
id stringlengths 6 6 | text stringlengths 20 17.2k | title stringclasses 1
value |
|---|---|---|
174148 | class SQLDatabase:
"""SQL Database.
This class provides a wrapper around the SQLAlchemy engine to interact with a SQL
database.
It provides methods to execute SQL commands, insert data into tables, and retrieve
information about the database schema.
It also supports optional features such as in... | |
174154 | """Pydantic output parser."""
import json
from typing import Any, List, Optional, Type
from llama_index.core.output_parsers.base import ChainableOutputParser
from llama_index.core.output_parsers.utils import extract_json_str
from llama_index.core.types import Model
PYDANTIC_FORMAT_TMPL = """
Here's a JSON schema to ... | |
174270 | import logging
from typing import Any, List, Optional, Tuple
from llama_index.core.base.llms.types import (
ChatMessage,
ChatResponse,
ChatResponseAsyncGen,
ChatResponseGen,
MessageRole,
)
from llama_index.core.base.response.schema import (
AsyncStreamingResponse,
StreamingResponse,
)
from ... | |
174279 | from typing import Any, List, Optional
from llama_index.core.base.base_retriever import BaseRetriever
from llama_index.core.base.llms.types import (
ChatMessage,
ChatResponse,
ChatResponseAsyncGen,
ChatResponseGen,
MessageRole,
)
from llama_index.core.base.response.schema import (
StreamingResp... | |
174280 | class ContextChatEngine(BaseChatEngine):
"""
Context Chat Engine.
Uses a retriever to retrieve a context, set the context in the system prompt,
and then uses an LLM to generate a response, for a fluid chat experience.
"""
def __init__(
self,
retriever: BaseRetriever,
ll... | |
174316 | from typing import List, Optional, Sequence
from llama_index.core.base.llms.types import ChatMessage, MessageRole
# Create a prompt that matches ChatML instructions
# <|im_start|>system
# You are Dolphin, a helpful AI assistant.<|im_end|>
# <|im_start|>user
# {prompt}<|im_end|>
# <|im_start|>assistant
B_SYS = "<|im... | |
174368 | "generate_cohere_reranker_finetuning_dataset": "llama_index.finetuning",
"CohereRerankerFinetuneEngine": "llama_index.finetuning",
"MistralAIFinetuneEngine": "llama_index.finetuning",
"BaseFinetuningHandler": "llama_index.finetuning.callbacks",
"OpenAIFineTuningHandler": "llama_index.finetuning.callbacks",
"M... | |
174405 | """Response schema."""
import asyncio
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
from llama_index.core.async_utils import asyncio_run
from llama_index.core.bridge.pydantic import BaseModel
from llama_index.core.schema import NodeWithScore
from llama_index.core.types i... | |
174468 | def test_nl_query_engine_parser(
patch_llm_predictor,
patch_token_text_splitter,
struct_kwargs: Tuple[Dict, Dict],
) -> None:
"""Test the sql response parser."""
index_kwargs, _ = struct_kwargs
docs = [Document(text="user_id:2,foo:bar"), Document(text="user_id:8,foo:hello")]
engine = create_... | |
174545 | from llama_index.core.node_parser.file.json import JSONNodeParser
from llama_index.core.schema import Document
def test_split_empty_text() -> None:
json_splitter = JSONNodeParser()
input_text = Document(text="")
result = json_splitter.get_nodes_from_documents([input_text])
assert result == []
def te... | |
174547 | def test_complex_md() -> None:
test_data = Document(
text="""
# Using LLMs
## Concept
Picking the proper Large Language Model (LLM) is one of the first steps you need to consider when building any LLM application over your data.
LLMs are a core component of LlamaIndex. They can be used as standalone modu... | |
174659 | """Test pydantic output parser."""
import pytest
from llama_index.core.bridge.pydantic import BaseModel
from llama_index.core.output_parsers.pydantic import PydanticOutputParser
class AttrDict(BaseModel):
test_attr: str
foo: int
class TestModel(BaseModel):
__test__ = False
title: str
attr_dict:... | |
174805 | "generate_cohere_reranker_finetuning_dataset": "llama_index.finetuning",
"CohereRerankerFinetuneEngine": "llama_index.finetuning",
"MistralAIFinetuneEngine": "llama_index.finetuning",
"BaseFinetuningHandler": "llama_index.finetuning.callbacks",
"OpenAIFineTuningHandler": "llama_index.finetuning.callbacks",
"M... | |
174841 | # How to work with large language models
## How large language models work
[Large language models][Large language models Blog Post] are functions that map text to text. Given an input string of text, a large language model predicts the text that should come next.
The magic of large language models is that by being t... | |
174842 | # Text comparison examples
The [OpenAI API embeddings endpoint](https://beta.openai.com/docs/guides/embeddings) can be used to measure relatedness or similarity between pieces of text.
By leveraging GPT-3's understanding of text, these embeddings [achieved state-of-the-art results](https://arxiv.org/abs/2201.10005) o... | |
174848 | # Techniques to improve reliability
When GPT-3 fails on a task, what should you do?
- Search for a better prompt that elicits more reliable answers?
- Invest in thousands of examples to fine-tune a custom model?
- Assume the model is incapable of the task, and move on?
There is no simple answer - it depends. However... | |
174983 | {
"cells": [
{
"cell_type": "markdown",
"id": "dd290eb8-ad4f-461d-b5c5-64c22fc9cc24",
"metadata": {},
"source": [
"# Using Tool Required for Customer Service\n",
"\n",
"The `ChatCompletion` endpoint now includes the ability to specify whether a tool **must** be called every time, by adding `t... | |
174995 | "source": [
"embeddings_model = \"text-embedding-3-large\"\n",
"\n",
"def get_embeddings(text):\n",
" embeddings = client.embeddings.create(\n",
" model=\"text-embedding-3-small\",\n",
" input=text,\n",
" encoding_format=\"float\"\n",
" )\n",
" return embeddin... | |
175073 | {
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# How to format inputs to ChatGPT models\n",
"\n",
"ChatGPT is powered by `gpt-3.5-turbo` and `gpt-4`, OpenAI's most advanced models.\n",
"\n",
"You can build your own applications with `gpt-3.5-tu... | |
175117 | "language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.5"
},
"vscode": {
"interpreter": {
"hash": "365536d... | |
175230 | {
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Embedding texts that are longer than the model's maximum context length\n",
"\n",
"OpenAI's embedding models cannot embed text that exceeds a maximum length. The maximum length varies by model, and is me... | |
175234 | @dataclass
class APIRequest:
"""Stores an API request's inputs, outputs, and other metadata. Contains a method to make an API call."""
task_id: int
request_json: dict
token_consumption: int
attempts_left: int
metadata: dict
result: list = field(default_factory=list)
async def call_api(... | |
175243 | " # Parse out the action and action input\n",
" regex = r\"Action: (.*?)[\\n]*Action Input:[\\s]*(.*)\"\n",
" match = re.search(regex, llm_output, re.DOTALL)\n",
" \n",
" # If it can't parse the output it raises an error\n",
" # You can add your own logic he... | |
175248 | system_message=system_message, user_request=user_request\n"," )\n"," return response\n","\n","\n","responses = await asyncio.gather(*[get_response(i) for i in range(5)])\n","average_distance = calculate_average_distance(responses)\n","print(f\"The average similarity between responses is: {average_distance}\")"]},... | |
175283 | {
"cells": [
{
"cell_type": "markdown",
"id": "30995a82",
"metadata": {},
"source": [
"# How to build a tool-using agent with LangChain\n",
"\n",
"This notebook takes you through how to use LangChain to augment an OpenAI model with access to external tools. In particular, you'll be able to cr... | |
175289 | "Title: sysk_with_transcripts_Can you live without a bank account.json; Yeah. 7% of Americans do not have bank accounts. About 9 million people last year in 2015 did not have bank accounts. 9 million people is a lot of people. No, it really is. And apparently that's household sorry, not people. Yeah, right. You're tha... | |
175319 | # Creates embedding vector from user query\n"," embedded_query = openai.Embedding.create(\n"," | |
175332 | {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Using Hologres as a vector database for OpenAI embeddings\n",
"\n",
"This notebook guides you step by step on using Hologres as a vector database for OpenAI embeddings.\n",
"\n",
"This notebook presents an end-to-end ... | |
175343 | {
"cells": [
{
"cell_type": "markdown",
"id": "cb1537e6",
"metadata": {},
"source": [
"# Using Chroma for Embeddings Search\n",
"\n",
"This notebook takes you through a simple flow to download some data, embed it, and then index and search it using a selection of vector databases. This is a c... | |
175351 | {
"cells": [
{
"cell_type": "markdown",
"id": "cb1537e6",
"metadata": {},
"source": [
"# Using Redis for Embeddings Search\n",
"\n",
"This notebook takes you through a simple flow to download some data, embed it, and then index and search it using a selection of vector databases. This is a co... | |
175367 | "from redis.commands.search.field import (\n",
" TextField,\n",
" VectorField\n",
")\n",
"\n",
"REDIS_HOST = \"localhost\"\n",
"REDIS_PORT = 6379\n",
"REDIS_PASSWORD = \"\" # default for passwordless Redis\n",
"\n",
"# Connect to Redis\n",
"redis_client = redis.Redis(\n",
... | |
175406 | " SearchableField(name=\"text\", type=SearchFieldDataType.String),\n",
" SearchField(\n",
" name=\"title_vector\",\n",
" type=SearchFieldDataType.Collection(SearchFieldDataType.Single),\n",
" vector_search_dimensions=1536,\n",
... | |
175412 | "1. **MongoDB Atlas cluster**: To create a forever free MongoDB Atlas cluster, first, you need to create a MongoDB Atlas account if you don't already have one. Visit the [MongoDB Atlas website](https://www.mongodb.com/atlas/database) and click on “Register.” Visit the [MongoDB Atlas](https://account.mongodb.com/accou... | |
175413 | "Now head over to [Atlas UI](cloud.mongodb.com) and create an Atlas Vector Search index using the steps descibed [here](https://www.mongodb.com/docs/atlas/atlas-vector-search/vector-search-tutorial/#create-the-atlas-vector-search-index). The 'dimensions' field with value 1536, corresponds to openAI text-embedding-ada0... | |
175414 | # MongoDB Atlas Vector Search
[Atlas Vector Search](https://www.mongodb.com/products/platform/atlas-vector-search) is a fully managed service that simplifies the process of effectively indexing high-dimensional vector data within MongoDB and being able to perform fast vector similarity searches. With Atlas Vector Sea... | |
175416 | # Semantic search using Supabase Vector
The purpose of this guide is to demonstrate how to store OpenAI embeddings in [Supabase Vector](https://supabase.com/docs/guides/ai) (Postgres + pgvector) for the purposes of semantic search.
[Supabase](https://supabase.com/docs) is an open-source Firebase alternative built on ... | |
175417 | ```js
const supabaseUrl = Deno.env.get("SUPABASE_URL");
const supabaseServiceRoleKey = Deno.env.get("SUPABASE_SERVICE_ROLE_KEY");
```
Next let's instantiate our `supabase` client:
```js
const supabase = createClient(supabaseUrl, supabaseServiceRoleKey, {
auth: { persistSession: false },
});
```
From here we use th... | |
175420 | ".rst .pdf Welcome to LangChain Contents Getting Started Modules Use Cases Reference Docs LangChain Ecosystem Additional Resources Welcome to LangChain# Large language models (LLMs) are emerging as a transformative technology, enabling developers to build applications that they previously could not. But using these LLM... | |
175421 | " 'text': '.ipynb .pdf Entity Memory Contents Using in a chain Inspecting the memory store Entity Memory# This notebook shows how to work with a memory module that remembers things about specific entities. It extracts information on entities (using LLMs) and builds up its knowledge about that entity over time (also usi... | |
175425 | "text/plain": [
"(1536, 1536)"
]
},
"execution_count": 69,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"len(res['data'][0]['embedding']), len(res['data'][1]['embedding'])"
]
},
{
"attac... | |
175426 | "query = \"how do I use the LLMChain in LangChain?\"\n",
"\n",
"res = openai.Embedding.create(\n",
" input=[query],\n",
" engine=embed_model\n",
")\n",
"\n",
"# retrieve from Pinecone\n",
"xq = res['data'][0]['embedding']\n",
"\n",
"#... | |
175428 | ".ipynb .pdf Getting Started Contents Why do we need chains? Query an LLM with the LLMChain Combine chains with the SequentialChain Create a custom chain with the Chain class Getting Started# In this tutorial, we will learn about creating simple chains in LangChain. We will learn how to create a chain, add components t... | |
175429 | "I don't know."
],
"text/plain": [
"<IPython.core.display.Markdown object>"
]
},
"metadata": {},
"output_type": "display_data"
}
],
"source": [
"res = openai.ChatCompletion.create(\n",
" model=\"gpt-4\... | |
175435 | "4 [0.021524671465158463, 0.018522677943110466, -... 4 "
]
},
"execution_count": 3,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"article_df.head()"
]
},
{
"cell_type": "code",
"execution_count": 4,
"id": "960b82af",
"metadata": {... | |
175444 | # Pinecone Vector Database
[Vector search](https://www.pinecone.io/learn/vector-search-basics/) is an innovative technology that enables developers and engineers to efficiently store, search, and recommend information by representing complex data as mathematical vectors. By comparing the similarities between these vec... | |
175479 | {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Question Answering with Langchain, Qdrant and OpenAI\n",
"\n",
"This notebook presents how to implement a Question Answering system with Langchain, Qdrant as a knowledge based and OpenAI embeddings. If you are not familiar wi... | |
175481 | "cell_type": "markdown",
"metadata": {},
"source": [
"At this stage all the possible answers are already stored in Qdrant, so we can define the whole QA chain."
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {
"ExecuteTime": {
"end_time": "2023-03-03T16:17:22.941289Z",... | |
175502 | {
"cells": [
{
"cell_type": "markdown",
"id": "46589cdf-1ab6-4028-b07c-08b75acd98e5",
"metadata": {},
"source": [
"# Philosophy with Vector Embeddings, OpenAI and Cassandra / Astra DB through CQL\n",
"\n",
"### CassIO version"
]
},
{
"cell_type": "markdown",
"id": "b3496d07-f473-... | |
175566 | {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Question Answering with Langchain, Tair and OpenAI\n",
"This notebook presents how to implement a Question Answering system with Langchain, Tair as a knowledge based and OpenAI embeddings. If you are not familiar with Tair, it’s ... | |
175567 | "Requirement already satisfied: urllib3<3,>=1.21.1 in /root/anaconda3/envs/notebook/lib/python3.10/site-packages (from requests>=2.20->openai) (2.0.4)\n",
"Requirement already satisfied: certifi>=2017.4.17 in /root/anaconda3/envs/notebook/lib/python3.10/site-packages (from requests>=2.20->openai) (2023.7.22)\n",
... | |
175569 | "Once the data is put into Tair we can start asking some questions. A question will be automatically vectorized by OpenAI model, and the created vector will be used to find some possibly matching answers in Tair. Once retrieved, the most similar answers will be incorporated into the prompt sent to OpenAI Large Language... | |
175623 | "- QUERY_PARAM: The search parameters to use\n",
"- BATCH_SIZE: How many movies to embed and insert at once"
]
},
{
"cell_type": "code",
"execution_count": 30,
"metadata": {},
"outputs": [],
"source": [
"import openai\n",
"\n",
"HOST = 'localhost'\n",
"PORT = 19530\n",
"COL... | |
175642 | "execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"import random\n",
"\n",
"random.seed(52)\n",
"selected_questions = random.choices(questions, k=5)"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"name": "stdout",
... | |
175662 | {
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Azure chat completion models with your own data (preview)\n",
"\n",
"> Note: There is a newer version of the openai library available. See https://github.com/openai/openai-python/discussions/742\n",
"\n",
"This exampl... | |
175673 | {
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Azure functions example\n",
"\n",
"> Note: There is a newer version of the openai library available. See https://github.com/openai/openai-python/discussions/742\n",
"\n",
"This notebook shows how... | |
175678 | " {\"role\": \"assistant\", \"content\": \"Who's there?\"},\n",
" {\"role\": \"user\", \"content\": \"Orange.\"},\n",
" ],\n",
" temperature=0,\n",
" stream=True\n",
")\n",
"\n",
"for chunk in response:\n",
" if len(chunk.choices) > 0:\n",
" delta = c... | |
175708 | {
"cells": [
{
"cell_type": "markdown",
"source": [
"# How to use GPT-4 Vision with Function Calling \n",
"\n",
"The new GPT-4 Turbo model, available as gpt-4-turbo-2024-04-09 as of April 2024, now enables function calling with vision capabilities, better reasoning and a knowledge cutoff date of De... | |
175772 | " <td>1. Thank the customer and ask for clarification:<br> a. \"Thank you for reaching out! Could you please specify whether you require a Business Associate Agreement (BAA) for using our API or for ChatGPT Enterprise?\"<br><br>2. If the customer requires a BAA for the API, then:<br> a. Inform the customer: \"... | |
175787 | " try:\n",
" result = future.result()\n",
" data.extend(result)\n",
" except Exception as e:\n",
" print(f\"Error processing file: {str(e)}\")\n",
"\n",
"# Write the data to a C... | |
175799 | const { Client } = require('@microsoft/microsoft-graph-client');
const pdfParse = require('pdf-parse');
const { Buffer } = require('buffer');
const path = require('path');
const axios = require('axios');
const qs = require('querystring');
const { OpenAI } = require("openai");
//// --------- ENVIRONMENT CONFIGURATION A... | |
175947 | "text": "RAG\nTechnique\n\nFebruary 2024\n\n\fOverview\n\nRetrieval-Augmented Generation \nenhances the capabilities of language \nmodels by combining them with a \nretrieval system. This allows the model \nto leverage external knowledge sources \nto generate more accurate and \ncontextually relevant responses.\n\nExam... | |
175948 | implementing a \n\ufb02ow where the LLM \ncan ask for \nclari\ufb01cation when \nthere is not enough \ninformation in the \noriginal user query \nto get a result\n(Especially relevant \nwith tool usage)\n\n* GPT-4 can do this for you with the right prompt\n\n12\n\n\fTechnical patterns\nInput processing: NER\n\nWhy use ... | |
175949 | "pages_description": ["Overview\n\nRetrieval-Augmented Generation models enhance the capabilities of language models by combining them with a retrieval system. This allows the model to leverage external knowledge sources to generate more accurate and contextually relevant responses.\n\nExample use cases include providi... | |
175952 | function calling, and more.\nReturns a maximum of 4,096\n\noutput tokens. Learn more.\n\nhttps://platform.openai.com/docs/models/overview\n\n4/10\n\n\f26/02/2024, 17:58\n\nModels - OpenAI API\n\nMODEL\n\nDE S CRIPTION\n\ngpt-3.5-turbo-instruct Similar capabilities as GPT-3\nera models. Compatible with\nlegacy Completio... | |
175960 | # RAG
### Technique
-----
## Overview
Retrieval-Augmented Generation
enhances the capabilities of language
models by combining them with a
retrieval system. This allows the model
to leverage external knowledge sources
to generate more accurate and
contextually relevant responses.
**Example use cases**
- Provide ... | |
175961 | E t t l k t 4 t h &
-----
## Technical patterns
##### Data preparation: chunking ● Overlap:
- Should chunks be independent or overlap one
another?
- If they overlap, by how much?
Size of chunks:
- What is the optimal chunk size for my use case?
- Do I want to include a lot in the context window or
just the... | |
175963 | [Documentation](https://platform.openai.com/docs) [API reference](https://platform.openai.com/docs/api-reference) [Forum](https://community.openai.com/categories) Help
# Models
## Overview
The OpenAI API is powered by a diverse set of models with different capabilities and
price points. You can also make customizati... | |
175964 | MODEL DESCRIPTION
`gpt-3.5-turbo-0125` New Updated GPT 3.5 Turbo
The latest GPT-3.5 Turbo
model with higher accuracy at
responding in requested
formats and a fix for a bug
which caused a text encoding
issue for non-English
language function calls.
Returns a maximum of 4,096
[output tokens. Learn more.](https://openai... | |
175965 | MODEL DESCRIPTION
`babbage-002` Replacement for the GPT-3 ada and
```
babbage base models.
```
`davinci-002` Replacement for the GPT-3 curie and
```
davinci base models.
## How we use your data
```
-----
As of March 1, 2023, data sent to the OpenAI API will not be used to train or improve
[OpenAI ... | |
175970 | Re-writes user query to be a self-contained search query.
```example-chat
SYSTEM: Given the previous conversation, re-write the last user query so it contains
all necessary context.
# Example
History: [{user: "What is your return policy?"},{assistant: "..."}]
User Query: "How long does it cover?"
Response: "How long ... | |
175974 | Fine-tuning is currently available for the following models: `gpt-3.5-turbo-0125` (recommended), `gpt-3.5-turbo-1106`, `gpt-3.5-turbo-0613`, `babbage-002`, `davinci-002`, `gpt-4-0613` (experimental), and `gpt-4o-2024-05-13`.
You can also fine-tune a fine-tuned model which is useful if you acquire additional data and d... | |
175975 | Token limits depend on the model you select. For `gpt-3.5-turbo-0125`, the maximum context length is 16,385 so each training example is also limited to 16,385 tokens. For `gpt-3.5-turbo-0613`, each training example is limited to 4,096 tokens. Examples longer than the default will be truncated to the maximum context len... | |
175987 | You can use the 'create and stream' helpers in the Python and Node SDKs to create a run and stream the response.
<CodeSample
title="Create and Stream a Run"
defaultLanguage="python"
code={{
python: `
from typing_extensions import override
from openai import AssistantEventHandler
# First, we creat... | |
175994 | ## Building an embeddings index
<Image
png="https://cdn.openai.com/API/docs/images/tutorials/web-qa/DALL-E-woman-turning-a-stack-of-papers-into-numbers-pixel-art.png"
webp="https://cdn.openai.com/API/docs/images/tutorials/web-qa/DALL-E-woman-turning-a-stack-of-papers-into-numbers-... | |
175995 | ---
Turning the embeddings into a NumPy array is the first step, which will provide more flexibility in how to use it given the many functions available that operate on NumPy arrays. It will also flatten the dimension to 1-D, which is the required format for many subsequent operations.
```python
import numpy as np
fr... | |
175996 | Error codes
This guide includes an overview on error codes you might see from both the [API](/docs/introduction) and our [official Python library](/docs/libraries/python-library). Each error code mentioned in the overview has a dedicated section with further guidance.
## API errors
| Code ... | |
175997 | This error message indicates that our servers are experiencing high traffic and are unable to process your request at the moment. This could happen for several reasons, such as:
- There is a sudden spike or surge in demand for our services.
- There is scheduled or unscheduled maintenance or update on our servers.
... | |
175998 | An `BadRequestError` (formerly `InvalidRequestError`) indicates that your request was malformed or missing some required parameters, such as a token or an input. This could be due to a typo, a formatting error, or a logic error in your code.
If you encounter an `BadRequestError`, please try the following steps:
- R... | |
176007 | # Models
## Flagship models
## Models overview
The OpenAI API is powered by a diverse set of models with different capabilities and price points. You can also make customizations to our models for your specific use case with [fine-tuning](/docs/guides/fine-tuning).
| Model ... | |
176011 | # Data retrieval with GPT Actions
One of the most common tasks an action in a GPT can perform is data retrieval. An action might:
1. Access an API to retrieve data based on a keyword search
2. Access a relational database to retrieve records based on a structured query
3. Access a vector database to retrieve text chu... | |
176012 | # Production best practices
This guide provides a comprehensive set of best practices to help you transition from prototype to production. Whether you are a seasoned machine learning engineer or a recent enthusiast, this guide should provide you with the tools you need to successfully put the platform to work in a pro... | |
176019 | Embeddings
Learn how to turn text into numbers, unlocking use cases like search.
<Notice
className="mt-2 mb-2"
icon={false}
color={NoticeColor.primary}
body={
New embedding models
text-embedding-3-small and
text-embedding-... | |
176021 | Question_answering_using_embeddings.ipynb
There are many common cases where the model is not trained on data which contains key facts and information you want to make accessible when generating responses to a user query. One way of solving this, as shown below, is to put additional information into the context window ... | |
176022 | User_and_product_embeddings.ipynb
We can obtain a user embedding by averaging over all of their reviews. Similarly, we can obtain a product embedding by averaging over all the reviews about that product. In order to showcase the usefulness of this approach we use a subset of 50k reviews to cover more reviews per user ... | |
176026 | # Text generation models
OpenAI's text generation models (often called generative pre-trained transformers or large language models) have been trained to understand natural language, code, and images. The models provide text outputs in response to their inputs. The text inputs to these models are also referred to as "... | |
176027 | A common way to use Chat Completions is to instruct the model to always return a JSON object that makes sense for your use case, by specifying this in the system message. While this does work in some cases, occasionally the models may generate output that does not parse to valid JSON objects.
To prevent these errors a... | |
176028 | Below is an example function for counting tokens for messages passed to `gpt-3.5-turbo-0613`.
The exact way that messages are converted into tokens may change from model to model. So when future model versions are released, the answers returned by this function may be only approximate.
```python
def num_tokens_from_m... | |
176029 | To illustrate how suffix context effects generated text, consider the prompt, “Today I decided to make a big change.” There’s many ways one could imagine completing the sentence. But if we now supply the ending of the story: “I’ve gotten many compliments on my new hair!”, the intended completion becomes clear.
> I wen... | |
176040 | # Optimizing LLMs for accuracy
### How to maximize correctness and consistent behavior when working with LLMs
Optimizing LLMs is hard.
We've worked with many developers across both start-ups and enterprises, and the reason optimization is hard consistently boils down to these reasons:
- Knowing **how to start** o... | |
176042 | We’ve seen that prompt engineering is a great place to start, and that with the right tuning methods we can push the performance pretty far.
However, the biggest issue with prompt engineering is that it often doesn’t scale - we either need dynamic context to be fed to allow the model to deal with a wider range of prob... | |
176043 | 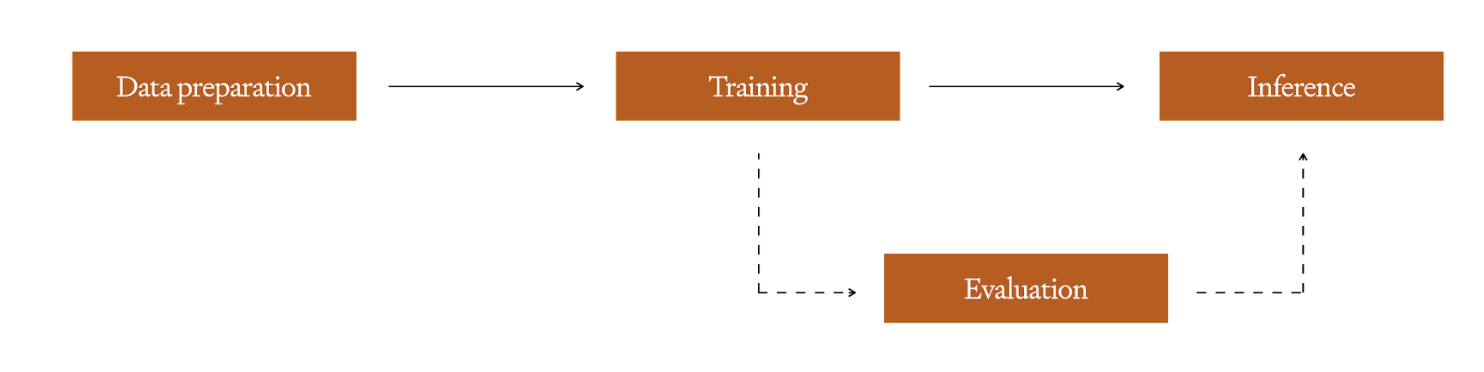
Once you have this clean set, you can train a fine-tuned model by performing a **training** run - depending on the platform or framework you’re using for training you may have hyperparamet... | |
176044 | We’ll continue building on the Icelandic correction example we used above. We’ll test out the following approaches:
- Our original hypothesis was that this was a behavior optimization problem, so our first step will be to fine-tune a model. We’ll try both gpt-3.5-turbo and gpt-4 here.
- We’ll also try RAG - in thi... | |
176050 | Prompt engineering
This guide shares strategies and tactics for getting better results from large language models (sometimes referred to as GPT models) like GPT-4o. The methods described here can sometimes be deployed in combination for greater effect. We encourage experimentation to find the methods that work best fo... | |
176051 | ## Six strategies for getting better results
### Write clear instructions
These models can’t read your mind. If outputs are too long, ask for brief replies. If outputs are too simple, ask for expert-level writing. If you dislike the format, demonstrate the format you’d like to see. The less the model has to guess at ... | |
176052 | Step 1 - The user will provide you with text in triple quotes. Summarize this text in one sentence with a prefix that says "Summary: ".
Step 2 - Translate the summary from Step 1 into Spanish, with a prefix that says "Translation: ".
USER: """insert text here"""
```
#### Tactic: Provide examples
Providing general i... | |
176068 | Python is a popular programming language that is commonly used for data applications, web development, and many other programming tasks due to its ease of use. OpenAI provides a custom [Python library](https://github.com/openai/openai-python) which makes working with the OpenAI API in Python simple and efficient.
## S... | |
176240 | # Structured Outputs Parsing Helpers
The OpenAI API supports extracting JSON from the model with the `response_format` request param, for more details on the API, see [this guide](https://platform.openai.com/docs/guides/structured-outputs).
The SDK provides a `client.beta.chat.completions.parse()` method which is a w... | |
176244 | # OpenAI Python API library
[](https://pypi.org/project/openai/)
The OpenAI Python library provides convenient access to the OpenAI REST API from any Python 3.7+
application. The library includes type definitions for all request params and response fields,
and ... | |
176245 | ## Pagination
List methods in the OpenAI API are paginated.
This library provides auto-paginating iterators with each list response, so you do not have to request successive pages manually:
```python
from openai import OpenAI
client = OpenAI()
all_jobs = []
# Automatically fetches more pages as needed.
for job in ... | |
176246 | ## Advanced
### Logging
We use the standard library [`logging`](https://docs.python.org/3/library/logging.html) module.
You can enable logging by setting the environment variable `OPENAI_LOG` to `debug`.
```shell
$ export OPENAI_LOG=debug
```
### How to tell whether `None` means `null` or missing
In an API respon... |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.