
content stringlengths 7 1.05M | fixed_cases stringlengths 1 1.28M |
|---|---|
"""
39.61%
return ['Fizz' * (not i % 3) + 'Buzz' * (not i % 5) or str(i) for i in range(1, n+1)]
"""
class Solution(object):
def fizzBuzz(self, n):
"""
:type n: int
:rtype: List[str]
"""
result = []
for i in range(1, n+1):
if i % 3 == 0 and i % 5 == 0:
result.append('FizzBuzz')
elif i % 3 == 0:
result.append('Fizz')
elif i % 5 == 0:
result.append('Buzz')
else:
result.append(str(i))
return result | """
39.61%
return ['Fizz' * (not i % 3) + 'Buzz' * (not i % 5) or str(i) for i in range(1, n+1)]
"""
class Solution(object):
def fizz_buzz(self, n):
"""
:type n: int
:rtype: List[str]
"""
result = []
for i in range(1, n + 1):
if i % 3 == 0 and i % 5 == 0:
result.append('FizzBuzz')
elif i % 3 == 0:
result.append('Fizz')
elif i % 5 == 0:
result.append('Buzz')
else:
result.append(str(i))
return result |
# AUTOGENERATED BY NBDEV! DO NOT EDIT!
__all__ = ["index", "modules", "custom_doc_links", "git_url"]
index = {"generate": "00_numpy.ipynb",
"square_root_by_exhaustive": "01_python03.ipynb",
"square_root_by_binary_search": "01_python03.ipynb",
"square_root_by_newton": "01_python03.ipynb",
"search": "01_python03.ipynb",
"select_sort": "01_python03.ipynb"}
modules = ["numpycore.py",
"py03.py"]
doc_url = "https://greyhawk.github.io/pandas_exercises/"
git_url = "https://github.com/greyhawk/pandas_exercises/tree/master/"
def custom_doc_links(name): return None
| __all__ = ['index', 'modules', 'custom_doc_links', 'git_url']
index = {'generate': '00_numpy.ipynb', 'square_root_by_exhaustive': '01_python03.ipynb', 'square_root_by_binary_search': '01_python03.ipynb', 'square_root_by_newton': '01_python03.ipynb', 'search': '01_python03.ipynb', 'select_sort': '01_python03.ipynb'}
modules = ['numpycore.py', 'py03.py']
doc_url = 'https://greyhawk.github.io/pandas_exercises/'
git_url = 'https://github.com/greyhawk/pandas_exercises/tree/master/'
def custom_doc_links(name):
return None |
class Solution(object):
def lengthOfLastWord(self, s):
"""
:type s: str
:rtype: int
"""
if len(s) == 0:
return 0
else:
words = s.split()
return len(words[len(words) - 1])
| class Solution(object):
def length_of_last_word(self, s):
"""
:type s: str
:rtype: int
"""
if len(s) == 0:
return 0
else:
words = s.split()
return len(words[len(words) - 1]) |
answer1 = widget_inputs["radio1"]
answer2 = widget_inputs["radio2"]
answer3 = widget_inputs["radio3"]
answer4 = widget_inputs["radio4"]
is_correct = False
comments = []
def commentizer(new):
if new not in comments:
comments.append(new)
if answer1 == True:
is_correct = True
else:
is_correct = is_correct and False
commentizer("Check the first one. Remember, an SVG animation will animate the rotation of an image, as opposed to a gif which is a series of raster images displayed one after another.")
if answer4 == True:
is_correct = is_correct and True
else:
is_correct = is_correct and False
commentizer("Check the second one. Will the image be reused? If so, an external file probably makes more sense.")
if is_correct:
commentizer("Great job!")
commentizer(" I love the internet :)")
grade_result["comment"] = "\n\n".join(comments)
grade_result["correct"] = is_correct | answer1 = widget_inputs['radio1']
answer2 = widget_inputs['radio2']
answer3 = widget_inputs['radio3']
answer4 = widget_inputs['radio4']
is_correct = False
comments = []
def commentizer(new):
if new not in comments:
comments.append(new)
if answer1 == True:
is_correct = True
else:
is_correct = is_correct and False
commentizer('Check the first one. Remember, an SVG animation will animate the rotation of an image, as opposed to a gif which is a series of raster images displayed one after another.')
if answer4 == True:
is_correct = is_correct and True
else:
is_correct = is_correct and False
commentizer('Check the second one. Will the image be reused? If so, an external file probably makes more sense.')
if is_correct:
commentizer('Great job!')
commentizer(' I love the internet :)')
grade_result['comment'] = '\n\n'.join(comments)
grade_result['correct'] = is_correct |
# -*- coding: utf-8 -*-
"""Top-level package for botorum."""
__author__ = """JP White"""
__email__ = 'jpwhite3@gmail.com'
__version__ = '0.1.0'
| """Top-level package for botorum."""
__author__ = 'JP White'
__email__ = 'jpwhite3@gmail.com'
__version__ = '0.1.0' |
# Open file for reading
inputFile = open('input_1', 'rt')
# Put values into array
inputValues = []
for x in inputFile:
inputValues.append(int(x))
inputFile.close()
"""
PUZZLE ONE
"""
increaseCount = 0
for currentIndex in range(len(inputValues)-1):
if inputValues[currentIndex+1]-inputValues[currentIndex] > 0:
increaseCount += 1
print("Increase Count: ", increaseCount)
"""
PUZZLE TWO
"""
increaseCount2 = 0
for currentIndex2 in range(len(inputValues)-3):
currentSum = inputValues[currentIndex2]+inputValues[currentIndex2+1]+inputValues[currentIndex2+2]
nextSum = inputValues[currentIndex2+1]+inputValues[currentIndex2+2]+inputValues[currentIndex2+3]
if nextSum - currentSum > 0:
increaseCount2 += 1
print("Increase Count 2: ", increaseCount2)
| input_file = open('input_1', 'rt')
input_values = []
for x in inputFile:
inputValues.append(int(x))
inputFile.close()
'\nPUZZLE ONE\n'
increase_count = 0
for current_index in range(len(inputValues) - 1):
if inputValues[currentIndex + 1] - inputValues[currentIndex] > 0:
increase_count += 1
print('Increase Count: ', increaseCount)
'\nPUZZLE TWO\n'
increase_count2 = 0
for current_index2 in range(len(inputValues) - 3):
current_sum = inputValues[currentIndex2] + inputValues[currentIndex2 + 1] + inputValues[currentIndex2 + 2]
next_sum = inputValues[currentIndex2 + 1] + inputValues[currentIndex2 + 2] + inputValues[currentIndex2 + 3]
if nextSum - currentSum > 0:
increase_count2 += 1
print('Increase Count 2: ', increaseCount2) |
"""Message type identifiers for Routing."""
MESSAGE_FAMILY = "did:sov:BzCbsNYhMrjHiqZDTUASHg;spec/routing/1.0"
FORWARD = f"{MESSAGE_FAMILY}/forward"
ROUTE_QUERY_REQUEST = f"{MESSAGE_FAMILY}/route-query-request"
ROUTE_QUERY_RESPONSE = f"{MESSAGE_FAMILY}/route-query-response"
ROUTE_UPDATE_REQUEST = f"{MESSAGE_FAMILY}/route-update-request"
ROUTE_UPDATE_RESPONSE = f"{MESSAGE_FAMILY}/route-update-response"
MESSAGE_PACKAGE = "aries_cloudagent.messaging.routing.messages"
MESSAGE_TYPES = {
FORWARD: f"{MESSAGE_PACKAGE}.forward.Forward",
ROUTE_QUERY_REQUEST: f"{MESSAGE_PACKAGE}.route_query_request.RouteQueryRequest",
ROUTE_QUERY_RESPONSE: f"{MESSAGE_PACKAGE}.route_query_response.RouteQueryResponse",
ROUTE_UPDATE_REQUEST: f"{MESSAGE_PACKAGE}.route_update_request.RouteUpdateRequest",
ROUTE_UPDATE_RESPONSE: (
f"{MESSAGE_PACKAGE}.route_update_response.RouteUpdateResponse"
),
}
| """Message type identifiers for Routing."""
message_family = 'did:sov:BzCbsNYhMrjHiqZDTUASHg;spec/routing/1.0'
forward = f'{MESSAGE_FAMILY}/forward'
route_query_request = f'{MESSAGE_FAMILY}/route-query-request'
route_query_response = f'{MESSAGE_FAMILY}/route-query-response'
route_update_request = f'{MESSAGE_FAMILY}/route-update-request'
route_update_response = f'{MESSAGE_FAMILY}/route-update-response'
message_package = 'aries_cloudagent.messaging.routing.messages'
message_types = {FORWARD: f'{MESSAGE_PACKAGE}.forward.Forward', ROUTE_QUERY_REQUEST: f'{MESSAGE_PACKAGE}.route_query_request.RouteQueryRequest', ROUTE_QUERY_RESPONSE: f'{MESSAGE_PACKAGE}.route_query_response.RouteQueryResponse', ROUTE_UPDATE_REQUEST: f'{MESSAGE_PACKAGE}.route_update_request.RouteUpdateRequest', ROUTE_UPDATE_RESPONSE: f'{MESSAGE_PACKAGE}.route_update_response.RouteUpdateResponse'} |
digit = input('Enter number:')
name = input("Name:")
if not digit.i:
print("Input must be a digit")
exit(1)
print(int(digit) + 1)
| digit = input('Enter number:')
name = input('Name:')
if not digit.i:
print('Input must be a digit')
exit(1)
print(int(digit) + 1) |
num1 = 11
num2 = 222
num3 = 3333333
num3 = 333
num4 = 44444
| num1 = 11
num2 = 222
num3 = 3333333
num3 = 333
num4 = 44444 |
# mock data
OP_STATIC_ATTRS = {
"objectClass": ["top", "oxAuthClient"],
"oxAuthScope": [
"inum=F0C4,ou=scopes,o=gluu",
"inum=C4F5,ou=scopes,o=gluu",
],
"inum": "w124asdgggAGs",
}
ADD_OP_TEST_ARGS = {
"oxAuthLogoutSessionRequired": False,
"oxAuthTrustedClient": False,
"oxAuthResponseType": "token",
"oxAuthTokenEndpointAuthMethod": "client_secret_basic",
"oxAuthRequireAuthTime": False,
"oxAccessTokenAsJwt": False,
"oxPersistClientAuthorizations": True,
"oxAuthGrantType": "client_credentials",
"oxAttributes":
'{"tlsClientAuthSubjectDn":null,"runIntrospectionScriptBeforeAccessTokenAsJwtCreationAndIncludeClaims":false,"keepClientAuthorizationAfterExpiration":false}',
"oxAuthAppType": "web",
"oxDisabled": False,
"oxIncludeClaimsInIdToken": False,
"oxRptAsJwt": False,
"displayName": "test-client2",
"oxAuthClientSecret": "somecoolsecret",
"oxAuthSubjectType": "pairwise",
}
MOCKED_SEARCH_S_VALID_RESPONSE = [(
"inum=59376804-e84b-411a-9492-653d14e52c24,ou=clients,o=gluu",
{
"objectClass": [b"top", b"oxAuthClient"],
"oxAuthLogoutSessionRequired": [b"false"],
"oxAuthScope": [
b"inum=F0C4,ou=scopes,o=gluu",
b"inum=C4F5,ou=scopes,o=gluu",
],
"oxAuthTrustedClient": [b"false"],
"oxAuthResponseType": [b"token"],
"oxAuthTokenEndpointAuthMethod": [b"client_secret_basic"],
"oxAuthRequireAuthTime": [b"false"],
"oxAccessTokenAsJwt": [b"false"],
"oxPersistClientAuthorizations": [b"true"],
"oxAuthGrantType": [b"client_credentials"],
"inum": [b"59376804-e84b-411a-9492-653d14e52c24"],
"oxAttributes": [
b'{"tlsClientAuthSubjectDn":null,"runIntrospectionScriptBeforeAccessTokenAsJwtCreationAndIncludeClaims":false,"keepClientAuthorizationAfterExpiration":false}'
],
"oxAuthAppType": [b"web"],
"oxLastLogonTime": [b"20200714072830.011Z"],
"oxAuthClientSecretExpiresAt": [b"21200623000000.000Z"],
"oxDisabled": [b"false"],
"oxIncludeClaimsInIdToken": [b"false"],
"oxRptAsJwt": [b"false"],
"displayName": [b"test-client"],
"oxAuthClientSecret": [b"gWxnjnUdCm8Rpc0WPmm9lQ=="],
"oxAuthSubjectType": [b"pairwise"],
"oxLastAccessTime": [b"20200714072830.011Z"],
},
)]
OP_ADD_OP_EXPECTED_RETURN = expected_created_op = (
"inum=w124asdgggAGs,ou=clients,o=gluu",
{
"objectClass": [b"top", b"oxAuthClient"],
"oxAuthLogoutSessionRequired": [b"false"],
"oxAuthTrustedClient": [b"false"],
"oxAuthScope":
[b"inum=F0C4,ou=scopes,o=gluu", b"inum=C4F5,ou=scopes,o=gluu"],
"oxAuthResponseType": [b"token"],
"oxAuthTokenEndpointAuthMethod": [b"client_secret_basic"],
"oxAuthRequireAuthTime": [b"false"],
"oxAccessTokenAsJwt": [b"false"],
"oxPersistClientAuthorizations": [b"true"],
"oxAuthGrantType": [b"client_credentials"],
"inum": [b"w124asdgggAGs"],
"oxAttributes": [
b'{"tlsClientAuthSubjectDn":null,"runIntrospectionScriptBeforeAccessTokenAsJwtCreationAndIncludeClaims":false,"keepClientAuthorizationAfterExpiration":false}'
],
"oxAuthAppType": [b"web"],
"oxIncludeClaimsInIdToken": [b"false"],
"oxRptAsJwt": [b"false"],
"oxDisabled": [b"false"],
"displayName": [b"test-client2"],
"oxAuthClientSecret": [b"somecoolsecret"],
"oxAuthSubjectType": [b"pairwise"],
},
)
| op_static_attrs = {'objectClass': ['top', 'oxAuthClient'], 'oxAuthScope': ['inum=F0C4,ou=scopes,o=gluu', 'inum=C4F5,ou=scopes,o=gluu'], 'inum': 'w124asdgggAGs'}
add_op_test_args = {'oxAuthLogoutSessionRequired': False, 'oxAuthTrustedClient': False, 'oxAuthResponseType': 'token', 'oxAuthTokenEndpointAuthMethod': 'client_secret_basic', 'oxAuthRequireAuthTime': False, 'oxAccessTokenAsJwt': False, 'oxPersistClientAuthorizations': True, 'oxAuthGrantType': 'client_credentials', 'oxAttributes': '{"tlsClientAuthSubjectDn":null,"runIntrospectionScriptBeforeAccessTokenAsJwtCreationAndIncludeClaims":false,"keepClientAuthorizationAfterExpiration":false}', 'oxAuthAppType': 'web', 'oxDisabled': False, 'oxIncludeClaimsInIdToken': False, 'oxRptAsJwt': False, 'displayName': 'test-client2', 'oxAuthClientSecret': 'somecoolsecret', 'oxAuthSubjectType': 'pairwise'}
mocked_search_s_valid_response = [('inum=59376804-e84b-411a-9492-653d14e52c24,ou=clients,o=gluu', {'objectClass': [b'top', b'oxAuthClient'], 'oxAuthLogoutSessionRequired': [b'false'], 'oxAuthScope': [b'inum=F0C4,ou=scopes,o=gluu', b'inum=C4F5,ou=scopes,o=gluu'], 'oxAuthTrustedClient': [b'false'], 'oxAuthResponseType': [b'token'], 'oxAuthTokenEndpointAuthMethod': [b'client_secret_basic'], 'oxAuthRequireAuthTime': [b'false'], 'oxAccessTokenAsJwt': [b'false'], 'oxPersistClientAuthorizations': [b'true'], 'oxAuthGrantType': [b'client_credentials'], 'inum': [b'59376804-e84b-411a-9492-653d14e52c24'], 'oxAttributes': [b'{"tlsClientAuthSubjectDn":null,"runIntrospectionScriptBeforeAccessTokenAsJwtCreationAndIncludeClaims":false,"keepClientAuthorizationAfterExpiration":false}'], 'oxAuthAppType': [b'web'], 'oxLastLogonTime': [b'20200714072830.011Z'], 'oxAuthClientSecretExpiresAt': [b'21200623000000.000Z'], 'oxDisabled': [b'false'], 'oxIncludeClaimsInIdToken': [b'false'], 'oxRptAsJwt': [b'false'], 'displayName': [b'test-client'], 'oxAuthClientSecret': [b'gWxnjnUdCm8Rpc0WPmm9lQ=='], 'oxAuthSubjectType': [b'pairwise'], 'oxLastAccessTime': [b'20200714072830.011Z']})]
op_add_op_expected_return = expected_created_op = ('inum=w124asdgggAGs,ou=clients,o=gluu', {'objectClass': [b'top', b'oxAuthClient'], 'oxAuthLogoutSessionRequired': [b'false'], 'oxAuthTrustedClient': [b'false'], 'oxAuthScope': [b'inum=F0C4,ou=scopes,o=gluu', b'inum=C4F5,ou=scopes,o=gluu'], 'oxAuthResponseType': [b'token'], 'oxAuthTokenEndpointAuthMethod': [b'client_secret_basic'], 'oxAuthRequireAuthTime': [b'false'], 'oxAccessTokenAsJwt': [b'false'], 'oxPersistClientAuthorizations': [b'true'], 'oxAuthGrantType': [b'client_credentials'], 'inum': [b'w124asdgggAGs'], 'oxAttributes': [b'{"tlsClientAuthSubjectDn":null,"runIntrospectionScriptBeforeAccessTokenAsJwtCreationAndIncludeClaims":false,"keepClientAuthorizationAfterExpiration":false}'], 'oxAuthAppType': [b'web'], 'oxIncludeClaimsInIdToken': [b'false'], 'oxRptAsJwt': [b'false'], 'oxDisabled': [b'false'], 'displayName': [b'test-client2'], 'oxAuthClientSecret': [b'somecoolsecret'], 'oxAuthSubjectType': [b'pairwise']}) |
#!/usr/bin/env python3
# Day 15: Non-overlapping Intervals
#
# Given a collection of intervals, find the minimum number of intervals you
# need to remove to make the rest of the intervals non-overlapping.
#
# Note:
# - You may assume the interval's end point is always bigger than its start
# point.
# - Intervals like [1,2] and [2,3] have borders "touching" but they don't
# overlap each other.
class Solution:
def eraseOverlapIntervals(self, intervals: [[int]]) -> int:
# Edge case
if len(intervals) == 0:
return 0
# Convenience functions for code clarity
start = lambda interval: interval[0]
end = lambda interval: interval[1]
# Sort intervals by their end
intervals = sorted(intervals, key = end)
# Greedy!
intervals_to_remove = 0
previous_start = start(intervals[0])
previous_end = end(intervals[0])
for interval in intervals[1:]:
if start(interval) < previous_end:
intervals_to_remove += 1
else:
previous_start = start(interval)
previous_end = end(interval)
return intervals_to_remove
# Tests
assert Solution().eraseOverlapIntervals([[1,2],[2,3],[3,4],[1,3]]) == 1
assert Solution().eraseOverlapIntervals([[1,2],[1,2],[1,2]]) == 2
assert Solution().eraseOverlapIntervals([[1,2],[2,3]]) == 0
| class Solution:
def erase_overlap_intervals(self, intervals: [[int]]) -> int:
if len(intervals) == 0:
return 0
start = lambda interval: interval[0]
end = lambda interval: interval[1]
intervals = sorted(intervals, key=end)
intervals_to_remove = 0
previous_start = start(intervals[0])
previous_end = end(intervals[0])
for interval in intervals[1:]:
if start(interval) < previous_end:
intervals_to_remove += 1
else:
previous_start = start(interval)
previous_end = end(interval)
return intervals_to_remove
assert solution().eraseOverlapIntervals([[1, 2], [2, 3], [3, 4], [1, 3]]) == 1
assert solution().eraseOverlapIntervals([[1, 2], [1, 2], [1, 2]]) == 2
assert solution().eraseOverlapIntervals([[1, 2], [2, 3]]) == 0 |
aux = 0
num = int(input("Ingrese un numero entero positivo: "))
if num>0:
for x in range(0,num+1):
aux = aux + x
print (aux) | aux = 0
num = int(input('Ingrese un numero entero positivo: '))
if num > 0:
for x in range(0, num + 1):
aux = aux + x
print(aux) |
start = [8,13,1,0,18,9]
last_said = None
history = {}
def say(num, turn_no):
print(f'turn {i}\tsay {num}')
for i in range(30000000):
if i < len(start):
num = start[i]
else:
# print(f'turn {i} last said {last_said} {history}')
if last_said in history:
# print('in')
num = i - history[last_said] - 1
else:
num = 0
# print(history)
if last_said is not None:
history[last_said] = i - 1
# say(num, i)
if i % 1000000 == 0: print(i, num)
last_said = num
print(i, num) | start = [8, 13, 1, 0, 18, 9]
last_said = None
history = {}
def say(num, turn_no):
print(f'turn {i}\tsay {num}')
for i in range(30000000):
if i < len(start):
num = start[i]
elif last_said in history:
num = i - history[last_said] - 1
else:
num = 0
if last_said is not None:
history[last_said] = i - 1
if i % 1000000 == 0:
print(i, num)
last_said = num
print(i, num) |
"""
******************************************************
Author: Mark Arakaki
October 15, 2017
Personal Practice Use
*****************************************************
Divisors:
Create a program that asks the user for a number and then prints out a list of all the divisors of that number. (If you don't know what a divisor is, it is a number that divides evently into another number. For example, 13 is divisor of 26 because 26 / 13 has no remainder.)
"""
number = input("Please enter in a number that you want divided: ")
list_of_divisors = []
print("Listed below are the list of possible divisors for the inputted integer: \n")
if number == 0:
print("")
else:
divisor = number / 2
while divisor > 0:
list_of_divisors.append(divisor)
divisor = divisor / 2
print(list_of_divisors)
| """
******************************************************
Author: Mark Arakaki
October 15, 2017
Personal Practice Use
*****************************************************
Divisors:
Create a program that asks the user for a number and then prints out a list of all the divisors of that number. (If you don't know what a divisor is, it is a number that divides evently into another number. For example, 13 is divisor of 26 because 26 / 13 has no remainder.)
"""
number = input('Please enter in a number that you want divided: ')
list_of_divisors = []
print('Listed below are the list of possible divisors for the inputted integer: \n')
if number == 0:
print('')
else:
divisor = number / 2
while divisor > 0:
list_of_divisors.append(divisor)
divisor = divisor / 2
print(list_of_divisors) |
num1 = '100'
num2 = '200'
# 100200
print(num1 + num2)
# Casting - 300
num1 = int(num1)
num2 = int(num2)
print(num1 + num2) | num1 = '100'
num2 = '200'
print(num1 + num2)
num1 = int(num1)
num2 = int(num2)
print(num1 + num2) |
# Databricks notebook source exported at Sun, 13 Mar 2016 23:07:00 UTC
# MAGIC %md # <img width="300px" src="http://cdn.arstechnica.net/wp-content/uploads/2015/09/2000px-Wikipedia-logo-v2-en-640x735.jpg"/> Clickstream Analysis
# MAGIC
# MAGIC ** Dataset: 3.2 billion requests collected during the month of February 2015 grouped by (src, dest) **
# MAGIC
# MAGIC ** Source: https://datahub.io/dataset/wikipedia-clickstream/ **
# MAGIC
# MAGIC <img width="700px" src="https://databricks-prod-cloudfront.s3.amazonaws.com/docs/images/ny.clickstream.png"/>
# MAGIC
# MAGIC <i>*This notebook requires Spark 1.6+</i>
# COMMAND ----------
# MAGIC %md
# MAGIC This is a copy of the original python notebook by Michael Armburst at Spark Summit East February 2016 (watch later)
# MAGIC
# MAGIC [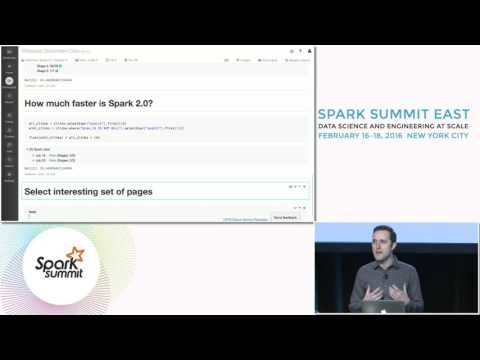](https://www.youtube.com/v/35Y-rqSMCCA)
# MAGIC
# MAGIC shared from [https://twitter.com/michaelarmbrust/status/699969850475737088](https://twitter.com/michaelarmbrust/status/699969850475737088)
# COMMAND ----------
# MAGIC %md
# MAGIC
# MAGIC
# MAGIC This is a data analysis workflow developed with [Databricks Community Edition](https://databricks.com/blog/2016/02/17/introducing-databricks-community-edition-apache-spark-for-all.html), a free version of Databricks designed for learning [Apache Spark](https://spark.apache.org/).
# MAGIC
# MAGIC You can [join the wait list](http://go.databricks.com/databricks-community-edition-beta-waitlist) for Community Edition today!
# COMMAND ----------
# MAGIC %scala if (org.apache.spark.BuildInfo.sparkBranch < "1.6") sys.error("Attach this notebook to a cluster running Spark 1.6+")
# COMMAND ----------
# Load the raw dataset stored as a CSV file
clickstreamRaw = sqlContext.read \
.format("com.databricks.spark.csv") \
.options(header="true", delimiter="\t", mode="PERMISSIVE", inferSchema="true") \
.load("dbfs:///databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed")
# Convert the dataset to a more efficent format to speed up our analysis
clickstreamRaw.write \
.mode("overwrite") \
.format("parquet") \
.save("/datasets/wiki-clickstream")
# COMMAND ----------
clicks = sqlContext.read.parquet("/datasets/wiki-clickstream")
# COMMAND ----------
clicks.printSchema
# COMMAND ----------
all_clicks = clicks.selectExpr("sum(n) AS clicks").first().clicks
wiki_clicks = clicks.where("prev_id IS NOT NULL").selectExpr("sum(n) AS clicks").first().clicks
float(wiki_clicks) / all_clicks * 100
# COMMAND ----------
# Make clicks available as a SQL table.
clicks.registerTempTable("clicks")
# COMMAND ----------
# MAGIC %sql
# MAGIC SELECT *
# MAGIC FROM clicks
# MAGIC WHERE
# MAGIC curr_title = 'Donald_Trump' AND
# MAGIC prev_id IS NOT NULL AND prev_title != 'Main_Page'
# MAGIC ORDER BY n DESC
# MAGIC LIMIT 20
# COMMAND ----------
# MAGIC %scala
# MAGIC package d3
# MAGIC // We use a package object so that we can define top level classes like Edge that need to be used in other cells
# MAGIC
# MAGIC import org.apache.spark.sql._
# MAGIC import com.databricks.backend.daemon.driver.EnhancedRDDFunctions.displayHTML
# MAGIC
# MAGIC case class Edge(src: String, dest: String, count: Long)
# MAGIC
# MAGIC case class Node(name: String)
# MAGIC case class Link(source: Int, target: Int, value: Long)
# MAGIC case class Graph(nodes: Seq[Node], links: Seq[Link])
# MAGIC
# MAGIC object graphs {
# MAGIC val sqlContext = SQLContext.getOrCreate(org.apache.spark.SparkContext.getOrCreate())
# MAGIC import sqlContext.implicits._
# MAGIC
# MAGIC def force(clicks: Dataset[Edge], height: Int = 100, width: Int = 960): Unit = {
# MAGIC val data = clicks.collect()
# MAGIC val nodes = (data.map(_.src) ++ data.map(_.dest)).map(_.replaceAll("_", " ")).toSet.toSeq.map(Node)
# MAGIC val links = data.map { t =>
# MAGIC Link(nodes.indexWhere(_.name == t.src.replaceAll("_", " ")), nodes.indexWhere(_.name == t.dest.replaceAll("_", " ")), t.count / 20 + 1)
# MAGIC }
# MAGIC showGraph(height, width, Seq(Graph(nodes, links)).toDF().toJSON.first())
# MAGIC }
# MAGIC
# MAGIC /**
# MAGIC * Displays a force directed graph using d3
# MAGIC * input: {"nodes": [{"name": "..."}], "links": [{"source": 1, "target": 2, "value": 0}]}
# MAGIC */
# MAGIC def showGraph(height: Int, width: Int, graph: String): Unit = {
# MAGIC
# MAGIC displayHTML(s"""
# MAGIC <!DOCTYPE html>
# MAGIC <html>
# MAGIC <head>
# MAGIC <meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
# MAGIC <title>Polish Books Themes - an Interactive Map</title>
# MAGIC <meta charset="utf-8">
# MAGIC <style>
# MAGIC
# MAGIC .node_circle {
# MAGIC stroke: #777;
# MAGIC stroke-width: 1.3px;
# MAGIC }
# MAGIC
# MAGIC .node_label {
# MAGIC pointer-events: none;
# MAGIC }
# MAGIC
# MAGIC .link {
# MAGIC stroke: #777;
# MAGIC stroke-opacity: .2;
# MAGIC }
# MAGIC
# MAGIC .node_count {
# MAGIC stroke: #777;
# MAGIC stroke-width: 1.0px;
# MAGIC fill: #999;
# MAGIC }
# MAGIC
# MAGIC text.legend {
# MAGIC font-family: Verdana;
# MAGIC font-size: 13px;
# MAGIC fill: #000;
# MAGIC }
# MAGIC
# MAGIC .node text {
# MAGIC font-family: "Helvetica Neue","Helvetica","Arial",sans-serif;
# MAGIC font-size: 17px;
# MAGIC font-weight: 200;
# MAGIC }
# MAGIC
# MAGIC </style>
# MAGIC </head>
# MAGIC
# MAGIC <body>
# MAGIC <script src="//d3js.org/d3.v3.min.js"></script>
# MAGIC <script>
# MAGIC
# MAGIC var graph = $graph;
# MAGIC
# MAGIC var width = $width,
# MAGIC height = $height;
# MAGIC
# MAGIC var color = d3.scale.category20();
# MAGIC
# MAGIC var force = d3.layout.force()
# MAGIC .charge(-700)
# MAGIC .linkDistance(180)
# MAGIC .size([width, height]);
# MAGIC
# MAGIC var svg = d3.select("body").append("svg")
# MAGIC .attr("width", width)
# MAGIC .attr("height", height);
# MAGIC
# MAGIC force
# MAGIC .nodes(graph.nodes)
# MAGIC .links(graph.links)
# MAGIC .start();
# MAGIC
# MAGIC var link = svg.selectAll(".link")
# MAGIC .data(graph.links)
# MAGIC .enter().append("line")
# MAGIC .attr("class", "link")
# MAGIC .style("stroke-width", function(d) { return Math.sqrt(d.value); });
# MAGIC
# MAGIC var node = svg.selectAll(".node")
# MAGIC .data(graph.nodes)
# MAGIC .enter().append("g")
# MAGIC .attr("class", "node")
# MAGIC .call(force.drag);
# MAGIC
# MAGIC node.append("circle")
# MAGIC .attr("r", 10)
# MAGIC .style("fill", function (d) {
# MAGIC if (d.name.startsWith("other")) { return color(1); } else { return color(2); };
# MAGIC })
# MAGIC
# MAGIC node.append("text")
# MAGIC .attr("dx", 10)
# MAGIC .attr("dy", ".35em")
# MAGIC .text(function(d) { return d.name });
# MAGIC
# MAGIC //Now we are giving the SVGs co-ordinates - the force layout is generating the co-ordinates which this code is using to update the attributes of the SVG elements
# MAGIC force.on("tick", function () {
# MAGIC link.attr("x1", function (d) {
# MAGIC return d.source.x;
# MAGIC })
# MAGIC .attr("y1", function (d) {
# MAGIC return d.source.y;
# MAGIC })
# MAGIC .attr("x2", function (d) {
# MAGIC return d.target.x;
# MAGIC })
# MAGIC .attr("y2", function (d) {
# MAGIC return d.target.y;
# MAGIC });
# MAGIC d3.selectAll("circle").attr("cx", function (d) {
# MAGIC return d.x;
# MAGIC })
# MAGIC .attr("cy", function (d) {
# MAGIC return d.y;
# MAGIC });
# MAGIC d3.selectAll("text").attr("x", function (d) {
# MAGIC return d.x;
# MAGIC })
# MAGIC .attr("y", function (d) {
# MAGIC return d.y;
# MAGIC });
# MAGIC });
# MAGIC </script>
# MAGIC </html>
# MAGIC """)
# MAGIC }
# MAGIC
# MAGIC def help() = {
# MAGIC displayHTML("""
# MAGIC <p>
# MAGIC Produces a force-directed graph given a collection of edges of the following form:</br>
# MAGIC <tt><font color="#a71d5d">case class</font> <font color="#795da3">Edge</font>(<font color="#ed6a43">src</font>: <font color="#a71d5d">String</font>, <font color="#ed6a43">dest</font>: <font color="#a71d5d">String</font>, <font color="#ed6a43">count</font>: <font color="#a71d5d">Long</font>)</tt>
# MAGIC </p>
# MAGIC <p>Usage:<br/>
# MAGIC <tt>%scala</tt></br>
# MAGIC <tt><font color="#a71d5d">import</font> <font color="#ed6a43">d3._</font></tt><br/>
# MAGIC <tt><font color="#795da3">graphs.force</font>(</br>
# MAGIC <font color="#ed6a43">height</font> = <font color="#795da3">500</font>,<br/>
# MAGIC <font color="#ed6a43">width</font> = <font color="#795da3">500</font>,<br/>
# MAGIC <font color="#ed6a43">clicks</font>: <font color="#795da3">Dataset</font>[<font color="#795da3">Edge</font>])</tt>
# MAGIC </p>""")
# MAGIC }
# MAGIC }
# COMMAND ----------
# MAGIC %scala
# MAGIC // print the help for the graphing library
# MAGIC d3.graphs.help()
# COMMAND ----------
# MAGIC %scala
# MAGIC import d3._
# MAGIC
# MAGIC graphs.force(
# MAGIC height = 800,
# MAGIC width = 1000,
# MAGIC clicks = sql("""
# MAGIC SELECT
# MAGIC prev_title AS src,
# MAGIC curr_title AS dest,
# MAGIC n AS count FROM clicks
# MAGIC WHERE
# MAGIC curr_title IN ('Donald_Trump', 'Bernie_Sanders', 'Hillary_Rodham_Clinton', 'Ted_Cruz') AND
# MAGIC prev_id IS NOT NULL AND NOT (curr_title = 'Main_Page' OR prev_title = 'Main_Page')
# MAGIC ORDER BY n DESC
# MAGIC LIMIT 20""").as[Edge])
# COMMAND ----------
| clickstream_raw = sqlContext.read.format('com.databricks.spark.csv').options(header='true', delimiter='\t', mode='PERMISSIVE', inferSchema='true').load('dbfs:///databricks-datasets/wikipedia-datasets/data-001/clickstream/raw-uncompressed')
clickstreamRaw.write.mode('overwrite').format('parquet').save('/datasets/wiki-clickstream')
clicks = sqlContext.read.parquet('/datasets/wiki-clickstream')
clicks.printSchema
all_clicks = clicks.selectExpr('sum(n) AS clicks').first().clicks
wiki_clicks = clicks.where('prev_id IS NOT NULL').selectExpr('sum(n) AS clicks').first().clicks
float(wiki_clicks) / all_clicks * 100
clicks.registerTempTable('clicks') |
"""This file contains constants used used by the Ethereum JSON RPC
interface."""
BLOCK_TAG_EARLIEST = "earliest"
BLOCK_TAG_LATEST = "latest"
BLOCK_TAG_PENDING = "pending"
BLOCK_TAGS = (BLOCK_TAG_EARLIEST, BLOCK_TAG_LATEST, BLOCK_TAG_PENDING)
| """This file contains constants used used by the Ethereum JSON RPC
interface."""
block_tag_earliest = 'earliest'
block_tag_latest = 'latest'
block_tag_pending = 'pending'
block_tags = (BLOCK_TAG_EARLIEST, BLOCK_TAG_LATEST, BLOCK_TAG_PENDING) |
# ------- FUNCTION BASICS --------
def allotEmail(firstName, surname):
return firstName+'.'+surname+'@pythonabc.org'
name = input("Enter your name: ")
fName, sName = name.split()
compEmail = allotEmail(fName, sName)
print(compEmail)
def get_sum(*args):
sum = 0
for i in args:
sum += i
return sum
print("sum =", get_sum(3,4,5,7)) | def allot_email(firstName, surname):
return firstName + '.' + surname + '@pythonabc.org'
name = input('Enter your name: ')
(f_name, s_name) = name.split()
comp_email = allot_email(fName, sName)
print(compEmail)
def get_sum(*args):
sum = 0
for i in args:
sum += i
return sum
print('sum =', get_sum(3, 4, 5, 7)) |
'''
An approximation of network latency in the Bitcoin network based on the
following paper: https://ieeexplore.ieee.org/document/6688704/.
From the green line in Fig 1, we can approximate the function as:
Network latency (sec) = 19/300 sec/KB * KB + 1 sec
If we assume a transaction is 500 bytes or 1/2 KB, we get the function
Network latency (sec) = 19/600 sec/tx * tx + 1 sec
We use this as a parameter into our exponential delay
'''
SEC_PER_TRANSACTION = 19.0/600
'''
Required depth for longest chain to consider a block to be finalized
'''
FINALIZATION_DEPTH = 6
'''
Transaction rate in transactions/sec used when generating a transaction
dataset
'''
TX_RATE = 1
'''
Transaction size used for computing network latency when broadcasting transactions
'''
TX_SIZE = 1
| """
An approximation of network latency in the Bitcoin network based on the
following paper: https://ieeexplore.ieee.org/document/6688704/.
From the green line in Fig 1, we can approximate the function as:
Network latency (sec) = 19/300 sec/KB * KB + 1 sec
If we assume a transaction is 500 bytes or 1/2 KB, we get the function
Network latency (sec) = 19/600 sec/tx * tx + 1 sec
We use this as a parameter into our exponential delay
"""
sec_per_transaction = 19.0 / 600
'\nRequired depth for longest chain to consider a block to be finalized\n'
finalization_depth = 6
'\nTransaction rate in transactions/sec used when generating a transaction\ndataset\n'
tx_rate = 1
'\nTransaction size used for computing network latency when broadcasting transactions \n'
tx_size = 1 |
class Spam(object):
'''
The Spam object contains lots of spam
Args:
arg (str): The arg is used for ...
*args: The variable arguments are used for ...
**kwargs: The keyword arguments are used for ...
Attributes:
arg (str): This is where we store arg,
'''
def __init__(self, arg, *args, **kwargs):
self.arg = arg
def eggs(self, amount, cooked):
'''We can't have spam without eggs, so here's the eggs
Args:
amount (int): The amount of eggs to return
cooked (bool): Should the eggs be cooked?
Raises:
RuntimeError: Out of eggs
Returns:
Eggs: A bunch of eggs
'''
pass
| class Spam(object):
"""
The Spam object contains lots of spam
Args:
arg (str): The arg is used for ...
*args: The variable arguments are used for ...
**kwargs: The keyword arguments are used for ...
Attributes:
arg (str): This is where we store arg,
"""
def __init__(self, arg, *args, **kwargs):
self.arg = arg
def eggs(self, amount, cooked):
"""We can't have spam without eggs, so here's the eggs
Args:
amount (int): The amount of eggs to return
cooked (bool): Should the eggs be cooked?
Raises:
RuntimeError: Out of eggs
Returns:
Eggs: A bunch of eggs
"""
pass |
'''
Given an integer array nums, return the length of the longest strictly increasing subsequence.
A subsequence is a sequence that can be derived from an array by deleting some or no elements without changing the order of the remaining elements. For example, [3,6,2,7] is a subsequence of the array [0,3,1,6,2,2,7].
Example 1:
Input: nums = [10,9,2,5,3,7,101,18]
Output: 4
Explanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4.
Example 2:
Input: nums = [0,1,0,3,2,3]
Output: 4
Example 3:
Input: nums = [7,7,7,7,7,7,7]
Output: 1
Constraints:
1 <= nums.length <= 2500
-104 <= nums[i] <= 104
Follow up:
Could you come up with the O(n2) solution?
Could you improve it to O(n log(n)) time complexity?
'''
# Bin Search Approach -> Time: O(NlogN), Space: O(n)
class Solution(object):
def binarySearch(self, temp_arr, low, high, target):
while low <= high:
mid = low + (high - low) // 2
if temp_arr[mid] == target:
return mid
if temp_arr[mid] > target:
high = mid - 1
else:
low = mid + 1
return low # low is always ending at the right position
def lengthOfLIS(self, nums):
if not nums or len(nums) == 0:
return 0
temp_arr = []
len_point = 1 # len_point put on temp_arr
temp_arr.append(nums[0])
for i in range(1, len(nums)):
if nums[i] > temp_arr[-1]:
temp_arr.append(nums[i])
len_point += 1
else:
bs_idx = self.binarySearch(temp_arr, 0, len(temp_arr)- 1, nums[i])
temp_arr[bs_idx] = nums[i]
return len_point
# DP Approach -> Time: O(n^2), Space: O(n)
class Solution(object):
def lengthOfLIS(self, nums):
res = 0
dp_table = [1] * len(nums)
for elem in range (1, len(nums)):
for elem1 in range (0, elem):
if (nums[elem] > nums[elem1] and dp_table[elem] < dp_table[elem1] + 1):
dp_table[elem] = dp_table[elem1] + 1
for elem in range (0, len(nums)):
res = max(res, dp_table[elem])
return res
| """
Given an integer array nums, return the length of the longest strictly increasing subsequence.
A subsequence is a sequence that can be derived from an array by deleting some or no elements without changing the order of the remaining elements. For example, [3,6,2,7] is a subsequence of the array [0,3,1,6,2,2,7].
Example 1:
Input: nums = [10,9,2,5,3,7,101,18]
Output: 4
Explanation: The longest increasing subsequence is [2,3,7,101], therefore the length is 4.
Example 2:
Input: nums = [0,1,0,3,2,3]
Output: 4
Example 3:
Input: nums = [7,7,7,7,7,7,7]
Output: 1
Constraints:
1 <= nums.length <= 2500
-104 <= nums[i] <= 104
Follow up:
Could you come up with the O(n2) solution?
Could you improve it to O(n log(n)) time complexity?
"""
class Solution(object):
def binary_search(self, temp_arr, low, high, target):
while low <= high:
mid = low + (high - low) // 2
if temp_arr[mid] == target:
return mid
if temp_arr[mid] > target:
high = mid - 1
else:
low = mid + 1
return low
def length_of_lis(self, nums):
if not nums or len(nums) == 0:
return 0
temp_arr = []
len_point = 1
temp_arr.append(nums[0])
for i in range(1, len(nums)):
if nums[i] > temp_arr[-1]:
temp_arr.append(nums[i])
len_point += 1
else:
bs_idx = self.binarySearch(temp_arr, 0, len(temp_arr) - 1, nums[i])
temp_arr[bs_idx] = nums[i]
return len_point
class Solution(object):
def length_of_lis(self, nums):
res = 0
dp_table = [1] * len(nums)
for elem in range(1, len(nums)):
for elem1 in range(0, elem):
if nums[elem] > nums[elem1] and dp_table[elem] < dp_table[elem1] + 1:
dp_table[elem] = dp_table[elem1] + 1
for elem in range(0, len(nums)):
res = max(res, dp_table[elem])
return res |
# Time: O(m * n)
# Space: O(m * n)
class Solution(object):
def numDistinctIslands(self, grid):
"""
:type grid: List[List[int]]
:rtype: int
"""
directions = {'l':[-1, 0], 'r':[ 1, 0], \
'u':[ 0, 1], 'd':[ 0, -1]}
def dfs(i, j, grid, island):
if not (0 <= i < len(grid) and \
0 <= j < len(grid[0]) and \
grid[i][j] > 0):
return False
grid[i][j] *= -1
for k, v in directions.iteritems():
island.append(k);
dfs(i+v[0], j+v[1], grid, island)
return True
islands = set()
for i in xrange(len(grid)):
for j in xrange(len(grid[0])):
island = []
if dfs(i, j, grid, island):
islands.add("".join(island))
return len(islands)
| class Solution(object):
def num_distinct_islands(self, grid):
"""
:type grid: List[List[int]]
:rtype: int
"""
directions = {'l': [-1, 0], 'r': [1, 0], 'u': [0, 1], 'd': [0, -1]}
def dfs(i, j, grid, island):
if not (0 <= i < len(grid) and 0 <= j < len(grid[0]) and (grid[i][j] > 0)):
return False
grid[i][j] *= -1
for (k, v) in directions.iteritems():
island.append(k)
dfs(i + v[0], j + v[1], grid, island)
return True
islands = set()
for i in xrange(len(grid)):
for j in xrange(len(grid[0])):
island = []
if dfs(i, j, grid, island):
islands.add(''.join(island))
return len(islands) |
"""
Given three integer arrays arr1, arr2 and arr3 sorted in strictly increasing order, return a sorted array of only the integers that appeared in all three arrays.
Example 1:
Input: arr1 = [1,2,3,4,5], arr2 = [1,2,5,7,9], arr3 = [1,3,4,5,8]
Output: [1,5]
Explanation: Only 1 and 5 appeared in the three arrays.
Constraints:
1 <= arr1.length, arr2.length, arr3.length <= 1000
1 <= arr1[i], arr2[i], arr3[i] <= 2000
"""
# Hash Map Solution
class Solution(object):
def arraysIntersection(self, arr1, arr2, arr3):
temp = collections.Counter(arr1 + arr2 + arr3)
res = []
for key, value in temp.iteritems():
if value == 3:
res.append(key)
return res
#Algorithm
#Initiate three pointers p1, p2, p3, and place them at the beginning of arr1, arr2, arr3 by initializing them to 0;
#while they are within the boundaries:
#if arr1[p1] == arr2[p2] && arr2[p2] == arr3[p3], we should store it because it appears three times in arr1, arr2, and arr3;
#else
#if arr1[p1] < arr2[p2], move the smaller one, i.e., p1;
#else if arr2[p2] < arr3[p3], move the smaller one, i.e., p2;
#if neither of the above conditions is met, it means arr1[p1] >= arr2[p2] && arr2[p2] >= arr3[p3], therefore move p3.
class Solution(object):
def arraysIntersection(self, arr1, arr2, arr3):
res = []
ptr1, ptr2, ptr3 = 0, 0, 0
while ptr1 < len(arr1) and ptr2 < len(arr2) and ptr3 < len(arr3):
if arr1[ptr1] == arr2[ptr2] == arr3[ptr3]:
res.append(arr1[ptr1])
ptr1 += 1
ptr2 += 1
ptr3 += 1
else:
if arr1[ptr1] < arr2[ptr2]:
ptr1 += 1
elif arr2[ptr2] < arr3[ptr3]:
ptr2 += 1
else:
ptr3 += 1
return res
| """
Given three integer arrays arr1, arr2 and arr3 sorted in strictly increasing order, return a sorted array of only the integers that appeared in all three arrays.
Example 1:
Input: arr1 = [1,2,3,4,5], arr2 = [1,2,5,7,9], arr3 = [1,3,4,5,8]
Output: [1,5]
Explanation: Only 1 and 5 appeared in the three arrays.
Constraints:
1 <= arr1.length, arr2.length, arr3.length <= 1000
1 <= arr1[i], arr2[i], arr3[i] <= 2000
"""
class Solution(object):
def arrays_intersection(self, arr1, arr2, arr3):
temp = collections.Counter(arr1 + arr2 + arr3)
res = []
for (key, value) in temp.iteritems():
if value == 3:
res.append(key)
return res
class Solution(object):
def arrays_intersection(self, arr1, arr2, arr3):
res = []
(ptr1, ptr2, ptr3) = (0, 0, 0)
while ptr1 < len(arr1) and ptr2 < len(arr2) and (ptr3 < len(arr3)):
if arr1[ptr1] == arr2[ptr2] == arr3[ptr3]:
res.append(arr1[ptr1])
ptr1 += 1
ptr2 += 1
ptr3 += 1
elif arr1[ptr1] < arr2[ptr2]:
ptr1 += 1
elif arr2[ptr2] < arr3[ptr3]:
ptr2 += 1
else:
ptr3 += 1
return res |
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 6 19:42:18 2019
@author: rounak
"""
num = int (input("Enter a number: "))
#if the elements in the range(2, num) evenly divides the num,
#then it is included in the divisors list
divisor = [x for x in range(2, num) if num % x == 0]
for x in divisor:
print(x)
| """
Created on Sat Apr 6 19:42:18 2019
@author: rounak
"""
num = int(input('Enter a number: '))
divisor = [x for x in range(2, num) if num % x == 0]
for x in divisor:
print(x) |
class Solution(object):
@staticmethod
def min_steps(candy, n, m):
min_step = float("inf")
def dfs(curr, i, j, num_candy, steps):
nonlocal min_step
if num_candy == m:
min_step = min(steps, min_step)
if steps > min_step:
return
if (i, j) in candy:
num_candy += 1
if 0 <= i+1 < n and 0 <= j < n and (i+1, j) not in curr:
curr.append((i+1, j))
dfs(curr, i+1, j, num_candy, steps+1)
curr.pop()
if 0 <= i < n and 0 <= j-1 < n and (i, j-1) not in curr:
curr.append((i, j-1))
dfs(curr, i, j-1, num_candy, steps+1)
curr.pop()
if 0 <= j+1 < n and 0 <= i < n and (i, j+1) not in curr:
curr.append((i, j+1))
dfs(curr, i, j+1, num_candy, steps+1)
curr.pop()
dfs([], 0, 0, 0, 0)
# need to -1 because last one should be exactly has candy, and in current
# implementation, step+1 then find candy == m
print(min_step-1)
return min_step-1
candy = [(0, 3), (1, 1), (2, 2), (3, 3)]
m = len(candy)
n = 4
s = Solution()
s.min_steps(candy, n, m)
| class Solution(object):
@staticmethod
def min_steps(candy, n, m):
min_step = float('inf')
def dfs(curr, i, j, num_candy, steps):
nonlocal min_step
if num_candy == m:
min_step = min(steps, min_step)
if steps > min_step:
return
if (i, j) in candy:
num_candy += 1
if 0 <= i + 1 < n and 0 <= j < n and ((i + 1, j) not in curr):
curr.append((i + 1, j))
dfs(curr, i + 1, j, num_candy, steps + 1)
curr.pop()
if 0 <= i < n and 0 <= j - 1 < n and ((i, j - 1) not in curr):
curr.append((i, j - 1))
dfs(curr, i, j - 1, num_candy, steps + 1)
curr.pop()
if 0 <= j + 1 < n and 0 <= i < n and ((i, j + 1) not in curr):
curr.append((i, j + 1))
dfs(curr, i, j + 1, num_candy, steps + 1)
curr.pop()
dfs([], 0, 0, 0, 0)
print(min_step - 1)
return min_step - 1
candy = [(0, 3), (1, 1), (2, 2), (3, 3)]
m = len(candy)
n = 4
s = solution()
s.min_steps(candy, n, m) |
class Employee:
# Constructor untuk Employee
def __init__(self, first_name, last_name, monthly_salary):
self._first_name = first_name
self._last_name = last_name
self._monthly_salary = monthly_salary
if monthly_salary < 0:
self._monthly_salary = 0
# Getter dan setter first_name
@property
def first_name(self):
return self._first_name
@first_name.setter
def first_name(self, new_first_name):
self._first_name = new_first_name
# Getter dan setter last_name
@property
def last_name(self):
return self._last_name
@last_name.setter
def last_name(self, new_last_name):
self._last_name = new_last_name
# Getter dan setter monthly_salary
@property
def monthly_salary(self):
return self._monthly_salary
@monthly_salary.setter
def monthly_salary(self, new_monthly_salary):
self._monthly_salary = new_monthly_salary
| class Employee:
def __init__(self, first_name, last_name, monthly_salary):
self._first_name = first_name
self._last_name = last_name
self._monthly_salary = monthly_salary
if monthly_salary < 0:
self._monthly_salary = 0
@property
def first_name(self):
return self._first_name
@first_name.setter
def first_name(self, new_first_name):
self._first_name = new_first_name
@property
def last_name(self):
return self._last_name
@last_name.setter
def last_name(self, new_last_name):
self._last_name = new_last_name
@property
def monthly_salary(self):
return self._monthly_salary
@monthly_salary.setter
def monthly_salary(self, new_monthly_salary):
self._monthly_salary = new_monthly_salary |
def test_Feeds(flamingo_env):
flamingo_env.settings.PLUGINS = ['flamingo.plugins.Feeds']
flamingo_env.settings.FEEDS_DOMAIN = 'www.example.org'
flamingo_env.settings.FEEDS = [
{
'id': 'www.example.org',
'title': 'Example.org',
'type': 'atom',
'output': 'en/feed.atom.xml',
'lang': 'en',
'contents': lambda ctx: ctx.contents,
'entry-id': lambda content: content['path'],
'updated': lambda content: '1970-01-01 00:00:00+01:00',
},
]
flamingo_env.write('/content/blog-post.html', """
title: blog-post
Blog post
=========
""")
flamingo_env.build()
| def test__feeds(flamingo_env):
flamingo_env.settings.PLUGINS = ['flamingo.plugins.Feeds']
flamingo_env.settings.FEEDS_DOMAIN = 'www.example.org'
flamingo_env.settings.FEEDS = [{'id': 'www.example.org', 'title': 'Example.org', 'type': 'atom', 'output': 'en/feed.atom.xml', 'lang': 'en', 'contents': lambda ctx: ctx.contents, 'entry-id': lambda content: content['path'], 'updated': lambda content: '1970-01-01 00:00:00+01:00'}]
flamingo_env.write('/content/blog-post.html', '\n title: blog-post\n\n\n Blog post\n =========\n ')
flamingo_env.build() |
class Solution:
def minFallingPathSum(self, arr: List[List[int]]) -> int:
min1 = min2 = -1
for j in range(len(arr[0])):
if min1 == -1 or arr[0][j] < arr[0][min1]:
min2 = min1
min1 = j
elif min2 == -1 or arr[0][j] < arr[0][min2]:
min2 = j
for i in range(1, len(arr)):
currMin1 = currMin2 = -1
for j in range(len(arr[i])):
if j == min1:
arr[i][j] += arr[i - 1][min2]
else:
arr[i][j] += arr[i - 1][min1]
if currMin1 == -1 or arr[i][j] < arr[i][currMin1]:
currMin2 = currMin1
currMin1 = j
elif currMin2 == -1 or arr[i][j] < arr[i][currMin2]:
currMin2 = j
min1, min2 = currMin1, currMin2
return arr[-1][min1]
| class Solution:
def min_falling_path_sum(self, arr: List[List[int]]) -> int:
min1 = min2 = -1
for j in range(len(arr[0])):
if min1 == -1 or arr[0][j] < arr[0][min1]:
min2 = min1
min1 = j
elif min2 == -1 or arr[0][j] < arr[0][min2]:
min2 = j
for i in range(1, len(arr)):
curr_min1 = curr_min2 = -1
for j in range(len(arr[i])):
if j == min1:
arr[i][j] += arr[i - 1][min2]
else:
arr[i][j] += arr[i - 1][min1]
if currMin1 == -1 or arr[i][j] < arr[i][currMin1]:
curr_min2 = currMin1
curr_min1 = j
elif currMin2 == -1 or arr[i][j] < arr[i][currMin2]:
curr_min2 = j
(min1, min2) = (currMin1, currMin2)
return arr[-1][min1] |
GENERAL_HELP = '''
Usage:
vt <command> [options]
Commands:
lists Get all lists
list Return items of a specific list
item Return a specific item
show Alias for item
done Mark an item done
complete Alias for done
undone Mark an item undone
uncomplete Alias for undone
modify Modify item by providing a comment
edit Alias for modify
comment Alias for modify
comments Alias for modify
add Create a new item
move Associate an item with a new list
mv Alias for move
categories Return a list of valid categories for a given list
categorize Provide a category for a given item
label Alias for categorize
help Get help on a command
'''
LISTS_HELP = '''
Usage:
vt lists
Description:
Return all lists
'''
LIST_HELP = '''
Usage:
vt list [GUID] [options]
Description:
Return all items of a specified list. GUID may be either the unique identifier of
a list or the name of the list if it is unique. If no GUID is provided, use the
default list defined in the VT_DEFAULT_LIST environment variable.
Options:
-e, --extended Show extended information about items.
-u, --unfinished Only display items that have not been completed yet.
-c, --categories Include item categories in output.
-q, --quiet Quiet mode. Remove any extraneous output.
-W, --no-wrap Do not apply any text wrapping to output.
'''
DONE_HELP = '''
Usage:
vt done [GUID] ...
vt complete [GUID] ...
Description:
Mark an item done. When run without a GUID, display all recently completed items.
'''
UNDONE_HELP = '''
Usage:
vt undone [GUID] ...
vt uncomplete [GUID] ...
Description:
Mark an item undone. When run without a GUID, display all recently completed items.
'''
COMMENT_HELP = '''
Usage:
vt modify GUID [options] [comment]
vt comment GUID [options] [comment]
vt comments GUID [options] [comment]
vt edit GUID [options] [comment]
Description:
Add a comment to the specified item. No comment should be provided when using the -d flag.
Options:
-a, --append Append comment rather than overwriting.
-d, --delete Remove comment from item.
'''
ADD_HELP = '''
Usage:
vt add [GUID] item
Description:
Create a new item. GUID is the unique identifier for the list the item will be placed on.
When GUID is not provided, use the default list defined in VT_DEFAULT_LIST environment variable.
'''
MOVE_HELP = '''
Usage:
vt move ITEM LIST
vt mv ITEM LIST
Description:
Move item to a new list where ITEM is the guid of the item and LIST is the guid of the new list.
'''
CATEGORIES_HELP = '''
Usage:
vt categories [GUID]
Description:
Display the available categories for a list. GUID is the unique identifier for a list.
When GUID is not provided, use the default list defined in VT_DEFAULT_LIST environment variable.
'''
CATEGORIZE_HELP = '''
Usage:
vt categorize GUID CATEGORY
vt label GUID CATEGORY
Description:
Assign CATEGORY to the item specified by GUID.
'''
| general_help = '\nUsage:\n vt <command> [options]\n\nCommands:\n lists Get all lists\n list Return items of a specific list\n item Return a specific item\n show Alias for item\n done Mark an item done\n complete Alias for done\n undone Mark an item undone\n uncomplete Alias for undone\n modify Modify item by providing a comment\n edit Alias for modify\n comment Alias for modify\n comments Alias for modify\n add Create a new item\n move Associate an item with a new list\n mv Alias for move\n categories Return a list of valid categories for a given list\n categorize Provide a category for a given item\n label Alias for categorize\n help Get help on a command\n'
lists_help = '\nUsage:\n vt lists\n\nDescription:\n Return all lists\n'
list_help = '\nUsage:\n vt list [GUID] [options]\n\nDescription:\n Return all items of a specified list. GUID may be either the unique identifier of\n a list or the name of the list if it is unique. If no GUID is provided, use the\n default list defined in the VT_DEFAULT_LIST environment variable.\n\nOptions:\n -e, --extended Show extended information about items.\n -u, --unfinished Only display items that have not been completed yet.\n -c, --categories Include item categories in output.\n -q, --quiet Quiet mode. Remove any extraneous output.\n -W, --no-wrap Do not apply any text wrapping to output.\n'
done_help = '\nUsage:\n vt done [GUID] ...\n vt complete [GUID] ...\n\nDescription:\n Mark an item done. When run without a GUID, display all recently completed items.\n'
undone_help = '\nUsage:\n vt undone [GUID] ...\n vt uncomplete [GUID] ...\n\nDescription:\n Mark an item undone. When run without a GUID, display all recently completed items.\n'
comment_help = '\nUsage:\n vt modify GUID [options] [comment]\n vt comment GUID [options] [comment]\n vt comments GUID [options] [comment]\n vt edit GUID [options] [comment]\n\nDescription:\n Add a comment to the specified item. No comment should be provided when using the -d flag.\n\nOptions:\n -a, --append Append comment rather than overwriting.\n -d, --delete Remove comment from item.\n'
add_help = '\nUsage:\n vt add [GUID] item\n\nDescription:\n Create a new item. GUID is the unique identifier for the list the item will be placed on.\n When GUID is not provided, use the default list defined in VT_DEFAULT_LIST environment variable.\n'
move_help = '\nUsage:\n vt move ITEM LIST\n vt mv ITEM LIST\n\nDescription:\n Move item to a new list where ITEM is the guid of the item and LIST is the guid of the new list.\n'
categories_help = '\nUsage:\n vt categories [GUID]\n\nDescription:\n Display the available categories for a list. GUID is the unique identifier for a list.\n When GUID is not provided, use the default list defined in VT_DEFAULT_LIST environment variable.\n'
categorize_help = '\nUsage:\n vt categorize GUID CATEGORY\n vt label GUID CATEGORY\n\nDescription:\n Assign CATEGORY to the item specified by GUID.\n' |
# -*- coding: utf-8 -*-
"""
@author: ashutosh
A simple program to add two numbers.
"""
def main():
"""
The main function to execute upon call.
Returns
-------
int
returns integer 0 for safe executions.
"""
print("Program to add two numbers.\n")
# two float values
num1 = 1.5
num2 = 4.5
# Adding the two given numbers
sum_val = float(num1) + float(num2)
# Displaying the result
print("The sum of given numbers is,")
print("{n1} + {n2} = {sm}".format(n1=num1, n2=num2, sm=sum_val))
return 0
if __name__ == "__main__":
main()
| """
@author: ashutosh
A simple program to add two numbers.
"""
def main():
"""
The main function to execute upon call.
Returns
-------
int
returns integer 0 for safe executions.
"""
print('Program to add two numbers.\n')
num1 = 1.5
num2 = 4.5
sum_val = float(num1) + float(num2)
print('The sum of given numbers is,')
print('{n1} + {n2} = {sm}'.format(n1=num1, n2=num2, sm=sum_val))
return 0
if __name__ == '__main__':
main() |
# slicing lab
def swap(seq):
return seq[-1:]+seq[1:-1]+seq[:1]
assert swap('something') == 'gomethins'
assert swap(tuple(range(10))) == (9,1,2,3,4,5,6,7,8,0)
def rem(seq):
return seq[::2]
assert rem('a word') == 'awr'
def rem4(seq):
return seq[4:-4:2]
print(rem4( (1,2,3,4,5,6,7,8,9,10,11), ) )
def reverse(seq):
return seq[::-1]
print(reverse('a string'))
def thirds(seq):
i = len(seq)//3
#return seq[i*2:i*3+1] + seq[:i] + seq[i:i*2]
return seq[i:-i] + seq[-i:] + seq[:i]
print (thirds(tuple(range(12))))
| def swap(seq):
return seq[-1:] + seq[1:-1] + seq[:1]
assert swap('something') == 'gomethins'
assert swap(tuple(range(10))) == (9, 1, 2, 3, 4, 5, 6, 7, 8, 0)
def rem(seq):
return seq[::2]
assert rem('a word') == 'awr'
def rem4(seq):
return seq[4:-4:2]
print(rem4((1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11)))
def reverse(seq):
return seq[::-1]
print(reverse('a string'))
def thirds(seq):
i = len(seq) // 3
return seq[i:-i] + seq[-i:] + seq[:i]
print(thirds(tuple(range(12)))) |
def minkowski(a, b, p) :
summ = 0
n = len(a)
for i in range(n) :
summ += (b[i]-a[i])**p
summ = summ ** (1/p)
return summ
a = [0, 3, 4, 5]
b = [7, 6, 3, -1]
p=3
print(minkowski(a, b, p))
| def minkowski(a, b, p):
summ = 0
n = len(a)
for i in range(n):
summ += (b[i] - a[i]) ** p
summ = summ ** (1 / p)
return summ
a = [0, 3, 4, 5]
b = [7, 6, 3, -1]
p = 3
print(minkowski(a, b, p)) |
inp = input()
points = inp.split(" ")
for i in range(len(points)):
points[i] = int(points[i])
points.sort()
result = points[len(points) - 1] - points[0]
print(result) | inp = input()
points = inp.split(' ')
for i in range(len(points)):
points[i] = int(points[i])
points.sort()
result = points[len(points) - 1] - points[0]
print(result) |
# Created by MechAviv
# ID :: [4000013]
# Maple Road : Inside the Small Forest
sm.showFieldEffect("maplemap/enter/40000", 0) | sm.showFieldEffect('maplemap/enter/40000', 0) |
# Define time, time constant
t = np.arange(0, 10, .1)
tau = 0.5
# Compute alpha function
f = t * np.exp(-t/tau)
# Define u(t), v(t)
u_t = t
v_t = np.exp(-t/tau)
# Define du/dt, dv/dt
du_dt = 1
dv_dt = -1/tau * np.exp(-t/tau)
# Define full derivative
df_dt = u_t * dv_dt + v_t * du_dt
# Uncomment below to visualize
with plt.xkcd():
plot_alpha_func(t, f, df_dt) | t = np.arange(0, 10, 0.1)
tau = 0.5
f = t * np.exp(-t / tau)
u_t = t
v_t = np.exp(-t / tau)
du_dt = 1
dv_dt = -1 / tau * np.exp(-t / tau)
df_dt = u_t * dv_dt + v_t * du_dt
with plt.xkcd():
plot_alpha_func(t, f, df_dt) |
al = 0
ga = 0
di = 0
x = 0
while x != 4:
x = int(input())
if x == 1:
al = al + 1
if x == 2:
ga = ga + 1
if x == 3:
di = di + 1
print('MUITO OBRIGADO')
print('Alcool: {}'.format(al))
print('Gasolina: {}'.format(ga))
print('Diesel: {}'.format(di))
| al = 0
ga = 0
di = 0
x = 0
while x != 4:
x = int(input())
if x == 1:
al = al + 1
if x == 2:
ga = ga + 1
if x == 3:
di = di + 1
print('MUITO OBRIGADO')
print('Alcool: {}'.format(al))
print('Gasolina: {}'.format(ga))
print('Diesel: {}'.format(di)) |
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def countNodes(self, root: TreeNode) -> int:
maxDepth = self.findLeftMaxDepth(root)
if maxDepth <= 1:
return maxDepth
else:
curRoot = root
curDepth = 1
totalNum = 0
while True:
if curRoot.left == None:
totalNum += 1
break
elif curRoot.right == None:
totalNum += 2
break
elif self.findLeftMaxDepth(curRoot.right) + curDepth == maxDepth:
totalNum += 2 ** (maxDepth-curDepth)
curRoot = curRoot.right
curDepth += 1
elif self.findRightMaxDepth(curRoot.left) + curDepth == maxDepth:
totalNum += 2 ** (maxDepth-curDepth-1)
totalNum += (2 ** (maxDepth-curDepth) - 1)
break
else:
totalNum += 2 ** (maxDepth-curDepth-1)
curRoot = curRoot.left
curDepth += 1
return totalNum
def findLeftMaxDepth(self, root):
if root == None:
return 0
elif root.left == None:
return 1
else:
return 1 + self.findLeftMaxDepth(root.left)
def findRightMaxDepth(self, root):
if root == None:
return 0
elif root.right == None:
return 1
else:
return 1 + self.findRightMaxDepth(root.right) | class Solution:
def count_nodes(self, root: TreeNode) -> int:
max_depth = self.findLeftMaxDepth(root)
if maxDepth <= 1:
return maxDepth
else:
cur_root = root
cur_depth = 1
total_num = 0
while True:
if curRoot.left == None:
total_num += 1
break
elif curRoot.right == None:
total_num += 2
break
elif self.findLeftMaxDepth(curRoot.right) + curDepth == maxDepth:
total_num += 2 ** (maxDepth - curDepth)
cur_root = curRoot.right
cur_depth += 1
elif self.findRightMaxDepth(curRoot.left) + curDepth == maxDepth:
total_num += 2 ** (maxDepth - curDepth - 1)
total_num += 2 ** (maxDepth - curDepth) - 1
break
else:
total_num += 2 ** (maxDepth - curDepth - 1)
cur_root = curRoot.left
cur_depth += 1
return totalNum
def find_left_max_depth(self, root):
if root == None:
return 0
elif root.left == None:
return 1
else:
return 1 + self.findLeftMaxDepth(root.left)
def find_right_max_depth(self, root):
if root == None:
return 0
elif root.right == None:
return 1
else:
return 1 + self.findRightMaxDepth(root.right) |
'''
A library to speed up physics data analysis.
Contains functions for error analysis and calculations
for various physics mechanics values.
''' | """
A library to speed up physics data analysis.
Contains functions for error analysis and calculations
for various physics mechanics values.
""" |
# Creating variables dynamically.
# To be able to pass arguments to variable file, we must define
# and use "get_variables" in a similar manner as follows:
def get_variables(server_uri, start_port):
# Note that the order in which the libraries are listed here must match
# that in 'server.py'.
port = int(start_port)
target_uri = "%s:%d" % (server_uri, port)
port += 1
common_uri = "%s:%d" % (server_uri, port)
port += 1
security_uri = "%s:%d" % (server_uri, port)
# The following variables will be available in the caller's
# file.
return { "target_uri" : target_uri,
"common_uri" : common_uri,
"security_uri" : security_uri }
| def get_variables(server_uri, start_port):
port = int(start_port)
target_uri = '%s:%d' % (server_uri, port)
port += 1
common_uri = '%s:%d' % (server_uri, port)
port += 1
security_uri = '%s:%d' % (server_uri, port)
return {'target_uri': target_uri, 'common_uri': common_uri, 'security_uri': security_uri} |
class StageOutputs:
execute_outputs = {
# Outputs from public Cisco docs:
# https://www.cisco.com/c/en/us/td/docs/routers/asr1000/release/notes/asr1k_rn_rel_notes/asr1k_rn_sys_req.html
'copy running-config startup-config': '''\
PE1#copy running-config startup-config
Destination filename [startup-config]?
%Error opening bootflash:running-config (Permission denied)
''',
'show boot': '''\
starfleet-1#show boot
BOOT variable = bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin;
Configuration Register is 0x102
MANUAL_BOOT variable = no
BAUD variable = 9600
ENABLE_BREAK variable does not exist
BOOTMODE variable does not exist
IPXE_TIMEOUT variable does not exist
CONFIG_FILE variable =
''',
}
parsed_outputs = {
'show boot': {
'active':
{'boot_variable': 'bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin;',
'configuration_register': '0x102'}}
}
config_outputs = {
'no boot system bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin': '',
'boot system bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin': '',
'config-register 0x2102': '',
}
def get_execute_output(arg, **kwargs):
'''Return the execute output of the given show command'''
return StageOutputs.execute_outputs[arg]
def get_parsed_output(arg, **kwargs):
'''Return the parsed output of the given show command '''
return StageOutputs.parsed_outputs[arg]
def get_config_output(arg, **kwargs):
'''Return the out of the given config string'''
return StageOutputs.config_outputs[arg]
| class Stageoutputs:
execute_outputs = {'copy running-config startup-config': ' PE1#copy running-config startup-config\n Destination filename [startup-config]?\n %Error opening bootflash:running-config (Permission denied)\n ', 'show boot': ' starfleet-1#show boot\n BOOT variable = bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin;\n Configuration Register is 0x102\n MANUAL_BOOT variable = no\n BAUD variable = 9600\n ENABLE_BREAK variable does not exist\n BOOTMODE variable does not exist\n IPXE_TIMEOUT variable does not exist\n CONFIG_FILE variable =\n '}
parsed_outputs = {'show boot': {'active': {'boot_variable': 'bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin;', 'configuration_register': '0x102'}}}
config_outputs = {'no boot system bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin': '', 'boot system bootflash:/cat9k_iosxe.BLD_V173_THROTTLE_LATEST_20200421_032634.SSA.bin': '', 'config-register 0x2102': ''}
def get_execute_output(arg, **kwargs):
"""Return the execute output of the given show command"""
return StageOutputs.execute_outputs[arg]
def get_parsed_output(arg, **kwargs):
"""Return the parsed output of the given show command """
return StageOutputs.parsed_outputs[arg]
def get_config_output(arg, **kwargs):
"""Return the out of the given config string"""
return StageOutputs.config_outputs[arg] |
class UnknownCommand(Exception):
pass
class ModuleNotFound(Exception):
pass
class VariableError(Exception):
pass
class ModuleError:
error = ""
def __init__(self, error):
self.error = error | class Unknowncommand(Exception):
pass
class Modulenotfound(Exception):
pass
class Variableerror(Exception):
pass
class Moduleerror:
error = ''
def __init__(self, error):
self.error = error |
# Copyright 2017 Bloomberg Finance L.P.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""This package provides Python interfaces to Comdb2 databases.
Two different Python submodules are provided for interacting with Comdb2
databases. Both submodules work from Python 2.7+ and from Python 3.5+.
`comdb2.dbapi2` provides an interface that conforms to `the Python Database API
Specification v2.0 <https://www.python.org/dev/peps/pep-0249/>`_. If you're
already familiar with the Python DB-API, or if you intend to use libraries that
expect to be given DB-API compliant connections, this module is likely to be
the best fit for you. Additionally, if a better way of communicating with
a Comdb2 database than ``libcdb2api`` is ever introduced, this module will be
upgraded to it under the hood.
`comdb2.cdb2` provides a thin, pythonic wrapper over cdb2api. If you're more
familiar with ``libcdb2api`` than with the Python DB-API and you don't
anticipate a need to interact with libraries that require DB-API compliant
connections, this module may be simpler to get started with.
"""
__version__ = "1.1.6"
| """This package provides Python interfaces to Comdb2 databases.
Two different Python submodules are provided for interacting with Comdb2
databases. Both submodules work from Python 2.7+ and from Python 3.5+.
`comdb2.dbapi2` provides an interface that conforms to `the Python Database API
Specification v2.0 <https://www.python.org/dev/peps/pep-0249/>`_. If you're
already familiar with the Python DB-API, or if you intend to use libraries that
expect to be given DB-API compliant connections, this module is likely to be
the best fit for you. Additionally, if a better way of communicating with
a Comdb2 database than ``libcdb2api`` is ever introduced, this module will be
upgraded to it under the hood.
`comdb2.cdb2` provides a thin, pythonic wrapper over cdb2api. If you're more
familiar with ``libcdb2api`` than with the Python DB-API and you don't
anticipate a need to interact with libraries that require DB-API compliant
connections, this module may be simpler to get started with.
"""
__version__ = '1.1.6' |
class Node:
def __init__(self,tag,valid_bit = 1,next = None,previous = None):
self.tag = tag
self.valid_bit = valid_bit
self.next = next
self.previous = previous
def set_next_pointer(self,next):
self.next = next
def set_previous_pointer(self,previous):
self.previous = previous
def get_tag(self):
return self.tag
def get_index(self):
return self.index
def get_next_pointer(self):
return self.next
def get_previous_pointer(self):
return self.previous
| class Node:
def __init__(self, tag, valid_bit=1, next=None, previous=None):
self.tag = tag
self.valid_bit = valid_bit
self.next = next
self.previous = previous
def set_next_pointer(self, next):
self.next = next
def set_previous_pointer(self, previous):
self.previous = previous
def get_tag(self):
return self.tag
def get_index(self):
return self.index
def get_next_pointer(self):
return self.next
def get_previous_pointer(self):
return self.previous |
# Do not hard code credentials
client = boto3.client(
's3',
# Hard coded strings as credentials, not recommended.
aws_access_key_id='AKIAIO5FODNN7EXAMPLE',
aws_secret_access_key='ABCDEF+c2L7yXeGvUyrPgYsDnWRRC1AYEXAMPLE'
)
# adding another line
| client = boto3.client('s3', aws_access_key_id='AKIAIO5FODNN7EXAMPLE', aws_secret_access_key='ABCDEF+c2L7yXeGvUyrPgYsDnWRRC1AYEXAMPLE') |
#!/usr/bin/env python3
#
## @file
# checkout_humble.py
#
# Copyright (c) 2020, Intel Corporation. All rights reserved.<BR>
# SPDX-License-Identifier: BSD-2-Clause-Patent
#
NO_COMBO = 'A combination named: {} does not exist in the workspace manifest'
| no_combo = 'A combination named: {} does not exist in the workspace manifest' |
cuda_code = '''
extern "C" __global__ void my_kernel(float* input_domain, int input_domain_n, int* layer_sizes, int layer_number, float* full_weights,
float* full_biases, float* results_cuda, int max_layer_size, int* activations) {
// Calculate all the bounds, node by node, for each layer. 'new_layer_values' is the current working layer, old layer is the prevoius (first step old layer is the input layer)
int thread_id = blockDim.x * blockIdx.x + threadIdx.x;
if (thread_id >= input_domain_n) return;
int area_start = thread_id * layer_sizes[0] * 2;
float* old_layer_values = new float[max_layer_size * 2]();
float* new_layer_values = new float[max_layer_size * 2]();
// Step 1: copy inputs in 'old_layer_values' ('new_layer_values' is the first hidden layer)
for (int i = 0; i < (2 * layer_sizes[0]); i++) old_layer_values[i] = input_domain[area_start + i];
// Step 2: starting the propagation cycle
int bias_index = 0;
int weights_index = 0;
for (int layer_idx = 0; layer_idx < layer_number - 1; layer_idx ++){
int old_layer_size = layer_sizes[layer_idx];
int new_layer_size = layer_sizes[layer_idx + 1];
for (int new_node_idx = 0; new_node_idx < new_layer_size*2; new_node_idx += 2){
for (int old_node_idx = 0; old_node_idx < old_layer_size*2; old_node_idx += 2){
if(full_weights[weights_index] > 0) {
new_layer_values[new_node_idx] += (old_layer_values[old_node_idx] * full_weights[weights_index]); //lower bound
new_layer_values[new_node_idx + 1] += (old_layer_values[old_node_idx + 1] * full_weights[weights_index]); //upper bound
} else {
new_layer_values[new_node_idx] += (old_layer_values[old_node_idx + 1] * full_weights[weights_index]); //lower bound
new_layer_values[new_node_idx + 1] += (old_layer_values[old_node_idx] * full_weights[weights_index]); //upper bound
}
weights_index += 1;
}
// Adding bias for each layer (including the output)
new_layer_values[new_node_idx] += full_biases[bias_index];
new_layer_values[new_node_idx+1] += full_biases[bias_index];
bias_index += 1;
// Application of the activation function
// ReLU
if (activations[layer_idx] == 1){
if (new_layer_values[new_node_idx] < 0) new_layer_values[new_node_idx] = 0;
if (new_layer_values[new_node_idx+1] < 0) new_layer_values[new_node_idx+1] = 0;
// TanH
} else if (activations[layer_idx] == 2){
new_layer_values[new_node_idx] = ( 1 - pow(2.71828f, -2*new_layer_values[new_node_idx]) ) / ( 1 + pow(2.71828f, -2*new_layer_values[new_node_idx]) );
new_layer_values[new_node_idx+1] = ( 1 - pow(2.71828f, -2*new_layer_values[new_node_idx+1]) ) / ( 1 + pow(2.71828f, -2*new_layer_values[new_node_idx+1]) );
// Sigmoid
} else if (activations[layer_idx] == 3){
new_layer_values[new_node_idx] = 1 / ( 1 + pow(2.71828f, -new_layer_values[new_node_idx]) );
new_layer_values[new_node_idx+1] = 1 / ( 1 + pow(2.71828f, -new_layer_values[new_node_idx+1]) );
}
}
for (int i = 0; i < max_layer_size * 2; i++) old_layer_values[i] = new_layer_values[i];
for (int i = 0; i < max_layer_size * 2; i++) new_layer_values[i] = 0;
}
// Step 3: copy the local output layer in the global 'results_cuda' array
int results_start = thread_id * layer_sizes[layer_number - 1] * 2;
for (int i=0; i < layer_sizes[layer_number - 1] * 2; i++) results_cuda[results_start + i] = old_layer_values[i];
// Free memory
delete[] old_layer_values;
delete[] new_layer_values;
}
''' | cuda_code = '\n\nextern "C" __global__ void my_kernel(float* input_domain, int input_domain_n, int* layer_sizes, int layer_number, float* full_weights, \n\t\t\tfloat* full_biases, float* results_cuda, int max_layer_size, int* activations) {\n\n\t// Calculate all the bounds, node by node, for each layer. \'new_layer_values\' is the current working layer, old layer is the prevoius (first step old layer is the input layer)\n\tint thread_id = blockDim.x * blockIdx.x + threadIdx.x;\n\tif (thread_id >= input_domain_n) return;\n\tint area_start = thread_id * layer_sizes[0] * 2;\n\t\n\tfloat* old_layer_values = new float[max_layer_size * 2]();\n\tfloat* new_layer_values = new float[max_layer_size * 2]();\n\n\t// Step 1: copy inputs in \'old_layer_values\' (\'new_layer_values\' is the first hidden layer)\n\tfor (int i = 0; i < (2 * layer_sizes[0]); i++) old_layer_values[i] = input_domain[area_start + i];\n\t\n\t// Step 2: starting the propagation cycle\n\tint bias_index = 0;\n\tint weights_index = 0;\n\tfor (int layer_idx = 0; layer_idx < layer_number - 1; layer_idx ++){\n\t\tint old_layer_size = layer_sizes[layer_idx];\n\t\tint new_layer_size = layer_sizes[layer_idx + 1];\n\t\t\n\t\tfor (int new_node_idx = 0; new_node_idx < new_layer_size*2; new_node_idx += 2){\n\t\t\tfor (int old_node_idx = 0; old_node_idx < old_layer_size*2; old_node_idx += 2){\n\t\t\t\tif(full_weights[weights_index] > 0) {\n\t\t\t\t\tnew_layer_values[new_node_idx] += (old_layer_values[old_node_idx] * full_weights[weights_index]); //lower bound\n\t\t\t\t\tnew_layer_values[new_node_idx + 1] += (old_layer_values[old_node_idx + 1] * full_weights[weights_index]); //upper bound\n\t\t\t\t} else {\n\t\t\t\t\tnew_layer_values[new_node_idx] += (old_layer_values[old_node_idx + 1] * full_weights[weights_index]); //lower bound\n\t\t\t\t\tnew_layer_values[new_node_idx + 1] += (old_layer_values[old_node_idx] * full_weights[weights_index]); //upper bound\n\t\t\t\t}\n\t\t\t\tweights_index += 1;\n\t\t\t}\n\n\t\t\t// Adding bias for each layer (including the output)\n\t\t\tnew_layer_values[new_node_idx] += full_biases[bias_index];\n\t\t\tnew_layer_values[new_node_idx+1] += full_biases[bias_index]; \n\t\t\tbias_index += 1;\n\n\t\t\t// Application of the activation function\n\t\t\t// ReLU\n\t\t\tif (activations[layer_idx] == 1){\n\t\t\t\tif (new_layer_values[new_node_idx] < 0) new_layer_values[new_node_idx] = 0;\n\t\t\t\tif (new_layer_values[new_node_idx+1] < 0) new_layer_values[new_node_idx+1] = 0;\n\t\t\t// TanH\n\t\t\t} else if (activations[layer_idx] == 2){\n\t\t\t\tnew_layer_values[new_node_idx] = ( 1 - pow(2.71828f, -2*new_layer_values[new_node_idx]) ) / ( 1 + pow(2.71828f, -2*new_layer_values[new_node_idx]) );\n\t\t\t\tnew_layer_values[new_node_idx+1] = ( 1 - pow(2.71828f, -2*new_layer_values[new_node_idx+1]) ) / ( 1 + pow(2.71828f, -2*new_layer_values[new_node_idx+1]) );\n\t\t\t// Sigmoid\n\t\t\t} else if (activations[layer_idx] == 3){\n\t\t\t\tnew_layer_values[new_node_idx] = 1 / ( 1 + pow(2.71828f, -new_layer_values[new_node_idx]) );\n\t\t\t\tnew_layer_values[new_node_idx+1] = 1 / ( 1 + pow(2.71828f, -new_layer_values[new_node_idx+1]) );\n\t\t\t}\n\t\t}\n\t\tfor (int i = 0; i < max_layer_size * 2; i++) old_layer_values[i] = new_layer_values[i];\n\t\tfor (int i = 0; i < max_layer_size * 2; i++) new_layer_values[i] = 0;\n\t}\n\n\t// Step 3: copy the local output layer in the global \'results_cuda\' array\n\tint results_start = thread_id * layer_sizes[layer_number - 1] * 2;\n\tfor (int i=0; i < layer_sizes[layer_number - 1] * 2; i++) results_cuda[results_start + i] = old_layer_values[i];\n\t// Free memory\n\tdelete[] old_layer_values;\n\tdelete[] new_layer_values; \n}\n\n' |
class Point:
def __init__(self, x, y):
self.x = float(x)
self.y = float(y)
def __str__(self):
return "(" + str(round(self.x, 1)) + ', ' + str(round(self.y, 1)) + ")"
class Triangle:
def __init__(self, points):
self.points = points
def get_centroid(self):
sum_x = 0
for point in self.points:
sum_x += point.x
sum_y = 0
for point in self.points:
sum_y += point.y
return Point(sum_x/3, sum_y/3)
def main():
info = input().split()
point1 = Point(x=info[0], y=info[1])
point2 = Point(x=info[2], y=info[3])
point3 = Point(x=info[4], y=info[5])
triangle1 = Triangle([point1, point2, point3])
centroid1 = triangle1.get_centroid()
print(centroid1)
if(__name__ == '__main__'):
main()
| class Point:
def __init__(self, x, y):
self.x = float(x)
self.y = float(y)
def __str__(self):
return '(' + str(round(self.x, 1)) + ', ' + str(round(self.y, 1)) + ')'
class Triangle:
def __init__(self, points):
self.points = points
def get_centroid(self):
sum_x = 0
for point in self.points:
sum_x += point.x
sum_y = 0
for point in self.points:
sum_y += point.y
return point(sum_x / 3, sum_y / 3)
def main():
info = input().split()
point1 = point(x=info[0], y=info[1])
point2 = point(x=info[2], y=info[3])
point3 = point(x=info[4], y=info[5])
triangle1 = triangle([point1, point2, point3])
centroid1 = triangle1.get_centroid()
print(centroid1)
if __name__ == '__main__':
main() |
class TrackableObject:
def __init__(self, objectID, centroid_frame_timestamp, detection_class_id, centroid, boxoid, bbox_rw_coords):
# store the object ID, then initialize a list of centroids
# using the current centroid
self.objectID = objectID
# initialize instance variable, 'oids' as a list
self.oids = []
# initialize instance variable, 'centroids' as a list
self.centroids = []
# initialize instance variable, 'boxoids' as a list
self.boxoids = []
# initialize instance variable, 'bbox_rw_coords' as a list
self.bbox_rw_coords = []
# initialize instance variable 'detection_class_id' as 0
self.detection_class_id = detection_class_id
# initialize a boolean used to indicate if the object has
# already been counted or not
self.counted = False
# initialize a boolean used to indicate if the object has left the node's field of view and the tracks complete
self.complete = False
# pass first boxoid to 'append_boxoids' method for processing
self.append_boxoid(boxoid)
# pass first centroid to 'append_centroids' method for processing
self.append_centroid(centroid)
self.append_oids(centroid_frame_timestamp, detection_class_id, centroid, boxoid, bbox_rw_coords)
def append_centroid(self, centroid):
pass
#self.centroids.append(list(centroid))
def append_boxoid(self, boxoid):
#self.boxoids.append(list(boxoid))
# if self.detection_class_id > 0 and boxoid[5] <= 0: # if object's class has been identified already but this isn't a new identification
# pass # ... then don't change the current detection class. Even if the new detection_class_id is a -1, which means that the detection has changed but we'll stick with the first detected object class
# else: # if the object's class hasn't been identified yet or this is a new identification from a detected frame or a -1
# self.detection_class_id = boxoid[5]
pass
def append_oids(self, centroid_frame_timestamp, detection_class_id, centroid, boxoid, bbox_rw_coords):
if self.detection_class_id > 0 and detection_class_id <= 0: # if object's class has been identified already but this isn't a new identification
pass # ... then don't change the current detection class. Even if the new detection_class_id is a -1, which means that the detection has changed but we'll stick with the first detected object class
else: # if the object's class hasn't been identified yet or this is a new identification from a detected frame or a -1
self.detection_class_id = detection_class_id
oid = {
"frame_timestamp": centroid_frame_timestamp,
"centroid": list(centroid),
"boxoid": list(boxoid),
"bbox_rw_coords": bbox_rw_coords
}
self.oids.append(oid)
| class Trackableobject:
def __init__(self, objectID, centroid_frame_timestamp, detection_class_id, centroid, boxoid, bbox_rw_coords):
self.objectID = objectID
self.oids = []
self.centroids = []
self.boxoids = []
self.bbox_rw_coords = []
self.detection_class_id = detection_class_id
self.counted = False
self.complete = False
self.append_boxoid(boxoid)
self.append_centroid(centroid)
self.append_oids(centroid_frame_timestamp, detection_class_id, centroid, boxoid, bbox_rw_coords)
def append_centroid(self, centroid):
pass
def append_boxoid(self, boxoid):
pass
def append_oids(self, centroid_frame_timestamp, detection_class_id, centroid, boxoid, bbox_rw_coords):
if self.detection_class_id > 0 and detection_class_id <= 0:
pass
else:
self.detection_class_id = detection_class_id
oid = {'frame_timestamp': centroid_frame_timestamp, 'centroid': list(centroid), 'boxoid': list(boxoid), 'bbox_rw_coords': bbox_rw_coords}
self.oids.append(oid) |
"""
STATEMENT
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path
from the root node down to the nearest leaf node.
CLARIFICATIONS
- The root is not leaf for trees with levels more than one? Yes.
EXAMPLES
(needs to be drawn)
COMMENTS
- A recursive solution checking the existence left and right subtree should work.
"""
def minDepth(root):
"""
:type root: TreeNode
:rtype: int
"""
if not root:
return 0
if not root.left:
return 1 + minDepth(root.right)
if not root.right:
return 1 + minDepth(root.left)
return 1 + min(minDepth(root.left), minDepth(root.right))
| """
STATEMENT
Given a binary tree, find its minimum depth.
The minimum depth is the number of nodes along the shortest path
from the root node down to the nearest leaf node.
CLARIFICATIONS
- The root is not leaf for trees with levels more than one? Yes.
EXAMPLES
(needs to be drawn)
COMMENTS
- A recursive solution checking the existence left and right subtree should work.
"""
def min_depth(root):
"""
:type root: TreeNode
:rtype: int
"""
if not root:
return 0
if not root.left:
return 1 + min_depth(root.right)
if not root.right:
return 1 + min_depth(root.left)
return 1 + min(min_depth(root.left), min_depth(root.right)) |
#---------------------------------------
# Selection Sort
#---------------------------------------
def selection_sort(A):
for i in range (0, len(A) - 1):
minIndex = i
for j in range (i+1, len(A)):
if A[j] < A[minIndex]:
minIndex = j
if minIndex != i:
A[i], A[minIndex] = A[minIndex], A[i]
A = [5,9,1,2,4,8,6,3,7]
print(A)
selection_sort(A)
print(A) | def selection_sort(A):
for i in range(0, len(A) - 1):
min_index = i
for j in range(i + 1, len(A)):
if A[j] < A[minIndex]:
min_index = j
if minIndex != i:
(A[i], A[minIndex]) = (A[minIndex], A[i])
a = [5, 9, 1, 2, 4, 8, 6, 3, 7]
print(A)
selection_sort(A)
print(A) |
games = ["chess", "soccer", "tennis"]
foods = ["chicken", "milk", "fruits"]
favorites = games + foods
print(favorites)
| games = ['chess', 'soccer', 'tennis']
foods = ['chicken', 'milk', 'fruits']
favorites = games + foods
print(favorites) |
# Given a matrix of m x n elements (m rows, n columns), return all elements of the matrix in spiral order.
# For example,
# Given the following matrix:
# [
# [ 1, 2, 3 ],
# [ 4, 5, 6 ],
# [ 7, 8, 9 ]
# ]
# You should return [1,2,3,6,9,8,7,4,5].
class Solution:
# @param {integer[][]} matrix
# @return {integer[]}
def spiralOrder(self, matrix):
if not matrix or not matrix[0]:
return []
total = len(matrix) * len(matrix[0])
spiral = []
l, r, u, d = -1, len(matrix[0]), 0, len(matrix)
s, i, j = 0, 0, 0
for c in range(total):
spiral.append(matrix[i][j])
s, i, j, l, r, u, d = self._next(s, i, j, l, r, u, d)
return spiral
def _next(self, s, i, j, l, r, u, d):
if s == 0: # step right
j += 1
if j == r:
i, j = i+1, r-1
r -= 1
s = 1
elif s == 1: # step down
i += 1
if i == d:
i, j = d-1, j-1
d -= 1
s = 2
elif s == 2: # step left
j -= 1
if j == l:
i, j = i-1, l+1
l += 1
s = 3
else: # step up
i -= 1
if i == u:
i, j = u+1, j+1
u += 1
s = 0
return s, i, j, l, r, u, d | class Solution:
def spiral_order(self, matrix):
if not matrix or not matrix[0]:
return []
total = len(matrix) * len(matrix[0])
spiral = []
(l, r, u, d) = (-1, len(matrix[0]), 0, len(matrix))
(s, i, j) = (0, 0, 0)
for c in range(total):
spiral.append(matrix[i][j])
(s, i, j, l, r, u, d) = self._next(s, i, j, l, r, u, d)
return spiral
def _next(self, s, i, j, l, r, u, d):
if s == 0:
j += 1
if j == r:
(i, j) = (i + 1, r - 1)
r -= 1
s = 1
elif s == 1:
i += 1
if i == d:
(i, j) = (d - 1, j - 1)
d -= 1
s = 2
elif s == 2:
j -= 1
if j == l:
(i, j) = (i - 1, l + 1)
l += 1
s = 3
else:
i -= 1
if i == u:
(i, j) = (u + 1, j + 1)
u += 1
s = 0
return (s, i, j, l, r, u, d) |
"""
[2016-05-04] Challenge #265 [Hard] Permutations with repeat
https://www.reddit.com/r/dailyprogrammer/comments/4i3xrm/20160504_challenge_265_hard_permutations_with/
The number of permutations of a list that includes repeats is `(factorial of list length) / (product of factorials of
each items repeat frequency)
for the list `0 0 1 2` the permutations in order are
0 0 1 2
0 0 2 1
0 1 0 2
0 1 2 0
0 2 0 1
0 2 1 0
1 0 0 2
1 0 2 0
1 2 0 0
2 0 0 1
2 0 1 0
2 1 0 0
#1. Calculate permutation number of list that may include repeats
The permutation number is similar to Monday and Wednesday's challenge. But only wednesday's approach of calculating it
without generating the full list will work (fast) for the longer inputs. The input varies from previous ones in that
you are provided a list rather than a number to account for possible repeats. If there are no repeats, then the answer
is the same as the part 2 (wednesday) challenge.
**input:**
5 4 3 2 1 0
2 1 0 0
5 0 1 2 5 0 1 2 0 0 1 1 5 4 3 2 1 0
8 8 8 8 8 8 8 8 8 7 7 7 6 5 0 1 2 5 0 1 2 0 0 1 1 5 4 3 2 1 0 6 7 8
**output:** (0 based indexes)
719
11
10577286119
3269605362042919527837624
# 2. retrieve list from permutation number and sorted list
input is in format: permutation_number, sorted list to permute
output format is above part 1 input rows.
**input:**
719, 0 1 2 3 4 5
11, 0 0 1 2
10577286119, 0 0 0 0 0 1 1 1 1 1 2 2 2 3 4 5 5 5
3269605362042919527837624, 0 0 0 0 0 1 1 1 1 1 2 2 2 3 4 5 5 5 6 6 7 7 7 7 8 8 8 8 8 8 8 8 8 8
# bonus
use the above function and wednesday's combination number (optional) to compress/encode a list into a fixed set of
numbers (with enough information to decode it)
**input:**
hello, heely owler world!
You might wish to convert to ascii, then calculate the combination number for the unique ascii codes, then calculate
the permutation number with each letter replaced by contiguous indexes.
"""
def main():
pass
if __name__ == "__main__":
main()
| """
[2016-05-04] Challenge #265 [Hard] Permutations with repeat
https://www.reddit.com/r/dailyprogrammer/comments/4i3xrm/20160504_challenge_265_hard_permutations_with/
The number of permutations of a list that includes repeats is `(factorial of list length) / (product of factorials of
each items repeat frequency)
for the list `0 0 1 2` the permutations in order are
0 0 1 2
0 0 2 1
0 1 0 2
0 1 2 0
0 2 0 1
0 2 1 0
1 0 0 2
1 0 2 0
1 2 0 0
2 0 0 1
2 0 1 0
2 1 0 0
#1. Calculate permutation number of list that may include repeats
The permutation number is similar to Monday and Wednesday's challenge. But only wednesday's approach of calculating it
without generating the full list will work (fast) for the longer inputs. The input varies from previous ones in that
you are provided a list rather than a number to account for possible repeats. If there are no repeats, then the answer
is the same as the part 2 (wednesday) challenge.
**input:**
5 4 3 2 1 0
2 1 0 0
5 0 1 2 5 0 1 2 0 0 1 1 5 4 3 2 1 0
8 8 8 8 8 8 8 8 8 7 7 7 6 5 0 1 2 5 0 1 2 0 0 1 1 5 4 3 2 1 0 6 7 8
**output:** (0 based indexes)
719
11
10577286119
3269605362042919527837624
# 2. retrieve list from permutation number and sorted list
input is in format: permutation_number, sorted list to permute
output format is above part 1 input rows.
**input:**
719, 0 1 2 3 4 5
11, 0 0 1 2
10577286119, 0 0 0 0 0 1 1 1 1 1 2 2 2 3 4 5 5 5
3269605362042919527837624, 0 0 0 0 0 1 1 1 1 1 2 2 2 3 4 5 5 5 6 6 7 7 7 7 8 8 8 8 8 8 8 8 8 8
# bonus
use the above function and wednesday's combination number (optional) to compress/encode a list into a fixed set of
numbers (with enough information to decode it)
**input:**
hello, heely owler world!
You might wish to convert to ascii, then calculate the combination number for the unique ascii codes, then calculate
the permutation number with each letter replaced by contiguous indexes.
"""
def main():
pass
if __name__ == '__main__':
main() |
def Sequential_Search(elements):
for i in range (len(elements)): #outer loop for comparison
for j in range (len(elements)):#inner loop to compare against outer loop
pos = 0
found = False
while pos < len(elements) and not found:
if j == i:
continue
else:
pos = pos + 1
return found, pos
elements = [1,2,3,4,5,6,6,7,8,9,10]
print(Sequential_Search(elements)) | def sequential__search(elements):
for i in range(len(elements)):
for j in range(len(elements)):
pos = 0
found = False
while pos < len(elements) and (not found):
if j == i:
continue
else:
pos = pos + 1
return (found, pos)
elements = [1, 2, 3, 4, 5, 6, 6, 7, 8, 9, 10]
print(sequential__search(elements)) |
def palcheck(s):
ns=""
for i in s:
ns=i+ns
if s==ns:
return True
return False
def cod(s):
l=len(s)
for i in range(2,l):
if palcheck(s[:i]):
t1=s[:i]
k=s[i:]
break
t=len(k)
for j in range(2,t):
if palcheck(k[:j]):
t2=k[:j]
k2=k[j:]
if palcheck(k2)==True:
print(t1,t2,k2)
return 1
print("Impossible")
return 0
us=input("Input String\n")
if len(us)>=1 and len(us)<=1000:
cod(us)
else:
print("Not Under Limitation")
| def palcheck(s):
ns = ''
for i in s:
ns = i + ns
if s == ns:
return True
return False
def cod(s):
l = len(s)
for i in range(2, l):
if palcheck(s[:i]):
t1 = s[:i]
k = s[i:]
break
t = len(k)
for j in range(2, t):
if palcheck(k[:j]):
t2 = k[:j]
k2 = k[j:]
if palcheck(k2) == True:
print(t1, t2, k2)
return 1
print('Impossible')
return 0
us = input('Input String\n')
if len(us) >= 1 and len(us) <= 1000:
cod(us)
else:
print('Not Under Limitation') |
# pylint: skip-file
# pylint: disable=too-many-instance-attributes
class Subnetwork(GCPResource):
'''Object to represent a gcp subnetwork'''
resource_type = "compute.v1.subnetwork"
# pylint: disable=too-many-arguments
def __init__(self,
rname,
project,
zone,
ip_cidr_range,
region,
network,
):
'''constructor for gcp resource'''
super(Subnetwork, self).__init__(rname,
Subnetwork.resource_type,
project,
zone)
self._ip_cidr_range = ip_cidr_range
self._region = region
self._network = '$(ref.%s.selfLink)' % network
@property
def ip_cidr_range(self):
'''property for resource ip_cidr_range'''
return self._ip_cidr_range
@property
def region(self):
'''property for resource region'''
return self._region
@property
def network(self):
'''property for resource network'''
return self._network
def to_resource(self):
""" return the resource representation"""
return {'name': self.name,
'type': Subnetwork.resource_type,
'properties': {'ipCidrRange': self.ip_cidr_range,
'network': self.network,
'region': self.region,
}
}
| class Subnetwork(GCPResource):
"""Object to represent a gcp subnetwork"""
resource_type = 'compute.v1.subnetwork'
def __init__(self, rname, project, zone, ip_cidr_range, region, network):
"""constructor for gcp resource"""
super(Subnetwork, self).__init__(rname, Subnetwork.resource_type, project, zone)
self._ip_cidr_range = ip_cidr_range
self._region = region
self._network = '$(ref.%s.selfLink)' % network
@property
def ip_cidr_range(self):
"""property for resource ip_cidr_range"""
return self._ip_cidr_range
@property
def region(self):
"""property for resource region"""
return self._region
@property
def network(self):
"""property for resource network"""
return self._network
def to_resource(self):
""" return the resource representation"""
return {'name': self.name, 'type': Subnetwork.resource_type, 'properties': {'ipCidrRange': self.ip_cidr_range, 'network': self.network, 'region': self.region}} |
class Solution:
def mostCommonWord(self, paragraph: str, banned: List[str]) -> str:
strs = []
tmp = ''
for s in paragraph:
if s in '!? \';.,':
if tmp:
strs.append(tmp)
tmp = ''
else:
tmp += s.lower()
if tmp:
strs.append(tmp)
cnt = {}
max_num = 0
res = ''
banned = set(banned)
for string in strs:
if string not in banned:
if string not in cnt:
cnt[string] = 1
else:
cnt[string] += 1
if cnt[string] > max_num:
max_num = cnt[string]
res = string
return res
| class Solution:
def most_common_word(self, paragraph: str, banned: List[str]) -> str:
strs = []
tmp = ''
for s in paragraph:
if s in "!? ';.,":
if tmp:
strs.append(tmp)
tmp = ''
else:
tmp += s.lower()
if tmp:
strs.append(tmp)
cnt = {}
max_num = 0
res = ''
banned = set(banned)
for string in strs:
if string not in banned:
if string not in cnt:
cnt[string] = 1
else:
cnt[string] += 1
if cnt[string] > max_num:
max_num = cnt[string]
res = string
return res |
"""
ShellSort is a variation of insertion sort.
Sometimes called as "diminishing increment sort".
How ShelSort improves insertion sort algorithm?
By breaking the original list into a number of sub-lists, each sublist is sorted using the insertion sort.
It will move the items nearer to its original index.
Algorithms:
1. Take the list of numbers
2. Find out the gap/incrementor
3. Create the sub-list based on gap and sort them using insertion sort algorithm
4. Reduce gap and repeat step 3.
5. Stop when gap is 0.
"""
def shell_sort(list1):
gap = len(list1) // 2
while gap > 0:
for index in range(gap, len(index)):
current_element = list1[index]
pos = index
while pos >= gap and current_element < list1[pos - gap]:
list1[pos] = list1[pos - gap]
pos = pos - gap
list1[pos] = current_element
gap = gap // 2
| """
ShellSort is a variation of insertion sort.
Sometimes called as "diminishing increment sort".
How ShelSort improves insertion sort algorithm?
By breaking the original list into a number of sub-lists, each sublist is sorted using the insertion sort.
It will move the items nearer to its original index.
Algorithms:
1. Take the list of numbers
2. Find out the gap/incrementor
3. Create the sub-list based on gap and sort them using insertion sort algorithm
4. Reduce gap and repeat step 3.
5. Stop when gap is 0.
"""
def shell_sort(list1):
gap = len(list1) // 2
while gap > 0:
for index in range(gap, len(index)):
current_element = list1[index]
pos = index
while pos >= gap and current_element < list1[pos - gap]:
list1[pos] = list1[pos - gap]
pos = pos - gap
list1[pos] = current_element
gap = gap // 2 |
class Solution:
def rob(self, nums: List[int]) -> int:
if len(nums) == 0:
return 0
if len(nums) == 1:
return nums[0]
dp = []
dp.append(nums[0])
dp.append(max(nums[0], nums[1]))
for i in range(2, len(nums)):
dp.append(max(nums[i] + dp[i - 2], dp[i - 1]))
return dp[-1]
nums = [2, 1, 1, 2, 4, 6]
| class Solution:
def rob(self, nums: List[int]) -> int:
if len(nums) == 0:
return 0
if len(nums) == 1:
return nums[0]
dp = []
dp.append(nums[0])
dp.append(max(nums[0], nums[1]))
for i in range(2, len(nums)):
dp.append(max(nums[i] + dp[i - 2], dp[i - 1]))
return dp[-1]
nums = [2, 1, 1, 2, 4, 6] |
def foo(x, y):
s = x + y
if s > 10:
print("s>10")
elif s > 5:
print("s>5")
else:
print("less")
print("over")
def bar():
s = 1 + 2
if s > 10:
print("s>10")
elif s > 5:
print("s>5")
else:
print("less")
print("over")
| def foo(x, y):
s = x + y
if s > 10:
print('s>10')
elif s > 5:
print('s>5')
else:
print('less')
print('over')
def bar():
s = 1 + 2
if s > 10:
print('s>10')
elif s > 5:
print('s>5')
else:
print('less')
print('over') |
#coding:utf-8
'''
filename:arabic2roman.py
chap:6
subject:6
conditions:translate Arabic numerals to Roman numerals
solution:class Arabic2Roman
'''
class Arabic2Roman:
trans = {1:'I',5:'V',10:'X',50:'L',100:'C',500:'D',1000:'M'}
# 'I(a)X(b)V(c)I(d)'
trans_unit = {1:(0,0,0,1),2:(0,0,0,2),3:(0,0,0,3),
4:(1,0,1,0),5:(0,0,1,0),
6:(0,0,1,1),7:(0,0,1,2),8:(0,0,1,3),
9:(1,1,0,0)}
def __init__(self,digit):
self.digit = digit
self.roman = self.get_roman()
def __str__(self):
return f'{self.digit:4} : {self.roman}'
def get_roman(self):
if self.digit >= 4000 or self.digit <=0:
raise ValueError('Input moust LT 4000 and GT 0')
lst = []
n = self.digit
for i in (1000,100,10,1):
q=n//i
r=n%i
n=r
lst.append(self.get_str(q,i))
return ''.join(lst)
def get_str(self,q:"0<= q <=9",i:'1,10,100,1000'):
rst = ''
if not q:
# q == 0
return rst
unit = self.trans_unit[q]
for s,u in zip((1,10,5,1),unit):
# 'I(a)X(b)V(c)I(d)'
rst += self.trans.get(s*i,'') * u
return rst
if __name__ == '__main__':
for i in range(1,120):
print(Arabic2Roman(i))
while True:
digit = int(input('Enter an integer :'))
print(Arabic2Roman(digit))
| """
filename:arabic2roman.py
chap:6
subject:6
conditions:translate Arabic numerals to Roman numerals
solution:class Arabic2Roman
"""
class Arabic2Roman:
trans = {1: 'I', 5: 'V', 10: 'X', 50: 'L', 100: 'C', 500: 'D', 1000: 'M'}
trans_unit = {1: (0, 0, 0, 1), 2: (0, 0, 0, 2), 3: (0, 0, 0, 3), 4: (1, 0, 1, 0), 5: (0, 0, 1, 0), 6: (0, 0, 1, 1), 7: (0, 0, 1, 2), 8: (0, 0, 1, 3), 9: (1, 1, 0, 0)}
def __init__(self, digit):
self.digit = digit
self.roman = self.get_roman()
def __str__(self):
return f'{self.digit:4} : {self.roman}'
def get_roman(self):
if self.digit >= 4000 or self.digit <= 0:
raise value_error('Input moust LT 4000 and GT 0')
lst = []
n = self.digit
for i in (1000, 100, 10, 1):
q = n // i
r = n % i
n = r
lst.append(self.get_str(q, i))
return ''.join(lst)
def get_str(self, q: '0<= q <=9', i: '1,10,100,1000'):
rst = ''
if not q:
return rst
unit = self.trans_unit[q]
for (s, u) in zip((1, 10, 5, 1), unit):
rst += self.trans.get(s * i, '') * u
return rst
if __name__ == '__main__':
for i in range(1, 120):
print(arabic2_roman(i))
while True:
digit = int(input('Enter an integer :'))
print(arabic2_roman(digit)) |
# AARD: function: __main__
# AARD: #1:1 -> #1:2 :: defs: %1 / uses: [@1 5:4-5:10] { call }
# AARD: #1:2 -> #1:3, #1:4 :: defs: / uses: %1 [@1 5:4-5:10]
if test():
# AARD: #1:3 -> #1:4 :: defs: %2 / uses: [@1 7:5-7:12]
foo = 3
# AARD: #1:4 -> :: defs: %3 / uses: [@1 10:1-10:8] { call }
print()
# AARD: @1 = if2.py
| if test():
foo = 3
print() |
class Node:
def __init__(self, value):
self._value = value
self._parent = None
self._children = []
@property
def value(self):
return self._value
@property
def children(self):
return self._children
@property
def parent(self):
return self._parent
@parent.setter
def parent(self, node):
if self._parent == node:
return
if self._parent is not None:
self._parent.remove_child(self)
self._parent = node
if node is not None:
node.add_child(self)
def add_child(self, node):
if node not in self._children:
self._children.append(node)
node.parent = self
def remove_child(self, node):
if node in self._children:
self._children.remove(node)
node.parent = None
def depth_search(self, value):
if self._value == value:
return self
for child in self._children:
node = child.depth_search(value)
if node is not None:
return node
return None
def breadth_search(self, value):
queue = list()
while queue:
node = queue.pop(0)
if node._value == value:
return node
queue.extend(node._children)
return None
# node1 = Node("root1")
# node2 = Node("root2")
# node3 = Node("root3")
# node3.parent = node1
# node3.parent = node2
# print(node1.children)
# print(node2.children) | class Node:
def __init__(self, value):
self._value = value
self._parent = None
self._children = []
@property
def value(self):
return self._value
@property
def children(self):
return self._children
@property
def parent(self):
return self._parent
@parent.setter
def parent(self, node):
if self._parent == node:
return
if self._parent is not None:
self._parent.remove_child(self)
self._parent = node
if node is not None:
node.add_child(self)
def add_child(self, node):
if node not in self._children:
self._children.append(node)
node.parent = self
def remove_child(self, node):
if node in self._children:
self._children.remove(node)
node.parent = None
def depth_search(self, value):
if self._value == value:
return self
for child in self._children:
node = child.depth_search(value)
if node is not None:
return node
return None
def breadth_search(self, value):
queue = list()
while queue:
node = queue.pop(0)
if node._value == value:
return node
queue.extend(node._children)
return None |
class Env:
def __init__(self):
self.played = False
def getTime(self):
pass
def playWavFile(self, file):
pass
def wavWasPlayed(self):
self.played = True
def resetWav(self):
self.played = False
| class Env:
def __init__(self):
self.played = False
def get_time(self):
pass
def play_wav_file(self, file):
pass
def wav_was_played(self):
self.played = True
def reset_wav(self):
self.played = False |
algorithm_parameter = {
'type': 'object',
'required': ['name', 'value'],
'properties': {
'name': {
'description': 'Name of algorithm parameter',
'type': 'string',
},
'value': {
'description': 'Value of algorithm parameter',
'oneOf': [
{'type': 'number'},
{'type': 'string'},
],
},
},
}
algorithm_launch_spec = {
'type': 'object',
'required': ['algorithm_name'],
'properties': {
'algorithm_name': {
'description': 'Name of the algorithm to execute.',
'type': 'string',
},
'media_query': {
'description': 'Query string used to filter media IDs. If '
'supplied, media_ids will be ignored.',
'type': 'string',
},
'media_ids': {
'description': 'List of media IDs. Must supply media_query '
'or media_ids.',
'type': 'array',
'items': {'type': 'integer'},
},
'extra_params': {
'description': 'Extra parameters to pass into the algorithm',
'type': 'array',
'items': {'$ref': '#/components/schemas/AlgorithmParameter'},
},
},
}
algorithm_launch = {
'type': 'object',
'properties': {
'message': {
'type': 'string',
'description': 'Message indicating successful launch.',
},
'uid': {
'type': 'array',
'description': 'A list of uuid strings identifying each job '
'started.',
'items': {'type': 'string'},
},
'gid': {
'type': 'string',
'description': 'A uuid string identifying the group of jobs '
'started.',
},
},
}
| algorithm_parameter = {'type': 'object', 'required': ['name', 'value'], 'properties': {'name': {'description': 'Name of algorithm parameter', 'type': 'string'}, 'value': {'description': 'Value of algorithm parameter', 'oneOf': [{'type': 'number'}, {'type': 'string'}]}}}
algorithm_launch_spec = {'type': 'object', 'required': ['algorithm_name'], 'properties': {'algorithm_name': {'description': 'Name of the algorithm to execute.', 'type': 'string'}, 'media_query': {'description': 'Query string used to filter media IDs. If supplied, media_ids will be ignored.', 'type': 'string'}, 'media_ids': {'description': 'List of media IDs. Must supply media_query or media_ids.', 'type': 'array', 'items': {'type': 'integer'}}, 'extra_params': {'description': 'Extra parameters to pass into the algorithm', 'type': 'array', 'items': {'$ref': '#/components/schemas/AlgorithmParameter'}}}}
algorithm_launch = {'type': 'object', 'properties': {'message': {'type': 'string', 'description': 'Message indicating successful launch.'}, 'uid': {'type': 'array', 'description': 'A list of uuid strings identifying each job started.', 'items': {'type': 'string'}}, 'gid': {'type': 'string', 'description': 'A uuid string identifying the group of jobs started.'}}} |
class solve_day(object):
with open('inputs/day02.txt', 'r') as f:
data = f.readlines()
def part1(self):
grid = [[1,2,3],
[4,5,6],
[7,8,9]]
code = []
## locations
# 1 - grid[0][0]
# 2 - grid[0][1]
# 3 - grid[0][2]
# 4 - grid[1][0]
# 5 - grid[1][1]
# 6 - grid[1][2]
# 7 - grid[2][0]
# 8 - grid[2][1]
# 9 - grid[2][2]
position = [0,0]
for i,d in enumerate(self.data):
d = d.strip()
if i == 0:
# set starting position
position = [1,1]
for x in d:
if x == 'U':
position[0] += -1 if position[0]-1 >= 0 and position[0]-1 <= 2 else 0
if x == 'D':
position[0] += 1 if position[0]+1 >= 0 and position[0]+1 <= 2 else 0
if x == 'R':
position[1] += 1 if position[1]+1 >= 0 and position[1]+1 <= 2 else 0
if x == 'L':
position[1] += -1 if position[1]-1 >= 0 and position[1]-1 <= 2 else 0
code.append(grid[position[0]][position[1]])
return ''.join([str(x) for x in code])
def part2(self):
grid = [['','',1,'',''],
['',2,3,4,''],
[5,6,7,8,9],
['','A','B','C',''],
['','','D','','']]
code = []
position = [0,0]
for i,d in enumerate(self.data):
d = d.strip()
if i == 0:
# set starting position
position = [2,0]
for x in d:
if x == 'U':
if position[1] in [0, 4]:
pass
if position[1] in [1, 3]:
position[0] += -1 if position[0]-1 in [1,2,3] else 0
if position[1] in [2]:
position[0] += -1 if position[0]-1 in [0,1,2,3,4] else 0
if x == 'D':
if position[1] in [0, 4]:
pass
if position[1] in [1, 3]:
position[0] += 1 if position[0]+1 in [1,2,3] else 0
if position[1] in [2]:
position[0] += 1 if position[0]+1 in [0,1,2,3,4] else 0
if x == 'R':
if position[0] in [0, 4]:
pass
if position[0] in [1, 3]:
position[1] += 1 if position[1]+1 in [1,2,3] else 0
if position[0] in [2]:
position[1] += 1 if position[1]+1 in [0,1,2,3,4] else 0
if x == 'L':
if position[0] in [0, 4]:
pass
if position[0] in [1, 3]:
position[1] += -1 if position[1]-1 in [1,2,3] else 0
if position[0] in [2]:
position[1] += -1 if position[1]-1 in [0,1,2,3,4] else 0
code.append(grid[position[0]][position[1]])
return ''.join([str(x) for x in code])
if __name__ == '__main__':
s = solve_day()
print(f'Part 1: {s.part1()}')
print(f'Part 2: {s.part2()}') | class Solve_Day(object):
with open('inputs/day02.txt', 'r') as f:
data = f.readlines()
def part1(self):
grid = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
code = []
position = [0, 0]
for (i, d) in enumerate(self.data):
d = d.strip()
if i == 0:
position = [1, 1]
for x in d:
if x == 'U':
position[0] += -1 if position[0] - 1 >= 0 and position[0] - 1 <= 2 else 0
if x == 'D':
position[0] += 1 if position[0] + 1 >= 0 and position[0] + 1 <= 2 else 0
if x == 'R':
position[1] += 1 if position[1] + 1 >= 0 and position[1] + 1 <= 2 else 0
if x == 'L':
position[1] += -1 if position[1] - 1 >= 0 and position[1] - 1 <= 2 else 0
code.append(grid[position[0]][position[1]])
return ''.join([str(x) for x in code])
def part2(self):
grid = [['', '', 1, '', ''], ['', 2, 3, 4, ''], [5, 6, 7, 8, 9], ['', 'A', 'B', 'C', ''], ['', '', 'D', '', '']]
code = []
position = [0, 0]
for (i, d) in enumerate(self.data):
d = d.strip()
if i == 0:
position = [2, 0]
for x in d:
if x == 'U':
if position[1] in [0, 4]:
pass
if position[1] in [1, 3]:
position[0] += -1 if position[0] - 1 in [1, 2, 3] else 0
if position[1] in [2]:
position[0] += -1 if position[0] - 1 in [0, 1, 2, 3, 4] else 0
if x == 'D':
if position[1] in [0, 4]:
pass
if position[1] in [1, 3]:
position[0] += 1 if position[0] + 1 in [1, 2, 3] else 0
if position[1] in [2]:
position[0] += 1 if position[0] + 1 in [0, 1, 2, 3, 4] else 0
if x == 'R':
if position[0] in [0, 4]:
pass
if position[0] in [1, 3]:
position[1] += 1 if position[1] + 1 in [1, 2, 3] else 0
if position[0] in [2]:
position[1] += 1 if position[1] + 1 in [0, 1, 2, 3, 4] else 0
if x == 'L':
if position[0] in [0, 4]:
pass
if position[0] in [1, 3]:
position[1] += -1 if position[1] - 1 in [1, 2, 3] else 0
if position[0] in [2]:
position[1] += -1 if position[1] - 1 in [0, 1, 2, 3, 4] else 0
code.append(grid[position[0]][position[1]])
return ''.join([str(x) for x in code])
if __name__ == '__main__':
s = solve_day()
print(f'Part 1: {s.part1()}')
print(f'Part 2: {s.part2()}') |
class IntegerStack(list):
def __init__(self):
stack = [] * 128
self.extend(stack)
def depth(self):
return len(self)
def tos(self):
return self[-1]
def push(self, v):
self.append(v)
def dup(self):
self.append(self[-1])
def drop(self):
self.pop()
def swap(self):
a = self[-2]
self[-2] = self[-1]
self[-1] = a
| class Integerstack(list):
def __init__(self):
stack = [] * 128
self.extend(stack)
def depth(self):
return len(self)
def tos(self):
return self[-1]
def push(self, v):
self.append(v)
def dup(self):
self.append(self[-1])
def drop(self):
self.pop()
def swap(self):
a = self[-2]
self[-2] = self[-1]
self[-1] = a |
# -*- coding: utf-8 -*-
# Part of Odoo. See LICENSE file for full copyright and licensing details.
{
'name': 'Collaborative Pads',
'version': '2.0',
'category': 'Extra Tools',
'description': """
Adds enhanced support for (Ether)Pad attachments in the web client.
===================================================================
Lets the company customize which Pad installation should be used to link to new
pads (by default, http://etherpad.com/).
""",
'website': 'https://www.odoo.com/page/notes',
'depends': ['web', 'base_setup'],
'data': [
'views/pad.xml',
'views/res_config_view.xml',
],
'demo': ['data/pad_demo.xml'],
'web': True,
'qweb': ['static/src/xml/pad.xml']
}
| {'name': 'Collaborative Pads', 'version': '2.0', 'category': 'Extra Tools', 'description': '\nAdds enhanced support for (Ether)Pad attachments in the web client.\n===================================================================\n\nLets the company customize which Pad installation should be used to link to new\npads (by default, http://etherpad.com/).\n ', 'website': 'https://www.odoo.com/page/notes', 'depends': ['web', 'base_setup'], 'data': ['views/pad.xml', 'views/res_config_view.xml'], 'demo': ['data/pad_demo.xml'], 'web': True, 'qweb': ['static/src/xml/pad.xml']} |
# Copyright 2019 The Bazel Authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
# Rollup rules for Bazel
The Rollup rules run the [rollup.js](https://rollupjs.org/) bundler with Bazel.
## Installation
Add the `@bazel/rollup` npm package to your `devDependencies` in `package.json`. (`rollup` itself should also be included in `devDependencies`, unless you plan on providing it via a custom target.)
### Installing with user-managed dependencies
If you didn't use the `yarn_install` or `npm_install` rule, you'll have to declare a rule in your root `BUILD.bazel` file to execute rollup:
```python
# Create a rollup rule to use in rollup_bundle#rollup_bin
# attribute when using user-managed dependencies
nodejs_binary(
name = "rollup_bin",
entry_point = "//:node_modules/rollup/bin/rollup",
# Point bazel to your node_modules to find the entry point
data = ["//:node_modules"],
)
```
## Usage
The `rollup_bundle` rule is used to invoke Rollup on some JavaScript inputs.
The API docs appear [below](#rollup_bundle).
Typical example:
```python
load("@npm//@bazel/rollup:index.bzl", "rollup_bundle")
rollup_bundle(
name = "bundle",
srcs = ["dependency.js"],
entry_point = "input.js",
config_file = "rollup.config.js",
)
```
Note that the command-line options set by Bazel override what appears in the rollup config file.
This means that typically a single `rollup.config.js` can contain settings for your whole repo,
and multiple `rollup_bundle` rules can share the configuration.
Thus, setting options that Bazel controls will have no effect, e.g.
```javascript
module.exports = {
output: { file: 'this_is_ignored.js' },
}
```
### Output types
You must determine ahead of time whether Rollup will write a single file or a directory.
Rollup's CLI has the same behavior, forcing you to pick `--output.file` or `--output.dir`.
Writing a directory is used when you have dynamic imports which cause code-splitting, or if you
provide multiple entry points. Use the `output_dir` attribute to specify that you want a
directory output.
Each `rollup_bundle` rule produces only one output by running the rollup CLI a single time.
To get multiple output formats, you can wrap the rule with a macro or list comprehension, e.g.
```python
[
rollup_bundle(
name = "bundle.%s" % format,
entry_point = "foo.js",
format = format,
)
for format in [
"cjs",
"umd",
]
]
```
This will produce one output per requested format.
### Stamping
You can stamp the current version control info into the output by writing some code in your rollup config.
See the [stamping documentation](stamping).
By passing the `--stamp` option to Bazel, two additional input files will be readable by Rollup.
1. The variable `bazel_version_file` will point to `bazel-out/volatile-status.txt` which contains
statuses that change frequently; such changes do not cause a re-build of the rollup_bundle.
2. The variable `bazel_info_file` will point to `bazel-out/stable-status.txt` file which contains
statuses that stay the same; any changed values will cause rollup_bundle to rebuild.
Both `bazel_version_file` and `bazel_info_file` will be `undefined` if the build is run without `--stamp`.
> Note that under `--stamp`, only the bundle is re-built, but not the compilation steps that produced the inputs.
> This avoids a slow cascading re-build of a whole tree of actions.
To use these files, you write JS code in your `rollup.config.js` to read from the status files and parse the lines.
Each line is a space-separated key/value pair.
```javascript
/**
* The status files are expected to look like
* BUILD_SCM_HASH 83c699db39cfd74526cdf9bebb75aa6f122908bb
* BUILD_SCM_LOCAL_CHANGES true
* STABLE_BUILD_SCM_VERSION 6.0.0-beta.6+12.sha-83c699d.with-local-changes
* BUILD_TIMESTAMP 1520021990506
*
* Parsing regex is created based on Bazel's documentation describing the status file schema:
* The key names can be anything but they may only use upper case letters and underscores. The
* first space after the key name separates it from the value. The value is the rest of the line
* (including additional whitespaces).
*
* @param {string} p the path to the status file
* @returns a two-dimensional array of key/value pairs
*/
function parseStatusFile(p) {
if (!p) return [];
const results = {};
const statusFile = require('fs').readFileSync(p, {encoding: 'utf-8'});
for (const match of `\n${statusFile}`.matchAll(/^([A-Z_]+) (.*)/gm)) {
// Lines which go unmatched define an index value of `0` and should be skipped.
if (match.index === 0) {
continue;
}
results[match[1]] = match[2];
}
return results;
}
const statuses = parseStatusFile(bazel_version_file);
// Parse the stamp file produced by Bazel from the version control system
let version = '<unknown>';
// Don't assume BUILD_SCM_VERSION exists
if (statuses['BUILD_SCM_VERSION']) {
version = 'v' + statuses['BUILD_SCM_VERSION'];
if (DEBUG) {
version += '_debug';
}
}
```
### Debug and Opt builds
When you use `--compilation_mode=dbg`, Bazel produces a distinct output-tree in `bazel-out/[arch]-dbg/bin`.
Code in your `rollup.config.js` can look in the environment to detect if a debug build is being performed,
and include extra developer information in the bundle that you wouldn't normally ship to production.
Similarly, `--compilation_mode=opt` is Bazel's signal to perform extra optimizations.
You could use this value to perform extra production-only optimizations.
For example you could define a constant for enabling Debug:
```javascript
const DEBUG = process.env['COMPILATION_MODE'] === 'dbg';
```
and configure Rollup differently when `DEBUG` is `true` or `false`.
### Increasing Heap memory for rollup
The `rollup_bin` attribute allows you to customize the rollup.js program we execute,
so you can use `nodejs_binary` to construct your own.
> You can always call `bazel query --output=build [default rollup_bin]` to see what
> the default definition looks like, then copy-paste from there to be sure yours
> matches.
```python
nodejs_binary(
name = "rollup_more_mem",
data = ["@npm//rollup:rollup"],
entry_point = "@npm//:node_modules/rollup/dist/bin/rollup",
templated_args = [
"--node_options=--max-old-space-size=<SOME_SIZE>",
],
)
rollup_bundle(
...
rollup_bin = ":rollup_more_mem",
)
```
"""
load(":rollup_bundle.bzl", _rollup_bundle = "rollup_bundle")
rollup_bundle = _rollup_bundle
| """
# Rollup rules for Bazel
The Rollup rules run the [rollup.js](https://rollupjs.org/) bundler with Bazel.
## Installation
Add the `@bazel/rollup` npm package to your `devDependencies` in `package.json`. (`rollup` itself should also be included in `devDependencies`, unless you plan on providing it via a custom target.)
### Installing with user-managed dependencies
If you didn't use the `yarn_install` or `npm_install` rule, you'll have to declare a rule in your root `BUILD.bazel` file to execute rollup:
```python
# Create a rollup rule to use in rollup_bundle#rollup_bin
# attribute when using user-managed dependencies
nodejs_binary(
name = "rollup_bin",
entry_point = "//:node_modules/rollup/bin/rollup",
# Point bazel to your node_modules to find the entry point
data = ["//:node_modules"],
)
```
## Usage
The `rollup_bundle` rule is used to invoke Rollup on some JavaScript inputs.
The API docs appear [below](#rollup_bundle).
Typical example:
```python
load("@npm//@bazel/rollup:index.bzl", "rollup_bundle")
rollup_bundle(
name = "bundle",
srcs = ["dependency.js"],
entry_point = "input.js",
config_file = "rollup.config.js",
)
```
Note that the command-line options set by Bazel override what appears in the rollup config file.
This means that typically a single `rollup.config.js` can contain settings for your whole repo,
and multiple `rollup_bundle` rules can share the configuration.
Thus, setting options that Bazel controls will have no effect, e.g.
```javascript
module.exports = {
output: { file: 'this_is_ignored.js' },
}
```
### Output types
You must determine ahead of time whether Rollup will write a single file or a directory.
Rollup's CLI has the same behavior, forcing you to pick `--output.file` or `--output.dir`.
Writing a directory is used when you have dynamic imports which cause code-splitting, or if you
provide multiple entry points. Use the `output_dir` attribute to specify that you want a
directory output.
Each `rollup_bundle` rule produces only one output by running the rollup CLI a single time.
To get multiple output formats, you can wrap the rule with a macro or list comprehension, e.g.
```python
[
rollup_bundle(
name = "bundle.%s" % format,
entry_point = "foo.js",
format = format,
)
for format in [
"cjs",
"umd",
]
]
```
This will produce one output per requested format.
### Stamping
You can stamp the current version control info into the output by writing some code in your rollup config.
See the [stamping documentation](stamping).
By passing the `--stamp` option to Bazel, two additional input files will be readable by Rollup.
1. The variable `bazel_version_file` will point to `bazel-out/volatile-status.txt` which contains
statuses that change frequently; such changes do not cause a re-build of the rollup_bundle.
2. The variable `bazel_info_file` will point to `bazel-out/stable-status.txt` file which contains
statuses that stay the same; any changed values will cause rollup_bundle to rebuild.
Both `bazel_version_file` and `bazel_info_file` will be `undefined` if the build is run without `--stamp`.
> Note that under `--stamp`, only the bundle is re-built, but not the compilation steps that produced the inputs.
> This avoids a slow cascading re-build of a whole tree of actions.
To use these files, you write JS code in your `rollup.config.js` to read from the status files and parse the lines.
Each line is a space-separated key/value pair.
```javascript
/**
* The status files are expected to look like
* BUILD_SCM_HASH 83c699db39cfd74526cdf9bebb75aa6f122908bb
* BUILD_SCM_LOCAL_CHANGES true
* STABLE_BUILD_SCM_VERSION 6.0.0-beta.6+12.sha-83c699d.with-local-changes
* BUILD_TIMESTAMP 1520021990506
*
* Parsing regex is created based on Bazel's documentation describing the status file schema:
* The key names can be anything but they may only use upper case letters and underscores. The
* first space after the key name separates it from the value. The value is the rest of the line
* (including additional whitespaces).
*
* @param {string} p the path to the status file
* @returns a two-dimensional array of key/value pairs
*/
function parseStatusFile(p) {
if (!p) return [];
const results = {};
const statusFile = require('fs').readFileSync(p, {encoding: 'utf-8'});
for (const match of `
${statusFile}`.matchAll(/^([A-Z_]+) (.*)/gm)) {
// Lines which go unmatched define an index value of `0` and should be skipped.
if (match.index === 0) {
continue;
}
results[match[1]] = match[2];
}
return results;
}
const statuses = parseStatusFile(bazel_version_file);
// Parse the stamp file produced by Bazel from the version control system
let version = '<unknown>';
// Don't assume BUILD_SCM_VERSION exists
if (statuses['BUILD_SCM_VERSION']) {
version = 'v' + statuses['BUILD_SCM_VERSION'];
if (DEBUG) {
version += '_debug';
}
}
```
### Debug and Opt builds
When you use `--compilation_mode=dbg`, Bazel produces a distinct output-tree in `bazel-out/[arch]-dbg/bin`.
Code in your `rollup.config.js` can look in the environment to detect if a debug build is being performed,
and include extra developer information in the bundle that you wouldn't normally ship to production.
Similarly, `--compilation_mode=opt` is Bazel's signal to perform extra optimizations.
You could use this value to perform extra production-only optimizations.
For example you could define a constant for enabling Debug:
```javascript
const DEBUG = process.env['COMPILATION_MODE'] === 'dbg';
```
and configure Rollup differently when `DEBUG` is `true` or `false`.
### Increasing Heap memory for rollup
The `rollup_bin` attribute allows you to customize the rollup.js program we execute,
so you can use `nodejs_binary` to construct your own.
> You can always call `bazel query --output=build [default rollup_bin]` to see what
> the default definition looks like, then copy-paste from there to be sure yours
> matches.
```python
nodejs_binary(
name = "rollup_more_mem",
data = ["@npm//rollup:rollup"],
entry_point = "@npm//:node_modules/rollup/dist/bin/rollup",
templated_args = [
"--node_options=--max-old-space-size=<SOME_SIZE>",
],
)
rollup_bundle(
...
rollup_bin = ":rollup_more_mem",
)
```
"""
load(':rollup_bundle.bzl', _rollup_bundle='rollup_bundle')
rollup_bundle = _rollup_bundle |
digit_mapping = {
'2': ['a', 'b', 'c'],
'3': ['d', 'e', 'f']
}
def get_letter_strings(number_string):
if not number_string:
return
if len(number_string) == 1:
return digit_mapping[number_string[0]]
possible_strings = list()
current_letters = digit_mapping[number_string[0]]
strings_of_rem_nums = get_letter_strings(number_string[1:])
for letter in current_letters:
for string in strings_of_rem_nums:
possible_strings.append(letter + string)
return possible_strings
assert get_letter_strings("2") == [
'a', 'b', 'c']
assert get_letter_strings("23") == [
'ad', 'ae', 'af', 'bd', 'be', 'bf', 'cd', 'ce', 'cf']
assert get_letter_strings("32") == [
'da', 'db', 'dc', 'ea', 'eb', 'ec', 'fa', 'fb', 'fc']
| digit_mapping = {'2': ['a', 'b', 'c'], '3': ['d', 'e', 'f']}
def get_letter_strings(number_string):
if not number_string:
return
if len(number_string) == 1:
return digit_mapping[number_string[0]]
possible_strings = list()
current_letters = digit_mapping[number_string[0]]
strings_of_rem_nums = get_letter_strings(number_string[1:])
for letter in current_letters:
for string in strings_of_rem_nums:
possible_strings.append(letter + string)
return possible_strings
assert get_letter_strings('2') == ['a', 'b', 'c']
assert get_letter_strings('23') == ['ad', 'ae', 'af', 'bd', 'be', 'bf', 'cd', 'ce', 'cf']
assert get_letter_strings('32') == ['da', 'db', 'dc', 'ea', 'eb', 'ec', 'fa', 'fb', 'fc'] |
class Solution:
def minTaps(self, n: int, A: List[int]) -> int:
dp = [math.inf] * (n + 1)
for i in range(0, n + 1):
left = max(0, i - A[i])
use = (dp[left] + 1) if i - A[i] > 0 else 1
dp[i] = min(dp[i], use)
for j in range(i, min(i + A[i] + 1, n + 1)):
dp[j] = min(dp[j], use)
# print(dp)
return dp[-1] if dp[-1] != math.inf else -1
| class Solution:
def min_taps(self, n: int, A: List[int]) -> int:
dp = [math.inf] * (n + 1)
for i in range(0, n + 1):
left = max(0, i - A[i])
use = dp[left] + 1 if i - A[i] > 0 else 1
dp[i] = min(dp[i], use)
for j in range(i, min(i + A[i] + 1, n + 1)):
dp[j] = min(dp[j], use)
return dp[-1] if dp[-1] != math.inf else -1 |
def fibo_recur(n):
if n == 0:
return 0
if n == 1:
return 1
if n == 2:
return 1
return fibo_recur(n-1) + fibo_recur(n-2)
def fibo_dp(n, dp=dict()):
if n == 0:
return 0
if n == 1 or n == 2:
return 1
if n in dp:
return dp[n]
dp[n] = fibo_dp(n-1, dp) + fibo_dp(n-2, dp)
return dp[n]
a = int(input())
print(fibo_dp(a))
print(fibo_recur(a))
| def fibo_recur(n):
if n == 0:
return 0
if n == 1:
return 1
if n == 2:
return 1
return fibo_recur(n - 1) + fibo_recur(n - 2)
def fibo_dp(n, dp=dict()):
if n == 0:
return 0
if n == 1 or n == 2:
return 1
if n in dp:
return dp[n]
dp[n] = fibo_dp(n - 1, dp) + fibo_dp(n - 2, dp)
return dp[n]
a = int(input())
print(fibo_dp(a))
print(fibo_recur(a)) |
class Square:
def __init__(self, sideLength = 0):
self.sideLength = sideLength
def area_square(self):
return self.sideLength ** 2
def perimeter_square(self):
return self.sideLength * 4
class Triangle:
def __init__(self, base : float, height : float):
self.base = base
self.height = height
def area_triangle(self):
area = (self.base * self.height)/2
return area
def perimeter_square(self, hypotenuse = 0):
perimeter = (self.base * 2) + hypotenuse
return perimeter
if __name__ == '__main__':
triangle = Triangle(10, 5.5)
print('Triangle area: %f' % triangle.area_triangle())
print('Triangle perimeter: %f' %triangle.perimeter_square(10))
square = Square(10)
print('Square area: %f' % square.area_square())
print('Square perimeter: %f' % square.perimeter_square())
| class Square:
def __init__(self, sideLength=0):
self.sideLength = sideLength
def area_square(self):
return self.sideLength ** 2
def perimeter_square(self):
return self.sideLength * 4
class Triangle:
def __init__(self, base: float, height: float):
self.base = base
self.height = height
def area_triangle(self):
area = self.base * self.height / 2
return area
def perimeter_square(self, hypotenuse=0):
perimeter = self.base * 2 + hypotenuse
return perimeter
if __name__ == '__main__':
triangle = triangle(10, 5.5)
print('Triangle area: %f' % triangle.area_triangle())
print('Triangle perimeter: %f' % triangle.perimeter_square(10))
square = square(10)
print('Square area: %f' % square.area_square())
print('Square perimeter: %f' % square.perimeter_square()) |
#! /usr/bin/python3
def parse():
prev_data_S = "-1,-1,-1,-1,-1"
prev_none_vga_data = "0"
while(1):
f_read = open("temp.txt","r")
data = f_read.read()
f_read.close()
data_S = data.split('S')
if(len(data_S)>2):
none_vga_data = data_S[2].split('T')
while ( len(data_S)<=2 or data_S[2] == prev_data_S or (none_vga_data[0] == prev_none_vga_data and data_S[len(data_S)-1]=='0')):
f_read = open("temp.txt","r")
data = f_read.read()
f_read.close()
data_S = data.split('S')
temp_data = data_S[2].split(',')
prev_data = prev_data_S.split(',')
prev_none_vga_data = none_vga_data[0]
if(temp_data[0]!=prev_data[0]):
f_hex5_3 = open("hex5_3.txt","w")
f_hex5_3.write(temp_data[0])
f_hex5_3.close()
print ("update hex 5,4,3")
if(temp_data[1]!=prev_data[1]):
f_hex2_0 = open("hex2_0.txt","w")
f_hex2_0.write(temp_data[1])
f_hex2_0.close()
print ("update hex 2,1,0")
if(temp_data[2]!=prev_data[2]):
f_ledr = open("ledr.txt","w")
f_ledr.write(temp_data[2])
f_ledr.close()
print ("update ledr")
if(temp_data[5]!=prev_data[5]):
f_ledr = open("vga_user.txt","w")
f_ledr.write(temp_data[5])
f_ledr.close()
print ("update vga_user")
prev_data_S = data_S[2]
else:
print("Read error and app is parsing again")
def main():
parse()
if __name__=="__main__":
main() | def parse():
prev_data_s = '-1,-1,-1,-1,-1'
prev_none_vga_data = '0'
while 1:
f_read = open('temp.txt', 'r')
data = f_read.read()
f_read.close()
data_s = data.split('S')
if len(data_S) > 2:
none_vga_data = data_S[2].split('T')
while len(data_S) <= 2 or data_S[2] == prev_data_S or (none_vga_data[0] == prev_none_vga_data and data_S[len(data_S) - 1] == '0'):
f_read = open('temp.txt', 'r')
data = f_read.read()
f_read.close()
data_s = data.split('S')
temp_data = data_S[2].split(',')
prev_data = prev_data_S.split(',')
prev_none_vga_data = none_vga_data[0]
if temp_data[0] != prev_data[0]:
f_hex5_3 = open('hex5_3.txt', 'w')
f_hex5_3.write(temp_data[0])
f_hex5_3.close()
print('update hex 5,4,3')
if temp_data[1] != prev_data[1]:
f_hex2_0 = open('hex2_0.txt', 'w')
f_hex2_0.write(temp_data[1])
f_hex2_0.close()
print('update hex 2,1,0')
if temp_data[2] != prev_data[2]:
f_ledr = open('ledr.txt', 'w')
f_ledr.write(temp_data[2])
f_ledr.close()
print('update ledr')
if temp_data[5] != prev_data[5]:
f_ledr = open('vga_user.txt', 'w')
f_ledr.write(temp_data[5])
f_ledr.close()
print('update vga_user')
prev_data_s = data_S[2]
else:
print('Read error and app is parsing again')
def main():
parse()
if __name__ == '__main__':
main() |
class ResultKey:
"""
Key for storing and searching Metrics.
"""
def __init__(self, data_set_date, tags):
self.data_set_date = data_set_date
self.tags = tags
def __str__(self):
return "DataSetDate: {}\nTags: {}".format(self.data_set_date, self.tags)
def __eq__(self, other):
if self.data_set_date != other.data_set_date:
return False
if len(self.tags) != len(other.tags):
return False
for k, v in self.tags.items():
if (k not in other.tags) or (v != other.tags[k]):
return False
return True
def __hash__(self):
return hash((self.data_set_date, frozenset(self.tags.items())))
def to_json(self):
return {
"DataSetDate": self.data_set_date,
"Tags": self.tags
}
@staticmethod
def from_json(d):
return ResultKey(d["DataSetDate"], d["Tags"])
| class Resultkey:
"""
Key for storing and searching Metrics.
"""
def __init__(self, data_set_date, tags):
self.data_set_date = data_set_date
self.tags = tags
def __str__(self):
return 'DataSetDate: {}\nTags: {}'.format(self.data_set_date, self.tags)
def __eq__(self, other):
if self.data_set_date != other.data_set_date:
return False
if len(self.tags) != len(other.tags):
return False
for (k, v) in self.tags.items():
if k not in other.tags or v != other.tags[k]:
return False
return True
def __hash__(self):
return hash((self.data_set_date, frozenset(self.tags.items())))
def to_json(self):
return {'DataSetDate': self.data_set_date, 'Tags': self.tags}
@staticmethod
def from_json(d):
return result_key(d['DataSetDate'], d['Tags']) |
class color:
PURPLE = '\033[95m'
CYAN = '\033[96m'
DARKCYAN = '\033[36m'
BLUE = '\033[94m'
GREEN = '\033[92m'
YELLOW = '\033[93m'
RED = '\033[91m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
END = '\033[0m'
class DictList(dict):
def __setitem__(self, key, value):
try:
# Assumes there is a list on the key
self[key].append(value)
except KeyError: # If it fails, because there is no key
super(DictList, self).__setitem__(key, value)
except AttributeError: # If it fails because it is not a list
super(DictList, self).__setitem__(key, [self[key], value])
| class Color:
purple = '\x1b[95m'
cyan = '\x1b[96m'
darkcyan = '\x1b[36m'
blue = '\x1b[94m'
green = '\x1b[92m'
yellow = '\x1b[93m'
red = '\x1b[91m'
bold = '\x1b[1m'
underline = '\x1b[4m'
end = '\x1b[0m'
class Dictlist(dict):
def __setitem__(self, key, value):
try:
self[key].append(value)
except KeyError:
super(DictList, self).__setitem__(key, value)
except AttributeError:
super(DictList, self).__setitem__(key, [self[key], value]) |
"""
For strings S and T, we say "T divides S" if and only if S = T + ... + T (T concatenated with itself 1 or more times)
Return the largest string X such that X divides str1 and X divides str2.
Example 1:
Input: str1 = "ABCABC", str2 = "ABC"
Output: "ABC"
Example 2:
Input: str1 = "ABABAB", str2 = "ABAB"
Output: "AB"
Example 3:
Input: str1 = "LEET", str2 = "CODE"
Output: ""
Note:
1 <= str1.length <= 1000
1 <= str2.length <= 1000
str1[i] and str2[i] are English uppercase letters.
"""
class Solution:
def gcdOfStrings(self, str1: str, str2: str) -> str:
def gcd(a, b):
while b != 0:
a, b = b, a % b
return a
def made_of(s, part, c):
for i in range(0, len(s), c):
p = s[i:i + c]
if p != part:
return False
return True
if not str1 or not str2:
return ''
if len(str1) < len(str2):
str1, str2 = str2, str1
c = gcd(len(str1), len(str2))
if made_of(str1, str2[:c], c) and made_of(str2, str1[:c], c):
return str1[:c]
return ''
class Solution2:
def gcdOfStrings(self, str1, str2):
# Euclidean Algorithm
if len(str1) < len(str2):
str1, str2 = str2, str1
# now can assume len(str1) >= len(str2)
DIV = True
while DIV:
DIV = False
n, m = len(str1), len(str2)
while(str1[:m] == str2):
DIV = True
str1 = str1[m:]
if not str1: # divisible
return str2
else:
str1, str2 = str2, str1
return "" | """
For strings S and T, we say "T divides S" if and only if S = T + ... + T (T concatenated with itself 1 or more times)
Return the largest string X such that X divides str1 and X divides str2.
Example 1:
Input: str1 = "ABCABC", str2 = "ABC"
Output: "ABC"
Example 2:
Input: str1 = "ABABAB", str2 = "ABAB"
Output: "AB"
Example 3:
Input: str1 = "LEET", str2 = "CODE"
Output: ""
Note:
1 <= str1.length <= 1000
1 <= str2.length <= 1000
str1[i] and str2[i] are English uppercase letters.
"""
class Solution:
def gcd_of_strings(self, str1: str, str2: str) -> str:
def gcd(a, b):
while b != 0:
(a, b) = (b, a % b)
return a
def made_of(s, part, c):
for i in range(0, len(s), c):
p = s[i:i + c]
if p != part:
return False
return True
if not str1 or not str2:
return ''
if len(str1) < len(str2):
(str1, str2) = (str2, str1)
c = gcd(len(str1), len(str2))
if made_of(str1, str2[:c], c) and made_of(str2, str1[:c], c):
return str1[:c]
return ''
class Solution2:
def gcd_of_strings(self, str1, str2):
if len(str1) < len(str2):
(str1, str2) = (str2, str1)
div = True
while DIV:
div = False
(n, m) = (len(str1), len(str2))
while str1[:m] == str2:
div = True
str1 = str1[m:]
if not str1:
return str2
else:
(str1, str2) = (str2, str1)
return '' |
### Do something - what - print
### Data source? - what data is being printed?
### Output device? - where the data is being printed?
### I think these are rather good questions, it would be cool
### to specify these in the code
print("Hello, World!\nI'm Ante")
| print("Hello, World!\nI'm Ante") |
# -*- coding: utf-8 -*-
"""
dbmanage Library
~~~~~~~~~~~~~~~~
"""
| """
dbmanage Library
~~~~~~~~~~~~~~~~
""" |
input_size = 512
model = dict(
type='SingleStageDetector',
backbone=dict(
type='SSDVGG',
depth=16,
with_last_pool=False,
ceil_mode=True,
out_indices=(3, 4),
out_feature_indices=(22, 34),
init_cfg=dict(
type='Pretrained', checkpoint='open-mmlab://vgg16_caffe')),
neck=dict(
type='SSDNeck',
in_channels=(512, 1024),
out_channels=(512, 1024, 512, 256, 256, 256, 256),
level_strides=(2, 2, 2, 2, 1),
level_paddings=(1, 1, 1, 1, 1),
l2_norm_scale=20,
last_kernel_size=4),
bbox_head=dict(
type='SSDHead',
in_channels=(512, 1024, 512, 256, 256, 256, 256),
num_classes=80,
anchor_generator=dict(
type='SSDAnchorGenerator',
scale_major=False,
input_size=512,
basesize_ratio_range=(0.1, 0.9),
strides=[8, 16, 32, 64, 128, 256, 512],
ratios=[[2], [2, 3], [2, 3], [2, 3], [2, 3], [2], [2]]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[0.1, 0.1, 0.2, 0.2])),
train_cfg=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.5,
min_pos_iou=0.0,
ignore_iof_thr=-1,
gt_max_assign_all=False),
smoothl1_beta=1.0,
allowed_border=-1,
pos_weight=-1,
neg_pos_ratio=3,
debug=False),
test_cfg=dict(
nms_pre=1000,
nms=dict(type='nms', iou_threshold=0.45),
min_bbox_size=0,
score_thr=0.02,
max_per_img=200))
cudnn_benchmark = True
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile', to_float32=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PhotoMetricDistortion',
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18),
dict(
type='Expand',
mean=[123.675, 116.28, 103.53],
to_rgb=True,
ratio_range=(1, 4)),
dict(
type='MinIoURandomCrop',
min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=(512, 512), keep_ratio=False),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[1, 1, 1],
to_rgb=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
]
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=False),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[1, 1, 1],
to_rgb=True),
# dict(type='ImageToTensor', keys=['img']),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
]
data = dict(
samples_per_gpu=8,
workers_per_gpu=3,
train=dict(
type='RepeatDataset',
times=5,
dataset=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_train2017.json',
img_prefix='data/coco/train2017/',
pipeline=[
dict(type='LoadImageFromFile', to_float32=True),
dict(type='LoadAnnotations', with_bbox=True),
dict(
type='PhotoMetricDistortion',
brightness_delta=32,
contrast_range=(0.5, 1.5),
saturation_range=(0.5, 1.5),
hue_delta=18),
dict(
type='Expand',
mean=[123.675, 116.28, 103.53],
to_rgb=True,
ratio_range=(1, 4)),
dict(
type='MinIoURandomCrop',
min_ious=(0.1, 0.3, 0.5, 0.7, 0.9),
min_crop_size=0.3),
dict(type='Resize', img_scale=(512, 512), keep_ratio=False),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[1, 1, 1],
to_rgb=True),
dict(type='RandomFlip', flip_ratio=0.5),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])
])),
val=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=False),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[1, 1, 1],
to_rgb=True),
# dict(type='ImageToTensor', keys=['img']),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
]),
test=dict(
type='CocoDataset',
ann_file='data/coco/annotations/instances_val2017.json',
img_prefix='data/coco/val2017/',
pipeline=[
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(512, 512),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=False),
dict(
type='Normalize',
mean=[123.675, 116.28, 103.53],
std=[1, 1, 1],
to_rgb=True),
# dict(type='ImageToTensor', keys=['img']),
dict(type='DefaultFormatBundle'),
dict(type='Collect', keys=['img'])
])
]))
evaluation = dict(interval=1, metric='bbox')
optimizer = dict(type='SGD', lr=0.002, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=0.001,
step=[16, 22])
runner = dict(type='EpochBasedRunner', max_epochs=24)
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [
dict(type='NumClassCheckHook'),
dict(type='CheckInvalidLossHook', interval=50, priority='VERY_LOW')
]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
work_dir = './work_dirs'
gpu_ids = range(0, 1)
| input_size = 512
model = dict(type='SingleStageDetector', backbone=dict(type='SSDVGG', depth=16, with_last_pool=False, ceil_mode=True, out_indices=(3, 4), out_feature_indices=(22, 34), init_cfg=dict(type='Pretrained', checkpoint='open-mmlab://vgg16_caffe')), neck=dict(type='SSDNeck', in_channels=(512, 1024), out_channels=(512, 1024, 512, 256, 256, 256, 256), level_strides=(2, 2, 2, 2, 1), level_paddings=(1, 1, 1, 1, 1), l2_norm_scale=20, last_kernel_size=4), bbox_head=dict(type='SSDHead', in_channels=(512, 1024, 512, 256, 256, 256, 256), num_classes=80, anchor_generator=dict(type='SSDAnchorGenerator', scale_major=False, input_size=512, basesize_ratio_range=(0.1, 0.9), strides=[8, 16, 32, 64, 128, 256, 512], ratios=[[2], [2, 3], [2, 3], [2, 3], [2, 3], [2], [2]]), bbox_coder=dict(type='DeltaXYWHBBoxCoder', target_means=[0.0, 0.0, 0.0, 0.0], target_stds=[0.1, 0.1, 0.2, 0.2])), train_cfg=dict(assigner=dict(type='MaxIoUAssigner', pos_iou_thr=0.5, neg_iou_thr=0.5, min_pos_iou=0.0, ignore_iof_thr=-1, gt_max_assign_all=False), smoothl1_beta=1.0, allowed_border=-1, pos_weight=-1, neg_pos_ratio=3, debug=False), test_cfg=dict(nms_pre=1000, nms=dict(type='nms', iou_threshold=0.45), min_bbox_size=0, score_thr=0.02, max_per_img=200))
cudnn_benchmark = True
dataset_type = 'CocoDataset'
data_root = 'data/coco/'
img_norm_cfg = dict(mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True)
train_pipeline = [dict(type='LoadImageFromFile', to_float32=True), dict(type='LoadAnnotations', with_bbox=True), dict(type='PhotoMetricDistortion', brightness_delta=32, contrast_range=(0.5, 1.5), saturation_range=(0.5, 1.5), hue_delta=18), dict(type='Expand', mean=[123.675, 116.28, 103.53], to_rgb=True, ratio_range=(1, 4)), dict(type='MinIoURandomCrop', min_ious=(0.1, 0.3, 0.5, 0.7, 0.9), min_crop_size=0.3), dict(type='Resize', img_scale=(512, 512), keep_ratio=False), dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])]
test_pipeline = [dict(type='LoadImageFromFile'), dict(type='MultiScaleFlipAug', img_scale=(512, 512), flip=False, transforms=[dict(type='Resize', keep_ratio=False), dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img'])])]
data = dict(samples_per_gpu=8, workers_per_gpu=3, train=dict(type='RepeatDataset', times=5, dataset=dict(type='CocoDataset', ann_file='data/coco/annotations/instances_train2017.json', img_prefix='data/coco/train2017/', pipeline=[dict(type='LoadImageFromFile', to_float32=True), dict(type='LoadAnnotations', with_bbox=True), dict(type='PhotoMetricDistortion', brightness_delta=32, contrast_range=(0.5, 1.5), saturation_range=(0.5, 1.5), hue_delta=18), dict(type='Expand', mean=[123.675, 116.28, 103.53], to_rgb=True, ratio_range=(1, 4)), dict(type='MinIoURandomCrop', min_ious=(0.1, 0.3, 0.5, 0.7, 0.9), min_crop_size=0.3), dict(type='Resize', img_scale=(512, 512), keep_ratio=False), dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True), dict(type='RandomFlip', flip_ratio=0.5), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img', 'gt_bboxes', 'gt_labels'])])), val=dict(type='CocoDataset', ann_file='data/coco/annotations/instances_val2017.json', img_prefix='data/coco/val2017/', pipeline=[dict(type='LoadImageFromFile'), dict(type='MultiScaleFlipAug', img_scale=(512, 512), flip=False, transforms=[dict(type='Resize', keep_ratio=False), dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img'])])]), test=dict(type='CocoDataset', ann_file='data/coco/annotations/instances_val2017.json', img_prefix='data/coco/val2017/', pipeline=[dict(type='LoadImageFromFile'), dict(type='MultiScaleFlipAug', img_scale=(512, 512), flip=False, transforms=[dict(type='Resize', keep_ratio=False), dict(type='Normalize', mean=[123.675, 116.28, 103.53], std=[1, 1, 1], to_rgb=True), dict(type='DefaultFormatBundle'), dict(type='Collect', keys=['img'])])]))
evaluation = dict(interval=1, metric='bbox')
optimizer = dict(type='SGD', lr=0.002, momentum=0.9, weight_decay=0.0005)
optimizer_config = dict()
lr_config = dict(policy='step', warmup='linear', warmup_iters=500, warmup_ratio=0.001, step=[16, 22])
runner = dict(type='EpochBasedRunner', max_epochs=24)
checkpoint_config = dict(interval=1)
log_config = dict(interval=50, hooks=[dict(type='TextLoggerHook')])
custom_hooks = [dict(type='NumClassCheckHook'), dict(type='CheckInvalidLossHook', interval=50, priority='VERY_LOW')]
dist_params = dict(backend='nccl')
log_level = 'INFO'
load_from = None
resume_from = None
workflow = [('train', 1)]
work_dir = './work_dirs'
gpu_ids = range(0, 1) |
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
class NoSuchTableError(Exception):
"""Raised when a referenced table is not found"""
class NoSuchNamespaceError(Exception):
"""Raised when a referenced name-space is not found"""
class NamespaceNotEmptyError(Exception):
"""Raised when a name-space being dropped is not empty"""
class AlreadyExistsError(Exception):
"""Raised when a table or name-space being created already exists in the catalog"""
| class Nosuchtableerror(Exception):
"""Raised when a referenced table is not found"""
class Nosuchnamespaceerror(Exception):
"""Raised when a referenced name-space is not found"""
class Namespacenotemptyerror(Exception):
"""Raised when a name-space being dropped is not empty"""
class Alreadyexistserror(Exception):
"""Raised when a table or name-space being created already exists in the catalog""" |
def operation():
"""
:return: Returns a number between 1 and 5 that represents the four fundamental mathematical operations and exit.
"""
print("Choose an option:")
print("[1] Addition (+)")
print("[2] Subtraction (-)")
print("[3] Multiplication (*)")
print("[4] Division (/)")
print("[5] Exit")
while True:
try:
option = int(input("Enter the number of the operation: "))
while not 1 <= option <= 5:
option = int(input("[ERROR] Enter a number present among the options: "))
return option
except (TypeError, ValueError):
print("[ERROR] Your option has to be an integer")
print("Text-based calculator")
while True: # Loop for the first number
try:
tot = float(input("Enter a number: "))
break
except (TypeError, ValueError):
print("[ERROR] The value has to be an integer or a decimal number.")
while True: # Main loop
operator = operation()
if operator < 5: # Verifies whether the user wants
while True: # to exit or not
try:
number = float(input("Enter a number: "))
break
except (TypeError, ValueError):
print("[ERROR] The value has to be an integer or a decimal number")
if operator == 1: # Addition
tot += number
elif operator == 2: # Subtraction
tot -= number
elif operator == 3: # Multiplication
tot *= number
else: # Division
tot /= number
if tot == int(tot): # It is just to avoid writing
print(int(tot)) # integers as floats (e.g. 6.0
else: # instead of 6)
print(tot)
| def operation():
"""
:return: Returns a number between 1 and 5 that represents the four fundamental mathematical operations and exit.
"""
print('Choose an option:')
print('[1] Addition (+)')
print('[2] Subtraction (-)')
print('[3] Multiplication (*)')
print('[4] Division (/)')
print('[5] Exit')
while True:
try:
option = int(input('Enter the number of the operation: '))
while not 1 <= option <= 5:
option = int(input('[ERROR] Enter a number present among the options: '))
return option
except (TypeError, ValueError):
print('[ERROR] Your option has to be an integer')
print('Text-based calculator')
while True:
try:
tot = float(input('Enter a number: '))
break
except (TypeError, ValueError):
print('[ERROR] The value has to be an integer or a decimal number.')
while True:
operator = operation()
if operator < 5:
while True:
try:
number = float(input('Enter a number: '))
break
except (TypeError, ValueError):
print('[ERROR] The value has to be an integer or a decimal number')
if operator == 1:
tot += number
elif operator == 2:
tot -= number
elif operator == 3:
tot *= number
else:
tot /= number
if tot == int(tot):
print(int(tot))
else:
print(tot) |
'''
LEADERS OF AN ARRAY
The task is to find all leaders in an array, where
a leader is an array element which is greater than all the elements
on its right side
'''
print("Enter the size of array : ")
num = int(input())
a = []
print("Enter array elements")
for i in range(0, num):
a.append(int(input()))
maximum = a[num - 1]
print("The following are the leaders of array : ")
print(a[num - 1], " ", end = '')
for i in range(num - 2, -1, -1):
if (a[i] > maximum):
print(a[i], " ", end = '')
'''
Input : num = 5
Array = [13, 4, 12, 1, 5]
Output :
The following are the leaders of array :
5 12 13
'''
| """
LEADERS OF AN ARRAY
The task is to find all leaders in an array, where
a leader is an array element which is greater than all the elements
on its right side
"""
print('Enter the size of array : ')
num = int(input())
a = []
print('Enter array elements')
for i in range(0, num):
a.append(int(input()))
maximum = a[num - 1]
print('The following are the leaders of array : ')
print(a[num - 1], ' ', end='')
for i in range(num - 2, -1, -1):
if a[i] > maximum:
print(a[i], ' ', end='')
'\nInput : num = 5\n Array = [13, 4, 12, 1, 5]\nOutput :\n The following are the leaders of array : \n 5 12 13\n' |
# |---------------------|
# <module> | |
# |---------------------|
#
# |---------------------|
# print_n | s--->'Hello' n--->2 | |
# |---------------------|
#
# |---------------------|
# print_n | s--->'Hello' n--->1 | |
# |---------------------|
def print_n(s, n):
if n <= 0:
return
print(s)
print_n(s, n-1)
print_n('Hello', 2)
| def print_n(s, n):
if n <= 0:
return
print(s)
print_n(s, n - 1)
print_n('Hello', 2) |
num_waves = 3
num_eqn = 3
# Conserved quantities
pressure = 0
x_velocity = 1
y_velocity = 2
| num_waves = 3
num_eqn = 3
pressure = 0
x_velocity = 1
y_velocity = 2 |
class RangeQuery:
def __init__(self, data, func=min):
self.func = func
self._data = _data = [list(data)]
i, n = 1, len(_data[0])
while 2 * i <= n:
prev = _data[-1]
_data.append([func(prev[j], prev[j + i]) for j in range(n - 2 * i + 1)])
i <<= 1
def query(self, begin, end):
depth = (end - begin).bit_length() - 1
return self.func(self._data[depth][begin], self._data[depth][end - (1 << depth)])
class LCA:
def __init__(self, root, graph):
self.time = [-1] * len(graph)
self.path = [-1] * len(graph)
P = [-1] * len(graph)
t = -1
dfs = [root]
while dfs:
node = dfs.pop()
self.path[t] = P[node]
self.time[node] = t = t + 1
for nei in graph[node]:
if self.time[nei] == -1:
P[nei] = node
dfs.append(nei)
self.rmq = RangeQuery(self.time[node] for node in self.path)
def __call__(self, a, b):
if a == b:
return a
a = self.time[a]
b = self.time[b]
if a > b:
a, b = b, a
return self.path[self.rmq.query(a, b)]
| class Rangequery:
def __init__(self, data, func=min):
self.func = func
self._data = _data = [list(data)]
(i, n) = (1, len(_data[0]))
while 2 * i <= n:
prev = _data[-1]
_data.append([func(prev[j], prev[j + i]) for j in range(n - 2 * i + 1)])
i <<= 1
def query(self, begin, end):
depth = (end - begin).bit_length() - 1
return self.func(self._data[depth][begin], self._data[depth][end - (1 << depth)])
class Lca:
def __init__(self, root, graph):
self.time = [-1] * len(graph)
self.path = [-1] * len(graph)
p = [-1] * len(graph)
t = -1
dfs = [root]
while dfs:
node = dfs.pop()
self.path[t] = P[node]
self.time[node] = t = t + 1
for nei in graph[node]:
if self.time[nei] == -1:
P[nei] = node
dfs.append(nei)
self.rmq = range_query((self.time[node] for node in self.path))
def __call__(self, a, b):
if a == b:
return a
a = self.time[a]
b = self.time[b]
if a > b:
(a, b) = (b, a)
return self.path[self.rmq.query(a, b)] |
# Source and destination file names.
test_source = "compact_lists.txt"
test_destination = "compact_lists.html"
# Keyword parameters passed to publish_file.
reader_name = "standalone"
parser_name = "rst"
writer_name = "html"
# Settings
# local copy of stylesheets:
# (Test runs in ``docutils/test/``, we need relative path from there.)
settings_overrides['stylesheet_dirs'] = ('.', 'functional/input/data')
| test_source = 'compact_lists.txt'
test_destination = 'compact_lists.html'
reader_name = 'standalone'
parser_name = 'rst'
writer_name = 'html'
settings_overrides['stylesheet_dirs'] = ('.', 'functional/input/data') |
#!/usr/bin/env python
dic = {'nome': 'Shirley Manson', 'banda': 'Garbage'}
print(dic['nome'])
del dic
dic = {'Yes': ['Close To The Edge', 'Fragile'],
'Genesis': ['Foxtrot', 'The Nursery Crime'],
'ELP': ['Brain Salad Surgery']}
print(dic['Yes'])
| dic = {'nome': 'Shirley Manson', 'banda': 'Garbage'}
print(dic['nome'])
del dic
dic = {'Yes': ['Close To The Edge', 'Fragile'], 'Genesis': ['Foxtrot', 'The Nursery Crime'], 'ELP': ['Brain Salad Surgery']}
print(dic['Yes']) |
#!/usr/bin/env python3
"""Configuration of builddataset."""
buildcfg = {}
# === Selection requirements === #
# Minimum clear pixel coverage in the constructed Source Mask
# Note: Due to water vapour, most rivers and lakes will be marked as not clear
buildcfg['min_clearance'] = 0.75
# Minimum number of LR images per set
# Note: SR requires at the very minimum n^2 LR images, where n is scale factor
buildcfg['nmin'] = 12
# === File and Folder names === #
buildcfg['normfilename'] = 'norm' # Name of the file containing the norm
buildcfg['HRname'] = 'HR' # Name of HR files
buildcfg['scoremaskname'] = 'SM' # Name of the score mask file
buildcfg['sources'] = 'sources.txt' # File name of list of source files
buildcfg['dirvalidate'] = 'validate' # Folder name of validation HRs
buildcfg['dirsubtest'] = 'submission-test' # Name of submission test folder
buildcfg['SRname'] = 'SR' # Name of SR submission-test files
buildcfg['subtestnoise'] = 1000 # standard dev of noise of sub test
| """Configuration of builddataset."""
buildcfg = {}
buildcfg['min_clearance'] = 0.75
buildcfg['nmin'] = 12
buildcfg['normfilename'] = 'norm'
buildcfg['HRname'] = 'HR'
buildcfg['scoremaskname'] = 'SM'
buildcfg['sources'] = 'sources.txt'
buildcfg['dirvalidate'] = 'validate'
buildcfg['dirsubtest'] = 'submission-test'
buildcfg['SRname'] = 'SR'
buildcfg['subtestnoise'] = 1000 |
class DictHelper:
@staticmethod
def split_path(path):
if isinstance(path, str):
path = path.split(" ")
elif isinstance(path, int):
path = str(path)
filename, *rpath = path
return (filename, rpath)
@staticmethod
def get_dict_by_path(dict_var, path):
head, *tail = path
if tail:
try:
return DictHelper.get_dict_by_path(dict_var[head], tail)
except TypeError:
try:
return DictHelper.get_dict_by_path(dict_var[int(head)], tail)
except ValueError:
raise KeyError("Could not get "+str(path)+" in "+str(dict_var))
else:
return dict_var
@staticmethod
def get_value_by_path(var, path):
head, *tail = path
if tail:
try:
return DictHelper.get_value_by_path(var[head], tail)
except TypeError:
try:
return DictHelper.get_value_by_path(var[int(head)], tail)
except ValueError:
raise KeyError("Could not get "+str(path)+" in "+str(var))
else:
try:
return var[head]
except TypeError:
try:
return var[int(head)]
except ValueError:
raise KeyError("Could not get "+str(path)+" in "+str(var))
| class Dicthelper:
@staticmethod
def split_path(path):
if isinstance(path, str):
path = path.split(' ')
elif isinstance(path, int):
path = str(path)
(filename, *rpath) = path
return (filename, rpath)
@staticmethod
def get_dict_by_path(dict_var, path):
(head, *tail) = path
if tail:
try:
return DictHelper.get_dict_by_path(dict_var[head], tail)
except TypeError:
try:
return DictHelper.get_dict_by_path(dict_var[int(head)], tail)
except ValueError:
raise key_error('Could not get ' + str(path) + ' in ' + str(dict_var))
else:
return dict_var
@staticmethod
def get_value_by_path(var, path):
(head, *tail) = path
if tail:
try:
return DictHelper.get_value_by_path(var[head], tail)
except TypeError:
try:
return DictHelper.get_value_by_path(var[int(head)], tail)
except ValueError:
raise key_error('Could not get ' + str(path) + ' in ' + str(var))
else:
try:
return var[head]
except TypeError:
try:
return var[int(head)]
except ValueError:
raise key_error('Could not get ' + str(path) + ' in ' + str(var)) |
"""Support ODT formatting.
Part of the PyWriter project.
Copyright (c) 2020 Peter Triesberger
For further information see https://github.com/peter88213/PyWriter
Published under the MIT License (https://opensource.org/licenses/mit-license.php)
"""
def to_odt(text):
"""Convert yw7 raw markup to odt. Return an xml string."""
try:
# process italics and bold markup reaching across linebreaks
italics = False
bold = False
newlines = []
lines = text.split('\n')
for line in lines:
if italics:
line = '[i]' + line
italics = False
while line.count('[i]') > line.count('[/i]'):
line += '[/i]'
italics = True
while line.count('[/i]') > line.count('[i]'):
line = '[i]' + line
line = line.replace('[i][/i]', '')
if bold:
line = '[b]' + line
bold = False
while line.count('[b]') > line.count('[/b]'):
line += '[/b]'
bold = True
while line.count('[/b]') > line.count('[b]'):
line = '[b]' + line
line = line.replace('[b][/b]', '')
newlines.append(line)
text = '\n'.join(newlines)
text = text.replace('&', '&')
text = text.replace('>', '>')
text = text.replace('<', '<')
text = text.rstrip().replace(
'\n', '</text:p>\n<text:p text:style-name="First_20_line_20_indent">')
text = text.replace(
'[i]', '<text:span text:style-name="Emphasis">')
text = text.replace('[/i]', '</text:span>')
text = text.replace(
'[b]', '<text:span text:style-name="Strong_20_Emphasis">')
text = text.replace('[/b]', '</text:span>')
except:
pass
return text
if __name__ == '__main__':
pass
| """Support ODT formatting.
Part of the PyWriter project.
Copyright (c) 2020 Peter Triesberger
For further information see https://github.com/peter88213/PyWriter
Published under the MIT License (https://opensource.org/licenses/mit-license.php)
"""
def to_odt(text):
"""Convert yw7 raw markup to odt. Return an xml string."""
try:
italics = False
bold = False
newlines = []
lines = text.split('\n')
for line in lines:
if italics:
line = '[i]' + line
italics = False
while line.count('[i]') > line.count('[/i]'):
line += '[/i]'
italics = True
while line.count('[/i]') > line.count('[i]'):
line = '[i]' + line
line = line.replace('[i][/i]', '')
if bold:
line = '[b]' + line
bold = False
while line.count('[b]') > line.count('[/b]'):
line += '[/b]'
bold = True
while line.count('[/b]') > line.count('[b]'):
line = '[b]' + line
line = line.replace('[b][/b]', '')
newlines.append(line)
text = '\n'.join(newlines)
text = text.replace('&', '&')
text = text.replace('>', '>')
text = text.replace('<', '<')
text = text.rstrip().replace('\n', '</text:p>\n<text:p text:style-name="First_20_line_20_indent">')
text = text.replace('[i]', '<text:span text:style-name="Emphasis">')
text = text.replace('[/i]', '</text:span>')
text = text.replace('[b]', '<text:span text:style-name="Strong_20_Emphasis">')
text = text.replace('[/b]', '</text:span>')
except:
pass
return text
if __name__ == '__main__':
pass |
'''
A program for warshall algorithm.It is a shortest path algorithm which is used to find the
distance from source node,which is the first node,to all the other nodes.
If there is no direct distance between two vertices then it is considered as -1
'''
def warshall(g,ver):
dist = list(map(lambda i: list(map(lambda j: j, i)), g))
for i in range(0,ver):
for j in range(0,ver):
dist[i][j] = g[i][j]
#Finding the shortest distance if found
for k in range(0,ver):
for i in range(0,ver):
for j in range(0,ver):
if dist[i][k] + dist[k][j] < dist[i][j] and dist[i][k]!=-1 and dist[k][j]!=-1:
dist[i][j] = dist[i][k] + dist[k][j]
#Prnting the complete short distance matrix
print("the distance matrix is")
for i in range(0,ver):
for j in range(0,ver):
if dist[i][j]>=0:
print(dist[i][j],end=" ")
else:
print(-1,end=" ")
print("\n")
#Driver's code
def main():
print("Enter number of vertices\n")
ver=int(input())
graph=[]
#Creating the distance matrix graph
print("Enter the distance matrix")
for i in range(ver):
a =[]
for j in range(ver):
a.append(int(input()))
graph.append(a)
warshall(graph,ver)
if __name__=="__main__":
main()
'''
Time Complexity:O(ver^3)
Space Complexity:O(ver^2)
Input/Output:
Enter number of vertices
4
Enter the graph
0
8
-1
1
-1
0
1
-1
4
-1
0
-1
-1
2
9
0
The distance matrix is
0 3 -1 1
-1 0 1 -1
4 -1 0 -1
-1 2 3 0
'''
| """
A program for warshall algorithm.It is a shortest path algorithm which is used to find the
distance from source node,which is the first node,to all the other nodes.
If there is no direct distance between two vertices then it is considered as -1
"""
def warshall(g, ver):
dist = list(map(lambda i: list(map(lambda j: j, i)), g))
for i in range(0, ver):
for j in range(0, ver):
dist[i][j] = g[i][j]
for k in range(0, ver):
for i in range(0, ver):
for j in range(0, ver):
if dist[i][k] + dist[k][j] < dist[i][j] and dist[i][k] != -1 and (dist[k][j] != -1):
dist[i][j] = dist[i][k] + dist[k][j]
print('the distance matrix is')
for i in range(0, ver):
for j in range(0, ver):
if dist[i][j] >= 0:
print(dist[i][j], end=' ')
else:
print(-1, end=' ')
print('\n')
def main():
print('Enter number of vertices\n')
ver = int(input())
graph = []
print('Enter the distance matrix')
for i in range(ver):
a = []
for j in range(ver):
a.append(int(input()))
graph.append(a)
warshall(graph, ver)
if __name__ == '__main__':
main()
'\nTime Complexity:O(ver^3)\nSpace Complexity:O(ver^2)\n\nInput/Output:\nEnter number of vertices \n4\nEnter the graph\n0\n8\n-1\n1\n-1\n0\n1\n-1\n4\n-1\n0\n-1\n-1\n2\n9\n0\nThe distance matrix is\n0 3 -1 1 \n-1 0 1 -1 \n4 -1 0 -1 \n-1 2 3 0 \n' |
class Solution:
"""
@param S: A set of numbers.
@return: A list of lists. All valid subsets.
"""
def subsetsWithDup(self, S):
# write your code here
# Revursive
if (not S):
return [[]]
S = sorted(S)
tmp = self.subsetsWithDup(S[:-1])
locked = True
res = [] + tmp
count = 0
for i in S[:-1]:
if (i == S[-1]):
count += 1
for i in tmp:
if ([S[-1]] * count == i):
locked = False
if (not locked):
res.append(i + [S[-1]])
return res
# Iterative
# res = [[]]
# S = sorted(S)
# for index, v in enumerate(S):
# locked = True
# count = 0
# for j in S[:index]:
# if (j == v):
# count += 1
# tmp = []
# for a in res:
# if ([v]*count == a):
# locked = False
# if (not locked):
# tmp.append(a + [v])
# res += tmp
# return res
| class Solution:
"""
@param S: A set of numbers.
@return: A list of lists. All valid subsets.
"""
def subsets_with_dup(self, S):
if not S:
return [[]]
s = sorted(S)
tmp = self.subsetsWithDup(S[:-1])
locked = True
res = [] + tmp
count = 0
for i in S[:-1]:
if i == S[-1]:
count += 1
for i in tmp:
if [S[-1]] * count == i:
locked = False
if not locked:
res.append(i + [S[-1]])
return res |
#-------------------------------------------------------------------------------
# importation
#-------------------------------------------------------------------------------
# Main class Ml_tools
class ml_tools:
def __init__(self):
pass | class Ml_Tools:
def __init__(self):
pass |
text = " I love apples very much "
# The number of characters in the text
text_size = len(text)
# Initialize a pointer to the position of the first character of 'text'
pos = 0
# This is a flag to indicate whether the character we are comparing
# to is a white space or not
is_space = text[0].isspace()
# Start tokenization
for i, char in enumerate(text):
# We are looking for a character that is the opposit of 'is_space'
# if 'is_space' is True, then we want to find a character that is
# not a space. and vice versa. This event marks the end of a token.
is_current_space = char.isspace()
if is_current_space != is_space:
print(text[pos:i])
if is_current_space:
pos = i + 1
else:
pos = i
# Update the character type of which we are searching
# the opposite (space vs. not space).
# prevent 'pos' from being out of bound
if pos < text_size:
is_space = text[pos].isspace()
# Create the last token if the end of the string is reached
if i == text_size - 1 and pos <= i:
print(text[pos:])
| text = ' I love apples very much '
text_size = len(text)
pos = 0
is_space = text[0].isspace()
for (i, char) in enumerate(text):
is_current_space = char.isspace()
if is_current_space != is_space:
print(text[pos:i])
if is_current_space:
pos = i + 1
else:
pos = i
if pos < text_size:
is_space = text[pos].isspace()
if i == text_size - 1 and pos <= i:
print(text[pos:]) |
"""Issue.
"""
class Issue:
"""Issue.
Issue must not contain subelements and attributes.
@see RPCBase._parse_issue(element)
:param creator: element.attrib["creator"]
:param value: element.text
"""
def __init__(self, creator=None, value=None):
self.creator = creator
self.value = value
| """Issue.
"""
class Issue:
"""Issue.
Issue must not contain subelements and attributes.
@see RPCBase._parse_issue(element)
:param creator: element.attrib["creator"]
:param value: element.text
"""
def __init__(self, creator=None, value=None):
self.creator = creator
self.value = value |
# PyJS does not support weak references,
# so this module provides stubs with usual references
typecls = __builtins__.TypeClass
class ReferenceType(typecls):
pass
class CallableProxyType(typecls):
pass
class ProxyType(typecls):
pass
ProxyTypes = (ProxyType, CallableProxyType)
WeakValueDictionary = dict
WeakKeyDictionary = dict
| typecls = __builtins__.TypeClass
class Referencetype(typecls):
pass
class Callableproxytype(typecls):
pass
class Proxytype(typecls):
pass
proxy_types = (ProxyType, CallableProxyType)
weak_value_dictionary = dict
weak_key_dictionary = dict |
#
# PySNMP MIB module TCP-ESTATS-MIB (http://pysnmp.sf.net)
# ASN.1 source http://mibs.snmplabs.com:80/asn1/TCP-ESTATS-MIB
# Produced by pysmi-0.0.7 at Sun Feb 14 00:31:06 2016
# On host bldfarm platform Linux version 4.1.13-100.fc21.x86_64 by user goose
# Using Python version 3.5.0 (default, Jan 5 2016, 17:11:52)
#
( Integer, ObjectIdentifier, OctetString, ) = mibBuilder.importSymbols("ASN1", "Integer", "ObjectIdentifier", "OctetString")
( NamedValues, ) = mibBuilder.importSymbols("ASN1-ENUMERATION", "NamedValues")
( ValueRangeConstraint, ValueSizeConstraint, ConstraintsUnion, ConstraintsIntersection, SingleValueConstraint, ) = mibBuilder.importSymbols("ASN1-REFINEMENT", "ValueRangeConstraint", "ValueSizeConstraint", "ConstraintsUnion", "ConstraintsIntersection", "SingleValueConstraint")
( ZeroBasedCounter64, ) = mibBuilder.importSymbols("HCNUM-TC", "ZeroBasedCounter64")
( ZeroBasedCounter32, ) = mibBuilder.importSymbols("RMON2-MIB", "ZeroBasedCounter32")
( ModuleCompliance, ObjectGroup, NotificationGroup, ) = mibBuilder.importSymbols("SNMPv2-CONF", "ModuleCompliance", "ObjectGroup", "NotificationGroup")
( MibScalar, MibTable, MibTableRow, MibTableColumn, MibIdentifier, mib_2, Integer32, ModuleIdentity, IpAddress, Bits, ObjectIdentity, iso, NotificationType, Gauge32, Counter64, Counter32, Unsigned32, TimeTicks, ) = mibBuilder.importSymbols("SNMPv2-SMI", "MibScalar", "MibTable", "MibTableRow", "MibTableColumn", "MibIdentifier", "mib-2", "Integer32", "ModuleIdentity", "IpAddress", "Bits", "ObjectIdentity", "iso", "NotificationType", "Gauge32", "Counter64", "Counter32", "Unsigned32", "TimeTicks")
( DateAndTime, TextualConvention, TimeStamp, DisplayString, TruthValue, ) = mibBuilder.importSymbols("SNMPv2-TC", "DateAndTime", "TextualConvention", "TimeStamp", "DisplayString", "TruthValue")
( tcpListenerEntry, tcpConnectionEntry, ) = mibBuilder.importSymbols("TCP-MIB", "tcpListenerEntry", "tcpConnectionEntry")
tcpEStatsMIB = ModuleIdentity((1, 3, 6, 1, 2, 1, 156)).setRevisions(("2007-05-18 00:00",))
if mibBuilder.loadTexts: tcpEStatsMIB.setLastUpdated('200705180000Z')
if mibBuilder.loadTexts: tcpEStatsMIB.setOrganization('IETF TSV Working Group')
if mibBuilder.loadTexts: tcpEStatsMIB.setContactInfo('Matt Mathis\n John Heffner\n Web100 Project\n Pittsburgh Supercomputing Center\n 300 S. Craig St.\n Pittsburgh, PA 15213\n Email: mathis@psc.edu, jheffner@psc.edu\n\n Rajiv Raghunarayan\n Cisco Systems Inc.\n San Jose, CA 95134\n Phone: 408 853 9612\n Email: raraghun@cisco.com\n\n Jon Saperia\n 84 Kettell Plain Road\n Stow, MA 01775\n Phone: 617-201-2655\n Email: saperia@jdscons.com ')
if mibBuilder.loadTexts: tcpEStatsMIB.setDescription('Documentation of TCP Extended Performance Instrumentation\n variables from the Web100 project. [Web100]\n\n All of the objects in this MIB MUST have the same\n persistence properties as the underlying TCP implementation.\n On a reboot, all zero-based counters MUST be cleared, all\n dynamically created table rows MUST be deleted, and all\n read-write objects MUST be restored to their default values.\n\n It is assumed that all TCP implementation have some\n initialization code (if nothing else to set IP addresses)\n that has the opportunity to adjust tcpEStatsConnTableLatency\n and other read-write scalars controlling the creation of the\n various tables, before establishing the first TCP\n connection. Implementations MAY also choose to make these\n control scalars persist across reboots.\n\n Copyright (C) The IETF Trust (2007). This version\n of this MIB module is a part of RFC 4898; see the RFC\n itself for full legal notices.')
tcpEStatsNotifications = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 0))
tcpEStatsMIBObjects = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 1))
tcpEStatsConformance = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 2))
tcpEStats = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 1, 1))
tcpEStatsControl = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 1, 2))
tcpEStatsScalar = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 1, 3))
class TcpEStatsNegotiated(Integer32, TextualConvention):
subtypeSpec = Integer32.subtypeSpec+ConstraintsUnion(SingleValueConstraint(1, 2, 3,))
namedValues = NamedValues(("enabled", 1), ("selfDisabled", 2), ("peerDisabled", 3),)
tcpEStatsListenerTableLastChange = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 3, 3), TimeStamp()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerTableLastChange.setDescription('The value of sysUpTime at the time of the last\n creation or deletion of an entry in the tcpListenerTable.\n If the number of entries has been unchanged since the\n last re-initialization of the local network management\n subsystem, then this object contains a zero value.')
tcpEStatsControlPath = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 1), TruthValue().clone('false')).setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsControlPath.setDescription("Controls the activation of the TCP Path Statistics\n table.\n\n A value 'true' indicates that the TCP Path Statistics\n table is active, while 'false' indicates that the\n table is inactive.")
tcpEStatsControlStack = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 2), TruthValue().clone('false')).setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsControlStack.setDescription("Controls the activation of the TCP Stack Statistics\n table.\n\n A value 'true' indicates that the TCP Stack Statistics\n table is active, while 'false' indicates that the\n table is inactive.")
tcpEStatsControlApp = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 3), TruthValue().clone('false')).setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsControlApp.setDescription("Controls the activation of the TCP Application\n Statistics table.\n\n A value 'true' indicates that the TCP Application\n Statistics table is active, while 'false' indicates\n that the table is inactive.")
tcpEStatsControlTune = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 4), TruthValue().clone('false')).setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsControlTune.setDescription("Controls the activation of the TCP Tuning table.\n\n A value 'true' indicates that the TCP Tuning\n table is active, while 'false' indicates that the\n table is inactive.")
tcpEStatsControlNotify = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 5), TruthValue().clone('false')).setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsControlNotify.setDescription("Controls the generation of all notifications defined in\n this MIB.\n\n A value 'true' indicates that the notifications\n are active, while 'false' indicates that the\n notifications are inactive.")
tcpEStatsConnTableLatency = MibScalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 6), Unsigned32()).setUnits('seconds').setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsConnTableLatency.setDescription('Specifies the number of seconds that the entity will\n retain entries in the TCP connection tables, after the\n connection first enters the closed state. The entity\n SHOULD provide a configuration option to enable\n\n\n\n customization of this value. A value of 0\n results in entries being removed from the tables as soon as\n the connection enters the closed state. The value of\n this object pertains to the following tables:\n tcpEStatsConnectIdTable\n tcpEStatsPerfTable\n tcpEStatsPathTable\n tcpEStatsStackTable\n tcpEStatsAppTable\n tcpEStatsTuneTable')
tcpEStatsListenerTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 1), )
if mibBuilder.loadTexts: tcpEStatsListenerTable.setDescription('This table contains information about TCP Listeners,\n in addition to the information maintained by the\n tcpListenerTable RFC 4022.')
tcpEStatsListenerEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1), )
tcpListenerEntry.registerAugmentions(("TCP-ESTATS-MIB", "tcpEStatsListenerEntry"))
tcpEStatsListenerEntry.setIndexNames(*tcpListenerEntry.getIndexNames())
if mibBuilder.loadTexts: tcpEStatsListenerEntry.setDescription('Each entry in the table contains information about\n a specific TCP Listener.')
tcpEStatsListenerStartTime = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 1), TimeStamp()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerStartTime.setDescription('The value of sysUpTime at the time this listener was\n established. If the current state was entered prior to\n the last re-initialization of the local network management\n subsystem, then this object contains a zero value.')
tcpEStatsListenerSynRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 2), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerSynRcvd.setDescription('The number of SYNs which have been received for this\n listener. The total number of failed connections for\n all reasons can be estimated to be tcpEStatsListenerSynRcvd\n minus tcpEStatsListenerAccepted and\n tcpEStatsListenerCurBacklog.')
tcpEStatsListenerInitial = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 3), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerInitial.setDescription('The total number of connections for which the Listener\n has allocated initial state and placed the\n connection in the backlog. This may happen in the\n SYN-RCVD or ESTABLISHED states, depending on the\n implementation.')
tcpEStatsListenerEstablished = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 4), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerEstablished.setDescription('The number of connections that have been established to\n this endpoint (e.g., the number of first ACKs that have\n been received for this listener).')
tcpEStatsListenerAccepted = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 5), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerAccepted.setDescription('The total number of connections for which the Listener\n has successfully issued an accept, removing the connection\n from the backlog.')
tcpEStatsListenerExceedBacklog = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 6), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerExceedBacklog.setDescription('The total number of connections dropped from the\n backlog by this listener due to all reasons. This\n includes all connections that are allocated initial\n resources, but are not accepted for some reason.')
tcpEStatsListenerHCSynRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 7), ZeroBasedCounter64()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerHCSynRcvd.setDescription('The number of SYNs that have been received for this\n listener on systems that can process (or reject) more\n than 1 million connections per second. See\n tcpEStatsListenerSynRcvd.')
tcpEStatsListenerHCInitial = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 8), ZeroBasedCounter64()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerHCInitial.setDescription('The total number of connections for which the Listener\n has allocated initial state and placed the connection\n in the backlog on systems that can process (or reject)\n more than 1 million connections per second. See\n tcpEStatsListenerInitial.')
tcpEStatsListenerHCEstablished = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 9), ZeroBasedCounter64()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerHCEstablished.setDescription('The number of connections that have been established to\n this endpoint on systems that can process (or reject) more\n than 1 million connections per second. See\n tcpEStatsListenerEstablished.')
tcpEStatsListenerHCAccepted = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 10), ZeroBasedCounter64()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerHCAccepted.setDescription('The total number of connections for which the Listener\n has successfully issued an accept, removing the connection\n from the backlog on systems that can process (or reject)\n more than 1 million connections per second. See\n tcpEStatsListenerAccepted.')
tcpEStatsListenerHCExceedBacklog = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 11), ZeroBasedCounter64()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerHCExceedBacklog.setDescription('The total number of connections dropped from the\n backlog by this listener due to all reasons on\n systems that can process (or reject) more than\n 1 million connections per second. See\n tcpEStatsListenerExceedBacklog.')
tcpEStatsListenerCurConns = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 12), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerCurConns.setDescription('The current number of connections in the ESTABLISHED\n state, which have also been accepted. It excludes\n connections that have been established but not accepted\n because they are still subject to being discarded to\n shed load without explicit action by either endpoint.')
tcpEStatsListenerMaxBacklog = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 13), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerMaxBacklog.setDescription('The maximum number of connections allowed in the\n backlog at one time.')
tcpEStatsListenerCurBacklog = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 14), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerCurBacklog.setDescription('The current number of connections that are in the backlog.\n This gauge includes connections in ESTABLISHED or\n SYN-RECEIVED states for which the Listener has not yet\n issued an accept.\n\n If this listener is using some technique to implicitly\n represent the SYN-RECEIVED states (e.g., by\n cryptographically encoding the state information in the\n initial sequence number, ISS), it MAY elect to exclude\n connections in the SYN-RECEIVED state from the backlog.')
tcpEStatsListenerCurEstabBacklog = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 15), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsListenerCurEstabBacklog.setDescription('The current number of connections in the backlog that are\n in the ESTABLISHED state, but for which the Listener has\n not yet issued an accept.')
tcpEStatsConnectIdTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 2), )
if mibBuilder.loadTexts: tcpEStatsConnectIdTable.setDescription('This table maps information that uniquely identifies\n each active TCP connection to the connection ID used by\n\n\n\n other tables in this MIB Module. It is an extension of\n tcpConnectionTable in RFC 4022.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcpEStatsConnectIdEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 2, 1), )
tcpConnectionEntry.registerAugmentions(("TCP-ESTATS-MIB", "tcpEStatsConnectIdEntry"))
tcpEStatsConnectIdEntry.setIndexNames(*tcpConnectionEntry.getIndexNames())
if mibBuilder.loadTexts: tcpEStatsConnectIdEntry.setDescription('Each entry in this table maps a TCP connection\n 4-tuple to a connection index.')
tcpEStatsConnectIndex = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 2, 1, 1), Unsigned32().subtype(subtypeSpec=ValueRangeConstraint(1,4294967295))).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsConnectIndex.setDescription('A unique integer value assigned to each TCP Connection\n entry.\n\n The RECOMMENDED algorithm is to begin at 1 and increase to\n some implementation-specific maximum value and then start\n again at 1 skipping values already in use.')
tcpEStatsPerfTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 3), )
if mibBuilder.loadTexts: tcpEStatsPerfTable.setDescription('This table contains objects that are useful for\n\n\n\n measuring TCP performance and first line problem\n diagnosis. Most objects in this table directly expose\n some TCP state variable or are easily implemented as\n simple functions (e.g., the maximum value) of TCP\n state variables.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcpEStatsPerfEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1), ).setIndexNames((0, "TCP-ESTATS-MIB", "tcpEStatsConnectIndex"))
if mibBuilder.loadTexts: tcpEStatsPerfEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcpEStatsPerfSegsOut = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 1), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSegsOut.setDescription('The total number of segments sent.')
tcpEStatsPerfDataSegsOut = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 2), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfDataSegsOut.setDescription('The number of segments sent containing a positive length\n data segment.')
tcpEStatsPerfDataOctetsOut = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 3), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfDataOctetsOut.setDescription('The number of octets of data contained in transmitted\n segments, including retransmitted data. Note that this does\n not include TCP headers.')
tcpEStatsPerfHCDataOctetsOut = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 4), ZeroBasedCounter64()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfHCDataOctetsOut.setDescription('The number of octets of data contained in transmitted\n segments, including retransmitted data, on systems that can\n transmit more than 10 million bits per second. Note that\n this does not include TCP headers.')
tcpEStatsPerfSegsRetrans = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 5), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSegsRetrans.setDescription('The number of segments transmitted containing at least some\n retransmitted data.')
tcpEStatsPerfOctetsRetrans = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 6), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfOctetsRetrans.setDescription('The number of octets retransmitted.')
tcpEStatsPerfSegsIn = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 7), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSegsIn.setDescription('The total number of segments received.')
tcpEStatsPerfDataSegsIn = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 8), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfDataSegsIn.setDescription('The number of segments received containing a positive\n\n\n\n length data segment.')
tcpEStatsPerfDataOctetsIn = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 9), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfDataOctetsIn.setDescription('The number of octets contained in received data segments,\n including retransmitted data. Note that this does not\n include TCP headers.')
tcpEStatsPerfHCDataOctetsIn = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 10), ZeroBasedCounter64()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfHCDataOctetsIn.setDescription('The number of octets contained in received data segments,\n including retransmitted data, on systems that can receive\n more than 10 million bits per second. Note that this does\n not include TCP headers.')
tcpEStatsPerfElapsedSecs = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 11), ZeroBasedCounter32()).setUnits('seconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfElapsedSecs.setDescription('The seconds part of the time elapsed between\n tcpEStatsPerfStartTimeStamp and the most recent protocol\n event (segment sent or received).')
tcpEStatsPerfElapsedMicroSecs = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 12), ZeroBasedCounter32()).setUnits('microseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfElapsedMicroSecs.setDescription('The micro-second part of time elapsed between\n tcpEStatsPerfStartTimeStamp to the most recent protocol\n event (segment sent or received). This may be updated in\n whatever time granularity is the system supports.')
tcpEStatsPerfStartTimeStamp = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 13), DateAndTime()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfStartTimeStamp.setDescription('Time at which this row was created and all\n ZeroBasedCounters in the row were initialized to zero.')
tcpEStatsPerfCurMSS = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 14), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCurMSS.setDescription('The current maximum segment size (MSS), in octets.')
tcpEStatsPerfPipeSize = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 15), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfPipeSize.setDescription("The TCP senders current estimate of the number of\n unacknowledged data octets in the network.\n\n While not in recovery (e.g., while the receiver is not\n reporting missing data to the sender), this is precisely the\n same as 'Flight size' as defined in RFC 2581, which can be\n computed as SND.NXT minus SND.UNA. [RFC793]\n\n During recovery, the TCP sender has incomplete information\n about the state of the network (e.g., which segments are\n lost vs reordered, especially if the return path is also\n dropping TCP acknowledgments). Current TCP standards do not\n mandate any specific algorithm for estimating the number of\n unacknowledged data octets in the network.\n\n RFC 3517 describes a conservative algorithm to use SACK\n\n\n\n information to estimate the number of unacknowledged data\n octets in the network. tcpEStatsPerfPipeSize object SHOULD\n be the same as 'pipe' as defined in RFC 3517 if it is\n implemented. (Note that while not in recovery the pipe\n algorithm yields the same values as flight size).\n\n If RFC 3517 is not implemented, the data octets in flight\n SHOULD be estimated as SND.NXT minus SND.UNA adjusted by\n some measure of the data that has left the network and\n retransmitted data. For example, with Reno or NewReno style\n TCP, the number of duplicate acknowledgment is used to\n count the number of segments that have left the network.\n That is,\n PipeSize=SND.NXT-SND.UNA+(retransmits-dupacks)*CurMSS")
tcpEStatsPerfMaxPipeSize = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 16), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfMaxPipeSize.setDescription('The maximum value of tcpEStatsPerfPipeSize, for this\n connection.')
tcpEStatsPerfSmoothedRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 17), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSmoothedRTT.setDescription('The smoothed round trip time used in calculation of the\n RTO. See SRTT in [RFC2988].')
tcpEStatsPerfCurRTO = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 18), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCurRTO.setDescription('The current value of the retransmit timer RTO.')
tcpEStatsPerfCongSignals = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 19), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCongSignals.setDescription('The number of multiplicative downward congestion window\n adjustments due to all forms of congestion signals,\n including Fast Retransmit, Explicit Congestion Notification\n (ECN), and timeouts. This object summarizes all events that\n invoke the MD portion of Additive Increase Multiplicative\n Decrease (AIMD) congestion control, and as such is the best\n indicator of how a cwnd is being affected by congestion.\n\n Note that retransmission timeouts multiplicatively reduce\n the window implicitly by setting ssthresh, and SHOULD be\n included in tcpEStatsPerfCongSignals. In order to minimize\n spurious congestion indications due to out-of-order\n segments, tcpEStatsPerfCongSignals SHOULD be incremented in\n association with the Fast Retransmit algorithm.')
tcpEStatsPerfCurCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 20), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCurCwnd.setDescription('The current congestion window, in octets.')
tcpEStatsPerfCurSsthresh = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 21), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCurSsthresh.setDescription('The current slow start threshold in octets.')
tcpEStatsPerfTimeouts = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 22), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfTimeouts.setDescription('The number of times the retransmit timeout has expired when\n the RTO backoff multiplier is equal to one.')
tcpEStatsPerfCurRwinSent = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 23), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCurRwinSent.setDescription('The most recent window advertisement sent, in octets.')
tcpEStatsPerfMaxRwinSent = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 24), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfMaxRwinSent.setDescription('The maximum window advertisement sent, in octets.')
tcpEStatsPerfZeroRwinSent = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 25), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfZeroRwinSent.setDescription('The number of acknowledgments sent announcing a zero\n\n\n\n receive window, when the previously announced window was\n not zero.')
tcpEStatsPerfCurRwinRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 26), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfCurRwinRcvd.setDescription('The most recent window advertisement received, in octets.')
tcpEStatsPerfMaxRwinRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 27), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfMaxRwinRcvd.setDescription('The maximum window advertisement received, in octets.')
tcpEStatsPerfZeroRwinRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 28), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfZeroRwinRcvd.setDescription('The number of acknowledgments received announcing a zero\n receive window, when the previously announced window was\n not zero.')
tcpEStatsPerfSndLimTransRwin = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 31), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSndLimTransRwin.setDescription("The number of transitions into the 'Receiver Limited' state\n from either the 'Congestion Limited' or 'Sender Limited'\n states. This state is entered whenever TCP transmission\n stops because the sender has filled the announced receiver\n window, i.e., when SND.NXT has advanced to SND.UNA +\n SND.WND - 1 as described in RFC 793.")
tcpEStatsPerfSndLimTransCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 32), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSndLimTransCwnd.setDescription("The number of transitions into the 'Congestion Limited'\n state from either the 'Receiver Limited' or 'Sender\n Limited' states. This state is entered whenever TCP\n transmission stops because the sender has reached some\n limit defined by congestion control (e.g., cwnd) or other\n algorithms (retransmission timeouts) designed to control\n network traffic. See the definition of 'CONGESTION WINDOW'\n\n\n\n in RFC 2581.")
tcpEStatsPerfSndLimTransSnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 33), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSndLimTransSnd.setDescription("The number of transitions into the 'Sender Limited' state\n from either the 'Receiver Limited' or 'Congestion Limited'\n states. This state is entered whenever TCP transmission\n stops due to some sender limit such as running out of\n application data or other resources and the Karn algorithm.\n When TCP stops sending data for any reason, which cannot be\n classified as Receiver Limited or Congestion Limited, it\n MUST be treated as Sender Limited.")
tcpEStatsPerfSndLimTimeRwin = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 34), ZeroBasedCounter32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSndLimTimeRwin.setDescription("The cumulative time spent in the 'Receiver Limited' state.\n See tcpEStatsPerfSndLimTransRwin.")
tcpEStatsPerfSndLimTimeCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 35), ZeroBasedCounter32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSndLimTimeCwnd.setDescription("The cumulative time spent in the 'Congestion Limited'\n state. See tcpEStatsPerfSndLimTransCwnd. When there is a\n retransmission timeout, it SHOULD be counted in\n tcpEStatsPerfSndLimTimeCwnd (and not the cumulative time\n for some other state.)")
tcpEStatsPerfSndLimTimeSnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 36), ZeroBasedCounter32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPerfSndLimTimeSnd.setDescription("The cumulative time spent in the 'Sender Limited' state.\n See tcpEStatsPerfSndLimTransSnd.")
tcpEStatsPathTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 4), )
if mibBuilder.loadTexts: tcpEStatsPathTable.setDescription('This table contains objects that can be used to infer\n detailed behavior of the Internet path, such as the\n extent that there is reordering, ECN bits, and if\n RTT fluctuations are correlated to losses.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcpEStatsPathEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1), ).setIndexNames((0, "TCP-ESTATS-MIB", "tcpEStatsConnectIndex"))
if mibBuilder.loadTexts: tcpEStatsPathEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcpEStatsPathRetranThresh = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 1), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathRetranThresh.setDescription('The number of duplicate acknowledgments required to trigger\n Fast Retransmit. Note that although this is constant in\n traditional Reno TCP implementations, it is adaptive in\n many newer TCPs.')
tcpEStatsPathNonRecovDAEpisodes = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 2), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathNonRecovDAEpisodes.setDescription("The number of duplicate acknowledgment episodes that did\n not trigger a Fast Retransmit because ACK advanced prior to\n the number of duplicate acknowledgments reaching\n RetranThresh.\n\n\n\n\n In many implementations this is the number of times the\n 'dupacks' counter is set to zero when it is non-zero but\n less than RetranThresh.\n\n Note that the change in tcpEStatsPathNonRecovDAEpisodes\n divided by the change in tcpEStatsPerfDataSegsOut is an\n estimate of the frequency of data reordering on the forward\n path over some interval.")
tcpEStatsPathSumOctetsReordered = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 3), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathSumOctetsReordered.setDescription('The sum of the amounts SND.UNA advances on the\n acknowledgment which ends a dup-ack episode without a\n retransmission.\n\n Note the change in tcpEStatsPathSumOctetsReordered divided\n by the change in tcpEStatsPathNonRecovDAEpisodes is an\n estimates of the average reordering distance, over some\n interval.')
tcpEStatsPathNonRecovDA = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 4), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathNonRecovDA.setDescription("Duplicate acks (or SACKS) that did not trigger a Fast\n Retransmit because ACK advanced prior to the number of\n duplicate acknowledgments reaching RetranThresh.\n\n In many implementations, this is the sum of the 'dupacks'\n counter, just before it is set to zero because ACK advanced\n without a Fast Retransmit.\n\n Note that the change in tcpEStatsPathNonRecovDA divided by\n the change in tcpEStatsPathNonRecovDAEpisodes is an\n estimate of the average reordering distance in segments\n over some interval.")
tcpEStatsPathSampleRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 11), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathSampleRTT.setDescription('The most recent raw round trip time measurement used in\n calculation of the RTO.')
tcpEStatsPathRTTVar = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 12), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathRTTVar.setDescription('The round trip time variation used in calculation of the\n RTO. See RTTVAR in [RFC2988].')
tcpEStatsPathMaxRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 13), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathMaxRTT.setDescription('The maximum sampled round trip time.')
tcpEStatsPathMinRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 14), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathMinRTT.setDescription('The minimum sampled round trip time.')
tcpEStatsPathSumRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 15), ZeroBasedCounter32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathSumRTT.setDescription('The sum of all sampled round trip times.\n\n Note that the change in tcpEStatsPathSumRTT divided by the\n change in tcpEStatsPathCountRTT is the mean RTT, uniformly\n averaged over an enter interval.')
tcpEStatsPathHCSumRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 16), ZeroBasedCounter64()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathHCSumRTT.setDescription('The sum of all sampled round trip times, on all systems\n that implement multiple concurrent RTT measurements.\n\n Note that the change in tcpEStatsPathHCSumRTT divided by\n the change in tcpEStatsPathCountRTT is the mean RTT,\n uniformly averaged over an enter interval.')
tcpEStatsPathCountRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 17), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathCountRTT.setDescription('The number of round trip time samples included in\n tcpEStatsPathSumRTT and tcpEStatsPathHCSumRTT.')
tcpEStatsPathMaxRTO = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 18), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathMaxRTO.setDescription('The maximum value of the retransmit timer RTO.')
tcpEStatsPathMinRTO = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 19), Gauge32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathMinRTO.setDescription('The minimum value of the retransmit timer RTO.')
tcpEStatsPathIpTtl = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 20), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathIpTtl.setDescription('The value of the TTL field carried in the most recently\n received IP header. This is sometimes useful to detect\n changing or unstable routes.')
tcpEStatsPathIpTosIn = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 21), OctetString().subtype(subtypeSpec=ValueSizeConstraint(1,1)).setFixedLength(1)).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathIpTosIn.setDescription('The value of the IPv4 Type of Service octet, or the IPv6\n traffic class octet, carried in the most recently received\n IP header.\n\n This is useful to diagnose interactions between TCP and any\n IP layer packet scheduling and delivery policy, which might\n be in effect to implement Diffserv.')
tcpEStatsPathIpTosOut = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 22), OctetString().subtype(subtypeSpec=ValueSizeConstraint(1,1)).setFixedLength(1)).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathIpTosOut.setDescription('The value of the IPv4 Type Of Service octet, or the IPv6\n traffic class octet, carried in the most recently\n transmitted IP header.\n\n This is useful to diagnose interactions between TCP and any\n IP layer packet scheduling and delivery policy, which might\n be in effect to implement Diffserv.')
tcpEStatsPathPreCongSumCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 23), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathPreCongSumCwnd.setDescription('The sum of the values of the congestion window, in octets,\n captured each time a congestion signal is received. This\n MUST be updated each time tcpEStatsPerfCongSignals is\n incremented, such that the change in\n tcpEStatsPathPreCongSumCwnd divided by the change in\n tcpEStatsPerfCongSignals is the average window (over some\n interval) just prior to a congestion signal.')
tcpEStatsPathPreCongSumRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 24), ZeroBasedCounter32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathPreCongSumRTT.setDescription('Sum of the last sample of the RTT (tcpEStatsPathSampleRTT)\n prior to the received congestion signals. This MUST be\n updated each time tcpEStatsPerfCongSignals is incremented,\n such that the change in tcpEStatsPathPreCongSumRTT divided by\n the change in tcpEStatsPerfCongSignals is the average RTT\n (over some interval) just prior to a congestion signal.')
tcpEStatsPathPostCongSumRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 25), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathPostCongSumRTT.setDescription('Sum of the first sample of the RTT (tcpEStatsPathSampleRTT)\n following each congestion signal. Such that the change in\n tcpEStatsPathPostCongSumRTT divided by the change in\n tcpEStatsPathPostCongCountRTT is the average RTT (over some\n interval) just after a congestion signal.')
tcpEStatsPathPostCongCountRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 26), ZeroBasedCounter32()).setUnits('milliseconds').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathPostCongCountRTT.setDescription('The number of RTT samples included in\n tcpEStatsPathPostCongSumRTT such that the change in\n tcpEStatsPathPostCongSumRTT divided by the change in\n tcpEStatsPathPostCongCountRTT is the average RTT (over some\n interval) just after a congestion signal.')
tcpEStatsPathECNsignals = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 27), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathECNsignals.setDescription('The number of congestion signals delivered to the TCP\n sender via explicit congestion notification (ECN). This is\n typically the number of segments bearing Echo Congestion\n\n\n\n Experienced (ECE) bits, but\n should also include segments failing the ECN nonce check or\n other explicit congestion signals.')
tcpEStatsPathDupAckEpisodes = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 28), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathDupAckEpisodes.setDescription('The number of Duplicate Acks Sent when prior Ack was not\n duplicate. This is the number of times that a contiguous\n series of duplicate acknowledgments have been sent.\n\n This is an indication of the number of data segments lost\n or reordered on the path from the remote TCP endpoint to\n the near TCP endpoint.')
tcpEStatsPathRcvRTT = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 29), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathRcvRTT.setDescription("The receiver's estimate of the Path RTT.\n\n Adaptive receiver window algorithms depend on the receiver\n to having a good estimate of the path RTT.")
tcpEStatsPathDupAcksOut = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 30), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathDupAcksOut.setDescription('The number of duplicate ACKs sent. The ratio of the change\n in tcpEStatsPathDupAcksOut to the change in\n tcpEStatsPathDupAckEpisodes is an indication of reorder or\n recovery distance over some interval.')
tcpEStatsPathCERcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 31), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathCERcvd.setDescription('The number of segments received with IP headers bearing\n Congestion Experienced (CE) markings.')
tcpEStatsPathECESent = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 32), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsPathECESent.setDescription('Number of times the Echo Congestion Experienced (ECE) bit\n in the TCP header has been set (transitioned from 0 to 1),\n due to a Congestion Experienced (CE) marking on an IP\n header. Note that ECE can be set and reset only once per\n RTT, while CE can be set on many segments per RTT.')
tcpEStatsStackTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 5), )
if mibBuilder.loadTexts: tcpEStatsStackTable.setDescription('This table contains objects that are most useful for\n determining how well some of the TCP control\n algorithms are coping with this particular\n\n\n\n path.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcpEStatsStackEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1), ).setIndexNames((0, "TCP-ESTATS-MIB", "tcpEStatsConnectIndex"))
if mibBuilder.loadTexts: tcpEStatsStackEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcpEStatsStackActiveOpen = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 1), TruthValue()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackActiveOpen.setDescription('True(1) if the local connection traversed the SYN-SENT\n state, else false(2).')
tcpEStatsStackMSSSent = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 2), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMSSSent.setDescription('The value sent in an MSS option, or zero if none.')
tcpEStatsStackMSSRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 3), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMSSRcvd.setDescription('The value received in an MSS option, or zero if none.')
tcpEStatsStackWinScaleSent = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 4), Integer32().subtype(subtypeSpec=ValueRangeConstraint(-1,14))).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackWinScaleSent.setDescription('The value of the transmitted window scale option if one was\n sent; otherwise, a value of -1.\n\n Note that if both tcpEStatsStackWinScaleSent and\n tcpEStatsStackWinScaleRcvd are not -1, then Rcv.Wind.Scale\n will be the same as this value and used to scale receiver\n window announcements from the local host to the remote\n host.')
tcpEStatsStackWinScaleRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 5), Integer32().subtype(subtypeSpec=ValueRangeConstraint(-1,14))).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackWinScaleRcvd.setDescription('The value of the received window scale option if one was\n received; otherwise, a value of -1.\n\n Note that if both tcpEStatsStackWinScaleSent and\n tcpEStatsStackWinScaleRcvd are not -1, then Snd.Wind.Scale\n will be the same as this value and used to scale receiver\n window announcements from the remote host to the local\n host.')
tcpEStatsStackTimeStamps = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 6), TcpEStatsNegotiated()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackTimeStamps.setDescription('Enabled(1) if TCP timestamps have been negotiated on,\n selfDisabled(2) if they are disabled or not implemented on\n the local host, or peerDisabled(3) if not negotiated by the\n remote hosts.')
tcpEStatsStackECN = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 7), TcpEStatsNegotiated()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackECN.setDescription('Enabled(1) if Explicit Congestion Notification (ECN) has\n been negotiated on, selfDisabled(2) if it is disabled or\n not implemented on the local host, or peerDisabled(3) if\n not negotiated by the remote hosts.')
tcpEStatsStackWillSendSACK = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 8), TcpEStatsNegotiated()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackWillSendSACK.setDescription('Enabled(1) if the local host will send SACK options,\n selfDisabled(2) if SACK is disabled or not implemented on\n the local host, or peerDisabled(3) if the remote host did\n not send the SACK-permitted option.\n\n Note that SACK negotiation is not symmetrical. SACK can\n enabled on one side of the connection and not the other.')
tcpEStatsStackWillUseSACK = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 9), TcpEStatsNegotiated()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackWillUseSACK.setDescription('Enabled(1) if the local host will process SACK options,\n selfDisabled(2) if SACK is disabled or not implemented on\n the local host, or peerDisabled(3) if the remote host sends\n\n\n\n duplicate ACKs without SACK options, or the local host\n otherwise decides not to process received SACK options.\n\n Unlike other TCP options, the remote data receiver cannot\n explicitly indicate if it is able to generate SACK options.\n When sending data, the local host has to deduce if the\n remote receiver is sending SACK options. This object can\n transition from Enabled(1) to peerDisabled(3) after the SYN\n exchange.\n\n Note that SACK negotiation is not symmetrical. SACK can\n enabled on one side of the connection and not the other.')
tcpEStatsStackState = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 10), Integer32().subtype(subtypeSpec=ConstraintsUnion(SingleValueConstraint(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12,))).clone(namedValues=NamedValues(("tcpESStateClosed", 1), ("tcpESStateListen", 2), ("tcpESStateSynSent", 3), ("tcpESStateSynReceived", 4), ("tcpESStateEstablished", 5), ("tcpESStateFinWait1", 6), ("tcpESStateFinWait2", 7), ("tcpESStateCloseWait", 8), ("tcpESStateLastAck", 9), ("tcpESStateClosing", 10), ("tcpESStateTimeWait", 11), ("tcpESStateDeleteTcb", 12),))).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackState.setDescription('An integer value representing the connection state from the\n TCP State Transition Diagram.\n\n The value listen(2) is included only for parallelism to the\n old tcpConnTable, and SHOULD NOT be used because the listen\n state in managed by the tcpListenerTable.\n\n The value DeleteTcb(12) is included only for parallelism to\n the tcpConnTable mechanism for terminating connections,\n\n\n\n although this table does not permit writing.')
tcpEStatsStackNagle = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 11), TruthValue()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackNagle.setDescription('True(1) if the Nagle algorithm is being used, else\n false(2).')
tcpEStatsStackMaxSsCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 12), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMaxSsCwnd.setDescription('The maximum congestion window used during Slow Start, in\n octets.')
tcpEStatsStackMaxCaCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 13), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMaxCaCwnd.setDescription('The maximum congestion window used during Congestion\n Avoidance, in octets.')
tcpEStatsStackMaxSsthresh = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 14), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMaxSsthresh.setDescription('The maximum slow start threshold, excluding the initial\n value.')
tcpEStatsStackMinSsthresh = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 15), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMinSsthresh.setDescription('The minimum slow start threshold.')
tcpEStatsStackInRecovery = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 16), Integer32().subtype(subtypeSpec=ConstraintsUnion(SingleValueConstraint(1, 2, 3,))).clone(namedValues=NamedValues(("tcpESDataContiguous", 1), ("tcpESDataUnordered", 2), ("tcpESDataRecovery", 3),))).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackInRecovery.setDescription('An integer value representing the state of the loss\n recovery for this connection.\n\n tcpESDataContiguous(1) indicates that the remote receiver\n is reporting contiguous data (no duplicate acknowledgments\n or SACK options) and that there are no unacknowledged\n retransmissions.\n\n tcpESDataUnordered(2) indicates that the remote receiver is\n reporting missing or out-of-order data (e.g., sending\n duplicate acknowledgments or SACK options) and that there\n are no unacknowledged retransmissions (because the missing\n data has not yet been retransmitted).\n\n tcpESDataRecovery(3) indicates that the sender has\n outstanding retransmitted data that is still\n\n\n\n unacknowledged.')
tcpEStatsStackDupAcksIn = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 17), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackDupAcksIn.setDescription('The number of duplicate ACKs received.')
tcpEStatsStackSpuriousFrDetected = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 18), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSpuriousFrDetected.setDescription("The number of acknowledgments reporting out-of-order\n segments after the Fast Retransmit algorithm has already\n retransmitted the segments. (For example as detected by the\n Eifel algorithm).'")
tcpEStatsStackSpuriousRtoDetected = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 19), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSpuriousRtoDetected.setDescription('The number of acknowledgments reporting segments that have\n already been retransmitted due to a Retransmission Timeout.')
tcpEStatsStackSoftErrors = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 21), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSoftErrors.setDescription('The number of segments that fail various consistency tests\n during TCP input processing. Soft errors might cause the\n segment to be discarded but some do not. Some of these soft\n errors cause the generation of a TCP acknowledgment, while\n others are silently discarded.')
tcpEStatsStackSoftErrorReason = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 22), Integer32().subtype(subtypeSpec=ConstraintsUnion(SingleValueConstraint(1, 2, 3, 4, 5, 6, 7, 8,))).clone(namedValues=NamedValues(("belowDataWindow", 1), ("aboveDataWindow", 2), ("belowAckWindow", 3), ("aboveAckWindow", 4), ("belowTSWindow", 5), ("aboveTSWindow", 6), ("dataCheckSum", 7), ("otherSoftError", 8),))).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSoftErrorReason.setDescription('This object identifies which consistency test most recently\n failed during TCP input processing. This object SHOULD be\n set every time tcpEStatsStackSoftErrors is incremented. The\n codes are as follows:\n\n belowDataWindow(1) - All data in the segment is below\n SND.UNA. (Normal for keep-alives and zero window probes).\n\n aboveDataWindow(2) - Some data in the segment is above\n SND.WND. (Indicates an implementation bug or possible\n attack).\n\n belowAckWindow(3) - ACK below SND.UNA. (Indicates that the\n return path is reordering ACKs)\n\n aboveAckWindow(4) - An ACK for data that we have not sent.\n (Indicates an implementation bug or possible attack).\n\n belowTSWindow(5) - TSecr on the segment is older than the\n current TS.Recent (Normal for the rare case where PAWS\n detects data reordered by the network).\n\n aboveTSWindow(6) - TSecr on the segment is newer than the\n current TS.Recent. (Indicates an implementation bug or\n possible attack).\n\n\n\n\n dataCheckSum(7) - Incorrect checksum. Note that this value\n is intrinsically fragile, because the header fields used to\n identify the connection may have been corrupted.\n\n otherSoftError(8) - All other soft errors not listed\n above.')
tcpEStatsStackSlowStart = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 23), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSlowStart.setDescription('The number of times the congestion window has been\n increased by the Slow Start algorithm.')
tcpEStatsStackCongAvoid = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 24), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackCongAvoid.setDescription('The number of times the congestion window has been\n increased by the Congestion Avoidance algorithm.')
tcpEStatsStackOtherReductions = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 25), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackOtherReductions.setDescription('The number of congestion window reductions made as a result\n of anything other than AIMD congestion control algorithms.\n Examples of non-multiplicative window reductions include\n Congestion Window Validation [RFC2861] and experimental\n algorithms such as Vegas [Bra94].\n\n\n\n\n All window reductions MUST be counted as either\n tcpEStatsPerfCongSignals or tcpEStatsStackOtherReductions.')
tcpEStatsStackCongOverCount = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 26), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackCongOverCount.setDescription("The number of congestion events that were 'backed out' of\n the congestion control state machine such that the\n congestion window was restored to a prior value. This can\n happen due to the Eifel algorithm [RFC3522] or other\n algorithms that can be used to detect and cancel spurious\n invocations of the Fast Retransmit Algorithm.\n\n Although it may be feasible to undo the effects of spurious\n invocation of the Fast Retransmit congestion events cannot\n easily be backed out of tcpEStatsPerfCongSignals and\n tcpEStatsPathPreCongSumCwnd, etc.")
tcpEStatsStackFastRetran = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 27), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackFastRetran.setDescription('The number of invocations of the Fast Retransmit algorithm.')
tcpEStatsStackSubsequentTimeouts = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 28), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSubsequentTimeouts.setDescription('The number of times the retransmit timeout has expired after\n the RTO has been doubled. See Section 5.5 of RFC 2988.')
tcpEStatsStackCurTimeoutCount = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 29), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackCurTimeoutCount.setDescription('The current number of times the retransmit timeout has\n expired without receiving an acknowledgment for new data.\n tcpEStatsStackCurTimeoutCount is reset to zero when new\n data is acknowledged and incremented for each invocation of\n Section 5.5 of RFC 2988.')
tcpEStatsStackAbruptTimeouts = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 30), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackAbruptTimeouts.setDescription('The number of timeouts that occurred without any\n immediately preceding duplicate acknowledgments or other\n indications of congestion. Abrupt Timeouts indicate that\n the path lost an entire window of data or acknowledgments.\n\n Timeouts that are preceded by duplicate acknowledgments or\n other congestion signals (e.g., ECN) are not counted as\n abrupt, and might have been avoided by a more sophisticated\n Fast Retransmit algorithm.')
tcpEStatsStackSACKsRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 31), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSACKsRcvd.setDescription('The number of SACK options received.')
tcpEStatsStackSACKBlocksRcvd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 32), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSACKBlocksRcvd.setDescription('The number of SACK blocks received (within SACK options).')
tcpEStatsStackSendStall = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 33), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSendStall.setDescription('The number of interface stalls or other sender local\n resource limitations that are treated as congestion\n signals.')
tcpEStatsStackDSACKDups = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 34), ZeroBasedCounter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackDSACKDups.setDescription('The number of duplicate segments reported to the local host\n by D-SACK blocks.')
tcpEStatsStackMaxMSS = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 35), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMaxMSS.setDescription('The maximum MSS, in octets.')
tcpEStatsStackMinMSS = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 36), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMinMSS.setDescription('The minimum MSS, in octets.')
tcpEStatsStackSndInitial = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 37), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackSndInitial.setDescription('Initial send sequence number. Note that by definition\n tcpEStatsStackSndInitial never changes for a given\n connection.')
tcpEStatsStackRecInitial = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 38), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackRecInitial.setDescription('Initial receive sequence number. Note that by definition\n tcpEStatsStackRecInitial never changes for a given\n connection.')
tcpEStatsStackCurRetxQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 39), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackCurRetxQueue.setDescription('The current number of octets of data occupying the\n retransmit queue.')
tcpEStatsStackMaxRetxQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 40), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMaxRetxQueue.setDescription('The maximum number of octets of data occupying the\n retransmit queue.')
tcpEStatsStackCurReasmQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 41), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackCurReasmQueue.setDescription('The current number of octets of sequence space spanned by\n the reassembly queue. This is generally the difference\n between rcv.nxt and the sequence number of the right most\n edge of the reassembly queue.')
tcpEStatsStackMaxReasmQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 42), Gauge32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsStackMaxReasmQueue.setDescription('The maximum value of tcpEStatsStackCurReasmQueue')
tcpEStatsAppTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 6), )
if mibBuilder.loadTexts: tcpEStatsAppTable.setDescription('This table contains objects that are useful for\n determining if the application using TCP is\n\n\n\n limiting TCP performance.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcpEStatsAppEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1), ).setIndexNames((0, "TCP-ESTATS-MIB", "tcpEStatsConnectIndex"))
if mibBuilder.loadTexts: tcpEStatsAppEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcpEStatsAppSndUna = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 1), Counter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppSndUna.setDescription('The value of SND.UNA, the oldest unacknowledged sequence\n number.\n\n Note that SND.UNA is a TCP state variable that is congruent\n to Counter32 semantics.')
tcpEStatsAppSndNxt = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 2), Unsigned32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppSndNxt.setDescription('The value of SND.NXT, the next sequence number to be sent.\n Note that tcpEStatsAppSndNxt is not monotonic (and thus not\n a counter) because TCP sometimes retransmits lost data by\n pulling tcpEStatsAppSndNxt back to the missing data.')
tcpEStatsAppSndMax = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 3), Counter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppSndMax.setDescription('The farthest forward (right most or largest) SND.NXT value.\n Note that this will be equal to tcpEStatsAppSndNxt except\n when tcpEStatsAppSndNxt is pulled back during recovery.')
tcpEStatsAppThruOctetsAcked = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 4), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppThruOctetsAcked.setDescription('The number of octets for which cumulative acknowledgments\n have been received. Note that this will be the sum of\n changes to tcpEStatsAppSndUna.')
tcpEStatsAppHCThruOctetsAcked = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 5), ZeroBasedCounter64()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppHCThruOctetsAcked.setDescription('The number of octets for which cumulative acknowledgments\n have been received, on systems that can receive more than\n 10 million bits per second. Note that this will be the sum\n of changes in tcpEStatsAppSndUna.')
tcpEStatsAppRcvNxt = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 6), Counter32()).setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppRcvNxt.setDescription('The value of RCV.NXT. The next sequence number expected on\n an incoming segment, and the left or lower edge of the\n receive window.\n\n Note that RCV.NXT is a TCP state variable that is congruent\n to Counter32 semantics.')
tcpEStatsAppThruOctetsReceived = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 7), ZeroBasedCounter32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppThruOctetsReceived.setDescription('The number of octets for which cumulative acknowledgments\n have been sent. Note that this will be the sum of changes\n to tcpEStatsAppRcvNxt.')
tcpEStatsAppHCThruOctetsReceived = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 8), ZeroBasedCounter64()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppHCThruOctetsReceived.setDescription('The number of octets for which cumulative acknowledgments\n have been sent, on systems that can transmit more than 10\n million bits per second. Note that this will be the sum of\n changes in tcpEStatsAppRcvNxt.')
tcpEStatsAppCurAppWQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 11), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppCurAppWQueue.setDescription('The current number of octets of application data buffered\n by TCP, pending first transmission, i.e., to the left of\n SND.NXT or SndMax. This data will generally be transmitted\n (and SND.NXT advanced to the left) as soon as there is an\n available congestion window (cwnd) or receiver window\n (rwin). This is the amount of data readily available for\n transmission, without scheduling the application. TCP\n performance may suffer if there is insufficient queued\n write data.')
tcpEStatsAppMaxAppWQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 12), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppMaxAppWQueue.setDescription('The maximum number of octets of application data buffered\n by TCP, pending first transmission. This is the maximum\n value of tcpEStatsAppCurAppWQueue. This pair of objects can\n be used to determine if insufficient queued data is steady\n state (suggesting insufficient queue space) or transient\n (suggesting insufficient application performance or\n excessive CPU load or scheduler latency).')
tcpEStatsAppCurAppRQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 13), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppCurAppRQueue.setDescription('The current number of octets of application data that has\n been acknowledged by TCP but not yet delivered to the\n application.')
tcpEStatsAppMaxAppRQueue = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 14), Gauge32()).setUnits('octets').setMaxAccess("readonly")
if mibBuilder.loadTexts: tcpEStatsAppMaxAppRQueue.setDescription('The maximum number of octets of application data that has\n been acknowledged by TCP but not yet delivered to the\n application.')
tcpEStatsTuneTable = MibTable((1, 3, 6, 1, 2, 1, 156, 1, 1, 7), )
if mibBuilder.loadTexts: tcpEStatsTuneTable.setDescription('This table contains per-connection controls that can\n be used to work around a number of common problems that\n plague TCP over some paths. All can be characterized as\n limiting the growth of the congestion window so as to\n prevent TCP from overwhelming some component in the\n path.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcpEStatsTuneEntry = MibTableRow((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1), ).setIndexNames((0, "TCP-ESTATS-MIB", "tcpEStatsConnectIndex"))
if mibBuilder.loadTexts: tcpEStatsTuneEntry.setDescription('Each entry in this table is a control that can be used to\n place limits on each active TCP connection.')
tcpEStatsTuneLimCwnd = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 1), Unsigned32()).setUnits('octets').setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsTuneLimCwnd.setDescription('A control to set the maximum congestion window that may be\n used, in octets.')
tcpEStatsTuneLimSsthresh = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 2), Unsigned32()).setUnits('octets').setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsTuneLimSsthresh.setDescription('A control to limit the maximum queue space (in octets) that\n this TCP connection is likely to occupy during slowstart.\n\n It can be implemented with the algorithm described in\n RFC 3742 by setting the max_ssthresh parameter to twice\n tcpEStatsTuneLimSsthresh.\n\n This algorithm can be used to overcome some TCP performance\n problems over network paths that do not have sufficient\n buffering to withstand the bursts normally present during\n slowstart.')
tcpEStatsTuneLimRwin = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 3), Unsigned32()).setUnits('octets').setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsTuneLimRwin.setDescription('A control to set the maximum window advertisement that may\n be sent, in octets.')
tcpEStatsTuneLimMSS = MibTableColumn((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 4), Unsigned32()).setUnits('octets').setMaxAccess("readwrite")
if mibBuilder.loadTexts: tcpEStatsTuneLimMSS.setDescription('A control to limit the maximum segment size in octets, that\n this TCP connection can use.')
tcpEStatsEstablishNotification = NotificationType((1, 3, 6, 1, 2, 1, 156, 0, 1)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsConnectIndex"),))
if mibBuilder.loadTexts: tcpEStatsEstablishNotification.setDescription('The indicated connection has been accepted\n (or alternatively entered the established state).')
tcpEStatsCloseNotification = NotificationType((1, 3, 6, 1, 2, 1, 156, 0, 2)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsConnectIndex"),))
if mibBuilder.loadTexts: tcpEStatsCloseNotification.setDescription('The indicated connection has left the\n established state')
tcpEStatsCompliances = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 2, 1))
tcpEStatsGroups = MibIdentifier((1, 3, 6, 1, 2, 1, 156, 2, 2))
tcpEStatsCompliance = ModuleCompliance((1, 3, 6, 1, 2, 1, 156, 2, 1, 1)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsListenerGroup"), ("TCP-ESTATS-MIB", "tcpEStatsConnectIdGroup"), ("TCP-ESTATS-MIB", "tcpEStatsPerfGroup"), ("TCP-ESTATS-MIB", "tcpEStatsPathGroup"), ("TCP-ESTATS-MIB", "tcpEStatsStackGroup"), ("TCP-ESTATS-MIB", "tcpEStatsAppGroup"), ("TCP-ESTATS-MIB", "tcpEStatsListenerHCGroup"), ("TCP-ESTATS-MIB", "tcpEStatsPerfOptionalGroup"), ("TCP-ESTATS-MIB", "tcpEStatsPerfHCGroup"), ("TCP-ESTATS-MIB", "tcpEStatsPathOptionalGroup"), ("TCP-ESTATS-MIB", "tcpEStatsPathHCGroup"), ("TCP-ESTATS-MIB", "tcpEStatsStackOptionalGroup"), ("TCP-ESTATS-MIB", "tcpEStatsAppHCGroup"), ("TCP-ESTATS-MIB", "tcpEStatsAppOptionalGroup"), ("TCP-ESTATS-MIB", "tcpEStatsTuneOptionalGroup"), ("TCP-ESTATS-MIB", "tcpEStatsNotificationsGroup"), ("TCP-ESTATS-MIB", "tcpEStatsNotificationsCtlGroup"),))
if mibBuilder.loadTexts: tcpEStatsCompliance.setDescription('Compliance statement for all systems that implement TCP\n extended statistics.')
tcpEStatsListenerGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 1)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsListenerTableLastChange"), ("TCP-ESTATS-MIB", "tcpEStatsListenerStartTime"), ("TCP-ESTATS-MIB", "tcpEStatsListenerSynRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsListenerInitial"), ("TCP-ESTATS-MIB", "tcpEStatsListenerEstablished"), ("TCP-ESTATS-MIB", "tcpEStatsListenerAccepted"), ("TCP-ESTATS-MIB", "tcpEStatsListenerExceedBacklog"), ("TCP-ESTATS-MIB", "tcpEStatsListenerCurConns"), ("TCP-ESTATS-MIB", "tcpEStatsListenerMaxBacklog"), ("TCP-ESTATS-MIB", "tcpEStatsListenerCurBacklog"), ("TCP-ESTATS-MIB", "tcpEStatsListenerCurEstabBacklog"),))
if mibBuilder.loadTexts: tcpEStatsListenerGroup.setDescription('The tcpEStatsListener group includes objects that\n provide valuable statistics and debugging\n information for TCP Listeners.')
tcpEStatsListenerHCGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 2)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsListenerHCSynRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsListenerHCInitial"), ("TCP-ESTATS-MIB", "tcpEStatsListenerHCEstablished"), ("TCP-ESTATS-MIB", "tcpEStatsListenerHCAccepted"), ("TCP-ESTATS-MIB", "tcpEStatsListenerHCExceedBacklog"),))
if mibBuilder.loadTexts: tcpEStatsListenerHCGroup.setDescription('The tcpEStatsListenerHC group includes 64-bit\n counters in tcpEStatsListenerTable.')
tcpEStatsConnectIdGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 3)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsConnTableLatency"), ("TCP-ESTATS-MIB", "tcpEStatsConnectIndex"),))
if mibBuilder.loadTexts: tcpEStatsConnectIdGroup.setDescription('The tcpEStatsConnectId group includes objects that\n identify TCP connections and control how long TCP\n connection entries are retained in the tables.')
tcpEStatsPerfGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 4)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsPerfSegsOut"), ("TCP-ESTATS-MIB", "tcpEStatsPerfDataSegsOut"), ("TCP-ESTATS-MIB", "tcpEStatsPerfDataOctetsOut"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSegsRetrans"), ("TCP-ESTATS-MIB", "tcpEStatsPerfOctetsRetrans"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSegsIn"), ("TCP-ESTATS-MIB", "tcpEStatsPerfDataSegsIn"), ("TCP-ESTATS-MIB", "tcpEStatsPerfDataOctetsIn"), ("TCP-ESTATS-MIB", "tcpEStatsPerfElapsedSecs"), ("TCP-ESTATS-MIB", "tcpEStatsPerfElapsedMicroSecs"), ("TCP-ESTATS-MIB", "tcpEStatsPerfStartTimeStamp"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCurMSS"), ("TCP-ESTATS-MIB", "tcpEStatsPerfPipeSize"), ("TCP-ESTATS-MIB", "tcpEStatsPerfMaxPipeSize"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSmoothedRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCurRTO"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCongSignals"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCurCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCurSsthresh"), ("TCP-ESTATS-MIB", "tcpEStatsPerfTimeouts"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCurRwinSent"), ("TCP-ESTATS-MIB", "tcpEStatsPerfMaxRwinSent"), ("TCP-ESTATS-MIB", "tcpEStatsPerfZeroRwinSent"), ("TCP-ESTATS-MIB", "tcpEStatsPerfCurRwinRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsPerfMaxRwinRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsPerfZeroRwinRcvd"),))
if mibBuilder.loadTexts: tcpEStatsPerfGroup.setDescription('The tcpEStatsPerf group includes those objects that\n provide basic performance data for a TCP connection.')
tcpEStatsPerfOptionalGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 5)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsPerfSndLimTransRwin"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSndLimTransCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSndLimTransSnd"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSndLimTimeRwin"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSndLimTimeCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsPerfSndLimTimeSnd"),))
if mibBuilder.loadTexts: tcpEStatsPerfOptionalGroup.setDescription('The tcpEStatsPerf group includes those objects that\n provide basic performance data for a TCP connection.')
tcpEStatsPerfHCGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 6)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsPerfHCDataOctetsOut"), ("TCP-ESTATS-MIB", "tcpEStatsPerfHCDataOctetsIn"),))
if mibBuilder.loadTexts: tcpEStatsPerfHCGroup.setDescription('The tcpEStatsPerfHC group includes 64-bit\n counters in the tcpEStatsPerfTable.')
tcpEStatsPathGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 7)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsControlPath"), ("TCP-ESTATS-MIB", "tcpEStatsPathRetranThresh"), ("TCP-ESTATS-MIB", "tcpEStatsPathNonRecovDAEpisodes"), ("TCP-ESTATS-MIB", "tcpEStatsPathSumOctetsReordered"), ("TCP-ESTATS-MIB", "tcpEStatsPathNonRecovDA"),))
if mibBuilder.loadTexts: tcpEStatsPathGroup.setDescription('The tcpEStatsPath group includes objects that\n control the creation of the tcpEStatsPathTable,\n and provide information about the path\n for each TCP connection.')
tcpEStatsPathOptionalGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 8)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsPathSampleRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathRTTVar"), ("TCP-ESTATS-MIB", "tcpEStatsPathMaxRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathMinRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathSumRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathCountRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathMaxRTO"), ("TCP-ESTATS-MIB", "tcpEStatsPathMinRTO"), ("TCP-ESTATS-MIB", "tcpEStatsPathIpTtl"), ("TCP-ESTATS-MIB", "tcpEStatsPathIpTosIn"), ("TCP-ESTATS-MIB", "tcpEStatsPathIpTosOut"), ("TCP-ESTATS-MIB", "tcpEStatsPathPreCongSumCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsPathPreCongSumRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathPostCongSumRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathPostCongCountRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathECNsignals"), ("TCP-ESTATS-MIB", "tcpEStatsPathDupAckEpisodes"), ("TCP-ESTATS-MIB", "tcpEStatsPathRcvRTT"), ("TCP-ESTATS-MIB", "tcpEStatsPathDupAcksOut"), ("TCP-ESTATS-MIB", "tcpEStatsPathCERcvd"), ("TCP-ESTATS-MIB", "tcpEStatsPathECESent"),))
if mibBuilder.loadTexts: tcpEStatsPathOptionalGroup.setDescription('The tcpEStatsPath group includes objects that\n provide additional information about the path\n for each TCP connection.')
tcpEStatsPathHCGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 9)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsPathHCSumRTT"),))
if mibBuilder.loadTexts: tcpEStatsPathHCGroup.setDescription('The tcpEStatsPathHC group includes 64-bit\n counters in the tcpEStatsPathTable.')
tcpEStatsStackGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 10)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsControlStack"), ("TCP-ESTATS-MIB", "tcpEStatsStackActiveOpen"), ("TCP-ESTATS-MIB", "tcpEStatsStackMSSSent"), ("TCP-ESTATS-MIB", "tcpEStatsStackMSSRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsStackWinScaleSent"), ("TCP-ESTATS-MIB", "tcpEStatsStackWinScaleRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsStackTimeStamps"), ("TCP-ESTATS-MIB", "tcpEStatsStackECN"), ("TCP-ESTATS-MIB", "tcpEStatsStackWillSendSACK"), ("TCP-ESTATS-MIB", "tcpEStatsStackWillUseSACK"), ("TCP-ESTATS-MIB", "tcpEStatsStackState"), ("TCP-ESTATS-MIB", "tcpEStatsStackNagle"), ("TCP-ESTATS-MIB", "tcpEStatsStackMaxSsCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsStackMaxCaCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsStackMaxSsthresh"), ("TCP-ESTATS-MIB", "tcpEStatsStackMinSsthresh"), ("TCP-ESTATS-MIB", "tcpEStatsStackInRecovery"), ("TCP-ESTATS-MIB", "tcpEStatsStackDupAcksIn"), ("TCP-ESTATS-MIB", "tcpEStatsStackSpuriousFrDetected"), ("TCP-ESTATS-MIB", "tcpEStatsStackSpuriousRtoDetected"),))
if mibBuilder.loadTexts: tcpEStatsStackGroup.setDescription('The tcpEStatsConnState group includes objects that\n control the creation of the tcpEStatsStackTable,\n and provide information about the operation of\n algorithms used within TCP.')
tcpEStatsStackOptionalGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 11)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsStackSoftErrors"), ("TCP-ESTATS-MIB", "tcpEStatsStackSoftErrorReason"), ("TCP-ESTATS-MIB", "tcpEStatsStackSlowStart"), ("TCP-ESTATS-MIB", "tcpEStatsStackCongAvoid"), ("TCP-ESTATS-MIB", "tcpEStatsStackOtherReductions"), ("TCP-ESTATS-MIB", "tcpEStatsStackCongOverCount"), ("TCP-ESTATS-MIB", "tcpEStatsStackFastRetran"), ("TCP-ESTATS-MIB", "tcpEStatsStackSubsequentTimeouts"), ("TCP-ESTATS-MIB", "tcpEStatsStackCurTimeoutCount"), ("TCP-ESTATS-MIB", "tcpEStatsStackAbruptTimeouts"), ("TCP-ESTATS-MIB", "tcpEStatsStackSACKsRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsStackSACKBlocksRcvd"), ("TCP-ESTATS-MIB", "tcpEStatsStackSendStall"), ("TCP-ESTATS-MIB", "tcpEStatsStackDSACKDups"), ("TCP-ESTATS-MIB", "tcpEStatsStackMaxMSS"), ("TCP-ESTATS-MIB", "tcpEStatsStackMinMSS"), ("TCP-ESTATS-MIB", "tcpEStatsStackSndInitial"), ("TCP-ESTATS-MIB", "tcpEStatsStackRecInitial"), ("TCP-ESTATS-MIB", "tcpEStatsStackCurRetxQueue"), ("TCP-ESTATS-MIB", "tcpEStatsStackMaxRetxQueue"), ("TCP-ESTATS-MIB", "tcpEStatsStackCurReasmQueue"), ("TCP-ESTATS-MIB", "tcpEStatsStackMaxReasmQueue"),))
if mibBuilder.loadTexts: tcpEStatsStackOptionalGroup.setDescription('The tcpEStatsConnState group includes objects that\n provide additional information about the operation of\n algorithms used within TCP.')
tcpEStatsAppGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 12)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsControlApp"), ("TCP-ESTATS-MIB", "tcpEStatsAppSndUna"), ("TCP-ESTATS-MIB", "tcpEStatsAppSndNxt"), ("TCP-ESTATS-MIB", "tcpEStatsAppSndMax"), ("TCP-ESTATS-MIB", "tcpEStatsAppThruOctetsAcked"), ("TCP-ESTATS-MIB", "tcpEStatsAppRcvNxt"), ("TCP-ESTATS-MIB", "tcpEStatsAppThruOctetsReceived"),))
if mibBuilder.loadTexts: tcpEStatsAppGroup.setDescription('The tcpEStatsConnState group includes objects that\n control the creation of the tcpEStatsAppTable,\n and provide information about the operation of\n algorithms used within TCP.')
tcpEStatsAppHCGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 13)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsAppHCThruOctetsAcked"), ("TCP-ESTATS-MIB", "tcpEStatsAppHCThruOctetsReceived"),))
if mibBuilder.loadTexts: tcpEStatsAppHCGroup.setDescription('The tcpEStatsStackHC group includes 64-bit\n counters in the tcpEStatsStackTable.')
tcpEStatsAppOptionalGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 14)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsAppCurAppWQueue"), ("TCP-ESTATS-MIB", "tcpEStatsAppMaxAppWQueue"), ("TCP-ESTATS-MIB", "tcpEStatsAppCurAppRQueue"), ("TCP-ESTATS-MIB", "tcpEStatsAppMaxAppRQueue"),))
if mibBuilder.loadTexts: tcpEStatsAppOptionalGroup.setDescription('The tcpEStatsConnState group includes objects that\n provide additional information about how applications\n are interacting with each TCP connection.')
tcpEStatsTuneOptionalGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 15)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsControlTune"), ("TCP-ESTATS-MIB", "tcpEStatsTuneLimCwnd"), ("TCP-ESTATS-MIB", "tcpEStatsTuneLimSsthresh"), ("TCP-ESTATS-MIB", "tcpEStatsTuneLimRwin"), ("TCP-ESTATS-MIB", "tcpEStatsTuneLimMSS"),))
if mibBuilder.loadTexts: tcpEStatsTuneOptionalGroup.setDescription('The tcpEStatsConnState group includes objects that\n control the creation of the tcpEStatsConnectionTable,\n which can be used to set tuning parameters\n for each TCP connection.')
tcpEStatsNotificationsGroup = NotificationGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 16)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsEstablishNotification"), ("TCP-ESTATS-MIB", "tcpEStatsCloseNotification"),))
if mibBuilder.loadTexts: tcpEStatsNotificationsGroup.setDescription('Notifications sent by a TCP extended statistics agent.')
tcpEStatsNotificationsCtlGroup = ObjectGroup((1, 3, 6, 1, 2, 1, 156, 2, 2, 17)).setObjects(*(("TCP-ESTATS-MIB", "tcpEStatsControlNotify"),))
if mibBuilder.loadTexts: tcpEStatsNotificationsCtlGroup.setDescription('The tcpEStatsNotificationsCtl group includes the\n object that controls the creation of the events\n in the tcpEStatsNotificationsGroup.')
mibBuilder.exportSymbols("TCP-ESTATS-MIB", tcpEStatsPerfSegsIn=tcpEStatsPerfSegsIn, tcpEStatsAppHCThruOctetsAcked=tcpEStatsAppHCThruOctetsAcked, tcpEStatsStackMSSSent=tcpEStatsStackMSSSent, tcpEStatsTuneLimRwin=tcpEStatsTuneLimRwin, tcpEStatsStackTimeStamps=tcpEStatsStackTimeStamps, tcpEStatsStackState=tcpEStatsStackState, tcpEStatsPerfZeroRwinRcvd=tcpEStatsPerfZeroRwinRcvd, tcpEStatsStackSpuriousFrDetected=tcpEStatsStackSpuriousFrDetected, tcpEStatsStackMaxMSS=tcpEStatsStackMaxMSS, tcpEStatsPerfDataOctetsIn=tcpEStatsPerfDataOctetsIn, tcpEStatsStackSACKsRcvd=tcpEStatsStackSACKsRcvd, tcpEStatsTuneTable=tcpEStatsTuneTable, TcpEStatsNegotiated=TcpEStatsNegotiated, tcpEStatsPathCERcvd=tcpEStatsPathCERcvd, tcpEStatsPerfEntry=tcpEStatsPerfEntry, tcpEStatsConnectIndex=tcpEStatsConnectIndex, tcpEStatsPerfSndLimTransSnd=tcpEStatsPerfSndLimTransSnd, tcpEStatsPerfZeroRwinSent=tcpEStatsPerfZeroRwinSent, tcpEStatsStackSACKBlocksRcvd=tcpEStatsStackSACKBlocksRcvd, tcpEStatsPerfSndLimTimeRwin=tcpEStatsPerfSndLimTimeRwin, tcpEStatsPerfTable=tcpEStatsPerfTable, tcpEStatsPathSampleRTT=tcpEStatsPathSampleRTT, tcpEStatsEstablishNotification=tcpEStatsEstablishNotification, tcpEStatsPerfMaxRwinRcvd=tcpEStatsPerfMaxRwinRcvd, tcpEStatsAppMaxAppRQueue=tcpEStatsAppMaxAppRQueue, tcpEStatsPerfCurSsthresh=tcpEStatsPerfCurSsthresh, tcpEStatsStackDSACKDups=tcpEStatsStackDSACKDups, tcpEStatsCloseNotification=tcpEStatsCloseNotification, tcpEStatsAppEntry=tcpEStatsAppEntry, tcpEStatsControlApp=tcpEStatsControlApp, tcpEStatsStackRecInitial=tcpEStatsStackRecInitial, tcpEStatsStackMaxReasmQueue=tcpEStatsStackMaxReasmQueue, tcpEStatsStackWillSendSACK=tcpEStatsStackWillSendSACK, tcpEStatsAppRcvNxt=tcpEStatsAppRcvNxt, tcpEStatsPerfHCGroup=tcpEStatsPerfHCGroup, tcpEStatsPerfSndLimTimeCwnd=tcpEStatsPerfSndLimTimeCwnd, tcpEStatsPerfStartTimeStamp=tcpEStatsPerfStartTimeStamp, tcpEStatsConnectIdTable=tcpEStatsConnectIdTable, tcpEStatsControlStack=tcpEStatsControlStack, tcpEStatsStackDupAcksIn=tcpEStatsStackDupAcksIn, tcpEStatsListenerGroup=tcpEStatsListenerGroup, tcpEStatsControlPath=tcpEStatsControlPath, tcpEStatsPathIpTosIn=tcpEStatsPathIpTosIn, tcpEStatsStackOtherReductions=tcpEStatsStackOtherReductions, tcpEStatsStackCurRetxQueue=tcpEStatsStackCurRetxQueue, tcpEStatsTuneEntry=tcpEStatsTuneEntry, tcpEStatsPerfHCDataOctetsIn=tcpEStatsPerfHCDataOctetsIn, tcpEStatsStackMaxSsCwnd=tcpEStatsStackMaxSsCwnd, tcpEStatsPathNonRecovDA=tcpEStatsPathNonRecovDA, tcpEStatsStackSoftErrorReason=tcpEStatsStackSoftErrorReason, tcpEStatsStackTable=tcpEStatsStackTable, tcpEStatsPathECESent=tcpEStatsPathECESent, tcpEStatsPerfPipeSize=tcpEStatsPerfPipeSize, tcpEStatsStackSlowStart=tcpEStatsStackSlowStart, tcpEStatsStackMSSRcvd=tcpEStatsStackMSSRcvd, tcpEStatsListenerAccepted=tcpEStatsListenerAccepted, tcpEStatsAppGroup=tcpEStatsAppGroup, tcpEStatsStackAbruptTimeouts=tcpEStatsStackAbruptTimeouts, tcpEStatsPathPostCongCountRTT=tcpEStatsPathPostCongCountRTT, tcpEStatsPathSumRTT=tcpEStatsPathSumRTT, tcpEStatsPathEntry=tcpEStatsPathEntry, tcpEStatsPathHCGroup=tcpEStatsPathHCGroup, tcpEStatsListenerSynRcvd=tcpEStatsListenerSynRcvd, tcpEStatsStackMinMSS=tcpEStatsStackMinMSS, tcpEStatsPathSumOctetsReordered=tcpEStatsPathSumOctetsReordered, tcpEStatsAppSndUna=tcpEStatsAppSndUna, tcpEStatsPerfTimeouts=tcpEStatsPerfTimeouts, tcpEStatsListenerExceedBacklog=tcpEStatsListenerExceedBacklog, tcpEStatsPathMinRTO=tcpEStatsPathMinRTO, tcpEStatsPerfOctetsRetrans=tcpEStatsPerfOctetsRetrans, tcpEStatsStackMaxSsthresh=tcpEStatsStackMaxSsthresh, tcpEStatsAppOptionalGroup=tcpEStatsAppOptionalGroup, tcpEStatsPathPreCongSumCwnd=tcpEStatsPathPreCongSumCwnd, tcpEStatsListenerMaxBacklog=tcpEStatsListenerMaxBacklog, tcpEStatsPerfCongSignals=tcpEStatsPerfCongSignals, tcpEStatsStackFastRetran=tcpEStatsStackFastRetran, tcpEStatsTuneOptionalGroup=tcpEStatsTuneOptionalGroup, tcpEStatsCompliance=tcpEStatsCompliance, tcpEStatsListenerCurBacklog=tcpEStatsListenerCurBacklog, tcpEStatsStackMaxCaCwnd=tcpEStatsStackMaxCaCwnd, tcpEStatsPathIpTosOut=tcpEStatsPathIpTosOut, tcpEStatsControlNotify=tcpEStatsControlNotify, tcpEStatsNotificationsCtlGroup=tcpEStatsNotificationsCtlGroup, tcpEStatsAppTable=tcpEStatsAppTable, tcpEStatsPerfSndLimTimeSnd=tcpEStatsPerfSndLimTimeSnd, tcpEStatsPathRcvRTT=tcpEStatsPathRcvRTT, tcpEStatsStackEntry=tcpEStatsStackEntry, tcpEStatsStackWillUseSACK=tcpEStatsStackWillUseSACK, tcpEStatsPerfSmoothedRTT=tcpEStatsPerfSmoothedRTT, tcpEStatsControl=tcpEStatsControl, tcpEStatsPathMaxRTO=tcpEStatsPathMaxRTO, tcpEStatsAppHCThruOctetsReceived=tcpEStatsAppHCThruOctetsReceived, tcpEStatsAppCurAppWQueue=tcpEStatsAppCurAppWQueue, tcpEStatsGroups=tcpEStatsGroups, tcpEStatsMIBObjects=tcpEStatsMIBObjects, tcpEStatsListenerEstablished=tcpEStatsListenerEstablished, tcpEStatsPerfCurMSS=tcpEStatsPerfCurMSS, tcpEStatsListenerHCEstablished=tcpEStatsListenerHCEstablished, tcpEStatsPathECNsignals=tcpEStatsPathECNsignals, tcpEStatsPerfCurCwnd=tcpEStatsPerfCurCwnd, tcpEStatsNotifications=tcpEStatsNotifications, tcpEStatsListenerHCExceedBacklog=tcpEStatsListenerHCExceedBacklog, tcpEStatsPerfSegsRetrans=tcpEStatsPerfSegsRetrans, tcpEStatsPerfMaxRwinSent=tcpEStatsPerfMaxRwinSent, tcpEStatsPathCountRTT=tcpEStatsPathCountRTT, tcpEStatsPerfSegsOut=tcpEStatsPerfSegsOut, tcpEStatsAppSndNxt=tcpEStatsAppSndNxt, tcpEStatsPerfDataSegsIn=tcpEStatsPerfDataSegsIn, tcpEStatsControlTune=tcpEStatsControlTune, tcpEStatsTuneLimMSS=tcpEStatsTuneLimMSS, tcpEStatsStackSpuriousRtoDetected=tcpEStatsStackSpuriousRtoDetected, tcpEStatsStackSendStall=tcpEStatsStackSendStall, tcpEStatsListenerTable=tcpEStatsListenerTable, tcpEStatsStackInRecovery=tcpEStatsStackInRecovery, tcpEStatsAppThruOctetsAcked=tcpEStatsAppThruOctetsAcked, tcpEStatsStackGroup=tcpEStatsStackGroup, tcpEStatsPathRTTVar=tcpEStatsPathRTTVar, tcpEStatsConnectIdEntry=tcpEStatsConnectIdEntry, tcpEStatsPathHCSumRTT=tcpEStatsPathHCSumRTT, tcpEStatsListenerHCInitial=tcpEStatsListenerHCInitial, tcpEStatsAppMaxAppWQueue=tcpEStatsAppMaxAppWQueue, tcpEStatsListenerCurEstabBacklog=tcpEStatsListenerCurEstabBacklog, tcpEStatsListenerHCSynRcvd=tcpEStatsListenerHCSynRcvd, tcpEStatsStackWinScaleRcvd=tcpEStatsStackWinScaleRcvd, tcpEStatsPerfOptionalGroup=tcpEStatsPerfOptionalGroup, tcpEStatsConformance=tcpEStatsConformance, tcpEStatsPerfHCDataOctetsOut=tcpEStatsPerfHCDataOctetsOut, tcpEStatsStackCurTimeoutCount=tcpEStatsStackCurTimeoutCount, tcpEStatsListenerInitial=tcpEStatsListenerInitial, tcpEStatsStackNagle=tcpEStatsStackNagle, tcpEStatsAppCurAppRQueue=tcpEStatsAppCurAppRQueue, tcpEStatsPerfElapsedMicroSecs=tcpEStatsPerfElapsedMicroSecs, tcpEStatsStackCurReasmQueue=tcpEStatsStackCurReasmQueue, tcpEStatsStackSubsequentTimeouts=tcpEStatsStackSubsequentTimeouts, tcpEStatsStackECN=tcpEStatsStackECN, tcpEStatsAppHCGroup=tcpEStatsAppHCGroup, tcpEStatsConnTableLatency=tcpEStatsConnTableLatency, tcpEStatsPathDupAckEpisodes=tcpEStatsPathDupAckEpisodes, tcpEStatsStackMinSsthresh=tcpEStatsStackMinSsthresh, tcpEStatsPathMaxRTT=tcpEStatsPathMaxRTT, tcpEStatsMIB=tcpEStatsMIB, tcpEStatsPathRetranThresh=tcpEStatsPathRetranThresh, tcpEStatsConnectIdGroup=tcpEStatsConnectIdGroup, tcpEStatsTuneLimSsthresh=tcpEStatsTuneLimSsthresh, tcpEStatsPerfSndLimTransCwnd=tcpEStatsPerfSndLimTransCwnd, tcpEStatsPerfCurRTO=tcpEStatsPerfCurRTO, tcpEStatsPathTable=tcpEStatsPathTable, PYSNMP_MODULE_ID=tcpEStatsMIB, tcpEStatsAppSndMax=tcpEStatsAppSndMax, tcpEStatsListenerHCGroup=tcpEStatsListenerHCGroup, tcpEStatsPathIpTtl=tcpEStatsPathIpTtl, tcpEStatsStackCongAvoid=tcpEStatsStackCongAvoid, tcpEStatsPathGroup=tcpEStatsPathGroup, tcpEStatsStackSndInitial=tcpEStatsStackSndInitial, tcpEStatsPathPostCongSumRTT=tcpEStatsPathPostCongSumRTT, tcpEStatsPathMinRTT=tcpEStatsPathMinRTT, tcpEStats=tcpEStats, tcpEStatsPathPreCongSumRTT=tcpEStatsPathPreCongSumRTT, tcpEStatsPathDupAcksOut=tcpEStatsPathDupAcksOut, tcpEStatsStackCongOverCount=tcpEStatsStackCongOverCount, tcpEStatsPathOptionalGroup=tcpEStatsPathOptionalGroup, tcpEStatsNotificationsGroup=tcpEStatsNotificationsGroup, tcpEStatsPerfMaxPipeSize=tcpEStatsPerfMaxPipeSize, tcpEStatsListenerEntry=tcpEStatsListenerEntry, tcpEStatsPerfSndLimTransRwin=tcpEStatsPerfSndLimTransRwin, tcpEStatsPerfGroup=tcpEStatsPerfGroup, tcpEStatsListenerHCAccepted=tcpEStatsListenerHCAccepted, tcpEStatsTuneLimCwnd=tcpEStatsTuneLimCwnd, tcpEStatsPerfElapsedSecs=tcpEStatsPerfElapsedSecs, tcpEStatsListenerStartTime=tcpEStatsListenerStartTime, tcpEStatsPerfCurRwinSent=tcpEStatsPerfCurRwinSent, tcpEStatsPathNonRecovDAEpisodes=tcpEStatsPathNonRecovDAEpisodes, tcpEStatsStackMaxRetxQueue=tcpEStatsStackMaxRetxQueue, tcpEStatsStackSoftErrors=tcpEStatsStackSoftErrors, tcpEStatsStackWinScaleSent=tcpEStatsStackWinScaleSent, tcpEStatsListenerTableLastChange=tcpEStatsListenerTableLastChange, tcpEStatsPerfDataSegsOut=tcpEStatsPerfDataSegsOut, tcpEStatsCompliances=tcpEStatsCompliances, tcpEStatsStackActiveOpen=tcpEStatsStackActiveOpen, tcpEStatsPerfCurRwinRcvd=tcpEStatsPerfCurRwinRcvd, tcpEStatsAppThruOctetsReceived=tcpEStatsAppThruOctetsReceived, tcpEStatsPerfDataOctetsOut=tcpEStatsPerfDataOctetsOut, tcpEStatsListenerCurConns=tcpEStatsListenerCurConns, tcpEStatsScalar=tcpEStatsScalar, tcpEStatsStackOptionalGroup=tcpEStatsStackOptionalGroup)
| (integer, object_identifier, octet_string) = mibBuilder.importSymbols('ASN1', 'Integer', 'ObjectIdentifier', 'OctetString')
(named_values,) = mibBuilder.importSymbols('ASN1-ENUMERATION', 'NamedValues')
(value_range_constraint, value_size_constraint, constraints_union, constraints_intersection, single_value_constraint) = mibBuilder.importSymbols('ASN1-REFINEMENT', 'ValueRangeConstraint', 'ValueSizeConstraint', 'ConstraintsUnion', 'ConstraintsIntersection', 'SingleValueConstraint')
(zero_based_counter64,) = mibBuilder.importSymbols('HCNUM-TC', 'ZeroBasedCounter64')
(zero_based_counter32,) = mibBuilder.importSymbols('RMON2-MIB', 'ZeroBasedCounter32')
(module_compliance, object_group, notification_group) = mibBuilder.importSymbols('SNMPv2-CONF', 'ModuleCompliance', 'ObjectGroup', 'NotificationGroup')
(mib_scalar, mib_table, mib_table_row, mib_table_column, mib_identifier, mib_2, integer32, module_identity, ip_address, bits, object_identity, iso, notification_type, gauge32, counter64, counter32, unsigned32, time_ticks) = mibBuilder.importSymbols('SNMPv2-SMI', 'MibScalar', 'MibTable', 'MibTableRow', 'MibTableColumn', 'MibIdentifier', 'mib-2', 'Integer32', 'ModuleIdentity', 'IpAddress', 'Bits', 'ObjectIdentity', 'iso', 'NotificationType', 'Gauge32', 'Counter64', 'Counter32', 'Unsigned32', 'TimeTicks')
(date_and_time, textual_convention, time_stamp, display_string, truth_value) = mibBuilder.importSymbols('SNMPv2-TC', 'DateAndTime', 'TextualConvention', 'TimeStamp', 'DisplayString', 'TruthValue')
(tcp_listener_entry, tcp_connection_entry) = mibBuilder.importSymbols('TCP-MIB', 'tcpListenerEntry', 'tcpConnectionEntry')
tcp_e_stats_mib = module_identity((1, 3, 6, 1, 2, 1, 156)).setRevisions(('2007-05-18 00:00',))
if mibBuilder.loadTexts:
tcpEStatsMIB.setLastUpdated('200705180000Z')
if mibBuilder.loadTexts:
tcpEStatsMIB.setOrganization('IETF TSV Working Group')
if mibBuilder.loadTexts:
tcpEStatsMIB.setContactInfo('Matt Mathis\n John Heffner\n Web100 Project\n Pittsburgh Supercomputing Center\n 300 S. Craig St.\n Pittsburgh, PA 15213\n Email: mathis@psc.edu, jheffner@psc.edu\n\n Rajiv Raghunarayan\n Cisco Systems Inc.\n San Jose, CA 95134\n Phone: 408 853 9612\n Email: raraghun@cisco.com\n\n Jon Saperia\n 84 Kettell Plain Road\n Stow, MA 01775\n Phone: 617-201-2655\n Email: saperia@jdscons.com ')
if mibBuilder.loadTexts:
tcpEStatsMIB.setDescription('Documentation of TCP Extended Performance Instrumentation\n variables from the Web100 project. [Web100]\n\n All of the objects in this MIB MUST have the same\n persistence properties as the underlying TCP implementation.\n On a reboot, all zero-based counters MUST be cleared, all\n dynamically created table rows MUST be deleted, and all\n read-write objects MUST be restored to their default values.\n\n It is assumed that all TCP implementation have some\n initialization code (if nothing else to set IP addresses)\n that has the opportunity to adjust tcpEStatsConnTableLatency\n and other read-write scalars controlling the creation of the\n various tables, before establishing the first TCP\n connection. Implementations MAY also choose to make these\n control scalars persist across reboots.\n\n Copyright (C) The IETF Trust (2007). This version\n of this MIB module is a part of RFC 4898; see the RFC\n itself for full legal notices.')
tcp_e_stats_notifications = mib_identifier((1, 3, 6, 1, 2, 1, 156, 0))
tcp_e_stats_mib_objects = mib_identifier((1, 3, 6, 1, 2, 1, 156, 1))
tcp_e_stats_conformance = mib_identifier((1, 3, 6, 1, 2, 1, 156, 2))
tcp_e_stats = mib_identifier((1, 3, 6, 1, 2, 1, 156, 1, 1))
tcp_e_stats_control = mib_identifier((1, 3, 6, 1, 2, 1, 156, 1, 2))
tcp_e_stats_scalar = mib_identifier((1, 3, 6, 1, 2, 1, 156, 1, 3))
class Tcpestatsnegotiated(Integer32, TextualConvention):
subtype_spec = Integer32.subtypeSpec + constraints_union(single_value_constraint(1, 2, 3))
named_values = named_values(('enabled', 1), ('selfDisabled', 2), ('peerDisabled', 3))
tcp_e_stats_listener_table_last_change = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 3, 3), time_stamp()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerTableLastChange.setDescription('The value of sysUpTime at the time of the last\n creation or deletion of an entry in the tcpListenerTable.\n If the number of entries has been unchanged since the\n last re-initialization of the local network management\n subsystem, then this object contains a zero value.')
tcp_e_stats_control_path = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 1), truth_value().clone('false')).setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsControlPath.setDescription("Controls the activation of the TCP Path Statistics\n table.\n\n A value 'true' indicates that the TCP Path Statistics\n table is active, while 'false' indicates that the\n table is inactive.")
tcp_e_stats_control_stack = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 2), truth_value().clone('false')).setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsControlStack.setDescription("Controls the activation of the TCP Stack Statistics\n table.\n\n A value 'true' indicates that the TCP Stack Statistics\n table is active, while 'false' indicates that the\n table is inactive.")
tcp_e_stats_control_app = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 3), truth_value().clone('false')).setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsControlApp.setDescription("Controls the activation of the TCP Application\n Statistics table.\n\n A value 'true' indicates that the TCP Application\n Statistics table is active, while 'false' indicates\n that the table is inactive.")
tcp_e_stats_control_tune = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 4), truth_value().clone('false')).setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsControlTune.setDescription("Controls the activation of the TCP Tuning table.\n\n A value 'true' indicates that the TCP Tuning\n table is active, while 'false' indicates that the\n table is inactive.")
tcp_e_stats_control_notify = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 5), truth_value().clone('false')).setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsControlNotify.setDescription("Controls the generation of all notifications defined in\n this MIB.\n\n A value 'true' indicates that the notifications\n are active, while 'false' indicates that the\n notifications are inactive.")
tcp_e_stats_conn_table_latency = mib_scalar((1, 3, 6, 1, 2, 1, 156, 1, 2, 6), unsigned32()).setUnits('seconds').setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsConnTableLatency.setDescription('Specifies the number of seconds that the entity will\n retain entries in the TCP connection tables, after the\n connection first enters the closed state. The entity\n SHOULD provide a configuration option to enable\n\n\n\n customization of this value. A value of 0\n results in entries being removed from the tables as soon as\n the connection enters the closed state. The value of\n this object pertains to the following tables:\n tcpEStatsConnectIdTable\n tcpEStatsPerfTable\n tcpEStatsPathTable\n tcpEStatsStackTable\n tcpEStatsAppTable\n tcpEStatsTuneTable')
tcp_e_stats_listener_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 1))
if mibBuilder.loadTexts:
tcpEStatsListenerTable.setDescription('This table contains information about TCP Listeners,\n in addition to the information maintained by the\n tcpListenerTable RFC 4022.')
tcp_e_stats_listener_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1))
tcpListenerEntry.registerAugmentions(('TCP-ESTATS-MIB', 'tcpEStatsListenerEntry'))
tcpEStatsListenerEntry.setIndexNames(*tcpListenerEntry.getIndexNames())
if mibBuilder.loadTexts:
tcpEStatsListenerEntry.setDescription('Each entry in the table contains information about\n a specific TCP Listener.')
tcp_e_stats_listener_start_time = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 1), time_stamp()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerStartTime.setDescription('The value of sysUpTime at the time this listener was\n established. If the current state was entered prior to\n the last re-initialization of the local network management\n subsystem, then this object contains a zero value.')
tcp_e_stats_listener_syn_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 2), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerSynRcvd.setDescription('The number of SYNs which have been received for this\n listener. The total number of failed connections for\n all reasons can be estimated to be tcpEStatsListenerSynRcvd\n minus tcpEStatsListenerAccepted and\n tcpEStatsListenerCurBacklog.')
tcp_e_stats_listener_initial = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 3), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerInitial.setDescription('The total number of connections for which the Listener\n has allocated initial state and placed the\n connection in the backlog. This may happen in the\n SYN-RCVD or ESTABLISHED states, depending on the\n implementation.')
tcp_e_stats_listener_established = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 4), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerEstablished.setDescription('The number of connections that have been established to\n this endpoint (e.g., the number of first ACKs that have\n been received for this listener).')
tcp_e_stats_listener_accepted = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 5), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerAccepted.setDescription('The total number of connections for which the Listener\n has successfully issued an accept, removing the connection\n from the backlog.')
tcp_e_stats_listener_exceed_backlog = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 6), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerExceedBacklog.setDescription('The total number of connections dropped from the\n backlog by this listener due to all reasons. This\n includes all connections that are allocated initial\n resources, but are not accepted for some reason.')
tcp_e_stats_listener_hc_syn_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 7), zero_based_counter64()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerHCSynRcvd.setDescription('The number of SYNs that have been received for this\n listener on systems that can process (or reject) more\n than 1 million connections per second. See\n tcpEStatsListenerSynRcvd.')
tcp_e_stats_listener_hc_initial = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 8), zero_based_counter64()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerHCInitial.setDescription('The total number of connections for which the Listener\n has allocated initial state and placed the connection\n in the backlog on systems that can process (or reject)\n more than 1 million connections per second. See\n tcpEStatsListenerInitial.')
tcp_e_stats_listener_hc_established = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 9), zero_based_counter64()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerHCEstablished.setDescription('The number of connections that have been established to\n this endpoint on systems that can process (or reject) more\n than 1 million connections per second. See\n tcpEStatsListenerEstablished.')
tcp_e_stats_listener_hc_accepted = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 10), zero_based_counter64()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerHCAccepted.setDescription('The total number of connections for which the Listener\n has successfully issued an accept, removing the connection\n from the backlog on systems that can process (or reject)\n more than 1 million connections per second. See\n tcpEStatsListenerAccepted.')
tcp_e_stats_listener_hc_exceed_backlog = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 11), zero_based_counter64()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerHCExceedBacklog.setDescription('The total number of connections dropped from the\n backlog by this listener due to all reasons on\n systems that can process (or reject) more than\n 1 million connections per second. See\n tcpEStatsListenerExceedBacklog.')
tcp_e_stats_listener_cur_conns = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 12), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerCurConns.setDescription('The current number of connections in the ESTABLISHED\n state, which have also been accepted. It excludes\n connections that have been established but not accepted\n because they are still subject to being discarded to\n shed load without explicit action by either endpoint.')
tcp_e_stats_listener_max_backlog = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 13), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerMaxBacklog.setDescription('The maximum number of connections allowed in the\n backlog at one time.')
tcp_e_stats_listener_cur_backlog = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 14), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerCurBacklog.setDescription('The current number of connections that are in the backlog.\n This gauge includes connections in ESTABLISHED or\n SYN-RECEIVED states for which the Listener has not yet\n issued an accept.\n\n If this listener is using some technique to implicitly\n represent the SYN-RECEIVED states (e.g., by\n cryptographically encoding the state information in the\n initial sequence number, ISS), it MAY elect to exclude\n connections in the SYN-RECEIVED state from the backlog.')
tcp_e_stats_listener_cur_estab_backlog = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 1, 1, 15), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsListenerCurEstabBacklog.setDescription('The current number of connections in the backlog that are\n in the ESTABLISHED state, but for which the Listener has\n not yet issued an accept.')
tcp_e_stats_connect_id_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 2))
if mibBuilder.loadTexts:
tcpEStatsConnectIdTable.setDescription('This table maps information that uniquely identifies\n each active TCP connection to the connection ID used by\n\n\n\n other tables in this MIB Module. It is an extension of\n tcpConnectionTable in RFC 4022.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcp_e_stats_connect_id_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 2, 1))
tcpConnectionEntry.registerAugmentions(('TCP-ESTATS-MIB', 'tcpEStatsConnectIdEntry'))
tcpEStatsConnectIdEntry.setIndexNames(*tcpConnectionEntry.getIndexNames())
if mibBuilder.loadTexts:
tcpEStatsConnectIdEntry.setDescription('Each entry in this table maps a TCP connection\n 4-tuple to a connection index.')
tcp_e_stats_connect_index = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 2, 1, 1), unsigned32().subtype(subtypeSpec=value_range_constraint(1, 4294967295))).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsConnectIndex.setDescription('A unique integer value assigned to each TCP Connection\n entry.\n\n The RECOMMENDED algorithm is to begin at 1 and increase to\n some implementation-specific maximum value and then start\n again at 1 skipping values already in use.')
tcp_e_stats_perf_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 3))
if mibBuilder.loadTexts:
tcpEStatsPerfTable.setDescription('This table contains objects that are useful for\n\n\n\n measuring TCP performance and first line problem\n diagnosis. Most objects in this table directly expose\n some TCP state variable or are easily implemented as\n simple functions (e.g., the maximum value) of TCP\n state variables.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcp_e_stats_perf_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1)).setIndexNames((0, 'TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'))
if mibBuilder.loadTexts:
tcpEStatsPerfEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcp_e_stats_perf_segs_out = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 1), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSegsOut.setDescription('The total number of segments sent.')
tcp_e_stats_perf_data_segs_out = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 2), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfDataSegsOut.setDescription('The number of segments sent containing a positive length\n data segment.')
tcp_e_stats_perf_data_octets_out = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 3), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfDataOctetsOut.setDescription('The number of octets of data contained in transmitted\n segments, including retransmitted data. Note that this does\n not include TCP headers.')
tcp_e_stats_perf_hc_data_octets_out = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 4), zero_based_counter64()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfHCDataOctetsOut.setDescription('The number of octets of data contained in transmitted\n segments, including retransmitted data, on systems that can\n transmit more than 10 million bits per second. Note that\n this does not include TCP headers.')
tcp_e_stats_perf_segs_retrans = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 5), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSegsRetrans.setDescription('The number of segments transmitted containing at least some\n retransmitted data.')
tcp_e_stats_perf_octets_retrans = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 6), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfOctetsRetrans.setDescription('The number of octets retransmitted.')
tcp_e_stats_perf_segs_in = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 7), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSegsIn.setDescription('The total number of segments received.')
tcp_e_stats_perf_data_segs_in = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 8), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfDataSegsIn.setDescription('The number of segments received containing a positive\n\n\n\n length data segment.')
tcp_e_stats_perf_data_octets_in = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 9), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfDataOctetsIn.setDescription('The number of octets contained in received data segments,\n including retransmitted data. Note that this does not\n include TCP headers.')
tcp_e_stats_perf_hc_data_octets_in = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 10), zero_based_counter64()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfHCDataOctetsIn.setDescription('The number of octets contained in received data segments,\n including retransmitted data, on systems that can receive\n more than 10 million bits per second. Note that this does\n not include TCP headers.')
tcp_e_stats_perf_elapsed_secs = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 11), zero_based_counter32()).setUnits('seconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfElapsedSecs.setDescription('The seconds part of the time elapsed between\n tcpEStatsPerfStartTimeStamp and the most recent protocol\n event (segment sent or received).')
tcp_e_stats_perf_elapsed_micro_secs = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 12), zero_based_counter32()).setUnits('microseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfElapsedMicroSecs.setDescription('The micro-second part of time elapsed between\n tcpEStatsPerfStartTimeStamp to the most recent protocol\n event (segment sent or received). This may be updated in\n whatever time granularity is the system supports.')
tcp_e_stats_perf_start_time_stamp = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 13), date_and_time()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfStartTimeStamp.setDescription('Time at which this row was created and all\n ZeroBasedCounters in the row were initialized to zero.')
tcp_e_stats_perf_cur_mss = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 14), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCurMSS.setDescription('The current maximum segment size (MSS), in octets.')
tcp_e_stats_perf_pipe_size = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 15), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfPipeSize.setDescription("The TCP senders current estimate of the number of\n unacknowledged data octets in the network.\n\n While not in recovery (e.g., while the receiver is not\n reporting missing data to the sender), this is precisely the\n same as 'Flight size' as defined in RFC 2581, which can be\n computed as SND.NXT minus SND.UNA. [RFC793]\n\n During recovery, the TCP sender has incomplete information\n about the state of the network (e.g., which segments are\n lost vs reordered, especially if the return path is also\n dropping TCP acknowledgments). Current TCP standards do not\n mandate any specific algorithm for estimating the number of\n unacknowledged data octets in the network.\n\n RFC 3517 describes a conservative algorithm to use SACK\n\n\n\n information to estimate the number of unacknowledged data\n octets in the network. tcpEStatsPerfPipeSize object SHOULD\n be the same as 'pipe' as defined in RFC 3517 if it is\n implemented. (Note that while not in recovery the pipe\n algorithm yields the same values as flight size).\n\n If RFC 3517 is not implemented, the data octets in flight\n SHOULD be estimated as SND.NXT minus SND.UNA adjusted by\n some measure of the data that has left the network and\n retransmitted data. For example, with Reno or NewReno style\n TCP, the number of duplicate acknowledgment is used to\n count the number of segments that have left the network.\n That is,\n PipeSize=SND.NXT-SND.UNA+(retransmits-dupacks)*CurMSS")
tcp_e_stats_perf_max_pipe_size = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 16), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfMaxPipeSize.setDescription('The maximum value of tcpEStatsPerfPipeSize, for this\n connection.')
tcp_e_stats_perf_smoothed_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 17), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSmoothedRTT.setDescription('The smoothed round trip time used in calculation of the\n RTO. See SRTT in [RFC2988].')
tcp_e_stats_perf_cur_rto = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 18), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCurRTO.setDescription('The current value of the retransmit timer RTO.')
tcp_e_stats_perf_cong_signals = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 19), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCongSignals.setDescription('The number of multiplicative downward congestion window\n adjustments due to all forms of congestion signals,\n including Fast Retransmit, Explicit Congestion Notification\n (ECN), and timeouts. This object summarizes all events that\n invoke the MD portion of Additive Increase Multiplicative\n Decrease (AIMD) congestion control, and as such is the best\n indicator of how a cwnd is being affected by congestion.\n\n Note that retransmission timeouts multiplicatively reduce\n the window implicitly by setting ssthresh, and SHOULD be\n included in tcpEStatsPerfCongSignals. In order to minimize\n spurious congestion indications due to out-of-order\n segments, tcpEStatsPerfCongSignals SHOULD be incremented in\n association with the Fast Retransmit algorithm.')
tcp_e_stats_perf_cur_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 20), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCurCwnd.setDescription('The current congestion window, in octets.')
tcp_e_stats_perf_cur_ssthresh = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 21), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCurSsthresh.setDescription('The current slow start threshold in octets.')
tcp_e_stats_perf_timeouts = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 22), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfTimeouts.setDescription('The number of times the retransmit timeout has expired when\n the RTO backoff multiplier is equal to one.')
tcp_e_stats_perf_cur_rwin_sent = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 23), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCurRwinSent.setDescription('The most recent window advertisement sent, in octets.')
tcp_e_stats_perf_max_rwin_sent = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 24), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfMaxRwinSent.setDescription('The maximum window advertisement sent, in octets.')
tcp_e_stats_perf_zero_rwin_sent = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 25), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfZeroRwinSent.setDescription('The number of acknowledgments sent announcing a zero\n\n\n\n receive window, when the previously announced window was\n not zero.')
tcp_e_stats_perf_cur_rwin_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 26), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfCurRwinRcvd.setDescription('The most recent window advertisement received, in octets.')
tcp_e_stats_perf_max_rwin_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 27), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfMaxRwinRcvd.setDescription('The maximum window advertisement received, in octets.')
tcp_e_stats_perf_zero_rwin_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 28), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfZeroRwinRcvd.setDescription('The number of acknowledgments received announcing a zero\n receive window, when the previously announced window was\n not zero.')
tcp_e_stats_perf_snd_lim_trans_rwin = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 31), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSndLimTransRwin.setDescription("The number of transitions into the 'Receiver Limited' state\n from either the 'Congestion Limited' or 'Sender Limited'\n states. This state is entered whenever TCP transmission\n stops because the sender has filled the announced receiver\n window, i.e., when SND.NXT has advanced to SND.UNA +\n SND.WND - 1 as described in RFC 793.")
tcp_e_stats_perf_snd_lim_trans_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 32), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSndLimTransCwnd.setDescription("The number of transitions into the 'Congestion Limited'\n state from either the 'Receiver Limited' or 'Sender\n Limited' states. This state is entered whenever TCP\n transmission stops because the sender has reached some\n limit defined by congestion control (e.g., cwnd) or other\n algorithms (retransmission timeouts) designed to control\n network traffic. See the definition of 'CONGESTION WINDOW'\n\n\n\n in RFC 2581.")
tcp_e_stats_perf_snd_lim_trans_snd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 33), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSndLimTransSnd.setDescription("The number of transitions into the 'Sender Limited' state\n from either the 'Receiver Limited' or 'Congestion Limited'\n states. This state is entered whenever TCP transmission\n stops due to some sender limit such as running out of\n application data or other resources and the Karn algorithm.\n When TCP stops sending data for any reason, which cannot be\n classified as Receiver Limited or Congestion Limited, it\n MUST be treated as Sender Limited.")
tcp_e_stats_perf_snd_lim_time_rwin = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 34), zero_based_counter32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSndLimTimeRwin.setDescription("The cumulative time spent in the 'Receiver Limited' state.\n See tcpEStatsPerfSndLimTransRwin.")
tcp_e_stats_perf_snd_lim_time_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 35), zero_based_counter32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSndLimTimeCwnd.setDescription("The cumulative time spent in the 'Congestion Limited'\n state. See tcpEStatsPerfSndLimTransCwnd. When there is a\n retransmission timeout, it SHOULD be counted in\n tcpEStatsPerfSndLimTimeCwnd (and not the cumulative time\n for some other state.)")
tcp_e_stats_perf_snd_lim_time_snd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 3, 1, 36), zero_based_counter32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPerfSndLimTimeSnd.setDescription("The cumulative time spent in the 'Sender Limited' state.\n See tcpEStatsPerfSndLimTransSnd.")
tcp_e_stats_path_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 4))
if mibBuilder.loadTexts:
tcpEStatsPathTable.setDescription('This table contains objects that can be used to infer\n detailed behavior of the Internet path, such as the\n extent that there is reordering, ECN bits, and if\n RTT fluctuations are correlated to losses.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcp_e_stats_path_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1)).setIndexNames((0, 'TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'))
if mibBuilder.loadTexts:
tcpEStatsPathEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcp_e_stats_path_retran_thresh = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 1), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathRetranThresh.setDescription('The number of duplicate acknowledgments required to trigger\n Fast Retransmit. Note that although this is constant in\n traditional Reno TCP implementations, it is adaptive in\n many newer TCPs.')
tcp_e_stats_path_non_recov_da_episodes = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 2), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathNonRecovDAEpisodes.setDescription("The number of duplicate acknowledgment episodes that did\n not trigger a Fast Retransmit because ACK advanced prior to\n the number of duplicate acknowledgments reaching\n RetranThresh.\n\n\n\n\n In many implementations this is the number of times the\n 'dupacks' counter is set to zero when it is non-zero but\n less than RetranThresh.\n\n Note that the change in tcpEStatsPathNonRecovDAEpisodes\n divided by the change in tcpEStatsPerfDataSegsOut is an\n estimate of the frequency of data reordering on the forward\n path over some interval.")
tcp_e_stats_path_sum_octets_reordered = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 3), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathSumOctetsReordered.setDescription('The sum of the amounts SND.UNA advances on the\n acknowledgment which ends a dup-ack episode without a\n retransmission.\n\n Note the change in tcpEStatsPathSumOctetsReordered divided\n by the change in tcpEStatsPathNonRecovDAEpisodes is an\n estimates of the average reordering distance, over some\n interval.')
tcp_e_stats_path_non_recov_da = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 4), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathNonRecovDA.setDescription("Duplicate acks (or SACKS) that did not trigger a Fast\n Retransmit because ACK advanced prior to the number of\n duplicate acknowledgments reaching RetranThresh.\n\n In many implementations, this is the sum of the 'dupacks'\n counter, just before it is set to zero because ACK advanced\n without a Fast Retransmit.\n\n Note that the change in tcpEStatsPathNonRecovDA divided by\n the change in tcpEStatsPathNonRecovDAEpisodes is an\n estimate of the average reordering distance in segments\n over some interval.")
tcp_e_stats_path_sample_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 11), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathSampleRTT.setDescription('The most recent raw round trip time measurement used in\n calculation of the RTO.')
tcp_e_stats_path_rtt_var = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 12), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathRTTVar.setDescription('The round trip time variation used in calculation of the\n RTO. See RTTVAR in [RFC2988].')
tcp_e_stats_path_max_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 13), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathMaxRTT.setDescription('The maximum sampled round trip time.')
tcp_e_stats_path_min_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 14), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathMinRTT.setDescription('The minimum sampled round trip time.')
tcp_e_stats_path_sum_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 15), zero_based_counter32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathSumRTT.setDescription('The sum of all sampled round trip times.\n\n Note that the change in tcpEStatsPathSumRTT divided by the\n change in tcpEStatsPathCountRTT is the mean RTT, uniformly\n averaged over an enter interval.')
tcp_e_stats_path_hc_sum_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 16), zero_based_counter64()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathHCSumRTT.setDescription('The sum of all sampled round trip times, on all systems\n that implement multiple concurrent RTT measurements.\n\n Note that the change in tcpEStatsPathHCSumRTT divided by\n the change in tcpEStatsPathCountRTT is the mean RTT,\n uniformly averaged over an enter interval.')
tcp_e_stats_path_count_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 17), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathCountRTT.setDescription('The number of round trip time samples included in\n tcpEStatsPathSumRTT and tcpEStatsPathHCSumRTT.')
tcp_e_stats_path_max_rto = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 18), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathMaxRTO.setDescription('The maximum value of the retransmit timer RTO.')
tcp_e_stats_path_min_rto = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 19), gauge32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathMinRTO.setDescription('The minimum value of the retransmit timer RTO.')
tcp_e_stats_path_ip_ttl = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 20), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathIpTtl.setDescription('The value of the TTL field carried in the most recently\n received IP header. This is sometimes useful to detect\n changing or unstable routes.')
tcp_e_stats_path_ip_tos_in = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 21), octet_string().subtype(subtypeSpec=value_size_constraint(1, 1)).setFixedLength(1)).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathIpTosIn.setDescription('The value of the IPv4 Type of Service octet, or the IPv6\n traffic class octet, carried in the most recently received\n IP header.\n\n This is useful to diagnose interactions between TCP and any\n IP layer packet scheduling and delivery policy, which might\n be in effect to implement Diffserv.')
tcp_e_stats_path_ip_tos_out = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 22), octet_string().subtype(subtypeSpec=value_size_constraint(1, 1)).setFixedLength(1)).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathIpTosOut.setDescription('The value of the IPv4 Type Of Service octet, or the IPv6\n traffic class octet, carried in the most recently\n transmitted IP header.\n\n This is useful to diagnose interactions between TCP and any\n IP layer packet scheduling and delivery policy, which might\n be in effect to implement Diffserv.')
tcp_e_stats_path_pre_cong_sum_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 23), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathPreCongSumCwnd.setDescription('The sum of the values of the congestion window, in octets,\n captured each time a congestion signal is received. This\n MUST be updated each time tcpEStatsPerfCongSignals is\n incremented, such that the change in\n tcpEStatsPathPreCongSumCwnd divided by the change in\n tcpEStatsPerfCongSignals is the average window (over some\n interval) just prior to a congestion signal.')
tcp_e_stats_path_pre_cong_sum_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 24), zero_based_counter32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathPreCongSumRTT.setDescription('Sum of the last sample of the RTT (tcpEStatsPathSampleRTT)\n prior to the received congestion signals. This MUST be\n updated each time tcpEStatsPerfCongSignals is incremented,\n such that the change in tcpEStatsPathPreCongSumRTT divided by\n the change in tcpEStatsPerfCongSignals is the average RTT\n (over some interval) just prior to a congestion signal.')
tcp_e_stats_path_post_cong_sum_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 25), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathPostCongSumRTT.setDescription('Sum of the first sample of the RTT (tcpEStatsPathSampleRTT)\n following each congestion signal. Such that the change in\n tcpEStatsPathPostCongSumRTT divided by the change in\n tcpEStatsPathPostCongCountRTT is the average RTT (over some\n interval) just after a congestion signal.')
tcp_e_stats_path_post_cong_count_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 26), zero_based_counter32()).setUnits('milliseconds').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathPostCongCountRTT.setDescription('The number of RTT samples included in\n tcpEStatsPathPostCongSumRTT such that the change in\n tcpEStatsPathPostCongSumRTT divided by the change in\n tcpEStatsPathPostCongCountRTT is the average RTT (over some\n interval) just after a congestion signal.')
tcp_e_stats_path_ec_nsignals = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 27), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathECNsignals.setDescription('The number of congestion signals delivered to the TCP\n sender via explicit congestion notification (ECN). This is\n typically the number of segments bearing Echo Congestion\n\n\n\n Experienced (ECE) bits, but\n should also include segments failing the ECN nonce check or\n other explicit congestion signals.')
tcp_e_stats_path_dup_ack_episodes = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 28), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathDupAckEpisodes.setDescription('The number of Duplicate Acks Sent when prior Ack was not\n duplicate. This is the number of times that a contiguous\n series of duplicate acknowledgments have been sent.\n\n This is an indication of the number of data segments lost\n or reordered on the path from the remote TCP endpoint to\n the near TCP endpoint.')
tcp_e_stats_path_rcv_rtt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 29), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathRcvRTT.setDescription("The receiver's estimate of the Path RTT.\n\n Adaptive receiver window algorithms depend on the receiver\n to having a good estimate of the path RTT.")
tcp_e_stats_path_dup_acks_out = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 30), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathDupAcksOut.setDescription('The number of duplicate ACKs sent. The ratio of the change\n in tcpEStatsPathDupAcksOut to the change in\n tcpEStatsPathDupAckEpisodes is an indication of reorder or\n recovery distance over some interval.')
tcp_e_stats_path_ce_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 31), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathCERcvd.setDescription('The number of segments received with IP headers bearing\n Congestion Experienced (CE) markings.')
tcp_e_stats_path_ece_sent = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 4, 1, 32), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsPathECESent.setDescription('Number of times the Echo Congestion Experienced (ECE) bit\n in the TCP header has been set (transitioned from 0 to 1),\n due to a Congestion Experienced (CE) marking on an IP\n header. Note that ECE can be set and reset only once per\n RTT, while CE can be set on many segments per RTT.')
tcp_e_stats_stack_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 5))
if mibBuilder.loadTexts:
tcpEStatsStackTable.setDescription('This table contains objects that are most useful for\n determining how well some of the TCP control\n algorithms are coping with this particular\n\n\n\n path.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcp_e_stats_stack_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1)).setIndexNames((0, 'TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'))
if mibBuilder.loadTexts:
tcpEStatsStackEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcp_e_stats_stack_active_open = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 1), truth_value()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackActiveOpen.setDescription('True(1) if the local connection traversed the SYN-SENT\n state, else false(2).')
tcp_e_stats_stack_mss_sent = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 2), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMSSSent.setDescription('The value sent in an MSS option, or zero if none.')
tcp_e_stats_stack_mss_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 3), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMSSRcvd.setDescription('The value received in an MSS option, or zero if none.')
tcp_e_stats_stack_win_scale_sent = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 4), integer32().subtype(subtypeSpec=value_range_constraint(-1, 14))).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackWinScaleSent.setDescription('The value of the transmitted window scale option if one was\n sent; otherwise, a value of -1.\n\n Note that if both tcpEStatsStackWinScaleSent and\n tcpEStatsStackWinScaleRcvd are not -1, then Rcv.Wind.Scale\n will be the same as this value and used to scale receiver\n window announcements from the local host to the remote\n host.')
tcp_e_stats_stack_win_scale_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 5), integer32().subtype(subtypeSpec=value_range_constraint(-1, 14))).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackWinScaleRcvd.setDescription('The value of the received window scale option if one was\n received; otherwise, a value of -1.\n\n Note that if both tcpEStatsStackWinScaleSent and\n tcpEStatsStackWinScaleRcvd are not -1, then Snd.Wind.Scale\n will be the same as this value and used to scale receiver\n window announcements from the remote host to the local\n host.')
tcp_e_stats_stack_time_stamps = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 6), tcp_e_stats_negotiated()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackTimeStamps.setDescription('Enabled(1) if TCP timestamps have been negotiated on,\n selfDisabled(2) if they are disabled or not implemented on\n the local host, or peerDisabled(3) if not negotiated by the\n remote hosts.')
tcp_e_stats_stack_ecn = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 7), tcp_e_stats_negotiated()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackECN.setDescription('Enabled(1) if Explicit Congestion Notification (ECN) has\n been negotiated on, selfDisabled(2) if it is disabled or\n not implemented on the local host, or peerDisabled(3) if\n not negotiated by the remote hosts.')
tcp_e_stats_stack_will_send_sack = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 8), tcp_e_stats_negotiated()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackWillSendSACK.setDescription('Enabled(1) if the local host will send SACK options,\n selfDisabled(2) if SACK is disabled or not implemented on\n the local host, or peerDisabled(3) if the remote host did\n not send the SACK-permitted option.\n\n Note that SACK negotiation is not symmetrical. SACK can\n enabled on one side of the connection and not the other.')
tcp_e_stats_stack_will_use_sack = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 9), tcp_e_stats_negotiated()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackWillUseSACK.setDescription('Enabled(1) if the local host will process SACK options,\n selfDisabled(2) if SACK is disabled or not implemented on\n the local host, or peerDisabled(3) if the remote host sends\n\n\n\n duplicate ACKs without SACK options, or the local host\n otherwise decides not to process received SACK options.\n\n Unlike other TCP options, the remote data receiver cannot\n explicitly indicate if it is able to generate SACK options.\n When sending data, the local host has to deduce if the\n remote receiver is sending SACK options. This object can\n transition from Enabled(1) to peerDisabled(3) after the SYN\n exchange.\n\n Note that SACK negotiation is not symmetrical. SACK can\n enabled on one side of the connection and not the other.')
tcp_e_stats_stack_state = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 10), integer32().subtype(subtypeSpec=constraints_union(single_value_constraint(1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12))).clone(namedValues=named_values(('tcpESStateClosed', 1), ('tcpESStateListen', 2), ('tcpESStateSynSent', 3), ('tcpESStateSynReceived', 4), ('tcpESStateEstablished', 5), ('tcpESStateFinWait1', 6), ('tcpESStateFinWait2', 7), ('tcpESStateCloseWait', 8), ('tcpESStateLastAck', 9), ('tcpESStateClosing', 10), ('tcpESStateTimeWait', 11), ('tcpESStateDeleteTcb', 12)))).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackState.setDescription('An integer value representing the connection state from the\n TCP State Transition Diagram.\n\n The value listen(2) is included only for parallelism to the\n old tcpConnTable, and SHOULD NOT be used because the listen\n state in managed by the tcpListenerTable.\n\n The value DeleteTcb(12) is included only for parallelism to\n the tcpConnTable mechanism for terminating connections,\n\n\n\n although this table does not permit writing.')
tcp_e_stats_stack_nagle = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 11), truth_value()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackNagle.setDescription('True(1) if the Nagle algorithm is being used, else\n false(2).')
tcp_e_stats_stack_max_ss_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 12), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMaxSsCwnd.setDescription('The maximum congestion window used during Slow Start, in\n octets.')
tcp_e_stats_stack_max_ca_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 13), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMaxCaCwnd.setDescription('The maximum congestion window used during Congestion\n Avoidance, in octets.')
tcp_e_stats_stack_max_ssthresh = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 14), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMaxSsthresh.setDescription('The maximum slow start threshold, excluding the initial\n value.')
tcp_e_stats_stack_min_ssthresh = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 15), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMinSsthresh.setDescription('The minimum slow start threshold.')
tcp_e_stats_stack_in_recovery = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 16), integer32().subtype(subtypeSpec=constraints_union(single_value_constraint(1, 2, 3))).clone(namedValues=named_values(('tcpESDataContiguous', 1), ('tcpESDataUnordered', 2), ('tcpESDataRecovery', 3)))).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackInRecovery.setDescription('An integer value representing the state of the loss\n recovery for this connection.\n\n tcpESDataContiguous(1) indicates that the remote receiver\n is reporting contiguous data (no duplicate acknowledgments\n or SACK options) and that there are no unacknowledged\n retransmissions.\n\n tcpESDataUnordered(2) indicates that the remote receiver is\n reporting missing or out-of-order data (e.g., sending\n duplicate acknowledgments or SACK options) and that there\n are no unacknowledged retransmissions (because the missing\n data has not yet been retransmitted).\n\n tcpESDataRecovery(3) indicates that the sender has\n outstanding retransmitted data that is still\n\n\n\n unacknowledged.')
tcp_e_stats_stack_dup_acks_in = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 17), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackDupAcksIn.setDescription('The number of duplicate ACKs received.')
tcp_e_stats_stack_spurious_fr_detected = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 18), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSpuriousFrDetected.setDescription("The number of acknowledgments reporting out-of-order\n segments after the Fast Retransmit algorithm has already\n retransmitted the segments. (For example as detected by the\n Eifel algorithm).'")
tcp_e_stats_stack_spurious_rto_detected = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 19), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSpuriousRtoDetected.setDescription('The number of acknowledgments reporting segments that have\n already been retransmitted due to a Retransmission Timeout.')
tcp_e_stats_stack_soft_errors = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 21), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSoftErrors.setDescription('The number of segments that fail various consistency tests\n during TCP input processing. Soft errors might cause the\n segment to be discarded but some do not. Some of these soft\n errors cause the generation of a TCP acknowledgment, while\n others are silently discarded.')
tcp_e_stats_stack_soft_error_reason = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 22), integer32().subtype(subtypeSpec=constraints_union(single_value_constraint(1, 2, 3, 4, 5, 6, 7, 8))).clone(namedValues=named_values(('belowDataWindow', 1), ('aboveDataWindow', 2), ('belowAckWindow', 3), ('aboveAckWindow', 4), ('belowTSWindow', 5), ('aboveTSWindow', 6), ('dataCheckSum', 7), ('otherSoftError', 8)))).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSoftErrorReason.setDescription('This object identifies which consistency test most recently\n failed during TCP input processing. This object SHOULD be\n set every time tcpEStatsStackSoftErrors is incremented. The\n codes are as follows:\n\n belowDataWindow(1) - All data in the segment is below\n SND.UNA. (Normal for keep-alives and zero window probes).\n\n aboveDataWindow(2) - Some data in the segment is above\n SND.WND. (Indicates an implementation bug or possible\n attack).\n\n belowAckWindow(3) - ACK below SND.UNA. (Indicates that the\n return path is reordering ACKs)\n\n aboveAckWindow(4) - An ACK for data that we have not sent.\n (Indicates an implementation bug or possible attack).\n\n belowTSWindow(5) - TSecr on the segment is older than the\n current TS.Recent (Normal for the rare case where PAWS\n detects data reordered by the network).\n\n aboveTSWindow(6) - TSecr on the segment is newer than the\n current TS.Recent. (Indicates an implementation bug or\n possible attack).\n\n\n\n\n dataCheckSum(7) - Incorrect checksum. Note that this value\n is intrinsically fragile, because the header fields used to\n identify the connection may have been corrupted.\n\n otherSoftError(8) - All other soft errors not listed\n above.')
tcp_e_stats_stack_slow_start = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 23), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSlowStart.setDescription('The number of times the congestion window has been\n increased by the Slow Start algorithm.')
tcp_e_stats_stack_cong_avoid = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 24), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackCongAvoid.setDescription('The number of times the congestion window has been\n increased by the Congestion Avoidance algorithm.')
tcp_e_stats_stack_other_reductions = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 25), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackOtherReductions.setDescription('The number of congestion window reductions made as a result\n of anything other than AIMD congestion control algorithms.\n Examples of non-multiplicative window reductions include\n Congestion Window Validation [RFC2861] and experimental\n algorithms such as Vegas [Bra94].\n\n\n\n\n All window reductions MUST be counted as either\n tcpEStatsPerfCongSignals or tcpEStatsStackOtherReductions.')
tcp_e_stats_stack_cong_over_count = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 26), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackCongOverCount.setDescription("The number of congestion events that were 'backed out' of\n the congestion control state machine such that the\n congestion window was restored to a prior value. This can\n happen due to the Eifel algorithm [RFC3522] or other\n algorithms that can be used to detect and cancel spurious\n invocations of the Fast Retransmit Algorithm.\n\n Although it may be feasible to undo the effects of spurious\n invocation of the Fast Retransmit congestion events cannot\n easily be backed out of tcpEStatsPerfCongSignals and\n tcpEStatsPathPreCongSumCwnd, etc.")
tcp_e_stats_stack_fast_retran = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 27), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackFastRetran.setDescription('The number of invocations of the Fast Retransmit algorithm.')
tcp_e_stats_stack_subsequent_timeouts = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 28), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSubsequentTimeouts.setDescription('The number of times the retransmit timeout has expired after\n the RTO has been doubled. See Section 5.5 of RFC 2988.')
tcp_e_stats_stack_cur_timeout_count = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 29), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackCurTimeoutCount.setDescription('The current number of times the retransmit timeout has\n expired without receiving an acknowledgment for new data.\n tcpEStatsStackCurTimeoutCount is reset to zero when new\n data is acknowledged and incremented for each invocation of\n Section 5.5 of RFC 2988.')
tcp_e_stats_stack_abrupt_timeouts = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 30), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackAbruptTimeouts.setDescription('The number of timeouts that occurred without any\n immediately preceding duplicate acknowledgments or other\n indications of congestion. Abrupt Timeouts indicate that\n the path lost an entire window of data or acknowledgments.\n\n Timeouts that are preceded by duplicate acknowledgments or\n other congestion signals (e.g., ECN) are not counted as\n abrupt, and might have been avoided by a more sophisticated\n Fast Retransmit algorithm.')
tcp_e_stats_stack_sac_ks_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 31), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSACKsRcvd.setDescription('The number of SACK options received.')
tcp_e_stats_stack_sack_blocks_rcvd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 32), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSACKBlocksRcvd.setDescription('The number of SACK blocks received (within SACK options).')
tcp_e_stats_stack_send_stall = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 33), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSendStall.setDescription('The number of interface stalls or other sender local\n resource limitations that are treated as congestion\n signals.')
tcp_e_stats_stack_dsack_dups = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 34), zero_based_counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackDSACKDups.setDescription('The number of duplicate segments reported to the local host\n by D-SACK blocks.')
tcp_e_stats_stack_max_mss = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 35), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMaxMSS.setDescription('The maximum MSS, in octets.')
tcp_e_stats_stack_min_mss = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 36), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMinMSS.setDescription('The minimum MSS, in octets.')
tcp_e_stats_stack_snd_initial = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 37), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackSndInitial.setDescription('Initial send sequence number. Note that by definition\n tcpEStatsStackSndInitial never changes for a given\n connection.')
tcp_e_stats_stack_rec_initial = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 38), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackRecInitial.setDescription('Initial receive sequence number. Note that by definition\n tcpEStatsStackRecInitial never changes for a given\n connection.')
tcp_e_stats_stack_cur_retx_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 39), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackCurRetxQueue.setDescription('The current number of octets of data occupying the\n retransmit queue.')
tcp_e_stats_stack_max_retx_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 40), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMaxRetxQueue.setDescription('The maximum number of octets of data occupying the\n retransmit queue.')
tcp_e_stats_stack_cur_reasm_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 41), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackCurReasmQueue.setDescription('The current number of octets of sequence space spanned by\n the reassembly queue. This is generally the difference\n between rcv.nxt and the sequence number of the right most\n edge of the reassembly queue.')
tcp_e_stats_stack_max_reasm_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 5, 1, 42), gauge32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsStackMaxReasmQueue.setDescription('The maximum value of tcpEStatsStackCurReasmQueue')
tcp_e_stats_app_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 6))
if mibBuilder.loadTexts:
tcpEStatsAppTable.setDescription('This table contains objects that are useful for\n determining if the application using TCP is\n\n\n\n limiting TCP performance.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcp_e_stats_app_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1)).setIndexNames((0, 'TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'))
if mibBuilder.loadTexts:
tcpEStatsAppEntry.setDescription('Each entry in this table has information about the\n characteristics of each active and recently closed TCP\n connection.')
tcp_e_stats_app_snd_una = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 1), counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppSndUna.setDescription('The value of SND.UNA, the oldest unacknowledged sequence\n number.\n\n Note that SND.UNA is a TCP state variable that is congruent\n to Counter32 semantics.')
tcp_e_stats_app_snd_nxt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 2), unsigned32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppSndNxt.setDescription('The value of SND.NXT, the next sequence number to be sent.\n Note that tcpEStatsAppSndNxt is not monotonic (and thus not\n a counter) because TCP sometimes retransmits lost data by\n pulling tcpEStatsAppSndNxt back to the missing data.')
tcp_e_stats_app_snd_max = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 3), counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppSndMax.setDescription('The farthest forward (right most or largest) SND.NXT value.\n Note that this will be equal to tcpEStatsAppSndNxt except\n when tcpEStatsAppSndNxt is pulled back during recovery.')
tcp_e_stats_app_thru_octets_acked = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 4), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppThruOctetsAcked.setDescription('The number of octets for which cumulative acknowledgments\n have been received. Note that this will be the sum of\n changes to tcpEStatsAppSndUna.')
tcp_e_stats_app_hc_thru_octets_acked = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 5), zero_based_counter64()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppHCThruOctetsAcked.setDescription('The number of octets for which cumulative acknowledgments\n have been received, on systems that can receive more than\n 10 million bits per second. Note that this will be the sum\n of changes in tcpEStatsAppSndUna.')
tcp_e_stats_app_rcv_nxt = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 6), counter32()).setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppRcvNxt.setDescription('The value of RCV.NXT. The next sequence number expected on\n an incoming segment, and the left or lower edge of the\n receive window.\n\n Note that RCV.NXT is a TCP state variable that is congruent\n to Counter32 semantics.')
tcp_e_stats_app_thru_octets_received = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 7), zero_based_counter32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppThruOctetsReceived.setDescription('The number of octets for which cumulative acknowledgments\n have been sent. Note that this will be the sum of changes\n to tcpEStatsAppRcvNxt.')
tcp_e_stats_app_hc_thru_octets_received = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 8), zero_based_counter64()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppHCThruOctetsReceived.setDescription('The number of octets for which cumulative acknowledgments\n have been sent, on systems that can transmit more than 10\n million bits per second. Note that this will be the sum of\n changes in tcpEStatsAppRcvNxt.')
tcp_e_stats_app_cur_app_w_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 11), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppCurAppWQueue.setDescription('The current number of octets of application data buffered\n by TCP, pending first transmission, i.e., to the left of\n SND.NXT or SndMax. This data will generally be transmitted\n (and SND.NXT advanced to the left) as soon as there is an\n available congestion window (cwnd) or receiver window\n (rwin). This is the amount of data readily available for\n transmission, without scheduling the application. TCP\n performance may suffer if there is insufficient queued\n write data.')
tcp_e_stats_app_max_app_w_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 12), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppMaxAppWQueue.setDescription('The maximum number of octets of application data buffered\n by TCP, pending first transmission. This is the maximum\n value of tcpEStatsAppCurAppWQueue. This pair of objects can\n be used to determine if insufficient queued data is steady\n state (suggesting insufficient queue space) or transient\n (suggesting insufficient application performance or\n excessive CPU load or scheduler latency).')
tcp_e_stats_app_cur_app_r_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 13), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppCurAppRQueue.setDescription('The current number of octets of application data that has\n been acknowledged by TCP but not yet delivered to the\n application.')
tcp_e_stats_app_max_app_r_queue = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 6, 1, 14), gauge32()).setUnits('octets').setMaxAccess('readonly')
if mibBuilder.loadTexts:
tcpEStatsAppMaxAppRQueue.setDescription('The maximum number of octets of application data that has\n been acknowledged by TCP but not yet delivered to the\n application.')
tcp_e_stats_tune_table = mib_table((1, 3, 6, 1, 2, 1, 156, 1, 1, 7))
if mibBuilder.loadTexts:
tcpEStatsTuneTable.setDescription('This table contains per-connection controls that can\n be used to work around a number of common problems that\n plague TCP over some paths. All can be characterized as\n limiting the growth of the congestion window so as to\n prevent TCP from overwhelming some component in the\n path.\n\n Entries are retained in this table for the number of\n seconds indicated by the tcpEStatsConnTableLatency\n object, after the TCP connection first enters the closed\n state.')
tcp_e_stats_tune_entry = mib_table_row((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1)).setIndexNames((0, 'TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'))
if mibBuilder.loadTexts:
tcpEStatsTuneEntry.setDescription('Each entry in this table is a control that can be used to\n place limits on each active TCP connection.')
tcp_e_stats_tune_lim_cwnd = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 1), unsigned32()).setUnits('octets').setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsTuneLimCwnd.setDescription('A control to set the maximum congestion window that may be\n used, in octets.')
tcp_e_stats_tune_lim_ssthresh = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 2), unsigned32()).setUnits('octets').setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsTuneLimSsthresh.setDescription('A control to limit the maximum queue space (in octets) that\n this TCP connection is likely to occupy during slowstart.\n\n It can be implemented with the algorithm described in\n RFC 3742 by setting the max_ssthresh parameter to twice\n tcpEStatsTuneLimSsthresh.\n\n This algorithm can be used to overcome some TCP performance\n problems over network paths that do not have sufficient\n buffering to withstand the bursts normally present during\n slowstart.')
tcp_e_stats_tune_lim_rwin = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 3), unsigned32()).setUnits('octets').setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsTuneLimRwin.setDescription('A control to set the maximum window advertisement that may\n be sent, in octets.')
tcp_e_stats_tune_lim_mss = mib_table_column((1, 3, 6, 1, 2, 1, 156, 1, 1, 7, 1, 4), unsigned32()).setUnits('octets').setMaxAccess('readwrite')
if mibBuilder.loadTexts:
tcpEStatsTuneLimMSS.setDescription('A control to limit the maximum segment size in octets, that\n this TCP connection can use.')
tcp_e_stats_establish_notification = notification_type((1, 3, 6, 1, 2, 1, 156, 0, 1)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'),))
if mibBuilder.loadTexts:
tcpEStatsEstablishNotification.setDescription('The indicated connection has been accepted\n (or alternatively entered the established state).')
tcp_e_stats_close_notification = notification_type((1, 3, 6, 1, 2, 1, 156, 0, 2)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsConnectIndex'),))
if mibBuilder.loadTexts:
tcpEStatsCloseNotification.setDescription('The indicated connection has left the\n established state')
tcp_e_stats_compliances = mib_identifier((1, 3, 6, 1, 2, 1, 156, 2, 1))
tcp_e_stats_groups = mib_identifier((1, 3, 6, 1, 2, 1, 156, 2, 2))
tcp_e_stats_compliance = module_compliance((1, 3, 6, 1, 2, 1, 156, 2, 1, 1)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsListenerGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsConnectIdGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsPathGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsStackGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsAppGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerHCGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfOptionalGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfHCGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsPathOptionalGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsPathHCGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsStackOptionalGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsAppHCGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsAppOptionalGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsTuneOptionalGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsNotificationsGroup'), ('TCP-ESTATS-MIB', 'tcpEStatsNotificationsCtlGroup')))
if mibBuilder.loadTexts:
tcpEStatsCompliance.setDescription('Compliance statement for all systems that implement TCP\n extended statistics.')
tcp_e_stats_listener_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 1)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsListenerTableLastChange'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerStartTime'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerSynRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerInitial'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerEstablished'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerAccepted'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerExceedBacklog'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerCurConns'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerMaxBacklog'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerCurBacklog'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerCurEstabBacklog')))
if mibBuilder.loadTexts:
tcpEStatsListenerGroup.setDescription('The tcpEStatsListener group includes objects that\n provide valuable statistics and debugging\n information for TCP Listeners.')
tcp_e_stats_listener_hc_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 2)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsListenerHCSynRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerHCInitial'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerHCEstablished'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerHCAccepted'), ('TCP-ESTATS-MIB', 'tcpEStatsListenerHCExceedBacklog')))
if mibBuilder.loadTexts:
tcpEStatsListenerHCGroup.setDescription('The tcpEStatsListenerHC group includes 64-bit\n counters in tcpEStatsListenerTable.')
tcp_e_stats_connect_id_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 3)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsConnTableLatency'), ('TCP-ESTATS-MIB', 'tcpEStatsConnectIndex')))
if mibBuilder.loadTexts:
tcpEStatsConnectIdGroup.setDescription('The tcpEStatsConnectId group includes objects that\n identify TCP connections and control how long TCP\n connection entries are retained in the tables.')
tcp_e_stats_perf_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 4)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsPerfSegsOut'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfDataSegsOut'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfDataOctetsOut'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSegsRetrans'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfOctetsRetrans'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSegsIn'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfDataSegsIn'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfDataOctetsIn'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfElapsedSecs'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfElapsedMicroSecs'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfStartTimeStamp'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCurMSS'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfPipeSize'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfMaxPipeSize'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSmoothedRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCurRTO'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCongSignals'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCurCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCurSsthresh'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfTimeouts'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCurRwinSent'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfMaxRwinSent'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfZeroRwinSent'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfCurRwinRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfMaxRwinRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfZeroRwinRcvd')))
if mibBuilder.loadTexts:
tcpEStatsPerfGroup.setDescription('The tcpEStatsPerf group includes those objects that\n provide basic performance data for a TCP connection.')
tcp_e_stats_perf_optional_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 5)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsPerfSndLimTransRwin'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSndLimTransCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSndLimTransSnd'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSndLimTimeRwin'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSndLimTimeCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfSndLimTimeSnd')))
if mibBuilder.loadTexts:
tcpEStatsPerfOptionalGroup.setDescription('The tcpEStatsPerf group includes those objects that\n provide basic performance data for a TCP connection.')
tcp_e_stats_perf_hc_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 6)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsPerfHCDataOctetsOut'), ('TCP-ESTATS-MIB', 'tcpEStatsPerfHCDataOctetsIn')))
if mibBuilder.loadTexts:
tcpEStatsPerfHCGroup.setDescription('The tcpEStatsPerfHC group includes 64-bit\n counters in the tcpEStatsPerfTable.')
tcp_e_stats_path_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 7)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsControlPath'), ('TCP-ESTATS-MIB', 'tcpEStatsPathRetranThresh'), ('TCP-ESTATS-MIB', 'tcpEStatsPathNonRecovDAEpisodes'), ('TCP-ESTATS-MIB', 'tcpEStatsPathSumOctetsReordered'), ('TCP-ESTATS-MIB', 'tcpEStatsPathNonRecovDA')))
if mibBuilder.loadTexts:
tcpEStatsPathGroup.setDescription('The tcpEStatsPath group includes objects that\n control the creation of the tcpEStatsPathTable,\n and provide information about the path\n for each TCP connection.')
tcp_e_stats_path_optional_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 8)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsPathSampleRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathRTTVar'), ('TCP-ESTATS-MIB', 'tcpEStatsPathMaxRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathMinRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathSumRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathCountRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathMaxRTO'), ('TCP-ESTATS-MIB', 'tcpEStatsPathMinRTO'), ('TCP-ESTATS-MIB', 'tcpEStatsPathIpTtl'), ('TCP-ESTATS-MIB', 'tcpEStatsPathIpTosIn'), ('TCP-ESTATS-MIB', 'tcpEStatsPathIpTosOut'), ('TCP-ESTATS-MIB', 'tcpEStatsPathPreCongSumCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsPathPreCongSumRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathPostCongSumRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathPostCongCountRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathECNsignals'), ('TCP-ESTATS-MIB', 'tcpEStatsPathDupAckEpisodes'), ('TCP-ESTATS-MIB', 'tcpEStatsPathRcvRTT'), ('TCP-ESTATS-MIB', 'tcpEStatsPathDupAcksOut'), ('TCP-ESTATS-MIB', 'tcpEStatsPathCERcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsPathECESent')))
if mibBuilder.loadTexts:
tcpEStatsPathOptionalGroup.setDescription('The tcpEStatsPath group includes objects that\n provide additional information about the path\n for each TCP connection.')
tcp_e_stats_path_hc_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 9)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsPathHCSumRTT'),))
if mibBuilder.loadTexts:
tcpEStatsPathHCGroup.setDescription('The tcpEStatsPathHC group includes 64-bit\n counters in the tcpEStatsPathTable.')
tcp_e_stats_stack_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 10)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsControlStack'), ('TCP-ESTATS-MIB', 'tcpEStatsStackActiveOpen'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMSSSent'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMSSRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsStackWinScaleSent'), ('TCP-ESTATS-MIB', 'tcpEStatsStackWinScaleRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsStackTimeStamps'), ('TCP-ESTATS-MIB', 'tcpEStatsStackECN'), ('TCP-ESTATS-MIB', 'tcpEStatsStackWillSendSACK'), ('TCP-ESTATS-MIB', 'tcpEStatsStackWillUseSACK'), ('TCP-ESTATS-MIB', 'tcpEStatsStackState'), ('TCP-ESTATS-MIB', 'tcpEStatsStackNagle'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMaxSsCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMaxCaCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMaxSsthresh'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMinSsthresh'), ('TCP-ESTATS-MIB', 'tcpEStatsStackInRecovery'), ('TCP-ESTATS-MIB', 'tcpEStatsStackDupAcksIn'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSpuriousFrDetected'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSpuriousRtoDetected')))
if mibBuilder.loadTexts:
tcpEStatsStackGroup.setDescription('The tcpEStatsConnState group includes objects that\n control the creation of the tcpEStatsStackTable,\n and provide information about the operation of\n algorithms used within TCP.')
tcp_e_stats_stack_optional_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 11)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsStackSoftErrors'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSoftErrorReason'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSlowStart'), ('TCP-ESTATS-MIB', 'tcpEStatsStackCongAvoid'), ('TCP-ESTATS-MIB', 'tcpEStatsStackOtherReductions'), ('TCP-ESTATS-MIB', 'tcpEStatsStackCongOverCount'), ('TCP-ESTATS-MIB', 'tcpEStatsStackFastRetran'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSubsequentTimeouts'), ('TCP-ESTATS-MIB', 'tcpEStatsStackCurTimeoutCount'), ('TCP-ESTATS-MIB', 'tcpEStatsStackAbruptTimeouts'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSACKsRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSACKBlocksRcvd'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSendStall'), ('TCP-ESTATS-MIB', 'tcpEStatsStackDSACKDups'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMaxMSS'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMinMSS'), ('TCP-ESTATS-MIB', 'tcpEStatsStackSndInitial'), ('TCP-ESTATS-MIB', 'tcpEStatsStackRecInitial'), ('TCP-ESTATS-MIB', 'tcpEStatsStackCurRetxQueue'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMaxRetxQueue'), ('TCP-ESTATS-MIB', 'tcpEStatsStackCurReasmQueue'), ('TCP-ESTATS-MIB', 'tcpEStatsStackMaxReasmQueue')))
if mibBuilder.loadTexts:
tcpEStatsStackOptionalGroup.setDescription('The tcpEStatsConnState group includes objects that\n provide additional information about the operation of\n algorithms used within TCP.')
tcp_e_stats_app_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 12)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsControlApp'), ('TCP-ESTATS-MIB', 'tcpEStatsAppSndUna'), ('TCP-ESTATS-MIB', 'tcpEStatsAppSndNxt'), ('TCP-ESTATS-MIB', 'tcpEStatsAppSndMax'), ('TCP-ESTATS-MIB', 'tcpEStatsAppThruOctetsAcked'), ('TCP-ESTATS-MIB', 'tcpEStatsAppRcvNxt'), ('TCP-ESTATS-MIB', 'tcpEStatsAppThruOctetsReceived')))
if mibBuilder.loadTexts:
tcpEStatsAppGroup.setDescription('The tcpEStatsConnState group includes objects that\n control the creation of the tcpEStatsAppTable,\n and provide information about the operation of\n algorithms used within TCP.')
tcp_e_stats_app_hc_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 13)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsAppHCThruOctetsAcked'), ('TCP-ESTATS-MIB', 'tcpEStatsAppHCThruOctetsReceived')))
if mibBuilder.loadTexts:
tcpEStatsAppHCGroup.setDescription('The tcpEStatsStackHC group includes 64-bit\n counters in the tcpEStatsStackTable.')
tcp_e_stats_app_optional_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 14)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsAppCurAppWQueue'), ('TCP-ESTATS-MIB', 'tcpEStatsAppMaxAppWQueue'), ('TCP-ESTATS-MIB', 'tcpEStatsAppCurAppRQueue'), ('TCP-ESTATS-MIB', 'tcpEStatsAppMaxAppRQueue')))
if mibBuilder.loadTexts:
tcpEStatsAppOptionalGroup.setDescription('The tcpEStatsConnState group includes objects that\n provide additional information about how applications\n are interacting with each TCP connection.')
tcp_e_stats_tune_optional_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 15)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsControlTune'), ('TCP-ESTATS-MIB', 'tcpEStatsTuneLimCwnd'), ('TCP-ESTATS-MIB', 'tcpEStatsTuneLimSsthresh'), ('TCP-ESTATS-MIB', 'tcpEStatsTuneLimRwin'), ('TCP-ESTATS-MIB', 'tcpEStatsTuneLimMSS')))
if mibBuilder.loadTexts:
tcpEStatsTuneOptionalGroup.setDescription('The tcpEStatsConnState group includes objects that\n control the creation of the tcpEStatsConnectionTable,\n which can be used to set tuning parameters\n for each TCP connection.')
tcp_e_stats_notifications_group = notification_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 16)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsEstablishNotification'), ('TCP-ESTATS-MIB', 'tcpEStatsCloseNotification')))
if mibBuilder.loadTexts:
tcpEStatsNotificationsGroup.setDescription('Notifications sent by a TCP extended statistics agent.')
tcp_e_stats_notifications_ctl_group = object_group((1, 3, 6, 1, 2, 1, 156, 2, 2, 17)).setObjects(*(('TCP-ESTATS-MIB', 'tcpEStatsControlNotify'),))
if mibBuilder.loadTexts:
tcpEStatsNotificationsCtlGroup.setDescription('The tcpEStatsNotificationsCtl group includes the\n object that controls the creation of the events\n in the tcpEStatsNotificationsGroup.')
mibBuilder.exportSymbols('TCP-ESTATS-MIB', tcpEStatsPerfSegsIn=tcpEStatsPerfSegsIn, tcpEStatsAppHCThruOctetsAcked=tcpEStatsAppHCThruOctetsAcked, tcpEStatsStackMSSSent=tcpEStatsStackMSSSent, tcpEStatsTuneLimRwin=tcpEStatsTuneLimRwin, tcpEStatsStackTimeStamps=tcpEStatsStackTimeStamps, tcpEStatsStackState=tcpEStatsStackState, tcpEStatsPerfZeroRwinRcvd=tcpEStatsPerfZeroRwinRcvd, tcpEStatsStackSpuriousFrDetected=tcpEStatsStackSpuriousFrDetected, tcpEStatsStackMaxMSS=tcpEStatsStackMaxMSS, tcpEStatsPerfDataOctetsIn=tcpEStatsPerfDataOctetsIn, tcpEStatsStackSACKsRcvd=tcpEStatsStackSACKsRcvd, tcpEStatsTuneTable=tcpEStatsTuneTable, TcpEStatsNegotiated=TcpEStatsNegotiated, tcpEStatsPathCERcvd=tcpEStatsPathCERcvd, tcpEStatsPerfEntry=tcpEStatsPerfEntry, tcpEStatsConnectIndex=tcpEStatsConnectIndex, tcpEStatsPerfSndLimTransSnd=tcpEStatsPerfSndLimTransSnd, tcpEStatsPerfZeroRwinSent=tcpEStatsPerfZeroRwinSent, tcpEStatsStackSACKBlocksRcvd=tcpEStatsStackSACKBlocksRcvd, tcpEStatsPerfSndLimTimeRwin=tcpEStatsPerfSndLimTimeRwin, tcpEStatsPerfTable=tcpEStatsPerfTable, tcpEStatsPathSampleRTT=tcpEStatsPathSampleRTT, tcpEStatsEstablishNotification=tcpEStatsEstablishNotification, tcpEStatsPerfMaxRwinRcvd=tcpEStatsPerfMaxRwinRcvd, tcpEStatsAppMaxAppRQueue=tcpEStatsAppMaxAppRQueue, tcpEStatsPerfCurSsthresh=tcpEStatsPerfCurSsthresh, tcpEStatsStackDSACKDups=tcpEStatsStackDSACKDups, tcpEStatsCloseNotification=tcpEStatsCloseNotification, tcpEStatsAppEntry=tcpEStatsAppEntry, tcpEStatsControlApp=tcpEStatsControlApp, tcpEStatsStackRecInitial=tcpEStatsStackRecInitial, tcpEStatsStackMaxReasmQueue=tcpEStatsStackMaxReasmQueue, tcpEStatsStackWillSendSACK=tcpEStatsStackWillSendSACK, tcpEStatsAppRcvNxt=tcpEStatsAppRcvNxt, tcpEStatsPerfHCGroup=tcpEStatsPerfHCGroup, tcpEStatsPerfSndLimTimeCwnd=tcpEStatsPerfSndLimTimeCwnd, tcpEStatsPerfStartTimeStamp=tcpEStatsPerfStartTimeStamp, tcpEStatsConnectIdTable=tcpEStatsConnectIdTable, tcpEStatsControlStack=tcpEStatsControlStack, tcpEStatsStackDupAcksIn=tcpEStatsStackDupAcksIn, tcpEStatsListenerGroup=tcpEStatsListenerGroup, tcpEStatsControlPath=tcpEStatsControlPath, tcpEStatsPathIpTosIn=tcpEStatsPathIpTosIn, tcpEStatsStackOtherReductions=tcpEStatsStackOtherReductions, tcpEStatsStackCurRetxQueue=tcpEStatsStackCurRetxQueue, tcpEStatsTuneEntry=tcpEStatsTuneEntry, tcpEStatsPerfHCDataOctetsIn=tcpEStatsPerfHCDataOctetsIn, tcpEStatsStackMaxSsCwnd=tcpEStatsStackMaxSsCwnd, tcpEStatsPathNonRecovDA=tcpEStatsPathNonRecovDA, tcpEStatsStackSoftErrorReason=tcpEStatsStackSoftErrorReason, tcpEStatsStackTable=tcpEStatsStackTable, tcpEStatsPathECESent=tcpEStatsPathECESent, tcpEStatsPerfPipeSize=tcpEStatsPerfPipeSize, tcpEStatsStackSlowStart=tcpEStatsStackSlowStart, tcpEStatsStackMSSRcvd=tcpEStatsStackMSSRcvd, tcpEStatsListenerAccepted=tcpEStatsListenerAccepted, tcpEStatsAppGroup=tcpEStatsAppGroup, tcpEStatsStackAbruptTimeouts=tcpEStatsStackAbruptTimeouts, tcpEStatsPathPostCongCountRTT=tcpEStatsPathPostCongCountRTT, tcpEStatsPathSumRTT=tcpEStatsPathSumRTT, tcpEStatsPathEntry=tcpEStatsPathEntry, tcpEStatsPathHCGroup=tcpEStatsPathHCGroup, tcpEStatsListenerSynRcvd=tcpEStatsListenerSynRcvd, tcpEStatsStackMinMSS=tcpEStatsStackMinMSS, tcpEStatsPathSumOctetsReordered=tcpEStatsPathSumOctetsReordered, tcpEStatsAppSndUna=tcpEStatsAppSndUna, tcpEStatsPerfTimeouts=tcpEStatsPerfTimeouts, tcpEStatsListenerExceedBacklog=tcpEStatsListenerExceedBacklog, tcpEStatsPathMinRTO=tcpEStatsPathMinRTO, tcpEStatsPerfOctetsRetrans=tcpEStatsPerfOctetsRetrans, tcpEStatsStackMaxSsthresh=tcpEStatsStackMaxSsthresh, tcpEStatsAppOptionalGroup=tcpEStatsAppOptionalGroup, tcpEStatsPathPreCongSumCwnd=tcpEStatsPathPreCongSumCwnd, tcpEStatsListenerMaxBacklog=tcpEStatsListenerMaxBacklog, tcpEStatsPerfCongSignals=tcpEStatsPerfCongSignals, tcpEStatsStackFastRetran=tcpEStatsStackFastRetran, tcpEStatsTuneOptionalGroup=tcpEStatsTuneOptionalGroup, tcpEStatsCompliance=tcpEStatsCompliance, tcpEStatsListenerCurBacklog=tcpEStatsListenerCurBacklog, tcpEStatsStackMaxCaCwnd=tcpEStatsStackMaxCaCwnd, tcpEStatsPathIpTosOut=tcpEStatsPathIpTosOut, tcpEStatsControlNotify=tcpEStatsControlNotify, tcpEStatsNotificationsCtlGroup=tcpEStatsNotificationsCtlGroup, tcpEStatsAppTable=tcpEStatsAppTable, tcpEStatsPerfSndLimTimeSnd=tcpEStatsPerfSndLimTimeSnd, tcpEStatsPathRcvRTT=tcpEStatsPathRcvRTT, tcpEStatsStackEntry=tcpEStatsStackEntry, tcpEStatsStackWillUseSACK=tcpEStatsStackWillUseSACK, tcpEStatsPerfSmoothedRTT=tcpEStatsPerfSmoothedRTT, tcpEStatsControl=tcpEStatsControl, tcpEStatsPathMaxRTO=tcpEStatsPathMaxRTO, tcpEStatsAppHCThruOctetsReceived=tcpEStatsAppHCThruOctetsReceived, tcpEStatsAppCurAppWQueue=tcpEStatsAppCurAppWQueue, tcpEStatsGroups=tcpEStatsGroups, tcpEStatsMIBObjects=tcpEStatsMIBObjects, tcpEStatsListenerEstablished=tcpEStatsListenerEstablished, tcpEStatsPerfCurMSS=tcpEStatsPerfCurMSS, tcpEStatsListenerHCEstablished=tcpEStatsListenerHCEstablished, tcpEStatsPathECNsignals=tcpEStatsPathECNsignals, tcpEStatsPerfCurCwnd=tcpEStatsPerfCurCwnd, tcpEStatsNotifications=tcpEStatsNotifications, tcpEStatsListenerHCExceedBacklog=tcpEStatsListenerHCExceedBacklog, tcpEStatsPerfSegsRetrans=tcpEStatsPerfSegsRetrans, tcpEStatsPerfMaxRwinSent=tcpEStatsPerfMaxRwinSent, tcpEStatsPathCountRTT=tcpEStatsPathCountRTT, tcpEStatsPerfSegsOut=tcpEStatsPerfSegsOut, tcpEStatsAppSndNxt=tcpEStatsAppSndNxt, tcpEStatsPerfDataSegsIn=tcpEStatsPerfDataSegsIn, tcpEStatsControlTune=tcpEStatsControlTune, tcpEStatsTuneLimMSS=tcpEStatsTuneLimMSS, tcpEStatsStackSpuriousRtoDetected=tcpEStatsStackSpuriousRtoDetected, tcpEStatsStackSendStall=tcpEStatsStackSendStall, tcpEStatsListenerTable=tcpEStatsListenerTable, tcpEStatsStackInRecovery=tcpEStatsStackInRecovery, tcpEStatsAppThruOctetsAcked=tcpEStatsAppThruOctetsAcked, tcpEStatsStackGroup=tcpEStatsStackGroup, tcpEStatsPathRTTVar=tcpEStatsPathRTTVar, tcpEStatsConnectIdEntry=tcpEStatsConnectIdEntry, tcpEStatsPathHCSumRTT=tcpEStatsPathHCSumRTT, tcpEStatsListenerHCInitial=tcpEStatsListenerHCInitial, tcpEStatsAppMaxAppWQueue=tcpEStatsAppMaxAppWQueue, tcpEStatsListenerCurEstabBacklog=tcpEStatsListenerCurEstabBacklog, tcpEStatsListenerHCSynRcvd=tcpEStatsListenerHCSynRcvd, tcpEStatsStackWinScaleRcvd=tcpEStatsStackWinScaleRcvd, tcpEStatsPerfOptionalGroup=tcpEStatsPerfOptionalGroup, tcpEStatsConformance=tcpEStatsConformance, tcpEStatsPerfHCDataOctetsOut=tcpEStatsPerfHCDataOctetsOut, tcpEStatsStackCurTimeoutCount=tcpEStatsStackCurTimeoutCount, tcpEStatsListenerInitial=tcpEStatsListenerInitial, tcpEStatsStackNagle=tcpEStatsStackNagle, tcpEStatsAppCurAppRQueue=tcpEStatsAppCurAppRQueue, tcpEStatsPerfElapsedMicroSecs=tcpEStatsPerfElapsedMicroSecs, tcpEStatsStackCurReasmQueue=tcpEStatsStackCurReasmQueue, tcpEStatsStackSubsequentTimeouts=tcpEStatsStackSubsequentTimeouts, tcpEStatsStackECN=tcpEStatsStackECN, tcpEStatsAppHCGroup=tcpEStatsAppHCGroup, tcpEStatsConnTableLatency=tcpEStatsConnTableLatency, tcpEStatsPathDupAckEpisodes=tcpEStatsPathDupAckEpisodes, tcpEStatsStackMinSsthresh=tcpEStatsStackMinSsthresh, tcpEStatsPathMaxRTT=tcpEStatsPathMaxRTT, tcpEStatsMIB=tcpEStatsMIB, tcpEStatsPathRetranThresh=tcpEStatsPathRetranThresh, tcpEStatsConnectIdGroup=tcpEStatsConnectIdGroup, tcpEStatsTuneLimSsthresh=tcpEStatsTuneLimSsthresh, tcpEStatsPerfSndLimTransCwnd=tcpEStatsPerfSndLimTransCwnd, tcpEStatsPerfCurRTO=tcpEStatsPerfCurRTO, tcpEStatsPathTable=tcpEStatsPathTable, PYSNMP_MODULE_ID=tcpEStatsMIB, tcpEStatsAppSndMax=tcpEStatsAppSndMax, tcpEStatsListenerHCGroup=tcpEStatsListenerHCGroup, tcpEStatsPathIpTtl=tcpEStatsPathIpTtl, tcpEStatsStackCongAvoid=tcpEStatsStackCongAvoid, tcpEStatsPathGroup=tcpEStatsPathGroup, tcpEStatsStackSndInitial=tcpEStatsStackSndInitial, tcpEStatsPathPostCongSumRTT=tcpEStatsPathPostCongSumRTT, tcpEStatsPathMinRTT=tcpEStatsPathMinRTT, tcpEStats=tcpEStats, tcpEStatsPathPreCongSumRTT=tcpEStatsPathPreCongSumRTT, tcpEStatsPathDupAcksOut=tcpEStatsPathDupAcksOut, tcpEStatsStackCongOverCount=tcpEStatsStackCongOverCount, tcpEStatsPathOptionalGroup=tcpEStatsPathOptionalGroup, tcpEStatsNotificationsGroup=tcpEStatsNotificationsGroup, tcpEStatsPerfMaxPipeSize=tcpEStatsPerfMaxPipeSize, tcpEStatsListenerEntry=tcpEStatsListenerEntry, tcpEStatsPerfSndLimTransRwin=tcpEStatsPerfSndLimTransRwin, tcpEStatsPerfGroup=tcpEStatsPerfGroup, tcpEStatsListenerHCAccepted=tcpEStatsListenerHCAccepted, tcpEStatsTuneLimCwnd=tcpEStatsTuneLimCwnd, tcpEStatsPerfElapsedSecs=tcpEStatsPerfElapsedSecs, tcpEStatsListenerStartTime=tcpEStatsListenerStartTime, tcpEStatsPerfCurRwinSent=tcpEStatsPerfCurRwinSent, tcpEStatsPathNonRecovDAEpisodes=tcpEStatsPathNonRecovDAEpisodes, tcpEStatsStackMaxRetxQueue=tcpEStatsStackMaxRetxQueue, tcpEStatsStackSoftErrors=tcpEStatsStackSoftErrors, tcpEStatsStackWinScaleSent=tcpEStatsStackWinScaleSent, tcpEStatsListenerTableLastChange=tcpEStatsListenerTableLastChange, tcpEStatsPerfDataSegsOut=tcpEStatsPerfDataSegsOut, tcpEStatsCompliances=tcpEStatsCompliances, tcpEStatsStackActiveOpen=tcpEStatsStackActiveOpen, tcpEStatsPerfCurRwinRcvd=tcpEStatsPerfCurRwinRcvd, tcpEStatsAppThruOctetsReceived=tcpEStatsAppThruOctetsReceived, tcpEStatsPerfDataOctetsOut=tcpEStatsPerfDataOctetsOut, tcpEStatsListenerCurConns=tcpEStatsListenerCurConns, tcpEStatsScalar=tcpEStatsScalar, tcpEStatsStackOptionalGroup=tcpEStatsStackOptionalGroup) |
def solve(arr: list) -> int:
""" This function returns the difference between the count of even numbers and the count of odd numbers. """
even = []
odd = []
for item in arr:
if str(item).isdigit():
if item % 2 == 0:
even.append(item)
else:
odd.append(item)
return len(even) - len(odd) | def solve(arr: list) -> int:
""" This function returns the difference between the count of even numbers and the count of odd numbers. """
even = []
odd = []
for item in arr:
if str(item).isdigit():
if item % 2 == 0:
even.append(item)
else:
odd.append(item)
return len(even) - len(odd) |
class Client:
def __init__(self, client_id):
self.client_id = client_id
self.available = 0
self.held = 0
self.total = 0
self.locked = False
def get_client_id(self):
return self.client_id
def get_available(self):
return self.available
def lock_client(self):
self.locked = True
def unlock_client(self):
self.locked = False
def modify_available(self, value):
self.available = self.available + value
def modify_held(self, value):
self.held = self.held + value
def modify_total(self, value):
self.total = self.total + value
def get_client_data(self):
return self.client_id, self.available, self.held, self.total, self.locked
| class Client:
def __init__(self, client_id):
self.client_id = client_id
self.available = 0
self.held = 0
self.total = 0
self.locked = False
def get_client_id(self):
return self.client_id
def get_available(self):
return self.available
def lock_client(self):
self.locked = True
def unlock_client(self):
self.locked = False
def modify_available(self, value):
self.available = self.available + value
def modify_held(self, value):
self.held = self.held + value
def modify_total(self, value):
self.total = self.total + value
def get_client_data(self):
return (self.client_id, self.available, self.held, self.total, self.locked) |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.