Next time we'll understand it more deeply by pondering left and right adjoints. But to warm up, you should compare how meets and joins work in the logic of subsets:
Puzzle 41. Let \(f : X \to Y \) and let \(f^{\ast} : PY \to PX \) be the function sending any subset of \(Y\) to its preimage in \(X\). Given \(S,T \in P(Y) \), is it always true that
$$ f^{\ast}(S \wedge T) = f^{\ast}(S) \wedge f^{\ast}(T ) ? $$ Is it always true that
$$ f^{\ast}(S \vee T) = f^{\ast}(S) \vee f^{\ast}(T ) ? $$
To read other lectures go here. |
Integrating the error term of a Taylor polynomial: example
Being a little more careful than for the previous example, let's keep track of the error term in the example we've been doing: we have $${1\over 1-x}=1+x+x^2+\ldots+x^n+ {1\over (n+1)}{ 1 \over (1-c)^{n+1 }}x^{n+1}$$ for some $c$ between $0$ and $x$, and also depending upon $x$ and $n$. One way to avoid having the ${ 1 \over (1-c)^{n+1 }}$ ‘blow up’ on us, is to keep $x$ itself in the range $[0,1)$ so that $c$ is in the range $[0,x)$ which is inside $[0,1)$, keeping $c$ away from $1$. To do this we might demand that we integrate over the interval $[0,T]$ with $0\le T <1$.
For simplicity, and to illustrate the point, let's just take $0\leT\le {1\over 2}$. Then in the
worst-case scenario$$\left|{ 1 \over (1-c)^{n+1 }}\right|\le { 1 \over (1-{1\over 2 })^{n+1}}=2^{n+1}$$
Thus,
integrating the error term, we have\begin{align*}\left|\int_0^T{1\over n+1}{ 1 \over (1-c)^{n+1 }}x^{n+1}\;dx\right|&\le \int {1\over n+1}2^{n+1}x^{n+1}\;dx={ 2^{n+1} \over n+1}\int_0^Tx^{n+1 }\;dx\\&=\frac{ 2^{n+1}}{n+1}\left[{x^{n+2} \over n+2}\right]_0^T={2^{n+1}T^{n+2} \over (n+1)(n+2) }\end{align*}Since we have cleverly required $0\le T\le {1\over 2}$, we actuallyhave\begin{align*}\left|\int_0^T{1\over n+1}{ 1 \over (1-c)^{n+1 }}x^{n+1}\;dx\right|&\le { 2^{n+1}T^{n+2} \over (n+1)(n+2) }\\&\le { 2^{n+1}({1\over 2})^{n+2} \over (n+1)(n+2)}={1\over 2(n+1)(n+2) }\end{align*}
That is, we have $$\left|-\log(1-T)-\left[T+{T^2\over 2}+\ldots+{T^n\over n}\right]\right|\le {1\over 2(n+1)(n+2)}$$ for all $T$ in the interval $[0,{1\over 2}]$. Actually, we had obtained $$\left|-\log(1-T)-\left[T+{T^2\over 2}+\ldots+{T^n\over n}\right]\right|\le { 2^{n+1}T^{n+2} \over 2(n+1)(n+2) }$$ and the latter expression shrinks rapidly as $T$ approaches $0$. |
I am trying to integrate this function:
$$I = \int_{-\infty }^0 \frac{e^u}{\left(\left(e^u (u-1)+1\right) \lambda -1\right){}^2} \, du$$
and I cannot do it.
So, what I want to try to do is to expand the numerator in its Taylor series and integrate term-by-term, I.e.,
$$I = \int_{-\infty }^0 \frac{1+u+\frac{u^2}{2}+\frac{u^3}{6}+\cdots}{\left(\left(e^u (u-1)+1\right) \lambda _R-1\right){}^2} \, du$$
$$= \int_{-\infty }^0 \frac{1}{\left(\left(e^u (u-1)+1\right) \lambda -1\right){}^2} \, du+\int_{-\infty }^0 \frac{u}{\left(\left(e^u (u-1)+1\right) \lambda-1\right){}^2} \, du\ + \cdots$$,
but each term individually diverges.
NOTE: $I$ does not diverge when $\lambda = 0.5$ - the value of the integral is 1.42537
How can this be? |
October 14, 2015. This is with $$ \frac{x^2 + y^2}{xy - t} = q > 0, $$which I believe to be the intent of the question.
THEOREM: $$ \color{red}{ q \leq (t+1)^2 + 1 } $$
I got some help from Gerry Myerson on MO to finish the thing. https://mathoverflow.net/questions/220834/optimal-bound-in-diophantine-representation-question/220844#220844
As far as rapid computer computations, for a fixed $t,$ we can demand $1 \leq x \leq 4 t.$ For each $x,$ we can then demand $1 \leq y \leq x$ along with the very helpful $x y \leq 4 t.$ Having found an integer quotient $q,$ we then keep only those solutions with $2x \leq qy$ and $2y \leq qx.$
In particular, for $t=1$ we find $q=5,$ then for $t=2$ we find $q=4,10.$ In both cases we have $q \leq (t+1)^2 + 1.$ We continue with $t \geq 3.$
With $t \geq 3, $ we also have $t^2 \geq 3t > 3t - 1.$
We are able to demand $xy \leq 4t$ by taking a Hurwitz Grundlösung, that is $2x \leq qy$ and $2y \leq qx.$ Define $k = xy - t \geq 1.$Now, $xy \leq 4t,$ then $k = xy - t \leq 3t,$ then $k-1 \leq 3t - 1.$ Reverse, $3t-1 \geq k-1.$ Since $t^2 > 3t - 1,$ we reach$$ t^2 > k-1. $$
Next, $k \geq 1,$ so $(k-1) \geq 0.$ We therefore might get equality in$$ (k-1)t^2 \geq (k-1)^2, $$but only when $k=1.$$$ 0 \geq t^2 - k t^2 + k^2 - 2 k + 1, $$$$ k t^2 + 2 k \geq t^2 + k^2 + 1. $$ Divide by $k,$$$ t^2 + 2 \geq \frac{t^2}{k} + k + \frac{1}{k}. $$ Add $2t,$$$ t^2 +2t + 2 \geq \frac{t^2}{k} + 2 t + k + \frac{1}{k}, $$with equality only when $k=1.$ Reverse,$$ \frac{t^2}{k} + 2 t + k + \frac{1}{k} \leq t^2 +2t + 2 $$with equality only when $k=1.$
Here is Gerry's best bit, this would not have occurred to me. Here we are back to considering all solutions $(x,y)$ and all $k=xy-t.$ Draw the graph of the quarter circle $x^2 + y^2 = k q.$ As $x,y \geq 1,$ there are boundary points at $(1, \sqrt{kq-1})$ and $( \sqrt{kq-1},1).$ The hyperbola $xy = \sqrt{kq-1}$ passes through both points, but in between stays within the quarter circle. It follows by convexity (or Lagrange multipliers again) that, along the circular arc,$$ \color{blue}{ xy \geq \sqrt{kq-1}}. $$ But, of course, $x^2 + y^2 = k q = qxy - t q$ is equivalent to our original equation $x^2 - q x y + y^2 = -tq.$We have$$ -tq = x^2 - q x y + y^2 = (x^2 + y^2 ) - q x y = k q - q x y \leq kq - q \sqrt{kq-1}, $$ or$$ -tq \leq kq - q \sqrt{kq-1}, $$ $$ -t \leq k - \sqrt{kq-1}, $$ $$ \sqrt{kq-1} \leq t + k, $$$$ kq -1 \leq t^2 + 2k t + k^2, $$$$ kq \leq t^2 + 2 kt + k^2 + 1, $$ divide by $k,$$$ q \leq \frac{t^2}{k} + 2 t + k + \frac{1}{k}. $$
For $t \geq 3$ and a solution with $xy < 4t,$ we showed$$ \frac{t^2}{k} + 2 t + k + \frac{1}{k} \leq t^2 +2t + 2 $$with equality only when $k=1.$ For all solutions, Gerry showed$$ q \leq \frac{t^2}{k} + 2 t + k + \frac{1}{k}. $$Put these together, we get$$ q \leq t^2 +2t + 2 $$with equality only when $k=1,$ that is $xy = t+1.$
ADDENDUM, October 15. Here is another way to get Gerry's main observation, with $k = xy - t,$ that $xy \geq \sqrt{kq-1}.$ We have $x,y \geq 1$ and$kq =x^2 + y^2 .$ So $kq \geq x^2 + 1$ and $kq -(x^2 + 1) \geq 0.$ We also have $x^2 - 1 \geq 0.$ Multiply,$$ (x^2 - 1) kq - (x^4 - 1) \geq 0. $$Next, $y^2 = kq - x^2,$ so $x^2 y^2 = kq x^2 - x^4.$ That is$$ x^2 y^2 = (kq-1) + (x^2 - 1)kq - (x^4 - 1). $$ However,$$ (x^2 - 1) kq - (x^4 - 1) \geq 0, $$ so$$ x^2 y^2 \geq kq - 1, $$$$ \color{blue}{ xy \geq \sqrt{kq-1}}. $$ |
Search
Now showing items 1-9 of 9
Measurement of $J/\psi$ production as a function of event multiplicity in pp collisions at $\sqrt{s} = 13\,\mathrm{TeV}$ with ALICE
(Elsevier, 2017-11)
The availability at the LHC of the largest collision energy in pp collisions allows a significant advance in the measurement of $J/\psi$ production as function of event multiplicity. The interesting relative increase ...
Multiplicity dependence of jet-like two-particle correlations in pp collisions at $\sqrt s$ =7 and 13 TeV with ALICE
(Elsevier, 2017-11)
Two-particle correlations in relative azimuthal angle (Δ ϕ ) and pseudorapidity (Δ η ) have been used to study heavy-ion collision dynamics, including medium-induced jet modification. Further investigations also showed the ...
The new Inner Tracking System of the ALICE experiment
(Elsevier, 2017-11)
The ALICE experiment will undergo a major upgrade during the next LHC Long Shutdown scheduled in 2019–20 that will enable a detailed study of the properties of the QGP, exploiting the increased Pb-Pb luminosity ...
Azimuthally differential pion femtoscopy relative to the second and thrid harmonic in Pb-Pb 2.76 TeV collisions from ALICE
(Elsevier, 2017-11)
Azimuthally differential femtoscopic measurements, being sensitive to spatio-temporal characteristics of the source as well as to the collective velocity fields at freeze-out, provide very important information on the ...
Charmonium production in Pb–Pb and p–Pb collisions at forward rapidity measured with ALICE
(Elsevier, 2017-11)
The ALICE collaboration has measured the inclusive charmonium production at forward rapidity in Pb–Pb and p–Pb collisions at sNN=5.02TeV and sNN=8.16TeV , respectively. In Pb–Pb collisions, the J/ ψ and ψ (2S) nuclear ...
Investigations of anisotropic collectivity using multi-particle correlations in pp, p-Pb and Pb-Pb collisions
(Elsevier, 2017-11)
Two- and multi-particle azimuthal correlations have proven to be an excellent tool to probe the properties of the strongly interacting matter created in heavy-ion collisions. Recently, the results obtained for multi-particle ...
Jet-hadron correlations relative to the event plane at the LHC with ALICE
(Elsevier, 2017-11)
In ultra relativistic heavy-ion collisions at the Large Hadron Collider (LHC), conditions are met to produce a hot, dense and strongly interacting medium known as the Quark Gluon Plasma (QGP). Quarks and gluons from incoming ...
Measurements of the nuclear modification factor and elliptic flow of leptons from heavy-flavour hadron decays in Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 and 5.02 TeV with ALICE
(Elsevier, 2017-11)
We present the ALICE results on the nuclear modification factor and elliptic flow of electrons and muons from open heavy-flavour hadron decays at mid-rapidity and forward rapidity in Pb--Pb collisions at $\sqrt{s_{\rm NN}}$ ...
Production of charged pions, kaons and protons at large transverse momenta in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(Elsevier, 2014-09)
Transverse momentum spectra of $\pi^{\pm}, K^{\pm}$ and $p(\bar{p})$ up to $p_T$ = 20 GeV/c at mid-rapidity, |y| $\le$ 0.8, in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV have been measured using the ALICE detector ... |
The idea of a probability density function An initial thought experiment
I'm thinking of a number, let's call it $X$, between 0 and 10 (inclusive). If I don't tell you anything else, what would you imagine is the probability that $X=0$? That $X=4$? Assuming that I don't have any preference for any particular number, you'd imagine that the probability of each of the eleven integers $0,1,2,\ldots, 10$ is the same. Since all the probabilities must add up to 1, a logical conclusion is to assign a probability of $1/11$ to each of the 11 options, i.e., you'd assume that the probability that $X=i$ is $1/11$ for any integer $i$ from 0 to 10, which we write as \begin{gather*} \Pr(X=i) = \frac{1}{11} \qquad \text{for } i=0,1,2, \ldots, 10. \end{gather*} Implicit in this description is the assumption that the probability that $X$ is any other number $x$ is zero. (Here we make a distinction between the random number $X$ and the variable $x$ which can stand for any fixed number.) We can write this implicit assumption as \begin{gather*} \Pr(X=x) = 0 \qquad \text{if $x$ is not one of } \{0,1,2, \ldots, 10\}. \end{gather*}
What would change if instead I told you that I was thinking of a number $X$ between 0 and 1 (inclusive)? You might assume that I was thinking of either the number 0 or the number 1, and you'd assign a probability 1/2 to both options. Or, you might guess that I had more than two options in mind. There was nothing in what I said that forces you to conclude that I was thinking of an integer. Maybe I was thinking of 1/2, or 1/4, or 7/8. Once you start going down that road, the possibilities are endless. I could be thinking of any fraction between 0 and 1. But who said I was limiting myself to rational numbers? I could even be thinking of irrational numbers like $1/\sqrt{2}$ or $\pi/5$. If we allow the possibility that the number $X$ could any real number in the interval $[0,1]$, then there are clearly an infinite number of possibilities. (Of course, I could have been thinking of non-integers for the number betwen 0 and 10 as well, but most people would think I was referring to integers in that case.)
Since we don't want to assume that I am favoring any particular number, then we should insist that the probability is the same for each number. In other words, the probability that the random number $X$ is any particular number $x \in [0,1]$ (confused?) should be some constant value; let's use $c$ to denote this probability of any single number. But, now we run into trouble due to the fact that there are an infinite number of possibilities. If each possibility has the same probability $c$ and the probabilities must add up to 1 and there are an infinite number of possibilities, what could the individual probability $c$ possibly be? If $c$ were any finite number greater than zero, once we add up an infinite number of the $c$'s, we must get to infinity, which is definitely larger than the required sum of 1. In order to prevent the sum from blowing up to infinity, we must have $c$ be infinitesimally small, i.e., we must insist that $c=0$. The probability that I chose any particular number, such as the probability that $X$ equals $1/2$, must be equal to zero. We can write this as \begin{gather*} \Pr(X=x) = 0 \qquad \text{for any real number $x$}. \end{gather*}
What went wrong here? We know all probabilities must not be zero, because we know that the total probability must add up to one. In fact, were know that, somehow, there must be something special for the probability of numbers $0 \le x \le 1$. We know that $X$ is somewhere in that interval with probability one, and the probability that $X$ is outside that interval is zero.
The probability density
It turns out, for the case where we allow $X$ to be any real number, we are just approaching the question in the wrong way. We should not ask for the probability that $X$ is exactly a single number (since that probability is zero). Instead, we need to think about the probability that $x$ is close to a single number.
We capture the notion of being close to a number with a
probability density function which is often denoted by $\rho(x)$. If the probability density around a point $x$ is large, that means the random variable $X$ is likely to be close to $x$. If, on the other hand, $\rho(x)=0$ in some interval, then $X$ won't be in that interval.
To translate the probability density $\rho(x)$ into a probability, imagine that $I_x$ is some small interval around the point $x$. Then, assuming $\rho$ is continuous, the probability that $X$ is in that interval will depend both on the density $\rho(x)$ and the length of the interval: \begin{gather} \Pr(X \in I_x) \approx \rho(x) \times \text{Length of $I_x$}. \label{eq:densityapprox} \end{gather} We don't have a true equality here, because the density $\rho$ may vary over the interval $I_x$. But, the approximation becomes better and better as the interval $I_x$ shrinks around the point $x$, as $\rho$ will be come closer and closer to a constant inside that small interval. The probability $\Pr(X \in I_x)$ approaches zero as $I_x$ shrinks down to the point $x$ (consistent with our above result for single numbers), but the information about $X$ is contained in the rate that this probability goes to zero as $I_x$ shrinks.
In general, to determine the probability that $X$ is in any subset $A$ of the real numbers, we simply add up the values of $\rho(x)$ in the subset. By “add up,” we mean integrate the function $\rho(x)$ over the set $A$. The probability that $X$ is in $A$ is precisely \begin{gather} \Pr(x \in A) = \int_A \rho(x)dx. \label{eq:density} \end{gather}
For example, if $I$ is the interval $I=[a,b]$ with $a \le b$, then the probability that $a \le X \le b$ is \begin{gather*} \Pr(x \in I) = \int_I \rho(x)dx = \int_a^b \rho(x)dx. \end{gather*}
For a function $\rho(x)$ to be a probability density function, it must satisfy two conditions. It must be non-negative, so the that integral \eqref{eq:density} is always non-negative, and it must integrate to one, so that the probability of $X$ being something is one: \begin{gather*} \rho(x) \ge 0 \quad \text{for all $x$}\\ \int \rho(x) dx = 1, \end{gather*} where the integral is implicitly taken over the whole real line.
Equation \eqref{eq:density} is the right way to define a probability density function. However, if we aren't worrying about being too precise or about discontinuities in $\rho$, we may sometimes state that \begin{gather*} \Pr(X \in (x,x+dx)) = \rho(x)dx. \end{gather*} Here, we are thinking of $dx$ as being an infinitesimally small number so that $(x,x+dx)$ is an infinitesimally small interval $I_x$ around $x$, in which case the approximation \eqref{eq:densityapprox} becomes exact, at least if $\rho$ is continuous.
Examples Example 1
Returning to the opening example of a number in the interval $[0,1]$, we can let $X$ be given by a uniform distribution in the interval $[0,1]$. The resulting probability density function of $X$ is given by \begin{gather*} \rho(x) = \begin{cases} 1 & \text{if $x \in [0,1]$}\\ 0 & \text{otherwise} \end{cases} \end{gather*} and is illustrated in the following figure.
The function $\rho(x)$ is a valid probability density function since it is non-negative and integrates to one.
If $I$ is an interval contained in $[0,1]$, say $I=[a,b]$ with $0 \le a \le b \le 1$, then $\rho(x)=1$ in the interval and \begin{align*} \Pr(x \in I) &= \int_I \rho(x)dx\\ &=\int_I 1 \, dx\\ &= \int_a^b 1\,dx = b-a=\text{Length of $I$}. \end{align*} For any interval $I$, $\Pr(x \in I)$ is equal to the length of the intersection of $I$ with the interval $[0,1]$.
Example 2
If \begin{gather*} \rho(x) = \begin{cases} x & \text{if $0 \lt x \lt 1$}\\ 2-x & \text{if $1 \lt x \lt 2$}\\ 0 & \text{otherwise}, \end{cases} \end{gather*} then $\rho(x)$ is a triangular probability density function centered around 1.
You can verify that $\int \rho(x)dx=1$ so $\rho$ is a valid density. The density is largest near 1. If a random variable $X$ is given by this density, you can verify that \begin{align*} \Pr\left(\frac{1}{2} \lt X \lt \frac{3}{2}\right) = \int_{1/2}^{3/2} \rho(x)dx = \frac{3}{4}. \end{align*}
In this definition of $\rho(x)$ it doesn't matter that we defined $\rho(1)=0$. The density at a single point doesn't matter. We would get the same random variable if we used the density \begin{gather*} \rho(x) = \begin{cases} x & \text{if $0 \lt x \le 1$}\\ 2-x & \text{if $1 \lt x \lt 2$}\\ 0 & \text{otherwise} \end{cases} \end{gather*} so that $\rho(1)=1$. This second definition is a little nicer because $\rho$ is continuous. However, the value of an integral doesn't depend on the value of its integrand at just one point, so given the definition of equation \eqref{eq:density}, the probability of the random variable $X$ being in any set is unchanged if we change $\rho$ at just one point (or at any finite number of points).
Example 3
One very important probability density function is that of a Gaussian random variable, also called a normal random variable. The probability density function looks like a bell-shaped curve.
One example is the density \begin{gather*} \rho(x) = \frac{1}{\sqrt{2\pi}} e^{-x^2/2}, \end{gather*} which is graphed below. One has to do some tricks to verify that indeed $\int \rho(x)dx=1$.
It turns out that Gaussian random variables show up naturally in many contexts in probability and statistics. |
I'm a first time TeX user and had typed out certain (long) equations in a single column format for submission to a journal (that part worked fine). Unfortunately, I accidentally missed the fact (!) that Physical Review journals have a two column format. Directly converting to the two column format results in them spilling over the column width. So, now, I need to break all these beautiful long equations so that nothing spills over columns.
Q.1 - Is there any way to do this automatically, without changing too much (time constraint)?
Q.2 - Using
eqnarray has one disadvantage -
\begin{eqnarray}LHS & = & RHS1 \nonumber \\\ & & + RHS2 \nonumber\\\ & & + RHS 3 \end{eqnarray}
Of course I want the three RHS to be aligned, so that the equation displays well, but even if LHS is not a very big string, I'm wasting some space = width of ``LHS = '' (which is conspicuously large in a two column format).
(THOSE OF YOU WHO ARE PLANNING TO MARK THIS AS A DUPLICATE, PLEASE ENSURE THAT YOU REFER TO THE RIGHT POST SO THAT MY QUERY GETS ADEQUATELY ANSWERED. THANKS.)
PS - As demanded by @egreg and @daleif, I'm also adding a sobered up Minimum Working Example (MWE) -
\documentclass{article} \begin{document} \begin{eqnarray} \Pi(\rho, \sigma, \delta) & = & \frac{1}{B} (4\rho_p + 2\rho_n + \rho_{\Lambda} + 2\rho_{\Sigma^+})-2\rho_{\Sigma^-} + 2\rho_{\Sigma^0} + 2\rho_{\Xi^0} - 2\rho_{\Xi^-}) - \frac{(\sigma_1 + (\sigma_3)_z)}{2\sigma_2\delta} \nonumber\\ & & + \frac{\sigma_1}{\sqrt{2}\delta}(4\rho^s_p + 2\rho^s_n + \rho^s_{\Lambda} + 2\rho^s_{\Sigma^+})-2\rho^s_{\Sigma^-} + 2\rho^s_{\Sigma^0} + 2\rho^s_{\Xi^0} - 2\rho^s_{\Xi^-}) \end{eqnarray} \end{document}
Now, of course, this has been `broken' at the appropriate places for a single column format, but needs to be revamped for a two column format. |
C.1 Summations and SeriesC.1 Summations and Series
Summations and Series are an important part of discrete probability theory. We provide a brief review of some of the series used in STAT 414. While it is important to recall these special series, you should also take the time to practice. For more in depth review, there are links to Khan Academy.
Summations
First, it is important to review the notation. The symbol, \(\sum\), is a summation. Suppose we have the sequence, \(a_1, a_2, \cdots, a_n\), denoted \(\{a_n\}\), and we want to sum all their values. This can be written as
\[\sum_{i=1}^n a_i\]
Here are some special sums:
\(\sum_{i=1}^n i=1+2+\cdots+n=\frac{n(n+1)}{2}\) \(\sum_{i=1}^n i^2=1^2+2^2+\cdots+n^2=\frac{n(n+1)(2n+1)}{6}\) The Binomial Theorem:
It is possible to expand any power of \(x+y\) to the sum
\[(x+y)^n=\sum_{i=0}^n {n \choose i} x^{n-i}y^i\]
where
\[{n\choose i}=\frac{n(n-1)(n-2)\cdots(n-i-1)}{i!}=\frac{n!}{(n-i)!i!}\]
Examples using the Binomial Theorem Video, (Khan Academy).
Series
When
n is a finite number, the value of the sum can be easily determined. How do we find the sum when the sequence is infinite? For example, suppose we have an infinite sequence, \(a_1, a_2, \cdots\). The infinite series is denoted:
\[S=\sum_{i=1}^\infty a_i\]
For infinite series, we consider the partial sums. Some partial sums are
\[\begin{align*}
& S_1=\sum_{i=1}^1 a_i=a_1 \\ & S_2=\sum_{i=1}^2 a_i=a_1+a_2 \\ & S_3=\sum_{i=1}^3 a_i=a_1+a_2+a_3\\ & \vdots\\ & S_n=\sum_{i=1}^n a_i=a_1+a_2+\cdots+a_n \end{align*}\]
An infinite series
converges and has sum S if the sequence of partial sums, \(\{S_n\}\) converges to S. Thus, if
\[S=\lim_{n\rightarrow \infty} \{S_n\}\]
then the series converges to
S. If \(\{S_n\}\) diverges, then the series diverges.
Review Convergence and Divergence of Series Video, (Khan Academy).
These are some of the special series used in STAT 414. It would be helpful to review more than what is listed below.
Geometric series
A geometric series has the form
\[S=\sum_{k=1}^\infty a r^{k-1}=a+ar+ar^2+ar^3+\cdots\]
where \(a\neq 0\). A geometric series converges to \(\frac{a}{1-r}\) if \(|r|<1\), but diverges if \(|r|\ge1\).
More examples and Explanation of the Geometric Series Video, (Khan Academy).
A special case of the geometric series
\[\frac{1}{1-x}=1+x+x^2+x^3+\cdots\]
for $-1<x<1$.
The Taylor (or Maclaurin) series of \(e^x\):
The series:
\[\sum_{i=0}^\infty \frac{x^i}{i!}=1+x+\frac{x^2}{2!}+\frac{x^3}{3!}+\cdots\]
for \(-1\le x\le 1\) converges to \(e^x\).
Review for the Taylor (or Maclaurin) Series Video, (Khan Academy).
Example C.1
\[S=\frac{1}{3}-\frac{1}{6}+\frac{1}{12}-\frac{1}{24}+\cdots=\sum_{x=0}^{\infty} \frac{1}{3(-2)^x}\]
This is a geometric series with \(a=\frac{1}{3}\) and \(r=-\frac{1}{2}\). Therefore, it converges to
\[\frac{a}{1-r}=\frac{\frac{1}{3}}{1+\frac{1}{2}}=\frac{2}{9}\] |
An offset is generally just a coefficient set to a specific value. To get more than one offset, in general you just need to combine the different variables in a way that is consistent to get that fixed value.
In a Poisson equation if you set $Z$ as the offset (or exposure its sometimes called):
$$\log(\mathbb{E}[Y]) = \beta_0 + \beta_1X + 1\cdot Z$$
And you exponentiate both sides you then have:
$$\mathbb{E}[Y] = \text{exp}(\beta_0 + \beta_1X) \cdot \text{exp}(Z)$$
You can then interpret this
as a rate per some unit $t$ if $Z = \text{log}(t)$:
$$\mathbb{E}[Y]/\text{exp}(\text{log}(t)) = \mathbb{E}[Y]/t = \text{exp}(\beta_0 + \beta_1X)$$
To get say two offsets we then start with:
$$\log(\mathbb{E}[Y]) = \beta_0 + \beta_1X + 1\cdot Z_1 + 1\cdot Z_2$$
Which we can exponentiate and regroup to be:
$$\mathbb{E}[Y] = \text{exp}(\beta_0 + \beta_1X) \cdot [\text{exp}(Z_1) \cdot \text{exp}(Z_2)]$$
Hopefully you see where I am going with this at this point. So if $Z_1 = \log(t_1)$ and $Z_2 = \log(t_2)$ we then have:
$$\mathbb{E}[Y]/(t_1 \cdot t_2) = \exp(\beta_0 + \beta_1X)$$
There are plenty of times to do this. Say you have people and then you have different exposure times for individuals, so you want the rate to be
# of people*exposure time.
So to get two offsets in any software you simply need to add $\log(t_1) + \log(t_2)$, or equivalently $\log(t_1 \cdot t_2)$, and then specify that new variable as the offset. So in R you would just have
offset(log(hours*no.males)) in your example. In other software you may need to calculate $\log(t_1 \cdot t_2)$ as one new variable and specify that (I think in Stata and SPSS you would need to do it that way at least).
Note for your particular example, that when setting an exposure term it is a restricted model compared to letting the effect of say
log(hours) be something other than one. So I would suggest testing this via a likelihood ratio test, so something like:
Mod1 <- glmer.nb(no.aggression ~ log(no.males) + log(no.females)
+ (1|id_target) + offset(log(hours)), data=x)
Mod2 <- glmer.nb(no.aggression ~ log(no.females)
+ (1|id_target) + offset(log(hours*no.males)), data=x)
anova(Mod1,Mod2)
Where
Mod2 is a more specific case of
Mod1.
You could even have
offset(log(hours*no.males*no.females)). This would make it a rate per all potential pairwise interactions (multiplied by hours). That does not sound too potentially inconsistent with what you have described, but currently you only have the linear
no.males and
no.females in the equation. |
Given a continuous time LTI system with impulse response $h(t)$ and determined with the transform $\mathcal{T}\{\cdot\}$, we define an input/output relationship as follows:
$$ y(t) = \mathcal{T}\{ x(t) \} $$ which can be evaluated based on the convolution integral as: $$y(t) = \mathcal{T}\{ x(t) \} = x(t) \star h(t) = \int_{-\infty}^{\infty} h(\tau) x(t-\tau) d\tau $$
Now we call a signal (function) $x(t)$ as an
eigenfunction of such a system if $$ y(t) = \mathcal{T}\{ x(t) \} = K_x x(t)$$
Where $K_x$ is a
complex constant (the eigenvalue corresponding to the eigenfunction) dependent on the system and input parameters. Note that the output $y(t)$ must be equal to the input waveform, scaled by K, for all $t$.
From this definition point of view, lets consider whether $x(t) = e^{j\omega_0 t}$ is an eigenfunction of LTI systems in general or not?
$$y(t) = \mathcal{T}\{ e^{j\omega_0 t} \} = \int_{-\infty}^{\infty} h(\tau) e^{j \omega_0 (t-\tau)} d\tau = e^{j \omega_0 t} \left( \int_{-\infty}^{\infty} h(\tau) e^{-j \omega_0 \tau} d\tau \right) = K \cdot e^{j \omega_0 t} $$
Where the complex constant $K$ (the eigenvalue) is recognized as the continuous-time Fourier transform, $H(\omega)$ evaluated at the frequency $\omega_0$, of the impulse response $h(t)$ of the system, which is also called as the Frequency response. Expressing $K$ as $K=H(\omega_0) = |H(\omega_0)| e^{j \phi_0}$ we can rewrite the output as $y(t) = K e^{j\omega_0 t} = |H(\omega_0)| e^{j \phi_0} e^{j\omega_0 t} = |H(\omega_0)| e^{j\omega_0 (t + \phi / \omega_0)} = |H(\omega_0)| e^{j\omega_0 (t - t_0)} $ where $t_0 = - \phi/\omega_0$.
We can show the relation as $$x(t) \longleftrightarrow |H(\omega_0)| e^{j\phi_0} x(t) $$Therefore we conclude that $x(t)=e^{j\omega t}$ in general is an
eigenfunction of arbitrary LTI systems.
What about the function $x(t)=e^{j \omega_1 t} + e^{j \omega_2 t}$ ? Using linearity property of LTI systems we can show that the respective outputs for each added term will be $ y_1(t) = |H(w_1)| e^{j\phi_1} e^{j\omega_1 t}$ and $ y_2(t) = |H(w_2)| e^{j\phi_2} e^{j\omega_2 t}$ therefore we have $$ y(t) = y_1(t) + y_2(t) = |H(w_1)| e^{j\phi_1} e^{j\omega_1 t} + |H(w_2)| e^{j\phi_2} e^{j\omega_2 t} = K_1 e^{j \omega_1 t} + K_2 e^{j \omega_2 t} \neq K \left( e^{j \omega_1 t} + e^{j \omega_2 t} \right) $$
Hence unless we have $K = K_1 = K_2$, the signal $x(t)=e^{j \omega_1 t} + e^{j \omega_2 t}$ is not an eigenfunction of LTI systems in general.
Finally note that for the signal $x(t)=\cos(w_0 t)$ there exist LTI systems having the property that their impulse responses, $h(t)$, are real and even will accept them as eigenfunctions, but not every LTI in general will accept $\cos(w_0 t)$ as an eigenfunction, hence $\cos(w_0 t)$ is
not an eigenfunction of LTI systems in general. On the other hand $e^{j \omega_0 t}$ or $e^{s t}$ with complex $s$ in general are eigenfunctions of every LTI system. |
Difference between revisions of "Timeline of prime gap bounds"
Line 948: Line 948:
127,277,395,046?# [m=5] ([http://terrytao.wordpress.com/2014/04/14/polymath8b-x-writing-the-paper-and-chasing-down-loose-ends/#comment-321171 Sutherland])
127,277,395,046?# [m=5] ([http://terrytao.wordpress.com/2014/04/14/polymath8b-x-writing-the-paper-and-chasing-down-loose-ends/#comment-321171 Sutherland])
| Fast admissibility testing for Hensley-Richards tuples
| Fast admissibility testing for Hensley-Richards tuples
+ + + + + + + + + + + + + + + + + + + + +
|}
|}
Revision as of 20:50, 4 May 2014
Date [math]\varpi[/math] or [math](\varpi,\delta)[/math] [math]k_0[/math] [math]H[/math] Comments Aug 10 2005 6 [EH] 16 [EH] ([Goldston-Pintz-Yildirim]) First bounded prime gap result (conditional on Elliott-Halberstam) May 14 2013 1/1,168 (Zhang) 3,500,000 (Zhang) 70,000,000 (Zhang) All subsequent work (until the work of Maynard) is based on Zhang's breakthrough paper. May 21 63,374,611 (Lewko) Optimises Zhang's condition [math]\pi(H)-\pi(k_0) \gt k_0[/math]; can be reduced by 1 by parity considerations May 28 59,874,594 (Trudgian) Uses [math](p_{m+1},\ldots,p_{m+k_0})[/math] with [math]p_{m+1} \gt k_0[/math] May 30 59,470,640 (Morrison)
58,885,998? (Tao)
59,093,364 (Morrison)
57,554,086 (Morrison)
Uses [math](p_{m+1},\ldots,p_{m+k_0})[/math] and then [math](\pm 1, \pm p_{m+1}, \ldots, \pm p_{m+k_0/2-1})[/math] following [HR1973], [HR1973b], [R1974] and optimises in m May 31 2,947,442 (Morrison)
2,618,607 (Morrison)
48,112,378 (Morrison)
42,543,038 (Morrison)
42,342,946 (Morrison)
Optimizes Zhang's condition [math]\omega\gt0[/math], and then uses an improved bound on [math]\delta_2[/math] Jun 1 42,342,924 (Tao) Tiny improvement using the parity of [math]k_0[/math] Jun 2 866,605 (Morrison) 13,008,612 (Morrison) Uses a further improvement on the quantity [math]\Sigma_2[/math] in Zhang's analysis (replacing the previous bounds on [math]\delta_2[/math]) Jun 3 1/1,040? (v08ltu) 341,640 (Morrison) 4,982,086 (Morrison)
4,802,222 (Morrison)
Uses a different method to establish [math]DHL[k_0,2][/math] that removes most of the inefficiency from Zhang's method. Jun 4 1/224?? (v08ltu)
1/240?? (v08ltu)
4,801,744 (Sutherland)
4,788,240 (Sutherland)
Uses asymmetric version of the Hensley-Richards tuples Jun 5 34,429? (Paldi/v08ltu) 4,725,021 (Elsholtz)
4,717,560 (Sutherland)
397,110? (Sutherland)
4,656,298 (Sutherland)
389,922 (Sutherland)
388,310 (Sutherland)
388,284 (Castryck)
388,248 (Sutherland)
387,982 (Castryck)
387,974 (Castryck)
[math]k_0[/math] bound uses the optimal Bessel function cutoff. Originally only provisional due to neglect of the kappa error, but then it was confirmed that the kappa error was within the allowed tolerance.
[math]H[/math] bound obtained by a hybrid Schinzel/greedy (or "greedy-greedy") sieve
Jun 6 387,960 (Angelveit)
387,904 (Angeltveit)
Improved [math]H[/math]-bounds based on experimentation with different residue classes and different intervals, and randomized tie-breaking in the greedy sieve. Jun 7
26,024? (vo8ltu)
387,534 (pedant-Sutherland)
Many of the results ended up being retracted due to a number of issues found in the most recent preprint of Pintz. Jun 8 286,224 (Sutherland)
285,752 (pedant-Sutherland)
values of [math]\varpi,\delta,k_0[/math] now confirmed; most tuples available on dropbox. New bounds on [math]H[/math] obtained via iterated merging using a randomized greedy sieve. Jun 9 181,000*? (Pintz) 2,530,338*? (Pintz) New bounds on [math]H[/math] obtained by interleaving iterated merging with local optimizations. Jun 10 23,283? (Harcos/v08ltu) 285,210 (Sutherland) More efficient control of the [math]\kappa[/math] error using the fact that numbers with no small prime factor are usually coprime Jun 11 252,804 (Sutherland) More refined local "adjustment" optimizations, as detailed here.
An issue with the [math]k_0[/math] computation has been discovered, but is in the process of being repaired.
Jun 12 22,951 (Tao/v08ltu)
22,949 (Harcos)
249,180 (Castryck) Improved bound on [math]k_0[/math] avoids the technical issue in previous computations. Jun 13 Jun 14 248,898 (Sutherland) Jun 15 [math]348\varpi+68\delta \lt 1[/math]? (Tao) 6,330? (v08ltu)
6,329? (Harcos)
6,329 (v08ltu)
60,830? (Sutherland) Taking more advantage of the [math]\alpha[/math] convolution in the Type III sums Jun 16 [math]348\varpi+68\delta \lt 1[/math] (v08ltu) 60,760* (Sutherland) Attempting to make the Weyl differencing more efficient; unfortunately, it did not work Jun 18 5,937? (Pintz/Tao/v08ltu)
5,672? (v08ltu)
5,459? (v08ltu)
5,454? (v08ltu)
5,453? (v08ltu)
60,740 (xfxie)
58,866? (Sun)
53,898? (Sun)
53,842? (Sun)
A new truncated sieve of Pintz virtually eliminates the influence of [math]\delta[/math] Jun 19 5,455? (v08ltu)
5,453? (v08ltu)
5,452? (v08ltu)
53,774? (Sun)
53,672*? (Sun)
Some typos in [math]\kappa_3[/math] estimation had placed the 5,454 and 5,453 values of [math]k_0[/math] into doubt; however other refinements have counteracted this Jun 20 [math]178\varpi + 52\delta \lt 1[/math]? (Tao)
[math]148\varpi + 33\delta \lt 1[/math]? (Tao)
Replaced "completion of sums + Weil bounds" in estimation of incomplete Kloosterman-type sums by "Fourier transform + Weyl differencing + Weil bounds", taking advantage of factorability of moduli Jun 21 [math]148\varpi + 33\delta \lt 1[/math] (v08ltu) 1,470 (v08ltu)
1,467 (v08ltu)
12,042 (Engelsma) Systematic tables of tuples of small length have been set up here and here (update: As of June 27 these tables have been merged and uploaded to an online database of current bounds on [math]H(k)[/math] for [math]k[/math] up to 5000). Jun 22 Slight improvement in the [math]\tilde \theta[/math] parameter in the Pintz sieve; unfortunately, it does not seem to currently give an actual improvement to the optimal value of [math]k_0[/math] Jun 23 1,466 (Paldi/Harcos) 12,006 (Engelsma) An improved monotonicity formula for [math]G_{k_0-1,\tilde \theta}[/math] reduces [math]\kappa_3[/math] somewhat Jun 24 [math](134 + \tfrac{2}{3}) \varpi + 28\delta \le 1[/math]? (v08ltu)
[math]140\varpi + 32 \delta \lt 1[/math]? (Tao)
1,268? (v08ltu) 10,206? (Engelsma) A theoretical gain from rebalancing the exponents in the Type I exponential sum estimates Jun 25 [math]116\varpi+30\delta\lt1[/math]? (Fouvry-Kowalski-Michel-Nelson/Tao) 1,346? (Hannes)
1,007? (Hannes)
10,876? (Engelsma) Optimistic projections arise from combining the Graham-Ringrose numerology with the announced Fouvry-Kowalski-Michel-Nelson results on d_3 distribution Jun 26 [math]116\varpi + 25.5 \delta \lt 1[/math]? (Nielsen)
[math](112 + \tfrac{4}{7}) \varpi + (27 + \tfrac{6}{7}) \delta \lt 1[/math]? (Tao)
962? (Hannes) 7,470? (Engelsma) Beginning to flesh out various "levels" of Type I, Type II, and Type III estimates, see this page, in particular optimising van der Corput in the Type I sums. Integrated tuples page now online. Jun 27 [math]108\varpi + 30 \delta \lt 1[/math]? (Tao) 902? (Hannes) 6,966? (Engelsma) Improved the Type III estimates by averaging in [math]\alpha[/math]; also some slight improvements to the Type II sums. Tuples page is now accepting submissions. Jul 1 [math](93 + \frac{1}{3}) \varpi + (26 + \frac{2}{3}) \delta \lt 1[/math]? (Tao)
873? (Hannes)
Refactored the final Cauchy-Schwarz in the Type I sums to rebalance the off-diagonal and diagonal contributions Jul 5 [math] (93 + \frac{1}{3}) \varpi + (26 + \frac{2}{3}) \delta \lt 1[/math] (Tao)
Weakened the assumption of [math]x^\delta[/math]-smoothness of the original moduli to that of double [math]x^\delta[/math]-dense divisibility
Jul 10 7/600? (Tao) An in principle refinement of the van der Corput estimate based on exploiting additional averaging Jul 19 [math](85 + \frac{5}{7})\varpi + (25 + \frac{5}{7}) \delta \lt 1[/math]? (Tao) A more detailed computation of the Jul 10 refinement Jul 20 Jul 5 computations now confirmed Jul 27 633 (Tao)
632 (Harcos)
4,686 (Engelsma) Jul 30 [math]168\varpi + 48\delta \lt 1[/math]# (Tao) 1,788# (Tao) 14,994# (Sutherland) Bound obtained without using Deligne's theorems. Aug 17 1,783# (xfxie) 14,950# (Sutherland) Oct 3 13/1080?? (Nelson/Michel/Tao) 604?? (Tao) 4,428?? (Engelsma) Found an additional variable to apply van der Corput to Oct 11 [math]83\frac{1}{13}\varpi + 25\frac{5}{13} \delta \lt 1[/math]? (Tao) 603? (xfxie) 4,422?(Engelsma)
12 [EH] (Maynard)
Worked out the dependence on [math]\delta[/math] in the Oct 3 calculation Oct 21 All sections of the paper relating to the bounds obtained on Jul 27 and Aug 17 have been proofread at least twice Oct 23 700#? (Maynard) Announced at a talk in Oberwolfach Oct 24 110#? (Maynard) 628#? (Clark-Jarvis) With this value of [math]k_0[/math], the value of [math]H[/math] given is best possible (and similarly for smaller values of [math]k_0[/math]) Nov 19 105# (Maynard)
5 [EH] (Maynard)
600# (Maynard/Clark-Jarvis) One also gets three primes in intervals of length 600 if one assumes Elliott-Halberstam Nov 20 Optimizing the numerology in Maynard's large k analysis; unfortunately there was an error in the variance calculation Nov 21 68?? (Maynard)
582#*? (Nielsen])
59,451 [m=2]#? (Nielsen])
42,392 [m=2]? (Nielsen)
356?? (Clark-Jarvis) Optimistically inserting the Polymath8a distribution estimate into Maynard's low k calculations, ignoring the role of delta Nov 22 388*? (xfxie)
448#*? (Nielsen)
43,134 [m=2]#? (Nielsen)
698,288 [m=2]#? (Sutherland) Uses the m=2 values of k_0 from Nov 21 Nov 23 493,528 [m=2]#? Sutherland Nov 24 484,234 [m=2]? (Sutherland) Nov 25 385#*? (xfxie) 484,176 [m=2]? (Sutherland) Using the exponential moment method to control errors Nov 26 102# (Nielsen) 493,426 [m=2]#? (Sutherland) Optimising the original Maynard variational problem Nov 27 484,162 [m=2]? (Sutherland) Nov 28 484,136 [m=2]? (Sutherland Dec 4 64#? (Nielsen) 330#? (Clark-Jarvis) Searching over a wider range of polynomials than in Maynard's paper Dec 6 493,408 [m=2]#? (Sutherland) Dec 19 59#? (Nielsen)
10,000,000? [m=3] (Tao)
1,700,000? [m=3] (Tao)
38,000? [m=2] (Tao)
300#? (Clark-Jarvis)
182,087,080? [m=3] (Sutherland)
179,933,380? [m=3] (Sutherland)
More efficient memory management allows for an increase in the degree of the polynomials used; the m=2,3 results use an explicit version of the [math]M_k \geq \frac{k}{k-1} \log k - O(1)[/math] lower bound. Dec 20
55#? (Nielsen)
36,000? [m=2] (xfxie)
175,225,874? [m=3] (Sutherland)
27,398,976? [m=3] (Sutherland)
Dec 21 1,640,042? [m=3] (Sutherland) 429,798? [m=2] (Sutherland) Optimising the explicit lower bound [math]M_k \geq \log k-O(1)[/math] Dec 22 1,628,944? [m=3] (Castryck)
75,000,000? [m=4] (Castryck)
3,400,000,000? [m=5] (Castryck)
5,511? [EH] [m=3] (Sutherland)
2,114,964#? [m=3] (Sutherland)
309,954? [EH] [m=5] (Sutherland)
395,154? [m=2] (Sutherland)
1,523,781,850? [m=4] (Sutherland)
82,575,303,678? [m=5] (Sutherland)
A numerical precision issue was discovered in the earlier m=4 calculations Dec 23 41,589? [EH] [m=4] (Sutherland) 24,462,774? [m=3] (Sutherland)
1,512,832,950? [m=4] (Sutherland)
2,186,561,568#? [m=4] (Sutherland)
131,161,149,090#? [m=5] (Sutherland)
Dec 24 474,320? [EH] [m=4] (Sutherland)
1,497,901,734? [m=4] (Sutherland)
Dec 28 474,296? [EH] [m=4] (Sutherland) Jan 2 2014 474,290? [EH] [m=4] (Sutherland) Jan 6 54# (Nielsen) 270# (Clark-Jarvis) Jan 8 4 [GEH] (Nielsen) 8 [GEH] (Nielsen) Using a "gracefully degrading" lower bound for the numerator of the optimisation problem. Calculations confirmed here. Jan 9 474,266? [EH] [m=4] (Sutherland) Jan 28 395,106? [m=2] (Sutherland) Jan 29 3 [GEH] (Nielsen) 6 [GEH] (Nielsen) A new idea of Maynard exploits GEH to allow for cutoff functions whose support extends beyond the unit cube Feb 9 Jan 29 results confirmed here Feb 17 53?# (Nielsen) 264?# (Clark-Jarvis) Managed to get the epsilon trick to be computationally feasible for medium k Feb 22 51?# (Nielsen) 252?# (Clark-Jarvis) More efficient matrix computation allows for higher degrees to be used Mar 4 Jan 6 computations confirmed Apr 14 50?# (Nielsen) 246?# (Clark-Jarvis) A 2-week computer calculation! Apr 17 35,410? [m=2]* (xfxie) 398,646? [m=2]* (Sutherland)
25,816,462? [m=3]* (Sutherland)
1,541,858,666? [m=4]* (Sutherland)
84,449,123,072? [m=5]* (Sutherland)
Redoing the m=2,3,4,5 computations using the confirmed MPZ estimates rather than the unconfirmed ones Apr 18 398,244? [m=2]* (Sutherland)
1,541,183,756? [m=4]* (Sutherland)
84,449,103,908? [m=5]* (Sutherland)
Apr 28 398,130? [m=2]* (Sutherland)
1,526,698,470? [m=4]* (Sutherland)
83,833,839,882? [m=5]* (Sutherland)
May 1 81,973,172,502? [m=5] (Sutherland)
2,165,674,446#? [m=4] (Sutherland)
130,235,143,908#? [m=5] (Sutherland)
faster admissibility testing May 3 1,460,493,420? [m=4] (Sutherland)
80,088,836,006? [m=5] (Sutherland)
1,488,227,220?* [m=4] (Sutherland)
81,912,638,914?* [m=5] (Sutherland)
2,111,605,786?# [m=4] (Sutherland)
127,277,395,046?# [m=5] (Sutherland)
Fast admissibility testing for Hensley-Richards tuples May 3 3,393,468,735? [m=5] (de Grey)
2,113,163?# [m=3] (de Grey)
105,754,479?# [m=4] (de Grey)
5,274,206,963?# [m=5] (de Grey)
Improved hillclimbing; also confirmation of previous k values May 4 79,929,339,154? [m=5] (Sutherland)
2,111,597,632?# [m=4] (Sutherland)
126,630,432,986?# [m=5] (Sutherland)
Legend: ? - unconfirmed or conditional ?? - theoretical limit of an analysis, rather than a claimed record * - is majorized by an earlier but independent result # - bound does not rely on Deligne's theorems [EH] - bound is conditional the Elliott-Halberstam conjecture [GEH] - bound is conditional the generalized Elliott-Halberstam conjecture [m=N] - bound on intervals containing N+1 consecutive primes, rather than two strikethrough - values relied on a computation that has now been retracted
See also the article on
Finding narrow admissible tuples for benchmark values of [math]H[/math] for various key values of [math]k_0[/math]. |
A family of quaternionic monodromy groups of the Kontsevich–Zorich cocycle
Institut de Mathématiques de Jussieu – Paris Rive Gauche, UMR 7586, Bátiment Sophie Germain, 75205 PARIS Cedex 13, France
For all $ d $ belonging to a density-$ 1/8 $ subset of the natural numbers, we give an example of a square-tiled surface conjecturally realizing the group $ \mathrm{SO}^*(2d) $ in its standard representation as the Zariski-closure of a factor of its monodromy. We prove that this conjecture holds for the first elements of this subset, showing that the group $ \mathrm{SO}^*(2d) $ is realizable for every $ 11 \leq d \leq 299 $ such that $ d = 3 \bmod 8 $, except possibly for $ d = 35 $ and $ d = 203 $.
Keywords:Translation surfaces, monodromy, square-tiled surfaces, moduli spaces of Abelian differentials, Teichmüller flow, Hodge bundle, Kontsevich–Zorich cocycle. Mathematics Subject Classification:Primary: 37D40; Secondary: 32G15. Citation:Rodolfo Gutiérrez-Romo. A family of quaternionic monodromy groups of the Kontsevich–Zorich cocycle. Journal of Modern Dynamics, 2019, 14: 227-242. doi: 10.3934/jmd.2019008
References:
[1]
A. Avila, C. Matheus and J.-C. Yoccoz,
The Kontsevich–Zorich cocycle over Veech–McMullen family of symmetric translation surfaces,
[2] [3] [4]
A. Eskin and M. Mirzakhani,
Invariant and stationary measures for the $ \mathfrak sl(2, \mathbb{R})$ action on moduli space,
[5]
A. Eskin, M. Mirzakhani and A. Mohammadi, Isolation, equidistribution, and orbit closures for the $ \mathfrak sl(2, \mathbb{R})$ action on moduli space,
[6]
S. Filip, G. Forni and C. Matheus,
Quaternionic covers and monodromy of the Kontsevich–Zorich cocycle in orthogonal groups,
[7] [8] [9]
G. Forni and C. Matheus,
Introduction to Teichmüller theory and its applications to dynamics of interval exchange transformations, flows on surfaces and billiards,
[10] [11] [12] [13] [14]
show all references
References:
[1]
A. Avila, C. Matheus and J.-C. Yoccoz,
The Kontsevich–Zorich cocycle over Veech–McMullen family of symmetric translation surfaces,
[2] [3] [4]
A. Eskin and M. Mirzakhani,
Invariant and stationary measures for the $ \mathfrak sl(2, \mathbb{R})$ action on moduli space,
[5]
A. Eskin, M. Mirzakhani and A. Mohammadi, Isolation, equidistribution, and orbit closures for the $ \mathfrak sl(2, \mathbb{R})$ action on moduli space,
[6]
S. Filip, G. Forni and C. Matheus,
Quaternionic covers and monodromy of the Kontsevich–Zorich cocycle in orthogonal groups,
[7] [8] [9]
G. Forni and C. Matheus,
Introduction to Teichmüller theory and its applications to dynamics of interval exchange transformations, flows on surfaces and billiards,
[10] [11] [12] [13] [14]
Dimension $1$ $-1$ $\pm i$ $\pm j$ $\pm k$ $\chi_1$ $1$ $1$ $1$ $1$ $1$ $1$ $\chi_i$ $1$ $1$ $1$ $1$ $-1$ $-1$ $\chi_j$ $1$ $1$ $1$ $-1$ $1$ $-1$ $\chi_k$ $1$ $1$ $1$ $-1$ $-1$ $1$ $\mathop{\mathrm{tr}} \chi_2$ $2$ $2$ $-2$ $0$ $0$ $0$
Dimension $1$ $-1$ $\pm i$ $\pm j$ $\pm k$ $\chi_1$ $1$ $1$ $1$ $1$ $1$ $1$ $\chi_i$ $1$ $1$ $1$ $1$ $-1$ $-1$ $\chi_j$ $1$ $1$ $1$ $-1$ $1$ $-1$ $\chi_k$ $1$ $1$ $1$ $-1$ $-1$ $1$ $\mathop{\mathrm{tr}} \chi_2$ $2$ $2$ $-2$ $0$ $0$ $0$
$d$ Index Genus Cusps $3$ $12$ $0$ $3$ $11$ $16896$ $225$ $960$ $19$ $1867776$ $30721$ $94208$
$d$ Index Genus Cusps $3$ $12$ $0$ $3$ $11$ $16896$ $225$ $960$ $19$ $1867776$ $30721$ $94208$
[1] [2]
Artur Avila, Carlos Matheus, Jean-Christophe Yoccoz.
The Kontsevich–Zorich cocycle over Veech–McMullen family of symmetric translation surfaces.
[3] [4] [5] [6] [7] [8]
Giovanni Forni, Carlos Matheus.
Introduction to Teichmüller theory and its applications to dynamics of interval exchange transformations,
flows on surfaces and billiards.
[9] [10]
Corentin Boissy.
Classification of Rauzy classes in the moduli space of Abelian and quadratic differentials.
[11] [12] [13] [14]
Jonathan Chaika, Yitwah Cheung, Howard Masur.
Winning games for bounded geodesics in moduli spaces of quadratic differentials.
[15] [16]
Guizhen Cui, Yunping Jiang, Anthony Quas.
Scaling functions and Gibbs measures and Teichmüller spaces of circle endomorphisms.
[17] [18] [19] [20]
Eugene Gutkin.
Insecure configurations in lattice translation surfaces, with applications to polygonal billiards.
2018 Impact Factor: 0.295
Tools
Article outline
Figures and Tables
[Back to Top] |
$let\;\lambda,\mu\in\mathbb{Q}$ such that the GCD($2X^3-7X^2+\lambda X+3, X^3-3X^2+ \mu X +3)$
IS A POLYNOMIAL OF DEGREE 2.
I know this problem may seem trivial to you, but for me it seems like I just can't get it right with the greatest common divisor. I tried to use euclid's algorithm.
First I divided $\frac {2X^3-7X^2+\lambda X+3}{X^3-3X^2+ \mu X +3}$ and obtained a remainder of: $-X^2+(\lambda -2\mu)X-3$ then continued with the algorithm... I divided $\frac {X^3-3X^2+ \mu X +3}{-X^2+(\lambda -2\mu)X-3}$ and obtained a remainder of $(\lambda-2\mu-3)X^2+(\mu-3)X+3$, then using the problem's condition i thought this should be equal to 0 but it can't be.. because of the constant.. so then I divided again $\frac{-X^2+(\lambda -2\mu)X-3}{(\lambda-2\mu-3)X^2+(\mu-3)X+3}$ and now the remainder i obtained was more pleasant to the problem's condition. It was: $(\frac{\mu-3}{\lambda-2\mu-3}+\lambda -2\mu)X+ \frac {3}{\lambda-2\mu-3}-3$ and then I set X coefficient to equal $0$ and the constant term to equal to $0$ too such that it's GCD would be a polynomial of degree 2.
Got into a 2x2 system but the solutions were no good.
Where do I go wrong?
In my book I have answer posibilities so the posibilities are:
a) $\lambda = -1, \mu = 2$ b) $\lambda = 0, \mu = 0$ c) $\lambda = 2, \mu = 0$
d) $\lambda = 2, \mu = -1$ e) $\lambda = -1, \mu = -1$ f) $\lambda = 0, \mu = 2$ |
The Standard Normal and The Chi-Square
We have one more theoretical topic to address before getting back to some practical applications on the next page, and that is the relationship between the normal distribution and the chi-square distribution. The following theorem clarifies the relationship.
\(V=\left(\dfrac{X-\mu}{\sigma}\right)^2=Z^2\)
is distributed as a chi-square random variable with 1 degree of freedom.
Proof. To prove this theorem, we need to show that the p.d.f. of the random variable V is the same as the p.d.f. of a chi-square random variable with 1 degree of freedom. That is, we need to show that:
\(g(v)=\dfrac{1}{\Gamma(1/2)2^{1/2}}v^{\frac{1}{2}-1} e^{-v/2}\)
The strategy we'll take is to find
G( v), the cumulative distribution function of V, and then differentiate it to get g( v), the probability density function of V. That said, we start with the definition of the cumulative distribution function of V:
\(G(v)=P(V\leq v)=P(Z^2 \leq v)\)
That second equality comes, of course, from the fact that
V = Z 2. Now, taking note of the behavior of a parabolic function:
we can simplify
G( v) to get:
\(G(v)=P(-\sqrt{v} < Z <\sqrt{v})\)
Now, to find the desired probability we need to integrate, over the given interval, the probability density function of a standard normal random variable
Z. That is:
\(G(v)= \int^{\sqrt{v}}_{-\sqrt{v}}\dfrac{1}{ \sqrt{2\pi}}\text{exp} \left(-\dfrac{z^2}{2}\right) dz\)
By the symmetry of the normal distribution, we can integrate over just the positive portion of the integral, and then multiply by two:
\(G(v)= 2\int^{\sqrt{v}}_0 \dfrac{1}{ \sqrt{2\pi}}\text{exp} \left(-\dfrac{z^2}{2}\right) dz\)
Okay, now let's do the following change of variables:
Doing so, we get:
\(G(v)= 2\int^v_0 \dfrac{1}{ \sqrt{2\pi}}\text{exp} \left(-\dfrac{y}{2}\right) \left(\dfrac{1}{2\sqrt{y}}\right) dy\)
\(G(v)= \int^v_0 \dfrac{1}{ \sqrt{\pi}\sqrt{2}} y^{\frac{1}{2}-1} \text{exp} \left(-\dfrac{y}{2}\right) dy\)
for
v > 0. Now, by one form of the Fundamental Theorem of Calculus:
we can take the derivative of
G( v) to get the probability density function g( v):
\(g(v)=G'(v)= \dfrac{1}{ \sqrt{\pi}\sqrt{2}} v^{\frac{1}{2}-1} e^{-v/2}\)
for 0 <
v < ∞. If you compare this g( v) to the first g(v) that we said we needed to find way back at the beginning of this proof, you should see that we are done if the following is true:
\(\Gamma \left(\dfrac{1}{2}\right)=\sqrt{\pi}\)
It is indeed true, as the following argument illustrates. Because g(v) is a p.d.f., the integral of the p.d.f. over the support must equal 1:
\(\int_0^\infty \dfrac{1}{ \sqrt{\pi}\sqrt{2}} v^{\frac{1}{2}-1} e^{-v/2} dv=1\)
Now, change the variables by letting
v = 2 x, so that dv = 2 dx. Making the change, we get:
\(\dfrac{1}{ \sqrt{\pi}} \int_0^\infty \dfrac{1}{ \sqrt{2}} (2x)^{\frac{1}{2}-1} e^{-x}2dx=1\)
Rewriting things just a bit, we get:
\(\dfrac{1}{ \sqrt{\pi}} \int_0^\infty \dfrac{1}{ \sqrt{2}}\dfrac{1}{ \sqrt{2}} x^{\frac{1}{2}-1} e^{-x}2dx=1\)
And simplifying, we get:
\(\dfrac{1}{ \sqrt{\pi}} \int_0^\infty x^{\frac{1}{2}-1} e^{-x} dx=1\)
Now, it's just a matter of recognizing that the integral is the gamma function of 1/2:
\(\dfrac{1}{ \sqrt{\pi}} \Gamma \left(\dfrac{1}{2}\right)=1\)
Our proof is complete.
So, now that we've taken care of the theoretical argument. Let's take a look at an example to see that the theorem is, in fact, believable in a practical sense.
Example
Find the probability that the standard normal random variable
Z falls between −1.96 and 1.96 in two ways: using the standard normal distribution using the chi-square distribution Solution. The standard normal table (Table V in the textbook) yields:
\(P(-1.96<Z<1.96)=P(Z<1.96)-P(Z>1.96)=0.975-0.025=0.95\)
The chi-square table (Table IV in the textbook) yields the same answer:
\(P(-1.96<Z<1.96)=P(|Z|<1.96)=P(Z^2<1.96^2)=P(\chi^2_{(1)})<3.8416)=0.95\) |
Searching online, I was not able to find construction of a confidence ellipse for $\mu$ in this case. Any help would be appreciated. Below is my attempt to construct $1- \alpha$ confidence ellipse.
(For simplicity suppose dim$(\vec{x})=2$) I try to use the fact that the statistics:
$$ T := (\overline{x} - \vec{\mu})^T \hat{\Sigma}^{-1} (\overline{x} - \vec{\mu})\,. $$
is distributed $T \sim \text{Hotteling's } T^2$ and draw ellipses
$$ (\bar{x} - \vec{r})^T\hat{\Sigma}^{-1}(\bar{x} - \vec{r}) = T^2_{\alpha}\, \quad\left(\text{with }T^2_{\alpha} := F_{T_{2, n-1}}^{-1}(1- \alpha)\right)\,,\tag{1} $$
(with the usual estimates $\bar{x} := \frac{1}{n}\sum_{i = 1}^n \vec{x}$ and $\hat{\Sigma} := \frac{1}{n-1}\sum_{i = 1}^n \left(\bar{x} - \vec{x}_i \right) \left(\bar{x} - \vec{x}_i \right)^T$)
But unlike the case where $\Sigma$ is known this seems not to work. So in the case where $\Sigma$ is know, then
$$ \chi:= (\overline{x} - \vec{\mu})^T {\Sigma}^{-1} (\overline{x} - \vec{\mu}) ~~\sim~~ \chi_2^2\,. $$
Take $\chi_{\alpha} = F_{\chi_2^2}^{-1}(1- \alpha)$, and draw the following random ellipses in $\vec{r}$ centered on $\overline{x}$.
$$ (\bar{x} - \vec{r})^T \Sigma^{-1}(\bar{x} - \vec{r}) = \chi_{\alpha}\,.\tag{2} $$
those random ellipses will cover $\vec{\mu}$, exactly $1 -\alpha$ percent of the time. This can be verified by the following observation: every time the realization of $\overline{x}$ happens to be inside the ellipse $(\vec{r} - \mu)^T\Sigma^{-1}(\vec{r} - \mu)$ (same ellipse but centered on unknown $\mu$) the ellipse (2) will covers $\mu$, now how often does this happen? With probability of $1 - \alpha$ therefor it yields the $1 - \alpha$ confidence procedure I was looking for.
Back to unknown $\Sigma$, then the ellipses (1), do not have constant principal axis, as those depend on random $\hat{\Sigma}$ and therefor it is not clear to me whether drawing (1) will actually cover the "center", $\mu $, $1 -\alpha$ percent of the time. |
Translating Code to Mathematics
Given a (more or less) formal operational semantics you can translate an algorithm's (pseudo-)code quite literally into a mathematical expression that gives you the result, provided you can manipulate the expression into a useful form. This works well for
additive cost measures such as number of comparisons, swaps, statements, memory accesses, cycles some abstract machine needs, and so on. Example: Comparisons in Bubblesort
Consider this algorithm that sorts a given array
A:
bubblesort(A) do 1
n = A.length; 2
for ( i = 0 to n-2 ) do 3
for ( j = 0 to n-i-2 ) do 4
if ( A[j] > A[j+1] ) then 5
tmp = A[j]; 6
A[j] = A[j+1]; 7
A[j+1] = tmp; 8
end 9
end 10
end 11
end 12
Let's say we want to perform the usual sorting algorithm analysis, that is count the number of element comparisons (line 5). We note immediately that this quantity does not depend on the content of array
A, only on its length $n$. So we can translate the (nested)
for-loops quite literally into (nested) sums; the loop variable becomes the summation variable and the range carries over. We get:
$\qquad\displaystyle C_{\text{cmp}}(n) = \sum_{i=0}^{n-2} \sum_{j=0}^{n-i-2} 1 = \dots = \frac{n(n-1)}{2} = \binom{n}{2}$,
where $1$ is the cost for each execution of line 5 (which we count).
Example: Swaps in Bubblesort
I'll denote by $P_{i,j}$ the subprogram that consists of lines
i to
j and by $C_{i,j}$ the costs for executing this subprogram (once).
Now let's say we want to count
swaps, that is how often $P_{6,8}$ is executed. This is a "basic block", that is a subprogram that is always executed atomically and has some constant cost (here, $1$). Contracting such blocks is one useful simplification that we often apply without thinking or talking about it.
With a similar translation as above we come to the following formula:
$\qquad\displaystyle C_{\text{swaps}}(A) = \sum_{i=0}^{n-2} \sum_{j=0}^{n-i-2} C_{5,9}(A^{(i,j)})$.
$A^{(i,j)}$ denotes the array's state before the $(i,j)$-th iteration of $P_{5,9}$.
Note that I use $A$ instead of $n$ as parameter; we'll soon see why. I don't add $i$ and $j$ as parameters of $C_{5,9}$ since the costs do not depend on them here (in the uniform cost model, that is); in general, they just might.
Clearly, the costs of $P_{5,9}$ depend on the content of $A$ (the values
A[j] and
A[j+1], specifically) so we have to account for that. Now we face a challenge: how do we "unwrap" $C_{5,9}$? Well, we can make the dependency on the content of $A$ explicit:
$\qquad\displaystyle C_{5,9}(A^{(i,j)}) = C_5(A^{(i,j)}) + \begin{cases} 1 &, \mathtt{A^{(i,j)}[j] > A^{(i,j)}[j+1]} \\ 0 &, \text{else} \end{cases}$.
For any given input array, these costs are well-defined, but we want a more general statement; we need to make stronger assumptions. Let us investigate three typical cases.
The worst case
Just from looking at the sum and noting that $C_{5,9}(A^{(i,j)}) \in \{0,1\}$, we can find a trivial upper bound for cost:
$\qquad\displaystyle C_{\text{swaps}}(A) \leq \sum_{i=0}^{n-2} \sum_{j=0}^{n-i-2} 1 = \frac{n(n-1)}{2} = \binom{n}{2}$.
But
can this happen, i.e. is there an $A$ for this upper bound is attained? As it turns out, yes: if we input an inversely sorted array of pairwise distinct elements, every iteration must perform a swap¹. Therefore, we have derived the exact worst-case number of swaps of Bubblesort.
The best case
Conversely, there is a trivial lower bound:
$\qquad\displaystyle C_{\text{swaps}}(A) \geq \sum_{i=0}^{n-2} \sum_{j=0}^{n-i-2} 0 = 0$.
This can also happen: on an array that is already sorted, Bubblesort does not execute a single swap.
The average case
Worst and best case open quite a gap. But what is the
typical number of swaps? In order to answer this question, we need to define what "typical" means. In theory, we have no reason to prefer one input over another and so we usually assume a uniform distribution over all possible inputs, that is every input is equally likely. We restrict ourselves to arrays with pairwise distinct elements and thus assume the random permutation model.
Then, we can rewrite our costs like this²:
$\qquad\displaystyle \mathbb{E}[C_{\text{swaps}}] = \frac{1}{n!} \sum_{A} \sum_{i=0}^{n-2} \sum_{j=0}^{n-i-2} C_{5,9}(A^{(i,j)})$
Now we have to go beyond simple manipulation of sums. By looking at the algorithm, we note that every swap removes exactly one inversion in $A$ (we only ever swap neighbours³). That is, the number of swaps performed on $A$ is exactly the number of inversions $\operatorname{inv}(A)$ of $A$. Thus, we can replace the inner two sums and get
$\qquad\displaystyle \mathbb{E}[C_{\text{swaps}}] = \frac{1}{n!} \sum_{A} \operatorname{inv}(A)$.
Lucky for us, the average number of inversions has been determined to be
$\qquad\displaystyle \mathbb{E}[C_{\text{swaps}}] = \frac{1}{2} \cdot \binom{n}{2}$
which is our final result. Note that this is
exactly half the worst-case cost. Note that the algorithm was carefully formulated so that "the last" iteration with
i = n-1 of the outer loop that never does anything is not executed.
"$\mathbb{E}$" is mathematical notation for "expected value", which here is just the average. We learn along the way that no algorithm that only swaps neighbouring elements can be asymptotically faster than Bubblesort (even on average) -- the number of inversions is a lower bound for all such algorithms. This applies to e.g. Insertion Sort and Selection Sort. The General Method
We have seen in the example that we have to translate control structure into mathematics; I will present a typical ensemble of translation rules. We have also seen that the cost of any given subprogram may depend on the current
state, that is (roughly) the current values of variables. Since the algorithm (usually) modifies the state, the general method is slightly cumbersome to notate. If you start feeling confused, I suggest you go back to the example or make up your own.
We denote with $\psi$ the current state (imagine it as a set of variable assignments). When we execute a program
P starting in state $\psi$, we end up in state $\psi / \mathtt{P}$ (provided
P terminates).
Individual statements
Given just a single statement
S;, you assign it costs $C_S(\psi)$. This will typically be a constant function.
Expressions
If you have an expression
E of the form
E1 ∘ E2 (say, an arithmetic expression where
∘ may be addition or multiplication, you add up costs recursively:
$\qquad\displaystyle C_E(\psi) = c_{\circ} + C_{E_1}(\psi) + C_{E_2}(\psi)$.
Note that
the operation cost $c_{\circ}$ may not be constant but depend on the values of $E_1$ and $E_2$ and evaluation of expressions may change the state in many languages,
so you may have to be flexible with this rule.
Sequence
Given a program
P as sequence of programs
Q;R, you add the costs to
$\qquad\displaystyle C_P(\psi) = C_Q(\psi) + C_R(\psi / \mathtt{Q})$.
Conditionals
Given a program
P of the form
if A then Q else R end, the costs depend on the state:
$\qquad\displaystyle C_P(\psi) = C_A(\psi) + \begin{cases} C_Q(\psi/\mathtt{A}) &, \mathtt{A} \text{ evaluates to true under } \psi \\ C_R(\psi/\mathtt{A}) &, \text{else} \end{cases}$
In general, evaluating
A may very well change the state, hence the update for the costs of the individual branches.
For-Loops
Given a program
P of the form
for x = [x1, ..., xk] do Q end, assign costs
$\qquad\displaystyle C_P(\psi) = c_{\text{init_for}} + \sum_{i=1}^k c_{\text{step_for}} + C_Q(\psi_i \circ \{\mathtt{x := xi\}})$
where $\psi_i$ is the state before processing
Q for value
xi, i.e. after the iteration with
x being set to
x1, ...,
xi-1.
Note the extra constants for loop maintenance; the loop variable has to be created ($c_{\text{init_for}}$) and assigned its values ($c_{\text{step_for}}$). This is relevant since
computing the next
xi may be costly and
a
for-loop with empty body (e.g. after simplifying in a best-case setting with a specific cost) does not have zero cost if it performs iterations.
While-Loops
Given a program
P of the form
while A do Q end, assign costs
$\qquad\displaystyle C_P(\psi) \\\qquad\ = C_A(\psi) + \begin{cases} 0 &, \mathtt{A} \text{ evaluates to false under } \psi \\ C_Q(\psi/\mathtt{A}) + C_P(\psi/\mathtt{A;Q}) &, \text{ else} \end{cases}$
By inspecting the algorithm, this recurrence can often be represented nicely as a sum similar to the one for for-loops.
Example: Consider this short algorithm:
while x > 0 do 1
i += 1 2
x = x/2 3
end 4
By applying the rule, we get
$\qquad\displaystyle C_{1,4}(\{i := i_0; x := x_0\}) \\\qquad\ = c_< + \begin{cases} 0 &, x_0 \leq 0 \\ c_{+=} + c_/ + C_{1,4}(\{i := i_0 + 1; x := \lfloor x_0/2 \rfloor\}) &, \text{ else} \end{cases}$
with some constant costs $c_{\dots}$ for the individual statements. We assume implicitly that these do
not depend on state (the values of
i and
x); this may or may not be true in "reality": think of overflows!
Now we have to solve this recurrence for $C_{1,4}$. We note that neither the number of iterations not the cost of the loop body depend on the value of
i, so we can drop it. We are left with this recurrence:
$\qquad\displaystyle C_{1,4}(x) = \begin{cases} c_> &, x \leq 0 \\ c_> + c_{+=} + c_/ + C_{1,4}(\lfloor x/2 \rfloor) &, \text{ else} \end{cases}$
This solves with elementary means to
$\qquad\displaystyle C_{1,4}(\psi) = \lceil \log_2 \psi(x) \rceil \cdot (c_> + c_{+=} + c_/) + c_>$,
reintroducing the full state symbolically; if $\psi = \{ \dots, x := 5, \dots\}$, then $\psi(x) = 5$.
Procedure Calls
Given a program
P of the form
M(x) for some parameter(s)
x where
M is a procedure with (named) parameter
p, assign costs
$\qquad\displaystyle C_P(\psi) = c_{\text{call}} + C_M(\psi_{\text{glob}} \circ \{p := x\})$.
Note again the extra constant $c_{\text{call}}$ (which might in fact depend on $\psi$!). Procedure calls are expensive due to how they are implemented on real machines, and sometimes even dominate runtime (e.g. evaluating the Fibonacci number recurrence naively).
I gloss over some semantic issues you might have with the state here. You will want to distinguish global state and such local to procedure calls. Let's just assume we pass only global state here and
M gets a new local state, initialized by setting the value of
p to
x. Furthermore,
x may be an expression which we (usually) assume to be evaluated before passing it.
Example: Consider the procedure
fac(n) do
if ( n <= 1 ) do 1
return 1 2
else 3
return n * fac(n-1) 4
end 5
end
As per the rule(s), we get:
$\qquad\displaystyle\begin{align*} C_{\text{fac}}(\{n := n_0\}) &= C_{1,5}(\{n := n_0\}) \\ &= c_{\leq} + \begin{cases} C_2(\{n := n_0 \}) &, n_0 \leq 1 \\ C_4(\{n := n_0 \}) &, \text{ else} \end{cases} \\ &= c_{\leq} + \begin{cases} c_{\text{return}} &, n_0 \leq 1 \\ c_{\text{return}} + c_* + c_{\text{call}} + C_{\text{fac}}(\{n := n_0 - 1\}) &, \text{ else} \end{cases}\end{align*}$
Note that we disregard global state, as
fac clearly does not access any. This particular recurrence is easy to solve to
$\qquad\displaystyle C_{\text{fac}}(\psi) = \psi(n) \cdot (c_{\leq} + c_{\text{return}}) + (\psi(n) - 1) \cdot (c_* + c_{\text{call}})$
We have covered the language features you will encounter in typical pseudo code. Beware hidden costs when analysing high-level pseudo code; if in doubt, unfold. The notation may seem cumbersome and is certainly a matter of taste; the concepts listed can not be ignored, though. However, with some experience you will be able to see right away which parts of the state are relevant for which cost measure, for instance "problem size" or "number of vertices". The rest can be dropped -- this simplifies things significantly!
If you think now that this is far too complicated, be advised: it
is! Deriving exact costs of algorithms in any model that is so close to real machines as to enable runtime predictions (even relative ones) is a tough endeavour. And that's not even considering caching and other nasty effects on real machines.
Therefore, algorithm analysis is often simplified to the point of being mathematically tractable. For instance, if you don't need exact costs, you can over- or underestimate at any point (for upper resp. lower bounds): reduce the set of constants, get rid of conditionals, simplify sums, and so on.
A note on asymptotic cost
What you will usually find in literature and on the webs is the "Big-Oh analysis". The proper term is
asymptotic analysis which means that instead of deriving exact costs as we did in the examples, you only give costs up to a constant factor and in the limit (roughly speaking, "for big $n$").
This is (often) fair since abstract statements have
some (generally unknown) costs in reality, depending on machine, operating system and other factors, and short runtimes may be dominated by the operating system setting up the process in the first place and whatnot. So you get some perturbation, anyway.
Here is how asymptotic analysis relates to this approach.
Identify
dominant operations (that induce costs), that is operations that occur most often (up to constant factors). In the Bubblesort example, one possible choice is the comparison in line 5.
Alternatively, bound all constants for elementary operations by their maximum (from above) resp. their minimum (from below) and perform the usual analysis.
Perform the analysis using execution counts of this operation as cost. When simplifying, allow estimations. Take care to only allow estimations from above if your goal is an upper bound ($O$) resp. from below if you want lower bounds ($\Omega$).
Make sure you understand the meaning of Landau symbols. Remember that such bounds exist for all three cases; using $O$ does not imply a worst-case analysis.
Further reading
There are many more challenges and tricks in algorithm analysis. Here is some recommended reading.
There are many questions tagged algorithm-analysis around that use techniques similar to this. |
I am trying to show that, if $X,Y$ are positive random variables, $$E((X+Y)^p)\leq 2^p\left( E(X^p)+E(Y^p)\right)$$where, if $0\leq p <1$, the $2^p$ can be replaced by $1$. I've been given the hint to think about the proof to Hölder's inequality, but I am not finding this tractable at all. Can anyone push me in the right direction?
$p \geq 1$: By Hölder's inequality, it holds for any real numbers $x,y \in \mathbb{R}$ that $$(x \cdot 1+y \cdot 1)^p \leq 2^p (x^p+y^p).$$ Set $x=X(\omega)$, $y=Y(\omega)$ and integrate both sides.
$p \in (0,1)$: Since the mapping $x \mapsto f(x) := x^p$ is concave, it is in particular sub-additive, i.e. $$f(x+y) \leq f(x)+f(y). $$ Again, integrating both sides yields the desired inequality.
The case when $0<p\le1$ follows from the inequality $$ (a+b)^p\le a^p+b^p, $$ where $a$ and $b$ are non-negative real numbers and $0<p\le1$.
Suppose that $a\ne0$. Define a function $$ f(a)=(a+b)^p-a^p-b^p, $$ where $a>0$ and $b$ is some fixed non-negative real number. Then $$ f'(a)=p[(a+b)^{p-1}-a^{p-1}]<0 $$ for all $a>0$. We have that $f(0)=0$ and $f'(a)<0$ for all $a>0$. Hence, $f(a)\le0$. |
Given Hamiltonian system with $2n$-dim phase space, if there exist $k\ge n$ independent integrals of motions then we call it integrable Hamiltonian system. The largest number of independent integrals of motions should be $2n-1$. As we know, if a Hamiltonian system is integrable, we can have action-angle variables with $m=2n-k$ independent frequencies $\omega_i$ with $i=1,\cdots, m$.
So we see if for $\forall \ i,j$, $\omega_i/ \omega_j \in \mathbb{Q}$ then the bounded orbit is closed. And certainly if there is only one independent frequency,i.e. maximal integrable $k=2n-1$, then all bounded orbits are closed.
My question:
At first glance, it seems that "a system with all bounded orbits closed" implies that "a system is maximal integrable($k=2n-1$)". But it's not true, I can come up an example $$H=\frac{p_x^2}{2} +\frac{p_y^2}{2} + \frac{1}{2}\omega_1^2 x^2 + \frac{1}{2}\omega_2^2 y^2 \tag{1}$$ with $\omega_1/ \omega_2 \in \mathbb{Q}$. I think this example is not maximal integrable if $\omega_1 \neq \omega_2$ since it have two independent frequencies. (Is this argument right?)
But this example is a little trivial, does there exist an example
$$H= \frac{\mathbf{p}^2}{2}+V(\mathbf{r}) \tag{2}$$ with $V(\mathbf{r})$ not necessary central potential, such that it has two independent frequencies $\omega_{1,2}(I_1,I_2,\cdots)$ which are not constant but the radio is always a rational number.
With action-angle variable, I can come up an example $H=\frac{1}{2} I_1^2+ 2 I_1 I_2+ 2 I_2^2$ with $\omega_2 = 2 \omega_1 = 4 I_2 + 2 I_1$ not a constant. But how to canonical transform to the form of $(2)$? Or any Hamitonian of form $(2)$ with above requirement must be anisotropy harmonic oscillator?
PS: It has no relation with Bertrand's theorem which require central force.
Another system also has all bounded orbits closed is a charged particle in $2$-dim plane with constant magnetic field perpendicular to the plane. All orbits are circle so it can be imagined that this system must be maximal integrable. I'm curious about what the three independent integrals of motions? |
I am studying relativity and was working on deriving stellar aberration using relativity. My derivation is as follows:
Suppose that the observer is traveling at a velocity $v$ in the $x$-direction. Consider a light beam coming from a star to the ship's crew, which has velocity $c$ and components $u_x=c\cos\theta$ and $u_y=c\sin\theta$. Using the Lorentz transformations, assuming that hte shit is at rest and that the star is moving in the $x$-direction at a velocity of $-v$, we see that $u'_x=\frac{u_x+v}{1+u_xv/c^2}$ and $u_y'=\frac{u_y}{\gamma(1+u_x v/c^2)}$, where $\gamma=\frac{1}{\sqrt{1-(v/c)^2}}$. Then the new angle is given by $$\tan\theta'=\frac{u_y'}{u'_x}=\frac{u_y}{\gamma(u_x+v)}=\frac{\sin\theta}{\gamma(\cos\theta+(v/c))}.$$
For most angles, this has the desired effect; it makes the angle smaller. However, at the angle $\theta=\arccos(-v/c)$, we encounter a discontinuity, such that the tangent of $\theta'$ is not defined. I am a little hesitant to say that this would thus correspond with $\theta'=\pi/2$, so that $\arccos(-v/c)$ is sent to $\pi/2$. Is this indeed the case?
Additionally, after this (i.e. for angles greater than $\arccos(-v/c)$), $\tan\theta'$ becomes negative. Moreover, for angles $\theta$ near $\arccos(-v/c)$, we can choose $\theta$ close enough to $\arccos(-v/c)$ to be arbitrarily large (in magnitude). But since these angles are naturally modded by $2\pi$, it would seem them that the apparent position of the star could be just about anywhere as observed by the observer. This seems very fishy, and occurs as well with angles just below $\arccos(-v/c)$. How should I interpret this? Indeed, how should I interpret the fact that the angles are negative? Does this means that it is reflected about the $x$-axis?
Note that I am not making (and do not want to make) assumptions about the relative size of $v$; $v$ can be arbitrarily large (while less than $c$).
Thank you for your time. |
determines the points $DFGE$ (see this post for details).
I am not sure of this claim. Therefore, I ask your advice both to assess if this is true and, otherwise,
to find the supplementary conditions needed.
Thanks for your help!
Mathematics Stack Exchange is a question and answer site for people studying math at any level and professionals in related fields. It only takes a minute to sign up.Sign up to join this community
determines the points $DFGE$ (see this post for details).
I am not sure of this claim. Therefore, I ask your advice both to assess if this is true and, otherwise,
to find the supplementary conditions needed.
Thanks for your help!
No, let $AD=x=2$ and $EB=z=1$ and $DE = y=2$. Then
$$\begin{eqnarray}c=x+y+z &=& 5\\ b=x+y &=& 4\\ a=y+z &=& 3\end{eqnarray}$$
Now, $$ \cos \alpha = {b^2+c^2-a^2\over 2bc} = {4\over 5}\in\mathbb{Q}$$ so $$DF^2 = 2x^2-2x^2\cos \alpha = x^2{2\over 5}\implies DF\notin \mathbb{Q}$$ |
X
Search Filters
Format
Subjects
Library Location
Language
Publication Date
Click on a bar to filter by decade
Slide to change publication date range
1. Observation of a peaking structure in the J/psi phi mass spectrum from B-+/- -> J/psi phi K-+/- decays
PHYSICS LETTERS B, ISSN 0370-2693, 06/2014, Volume 734, Issue 370-2693 0370-2693, pp. 261 - 281
A peaking structure in the J/psi phi mass spectrum near threshold is observed in B-+/- -> J/psi phi K-+/- decays, produced in pp collisions at root s = 7 TeV...
PHYSICS, NUCLEAR | ASTRONOMY & ASTROPHYSICS | PHYSICS, PARTICLES & FIELDS | Physics - High Energy Physics - Experiment | Physics | High Energy Physics - Experiment | scattering [p p] | J/psi --> muon+ muon | experimental results | Particle Physics - Experiment | Nuclear and High Energy Physics | Phi --> K+ K | vertex [track data analysis] | CERN LHC Coll | B+ --> J/psi Phi K | Peaking structure | hadronic decay [B] | Integrated luminosity | Data sample | final state [dimuon] | mass enhancement | width [resonance] | (J/psi Phi) [mass spectrum] | Breit-Wigner [resonance] | 7000 GeV-cms | leptonic decay [J/psi] | PHYSICS OF ELEMENTARY PARTICLES AND FIELDS
PHYSICS, NUCLEAR | ASTRONOMY & ASTROPHYSICS | PHYSICS, PARTICLES & FIELDS | Physics - High Energy Physics - Experiment | Physics | High Energy Physics - Experiment | scattering [p p] | J/psi --> muon+ muon | experimental results | Particle Physics - Experiment | Nuclear and High Energy Physics | Phi --> K+ K | vertex [track data analysis] | CERN LHC Coll | B+ --> J/psi Phi K | Peaking structure | hadronic decay [B] | Integrated luminosity | Data sample | final state [dimuon] | mass enhancement | width [resonance] | (J/psi Phi) [mass spectrum] | Breit-Wigner [resonance] | 7000 GeV-cms | leptonic decay [J/psi] | PHYSICS OF ELEMENTARY PARTICLES AND FIELDS
Journal Article
2. Measurement of the ratio of the production cross sections times branching fractions of B c ± → J/ψπ ± and B± → J/ψK ± and ℬ B c ± → J / ψ π ± π ± π ∓ / ℬ B c ± → J / ψ π ± $$ \mathrm{\mathcal{B}}\left({\mathrm{B}}_{\mathrm{c}}^{\pm}\to \mathrm{J}/\psi {\pi}^{\pm }{\pi}^{\pm }{\pi}^{\mp}\right)/\mathrm{\mathcal{B}}\left({\mathrm{B}}_{\mathrm{c}}^{\pm}\to \mathrm{J}/\psi {\pi}^{\pm}\right) $$ in pp collisions at s = 7 $$ \sqrt{s}=7 $$ TeV
Journal of High Energy Physics, ISSN 1029-8479, 1/2015, Volume 2015, Issue 1, pp. 1 - 30
The ratio of the production cross sections times branching fractions σ B c ± ℬ B c ± → J / ψ π ± / σ B ± ℬ B ± → J / ψ K ± $$ \left(\sigma...
B physics | Branching fraction | Hadron-Hadron Scattering | Quantum Physics | Quantum Field Theories, String Theory | Classical and Quantum Gravitation, Relativity Theory | Physics | Elementary Particles, Quantum Field Theory
B physics | Branching fraction | Hadron-Hadron Scattering | Quantum Physics | Quantum Field Theories, String Theory | Classical and Quantum Gravitation, Relativity Theory | Physics | Elementary Particles, Quantum Field Theory
Journal Article
3. Evidence for a Narrow Near-Threshold Structure in the J/psi phi Mass Spectrum in B+ -> J/psi phi K+ Decays
PHYSICAL REVIEW LETTERS, ISSN 0031-9007, 06/2009, Volume 102, Issue 24
Journal Article
Physics Letters B, ISSN 0370-2693, 05/2016, Volume 756, Issue C, pp. 84 - 102
A measurement of the ratio of the branching fractions of the meson to and to is presented. The , , and are observed through their decays to , , and ,...
scattering [p p] | pair production [pi] | statistical | Physics, Nuclear | 114 Physical sciences | Phi --> K+ K | Astronomy & Astrophysics | LHC, CMS, B physics, Nuclear and High Energy Physics | f0 --> pi+ pi | High Energy Physics - Experiment | Compact Muon Solenoid | pair production [K] | Science & Technology | mass spectrum [K+ K-] | Ratio B | Large Hadron Collider (LHC) | Nuclear & Particles Physics | 7000 GeV-cms | leptonic decay [J/psi] | J/psi --> muon+ muon | experimental results | Nuclear and High Energy Physics | Physics and Astronomy | branching ratio [B/s0] | CERN LHC Coll | B/s0 --> J/psi Phi | CMS collaboration ; proton-proton collisions ; CMS ; B physics | Physics | Física | Physical Sciences | hadronic decay [f0] | [PHYS.HEXP]Physics [physics]/High Energy Physics - Experiment [hep-ex] | Physics, Particles & Fields | 0202 Atomic, Molecular, Nuclear, Particle And Plasma Physics | colliding beams [p p] | hadronic decay [Phi] | mass spectrum [pi+ pi-] | B/s0 --> J/psi f0
scattering [p p] | pair production [pi] | statistical | Physics, Nuclear | 114 Physical sciences | Phi --> K+ K | Astronomy & Astrophysics | LHC, CMS, B physics, Nuclear and High Energy Physics | f0 --> pi+ pi | High Energy Physics - Experiment | Compact Muon Solenoid | pair production [K] | Science & Technology | mass spectrum [K+ K-] | Ratio B | Large Hadron Collider (LHC) | Nuclear & Particles Physics | 7000 GeV-cms | leptonic decay [J/psi] | J/psi --> muon+ muon | experimental results | Nuclear and High Energy Physics | Physics and Astronomy | branching ratio [B/s0] | CERN LHC Coll | B/s0 --> J/psi Phi | CMS collaboration ; proton-proton collisions ; CMS ; B physics | Physics | Física | Physical Sciences | hadronic decay [f0] | [PHYS.HEXP]Physics [physics]/High Energy Physics - Experiment [hep-ex] | Physics, Particles & Fields | 0202 Atomic, Molecular, Nuclear, Particle And Plasma Physics | colliding beams [p p] | hadronic decay [Phi] | mass spectrum [pi+ pi-] | B/s0 --> J/psi f0
Journal Article
2011, ISBN 9780567264367, xiv, 221
Book
PHYSICAL REVIEW LETTERS, ISSN 0031-9007, 10/2009, Volume 103, Issue 15, p. 152001
Journal Article
PHYSICAL REVIEW LETTERS, ISSN 0031-9007, 03/2007, Volume 98, Issue 13, p. 132002
We present an analysis of angular distributions and correlations of the X(3872) particle in the exclusive decay mode X(3872)-> J/psi pi(+)pi(-) with J/psi...
PHYSICS, MULTIDISCIPLINARY | CHARMONIUM | DETECTOR | Physics - High Energy Physics - Experiment | PARTICLE DECAY | PHYSICS OF ELEMENTARY PARTICLES AND FIELDS | SPIN | PIONS MINUS | QUANTUM NUMBERS | FERMILAB COLLIDER DETECTOR | MUONS PLUS | PARITY | ANGULAR DISTRIBUTION | J PSI-3097 MESONS | MUONS MINUS | TEV RANGE 01-10 | PIONS PLUS | PROTON-PROTON INTERACTIONS | PAIR PRODUCTION
PHYSICS, MULTIDISCIPLINARY | CHARMONIUM | DETECTOR | Physics - High Energy Physics - Experiment | PARTICLE DECAY | PHYSICS OF ELEMENTARY PARTICLES AND FIELDS | SPIN | PIONS MINUS | QUANTUM NUMBERS | FERMILAB COLLIDER DETECTOR | MUONS PLUS | PARITY | ANGULAR DISTRIBUTION | J PSI-3097 MESONS | MUONS MINUS | TEV RANGE 01-10 | PIONS PLUS | PROTON-PROTON INTERACTIONS | PAIR PRODUCTION
Journal Article
8. Search for rare decays of $$\mathrm {Z}$$ Z and Higgs bosons to $${\mathrm {J}/\psi } $$ J/ψ and a photon in proton-proton collisions at $$\sqrt{s}$$ s = 13$$\,\text {TeV}$$ TeV
The European Physical Journal C, ISSN 1434-6044, 2/2019, Volume 79, Issue 2, pp. 1 - 27
A search is presented for decays of $$\mathrm {Z}$$ Z and Higgs bosons to a $${\mathrm {J}/\psi } $$ J/ψ meson and a photon, with the subsequent decay of the...
Nuclear Physics, Heavy Ions, Hadrons | Measurement Science and Instrumentation | Nuclear Energy | Quantum Field Theories, String Theory | Physics | Elementary Particles, Quantum Field Theory | Astronomy, Astrophysics and Cosmology
Nuclear Physics, Heavy Ions, Hadrons | Measurement Science and Instrumentation | Nuclear Energy | Quantum Field Theories, String Theory | Physics | Elementary Particles, Quantum Field Theory | Astronomy, Astrophysics and Cosmology
Journal Article
Physical Review Letters, ISSN 0031-9007, 06/2009, Volume 102, Issue 24
Journal Article
Journal of High Energy Physics, ISSN 1126-6708, 2012, Volume 2012, Issue 5
Journal Article
Physics Letters B, ISSN 0370-2693, 06/2014, Volume 734, pp. 261 - 281
A peaking structure in the mass spectrum near threshold is observed in decays, produced in pp collisions at collected with the CMS detector at the LHC. The...
Journal Article
12. Suppression of non-prompt J/psi, prompt J/psi, and Upsilon(1S) in PbPb collisions at root s(NN)=2.76 TeV
JOURNAL OF HIGH ENERGY PHYSICS, ISSN 1029-8479, 05/2012, Issue 5 |
Archive:
Subtopics:
Comments disabled
Thu, 26 Jul 2018
There are well-known tests if a number (represented as a base-10 numeral) is divisible by 2, 3, 5, 9, or 11. What about 7?
Let's look at where the divisibility-by-9 test comes from. We add up the digits of our number !!n!!. The sum !!s(n)!! is divisible by !!9!! if and only if !!n!! is. Why is that?
Say that !!d_nd_{n-1}\ldots d_0!! are the digits of our number !!n!!. Then
$$n = \sum 10^id_i.$$
The sum of the digits is
$$s(n) = \sum d_i$$
which differs from !!n!! by $$\sum (10^i-1)d_i.$$ Since !!10^i-1!! is a multiple of !!9!! for every !!i!!, every term in the last sum is a multiple of !!9!!. So by passing from !!n!! to its digit sum, we have subtracted some multiple of !!9!!, and the residue mod 9 is unchanged. Put another way:
$$\begin{align} n &= \sum 10^id_i \\ &\equiv \sum 1^id_i \pmod 9 \qquad\text{(because $10 \equiv 1\pmod 9$)} \\ &= \sum d_i \end{align} $$
The same argument works for the divisibility-by-3 test.
For !!11!! the analysis is similar. We add up the digits !!d_0+d_2+\ldots!! and !!d_1+d_3+\ldots!! and check if the sums are equal mod 11. Why alternating digits? It's because !!10\equiv -1\pmod{11}!!, so $$n\equiv \sum (-1)^id_i \pmod{11}$$
and the sum is zero only if the sum of the positive terms is equal to the sum of the negative terms.
The same type of analysis works similarly for !!2, 4, 5, !! and !!8!!. For !!4!! we observe that !!10^i\equiv 0\pmod 4!! for all !!i>1!!, so all but two terms of the sum vanish, leaving us with the rule that !!n!! is a multiple of !!4!! if and only if !!10d_1+d_0!! is. We could simplify this a bit: !!10\equiv 2\pmod 4!! so !!10d_1+d_0 \equiv 2d_1+d_0\pmod 4!!, but we don't usually bother. Say we are investigating !!571496!!; the rule tells us to just consider !!96!!. The "simplified" rule says to consider !!2\cdot9+6 = 24!! instead. It's not clear that that is actually easier.
This approach works badly for divisibility by 7, because !!10^i\bmod 7!! is not simple. It repeats with period 6.
$$\begin{array}{c|cccccc|ccc} i & 0 & 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10 & 11 \\ %10^i & 1 & 10 & 100 & 1000 & 10000 & \ldots \\ 10^i\bmod 7 & 1 & 3 & 2 & 6 & 4 & 5 & 1 & 3 & 2 & 6 & 4 &\ldots \\ \end{array} $$
The rule we get from this is:
Take the units digit. Add three times the ones digit, twice the hundreds digit, six times the thousands digit… (blah blah blah) and the original number is a multiple of !!7!! if and only if the sum is also.
For example, considering !!12345678!! we must calculate $$\begin{align} 12345678 & \Rightarrow & 3\cdot1 + 1\cdot 2 + 5\cdot 3 + 4\cdot 4 + 6\cdot 5 + 2\cdot6 + 3\cdot 7 + 1\cdot 8 & = & 107 \\\\ 107 & \Rightarrow & 2\cdot1 + 3\cdot 0 + 1\cdot7 & = & 9 \end{align} $$ and indeed !!12345678\equiv 107\equiv 9\pmod 7!!.
My kids were taught the practical divisibility tests in school, or perhaps learned them from YouTube or something like that. Katara was impressed by my ability to test large numbers for divisibility by 7 and asked how I did it. At first I didn't think about my answer enough, and just said “Oh, it's not hard, just divide by 7 and look at the remainder.” (“Just count the legs and divide by 4.”) But I realized later that there are several tricks I was using that are not obvious. First, she had never learned short division. When I was in school I had been tormented extensively with long division, which looks like this:
This was all Katara had been shown, so when I said “just divide by 7” this is what she was thinking of. But you only need long division for large divisors. For simple divisors like !!7!!, I was taught short division, an easier technique:
Yeah, I wrote 4 when I meant 3. It doesn't matter, we don't care about the quotient anyway.
But that's one of the tricks I was using that wasn't obvious to Katara: we don't care about the quotient anyway, only the remainder. So when I did this in my head, I discarded the parts of the calculation that were about the quotient, and only kept the steps that pertained to the remainder. The way I was actually doing this sounded like this in my mind:
7 into 12 leaves 5. 7 into 53 leaves 4. 7 into 44 leaves 2. 7 into 25 leaves 4. 7 into 46 leaves 4. 7 into 57 leaves 5. 7 into 58 leaves 9. The answer is 9.
At each step, we consider only the leftmost part of the number, starting with !!12!!. !!12\div 7 !! has a remainder of 5, and to this 5 we append the next digit of the dividend, 3, giving 53. Then we continue in the same way: !!53\div 7!! has a remainder of 4, and to this 4 we append the next digit, giving 44. We never calculate the quotient at all.
I explained the idea with a smaller example, like this:
Suppose you want to see if 1234 is divisible by 7. It's 1200-something, so take away 700, which leaves 500-something. 500-what? 530-something. So take away 490, leaving 40-something. 40-what? 44. Now take away 42, leaving 2. That's not 0, so 1234 is not divisible by 7.
This is how I actually do it. For me this works reasonably well up to 13, and after that it gets progressively more difficult until by 37 I can't effectively do it at all. A crucial element is having the multiples of the divisor memorized. If you're thinking about the mod-13 residue of 680-something, it is a big help to know immediately that you can subtract 650.
A year or two ago I discovered a different method, which I'm sure must be ancient, but is interesting because it's quite different from the other methods I described.
Suppose that the final digit of !!n!! is !!b!!, so that !!n=10a+b!!. Then !!-2n = -20a-2b!!, and this is a multiple of !!7!! if and only if !!n!! is. But !!-20a\equiv a\pmod7 !!, so !!a-2b!! is a multiple of !!7!! if and only if !!n!! is. This gives us the rule:
To check if !!n!! is a multiple of 7, chop off the last digit, double it, and subtract it from the rest of the number. Repeat until the answer becomes obvious.
For !!1234!! we first chop off the !!4!! and subtract !!2\cdot4!! from !!123!! leaving !!115!!. Then we chop off the !!5!! and subtract !!2\cdot5!! from !!11!!, leaving !!1!!. This is not a multiple of !!7!!, so neither is !!1234!!. But with !!1239!!, which is a multiple of !!7!!, we get !!123-2\cdot 9 = 105!! and then !!10-2\cdot5 = 0!!, and we win.
In contrast to the other methods in this article, this method does
There are some shortcuts in this method too. If the final digit is !!7!!, then rather than doubling it and subtracting 14 you can just chop it off and throw it away, going directly from !!10a+7!! to !!a!!. If your number is !!10a+8!! you can subtract !!7!! from it to make it easier to work with, getting !!10a+1!! and then going to !!a-2!! instead of to !!a-16!!. Similarly when your number ends in !!9!! you can go to !!a-4!! instead of to !!a-18!!. And on the other side, if it ends in !!4!! it is easier to go to !!a-1!! instead of to !!a-8!!.
But even with these tricks it's not clear that this is faster or easier than just doing the short division. It's the same number of steps, and it seems like each step is about the same amount of work.
Finally, I once wowed Katara on an airplane ride by showing her this:
To check !!1429!! using this device, you start at ⓪. The first digit is !!1!!, so you follow one black arrow, to ①, and then a blue arrow, to ③. The next digit is !!4!!, so you follow four black arrows, back to ⓪, and then a blue arrow which loops around to ⓪ again. The next digit is !!2!!, so you follow two black arrows to ② and then a blue arrow to ⑥. And the last digit is 9 so you then follow 9 black arrows to ① and then stop. If you end where you started, at ⓪, the number is divisible by 7. This time we ended at ①, so !!1429!! is not divisible by 7. But if the last digit had been !!1!! instead, then in the last step we would have followed only one black arrow from ⑥ to ⓪, before we stopped, so !!1421!! is a multiple of 7.
This probably isn't useful for mental calculations, but I can imagine that if you were stuck on a long plane ride with no calculator and you needed to compute a lot of mod-7 residues for some reason, it could be quicker than the short division method. The chart is easy to construct and need not be memorized. The black arrows obviously point from !!n!! to !!n+1!!, and the blue arrows all point from !!n!! to !!10n!!.
I made up a whole set of these diagrams and I think it's fun to see how the conventional divisibility rules turn up in them. For example, the rule for divisibility by 3 that says just add up the digits:
Or the rule for divisibility by 5 that says to ignore everything but the last digit: |
In fact being able to express $B$ in that form and saying that $B$ is recursively enumerable are equivalent.
Here's a proof using Kleene Normal Form when $P$ is any partial recursive relation. First I'll show that if $B\subseteq\mathbb{N}^n$ is r.e., then there is a recursive relation $P\subseteq\mathbb{N}^{n+1}$ such that $$B(x_1,\ldots, x_n)\iff\exists y P(x_1,\ldots, x_n,y).$$
If $B=\emptyset$ the result is clear. Else let $f:\mathbb{N}\to\mathbb{N}^n$ be a total recursive function such that $B=\operatorname{range}(f)$. Then we have \begin{align*}B(x_1,\ldots, x_n) &\iff\exists y (f(y) = x_1,\ldots, x_n) \\ &\iff\exists y\forall i\le n (f_i(y) = x_i)\end{align*} which is in the desired form.
Now we show that there is a partial recursive function $f:\mathbb{N}^n\to\mathbb{N}$ such that $B=\operatorname{dom}(f)$. We can write $B(x_1,\ldots, x_n)\iff\exists y P(x_1,\ldots, x_n,y)$ where $P$ is a recursive relation. Then we simply take $$f(x_1,\ldots, x_n)=\mu y P(x_1,\ldots, x_n, y).$$ $f$ is recursive and $f(x_1,\ldots, x_n)\downarrow\iff B(x_1,\ldots, x_n)$.
Finally, we'll use the Kleene Normal form theorem get a primitive recursive function $f:\mathbb{N}\to\mathbb{N}^n$ such that $B=\operatorname{range}(f)$ or $B=\emptyset$. Indeed, write $B=\operatorname{dom}(f)$ for partial recursive $f$. Then, there are primitive recursive functions $U$ and $T$ and some $e\in\mathbb{N}$ such that $$f(x_1,\ldots, x_n)=U(\mu c T(e, \langle x_1,\ldots, x_n\rangle, c)).$$ Then $$B(x_1,\ldots, x_n)\iff f(x_1,\ldots, x_n)\downarrow\iff\exists c T(e,\langle x_1,\ldots, x_n\rangle, c),$$ which is in the form we wanted.
It is easy to see that the last condition implies the usual definition for r.e. sets, so we are done. |
The problem statement is as follows:
A triangle is dissected into six smaller triangles by its angle bisectors. Prove that the intersections of the angle bisectors of each of these smaller triangles lie on an ellipse.
Could anybody here solve it?
Mathematics Stack Exchange is a question and answer site for people studying math at any level and professionals in related fields. It only takes a minute to sign up.Sign up to join this community
The problem statement is as follows:
A triangle is dissected into six smaller triangles by its angle bisectors. Prove that the intersections of the angle bisectors of each of these smaller triangles lie on an ellipse.
Could anybody here solve it?
[Deleting previous answer, and starting over.]
This is a special case of a more general result (which I suspect
must be known, but wasn't terribly difficult to derive independently) about when the endpoints of three concurrent segments lie on a conic (are "co-conicear"?).
Proposition.Suppose six distinct points, $P_0$, $P_1$, $P_2$, $Q_0$, $Q_1$, $Q_2$ are such that the lines $P_i Q_i$ are distinct and concur at a distinct seventh point, $R$. Write $p_i := \pm|RP_i|$, $q_i := \pm|RQ_i|$, and $\theta_i = \angle P_{i-1}RP_{i+1}$; for each $i$, we assign $p_i$ and $q_i$ opposite signs if $R$ is between $P_i$ and $Q_i$, and identical signs otherwise. (The $p_i$ and $q_i$ cannot be zero, nor equal.) Then, those six points lie on a common conic if and only if
$$ \sum_i \left(\frac{1}{p_i}+\frac{1}{q_i}\right)\sin\theta_i = 0$$
Proof. Take $R$ to be the origin, and assign coordinates to the points:
$$\begin{eqnarray*} P_0 = p_0 (1, 0) \hspace{0.25in} P_1 = p_1(\cos\phi_1, \sin\phi_1) \hspace{0.25in} P_2 = p_2 (\cos\phi_2,\sin\phi_2)\\ Q_0 = q_0 (1, 0) \hspace{0.25in} Q_1 = q_1(\cos\phi_1, \sin\phi_1) \hspace{0.25in} Q_2 = q_2 (\cos\phi_2,\sin\phi_2) \end{eqnarray*}$$
Substitute the coordinates into the conic template $A x^2 + 2 B xy + Cy^2 + 2 D x + 2 Ey + 1 = 0$ to get a system of six equations in five unknown coefficients. (Note that any such conic will not pass through the origin, or $R$ in the general context.) A computer algebra system helps to determine that the system imposes a dependency among the $p_i$, $q_i$, and $\theta_i$ ---for instance, evaluating the determinant in equation (8) of MathWorld's "Conic Section" entry, with the sixth point's coordinates entered into the top row--- that dependency can be expressed as the summation above, with (taking $\phi_0 := 0$) $\sin\theta_i := \sin(\phi_{i+1}-\phi_{i-1})$. Note that our assumptions provide that $p_i \ne 0$, $q_i \ne 0$, $p_i \ne q_i$, and that $\sin\theta_i\ne 0$.
To the problem at hand ...
The Proposition is clearly relevant, since pairs of a triangle's "sub-incenters" determine three segments that concur at the triangle's incenter. We just have to figure out the lengths and angles involved to run the "co-conicearity test".
First, some notation: Let $\triangle ABC$ have incenter $I$, and let $N_A$, $N_B$, $N_C$ be the points where angle bisectors $AI$, $BI$, and $CI$ meet sides $BC$, $CA$, and $AB$, respectively. (If you consult the first figure in MathWorld's "Incircle" entry, my $N$s are close to their $M$s ... which is why I chose "$N$" to denote them.) Let $P_{AB}$ be the incenter of $\triangle IAN_C$; the "$AB$" indicates that the triangle lies along $A$'s end of side $AB$. Likewise, let $P_{BC}$ and $P_{CA}$ be the incenters of $\triangle IBN_A$ and $\triangle ICN_B$; and let $Q_{BA}$, $Q_{CB}$, $Q_{AC}$ be the incenters of $\triangle IBN_C$, $\triangle ICN_A$, and $\triangle IAN_B$. (The concurrent segments are then $P_{CA}Q_{BA}$, $P_{AB}Q_{CB}$, $P_{BC}Q_{AC}$.)
Because $AI$, $BI$, and $CI$ bisect vertex angles, and each $P_\star I$ and $Q_\star I$ bisects an angle at $I$, finding (the sines of) the angles between segments is straightforward, as shown below.
Note.To save space, I write "$\theta_n$" for "$\frac{\theta}{n}$". Observe that $\alpha_n+\beta_n+\gamma_n = \pi_n$.
$$\begin{eqnarray*} \sin\angle P_{BC}IP_{CA} &=& \sin(\angle BIN_B - \angle BIP_{BC} - \angle N_B IP_{CA} \\ &=& \sin\left( \pi - \frac{1}{2} \angle BIN_A - \frac{1}{2}\angle CIN_B \right) \\ &=& \sin\left(\frac{1}{2}(\alpha_2+\beta_2)+\frac{1}{2}(\gamma_2+\beta_2)\right) = \sin\left(\alpha_4 + 2\beta_4+\gamma_4\right) \\ &=& \sin\left( \pi_4 + \beta_4 \right) \end{eqnarray*}$$
For the length information, we need to formulate the distance from a triangle's incenter to one of its vertices.
Let $\triangle ABC$ have edge lengths $a$, $b$, and $c$ (in the standard arrangement), and let $d$ be the triangle's circumdiameter (which of course, satisfies $d = \frac{a}{\sin\alpha} = \frac{b}{\sin\beta}=\frac{c}{\sin\gamma}$). Invoke the Law of Sines in $\triangle IBA$, and manipulate appropriately, to get the following
$$|IA| = \frac{|AB|\sin\angle IBA}{\sin(\pi-\angle IBA-\angle IAB)} = \frac{c\sin\beta_2}{\sin(\alpha_2+\beta_2)} = \frac{d\sin\gamma\sin\beta_2}{\cos\gamma_2}= 2 d \sin\beta_2\sin\gamma_2$$
(The use of the circumdiameter makes the symmetry clear.)
We want to apply that formula to, say, $\triangle IAN_C$, which has incenter $P_{AB}$. Within this triangle, the angles at $A$ and $N_C$ are, respectively $\alpha_2$ and (from looking at $ACN_C$) $\pi-\alpha-\gamma_2=\pi_2+\beta_2-\alpha_2$. The circumdiameter is
$$d_{AB} = \frac{|IA|}{\sin\angle N_C} = \frac{2d\sin\beta_2\sin\gamma_2}{\sin(\pi_2+\beta_2-\alpha_2)}=\frac{2d\sin\beta_2\sin\gamma_2}{\cos(\beta_2-\alpha_2)}$$
and we can compute
$$|IP_{AB}| = 2 d_{AB} \sin\frac{\alpha_2}{2}\sin\frac{\pi_2+\beta_2-\alpha_2}{2} = \frac{4d\sin\alpha_4 \sin\beta_2\sin\gamma_2\sin(\pi_4+\beta_4-\alpha_4)}{\cos(\beta_2-\alpha_2)}$$
That's a little ugly. If we conveniently scale $\triangle ABC$ so that $d\sin\alpha_2\sin\beta_2\sin\gamma_2=1$, then we have
$$\begin{eqnarray*} |IP_{AB}| &=& \frac{2\sin(\pi_4+\beta_4-\alpha_4)}{\cos\alpha_4\cos(\beta_2-\alpha_2)} = \frac{\sqrt{2}\left( \cos(\beta_4-\alpha_4)+\sin(\beta_4-\alpha_4)\right)}{\cos\alpha_4 \left( \cos^2(\beta_4-\alpha_4)-\sin^2(\beta_4-\alpha_4)\right)} \\ &=& \frac{\sqrt{2}}{\cos\alpha_4 \left(\cos(\beta_4-\alpha_4)-\sin(\beta_4-\alpha_4)\right)} = \frac{1}{\cos\alpha_4\cos\left(\pi_4+\beta_4-\alpha_4\right)} \end{eqnarray*}$$
Recall that the co-conicearity test requires reciprocating these lengths; convenient, indeed!
All we need to do now is compute the terms from the test's sum. With $I$ indisputably separating members of each $PQ$ pair, we know to assign opposite signs to the corresponding segment lengths, giving this factor
$$\begin{eqnarray*} \frac{1}{|IP_{AB}|}-\frac{1}{|IQ_{CB}|} &=& \cos\alpha_4 \cos(\pi_4+\beta_4-\alpha_4)-\cos\gamma_4\cos(\pi_4+\beta_4-\gamma_4) \\ &=& \frac{1}{2}\left( \cos(\pi_4-2\alpha_4+\beta_4)-\cos(\pi_4+\beta_4-2\gamma_4)\right) \\ &=& -\sin(\pi_4-\alpha_4+\beta_4-\gamma_4)\sin(\gamma_4-\alpha_4)\\ &=& -\sin\beta_2 \sin(\gamma_4-\alpha_4) \end{eqnarray*}$$
so that
$$\begin{eqnarray*} \left( \frac{1}{|IP_{AB}|}-\frac{1}{|IQ_{CB}|} \right) \sin\angle P_{BC}IP_{CA} &=& -\sin\beta_2 \sin(\gamma_4-\alpha_4)\sin(\pi_4+\beta_4) \\ &=& \frac{1}{2} \sin\beta_2 \left( \sin\gamma_2 - \sin\alpha_2 \right) \end{eqnarray*}$$
(The utter simplicity here makes me think that my approach has ignored a Putnamian insight.)
Clearly, the Proposition's cyclic sum vanishes, so that the six sub-incenters lie on a common conic.
Verification that the conic is, specifically, an ellipse is --for now-- left to the reader. |
I know this question has been asked previously but the answers didn't satisfy my query. Why choose gradient ascent instead of gradient descent when our aim is to minimize the cost function when we know that gradient ascent will maximize the cost function. Andrew Ng himself used gradient descent for logistic regression in his ML tutorial in Coursera. Please help me clear my doubt.
Gradient descent and gradient ascent are the same algorithm. More precisely
Gradient ascent applied to $f(x)$, starting at $x_0$
is
the same as
Gradient descent applied to $-f(x)$, starting at $x_0$.
This is true in the sense that gradient ascent in the first case and gradient descent in the second generate the
same sequence of points, the first converges if and only if the second converges, and in case they both converge, they both converge to the same place.
For logistic regression, the cost function is
$$ \pm \sum_i y_i \log(p_i) + (1 - y_i) \log(1 - p_i) $$
you get to choose one of these two options, it doesn't matter which, as long as you are consistent.
Since $p_i$ is between zero and one, $\log(p_i)$ is negative, hence
$ \sum_i y_i \log(p_i) + (1 - y_i) \log(1 - p_i) $ is always
negative.
Further, by letting $p_i \rightarrow 0$ for a point with $y_i = 1$, we can drive this cost function all the way to $- \infty$ (which can also be accomplished by lettinf $p_i \rightarrow 1$ for a point with $y_i = 0$. So this cost function has the shape of an upside-down bowl, hence it should be
maximized, using gradient ascent.
If we use the
negative of this cost function
$ - \sum_i y_i \log(p_i) + (1 - y_i) \log(1 - p_i) $ is always
positive.
We can get exactly the opposite results (we can force it to $+ \infty$). So this is a rightside up bowl, and we should use gradient
descent to minimize it. |
Directional derivative and gradient examples Example 1
Let $f(x,y) = x^2y.$ (a) Find $\nabla f(3,2)$. (b) Find the derivative of $f$ in the direction of (1,2) at the point (3,2).
Solution: (a) The gradient is just the vector of partialderivatives. The partial derivatives of$f$ at the point $(x,y)=(3,2)$ are:\begin{align*} \pdiff{f}{x}(x,y) & = 2xy & \pdiff{f}{y}(x,y) & = x^2\\ \pdiff{f}{x}(3,2) & = 12 & \pdiff{f}{y}(3,2) & = 9\end{align*}Therefore, the gradient is\begin{align*} \nabla f (3,2) = 12 \vc{i} + 9 \vc{j} = (12,9).\end{align*}
(b) Let $\vc{u}=u_1\vc{i} + u_2 \vc{j}$ be a unit vector. The directional derivative at (3,2) in the direction of $\vc{u}$ is \begin{align} D_{\vc{u}}f(3,2) &= \nabla f(3,2) \cdot \vc{u}\notag\\ &= (12 \vc{i} + 9 \vc{j}) \cdot (u_1\vc{i} + u_2 \vc{j})\notag\\ &= 12 u_1 + 9 u_2. \label{Dub} \end{align}
To find the directional derivative in the direction of the vector (1,2), we need to find a unit vector in the direction of the vector (1,2). We simply divide by the magnitude of $(1,2)$. \begin{align*} \vc{u} = \frac{(1,2)}{\| (1,2) \|} = \frac{(1,2)}{\sqrt{1^2+2^2}} = \frac{(1,2)}{\sqrt{5}} = (1/\sqrt{5},2/\sqrt{5}). \end{align*} Plugging this expression for $\vc{u} = (u_1, u_2)$ into equation \eqref{Dub} for the directional derivative, and we find that the directional derivative at the point $(3,2)$ in the direction of $(1,2)$ is \begin{align*} D_{\vc{u}}f(3,2) &= 12 u_1 + 9 u_2\\ &= \frac{12}{\sqrt{5}} + \frac{18}{\sqrt{5}} = \frac{30}{\sqrt{5}}. \end{align*}
Example 2
For the $f$ of Example 1, find the directional derivative of $f$ at the point (3,2) in the direction of $(2,1)$.
Solution: The unit vector in the direction of $(2,1)$ is \begin{align*} \vc{u} = \frac{(2,1)}{\sqrt{5}} = (2/\sqrt{5},1/\sqrt{5}).\end{align*}Since we are still at the point (3,2), equation \eqref{Dub}is stillvalid. We plug in our new $\vc{u}$ to obtain\begin{align*} D_{\vc{u}}f(3,2) &= 12 u_1 + 9 u_2\\ &= \frac{24}{\sqrt{5}} + \frac{9}{\sqrt{5}} = \frac{33}{\sqrt{5}}\end{align*} Example 3
For the $f$ of Example 1 at the point (3,2), (a) in which direction is the directional derivative maximal, (b) what is the directional derivative in that direction?
Solution: (a) The gradient points in the direction of the maximaldirectional derivative. The directional derivative is maximal in thedirection of (12,9). (A unit vector in that direction is$\vc{u} = (12,9)/\sqrt{12^2+9^2} = (4/5, 3/5)$.)
(b) The magnitude of the gradient is this maximal directional derivative, which is $\|(12,9)\| = \sqrt{12^2+9^2} = 15$. Hence the directional derivative at the point (3,2) in the direction of (12,9) is 15.
We could double-check by calculating the result using equation \eqref{Dub} and the unit vector $\vc{u} = (4/5,3/5)$. Then we find that \begin{align*} D_{\vc{u}}f(3,2) &= 12 u_1 + 9 u_2\\ &= \frac{48}{5} + \frac{27}{5} = \frac{75}{5}=15, \end{align*} which agrees with our result.
Example 4
For the $f$ of Example 1 at the point (3,2), (a) what is the directional derivative in the direction (-3,4) (which is perpendicular to $\nabla f(3,2)$), and (b) what is the directional derivative in the direction (-4,-3) (which is opposite of the direction of $\nabla f(3,2)$)?
Solution: (a) The directional derivative must be zero. (b)The directional derivative must be $-\| \nabla f(3,2)\|$, which is$-15$. (You can verify these by calculating the results directlyusing equation \eqref{Dub}.) Example 5
Let $f(x,y,z) = xye^{x^2+z^2-5}$. Calculate the gradient of $f$ at the point $(1,3,-2)$ and calculate the directional derivative $D_{\vc{u}}f$ at the point $(1,3,-2)$ in the direction of the vector $\vc{v}=(3,-1,4)$.
Solution: The gradient vector in three-dimensions is similar to the two-dimesional case. To calculate the gradient of $f$ at the point $(1,3,-2)$ we just need to calculate the three partial derivatives of $f$.\begin{align*} \nabla f(x,y,z) &= \left(\pdiff{f}{x},\pdiff{f}{y},\pdiff{f}{z}\right) = \bigl((y+2x^2y)e^{x^2+z^2-5}, xe^{x^2+z^2-5}, 2xyze^{x^2+z^2-5}\bigr)\\ \nabla f(1,3,-2) &= \bigl(3+2(1)^23e^{0}, 1e^{0},2(1)(3)(-2)e^{0}\bigr) = (9,1,-12)\end{align*}
Just as for the above two-dimensional examples, the directional derivative is $D_{\vc{u}}f(x,y,z)=\nabla f(x,y,z) \cdot \vc{u}$ where $\vc{u}$ is a unit vector. To calculate $\vc{u}$ in the direction of $\vc{v}$, we just need to divide by its magnitude. Since $\|\vc{v}\| = \sqrt{3^2+(-1)^2+4^2} = \sqrt{26}$, \begin{align*} \vc{u}=\frac{\vc{v}}{\sqrt{26}} = \left(\frac{3}{\sqrt{26}}, \frac{-1}{\sqrt{26}}, \frac{4}{\sqrt{26}}\right) \end{align*} and \begin{align*} D_{\vc{u}}f(1,3,-2) &= \nabla f(1,3,-2) \cdot \vc{u}\\ &=(9,1,-12) \cdot \left(\frac{3}{\sqrt{26}}, \frac{-1}{\sqrt{26}}, \frac{4}{\sqrt{26}}\right)\\ &= \frac{9\cdot 3- 1-12\cdot 4}{\sqrt{26}}=\frac{-22}{\sqrt{26}}. \end{align*} |
Motivated by the public's desire to learn as much as possible following the occurrence of damaging events, we have developed a methodology to spatially map the probability of earthquake occurrence in the next 24 hours. We start with the simple aftershock model of Reasenberg and Jones (1989, 1990, 1994):
\[\ {\lambda}(t,M)=\frac{10^{a^{{^\prime}}+b(M_{m}-M)}}{(t+c)^{P}},{\ }M{\geq}M_{c}\]
(1)
where λ(
t, M) is the rate of aftershocks larger than a magnitude threshold, M c, and occurring at time t. The constants á and bare derived from the Gutenberg-Richter relationship (Gutenberg and Richter 1944), and p... |
Homology, Homotopy and Applications Homology Homotopy Appl. Volume 16, Number 1 (2014), 89-118. Holohonies for connections with values in $L_\infty$-algebras Abstract
Given a flat connection $\alpha$ on a manifold $M$ with values in a filtered $L_\infty$-algebra $\mathfrak{g}$, we construct a morphism $\mathsf{hol}^{\infty}_\alpha \colon C_\bullet(M) \rightarrow \mathsf{B} \hat{\mathbb{U}}_\infty(\mathfrak{g})$, which generalizes the holonomy map associated to a flat connection with values in a Lie algebra. The construction is based on Gugenheim's $\mathsf{A}_{\infty}$-version of de Rham's theorem, which in turn is based on Chen's iterated integrals. Finally, we discuss examples related to the geometry of configuration spaces of points in Euclidean space $\mathbb{R}^d$, and to generalizations of the holonomy representations of braid groups.
Article information Source Homology Homotopy Appl., Volume 16, Number 1 (2014), 89-118. Dates First available in Project Euclid: 3 June 2014 Permanent link to this document https://projecteuclid.org/euclid.hha/1401800074 Mathematical Reviews number (MathSciNet) MR3192766 Zentralblatt MATH identifier 1300.17016 Subjects Primary: 18G55: Homotopical algebra 55R65: Generalizations of fiber spaces and bundles Citation
Abad, Camilo Arias; Schätz, Florian. Holohonies for connections with values in $L_\infty$-algebras. Homology Homotopy Appl. 16 (2014), no. 1, 89--118. https://projecteuclid.org/euclid.hha/1401800074 |
Search
Now showing items 1-10 of 32
The ALICE Transition Radiation Detector: Construction, operation, and performance
(Elsevier, 2018-02)
The Transition Radiation Detector (TRD) was designed and built to enhance the capabilities of the ALICE detector at the Large Hadron Collider (LHC). While aimed at providing electron identification and triggering, the TRD ...
Constraining the magnitude of the Chiral Magnetic Effect with Event Shape Engineering in Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 TeV
(Elsevier, 2018-02)
In ultrarelativistic heavy-ion collisions, the event-by-event variation of the elliptic flow $v_2$ reflects fluctuations in the shape of the initial state of the system. This allows to select events with the same centrality ...
First measurement of jet mass in Pb–Pb and p–Pb collisions at the LHC
(Elsevier, 2018-01)
This letter presents the first measurement of jet mass in Pb-Pb and p-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 TeV and 5.02 TeV, respectively. Both the jet energy and the jet mass are expected to be sensitive to jet ...
First measurement of $\Xi_{\rm c}^0$ production in pp collisions at $\mathbf{\sqrt{s}}$ = 7 TeV
(Elsevier, 2018-06)
The production of the charm-strange baryon $\Xi_{\rm c}^0$ is measured for the first time at the LHC via its semileptonic decay into e$^+\Xi^-\nu_{\rm e}$ in pp collisions at $\sqrt{s}=7$ TeV with the ALICE detector. The ...
D-meson azimuthal anisotropy in mid-central Pb-Pb collisions at $\mathbf{\sqrt{s_{\rm NN}}=5.02}$ TeV
(American Physical Society, 2018-03)
The azimuthal anisotropy coefficient $v_2$ of prompt D$^0$, D$^+$, D$^{*+}$ and D$_s^+$ mesons was measured in mid-central (30-50% centrality class) Pb-Pb collisions at a centre-of-mass energy per nucleon pair $\sqrt{s_{\rm ...
Search for collectivity with azimuthal J/$\psi$-hadron correlations in high multiplicity p-Pb collisions at $\sqrt{s_{\rm NN}}$ = 5.02 and 8.16 TeV
(Elsevier, 2018-05)
We present a measurement of azimuthal correlations between inclusive J/$\psi$ and charged hadrons in p-Pb collisions recorded with the ALICE detector at the CERN LHC. The J/$\psi$ are reconstructed at forward (p-going, ...
Systematic studies of correlations between different order flow harmonics in Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 TeV
(American Physical Society, 2018-02)
The correlations between event-by-event fluctuations of anisotropic flow harmonic amplitudes have been measured in Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 TeV with the ALICE detector at the LHC. The results are ...
$\pi^0$ and $\eta$ meson production in proton-proton collisions at $\sqrt{s}=8$ TeV
(Springer, 2018-03)
An invariant differential cross section measurement of inclusive $\pi^{0}$ and $\eta$ meson production at mid-rapidity in pp collisions at $\sqrt{s}=8$ TeV was carried out by the ALICE experiment at the LHC. The spectra ...
J/$\psi$ production as a function of charged-particle pseudorapidity density in p-Pb collisions at $\sqrt{s_{\rm NN}} = 5.02$ TeV
(Elsevier, 2018-01)
We report measurements of the inclusive J/$\psi$ yield and average transverse momentum as a function of charged-particle pseudorapidity density ${\rm d}N_{\rm ch}/{\rm d}\eta$ in p-Pb collisions at $\sqrt{s_{\rm NN}}= 5.02$ ...
Energy dependence and fluctuations of anisotropic flow in Pb-Pb collisions at √sNN=5.02 and 2.76 TeV
(Springer Berlin Heidelberg, 2018-07-16)
Measurements of anisotropic flow coefficients with two- and multi-particle cumulants for inclusive charged particles in Pb-Pb collisions at 𝑠NN‾‾‾‾√=5.02 and 2.76 TeV are reported in the pseudorapidity range |η| < 0.8 ... |
Search
Now showing items 1-9 of 9
Production of $K*(892)^0$ and $\phi$(1020) in pp collisions at $\sqrt{s}$ =7 TeV
(Springer, 2012-10)
The production of K*(892)$^0$ and $\phi$(1020) in pp collisions at $\sqrt{s}$=7 TeV was measured by the ALICE experiment at the LHC. The yields and the transverse momentum spectra $d^2 N/dydp_T$ at midrapidity |y|<0.5 in ...
Transverse sphericity of primary charged particles in minimum bias proton-proton collisions at $\sqrt{s}$=0.9, 2.76 and 7 TeV
(Springer, 2012-09)
Measurements of the sphericity of primary charged particles in minimum bias proton--proton collisions at $\sqrt{s}$=0.9, 2.76 and 7 TeV with the ALICE detector at the LHC are presented. The observable is linearized to be ...
Pion, Kaon, and Proton Production in Central Pb--Pb Collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(American Physical Society, 2012-12)
In this Letter we report the first results on $\pi^\pm$, K$^\pm$, p and pbar production at mid-rapidity (|y|<0.5) in central Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV, measured by the ALICE experiment at the LHC. The ...
Measurement of prompt J/psi and beauty hadron production cross sections at mid-rapidity in pp collisions at root s=7 TeV
(Springer-verlag, 2012-11)
The ALICE experiment at the LHC has studied J/ψ production at mid-rapidity in pp collisions at s√=7 TeV through its electron pair decay on a data sample corresponding to an integrated luminosity Lint = 5.6 nb−1. The fraction ...
Suppression of high transverse momentum D mesons in central Pb--Pb collisions at $\sqrt{s_{NN}}=2.76$ TeV
(Springer, 2012-09)
The production of the prompt charm mesons $D^0$, $D^+$, $D^{*+}$, and their antiparticles, was measured with the ALICE detector in Pb-Pb collisions at the LHC, at a centre-of-mass energy $\sqrt{s_{NN}}=2.76$ TeV per ...
J/$\psi$ suppression at forward rapidity in Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(American Physical Society, 2012)
The ALICE experiment has measured the inclusive J/ψ production in Pb-Pb collisions at √sNN = 2.76 TeV down to pt = 0 in the rapidity range 2.5 < y < 4. A suppression of the inclusive J/ψ yield in Pb-Pb is observed with ...
Production of muons from heavy flavour decays at forward rapidity in pp and Pb-Pb collisions at $\sqrt {s_{NN}}$ = 2.76 TeV
(American Physical Society, 2012)
The ALICE Collaboration has measured the inclusive production of muons from heavy flavour decays at forward rapidity, 2.5 < y < 4, in pp and Pb-Pb collisions at $\sqrt {s_{NN}}$ = 2.76 TeV. The pt-differential inclusive ...
Particle-yield modification in jet-like azimuthal dihadron correlations in Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(American Physical Society, 2012-03)
The yield of charged particles associated with high-pT trigger particles (8 < pT < 15 GeV/c) is measured with the ALICE detector in Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV relative to proton-proton collisions at the ...
Measurement of the Cross Section for Electromagnetic Dissociation with Neutron Emission in Pb-Pb Collisions at √sNN = 2.76 TeV
(American Physical Society, 2012-12)
The first measurement of neutron emission in electromagnetic dissociation of 208Pb nuclei at the LHC is presented. The measurement is performed using the neutron Zero Degree Calorimeters of the ALICE experiment, which ... |
Search
Now showing items 1-1 of 1
Production of charged pions, kaons and protons at large transverse momenta in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(Elsevier, 2014-09)
Transverse momentum spectra of $\pi^{\pm}, K^{\pm}$ and $p(\bar{p})$ up to $p_T$ = 20 GeV/c at mid-rapidity, |y| $\le$ 0.8, in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV have been measured using the ALICE detector ... |
Centers of mass (centroids)
For many (but certainly not all!) purposes in physics and mechanics,it is necessary or useful to be able to consider a physical object asbeing a mass concentrated at a single point, its
geometriccenter, also called its centroid. The centroid is essentiallythe ‘average’ of all the points in the object. For simplicity, we willjust consider the two-dimensional version of this, looking only atregions in the plane.
The simplest case is that of a rectangle: it is pretty clear that the centroid is the ‘center’ of the rectangle. That is, if the corners are $(0,0), (u,0), (0,v)$ and $(u,v)$, then the centroid is $$\biggl({u\over 2},{v\over 2}\biggr)$$ The formulas below are obtained by ‘integrating up’ this simple idea:
For the center of mass (centroid) of the plane region described by $f(x)\le y\le g(x)$ and $a\le x\le b$, we have \begin{align*} \hbox{ $x$-coordinate of the centroid }&= \hbox{ average $x$-coordinate}\\ &={\int_a^b x[g(x)-f(x)]\;dx\over \int_a^b [g(x)-f(x)]\;dx}\\ &={ \int_{\textit{ left}}^{\textit{ right}} x[\textit{ upper}-\textit{ lower}]\;dx \over \int_{\textit{ left }}^{\textit{ right }} [\textit{ upper}-\textit{ lower}]\;dx } \\ &={ \int_{\textit{ left }}^{\textit{ right }} x[\textit{ upper}-\textit{ lower}]\;dx \over \hbox{ area of the region } } \end{align*}
And also \begin{align*} \hbox{ $y$-coordinate of the centroid }&= \hbox{ average $y$-coordinate}\\ &={\int_a^b {1\over 2}[g(x)^2-f(x)^2]\;dx \over \int_a^b [g(x)-f(x)]\;dx}\\ &={\int_{\textit{ left }}^{\textit{ right }} {1\over 2}[\textit{ upper}^2-\textit{ lower}^2]\;dx \over \int_{\textit{ left }}^{\textit{ right }} [\textit{ upper}-\textit{ lower}]\;dx}\\ &={\int_{\textit{ left }}^{\textit{ right }} {1\over 2}[\textit{ upper}^2-\textit{ lower}^2]\;dx \over \hbox{ area of the region }} \end{align*}
Heuristic: For the $x$-coordinate: there is an amount$(g(x)-f(x))dx$ of the region at distance $x$ from the $y$-axis. This isintegrated, and then averaged dividing by the total, that is, dividing bythe area of the entire region.
For the $y$-coordinate: in each vertical band of width $dx$ there is amount $dx\;dy$ of the region at distance $y$ from the $x$-axis. This is integrated up and then averaged by dividing by the total area.
For example, let's find the centroid of the region bounded by $x=0$, $x=1$, $y=x^2$, and $y=0$. \begin{align*} \hbox{ $x$-coordinate of the centroid }&= {\int_0^1 x[x^2-0]\;dx\over \int_0^1 [x^2-0]\;dx}\\ &={[x^4/4]_0^1 \over [x^3/3]_0^1} = {1/4-0 \over 1/3-0}={3 \over 4} \end{align*} And \begin{align*}\hbox{ $y$-coordinate of the centroid }&= {\int_0^1 {1\over 2}[(x^2)^2-0]\;dx \over \int_0^1 [x^2-0]\;dx}\\ &={{1\over 2}[x^5/5]_0^1 \over [x^3/3]_0^1}={{1\over 2}(1/5-0) \over 1/3-0}={3 \over 10} \end{align*}
Exercises Find the center of mass (centroid) of the region $0\leq x\leq 1$ and $0\leq y\leq x^2$. Find the center of mass (centroid) of the region defined by $0\leq x\leq 1, 0\leq y\leq 1$ and $x+y\leq 1$. Find the center of mass (centroid) of a homogeneous plate in the shape of an equilateral triangle. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.