
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
miguelgrinberg/Flask-SocketIO | flask | 751 | Fetch and display real time data on to screen using Flask-SocketIO | Below is my app.py
```
#!/usr/bin/env python
from threading import Lock
from subprocess import Popen, PIPE
import flask
import subprocess
from flask import Flask, render_template, session, request
from flask_socketio import SocketIO, emit, join_room, leave_room, \
close_room, rooms, disconnect
import t... | closed | 2018-07-26T10:02:10Z | 2019-01-18T20:47:15Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/751 | [
"question"
] | pavansai1 | 2 |
JaidedAI/EasyOCR | pytorch | 325 | difference between farsi and arabic in digit 5 | Hi
There is a difference between Farsi "۵" and Arabic "٥" and this issue make problem in Farsi number five detection.
How can I solve this problem?
Thanks | closed | 2020-12-06T13:02:00Z | 2024-05-24T17:11:24Z | https://github.com/JaidedAI/EasyOCR/issues/325 | [] | be42day | 5 |
modAL-python/modAL | scikit-learn | 19 | Replace np.sum(generator) with np.sum(np.from_iter(generator)) in modAL.utils.combination | ```np.sum(generator)``` throws ```DeprecationWarning```, should replace this with ```np.sum(np.from_iter(generator))```. | closed | 2018-08-29T15:15:53Z | 2018-10-18T16:27:11Z | https://github.com/modAL-python/modAL/issues/19 | [] | cosmic-cortex | 0 |
sktime/sktime | data-science | 7,201 | [ENH] Avoid reloading TimesFM each time in expanding window | **Is your feature request related to a problem? Please describe.**
TimesFM is zero-shot, and there is no fitting. However, in the expanding window strategy, when `ExpandingWindowSplitter` is used, the `_fit()` method is used every time. This results in very slow forecasting and huge memory requirements.
Concretel... | closed | 2024-09-30T11:35:11Z | 2024-10-09T11:06:57Z | https://github.com/sktime/sktime/issues/7201 | [
"module:forecasting",
"enhancement"
] | j-adamczyk | 13 |
raphaelvallat/pingouin | pandas | 178 | Generalized Estimating Equations | Hello,
Pingouin is just what statisticians needed in the Python environment, thanks for your great job. I believe the addition of generalized linear models, specifically Generalized Estimating Equations (GEE), can provide considerable added value. GEE can be used for panel, cluster, or repeated measures data when the ... | closed | 2021-06-01T05:52:52Z | 2021-06-24T23:30:00Z | https://github.com/raphaelvallat/pingouin/issues/178 | [
"feature request :construction:"
] | malekpour-mreza | 2 |
JaidedAI/EasyOCR | pytorch | 327 | Error occurs when i install | error: package directory 'libfuturize\tests' does not exist | closed | 2020-12-10T07:09:44Z | 2022-03-02T09:24:10Z | https://github.com/JaidedAI/EasyOCR/issues/327 | [] | AndyJMR | 3 |
gradio-app/gradio | data-science | 10,408 | How to update button status when there's no Button update function call in version 5 | - [ X ] I have searched to see if a similar issue already exists.
**Is your feature request related to a problem? Please describe.**
Not A problem, but incompatible with previous interface
**Describe the solution you'd like**
More docs support
**Additional context**
In some reason, I have to upgrade my gradio... | closed | 2025-01-22T08:21:21Z | 2025-01-22T08:55:25Z | https://github.com/gradio-app/gradio/issues/10408 | [] | Yb2S3Man | 0 |
falconry/falcon | api | 2,376 | Falcon 3.1.3 installation breaks on python 3.13 | Hi, not sure if this bug was already known, but I did not find anything in the issue tracker.
It seems that installing `falcon==3.1.3` in a python 3.13 virtualenv fails with the error `AttributeError: module 'falcon' has no attribute '__version__'`. The `4.0.0rc1` version installs just fine.
Tried on both linux (... | closed | 2024-10-16T17:47:02Z | 2024-10-18T18:18:20Z | https://github.com/falconry/falcon/issues/2376 | [
"duplicate",
"maintenance",
"question",
"community"
] | DavideCanton | 5 |
vaexio/vaex | data-science | 1,898 | [BUG-REPORT] Too much memory Consumption and not releasing it. | Hey There Vaex Team,
Basically I'm working over some task in which I'm using vaex. So in that I have 3 million rows and 7 columns dataset. I made an function in which I'm doing 3-4 groupby, 2-3 joins & 2-3 timedelta operations. Whenever i uses this function my memory usage jumps from 6.7 Gb to 18 Gb consumption and ... | closed | 2022-02-09T18:55:24Z | 2022-12-15T06:04:48Z | https://github.com/vaexio/vaex/issues/1898 | [] | ashsharma96 | 17 |
inducer/pudb | pytest | 107 | Ability to sort variables by most recently changed | It would be nice if the variables view could be sorted with the most recently changed variables at the top, rather than alphabetically. It's often quite hard to follow the view because things change in different places, and most of the time you don't care about most of the variables in the list.
Something from https:... | open | 2014-02-21T16:46:42Z | 2014-06-07T01:44:58Z | https://github.com/inducer/pudb/issues/107 | [
"enhancement"
] | asmeurer | 0 |
ultralytics/yolov5 | machine-learning | 12,964 | Hello, I have some questions about the YOLOv5 code. Could you please help me answer them? | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
Here are my questions:
In dataloader.py, why does the following occur:
if rect and sh... | closed | 2024-04-26T08:07:36Z | 2024-10-20T19:44:52Z | https://github.com/ultralytics/yolov5/issues/12964 | [
"question",
"Stale"
] | enjoynny | 3 |
lukasmasuch/streamlit-pydantic | streamlit | 43 | Publish version compatible with pydantic 2.x | Fixes for problems with pydantic 2.x have been merged into master.
Please publish the pydantic 2.x-compatible version to pypi (after proper testing).
Thanks!
| open | 2023-09-25T08:40:10Z | 2023-10-04T14:28:02Z | https://github.com/lukasmasuch/streamlit-pydantic/issues/43 | [] | szabi | 1 |
huggingface/datasets | tensorflow | 7,472 | Label casting during `map` process is canceled after the `map` process | ### Describe the bug
When preprocessing a multi-label dataset, I introduced a step to convert int labels to float labels as [BCEWithLogitsLoss](https://pytorch.org/docs/stable/generated/torch.nn.BCEWithLogitsLoss.html) expects float labels and forward function of models in transformers package internally use `BCEWithL... | open | 2025-03-21T07:56:22Z | 2025-03-21T07:58:14Z | https://github.com/huggingface/datasets/issues/7472 | [] | yoshitomo-matsubara | 0 |
aminalaee/sqladmin | fastapi | 715 | After deleting objects, page size is not maintained | ### Checklist
- [X] The bug is reproducible against the latest release or `master`.
- [X] There are no similar issues or pull requests to fix it yet.
### Describe the bug
After deleting entries using the delete action, the page size is not kept as part of the redirect URL
### Steps to reproduce the bug
How to rep... | closed | 2024-02-19T15:33:16Z | 2024-05-13T09:33:49Z | https://github.com/aminalaee/sqladmin/issues/715 | [] | lorg | 0 |
gunthercox/ChatterBot | machine-learning | 1,883 | build dependencies error | closed | 2019-12-09T13:32:49Z | 2020-08-22T19:10:28Z | https://github.com/gunthercox/ChatterBot/issues/1883 | [
"invalid"
] | muhammmadrabi72 | 0 | |
davidsandberg/facenet | computer-vision | 937 | Guideline | Hi there, Is there any guideline for following up this project? | open | 2018-12-20T21:13:00Z | 2018-12-20T21:13:00Z | https://github.com/davidsandberg/facenet/issues/937 | [] | cod3r0k | 0 |
polarsource/polar | fastapi | 5,147 | Getting `500 Internal Server Error` while trying to create a customer | ### Description
So, am trying to create a customer, against a sandboxed organisation `https://sandbox-api.polar.sh/v1/customers/` with the Polar.sh sdk
And I have gotten a very weird behavior, whereby the email I am trying to use create a customer with, does not already exist - when i run `customers.list` it does not... | closed | 2025-03-03T13:10:31Z | 2025-03-07T13:40:13Z | https://github.com/polarsource/polar/issues/5147 | [
"bug"
] | wanjohiryan | 2 |
frappe/frappe | rest-api | 29,883 | chore: Update CODE_OF_CONDUCT.md file | Fixing Grammar on the CODE_OF_CONDUCT.md file.
| open | 2025-01-22T06:07:44Z | 2025-01-22T06:07:44Z | https://github.com/frappe/frappe/issues/29883 | [
"feature-request"
] | chrisfrancis-dev | 0 |
neuml/txtai | nlp | 394 | What are the API endpoints to use semantic graph ? | Glad to know that txtAI brought Semantic graph as it's new feature. By the way how to actually use it if we have other language programmes and we expect it as an API ?.
Are there any API endpoints out like search and extract? Anybody using it ? Please let me know. It will be better(atleast for me) if we get the det... | closed | 2022-12-06T07:59:22Z | 2023-01-24T03:17:04Z | https://github.com/neuml/txtai/issues/394 | [] | akset2X | 6 |
Python3WebSpider/ProxyPool | flask | 90 | 关于可配置项中部分配置的疑问 | 大佬,能问下 setting.py 中的环境配置项 **APP_ENV** 和 **APP_DEBUG** 影响的是哪部分的环境么,我无论修改还是删除那一部分代码对程序都没有任何影响,并且 server 部分永远是 production 环境,如果是控制 flask 环境,不应该是 **FLASK_ENV** 和 **FLASK_DEBUG** 么? | closed | 2020-08-28T11:22:07Z | 2020-09-01T10:45:29Z | https://github.com/Python3WebSpider/ProxyPool/issues/90 | [] | Hui4401 | 3 |
sgl-project/sglang | pytorch | 3,890 | [Bug] --dp-size issue with AMD 8xMI300X and Llama 3.1 70B | ### Checklist
- [x] 1. I have searched related issues but cannot get the expected help.
- [x] 2. The bug has not been fixed in the latest version.
- [x] 3. Please note that if the bug-related issue you submitted lacks corresponding environment info and a minimal reproducible demo, it will be challenging for us to repr... | open | 2025-02-26T12:26:17Z | 2025-03-12T10:24:50Z | https://github.com/sgl-project/sglang/issues/3890 | [] | RonanKMcGovern | 9 |
alpacahq/alpaca-trade-api-python | rest-api | 422 | 422 Client Error: Unprocessable Entity for url | Was trying the demo,
```
from alpaca_trade_api.rest import REST
api = REST()
api.get_bars("AAPL", TimeFrame.Hour, "2021-02-08", "2021-02-08", limit=10, adjustment='raw').df
```
got that error with this message at the bottom
```
alpaca_trade_api.rest.APIError: limit must be large enough to compute an aggregat... | closed | 2021-04-26T20:10:22Z | 2021-07-02T09:17:21Z | https://github.com/alpacahq/alpaca-trade-api-python/issues/422 | [] | edukaded | 2 |
microsoft/nni | machine-learning | 5,072 | ProxylessNAS example accuracy and loss not updated + strategy.Proxyless() support | **Describe the issue**:
I'm running running ProxylessNAS example. The accuracy and loss haven't been updated after 112 epochs.

What is the expected behavior?
I found out that in 2.8 version strategy.P... | open | 2022-08-17T23:45:21Z | 2022-08-19T03:36:23Z | https://github.com/microsoft/nni/issues/5072 | [] | mahdihey | 4 |
keras-team/keras | python | 20,320 | Model Accuracy Degradation by 6x when Switching TF_USE_LEGACY_KERAS from "1" (Keras 2) to "0" (Keras 3) | ### Summary
There is a significant degradation in model performance when changing the `TF_USE_LEGACY_KERAS` environment variable between Keras 2 and Keras 3 in an Encoder-Decoder Network for Neural Machine Translation. With `os.environ["TF_USE_LEGACY_KERAS"] = "1"` (Keras 2), the validation set accuracy is much high... | closed | 2024-10-03T13:08:56Z | 2024-11-06T02:00:48Z | https://github.com/keras-team/keras/issues/20320 | [
"type:support",
"stat:awaiting response from contributor",
"stale"
] | Lw-Cui | 6 |
streamlit/streamlit | data-visualization | 10,863 | Enable "Download as CSV" for large dataframes | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar issues.
- [x] I added a very descriptive title to this issue.
- [x] I have provided sufficient information below to help reproduce this issue.
### Summary
Hi,
"Download as CSV" is not shown for large... | open | 2025-03-20T10:46:55Z | 2025-03-20T17:11:03Z | https://github.com/streamlit/streamlit/issues/10863 | [
"type:enhancement",
"feature:st.dataframe",
"feature:st.data_editor"
] | ghilesmeddour | 6 |
mlfoundations/open_clip | computer-vision | 861 | Training speed slow | Hi,
I found that training speed was slow down if number of gpus is more than 2, is it because more gpus brings larger batch size to compute and gather_all will take up some time?
Best | closed | 2024-04-14T02:41:03Z | 2024-05-09T05:08:56Z | https://github.com/mlfoundations/open_clip/issues/861 | [] | lezhang7 | 1 |
serengil/deepface | deep-learning | 1,058 | Efficiency: multiple overlaying copies of data in face detection | I noticed the process for faces detecion is quite expensive.
For instance when we call `DeepFace.extract_faces` the call stack is
```
DeepFace.extract_faces
detection.extract_faces
DetectorWrapper.detect_faces
[whateverdetector].detect_faces
```
- Face detector returns a `List... | closed | 2024-03-01T16:06:35Z | 2024-03-01T16:13:46Z | https://github.com/serengil/deepface/issues/1058 | [
"question"
] | AndreaLanfranchi | 3 |
deepset-ai/haystack | machine-learning | 9,017 | Add run_async for `AzureOpenAITextEmbedder` | We should be able to reuse the implementation when it is made for `OpenAITextEmbedder` | open | 2025-03-11T11:07:32Z | 2025-03-21T08:59:04Z | https://github.com/deepset-ai/haystack/issues/9017 | [
"Contributions wanted!",
"P2"
] | sjrl | 0 |
proplot-dev/proplot | matplotlib | 58 | transform=ccrs.PlateCarree() now required when making maps | I think after 77f2b71b4927f9aa8b7024bbca53b87239203f2f, this issue arose.
Previously, one could do something like:
```python
import numpy as np
import proplot as plot
% import cartopy.crs as ccrs
data = np.random.rand(180, 360)
lats = np.linspace(-89.5, 89.5, 180)
lons = np.linspace(-179.5, 179.5, 360)
... | closed | 2019-10-25T21:58:15Z | 2019-10-29T21:36:28Z | https://github.com/proplot-dev/proplot/issues/58 | [
"bug"
] | bradyrx | 2 |
Johnserf-Seed/TikTokDownload | api | 352 | [BUG] | 已按照readme运行了Util目录下的Server.py,终端窗口已经启动服务,也按照其他帖子上在终端窗口按了Enter,目前重复报同一错误,请各位老师帮忙看下。
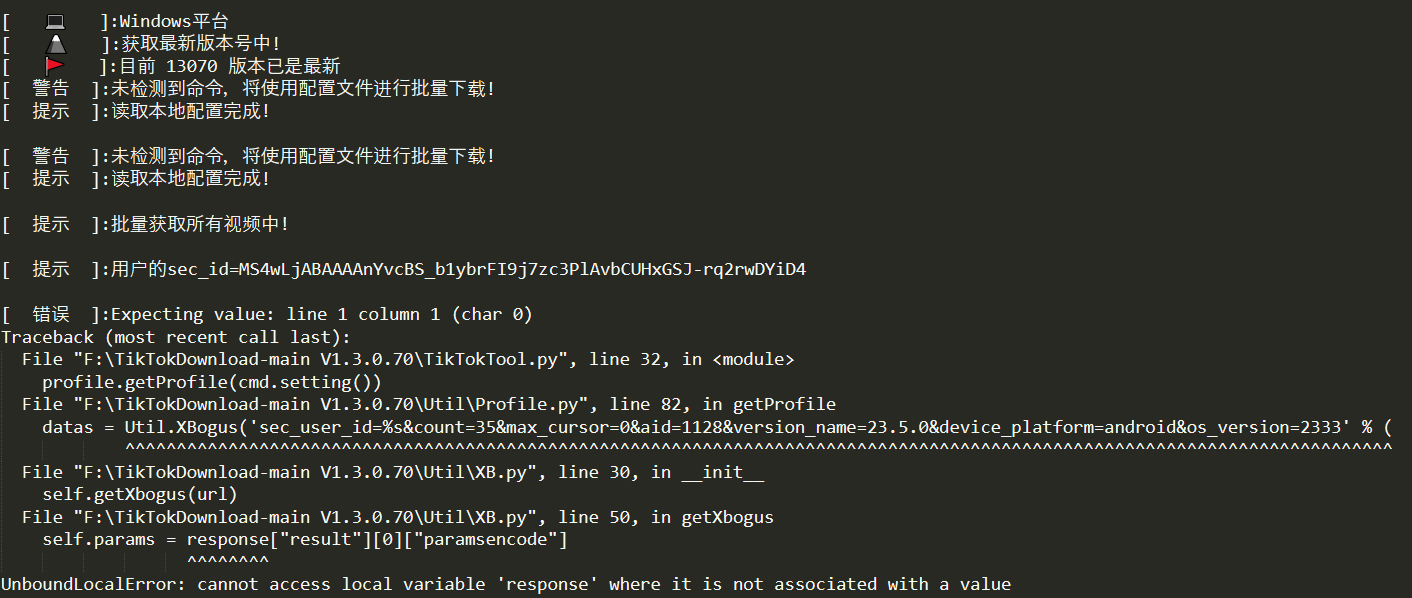

| closed | 2023-03-16T12:27:59Z | 2023-03-24T06:56:58Z | https://github.com/Johnserf-Seed/TikTokDownload/issues/352 | [
"故障(bug)",
"额外求助(help wanted)",
"无效(invalid)"
] | huyin324 | 2 |
wkentaro/labelme | deep-learning | 754 | [BUG]about the json to dataset | the labelme version is 4.5.6
I have encountered such a problem. The first image is marked with three types of objects, and the second picture is marked with two types of objects. After running jiso to dataset, in two label.png, the same kind of object marking color is different, it's my operation problem? What shoul... | closed | 2020-08-17T11:10:25Z | 2020-08-17T11:20:23Z | https://github.com/wkentaro/labelme/issues/754 | [
"issue::bug"
] | bao258456 | 0 |
dagster-io/dagster | data-science | 27,943 | Failing to materialize a single output of a multi asset fails the whole execution | ### What's the issue?
Hello Dagster!
It seems that when a single output of a multi asset fails during HANDLE_OUTPUT, the whole multi asset is aborted.
It seems that there is no way to continue the execution of the multiasset and materialize the other outputs in case one of them fails.
The obvious api would be
```pyt... | open | 2025-02-20T14:18:43Z | 2025-02-20T14:18:43Z | https://github.com/dagster-io/dagster/issues/27943 | [
"type: bug"
] | vladidobro | 0 |
plotly/dash | data-science | 3,050 | investigate ways to reduce bundle size | The dash bundle is approx. 1o Mbyte, which will be a problem for WASM deploys. We should investigate ways to reduce its size.
cf. https://github.com/plotly/plotly.py/issues/4817 | open | 2024-10-22T13:58:41Z | 2024-11-12T14:37:38Z | https://github.com/plotly/dash/issues/3050 | [
"performance",
"feature",
"P2"
] | gvwilson | 1 |
PokeAPI/pokeapi | api | 292 | Pokemon Sound? | I'm developing a Pokedex Alexa Skill (you can found as Unofficial Pokedex), that can be so awesome if I include the sound of each Pokemon, like a 'pika pika' hehehe.
Exists in any place all pokemon sound audio files?
| closed | 2017-06-07T21:28:25Z | 2019-09-19T17:12:47Z | https://github.com/PokeAPI/pokeapi/issues/292 | [] | laurenceHR | 3 |
iMerica/dj-rest-auth | rest-api | 133 | How to override LoginView? | Hello! I need to return a different token serializer response based on the type of user (regular and API user). I think I can do the selection of the serializer by overriding the method `get_response_serializer `in the `LoginView`. My question is: how do I override the LoginView in my code? To override the `LoginSerial... | closed | 2020-08-25T19:47:41Z | 2020-08-25T22:33:41Z | https://github.com/iMerica/dj-rest-auth/issues/133 | [] | fessacchiotto | 3 |
sanic-org/sanic | asyncio | 2,559 | Failure to find registered application | **Describe the bug**
Since version 22.9.0 and I believe https://github.com/sanic-org/sanic/pull/2499, I get errors for "app not found" during startup:
```
return cls._app_registry[name]
KeyError: 'api-server'
...
sanic.exceptions.SanicException: Sanic app name "api-server" not found.
```
**Code snip... | closed | 2022-10-02T15:53:28Z | 2022-10-06T14:49:15Z | https://github.com/sanic-org/sanic/issues/2559 | [] | LiraNuna | 14 |
pytorch/vision | computer-vision | 8,364 | Improved functionality for Oxford IIIT Pet data loader | ### 🚀 The feature
Add the following functionality to the Oxford IIIT Pet data loader
1. Support binary classification of cat vs dog
2. With the segmentation target type, produce trimaps with class/background/don't care regions instead of target/background/don't care when the output is a tensor
3. Support detecti... | open | 2024-04-02T00:35:46Z | 2024-04-19T20:11:21Z | https://github.com/pytorch/vision/issues/8364 | [] | matlabninja | 2 |
exaloop/codon | numpy | 643 | Metaprogramming and AST manipulation from Codon | Is there a way to build AST directly from Codon and resolve it at compile time (essentially metaprogramming / macros) ? | open | 2025-03-21T09:22:47Z | 2025-03-24T19:07:56Z | https://github.com/exaloop/codon/issues/643 | [] | Clonkk | 1 |
huggingface/datasets | numpy | 7,412 | Index Error Invalid Ket is out of bounds for size 0 for code-search-net/code_search_net dataset | ### Describe the bug
I am trying to do model pruning on sentence-transformers/all-mini-L6-v2 for the code-search-net/code_search_net dataset using INCTrainer class
However I am getting below error
```
raise IndexError(f"Invalid Key: {key is our of bounds for size {size}")
IndexError: Invalid key: 1840208 is out of b... | open | 2025-02-18T05:58:33Z | 2025-02-18T06:42:07Z | https://github.com/huggingface/datasets/issues/7412 | [] | harshakhmk | 0 |
matplotlib/matplotlib | data-science | 29,551 | [Bug]: 3D tick label position jitter when rotating the plot view | It seems like there is some rounding going on with 3D tick label positions. When rotating the plot, the position of the labels move around a bit. This may be intentional to line up pixel values, or it may be an artifact, but the result is "jittering" that looks bad.
This becomes most noticeable in animations:
https:/... | open | 2025-01-30T17:38:36Z | 2025-02-02T02:00:14Z | https://github.com/matplotlib/matplotlib/issues/29551 | [
"topic: text",
"backend: agg"
] | scottshambaugh | 7 |
wger-project/wger | django | 1,126 | Rework the user preferences | The current user preferences need to be cleaned up somewhat
- Remove obsolete options
- Birthdate shouldn't be a required field
- Better error messages for birthdate
- Possibly: reimplement the settings page in react | closed | 2022-09-24T14:56:18Z | 2022-10-05T11:46:37Z | https://github.com/wger-project/wger/issues/1126 | [] | rolandgeider | 1 |
mljar/mljar-supervised | scikit-learn | 346 | Add support for `RMSLE` eval_metric | - dont need to do logarithm on the target because log transform is in the metric
- target values need to be positive | closed | 2021-03-23T12:28:36Z | 2021-04-27T08:04:36Z | https://github.com/mljar/mljar-supervised/issues/346 | [] | pplonski | 1 |
tflearn/tflearn | tensorflow | 324 | Multiple Input layers? | I would like to feed the metadata of an image to my network.
How should I get started with implementing a network with two input layers?
Is it possible with tflearn?
Let's say I have an input image with the following shape 3x32x32 and a 10 metadata features.
I define two input layers:
```
# Building network
network ... | open | 2016-09-01T20:53:24Z | 2017-11-10T08:48:41Z | https://github.com/tflearn/tflearn/issues/324 | [] | EliasVansteenkiste | 2 |
Lightning-AI/pytorch-lightning | machine-learning | 20,664 | MLFlowLogger fails to log artifact on Windows | ### Bug description
Error when training with "MLFlowLogger" and with `log_models="all"`, running on Windows:
```
mlflow.exceptions.MlflowException: Invalid artifact path: 'epoch=0-step=43654'. Names may be treated as files in certain cases, and must not resolve to other names when treated as such. This name would res... | open | 2025-03-22T02:00:08Z | 2025-03-24T15:08:05Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20664 | [
"bug",
"needs triage",
"ver: 2.5.x"
] | niander | 1 |
minimaxir/textgenrnn | tensorflow | 144 | TPU Support? | Is there a way to use a tensor processing unit for acceleration? If not, is this feature going to be added in the future? | open | 2019-07-27T21:12:39Z | 2022-07-06T00:19:30Z | https://github.com/minimaxir/textgenrnn/issues/144 | [] | aidanmclaughlin | 2 |
Evil0ctal/Douyin_TikTok_Download_API | api | 14 | tiktok | 国内解析没问题。
tiktok就不成功一个。
web端直接百分百不动了。
api无反应。
不知道,是否又更新了。。。。 | closed | 2022-04-18T09:28:28Z | 2022-04-23T22:08:04Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/14 | [] | pengneal | 8 |
vitalik/django-ninja | django | 702 | [BUG] Get operations to not respect Pydantic config options | **Describe the bug**
When using a Schema for GET parameters (as documented [here](https://django-ninja.rest-framework.com/guides/input/query-params/#using-schema), django-ninja ignores the `extra=Extra.forbid` declaration on the schema. The intended purpose of this configuration option is to cause validation to fail i... | open | 2023-03-14T22:41:35Z | 2023-04-21T22:05:10Z | https://github.com/vitalik/django-ninja/issues/702 | [
"help wanted"
] | scott-8 | 2 |
fbdesignpro/sweetviz | data-visualization | 177 | compare_intra method should limit the name parameter length to 2 | Hi, I was just exploring your package and I found the compare_intra feature pretty interesting. So, just thought it would be better if we can limit the `names` tuple size to 2.
my_report = sv.compare_intra(source_df=df, condition_series=df["Type"] == "SUV", names=['SUV', 'Sedan', 'Sports Car', 'Wagon', 'Minivan']) | open | 2024-08-29T10:40:03Z | 2024-08-29T10:40:03Z | https://github.com/fbdesignpro/sweetviz/issues/177 | [] | Ruchita-debug | 0 |
PaddlePaddle/models | nlp | 4,770 | 文档中链接失效 | 文档地址:https://github.com/PaddlePaddle/models/blob/release/1.8/README.md#%E8%AF%AD%E4%B9%89%E8%A1%A8%E7%A4%BA
链接:

| open | 2020-07-27T04:24:47Z | 2020-07-28T03:30:56Z | https://github.com/PaddlePaddle/models/issues/4770 | [] | howl-anderson | 0 |
jeffknupp/sandman2 | rest-api | 116 | sqlalchemy.exc.ArgumentError | I am getting an error from the get go, thoughts? This is for mssql 2012
```
sandman2ctl mssql+pymssql://USERNAMEHERE:PASSWORDHERE@HOSTHERE/DBNAMEHERE
Traceback (most recent call last):
File "/Users/rustanacecorpuz/.virtualenvs/sandman2/bin/sandman2ctl", line 10, in <module>
sys.exit(main())
File "/Users... | open | 2019-07-23T01:15:55Z | 2019-07-29T22:45:03Z | https://github.com/jeffknupp/sandman2/issues/116 | [
"bug",
"question"
] | rustanacexd | 1 |
jmcnamara/XlsxWriter | pandas | 583 | unable to close(); saves a corrupted workbook | ```python
import xlsxwriter
workbook = xlsxwriter.Workbook('hello.xlsx')
worksheet = workbook.add_worksheet()
worksheet.write('A1', 'Hello world')
workbook.close()
```
PermissionError: [WinError 32] The process cannot access the file because it is being used by another process: 'C:\\Users\\DOUGHE~1.ROS\\... | closed | 2018-11-16T22:27:27Z | 2018-11-26T14:37:14Z | https://github.com/jmcnamara/XlsxWriter/issues/583 | [
"question"
] | jefdough | 20 |
streamlit/streamlit | streamlit | 10,257 | Chart builder | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
It would be nice if Chart Builder feature can be bumped up in the priority list.
### Why?
This feature coul... | open | 2025-01-27T02:37:34Z | 2025-01-27T11:48:05Z | https://github.com/streamlit/streamlit/issues/10257 | [
"type:enhancement",
"feature:charts"
] | dmslowmo | 1 |
ansible/awx | django | 15,001 | Remove Inventory Source for "Template additional groups and hostvars at runtime" option | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | open | 2024-03-15T00:01:44Z | 2024-03-15T00:01:58Z | https://github.com/ansible/awx/issues/15001 | [
"type:bug",
"component:api",
"component:ui",
"needs_triage"
] | tvo318 | 0 |
plotly/dash | dash | 2,606 | [BUG] Duplicate callback outputs error when background callbacks or long_callbacks share a cancel input | **Describe your context**
Currently I am trying to migrate a Dash application from using versions 2.5.1 to a newer one, and as suggested for Dash >2.5.1 I am moving from using ```long_callbacks``` to using the ```dash.callback``` with ```background=True```, along with moving to using ```background_callback_manager```.... | closed | 2023-07-31T19:02:22Z | 2023-08-01T11:57:05Z | https://github.com/plotly/dash/issues/2606 | [] | C-C-Shen | 1 |
huggingface/datasets | numpy | 7,208 | Iterable dataset.filter should not override features | ### Describe the bug
When calling filter on an iterable dataset, the features get set to None
### Steps to reproduce the bug
import numpy as np
import time
from datasets import Dataset, Features, Array3D
```python
features=Features(**{"array0": Array3D((None, 10, 10), dtype="float32"), "array1": Array3D((None,... | closed | 2024-10-09T10:23:45Z | 2024-10-09T16:08:46Z | https://github.com/huggingface/datasets/issues/7208 | [] | alex-hh | 1 |
flasgger/flasgger | rest-api | 524 | Load Default APIKey in UI | Hello,
Is there a way to load by default the Authentication (e.g. in development) so that we don't have to enter it every time we refresh? This is specifically useful in development to avoid having to copy paste the API Key all the time
Thank you
<img width="647" alt="Screen Shot 2022-03-30 at 7 11 41 PM" src=... | open | 2022-03-30T23:13:02Z | 2022-10-27T21:49:54Z | https://github.com/flasgger/flasgger/issues/524 | [] | ftheo | 2 |
piccolo-orm/piccolo | fastapi | 764 | Getting TypeError: 'PostgresTransaction' object does not support the context manager protocol | Getting Type error while running queries in transaction using piccolo.engine
```
from piccolo.engine.finder import engine_finder
engine = engine_finder()
with engine.transaction():
```
```
E TypeError: 'PostgresTransaction' object does not support the context manager protocol
``` | closed | 2023-02-16T10:37:48Z | 2023-02-16T10:46:16Z | https://github.com/piccolo-orm/piccolo/issues/764 | [] | deserve-shubham | 2 |
Textualize/rich | python | 3,144 | [BUG] default syntax highlighting of yaml is unreadable in light terminals | - [x] I've checked [docs](https://rich.readthedocs.io/en/latest/introduction.html) and [closed issues](https://github.com/Textualize/rich/issues?q=is%3Aissue+is%3Aclosed) for possible solutions.
- [x] I can't find my issue in the [FAQ](https://github.com/Textualize/rich/blob/master/FAQ.md).
**Describe the bug**
De... | open | 2023-10-06T18:25:12Z | 2023-10-06T18:26:39Z | https://github.com/Textualize/rich/issues/3144 | [
"Needs triage"
] | xton-stripe | 2 |
globaleaks/globaleaks-whistleblowing-software | sqlalchemy | 3,202 | Make it possible to define language-specific user PublicName |
An user is able to define public name in their profile.
In a multilingual setup, the value is constant across available languages.
Out users would like to be able to define language-specific values for the property.
| open | 2022-03-18T13:36:53Z | 2022-03-26T07:30:25Z | https://github.com/globaleaks/globaleaks-whistleblowing-software/issues/3202 | [] | aetdr | 1 |
csu/quora-api | web-scraping | 23 | Add routes for get_latest_answers | open | 2014-12-24T10:18:38Z | 2014-12-24T10:18:51Z | https://github.com/csu/quora-api/issues/23 | [
"enhancement"
] | csu | 0 | |
pydantic/pydantic-ai | pydantic | 1,037 | Add support for Google's `gemini-2.0-pro-exp-02-05` model | ### Description
It is available from both vertex and google ai studio.
### References

https://cloud.google.com/vertex-ai/generative-ai/docs/learn/models | closed | 2025-03-03T18:05:23Z | 2025-03-04T08:18:18Z | https://github.com/pydantic/pydantic-ai/issues/1037 | [] | barapa | 0 |
jmcarpenter2/swifter | pandas | 106 | Swifter incorrectly comparing results of pandas and dask applies | Wrong comparison of 2 pandas Series
```
swifter==0.302
dask==2.14.0
pandas==1.0.3
```
file **swifter.py:289**
```
self._validate_apply(
tmp_df.equals(meta), error_message="Dask apply sample does not match pandas apply sample."
)
```
It compares 2 Series (in my case):
**meta** = (0, 0.0026893169... | closed | 2020-04-20T14:29:48Z | 2020-04-28T14:26:02Z | https://github.com/jmcarpenter2/swifter/issues/106 | [] | sann05 | 5 |
Gozargah/Marzban | api | 827 | وارد کردن لینک اشتراک در هیدیفای نکست | در اپدیت جدید نسخه dev که همین ۳ ساعت پیش عرضه شده . هنگام وارد کردن لینک اشتراک بر برنامه hiddify next به مشکل میخوره
در اندروید که کلا میپره بیرون از برنامه
در ویندوز این پنجره نمایش داده میشه

این مشکل در نسخه پ... | closed | 2024-02-28T22:35:09Z | 2024-07-01T14:20:14Z | https://github.com/Gozargah/Marzban/issues/827 | [
"Bug"
] | LonUp | 6 |
explosion/spaCy | deep-learning | 13,684 | Memory leak of MorphAnalysis object. | I have encountered a crucial bug, which makes running a continuous tokenization using Japanese tokenizer close to impossible. It's all due so memory leak of MorphAnalysis
## How to reproduce the behaviour
```
import spacy
import tracemalloc
tracemalloc.start()
tokenizer = spacy.blank("ja")
tokenizer.add_pipe... | open | 2024-11-04T18:18:58Z | 2024-12-28T14:07:29Z | https://github.com/explosion/spaCy/issues/13684 | [] | hynky1999 | 3 |
deepfakes/faceswap | deep-learning | 1,154 | deepfakes/faceswap:换脸技术详细教程中文版链接。 | deepfakes/faceswap:换脸技术详细教程[中文版链接](https://zhuanlan.zhihu.com/p/376853800):https://zhuanlan.zhihu.com/p/376853800 | closed | 2021-06-02T07:13:25Z | 2021-06-30T10:12:25Z | https://github.com/deepfakes/faceswap/issues/1154 | [] | wusaifei | 0 |
miguelgrinberg/Flask-SocketIO | flask | 1,619 | Performance issue | I am experiencing a massive delay in establishing a connection and then frequent stalling.
The setup:
- 10 Instances of the server app, only serving websockets using Flask SocketIO
- 3 nginx proxy servers with sticky sessions for all ws traffic
- 1 redis instance (exclusive for pubsub)
The app uses `gevent` in... | closed | 2021-07-04T09:41:33Z | 2021-07-04T10:23:14Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1619 | [] | pistol-whip | 1 |
huggingface/text-generation-inference | nlp | 2,887 | Unclear Metrics list | ### System Info
Latest docker
### Information
- [X] Docker
- [ ] The CLI directly
### Tasks
- [X] An officially supported command
- [ ] My own modifications
### Reproduction
Run tgi and monitor with graphana
### Expected behavior
Can you please provide a more thorough explanation regarding the exported metrics... | open | 2025-01-07T14:58:13Z | 2025-01-08T15:11:39Z | https://github.com/huggingface/text-generation-inference/issues/2887 | [] | vitalyshalumov | 1 |
python-visualization/folium | data-visualization | 1,682 | . | closed | 2022-12-22T17:42:23Z | 2022-12-22T21:15:56Z | https://github.com/python-visualization/folium/issues/1682 | [] | Mukund2900 | 0 | |
ultralytics/ultralytics | pytorch | 19,509 | How to generate a onxx and a nms file ? | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
from ultralytics import YOLO
# Load a model
model = YOLO("maskbest-ptbr.pt"... | open | 2025-03-04T02:33:57Z | 2025-03-04T15:39:46Z | https://github.com/ultralytics/ultralytics/issues/19509 | [
"question",
"exports"
] | xmaxmex | 4 |
zappa/Zappa | django | 1,034 | Add support for python 3.9 | <!--- Provide a general summary of the issue in the Title above -->
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
<!--- Also, please make sure that you are running Zappa _from a virtual environment_ and are using Python 3.6/3.7/3.8 -->
AWS [announ... | closed | 2021-09-04T05:12:01Z | 2021-10-28T09:19:01Z | https://github.com/zappa/Zappa/issues/1034 | [] | tsuga | 3 |
plotly/dash | plotly | 2,598 | [BUG] Missing Dash import in Documentation for Upload in Dash Core Components | **Describe your context**
Viewing the documentation of plotly-dash. And visiting the documentation of the Upload component.
- replace the result of `pip list | grep dash` below
```
dash 0.42.0
dash-core-components 0.47.0
dash-html-components 0.16.0
dash-renderer 0.23.0
dash-table ... | closed | 2023-07-12T16:40:25Z | 2023-07-14T17:24:06Z | https://github.com/plotly/dash/issues/2598 | [] | manavkush | 2 |
marshmallow-code/flask-smorest | rest-api | 447 | typo in doc: Reponse -> Response | In some comments, the Response object is incorrectly called Reponse. | closed | 2023-01-22T17:24:32Z | 2023-01-22T21:38:17Z | https://github.com/marshmallow-code/flask-smorest/issues/447 | [] | ElDavoo | 1 |
miguelgrinberg/Flask-SocketIO | flask | 1,064 | Flask-SocketIO: requests to upgrade to websocket fail in some cases | I am building sample web-based calculator where all clients must immediately see updates other clients make.
Locally it works beautiful, however when deployed to AWS EC2 client requests to upgrade to websocket fail in some cases both in Chrome(77.x) and Firefox(60.x). As I understand it, the server blocks everything t... | closed | 2019-09-19T16:19:43Z | 2019-12-19T16:59:29Z | https://github.com/miguelgrinberg/Flask-SocketIO/issues/1064 | [
"question"
] | DataDrivenEngineer | 3 |
keras-team/keras | tensorflow | 20,548 | ValueError: No model config found in the file at C:\Users\gnanar\.deepface\weights\age_model_weights.h5. | I am trying to convert the age_model_weights.h5 to onnx .But it give me the following error
ValueError: No model config found in the file at C:\Users\gnanar\.deepface\weights\age_model_weights.h5.
This is my code:
import tensorflow as tf
import tf2onnx
import onnx
from tensorflow.keras.models import load_... | closed | 2024-11-26T05:30:25Z | 2025-01-01T02:06:54Z | https://github.com/keras-team/keras/issues/20548 | [
"stat:awaiting response from contributor",
"stale",
"type:Bug"
] | Gnanapriya2000 | 6 |
sloria/TextBlob | nlp | 416 | is Textblob use for text classification? | open | 2023-01-30T08:41:05Z | 2023-01-31T05:55:35Z | https://github.com/sloria/TextBlob/issues/416 | [] | swatijibhkatesj | 1 | |
open-mmlab/mmdetection | pytorch | 11,431 | coco dataset not respecting backend_args | I am using:
- "mmengine==0.10.2"
- "mmcv==2.1.0"
- "mmdet==3.3.0"
and trying to run the rtmdet_tiny_8xb32-300e-coco example.
It works find with the default settings so I tried writing a custom backend to work with AWS S3 instead.
It can read the images fine but I get a file not found error loading the annot... | open | 2024-01-25T14:19:02Z | 2024-01-25T14:19:19Z | https://github.com/open-mmlab/mmdetection/issues/11431 | [] | Data-drone | 0 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,985 | 【solved】How to do can solve Fatal server error: (EE) Server is already active for display 1 | Fatal server error:
(EE) Server is already active for display 1
If this server is no longer running, remove /tmp/.X1-lock
and start again.
(EE)
<img width="1709" alt="image" src="https://github.com/user-attachments/assets/331762aa-1d0a-4e15-96bc-4995028f9668">
| open | 2024-08-12T11:56:32Z | 2024-08-12T13:20:56Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1985 | [] | mouyong | 9 |
amdegroot/ssd.pytorch | computer-vision | 420 | box_utils.py decode | ```
def decode(loc, priors, variances):
boxes = torch.cat((
priors[:, :2] + loc[:, :2] * variances[0] * priors[:, 2:],
priors[:, 2:] * torch.exp(loc[:, 2:] * variances[1])), 1)
boxes[:, :2] -= boxes[:, 2:] / 2
boxes[:, 2:] += boxes[:, :2]
return boxes
```
why boxes[:, :2] -= box... | closed | 2019-10-17T11:38:36Z | 2019-10-18T03:44:59Z | https://github.com/amdegroot/ssd.pytorch/issues/420 | [] | sdu2011 | 1 |
huggingface/text-generation-inference | nlp | 2,113 | how to launch a service using downloaded model weights? | ### System Info
I have downloaded model weights of bge-models, and I want to launch a model service using TGI, the command is :
```
model=/storage/nfs2/ModelHub/embedding/BAAI/bge-small-zh-v1.5
revision=refs/pr/5
volume=$PWD/data # share a volume with the Docker container to avoid downloading weights every run
... | closed | 2024-06-25T03:18:14Z | 2024-06-28T03:50:10Z | https://github.com/huggingface/text-generation-inference/issues/2113 | [] | chenchunhui97 | 2 |
holoviz/panel | jupyter | 7,708 | IPywidgets do not work with fastapi server | Hi,
Thanks for adding support for panel with fastapi, I have an application which also renders IPywidgets and I see that they do not work with fast api server while the same work with panel serve. Is this expected?
Reproducer code
```
import panel as pn
from fastapi import FastAPI
import ipywidgets as widgets
from... | open | 2025-02-13T08:41:56Z | 2025-02-13T11:28:56Z | https://github.com/holoviz/panel/issues/7708 | [
"component: ipywidget"
] | singharpit94 | 0 |
stanfordnlp/stanza | nlp | 1,300 | [QUESTION] | Trying to run a gunicorn/Flask Stanza app in a Docker container.
Tried with different worker types and numbers but see each worker being killed.
Current ending of Dockerfile is:
```
EXPOSE 20900
ENTRYPOINT poetry run python -m gunicorn --worker-tmp-dir /dev/shm -workers=2 --threads=4 --worker-class=sync 'isagog_a... | closed | 2023-10-18T14:40:05Z | 2024-02-25T00:11:31Z | https://github.com/stanfordnlp/stanza/issues/1300 | [
"question"
] | rjalexa | 2 |
manbearwiz/youtube-dl-server | rest-api | 61 | output folder | Hi, is there a way to specify the output folder? | closed | 2020-05-01T09:10:18Z | 2020-12-05T03:39:22Z | https://github.com/manbearwiz/youtube-dl-server/issues/61 | [] | JokerShades | 2 |
scikit-optimize/scikit-optimize | scikit-learn | 1,064 | list of numeric categories of length 2 is considered as Real or Integer dimensions | In skopt.Optimizer [docs](https://scikit-optimize.github.io/stable/modules/generated/skopt.Optimizer.html) it said:
> - a (lower_bound, upper_bound) **tuple** (for Real or Integer dimensions) ...
> - as a **list** of categories (for Categorical dimensions) ...
however a list of length 2 is considered the same as... | open | 2021-09-29T23:19:51Z | 2021-10-20T12:31:34Z | https://github.com/scikit-optimize/scikit-optimize/issues/1064 | [] | Abdelgha-4 | 1 |
babysor/MockingBird | deep-learning | 19 | Python | closed | 2021-08-18T14:38:21Z | 2021-08-18T14:38:37Z | https://github.com/babysor/MockingBird/issues/19 | [] | twochengxu | 0 | |
pbugnion/gmaps | jupyter | 146 | rgba regex errors when the alpha channel is 1.0 | I think rgba should allow a max of 1.0 but the regex is throwing errors if the alpha doesn't start with a 0.x
error message:
```Element of the 'gradient' trait of a WeightedHeatmap instance must be an HTML color recognized by Google maps or a tuple or a tuple, but a value of 'rgba(72,209,204,1.0)' <type 'str'> was ... | closed | 2017-06-12T20:50:52Z | 2017-06-25T10:29:10Z | https://github.com/pbugnion/gmaps/issues/146 | [] | mlwohls | 7 |
axnsan12/drf-yasg | django | 303 | Add ArrayField Solution to Docs | Hi,
i was looking for "How to implement the ArrayField(models.CharField(choices=TYPES, max_length=3))".
And the 'serializers.MultipleChoiceField()` from #102 solution worked for me.
Could this be added to the Docs in a Section like "Tipps 'n Tricks "? | closed | 2019-01-29T21:31:19Z | 2019-01-29T21:40:36Z | https://github.com/axnsan12/drf-yasg/issues/303 | [] | chgad | 1 |
horovod/horovod | pytorch | 3,886 | [Question] How to generate horovod timeline avoid preprocessing ? | I have a training task that does a lot of preprocessing before starting actual training.
I want to avoid recording the preprocessing part, but only later part.
How can I achieve this?
BTW, if the long running task is start with --timeline-filename xxx.json and stop later using Ctrl+c, it seems that the timeline fi... | closed | 2023-04-14T03:37:29Z | 2023-04-19T11:42:54Z | https://github.com/horovod/horovod/issues/3886 | [] | Nov11 | 1 |
rio-labs/rio | data-visualization | 60 | NumberInput Field with Decimals != 0 Changes Input When Numbers Are Entered "Slowly" | ### Describe the bug
When using a NumberInput field with decimals set to a value other than 0, the input behaves unexpectedly if numbers are entered slowly. Specifically, when decimals is set to 2, entering the number "20" results in "2.000" and then immediately changes to "2.00".
### Steps to Reproduce
1. Create a ... | closed | 2024-06-12T14:43:11Z | 2024-06-14T05:03:15Z | https://github.com/rio-labs/rio/issues/60 | [
"bug"
] | Sn3llius | 1 |
cvat-ai/cvat | computer-vision | 8,454 | Generalized 'Oriented Rectangle' with polygon for OpenCV:TrackerMIL | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Is your feature request related to a problem? Please describe.
Currently, polygon can only perform track in interpolation style between key fr... | open | 2024-09-18T18:03:16Z | 2024-10-09T04:57:11Z | https://github.com/cvat-ai/cvat/issues/8454 | [
"enhancement"
] | JuliusLin | 2 |
vvbbnn00/WARP-Clash-API | flask | 118 | [Bug] unsupport proxy type | 
| closed | 2024-03-01T05:28:56Z | 2024-03-01T05:30:06Z | https://github.com/vvbbnn00/WARP-Clash-API/issues/118 | [] | D3ngX1n | 0 |
dask/dask | numpy | 11,133 | I'm not sure what ’b_dict‘ is, I couldn't find any relevant content | - https://docs.dask.org/en/stable/_modules/dask/bag/core.html#to_textfiles
```
b_dict.map(json.dumps).to_textfiles("/path/to/data/*.json")
``` | closed | 2024-05-20T13:20:17Z | 2024-05-21T06:16:58Z | https://github.com/dask/dask/issues/11133 | [
"needs triage"
] | simplew2011 | 1 |
MycroftAI/mycroft-core | nlp | 3,164 | ./dev_setup.sh problem | My problem is that after downloading mycroft, even if I run the ./dev_setup.sh file and install it, it wants to run ./dev_setup.sh again to run mycroft.
I'm using linux penguin in chromebook
That's a codes
fatihgztk@penguin:~/mycroft-core$ ./start-mycroft.sh all
Please update dependencies by running ./dev_... | closed | 2024-07-20T06:04:48Z | 2024-09-08T08:14:42Z | https://github.com/MycroftAI/mycroft-core/issues/3164 | [
"bug"
] | Krsth | 2 |
django-import-export/django-import-export | django | 1,275 | import_fields attribute | I did not find a way to specify `import_fields` - this might be helpful to export columns (e.g. for analytics) but only import a sub set of fields.
It might work overwriting `get_import_fields()` to check for `import_fields` attribute being set, use it if so and otherwise use `get_fields`.
If thats something you... | closed | 2021-04-20T08:32:02Z | 2021-11-24T06:23:53Z | https://github.com/django-import-export/django-import-export/issues/1275 | [
"question"
] | jensneuhaus | 2 |
widgetti/solara | flask | 626 | `solara.Meta` adds an empty span to DOM | This can have unexpected consequences for spacing when, for instance, using flex-boxes with a set gap, like the ones that are automatically added if an element has more than one direct child.
An example issue can be found in the linked PR | open | 2024-05-01T11:57:35Z | 2024-07-04T09:54:38Z | https://github.com/widgetti/solara/issues/626 | [] | iisakkirotko | 1 |
numba/numba | numpy | 9,084 | CUDA kernels should not make const copies of global and closure variables | Noted whilst investigating https://numba.discourse.group/t/avoid-multiple-copies-of-large-numpy-array-in-closure/2017
In many cases Numba will copy global and closure variables as constant arrays inside jitted functions and kernels (and will always attempt to do this for kernels). This is a problem because const mem... | open | 2023-07-21T16:00:24Z | 2024-10-01T14:49:39Z | https://github.com/numba/numba/issues/9084 | [
"CUDA",
"bug - incorrect behavior"
] | gmarkall | 9 |
sunscrapers/djoser | rest-api | 802 | "Authentication credentials were not provided" on log out TokenAuthentication | Hi,
I keep getting the following error when I log out with `TokenAuthentication`: `Authentication credentials were not provided.`.
Any idea why this is happening?
`curl -X POST http://localhost:8000/auth/token/logout/ --data 'f4c30aed2268e8d952a742e82fe24b012766fe5f' -H 'Authorization: Token f4c30aed2268e8d952... | closed | 2024-03-11T04:49:42Z | 2024-03-31T04:35:46Z | https://github.com/sunscrapers/djoser/issues/802 | [] | engin-can | 1 |
inventree/InvenTree | django | 8,410 | Environmental variable formatting (e.g. INVENTREE_TRUSTED_ORIGINS). | ### Describe the bug*
This issue has been reported due to my miscoception about the proper formatting of env variables.
Inventree's documentions refers to django documentation in terms of `INVENTREE_TRUSTED_ORIGINS` variable.
For django the variable format is a list, while for .env file it should be just a comma-sepa... | closed | 2024-11-02T12:36:21Z | 2024-11-16T05:15:30Z | https://github.com/inventree/InvenTree/issues/8410 | [
"question",
"setup",
"documentation"
] | mjktfw | 3 |
deezer/spleeter | tensorflow | 860 | [Discussion] How to use spleeter with multi gpus? | <!-- Please respect the title [Discussion] tag. -->
I want to use spleeter to process a large amount of video data, and I want to use multi gpus to speed up my processing, is multi gpus currently supported?
Thank you very much. | open | 2023-07-06T09:38:36Z | 2023-07-21T22:42:07Z | https://github.com/deezer/spleeter/issues/860 | [
"question"
] | Zth9730 | 3 |
mljar/mljar-supervised | scikit-learn | 550 | explain mode with metric_type=accuracy results seems abnormal? | Hi @pplonski
I use mljar-AutoML to run a medical dataset (task mission:binary_classification).
Mode selected=explain mode
metric_type=accuracy
The results seems abnormal as figure below...

All the metr... | open | 2022-06-23T05:34:49Z | 2022-11-21T14:44:22Z | https://github.com/mljar/mljar-supervised/issues/550 | [] | Tonywhitemin | 7 |
ivy-llc/ivy | numpy | 28,044 | Wrong key-word argument `name` in `ivy.remainder()` function call | In the following line, the name argument is passed,
https://github.com/unifyai/ivy/blob/bec4752711c314f01298abc3845f02c24a99acab/ivy/functional/frontends/tensorflow/variable.py#L191
From the actual function definition, there is no such argument
https://github.com/unifyai/ivy/blob/8ff497a8c592b75f010160b313dc431218c2... | closed | 2024-01-25T14:03:42Z | 2024-01-25T14:51:02Z | https://github.com/ivy-llc/ivy/issues/28044 | [] | Sai-Suraj-27 | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.