
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ryfeus/lambda-packs | numpy | 20 | Magpie package : Multi label text classification | Hi, great work ! You inspired me to build my own package for a project that you can find on my [repo](https://github.com/Sach97/serverless-multilabel-text-classification). Unfortunately I'm facing an issue.
I have this [error](https://github.com/Sach97/serverless-multilabel-text-classification/issues/1). Have you al... | closed | 2018-04-30T20:50:46Z | 2018-05-02T18:15:10Z | https://github.com/ryfeus/lambda-packs/issues/20 | [] | sachaarbonel | 1 |
aiortc/aiortc | asyncio | 332 | Receiving parallel to sending frames | I am trying to modify server example to make receiving and sending frames parallel.
The problem appeared when I've modified frame processing and it became too long. So I need to find out the way to deal with it. Now I see 2 ways to do it.
1. Understand input frame queue length. So I can read more when queue is too ... | closed | 2020-04-09T10:22:19Z | 2021-03-07T14:52:33Z | https://github.com/aiortc/aiortc/issues/332 | [] | Alick09 | 3 |
feder-cr/Jobs_Applier_AI_Agent_AIHawk | automation | 293 | Non Descriptive errors any advice: | ```
Traceback (most recent call last):
File "App/HawkAI/src/linkedIn_job_manager.py", line 138, in apply_jobs
self.easy_applier_component.job_apply(job)
File "App/HawkAI/src/linkedIn_easy_applier.py", line 67, in job_apply
raise Exception(f"Failed to apply to job! Original exception: \nTraceback:\n{tb_... | closed | 2024-09-05T19:39:07Z | 2024-09-11T02:01:47Z | https://github.com/feder-cr/Jobs_Applier_AI_Agent_AIHawk/issues/293 | [] | elonbot | 3 |
deepfakes/faceswap | deep-learning | 595 | Adjust convert does not work for GAN and GAN128 model | Adjust Convert plugin fails in case of GAN or GAN128 model
## Expected behavior
Adjust convert completes w/o errors
## Actual behavior
GAN and GAN128 fails with errors (please see pic attached)
## Steps to reproduce
1) Extract faces from images and train GAN or GAN128 model
2) Perform python faceswap c... | closed | 2019-01-23T23:19:49Z | 2019-01-23T23:37:18Z | https://github.com/deepfakes/faceswap/issues/595 | [] | temp-42 | 2 |
supabase/supabase-py | fastapi | 280 | Error when running this code | When i run this code i get an error
```
import os
from supabase import create_client, Client
url: str = os.environ.get("SUPABASE_URL")
key: str = os.environ.get("SUPABASE_KEY")
supabase: Client = create_client(url, key)
# Create a random user login email and password.
random_email: str = "cam@example.com"
ra... | closed | 2022-09-27T23:50:54Z | 2022-10-07T08:35:21Z | https://github.com/supabase/supabase-py/issues/280 | [] | camnoalive | 1 |
ipyflow/ipyflow | jupyter | 22 | add binder launcher | See e.g. [here](https://github.com/jtpio/jupyterlab-cell-flash) | closed | 2020-05-11T01:12:44Z | 2020-05-12T22:54:34Z | https://github.com/ipyflow/ipyflow/issues/22 | [] | smacke | 0 |
BayesWitnesses/m2cgen | scikit-learn | 525 | The converted C model compiles very slow,how can i fix it? | open | 2022-06-17T07:29:37Z | 2022-06-17T07:29:37Z | https://github.com/BayesWitnesses/m2cgen/issues/525 | [] | miszuoer | 0 | |
python-visualization/folium | data-visualization | 1,701 | On click circle radius changes not available | **Is your feature request related to a problem? Please describe.**
After adding the folium.Circle feature to the map I just get circles defined by radius. Having them several, they overlap each other when close enough and it seems like there is no option for switching them on/off by clicking on the marker too, which... | closed | 2023-01-13T09:31:00Z | 2023-02-17T10:47:52Z | https://github.com/python-visualization/folium/issues/1701 | [] | Krukarius | 1 |
CPJKU/madmom | numpy | 175 | madmom.features.notes module incomplete | There should be something like a `NoteOnsetProcessor` to pick the note onsets from a 2-d note activation function. The respective functionality could then be removed from `madmom.features.onsets.PeakPickingProcessor`. Be aware that this processor returns MIDI note numbers right now which is quite counter-intuitive.
Fu... | closed | 2016-07-20T09:56:45Z | 2017-03-02T07:42:43Z | https://github.com/CPJKU/madmom/issues/175 | [] | superbock | 0 |
vitalik/django-ninja | django | 430 | [BUG] Schema defaults when using Pagination | **The bug**
It seems that when I'm setting default values with Field() Pagination does not work as expected.
In this case: it returns the default values of the schema (Bob, age 21)
**Versions**
- Python version: [3.10]
- Django version: [4.0.4]
- Django-Ninja version: [0.17.0]
**How to reproduce:**
Use t... | closed | 2022-04-25T14:40:20Z | 2022-04-25T16:15:07Z | https://github.com/vitalik/django-ninja/issues/430 | [] | florisgravendeel | 2 |
ploomber/ploomber | jupyter | 461 | Document command tester | closed | 2022-01-03T19:02:56Z | 2022-01-04T04:13:18Z | https://github.com/ploomber/ploomber/issues/461 | [] | edublancas | 0 | |
tqdm/tqdm | jupyter | 855 | Merge to progressbar2 | - [x] I have marked all applicable categories:
+ [x] new feature request
- [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
[progressbar2](https://github.com/WoLpH/python-progressbar) has a concept of widgets... | open | 2019-11-30T07:40:11Z | 2019-12-02T23:03:56Z | https://github.com/tqdm/tqdm/issues/855 | [
"question/docs ‽",
"p4-enhancement-future 🧨",
"submodule ⊂"
] | KOLANICH | 11 |
streamlit/streamlit | python | 10,603 | Rerun fragment from anywhere, not just from within itself | ### Checklist
- [x] I have searched the [existing issues](https://github.com/streamlit/streamlit/issues) for similar feature requests.
- [x] I added a descriptive title and summary to this issue.
### Summary
Related to #8511 and #10045.
Currently the only way to rerun a fragment is calling `st.rerun(scope="fragment... | open | 2025-03-03T14:55:41Z | 2025-03-13T04:44:33Z | https://github.com/streamlit/streamlit/issues/10603 | [
"type:enhancement",
"feature:st.fragment"
] | Abdelgha-4 | 1 |
ultrafunkamsterdam/undetected-chromedriver | automation | 1,758 | InvalidArgumentException | this is my code
import undetected_chromedriver as uc
options = uc.ChromeOptions()
driver = uc.Chrome()
if __name__ == '__main__':
page = driver.get(url='www.google.com')
print(page.title)
and this is the error message
python app.py
Traceback (most recent call last):
File "C:\Users\user... | open | 2024-02-23T08:04:44Z | 2024-02-23T08:05:20Z | https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1758 | [] | idyweb | 0 |
mirumee/ariadne-codegen | graphql | 30 | Handle fragments in provided queries | Given example schema:
```gql
schema {
query: Query
}
type Query {
testQuery: ResultType
}
type ResultType {
field1: Int!
field2: String!
field3: Boolean!
}
```
and query with fragment:
```gql
query QueryName {
testQuery {
...TestFragment
}
}
fragment TestFr... | closed | 2022-11-15T10:22:17Z | 2022-11-17T07:35:52Z | https://github.com/mirumee/ariadne-codegen/issues/30 | [] | mat-sop | 0 |
dnouri/nolearn | scikit-learn | 191 | Update Version of Lasagne Required in requirements.txt | closed | 2016-01-13T18:19:13Z | 2016-01-14T21:03:43Z | https://github.com/dnouri/nolearn/issues/191 | [] | cancan101 | 0 | |
python-visualization/folium | data-visualization | 1,384 | search plugin display multiple places | **Describe the issue**
I display places where certain historic persons appear at different places on a stamen map. They are coded in geojson. Search works fine: it shows found places in search combo box and I after selecting one value it zooms to that place on the map.
My question:
Is it possible after search to ... | closed | 2020-08-30T10:49:38Z | 2022-11-28T12:36:10Z | https://github.com/python-visualization/folium/issues/1384 | [] | uli22 | 1 |
ContextLab/hypertools | data-visualization | 51 | demo scripts: naming and paths | all of the demo scripts have names that start with `hypertools_demo-`, which is redundant. i propose removing `hypertools_demo-` from each script name.
also, some of the paths are relative rather than absolute. for example, the `sample_data` folder is only visible within the `examples` folder, but it is referenced... | closed | 2017-01-02T23:27:43Z | 2017-01-03T02:55:08Z | https://github.com/ContextLab/hypertools/issues/51 | [
"bug"
] | jeremymanning | 2 |
aiortc/aiortc | asyncio | 1,102 | Connection(0) ICE failed when using mobile Internet. Connection(0) ICE completed in local network. | I use the latest (1.8.0) version of aiortc. The "server" example (aiortc/tree/main/examples/server) works well on a local network and with mobile internet. My project uses django-channels for "offer/answer" message exchange, and a connection establishes perfectly when I use a local network (both computers on the same W... | closed | 2024-05-23T12:25:46Z | 2024-05-29T22:20:35Z | https://github.com/aiortc/aiortc/issues/1102 | [] | Aroxed | 0 |
CTFd/CTFd | flask | 2,103 | backport core theme for compatibility with new plugins | During updating of our plugins for compatibility with the currently developed theme It would be beneficial to move certain functions from the plugins to ctfd.js. It's working fine with the new theme however the current core theme needs to be backported for compatibility. | closed | 2022-04-28T11:36:34Z | 2022-04-29T04:17:12Z | https://github.com/CTFd/CTFd/issues/2103 | [] | MilyMilo | 0 |
AirtestProject/Airtest | automation | 706 | 红米8aJAVACAP截图不正确 | **(重要!问题分类)**
* 图像识别、设备控制相关问题
**描述问题bug**
JAVACAP在所有横屏应用下返回的图像方向正确但尺寸不正确,就像是把一块横着放的海绵塞进了竖着放的盒子里
JAVACAP返回的图片是经过压缩编码的,这个被编码的图片就是错误的
**相关截图**

 (some might be double hits but that is beside the point). The values I fill the dataframe with are values between 0-1 to tell the function how to color each sample
W... | closed | 2023-12-11T11:45:03Z | 2023-12-11T16:34:24Z | https://github.com/mwaskom/seaborn/issues/3591 | [] | dansteiert | 5 |
sqlalchemy/sqlalchemy | sqlalchemy | 12,441 | Remove features deprecated in 1.3 and earlier | Compation to #12437 that covers the other deprecated features | closed | 2025-03-17T20:01:01Z | 2025-03-18T16:12:31Z | https://github.com/sqlalchemy/sqlalchemy/issues/12441 | [
"deprecations"
] | CaselIT | 1 |
3b1b/manim | python | 1,167 | [Hiring] Need help creating animation | Hello,
I have a simple project which requires a simple animation and though manim would be perfect. Since there is a time contraint, I won't be able to create an animation. Would anyone be willing to for hire? | closed | 2020-07-14T17:59:48Z | 2020-08-18T03:44:19Z | https://github.com/3b1b/manim/issues/1167 | [] | OGALI | 3 |
ResidentMario/geoplot | matplotlib | 69 | Failing voronoi example with the new 0.2.2 release | The geoplot release seems to have broken the geopandas examples (the voronoi one). I am getting the following error on our readthedocs build:
```
Unexpected failing examples:
/home/docs/checkouts/readthedocs.org/user_builds/geopandas/checkouts/latest/examples/plotting_with_geoplot.py failed leaving traceback:
Tra... | closed | 2019-01-07T14:10:45Z | 2019-03-17T04:24:29Z | https://github.com/ResidentMario/geoplot/issues/69 | [] | jorisvandenbossche | 12 |
CorentinJ/Real-Time-Voice-Cloning | python | 394 | Is there any way to change the language? | Hey, i have successfully installed it,
And I just wanted to ask if there was any way to
Change the pronunciation language to German? | closed | 2020-07-02T10:16:08Z | 2020-07-04T15:03:11Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/394 | [] | ozanaaslan | 2 |
WZMIAOMIAO/deep-learning-for-image-processing | deep-learning | 572 | 关于MobileNetV3的训练问题 | 您好,我在使用MobileNetV3进行自定义数据集训练时,调用
`net = MobileNetV3(num_classes=16)`
时报错如下:
> TypeError: __init__() missing 2 required positional arguments: 'inverted_residual_setting' and 'last_channel'
请问如何解决?感谢。
| closed | 2022-06-13T06:52:35Z | 2022-06-15T02:38:15Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/572 | [] | myfeet2cold | 1 |
dmlc/gluon-cv | computer-vision | 1,032 | NMS code question | I am a fresher of gluon-cv, I want to know how you implement nms in ssd model.
Anyone can tell me where the code is? I see there is a tvm convert tutorials of gluon-cv ssd models which includes nms and post-processing operations which can be converted to tvm model directly, I want to know how it works so as to use it ... | closed | 2019-11-07T09:03:23Z | 2019-12-19T06:49:49Z | https://github.com/dmlc/gluon-cv/issues/1032 | [] | Edwardmark | 3 |
InstaPy/InstaPy | automation | 6,452 | Ubuntu server // Hide Selenium Extension: error | I use Droplet on Digital Ocean _(Ubuntu 20.04 (LTS) x64)_
When I start my quickstart.py, it's fail cause "Hide Selenium Extension: error", I don't found solution for this time, somebody can help me ?
> InstaPy Version: 0.6.15
._. ._. ._. ._. ._. ._. ._.
Workspace in use: "/root/InstaPy"
OOOOOOOOOOOOO... | closed | 2022-01-03T23:37:58Z | 2022-02-01T14:54:18Z | https://github.com/InstaPy/InstaPy/issues/6452 | [] | celestinsoum | 8 |
modin-project/modin | data-science | 7,409 | BUG: can't use list of tuples of select multiple columns when columns are multiindex | ### Modin version checks
- [X] I have checked that this issue has not already been reported.
- [X] I have confirmed this bug exists on the latest released version of Modin.
- [X] I have confirmed this bug exists on the main branch of Modin. (In order to do this you can follow [this guide](https://modin.readthedocs.i... | open | 2024-11-13T08:15:15Z | 2024-11-13T11:17:32Z | https://github.com/modin-project/modin/issues/7409 | [
"bug 🦗",
"Triage 🩹"
] | MarcoGorelli | 1 |
recommenders-team/recommenders | deep-learning | 1,813 | [ASK] Recommendation algorithms leveraging user attributes as input | Hi Recommenders,
Thank you for the interesting repository. I came across `recommenders` repository very recently. I am still exploring different algorithms. I have a particular interest to recommendation algorithms leveraging or taking user attributes i.e., gender, age, occupation as input.
### Description
<!--- De... | closed | 2022-08-18T14:36:28Z | 2022-10-19T07:58:51Z | https://github.com/recommenders-team/recommenders/issues/1813 | [
"help wanted"
] | SlokomManel | 1 |
wandb/wandb | data-science | 9,046 | [Feature]: Better grouping of runs | ### Description
Hi,
I would suggest an option to group better the runs.
Let us suppose we have 3 methods with some common (hyper)-parameters such as LR, WD but also they have some specific parameters such as attr_A (values B,C,...), attr_0 (values 1,2,3,...), attr_i (values ii,iii,iv,...)
The problem is to compare ... | closed | 2024-12-09T00:31:19Z | 2024-12-14T00:22:10Z | https://github.com/wandb/wandb/issues/9046 | [
"ty:feature",
"a:app"
] | matekrk | 3 |
0xTheProDev/fastapi-clean-example | pydantic | 6 | question on service-to-service | Is it an issue that we expose models directly? For example in BookService we expose model in get method, and we also use models of Author repository.
This implies that we are allowed to use those interfaces - CRUD, read all properties, call other relations, etc.
Is exposing schemas objects between domains is a better... | closed | 2023-02-13T10:09:41Z | 2023-04-25T07:10:49Z | https://github.com/0xTheProDev/fastapi-clean-example/issues/6 | [] | Murtagy | 1 |
kensho-technologies/graphql-compiler | graphql | 698 | register_macro_edge builds a schema for macro definitions every time its called | `register_macro_edge` calls `make_macro_edge_descriptor` which calls `get_and_validate_macro_edge_info` which calls `_validate_ast_with_builtin_graphql_validation` which calls `get_schema_for_macro_edge_definitions` which builds the macro edge definition schema. Building the macro edge definition schema involves copyin... | open | 2019-12-10T03:42:49Z | 2019-12-10T03:43:30Z | https://github.com/kensho-technologies/graphql-compiler/issues/698 | [
"enhancement"
] | pmantica1 | 0 |
explosion/spacy-course | jupyter | 31 | Chapter 4.4 evaluates correct with no entities | <img width="859" alt="Screen Shot 2019-05-30 at 1 12 58 am" src="https://user-images.githubusercontent.com/21038129/58568874-6729f480-8278-11e9-8802-730ec6ea13d2.png">
I put `doc.ents` instead of `entities` but it was still marked correct | closed | 2019-05-29T15:16:23Z | 2020-04-17T01:32:50Z | https://github.com/explosion/spacy-course/issues/31 | [] | natashawatkins | 3 |
kubeflow/katib | scikit-learn | 1,581 | [chore] Upgrade CRDs to apiextensions.k8s.io/v1 | /kind feature
**Describe the solution you'd like**
[A clear and concise description of what you want to happen.]
> The api group apiextensions.k8s.io/v1beta1 is no longer served in k8s 1.22 https://kubernetes.io/docs/reference/using-api/deprecation-guide/#customresourcedefinition-v122
>
> kubeflow APIs need to... | closed | 2021-07-19T03:27:14Z | 2021-08-10T23:31:25Z | https://github.com/kubeflow/katib/issues/1581 | [
"help wanted",
"area/operator",
"kind/feature"
] | gaocegege | 2 |
python-visualization/folium | data-visualization | 1,942 | Add example pattern for pulling JsCode snippets from external javascript files | **Is your feature request related to a problem? Please describe.**
I have found myself embedding a lot of javascript code via `JsCode` when using the `Realtime` plugin. This gets messy for a few reasons:
- unit testing the javascript code is not possible
- adding leaflet plugins can result in a huge amount of javas... | closed | 2024-04-30T17:03:24Z | 2024-05-19T08:46:33Z | https://github.com/python-visualization/folium/issues/1942 | [] | thomasegriffith | 9 |
learning-at-home/hivemind | asyncio | 158 | Optimize the tests | Right now, our tests can take upwards of 10 minutes both in CircleCI and locally, which slows down the development workflow and leads to unnecessary context switches. We should find a way to reduce the time requirements and make sure it stays that way.
* Identify and speed up the slow tests. Main culprits: multiple ... | closed | 2021-02-28T15:35:48Z | 2021-08-03T17:43:27Z | https://github.com/learning-at-home/hivemind/issues/158 | [
"ci"
] | mryab | 2 |
mwaskom/seaborn | data-science | 3,608 | 0.13.1: test suite needs `husl` module | <details>
<summary>Looks like test suite needs husl module</summary>
```console
+ PYTHONPATH=/home/tkloczko/rpmbuild/BUILDROOT/python-seaborn-0.13.1-2.fc35.x86_64/usr/lib64/python3.8/site-packages:/home/tkloczko/rpmbuild/BUILDROOT/python-seaborn-0.13.1-2.fc35.x86_64/usr/lib/python3.8/site-packages
+ /usr/bin/pyte... | closed | 2024-01-01T10:39:07Z | 2024-01-01T13:11:23Z | https://github.com/mwaskom/seaborn/issues/3608 | [] | kloczek | 1 |
donnemartin/data-science-ipython-notebooks | deep-learning | 16 | Add SAWS: A Supercharged AWS Command Line Interface (CLI) to AWS Section. | closed | 2015-10-04T10:40:50Z | 2016-05-18T02:09:55Z | https://github.com/donnemartin/data-science-ipython-notebooks/issues/16 | [
"feature-request"
] | donnemartin | 1 | |
deeppavlov/DeepPavlov | nlp | 1,693 | Github Security Lab Vulnerability Contact | Greetings DeepPavlov maintainers,
Github has found a potentail vulnerability in DeepPavlov. Please let us know of a point of contact so that we can discuss this privately. We have the [Private Vulnerability Reporting](https://docs.github.com/en/code-security/security-advisories/working-with-repository-security-advisor... | open | 2024-08-20T00:54:31Z | 2024-08-20T00:54:31Z | https://github.com/deeppavlov/DeepPavlov/issues/1693 | [
"bug"
] | Kwstubbs | 0 |
serengil/deepface | machine-learning | 845 | Can't detect faces when calling represent trough API and Facenet detector | Here's the image being used:
https://cdn.alboompro.com/5dc181967fac6b000152f3ae_650b3f428274300001d1815a/medium/whatsapp_image_2023-09-18_at_16-41-06.jpeg?v=1
I'm sending it to an API that running the dockerized image present in the repository on an EKS cluster (no GPU). When I send a request to the represent en... | closed | 2023-09-20T18:57:45Z | 2024-01-11T03:09:50Z | https://github.com/serengil/deepface/issues/845 | [] | elisoncampos | 6 |
yinkaisheng/Python-UIAutomation-for-Windows | automation | 198 | 如何快速的查找元素? | 作者你好,我是刚刚接触这个库,觉得非常好用;我想问一下,如何快速的查找控件。
我通过光标获取到了元素控件,然后我把元素控件里面的Name,automationId, ClassName, ControlType这几个属性存储在了本地文件。我想实现快速的根据存储信息查找元素。我目前是通过这种方式找的,但是感觉不是很快,下面是部分代码截图:
tips: 是通过读取本地存储的元素信息进行查找的。
with open(self._locators_path, 'r') as f:
locators_data = json.loads(f.read())[name]
... | open | 2022-03-18T12:10:18Z | 2023-06-23T10:05:42Z | https://github.com/yinkaisheng/Python-UIAutomation-for-Windows/issues/198 | [] | shidecheng | 2 |
tensorpack/tensorpack | tensorflow | 788 | FullyConnected output | An issue has to be one of the following:
1. Unexpected Problems / Potential Bugs
For any unexpected problems, __PLEASE ALWAYS INCLUDE__:
1. What you did:
```
xw = FullyConnected('FC',
inputs,
W_init=tf.random_uniform_initializer(0.0, 1.0),
... | closed | 2018-06-09T06:58:12Z | 2018-06-09T19:09:47Z | https://github.com/tensorpack/tensorpack/issues/788 | [
"duplicate"
] | kamwoh | 1 |
tensorflow/datasets | numpy | 5,390 | [data request] <poker> | * Name of dataset: <name>
* URL of dataset: <url>
* License of dataset: <license type>
* Short description of dataset and use case(s): <description>
Folks who would also like to see this dataset in `tensorflow/datasets`, please thumbs-up so the developers can know which requests to prioritize.
And if you'd lik... | closed | 2024-04-26T12:43:40Z | 2024-04-26T12:44:30Z | https://github.com/tensorflow/datasets/issues/5390 | [
"dataset request"
] | Loicgrd | 0 |
pyppeteer/pyppeteer | automation | 416 | the different with pyppeteer and puppeteer-case by case | url:https://open.jd.com/
Using puppeteer to request the link response page content is richer than pyppeteer. The page content produced by pyppeteer is same with the page source code, but puppeteer produced the page content is after rendering.
you can try!
version:
chromium-browser-Chromium 90.0.4430.212 Fedor... | closed | 2022-09-27T04:10:52Z | 2022-09-27T09:05:33Z | https://github.com/pyppeteer/pyppeteer/issues/416 | [] | runningabcd | 0 |
numba/numba | numpy | 9,278 | Searching `%PREFIX%\Library` for new CTK Windows packages | In PR ( https://github.com/numba/numba/pull/7255 ) logic was added to Numba to handle the new-style CTK Conda packages on the `nvidia` channel (and now also on `conda-forge`)
In particular this added a series of `get_nvidia...` functions to search for libraries as part of `numba/cuda /cuda_paths.py`. For example
... | closed | 2023-11-11T03:23:01Z | 2023-12-11T16:10:20Z | https://github.com/numba/numba/issues/9278 | [
"needtriage",
"CUDA",
"bug - build/packaging"
] | jakirkham | 4 |
ijl/orjson | numpy | 139 | Regression in parsing JSON between 3.4.1 and 3.4.2 | ```Python
import orjson
s = '{"cf_status_firefox67": "---", "cf_status_firefox57": "verified"}'
orjson.loads(s)["cf_status_firefox57"]
```
This works in 3.4.1, throws `KeyError: 'cf_status_firefox57'` in 3.4.2. | closed | 2020-10-30T13:55:18Z | 2020-10-30T14:11:03Z | https://github.com/ijl/orjson/issues/139 | [] | marco-c | 2 |
schemathesis/schemathesis | graphql | 2,504 | Specifying --hypothesis-seed=# does not recreate tests with the same data | ### Checklist
- [x] I checked the [FAQ section](https://schemathesis.readthedocs.io/en/stable/faq.html#frequently-asked-questions) of the documentation
- [x] I looked for similar issues in the [issue tracker](https://github.com/schemathesis/schemathesis/issues)
- [x] I am using the latest version of Schemathesis
... | open | 2024-10-09T20:26:42Z | 2024-10-20T01:56:38Z | https://github.com/schemathesis/schemathesis/issues/2504 | [
"Type: Bug",
"Status: Needs Triage"
] | hydroculator | 2 |
ansible/awx | automation | 15,071 | Job output not refreshing automatically in AWX 24.1.0 wit operator 2.14.0 | ### Please confirm the following
- [X] I agree to follow this project's [code of conduct](https://docs.ansible.com/ansible/latest/community/code_of_conduct.html).
- [X] I have checked the [current issues](https://github.com/ansible/awx/issues) for duplicates.
- [X] I understand that AWX is open source software provide... | closed | 2024-04-06T08:05:20Z | 2024-05-29T15:03:23Z | https://github.com/ansible/awx/issues/15071 | [
"type:bug",
"component:ui",
"needs_triage",
"community",
"component:ui_next"
] | sysadmin-info | 6 |
BayesWitnesses/m2cgen | scikit-learn | 582 | How to use model for jpg photo? | Hello. I converted a model into pure python, which I trained to determine the presence or absence of an object.
```
import os
import pickle
import sys
from skimage.io import imread
from skimage.transform import resize
import numpy as np
from sklearn import svm
from sklearn.model_selection import train_test... | open | 2023-08-31T11:52:19Z | 2023-08-31T11:52:19Z | https://github.com/BayesWitnesses/m2cgen/issues/582 | [] | Flashton91 | 0 |
roboflow/supervision | computer-vision | 1,619 | Bug found in ConfusionMatrix.from_detections | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar bug report.
### Bug
Issue found in code when producing a confusion matrix for object detection. It seems like the FN was being added incorrectly to the matrix. Here is the cod... | open | 2024-10-24T15:02:23Z | 2025-01-28T22:37:40Z | https://github.com/roboflow/supervision/issues/1619 | [
"bug"
] | chiggins2024 | 3 |
AutoGPTQ/AutoGPTQ | nlp | 292 | [BUG] Exllama seems to crash without a group size | **Describe the bug**
Our entire KoboldAI software crashes when AutoGPTQ is trying to load a GPTQ model with act order true but no group size.
First Huggingface shows an error that many keys such as model.layers.12.self_attn.q_proj.g_idx are missing, then the program closes without the real error and our fallbacks do ... | closed | 2023-08-27T19:12:36Z | 2023-10-31T17:31:12Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/292 | [
"bug"
] | henk717 | 4 |
deepspeedai/DeepSpeed | pytorch | 5,656 | [BUG] Running llama2-7b step3 with tensor parallel and HE fails due to incompatible shapes | Hi, I get an error when trying to run step3 of llama2-7b with tensor parallel. The error happens in merge_qkv:
` return self._call_impl(*args, **kwargs)
File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1569, in _call_impl
result = forward_call(*args, **kwargs)
File "/usr/... | open | 2024-06-13T07:00:06Z | 2024-06-13T13:21:28Z | https://github.com/deepspeedai/DeepSpeed/issues/5656 | [
"bug",
"deepspeed-chat"
] | ShellyNR | 0 |
lux-org/lux | jupyter | 217 | Improve automatic bin determination for histograms | Currently, the formula for histogram binning sometimes results in bins that are very "skinny" and sometimes bins that are very "wide". We need to improve histogram bin width and size determination to ensure more accurate histograms are plotted.
This is especially true for the "Filter" action.
Example:
```pytho... | closed | 2021-01-11T12:46:22Z | 2021-03-03T22:27:56Z | https://github.com/lux-org/lux/issues/217 | [
"enhancement",
"easy"
] | dorisjlee | 1 |
strawberry-graphql/strawberry | graphql | 2,941 | tests on windows broken? | Seemingly the hook tests on windows are broken.
First there are many deprecation warnings, second my code change works for all other tests.
PR on which "tests on windows" fail (there are also some other):
https://github.com/strawberry-graphql/strawberry/pull/2938 | closed | 2023-07-12T13:22:52Z | 2025-03-20T15:56:17Z | https://github.com/strawberry-graphql/strawberry/issues/2941 | [
"bug"
] | devkral | 2 |
microsoft/MMdnn | tensorflow | 206 | TensorFlow2IR | Platform (CentOS 6.6):
Python version:2.7.14
Source framework with version (like Tensorflow 1.6.1 with GPU):
Pre-trained model path (own):
Running scripts:
python -m mmdnn.conversion._script.convertToIR -f tensorflow -d resnet101 -n tests/resnet_v1_101.ckpt.meta --dstNodeName muli_predictions
. It does seem there is some support for long sentences in embeddings via the `allow_long_sentences` option, but it does not appear that this applies to sequence tag... | open | 2024-08-03T01:06:08Z | 2024-08-23T13:14:02Z | https://github.com/flairNLP/flair/issues/3519 | [
"feature"
] | MattGPT-ai | 7 |
jumpserver/jumpserver | django | 14,908 | [Feature] mysql ssl链接是否可以跳过服务端ca证书认证 | ### 产品版本
v4.6.0
### 版本类型
- [x] 社区版
- [ ] 企业版
- [ ] 企业试用版
### 安装方式
- [ ] 在线安装 (一键命令安装)
- [ ] 离线包安装
- [x] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] 源码安装
### ⭐️ 需求描述
目前版本配置mysql使用证书,则必须指定mysql服务端ca证书,是否可以支持 --ssl-mode=REQUIRED 这种ssl链接模式
### 解决方案
支持 --ssl-mode=REQUIRED 的mysql链接
### 补充信息
_No response_ | closed | 2025-02-20T11:06:32Z | 2025-03-05T12:54:48Z | https://github.com/jumpserver/jumpserver/issues/14908 | [
"⭐️ Feature Request"
] | wppzxc | 8 |
dask/dask | scikit-learn | 11,494 | `align_partitions` creates mismatched partitions. | **Describe the issue**:
The `divisions` attribute doesn't match between data frames even after applying `align_partitions` on them.
**Minimal Complete Verifiable Example**:
```python
import numpy as np
from distributed import Client, LocalCluster
from dask import dataframe as dd
from dask.dataframe.multi... | closed | 2024-11-05T12:26:04Z | 2024-11-05T13:53:43Z | https://github.com/dask/dask/issues/11494 | [
"needs triage"
] | trivialfis | 6 |
FactoryBoy/factory_boy | django | 397 | factory.Maybe doesn't work with factory.RelatedFactory | I'm trying to set a RelatedFactoy combine with Maybe, so that it's only created if a condition is fulfiled .
```
class PaymentModeFactory(factory.DjangoModelFactory):
class Meta:
model = models.PaymentMode
kind = enums.MANUAL
authorization = factory.Maybe(
factory.LazyAttribute(la... | closed | 2017-07-31T15:51:11Z | 2018-01-28T21:56:24Z | https://github.com/FactoryBoy/factory_boy/issues/397 | [] | tonial | 3 |
open-mmlab/mmdetection | pytorch | 11,730 | i cannot handle this issue i need some help | File "C:\Users\mistletoe\.conda\envs\d2l\lib\site-packages\mmdet\models\dense_heads\anchor_head.py", line 284, in _get_targets_single
bbox_weights[pos_inds, :] = 1.0
RuntimeError: linearIndex.numel()*sliceSize*nElemBefore == expandedValue.numel() INTERNAL ASSERT FAILED at "C:\\actions-runner\\_work\\pytorch\\pyt... | open | 2024-05-21T09:19:33Z | 2025-02-27T14:40:14Z | https://github.com/open-mmlab/mmdetection/issues/11730 | [] | mistletoe111 | 2 |
ivy-llc/ivy | pytorch | 28,485 | Fix Frontend Failing Test: jax - tensor.paddle.Tensor.mean | To-do List: https://github.com/unifyai/ivy/issues/27496 | open | 2024-03-05T15:58:41Z | 2024-03-09T20:51:36Z | https://github.com/ivy-llc/ivy/issues/28485 | [
"Sub Task"
] | ZJay07 | 0 |
open-mmlab/mmdetection | pytorch | 11,535 | Output object detection per class mAP using faster rcnn model, classwise has been modified to True,but doesn't work. | I tried to change the \mmdetection\mmdet\evaluation\metrics\coco_metric.py **classwise: bool = False** to **classwise: bool = True**, but it doesn't work. I have searched related issues but cannot get the expected help.
My system is windows10.Most likely it's because the code is running from source mmdet 3.1.0, which... | open | 2024-03-09T07:05:53Z | 2024-03-10T05:41:51Z | https://github.com/open-mmlab/mmdetection/issues/11535 | [] | LiuChar1esM | 0 |
allenai/allennlp | pytorch | 5,558 | conda-forge support for mac M1 (osx-arm) | In #5258, @RoyLiberman [requested](https://github.com/allenai/allennlp/issues/5258#issuecomment-1014461862):
> can you please add support for mac M1 systems on conda-forge?
Since that issue is closed, it's exceedingly easy to overlook this, and so I thought I'd open a new issue.
The migration will be kicked off ... | closed | 2022-02-05T07:10:41Z | 2022-02-07T05:40:18Z | https://github.com/allenai/allennlp/issues/5558 | [
"Feature request"
] | h-vetinari | 1 |
huggingface/datasets | pytorch | 7,018 | `load_dataset` fails to load dataset saved by `save_to_disk` | ### Describe the bug
This code fails to load the dataset it just saved:
```python
from datasets import load_dataset
from transformers import AutoTokenizer
MODEL = "google-bert/bert-base-cased"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
dataset = load_dataset("yelp_review_full")
def tokenize_functi... | open | 2024-07-01T12:19:19Z | 2024-12-03T11:26:17Z | https://github.com/huggingface/datasets/issues/7018 | [] | sliedes | 4 |
deepfakes/faceswap | machine-learning | 547 | intel phi card useful on this project? | Can I use intel phi card to make my training faster?Does this project support intel phi? | closed | 2018-12-12T06:04:56Z | 2018-12-12T11:47:03Z | https://github.com/deepfakes/faceswap/issues/547 | [] | bxjxxyy | 1 |
RomelTorres/alpha_vantage | pandas | 279 | Uncorrect dates | Hello!
alpha_vantage library:
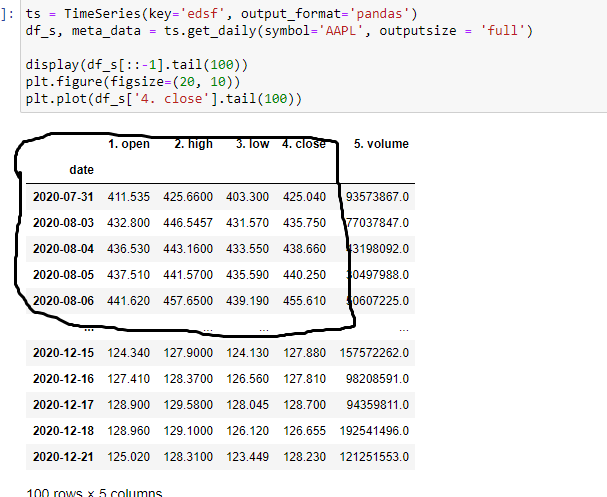
yfinance:
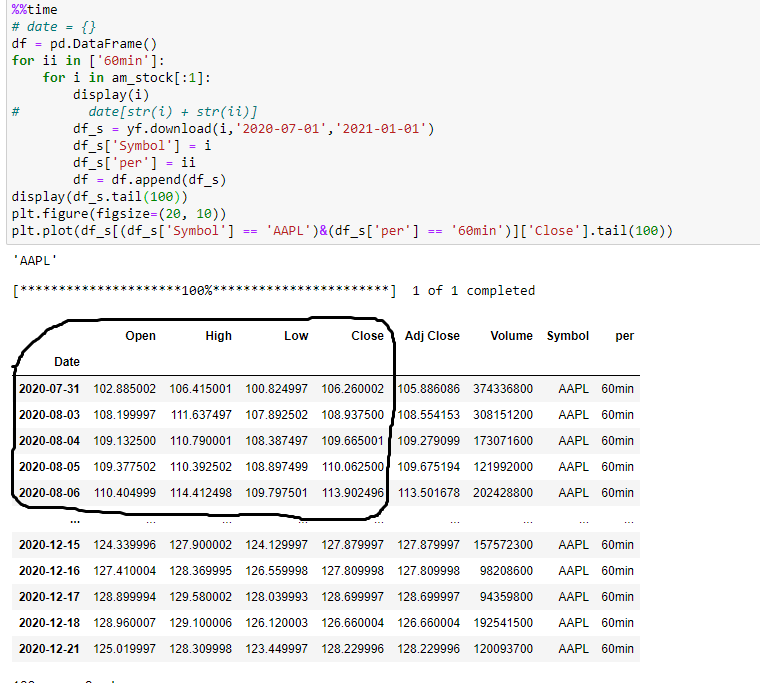
For example:
2020-07-31 | 102.885002 | 106.415001 | 10... | closed | 2020-12-22T07:45:01Z | 2020-12-22T15:13:33Z | https://github.com/RomelTorres/alpha_vantage/issues/279 | [] | Taram1980 | 1 |
AutoGPTQ/AutoGPTQ | nlp | 9 | bloom quantize problems | error info:
model.quantize([example])
File "/usr/local/lib/python3.7/dist-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/ansible/online/operator/udf_pod_git/chat-gpt/AutoGPTQ/auto_gptq/modeling/_base.py", line 189, in quantize
layer(layer_input, **addit... | closed | 2023-04-23T14:27:45Z | 2023-04-25T03:21:44Z | https://github.com/AutoGPTQ/AutoGPTQ/issues/9 | [] | hao-xyz | 4 |
ymcui/Chinese-LLaMA-Alpaca | nlp | 215 | 预测字符的速度与文档中宣称的不一致 | ### 问前必查项目
- [ ] 由于相关依赖频繁更新,请确保按照[Wiki](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki)中的相关步骤执行
- [ ] 我已阅读[FAQ章节](https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/常见问题)并且已在Issue中对问题进行了搜索,没有找到相似问题和解决方案
- [ ] 第三方插件问题:例如[llama.cpp](https://github.com/ggerganov/llama.cpp)、[text-generation-webui](https://github.c... | closed | 2023-04-27T09:11:48Z | 2023-05-12T01:49:25Z | https://github.com/ymcui/Chinese-LLaMA-Alpaca/issues/215 | [] | YulongXia | 6 |
robotframework/robotframework | automation | 4,762 | Unresolved library: CourseService.modules.courseServiceAPIHelper. Error generating libspec: Importing library 'CourseService.modules.courseServiceAPIHelper' failed: ModuleNotFoundError: No module named 'CourseService' Consider adding the needed paths to the "robot.pythonpath" setting and calling the "Robot Framework: C... | Hi I am getting this error in my robot class:
Unresolved library: CourseService.modules.courseServiceAPIHelper. Error generating libspec: Importing library 'CourseService.modules.courseServiceAPIHelper' failed: ModuleNotFoundError: No module named 'CourseService' Consider adding the needed paths to the "robot.pythonpa... | closed | 2023-05-11T07:11:22Z | 2023-05-31T22:33:34Z | https://github.com/robotframework/robotframework/issues/4762 | [] | vinayakvardhan | 1 |
ray-project/ray | python | 51,636 | [<Ray component: Core|RLlib|etc...>] No action space and observation space in MASAC algorithm in the tune_example | ### What happened + What you expected to happen
In tune_examples, when I use the multi-agent sac algorithm to tune the pendulm environment, there is no observation space and action space as I print them
### Versions / Dependencies
ray2.42.1 python 3.12.9. centos7
### Reproduction script
from torch import nn
from ... | open | 2025-03-24T09:11:44Z | 2025-03-24T09:11:44Z | https://github.com/ray-project/ray/issues/51636 | [
"bug",
"triage"
] | HaoningJiang-space | 0 |
ultralytics/yolov5 | deep-learning | 12,865 | Assertion Error : Image not found | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and [discussions](https://github.com/ultralytics/yolov5/discussions) and found no similar questions.
### Question
I am currently trying to train a yolov6 model in google colab and I am getting err... | closed | 2024-04-01T08:33:15Z | 2024-10-20T19:42:37Z | https://github.com/ultralytics/yolov5/issues/12865 | [
"question",
"Stale"
] | Cho-Hong-Seok | 5 |
nolar/kopf | asyncio | 164 | kopf can't post events | > <a href="https://github.com/olivier-mauras"><img align="left" height="50" src="https://avatars3.githubusercontent.com/u/1299371?v=4"></a> An issue by [olivier-mauras](https://github.com/olivier-mauras) at _2019-08-05 15:27:11+00:00_
> Original URL: https://github.com/zalando-incubator/kopf/issues/164
>
... | closed | 2020-08-18T19:57:50Z | 2022-10-12T05:13:34Z | https://github.com/nolar/kopf/issues/164 | [
"bug",
"archive"
] | kopf-archiver[bot] | 2 |
littlecodersh/ItChat | api | 314 | 怎么转发一个转发过来的消息? | ```python
@itchat.msg_register(SHARING)
def text_reply(msg):
msg.user.send(msg.Url.replace('&', '&'))
```
尝试过这样发送,但是发出去的消息收到是个url,怎么做才能有转发的效果呢? | closed | 2017-04-09T18:12:17Z | 2017-04-10T02:36:43Z | https://github.com/littlecodersh/ItChat/issues/314 | [] | tofuli | 1 |
xlwings/xlwings | automation | 1,830 | support python strftime format for range.number_format | The formatting of range in Excel is notoriously difficult to handle as it depends on the locale of the Excel application.
It would be nice to be able to support the standard python notation for datetime to format a range containing a datetime.
It is a matter of converting a string like "%m/%d/%y, %H:%M:%S" to e.g. "m... | open | 2022-02-12T13:25:01Z | 2022-02-14T12:53:28Z | https://github.com/xlwings/xlwings/issues/1830 | [] | sdementen | 2 |
netbox-community/netbox | django | 17,867 | Dropdowns for all forms appear empty after upgrade | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
v4.1.3
### Python Version
3.12
### Steps to Reproduce
1. Beginning on v3.7.8, add data (device roles, for example)
2. Upgrade to v4.1.3
3. Attempt to create a device using the previously created device role
### Ex... | closed | 2024-10-27T04:04:21Z | 2025-02-06T03:03:47Z | https://github.com/netbox-community/netbox/issues/17867 | [] | ethnt | 4 |
yt-dlp/yt-dlp | python | 12,219 | Youtube Cookie Issue | ### DO NOT REMOVE OR SKIP THE ISSUE TEMPLATE
- [x] I understand that I will be **blocked** if I *intentionally* remove or skip any mandatory\* field
### Checklist
- [x] I'm reporting that yt-dlp is broken on a **supported** site
- [x] I've verified that I have **updated yt-dlp to nightly or master** ([update instruc... | closed | 2025-01-28T01:05:53Z | 2025-02-17T07:33:01Z | https://github.com/yt-dlp/yt-dlp/issues/12219 | [
"duplicate",
"site-bug",
"site:youtube"
] | Bonboon229 | 8 |
roboflow/supervision | tensorflow | 1,218 | tflite with supervison | ### Search before asking
- [X] I have searched the Supervision [issues](https://github.com/roboflow/supervision/issues) and found no similar feature requests.
### Question
Hi, does supervsion support tflite detection results? If not, is there a way to convert tflite outputs to the Detections class format?
### Addi... | closed | 2024-05-21T15:38:18Z | 2024-11-02T17:22:19Z | https://github.com/roboflow/supervision/issues/1218 | [
"question"
] | abichoi | 4 |
aio-libs/aiopg | sqlalchemy | 105 | Why is only ISOLATION_LEVEL_READ_COMMITTED supported? | As the title states, I'm curious to know why the documentation states that only `ISOLATION_LEVEL_READ_COMMITTED` is supported.
**Edit:** I've just been looking at the `psycopg2` documentation. Would I be correct to assume that other isolation levels are actually supported, but **setting** them using the `set_isolation... | closed | 2016-02-14T21:52:31Z | 2016-02-17T13:35:34Z | https://github.com/aio-libs/aiopg/issues/105 | [] | TimNN | 2 |
davidteather/TikTok-Api | api | 311 | [BUG] - Getting "Access Denied" when trying to download user videos, only works with trending() method | I'm trying to download the videos for some specific TikTok user. When I do this, instead of the video file I get a "Access Denied" error like this:
```
Access Denied
You don't have permission to access "http://v16-web.tiktok.com/video/tos/useast2a/tos-useast2a-ve-0068c001/ba7ff9409cc74e98b41a20b81b999d4f/?" on thi... | closed | 2020-11-03T11:13:56Z | 2020-11-09T02:41:28Z | https://github.com/davidteather/TikTok-Api/issues/311 | [
"bug"
] | frankelia | 3 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 1,192 | ost vram | closed | 2023-04-14T22:03:24Z | 2023-04-14T22:03:41Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/1192 | [] | jhuebner79 | 0 | |
litestar-org/litestar | asyncio | 3,778 | Docs: SerializationPluginProtocol example is cut off | ### Summary
It seems the source has changed (https://docs.advanced-alchemy.litestar.dev/latest/reference/extensions/litestar/plugins/serialization.html#advanced_alchemy.extensions.litestar.plugins.serialization.SQLAlchemySerializationPlugin.supports_type) and the example is missing quite a bit:
<img width="915" a... | open | 2024-10-04T06:20:04Z | 2025-03-20T15:54:57Z | https://github.com/litestar-org/litestar/issues/3778 | [
"Documentation :books:",
"Help Wanted :sos:",
"Good First Issue"
] | JacobCoffee | 0 |
onnx/onnx | tensorflow | 6,295 | Build Error: Protobuf pinned version missing `<cstdint>` definition on its headers | # Bug Report
### Is the issue related to model conversion?
N/A
### Describe the bug
Have setup a C++ project that tries to build ONNX to make use of it as a library.
Using CMake and fetching the onnx repo fixing the v1.16.2.
It tries to compile onnx and its dependencies, but it throws an error while trying to... | closed | 2024-08-13T16:42:46Z | 2025-01-04T16:01:01Z | https://github.com/onnx/onnx/issues/6295 | [
"bug",
"topic: build"
] | lmariscal | 1 |
numpy/numpy | numpy | 28,384 | DOC: numpy.char.encode example is for numpy.strings.encode | ### Issue with current documentation:
The example for numpy.char.encode is the following
import numpy as np
a = np.array(['aAaAaA', ' aA ', 'abBABba'])
np.strings.encode(a, encoding='cp037')
### Idea or request for content:
Update for example of numpy.char.encode instead of np.strings.encode | closed | 2025-02-23T13:48:15Z | 2025-02-23T17:04:55Z | https://github.com/numpy/numpy/issues/28384 | [
"04 - Documentation"
] | mturnansky | 1 |
PokeAPI/pokeapi | graphql | 728 | Can't get sprites from graphql API | I'm making an app that needs to get the some data from all the pokemons, so i decided to use graphql for it, and while i was testing the web interface i noticed i am not able to get any sprite, the returned json from "sprites" has just null values.
My Query:
```graphql
query MyQuery {
pokemon_v2_pokemon(where: ... | closed | 2022-06-27T17:46:15Z | 2022-06-28T13:11:35Z | https://github.com/PokeAPI/pokeapi/issues/728 | [] | ZeroKun265 | 1 |
koxudaxi/datamodel-code-generator | fastapi | 1,423 | const fields and discriminators seem lost when using `--output-model-type pydantic_v2.BaseModel` flag | **Describe the bug**
const fields and discriminators seem ignored when using `--output-model-type pydantic_v2.BaseModel` flag.
**To Reproduce**
Example schema:
```json
{
"openapi": "3.1.0",
"info": { "title": "FastAPI", "version": "0.1.0" },
"paths": {
"/polymorphic_dict_response": {
"ge... | closed | 2023-07-12T14:24:24Z | 2023-08-24T08:23:43Z | https://github.com/koxudaxi/datamodel-code-generator/issues/1423 | [] | tomjelen | 1 |
deepfakes/faceswap | deep-learning | 1,296 | Faceswap Gui Crashes On Launch | Hello, I've been following the faceswap install guide as I had to start a new virtual environment again, but every-time I load up the gui it crashes. I've also tried to update everything, but nothing seems to be working and it takes me around in loops. I'm using a Mac on CPU, so it's probably a dinosaur here, but I'm h... | closed | 2023-01-17T12:07:09Z | 2023-01-20T13:05:03Z | https://github.com/deepfakes/faceswap/issues/1296 | [] | DrDreGFunk | 1 |
apache/airflow | data-science | 47,810 | Old asset is also displayed on the UI after updating the method name decorated by an asset decorator | ### Apache Airflow version
3.0.0
### If "Other Airflow 2 version" selected, which one?
_No response_
### What happened?
Old asset is also displayed on the UI after updating the method name decorated by an asset decorator
<img width="1707" alt="Image" src="https://github.com/user-attachments/assets/46de77aa-64a9-4... | closed | 2025-03-15T10:26:50Z | 2025-03-19T18:23:34Z | https://github.com/apache/airflow/issues/47810 | [
"kind:bug",
"priority:high",
"area:core",
"area:UI",
"area:datasets",
"area:task-execution-interface-aip72",
"area:task-sdk",
"affected_version:3.0.0beta"
] | atul-astronomer | 6 |
junyanz/pytorch-CycleGAN-and-pix2pix | computer-vision | 1,490 | CUDA version | I followed readme to install the environment but come across this issue "NVIDIA GeForce RTX 3080 Laptop GPU with CUDA capability sm_86 is not compatible with the current PyTorch installation.The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_61 sm_70 sm_75 compute_37."
I changed cuda version t... | open | 2022-10-06T14:23:59Z | 2024-03-12T03:11:53Z | https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/issues/1490 | [] | AriaZiyanYang | 2 |
nteract/papermill | jupyter | 568 | Papermill raises error for id field when running jupyter-notebook 6.2 with the -p flag | When running papermill v2.2.1 in an environment where jupyter-notebook v6.2 is installed I am seeing the following error when running with parameters (-p flag)
papermill notebook.ipynb outputs/notebook.ipynb -p my_config --no-progress-bar --log-output
Output:
```
[NbConvertApp] ERROR | Notebook JSON is invali... | closed | 2021-01-18T10:30:14Z | 2022-01-31T15:41:20Z | https://github.com/nteract/papermill/issues/568 | [] | malcolmbovey | 16 |
ageitgey/face_recognition | machine-learning | 730 | about clf file | * face_recognition version:
* Python version: 3.4
* Operating System: ubuntu 16.04
### Description
since .clf file is binary format, after recognising a face, i just want to extract its featuresof recognised face from clf file. so that one of requirement will get solved.
please suggest me in this, whether it's ... | open | 2019-01-29T10:46:54Z | 2019-01-29T10:46:54Z | https://github.com/ageitgey/face_recognition/issues/730 | [] | saideepthik | 0 |
apachecn/ailearning | python | 582 | 机器学习 | NULL | closed | 2020-04-09T04:03:19Z | 2020-04-09T04:07:10Z | https://github.com/apachecn/ailearning/issues/582 | [] | dabaozizhang | 0 |
iMerica/dj-rest-auth | rest-api | 301 | Auto refresh | Currently my rest api has a middleware where I create a cookie with the expiration date every time I login or refresh.
```python
from django.utils import timezone
from django.conf import settings
from rest_framework_simplejwt.settings import api_settings as jwt_settings
class CustomMiddleware(object):
def... | open | 2021-08-09T13:16:39Z | 2021-08-09T13:23:13Z | https://github.com/iMerica/dj-rest-auth/issues/301 | [] | lcsjunior | 0 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 292 | 用了tf.function修饰器就出现了警告 | WARNING:tensorflow:AutoGraph could not transform <bound method MyModel.call of <model.MyModel object at 0x00000172D60EA898>> and will run it as-is.
Please report this to the TensorFlow team. When filing the bug, set the verbosity to 10 (on Linux, `export AUTOGRAPH_VERBOSITY=10`) and attach the full output.
Cause: No ... | closed | 2021-06-05T16:05:53Z | 2021-06-07T05:35:38Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/292 | [] | dianjxu | 2 |
developmentseed/lonboard | data-visualization | 742 | [BUG] Panel tutorial is out of date with geopandas 1.X | ## Context
I was attempting to run this example: https://developmentseed.org/lonboard/latest/ecosystem/panel/#tutorial
## Resulting behaviour, error message or logs
The dataset referenced in the tutorial is no longer available inside of geopandas
```
raise AttributeError(error_msg)
AttributeError: The geopandas.d... | closed | 2025-02-04T23:25:52Z | 2025-02-06T23:10:29Z | https://github.com/developmentseed/lonboard/issues/742 | [
"bug"
] | j-carson | 6 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.