
repo_name stringlengths 9 75 | topic stringclasses 30
values | issue_number int64 1 203k | title stringlengths 1 976 | body stringlengths 0 254k | state stringclasses 2
values | created_at stringlengths 20 20 | updated_at stringlengths 20 20 | url stringlengths 38 105 | labels listlengths 0 9 | user_login stringlengths 1 39 | comments_count int64 0 452 |
|---|---|---|---|---|---|---|---|---|---|---|---|
ijl/orjson | numpy | 132 | Unable to build dependency packed_simd on windows | I am using `rustc 1.49.0-nightly (beb5ae474 2020-10-04)` and python 3.9 on windows 10.
It's an upstream issue that has already been fixed. see https://github.com/rust-lang/packed_simd/issues/288#event-3799467220
Any workaround? | closed | 2020-10-05T19:38:44Z | 2020-10-06T21:49:55Z | https://github.com/ijl/orjson/issues/132 | [] | Congee | 1 |
igorbenav/FastAPI-boilerplate | sqlalchemy | 153 | Wrong Blacklist for Logout (Refresh/Access Token ) | ### Discussed in https://github.com/igorbenav/FastAPI-boilerplate/discussions/152
<div type='discussions-op-text'>
<sup>Originally posted by **kunkoala** January 13, 2025</sup>
Hi all,
first of all massive credit and big thanks to author @igorbenav for creating this fastAPI-boilerplate, as I could learn so mu... | closed | 2025-01-13T18:28:28Z | 2025-02-10T22:15:43Z | https://github.com/igorbenav/FastAPI-boilerplate/issues/153 | [
"bug"
] | igorbenav | 0 |
babysor/MockingBird | deep-learning | 801 | Intel MacOS平台报错 No module named 'typer' | **Summary[问题简述(一句话)]**
Intel MacOS平台报错 No module named 'typer'
**Env & To Reproduce[复现与环境]**
```
% python3.7 -m pip install torch torchvision torchaudio
Defaulting to user installation because normal site-packages is not writeable
Requirement already satisfied: torch in /opt/local/Library/Frameworks/Python.... | open | 2022-12-13T06:19:38Z | 2022-12-15T13:39:16Z | https://github.com/babysor/MockingBird/issues/801 | [] | migraine-sudo | 1 |
deepspeedai/DeepSpeed | pytorch | 6,636 | [BUG] if not install cuda,pip3 install deepspeed==0.14.0, failed in installed_cuda_version() | **Describe the bug**
not install cuda, and not cpu,gpu device.
pip3 install deepspeed==0.14.0, failed in installed_cuda_version()
**To Reproduce**
Steps to reproduce the behavior:
not install cuda in sys,
pip3 install deepspeed==0.14.0
**Expected behavior**
A clear and concise description of what you expected to ... | closed | 2024-10-17T09:12:14Z | 2024-10-22T01:50:29Z | https://github.com/deepspeedai/DeepSpeed/issues/6636 | [
"bug",
"build"
] | hijeffwu | 4 |
tqdm/tqdm | jupyter | 970 | .close method to raise a ValueError | - [ ] I have marked all applicable categories:
+ [ ] exception-raising bug
+ [X] visual output bug
+ [ ] documentation request (i.e. "X is missing from the documentation." If instead I want to ask "how to use X?" I understand [StackOverflow#tqdm] is more appropriate)
+ [ ] new feature request
- [ ]... | closed | 2020-05-13T16:30:44Z | 2020-05-16T14:00:43Z | https://github.com/tqdm/tqdm/issues/970 | [
"duplicate 🗐",
"invalid ⛔",
"need-feedback 📢"
] | andreamoro | 2 |
marshmallow-code/marshmallow-sqlalchemy | sqlalchemy | 62 | sqlalchemy marshmallow avoid loading data into session | Is there a way to avoid inserting the data into session while using Marshmallow - sqlalchemy .load()
Because we tried to manage the objects by ourself (adding them into session if required) . Will add into the session if required , but for only validation I need to use load () method which is provided by marshmallow-s... | closed | 2016-04-11T15:28:08Z | 2019-02-04T02:11:27Z | https://github.com/marshmallow-code/marshmallow-sqlalchemy/issues/62 | [] | ShankarGanesh | 13 |
pydantic/logfire | fastapi | 438 | Web Server Monitoring Dashboard: Requests Average Duration Query error | ### Description
In the default web dashboard, the underlying query fails with:
```
External error: Execution error: Cannot convert Duration(Microsecond) to epoch
```
I looked at the underlying query - it looks like valid postgres syntax to me but it is not running.
```
WITH dataset AS (
SELECT
(attr... | closed | 2024-09-23T15:15:25Z | 2024-10-04T10:10:47Z | https://github.com/pydantic/logfire/issues/438 | [
"bug"
] | tamir-alltrue-ai | 2 |
modin-project/modin | data-science | 6,819 | Update Modin on cluster documentation | closed | 2023-12-12T20:01:25Z | 2023-12-13T14:27:28Z | https://github.com/modin-project/modin/issues/6819 | [
"documentation 📜"
] | anmyachev | 0 | |
alphasecio/langchain-examples | streamlit | 34 | problem with this line: search = vectordb.similarity_search(" ") | search = vectordb.similarity_search(" ")
this returns only 4 docs.
is there a way to return all documents from vectordb?
isn't this what you want since the purpose is to get a summary of a corpus which comprises of all texts? | open | 2023-12-04T22:08:15Z | 2023-12-04T22:08:15Z | https://github.com/alphasecio/langchain-examples/issues/34 | [] | nguaki | 0 |
benbusby/whoogle-search | flask | 938 | [QUESTION] Replace Whoogle Farside link in "Instance limited" page | When self-hosting the service, is it possibile to replace the Whoogle farside link in the "instance limited" error page with a link to a particular Whoogle instance we prefer? Would be amazing to have direct redirect to another personal Whoogle instance as a back-up for the main one | closed | 2023-01-26T11:17:44Z | 2023-01-30T18:41:16Z | https://github.com/benbusby/whoogle-search/issues/938 | [
"question"
] | askabaz22 | 4 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 112 | [BUG] | Tiktok api not working in your code any more
This message appear :
{"function":"webapi()","reason":"Object of type JSONDecodeError is not JSON serializable","status":"failed","time":"1.5905s","value":"https://vm.tiktok.com/ZMFQEuNqE"}
| closed | 2022-12-01T12:41:57Z | 2022-12-02T10:13:03Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/112 | [
"BUG",
"Fixed"
] | davidleboblai | 3 |
thtrieu/darkflow | tensorflow | 984 | Visualizing training Accuracy | Is it possible to see how the accuracy increments during training? Adding code strings or new commands maybe? Or am I missing something yet existing and already implemented? | open | 2019-02-11T22:13:34Z | 2019-02-11T22:13:34Z | https://github.com/thtrieu/darkflow/issues/984 | [] | Alemolet | 0 |
quokkaproject/quokka | flask | 28 | Create quokka-admin binary and release PyPi package | closed | 2013-08-23T00:29:48Z | 2015-07-16T02:56:57Z | https://github.com/quokkaproject/quokka/issues/28 | [
"enhancement",
"wontfix"
] | rochacbruno | 1 | |
graphql-python/graphene-django | graphql | 892 | Freezing the Page (ListView and so on) | Hi,
Canceled....
I really appreciate the attention,
Roberto Morati | closed | 2020-03-05T01:54:40Z | 2020-03-05T02:03:26Z | https://github.com/graphql-python/graphene-django/issues/892 | [] | robertomorati | 0 |
3b1b/manim | python | 1,209 | Manim is not correctly drawing tikzpictures | I'm very very new to coding and am mostly trying to learn on my own. I'm starting to pick up the basics of manim, but am still having difficulties with troubleshooting. I've been trying to get manim to draw tikz diagrams and I've spent hours digging through what seemed like similar issues. I finally got it to draw the ... | open | 2020-08-20T05:22:02Z | 2022-03-28T16:39:13Z | https://github.com/3b1b/manim/issues/1209 | [
"LaTeX"
] | rdownieMath | 4 |
pydata/xarray | numpy | 9,278 | DataArray.set_index can add new dimensions that are absent on the underlying array. | ### What is your issue?
I know we've done lots of great work on indexes. But I worry that we've made some basic things confusing. (Or at least I'm confused, very possibly I'm being slow this morning?)
A colleague asked how to group by multiple coords. I told them to `set_index(foo=coord_list).groupby("foo")`. But t... | open | 2024-07-25T16:36:12Z | 2024-07-27T15:09:10Z | https://github.com/pydata/xarray/issues/9278 | [
"bug",
"topic-indexing"
] | max-sixty | 6 |
bigscience-workshop/petals | nlp | 147 | Getting Petals to run on macOS | The primary motivation, is
- to get as much high bandwidth memory, in a low cost way (thanks to its unified memory model)
- to be easily used for training / inference
- its probably gonna be slower then 3090's (i have no idea), but i dun think thats the point here
- could potentially also be used with large number... | closed | 2022-12-11T04:19:26Z | 2023-08-29T04:00:38Z | https://github.com/bigscience-workshop/petals/issues/147 | [
"documentation",
"enhancement"
] | PicoCreator | 18 |
abhiTronix/vidgear | dash | 179 | Python 3.9 Support for VidGear | <!--- Add a brief but descriptive title for your issue above -->
## Detailed Description
<!--- Provide a detailed description of the change or addition you are proposing -->
This issue will track implementation of official support for for new python v3.9 series in VidGear through testing it in various CIs environm... | closed | 2020-12-14T12:17:18Z | 2021-01-13T07:31:18Z | https://github.com/abhiTronix/vidgear/issues/179 | [
"ENHANCEMENT :zap:",
"SOLVED :checkered_flag:",
"MAINTENANCE :building_construction:"
] | abhiTronix | 1 |
tableau/server-client-python | rest-api | 1,194 | datasource_id from workbook connections does not match ids from datasources themselves | **Describe the bug**
After populating workbook connections, the `datasource_id`s in `workbooks.connections.datasource_id` don't appear to match with any of the `id`s from the `datasources.id` fields in our instance of Tableau Server.
It's totally possible I am being a dunce somehow or that there is some "duh" so... | open | 2023-02-17T22:35:54Z | 2023-03-02T16:24:06Z | https://github.com/tableau/server-client-python/issues/1194 | [] | alexepperly | 3 |
autokey/autokey | automation | 151 | Phrases are sometimes incorrectly expanded, missing character(s) | ## Classification:
Bug
## Reproducibility:
Sometimes (fails ~ 30% of the time)
## Summary
Phrases are sometimes incorrectly expanded, missing character(s).
## Steps to Reproduce
- Create phrase `myname@gmail.com`
- Bind it to abbreviation `m@g`, with options:
- Remove typed abbreviation
- ... | open | 2018-05-24T14:54:07Z | 2023-03-13T13:12:50Z | https://github.com/autokey/autokey/issues/151 | [] | ronjouch | 69 |
nvbn/thefuck | python | 660 | Slow execution time | The command output is very slow on macOS w/ fish shell. Reproduction rate is ~80% for me.
Version: The Fuck 3.18 using Python 2.7.10
Shell: fish, version 2.6.0
OS: macOS 10.12.5
Debug Output:
```
❯ fuck 333ms
DEBUG: Run... | closed | 2017-06-17T19:07:59Z | 2020-05-09T14:28:55Z | https://github.com/nvbn/thefuck/issues/660 | [] | shaunbennett | 5 |
JaidedAI/EasyOCR | deep-learning | 465 | FineTune easyOCR | I signed up with http://www.jaided.ai/projects/finetune and there exists an option to fine tune models for one's usage.
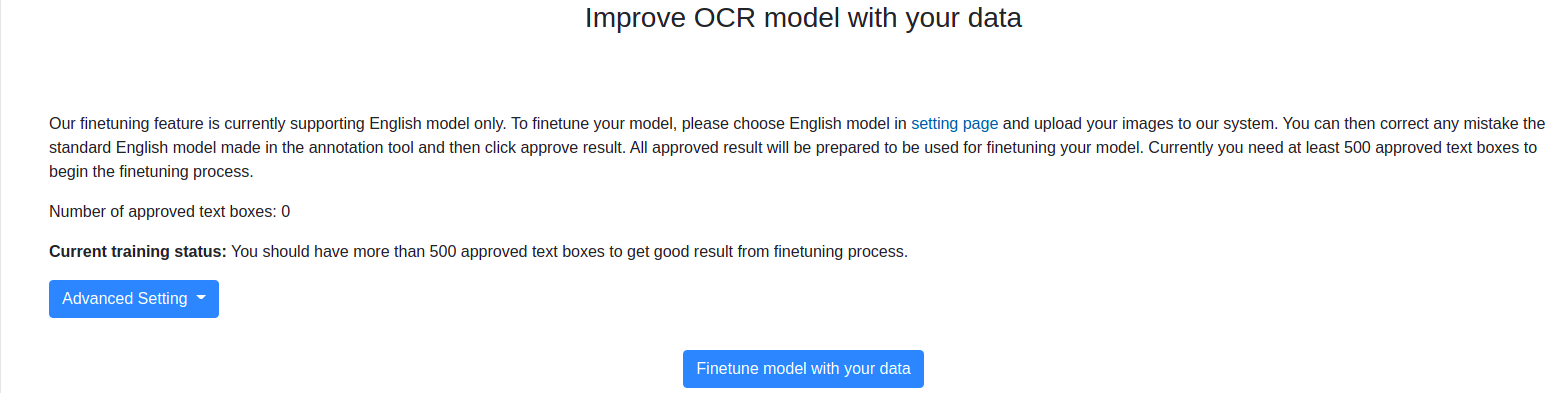
Is one able to do via code by ourselves from using the repo or is it part of an e... | closed | 2021-06-17T13:53:30Z | 2021-07-02T08:55:24Z | https://github.com/JaidedAI/EasyOCR/issues/465 | [] | groupgithub21 | 1 |
thtrieu/darkflow | tensorflow | 362 | Gray scale trainig | I was able to train multiple custom objects using 3 channel images but in not able to set single channel image ("gray scale"). Any idea how can i load gray scale images? | open | 2017-07-30T00:36:38Z | 2018-07-01T04:55:16Z | https://github.com/thtrieu/darkflow/issues/362 | [] | andresredspace | 3 |
modelscope/modelscope | nlp | 417 | 无法利用gpu进行推理 |
推理很慢!!!如何利用gpu进行推理????
```python
pipeline = pipeline(Tasks.faq_question_answering, 'damo/nlp_mgimn_faq-question-answering_chinese-base',
model_revision="v1.0.0", device='gpu')
```
虽然打印设备显示是 gpu ,但是貌似不支持gpu推理,还没有用cpu快。 | closed | 2023-07-26T10:29:00Z | 2024-07-14T01:57:42Z | https://github.com/modelscope/modelscope/issues/417 | [
"Stale"
] | 312shan | 7 |
pyjanitor-devs/pyjanitor | pandas | 1,168 | [BUG]`sort_by_appearance` parameter fails when `dropna=True` in `pivot_longer` | # Brief Description
`sort_by_appearance` fails when `dropna=True` in pivot_longer
# System Information
- Operating system: macOS
- Python version (required): 3.9
# Minimally Reproducible Code
```py
url = 'https://raw.githubusercontent.com/tidyverse/tidyr/main/data-raw/billboard.csv'
df = pd.read_csv... | closed | 2022-09-10T00:04:12Z | 2022-09-19T15:23:40Z | https://github.com/pyjanitor-devs/pyjanitor/issues/1168 | [] | samukweku | 0 |
sanic-org/sanic | asyncio | 2,839 | Rewrite request and re-route | ### Is there an existing issue for this?
- [X] I have searched the existing issues
### Is your feature request related to a problem? Please describe.
Web servers such as Apache, Nginx and Caddy make heavy use of rewrites, which are essentially internal redirects. Rather than ask the client do another request some pl... | open | 2023-10-15T03:09:30Z | 2024-09-24T14:36:51Z | https://github.com/sanic-org/sanic/issues/2839 | [
"feature request"
] | Tronic | 3 |
keras-team/keras | pytorch | 20,715 | autoencoder.fit() raises 'KeyError: 'Exception encountered when calling Functional.call()' | I'm trying to build a stacked LSTM sequence auto-encoder that takes a signal of 430 timesteps with each timestep having 1 value. You can see the code for the model below:
```py
feat_dim = 1
timesteps = 430
inputs = keras.Input(shape = (timesteps, feat_dim), dtype = 'float32')
x = layers.LSTM(320, activation = 'r... | closed | 2025-01-02T19:30:37Z | 2025-01-10T06:23:45Z | https://github.com/keras-team/keras/issues/20715 | [
"type:Bug"
] | albas99 | 4 |
biolab/orange3 | scikit-learn | 7,035 | Hierarchical Clustering: smaller ControlArea | **What's wrong?**
Hierarchical Clustering has a very wide ControlArea, depending on the initial input data.
ControlArea could be smaller (narrower).
**How can we reproduce the problem?**
1. File (iris) - Distances - Hierarchical Clustering. Everything ok.
2. New Orange instance. Datasets (HDI) - Distances - Hierarch... | open | 2025-02-19T08:44:37Z | 2025-03-06T18:20:36Z | https://github.com/biolab/orange3/issues/7035 | [
"wish",
"snack"
] | ajdapretnar | 1 |
ranaroussi/yfinance | pandas | 2,359 | Does yfinance support "Quote Lookup"? | I know there is the search functionality: https://yfinance-python.org/reference/yfinance.search.html
Is there also a way to access the "Quote Lookup" functionality on Yahoo Finance, i.e., this page? → https://finance.yahoo.com/lookup/?s=apple
I would allow for much more comprehensive search with better filtering.
| open | 2025-03-13T20:04:07Z | 2025-03-22T18:31:35Z | https://github.com/ranaroussi/yfinance/issues/2359 | [] | ymyke | 4 |
davidteather/TikTok-Api | api | 1,018 | [BUG] - Comments are no longer retrievable | Using the comments example, an empty response is returned
Tried setting the json cookie which is needed for the trending videos example to run, but it didn't help with the comments.
```
Traceback (most recent call last):
File "/Users/redacted/.pyenv/versions/3.10.3/lib/python3.10/runpy.py", line 196, in _ru... | closed | 2023-05-03T15:43:47Z | 2023-12-01T17:36:40Z | https://github.com/davidteather/TikTok-Api/issues/1018 | [
"bug"
] | vesper8 | 8 |
python-visualization/folium | data-visualization | 1,612 | Folium Map not loading with large quantities of markers and lines in Qt | I'm a student working with folium to visualize data for routes taken by electric vehicles. I've been parsing data from CSV files that include the latitude and longitude of routes and markers for points of interest along the route. I've created a GUI using PyQt5 to run the python scripts that parse the CSV data. The GUI... | closed | 2022-08-05T20:10:38Z | 2023-05-25T13:17:52Z | https://github.com/python-visualization/folium/issues/1612 | [] | ConfusedPrimates | 3 |
gradio-app/gradio | data-science | 10,075 | `gr.load` doesn't work for `gr.ChatInterface` Spaces | ### Describe the bug
When loading `gr.ChatInterface` Space with `gr.load`, an error occurs in the called Space.
For example, if you load this Space
```py
import gradio as gr
def fn(message, history):
return message
gr.ChatInterface(fn=fn).launch()
```
with `gr.load` like this
```py
import gra... | closed | 2024-11-29T07:50:53Z | 2024-12-13T07:53:16Z | https://github.com/gradio-app/gradio/issues/10075 | [
"bug"
] | hysts | 1 |
huggingface/pytorch-image-models | pytorch | 2,004 | [BUG] Wrong shape substitution in _pos_embed for ViTs | In [vision_transformers.py:576](https://github.com/huggingface/pytorch-image-models/blob/e1e7cf5275600ea74d7b6ed80cc105701bddefdb/timm/models/vision_transformer.py#L576C21-L576C21) should not it be `B, C, H, W = x.shape` instead of `B, H, W, C = x.shape`?
Optionally, I am asking because I tried to input variable ima... | closed | 2023-10-23T09:40:08Z | 2023-10-23T17:52:50Z | https://github.com/huggingface/pytorch-image-models/issues/2004 | [
"bug"
] | mohwald | 2 |
apify/crawlee-python | automation | 646 | Potential for Mismatched Type Expectations | If you use deferred annotations but rely on dynamic type evaluation, such as using isinstance or other type-checking functions directly, it can cause mismatches. For instance, code that expects an actual class reference (rather than a string) may fail if it tries to perform type comparisons or dynamic operations. In th... | closed | 2024-11-02T15:32:50Z | 2024-11-04T09:02:21Z | https://github.com/apify/crawlee-python/issues/646 | [
"t-tooling"
] | mgunawardhana | 1 |
Evil0ctal/Douyin_TikTok_Download_API | web-scraping | 167 | 使用1.2.0,获取抖音视频数据失败 | 正在获取抖音视频数据...
生成的X-Bogus签名为: DFSzswSLjsxANJ96taHVaU9WcBnW
正在获取视频数据API: https://www.douyin.com/aweme/v1/web/aweme/detail/?device_platform=webapp&aid=6383&channel=channel_pc_web&aweme_id=7207983870262791483&pc_client_type=1&version_code=190500&version_name=19.5.0&cookie_enabled=true&screen_width=1344&screen_height=756&... | closed | 2023-03-09T01:59:29Z | 2023-03-09T05:47:02Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/167 | [
"BUG"
] | Cestb0n | 2 |
strawberry-graphql/strawberry | graphql | 3,224 | Support the `extensions` Request Parameter for the HTTP protocol | Hello! The GQL spec specifies a field called `extensions` as part of the [request parameters spec](https://github.com/graphql/graphql-over-http/blob/main/spec/GraphQLOverHTTP.md#request-parameters) in the HTTP protocol. We have recently come into a usecase where we would like to make use of this field to provide extra ... | open | 2023-11-14T14:11:28Z | 2025-03-20T15:56:28Z | https://github.com/strawberry-graphql/strawberry/issues/3224 | [] | omarzouk | 8 |
yihong0618/running_page | data-visualization | 159 | 咕咚导出的gpx文件时区不对,作者能否修复一下? | 我想把咕咚的记录导到佳明上去,结果导出的文件的时间戳是+8时区的,但是佳明是按标准的0时区导入,结果显示时间和实际的时间多了个8小时。
我觉得把时间戳减个8个小时应该就可以了,于是尝试修改一下codoon_sync.py文件,几个小时还搞不定,最后放弃,还望作者能修复一下, | closed | 2021-08-12T15:12:56Z | 2021-08-14T00:10:52Z | https://github.com/yihong0618/running_page/issues/159 | [] | nnkn | 1 |
mwaskom/seaborn | data-science | 3,768 | sns.pairplot in same code, but show different result in different version. | Hello I found a problem between 0.11.0 version and 0.13.2.
In the same code, there are different results.
```Python
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_theme(style="white")
tips = sns.load_dataset("tips")
sns.pairplot(data=tips)
```
0.11.0 version result
.
The proposal is for a more declarative approach for `move` function. At the moment, the API is as such:
```python
# present API
>>> imp... | open | 2022-01-26T13:47:32Z | 2022-01-26T13:47:32Z | https://github.com/pyjanitor-devs/pyjanitor/issues/999 | [] | thatlittleboy | 0 |
Evil0ctal/Douyin_TikTok_Download_API | fastapi | 435 | [BUG] 更换了初始Cookie后,返回请求依然为空。应该是个常见的问题,但是不清楚如何解决。 | ***发生错误的平台?***
如:抖音/
***发生错误的端点?***
如:本地部署后,通过浏览器访问
***提交的输入值?***
如:https://www.douyin.com/video/7351452881150545171
***是否有再次尝试?***
如:是,错误一直发生
***你有查看本项目的自述文件或接口文档吗?***
如:有,并且很确定该问题是程序导致的。
应该是更新的Cookie后,这次第一次使用,之前也没有使用成功过。
后端显示的错误为
第1次响应内容为空,状态码200,直到第3次为空,然后放弃。
https://www.douyin... | closed | 2024-06-26T15:56:18Z | 2024-07-27T21:53:19Z | https://github.com/Evil0ctal/Douyin_TikTok_Download_API/issues/435 | [
"BUG"
] | zddllc | 4 |
scikit-multilearn/scikit-multilearn | scikit-learn | 129 | Train and test inverted | Hi,
I may be mistaken, but it seems that the output of `iterative_train_test_split` is inverted.
The expected output of the function is
```
Returns
-------
X_train, y_train, X_test, y_test
stratified division into train/test split
```
but if I run it like
`x_train,y_train,x_... | closed | 2018-10-16T15:40:40Z | 2018-10-16T18:20:54Z | https://github.com/scikit-multilearn/scikit-multilearn/issues/129 | [] | fcomitani | 2 |
assafelovic/gpt-researcher | automation | 957 | Error occurred when using Custom OpenAI API LLM | **Describe the bug**
I am using Custom OpenAI API LLM([llama.cpp Server](https://github.com/ggerganov/llama.cpp/blob/master/examples/server/README.md#quick-start)) as LLM according to the manual below, when I searched something I got the error. (I tested the llama.cpp Server, and it worked well independently)
https:/... | closed | 2024-10-27T12:47:22Z | 2024-11-20T19:48:23Z | https://github.com/assafelovic/gpt-researcher/issues/957 | [] | ki-ri | 1 |
matplotlib/matplotlib | matplotlib | 29,219 | [Bug]: Missing axes limits auto-scaling support for LineCollection | ### Bug summary
Matplotlib is missing auto-scale support for LineCollection.
Related issues:
- https://github.com/matplotlib/matplotlib/issues/23317/
- https://github.com/matplotlib/matplotlib/pull/28403
### Code for reproduction
```Python
from matplotlib import pyplot as plt
from matplotlib.collections import... | open | 2024-12-02T19:38:32Z | 2024-12-07T12:35:01Z | https://github.com/matplotlib/matplotlib/issues/29219 | [
"status: confirmed bug"
] | carlosgmartin | 13 |
CorentinJ/Real-Time-Voice-Cloning | python | 387 | cant run demo_toolbox.py | <h1>i tryed to run demo_toolbox.py (in a termanal and i just get this)<h1>
<p>File "demo_cli.py", line 66, in <module>
encoder.load_model(args.enc_model_fpath)
File "/content/Real-Time-Voice-Cloning-master/encoder/inference.py", line 33, in load_model
checkpoint = torch.load(weights_fpath, _device)
... | closed | 2020-06-28T21:46:50Z | 2020-06-30T01:21:04Z | https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/387 | [] | shrek231 | 1 |
pydantic/pydantic-ai | pydantic | 1,124 | Mermaid Control flow diagram not rendered in docs anymore | https://ai.pydantic.dev/multi-agent-applications
Somehow none of the mermaid diagrams are rendering in the docs anymore. Raw source code is displayed instead. Here are some examples:
<img width="761" alt="Image" src="https://github.com/user-attachments/assets/a9734f59-59a4-445f-b211-4e82138ffd0a" /> | closed | 2025-03-15T01:43:07Z | 2025-03-16T07:55:58Z | https://github.com/pydantic/pydantic-ai/issues/1124 | [] | odysseus0 | 2 |
ccxt/ccxt | api | 25,246 | bitmart calculate_fees returns None for rate and cost | ### Operating System
linux
### Programming Languages
Python
### CCXT Version
4.4.57
### Description
Bitmart does no longer return a valid response for `calculate_fee()`.
It still worked in 4.4.52 - but broke in 4.4.53 - though i currently fail to identify what could've broken this.
the fee itself seems to be s... | closed | 2025-02-10T18:21:29Z | 2025-02-11T10:32:07Z | https://github.com/ccxt/ccxt/issues/25246 | [
"bug"
] | xmatthias | 1 |
ddbourgin/numpy-ml | machine-learning | 61 | Bug in transfer learning | **System information**
- OS Platform and Distribution: Linux Ubuntu 18.04
- Python version: 3.6.9
- NumPy version: 1.19.5
**Describe the current behavior**
There is a problem when trying to perform simple transfer learning techniques (loading the same parameters from another trained layers/models).
When setting... | closed | 2021-03-04T13:39:15Z | 2021-03-05T18:18:13Z | https://github.com/ddbourgin/numpy-ml/issues/61 | [] | RaulMurillo | 0 |
tfranzel/drf-spectacular | rest-api | 834 | how to customize the request or requestBody for POST/PUT request in @extend_schema for OpenAPI 3 file | We are required to customize the Create/Update request for our project, below is the request body:
```
"data":
{
"type": "collection",
"attributes": {
"emailId": "peter@gmail.com",
"fname": "peter",
"lname": "king",
},
"links": {
... | closed | 2022-10-12T18:40:08Z | 2023-08-18T09:45:18Z | https://github.com/tfranzel/drf-spectacular/issues/834 | [] | pshk04 | 6 |
desec-io/desec-stack | rest-api | 484 | api: Allow setting extra DNSKEYs | For RFC 8901. Should be possible by enabling [`direct-dnskey`](https://doc.powerdns.com/authoritative/settings.html#direct-dnskey). We need to test input validation etc.
@ulrichwisser | closed | 2020-12-02T14:06:23Z | 2024-10-07T17:22:25Z | https://github.com/desec-io/desec-stack/issues/484 | [
"enhancement",
"api",
"prio: medium"
] | peterthomassen | 0 |
JaidedAI/EasyOCR | deep-learning | 1,385 | Error while loading model for language `ta` | When target language `ta` is used i have this error:
```
Error: Error(s) in loading state_dict for Model:
size mismatch for Prediction.weight: copying a param with shape torch.Size([143, 512]) from checkpoint, the shape in current model is torch.Size([127, 512]).
size mismatch for Prediction.bias: copying a pa... | open | 2025-03-10T03:09:00Z | 2025-03-10T03:09:00Z | https://github.com/JaidedAI/EasyOCR/issues/1385 | [] | vitonsky | 0 |
recommenders-team/recommenders | data-science | 1,256 | [FEATURE] remove TF warning messages in all TF notebooks | ### Description
<!--- Describe your expected feature in detail -->
```
tf.get_logger().setLevel('ERROR') # only show error messages
```
### Expected behavior with the suggested feature
<!--- For example: -->
<!--- *Adding algorithm xxx will help people understand more about xxx use case scenarios. -->
##... | closed | 2020-12-04T12:45:21Z | 2021-01-18T16:42:36Z | https://github.com/recommenders-team/recommenders/issues/1256 | [
"enhancement"
] | miguelgfierro | 0 |
plotly/dash-table | plotly | 510 | derived_virtual_selected_row_ids is displaying incorrect results | Hi,
I am noticing that property `derived_virtual_selected_row_id` seems to display a list of Nulls when used as a callback input. I attempted this with sorting as well. Same behavior.
I've attached the code below.
I also noticed interesting behavior where `derived_data` shouldn't be used alongside with `derived_... | open | 2019-07-20T00:20:54Z | 2019-07-20T01:02:10Z | https://github.com/plotly/dash-table/issues/510 | [] | CloudZazu | 1 |
google-deepmind/sonnet | tensorflow | 138 | relational_memory.py: InvalidArgumentError: node has inputs from different frames. | I train a GAN model with relational rnn as my discriminator, I use tensorflow 1.12.0 and python 2.7. I use tf.contrib.framework.gan.gan_model() as my GAN model.
Part of code :
```
from sonnet.python.modules import relational_memory
...
def discriminator():
...
cell = relational_memory.RelationalMemory( mem_s... | open | 2019-07-24T11:34:45Z | 2019-07-24T11:34:45Z | https://github.com/google-deepmind/sonnet/issues/138 | [] | songpipi | 0 |
quantmind/pulsar | asyncio | 163 | Cannot runtests after CTRL+C | I'm using Python 3.4 on a Debian Jessie
I'm using a virtualenv
- Run `python -m runtests --coverage`
- Stop it with ctrl+C
- Run `python -m runtests --coverage` again. It fails with the following output :
```
$ python -m runtests --coverage [15-10-02 14:56]
3.4.3 (default... | closed | 2015-10-02T14:25:19Z | 2016-03-17T08:08:27Z | https://github.com/quantmind/pulsar/issues/163 | [
"bug",
"moved"
] | msornay | 6 |
Lightning-AI/pytorch-lightning | machine-learning | 20,562 | `BatchSizeFinder` with method `fit` and separate batch_size attributes for train and val (e.g., `self.train_batch_size` and `self.val_batch_size`) | ### Outline & Motivation
I suggest allowing `batch_arg_name` to accept a list of arg names. E.g. `tuner.scale_batch_size(..., batch_arg_name=["train_batch_size", "val_batch_size").
### Pitch
Fit uses both train and val dataloaders. They can have their own batch sizes.
### Additional context
_No response_
cc @lant... | open | 2025-01-24T18:21:04Z | 2025-01-24T18:21:26Z | https://github.com/Lightning-AI/pytorch-lightning/issues/20562 | [
"refactor",
"needs triage"
] | ibro45 | 0 |
aiortc/aiortc | asyncio | 1,010 | Missing import of AudioStreamTrack from mediastreams.py in __init__.py | In the file \_\_init__.py there is no import of the AudioStreamTrack class from the mediastreams.py module. Please check this [pull request](https://github.com/aiortc/aiortc/pull/1009). | closed | 2023-12-04T15:05:02Z | 2024-01-07T09:43:04Z | https://github.com/aiortc/aiortc/issues/1010 | [] | hentaibaka | 1 |
milesmcc/shynet | django | 297 | Question regarding Requests | Hello,
i have a question regarding the script which i put on the website. Why does it request the script.js every few seconds when
checking inside my console? Is that normal?
Thanks | closed | 2023-11-01T15:30:36Z | 2023-11-02T16:47:05Z | https://github.com/milesmcc/shynet/issues/297 | [] | webmastermario | 2 |
LAION-AI/Open-Assistant | machine-learning | 3,518 | oasst-data can't working with Python 3.8 | Hello! I found Open Assistant Data Module (oasst_data) don't working with Python 3.8. I think oasst_data should can working with Python 3.8 because many deep learning library can't working with Python 3.10/3.11. | closed | 2023-06-26T11:55:20Z | 2023-06-27T13:15:06Z | https://github.com/LAION-AI/Open-Assistant/issues/3518 | [] | wannaphong | 0 |
comfyanonymous/ComfyUI | pytorch | 6,271 | ability to disable copypaste with middleclick or clear paste buffer | ### Feature Idea
as a blender user im extremely used to using middle mouse to pan around the node workflow, but if i had copied something it pasted every time i pan, its very annoying. if there was a way to remove that from the keybinding settings that would be awesome, ir if you cant do that, have a method to clear t... | open | 2024-12-29T21:00:19Z | 2024-12-29T22:57:26Z | https://github.com/comfyanonymous/ComfyUI/issues/6271 | [
"Feature",
"Frontend"
] | jurassicjordan | 0 |
jessevig/bertviz | nlp | 59 | How to use the visualization for custom BERT | Hi, I have a model, in which I have a fully connected layer after BERT. How do I visualize the attention weights with this model where the BERT output is an intermediate result?
My foward function of the model looks like
` _, pooled_output = self.bert(tokens, attention_mask=masks, output_all_encoded_layers=False... | closed | 2020-11-02T11:16:46Z | 2020-12-28T13:29:52Z | https://github.com/jessevig/bertviz/issues/59 | [] | QinghangHong1 | 1 |
Hironsan/BossSensor | computer-vision | 35 | 能否做个简易安装包 | 有没有大神包装成exe文件,配置环境比较麻烦 | open | 2023-08-25T02:08:50Z | 2023-08-25T02:08:50Z | https://github.com/Hironsan/BossSensor/issues/35 | [] | musaart | 0 |
scikit-hep/awkward | numpy | 3,061 | from_rdataframe does not work for distributed rdataframe | ### Version of Awkward Array
2.6.2
### Description and code to reproduce
For distributed RDataFrames, e.g. with dask or spark backends, some operations are not exposed including `GetColumnType` which is used by the `ak.from_rdataframe` method.
Reproducer:
```
import ROOT
import awkward as ak
from dask.distrib... | closed | 2024-03-24T09:33:54Z | 2024-04-25T15:27:13Z | https://github.com/scikit-hep/awkward/issues/3061 | [
"bug (unverified)"
] | AlkaidCheng | 2 |
microsoft/nni | deep-learning | 5,709 | Adding back the sensitivity analysis tool to v3.0 | <!-- Please only use this template for submitting enhancement requests -->
**What would you like to be added**:
Are there any plans to add back the sensitivty analysis tool to v3.0 ?
**Why is this needed**:
It would be great to have this tool back as a debug tool, to target better the layers that are not sen... | open | 2023-11-08T15:01:19Z | 2023-11-08T15:01:19Z | https://github.com/microsoft/nni/issues/5709 | [] | mehdi-nait | 0 |
babysor/MockingBird | deep-learning | 572 | vocoder comparison | Is there a comparison between vocoders? | closed | 2022-05-23T15:46:08Z | 2022-05-30T12:41:18Z | https://github.com/babysor/MockingBird/issues/572 | [] | ireneb612 | 4 |
tableau/server-client-python | rest-api | 1,189 | Databricks Workbook Table Name Length Limit | **Describe the bug**
When using TSC and attempting to publish a Tableau Workbook created with Tableau Desktop 2022.1.10, there seems to be a table name char limit that Tableau is using internally for the references. When a table name (note that connection names in a workbook's xml) exceeds 63 chars, the name of the co... | open | 2023-02-14T03:37:01Z | 2023-10-23T16:45:53Z | https://github.com/tableau/server-client-python/issues/1189 | [
"bug",
"Server-Side Enhancement",
"needs investigation"
] | williamdphillips | 2 |
napari/napari | numpy | 7,579 | Export figure does not properly calculate canvas size for non-symmetric grid shapes | ### 🐛 Bug Report
When using `viewer.export_figure()` in grid mode, the canvas size is not properly set, at least for non-symmetric grid shapes. This is important if users want to export non-symmetric grids, and they would expect there to be no black margin if using `export_figure`. (bounding box to show screenshot sh... | open | 2025-02-03T18:48:44Z | 2025-02-04T23:38:01Z | https://github.com/napari/napari/issues/7579 | [
"bug"
] | TimMonko | 4 |
huggingface/datasets | tensorflow | 6,881 | AttributeError: module 'PIL.Image' has no attribute 'ExifTags' | When trying to load an image dataset in an old Python environment (with Pillow-8.4.0), an error is raised:
```Python traceback
AttributeError: module 'PIL.Image' has no attribute 'ExifTags'
```
The error traceback:
```Python traceback
~/huggingface/datasets/src/datasets/iterable_dataset.py in __iter__(self)
1... | closed | 2024-05-08T06:33:57Z | 2024-07-18T06:49:30Z | https://github.com/huggingface/datasets/issues/6881 | [
"bug"
] | albertvillanova | 3 |
lorien/grab | web-scraping | 377 | Fix simple typo: shuld -> should | There is a small typo in tests/ext_lxml.py, tests/ext_rex.py.
Should read `should` rather than `shuld`.
| closed | 2020-02-29T19:57:08Z | 2020-12-08T03:50:03Z | https://github.com/lorien/grab/issues/377 | [] | timgates42 | 0 |
jumpserver/jumpserver | django | 14,811 | [Bug] 使用自定义ldap端口同步的时候,报端口错误 | ### Product Version
3.10.17
### Product Edition
- [ ] Community Edition
- [ ] Enterprise Edition
- [X] Enterprise Trial Edition
### Installation Method
- [ ] Online Installation (One-click command installation)
- [ ] Offline Package Installation
- [X] All-in-One
- [ ] 1Panel
- [ ] Kubernetes
- [ ] Source Code
###... | closed | 2025-01-14T12:04:40Z | 2025-01-14T12:06:04Z | https://github.com/jumpserver/jumpserver/issues/14811 | [
"🐛 Bug"
] | Ankers-liu | 1 |
omnilib/aiomultiprocess | asyncio | 88 | Close versus terminate | ### Description
I would like to know the difference between Pool.close() and Pool.terminate. The documentation has the following to say:
```
close() → None
Close the pool to new visitors.
terminate() → None
No running by the pool!
```
Which is unclear. I thought `close` would prevent new tasks from being ... | open | 2021-03-18T20:58:38Z | 2021-03-19T01:12:18Z | https://github.com/omnilib/aiomultiprocess/issues/88 | [
"documentation"
] | ChriZiegler | 1 |
xuebinqin/U-2-Net | computer-vision | 318 | I am a student of the second year of Tsinghua graduate school. I sincerely ask a question: does it support real-time verification during training? For example, do you consider adding a new function, that is, each time you complete an epoch training, you will verify on the specified verification data set and print the l... | I am a student of the second year of Tsinghua graduate school. I sincerely ask a question: does it support real-time verification during training? For example, do you consider adding a new function, that is, each time you complete an epoch training, you will verify on the specified verification data set and print the l... | open | 2022-07-18T07:46:03Z | 2022-07-22T09:31:23Z | https://github.com/xuebinqin/U-2-Net/issues/318 | [] | xianglei3 | 2 |
AUTOMATIC1111/stable-diffusion-webui | pytorch | 16,732 | [Bug]: ImportError: cannot import name 'computed_field' from 'pydantic' | ### Checklist
- [ ] The issue exists after disabling all extensions
- [X] The issue exists on a clean installation of webui
- [ ] The issue is caused by an extension, but I believe it is caused by a bug in the webui
- [X] The issue exists in the current version of the webui
- [X] The issue has not been reported before... | closed | 2024-12-19T11:25:20Z | 2024-12-19T12:18:08Z | https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/16732 | [
"bug-report"
] | nagikoru | 1 |
tortoise/tortoise-orm | asyncio | 903 | Why foreign keys created with `_id` suffix? | It doesn't obvious, because in some places I should use field name with `_id`, in some - without. Why is it happened, or am I doing something wrong?
Model's part:
```python
state: int = fields.ForeignKeyField(
"models.State",
"state's id",
)
```
Database:

| closed | 2023-04-10T06:36:33Z | 2023-04-10T06:58:37Z | https://github.com/microsoft/JARVIS/issues/117 | [] | liujie316316 | 3 |
RobertCraigie/prisma-client-py | pydantic | 680 | Select method on client | ## Problem
Overfetching data from database.
## Suggested solution
Develop a select method, who already exists on original prisma for javascript.
| closed | 2023-01-23T20:25:07Z | 2023-01-23T22:59:35Z | https://github.com/RobertCraigie/prisma-client-py/issues/680 | [] | Gabriel-Fachini | 1 |
marimo-team/marimo | data-science | 4,231 | Login failed when running marimo app with --token-password and --base-path | ### Describe the bug
I want to deploy several marimo apps/dashboards on our internal server. The dashboards should be available under subpaths. (e.g. https://our.internal.server.com/dashboard1) using nginx as a reverse proxy.
This works, when starting the marimo app with
```bash
marimo run dashboard1.py --base-path /... | open | 2025-03-24T16:10:21Z | 2025-03-24T16:25:00Z | https://github.com/marimo-team/marimo/issues/4231 | [
"bug"
] | legout | 1 |
okken/pytest-check | pytest | 130 | Add option to skip additional levels in pseudotraceback | It would be great to have an option for the various check functions to skip additional traceback levels.
This would benefit situations where the actual check is encapsulated into a helper function (e.g. to check multiple things at a time, and not directly done in the test method.
Example:
checkResponse could be om... | closed | 2023-06-07T09:56:27Z | 2023-07-16T11:43:58Z | https://github.com/okken/pytest-check/issues/130 | [
"enhancement"
] | mbergen | 4 |
jupyterhub/repo2docker | jupyter | 905 | A simple question: where is the output of repo2docker | Hi,
I have build a complex Docker image using repo2docker.
I'm using it in debian, starting from a system folder. But I have no idea on where is the repo2docker output and what's the right way to delete it.
Thank you | closed | 2020-06-04T14:49:59Z | 2020-09-18T15:59:34Z | https://github.com/jupyterhub/repo2docker/issues/905 | [
"support"
] | aborruso | 2 |
autogluon/autogluon | scikit-learn | 4,125 | Multi-Window for TimeSeriesPredictor.feature_importance | Hi,
it would be great if the known multi-window-splitter logic which is used for extended testing ( predictor.evaluate() )would be natively available for more robust feature-importance testing. Right now I am calling the feature_importance in a loop on the test_set which is sliced in each iteration and in the end su... | open | 2024-04-23T14:01:21Z | 2024-11-08T15:54:12Z | https://github.com/autogluon/autogluon/issues/4125 | [
"enhancement",
"module: timeseries"
] | obwohl | 1 |
jeffknupp/sandman2 | sqlalchemy | 77 | Error when using both page and limit | When I make a request containing both `page` and `limit` (e.g. `/foo/bar/?limit=50&page=1`), I'm getting the following error:
```
Traceback (most recent call last):
File "/var/task/flask/app.py", line 2292, in wsgi_app
response = self.full_dispatch_request()
File "/var/task/flask/app.py", line 1815, in ful... | closed | 2018-12-04T17:21:06Z | 2018-12-16T22:14:40Z | https://github.com/jeffknupp/sandman2/issues/77 | [] | berislavlopac | 2 |
axnsan12/drf-yasg | django | 373 | Add support for custom Pagination | I have been writing my API docs using this library, and encountered situations like this:
I customized my api pagination scheme like this:
```json
{
"count": 0,
"data": [
{}
],
"paging": {
"previous": "http://example.com",
"next": "http://example.com",
}
}
```
However, the auto-gen... | closed | 2019-05-27T21:27:20Z | 2019-06-12T23:38:42Z | https://github.com/axnsan12/drf-yasg/issues/373 | [] | joeyworld | 1 |
tortoise/tortoise-orm | asyncio | 1,058 | Packet sequence number wrong - got 0 expected 1 | **Describe the bug**
Sometimes my app stops working and in logs I see this:
tortoise.exceptions.OperationalError: Packet sequence number wrong - got 0 expected 1
**Additional context**
My app is multitask but I think it must be ok.
| closed | 2022-01-28T08:30:35Z | 2024-05-14T10:51:23Z | https://github.com/tortoise/tortoise-orm/issues/1058 | [] | draklowell | 2 |
pytest-dev/pytest-html | pytest | 755 | Missing collection errors in pytest-html v4 | Thanks for the rewrite and a revamped report in the pytest-html!
I noticed that the collection errors are not reported as part of pytest-html v4 but they were reported till pytest-html==3.2.0
Reproducer:
**test_sample.py**
```
import pytest
raise ImportError("Non existent module")
```
Run:
```
pyt... | closed | 2023-10-31T16:43:48Z | 2023-11-01T16:49:14Z | https://github.com/pytest-dev/pytest-html/issues/755 | [] | akhilramkee | 3 |
autogluon/autogluon | scikit-learn | 4,705 | ValueError when calling TimeSeriesPredictor.predict with known_covariates : known "weekend" Time-varying covariates | ### Description:
I am encountering an issue when using the `TimeSeriesPredictor` in AutoGluon. The problem arises when I call the predict method with the `known_covariates` argument.
### Code:
Here is my code:
```
# data has a MultiIndex ('item_id', 'timestamp') has column 'target'
predictor = TimeSeriesP... | closed | 2024-12-02T15:07:29Z | 2024-12-03T10:43:08Z | https://github.com/autogluon/autogluon/issues/4705 | [
"module: timeseries"
] | Ceciile | 2 |
tensorflow/tensor2tensor | machine-learning | 1,002 | Undefined name 'loss' in the creation of 'training_loss_dict' | ### Description
Undefined name __loss__ caused by an invalid comprehension in the code:
```python
training_loss_dict = average_sharded_losses([{
"training": l
} for l in loss for loss in sharded_losses.values()])
```
https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/t2t_... | closed | 2018-08-17T11:44:50Z | 2019-01-08T19:20:06Z | https://github.com/tensorflow/tensor2tensor/issues/1002 | [] | cclauss | 0 |
raphaelvallat/pingouin | pandas | 56 | Add support for pairwise deletion in pairwise_ttests | See Gitter chat | closed | 2019-08-22T15:46:43Z | 2019-08-27T00:32:39Z | https://github.com/raphaelvallat/pingouin/issues/56 | [
"feature request :construction:"
] | raphaelvallat | 1 |
mkhorasani/Streamlit-Authenticator | streamlit | 69 | Your app is having trouble loading the extra_streamlit_components.CookieManager.cookie_manager component. | I'm trying to implement login option on my app. But getting this error & can't login to the main body.
Please help.
```Your app is having trouble loading the extra_streamlit_components.CookieManager.cookie_manager component.
(The app is attempting to load the component from ****, and hasn't received its "strea... | closed | 2023-06-03T09:00:42Z | 2023-08-30T13:24:02Z | https://github.com/mkhorasani/Streamlit-Authenticator/issues/69 | [] | ihpolash | 7 |
PaddlePaddle/ERNIE | nlp | 526 | Ernie1.0 how to use 2 gpu not 8 gpu. | When I change number of GPUs from 8 to 2, in log it shows an error below.
server not ready, wait 3 second to retry...
Could you give me some suggestions about this error? Many thanks. | closed | 2020-07-25T13:28:37Z | 2020-10-03T13:48:02Z | https://github.com/PaddlePaddle/ERNIE/issues/526 | [
"wontfix"
] | CuiMingyu | 2 |
plotly/dash | jupyter | 2,372 | [BUG] Background callback returns 502 | Thank you so much for helping improve the quality of Dash!
We do our best to catch bugs during the release process, but we rely on your help to find the ones that slip through.
**Describe your context**
I have some high CPU/RAM efficient workflow that handling by celery and in the same time I have background c... | closed | 2022-12-29T03:29:51Z | 2024-07-25T13:06:03Z | https://github.com/plotly/dash/issues/2372 | [] | ArtsiomAntropau | 2 |
donnemartin/system-design-primer | python | 780 | Github Night Theme Makes Images With Transparent Background Illegible | Hi there, I was just checking out this repository for the first time and noticed your flow chart of system architecture has arrows that end up being hidden if you're viewing github using "night theme".

... | open | 2023-05-25T17:16:17Z | 2024-06-23T17:40:03Z | https://github.com/donnemartin/system-design-primer/issues/780 | [
"needs-review"
] | ghost | 4 |
zappa/Zappa | django | 559 | [Migrated] How can I deploy project with dlib by Zappa? | Originally from: https://github.com/Miserlou/Zappa/issues/1477 by [wkentaro](https://github.com/wkentaro)
## Context
<!--- Provide a more detailed introduction to the issue itself, and why you consider it to be a bug -->
<!--- Also, please make sure that you are running Zappa _from a virtual environment_ and are usi... | closed | 2021-02-20T12:22:45Z | 2022-07-16T07:07:15Z | https://github.com/zappa/Zappa/issues/559 | [] | jneves | 1 |
kizniche/Mycodo | automation | 1,072 | Camera widget cannot get most recent timelapse image if custom path is defined | ### Describe the problem/bug
I have a camera defined with a custom timelapse path. When I configure a camera widget on my dashboard and select "most recent timelapse image", it will never find a valid one because it doesn't flex on the custom path.
The logic in `routes_general.camera_img_latest_timelapse()` is h... | closed | 2021-08-18T21:26:29Z | 2021-08-30T02:43:42Z | https://github.com/kizniche/Mycodo/issues/1072 | [
"bug",
"Fixed and Committed"
] | kimbernator | 5 |
biolab/orange3 | scikit-learn | 6,841 | Edit Domain interpret as time: add more dd-mm options | <!--
Thanks for taking the time to submit a feature request!
For the best chance at our team considering your request, please answer the following questions to the best of your ability.
-->
**What's your use case?**
<img width="659" alt="image" src="https://github.com/biolab/orange3/assets/55989717/9f1691a4-b4c... | open | 2024-06-26T10:05:10Z | 2024-11-23T09:20:35Z | https://github.com/biolab/orange3/issues/6841 | [
"meal"
] | wvdvegte | 2 |
axnsan12/drf-yasg | django | 336 | Specify different serializer classes for request and response | I'm pretty satisfied with drf-yasg, but unable to find the way to specify different serializer classes for request and response. By default Swagger UI shows the model derived from `<view-set>.serializer_class` value for both request and response no matter what serializer the response really uses.
Should I use ManualSc... | closed | 2019-03-24T19:27:46Z | 2019-03-25T06:54:37Z | https://github.com/axnsan12/drf-yasg/issues/336 | [] | symonsoft | 1 |
satwikkansal/wtfpython | python | 275 | airodump-ng mon0 | closed | 2021-10-02T13:12:18Z | 2021-10-30T17:26:28Z | https://github.com/satwikkansal/wtfpython/issues/275 | [] | Mateotola | 0 | |
DistrictDataLabs/yellowbrick | matplotlib | 923 | Remove duplicate code from sub classes of DataVisualizer. | `DataVisualizer` now handles target_type_identification(implemented in #893). The visualizer which extends `DataVisualizer` have been handling these functionalities internally. Now we can update these visualizers to remove the duplicate codes.
For e.g., ParallelCoordinates(which handles only discrete target for now)... | closed | 2019-07-15T19:53:07Z | 2019-07-23T17:52:12Z | https://github.com/DistrictDataLabs/yellowbrick/issues/923 | [] | naresh-bachwani | 0 |
iperov/DeepFaceLab | deep-learning | 912 | rtx 30x can use DFL1.0 OpenCL fast,make DFL2.0 OpencL for RTX 30x? | =========================== Model Summary ===========================
== ==
== Model name: H64 ==
== ==
== Current iteration: 0 ... | open | 2020-09-28T17:40:07Z | 2023-06-08T21:28:18Z | https://github.com/iperov/DeepFaceLab/issues/912 | [] | yuanshiyuanyi | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.