
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
google-research/bert | nlp | 1,276 | How to evaluate the MLM-accuracy of the pre-trained models? | Hello all,
I am curious on what is the MLM-accuracy of my eval-set run on the pre-trained model that google-research provided. Specifically, the bert-large-uncased model. However, when trying to execute the `run_pretraining.py` script to evaluate the model, I encounter the following error:
```
tensorflow.python.... | open | 2021-11-10T09:49:22Z | 2021-11-10T09:49:22Z | https://github.com/google-research/bert/issues/1276 | [] | nikhildurgam95 | 0 |
graphql-python/graphene-sqlalchemy | graphql | 194 | Simplify installation and add tests to examples | We should replace requirements.txt with a Pipfile to make the installation of the [examples](https://github.com/graphql-python/graphene-sqlalchemy/tree/master/examples) even easier with Pipenv (the READMEs the should be adapted, too).
And we should add tests for the examples (e.g. running this [`default_query`](http... | open | 2019-03-31T10:39:29Z | 2019-04-01T00:43:37Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/194 | [
"enhancement"
] | Cito | 3 |
pallets-eco/flask-sqlalchemy | flask | 478 | `InvalidRequestError: Table … is already defined for this MetaData instance` (table inheritance on v2.2) | On Flask-SQLAlchemy 2.2 (Flask 0.12, SQLAlchemy 1.1.6, Python 3.5.3) I the following traceback that does not occur with Flask-SQLAlchemy 2.1:
```pytb
Traceback (most recent call last):
File "application.py", line 19, in <module>
class ChildA(Parent):
File "/home/user/project/venv/lib/python3.5/site-packa... | closed | 2017-03-01T21:04:41Z | 2020-07-24T13:31:47Z | https://github.com/pallets-eco/flask-sqlalchemy/issues/478 | [
"bug",
"tablename"
] | homeworkprod | 7 |
assafelovic/gpt-researcher | automation | 356 | Seperate Token Limit for Inferencing & Writing | I want the smart model (GPT 4 in my case) to be able to read large amounts of text ( > 4096 tokens), but the model has a limit of 4096 tokens for output. Can we get separate token limits for these? Since to get it to work, I have to set the smart token limit to 4096. My apologies if the smart model isn't used to read a... | closed | 2024-02-12T02:55:10Z | 2024-02-25T18:34:08Z | https://github.com/assafelovic/gpt-researcher/issues/356 | [] | murtaza-nasir | 2 |
unit8co/darts | data-science | 2,630 | [BUG] - TCNModel - save/load does not work anymore - darts [0.32.0] | **Describe the bug**
save/load does not work anymore when using TCNModel with weight_norm=True, Pytorch ask for model.state_dict()
probably related to this update
Replaced the deprecated torch.nn.utils.weight_norm function with torch.nn.utils.parametrizations.weight_norm. [#2593](https://github.com/unit8co/da... | closed | 2024-12-22T02:48:49Z | 2025-03-05T13:39:43Z | https://github.com/unit8co/darts/issues/2630 | [
"bug",
"triage"
] | forklife | 2 |
Kludex/mangum | fastapi | 295 | Question: How does one keep state between AWS Lambda cold starts? | Hi, I hope this is the right place for questions.
To work on an example, I have an app that needs to fetch a JWKS from another remote, where would I store that so I don't have to fetch the JWKS on each request? Is this a place for a `global` initializer in the lifespan on startup? Is there another "trick" or am I b... | closed | 2023-05-15T18:35:34Z | 2023-11-04T17:36:16Z | https://github.com/Kludex/mangum/issues/295 | [] | pkucmus | 5 |
gunthercox/ChatterBot | machine-learning | 2,292 | Chatbot | closed | 2023-02-17T06:33:19Z | 2023-02-23T04:54:06Z | https://github.com/gunthercox/ChatterBot/issues/2292 | [] | karishmakhan05 | 0 | |
tqdm/tqdm | pandas | 723 | Use setuptools setup.cfg (a declarative way to provide metadata to `setup`) to store metadata and import the text files | depends on #721 | closed | 2019-04-26T08:00:49Z | 2019-05-09T20:36:12Z | https://github.com/tqdm/tqdm/issues/723 | [] | KOLANICH | 1 |
google-research/bert | nlp | 1,083 | Adding custom domain words and abbreviations to vocab.txt | Hi i am working on adding a few terms from my domain to the vocab.txt. I am working with the multi language cased pre-trained model 'multi_cased_L-12_H-768_A-12' . However i am unsure of what words should be added. So my question is should the new words added to the [unused X] lines be words not found in the english di... | open | 2020-05-13T06:24:30Z | 2020-09-25T14:23:06Z | https://github.com/google-research/bert/issues/1083 | [] | saklanipankaj | 1 |
d2l-ai/d2l-en | pytorch | 1,741 | remove all `torch.no_grad():` | I don't think it is necessary, but there are still multiple notebooks containing this sentence:
```
(base) $ ack no_grad
chapter_linear-networks/linear-regression-scratch.md
308: with torch.no_grad():
387: with torch.no_grad():
chapter_convolutional-neural-networks/lenet.md
355: with torch... | closed | 2021-05-08T21:20:27Z | 2021-06-02T19:42:56Z | https://github.com/d2l-ai/d2l-en/issues/1741 | [] | mli | 2 |
sanic-org/sanic | asyncio | 2,169 | Production and development modes (default workers) | While it is possible to specify these individual features by hand, I would rather see a simple mode flag to get sensible defaults:
- Production: no access logs, workers=os.cpu_count()
- Development: debug, access logs, auto-reloader
Sanic server by default runs with a single worker process and doesn't enable featu... | closed | 2021-06-17T16:53:43Z | 2021-11-07T19:39:03Z | https://github.com/sanic-org/sanic/issues/2169 | [
"feature request",
"RFC"
] | Tronic | 14 |
mirumee/ariadne | graphql | 931 | `https://<api_host>/graphql` results in 307 redirect to `http` | ### Context
When using `https://<api_host>/graphql` endpoint instead of `https://<api_host>/graphql/` Ariadne sends a `307` redirect to the trailing-slash one.
### Expected behavior
Initial scheme (`http` or `https`) should be respected in the redirect
### Actual behavior
You get always redirected to `ht... | closed | 2022-09-20T09:45:57Z | 2022-10-07T17:57:53Z | https://github.com/mirumee/ariadne/issues/931 | [
"question"
] | liqwid | 3 |
jupyterhub/zero-to-jupyterhub-k8s | jupyter | 2,854 | Server culling along with the PVC in GKE | ```
cull:
enabled: true
users: false # --cull-users
removeNamedServers: false # --remove-named-servers
timeout: 3600# --timeout
every: 1800# --cull-every
concurrency: 10 # --concurrency
maxAge: 12 # --max-age
```
I am using this configuration for IDLE-CULLER
I want my server to shutdown when ... | closed | 2022-08-26T18:57:01Z | 2022-08-27T15:34:09Z | https://github.com/jupyterhub/zero-to-jupyterhub-k8s/issues/2854 | [
"bug"
] | franklin-degirum | 1 |
KaiyangZhou/deep-person-reid | computer-vision | 117 | is there a document which explain the project? | closed | 2019-03-01T07:54:01Z | 2019-05-09T23:00:41Z | https://github.com/KaiyangZhou/deep-person-reid/issues/117 | [
"new_feature"
] | chanajianyu | 3 | |
lux-org/lux | pandas | 338 | Lux Installed correctly but wont produce visualizations | **Describe the bug**
Lux installed but the Toggle/Pandas/Lux bottom does not produce visualizations as seen in screen shot.
**Screenshots**
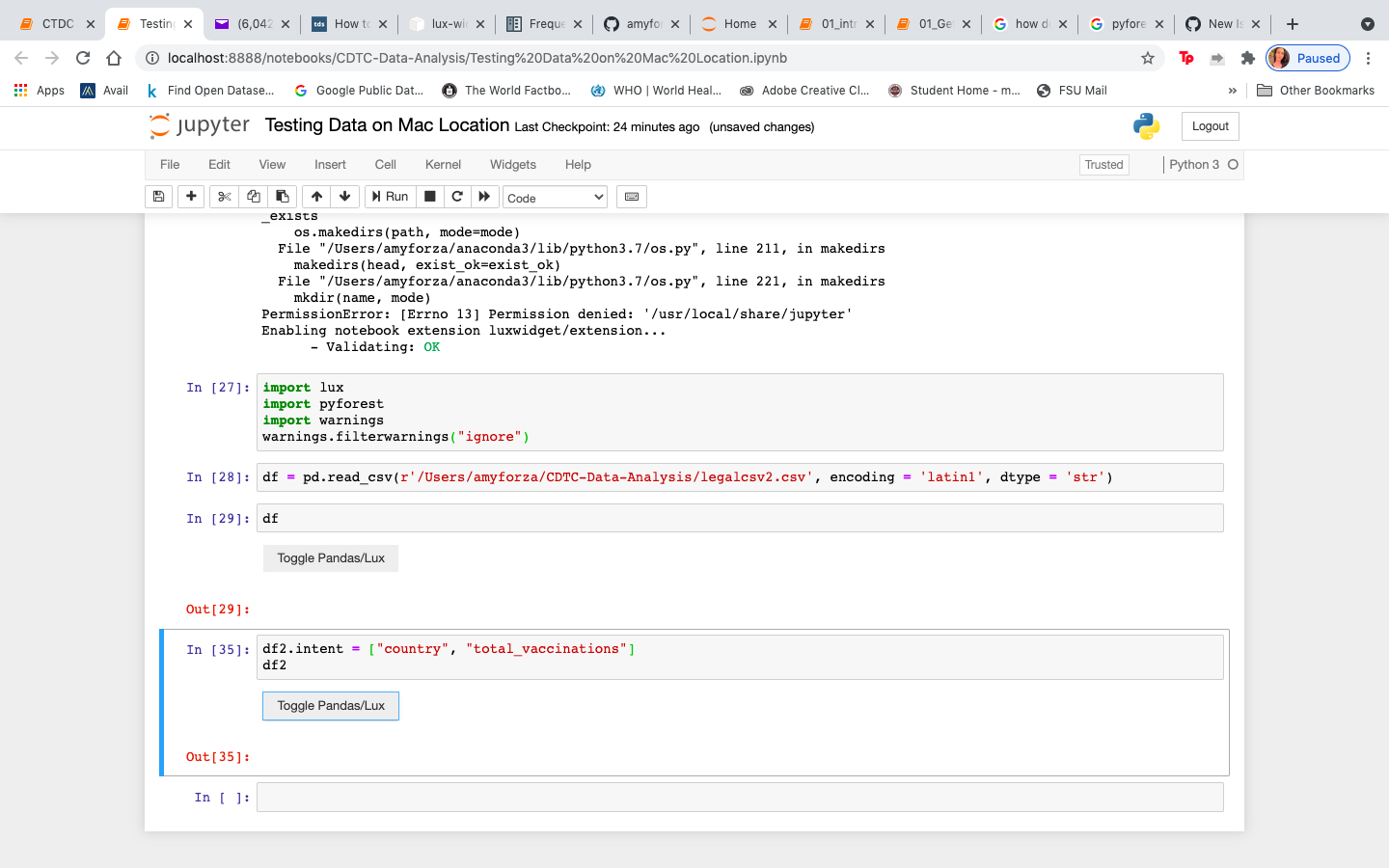
| closed | 2021-04-02T17:10:32Z | 2021-08-09T16:06:47Z | https://github.com/lux-org/lux/issues/338 | [] | amyforza | 6 |
wagtail/wagtail | django | 12,214 | Incorrect positioning and appearance of comment buttons with TimeField and DateTimeFields | ### Issue Summary
There are two, possibly related issues here.
`TimeField` and `DateTimeField`s show comment buttons below the field rather than beside the field:

`TimeField` and `DateTimeField`s in an `Orderable` (inl... | closed | 2024-08-07T13:43:35Z | 2025-01-13T12:17:58Z | https://github.com/wagtail/wagtail/issues/12214 | [
"type:Bug",
"component:Panels"
] | dkirkham | 5 |
gevent/gevent | asyncio | 1,668 | Possibly more graceful ERRNO (11) EAGAIN handling? | * gevent version: 20.6.2
* gunicorn version: 20.0.4
* Flask Version: 1.1.2
* Python version: Heroku cPython 3.8.5
* Operating System: Heroku-18 Stack (Ubuntu 18.4) [Here is the DockerFile if that is helpful](https://github.com/heroku/stack-images/tree/main/heroku-18)
### Description:
We have a web applicatio... | closed | 2020-09-09T16:38:08Z | 2020-12-08T13:14:55Z | https://github.com/gevent/gevent/issues/1668 | [] | compyman | 8 |
feature-engine/feature_engine | scikit-learn | 379 | Allow discretisers to output bins as user defined strings instead of integers or boundaries. | I suggest some new functionality in class
`class feature_engine.discretisation.EqualFrequencyDiscretiser(variables=None, q=10, return_object=False, return_boundaries=False)`
now q is integer type, but it can e defined as list with strings like:
`
q=['very_low','low','medium','high','very_high']`
Number of b... | open | 2022-02-22T07:23:44Z | 2022-05-09T07:36:29Z | https://github.com/feature-engine/feature_engine/issues/379 | [] | PeterPirog | 5 |
microsoft/MMdnn | tensorflow | 69 | [GAN support] how to convert from tensorflow to keras | Thank you for a great covert tool!
I want to convert tensorflow model to keras model.
However, the following error occurred.
Platform:ubuntu 16.04
Python version:2.7.12
Source framework with version :Tensorflow 1.3.0 with GPU
Destination framework with version :keras with 2.1.3
Pre-trained model path :https://... | open | 2018-02-06T03:37:54Z | 2018-02-07T02:48:37Z | https://github.com/microsoft/MMdnn/issues/69 | [
"enhancement",
"help wanted"
] | nenoNaninu | 1 |
pydata/pandas-datareader | pandas | 599 | Adding get_symbols_list method to base class ... | Am having a look at various methods here, possibly fixing some things. Along the way I've noticed there really aren't many sources that have what I like to call an "arg-gen" method that might yield the list of symbols or datasets query-able by the class. Is this something that has been avoided due to worries of abuse?
... | open | 2018-12-08T17:11:22Z | 2019-09-18T08:06:45Z | https://github.com/pydata/pandas-datareader/issues/599 | [] | cottrell | 1 |
aimhubio/aim | data-visualization | 2,374 | UI hangon searching for runs | ## 🐛 Bug
<!-- A clear and concise description of what the bug is. -->
Unable to display runs or any kind of information from Aim running on a remote server.
The /runs page is stuck on "Searching over runs..." with "34 of 34 checked ------ 33 matched run(s)"
There's an error in the console log:
> encoder.... | closed | 2022-11-22T16:11:38Z | 2022-11-24T17:03:02Z | https://github.com/aimhubio/aim/issues/2374 | [
"type / bug",
"help wanted",
"phase / ready-to-go",
"area / Web-UI"
] | Natlem | 5 |
adamerose/PandasGUI | pandas | 226 | Zoom +- support | it could be great to zoom in-out. on hotkeys, buttons or through kwarg passed to show().
| closed | 2023-05-07T14:43:04Z | 2024-07-31T13:05:27Z | https://github.com/adamerose/PandasGUI/issues/226 | [
"enhancement"
] | slavanorm | 0 |
sunscrapers/djoser | rest-api | 220 | Add logging | We should have overridable logging defined for each action. | open | 2017-07-28T17:25:54Z | 2019-01-24T14:34:37Z | https://github.com/sunscrapers/djoser/issues/220 | [] | pszpetkowski | 0 |
twopirllc/pandas-ta | pandas | 475 | AttributeError: 'Int64Index' object has no attribute 'to_period' | **Which version are you running? The lastest version is on Github. Pip is for major releases.**
```
0.3.14b0
```
**Do you have _TA Lib_ also installed in your environment?**
```
yes
```
**Describe the bug**
```sh
/pandas_ta/overlap/vwap.py:23
21 # Calculate Result
22 wp = typical_price * volum... | closed | 2022-01-30T20:09:26Z | 2022-02-02T19:07:53Z | https://github.com/twopirllc/pandas-ta/issues/475 | [
"info"
] | rava-dosa | 3 |
akfamily/akshare | data-science | 5,839 | stock_board_industry_cons_em分页处理 | stock_board_industry_cons_em这个接口只能返回100行数据,还没有被修复。 | closed | 2025-03-10T12:37:16Z | 2025-03-10T13:11:48Z | https://github.com/akfamily/akshare/issues/5839 | [
"bug"
] | yuhorun | 2 |
manrajgrover/halo | jupyter | 186 | there is logical bug in code | <!-- Please use the appropriate issue title format:
BUG REPORT
Bug: MemoryError occurs when handling long text in Halo package
SUGGESTION
Suggestion: {Short description of suggestion}
The root cause is in the _get_text method of the halo.py file, specifically in the following conditional statemen... | open | 2024-11-04T14:50:29Z | 2024-11-04T14:51:50Z | https://github.com/manrajgrover/halo/issues/186 | [] | kim2002zz | 1 |
chaos-genius/chaos_genius | data-visualization | 305 | Add Day Of Week to Datetime in Anomaly Chart Tooltip | Day of week is needed in the Datetime display on the tooltip for Anomaly Charts. This can provide quick reference needed to identify weekly changes
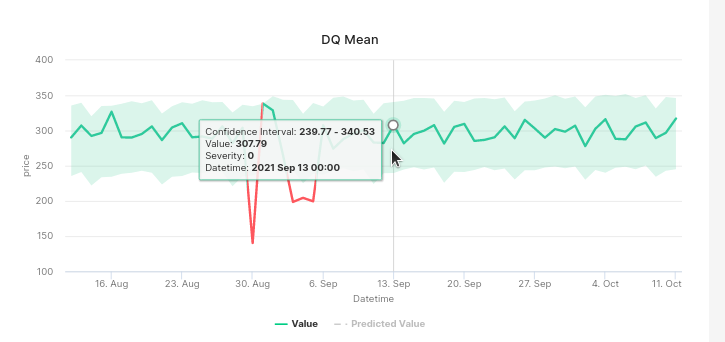 | closed | 2021-10-12T13:10:39Z | 2021-10-13T11:19:26Z | https://github.com/chaos-genius/chaos_genius/issues/305 | [
"✨ enhancement",
"🖥️ frontend"
] | Fletchersan | 0 |
SYSTRAN/faster-whisper | deep-learning | 931 | For audio with a sample rate of 16kHz | For audio with a sample rate of 16kHz, does faster-whisper translate more accurately than other sample rates? thanks! | closed | 2024-07-25T08:05:18Z | 2024-07-29T06:58:24Z | https://github.com/SYSTRAN/faster-whisper/issues/931 | [] | joseph16388 | 2 |
PokeAPI/pokeapi | api | 410 | New Java wrapper | Hi! I'm opening this issue to have my new Java wrapper linked into the documentation page, as Naramsim told me via e-mail.
Repo: https://github.com/iAmGio/pokedex-java-api
It supports Pokémon only at the moment, other components such as Berries will be supported as soon as possible.
Thanks!
| closed | 2019-01-24T16:10:55Z | 2019-06-22T22:49:08Z | https://github.com/PokeAPI/pokeapi/issues/410 | [] | iamgio | 2 |
Anjok07/ultimatevocalremovergui | pytorch | 1,171 | Delete | Delete the audio that was just processed here, thanks | closed | 2024-02-16T12:34:32Z | 2024-02-16T13:26:17Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1171 | [] | xiaokecai | 0 |
davidsandberg/facenet | tensorflow | 956 | Accuracy reaching 100% | @davidsandberg
I am training on my own dataset, 92 classes approx. 15 images per class, using softmax loss but the training accuracy is reaching 100%. this is very unusual. There must be something very fishy going on. Can you point me to the right direction? | open | 2019-01-21T09:24:02Z | 2019-01-24T09:56:53Z | https://github.com/davidsandberg/facenet/issues/956 | [] | taureanamir | 4 |
writer/writer-framework | data-visualization | 230 | use poetry instead of setup tools as package manager | The migration to poetry is done in an iso-functional way. The goal is to automate the management of the development environment and fix dev dependencies to make working together easier.
[more about why I advocate to use poetry as packaging system](https://dev.to/farcellier/i-migrate-to-poetry-in-2023-am-i-right--115... | closed | 2024-02-07T07:13:27Z | 2024-02-11T06:40:29Z | https://github.com/writer/writer-framework/issues/230 | [
"enhancement"
] | FabienArcellier | 0 |
cvat-ai/cvat | pytorch | 8,886 | "docker-compose up" got error... | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. git clone http://192.168.1.122:5000/polonii/cvat
### Expected Behavior
_No response_
### Possible Solution
_No respo... | closed | 2024-12-28T20:54:39Z | 2024-12-28T20:55:02Z | https://github.com/cvat-ai/cvat/issues/8886 | [
"bug"
] | PospelovDaniil | 0 |
milesmcc/shynet | django | 136 | Preserve date range across pages | Currently, if I set a custom date range in the dashboard and then select one of my services, that date range is lost. Same for going from service page to sessions page.
I think it would be a better user experience if the `startDate=2021-4-21&endDate=2021-4-22` query parameters were passed to pages that can use that... | closed | 2021-05-06T15:47:02Z | 2021-05-14T16:25:47Z | https://github.com/milesmcc/shynet/issues/136 | [] | CasperVerswijvelt | 0 |
snarfed/granary | rest-api | 57 | test_app fails because of messed up sys.path | running `python -m unittest granary.test.test_source test_app.AppTest.test_url_activitystreams_to_json_mf2` fails because it thinks `import app` refers to `~/oauth-dropins/app.pyc` ... how did oauth-dropins get on the path at all??
I suspect the culprit is `webutil.handlers` which calls:
```
from google.appengine.ext... | closed | 2015-11-17T07:14:08Z | 2015-11-17T16:24:06Z | https://github.com/snarfed/granary/issues/57 | [] | karadaisy | 3 |
custom-components/pyscript | jupyter | 687 | Detected blocking call to open with args ('/usr/local/lib/python3.13/site-packages/pytz/zoneinfo/Africa/Abidjan', 'rb') | I am getting this warning which suggests to file a bug here. Running the latest HA Version 2025.1.3. Any advice what to do? Thanks!
```
2025-01-21 23:04:59.386 WARNING (MainThread) [homeassistant.util.loop] Detected blocking call to open with args ('/usr/local/lib/python3.13/site-packages/pytz/zoneinfo/Africa/Abidjan'... | closed | 2025-01-21T22:09:29Z | 2025-01-26T14:17:31Z | https://github.com/custom-components/pyscript/issues/687 | [] | redlefloh | 6 |
mjhea0/flaskr-tdd | flask | 34 | Refactor out jQuery for vanilla JS | closed | 2018-02-05T12:53:34Z | 2018-05-08T19:10:48Z | https://github.com/mjhea0/flaskr-tdd/issues/34 | [] | mjhea0 | 0 | |
MaxHalford/chime | streamlit | 5 | Add a `chime` command for cli usage | Cool library!
Would be great if we named the command so you could call the script from the command line using
```sh
% chime
```
instead of having to use
```sh
% python -m chime
```
This would also allow users to install the library using installers like [pipx](https://github.com/pipxproject/pipx) if ... | closed | 2020-11-13T01:44:06Z | 2020-11-14T04:41:23Z | https://github.com/MaxHalford/chime/issues/5 | [] | paw-lu | 8 |
matplotlib/mplfinance | matplotlib | 71 | Logarithmic Axis plot for candlestick figure | is there any feature for mplfinance to change the vertical axis from linear to logarithmic? | closed | 2020-03-28T09:58:16Z | 2020-03-29T01:26:53Z | https://github.com/matplotlib/mplfinance/issues/71 | [] | mstfox | 1 |
widgetti/solara | jupyter | 971 | have use_reactive work like use_state | `use_reactive` can trigger on_value on a re-render, which can trigger an infinite render loop
See https://github.com/widgetti/solara/issues/472
Documented https://github.com/widgetti/solara/commit/021c2e898909f35fb51bce5af1ab415fca390033
Demo:
https://py.cafe/snippet/solara/v1?#c=H4sIAB4iiWcEA3VWbWvjRhD-K8L3xYFIWLLjOA... | open | 2025-01-16T15:20:11Z | 2025-01-16T15:20:53Z | https://github.com/widgetti/solara/issues/971 | [] | maartenbreddels | 0 |
kaliiiiiiiiii/Selenium-Driverless | web-scraping | 185 | Task code 20 USDT | site: https://www.kleinanzeigen.de/m-passwort-vergessen.html
what needs to be done:
1) accept cookies
2) enter mail
3) send the request by pressing submit or by pressing enter in the mail line
```
import asyncio
#from checkers.proxy_module.get_proxy import generator_proxy
from selenium_driverless import webdr... | closed | 2024-03-11T07:08:06Z | 2024-08-20T13:16:49Z | https://github.com/kaliiiiiiiiii/Selenium-Driverless/issues/185 | [
"invalid"
] | FreeM1ne | 6 |
psf/requests | python | 6,072 | HTTPS-proxy [Errno 111] Connection refused | <!-- Summary. -->
While all other protocols are working, I can't access an URL using an HTTPS-proxy ([StackOverflow](https://stackoverflow.com/questions/71150284/python-request-https-proxy-errno-111-connection-refused))
## Expected Result
Open an HTTPS-URL using HTTPS-proxy.
<!-- What you expected. -->
## Actu... | closed | 2022-02-23T22:52:05Z | 2022-05-25T01:29:44Z | https://github.com/psf/requests/issues/6072 | [] | karray | 1 |
graphql-python/graphene-sqlalchemy | graphql | 124 | Better approach to `is_mapped_class` | `sqlalchemy.orm.class_mapper` relies on `sqlalchemy.orm.configure_mappers` to have been called - either explicitly or implicitly by attempting to interact with the mapper. This means that `graphene_sqlalchemy.utils.class_mapper` forces a call to `configure_mappers` – which in turn throws an error unless every model ref... | open | 2018-04-17T23:56:45Z | 2018-04-17T23:56:45Z | https://github.com/graphql-python/graphene-sqlalchemy/issues/124 | [] | dfee | 0 |
holoviz/panel | jupyter | 6,862 | Generators are blocking if not wrapped in pane | This blocks events:
```python
import time
import numpy as np
import panel as pn
pn.extension()
run = pn.widgets.Toggle(name="Press to run calculation", align="center")
show = pn.widgets.Button(name="Show result", align="center")
def runner(running):
if not running:
yield "Calculation did n... | closed | 2024-05-23T20:05:09Z | 2024-05-31T17:29:09Z | https://github.com/holoviz/panel/issues/6862 | [] | ahuang11 | 0 |
plotly/dash-table | plotly | 153 | Add dropdown flag to column + remove 'dropdown' column type | With the addition of data types, using type 'dropdown' will become an issue as we'll probably be interested in the underlying data type of the column. We could add a flag like dropdown: true|false to denotate that instead of using the type or check all cells for a dropdown that applies to it. The 2nd approach would hav... | closed | 2018-10-22T18:38:00Z | 2019-06-27T01:00:12Z | https://github.com/plotly/dash-table/issues/153 | [] | Marc-Andre-Rivet | 1 |
Anjok07/ultimatevocalremovergui | pytorch | 1,047 | [Feature Request] BandIt model support | BandIt is a DNR model for separating cinematic sounds such as speech, sfx and background music. It is incredibly useful for audio editing and I'd love it to be included in UVR.
https://github.com/karnwatcharasupat/bandit
https://zenodo.org/records/10160698
https://ieeexplore.ieee.org/document/10342812 | open | 2023-12-22T19:11:03Z | 2024-11-24T10:34:54Z | https://github.com/Anjok07/ultimatevocalremovergui/issues/1047 | [] | iGerman00 | 5 |
CorentinJ/Real-Time-Voice-Cloning | deep-learning | 268 | Collection of pretrained models? Easy way to accommodate shorter or longer sentences? | Hey all,
From reading through issues - many of us are working on models or have generated models which are shared in multiple threads. Could we get a pinned thread to have us post models that we’ve worked on and get feedback on?
Additionally - this is just a general question about the project, I’ve been able to ... | closed | 2020-01-24T05:48:23Z | 2020-07-05T20:41:08Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/268 | [] | bmccallister | 1 |
explosion/spaCy | deep-learning | 12,669 | ImportError: cannot import name util | I am using a model trained using Allennlp which makes use of spaCy.
When I try to just import form Allennlp, I am getting the below error:
```
ImportError Traceback (most recent call last)
Cell In[4], line 2
1 import pkgutil, importlib, sys, re
----> 2 from allennlp.data i... | closed | 2023-05-24T12:15:40Z | 2023-06-24T00:02:42Z | https://github.com/explosion/spaCy/issues/12669 | [
"duplicate"
] | martina-dev-11 | 3 |
healthchecks/healthchecks | django | 1,106 | [Feature Request] support setting a default time setting globally/per check | For many checks I have 3 options to view the date/time, e.g. "UTC", "America/Denver" & "Browser's time zone". It'd be helpful if I could set this to always use the browser's time zone by default, possibly enabling overriding this at the "check" level. | open | 2024-12-16T15:29:52Z | 2025-03-16T11:06:16Z | https://github.com/healthchecks/healthchecks/issues/1106 | [] | seidnerj | 4 |
minimaxir/textgenrnn | tensorflow | 120 | More training = Higher Loss | I've been loving this utility and have been amused with the results so far.
Something strange that I've been noticing though; I've given it various texts and it seems like it's been choking after several training epochs.
Example code:
```
#!/usr/bin/env python
# -*- coding: utf-8 -*-
'''
Generate text from... | open | 2019-04-11T01:14:39Z | 2022-07-06T00:26:02Z | https://github.com/minimaxir/textgenrnn/issues/120 | [] | TylerGubala | 12 |
saulpw/visidata | pandas | 2,433 | [fec] opening rows in FEC files does not seem to work | **Small description**
FEC files can be opened, but rows cannot be browsed.
**Data to reproduce**
Using [a sample file 1326070.fec](https://docquery.fec.gov/dcdev/posted/1326070.fec).
**Steps to reproduce**
**Expected result**
When the user presses `Enter`, rows should open as in [jsvine's demo video at 13 s... | closed | 2024-06-27T07:50:26Z | 2024-07-09T04:23:29Z | https://github.com/saulpw/visidata/issues/2433 | [
"bug"
] | midichef | 0 |
MorvanZhou/tutorials | numpy | 85 | Is this your website? https://www.echenshe.com/class/tensorflow/ | https://www.echenshe.com/class/tensorflow/
Is this your website?
It has the same tutorials with yours. | closed | 2020-02-10T01:25:52Z | 2020-02-10T01:45:04Z | https://github.com/MorvanZhou/tutorials/issues/85 | [] | recoversu | 1 |
deepfakes/faceswap | deep-learning | 620 | Compatible Cuda and cuDNN installed, but no compatible tensorflow wheel available | getting the following problem when running setup.py on linux, can't seem to find the issue. Any help would be appreciated.
WARNING Running without root/admin privileges
INFO The tool provides tips for installation
and installs required python packages
INFO Setup in Linux 4.20.11-1-MANJARO
INFO I... | closed | 2019-02-24T08:15:48Z | 2019-02-24T12:54:11Z | https://github.com/deepfakes/faceswap/issues/620 | [] | fetchlister | 3 |
nl8590687/ASRT_SpeechRecognition | tensorflow | 114 | 模型中Dropout的效果 | 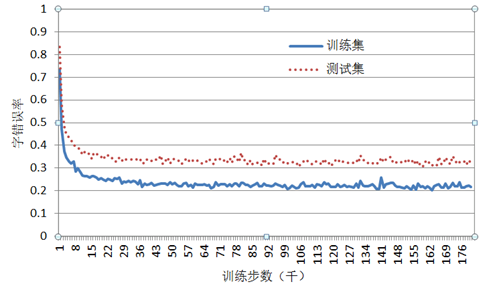
我使用了全部4个开源数据集,没有Dropout时测试集跟训练集错误率相差10%;在最后几层加入Dropout后测试集跟训练集错误率仍然相差10%,并且比不加Dropout时要高。我如何提高模型的泛化性能? | closed | 2019-05-03T15:44:47Z | 2020-05-11T05:49:54Z | https://github.com/nl8590687/ASRT_SpeechRecognition/issues/114 | [] | mlxu995 | 1 |
littlecodersh/ItChat | api | 664 | pycharm运行报错 | 在提交前,请确保您已经检查了以下内容!
- [ ] 您可以在浏览器中登陆微信账号,但不能使用`itchat`登陆
- [ ] 我已经阅读并按[文档][document] 中的指引进行了操作
- [ ] 您的问题没有在[issues][issues]报告,否则请在原有issue下报告
- [ ] 本问题确实关于`itchat`, 而不是其他项目.
- [ ] 如果你的问题关于稳定性,建议尝试对网络稳定性要求极低的[itchatmp][itchatmp]项目
请使用`itchat.run(debug=True)`运行,并将输出粘贴在下面:
```
/Library/Frameworks/Python.fram... | closed | 2018-05-21T15:35:15Z | 2018-06-05T15:51:42Z | https://github.com/littlecodersh/ItChat/issues/664 | [] | Michel-liu | 1 |
jupyterlab/jupyter-ai | jupyter | 647 | Define a set of models that Jupyter AI should be tested with when adding new functionality | <!-- Welcome! Thank you for contributing. These HTML comments will not render in the issue, but you can delete them once you've read them if you prefer! -->
<!--
Thanks for thinking of a way to improve JupyterLab. If this solves a problem for you, then it probably solves that problem for lots of people! So the whol... | open | 2024-02-16T17:47:44Z | 2024-02-16T17:47:45Z | https://github.com/jupyterlab/jupyter-ai/issues/647 | [
"enhancement"
] | andrii-i | 0 |
ydataai/ydata-profiling | pandas | 1,104 | Bug Report (Empty column tagged as Unsupported) | ### Current Behaviour
An empty non-object datatype column must be tagged with an 'Empty' alert.
### Expected Behaviour
An empty non-object datatype column returns tagged with an 'Unsupported' alert.
### Data Description
An empty non-object datatype column.
### Code that reproduces the bug
```Python
import pandas... | open | 2022-10-10T10:21:24Z | 2023-01-20T13:33:36Z | https://github.com/ydataai/ydata-profiling/issues/1104 | [
"bug 🐛",
"feature request 💬"
] | joshua-lagasca | 9 |
dask/dask | pandas | 11,046 | ValueError: memoryview is too large (dask.array.histogram) | <!-- Please include a self-contained copy-pastable example that generates the issue if possible.
Please be concise with code posted. See guidelines below on how to provide a good bug report:
- Craft Minimal Bug Reports http://matthewrocklin.com/blog/work/2018/02/28/minimal-bug-reports
- Minimal Complete Verifiab... | open | 2024-04-11T14:23:16Z | 2024-04-11T16:06:29Z | https://github.com/dask/dask/issues/11046 | [
"needs triage"
] | dwahdany | 4 |
wandb/wandb | tensorflow | 8,736 | [Q]: Download the best model file from a sweep - wandb.errors.errors.CommError: It appears that you do not have permission to access the requested resource | ### Ask your question
I followed the exact steps in https://docs.wandb.ai/guides/track/public-api-guide/#download-the-best-model-file-from-a-sweep. For the line `runs[0].file("model.h5").download(replace=True)` I get the following error:
`wandb.errors.errors.CommError: It appears that you do not have permission to ac... | open | 2024-10-31T12:41:43Z | 2024-11-12T16:37:07Z | https://github.com/wandb/wandb/issues/8736 | [
"ty:question",
"c:sweeps"
] | arunraja-hub | 6 |
proplot-dev/proplot | data-visualization | 298 | Creating a legend when `"legend.facecolor"` is set to `"inherit"` raises an error | <!-- Thanks for helping us make proplot a better package! If this is a bug report, please use the template provided below. If this is a feature request, you can delete the template text (just try to be descriptive with your request). -->
### Description
I initially made a comment in #272, but this issue appears t... | closed | 2021-10-28T14:46:27Z | 2021-11-03T00:56:08Z | https://github.com/proplot-dev/proplot/issues/298 | [
"bug"
] | spencerkclark | 5 |
microsoft/Bringing-Old-Photos-Back-to-Life | pytorch | 189 | Supports the restoration of high-resolution input broken? | Trying to process HR images 1974 x 2707 (top) and 1461x 2026 (bottom) using Colab. Restored images have noticeable defects.
It looks like generated masks still low-res.
If I lower input resolution of each sample to (let's say) 467 x 640 and 462 x 640 respectively - everything works fine.
 Exception (1337x): FlareSolverr was unable to process the request, please check FlareSolverr logs. Message: Error: Unable to process browser request. TimeoutError: Navigation timeout of 18333.333333333332 ms exceeded: FlareSolverr was unable to process the request, please check FlareSolverr logs. Mess... | ### Environment
* **FlareSolverr version**: v2.2.4
* **Last working FlareSolverr version**: v2.1.0
* **Operating system**: Linux
* **Are you using Docker**: [yes/no] yes
* **FlareSolverr User-Agent (see log traces or / endpoint)**: `Mozilla/5.0 (X11; Linux x86_64; rv:94.0) Gecko/20100101 Firefox/94.0`
* **Are y... | closed | 2022-05-01T19:56:09Z | 2022-05-02T09:45:09Z | https://github.com/FlareSolverr/FlareSolverr/issues/389 | [
"more information needed"
] | Chiggy-Playz | 8 |
man-group/arctic | pandas | 607 | write to TickStore, maximum 100000 items | #### Arctic Version
```
1.68.0
```
#### Arctic Store
```
TickStore
```
#### Description of problem and/or code sample that reproduces the issue
https://gist.github.com/eduedix/6ea4381f424a5b9de45faf939ed66574
As seen in the code above, the written and read `df`s do not match. I have also tried ... | closed | 2018-08-23T11:27:41Z | 2018-08-25T18:11:21Z | https://github.com/man-group/arctic/issues/607 | [] | eduedix | 5 |
huggingface/datasets | numpy | 7,447 | Epochs shortened after resuming mid-epoch with Iterable dataset+StatefulDataloader(persistent_workers=True) | ### Describe the bug
When `torchdata.stateful_dataloader.StatefulDataloader(persistent_workers=True)` the epochs after resuming only iterate through the examples that were left in the epoch when the training was interrupted. For example, in the script below training is interrupted on step 124 (epoch 1) when 3 batches ... | closed | 2025-03-12T21:41:05Z | 2025-03-14T17:26:59Z | https://github.com/huggingface/datasets/issues/7447 | [] | dhruvdcoder | 5 |
QingdaoU/OnlineJudge | django | 432 | LIOJ #1047 搜尋數字 PY3 TLE | def search(arr , t):
for i in range(len(arr)):
if arr[i] == t:
return i
return "-1"
n, m = map(int, input().split())
nums = [int(input()) for _ in range(n)]
for _ in range(m):
t = int(input())
print(search(nums,t))
按照老師的作法,沒有辦法在同樣的時間複雜度下通過測試,希望放開一些標準, | open | 2022-11-18T07:12:40Z | 2022-11-18T07:16:23Z | https://github.com/QingdaoU/OnlineJudge/issues/432 | [] | aa846301 | 0 |
pytest-dev/pytest-django | pytest | 1,147 | Unblock not cleaned up at the end of pytest execution? | I realize this is a bit of an edge case, but there seems to be something off about the cleanup for `pytest.mark.django_db`. If you run pytest twice in the same process all tests that are marked `django_db` fail with the error reproduced below.
A reproduction repo is at https://github.com/boxed/pytest_django_block_db... | closed | 2024-09-24T12:39:36Z | 2024-09-26T06:54:48Z | https://github.com/pytest-dev/pytest-django/issues/1147 | [] | boxed | 3 |
geopandas/geopandas | pandas | 3,390 | BUG: fiona.path module is being deprecated in 1.10.0 | - [x] I have checked that this issue has not already been reported.
- [ ] I have confirmed this bug exists on the latest version of geopandas.
- [ ] (optional) I have confirmed this bug exists on the main branch of geopandas.
---
#### Code Sample, a copy-pastable example
```python
import geopandas as gp... | closed | 2024-07-23T16:54:45Z | 2024-07-23T21:11:07Z | https://github.com/geopandas/geopandas/issues/3390 | [
"bug",
"needs triage"
] | philiporlando | 2 |
jmcnamara/XlsxWriter | pandas | 319 | Invalid table names lead to corrupted files | Since you explicitly asked for examples that end up with corrupted (but reparable) xlsx files, here is an easy one to reproduce:
If you start with your example file: http://xlsxwriter.readthedocs.org/example_tables.html
And then name the empty data table on line 53 like this:
```
worksheet1.add_table('B3:F7', {... | closed | 2015-12-17T17:52:31Z | 2016-01-06T01:40:51Z | https://github.com/jmcnamara/XlsxWriter/issues/319 | [
"bug",
"short term"
] | rotten | 3 |
huggingface/datasets | numpy | 6,827 | Loading a remote dataset fails in the last release (v2.19.0) | While loading a dataset with multiple splits I get an error saying `Couldn't find file at <URL>`
I am loading the dataset like so, nothing out of the ordinary.
This dataset needs a token to access it.
```
token="hf_myhftoken-sdhbdsjgkhbd"
load_dataset("speechcolab/gigaspeech", "test", cache_dir=f"gigaspeech/test... | open | 2024-04-19T21:11:58Z | 2024-04-19T21:13:42Z | https://github.com/huggingface/datasets/issues/6827 | [] | zrthxn | 0 |
pytest-dev/pytest-mock | pytest | 118 | Make spy a context manager | #### Capture return value
**NOTE: already implemented in 1.11**
```python
class SomeClass:
def method(self, a):
return a * 2
def facade(self):
self.method(4)
return 'Done'
def test_some_class(mocker):
spy = mocker.spy(SomeClass, 'method')
o = SomeClass()
... | open | 2018-06-14T17:55:00Z | 2019-11-18T20:57:29Z | https://github.com/pytest-dev/pytest-mock/issues/118 | [
"enhancement"
] | neumond | 5 |
pytorch/pytorch | python | 149,734 | [RFC] Multi-backend, multi-device test class instantiation for Inductor | ### 🚀 The feature, motivation and pitch
## Background
Out-of-tree backends (like Graphcore's) are able to utilise the PyTorch test suite to verify their implementation.
For eager tests, to instantiate device-specific test classes, out-of-tree backends can subclass from `DeviceTypeTestBase` and register their device... | open | 2025-03-21T15:02:31Z | 2025-03-24T09:43:08Z | https://github.com/pytorch/pytorch/issues/149734 | [
"triaged",
"module: testing",
"oncall: pt2",
"module: inductor"
] | kundaMwiza | 1 |
lorien/grab | web-scraping | 346 | Spider does not process initial_urls | Does nothing
```
# coding: utf-8
import urllib
import csv
import logging
from grab.spider import Spider, Task
class ExampleSpider(Spider):
# List of initial tasks
# For each URL in this list the Task object will be created
initial_urls = ['http://habrahabr.ru/']
def prepare(self):
... | closed | 2018-05-12T19:57:16Z | 2018-05-13T18:01:00Z | https://github.com/lorien/grab/issues/346 | [] | lorien | 0 |
521xueweihan/HelloGitHub | python | 2,612 | 【开源自荐】🤯 Lobe Theme: Stable Diffusion WebUI 现代化主题,提供交互体验效率优化 | ## 推荐项目
<!-- 这里是 HelloGitHub 月刊推荐项目的入口,欢迎自荐和推荐开源项目,唯一要求:请按照下面的提示介绍项目。-->
<!-- 点击上方 “Preview” 立刻查看提交的内容 -->
<!--仅收录 GitHub 上的开源项目,请填写 GitHub 的项目地址-->
- 项目地址:https://github.com/lobehub/sd-webui-lobe-theme
<!--请从中选择(C、C#、C++、CSS、Go、Java、JS、Kotlin、Objective-C、PHP、Python、Ruby、Rust、Swift、其它、书籍、机器学习)-->
- 类别... | open | 2023-09-20T15:23:55Z | 2023-10-24T07:14:44Z | https://github.com/521xueweihan/HelloGitHub/issues/2612 | [
"机器学习"
] | canisminor1990 | 0 |
allenai/allennlp | pytorch | 5,310 | Move `cached_path` to a separate library | What if we move `cached_path` to a separate library? It's useful on its own, without AllenNLP.
**Is your feature request related to a problem? Please describe.**
I find it very useful to just specify URLs around (outside AllenNLP) and have things automatically downloaded if needed. I feel that `allennlp.common.file... | closed | 2021-07-14T17:56:17Z | 2021-09-10T19:21:16Z | https://github.com/allenai/allennlp/issues/5310 | [
"Contributions welcome",
"Feature request"
] | bryant1410 | 8 |
lux-org/lux | pandas | 179 | [BUG] Problem with setting intent on a column containing NaNs | Hiya,
I received the below issue when trying to use Lux in Jupyter notebooks.
My dataframe is a pandas dataframe that i have populated using the BigQuery read_gbq function.
any suggestions?
C:\Users\bmussa\Anaconda3\lib\site-packages\IPython\core\formatters.py:345: UserWarning:
Unexpected error in rendering Lu... | closed | 2020-12-14T13:32:44Z | 2020-12-21T14:31:24Z | https://github.com/lux-org/lux/issues/179 | [
"bug",
"priority"
] | bilalmussaukfd | 5 |
sinaptik-ai/pandas-ai | pandas | 1,062 | Missing store vector when using training feature | ### System Info
pandasai version 2.0.23
Azure OpenAI
Chatgpt 3.5
### 🐛 Describe the bug
When trying to run the example provided in the documentation of pandasai, I get the following error:
raise MissingVectorStoreError(
pandasai.exceptions.MissingVectorStoreError: No vector store provided. Please provide a ve... | closed | 2024-03-26T09:36:24Z | 2024-04-17T13:03:13Z | https://github.com/sinaptik-ai/pandas-ai/issues/1062 | [] | epicvhbennetts | 6 |
wagtail/wagtail | django | 12,189 | Discrepancies in accessibility check results between active panels | ### Issue Summary
Follow-up to #12157. In the page editor, depending on what panel is active, the checker shows different accessibility issues. This might be a similar bug to #11677 but requires further investigation.
### Steps to Reproduce
1. In the bakerydemo, create a child page of "Contact us" configured t... | open | 2024-07-31T08:12:49Z | 2024-10-21T08:46:38Z | https://github.com/wagtail/wagtail/issues/12189 | [
"type:Bug",
"status:Unconfirmed"
] | thibaudcolas | 3 |
benlubas/molten-nvim | jupyter | 101 | [Feature Request] Configuration to Allow Offset of Output Window | While trying to integrate Molten into https://github.com/GCBallesteros/NotebookNavigator.nvim/pull/25, we have some odd placement of the output window, mainly because we are using `MoltenEvaluateRange` with an extended cell. See https://github.com/GCBallesteros/NotebookNavigator.nvim/pull/25#issuecomment-1848240254 for... | closed | 2023-12-21T17:57:13Z | 2024-02-23T16:34:18Z | https://github.com/benlubas/molten-nvim/issues/101 | [
"enhancement"
] | TillerBurr | 9 |
recommenders-team/recommenders | deep-learning | 1,741 | [FEATURE] Is there a tutorial on how to select recommender algorithm? | This page is well-organized https://github.com/microsoft/recommenders, however, what tips you suggest on choose one of algorithm under what condition? | closed | 2022-06-13T12:11:31Z | 2022-10-19T07:57:15Z | https://github.com/recommenders-team/recommenders/issues/1741 | [
"enhancement"
] | wanglu2014 | 3 |
home-assistant/core | python | 140,511 | Backup stopped working | ### The problem
Backups don't work anymore. I'm also not able to see previous backups via the GUI.
Via the console I can find them.
Got those errors:
Automatic backup could not be created
The backup location hassio.local is unavailable
### What version of Home Assistant Core has the issue?
core-2025.3.2
### What... | closed | 2025-03-13T12:49:18Z | 2025-03-14T09:27:35Z | https://github.com/home-assistant/core/issues/140511 | [
"needs-more-information",
"integration: backup"
] | simon1964 | 4 |
vaexio/vaex | data-science | 2,078 | [FEATURE-REQUEST] Maintain a CIRCULAR MEMORY BUFFER using vaex - Simultaneous write and read HDF5 | **USER CASE**
Data acquisition from sensor and post-processing real time
**DESCRIPTION**
1. Sensor data are logged using a data acquisition system
2. Latest 1 million data is required for post-processing in real time
3. Since the buffer in the data acquisition system is only a few MegaBytes. The data has to b... | closed | 2022-06-12T11:53:34Z | 2022-08-27T11:49:32Z | https://github.com/vaexio/vaex/issues/2078 | [] | nithintito | 3 |
cvat-ai/cvat | pytorch | 8,364 | Modifying cvat_worker_export not reflecting in dataset export | ### Actions before raising this issue
- [X] I searched the existing issues and did not find anything similar.
- [X] I read/searched [the docs](https://docs.cvat.ai/docs/)
### Steps to Reproduce
1. Made the following test changes to check if the directory is valid and can later be split by rearranging the files and f... | closed | 2024-08-28T04:36:20Z | 2024-08-30T09:20:43Z | https://github.com/cvat-ai/cvat/issues/8364 | [
"question"
] | ilyasofficial1617 | 5 |
proplot-dev/proplot | matplotlib | 198 | Show labels of grouped pandas dataframe in one legend | ### Description
Proplot plots the legend for each label instead of listing labels on one legend.
As a result, several legends are stacked together.
### Steps to reproduce
```python
import proplot as plot
df = pd.DataFrame({'A' : ['foo', 'bar', 'foo', 'bar',
'foo', 'bar', 'foo', 'f... | closed | 2020-06-26T09:46:52Z | 2021-07-03T16:03:56Z | https://github.com/proplot-dev/proplot/issues/198 | [
"integration"
] | zxdawn | 2 |
ultralytics/yolov5 | deep-learning | 13,292 | Low disk space causes memory leak | ### Search before asking
- [X] I have searched the YOLOv5 [issues](https://github.com/ultralytics/yolov5/issues) and found no similar bug report.
### YOLOv5 Component
Training
### Bug
Having only a few gbs of disk space left when running yolov5's train.py causes a memory leak that will cause the computer to lag a... | open | 2024-09-02T18:45:00Z | 2024-10-27T13:30:41Z | https://github.com/ultralytics/yolov5/issues/13292 | [
"bug"
] | oliver408i | 3 |
modelscope/data-juicer | data-visualization | 176 | [Bug]: 质量分类器无法正确运行 | ### Before Reporting 报告之前
- [x] I have pulled the latest code of main branch to run again and the bug still existed. 我已经拉取了主分支上最新的代码,重新运行之后,问题仍不能解决。
- [X] I have read the [README](https://github.com/alibaba/data-juicer/blob/main/README.md) carefully and no error occurred during the installation process. (Otherwise, w... | closed | 2024-01-12T08:06:17Z | 2024-08-20T01:58:27Z | https://github.com/modelscope/data-juicer/issues/176 | [
"bug",
"stale-issue"
] | BiqiangWang | 5 |
littlecodersh/ItChat | api | 142 | console中如何输出群列表,直接回复群列表应该怎么弄? | 第一次用itchat 我想输出群列表.报错了,不知道改怎么弄这个转码,会送给发信息的好友也不知道该怎么发,希望大神指点下,python不太熟悉,请见谅
```python
#coding=utf8
import itchat, time
from itchat.content import *
@itchat.msg_register([TEXT, MAP, CARD, NOTE, SHARING])
def text_reply(msg):
print("1111")
qun=itchat.get_chatrooms()
print(qun)
itchat.send('%s:... | closed | 2016-11-04T13:29:19Z | 2016-11-04T14:32:19Z | https://github.com/littlecodersh/ItChat/issues/142 | [
"invalid"
] | issmile | 1 |
Gozargah/Marzban | api | 697 | the panel works with delays | If there are more than 100 inbounds, setting them up in the drop-down menu takes much longer, loading after a click takes several seconds with a noticeable delay, a more powerful server did not solve the problem. | closed | 2023-12-13T14:57:44Z | 2023-12-13T18:08:12Z | https://github.com/Gozargah/Marzban/issues/697 | [
"Invalid"
] | yremac | 3 |
writer/writer-framework | data-visualization | 100 | How to run streamsync from cloned source | On a windows computer with python 3.10 and streamsync 0.2.6 installed
The hello app is not starting/loading
see screenshot,

I also tried
```
streamsync create app1
streamsync edit app... | closed | 2023-09-07T12:20:03Z | 2023-10-04T21:05:30Z | https://github.com/writer/writer-framework/issues/100 | [] | wgong | 3 |
ned2/slapdash | plotly | 32 | Docker setup? | Hey @ned2 - first off thanks for this amazing repo, it has helped me organize my own project substantially.
I'm working on a project that would let users self-host an analytical fitness application:
https://github.com/ethanopp/fitly
I'd like to add the ability for the users to be able to deploy via docker, and ... | open | 2020-03-20T11:56:29Z | 2020-05-04T00:19:34Z | https://github.com/ned2/slapdash/issues/32 | [] | ethanopp | 1 |
X-PLUG/MobileAgent | automation | 71 | V3 是端侧本地部署推理,非云上API吗?另外,V3大概什么时候开源呢? | open | 2024-10-31T01:32:31Z | 2024-11-02T03:01:29Z | https://github.com/X-PLUG/MobileAgent/issues/71 | [] | leo4678 | 3 | |
dmlc/gluon-nlp | numpy | 1,040 | example code for learning a vocabulary | ## Description
bert vocabulary tokens are directly downloaded but the code to generate a new vocabulary from plain text is not give.
Three ways are now available according to google team. [1]
1.Google's SentencePiece library
2.tensor2tensor's WordPiece generation script
3.Rico Sennrich's Byte Pair Encoding libra... | closed | 2019-12-11T05:36:14Z | 2019-12-14T12:27:35Z | https://github.com/dmlc/gluon-nlp/issues/1040 | [
"enhancement"
] | timespaceuniverse | 2 |
coleifer/sqlite-web | flask | 5 | pip install: dependencies are missing from setup.py | I expect `pip install` to install all of the dependencies needed to run the application.
from the README:
> ### Installation
>
> ``` sh
> $ pip install sqlite-browser flask peewee
> ```
setup.py has support for dependencies via the parameter `install_requires`! Indeed this parameter is existing but empty in the pr... | closed | 2015-04-07T15:19:39Z | 2015-04-14T01:25:06Z | https://github.com/coleifer/sqlite-web/issues/5 | [] | e3krisztian | 0 |
microsoft/qlib | machine-learning | 1,834 | [20964:MainThread](2024-07-26 23:06:46,892) INFO - qlib.ALSTM - [pytorch_alstm.py:245] - train nan, valid nan | I encountered a problem: there was no issue when running LightGBM Alpha158 in the example file, but both ALSTM and KRNN resulted in train nan and valid nan issues, regardless of whether it was Alpha158 or Alpha360. Here is the error report:
[20964:MainThread](2024-07-26 23:03:01,094) INFO - qlib.qrun - [cli.py:78] - R... | open | 2024-07-26T15:26:57Z | 2025-02-28T13:48:06Z | https://github.com/microsoft/qlib/issues/1834 | [
"question"
] | SweetCone1 | 2 |
onnx/onnx | pytorch | 5,852 | with pow function is rhs or output typecast? | # Ask a Question
### Question
After reading the docs regarding the [pow function](https://onnx.ai/onnx/operators/onnx__Pow.html#pow-15) is when type conversion happens.
The output tensor's type is the same as the rhs, but say you have an rhs of `[[4]]` and a lhs of `4.5`, is the lhs converted to an int (yielding ... | closed | 2024-01-10T23:22:30Z | 2025-02-06T06:44:47Z | https://github.com/onnx/onnx/issues/5852 | [
"question",
"topic: operator",
"topic: spec clarification",
"stale"
] | skewballfox | 1 |
tiangolo/uvicorn-gunicorn-fastapi-docker | fastapi | 8 | Server crashes in production but not in development | I'm sending 217 calls with a 797KB payload each to a FastAPI endpoint. When I run the project with `/start-reload.sh` it works great. When I run it in production, I get `[CRITICAL] WORKER TIMEOUT`. I'm assuming this is related to gunicorn. I've read that, under non-async circumstances, worker_class='gevent' might fix t... | closed | 2019-04-04T14:09:55Z | 2020-05-08T00:20:55Z | https://github.com/tiangolo/uvicorn-gunicorn-fastapi-docker/issues/8 | [] | israelpasos | 15 |
SYSTRAN/faster-whisper | deep-learning | 803 | Long video processing failure without error | I tested a long video (8 hours) on aws ec2 g4dn.xlarge and it has been killed some minutes after model.transcribe() function call.
`INFO in transcribe: Processing audio with duration 08:10:38.653`
faster-whisper: 1.0.1
model: large-v2
compute_type: float16 | open | 2024-04-24T13:23:37Z | 2024-04-25T02:57:27Z | https://github.com/SYSTRAN/faster-whisper/issues/803 | [] | fittodaycare | 2 |
google-research/bert | nlp | 532 | Cannot find Synthetic self-training in this repository. | The SQuAD leader board's (https://rajpurkar.github.io/SQuAD-explorer/) 3rd highest scored model uses 'synthetic self-training'.
There is a PDF explaining it: https://nlp.stanford.edu/seminar/details/jdevlin.pdf?fbclid=IwAR2TBFCJOeZ9cGhxB-z5cJJ17vHN4W25oWsjI8NqJoTEmlYIYEKG7oh4tlY but I have found no such model within ... | open | 2019-03-30T11:05:41Z | 2019-03-30T11:13:18Z | https://github.com/google-research/bert/issues/532 | [] | Dogy06 | 0 |
matterport/Mask_RCNN | tensorflow | 2,890 | the following arguments are required (Solved) | <img width="441" alt="image" src="https://user-images.githubusercontent.com/7828483/194075743-504ce6f6-0605-4f17-b746-764025b10151.png">
<img width="389" alt="image" src="https://user-images.githubusercontent.com/7828483/194075792-ad3e577f-a23f-436b-ac10-ddbce5976a99.png">
| open | 2022-10-05T13:45:21Z | 2022-10-05T13:45:21Z | https://github.com/matterport/Mask_RCNN/issues/2890 | [] | liaojinpiao | 0 |
LAION-AI/Open-Assistant | python | 3,484 | free chatgpt https://zyq-chatgpt.github.io/ | https://zyq-chatgpt.github.io/ | closed | 2023-06-16T14:12:47Z | 2023-06-16T15:09:21Z | https://github.com/LAION-AI/Open-Assistant/issues/3484 | [] | zyq-chatgpt | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.