
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
sherlock-project/sherlock | python | 1,938 | Would modern versions of Sherlock still(?) work for iSH installations? | <!--
######################################################################
WARNING!
IGNORING THE FOLLOWING TEMPLATE WILL RESULT IN ISSUE CLOSED AS INCOMPLETE.
######################################################################
-->
## Checklist
<!--
Put x into all boxes (like this [x]) once you hav... | open | 2023-11-09T19:41:20Z | 2023-11-09T19:41:33Z | https://github.com/sherlock-project/sherlock/issues/1938 | [
"question"
] | GenowJ24 | 0 |
encode/databases | sqlalchemy | 222 | i have a question.when i test the process code , the service "/v1/test/" is very low. which can not suport high Concurrent access. | #!/usr/bin/env python
# -*- coding: utf-8 -*-
import asyncio
import uvicorn
from fastapi import FastAPI
import databases
from databases import Database
from asyncio import gather
from pydantic import BaseModel
from databases.core import Connection
app = FastAPI()
mysql_url = 'mysql://username:passwor... | open | 2020-06-19T09:07:36Z | 2020-06-19T09:07:36Z | https://github.com/encode/databases/issues/222 | [] | dtMndas | 0 |
PeterL1n/BackgroundMattingV2 | computer-vision | 27 | [mov,mp4,m4a,3gp,3g2,mj2 @ 0xc5867600] moov atom not found | I uploaded a video file and background image and tried using BackgroundMattingV2-VideoMatting.ipynb, but it gives me the following error:
[mov,mp4,m4a,3gp,3g2,mj2 @ 0xc5867600] moov atom not found
VIDIOC_REQBUFS: Inappropriate ioctl for device
0% 0/1 [00:00<?, ?it/s]Traceback (most recent call last):
File "in... | closed | 2021-01-01T16:38:36Z | 2022-06-21T16:32:39Z | https://github.com/PeterL1n/BackgroundMattingV2/issues/27 | [] | KinjalParikh | 3 |
fastapi-admin/fastapi-admin | fastapi | 9 | 404 not found | ```
app = FastAPI()
register_tortoise(
app,
config={
'connections': {
'default': 'sqlite://database.sqlite',
},
'apps': {
'models': {
'models': ['fastapi_admin.models', 'models'],
'default_connection': 'default',
... | closed | 2020-08-06T18:49:28Z | 2020-08-10T08:35:19Z | https://github.com/fastapi-admin/fastapi-admin/issues/9 | [
"question"
] | BezBartek | 2 |
hpcaitech/ColossalAI | deep-learning | 5,597 | [BUG]: pretraing llama2 using "gemini" plugin, can not resume from saved checkpoints | ### 🐛 Describe the bug
pretrain llama2-7b can resume when using "zero2" plugin, but can not resume when using "gemini" plugin, when using "gemini" plugin, the resume process will stuck, the cuda memory do not change in "nvtop" monitor.
### Environment
16 * 8 * H100
torch 2.0.0 | open | 2024-04-15T07:13:05Z | 2024-05-07T23:47:17Z | https://github.com/hpcaitech/ColossalAI/issues/5597 | [
"bug"
] | jiejie1993 | 1 |
sqlalchemy/alembic | sqlalchemy | 620 | Does alembic plan to add data migrations? | These ones: https://docs.djangoproject.com/en/2.2/topics/migrations/#data-migrations
I understand that it is not an easy thing to add, but probably out-of-the-box way to run data migrations in ["database reflection"](https://docs.sqlalchemy.org/en/13/core/reflection.html) mode?
Also, the docs say nothing about da... | closed | 2019-11-11T10:27:45Z | 2020-02-12T15:03:49Z | https://github.com/sqlalchemy/alembic/issues/620 | [
"question"
] | abetkin | 6 |
alteryx/featuretools | scikit-learn | 2,066 | Add IsLeapYear primitive | - This primitive determine the `is_leap_year` attribute of a datetime column | closed | 2022-05-11T20:07:11Z | 2022-06-22T13:50:14Z | https://github.com/alteryx/featuretools/issues/2066 | [
"good first issue"
] | gsheni | 0 |
serengil/deepface | machine-learning | 1,403 | [BUG]: Multipart-form data not being accepted | ### Before You Report a Bug, Please Confirm You Have Done The Following...
- [X] I have updated to the latest version of the packages.
- [X] I have searched for both [existing issues](https://github.com/serengil/deepface/issues) and [closed issues](https://github.com/serengil/deepface/issues?q=is%3Aissue+is%3Aclosed) ... | closed | 2024-12-19T04:58:09Z | 2024-12-19T11:20:44Z | https://github.com/serengil/deepface/issues/1403 | [
"bug",
"dependencies"
] | mr-staun | 3 |
sqlalchemy/alembic | sqlalchemy | 666 | Numeric fields with scale but no precision do not work as expected. | When defining a field in a model as `sa.Numeric(scale=2, asdecimal=True)` I expect the database to do the rounding for me, in this case with two decimal digits in the fractional part.
However if `scale` is given but no `precision` is given then `alembic` generates SQL resulting in ` price NUMERIC,`, **without the sc... | closed | 2020-02-26T17:55:54Z | 2020-02-26T18:21:16Z | https://github.com/sqlalchemy/alembic/issues/666 | [
"question"
] | wapiflapi | 2 |
lorien/grab | web-scraping | 119 | Queue backend tests fail some times | Example: https://travis-ci.org/lorien/grab/jobs/61755664
| closed | 2015-05-08T13:41:14Z | 2016-12-31T14:19:52Z | https://github.com/lorien/grab/issues/119 | [] | lorien | 1 |
facebookresearch/fairseq | pytorch | 5,154 | 10ms shift VS 320 upsample of hubert | https://github.com/facebookresearch/fairseq/blob/3f6ba43f07a6e9e2acf957fc24e57251a7a3f55c/examples/hubert/simple_kmeans/dump_mfcc_feature.py#L42
How can they align? | open | 2023-05-25T09:33:48Z | 2023-05-25T09:33:48Z | https://github.com/facebookresearch/fairseq/issues/5154 | [] | hdmjdp | 0 |
WZMIAOMIAO/deep-learning-for-image-processing | pytorch | 693 | Add new transformation class to save memory in training MaskRCNN | Hi. Thank you for the informative notebook:) For my environment(RTX2080 and RTX2080 super), I could not run even with small COCO dataset available from https://github.com/giddyyupp/coco-minitrain
So I cropped images with new `FixedSizeCrop` class added in `transforms.py`.
Then I could train model with no memory iss... | closed | 2022-11-20T00:54:05Z | 2022-11-20T04:42:36Z | https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/issues/693 | [] | r-matsuzaka | 2 |
explosion/spaCy | deep-learning | 13,223 | Example from https://spacy.io/universe/project/neuralcoref doesn't work for polish | ## How to reproduce the behaviour
Example from https://spacy.io/universe/project/neuralcoref works with english models:
```python
import spacy
import neuralcoref
nlp = spacy.load('en')
neuralcoref.add_to_pipe(nlp)
doc1 = nlp('My sister has a dog. She loves him.')
print(doc1._.coref_clusters)
doc2 = nlp... | closed | 2024-01-08T10:42:48Z | 2024-01-08T15:10:48Z | https://github.com/explosion/spaCy/issues/13223 | [
"feat / coref"
] | Zydnar | 1 |
floodsung/Deep-Learning-Papers-Reading-Roadmap | deep-learning | 129 | Is this repository maintained? How can us help you? | Hi, I am a freshman in the Deep Learning field. I love reading Deep Learning papers and your work likes the guide help me so much. But it seem so far from the last update.
Are there anyone maintain this project. If not, how can us help you? | open | 2020-12-02T03:43:32Z | 2020-12-03T15:27:42Z | https://github.com/floodsung/Deep-Learning-Papers-Reading-Roadmap/issues/129 | [] | damminhtien | 0 |
aio-libs/aiomysql | sqlalchemy | 504 | ENH: Remove show warnings when "forced" | Hi folks, i'm executing +/- 10k qps in a single process
I checked that i have a bottleneck here:
https://github.com/aio-libs/aiomysql/blob/2eb8533d18b3a231231561a3ac881ce334f01312/aiomysql/cursors.py#L478
could be possible include a parameter to forcely don't execute "SHOW WARNINGS" ?
this changed my app to r... | open | 2020-06-17T01:56:48Z | 2022-01-13T00:38:03Z | https://github.com/aio-libs/aiomysql/issues/504 | [
"enhancement"
] | rspadim | 1 |
ultralytics/ultralytics | computer-vision | 19,303 | How should i modify the YAML file of yolov8 default architecture | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi, I’d like to ask how I should modify the layers and parameters in the YOL... | closed | 2025-02-19T02:30:03Z | 2025-03-18T01:28:38Z | https://github.com/ultralytics/ultralytics/issues/19303 | [
"enhancement",
"question",
"detect"
] | karfong | 2 |
deepfakes/faceswap | machine-learning | 1,155 | Swap Model to convert From A->B to B->A | Hi,
I am trying to swap the model by passing -s argument, but the output gives the original mp4 file in return.
In short, the swap model does not swap.
The commad i am running,
This works ( A -> B)
python faceswap.py convert -i output/00099.mp4 -o output/ -m output/mo -al output/AA/alignments.fsa -w ffmpe
g
... | closed | 2021-06-04T05:33:13Z | 2021-06-04T14:41:35Z | https://github.com/deepfakes/faceswap/issues/1155 | [] | hasamkhalid | 1 |
google-research/bert | nlp | 933 | Too much Prediction Time | After training the Bert classification model it is taking 8 sec to predict.
I have following questions
1) is it because of loading time? If yes, can we load one time and use it for multiple inference.
2) Or is it because of computation time? If yes, what are possible way to reduce it?
3) If I use the quantization w... | open | 2019-11-22T17:01:16Z | 2019-11-22T17:01:16Z | https://github.com/google-research/bert/issues/933 | [] | hegebharat | 0 |
JaidedAI/EasyOCR | deep-learning | 1,121 | Training a custom model : how to improve accuracy? | Hello All,
I am trying to train a new model dedicated to french characters set and domain specific fonts set.
After a bunch of difficulties ;-) I managed to make the training and testing working!
I looked at the train.py code and as far as I understand:
- each training loop consumes 32 images (1 torch data batch)... | open | 2023-08-23T11:14:05Z | 2023-10-01T17:38:22Z | https://github.com/JaidedAI/EasyOCR/issues/1121 | [] | averatio | 1 |
apify/crawlee-python | automation | 1,111 | Integrate web automation tool `DrissionPage` | Would you plan to integrate DrissionPage (https://github.com/g1879/DrissionPage) as an alternative to the browser dependent flow? | open | 2025-03-20T17:31:55Z | 2025-03-24T10:50:37Z | https://github.com/apify/crawlee-python/issues/1111 | [
"t-tooling"
] | meanguins | 2 |
pytorch/pytorch | numpy | 149,462 | Avoid recompilation caused by is_mm_compute_bound | From @Elias Ellison
is_mm_compute_bound is just to avoid benchmarking cases where it is reliably unprofitable.
so in the case of dynamic we probably should just return keep it on and not guard.
Here is my proposal to address this
The benchmarking is on by default, we disable it iff some conditions are statically know... | open | 2025-03-18T23:30:28Z | 2025-03-24T10:37:49Z | https://github.com/pytorch/pytorch/issues/149462 | [
"triaged",
"oncall: pt2",
"module: dynamic shapes"
] | laithsakka | 0 |
peerchemist/finta | pandas | 48 | Should return type in signature be DataFrame when returning pd.concat()? | Great library, and I like your coding style.
In functions that return using the Pandas concat() function, the return type is currently specified as Pandas Series. Shouldn't it be DataFrame?
Example:
https://github.com/peerchemist/finta/blob/22460ba4a73272895ee162b0b8125988bbefe88c/finta/finta.py#L408
So shoul... | closed | 2019-12-30T22:56:47Z | 2020-01-11T11:59:46Z | https://github.com/peerchemist/finta/issues/48 | [] | BillEndow | 2 |
dgtlmoon/changedetection.io | web-scraping | 2,594 | Telegram notification | Docker Qnap nas.
When configuring the Telegram bot it always gives the same error, I have other dockers that notify by telegram bot and I don't have any problem.


I can see that the js library can be dark styled:
- https://github.com/josdejong/jsoneditor/blob/develop/examples/06_custom_styling.html
- https://github.com/josdejong/j... | open | 2024-10-24T18:46:42Z | 2025-01-21T13:44:00Z | https://github.com/holoviz/panel/issues/7441 | [
"type: enhancement"
] | MarcSkovMadsen | 0 |
paperless-ngx/paperless-ngx | django | 8,664 | [BUG] PAPERLESS_IGNORE_DATES is ignored | ### Description
Paperless ignores the date set in PAPERLESS_IGNORE_DATES.
The standard for dates is DMY (this only affects the order, it does not set the specific format like DDMMYYYY as far as I understand), as stated in the documentation. I have set my ignore date to "03-03-2005" but it still uses it as the creat... | closed | 2025-01-10T01:20:06Z | 2025-01-10T03:16:23Z | https://github.com/paperless-ngx/paperless-ngx/issues/8664 | [
"not a bug"
] | lx05 | 1 |
15r10nk/inline-snapshot | pytest | 116 | `Error: one snapshot has incorrect values (--inline-snapshot=fix)` is confusing when all tests pass | Again, thank you for inline-snaphots, we use it all the time and it's great.
I think use of the word "Error" is pretty confusing here:
<img width="772" alt="image" src="https://github.com/user-attachments/assets/73408bbb-aa3f-4eec-9508-6e47b72751cd">
If I understand this correctly, inline-snapshots is really j... | closed | 2024-09-21T15:01:20Z | 2024-09-24T09:20:52Z | https://github.com/15r10nk/inline-snapshot/issues/116 | [] | samuelcolvin | 3 |
jschneier/django-storages | django | 1,431 | [azure] Broken listdir | Since #1403 the logic of listdir was changed and this is not compatible with standard lib os.listdir. Do you plane do leave it as is or fix this behavior?
Issue occurs since v.1.14.4
thanx | open | 2024-07-11T08:24:51Z | 2025-01-21T07:59:56Z | https://github.com/jschneier/django-storages/issues/1431 | [] | marcinfair | 9 |
aiortc/aiortc | asyncio | 903 | RuntimeWarning: coroutine 'RTCSctpTransport._data_channel_flush' was never awaited | Trying to run `RTCDataChannel.send` in parallel and facing the error in the title.
What I want to do as a minimal reproducible example:
```python
import asyncio
def say_hi(num: int):
print(f"Hello {num}")
async def main():
loop = asyncio.get_running_loop()
tasks = []
for i in range(5):
... | closed | 2023-07-06T22:10:23Z | 2023-11-18T02:03:54Z | https://github.com/aiortc/aiortc/issues/903 | [
"stale"
] | vivere-dally | 1 |
roboflow/supervision | deep-learning | 1,114 | [DetectionDataset] - extend `from_coco` and `as_coco` with support for masks in RLE format | ### Description
The COCO dataset format allows for the storage of segmentation masks in two ways:
- Polygon Masks: These masks use a series of vertices on an x-y plane to represent segmented object areas. The vertices are connected by straight lines to form polygons that approximate the shapes of objects.
Run-Le... | closed | 2024-04-12T15:06:27Z | 2024-05-21T11:30:15Z | https://github.com/roboflow/supervision/issues/1114 | [
"enhancement",
"help wanted",
"api:datasets",
"Q2.2024"
] | LinasKo | 11 |
chiphuyen/stanford-tensorflow-tutorials | nlp | 84 | ValueError: Sample larger than population | i used python3.5 and tensorflow1.3 , I got below error while running data.py
I tried to edit random.py but it's read only
File "/usr/lib/python3.5/random.py", line 324, in sample
raise ValueError("Sample larger than population")
ValueError: Sample larger than population
how to fix it | open | 2017-12-30T11:14:25Z | 2018-01-30T23:02:51Z | https://github.com/chiphuyen/stanford-tensorflow-tutorials/issues/84 | [] | bandarikanth | 1 |
skypilot-org/skypilot | data-science | 4,853 | [Test] support run specific cases in sandbox in smoke test | The API server is shared globally in smoke test, but we also want to run some cases in isolated sandbox with its dedicated API server, e.g.:
> It is a bit complicated to run smoke test for --foreground since we need an isolated sandbox to avoid intervening other cases, for this PR, the test are done manually.
https:/... | open | 2025-02-28T06:04:23Z | 2025-03-05T02:22:07Z | https://github.com/skypilot-org/skypilot/issues/4853 | [
"api server"
] | aylei | 0 |
horovod/horovod | tensorflow | 3,119 | Spark Lightning MNIST fails on GPU | From buildkite.
```
/horovod/examples/spark/pytorch/pytorch_lightning_spark_mnist.py --num-proc 2 --work-dir /work --data-dir /data --epochs 3"' in service test-gpu-gloo-py3_8-tf2_4_3-keras2_3_1-torch1_7_1-mxnet1_6_0_p0-pyspark3_1_2 | 2m 46s
-- | --
| $ docker-compose -f docker-compose.test.yml -p buildkite27b2... | closed | 2021-08-18T18:00:13Z | 2021-08-19T17:10:12Z | https://github.com/horovod/horovod/issues/3119 | [
"bug"
] | chongxiaoc | 2 |
google/seq2seq | tensorflow | 297 | Ho wto initialize tables in my own model? | Hi, I created a new model based on the base model, and there are hashtables in my model that require table initialization. Where should I insert the tables_initializer command? Without table initialization, I'd always get the following error messasge:
FailedPreconditionError (see above for traceback): Table not init... | open | 2017-09-07T14:58:10Z | 2018-03-18T10:34:45Z | https://github.com/google/seq2seq/issues/297 | [] | anglil | 3 |
mwaskom/seaborn | matplotlib | 3,412 | seaborn.objects so.Plot() accept drawstyle argument | Currently there seems to be no way to do something like:
```
import pandas as pd
import seaborn.objects as so
dataset = pd.DataFrame(dict(
x=[1, 2, 3, 4],
y=[1, 2, 3, 4],
group=['g1', 'g1', 'g2', 'g2'],
))
p = (
so.Plot(dataset,
x='x',
y='y',
drawst... | closed | 2023-06-29T17:19:14Z | 2023-08-28T11:41:23Z | https://github.com/mwaskom/seaborn/issues/3412 | [] | subsurfaceiodev | 3 |
ultralytics/ultralytics | computer-vision | 19,553 | Build a dataloader without training | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
### Question
Hi. I would like to examine data in a train dataloader. How can I build one ... | closed | 2025-03-06T12:17:34Z | 2025-03-06T14:01:49Z | https://github.com/ultralytics/ultralytics/issues/19553 | [
"question",
"dependencies",
"detect"
] | daniellehot | 3 |
numpy/numpy | numpy | 27,937 | BUG: Incorrectly merged code in meson fork | ### Describe the issue:
I am working on numpy support for Nuitka-Python, a fully static, cross-platform, Python ecosystem. This means that I need to use the static library building functionality of meson that numpy typically wouldn't use.
I noticed that a section of static library code was not properly merged: http... | open | 2024-12-08T20:07:23Z | 2024-12-08T21:14:49Z | https://github.com/numpy/numpy/issues/27937 | [
"00 - Bug"
] | Maxwell175 | 1 |
glumpy/glumpy | numpy | 98 | TypeError in Hello world example | Here's the traceback when I tried to run the examples/hello-world.py using python3.5 in kubuntu zesty:
```
[i] Using GLFW (GL 4.5)
Traceback (most recent call last):
File "hello-world.py", line 22, in <module>
origin=(x,y,z), color=(1,1,1,1))
File "/usr/local/lib/python3.5/dist-packages/glumpy/graphics/... | closed | 2017-01-18T11:43:13Z | 2017-03-12T21:02:43Z | https://github.com/glumpy/glumpy/issues/98 | [] | lourenko | 3 |
PokeAPI/pokeapi | api | 499 | giratina is not a pokemon? | 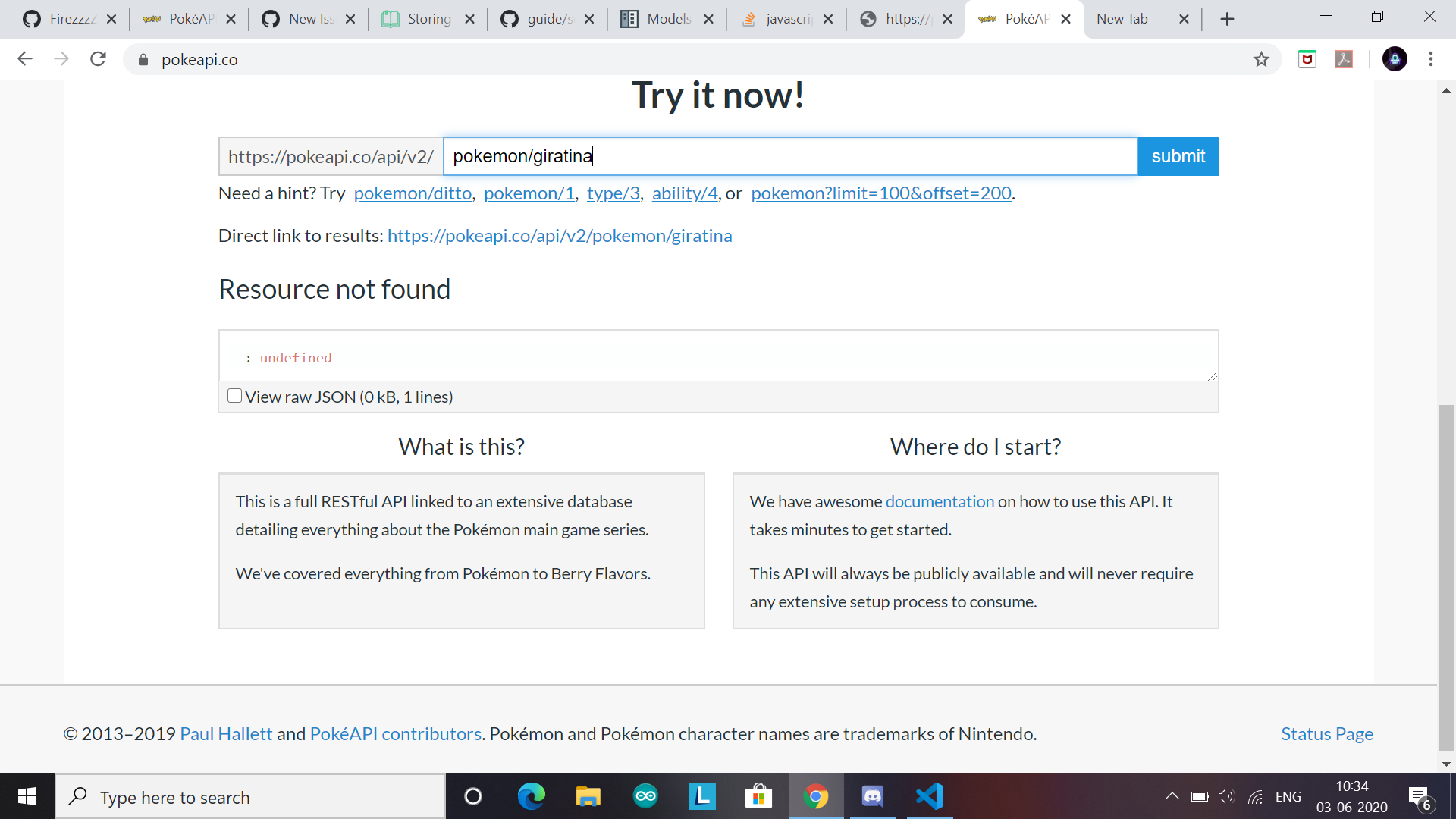
| closed | 2020-06-03T05:04:32Z | 2020-06-03T05:15:38Z | https://github.com/PokeAPI/pokeapi/issues/499 | [] | FirezTheGreat | 1 |
huggingface/transformers | machine-learning | 36,473 | Confusing behavior when loading PEFT models with pipeline | ### Feature request
Currently, when using transformers.pipeline to load a PEFT fine-tuned model (e.g., "ybelkada/opt-350m-lora"), the pipeline loads only the base model without applying the LoRA adapters. This behavior is misleading because users would expect to get the fine-tuned version of the model rather than just... | closed | 2025-02-28T05:52:24Z | 2025-03-03T18:01:44Z | https://github.com/huggingface/transformers/issues/36473 | [
"Feature request"
] | XEric7 | 3 |
widgetti/solara | jupyter | 411 | Does Solara has a time selection element ? | First of all, thank you for providing a great library.
I was going through the solara documentation - (https://solara.dev/api/input_date) but I could not find any option to selection of time.
Is there any option to do so via solara (where in I can select the time as well, and time ranges)
| open | 2023-12-02T05:21:16Z | 2023-12-03T10:09:23Z | https://github.com/widgetti/solara/issues/411 | [] | mobvarun | 2 |
autogluon/autogluon | computer-vision | 4,807 | Add instructions for development: Docstrings, etc. | We should communicate with contributors our project's docstring format, which is the numpy format: https://numpydoc.readthedocs.io/en/latest/format.html
If possible, we should make IDE's automatically detect this format when working with the AutoGluon project. I'm unsure if this is possible, but I suspect it is, maybe... | open | 2025-01-17T00:45:38Z | 2025-01-17T18:07:29Z | https://github.com/autogluon/autogluon/issues/4807 | [
"API & Doc",
"help wanted",
"discussion"
] | Innixma | 5 |
xlwings/xlwings | automation | 2,398 | Allow the `arg` decorator to be applied to `*args` | Currently, you can only use `xw.arg` or `server.arg` to set the converter for a single argument. It should allow to the the converter for `*args` also. | closed | 2024-02-19T21:08:01Z | 2024-02-22T14:04:55Z | https://github.com/xlwings/xlwings/issues/2398 | [
"UDFs",
"Server"
] | fzumstein | 1 |
kornia/kornia | computer-vision | 2,149 | output range of rgb_to_lab function | ### Describe the bug
the range of a b channel of Lab color space is from -128 to +127, see [this](https://opentextbc.ca/graphicdesign/chapter/4-4-lab-colour-space-and-delta-e-measurements/#:~:text=It%E2%80%99s%20comprised%20of%20three%20axes%3A%20L%20represents%20darkness%20to%20lightness%2C%20with%20values%20ranging%... | closed | 2023-01-16T05:16:43Z | 2023-01-22T14:54:11Z | https://github.com/kornia/kornia/issues/2149 | [
"help wanted",
"docs :books:",
"module: color"
] | gravitychen | 2 |
s3rius/FastAPI-template | asyncio | 1 | Add different databases support | For now, we have only PostgreSQL as a database. We need to add at least MS SQL Server, MySQL. | closed | 2020-11-13T12:50:12Z | 2021-08-30T01:24:29Z | https://github.com/s3rius/FastAPI-template/issues/1 | [] | s3rius | 1 |
benbusby/whoogle-search | flask | 334 | [BUG] 0.5.1 breaks some searches | **Describe the bug**
Only some searches ("libera drop account" e.g. `http://localhost:5000/search?q=libera+drop+account`) leads to an internal server error:
```
whoogle | ERROR:app:Exception on /search [GET]
whoogle | Traceback (most recent call last):
whoogle | File "/usr/local/lib/python3.8/site-packages... | closed | 2021-05-28T23:53:59Z | 2021-05-29T16:56:26Z | https://github.com/benbusby/whoogle-search/issues/334 | [
"bug"
] | mrckndt | 1 |
plotly/dash-bio | dash | 682 | Callbacks of ideogram's brush failing both as input and output elements | **Describe the bug**
I cannot use brush data neither as input nor as output of callbacks.
**To Reproduce**
My ideogram code is quite simple. It is as follows:
```
app = DjangoDash('Example', prevent_initial_callbacks= True)
app.layout = html.Div(children=[
dashbio.Ideogram(
id='ideogram-... | open | 2022-04-05T10:24:13Z | 2022-04-05T10:25:45Z | https://github.com/plotly/dash-bio/issues/682 | [] | asdrgil-dev | 0 |
microsoft/qlib | machine-learning | 1,036 | How to get optimal parameters for models? | ## ❓ Questions and Help
Qlib comes with some benchmarks models, such as XGBoost, examples for china stock market. And such models already come with some predefined parameters that, if I understood correctly, are optimal paramters.
However, if I modify the china dataset or use another dataset from a different stock ... | closed | 2022-04-07T03:13:02Z | 2022-07-13T21:02:12Z | https://github.com/microsoft/qlib/issues/1036 | [
"question",
"stale"
] | igor17400 | 4 |
pandas-dev/pandas | pandas | 60,616 | ENH: RST support | ### Feature Type
- [X] Adding new functionality to pandas
- [ ] Changing existing functionality in pandas
- [ ] Removing existing functionality in pandas
### Problem Description
I wish I could use ReStructured Text with pandas
### Feature Description
The end users code:
```python
import panda... | open | 2024-12-29T17:41:50Z | 2025-01-11T18:28:22Z | https://github.com/pandas-dev/pandas/issues/60616 | [
"Enhancement",
"Needs Triage"
] | R5dan | 4 |
graphdeco-inria/gaussian-splatting | computer-vision | 1,007 | Viewer Problem: How to release the GPU memory while loading next scene? | I wanted to load a new area data without closing the main window.
However when i loaded a area using 2G VRAM and tried to load a new area which need 1G VRAM,I found that it would cost more than 3GB (2GB + 1GB) VRAM rather than the 1G (2GB - 2GB + 1GB) VRAM i needed.
I changed the code in function loadNewArea in Gau... | open | 2024-10-09T14:57:55Z | 2024-10-09T14:59:25Z | https://github.com/graphdeco-inria/gaussian-splatting/issues/1007 | [] | anonymouslosty | 0 |
sinaptik-ai/pandas-ai | pandas | 1,402 | Unexpected results when generating graphs | ### System Info
**System info: pandasai version 2.2.15, Windows 10, Python 3.12.2, Azure OpenAI model gpt-4o-mini**
Hi,
I'm testing the library (By the way, great work!). I would like please to have your feedback on some tests that I've done.
My test consists to read an Excel file with sales data (this file come... | closed | 2024-10-21T14:44:15Z | 2024-12-16T11:32:49Z | https://github.com/sinaptik-ai/pandas-ai/issues/1402 | [] | Freddeb | 2 |
tableau/server-client-python | rest-api | 631 | Update Connection sample not working with BigQuery | I've run the sample for updating connection as written but it doesn't actually update the connection. I'm trying to move a BQ connection from a non-embedded to embedded by supplying username and password but while the sample completes successfully the connection on the server has nothing embedded. | closed | 2020-06-11T06:47:06Z | 2023-02-16T23:05:16Z | https://github.com/tableau/server-client-python/issues/631 | [
"help wanted",
"Server-Side Enhancement",
"document-api"
] | alexisnotonffire | 1 |
netbox-community/netbox | django | 18,987 | Loss of Object Properties When Editing with Restricted View Permissions | ### Deployment Type
Self-hosted
### NetBox Version
v4.2.5
### Python Version
3.12
### Steps to Reproduce
As Superuser:
1. Create site s1, devicetype dt1, device role dr1
3. Create Tag tag1
4. Create custom field cf1 with object type dcim>device
5. Create device device1 with tag1, tag2 and every required field (... | open | 2025-03-24T10:34:51Z | 2025-03-24T10:37:11Z | https://github.com/netbox-community/netbox/issues/18987 | [
"type: bug",
"status: needs triage"
] | julianstolp | 0 |
fastapi/sqlmodel | pydantic | 502 | Decoupling data schema from sql schema (pydantic integration) | ### First Check
- [X] I added a very descriptive title to this issue.
- [X] I used the GitHub search to find a similar issue and didn't find it.
- [X] I searched the SQLModel documentation, with the integrated search.
- [X] I already searched in Google "How to X in SQLModel" and didn't find any information.
- [X... | open | 2022-11-15T21:01:34Z | 2024-10-04T15:32:36Z | https://github.com/fastapi/sqlmodel/issues/502 | [
"question",
"investigate"
] | dmsfabiano | 9 |
seleniumbase/SeleniumBase | pytest | 2,106 | Chrome v117 Headless is Detected in UC Mode | This relates to https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1559. I'm attempting to log in to https://mobile.southwest.com in headless mode. While it works in Chrome 116 flawlessly, it isn't working in Chrome 117 (it works in headed mode though). I'm not sure what changed in Chrome 117, but som... | closed | 2023-09-13T17:48:23Z | 2023-09-13T22:02:06Z | https://github.com/seleniumbase/SeleniumBase/issues/2106 | [
"bug",
"UC Mode / CDP Mode"
] | jdholtz | 7 |
miguelgrinberg/Flask-Migrate | flask | 38 | Wrap new alembic commands | Alembic was just updated and received some new commands. Perhaps you should wrap them?
http://alembic.readthedocs.org/en/latest/changelog.html#change-4efddca1a4935691140cffea05fbb63c
| closed | 2014-11-27T16:39:38Z | 2014-12-01T02:52:16Z | https://github.com/miguelgrinberg/Flask-Migrate/issues/38 | [] | svenstaro | 2 |
influxdata/influxdb-client-python | jupyter | 516 | Add uint64 support to line protocol serializer | <!--
Thank you for suggesting an idea to improve this client.
* Please add a :+1: or comment on a similar existing feature request instead of opening a new one.
* https://github.com/influxdata/influxdb-client-python/issues?utf8=%E2%9C%93&q=is%3Aissue+is%3Aopen+is%3Aclosed+sort%3Aupdated-desc+label%3A%22enha... | closed | 2022-10-12T17:54:08Z | 2022-12-12T12:39:21Z | https://github.com/influxdata/influxdb-client-python/issues/516 | [
"enhancement"
] | drcraig | 4 |
ymcui/Chinese-BERT-wwm | nlp | 40 | 关于模型的tokenizer | 在pytorch版本中,载入bert-wwm,chinese的模型,调用 tokenizer.tokenize,得到的仍旧是以字为单位的分割,这个是否会导致使用的时候输入和模型不匹配,毕竟模型是wwm的 | closed | 2019-09-09T08:09:41Z | 2019-10-29T08:22:57Z | https://github.com/ymcui/Chinese-BERT-wwm/issues/40 | [] | 980202006 | 4 |
chatanywhere/GPT_API_free | api | 142 | 这个服务器是否支持openai的那种图片生成功能 | 这个服务器是否支持openai的那种图片生成功能。就是我们请求发送要求它给我们生成一些图片的话能成功生成吗? | closed | 2023-11-21T07:23:20Z | 2023-12-15T12:20:56Z | https://github.com/chatanywhere/GPT_API_free/issues/142 | [] | Lemondogdog | 1 |
s3rius/FastAPI-template | graphql | 175 | alembic upgrade "head" Error. | Error:
raise OSError(err, f'Connect call failed {address}')
ConnectionRefusedError: [Errno 111] Connect call failed ('127.0.0.1', 5432)
| closed | 2023-06-27T07:52:47Z | 2023-09-27T10:58:02Z | https://github.com/s3rius/FastAPI-template/issues/175 | [] | shpilevskiyevgeniy | 10 |
RobertCraigie/prisma-client-py | asyncio | 858 | Pydantic >2.0 makes `prisma generate` crash | Thank you for the awesome work on this project.
## Bug description
Prisma Generate fails when using Pydantic >2.0 because of a warning
## How to reproduce
* Step 1. In a project with an existing prisma.schema, install Prisma as well as Pydantic > 2.0.
* Step 2. Run `prisma generate`
Generation fails wi... | closed | 2023-12-19T05:08:53Z | 2024-02-15T23:08:12Z | https://github.com/RobertCraigie/prisma-client-py/issues/858 | [
"bug/2-confirmed",
"kind/bug",
"priority/high",
"level/unknown",
"topic: crash"
] | monarchwadia | 2 |
plotly/dash | plotly | 2,741 | [BUG] `dcc.Graph` inserts phantom rectangular shape on callback update seemingly randomly |
**Describe your context**
Please provide us your environment, so we can easily reproduce the issue.
- replace the result of `pip list | grep dash` below
```
dash 2.10.2
dash-ag-grid 2.3.0
dash-auth 2.0.0
dash-bootstrap-components 1.4.1
dash-... | closed | 2024-02-01T16:00:50Z | 2024-04-19T12:53:50Z | https://github.com/plotly/dash/issues/2741 | [
"bug",
"sev-4"
] | matt-sd-watson | 5 |
facebookresearch/fairseq | pytorch | 5,056 | bug in command-line tool "fairseq-score" when using the "--sentence-bleu" argument | ## 🐛 Bug
bug when using command-line tool "fairseq-score" with argument "--sentence-bleu"
### To Reproduce
Steps to reproduce the behavior (**always include the command you ran**):
1. Run cmd > fairseq-score -s sys -r ref --sentence-bleu
2. See error
#### Error messages
File "fairseq\fairseq_cli\... | open | 2023-04-04T06:25:29Z | 2024-07-07T08:00:24Z | https://github.com/facebookresearch/fairseq/issues/5056 | [
"bug",
"needs triage"
] | DragonMengLong | 1 |
dask/dask | pandas | 11,679 | dask shuffle pyarrow.lib.ArrowTypeError: struct fields don't match or are in the wrong orders | Hello, I met a problem when I shuffle the data among 160 dask partitions.
I got the error when each partition contains 200 samples. But the error is gone when it contains 400 samples or more. I really appreciate it if someone can help me.
```bash
pyarrow.lib.ArrowTypeError: struct fields don't match or are in the wrong... | open | 2025-01-17T22:27:22Z | 2025-03-24T02:06:10Z | https://github.com/dask/dask/issues/11679 | [
"dataframe",
"needs attention",
"bug",
"dask-expr"
] | MikeChenfu | 0 |
mljar/mercury | jupyter | 305 | Option to auto-update the URL | It could be nice to have an option to `app` to specify if you want to have the URL auto-updated after each time a user updates a field. This way, the URL is always up-to-date if you want to copy it. | open | 2023-06-01T14:37:36Z | 2023-06-02T06:37:18Z | https://github.com/mljar/mercury/issues/305 | [] | kapily | 3 |
huggingface/datasets | tensorflow | 6,565 | `drop_last_batch=True` for IterableDataset map function is ignored with multiprocessing DataLoader | ### Describe the bug
Scenario:
- Interleaving two iterable datasets of unequal lengths (`all_exhausted`), followed by a batch mapping with batch size 2 to effectively merge the two datasets and get a sample from each dataset in a single batch, with `drop_last_batch=True` to skip the last batch in case it doesn't ha... | closed | 2024-01-07T02:46:50Z | 2025-03-08T09:46:05Z | https://github.com/huggingface/datasets/issues/6565 | [] | naba89 | 2 |
TencentARC/GFPGAN | pytorch | 460 | AttributeError: Caught AttributeError in DataLoader worker process 0. AttributeError: 'NoneType' object has no attribute 'astype' subprocess.CalledProcessError: Command '['/home/liu/anaconda3/envs/pytorch-CycleGAN-and-pix2pix/bin/python', '-u', 'gfpgan/train.py', '-opt', 'options/train_gfpgan_v1.yml', '--launcher', 'py... | open | 2023-11-02T08:53:59Z | 2023-11-02T08:56:15Z | https://github.com/TencentARC/GFPGAN/issues/460 | [] | fengfenglong123 | 1 | |
mwaskom/seaborn | data-visualization | 3,522 | sns.catplot raises AttributeError: 'NoneType' object has no attribute 'get_legend_handles_labels' | Hey,
thanks for creating and maintaining this awesome package!
We have came across a feature which seems to not work in `0.13.0` anymore, but did so in `0.12.2` - maybe a bug, maybe me not having immediately grasped a changed usage.
**Reproducible Example**
```python
import seaborn as sns
import matplotlib.... | open | 2023-10-16T12:17:41Z | 2024-05-17T13:01:48Z | https://github.com/mwaskom/seaborn/issues/3522 | [] | eroell | 7 |
keras-team/keras | machine-learning | 20,754 | Problem with using masking in Embedding Layer for POS Tagging Model | Hello, I am training a Part-of-Speech (POS) tagging model . My model includes an Embedding layer with `mask_zero = True`
parameter to handle padding tokens. However, when I attempt to train the model, I encounter an error, but when I don't use masking the code works fine. I don't really know what am I doing wrong.
Than... | closed | 2025-01-13T18:50:37Z | 2025-02-07T22:16:16Z | https://github.com/keras-team/keras/issues/20754 | [
"type:Bug"
] | N0-Regrets | 7 |
aiortc/aiortc | asyncio | 531 | Get camera stream that is connected to the server instead of loopback | Can I achieve this with some code from example section? | closed | 2021-05-07T10:28:07Z | 2022-03-13T10:29:47Z | https://github.com/aiortc/aiortc/issues/531 | [
"invalid"
] | WinterOdin | 1 |
coqui-ai/TTS | deep-learning | 2,719 | [Bug] Tacotron2-DDC denial of service + bizarre behavior when input ends with "?!?!" | ### Describe the bug
Before I start, I just want to say this is funniest bug I've come across in my 20+ years of software development.
To keep the issue a bit more readable, I've put the audio uploads in detail tags. Click on the arrow by each sample to hear it.
---
Adding on `?!?!` to the end of a prompt u... | closed | 2023-06-28T15:58:21Z | 2023-06-29T11:36:26Z | https://github.com/coqui-ai/TTS/issues/2719 | [
"bug"
] | Qix- | 3 |
biolab/orange3 | numpy | 6,936 | Edit Domain: Converting to time fails on years < 1677 | **What's wrong?**
I am working with historical data, with my timeseries representing years. I have two problems:
1) When loading the data, the years are recognized as a Numeric column. Thus I have no option to define the format for datetime conversion. I'd like to specify these are years, not seconds.
2) The years g... | open | 2024-11-21T13:36:32Z | 2024-11-22T08:21:23Z | https://github.com/biolab/orange3/issues/6936 | [
"bug report"
] | ajdapretnar | 1 |
scikit-learn-contrib/metric-learn | scikit-learn | 170 | Add test coverage badge | Running pytest coverage on the package returned 94%, which I believe is a pretty good score (but we'll do even better :) )
So I think it would be good to have the badge on the README page | closed | 2019-02-15T08:19:39Z | 2019-03-12T13:18:13Z | https://github.com/scikit-learn-contrib/metric-learn/issues/170 | [] | wdevazelhes | 2 |
sktime/sktime | scikit-learn | 7,934 | [BUG] _StatsModelsAdapter breaks when `y`is a pd.Series with numeric name | **Describe the bug**
StatsModelsAdapter is breaking because the adapter is passing series with a numeric name (e.g. the integer 1). Then, statsmodels tries to add a suffix to the series names and fails.
**To Reproduce**
Running the unit tests highlighted in #7930, and every other statsmodels as highlighted in #7928.
... | open | 2025-03-03T13:41:02Z | 2025-03-03T13:51:22Z | https://github.com/sktime/sktime/issues/7934 | [
"bug"
] | felipeangelimvieira | 0 |
serengil/deepface | deep-learning | 859 | Build my face recognition with Deepface | Hello, i am using deepface to build a face recognition. My flow is using Dlib and Arcface to get embedding vector from only 1 frontal face image, then i store embedding vector to my database. I using cosine to find similar face with new embedding vector in my db. My problem is that with same person i have stored, when ... | closed | 2023-10-12T08:01:41Z | 2023-10-12T08:17:44Z | https://github.com/serengil/deepface/issues/859 | [
"question"
] | HoangSang1510 | 1 |
joerick/pyinstrument | django | 205 | ModuleNotFoundError: No module named 'pyinstrument.low_level.stat_profile' | version:pyinstrument 4.2.0 pypi_0 pypi
Python 3.7.13
from pyinstrument import Profiler
profiler = Profiler()
profiler.start()
...
profiler.stop()
profiler.print()
raise ModuleNotFoundError: No module named 'pyinstrument.low_level.stat_profile' | closed | 2022-07-28T03:47:04Z | 2022-11-05T11:54:10Z | https://github.com/joerick/pyinstrument/issues/205 | [] | wjunneng | 4 |
home-assistant/core | asyncio | 140,389 | PECO does not work with mandatory MFA | ### The problem
The PECO integration (via OPower) can no longer be setup because MFA cannot be disabled and is now mandatory for accounts. For Exelon companies like PECO, the docs currently state that MFA must be disabled for the integration to authenticate.
### What version of Home Assistant Core has the issue?
20... | closed | 2025-03-11T15:24:12Z | 2025-03-24T16:30:43Z | https://github.com/home-assistant/core/issues/140389 | [
"integration: opower"
] | steverep | 4 |
aleju/imgaug | machine-learning | 660 | aug_bbs coordinates | How to extract separately x1, x2, y1, y2 of augmented bounding box? | closed | 2020-05-07T09:24:07Z | 2020-05-07T09:29:02Z | https://github.com/aleju/imgaug/issues/660 | [] | SushiDay | 0 |
Textualize/rich | python | 3,172 | Typo in Portuguese README | I noticed a small typo in the Portuguese version of the README. I would like to contribute by fixing it. Can I do so and submit a pull request? | closed | 2023-10-28T19:53:17Z | 2023-10-30T17:17:13Z | https://github.com/Textualize/rich/issues/3172 | [] | DavdSamuel | 3 |
aio-libs/aiopg | sqlalchemy | 535 | Inner async for loop caused cursor already closed error | After upgrade to `aiopg==0.16.0` next pseudo-code caused `cursor already closed` `InterfaceError`,
```py
async def view(request: web.Request) -> web.Response:
async with request.app['db'].acquire() as conn:
data = await fetch_data(conn)
return web.json_response(convert_data(data))
async def f... | closed | 2019-02-01T15:20:02Z | 2021-03-22T10:49:34Z | https://github.com/aio-libs/aiopg/issues/535 | [
"bug"
] | playpauseandstop | 8 |
Zeyi-Lin/HivisionIDPhotos | machine-learning | 52 | 佬哥,可以不局限于人脸的识别抠图,比如动物抠图、宠物证件照也挺有需求的。 | open | 2024-09-05T06:48:09Z | 2024-09-05T07:53:02Z | https://github.com/Zeyi-Lin/HivisionIDPhotos/issues/52 | [] | bbbfishhh | 2 | |
AUTOMATIC1111/stable-diffusion-webui | deep-learning | 16,307 | [Bug]: Defaults in settings shows no changes when removing the last style | ### Checklist
- [ ] The issue exists after disabling all extensions
- [ ] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [ ] The issue has not been reported before... | open | 2024-08-01T08:24:50Z | 2024-08-01T18:23:52Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16307 | [
"bug-report"
] | MNeMoNiCuZ | 10 |
jonaswinkler/paperless-ng | django | 1,672 | [BUG] `imap_tools` is sending `UserWarning`s | <!---
=> Before opening an issue, please check the documentation and see if it helps you resolve your issue: https://paperless-ng.readthedocs.io/en/latest/troubleshooting.html
=> Please also make sure that you followed the installation instructions.
=> Please search the issues and look for similar issues before open... | closed | 2022-02-27T20:15:42Z | 2022-03-02T17:50:12Z | https://github.com/jonaswinkler/paperless-ng/issues/1672 | [] | jschpp | 1 |
jwkvam/bowtie | jupyter | 166 | use the latest bundle to serve the app | Bowtie serves the production bundle if it sees it, regardless of whether there's a more recent dev bundle. This can cause confusion if you've built a production bundle then modify behavior and run a dev build and not see the new behavior.
Solution: modify the flask route to use the newest bundle if both exist. | closed | 2017-11-21T01:03:51Z | 2018-02-01T05:56:41Z | https://github.com/jwkvam/bowtie/issues/166 | [
"good first issue"
] | jwkvam | 0 |
QingdaoU/OnlineJudge | django | 191 | Add Sample问题 | 在`Create Problem`中,想添加第二组 Sample 时候发现,那个`Add Sample`按钮不在 Sample 版块,而是被挪到了 Hint 版块下面,依稀记得在 6 月份的版本是没有这个 Bug 的,希望能及时修复一下! | closed | 2018-11-21T03:42:38Z | 2018-11-26T03:47:10Z | https://github.com/QingdaoU/OnlineJudge/issues/191 | [] | shuibinlong | 3 |
mithi/hexapod-robot-simulator | dash | 95 | Hexapod should twist when all femur joints are on the ground | <img width="1280" alt="Screen Shot 2020-05-29 at 2 56 48 AM" src="https://user-images.githubusercontent.com/1670421/83181979-382eb300-a158-11ea-9848-07afb640ed91.png">
| closed | 2020-05-28T18:58:24Z | 2020-06-22T21:00:20Z | https://github.com/mithi/hexapod-robot-simulator/issues/95 | [
"bug",
"wontfix"
] | mithi | 1 |
sinaptik-ai/pandas-ai | data-science | 955 | Regarding saving relative path in json reponse | ### System Info
MAC os.
### 🐛 Describe the bug
When i am passing query to user for creating graph it will show local file path response in that i want relative file path response. so please tell me for this what i have to do
smart_df = SmartDataframe(df, config={"llm": llm, "enable_cache": False, "... | closed | 2024-02-23T12:58:25Z | 2024-06-08T16:03:43Z | https://github.com/sinaptik-ai/pandas-ai/issues/955 | [] | shreya386 | 0 |
JoeanAmier/TikTokDownloader | api | 29 | 关于抖音搜索结果采集功能的说明 | # 输入格式
**格式:**`关键词` `类型` `页数` `排序规则` `时间筛选`
* 类型:`综合搜索` `视频搜索` `用户搜索`
* 排序规则:`综合排序` `最新发布` `最多点赞`
* 时间筛选:`0`:不限;`1`:一天内;`7`:一周内;`182`:半年内
参数之间使用空格分隔,`类型` 和 `排序规则` 支持输入中文或者对应索引,`页数` 和 `时间筛选` 仅支持输入整数。
程序采集的抖音搜索结果会储存至文件,不支持直接下载搜索结果作品;必须设置 `save` 参数,否则程序不会储存任何数据。
# 输入示例
**输入:**`猫咪`
**含义:** 关键词:`猫咪`;类... | closed | 2023-07-12T15:23:17Z | 2023-07-31T13:05:33Z | https://github.com/JoeanAmier/TikTokDownloader/issues/29 | [
"文档补充(docs)"
] | JoeanAmier | 0 |
jupyter/nbviewer | jupyter | 948 | 404 error not resolving | **Describe the bug**
I have a notebook that renders a 404, generally this clears in a day or so but I have one that still doesn't render (even with flush cache) after around 5 days. I've attempted removing and re-adding 3 times (this helped other notebooks that had this problem). Any clue if I'm missing something here... | closed | 2020-08-09T16:25:09Z | 2020-08-14T03:13:34Z | https://github.com/jupyter/nbviewer/issues/948 | [] | kaledev | 0 |
netbox-community/netbox | django | 18,259 | Server Error: <class 'AttributeError'>, 'VirtualMachine' object has no attribute 'oob_ip_id' | ### Deployment Type
Self-hosted
### Triage priority
N/A
### NetBox Version
v4.1.8
### Python Version
3.10
### Steps to Reproduce
1. Create a Virtual Machine
2. Create an Interface and attach it to VM
3. Assign IP Address to the Interface
4. Try to Edit the IP Address => Server Error
### Expected Behavior
... | closed | 2024-12-18T16:07:55Z | 2025-03-24T03:14:48Z | https://github.com/netbox-community/netbox/issues/18259 | [
"type: bug",
"status: duplicate"
] | lucafabbri365 | 2 |
CTFd/CTFd | flask | 2,366 | Test Translations & Support Spanish | We need to test translations before release and make sure we support Spanish | closed | 2023-07-14T15:18:06Z | 2023-07-19T04:33:31Z | https://github.com/CTFd/CTFd/issues/2366 | [] | ColdHeat | 0 |
open-mmlab/mmdetection | pytorch | 11,755 | Progress bar in in DetInferencer API | ```
from mmdet.apis import DetInferencer
inferencer = DetInferencer('rtmdet_tiny_8xb32-300e_coco')
result = inferencer('image.jpg')
```
The code shows a loading bar lke this:
Inference ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
how can I avoid printing it? | closed | 2024-05-30T06:46:44Z | 2025-03-06T13:04:16Z | https://github.com/open-mmlab/mmdetection/issues/11755 | [] | anisfakhfakh | 1 |
awesto/django-shop | django | 749 | Dropdown in the menu not expanding | Hi
I encountered the issue, while programming, that my dropdown menu in the shop (see picture):
is not expanding, showing my categories.
When navigating to a product, the breadcrumb shows the right path, a... | closed | 2018-09-10T13:00:04Z | 2018-09-14T19:43:59Z | https://github.com/awesto/django-shop/issues/749 | [] | markusmo | 3 |
ultralytics/ultralytics | pytorch | 19,336 | Yolo11 Performance Issues on Edge TPU: Stuck Display Window & Slow Inference Despite Correct Annotations | ### Search before asking
- [x] I have searched the Ultralytics YOLO [issues](https://github.com/ultralytics/ultralytics/issues) and [discussions](https://github.com/orgs/ultralytics/discussions) and found no similar questions.
Hello everyone,
I'm running a YOLO 11 detection model on an Edge TPU. Although the detec... | open | 2025-02-20T15:05:50Z | 2025-02-20T18:04:52Z | https://github.com/ultralytics/ultralytics/issues/19336 | [
"question",
"embedded",
"exports"
] | AlaaArboun | 2 |
pyro-ppl/numpyro | numpy | 1,276 | [FR] raise missing plate warning in MCMC inference | basically extend #1245 to be enforced more globally | closed | 2022-01-05T16:17:29Z | 2022-01-29T18:43:05Z | https://github.com/pyro-ppl/numpyro/issues/1276 | [
"enhancement"
] | martinjankowiak | 4 |
influxdata/influxdb-client-python | jupyter | 579 | The batch item wasn't processed successfully because: __init__() got an unexpected keyword argument 'method_whitelist' | ### Specifications
* Client Version: 1.24.0
* InfluxDB Version: 2.4
* Platform: python:3.9.13 docker container
### Code sample to reproduce problem
```python
points = ['mes,item=4432,name=n val=-8i 1685395248425443, 'mes,item=4432,name=n val=-19i 1685395248434435']
rite_api.write('bucket', 'org', points, write... | closed | 2023-05-29T21:31:23Z | 2023-07-28T05:07:29Z | https://github.com/influxdata/influxdb-client-python/issues/579 | [
"question"
] | ronytigo | 2 |
tqdm/tqdm | jupyter | 1,247 | requests.get example in README will not finish saving until the end of the same function | - [x] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [x] visual output bug
- [x] I have visited the [source website], and in particular
read the [known issues]
- [x] I have searched through the [issue tracker] for duplicates
- [x] I have mentioned version numbers, operating syste... | open | 2021-09-13T09:30:32Z | 2024-09-24T15:09:09Z | https://github.com/tqdm/tqdm/issues/1247 | [] | grimmerk | 1 |
tensorpack/tensorpack | tensorflow | 682 | TypeError:call() got an unexpected keyword argument 'scope' | Potential Bugs/Feature Requests/Usage Questions Only:
Any unexpected problems: __PLEASE ALWAYS INCLUDE__:
1. What you did:
+ If you're using examples:
+ What's the command you run:
+ Have you made any changes to code? Paste them if any:
+ If not, tell us what you did that may be relevant.
But we may no... | closed | 2018-03-02T08:11:42Z | 2018-05-30T20:59:38Z | https://github.com/tensorpack/tensorpack/issues/682 | [
"unrelated"
] | liuxiaowei199345 | 1 |
alteryx/featuretools | data-science | 2,269 | OSError: Timed out trying to connect to tcp://127.0.0.1:32832 after 30 s | Got an OSError after featuretools started for hours.
#### Part of traceback (cannot retrieve the whole log)
<details>
File "/home/zzz/.conda/envs/test/lib/python3.9/site-packages/distributed/utils.py", line 338, in sync
return sync(
File "/home/zzz/.conda/envs/test/lib/python3.9/site-packages/distribut... | closed | 2022-08-31T03:35:17Z | 2022-10-08T10:15:36Z | https://github.com/alteryx/featuretools/issues/2269 | [
"bug"
] | dehiker | 13 |
pytest-dev/pytest-selenium | pytest | 263 | Chromium support | I'm not sure if Chromium is supported at the moment – I could only see Chrome when selecting a driver. If it isn't, would it be possible to add support for Chromium too? | closed | 2021-02-22T10:22:29Z | 2021-02-27T10:49:37Z | https://github.com/pytest-dev/pytest-selenium/issues/263 | [] | GergelyKalmar | 7 |
iperov/DeepFaceLab | deep-learning | 5,368 | Change `tensorflow-gpu` to `tensorflow` | Hey there,
Wanted to check with you first, currently in `requirements-cuda.txt` we find `tensorflow-gpu=2.4.0` which if I am not mistaken is legacy, and `tensorflow=2.4.0` would just work as well, this is since tensorflow > 2.
I've wasted some time trying to set this up on linux, and this was one of the things th... | open | 2021-07-23T16:06:23Z | 2023-06-14T09:36:27Z | https://github.com/iperov/DeepFaceLab/issues/5368 | [] | Minkiu | 4 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.