
text
stringlengths 256
16.4k
|
|---|
Suppose $G$ a reductive Lie group with finitely many connected components, and suppose in addition that the connected component $G^0$ of the identity can be expressed as a finite cover of a linear Lie group. Denote by $\mathfrak{g}$ the complexified Lie algebra, and denote by $K$ a maximal compact in the complexification of $G$.
Denote by $\mathbf{HC}(\mathfrak{g},K)$ the category of admissible $(\mathfrak{g},K)$-modules or (
Harish Chandra modules), and $(\mathfrak{g},K)$-module homomorphisms. Denote by $\mathbf{Rep}(G)$ the category of admissible representations of finite length (on complete locally convex Hausdorff topological vector spaces), with continuous linear $G$-maps.
The Harish Chandra functor $\mathcal{M}\colon\mathbf{Rep}(G)\to\mathbf{HC}(\mathfrak{g},K)$ assigns to any admissible representation $V$ the Harish Chandra module of $K$-finite vectors of $V$. This is a faithful, exact functor. Let us call an exact functor $\mathcal{G}\colon\mathbf{HC}(\mathfrak{g},K)\to\mathbf{Rep}(G)$ along with a
comparison isomorphism $\eta_{\mathcal{G}}\colon\mathcal{M}\circ\mathcal{G}\simeq\mathrm{id}$ a globalization functor.
Our first observation is that globalization functors exist.
Theorem. [Casselman-Wallach] The restriction of $\mathcal{M}$ to the full subcategory of smooth admissible Fréchet spaces is an equivalence. Moreover, for any Harish Chandra module $M$, the essentially unique smooth admissible representation $(\pi,V)$ such that $M\cong\mathcal{M}(\pi,V)$ has the property $\pi(\mathcal{S}(G))M=V$, where $\mathcal{S}(G)$ is the Schwartz algebra of $G$.
If we do not restrict $\mathcal{M}$ to smooth admissible Fréchet spaces, then we have a minimal globalization and a maximal one.
Theorem. [Kashiwara-Schmid] $\mathcal{M}$ admits both a left adjoint $\mathcal{G}_0$ and right adjoint $\mathcal{G}_{\infty}$, and the counit and unit give these functors the structure of globalization functors. Construction. Here, briefly, are descriptions of the minimal and maximal globalizations. The minimal globalization is
$$\mathcal{G}_0=\textit{Dist}_c(G)\otimes_{U(\mathfrak{g})}-$$
where $\textit{Dist}_c(G)$ denotes the space of compactly supported distributions on $G$, and the maximal one is
$$\mathcal{G}_{\infty}=\mathrm{Hom}_{U(\mathfrak{g})}((-)^{\vee},C^{\infty}(G))$$
where $M^{\vee}$ is the dual Harish Chandra module of $M$ (i.e., the $K$-finite vectors of the algebraic dual of $M$).
For any Harish Chandra module $M$, the minimal globalization $\mathcal{G}_0(M)$ is a dual Fréchet nuclear space, and the maximal globalization $\mathcal{G}_{\infty}(M)$ is a Fréchet nuclear space.
Example. If $P\subset G$ is a parabolic subgroup, then the space $L^2(G/P)$ of $L^2$-functions on the homogeneous space $G/P$ is an admissible representation, and $M=\mathcal{M}(L^2(G/P))$ is a particularly interesting Harish Chandra module. In this case, one may identify $\mathcal{G}_0(M)$ with the real analytic functions on $G/P$, and one may identify $\mathcal{G}_{\infty}(M)$ with the hyperfunctions on $G/P$.
[I think other globalizations with different properties are known or expected; I don't yet know much about these, however.]
Consider the category $\mathbf{Glob}(G)$ of globalization functors for $G$; morphisms $\mathcal{G}'\to\mathcal{G}$ are natural transformations that are required to be compatible with the comparison isomorphisms $\eta_{\mathcal{G}'}$ and $\eta_{\mathcal{G}}$. Since $\mathcal{M}$ is faithful, this category is actually a poset, and it has both an inf and a sup, namely $\mathcal{G}_0$ and $\mathcal{G}_{\infty}$. This is the
poset of globalizations for $G$.
I'd like to know more about the structure of the poset $\mathbf{Glob}(G)$ — really, anything at all, but let me ask the following concrete question.
Question.Does every finite collection of elements of $\mathbf{Glob}(G)$ admit both an inf and a sup? [Added later]
Emerton (below) mentions a geometric picture that appears to be very well adapted to the study of our poset $\mathbf{Glob}(G)$. Let me at introduce the main ideas of the objects of interest, and what I learned about our poset. [What I'm going to say was essentially outlined by Kashiwara in 1987.] For this, we probably need to assume that $G$ is connected.
Notation. Let $X$ be the flag manifold of the complexification of $G$. Let $\lambda\in\mathfrak{h}^{\vee}$ be a dominant element of the dual space of the universal Cartan; for simplicity, let's assume that it is regular. Now one can define the twisted equivariant bounded derived categories $D^b_G(X)_{-\lambda}$ and $D^b_K(X)_{-\lambda}$ of constructible sheaves on $X$. Now let $\mathbf{Glob}(G,\lambda)$ denote the poset of globalizations for admissible representations with infinitesimal character $\chi_{\lambda}$, so the objects are exact functors $\mathcal{G}\colon\mathbf{HC}(\mathfrak{g},K)_{\chi_{\lambda}}\to\mathbf{Rep}(G)_{\chi_{\lambda}}$ equipped with natural isomorphisms $\eta_{\mathcal{G}}:\mathcal{M}\circ\mathcal{G}\simeq\mathrm{id}$. Matsuki correspondence. [Mirkovic-Uzawa-Vilonen] There is a canonical equivalence $\Phi\colon D^b_G(X)_{-\lambda}\simeq D^b_K(X)_{-\lambda}$. The perverse t-structure on the latter can be lifted along this correspondence to obtain a t-structure on $D^b_G(X)_{-\lambda}$ as well. The Matsuki correspondence then restricts to an equivalence $\Phi\colon P_G(X)_{-\lambda}\simeq P_K(X)_{-\lambda}$ between the corresponding hearts. Beilinson-Bernstein construction. There is a canonical equivalence $\alpha\colon P_K(X)_{-\lambda}\simeq\mathbf{HC}(\mathfrak{g},K)_{\chi_{\lambda}}$, given by Riemann-Hilbert, followed by taking cohomology. [If $\lambda$ is not regular, then this isn't quite an equivalence.]
Now we deduce a geometric description of an object of $\mathbf{Glob}(G,\lambda)$ as an exact functor $\mathcal{H}\colon P_G(X)_{-\lambda}\to\mathbf{Rep}(G)_{\chi_{\lambda}}$ equipped with a natural isomorphism $\mathcal{M}\circ\mathcal{H}\simeq\alpha\circ\Phi$, or equivalently, as a suitably t-exact functor $\mathcal{H}\colon D^b_G(X)_{-\lambda}\to D^b\mathbf{Rep}(G)_{\chi_{\lambda}}$ equipped with a functorial identification between the (complex of) Harish Chandra module(s) of $K$-finite vectors of $\mathcal{H}(F)$ and $\mathrm{RHom}(\mathbf{D}\Phi F,\mathcal{O}_X(\lambda))$ for any $F\in D^b_G(X)_{-\lambda}$. In particular, as Emerton observes, the maximal and minimal globalizations can be expressed as
$$\mathcal{H}_{\infty}(F)=\mathrm{RHom}(\mathbf{D}F,\mathcal{O}_X(\lambda))$$
and
$$\mathcal{H}_0(F)=F\otimes^L\mathcal{O}_X(\lambda)$$
Note that Verdier duality gives rise to an anti-involution $\mathcal{H}\mapsto(\mathcal{H}\circ\mathbf{D})^{\vee}$ of the poset $\mathbf{Glob}(G,\lambda)$; in particular, it exchanges $\mathcal{H}_{\infty}$ and $\mathcal{H}_0$.
I now expect that one can show the following (though I don't claim to have thought about this point carefully enough to call it a proposition).
Conjecture. All globalization functors are representable. That is, every element of $\mathbf{Glob}(G,\lambda)$ is of the form $\mathrm{RHom}(\mathbf{D}(-),E)$ for some object $E\in D^b_G(X)_{-\lambda}$.
Question.Can one characterize those objects $E\in D^b_G(X)_{-\lambda}$ such that the functor $\mathrm{RHom}(\mathbf{D}(-),E)$ is a globalization functor? Given a map between any two of these, under what circumstances do they induce a morphism of globalization functors (as defined above)?
In particular, note that if my expectation holds, then one should be able to find a copy of the poset $\mathbf{Glob}(G,\lambda)$ embedded in $D^b_G(X)_{-\lambda}$.
|
I want to find ground state energy (as well as wavefunction) for spinless $tV$ model using Real-Space Renormalization Group (RSRG) approximation. The $tV$ model is defined as $$H=H_t+H_{int}=-t\sum_{i=1}^N (c_i^\dagger c_{i+1}+c_{i+1}^\dagger c_i) + V\sum_{i=1}^N n_i n_{i+1}$$ where $n_i$ is number operator.
The RSRG works on hypothesis that the groundstate of a system is composed of low-energy states of the system's bipartitions. And an algorithm of RSRG is:
Construct Hamiltonian $H_N$ for exactly diagonalizable $N$ sites Diagonalize $H_N=\sum E_i|E_i\rangle\langle E_i|$ where $E_i$ are eigenvalues in incrasing order Apply a projector $P$ on $H_N$ to find space spanned by lowest $m$ eigenstates, $P=\sum_{i=1}^m |E_i\rangle\langle E_i|$ Calculate projected Hamiltonian $\tilde{H}_N=P^\dagger H_N P$ Construct Hamiltonian of size $2N$ by $$H_{2N}=\tilde{H}_N\otimes I + I\otimes \tilde{H}_N + \tilde{H}_{int}$$ where $\tilde{H}_{int}=\tilde{A}_N\otimes \tilde{B}_N$ and $\tilde{A}_N(\tilde{B}_N)$ are the projected operator acting on each bipartition $\tilde{A}=P^\dagger A P(\tilde{B}=P^\dagger B P)$ repeat step 2-5 until desired system size is acheived My attempt
For simplicity, I considered a system at half-filling and used the binary basis to write $H$ for 4 sites, $H_4$. Using $t=1, V=1$, $H_4$ is
Step:1
$$H_4= \begin{bmatrix} 1 & -1 & 0 & 0 & 1 & 0 \\ -1 & 0 & -1 & -1 & 0 & 1 \\ 0 & -1 & 1 & 0 & -1 & 0 \\ 0 & -1 & 0 & 1 & -1 & 0 \\ 1 & 0 & -1 & -1 & 0 & -1 \\ 0 & 1 & 0 & 0 & -1 & 1 \\ \end{bmatrix} $$
Step:2-3
It is easy to diagonalize $H_4$ and calculate $P$ for $m=3$ $$P= \begin{bmatrix} 0.69 & 0.24 & 0 & 0 & -0.24 & 0.31\\ 0.24 & 0.62 & 0.24 & 0.24 & 0 & -0.24\\ 0 & 0.24 & 0.19 & 0.19 & 0.24 & 0\\ 0 & 0.24 & 0.19 & 0.19 & 0.24 & 0\\ -0.24 & 0 & 0.24 & 0.24 & 0.62 & 0.24\\ 0.31 & -0.24 & 0 & 0 & 0.24 & 0.69 \end{bmatrix} $$
Step:4 is also straightforward.
Step:5 I am having trouble in calculating the $\tilde{H}_{int}$. What are $A$ and $B$ operators here? Are they just equal to $H_{int}=diagonal[1,0,1,1,0,1]$ i.e. $\tilde{H}_{int}=[P^\dagger H_{int} P] \otimes [P^\dagger H_{int} P]$ Another little confusion: After projecting out $m$ (which is 3 in my attempt) low-energy eigenstates, the size of Hamiltonian is still $6\times 6$ (it is not changed). If the size of Hamiltonian is not changed then how is RSRG efficient in saving the computational memory?
|
Recently I have discovered the method of constructing of GR from massless field with helicity 2 theory. It is considered here, in an article "Self-Interaction and Gauge Invariance" written by Deser S.
By the few words, the idea of the method is following. When starting from massless equations for field with helicity 2 we note that it doesn't provide stress-energy momentum tensor conservation:
$$\tag 1 G_{\mu \nu}(\partial h , \partial^{2}h) = T_{\mu \nu} \Rightarrow \partial^{\mu}T_{\mu \nu} \neq 0 $$ (here $h_{\mu \nu}$ is symmetric tensor field).
But we may change this situation by adding some tensor to the left side of equation which provides stress-tensor conservation:$$G \to \tilde {G}: \partial \tilde{G} = 0.$$
Deser says that it might be done by modifying the action which gives $(2)$ by the following way: $$\eta_{\mu \nu} \to \psi_{\mu \nu}, \quad \partial \Gamma \to D \Gamma .$$Here $\eta $ is just Minkowski spacetime metric, $\Gamma$ is the Christoffel symbol with respect to $h$, $\psi^{\mu \nu}$ is some fictive field without geometrical interpretation, and $\partial \to D$ means replacing usual derivative to a covariant one with respect to $\psi $ (this means appearance of Christoffel symbols $C^{\alpha}_{\beta \gamma}$ in terms of $\psi$). By varying an action on $\psi$ we can get the expression for correction of $(1)$ which leads to stress-energy conservation.
Here is the question: I don't understand the idea of this method. Why do we admit that we must to introduce some fictive field $\psi_{\mu \nu}$ for providing conservation law? Why do we replace partial derivatives by covariant ones using $\psi $? How to "guess" this substitution? I don't understand the explanation given in an article.This post imported from StackExchange Physics at 2014-08-15 09:37 (UCT), posted by SE-user Andrew McAddams
|
Banach Journal of Mathematical Analysis Banach J. Math. Anal. Volume 9, Number 2 (2015), 127-133. On the spectral radius of Hadamard products of nonnegative matrices Abstract
We present some spectral radius inequalities for nonnegative matrices. Using the ideas of Audenaert, we then prove the inequality which may be regarded as a Cauchy--Schwarz inequality for spectral radius of nonnegative matrices $$ \rho(A \circ B) \leq [\rho(A \circ A)]^{\frac{1}{2}}[\rho(B\circ B)]^{\frac{1}{2}}. $$ In addition, new proofs of some related results due to Horn and Zhang, Huang are also given. Finally, we interpolate Huang's inequality by proving $$ \rho(A_{1}\circ A_{2} \circ \cdots \circ A_{k}) \leq [\rho(A_{1}A_2\cdots A_{k})]^{1-\frac{2}{k}}[\rho((A_{1}\circ A_{1})\cdots (A_{k}\circ A_{k})]^{\frac{1}{k}} \leq \rho(A_{1}A_2 \cdots A_{k}).$$
Article information Source Banach J. Math. Anal., Volume 9, Number 2 (2015), 127-133. Dates First available in Project Euclid: 19 December 2014 Permanent link to this document https://projecteuclid.org/euclid.bjma/1419001109 Digital Object Identifier doi:10.15352/bjma/09-2-10 Mathematical Reviews number (MathSciNet) MR3296110 Zentralblatt MATH identifier 1314.15008 Citation
Chen, Dongjun; Zhang, Yun. On the spectral radius of Hadamard products of nonnegative matrices. Banach J. Math. Anal. 9 (2015), no. 2, 127--133. doi:10.15352/bjma/09-2-10. https://projecteuclid.org/euclid.bjma/1419001109
|
Main Page The Problem
Let [math][3]^n[/math] be the set of all length [math]n[/math] strings over the alphabet [math]1, 2, 3[/math]. A
combinatorial line is a set of three points in [math][3]^n[/math], formed by taking a string with one or more wildcards [math]x[/math] in it, e.g., [math]112x1xx3\ldots[/math], and replacing those wildcards by [math]1, 2[/math] and [math]3[/math], respectively. In the example given, the resulting combinatorial line is: [math]\{ 11211113\ldots, 11221223\ldots, 11231333\ldots \}[/math]. A subset of [math][3]^n[/math] is said to be line-free if it contains no lines. Let [math]c_n[/math] be the size of the largest line-free subset of [math][3]^n[/math]. Density Hales-Jewett (DHJ) theorem: [math]\lim_{n \rightarrow \infty} c_n/3^n = 0[/math]
The original proof of DHJ used arguments from ergodic theory. The basic problem to be consider by the Polymath project is to explore a particular combinatorial approach to DHJ, suggested by Tim Gowers.
Threads (1-199) A combinatorial approach to density Hales-Jewett (inactive) (200-299) Upper and lower bounds for the density Hales-Jewett problem (active) (300-399) The triangle-removal approach (inactive) (400-499) Quasirandomness and obstructions to uniformity (final call) (500-599) TBA (600-699) A reading seminar on density Hales-Jewett (active)
A spreadsheet containing the latest lower and upper bounds for [math]c_n[/math] can be found here.
Unsolved questions
Gowers.462: Incidentally, it occurs to me that we as a collective are doing what I as an individual mathematician do all the time: have an idea that leads to an interesting avenue to explore, get diverted by some temporarily more exciting idea, and forget about the first one. I think we should probably go through the various threads and collect together all the unsolved questions we can find (even if they are vague ones like, “Can an approach of the following kind work?”) and write them up in a single post. If this were a more massive collaboration, then we could work on the various questions in parallel, and update the post if they got answered, or reformulated, or if new questions arose.
IP-Szemeredi (a weaker problem than DHJ)
Solymosi.2: In this note I will try to argue that we should consider a variant of the original problem first. If the removal technique doesn’t work here, then it won’t work in the more difficult setting. If it works, then we have a nice result! Consider the Cartesian product of an IP_d set. (An IP_d set is generated by d numbers by taking all the [math]2^d[/math] possible sums. So, if the n numbers are independent then the size of the IP_d set is [math]2^d[/math]. In the following statements we will suppose that our IP_d sets have size [math]2^n[/math].)
Prove that for any [math]c\gt0[/math] there is a [math]d[/math], such that any c-dense subset of the Cartesian product of an IP_d set (it is a two dimensional pointset) has a corner.
The statement is true. One can even prove that the dense subset of a Cartesian product contains a square, by using the density HJ for k=4. (I will sketch the simple proof later) What is promising here is that one can build a not-very-large tripartite graph where we can try to prove a removal lemma. The vertex sets are the vertical, horizontal, and slope -1 lines, having intersection with the Cartesian product. Two vertices are connected by an edge if the corresponding lines meet in a point of our c-dense subset. Every point defines a triangle, and if you can find another, non-degenerate, triangle then we are done. This graph is still sparse, but maybe it is well-structured for a removal lemma.
Finally, let me prove that there is square if d is large enough compare to c. Every point of the Cartesian product has two coordinates, a 0,1 sequence of length d. It has a one to one mapping to [4]^d; Given a point ((x_1,…,x_d),(y_1,…,y_d)) where x_i,y_j are 0 or 1, it maps to (z_1,…,z_d), where z_i=0 if x_i=y_i=0, z_i=1 if x_i=1 and y_i=0, z_i=2 if x_i=0 and y_i=1, and finally z_i=3 if x_i=y_i=1. Any combinatorial line in [4]^d defines a square in the Cartesian product, so the density HJ implies the statement.
Gowers.7: With reference to Jozsef’s comment, if we suppose that the d numbers used to generate the set are indeed independent, then it’s natural to label a typical point of the Cartesian product as (\epsilon,\eta), where each of \epsilon and \eta is a 01-sequence of length d. Then a corner is a triple of the form (\epsilon,\eta), (\epsilon,\eta+\delta), (\epsilon+\delta,\eta), where \delta is a \{-1,0,1\}-valued sequence of length d with the property that both \epsilon+\delta and \eta+\delta are 01-sequences. So the question is whether corners exist in every dense subset of the original Cartesian product.
This is simpler than the density Hales-Jewett problem in at least one respect: it involves 01-sequences rather than 012-sequences. But that simplicity may be slightly misleading because we are looking for corners in the Cartesian product. A possible disadvantage is that in this formulation we lose the symmetry of the corners: the horizontal and vertical lines will intersect this set in a different way from how the lines of slope -1 do.
I feel that this is a promising avenue to explore, but I would also like a little more justification of the suggestion that this variant is likely to be simpler.
Gowers.22: A slight variant of the problem you propose is this. Let’s take as our ground set the set of all pairs (U,V) of subsets of \null [n], and let’s take as our definition of a corner a triple of the form (U,V), (U\cup D,V), (U,V\cup D), where both the unions must be disjoint unions. This is asking for more than you asked for because I insist that the difference D is positive, so to speak. It seems to be a nice combination of Sperner’s theorem and the usual corners result. But perhaps it would be more sensible not to insist on that positivity and instead ask for a triple of the form (U,V), ((U\cup D)\setminus C,V), (U, (V\cup D)\setminus C, where D is disjoint from both U and V and C is contained in both U and V. That is your original problem I think.
I think I now understand better why your problem could be a good toy problem to look at first. Let’s quickly work out what triangle-removal statement would be needed to solve it. (You’ve already done that, so I just want to reformulate it in set-theoretic language, which I find easier to understand.) We let all of X, Y and Z equal the power set of \null [n]. We join U\in X to V\in Y if (U,V)\in A.
Ah, I see now that there’s a problem with what I’m suggesting, which is that in the normal corners problem we say that (x,y+d) and (x+d,y) lie in a line because both points have the same coordinate sum. When should we say that (U,V\cup D) and (U\cup D,V) lie in a line? It looks to me as though we have to treat the sets as 01-sequences and take the sum again. So it’s not really a set-theoretic reformulation after all.
O'Donnell.35: Just to confirm I have the question right…
There is a dense subset A of {0,1}^n x {0,1}^n. Is it true that it must contain three nonidentical strings (x,x’), (y,y’), (z,z’) such that for each i = 1…n, the 6 bits
[ x_i x'_i ] [ y_i y'_i ] [ z_i z'_i ]
are equal to one of the following:
[ 0 0 ] [ 0 0 ] [ 0, 1 ] [ 1 0 ] [ 1 1 ] [ 1 1 ] [ 0 0 ], [ 0 1 ], [ 0, 1 ], [ 1 0 ], [ 1 0 ], [ 1 1 ], [ 0 0 ] [ 1 0 ] [ 0, 1 ] [ 1 0 ] [ 0 1 ] [ 1 1 ]
?
McCutcheon.469: IP Roth:
Just to be clear on the formulation I had in mind (with apologies for the unprocessed code): for every $\delta>0$ there is an $n$ such that any $E\subset [n]^{[n]}\times [n]^{[n]}$ having relative density at least $\delta$ contains a corner of the form $\{a, a+(\sum_{i\in \alpha} e_i ,0),a+(0, \sum_{i\in \alpha} e_i)\}$. Here $(e_i)$ is the coordinate basis for $[n]^{[n]}$, i.e. $e_i(j)=\delta_{ij}$.
Presumably, this should be (perhaps much) simpler than DHJ, k=3.
High-dimensional Sperner Kalai.29: There is an analogous for Sperner but with high dimensional combinatorial spaces instead of "lines" but I do not remember the details (Kleitman(?) Katona(?) those are ususal suspects.)
Fourier approach
Kalai.29: A sort of generic attack one can try with Sperner is to look at f=1_A and express using the Fourier expansion of f the expression \int f(x)f(y)1_{x<y} where x<y is the partial order (=containment) for 0-1 vectors. Then one may hope that if f does not have a large Fourier coefficient then the expression above is similar to what we get when A is random and otherwise we can raise the density for subspaces. (OK, you can try it directly for the k=3 density HJ problem too but Sperner would be easier;) This is not unrealeted to the regularity philosophy. Gowers.31: Gil, a quick remark about Fourier expansions and the k=3 case. I want to explain why I got stuck several years ago when I was trying to develop some kind of Fourier approach. Maybe with your deep knowledge of this kind of thing you can get me unstuck again.
The problem was that the natural Fourier basis in \null [3]^n was the basis you get by thinking of \null [3]^n as the group \mathbb{Z}_3^n. And if that’s what you do, then there appear to be examples that do not behave quasirandomly, but which do not have large Fourier coefficients either. For example, suppose that n is a multiple of 7, and you look at the set A of all sequences where the numbers of 1s, 2s and 3s are all multiples of 7. If two such sequences lie in a combinatorial line, then the set of variable coordinates for that line must have cardinality that’s a multiple of 7, from which it follows that the third point automatically lies in the line. So this set A has too many combinatorial lines. But I’m fairly sure — perhaps you can confirm this — that A has no large Fourier coefficient.
You can use this idea to produce lots more examples. Obviously you can replace 7 by some other small number. But you can also pick some arbitrary subset W of \null[n] and just ask that the numbers of 0s, 1s and 2s inside W are multiples of 7.
DHJ for dense subsets of a random set
Tao.18: A sufficiently good Varnavides type theorem for DHJ may have a separate application from the one in this project, namely to obtain a “relative” DHJ for dense subsets of a sufficiently pseudorandom subset of {}[3]^n, much as I did with Ben Green for the primes (and which now has a significantly simpler proof by Gowers and by Reingold-Trevisan-Tulsiani-Vadhan). There are other obstacles though to that task (e.g. understanding the analogue of “dual functions” for Hales-Jewett), and so this is probably a bit off-topic.
|
Difference between revisions of "Demand/Dynamic User Assignment"
(using vtypes from additional file)
(8 intermediate revisions by 2 users not shown) Line 1: Line 1: + + + + + + + +
The tool '' {{SUMO}}/tools/assign/duaIterate.py '' can be used to compute the (approximate) dynamic user equilibrium.
The tool '' {{SUMO}}/tools/assign/duaIterate.py '' can be used to compute the (approximate) dynamic user equilibrium.
{{Caution|This script will require copious amounts of disk space}}
{{Caution|This script will require copious amounts of disk space}}
Line 4: Line 12:
python duaIterate.py -n '''''<network-file>''''' -t '''''<trip-file>''''' -l '''''<nr-of-iterations>'''''
python duaIterate.py -n '''''<network-file>''''' -t '''''<trip-file>''''' -l '''''<nr-of-iterations>'''''
− + −
This script tries to calculate a user equilibrium, that is, it tries to find a route for each vehicle (each trip from the trip-file above) such that each vehicle cannot reduce its travel cost (usually the travel time) by using a different route. It does so iteratively (hence the name) by
+ + +
This script tries to calculate a user equilibrium, that is, it tries to find a route for each vehicle (each trip from the trip-file above) such that each vehicle cannot reduce its travel cost (usually the travel time) by using a different route. It does so iteratively (hence the name) by
+ +
the vehicles in a network with edge costs (travel )
+
the calculated routesedge costs are the .
+ +
The number of iterations fixed . In order to ensure convergence there are different methods employed to calculate the route choice probability from the route cost (so the vehicle does not always choose the "cheapest" route). In general, new routes will be added by the router to the route set of each vehicle in each iteration (at least if none of the present routes is the "cheapest") and may be chosen according to the route choice mechanisms described below
+ + + + +
.
− +
Gawron ()
+
The for a of
+
the the in the step
+
for a set of routes
+
probability a
−
= Logit =
+
= Logit =
The Logit mechanism applies a fixed formula to each route to calculate the new probability. It ignores old costs and old probabilities and takes the route cost directly as the sum of the edge costs from the last simulation.
The Logit mechanism applies a fixed formula to each route to calculate the new probability. It ignores old costs and old probabilities and takes the route cost directly as the sum of the edge costs from the last simulation.
Line 18: Line 42:
<math>p_r' = \frac{\exp(\theta c_r')}{\sum_{s\in R}\exp(\theta c_s')}</math>
<math>p_r' = \frac{\exp(\theta c_r')}{\sum_{s\in R}\exp(\theta c_s')}</math>
−
=
+ −
=
+ + + + + + + + + + + + + + + + +
= =
+ + + + +
= =
+ Latest revision as of 13:02, 12 February 2018 Contents Introduction
For a given set of vehicles with of origin-destination relations (trips), the simulation must determine routes through the network (list of edges) that are used to reach the destination from the origin edge. The simplest method to find these routes is by computing shortest or fastest routes through the network using a routing algorithm such as Djikstra or A*. These algorithms require assumptions regarding the travel time for each network edge which is commonly not known before running the simulation due to the fact that travel times depend on the number of vehicles in the network.
.
The problem of determining suitable routes that take into account travel times in a traffic-loaded network is called
user assignment.SUMO provides different tools to solve this problem and they are described below. Iterative Assignment ( Dynamic User Equilibrium)
The tool
<SUMO_HOME> /tools/assign/duaIterate.py can be used to compute the (approximate) dynamic user equilibrium. python duaIterate.py -n -t <network-file> -l <trip-file> <nr-of-iterations> duaIterate.py supports many of the same options as SUMO. Any options not listed when calling duaIterate.py --help can be passed to SUMO by adding sumo--long-option-name arg after the regular options (i.e. sumo--step-length 0.5. This script tries to calculate a user equilibrium, that is, it tries to find a route for each vehicle (each trip from the trip-file above) such that each vehicle cannot reduce its travel cost (usually the travel time) by using a different route. It does so iteratively (hence the name) by calling DUAROUTER to route the vehicles in a network with the last known edge costs (starting with empty-network travel times) calling SUMO to simulate "real" travel times result from the calculated routes. The result edge costs are used in the net routing step.
The number of iterations may be set to a fixed number of determined dynamically depending on the used options. In order to ensure convergence there are different methods employed to calculate the route choice probability from the route cost (so the vehicle does not always choose the "cheapest" route). In general, new routes will be added by the router to the route set of each vehicle in each iteration (at least if none of the present routes is the "cheapest") and may be chosen according to the route choice mechanisms described below.
Between successive calls of DUAROUTER, the
.rou.alt.xml format is used to record not only the current best route but also previously computed alternative routes. These routes are collected within a route distribution and used when deciding the actual route to drive in the next simulation step. This isn't always the one with the currently lowest cost but is rather sampled from the distribution of alternative routes by a configurable algorithm described below. Route-Choice algorithm
The two methods which are implemented are called Gawron and Logit in the following. The input for each of the methods is a weight or cost function on the edges of the net, coming from the simulation or default costs (in the first step or for edges which have not been traveled yet), and a set of routes where each route has an old cost and an old probability (from the last iteration) and needs a new cost and a new probability .
Gawron (default)
The Gawron algorithm computes probabilities for chosing from a set of alterantive routes for each driver. The following values are considered to compute these probabilities:
the travel time along the used route in the previous simulation step the sum of edge travel times for a set of alternative routes the previous probability of chosing a route Logit
The Logit mechanism applies a fixed formula to each route to calculate the new probability. It ignores old costs and old probabilities and takes the route cost directly as the sum of the edge costs from the last simulation.
The probabilities are calculated from an exponential function with parameter scaled by the sum over all route values:
Termination
The option --max-convergence-deviation may be used to detect convergence and abort iterations automatically. Otherwise, a fixed number of iterations is used. Once the script finishes any of the resulting
.rou.xml files may be used for simulation but the last one(s) should be the best. Usage Examples Loading vehicle types from an additional file
By default, vehicle types are taken from the input trip file and are then propagated through DUAROUTER iterations (always as part of the written route file).
In order to use vehicle type definitions from an
additional-file, further options must be set duaIterate.py -n ... -t ... -l ... --additional-file <FILE_WITH_VTYPES>duarouter--aditional-file <FILE_WITH_VTYPES>duarouter--vtype-output dummy.xml
Options preceeded by the string
duarouter-- are passed directly to duarouter and the option vtype-output dummy.xml must be used to prevent duplicate definition of vehicle types in the generated output files. oneShot-assignment
An alternative to the iterative user assignment above is incremental assignment. This happens automatically when using <trip> input directly in SUMO instead of <vehicle>s with pre-defined routes. In this case each vehicle will compute a fastest-path computation at the time of departure which prevents all vehicles from driving blindly into the same jam and works pretty well empirically (for larger scenarios).
The routes for this incremental assignment are computed using the Automatic Routing / Routing Device mechanism. Since this device allows for various configuration options, the script Tools/Assign#one-shot.py may be used to automatically try different parameter settings.
The MAROUTER application computes a
classic macroscopic assignment. It employs mathematical functions (resistive functions) that approximate travel time increases when increasing flow. This allows to compute an iterative assignment without the need for time-consuming microscopic simulation.
|
Main Page The Problem
Let [math][3]^n[/math] be the set of all length [math]n[/math] strings over the alphabet [math]1, 2, 3[/math]. A
combinatorial line is a set of three points in [math][3]^n[/math], formed by taking a string with one or more wildcards [math]x[/math] in it, e.g., [math]112x1xx3\ldots[/math], and replacing those wildcards by [math]1, 2[/math] and [math]3[/math], respectively. In the example given, the resulting combinatorial line is: [math]\{ 11211113\ldots, 11221223\ldots, 11231333\ldots \}[/math]. A subset of [math][3]^n[/math] is said to be line-free if it contains no lines. Let [math]c_n[/math] be the size of the largest line-free subset of [math][3]^n[/math]. Density Hales-Jewett (DHJ) theorem: [math]\lim_{n \rightarrow \infty} c_n/3^n = 0[/math]
The original proof of DHJ used arguments from ergodic theory. The basic problem to be consider by the Polymath project is to explore a particular combinatorial approach to DHJ, suggested by Tim Gowers.
Threads (1-199) A combinatorial approach to density Hales-Jewett (inactive) (200-299) Upper and lower bounds for the density Hales-Jewett problem (active) (300-399) The triangle-removal approach (inactive) (400-499) Quasirandomness and obstructions to uniformity (final call) (500-599) TBA (600-699) A reading seminar on density Hales-Jewett (active)
A spreadsheet containing the latest lower and upper bounds for [math]c_n[/math] can be found here.
Unsolved questions
Gowers.462: Incidentally, it occurs to me that we as a collective are doing what I as an individual mathematician do all the time: have an idea that leads to an interesting avenue to explore, get diverted by some temporarily more exciting idea, and forget about the first one. I think we should probably go through the various threads and collect together all the unsolved questions we can find (even if they are vague ones like, “Can an approach of the following kind work?”) and write them up in a single post. If this were a more massive collaboration, then we could work on the various questions in parallel, and update the post if they got answered, or reformulated, or if new questions arose.
IP-Szemeredi (a weaker problem than DHJ)
Solymosi.2: In this note I will try to argue that we should consider a variant of the original problem first. If the removal technique doesn’t work here, then it won’t work in the more difficult setting. If it works, then we have a nice result! Consider the Cartesian product of an IP_d set. (An IP_d set is generated by d numbers by taking all the [math]2^d[/math] possible sums. So, if the n numbers are independent then the size of the IP_d set is [math]2^d[/math]. In the following statements we will suppose that our IP_d sets have size [math]2^n[/math].)
Prove that for any [math]c\gt0[/math] there is a [math]d[/math], such that any c-dense subset of the Cartesian product of an IP_d set (it is a two dimensional pointset) has a corner.
The statement is true. One can even prove that the dense subset of a Cartesian product contains a square, by using the density HJ for [math]k=4[/math]. (I will sketch the simple proof later) What is promising here is that one can build a not-very-large tripartite graph where we can try to prove a removal lemma. The vertex sets are the vertical, horizontal, and slope -1 lines, having intersection with the Cartesian product. Two vertices are connected by an edge if the corresponding lines meet in a point of our c-dense subset. Every point defines a triangle, and if you can find another, non-degenerate, triangle then we are done. This graph is still sparse, but maybe it is well-structured for a removal lemma.
Finally, let me prove that there is square if [math]d[/math] is large enough compare to [math]c[/math]. Every point of the Cartesian product has two coordinates, a 0,1 sequence of length [math]d[/math]. It has a one to one mapping to [4]^d; Given a point ((x_1,…,x_d),(y_1,…,y_d)) where x_i,y_j are 0 or 1, it maps to (z_1,…,z_d), where z_i=0 if x_i=y_i=0, z_i=1 if x_i=1 and y_i=0, z_i=2 if x_i=0 and y_i=1, and finally z_i=3 if x_i=y_i=1. Any combinatorial line in [4]^d defines a square in the Cartesian product, so the density HJ implies the statement.
Gowers.7: With reference to Jozsef’s comment, if we suppose that the d numbers used to generate the set are indeed independent, then it’s natural to label a typical point of the Cartesian product as (\epsilon,\eta), where each of \epsilon and \eta is a 01-sequence of length d. Then a corner is a triple of the form (\epsilon,\eta), (\epsilon,\eta+\delta), (\epsilon+\delta,\eta), where \delta is a \{-1,0,1\}-valued sequence of length d with the property that both \epsilon+\delta and \eta+\delta are 01-sequences. So the question is whether corners exist in every dense subset of the original Cartesian product.
This is simpler than the density Hales-Jewett problem in at least one respect: it involves 01-sequences rather than 012-sequences. But that simplicity may be slightly misleading because we are looking for corners in the Cartesian product. A possible disadvantage is that in this formulation we lose the symmetry of the corners: the horizontal and vertical lines will intersect this set in a different way from how the lines of slope -1 do.
I feel that this is a promising avenue to explore, but I would also like a little more justification of the suggestion that this variant is likely to be simpler.
Gowers.22: A slight variant of the problem you propose is this. Let’s take as our ground set the set of all pairs (U,V) of subsets of \null [n], and let’s take as our definition of a corner a triple of the form (U,V), (U\cup D,V), (U,V\cup D), where both the unions must be disjoint unions. This is asking for more than you asked for because I insist that the difference D is positive, so to speak. It seems to be a nice combination of Sperner’s theorem and the usual corners result. But perhaps it would be more sensible not to insist on that positivity and instead ask for a triple of the form (U,V), ((U\cup D)\setminus C,V), (U, (V\cup D)\setminus C, where D is disjoint from both U and V and C is contained in both U and V. That is your original problem I think.
I think I now understand better why your problem could be a good toy problem to look at first. Let’s quickly work out what triangle-removal statement would be needed to solve it. (You’ve already done that, so I just want to reformulate it in set-theoretic language, which I find easier to understand.) We let all of X, Y and Z equal the power set of \null [n]. We join U\in X to V\in Y if (U,V)\in A.
Ah, I see now that there’s a problem with what I’m suggesting, which is that in the normal corners problem we say that (x,y+d) and (x+d,y) lie in a line because both points have the same coordinate sum. When should we say that (U,V\cup D) and (U\cup D,V) lie in a line? It looks to me as though we have to treat the sets as 01-sequences and take the sum again. So it’s not really a set-theoretic reformulation after all.
O'Donnell.35: Just to confirm I have the question right…
There is a dense subset A of {0,1}^n x {0,1}^n. Is it true that it must contain three nonidentical strings (x,x’), (y,y’), (z,z’) such that for each i = 1…n, the 6 bits
[ x_i x'_i ] [ y_i y'_i ] [ z_i z'_i ]
are equal to one of the following:
[ 0 0 ] [ 0 0 ] [ 0, 1 ] [ 1 0 ] [ 1 1 ] [ 1 1 ] [ 0 0 ], [ 0 1 ], [ 0, 1 ], [ 1 0 ], [ 1 0 ], [ 1 1 ], [ 0 0 ] [ 1 0 ] [ 0, 1 ] [ 1 0 ] [ 0 1 ] [ 1 1 ]
?
McCutcheon.469: IP Roth:
Just to be clear on the formulation I had in mind (with apologies for the unprocessed code): for every $\delta>0$ there is an $n$ such that any $E\subset [n]^{[n]}\times [n]^{[n]}$ having relative density at least $\delta$ contains a corner of the form $\{a, a+(\sum_{i\in \alpha} e_i ,0),a+(0, \sum_{i\in \alpha} e_i)\}$. Here $(e_i)$ is the coordinate basis for $[n]^{[n]}$, i.e. $e_i(j)=\delta_{ij}$.
Presumably, this should be (perhaps much) simpler than DHJ, k=3.
High-dimensional Sperner Kalai.29: There is an analogous for Sperner but with high dimensional combinatorial spaces instead of "lines" but I do not remember the details (Kleitman(?) Katona(?) those are ususal suspects.)
Fourier approach
Kalai.29: A sort of generic attack one can try with Sperner is to look at f=1_A and express using the Fourier expansion of f the expression \int f(x)f(y)1_{x<y} where x<y is the partial order (=containment) for 0-1 vectors. Then one may hope that if f does not have a large Fourier coefficient then the expression above is similar to what we get when A is random and otherwise we can raise the density for subspaces. (OK, you can try it directly for the k=3 density HJ problem too but Sperner would be easier;) This is not unrealeted to the regularity philosophy. Gowers.31: Gil, a quick remark about Fourier expansions and the k=3 case. I want to explain why I got stuck several years ago when I was trying to develop some kind of Fourier approach. Maybe with your deep knowledge of this kind of thing you can get me unstuck again.
The problem was that the natural Fourier basis in \null [3]^n was the basis you get by thinking of \null [3]^n as the group \mathbb{Z}_3^n. And if that’s what you do, then there appear to be examples that do not behave quasirandomly, but which do not have large Fourier coefficients either. For example, suppose that n is a multiple of 7, and you look at the set A of all sequences where the numbers of 1s, 2s and 3s are all multiples of 7. If two such sequences lie in a combinatorial line, then the set of variable coordinates for that line must have cardinality that’s a multiple of 7, from which it follows that the third point automatically lies in the line. So this set A has too many combinatorial lines. But I’m fairly sure — perhaps you can confirm this — that A has no large Fourier coefficient.
You can use this idea to produce lots more examples. Obviously you can replace 7 by some other small number. But you can also pick some arbitrary subset W of \null[n] and just ask that the numbers of 0s, 1s and 2s inside W are multiples of 7.
DHJ for dense subsets of a random set
Tao.18: A sufficiently good Varnavides type theorem for DHJ may have a separate application from the one in this project, namely to obtain a “relative” DHJ for dense subsets of a sufficiently pseudorandom subset of {}[3]^n, much as I did with Ben Green for the primes (and which now has a significantly simpler proof by Gowers and by Reingold-Trevisan-Tulsiani-Vadhan). There are other obstacles though to that task (e.g. understanding the analogue of “dual functions” for Hales-Jewett), and so this is probably a bit off-topic.
|
Forgot password? New user? Sign up
Existing user? Log in
Note by Aditya Kumar 6 years, 4 months ago
Easy Math Editor
This discussion board is a place to discuss our Daily Challenges and the math and science related to those challenges. Explanations are more than just a solution — they should explain the steps and thinking strategies that you used to obtain the solution. Comments should further the discussion of math and science.
When posting on Brilliant:
*italics*
_italics_
**bold**
__bold__
- bulleted- list
1. numbered2. list
paragraph 1paragraph 2
paragraph 1
paragraph 2
[example link](https://brilliant.org)
> This is a quote
This is a quote
# I indented these lines # 4 spaces, and now they show # up as a code block. print "hello world"
# I indented these lines# 4 spaces, and now they show# up as a code block.print "hello world"
\(
\)
\[
\]
2 \times 3
2^{34}
a_{i-1}
\frac{2}{3}
\sqrt{2}
\sum_{i=1}^3
\sin \theta
\boxed{123}
Sort by:
Try and identify the reason that you are unable to proceed, for example: 1. Being too tired after spending 5 consecutive hours solving problems. If so, go to sleep. 2. Being too panicked about not being able to solve the problem. If so, take a short break. I've gotten a lot of inspiration in my trips to the bathroom. 3. Not knowing the basic terms in the question (for example, probability, expected value, etc. ). If so, read up on that chapter, make sure you understand the terms and basic techniques. 4. Not knowing various approaches that can be used for the question. If so, reading and learning from the solutions can be very helpful.
There will always be questions that you can't solve, and it doesn't help to become frustrated about it, as that simply clouds your thinking. As you work your way through the education system, you will slowly find that there are various gems which seemed impossible that were finally cracked. A famous example would be Fermat's Last Theorem, which stood for over 350 years, till Andrew Wiles solved it.
One of my proudest achievements, was spending 8 weeks over summer to solve a math problem given by my professor. Each step of the way, I didn't know what I was doing, nor what I was looking for. I tried different interpretations of the problem, viewing it first one way and then the other. I'd pick an approach which seems the most viable, and if that fails move on to another approach (or go out and enjoy the summer).
Log in to reply
My suggestion is ....
Try to understand the question differently or simply don't overthink the question that you are working on.
READ REFERENCES FOR SURE! When you are completely zero about the question, read the references of its theory is really helpful, especiallny in physics.
Always think that you are having fun! XD
Some frustration is good; that's how you improve. :)
If you can't solve a problem there are two things you can do:1. Don't freak out about that one problem constantly. Leave it alone, come back in a few days when you can have a different perspective on it. Don't always try to solve it in the same way as you are used to or have been doing.2. If you keep trying to solve a problem and you can't do it you can always GIVE UP. A lot of people seem to think that if they just keep plowing at a problem they will eventually solve it. Though this may be true it is not beneficial for them in the long run. Knowing when to give up on a problem can be a great advantage to your learning. Just make sure you get a few different solutions to that problem and truly understand why you could not overcome it and how you can improve those areas. Inside of you is a great mathematician waiting to be born, just let them flourish by themselves.
can't sleep well
yes i agree with the second point. i also get some of my solutions in the bathroom.
just have a walk wait till ur brain is back in equilibrium.....then i bet u can solve the problem.(make sure u knw the concept use in the question)
just be fustrated :p
i know its annoying
Even I know Its annoying...Diganta B. ,,,,,,, To overcome the Frustration.. I suggest to ask Others who could solve it.... hahahaha :) :)
@Vamsi Krishna Appili – I hate talking help but I love learning the wanted concept in Google
Problem Loading...
Note Loading...
Set Loading...
|
$\newcommand{\al}{\alpha} \newcommand{\be}{\beta} \newcommand{\de}{\delta} \newcommand{\De}{\Delta} \newcommand{\ep}{\varepsilon} \newcommand{\ga}{\gamma} \newcommand{\Ga}{\Gamma} \newcommand{\la}{\lambda} \newcommand{\si}{\sigma} \newcommand{\Si}{\Sigma} \newcommand{\thh}{\theta} \newcommand{\om}{\omega} \newcommand{\R}{\mathbb{R}} \newcommand{\Z}{\mathbb{Z}} \newcommand{\F}{\mathcal{F}} \newcommand{\E}{\operatorname{\mathsf E}} \newcommand{\Var}{\operatorname{\mathsf Var}} \renewcommand{\P}{\operatorname{\mathsf P}} \newcommand{\ii}[1]{\operatorname{\mathsf I}\{#1\}} \newcommand{\eD}{\overset{\text{D}}\to} \newcommand{\D}{\overset{\text{D}}=} \newcommand{\tsi}{\tilde\si}$
This question is a follow-up to the previous question on symmetric matrices. Thanks to the responses by Christian Remling and Geoff Robinson to that question, the problem now becomes much more specific, as follows.
Suppose that a symmetric matrix $M\in\R^{n\times n}$ is orthogonal or, equivalently, satisfies the condition $M^2=I_n$, where $I_n$ is the $n\times n$ identity matrix. Suppose also that all the diagonal entries of $M$ are equal to one another. Is it then true that $M$ is of the form $aI_n+b\,\de\de^T$, where $\de$ belongs to the set (say $\De_n$) of all $n\times 1$ column matrices with all entries from the set $\{-1,1\}$; $a\in\{-1,1\}$; and $b\in\{0,-2a/n\}$?
This is true for $n\in\{2,3\}$.
Comment 1. Let $\mathcal M_n$ denote the set of all matrices $M$ satisfying the stated conditions, that is, the set of all symmetric orthogonal matrices $M\in\R^{n\times n}$ with constant diagonal entries. The actual problem here is to show that for each $M\in\mathcal M_n$ all the off-diagonal entries $M_{ij}$ of $M$ with $i\ne j$ are of the form $c\de_i\de_j$ for some real $c$ and some $\de\in\De_n$; it is then easy to specify the appropriate $a$ and $b$, given in the above question. So, it is enough to show that \begin{equation} \prod_{\de\in\De_n}\Big(\sum_{1\le i<j\le n}\sum_{1\le k<\ell\le n}(M_{ij}\de_i\de_j-M_{k\ell}\de_k\de_\ell)^2\Big)=0, \end{equation} which is how the cases the cases of $n\in\{2,3\}$ were verified. Comment 2. More generally, even without the condition on the diagonal entries of $M$, it is enough to show that $M-aI_n$ is of rank $1$ for some real $a$.
|
OK, here is my argument (sorry for the delay).
First of all, $Z$ is essentially the maximum of the absolute value of the polynomial $P(z)=\prod_j(1-z_jz)$ on the unit circumference (up to a factor of $n$, but it is not noticeable on the scale we are talking about).
Second, the maximum of the absolute value of a (trigonometric) polynomial of degree $K$ can be read from any $AK$ uniformly distributed points on the unit circumference $\mathbb T$ (say, roots of unity of degree $AK$) with relative error of order $A^{-1}$.
Now let $\psi(z)=\log(1-z)$. We want to find the asymptotic distribution of the $\max_z n^{-1/2}Re\sum_j \psi(zz_j)$ where $z_j$ are i.i.d. random variables uniformly. Since it is the logarithm of $|P(z)|$, the maximum can be found using $10n$ points.
Decompose $\psi(z)$ into its Fourier series $-\sum_{k\ge 1}\frac 1kz^k$. Then, formally, we have $n^{-1/2}\sum_j \psi(zz_j)=-\sum_k\left(n^{-1/2}\sum_j z_j^k\right)\frac{z^k}{k}$. It is tempting to say that the random variables $\xi_n,k=n^{-1/2}\sum_j z_j^k$ converge to the uncorrelated standard complex Gaussians $\xi_k$ by the CLT in distribution and, therefore, the whole sum converges in distribution to the random function $F(z)=\sum_k\xi_k\frac{z^k}k$, so $n^{-1/2}\log Z$ converges to $\max_z\Re F(z)$ (the $-$ sign doesn't matter because the limiting distribution is symmetric). This argument would be valid literally if we had a finite sum in $k$ but, of course, it is patently false for the infinite series (just because if we replace $\max$ by $\min$, we get an obvious nonsense in the end). Still, it can be salvaged if we do it more carefully.
Let $K$ run over the powers of $2$. Choose some big $K_0$ and apply the above naiive argument to $\sum_{k=1}^{K_0}$. Then we can safely say that the first $K_0$ terms in the series give us essentially the random function $F_{K_0}(z)$ which is the $K_0$-th partial sum of $F$ when $n$ is large enough.
Our main task will be to show that the rest of the series cannot really change the maximum too much. More precisely, it contributes only a small absolute error with high probability.
To this end, we need
Lemma: Let $f(z)$ be an analytic in the unit disk function with $f(0)=0$, $|\Im f|\le \frac 12$. Then we have $\int_{\mathbb T}e^{\Re f}dm\le \exp\left(2\int_{\mathbb T}|f|^2dm\right)$ where $m$ is the Haar measure on $\mathbb T$.
Proof: By Cauchy-Schwartz, $$\left(\int_{\mathbb T}e^{\Re f}dm\right)^2\le \left(\int_{\mathbb T}e^{2\Re f}e^{-2|\Im f|^2}dm\right)\left(\int_{\mathbb T}e^{2|\Im f|^2}dm\right)$$Note that if$|\Im w|\le 1$, we have $e^{\Re w}e^{-|\Im w|^2}\le \Re e^w$. So the first integral does not exceed $\int_{\mathbb T}\Re e^{2f}dm=\Re e^{2f(0)}=1$. Next, $e^s\le 1+2s$ for $0\le s\le\frac 12$, so $\int_{\mathbb T}e^{2|\Im f|^2}dm\le 1+4\int_{\mathbb T}|\Im f|^2dm\le 1+4\int_{\mathbb T}|f|^2dm$. Taking the square root turns $4$ into $2$ and it remains to use that $1+s\le e^s$
The immediate consequence of Lemma 1 is a Bernstein type estimate for $G_K(z)=\sum_{k\in (K,2K]}\left(n^{-1/2}\sum_j z_j^k\right)\frac{z^k}{k}$$$P(\max|\Re G_K|\ge 2T)\le 20Ke^{-T^2K/9}$$if $0\le TK\le \sqrt n$, say.
Indeed, just use the Bernstein trick on the independent random shifts of $g_K(z)=\sum_{k\in (K,2K]}\frac{z^k}{k}$:$$E e^{\pm t\Re G_K(z)}\le \left(\int_{\mathbb T}e^{\Re tn^{-1/2}g_K}dm\right)^n\le e^{2t^2/K}$$for every $t\le \sqrt n/2$ (we used the Lemma to make the last estimate) and put $t=\frac{TK}{3}$. After that read the maximum from $10K$ points with small relative error and do the trivial union bound.
Choosing $T=K^{-1/3}$, we see that we can safely ignore the sum from $K=K_0$ to $K=\sqrt n$ if $K_0$ is large enough. Now we are left with $$G_K(z)=\sum_{k\ge \sqrt n}\left(n^{-1/2}\sum_j z_j^k)\right)\frac{z^k}{k}$$to deal with. Recall that all we want here is to show that it is small at $10n$ uniformly distributed points. Again, if $g(z)=\sum_{k\ge \sqrt n}\frac{z^k}{k}$, we have $|\Im g|\le 10$, say so we can use the same trick and get $$P(\max_{10n\text{ points}}|\Re G|\ge 2T)\le 20n e^{n^{-1/2}t^2-tT}$$if $0\le t\le \sqrt n/20$, say.Here we do not need to be greedy at all: just take a fixed small $T$ and choose $t=\frac{2\log n}T$.
Now, returning to your original determinant problem, we see that the norm of the inverse matrix is essentially $Z/D$ where $D=\min_i\prod_{j:j\ne i}|z_i-z_j|$. We know the distribution of $\log Z$ and we have the trivial Hadamard bound $D\le n$. This already tells you that the typical $\lambda_1$ is at most $e^{-c\sqrt n}$. The next logical step would be to investigate the distribution of $\log D$.
|
Sequences
Definition: A Sequence $\{ a_n \}_{n=1}^{\infty}$ is an ordered list of numbers $a_1, a_2, ...$ where $a_j$ denotes the $j^{\mathrm{th}}$ term of the sequence.
One of the most famous sequences is the
Fibonacci Sequence that is recursively defined by $f_{1} = 1$, $f_{2} = 1$, and $f_{n} = f_{n-1} + f_{n-2}$ for $n \in \mathrm{N}$ and $n ≥ 3$. In other words, each number of the Fibonacci sequence is obtained by taking the preceding two terms of the Fibonacci sequence and summing them. The first few terms of the Fibonacci sequence are $\{ 1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89, 144, ... \}$.
Another example of a sequence is when $a_n = \frac{n}{n+1}$. We can calculate the $n^{\mathrm{th}}$ term of this sequence by plugging in some $n \in \mathbb{N}$, for example, the 4th term of this sequence is $a_4 = \frac{4}{4 + 1} = \frac{4}{5}$, and thus $\left \{ a_n \right \} = \left \{ \frac{n}{n + 1} \right \}_{n=1}^{\infty} = \left \{ \frac{1}{2}, \frac{2}{3}, \frac{3}{4}, ... \right \}$.
One other great example of a sequence is when $a_n = (-1)^n$ and $\{ (-1)^n \}_{n=1}^{\infty} = \{ -1, 1, -1, 1, -1, ... \}$. This might not be the most interesting sequence as there are only two distinct terms in it, but alas, it definitely is a sequence.
We will now look at some important definitions of sequences, many of which are relatively straightforward.
Definition: The sequence $\{ a_n \}$ is said to be Bounded between $m$ and $M$ where $m ≤ M$ if $\forall n \in \mathbb{N}$, $m ≤ a_n ≤ M$. The sequence is said to be Bounded Above if $\forall n$, $a_n ≤ M$, and Bounded Below if $\forall n$, $m ≤ a_n$.
Definition: The sequence $\{ a_n \}$ is said to be Strictly Increasing denoted $\{ a_n \} \uparrow$ if $a_{n+1} > a_{n}$ and for every term in the sequence and is said to be Strictly Decreasing denoted $\{ a_n \} \downarrow$ if $a_{n+1} < a_{n}$ for every term in the sequence. If a sequence is increasing or decreasing, we classify the sequence as Monotonic.
Definition: The sequence $\{ a_n \}$ is said to be Ultimately Increasing if $a_{n+1} > a_{n}$ whenever $n ≥ N$, and is said to be **Ultimately Decreasing if $a_{n+1} < a_{n}$ whenever $n ≥ N$.
We note that the definitions of a sequence being strictly increasing/decreasing different from a sequence being ultimately increasing/decreasing. A sequence that is increasing/decreasing is increasing/decreasing for ALL terms in the sequence. A sequence that is ultimately increasing/decreasing need not increase/decrease for a finite number of terms, but after some $N^{\mathrm{th}}$ term it must indefinitely increase/decrease.
Definition: The sequence $\{ a_n \}$ is said to be Positive if $a_n > 0$ for all $n \in N$ and the sequence is said to be Negative if $a_n < 0$.
Definition: The sequence $\{ a_n \}$ is said to be Ultimately Positive if $a_n > 0$ whenever $n ≥ N$ and the sequence is said to be Ultimately Negative if $a_n < 0$ whenever $n ≥ N$.
Like the distinction we made above regarding increasing/decreasing sequences and ultimately increasing/decreasing sequences, the same applies here. A sequence that is positive/negative is positive/negative for ALL of its terms. A sequence that is ultimately positive/negative need not always be one or the other for a finite number of terms, but after the $N^{\mathrm{th}}$ term, all the terms in the sequence must be positive/negative.
Example 1 Consider the sequence $\{ \frac{2}{2}, \frac{4}{8}, \frac{8}{26}, \frac{16}{80}, ... \}$. Find a formula for the $n^{\mathrm{th}}$ term of this sequence. Determine whether this set is bounded.
We note that the numerators of this sequence are $2^1, 2^2, 2^3, 2^4, ...$, while the denominators seem to be $3^1 - 1, 3^2 - 1, 3^3 - 1, 3^4 - 1, ...$. Therefore a general formula for the $n^{\mathrm{th}}$ term is:(1)
Since $\forall n \in \mathbb{N}$, $2^n ≤ 3^n - 1$ so the fraction $\frac{2^n}{3^n - 1} ≤ 1$ and thus our sequence is bounded above by $M = 1$, that is $a_n ≤ 1$.
Example 2 Consider the sequence $\{ \frac{1}{1}, \frac{-1}{\sqrt{2}}, \frac{1}{\sqrt{3}}, \frac{-1}{2}, ... \}$. Find a formula for the $n^{\mathrm{th}}$ term of this sequence.
We note that the numerators of this sequence are $1, -1, 1, -1, ...$, while the denominators seem to be the squareroot of successive natural numbers. Therefore a general formula for the $n^{\mathrm{th}}$ term is:(2)
Sequences as Functions
We can represent a sequence in a variety of ways such as on a number line. For example, consider the sequence in example 1 plotted on a number line:
Alternatively, we could represent the sequence as a function whose domain $A := \{ n : n \in \mathbb{N} \}$. For example, the following graph illustrates example 1:
|
Main Page Contents The Problem
Let [math][3]^n[/math] be the set of all length [math]n[/math] strings over the alphabet [math]1, 2, 3[/math]. A
combinatorial line is a set of three points in [math][3]^n[/math], formed by taking a string with one or more wildcards [math]x[/math] in it, e.g., [math]112x1xx3\ldots[/math], and replacing those wildcards by [math]1, 2[/math] and [math]3[/math], respectively. In the example given, the resulting combinatorial line is: [math]\{ 11211113\ldots, 11221223\ldots, 11231333\ldots \}[/math]. A subset of [math][3]^n[/math] is said to be line-free if it contains no lines. Let [math]c_n[/math] be the size of the largest line-free subset of [math][3]^n[/math]. Density Hales-Jewett (DHJ) theorem: [math]\lim_{n \rightarrow \infty} c_n/3^n = 0[/math]
The original proof of DHJ used arguments from ergodic theory. The basic problem to be consider by the Polymath project is to explore a particular combinatorial approach to DHJ, suggested by Tim Gowers.
Threads (1-199) A combinatorial approach to density Hales-Jewett (inactive) (200-299) Upper and lower bounds for the density Hales-Jewett problem (active) (300-399) The triangle-removal approach (inactive) (400-499) Quasirandomness and obstructions to uniformity (final call) (500-599) TBA (600-699) A reading seminar on density Hales-Jewett (active)
A spreadsheet containing the latest lower and upper bounds for [math]c_n[/math] can be found here.
Unsolved questions Gowers.462: Incidentally, it occurs to me that we as a collective are doing what I as an individual mathematician do all the time: have an idea that leads to an interesting avenue to explore, get diverted by some temporarily more exciting idea, and forget about the first one. I think we should probably go through the various threads and collect together all the unsolved questions we can find (even if they are vague ones like, “Can an approach of the following kind work?”) and write them up in a single post. If this were a more massive collaboration, then we could work on the various questions in parallel, and update the post if they got answered, or reformulated, or if new questions arose. IP-Szemeredi (a weaker problem than DHJ) Solymosi.2: In this note I will try to argue that we should consider a variant of the original problem first. If the removal technique doesn’t work here, then it won’t work in the more difficult setting. If it works, then we have a nice result! Consider the Cartesian product of an IP_d set. (An IP_d set is generated by d numbers by taking all the [math]2^d[/math] possible sums. So, if the n numbers are independent then the size of the IP_d set is [math]2^d[/math]. In the following statements we will suppose that our IP_d sets have size [math]2^n[/math].)
Prove that for any [math]c\gt0[/math] there is a [math]d[/math], such that any [math]c[/math]-dense subset of the Cartesian product of an IP_d set (it is a two dimensional pointset) has a corner.
The statement is true. One can even prove that the dense subset of a Cartesian product contains a square, by using the density HJ for [math]k=4[/math]. (I will sketch the simple proof later) What is promising here is that one can build a not-very-large tripartite graph where we can try to prove a removal lemma. The vertex sets are the vertical, horizontal, and slope -1 lines, having intersection with the Cartesian product. Two vertices are connected by an edge if the corresponding lines meet in a point of our [math]c[/math]-dense subset. Every point defines a triangle, and if you can find another, non-degenerate, triangle then we are done. This graph is still sparse, but maybe it is well-structured for a removal lemma.
Finally, let me prove that there is square if [math]d[/math] is large enough compare to [math]c[/math]. Every point of the Cartesian product has two coordinates, a 0,1 sequence of length [math]d[/math]. It has a one to one mapping to [math][4]^d[/math]; Given a point [math]( (x_1,…,x_d),(y_1,…,y_d) )[/math] where [math]x_i,y_j[/math] are 0 or 1, it maps to [math](z_1,…,z_d)[/math], where [math]z_i=0[/math] if [math]x_i=y_i=0[/math], [math]z_i=1[/math] if [math]x_i=1[/math] and [math]y_i=0, z_i=2[/math] if [math]x_i=0[/math] and [math]y_i=1[/math], and finally [math]z_i=3[/math] if [math]x_i=y_i=1[/math]. Any combinatorial line in [math][4]^d[/math] defines a square in the Cartesian product, so the density HJ implies the statement.
Gowers.7: With reference to Jozsef’s comment, if we suppose that the d numbers used to generate the set are indeed independent, then it’s natural to label a typical point of the Cartesian product as (\epsilon,\eta), where each of \epsilon and \eta is a 01-sequence of length d. Then a corner is a triple of the form (\epsilon,\eta), (\epsilon,\eta+\delta), (\epsilon+\delta,\eta), where \delta is a \{-1,0,1\}-valued sequence of length d with the property that both \epsilon+\delta and \eta+\delta are 01-sequences. So the question is whether corners exist in every dense subset of the original Cartesian product.
This is simpler than the density Hales-Jewett problem in at least one respect: it involves 01-sequences rather than 012-sequences. But that simplicity may be slightly misleading because we are looking for corners in the Cartesian product. A possible disadvantage is that in this formulation we lose the symmetry of the corners: the horizontal and vertical lines will intersect this set in a different way from how the lines of slope -1 do.
I feel that this is a promising avenue to explore, but I would also like a little more justification of the suggestion that this variant is likely to be simpler.
Gowers.22: A slight variant of the problem you propose is this. Let’s take as our ground set the set of all pairs (U,V) of subsets of \null [n], and let’s take as our definition of a corner a triple of the form (U,V), (U\cup D,V), (U,V\cup D), where both the unions must be disjoint unions. This is asking for more than you asked for because I insist that the difference D is positive, so to speak. It seems to be a nice combination of Sperner’s theorem and the usual corners result. But perhaps it would be more sensible not to insist on that positivity and instead ask for a triple of the form (U,V), ((U\cup D)\setminus C,V), (U, (V\cup D)\setminus C, where D is disjoint from both U and V and C is contained in both U and V. That is your original problem I think.
I think I now understand better why your problem could be a good toy problem to look at first. Let’s quickly work out what triangle-removal statement would be needed to solve it. (You’ve already done that, so I just want to reformulate it in set-theoretic language, which I find easier to understand.) We let all of X, Y and Z equal the power set of \null [n]. We join U\in X to V\in Y if (U,V)\in A.
Ah, I see now that there’s a problem with what I’m suggesting, which is that in the normal corners problem we say that (x,y+d) and (x+d,y) lie in a line because both points have the same coordinate sum. When should we say that (U,V\cup D) and (U\cup D,V) lie in a line? It looks to me as though we have to treat the sets as 01-sequences and take the sum again. So it’s not really a set-theoretic reformulation after all.
O'Donnell.35: Just to confirm I have the question right…
There is a dense subset A of {0,1}^n x {0,1}^n. Is it true that it must contain three nonidentical strings (x,x’), (y,y’), (z,z’) such that for each i = 1…n, the 6 bits
[ x_i x'_i ] [ y_i y'_i ] [ z_i z'_i ]
are equal to one of the following:
[ 0 0 ] [ 0 0 ] [ 0, 1 ] [ 1 0 ] [ 1 1 ] [ 1 1 ] [ 0 0 ], [ 0 1 ], [ 0, 1 ], [ 1 0 ], [ 1 0 ], [ 1 1 ], [ 0 0 ] [ 1 0 ] [ 0, 1 ] [ 1 0 ] [ 0 1 ] [ 1 1 ]
?
McCutcheon.469: IP Roth:
Just to be clear on the formulation I had in mind (with apologies for the unprocessed code): for every $\delta>0$ there is an $n$ such that any $E\subset [n]^{[n]}\times [n]^{[n]}$ having relative density at least $\delta$ contains a corner of the form $\{a, a+(\sum_{i\in \alpha} e_i ,0),a+(0, \sum_{i\in \alpha} e_i)\}$. Here $(e_i)$ is the coordinate basis for $[n]^{[n]}$, i.e. $e_i(j)=\delta_{ij}$.
Presumably, this should be (perhaps much) simpler than DHJ, k=3.
High-dimensional Sperner Kalai.29: There is an analogous for Sperner but with high dimensional combinatorial spaces instead of "lines" but I do not remember the details (Kleitman(?) Katona(?) those are ususal suspects.)
Fourier approach
Kalai.29: A sort of generic attack one can try with Sperner is to look at f=1_A and express using the Fourier expansion of f the expression \int f(x)f(y)1_{x<y} where x<y is the partial order (=containment) for 0-1 vectors. Then one may hope that if f does not have a large Fourier coefficient then the expression above is similar to what we get when A is random and otherwise we can raise the density for subspaces. (OK, you can try it directly for the k=3 density HJ problem too but Sperner would be easier;) This is not unrealeted to the regularity philosophy. Gowers.31: Gil, a quick remark about Fourier expansions and the k=3 case. I want to explain why I got stuck several years ago when I was trying to develop some kind of Fourier approach. Maybe with your deep knowledge of this kind of thing you can get me unstuck again.
The problem was that the natural Fourier basis in \null [3]^n was the basis you get by thinking of \null [3]^n as the group \mathbb{Z}_3^n. And if that’s what you do, then there appear to be examples that do not behave quasirandomly, but which do not have large Fourier coefficients either. For example, suppose that n is a multiple of 7, and you look at the set A of all sequences where the numbers of 1s, 2s and 3s are all multiples of 7. If two such sequences lie in a combinatorial line, then the set of variable coordinates for that line must have cardinality that’s a multiple of 7, from which it follows that the third point automatically lies in the line. So this set A has too many combinatorial lines. But I’m fairly sure — perhaps you can confirm this — that A has no large Fourier coefficient.
You can use this idea to produce lots more examples. Obviously you can replace 7 by some other small number. But you can also pick some arbitrary subset W of \null[n] and just ask that the numbers of 0s, 1s and 2s inside W are multiples of 7.
DHJ for dense subsets of a random set
Tao.18: A sufficiently good Varnavides type theorem for DHJ may have a separate application from the one in this project, namely to obtain a “relative” DHJ for dense subsets of a sufficiently pseudorandom subset of {}[3]^n, much as I did with Ben Green for the primes (and which now has a significantly simpler proof by Gowers and by Reingold-Trevisan-Tulsiani-Vadhan). There are other obstacles though to that task (e.g. understanding the analogue of “dual functions” for Hales-Jewett), and so this is probably a bit off-topic.
Bibliography H. Furstenberg, Y. Katznelson, “A density version of the Hales-Jewett theorem for k=3“, Graph Theory and Combinatorics (Cambridge, 1988). Discrete Math. 75 (1989), no. 1-3, 227–241. R. McCutcheon, “The conclusion of the proof of the density Hales-Jewett theorem for k=3“, unpublished. H. Furstenberg, Y. Katznelson, “A density version of the Hales-Jewett theorem“, J. Anal. Math. 57 (1991), 64–119.
|
No. In fact, every Lebesgue measurable function $f\colon I\to E$ is equal almost everywhere to a limit of simple Lebesgue measurable functions. As you hint at in the question, this is easy to show in the case where $E$ is separable. The general situation reduces to the separable case due to the following result. For a full proof, see Fremlin,
Measure Theory, Volume 4 Part I, Lemma 451Q.
Theorem 1: Let $(X,\Sigma,\mu)$ be a finite compact measure space, $Y$ a metrizable space, and $f\colon X\to Y$ a measurable function. Then, there is a closed separable subspace $Y_0$ of $Y$ such that $f^{-1}(Y\setminus Y_0)$ is negligible.
That is, $f$ has essentially separable image. Restricting $f$ to the complement of a negligible set reduces the problem to the situation where the codomain is separable, in which case it is a limit of simple functions. Compactness of the space $(X,\Sigma,\mu)$ means that there is a family $\mathcal{K}\subseteq\Sigma$ such that any subset of $\mathcal{K}$ with the finite intersection property has nonempty intersection, and such that $\mu$ is inner-regular with respect to $\mathcal{K}$. That is, $\mu(E)=\sup\{\mu(K)\colon K\in\mathcal{K},K\subseteq E\}$ for every $E\in\Sigma$. In particular, the Lebesgue measure is compact by taking $\mathcal{K}$ to be the collection of compact sets under the standard topology.
The proof of Theorem 1 is rather tricky, involving what Fremlin describes as "non-trivial set theory". It rests on the following two results.
Theorem 2: Any metrizable space has a $\sigma$-disjoint base $\mathcal{U}$. That is, $\mathcal{U}$ is a base for the topology, and can be written as $\bigcup_{n=1}^\infty\mathcal{U}_n$ where each $\mathcal{U}_n$ is a disjoint collection of sets.
(Fremlin,
Measure Theory, Volume 4 II, 4A2L (g-ii))
Theorem 3: Let $(X,\Sigma,\mu)$ be a finite compact measure space and $\{E_i\}_{i\in I}$ be a disjoint family of subsets of $X$ such that $\bigcup_{i\in J}E_i\in\Sigma$ for every $J\subseteq I$. Then, $\mu\left(\bigcup_{i\in I}E_i\right)=\sum_{i\in I}\mu(E_i)$.
(Fremlin,
Measure Theory, Volume 4 I, 451P).
Theorem 3 is particularly remarkable, as it extends the countable additivity of the measure to arbitrarily large unions of sets.
Once these two results are known, the proof that $f$ has essentially separable image in Theorem 1 is straightforward. Let $\mathcal{U}=\bigcup_{n=1}^\infty\mathcal{U}_n$ be a $\sigma$-disjoint base for $Y$. Let $\mathcal{V}_n$ be the collection of $U\in\mathcal{U}_n$ such that $\mu(f^{-1}(U)) = 0$. By countable additivity, $\mathcal{U}_n\setminus\mathcal{V}_n$ is countable. Also, $\{f^{-1}(U)\colon U\in\mathcal{V}_n\}$ is a disjoint collection of negligible subsets of $X$ and, by measurability of $f$, any union of a subcollection of these is measurable. It follows from Theorem 3 that its union is negligible. That is, $f^{-1}\left(\bigcup\mathcal{V}_n\right)$ is negligible. Setting $Y_0=Y\setminus\bigcup_n\bigcup\mathcal{V}_n$ then, by countable additivity, $f^{-1}(Y\setminus Y_0)$ is negligible. Also, $\bigcup_n(\mathcal{U}_n\setminus\mathcal{V}_n)$ restricts to a countable base for the topology on $Y_0$, so it is separable (in fact, it is second-countable).
Finding a $\sigma$-disjoint base for the topology on $Y$ is easy enough. Following Fremlin, you can do this by well-ordering $Y$ and letting $(q_n,q^\prime_n)$ be a sequence running through the pairs $(q,q^\prime)$ of rationals with $0 < q < q^\prime$. Letting $\mathcal{U}_n$ be the collection of sets of the form$$G_{ny}=\left\{x\in Y\colon d(x,y) < q_n, \inf_{z < y}\,d(x,z) > q_n^\prime\right\}$$(over $y\in Y$) gives a $\sigma$-disjoint base.
The really involved part of the proof is in establishing Theorem 3. I suggest you look in Fremlin for the details, but the idea is as follows. By countable additivity, only countably many $E_i$ can have positive measure so, removing these, we can suppose that every $E_i$ is negligible. Also, restricting $X$ to the union of the $E_i$ if necessary, we can suppose that $X=\bigcup_iE_i$. Then define the function $f\colon X\to I$ by $f(x)=i$ for $x\in E_i$. Using the power set $\mathcal{P}I$ for the sigma-algebra on $I$, $f$ will be measurable. Then let $\nu=\mu\circ f^{-1}$ be the image measure on $(I,\mathcal{P}I)$. Fremlin breaks this down into two cases.
a) $\nu$ is atomless. As with any finite atomless measure space, there will be a measure preserving map $g\colon I\to[0,\gamma]$ for some $\gamma\ge0$, with respect to the Lebesgue measure $\lambda$ on $[0,\gamma]$. Using compactness, it can be shown that the sets on which $\lambda$ and $\nu\circ g^{-1}$ are well-defined coincide (precisely, $\mu$ is compact, so it is perfect, so $\nu\circ g^{-1}$ is perfect and therefore is Radon). The existence of non-Lebesgue sets will then give a contradiction unless $\gamma=0$, so $\mu(X)=0$.
b) $\nu$ has an atom $M\subseteq I$: In this case, $\mathcal{F}=\{F\subseteq M\colon\nu(M\setminus F)=0\}$ is a non-principal ultrafilter on $M$ which is closed under countable intersections. Again making use of compactness of $\mu$, this can be used to derive a contradition, but it requires some tricky set theory. I refer you to Fremlin (451P) for the full details of this argument.
Update: I will, however, give a brief overview of the ideas involved in (b). It is possible to reduce the problem to the case where $M$ is a regular uncountable ordinal and $\mathcal{F}$ is a normal ultrafilter. Using $[S]^n$ to denote the collection of size-$n$ subsets of a set $S$ and $[S]^{ < \omega}=\bigcup_{n=0}^\infty[S]^n$ for the collection of finite subsets, normal ultrafilters have the following property.
If $\mathcal{S}\subseteq[M]^{ < \omega}$ then there exists an $F\in\mathcal{F}$ such that, for each $n\ge0$, $[F]^n$ is either a subset of $\mathcal{S}$ or disjoint from $\mathcal{S}$.
See, Frelim (4A1L). This contradicts compactness as follows. Set $G_i=\bigcup\{E_j\colon j\in M, j\ge i\}$. Then choose $K_i\in\mathcal{K}$ with $K_i\subseteq G_i$ and $\mu(K_i) > 0$. Let $\mathcal{S}$ consist of the finite subsets $S\subset M$ such that $\bigcap_{i\in S}K_i=\emptyset$. Choose $F\in\mathcal{F}$ as above. It is not possible for $[F]^n$ to be a subset of $\mathcal{S}$. Otherwise, every $x\in X$ would be contained in no more than $n$ of the sets $\mathcal{K}^\prime=\{K_i\colon i\in F\}$. So, $\sum_{i\in F}\mu(K_i)\le n\nu(M)$. But, as this sum is over an uncountably infinite set of positive numbers, it should be infinite. Therefore, $[F]^{ < \omega}\cap\mathcal{S}=\emptyset$, and $\mathcal{K}^\prime$ satisfies the finite intersection property. So, by compactness, $\bigcap_{i\in F}G_i\supseteq\bigcap\mathcal{K}^\prime\not=\emptyset$. This contradicts the fact that, as $F\in\mathcal{F}$ is an unbounded subset of $M$, this intersection is empty.
|
Suppose I had a ray of unpolarized light, and I was sitting inside the beam and looking at the electric fields oscillating, then , if I am looking at a point how would the oscillations look like? I cannot seem to understand it.
I guess you have this image in mind:
This hods just for a single photon, or elementary packet of light. An unpolarized beam of light contains a bunch of photons with many different polarizations. The total electric field will randomly jump all around, still the interactions with matter typically involve a single photon at a time. This means that if you ride the beam, you are allowed to look at the photons one by one, each time seeing a different, but consistent with itself, oscillating field.
They will look all over the place. If you take a particular photon, you will see it in a particular polarisation state, but it will have nothing to do with the photon next to it, or the one before.
Actually, getting a perfectly unpolarised source of light is quite difficult. One of the best cheap options are the sodium discharge lamps, used extensively in undergrad optics labs. They work by passing an electric current through some sodium vapour, so that each individual atom gets excited, and then releases the energy in light. They are very hot, so the state when the light is emitted is quite random; but still you will see a faint polarisation in the direction of the discharge. That is, if you measure the intensity of the light through a
very good polariser at 90º, you will see a small difference.
A full classical answer to your question is actually rather subtle and tricky, but its summary is pretty much as in Davidmh and DarioP's answer, both good answers: the electric field vector's direction is changing wildly. The classical description of the nature of depolarised light is bound up with decoherence and partially coherence, a topic which Born and Wolf in "Principles of Optics" give a whole chapter to. The following is roughly analogous to Born and Wolf's desctipyion: if the transverse (normal to propagation) plane is the $x,y$ plane, then we represent the electric field at a point as:
$$\mathbf{E} = \left(\begin{array}{cc}E_x(t) \cos(\omega t + \phi_x(t))\\E_y(t) \cos(\omega t + \phi_y(t))\end{array}\right)\tag{1}$$
where $\omega$ is the centre frequency and the phases $\phi_x(t)$, $\phi_y(t)$ and envelopes $E_x(t)$, $E_y(t)$ are stochastic processes, which can be as complicated as you like. The formulas I cite above just assume that:
$E_x$, $E_y$ and $\phi$ behave like independent random variables, and They vary with time swiftly compared to your observation interval (the time interval whereover you gather light in a sensor to come up with an "intensity" measurement) but not so swiftly that the light's spectrum broadened so much that we cannot still think of the light as roughly monochromatic.
Although it cannot really be "visualised", I actually find the quantum description of depolarised light is a great deal clearer and easier: certainly it involves a great deal less of the heavy duty stochastic process theory expounded on in Born and Wolf. We think of a lone photon; it propagates following Maxwell's equations, which are the first quantised propagation equations for the photon (only here the $\vec{E},\,\vec{B}$ represent a quantum state, not measurable electric and magnetic fields). Then we think of an ensemble of pure quantum states, exactly analogous to classical, fully polarised light states. A partially depolarised state is nothing more than a
classical mixture of pure polarisation states: what this means is illustrated by the Wigner's Friend Thought Experiment. For a large ensemble of photons, you simply do any calculations you need for all the different pure polarisation states present in the classical mixture, then sum the squared amplitudes weighted by the classical probabilities. The density matrix formalism is invaluable for such calculations, and I talk about these calcualtions for light in this answer here.
|
Table of Contents
The Fundamental Theorem of Riemann Integral Calculus Part 1
Perhaps one of the most famous "fundamental" theorems in mathematics are the Fundamental Theorems of Calculus that are first introduced in an introductory calculus course. There are two parts of the fundamental theorem.
The first part of the Fundamental Theorem of Calculus states that if $f$ is a continuous function on the interval $[a, b]$ and $F(x) = \int_a^x f(t) \: dt$ then:(1)
The second part of the Fundamental Theorem of Calculus states that if $f$ is continuous on the interval $[a, b]$ and $F$ is any antiderivative of $f$ then:(2)
We will first derive the Fundamental Theorem of Calculus Part 1 which we will call the Fundamental Theorem of Riemann Integral Calculus Part 1. We derive The Fundamental Theorem of Riemann Integral Calculus Part 2 subsequently.
Theorem 1 (The Fundamental Theorem of Riemann Integral Calculus Part 1) If $f$ is continuous on $[a, b]$ and $F(x) = \int_a^x f(x) \: dx$ then $F'(x) = f(x)$ on $[a, b]$. Proof:Let $f$ be any continuous function on $[a, b]$. Let $\alpha (x) = x$. Then $\alpha$ is an increasing function on $[a, b]$ and is clearly of bounded variation on $[a, b]$. Furthermore, $\alpha'(x) = 1$ exists for all $x \in [a, b]$. Clearly $f$ is Riemann-Stieltjes integrable with respect to $\alpha$ on $[a, b]$, and so add of the hypotheses from part (c) of the theorem on the Riemann-Stieltjes Integral Defined Functions page is satisfied, so for the function: We have that $F'(x)$ exists for all $x \in [a, b]$ and so for all $x \in [a, b]$ we have that:
|
The adjoint map at the level of the lie algebra is such that $$\text{ad}: \mathfrak{g} \rightarrow \text{End}(\mathfrak g),$$ taking $\lambda_a \mapsto \text{ad}_{\lambda_a}$ where $$\text{ad}_{\lambda_a}: \mathfrak{g} \rightarrow \mathfrak{g}\,\,\,\,\,\text{with}\,\,\, \lambda_b \mapsto [\lambda_a, \lambda_b].$$
So, this means that $$\lambda_b \rightarrow \text{ad}_{\lambda_a} \lambda_b = [\lambda_a, \lambda_b] = if_{abc}\lambda_c.$$
The map $\text{ad}$ is equivalent to $\rho$ for matrix lie groups so $\rho: \mathfrak{g} \rightarrow \mathfrak{gl}(V=\mathfrak{g}) \equiv \text{End}(V = \mathfrak{g}) $ is the map such that $\rho(\lambda_a)_{cb}\lambda_c = [\lambda_a, \lambda_b] = if_{abc}\lambda_c$, which is to say $\rho(\lambda_a) (\lambda_b) = [\lambda_a, \lambda_b].$ Peeling off the $\lambda_c$ we obtain $$\rho(\lambda_a)_{cb} = i f_{abc}.$$
So the indices $\left\{b,c\right\} \in \left\{1, \dots , \text{dim}(\mathfrak{g})\right\}$ attached to the $\text{dim}(\mathfrak{g}) \times \text{dim}(\mathfrak{g})$ matrix representations $\rho(\lambda_a)_{bc}$ of the lie algebra adjoint action mix around the real $\text{dim}(\mathfrak{g}) \times 1$ basis vectors $\left\{\lambda \right\}$ of the lie algebra.
Alternatively, since $\rho$ is a linear operator acting on the vector space $V = \mathfrak{g}$, an equivalent operation is one in which $\rho$ mixes around the
components $(\lambda_b)_d$ of some $\lambda_b$, so we can equally rewrite the transformation law$$\rho(\lambda_a)_{cd} (\lambda_b)_d = \rho(\lambda_a)_{cd} \delta_{bd} = \rho(\lambda_a)_{cb} \overset{!}{=} [\lambda_a, \lambda_b]_c = if_{abd} (\lambda_d)_c = if_{abd} \delta_{dc} = if_{abc}$$ and thus arrive at the same conclusion $$\rho(\lambda_a)_{cb} = if_{abc},$$ where $(\lambda_i)_j = \delta_{ij}$ WLOG (if there is an overall normalisation, this cancels between the two sides of the equation) and $|\lambda_b \rangle = (\lambda_b)_d |\lambda_d \rangle$.
$\mathbf{Aside}$
One may ask why $\rho(\lambda_a)_{cb} \lambda_c$ and not, say, $\rho(\lambda_a)_{bc} \lambda_c$? We define the action of a generator $\lambda_a$ on a basis vector $|\lambda_b \rangle$ through the Lie bracket as noted above. This is to say $\lambda_a |\lambda_b \rangle = \rho(\lambda_a)_{cb} |\lambda_c \rangle$ so that $\langle \lambda_c | \lambda_a |\lambda_b \rangle = \rho(\lambda_a)_{cb}$ are the matrix elements of the matrix representation of the operator $\rho$ in the basis $\left\{\lambda\right\}$. Consider some arbitrary vector built up from the basis vectors of $\mathfrak{g}$, that is $|\Psi \rangle = \sum c_b |\lambda_b \rangle$. Then $$|\Psi \rangle' = c_d' |\lambda_d \rangle \equiv \lambda_a |\Psi \rangle = c_b \lambda_a |\lambda_b \rangle = c_b \rho(\lambda_a)_{cb} |\lambda_c \rangle $$ Relabelling indices at the first equality allows us to write the transformation of the
components of the vector $|\Psi \rangle$ in the basis spanned by $\left\{\lambda \right\}$ as $c_c' = \rho_{cb} c_b$.
All of this makes contact with the familiar matrix/vector product $\mathbf v' = M \mathbf v$ or in component form $v_i' = M_{ij}v_j$ and $\mathbf v = v_i e_i$ where $v_i$ are the
components of $\mathbf v$ in the basis $\left\{e_j \right\}$.
In the notation of the aside, the $\rho(\lambda_a)$, $|\Psi \rangle, |\lambda_b \rangle$ and $c_b$ would be equivalent to the $M$, $\mathbf v$, $e_j$ and $v_j$ above respectively. So, we see that with the used indicial writing of the $\rho$ we obtain the familiar transformation law for components of vectors.
|
On the tail section of the YF-22 further back in the image below, there is a red canister. What is that canister for? I suppose it is for some flight testing purposes from what I can see.
I can't pinpoint the image source.
Aviation Stack Exchange is a question and answer site for aircraft pilots, mechanics, and enthusiasts. It only takes a minute to sign up.Sign up to join this community
It is a spin recovery/stabilization chute, installed during testing for high AoA test flights. The following image shows it being deployed on the ground.
Image from fas.org
The canister contains a small parachute and either a spring or an explosive charge to kick the chute out when it is needed. It is a precaution for spin flight tests, that's why it is called a spin chute. See here for a video of the spin chute of the F-35.
I guess now I should explain how a spin chute works.
When an aircraft spins, it will rotate around a vertical axis which is somewhere between slightly ahead of the aircraft (regular spin) or near the leading edge (flat spin). The pitch angle $\Theta$ is nose down and the angle of attack $\alpha$ is high (around 45° in a regular spin, up to 90° in a flat spin), so the airflow over most of the wing and horizontal tail is separated. But the rotation, which is a mix of rolling and yawing, will induce an angle of attack variation over span, so a part of one wing will operate in the normal angle of attack range, where lift is high and drag is low.
Now we have a receding wing with separated flow, at high angle of attack, with low lift and high drag so the resulting air force vector R (green, below) points mostly into the direction of local flow (which is up). The other wing has partially attached flow, a lower angle of attack, high lift and moderate drag, so the resulting air force vector is almost perpendicular to the local flow, pointing up and forward. This difference in lift and drag propels the rotation.
Speeds an resulting force on spinning wing sections. $\omega_z$ is the rotation speed around the vertical axis, $y$ is the local wing station and the green $v$ shows the local flow direction.
Without the rotation the aircraft would immediately pitch nose down, pick up speed and can be pulled out of the resulting dive. With the rotation, however, we get an inertial pitch moment due to the fuselage masses. All parts of the aircraft rotate with the same yaw rate, and the centrifugal force from this yawing motion grows linearly with distance from the spin axis. This difference in centrifugal force along the lengthwise coordinate of the aircraft adds a powerful nose-up moment which in some cases cannot be overcome by the tail surfaces - remember, they have less effectivity in separated flow. Flat spins are almost impossible to escape from.
This can be tested in spin tunnels, but Murphy's Law is very relevant to spin tests. So it is a good precaution to add a spin chute for the first tests: If the aircraft cannot end the spin with control surface deflections, it is in a trap from which it can only escape with something that will add a strong nose-down moment. In the chaotic airflow behind a rapidly spinning airplane. That is why the spin chute is not bolted to the skin of the airplane, but sits in an elevated position hanging out at the back. From there it will not be caught by the tail surfaces but will work as intended in all conceivable situations (save an inverted spin ...)
|
Continuity at a Point
Definition: Let $f : A \to \mathbb{R}$ be a function and let $c \in A$. We say that $f$ is continuous at the point $c$ if $\forall \epsilon > 0$ $\exists \delta > 0$ such that $\forall x \in A$ with $\mid x - c \mid < \delta$ then $\mid f(x) - f(c) \mid < \epsilon$. Another definition of continuity of $f$ at $c$ is $\forall x \in A \cap V_{\delta} (c)$ we have that $f(x) \in V_{\epsilon} (f(c))$.
The graphic below illustrates the definition a function being continuous at a point $c$ in its domain.
Therefore, a function $f$ is continuous at the point $c$ if for every such $\epsilon > 0$ and corresponding $\delta > 0$, when $x$ in in the domain of $A$ and is $\delta$-close $c$, then $f(x)$ is $\epsilon$-close to $f(c)$.
Continuity at Cluster and Isolated Points
If $c$ is a cluster point of the set $A$, then $f$ is continuous at $c$ if and only if $\lim_{x \to c} f(x) = f(c)$.
If $c$ is an isolated point of the set $A$, then $f$ is always continuous at $c$. Why? For all $\epsilon > 0$ there will exist a $\delta > 0$ such that if $x \in A$ and $\mid x - c \mid < \delta$ (notice how we aren't restricting $x$ to be $c$) then $\mid f(x) - f(c) \mid < \epsilon$. In other words, if we get choose $\epsilon$ small enough, then the corresponding $\delta$-neighbourhood around $c$ will only contain $c$ and thus the corresponding $\epsilon$-neighbourhood around $f(c)$ will only contain $f(c)$ and clearly $\mid f(c) - f(c) \mid = 0 < \epsilon$ since $\epsilon$ is positive.
Continuity on a Set
Definition: Let $f : A \to \mathbb{R}$ be a function and let $B \subseteq A$. Then $f$ is continuous on the set $B$ if $\forall b \in B$, $f$ is continuous at $b$.
For example, consider the function $f : \mathbb{R} \to \mathbb{R}$ defined by $f(x) = 5$ which can geometrically be represented as a horizontal line that crosses the $x$-axis at the point $(0, 5)$. Since $f(x) = 5$ for all $x \in \mathbb{R}$, it shouldn't be too hard to understand that $f$ is continuous on all of $\mathbb{R}$.
Another example if the function $f(x) = x$ which is the diagonal line that intersects the origin.
Yet another example is any function $p : \mathbb{R} \to \mathbb{R}$ that is an $n^{\mathrm{th}}$-degree polynomial defined by $p(x) = a_0 + a_1x + a_2x^2 + ... + a_nx^n$ where $a_0, a_1, ..., a_n \in \mathbb{R}$. $p$ will be continuous on all of $\mathbb{R}$ as well.
The last three examples depicted functions there were continuous on all of $\mathbb{R}$. This is not always the case though. For example, consider the function $f : (0, \infty) \to \mathbb{R}$ defined by $f(x) = \frac{1}{x}$. The domain of this function is $\{ x \in \mathbb{R} : x > 0 \}$. We will show that $f$ is continuous on its entire domain.
Let $c$ be a member of the domain of $f$, i.e., $c \in D(f) = (0, \infty)$. Let $\epsilon > 0$ be given. We need to find $\delta > 0$ such that $\forall x \in D(f)$ where $\mid x - c \mid < \delta$ then $\biggr \rvert \frac{1}{x} - \frac{1}{c} \biggr \rvert < \epsilon$. Now:(1)
We want $\frac{\mid x - c \mid}{xc} < \epsilon$. Let $\delta = \mathrm{min} \{ \frac{c}{2}, \frac{\epsilon c^2}{2} \}$. Then:(2)
Therefore $f$ is continuous for all $c$ in its domain $D(f)$.
|
Pointwise Cauchy Sequences of Functions
Definition: A sequence of functions $(f_n(x))_{n=1}^{\infty}$ with common domain $X$ is said to be Pointwise Cauchy on $X$ if for all $\epsilon > 0$ and for all $x \in X$ there exists an $N \in \mathbb{N}$ such that if $m, n \geq N$ then $\mid f_m(x) - f_n(x) \mid < \epsilon$.
In essence, a sequence of functions $(f_n(x))_{n=1}^{\infty}$ is pointwise Cauchy if for each $x_0 \in X$ we have that the numerical sequence $(f_n(x_0))_{n=1}^{\infty}$ is Cauchy.
For example, consider the following sequence of functions with common domain $X = [0, 1]$:(1)
We claim that this sequence of functions is pointwise Cauchy. To prove this, let $\epsilon > 0$ and let $x_0 \in X$. If $x_0 = 0$ then $(f_n(x_0))_{n=1}^{\infty} = (0, 0, ... )$ which is clearly Cauchy, so assume that $x_0 \neq 0$ and consider:(2)
Let $N \in \mathbb{N}$ be such that $N > \frac{2x_0^2}{\epsilon}$. Then if $m, n \geq N$ we have that:(3)
So then:(4)
So for all $\epsilon > 0$ and for all $x \in X$ there exists an $N \in \mathbb{N}$ such that if $m, n \geq N$ then $\mid f_m(x) - f_n(x) \mid < \epsilon$, so the sequence of functions $(f_n(x))_{n=1}^{\infty}$ is pointwise Cauchy.
We now look at a theorem which says that a sequence of real-valued functions is pointwise Cauchy if and only if it is pointwise convergent.
Theorem 1: Every sequence of real-valued functions $(f_n(x))_{n=1}^{\infty}$, $f_n : X \to \mathbb{R}$ for all $n \in \mathbb{N}$, is pointwise Cauchy on $X$ if and only if it is pointwise convergent on $X$. Note that Theorem 1 relies on the fact that $\mathbb{R}$ is a complete metric space. Proof:$\Rightarrow$ Suppose that the sequence of functions $(f_n(x))_{n=1}^{\infty}$ is pointwise Cauchy. Then each of the numerical sequences $(f_n(x_0))_{n=1}^{\infty}$ for $x_0 \in X$ is a Cauchy sequence. Since this sequence is a Cauchy sequence in the complete metric space $\mathbb{R}$ we have that every Cauchy sequence converges in $\mathbb{R}$, so each numerical sequence $(f_n(x_0))_{n=1}^{\infty}$ converges. Therefore $(f_n(x))_{n=1}^{\infty}$ is pointwise convergent on $X$. $\Leftarrow$ Suppose that the sequence of functions $(f_n(x))_{n=1}^{\infty}$ is pointwise convergent. Then each of the numerical sequnces $(f_n(x_0))_{n=1}^{\infty}$ for $x_0 \in X$ is a convergent sequence. But we know that every numerical convergent sequence is Cauchy, so each of the numerical sequences $(f_n(x_0))_{n=1}^{\infty}$ is a Cauchy sequence. Therefore, $(f_n(x))_{n=1}^{\infty}$ is pointwise Cauchy on $X$. $\blacksquare$
|
Main Page Contents The Problem
Let [math][3]^n[/math] be the set of all length [math]n[/math] strings over the alphabet [math]1, 2, 3[/math]. A
combinatorial line is a set of three points in [math][3]^n[/math], formed by taking a string with one or more wildcards [math]x[/math] in it, e.g., [math]112x1xx3\ldots[/math], and replacing those wildcards by [math]1, 2[/math] and [math]3[/math], respectively. In the example given, the resulting combinatorial line is: [math]\{ 11211113\ldots, 11221223\ldots, 11231333\ldots \}[/math]. A subset of [math][3]^n[/math] is said to be line-free if it contains no lines. Let [math]c_n[/math] be the size of the largest line-free subset of [math][3]^n[/math]. Density Hales-Jewett (DHJ) theorem: [math]\lim_{n \rightarrow \infty} c_n/3^n = 0[/math]
The original proof of DHJ used arguments from ergodic theory. The basic problem to be consider by the Polymath project is to explore a particular combinatorial approach to DHJ, suggested by Tim Gowers.
Threads (1-199) A combinatorial approach to density Hales-Jewett (inactive) (200-299) Upper and lower bounds for the density Hales-Jewett problem (active) (300-399) The triangle-removal approach (inactive) (400-499) Quasirandomness and obstructions to uniformity (final call) (500-599) TBA (600-699) A reading seminar on density Hales-Jewett (active)
A spreadsheet containing the latest lower and upper bounds for [math]c_n[/math] can be found here.
Unsolved questions Gowers.462: Incidentally, it occurs to me that we as a collective are doing what I as an individual mathematician do all the time: have an idea that leads to an interesting avenue to explore, get diverted by some temporarily more exciting idea, and forget about the first one. I think we should probably go through the various threads and collect together all the unsolved questions we can find (even if they are vague ones like, “Can an approach of the following kind work?”) and write them up in a single post. If this were a more massive collaboration, then we could work on the various questions in parallel, and update the post if they got answered, or reformulated, or if new questions arose. IP-Szemeredi (a weaker problem than DHJ) Solymosi.2: In this note I will try to argue that we should consider a variant of the original problem first. If the removal technique doesn’t work here, then it won’t work in the more difficult setting. If it works, then we have a nice result! Consider the Cartesian product of an IP_d set. (An IP_d set is generated by d numbers by taking all the [math]2^d[/math] possible sums. So, if the n numbers are independent then the size of the IP_d set is [math]2^d[/math]. In the following statements we will suppose that our IP_d sets have size [math]2^n[/math].)
Prove that for any [math]c\gt0[/math] there is a [math]d[/math], such that any [math]c[/math]-dense subset of the Cartesian product of an IP_d set (it is a two dimensional pointset) has a corner.
The statement is true. One can even prove that the dense subset of a Cartesian product contains a square, by using the density HJ for [math]k=4[/math]. (I will sketch the simple proof later) What is promising here is that one can build a not-very-large tripartite graph where we can try to prove a removal lemma. The vertex sets are the vertical, horizontal, and slope -1 lines, having intersection with the Cartesian product. Two vertices are connected by an edge if the corresponding lines meet in a point of our [math]c[/math]-dense subset. Every point defines a triangle, and if you can find another, non-degenerate, triangle then we are done. This graph is still sparse, but maybe it is well-structured for a removal lemma.
Finally, let me prove that there is square if [math]d[/math] is large enough compare to [math]c[/math]. Every point of the Cartesian product has two coordinates, a 0,1 sequence of length [math]d[/math]. It has a one to one mapping to [math][4]^d[/math]; Given a point [math]( (x_1,…,x_d),(y_1,…,y_d) )[/math] where [math]x_i,y_j[/math] are 0 or 1, it maps to [math](z_1,…,z_d)[/math], where [math]z_i=0[/math] if [math]x_i=y_i=0[/math], [math]z_i=1[/math] if [math]x_i=1[/math] and [math]y_i=0, z_i=2[/math] if [math]x_i=0[/math] and [math]y_i=1[/math], and finally [math]z_i=3[/math] if [math]x_i=y_i=1[/math]. Any combinatorial line in [math][4]^d[/math] defines a square in the Cartesian product, so the density HJ implies the statement.
Gowers.7: With reference to Jozsef’s comment, if we suppose that the d numbers used to generate the set are indeed independent, then it’s natural to label a typical point of the Cartesian product as (\epsilon,\eta), where each of \epsilon and \eta is a 01-sequence of length d. Then a corner is a triple of the form (\epsilon,\eta), (\epsilon,\eta+\delta), (\epsilon+\delta,\eta), where \delta is a \{-1,0,1\}-valued sequence of length d with the property that both \epsilon+\delta and \eta+\delta are 01-sequences. So the question is whether corners exist in every dense subset of the original Cartesian product.
This is simpler than the density Hales-Jewett problem in at least one respect: it involves 01-sequences rather than 012-sequences. But that simplicity may be slightly misleading because we are looking for corners in the Cartesian product. A possible disadvantage is that in this formulation we lose the symmetry of the corners: the horizontal and vertical lines will intersect this set in a different way from how the lines of slope -1 do.
I feel that this is a promising avenue to explore, but I would also like a little more justification of the suggestion that this variant is likely to be simpler.
Gowers.22: A slight variant of the problem you propose is this. Let’s take as our ground set the set of all pairs (U,V) of subsets of \null [n], and let’s take as our definition of a corner a triple of the form (U,V), (U\cup D,V), (U,V\cup D), where both the unions must be disjoint unions. This is asking for more than you asked for because I insist that the difference D is positive, so to speak. It seems to be a nice combination of Sperner’s theorem and the usual corners result. But perhaps it would be more sensible not to insist on that positivity and instead ask for a triple of the form (U,V), ((U\cup D)\setminus C,V), (U, (V\cup D)\setminus C, where D is disjoint from both U and V and C is contained in both U and V. That is your original problem I think.
I think I now understand better why your problem could be a good toy problem to look at first. Let’s quickly work out what triangle-removal statement would be needed to solve it. (You’ve already done that, so I just want to reformulate it in set-theoretic language, which I find easier to understand.) We let all of X, Y and Z equal the power set of \null [n]. We join U\in X to V\in Y if (U,V)\in A.
Ah, I see now that there’s a problem with what I’m suggesting, which is that in the normal corners problem we say that (x,y+d) and (x+d,y) lie in a line because both points have the same coordinate sum. When should we say that (U,V\cup D) and (U\cup D,V) lie in a line? It looks to me as though we have to treat the sets as 01-sequences and take the sum again. So it’s not really a set-theoretic reformulation after all.
O'Donnell.35: Just to confirm I have the question right…
There is a dense subset A of {0,1}^n x {0,1}^n. Is it true that it must contain three nonidentical strings (x,x’), (y,y’), (z,z’) such that for each i = 1…n, the 6 bits
[ x_i x'_i ] [ y_i y'_i ] [ z_i z'_i ]
are equal to one of the following:
[ 0 0 ] [ 0 0 ] [ 0, 1 ] [ 1 0 ] [ 1 1 ] [ 1 1 ] [ 0 0 ], [ 0 1 ], [ 0, 1 ], [ 1 0 ], [ 1 0 ], [ 1 1 ], [ 0 0 ] [ 1 0 ] [ 0, 1 ] [ 1 0 ] [ 0 1 ] [ 1 1 ]
?
McCutcheon.469: IP Roth:
Just to be clear on the formulation I had in mind (with apologies for the unprocessed code): for every $\delta>0$ there is an $n$ such that any $E\subset [n]^{[n]}\times [n]^{[n]}$ having relative density at least $\delta$ contains a corner of the form $\{a, a+(\sum_{i\in \alpha} e_i ,0),a+(0, \sum_{i\in \alpha} e_i)\}$. Here $(e_i)$ is the coordinate basis for $[n]^{[n]}$, i.e. $e_i(j)=\delta_{ij}$.
Presumably, this should be (perhaps much) simpler than DHJ, k=3.
High-dimensional Sperner Kalai.29: There is an analogous for Sperner but with high dimensional combinatorial spaces instead of "lines" but I do not remember the details (Kleitman(?) Katona(?) those are ususal suspects.) Fourier approach Kalai.29: A sort of generic attack one can try with Sperner is to look at [math]f=1_A[/math] and express using the Fourier expansion of [math]f[/math] the expression [math]\int f(x)f(y)1_{x\lty}[/math] where [math]x\lty[/math] is the partial order (=containment) for 0-1 vectors. Then one may hope that if [math]f[/math] does not have a large Fourier coefficient then the expression above is similar to what we get when [math]A[/math] is random and otherwise we can raise the density for subspaces. (OK, you can try it directly for the [math]k=3[/math] density HJ problem too but Sperner would be easier;)This is not unrealeted to the regularity philosophy. Gowers.31: Gil, a quick remark about Fourier expansions and the [math]k=3[/math] case. I want to explain why I got stuck several years ago when I was trying to develop some kind of Fourier approach. Maybe with your deep knowledge of this kind of thing you can get me unstuck again.
The problem was that the natural Fourier basis in [math]\null [3]^n[/math] was the basis you get by thinking of [math]\null [3]^n[/math] as the group [math]\mathbb{Z}_3^n[/math]. And if that’s what you do, then there appear to be examples that do not behave quasirandomly, but which do not have large Fourier coefficients either. For example, suppose that [math]n[/math] is a multiple of 7, and you look at the set [math]A[/math] of all sequences where the numbers of 1s, 2s and 3s are all multiples of 7. If two such sequences lie in a combinatorial line, then the set of variable coordinates for that line must have cardinality that’s a multiple of 7, from which it follows that the third point automatically lies in the line. So this set [math]A[/math] has too many combinatorial lines. But I’m fairly sure — perhaps you can confirm this — that [math]A[/math] has no large Fourier coefficient.
You can use this idea to produce lots more examples. Obviously you can replace 7 by some other small number. But you can also pick some arbitrary subset [math]W[/math] of [math]\null[n][/math] and just ask that the numbers of 0s, 1s and 2s inside [math]W[/math] are multiples of 7. DHJ for dense subsets of a random set
Tao.18: A sufficiently good Varnavides type theorem for DHJ may have a separate application from the one in this project, namely to obtain a “relative” DHJ for dense subsets of a sufficiently pseudorandom subset of {}[3]^n, much as I did with Ben Green for the primes (and which now has a significantly simpler proof by Gowers and by Reingold-Trevisan-Tulsiani-Vadhan). There are other obstacles though to that task (e.g. understanding the analogue of “dual functions” for Hales-Jewett), and so this is probably a bit off-topic.
Bibliography H. Furstenberg, Y. Katznelson, “A density version of the Hales-Jewett theorem for k=3“, Graph Theory and Combinatorics (Cambridge, 1988). Discrete Math. 75 (1989), no. 1-3, 227–241. R. McCutcheon, “The conclusion of the proof of the density Hales-Jewett theorem for k=3“, unpublished. H. Furstenberg, Y. Katznelson, “A density version of the Hales-Jewett theorem“, J. Anal. Math. 57 (1991), 64–119.
|
Group Homomorphisms From Group of Order 21 to Group of Order 49
Problem 346
Let $G$ be a finite group of order $21$ and let $K$ be a finite group of order $49$.Suppose that $G$ does not have a normal subgroup of order $3$.Then determine all group homomorphisms from $G$ to $K$.
Let $e$ be the identity element of the group $K$.We claim that every group homomorphism from $G$ to $K$ is trivial.Namely, if $\phi:G \to K$ is a group homomorphism, then we have $\phi(g)=e$ for every $g\in G$.
The first isomorphism theorem gives the isomorphism\[G/\ker(\phi)\cong \im(\phi) < K.\]It follows that the order $|\im(\phi)|$ of the image $\im(\phi)$ is a divisor of the order of $G$ and that of $K$.Hence the order $|\im(\phi)|$ divides the greatest common divisor of $|G|=3\cdot 7$ and $|K|=7^2$, which is $7$.So, the possibilities are $|\im(\phi)|=1, 7$.If $|\im(\phi)|=7$, then we have\[\frac{|G|}{|\ker(\phi)|}=|\im(\phi)|=7,\]and we obtain $|\ker(\phi)|=3$.Since the kernel of a group homomorphism is a normal subgroup, this contradicts the assumption that $G$ does not have a normal subgroup of order $3$.Therefore, we must have $|\im(\phi)|=1$, and this implies that $\phi$ is a trivial homomorphism.Thus we conclude that every group homomorphism from $G$ to $K$ is trivial.
Abelian Normal subgroup, Quotient Group, and Automorphism GroupLet $G$ be a finite group and let $N$ be a normal abelian subgroup of $G$.Let $\Aut(N)$ be the group of automorphisms of $G$.Suppose that the orders of groups $G/N$ and $\Aut(N)$ are relatively prime.Then prove that $N$ is contained in the center of […]
Subgroup of Finite Index Contains a Normal Subgroup of Finite IndexLet $G$ be a group and let $H$ be a subgroup of finite index. Then show that there exists a normal subgroup $N$ of $G$ such that $N$ is of finite index in $G$ and $N\subset H$.Proof.The group $G$ acts on the set of left cosets $G/H$ by left multiplication.Hence […]
Group Homomorphism, Preimage, and Product of GroupsLet $G, G'$ be groups and let $f:G \to G'$ be a group homomorphism.Put $N=\ker(f)$. Then show that we have\[f^{-1}(f(H))=HN.\]Proof.$(\subset)$ Take an arbitrary element $g\in f^{-1}(f(H))$. Then we have $f(g)\in f(H)$.It follows that there exists $h\in H$ […]
Group Homomorphism from $\Z/n\Z$ to $\Z/m\Z$ When $m$ Divides $n$Let $m$ and $n$ be positive integers such that $m \mid n$.(a) Prove that the map $\phi:\Zmod{n} \to \Zmod{m}$ sending $a+n\Z$ to $a+m\Z$ for any $a\in \Z$ is well-defined.(b) Prove that $\phi$ is a group homomorphism.(c) Prove that $\phi$ is surjective.(d) Determine […]
Every Group of Order 24 Has a Normal Subgroup of Order 4 or 8Prove that every group of order $24$ has a normal subgroup of order $4$ or $8$.Proof.Let $G$ be a group of order $24$.Note that $24=2^3\cdot 3$.Let $P$ be a Sylow $2$-subgroup of $G$. Then $|P|=8$.Consider the action of the group $G$ on […]
A Group Homomorphism is Injective if and only if MonicLet $f:G\to G'$ be a group homomorphism. We say that $f$ is monic whenever we have $fg_1=fg_2$, where $g_1:K\to G$ and $g_2:K \to G$ are group homomorphisms for some group $K$, we have $g_1=g_2$.Then prove that a group homomorphism $f: G \to G'$ is injective if and only if it is […]
|
Description
This data set contains approximately 140,000 shear-stabilized jammed packings, as described in [1].
These packings contain (N = 16... 4096) particles with harmonic interactions, under a confining pressure p=10^{-7}\...10^{-2}\). Ensemble sizes range from 10 (N=4096) to 5000 (N=16). Particle interactions The simulation code minimizes the enthalpy H = \sum_{} \frac{k}{2} \delta_{ij}^2 + pL^2\) where L² is the simulation box area, p the externally applied pressure, k=1 the spring constant and \delta_{ij} = \left\{ \begin{array}{ll} R_i + R_j - |\vec{r_{ij}}| & \textrm{if } |\vec{r_{ij}}| < R_i + R_j, \\ 0 & \textrm{otherwise.} \end{array}\right. Data files The packings are stored in an HDF5 data file, with the following format: Example name: N1024P3162e-3_tables.h5 Packings with N=1024 particles Pressure p = 3.162\cdot 10^{-3} packing_attr_cache is a data table containing properties of each packing, such as the lattice vectors L1 and L2, describing the positions of periodic copies, sxx, syy, sxy, the boundary stresses, phi, the packing fraction, N - Ncorrected, the effective number of particles, Z, the contact number, and path, the path in the HDF5 file this packing can be found Packings are stored in a directory structure, e.g. /N1024/P3.1620e-03/0090 Each directory has attributes with the same data as packing_attr_cache Each directory contains a table 'particles' which stores x,y and r. HDF5 does not support float128 values, so the positions are stored as two float64 values x and x_err. Sum them as float128 to get the full-resolution value. [1] Simon Dagois-Bohy, Brian P. Tighe, Johannes Simon, Silke Henkes, and Martin van Hecke. Soft-Sphere Packings at Finite Pressure but Unstable to Shear. Phys. Rev. Lett. 109, 095703. http://dx.doi.org/10.1103/PhysRevLett.109.095703 dataset licensed under Creative Commons Attribution 4.0 International
These packings contain (N = 16... 4096) particles with harmonic interactions, under a confining pressure p=10^{-7}\...10^{-2}\). Ensemble sizes range from 10 (N=4096) to 5000 (N=16).
Particle interactions
The simulation code minimizes the enthalpy
H = \sum_{} \frac{k}{2} \delta_{ij}^2 + pL^2\)
where L² is the simulation box area, p the externally applied pressure, k=1 the spring constant and
\delta_{ij} = \left\{ \begin{array}{ll} R_i + R_j - |\vec{r_{ij}}| & \textrm{if } |\vec{r_{ij}}| < R_i + R_j, \\ 0 & \textrm{otherwise.} \end{array}\right.
Data files
The packings are stored in an HDF5 data file, with the following format:
Example name: N1024P3162e-3_tables.h5
Packings with N=1024 particles
Pressure p = 3.162\cdot 10^{-3}
packing_attr_cache is a data table containing properties of each packing, such as
the lattice vectors L1 and L2, describing the positions of periodic copies,
sxx, syy, sxy, the boundary stresses,
phi, the packing fraction,
N - Ncorrected, the effective number of particles,
Z, the contact number, and
path, the path in the HDF5 file this packing can be found
Packings are stored in a directory structure, e.g. /N1024/P3.1620e-03/0090
Each directory has attributes with the same data as packing_attr_cache
Each directory contains a table 'particles' which stores x,y and r.
HDF5 does not support float128 values, so the positions are stored as two float64 values x and x_err. Sum them as float128 to get the full-resolution value.
[1] Simon Dagois-Bohy, Brian P. Tighe, Johannes Simon, Silke Henkes, and Martin van Hecke. Soft-Sphere Packings at Finite Pressure but Unstable to Shear. Phys. Rev. Lett. 109, 095703. http://dx.doi.org/10.1103/PhysRevLett.109.095703
dataset licensed under Creative Commons Attribution 4.0 International
Date made available 9 Jul 2015 Publisher Zenodo Cite this
Dagois-Bohy, S. (Creator), Henkes, S. (Creator), Simon, J. (Creator), Tighe, B. P. (Creator), van Deen, M. S. (Creator), Zeravcic, Z. (Creator), Schelter, B. O. (Data Manager)(9 Jul 2015). Shear-stabilized jammed packings. Zenodo. 10.5281/zenodo.59216
|
Question:-Use Chebychev's inequality to show that for any $k>1$, $e^{k+1}\ge k^2$
Chebychev's inequality states that for any random variable $X$ with finite mean, and for $k>0$ $$P(|X-\mu|\le k\sigma)\ge 1-\frac {1}{k^2}$$ Or $$P(|X-\mu|\ge k\sigma)\le \frac {1}{k^2}$$ A general for of the inequality is given in the book of Casella-Berger, $$P(h(X)\ge\epsilon)\le\frac{Eh(X)}{\epsilon}$$ I tried to do it using the argument that for $k>1$ we have to show $P(k^2\le e^{k+1})\ge$ a no. quite close to $1$.
However,I am getting problem in thinking a random variable which will serve the work. I can't even consider the function as $h(k)$ because both the function on either side of the inequality contains $k$.
Hoping to get a hint by my fellow mates.
|
Illinois Journal of Mathematics Illinois J. Math. Volume 54, Number 2 (2010), 621-647. Spectral multipliers for Schrödinger operators Abstract
We prove a sharp Hörmander multiplier theorem for Schrödinger operators $H=-\Delta+V$ on $\mathbb{R}^n$. The result is obtained under certain condition on a weighted $L^\infty$ estimate, coupled with a weighted $L^2$ estimate for $H$, which is a weaker condition than that for nonnegative operators via the heat kernel approach. Our approach is elaborated in one dimension with potential $V$ belonging to certain critical weighted $L^1$ class. Namely, we assume that $\int(1+|x|) |V(x)|\,dx$ is finite and $H$ has no resonance at zero. In the resonance case, we assume $\int(1+|x|^2) |V(x)|\, dx$ is finite.
Article information Source Illinois J. Math., Volume 54, Number 2 (2010), 621-647. Dates First available in Project Euclid: 14 October 2011 Permanent link to this document https://projecteuclid.org/euclid.ijm/1318598675 Digital Object Identifier doi:10.1215/ijm/1318598675 Mathematical Reviews number (MathSciNet) MR2846476 Zentralblatt MATH identifier 1235.42008 Citation
Zheng, Shijun. Spectral multipliers for Schrödinger operators. Illinois J. Math. 54 (2010), no. 2, 621--647. doi:10.1215/ijm/1318598675. https://projecteuclid.org/euclid.ijm/1318598675
|
The point is that sometimes, different models (for the same data) can lead to likelihood functions which differ by a multiplicative constant, but the information content must clearly be the same. An example:
We model $n$ independent Bernoulli experiments, leading to data $X_1, \dots, X_n$, each with a Bernoulli distribution with (probability) parameter $p$. This leads to the likelihood function$$ \prod_{i=1}^n p^{x_i} (1-p)^{1-x_i}$$Or we can summarize the data by the binomially distributed variable $Y=X_1+X_2+\dotsm+X_n$, which has a binomial distribution, leading to the likelihood function$$ \binom{n}{y} p^y (1-p)^{n-y}$$which, as a function of the unknown parameter $p$, is proportional to the former likelihood function. The two likelihood functions clearly contains the same information, and should lead to the same inferences!
And indeed, by definition, they are considered the same likelihood function.
Another viewpoint: observe that when the likelihood functions are used in Bayes theorem, as needed for bayesian analysis, such multiplicative constants simply cancel! so they are clearly irrelevant to bayesian inference. Likewise, it will cancel when calculating likelihood ratios, as used in optimal hypothesis tests (Neyman-Pearson lemma.) And it will have no influence on the value of maximum likelihood estimators. So we can see that in much of frequentist inference it cannot play a role.
We can argue from still another viewpoint. The Bernoulli probability function (hereafter we use the term "density") above is really a density with respect to counting measure, that is, the measure on the non-negative integers with mass one for each non-negative integer. But we could have defined a density with respect to some other dominating measure. In this example this will seem (and is) artificial, but in larger spaces (function spaces) it is really fundamental! Let us, for the purpose of illustration, use the specific geometric distribution, written $\lambda$, with $\lambda(0)=1/2$, $\lambda(1)=1/4$, $\lambda(2)=1/8$ and so on. Then the density of the Bernoulli distribution
with respect to $\lambda$ is given by$$ f_{\lambda}(x) = p^x (1-p)^{1-x}\cdot 2^{x+1}$$meaning that $$ P(X=x)= f_\lambda(x) \cdot \lambda(x)$$With this new, dominating, measure, the likelihood function becomes (with notation from above) $$ \prod_{i=1}^n p^{x_i} (1-p)^{1-x_i} 2^{x_i+1} = p^y (1-p)^{n-y} 2^{y+n}$$note the extra factor $2^{y+n}$. So when changing the dominating measure used in the definition of the likelihood function, there arises a new multiplicative constant, which does not depend on the unknown parameter $p$, and is clearly irrelevant. That is another way to see how multiplicative constants must be irrelevant. This argument can be generalized using Radon-Nikodym derivatives (as the argument above is an example of.)
|
Assume on the contrary that each matrix equation $A\mathbf{x}=\mathbf{e}_i$ has a solution.Let $\mathbf{b}_i\in \R^n$ be a solution of $A\mathbf{x}=\mathbf{e}_i$ for each $i=1, \dots, n$.That is, we have\[A\mathbf{b}_i=\mathbf{e}_i.\]Let $B=[\mathbf{b}_1, \mathbf{b}_2, \dots, \mathbf{b}_n]$ be the $n\times n$ matrix whose $i$-th column vector is $\mathbf{b}_i$.
Then we have\begin{align*}AB&=A[\mathbf{b}_1, \mathbf{b}_2, \dots, \mathbf{b}_n]\\[6pt]&=[A\mathbf{b}_1, A\mathbf{b}_2, \dots, A\mathbf{b}_n]\\[6pt]&=[\mathbf{e}_1, \mathbf{e}_2, \dots, \mathbf{e}_n]=I,\end{align*}where $I$ is the $n\times n$ identity matrix.
Since $I$ is the nonsingular matrix, the matrix $A$ must also be nonsingular.However this contradicts the assumption that $A$ is singular.It follows that at least one of the matrix equations $A\mathbf{x}=\mathbf{e}_i$ has no solution.
Perturbation of a Singular Matrix is NonsingularSuppose that $A$ is an $n\times n$ singular matrix.Prove that for sufficiently small $\epsilon>0$, the matrix $A-\epsilon I$ is nonsingular, where $I$ is the $n \times n$ identity matrix.Hint.Consider the characteristic polynomial $p(t)$ of the matrix $A$.Note […]
Unit Vectors and Idempotent MatricesA square matrix $A$ is called idempotent if $A^2=A$.(a) Let $\mathbf{u}$ be a vector in $\R^n$ with length $1$.Define the matrix $P$ to be $P=\mathbf{u}\mathbf{u}^{\trans}$.Prove that $P$ is an idempotent matrix.(b) Suppose that $\mathbf{u}$ and $\mathbf{v}$ be […]
|
How does he do the algebra? (page 134 Rudin, chapter 6 ,theorem 6.20)
$\left| \frac {F(t)- F(s)}{t-s} -f(x_o) \right| = \left| \frac{1}{t-s} \int_s^t[f(u) - f(x_o)]du \right|< \epsilon $
also, how does he conclude that $F'(x_o) = f(x_0)$
: here is the theorem(and the proof by rudin)
Let $f \in \Re$ on $[a,b]$. For $ a \leq x \leq b$, put: $F(x) = \int_a^x f(t)dt$, Then $F$ is continuous on $[a,b]$; furthermore, if $f$ is continuous at a point $x_0$ of $[a,b]$, then $F$ is differentiable at $x_o$ and $F'(x_0) = f(x_0)$.
(i will omit the proof of continuity of $F$ on $[a,b]$)
Suppose $f$ is continuous at $x_0$. Given $\epsilon > 0 $ choose $\delta > 0$ such that:
$\vert f(t)- f(x_o) \vert < \epsilon $
if $\vert t- x_0 \vert < \delta$, and $a \leq t \leq b $.Hence, if
$x_0 - \delta < s \leq x_0 \leq t < x_0 + \delta$ $\enspace$ with: $a\ \leq s < t \leq b$
we have by theorem 6.12(d)
$\left| \frac{F(t) - F(s)}{t-s} - f(x_0) \right| = \left| \frac{1}{t-s} \int_s^t [f(u) - f(x_0)]du \right| < \epsilon$
it follows that $F'(x_0) = f(x_0)$
|
Let $A_1, A_2, A_3, \,\ldots$ be sets such that $A_1 \cap A_2 \cap \cdots \cap A_n \ne \emptyset$ holds for all $n$.
Must it be that $\bigcap_{n = 1}^{\infty}A_n \ne \emptyset$?
I answered no. Here is my "proof".
Define $A_n = \{n+1, n+2, \,\ldots\}$.
Then $A_1 \cap A_2 \cap \cdots \cap A_n = \{n+1, n+2, \,\ldots\}$.
For all integers $n$, $\{n+1, n+2, \,\ldots\} \ne \emptyset$, since it contains $n+1$, and there is no largest integer.
Now consider $\bigcap_{n = 1}^{\infty} A_n$.
Suppose it contains an integer $m$. But $m \notin A_{m}$ by definition, hence $m \notin \bigcap_{n = 1}^{\infty} A_n$, so $\bigcap_{n = 1}^{\infty} A_n = \emptyset$.$$\tag*{$\blacksquare$}$$
Is that correct?
I ask because in my lecture notes, the definition of $\bigcap_{n = 1}^{\infty} A_n$ is $\{x : x \in A_n \ \forall n \}$ which (to me) seems to be equivalent to "$A_1 \cap A_2 \cap \cdots \cap A_n \ne \emptyset$ holds for all $n$", which would of course mean the answer is yes.
|
I'm having trouble with the understanding on this last problem from my homework set.
Two cars playing demolition derby are moving towards each other with constant velocity, as measured by Marvin, who is a stationary observer. As measured by Marvin, a green car on the left is moving rightward at 0.80 c and an orange car on the right is moving leftward at 0.60c.
(b) At the moment the green car passes Marvin, the separation between the two cars is 900 m in Marvin’s reference frame. What is the time interval between the green car passing Marvin and the collision of the two cars, as measured by Marvin?
I tried converting the orange car on the right's speed to green car's reference frame which gave me
$$v = -0.946c,$$
and then converted the 900m to that reference frame, by dividing by
$$\gamma = \frac{1}{\sqrt{1 - 0.8^2}} = 1.67.$$
So the distance in the green car on the left's reference frame is
$$\frac{900m}{1.67} = 540 m.$$
Then,
$$v = \frac{\triangle{x}}{\triangle{t}}.$$
so
$$\triangle{t} =\frac{540m}{0.946c} = 1.90 \mu{s}.$$
Then we multiply by $\gamma$ to get back to Marvin's reference frame and we get
$$t = 3.17\mu{s}.$$
My professor gave the hint that the distance should be 514 m in Marvin's reference frame. Which means that
$$\frac{0.8c}{514m} = 2.14 \mu{s}.$$
What am I doing wrong? Any help is much appreciated.
|
Motivating examples:
Let $V$ be a
real vector spacewith Haar measure $dv$. The fourier transform induces the following topological isomorphism: $$H^s(V,dv) \cong L^2(V^*,(1+|v^*|^2)^sdv^*)$$ The LHS being the $W^{s,2}$-type Sobolev space and the RHS a weighted $L^2$ space on the dual.
Consider $S^1$ a
circlewith haar measure $d\theta$. Fourier transform Induces a topological isomorphism: $$H^s(S^1,d\theta) \cong l^2(\mathbb{Z},(1+|n|^2)^s dn)$$ Here the LHS is again the sobolev space and on the RHS $dn$ is the counting measure on $\mathbb{Z}$ (This example can be generalized to any finite dimensional torus by suitably modifying both sides).
Notice we get the usual Fourier transform isomorphism by putting $s=0$.
Question:Is there a generalization of the above to non-abelian Fourier transformson (locally?) compact lie groups? (assuming of course the existence of a Plancherel measure). Elaboration:
Suppose $G$ is a compact (connected) lie group (for simplicity), let $dg$ denote the Haar measure and $d\mu$ the Plancherel measure on $\hat{G}$. Does there exist a function $q: \hat{G} \to \mathbb{R}$ (a weight, hopefully $q$ will be just the eigenvalue of the Caisimir) s.t. the non-abelian Fourier transform induces a topological isomorphism
$$H^s(G,dg) \cong \{ T \in\hat \oplus_{\pi \in \hat{G}} End(V_{\pi}): [ \pi \mapsto ||T_{\pi}||_{HS}] \in L^2(\hat{G},q^sd\mu) \}$$
|
Expressing a Linear Functional as a Linear Combination of Other Linear Functionals
If $X$ is a linear space and $\varphi, \psi_1, \psi_2, ..., \psi_n$ are linear functionals, we would like to obtain a criterion for when $\varphi$ is a linear combination of $\psi_1, \psi_2, ..., \psi_n$.
The theorem below gives us such a criterion.
Theorem 1: Let $X$ be a linear space and let $\varphi, \psi_1, \psi_2, ..., \psi_n \in X^{\#}$. Then $\varphi$ is a linear combination of $\psi_1, \psi_2, ..., \psi_n$ if and only if $\displaystyle{\bigcap_{k=1}^{n} \ker \psi_k \subseteq \ker \varphi}$. We only prove the forward direction of the theorem above. The converse is rather complicated so we omit it. Proof:$\Rightarrow$ Suppose that $\varphi$ is a linear combination of $\psi_1, \psi_2, ..., \psi_n$. Then there exists $a_1, a_2, ..., a_n \in \mathbb{C}$ such that: Let $x \in \bigcap_{k=1}^{n} \ker \psi_k$. Then $\psi_k(x) = 0$ for all $k \in \{ 1, 2, ..., n \}$. Therefore $\varphi(x) = 0$ from $(*)$. So:
|
1. UNNECESSARY PROBABILITIES.
The next two sections of this note analyze the "guess which is larger" and "two envelope" problems using standard tools of decision theory (2). This approach, although straightforward, appears to be new. In particular, it identifies a set of decision procedures for the two envelope problem that are demonstrably superior to the “always switch” or “never switch” procedures.
Section 2 introduces (standard) terminology, concepts, and notation. It analyzes all possible decision procedures for the "guess which is larger problem." Readers familiar with this material might like to skip this section. Section 3 applies a similar analysis to the two envelope problem. Section 4, the conclusions, summarizes the key points.
All published analyses of these puzzles assume there is a probability distribution governing the possible states of nature. This assumption, however, is not part of the puzzle statements. The key idea to these analyses is that dropping this (unwarranted) assumption leads to a simple resolution of the apparent paradoxes in these puzzles.
2. THE “GUESS WHICH IS LARGER” PROBLEM.
An experimenter is told that different real numbers $x_1$ and $x_2$ are written on two slips of paper. She looks at the number on a randomly chosen slip. Based only on this one observation, she must decide whether it is the smaller or larger of the two numbers.
Simple but open-ended problems like this about probability are notorious for being confusing and counter-intuitive. In particular, there are at least three distinct ways in which probability enters the picture. To clarify this, let's adopt a formal experimental point of view (2).
Begin by specifying a
loss function. Our goal will be to minimize its expectation, in a sense to be defined below. A good choice is to make the loss equal to $1$ when the experimenter guesses correctly and $0$ otherwise. The expectation of this loss function is the probability of guessing incorrectly. In general, by assigning various penalties to wrong guesses, a loss function captures the objective of guessing correctly. To be sure, adopting a loss function is as arbitrary as assuming a prior probability distribution on $x_1$ and $x_2$, but it is more natural and fundamental. When we are faced with making a decision, we naturally consider the consequences of being right or wrong. If there are no consequences either way, then why care? We implicitly undertake considerations of potential loss whenever we make a (rational) decision and so we benefit from an explicit consideration of loss, whereas the use of probability to describe the possible values on the slips of paper is unnecessary, artificial, and-—as we shall see—-can prevent us from obtaining useful solutions.
Decision theory models observational results and our analysis of them. It uses three additional mathematical objects: a sample space, a set of “states of nature,” and a decision procedure.
The sample space $S$ consists of all possible observations; here it can be identified with $\mathbb{R}$ (the set of real numbers).
The states of nature $\Omega$ are the possible probability distributions governing the experimental outcome. (This is the first sense in which we may talk about the “probability” of an event.) In the “guess which is larger” problem, these are the discrete distributions taking values at distinct real numbers $x_1$ and $x_2$ with equal probabilities of $\frac{1}{2}$ at each value. $\Omega$ can be parameterized by $\{\omega = (x_1, x_2) \in \mathbb{R}\times\mathbb{R}\ |\ x_1 \gt x_2\}.$
The decision space is the binary set $\Delta = \{\text{smaller}, \text{larger}\}$ of possible decisions.
In these terms, the loss function is a real-valued function defined on $\Omega \times \Delta$. It tells us how “bad” a decision is (the second argument) compared to reality (the first argument).
The
most general decision procedure $\delta$ available to the experimenter is a randomized one: its value for any experimental outcome is a probability distribution on $\Delta$. That is, the decision to make upon observing outcome $x$ is not necessarily definite, but rather is to be chosen randomly according to a distribution $\delta(x)$. (This is the second way in which probability may be involved.)
When $\Delta$ has just two elements, any randomized procedure can be identified by the probability it assigns to a prespecified decision, which to be concrete we take to be “larger.”
A physical spinner implements such a binary randomized procedure: the freely-spinning pointer will come to stop in the upper area, corresponding to one decision in $\Delta$, with probability $\delta$, and otherwise will stop in the lower left area with probability $1-\delta(x)$. The spinner is completely determined by specifying the value of $\delta(x)\in[0,1]$.
Thus a decision procedure can be thought of as a function
$$\delta^\prime:S\to[0,1],$$
where
$${\Pr}_{\delta(x)}(\text{larger}) = \delta^\prime(x)\ \text{ and }\ {\Pr}_{\delta(x)}(\text{smaller})=1-\delta^\prime(x).$$
Conversely, any such function $\delta^\prime$ determines a randomized decision procedure. The randomized decisions include deterministic decisions in the special case where the range of $\delta^\prime$ lies in $\{0,1\}$.
Let us say that the
cost of a decision procedure $\delta$ for an outcome $x$ is the expected loss of $\delta(x)$. The expectation is with respect to the probability distribution $\delta(x)$ on the decision space $\Delta$. Each state of nature $\omega$ (which, recall, is a Binomial probability distribution on the sample space $S$) determines the expected cost of any procedure $\delta$; this is the risk of $\delta$ for $\omega$, $\text{Risk}_\delta(\omega)$. Here, the expectation is taken with respect to the state of nature $\omega$.
Decision procedures are compared in terms of their risk functions. When the state of nature is truly unknown, $\varepsilon$ and $\delta$ are two procedures, and $\text{Risk}_\varepsilon(\omega)\ge \text{Risk}_\delta(\omega)$ for all $\omega$, then there is no sense in using procedure $\varepsilon$, because procedure $\delta$ is never any worse (and might be better in some cases). Such a procedure $\varepsilon$ is inadmissible; otherwise, it is admissible. Often many admissible procedures exist. We shall consider any of them “good” because none of them can be consistently out-performed by some other procedure.
Note that no prior distribution is introduced on $\Omega$ (a “mixed strategy for $C$” in the terminology of (1)). This is the third way in which probability may be part of the problem setting. Using it makes the present analysis more general than that of (1) and its references, while yet being simpler.
Table 1 evaluates the risk when the true state of nature is given by $\omega=(x_1, x_2).$ Recall that $x_1 \gt x_2.$
Table 1.
$$\matrix {\text{Decision:}& & \text{Larger} & \text{Larger} & \text{Smaller} & \text{Smaller}\\\text{Outcome} & \text{Probability} & \text{Probability} & \text{Loss} & \text{Probability} & \text{Loss} & \text{Cost} \\x_1 & 1/2 & \delta^\prime(x_1) & 0 & 1 - \delta^\prime(x_1) & 1 & 1 - \delta^\prime(x_1) \\x_2 & 1/2 & \delta^\prime(x_2) & 1 & 1 - \delta^\prime(x_2) & 0 & 1 - \delta^\prime(x_2)}$$
$$\text{Risk}(x_1,x_2):\ (1 - \delta^\prime(x_1) + \delta^\prime(x_2))/2.$$
In these terms the “guess which is larger” problem becomes
Given you know nothing about $x_1$ and $x_2$, except that they are distinct, can you find a decision procedure $\delta$ for which the risk $[1 – \delta^\prime(\max(x_1, x_2)) + \delta^\prime(\min(x_1, x_2))]/2$ is surely less than $\frac{1}{2}$?
This statement is equivalent to requiring $\delta^\prime(x)\gt \delta^\prime(y)$ whenever $x \gt y.$ Whence, it is necessary and sufficient for the experimenter's decision procedure to be specified by some strictly increasing function $\delta^\prime: S\to [0, 1].$ This set of procedures includes, but is larger than, all the “mixed strategies $Q$” of 1. There are
lots of randomized decision procedures that are better than any unrandomized procedure! 3. THE “TWO ENVELOPE” PROBLEM.
It is encouraging that this straightforward analysis disclosed a large set of solutions to the “guess which is larger” problem,
including good ones that have not been identified before. Let us see what the same approach can reveal about the other problem before us, the “two envelope” problem (or “box problem,” as it is sometimes called). This concerns a game played by randomly selecting one of two envelopes, one of which is known to have twice as much money in it as the other. After opening the envelope and observing the amount $x$ of money in it, the player decides whether to keep the money in the unopened envelope (to “switch”) or to keep the money in the opened envelope. One would think that switching and not switching would be equally acceptable strategies, because the player is equally uncertain as to which envelope contains the larger amount. The paradox is that switching seems to be the superior option, because it offers “equally probable” alternatives between payoffs of $2x$ and $x/2,$ whose expected value of $5x/4$ exceeds the value in the opened envelope. Note that both these strategies are deterministic and constant.
In this situation, we may formally write
$$\eqalign{S &= \{ x\in \mathbb{R}\ |\ x \gt 0\}, \\\Omega &= \{\text{Discrete distributions supported on }\{\omega, 2\omega\}\ |\ \omega \gt 0 \text{ and }\Pr(\omega) = \frac{1}{2}\}, \text{and}\\\Delta &= \{\text{Switch}, \text{Do not switch}\}.}$$
As before, any decision procedure $\delta$ can be considered a function from $S$ to $[0, 1],$ this time by associating it with the probability of not switching, which again can be written $\delta^\prime(x)$. The probability of switching must of course be the complementary value $1–\delta^\prime(x).$
The loss, shown in
Table 2, is the negative of the game's payoff. It is a function of the true state of nature $\omega$, the outcome $x$ (which can be either $\omega$ or $2\omega$), and the decision, which depends on the outcome.
Table 2.
$$\matrix{& \text{Loss}&\text{Loss} &\\\text{Outcome}(x) & \text{Switch} & \text{Do not switch} & \text{Cost}\\\omega & -2\omega & -\omega & -\omega[2(1-\delta^\prime(\omega)) + \delta^\prime(\omega)]\\2\omega & -\omega & -2\omega & -\omega[1 - \delta^\prime(2\omega) + 2\delta^\prime(2\omega)]}$$
In addition to displaying the loss function, Table 2 also computes the cost of an arbitrary decision procedure $\delta$. Because the game produces the two outcomes with equal probabilities of $\frac{1}{2}$, the risk when $\omega$ is the true state of nature is
$$\eqalign{\text{Risk}_\delta(\omega) &=-\omega[2(1-\delta^\prime(\omega)) + \delta^\prime(\omega)]/2 + -\omega[1 - \delta^\prime(2\omega) + 2\delta^\prime(2\omega)]/2 \\&= (-\omega/2)[3 + \delta^\prime(2\omega) - \delta^\prime(\omega)].}$$
A constant procedure, which means always switching ($\delta^\prime(x)=0$) or always standing pat ($\delta^\prime(x)=1$), will have risk $-3\omega/2$. Any strictly increasing function, or more generally, any function $\delta^\prime$ with range in $[0, 1]$ for which $\delta^\prime(2x) \gt \delta^\prime(x)$ for all positive real $x,$ determines a procedure $\delta$ having a risk function that is always strictly less than $-3\omega/2$ and thus is superior to either constant procedure, regardless of the true state of nature $\omega$!
The constant procedures therefore are inadmissible because there exist procedures with risks that are sometimes lower, and never higher, regardless of the state of nature.
Comparing this to the preceding solution of the “guess which is larger” problem shows the close connection between the two. In both cases,
an appropriately chosen randomized procedure is demonstrably superior to the “obvious” constant strategies.
These randomized strategies have some notable properties:
There are no bad situations for the randomized strategies: no matter how the amount of money in the envelope is chosen, in the long run these strategies will be no worse than a constant strategy.
No randomized strategy with limiting values of $0$ and $1$ dominates any of the others: if the expectation for $\delta$ when $(\omega, 2\omega)$ is in the envelopes exceeds the expectation for $\varepsilon$, then there exists some other possible state with $(\eta, 2\eta)$ in the envelopes and the expectation of $\varepsilon$ exceeds that of $\delta$ .
The $\delta$ strategies include, as special cases, strategies equivalent to many of the Bayesian strategies. Any strategy that says “switch if $x$ is less than some threshold $T$ and stay otherwise” corresponds to $\delta(x)=1$ when $x \ge T, \delta(x) = 0$ otherwise.
What, then, is the fallacy in the argument that favors always switching? It lies in the implicit assumption that there is any probability distribution at all for the alternatives. Specifically, having observed $x$ in the opened envelope, the intuitive argument for switching is based on the conditional probabilities Prob(Amount in unopened envelope | $x$ was observed), which are probabilities defined on the set of underlying states of nature. But these are not computable from the data. The decision-theoretic framework does not require a probability distribution on $\Omega$ in order to solve the problem, nor does the problem specify one.
This result differs from the ones obtained by (1) and its references in a subtle but important way. The other solutions all assume (even though it is irrelevant) there is a prior probability distribution on $\Omega$ and then show, essentially, that it must be uniform over $S.$ That, in turn, is impossible. However, the solutions to the two-envelope problem given here do not arise as the best decision procedures for some given prior distribution and thereby are overlooked by such an analysis. In the present treatment, it simply does not matter whether a prior probability distribution can exist or not. We might characterize this as a contrast between being uncertain what the envelopes contain (as described by a prior distribution) and being completely ignorant of their contents (so that no prior distribution is relevant). 4. CONCLUSIONS.
In the “guess which is larger” problem, a good procedure is to decide randomly that the observed value is the larger of the two, with a probability that increases as the observed value increases. There is no single best procedure. In the “two envelope” problem, a good procedure is again to decide randomly that the observed amount of money is worth keeping (that is, that it is the larger of the two), with a probability that increases as the observed value increases. Again there is no single best procedure. In both cases, if many players used such a procedure and independently played games for a given $\omega$, then (regardless of the value of $\omega$) on the whole they would win more than they lose, because their decision procedures favor selecting the larger amounts.
In both problems, making an additional assumption-—a prior distribution on the states of nature—-that is not part of the problem gives rise to an apparent paradox. By focusing on what is specified in each problem, this assumption is altogether avoided (tempting as it may be to make), allowing the paradoxes to disappear and straightforward solutions to emerge.
REFERENCES
(1) D. Samet, I. Samet, and D. Schmeidler,
One Observation behind Two-Envelope Puzzles. American Mathematical Monthly 111 (April 2004) 347-351.
(2) J. Kiefer,
Introduction to Statistical Inference. Springer-Verlag, New York, 1987.
|
From this, we see that the matrix $A$ is nonsingular if and only if the $(3, 3)$-entry $4a^2+a+1$ is not zero.By the quadratic formula, we see that\[a=\frac{-1\pm \sqrt{-15}}{8}\]are solutions of $4a^2+a+1=0$.
Note that these are not real numbers. Thus, for any real number $a$, we have $4a^2+a+1\neq 0$.
Hence, we can divide the third row by this number, and eventually we can reduce it to the identity matrix.So the rank of $A$ is $3$, and $A$ is nonsingular for any real number $a$.
Determine whether the Given 3 by 3 Matrices are NonsingularDetermine whether the following matrices are nonsingular or not.(a) $A=\begin{bmatrix}1 & 0 & 1 \\2 &1 &2 \\1 & 0 & -1\end{bmatrix}$.(b) $B=\begin{bmatrix}2 & 1 & 2 \\1 &0 &1 \\4 & 1 & 4\end{bmatrix}$.Solution.Recall that […]
Find the Rank of a Matrix with a ParameterFind the rank of the following real matrix.\[ \begin{bmatrix}a & 1 & 2 \\1 &1 &1 \\-1 & 1 & 1-a\end{bmatrix},\]where $a$ is a real number.(Kyoto University, Linear Algebra Exam)Solution.The rank is the number of nonzero rows of a […]
If Two Matrices Have the Same Rank, Are They Row-Equivalent?If $A, B$ have the same rank, can we conclude that they are row-equivalent?If so, then prove it. If not, then provide a counterexample.Solution.Having the same rank does not mean they are row-equivalent.For a simple counterexample, consider $A = […]
Find Values of $a$ so that the Matrix is NonsingularLet $A$ be the following $3 \times 3$ matrix.\[A=\begin{bmatrix}1 & 1 & -1 \\0 &1 &2 \\1 & 1 & a\end{bmatrix}.\]Determine the values of $a$ so that the matrix $A$ is nonsingular.Solution.We use the fact that a matrix is nonsingular if and only if […]
|
Let $V$ be the vector space of $n \times n$ matrices with real coefficients, and define\[ W = \{ \mathbf{v} \in V \mid \mathbf{v} \mathbf{w} = \mathbf{w} \mathbf{v} \mbox{ for all } \mathbf{w} \in V \}.\]The set $W$ is called the center of $V$.
We must show that $W$ satisfies the three criteria for vector subspaces.Namely, the zero vector of $V$ is in $W$, and $W$ is closed under addition and scalar multiplication.
First, the zero element in $V$ is the matrix $\mathbf{0}$ whose entries are all $0$. For any other matrix $\mathbf{x} \in V$, we have $\mathbf{0} \mathbf{x} = \mathbf{0} = \mathbf{x} \mathbf{0}$. So we see that $\mathbf{0} \in W$.
Now suppose $\mathbf{v}, \mathbf{w} \in W$ and $c \in \mathbb{R}$. Then for any $\mathbf{x} \in V$, we have\[(\mathbf{v} + \mathbf{w} ) \mathbf{x} = \mathbf{v} \mathbf{x} + \mathbf{w} \mathbf{x} = \mathbf{x} \mathbf{v} + \mathbf{x} \mathbf{w} = \mathbf{x} ( \mathbf{v} + \mathbf{w} ),\]where the second equality follows because $\mathbf{v}$ and $\mathbf{w}$ lie in $W$. So we see that $\mathbf{v} + \mathbf{w} \in W$ as well, and so $W$ is closed under addition.
Finally we must show that $c \mathbf{v} \in W$ as well. For any other $\mathbf{x} \in V$, we have\[(c \mathbf{v} ) \mathbf{x} = c ( \mathbf{v} \mathbf{x}) = c ( \mathbf{x} \mathbf{v} ) = \mathbf{x} ( c \mathbf{v} ),\]where the second equality follows from the fact that $\mathbf{v} \in W$ and so $\mathbf{v} \mathbf{x} = \mathbf{x} \mathbf{v}$.
Thus we see that $c \mathbf{v} \in W$, finishing the proof.
For Fixed Matrices $R, S$, the Matrices $RAS$ form a SubspaceLet $V$ be the vector space of $k \times k$ matrices. Then for fixed matrices $R, S \in V$, define the subset $W = \{ R A S \mid A \in V \}$.Prove that $W$ is a vector subspace of $V$.Proof.We verify the subspace criteria: the zero vector of $V$ is in $W$, and […]
The Centralizer of a Matrix is a SubspaceLet $V$ be the vector space of $n \times n$ matrices, and $M \in V$ a fixed matrix. Define\[W = \{ A \in V \mid AM = MA \}.\]The set $W$ here is called the centralizer of $M$ in $V$.Prove that $W$ is a subspace of $V$.Proof.First we check that the zero […]
Subspaces of Symmetric, Skew-Symmetric MatricesLet $V$ be the vector space over $\R$ consisting of all $n\times n$ real matrices for some fixed integer $n$. Prove or disprove that the following subsets of $V$ are subspaces of $V$.(a) The set $S$ consisting of all $n\times n$ symmetric matrices.(b) The set $T$ consisting of […]
Determine the Values of $a$ so that $W_a$ is a SubspaceFor what real values of $a$ is the set\[W_a = \{ f \in C(\mathbb{R}) \mid f(0) = a \}\]a subspace of the vector space $C(\mathbb{R})$ of all real-valued functions?Solution.The zero element of $C(\mathbb{R})$ is the function $\mathbf{0}$ defined by […]
Sequences Satisfying Linear Recurrence Relation Form a SubspaceLet $V$ be a real vector space of all real sequences\[(a_i)_{i=1}^{\infty}=(a_1, a_2, \cdots).\]Let $U$ be the subset of $V$ defined by\[U=\{ (a_i)_{i=1}^{\infty} \in V \mid a_{k+2}-5a_{k+1}+3a_{k}=0, k=1, 2, \dots \}.\]Prove that $U$ is a subspace of […]
|
Wave energy converters in coastal structures Introduction
Fig 1: Construction of a coastal structure.
Coastal works along European coasts are composed of very diverse structures. Many coastal structures are ageing and facing problems of stability, sustainability and erosion. Moreover climate change and especially sea level rise represent a new danger for them. Coastal dykes in Europe will indeed be exposed to waves with heights that are greater than the dykes were designed to withstand, in particular all the structures built in shallow water where the depth imposes the maximal amplitude because of wave breaking.
This necessary adaptation will be costly but will provide an opportunity to integrate converters of sustainable energy in the new maritime structures along the coasts and in particular in harbours. This initiative will contribute to the reduction of the greenhouse effect. Produced energy can be directly used for the energy consumption in harbour area and will reduce the carbon footprint of harbours by feeding the docked ships with green energy. Nowadays these ships use their motors to produce electricity power on board even if they are docked. Integration of wave energy converters (WEC) in coastal structures will favour the emergence of the new concept of future harbours with zero emissions.
Inhoud Wave energy and wave energy flux
For regular water waves, the time-mean wave energy density E per unit horizontal area on the water surface (J/m²) is the sum of kinetic and potential energy density per unit horizontal area. The potential energy density is equal to the kinetic energy
[1] both contributing half to the time-mean wave energy density E that is proportional to the wave height squared according to linear wave theory [1]:
(1)
[math]E= \frac{1}{8} \rho g H^2[/math]
g is the gravity and [math]H[/math] the wave height of regular water waves. As the waves propagate, their energy is transported. The energy transport velocity is the group velocity. As a result, the time-mean wave energy flux per unit crest length (W/m) perpendicular to the wave propagation direction, is equal to
[1]:
(2)
[math] P= Ec_{g}[/math]
with [math]c_{g}[/math] the group velocity (m/s). Due to the dispersion relation for water waves under the action of gravity, the group velocity depends on the wavelength λ (m), or equivalently, on the wave period T (s). Further, the dispersion relation is a function of the water depth h (m). As a result, the group velocity behaves differently in the limits of deep and shallow water, and at intermediate depths:
[math](\frac{\lambda}{20} \lt h \lt \frac{\lambda}{2})[/math]
Application for wave energy convertersFor regular waves in deep water:
[math]c_{g} = \frac{gT}{4\pi} [/math] and [math]P_{w1} = \frac{\rho g^2}{32 \pi} H^2 T[/math]
The time-mean wave energy flux per unit crest length is used as one of the main criteria to choose a site for wave energy converters.
For real seas, whose waves are random in height, period (and direction), the spectral parameters have to be used. [math]H_{m0} [/math] the spectral estimate of significant wave height is based on zero-order moment of the spectral function as [math]H_{m0} = 4 \sqrt{m_0} [/math] Moreover the wave period is derived as follows
[2].
[math]P_{w1} = \frac{\rho g^2}{64 \pi} H_{m0}^2 T_e[/math]
If local data are available ([math]H_{m0}^2 [/math], T) for a sea state through in-situ wave buoys for example, satellite data or numerical modelling, the last equation giving wave energy flux [math]P_{w1}[/math] gives a first estimation. Averaged over a season or a year, it represents the maximal energetic resource that can be theoretically extracted from wave energy. If the directional spectrum of sea state variance F (f,[math]\theta[/math]) is known with f the wave frequency (Hz) and [math]\theta[/math] the wave direction (rad), a more accurate formulation is used:
[math]P_{w2} = \rho g\int\int c_{g}(f,h)F(f,\theta) dfd \theta[/math]
Fig 2: Time-mean wave energy flux along
West European coasts
[3] .
It can be shown easily that equation (4) can be reduced to (3) with the hypothesis of regular waves in deep water. The directional spectrum is deduced from directional wave buoys, SAR images or advanced spectral wind-wave models, known as third-generation models, such as WAM, WAVEWATCH III, TOMAWAC or SWAN. These models solve the spectral action balance equation without any a priori restrictions on the spectrum for the evolution of wave growth.
From TOMAWAC model, the near shore wave atlas ANEMOC along the coasts of Europe and France based on the numerical modelling of wave climate over 25 years has been produced
[4]. Using equation (4), the time-mean wave energy flux along West European coasts is obtained (see Fig. 2). This equation (4) still presents some limits like the definition of the bounds of the integration. Moreover, the objective to get data on the wave energy near coastal structures in shallow or intermediate water requires the use of numerical models that are able to represent the physical processes of wave propagation like the refraction, shoaling, dissipation by bottom friction or by wave breaking, interactions with tides and diffraction by islands.
The wave energy flux is therefore calculated usually for water depth superior to 20 m. This maximal energetic resource calculated in deep water will be limited in the coastal zone:
at low tide by wave breaking; at high tide in storm event when the wave height exceeds the maximal operating conditions; by screen effect due to the presence of capes, spits, reefs, islands,...
Technologies
According to the International Energy Agency (IEA), more than hundred systems of wave energy conversion are in development in the world. Among them, many can be integrated in coastal structures. Evaluations based on objective criteria are necessary in order to sort theses systems and to determine the most promising solutions.
Criteria are in particular:
the converter efficiency : the aim is to estimate the energy produced by the converter. The efficiency gives an estimate of the number of kWh that is produced by the machine but not the cost. the converter survivability : the capacity of the converter to survive in extreme conditions. The survivability gives an estimate of the cost considering that the weaker are the extreme efforts in comparison with the mean effort, the smaller is the cost.
Unfortunately, few data are available in literature. In order to determine the characteristics of the different wave energy technologies, it is necessary to class them first in four main families
[3].
An interesting result is that the maximum average wave power that a point absorber can absorb [math]P_{abs} [/math](W) from the waves does not depend on its dimensions
[5]. It is theoretically possible to absorb a lot of energy with only a small buoy. It can be shown that for a body with a vertical axis of symmetry (but otherwise arbitrary geometry) oscillating in heave the capture (or absorption) width [math]L_{max}[/math](m) is as follows [5]:
[math]L_{max} = \frac{P_{abs}}{P_{w}} = \frac{\lambda}{2\pi}[/math] or [math]1 = \frac{P_{abs}}{P_{w}} \frac{2\pi}{\lambda}[/math]
Fig 4: Upper limit of mean wave power
absorption for a heaving point absorber.
where [math]{P_{w}}[/math] is the wave energy flux per unit crest length (W/m). An optimally damped buoy responds however efficiently to a relatively narrow band of wave periods.
Babarit et Hals propose
[6] to derive that upper limit for the mean annual power in irregular waves at some typical locations where one could be interested in putting some wave energy devices. The mean annual power absorption tends to increase linearly with the wave power resource. Overall, one can say that for a typical site whose resource is between 20-30 kW/m, the upper limit of mean wave power absorption is about 1 MW for a heaving WEC with a capture width between 30-50 m.
In order to complete these theoretical results and to describe the efficiency of the WEC in practical situations, the capture width ratio [math]\eta[/math] is also usually introduced. It is defined as the ratio between the absorbed power and the available wave power resource per meter of wave front times a relevant dimension B [m].
[math]\eta = \frac{P_{abs}}{P_{w}B} [/math]
The choice of the dimension B will depend on the working principle of the WEC. Most of the time, it should be chosen as the width of the device, but in some cases another dimension is more relevant. Estimations of this ratio [math]\eta[/math] are given
[6]: 33 % for OWC, 13 % for overtopping devices, 9-29 % for heaving buoys, 20-41 % for pitching devices. For energy converted to electricity, one must take into account moreover the energy losses in other components of the system.
Civil engineering
Never forget that the energy conversion is only a secondary function for the coastal structure. The primary function of the coastal structure is still protection. It is necessary to verify whether integration of WEC modifies performance criteria of overtopping and stability and to assess the consequences for the construction cost.
Integration of WEC in coastal structures will always be easier for a new structure than for an existing one. In the latter case, it requires some knowledge on the existing coastal structures. Solutions differ according to sea state but also to type of structures (rubble mound breakwater, caisson breakwaters with typically vertical sides). Some types of WEC are more appropriate with some types of coastal structures.
Fig 5: Several OWC (Oscillating water column) configurations (by Wavegen – Voith Hydro).
Environmental impact
Wave absorption if it is significant will change hydrodynamics along the structure. If there is mobile bottom in front of the structure, a sand deposit can occur. Ecosystems can also be altered by change of hydrodynamics and but acoustic noise generated by the machines.
Fig 6: Finistere area and locations of
the six sites (google map).
Study case: Finistere area
Finistere area is an interesting study case because it is located in the far west of Brittany peninsula and receives in consequence the largest wave energy flux along the French coasts (see Fig.2). This area with a very ragged coast gathers moreover many commercial ports, fishing ports, yachting ports. The area produces a weak part of its consumption and is located far from electricity power plants. There are therefore needs for renewable energies that are produced locally. This issue is important in particular in islands. The production of electricity by wave energy will have seasonal variations. Wave energy flux is indeed larger in winter than in summer. The consumption has peaks in winter due to heating of buildings but the consumption in summer is also strong due to the arrival of tourists.
Six sites are selected (see figure 7) for a preliminary study of wave energy flux and capacity of integration of wave energy converters. The wave energy flux is expected to be in the range of 1 – 10 kW/m. The length of each breakwater exceeds 200 meters. The wave power along each structure is therefore estimated between 200 kW and 2 MW. Note that there exist much longer coastal structures like for example Cherbourg (France) with a length of 6 kilometres.
(1) Roscoff (300 meters) (2) Molène (200 meters) (3) Le Conquet (200 meters) (4) Esquibien (300 meters) (5) Saint-Guénolé (200 meters) (6) Lesconil (200 meters) Fig.7: Finistere area, the six coastal structures and their length (google map).
Wave power flux along the structure depends on local parameters: bottom depth that fronts the structure toe, the presence of caps, the direction of waves and the orientation of the coastal structure. See figure 8 for the statistics of wave directions measured by a wave buoy located at the Pierres Noires Lighthouse. These measurements show that structures well-oriented to West waves should be chosen in priority. Peaks of consumption occur often with low temperatures in winter coming with winds from East- North-East directions. Structures well-oriented to East waves could therefore be also interesting even if the mean production is weak.
Fig 8: Wave measurements at the Pierres Noires Lighthouse.
Conclusion
Wave energy converters (WEC) in coastal structures can be considered as a land renewable energy. The expected energy can be compared with the energy of land wind farms but not with offshore wind farms whose number and power are much larger. As a land system, the maintenance will be easy. Except the energy production, the advantages of such systems are :
a “zero emission” port industrial tourism test of WEC for future offshore installations.
Acknowledgement
This work is in progress in the frame of the national project EMACOP funded by the French Ministry of Ecology, Sustainable Development and Energy.
See also Waves Wave transformation Groynes Seawall Seawalls and revetments Coastal defense techniques Wave energy converters Shore protection, coast protection and sea defence methods Overtopping resistant dikes
References Mei C.C. (1989) The applied dynamics of ocean surface waves. Advanced series on ocean engineering. World Scientific Publishing Ltd Vicinanza D., Cappietti L., Ferrante V. and Contestabile P. (2011) : Estimation of the wave energy along the Italian offshore, journal of coastal research, special issue 64, pp 613 - 617. Mattarolo G., Benoit M., Lafon F. (2009), Wave energy resource off the French coasts: the ANEMOC database applied to the energy yield evaluation of Wave Energy, 10th European Wave and Tidal Energy Conference Series (EWTEC’2009), Uppsala (Sweden) Benoit M. and Lafon F. (2004) : A nearshore wave atlas along the coasts of France based on the numerical modeling of wave climate over 25 years, 29th International Conference on Coastal Engineering (ICCE’2004), Lisbonne (Portugal), 714-726. De O. Falcão A. F. (2010) Wave energy utilization: A review of the technologies. Renewable and Sustainable Energy Reviews, Volume 14, Issue 3, April 2010, Pages 899–918. Babarit A. and Hals J. (2011) On the maximum and actual capture width ratio of wave energy converters – 11th European Wave and Tidal Energy Conference Series (EWTEC’2011) – Southampton (U-K).
|
Looking for an example of a group homomorphism to better grasp the concept. Something along the lines of defining a simple group such as $X = \{1,0\}$ and $G = (X, \circ)$, and $A = \{1,2,3\}$ is an arbitrary set. Then taking that (or preferrably a better example) and demonstrating explicitly how the group homomorphism works by plugging in values to the function.
Background
This excerpt on group action says:
Thus, if $G$ is a group and $X$ is a set, then an action of $G$ on $X$ may be formally defined as a
group homomorphism$\varphi$ from $G$ to the symmetric group of $X$.
The symmetric group is defined as:
the group whose elements are all the bijections from the set to itself, and whose group operation is the composition of functions.
A bijection is defined as:
a function between the elements of two sets, where each element of one set is paired with exactly one element of the other set, and each element of the other set is paired with exactly one element of the first set... A bijection from the set X to the set Y has an inverse function from Y to X.
A group homomorphism is defined as:
a function $h : G → H$ such that for all $u$ and $v$ in $G$ it holds that $h(u*v)=h(u)\cdot h(v)$, where the group operation on the left hand side of the equation is that of $G$ and on the right hand side that of $H$.
So we have a homomorphism is $\varphi : G \to \dot{X}$ let's say, where $\dot{X}$ is the symmetric group of X.
Question
I am wondering exactly what this looks like through plugging in examples to the function $\varphi$. The way I am currently looking at it, it seems that these are all equivalent definitions:
\begin{align*} \varphi_a &: G \to \dot{X}\\ \varphi_b &: G \to X \times X\\ \varphi_c &: G \to X \to X\\ \varphi_d &: G \times X \to X \end{align*}
Plugging in values would look
something like this (I am very confused by this point):
\begin{align*} \varphi(1) &\mapsto 1\\ \varphi(1) &\mapsto (1,2)\\ \varphi(1) &\mapsto (1,2,3)\\ \varphi(1,2) &\mapsto 1\\ \varphi(1,2) &\mapsto (1,2)\\ \varphi(1,2) &\mapsto (1,2,3)\\ \end{align*}
(Don't know how many args it takes, how currying is applied here if at all, or what the output is)
My main source of confusion is in the definition of bijection and the symetric group:
Is a bijection an ordered pair $((a,b),(b,a))$, or just $(a,b)$, or is it a function $f : a \mapsto b$, or should I interpret a function as simply an ordered pair and nothing else. (Coming from a programming background). What does it look like applying the group operation of a symmetric group (composition of functions) to a bijective function? Specifically, what are some example inputs/outputs in 1 or 2 different notational variations so I can get a sense of exactly what is meant. Combining it all together, what are some example inputs/outputs of a group homomorphism, having now seen examples of bijections and symmetry groups.
I am having difficulty visualizing how bijection -> symmetry group -> group homomorphism maps together, using values from an arbitrary example group and set for demonstration purposes.
|
My issue is about the proper development of the action of the momentum operator $P^{\mu}$ - the generator of spacetime translations - on multi-particle states. I'm a little clueless on this, so I'm going to build up my question without developing it at all. Hopefully somebody can fill in the holes.
Consider a scalar quantum field theory with underlying spacetime symmetry group being the orthochronous restricted Poincare transformations. A scalar field operator $\phi (x)$ can be generated by the (unitary) translation operator $T(x)= \exp (iP^{\mu}x_{\mu})$ and the operator at some other point (say, the origin):
$$\phi(x)=\exp(iP^{\mu}x_{\mu})\phi(0)\exp (-iP^{\mu}x_{\mu})$$
The generator(s) of space-transformations, $P^{\mu}$, act on single-particle states $|p\rangle$ as follows:
$$P^{\mu}|p\rangle=p^{\mu}|p\rangle$$
My question is, how does the operator $P^{\mu}$ act on multi-particle states? For example, how does the 4-momentum operator act on a two-particle state:
$$P^{\mu}|k_1,k_2\rangle = ?$$
Is a two-particle state simply not an eigenstate of the 4-momentum operator? Or maybe it's an eigenstate when the two are equal? Or maybe we need to define 4-momentum operators that act on different $n$-particle Hilbert spaces ((anti-)symmetrized appropriately)?
|
Table of Content What is Radiation?
The process of the transfer of heat from one place to another place without heating the intervening medium is called radiation. The term radiation used here is another word for electromagnetic waves. These waves are formed due to the superposition of electric and magnetic fields perpendicular to each other and carry energy.
Properties of Radiation (a) All objects emit radiations simply because their temperature is above alsolute zero, and all objects absorb some of the radiation that falls on them from other objects. (b) Maxwell on the basis of his electromagnetic theory proved that all radiations are electromagnetic waves and their sources are vibrations of charged particles in atoms and molecules. (c) More radiations are emitted at higher temperature of a body and lesser at lower temperature. (d) The wavelength corresponding to maximum emission of radiations shifts from longer wavelength to shorter wavelength as the temperature increases. Due to this the colour of a body appears to be changing. Radiations from a body at NTP has predominantly infrared waves. (e) Thermal radiations travels with the speed of light and move in a straight line. (f) Radiations are electromagnetic waves and can also travel through vacuum. (g) Similar to light, thermal radiations can be reflected, refracted, diffracted and polarized. (h) Radiation from a point source obeys inverse square law (intensity a \(\frac{1}{r^{2}}\)). Prevost Theory of Exchange
According to this theory, all bodies radiate thermal radiation at all temperatures. The amount of thermal radiation radiated per unit time depends on the nature of the emitting surface, its area and its temperature. The rate is faster at higher temperatures. Besides, a body also absorbs part of the thermal radiation emitted by the surrounding bodies when this radiation falls on it. If a body radiates more then what it absorbs, its temperature falls. If a body radiates less than what it absorbs, its temperature rises. And if the temperature of a body is equal to the temperature of its surroundings it radiates at the same rate as it absorbs.
Black Body Radiation (Fery’s black body)
Perfectly black body
A perfectly black body is one which absorbs all the heat radiations of whatever wavelength, incident on it. It neither reflects nor transmits any of the incident radiation and therefore appears
black whatever be the colour of the incident radiation.
In actual practice, no natural object possesses strictly the properties of a perfectly black body. But the lamp-black and platinum black are good approximation of black body. They absorb about 99 % of the incident radiation. The most simple and commonly used black body was designed by Fery. It consists of an enclosure with a small opening which is painted black from inside. The opeining acts as a perfect black body. Any radiation that falls on the opening goes inside and has very little chance of escaping the enclosure before getting absorbed through multiple reflections. The cone opposite to the opening ensures that no radiation is reflected back directly.
Absorption, Reflection, and Emission of Radiations
Q = Q
r + Q t + Q a
1 = r + t + a
where r = reflecting power , a = absorptive power
and t = transmission power.
(i) r = 0, t = 0, a = 1, perfect black body
(ii) r = 1, t = 0, a = 0, perfect reflector
(iii) r = 0, t = 1, a = 0, perfect transmitter
Absorptive power
In particular the absorptive power of a body can be defined as the fraction of incident radiation that is absorbed by the body.\(a = \frac{Enerdy\; absorbes}{Energy \;incident}\)
As all the raditions incident on a black body are absorbed, a = 1 for a black body.
Emissive power
Energy radiated per unit time per unit area along the normal to the area is known as emissive power.\(E = \frac{Q}{\Delta A\Delta t}\)
(Notice that unlike absorptive power, emissive power is not a dimensionless quantity).
Spectral Emissive power (E l)
Emissive power per unit wavelength range at wavelength l is known as spectral emissive power, E
l. If E is the total emissive power and E l is spectral emissive power, they are related as follows, \(E = \int_{0}^{\infty }E_\lambda d_\lambda\;\; and\;\; \frac{dE}{d\lambda} = E_\lambda\) Emissivity\(e= \frac{Emissive \; power\;of\;a\;body\;at\;temperature\; T}{Emissive power \;of\; a\;black\; at \; same\;temperature\;T}= \frac{E}{E_o}\). Kirchoff’s Law
The ratio of the emissive power to the absorptive power for the radiation of a given wavelength is same for all substances at the same temperature and is equal to the emissive power of a perfectly black body for the same wavelength and temperature.\(\frac{E(body)}{a(body)}-E(black \;body)\)
Hence we can conclude that good emitters are also good absorbers.
Wien’s Displacement Law – Nature of thermal radiations
From the energy distribution curve of black body radiation, the following conclusions can be drawn :
(a) The higher the temperature of a body, the higher is the area under the curve i.e. more amount of energy is emitted by the body at higher temperature. (b) The energy emitted by the body at different temperatures is not uniform. For both long and short wavelengths, the energy emitted is very small. (c) For a given temperature, there is a particular wavelength (l m) for which the energy emitted (E l) is maximum. (d) With an increase in the temperature of the black body, the maxima of the curves shift towards shorter wavelengths.
From the study of the energy distribution of black body radiation discussed as above, it was established experimentally that the wavelength (l
m) corresponding to the maximum intensity of emission decreases inversely with the increase in the temperature of the black body. i.e.
l
m µ or l m T = b
This is called Wien’s displacement law.
Here b = 0.282 cm-K, is the Wien’s constant.
Ex: Solar radiation is found to have an intensity maximum near the wavelength range of 470 nm. Assuming the surface of sun to be perfectly absorbing (a = 1), calculate the temperature of solar surface. Sol. Since a =1, sun can be assumed to be emitting as a black body
from Wien’s law for a black body
l
m . T = b
Þ \(T=\frac{b}{\lambda_m} = \frac{0.282(cm-K)}{(470\times10^{-7}cm)}\)
~ 6125 K.
Ans.
|
I want to simplify the expression $\tan(\arctan(a) - \arctan(b))$ to $\tfrac{a-b}{1+a\cdot b}$ (if $b \neq - \tfrac{1}{a}$). Right now, the output of
FullSimplify[Tan[ArcTan[a] - ArcTan[b]], {a > 0, b > 0, a < Pi/2, b < Pi/2}]
is the same as the input. The assumptions are to assure that $b \neq -\tfrac{1}{a}$ and to give the right branch for the inverse
ArcTan.
Previous answers suggest the use of
ComplexityFunction, although I'm not sure how to use that in this case. Is Mathematica able to simplify this?
|
Let $G$ be a finite group of order $n$ and let $m$ be an integer that is relatively prime to $n=|G|$. Show that for any $a\in G$, there exists a unique element $b\in G$ such that\[b^m=a.\]Add to solve later
Since $m$ and $n$ are relatively prime integers, there exists integers $s, t$ such that\[sm+tn=1.\]
Then we have\begin{align*}a&=a^1=a^{sm+tn}=a^{sm}a^{tn} \tag{*}\end{align*}Note that since the order of the group $G$ is $n$, any element of $G$ raised by the power of $n$ is the identity element $e$ of $G$.Thus we have\[a^{tn}=(a^n)^t=e^t=e.\]Putting $b:=a^s$, we have from (*) that\[a=b^me=b^m.\]
Now we show the uniqueness of such $b$. Suppose there is another $g’\in G$ such that\[a=b’^m.\]Then we have\begin{align*}&\quad b^m=a=b’^m\\&\Rightarrow b^{sm}=b’^{sm} \quad \text{ by taking $s$-th power}\\&\Rightarrow b^{1-tn}=b’^{1-tn}\\&\Rightarrow b(b^n)^t=b'(b’^n)^t\\&\Rightarrow b=b’ \quad \text{ since } b^n=e=b’^n.\end{align*}Therefore, we have $b=b’$ and the element $b$ satisfying $a=b^m$ is unique.
Proof 2.
Consider a map $f$ from $G$ to $G$ itself defined by sending $g$ to $f(g)=g^m$.We show that this map is injective.Suppose that $f(g)=f(g’)$.
Since $m$ and $n$ are relatively prime integers, there exists integers $s, t$ such that\[sm+tn=1.\]
We have\begin{align*}f(g)&=f(g’)\\&\Rightarrow g^m=g’^m \\&\Rightarrow g^{sm}=g’^{sm} \quad \text{ by taking $s$-th power}\\&\Rightarrow g^{1-tn}=g’^{1-tn}\\&\Rightarrow g(g^n)^t=g'(g’^n)^t\\&\Rightarrow g=g’ \quad \text{ since } g^n=e=g’^n, n=|G|.\end{align*}
Therefore the map $f$ is injective. Since $G$ is a finite set, it also follows that the map is bijective.Thus for any $a \in G$, there is a unique $b \in G$ such that $f(b)=a$, namely, $b^m=a$.
Are Groups of Order 100, 200 Simple?Determine whether a group $G$ of the following order is simple or not.(a) $|G|=100$.(b) $|G|=200$.Hint.Use Sylow's theorem and determine the number of $5$-Sylow subgroup of the group $G$.Check out the post Sylow’s Theorem (summary) for a review of Sylow's […]
Abelian Groups and Surjective Group HomomorphismLet $G, G'$ be groups. Suppose that we have a surjective group homomorphism $f:G\to G'$.Show that if $G$ is an abelian group, then so is $G'$.Definitions.Recall the relevant definitions.A group homomorphism $f:G\to G'$ is a map from $G$ to $G'$ […]
A Group Homomorphism is Injective if and only if MonicLet $f:G\to G'$ be a group homomorphism. We say that $f$ is monic whenever we have $fg_1=fg_2$, where $g_1:K\to G$ and $g_2:K \to G$ are group homomorphisms for some group $K$, we have $g_1=g_2$.Then prove that a group homomorphism $f: G \to G'$ is injective if and only if it is […]
|
Search
Now showing items 1-1 of 1
Production of charged pions, kaons and protons at large transverse momenta in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(Elsevier, 2014-09)
Transverse momentum spectra of $\pi^{\pm}, K^{\pm}$ and $p(\bar{p})$ up to $p_T$ = 20 GeV/c at mid-rapidity, |y| $\le$ 0.8, in pp and Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV have been measured using the ALICE detector ...
|
Search
Now showing items 1-10 of 24
Production of Σ(1385)± and Ξ(1530)0 in proton–proton collisions at √s = 7 TeV
(Springer, 2015-01-10)
The production of the strange and double-strange baryon resonances ((1385)±, Ξ(1530)0) has been measured at mid-rapidity (|y|< 0.5) in proton–proton collisions at √s = 7 TeV with the ALICE detector at the LHC. Transverse ...
Forward-backward multiplicity correlations in pp collisions at √s = 0.9, 2.76 and 7 TeV
(Springer, 2015-05-20)
The strength of forward-backward (FB) multiplicity correlations is measured by the ALICE detector in proton-proton (pp) collisions at s√ = 0.9, 2.76 and 7 TeV. The measurement is performed in the central pseudorapidity ...
Inclusive photon production at forward rapidities in proton-proton collisions at $\sqrt{s}$ = 0.9, 2.76 and 7 TeV
(Springer Berlin Heidelberg, 2015-04-09)
The multiplicity and pseudorapidity distributions of inclusive photons have been measured at forward rapidities ($2.3 < \eta < 3.9$) in proton-proton collisions at three center-of-mass energies, $\sqrt{s}=0.9$, 2.76 and 7 ...
Rapidity and transverse-momentum dependence of the inclusive J/$\mathbf{\psi}$ nuclear modification factor in p-Pb collisions at $\mathbf{\sqrt{\textit{s}_{NN}}}=5.02$ TeV
(Springer, 2015-06)
We have studied the transverse-momentum ($p_{\rm T}$) dependence of the inclusive J/$\psi$ production in p-Pb collisions at $\sqrt{s_{\rm NN}} = 5.02$ TeV, in three center-of-mass rapidity ($y_{\rm cms}$) regions, down to ...
Measurement of pion, kaon and proton production in proton–proton collisions at √s = 7 TeV
(Springer, 2015-05-27)
The measurement of primary π±, K±, p and p¯¯¯ production at mid-rapidity (|y|< 0.5) in proton–proton collisions at s√ = 7 TeV performed with a large ion collider experiment at the large hadron collider (LHC) is reported. ...
Two-pion femtoscopy in p-Pb collisions at $\sqrt{s_{\rm NN}}=5.02$ TeV
(American Physical Society, 2015-03)
We report the results of the femtoscopic analysis of pairs of identical pions measured in p-Pb collisions at $\sqrt{s_{\mathrm{NN}}}=5.02$ TeV. Femtoscopic radii are determined as a function of event multiplicity and pair ...
Measurement of charm and beauty production at central rapidity versus charged-particle multiplicity in proton-proton collisions at $\sqrt{s}$ = 7 TeV
(Springer, 2015-09)
Prompt D meson and non-prompt J/$\psi$ yields are studied as a function of the multiplicity of charged particles produced in inelastic proton-proton collisions at a centre-of-mass energy of $\sqrt{s}=7$ TeV. The results ...
Charged jet cross sections and properties in proton-proton collisions at $\sqrt{s}=7$ TeV
(American Physical Society, 2015-06)
The differential charged jet cross sections, jet fragmentation distributions, and jet shapes are measured in minimum bias proton-proton collisions at centre-of-mass energy $\sqrt{s}=7$ TeV using the ALICE detector at the ...
Centrality dependence of high-$p_{\rm T}$ D meson suppression in Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 2.76 TeV
(Springer, 2015-11)
The nuclear modification factor, $R_{\rm AA}$, of the prompt charmed mesons ${\rm D^0}$, ${\rm D^+}$ and ${\rm D^{*+}}$, and their antiparticles, was measured with the ALICE detector in Pb-Pb collisions at a centre-of-mass ...
K*(892)$^0$ and $\Phi$(1020) production in Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV
(American Physical Society, 2015-02)
The yields of the K*(892)$^0$ and $\Phi$(1020) resonances are measured in Pb-Pb collisions at $\sqrt{s_{NN}}$ = 2.76 TeV through their hadronic decays using the ALICE detector. The measurements are performed in multiple ...
|
Why does the following DFA have (to have) the state $b_4$?
Shouldn't states $b_1,b_2,b_3$ already cover "exactly two 1s"? Wouldn't state $b_4$ mean "more than two 1s", even if it doesn't trigger an accept state?
Computer Science Stack Exchange is a question and answer site for students, researchers and practitioners of computer science. It only takes a minute to sign up.Sign up to join this community
$b_4$ is what is called a
trap state, that is, a state that exists just so that all possible transitions are explicitly represented, even those that do not lead to a final state.
It doesn't change the language that is being defined, and can be omitted for the sake of brevity.
b4 exists to cover the entire alphabet ([0,1], in this case) for each state. While this is not strictly necessary, it is a hot topic of discussion in the field.
By showing the complete graph, it is more obvious that a third '1' in your input string permanently moves you out of the 'accept' state b3.
The formal definition of a DFA is $M = (Q, \Sigma, \delta, q_0, F)$, were $Q$ is the finite set of states, $\Sigma$ is the alphabet, $\delta$ is the transition function, $q_0 \in Q$ is the start state, and $F \subseteq Q$ is the set of final states. Note that $\delta \colon Q \times \Sigma \to Q$ is specified to be a
function, i.e., it has to be defined for all states and symbols. The graphical depiction of the DFA is complete in this sense with $b_4$. Often such dead states are just omitted in the sake of clarity of the diagram, the reader is surely capable of adding them if required.
Answering your question I have to say(sadly) that it depend. It depends on the definition of DFA that you are using because it appears to not be concensus in a unique definition.
For example I use the definition of the DFA where $\delta$ is a function. The next question is: Is $\delta$ a total function or a partial function?
Personally when I use the term function I am refering to total functions by default. But someone can disagree with me. More importantly when I studied the definition of a DFA my teacher told me that $\delta$ is a total function.
Summarizing I use a particular definition of a DFA where the $b_4$ state have to exist. I can skip drawing it for the sake of laziness or clarity, but I know it exist.
Finally to answer your question more precisely we have to know what definition of DFA you use.
Wouldn't state b4 mean "more than two 1s", even if it doesn't trigger an accept state?
The state $b_4$ means that if a word $\sigma$ have more than two "1" it will never reach an accepting state so $\sigma\notin L = \{w\,|\, \text{contains exactly two ones}\}$.
|
I'm top-editing this since it answers the question directly.
The sinc series is fundamentally a $C/x$, so you can extract as many absolutely convergent series out of it as you want, but what is left over is still only conditionally convergent. Also, you can rescale $x$ and it is still a $C/x$ series.
Saying you have a summation to or from infinity is an informality. Formally, you have a finite sum to some value, and take the limit as that value goes to infinity.
Therefore, your first and second series should have been done like this:
$$ \lim_{L \to \infty} \sum_{k=-L}^{L} f(k) = \lim_{L \to \infty} \left[ \sum_{k=0}^{L} f(-k) + f(k+1) \right] $$$$ = \lim_{L \to \infty} \left[ \sum_{k=0}^{L} \left( f(-k) + f(2k+1) + f(2k+2) \right) + \sum_{k=0}^{L+1} f(-k-L-1) \right] $$
Likewise, your third should have added this:
$$ \sum_{k=0}^{L+1} \left( f(-k-L-1) + f(-k-2L-3) \right) $$
Sometimes it takes a while to get around to where you should have been in the first place. I'm deleting the rest. Whoever is curious can find it in the edit history.
Proceeding informally....
First rearrange it:
$$\begin{aligned}y_m &= \sum_{n=0}^{N-1} x[n] \sum_{k=-\infty}^{\infty} \operatorname{sinc} \left( \frac{Nm}{M} - n - Nk \right) \\&= \sum_{n=0}^{N-1} x[n] W_m[n]\end{aligned}$$
One way to look at that is a resampled value is a linear combination (weighted average) of the sample points.
Another way is that you now have $N$ separate infinite series, all of the form:
$$\begin{aligned}W_m[n] &= \sum_{k=-\infty}^{\infty} \operatorname{sinc} \left( \frac{Nm}{M} - n - Nk \right) \\ &= \sum_{k=-\infty}^{\infty} \frac{ \sin \left( ( Nm/M - n - Nk ) \pi\right) }{ (Nm/M - n - Nk) \pi } \\\end{aligned}$$
Even $N$ Case:
$$ W_m[n] = \sin \left( ( Nm/M - n ) \pi\right) \sum_{k=-\infty}^{\infty} \frac{ 1 }{ (Nm/M - n - Nk) \pi } $$
Odd $N$ Case:
$$ W_m[n] = \sin \left( ( Nm/M - n ) \pi\right) \sum_{k=-\infty}^{\infty} \frac{ (-1)^k }{ (Nm/M - n - Nk) \pi } $$
Clearly, both are cases of $C/x$ series and not absolutely convergent. If $Nm/N$ is an integer all the terms are zero except perhaps the zeroth terms.
As for the second comment, if I remember correctly (and I've already proven I didn't remember well), doing it formally does away with all the rearrangement tricks. And yes, If I remember correctly, absolutely convergent series are immune to rearrangement tricks.
This too:
A series converges if and only if the sequence of partial sums converges.
A sequence converges if and only if for any given $\epsilon$ there exist a $\delta$ so for every $k > \delta$ the absolute value of the difference of the limit and the sequence value is less than $\epsilon$.
Stamp it on your forehead for formal occasions.
Disclaimer: Been a long time ...
As clearly as I think I can say it:
The only conditions for which the series in Olli's Eq (1) will converge absolutely is when all the terms heading towards infinity are zero, since then their absolute values are zero. This happens when all the $x_n$ are zero (the trivial solution) or $Nm/M$ is an integer. Both the even and odd cases under any different conditions can be rearranged to be summations of alternating monotonically decreasing sequences, therefore they converge conditionally since they diverge absolutely.
Epilogue:
There is no need to do the infinite summation at all. Direct closed form expressions exist for the odd and then even case based on the interpolation functions found when considering an inverse DFT as a continuous function. The derivation of the functions can be found in the epilogue of my answer here:
How to get Fourier coefficients to draw any shape using DFT?
The derivation is based on the definitions of the DFT, the inverse DFT, and a finite geometric summation.
Resampling the continuous function at $M$ evenly spaced (in the cycle domain) points can be done by a simple variable substitution.
$$ t = \frac{m}{M} 2\pi $$
The direct sample set to sample set equations are then as follows.
Odd case:
$$ y_m = \sum_{n=0}^{N-1} x[n] \left[ \frac{ \sin \left( N \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) } { N \sin \left( \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) }\right] $$
Even case, evenly split Nyquist bin:
$$ y_m = \sum_{n=0}^{N-1} x[n] \left[ \frac{ \sin \left( N \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) } { N \sin \left( \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) }\right] \cos \left( \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) $$
These are mathematically equivalent to taking the DFT of size $N$, zero padding it at the Nyquist frequency to size $M$ (splitting the Nyquist bin in the even case), then taking the inverse DFT to recover a $M$ point upsampled sequence. All the upsampled points lie on the underlying continuous interpolation function no matter what the point count.
For the $N=2$, $M=4$ case:
$$\begin{aligned}y_0 &= x_0 ( 1 ) + x_1 ( 0 ) = x_0 \\y_1 &= x_0 \left( \frac{ \sin( \pi / 2 ) }{ 2 \sin( \pi / 4 ) } \cos( \pi / 4 ) \right) + x_1 \left( \frac{ \sin( -\pi / 2 ) }{ 2 \sin( -\pi / 4 ) } \cos( -\pi / 4 ) \right) \\&= \frac{1}{2} ( x_0 + x_1 ) \\y_2 &= x_0 ( 0 ) + x_1 ( 1 ) = x_1 \\y_3 &= x_0 \left( \frac{ \sin( 3 \pi / 2 ) }{ 2 \sin( 3 \pi / 4 ) } \cos( 3 \pi / 4 ) \right) + x_1 \left( \frac{ \sin( \pi / 2 ) }{ 2 \sin( \pi / 4 ) } \cos( \pi / 4 ) \right) \\&= \frac{1}{2} ( x_0 + x_1 ) \end{aligned}$$Which should be the results you are expecting.
An infinite number of sinc functions can now take the day off.
Suppose that instead of doing halfsies on the Nyquist bin we apportioned them as $(1/2+g)$ and $(1/2-g)$, this would alter the continuous interpolation function as follows.
$$\begin{aligned}D(t_n) &= \left( \frac{1}{2} + g \right) e^{i(N/2) t_n } + \left( \frac{1}{2} - g \right) e^{i(-N/2) t_n } + \sum_{l=0}^{N-2} e^{i ( l - N/2 + 1 ) t_n } \\ &= \cos \left( \frac{N}{2} t_n \right) + i 2 g\sin \left( \frac{N}{2} t_n \right) + \frac{ \sin( t_n N /2 ) } { \sin( t_n / 2 ) } \cos( t_n / 2 ) - \cos( t_n N /2 ) \\&= \frac{ \sin( N t_n/2 ) }{ \sin( t_n / 2 ) } \cos( t_n / 2 ) + i 2g\sin \left( \frac{N}{2} t_n \right)\end{aligned}$$
The extra term introduced is purely imaginary. That can be folded in, but I prefer to leave it separate when put back into the function definition.
$$\begin{aligned}z(t) &= \sum_{n=0}^{N-1} x[n] \left[ \frac{ \sin( N (t - \frac{n}{N}2\pi) / 2 ) } { N \tan( (t - \frac{n}{N}2\pi) / 2 ) } + i \frac{2g}{N}\sin \left( N (t - \frac{n}{N}2\pi) / 2 \right) \right]\end{aligned}$$
If is obvious that any non-zero value of $g$ will add "energy" to the signal, thus the $g=0$ solution, corresponding to halfsies on the Nyquist bin, is the most natural solution, or lowest energy, out of a whole family of solutions of periodic bandlimited at $N/2$ functions.
The more signifinant convincer for me is that it also introduces imaginary values into what is other wise fully real set of weighting values.
Whether R B-J's series converges uniquely to this "natural" solution, or the "natural solution" is a unique solution (it is not) are two totally separate issues.
Olli, I hope this makes you smile.
Start with the discrete resampling formula for the odd $N$ case.
$$ y_m = \sum_{n=0}^{N-1} x[n] \left[ \frac{ \sin \left( N \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) } { N \sin \left( \left( \frac{m}{M} - \frac{n}{N} \right) \pi \right) }\right] $$
Since the sequence of $N$ points is periodic $( x[n] = x[n+N] )$ and all the points are covered, we can shift the summation range to be zero centered.
$$ L = (N-1) / 2 $$
Also, the $m$th point can be located on the $n$ scale.
$$ w = m \frac{N}{M} = \frac{m}{M} N $$
Since the $M$ resampled points are evenly spaced along the cycle, they too can be arbitrarily shifted to be zero centered, though strictly that is not necessary.
Since "$t$" has already been used above, the scale of the domain of the continuous interpolation function, both will get new names. "$z(t)$" and "$Y(\omega)$" describe the same function. Plug all the defined values in.
$$\begin{aligned}y_m = Y(w) &= \sum_{n=-L}^{L} x[n]\left[ \frac{ \sin \left( \left( w - n \right) \pi \right) } { N \sin \left( \frac{1}{N} \left( w - n \right) \pi \right) }\right] \\&= \sum_{n=-L}^{L} x[n]\left[\frac{\frac{\sin \left( \left( w - n \right) \pi \right)}{ \left( \omega - n \right) \pi }}{\frac{\sin \left( \frac{1}{N} \left( w - n \right) \pi \right)}{\frac{1}{N} \left( w - n \right) \pi }}\right] \\&= \sum_{n=-L}^{L} x[n]\left[\frac{\operatorname{sinc} \left( w - n \right) } {\operatorname{sinc} \left( \frac{1}{N} \left( w - n \right) \right)}\right] \\\end{aligned}$$
Now it's time to take the big step, that is, big stroll out to infinity. The cycle of $N$ points grows until one cycle spans negative to positive infinity. As it gets bigger, the circular nature gets more remote.
$$\begin{aligned}\lim_{N \to \infty} y_m &= \lim_{N \to \infty} Y(w) \\&= \lim_{N \to \infty} \sum_{n=-L}^{L} x[n]\left[\frac{\operatorname{sinc} \left( w - n \right) } {\operatorname{sinc} \left( \frac{1}{N} \left( w - n \right) \right)}\right] \\&= \sum_{n=-\infty}^{\infty} x[n]\left[\frac{\operatorname{sinc} \left( w - n \right) } {1}\right] \\&= \sum_{n=-\infty}^{\infty} x[n] \operatorname{sinc} \left( w - n \right) \\&= \sum_{n=-\infty}^{\infty} x[n] \operatorname{sinc} \left( \frac{Nm}{M} - n \right)\end{aligned}$$
Now look at that. The Whittaker–Shannon interpolation formula has been derived from scratch and we are right at your starting point.
The even case can be done similarly and ends up with the same formula.
Definition of DFT of $N$ samples Inverse DFT used as Fourier Series Coefficients for interpolation function Dirichlet Kernel form of interpolation function Interpolation function used for $M$ samples Even and Odd Discrete Weighted Average Resampling Formulas N goes to infinity Whittaker–Shannon emerges Whittaker–Shannon applied to a repeating sequence of $N$ Convergence questioned
I hope realizing using step 7 to achieve what step 2 has already answered will put a smile on R B-J as well. Your proof lies there.
For $ N = 2 $
$$\begin{aligned}y_m &= \sum_{n=0}^{1} x[n] \left[ \frac{ \sin \left( 2 \left( \frac{m}{M} - \frac{n}{2} \right) \pi \right) } { 2 \sin \left( \left( \frac{m}{M} - \frac{n}{2} \right) \pi \right) }\right] \cos \left( \left( \frac{m}{M} - \frac{n}{2} \right) \pi \right) \\&= \sum_{n=0}^{1} x[n] \cos^2 \left( \left( \frac{m}{M} - \frac{n}{2} \right) \pi \right) \\&= x_0 \cos^2 \left( \frac{m}{M} \pi \right) + x_1 \sin^2 \left( \frac{m}{M} \pi \right)\end{aligned}$$
For $ x_0 = 1 $ and $ x_1 = -1 $
$$\begin{aligned}y_m &= \cos^2 \left( \frac{m}{M} \pi \right) - \sin^2 \left( \frac{m}{M} \pi \right) \\&= \cos \left( \frac{m}{M} 2 \pi \right)\end{aligned}$$
I'm going to have to be done with this for a while. Neat stuff.
Olli, thanks for the bounty points.
This little exercise has deepened my understanding of W-S considerably. I hope that is true for you and Robert (and others) too.
It is still a precarious foundation though. I wanted to convince myself that it would work for a sinusoid of any frequency. To wit:
$$ x[n] = M \cos( \alpha n + \phi ) $$
$$\begin{aligned}x(t) &= \sum_{n=-\infty}^{\infty} x[n] \operatorname{sinc}(t-n) \\&= \sum_{n=-\infty}^{\infty} M \cos( \alpha n + \phi ) \operatorname{sinc}(t-n) \\&= \sum_{n=-\infty}^{\infty} M \cos( \alpha t + \phi - \alpha( t - n ) ) \operatorname{sinc}(t-n) \\&= \sum_{n=-\infty}^{\infty} M \left[ \cos( \alpha t + \phi ) \cos( \alpha( t - n ) ) + \sin( \alpha t + \phi ) \sin( \alpha( t - n ) ) \right] \operatorname{sinc}(t-n) \\&= M \cos( \alpha t + \phi ) \sum_{n=-\infty}^{\infty} \cos( \alpha( t - n ) ) \operatorname{sinc}(t-n) \\& \qquad \qquad + M \sin( \alpha t + \phi ) \sum_{n=-\infty}^{\infty} \sin( \alpha( t - n ) ) \operatorname{sinc}(t-n) \\&= M \cos( \alpha t + \phi ) \cos( \alpha( t - t ) ) + M \sin( \alpha t + \phi ) \sin( \alpha( t - t ) ) \\&= M \cos( \alpha t + \phi ) \cdot 1 + M \sin( \alpha t + \phi ) \cdot 0 \\&= M \cos( \alpha t + \phi )\end{aligned}$$
I seem to have accomplished my goal. However, there is nothing in this proof that prohibits $\alpha \ge \pi$, though that is a condition for the validity of the theorem. So, knowing that, you are okay. If you didn't know that, the formula itself does not reveal it. To me, that's troubling.
Reply to R B-J:
First off, no where is it stipulated that $x[n]$ must be real. Even for a real valued function, you don't have to split the Nyquist bin halfsies to get a real interpolation function. Just pick $g$ to be a multiple of $i$ above.
Suppose you have the function:
$$ z(\tau) = \sum_{k=-L}^{L} c_k e^{ik\tau} $$
Its band limit is $L$ or less. Every k term, except 0, can be paired up with it's conjugate bin and the sum can be decomposed into a cosine and sine term.
let $ A = \frac{c_k + c_{-k}}{2} $ and $ B = \frac{c_k - c_{-k}}{2} $
$$ \begin{aligned}c_k e^{ik\tau} + c_{-k} e^{-ik\tau} &= (A+B) e^{ik\tau} + (A-B) e^{-ik\tau} \\&= 2A \cos(\tau) - i 2B \sin(\tau) \end{aligned}$$
For a regular bin, we can only say $X[k] = c_k$ if $k+N>L$, otherwise I have more than one k in the bin and cannot separate them. At the Nyquist bin $X[k] = c_k + c_{-k}$
Think in terms of degrees of freedom. For a complex signal, $c_k + c_{-k}$ has four and the Nyquist bin two. Therefore there are two free. Just enough to put a complex parameter on the Sine function at the Nyquist frequency. With a real signal, $c_k + c_{-k}$ has two degrees of freedom and the Nyquist bin value restricts one of those leaving one left over. Just enough for a real valued parameter times the Sine function to remain a real valued signal.
I showed earlier the translation between not doing halfsies and the consequence on the interpolation function. Nothing prohibits that and it doesn't increase the bandwidth of the solution one iota.
R B-J asks:
// //"But we do know A will be zero in the halfsies and W-S reconstructions."// how do you know that? //
The halfsies is easy. Without loss of generality, consider the $N=2$ case.
$$ x[n] = [1,-1] $$
$$ \frac{1}{N} X[k] = [0,1] $$
Halfsies on the Nyquist of 1. Doing an unfurled inverse DFT with split Nyquist:
$$ x[n] = \frac{1}{2} e^{i\pi n} + \frac{1}{2} e^{-i\pi n} = \cos(\pi n) $$
Now allow $n$ to be real, call it $t$ to indicate the change. This defines an interpolation function (still called $x$).
$$ x(t) = \cos(\pi t) $$
For every other even N, the unnormalized DFT will be (0,0,0,....,N), so the result remains the same.
For the W-S summation, look at the section where "omega" temporarily lived, the "Sinc is the limit of the Dirichlet Kernel" section. The left side $y_m=Y(w)$ is known to be $ \cos( \pi w ) $. I even did the specific $N=2$ case after the dependency list. Just set "M=2" which makes $w = m$. The limit reached at the end of the second chunk gives your summation. Just reverse the order of the equation and you get:
$$ \sum_{n=-\infty}^{\infty} (-1)^n \operatorname{sinc}( w - n ) = \cos( \pi w ) $$
The fact that your summation is the limit of something is why proving it differently has been hard.
I think your time reversal argument is good, too. The sampled points are time reversible on the discrete $n$ scale, but that does not mean the source x(t) is, but it does mean Y(w) is.
P.S. From now on, when a fresh context can be established, I'm going to use $\tau$ for a $ 0 \to 2\pi $ cycle scale, $t$ to be on the sampling scale ($=n$).
|
Fourier transformations:
$$\phi(\vec{k}) = \left( \frac{1}{\sqrt{2 \pi}} \right)^3 \int_{r\text{ space}} \psi(\vec{r}) e^{-i \mathbf{k} \cdot \mathbf{r}} d^3r$$
for momentum space and
$$\psi(\vec{r}) = \left( \frac{1}{\sqrt{2 \pi}} \right)^3 \int_{k\text{ space}} \phi(\vec{k}) e^{i \mathbf{k} \cdot \mathbf{r}} d^3k$$
for position space.
How do we know that $\psi$ is not the Fourier transform of $\phi$ but we suppose that its the other way around ($\psi$ would be proportional to $\exp[-ikr]$ and $\phi$ would be proportional to $\exp[ikr]$)? If there was no difference in the signs, wouldn't there be a problem in the integration from minus inf. to plus inf. if the probability is asymmetric around zero?
What is the physical reason that in the integral for momentum space we have $\exp[-ikr]$? I agree about the exponent for position space which can be explained as follows: its the sum of all definite momentum states of the system, but what about the Fourier of the momentum space? How can we explain the integral (not mathematically)?
|
Class Member of Class Builder
Jump to navigation Jump to search
Theorem
Let $A$ be a class.
Let $x$ be a set.
Let $P \left({A}\right)$ denote the formula $P\left({x}\right)$ with all free instances of $x$ replaced with instances of $A$.
Then: $A \in \left\{{x : P \left({x}\right)}\right\} \iff \left({\exists x: x = A \land P \left({A}\right)}\right)$ Proof
\(\displaystyle A \in \left\{ {x : P \left({x}\right)}\right\}\) \(\implies\) \(\displaystyle \exists x \in \left\{ {x : P \left({x}\right)}\right\}: A = x\) Definition of class membership \(\displaystyle \) \(\implies\) \(\displaystyle \exists x: \left({x = A \land P \left({x}\right)}\right)\) Definition of bounded existential quantifier \(\displaystyle \) \(\implies\) \(\displaystyle \exists x: \left({x = A \land P \left({A}\right)}\right)\) Substitutivity of Class Equality
$\blacksquare$
Also see
|
Blow-up phenomena for nonlinear pseudo-parabolic equations with gradient term
Università di Cagliari, Dipartimento di Matematica e Informatica, V.le Merello 92,09123 Cagliari, Italy
$\left\{ \begin{array}{l}\begin{split}u_t- \lambda \triangle u_t=& k(t) \text{div}(g(| \nabla u|^2) \nabla u) +f(t,u,| \nabla u| ) \quad {\rm in} \ \Omega \times (0, t^*), \\[6pt] u=&0 \ \qquad {\rm on} \ \partial \Omega \times (0,t^*),\\[6pt] u ({ x},0) =& u_0 ({ x}) \quad {\rm in} \ \Omega,\\[6pt]\end{split}\end{array} \right.$
$\Omega$
$\mathbb{R}^n, \ n\geq 2$
$ \partial \Omega$
$ k$
$t$
$u(x,t)$
$t^*$
$[0,t^*)$
$u(x,t).$ Mathematics Subject Classification:Primary: 35K70, 35B44; Secondary: 35B4. Citation:Monica Marras, Stella Vernier-Piro, Giuseppe Viglialoro. Blow-up phenomena for nonlinear pseudo-parabolic equations with gradient term. Discrete & Continuous Dynamical Systems - B, 2017, 22 (6) : 2291-2300. doi: 10.3934/dcdsb.2017096
References:
[1]
A. B. Al'Shin, M. O. Korpusov and A. G. Sveshnikov, Blow-up in Nonlinear Sobolev Type Equations, De Gruyter Series in Nonlinear Analysis and Applications, 2011.Google Scholar
[2] [3] [4] [5] [6] [7] [8]
M. Marras and S. Vernier Piro,
On global existence and bounds for blow-up time in non linear parabolic problems with time dependent coefficients,
[9] [10]
M. Marras, S. Vernier-Piro and G. Viglialoro,
Estimates from below of blow-up time in a parabolic system with gradient term,
[11]
M. Marras, S. Vernier-Piro and G. Viglialoro,
Lower bounds for blow-up time in a parabolic problem with a gradient term under various boundary conditions,
[12] [13] [14] [15] [16] [17]
show all references
References:
[1]
A. B. Al'Shin, M. O. Korpusov and A. G. Sveshnikov, Blow-up in Nonlinear Sobolev Type Equations, De Gruyter Series in Nonlinear Analysis and Applications, 2011.Google Scholar
[2] [3] [4] [5] [6] [7] [8]
M. Marras and S. Vernier Piro,
On global existence and bounds for blow-up time in non linear parabolic problems with time dependent coefficients,
[9] [10]
M. Marras, S. Vernier-Piro and G. Viglialoro,
Estimates from below of blow-up time in a parabolic system with gradient term,
[11]
M. Marras, S. Vernier-Piro and G. Viglialoro,
Lower bounds for blow-up time in a parabolic problem with a gradient term under various boundary conditions,
[12] [13] [14] [15] [16] [17]
[1]
Hua Chen, Huiyang Xu.
Global existence and blow-up of solutions for infinitely degenerate semilinear pseudo-parabolic equations with logarithmic nonlinearity.
[2]
Xiaoli Zhu, Fuyi Li, Ting Rong.
Global existence and blow up of solutions to a class of pseudo-parabolic equations with an exponential source.
[3] [4]
Mu-Ming Zhang, Tian-Yuan Xu, Jing-Xue Yin.
Controllability properties of degenerate pseudo-parabolic boundary control problems.
[5]
Huafei Di, Yadong Shang, Xiaoxiao Zheng.
Global well-posedness for a fourth order pseudo-parabolic equation with memory and source terms.
[6] [7]
Monica Marras, Stella Vernier Piro.
On global existence and bounds for blow-up time in nonlinear parabolic problems with time dependent coefficients.
[8]
Ronghua Jiang, Jun Zhou.
Blow-up and global existence of solutions to a parabolic equation associated with the fraction
[9] [10] [11] [12]
Sachiko Ishida, Tomomi Yokota.
Blow-up in finite or infinite time for
quasilinear degenerate Keller-Segel systems of
parabolic-parabolic type.
[13]
Hua Chen, Nian Liu.
Asymptotic stability and blow-up of solutions for semi-linear edge-degenerate parabolic equations with singular potentials.
[14]
Jong-Shenq Guo.
Blow-up behavior for a quasilinear parabolic equation with nonlinear boundary condition.
[15]
Pavol Quittner, Philippe Souplet.
Blow-up rate of solutions of parabolic poblems
with nonlinear boundary conditions.
[16]
Huiling Li, Mingxin Wang.
Properties of blow-up solutions to a parabolic system with nonlinear localized terms.
[17]
Julián López-Gómez, Pavol Quittner.
Complete and energy blow-up in indefinite superlinear parabolic problems.
[18] [19]
Shiming Li, Yongsheng Li, Wei Yan.
A global existence and blow-up threshold for Davey-Stewartson equations in $\mathbb{R}^3$.
[20]
Zaihui Gan, Jian Zhang.
Blow-up, global existence and standing waves for the magnetic nonlinear Schrödinger equations.
2018 Impact Factor: 1.008
Tools Metrics Other articles
by authors
[Back to Top]
|
Search
Now showing items 1-10 of 192
J/Ψ production and nuclear effects in p-Pb collisions at √sNN=5.02 TeV
(Springer, 2014-02)
Inclusive J/ψ production has been studied with the ALICE detector in p-Pb collisions at the nucleon–nucleon center of mass energy √sNN = 5.02TeV at the CERN LHC. The measurement is performed in the center of mass rapidity ...
Measurement of electrons from beauty hadron decays in pp collisions at root √s=7 TeV
(Elsevier, 2013-04-10)
The production cross section of electrons from semileptonic decays of beauty hadrons was measured at mid-rapidity (|y| < 0.8) in the transverse momentum range 1 < pT <8 GeV/c with the ALICE experiment at the CERN LHC in ...
Suppression of ψ(2S) production in p-Pb collisions at √sNN=5.02 TeV
(Springer, 2014-12)
The ALICE Collaboration has studied the inclusive production of the charmonium state ψ(2S) in proton-lead (p-Pb) collisions at the nucleon-nucleon centre of mass energy √sNN = 5.02TeV at the CERN LHC. The measurement was ...
Event-by-event mean pT fluctuations in pp and Pb–Pb collisions at the LHC
(Springer, 2014-10)
Event-by-event fluctuations of the mean transverse momentum of charged particles produced in pp collisions at s√ = 0.9, 2.76 and 7 TeV, and Pb–Pb collisions at √sNN = 2.76 TeV are studied as a function of the ...
Kaon femtoscopy in Pb-Pb collisions at $\sqrt{s_{\rm{NN}}}$ = 2.76 TeV
(Elsevier, 2017-12-21)
We present the results of three-dimensional femtoscopic analyses for charged and neutral kaons recorded by ALICE in Pb-Pb collisions at $\sqrt{s_{\rm{NN}}}$ = 2.76 TeV. Femtoscopy is used to measure the space-time ...
Anomalous evolution of the near-side jet peak shape in Pb-Pb collisions at $\sqrt{s_{\mathrm{NN}}}$ = 2.76 TeV
(American Physical Society, 2017-09-08)
The measurement of two-particle angular correlations is a powerful tool to study jet quenching in a $p_{\mathrm{T}}$ region inaccessible by direct jet identification. In these measurements pseudorapidity ($\Delta\eta$) and ...
Online data compression in the ALICE O$^2$ facility
(IOP, 2017)
The ALICE Collaboration and the ALICE O2 project have carried out detailed studies for a new online computing facility planned to be deployed for Run 3 of the Large Hadron Collider (LHC) at CERN. Some of the main aspects ...
Evolution of the longitudinal and azimuthal structure of the near-side peak in Pb–Pb collisions at $\sqrt{s_{\rm NN}}=2.76$ TeV
(American Physical Society, 2017-09-08)
In two-particle angular correlation measurements, jets give rise to a near-side peak, formed by particles associated to a higher $p_{\mathrm{T}}$ trigger particle. Measurements of these correlations as a function of ...
J/$\psi$ elliptic flow in Pb-Pb collisions at $\sqrt{s_{\rm NN}}$ = 5.02 TeV
(American Physical Society, 2017-12-15)
We report a precise measurement of the J/$\psi$ elliptic flow in Pb-Pb collisions at $\sqrt{s_{\rm NN}} = 5.02$ TeV with the ALICE detector at the LHC. The J/$\psi$ mesons are reconstructed at mid-rapidity ($|y| < 0.9$) ...
Highlights of experimental results from ALICE
(Elsevier, 2017-11)
Highlights of recent results from the ALICE collaboration are presented. The collision systems investigated are Pb–Pb, p–Pb, and pp, and results from studies of bulk particle production, azimuthal correlations, open and ...
|
Given a functional $$J(y)=\int_a^b F(x,y,y')dx, \tag{1}$$
where $y$ is a function of $x$, and a constraint $$\int_a^b K(x,y,y')dx=l, \tag{2}$$ if $y=y(x)$ is an extreme of (1) under the constraint (2), then there exists a constant $\lambda$ such that $y=y(x)$ is also an extreme of the functional $$\int_a^b [F(x,y,y')+\lambda K(x,y,y')]dx. \tag{3}$$ Similarly, if the constraint is $$g(x,y,y')=0, \tag{4}$$ then there exists a function $\lambda(x)$ such that the extreme also holds for the functional $$\int_a^b [F(x,y,y')+\lambda(x)g(x,y,y')]dx. \tag{5}$$
This is known as the Lagrange multiplier rule for calculus of variations. However, I have two questions about this statement.
If the functional (1) has two constraints (2) and (4), does the extreme also hold for the functional $$\int_a^b [F(x,y,y')+\lambda K(x,y,y') +\lambda(x) g(x,y,y')]dx ? \tag{6}$$ Is this statement also valid for multiple variable case? For example, if $J=\iint F(x_1,x_2,y(x_1,x_2))dx_1 dx_2$, and $\iint K(x_1,x_2,y(x_1,x_2))dx_1 dx_2=l$, is this equivalent to $J=\iint F(x_1,x_2,y(x_1,x_2))+\lambda K(x_1,x_2,y(x_1,x_2))dx_1 dx_2$?
Thanks in advance and any suggestion will be appreciated. It is better if you have any reference.
|
In this section,
sdr means complete sdr.It is easy to see that not every collection of sets has an sdr. Forexample,$$A_1=\{a,b\}, A_2=\{a,b\}, A_3=\{a,b\}.$$The problem is clear: there are only two possible representatives, soa set of three distinct representatives cannot be found. This exampleis a bit more general than it may at first appear. Consider$$A_1=\{a,b\}, A_2=\{a,b\}, A_3=\{a,b\}, A_4=\{b,c,d,e\}.$$Now the total number of possible representatives is 5, and we onlyneed 4. Nevertheless, this is impossible, because the first three setshave no sdr considered by themselves. Thus the following condition,called Hall's Condition, isclearly necessary for the existence of an sdr: For every $k\ge1$, andevery set $\{i_1,i_2,\ldots,i_k\}\subseteq [n]$, $|\bigcup_{j=1}^k A_{i_j}|\ge k$. That is, the number of possiblerepresentatives in any collection of sets must be at least as large asthe number of sets. Both examples fail to have this propertybecause $|A_1\cup A_2\cup A_3|=2< 3$.
Remarkably, this condition is both necessary and sufficient.
Theorem 4.1.1 (Hall's Theorem) A collection of sets $A_1,A_2,\ldots,A_n$ has an
sdr if and onlyif for every $k\ge1$, andevery set $\{i_1,i_2,\ldots,i_k\}\subseteq [n]$, $|\bigcup_{j=1}^k A_{i_j}|\ge k$.
Proof. We already know the condition is necessary, so we prove sufficiency by induction on $n$.
Suppose $n=1$; the condition is simply that $|A_1|\ge 1$. If this istrue then $A_1$ is non-empty and so there is an
sdr. Thisestablishes the base case.
Now suppose that the theorem is true for a collection of $k< n$ sets,and suppose we have sets $A_1,A_2,\ldots,A_n$ satisfying Hall's Condition.We need to show there is an
sdr.
Suppose first that for every $k< n$ and every $\{i_1,i_2,\ldots,i_k\}\subseteq [n]$, that $|\bigcup_{j=1}^k A_{i_j}|\ge k+1$, that is, that these unions arelarger than required. Pick any element $x_n\in A_n$, and define$B_i=A_i\backslash\{x_n\}$ for each $i< n$. Consider the collection of sets $B_1,\ldots,B_{n-1}$, and any union$\bigcup_{j=1}^k B_{i_j}$ of a subcollection of the sets.There are two possibilities: either $\bigcup_{j=1}^kB_{i_j}=\bigcup_{j=1}^k A_{i_j}$ or $\bigcup_{j=1}^kB_{i_j}=\bigcup_{j=1}^k A_{i_j}\backslash\{x_n\}$, so that $|\bigcup_{j=1}^kB_{i_j}|=|\bigcup_{j=1}^k A_{i_j}|$ or $|\bigcup_{j=1}^kB_{i_j}|=|\bigcup_{j=1}^k A_{i_j}|-1$. In either case, since$|\bigcup_{j=1}^k A_{i_j}|\ge k+1$, $|\bigcup_{j=1}^k B_{i_j}|\ge k$.Thus, by the induction hypothesis, the collection$B_1,\ldots,B_{n-1}$ has an
sdr $\{x_1,x_2,\ldots,x_{n-1}\}$, and forevery $i< n$, $x_i\not= x_n$, by the definition of the $B_i$. Thus $\{x_1,x_2,\ldots,x_{n}\}$ is an sdr for $A_1,A_2,\ldots,A_n$.
If it is not true that for every $k< n$ and every $\{i_1,i_2,\ldots,i_k\}\subseteq [n]$, $|\bigcup_{j=1}^k A_{i_j}|\ge k+1$, then for some $k< n$ and$\{i_1,i_2,\ldots,i_k\}$, $|\bigcup_{j=1}^k A_{i_j}|= k$.Without loss of generality, we may assume that$|\bigcup_{j=1}^k A_{j}|= k$.By the induction hypothesis, $A_1,A_2,\ldots,A_k$ has an
sdr,$\{x_1,\ldots,x_k\}$.
Define $B_i=A_i\backslash \bigcup_{j=1}^k A_{j}$ for $i> k$. Suppose that $\{x_{k+1},\ldots,x_{n}\}$ isan
sdrfor $B_{k+1},\ldots,B_{n}$; then it is also an sdr for$A_{k+1},\ldots,A_{n}$. Moreover, $\{x_1,\ldots,x_n\}$ is an sdr for$A_{1},\ldots,A_{n}$. Thus, to finish the proof it suffices to showthat $B_{k+1},\ldots,B_{n}$ has an sdr. The number of sets here is$n-k< n$, so we need only show that the sets satisfy Hall's Condition.
So consider some sets $B_{i_1},B_{i_2},…,B_{i_l}$. First we noticethat $$|A_1\cup A_2\cup\cdots\cup A_k\cup B_{i_1}\cup B_{i_2}\cup\cdotsB_{i_l}|=k+|B_{i_1}\cup B_{i_2}\cup\cdotsB_{i_l}|.$$Also $$|A_1\cup A_2\cup\cdots\cup A_k\cup B_{i_1}\cup B_{i_2}\cup\cdotsB_{i_l}|=|A_1\cup A_2\cup\cdots\cup A_k\cup A_{i_1}\cup A_{i_2}\cup\cdotsA_{i_l}|$$and $$|A_1\cup A_2\cup\cdots\cup A_k\cup A_{i_1}\cup A_{i_2}\cup\cdotsA_{i_l}|\ge k+l.$$Putting these together gives$$\eqalign{k+|B_{i_1}\cup B_{i_2}\cup\cdots\cup B_{i_l}|&\ge k+l\cr|B_{i_1}\cup B_{i_2}\cup\cdots\cup B_{i_l}|&\ge l\cr.}$$Thus, $B_{k+1},\ldots,B_{n}$ has an
sdr, which finishes the proof.
Exercises 4.1
Ex 4.1.2How many different systems of distinctrepresentatives are there for the sets $A_i=[n]\backslash{i}$, $i=1,2,\ldots,n$, $n\ge2$?
Ex 4.1.3Suppose the set system $A_1,A_2,\ldots,A_n$ has an sdr,and that $x\in A_i$. Show the set system has an sdr containing$x$. Show that $x$ cannot necessarily be chosen to represent $A_i$.
Ex 4.1.4Suppose the set system $A_1,A_2,\ldots,A_n$ satisfies$|\bigcup_{j=1}^k A_{i_j}|\ge k+1$ for every $1\le k< n$ and$\{i_1,i_2,\ldots,i_k\}\subseteq [n]$, and that $x\in A_i$. Show theset system has an sdr in which $x$ represents $A_i$.
Ex 4.1.5An $m\times n$ chessboard, with $m$ even and both $m$ and$n$ at least 2, has one white and one black square removed. Show thatthe board can be covered by dominoes.
|
14.1. Generative Adversarial Networks¶
Throughout most of this book, we’ve talked about how to make predictions. In some form or another, we used deep neural networks learned mappings from data points to labels. This kind of learning is called discriminative learning, as in, we’d like to be able to discriminate between photos cats and photos of dogs. Classifiers and regressors are both examples of discriminative learning. And neural networks trained by backpropagation have upended everything we thought we knew about discriminative learning on large complicated datasets. Classification accuracies on high-res images has gone from useless to human-level (with some caveats) in just 5-6 years. We’ll spare you another spiel about all the other discriminative tasks where deep neural networks do astoundingly well.
But there’s more to machine learning than just solving discriminative tasks. For example, given a large dataset, without any labels, we might want to learn a model that concisely captures the characteristics of this data. Given such a model, we could sample synthetic data points that resemble the distribution of the training data. For example, given a large corpus of photographs of faces, we might want to be able to generate a new photorealistic image that looks like it might plausibly have come from the same dataset. This kind of learning is called generative modeling.
Until recently, we had no method that could synthesize novel photorealistic images. But the success of deep neural networks for discriminative learning opened up new possibilities. One big trend over the last three years has been the application of discriminative deep nets to overcome challenges in problems that we don’t generally think of as supervised learning problems. The recurrent neural network language models are one example of using a discriminative network (trained to predict the next character) that once trained can act as a generative model.
In 2014, a breakthrough paper introduced Generative adversarial networks (GANs) [Goodfellow.Pouget-Abadie.Mirza.ea.2014], a clever new way to leverage the power of discriminative models to get good generative models. At their heart, GANs rely on the idea that a data generator is good if we cannot tell fake data apart from real data. In statistics, this is called a two-sample test - a test to answer the question whether datasets \(X=\{x_1,\ldots,x_n\}\) and \(X'=\{x'_1,\ldots,x'_n\}\) were drawn from the same distribution. The main difference between most statistics papers and GANs is that the latter use this idea in a constructive way. In other words, rather than just training a model to say “hey, these two datasets don’t look like they came from the same distribution”, they use the two-sample test to provide training signal to a generative model. This allows us to improve the data generator until it generates something that resembles the real data. At the very least, it needs to fool the classifier. And if our classifier is a state of the art deep neural network.
The GANs architecture is illustrated in Fig. 14.1.1. As you can see, there are two pieces to GANs - first off, we need a device (say, a deep network but it really could be anything, such as a game rendering engine) that might potentially be able to generate data that looks just like the real thing. If we are dealing with images, this needs to generate images. If we’re dealing with speech, it needs to generate audio sequences, and so on. We call this the generator network. The second component is the discriminator network. It attempts to distinguish fake and real data from each other. Both networks are in competition with each other. The generator network attempts to fool the discriminator network. At that point, the discriminator network adapts to the new fake data. This information, in turn is used to improve the generator network, and so on.
The discriminator is a binary classifier to distinguish if the input \(x\) is real (from real data) or fake (from the generator). Typically, the discriminator outputs a scalar prediction \(o\in\mathbb R\) for input \(\mathbf x\), such as using a dense layer with hidden size 1, and then applies sigmoid function to obtain the predicted probability \(D(\mathbf x) = 1/(1+e^{-o})\). Assume the label \(y\) for true data is \(1\) and \(0\) for fake data. We train the discriminator to minimize the cross-entropy loss, i.e.
For the generator, it first draws some parameter \(\mathbf z\in\mathbb R^d\) from a source of randomness, e.g. a normal distribution \(\mathbf z\sim\mathcal(0,1)\). We often call \(\mathbf z\) the latent variable. It then applies a function to generate \(\mathbf x'=G(\mathbf z)\). The goal of the generator is to fool the discriminator to classify \(\mathbf x'\) as true data. In other words, we update the parameters of the generator to maximize the cross-entropy loss when \(y=0\), i.e.
If the discriminator does a perfect job, then \(D(\mathbf x')\approx 1\) so the above loss near 0, which results the gradients are too small to make a good progress for the discriminator. So commonly we minimize the following loss
which is just feed \(\mathbf x'\) into the discriminator but giving label \(y=1\).
Many of the GANs applications are in the context of images. As a demonstration purpose, we’re going to content ourselves with fitting a much simpler distribution first. We will illustrate what happens if we use GANs to build the world’s most inefficient estimator of parameters for a Gaussian. Let’s get started.
%matplotlib inlineimport d2lfrom mxnet import nd, gluon, autograd, initfrom mxnet.gluon import nn
14.1.1. Generate some “real” data¶
Since this is going to be the world’s lamest example, we simply generate data drawn from a Gaussian.
X = nd.random.normal(shape=(1000, 2))A = nd.array([[1, 2], [-0.1, 0.5]])b = nd.array([1, 2])data = nd.dot(X, A) + b
Let’s see what we got. This should be a Gaussian shifted in some rather arbitrary way with mean \(b\) and covariance matrix \(A^TA\).
d2l.set_figsize((3.5, 2.5))#d2l.plt.figure(figsize=())d2l.plt.scatter(data[:100,0].asnumpy(), data[:100,1].asnumpy());print("The covariance matrix is", nd.dot(A.T,A))
The covariance matrix is[[1.01 1.95] [1.95 4.25]]<NDArray 2x2 @cpu(0)>
batch_size = 8data_iter = d2l.load_array((data,), batch_size)
14.1.2. Generator¶
Our generator network will be the simplest network possible - a single layer linear model. This is since we’ll be driving that linear network with a Gaussian data generator. Hence, it literally only needs to learn the parameters to fake things perfectly.
net_G = nn.Sequential()net_G.add(nn.Dense(2))
14.1.3. Discriminator¶
For the discriminator we will be a bit more discriminating: we will use an MLP with 3 layers to make things a bit more interesting.
net_D = nn.Sequential()net_D.add(nn.Dense(5, activation='tanh'), nn.Dense(3, activation='tanh'), nn.Dense(1))
14.1.4. Training¶
First we define a function to update the discriminator.
# Save to the d2l package.def update_D(X, Z, net_D, net_G, loss, trainer_D): """Update discriminator""" batch_size = X.shape[0] ones = nd.ones((batch_size,), ctx=X.context) zeros = nd.zeros((batch_size,), ctx=X.context) with autograd.record(): real_Y = net_D(X) fake_X = net_G(Z) # Don't need to compute gradient for net_G, detach it from # computing gradients. fake_Y = net_D(fake_X.detach()) loss_D = (loss(real_Y, ones) + loss(fake_Y, zeros)) / 2 loss_D.backward() trainer_D.step(batch_size) return loss_D.sum().asscalar()
The generator is updated similarly. Here we reuse the cross-entropy loss but change the label of the fake data from \(0\) to \(1\).
# Save to the d2l package.def update_G(Z, net_D, net_G, loss, trainer_G): # saved in d2l """Update generator""" batch_size = Z.shape[0] ones = nd.ones((batch_size,), ctx=Z.context) with autograd.record(): # We could reuse fake_X from update_D to save computation. fake_X = net_G(Z) # Recomputing fake_Y is needed since net_D is changed. fake_Y = net_D(fake_X) loss_G = loss(fake_Y, ones) loss_G.backward() trainer_G.step(batch_size) return loss_G.sum().asscalar()
Both the discriminator and the generator performs a binary logistic regression with the cross-entropy loss. We use Adam to smooth the training process. In each iteration, we first update the discriminator and then the generator. We visualize both losses and generated examples.
def train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G, latent_dim, data): loss = gluon.loss.SigmoidBCELoss() net_D.initialize(init=init.Normal(0.02), force_reinit=True) net_G.initialize(init=init.Normal(0.02), force_reinit=True) trainer_D = gluon.Trainer(net_D.collect_params(), 'adam', {'learning_rate': lr_D}) trainer_G = gluon.Trainer(net_G.collect_params(), 'adam', {'learning_rate': lr_G}) animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[1, num_epochs], nrows=2, figsize=(5,5), legend=['generator', 'discriminator']) animator.fig.subplots_adjust(hspace=0.3) for epoch in range(1, num_epochs+1): # Train one epoch timer = d2l.Timer() metric = d2l.Accumulator(3) # loss_D, loss_G, num_examples for X in data_iter: batch_size = X.shape[0] Z = nd.random.normal(0, 1, shape=(batch_size, latent_dim)) metric.add(update_D(X, Z, net_D, net_G, loss, trainer_D), update_G(Z, net_D, net_G, loss, trainer_G), batch_size) # Visualize generated examples Z = nd.random.normal(0, 1, shape=(100, latent_dim)) fake_X = net_G(Z).asnumpy() animator.axes[1].cla() animator.axes[1].scatter(data[:,0], data[:,1]) animator.axes[1].scatter(fake_X[:,0], fake_X[:,1]) animator.axes[1].legend(['real', 'generated']) # Show the losses loss_D, loss_G = metric[0]/metric[2], metric[1]/metric[2] animator.add(epoch, (loss_D, loss_G)) print('loss_D %.3f, loss_G %.3f, %d examples/sec' % ( loss_D, loss_G, metric[2]/timer.stop()))
Now we specify the hyper-parameters to fit the Gaussian distribution.
lr_D, lr_G, latent_dim, num_epochs = 0.05, 0.005, 2, 20train(net_D, net_G, data_iter, num_epochs, lr_D, lr_G, latent_dim, data[:100].asnumpy())
loss_D 0.693, loss_G 0.693, 777 examples/sec
14.1.5. Summary¶ Generative adversarial networks (GANs) composes of two deep networks, the generator and the discriminator. The generator generates the image as much closer to the true image as possible to fool the discriminator, via maximizing the cross-entropy loss, i.e., \(\max \log(D(\mathbf{x'}))\). The discriminator tries to distinguish the generated images from the true images, via minimizing the cross-entropy loss, i.e., \(\min - y \log D(\mathbf{x}) - (1-y)\log(1-D(\mathbf{x}))\).
|
Suppose I have a high-dimensional vector space $X$, a subspace $V \subset X$, and a collection of $n$ vectors $\{x_i\}_{i=1}^n \subset X$.
My question is: How can I choose a small collection $k < n$ of the vectors $x_i$ so that the span of this smaller collection "well-approximates" the subspace $V$?
The notion of "well-approximation" is intentionally left vague since, although it's intuitive that some subspaces approximate each other better than others, it's not clear to me the best way to introduce definitions that make this precise.
For concreteness, in my scenario the sizes of the various objects are of the following orders $dim(X)\approx 10000$, $dim(V)\approx 20$, $n\approx 5000$, and $k$ can be varied but has a target of $k \approx 100$.
It seems like this should be well studied, but I'm having trouble finding the right terms to search for. In particular, the subject of "subspace approximation" appears to deal with the opposite problem of choosing a subspace to approximate vectors, and the topic of "basis selection" appear to be interested with choosing linear combinations of basis vectors that make certain things sparse - both very different problems from this (as far as I can tell).
Edit: some clarifications based on discussion below The dimension of the space $X$ is larger than the number of candidate basis vectors $x_i$, and the subspace $V$ does not necessairily lie in the span of the $x_i$'s. As an illustrative example of where it might be useful to consider more basis vectors than the dimension of the space being approximated, consider the following situation: $X=\mathbb{R}^4$, $V=span((1,0,0,0))$, $x_1=(1,1,\epsilon,0)$, $x_2=(1,-1,\epsilon,0)$, $x_3=(0,0,0,1)$. It would be useful to choose 2 vectors $x_1$ and $x_2$, even though the space to be approximated, $V$, has dimension 1. Or in 3D, consider the situation in the following picture. You can approximate the space 1D $V$ perfectly with 3 vectors $x_1,x_2,x_3$, very well with 2 vectors $x_1,x_2$, and poorly with only one vector. One possible measure of how well a candidate space $\tilde V$ approximates the target space $V$ would be the expected value of the size of the projection of a random unit vector in $V$ onto $\tilde V$. Ie, for a uniformly distributed random unit vector $v \in V$, maximize $\mathbb{E}||\Pi_{\tilde V} v||$. If the approximation is exact this will be 1, otherwise it will be less than 1. Other definitions of "well approximation" may be better, this is just the first thing I thought of.
|
To send content items to your account,please confirm that you agree to abide by our usage policies.If this is the first time you use this feature, you will be asked to authorise Cambridge Core to connect with your account.Find out more about sending content to .
To send content items to your Kindle, first ensure no-reply@cambridge.orgis added to your Approved Personal Document E-mail List under your Personal Document Settingson the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ partof your Kindle email address below.Find out more about sending to your Kindle.
Note you can select to send to either the @free.kindle.com or @kindle.com variations.‘@free.kindle.com’ emails are free but can only be sent to your device when it is connected to wi-fi.‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
We give a short proof of a result of T. Bates and T. Giordano stating that any uniformly bounded Borel cocycle into a finite von Neumann algebra is cohomologous to a unitary cocycle. We also point out a separability issue in their proof. Our approach is based on the existence of a non-positive curvature metric on the positive cone of a finite von Neumann algebra.
We investigate Cartan subalgebras in nontracial amalgamated free product von Neumann algebras${\mathop{M{}_{1} \ast }\nolimits}_{B} {M}_{2} $over an amenable von Neumann subalgebra$B$. First, we settle the problem of the absence of Cartan subalgebra in arbitrary free product von Neumann algebras. Namely, we show that any nonamenable free product von Neumann algebra$({M}_{1} , {\varphi }_{1} )\ast ({M}_{2} , {\varphi }_{2} )$with respect to faithful normal states has no Cartan subalgebra. This generalizes the tracial case that was established by A. Ioana [Cartan subalgebras of amalgamated free product${\mathrm{II} }_{1} $factors, arXiv:1207.0054]. Next, we prove that any countable nonsingular ergodic equivalence relation$ \mathcal{R} $defined on a standard measure space and which splits as the free product$ \mathcal{R} = { \mathcal{R} }_{1} \ast { \mathcal{R} }_{2} $of recurrent subequivalence relations gives rise to a nonamenable factor$\mathrm{L} ( \mathcal{R} )$with a unique Cartan subalgebra, up to unitary conjugacy. Finally, we prove unique Cartan decomposition for a class of group measure space factors${\mathrm{L} }^{\infty } (X)\rtimes \Gamma $arising from nonsingular free ergodic actions$\Gamma \curvearrowright (X, \mu )$on standard measure spaces of amalgamated groups$\Gamma = {\mathop{\Gamma {}_{1} \ast }\nolimits}_{\Sigma } {\Gamma }_{2} $over a finite subgroup$\Sigma $.
Recommend this
Email your librarian or administrator to recommend adding this to your organisation's collection.
|
Skills to Develop
Identify the age of materials that can be approximately determined using radiocarbon dating.
When we speak of the element Carbon, we most often refer to the most naturally abundant stable isotope
12C. Although 12C is definitely essential to life, its unstable sister isotope 14C has become of extreme importance to the science world. Radiocarbon Dating is the process of determining the age of a sample by examining the amount of 14C remaining against the known half-life, 5,730 years. The reason this process works is because when organisms are alive they are constantly replenishing their 14C supply through respiration, providing them with a constant amount of the isotope. However, when an organism ceases to exist, it no longer takes in carbon from its environment and the unstable 14C isotope begins to decay. From this science, we are able to approximate the date at which the organism were living on Earth. Radiocarbon dating is used in many fields to learn information about the past conditions of organisms and the environments present on Earth. The Carbon-14 cycle
Radiocarbon dating (usually referred to simply as carbon-14 dating) is a radiometric dating method. It uses the naturally occurring radioisotope carbon-14 (14C) to estimate the age of carbon-bearing materials up to about 58,000 to 62,000 years old. Carbon has two stable, nonradioactive isotopes: carbon-12 (
12C) and carbon-13 ( 13C). There are also trace amounts of the unstable radioisotope carbon-14 ( 14C) on Earth. Carbon-14 has a relatively short half-life of 5,730 years, meaning that the fraction of carbon-14 in a sample is halved over the course of 5,730 years due to radioactive decay to nitrogen-14. The carbon-14 isotope would vanish from Earth's atmosphere in less than a million years were it not for the constant influx of cosmic rays interacting with molecules of nitrogen (N 2) and single nitrogen atoms (N) in the stratosphere. Both processes of formation and decay of carbon-14 are shown in Figure 1.
When plants fix atmospheric carbon dioxide (CO
2) into organic compounds during photosynthesis, the resulting fraction of the isotope 14C in the plant tissue will match the fraction of the isotope in the atmosphere (and biosphere since they are coupled). After a plants die, the incorporation of all carbon isotopes, including 14C, stops and the concentration of 14C declines due to the radioactive decay of 14C following.
\[ \ce{ ^{14}C -> ^{14}N + e^-} + \mu_e \label{E2}\]
This follows first-order kinetics.
\[N_t= N_o e^{-kt} \label{E3}\]
where
\(N_0\) is the number of atoms of the isotope in the original sample (at time t= 0, when the organism from which the sample was decoupled from the biosphere), and \(N_t\) is the number of atoms left after time \(t\). and \(k\) is the rate constant for the radioactive decay.
The half-life of a radioactive isotope (usually denoted by \(t_{1/2}\)) is a more familiar concept than \(k\) for radioactivity, so although Equation \(\ref{E3}\) is expressed in terms of \(k\), it is more usual to quote the value of \(t_{1/2}\). The currently accepted value for the half-life of 14C is 5,730 years. This means that after 5,730 years, only half of the initial 14C will remain; a quarter will remain after 11,460 years; an eighth after 17,190 years; and so on.
The equation relating rate constant to half-life for first order kinetics is
\[ k = \dfrac{\ln 2}{ t_{1/2} } \label{E4}\]
so the rate constant is then
\[ k = \dfrac{\ln 2}{5.73 \times 10^3} = 1.21 \times 10^{-4} \text{year}^{-1} \label{E5}\]
and Equation \(\ref{E2}\) can be rewritten as
\[N_t= N_o e^{-\ln 2 \;t/t_{1/2}} \label{E6}\]
or
\[t = \left(\dfrac{\ln \dfrac{N_o}{N_t}}{\ln 2} \right) t_{1/2} = 8267 \ln \dfrac{N_o}{N_t} = 19035 \log_{10} \dfrac{N_o}{N_t} \;\;\; (\text{in years}) \label{E7}\]
The sample is assumed to have originally had the same
14C/ 12C ratio as the ratio in the atmosphere, and since the size of the sample is known, the total number of atoms in the sample can be calculated, yielding \(N_0\), the number of 14C atoms in the original sample. Measurement of N, the number of 14C atoms currently in the sample, allows the calculation of \(t\), the age of the sample, using the Equation \(\ref{E7}\).
Note
Deriving Equation \(\ref{E7}\) assumes that the level of 14C in the atmosphere has remained constant over time. However, the level of 14C in the atmosphere has varied significantly so time estimated by Equation \(\ref{E7}\) must be corrected by using data from other sources.
Example 1: Dead Sea Scrolls
In 1947 samples of the Dead Sea Scrolls were analyzed by carbon dating. It was found that the carbon-14 present had an
activity (rate of decay) of d/min.g (where d = disintegration). In contrast, living material exhibit an activity of 14 d/min.g. Thus, using Equation \(\ref{E3}\),
\[\ln \dfrac{14}{11} = (1.21 \times 10^{-4}) t \nonumber\]
Thus,
\[t= \dfrac{\ln 1.272}{1.21 \times 10^{-4}} = 2 \times 10^3 \text{years} \nonumber\]
From the measurement performed in 1947 the Dead Sea Scrolls were determined to be 2000 years old giving them a date of 53 BC, and confirming their authenticity. This discovery is in contrast to the carbon dating results for the Turin Shroud that was supposed to have wrapped Jesus’ body. Carbon dating has shown that the cloth was made between 1260 and 1390 AD. Thus, the Turin Shroud was made over a thousand years after the death of Jesus.
Describes radioactive half life and how to do some simple calculations using half life. History
The technique of radiocarbon dating was developed by Willard Libby and his colleagues at the University of Chicago in 1949. Emilio Segrè asserted in his autobiography that Enrico Fermi suggested the concept to Libby at a seminar in Chicago that year. Libby estimated that the steady-state radioactivity concentration of exchangeable carbon-14 would be about 14 disintegrations per minute (dpm) per gram. In 1960, Libby was awarded the Nobel Prize in chemistry for this work. He demonstrated the accuracy of radiocarbon dating by accurately estimating the age of wood from a series of samples for which the age was known, including an ancient Egyptian royal barge dating from 1850 BCE. Before Radiocarbon dating was able to be discovered, someone had to find the existence of the
14C isotope. In 1940 Martin Kamen and Sam Ruben at the University of California, Berkeley Radiation Laboratory did just that. They found a form, isotope, of Carbon that contained 8 neutrons and 6 protons. Using this finding Willard Libby and his team at the University of Chicago proposed that Carbon-14 was unstable and underwent a total of 14 disintegrations per minute per gram. Using this hypothesis, the initial half-life he determined was 5568 give or take 30 years. The accuracy of this proposal was proven by dating a piece of wood from an Ancient Egyptian barge, of whose age was already known. From that point on, scientist have used these techniques to examine fossils, rocks, and ocean currents and determine age and event timing. Throughout the years measurement tools have become more technologically advanced allowing researchers to be more precise and we now use what is known as the Cambridge half-life of 5730+/- 40 years for Carbon-14. Although it may be seen as outdated, many labs still use Libby's half-life in order to stay consistent in publications and calculations within the laboratory. From the discovery of Carbon-14 to radiocarbon dating of fossils, we can see what an essential role Carbon has played and continues to play in our lives today. Summary
The entire process of Radiocarbon dating depends on the decay of carbon-14. This process begins when an organism is no longer able to exchange Carbon with their environment. Carbon-14 is first formed when cosmic rays in the atmosphere allow for excess neutrons to be produced, which then react with Nitrogen to produce a constantly replenishing supply of carbon-14 to exchange with organisms.
Carbon-14 dating can be used to estimate the age of carbon-bearing materials up to about 58,000 to 62,000 years old. The carbon-14 isotope would vanish from Earth's atmosphere in less than a million years were it not for the constant influx of cosmic rays interacting with atmospheric nitrogen. One of the most frequent uses of radiocarbon dating is to estimate the age of organic remains from archeological sites. References Hua, Quan. "Radiocarbon: A Chronological Tool for the Recent Past." Quaternary Geochronology4.5(2009):378-390. Science Direct. Web. 22 Nov. 2009. Petrucci, Raplh H. General Chemistry: Principles and Modern Applications 9th Ed.New Jersey: Pearson Education Inc. 2007. "Radio Carbon Dating." BBC- Homepage. 25 Oct. 2001. Web. 22 Nov. 2009. http://www.bbc.co.uk. Willis, E.H., H. Tauber, and K. O. Munnich. "Variations in the Atmospheric Radiocarbon Concentration Over the Past 1300 Years." American Journal of Science Radiocarbon Supplement2(1960) 1-4. Print. Problems If when a hippopotamus was breathing there was a total of 25 grams of Carbon-14, how many grams will remain 5730 years after he is laid to rest? 12.5 grams, because one half life has occurred. How many grams of Carbon-14 will be present in the hippos remains after 3 half-lives have passed? 3.125 grams of Carbon-14 will remain after 3 half lives. Contributors Template:ContribBarron
Boundless (www.boundless.com)
Wikipedia
|
Your presumption in the first paragraph is incorrect. The fact that more particles collide with enough energy to make the activation energy with an increase in temperature means that the
rate of reaction increases as temperature goes up, but that doesn't affect the equilibrium of the reaction.
Instead, the effect on temperature has to do with the comparative free energy of the two sides of the equilibrium. The controlling factor in where the equilibrium lies is the difference in free energy between the reactants and products (the ΔG). In fact, the equilibrium constant has a very simple relationship to the free energy: $\ce{\Delta G = -RT ln K }$ ... or $\ce{K = e^{-\frac{\Delta G}{RT} }}$. The ΔG is made up of two components - the enthalpy and the entropy: $\ce{\Delta G = \Delta H -T\Delta S}$, where T is the (absolute) temperature. The side of the reaction which is favored is the one with the lowest (most negative) free energy.
So when we substitute, we get the following relationship for the temperature dependence of the equilibrium constant, in terms of entropy and enthalpy:
$$ K = e^{-\frac{\Delta H}{RT} } \cdot e^{\frac{\Delta S}{R} } $$
The temperature dependence is only in the enthalpy ($\ce{\Delta H}$). Enthalpy, by the way, is what we normally think of as endothermic/exothermic. Roughly, reactions with a positive $\ce{\Delta H}$ absorb heat and are thus endothermic, and those with a negative $\ce{\Delta H}$ give off heat and are thus exothermic.
So imagine we have an endothermic reaction (positive $\ce{\Delta H}$), which means that the exponent for enthalpy in the above equation is negative. When we increase the temperature, that exponent gets smaller in magnitude (closer to zero), which means it becomes less negative. This causes an increase in $e^x$, which means that K gets bigger, which means the equilibrium shifts in the forward (endothermic) reaction. Likewise, if you have the reaction written in the exothermic direction, $\ce{\Delta H}$ is negative, the exponent is positive, an increase in temperature causes the exponent to become less positive, causing a decrease in the $e^x$, which results in a decrease of K -- the equilibrium now shifts in the reverse (endothermic) direction.
So while the statement that increasing temperatures means that the equilibrium shifts in the endothermic direction is true, it has nothing to do with the activation energy of the reaction. The arguments above are from a purely thermodynamic standpoint, and don't involve any consideration about the mechanism of reaction or the activation energy.
|
First, I propose to rewrite your original system (by multiplyingnumerator and denominator by $x\,y$) as\begin{align} x' &= \frac{d_2 r_1\,x + (r_1 a_{22} - r_2 a_{12})\,x\,y}{a_{12}a_{21}\, x\, y - (d_1 + a_{11}\,x)(d_2 + a_{22}\,y)}, \tag{1a}\\ y' &= \frac{d_1 r_2\,y + (r_2 a_{11} - r_1 a_{21})\,x\,y}{a_{12}a_{21}\,x\,y - (d_1 + a_{11}\,x)(d_2 + a_{22}\,y)}. \tag{1b}\end{align}If I understand you correctly, you want to see whether the following holds:
CLAIM: Given an arbitrary pair of initial conditions $x(0) =
x_0$, $y(0) = y_0$ such that $x_0 > 0$ and $y_0 < 0$, we have that $x(t)
> 0$ and $y(t) < 0$ for all time $t$.
System $(1)$ is a nonlinear dynamical system, so explicitly solving itwill be difficult. However, we can apply some dynamical systemstechniques to see whether the claim is true.
As a first step, we determine the equilibria of system $(1)$, i.e. thepoints $(x,y)$ where $x'=y'=0$. It turns out (I invite you to checkthis) that the origin $(x,y)=(0,0)$ is the only equilibrium of the system.Next, we determine the stability of this equilibrium. We do this bytaking the Jacobian of the right hand side of system $(1)$, and evaluateit at $(x,y)=(0,0)$. This yields the matrix\begin{equation} J((0,0)) = \begin{pmatrix} r_1/d_1 & 0 \\ 0 & r_2 / d_2\end{pmatrix}.\tag{2}\end{equation}The eigenvalues and eigenfunctions of this matrix can readily be readoff: we have $\lambda_1 = r_1/d_1 > 0$ with eigenvector $(1,0)^T$, and$\lambda_2 = r_2/d_2 < 0$ with eigenvector $(0,1)^T$. This means (by theGrobman-Hartman theorem) that we can approximate the phase plane ofsystem $(1)$ around the origin by the linearised system $(x',y')^T =J((0,0))(x,y)^T$; from the eigenvalues, we see that the origin is asaddle. Moreover, the stable manifold of the origin is given by the line$\{ x=0 \}$, and the unstable manifold of the origin is given by theline $\{ y=0 \}$. These manifolds act as separatrices in the phaseplane: in other words, because they consist of orbits, other orbitscannot cross these manifolds and are therefore `caught' between them. Inparticular, any orbit which starts in the lower right quadrant will staythere. So, the claim seems to be true.
However, this linear approximation of the system only holds
locally,that is, sufficiently close to the origin. Because the origin is asaddle, every orbit (except the ones on the stable manifold) will flow away from the origin, where the local linear approximation does nothold anymore. Of course, the stable and unstable manifolds still act asseparatrices, but these are only locally straight. If we zoom out alittle bit, can we still determine what will happen?
Generally, one would now do a so-called manifold expansion, but in the case of system $(1)$, it turns out to be quite easy, because:
OBSERVATION: The line $\{ x=0 \}$ and the line $\{ y=0\}$ are both invariant under the flow of system $(1)$.
So, as you zoom out, you see that the unstable manifold of the origin is
exactly equal to the line $\{ y = 0 \}$; also, the stable manifold of the origin is exactly equal to the line $\{x=0\}$. To reiterate, both manifolds consist of orbits, and orbits cannot cross each other, so orbits that are caught in between these two manifolds in the lower right quadrant will stay in the lower right quadrant for all time -- which is exactly the content of the claim.
Obviously, the same statement holds for every other quadrant, so this system indeed preserves some kind of 'monotonicity'.
Question: I'm curious, where does this system come from? It has the form\begin{equation} \vec{x}' = M R \vec{x},\end{equation}with $R = \text{diag}(r_1,r_2)$ and $M = \frac{1}{\text{det} B} B^T$, where$B = S^{-1} \left(D + A\right) S$, with\begin{equation}S = \begin{pmatrix} 0 & 1 \\ -1 & 0\end{pmatrix} \quad\text{and}\quad A = \begin{pmatrix} a_{11} x & a_{12} x \\ a_{21} y & a_{22} y \end{pmatrix},\end{equation}which seems suggestive.
|
Lahiri's A First Book on Quantum Field Theory states on problem 4.24 that from the Pauli-Lubansky vector $$W_\mu=-\frac{1}{2}\epsilon_{\mu\nu\lambda\rho}P^\nu J^{\lambda\rho}$$ one can prove that for eigenstates of momentum and angular momentum $W^\mu W_\mu=-m^2s(s+1)$ where $m$ is the mass of the particle and $s$ is the spin of the particle. I don't understand however how it is that one actually constructs those states from a given field theory.
On the other hand, I am asked to show by using $$J_{\mu\nu}=i(x_\mu\partial_\nu-x_\nu\partial_\mu)+\frac{1}{2}\sigma_{\mu\nu}$$ where $\sigma_{\mu\nu}=\frac{i}{2}[\gamma_\mu,\gamma_\nu]$ that the spin of a particle satisfying Dirac's equation is $1/2$. I don't even know how to begin since I don't know how to construct an eigenstate of momentum and angular momentum from a Dirac field. I don't think they want us to naively apply the Pauli-Lubansky vector to the field by assuming $P_\nu=-i\partial_\nu$. I've tried this and the math becomes quite unbearable.
As you may observe, I am quite confused with the relationship particle-field. In my mind the Fourier decomposition of a field yields the creation and anhilation operators to construct the momentum eigenstates. On the other hand, through the Lagrangian one can construct from the field a unitary representation of the Poincaré group by calculating its generators from the conserved quantities. So, do I have to go through the whole quantization procedure and construct the correct operators for $P^\nu$ and $J^{\mu\nu}$ to apply to a state created from the creation operators of the field?
Any help in the right direction is much appreciated!
|
This is a slightly more advanced version of another question here.
Let $\textbf{CRing}$ be the category of commutative rings with unit. Let $\textbf{Dom}$ be the category of integral domains – by which I mean a non-trivial commutative ring with unit such that the zero ideal is prime. Let $\textbf{Fld}$ be the category of fields – by which I mean an integral domain such that every non-zero element is invertible. (Homomorphisms preserve the unit, etc.; in the case of $\textbf{Dom}$ we only allow injective homomorphisms.)
There is an evident inclusion of categories $\textbf{Fld} \hookrightarrow \textbf{Dom}$, and it has a left adjoint $\operatorname{Frac} : \textbf{Dom} \to \textbf{Fld}$. Since $\operatorname{Frac}$ is a left adjoint, it preserves coproducts, and it is clear that $\operatorname{Frac} K \cong K$ if $K$ is a field. Thus, coproducts in $\textbf{Fld}$,
if they exist, must be the same as coproducts in $\textbf{Dom}$, if they exist. Question 1. What are necessary and sufficient conditions for the coproduct of two integral domains / fields to exist?
Now, since $\textbf{Fld}$ is a full subcategory of $\textbf{Dom}$ and a full subcategory of $\textbf{CRing}$, by more general nonsense, any $\textbf{CRing}$-coproduct (or $\textbf{Dom}$-coproduct) of fields
that happens to be a field is also the coproduct in $\textbf{Fld}$ Question 2. Is it possible for a coproduct to exist in $\textbf{Dom}$ without being the coproduct in $\textbf{CRing}$?
(As a concrete example of why this matters, observe that $\textbf{CRing}^\textrm{op}$ is a full subcategory of $\textbf{Sch}$, but limits computed in $\textbf{CRing}$ in general differ from colimits computed in $\textbf{Sch}$.)
Some remarks. For every pair of fields $K$ and $L$, we can take their $\textbf{CRing}$-coproduct $K \otimes_{\mathbb{Z}} L$. For each prime $\mathfrak{p}$ in $\operatorname{Spec} K \otimes_{\mathbb{Z}} L$, there is an integral domain $(K \otimes_\mathbb{Z} L) \mathbin{/} \mathfrak{p}$, and we can take the fraction field $\operatorname{Frac} ((K \otimes_\mathbb{Z} L) \mathbin{/} \mathfrak{p})$ to get a quasi-coproduct. There is only a set of these quasi-coproducts, and if $F$ is a field, every pair of maps $(K \to F, L \to F)$ must factor through at least one (or exactly one...?) of these quasi-coproducts. So the category of fields equipped with a homomorphism from $K$ and a homomorphism from $L$ has a "weakly initial set", and a genuine coproduct exists if and only if this category has an initial object.
Thus, the failure of $K \sqcup L$ to exist can be quantified in terms of the structure of the subcategory of quasi-coproducts. What are the possibilities?
|
Let $\xi$ be a positive parameter. We say a positive integer $n$ is $\xi$-smooth, or friable, if for all primes $p$ dividing $n$, we have $p \leq \xi$. Let $T(X, \xi)$ denote the set of $\xi$-smooth numbers up to $X$, and $\Psi(X,\xi) = \# T(X,\xi)$. Then it is known that for all $a > 0$, we have $\Psi(X,X^{1/a}) \sim \rho(a) X$, where $\rho$ is Dickman's function.
Let $f(x) \in \mathbb{Z}[x]$ be of degree $d$ at least $3$, irreducible, and have no fixed prime divisor. Define $$\displaystyle \mathcal{S}_f(B) = \{n \in \mathbb{N} : n \leq B, \text{there exists } t \in \mathbb{N} \text{ s.t. } f(t) = n\}.$$ It is clear that $\# \mathcal{S}_f(B) \sim B^{1/d}$ as $B \rightarrow \infty$. However, it is usually difficult to obtain finer arithmetic properties for $\mathcal{S}_f(B)$. For instance, it is not known whether $\mathcal{S}_f(B)$ contains infinitely many primes when $\deg f > 1$.
What about smooth numbers? That is, can we confirm that
$$\displaystyle \# (T(B, B^{\kappa(d)}) \cap \mathcal{S}_f(B)) \ll \rho(1/\kappa(d)) \# \mathcal{S}_f(B)$$
for, say, $\kappa(d) = 1/(d-1)$?
|
New Impedance Boundary Conditions for Acoustics Simulations
When developing a new product or functionality, the first step is typically to understand the functional properties in isolation. To achieve reliable and accurate predictions via mathematical modeling, it is essential that the critical components, test setup, and boundary conditions are specified in great detail. Most engineers, however, would prefer to focus on the critical components rather than “irrelevant” boundary conditions. New impedance boundary conditions in the Acoustics Module of COMSOL Multiphysics help to close this gap.
What Is an Impedance Boundary Condition?
Before answering the above question, let’s first consider the definition of a boundary condition. Heuristically, introducing a boundary condition means that “we know what happens” on the specific boundary. The boundary condition provides additional constraints to the dynamics of the governing equation that is being solved inside the domain. The additions could be, for example, a known vibration velocity, a sound hard wall, or a symmetry plane. Imposing such constraints, COMSOL Multiphysics looks for a solution that satisfies the acoustical dynamics
and the boundary condition.
Impedance models are really models of a “full flow”, that is, a condition imposed simultaneously on the acoustic pressure and acoustic velocity, defining a given relation between the two elements. Such relations are known in some idealized cases. Introducing an impedance condition essentially forces a certain idealized acoustic behavior. An
impedance boundary condition is therefore a powerful yet simple condition that is applied to situations in which the idealized dynamics are obvious. Microphone cavities with well-known membrane dynamics, acoustics in long pipes, and plane-wave acoustics at porous surfaces are some relevant examples.
Mathematically, the specific impedance boundary condition specifies a linear relation between pressure p and velocity v
(1)
where Z_\textrm{s} is the so-called impedance containing the dynamics (SI unit: Pa*s/m). The most advanced impedance models are given in the frequency domain. As such, Z_\textrm{s} is generally a frequency-dependent parameter, Z_\textrm{s}=Z_\textrm{s}(\omega).
Rather than specifying a
specific impedance that relates the velocity to the pressure at every single point (as in Eq. (1)), the acoustic impedance Z (SI unit: Pa*s/m^3) relates the pressure acting on a surface to the volumetric flow Q rate at that surface, such that
(2)
Finally, we have the
characteristic specific impedances Z_\textrm{c} defined for traveling waves. These types of impedances relate the particle velocity and pressure at every point as the wave moves through the domain, making them useful low-order models for an infinite domain. One example is the well-known relation for plane traveling waves, Z_\textrm{c}=\rho c. New Impedance Models in the Acoustics Module
The Impedance boundary condition — part of the Acoustics Module in COMSOL Multiphysics — features several new models that are directly applicable to a range of acoustics applications. All of the additions contain frequency dependencies and are available only in the frequency domain. (To define an impedance boundary condition in the time domain, you can use the
User defined impedance boundary condition.) The table below describes the models, included under the Impedance boundary condition in the Pressure Acoustics physics interface.
Name Description Applications RCL Lumped-parameter circuit element models, allowing for any combination of an acoustic resistance (R), compliance (C), and inertance (L). Electroacoustics: Models of microphone membranes, transducers, etc. for mobile devices and consumer electronics. Physiological Experimentally verified models of the human ear and human skin. Hearing aids: Appropriate boundary conditions for hearing aids used within the ear. Waveguide end impedance Models of the acoustics at waveguide ends, with options for flanged and unflanged configurations. Long pipes and ducts: Used to truncate the simulation domain when pipes and ducts end. The relations are good approximations when the propagating waves are plane waves. Porous layer General model of normal-incidence acoustics on a layer of porous material backed by a hard wall. Room acoustics: Simple boundary condition for room acoustics simulations with sound-absorbing layers. Characteristic specific impedance Idealized models of traveling-wave acoustics of infinite domains for plane, cylindrical, and spherical waves. Infinite domains: Crude models of an infinite domain, assuming that the acoustic radiation from the region of interest can adequately be approximated as plane waves, cylindrical waves, or spherical waves. The radiation boundary conditions are more elaborate versions of this condition.
As the screenshots below indicate, toggling between the array of impedance models is quite easy. For the more complex options, we have included an illustration to offer a better description.
Working with Impedance Boundary Conditions in Acoustics Simulations
In the rest of the blog post, we will walk through a few examples that demonstrate how to exploit the
RCL functionality option in the impedance boundary conditions. The first model focuses on the use of an RCL circuit to represent a measurement microphone. The last two examples are based on the same system, with a complex COMSOL Multiphysics model treated as an “experiment” in which certain parts (a submodel) can be parameterized by an impedance. In the first case, the impedance is given as an interpolation function. In the second case, an RCL model is fitted to the data using optimization. An RCL Condition in Electroacoustics
We can begin by considering a case in which parameters for an impedance boundary condition are known. Such a situation is common in electroacoustics, as lumped-parameter values are often specified for devices.
In many engineering branches, acoustics included, lumped-parameter modeling is a recognized strategy for establishing useful models without spatial resolution. In the new Impedance boundary condition, a general framework for simple lumped-parameter models is available under the
RCL option. Let’s use the example of a simple microphone, as demonstrated in our lumped receiver tutorial. Here, the behavior of a receiver (miniature loudspeaker) is analyzed, with a microphone placed at the opposite end to read out the signal. Model geometry of a receiver (miniature loudspeaker) placed in a test setup.
To model the microphone, we use a serial RCL impedance condition
(3)
C is the compliance of the microphone (a measure of the air volume behind the diaphragm as it is pushed back), R is the losses of the system (thermoviscous damping), and L is the acoustic mass of the diaphragm. The condition is applied evenly across the entire end of the outlet, implicitly neglecting variations in diaphragm displacement at different radial coordinates that would occur if a full microphone model was included.
Compared with experimental measurements, the model offers excellent predictions across a broad frequency band using the simple boundary condition in Eq. (3) for the microphone. The impedance provides a boundary condition with sufficiently realistic dynamics, keeping the focus on the detailed modeling of the receiver and other elements.
A plot comparing pressure inside the coupler region. How to Model a Subcomponent Using an Impedance
Shifting gears, we’ll now look at how to extract an impedance model in order to represent a complex subcomponent. You can download the model presented here from our Application Gallery.
The example involves a simple muffler-like system (or it could be a part of a muffler) consisting of a long tube with a 2D axisymmetric Helmholtz resonator (see figure below). A plane wave of amplitude p_\textrm{in} is incident at the inlet with radiation conditions applied at the inlet and outlet. Noticeable viscothermal damping is present in the narrow neck of the Helmholtz resonator. Because of such losses, the
Pressure Acoustics interface is insufficient and the full model uses the Thermoacoustics interface in that region. In the main parts of the duct, the Pressure Acoustics interface suffices. The model utilizes the Pressure Acoustics and Thermoacoustics interfaces, along with the Acoustic-Thermoacoustic Boundary multiphysics coupling. Muffler-like system with a Helmholtz resonator. The schematic on the left corresponds to the 2D axisymmetric geometry implemented in COMSOL Multiphysics. Notice the very narrow neck into the resonator, which is responsible for viscothermal losses. User-Defined Impedance Given by an Interpolation Function
When moving from component simulation to system simulation, it can be advantageous to lump certain parts or full components (i.e., solving the thermoacoustic model in the current resonator is computationally expensive). To do so, we can replace the
Thermoacoustics submodel (the Helmholtz resonator) with an impedance boundary condition, applying the condition to the area where the inlet to the neck is located. In this way, it is possible to simulate the whole model with only the Pressure Acoustics interface.
First, we extract the effective impedance Z_{\textrm{func}} at the neck from the full model. We compute the ratio of the average inlet pressure to the average inlet velocity, as
(4)
The figure below illustrates the real and imaginary parts of Z_{\textrm{func}}. The data is used to create two interpolation functions for Z_{\textrm{func}}: one for the real part (Zfunc_real) and one for the imaginary part (Zfunc_imag). The functions contain all of the information about the impedance and can be called from inside the
User Defined impedance boundary condition by writing:
Zfunc_real(freq)+i*Zfunc_imag(freq). Using the impedance, we set up a simplified version of the model with only the
Pressure Acoustics interface. The Helmholtz resonator is no longer included in the setup, but it is represented by the impedance.
To evaluate the performance of the simplified model, we compute the
transmission coefficient \tau across the main tube. The transmission coefficient is defined as the ratio of the transmitted power (W_{\textrm{out}}) relative to the incident inlet power (W_{\textrm{in}}). We also plot the “energy balance”, that is, the dissipated energy in the system. This is given as the difference between the incident and reflected and transmitted power,
(5)
where W_{\textrm{ref}} is the reflected power.
The results are depicted in the following two figures. Good agreement is shown in both of the graphs, with little difference between the full model and the simplified model using the interpolated impedance. Shorter solution times are an added benefit, as the simplified version takes only 3 seconds to solve (the fully coupled model took 25 seconds). While the numbers are hardware-dependent, they do reflect the computational efficiency of removing the need to solve the thermoacoustic model in the resonator.
Transmission coefficient plot (left) and power balance plot showing the dissipated energy (right).
In most realistic situations, however, it is not particularly advantageous to first solve a complicated version of a model and then reduce it. Single subcomponents can be modeled individually and characterized. The detailed impedance models of the complex subcomponents derived from full models should be kept in a library and called upon when necessary. COMSOL Multiphysics has functionality to support such a practice: Tabulated values of the results from complex subcomponents can be saved to files and brought in as needed.
A Fitted RCL Model Using Optimization
In cases where
a priori knowledge is used to deduce the mathematical form of the impedance, or when the data obviously lends itself to simple mathematical forms, the preferred route may be to fit a simple theoretical model to the full detailed COMSOL model. In the former case, the parameter values of the impedance model reflect characteristics of the underlying physics and offer insight into the system. For instance, if the data is described well by an RCL-type model, such as Eq. (3), the resonance frequencies are immediately available.
We will illustrate the steps for fitting a theoretical model to an impedance boundary condition. The Helmholtz resonator has a moving acoustic mass (the air in the neck), a compliance (the compressible air in the resonator volume), and losses (the thermoviscous losses). Thus, a good model across the entire frequency range is
(6)
where R_{\textrm{func}}, C_{\textrm{func}}, and L_{\textrm{func}} are unknown parameters to be fitted. The Optimization Module is used to perform a best fit of Eq. (6) to Z_{\textrm{func}} with the objective function \left| \left( Z_{\textrm{theo}}- Z_{\textrm{func}} \right)^2 \right|. The following fitted parameter values are obtained
The values are entered directly into the Impedance boundary condition via the
RCL option. (For general theoretical models, the User defined option can be used as it accepts any model, no matter the level of complexity.) Using only the Pressure Acoustics interface and the RCL impedance model, we once again compare the results from the new simplified version to the fully coupled model. We plot the transmission coefficient \tau and the power balance from Eq. (5). Transmission coefficient (left) and power balance (right) plots. Results are shown for the simplified model (red), the full impedance model (green), and the fully coupled model (blue). The latter two results were presented in this earlier figure.
We again observe good agreement for both metrics across the entire frequency range. The high-frequency response provides a slightly better representation of the fully coupled model than in the initial example, while the situation is opposite for low frequencies.
As mentioned earlier, simple, well-known boundary impedance models can be used to obtain even more insight about the system. Let’s apply such an approach to our present simple muffler case.
The resonance frequency for series-coupled RCL models, such as Eq. (6), is given by f_{\textrm{res}}=\frac{1}{2 \pi \sqrt{C_{\textrm{func}} L_{\textrm{func}}}}. It is, therefore, expected that the optimal muffler working conditions (lowest transmission coefficient) will be achieved at the frequency
Indeed, this is found to be the case. Dashed vertical lines indicate the resonant frequency in the figures above, predicting the minimum transmission coefficient very well.
If you have any questions, please contact us.
Comments (0) CATEGORIES Chemical COMSOL Now Electrical Fluid General Interfacing Mechanical Today in Science
|
Interactions between ions, dipoles, and induced dipoles account for many properties of molecules - deviations from ideal gas behavior in the vapor state, and the condensation of gases to the liquid or solid states. In general, stronger interactions allow the solid and liquid states to persist to higher temperatures. However, non-polar molecules show similar behavior, indicating that there are some types of intermolecular interactions that cannot be attributed to simple electrostatic attractions. These interactions are generally called
dispersion forces. The London dispersion force is the weakest intermolecular force. It is a temporary attractive force that results when the electrons in two adjacent atoms occupy positions that make the atoms form temporary dipoles. Introduction
Electrostatic forces operate when the molecules are several molecular diameters apart, and become stronger as the molecules or ions approach each other. Dispersion forces are very weak until the molecules or ions are almost touching each other, as in the liquid state. These forces appear to increase with the number of "contact points" with other molecules, so that long non-polar molecules such as n-octane (\(C_8H_{18}\)) may have stronger intermolecular interactions than very polar molecules such as water (\(H_2O\)), and the boiling point of n-octane is actually higher than that of water.
Unequal sharing of electrons causes rapid polarization and counter-polarization of the electron cloud forming short lived dipoles. These dipole interact with the electron clouds of neighboring molecules forming more dipoles. The attractive interaction of these dipole are called
dispersion or London Dispersion forces. These forces are weaker than other intermolecular forces and do not extend over long distances.The strength of these interactions within a given molecule depends directly on how easily the electrons in the molecules can move (i.e., be polarized). Large molecules in which the electrons are far from the nucleus are relatively easy to polarize and therefore possess greater dispersion
Figure 1: Dispersion Interaction with an instantaneous dipole on one He atom inducing a dipole on a nearby He atom.
If it were not for dispersion forces, the noble gases would not liquefy at any temperature since no other intermolecular force exists between the noble gas atoms. The low temperature at which the noble gases liquefy is to some extent indicative of the magnitude of dispersion forces between the atoms. Electron distribution around an atom or molecule can be distorted. This distortion is called the polarizability.
Figure 2: Dispersion interaction in the gas phase
It is possible that these forces arise from the fluctuating dipole of one molecule inducing an opposing dipole in the other molecule, giving an electrical attraction. It is also possible that these interactions are due to some sharing of electrons between the molecules in "intermolecular orbitals", similar to the "molecular orbitals" in which electrons from two atoms are shared to form a chemical bond. These dispersion forces are assumed to exist between all molecules and/or ions when they are sufficiently close to each other. The stronger farther-reaching electrical forces from ions and dipoles are considered to operate in addition to these forces.
Polarizability
The polarizability is used to describe the tendency of molecules to form charge separation.
Induced dipole occurs when a molecule with an instantaneous dipole induces a charge separation on other molecule. The result is a dipole-dipole attraction. The strength of the induced dipole moment, \(\mu\), is directly proportional to the strength of the electric field, \(E\) with a proportionality constant \(\alpha\) called the polarizability. The strength of the electric field causes the distortion in the molecule. Therefore, greater the strength of the electric field, the greater the distortion and to a larger interaction:
\[\mu = \alpha'{E}\]
where,
\(\mu\) = the induced dipole moment \(\alpha\) = the polarizability \(E\) = the electric field Interaction Energy
Interaction energy can be approximated using the
London formula (Equation 1). A German physicist, Fritz London proved that potential energy of two uncharged molecules or identical atoms can be measured by following equation:
\[V_{11} = -\dfrac{3}{4} \dfrac{\alpha_2I}{r^6} \tag{1}\]
Equation 1 is modified for non-identical atoms or molecules
\[V_{12} = -\dfrac{3}{2} \dfrac{I_1I_2}{I_1 + I_2} \dfrac{\alpha _1' \alpha _2'}{r^6} \tag{2}\]
with
\(I\) is the first ionization energy of each molecule \(\alpha\) is the polarizability \(r\) is the distance between molecules
Example
Calculate the potential energy between two Ar atoms separated by 4.0 Angstroms (\(10^{-10}\)).
Solution: -0.77 KJ/mol References Atkins, Peter and Julio de Paula. Physical Chemistry for the Life Sciences. Oxford, UK: Oxford University Press. 2006. pg 466-467. Garrett, Reginald H. and Charles M. Grisham. Biochemistry 3rd edition. United Stated of America: Thomson Brooks/Cole. 2005. pg 13. Harwood, William S., Herring, Geoffrey F., and Ralph H. Petrucci. General Chemistry: Principles and Modern Applications 8 thedition. Upper Saddle River, New Jersey. 2002. pg 497-499. Chang, Raymond. Physical Chemistry for the Biosciences. University Science Books. 2005. pg 497-498. Contributors Ryan Ilagan (UCD)
Gary L Bertrand, Professor of Chemistry, University of Missouri-Rolla
|
This site is going to need TeX markup to express mathematical symbols and formulas well.
I have already started using TeX in my markup.
The way that Math Overflow does it is to surround the TeX with dollar signs, using the jsMath library.
I suggest we stick with that convention, so that when we have support for it, our old posts will "light up".
EDIT:
I have created a quick-hack grease monkey script to get this done in the mean time:
http://userscripts.org/scripts/show/81977 EDIT2:
I have updated the script to work on Stats.stackexchange.com, and have added in transparency, and options to use other services, as well.
EDIT3:
I have incorporated Isaac's changes, and added an additional rendering service.
The developers should come and ask the moderators of MathOverflow (e.g. me) about this, and we'll happily help out!
By the way, I'd recommend actually using MathJax, the brand new replacement for jsMath. It's still not quite as fast as jsMath, but it's the way of the future. MathOverflow will switch soon.
Temporary workarounds:
Images can be embedded in questions and answers with
 like so:
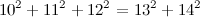 becomes
Combine this with: http://mathurl.com/ - type in latex, get a minified image url to link to in your posts http://www.codecogs.com/latex/eqneditor.php - as above, but no minification, and you have to rightclick to get the image url.
For simple formulas, where LaTeX is not needed:
You can use
<sup></sup> to write superscripts and
<sub></sub> for subscripts:
y<sub>1</sub>=x<sup>2</sup>+3becomes y
1=x 2+3
I've posted a walk-through of how we've implemented math rendering on MathOverflow on meta.SO. As Scott said, we'll be switching to MathJax in the near future, so it probably makes sense for new SE sites to just use MathJax from the get-go. Once we switch, I'll try to remember to update that answer to reflect the changes.
We have added MathJax to support TeX equations based on feedback. MathJax is on the cusp of a 1.0 release and we will update this library once it's final.
Three Four Five observations:
If one escapes a latex fragment using backticks (this is frequently needed in order to arbitrate between Markdown and the latex rendered) the latex piece gets colored in gray due to the stylesheet in a rather unsightly way.
Display math using
$$does not seem to work.
It would be immensely useful if the preview of answers rendered latex too.
Something's amiss with things like \mathbb{Z}/3\mathbb{Z}, which gets rendered as $\mathbb{Z}/3\mathbb{Z}$. (Hmm, here it looks fine, but in Group With an Endomorphism That is "Almost" Abelian is Abelian. it doesn't)
Editing a comment kills everything within dollar signs.
If the formula is not complicated, besides <sup> and <sub> I also use character entities in html. Some examples:
bold ∏ displays as
∏ bold ∑ displays as ∑
in general, Greek letters are displayed by writing &letter; other symbols are
ℵ ℵ
∀ ∀ ∃ ∃ ∈ ∈ ∩ ∩ ∪ ∪
Look here for the complete list of allowed characters. I know that this is not enough to write decent mathematics, but it's a start.
I do believe that this is of utmost urgency, and should be first priority for any developers working on this site.
Is this thing on?
$\begin{equation} \sum_{i=1}^{\infty}x_{i} \end{equation}$
...yep!
$\begin{tabular}{r|c|l} symbol & read as & example \ \hline $\to$ & ``maps to" & $f:\mathbb{R} \to \mathbb{Z}$ \ $\forall$ & "for all" & $\forall x \in E$ \end{tabular}$
... what environments are going to work here? (clearly not
tabular)
EDUT Oh, didnt read the comments. Thanks guys for working on this!
Is anyone else seeing the symbols as monstrously huge?
Agreed. I think everyone is begging for this feature. It's been requested numerous times on Meta StackOverflow, the latest one specifically for Area 51/StackExchange being here.
Personally I would like to see
jsMath implemented on StackExchange sites. It's virtually trivial, a script reference simply needs to be added to the page.
In the meantime, there's Google Chart.
edit: except that it doesn't appear to show up. :P
LaTeX rendering is needed, but I would like to see a server-side solution rather than a client-side solution such as jsMath. The biggest problem for me with jsMath is that it takes such a long time to completely load a web page on some popular MathOverflow questions. Often I have to simply disable jsMath or else the web browser consumes so much memory that my computer starts swapping pages of RAM to the disk.
What about adding a toolbar button to convert a LaTeX expression to an image using the mathURL service?
I am running John Gietzen's awesome Greasemonkey script in my browser and everyone's TeX is showing up great - but
I am having a problem composing TeX. Specifically, I seem to be completely unable to include addition signs in my formulas. This makes zero sense to me, can somebody explain?
For example: "P of x equals a x squared
plus bx plus c" looks like: $P(x)=ax^2 + bx + c$
I have typed
$</code><code>P(x)=ax^2 + bx + c</code><code>$
EDIT: Isaac has fixed the script, it looks like it's working pretty good now.
As mentioned before, one option that doesn't involve a third party rendering service is MathJax, the spiritual successor to jsMath. Here is a small userscript that inserts MathJax (currently hosted on my own web server, but presumably would be hosted by stack exchange on a permanent basis) into the head of math and meta.math.
You can use a number of math formats for display, like regular ol' TeX markup:
$P(x)=ax^2 + bx + c$
Or some more complex TeX formatting:
$\left( \sum_{k=1}^n a_k b_k \right)^2 \leq \left( \sum_{k=1}^n a_k^2 \right) \left( \sum_{k=1}^n b_k^2 \right)$
And eventually, if Stack Exchange allows MathML to be inserted into pages, code like this:
<math display='block'><mrow><mi>x</mi><mo>=</mo><mfrac><mrow><mo>−</mo><mi>b</mi><mo>±</mo><msqrt><mrow><msup><mi>b</mi><mn>2</mn></msup><mo>−</mo><mn>4</mn><mi>a</mi><mi>c</mi></mrow></msqrt></mrow><mrow><mn>2</mn><mi>a</mi></mrow></mfrac></mrow></math>
(something seems a little slow when loading MathJax here - it may be a configuration problem on my end. I will look into it later today. Reference the official preview page if you want a better idea of the latency with translating lots of TeX on a page with javascript - it's quick)
I vote for
MathJax to be used instead of jsMath if a Javascript library is decided over a server-side LaTeX image generator.
Equation rendering is exceptional over jsMath, and all major browsers are supported. (Even IE6!! See Browser Compatibility.) Most operating systems and browsers anti-alias the LaTeX, and the equations seem to fit in to the native look, whatever browser that may be.
|
To small numerical factors, the fusion reaction rate is $r_{AB} \propto n_A n_B <\sigma_{AB}\, v>$, where $<\sigma_{AB}\, v>$ is the (temperature-dependent) "reactivity" for the reaction, formed from the averaging the cross-section over an appropriate Maxwellian velocity distribution, and $n$ are the number densities of the reactants.
The proton density at the centre of the Sun is about $10^{32}$ m$^{-3}$, the temperature is $1.5\times 10^{7}$ K. The initial (rate-determining) step in the p-p chain is the formation and subsequent beta decay of a diproton. The cross-section for this reaction is $\sim 10^{-23}$ barns and $<\sigma_{pp}\, v> \sim 10^{-43}$ cm$^{3}$ s$^{-1}$ at the solar core temperature.
For the deuterium-tritium reaction used in controlled fusion experiments, the temperatures are $\sim 10^{8}$ K and the number densities of the reactants $\sim 10^{20}$ m$^{-3}$ (roughly correct for the JET and ITER reactors). The cross-section of the reaction at this temperature is a few barns, much higher than the p-p reaction, and the reactivity is $<\sigma_{DT}\, v> \sim 10^{-15}$ cm$^3$ s$^{-1}$.
Putting these
order of magnitude estimates together, the ratio of reaction rates multiplied by the energy released per reaction is$$ \frac{r_{DT} \times Q_{DT}}{r_{pp} \times Q_{pp}} \sim \frac{10^{40} 10^{-15}}{10^{64} 10^{-43}} \times \frac{18\ MeV}{26\ MeV} = 10^{4}$$
In other words, controlled nuclear fusion experiments (briefly) yielding roughly $2.5 \times 10^{6}$ W m$^{-3}$ Thus the energy released per unit volume and the reaction rate per unit volume are about
4 orders of magnitude larger/faster than in the core of the Sun.
|
Product Rule for Derivatives Theorem
Let $\xi \in I$ be a point in $I$ at which both $j$ and $k$ are differentiable.
Let $\map f x = \map j x \, \map k x$. Then: $\map {f'} \xi = \map j \xi \, \map {k'} \xi + \map {j'} \xi \, \map k \xi$ $\forall x \in I: \map {f'} x = \map j x \, \map {k'} x + \map {j'} x \, \map k x$ Using Leibniz's notation for derivatives, this can be written as: $\map {\dfrac \d {\d x} } {y \, z} = y \dfrac {\d z} {\d x} + \dfrac {\d y} {\d x} z$
where $y$ and $z$ represent functions of $x$.
then:
$\forall x \in I: \displaystyle D_x \left({\prod_{i \mathop = 1}^n f_i \left({x}\right)}\right) = \sum_{i \mathop = 1}^n \left({D_x \left({f_i \left({x}\right)}\right) \prod_{j \mathop \ne i} f_j \left({x}\right)}\right)$ Proof
\(\displaystyle \map {f'} \xi\) \(=\) \(\displaystyle \lim_{h \mathop \to 0} \frac {\map f {\xi + h} - \map f \xi} h\) \(\displaystyle \) \(=\) \(\displaystyle \lim_{h \mathop \to 0} \frac {\map j {\xi + h} \, \map k {\xi + h} - \map j \xi \, \map k \xi} h\) \(\displaystyle \) \(=\) \(\displaystyle \lim_{h \mathop \to 0} \frac {\map j {\xi + h} \, \map k {\xi + h} - \map j {\xi + h} \, \map k \xi + \map j {\xi + h} \, \map k \xi - \map j \xi \, \map k \xi} h\) \(\displaystyle \) \(=\) \(\displaystyle \lim_{h \mathop \to 0} \paren {\map j {\xi + h} \frac {\map k {\xi + h} - \map k \xi} h + \frac {\map j {\xi + h} - \map j \xi} h \map k \xi}\) \(\displaystyle \) \(=\) \(\displaystyle \map j \xi \, \map {k'} \xi + \map {j'} \xi \, \map k \xi\) Note that $\map j {\xi + h} \to \map j \xi$ as $h \to 0$ because, from Differentiable Function is Continuous, $j$ is continuous at $\xi$.
$\blacksquare$
Also see Derivative of Product of Real Function and Vector-Valued Function Derivative of Vector Cross Product of Vector-Valued Functions Derivative of Dot Product of Vector-Valued Functions Sources 1968: Murray R. Spiegel: Mathematical Handbook of Formulas and Tables... (previous) ... (next): $\S 13$: General Rules of Differentiation: $13.7$ 1977: K.G. Binmore: Mathematical Analysis: A Straightforward Approach... (previous) ... (next): $\S 10.9 \ \text{(ii)}$ 2008: David Nelson: The Penguin Dictionary of Mathematics(4th ed.) ... (previous) ... (next): Entry: Leibniz theorem
|
Answer
56.55 $ mm ^ 2 $
Work Step by Step
We know that the area is equal to: $$A=\pi r^2 \times \frac{\theta}{2\pi \ radians}$$ We know that the area is equal to: $$A=r^2 \times \frac{\theta}{2}$$ $$A=12^2 \times \frac{\pi/4}{2}=56.55$$
You can help us out by revising, improving and updating this answer.Update this answer
After you claim an answer you’ll have
24 hours to send in a draft. An editorwill review the submission and either publish your submission or provide feedback.
|
Let assume that running a
single DES key search operation requires 1 key schedule, encryption, and 1 comparison that now we omit.
for key in 2^56
k = key_schedule(key) //note to distingush the key schedule has a funtion
test (E(k,m), c)
Your 3DES requires3 encryptions, only 2 schedule runs if we want to attack brute-force. The key space is still $2^{56}$ since we don't need a sperate key search for the complement $k'$, just complement the current key and run the key schedule.
for k in 2^56
k1 = key_schedule(k)
k2 = key_schedule(k')
test ( E(E(E(m,k1),k2),k1), c)
So in, the total we need at most 3-times single DES operations and 2-times DES key schedules. If we assume that the running time of the key schedule and the encryption are same, then your 3DES is $5/2=2.5$ slower than brute-forcing a single DES.
Now, turn into 2DES with two different keys. In the complexity calculations of the meet-in-middle attack the big $\mathcal{O}$ notation hides some details;
A memory for a table requirement for storing the encryption with each key; we need to store $6\cdot 2 \cdot 2^{56}$-byte $\approx 1152$ PetaByte. This is still very huge amount to store and process. Google has 15 exabytes = 15000 petabytes. Sorting the table $n \log n$ step, therefor we have $ 56 \cdot 2^{56}$ Searching within the table $56$ steps by binary search.
When these values are added
1, 3DES search will be faster than the 2DES, and can be calculated by using in quite reasonable time if you can access the Titan, you can brute-force in couple hours. The Titan that can reach $2^{60}$ every easily.
1 I would like to note here that, DES encryption and sorting cannot be directly compared. A deeper calculation is required.
|
$\ce{NH3}$ is a weak base so I would have expected $\ce{NH4+}$ to be a strong acid. I can't find a good explanation anywhere and am very confused. Since only a small proportion of $\ce{NH3}$ molecules turn into $\ce{NH4+}$ molecules, I would have expected a large amount of $\ce{NH4+}$ molecules to become $\ce{NH3}$ molecules.
First, let’s get the definition of
weak and strong acids or bases out of the way. The way I learnt it (and the way everybody seems to be using it) is:
$\displaystyle \mathrm{p}K_\mathrm{a} < 0$ for a strong acid
$\displaystyle \mathrm{p}K_\mathrm{b} < 0$ for a strong base
$\displaystyle \mathrm{p}K_\mathrm{a} > 0$ for a weak acid
$\displaystyle \mathrm{p}K_\mathrm{b} > 0$ for a weak base
Thus
strong acid and weak base are not arbitrary labels but clear definitions based on an arbitrary measurable physical value — which becomes a lot less arbitrary if you remember that this conincides with acids stronger than $\ce{H3O+}$ or acids weaker than $\ce{H3O+}$.
Your point of confusion seems to be a statement that is commonly taught and unquestionably physically correct, which, however, students have a knack of misusing:
The conjugate base of a strong acid is a weak base.
Maybe we should write that in a more mathematical way:
If an acid is strong, its conjugate base is a weak base.
Or in mathematical symbolism:
$$\mathrm{p}K_\mathrm{a} (\ce{HA}) < 0 \Longrightarrow \mathrm{p}K_\mathrm{b} (\ce{A-}) > 0\tag{1}$$
Note that I used a
one-sided arrow. These two expressions are not equivalent. One is the consequence of another. This is in line with another statement that we can write pseudomathematically:
If it is raining heavily the street will be wet.
$$n(\text{raindrops}) \gg 0 \Longrightarrow \text{state}(\text{street}) = \text{wet}\tag{2}$$
I think we immediately all agree that this is true. And we should also all agree that the reverse is not necessarily true: if I empty a bucket of water on the street, then te street will be wet but it is not raining. Thus:
$$\text{state}(\text{street}) = \text{wet} \rlap{\hspace{0.7em}/}\Longrightarrow n(\text{raindrops}) \gg 0\tag{2'}$$
This should serve to show that sometimes, consequences are only true in one direction. Spoiler: this is also the case for the strength of conjugate acids and bases.
Why is the clause above on strength and weakness only true in one direction? Well, remember the way how $\mathrm{p}K_\mathrm{a}$ values are defined:
$$\begin{align}\ce{HA + H2O &<=> H3O+ + A-} && K_\mathrm{a} (\ce{HA}) = \frac{[\ce{A-}][\ce{H3O+}]}{[\ce{HA}]}\tag{3}\\[0.6em] \ce{A- + H2O &<=> HA + OH-} && K_\mathrm{b} (\ce{A-}) = \frac{[\ce{HA}][\ce{OH-}]}{[\ce{A-}]}\tag{4}\end{align}$$
Mathematically and physically, we can add equations $(3)$ and $(4)$ together giving us $(5)$:
$$\begin{align}\ce{HA + H2O + A- + H2O &<=> A- + H3O+ + HA + OH-}&& K = K_\mathrm{a}\times K_\mathrm{b}\tag{5.1}\\[0.6em] \ce{2 H2O &<=> H3O+ + OH-}&&K = K_\mathrm{w}\tag{5.2}\end{align}$$
We see that everything connected to the acid $\ce{HA}$ cancels out in equation $(5)$ (see $(\text{5.2})$) and thus that the equilibrium constant of that reaction is the autodissociation constant of water $K_\mathrm{w}$. From that, equations $(6)$ and $(7)$ show us how to arrive at a well-known and important formula:
$$\begin{align}K_\mathrm{w} &= K_\mathrm{a} \times K_\mathrm{b}\tag{6}\\[0.6em] 10^{-14} &= K_\mathrm{a} \times K_\mathrm{b}\\[0.6em] 14 &= \mathrm{p}K_\mathrm{a} (\ce{HA}) + \mathrm{p}K_\mathrm{b} (\ce{A-})\tag{7}\end{align}$$
Now let us assume the acid in question is strong, e.g. $\mathrm{p}K_\mathrm{a} (\ce{HA}) = -1$. Then, by definition the conjugate base must be (very) weak: $$\mathrm{p}K_\mathrm{b}(\ce{A-}) = 14- \mathrm{p}K_\mathrm{a}(\ce{HA}) = 14-(-1) = 15\tag{8}$$
Hence, our forward direction of statement $(1)$ holds true. However, the same is
not true if we add an arbitrary weak acid to the equation; say $\mathrm{p}K_\mathrm{a} (\ce{HB}) = 5$. Then we get:
$$\mathrm{p}K_\mathrm{b} (\ce{B-}) = 14-\mathrm{p}K_\mathrm{a}(\ce{HB}) = 14-5 = 9\tag{9}$$
A base with a $\mathrm{p}K_\mathrm{b} = 9$ is a
weak base. Thus, the conjugate base of the weak acid $\ce{HB}$ is a weak base.
We realise that we can generate a weak base in two ways: by plugging a strong acid into equation $(7)$ or by plugging a certain weak base. Since the sum of $\mathrm{p}K_\mathrm{a} + \mathrm{p}K_\mathrm{b}$ must equal $14$, it is easy to see that both
cannot be strong. However, it is very possible that both the base and the acid are weak.
Thus, the reverse statement of $(1)$ is
not true.
$$\mathrm{p}K_\mathrm{a}(\ce{HA}) < 0 \rlap{\hspace{1em}/}\Longleftarrow \mathrm{p}K_\mathrm{b} (\ce{A-}) > 0\tag{1'}$$
First, let's understand the perspective of
weak acid and weak base. This is in relation to pure water — like in most general chemistry courses.
Pure Water has a $\mathrm{p}K_\mathrm{a}$ of 14.
$\ce{NH3/NH4+}$ has a $\mathrm{p}K_\mathrm{a}$ of 9.25.
We know: $$\ce{NH4+ + H2O <--> NH3 + H3O+}$$
Thus, we solve for the $K_\mathrm{a}$ (which depends on the concentration of each of your chemicals):
$$K_\mathrm{a} = \frac{[\ce{NH3}][\ce{H3O+}]}{[\ce{NH4+}]}$$
Similarly, we can solve for $K_\mathrm{b}$:
We know the ionization equation for a base is: $$\ce{B + H2O <--> HB+ + OH-}$$
Which means: $$\ce{NH3 + H2O <--> NH4+ + OH-}$$
So in order to solve for the $K_\mathrm{b}$, plug the concentration of your chemicals in:
$$K_\mathrm{b} = \frac{[\ce{NH4+}][\ce{OH-}]}{[\ce{NH3}]}$$
tl;dr: As the math shows, you can think of these as a "weak but not meaningless" acid/base. Don't let your assumptions throw you off — a weak acid generates a weak base, and vice versa. See the Henderson-Hasselbalch Equation.
$\ce{NH3}$ is not in the same class of weak bases as say, $\ce{Cl-}$. The acid to base curve isn't extreme like $\ce{HCl + H2O -> Cl- + H3O+}$.
In case a less abstract answer will help:
A base, like $\ce{NH_3}$, is a base because it has a significant chance of picking up protons in water. You can almost think of it as a competition between the $\ce{NH_3}$'s and the $\ce{H_2O}$'s to pick up the free protons.
It is a weak base because it is not a certainty that all the $\ce{NH_3}$'s in a given sample will pick up a proton and hold onto it. In any given sample at any point in time, a certain portion of the $\ce{NH_4^+}$'s ($\ce{NH_3}$'s that
won the proton) will give their protons up and a certain number of $\ce{NH_3}$'s will pick up new protons. Eventually, the system reaches a steady state (quantifiable with $K_b$).
Our definition of an "acid" is just something that donates protons, as the $\ce{NH_4^+}$ does above.
It's not that they're really different things: the $\ce{NH_3}$'s a base when its picking up protons and its an acid when it lets them go.
|
Hi I am trying to evaluate the integral $$ \mathcal{I}(\omega)=\int_{-\infty}^\infty J^3_0(x) e^{i\omega x}\mathrm dx $$ analytically. We can also write $$ \mathcal{I}(\omega)=\mathcal{FT}\big(J^3_0(x)\big) $$ which is the Fourier Transform of the cube of Bessel function. The Bessel function $J_0$ is given by $$ J_0(x)=\frac{1}{2\pi}\int_{-\pi}^\pi e^{-ix\sin t} \mathrm dt. $$ If it helps, we can represent the cube of the Bessel function by $$ J^3_0(x)=-3\int J^2_0(x) J_1(x) \mathrm dx, \ \ \ \ \ J_1(x)=\frac{1}{2\pi}\int_{-\pi}^\pi e^{i(t-x\sin t)} \mathrm dt. $$ In general $$ J_n(x)=\frac{1}{2\pi}\int_{-\pi}^\pi e^{i(nt-x\sin t)}\mathrm dt. $$ The Fourier Transforms of the Bessel function and its square is given by $$ \mathcal{FT}\big(J_0(x)\big)=\sqrt{\frac{2}{\pi}}\frac{\theta(\omega+1)-\theta(\omega-1)}{\sqrt{1-\omega^2}} $$ and $$ \mathcal{FT}\big(J^2_0(x)\big)=\frac{\sqrt{2}K\big(1-\frac{\omega^2}{4}\big)\big(\theta(-\omega-2)-1\big)\big(\theta(\omega-2)-1\big)}{\pi^{3/2}} $$ where K is the elliptic-K function and $\theta$ is the heaviside step function. However I need the cube...
It turns out that the Fourier transform of $J_0^3$ can still be expressed in terms of complete elliptic integrals, but it's considerably more complicated than the formula for ${\cal FT}(J_0^2)$: for starters, it involves the periods of a curve $E$ defined over ${\bf C}$ but (except for a few special values of $\omega$) not over ${\bf R}$.
Assume $|\omega| < 3$, else $I(\omega) = 0$. Then the relevant curve is$$E : Y^2 = X^3 - \bigl(\frac{3}{4} f^2 + \frac{27}{2} f - \frac{81}{4}\bigr) X^2 + 9 f^3 X$$where$$f = \frac12 \bigl( e + 1 + \sqrt{e^2-34e+1} \bigr)$$and$$e = \bigl( |\omega| + \sqrt{\omega^2-1} \, \bigr)^2.$$Let $\lambda_1, \lambda_2$ be generators of the period lattice of $E$with respect to the differential $dx/y$ (note that these are twicethe periods that
gp reports, because gp integrates $dx/2y$for reasons coming from the arithmetic of elliptic curves). Then:if $|\omega| \leq 1$ then$$I(\omega) = \left|\,f\,\right|^{5/2}\, \left|\,f-1\right| \frac{\Delta}{(2\pi)^2},$$where $\Delta = \bigl|{\rm Im} (\lambda_1 \overline{\lambda_2}) \bigr|$is the area of the period lattice of $E$. If $1 \leq |\omega| \leq 3$ then$$I(\omega) = \left|\,f\,\right|^{-4}\, \left|\,f-1\right|^5 (3/2)^{13/2} \frac{\Delta'}{(2\pi)^2},$$where $\Delta' = \bigl| {\rm Re}(\lambda_1 \overline{\lambda_2}) \bigr|$for an appropriate choice of generators $\lambda_1,\lambda_2$(these "appropriate" generators satisfy $|\lambda_1|^2 = \frac32 |\lambda_2|^2$,which determines them uniquely up to $\pm$ except for finitely manychoices of $\omega$).
The proof, alas, is too long to reproduce here, but here's the basic idea. The Fourier transform of $J_0$ is $(1-\omega^2)^{-1/2}$ for $|\omega|<1$ and zero else. Hence the Fourier transforms of $J_0^2$ and $J_0^3$ are the convolution square and cube of $(1-\omega^2)^{-1/2}$. For $J_0^2$, this convolution square is supported on $|\omega| \leq 2$, and in this range equals $$ \int_{t=|\omega|-1}^1 \left( (1-t^2) (1-(|\omega|-t)^2) \right)^{-1/2} \, dt, $$ which is a period of an elliptic curve [namely the curve $u^2 = (1-t^2) (1-(|\omega|-t)^2)$], a.k.a. a complete eliptic integral. For $J_0^3$, we likewise get a two-dimensional integral, over a hexagon for $|\omega|<1$ and a triangle for $1 \leq |\omega| < 3$, that is a period of the K3 surface $$ u^2 = (1-s^2) (1-t^2) (1-(|\omega|-s-t)^2). $$ (The phase change at $|\omega|=1$ was already noted here in a now-deleted partial answer.) In general, periods of K3 surfaces are hard to compute, but this one turns out to have enough structure that we can convert the period into a period of the surface $E \times \overline E$ where $\overline E$ is the complex conjugate.
Now to be honest I have only the formulas for the "correspondence" betweenour K3 surface and $E \times \overline E$, which was hard enough to do,but didn't keep track of the elementary multiplying factorthat I claim to be $\left|\,f\,\right|^{5/2}\, \left|\,f-1\right|$or $\left|\,f\,\right|^{-4}\, \left|\,f-1\right|^5 (3/2)^{13/2}$.I obtained these factors by comparing numerical values for the fewchoices of $\omega$ for which I was able to compute $I(\omega)$to high precision (basically rational numbers with an even numeratoror denominator); for example $I(2/5)$ can be computed in
gpin under a minute as
intnum(x=0,5*Pi,2*cos(2*x/5) * sumalt(n=0,besselj(0,x+5*n*Pi)^3))
There were enough such $c$, and the formulas are sufficiently simple, that they're virtually certain to be correct.
Here's
gp code to get $e$, $f$, $E$, and generators $\lambda_1,\lambda_2$of the period lattice:
e = (omega+sqrt(omega^2-1))^2f = (sqrt(e^2-34*e+1)+(e+1)) / 2E = ellinit( [0, -3/4*f^2-27/2*f+81/4, 0, 9*f^3, 0] )L = 2*ellperiods(E)lambda1 = L[1]lambda2 = L[2]
NB the last line requires use of
gp version 2.6.x; earlier versionsdid not directly implement periods of curves over $\bf C$.
For $\omega=0$ we have $e=1$, $f=3$, and $E$ is the curve $Y^2 = X^3 - 27 X^2 + 243 X = (X-9)^3 + 3^6$, so the periods can be expressed in terms of beta functions and we recover the case $\nu=0$ of Question 404222, How to prove $\int_0^\infty J_\nu(x)^3dx\stackrel?=\frac{\Gamma(1/6)\ \Gamma(1/6+\nu/2)}{2^{5/3}\ 3^{1/2}\ \pi^{3/2}\ \Gamma(5/6+\nu/2)}$? .
|
Contents Procedural Texturing
Texturing in computer graphics is a very common technique used to add details to the surface of an object. The principle is similar to wallpaper in a way. The only thing you can do with objects is to render them as diffuse object for example using a solid color for the entire object. The alternative solution is to break the object into smaller part and to give a unique albedo value or color to each part of the object. Breaking the object to follow the form of the texture details you want to apply to the surface of an object is of course time consuming and while it works if the pattern applied is only made out of solid colors, it doesn't work if you wish to apply some gradients of colors on the surface of the object.
Texturing is the solution to these problems. As mentioned, the principle is the same as wallpaper. Some complex pattern is painted on the surface of a flat sheet of paper, and the paper is then laid on the surface of walls. In CG, the patten applied to the surface of an object, can either be an image but it can also be generated using some sort of mathematical equation. The second technique is called
procedural texturing. We will study this technique in this lesson. A lesson devoted to the topic of texturing using images can be found later in this section.
As explained in the lesson Introduction to Polygon Meshes, to apply any sort of image or pattern procedurally generated on the surface of an image, we need
texture coordinates. Texture coordinates are just the coordinates of the object vertices in a 2D space, which we generally call the uv or st or simply texture space. This process as explained in detail in the aforementioned lesson. We assume the reader is already familiar with this concept. Texture coordinates gives us a frame of reference with which we can work and create all sort of 2D procedural patterns. Texture coordinates as we know are defined in a 2D space. Along the x-axis, we generally denote the coordinate, the s- or v- coordinate. Along the y axis, the texture coordinates is denoted t- or v-coordinate. In this lesson, we will stick to the convention s and t.
The image above shows a 3D plane and its associated texture coordinates. As you can see, the 4 vertices of the quad fill up the entire st or coordinate space, which generally goes from 0 to 1 but this is not a limitation, texture space, is not limited to the range [0,1]. However for now, we will just look at this simple most basic and common case. Later on in the chapter, we will see what happens when the quad in 3D space doesn't have a square shape in texture space.
Let's only consider the texture coordinate along the s-axis or horizontal axis. At v0 the value of the s-coordinate is 0 and for v1, the value of the s-coordinate is 1. The s-coordinate of any between v0 and v1 can be computed by linearly interpolating the s-coordinates of v0 and v1 respectively (this assumes that we know the distance from at least v0 or v1). In our particular case, the s-coordinate simply from v0 to v1 simply varies linearly between 0 (the s-coordinate value of v0) and 1 (the s-coordinate of v1). Though if we remap this simple linear function into some sort of mathematical function such as for example a cosine or sine function, we then obtain a more complex
pattern (a sine wave) which we can then apply to the surface of the object in the image below. A sine wave varies in the range [-1,1] and since colors can't be negative we can't directly use the result of this remapping as a color but with another simple remapping of the result, we can get a value that fits in the range [0,1]. Note though that our s-coordinates only goes from 0 to 1. However to complete a full turn around the unit circle we need to go from 0 to \(2\pi\). Thus we also need to remap the s-coordinates to the range [0,\(2\pi\)]. Finally we can control the number of sine waves across the width of the quad by scaling this remapped s-coordinate up or down. Here is the code we used to produce the image on the right below:
We produced a pattern by using the s-coordinate. But we can also produce a similar pattern in the "perpendicular" direction using the t-coordinate. By combining or multiplying the result of one by the other we can also get some more interesting two-dimensional patterns as shown in the following image:
Creating a
checkerboard pattern is also quite simple. To do so we will rely on the fmod function from the C++ library:
The function returns the floating-point remainder of
numer/denom (rounded towards zero):
Where
tquot is the truncated (i.e., rounded towards zero) result of: numer/ denom. If we set the number to be one of the texture coordinates and set denim to be 1, then we get a function like the one plotted in figure 2 (black). As you can see, we get some sort of function that keeps repeating itself. We can use the result this function to make another test, and return true if the function is lower than 0.5 and false otherwise (figure 2, in red):
If we do the same thing for the t-coordinate and combine the result of the two functions with each other using the ^ or bitwise exclusive-Or (XOR operator), then we get a checkerboard pattern:
Though note that we haven't used the C++ fmodf() function. The reason is that this function doesn't work for us when the numbers are negative. Indeed if x is equal to -1.1 we would like the function to return 0.9, so that the function is continuous as we switch from negative to positive numbers. Though the C++ function returns -0.1 instead. The solution is to write our own function, taking advantage of the C++ std::floor() which returns -2 when x is equal to -1.1 for example. And -1.1 - - 2 returns 0.9 as required.
It is also quite easy to rotate the pattern. The texture coordinates are just 2D coordinates. Rotating a point (or texture coordinates) around the centre of the texture coordinate system origin is really simple. Let's assume that we first rotate a point by an angle \(q\). When then want to rotate this point even further by an angle \(f\) (as shown in figure 3).$$ \begin{array}{l} x &=& r \cos q,\\ y &=& r \sin q\\ x' &=& r \cos ( q + f )\\ &=& r \cos q \cos f - r \sin q \sin f,\\ y' &=& r \sin ( q + w )\\ &=& r \sin q \cos f + r \cos q \sin f. \end{array} $$
Where (x, y) are the points original coordinates, and (x', y') the coordinates of the new point. The trick here is to notice that \(r\cos q\) and \(r\sin q\) are nothing else that the original point's coordinates (in our example, the texture coordinates that we want to rotate). Therefore if we replace these terms by the coordinates (x, y) in the above equations, we get:$$ \begin{array}{l} x' &=& x \cos f - y \sin f,\\ y' &=& y \cos f + x \sin f. \end{array} $$
Let's use this finding in our code to rotate the texture coordinates (you can set the angle to whatever you like):
You can create a great variety of patterns using this technique. All you need to do is find clever ways of using mathematical equations to create such patterns. Try now to create your own (if you search on the web for procedural texturing, you should find more pattern examples).
Noise which is a term you may have heard about already, is another kind of procedural pattern. A lesson is specifically devoted to studying the creation of noise patterns.
In the image below, we used a combination of the techniques we learned in this lesson. Diffuse lighting, procedural texturing, reflection and refraction. Notice how the reflection of the stripes in the water on the right matches the refraction in the real glasses in the image on the left.
Aliasing and Anti-Aliasing
The problem with texturing and especially the kind of pattern we created in this lesson is that as the pattern becomes smaller and smaller in the distance, there is a point when there is not enough resolution in the image to differentiate the black and white lines from each other. In nature this problem arises as well because even human eyes have a limited resolution. Though nature does things well. When a pattern becomes so small that we can't see what it is made off, the colors of the pattern generally sort of elegantly blend with each other. In computer graphics things are very different. Rather than being a composite of the pattern's colors, each individual pixel in the image picks up one color of the pattern instead. Because pixels are regularly spaced, if the pattern is also regular, we generally end up with some other strange pattern than has nothing to do with the original one. With regular stripes this often gives an effort called the
moire pattern which you can see an example of in the image on the right. The problem of not having resolution in the image to properly resolve the fine details in the distance and the visual artefact this produces, is called aliasing. This phenomenon is very well studied and pretty well understood. It finds its root in signal processing theory which is a very large (and reasonably complex) field of science. Solving aliasing though is a complex problems for which we don't have the perfect miracle solution. Though generally you should know that it is naturally called anti-aliasing. It is the art (as it is as much an art than a science) of fighting aliasing.
Aliasing itself and everything else you need to know about it to understand it, is a very large topic. We won't even cover this topic in this first section, as it relies on signal processing theory. Teaching signal processing is on its own, is a very ambitious undertaking, which we will tackle at some point. It is enough for you for now to know about the term aliasing and understand that using procedural texturing as well as any sort of texturing techniques in fact, can produce aliasing.
|
October 5th, 2017, 04:38 PM
# 31
Senior Member
Joined: Sep 2016
From: USA
Posts: 666
Thanks: 437
Math Focus: Dynamical systems, analytic function theory, numerics
Quote:
Quote:
Quote:
$f(x) = x$ maps continuously to the entire real line. Therefore $xf(x) = x^2$ must also map to the entire real line.
Quote:
Quote:
Quote:
October 6th, 2017, 07:02 AM
# 32
Banned Camp
Joined: Mar 2015
From: New Jersey
Posts: 1,720
Thanks: 126
Post #18 "Topological" proof
Post #26 "Mapping" proof
----------------------------------------------------------------------------------------
Post # 28:
1) Given 3rd degree complex polynomial
$\displaystyle z(z^{2}+pz+q)=zf(z)=c$
2) By induction applied to the second degree polynomial, $\displaystyle f(z)$ maps z to entire complex plane.
3) $\displaystyle zf(z)$ maps continuously to entire complex plane (from 0 to infinity).
4) $\displaystyle zf(z)=c$ has a solution (root) z=d for any c.
4) Same argument for any degree.
---------------------------------------------------------------------------------
===============================================
Post # 29
Given any n degree complex polynomial written as:
1) $\displaystyle F_{n}(z)=-a_{0}$
2) $\displaystyle F_{n}(z)$ is continuous for all $\displaystyle z$ and varies continuously from complex $\displaystyle 0$ to complex $\displaystyle \infty$ (eventually $\displaystyle z^{n}$ predominates).
3) It follows $\displaystyle F_{n}(z)=-a_{0}$ has a root for any $\displaystyle a_{0}$.[/QUOTE]
===============================================
If $\displaystyle F_{n}(z)=u+iv$, The ray $\displaystyle \theta=constant$ maps to continuous curve in u,v plane which goes from 0 to infinity.
Induction: If $\displaystyle P_{1}$ is true and $\displaystyle P_{n-1} \rightarrow P_{n}, P_{n}$ is true for all n.
CORE ASSERTIONS: 28-3 and 29-2
Last edited by zylo; October 6th, 2017 at 07:41 AM.
Reason: remove comment about 28-3
October 6th, 2017, 08:28 AM
# 33
Senior Member
Joined: Sep 2016
From: USA
Posts: 666
Thanks: 437
Math Focus: Dynamical systems, analytic function theory, numerics
I agree that the statement in 28-3 is the crux of your proof. If that is your point then I misunderstood you as I thought you were claiming to have proved this assertion.
Just to be clear, you haven't proved that claim anywhere and it appeared to me that you were claiming it to be obvious. My point was that this fact is highly nontrivial and far from obvious. The counterexample above shows it can fail on $\mathbb{R}$.
However, if you want an example which is complex, consider $f(z) = \bar{z}$ which is clearly surjective. However, $zf(z) = \left|z \right|^2 \in \mathbb{R}$ is clearly not.
If you want to prove that $zf(z)$ is a surjective map onto $\mathbb{C}$, then it becomes very important that $f$ is a polynomial should be used somewhere. However, this is nothing more than a restatement of the FTA and proving this claim is equivalent to proving FTA.
October 6th, 2017, 02:06 PM
# 34
Banned Camp
Joined: Mar 2015
From: New Jersey
Posts: 1,720
Thanks: 126
Given the n-degree polynomial F(z)=F$\displaystyle _{n}$(z)=c
1) F(z) is continuous and F(0)=0 and $\displaystyle \lim_{z\rightarrow \infty}$F(z)=$\displaystyle \infty$
2) Assume there is no z st F(z)=c where c is a point in w plane, and F(z) exists in a neighborhood of c. Then z exists st F(z)=c by continuity.
3) If there is a hole in w plane, let c be a border point. Then F(z) exists in a neighborhood of c by continuity. Contradiction.
4) FTA
October 6th, 2017, 02:41 PM
# 35
Senior Member
Joined: Sep 2016
From: USA
Posts: 666
Thanks: 437
Math Focus: Dynamical systems, analytic function theory, numerics
Quote:
Quote:
Last edited by skipjack; October 7th, 2017 at 02:11 AM.
October 7th, 2017, 03:39 AM
# 36
Banned Camp
Joined: Mar 2015
From: New Jersey
Posts: 1,720
Thanks: 126
A complex polynomial always has a solution because F(z)=$\displaystyle F_{n}(z)=z^{n}+a_{n-1}z^{n-1}+.....+a_{1}z$ is continuous everywhere and maps z from 0 to $\displaystyle \infty$.
Proof: If there were any "holes" in the map, F(z) would be discontinuous there.
For example, The ray $\displaystyle \theta$ = constant maps to a curve in the w plane (F(z)) which goes from 0 to $\displaystyle \infty$. If there were a break in the curve, F(z) would be discontinuous there.
October 9th, 2017, 09:13 PM
# 37
Senior Member
Joined: Sep 2016
From: USA
Posts: 666
Thanks: 437
Math Focus: Dynamical systems, analytic function theory, numerics
Quote:
October 10th, 2017, 08:01 AM
# 38
Banned Camp
Joined: Mar 2015
From: New Jersey
Posts: 1,720
Thanks: 126
Quote:
$\displaystyle \therefore z^{n}+a_{n-1}z^{n-1}+...+a_{1}z=-a_{0}$ always has a solution.
Just in case anyone else missed it.
All the difficulties and complexities of the other solutions are due to the fact that they
start with $\displaystyle z^{n}+a_{n-1}z^{n-1}+...+a_{1}z+a_{0}=0$ and try to show it has a solution.
My unique approach makes it virtually trivial. All you have to see is that z^{n}+a_{n-1}z^{n-1}+...+a_{1}z maps continuously to the
entire complex plane (from 0 to $\displaystyle \infty$).
October 10th, 2017, 12:50 PM
# 39
Senior Member
Joined: Aug 2017
From: United Kingdom
Posts: 313
Thanks: 112
Math Focus: Number Theory, Algebraic Geometry
Quote:
Quote:
In fact, the two proofs I can currently remember (one uses Liouville's theorem, the other uses the fundamental group of the circle) start with the opposite assumption, that no such $z$ exists, to get a contradiction. So the difficulties/complexities of those proofs certainly couldn't be down to the reason you've given.
Last edited by cjem; October 10th, 2017 at 12:52 PM.
October 18th, 2017, 09:52 AM
# 40
Banned Camp
Joined: Mar 2015
From: New Jersey
Posts: 1,720
Thanks: 126
Fundamental Theorem of Algebra: Every complex polynomial has a root.
$\displaystyle P_{n}(z)=z^{n}+a_{n-1}z^{n-1}+..+a_{1}z+a_{0}=z(z^{n-1}+a_{n-1}z^{n-2}+..+a_{2}z+a_{1})+a_{0}$
$\displaystyle P_{n}(z)=zP_{n-1}(z)+a_{0}$
Example:
$\displaystyle P_{3}(z)=z^{3}+a_{2}z^{2}+a_{1}z+a_{0}=z(z^{2}+a_{ 2}z+a_{1})+a_{0}=zP_{2}(z)+a_{0}.$
Proof by induction:
$\displaystyle P_{2}=0$ has a solution.
$\displaystyle P_{n-1}(z)=0$ has a solution $\displaystyle \rightarrow P_{n}(z)=0$ has a solution.
$\displaystyle P_{n}(z)=0$ has a solution if $\displaystyle zP_{n-1}(z)$ maps all z to entire complex plane. $\displaystyle P_{n-1}(z)$ maps to entire complex plane (given). It is shown* that $\displaystyle zP_{n-1}(z)$ maps to entire complex plane if $\displaystyle P_{n-1}(z)$ does.
Note complex polynomials have a derivative for all z.
--------------------------------------------------------------------------------
* Range of Analytic Function
From Post #8
Assume F(z) has a derivative for all z and maps to w plane with a hole in it (area where F(z) doesn't map to). The hole is closed because F'(z) is undefined on it's border. In this case, F'(z) is defined and F'(z)$\displaystyle \Delta$z exists in F(z) for $\displaystyle \Delta$z sufficiently small no matter how close you get to the border.
For example, F(z) could map to the
inside of a circle for all z and F'(z) exist everywhere inside the circle.
The only way out would be to show that at a point near the border F'(z)$\displaystyle \Delta$z is greater than the distance to the border.
If F(z) = zf(z) where f(z) exists, has a derivative everywhere, and maps to entire complex plane, then so does F(z).
From Post # 10
Again, assume a closed island in w where F(z) undefined. Let F(z) be arbitrarily close to the border.
F(z+$\displaystyle \Delta$z) = (z+$\displaystyle \Delta$z)f(z+$\displaystyle \Delta$z)= (z+$\displaystyle \Delta$z}(f(z)+f'(z)$\displaystyle \Delta$z)
F(z+$\displaystyle \Delta$z)=F(z)+(f(z)+f'(z)$\displaystyle \Delta$z)
where f(z) and f'(z) exist and $\displaystyle \Delta$z is associated with f'(z) so not restricted by the border.
It follows F(z) can cross the border, a contradiction, so the island doesn't exist and F(z) maps to entire complex plane.
Example: Proof of FTA by induction where f(z) and zf(z) are polynomials.
Comment:
In other words, F(z) can't cross border (no contradiction) but zf(z) can (contradiction).
Tags algebra, fundamental, proof, theorem
Thread Tools Display Modes
Similar Threads Thread Thread Starter Forum Replies Last Post proof of fundamental theorem of arithmetic AspiringPhysicist Abstract Algebra 3 October 2nd, 2014 12:19 AM Is this proof of the fundamental theorem of arithmetic ok? king.oslo Algebra 2 September 19th, 2013 10:48 PM the fundamental theorem ray Algebra 6 April 22nd, 2012 03:50 AM Herstein: Abstract Algebra Proof (Sylow's Theorem) ThatPinkSock Abstract Algebra 1 November 11th, 2011 04:25 AM Fundamental Theorem of Algebra johnny Algebra 11 December 21st, 2007 09:51 PM
|
Forgot password? New user? Sign up
Existing user? Log in
Hmm, my points just went from ~111,000 to 77,000. Did I miss something?
Note: I'm not actually too awfully concerned about points, just wondering.
Note by Cody Johnson 5 years, 2 months ago
Easy Math Editor
This discussion board is a place to discuss our Daily Challenges and the math and science related to those challenges. Explanations are more than just a solution — they should explain the steps and thinking strategies that you used to obtain the solution. Comments should further the discussion of math and science.
When posting on Brilliant:
*italics*
_italics_
**bold**
__bold__
- bulleted- list
1. numbered2. list
paragraph 1paragraph 2
paragraph 1
paragraph 2
[example link](https://brilliant.org)
> This is a quote
This is a quote
# I indented these lines # 4 spaces, and now they show # up as a code block. print "hello world"
# I indented these lines# 4 spaces, and now they show# up as a code block.print "hello world"
\(
\)
\[
\]
2 \times 3
2^{34}
a_{i-1}
\frac{2}{3}
\sqrt{2}
\sum_{i=1}^3
\sin \theta
\boxed{123}
Sort by:
Have a look at the first comment on this page
Log in to reply
Yeah, but I think the knowledge we gained from each problem is much more important!
Same thing happened, what change is it this time? (I'm saying this in a good way) :)
Me too! I guess they changed something again :o
Yeah even i think so.. I think i am back to my (original points + those that i have done after it went up to 99945)Really missed the CHARM of 100000100000100000
Hahaha. See the first comment anyway :)
@Astro Enthusiast – Which one ??of this note or that old one's comment.
@Arya Samanta – The latter. :) It's connected anyway. HAHA
Me too from 286000 to 97000 why they did so??
Same, 194,000 to 70,000 :P
345000 → 204750345000 ~\to ~ 204750345000 → 204750
Mine went from 583000 to 283605. WTF? :(
I think it is the same you would have got if the sudden increase in pts was not done..so be happy.. :)
my drop to 95000 to 45000 ......... :(
Same Here- From around 225000 to around 77000.
They had made a BLUNDER earlier by increasing the points....
Went from 450,000 to like 150,000 in like 1 day... :P
me too, 80000 to 30000
Problem Loading...
Note Loading...
Set Loading...
|
Zurek 2001 is a review article on decoherence in quantum mechanics. Equation 5.36 on p. 24 gives an estimate of the decoherence time, which I'll paraphrase as follows:
$ \frac{t_D}{t_R} = \left(\frac{\lambda_T}{x-x'}\right)^2 $ .
My attempt to interpret the meaning of the variables is:
$t_D$ is the decoherence time
$t_R$ is the thermal relaxation time for the object, which isn't perfectly isolated from its environment
$\lambda_T$ is the de Broglie wavelength for the mass of the whole object at an energy corresponding to the temperature of the environment
$x-x'$ is the difference in position between two states of interest, i.e., $t_D$ is going to be the time-scale for the exponential decay of the off-diagonal element of the density matrix corresponding to $x$ and $x'$
The result is that for a macroscopic object such as Schrodinger's cat at room temperature, we have $t_D/t_R\sim10^{-40}$.
Question 1: Am I correctly interpreting the meaning of the variables?
Question 2: Can anyone give a hand-waving argument for why we have this particular dependence on the variables?
Zurek arrives at this estimate after a very long derivation that to me is not very understandable. All I've been able to accomplish is some plausibility arguments:
In the classical limit we expect the ratio inside the parens to go to zero, and it does, since the de Broglie wavelength goes to zero.
Coherence is more difficult to maintain at macroscopic scales, where $|x-x'|$ is large.
The result is positive, since the exponent is even.
Zurek, "Decoherence, einselection, and the quantum origins of the classical," http://arxiv.org/abs/quant-ph/0105127
|
I am working on my master thesis on acoustic pattern recognition and have a question to the calculation of cepstral coefficients.I understand the step with a filter bank in MFCC calculation, it is ...
I've seen different equations that calculate cepstrum from power spectrum, but the equations are not consistent. Some people use Fourier transform, some use the inverse Fourier transform, and some use ...
In Acero's Spoken language processing (p. 309) it says that the cepstrum of a finite length impulse train$$x[n] = \sum^{M-1}_{k=0} \delta[n-kN]$$is given by$$\hat{x}[n] = \sum^{ \infty}_{r=1} \frac{...
I feel like I've got a decent intuition for what the magnitude of a cepstral coefficient represents (i.e. how much of the signal's energy is contained in harmonics of a given wavelength), but I don't ...
For audio classification we are using the cepstral coefficients and their derivatives. Which I calculate using the Matlab libary voicebox.I am looking for some literature for how to choose the frame ...
I am a newbie in speech processing and experimenting to get a feel. I have extracted some speech segments using a window function and I want to find distance between a pair of segments. First, I took ...
I'm working on a little project, which centers around steganography. As part of it, I want to implement the audio echo hiding method, but the problem is, I've never done anything related to digital ...
I need some verification on steps required to extract MFCCs from raw audio as I'm finding that some sources outline them slightly differently.Get raw audio frameRun window function (eg Blackman) on ...
|
Please help to solve this question:
Instability of a difference scheme under small perturbations does not exclude the possibility that in special cases the scheme converges towards the correct function, if no errors are permitted in the data or the computation. In particular let $f(x)=e^{\alpha x}$ with a complex constant ${\alpha }$. Show that for fixed $x,t$ and any fixed positive $\lambda = k/h$ whatsoever both the expression $(3.9)$ and $(3.14)$ converge for $n\rightarrow \infty$ towards the correct limit $e^{\alpha (x-ct)}$. (This is consistent with the Courant-Friedrichs-Lewy test, since for an
analytic$f$ the values of $f$ in any interval determine those at the point $\xi=x-ct $ uniquely).
The PDE is a scalar linear conservation law $$ v_t + c v_x = 0$$ with initial data $v(x,0) = f(x)$, and the
method of finite differences is used. The equations are
$$\begin{aligned} v(x,t)&=v(x,nk) \\ & = \dots \\ &={\sum_{m=0}^{n}}\binom{n}{m}(1+\lambda c)^m(-\lambda c)^{n-m}f (x+(n-m)h) \end{aligned} \tag{3.9}$$ and $$v(x,t)=v(x,nk)={\sum_{m=0}^{n}}\binom{n}{m}(1-\lambda c)^m(\lambda c)^{n-m}f (x-(n-m)h) \, . \tag{3.14}$$
This is problem 3 page 8 from the book by Fritz John [1].
Please help. Thanks
[1] F. John:
Partial Differential Equations, 4th Edition, Springer, 1991.
|
I am reading mixed opinions comparing bayesian A/B testing and frequentist ones.
Basically my understanding is the following; consider the case of A/B testing with binary outcomes (https://www.evanmiller.org/bayesian-ab-testing.html#mjx-eqn-binary_ab_pr_alpha_b):
With frequentist approach, you basically calculate the $p-value$ from a contingency table, then you reject the null hypothesis that $A$ and $B$ are the same if the $p-value$ is smaller than the significance level $\sigma$, using a $\chi^2$ test. (https://docs.scipy.org/doc/scipy-0.15.1/reference/generated/scipy.stats.chi2_contingency.html).
With Bayesian approach, you fix a prior, you update it with the data of the contingency table, and then you come out with two probability distributions, that of $P_a$, the conversion rate in scenario $A$, and that of $P_B$. A typical choice of a prior is a Beta distribution, that remains a Beta after the update, but with updated parameters. For example, if I set the uniform prior, then after the update I will have that $$P_i \approx \beta(Success_i,Failures_i)$$ for $i=A,B$. At this point, I can calculate $Prob(P_a>P_B)$.
In the Bayesian approach, I can easily set the decision rule that I reject the null hypothesis if $$ Prob(P_a>P_B)>1-\sigma/2\;\;\;\;or\;\;\;\;Prob(P_a>P_B)<\sigma/2 $$ How will this test relate with the standard $\chi^2$ test?
I read many people saying that if we use uniform prior, frequentist and Bayesian are equivalent. This means that the test above would return the same results of a standard $\chi^2$ test?
|
The capillary forces referred to the fact that surface tension causes liquid to rise or penetrate into area (volume), otherwise it will not be there. It can be shown that the height that the liquid raised in a tube due to the surface tension is \[h = \frac{2\sigma\cos(\beta)}{g\Delta\rho r}\tag{73}\] Where \(\Delta\rho\) is the difference of liquid density to the gas density and \(r\) is the radius of the tube.
Fig. 1.24. The raising height as a function of the radii.
But this simplistic equation is unusable and useless unless the contact angle (assuming that the contact angel is constant or a repressive average can be found or provided or can be measured) is given. However, in reality there is no readily information for contact angle and therefore this equation is useful to show the treads. The maximum that the contact angle can be obtained in equation (73) when \(\beta\) = - and thus \(\cos(\beta) = 1\). This angle is obtained when a perfect half a sphere shape exist of the liquid surface. In that case equation (73) becomes \[h_{max} = \frac{2\sigma}{g\Delta\rho r}\tag{74}\]
Fig. 1.25. The raising height as a function of the radius.
Figure 1.25 exhibits the height as a function of the radius of the tube. The height based on equation (74) is shown in Figure 1.24 as a blue line. The actual height is shown in the red line. Equation (74) provides reasonable results only in a certain range. for a small tube radius, equation (62) proved better results because the curve approaches hemispherical sphere(small gravity effect). For large radii equation (62) approaches the strait line (the liquid line) strong gravity effect. On the other hand, for extremely small radii equation (74) indicates that the high height which indicates a negative pressure. The liquid at a certain pressure will be vaporized and will breakdown the model upon this equation was constructed. Furthermore, the small scale indicates that the simplistic and continuous approach is not appropriate and a different model is needed. The conclusion of this discussion are shown in Figure 1.24. The actual dimension for many liquids (even water) is about 1-5 \([mm]\).
The discussion above was referred to "wetting'' contact angle. The depression of the liquid occurs in a "negative'' contact angle similarly to ``wetting.'' The depression height, \(h\) is similar to equation (74) with a minus sign. However, the gravity is working against the surface tension and reducing the range and quality of the predictions of equation (74) The measurements of the height of distilled water and mercury are presented in Figure 1.25. The experimental results of these materials are with agreement with the discussion above. The surface tension of a selected material is given in Table 1.7.
In conclusion, the surface tension issue is important only in case where the radius is very small and gravity is negligible. The surface tension depends on the two materials or mediums that it separates.
Example 1.19
Calculate the diameter of a water droplet to attain pressure difference of 1000[\(N/m^2\)]. You can assume that temperature is \(20^{\circ}C\).
Solution 1.19
The pressure inside the droplet is given by equation (50).
\[D = 2\,R = \dfrac{2\,2\,\sigma}{\Delta P} =
\dfrac{4\times 0.0728 }{1000} \sim 2.912\,{10}^{-4} [m] \tag{75}\]
Example 1.20
Calculate the pressure difference between a droplet of water at \(20^{\circ}C\) when the droplet has a diameter of 0.02 cm.
Solution 1.20
using equation
\[\Delta P = \dfrac{2\,\sigma}{r} \sim \dfrac{2\times 0.0728}{0.0002} \sim 728.0 [N/m^2] \tag{76}\]
Example 1.21
Calculate the maximum force necessary to lift a thin wire ring of 0.04[m] diameter from a water surface at \(20^{\circ}C\) . Neglect the weight of the ring.
Solution 1.21
\[
F = 2(2\,\pi\,r\,\sigma)\cos\beta \tag{77} \] The actual force is unknown since the contact angle is unknown. However, the maximum Force is obtained when \(\beta = 0\) and thus \(\cos\beta = 1\). Therefore, \[ F = 4\,\pi\,r\,\sigma = 4\times \pi \times 0.04\times 0.0728 \sim .0366 [N] \tag{78} \] In this value the gravity is not accounted for.
Example 1.22
A small liquid drop is surrounded with the air and has a diameter of 0.001 [m]. The pressure difference between the inside and outside droplet is 1[kPa]. Estimate the surface tension?
Solution 1.22
To be continue
Chemical formula Temperature, \(T\,[^{\circ}C]\) Surface Tension, \(\left[\dfrac{ N}{m} \right]\) correction Acetic Acid 27.6 20 n/a Acetone 25.20 - -0.1120 Aniline 43.4 22 -0.1085 Benzene 28.88 - -0.1291 Benzylalcohol 39.00 - -0.0920 Benzylbenzoate 45.95 - -0.1066 Bromobenzene 36.50 - -0.1160 Bromobenzene 36.50 - -0.1160 Bromoform 41.50 - -0.1308 Butyronitrile 28.10 - -0.1037 Carbon disulfid 32.30 - -0.1484 Quinoline 43.12 - -0.1063 Chloro benzene 33.60 - -0.1191 Chloroform 27.50 - -0.1295 Cyclohexane 24.95 - -0.1211 Cyclohexanol 34.40 \(25^{\circ}C\) -0.0966 Cyclopentanol 32.70 - -0.1011 Carbon Tetrachloride 26.8 - n/a Carbon disulfid 32.30 - -0.1484 Chlorobutane 23.10 - -0.1117 Ethyl Alcohol 22.3 - n/a Ethanol 22.10 - -0.0832 Ethylbenzene 29.20 - -0.1094 Ethylbromide 24.20 - -0.1159 Ethylene glycol 47.70 - -0.0890 Formamide 58.20 - -0.0842 Gasoline 21 - n/a Glycerol 64.0 - -0.0598 Helium 0.12 \(-269^{\circ}C\) n/a Mercury 425-465.0 - -0.2049 Methanol 22.70 - -0.0773 Methyl naphthalene 38.60 - -0.1118 Methyl Alcohol 22.6 - n/a Neon 5.15 \(-247^{\circ}C\) n/a Nitrobenzene 43.90 - -0.1177 Olive Oil 43.0-48.0 - -0.067 Perfluoroheptane 12.85 - -0.0972 Perfluorohexane 11.91 - -0.0935 Perfluorooctane 14.00 - -0.0902 Phenylisothiocyanate 41.50 - -0.1172 Propanol 23.70 \( 25^{\circ}C\) -0.0777 Pyridine 38.00 - -0.1372 Pyrrol 36.60 - -0.1100 SAE 30 Oil n/a - n/a Seawater 54-69 - n/a Toluene 28.4 - -0.1189 Turpentine 27 - n/a Water 72.80 - -0.1514 o-Xylene 30.10 - -0.1101 m-Xylene 28.90 - -0.1104 Contributors
Dr. Genick Bar-Meir. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or later or Potto license.
|
Sometime ago we came across invariant quantities under twisting of all affine algebra. (See the appendix E of http://arxiv.org/abs/hep-th/0403076 .) Choose the convention so that the longest root has length $\sqrt{2}$, and the co-root of a root $\alpha$ is $\alpha^*=2\alpha/\alpha^2$. The lowest negative root $\alpha_0$ is a long root for untwisted affine algebras. The extended Dynkin diagram of untwisted affine algebra $G^{(1)}$ is given by the extended simple roots $\alpha_a, a=0,1,...r$ where $r$ is the rank of $G^{(1)}$. The co-marks $k_a^*$ are such that $k_0^*=1$ and $\sum_{a=0}^r k_a^* \alpha_a^* =0 $. The dual Coxeter number $h=\sum_{a=0}^r k_a^*$. For the corresponding twisted algebra $G^{(L)}$ if it exists, we have dual simple roots $\beta_b, b=0,1,2,...r'$ where $r'$ is the rank of $G^{(L)}$. Twisting parameter $L$ is 2 or 3 at best. We define co-marks $\tilde k_b^*$ as minimal natural numbers such that $\sum_{b=0}^{r'}\tilde k_a^*\beta_a^*=0$. Note that $\tilde k_0^*=1$ except for $A_{2r}^{(2)}$, for which $\tilde k_0^*=2$.
Invariants under twisting are:
1) The Coxeter number defined as $h(G^{(1)})=\sum_{a=0}^r k_a^*$ for the untwisted affine algebra is identical to that of twisted one defined by $h(G^{(L)})=\sum_{b=0}^{r'} \tilde k_b^*$.
2) $1= 2/\alpha_0^2=2\tilde k_0/(L\beta_0^2)$. Here $L$ is the number characterizing twisting.
3) $\prod_{a=0}^r\Big[\frac{k_a^*\alpha_a^2}{2}\Big]^{k_a^*} = \prod_{b=0}^{r'}\Big[\frac{\tilde k_b^*\beta_b^2}{2}\Big]^{\tilde k_b^*} $ . This quantity turns out to be unity for $A_r$.
4) A lot more complicated on related to modular functions. For example with group $A_2$, there are two related modular functions:
(a) $ W_{A_2^{(1)}}({\bf X})= \wp(\alpha_0\cdot {\bf X}) + \wp(\alpha_1\cdot {\bf X} )+\wp(\alpha_2\cdot{\bf X})$ on $C^2$ and (b) $W_{A_2^{(2)}}= \wp(\alpha_0\cdot X) + \wp(\alpha_0\cdot {\bf X}+\pi i)+\wp(\alpha_0\cdot{\bf X}+\pi i \tau)$ on $C$.
Both are good under $SL(2,Z)$ if one allows the shift of ${\bf X}$ for the second one. Two modular functions have many common properties, including their critical points modulo Weyl group.
We can prove first three explicitly, and last one indirectly. For the last invariant two, have they appeared in anywhere before or after? If so, how? In our case, the reason for these invariants is the invariance of the vacuum structure of $N=1^*$ supersymmetric Yang-Mills theories on $R^{1+2}\times S^1$ under twisting.
|
Consider the Heston model given by the following set of stochastic differential equations: $$\frac{dS_{t}}{S_{t}}=\mu_{t}dt+\sqrt{V_{t}}dW_{t}, S_{0}>0,$$ $$dV_{t}=\kappa(\theta-V_{t})dt+\xi\sqrt{V_{t}}dZ_{t}, V_{0}=v_{0}>0,$$ $$d<W,Z>_{t}=\rho dt$$ where $W_{t}$ and $Z_{t}$ are two brownian motion, $\kappa,\theta,\xi>0, \rho\in(-1,1).$ I don't understand what impact would $\rho$ have on the shape of volatility smile when it's negative or positive. In addition, How the volatility smile would change if $\xi$ increases? Thank you.
Intuition: You can think of the vol smile as a reflection of the risk neutral distribution (compared to the Black Scholes Gaussian density). A fat tailed distribution creates the smile: fat tail -> higher prob of exercise than Gaussian with constant stdev -> higher option price than BS with ATM vol -> higher implied vol for given strike. Skewed distributions cause skewed smile: neg skew -> left tail thicker than right -> OTM put impl vol higher than OTM call impl vol.
Also you can think of a stoch vol model as mixture of Gaussians, each with different volatility. The way that this mix is produced generates fat tailed and skewed distributions.
Non-zero Rho will produce asymmetric volatility smiles (that look more like skews). Negative correlation means that a negative spot shock is more likely accompanied by a positive vol shock -> as spot goes down we mix with higher vols -> will produce a fatter left tail than right -> negatively skewed risk neutral density -> downward sloping skew.
Large Xi produces a steeper, more pronounced smile/skew, as we increase the vol-of-vol potentially mixing with higher volatilities which generate more leptokurtic risk neutral distributions. Zero Xi would correspond to the Black Scholes case where the smile becomes flat.
To be more rigorous you can take the Heston char function, take derivatives to compute moments and show the relation of Rho/Xi with Skewness/Kurtosis.
|
Entropy is a notoriously tricky subject. There is a famous anecdote of John von Neumann telling Claude Shannon, the father of information theory, to use the word “entropy” for the concept he had just invented, because “nobody knows what entropy really is, so in a debate you will always have the advantage“.
Entropy means many different things in different contexts, but there is a wonderful notion of entropy which is purely topological. It only requires a space, and a map on it. It is independent of geometry, or any other arbitrary features — it is a purely intrinsic concept. This notion, not surprisingly, is known as
topological entropy.
There are a few equivalent definitions; we’ll just discuss one, which is not the most general. As we’ll see, it can be described as the rate of information you gain about the space by applying the function, when you have poor eyesight — in the limit where your eyesight becomes perfect.
Let \(X\) be a metric space. It could be a surface, it could be a manifold, it could be a Riemannian manifold. Just some space with an idea of distance on it. We’ll write \(d(x,y)\) for the distance between \(x\) and \(y\). So, for instance, \(d(x,x) = 0\); the distance from a point to itself is zero. Additionally, \(d(x,y) = d(y,x)\); the distance from \(x\) to \(y\) is the same as the distance from \(y\) to \(x\); the triangle inequality applies as well. And if \(x \neq y\) then \(d(x,y) > 0\); to get from one point to a different point you have to travel over more than zero distance!
We assume \(X\) is compact, so roughly speaking, it has no holes, it doesn’t go off to infinity, its volume (if it has a volume) is finite.
Now, we will think of \(X\) as a space we are looking at, but we can’t see precisely. We have myopia. Our eyes are not that good, and we can only tell if two points are different if they are sufficiently far apart. We can only resolve points which have a certain degree of separation. Let this resolution be \(\varepsilon\). So if two points \(x,y\) are distance less than \(\varepsilon \) apart, then our eyes can’t tell them apart.
Rather than thinking of this situation as poor vision, you can alternatively suppose that \(X\) is quantum mechanical: there is uncertainty in the position of points, so if \(x\) and \(y\) are sufficently close, your measurement can’t be guaranteed to distinguish between them. Only when \(x\) and \(y\) are sufficiently far apart can your measurement definitely tell them apart.
We suppose that we have a function \(f \colon X \rightarrow X\). So \(f\) sends points of \(X\) to points of \(X\). We assume \(f\) is continuous, but nothing more. So, roughly, if \(x\) and \(y\) are close then \(f(x)\) and \(f(y)\) are close. (Making that rough statement precise is what the beginning of analysis is about.) We do not assume that \(f\) is injective; it could send many points to the same point. Nor do we assume \(f\) is surjective; it might send all the points of \(X\) to a small region of \(X\). All we know about \(f\) is that it jumbles up the points of \(f\), moving them around, in a continuous fashion.
We are going to define the topological entropy of \(f\), as a
measure of the rate of information we can get out of \(f\), under the constraints of our poor eyesight (or our quantum uncertainty). The topological entropy of \(f\) is just a real number associated to \(f\), denoted \(h_{top}(f)\). In fact it’s a non-negative number. It could be as low as zero, and it can be infinite; and it can be any real number in between.
We ask: what is the maximum number of points can we distinguish, despite our poor eyesight / quantum uncertainty? If the answer is \(N\), then there exist \(N\) points \(x_1, \ldots, x_N\) in \(X\), such that any two of them are separated by a distance of at least \(\varepsilon\). In other words, for any two points \(x_i, x_j\) (with \(i \neq j\)) among these \(N\) points, we have \(d(x_i, x_j) \geq \varepsilon\). And if the answer is \(N\), then this is the
maximum number; so there do not exist \(N+1\) points which are all separated by a distance of at least \(\varepsilon\).
Call this number \(N(\varepsilon)\). So \(N(\varepsilon)\) is the maximum number of points of \(X\) our poor eyes can tell apart.
(Note that the number of points you can distinguish is necessarily finite, since they all lie in the compact space \(X\). There’s no way your shoddy eyesight can tell apart infinitely many points in a space of finite volume! So \(N(\varepsilon)\) is always finite.)
Clearly, if our eyesight deteriorates, then we see less, and we can distinguish fewer points. Similarly, if our eyes improve, then we see more, so we can distinguish more points. Eyesight deterioration means \(\varepsilon\) increases: we can only distinguish points if they are further apart. Similarly, eyesight improvement means \(\varepsilon\) decreases: we can tell apart points that are closer together.
Therefore, \(N(\varepsilon)\) is a decreasing function of \(\varepsilon\). As \(\varepsilon\) increases, our eyesight deteriorates, and we can distinguish fewer points.
Now, we haven’t yet used the function \(f\). Time to bring it into the picture.
So far, we’ve thought of our eyesight as being limited by space — by the spatial resolution it can distinguish. But our eyesight also applies over
time.
We can think of the function \(f\) as describing a “time step”. After each second, say, each point \(x\) of \(X\) moves to \(f(x)\). So a point \(x\) moves to \(f(x)\) after 1 second, to \(f(f(x))\) after 2 seconds, to \(f(f(f(x)))\) after 3 seconds, and so on. In other words, we
iterate the function \(f\). If \(f\) is applied \(n\) times to \(x\), we denote this by \(f^{(n)}(x)\). So, for instance, \(f^{(3)}(x) = f(f(f(x)))\).
The idea is that, if you stare at two
moving points for long enough, you might not be able to distinguish them at first, but if eventually you may be able to. If they move apart at some point, then you may be able to distinguish them.
So while your eyes are encumbered by space, the are assisted by time. Your shoddy eyes have a finite spatial resolution they can distinguish, but over time points may move apart enough for you to resolve them.
(You can also think about this in a “quantum” way. The uncertainty principle says that uncertainties in space and time are complementary. If you look over a longer time period, you allow a greater uncertainty in time, which allows for smaller uncertainty in position. But from now on I’ll stick to my non-quantum myopia analogy.)
We can then ask a similar question: what is the maximum number of points we can distinguish, despite our myopia, while viewing the system for \(T\) seconds? If the answer is \(N\), then there exist \(N\) points \(x_1, \ldots, x_N\) in \(X\), such that at some point over \(T\) seconds, i.e. \(T\) iterations of the function \(f\), any two of them become separated by a distance of at least \(\varepsilon\). In other words, for any two points \(x_i, x_j\) (with \(i \neq j\)) among these \(N\) points, there exists some time \(t\), where \(0 \leq t \leq T\), such that \(d(f^{(t)}(x_i), f^{(t)}(x_j)) \geq \varepsilon\). And if the answer is \(N\), then this is again the maximal number, so there do not exist \(N+1\) points which all become separated at some instant over \(T\) seconds.
Call this number \(N(f, \varepsilon, T)\). So \(N(\varepsilon)\) is the maximum number of points of \(X\) our decrepit eyes can distinguish over \(T\) seconds, i.e. \(T\) iterations of the function \(f\).
Now if we allow ourselves more time, then we have a better chance to see points separating. As long as there is one instant of time at which two points separate, we can distinguish them. So as \(T\) increases, we can distinguish more points. In other words, \(N(f, \varepsilon, T)\) is an increasing function of \(T\).
And by our previous argument about \(\varepsilon\), \(N(f, \varepsilon, T)\) is a decreasing function of \(\varepsilon\).
So we’ve deduced that the number of points we can distinguish over time, \(N(f, \varepsilon, T)\), is a decreasing function of \(\varepsilon\), and an increasing function of \(T\).
We can think of the number \(N(f, \varepsilon, T)\) as an amount of
information: the number of points we can tell apart is surely some interesting data!
But rather than think about a single instant in time, we want to think of the
rate of information we obtain, as time passes. How much more information do we get each time we iterate \(f\)?
As we iterate \(f\), and we look at our space \(X\) over a longer time interval, we know that we can distinguish more points: \(N(f, \varepsilon, T)\) is an increasing function of \(T\). But how fast is it increasing?
To pick one possibility out of thin air, it might be the case, that every time we iterate \(f\), i.e. when we increase \(T\) by \(1\), that we can distinguish twice as many points. In that case, \(N(f, \varepsilon, T)\) doubles every time we increment \(T\) by 1, and we will have something like \(N(f, \varepsilon, T) = 2^T\). In this case, \(N\) is increasing exponentially, and the (exponential) growth rate is given by the base 2.
(Note that doubling the number of points you can distinguish is just like having 1 extra bit of information: with 3 bits you can describe \(2^3 = 8\) different things, but with 4 bits you can describe \(2^4 = 16\) things — twice as many!)
Similarly, to pick another possibility out of thin air, if it were the case that \(N(f, \varepsilon, T)\)
tripled every time we incremented \(T\) by \(1\), then we would have something like \(N(f, \varepsilon, T) = 3^T\), and the growth rate would be 3.
But in general, \(N(f, \varepsilon, T)\) will not increase in such a simple way. However, there is a standard way to describe the growth rate: look at the
logarithm of \(N(f, \varepsilon, T)\), and divide by \(T\). For instance, if \(N(f, \varepsilon, T) \sim 2^T\), then we have \(\frac{1}{T} \log N(f, \varepsilon, T) \sim 2\). And then see what happens as \(T\) becomes larger and larger. As \(T\) becomes very large, you’ll get an asymptotic rate of information gain from each iteration of \(f\).
(In describing a logarithm, we should technically specify what the base of the logarithm is. It could be anything; I don’t care. Pick your favourite base. Since we’re talking about information, I’d pick base 2.)
This leads us to think that we should consider the limit
\[ \lim_{T \rightarrow \infty} \frac{1}{T} \log N (f, \varepsilon, N). \] This is a great idea, except that if \(N (f, \varepsilon, N)\) grows in an irregular fashion, this limit might not exist! But that’s OK, there’s a standard analysis trick to get around these kinds of situations. Rather than taking a limit, we’ll take a lim inf, which always exists. \[ \liminf_{T \rightarrow \infty} \frac{1}{T} \log N (f, \varepsilon, N). \]
(The astute reader might ask, why lim inf and not lim sup? We could actually use either: they both give the same result. In our analogy, we might want to know the rate of information we’re
guaranteed to get out of \(f\), so we’ll take the lower bound.)
And this is
almost the definition of topological entropy! By taking a limit (or rather, a lim inf), we have eliminated the dependence on \(T\). But this limit still depends on \(\varepsilon\), the resolution of our eyesight.
Although our eyesight is shoddy, mathematics is not! So in fact, to obtain the ideal rate of information gain, we will take a limit as our eyesight becomes perfect! That is, we take a limit as \(\varepsilon\) approaches zero.
And
this is the definition of the topological entropy of \(f\): \[ h_{top}(f) = \lim_{\varepsilon \rightarrow 0} \liminf_{T \rightarrow \infty} \frac{1}{T} \log N(f, \varepsilon, n). \] So the topological entropy is, as we said in the beginning, the asymptotic rate of information we gain in our ability to distinguish points in \(X\) as we iterate \(f\), in the limit of perfect eyesight!
As it turns out, even though we heavily relied on distances in \(X\) throughout this definition, \(h_{top}(f)\) is completely independent of our notion of distance! If we replace our metric, or distance function \(d(x,y)\) with a different one, we will obtain the same result for \(h_{top}\). So the topological entropy really is topological — it has nothing to do with any notion of distance at all.
This is just one of several ways to define topological entropy. There are many others, just as wonderful and surprising and which scratch the tip of an iceberg.
References:
|
I have a 3-dimensional domain D, with 3 types of BC which I am trying to solve the Poisson equation on. $$-\nabla \cdot (\sigma(x,y,z)\nabla u)=0$$
Insulator (Neumann BC) Electrode set at some potential (Dirichlet BC). Additionally I have some electrodes $E_l$ which are set to have a fixed current $I_l$, so on these the boundary condition is $\int_{E_l} \sigma(x,y,z)(du/dn) dA=I_l$.
This boundary condition can given a mesh be translated into equations of the form $\sum a_iu_i=0$, where $u_i$ is the potential at node i and $a_i$ are known mesh dependend constants. But I dont know how to add this equation to the matrix to be solved, or what equations to replace it with.
I cannot assume that the current density is constant on each electrode, for instance some electrodes have net current 0 but current flowing in on one side and out the other, I know commercial software solves this problem just as efficiently as with regular BC.
How would I go about incoprorating this third type of BC into FEM? Any description or references is what im looking for.
|
J. D. Hamkins and R. Yang, “Satisfaction is not absolute,” to appear in the Review of Symbolic Logic, pp. 1-34, 2014.
@ARTICLE{HamkinsYang:SatisfactionIsNotAbsolute,
author = {Joel David Hamkins and Ruizhi Yang},
title = {Satisfaction is not absolute},
journal = {to appear in the Review of Symbolic Logic},
year = {2014},
volume = {},
number = {},
pages = {1--34},
month = {},
note = {},
abstract = {},
keywords = {to-appear},
source = {},
eprint = {1312.0670},
archivePrefix = {arXiv},
primaryClass = {math.LO},
url = {http://wp.me/p5M0LV-Gf},
doi = {},
}
$\newcommand\N{\mathbb{N}}\newcommand\satisfies{\models}$
Abstract. We prove that the satisfaction relation $\mathcal{N}\satisfies\varphi[\vec a]$ of first-order logic is not absolute between models of set theory having the structure $\mathcal{N}$ and the formulas $\varphi$ all in common. Two models of set theory can have the same natural numbers, for example, and the same standard model of arithmetic $\langle\N,{+},{\cdot},0,1,{\lt}\rangle$, yet disagree on their theories of arithmetic truth; two models of set theory can have the same natural numbers and the same arithmetic truths, yet disagree on their truths-about-truth, at any desired level of the iterated truth-predicate hierarchy; two models of set theory can have the same natural numbers and the same reals, yet disagree on projective truth; two models of set theory can have the same $\langle H_{\omega_2},{\in}\rangle$ or the same rank-initial segment $\langle V_\delta,{\in}\rangle$, yet disagree on which assertions are true in these structures. On the basis of these mathematical results, we argue that a philosophical commitment to the determinateness of the theory of truth for a structure cannot be seen as a consequence solely of the determinateness of the structure in which that truth resides. The determinate nature of arithmetic truth, for example, is not a consequence of the determinate nature of the arithmetic structure $\N=\{ 0,1,2,\ldots\}$ itself, but rather, we argue, is an additional higher-order commitment requiring its own analysis and justification.
Many mathematicians and philosophers regard the natural numbers $0,1,2,\ldots\,$, along with their usual arithmetic structure, as having a privileged mathematical existence, a Platonic realm in which assertions have definite, absolute truth values, independently of our ability to prove or discover them. Although there are some arithmetic assertions that we can neither prove nor refute—such as the consistency of the background theory in which we undertake our proofs—the view is that nevertheless there is a fact of the matter about whether any such arithmetic statement is true or false in the intended interpretation. The definite nature of arithmetic truth is often seen as a consequence of the definiteness of the structure of arithmetic $\langle\N,{+},{\cdot},0,1,{\lt}\rangle$ itself, for if the natural numbers exist in a clear and distinct totality in a way that is unambiguous and absolute, then (on this view) the first-order theory of truth residing in that structure—arithmetic truth—is similarly clear and distinct.
Feferman provides an instance of this perspective when he writes (Feferman 2013, Comments for EFI Workshop, p. 6-7) :
In my view, the conception [of the bare structure of the natural numbers] is completely clear , and thence all arithmetical statements are definite .
It is Feferman’s `thence’ to which we call attention. Martin makes a similar point (Martin, 2012, Completeness or incompleteness of basic mathematical concepts):
What I am suggesting is that the real reason for confidence in first-order completeness is our confidence in the full determinateness of the concept of the natural numbers.
Many mathematicians and philosophers seem to share this perspective. The truth of an arithmetic statement, to be sure, does seem to depend entirely on the structure $\langle\N,{+},{\cdot},0,1,{\lt}\rangle$, with all quantifiers restricted to $\N$ and using only those arithmetic operations and relations, and so if that structure has a definite nature, then it would seem that the truth of the statement should be similarly definite.
Nevertheless, in this article we should like to tease apart these two ontological commitments, arguing that the definiteness of truth for a given mathematical structure, such as the natural numbers, the reals or higher-order structures such as $H_{\omega_2}$ or $V_\delta$, does not follow from the definite nature of the underlying structure in which that truth resides. Rather, we argue that the commitment to a theory of truth for a structure is a higher-order ontological commitment, going strictly beyond the commitment to a definite nature for the underlying structure itself.
We make our argument in part by proving that different models of set theory can have a structure identically in common, even the natural numbers, yet disagree on the theory of truth for that structure.
Theorem. Two models of set theory can have the same structure of arithmetic $$\langle\N,{+},{\cdot},0,1,{\lt}\rangle^{M_1}=\langle\N,{+},{\cdot},0,1,{\lt}\rangle^{M_2},$$yet disagree on the theory of arithmetic truth. Two models of set theory can have the same natural numbers and a computable linear order in common, yet disagree about whether it is a well-order. Two models of set theory that have the same natural numbers and the same reals, yet disagree on projective truth. Two models of set theory can have a transitive rank initial segment in common $$\langle V_\delta,{\in}\rangle^{M_1}=\langle V_\delta,{\in}\rangle^{M_2},$$yet disagree about whether it is a model of ZFC.
The proofs use only elementary classical methods, and might be considered to be a part of the folklore of the subject of models of arithmetic. The paper includes many further examples of the phenomenon, and concludes with a philosophical discussion of the issue of definiteness, concerning the question of whether one may deduce definiteness-of-truth from definiteness-of-objects and definiteness-of-structure.
|
The following is a theorem given in Bella Bollobas's Modern graph theory(Springer 2002) Page-73
If $G$ is nontrivial (that is, has at least two vertices), then the parameters $\delta(G)$, $\lambda(G)$ and $\kappa(G)$ satisfy the following inequality: $\kappa(G) \le \lambda(G) \le \delta(G)$, where $\delta(G)$ is the minimum degree of a vertex, $\lambda(G)$ is the edge connectivity, and $\kappa(G)$ is the vertex connectivity.
Proof:
Indeed, if we delete all the edges incident with a vertex, the graph becomes disconnected, so the second inequality holds. To see the other inequality, note first that if $G$ is complete then $\kappa(G) = \lambda(G) = |G| - 1$, and if $\lambda(G) \le 1$ then $\lambda(G) = \kappa(G)$. Suppose now that $G$ is not complete, $\lambda(G) = k \ge 2$, and $\{x_1 y_1, x_2 y_2, \ldots , x_k y_k\}$ is a set of edges disconnecting $G$. If $G - \{x_1, x_2, \ldots , x_k\}$ is disconnected then $\kappa(G) \le k$. Otherwise, each vertex $x_i$ has degree at most $k$ (and so exactly $k$). Deleting the neighbours of $x_1$, we disconnect $G$. Hence $\kappa(G)\le \lambda(G)$.
I did not understand the following part of the proof: "Otherwise, each vertex $x_i$ has degree at most $k$ (and so exactly $k$)" . Why is this true? I would really appreciate an elaborate answer to this.
|
When I try Find the volume of the region $R$ lying below the plane $z = 3-2y$ and above the paraboloid $z = x^2 + y^2$
Solving the 2 equations together yields the cylinder $x^2 + (y+1)^2 = 4 $ How do I get the volume then???
Mathematics Stack Exchange is a question and answer site for people studying math at any level and professionals in related fields. It only takes a minute to sign up.Sign up to join this community
First of all, I draw a plot for $x^2+(y+1)^2=4$ or $r^2+2r\sin(\theta)=3$ which is our integration area on plane $z=0$.
You see that $r$ varies from $r=3$ to $r=-\sin(\theta)+\sqrt{\sin(\theta)^2+3}$ and $\theta$ from $0$ to $pi/2$. As the volume is symmetric so you should double the result.
|
Denote the following:
$S_i$ to be the sum of the digits in column $i$. $D_i$ to be the digit in column $i$ of the sum. Thus $D_i = S_i \mod 10$ $C_i$ to be the carry over of $S_i$.
Given that all the numbers are even, we know that $N,X,E \in \{0,2,4,6,8\}$. Looking at $S_1=N+N+X+E \le 8+8+6+4=26 \implies C_1 \le 2$.
Lets look at $S_2=U+U+U+Z+C_1$ and $D_2=Z$. We know that $3\times U + C_1 \mod 10 = 0$ in order to make this work. If $C_1=0 \implies U=0$, which can't happen. $C_1=1 \implies U=3$ and $C_1=2 \implies U=6$.
We can also see that $C_4 \le 1$ and since $S \ne D$, we have $C_4=1$ and $S=D+1$.
Now look at $S_1=N+N+X+E$ and $D_1=E$. This implies that $N+N+X \mod 10 = 0$. If $N=0$ then $X=0$, which can't happen.
$N=2 \implies X=6$ and $C_1=1$ and $U=3$ and $C_2=1$ $N=4 \implies X=2$ and $C_1=1$ and $U=3$ and $C_2=1$ $N=6 \implies X=8$ and $C_1=2$ and $U=6$ which can't happen $N=8 \implies X=4$ and $C_1=2$ and $U=6$ and $C_2=2$
We also know that $C_3 \le 1$ and $C_4=1$ and $S=D+1$
Let assume $U=6$.
Thus, $N=8$, $X=4$, and $C_1=C_2=2$.
Then $S_3=E+6+2$. The valid choices for $E \in \{2,0\}$ If $E=0$ then $D_3=I=8$ which is already used. Thus $E=2$, and $I=0$ and $C_3=1$
In $S_4=D+O+C_3=D+O+1$ and $D_4=E=2$. Thus, $D+O=11$. But all the even numbers are already taken, so there is no way to make this equality work.
Thus $U \ne 6$.
Thus $U=3$
So we know that $N \in \{2,4\}$, $X \in \{6,2\}$, and $C_1=C_2=1$. In either case, $N$ or $X$ is $2$, so no other letter can be $2$. So $E \in \{0,4,6,8\}$.
If $E=8$, then $C_3=1$ and $S_4=D+O+C_3=D+O+1$ and $D_4=E$. This would require one of $D$ or $O$ to be 9, an the other 8.
If $E=4$, then $N=2$ and $X=6$. In $S_3=E+U+C_2=4+3+1=8$, so $D_3=I=8$ and $C_3=0$. From $S_4=D+O+C_3=D+O$ and $D_4=E=4$. The only combination that works are $D+O=9+5$. But either solution for $D$ results in an invalid $S$ since $S=D+1$.
If $E=0$, then from $S_3=E+U+C_2=0+3+1=4$ means that $D_3=I=4$ and $C_3=0$. Thus, $N=2$ and $X=6$. From $S_4=D+O+C_3=D+O$ and $D_4=E=0$. The only combinations of remaining numbers that work for $D$ and $O$ are $9$ and $1$. But neither result in a valid $S$ since $S=D+1$.
Thus $E=6$, then means that one of $D$ or $O$ is 8, and the other is 7. Since $S=D+1$, if $D=7$ then both $N=O=8$. Thus, $D=8$, $O=7$, and $S=9$. Also, $X=2$ and $N=4$. Also, from $S_3=E+U+C_2=6+3+1=10$, so $D_3=I=0$
The final solution is:
$$U=3, E=6, D=8, O=7, S=9, X=2, N=4, I=0, Z\in\{1,5\}$$
|
I am looking at Kemna and Vorst's paper:
A PRICING METHOD FOR OPTIONS BASED ON AVERAGE ASSET VALUES. see http://www.javaquant.net/papers/Kemna-Vorst.pdf
Let $\text{d}S_t = S_tr\text{d}t + S_t\sigma\text{d}W_t$. Let $t_0 \leq t \leq T$, define $A(t)=\frac{1}{T-t_0}\int^T_{t_0}S_\tau\text{d}\tau$.
The Asian option has pay off $(A(T)-K)^+$. Let $C(s,a,t)$ be the time $t$ price the Asian option with $S(t)=s, A(t)=a$. This paper claims on the top of page 5 that
$\lim\limits_{s\rightarrow\infty}\frac{\partial C(s,a,t)}{\partial s}=\frac{T-t}{T-t_0}e^{-r(T-t)}$, but this is not what I arrived at.
Here is my heuristic/non-rigorous derivation. When $S(t)$ is sufficiently large, then you will almost certainly be in the money. Then
the value of the option should approximately be $C(a,s,t) = e^{-r(T-t)}\bigg((a-K)+\mathbb E\bigg(\frac{1}{T-t_0}\int^T_tS_\tau\text{d}\tau\bigg)\bigg)= e^{-r(T-t)}\bigg((a-K)+\bigg(\frac{s}{r(T-t_0)}(e^{r(T-t)}-1)\bigg)\bigg)$.
(This agrees with (15) in the paper, even)
so I calculate the derivative to be $\frac{1}{r(T-t_0)}(1-e^{-r(T-t)})$
What is stated the paper seems to be the time derivative of my answer, see (13). Did I make a mistake or there is a mistake in this classical paper?
|
Search
Now showing items 1-2 of 2
D-meson nuclear modification factor and elliptic flow measurements in Pb–Pb collisions at $\sqrt {s_{NN}}$ = 5.02TeV with ALICE at the LHC
(Elsevier, 2017-11)
ALICE measured the nuclear modification factor ($R_{AA}$) and elliptic flow ($\nu_{2}$) of D mesons ($D^{0}$, $D^{+}$, $D^{⁎+}$ and $D^{s+}$) in semi-central Pb–Pb collisions at $\sqrt{s_{NN}} =5.02$ TeV. The increased ...
ALICE measurement of the $J/\psi$ nuclear modification factor at mid-rapidity in Pb–Pb collisions at $\sqrt{{s}_{NN}}=$ 5.02 TeV
(Elsevier, 2017-11)
ALICE at the LHC provides unique capabilities to study charmonium production at low transverse momenta ( p T ). At central rapidity, ( |y|<0.8 ), ALICE can reconstruct J/ ψ via their decay into two electrons down to zero ...
|
The question asks: if $\sum a_n$ converges, $\{b_n\}$ is monotonic and bounded, prove that $\sum a_nb_n$ converges.
My proof goes as follows:
Let $\varepsilon>0$, and let $S_k$ denote $k$-th partial sum of $\sum a_nb_n$. Now, $\{b_n\}$ is monotonic and bounded, so it converges, say to $b$.
Since $\{b_n\}$ converges, we know that $\|b_n\| < \|b\|+1$, for large enough $n$. Also, $\sum a_n$ converges, thus $\|\sum_{j+1}^{k} a_n\| < \frac{\varepsilon}{\|b\|+1}$ for large enough $k,j$.
Therefore $\|S_k-S_j\| = \|\sum_{j+1}^{k} a_nb_n\| < (\|b\|+1)\|\sum_{j+1}^{k} a_n\|<(\|b\|+1)\times\frac{\varepsilon}{\|b\|+1}=\varepsilon,$ for large enough $k,j$.
Thus, $\sum a_nb_n$ is Cauchy, hence convergent.
Now, is my proof correct? Thanks for the help.
|
I am trying to design an efficient algorithm that retrieves the ith to jth largest elements in an array. For example, if the following array is the input:
[10, 14, 18, 3, 21, 25, 27] i = 2 j = 4
The following array is returned:
[25, 21, 18]
18 is the 4th largest element in the array and 25 is the 2nd smallest element in an array. I’ve done a problem where you retrieve a list of the K largest elements in an array: in such a problem, the solution is pretty trivial (using a fixed-size minimum heap of size K to keep track of the K largest elements). In this case however, a heap seems out of reach to use because the minimum heap can only remove the smallest element from the heap (removing the kth smallest element within the heap seems really inefficient).
I could do QuickSelect (j – i) times to get all the elements, but that means doing a linear O(n) walkthrough (j – i) times, which yields a total time complexity of O((j-i) * n), but I was thinking about if it’s possible to quicken the algorithm’s time complexity to just O(n). Is there an O(n) algorithm to solve this problem?
Given a set of intervals on the real line, compute the largest subset of pairwise intersecting intervals (an interval in the subset must intersect with every other interval in the subset). Design a greedy algorithm that computes an optimal solution.
So I am working on this problem involving finding the largest word in a given text file using python. I already Wrote a Code But want to find if there is a more efficient way to go by this problem. Help is appreciated!!
I’ve already achieved the goal i just want to find a more efficient way to do this.
Here’s my code:
def largestWord(filename): length = {} maxValue = 0 with open(filename, ‘r’) as infile: for line in infile.readlines(): listOfWords = line.split() for word in listOfWords: length[word] = len(word) //makes a dictionary where the key is the word and the value is the length of the word. for value in length.values(): //Iterating through the values of the if value > maxValue: maxValue = value dictionary to find the highest value and then comparing with values form the keys to return the word
for k in length.keys(): if length[k] == maxValue: print(k)
largestWord(filename)
Want a shorter piece of code.
Are there any efficient ways to solve this problem, for example using bitwise operator?
public static boolean isPal(long num) { String numStr = Long.toString(num); String rNumStr = ""; boolean result = false; for (int i = numStr.length() - 1; i >= 0 ; --i) rNumStr += numStr.charAt(i); //System.out.println(numStr + "," + rNumStr); try { if (Long.parseLong(numStr) == Long.parseLong(rNumStr)) result = true; else result = false; }catch (NumberFormatException e) { //System.err.println("Unable to format. " + e); } return result; } public static void calcPal(int rangeMin, int rangeMax) { long maxp = 0, maxq = 0, maxP = 0; for (int p = rangeMax; p > rangeMin; p--) for (int q = rangeMax; q > rangeMin; q--) { long P = p * q; if (isPal(P)) if (P > maxP) { maxp = p; maxq = q; maxP = P; } } System.out.println(maxp + "*" + maxq + "=" + maxP); } public static void main(String[] args) { calcPal(10, 99); calcPal(100, 999); calcPal(9000, 9999); calcPal(10000, 99999); calcPal(990000, 999999); }
The largest palindrome which can be made from the product of two 2-digit (10 to 99) numbers is 9009 (91 × 99). Write a function to calculate the largest palindromic number from the product of two 6-digit numbers (100000 to 999999).
For the second largest element, I know that the formula is n+ ceil(log n) -2 but is there any formula for the third largest element? and if so, what is the derivation?
I have been wondering over the following problem:
Given a set $ S$ of intervals on the number line. We can do two operations on them:
Add a new interval $ [l,r]$ to $ S$ Given an interval $ [ql, qr]$ , which is possibly not in $ S$ , find the longest interval from $ S$ which is contained entirely in $ [ql, qr]$
If I didn’t have operation $ 1$ I have found a solution using a persistent segment tree.
For the full version, there is the trivial solution which runs in $ O(QN)$ . I also found that using interval tree, I can directly find which intervals intersect the query interval and then I can check them manually. However, is there an even better solution? Maybe $ O(NlogN)$ or $ O(Nlog^2N)$
This task is taken from www.interviewbit.com
Given an array of integers, return the highest product possible by multiplying 3 numbers from the array
Input:
array of integers e.g {1, 2, 3}
Example:
[0, -1, 3, 100, 70, 50] => 70*50*100 = 350000
NOTE: Solution will fit in a 32-bit signed integer
My approach: First sort the array, then return the maximum the following numbers: The product of the first two smallest numbers and the last number (largest) or the product of the three largest numbers.
My solution as a runtime of $ O(nlogn)$ due to the sort and a space complexity of $ O(1)$ . I wonder whether there is a faster solution than $ O(nlogn)$ .
function highesProd(a) { a.sort((a,b) => a - b); return Math.max(a[0] * a[1] * a[a.length - 1], a[a.length - 3] * a[a.length - 2] * a[a.length - 1]); }
I’m looking at $ N\times N$ matrices $ M_N$ with elements $ $ M_N=\left( \rho^{|i-j|} \right)_{i,j=1}^N,$ $ where $ \rho$ is a complex number of unit modulus. These matrices with $ \rho\in\mathbb R$ and $ |\rho|<1$ have been studied in detail before, with a nice exposition to be found here, which includes some more references.
In the cited article, there is an implicit form of the eigenvalues, given through $ $ \lambda_j = \frac{1-\rho^2}{1-2\rho\cos\theta_j+\rho^2}, $ $ where $ \theta_j$ are roots of the following function $ $ G(\theta) = \sin[(n+1)\theta]-2\rho\sin[n\theta]+\rho^2\sin[(n-1)\theta]. $ $ (Even though only real $ \rho$ were considered in the article, this works for complex $ \rho$ also.)
Intriguingly, if $ \rho=e^{i\phi}$ , the largest eigenvalue of $ M_N$ seems to be essentially independent of $ \phi$ (as long as $ \phi$ is sufficiently different from 0 (i.e., $ \mathcal O(1/N)$ ). Since the inverse of $ M_N$ is almost tridiagonal (see the article for its form), it can be efficiently diagonalized numerically. I’ve checked up to $ N=10^6$ and the largest eigenvalue (mostly real) seems to
almost follow a power law (roughly $ N^{0.85}$ ), but not quite. In fact, it looks slightly curved, so perhaps it is approaching $ N$ .
Another important thing I’ve noticed is that the $ \theta$ corresponding to the largest eigenvalue is very close to $ \phi$ , and seems to approach $ \phi$ as $ N\to\infty$ . Indeed, it is the same scaling as the actual eigenvalue $ \lambda$ , which follows from the fact that $ \theta=\phi$ makes the denominator of the formula for $ \lambda$ vanish. Expanding $ \theta=\phi+\delta\phi$ it becomes clear that $ $ \ln\lambda\to -\ln(\theta-\phi) + \text{const.} $ $
So I’ve been trying for a long time to extract how $ \theta$ approaches $ \phi$ from $ G(\theta)$ , but failed. I’d appreciate any pointers to a solution.
Let $ 1\leq p<\infty.$ Denote $ S_p(\ell_2)$ be the set of all compact operator $ x$ on $ \ell_2$ such that $ Tr(|x|^p)<\infty.$ Define $ \|x\|_{S_p(\ell_2)}:=Tr(|x|^p)^{\frac{1}{p}}.$ This makes $ S_p(\ell_2)$ a Banach space. What is the largest closed two-sided ideal in the Banach algebra of set of all bounded linear maps on $ S_p(\ell_2)$ ?
This question already has an answer here:
How large is it possible for a PC to get? 2 answers
I was presented a concept for a one shot session from one of my players. He comes up with some strange ideas, and I’d like to see if this one would be viable:
The scenario goes that the Tarrasque has a prophesied date of awakening, so an elite order was created for the sole purpose of combating the creature to put it back in the ground. Using a combination of training courses over the course of many years (multiclassing into very specific classes), each of the group can become as large, if not larger than the Tarrasque and, for the lack of a better term, wrestle it to death.
My question is: Is there actually a combination of class features and spells that can push a character to get larger than a Tarrasque?
|
MathJax TeX Test PageThe moment of inertia of a point particle is $\boxed{mr^2}$. $r$ is the distance from the axis of rotation. For future reference, it is important to note that moments of inertia always add.
Rod rotated about End
MathJax TeX Test PageBecause moments of inertia always add, we can think of a road as a lot of individual points, so we create this integral.So, the moment of inertia of one small point is$$\mathrm{d}I = r^2 \mathrm{d}m$$$$\mathrm{d}m = \rho (\text{density}) * \mathrm{d}x = \dfrac{M}{L}\mathrm{d}x$$Now, we can express $dI$.$$\mathrm{d}I = r^2 \dfrac{M}{L}dx$$$$\int_0^L \dfrac{M}{L}r^2\, \mathrm{d}x = \dfrac{M}{L}\dfrac{L^3}{3} = \boxed{\dfrac{ML^2}{3}}$$
Rod rotated about Center
MathJax TeX Test PageWe keep coming back to one principle which is that moment of inertias add. The moment of inertia of a rotated rod about its center equals 2 * (rod cut in half about its end)That's just what we do! The length is cut in half, and because the density of the rod doesn't change, the mass is halved as well.$$2 * \dfrac{\left(\dfrac{M}{2}\right)\left(\dfrac{L}{2}\right)^2}{3} = \boxed{\dfrac{ML^2}{12}}$$
Solid Disk
MathJax TeX Test Page
Solid Cone
MathJax TeX Test PageThe important thing to remember is that the total inertia is the sum of many moment of inertias of solid discs.$$dI = \dfrac{1}{2}dm*r^2$$Why is this true? Because the total moment of inertia is the sum of moment of inertias of solid disc, and the formula is $\frac{1}{2}mr^2$.$$dm = \rho \text{ (density) } * \pi{}r^2 \text{ (area) } \mathrm{d}x \text{ (width) }$$$$\rho = \dfrac{M}{\pi{}R^2h\frac{1}{3}} = \dfrac{3M}{\pi{}R^2h}$$$$\mathrm{d}m = \dfrac{3M}{hR^2}*r^2\mathrm{d}x$$$$\int_0^h \frac{1}{2}\left(\dfrac{3M}{hR^2}*r^2\right)* r^2\mathrm{d}x$$$r$ is equal to $y$, which is equal to $\frac{R}{h}x$$$\dfrac{3M}{2hR^2}\int_0^h y^4 \,\mathrm{d}x$$Looking at the picture above, $y = \dfrac{R}{h}x$, so the integral is$$\dfrac{3M}{2hR^2}\int_0^h \frac{R^4}{h^4}x^2 \,\mathrm{d}x$$$$\dfrac{3MR^2}{2h^5}\int_0^h x^4 \,\mathrm{d}x$$$$\dfrac{3MR^2}{2h^5} * \frac{h^5}{5} = \boxed{\frac{3MR^2}{10}}$$
|
The other person is likely thinking about the concept of escape velocity. There are people who claim no man-made spaceship could ever have gone into space because they cannot reach the escape velocity for the earth. What they fail to acknowledge is that the escape velocity for the earth is not a constant, it depends on how high above the surface you are.
So what you do to get into space is to reach the escape velocity at the height above the surface you are at. This is in practice obtained by maintaining an energy output until $v(t) = v_{\text{escape}}(h)$ where $h = y(t)$ is the vertical distance of the spacecraft to the earth's surface at time $t$. (see also this answer) When that condition is fulfilled, no additional thrust is needed and the spacecraft will escape the earth.
However, things are different in the case of a black hole. Within the event horizon the (timelike) geodesics of Schwarzschild spacetime are closed curves leading inevitably to the singularity at $r=0$. A clear picture is painted by the Kruskal spacetime diagram:
Here, the event horizon $r=2GM$ is a diagonal line bisecting the right angle between the Kruskal coordinate axes $X$ and $T$ and the singularity $r = 0$ is contained within the blue region marked $II$. The benefit of using Kruskal coordinates to describe Schwarzschild's spacetime is that (radial) light cones are defined by $X = \pm T$ and therefore the causal structure of spacetime is very clear.
Indeed, any observer inside the blue region of spacetime is doomed. Their light cones are completely contained within this region and the singularity is unavoidable. Another interesting way to see this is by simply looking at the Schwarzschild metric:
$$ds^2 = -\left(1-\frac{2GM}{r}\right) \text{d}t^2 + \left(1-\frac{2GM}{r}\right)^{-1} \text{d}r^2 + r^2 d\Omega_2^2$$
where $d\Omega_2^2$ is the metric on a unit two-sphere (don't worry about this part, it contains angular coordinates only and we're interested in radial curves, i.e. curves without angular dependence).
Shamelessly ignoring the coordinate singularity at $r=2GM$, let's see what happens on either side of the event horizon. We notice that for $r>2GM$ this metric has signature (-+++). But when $r<2GM$, the factor in front of $\text{d}t$ becomes positive while that in front of $\text{d}r$ becomes negative. So for $r<2GM$ the time-coordinate becomes spacelike and the space-coordinate becomes timelike! Thus you can no more stop yourself from moving toward the singularity than you can stop yourself from getting older.
Outside the event horizon (region $I$ in the above diagram), a (Schwarzschild) black hole behaves like any other celestial body and you can perfectly well have stable orbits and talk about escape velocities in this region of spacetime. But inside the event horizon there isn't even a notion of escape velocity, since it is defined as the velocity needed to reach infinity without additional forces and everything inside the event horizon is completely cut off from spacelike infinity.
|
Let's say we have an object in 3D space located at
P(1,1,1) and if we decided we wanted to rotate this object within any of the planes
XY,
XZ,
YZ along any of the 3 axis where this is a basic 3D Cartesian system in a Right-Hand System the rotation matrices $R_n$ for
P will look like these:
$$ R_x \space|| \space R_y \space || \space R_z $$
$$R_x(\theta) P = \begin{bmatrix} 1 & 0 & 0 \\ 0 & \cos\theta & -\sin\theta \\ 0 & \sin\theta & \space\space\cos\theta \\\end{bmatrix} \begin{bmatrix} P_x \\ P_y \\ P_z \\ \end{bmatrix},$$
$$R_y(\theta) P = \begin{bmatrix} \space\cos\theta & 0 & \sin\theta \\ 0 & 1 & 0 \\ -\sin\theta & 0 & \cos\theta \\\end{bmatrix} \begin{bmatrix} P_x \\ P_y \\ P_z \\\end{bmatrix},$$
$$R_z(\theta) P= \begin{bmatrix} \cos\theta & -\sin \theta & 0 \\ \sin\theta & \space\space\cos \theta & 0 \\ 0 & 0 & 1 \\\end{bmatrix}\begin{bmatrix} P_x \\ P_y \\ P_z \\ \end{bmatrix}$$
When doing rotations in 3D among any of the arbitrary axis, the order of the rotations, the handedness of the system, the direction of the rotations and doing rotations among multiple axis does matter. To demonstrate this let's say angle $\theta = 90°$ and we apply this rotation consecutively in multiple dimensions you will see that we eventually end up with Gimbal Lock. First we will do $R_x$ by 90° then $R_y$ and finally try $R_z$
Here we are going to apply a 90° rotation to the point or vector
P(1,1,1) on the $R_x$ axis
$R_x(90°)$ $\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}$ = $\begin{bmatrix} 1 & 0 & 0 \\ 0 & \cos 90° & -\sin 90° \\ 0 & \sin 90° & \space\space\cos 90° \\\end{bmatrix}$ $\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}$ = $\begin{bmatrix} 1 & 0 & \space\space 0 \\ 0 & 0 & -1 \\ 0 & 1 & \space\space 0 \\\end{bmatrix}$ $\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}$ = $\begin{bmatrix} 1 \\ -1 \\ 1 \\\end{bmatrix}$
Now that our vector
P has been transformed we will apply another 90° rotation but this time to the $R_y$ axis with the new values.
$R_y(90°)$ $\begin{bmatrix} 1 \\ -1 \\ 1 \\ \end{bmatrix}$ =$\begin{bmatrix} \cos 90° & 0 & \sin 90°\\ 0 & 1 & 0 \\ -\sin 90° & 0 & \cos 90°\\ \end{bmatrix}$$\begin{bmatrix} 1 \\ -1 \\ 1 \\\end{bmatrix}$ =$\begin{bmatrix} 0 & 0 & 1 \\ 0 & 1 & 0 \\ -1 & 0 & 0\\\end{bmatrix}$ $\begin{bmatrix} 1 \\ -1 \\ 1 \\ \end{bmatrix}$ = $\begin{bmatrix} 1 \\ -1 \\ -1 \\ \end{bmatrix}$
We can now finish with $R_z$
$R_z(90°)$ $\begin{bmatrix} 1 \\ -1 \\ -1 \\ \end{bmatrix}$ = $\begin{bmatrix} \cos 90° & -\sin 90° & 0 \\ \sin 90° & \cos 90° & 0 \\ 0 & 0 & 1 \\ \end{bmatrix}$ $\begin{bmatrix} 1 \\ -1 \\ -1 \\ \end{bmatrix}$ =$\begin{bmatrix} 0 & -1 & 0 \\ 1 & 0 & 0 \\ 0 & 0 & 1 \\\end{bmatrix}$ $\begin{bmatrix} 1 \\ -1 \\ -1 \\ \end{bmatrix}$ =$\begin{bmatrix} 1 \\ 1 \\ -1 \\ \end{bmatrix}$
And as you can see in the calculations of the matrices there has been a change in direction for each time we rotated by 90 degrees. Here we have lost a degree of freedom of rotation. What this means is we rotated the X components by 90° which happens to be perpendicular or orthogonal to both the Y & Z axis which is evident of the fact that
$\cos(90°) = 0$. Then when we rotate again by 90° along the Y axis and once again the Y axis is perpendicular to both the X & Z axis now we have 2 axis of rotations that are aligned so when we try to rotate in the 3rd dimension of space we lost a degree of freedom because we can no longer distinguish between the X & Y as they will both rotate simultaneously and there is no method to separate them. This can be seen from the calculations that were done by the matrices. It may not be completely evident now, but if you were to do all 6 permutations of the order of axis rotations you will see the pattern emerge. These kind of rotations are called Euler Angles.
It also doesn't matter what combination of axis you rotate with because it will happen with every combination when two axis of rotations become parallel.
$$R_x(90°)P \to R_y(90°)P \to R_z(90°)P \implies Gimbal Lock$$$$R_x(90°)P \to R_z(90°)P \to R_y(90°)P \implies Gimbal Lock$$$$R_y(90°)P \to R_x(90°)P \to R_z(90°)P \implies Gimbal Lock$$$$R_y(90°)P \to R_z(90°)P \to R_x(90°)P \implies Gimbal Lock$$$$R_z(90°)P \to R_x(90°)P \to R_y(90°)P \implies Gimbal Lock$$$$R_z(90°)P \to R_y(90°)P \to R_x(90°)P \implies Gimbal Lock$$
If I simplify this by showing all 6 combinations with the ending transformation vectors or matrices for that same point you should see the pattern and these transformations are:
$$R_x(90°) P(1,1,1) \to \begin{bmatrix} 1 \\ -1 \\ 1 \\ \end{bmatrix}R_y(90°) \to\begin{bmatrix} 1 \\ -1 \\ -1 \\ \end{bmatrix}R_z(90°) \to\begin{bmatrix} 1 \\ 1 \\ -1 \\ \end{bmatrix}$$
$$R_x(90°) P(1,1,1) \to \begin{bmatrix} 1 \\ -1 \\ 1 \\ \end{bmatrix}R_z(90°) \to\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}R_y(90°) \to\begin{bmatrix} 1 \\ 1 \\ -1 \\ \end{bmatrix}$$
$$R_y(90°) P(1,1,1) \to \begin{bmatrix} 1 \\ 1 \\ -1 \\ \end{bmatrix}R_x(90°) \to\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}R_z(90°) \to\begin{bmatrix} -1 \\ 1 \\ 1 \\ \end{bmatrix}$$
$$R_y(90°) P(1,1,1) \to \begin{bmatrix} 1 \\ 1 \\ -1 \\ \end{bmatrix}R_z(90°) \to\begin{bmatrix} -1 \\ 1 \\ -1 \\ \end{bmatrix}R_x(90°) \to\begin{bmatrix} -1 \\ 1 \\ 1 \\ \end{bmatrix}$$
$$R_z(90°) P(1,1,1) \to \begin{bmatrix} -1 \\ 1 \\ 1 \\ \end{bmatrix}R_x(90°) \to\begin{bmatrix} -1 \\ -1 \\ 1 \\ \end{bmatrix}R_y(90°) \to\begin{bmatrix} 1 \\ -1 \\ 1 \\ \end{bmatrix}$$
$$R_z(90°) P(1,1,1) \to\begin{bmatrix} -1 \\ 1 \\ 1 \\ \end{bmatrix}R_y(90°) \to\begin{bmatrix} 1 \\ 1 \\ 1 \\ \end{bmatrix}R_x(90°) \to\begin{bmatrix} 1 \\ -1 \\ 1 \\ \end{bmatrix}$$
If you look at the combinations of the axis that you started with it doesn't matter the order of which two you finished with because the result will be the same for that starting axis of rotation. So intuitively we can say this about using Euler Angles of Rotation in 3D while considering the handedness of the coordinate system; the handedness matters because it will change the rotation matrices along with the trig functions and their signs for they will be different and so will your results. Now as for this particular coordinate system we can visually conclude this about Euler Angles:
$$R_x(\theta) P \implies \begin{bmatrix} a \\ a \\ -a \\ \end{bmatrix}$$
$$R_y(\theta) P \implies \begin{bmatrix} -a \\ a \\ a \\ \end{bmatrix}$$
$$R_z(\theta) P \implies \begin{bmatrix} a \\ -a \\ a \\ \end{bmatrix}$$
It may not seem quite apparent by the numbers as to what exactly is causing the gimbal lock, but the results of the transformations should give you some insight to what is going on. It might be easier to visualize than just by looking at the math. So I provided a link to a good video below. Now if you are interested in proofs then you have plenty of work ahead of you for there are also some other factors that cause this to happen such as the relationships of the $\cos(\theta)$ between two vectors being equal to the dot product between those vectors divided by their magnitudes.
$$\cos(\theta) = \frac{ V_1 \cdot V_2}{ \lvert V_1 \rvert \lvert V_2 \rvert } $$
Other contributing factors are the rules of calculus on the trigonometric functions especially the $\sin$ and $\cos$ functions.
$$(\sin{x})' = \cos{x}$$
$$(\cos{x})' = -\sin{x}$$
$$\int \sin{ax} \space dx = -\frac{1}{a}\cos{ax} + C$$
$$\int \cos{ax} \space dx = \frac{1}{a}\sin{ax} + C$$
Another interesting fact that I think that may lead to the reasoning of Gimbal Lock is quite interesting but that is a topic for another day as that in itself would merit its own page, but do forgive me if the math formatting isn't perfect I am new to this particular stack exchange site and I'm learning the math tags and formatting as I go.
Here is an excellent video illustrating Gimbal Lock: Youtube : Gimbal Lock
|
Electronic Communications in Probability Electron. Commun. Probab. Volume 23 (2018), paper no. 73, 14 pp. Approximation of a generalized continuous-state branching process with interaction Abstract
In this work, we consider a continuous–time branching process with interaction where the birth and death rates are non linear functions of the population size. We prove that after a proper renormalization our model converges to a generalized continuous state branching process solution of the SDE \[\begin{aligned} Z_t^x=& x + \int _{0}^{t} f(Z_r^x) dr + \sqrt{2c} \int _{0}^{t} \int _{0}^{Z_{r}^x }W(dr,du) + \int _{0}^{t}\int _{0}^{1}\int _{0}^{Z_{r^-}^x}z \ \overline{M} (ds, dz, du)\\ &+ \int _{0}^{t}\int _{1}^{\infty }\int _{0}^{Z_{r^-}^x}z \ M(ds, dz, du), \end{aligned} \] where $W$ is a space-time white noise on $(0,\infty )^2$ and $\overline{M} (ds, dz, du)= M(ds, dz, du)- ds \mu (dz) du$, with $M$ being a Poisson random measure on $(0,\infty )^3$ independent of $W,$ with mean measure $ds\mu (dz)du$, where $(1\wedge z^2)\mu (dz)$ is a finite measure on $(0, \infty )$.
Article information Source Electron. Commun. Probab., Volume 23 (2018), paper no. 73, 14 pp. Dates Received: 25 May 2018 Accepted: 2 October 2018 First available in Project Euclid: 17 October 2018 Permanent link to this document https://projecteuclid.org/euclid.ecp/1539763346 Digital Object Identifier doi:10.1214/18-ECP176 Mathematical Reviews number (MathSciNet) MR3866046 Zentralblatt MATH identifier 1401.60159 Citation
Dramé, Ibrahima; Pardoux, Étienne. Approximation of a generalized continuous-state branching process with interaction. Electron. Commun. Probab. 23 (2018), paper no. 73, 14 pp. doi:10.1214/18-ECP176. https://projecteuclid.org/euclid.ecp/1539763346
|
Does Smeaton's coefficient, k, have a modern value or it is dependent of the air density?
Why is the accepted value of k so high?
In various texts about the Wright brothers (see 1 and 2) one can read about Smeaton's coefficient that troubled them a lot and that they finally discovered the parameter had a much lower value reaching the conclusion $k = 0.0033 lbf/ft^2/mph^2 = 0.79 kg/m^3$ (instead of $k = 0.005$), a fact also noticed by others before them.
"the Wright brothers calculated a new average value of 0.0033. Modern aerodynamicists have confirmed this figure to be accurate within a few percent." Source: Correcting Smeaton's Coefficient
$L = k \cdot S \cdot V^2 \cdot C_L$
$L$ = lift in pounds
$k$ = coefficient of air pressure (Smeaton coefficient)
$S$ = total area of lifting surface in square feet
$V$ = velocity (headwind plus ground speed) in miles per hour
$C_L$ = coefficient of lift (varies with wing shape)"
However, knowing that the modern formula for lift is $$L = 0.5 \cdot \rho \cdot S \cdot V^2 \cdot C_L$$ Where $\rho$ = the air density.
It appears that $k = 0.5 \cdot \rho$ and so it does not have a standard average value. Also a $k = 0.0033 lbf/ft^2/mph^2 = 0.79 kg/m^3$ leads to a $\rho = k/0.5 = 1.58 kg/m^3$ that corresponds to a sea level air temperature well below -25 C, which is unusual.
If the two relations for lift are correct, the Smeaton's coefficient can not be 0.0033 but closer to 0.0025 a value corresponding to a standard air density at $20 ^\circ C$ close to $1.2 kg/m^3$.
|
Forgot password? New user? Sign up
Existing user? Log in
Let ωn=eiπ/n\omega_n=e^{i\pi/n}ωn=eiπ/n. The value of ∣∏j=12014(∏i=1j(ωj2i−1−1))∣\left|\prod_{j=1}^{2014}\left(\prod_{i=1}^j\left(\omega_j^{2i-1}-1\right)\right)\right|∣∣∣∣∣j=1∏2014(i=1∏j(ωj2i−1−1))∣∣∣∣∣ can be expressed as aba^bab where a,ba,ba,b are positive integers and aaa is as small as possible. What is a+ba+ba+b?
Problem Loading...
Note Loading...
Set Loading...
|
Hi, Can someone provide me some self reading material for Condensed matter theory? I've done QFT previously for which I could happily read Peskin supplemented with David Tong. Can you please suggest some references along those lines? Thanks
@skullpatrol The second one was in my MSc and covered considerably less than my first and (I felt) didn't do it in any particularly great way, so distinctly average. The third was pretty decent - I liked the way he did things and was essentially a more mathematically detailed version of the first :)
2. A weird particle or state that is made of a superposition of a torus region with clockwise momentum and anticlockwise momentum, resulting in one that has no momentum along the major circumference of the torus but still nonzero momentum in directions that are not pointing along the torus
Same thought as you, however I think the major challenge of such simulator is the computational cost. GR calculations with its highly nonlinear nature, might be more costy than a computation of a protein.
However I can see some ways approaching it. Recall how Slereah was building some kind of spaceitme database, that could be the first step. Next, one might be looking for machine learning techniques to help on the simulation by using the classifications of spacetimes as machines are known to perform very well on sign problems as a recent paper has shown
Since GR equations are ultimately a system of 10 nonlinear PDEs, it might be possible the solution strategy has some relation with the class of spacetime that is under consideration, thus that might help heavily reduce the parameters need to consider to simulate them
I just mean this: The EFE is a tensor equation relating a set of symmetric 4 × 4 tensors. Each tensor has 10 independent components. The four Bianchi identities reduce the number of independent equations from 10 to 6, leaving the metric with four gauge fixing degrees of freedom, which correspond to the freedom to choose a coordinate system.
@ooolb Even if that is really possible (I always can talk about things in a non joking perspective), the issue is that 1) Unlike other people, I cannot incubate my dreams for a certain topic due to Mechanism 1 (consicous desires have reduced probability of appearing in dreams), and 2) For 6 years, my dream still yet to show any sign of revisiting the exact same idea, and there are no known instance of either sequel dreams nor recurrence dreams
@0celo7 I felt this aspect can be helped by machine learning. You can train a neural network with some PDEs of a known class with some known constraints, and let it figure out the best solution for some new PDE after say training it on 1000 different PDEs
Actually that makes me wonder, are the space of all coordinate choices more than all possible moves of Go?
enumaris: From what I understood from the dream, the warp drive showed here may be some variation of the alcuberrie metric with a global topology that has 4 holes in it whereas the original alcuberrie drive, if I recall, don't have holes
orbit stabilizer: h bar is my home chat, because this is the first SE chat I joined. Maths chat is the 2nd one I joined, followed by periodic table, biosphere, factory floor and many others
Btw, since gravity is nonlinear, do we expect if we have a region where spacetime is frame dragged in the clockwise direction being superimposed on a spacetime that is frame dragged in the anticlockwise direction will result in a spacetime with no frame drag? (one possible physical scenario that I can envision such can occur may be when two massive rotating objects with opposite angular velocity are on the course of merging)
Well. I'm a begginer in the study of General Relativity ok? My knowledge about the subject is based on books like Schutz, Hartle,Carroll and introductory papers. About quantum mechanics I have a poor knowledge yet.
So, what I meant about "Gravitational Double slit experiment" is: There's and gravitational analogue of the Double slit experiment, for gravitational waves?
@JackClerk the double slits experiment is just interference of two coherent sources, where we get the two sources from a single light beam using the two slits. But gravitational waves interact so weakly with matter that it's hard to see how we could screen a gravitational wave to get two coherent GW sources.
But if we could figure out a way to do it then yes GWs would interfere just like light wave.
Thank you @Secret and @JohnRennie . But for conclude the discussion, I want to put a "silly picture" here: Imagine a huge double slit plate in space close to a strong source of gravitational waves. Then like water waves, and light, we will see the pattern?
So, if the source (like a Black Hole binary) are sufficent away, then in the regions of destructive interference, space-time would have a flat geometry and then with we put a spherical object in this region the metric will become schwarzschild-like.
if**
Pardon, I just spend some naive-phylosophy time here with these discussions**
The situation was even more dire for Calculus and I managed!
This is a neat strategy I have found-revision becomes more bearable when I have The h Bar open on the side.
In all honesty, I actually prefer exam season! At all other times-as I have observed in this semester, at least-there is nothing exciting to do. This system of tortuous panic, followed by a reward is obviously very satisfying.
My opinion is that I need you kaumudi to decrease the probabilty of h bar having software system infrastructure conversations, which confuse me like hell and is why I take refugee in the maths chat a few weeks ago
(Not that I have questions to ask or anything; like I said, it is a little relieving to be with friends while I am panicked. I think it is possible to gauge how much of a social recluse I am from this, because I spend some of my free time hanging out with you lot, even though I am literally inside a hostel teeming with hundreds of my peers)
that's true. though back in high school ,regardless of code, our teacher taught us to always indent your code to allow easy reading and troubleshooting. We are also taught the 4 spacebar indentation convention
@JohnRennie I wish I can just tab because I am also lazy, but sometimes tab insert 4 spaces while other times it inserts 5-6 spaces, thus screwing up a block of if then conditions in my code, which is why I had no choice
I currently automate almost everything from job submission to data extraction, and later on, with the help of the machine learning group in my uni, we might be able to automate a GUI library search thingy
I can do all tasks related to my work without leaving the text editor (of course, such text editor is emacs). The only inconvenience is that some websites don't render in a optimal way (but most of the work-related ones do)
Hi to all. Does anyone know where I could write matlab code online(for free)? Apparently another one of my institutions great inspirations is to have a matlab-oriented computational physics course without having matlab on the universities pcs. Thanks.
@Kaumudi.H Hacky way: 1st thing is that $\psi\left(x, y, z, t\right) = \psi\left(x, y, t\right)$, so no propagation in $z$-direction. Now, in '$1$ unit' of time, it travels $\frac{\sqrt{3}}{2}$ units in the $y$-direction and $\frac{1}{2}$ units in the $x$-direction. Use this to form a triangle and you'll get the answer with simple trig :)
@Kaumudi.H Ah, it was okayish. It was mostly memory based. Each small question was of 10-15 marks. No idea what they expect me to write for questions like "Describe acoustic and optic phonons" for 15 marks!! I only wrote two small paragraphs...meh. I don't like this subject much :P (physical electronics). Hope to do better in the upcoming tests so that there isn't a huge effect on the gpa.
@Blue Ok, thanks. I found a way by connecting to the servers of the university( the program isn't installed on the pcs on the computer room, but if I connect to the server of the university- which means running remotely another environment, i found an older version of matlab). But thanks again.
@user685252 No; I am saying that it has no bearing on how good you actually are at the subject - it has no bearing on how good you are at applying knowledge; it doesn't test problem solving skills; it doesn't take into account that, if I'm sitting in the office having forgotten the difference between different types of matrix decomposition or something, I can just search the internet (or a textbook), so it doesn't say how good someone is at research in that subject;
it doesn't test how good you are at deriving anything - someone can write down a definition without any understanding, while someone who can derive it, but has forgotten it probably won't have time in an exam situation. In short, testing memory is not the same as testing understanding
If you really want to test someone's understanding, give them a few problems in that area that they've never seen before and give them a reasonable amount of time to do it, with access to textbooks etc.
|
A local system is a sheaf of finite dimensional vector spaces that is locally isomorphic to the constant sheaf $k^n$. If $\gamma: [0,1] \to X$ is a continuous path in $X$, $\gamma^{-1}(L)$ is again local system on $[0,1]$ but one shows that any locally constant sheaf on $[0,1]$ is actually constant. So the fibers at 0 and 1 are canonically identified. This means that we have a map $$ \gamma_{*} : L_{\gamma(0)} \to L_{\gamma(1)} $$
Moreover this is
linear: $\gamma_* (v + \lambda w) = \gamma_* (v) + \lambda \gamma_* (w)$ invariant by homotopy: if $\gamma \sim \gamma'$, $\gamma_*v = \gamma'_*v$. compatible with composition of homotopy classes of paths: $(\gamma')_*(\gamma_*x) = (\gamma'\gamma)_*x$.
So to any local system $L$ corresponds a representation $\pi_1(X,x) \to GL(L_x)$ of the fundamental group at $x$. This is the monodromy representation. You can rebuild $L$ from it: this is the sheaf of sections of $(\tilde{X}\times V)/\pi_1(X,x) \to X$ where $\tilde{X}$ is the universal covering of $X$. We have sketched:
Theorem: If $X$ is connected, the functor "fiber at $x$" induces an equivalence of categories $LS(X) \to Rep(\pi_1(X,x))$.
This is all very abstract so let us look at an example.
Consider $\mathcal{K}$, the trivial rank 2 vector bundle $\cal{O}_{\mathbb{C}^\times}^2$ and connection $$ \nabla \begin{pmatrix} f_1 \cr f_2 \end{pmatrix} = d\begin{pmatrix} f_1 \cr f_2 \end{pmatrix} - \begin{pmatrix}0 & 0 \cr 1 &0 \end{pmatrix} \begin{pmatrix} f_1 \cr f_2 \end{pmatrix} \frac{dz}{z} = \begin{pmatrix} df_1 \cr df_2 - f_1 \frac{dz}{z} \end{pmatrix} $$
Horizontal sections are the solutions of $\nabla f = 0$. This is a system of two first order linear differential equations. On any simply connected $U$ we can chose a determination of the logarithm and the solution can be written $$ \begin{pmatrix} f_1 \cr f_2 \end{pmatrix} = \begin{pmatrix} A \cr A \log z + B \end{pmatrix}$$where $\log$ is any determination of the logarithm function. This means that the sections $$ e_1 = \begin{pmatrix} 1 \cr \log z \end{pmatrix} \qquad e_0 = \begin{pmatrix} 0 \cr 1\end{pmatrix} $$trivialize the sheaf of solutions on $U$. Covering $\mathbb{C}^\times$ by simply connected open sets we see that the solutions form a local system $L$.
When we turn once around 0 following the orientation, our determination $\log z$ changes to $\log z + 2\pi i$. So if $\gamma(t) = xe^{2\pi i t}$
$$ v = \begin{pmatrix} A \cr A\log x + B \end{pmatrix} \mapsto \begin{pmatrix} A \cr A(\log x + 2\pi i) + B \end{pmatrix} = \gamma_*(v) $$The monodromy representation is $$ \pi_1(\mathbb{C}^\times,x) = \mathbb{Z} \to GL_2(\mathbb{C}) \qquad 1 \mapsto \begin{pmatrix} 1 & 0 \cr 2\pi i & 1 \end{pmatrix} $$It tells you everything there is to know about our differential equation (because it has regular singularities). For example, the space of global solutions is identified with the space of invariant of the representation: $$ \Gamma(\mathbb{C}^\times,L) = Hom(k_{\mathbb{C}^\times},L) = Hom_{\pi_1(X,x)}(k,L_x) = L_x^{\pi_1(X,x)}$$This is the 1 dimensional space generated by $e_0$.
Another good example to work out is the equation $df = \alpha f\frac{dz}{z}$ (the monodromy can be quite different depending on $\alpha$).
Pierre Schapira's webpage has notes of a course on sheaves and algebraic topology focussing on local systems. Claire Voisin's book on Hodge theory is a good reference for variations of Hodge structures.
|
Hello,Is the Berry connection compatible with the metric(covariant derivative of metric vanishes) in the same way that the Levi-Civita connection is compatible with the metric(as in Riemannanian Geometry and General Relativity)?Also, does it have torsion? It must either have torsion or not be...
Hello!I have learned Riemannian Geometry, so the only connection I have ever worked with is the Levi-Civita connection(covariant derivative of metric tensor vanishes and the Chrystoffel symbols are symmetric).When performing a parallel transport with the L-C connection, angles and lengths are...
I’m hoping to clear up some confusion I have over what the Lie derivative of a metric determinant is.Consider a 4-dimensional (pseudo-) Riemannian manifold, with metric ##g_{\mu\nu}##. The determinant of this metric is given by ##g:=\text{det}(g_{\mu\nu})##. Given this, now consider the...
Hello!I was thinking about the Riemann curvature tensor(and the torsion tensor) and the way they are defined and it seems to me that they just need a connection(not Levi-Civita) to be defined. They don't need a metric. So, in reality, we can talk about the Riemann curvature tensor of smooth...
Hi!With the re-release of the textbook "Gravitation" by Misner, Thorne and Wheeler, I was wondering if it is worth buying and if it's outdated.Upon checking the older version at the library, I found that the explanations and visualization techniques in the sections on differential(Riemannian)...
I am taking my first graduate math course and I am not really familiar with the thought process. My professor told us to think about how to prove that the differential map (pushforward) is well-defined.The map$$f:M\rightarrow N$$ is a smooth map, where ##M, N## are two smooth manifolds. If...
Source:Basically the video talk about how moving from A to A'(which is basically A) in an anticlockwise manner will give a vector that is different from when the vector is originally in A in curved space.$$[(v_C-v_D)-(v_B-v_A)]$$ will equal zero in flat space...
I do not get the conceptual difference between Riemann and Ricci tensors. It's obvious for me that Riemann have more information that Ricci, but what information?The Riemann tensor contains all the informations about your space.Riemann tensor appears when you compare the change of the sabe...
I have found the following entry on his blog by Terence Tao about embeddings of compact manifolds into Euclidean space (Whitney, Nash). It contains the theorems and (sketches of) proofs. Since it is rather short some of you might be interested in.
Hi friends,I'm learning Riemannian geometry. I'm in trouble with understanding the meaning of ##g^{jk}\Gamma^{i}{}_{jk}##. I know it is a contracting relation on the Christoffel symbols and one can show that ##g^{jk}\Gamma^i{}_{jk}=\frac{-1}{\sqrt{g}}\partial_j(\sqrt{g}g^{ij})## using the...
I'm currently working through chapter 7 on Riemannian geometry in Nakahara's book "Geometry, topology & physics" and I'm having a bit of trouble reproducing his calculation for the metric compatibility in a non-coordinate basis, using the Ricci rotation coefficients...
Hi,Want to know (i) what does Riemannian metric tensor and Christoffel symbols on R2 mean? (ii) How does metric tensor and Christoffel symbols look like on R2? It would be great with an example as I am new to this Differential Geometry.
How does one derive the general form of the Riemann tensor components when it is defined with respect to the Levi-Civita connection?I assumed it was just a "plug-in and play" situation, however I end up with extra terms that don't agree with the form I've looked up in a book. In a general...
|
\( \newcommand{\norm}[1]{\left \lVert #1 \right \rVert} \)
\( \newcommand{\Real}{\mathbb{R}}\)
Hello! So this semester has been a fairly busy one for me and so I have not made much time to get anything new written.. until now!
Lately I’ve been having some real fun with optimization, especially convex optimization and some duality, but I recently got posed an interesting problem of bounding the error between an iterate and the local minimum for a quadratic form when using an approximate gradient instead of an exact one. I thought this was a fairly fun problem to investigate and thought I would share my proof and some numerical results! So let’s get to it..
First, let us take a look at the recursive gradient descent approach in question. Consider the steepest descent method with bounded error:
\begin{align*}
x_{k+1} &= x_k – s \left( \nabla f(x_k) + \epsilon_k\right) \end{align*}
where $s$ is a positive constant stepsize, $\epsilon_k$ is an error term satisfying $\norm{\epsilon_k} \leq \delta$ for all $k$, and $f$ is the positive definite quadratic form defined as
\begin{align*}
f(x) = \frac{1}{2} (x – x^*)^T Q (x – x^*) \end{align*}
Let $q = \max \lbrace|1 – s \lambda_{min}(Q)|,|1 – s \lambda_{max}(Q)| \rbrace$, and assume that $q < 1$. Using the above gradient descent approach, I will show that for all $k$, we can bound the distance between the $k^{th}$ iterate and a local optima by the following: \begin{align*} \norm{x_k - x^*} \leq \frac{s \delta}{1 - q} + q^k \norm{x_0 - x^*} \end{align*} where $x_0$ is the starting point for the iterate sequence and $x^*$ is the local optima.
Lemma 1
Given a value $0 \leq c < 1$ and that \begin{align*} \norm{x_{k+1} - x^*} \leq s \delta + c \norm{x_k - x^*} \end{align*} we can find a bound for $\norm{x_k - x^*}$ to be \begin{align*} \norm{x_{k} - x^*} \leq \frac{s \delta}{1 - c} + c^k \norm{x_0 - x^*} \end{align*}
Proof
\begin{align*}
\norm{ x_{k} – x^* } &\leq s \delta + c \norm{ x_{k-1} – x^* } \\ &\leq \left(1 + c\right)s \delta + c^2 \norm{ x_{k-2} – x^* } \\ &\;\;\vdots \\ &\leq \left(\sum_{i=0}^{k} c^i\right) s \delta + c^{k} \norm{ x_{0} – x^* } \\ &\leq \left(\sum_{i=0}^{\infty} c^i\right) s \delta + c^{k} \norm{ x_{0} – x^* } \\ &= \frac{s \delta}{1-c} + c^{k} \norm{ x_{0} – x^* } \\ \end{align*} Lemma 2
For some symmetric, positive definite matrix $A$ and positive scalar $s$, the following is true:
\begin{align*}
\norm{I – s A} &\leq \max \lbrace |1 – s \lambda_{min}(A)|, |1 – s \lambda_{max}(A)|\rbrace \end{align*} Proof
Recall that some positive definite matrix $A = U^T \Lambda U \in \Real^{n \times n}$ where $U$ is a unitary matrix of eigenvectors and $\Lambda$ is a diagonal matrix with positive eigenvalues. Recall as well that for a matrix 2-norm, $\norm{B} = \sqrt{\lambda_{max}(B^T B)}$ for some matrix $B$. With that, we can proceed with the proof.
\begin{align*}
\norm{ I – s A } &= \norm{U^T U – s U^T \Lambda U} \\ &= \norm{U^T \left(I – s \Lambda \right)U} \\ &\leq \norm{U^T} \norm{I – s \Lambda} \norm{U} \\ &= \norm{I – s \Lambda} \\ &= \sqrt{\max \lbrace (1 – s \lambda_1)^2, \cdots, (1 – s \lambda_n)^2\rbrace} \\ &= \max \lbrace |1 – s \lambda_1|, |1 – s \lambda_2|\cdots, |1 – s \lambda_n|\rbrace \\ &= \max \lbrace |1 – s \lambda_{min}(A)|, |1 – s \lambda_{max}(A)|\rbrace \end{align*} Proof of main result
Our goal in this proof is to arrive at the end result by arriving at statements that allow us to benefit from Lemma 1 and Lemma 2. With that said, we can proceed with this proof as follows:
\begin{align*}
\norm{x_{k+1} – x^*} &= \norm{\left(x_k – x^*\right) – s \left(\nabla f(x_k) + \epsilon_k\right)} \\ &= \norm{\left(x_k – x^*\right) – s \left(Q \left(x_k – x^*\right) + \epsilon_k\right)} \\ &= \norm{\left(I – s Q\right)\left(x_k – x^*\right) – s \epsilon_k } \\ &\leq \norm{\left(I – s Q\right)\left(x_k – x^*\right)} + s \norm{\epsilon_k} \\ &\leq \norm{ I – s Q }\norm{ x_k – x^* } + s \delta \\ &\leq \max\lbrace |1 – s \lambda_{max}(Q)|,|1 – s \lambda_{min}(Q)|\rbrace \norm{ x_k – x^* } + s \delta \\ &= q \norm{ x_k – x^* } + s \delta \\ \end{align*}
Since we assume we choose $s$ to be small enough such that $q < 1$, we can use Lemma 1 to further show that \begin{align*} \norm{x_{k+1} - x^*} &\leq q \norm{ x_k - x^* } + s \delta \\ &\leq \frac{s \delta}{1-q} + q^{k+1} \norm{ x_{0} - x^* } \end{align*} Thus showing the result we hope for!
Numerical Results
I thought it could be cool to do a numerical experiment to see how the bound compares to the convergence in practice. To do this experiment, a noise vector $\epsilon$ was added onto the exact gradient of the quadratic form for a random, positive definite $Q$ such that $\left \lVert \epsilon \right \rVert \leq \delta$ for some $\delta$ that is specified. Multiple sequences were run with different starting random seeds and the plot below is a visualization of the convergence results against the bound.
Based on the figure above, it looks like the bound works out nicely! Some observations to note are the following. As $q \rightarrow 1$, the bound term independent of $k$ in the inequality becomes quite large and the convergence of the $q^k$ term to $0$ slows down. This implies that the spectrum of $s Q$ are within a unit ball centered around a value of $1$ and that the extreme values of $s \lambda_{min}$ and $s \lambda_{max}$ are near the boundary of this ball. $q \rightarrow 1$ also means we are approaching a situation where we will diverge as the number of iterations approach infinity, so it makes sense that things would be bounded more and converge more slowly when $q$ is close to $1$.
Conclusion
In any event, we have seen that if we approximate our gradient in a way that is bounded (say using Finite Differences or mini-batch estimates in Machine Learning), it is possible to bound our convergence error and get a clearer idea of what to expect in terms of run-time, long term accuracy, and potentially more! Thus, this is a pretty neat result and something to keep in mind!
|
Maxwell's equations are the set of four equations by James Clerk Maxwell that describe the behavior of both the electric and magnetic fields. Maxwell's equations provided the basis for the unification of electric field and magnetic field, the electromagnetic description of light, and ultimately, Albert Einstein's theory of relativity.
The modern mathematical formulation of Maxwell's equations is due to Oliver Heaviside and Willard Gibbs, who in 1884 reformulated Maxwell's original equations using vector calculus. (Maxwell's 1865 formulation was in terms of 20 equations in 20 variables, he later attempted a quaternion formulation). The change to the vector notation produced a symmetric mathematical representation that reinforced the perception of physical symmetries between the various fields.
In the late 19th century, Maxwell's equations were only thought to express electromagnetism in the rest frame of the Luminiferous aether (the postulated medium for light, whose interpretation was considerably debated). When the Michelson-Morley experiment conducted by Edward Morley and Albert Abraham Michelson produced a null result for the change of the velocity of light due to the Earth's motion through the aether, however, alternative explanations were sought by Lorentz and others. This culminated in Einstein's theory of special relativity, which postulated the absence of any absolute rest frame (or aether) and the invariance of Maxwell's equations in all frames of reference.
The electromagnetic field equations have an intimate link with special relativity: the magnetic field equations can be derived from consideration of the transformation of the electric field equations under relativistic transformations at low velocities. (In relativity, the equations are written in an even more compact, "manifestly covariant" form, in terms of the rank-2 antisymmetric field-strength 4-tensor.)
where <math>{\rho}</math> is the electric charge density (in units of C/m
3), and <math>\mathbf{D}</math> is the electric displacement field[?] (in units of C/m 2) which in a linear material is related to the electric field <math>\mathbf{E}</math> via a material-dependent constant called the permittivity, <math>\epsilon</math>: <math>\mathbf{D} = \epsilon\mathbf{E}</math>. Any material can be treated as linear, as long as the electric field is not extremely strong. The permittivity of free space is referred to as <math>\epsilon_0</math>, resulting in the equation for free space:
where, again, <math>\mathbf{E}</math> is the electric field (in units of V/m), <math>\rho</math> is the charge density, and <math>\epsilon_0</math> (approximately 8.854 pF/m) is the permittivity of free space. In a linear material, however, <math>\epsilon_0</math> would be replaced with <math>\epsilon</math>, where <math>\epsilon = \epsilon_0 \times \epsilon_r</math>, and <math>\epsilon_r</math> is the material's relative dielectric constant.
Equivalent integral form:
where <math>d\mathbf{A}</math> is the area of a differential square on the surface A with an outward facing surface normal defining its direction, <math>Q_\mbox{enclosed}</math> is the charge enclosed by the surface.
Note: the integral form only works if the integral is over a closed surface. Shape and size do not matter. The integral form is also known as Gauss's Law.
This equation corresponds to Coulomb's law for stationary charges.
<math>\mathbf{B}</math> is the magnetic flux density (in units of tesla, T), also called the magnetic induction.
Equivalent integral form:
<math>d\mathbf{A}</math> is the area of a differential square on the surface <math>A</math> with an outward facing surface normal defining its direction.
Note: like the electric field's integral form, this equation only works if the integral is done over a closed surface.
This equation is related to the magnetic field's structure because it states that given any volume element, the net magnitude of the vector components that point outward from the surface must be equal to the net magnitude of the vector components that point inward. Structurally, this means that the magnetic field lines must be closed loops. Another way of putting it is that the field lines cannot originate from somewhere; attempting to follow the lines backwards to their source or forward to their terminus ultimately leads back to the starting position. This implies that there are no magnetic monopoles. If a monopole were to be discovered, this equation would need to be modified to read
where <math>\rho_m</math> would be the density of magnetic monopoles.
Equivalent Integral Form:
Φ
is the magnetic flux through the area A described by the second equation, ε is the electromotive force around the edge of the surface A.
B
Note: this equation only works of the surface A
is not closed because the net magnetic flux through a closed surface will always be zero, as stated by the previous equation. That, and the electromotive force is measured along the edge of the surface; a closed surface has no edge. Some textbooks list the Integral form with an N (representing the number of coils of wire that are around the edge of A) in front of the flux derivative. The N can be taken care of in calculating A (multiple wire coils means multiple surfaces for the flux to go through), and it is an engineering detail so it has been omitted here.
Note the negative sign; it is necessary to maintain conservation of energy. It is so important that it even has its own name, Lenz's Law.
Note: Maxwell's equations apply to a right-handed coordinate system. To apply them unmodified to a left handed system would mean a reversal of polarity of magnetic fields (not inconsistent, but confusingly against convention).
where
H is the magnetic field strength[?] (in units of A/m), related to the magnetic flux B by a constant called the permeability, μ ( B = μ H), and J is the current density, defined by: J = ∫ρ q vdV where v is a vector field called the drift velocity that describes the velocities of that charge carriers which have a density described by the scalar function ρ q.
In free space, the permeability μ is the permeability of free space, μ
0, which is defined to be exactly 4π×10 -7 W/Am. Thus, in free space, the equation becomes:
Equivalent integral form:
s is the edge of the open surface A (any surface with the curve s as its edge will do), and I
encircled is the current encircled by the curve s (the current through any surface is defined by the equation: I through A = ∫ A J·d A).
Note: unless there is a capacitor or some other place where <math>\nabla \cdot \mathbf{J} \ne 0</math>, the second term on the right hand side is generally negligable and ignored. Any time this applies, the integral form is known as Ampere's Law.
In linear media, the macroscopic field strengths
D and H are related to the bare field strengths E and B by
In linear and isotropic media, ε and μ are constants, and Maxwell's equations reduce to
The vacuum is such a medium, and the proportionality constants in the vacuum are denoted by ε
0 and μ 0. If there is no current or electric charge present in the vacuum, we obtain the Maxwell equation's in free space:
This equation has a simple solution in terms of travelling sinusoidal plane waves, with the elecric and magnetic field directions orthogonal to one another and the direction of travel, and with the two fields 90° out of phase, travelling at the speed
Maxwell discovered that this quantity
c is simply the speed of light in vacuum, and thus that light is a form of electromagnetic radiation.
The above equations are all in a unit system called mks (short for meter, kilogram, second; also know as the International System of Units (or SI for short). This is more commonly known as the metric system. In a related unit system, called cgs (short for centimeter, gram, second), the equations take on a more symmetrical form, as follows:
Where
c is the speed of light in a vacuum. The symmetry is more apparent when the electromagnetic field is considered in a vacuum. The equations take on the following, highly symmetric form:
Search Encyclopedia
Featured Article
|
I am working with a product of $n\times n$ matrices $A_1,\ldots,A_k$. Under which conditions can I assume that
$$\|A_1\cdots A_k\|_\infty \leq \|A_1\cdots \hat{A_i}\cdots A_k\|_\infty \|A_i\|_\infty,$$
where $\|\cdot\|_\infty$ denotes the operator norm, and $\hat{A_i}$ denotes the omission of $A_i$.
E.g. if all products of subsets of $\{A_1,\ldots,A_k\}$ are normal, then the above inequality should follow from the submultiplicativity of the operator norm and the fact that $AB$ and $BA$ have the same singular values for normal $A$ and $B$. However, this condition seems rather artifical and I am wondering if something more powerful holds. What if all $A_i$ are normal, self-adjoint, unitary or orthogonal projectors?
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.