
code stringlengths 5 1M | repo_name stringlengths 5 109 | path stringlengths 6 208 | language stringclasses 1 value | license stringclasses 15 values | size int64 5 1M |
|---|---|---|---|---|---|
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.sparklinedata.druid.client.test
import org.apache.spark.sql.SPLLogging
import org.scalatest.BeforeAndAfterAll
class CodeGenTest extends BaseTest with BeforeAndAfterAll with SPLLogging {
test("gbexprtest1",
"select sum(c_acctbal) as bal from orderLineItemPartSupplier group by " +
"(substr(CAST(Date_Add(TO_DATE(CAST(CONCAT(TO_DATE(o_orderdate), 'T00:00:00.000')" +
" AS TIMESTAMP)), 5) AS TIMESTAMP), 1, 10)) order by bal",
1,
true, true)
test("gbexprtest1B",
"select sum(c_acctbal) as bal from orderLineItemPartSupplierBase group by " +
"(substr(CAST(Date_Add(TO_DATE(CAST(CONCAT(TO_DATE(o_orderdate), 'T00:00:00.000')" +
" AS TIMESTAMP)), 5) AS TIMESTAMP), 1, 10)) order by bal",
0,
true, true)
test("gbexprtest2",
"select o_orderdate, " +
"(substr(CAST(Date_Add(TO_DATE(CAST(CONCAT(TO_DATE(o_orderdate), 'T00:00:00.000Z') " +
"AS TIMESTAMP)), 5) AS TIMESTAMP), 1, 10)) x," +
"sum(c_acctbal) as bal from orderLineItemPartSupplier group by " +
"o_orderdate, (substr(CAST(Date_Add(TO_DATE(CAST(CONCAT(TO_DATE(o_orderdate)," +
" 'T00:00:00.000Z') AS TIMESTAMP)), 5) AS TIMESTAMP), 1, 10)) order by o_orderdate, x, bal",
1,
true, true)
test("gbexprtest2B",
"select o_orderdate, " +
"(substr(CAST(Date_Add(TO_DATE(CAST(CONCAT(TO_DATE(o_orderdate), 'T00:00:00.000Z') " +
"AS TIMESTAMP)), 5) AS TIMESTAMP), 1, 10)) x," +
"sum(c_acctbal) as bal from orderLineItemPartSupplierBase group by " +
"o_orderdate, (substr(CAST(Date_Add(TO_DATE(CAST(CONCAT(TO_DATE(o_orderdate)," +
" 'T00:00:00.000Z') AS TIMESTAMP)), 5) AS TIMESTAMP), 1, 10)) order by o_orderdate, x, bal",
0,
true, true)
test("gbexprtest3",
"select o_orderdate, " +
"(DateDiff(cast(o_orderdate as date), cast('2015-07-21 10:10:10 PST' as date))) as x " +
"from orderLineItemPartSupplier group by o_orderdate, " +
"cast('2015-07-21 10:10:10 PST' as date), " +
" (DateDiff(cast(o_orderdate as date), cast('2015-07-21 10:10:10 PST' as date))) " +
"order by o_orderdate, x",
1,
true, true)
test("gbexprtest3B",
"select o_orderdate, " +
"(DateDiff(cast(o_orderdate as date), cast('2015-07-21 10:10:10 PST' as date))) as x " +
"from orderLineItemPartSupplierBase group by o_orderdate, " +
"cast('2015-07-21 10:10:10 PST' as date), " +
" (DateDiff(cast(o_orderdate as date), cast('2015-07-21 10:10:10 PST' as date))) " +
"order by o_orderdate, x",
0,
true, true)
test("gbexprtest4",
"select (Date_add(cast(o_orderdate as date), 360+3)) as x " +
"from orderLineItemPartSupplier group by " +
"(Date_add(cast(o_orderdate as date), 360+3)) order by x",
1,
true, true)
test("gbexprtest4B",
"select (Date_add(cast(o_orderdate as date), 360+3)) as x " +
"from orderLineItemPartSupplierBase group by " +
"(Date_add(cast(o_orderdate as date), 360+3)) order by x",
0,
true, true)
test("gbexprtest5",
"select (Date_sub(cast(o_orderdate as date), 360+3)) as x " +
"from orderLineItemPartSupplier group by " +
"(Date_sub(cast(o_orderdate as date), 360+3)) order by x",
1,
true, true)
test("gbexprtest5B",
"select (Date_sub(cast(o_orderdate as date), 360+3)) as x " +
"from orderLineItemPartSupplierBase group by " +
"(Date_sub(cast(o_orderdate as date), 360+3)) order by x",
0,
true, true)
test("gbexprtest6",
"select o_orderdate, (weekofyear(Date_Add(cast(o_orderdate as date), 1))) as x " +
"from orderLineItemPartSupplier group by o_orderdate, " +
"(weekofyear(Date_Add(cast(o_orderdate as date), 1))) order by o_orderdate",
1,
true, true)
test("gbexprtest6B",
"select o_orderdate, (weekofyear(Date_Add(cast(o_orderdate as date), 1))) as x " +
"from orderLineItemPartSupplierBase group by o_orderdate, " +
"(weekofyear(Date_Add(cast(o_orderdate as date), 1))) order by o_orderdate",
0,
true, true)
test("gbexprtest7",
"select o_orderdate, (unix_timestamp(Date_Add(cast(o_orderdate as date), 1))) as x " +
"from orderLineItemPartSupplier group by o_orderdate, " +
"(unix_timestamp(Date_Add(cast(o_orderdate as date), 1))) order by o_orderdate, x",
1,
true, true)
test("gbexprtest7B",
"select o_orderdate, (unix_timestamp(Date_Add(cast(o_orderdate as date), 1))) as x " +
"from orderLineItemPartSupplierBase group by o_orderdate, " +
"(unix_timestamp(Date_Add(cast(o_orderdate as date), 1))) order by o_orderdate, x",
0,
true, true)
test("gbexprtest8",
"SELECT o_orderdate, Cast(Concat(Year(Cast(o_orderdate AS TIMESTAMP)), " +
"(CASE WHEN Month(Cast(o_orderdate AS TIMESTAMP))<4 " +
"THEN '-01' WHEN Month(Cast(o_orderdate AS TIMESTAMP))<7 " +
"THEN '-04' WHEN Month(Cast(o_orderdate AS TIMESTAMP))<10 " +
"THEN '-07' ELSE '-10' END), '-01 00:00:00') " +
"AS TIMESTAMP) AS x " +
"FROM (SELECT * FROM orderLineItemPartSupplier) m " +
"GROUP BY o_orderdate, cast(concat(year(cast(o_orderdate AS timestamp)), " +
"(CASE WHEN month(cast(o_orderdate AS timestamp))<4 THEN '-01' " +
"WHEN month(cast(o_orderdate AS timestamp))<7 THEN '-04' " +
"WHEN month(cast(o_orderdate AS timestamp))<10 " +
"THEN '-07' ELSE '-10' END), '-01 00:00:00') AS timestamp)" +
" order by o_orderdate, x ",
1,
true, true)
test("gbexprtest8B",
"SELECT o_orderdate, Cast(Concat(Year(Cast(o_orderdate AS TIMESTAMP)), " +
"(CASE WHEN Month(Cast(o_orderdate AS TIMESTAMP))<4 " +
"THEN '-01' WHEN Month(Cast(o_orderdate AS TIMESTAMP))<7 " +
"THEN '-04' WHEN Month(Cast(o_orderdate AS TIMESTAMP))<10 " +
"THEN '-07' ELSE '-10' END), '-01 00:00:00') " +
"AS TIMESTAMP) AS x " +
"FROM (SELECT * FROM orderLineItemPartSupplierBase) m " +
"GROUP BY o_orderdate, cast(concat(year(cast(o_orderdate AS timestamp)), " +
"(CASE WHEN month(cast(o_orderdate AS timestamp))<4 THEN '-01' " +
"WHEN month(cast(o_orderdate AS timestamp))<7 THEN '-04' " +
"WHEN month(cast(o_orderdate AS timestamp))<10 " +
"THEN '-07' ELSE '-10' END), '-01 00:00:00') AS timestamp)" +
" order by o_orderdate, x ",
0,
true, true)
test("gbexprtest9",
"select o_orderdate as x " +
"from orderLineItemPartSupplier group by " +
"o_orderdate, (unix_timestamp(Date_Add(cast(o_orderdate as date), 1))) " +
"order by o_orderdate, x",
1,
true, true)
test("gbexprtest9B",
"select o_orderdate as x " +
"from orderLineItemPartSupplierBase group by " +
"o_orderdate, (unix_timestamp(Date_Add(cast(o_orderdate as date), 1))) " +
"order by o_orderdate, x",
0,
true, true)
test("gbexprtest10",
" SELECT CAST((MONTH(CAST(o_orderdate AS TIMESTAMP)) - 1) / 3 + 1 AS BIGINT) " +
"AS `qr_row_hr_ok`, YEAR(CAST(o_orderdate AS TIMESTAMP)) AS `yr_row_hr_ok` " +
"FROM ( select * from orderLineItemPartSupplier) custom_sql_query " +
"GROUP BY " +
"CAST((MONTH(CAST(o_orderdate AS TIMESTAMP)) - 1) / 3 + 1 AS BIGINT), " +
"YEAR(CAST(o_orderdate AS TIMESTAMP)) order by qr_row_hr_ok, yr_row_hr_ok",
1,
true, true)
test("gbexprtest10B",
" SELECT CAST((MONTH(CAST(o_orderdate AS TIMESTAMP)) - 1) / 3 + 1 AS BIGINT) " +
"AS `qr_row_hr_ok`, YEAR(CAST(o_orderdate AS TIMESTAMP)) AS `yr_row_hr_ok` " +
"FROM ( select * from orderLineItemPartSupplierBase) custom_sql_query " +
"GROUP BY " +
"CAST((MONTH(CAST(o_orderdate AS TIMESTAMP)) - 1) / 3 + 1 AS BIGINT), " +
"YEAR(CAST(o_orderdate AS TIMESTAMP)) order by qr_row_hr_ok, yr_row_hr_ok",
0,
true, true)
test("gbexprtest11",
" SELECT CAST(((MONTH(CAST(l_shipdate AS TIMESTAMP)) - 1) / 3) * 2 AS BIGINT) " +
"AS `qr_row_hr_ok`, YEAR(CAST(l_shipdate AS TIMESTAMP)) AS `yr_row_hr_ok` " +
"FROM ( select * from orderLineItemPartSupplier) custom_sql_query " +
"GROUP BY " +
"CAST(((MONTH(CAST(l_shipdate AS TIMESTAMP)) - 1) / 3) * 2 AS BIGINT), " +
"YEAR(CAST(l_shipdate AS TIMESTAMP)) order by qr_row_hr_ok, yr_row_hr_ok",
1,
true, true)
test("gbexprtest11B",
" SELECT CAST(((MONTH(CAST(l_shipdate AS TIMESTAMP)) - 1) / 3) * 2 AS BIGINT) " +
"AS `qr_row_hr_ok`, YEAR(CAST(l_shipdate AS TIMESTAMP)) AS `yr_row_hr_ok` " +
"FROM ( select * from orderLineItemPartSupplierBase) custom_sql_query " +
"GROUP BY " +
"CAST(((MONTH(CAST(l_shipdate AS TIMESTAMP)) - 1) / 3) * 2 AS BIGINT), " +
"YEAR(CAST(l_shipdate AS TIMESTAMP)) order by qr_row_hr_ok, yr_row_hr_ok",
0,
true, true)
test("gbexprtest12",
"select o_orderdate, (from_unixtime(second(Date_Add(cast(o_orderdate as date), 1)))) as x " +
"from orderLineItemPartSupplier group by " +
"o_orderdate, (from_unixtime(second(Date_Add(cast(o_orderdate as date), 1)))) " +
"order by o_orderdate, x",
1,
true, true)
test("gbexprtest12B",
"select o_orderdate, (from_unixtime(second(Date_Add(cast(o_orderdate as date), 1)))) as x " +
"from orderLineItemPartSupplierBase group by " +
"o_orderdate, (from_unixtime(second(Date_Add(cast(o_orderdate as date), 1)))) " +
"order by o_orderdate, x",
0,
true, true)
test("gbexprtest13",
"select o_orderdate, " +
"datediff(" +
"date_add(to_date(cast(o_orderdate as timestamp)), (year(cast(o_orderdate as date))%100)), " +
"date_sub(to_date(cast(o_orderdate as timestamp)), quarter(cast(o_orderdate as date))*2)" +
") as c1, " +
"datediff( " +
"date_add(to_date(cast(o_orderdate as timestamp)), month(cast(o_orderdate as date))), " +
"date_sub(to_date(cast(o_orderdate as timestamp)), weekofyear(cast(o_orderdate as date)))" +
")as c2, " +
"datediff( " +
"date_add(to_date(cast(o_orderdate as timestamp)), day(cast(o_orderdate as date))), " +
"date_sub(to_date(cast(o_orderdate as timestamp)), hour(cast(o_orderdate as date))+10))" +
"as c3, " +
"datediff( " +
"date_add(to_date(cast(o_orderdate as timestamp)), minute(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), second(cast(o_orderdate as date))+10))" +
" as c4 " +
"from orderLineItemPartSupplier group by " +
"o_orderdate, " +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"year(cast(o_orderdate as date))%100)," +
"date_sub(to_date(cast(o_orderdate as timestamp)), quarter(cast(o_orderdate as date))*2))," +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"month(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), weekofyear(cast(o_orderdate as date))))," +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"day(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), hour(cast(o_orderdate as date))+10))," +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"minute(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), second(cast(o_orderdate as date))+10)) " +
"order by o_orderdate, c1, c2, c3, c4",
1,
true, true)
test("gbexprtest13B",
"select o_orderdate, " +
"datediff(" +
"date_add(to_date(cast(o_orderdate as timestamp)), (year(cast(o_orderdate as date))%100)), " +
"date_sub(to_date(cast(o_orderdate as timestamp)), quarter(cast(o_orderdate as date))*2)" +
") as c1, " +
"datediff( " +
"date_add(to_date(cast(o_orderdate as timestamp)), month(cast(o_orderdate as date))), " +
"date_sub(to_date(cast(o_orderdate as timestamp)), weekofyear(cast(o_orderdate as date)))" +
")as c2, " +
"datediff( " +
"date_add(to_date(cast(o_orderdate as timestamp)), day(cast(o_orderdate as date))), " +
"date_sub(to_date(cast(o_orderdate as timestamp)), hour(cast(o_orderdate as date))+10))" +
"as c3, " +
"datediff( " +
"date_add(to_date(cast(o_orderdate as timestamp)), minute(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), second(cast(o_orderdate as date))+10))" +
" as c4 " +
"from orderLineItemPartSupplierBase group by " +
"o_orderdate, " +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"year(cast(o_orderdate as date))%100)," +
"date_sub(to_date(cast(o_orderdate as timestamp)), quarter(cast(o_orderdate as date))*2))," +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"month(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), weekofyear(cast(o_orderdate as date))))," +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"day(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), hour(cast(o_orderdate as date))+10))," +
"datediff(date_add(to_date(cast(o_orderdate as timestamp)), " +
"minute(cast(o_orderdate as date)))," +
"date_sub(to_date(cast(o_orderdate as timestamp)), second(cast(o_orderdate as date))+10)) " +
"order by o_orderdate, c1, c2, c3, c4",
0,
true, true)
test("gbexprtest14",
"select o_orderdate, " +
"date_add(cast(upper(concat(concat(substr(cast(cast(o_orderdate as timestamp) as string)," +
" 1, 10), 't'), substr(cast(cast(o_orderdate as timestamp) as string), 12, 8))) as date)," +
" 20) as x " +
"from orderLineItemPartSupplier group by " +
"o_orderdate, " +
"date_add(cast(upper(concat(concat(substr(cast(cast(o_orderdate as timestamp) as string)," +
" 1, 10), 't'), substr(cast(cast(o_orderdate as timestamp) as string), 12, 8))) as date)," +
" 20)" +
"order by o_orderdate, x",
1,
true, true)
test("gbexprtest14B",
"select o_orderdate, " +
"date_add(cast(upper(concat(concat(substr(cast(cast(o_orderdate as timestamp) as string)," +
" 1, 10), 't'), substr(cast(cast(o_orderdate as timestamp) as string), 12, 8))) as date)," +
" 20) as x " +
"from orderLineItemPartSupplierBase group by " +
"o_orderdate, " +
"date_add(cast(upper(concat(concat(substr(cast(cast(o_orderdate as timestamp) as string)," +
" 1, 10), 't'), substr(cast(cast(o_orderdate as timestamp) as string), 12, 8))) as date)," +
" 20)" +
"order by o_orderdate, x",
0,
true, true)
test("gbexprtest15",
"select o_orderdate, " +
"Coalesce((CASE WHEN Month(Cast(o_orderdate AS date)) > 0 and " +
"Month(Cast(o_orderdate AS date)) < 4 THEN \\"Q1\\" else null END), " +
" (CASE WHEN Month(Cast(o_orderdate AS date)) >= 4 and Month(Cast(o_orderdate AS date))" +
" <= 6 THEN \\"Q2\\" else null END), (CASE WHEN Month(Cast(o_orderdate AS date)) > 6" +
" and Month(Cast(o_orderdate AS date)) <= 8 THEN \\"Q3\\" else null END)," +
" (CASE WHEN Month(Cast(o_orderdate AS date)) <> 12 THEN \\"Not Dec\\" else null END)," +
" (CASE WHEN Month(Cast(o_orderdate AS date)) = 12 THEN \\"Dec\\" else null END))as x " +
"from orderLineItemPartSupplier group by " +
"o_orderdate, " +
"Coalesce((CASE WHEN Month(Cast(o_orderdate AS date)) > 0 and " +
"Month(Cast(o_orderdate AS date)) < 4 THEN \\"Q1\\" else null END), " +
"(CASE WHEN Month(Cast(o_orderdate AS date)) >= 4 and " +
"Month(Cast(o_orderdate AS date)) <= 6 THEN \\"Q2\\" else null END), " +
"(CASE WHEN Month(Cast(o_orderdate AS date)) > 6 and " +
"Month(Cast(o_orderdate AS date)) <= 8 THEN \\"Q3\\" else null END), " +
"(CASE WHEN Month(Cast(o_orderdate AS date)) <> 12 " +
"THEN \\"Not Dec\\" else null END), (CASE WHEN Month(Cast(o_orderdate AS date)) = 12 " +
"THEN \\"Dec\\" else null END))" +
"order by o_orderdate, x",
1,
true, true)
test("gbexprtest15B",
"select o_orderdate, " +
"Coalesce((CASE WHEN Month(Cast(o_orderdate AS date)) > 0 and " +
"Month(Cast(o_orderdate AS date)) < 4 THEN \\"Q1\\" else null END), " +
" (CASE WHEN Month(Cast(o_orderdate AS date)) >= 4 and Month(Cast(o_orderdate AS date))" +
" <= 6 THEN \\"Q2\\" else null END), (CASE WHEN Month(Cast(o_orderdate AS date)) > 6" +
" and Month(Cast(o_orderdate AS date)) <= 8 THEN \\"Q3\\" else null END)," +
" (CASE WHEN Month(Cast(o_orderdate AS date)) <> 12 THEN \\"Not Dec\\" else null END)," +
" (CASE WHEN Month(Cast(o_orderdate AS date)) = 12 THEN \\"Dec\\" else null END))as x " +
"from orderLineItemPartSupplierBase group by " +
"o_orderdate, " +
"Coalesce((CASE WHEN Month(Cast(o_orderdate AS date)) > 0 and " +
"Month(Cast(o_orderdate AS date)) < 4 THEN \\"Q1\\" else null END), " +
"(CASE WHEN Month(Cast(o_orderdate AS date)) >= 4 and " +
"Month(Cast(o_orderdate AS date)) <= 6 THEN \\"Q2\\" else null END), " +
"(CASE WHEN Month(Cast(o_orderdate AS date)) > 6 and " +
"Month(Cast(o_orderdate AS date)) <= 8 THEN \\"Q3\\" else null END), " +
"(CASE WHEN Month(Cast(o_orderdate AS date)) <> 12 " +
"THEN \\"Not Dec\\" else null END), (CASE WHEN Month(Cast(o_orderdate AS date)) = 12 " +
"THEN \\"Dec\\" else null END))" +
"order by o_orderdate, x",
0,
true, true)
test("aggTest1",
"""
|SELECT MIN(CAST(CAST(l_shipdate AS TIMESTAMP) AS TIMESTAMP)) AS x,
| MAX(CAST(CAST(l_shipdate AS TIMESTAMP) AS TIMESTAMP)) AS y,
| COUNT(1) AS c
| FROM ( select * from orderLineItemPartSupplier ) custom_sql_query
| HAVING (COUNT(1) > 0)
""".stripMargin,
1, true, true
)
test("aggTest1B",
"""
|SELECT MIN(CAST(CAST(l_shipdate AS TIMESTAMP) AS TIMESTAMP)) AS x,
| MAX(CAST(CAST(l_shipdate AS TIMESTAMP) AS TIMESTAMP)) AS y,
| COUNT(1) AS c
| FROM ( select * from orderLineItemPartSupplierBase ) custom_sql_query
| HAVING (COUNT(1) > 0)
""".stripMargin,
0, true, true
)
test("aggTest2",
"""
|SELECT sum(l_quantity + 10) as s, MIN(l_quantity + 10) AS mi,
| MAX(l_quantity + 10) ma, COUNT(1) AS c
| FROM ( select * from orderLineItemPartSupplier ) custom_sql_query
| HAVING (COUNT(1) > 0) order by s, mi, ma
""".stripMargin,
1, true, true
)
test("aggTest2B",
"""
|SELECT sum(l_quantity + 10) as s, MIN(l_quantity + 10) AS mi,
| MAX(l_quantity + 10) ma, COUNT(1) AS c
| FROM ( select * from orderLineItemPartSupplierBase ) custom_sql_query
| HAVING (COUNT(1) > 0) order by s, mi, ma
""".stripMargin,
0, true, true
)
test("aggTest3",
s"""
|SELECT Min(Cast(Concat(To_date(Cast(Concat(To_date(l_shipdate),' 00:00:00')
|AS TIMESTAMP)),' 00:00:00') AS TIMESTAMP)) AS mi,
|max(cast(concat(to_date(cast(concat(to_date(l_shipdate),' 00:00:00') AS timestamp)),
|' 00:00:00') AS timestamp)) AS ma,
|count(1) as c
|FROM orderLineItemPartSupplier
|HAVING (count(1) > 0)
""".stripMargin,
1,
true, true)
test("aggTest3B",
s"""
|SELECT Min(Cast(Concat(To_date(Cast(Concat(To_date(l_shipdate),' 00:00:00')
|AS TIMESTAMP)),' 00:00:00') AS TIMESTAMP)) AS mi,
|max(cast(concat(to_date(cast(concat(to_date(l_shipdate),' 00:00:00') AS timestamp)),
|' 00:00:00') AS timestamp)) AS ma,
|count(1) as c
|FROM orderLineItemPartSupplierBase
|HAVING (count(1) > 0)
""".stripMargin,
0,
true, true)
test("aggTest4",
s"""
|SELECT max(cast(FROM_UNIXTIME(unix_timestamp(l_shipdate)*1000, 'yyyy-MM-dd 00:00:00') as timestamp))
|FROM orderLineItemPartSupplier
|group by s_region
""".stripMargin,
1,
true, true)
test("aggTest5",
s"""
|SELECT avg((l_quantity + ps_availqty)/10) as x
|FROM orderLineItemPartSupplier
|group by s_region
|order by x
""".stripMargin,
1,
true, true)
test("aggTest5B",
s"""
|SELECT avg((l_quantity + ps_availqty)/10) as x
|FROM orderLineItemPartSupplierBase
|where cast(l_shipdate as date) >= cast('1993-01-01' as date) and
|cast(l_shipdate as date) <= cast('1997-12-30' as date)
|group by s_region
|order by x
""".stripMargin,
0,
true, true)
test("aggTest6",
s"""
|SELECT avg(unix_timestamp(l_shipdate)*1000) as x
|FROM orderLineItemPartSupplier
|group by s_region
|order by x
""".stripMargin,
1,
true, true)
test("aggTest7",
"""
|SELECT MIN(CAST(CAST(o_orderdate AS TIMESTAMP) AS TIMESTAMP)) AS x,
| MAX(CAST(CAST(o_orderdate AS TIMESTAMP) AS TIMESTAMP)) AS y,
| COUNT(1) AS c
| FROM ( select * from orderLineItemPartSupplier ) custom_sql_query
| HAVING (COUNT(1) > 0)
""".stripMargin,
1, true, true
)
test("pmod1",
"""
|SELECT max(pmod(o_totalprice, -5)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("pmod1B",
"""
|SELECT max(pmod(o_totalprice, -5)) as s
| FROM orderLineItemPartSupplierBase
| group by s_region
| order by s
""".stripMargin,
0, true, true
)
test("pmod2",
"""
|SELECT max(pmod(-5, o_totalprice)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("pmod2B",
"""
|SELECT max(pmod(-5, o_totalprice)) as s
| FROM orderLineItemPartSupplierBase
| group by s_region
| order by s
""".stripMargin,
0, true, true
)
test("abs1",
"""
|SELECT sum(abs(o_totalprice * -5)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("floor1",
"""
|SELECT sum(floor(o_totalprice/3.5)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("ceil1",
"""
|SELECT sum(ceil(o_totalprice/3.5)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("sqrt1",
"""
|SELECT sum(sqrt(o_totalprice)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("Log1",
"""
|SELECT sum(Log(o_totalprice)) as s
| FROM orderLineItemPartSupplier
| group by s_region
| order by s
""".stripMargin,
1, true, true
)
test("simplifyCastTst1",
"""
|SELECT sum(Log(o_totalprice)) as s
| FROM orderLineItemPartSupplier
| group by
| cast(l_shipdate as int)
| order by s
""".stripMargin,
1, true, true
)
test("unaryMinus1",
"""
|SELECT
| cast(concat(date_add(cast(l_shipdate AS timestamp),
| cast(-((1 + pmod(datediff(to_date(cast(l_shipdate AS timestamp)),
| '1995-01-01'), 7)) - 1) AS int)),' 00:00:00') AS timestamp)
|as s
| FROM orderLineItemPartSupplier
| group by
| cast(concat(date_add(cast(l_shipdate AS timestamp),
| cast(-((1 + pmod(datediff(to_date(cast(l_shipdate AS timestamp)), '1995-01-01'), 7))
| - 1) AS int)),' 00:00:00') AS timestamp)
| order by s
""".stripMargin,
1, true, true
)
test("unaryPlus1",
"""
|SELECT
| cast(concat(date_add(cast(l_shipdate AS timestamp),
| cast(+((1 + pmod(datediff(to_date(cast(l_shipdate AS timestamp)),
| '1995-01-01'), 7)) - 1) AS int)),' 00:00:00') AS timestamp)
|as s
| FROM orderLineItemPartSupplier
| group by
| cast(concat(date_add(cast(l_shipdate AS timestamp),
| cast(+((1 + pmod(datediff(to_date(cast(l_shipdate AS timestamp)), '1995-01-01'), 7))
| - 1) AS int)),' 00:00:00') AS timestamp)
| order by s
""".stripMargin,
1, true, true
)
test("strGTLTEq1",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplier
|where (o_orderdate <= '1993-12-12') and
|(o_orderdate >= '1993-10-12')
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,1,true,true)
test("strGTLTEq1B",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplierBase
|where (o_orderdate <= '1993-12-12') and
|(o_orderdate >= '1993-10-12')
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,0,true,true)
test("dateEq1",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplier
|where cast(o_orderdate as date) = cast('1994-06-30' as Date)
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,1,true,true)
test("dateEq1B",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplierBase
|where cast(o_orderdate as date) = cast('1994-06-30' as Date)
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,0,true,true)
test("dateGTLTEq1",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplier
|where (cast(o_orderdate as date) <= cast('1993-12-12' as Date))
| and (cast(o_orderdate as date) >= cast('1993-10-12' as Date))
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,1,true,true)
test("dateGTLTEq1B",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplierBase
|where (cast(o_orderdate as date) <= cast('1993-12-12' as Date))
| and (cast(o_orderdate as date) >= cast('1993-10-12' as Date))
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,0,true,true)
test("tsEq1",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplier
|where cast(l_shipdate as timestamp) = cast('1996-05-17T17:00:00.000-07:00' as timestamp)
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,1,true,true)
test("tsGTLTEq1",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplier
|where (cast(l_shipdate as timestamp) <= cast('1993-12-12 00:00:00' as timestamp))
| and (cast(l_shipdate as timestamp) >= cast('1993-10-12 00:00:00' as timestamp))
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,1,true,true)
test("tsGTLTEq1B",
"""
|select o_orderstatus as x, cast(o_orderdate as date) as y
|from orderLineItemPartSupplierBase
|where (cast(l_shipdate as timestamp) <= cast('1993-12-12 00:00:00' as timestamp))
| and (cast(l_shipdate as timestamp) >= cast('1993-10-12 00:00:00' as timestamp))
|group by o_orderstatus, cast(o_orderdate as date)
|order by x, y
""".stripMargin
,0,true,true)
test("inclause-insetTest1",
s"""select c_name, sum(c_acctbal) as bal
from orderLineItemPartSupplier
where to_Date(o_orderdate) >= cast('1993-01-01' as date) and to_Date(o_orderdate) <= cast('1997-12-31' as date)
and cast(order_year as int) in (1985,1986,1987,1988,1989,1990,1991,1992,
1993,1994,1995,1996,1997,1998,1999,2000, null)
group by c_name
order by c_name, bal""".stripMargin,
1,
true, true)
test("inclause-insetTest1B",
s"""select c_name, sum(c_acctbal) as bal
from orderLineItemPartSupplierBase
where to_Date(o_orderdate) >= cast('1993-01-01' as date) and to_Date(o_orderdate) <= cast('1997-12-31' as date)
and cast(order_year as int) in (1985,1986,1987,1988,1989,1990,1991,1992,
1993,1994,1995,1996,1997,1998,1999,2000, null)
group by c_name
order by c_name, bal""".stripMargin,
0,
true, true)
test("inclause-inTest1",
s"""select c_name, sum(c_acctbal) as bal
from orderLineItemPartSupplier
where to_Date(o_orderdate) >= cast('1993-01-01' as date) and to_Date(o_orderdate) <= cast('1997-12-31' as date)
and cast(order_year as int) in (1993,1994,1995, null)
group by c_name
order by c_name, bal""".stripMargin,
1,
true, true)
test("inclause-inTest1B",
s"""select c_name, sum(c_acctbal) as bal
from orderLineItemPartSupplierBase
where to_Date(o_orderdate) >= cast('1993-01-01' as date) and to_Date(o_orderdate) <= cast('1997-12-31' as date)
and cast(order_year as int) in (1993,1994,1995, null)
group by c_name
order by c_name, bal""".stripMargin,
0,
true, true)
test("caseWhen",
s"""select SUM((CASE WHEN 1000 = 0 THEN NULL ELSE CAST(l_suppkey AS DOUBLE) / 1000 END)) as x1
|from orderLineItemPartSupplier
|group by s_region
|order by x1""".stripMargin,
1,
true, true)
test("trunc1",
"""
|select o_orderstatus as x, trunc(cast(o_orderdate as date), 'MM') as y
|from orderLineItemPartSupplier
|group by o_orderstatus, trunc(cast(o_orderdate as date), 'MM')
|order by x, y
""".stripMargin
,1,true,true)
test("trunc1B",
"""
|select o_orderstatus as x, trunc(cast(o_orderdate as date), 'MM') as y
|from orderLineItemPartSupplierBase
|group by o_orderstatus, trunc(cast(o_orderdate as date), 'MM')
|order by x, y
""".stripMargin
,0,true,true)
test("trunc2",
"""
|select o_orderstatus as x, trunc(cast(o_orderdate as date), 'YY') as y
|from orderLineItemPartSupplier
|group by o_orderstatus, trunc(cast(o_orderdate as date), 'YY')
|order by x, y
""".stripMargin
,1,true,true)
test("trunc2B",
"""
|select o_orderstatus as x, trunc(cast(o_orderdate as date), 'YY') as y
|from orderLineItemPartSupplierBase
|group by o_orderstatus, trunc(cast(o_orderdate as date), 'YY')
|order by x, y
""".stripMargin
,0,true,true)
test("date_format1",
"""
|select o_orderstatus as x, date_format(cast(o_orderdate as date), 'YY') as y
|from orderLineItemPartSupplier
|group by o_orderstatus, date_format(cast(o_orderdate as date), 'YY')
|order by x, y
""".stripMargin
,1,true,true)
test("date_format2",
"""
|select o_orderstatus as x, date_format(cast(o_orderdate as date), 'u') as y
|from orderLineItemPartSupplier
|group by o_orderstatus, date_format(cast(o_orderdate as date), 'u')
|order by x, y
""".stripMargin
,1,true,true)
test("if1",
"""
|select o_orderstatus as a,
|date_format(cast(o_orderdate as date), 'u') as b,
|if(date_format(cast(o_orderdate as date), 'u') = 1, 'true', 'false') as c
|from orderLineItemPartSupplier
|group by o_orderstatus, date_format(cast(o_orderdate as date), 'u'),
|if(date_format(cast(o_orderdate as date), 'u') = 1, 'true', 'false')
|order by a, b, c
""".stripMargin
,1,true,true)
test("if2",
"""
|select o_orderstatus as a,
|date_format(cast(o_orderdate as date), 'yy') as b,
|if(date_format(cast(o_orderdate as date), 'yy') = 94, 'true', 'false') as c
|from orderLineItemPartSupplier
|group by o_orderstatus, date_format(cast(o_orderdate as date), 'yy'),
|if(date_format(cast(o_orderdate as date), 'yy') = 94, 'true', 'false')
|order by a, b, c
""".stripMargin
,1,true,true)
test("if3",
"""
|select o_orderstatus as a,
|date_format(cast(o_orderdate as date), 'yy') as b,
|if(date_format(cast(o_orderdate as date), 'yy') = 94, 1, null) as c
|from orderLineItemPartSupplier
|group by o_orderstatus, date_format(cast(o_orderdate as date), 'yy'),
|if(date_format(cast(o_orderdate as date), 'yy') = 94, 1, null)
|order by a, b, c
""".stripMargin
,1,true,true)
test("substr1",
"""
|select o_orderstatus as x, date_format(cast(o_orderdate as date), 'YYY') y,
|cast(Substring(date_format(cast(o_orderdate as date), 'YYY'), 1,1) as int)as z
|from orderLineItemPartSupplier
|group by
|o_orderstatus,
|date_format(cast(o_orderdate as date), 'YYY'),
|cast(Substring(date_format(cast(o_orderdate as date), 'YYY'), 1,1) as int)
|order by x, y, z
""".stripMargin
,1,true,true)
test("substr2",
"""
|select o_orderstatus as x, date_format(cast(o_orderdate as date), 'YYY') y,
|cast(Substring(date_format(cast(o_orderdate as date), 'YYY'), 0,4) as int)as z
|from orderLineItemPartSupplier
|group by
|o_orderstatus,
|date_format(cast(o_orderdate as date), 'YYY'),
|cast(Substring(date_format(cast(o_orderdate as date), 'YYY'), 0,4) as int)
|order by x, y, z
""".stripMargin
,1,true,true)
test("substr3",
"""
|select o_orderstatus as x, l_shipdate as y,
|Substring(l_shipdate, -1, 2)as z
|from orderLineItemPartSupplier
|group by
|o_orderstatus, l_shipdate,
|Substring(l_shipdate, -1, 2)
|order by x, y, z
""".stripMargin
,0,true,true)
test("substr4",
"""
|select o_orderstatus as x, l_shipdate as y,
|Substring(l_shipdate, 1, 0)as z
|from orderLineItemPartSupplier
|group by
|o_orderstatus, l_shipdate,
|Substring(l_shipdate, 1, 0)
|order by x, y, z
""".stripMargin
,0,true,true)
test("substr5",
"""
|select o_orderstatus as x, l_shipdate as y,
|Substring(l_shipdate, 1, -2)as z
|from orderLineItemPartSupplier
|group by
|o_orderstatus, l_shipdate,
|Substring(l_shipdate, 1, -2)
|order by x, y, z
""".stripMargin
,0,true,true)
test("substr6",
"""
|select (SUBSTRING(c_name, 5) = 'PROMO') as x from orderLineItemPartSupplier
|group by (SUBSTRING(c_name, 5) = 'PROMO')
""".stripMargin
, 1, true, true)
test("substr7",
"""
|select (SUBSTRING(SUBSTRING(c_name, 1), 2) = 'PROMO') as x from orderLineItemPartSupplier
|group by (SUBSTRING(SUBSTRING(c_name, 1), 2) = 'PROMO')
""".stripMargin
, 1, true, true)
test("subquery1",
"""
select x, sum(z) as z from
( select
Substring(o_orderstatus, 1, 2) x, Substring(l_shipdate, 1, 2) as y, c_acctbal as z
from orderLineItemPartSupplier) r1 group by x, y
""".stripMargin
, 1, true, true)
test("subquery2",
"""
select x, sum(z) as z from
( select
Substring(o_orderstatus, 1, rand()) x, Substring(l_shipdate, 1, 2) as y, c_acctbal as z
from orderLineItemPartSupplier) r1 group by x, y
""".stripMargin
, 0, true, true)
test("tscomp1",
"""
|select sum(c_acctbal) from orderLineItemPartSupplier
|where (CAST(CONCAT(TO_DATE(o_orderdate), 'T00:00:00.000Z') AS TIMESTAMP) <
|CAST(CONCAT(TO_DATE(l_shipdate), 'T00:00:00.000Z') AS TIMESTAMP))
|group by c_name
""".stripMargin
, 0, true, true)
test("tscomp2",
"""
|select sum(c_acctbal) from orderLineItemPartSupplier
|where (CAST(CONCAT(TO_DATE(o_orderdate), 'T00:00:00.000Z') AS TIMESTAMP) <
|CAST('1995-12-31T00:00:00.000Z' AS TIMESTAMP))
|group by c_name
""".stripMargin
, 1, true, true)
test("tscomp3",
"""
|select sum(c_acctbal), o_orderdate from orderLineItemPartSupplier
|where CAST((MONTH(CAST(CONCAT(TO_DATE(o_orderdate),' 00:00:00') AS TIMESTAMP)) - 1) / 3 + 1 AS BIGINT) < 2
|group by c_name, o_orderdate
""".stripMargin
, 1, true, true)
test("binaryunhex1",
"""
|select sum(c_acctbal), o_orderdate from orderLineItemPartSupplier
|where c_nation < concat(CAST(UNHEX('c2a3') AS string), '349- W10_HulfordsOLVPen15Sub_UK_640x480_ISV_V2_x264')
|group by c_name, o_orderdate
""".stripMargin
, 1, true, true)
test("isNull1",
"""
|select sum(c_acctbal), c_name from orderLineItemPartSupplier
|where l_shipdate is null
|group by c_name
""".stripMargin
, 1, true, true)
test("isNull2",
"""
|select sum(c_acctbal), c_name from orderLineItemPartSupplier
|where l_shipdate is null and (cast(l_shipdate as bigint) + 10) is not null
|group by c_name
""".stripMargin
, 1, true, true)
test("isNull3",
"""
|select sum(c_acctbal), c_name from orderLineItemPartSupplier
|where o_orderdate is not null and l_commitdate is null and (cast(l_shipdate as bigint) + 10) is not null
|group by c_name
""".stripMargin
, 1, true, true)
test("isNull4",
"""
|select sum(c_acctbal), c_name from orderLineItemPartSupplier
|where (o_orderdate is not null and l_commitdate is null) or ((cast(l_shipdate as bigint) + 10) is null)
|group by c_name
""".stripMargin
, 1, true, true)
}
| SparklineData/spark-druid-olap | src/test/scala/org/sparklinedata/druid/client/test/CodeGenTest.scala | Scala | apache-2.0 | 38,394 |
package lore.compiler.resolution
import lore.compiler.core.UniqueKey
import lore.compiler.feedback.Reporter
import lore.compiler.semantics.functions.ParameterDefinition
import lore.compiler.semantics.scopes.{BindingScope, TypeScope}
import lore.compiler.syntax.DeclNode
import lore.compiler.types.BasicType
object ParameterDefinitionResolver {
def resolve(node: DeclNode.ParameterNode)(implicit typeScope: TypeScope, bindingScope: BindingScope, reporter: Reporter): ParameterDefinition = {
val tpe = TypeExpressionEvaluator.evaluate(node.tpe).getOrElse(BasicType.Any)
ParameterDefinition(UniqueKey.fresh(), node.name, tpe, node.nameNode.map(_.position).getOrElse(node.position))
}
}
| marcopennekamp/lore | compiler/src/lore/compiler/resolution/ParameterDefinitionResolver.scala | Scala | mit | 699 |
package almhirt.almvalidation
import scala.reflect.ClassTag
import scalaz.syntax.validation._
import almhirt.common._
object CastHelper {
/** Taken from scala.concurrent, unfortunately its a private val there
*
*/
private[almvalidation] val toBoxed = Map[Class[_], Class[_]](
classOf[Boolean] → classOf[java.lang.Boolean],
classOf[Byte] → classOf[java.lang.Byte],
classOf[Char] → classOf[java.lang.Character],
classOf[Short] → classOf[java.lang.Short],
classOf[Int] → classOf[java.lang.Integer],
classOf[Long] → classOf[java.lang.Long],
classOf[Float] → classOf[java.lang.Float],
classOf[Double] → classOf[java.lang.Double],
classOf[Unit] → classOf[scala.runtime.BoxedUnit])
}
trait AlmValidationCastFunctions {
/** A cast with runtime safety
*
* Includes code from scala.concurrent.Future
*/
def almCast[To](what: Any)(implicit tag: ClassTag[To]): AlmValidation[To] = {
// Taken from scala.concurrent.Future.mapTo
def boxedType(c: Class[_]): Class[_] = {
if (c.isPrimitive) CastHelper.toBoxed(c) else c
}
try {
scalaz.Success(boxedType(tag.runtimeClass).cast(what).asInstanceOf[To])
} catch {
case exn: ClassCastException ⇒ InvalidCastProblem(s"""I cannot cast from "${what.getClass.getName()}" to "${tag.runtimeClass.getName()}"""", cause = Some(exn)).failure
}
}
} | chridou/almhirt | almhirt-common/src/main/scala/almhirt/almvalidation/AlmValidationCastFunctions.scala | Scala | apache-2.0 | 1,393 |
package com.avast.metrics.scalaeffectapi.impl
import cats.effect.Sync
import com.avast.metrics.scalaapi.{Counter => SCounter}
import com.avast.metrics.scalaeffectapi.Counter
private class CounterImpl[F[_]: Sync](inner: SCounter) extends Counter[F] {
override def inc: F[Unit] = Sync[F].delay(inner.inc())
override def inc(n: Long): F[Unit] = Sync[F].delay(inner.inc(n))
override def dec: F[Unit] = Sync[F].delay(inner.dec())
override def dec(n: Int): F[Unit] = Sync[F].delay(inner.dec(n))
override def count: F[Long] = Sync[F].delay(inner.count)
override def name: String = inner.name
}
| avast/metrics | scala-effect-api/src/main/scala/com/avast/metrics/scalaeffectapi/impl/CounterImpl.scala | Scala | mit | 606 |
package mesosphere.marathon
package core.deployment.impl
import mesosphere.UnitTest
import mesosphere.marathon.core.condition.Condition
import mesosphere.marathon.core.deployment.ScalingProposition
import mesosphere.marathon.core.instance.{Instance, TestInstanceBuilder}
import mesosphere.marathon.state.{KillSelection, PathId, Timestamp}
import scala.concurrent.duration._
class ScalingPropositionTest extends UnitTest {
"ScalingProposition.propose" when {
"given no running tasks" should {
val f = new Fixture
val proposition = ScalingProposition.propose(
instances = f.noTasks,
toDecommission = f.noTasks,
meetConstraints = f.noConstraintsToMeet,
scaleTo = 0,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"lead to ScalingProposition(None, _)" in {
proposition.toDecommission shouldBe empty
}
}
"given a staged task to kill" should {
val f = new Fixture
val instance = TestInstanceBuilder.newBuilder(f.appId).addTaskStaged().getInstance()
val proposition = ScalingProposition.propose(
instances = Seq(instance),
toDecommission = Seq(instance),
meetConstraints = f.noConstraintsToMeet,
scaleTo = 0,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"lead to ScalingProposition list of instances to decommission" in {
proposition.toDecommission shouldBe Seq(instance)
}
}
"given no tasks and scaleTo = 0" should {
val f = new Fixture
val proposition = ScalingProposition.propose(
instances = f.noTasks,
toDecommission = f.noTasks,
meetConstraints = f.noConstraintsToMeet,
scaleTo = 0,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"lead to ScalingProposition(_, None)" in {
proposition.toStart shouldBe 0
}
}
"given no tasks and negative scaleTo" should {
val f = new Fixture
val proposition = ScalingProposition.propose(
instances = f.noTasks,
toDecommission = f.noTasks,
meetConstraints = f.noConstraintsToMeet,
scaleTo = -42,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"lead to ScalingProposition(_, None)" in {
proposition.toStart shouldBe 0
}
}
"given no running tasks and a positive scaleTo" should {
val f = new Fixture
val proposition = ScalingProposition.propose(
instances = f.noTasks,
toDecommission = f.noTasks,
meetConstraints = f.noConstraintsToMeet,
scaleTo = 42,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"lead to ScalePropositionof 42" in {
proposition.toStart shouldBe 42
}
}
"none are sentenced and need to scale" should {
val f = new Fixture
val proposition = ScalingProposition.propose(
instances = Seq(f.createInstance(1), f.createInstance(2), f.createInstance(3)),
toDecommission = f.noTasks,
meetConstraints = f.noConstraintsToMeet,
scaleTo = 5,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"determine tasks to kill" in {
proposition.toDecommission shouldBe empty
}
"determine tasks to start" in {
proposition.toStart shouldBe 2
}
}
"scaling to 0" should {
val f = new Fixture
val runningTasks: Seq[Instance] = Seq(f.createInstance(1), f.createInstance(2), f.createInstance(3))
val proposition = ScalingProposition.propose(
instances = runningTasks,
toDecommission = f.noTasks,
meetConstraints = f.noConstraintsToMeet,
scaleTo = 0,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"determine tasks to kill" in {
proposition.toDecommission.nonEmpty shouldBe true
proposition.toDecommission shouldEqual runningTasks.reverse
}
"determine no tasks to start" in {
proposition.toStart shouldBe 0
}
}
"given invalid tasks" should {
val f = new Fixture
val task_1: Instance = f.createInstance(1)
val task_2: Instance = f.createInstance(2)
val task_3: Instance = f.createInstance(3)
val alreadyKilled: Instance = f.createInstance(42)
val proposition = ScalingProposition.propose(
instances = Seq(task_1, task_2, task_3),
toDecommission = Seq(task_2, task_3, alreadyKilled),
meetConstraints = f.noConstraintsToMeet,
scaleTo = 3,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"determine tasks to kill" in {
proposition.toDecommission.nonEmpty shouldBe true
proposition.toDecommission shouldEqual Seq(task_2, task_3)
}
"determine tasks to start" in {
proposition.toStart shouldBe 2
}
}
"given already killed tasks" should {
val f = new Fixture
val instance_1 = f.createInstance(1)
val instance_2 = f.createInstance(2)
val instance_3 = f.createInstance(3)
val instance_4 = f.createInstance(4)
val alreadyKilled = f.createInstance(42)
val proposition = ScalingProposition.propose(
instances = Seq(instance_1, instance_2, instance_3, instance_4),
toDecommission = Seq(alreadyKilled),
meetConstraints = f.noConstraintsToMeet,
scaleTo = 3,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"determine tasks to kill" in {
proposition.toDecommission.nonEmpty shouldBe true
proposition.toDecommission shouldEqual Seq(instance_4)
}
"determine no tasks to start" in {
proposition.toStart shouldBe 0
}
}
"given sentenced, constraints and scaling" should {
val f = new Fixture
val instance_1 = f.createInstance(1)
val instance_2 = f.createInstance(2)
val instance_3 = f.createInstance(3)
val instance_4 = f.createInstance(4)
val proposition = ScalingProposition.propose(
instances = Seq(instance_1, instance_2, instance_3, instance_4),
toDecommission = Seq(instance_2),
meetConstraints = f.killToMeetConstraints(instance_3),
scaleTo = 1,
killSelection = KillSelection.DefaultKillSelection,
f.appId
)
"determine tasks to kill" in {
proposition.toDecommission.nonEmpty shouldBe true
proposition.toDecommission shouldEqual Seq(instance_2, instance_3, instance_4)
}
"determine no tasks to start" in {
proposition.toStart shouldBe 0
}
}
}
"ScalingProposition.sortByConditionAndDate" when {
"sorting a unreachable, unhealthy, running, staging and healthy tasks" should {
val f = new Fixture
val runningInstance = f.createInstance(1)
val runningInstanceOlder = f.createInstance(0)
val lostInstance = f.createUnreachableInstance()
val startingInstance = f.createStartingInstance(Timestamp.now())
val startingInstanceOlder = f.createStartingInstance(Timestamp.now - 1.hours)
val stagingInstance = f.createStagingInstance()
val stagingInstanceOlder = f.createStagingInstance(Timestamp.now - 1.hours)
"put unreachable before running" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(lostInstance, runningInstance) shouldBe true
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(runningInstance, lostInstance) shouldBe false
}
"put unreachable before staging" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(lostInstance, stagingInstance) shouldBe true
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(stagingInstance, lostInstance) shouldBe false
}
"put unreachable before starting" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(lostInstance, startingInstance) shouldBe true
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(startingInstance, lostInstance) shouldBe false
}
"put staging before starting" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(startingInstance, stagingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(startingInstance, runningInstance) shouldBe true
}
"put staging before running" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(runningInstance, stagingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(stagingInstance, runningInstance) shouldBe true
}
"put starting before running" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(runningInstance, startingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(startingInstance, runningInstance) shouldBe true
}
"put younger staging before older staging" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(stagingInstanceOlder, stagingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(stagingInstance, stagingInstanceOlder) shouldBe true
}
"put younger starting before older starting" in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(startingInstanceOlder, startingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(startingInstance, startingInstanceOlder) shouldBe true
}
"put younger running before older running " in {
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(runningInstance, runningInstanceOlder) shouldBe true
ScalingProposition.sortByConditionAndDate(KillSelection.DefaultKillSelection)(runningInstanceOlder, runningInstance) shouldBe false
}
"put younger staging before younger staging" in {
ScalingProposition.sortByConditionAndDate(KillSelection.YoungestFirst)(stagingInstanceOlder, stagingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.YoungestFirst)(stagingInstance, stagingInstanceOlder) shouldBe true
}
"put younger starting before younger starting" in {
ScalingProposition.sortByConditionAndDate(KillSelection.YoungestFirst)(startingInstanceOlder, startingInstance) shouldBe false
ScalingProposition.sortByConditionAndDate(KillSelection.YoungestFirst)(startingInstance, startingInstanceOlder) shouldBe true
}
"put younger running before younger running " in {
ScalingProposition.sortByConditionAndDate(KillSelection.YoungestFirst)(runningInstance, runningInstanceOlder) shouldBe true
ScalingProposition.sortByConditionAndDate(KillSelection.YoungestFirst)(runningInstanceOlder, runningInstance) shouldBe false
}
}
}
class Fixture {
val appId = PathId("/test")
def createInstance(index: Long) = {
val instance = TestInstanceBuilder.newBuilder(appId, version = Timestamp(index)).addTaskRunning(startedAt = Timestamp.now().+(index.hours)).getInstance()
val state = instance.state.copy(condition = Condition.Running)
instance.copy(state = state)
}
def createUnreachableInstance(): Instance = {
val instance = TestInstanceBuilder.newBuilder(appId).addTaskUnreachable().getInstance()
val state = instance.state.copy(condition = Condition.Unreachable)
instance.copy(state = state)
}
def createStagingInstance(stagedAt: Timestamp = Timestamp.now()) = {
val instance = TestInstanceBuilder.newBuilder(appId).addTaskStaged(stagedAt).getInstance()
val state = instance.state.copy(condition = Condition.Staging)
instance.copy(state = state)
}
def createStartingInstance(since: Timestamp) = {
val instance = TestInstanceBuilder.newBuilder(appId).addTaskStarting(since).getInstance()
val state = instance.state.copy(condition = Condition.Starting, since = since)
instance.copy(state = state)
}
def noConstraintsToMeet(running: Seq[Instance], killCount: Int) = // linter:ignore:UnusedParameter
Seq.empty[Instance]
def killToMeetConstraints(tasks: Instance*): (Seq[Instance], Int) => Seq[Instance] =
(running: Seq[Instance], killCount: Int) => tasks.to[Seq]
def noTasks = Seq.empty[Instance]
}
}
| gsantovena/marathon | src/test/scala/mesosphere/marathon/core/deployment/impl/ScalingPropositionTest.scala | Scala | apache-2.0 | 12,837 |
package name.abhijitsarkar.scala.scalaimpatient.types
import name.abhijitsarkar.scala.scalaimpatient.UnitSpec
import name.abhijitsarkar.scala.scalaimpatient.types.Network.process
import name.abhijitsarkar.scala.scalaimpatient.types.Network.processQ5
class NetworkSpec extends UnitSpec {
"Only members from the same network" should "be equal" in {
val chatter = new Network
val fred = chatter.join("Fred")
val barney = chatter.join("Barney")
fred equals barney should be(true)
val myFace = new Network
val wilma = myFace.join("Wilma")
fred equals wilma should be(false)
barney equals wilma should be(false)
}
"Method process with existential type" should "only accept members from same network" in {
val chatter = new Network
val myFace = new Network
val fred = chatter.join("Fred")
val barney = chatter.join("Barney")
val wilma = myFace.join("Wilma")
process(fred, barney)
processQ5(fred, wilma)
}
} | abhijitsarkar/scala-impatient | src/test/scala/name/abhijitsarkar/scala/scalaimpatient/types/NetworkSpec.scala | Scala | gpl-3.0 | 981 |
/*
* Artificial Intelligence for Humans
* Volume 1: Fundamental Algorithms
* Scala Version
* http://www.aifh.org
* http://www.jeffheaton.com
*
* Code repository:
* https://github.com/jeffheaton/aifh
* Copyright 2013 by Jeff Heaton
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
* For more information on Heaton Research copyrights, licenses
* and trademarks visit:
* http://www.heatonresearch.com/copyright
*/
package com.heatonresearch.aifh.general.fns
import scala.collection.mutable.ArrayBuffer
/**
* The Inverse Multiquadric Radial Basis Function.
* <p/>
* http://en.wikipedia.org/wiki/Radial_basis_function
* Construct the Inverse Multiquadric RBF. Each RBF will require space equal to (dimensions + 1) in the
* params vector.
*
* @param theDimensions The number of dimensions.
* @param theParams A vector to hold the parameters.
* @param theIndex The index into the params vector. You can store multiple RBF's in a vector.
*/
class InverseMultiquadricFunction(theDimensions: Int, theParams: ArrayBuffer[Double], theIndex: Int)
extends AbstractRBF(theDimensions, theParams, theIndex) {
override def evaluate(x: Vector[Double]): Double = {
var value: Double = 0
val width: Double = getWidth
for(i <- 0 until getDimensions) {
val center: Double = getCenter(i)
value += Math.pow(x(i) - center, 2) + (width * width)
}
1 / Math.sqrt(value)
}
} | HairyFotr/aifh | vol1/scala-examples/src/main/scala/com/heatonresearch/aifh/general/fns/InverseMultiquadricFunction.scala | Scala | apache-2.0 | 1,933 |
/*
Copyright 2013 Twitter, Inc.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package com.twitter.summingbird.batch
import com.twitter.algebird.{ Universe, Empty, Interval, Intersection,
InclusiveLower, ExclusiveUpper, InclusiveUpper, ExclusiveLower, Lower, Upper }
import scala.collection.immutable.SortedSet
import java.util.{ Comparator, Date }
import java.util.concurrent.TimeUnit
import java.io.Serializable
/**
* For the purposes of batching, each Event object has exactly one
* Time (in millis). The Batcher uses this time to assign each Event
* to a specific BatchID. A Batcher can return the minimum time for
* each BatchID.
*
* @author Oscar Boykin
* @author Sam Ritchie
* @author Ashu Singhal
*/
object Batcher {
/**
* Returns a batcher that assigns batches based on multiples of the
* supplied TimeUnit from the epoch.
*/
def apply(value: Long, unit: TimeUnit) =
new MillisecondBatcher(unit.toMillis(value))
/**
* Returns a batcher that generates batches of the supplied number
* of minutes.
*/
def ofMinutes(count: Long) = Batcher(count, TimeUnit.MINUTES)
/**
* Returns a batcher that generates batches of the supplied number
* of hours.
*/
def ofHours(count: Long) = Batcher(count, TimeUnit.HOURS)
/**
* Returns a batcher that generates batches of the supplied number
* of days.
*/
def ofDays(count: Long) = Batcher(count, TimeUnit.DAYS)
/**
* Returns a batcher that assigns every input tuple to the same
* batch.
*/
val unit: Batcher = new AbstractBatcher {
override val currentBatch = BatchID(0L)
def batchOf(t: Timestamp) = currentBatch
def earliestTimeOf(batch: BatchID) = Timestamp.Min
override def latestTimeOf(batch: BatchID) = Timestamp.Max
override def toInterval(b: BatchID): Interval[Timestamp] =
if(b == BatchID(0))
Intersection(
InclusiveLower(Timestamp.Min),
InclusiveUpper(Timestamp.Max)
)
else
Empty[Timestamp]()
val totalBatchInterval = Intersection(
InclusiveLower(currentBatch), ExclusiveUpper(currentBatch.next)
)
override def batchesCoveredBy(interval: Interval[Timestamp]): Interval[BatchID] =
interval match {
case Empty() => Empty()
case Universe() => totalBatchInterval
case ExclusiveUpper(upper) => Empty()
case InclusiveLower(lower) =>
if(lower == Timestamp.Min) totalBatchInterval
else Empty()
case InclusiveUpper(upper) =>
if(upper == Timestamp.Max) totalBatchInterval
else Empty()
case ExclusiveLower(lower) => Empty()
case Intersection(low, high) => batchesCoveredBy(low) && batchesCoveredBy(high)
}
override def cover(interval: Interval[Timestamp]): Interval[BatchID] =
interval match {
case Empty() => Empty()
case _ => totalBatchInterval
}
}
}
trait Batcher extends Serializable {
/** Returns the batch into which the supplied Date is bucketed. */
def batchOf(t: Timestamp): BatchID
private def truncateDown(ts: Timestamp): BatchID = batchOf(ts)
private def truncateUp(ts: Timestamp): BatchID = {
val batch = batchOf(ts)
if(earliestTimeOf(batch) != ts) batch.next else batch
}
/** Return the largest interval of batches completely covered by
* the interval of time.
*/
private def dateToBatch(interval: Interval[Timestamp])(onIncLow: (Timestamp) => BatchID)(onExcUp: (Timestamp) => BatchID): Interval[BatchID] = {
interval match {
case Empty() => Empty()
case Universe() => Universe()
case ExclusiveUpper(upper) => ExclusiveUpper(onExcUp(upper))
case InclusiveLower(lower) => InclusiveLower(onIncLow(lower))
case InclusiveUpper(upper) => ExclusiveUpper(onExcUp(upper.next))
case ExclusiveLower(lower) => InclusiveLower(onIncLow(lower.next))
case Intersection(low, high) =>
// Convert to inclusive:
val lowdate = low match {
case InclusiveLower(lb) => lb
case ExclusiveLower(lb) => lb.next
}
//convert it exclusive:
val highdate = high match {
case InclusiveUpper(hb) => hb.next
case ExclusiveUpper(hb) => hb
}
val upperBatch = onExcUp(highdate)
val lowerBatch = onIncLow(lowdate)
Interval.leftClosedRightOpen(lowerBatch, upperBatch)
}
}
/**
* Returns true if the supplied timestamp sits at the floor of the
* supplied batch.
*/
def isLowerBatchEdge(ts: Timestamp): Boolean =
!BatchID.equiv.equiv(batchOf(ts), batchOf(ts.prev))
def batchesCoveredBy(interval: Interval[Timestamp]): Interval[BatchID] =
dateToBatch(interval)(truncateUp)(truncateDown)
def toInterval(b: BatchID): Interval[Timestamp] =
Intersection(InclusiveLower(earliestTimeOf(b)), ExclusiveUpper(earliestTimeOf(b.next)))
def toTimestamp(b: Interval[BatchID]): Interval[Timestamp] =
b match {
case Empty() => Empty[Timestamp]()
case Universe() => Universe[Timestamp]()
case ExclusiveUpper(upper) => ExclusiveUpper(earliestTimeOf(upper))
case InclusiveUpper(upper) => InclusiveUpper(latestTimeOf(upper))
case InclusiveLower(lower) => InclusiveLower(earliestTimeOf(lower))
case ExclusiveLower(lower) => ExclusiveLower(latestTimeOf(lower))
case Intersection(low, high) => toTimestamp(low) && toTimestamp(high)
}
/** Returns the (inclusive) earliest time of the supplied batch. */
def earliestTimeOf(batch: BatchID): Timestamp
/** Returns the latest time in the given batch */
def latestTimeOf(batch: BatchID): Timestamp = earliestTimeOf(batch.next).prev
/** Returns the current BatchID. */
def currentBatch: BatchID = batchOf(Timestamp.now)
/** What batches are needed to cover the given interval
* or: for all t in interval, batchOf(t) is in the result
*/
def cover(interval: Interval[Timestamp]): Interval[BatchID] =
dateToBatch(interval)(truncateDown)(truncateUp)
/**
* Returns the sequence of BatchIDs that the supplied `other`
* batcher would need to fetch to fully enclose the supplied
* `batchID`.
*/
def enclosedBy(batchID: BatchID, other: Batcher): Iterable[BatchID] = {
val earliestInclusive = earliestTimeOf(batchID)
val latestInclusive = latestTimeOf(batchID)
BatchID.range(
other.batchOf(earliestInclusive),
other.batchOf(latestInclusive)
)
}
def enclosedBy(extremities: (BatchID, BatchID), other: Batcher): Iterable[BatchID] = {
val (bottom, top) = extremities
SortedSet(
BatchID.range(bottom, top).toSeq
.flatMap(enclosedBy(_, other)):_*
)
}
}
/**
* Abstract class to extend for easier java interop.
*/
abstract class AbstractBatcher extends Batcher
| surabhiiyer/summingbird | summingbird-batch/src/main/scala/com/twitter/summingbird/batch/Batcher.scala | Scala | apache-2.0 | 7,303 |
package controllers
import %%PACKAGE_NAME%%.Client
import %%PACKAGE_NAME%%.models.Healthcheck
import play.api.test._
import play.api.test.Helpers._
import org.scalatestplus.play._
class HealthchecksSpec extends PlaySpec with OneServerPerSuite {
import scala.concurrent.ExecutionContext.Implicits.global
implicit override lazy val port = 9010
implicit override lazy val app: FakeApplication = FakeApplication()
lazy val client = new Client(s"http://localhost:$port")
"GET /_internal_/healthcheck" in new WithServer {
await(
client.healthchecks.getHealthcheck()
) must beEqualTo(
Some(Healthcheck("healthy"))
)
}
}
| mbryzek/play-apidoc | template/api/test/controllers/HealthchecksSpec.scala | Scala | mit | 657 |
package com.twitter.finagle.mux.pushsession
import com.twitter.finagle.pushsession.utils.MockChannelHandle
import com.twitter.finagle.mux.transport.Message
import com.twitter.finagle.{Dtab, Path}
import com.twitter.finagle.mux.transport.Message.Tdispatch
import com.twitter.finagle.stats.{InMemoryStatsReceiver, NullStatsReceiver}
import com.twitter.io.Buf
import com.twitter.util.Return
import org.scalatest.funsuite.AnyFunSuite
class FragmentingMessageWriterTest extends AnyFunSuite {
private class PendingStreamStatsReceiver extends InMemoryStatsReceiver {
def pendingStreamCount: Int = gauges(Seq("mux", "framer", "pending_write_streams"))().toInt
def writes: Seq[Int] = stats(Seq("mux", "framer", "write_stream_bytes")).map(_.toInt)
}
private val Tag = 2
private val Data = Buf.ByteArray((0 until 1024).map(_.toByte): _*)
private def concat(msgs: Iterable[Buf]): Buf = msgs.foldLeft(Buf.Empty)(_.concat(_))
test("writes that don't overflow the max frame size are not fragmented") {
val sr = new PendingStreamStatsReceiver
val handle = new MockChannelHandle[Any, Buf]()
val msg = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
val writer = new FragmentingMessageWriter(handle, msg.buf.length, sr)
writer.write(msg)
assert(Message.decode(concat(handle.pendingWrites.dequeue().msgs)) == msg)
assert(sr.pendingStreamCount == 0)
}
test("writes that do overflow the max frame size are fragmented") {
val sr = new PendingStreamStatsReceiver
val handle = new MockChannelHandle[Any, Buf]()
val msg = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
val writer = new FragmentingMessageWriter(handle, msg.buf.length - 1, sr)
writer.write(msg)
assert(handle.pendingWrites.size == 1)
assert(sr.pendingStreamCount == 1)
assert(sr.writes == Seq(msg.buf.length - 1 + 4))
val handle.SendOne(data1, thunk) = handle.pendingWrites.dequeue()
thunk(Return.Unit)
assert(handle.pendingWrites.size == 1)
assert(sr.pendingStreamCount == 0)
assert(sr.writes == Seq(msg.buf.length - 1 + 4, 1 + 4))
val handle.SendOne(data2, _) = handle.pendingWrites.dequeue()
val fullMessage =
data2.slice(0, 4).concat(data1.slice(4, Int.MaxValue)).concat(data2.slice(4, Int.MaxValue))
assert(Message.decode(fullMessage) == msg)
}
test("write interests can be discarded") {
val sr = new PendingStreamStatsReceiver
val handle = new MockChannelHandle[Any, Buf]()
val msg = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
val writer = new FragmentingMessageWriter(handle, msg.buf.length - 1, sr)
writer.write(msg)
assert(sr.pendingStreamCount == 1)
assert(writer.removeForTag(Tag) == MessageWriter.DiscardResult.PartialWrite)
assert(sr.pendingStreamCount == 0)
}
test("we don't remove interests for non-matching tags") {
val sr = new PendingStreamStatsReceiver
val handle = new MockChannelHandle[Any, Buf]()
val msg = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
val writer = new FragmentingMessageWriter(handle, msg.buf.length - 1, sr)
writer.write(msg)
assert(sr.pendingStreamCount == 1)
assert(writer.removeForTag(Tag + 1) == MessageWriter.DiscardResult.NotFound)
assert(sr.pendingStreamCount == 1)
}
test("Removes interests that have not had any fragments written") {
val sr = new PendingStreamStatsReceiver
val handle = new MockChannelHandle[Any, Buf]()
val msg1 = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
val msg2 = Tdispatch(Tag + 1, Seq.empty, Path(), Dtab.empty, Data)
val writer = new FragmentingMessageWriter(handle, msg1.buf.length - 1, sr)
writer.write(msg1)
assert(sr.pendingStreamCount == 1)
writer.write(msg2)
assert(sr.pendingStreamCount == 2)
assert(writer.removeForTag(Tag + 1) == MessageWriter.DiscardResult.Unwritten)
assert(sr.pendingStreamCount == 1)
}
test("drain() notifies after writes finish") {
val handle = new MockChannelHandle[Any, Buf]()
val writer = new FragmentingMessageWriter(handle, Int.MaxValue, NullStatsReceiver)
// We reuse the same message, even though its illegal per the mux spec, for convenience
val msg = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
// write one message
writer.write(msg)
val drainP = writer.drain()
assert(!drainP.isDefined)
handle.dequeAndCompleteWrite() // Don't care about the data
assert(drainP.isDefined) // should be done now
}
test("drain() will allow further writes if we're draining") {
val handle = new MockChannelHandle[Any, Buf]()
val writer = new FragmentingMessageWriter(handle, Int.MaxValue, NullStatsReceiver)
// We reuse the same message, even though its illegal per the mux spec, for convenience
val msg = Tdispatch(Tag, Seq.empty, Path(), Dtab.empty, Data)
// write one message
writer.write(msg)
val drainP = writer.drain()
assert(!drainP.isDefined)
// Now two messages
writer.write(msg)
handle.dequeAndCompleteWrite() // Don't care about the data
assert(!drainP.isDefined) // Still a pending message
handle.dequeAndCompleteWrite() // Don't care about the data
assert(drainP.isDefined) // Should be done now
}
test("drain() notifies immediately if nothing is pending") {
val handle = new MockChannelHandle[Any, Buf]()
val writer = new FragmentingMessageWriter(handle, Int.MaxValue, NullStatsReceiver)
// Already idle
assert(writer.drain().isDefined)
}
}
| twitter/finagle | finagle-mux/src/test/scala/com/twitter/finagle/mux/pushsession/FragmentingMessageWriterTest.scala | Scala | apache-2.0 | 5,531 |
package docs.scaladsl.logging
import org.slf4j.{ Logger, LoggerFactory }
class LoggingExample {
private final val log: Logger =
LoggerFactory.getLogger(classOf[LoggingExample])
def demonstrateLogging(msg: String): Unit = {
log.debug("Here is a message at debug level: {}.", msg)
}
}
| rstento/lagom | docs/manual/scala/guide/logging/code/docs/scaladsl/logging/LoggingExample.scala | Scala | apache-2.0 | 300 |
/*
* Copyright 2016 The BigDL Authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.intel.analytics.bigdl.example.treeLSTMSentiment
import com.intel.analytics.bigdl._
import com.intel.analytics.bigdl.nn._
import com.intel.analytics.bigdl.numeric.NumericFloat
import com.intel.analytics.bigdl.tensor.Tensor
import scala.language.existentials
object TreeLSTMSentiment {
def apply(
word2VecTensor: Tensor[Float],
hiddenSize: Int,
classNum: Int,
p: Double = 0.5
): Module[Float] = {
val vocabSize = word2VecTensor.size(1)
val embeddingDim = word2VecTensor.size(2)
val embedding = LookupTable(vocabSize, embeddingDim)
embedding.weight.set(word2VecTensor)
val treeLSTMModule = Sequential()
.add(BinaryTreeLSTM(
embeddingDim, hiddenSize, withGraph = true))
.add(Dropout(p))
.add(TimeDistributed(Linear(hiddenSize, classNum)))
.add(TimeDistributed(LogSoftMax()))
Sequential()
.add(MapTable(Squeeze(3)))
.add(ParallelTable()
.add(embedding)
.add(Identity()))
.add(treeLSTMModule)
}
}
| JerryYanWan/BigDL | spark/dl/src/main/scala/com/intel/analytics/bigdl/example/treeLSTMSentiment/TreeSentiment.scala | Scala | apache-2.0 | 1,623 |
package edu.stanford.graphics.shapenet.util
import org.slf4j.LoggerFactory
import java.io.File
import org.slf4j.bridge.SLF4JBridgeHandler
import uk.org.lidalia.sysoutslf4j.context.SysOutOverSLF4J
/**
* Logging utilities
* @author Angel Chang
*/
object Logger {
setup()
private def setup(): Unit = {
// Forward system out and err to slf4j
SysOutOverSLF4J.sendSystemOutAndErrToSLF4J()
Console.setOut(System.out)
Console.setErr(System.err)
// Forward j.u.l to slf4j
// Optionally remove existing handlers attached to j.u.l root logger
SLF4JBridgeHandler.removeHandlersForRootLogger() // (since SLF4J 1.6.5)
// add SLF4JBridgeHandler to j.u.l's root logger, should be done once during
// the initialization phase of your application
SLF4JBridgeHandler.install()
}
private val DEFAULT_PATTERN = "%date %level [%thread] %logger{10} [%file:%line] %msg%n"
def appendToFile(filename: String,
pattern: String = DEFAULT_PATTERN,
loggerName: String = org.slf4j.Logger.ROOT_LOGGER_NAME,
/* set to true if root should log too */
additive: Boolean = false) = {
import ch.qos.logback.classic.spi.ILoggingEvent
import ch.qos.logback.classic.Level
import ch.qos.logback.classic.LoggerContext
import ch.qos.logback.classic.encoder.PatternLayoutEncoder
import ch.qos.logback.core.FileAppender
// Make sure log directory is created
val file: File = new File(filename)
val parent: File = file.getParentFile
if (parent != null) parent.mkdirs
val loggerContext = LoggerFactory.getILoggerFactory().asInstanceOf[LoggerContext]
val logger = loggerContext.getLogger(loggerName)
// Setup pattern
val patternLayoutEncoder = new PatternLayoutEncoder()
patternLayoutEncoder.setPattern(pattern)
patternLayoutEncoder.setContext(loggerContext)
patternLayoutEncoder.start()
// Setup appender
val fileAppender = new FileAppender[ILoggingEvent]()
fileAppender.setFile(filename)
fileAppender.setEncoder(patternLayoutEncoder)
fileAppender.setContext(loggerContext)
fileAppender.start()
// Attach appender to logger
logger.addAppender(fileAppender)
//logger.setLevel(Level.DEBUG)
logger.setAdditive(additive)
fileAppender.getName
}
def detachAppender(appenderName: String, loggerName: String = org.slf4j.Logger.ROOT_LOGGER_NAME): Unit = {
import ch.qos.logback.classic.LoggerContext
val loggerContext = LoggerFactory.getILoggerFactory().asInstanceOf[LoggerContext]
val logger = loggerContext.getLogger(loggerName)
logger.detachAppender(appenderName)
}
def getLogger(clazz: Class[_]): org.slf4j.Logger = {
LoggerFactory.getLogger(clazz)
}
def getLogger(name: String): org.slf4j.Logger = {
LoggerFactory.getLogger(name)
}
}
trait Loggable {
lazy val logger = Logger.getLogger(this.getClass)
def startTrack(name: String): Unit = {
logger.debug("Starting " + name)
}
def endTrack(name: String): Unit = {
logger.debug("Finished " + name)
}
}
| ShapeNet/shapenet-viewer | src/main/scala/edu/stanford/graphics/shapenet/util/Logger.scala | Scala | mit | 3,114 |
package blended.updater.remote
import blended.updater.config.RuntimeConfig
import scala.collection.immutable
class TransientRuntimeConfigPersistor extends RuntimeConfigPersistor {
private[this] var state: immutable.Set[RuntimeConfig] = Set.empty
override def persistRuntimeConfig(rCfg: RuntimeConfig): Unit = state += rCfg
override def findRuntimeConfigs(): List[RuntimeConfig] = state.toList
}
| lefou/blended | blended.updater.remote/src/main/scala/blended/updater/remote/TransientRuntimeConfigPersistor.scala | Scala | apache-2.0 | 407 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.catalyst.analysis
import java.util.Locale
import scala.collection.mutable
import org.apache.spark.sql.AnalysisException
import org.apache.spark.sql.catalyst.expressions.{Ascending, Expression, IntegerLiteral, SortOrder}
import org.apache.spark.sql.catalyst.plans.logical._
import org.apache.spark.sql.catalyst.rules.Rule
import org.apache.spark.sql.catalyst.trees.CurrentOrigin
import org.apache.spark.sql.internal.SQLConf
/**
* Collection of rules related to hints. The only hint currently available is join strategy hint.
*
* Note that this is separately into two rules because in the future we might introduce new hint
* rules that have different ordering requirements from join strategies.
*/
object ResolveHints {
/**
* The list of allowed join strategy hints is defined in [[JoinStrategyHint.strategies]], and a
* sequence of relation aliases can be specified with a join strategy hint, e.g., "MERGE(a, c)",
* "BROADCAST(a)". A join strategy hint plan node will be inserted on top of any relation (that
* is not aliased differently), subquery, or common table expression that match the specified
* name.
*
* The hint resolution works by recursively traversing down the query plan to find a relation or
* subquery that matches one of the specified relation aliases. The traversal does not go past
* beyond any view reference, with clause or subquery alias.
*
* This rule must happen before common table expressions.
*/
class ResolveJoinStrategyHints(conf: SQLConf) extends Rule[LogicalPlan] {
private val STRATEGY_HINT_NAMES = JoinStrategyHint.strategies.flatMap(_.hintAliases)
private val hintErrorHandler = conf.hintErrorHandler
def resolver: Resolver = conf.resolver
private def createHintInfo(hintName: String): HintInfo = {
HintInfo(strategy =
JoinStrategyHint.strategies.find(
_.hintAliases.map(
_.toUpperCase(Locale.ROOT)).contains(hintName.toUpperCase(Locale.ROOT))))
}
// This method checks if given multi-part identifiers are matched with each other.
// The [[ResolveJoinStrategyHints]] rule is applied before the resolution batch
// in the analyzer and we cannot semantically compare them at this stage.
// Therefore, we follow a simple rule; they match if an identifier in a hint
// is a tail of an identifier in a relation. This process is independent of a session
// catalog (`currentDb` in [[SessionCatalog]]) and it just compares them literally.
//
// For example,
// * in a query `SELECT /*+ BROADCAST(t) */ * FROM db1.t JOIN t`,
// the broadcast hint will match both tables, `db1.t` and `t`,
// even when the current db is `db2`.
// * in a query `SELECT /*+ BROADCAST(default.t) */ * FROM default.t JOIN t`,
// the broadcast hint will match the left-side table only, `default.t`.
private def matchedIdentifier(identInHint: Seq[String], identInQuery: Seq[String]): Boolean = {
if (identInHint.length <= identInQuery.length) {
identInHint.zip(identInQuery.takeRight(identInHint.length))
.forall { case (i1, i2) => resolver(i1, i2) }
} else {
false
}
}
private def extractIdentifier(r: SubqueryAlias): Seq[String] = {
r.identifier.qualifier :+ r.identifier.name
}
private def applyJoinStrategyHint(
plan: LogicalPlan,
relationsInHint: Set[Seq[String]],
relationsInHintWithMatch: mutable.HashSet[Seq[String]],
hintName: String): LogicalPlan = {
// Whether to continue recursing down the tree
var recurse = true
def matchedIdentifierInHint(identInQuery: Seq[String]): Boolean = {
relationsInHint.find(matchedIdentifier(_, identInQuery))
.map(relationsInHintWithMatch.add).nonEmpty
}
val newNode = CurrentOrigin.withOrigin(plan.origin) {
plan match {
case ResolvedHint(u @ UnresolvedRelation(ident, _), hint)
if matchedIdentifierInHint(ident) =>
ResolvedHint(u, createHintInfo(hintName).merge(hint, hintErrorHandler))
case ResolvedHint(r: SubqueryAlias, hint)
if matchedIdentifierInHint(extractIdentifier(r)) =>
ResolvedHint(r, createHintInfo(hintName).merge(hint, hintErrorHandler))
case UnresolvedRelation(ident, _) if matchedIdentifierInHint(ident) =>
ResolvedHint(plan, createHintInfo(hintName))
case r: SubqueryAlias if matchedIdentifierInHint(extractIdentifier(r)) =>
ResolvedHint(plan, createHintInfo(hintName))
case _: ResolvedHint | _: View | _: With | _: SubqueryAlias =>
// Don't traverse down these nodes.
// For an existing strategy hint, there is no chance for a match from this point down.
// The rest (view, with, subquery) indicates different scopes that we shouldn't traverse
// down. Note that technically when this rule is executed, we haven't completed view
// resolution yet and as a result the view part should be deadcode. I'm leaving it here
// to be more future proof in case we change the view we do view resolution.
recurse = false
plan
case _ =>
plan
}
}
if ((plan fastEquals newNode) && recurse) {
newNode.mapChildren { child =>
applyJoinStrategyHint(child, relationsInHint, relationsInHintWithMatch, hintName)
}
} else {
newNode
}
}
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsUp {
case h: UnresolvedHint if STRATEGY_HINT_NAMES.contains(h.name.toUpperCase(Locale.ROOT)) =>
if (h.parameters.isEmpty) {
// If there is no table alias specified, apply the hint on the entire subtree.
ResolvedHint(h.child, createHintInfo(h.name))
} else {
// Otherwise, find within the subtree query plans to apply the hint.
val relationNamesInHint = h.parameters.map {
case tableName: String => UnresolvedAttribute.parseAttributeName(tableName)
case tableId: UnresolvedAttribute => tableId.nameParts
case unsupported => throw new AnalysisException("Join strategy hint parameter " +
s"should be an identifier or string but was $unsupported (${unsupported.getClass}")
}.toSet
val relationsInHintWithMatch = new mutable.HashSet[Seq[String]]
val applied = applyJoinStrategyHint(
h.child, relationNamesInHint, relationsInHintWithMatch, h.name)
// Filters unmatched relation identifiers in the hint
val unmatchedIdents = relationNamesInHint -- relationsInHintWithMatch
hintErrorHandler.hintRelationsNotFound(h.name, h.parameters, unmatchedIdents)
applied
}
}
}
/**
* COALESCE Hint accepts names "COALESCE", "REPARTITION", and "REPARTITION_BY_RANGE".
*/
class ResolveCoalesceHints(conf: SQLConf) extends Rule[LogicalPlan] {
/**
* This function handles hints for "COALESCE" and "REPARTITION".
* The "COALESCE" hint only has a partition number as a parameter. The "REPARTITION" hint
* has a partition number, columns, or both of them as parameters.
*/
private def createRepartition(
shuffle: Boolean, hint: UnresolvedHint): LogicalPlan = {
val hintName = hint.name.toUpperCase(Locale.ROOT)
def createRepartitionByExpression(
numPartitions: Option[Int], partitionExprs: Seq[Any]): RepartitionByExpression = {
val sortOrders = partitionExprs.filter(_.isInstanceOf[SortOrder])
if (sortOrders.nonEmpty) throw new IllegalArgumentException(
s"""Invalid partitionExprs specified: $sortOrders
|For range partitioning use REPARTITION_BY_RANGE instead.
""".stripMargin)
val invalidParams = partitionExprs.filter(!_.isInstanceOf[UnresolvedAttribute])
if (invalidParams.nonEmpty) {
throw new AnalysisException(s"$hintName Hint parameter should include columns, but " +
s"${invalidParams.mkString(", ")} found")
}
RepartitionByExpression(
partitionExprs.map(_.asInstanceOf[Expression]), hint.child, numPartitions)
}
hint.parameters match {
case Seq(IntegerLiteral(numPartitions)) =>
Repartition(numPartitions, shuffle, hint.child)
case Seq(numPartitions: Int) =>
Repartition(numPartitions, shuffle, hint.child)
// The "COALESCE" hint (shuffle = false) must have a partition number only
case _ if !shuffle =>
throw new AnalysisException(s"$hintName Hint expects a partition number as a parameter")
case param @ Seq(IntegerLiteral(numPartitions), _*) if shuffle =>
createRepartitionByExpression(Some(numPartitions), param.tail)
case param @ Seq(numPartitions: Int, _*) if shuffle =>
createRepartitionByExpression(Some(numPartitions), param.tail)
case param @ Seq(_*) if shuffle =>
createRepartitionByExpression(None, param)
}
}
/**
* This function handles hints for "REPARTITION_BY_RANGE".
* The "REPARTITION_BY_RANGE" hint must have column names and a partition number is optional.
*/
private def createRepartitionByRange(hint: UnresolvedHint): RepartitionByExpression = {
val hintName = hint.name.toUpperCase(Locale.ROOT)
def createRepartitionByExpression(
numPartitions: Option[Int], partitionExprs: Seq[Any]): RepartitionByExpression = {
val invalidParams = partitionExprs.filter(!_.isInstanceOf[UnresolvedAttribute])
if (invalidParams.nonEmpty) {
throw new AnalysisException(s"$hintName Hint parameter should include columns, but " +
s"${invalidParams.mkString(", ")} found")
}
val sortOrder = partitionExprs.map {
case expr: SortOrder => expr
case expr: Expression => SortOrder(expr, Ascending)
}
RepartitionByExpression(sortOrder, hint.child, numPartitions)
}
hint.parameters match {
case param @ Seq(IntegerLiteral(numPartitions), _*) =>
createRepartitionByExpression(Some(numPartitions), param.tail)
case param @ Seq(numPartitions: Int, _*) =>
createRepartitionByExpression(Some(numPartitions), param.tail)
case param @ Seq(_*) =>
createRepartitionByExpression(None, param)
}
}
def apply(plan: LogicalPlan): LogicalPlan = plan.resolveOperators {
case hint @ UnresolvedHint(hintName, _, _) => hintName.toUpperCase(Locale.ROOT) match {
case "REPARTITION" =>
createRepartition(shuffle = true, hint)
case "COALESCE" =>
createRepartition(shuffle = false, hint)
case "REPARTITION_BY_RANGE" =>
createRepartitionByRange(hint)
case _ => hint
}
}
}
object ResolveCoalesceHints {
val COALESCE_HINT_NAMES: Set[String] = Set("COALESCE", "REPARTITION", "REPARTITION_BY_RANGE")
}
/**
* Removes all the hints, used to remove invalid hints provided by the user.
* This must be executed after all the other hint rules are executed.
*/
class RemoveAllHints(conf: SQLConf) extends Rule[LogicalPlan] {
private val hintErrorHandler = conf.hintErrorHandler
def apply(plan: LogicalPlan): LogicalPlan = plan resolveOperatorsUp {
case h: UnresolvedHint =>
hintErrorHandler.hintNotRecognized(h.name, h.parameters)
h.child
}
}
/**
* Removes all the hints when `spark.sql.optimizer.disableHints` is set.
* This is executed at the very beginning of the Analyzer to disable
* the hint functionality.
*/
class DisableHints(conf: SQLConf) extends RemoveAllHints(conf: SQLConf) {
override def apply(plan: LogicalPlan): LogicalPlan = {
if (conf.getConf(SQLConf.DISABLE_HINTS)) super.apply(plan) else plan
}
}
}
| rednaxelafx/apache-spark | sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/analysis/ResolveHints.scala | Scala | apache-2.0 | 12,845 |
package domala.async.jdbc
import java.lang.reflect.Method
import domala.internal.jdbc.dao.DaoUtil
import domala.internal.macros.reflect.AsyncEntityManagerMacros
import scala.language.experimental.macros
/** Generate and execute SQL automatically from a entity type
*
* {{{
* implicit val config: AsyncConfig with AsyncWritable = ...
* val employee: Employee = ...
* Async {
* AsyncEntityManager.insert(employee)
* }
* }}}
*
*/
object AsyncEntityManager {
/** Generate and execute a insert SQL automatically from a entity type.
*
* @tparam ENTITY a entity type
* @param entity a entity
* @param config a DB connection configuration
*/
def insert[ENTITY](entity: ENTITY)(implicit config: AsyncConfig with AsyncWritable): AsyncResult[ENTITY] = macro AsyncEntityManagerMacros.insert[ENTITY]
/** Generate and execute a update SQL automatically from a entity type. A entity type requires @ID annotation.
*
* @tparam ENTITY a entity type
* @param entity a entity
* @param config a DB connection configuration
*/
def update[ENTITY](entity: ENTITY)(implicit config: AsyncConfig with AsyncWritable): AsyncResult[ENTITY] = macro AsyncEntityManagerMacros.update[ENTITY]
/** Generate and execute a delete SQL automatically from a entity type. A entity type requires @ID annotation.
*
* @tparam ENTITY a entity type
* @param entity a entity
* @param config a DB connection configuration
*/
def delete[ENTITY](entity: ENTITY)(implicit config: AsyncConfig with AsyncWritable): AsyncResult[ENTITY] = macro AsyncEntityManagerMacros.delete[ENTITY]
/** Generate and execute a batch insert SQL automatically from a entity type.
*
* @tparam ENTITY a entity type
* @param entities iterable entities
* @param config a DB connection configuration
*/
def batchInsert[ENTITY](entities: Iterable[ENTITY])(implicit config: AsyncConfig with AsyncWritable): AsyncBatchResult[ENTITY] = macro AsyncEntityManagerMacros.batchInsert[ENTITY]
/** Generate and execute a batch update SQL automatically from a entity type. A entity type requires @ID annotation.
*
* @tparam ENTITY a entity type
* @param entities iterable entities
* @param config a DB connection configuration
*/
def batchUpdate[ENTITY](entities: Iterable[ENTITY])(implicit config: AsyncConfig with AsyncWritable): AsyncBatchResult[ENTITY] = macro AsyncEntityManagerMacros.batchUpdate[ENTITY]
/** Generate and execute a batch delete SQL automatically from a entity type. A entity type requires @ID annotation.
*
* @tparam ENTITY a entity type
* @param entities iterable entities
* @param config a DB connection configuration
*/
def batchDelete[ENTITY](entities: Iterable[ENTITY])(implicit config: AsyncConfig with AsyncWritable): AsyncBatchResult[ENTITY] = macro AsyncEntityManagerMacros.batchDelete[ENTITY]
}
object AsyncEntityManagerMethods {
val insertMethod: Method = DaoUtil.getDeclaredMethod(classOf[AsyncEntityManager], "insert", classOf[Any], classOf[AsyncConfig])
val updateMethod: Method = DaoUtil.getDeclaredMethod(classOf[AsyncEntityManager], "update", classOf[Any], classOf[AsyncConfig])
val deleteMethod: Method = DaoUtil.getDeclaredMethod(classOf[AsyncEntityManager], "delete", classOf[Any], classOf[AsyncConfig])
val batchInsertMethod: Method = DaoUtil.getDeclaredMethod(classOf[AsyncEntityManager], "batchInsert", classOf[Any], classOf[AsyncConfig])
val batchUpdateMethod: Method = DaoUtil.getDeclaredMethod(classOf[AsyncEntityManager], "batchUpdate", classOf[Any], classOf[AsyncConfig])
val batchDeleteMethod: Method = DaoUtil.getDeclaredMethod(classOf[AsyncEntityManager], "batchDelete", classOf[Any], classOf[AsyncConfig])
}
// Dummy trait for logging
trait AsyncEntityManager {
def insert[ENTITY](entity: ENTITY)(implicit config: AsyncConfig with AsyncWritable): AsyncResult[ENTITY]
def update[ENTITY](entity: ENTITY)(implicit config: AsyncConfig with AsyncWritable): AsyncResult[ENTITY]
def delete[ENTITY](entity: ENTITY)(implicit config: AsyncConfig with AsyncWritable): AsyncResult[ENTITY]
def batchInsert[ENTITY](entities: Iterable[ENTITY])(implicit config: AsyncConfig with AsyncWritable): AsyncBatchResult[ENTITY]
def batchUpdate[ENTITY](entities: Iterable[ENTITY])(implicit config: AsyncConfig with AsyncWritable): AsyncBatchResult[ENTITY]
def batchDelete[ENTITY](entities: Iterable[ENTITY])(implicit config: AsyncConfig with AsyncWritable): AsyncBatchResult[ENTITY]
}
| bakenezumi/domala | core/src/main/scala/domala/async/jdbc/AsyncEntityManager.scala | Scala | apache-2.0 | 4,527 |
/*
* Copyright 2014-2022 Netflix, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.netflix.atlas.chart.util
import java.io.InputStream
import com.netflix.atlas.core.util.Streams
import munit.FunSuite
class PngImageSuite extends FunSuite {
// SBT working directory gets updated with fork to be the dir for the project
private val baseDir = SrcPath.forProject("atlas-chart")
private val goldenDir = s"$baseDir/src/test/resources/pngimage"
private val targetDir = s"$baseDir/target/pngimage"
private val graphAssertions =
new GraphAssertions(goldenDir, targetDir, (a, b) => assertEquals(a, b))
private val bless = false
// From: http://en.wikipedia.org/wiki/Atlas_(mythology)
val sampleText = """
|In Greek mythology, Atlas (English pronunciation: /ˈætləs/)
| was the primordial Titan who supported the heavens. Although associated
| with various places, he became commonly identified with the Atlas
| Mountains in northwest Africa (Modern-day Morocco and Algeria).
| The etymology of the name Atlas is uncertain and still debated. Virgil
| took pleasure in translating etymologies of Greek names by combining them
| with adjectives that explained them: for Atlas his adjective is durus,
| "hard, enduring", which suggested to George Doig that Virgil was aware of
| the Greek τλήναι "to endure"; Doig offers the further possibility that
| Virgil was aware of Strabo's remark that the native North African name
| for this mountain was Douris. Since the Atlas mountains rise in the
| region inhabited by Berbers, it has been suggested that the name might be
| taken from one of the Berber languages, specifically adrar, Berber for
| "mountain".
""".stripMargin
def getInputStream(file: String): InputStream = {
Streams.resource("pngimage/" + file)
}
def getImage(file: String): PngImage = {
PngImage(getInputStream(file))
}
test("load image") {
val image = getImage("test.png")
assertEquals(image.metadata.size, 2)
assertEquals(image.metadata("identical"), "false")
assertEquals(image.metadata("diff-pixel-count"), "48302")
}
test("diff image, identical") {
val i1 = PngImage.error("", 800, 100)
val i2 = PngImage.error("", 800, 100)
val diff = PngImage.diff(i1.data, i2.data)
assertEquals(diff.metadata("identical"), "true")
assertEquals(diff.metadata("diff-pixel-count"), "0")
}
test("diff image, with delta") {
val i1 = PngImage.error("", 800, 100)
val i2 = PngImage.error("", 801, 121)
val diff = PngImage.diff(i1.data, i2.data)
assertEquals(diff.metadata("identical"), "false")
assertEquals(diff.metadata("diff-pixel-count"), "16921")
}
test("error image, 400x300") {
val found = PngImage.error(sampleText, 400, 300)
graphAssertions.assertEquals(found, "test_error_400x300.png", bless)
}
test("error image, 800x100") {
val found = PngImage.error(sampleText, 800, 100)
graphAssertions.assertEquals(found, "test_error_800x100.png", bless)
}
test("error diff image, 800x100") {
val i1 = PngImage.error(sampleText, 800, 100)
val i2 = PngImage.error(sampleText.toLowerCase, 800, 120)
val diff = PngImage.diff(i1.data, i2.data)
graphAssertions.assertEquals(diff, "test_diff.png", bless)
}
test("user error image matches expected") {
val found = PngImage.userError("User Error Text", 800, 100)
graphAssertions.assertEquals(found, "test_user_error.png", bless)
}
test("system error image matches expected") {
val found = PngImage.systemError("System Error Text", 800, 100)
graphAssertions.assertEquals(found, "test_system_error.png", bless)
}
test("user error image is different than system error image") {
val userErrorImage = PngImage.userError("", 800, 100)
val systemErrorImage = PngImage.systemError("", 800, 100)
val diff = PngImage.diff(userErrorImage.data, systemErrorImage.data)
assertEquals(diff.metadata("identical"), "false")
assertEquals(diff.metadata("diff-pixel-count"), "80000")
}
test("image metadata") {
val metadata = Map(
"english" -> "source url",
"japanese" -> "ソースURL",
"compressed" -> (0 until 10000).mkString(",")
)
val img = PngImage.error("test", 100, 100).copy(metadata = metadata)
val bytes = img.toByteArray
val decoded = PngImage(bytes)
assertEquals(metadata, decoded.metadata)
}
}
| Netflix/atlas | atlas-chart/src/test/scala/com/netflix/atlas/chart/util/PngImageSuite.scala | Scala | apache-2.0 | 4,978 |
package com.voldy.exception
import java.util.Collections
import java.util.Arrays
import scala.beans.BeanProperty
import java.util.List
class ErrorMessage() {
@BeanProperty
var errors: List[String] = _
def this(errors: List[String]) {
this()
this.errors = errors
}
def this(error: String) {
this(Collections.singletonList(error))
}
def this(errors: String*) {
this(Arrays.asList(errors:_*))
}
} | amoghrao2003/cmpe273-assignment2 | src/main/scala/com/voldy/exception/ErrorMessage.scala | Scala | mit | 432 |
package com.toscaruntime.cli.command
import com.toscaruntime.cli.util.AgentUtil
import com.toscaruntime.cli.{Args, Attributes}
import com.toscaruntime.constant.ProviderConstant
import sbt.complete.DefaultParsers._
import sbt.{Command, Help}
import scala.language.postfixOps
/**
* Teardown bootstrap installation
*/
object TeardownCommand {
val commandName = "teardown"
private lazy val teardownArgsParser = Space ~> (Args.providerOptParser | Args.targetOptParser) +
private lazy val teardownHelp = Help(commandName, (commandName, s"Tear down bootstrap installation, execute 'help $commandName' for more details"),
f"""
|$commandName ${Args.providerOpt}=<provider name> ${Args.targetOpt}=<target>
|OPTIONS:
| ${Args.providerOpt}%-30s name of the provider, default value is ${ProviderConstant.OPENSTACK}
| ${Args.targetOpt}%-30s target/configuration for the provider, default values is ${ProviderConstant.DEFAULT_TARGET}
""".stripMargin
)
lazy val instance = Command("teardown", teardownHelp)(_ => teardownArgsParser) { (state, args) =>
val argsMap = args.toMap
val client = state.attributes.get(Attributes.clientAttribute).get
val providerName = argsMap.getOrElse(Args.providerOpt, ProviderConstant.OPENSTACK)
val target = argsMap.getOrElse(Args.targetOpt, ProviderConstant.DEFAULT_TARGET)
val logCallback = client.tailBootstrapLog(providerName, target, System.out)
try {
val details = AgentUtil.teardown(client, providerName, target)
client.deleteBootstrapAgent(providerName, target)
client.deleteBootstrapImage(providerName, target)
AgentUtil.printDetails(s"Bootstrap $providerName", details)
} finally {
logCallback.close()
}
state
}
}
| vuminhkh/tosca-runtime | cli/src/main/scala/com/toscaruntime/cli/command/TeardownCommand.scala | Scala | mit | 1,765 |
package com.github.fellowship_of_the_bus
package eshe
package state
import lib.slick2d.ui.{Button, ToggleButton, InteractableUIElement}
import game.IDMap._
import lib.game.GameConfig
import lib.game.GameConfig.{Width,Height}
import org.newdawn.slick.{GameContainer, Graphics, Color, Input, KeyListener}
import org.newdawn.slick.state.{BasicGameState, StateBasedGame}
object MenuState {
val arrow = images(SelectArrow)
val fotb = images(FotBLogoID)
val logo = images(LogoID)
val background = images(BackgroundFullID)
// images are created with GameArea's scaleFactor by default. Need to set back to 1 to calculate correct scaleFactor
arrow.scaleFactor = 1
arrow.scaleFactor = Button.height/arrow.height // same height as a button
fotb.scaleFactor = 1
logo.scaleFactor = 1
background.scaleFactor = state.ui.GameArea.ratio
}
import MenuState._
trait MenuState extends BasicGameState {
implicit var input: Input = null
implicit var SBGame: StateBasedGame = null
var container: GameContainer = null
val centerx = Width/2-Button.width/2
val startY = 400
val padding = 30 // space from start of one button to start of next
val logoStartY = 200
private var currentOption = 0
def confirm(): Unit = choices(currentOption).doAction()
def next(): Unit = currentOption = (currentOption+1)%choices.length
def previous(): Unit = currentOption = (currentOption+choices.length-1)%choices.length
def back(): Unit
def update(gc: GameContainer, game: StateBasedGame, delta: Int) = {}
val bgColor = new Color(0, 20, 46)
def render(gc: GameContainer, game: StateBasedGame, g: Graphics): Unit = {
gc.getGraphics.setBackground(bgColor)
background.draw(0,0)
background.draw(background.width,0)
background.draw(2*background.width,0)
fotb.draw(Width/2-fotb.getWidth/2, 3*Height/4)
logo.draw(Width/2-logo.getWidth/2, logoStartY)
for ( item <- choices ) {
item.render(gc, game, g)
}
// draw selection arrow next to highlighted choice
arrow.draw(choices(currentOption).x-arrow.width, choices(currentOption).y)
}
def init(gc: GameContainer, game: StateBasedGame) = {
input = gc.getInput
SBGame = game
container = gc
}
def choices: List[InteractableUIElement]
}
object Menu extends MenuState {
implicit val id = getID
lazy val choices = List(
Button("New Game", centerx, startY, () => {
Battle.newGame()
SBGame.enterState(Mode.BattleID)
}),
Button("Options", centerx, startY+padding, () => SBGame.enterState(Mode.OptionsID)),
Button("Quit", centerx, startY+2*padding, () => System.exit(0)))
def back() = ()
def getID() = Mode.MenuID
}
object Options extends MenuState {
implicit val id = getID
lazy val choices = List(
ToggleButton("Display Lifebars", centerx, startY,
() => GameConfig.showLifebars = !GameConfig.showLifebars, // update
() => GameConfig.showLifebars), // query
ToggleButton("Full Screen", centerx, startY+padding,
() => container.setFullscreen(! container.isFullscreen), // update
() => container.isFullscreen), // query
ToggleButton("Show FPS", centerx, startY+2*padding,
() => container.setShowFPS(! container.isShowingFPS()), // update
() => container.isShowingFPS()), // query
Button("Back", centerx, startY+3*padding, () => back()))
def back() = SBGame.enterState(Mode.MenuID)
def getID() = Mode.OptionsID
}
| Fellowship-of-the-Bus/Elder-Strolls-Hallows-Eve | src/main/scala/state/Menu.scala | Scala | apache-2.0 | 3,433 |
/*
* Copyright © 2011-2012 Sattvik Software & Technology Resources, Ltd. Co.
* All rights reserved.
*
* Licensed under the Apache License, Version 2.0 (the "License"); you may
* not use this file except in compliance with the License. You may
* obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
* implied. See the License for the specific language governing
* permissions and limitations under the License.
*/
package com.sattvik.baitha
import android.view.View
import android.widget._
import com.sattvik.baitha.views._
import scala.language.implicitConversions
/** The EnhancedViews trait adds an implicit conversion that makes working with
* Views a bit easier.
*
* @author Daniel Solano Gómez */
trait EnhancedViews {
implicit def enhanceView(view: View): EnhancedView = {
new EnhancedView(view)
}
implicit def enhanceRadioGroup(radioGroup: RadioGroup): EnhancedRadioGroup = {
new EnhancedRadioGroup(radioGroup)
}
implicit def enhanceAdapterView(v: AdapterView[_]): EnhancedAdapterView = {
new EnhancedAdapterView(v)
}
implicit def enhanceSeekBar(v: SeekBar): EnhancedSeekBar = {
new EnhancedSeekBar(v)
}
implicit def enhanceCompoundButtond(v: CompoundButton): EnhancedCompoundButton = {
new EnhancedCompoundButton(v)
}
}
/** The companion object to the EnhancedViews trait. This allows declaration
* of the EnhancedView class without an implicit reference to an instance of
* a class that has the EnhancedViews trait.
*
* @author Daniel Solano Gómez */
object EnhancedViews extends EnhancedViews
| sattvik/baitha | src/main/scala/com/sattvik/baitha/EnhancedViews.scala | Scala | apache-2.0 | 1,819 |
package com.twitter.finagle.mux
import com.twitter.concurrent.AsyncQueue
import com.twitter.conversions.time._
import com.twitter.finagle.liveness.FailureDetector
import com.twitter.finagle.mux.transport.Message
import com.twitter.finagle.stats.InMemoryStatsReceiver
import com.twitter.finagle.transport.QueueTransport
import com.twitter.finagle.{Failure, Dtab, Path, Status}
import com.twitter.io.Buf
import com.twitter.util.{Await, Throw, Time}
import org.junit.runner.RunWith
import org.scalatest.FunSuite
import org.scalatest.junit.JUnitRunner
@RunWith(classOf[JUnitRunner])
private class ClientSessionTest extends FunSuite {
private class Ctx {
val clientToServer = new AsyncQueue[Message]
val serverToClient = new AsyncQueue[Message]
val transport = new QueueTransport(writeq=clientToServer, readq=serverToClient)
val stats = new InMemoryStatsReceiver
val session = new ClientSession(transport, FailureDetector.NullConfig, "test", stats)
def send(msg: Message) = {
Await.result(session.write(msg), 10.seconds)
Await.result(clientToServer.poll(), 10.seconds)
}
def recv(msg: Message) = {
serverToClient.offer(msg)
Await.result(session.read(), 10.seconds)
}
}
test("responds to leases") {
Time.withCurrentTimeFrozen { ctl =>
val ctx = new Ctx
import ctx._
assert(transport.status == Status.Open)
assert(session.status === Status.Open)
recv(Message.Tlease(1.millisecond))
ctl.advance(2.milliseconds)
assert(session.status == Status.Busy)
assert(transport.status == Status.Open)
recv(Message.Tlease(Message.Tlease.MaxLease))
assert(session.status === Status.Open)
}
}
test("drains requests") {
Time.withCurrentTimeFrozen { ctl =>
val ctx = new Ctx
import ctx._
val buf = Buf.Utf8("OK")
val req = Message.Tdispatch(2, Seq.empty, Path.empty, Dtab.empty, buf)
// 2 outstanding req, it's okay to use the same tag
// since the session doesn't verify our tags
send(req)
send(req)
val tag = 5
recv(Message.Tdrain(tag))
assert(Await.result(clientToServer.poll(), 10.seconds) == Message.Rdrain(tag))
assert(session.status == Status.Busy)
session.write(req).poll match {
case Some(Throw(f: Failure)) =>
assert(f.isFlagged(Failure.Restartable))
assert(f.getMessage == "The request was Nacked by the server")
case _ => fail()
}
val rep = Message.RdispatchOk(2, Seq.empty, buf)
recv(rep)
assert(session.status == Status.Busy)
recv(rep)
assert(session.status == Status.Closed)
assert(stats.counters(Seq("drained")) == 1)
assert(stats.counters(Seq("draining")) == 1)
}
}
test("pings") {
val ctx = new Ctx
import ctx._
val ping0 = session.ping()
assert(!ping0.isDefined)
session.ping().poll match {
case Some(Throw(f: Failure)) =>
assert(f.getMessage == "A ping is already outstanding on this session.")
case _ => fail()
}
recv(Message.Rping(Message.Tags.PingTag))
assert(ping0.isDefined)
val ping1 = session.ping()
recv(Message.Rping(Message.Tags.PingTag))
assert(ping1.isDefined)
}
}
| koshelev/finagle | finagle-mux/src/test/scala/com/twitter/finagle/mux/ClientSessionTest.scala | Scala | apache-2.0 | 3,272 |
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.table.planner.runtime.batch.sql.agg
import org.apache.flink.api.java.typeutils.RowTypeInfo
import org.apache.flink.table.api.Types
import org.apache.flink.table.planner.runtime.utils.BatchTestBase
import org.apache.flink.table.planner.runtime.utils.BatchTestBase.row
import org.apache.flink.table.planner.runtime.utils.TestData._
import org.apache.flink.table.planner.utils.DateTimeTestUtil._
import org.junit.{Before, Test}
import scala.collection.Seq
class GroupingSetsITCase extends BatchTestBase {
private val TABLE_NAME = "MyTable"
private val TABLE_WITH_NULLS_NAME = "MyTableWithNulls"
private val TABLE_NAME_EMPS = "emps"
private val empsTypes = new RowTypeInfo(Types.LONG, Types.STRING, Types.INT, Types.STRING,
Types.STRING, Types.LONG, Types.INT, Types.BOOLEAN, Types.BOOLEAN, Types.LOCAL_DATE)
private val empsNames =
"empno, name, deptno, gender, city, empid, age, slacker, manager, joinedat"
private val nullableOfEmps: Array[Boolean] =
Array(false, false, false, true, true, false, true, true, false, false)
private lazy val empsData = Seq(
row(100L, "Fred", 10, null, null, 40L, 25, true, false, localDate("1996-08-03")),
row(110L, "Eric", 20, "M", "San Francisco", 3L, 80, null, false, localDate("2001-01-01")),
row(110L, "John", 40, "M", "Vancouver", 2L, null, false, true, localDate("2002-05-03")),
row(120L, "Wilma", 20, "F", null, 1L, 5, null, true, localDate("2005-09-07")),
row(130L, "Alice", 40, "F", "Vancouver", 2L, null, false, true, localDate("2007-01-01"))
)
private val TABLE_NAME_EMP = "emp"
private val empTypes = new RowTypeInfo(Types.STRING, Types.INT, Types.STRING)
private val empNames = "ename, deptno, gender"
private val nullableOfEmp = Array(false, true, false)
private lazy val empData = Seq(
row("Adam", 50, "M"),
row("Alice", 30, "F"),
row("Bob", 10, "M"),
row("Eric", 20, "M"),
row("Eve", 50, "F"),
row("Grace", 60, "F"),
row("Jane", 10, "F"),
row("Susan", 30, "F"),
row("Wilma", null, "F")
)
private val TABLE_NAME_DEPT = "dept"
private val deptTypes = new RowTypeInfo(Types.INT, Types.STRING)
private val deptNames = "deptno, dname"
private val nullableOfDept = Array(false, false)
private lazy val deptData = Seq(
row(10, "Sales"),
row(20, "Marketing"),
row(30, "Engineering"),
row(40, "Empty")
)
private val TABLE_NAME_SCOTT_EMP = "scott_emp"
private val scottEmpTypes = new RowTypeInfo(Types.INT, Types.STRING, Types.STRING, Types.INT,
Types.LOCAL_DATE, Types.DOUBLE, Types.DOUBLE, Types.INT)
private val scottEmpNames = "empno, ename, job, mgr, hiredate, sal, comm, deptno"
private val nullableOfScottEmp = Array(false, false, false, true, false, false, true, false)
private lazy val scottEmpData = Seq(
row(7369, "SMITH", "CLERK", 7902, localDate("1980-12-17"), 800.00, null, 20),
row(7499, "ALLEN", "SALESMAN", 7698, localDate("1981-02-20"), 1600.00, 300.00, 30),
row(7521, "WARD", "SALESMAN", 7698, localDate("1981-02-22"), 1250.00, 500.00, 30),
row(7566, "JONES", "MANAGER", 7839, localDate("1981-02-04"), 2975.00, null, 20),
row(7654, "MARTIN", "SALESMAN", 7698, localDate("1981-09-28"), 1250.00, 1400.00, 30),
row(7698, "BLAKE", "MANAGER", 7839, localDate("1981-01-05"), 2850.00, null, 30),
row(7782, "CLARK", "MANAGER", 7839, localDate("1981-06-09"), 2450.00, null, 10),
row(7788, "SCOTT", "ANALYST", 7566, localDate("1987-04-19"), 3000.00, null, 20),
row(7839, "KING", "PRESIDENT", null, localDate("1981-11-17"), 5000.00, null, 10),
row(7844, "TURNER", "SALESMAN", 7698, localDate("1981-09-08"), 1500.00, 0.00, 30),
row(7876, "ADAMS", "CLERK", 7788, localDate("1987-05-23"), 1100.00, null, 20),
row(7900, "JAMES", "CLERK", 7698, localDate("1981-12-03"), 950.00, null, 30),
row(7902, "FORD", "ANALYST", 7566, localDate("1981-12-03"), 3000.00, null, 20),
row(7934, "MILLER", "CLERK", 7782, localDate("1982-01-23"), 1300.00, null, 10)
)
@Before
override def before(): Unit = {
super.before()
registerCollection(TABLE_NAME, data3, type3, "f0, f1, f2", nullablesOfData3)
val nullableData3 = data3.map { r =>
val newField2 = if (r.getField(2).asInstanceOf[String].contains("world")) {
null.asInstanceOf[String]
} else {
r.getField(2)
}
row(r.getField(0), r.getField(1), newField2)
}
val nullablesOfNullsData3 = Array(false, false, true)
registerCollection(TABLE_WITH_NULLS_NAME, nullableData3, type3, "f0, f1, f2",
nullablesOfNullsData3)
registerCollection(TABLE_NAME_EMPS, empsData, empsTypes, empsNames, nullableOfEmps)
registerCollection(TABLE_NAME_EMP, empData, empTypes, empNames, nullableOfEmp)
registerCollection(TABLE_NAME_DEPT, deptData, deptTypes, deptNames, nullableOfDept)
registerCollection(TABLE_NAME_SCOTT_EMP, scottEmpData, scottEmpTypes, scottEmpNames,
nullableOfScottEmp)
}
@Test
def testGroupingSetsWithOneGrouping(): Unit = {
checkResult(
"select deptno, avg(age) as a, group_id() as g," +
" grouping(deptno) as gb, grouping_id(deptno)as gib" +
" from emps group by grouping sets (deptno)",
Seq(row(10, 25, 0, 0, 0), row(20, 42, 0, 0, 0), row(40, null, 0, 0, 0))
)
}
@Test
def testBasicGroupingSets(): Unit = {
checkResult(
"select deptno, count(*) as c from emps group by grouping sets ((), (deptno))",
Seq(row(10, 1), row(20, 2), row(40, 2), row(null, 5))
)
}
@Test
def testGroupingSetsOnExpression(): Unit = {
checkResult(
"select deptno + 1, count(*) as c from emps group by grouping sets ((), (deptno + 1))",
Seq(row(11, 1), row(21, 2), row(41, 2), row(null, 5))
)
}
@Test
def testCube(): Unit = {
checkResult(
"select deptno + 1, count(*) as c from emp group by cube(deptno, gender)",
Seq(row(11, 1), row(11, 1), row(11, 2), row(21, 1), row(21, 1), row(31, 2), row(31, 2),
row(51, 1), row(51, 1), row(51, 2), row(61, 1), row(61, 1), row(null, 1), row(null, 1),
row(null, 3), row(null, 6), row(null, 9))
)
}
@Test
def testRollupOn1Column(): Unit = {
checkResult(
"select deptno + 1, count(*) as c from emp group by rollup(deptno)",
Seq(row(11, 2), row(21, 1), row(31, 2), row(51, 2), row(61, 1), row(null, 1), row(null, 9))
)
}
@Test
def testRollupOn2Column(): Unit = {
checkResult(
"select gender, deptno + 1, count(*) as c from emp group by rollup(deptno, gender)",
Seq(row("M", 21, 1), row("F", 11, 1), row("F", 31, 2), row("F", 51, 1),
row("F", 61, 1), row("F", null, 1), row("M", 11, 1), row("M", 51, 1),
row(null, 11, 2), row(null, 21, 1), row(null, 31, 2), row(null, 51, 2),
row(null, 61, 1), row(null, null, 1), row(null, null, 9))
)
}
@Test
def testRollupOnColumnWithNulls(): Unit = {
//Note the two rows with NULL key (one represents ALL)
checkResult(
"select gender, count(*) as c from emp group by rollup(gender)",
Seq(row("F", 6), row("M", 3), row(null, 9))
)
}
@Test
def testRollupPlusOrderBy(): Unit = {
checkResult(
"select gender, count(*) as c from emp group by rollup(gender) order by c desc",
Seq(row(null, 9), row("F", 6), row("M", 3))
)
}
@Test
def testRollupCartesianProduct(): Unit = {
checkResult(
"select deptno, count(*) as c from emp group by rollup(deptno), rollup(gender)",
Seq(row("10", 1), row("10", 1), row("20", 1), row("20", 1), row(null, 1), row("10", 2),
row("30", 2), row("30", 2), row("50", 1), row("50", 1), row("50", 2), row("60", 1),
row("60", 1), row(null, 1), row(null, 3), row(null, 6), row(null, 9))
)
}
@Test
def testRollupCartesianProductOfWithTupleWithExpression(): Unit = {
checkResult(
"select deptno / 2 + 1 as half1, count(*) as c from emp " +
"group by rollup(deptno / 2, gender), rollup(substring(ename FROM 1 FOR 1))",
Seq(row(11, 1), row(11, 1), row(11, 1), row(11, 1), row(16, 1), row(16, 1),
row(16, 1), row(16, 1), row(16, 2), row(16, 2), row(26, 1), row(26, 1),
row(26, 1), row(26, 1), row(26, 1), row(26, 1), row(26, 2), row(31, 1),
row(31, 1), row(31, 1), row(31, 1), row(6, 1), row(6, 1), row(6, 1),
row(6, 1), row(6, 1), row(6, 1), row(6, 2), row(null, 1), row(null, 1),
row(null, 1), row(null, 1), row(null, 1), row(null, 1), row(null, 1),
row(null, 1), row(null, 1), row(null, 2), row(null, 2), row(null, 9))
)
}
@Test
def testRollupWithHaving(): Unit = {
checkResult(
"select deptno + 1 as d1, count(*) as c from emp " +
"group by rollup(deptno)having count(*) > 3",
Seq(row(null, 9))
)
}
@Test
def testCubeAndDistinct(): Unit = {
checkResult(
"select distinct count(*) from emp group by cube(deptno, gender)",
Seq(row(1), row(2), row(3), row(6), row(9))
)
}
@Test
def testCubeAndJoin(): Unit = {
checkResult(
"select e.deptno, e.gender, min(e.ename) as min_name " +
"from emp as e join dept as d using (deptno) " +
"group by cube(e.deptno, d.deptno, e.gender) " +
"having count(*) > 2 or gender = 'M' and e.deptno = 10",
Seq(row(10, "M", "Bob"), row(10, "M", "Bob"),
row(null, "F", "Alice"), row(null, null, "Alice"))
)
}
@Test
def testGroupingInSelectClauseOfGroupByQuery(): Unit = {
checkResult(
"select count(*) as c, grouping(deptno) as g from emp group by deptno",
Seq(row(1, 0), row(1, 0), row(1, 0), row(2, 0), row(2, 0), row(2, 0))
)
}
@Test
def testGroupingInSelectClauseOfCubeQuery(): Unit = {
checkResult(
"select deptno, job, count(*) as c, grouping(deptno) as d, grouping(job) j, " +
"grouping(deptno, job) as x from scott_emp group by cube(deptno, job)",
Seq(row(10, "CLERK", 1, 0, 0, 0),
row(10, "MANAGER", 1, 0, 0, 0),
row(10, "PRESIDENT", 1, 0, 0, 0),
row(10, null, 3, 0, 1, 1),
row(20, "ANALYST", 2, 0, 0, 0),
row(20, "CLERK", 2, 0, 0, 0),
row(20, "MANAGER", 1, 0, 0, 0),
row(20, null, 5, 0, 1, 1),
row(30, "CLERK", 1, 0, 0, 0),
row(30, "MANAGER", 1, 0, 0, 0),
row(30, "SALESMAN", 4, 0, 0, 0),
row(30, null, 6, 0, 1, 1),
row(null, "ANALYST", 2, 1, 0, 2),
row(null, "CLERK", 4, 1, 0, 2),
row(null, "MANAGER", 3, 1, 0, 2),
row(null, "PRESIDENT", 1, 1, 0, 2),
row(null, "SALESMAN", 4, 1, 0, 2),
row(null, null, 14, 1, 1, 3))
)
}
@Test
def testGroupingGroup_idGrouping_idInSelectClauseOfGroupByQuery(): Unit = {
checkResult(
"select count(*) as c, grouping(deptno) as g, group_id() as gid, " +
"grouping_id(deptno) as gd, grouping_id(gender) as gg, " +
"grouping_id(gender, deptno) as ggd, grouping_id(deptno, gender) as gdg " +
"from emp group by rollup(deptno, gender)",
Seq(row(1, 0, 0, 0, 0, 0, 0), row(1, 0, 0, 0, 0, 0, 0), row(1, 0, 0, 0, 0, 0, 0),
row(1, 0, 0, 0, 0, 0, 0), row(1, 0, 0, 0, 0, 0, 0), row(1, 0, 0, 0, 0, 0, 0),
row(1, 0, 0, 0, 0, 0, 0), row(2, 0, 0, 0, 0, 0, 0), row(9, 1, 0, 1, 1, 3, 3),
row(1, 0, 0, 0, 1, 2, 1), row(1, 0, 0, 0, 1, 2, 1), row(1, 0, 0, 0, 1, 2, 1),
row(2, 0, 0, 0, 1, 2, 1), row(2, 0, 0, 0, 1, 2, 1), row(2, 0, 0, 0, 1, 2, 1))
)
}
@Test
def testGroupingAcceptsMultipleArgumentsGivesSameResultAsGrouping_id(): Unit = {
checkResult(
"select count(*) as c, grouping(deptno) as gd, " +
"grouping_id(deptno) as gid, " +
"grouping(deptno, gender, deptno) as gdgd, " +
"grouping_id(deptno, gender, deptno) as gidgd " +
"from emp group by rollup(deptno, gender) " +
"having grouping(deptno) <= grouping_id(deptno, gender, deptno)",
Seq(row(1, 0, 0, 0, 0), row(1, 0, 0, 0, 0), row(1, 0, 0, 0, 0),
row(1, 0, 0, 0, 0), row(1, 0, 0, 0, 0), row(1, 0, 0, 0, 0),
row(1, 0, 0, 0, 0), row(2, 0, 0, 0, 0), row(1, 0, 0, 2, 2),
row(1, 0, 0, 2, 2), row(1, 0, 0, 2, 2), row(2, 0, 0, 2, 2),
row(2, 0, 0, 2, 2), row(2, 0, 0, 2, 2), row(9, 1, 1, 7, 7))
)
}
@Test
def testGroupingInOrderByClause(): Unit = {
checkResult(
"select count(*) as c from emp group by rollup(deptno) order by grouping(deptno), c",
Seq(row(1), row(1), row(1), row(2), row(2), row(2), row(9))
)
}
@Test
def testDuplicateArgumentToGrouping_id(): Unit = {
checkResult(
"select deptno, gender, grouping_id(deptno, gender, deptno), count(*) as c " +
"from emp where deptno = 10 group by rollup(gender, deptno)",
Seq(row(10, "F", 0, 1), row(10, "M", 0, 1), row(null, "F", 5, 1),
row(null, "M", 5, 1), row(null, null, 7, 2))
)
}
@Test
def testGroupingInSelectClauseOfRollupQuery(): Unit = {
checkResult(
"select count(*) as c, deptno, grouping(deptno) as g from emp group by rollup(deptno)",
Seq(row(1, 20, 0), row(1, 60, 0), row(1, null, 0), row(2, 10, 0),
row(2, 30, 0), row(2, 50, 0), row(9, null, 1))
)
}
@Test
def testGroupingGrouping_idAndGroup_id(): Unit = {
checkResult(
"select deptno, gender, grouping(deptno) gd, grouping(gender) gg, " +
"grouping_id(deptno, gender) dg, grouping_id(gender, deptno) gd, " +
"group_id() gid, count(*) c from emp group by cube(deptno, gender)",
Seq(row(10, "F", 0, 0, 0, 0, 0, 1), row(10, "M", 0, 0, 0, 0, 0, 1),
row(20, "M", 0, 0, 0, 0, 0, 1), row(30, "F", 0, 0, 0, 0, 0, 2),
row(50, "F", 0, 0, 0, 0, 0, 1), row(50, "M", 0, 0, 0, 0, 0, 1),
row(60, "F", 0, 0, 0, 0, 0, 1), row(null, "F", 0, 0, 0, 0, 0, 1),
row(null, null, 1, 1, 3, 3, 0, 9), row(10, null, 0, 1, 1, 2, 0, 2),
row(20, null, 0, 1, 1, 2, 0, 1), row(30, null, 0, 1, 1, 2, 0, 2),
row(50, null, 0, 1, 1, 2, 0, 2), row(60, null, 0, 1, 1, 2, 0, 1),
row(null, "F", 1, 0, 2, 1, 0, 6), row(null, "M", 1, 0, 2, 1, 0, 3),
row(null, null, 0, 1, 1, 2, 0, 1))
)
}
@Test
def testAllowExpressionInCubeAndRollup(): Unit = {
checkResult(
"select deptno + 1 as d1, deptno + 1 - 1 as d0, count(*) as c " +
"from emp group by rollup (deptno + 1)",
Seq(row(11, 10, 2), row(21, 20, 1), row(31, 30, 2), row(51, 50, 2),
row(61, 60, 1), row(null, null, 1), row(null, null, 9))
)
checkResult(
"select mod(deptno, 20) as d, count(*) as c, gender as g " +
"from emp group by cube(mod(deptno, 20), gender)",
Seq(row(0, 1, "F"), row(0, 1, "M"), row(0, 2, null), row(10, 2, "M"),
row(10, 4, "F"), row(10, 6, null), row(null, 1, "F"), row(null, 1, null),
row(null, 3, "M"), row(null, 6, "F"), row(null, 9, null))
)
checkResult(
"select mod(deptno, 20) as d, count(*) as c, gender as g " +
"from emp group by rollup(mod(deptno, 20), gender)",
Seq(row(0, 1, "F"), row(0, 1, "M"), row(0, 2, null), row(10, 2, "M"), row(10, 4, "F"),
row(10, 6, null), row(null, 1, "F"), row(null, 1, null), row(null, 9, null))
)
checkResult(
"select count(*) as c from emp group by cube(1)",
Seq(row(9), row(9))
)
checkResult(
"select count(*) as c from emp group by cube(1)",
Seq(row(9), row(9))
)
}
@Test
def testCALCITE1824(): Unit = {
// TODO:
// When "[CALCITE-1824] GROUP_ID returns wrong result" is fixed,
// there will be an extra row (null, 1, 14).
checkResult(
"select deptno, group_id() as g, count(*) as c " +
"from scott_emp group by grouping sets (deptno, (), ())",
Seq(row(10, 0, 3), row(20, 0, 5), row(30, 0, 6), row(null, 0, 14))
)
}
@Test
def testFromBlogspot(): Unit = {
// From http://rwijk.blogspot.com/2008/12/groupid.html
checkResult(
"select deptno, job, empno, ename, sum(sal) sumsal, " +
"case grouping_id(deptno, job, empno)" +
" when 0 then cast('grouped by deptno,job,empno,ename' as varchar)" +
" when 1 then cast('grouped by deptno,job' as varchar)" +
" when 3 then cast('grouped by deptno' as varchar)" +
" when 7 then cast('grouped by ()' as varchar)" +
"end gr_text " +
"from scott_emp group by rollup(deptno, job, (empno,ename)) " +
"order by deptno, job, empno",
Seq(row(10, "CLERK", 7934, "MILLER", 1300.00, "grouped by deptno,job,empno,ename"),
row(10, "CLERK", null, null, 1300.00, "grouped by deptno,job"),
row(10, "MANAGER", 7782, "CLARK", 2450.00, "grouped by deptno,job,empno,ename"),
row(10, "MANAGER", null, null, 2450.00, "grouped by deptno,job"),
row(10, "PRESIDENT", 7839, "KING", 5000.00, "grouped by deptno,job,empno,ename"),
row(10, "PRESIDENT", null, null, 5000.00, "grouped by deptno,job"),
row(10, null, null, null, 8750.00, "grouped by deptno"),
row(20, "ANALYST", 7788, "SCOTT", 3000.00, "grouped by deptno,job,empno,ename"),
row(20, "ANALYST", 7902, "FORD", 3000.00, "grouped by deptno,job,empno,ename"),
row(20, "ANALYST", null, null, 6000.00, "grouped by deptno,job"),
row(20, "CLERK", 7369, "SMITH", 800.00, "grouped by deptno,job,empno,ename"),
row(20, "CLERK", 7876, "ADAMS", 1100.00, "grouped by deptno,job,empno,ename"),
row(20, "CLERK", null, null, 1900.00, "grouped by deptno,job"),
row(20, "MANAGER", 7566, "JONES", 2975.00, "grouped by deptno,job,empno,ename"),
row(20, "MANAGER", null, null, 2975.00, "grouped by deptno,job"),
row(20, null, null, null, 10875.00, "grouped by deptno"),
row(30, "CLERK", 7900, "JAMES", 950.00, "grouped by deptno,job,empno,ename"),
row(30, "CLERK", null, null, 950.00, "grouped by deptno,job"),
row(30, "MANAGER", 7698, "BLAKE", 2850.00, "grouped by deptno,job,empno,ename"),
row(30, "MANAGER", null, null, 2850.00, "grouped by deptno,job"),
row(30, "SALESMAN", 7499, "ALLEN", 1600.00, "grouped by deptno,job,empno,ename"),
row(30, "SALESMAN", 7521, "WARD", 1250.00, "grouped by deptno,job,empno,ename"),
row(30, "SALESMAN", 7654, "MARTIN", 1250.00, "grouped by deptno,job,empno,ename"),
row(30, "SALESMAN", 7844, "TURNER", 1500.00, "grouped by deptno,job,empno,ename"),
row(30, "SALESMAN", null, null, 5600.00, "grouped by deptno,job"),
row(30, null, null, null, 9400.00, "grouped by deptno"),
row(null, null, null, null, 29025.00, "grouped by ()"))
)
}
@Test
def testGroupingSets(): Unit = {
val query =
"SELECT f1, f2, avg(f0) as a, GROUP_ID() as g, " +
" GROUPING(f1) as gf1, GROUPING(f2) as gf2, " +
" GROUPING_ID(f1) as gif1, GROUPING_ID(f2) as gif2, " +
" GROUPING_ID(f1, f2) as gid, " +
" COUNT(*) as cnt" +
" FROM " + TABLE_NAME + " GROUP BY " +
" GROUPING SETS (f1, f2, ())"
val expected = Seq(
row(1, null, 1, 0, 0, 1, 0, 1, 1, 1),
row(6, null, 18, 0, 0, 1, 0, 1, 1, 6),
row(2, null, 2, 0, 0, 1, 0, 1, 1, 2),
row(4, null, 8, 0, 0, 1, 0, 1, 1, 4),
row(5, null, 13, 0, 0, 1, 0, 1, 1, 5),
row(3, null, 5, 0, 0, 1, 0, 1, 1, 3),
row(null, "Comment#11", 17, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#8", 14, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#2", 8, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#1", 7, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#14", 20, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#7", 13, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#6", 12, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#3", 9, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#12", 18, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#5", 11, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#15", 21, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#4", 10, 0, 1, 0, 1, 0, 2, 1),
row(null, "Hi", 1, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#10", 16, 0, 1, 0, 1, 0, 2, 1),
row(null, "Hello world", 3, 0, 1, 0, 1, 0, 2, 1),
row(null, "I am fine.", 5, 0, 1, 0, 1, 0, 2, 1),
row(null, "Hello world, how are you?", 4, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#9", 15, 0, 1, 0, 1, 0, 2, 1),
row(null, "Comment#13", 19, 0, 1, 0, 1, 0, 2, 1),
row(null, "Luke Skywalker", 6, 0, 1, 0, 1, 0, 2, 1),
row(null, "Hello", 2, 0, 1, 0, 1, 0, 2, 1),
row(null, null, 11, 0, 1, 1, 1, 1, 3, 21))
checkResult(query, expected)
}
@Test
def testGroupingSetsWithNulls(): Unit = {
val query = "SELECT f1, f2, avg(f0) as a, GROUP_ID() as g FROM " +
TABLE_WITH_NULLS_NAME + " GROUP BY GROUPING SETS (f1, f2)"
val expected = Seq(
row(6, null, 18, 0),
row(5, null, 13, 0),
row(4, null, 8, 0),
row(3, null, 5, 0),
row(2, null, 2, 0),
row(1, null, 1, 0),
row(null, "Luke Skywalker", 6, 0),
row(null, "I am fine.", 5, 0),
row(null, "Hi", 1, 0),
row(null, null, 3, 0),
row(null, "Hello", 2, 0),
row(null, "Comment#9", 15, 0),
row(null, "Comment#8", 14, 0),
row(null, "Comment#7", 13, 0),
row(null, "Comment#6", 12, 0),
row(null, "Comment#5", 11, 0),
row(null, "Comment#4", 10, 0),
row(null, "Comment#3", 9, 0),
row(null, "Comment#2", 8, 0),
row(null, "Comment#15", 21, 0),
row(null, "Comment#14", 20, 0),
row(null, "Comment#13", 19, 0),
row(null, "Comment#12", 18, 0),
row(null, "Comment#11", 17, 0),
row(null, "Comment#10", 16, 0),
row(null, "Comment#1", 7, 0))
checkResult(query, expected)
}
@Test
def testCubeAsGroupingSets(): Unit = {
val cubeQuery = "SELECT f1, f2, avg(f0) as a, GROUP_ID() as g, " +
" GROUPING(f1) as gf1, GROUPING(f2) as gf2, " +
" GROUPING_ID(f1) as gif1, GROUPING_ID(f2) as gif2, " +
" GROUPING_ID(f1, f2) as gid " + " FROM " +
TABLE_NAME + " GROUP BY CUBE (f1, f2)"
val groupingSetsQuery = "SELECT f1, f2, avg(f0) as a, GROUP_ID() as g, " +
" GROUPING(f1) as gf1, GROUPING(f2) as gf2, " +
" GROUPING_ID(f1) as gif1, GROUPING_ID(f2) as gif2, " +
" GROUPING_ID(f1, f2) as gid " +
" FROM " + TABLE_NAME + " GROUP BY GROUPING SETS ((f1, f2), (f1), (f2), ())"
val expected = executeQuery(parseQuery(groupingSetsQuery))
checkResult(cubeQuery, expected)
}
@Test
def testRollupAsGroupingSets(): Unit = {
val rollupQuery = "SELECT f1, f2, avg(f0) as a, GROUP_ID() as g, " +
" GROUPING(f1) as gf1, GROUPING(f2) as gf2, " +
" GROUPING_ID(f1) as gif1, GROUPING_ID(f2) as gif2, " +
" GROUPING_ID(f1, f2) as gid " +
" FROM " + TABLE_NAME + " GROUP BY ROLLUP (f1, f2)"
val groupingSetsQuery = "SELECT f1, f2, avg(f0) as a, GROUP_ID() as g, " +
" GROUPING(f1) as gf1, GROUPING(f2) as gf2, " +
" GROUPING_ID(f1) as gif1, GROUPING_ID(f2) as gif2, " +
" GROUPING_ID(f1, f2) as gid " +
" FROM " + TABLE_NAME + " GROUP BY GROUPING SETS ((f1, f2), (f1), ())"
val expected = executeQuery(parseQuery(groupingSetsQuery))
checkResult(rollupQuery, expected)
}
}
| fhueske/flink | flink-table/flink-table-planner-blink/src/test/scala/org/apache/flink/table/planner/runtime/batch/sql/agg/GroupingSetsITCase.scala | Scala | apache-2.0 | 24,001 |
/***********************************************************************
* Copyright (c) 2013-2017 Commonwealth Computer Research, Inc.
* All rights reserved. This program and the accompanying materials
* are made available under the terms of the Apache License, Version 2.0
* which accompanies this distribution and is available at
* http://www.opensource.org/licenses/apache2.0.php.
***********************************************************************/
package org.locationtech.geomesa.process.query
import org.geotools.data.store.ReTypingFeatureCollection
import org.junit.runner.RunWith
import org.locationtech.geomesa.accumulo.TestWithMultipleSfts
import org.locationtech.geomesa.features.ScalaSimpleFeature
import org.locationtech.geomesa.utils.collection.SelfClosingIterator
import org.locationtech.geomesa.utils.geotools.SimpleFeatureTypes
import org.specs2.runner.JUnitRunner
import scala.util.Random
@RunWith(classOf[JUnitRunner])
class RouteSearchProcessTest extends TestWithMultipleSfts {
sequential
val r = new Random(-10)
val routeSft = createNewSchema("*geom:LineString:srid=4326", None)
val sft = createNewSchema("track:String,heading:Double,dtg:Date,*geom:Point:srid=4326")
val process = new RouteSearchProcess
addFeature(routeSft, ScalaSimpleFeature.create(routeSft, "r0", "LINESTRING (40 40, 40.5 40.5, 40.5 41)"))
// features along the lower angled part of the route, headed in the opposite direction
val features0 = (0 until 10).map { i =>
val sf = new ScalaSimpleFeature(sft, s"0$i")
sf.setAttribute("track", "0")
sf.setAttribute("heading", Double.box(217.3 + (r.nextDouble * 10) - 5))
sf.setAttribute("dtg", s"2017-02-20T00:00:0$i.000Z")
val route = (40.0 + (10 - i) * 0.05) - (r.nextDouble / 100) - 0.005
sf.setAttribute("geom", s"POINT($route $route)")
sf
}
// features along the upper vertical part of the route
val features1 = (0 until 10).map { i =>
val sf = new ScalaSimpleFeature(sft, s"1$i")
sf.setAttribute("track", "1")
sf.setAttribute("heading", Double.box((r.nextDouble * 10) - 5))
sf.setAttribute("dtg", s"2017-02-20T00:01:0$i.000Z")
sf.setAttribute("geom", s"POINT(${40.5 + (r.nextDouble / 100) - 0.005} ${40.5 + (i + 1) * 0.005})")
sf
}
// features along the upper vertical part of the route, but with a heading off by 5-15 degrees
val features2 = (0 until 10).map { i =>
val sf = new ScalaSimpleFeature(sft, s"2$i")
sf.setAttribute("track", "2")
sf.setAttribute("heading", Double.box(10 + (r.nextDouble * 10) - 5))
sf.setAttribute("dtg", s"2017-02-20T00:02:0$i.000Z")
sf.setAttribute("geom", s"POINT(${40.5 + (r.nextDouble / 100) - 0.005} ${40.5 + (i + 1) * 0.005})")
sf
}
// features headed along the upper vertical part of the route, but not close to the route
val features3 = (0 until 10).map { i =>
val sf = new ScalaSimpleFeature(sft, s"3$i")
sf.setAttribute("track", "3")
sf.setAttribute("heading", Double.box((r.nextDouble * 10) - 5))
sf.setAttribute("dtg", s"2017-02-20T00:03:0$i.000Z")
sf.setAttribute("geom", s"POINT(${40.7 + (r.nextDouble / 10) - 0.005} ${40.5 + (i + 1) * 0.005})")
sf
}
addFeatures(sft, features0 ++ features1 ++ features2 ++ features3)
"RouteSearch" should {
"return features along a route" in {
val input = ds.getFeatureSource(sft.getTypeName).getFeatures()
val routes = ds.getFeatureSource(routeSft.getTypeName).getFeatures()
val collection = process.execute(input, routes, 1000.0, 5.0, null, null, false, "heading")
val results = SelfClosingIterator(collection.features).toSeq
results must containTheSameElementsAs(features1)
}
"return features along a route with a wider heading tolerance" in {
val input = ds.getFeatureSource(sft.getTypeName).getFeatures()
val routes = ds.getFeatureSource(routeSft.getTypeName).getFeatures()
val collection = process.execute(input, routes, 1000.0, 15.0, null, null, false, "heading")
val results = SelfClosingIterator(collection.features).toSeq
results must containTheSameElementsAs(features1 ++ features2)
}
"return features along a wide buffered route" in {
val input = ds.getFeatureSource(sft.getTypeName).getFeatures()
val routes = ds.getFeatureSource(routeSft.getTypeName).getFeatures()
val collection = process.execute(input, routes, 100000.0, 5.0, null, null, false, "heading")
val results = SelfClosingIterator(collection.features).toSeq
results must containTheSameElementsAs(features1 ++ features3)
}
"return features along a bidirectional route" in {
val input = ds.getFeatureSource(sft.getTypeName).getFeatures()
val routes = ds.getFeatureSource(routeSft.getTypeName).getFeatures()
val collection = process.execute(input, routes, 1000.0, 5.0, null, null, true, "heading")
val results = SelfClosingIterator(collection.features).toSeq
results must containTheSameElementsAs(features0 ++ features1)
}
"work for wrapped feature collections" in {
val retyped = SimpleFeatureTypes.createType("retype", SimpleFeatureTypes.encodeType(sft))
val input = new ReTypingFeatureCollection(ds.getFeatureSource(sft.getTypeName).getFeatures(), retyped)
val routes = ds.getFeatureSource(routeSft.getTypeName).getFeatures()
val collection = process.execute(input, routes, 1000.0, 5.0, null, null, false, "heading")
val results = SelfClosingIterator(collection.features).toSeq
results.map(_.getAttributes) must containTheSameElementsAs(features1.map(_.getAttributes))
}
}
}
| ronq/geomesa | geomesa-accumulo/geomesa-accumulo-datastore/src/test/scala/org/locationtech/geomesa/process/query/RouteSearchProcessTest.scala | Scala | apache-2.0 | 5,649 |
/* ______
** | ___ \\
** ___ _ _ _ __ | |_/ /_ _ _ __ _ __
** / __| | | | '_ \\| ___ \\ | | | '__| '_ \\
** \\__ \\ |_| | | | | |_/ / |_| | | | | | |
** |___/\\__,_|_| |_\\____/ \\__,_|_| |_| |_|
**
** SunBurn RayTracer
** http://www.hsyl20.fr/sunburn
** GPLv3
*/
package fr.hsyl20.sunburn.geometry
class Vector3D(val x: Double, val y: Double, val z: Double) extends Tuple3(x,y,z) {
def + (v : Vector3D) : Vector3D = Vector3D(x+v.x, y+v.y, z+v.z)
def - (v: Vector3D) : Vector3D = Vector3D(x-v.x, y-v.y, z-v.z)
def unary_- : Vector3D = Vector3D(-x, -y, -z)
def * (a: Double) : Vector3D = Vector3D(a*x, a*y, a*z)
def / (a: Double) : Vector3D = Vector3D(x/a, y/a, z/a)
lazy val N : Double = scala.math.sqrt(N2)
lazy val N2 : Double = x*x + y*y + z*z
def * (v: Vector3D) : Double = x*v.x + y*v.y + z*v.z
def ^ (v: Vector3D) : Vector3D = Vector3D (y*v.z - z*v.y, z*v.x - v.z*x, x*v.y - y*v.x)
//Called "hat()" in RTftGU
def normalize() : Vector3D = Vector3D(x/N, y/N, z/N)
}
object Vector3D {
def apply(x:Double, y:Double, z:Double) = new Vector3D(x,y,z)
def apply(d: Double) = new Vector3D(d,d,d)
implicit def doubleWrapper(d : Double) = new VectorDoubleWrapper(d)
implicit def tupleWrapper(t: Tuple3[Double, Double, Double]) = Vector3D(t._1, t._2, t._3)
}
class VectorDoubleWrapper(d: Double) {
def * (v: Vector3D) : Vector3D = v * d
}
| hsyl20/SunBurn | src/main/scala/geometry/Vector3D.scala | Scala | gpl-3.0 | 1,527 |
object print_param {
def main(args: Array[String]) {
// Put code here
}
}
| LoyolaChicagoBooks/introcs-scala-examples | print_param/print_param.scala | Scala | gpl-3.0 | 82 |
package chandu0101.scalajs.facades.leaflet
import org.scalajs.dom.raw.HTMLElement
import scala.scalajs.js
import scala.scalajs.js.annotation.JSName
import scala.scalajs.js.{UndefOr, undefined}
/**
* Created by chandrasekharkode on 3/3/15.
*/
@JSName("L.Browser")
object LBrowser extends js.Object {
val ie : Boolean = js.native
val ie6 : Boolean = js.native
val ie7 : Boolean = js.native
val webkit : Boolean = js.native
val webkit3d : Boolean = js.native
val android : Boolean = js.native
val android23 : Boolean = js.native
val mobile : Boolean = js.native
val opera : Boolean = js.native
val mobileWebkit : Boolean = js.native
val mobileOpera : Boolean = js.native
val touch : Boolean = js.native
val msTouch : Boolean = js.native
val retina : Boolean = js.native
}
@JSName("L.DomUtil")
object LDomUtil extends js.Object {
def get(id : String) : HTMLElement = js.native
def getStyle(el : HTMLElement,style : String) : String = js.native
def getViewportOffset(el : HTMLElement) : LPoint = js.native
def create( tagName : String,className : String,container : UndefOr[HTMLElement] = undefined) : HTMLElement = js.native
def disableTextSelection() : Unit = js.native
def enableTextSelection() : Unit = js.native
def hasCLass(el : HTMLElement,name : String) : Boolean = js.native
def addClass(el : HTMLElement,name : String) : Unit = js.native
def removeClass(el : HTMLElement,name : String) : Unit = js.native
def setOpacity(el : HTMLElement,value : Double) : Unit = js.native
def testProp(props : js.Array[String]) : js.Dynamic = js.native
def getTranslateString(point : LPoint) : String = js.native
def getScaleString( scale : Double,origin : LPoint) : String = js.native
def setPosition(el : HTMLElement,point : LPoint,diable3D : UndefOr[Boolean] = undefined) : Unit = js.native
def getPosition(el : HTMLElement) : LPoint = js.native
val TRANSITION : String = js.native
val TRANSFORM : String = js.native
}
@JSName("L.PosAnimation")
class LPosAnimation extends js.Object with LEventEmitter {
def run(el : HTMLElement,newPos : LPoint,duration : UndefOr[Double] = undefined,easeLinearity : UndefOr[Double] = undefined) : LPosAnimation = js.native
}
object LPosAnimation {
def apply() = new LPosAnimation()
}
@JSName("L.Draggable")
class LDraggable extends js.Object with LEventEmitter{
def this(el : HTMLElement , dragHandle : UndefOr[HTMLElement] = undefined) = this()
def enable() : Unit = js.native
def disable() : Unit = js.native
}
object LDraggable {
def apply(el : HTMLElement , dragHandle : UndefOr[HTMLElement] = undefined) = new LDraggable(el,dragHandle)
}
| CapeSepias/scalajs-facades | core/src/main/scala/chandu0101/scalajs/facades/leaflet/utils.scala | Scala | mit | 2,682 |
package net.sansa_stack.query.spark.sparqlify
import net.sansa_stack.query.spark.SPARQLTestSuiteRunnerSpark
import net.sansa_stack.query.spark.api.domain.QueryEngineFactory
import net.sansa_stack.query.spark.sparqlify.SPARQLTestSuiteRunnerSparkSparqlify.CUSTOM_TS_QUERY
import net.sansa_stack.query.tests.{SPARQLQueryEvaluationTest, SPARQLQueryEvaluationTestSuite}
import org.apache.jena.query.{Query, QueryFactory}
object SPARQLTestSuiteRunnerSparkSparqlify {
val CUSTOM_TS_QUERY: Query = QueryFactory.create(
"""
|prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
|prefix : <http://www.w3.org/2009/sparql/docs/tests/data-sparql11/construct/manifest#>
|prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>
|prefix mf: <http://www.w3.org/2001/sw/DataAccess/tests/test-manifest#>
|prefix qt: <http://www.w3.org/2001/sw/DataAccess/tests/test-query#>
|prefix dawgt: <http://www.w3.org/2001/sw/DataAccess/tests/test-dawg#>
|
|SELECT * {
|?test rdf:type mf:QueryEvaluationTest ;
| mf:action
| [ qt:query ?queryFile ;
| qt:data ?dataFile ] .
| OPTIONAL { ?test mf:name ?name }
| OPTIONAL { ?test mf:result ?resultsFile }
| OPTIONAL { ?test rdfs:comment ?description }
|}
|""".stripMargin)
}
class SPARQLTestSuiteRunnerSparkSparqlify
extends SPARQLTestSuiteRunnerSpark(new SPARQLQueryEvaluationTestSuite(
"/sansa-sparql-ts/manifest.ttl",
SPARQLTestSuiteRunnerSparkSparqlify.CUSTOM_TS_QUERY)) {
override def getEngineFactory: QueryEngineFactory = new QueryEngineFactorySparqlify(spark)
// override lazy val IGNORE_FILTER: SPARQLQueryEvaluationTest => Boolean
// = _.name.contains("15-q1")
} | SANSA-Stack/SANSA-RDF | sansa-query/sansa-query-spark/src/test/scala/net/sansa_stack/query/spark/sparqlify/SPARQLTestSuiteRunnerSparkSparqlify.scala | Scala | apache-2.0 | 1,729 |
package org.jetbrains.plugins.scala.annotator.intention.sbt.ui
import java.awt.BorderLayout
import javax.swing._
import javax.swing.event._
import com.intellij.icons.AllIcons
import com.intellij.util.text.VersionComparatorUtil.compare
import com.intellij.ui._
import com.intellij.ui.components.JBList
import org.jetbrains.sbt.resolvers.ArtifactInfo
import scala.collection.JavaConverters.asJavaCollectionConverter
/**
* Created by afonichkin on 7/13/17.
*/
class SbtArtifactSearchPanel(wizard: SbtArtifactSearchWizard, artifactInfoSet: Set[ArtifactInfo]) extends JPanel {
val myResultList = new JBList[ArtifactInfo]()
init()
def init(): Unit = {
val artifacts = artifactInfoSet
.toSeq
.sortWith((a, b) =>
a.groupId >= b.groupId &&
a.artifactId >= b.artifactId &&
compare(a.version, b.version) >= 0
)
myResultList.setModel(new DependencyListModel(artifacts))
myResultList.getSelectionModel.setSelectionMode(ListSelectionModel.SINGLE_SELECTION)
setLayout(new BorderLayout())
val pane = ScrollPaneFactory.createScrollPane(myResultList)
pane.setVerticalScrollBarPolicy(ScrollPaneConstants.VERTICAL_SCROLLBAR_ALWAYS) // Don't remove this line.
add(pane, BorderLayout.CENTER)
myResultList.setCellRenderer(new DependencyListCellRenderer())
myResultList.addListSelectionListener((_: ListSelectionEvent) => wizard.updateButtons(false, !myResultList.isSelectionEmpty, true))
}
private class DependencyListModel(elems: Seq[ArtifactInfo]) extends CollectionListModel[ArtifactInfo](elems.asJavaCollection)
private class DependencyListCellRenderer extends ColoredListCellRenderer[ArtifactInfo] {
override def customizeCellRenderer(list: JList[_ <: ArtifactInfo], value: ArtifactInfo, index: Int, selected: Boolean, hasFocus: Boolean): Unit = {
setIcon(AllIcons.Modules.Library)
append(s"${value.groupId}:", SimpleTextAttributes.GRAY_ATTRIBUTES)
append(value.artifactId)
append(s":${value.version}", SimpleTextAttributes.GRAY_ATTRIBUTES)
}
}
}
| triplequote/intellij-scala | scala/scala-impl/src/org/jetbrains/plugins/scala/annotator/intention/sbt/ui/SbtArtifactSearchPanel.scala | Scala | apache-2.0 | 2,067 |
/*
* Copyright 2022 HM Revenue & Customs
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package iht.controllers.application.tnrb
import iht.config.AppConfig
import iht.controllers.application.ApplicationControllerTest
import iht.testhelpers.CommonBuilder
import iht.views.html.application.tnrb.tnrb_success
import play.api.mvc.MessagesControllerComponents
import play.api.test.Helpers._
import play.api.test.{FakeHeaders, FakeRequest}
import uk.gov.hmrc.http.HeaderCarrier
import uk.gov.hmrc.play.bootstrap.frontend.controller.FrontendController
import scala.concurrent.Future
class TnrbSuccessControllerTest extends ApplicationControllerTest {
protected abstract class TestController extends FrontendController(mockControllerComponents) with TnrbSuccessController {
override val cc: MessagesControllerComponents = mockControllerComponents
override implicit lazy val appConfig: AppConfig = mockAppConfig
override val tnrbSuccessView: tnrb_success = app.injector.instanceOf[tnrb_success]
}
implicit val headerCarrier = FakeHeaders()
implicit val request = FakeRequest()
implicit val hc = new HeaderCarrier
val registrationDetails = CommonBuilder.buildRegistrationDetails copy (
deceasedDetails = Some(CommonBuilder.buildDeceasedDetails),
deceasedDateOfDeath=Some(CommonBuilder.buildDeceasedDateOfDeath),
ihtReference=Some("AI123456")
)
def tnrbSuccessController = new TestController {
override val cachingConnector = mockCachingConnector
override val ihtConnector = mockIhtConnector
override val authConnector = mockAuthConnector
}
def tnrbSuccessControllerNotAuthorised = new TestController {
override val cachingConnector = mockCachingConnector
override val ihtConnector = mockIhtConnector
override val authConnector = mockAuthConnector
}
"TnrbSuccessController" must {
"redirect to GG login page on PageLoad if the user is not logged in" in {
val result = tnrbSuccessControllerNotAuthorised.onPageLoad()(createFakeRequest(isAuthorised = false))
status(result) must be(SEE_OTHER)
redirectLocation(result) must be (Some(loginUrl))
}
"respond with OK on page load" in {
val buildWidowCheck = CommonBuilder.buildWidowedCheck
val buildTnrbModel = CommonBuilder.buildTnrbEligibility
val applicationDetails = CommonBuilder.buildApplicationDetails copy (widowCheck= Some(buildWidowCheck),
increaseIhtThreshold = Some(buildTnrbModel))
createMockToGetRegDetailsFromCacheNoOption(mockCachingConnector, Future.successful(Some(registrationDetails)))
createMockToGetApplicationDetails(mockIhtConnector, Some(applicationDetails))
val result = tnrbSuccessController.onPageLoad()(createFakeRequest())
status(result) must be (OK)
}
behave like controllerOnPageLoadWithNoExistingRegistrationDetails(mockCachingConnector,
tnrbSuccessController.onPageLoad(createFakeRequest()))
}
}
| hmrc/iht-frontend | test/iht/controllers/application/tnrb/TnrbSuccessControllerTest.scala | Scala | apache-2.0 | 3,489 |
package napplelabs.swish.commands
import napplelabs.swish.{Swish, ServerConfig, ServerConnection}
import java.util.UUID
/**
* Created by IntelliJ IDEA.
* User: zkim
* Date: Nov 30, 2009
* Time: 7:54:07 PM
* To change this template use File | Settings | File Templates.
*/
object DownloadDirectory {
def apply(ssh: ServerConnection, remotePath: String, localPath: String = "/tmp/" + UUID.randomUUID.toString) = {
val gzipPath = GZipDirectory(remotePath, ssh)
val localGzipPath = "/tmp/" + UUID.randomUUID.toString + ".tar.gz"
ScpPullFile(gzipPath, localGzipPath, ssh.sc)
ssh.exec("rm -f " + gzipPath)
Swish.exec("mkdir " + localPath)
Swish.exec("tar -xvf " + localGzipPath + " -C " + localPath)
Swish.exec("rm -f " + localGzipPath)
DownloadDirectoryResult(localPath)
}
}
case class DownloadDirectoryResult(localPath: String) | zk/swish-scala | src/main/scala/napplelabs/swish/commands/DownloadDirectory.scala | Scala | mit | 906 |
package models
import scalikejdbc._
import skinny.orm.{Alias, SkinnyCRUDMapperWithId}
case class Fare(id: Long, companyId: Long, trainType: TrainType, km: Double, cost: Int) {
def save()(implicit session: DBSession): Long = Fare.save(this)
}
object Fare extends SkinnyCRUDMapperWithId[Long, Fare] {
override val defaultAlias: Alias[Fare] = createAlias("f")
override def extract(rs: WrappedResultSet, n: ResultName[Fare]): Fare = autoConstruct(rs, n)
override def idToRawValue(id: Long): Any = id
override def rawValueToId(value: Any): Long = value.toString.toLong
def save(fare: Fare)(implicit session: DBSession): Long =
createWithAttributes(
'companyId -> fare.companyId,
'trainType -> fare.trainType.value,
'km -> fare.km,
'cost -> fare.cost
)
def existsFare()(implicit session: DBSession): Seq[FareType] = withSQL {
val f = defaultAlias
select(sqls.distinct(f.companyId, f.trainType)).from(Fare as f)
}.map(FareType.extract).list().apply()
case class FareType(companyId: Long, trainType: TrainType)
object FareType {
def extract(rs: WrappedResultSet): FareType = {
val f = defaultAlias
FareType(rs.long(f.companyId), TrainType.find(rs.int(f.trainType)).getOrElse(TrainType.Local))
}
}
}
| ponkotuy/train-stamp-rally | app/models/Fare.scala | Scala | apache-2.0 | 1,280 |
package org.example
import eu.timepit.refined.auto._
import eu.timepit.refined.pureconfig._
import eu.timepit.refined.types.net.PortNumber
import eu.timepit.refined.types.string.NonEmptyString
import fs2.Task
final case class Config(
http: Http = Http()
)
final case class Http(
host: NonEmptyString = "::",
port: PortNumber = 8080
)
object Config {
def load: Task[Config] =
Task.delay(pureconfig.loadConfigOrThrow[Config])
}
| fthomas/scala-web-stack | modules/server/jvm/src/main/scala/org/example/Config.scala | Scala | apache-2.0 | 448 |
/*
* The MIT License (MIT)
*
* Copyright (c) 2016 Algolia
* http://www.algolia.com/
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
*/
package algolia.objects
case class Strategy(
eventsScoring: Option[Map[String, ScoreType]] = None,
facetsScoring: Option[Map[String, Score]] = None
)
case class ScoreType(score: Int, `type`: String)
case class Score(score: Int)
| algolia/algoliasearch-client-scala | src/main/scala/algolia/objects/Strategy.scala | Scala | mit | 1,407 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.ui.exec
import java.util.Locale
import javax.servlet.http.HttpServletRequest
import scala.xml.{Node, Text}
import org.apache.spark.SparkContext
import org.apache.spark.ui.{SparkUITab, UIUtils, WebUIPage}
private[ui] class ExecutorThreadDumpPage(
parent: SparkUITab,
sc: Option[SparkContext]) extends WebUIPage("threadDump") {
// stripXSS is called first to remove suspicious characters used in XSS attacks
def render(request: HttpServletRequest): Seq[Node] = {
val executorId =
Option(UIUtils.stripXSS(request.getParameter("executorId"))).map { executorId =>
UIUtils.decodeURLParameter(executorId)
}.getOrElse {
throw new IllegalArgumentException(s"Missing executorId parameter")
}
val time = System.currentTimeMillis()
val maybeThreadDump = sc.get.getExecutorThreadDump(executorId)
val content = maybeThreadDump.map { threadDump =>
val dumpRows = threadDump.sortWith {
case (threadTrace1, threadTrace2) =>
val v1 = if (threadTrace1.threadName.contains("Executor task launch")) 1 else 0
val v2 = if (threadTrace2.threadName.contains("Executor task launch")) 1 else 0
if (v1 == v2) {
threadTrace1.threadName.toLowerCase(Locale.ROOT) <
threadTrace2.threadName.toLowerCase(Locale.ROOT)
} else {
v1 > v2
}
}.map { thread =>
val threadId = thread.threadId
val blockedBy = thread.blockedByThreadId match {
case Some(_) =>
<div>
Blocked by <a href={s"#${thread.blockedByThreadId}_td_id"}>
Thread {thread.blockedByThreadId} {thread.blockedByLock}</a>
</div>
case None => Text("")
}
val heldLocks = thread.holdingLocks.mkString(", ")
<tr id={s"thread_${threadId}_tr"} class="accordion-heading"
onclick={s"toggleThreadStackTrace($threadId, false)"}
onmouseover={s"onMouseOverAndOut($threadId)"}
onmouseout={s"onMouseOverAndOut($threadId)"}>
<td id={s"${threadId}_td_id"}>{threadId}</td>
<td id={s"${threadId}_td_name"}>{thread.threadName}</td>
<td id={s"${threadId}_td_state"}>{thread.threadState}</td>
<td id={s"${threadId}_td_locking"}>{blockedBy}{heldLocks}</td>
<td id={s"${threadId}_td_stacktrace"} class="hidden">{thread.stackTrace}</td>
</tr>
}
<div class="row-fluid">
<p>Updated at {UIUtils.formatDate(time)}</p>
{
// scalastyle:off
<p><a class="expandbutton" onClick="expandAllThreadStackTrace(true)">
Expand All
</a></p>
<p><a class="expandbutton hidden" onClick="collapseAllThreadStackTrace(true)">
Collapse All
</a></p>
<div class="form-inline">
<div class="bs-example" data-example-id="simple-form-inline">
<div class="form-group">
<div class="input-group">
Search: <input type="text" class="form-control" id="search" oninput="onSearchStringChange()"></input>
</div>
</div>
</div>
</div>
<p></p>
// scalastyle:on
}
<table class={UIUtils.TABLE_CLASS_STRIPED + " accordion-group" + " sortable"}>
<thead>
<th onClick="collapseAllThreadStackTrace(false)">Thread ID</th>
<th onClick="collapseAllThreadStackTrace(false)">Thread Name</th>
<th onClick="collapseAllThreadStackTrace(false)">Thread State</th>
<th onClick="collapseAllThreadStackTrace(false)">Thread Locks</th>
</thead>
<tbody>{dumpRows}</tbody>
</table>
</div>
}.getOrElse(Text("Error fetching thread dump"))
UIUtils.headerSparkPage(s"Thread dump for executor $executorId", content, parent)
}
}
| cin/spark | core/src/main/scala/org/apache/spark/ui/exec/ExecutorThreadDumpPage.scala | Scala | apache-2.0 | 4,641 |
package com.mz.training.domains.address
import java.sql.ResultSet
import com.mz.training.domains.address.Address
import com.mz.training.common.mappers.SqlDomainMapper
/**
* Created by zemo on 17/10/15.
*/
trait AddressMapper extends SqlDomainMapper[Address] {
/*
CREATE TABLE addresses (
id bigserial NOT NULL,
street VARCHAR(255),
house_number INTEGER,
zip VARCHAR(5),
city VARCHAR(255),
*/
val TABLE_NAME = "addresses"
val STREET_COL = "street"
val HOUSE_NUMBER_COL = "house_number"
val ZIP_COL = "zip"
val CITY_COL = "city"
val SQL_PROJECTION = s"$ID_COL, $STREET_COL, $ZIP_COL, $CITY_COL, $HOUSE_NUMBER_COL"
val COLUMNS = s"$STREET_COL, $ZIP_COL, $CITY_COL, $HOUSE_NUMBER_COL"
override def sqlProjection: String = SQL_PROJECTION
override def values(implicit entity: Address): String = s"'${entity.street}', '${entity.zip}', '${entity.city}', '${entity.houseNumber}'"
override def columns: String = COLUMNS
override def tableName: String = TABLE_NAME
override def setValues(implicit entity: Address): String = s"$STREET_COL = '${entity.street}', $HOUSE_NUMBER_COL = '${entity.houseNumber}', " +
s"$ZIP_COL = '${entity.zip}', $CITY_COL = '${entity.city}'"
/**
* Map ResultSet to User
*
* @param resultSet
* @return Address(id: Long, street: String, zip: String, houseNumber: String, city: String)
*/
def mapResultSetDomain(resultSet: ResultSet): Address = {
Address(resultSet.getLong(ID_COL), resultSet.getString(STREET_COL), resultSet.getString(ZIP_COL),
resultSet.getString(HOUSE_NUMBER_COL), resultSet.getString(CITY_COL))
}
}
| michalzeman/angular2-training | akka-http-server/src/main/scala/com/mz/training/domains/address/AddressMapper.scala | Scala | mit | 1,659 |
package io.scalac.amqp
/** Exchanges take a message and route it into zero or more queues.
* The routing algorithm used depends on the exchange type and rules called bindings. */
sealed trait Type
/** A direct exchange delivers messages to queues based on the message routing key.
* A direct exchange is ideal for the unicast routing of messages
* (although they can be used for multicast routing as well). */
case object Direct extends Type
/** A fanout exchange routes messages to all of the queues that are bound to it and the routing key is ignored.
* If N queues are bound to a fanout exchange, when a new message is published to that exchange a copy of
* the message is delivered to all N queues. Fanout exchanges are ideal for the broadcast routing of messages. */
case object Fanout extends Type
/** Topic exchanges route messages to one or many queues based on matching between a message routing key
* and the pattern that was used to bind a queue to an exchange. The topic exchange type is often used
* to implement various publish/subscribe pattern variations. Topic exchanges are commonly used for
* the multicast routing of messages. */
case object Topic extends Type
/** A headers exchange is designed to for routing on multiple attributes that are more easily expressed
* as message headers than a routing key. Headers exchanges ignore the routing key attribute. Instead,
* the attributes used for routing are taken from the headers attribute. A message is considered matching
* if the value of the header equals the value specified upon binding. */
case object Headers extends Type | iozozturk/reactive-rabbit | src/main/scala/io/scalac/amqp/Type.scala | Scala | apache-2.0 | 1,625 |
/*
* Copyright 2016 Spotify AB.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
// Example: Compute Top K Items Globally
// Input is a collection of (user, item, score)
package com.spotify.bdrc.pipeline
import com.spotify.bdrc.util.Records.Rating
import com.spotify.scio.values.SCollection
import com.twitter.scalding.TypedPipe
import org.apache.spark.rdd.RDD
object TopItems {
val topK = 100
// ## Scalding
def scalding(input: TypedPipe[Rating]): TypedPipe[(String, Double)] = {
input
.map(x => (x.item, x.score))
.group
// Sum values with an implicit `Semigroup[Double]`
.sum
// Group all elements with a single key `Unit`
.groupAll
// Take top K with a priority queue
.sortedReverseTake(topK)(Ordering.by(_._2))
// Drop `Unit` key
.values
// Flatten result `Seq[(String, Double)]`
.flatten
}
// ## Scalding with Algebird `Aggregator`
def scaldingWithAlgebird(input: TypedPipe[Rating]): TypedPipe[(String, Double)] = {
import com.twitter.algebird.Aggregator.sortedReverseTake
val aggregator = sortedReverseTake[(String, Double)](topK)(Ordering.by(_._2))
input
.map(x => (x.item, x.score))
.group
// Sum values with an implicit `Semigroup[Double]`
.sum
.toTypedPipe
// Aggregate globally into a single `Seq[(String, Double)]`
.aggregate(aggregator)
// Flatten result `Seq[(String, Double)]`
.flatten
}
// ## Scio
def scio(input: SCollection[Rating]): SCollection[(String, Double)] = {
input
.map(x => (x.item, x.score))
// Sum values with an implicit `Semigroup[Double]`
.sumByKey
// Compute top K as an `Iterable[(String, Double)]`
.top(topK)(Ordering.by(_._2))
// Flatten result `Iterable[(String, Double)]`
.flatten
}
// ## Scio with Algebird `Aggregator`
def scioWithAlgebird(input: SCollection[Rating]): SCollection[(String, Double)] = {
import com.twitter.algebird.Aggregator.sortedReverseTake
val aggregator = sortedReverseTake[(String, Double)](topK)(Ordering.by(_._2))
input
.map(x => (x.item, x.score))
// Sum values with an implicit `Semigroup[Double]`
.sumByKey
// Aggregate globally into a single `Seq[(String, Double)]`
.aggregate(aggregator)
// Flatten result `Seq[(String, Double)]`
.flatten
}
// ## Spark
def spark(input: RDD[Rating]): Seq[(String, Double)] = {
input
.map(x => (x.item, x.score))
// Sum values with addition
.reduceByKey(_ + _)
// `top` is an action and collects data back to the driver node
.top(topK)(Ordering.by(_._2))
}
// ## Spark with Algebird `Aggregator`
def sparkWithAlgebird(input: RDD[Rating]): Seq[(String, Double)] = {
import com.twitter.algebird.Aggregator.sortedReverseTake
import com.twitter.algebird.spark._
val aggregator = sortedReverseTake[(String, Double)](topK)(Ordering.by(_._2))
input
.map(x => (x.item, x.score))
// Sum values with addition
.reduceByKey(_ + _)
.algebird
// `aggregate` is an action and collects data back to the driver node
.aggregate(aggregator)
}
}
| spotify/big-data-rosetta-code | src/main/scala/com/spotify/bdrc/pipeline/TopItems.scala | Scala | apache-2.0 | 3,724 |
/*
* Copyright (c) 2014 Snowplow Analytics Ltd. All rights reserved.
*
* This program is licensed to you under the Apache License Version 2.0,
* and you may not use this file except in compliance with the Apache License Version 2.0.
* You may obtain a copy of the Apache License Version 2.0 at http://www.apache.org/licenses/LICENSE-2.0.
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the Apache License Version 2.0 is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the Apache License Version 2.0 for the specific language governing permissions and limitations there under.
*/
package com.snowplowanalytics.snowplow.enrich
package hadoop
package jobs
package bad
// Scalding
import com.twitter.scalding._
// Cascading
import cascading.tuple.TupleEntry
import cascading.tap.SinkMode
// This project
import JobSpecHelpers._
// Specs2
import org.specs2.mutable.Specification
/**
* Holds the input data for the test,
* plus a lambda to create the expected
* output.
*/
object InvalidJsonsSpec {
val lines = Lines(
"""snowplowweb web 2014-06-01 14:04:11.639 2014-05-29 18:04:12.000 2014-05-29 18:04:11.639 page_view a4583919-4df8-496a-917b-d40fa1c8ca7f 836413 clojure js-2.0.0-M2 clj-0.6.0-tom-0.0.4 hadoop-0.5.0-common-0.4.0 216.207.42.134 3499345421 3b1d1a375044eede 3 2bad2a4e-aae4-4bea-8acd-399e7fe0366a US CA South San Francisco 37.654694 -122.4077 http://snowplowanalytics.com/blog/2013/02/08/writing-hive-udfs-and-serdes/ Writing Hive UDFs - a tutorial http snowplowanalytics.com 80 /blog/2013/02/08/writing-hive-udfs-and-serdes/ &&& |%| Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.75.14 (KHTML, like Gecko) Version/7.0.3 Safari/537.75.14 Safari Safari Browser WEBKIT en-us 0 0 0 0 0 0 0 0 0 1 24 1440 1845 Mac OS Mac OS Apple Inc. America/Los_Angeles Computer 0 1440 900 UTF-8 1440 6015"""
)
val expected = (line: String) =>
s"""|{
|"line":"${line}",
|"errors":[
|{"level":"error","message":"Field [ue_properties]: invalid JSON [|%|] with parsing error: Unexpected character ('|' (code 124)): expected a valid value (number, String, array, object, 'true', 'false' or 'null') at [Source: java.io.StringReader@xxxxxx; line: 1, column: 2]"},
|{"level":"error","message":"Field [context]: invalid JSON [&&&] with parsing error: Unexpected character ('&' (code 38)): expected a valid value (number, String, array, object, 'true', 'false' or 'null') at [Source: java.io.StringReader@xxxxxx; line: 1, column: 2]"}
|]
|}""".stripMargin.replaceAll("[\\n\\r]","").replaceAll("[\\t]","\\\\\\\\t")
}
/**
* Integration test for the EtlJob:
*
* The JSON Schema for the context
* cannot be located.
*/
class InvalidJsonsSpec extends Specification {
import Dsl._
"A job which contains invalid JSONs" should {
ShredJobSpec.
source(MultipleTextLineFiles("inputFolder"), InvalidJsonsSpec.lines).
sink[String](PartitionedTsv("outputFolder", ShredJob.ShreddedPartition, false, ('json), SinkMode.REPLACE)){ output =>
"not write any events" in {
output must beEmpty
}
}.
sink[TupleEntry](Tsv("exceptionsFolder")){ trap =>
"not trap any exceptions" in {
trap must beEmpty
}
}.
sink[String](Tsv("badFolder")){ json =>
"write a bad row JSON with input line and error message for each bad JSON" in {
for (i <- json.indices) {
json(i) must_== InvalidJsonsSpec.expected(InvalidJsonsSpec.lines(i)._2)
}
}
}.
run.
finish
}
}
| wesley1001/snowplow | 3-enrich/scala-hadoop-shred/src/test/scala/com.snowplowanalytics.snowplow.enrich.hadoop/jobs/bad/InvalidJsonsSpec.scala | Scala | apache-2.0 | 3,741 |
/**
* Copyright (C) 2013 Orbeon, Inc.
*
* This program is free software; you can redistribute it and/or modify it under the terms of the
* GNU Lesser General Public License as published by the Free Software Foundation; either version
* 2.1 of the License, or (at your option) any later version.
*
* This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY;
* without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
* See the GNU Lesser General Public License for more details.
*
* The full text of the license is available at http://www.gnu.org/copyleft/lesser.html
*/
package org.orbeon.oxf.xforms.submission
import cats.Eval
import org.orbeon.dom._
import org.orbeon.dom.saxon.DocumentWrapper
import org.orbeon.oxf.common.OXFException
import org.orbeon.oxf.externalcontext.ExternalContext
import org.orbeon.oxf.http.HttpMethod
import org.orbeon.oxf.util.Logging._
import org.orbeon.oxf.util.PathUtils.decodeSimpleQuery
import org.orbeon.oxf.util.StaticXPath.VirtualNodeType
import org.orbeon.oxf.util.StringUtils._
import org.orbeon.oxf.util.{ContentTypes, IndentedLogger, StaticXPath, XPath}
import org.orbeon.oxf.xforms.XFormsContainingDocument
import org.orbeon.oxf.xforms.analysis.model.ModelDefs.Relevant
import org.orbeon.oxf.xforms.control.XFormsSingleNodeControl
import org.orbeon.oxf.xforms.model.{BindNode, InstanceData}
import org.orbeon.oxf.xml.dom.Extensions
import org.orbeon.oxf.xml.dom.Extensions._
import org.orbeon.saxon.om
import org.orbeon.xforms.RelevanceHandling
import org.orbeon.xforms.XFormsNames._
import org.orbeon.xforms.analysis.model.ValidationLevel
import scala.collection.mutable
import scala.util.{Failure, Success}
object XFormsModelSubmissionSupport {
import Private._
import RelevanceHandling._
// Run the given submission `Eval`. This must be for a `replace="all"` submission.
def runDeferredSubmission(eval: Eval[ConnectResult], response: ExternalContext.Response): Unit =
eval.value.result match {
case Success((replacer, cxr)) =>
try {
replacer match {
case _: AllReplacer => AllReplacer.forwardResultToResponse(cxr, response)
case _: RedirectReplacer => RedirectReplacer.updateResponse(cxr, response)
case _: NoneReplacer => ()
case r => throw new IllegalArgumentException(r.getClass.getName)
}
} finally {
cxr.close()
}
case Failure(throwable) =>
// Propagate throwable, which might have come from a separate thread
throw new OXFException(throwable)
}
// Prepare XML for submission
//
// - re-root if `ref` points to an element other than the root element
// - annotate with `xxf:id` if requested
// - prune or blank non-relevant nodes if requested
// - annotate with alerts if requested
def prepareXML(
xfcd : XFormsContainingDocument,
ref : om.NodeInfo,
relevanceHandling : RelevanceHandling,
namespaceContext : Map[String, String],
annotateWith : Set[String],
relevantAttOpt : Option[QName]
): Document =
ref match {
case virtualNode: VirtualNodeType =>
// "A node from the instance data is selected, based on attributes on the submission
// element. The indicated node and all nodes for which it is an ancestor are considered for
// the remainder of the submit process. "
val copy =
virtualNode.getUnderlyingNode match {
case e: Element => e.createDocumentCopyParentNamespaces(detach = false)
case n: Node => Document(n.getDocument.getRootElement.createCopy)
case _ => throw new IllegalStateException
}
val attributeNamesForTokens =
annotateWith.iterator map { token =>
decodeSimpleQuery(token).headOption match {
case Some((name, value)) =>
name -> {
value.trimAllToOpt flatMap
(Extensions.resolveQName(namespaceContext.get, _, unprefixedIsNoNamespace = true)) getOrElse
QName(name, XXFORMS_NAMESPACE_SHORT)
}
case None =>
throw new IllegalArgumentException(s"invalid format for `xxf:annotate` value: `$annotateWith`")
}
} toMap
// Annotate ids before pruning so that it is easier for other code (Form Runner) to infer the same ids
attributeNamesForTokens.get("id") foreach
(annotateWithHashes(copy, _))
processRelevant(
doc = copy,
relevanceHandling = relevanceHandling,
relevantAttOpt = relevantAttOpt,
relevantAnnotationAttQNameOpt = attributeNamesForTokens.get(Relevant.name)
)
val root = copy.getRootElement
attributeNamesForTokens.map(_._2.namespace).toSet.foreach { (ns: Namespace) =>
Option(root.getNamespaceForPrefix(ns.prefix)) match {
case None =>
root.add(ns)
case Some(existingNs) if existingNs != ns =>
throw new IllegalArgumentException(s"incompatible namespace prefix on root element: `${ns.prefix}` maps to `${existingNs.uri}` and `${ns.uri} is expected`")
case _ =>
}
}
annotateWithAlerts(
xfcd = xfcd,
doc = copy,
levelsToAnnotate =
attributeNamesForTokens.keySet collect
ValidationLevel.LevelByName map { level =>
level -> attributeNamesForTokens(level.entryName)
} toMap
)
copy
// Submitting read-only instance backed by TinyTree (no MIPs to check)
// TODO: What about re-rooting and annotations?
case ref if ref.getNodeKind == org.w3c.dom.Node.ELEMENT_NODE =>
StaticXPath.tinyTreeToOrbeonDom(ref)
case ref =>
StaticXPath.tinyTreeToOrbeonDom(ref.getRoot)
}
def processRelevant(
doc : Document,
relevanceHandling : RelevanceHandling,
relevantAttOpt : Option[QName],
relevantAnnotationAttQNameOpt : Option[QName]
): Unit = {
// If we have `xxf:relevant-attribute="fr:relevant"`, say, then we use that attribute to also determine
// the relevance of the element. See https://github.com/orbeon/orbeon-forms/issues/3568.
val isNonRelevantSupportAnnotationIfPresent: Node => Boolean =
relevantAttOpt map
isLocallyNonRelevantSupportAnnotation getOrElse
isLocallyNonRelevant _
relevanceHandling match {
case RelevanceHandling.Keep | RelevanceHandling.Empty =>
if (relevanceHandling == RelevanceHandling.Empty)
blankNonRelevantNodes(
doc = doc,
attsToPreserve = relevantAnnotationAttQNameOpt.toSet ++ relevantAttOpt,
isLocallyNonRelevant = isNonRelevantSupportAnnotationIfPresent
)
relevantAnnotationAttQNameOpt foreach { relevantAnnotationAttName =>
annotateNonRelevantElements(
doc = doc,
relevantAnnotationAttQName = relevantAnnotationAttName,
isNonRelevant = isNonRelevantSupportAnnotationIfPresent
)
}
if (relevantAnnotationAttQNameOpt != relevantAttOpt)
relevantAttOpt foreach { relevantAtt =>
removeNestedAnnotations(doc.getRootElement, relevantAtt, includeSelf = true)
}
case RelevanceHandling.Remove =>
pruneNonRelevantNodes(doc, isNonRelevantSupportAnnotationIfPresent)
// There can be leftover annotations, in particular attributes with value `true`!
val attsToRemove = relevantAttOpt.toList :::
(if (relevantAnnotationAttQNameOpt != relevantAttOpt) relevantAnnotationAttQNameOpt.toList else Nil)
attsToRemove foreach { attQName =>
removeNestedAnnotations(doc.getRootElement, attQName, includeSelf = true)
}
}
}
def annotateWithHashes(doc: Document, attQName: QName): Unit = {
val wrapper = new DocumentWrapper(doc, null, XPath.GlobalConfiguration)
var annotated = false
doc.accept(new VisitorSupport {
override def visit(element: Element): Unit = {
val hash = SubmissionUtils.dataNodeHash(wrapper.wrap(element))
element.addAttribute(attQName, hash)
annotated = true
}
})
if (annotated)
addRootElementNamespace(doc)
}
// Annotate elements which have failed constraints with an xxf:error, xxf:warning or xxf:info attribute containing
// the alert message. Only the levels passed in `annotate` are handled.
def annotateWithAlerts(
xfcd : XFormsContainingDocument,
doc : Document,
levelsToAnnotate : Map[ValidationLevel, QName]
): Unit =
if (levelsToAnnotate.nonEmpty) {
val elementsToAnnotate = mutable.Map[ValidationLevel, mutable.Map[Set[String], Element]]()
// Iterate data to gather elements with failed constraints
doc.accept(new VisitorSupport {
override def visit(element: Element): Unit = {
val failedValidations = BindNode.failedValidationsForAllLevelsPrioritizeRequired(element)
for (level <- levelsToAnnotate.keys) {
// NOTE: Annotate all levels specified. If we decide to store only one level of validation
// in bind nodes, then we would have to change this to take the highest level only and ignore
// the other levels.
val failedValidationsForLevel = failedValidations.getOrElse(level, Nil)
if (failedValidationsForLevel.nonEmpty) {
val map = elementsToAnnotate.getOrElseUpdate(level, mutable.Map[Set[String], Element]())
map += (failedValidationsForLevel map (_.id) toSet) -> element
}
}
}
})
if (elementsToAnnotate.nonEmpty) {
val controls = xfcd.controls.getCurrentControlTree.effectiveIdsToControls
val relevantLevels = elementsToAnnotate.keySet
def controlsIterator: Iterator[XFormsSingleNodeControl] =
controls.iterator collect {
case (_, control: XFormsSingleNodeControl)
if control.isRelevant && control.alertLevel.toList.toSet.subsetOf(relevantLevels) => control
}
var annotated = false
def annotateElementIfPossible(control: XFormsSingleNodeControl): Unit = {
// NOTE: We check on the whole set of constraint ids. Since the control reads in all the failed
// constraints for the level, the sets of ids must match.
for {
level <- control.alertLevel
controlAlert <- Option(control.getAlert)
failedValidationsIds = control.failedValidations.map(_.id).toSet
elementsMap <- elementsToAnnotate.get(level)
element <- elementsMap.get(failedValidationsIds)
qName <- levelsToAnnotate.get(level)
} locally {
// There can be an existing attribute if more than one control bind to the same element
Option(element.attribute(qName)) match {
case Some(existing) => existing.setValue(existing.getValue + controlAlert)
case None => element.addAttribute(qName, controlAlert)
}
annotated = true
}
}
// Iterate all controls with warnings and try to annotate the associated element nodes
controlsIterator foreach annotateElementIfPossible
// If there is any annotation, make sure the attribute's namespace prefix is in scope on the root
// element
if (annotated)
addRootElementNamespace(doc)
}
}
def isSatisfiesValidity(
startNode : Node,
relevantHandling : RelevanceHandling)(implicit
indentedLogger : IndentedLogger
): Boolean =
findFirstElementOrAttributeWith(
startNode,
relevantHandling match {
case Keep | Remove => node => ! InstanceData.getValid(node)
case Empty => node => ! InstanceData.getValid(node) && InstanceData.getInheritedRelevant(node)
}
) match {
case Some(e: Element) =>
logInvalidNode(e)
false
case Some(a: Attribute) =>
logInvalidNode(a)
false
case Some(_) =>
throw new IllegalArgumentException
case None =>
true
}
def logInvalidNode(node: Node)(implicit indentedLogger: IndentedLogger): Unit =
if (indentedLogger.debugEnabled)
node match {
case e: Element =>
debug(
"found invalid node",
List("element name" -> e.toDebugString)
)
case a: Attribute =>
debug(
"found invalid attribute",
List(
"attribute name" -> a.toDebugString,
"parent element" -> a.getParent.toDebugString
)
)
case _ =>
throw new IllegalArgumentException
}
def requestedSerialization(
xformsSerialization : Option[String],
xformsMethod : String,
httpMethod : HttpMethod
): Option[String] =
xformsSerialization flatMap (_.trimAllToOpt) orElse defaultSerialization(xformsMethod, httpMethod)
def getRequestedSerialization(
xformsSerialization : Option[String],
xformsMethod : String,
httpMethod : HttpMethod
): Option[String] =
requestedSerialization(xformsSerialization, xformsMethod, httpMethod)
private object Private {
def defaultSerialization(xformsMethod: String, httpMethod: HttpMethod): Option[String] =
xformsMethod.trimAllToOpt collect {
case "multipart-post" => "multipart/related"
case "form-data-post" => "multipart/form-data"
case "urlencoded-post" => "application/x-www-form-urlencoded"
case _ if httpMethod == HttpMethod.POST || httpMethod == HttpMethod.PUT ||
httpMethod == HttpMethod.LOCK || httpMethod == HttpMethod.UNLOCK => ContentTypes.XmlContentType
case _ if httpMethod == HttpMethod.GET || httpMethod == HttpMethod.DELETE => "application/x-www-form-urlencoded"
}
def isLocallyNonRelevant(node: Node): Boolean =
! InstanceData.getLocalRelevant(node)
// NOTE: Optimize by not calling `getInheritedRelevant`, as we go from root to leaf. Also, we know
// that MIPs are not stored on `Document` and other nodes.
def isLocallyNonRelevantSupportAnnotation(attQname: QName): Node => Boolean = {
case e: Element => ! InstanceData.getLocalRelevant(e) || (e.attributeValueOpt(attQname) contains false.toString)
case a: Attribute => ! InstanceData.getLocalRelevant(a)
case _ => false
}
def pruneNonRelevantNodes(doc: Document, isLocallyNonRelevant: Node => Boolean): Unit = {
def processElement(e: Element): List[Node] =
if (isLocallyNonRelevant(e)) {
List(e)
} else {
e.attributes.filter(isLocallyNonRelevant) ++:
e.elements.toList.flatMap(processElement)
}
processElement(doc.getRootElement) foreach (_.detach())
}
def blankNonRelevantNodes(
doc : Document,
attsToPreserve : Set[QName],
isLocallyNonRelevant : Node => Boolean
): Unit = {
def processElement(e: Element, parentNonRelevant: Boolean): Unit = {
val elemNonRelevant = parentNonRelevant || isLocallyNonRelevant(e)
// NOTE: Make sure not to blank attributes corresponding to annotations if present!
e.attributeIterator filter
(a => ! attsToPreserve(a.getQName) && (elemNonRelevant || isLocallyNonRelevant(a))) foreach
(_.setValue(""))
if (e.containsElement)
e.elements foreach (processElement(_, elemNonRelevant))
else if (elemNonRelevant)
e.setText("")
}
processElement(doc.getRootElement, parentNonRelevant = false)
}
def annotateNonRelevantElements(
doc : Document,
relevantAnnotationAttQName : QName,
isNonRelevant : Node => Boolean
): Unit = {
def processElem(e: Element): Unit =
if (isNonRelevant(e)) {
e.addAttribute(relevantAnnotationAttQName, false.toString)
removeNestedAnnotations(e, relevantAnnotationAttQName, includeSelf = false)
} else {
e.removeAttribute(relevantAnnotationAttQName)
e.elements foreach processElem
}
processElem(doc.getRootElement)
}
def removeNestedAnnotations(startElem: Element, attQname: QName, includeSelf: Boolean): Unit = {
def processElem(e: Element): Unit = {
e.removeAttribute(attQname)
e.elements foreach processElem
}
if (includeSelf)
processElem(startElem)
else
startElem.elements foreach processElem
}
def findFirstElementOrAttributeWith(startNode: Node, check: Node => Boolean): Option[Node] = {
val breaks = new scala.util.control.Breaks
import breaks._
var foundNode: Node = null
tryBreakable[Option[Node]] {
startNode.accept(
new VisitorSupport {
override def visit(element: Element) : Unit = checkNodeAndBreakIfFail(element)
override def visit(attribute: Attribute): Unit = checkNodeAndBreakIfFail(attribute)
def checkNodeAndBreakIfFail(node: Node): Unit =
if (check(node)) {
foundNode = node
break()
}
}
)
None
} catchBreak {
Some(foundNode)
}
}
def addRootElementNamespace(doc: Document): Unit =
doc.getRootElement.addNamespace(XXFORMS_NAMESPACE_SHORT.prefix, XXFORMS_NAMESPACE_SHORT.uri)
}
} | orbeon/orbeon-forms | xforms-runtime/shared/src/main/scala/org/orbeon/oxf/xforms/submission/XFormsModelSubmissionSupport.scala | Scala | lgpl-2.1 | 18,367 |
package spark
import org.scalatest.FunSuite
import akka.actor._
import spark.scheduler.MapStatus
import spark.storage.BlockManagerId
import spark.util.AkkaUtils
class MapOutputTrackerSuite extends FunSuite with LocalSparkContext {
test("compressSize") {
assert(MapOutputTracker.compressSize(0L) === 0)
assert(MapOutputTracker.compressSize(1L) === 1)
assert(MapOutputTracker.compressSize(2L) === 8)
assert(MapOutputTracker.compressSize(10L) === 25)
assert((MapOutputTracker.compressSize(1000000L) & 0xFF) === 145)
assert((MapOutputTracker.compressSize(1000000000L) & 0xFF) === 218)
// This last size is bigger than we can encode in a byte, so check that we just return 255
assert((MapOutputTracker.compressSize(1000000000000000000L) & 0xFF) === 255)
}
test("decompressSize") {
assert(MapOutputTracker.decompressSize(0) === 0)
for (size <- Seq(2L, 10L, 100L, 50000L, 1000000L, 1000000000L)) {
val size2 = MapOutputTracker.decompressSize(MapOutputTracker.compressSize(size))
assert(size2 >= 0.99 * size && size2 <= 1.11 * size,
"size " + size + " decompressed to " + size2 + ", which is out of range")
}
}
test("master start and stop") {
val actorSystem = ActorSystem("test")
val tracker = new MapOutputTracker()
tracker.trackerActor = actorSystem.actorOf(Props(new MapOutputTrackerActor(tracker)))
tracker.stop()
}
test("master register and fetch") {
val actorSystem = ActorSystem("test")
val tracker = new MapOutputTracker()
tracker.trackerActor = actorSystem.actorOf(Props(new MapOutputTrackerActor(tracker)))
tracker.registerShuffle(10, 2)
val compressedSize1000 = MapOutputTracker.compressSize(1000L)
val compressedSize10000 = MapOutputTracker.compressSize(10000L)
val size1000 = MapOutputTracker.decompressSize(compressedSize1000)
val size10000 = MapOutputTracker.decompressSize(compressedSize10000)
tracker.registerMapOutput(10, 0, new MapStatus(BlockManagerId("a", "hostA", 1000, 0),
Array(compressedSize1000, compressedSize10000)))
tracker.registerMapOutput(10, 1, new MapStatus(BlockManagerId("b", "hostB", 1000, 0),
Array(compressedSize10000, compressedSize1000)))
val statuses = tracker.getServerStatuses(10, 0)
assert(statuses.toSeq === Seq((BlockManagerId("a", "hostA", 1000, 0), size1000),
(BlockManagerId("b", "hostB", 1000, 0), size10000)))
tracker.stop()
}
test("master register and unregister and fetch") {
val actorSystem = ActorSystem("test")
val tracker = new MapOutputTracker()
tracker.trackerActor = actorSystem.actorOf(Props(new MapOutputTrackerActor(tracker)))
tracker.registerShuffle(10, 2)
val compressedSize1000 = MapOutputTracker.compressSize(1000L)
val compressedSize10000 = MapOutputTracker.compressSize(10000L)
val size1000 = MapOutputTracker.decompressSize(compressedSize1000)
val size10000 = MapOutputTracker.decompressSize(compressedSize10000)
tracker.registerMapOutput(10, 0, new MapStatus(BlockManagerId("a", "hostA", 1000, 0),
Array(compressedSize1000, compressedSize1000, compressedSize1000)))
tracker.registerMapOutput(10, 1, new MapStatus(BlockManagerId("b", "hostB", 1000, 0),
Array(compressedSize10000, compressedSize1000, compressedSize1000)))
// As if we had two simulatenous fetch failures
tracker.unregisterMapOutput(10, 0, BlockManagerId("a", "hostA", 1000, 0))
tracker.unregisterMapOutput(10, 0, BlockManagerId("a", "hostA", 1000, 0))
// The remaining reduce task might try to grab the output despite the shuffle failure;
// this should cause it to fail, and the scheduler will ignore the failure due to the
// stage already being aborted.
intercept[FetchFailedException] { tracker.getServerStatuses(10, 1) }
}
test("remote fetch") {
val hostname = "localhost"
val (actorSystem, boundPort) = AkkaUtils.createActorSystem("spark", hostname, 0)
System.setProperty("spark.driver.port", boundPort.toString) // Will be cleared by LocalSparkContext
System.setProperty("spark.hostPort", hostname + ":" + boundPort)
val masterTracker = new MapOutputTracker()
masterTracker.trackerActor = actorSystem.actorOf(
Props(new MapOutputTrackerActor(masterTracker)), "MapOutputTracker")
val (slaveSystem, _) = AkkaUtils.createActorSystem("spark-slave", hostname, 0)
val slaveTracker = new MapOutputTracker()
slaveTracker.trackerActor = slaveSystem.actorFor(
"akka://spark@localhost:" + boundPort + "/user/MapOutputTracker")
masterTracker.registerShuffle(10, 1)
masterTracker.incrementGeneration()
slaveTracker.updateGeneration(masterTracker.getGeneration)
intercept[FetchFailedException] { slaveTracker.getServerStatuses(10, 0) }
val compressedSize1000 = MapOutputTracker.compressSize(1000L)
val size1000 = MapOutputTracker.decompressSize(compressedSize1000)
masterTracker.registerMapOutput(10, 0, new MapStatus(
BlockManagerId("a", "hostA", 1000, 0), Array(compressedSize1000)))
masterTracker.incrementGeneration()
slaveTracker.updateGeneration(masterTracker.getGeneration)
assert(slaveTracker.getServerStatuses(10, 0).toSeq ===
Seq((BlockManagerId("a", "hostA", 1000, 0), size1000)))
masterTracker.unregisterMapOutput(10, 0, BlockManagerId("a", "hostA", 1000, 0))
masterTracker.incrementGeneration()
slaveTracker.updateGeneration(masterTracker.getGeneration)
intercept[FetchFailedException] { slaveTracker.getServerStatuses(10, 0) }
// failure should be cached
intercept[FetchFailedException] { slaveTracker.getServerStatuses(10, 0) }
}
}
| baeeq/incubator-spark | core/src/test/scala/spark/MapOutputTrackerSuite.scala | Scala | bsd-3-clause | 5,713 |
/**
* Copyright 2015 Thomson Reuters
*
* Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
* an “AS IS” BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
*
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package cmwell.tools.data.sparql
import java.nio.file.Paths
import java.time.{Instant, LocalDateTime, ZoneId}
import akka.actor.{Actor, ActorRef, ActorSystem, Cancellable, PoisonPill, Status}
import akka.pattern._
import akka.stream._
import akka.stream.scaladsl._
import akka.util.Timeout
import cmwell.ctrl.checkers.StpChecker.{RequestStats, ResponseStats, Row, Table}
import cmwell.tools.data.ingester._
import cmwell.tools.data.sparql.InfotonReporter.{RequestDownloadStats, ResponseDownloadStats}
import cmwell.tools.data.sparql.SparqlProcessorManager._
import cmwell.tools.data.utils.akka._
import cmwell.tools.data.utils.chunkers.GroupChunker
import cmwell.tools.data.utils.chunkers.GroupChunker._
import cmwell.util.http.SimpleResponse
import cmwell.util.string.Hash
import cmwell.util.http.SimpleResponse.Implicits.UTF8StringHandler
import cmwell.util.concurrent._
import com.typesafe.scalalogging.LazyLogging
import k.grid.GridReceives
import net.jcazevedo.moultingyaml._
import org.apache.commons.lang3.time.DurationFormatUtils
import io.circe.Json
import scala.concurrent.{ExecutionContext, Future}
import scala.concurrent.duration.{FiniteDuration, _}
import scala.util.{Failure, Success, Try}
import ExecutionContext.Implicits.global
case class Job(name: String, config: Config) {
val jobString = {
val sensors = config.sensors.map(_.name).mkString(", ")
s"[job: $name, config name:${config.name}, sensors: $sensors]"
}
override def toString: String = jobString
}
case class JobRead(job: Job, active: Boolean)
case class StartJob(job: JobRead)
case class JobHasFailed(job: Job, ex: Throwable)
case class JobHasFinished(job: Job)
case class PauseJob(job: Job)
case class StopAndRemoveJob(job: Job)
case object CheckConfig
case class AnalyzeReceivedJobs(jobsRead: Set[JobRead])
sealed trait JobStatus {
val statusString : String
val job: Job
val canBeRestarted: Boolean = false
}
sealed trait JobActive extends JobStatus {
val reporter: ActorRef
}
case class JobRunning(job: Job, killSwitch: KillSwitch, reporter: ActorRef) extends JobActive {
override val statusString = "Running"
}
case class JobPausing(job: Job, killSwitch: KillSwitch, reporter: ActorRef) extends JobActive {
override val statusString = "Pausing"
}
case class JobStopping(job: Job, killSwitch: KillSwitch, reporter: ActorRef) extends JobActive {
override val statusString: String = "Stopping"
}
case class JobFailed(job: Job, ex: Throwable) extends JobStatus {
override val statusString = "Failed"
override val canBeRestarted = true
}
case class JobPaused(job: Job) extends JobStatus {
override val canBeRestarted = true
override val statusString = "Paused"
}
object SparqlProcessorManager {
val name = "sparql-triggered-processor-manager"
private val formatter = java.text.NumberFormat.getNumberInstance
val client = cmwell.util.http.SimpleHttpClient
}
class SparqlProcessorManager (settings: SparqlProcessorManagerSettings) extends Actor with LazyLogging {
type Jobs = Map[String, JobStatus]
//todo: should we use injected ec??? implicit val ec = context.dispatcher
implicit val system: ActorSystem = context.system
implicit val mat = ActorMaterializer()
if (mat.isInstanceOf[ActorMaterializer]) {
require(mat.asInstanceOf[ActorMaterializer].system eq context.system, "ActorSystem of materializer MUST be the same as the one used to create current actor")
}
var currentJobs: Jobs = Map.empty
var configMonitor: Cancellable = _
override def preStart(): Unit = {
logger.info("starting sparql-processor manager instance on this machine")
configMonitor = context.system.scheduler.schedule(settings.initDelay, settings.interval, self, CheckConfig)
}
override def receive: Receive = {
import akka.pattern._
GridReceives.monitoring(sender).orElse {
case RequestStats => stringifyActiveJobs(currentJobs).map(ResponseStats.apply) pipeTo sender()
case CheckConfig => getJobConfigsFromTheUser.map(AnalyzeReceivedJobs.apply) pipeTo self
case AnalyzeReceivedJobs(jobsReceived) => handleReceivedJobs(jobsReceived, currentJobs)
case Status.Failure(e) => logger.warn("Received Status failure ", e)
case StartJob(job) => handleStartJob(job)
case JobHasFinished(job: Job) => handleJobHasFinished(job)
case JobHasFailed(job: Job, ex: Throwable) => handleJobHasFailed(job, ex)
case PauseJob(job: Job) => handlePauseJob(job)
case StopAndRemoveJob(job: Job) => handleStopAndRemoveJob(job)
case other => logger.error(s"received unexpected message: $other")
}
}
/**
* This method MUST be run from the actor's thread (it changes the actor state)!
* @param job
*/
def handleJobHasFinished(job: Job): Unit = {
currentJobs.get(job.name).fold {
logger.error(s"Got finished signal for job $job that doesn't exist in the job map. Not reasonable! Current job in map are: ${currentJobs.keys.mkString(",")}")
} {
case JobPausing(runningJob, _, _) =>
logger.info(s"Job $runningJob has finished. Saving the job state.")
currentJobs = currentJobs + (job.name -> JobPaused(runningJob))
case JobStopping(runningJob, _, _) =>
logger.info(s"Job $runningJob has finished. Removing the job from the job list.")
currentJobs = currentJobs - runningJob.name
case other =>
logger.error(s"Got finished signal for jog $job but the actual state in current jobs is $other. Not reasonable!")
currentJobs = currentJobs - job.name
}
}
/**
* This method MUST be run from the actor's thread (it changes the actor state)!
* @param job
* @param ex
*/
def handleJobHasFailed(job: Job, ex: Throwable): Unit = {
currentJobs.get(job.name).fold {
logger.error(s"Got failed signal for job $job that doesn't exist in the job map. Not reasonable! Current job in map are: ${currentJobs.keys.mkString(",")}")
} {
case _: JobRunning | _: JobPausing | _:JobStopping =>
logger.info(s"Job $job has failed. Saving the job failure in current jobs.")
currentJobs = currentJobs + (job.name -> JobFailed(job, ex))
case other =>
logger.error(s"Got failed signal for jog $job but the actual state in current jobs is $other. Not reasonable!")
currentJobs = currentJobs - job.name
}
}
/**
* This method MUST be run from the actor's thread (it changes the actor state)!
* @param job
*/
def handlePauseJob(job: Job): Unit = {
currentJobs.get(job.name).fold {
logger.error(s"Got pause request for job $job that doesn't exist in the job map. Not reasonable! Current job in map are: ${currentJobs.keys.mkString(",")}")
} {
case JobRunning(runningJob, killSwitch, reporter) =>
logger.info(s"Pausing job $runningJob. The job will actually pause only after it will finish all its current operations")
currentJobs = currentJobs + (job.name -> JobPausing(job, killSwitch, reporter))
killSwitch.shutdown()
case other =>
logger.error(s"Got pause request for jog $job but the actual state in current jobs is $other. Not reasonable!")
}
}
/**
* This method MUST be run from the actor's thread (it changes the actor state)!
* @param job
*/
def handleStopAndRemoveJob(job: Job): Unit = {
currentJobs.get(job.name).fold {
logger.error(s"Got stop and remove request for job $job that doesn't exist in the job map. Not reasonable! Current job in map are: ${currentJobs.keys.mkString(",")}")
} {
case JobRunning(runningJob, killSwitch, reporter) =>
logger.info(s"Stopping job $runningJob. The job will actually stopped only after it will finish all its current operations")
currentJobs = currentJobs + (job.name -> JobStopping(job, killSwitch, reporter))
killSwitch.shutdown()
case JobFailed(failedJob, _) =>
logger.info(s"Stopping job $failedJob. The job has already failed. Removing it from the job list.")
currentJobs = currentJobs - job.name
case JobPaused(pausedJob) =>
logger.info(s"Stopping job $pausedJob. The job is currently paused. Removing it from the job list.")
currentJobs = currentJobs - job.name
case other =>
logger.error(s"Got stop and remove request for jog $job but the actual state in current jobs is $other. Not reasonable!")
}
}
def shouldStartJob(currentJobs: Map[String, JobStatus])(jobRead: JobRead): Boolean = {
jobRead.active && currentJobs.get(jobRead.job.name).fold(true)(_.canBeRestarted)
}
def handleReceivedJobs(jobsRead: Set[JobRead], currentJobs: Map[String, JobStatus]): Unit = {
//jobs to start
val jobsToStart = jobsRead.filter(shouldStartJob(currentJobs))
jobsToStart.foreach { jobRead =>
logger.info(s"Got start request for job ${jobRead.job} from the user")
self ! StartJob(jobRead)
}
//jobs to pause or to totally remove
currentJobs.foreach{
case (currentJobName, currentJob@(_: JobRunning | _: JobFailed | _: JobPaused)) if !jobsRead.exists(_.job.name == currentJobName) =>
logger.info(s"Got stop and remove request for job ${currentJob.job} from the user")
self ! StopAndRemoveJob(currentJob.job)
case (currentJobName, jobRunning: JobRunning) if !jobsRead.find(_.job.name == currentJobName).get.active =>
logger.info(s"Got pause request for job ${jobRunning.job} from the user")
self ! PauseJob(jobRunning.job)
case _ => //nothing to do on other cases
}
}
/**
* Generates data for tables in cm-well monitor page
*/
def stringifyActiveJobs(jobs: Jobs): Future[Iterable[Table]] = {
implicit val timeout = Timeout(1.minute)
def generateNonActiveTables(jobs: Jobs) = jobs.collect { case (path, jobStatus@(_: JobPaused | _:JobFailed)) =>
val (colour, status) = jobStatus match {
case jobFailed@(_:JobFailed) =>
("red","Exception : " + jobFailed.ex.getMessage)
case _: JobPaused =>
("green", "No exceptions reported")
}
val sensorNames = jobStatus.job.config.sensors.map(_.name)
val title = Seq(s"""<span style="color:${colour}"> **Non-Active - ${jobStatus.statusString} ** </span> ${path} <br/><span style="color:${colour}">${status}</span>""")
val header = Seq("Sensor", "Token Time")
StpUtil.readPreviousTokens(settings.hostConfigFile, settings.pathAgentConfigs + "/" + path, "ntriples").map { storedTokens =>
val pathsWithoutSavedToken = sensorNames.toSet diff storedTokens.keySet
val allSensorsWithTokens = storedTokens ++ pathsWithoutSavedToken.map(_ -> "")
val body : Iterable[Row] = allSensorsWithTokens.map { case (sensorName, token) =>
val decodedToken = if (token.nonEmpty) {
val from = cmwell.tools.data.utils.text.Tokens.getFromIndexTime(token)
LocalDateTime.ofInstant(Instant.ofEpochMilli(from), ZoneId.systemDefault()).toString
}
else ""
Seq(sensorName, decodedToken)
}
Table(title = title, header = header, body = body)
}
}
def generateActiveTables(jobs: Jobs) = jobs.collect { case (path, jobStatus@(_: JobActive)) =>
val jobConfig = jobStatus.job.config
val title = Seq(s"""<span style="color:green"> **${jobStatus.statusString}** </span> ${path}""")
val header = Seq("Sensor", "Token Time", "Received Infotons", "Infoton Rate", "Statistics Updated")
val statsFuture = (jobStatus.reporter ? RequestDownloadStats).mapTo[ResponseDownloadStats]
val storedTokensFuture = (jobStatus.reporter ? RequestPreviousTokens).mapTo[ResponseWithPreviousTokens]
for {
statsRD <- statsFuture
stats = statsRD.stats
storedTokensRWPT <- storedTokensFuture
storedTokens = storedTokensRWPT.tokens
} yield {
val sensorNames = jobConfig.sensors.map(_.name)
val pathsWithoutSavedToken = sensorNames.toSet diff storedTokens.keySet
val allSensorsWithTokens = storedTokens ++ pathsWithoutSavedToken.map(_ -> "")
val body : Iterable[Row] = allSensorsWithTokens.map { case (sensorName, token) =>
val decodedToken = if (token.nonEmpty) {
val from = cmwell.tools.data.utils.text.Tokens.getFromIndexTime(token)
LocalDateTime.ofInstant(Instant.ofEpochMilli(from), ZoneId.systemDefault()).toString
}
else ""
val sensorStats = stats.get(sensorName).map { s =>
val statsTime = s.statsTime match {
case 0 => "Not Yet Updated"
case _ => LocalDateTime.ofInstant(Instant.ofEpochMilli(s.statsTime), ZoneId.systemDefault()).toString
}
Seq(s.receivedInfotons.toString, s"${formatter.format(s.infotonRate)}/sec", statsTime)
}.getOrElse(Seq.empty[String])
Seq(sensorName, decodedToken) ++ sensorStats
}
val configName = Paths.get(path).getFileName
val sparqlMaterializerStats = stats.get(s"$configName-${SparqlTriggeredProcessor.sparqlMaterializerLabel}").map { s =>
val totalRunTime = DurationFormatUtils.formatDurationWords(s.runningTime, true, true)
s"""Materialized <span style="color:green"> **${s.receivedInfotons}** </span> infotons [$totalRunTime]""".stripMargin
}.getOrElse("")
Table(title = title :+ sparqlMaterializerStats, header = header, body = body)
}
}
Future.sequence{
generateActiveTables(jobs) ++ generateNonActiveTables(jobs)
}
}
/**
* This method MUST be run from the actor's thread (it changes the actor state)!
* @param jobRead
*/
def handleStartJob(jobRead: JobRead): Unit = {
val job = jobRead.job
//this method MUST BE RUN from the actor's thread and changing the state is allowed. the below will replace any existing state.
//The state is changed instantly and every change that follows (even from another thread/Future) will be later.
val tokenReporter = context.actorOf(
props = InfotonReporter(baseUrl = settings.hostConfigFile, path = settings.pathAgentConfigs + "/" + job.name),
name = s"${job.name}-${Hash.crc32(job.config.toString)}"
)
val hostUpdatesSource = job.config.hostUpdatesSource.getOrElse(settings.hostUpdatesSource)
val agent = SparqlTriggeredProcessor.listen(job.config, hostUpdatesSource, false, Some(tokenReporter), Some(job.name))
.map { case (data, _) => data }
.via(GroupChunker(formatToGroupExtractor(settings.materializedViewFormat)))
.map(concatByteStrings(_, endl))
val (killSwitch, jobDone) = Ingester.ingest(baseUrl = settings.hostWriteOutput,
format = settings.materializedViewFormat,
source = agent,
force = job.config.force.getOrElse(false),
label = Some(s"ingester-${job.name}"))
.viaMat(KillSwitches.single)(Keep.right)
.toMat(Sink.ignore)(Keep.both)
.run()
currentJobs = currentJobs + (job.name -> JobRunning(job, killSwitch, tokenReporter))
logger.info(s"starting job $job")
jobDone.onComplete {
case Success(_) => {
logger.info(s"job: $job finished successfully")
//The stream has already finished - kill the token actor
tokenReporter ! PoisonPill
self ! JobHasFinished(job)
}
case Failure(ex) => {
logger.error(s"job: $job finished with error (In case this job should be running it will be restarted on the next periodic check):", ex)
//The stream has already finished - kill the token actor
tokenReporter ! PoisonPill
self ! JobHasFailed(job, ex)
}
}
}
def getJobConfigsFromTheUser: Future[Set[JobRead]] = {
logger.info("Checking the current status of the Sparql Triggered Processor manager config infotons")
//val initialRetryState = RetryParams(2, 2.seconds, 1)
//retryUntil(initialRetryState)(shouldRetry("Getting config information from local cm-well")) {
safeFuture(
client.get(s"http://${settings.hostConfigFile}${settings.pathAgentConfigs}",
queryParams = List("op" -> "search", "with-data" -> "", "format" -> "json"))).
map(response => parseJobsJson(response.payload)).
andThen {
case Failure(ex) => logger.warn("Reading the config infotons failed. It will be checked on the next schedule check. The exception was: ", ex)
}
}
private[this] val parsedJsonsBreakOut = scala.collection.breakOut[Vector[Json], JobRead, Set[JobRead]]
def parseJobsJson(configJson: String): Set[JobRead] = {
import cats.syntax.either._
import io.circe._, io.circe.parser._
//This method is run from map of a future - no need for try/catch (=can throw exceptions here). Each exception will be mapped to a failed future.
val parsedJson = parse(configJson)
parsedJson match {
case Left(parseFailure@ParsingFailure(message, ex)) =>
logger.error(s"Parsing the agent config files failed with message: $message. Cancelling this configs check. It will be checked on the next iteration. The exception was: ", ex)
throw parseFailure
case Right(json) => {
try {
val infotons = json.hcursor.downField("results").downField("infotons").values.get
infotons.map { infotonJson =>
val name = infotonJson.hcursor.downField("system").get[String]("path").toOption.get.drop(settings.pathAgentConfigs.length + 1)
val configStr = infotonJson.hcursor.downField("content").get[String]("data").toOption.get
val configRead = yamlToConfig(configStr)
val modifiedSensors = configRead.sensors.map(sensor => sensor.copy(name = s"$name${sensor.name}"))
//The active field enables the user to disable the job. In case it isn't there, it's active.
val active = infotonJson.hcursor.downField("fields").downField("active").downArray.as[Boolean].toOption.getOrElse(true)
JobRead(Job(name, configRead.copy(sensors = modifiedSensors)), active)
}(parsedJsonsBreakOut)
}
catch {
case ex: Throwable =>
logger.warn(s"The manager failed to parse the json of the config infotons failed with exception! The json was: $json")
throw ex
}
}
}
}
def yamlToConfig(yaml: String): Config = {
// parse sensor configuration
object SensorYamlProtocol extends DefaultYamlProtocol {
implicit object DurationYamlFormat extends YamlFormat[FiniteDuration] {
override def write(obj: FiniteDuration): YamlValue = YamlObject(
YamlString("updateFreq") -> YamlString(obj.toString)
)
override def read(yaml: YamlValue): FiniteDuration = {
val d = Duration(yaml.asInstanceOf[YamlString].value)
FiniteDuration(d.length, d.unit)
}
}
implicit val sensorFormat = yamlFormat6(Sensor)
implicit val sequenceFormat = seqFormat[Sensor](sensorFormat)
implicit val configFormat = yamlFormat6(Config)
}
import SensorYamlProtocol._
import net.jcazevedo.moultingyaml._
val yamlConfig = yaml.parseYaml
yamlConfig.convertTo[Config]
}
override def postStop(): Unit = {
logger.warn(s"${this.getClass.getSimpleName} died, stopping all running jobs")
configMonitor.cancel()
currentJobs.collect {
case (_, job: JobRunning) => job
}.foreach { jobRunning =>
logger.info(s"Stopping job ${jobRunning.job} due to STP manager actor's death")
jobRunning.killSwitch.shutdown()
}
}
override def preRestart(reason: Throwable, message: Option[Any]): Unit = {
logger.error(s"Sparql triggered processor manager died during processing of $message. The exception was: ", reason)
super.preRestart(reason, message)
}
def shouldRetry(action: String): (Try[SimpleResponse[String]], RetryParams) => ShouldRetry[RetryParams] = {
import scala.language.implicitConversions
implicit def asFiniteDuration(d: Duration) = scala.concurrent.duration.Duration.fromNanos(d.toNanos);
{
//a successful post - don't retry
case (Success(simpleResponse), _) if simpleResponse.status == 200 => DoNotRetry
/*
//Currently, the shouldRetry function is used only to check the config - no need for special 503 treatment is will be retried anyway (and it can cause a bug the a current config check
//is still running while a new one will be started and a new one and so on...)
//The "contract" is that with 503 keep retrying indefinitely, but don't spam the server - increase the delay (cap it with a maxDelay)
case (Success(SimpleResponse(status, headers, body)), state) if status == 503 => {
logger.warn(s"$action failed. Cm-Well returned bad response: status: $status headers: ${StpUtil.headersString(headers)} body: $body. Will retry indefinitely on this error.")
RetryWith(state.copy(delay = (state.delay * state.delayFactor).min(settings.maxDelay)))
}
*/
case (Success(SimpleResponse(status, headers, body)), state) if state.retriesLeft == 0 => {
logger.error(s"$action failed. Cm-Well returned bad response: status: $status headers: ${StpUtil.headersString(headers)} body: $body. No more retries left, will fail the request!")
DoNotRetry
}
case (Success(SimpleResponse(status, headers, body)), state@RetryParams(retriesLeft, delay, delayFactor)) => {
val newDelay = delay * delayFactor
logger.warn(s"$action failed. Cm-Well returned bad response: status: $status headers: ${StpUtil.headersString(headers)} body: $body. $retriesLeft retries left. Will retry in $newDelay")
RetryWith(state.copy(delay = newDelay, retriesLeft = retriesLeft - 1))
}
case (Failure(ex), state) if state.retriesLeft == 0 => {
logger.error(s"$action failed. The HTTP request failed with an exception. No more retries left, will fail the request! The exception was: ", ex)
DoNotRetry
}
case (Failure(ex), state@RetryParams(retriesLeft, delay, delayFactor)) => {
val newDelay = delay * delayFactor
logger.warn(s"$action failed. The HTTP request failed with an exception. $retriesLeft retries left. Will retry in $newDelay. The exception was: ", ex)
RetryWith(state.copy(delay = newDelay, retriesLeft = retriesLeft - 1))
}
}
}
}
| nruppin/CM-Well | server/cmwell-sparql-agent/src/main/scala/cmwell/tools/data/sparql/SparqlProcessorManager.scala | Scala | apache-2.0 | 23,055 |
package com.atomist.rug.kind.core
/**
* Extended by files or sections of files (such as Java classes) to report size information.
*/
trait FileMetrics {
def lineCount: Int
}
object FileMetrics {
def lineCount(s: String): Int =
s.lines.size
} | atomist/rug | src/main/scala/com/atomist/rug/kind/core/FileMetrics.scala | Scala | gpl-3.0 | 257 |
package org.jetbrains.plugins.scala.debugger.positionManager
import com.intellij.debugger.SourcePosition
import com.intellij.openapi.vfs.VfsUtil
import com.intellij.psi.{PsiFile, PsiManager}
import com.sun.jdi.Location
import org.jetbrains.plugins.scala.debugger.{Loc, ScalaDebuggerTestCase, ScalaPositionManager}
import org.jetbrains.plugins.scala.extensions.inReadAction
import org.junit.Assert
import scala.jdk.CollectionConverters._
import scala.collection.mutable
import scala.collection.mutable.ArrayBuffer
/**
* @author Nikolay.Tropin
*/
abstract class PositionManagerTestBase extends ScalaDebuggerTestCase {
protected val offsetMarker = "<offset>"
protected val sourcePositionsOffsets = mutable.HashMap[String, Seq[Int]]()
protected def checkGetAllClassesInFile(fileName: String, mainClass: String = mainClassName)(expectedClassNames: String*): Unit = {
val sourcePositions = sourcePositionsInFile(fileName)
runDebugger(mainClass) {
waitForBreakpoint()
for ((position, className) <- sourcePositions.zip(expectedClassNames)) {
val classes = managed {
positionManager.getAllClasses(position)
}
val classNames = classes.asScala.map(_.name())
Assert.assertTrue(
s"Wrong classes are found at ${position.toString} (found: ${classNames.mkString(", ")}, expected: $className",
classNames.contains(className)
)
}
}
}
protected def checkGetAllClassesRunning(mainClass: String)(expectedClassNames: String*): Unit =
checkGetAllClassesInFile(mainFileName, mainClass)(expectedClassNames: _*)
protected def checkGetAllClasses(expectedClassNames: String*): Unit =
checkGetAllClassesRunning(mainClassName)(expectedClassNames: _*)
protected def checkLocationsOfLine(expectedLocations: Set[Loc]*): Unit =
checkLocationsOfLine(mainClassName, expectedLocations: _*)
protected def checkLocationsOfLine(mainClass: String, expectedLocations: Set[Loc]*): Unit = {
val sourcePositions = sourcePositionsInFile(mainFileName)
Assert.assertEquals("Wrong number of expected locations sets: ", sourcePositions.size, expectedLocations.size)
runDebugger(mainClass) {
waitForBreakpoint()
def checkSourcePosition(initialPosition: SourcePosition, location: Location): Unit = {
inReadAction {
val newPosition = positionManager.getSourcePosition(location)
Assert.assertEquals(initialPosition.getFile, newPosition.getFile)
Assert.assertEquals(initialPosition.getLine, newPosition.getLine)
}
}
for ((position, locationSet) <- sourcePositions.zip(expectedLocations)) {
val foundLocations: Set[Loc] = managed {
val classes = positionManager.getAllClasses(position)
val locations = classes.asScala.flatMap(refType => positionManager.locationsOfLine(refType, position).asScala)
locations.foreach(checkSourcePosition(position, _))
locations.map(toSimpleLocation).toSet
}
Assert.assertTrue(s"Wrong locations are found at ${position.toString} (found: $foundLocations, expected: $locationSet", locationSet.subsetOf(foundLocations))
}
}
}
private def toSimpleLocation(location: Location) = Loc(location.declaringType().name(), location.method().name(), location.lineNumber())
protected def setupFile(fileName: String, fileText: String, hasOffsets: Boolean = true): Unit = {
val breakpointLine = fileText.linesIterator.indexWhere(_.contains(bp))
var cleanedText = fileText.replace(bp, "").replace("\\r", "")
val offsets = ArrayBuffer[Int]()
var offset = cleanedText.indexOf(offsetMarker)
while (offset >= 0) {
offsets += offset
cleanedText = cleanedText.substring(0, offset) + cleanedText.substring(offset + offsetMarker.length)
offset = cleanedText.indexOf(offsetMarker)
}
assert(!hasOffsets || offsets.nonEmpty, s"Not specified offset marker in test case. Use $offsetMarker in provided text of the file.")
sourcePositionsOffsets += (fileName -> offsets.toSeq)
addSourceFile(fileName, cleanedText)
if (breakpointLine >= 0)
addBreakpoint(breakpointLine, fileName)
}
private def createLineSourcePositionFromOffset(file: PsiFile, offset: Int) = {
val fromOffset = SourcePosition.createFromOffset(file, offset)
SourcePosition.createFromLine(file, fromOffset.getLine)
}
private def sourcePositionsInFile(fileName: String) = inReadAction {
val psiManager = PsiManager.getInstance(getProject)
val vFile = VfsUtil.findFileByIoFile(getFileInSrc(fileName), false)
val psiFile = psiManager.findFile(vFile)
val offsets = sourcePositionsOffsets(fileName)
offsets.map(createLineSourcePositionFromOffset(psiFile, _))
}
} | JetBrains/intellij-scala | scala/scala-impl/test/org/jetbrains/plugins/scala/debugger/positionManager/PositionManagerTestBase.scala | Scala | apache-2.0 | 4,774 |
/*
* Copyright 2014 Treode, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.treode.disk
import scala.util.Random
class Stuff (val seed: Long, val items: Seq [Int]) {
override def equals (other: Any): Boolean =
other match {
case that: Stuff => seed == that.seed && items == that.items
case _ => false
}
override def toString = f"Stuff(0x${seed}%016X, 0x${items.hashCode}%08X)"
}
object Stuff {
val countLimit = 100
val valueLimit = Int.MaxValue
def apply (seed: Long): Stuff = {
val r = new Random (seed)
val xs = Seq.fill (r.nextInt (countLimit)) (r.nextInt (valueLimit))
new Stuff (seed, xs)
}
def apply (seed: Long, length: Int): Stuff = {
val r = new Random (seed)
val xs = Seq.fill (length) (r.nextInt (valueLimit))
new Stuff (seed, xs)
}
val pickler = {
import DiskPicklers._
wrap (ulong, seq (int))
.build (v => new Stuff (v._1, v._2))
.inspect (v => (v.seed, v.items))
}
val pager = PageDescriptor (0x26, Stuff.pickler)
}
| Treode/store | disk/test/com/treode/disk/Stuff.scala | Scala | apache-2.0 | 1,555 |
// Databricks notebook source exported at Tue, 23 Feb 2016 07:26:03 UTC
// MAGIC %md
// MAGIC # groupBy
// MAGIC Group the data in the original RDD. Create pairs where the key is the output of a user function, and the value is all items for which the function yield this key.
// MAGIC
// MAGIC Let us look at the [legend and overview of the visual RDD Api](/#workspace/scalable-data-science/xtraResources/visualRDDApi/guide).
// COMMAND ----------
// MAGIC %md
// MAGIC 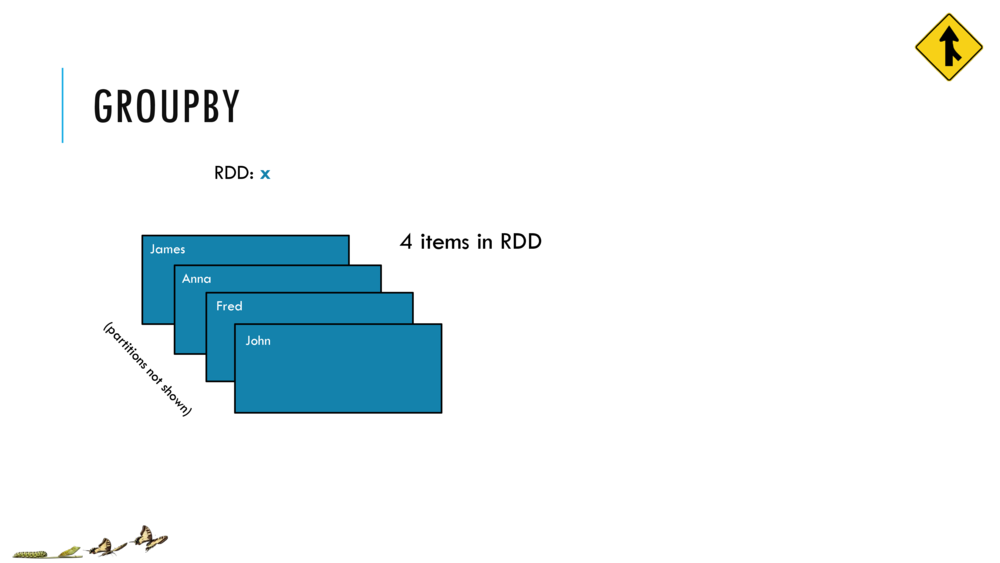
// COMMAND ----------
// MAGIC %md
// MAGIC 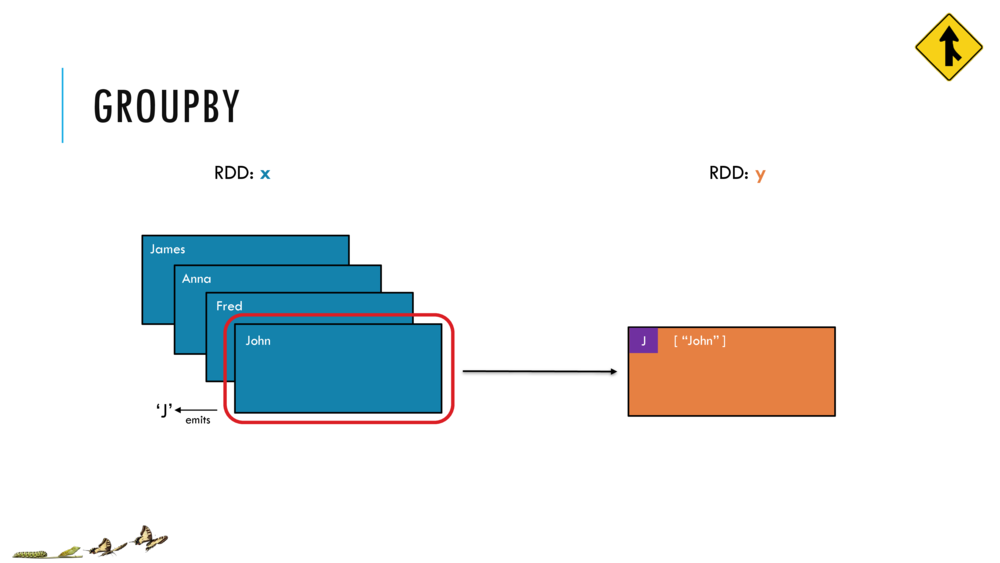
// COMMAND ----------
// MAGIC %md
// MAGIC 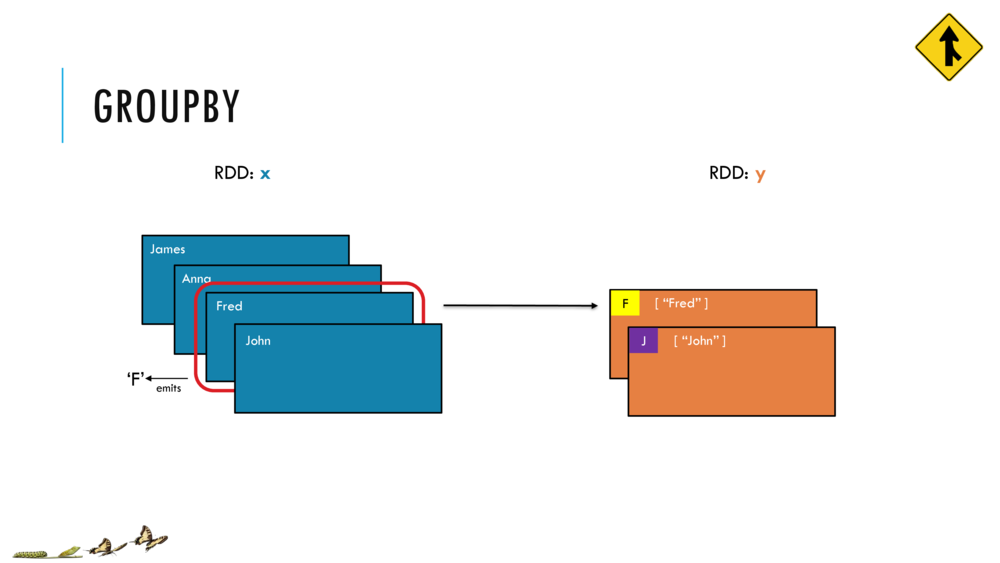
// COMMAND ----------
// MAGIC %md
// MAGIC 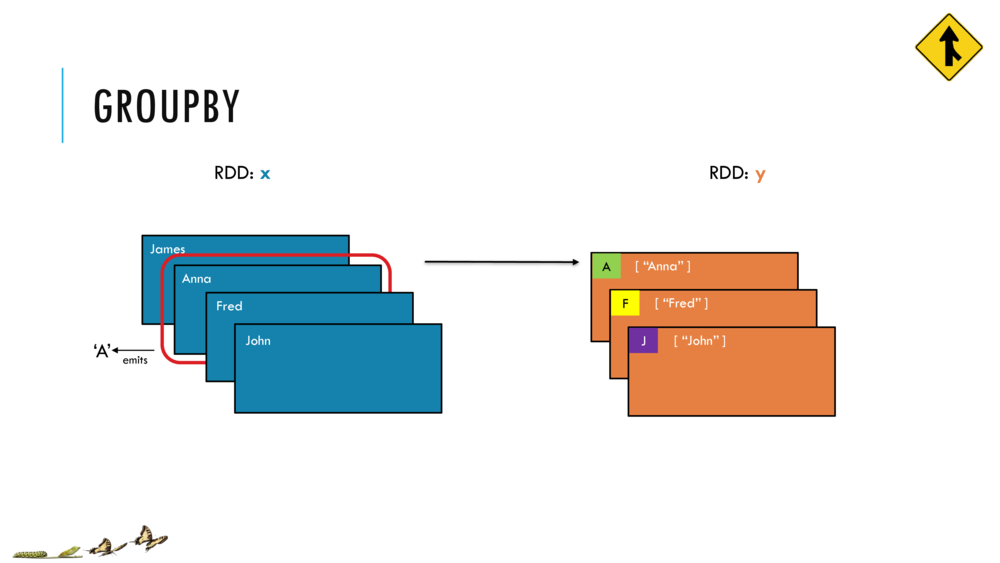
// COMMAND ----------
// MAGIC %md
// MAGIC 
// COMMAND ----------
// MAGIC %md
// MAGIC 
// COMMAND ----------
val x = sc.parallelize(Array("John", "Fred", "Anna", "James"))
val y = x.groupBy(w => w.charAt(0))
// COMMAND ----------
println(x.collect().mkString(", "))
println(y.collect().mkString(", "))
// COMMAND ----------
| raazesh-sainudiin/scalable-data-science | db/xtraResources/visualRDDApi/recall/transformations/groupBy.scala | Scala | unlicense | 1,667 |
/*
* Copyright 2013-2015 Websudos, Limited.
*
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* - Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
*
* - Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
*
* - Explicit consent must be obtained from the copyright owner, Websudos Limited before any redistribution is made.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
* POSSIBILITY OF SUCH DAMAGE.
*/
package com.websudos.phantom.builder.query.db.crud
import com.websudos.phantom.dsl._
import com.websudos.phantom.tables._
import com.websudos.phantom.testkit._
import com.websudos.util.testing._
class SetOperationsTest extends PhantomCassandraTestSuite {
override def beforeAll(): Unit = {
super.beforeAll()
TestTable.insertSchema()
}
it should "append an item to a set column" in {
val item = gen[TestRow]
val someItem = "test5"
val chain = for {
insertDone <- TestTable.store(item).future()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText add someItem).future()
db <- TestTable.select(_.setText).where(_.key eqs item.key).one()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe item.setText + someItem
}
}
}
it should "append an item to a set column with Twitter Futures" in {
val item = gen[TestRow]
val someItem = "test5"
val chain = for {
insertDone <- TestTable.store(item).execute()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText add someItem).execute()
db <- TestTable.select(_.setText).where(_.key eqs item.key).get()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe item.setText + someItem
}
}
}
it should "append several items to a set column" in {
val item = gen[TestRow]
val someItems = Set("test5", "test6")
val chain = for {
insertDone <- TestTable.store(item).future()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText addAll someItems).future()
db <- TestTable.select(_.setText).where(_.key eqs item.key).one()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe item.setText ++ someItems
}
}
}
it should "append several items to a set column with Twitter Futures" in {
val item = gen[TestRow]
val someItems = Set("test5", "test6")
val chain = for {
insertDone <- TestTable.store(item).execute()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText addAll someItems).execute()
db <- TestTable.select(_.setText).where(_.key eqs item.key).get()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe item.setText ++ someItems
}
}
}
it should "remove an item from a set column" in {
val someItems = Set("test3", "test4", "test5", "test6")
val item = gen[TestRow].copy(setText = someItems)
val removal = "test6"
val chain = for {
insertDone <- TestTable.store(item).future()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText remove removal).future()
db <- TestTable.select(_.setText).where(_.key eqs item.key).one()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe someItems.diff(Set(removal))
}
}
}
it should "remove an item from a set column with Twitter Futures" in {
val someItems = Set("test3", "test4", "test5", "test6")
val item = gen[TestRow].copy(setText = someItems)
val removal = "test6"
val chain = for {
insertDone <- TestTable.store(item).execute()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText remove removal).execute()
db <- TestTable.select(_.setText).where(_.key eqs item.key).get()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe someItems.diff(Set(removal))
}
}
}
it should "remove several items from a set column" in {
val someItems = Set("test3", "test4", "test5", "test6")
val item = gen[TestRow].copy(setText = someItems)
val removal = Set("test5", "test6")
val chain = for {
insertDone <- TestTable.store(item).future()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText removeAll removal).future()
db <- TestTable.select(_.setText).where(_.key eqs item.key).one()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe someItems.diff(removal)
}
}
}
it should "remove several items from a set column with Twitter Futures" in {
val someItems = Set("test3", "test4", "test5", "test6")
val item = gen[TestRow].copy(setText = someItems)
val removal = Set("test5", "test6")
val chain = for {
insertDone <- TestTable.store(item).execute()
update <- TestTable.update.where(_.key eqs item.key).modify(_.setText removeAll removal).execute()
db <- TestTable.select(_.setText).where(_.key eqs item.key).get()
} yield db
chain.successful {
items => {
items.isDefined shouldBe true
items.get shouldBe someItems.diff(removal)
}
}
}
}
| nkijak/phantom | phantom-dsl/src/test/scala/com/websudos/phantom/builder/query/db/crud/SetOperationsTest.scala | Scala | bsd-2-clause | 6,515 |
package com.productfoundry.akka.cqrs.process
import com.productfoundry.akka.cqrs.EntityIdResolution
import scala.reflect.ClassTag
/**
* Simplifies registration of process managers
*/
abstract class ProcessManagerCompanion[P <: ProcessManager[_, _]: ClassTag] {
/**
* Name of the process manager, based on class name
*/
val name = implicitly[ClassTag[P]].runtimeClass.getSimpleName
/**
* Defines how to resolve ids for this process manager.
*
* Allows correlation of events for a process. The process manager will receive any event that resolves to an id.
* @return id to correlate events.
*/
def idResolution: EntityIdResolution[P]
implicit val ProcessManagerCompanionObject: ProcessManagerCompanion[P] = this
}
| odd/akka-cqrs | core/src/main/scala/com/productfoundry/akka/cqrs/process/ProcessManagerCompanion.scala | Scala | apache-2.0 | 751 |
package gsn.meta.wiki
import org.scalatest.FunSpec
import org.scalatest.Matchers
import scala.concurrent.ExecutionContext
import scala.concurrent.Await
import concurrent.duration._
import es.upm.fi.oeg.morph.relational.RelationalModel
import java.sql.ResultSet
class QueryTest extends FunSpec with Matchers {
describe("Query all fieldsites on wiki"){
implicit val context = ExecutionContext.Implicits.global
val qm=new QueryManager("http://www.swiss-experiment.ch/")
ignore ("should parse sites"){
val fsites=qm.getSites
fsites.onComplete {a=>
println("finished")
}
println("now wait")
while (!fsites.isCompleted){
}
}
it("should get titles"){
val titlesFut=qm.getMemberTitles("Category:Measurement Record")
val titles=Await.result(titlesFut,10 seconds)
println("the number of titles: " +titles.size)
}
}
}
| jpcik/gsn-metadata | src/test/scala/gsn/meta/wiki/QueryTest.scala | Scala | apache-2.0 | 916 |
/*
* Copyright ActionML, LLC under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* ActionML licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.actionml.engines.urnavhinting
import cats.data.Validated
import cats.data.Validated.{Invalid, Valid}
import com.actionml.core.BadParamsException
import com.actionml.core.engine.Dataset
import com.actionml.core.model.{Comment, Response}
import com.actionml.core.store.{DAO, DaoQuery, Store}
import com.actionml.core.validate._
import com.actionml.engines.ur.URDataset
import com.actionml.engines.ur.UREngine.UREvent
import com.actionml.engines.urnavhinting.URNavHintingAlgorithm.{DefaultURAlgoParams, URAlgorithmParams}
import com.actionml.engines.urnavhinting.URNavHintingEngine.{ItemProperties, URNavHintingEvent}
import scala.concurrent.Future
import scala.language.reflectiveCalls
/** Scaffold for a Dataset, does nothing but is a good starting point for creating a new Engine
* Extend with the store of choice, like Mongo or other Store trait.
* This is not the minimal Template because many methods are implemented generically in the
* base classes but is better used as a starting point for new Engines.
*
* @param engineId The Engine ID
*/
class URNavHintingDataset(engineId: String, val store: Store, val noSharedDb: Boolean = true)
extends Dataset[URNavHintingEvent](engineId) with JsonSupport {
// todo: make sure to index the timestamp for descending ordering, and the name field for filtering
private val activeJourneysDao = store.createDao[URNavHintingEvent]("active_journeys")
private val indicatorsDao = store.createDao[URNavHintingEvent]("indicator_events")
// This holds a place for any properties that should go into the model at training time
private val esIndex = store.dbName // index and db name should be the same
private val esType = DefaultURAlgoParams.ModelType
private val itemsDao = store.createDao[ItemProperties](esType) // the _id can be the name, it should be unique and indexed
def getItemsDbName = esIndex
def getItemsCollectionName = esType
def getIndicatorEventsCollectionName = "indicator_events"
def getItemsDao = itemsDao
def getActiveJourneysDao = activeJourneysDao
def getIndicatorsDao = indicatorsDao
private var params: URAlgorithmParams = _
// we assume the findMany of event names is in the params if not the config is rejected by some earlier stage since
// this is not calculated until an engine is created with the config and taking input
private var indicatorNames: Seq[String] = _
// These should only be called from trusted source like the CLI!
override def init(jsonConfig: String, deepInit: Boolean = true): Validated[ValidateError, Response] = {
parseAndValidate[URAlgorithmParams](
jsonConfig,
errorMsg = s"Error in the Algorithm part of the JSON config for engineId: $engineId, which is: " +
s"$jsonConfig",
transform = _ \\ "algorithm").andThen { p =>
params = p
indicatorNames = if(params.indicators.isEmpty) {
if(params.eventNames.isEmpty) {
// yikes both empty so error so bad we can't init!
throw BadParamsException("No indicator or eventNames in the config JSON file")
} else {
params.eventNames.get
}
} else {
params.indicators.get.map(_.name)
}
Valid(p)
}
Valid(Comment("URNavHintingDataset initialized"))
}
/** Cleanup all persistent data or processes created by the Dataset */
override def destroy(): Unit = {
// todo: Yikes this cannot be used with the sharedDb or all data from all engines will be dropped!!!!!
// must drop only the data from collections
if(noSharedDb) store.drop // todo: should do references counting and drop on last reference??? Maybe not
}
// Parse, validate, drill into the different derivative event types, andThen(persist)?
override def input(jsonEvent: String): Validated[ValidateError, URNavHintingEvent] = {
import DaoQuery.syntax._
parseAndValidate[URNavHintingEvent](jsonEvent, errorMsg = s"Invalid URNavHintingEvent JSON: $jsonEvent").andThen { event =>
if (indicatorNames.contains(event.event)) { // only store the indicator events here
// todo: make sure to index the timestamp for descending ordering, and the name field for filtering
if (indicatorNames.head == event.event && event.properties.get("conversion").isDefined) {
// this handles a conversion
if(event.properties.getOrElse("conversion", false)) {
// a conversion nav-event means that the active journey keyed to the user gets moved to the indicatorsDao
val conversionJourney = activeJourneysDao.findMany("entityId" === event.entityId).toSeq
if(conversionJourney.size != 0) {
val taggedConvertedJourneys = conversionJourney.map(e => e.copy(conversionId = event.targetEntityId))
// tag these so they can be removed when the model is $deleted
indicatorsDao.insertMany(taggedConvertedJourneys)
activeJourneysDao.removeMany("entityId" === event.entityId)
}
Valid(event)
} else {
// save in journeys until a conversion happens
try {
activeJourneysDao.insert(event)
Valid(event)
} catch {
case e: Throwable =>
logger.error(s"Can't save input $jsonEvent", e)
Invalid(ValidRequestExecutionError(e.getMessage))
}
}
} else { // must be secondary indicator so no conversion, but accumulate in journeys
try {
activeJourneysDao.insert(event)
Valid(event)
} catch {
case e: Throwable =>
logger.error(s"Can't save input $jsonEvent", e)
Invalid(ValidRequestExecutionError(e.getMessage))
}
}
} else { // not an indicator so check for reserved events the dataset cares about
event.event match {
case "$delete" =>
event.entityType match {
case "user" =>
indicatorsDao.removeMany("entityId" === event.entityId)
logger.info(s"Deleted data for user: ${event.entityId}, retrain to get it reflected in new queries")
Valid(jsonComment(s"deleted data for user: ${event.entityId}"))
case "model" =>
logger.info(s"Deleted data for model: ${event.entityId}, retrain to get it reflected in new queries")
Valid(jsonComment(s"Deleted data for model: ${event.entityId}, " +
s"retrain to get it reflected in new queries"))
if (event.entityType == "user") {
// this will only delete a user's data
//itemsDao.removeOne(filter = ("entityId", event.entityId)) // removeOne all events by a user
} // ignore any other reserved event types, they will be caught by the Algorithm if at all
case _ =>
logger.error(s"Unknown entityType: ${event.entityType} for $$delete")
Invalid(NotImplemented(jsonComment(s"Unknown entityType: ${event.entityType} for $$delete")))
}
}
Valid(event)
}
}
}
override def inputAsync(datum: String): Validated[ValidateError, Future[Response]] = Invalid(NotImplemented())
override def getUserData(userId: String, num: Int, from: Int): Validated[ValidateError, List[Response]] =
throw new NotImplementedError
override def deleteUserData(userId: String): Unit =
throw new NotImplementedError
}
| actionml/harness | rest-server/engines/src/main/scala/com/actionml/engines/urnavhinting/URNavHintingDataset.scala | Scala | apache-2.0 | 8,299 |
package io.scalac.seed
import akka.actor.{ActorSystem, Props}
import akka.io.IO
import spray.can._
object Boot extends App {
implicit val system = ActorSystem("seed-actor-system")
implicit val executionContext = system.dispatcher
val service = system.actorOf(Props(new ServiceActor), "seed-service")
IO(Http) ! Http.Bind(service, interface = "0.0.0.0", port = 8080)
} | ScalaConsultants/akka-persistence-eventsourcing | src/main/scala/io/scalac/seed/Boot.scala | Scala | apache-2.0 | 383 |
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.flink.table.planner.expressions
import org.apache.flink.table.api.TableException
import org.apache.flink.table.types.logical.{BigIntType, LogicalType, TimestampKind, TimestampType}
trait PlannerWindowProperty {
def resultType: LogicalType
}
abstract class AbstractPlannerWindowProperty(
reference: PlannerWindowReference) extends PlannerWindowProperty {
override def toString = s"WindowProperty($reference)"
}
/**
* Indicate timeField type.
*/
case class PlannerWindowReference(name: String, tpe: Option[LogicalType] = None) {
override def toString: String = s"'$name"
}
case class PlannerWindowStart(
reference: PlannerWindowReference) extends AbstractPlannerWindowProperty(reference) {
override def resultType: TimestampType = new TimestampType(3)
override def toString: String = s"start($reference)"
}
case class PlannerWindowEnd(
reference: PlannerWindowReference) extends AbstractPlannerWindowProperty(reference) {
override def resultType: TimestampType = new TimestampType(3)
override def toString: String = s"end($reference)"
}
case class PlannerRowtimeAttribute(
reference: PlannerWindowReference) extends AbstractPlannerWindowProperty(reference) {
override def resultType: LogicalType = {
reference match {
case PlannerWindowReference(_, Some(tpe))
if tpe.isInstanceOf[TimestampType] &&
tpe.asInstanceOf[TimestampType].getKind == TimestampKind.ROWTIME =>
// rowtime window
new TimestampType(true, TimestampKind.ROWTIME, 3)
case PlannerWindowReference(_, Some(tpe))
if tpe.isInstanceOf[BigIntType] || tpe.isInstanceOf[TimestampType] =>
// batch time window
new TimestampType(3)
case _ =>
throw new TableException("WindowReference of RowtimeAttribute has invalid type. " +
"Please report this bug.")
}
}
override def toString: String = s"rowtime($reference)"
}
case class PlannerProctimeAttribute(reference: PlannerWindowReference)
extends AbstractPlannerWindowProperty(reference) {
override def resultType: LogicalType =
new TimestampType(true, TimestampKind.PROCTIME, 3)
override def toString: String = s"proctime($reference)"
}
| jinglining/flink | flink-table/flink-table-planner-blink/src/main/scala/org/apache/flink/table/planner/expressions/plannerWindowProperties.scala | Scala | apache-2.0 | 3,036 |
package com.sksamuel.scrimage.nio
import java.awt.image.BufferedImage
import java.io.OutputStream
import javax.imageio.stream.MemoryCacheImageOutputStream
import javax.imageio.{IIOImage, ImageIO, ImageWriteParam}
import com.sksamuel.scrimage.Image
import org.apache.commons.io.IOUtils
case class JpegWriter(compression: Int, progressive: Boolean) extends ImageWriter {
def withCompression(compression: Int): JpegWriter = {
require(compression >= 0)
require(compression <= 100)
copy(compression = compression)
}
def withProgressive(progressive: Boolean): JpegWriter = copy(progressive = progressive)
override def write(image: Image, out: OutputStream): Unit = {
val writer = ImageIO.getImageWritersByFormatName("jpeg").next()
val params = writer.getDefaultWriteParam
if (compression < 100) {
params.setCompressionMode(ImageWriteParam.MODE_EXPLICIT)
params.setCompressionQuality(compression / 100f)
}
if (progressive) {
params.setProgressiveMode(ImageWriteParam.MODE_DEFAULT)
} else {
params.setProgressiveMode(ImageWriteParam.MODE_DISABLED)
}
// in openjdk, awt cannot write out jpegs that have a transparency bit, even if that is set to 255.
// see http://stackoverflow.com/questions/464825/converting-transparent-gif-png-to-jpeg-using-java
// so have to convert to a non alpha type
val noAlpha = if (image.awt.getColorModel.hasAlpha) {
image.removeTransparency(java.awt.Color.WHITE).toNewBufferedImage(BufferedImage.TYPE_INT_RGB)
} else {
image.awt
}
val output = new MemoryCacheImageOutputStream(out)
writer.setOutput(output)
writer.write(null, new IIOImage(noAlpha, null, null), params)
output.close()
writer.dispose()
IOUtils.closeQuietly(out)
}
}
object JpegWriter {
val NoCompression = JpegWriter(100, false)
val Default = JpegWriter(80, false)
def apply(): JpegWriter = Default
} | carlosFattor/scrimage | scrimage-core/src/main/scala/com/sksamuel/scrimage/nio/JpegWriter.scala | Scala | apache-2.0 | 1,937 |
object SCL4576 {
val zz = 1
def foo() {
val x = 1
/*start*/
//some text
print(x + zz)
/*end*/
}
}
/*
object SCL4576 {
val zz = 1
def foo() {
val x = 1
/*start*/
testMethodName(x)
/*end*/
}
def testMethodName(x: Int): Unit = {
//some text
print(x + zz)
}
}
*/ | triggerNZ/intellij-scala | testdata/extractMethod/simple/SCL4576.scala | Scala | apache-2.0 | 323 |
/*
* Copyright 2014 IBM Corp.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.ibm.spark.kernel.protocol.v5.content
import org.scalatest.FunSuite
import org.scalatest.{Matchers, FunSpec}
import play.api.data.validation.ValidationError
import play.api.libs.json._
import com.ibm.spark.kernel.protocol.v5._
class DisplayDataSpec extends FunSpec with Matchers {
val displayDataJson: JsValue = Json.parse("""
{
"source": "<STRING>",
"data": {},
"metadata": {}
}
""")
val displayData: DisplayData = DisplayData(
"<STRING>", Map(), Map()
)
describe("DisplayData") {
describe("#toTypeString") {
it("should return correct type") {
DisplayData.toTypeString should be ("display_data")
}
}
describe("implicit conversions") {
it("should implicitly convert from valid json to a displayData instance") {
// This is the least safe way to convert as an error is thrown if it fails
displayDataJson.as[DisplayData] should be (displayData)
}
it("should also work with asOpt") {
// This is safer, but we lose the error information as it returns
// None if the conversion fails
val newDisplayData = displayDataJson.asOpt[DisplayData]
newDisplayData.get should be (displayData)
}
it("should also work with validate") {
// This is the safest as it collects all error information (not just first error) and reports it
val displayDataResults = displayDataJson.validate[DisplayData]
displayDataResults.fold(
(invalid: Seq[(JsPath, Seq[ValidationError])]) => println("Failed!"),
(valid: DisplayData) => valid
) should be (displayData)
}
it("should implicitly convert from a displayData instance to valid json") {
Json.toJson(displayData) should be (displayDataJson)
}
}
}
}
| yeghishe/spark-kernel | protocol/src/test/scala/com/ibm/spark/kernel/protocol/v5/content/DisplayDataSpec.scala | Scala | apache-2.0 | 2,410 |
/*
Copyright 2012 Denis Bardadym
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package daemon.sshd
import java.security.PublicKey
import org.apache.commons.codec.binary.Base64
import org.eclipse.jgit.lib.Constants
import org.apache.sshd.common.util.Buffer
import code.model.SshKeyBase
/**
* Created by IntelliJ IDEA.
* User: den
* Date: 07.08.11
* Time: 17:35
* To change this template use File | Settings | File Templates.
*/
object SshUtil {
def parse(key:SshKeyBase[_]): PublicKey = {
val bin = Base64.decodeBase64(Constants.encodeASCII(key.encodedKey))
new Buffer(bin).getRawPublicKey();
}
} | btd/luna | src/main/scala/daemon/sshd/SshUtil.scala | Scala | apache-2.0 | 1,129 |
package regolic.sat
import org.scalatest.FunSuite
class InterpolationSuite extends FunSuite {
private val a = new Literal(0, true)
private val na = new Literal(0, false)
private val b = new Literal(1, true)
private val nb = new Literal(1, false)
private val c = new Literal(2, true)
private val nc = new Literal(2, false)
private val emptyClause = Set[Literal]()
test("Basic Interpolant") {
{
val cl1 = Set(na)
val cl2 = Set(a, b)
val cl3 = Set(a, nb)
val cl4 = Set(b)
val cl5 = Set(nb)
val proof = new Proof(Set(cl1, cl2, cl3))
proof.infer(cl1, cl2, cl4)
proof.infer(cl1, cl3, cl5)
proof.infer(cl4, cl5, emptyClause)
proof.linearize(emptyClause)
println(Interpolation(proof, Set(cl2, cl3), Set(cl1))) //should be a
println(Interpolation(proof, Set(cl1), Set(cl2, cl3))) //should be Not(a)
}
{
val cl1 = Set(a, b)
val cl2 = Set(na, c)
val cl3 = Set(nb, c)
val cl4 = Set(nc)
val cl5 = Set(b, c)
val cl6 = Set(c)
val proof = new Proof(Set(cl1, cl2, cl3, cl4))
proof.infer(cl1, cl2, cl5)
proof.infer(cl5, cl3, cl6)
proof.infer(cl6, cl4, emptyClause)
proof.linearize(emptyClause)
println(Interpolation(proof, Set(cl1, cl3), Set(cl2, cl4))) // should be Or(a, c)
}
}
}
| regb/scabolic | src/test/scala/regolic/sat/InterpolationSuite.scala | Scala | mit | 1,352 |
package katas.scala.bsearchtree
import org.junit.Test
import org.scalatest.junit.AssertionsForJUnit
/*
* User: dima
* Date: 23/2/11
* Time: 5:41 AM
*/
class BST1 extends AssertionsForJUnit {
@Test def shouldKeepBinaryTreeSorted() {
var tree: ANode = new Node(2)
assert(traverseTreeInOrder(tree) === List(2))
tree = add(tree, 0) // forgot to reassign "tree"
assert(traverseTreeInOrder(tree) === List(0, 2))
tree = add(tree, 4)
assert(traverseTreeInOrder(tree) === List(0, 2, 4))
tree = add(tree, 1)
assert(traverseTreeInOrder(tree) === List(0, 1, 2, 4))
tree = add(tree, 3)
assert(traverseTreeInOrder(tree) === List(0, 1, 2, 3, 4))
}
@Test def shouldTraverseTreeInOrder() {
val tree = Node(2,
new Node(1), // used "Node" instead of "new Node"
Node(3,
EmptyNode,
new Node(4)) // forgot emptynode arguments
)
assert(traverseTreeInOrder(tree) === List(1, 2, 3, 4))
}
def add(node: ANode, newValue: Int): ANode = node match {
case EmptyNode => new Node(newValue)
case Node(value, left, right) =>
if (value > newValue)
Node(value, add(left, newValue), right)
else
Node(value, left, add(right, newValue))
}
def traverseTreeInOrder(node: ANode): List[Int] = node match {
case EmptyNode => List()
case Node(value, left, right) => traverseTreeInOrder(left) ::: List(value) ::: traverseTreeInOrder(right)
}
abstract class ANode
case object EmptyNode extends ANode // used "class" instead of "object".. couldn't compile for few minutes
case class Node(value: Int, left: ANode, right: ANode) extends ANode {
def this(value: Int) = this (value, EmptyNode, EmptyNode)
}
}
| dkandalov/katas | scala/src/katas/scala/bsearchtree/BST1.scala | Scala | unlicense | 1,718 |
/*
* Copyright 2012 Twitter Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
*/
package com.twitter.zipkin.common
import com.twitter.util.NonFatal
import com.twitter.zipkin.Constants
import scala.collection.breakOut
/**
* A span represents one RPC request. A trace is made up of many spans.
*
* A span can contain multiple annotations, some are always included such as
* Client send -> Server received -> Server send -> Client receive.
*
* Some are created by users, describing application specific information,
* such as cache hits/misses.
*/
object Span {
// TODO(jeff): what?!
def apply(span: Span): Span = span
def apply(_traceId: String, _name: String, _id: String, _parentId: Option[String], _annotations: List[Annotation], _binaryAnnotations: Seq[BinaryAnnotation], _debug: Boolean = false): Span = new Span {
def traceId: String = _traceId
def name = _name
def id: String = _id
def parentId: Option[String] = _parentId
def annotations = _annotations
def binaryAnnotations = _binaryAnnotations
def debug = _debug
}
def unapply(span: Span): Option[(String, String, String, Option[String], List[Annotation], Seq[BinaryAnnotation], Boolean)] =
try {
Some(
span.traceId,
span.name,
span.id,
span.parentId,
span.annotations,
span.binaryAnnotations,
span.debug
)
} catch {
case NonFatal(_) => None
}
/**
* Order annotations by timestamp.
*/
val timestampOrdering = new Ordering[Annotation] {
def compare(a: Annotation, b: Annotation) = a.timestamp.compare(b.timestamp)
}
}
/**
* @param traceId random long that identifies the trace, will be set in all spans in this trace
* @param name name of span, can be rpc method name for example
* @param id random long that identifies this span
* @param parentId reference to the parent span in the trace tree
* @param annotations annotations, containing a timestamp and some value. both user generated and
* some fixed ones from the tracing framework
* @param binaryAnnotations binary annotations, can contain more detailed information such as
* serialized objects
* @param debug if this is set we will make sure this span is stored, no matter what the samplers want
*/
trait Span { self =>
def traceId: String
def name: String
def id: String
def parentId: Option[String]
def annotations: List[Annotation]
def binaryAnnotations: Seq[BinaryAnnotation]
def debug: Boolean
def copy(traceId: String = self.traceId, name: String = self.name, id: String = self.id, parentId: Option[String] = self.parentId, annotations: List[Annotation] = self.annotations, binaryAnnotations: Seq[BinaryAnnotation] = self.binaryAnnotations, debug: Boolean = self.debug): Span = Span(traceId, name, id, parentId, annotations, binaryAnnotations, debug)
private def tuple = (traceId, name, id, parentId, annotations, binaryAnnotations, debug)
override def equals(other: Any): Boolean = other match {
case o: Span => o.tuple == self.tuple
case _ => false
}
override def hashCode: Int = tuple.hashCode
override def toString: String = s"Span${tuple}"
def serviceNames: Set[String] =
annotations.flatMap(a => a.host.map(h => h.serviceName.toLowerCase)).toSet
/**
* Tries to extract the best possible service name
*/
def serviceName: Option[String] = {
if (annotations.isEmpty) None else {
serverSideAnnotations.flatMap(_.host).headOption.map(_.serviceName) orElse {
clientSideAnnotations.flatMap(_.host).headOption.map(_.serviceName)
}
}
}
/**
* Iterate through list of annotations and return the one with the given value.
*/
def getAnnotation(value: String): Option[Annotation] =
annotations.find(_.value == value)
/**
* Iterate through list of binaryAnnotations and return the one with the given key.
*/
def getBinaryAnnotation(key: String): Option[BinaryAnnotation] =
binaryAnnotations.find(_.key == key)
/**
* Take two spans with the same span id and merge all data into one of them.
*/
def mergeSpan(mergeFrom: Span): Span = {
if (id != mergeFrom.id) {
throw new IllegalArgumentException("Span ids must match")
}
// ruby tracing can give us an empty name in one part of the span
val selectedName = name match {
case "" => mergeFrom.name
case "Unknown" => mergeFrom.name
case _ => name
}
new Span {
def traceId: String = self.traceId
def name = selectedName
def id: String = self.id
def parentId = self.parentId
def annotations = self.annotations ++ mergeFrom.annotations
def binaryAnnotations = self.binaryAnnotations ++ mergeFrom.binaryAnnotations
def debug = self.debug | mergeFrom.debug
}
}
/**
* Get the first annotation by timestamp.
*/
def firstAnnotation: Option[Annotation] = {
try {
Some(annotations.min(Span.timestampOrdering))
} catch {
case e: UnsupportedOperationException => None
}
}
/**
* Get the last annotation by timestamp.
*/
def lastAnnotation: Option[Annotation] = {
try {
Some(annotations.max(Span.timestampOrdering))
} catch {
case e: UnsupportedOperationException => None
}
}
/**
* Endpoints involved in this span
*/
def endpoints: Set[Endpoint] =
annotations.flatMap(_.host).toSet
/**
* Endpoint that is likely the owner of this span
*/
def clientSideEndpoint: Option[Endpoint] =
clientSideAnnotations.map(_.host).flatten.headOption
/**
* Assuming this is an RPC span, is it from the client side?
*/
def isClientSide(): Boolean =
annotations.exists(a => {
a.value.equals(Constants.ClientSend) || a.value.equals(Constants.ClientRecv)
})
/**
* Pick out the core client side annotations
*/
def clientSideAnnotations: Seq[Annotation] =
annotations.filter(a => Constants.CoreClient.contains(a.value))
/**
* Pick out the core server side annotations
*/
def serverSideAnnotations: Seq[Annotation] =
annotations.filter(a => Constants.CoreServer.contains(a.value))
/**
* Duration of this span. May be None if we cannot find any annotations.
*/
def duration: Option[Long] =
for (first <- firstAnnotation; last <- lastAnnotation)
yield last.timestamp - first.timestamp
/**
* @return true if Span contains at most one of each core annotation
* false otherwise
*/
def isValid: Boolean = {
Constants.CoreAnnotations.map { c =>
annotations.filter(_.value == c).length > 1
}.count(b => b) == 0
}
/**
* Get the annotations as a map with value to annotation bindings.
*/
def getAnnotationsAsMap(): Map[String, Annotation] =
annotations.map(a => a.value -> a)(breakOut)
def lastTimestamp: Option[Long] = lastAnnotation.map(_.timestamp)
def firstTimestamp: Option[Long] = firstAnnotation.map(_.timestamp)
}
| cogitate/twitter-zipkin-uuid | zipkin-common/src/main/scala/com/twitter/zipkin/common/Span.scala | Scala | apache-2.0 | 7,485 |
package edu.gemini.util.trpc
import edu.gemini.util.trpc.common._
import scalaz._
import Scalaz._
import javax.servlet.http.{HttpServletResponse, HttpServletRequest}
import java.{lang => jl}
import java.lang.reflect.Method
import java.io.{InvalidClassException, ByteArrayOutputStream, ByteArrayInputStream, ObjectInputStream}
import edu.gemini.spModel.core.{VersionException, Version}
import edu.gemini.util.security.auth.keychain._
package object server {
implicit class RichHttpServletRequest(req: HttpServletRequest) {
lazy val pathElems = req.getPathInfo.split("/").drop(1)
def param(s: String): Try[String] =
Option(req.getParameter(s)) \\/> new IllegalArgumentException("Required request parameter %s was not found.".format(s))
def payload: Try[(Array[AnyRef], Set[Key])] =
lift {
// Get our object stream
val ios = req.getInputStream.readRaw
// Check serial compatibility
try {
val actualVersion = ios.next[Version]
if (!Version.current.isCompatible(actualVersion, Version.Compatibility.serial))
throw new VersionException(Version.current, actualVersion, Version.Compatibility.serial);
} catch {
case ice: InvalidClassException =>
// the version itself is incompatible!
throw new VersionException(Version.current, Version.Compatibility.serial);
}
// Next hunk is our payload
ios.next[(Array[AnyRef], Set[Key])]
}
def path(n: Int): Try[String] =
pathElems.lift(n) \\/> new IllegalArgumentException("Path element %d was not found.".format(n))
}
implicit class ClassOps[A](c: Class[A]) {
// Unboxed -> Boxed
def boxed: Map[Class[_], Class[_]] = Map(
jl.Boolean.TYPE -> classOf[jl.Boolean],
jl.Byte.TYPE -> classOf[jl.Byte],
jl.Character.TYPE -> classOf[jl.Character],
jl.Double.TYPE -> classOf[jl.Double],
jl.Float.TYPE -> classOf[jl.Float],
jl.Integer.TYPE -> classOf[jl.Integer],
jl.Long.TYPE -> classOf[jl.Long],
jl.Short.TYPE -> classOf[jl.Short])
// True if param (which may be primitive) is assignable from arg (which is not primitive but may be boxed)
def isCompatible(param: Class[_], arg: Class[_]) =
arg == null || (param.isAssignableFrom(arg) || param.isPrimitive && boxed(param) == arg)
/**
* Returns a method of the given name that can be invoked with the specified arguments (handling unboxing properly),
* or throws an exception if no such method exists. The intent is to mimic other such methods on Class.
*/
@throws(classOf[NoSuchMethodException])
def getCompatibleMethod(name: String, args: Seq[AnyRef]): Try[Method] = {
val argTypes: List[Class[_ <: AnyRef]] =
for {
a <- ~Option(args).map(_.toList)
} yield Option(a).map(_.getClass).orNull
val om = getCompatibleMethod0(c, name, argTypes)
om.\\/>(new NoSuchMethodException("%s.%s(%s)".format(c.getName, name, argTypes.mkString(", "))))
}
// Walk up the inheritance tree to find the specified method
def getCompatibleMethod0(c: Class[_], name: String, argTypes: List[Class[_]]): Option[Method] =
Option(c).flatMap(_.getDeclaredMethods.filter(_.getName == name).find(_.getParameterTypes.corresponds(argTypes)(isCompatible))
.orElse(getCompatibleMethod0(c.getSuperclass, name, argTypes)))
}
}
| arturog8m/ocs | bundle/edu.gemini.util.trpc/src/main/scala/edu/gemini/util/trpc/server/package.scala | Scala | bsd-3-clause | 3,453 |
package org.deepdive.datastore
import org.deepdive.settings._
// import org.deepdive.datastore.JdbcDataStore
import org.deepdive.Logging
import org.deepdive.Context
import org.deepdive.helpers.Helpers
import org.deepdive.helpers.Helpers.{Psql, Mysql}
import scala.sys.process._
import scala.util.{Try, Success, Failure}
import java.io._
import org.postgresql.util.PSQLException
class DataLoader extends JdbcDataStore with Logging {
// def ds : JdbcDataStore
/** Unload data of a SQL query from database to a TSV file
*
* For Greenplum, use gpfdist. Must specify gpport, gppath, gphost in dbSettings. No need for filepath
* For Postgresql, filepath is an abosulute path. No need for dbSettings or filename.
* For greenplum, use gpload; for postgres, use \\copy
*
* @param filename: the name of the output file
* @param filepath: the absolute path of the output file (including file name)
* @param dbSettings: database settings (DD's class)
* @param usingGreenplum: whether to use greenplum's gpunload
* @param query: the query to be dumped
*/
def unload(filename: String, filepath: String, dbSettings: DbSettings, usingGreenplum: Boolean, query: String) : Unit = {
if (usingGreenplum) {
val hostname = dbSettings.gphost
val port = dbSettings.gpport
val path = dbSettings.gppath
if (path != "" && filename != "" && hostname != "") {
new File(s"${path}/${filename}").delete()
} else {
throw new RuntimeException("greenplum parameters gphost, gpport, gppath are not set!")
}
// hacky way to get schema from a query...
executeSqlQueries(s"""
DROP VIEW IF EXISTS _${filename}_view CASCADE;
DROP TABLE IF EXISTS _${filename}_tmp CASCADE;
CREATE VIEW _${filename}_view AS ${query};
CREATE TABLE _${filename}_tmp AS SELECT * FROM _${filename}_view LIMIT 0;
""")
executeSqlQueries(s"""
DROP EXTERNAL TABLE IF EXISTS _${filename} CASCADE;
CREATE WRITABLE EXTERNAL TABLE _${filename} (LIKE _${filename}_tmp)
LOCATION ('gpfdist://${hostname}:${port}/${filename}')
FORMAT 'TEXT';
""")
executeSqlQueries(s"""
DROP VIEW _${filename}_view CASCADE;
DROP TABLE _${filename}_tmp CASCADE;""")
executeSqlQueries(s"""
INSERT INTO _${filename} ${query};
""")
} else { // psql / mysql
// Branch by database driver type (temporary solution)
val dbtype = Helpers.getDbType(dbSettings)
val sqlQueryPrefixRun = dbtype match {
case Psql => "psql " + Helpers.getOptionString(dbSettings) + " -c "
// -N: skip column names
case Mysql => "mysql " + Helpers.getOptionString(dbSettings) + " --silent -N -e "
}
val outfile = new File(filepath)
outfile.getParentFile().mkdirs()
// Trimming ending semicolons
val trimmedQuery = query.replaceAll("""(?m)[;\\s\\n]+$""", "")
// This query can contain double-quotes (") now.
val copyStr = dbtype match {
case Psql => s"COPY (${trimmedQuery}) TO STDOUT;"
case Mysql => trimmedQuery
}
Helpers.executeSqlQueriesByFile(dbSettings, copyStr, filepath)
}
}
/** Load data from a TSV file to database
*
* For greenplum, use gpload; for postgres, use \\copy
*
* For MySQL, make sure file basenames are the same as table name.
*
* @param filepath: the absolute path of the input file, it can contain wildchar characters
* @param tablename: the table to be copied to
* @param dbSettings: database settings (DD's class)
* @param usingGreenplum: whether to use greenplum's gpload
*/
def load(filepath: String, tablename: String, dbSettings: DbSettings, usingGreenplum: Boolean) : Unit = {
if (usingGreenplum) {
val loadyaml = File.createTempFile(s"gpload", ".yml")
val dbname = dbSettings.dbname
val pguser = dbSettings.user
val pgport = dbSettings.port
val pghost = dbSettings.host
if (dbname == null || pguser == null || pgport == null || pghost == null) {
throw new RuntimeException("database settings (user, port, host, dbname) missing!")
}
val gpload_setting = s"""
|VERSION: 1.0.0.1
|DATABASE: ${dbname}
|USER: ${pguser}
|HOST: ${pghost}
|PORT: ${pgport}
|GPLOAD:
| INPUT:
| - MAX_LINE_LENGTH: 3276800
| - SOURCE:
| FILE:
| - ${filepath}
| - FORMAT: text
| - DELIMITER: E'\\\\t'
| OUTPUT:
| - TABLE: ${tablename}
""".stripMargin
val gploadwriter = new PrintWriter(loadyaml)
gploadwriter.println(gpload_setting)
gploadwriter.close()
val cmdfile = File.createTempFile(s"gpload", ".sh")
val cmdwriter = new PrintWriter(cmdfile)
val cmd = s"gpload -f ${loadyaml.getAbsolutePath()}"
cmdwriter.println(cmd)
cmdwriter.close()
log.info(cmd)
Helpers.executeCmd(cmdfile.getAbsolutePath())
cmdfile.delete()
loadyaml.delete()
} else {
// Generate SQL query prefixes
val dbtype = Helpers.getDbType(dbSettings)
val cmdfile = File.createTempFile(s"${tablename}.copy", ".sh")
val writer = new PrintWriter(cmdfile)
val writebackPrefix = s"find ${filepath} -print0 | xargs -0 -P 1 -L 1 bash -c ";
val writebackCmd = dbtype match {
case Psql => writebackPrefix + s"'psql " + Helpers.getOptionString(dbSettings) +
"-c \\"COPY " + s"${tablename} FROM STDIN;" +
" \\" < $0'"
case Mysql =>
writebackPrefix + s"'mysqlimport --local " + Helpers.getOptionString(dbSettings) +
" $0'"
// mysqlimport requires input file to have basename that is same as
// tablename.
}
log.info(writebackCmd)
writer.println(writebackCmd)
writer.close()
Helpers.executeCmd(cmdfile.getAbsolutePath())
cmdfile.delete()
}
}
/**
* Load data from a TSV file to database using NDB Loader for MySQL Cluster.
*
* @param fileDirPath: the path of directory for the input files. e.g. /tmp/
* @param fileNamePattern: the relative filenames. Can contain wildchars. e.g. split-files.*
* @param tablename: the table to be copied to
* @param dbSettings: database settings (DD's class)
* @param schemaFilePath: schema file that defines the format of table to be copied to
* @param threadNum: number of threads that calls the ndbloader in parallel
* @param parallelTransactionNum: number of parallel transactions sent to database for each thread
*/
def ndbLoad(fileDirPath: String, fileNamePattern: String,
dbSettings: DbSettings, schemaFilePath: String,
ndbConnectionString: String,
threadNum: Integer, parallelTransactionNum: Integer): Unit = {
// Generate SQL query prefixes
val dbtype = Helpers.getDbType(dbSettings)
assert(dbtype == Mysql)
log.info(s"Running ndbloader with ${threadNum} threads and allowing ${
parallelTransactionNum} parallel transactions for each thread")
val writebackPrefix = s"find ${fileDirPath} -name '${fileNamePattern}' -print0 | xargs -0" +
s" -P ${threadNum} -L 1 bash -c "
val ndbLoader = {
val osname = System.getProperty("os.name")
if (osname.startsWith("Linux")) {
s"${Context.deepdiveHome}/util/ndbloader/ndbloader-linux"
}
else {
s"${Context.deepdiveHome}/util/ndbloader/ndbloader-mac"
}
}
val writebackCmd = writebackPrefix + s"'${ndbLoader} ${ndbConnectionString} ${dbSettings.dbname}" +
" $0 " + s"${schemaFilePath} ${parallelTransactionNum}'"
val cmdfile = File.createTempFile(s"ndbloader", ".sh")
val writer = new PrintWriter(cmdfile)
log.info(writebackCmd)
writer.println(writebackCmd)
writer.close()
Helpers.executeCmd(cmdfile.getAbsolutePath())
cmdfile.delete()
}
}
| gaapt/deepdive | src/main/scala/org/deepdive/datastore/Dataloader.scala | Scala | apache-2.0 | 8,041 |
package nlpdata.datasets.conll
import cats.free.Free
import cats.~>
import cats.Monad
import cats.implicits._
trait CoNLLService[M[_]] {
protected implicit def monad: Monad[M]
def getFile(path: CoNLLPath): M[CoNLLFile]
def getAllPaths: M[List[CoNLLPath]]
def getSentence(path: CoNLLSentencePath): M[CoNLLSentence] =
getFile(path.filePath).map(_.sentences(path.sentenceNum))
def getAllSentencePaths: M[List[CoNLLSentencePath]] =
for {
paths <- getAllPaths
files <- paths.map(getFile).sequence
} yield files.flatMap(_.sentences.map(_.path))
final def interpreter: (CoNLLServiceRequestA ~> M) =
new (CoNLLServiceRequestA ~> M) {
import CoNLLServiceRequestA._
def apply[A](op: CoNLLServiceRequestA[A]): M[A] = op match {
case GetFile(path) => getFile(path)
case GetAllPaths => getAllPaths
case GetSentence(sentencePath) => getSentence(sentencePath)
case GetAllSentencePaths => getAllSentencePaths
}
}
final def interpretThrough[G[_]: Monad](transform: M ~> G): CoNLLService[G] =
new CoNLLService.CompoundCoNLLService(this, transform)
}
object CoNLLService {
private class CompoundCoNLLService[M[_], G[_]](base: CoNLLService[M], transform: M ~> G)(
implicit M: Monad[M],
G: Monad[G]
) extends CoNLLService[G] {
override protected implicit val monad = G
def getFile(path: CoNLLPath): G[CoNLLFile] =
transform(base.getFile(path))
def getAllPaths: G[List[CoNLLPath]] =
transform(base.getAllPaths)
override def getSentence(path: CoNLLSentencePath): G[CoNLLSentence] =
transform(base.getSentence(path))
override def getAllSentencePaths: G[List[CoNLLSentencePath]] =
transform(base.getAllSentencePaths)
}
}
sealed trait CoNLLServiceRequestA[A]
object CoNLLServiceRequestA {
case class GetFile(path: CoNLLPath) extends CoNLLServiceRequestA[CoNLLFile]
case object GetAllPaths extends CoNLLServiceRequestA[List[CoNLLPath]]
case class GetSentence(sentencePath: CoNLLSentencePath)
extends CoNLLServiceRequestA[CoNLLSentence]
case object GetAllSentencePaths extends CoNLLServiceRequestA[List[CoNLLSentencePath]]
}
object FreeCoNLLService extends CoNLLService[Free[CoNLLServiceRequestA, ?]] {
type CoNLLServiceRequest[A] = Free[CoNLLServiceRequestA, A]
protected implicit override val monad: Monad[CoNLLServiceRequest] =
implicitly[Monad[CoNLLServiceRequest]]
def getFile(path: CoNLLPath): CoNLLServiceRequest[CoNLLFile] =
Free.liftF[CoNLLServiceRequestA, CoNLLFile](CoNLLServiceRequestA.GetFile(path))
def getAllPaths: CoNLLServiceRequest[List[CoNLLPath]] =
Free.liftF[CoNLLServiceRequestA, List[CoNLLPath]](CoNLLServiceRequestA.GetAllPaths)
override def getSentence(sentencePath: CoNLLSentencePath): CoNLLServiceRequest[CoNLLSentence] =
Free.liftF[CoNLLServiceRequestA, CoNLLSentence](CoNLLServiceRequestA.GetSentence(sentencePath))
override def getAllSentencePaths: CoNLLServiceRequest[List[CoNLLSentencePath]] =
Free.liftF[CoNLLServiceRequestA, List[CoNLLSentencePath]](
CoNLLServiceRequestA.GetAllSentencePaths
)
}
| julianmichael/nlpdata | nlpdata/src/nlpdata/datasets/conll/CoNLLService.scala | Scala | mit | 3,172 |
/*
* Copyright 2022 HM Revenue & Customs
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package services.onlinetesting.phase2
import akka.actor.ActorSystem
import config._
import connectors.ExchangeObjects.{ toString => _, _ }
import connectors.{ OnlineTestEmailClient, OnlineTestsGatewayClient }
import factories.{ DateTimeFactory, DateTimeFactoryMock, UUIDFactory }
import model.Commands.PostCode
import model.Exceptions._
import model.OnlineTestCommands.OnlineTestApplication
import model.Phase2TestExamples._
import model.ProgressStatuses.{ toString => _, _ }
import model._
import model.command.{ Phase2ProgressResponse, ProgressResponse }
import model.exchange.PsiRealTimeResults
import model.persisted.{ ContactDetails, Phase2TestGroup, Phase2TestGroupWithAppId, _ }
import org.joda.time.{ DateTime, DateTimeZone, LocalDate }
import org.mockito.ArgumentMatchers.{ eq => eqTo, _ }
import org.mockito.Mockito._
import play.api.mvc.RequestHeader
import repositories.application.GeneralApplicationRepository
import repositories.contactdetails.ContactDetailsRepository
import repositories.onlinetesting.Phase2TestRepository
import services.AuditService
import services.onlinetesting.Exceptions.{ TestCancellationException, TestRegistrationException }
import services.onlinetesting.phase3.Phase3TestService
import services.sift.ApplicationSiftService
import services.stc.StcEventServiceFixture
import testkit.MockitoImplicits._
import testkit.{ ExtendedTimeout, UnitSpec }
import uk.gov.hmrc.http.HeaderCarrier
import scala.concurrent.Future
import scala.language.postfixOps
class Phase2TestServiceSpec extends UnitSpec with ExtendedTimeout {
"Verify access code" should {
"return an invigilated test url for a valid candidate" in new TestFixture {
when(cdRepositoryMock.findUserIdByEmail(any[String])).thenReturnAsync(userId)
val accessCode = "TEST-CODE"
val phase2TestGroup = Phase2TestGroup(
expirationDate,
List(phase2Test.copy(invigilatedAccessCode = Some(accessCode)))
)
when(phase2TestRepositoryMock.getTestGroupByUserId(any[String])).thenReturnAsync(Some(phase2TestGroup))
val result = phase2TestService.verifyAccessCode("test-email.com", accessCode).futureValue
result mustBe authenticateUrl
}
"return a Failure if the access code does not match" in new TestFixture {
when(cdRepositoryMock.findUserIdByEmail(any[String])).thenReturn(Future.successful(authenticateUrl))
val accessCode = "TEST-CODE"
val phase2TestGroup = Phase2TestGroup(
expirationDate,
phase2Test.copy(invigilatedAccessCode = Some(accessCode)) :: Nil
)
when(phase2TestRepositoryMock.getTestGroupByUserId(any[String])).thenReturnAsync(Some(phase2TestGroup))
val result = phase2TestService.verifyAccessCode("test-email.com", "I-DO-NOT-MATCH").failed.futureValue
result mustBe an[InvalidTokenException]
}
"return a Failure if the user cannot be located by email" in new TestFixture {
when(cdRepositoryMock.findUserIdByEmail(any[String])).thenReturn(Future.failed(ContactDetailsNotFoundForEmail()))
val result = phase2TestService.verifyAccessCode("test-email.com", "ANY-CODE").failed.futureValue
result mustBe an[ContactDetailsNotFoundForEmail]
}
"return A Failure if the test is Expired" in new TestFixture {
when(cdRepositoryMock.findUserIdByEmail(any[String])).thenReturnAsync(authenticateUrl)
val accessCode = "TEST-CODE"
val phase2TestGroup = Phase2TestGroup(
expiredDate,
List(phase2Test.copy(invigilatedAccessCode = Some(accessCode)))
)
when(phase2TestRepositoryMock.getTestGroupByUserId(any[String])).thenReturnAsync(Some(phase2TestGroup))
val result = phase2TestService.verifyAccessCode("test-email.com", accessCode).failed.futureValue
result mustBe an[ExpiredTestForTokenException]
}
}
"Invite applicants to PHASE 2" must {
"successfully register 2 candidates" in new TestFixture {
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile))
when(phase2TestRepositoryMock.insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])).thenReturnAsync()
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturnAsync(aoa)
phase2TestService.registerAndInvite(candidates).futureValue
verify(onlineTestsGatewayClientMock, times(4)).psiRegisterApplicant(any[RegisterCandidateRequest])
verify(phase2TestRepositoryMock, times(4)).insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])
verify(emailClientMock, times(2)).sendOnlineTestInvitation(any[String], any[String], any[DateTime])(any[HeaderCarrier])
}
"deal with a failed registration when registering a single candidate" in new TestFixture {
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile))
when(phase2TestRepositoryMock.insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])).thenReturnAsync()
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturn(Future.failed(new Exception("Dummy error for test")))
phase2TestService.registerAndInvite(List(onlineTestApplication)).futureValue
verify(onlineTestsGatewayClientMock, times(2)).psiRegisterApplicant(any[RegisterCandidateRequest])
verify(phase2TestRepositoryMock, never).insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])
verify(emailClientMock, never).sendOnlineTestInvitation(any[String], any[String], any[DateTime])(any[HeaderCarrier])
}
"first candidate registers successfully, 2nd candidate fails" in new TestFixture {
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile))
when(phase2TestRepositoryMock.insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])).thenReturnAsync()
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturnAsync(aoa) // candidate 1 test 1
.thenReturnAsync(aoa) // candidate 1 test 2
.thenReturnAsync(aoa) // candidate 2 test 1
.thenReturn(Future.failed(new Exception("Dummy error for test"))) // candidate 2 test 2
phase2TestService.registerAndInvite(candidates).futureValue
verify(onlineTestsGatewayClientMock, times(4)).psiRegisterApplicant(any[RegisterCandidateRequest])
// Called 2 times for 1st candidate who registered successfully for both tests and once for 2nd candidate whose
// 1st registration was successful only
verify(phase2TestRepositoryMock, times(3)).insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])
// Called for 1st candidate only who registered successfully
verify(emailClientMock, times(1)).sendOnlineTestInvitation(any[String], any[String], any[DateTime])(any[HeaderCarrier])
}
"first candidate fails registration, 2nd candidate is successful" in new TestFixture {
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile))
when(phase2TestRepositoryMock.insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])).thenReturnAsync()
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturnAsync(aoa) // candidate 1 test 1
.thenReturn(Future.failed(new Exception("Dummy error for test"))) // candidate 1 test 2
.thenReturnAsync(aoa) // candidate 2 test 1
.thenReturnAsync(aoa) // candidate 2 test 2
phase2TestService.registerAndInvite(candidates).futureValue
verify(onlineTestsGatewayClientMock, times(4)).psiRegisterApplicant(any[RegisterCandidateRequest])
// Called once for 1st candidate who registered successfully for 1st test only tests and twice for 2nd candidate whose
// registrations were both successful
verify(phase2TestRepositoryMock, times(3)).insertOrUpdateTestGroup(any[String], any[Phase2TestGroup])
// Called for 2nd candidate only who registered successfully
verify(emailClientMock, times(1)).sendOnlineTestInvitation(any[String], any[String], any[DateTime])(any[HeaderCarrier])
}
}
"processNextExpiredTest" should {
val phase2ExpirationEvent = Phase2ExpirationEvent(gracePeriodInSecs = 0)
"do nothing if there is no expired application to process" in new TestFixture {
when(phase2TestRepositoryMock.nextExpiringApplication(phase2ExpirationEvent)).thenReturnAsync(None)
phase2TestService.processNextExpiredTest(phase2ExpirationEvent).futureValue mustBe unit
}
"update progress status and send an email to the user when a Faststream application is expired" in new TestFixture {
when(phase2TestRepositoryMock.nextExpiringApplication(phase2ExpirationEvent))
.thenReturnAsync(Some(expiredApplication))
when(cdRepositoryMock.find(any[String])).thenReturnAsync(contactDetails)
when(appRepositoryMock.getApplicationRoute(any[String])).thenReturnAsync(ApplicationRoute.Faststream)
val results = List(SchemeEvaluationResult("Commercial", "Green"))
when(appRepositoryMock.addProgressStatusAndUpdateAppStatus(any[String], any[ProgressStatuses.ProgressStatus])).thenReturn(success)
when(emailClientMock.sendEmailWithName(any[String], any[String], any[String])(any[HeaderCarrier])).thenReturn(success)
val result = phase2TestService.processNextExpiredTest(phase2ExpirationEvent)
result.futureValue mustBe unit
verify(cdRepositoryMock).find(userId)
verify(appRepositoryMock).addProgressStatusAndUpdateAppStatus(applicationId, PHASE2_TESTS_EXPIRED)
verify(appRepositoryMock, never()).addProgressStatusAndUpdateAppStatus(applicationId, SIFT_ENTERED)
verify(appRepositoryMock, never()).getCurrentSchemeStatus(applicationId)
verify(appRepositoryMock, never()).updateCurrentSchemeStatus(applicationId, results)
verify(siftServiceMock, never()).sendSiftEnteredNotification(eqTo(applicationId), any[DateTime])(any[HeaderCarrier])
verify(emailClientMock).sendEmailWithName(emailContactDetails, preferredName, TestExpirationEmailTemplates.phase2ExpirationTemplate)
}
"update progress status and send an email to the user when an sdip faststream application is expired" in new TestFixture {
when(phase2TestRepositoryMock.nextExpiringApplication(phase2ExpirationEvent))
.thenReturnAsync(Some(expiredApplication))
when(cdRepositoryMock.find(any[String])).thenReturnAsync(contactDetails)
when(appRepositoryMock.getApplicationRoute(any[String])).thenReturn(Future.successful(ApplicationRoute.SdipFaststream))
val results = List(SchemeEvaluationResult("Sdip", "Green"), SchemeEvaluationResult("Commercial", "Green"))
when(appRepositoryMock.addProgressStatusAndUpdateAppStatus(any[String], any[ProgressStatuses.ProgressStatus])).thenReturn(success)
when(emailClientMock.sendEmailWithName(any[String], any[String], any[String])(any[HeaderCarrier])).thenReturn(success)
val result = phase2TestService.processNextExpiredTest(phase2ExpirationEvent)
result.futureValue mustBe unit
verify(cdRepositoryMock).find(userId)
verify(appRepositoryMock).addProgressStatusAndUpdateAppStatus(applicationId, PHASE2_TESTS_EXPIRED)
verify(appRepositoryMock, never()).addProgressStatusAndUpdateAppStatus(applicationId, SIFT_ENTERED)
verify(appRepositoryMock, never()).getCurrentSchemeStatus(applicationId)
verify(appRepositoryMock, never()).updateCurrentSchemeStatus(applicationId, results)
verify(siftServiceMock, never()).sendSiftEnteredNotification(eqTo(applicationId), any[DateTime])(any[HeaderCarrier])
verify(emailClientMock).sendEmailWithName(emailContactDetails, preferredName, TestExpirationEmailTemplates.phase2ExpirationTemplate)
}
}
"mark as started" should {
"change progress to started" in new TestFixture {
when(phase2TestRepositoryMock.updateTestStartTime(any[String], any[DateTime])).thenReturnAsync()
when(phase2TestRepositoryMock.getTestProfileByOrderId(orderId))
.thenReturnAsync(Phase2TestGroupWithAppId("appId123", phase2TestProfile))
when(phase2TestRepositoryMock.updateProgressStatus("appId123", ProgressStatuses.PHASE2_TESTS_STARTED))
.thenReturnAsync()
when(appRepositoryMock.getProgressStatusTimestamps(anyString())).thenReturnAsync(Nil)
phase2TestService.markAsStarted2(orderId).futureValue
verify(phase2TestRepositoryMock, times(1)).updateProgressStatus("appId123", ProgressStatuses.PHASE2_TESTS_STARTED)
}
//TODO: add back in at end of campaign 2019
"not change progress to started if status exists" ignore new TestFixture {
when(phase2TestRepositoryMock.updateTestStartTime(any[String], any[DateTime])).thenReturnAsync()
when(phase2TestRepositoryMock.getTestProfileByOrderId(orderId))
.thenReturnAsync(Phase2TestGroupWithAppId("appId123", phase2TestProfile))
when(phase2TestRepositoryMock.updateProgressStatus("appId123", ProgressStatuses.PHASE2_TESTS_STARTED))
.thenReturnAsync()
when(appRepositoryMock.getProgressStatusTimestamps(anyString()))
.thenReturnAsync(List(("FAKE_STATUS", DateTime.now()), ("PHASE2_TESTS_STARTED", DateTime.now())))
phase2TestService.markAsStarted2(orderId).futureValue
verify(phase2TestRepositoryMock, never()).updateProgressStatus("appId123", ProgressStatuses.PHASE2_TESTS_STARTED)
}
}
"mark as completed" should {
"change progress to completed if there are all tests completed" in new TestFixture {
when(phase2TestRepositoryMock.updateTestCompletionTime2(any[String], any[DateTime])).thenReturnAsync()
val phase2Tests = phase2TestProfile.copy(tests = phase2TestProfile.tests.map(t => t.copy(completedDateTime = Some(DateTime.now()))),
expirationDate = DateTime.now().plusDays(2)
)
when(phase2TestRepositoryMock.getTestProfileByOrderId(orderId))
.thenReturnAsync(Phase2TestGroupWithAppId("appId123", phase2Tests))
when(phase2TestRepositoryMock.updateProgressStatus("appId123", ProgressStatuses.PHASE2_TESTS_COMPLETED))
.thenReturnAsync()
phase2TestService.markAsCompleted2(orderId).futureValue
verify(phase2TestRepositoryMock).updateProgressStatus("appId123", ProgressStatuses.PHASE2_TESTS_COMPLETED)
}
}
"Reset tests" should {
"throw exception if test group cannot be found" in new TestFixture {
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(None)
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.failed.futureValue mustBe an[CannotFindTestGroupByApplicationIdException]
}
"throw exception if test by orderId cannot be found" in new TestFixture {
val newTests = phase2Test.copy(orderId = "unknown-uuid") :: Nil
when(phase2TestRepositoryMock.getTestGroup(any[String]))
.thenReturnAsync(Some(phase2TestProfile.copy(tests = newTests)))
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.failed.futureValue mustBe an[CannotFindTestByOrderIdException]
}
// we are not sending a cancellation request anymore so this test should be ignored for now
"not register candidate if cancellation request fails" ignore new TestFixture {
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile))
when(onlineTestsGatewayClientMock.psiCancelTest(any[CancelCandidateTestRequest]))
.thenReturnAsync(acaError)
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.failed.futureValue mustBe a[TestCancellationException]
verify(onlineTestsGatewayClientMock, times(0)).psiRegisterApplicant(any[RegisterCandidateRequest])
verify(auditServiceMock, times(0)).logEventNoRequest("TestCancelledForCandidate", auditDetails)
verify(auditServiceMock, times(0)).logEventNoRequest("UserRegisteredForOnlineTest", auditDetails)
verify(auditServiceMock, times(0)).logEventNoRequest("OnlineTestInvitationEmailSent", auditDetailsWithEmail)
verify(auditServiceMock, times(0)).logEventNoRequest("OnlineTestInvited", auditDetails)
}
"throw exception if config can't be found" in new TestFixture {
val newTests = phase2Test.copy(inventoryId = "unknown-uuid") :: Nil
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile.copy(tests = newTests)))
when(onlineTestsGatewayClientMock.psiCancelTest(any[CancelCandidateTestRequest]))
.thenReturnAsync(acaCompleted)
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.failed.futureValue mustBe a[CannotFindTestByInventoryIdException]
}
"not complete invitation if re-registration request connection fails" in new TestFixture {
val newTests = phase2Test.copy(inventoryId = "inventory-id-1") :: Nil
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile.copy(tests = newTests)))
when(onlineTestsGatewayClientMock.psiCancelTest(any[CancelCandidateTestRequest]))
.thenReturnAsync(acaCompleted)
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturn(Future.failed(new ConnectorException(connectorErrorMessage)))
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.failed.futureValue mustBe a[ConnectorException]
verify(onlineTestsGatewayClientMock, times(1)).psiRegisterApplicant(any[RegisterCandidateRequest])
verify(emailClientMock, times(0))
.sendOnlineTestInvitation(eqTo(emailContactDetails), eqTo(preferredName), eqTo(expirationDate))(any[HeaderCarrier])
verify(auditServiceMock, times(0)).logEventNoRequest("TestCancelledForCandidate", auditDetails)
verify(auditServiceMock, times(0)).logEventNoRequest("UserRegisteredForPhase2Test", auditDetails)
verify(auditServiceMock, times(0)).logEventNoRequest("OnlineTestInvitationEmailSent", auditDetailsWithEmail)
verify(auditServiceMock, times(0)).logEventNoRequest("OnlineTestInvited", auditDetails)
}
"not complete invitation if re-registration fails" in new TestFixture {
val newTests = phase2Test.copy(inventoryId = "inventory-id-1") :: Nil
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile.copy(tests = newTests)))
when(onlineTestsGatewayClientMock.psiCancelTest(any[CancelCandidateTestRequest]))
.thenReturnAsync(acaCompleted)
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturnAsync(aoaFailed)
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.failed.futureValue mustBe a[TestRegistrationException]
verify(onlineTestsGatewayClientMock, times(1)).psiRegisterApplicant(any[RegisterCandidateRequest])
verify(emailClientMock, times(0))
.sendOnlineTestInvitation(eqTo(emailContactDetails), eqTo(preferredName), eqTo(expirationDate))(any[HeaderCarrier])
verify(auditServiceMock, times(0)).logEventNoRequest("TestCancelledForCandidate", auditDetails)
verify(auditServiceMock, times(1)).logEventNoRequest("UserRegisteredForPhase2Test", auditDetails)
verify(auditServiceMock, times(0)).logEventNoRequest("OnlineTestInvitationEmailSent", auditDetailsWithEmail)
verify(auditServiceMock, times(0)).logEventNoRequest("OnlineTestInvited", auditDetails)
}
"complete reset successfully" in new TestFixture {
val newTests = phase2Test.copy(inventoryId = "inventory-id-1") :: Nil
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestProfile.copy(tests = newTests)))
when(onlineTestsGatewayClientMock.psiCancelTest(any[CancelCandidateTestRequest]))
.thenReturnAsync(acaCompleted)
when(onlineTestsGatewayClientMock.psiRegisterApplicant(any[RegisterCandidateRequest]))
.thenReturnAsync(aoa)
val result = phase2TestService.resetTest(onlineTestApplication, phase2Test.orderId, "")
result.futureValue mustBe unit
verify(onlineTestsGatewayClientMock, times(1)).psiRegisterApplicant(any[RegisterCandidateRequest])
verify(emailClientMock, times(1))
.sendOnlineTestInvitation(eqTo(emailContactDetails), eqTo(onlineTestApplication.preferredName), eqTo(expirationDate))(any[HeaderCarrier])
verify(auditServiceMock, times(0)).logEventNoRequest("TestCancelledForCandidate", auditDetails)
verify(auditServiceMock, times(1)).logEventNoRequest("UserRegisteredForPhase2Test", auditDetails)
verify(auditServiceMock, times(1)).logEventNoRequest("OnlineTestInvitationEmailSent", auditDetailsWithEmail)
}
}
"Extend time for expired test" should {
val progress = phase2Progress(
Phase2ProgressResponse(
phase2TestsExpired = true,
phase2TestsFirstReminder = true,
phase2TestsSecondReminder = true
))
"extend the test to 5 days from now and remove: expired and two reminder progress statuses" in new TestFixture {
when(appRepositoryMock.findProgress(any[String])).thenReturn(Future.successful(progress))
val phase2TestProfileWithExpirationInPast = Phase2TestGroup(now.minusDays(1), List(phase2Test))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturn(Future.successful(Some(phase2TestProfileWithExpirationInPast)))
phase2TestService.extendTestGroupExpiryTime("appId", 5, "admin").futureValue
verify(phase2TestRepositoryMock).updateGroupExpiryTime("appId", now.plusDays(5), "phase2")
verify(appRepositoryMock).removeProgressStatuses("appId", List(
PHASE2_TESTS_EXPIRED, PHASE2_TESTS_SECOND_REMINDER, PHASE2_TESTS_FIRST_REMINDER)
)
}
"extend the test to 3 days from now and remove: expired and only one reminder progress status" in new TestFixture {
when(appRepositoryMock.findProgress(any[String])).thenReturn(Future.successful(progress))
val phase2TestProfileWithExpirationInPast = Phase2TestGroup(now.minusDays(1), List(phase2Test))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturn(Future.successful(Some(phase2TestProfileWithExpirationInPast)))
phase2TestService.extendTestGroupExpiryTime("appId", 3, "admin").futureValue
verify(phase2TestRepositoryMock).updateGroupExpiryTime("appId", now.plusDays(3), "phase2")
verify(appRepositoryMock).removeProgressStatuses("appId", List(
PHASE2_TESTS_EXPIRED, PHASE2_TESTS_SECOND_REMINDER)
)
}
"extend the test to 1 day from now and remove: expired progress status" in new TestFixture {
when(appRepositoryMock.findProgress(any[String])).thenReturn(Future.successful(progress))
val phase2TestProfileWithExpirationInPast = Phase2TestGroup(now.minusDays(1), List(phase2Test))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturn(Future.successful(Some(phase2TestProfileWithExpirationInPast)))
phase2TestService.extendTestGroupExpiryTime("appId", 1, "admin").futureValue
verify(phase2TestRepositoryMock).updateGroupExpiryTime("appId", now.plusDays(1), "phase2")
verify(appRepositoryMock).removeProgressStatuses("appId", List(PHASE2_TESTS_EXPIRED))
}
}
"Extend time for test which has not expired yet" should {
"extend the test to 5 days from expiration date which is in 1 day, remove two reminder progresses" in new TestFixture {
val progress = phase2Progress(
Phase2ProgressResponse(
phase2TestsFirstReminder = true,
phase2TestsSecondReminder = true
))
when(appRepositoryMock.findProgress(any[String])).thenReturn(Future.successful(progress))
val phase2TestProfileWithExpirationInPast = Phase2TestGroup(now.plusDays(1), List(phase2Test))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturn(Future.successful(Some(phase2TestProfileWithExpirationInPast)))
phase2TestService.extendTestGroupExpiryTime("appId", 5, "admin").futureValue
verify(phase2TestRepositoryMock).updateGroupExpiryTime("appId", now.plusDays(6), "phase2")
verify(appRepositoryMock).removeProgressStatuses("appId", List(
PHASE2_TESTS_SECOND_REMINDER, PHASE2_TESTS_FIRST_REMINDER)
)
}
"extend the test to 2 days from expiration date which is in 1 day, remove one reminder progress" in new TestFixture {
val progress = phase2Progress(
Phase2ProgressResponse(
phase2TestsFirstReminder = true,
phase2TestsSecondReminder = true
))
when(appRepositoryMock.findProgress(any[String])).thenReturn(Future.successful(progress))
val phase2TestProfileWithExpirationInPast = Phase2TestGroup(now.plusDays(1), List(phase2Test))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturn(Future.successful(Some(phase2TestProfileWithExpirationInPast)))
phase2TestService.extendTestGroupExpiryTime("appId", 2, "admin").futureValue
val newExpirationDate = now.plusDays(3)
verify(phase2TestRepositoryMock).updateGroupExpiryTime("appId", newExpirationDate, "phase2")
verify(appRepositoryMock).removeProgressStatuses("appId", List(PHASE2_TESTS_SECOND_REMINDER))
}
"extend the test to 1 day from expiration date which is set to today, does not remove any progresses" in new TestFixture {
val progress = phase2Progress(
Phase2ProgressResponse(
phase2TestsFirstReminder = true,
phase2TestsSecondReminder = true
))
when(appRepositoryMock.findProgress(any[String])).thenReturn(Future.successful(progress))
val phase2TestProfileWithExpirationInPast = Phase2TestGroup(now, List(phase2Test))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturn(Future.successful(Some(phase2TestProfileWithExpirationInPast)))
phase2TestService.extendTestGroupExpiryTime("appId", 1, "admin").futureValue
val newExpirationDate = now.plusDays(1)
verify(phase2TestRepositoryMock).updateGroupExpiryTime("appId", newExpirationDate, "phase2")
verify(appRepositoryMock, never).removeProgressStatuses(any[String], any[List[ProgressStatus]])
}
}
"build time adjustments" should {
"return Nil when there is no need for adjustments and no gis" in new TestFixture {
val onlineTestApplicationWithNoAdjustments = OnlineTestApplication("appId1", "PHASE1_TESTS", "userId1", "testAccountId",
guaranteedInterview = false, needsOnlineAdjustments = false, needsAtVenueAdjustments = false, preferredName = "PrefName1",
lastName = "LastName1", eTrayAdjustments = None, videoInterviewAdjustments = None)
val result = phase2TestService.buildTimeAdjustments(5, onlineTestApplicationWithNoAdjustments)
result mustBe List()
}
"return time adjustments when gis" in new TestFixture {
val onlineTestApplicationGisWithAdjustments = OnlineTestApplication("appId1", "PHASE1_TESTS", "userId1", "testAccountId",
guaranteedInterview = true, needsOnlineAdjustments = false, needsAtVenueAdjustments = false, preferredName = "PrefName1",
lastName = "LastName1", eTrayAdjustments = Some(AdjustmentDetail(Some(25), None, None)), videoInterviewAdjustments = None)
val result = phase2TestService.buildTimeAdjustments(5, onlineTestApplicationGisWithAdjustments)
result mustBe List(TimeAdjustments(5, 1, 100))
}
"return time adjustments when adjustments needed" in new TestFixture {
val onlineTestApplicationGisWithAdjustments = OnlineTestApplication("appId1", "PHASE1_TESTS", "userId1", "testAccountId",
guaranteedInterview = false, needsOnlineAdjustments = true, needsAtVenueAdjustments = false, preferredName = "PrefName1",
lastName = "LastName1", eTrayAdjustments = Some(AdjustmentDetail(Some(50), None, None)), videoInterviewAdjustments = None)
val result = phase2TestService.buildTimeAdjustments(5, onlineTestApplicationGisWithAdjustments)
result mustBe List(TimeAdjustments(5, 1, 120))
}
}
"calculate absolute time with adjustments" should {
"return 140 when adjustment is 75%" in new TestFixture {
val onlineTestApplicationGisWithAdjustments = OnlineTestApplication("appId1", "PHASE1_TESTS", "userId1", "testAccountId",
guaranteedInterview = true, needsOnlineAdjustments = true, needsAtVenueAdjustments = false, preferredName = "PrefName1",
lastName = "LastName1", eTrayAdjustments = Some(AdjustmentDetail(Some(75), None, None)), videoInterviewAdjustments = None)
val result = phase2TestService.calculateAbsoluteTimeWithAdjustments(onlineTestApplicationGisWithAdjustments)
result mustBe 140
}
"return 80 when no adjustments needed" in new TestFixture {
val onlineTestApplicationGisWithNoAdjustments = OnlineTestApplication("appId1", "PHASE1_TESTS", "userId1", "testAccountId",
guaranteedInterview = true, needsOnlineAdjustments = false, needsAtVenueAdjustments = false, preferredName = "PrefName1",
lastName = "LastName1", eTrayAdjustments = None, videoInterviewAdjustments = None)
val result = phase2TestService.calculateAbsoluteTimeWithAdjustments(onlineTestApplicationGisWithNoAdjustments)
result mustBe 80
}
}
"email Invite to Applicants" should {
"not be sent for invigilated e-tray" in new TestFixture {
override val candidates = List(OnlineTestApplicationExamples.InvigilatedETrayCandidate)
implicit val date: DateTime = invitationDate
phase2TestService.emailInviteToApplicants(candidates).futureValue
verifyNoInteractions(emailClientMock)
}
}
// PSI specific no cubiks equivalent
"store real time results" should {
"handle not finding an application for the given order id" in new TestFixture {
when(phase2TestRepositoryMock.getApplicationIdForOrderId(any[String], any[String])).thenReturnAsync(None)
val result = phase2TestService.storeRealTimeResults(orderId, realTimeResults)
val exception = result.failed.futureValue
exception mustBe an[CannotFindTestByOrderIdException]
exception.getMessage mustBe s"Application not found for test for orderId=$orderId"
}
"handle not finding a test profile for the given order id" in new TestFixture {
when(phase2TestRepositoryMock.getApplicationIdForOrderId(any[String], any[String])).thenReturnAsync(Some(applicationId))
when(phase2TestRepositoryMock.getTestProfileByOrderId(any[String])).thenReturn(Future.failed(
CannotFindTestByOrderIdException(s"Cannot find test group by orderId=$orderId")
))
val result = phase2TestService.storeRealTimeResults(orderId, realTimeResults)
val exception = result.failed.futureValue
exception mustBe an[CannotFindTestByOrderIdException]
exception.getMessage mustBe s"Cannot find test group by orderId=$orderId"
}
"handle not finding the test group when checking to update the progress status" in new TestFixture {
when(phase2TestRepositoryMock.getApplicationIdForOrderId(any[String], any[String])).thenReturnAsync(Some(applicationId))
when(phase2TestRepositoryMock.getTestProfileByOrderId(any[String])).thenReturnAsync(phase2CompletedTestGroupWithAppId)
when(phase2TestRepositoryMock.insertTestResult2(any[String], any[PsiTest], any[model.persisted.PsiTestResult])).thenReturnAsync()
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(None)
val result = phase2TestService.storeRealTimeResults(orderId, realTimeResults)
val exception = result.failed.futureValue
exception mustBe an[Exception]
exception.getMessage mustBe s"No test profile returned for $applicationId"
verify(phase2TestRepositoryMock, never()).updateTestCompletionTime2(any[String], any[DateTime])
verify(phase2TestRepositoryMock, never()).updateProgressStatus(any[String], any[ProgressStatuses.ProgressStatus])
}
"process the real time results and update the progress status" in new TestFixture {
when(phase2TestRepositoryMock.getApplicationIdForOrderId(any[String], any[String])).thenReturnAsync(Some(applicationId))
when(phase2TestRepositoryMock.getTestProfileByOrderId(any[String])).thenReturnAsync(phase2CompletedTestGroupWithAppId)
when(phase2TestRepositoryMock.insertTestResult2(any[String], any[PsiTest], any[model.persisted.PsiTestResult])).thenReturnAsync()
val phase2TestGroup = Phase2TestGroup(expirationDate = now, tests = List(fifthPsiTest, sixthPsiTest))
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestGroup))
when(phase2TestRepositoryMock.updateProgressStatus(any[String], any[ProgressStatuses.ProgressStatus])).thenReturnAsync()
phase2TestService.storeRealTimeResults(orderId, realTimeResults).futureValue
verify(phase2TestRepositoryMock, never()).updateTestCompletionTime2(any[String], any[DateTime])
verify(phase2TestRepositoryMock, times(1)).updateProgressStatus(any[String],
eqTo(ProgressStatuses.PHASE2_TESTS_RESULTS_RECEIVED))
}
"process the real time results, mark the test as completed and update the progress status" in new TestFixture {
when(phase2TestRepositoryMock.getApplicationIdForOrderId(any[String], any[String])).thenReturnAsync(Some(applicationId))
//First call return tests that are not completed second call return tests that are are completed
when(phase2TestRepositoryMock.getTestProfileByOrderId(any[String]))
.thenReturnAsync(phase2NotCompletedTestGroupWithAppId)
.thenReturnAsync(phase2CompletedTestGroupWithAppId)
when(phase2TestRepositoryMock.insertTestResult2(any[String], any[PsiTest], any[model.persisted.PsiTestResult])).thenReturnAsync()
when(phase2TestRepositoryMock.updateTestCompletionTime2(any[String], any[DateTime])).thenReturnAsync()
when(phase2TestRepositoryMock.updateProgressStatus(any[String], eqTo(ProgressStatuses.PHASE2_TESTS_COMPLETED))).thenReturnAsync()
val phase2TestGroup = Phase2TestGroup(expirationDate = now, tests = List(fifthPsiTest, sixthPsiTest))
val phase2TestsCompleted: Phase2TestGroup = phase2TestGroup.copy(
tests = phase2TestGroup.tests.map(t => t.copy(orderId = orderId, completedDateTime = Some(DateTime.now()))),
expirationDate = DateTime.now().plusDays(2)
)
when(phase2TestRepositoryMock.getTestGroup(any[String])).thenReturnAsync(Some(phase2TestsCompleted))
when(phase2TestRepositoryMock.updateProgressStatus(any[String], eqTo(ProgressStatuses.PHASE2_TESTS_RESULTS_RECEIVED))).thenReturnAsync()
phase2TestService.storeRealTimeResults(orderId, realTimeResults).futureValue
verify(phase2TestRepositoryMock, times(1)).updateTestCompletionTime2(any[String], any[DateTime])
verify(phase2TestRepositoryMock, times(1)).updateProgressStatus(any[String], eqTo(ProgressStatuses.PHASE2_TESTS_COMPLETED))
verify(phase2TestRepositoryMock, times(1)).updateProgressStatus(any[String], eqTo(ProgressStatuses.PHASE2_TESTS_RESULTS_RECEIVED))
}
}
private def phase2Progress(phase2ProgressResponse: Phase2ProgressResponse) =
ProgressResponse("appId", phase2ProgressResponse = phase2ProgressResponse)
trait TestFixture extends StcEventServiceFixture {
implicit val hc: HeaderCarrier = mock[HeaderCarrier]
implicit val rh: RequestHeader = mock[RequestHeader]
val dateTimeFactoryMock: DateTimeFactory = mock[DateTimeFactory]
implicit val now: DateTime = DateTimeFactoryMock.nowLocalTimeZone.withZone(DateTimeZone.UTC)
when(dateTimeFactoryMock.nowLocalTimeZone).thenReturn(now)
val scheduleCompletionBaseUrl = "http://localhost:9284/fset-fast-stream/online-tests/phase2"
val inventoryIds: Map[String, String] = Map[String, String]("test3" -> "test3-uuid", "test4" -> "test4-uuid")
def testIds(idx: Int): PsiTestIds =
PsiTestIds(s"inventory-id-$idx", s"assessment-id-$idx", s"report-id-$idx", s"norm-id-$idx")
val tests = Map[String, PsiTestIds](
"test1" -> testIds(1),
"test2" -> testIds(2),
"test3" -> testIds(3),
"test4" -> testIds(4)
)
val mockPhase1TestConfig = Phase1TestsConfig(
expiryTimeInDays = 5, gracePeriodInSecs = 0, testRegistrationDelayInSecs = 1, tests, standard = List("test1", "test2", "test3", "test4"),
gis = List("test1", "test4")
)
val mockPhase2TestConfig = Phase2TestsConfig(
expiryTimeInDays = 5, expiryTimeInDaysForInvigilatedETray = 90, gracePeriodInSecs = 0, testRegistrationDelayInSecs = 1, tests,
standard = List("test1", "test2")
)
val mockNumericalTestsConfig = NumericalTestsConfig(gracePeriodInSecs = 0, tests = tests, standard = List("test1"))
val gatewayConfig = OnlineTestsGatewayConfig(
url = "",
phase1Tests = mockPhase1TestConfig,
phase2Tests = mockPhase2TestConfig,
numericalTests = mockNumericalTestsConfig,
reportConfig = ReportConfig(1, 2, "en-GB"),
candidateAppUrl = "http://localhost:9284",
emailDomain = "test.com"
)
val orderId = uuid
val token = "token"
val authenticateUrl = "http://localhost/authenticate"
val invitationDate = now
val startedDate = invitationDate.plusDays(1)
val expirationDate = invitationDate.plusDays(5)
val expiredDate = now.minusMinutes(1)
val invigilatedExpirationDate = invitationDate.plusDays(90)
val applicationId = "appId"
val userId = "userId"
val preferredName = "Preferred\\tName"
val expiredApplication = ExpiringOnlineTest(applicationId, userId, preferredName)
val aoa = AssessmentOrderAcknowledgement(
customerId = "cust-id", receiptId = "receipt-id", orderId = orderId, testLaunchUrl = authenticateUrl,status =
AssessmentOrderAcknowledgement.acknowledgedStatus, statusDetails = "", statusDate = LocalDate.now())
val aoaFailed = AssessmentOrderAcknowledgement(
customerId = "cust-id", receiptId = "receipt-id", orderId = orderId, testLaunchUrl = authenticateUrl,
status = AssessmentOrderAcknowledgement.errorStatus, statusDetails = "", statusDate = LocalDate.now())
val acaCompleted = AssessmentCancelAcknowledgementResponse(
AssessmentCancelAcknowledgementResponse.completedStatus,
"Everything is fine!", statusDate = LocalDate.now()
)
val acaError = AssessmentCancelAcknowledgementResponse(
AssessmentCancelAcknowledgementResponse.errorStatus,
"Something went wrong!", LocalDate.now()
)
val postcode : Option[PostCode]= Some("WC2B 4")
val emailContactDetails = "emailfjjfjdf@mailinator.com"
val contactDetails = ContactDetails(outsideUk = false, Address("Aldwych road"), postcode, Some("UK"), emailContactDetails, "111111")
val connectorErrorMessage = "Error in connector"
val auditDetails = Map("userId" -> userId)
val auditDetailsWithEmail = auditDetails + ("email" -> emailContactDetails)
val success = Future.successful(unit)
val appRepositoryMock = mock[GeneralApplicationRepository]
val cdRepositoryMock = mock[ContactDetailsRepository]
val phase2TestRepositoryMock = mock[Phase2TestRepository]
val onlineTestsGatewayClientMock = mock[OnlineTestsGatewayClient]
val tokenFactoryMock = mock[UUIDFactory]
val emailClientMock = mock[OnlineTestEmailClient]
val auditServiceMock = mock[AuditService]
val phase3TestServiceMock = mock[Phase3TestService]
val siftServiceMock = mock[ApplicationSiftService]
val appConfigMock = mock[MicroserviceAppConfig]
when(appConfigMock.onlineTestsGatewayConfig).thenReturn(gatewayConfig)
val onlineTestApplication = OnlineTestApplication(applicationId = "appId",
applicationStatus = ApplicationStatus.SUBMITTED,
userId = "userId",
testAccountId = "testAccountId",
guaranteedInterview = false,
needsOnlineAdjustments = false,
needsAtVenueAdjustments = false,
preferredName = "Optimus",
lastName = "Prime1",
None,
None
)
val preferredNameSanitized = "Preferred Name"
val lastName = ""
val onlineTestApplication2 = onlineTestApplication.copy(applicationId = "appId2", userId = "userId2", lastName = "Prime2")
val adjustmentApplication = onlineTestApplication.copy(applicationId = "appId3", userId = "userId3", needsOnlineAdjustments = true)
val adjustmentApplication2 = onlineTestApplication.copy(applicationId = "appId4", userId = "userId4", needsOnlineAdjustments = true)
val candidates = List(onlineTestApplication, onlineTestApplication2)
def uuid: String = UUIDFactory.generateUUID()
val phase2Test = PsiTest(
inventoryId = uuid, orderId = uuid, assessmentId = uuid, reportId = uuid, normId = uuid, usedForResults = true,
testUrl = authenticateUrl, invitationDate = invitationDate
)
val phase2TestProfile = Phase2TestGroup(expirationDate,
List(phase2Test, phase2Test.copy(inventoryId = uuid))
)
val phase2TestProfileWithNoTest = Phase2TestGroup(expirationDate, Nil)
val phase2CompletedTestGroupWithAppId: Phase2TestGroupWithAppId = Phase2TestGroupWithAppId(
applicationId,
testGroup = phase2TestProfile.copy(
tests = phase2TestProfile.tests.map( t =>
t.copy(orderId = orderId, completedDateTime = Some(DateTime.now()))
)
)
)
val phase2NotCompletedTestGroupWithAppId: Phase2TestGroupWithAppId = Phase2TestGroupWithAppId(
applicationId,
testGroup = phase2TestProfile.copy(
tests = phase2TestProfile.tests.map( t =>
t.copy(orderId = orderId, completedDateTime = None)
)
)
)
val invigilatedTestProfile = Phase2TestGroup(
invigilatedExpirationDate, List(phase2Test.copy(inventoryId = uuid, invigilatedAccessCode = Some("accessCode")))
)
val invigilatedETrayApp = onlineTestApplication.copy(
needsOnlineAdjustments = true,
eTrayAdjustments = Some(AdjustmentDetail(invigilatedInfo = Some("e-tray help needed")))
)
val nonInvigilatedETrayApp = onlineTestApplication.copy(needsOnlineAdjustments = false)
when(phase2TestRepositoryMock.insertOrUpdateTestGroup(any[String], any[Phase2TestGroup]))
.thenReturnAsync()
when(phase2TestRepositoryMock.getTestGroup(any[String]))
.thenReturnAsync(Some(phase2TestProfile))
when(phase2TestRepositoryMock.resetTestProfileProgresses(any[String], any[List[ProgressStatus]]))
.thenReturnAsync()
// when(cdRepositoryMock.find(any[String])).thenReturn(Future.successful(
// ContactDetails(outsideUk = false, Address("Aldwych road"), Some("QQ1 1QQ"), Some("UK"), "email@test.com", "111111")))
when(cdRepositoryMock.find(any[String])).thenReturnAsync(contactDetails)
when(emailClientMock.sendOnlineTestInvitation(any[String], any[String], any[DateTime])(any[HeaderCarrier]))
.thenReturnAsync()
when(phase2TestRepositoryMock.updateGroupExpiryTime(any[String], any[DateTime], any[String]))
.thenReturnAsync()
when(appRepositoryMock.removeProgressStatuses(any[String], any[List[ProgressStatus]]))
.thenReturnAsync()
when(phase2TestRepositoryMock.phaseName).thenReturn("phase2")
val realTimeResults = PsiRealTimeResults(tScore = 10.0, rawScore = 20.0, reportUrl = None)
val actor = ActorSystem()
val phase2TestService = new Phase2TestService(
appRepositoryMock,
cdRepositoryMock,
phase2TestRepositoryMock,
onlineTestsGatewayClientMock,
tokenFactoryMock,
dateTimeFactoryMock,
emailClientMock,
auditServiceMock,
authProviderClientMock,
phase3TestServiceMock,
siftServiceMock,
appConfigMock,
stcEventServiceMock,
actor
)
}
}
| hmrc/fset-faststream | test/services/onlinetesting/phase2/Phase2TestServiceSpec.scala | Scala | apache-2.0 | 44,698 |
package models.generator
import io.apibuilder.generator.v0.models.{File, InvocationForm}
import io.apibuilder.spec.v0.models.{Enum, EnumValue, Field, Model, Service, Union, UnionType}
import lib.Text
import lib.generator.{CodeGenerator, GeneratorUtil}
import models.generator.JavaDatatypes.NativeDatatype
/**
*
* Author: jkenny
* Date: 28/05/2015
*/
object JavaClasses extends CodeGenerator {
/**
* Invokes the code generators, returning either a list of errors
* or the result of the code generation.
*/
override def invoke(form: InvocationForm): Either[Seq[String], Seq[File]] = invoke(form, addHeader = true)
def invoke(form: InvocationForm, addHeader: Boolean = false): Either[Seq[String], Seq[File]] = Right(generateCode(form, addHeader))
private def generateCode(form: InvocationForm, addHeader: Boolean): Seq[File] = {
val header =
if (addHeader) Some(new ApidocComments(form.service.version, form.userAgent).forClassFile)
else None
new Generator(form.service, header).generateSourceFiles()
}
class Generator(service: Service, header: Option[String]) {
private val datatypeResolver = GeneratorUtil.datatypeResolver(service)
private val safeNamespace = service.namespace.split("\\\\.").map { JavaUtil.checkForReservedWord }.mkString(".")
def createDirectoryPath(namespace: String) = namespace.replace('.', '/')
// Keep everything (unions, enums, models, etc) in the same package to avoid headaches around importing
private val modelsPackageDeclaration = s"package $safeNamespace.models;"
private val modelsDirectoryPath = createDirectoryPath(s"$safeNamespace.models")
def generateSourceFiles() = {
val generatedEnums = service.enums.map { generateEnum }
val generatedUnionTypes = service.unions.map { generateUnionType }
val generatedUndefinedUnionTypes = service.unions.map { generateUndefinedUnionType }
val generatedNativeWrappers = service.unions.flatMap { union =>
union.types.map(toJavaDatatype(_)).flatten.collect {
case ndt: NativeDatatype => generateNativeWrapper(union, ndt)
}
}
val generatedModels = service.models.map { model =>
val relatedUnions = service.unions.filter(_.types.exists(_.`type` == model.name))
generateModel(model, relatedUnions)
}
generatedEnums ++
generatedUnionTypes ++
generatedUndefinedUnionTypes ++
generatedNativeWrappers ++
generatedModels
}
private def toJavaDatatype(unionType: UnionType): Option[JavaDatatype] = {
datatypeResolver.parse(unionType.`type`, true).map(JavaDatatype(_)).toOption
}
def generateEnum(enum: Enum): File = {
def generateEnumValue(enumValue: EnumValue): String = {
commentFromOpt(enumValue.description) +
enumValue.name.toUpperCase
}
val className = JavaUtil.toClassName(enum.name)
val enumDeclaration = {
import lib.Text._
commentFromOpt(enum.description) +
s"public enum $className {\\n" +
enum.values.map { generateEnumValue }.mkString(",\\n").indentString(4) + "\\n" +
"}"
}
val source = header.fold(""){ _ + "\\n" } +
modelsPackageDeclaration + "\\n\\n" +
enumDeclaration
File(s"$className.java", Some(modelsDirectoryPath), source)
}
def generateUnionType(union: Union): File = {
val className = JavaUtil.toClassName(union.name)
val unionDeclaration = commentFromOpt(union.description) +
s"public interface $className {}"
val source = header.fold(""){ _ + "\\n" } +
modelsPackageDeclaration + "\\n\\n" +
unionDeclaration
File(s"$className.java", Some(modelsDirectoryPath), source)
}
def generateUndefinedUnionType(union: Union): File = {
import lib.Datatype
val className = JavaUtil.toClassName(union.name)
val name = s"${className}UndefinedType"
val undefinedUnionTypeModel = Model(
name = name,
plural = s"${name}s",
description = Some(s"Provides future compatibility in clients - in the future, when a type is added to the union $className, it will need to be handled in the client code. This implementation will deserialize these future types as an instance of this class."),
fields = Seq(
Field(
name = "description",
description = Some(s"Information about the type that we received that is undefined in this version of the client."),
`type` = Datatype.Primitive.String.name,
required = true
)
)
)
generateModel(undefinedUnionTypeModel, Seq(union))
}
def generateNativeWrapper(union: Union, nativeDatatype: NativeDatatype): File = {
val className = JavaUtil.toClassName(union.name)
val datatypeClassName = JavaUtil.toClassName(nativeDatatype.shortName)
val name = s"${className}${datatypeClassName}"
val wrapperModel = Model(
name = name,
plural = s"${name}s",
description = Some(s"Wrapper class to support the datatype '${nativeDatatype.apidocType}' in the union $className."),
fields = Seq(
Field(
name = "value",
`type` = nativeDatatype.apidocType,
required = true
)
)
)
generateModel(wrapperModel, Seq(union))
}
def generateModel(model: Model, relatedUnions: Seq[Union]): File = {
def generateClassMember(field: Field) = {
val datatype = datatypeResolver.parse(field.`type`, field.required).getOrElse {
sys.error(s"Unable to parse datatype ${field.`type`}")
}
val javaDatatype = JavaDatatype(datatype)
val defaultValue = field.default.fold("") { " = " + javaDatatype.valueFromString(_) }
val name = JavaUtil.checkForReservedWord(
Text.snakeToCamelCase(field.name)
)
commentFromOpt(field.description) +
s"private ${javaDatatype.name} ${name}$defaultValue;"
}
val className = JavaUtil.toClassName(model.name)
val classDeclaration = {
import lib.Text._
val noArgsConstructor = s"public $className() {}"
val unionClassNames = relatedUnions.map { u => JavaUtil.toClassName(u.name) }
val implementsClause =
if (unionClassNames.isEmpty) ""
else unionClassNames.mkString(" implements ", ", ", "")
commentFromOpt(model.description) +
s"public class $className$implementsClause {\\n" +
(
model.fields.map { generateClassMember }.mkString("\\n\\n") + "\\n\\n" +
noArgsConstructor
).indentString(4) + "\\n" +
"}"
}
val source = header.fold(""){ _ + "\\n" } +
modelsPackageDeclaration + "\\n\\n" +
classDeclaration
File(s"$className.java", Some(modelsDirectoryPath), source)
}
private def commentFromOpt(opt: Option[String]) = {
opt.fold("") { s => JavaUtil.textToComment(s) + "\\n" }
}
}
}
| gheine/apidoc-generator | java-generator/src/main/scala/models/generator/JavaClasses.scala | Scala | mit | 7,069 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.execution.python
import java.io.File
import scala.collection.mutable.ArrayBuffer
import org.apache.spark.{SparkEnv, TaskContext}
import org.apache.spark.api.python.ChainedPythonFunctions
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.catalyst.InternalRow
import org.apache.spark.sql.catalyst.expressions._
import org.apache.spark.sql.execution.{SparkPlan, UnaryExecNode}
import org.apache.spark.sql.types.{DataType, StructField, StructType}
import org.apache.spark.util.Utils
/**
* A physical plan that evaluates a [[PythonUDF]], one partition of tuples at a time.
*
* Python evaluation works by sending the necessary (projected) input data via a socket to an
* external Python process, and combine the result from the Python process with the original row.
*
* For each row we send to Python, we also put it in a queue first. For each output row from Python,
* we drain the queue to find the original input row. Note that if the Python process is way too
* slow, this could lead to the queue growing unbounded and spill into disk when run out of memory.
*
* Here is a diagram to show how this works:
*
* Downstream (for parent)
* / \
* / socket (output of UDF)
* / \
* RowQueue Python
* \ /
* \ socket (input of UDF)
* \ /
* upstream (from child)
*
* The rows sent to and received from Python are packed into batches (100 rows) and serialized,
* there should be always some rows buffered in the socket or Python process, so the pulling from
* RowQueue ALWAYS happened after pushing into it.
*/
abstract class EvalPythonExec(udfs: Seq[PythonUDF], resultAttrs: Seq[Attribute], child: SparkPlan)
extends UnaryExecNode {
override def output: Seq[Attribute] = child.output ++ resultAttrs
override def producedAttributes: AttributeSet = AttributeSet(resultAttrs)
private def collectFunctions(udf: PythonUDF): (ChainedPythonFunctions, Seq[Expression]) = {
udf.children match {
case Seq(u: PythonUDF) =>
val (chained, children) = collectFunctions(u)
(ChainedPythonFunctions(chained.funcs ++ Seq(udf.func)), children)
case children =>
// There should not be any other UDFs, or the children can't be evaluated directly.
assert(children.forall(_.find(_.isInstanceOf[PythonUDF]).isEmpty))
(ChainedPythonFunctions(Seq(udf.func)), udf.children)
}
}
protected def evaluate(
funcs: Seq[ChainedPythonFunctions],
argOffsets: Array[Array[Int]],
iter: Iterator[InternalRow],
schema: StructType,
context: TaskContext): Iterator[InternalRow]
protected override def doExecute(): RDD[InternalRow] = {
val inputRDD = child.execute().map(_.copy())
inputRDD.mapPartitions { iter =>
val context = TaskContext.get()
// The queue used to buffer input rows so we can drain it to
// combine input with output from Python.
val queue = HybridRowQueue(context.taskMemoryManager(),
new File(Utils.getLocalDir(SparkEnv.get.conf)), child.output.length)
context.addTaskCompletionListener[Unit] { ctx =>
queue.close()
}
val (pyFuncs, inputs) = udfs.map(collectFunctions).unzip
// flatten all the arguments
val allInputs = new ArrayBuffer[Expression]
val dataTypes = new ArrayBuffer[DataType]
val argOffsets = inputs.map { input =>
input.map { e =>
if (allInputs.exists(_.semanticEquals(e))) {
allInputs.indexWhere(_.semanticEquals(e))
} else {
allInputs += e
dataTypes += e.dataType
allInputs.length - 1
}
}.toArray
}.toArray
val projection = MutableProjection.create(allInputs, child.output)
val schema = StructType(dataTypes.zipWithIndex.map { case (dt, i) =>
StructField(s"_$i", dt)
})
// Add rows to queue to join later with the result.
val projectedRowIter = iter.map { inputRow =>
queue.add(inputRow.asInstanceOf[UnsafeRow])
projection(inputRow)
}
val outputRowIterator = evaluate(
pyFuncs, argOffsets, projectedRowIter, schema, context)
val joined = new JoinedRow
val resultProj = UnsafeProjection.create(output, output)
outputRowIterator.map { outputRow =>
resultProj(joined(queue.remove(), outputRow))
}
}
}
}
| jkbradley/spark | sql/core/src/main/scala/org/apache/spark/sql/execution/python/EvalPythonExec.scala | Scala | apache-2.0 | 5,303 |
/*
* Copyright (c) Microsoft. All rights reserved.
* Licensed under the MIT license. See LICENSE file in the project root for full license information.
*/
package org.apache.spark.streaming.api.csharp
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.csharp.SparkCLRFunSuite
class RddPreComputeProcessorSuite extends SparkCLRFunSuite {
test("RddPreComputeProcessor") {
val conf = new SparkConf().setAppName("test").setMaster("local").set("spark.testing", "true")
val sc = new SparkContext(conf)
val preComputeProcessor = new RddPreComputeProcessor[Long](
sc, "RddPreComputeProcessor-test", 1, 1, 1, StorageLevel.MEMORY_ONLY)
try {
val rdd1 = sc.range(1L, 10L, 1L)
preComputeProcessor.put(rdd1)
var stop = false
while (!stop) {
var preComputedResult1 = preComputeProcessor.get()
if (preComputedResult1.isEmpty) {
Thread.sleep(100)
} else {
stop = true
assert(preComputedResult1.size == 1)
}
}
// test bypass scenario because ackRdd() is not called
val rdd2 = sc.range(1L, 5L, 1L)
preComputeProcessor.put(rdd2)
var preComputedResult2 = preComputeProcessor.get()
assert(preComputedResult2.size == 1)
} finally {
preComputeProcessor.stop()
sc.stop()
}
}
}
| skaarthik/Mobius | scala/src/test/scala/org/apache/spark/streaming/api/csharp/RddPreComputeProcessorSuite.scala | Scala | mit | 1,391 |
/*
* Copyright 2016 Carlo Micieli
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.hascalator
package data
import Prelude._
/** A mergeable heap (also called a ''meldable'' heap) is an abstract data type, which is a heap supporting
* a merge operation.
*
* @tparam A the heap item type
* @author Carlo Micieli
* @since 0.0.1
*/
trait MergeableHeap[+A] extends Heap[A] {
type MH[B] <: MergeableHeap[B]
/** Combine the elements of `this` and `that` into a single heap.
*
* @usecase def merge(that: MergeableHeap[A]): MergeableHeap[A]
* @param that the other heap
* @param ord
* @return
*/
def merge[A1 >: A](that: MH[A1])(implicit ord: Ord[A1]): MH[A1]
}
object MergeableHeap {
/** Create an empty mergeable heap.
* @tparam A the key type
* @return an empty mergeable Heap
*/
def makeHeap[A: Ord]: MergeableHeap[A] = undefined
/** Build a new mergeable heap from a list
* @param xs a List
* @tparam A the key type
* @return a new Heap
*/
def fromList[A: Ord](xs: List[A]): MergeableHeap[A] = undefined
} | CarloMicieli/hascalator | core/src/main/scala/io/hascalator/data/MergeableHeap.scala | Scala | apache-2.0 | 1,611 |
package com.wbillingsley.handy;
import org.specs2.mutable._
import scala.concurrent.ExecutionContext.Implicits.global
import Ref._
import org.specs2.concurrent.ExecutionEnv
class RefSpec(implicit ee: ExecutionEnv) extends Specification {
case class TItem(id: Long, name: String)
/*
* Mimics a synchronous database
*/
class SynchronousDB {
val objMap = scala.collection.mutable.Map.empty[Long, TItem]
implicit val lum = new LookUp[TItem, Long] {
def one[K <: Long](r:Id[TItem, K]):Ref[TItem] = {
objMap.get(r.id) match {
case Some(x) => RefItself(x)
case _ => RefFailed(new NoSuchElementException("Nothing to look up"))
}
}
def many[K <: Long](r:Ids[TItem, K]):RefMany[TItem] = {
import Id._
for {
id <- r.ids.toRefMany
item <- one(id.asId[TItem])
} yield item
}
}
}
"Ref" should {
"support flatMap redirection OneToOne" in {
def x(i:Int):Ref[Int] = RefItself(i)
x(1) flatMap x must be_==(x(1))
}
"support flatMap redirection OneToOpt" in {
def x(i:Int):Ref[Int] = RefItself(i)
def xo(i:Int):RefOpt[Int] = RefSome(i)
x(1) flatMap xo must be_==(xo(1))
}
"support flatMap redirection OneToNone" in {
def x(i:Int):Ref[Int] = RefItself(i)
def xo(i:Int) = RefNone
x(1) flatMap xo must be_==(xo(1))
}
"support flatMap redirection OneToMany" in {
def x(i:Int):Ref[Int] = RefItself(i)
def xm(i:Int):RefMany[Int] = RefIterableOnce(Seq.fill(i)(i))
x(1) flatMap xm must be_==(xm(1))
}
"support 'for' syntactic sugar across Option" in {
val rfoo = "foo".itself
val optSome = Some(1)
val rRes = for {
foo <- rfoo
num <- optSome.toRef
foo2 <- rfoo
} yield foo.length + num + foo2.length
rRes.require.toFuture must be_==(7).await
}
"support 'for' syntactic sugar across Try" in {
import scala.util.{Try, Success, Failure}
val rfoo = "foo".itself
val optTry = Try { 1 }
val rRes = for {
foo <- rfoo
num <- optTry.toRef
foo2 <- rfoo
} yield foo.length + num + foo2.length
rRes.toFuture must be_==(7).await
}
"support GetId for objects extending HasStringId" in {
import Id._
case class MyFoo(_id:String, foo:String) extends HasStringId[MyFoo] {
def id = _id.asId[MyFoo]
}
val foo1 = MyFoo("1", "foo")
val foo1itself = foo1.itself
foo1itself.refId.require.toFuture must be_==("1".asId[MyFoo]).await
}
"support successful synchronous lookups" in {
val db = new SynchronousDB
// Put an item in the database
val item = TItem(1, "one")
db.objMap.put(1, item)
// import the implicit lookUp method
import db.lum
val a = LazyId(1L).apply[TItem]
a.lookUp.toFuture must be_==(TItem(1, "one")).await
}
"support unsuccessful synchronous lookups" in {
val db = new SynchronousDB
// Put an item in the database
val item = TItem(1, "one")
db.objMap.put(1, item)
// import the implicit lookUp method
import db.lum
LazyId.of[TItem](2L).toFuture must throwAn[NoSuchElementException].await
}
"implicitly find a lookup that takes a supertype of the key" in {
trait MyId {
def canonical:String
}
case class IntId(k:Int) extends MyId {
def canonical:String = k.toString
}
case class StringId(s:String) extends MyId {
def canonical:String = s
}
// a map with some dummy data
val objMap = scala.collection.mutable.Map("1" -> TItem(1L, "one"))
// a LookUp that accepts the superclass
implicit val lum = new LookUp[TItem, MyId] {
def one[K <: MyId](r:Id[TItem, K]):Ref[TItem] = {
objMap.get(r.id.canonical) match {
case Some(x) => RefItself(x)
case _ => RefFailed(new NoSuchElementException)
}
}
def many[K <: MyId](r:Ids[TItem, K]):RefMany[TItem] = {
for { id <- r.toSeqId.toRefMany; item <- one(id) } yield item
}
}
/*
* create refs using both notations. If these compile, the implicit has been found
*/
import Id._
val oneStr = LazyId.of[TItem](StringId("1"))
val oneInt = IntId(1).asId[TItem]
// Just check they resolve the same
val check = for {
s <- oneStr.lookUp
i <- oneInt.lookUp
} yield s == i
check.toFuture must be_==(true).await
}
"Support empty look ups" in {
var foo:LazyId[TItem, _] = LazyId.empty
foo.toRefOpt.toFutureOpt must be_==(None).await
}
"Support lookups of RefManys" in {
val db = new SynchronousDB
// Put items in the database
db.objMap.put(1, TItem(1, "one"))
db.objMap.put(2, TItem(2, "two"))
db.objMap.put(3, TItem(3, "three"))
db.objMap.put(4, TItem(4, "four"))
// import the implicit lookUp method
import db.lum
val str = Seq(1L, 2L, 3L, 4L)
val rm = RefManyById(str).of[TItem]
rm.collect.toFuture must be_==(
List(TItem(1, "one"), TItem(2, "two"), TItem(3, "three"), TItem(4, "four"))
).await
}
}
}
| wbillingsley/handy | handy/src/test/scala/com/wbillingsley/handy/RefSpec.scala | Scala | mit | 5,432 |
package org.alcaudon.core
import akka.actor.{Actor, ActorLogging}
import akka.cluster.ClusterEvent._
import akka.cluster.{Cluster, MemberStatus}
import org.alcaudon.clustering.Coordinator
class ClusterStatusListener extends Actor with ActorLogging {
import Coordinator.Protocol._
Cluster(context.system).subscribe(self, classOf[ClusterDomainEvent])
def receive = {
case MemberUp(member) => log.info(s"$member UP.")
case MemberExited(member) =>
context.parent ! NodeLeft(member.address)
log.info(s"$member EXITED.")
case MemberRemoved(m, previousState) =>
if (previousState == MemberStatus.Exiting) {
log.info(s"Member $m gracefully exited, REMOVED.")
} else {
log.info(s"$m downed after unreachable, REMOVED.")
}
context.parent ! NodeLeft(m.address)
case UnreachableMember(m) => log.info(s"$m UNREACHABLE")
case ReachableMember(m) => log.info(s"$m REACHABLE")
case s: CurrentClusterState => log.info(s"cluster state: $s")
}
override def postStop(): Unit = {
Cluster(context.system).unsubscribe(self)
super.postStop()
}
}
| fcofdez/alcaudon | src/main/scala/org/alcaudon/core/ClusterStatusListener.scala | Scala | apache-2.0 | 1,123 |
/*
,i::,
:;;;;;;;
;:,,::;.
1ft1;::;1tL
t1;::;1,
:;::; _____ __ ___ __
fCLff ;:: tfLLC / ___/ / |/ /____ _ _____ / /_
CLft11 :,, i1tffLi \\__ \\ ____ / /|_/ // __ `// ___// __ \\
1t1i .;; .1tf ___/ //___// / / // /_/ // /__ / / / /
CLt1i :,: .1tfL. /____/ /_/ /_/ \\__,_/ \\___//_/ /_/
Lft1,:;: , 1tfL:
;it1i ,,,:::;;;::1tti s_mach.explain_json
.t1i .,::;;; ;1tt Copyright (c) 2016 S-Mach, Inc.
Lft11ii;::;ii1tfL: Author: lance.gatlin@gmail.com
.L1 1tt1ttt,,Li
...1LLLL...
*/
package s_mach.explain_json.example
import org.scalatest.{FlatSpec, Matchers}
import ExtendedExampleUsage._
import s_mach.explain_json.Util._
import s_mach.explain_json.TestDI._
class JsonExplanationPrintJsonSchemaTest extends FlatSpec with Matchers {
"printJsonSchema" should "correctly render JsonSchema for String" in {
jsonExplanation_String.printJsonSchema[String]("http://test.org").prettyJson should be(
"""{
"$schema" : "http://json-schema.org/draft-04/schema#",
"id" : "http://test.org",
"type" : "string",
"additionalRules" : [ "string_rule1", "string_rule2" ],
"comments" : [ "string_comment1", "string_comment2" ]
}"""
)
}
"printJsonSchema[Int]" should "correctly render JsonSchema for Int" in {
jsonExplanation_Int.printJsonSchema[String]("http://test.org").prettyJson should be(
"""{
"$schema" : "http://json-schema.org/draft-04/schema#",
"id" : "http://test.org",
"type" : "integer",
"additionalRules" : [ "int_rule1", "int_rule2" ],
"comments" : [ "int_comment1", "int_comment2" ]
}"""
)
}
// Note: Option are elided when converting to JSON
"printJsonSchema[Option[String]]" should "correctly render JsonSchema for Option[String]" in {
jsonExplanation_Option_String.printJsonSchema[String]("http://test.org").prettyJson should be(
"""{
"$schema" : "http://json-schema.org/draft-04/schema#",
"id" : "http://test.org",
"type" : "string",
"additionalRules" : [ "string_rule1", "string_rule2" ],
"comments" : [ "string_comment1", "string_comment2" ]
}"""
)
}
"printJsonSchema[Name]" should "correctly render JsonSchema for Name" in {
jsonExplanation_Name.printJsonSchema[String]("http://test.org").prettyJson should be(
"""{
"$schema" : "http://json-schema.org/draft-04/schema#",
"id" : "http://test.org",
"type" : "object",
"properties" : {
"first" : {
"id" : "http://test.org/first",
"type" : "string",
"additionalRules" : [ "first_field_rule1", "first_field_rule2", "string_rule1", "string_rule2" ],
"comments" : [ "first_field_comment1", "first_field_comment2", "string_comment1", "string_comment2" ]
},
"middle" : {
"id" : "http://test.org/middle",
"type" : "string",
"additionalRules" : [ "string_rule1", "string_rule2" ],
"comments" : [ "string_comment1", "string_comment2" ]
},
"last" : {
"id" : "http://test.org/last",
"type" : "string",
"additionalRules" : [ "string_rule1", "string_rule2" ],
"comments" : [ "string_comment1", "string_comment2" ]
}
},
"additionalProperties" : true,
"required" : [ "first", "last" ],
"additionalRules" : [ "name_type_rule1", "name_type_rule2" ],
"comments" : [ "name_type_comment1", "name_type_comment2" ]
}"""
)
}
"printJsonSchema[Person]" should "correctly render JsonSchema for Person" in {
jsonExplanation_Person.printJsonSchema[String]("http://test.org").prettyJson should be(
"""{
"$schema" : "http://json-schema.org/draft-04/schema#",
"id" : "http://test.org",
"type" : "object",
"properties" : {
"name" : {
"id" : "http://test.org/name",
"type" : "object",
"properties" : {
"first" : {
"id" : "http://test.org/name/first",
"type" : "string",
"additionalRules" : [ "first_field_rule1", "first_field_rule2", "string_rule1", "string_rule2" ],
"comments" : [ "first_field_comment1", "first_field_comment2", "string_comment1", "string_comment2" ]
},
"middle" : {
"id" : "http://test.org/name/middle",
"type" : "string",
"additionalRules" : [ "string_rule1", "string_rule2" ],
"comments" : [ "string_comment1", "string_comment2" ]
},
"last" : {
"id" : "http://test.org/name/last",
"type" : "string",
"additionalRules" : [ "string_rule1", "string_rule2" ],
"comments" : [ "string_comment1", "string_comment2" ]
}
},
"additionalProperties" : true,
"required" : [ "first", "last" ],
"additionalRules" : [ "name_field_rule1", "name_field_rule2", "name_type_rule1", "name_type_rule2" ],
"comments" : [ "name_field_comment1", "name_field_comment2", "name_type_comment1", "name_type_comment2" ]
},
"age" : {
"id" : "http://test.org/age",
"type" : "integer",
"additionalRules" : [ "int_rule1", "int_rule2" ],
"comments" : [ "int_comment1", "int_comment2" ]
},
"friendIds" : {
"id" : "http://test.org/friendIds",
"type" : "array",
"minItems" : 0,
"uniqueItems" : false,
"additionalItems" : false,
"items" : {
"id" : "http://test.org/friendIds/1",
"type" : "integer",
"additionalRules" : [ "int_rule1", "int_rule2" ],
"comments" : [ "int_comment1", "int_comment2" ]
}
}
},
"additionalProperties" : true,
"required" : [ "name", "age", "friendIds" ],
"additionalRules" : [ "person_type_rule1", "person_type_rule2" ],
"comments" : [ "person_type_comment1", "person_type_comment2" ]
}"""
)
}
}
| S-Mach/s_mach.explain | explain_json/src/test/scala/s_mach/explain_json/example/JsonExplanationPrintJsonSchemaTest.scala | Scala | mit | 5,855 |
package com.tekacs.codegen
import java.sql.{Connection, ResultSet}
class DatabaseOps(val db: Connection, val schema: String, val excludedTables: Set[String]) {
import DatabaseOps._
lazy val foreignKeys: Set[ForeignKey] = {
val foreignKeys = db.getMetaData.getExportedKeys(null, schema, null)
results(foreignKeys).map { row =>
ForeignKey(
from = ColumnName(TableName(row.getString(FK_TABLE_NAME)), row.getString(FK_COLUMN_NAME)),
to = ColumnName(TableName(row.getString(PK_TABLE_NAME)), row.getString(PK_COLUMN_NAME))
)
}.toSet
}
def tables: Seq[Table] = {
val rs: ResultSet = db.getMetaData.getTables(null, schema, "%", Array("TABLE"))
results(rs).flatMap { row =>
val name = TableName(row.getString(TABLE_NAME))
if (excludedTables.contains(name.name)) None
else Some(Table(name, columns(name)))
}.toVector
}
def columns(tableName: TableName): Seq[Column] = {
val primaryKeySet = primaryKeys(tableName)
val cols = db.getMetaData.getColumns(null, schema, tableName.name, null)
results(cols).map { row =>
val name = ColumnName(tableName, cols.getString(COLUMN_NAME))
val isNullable = cols.getBoolean(NULLABLE)
val isPrimaryKey = primaryKeySet contains cols.getString(COLUMN_NAME)
val ref = foreignKeys.find(_.from == name).map(_.to)
val typ = cols.getString(TYPE_NAME)
Column(name, TypeName(typ), isNullable, isPrimaryKey, ref)
}.toVector
}
def primaryKeys(tableName: TableName): Set[String] = {
val resultSet = db.getMetaData.getPrimaryKeys(null, null, tableName.name)
results(resultSet).map(_.getString(COLUMN_NAME)).toSet
}
}
object DatabaseOps {
val TABLE_NAME = "TABLE_NAME"
val COLUMN_NAME = "COLUMN_NAME"
val TYPE_NAME = "TYPE_NAME"
val NULLABLE = "NULLABLE"
val PK_NAME = "pk_name"
val FK_TABLE_NAME = "fktable_name"
val FK_COLUMN_NAME = "fkcolumn_name"
val PK_TABLE_NAME = "pktable_name"
val PK_COLUMN_NAME = "pkcolumn_name"
def results(resultSet: ResultSet): Iterator[ResultSet] = {
new Iterator[ResultSet] {
def hasNext: Boolean = resultSet.next()
def next(): ResultSet = resultSet
}
}
case class ForeignKey(from: ColumnName, to: ColumnName)
trait DBName
case class TableName(name: String) extends DBName {
override def toString: String = name
}
trait DBType extends DBName
case class ColumnName(table: TableName, column: String) extends DBType {
override def toString: String = s"$table.$column"
}
case class TypeName(typ: String) extends DBType {
override def toString: String = typ
}
case class Column(name: ColumnName,
dbType: DBType,
isNullable: Boolean,
isPrimaryKey: Boolean,
ref: Option[ColumnName])
case class Table(name: TableName,
columns: Seq[Column])
}
| tekacs/scala-db-codegen | src/main/scala/com/tekacs/codegen/DatabaseOps.scala | Scala | apache-2.0 | 2,914 |
/*
Copyright (c) 2014, Marco Franzoni, Università di Bologna
All rights reserved.
Redistribution and use in source and binary forms, with or without modification,
are permitted provided that the following conditions are met:
1. Redistributions of source code must retain the above copyright notice, this list
of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright notice, this
list of conditions and the following disclaimer in the documentation and/or
other materials provided with the distribution.
3. Neither the name of the copyright holder nor the names of its contributors may
be used to endorse or promote products derived from this software without specific
prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY
EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT
SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT
OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR
TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE,
EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
*/
package extension
import akka.actor.ActorRef
import com.rti.dds.subscription.DataReader
class DDSNode[T](
val dataReader : DataReader,
val actor : ActorRef,
val adapter : DataReaderAdapter[T],
val take : Boolean) {
} | marcofranzoni/Akka-DDS-Extension | src/extension/DDSNode.scala | Scala | bsd-3-clause | 1,759 |
import XmlQuote.*
object Test {
def main(args: Array[String]): Unit = {
assert(xml"Hello Allan!" == Xml("Hello Allan!", Nil))
val name = new Object{}
assert(xml"Hello $name!" == Xml("Hello ??!", List(name)))
}
}
| dotty-staging/dotty | tests/run-macros/xml-interpolation-3/Test_2.scala | Scala | apache-2.0 | 231 |
package com.besuikerd.autologistics.common.lib
import scala.collection.mutable.Stack
package object extensions {
implicit class StackExtensions[A](val stack:Stack[A]) extends AnyVal{
}
implicit class IntStringExtensions(val s:String){
def optToInt:Option[Int] = try{
Some(s.toInt)
} catch{
case e:NumberFormatException => None
}
}
}
| besuikerd/AutoLogistics | src/main/scala/com/besuikerd/autologistics/common/lib/extensions/package.scala | Scala | gpl-2.0 | 386 |
/*
* Copyright (c) 2014 - 2015 Contributor. All rights reserved.
*/
package org.scalaide.debug.internal.expression
import scala.reflect.runtime.universe
import Names.Debugger
import Names.Scala
/**
* Sealed hierarchy for defining where `TransformationPhase` is
* relative to [[org.scalaide.debug.internal.expression.proxies.phases.TypeCheck]].
*/
sealed trait TypecheckRelation
class BeforeTypecheck extends TypecheckRelation
class IsTypecheck extends TypecheckRelation
class AfterTypecheck extends TypecheckRelation
/**
* Abstract representation of transformation phase, just transform expression tree to another tree
*
* @tparam Tpe where this phase is placed relative to `TypeCheck` phase
*/
trait TransformationPhase[+Tpe <: TypecheckRelation] {
/**
* Transforms current tree to new form.
* It is called only once per object lifetime.
*
* Result of this method is passed to another TransformationPhase instance.
*
* @param data data for transformation. Contains tree and metadata.
*/
def transform(data: TransformationPhaseData): TransformationPhaseData
/** Name of this phase - by default just simpleName of class */
def phaseName = this.getClass.getSimpleName
}
/**
* This is proxy-aware transformer.
* It works like TransformationPhase but skip all part of tree that is dynamic or is not a part of original expression.
*
* @tparam Tpe where this phase is placed relative to `TypeCheck` phase
*/
abstract class AstTransformer[+Tpe <: TypecheckRelation]
extends TransformationPhase[Tpe]
with AstHelpers {
import universe._
private var _data: TransformationPhaseData = _
/** Initial data passed to this transformer */
protected final def data: TransformationPhaseData = _data
/**
* Basic method for transforming a tree
* for setting further in tree it should call transformFurther but not transformSingleTree or transform method
* @param baseTree tree to transform
* @param transformFurther call it on tree node to recursively transform it further
*/
protected def transformSingleTree(baseTree: universe.Tree, transformFurther: universe.Tree => universe.Tree): universe.Tree
/**
* Main method for transformer, applies transformation.
*
* To modify the result (for example to add some meta-data) override it and use `super.transform`.
*/
override def transform(data: TransformationPhaseData): TransformationPhaseData = {
_data = data
val newTree = transformer.transform(data.tree)
data.after(phaseName, newTree)
}
/** Checks if symbol corresponds to some of methods on `scala.Dynamic`. */
private def isDynamicMethod(methodName: String) =
Scala.dynamicTraitMethods.contains(methodName)
/** Construction/destruction for `__context.newInstance` */
object NewInstanceCall {
import Debugger._
def apply(className: Tree, argList: Tree): Tree =
Apply(SelectMethod(contextParamName, newInstance), List(className, argList))
def unapply(tree: Tree): Option[(Tree, Tree)] = tree match {
case Apply(Select(Ident(TermName(`contextParamName`)), TermName(`newInstance`)), List(className, argList)) =>
Some(className → argList)
case _ => None
}
}
/** Transformer that skip all part of tree that is dynamic and it is not a part of original expression */
private val transformer = new universe.Transformer {
override def transform(baseTree: universe.Tree): universe.Tree = baseTree match {
// dynamic calls
case Apply(Select(on, name), args) if isDynamicMethod(name.toString) =>
Apply(Select(transformSingleTree(on, super.transform), name), args)
// on calls to `__context.newInstance` do not process the first argument
case NewInstanceCall(className, argList) =>
NewInstanceCall(className, transformSingleTree(argList, super.transform))
case tree =>
transformSingleTree(tree, super.transform)
}
}
}
| dragos/scala-ide | org.scala-ide.sdt.debug.expression/src/org/scalaide/debug/internal/expression/Transformers.scala | Scala | bsd-3-clause | 3,938 |
package colang.ast.parsed
/**
* Represents a type constructor.
* @param type_ container type
* @param parameters constructor parameters
* @param body constructor body
* @param native whether constructor is native
*/
class Constructor(val type_ : Type,
val parameters: Seq[Variable],
val body: CodeBlock,
val native: Boolean = false) extends Applicable {
val definitionSite = None
/**
* Checks if the constructor is a copy constructor
*/
def isCopyConstructor: Boolean = (parameters map { _.type_ }) == Seq(type_)
/**
* Checks if the constructor is default constructor.
*/
def isDefaultConstructor: Boolean = parameters.isEmpty
/**
* Constructs a string from the constructor's signature: its parameter types.
* @return signature string
*/
def signatureString: String = {
val typeName = type_.qualifiedName
val parameterTypes = parameters map { _.type_.qualifiedName } mkString ", "
s"$typeName.constructor($parameterTypes)"
}
}
| merkispavel/colang | src/main/scala/colang/ast/parsed/Constructor.scala | Scala | mit | 1,054 |
/**
* Copyright (c) 2007-2011 Eric Torreborre <etorreborre@yahoo.com>
*
* Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated
* documentation files (the "Software"), to deal in the Software without restriction, including without limitation
* the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software,
* and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in all copies or substantial portions of
* the Software. Neither the name of specs nor the names of its contributors may be used to endorse or promote
* products derived from this software without specific prior written permission.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED
* TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
* THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF
* CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
* DEALINGS IN THE SOFTWARE.
*/
package org.specs.samples
import org.specs._
/**
* Sample specification.
* This specification can be executed with: scala -cp <your classpath> ${package}.ListTest
* Or using maven: mvn test
*
* For more information on how to write or run specifications, please visit: http://code.google.com/p/specs.
*
*/
class ListTest extends SpecificationWithJUnit {
"A List" should {
"have a size method returning the number of elements in the list" in {
List(1, 2, 3).size must_== 3
}
// add more examples here
// ...
}
}
| stuhood/specs | src/test/scala/org/specs/samples/mavenArchetypeSpec.scala | Scala | mit | 1,860 |
package com.art4ul.graph.undirected
import com.art4ul.graph.undirected.UndirectedGraph._
import org.scalatest.{FunSpec, Matchers}
/**
* Created by artsemsemianenka on 4/26/16.
*/
class GraphSearchSpec extends FunSpec with Matchers {
describe("Common Search Spec") {
describe("BreadthFirstSearch"){
/**
* Graph :
*
* 0 -- 2
* | /
* 1 3
*
*/
it("should find connected vertex") {
val graph = new UndirectedGraph(4)
graph += 0 <-> 2 += 0 <-> 1 += 1 <-> 2
val search = new BreadthFirstSearch(graph,0)
search.connected(2) shouldBe true
search.connected(1) shouldBe true
search.connected(3) shouldBe false
search.vertexConnected() shouldBe 3
}
/**
* Graph :
*
* 1 - 3 - 7 - 12
* / \\
* 0 11
* \\ /
* 2 - 4 -5 - 8 - 10
* \\ /
* 6 - 9
*/
it("should return path to vertex"){
val graph = new UndirectedGraph(
0 <-> 1,
0 <-> 2,
1 <-> 3,
3 <-> 7,
7 <-> 12,
12 <-> 11,
11 <-> 10,
10 <-> 8,
10 <-> 9,
8 <-> 5,
5 <-> 4,
9 <-> 6,
6 <-> 4,
4 <-> 2
)
val search = new BreadthFirstSearch(graph,0)
search.hasPathTo(7) shouldBe true
search.path(7) shouldBe List(0,1,3,7)
search.hasPathTo(8) shouldBe true
search.path(8) shouldBe List(0,2,4,5,8)
}
}
describe("DepthFirstSearch"){
/**
* Graph :
*
* 0 -> 2
* | /
* V/
* 1 3
*/
it("should find connected vertex") {
val graph = new UndirectedGraph(4)
graph += 0 <-> 2 += 0 <-> 1 += 1 <-> 2
val search = new DepthFirstSearch(graph,0)
search.connected(2) shouldBe true
search.connected(1) shouldBe true
search.connected(3) shouldBe false
search.vertexConnected() shouldBe 3
}
/**
* Graph :
*
* 1 - 3 - 8
* /
* 0 6
* \\ / \\
* 2 - 4 7
* \\ /
* 5
*/
it("should return path to vertex"){
val graph = new UndirectedGraph(
0 <-> 1,
0 <-> 2,
1 <-> 3,
3 <-> 8,
2 <-> 4,
4 <-> 6,
4 <-> 5,
6 <-> 7,
5 <-> 7
)
val search = new DepthFirstSearch(graph,0)
search.hasPathTo(8) shouldBe true
search.path(8) shouldBe List(0,1,3,8)
search.hasPathTo(7) shouldBe true
search.path(6) shouldBe List(0,2,4,5,7,6)
}
}
}
}
| art4ul/AlgorithmSandbox | src/test/scala/com/art4ul/graph/undirected/GraphSearchSpec.scala | Scala | apache-2.0 | 2,959 |
package com.arcusys.learn.liferay.util
import java.util.Locale
import com.liferay.portal.kernel.model.Country
/**
* User: Yulia.Glushonkova
* Date: 18.08.14
*/
object CountryUtilHelper {
def getName(country: Country) = country.getName(Locale.getDefault)
}
| arcusys/Valamis | learn-liferay700-services/src/main/scala/com/arcusys/learn/liferay/util/CountryUtilHelper.scala | Scala | gpl-3.0 | 265 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.shuffle
import java.util.concurrent.CountDownLatch
import java.util.concurrent.atomic.AtomicInteger
import org.mockito.Mockito._
import org.scalatest.concurrent.Timeouts
import org.scalatest.time.SpanSugar._
import org.apache.spark.{SparkConf, SparkFunSuite, TaskContext}
class ShuffleMemoryManagerSuite extends SparkFunSuite with Timeouts {
val nextTaskAttemptId = new AtomicInteger()
/** Launch a thread with the given body block and return it. */
private def startThread(name: String)(body: => Unit): Thread = {
val thread = new Thread("ShuffleMemorySuite " + name) {
override def run() {
try {
val taskAttemptId = nextTaskAttemptId.getAndIncrement
val mockTaskContext = mock(classOf[TaskContext], RETURNS_SMART_NULLS)
when(mockTaskContext.taskAttemptId()).thenReturn(taskAttemptId)
TaskContext.setTaskContext(mockTaskContext)
body
} finally {
TaskContext.unset()
}
}
}
thread.start()
thread
}
test("single task requesting memory") {
val manager = ShuffleMemoryManager.createForTesting(maxMemory = 1000L)
assert(manager.tryToAcquire(100L) === 100L)
assert(manager.tryToAcquire(400L) === 400L)
assert(manager.tryToAcquire(400L) === 400L)
assert(manager.tryToAcquire(200L) === 100L)
assert(manager.tryToAcquire(100L) === 0L)
assert(manager.tryToAcquire(100L) === 0L)
manager.release(500L)
assert(manager.tryToAcquire(300L) === 300L)
assert(manager.tryToAcquire(300L) === 200L)
manager.releaseMemoryForThisTask()
assert(manager.tryToAcquire(1000L) === 1000L)
assert(manager.tryToAcquire(100L) === 0L)
}
test("two threads requesting full memory") {
// Two threads request 500 bytes first, wait for each other to get it, and then request
// 500 more; we should immediately return 0 as both are now at 1 / N
val manager = ShuffleMemoryManager.createForTesting(maxMemory = 1000L)
class State {
var t1Result1 = -1L
var t2Result1 = -1L
var t1Result2 = -1L
var t2Result2 = -1L
}
val state = new State
val t1 = startThread("t1") {
val r1 = manager.tryToAcquire(500L)
state.synchronized {
state.t1Result1 = r1
state.notifyAll()
while (state.t2Result1 === -1L) {
state.wait()
}
}
val r2 = manager.tryToAcquire(500L)
state.synchronized { state.t1Result2 = r2 }
}
val t2 = startThread("t2") {
val r1 = manager.tryToAcquire(500L)
state.synchronized {
state.t2Result1 = r1
state.notifyAll()
while (state.t1Result1 === -1L) {
state.wait()
}
}
val r2 = manager.tryToAcquire(500L)
state.synchronized { state.t2Result2 = r2 }
}
failAfter(20 seconds) {
t1.join()
t2.join()
}
assert(state.t1Result1 === 500L)
assert(state.t2Result1 === 500L)
assert(state.t1Result2 === 0L)
assert(state.t2Result2 === 0L)
}
test("tasks cannot grow past 1 / N") {
// Two tasks request 250 bytes first, wait for each other to get it, and then request
// 500 more; we should only grant 250 bytes to each of them on this second request
val manager = ShuffleMemoryManager.createForTesting(maxMemory = 1000L)
class State {
var t1Result1 = -1L
var t2Result1 = -1L
var t1Result2 = -1L
var t2Result2 = -1L
}
val state = new State
val t1 = startThread("t1") {
val r1 = manager.tryToAcquire(250L)
state.synchronized {
state.t1Result1 = r1
state.notifyAll()
while (state.t2Result1 === -1L) {
state.wait()
}
}
val r2 = manager.tryToAcquire(500L)
state.synchronized { state.t1Result2 = r2 }
}
val t2 = startThread("t2") {
val r1 = manager.tryToAcquire(250L)
state.synchronized {
state.t2Result1 = r1
state.notifyAll()
while (state.t1Result1 === -1L) {
state.wait()
}
}
val r2 = manager.tryToAcquire(500L)
state.synchronized { state.t2Result2 = r2 }
}
failAfter(20 seconds) {
t1.join()
t2.join()
}
assert(state.t1Result1 === 250L)
assert(state.t2Result1 === 250L)
assert(state.t1Result2 === 250L)
assert(state.t2Result2 === 250L)
}
test("tasks can block to get at least 1 / 2N memory") {
// t1 grabs 1000 bytes and then waits until t2 is ready to make a request. It sleeps
// for a bit and releases 250 bytes, which should then be granted to t2. Further requests
// by t2 will return false right away because it now has 1 / 2N of the memory.
val manager = ShuffleMemoryManager.createForTesting(maxMemory = 1000L)
class State {
var t1Requested = false
var t2Requested = false
var t1Result = -1L
var t2Result = -1L
var t2Result2 = -1L
var t2WaitTime = 0L
}
val state = new State
val t1 = startThread("t1") {
state.synchronized {
state.t1Result = manager.tryToAcquire(1000L)
state.t1Requested = true
state.notifyAll()
while (!state.t2Requested) {
state.wait()
}
}
// Sleep a bit before releasing our memory; this is hacky but it would be difficult to make
// sure the other thread blocks for some time otherwise
Thread.sleep(300)
manager.release(250L)
}
val t2 = startThread("t2") {
state.synchronized {
while (!state.t1Requested) {
state.wait()
}
state.t2Requested = true
state.notifyAll()
}
val startTime = System.currentTimeMillis()
val result = manager.tryToAcquire(250L)
val endTime = System.currentTimeMillis()
state.synchronized {
state.t2Result = result
// A second call should return 0 because we're now already at 1 / 2N
state.t2Result2 = manager.tryToAcquire(100L)
state.t2WaitTime = endTime - startTime
}
}
failAfter(20 seconds) {
t1.join()
t2.join()
}
// Both threads should've been able to acquire their memory; the second one will have waited
// until the first one acquired 1000 bytes and then released 250
state.synchronized {
assert(state.t1Result === 1000L, "t1 could not allocate memory")
assert(state.t2Result === 250L, "t2 could not allocate memory")
assert(state.t2WaitTime > 200, s"t2 waited less than 200 ms (${state.t2WaitTime})")
assert(state.t2Result2 === 0L, "t1 got extra memory the second time")
}
}
test("releaseMemoryForThisTask") {
// t1 grabs 1000 bytes and then waits until t2 is ready to make a request. It sleeps
// for a bit and releases all its memory. t2 should now be able to grab all the memory.
val manager = ShuffleMemoryManager.createForTesting(maxMemory = 1000L)
class State {
var t1Requested = false
var t2Requested = false
var t1Result = -1L
var t2Result1 = -1L
var t2Result2 = -1L
var t2Result3 = -1L
var t2WaitTime = 0L
}
val state = new State
val t1 = startThread("t1") {
state.synchronized {
state.t1Result = manager.tryToAcquire(1000L)
state.t1Requested = true
state.notifyAll()
while (!state.t2Requested) {
state.wait()
}
}
// Sleep a bit before releasing our memory; this is hacky but it would be difficult to make
// sure the other task blocks for some time otherwise
Thread.sleep(300)
manager.releaseMemoryForThisTask()
}
val t2 = startThread("t2") {
state.synchronized {
while (!state.t1Requested) {
state.wait()
}
state.t2Requested = true
state.notifyAll()
}
val startTime = System.currentTimeMillis()
val r1 = manager.tryToAcquire(500L)
val endTime = System.currentTimeMillis()
val r2 = manager.tryToAcquire(500L)
val r3 = manager.tryToAcquire(500L)
state.synchronized {
state.t2Result1 = r1
state.t2Result2 = r2
state.t2Result3 = r3
state.t2WaitTime = endTime - startTime
}
}
failAfter(20 seconds) {
t1.join()
t2.join()
}
// Both tasks should've been able to acquire their memory; the second one will have waited
// until the first one acquired 1000 bytes and then released all of it
state.synchronized {
assert(state.t1Result === 1000L, "t1 could not allocate memory")
assert(state.t2Result1 === 500L, "t2 didn't get 500 bytes the first time")
assert(state.t2Result2 === 500L, "t2 didn't get 500 bytes the second time")
assert(state.t2Result3 === 0L, s"t2 got more bytes a third time (${state.t2Result3})")
assert(state.t2WaitTime > 200, s"t2 waited less than 200 ms (${state.t2WaitTime})")
}
}
test("tasks should not be granted a negative size") {
val manager = ShuffleMemoryManager.createForTesting(maxMemory = 1000L)
manager.tryToAcquire(700L)
val latch = new CountDownLatch(1)
startThread("t1") {
manager.tryToAcquire(300L)
latch.countDown()
}
latch.await() // Wait until `t1` calls `tryToAcquire`
val granted = manager.tryToAcquire(300L)
assert(0 === granted, "granted is negative")
}
}
| ArvinDevel/onlineAggregationOnSparkV2 | core/src/test/scala/org/apache/spark/shuffle/ShuffleMemoryManagerSuite.scala | Scala | apache-2.0 | 10,200 |
/*
* Copyright 2001-2016 Artima, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.scalatest
import matchers.{AMatcher, AnMatcher}
import exceptions.TestFailedException
import SharedHelpers.serializeRoundtrip
import org.scalatest.matchers.{BePropertyMatchResult, BePropertyMatcher}
class MatchersSerializableSpec extends FunSpec {
import Matchers._
describe("Matchers") {
it("'a should be a AMatcher' syntax should produce Serializable TestFailedException") {
val positiveNumber = AMatcher[Int]("positive number") { _ > 0 }
val e = intercept[TestFailedException] {
-1 should be a positiveNumber
}
serializeRoundtrip(e)
}
it("'a should be a AnMatcher' syntax should produce Serializable TestFailedException") {
val evenNumber = AnMatcher[Int]("even number") { _ % 2 == 0 }
val e = intercept[TestFailedException] {
11 should be an evenNumber
}
serializeRoundtrip(e)
}
it("'a should be theSameInstanceAs b' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test 1" should be theSameInstanceAs "test 2"
}
serializeRoundtrip(e)
}
// SKIP-SCALATESTJS,NATIVE-START
it("'a should be a 'file' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
class NotFileMock extends Serializable {
def file: Boolean = false
def directory: Boolean = true
def exists: Boolean = true
override def toString = "NotFileMock"
}
(new NotFileMock) should be a 'file
}
serializeRoundtrip(e)
}
it("'a should be an 'file' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
class NotFileMock extends Serializable {
def file: Boolean = false
def directory: Boolean = true
def exists: Boolean = true
override def toString = "NotFileMock"
}
(new NotFileMock) should be an 'file
}
serializeRoundtrip(e)
}
// SKIP-SCALATESTJS,NATIVE-END
it("'a should be a BePropertyMatcher' should produce Serializable TestFailedException") {
class NonEmptyStringBePropertyMatcher extends BePropertyMatcher[String] {
def apply(value: String) = {
new BePropertyMatchResult(!value.isEmpty, "non-empty string")
}
}
val e = intercept[TestFailedException] {
"" should be a (new NonEmptyStringBePropertyMatcher)
}
serializeRoundtrip(e)
}
it("'a should be an BePropertyMatcher' should produce Serializable TestFailedException") {
class EmptyStringBePropertyMatcher extends BePropertyMatcher[String] {
def apply(value: String) = {
new BePropertyMatchResult(value.isEmpty, "empty string")
}
}
val e = intercept[TestFailedException] {
"test" should be an (new EmptyStringBePropertyMatcher)
}
serializeRoundtrip(e)
}
it("'a should be definedAt b' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
List(1, 2, 3) should be definedAt 4
}
serializeRoundtrip(e)
}
it("'a should include regex (\\"a(b*)c\\" withGroup \\"bb\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should include regex ("a(b*)c" withGroup "bb")
}
serializeRoundtrip(e)
}
it("'a should include regex (\\"a(b*)c\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should include regex ("a(b*)c")
}
serializeRoundtrip(e)
}
it("'a should startWith regex (\\"a(b*)c\\" withGroup \\"bb\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should startWith regex ("a(b*)c" withGroup "bb")
}
serializeRoundtrip(e)
}
it("'a should startWith regex (\\"a(b*)c\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should startWith regex ("a(b*)c")
}
serializeRoundtrip(e)
}
it("'a should endWith regex (\\"a(b*)c\\" withGroup \\"bb\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should endWith regex ("a(b*)c" withGroup "bb")
}
serializeRoundtrip(e)
}
it("'a should endWith regex (\\"a(b*)c\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should endWith regex ("a(b*)c")
}
serializeRoundtrip(e)
}
it("'a should fullyMatch regex (\\"a(b*)c\\" withGroup \\"bb\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should fullyMatch regex ("a(b*)c" withGroup "bb")
}
serializeRoundtrip(e)
}
it("'a should fullyMatch regex (\\"a(b*)c\\")' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should fullyMatch regex ("a(b*)c")
}
serializeRoundtrip(e)
}
it("'a should have length (2L)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should have length (2L)
}
serializeRoundtrip(e)
}
it("'a should have size (2L)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
"test" should have size (2L)
}
serializeRoundtrip(e)
}
it("'a should have message (xxx)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
new RuntimeException("test") should have message ("testing")
}
serializeRoundtrip(e)
}
it("'all(a) should not equal (b)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
all(List(1, 2, 3)) should not equal (2)
}
serializeRoundtrip(e)
}
it("'all(a) should not be (b)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
all(List(1, 2, 3)) should not be (2)
}
serializeRoundtrip(e)
}
it("'all(a) should not be <= (b)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
all(List(1, 2, 3)) should not be <= (2)
}
serializeRoundtrip(e)
}
it("'all(a) should not be >= (b)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
all(List(1, 2, 3)) should not be >= (2)
}
serializeRoundtrip(e)
}
it("'all(a) should not be < (b)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
all(List(1, 2, 3)) should not be < (2)
}
serializeRoundtrip(e)
}
it("'all(a) should not be > (b)' should produce Serializable TestFailedException") {
val e = intercept[TestFailedException] {
all(List(1, 2, 3)) should not be > (2)
}
serializeRoundtrip(e)
}
}
} | dotty-staging/scalatest | scalatest-test/src/test/scala/org/scalatest/MatchersSerializableSpec.scala | Scala | apache-2.0 | 7,865 |
package com.blogspot.nurkiewicz.akka.demo.fs
import java.io.File
import java.nio.file.Path
/**
* @author Tomasz Nurkiewicz
* @since 3/30/13, 10:13 PM
*/
sealed trait FileSystemChange
case class Created(fileOrDir: File) extends FileSystemChange
case class Deleted(fileOrDir: File) extends FileSystemChange
case class MonitorDir(path: Path)
| nurkiewicz/learning-akka | src/main/scala/com/blogspot/nurkiewicz/akka/demo/fs/FileSystemChange.scala | Scala | apache-2.0 | 347 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.mxnet
class TestUtil {
/**
* Allow override of data path. Default is <current directory>/data
* @return Data direcotry path ()may be relative)
*/
def getDataDirectory: String = {
var dataDir = System.getenv("MXNET_HOME")
if(dataDir == null) {
dataDir = "data"
} else {
if (dataDir.isEmpty) {
dataDir = "data"
}
}
dataDir
}
/**
* Create data file path based upon getDataDirectory
* @param relFile
* @return file path
*/
def dataFile(relFile: String): String = {
getDataDirectory + "/" + relFile
}
}
| dmlc/mxnet | scala-package/core/src/test/scala/org/apache/mxnet/TestUtil.scala | Scala | apache-2.0 | 1,413 |
package org.bitcoins.chain.config
import com.typesafe.config.Config
import org.bitcoins.chain.db.ChainDbManagement
import org.bitcoins.db._
import org.bitcoins.chain.models.{BlockHeaderDAO, BlockHeaderDbHelper}
import org.bitcoins.core.util.FutureUtil
import scala.concurrent.ExecutionContext
import scala.concurrent.Future
import scala.concurrent.Promise
import scala.util.Success
import scala.util.Failure
import java.nio.file.Path
/** Configuration for the Bitcoin-S chain verification module
* @param directory The data directory of the module
* @param confs Optional sequence of configuration overrides
*/
case class ChainAppConfig(
private val directory: Path,
private val confs: Config*)
extends AppConfig {
override protected[bitcoins] def configOverrides: List[Config] = confs.toList
override protected[bitcoins] val moduleName: String = "chain"
override protected[bitcoins] type ConfigType = ChainAppConfig
override protected[bitcoins] def newConfigOfType(
configs: Seq[Config]): ChainAppConfig =
ChainAppConfig(directory, configs: _*)
protected[bitcoins] def baseDatadir: Path = directory
/**
* Checks whether or not the chain project is initialized by
* trying to read the genesis block header from our block
* header table
*/
def isInitialized()(implicit ec: ExecutionContext): Future[Boolean] = {
val bhDAO =
BlockHeaderDAO()(ec = implicitly[ExecutionContext], appConfig = this)
val p = Promise[Boolean]()
val isDefinedOptF = {
bhDAO.read(chain.genesisBlock.blockHeader.hashBE).map(_.isDefined)
}
isDefinedOptF.onComplete {
case Success(bool) =>
logger.debug(s"Chain project is initialized")
p.success(bool)
case Failure(_) =>
logger.info(s"Chain project is not initialized")
p.success(false)
}
p.future
}
/** Initializes our chain project if it is needed
* This creates the necessary tables for the chain project
* and inserts preliminary data like the genesis block header
* */
override def initialize()(implicit ec: ExecutionContext): Future[Unit] = {
val isInitF = isInitialized()
isInitF.flatMap { isInit =>
if (isInit) {
FutureUtil.unit
} else {
val createdF = ChainDbManagement.createAll()(this, ec)
val genesisHeader =
BlockHeaderDbHelper.fromBlockHeader(height = 0,
bh =
chain.genesisBlock.blockHeader)
val blockHeaderDAO =
BlockHeaderDAO()(ec = implicitly[ExecutionContext], appConfig = this)
val bhCreatedF =
createdF.flatMap(_ => blockHeaderDAO.create(genesisHeader))
bhCreatedF.flatMap { _ =>
logger.info(s"Inserted genesis block header into DB")
FutureUtil.unit
}
}
}
}
lazy val filterHeaderBatchSize: Int =
config.getInt(s"${moduleName}.neutrino.filter-header-batch-size")
lazy val filterBatchSize: Int =
config.getInt(s"${moduleName}.neutrino.filter-batch-size")
}
object ChainAppConfig {
/** Constructs a chain verification configuration from the default Bitcoin-S
* data directory and given list of configuration overrides.
*/
def fromDefaultDatadir(confs: Config*): ChainAppConfig =
ChainAppConfig(AppConfig.DEFAULT_BITCOIN_S_DATADIR, confs: _*)
}
| bitcoin-s/bitcoin-s-core | chain/src/main/scala/org/bitcoins/chain/config/ChainAppConfig.scala | Scala | mit | 3,412 |
import scala.quoted.{ Quotes, Expr }
def h(m: Expr[M[String]])(using Quotes): Expr[Any] = g(m) | dotty-staging/dotty | tests/pos-macros/i7322/Test_2.scala | Scala | apache-2.0 | 95 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.catalyst.catalog
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.scalatest.BeforeAndAfterEach
import org.apache.spark.SparkFunSuite
import org.apache.spark.sql.AnalysisException
import org.apache.spark.sql.catalyst.{FunctionIdentifier, TableIdentifier}
import org.apache.spark.sql.catalyst.analysis.{FunctionAlreadyExistsException, NoSuchDatabaseException, NoSuchFunctionException}
import org.apache.spark.sql.catalyst.analysis.TableAlreadyExistsException
import org.apache.spark.sql.types.StructType
import org.apache.spark.util.Utils
/**
* A reasonable complete test suite (i.e. behaviors) for a [[ExternalCatalog]].
*
* Implementations of the [[ExternalCatalog]] interface can create test suites by extending this.
*/
abstract class ExternalCatalogSuite extends SparkFunSuite with BeforeAndAfterEach {
protected val utils: CatalogTestUtils
import utils._
protected def resetState(): Unit = { }
// Clear all state after each test
override def afterEach(): Unit = {
try {
resetState()
} finally {
super.afterEach()
}
}
// --------------------------------------------------------------------------
// Databases
// --------------------------------------------------------------------------
test("basic create and list databases") {
val catalog = newEmptyCatalog()
catalog.createDatabase(newDb("default"), ignoreIfExists = true)
assert(catalog.databaseExists("default"))
assert(!catalog.databaseExists("testing"))
assert(!catalog.databaseExists("testing2"))
catalog.createDatabase(newDb("testing"), ignoreIfExists = false)
assert(catalog.databaseExists("testing"))
assert(catalog.listDatabases().toSet == Set("default", "testing"))
catalog.createDatabase(newDb("testing2"), ignoreIfExists = false)
assert(catalog.listDatabases().toSet == Set("default", "testing", "testing2"))
assert(catalog.databaseExists("testing2"))
assert(!catalog.databaseExists("does_not_exist"))
}
test("get database when a database exists") {
val db1 = newBasicCatalog().getDatabase("db1")
assert(db1.name == "db1")
assert(db1.description.contains("db1"))
}
test("get database should throw exception when the database does not exist") {
intercept[AnalysisException] { newBasicCatalog().getDatabase("db_that_does_not_exist") }
}
test("list databases without pattern") {
val catalog = newBasicCatalog()
assert(catalog.listDatabases().toSet == Set("default", "db1", "db2"))
}
test("list databases with pattern") {
val catalog = newBasicCatalog()
assert(catalog.listDatabases("db").toSet == Set.empty)
assert(catalog.listDatabases("db*").toSet == Set("db1", "db2"))
assert(catalog.listDatabases("*1").toSet == Set("db1"))
assert(catalog.listDatabases("db2").toSet == Set("db2"))
}
test("drop database") {
val catalog = newBasicCatalog()
catalog.dropDatabase("db1", ignoreIfNotExists = false, cascade = false)
assert(catalog.listDatabases().toSet == Set("default", "db2"))
}
test("drop database when the database is not empty") {
// Throw exception if there are functions left
val catalog1 = newBasicCatalog()
catalog1.dropTable("db2", "tbl1", ignoreIfNotExists = false, purge = false)
catalog1.dropTable("db2", "tbl2", ignoreIfNotExists = false, purge = false)
intercept[AnalysisException] {
catalog1.dropDatabase("db2", ignoreIfNotExists = false, cascade = false)
}
resetState()
// Throw exception if there are tables left
val catalog2 = newBasicCatalog()
catalog2.dropFunction("db2", "func1")
intercept[AnalysisException] {
catalog2.dropDatabase("db2", ignoreIfNotExists = false, cascade = false)
}
resetState()
// When cascade is true, it should drop them
val catalog3 = newBasicCatalog()
catalog3.dropDatabase("db2", ignoreIfNotExists = false, cascade = true)
assert(catalog3.listDatabases().toSet == Set("default", "db1"))
}
test("drop database when the database does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.dropDatabase("db_that_does_not_exist", ignoreIfNotExists = false, cascade = false)
}
catalog.dropDatabase("db_that_does_not_exist", ignoreIfNotExists = true, cascade = false)
}
test("alter database") {
val catalog = newBasicCatalog()
val db1 = catalog.getDatabase("db1")
// Note: alter properties here because Hive does not support altering other fields
catalog.alterDatabase(db1.copy(properties = Map("k" -> "v3", "good" -> "true")))
val newDb1 = catalog.getDatabase("db1")
assert(db1.properties.isEmpty)
assert(newDb1.properties.size == 2)
assert(newDb1.properties.get("k") == Some("v3"))
assert(newDb1.properties.get("good") == Some("true"))
}
test("alter database should throw exception when the database does not exist") {
intercept[AnalysisException] {
newBasicCatalog().alterDatabase(newDb("does_not_exist"))
}
}
// --------------------------------------------------------------------------
// Tables
// --------------------------------------------------------------------------
test("the table type of an external table should be EXTERNAL_TABLE") {
val catalog = newBasicCatalog()
val table =
newTable("external_table1", "db2").copy(tableType = CatalogTableType.EXTERNAL)
catalog.createTable(table, ignoreIfExists = false)
val actual = catalog.getTable("db2", "external_table1")
assert(actual.tableType === CatalogTableType.EXTERNAL)
}
test("create table when the table already exists") {
val catalog = newBasicCatalog()
assert(catalog.listTables("db2").toSet == Set("tbl1", "tbl2"))
val table = newTable("tbl1", "db2")
intercept[TableAlreadyExistsException] {
catalog.createTable(table, ignoreIfExists = false)
}
}
test("drop table") {
val catalog = newBasicCatalog()
assert(catalog.listTables("db2").toSet == Set("tbl1", "tbl2"))
catalog.dropTable("db2", "tbl1", ignoreIfNotExists = false, purge = false)
assert(catalog.listTables("db2").toSet == Set("tbl2"))
}
test("drop table when database/table does not exist") {
val catalog = newBasicCatalog()
// Should always throw exception when the database does not exist
intercept[AnalysisException] {
catalog.dropTable("unknown_db", "unknown_table", ignoreIfNotExists = false, purge = false)
}
intercept[AnalysisException] {
catalog.dropTable("unknown_db", "unknown_table", ignoreIfNotExists = true, purge = false)
}
// Should throw exception when the table does not exist, if ignoreIfNotExists is false
intercept[AnalysisException] {
catalog.dropTable("db2", "unknown_table", ignoreIfNotExists = false, purge = false)
}
catalog.dropTable("db2", "unknown_table", ignoreIfNotExists = true, purge = false)
}
test("rename table") {
val catalog = newBasicCatalog()
assert(catalog.listTables("db2").toSet == Set("tbl1", "tbl2"))
catalog.renameTable("db2", "tbl1", "tblone")
assert(catalog.listTables("db2").toSet == Set("tblone", "tbl2"))
}
test("rename table when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.renameTable("unknown_db", "unknown_table", "unknown_table")
}
intercept[AnalysisException] {
catalog.renameTable("db2", "unknown_table", "unknown_table")
}
}
test("rename table when destination table already exists") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.renameTable("db2", "tbl1", "tbl2")
}
}
test("alter table") {
val catalog = newBasicCatalog()
val tbl1 = catalog.getTable("db2", "tbl1")
catalog.alterTable(tbl1.copy(properties = Map("toh" -> "frem")))
val newTbl1 = catalog.getTable("db2", "tbl1")
assert(!tbl1.properties.contains("toh"))
assert(newTbl1.properties.size == tbl1.properties.size + 1)
assert(newTbl1.properties.get("toh") == Some("frem"))
}
test("alter table when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.alterTable(newTable("tbl1", "unknown_db"))
}
intercept[AnalysisException] {
catalog.alterTable(newTable("unknown_table", "db2"))
}
}
test("get table") {
assert(newBasicCatalog().getTable("db2", "tbl1").identifier.table == "tbl1")
}
test("get table when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.getTable("unknown_db", "unknown_table")
}
intercept[AnalysisException] {
catalog.getTable("db2", "unknown_table")
}
}
test("list tables without pattern") {
val catalog = newBasicCatalog()
intercept[AnalysisException] { catalog.listTables("unknown_db") }
assert(catalog.listTables("db1").toSet == Set.empty)
assert(catalog.listTables("db2").toSet == Set("tbl1", "tbl2"))
}
test("list tables with pattern") {
val catalog = newBasicCatalog()
intercept[AnalysisException] { catalog.listTables("unknown_db", "*") }
assert(catalog.listTables("db1", "*").toSet == Set.empty)
assert(catalog.listTables("db2", "*").toSet == Set("tbl1", "tbl2"))
assert(catalog.listTables("db2", "tbl*").toSet == Set("tbl1", "tbl2"))
assert(catalog.listTables("db2", "*1").toSet == Set("tbl1"))
}
test("column names should be case-preserving and column nullability should be retained") {
val catalog = newBasicCatalog()
val tbl = CatalogTable(
identifier = TableIdentifier("tbl", Some("db1")),
tableType = CatalogTableType.MANAGED,
storage = storageFormat,
schema = new StructType()
.add("HelLo", "int", nullable = false)
.add("WoRLd", "int", nullable = true),
provider = Some("hive"),
partitionColumnNames = Seq("WoRLd"),
bucketSpec = Some(BucketSpec(4, Seq("HelLo"), Nil)))
catalog.createTable(tbl, ignoreIfExists = false)
val readBack = catalog.getTable("db1", "tbl")
assert(readBack.schema == tbl.schema)
assert(readBack.partitionColumnNames == tbl.partitionColumnNames)
assert(readBack.bucketSpec == tbl.bucketSpec)
}
// --------------------------------------------------------------------------
// Partitions
// --------------------------------------------------------------------------
test("basic create and list partitions") {
val catalog = newEmptyCatalog()
catalog.createDatabase(newDb("mydb"), ignoreIfExists = false)
catalog.createTable(newTable("tbl", "mydb"), ignoreIfExists = false)
catalog.createPartitions("mydb", "tbl", Seq(part1, part2), ignoreIfExists = false)
assert(catalogPartitionsEqual(catalog, "mydb", "tbl", Seq(part1, part2)))
}
test("create partitions when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.createPartitions("does_not_exist", "tbl1", Seq(), ignoreIfExists = false)
}
intercept[AnalysisException] {
catalog.createPartitions("db2", "does_not_exist", Seq(), ignoreIfExists = false)
}
}
test("create partitions that already exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.createPartitions("db2", "tbl2", Seq(part1), ignoreIfExists = false)
}
catalog.createPartitions("db2", "tbl2", Seq(part1), ignoreIfExists = true)
}
test("create partitions without location") {
val catalog = newBasicCatalog()
val table = CatalogTable(
identifier = TableIdentifier("tbl", Some("db1")),
tableType = CatalogTableType.MANAGED,
storage = CatalogStorageFormat(None, None, None, None, false, Map.empty),
schema = new StructType()
.add("col1", "int")
.add("col2", "string")
.add("partCol1", "int")
.add("partCol2", "string"),
provider = Some("hive"),
partitionColumnNames = Seq("partCol1", "partCol2"))
catalog.createTable(table, ignoreIfExists = false)
val partition = CatalogTablePartition(Map("partCol1" -> "1", "partCol2" -> "2"), storageFormat)
catalog.createPartitions("db1", "tbl", Seq(partition), ignoreIfExists = false)
val partitionLocation = catalog.getPartition(
"db1",
"tbl",
Map("partCol1" -> "1", "partCol2" -> "2")).location
val tableLocation = catalog.getTable("db1", "tbl").location
val defaultPartitionLocation = new Path(new Path(tableLocation, "partCol1=1"), "partCol2=2")
assert(new Path(partitionLocation) == defaultPartitionLocation)
}
test("list partition names") {
val catalog = newBasicCatalog()
val newPart = CatalogTablePartition(Map("a" -> "1", "b" -> "%="), storageFormat)
catalog.createPartitions("db2", "tbl2", Seq(newPart), ignoreIfExists = false)
val partitionNames = catalog.listPartitionNames("db2", "tbl2")
assert(partitionNames == Seq("a=1/b=%25%3D", "a=1/b=2", "a=3/b=4"))
}
test("list partition names with partial partition spec") {
val catalog = newBasicCatalog()
val newPart = CatalogTablePartition(Map("a" -> "1", "b" -> "%="), storageFormat)
catalog.createPartitions("db2", "tbl2", Seq(newPart), ignoreIfExists = false)
val partitionNames1 = catalog.listPartitionNames("db2", "tbl2", Some(Map("a" -> "1")))
assert(partitionNames1 == Seq("a=1/b=%25%3D", "a=1/b=2"))
// Partial partition specs including "weird" partition values should use the unescaped values
val partitionNames2 = catalog.listPartitionNames("db2", "tbl2", Some(Map("b" -> "%=")))
assert(partitionNames2 == Seq("a=1/b=%25%3D"))
val partitionNames3 = catalog.listPartitionNames("db2", "tbl2", Some(Map("b" -> "%25%3D")))
assert(partitionNames3.isEmpty)
}
test("list partitions with partial partition spec") {
val catalog = newBasicCatalog()
val parts = catalog.listPartitions("db2", "tbl2", Some(Map("a" -> "1")))
assert(parts.length == 1)
assert(parts.head.spec == part1.spec)
// if no partition is matched for the given partition spec, an empty list should be returned.
assert(catalog.listPartitions("db2", "tbl2", Some(Map("a" -> "unknown", "b" -> "1"))).isEmpty)
assert(catalog.listPartitions("db2", "tbl2", Some(Map("a" -> "unknown"))).isEmpty)
}
test("drop partitions") {
val catalog = newBasicCatalog()
assert(catalogPartitionsEqual(catalog, "db2", "tbl2", Seq(part1, part2)))
catalog.dropPartitions(
"db2", "tbl2", Seq(part1.spec), ignoreIfNotExists = false, purge = false, retainData = false)
assert(catalogPartitionsEqual(catalog, "db2", "tbl2", Seq(part2)))
resetState()
val catalog2 = newBasicCatalog()
assert(catalogPartitionsEqual(catalog2, "db2", "tbl2", Seq(part1, part2)))
catalog2.dropPartitions(
"db2", "tbl2", Seq(part1.spec, part2.spec), ignoreIfNotExists = false, purge = false,
retainData = false)
assert(catalog2.listPartitions("db2", "tbl2").isEmpty)
}
test("drop partitions when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.dropPartitions(
"does_not_exist", "tbl1", Seq(), ignoreIfNotExists = false, purge = false,
retainData = false)
}
intercept[AnalysisException] {
catalog.dropPartitions(
"db2", "does_not_exist", Seq(), ignoreIfNotExists = false, purge = false,
retainData = false)
}
}
test("drop partitions that do not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.dropPartitions(
"db2", "tbl2", Seq(part3.spec), ignoreIfNotExists = false, purge = false,
retainData = false)
}
catalog.dropPartitions(
"db2", "tbl2", Seq(part3.spec), ignoreIfNotExists = true, purge = false, retainData = false)
}
test("get partition") {
val catalog = newBasicCatalog()
assert(catalog.getPartition("db2", "tbl2", part1.spec).spec == part1.spec)
assert(catalog.getPartition("db2", "tbl2", part2.spec).spec == part2.spec)
intercept[AnalysisException] {
catalog.getPartition("db2", "tbl1", part3.spec)
}
}
test("get partition when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.getPartition("does_not_exist", "tbl1", part1.spec)
}
intercept[AnalysisException] {
catalog.getPartition("db2", "does_not_exist", part1.spec)
}
}
test("rename partitions") {
val catalog = newBasicCatalog()
val newPart1 = part1.copy(spec = Map("a" -> "100", "b" -> "101"))
val newPart2 = part2.copy(spec = Map("a" -> "200", "b" -> "201"))
val newSpecs = Seq(newPart1.spec, newPart2.spec)
catalog.renamePartitions("db2", "tbl2", Seq(part1.spec, part2.spec), newSpecs)
assert(catalog.getPartition("db2", "tbl2", newPart1.spec).spec === newPart1.spec)
assert(catalog.getPartition("db2", "tbl2", newPart2.spec).spec === newPart2.spec)
// The old partitions should no longer exist
intercept[AnalysisException] { catalog.getPartition("db2", "tbl2", part1.spec) }
intercept[AnalysisException] { catalog.getPartition("db2", "tbl2", part2.spec) }
}
test("rename partitions should update the location for managed table") {
val catalog = newBasicCatalog()
val table = CatalogTable(
identifier = TableIdentifier("tbl", Some("db1")),
tableType = CatalogTableType.MANAGED,
storage = CatalogStorageFormat(None, None, None, None, false, Map.empty),
schema = new StructType()
.add("col1", "int")
.add("col2", "string")
.add("partCol1", "int")
.add("partCol2", "string"),
provider = Some("hive"),
partitionColumnNames = Seq("partCol1", "partCol2"))
catalog.createTable(table, ignoreIfExists = false)
val tableLocation = catalog.getTable("db1", "tbl").location
val mixedCasePart1 = CatalogTablePartition(
Map("partCol1" -> "1", "partCol2" -> "2"), storageFormat)
val mixedCasePart2 = CatalogTablePartition(
Map("partCol1" -> "3", "partCol2" -> "4"), storageFormat)
catalog.createPartitions("db1", "tbl", Seq(mixedCasePart1), ignoreIfExists = false)
assert(
new Path(catalog.getPartition("db1", "tbl", mixedCasePart1.spec).location) ==
new Path(new Path(tableLocation, "partCol1=1"), "partCol2=2"))
catalog.renamePartitions("db1", "tbl", Seq(mixedCasePart1.spec), Seq(mixedCasePart2.spec))
assert(
new Path(catalog.getPartition("db1", "tbl", mixedCasePart2.spec).location) ==
new Path(new Path(tableLocation, "partCol1=3"), "partCol2=4"))
// For external tables, RENAME PARTITION should not update the partition location.
val existingPartLoc = catalog.getPartition("db2", "tbl2", part1.spec).location
catalog.renamePartitions("db2", "tbl2", Seq(part1.spec), Seq(part3.spec))
assert(
new Path(catalog.getPartition("db2", "tbl2", part3.spec).location) ==
new Path(existingPartLoc))
}
test("rename partitions when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.renamePartitions("does_not_exist", "tbl1", Seq(part1.spec), Seq(part2.spec))
}
intercept[AnalysisException] {
catalog.renamePartitions("db2", "does_not_exist", Seq(part1.spec), Seq(part2.spec))
}
}
test("rename partitions when the new partition already exists") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.renamePartitions("db2", "tbl2", Seq(part1.spec), Seq(part2.spec))
}
}
test("alter partitions") {
val catalog = newBasicCatalog()
try {
val newLocation = newUriForDatabase()
val newSerde = "com.sparkbricks.text.EasySerde"
val newSerdeProps = Map("spark" -> "bricks", "compressed" -> "false")
// alter but keep spec the same
val oldPart1 = catalog.getPartition("db2", "tbl2", part1.spec)
val oldPart2 = catalog.getPartition("db2", "tbl2", part2.spec)
catalog.alterPartitions("db2", "tbl2", Seq(
oldPart1.copy(storage = storageFormat.copy(locationUri = Some(newLocation))),
oldPart2.copy(storage = storageFormat.copy(locationUri = Some(newLocation)))))
val newPart1 = catalog.getPartition("db2", "tbl2", part1.spec)
val newPart2 = catalog.getPartition("db2", "tbl2", part2.spec)
assert(newPart1.storage.locationUri == Some(newLocation))
assert(newPart2.storage.locationUri == Some(newLocation))
assert(oldPart1.storage.locationUri != Some(newLocation))
assert(oldPart2.storage.locationUri != Some(newLocation))
// alter other storage information
catalog.alterPartitions("db2", "tbl2", Seq(
oldPart1.copy(storage = storageFormat.copy(serde = Some(newSerde))),
oldPart2.copy(storage = storageFormat.copy(properties = newSerdeProps))))
val newPart1b = catalog.getPartition("db2", "tbl2", part1.spec)
val newPart2b = catalog.getPartition("db2", "tbl2", part2.spec)
assert(newPart1b.storage.serde == Some(newSerde))
assert(newPart2b.storage.properties == newSerdeProps)
// alter but change spec, should fail because new partition specs do not exist yet
val badPart1 = part1.copy(spec = Map("a" -> "v1", "b" -> "v2"))
val badPart2 = part2.copy(spec = Map("a" -> "v3", "b" -> "v4"))
intercept[AnalysisException] {
catalog.alterPartitions("db2", "tbl2", Seq(badPart1, badPart2))
}
} finally {
// Remember to restore the original current database, which we assume to be "default"
catalog.setCurrentDatabase("default")
}
}
test("alter partitions when database/table does not exist") {
val catalog = newBasicCatalog()
intercept[AnalysisException] {
catalog.alterPartitions("does_not_exist", "tbl1", Seq(part1))
}
intercept[AnalysisException] {
catalog.alterPartitions("db2", "does_not_exist", Seq(part1))
}
}
// --------------------------------------------------------------------------
// Functions
// --------------------------------------------------------------------------
test("basic create and list functions") {
val catalog = newEmptyCatalog()
catalog.createDatabase(newDb("mydb"), ignoreIfExists = false)
catalog.createFunction("mydb", newFunc("myfunc"))
assert(catalog.listFunctions("mydb", "*").toSet == Set("myfunc"))
}
test("create function when database does not exist") {
val catalog = newBasicCatalog()
intercept[NoSuchDatabaseException] {
catalog.createFunction("does_not_exist", newFunc())
}
}
test("create function that already exists") {
val catalog = newBasicCatalog()
intercept[FunctionAlreadyExistsException] {
catalog.createFunction("db2", newFunc("func1"))
}
}
test("drop function") {
val catalog = newBasicCatalog()
assert(catalog.listFunctions("db2", "*").toSet == Set("func1"))
catalog.dropFunction("db2", "func1")
assert(catalog.listFunctions("db2", "*").isEmpty)
}
test("drop function when database does not exist") {
val catalog = newBasicCatalog()
intercept[NoSuchDatabaseException] {
catalog.dropFunction("does_not_exist", "something")
}
}
test("drop function that does not exist") {
val catalog = newBasicCatalog()
intercept[NoSuchFunctionException] {
catalog.dropFunction("db2", "does_not_exist")
}
}
test("get function") {
val catalog = newBasicCatalog()
assert(catalog.getFunction("db2", "func1") ==
CatalogFunction(FunctionIdentifier("func1", Some("db2")), funcClass,
Seq.empty[FunctionResource]))
intercept[NoSuchFunctionException] {
catalog.getFunction("db2", "does_not_exist")
}
}
test("get function when database does not exist") {
val catalog = newBasicCatalog()
intercept[NoSuchDatabaseException] {
catalog.getFunction("does_not_exist", "func1")
}
}
test("rename function") {
val catalog = newBasicCatalog()
val newName = "funcky"
assert(catalog.getFunction("db2", "func1").className == funcClass)
catalog.renameFunction("db2", "func1", newName)
intercept[NoSuchFunctionException] { catalog.getFunction("db2", "func1") }
assert(catalog.getFunction("db2", newName).identifier.funcName == newName)
assert(catalog.getFunction("db2", newName).className == funcClass)
intercept[NoSuchFunctionException] { catalog.renameFunction("db2", "does_not_exist", "me") }
}
test("rename function when database does not exist") {
val catalog = newBasicCatalog()
intercept[NoSuchDatabaseException] {
catalog.renameFunction("does_not_exist", "func1", "func5")
}
}
test("rename function when new function already exists") {
val catalog = newBasicCatalog()
catalog.createFunction("db2", newFunc("func2", Some("db2")))
intercept[FunctionAlreadyExistsException] {
catalog.renameFunction("db2", "func1", "func2")
}
}
test("list functions") {
val catalog = newBasicCatalog()
catalog.createFunction("db2", newFunc("func2"))
catalog.createFunction("db2", newFunc("not_me"))
assert(catalog.listFunctions("db2", "*").toSet == Set("func1", "func2", "not_me"))
assert(catalog.listFunctions("db2", "func*").toSet == Set("func1", "func2"))
}
// --------------------------------------------------------------------------
// File System operations
// --------------------------------------------------------------------------
private def exists(uri: String, children: String*): Boolean = {
val base = new Path(uri)
val finalPath = children.foldLeft(base) {
case (parent, child) => new Path(parent, child)
}
base.getFileSystem(new Configuration()).exists(finalPath)
}
test("create/drop database should create/delete the directory") {
val catalog = newBasicCatalog()
val db = newDb("mydb")
catalog.createDatabase(db, ignoreIfExists = false)
assert(exists(db.locationUri))
catalog.dropDatabase("mydb", ignoreIfNotExists = false, cascade = false)
assert(!exists(db.locationUri))
}
test("create/drop/rename table should create/delete/rename the directory") {
val catalog = newBasicCatalog()
val db = catalog.getDatabase("db1")
val table = CatalogTable(
identifier = TableIdentifier("my_table", Some("db1")),
tableType = CatalogTableType.MANAGED,
storage = CatalogStorageFormat(None, None, None, None, false, Map.empty),
schema = new StructType().add("a", "int").add("b", "string"),
provider = Some("hive")
)
catalog.createTable(table, ignoreIfExists = false)
assert(exists(db.locationUri, "my_table"))
catalog.renameTable("db1", "my_table", "your_table")
assert(!exists(db.locationUri, "my_table"))
assert(exists(db.locationUri, "your_table"))
catalog.dropTable("db1", "your_table", ignoreIfNotExists = false, purge = false)
assert(!exists(db.locationUri, "your_table"))
val externalTable = CatalogTable(
identifier = TableIdentifier("external_table", Some("db1")),
tableType = CatalogTableType.EXTERNAL,
storage = CatalogStorageFormat(
Some(Utils.createTempDir().getAbsolutePath),
None, None, None, false, Map.empty),
schema = new StructType().add("a", "int").add("b", "string"),
provider = Some("hive")
)
catalog.createTable(externalTable, ignoreIfExists = false)
assert(!exists(db.locationUri, "external_table"))
}
test("create/drop/rename partitions should create/delete/rename the directory") {
val catalog = newBasicCatalog()
val table = CatalogTable(
identifier = TableIdentifier("tbl", Some("db1")),
tableType = CatalogTableType.MANAGED,
storage = CatalogStorageFormat(None, None, None, None, false, Map.empty),
schema = new StructType()
.add("col1", "int")
.add("col2", "string")
.add("partCol1", "int")
.add("partCol2", "string"),
provider = Some("hive"),
partitionColumnNames = Seq("partCol1", "partCol2"))
catalog.createTable(table, ignoreIfExists = false)
val tableLocation = catalog.getTable("db1", "tbl").location
val part1 = CatalogTablePartition(Map("partCol1" -> "1", "partCol2" -> "2"), storageFormat)
val part2 = CatalogTablePartition(Map("partCol1" -> "3", "partCol2" -> "4"), storageFormat)
val part3 = CatalogTablePartition(Map("partCol1" -> "5", "partCol2" -> "6"), storageFormat)
catalog.createPartitions("db1", "tbl", Seq(part1, part2), ignoreIfExists = false)
assert(exists(tableLocation, "partCol1=1", "partCol2=2"))
assert(exists(tableLocation, "partCol1=3", "partCol2=4"))
catalog.renamePartitions("db1", "tbl", Seq(part1.spec), Seq(part3.spec))
assert(!exists(tableLocation, "partCol1=1", "partCol2=2"))
assert(exists(tableLocation, "partCol1=5", "partCol2=6"))
catalog.dropPartitions("db1", "tbl", Seq(part2.spec, part3.spec), ignoreIfNotExists = false,
purge = false, retainData = false)
assert(!exists(tableLocation, "partCol1=3", "partCol2=4"))
assert(!exists(tableLocation, "partCol1=5", "partCol2=6"))
val tempPath = Utils.createTempDir()
// create partition with existing directory is OK.
val partWithExistingDir = CatalogTablePartition(
Map("partCol1" -> "7", "partCol2" -> "8"),
CatalogStorageFormat(
Some(tempPath.getAbsolutePath),
None, None, None, false, Map.empty))
catalog.createPartitions("db1", "tbl", Seq(partWithExistingDir), ignoreIfExists = false)
tempPath.delete()
// create partition with non-existing directory will create that directory.
val partWithNonExistingDir = CatalogTablePartition(
Map("partCol1" -> "9", "partCol2" -> "10"),
CatalogStorageFormat(
Some(tempPath.getAbsolutePath),
None, None, None, false, Map.empty))
catalog.createPartitions("db1", "tbl", Seq(partWithNonExistingDir), ignoreIfExists = false)
assert(tempPath.exists())
}
test("drop partition from external table should not delete the directory") {
val catalog = newBasicCatalog()
catalog.createPartitions("db2", "tbl1", Seq(part1), ignoreIfExists = false)
val partPath = new Path(catalog.getPartition("db2", "tbl1", part1.spec).location)
val fs = partPath.getFileSystem(new Configuration)
assert(fs.exists(partPath))
catalog.dropPartitions(
"db2", "tbl1", Seq(part1.spec), ignoreIfNotExists = false, purge = false, retainData = false)
assert(fs.exists(partPath))
}
}
/**
* A collection of utility fields and methods for tests related to the [[ExternalCatalog]].
*/
abstract class CatalogTestUtils {
// Unimplemented methods
val tableInputFormat: String
val tableOutputFormat: String
def newEmptyCatalog(): ExternalCatalog
// These fields must be lazy because they rely on fields that are not implemented yet
lazy val storageFormat = CatalogStorageFormat(
locationUri = None,
inputFormat = Some(tableInputFormat),
outputFormat = Some(tableOutputFormat),
serde = None,
compressed = false,
properties = Map.empty)
lazy val part1 = CatalogTablePartition(Map("a" -> "1", "b" -> "2"), storageFormat)
lazy val part2 = CatalogTablePartition(Map("a" -> "3", "b" -> "4"), storageFormat)
lazy val part3 = CatalogTablePartition(Map("a" -> "5", "b" -> "6"), storageFormat)
lazy val partWithMixedOrder = CatalogTablePartition(Map("b" -> "6", "a" -> "6"), storageFormat)
lazy val partWithLessColumns = CatalogTablePartition(Map("a" -> "1"), storageFormat)
lazy val partWithMoreColumns =
CatalogTablePartition(Map("a" -> "5", "b" -> "6", "c" -> "7"), storageFormat)
lazy val partWithUnknownColumns =
CatalogTablePartition(Map("a" -> "5", "unknown" -> "6"), storageFormat)
lazy val funcClass = "org.apache.spark.myFunc"
/**
* Creates a basic catalog, with the following structure:
*
* default
* db1
* db2
* - tbl1
* - tbl2
* - part1
* - part2
* - func1
*/
def newBasicCatalog(): ExternalCatalog = {
val catalog = newEmptyCatalog()
// When testing against a real catalog, the default database may already exist
catalog.createDatabase(newDb("default"), ignoreIfExists = true)
catalog.createDatabase(newDb("db1"), ignoreIfExists = false)
catalog.createDatabase(newDb("db2"), ignoreIfExists = false)
catalog.createTable(newTable("tbl1", "db2"), ignoreIfExists = false)
catalog.createTable(newTable("tbl2", "db2"), ignoreIfExists = false)
catalog.createPartitions("db2", "tbl2", Seq(part1, part2), ignoreIfExists = false)
catalog.createFunction("db2", newFunc("func1", Some("db2")))
catalog
}
def newFunc(): CatalogFunction = newFunc("funcName")
def newUriForDatabase(): String = Utils.createTempDir().toURI.toString.stripSuffix("/")
def newDb(name: String): CatalogDatabase = {
CatalogDatabase(name, name + " description", newUriForDatabase(), Map.empty)
}
def newTable(name: String, db: String): CatalogTable = newTable(name, Some(db))
def newTable(name: String, database: Option[String] = None): CatalogTable = {
CatalogTable(
identifier = TableIdentifier(name, database),
tableType = CatalogTableType.EXTERNAL,
storage = storageFormat.copy(locationUri = Some(Utils.createTempDir().getAbsolutePath)),
schema = new StructType()
.add("col1", "int")
.add("col2", "string")
.add("a", "int")
.add("b", "string"),
provider = Some("hive"),
partitionColumnNames = Seq("a", "b"),
bucketSpec = Some(BucketSpec(4, Seq("col1"), Nil)))
}
def newFunc(name: String, database: Option[String] = None): CatalogFunction = {
CatalogFunction(FunctionIdentifier(name, database), funcClass, Seq.empty[FunctionResource])
}
/**
* Whether the catalog's table partitions equal the ones given.
* Note: Hive sets some random serde things, so we just compare the specs here.
*/
def catalogPartitionsEqual(
catalog: ExternalCatalog,
db: String,
table: String,
parts: Seq[CatalogTablePartition]): Boolean = {
catalog.listPartitions(db, table).map(_.spec).toSet == parts.map(_.spec).toSet
}
}
| Panos-Bletsos/spark-cost-model-optimizer | sql/catalyst/src/test/scala/org/apache/spark/sql/catalyst/catalog/ExternalCatalogSuite.scala | Scala | apache-2.0 | 35,226 |
package cromwell.engine.io
import java.net.{SocketException, SocketTimeoutException}
import javax.net.ssl.SSLException
import akka.NotUsed
import akka.actor.{Actor, ActorLogging, ActorRef, Props}
import akka.stream._
import akka.stream.scaladsl.{Flow, GraphDSL, Merge, Partition, Sink, Source}
import com.google.cloud.storage.StorageException
import com.typesafe.config.ConfigFactory
import cromwell.core.Dispatcher
import cromwell.core.Dispatcher.IoDispatcher
import cromwell.core.actor.StreamActorHelper
import cromwell.core.actor.StreamIntegration.StreamContext
import cromwell.core.io.{IoAck, IoCommand, Throttle}
import cromwell.engine.instrumentation.IoInstrumentation
import cromwell.engine.io.IoActor._
import cromwell.engine.io.gcs.GcsBatchFlow.BatchFailedException
import cromwell.engine.io.gcs.{GcsBatchCommandContext, ParallelGcsBatchFlow}
import cromwell.engine.io.nio.NioFlow
import cromwell.filesystems.gcs.batch.GcsBatchIoCommand
/**
* Actor that performs IO operations asynchronously using akka streams
*
* @param queueSize size of the queue
* @param throttle optional throttler to control the throughput of requests.
* Applied to ALL incoming requests
* @param materializer actor materializer to run the stream
* @param serviceRegistryActor actorRef for the serviceRegistryActor
*/
final class IoActor(queueSize: Int,
throttle: Option[Throttle],
override val serviceRegistryActor: ActorRef)(implicit val materializer: ActorMaterializer)
extends Actor with ActorLogging with StreamActorHelper[IoCommandContext[_]] with IoInstrumentation {
implicit private val system = context.system
implicit val ec = context.dispatcher
/**
* Method for instrumentation to be executed when a IoCommand failed and is being retried.
* Can be passed to flows so they can invoke it when necessary.
*/
private def onRetry(commandContext: IoCommandContext[_])(throwable: Throwable): Unit = {
incrementIoRetry(commandContext.request, throwable)
}
private [io] lazy val defaultFlow = new NioFlow(parallelism = 100, context.system.scheduler, onRetry).flow.withAttributes(ActorAttributes.dispatcher(Dispatcher.IoDispatcher))
private [io] lazy val gcsBatchFlow = new ParallelGcsBatchFlow(parallelism = 10, batchSize = 100, context.system.scheduler, onRetry).flow.withAttributes(ActorAttributes.dispatcher(Dispatcher.IoDispatcher))
protected val source = Source.queue[IoCommandContext[_]](queueSize, OverflowStrategy.dropNew)
protected val flow = GraphDSL.create() { implicit builder =>
import GraphDSL.Implicits._
val input = builder.add(Flow[IoCommandContext[_]])
// Partitions requests between gcs batch, and single nio requests
val batchPartitioner = builder.add(Partition[IoCommandContext[_]](2, {
case _: GcsBatchCommandContext[_, _] => 0
case _ => 1
}))
// Sub flow for batched gcs requests
val batches = batchPartitioner.out(0) collect { case batch: GcsBatchCommandContext[_, _] => batch }
// Sub flow for single nio requests
val defaults = batchPartitioner.out(1) collect { case default: DefaultCommandContext[_] => default }
// Merge results from both flows back together
val merger = builder.add(Merge[IoResult](2))
// Flow processing nio requests
val defaultFlowPorts = builder.add(defaultFlow)
// Flow processing gcs batch requests
val batchFlowPorts = builder.add(gcsBatchFlow)
input ~> batchPartitioner
defaults.outlet ~> defaultFlowPorts ~> merger
batches.outlet ~> batchFlowPorts ~> merger
FlowShape[IoCommandContext[_], IoResult](input.in, merger.out)
}
protected val throttledFlow = throttle map { t =>
Flow[IoCommandContext[_]]
.throttle(t.elements, t.per, t.maximumBurst, ThrottleMode.Shaping)
.via(flow)
} getOrElse flow
private val instrumentationSink = Sink.foreach[IoResult](incrementIoResult)
override protected lazy val streamSource = source
.via(throttledFlow)
.alsoTo(instrumentationSink)
.withAttributes(ActorAttributes.dispatcher(Dispatcher.IoDispatcher))
override def actorReceive: Receive = {
/* GCS Batch command with context */
case (clientContext: Any, gcsBatchCommand: GcsBatchIoCommand[_, _]) =>
val replyTo = sender()
val commandContext= GcsBatchCommandContext(gcsBatchCommand, replyTo, Option(clientContext))
sendToStream(commandContext)
/* GCS Batch command without context */
case gcsBatchCommand: GcsBatchIoCommand[_, _] =>
val replyTo = sender()
val commandContext= GcsBatchCommandContext(gcsBatchCommand, replyTo)
sendToStream(commandContext)
/* Default command with context */
case (clientContext: Any, command: IoCommand[_]) =>
val replyTo = sender()
val commandContext= DefaultCommandContext(command, replyTo, Option(clientContext))
sendToStream(commandContext)
/* Default command without context */
case command: IoCommand[_] =>
val replyTo = sender()
val commandContext= DefaultCommandContext(command, replyTo)
sendToStream(commandContext)
}
}
trait IoCommandContext[T] extends StreamContext {
def request: IoCommand[T]
def replyTo: ActorRef
def fail(failure: Throwable): IoResult = (request.fail(failure), this)
def success(value: T): IoResult = (request.success(value), this)
}
object IoActor {
import net.ceedubs.ficus.Ficus._
/** Flow that can consume an IoCommandContext and produce an IoResult */
type IoFlow = Flow[IoCommandContext[_], IoResult, NotUsed]
/** Result type of an IoFlow, contains the original command context and the final IoAck response. */
type IoResult = (IoAck[_], IoCommandContext[_])
private val ioConfig = ConfigFactory.load().getConfig("system.io")
/** Maximum number of times a command will be attempted: First attempt + 5 retries */
val MaxAttemptsNumber = ioConfig.getOrElse[Int]("number-of-attempts", 5)
case class DefaultCommandContext[T](request: IoCommand[T], replyTo: ActorRef, override val clientContext: Option[Any] = None) extends IoCommandContext[T]
/**
* ATTENTION: Transient failures are retried *forever*
* Be careful when adding error codes to this method.
* Currently only 429 (= quota exceeded are considered truly transient)
*/
def isTransient(failure: Throwable): Boolean = failure match {
case gcs: StorageException => gcs.getCode == 429
case _ => false
}
val AdditionalRetryableHttpCodes = List(
// HTTP 410: Gone
// From Google doc (https://cloud.google.com/storage/docs/json_api/v1/status-codes):
// "You have attempted to use a resumable upload session that is no longer available.
// If the reported status code was not successful and you still wish to upload the file, you must start a new session."
410,
// Some 503 errors seem to yield "false" on the "isRetryable" method because they are not retried.
// The CloudStorage exception mechanism is not flawless yet (https://github.com/GoogleCloudPlatform/google-cloud-java/issues/1545)
// so that could be the cause.
// For now explicitly lists 503 as a retryable code here to work around that.
503
)
/**
* Failures that are considered retryable.
* Retrying them should increase the "retry counter"
*/
def isRetryable(failure: Throwable): Boolean = failure match {
case gcs: StorageException => gcs.isRetryable || AdditionalRetryableHttpCodes.contains(gcs.getCode) || isRetryable(gcs.getCause)
case _: SSLException => true
case _: BatchFailedException => true
case _: SocketException => true
case _: SocketTimeoutException => true
case other => isTransient(other)
}
def isFatal(failure: Throwable) = !isRetryable(failure)
def props(queueSize: Int, throttle: Option[Throttle], serviceRegistryActor: ActorRef)(implicit materializer: ActorMaterializer) = {
Props(new IoActor(queueSize, throttle, serviceRegistryActor)).withDispatcher(IoDispatcher)
}
}
| ohsu-comp-bio/cromwell | engine/src/main/scala/cromwell/engine/io/IoActor.scala | Scala | bsd-3-clause | 8,110 |
package io.vamp.operation.sla
import java.time.OffsetDateTime
import java.time.temporal.ChronoUnit
import akka.actor._
import akka.pattern.ask
import io.vamp.common.akka.IoC._
import io.vamp.common.akka._
import io.vamp.common.notification.Notification
import io.vamp.model.artifact._
import io.vamp.model.event.{ Aggregator, Event, EventQuery, TimeRange, _ }
import io.vamp.model.notification.{ DeEscalate, Escalate, SlaEvent }
import io.vamp.operation.notification._
import io.vamp.operation.sla.SlaActor.SlaProcessAll
import io.vamp.persistence.{ ArtifactPaginationSupport, EventPaginationSupport, PersistenceActor }
import io.vamp.pulse.PulseActor.Publish
import io.vamp.pulse.{ EventRequestEnvelope, PulseActor }
import scala.concurrent.Future
class SlaSchedulerActor extends SchedulerActor with OperationNotificationProvider {
def tick() = IoC.actorFor[SlaActor] ! SlaProcessAll
}
object SlaActor {
object SlaProcessAll
}
class SlaActor extends SlaPulse with ArtifactPaginationSupport with EventPaginationSupport with CommonSupportForActors with OperationNotificationProvider {
def receive: Receive = {
case SlaProcessAll ⇒
implicit val timeout = PersistenceActor.timeout()
forAll(allArtifacts[Deployment], check)
}
override def info(notification: Notification): Unit = {
notification match {
case se: SlaEvent ⇒ actorFor[PulseActor] ! Publish(Event(Set("sla") ++ se.tags, se.value, se.timestamp))
case _ ⇒
}
super.info(notification)
}
private def check(deployments: List[Deployment]) = {
deployments.foreach(deployment ⇒ {
try {
deployment.clusters.foreach(cluster ⇒
cluster.sla match {
case Some(sla: ResponseTimeSlidingWindowSla) ⇒ responseTimeSlidingWindow(deployment, cluster, sla)
case Some(s: EscalationOnlySla) ⇒
case Some(s: GenericSla) ⇒ info(UnsupportedSlaType(s.`type`))
case Some(s: Sla) ⇒ throwException(UnsupportedSlaType(s.name))
case None ⇒
})
}
catch {
case any: Throwable ⇒ reportException(InternalServerError(any))
}
})
}
private def responseTimeSlidingWindow(deployment: Deployment, cluster: DeploymentCluster, sla: ResponseTimeSlidingWindowSla) = {
log.debug(s"response time sliding window sla check for: ${deployment.name}/${cluster.name}")
if (cluster.services.forall(_.status.isDone)) {
val from = OffsetDateTime.now().minus((sla.interval + sla.cooldown).toSeconds, ChronoUnit.SECONDS)
eventExists(deployment, cluster, from) map {
case true ⇒ log.debug(s"escalation event found within cooldown + interval period for: ${deployment.name}/${cluster.name}.")
case false ⇒
log.debug(s"escalation event not found within cooldown + interval period for: ${deployment.name}/${cluster.name}.")
val to = OffsetDateTime.now()
val from = to.minus(sla.interval.toSeconds, ChronoUnit.SECONDS)
val portMapping = cluster.gateways.map { gateway ⇒ GatewayPath(gateway.name).segments.last }
Future.sequence(portMapping.map({ portName ⇒
responseTime(deployment, cluster, portName, from, to)
})) map { optionalResponseTimes ⇒
val responseTimes = optionalResponseTimes.flatten
if (responseTimes.nonEmpty) {
val maxResponseTimes = responseTimes.max
log.debug(s"escalation max response time for ${deployment.name}/${cluster.name}: $maxResponseTimes.")
if (maxResponseTimes > sla.upper.toMillis)
info(Escalate(deployment, cluster))
else if (maxResponseTimes < sla.lower.toMillis)
info(DeEscalate(deployment, cluster))
}
}
}
}
}
}
trait SlaPulse {
this: CommonSupportForActors ⇒
implicit lazy val timeout = PulseActor.timeout()
def eventExists(deployment: Deployment, cluster: DeploymentCluster, from: OffsetDateTime): Future[Boolean] = {
eventCount(SlaEvent.slaTags(deployment, cluster), from, OffsetDateTime.now(), 1) map { count ⇒ count > 0 }
}
def responseTime(deployment: Deployment, cluster: DeploymentCluster, portName: String, from: OffsetDateTime, to: OffsetDateTime): Future[Option[Double]] = {
cluster.gateways.find(gateway ⇒ GatewayPath(gateway.name).segments.last == portName) match {
case Some(gateway) ⇒
val tags = Set(s"gateways:${gateway.name}", "metrics:responseTime")
eventCount(tags, from, to, -1) flatMap {
case count if count >= 0 ⇒
val eventQuery = EventQuery(tags, None, Some(TimeRange(Some(from), Some(to), includeLower = true, includeUpper = true)), Some(Aggregator(Aggregator.average, Option("metrics"))))
actorFor[PulseActor] ? PulseActor.Query(EventRequestEnvelope(eventQuery, 1, 1)) map {
case DoubleValueAggregationResult(value) ⇒ Some(value)
case other ⇒ log.error(other.toString); None
}
case _ ⇒ Future.successful(None)
}
case None ⇒ Future.successful(None)
}
}
def eventCount(tags: Set[String], from: OffsetDateTime, to: OffsetDateTime, onError: Long): Future[Long] = {
val eventQuery = EventQuery(tags, None, Some(TimeRange(Some(from), Some(OffsetDateTime.now()), includeLower = true, includeUpper = true)), Some(Aggregator(Aggregator.count)))
actorFor[PulseActor] ? PulseActor.Query(EventRequestEnvelope(eventQuery, 1, 1)) map {
case LongValueAggregationResult(count) ⇒ count
case other ⇒ onError
}
}
}
| dragoslav/vamp | operation/src/main/scala/io/vamp/operation/sla/SlaActor.scala | Scala | apache-2.0 | 5,801 |
package HackerRank.Training.Regex
import java.io.{ByteArrayInputStream, IOException, InputStream, PrintWriter}
import java.util.InputMismatchException
import scala.collection.generic.CanBuildFrom
import scala.language.higherKinds
import scala.reflect.ClassTag
/**
* Copyright (c) 2017 A. Roberto Fischer
*
* @author A. Roberto Fischer <a.robertofischer@gmail.com> on 8/24/2017
*/
private[this] object HackerRankLanguage {
import Reader._
import Writer._
private[this] val TEST_INPUT: Option[String] = None
//------------------------------------------------------------------------------------------//
// Solution
//------------------------------------------------------------------------------------------//
private[this] def solve(): Unit = {
val n = next[Int]()
next[String, Vector](nextLine(), n)
.map("\\\\d{5}\\\\s(C|CPP|JAVA|PYTHON|PERL|PHP|RUBY|CSHARP|HASKELL|CLOJURE|BASH|SCALA|ERLANG|CLISP|LUA|BRAINFUCK|JAVASCRIPT|GO|D|OCAML|R|PASCAL|SBCL|DART|GROOVY|OBJECTIVEC)".r.unapplySeq)
.map(_.fold("INVALID")(_ => "VALID"))
.foreach(println)
}
//------------------------------------------------------------------------------------------//
// Run
//------------------------------------------------------------------------------------------//
@throws[Exception]
def main(args: Array[String]): Unit = {
val s = System.currentTimeMillis
solve()
flush()
if (TEST_INPUT.isDefined) System.out.println(System.currentTimeMillis - s + "ms")
}
//------------------------------------------------------------------------------------------//
// Input
//------------------------------------------------------------------------------------------//
private[this] final object Reader {
private[this] implicit val in: InputStream = TEST_INPUT.fold(System.in)(s => new ByteArrayInputStream(s.getBytes))
def nextLine(): String = {
val builder = StringBuilder.newBuilder
var char = next[Char]()
while (char != '\\n' && char != 65535) {
builder += char
char = next[Char]()
}
builder.result()
}
def next[T: ClassTag](): T = {
implicitly[ClassTag[T]].runtimeClass match {
case java.lang.Integer.TYPE => nextInt().asInstanceOf[T]
case java.lang.Long.TYPE => nextLong().asInstanceOf[T]
case java.lang.Double.TYPE => nextDouble().asInstanceOf[T]
case java.lang.Character.TYPE => nextChar().asInstanceOf[T]
case s if Class.forName("java.lang.String") == s => nextString().asInstanceOf[T]
case b if Class.forName("scala.math.BigInt") == b => BigInt(nextString()).asInstanceOf[T]
case b if Class.forName("scala.math.BigDecimal") == b => BigDecimal(nextString()).asInstanceOf[T]
case _ => throw new RuntimeException("Unsupported input type.")
}
}
def next[T, Coll[_]](reader: => T, n: Int)
(implicit cbf: CanBuildFrom[Coll[T], T, Coll[T]]): Coll[T] = {
val builder = cbf()
builder.sizeHint(n)
for (_ <- 0 until n) {
builder += reader
}
builder.result()
}
def nextWithIndex[T, Coll[_]](reader: => T, n: Int)
(implicit cbf: CanBuildFrom[Coll[(T, Int)], (T, Int), Coll[(T, Int)]]): Coll[(T, Int)] = {
val builder = cbf()
builder.sizeHint(n)
for (i <- 0 until n) {
builder += ((reader, i))
}
builder.result()
}
def next[T: ClassTag, Coll[_]](n: Int)
(implicit cbf: CanBuildFrom[Coll[T], T, Coll[T]]): Coll[T] = {
val builder = cbf()
builder.sizeHint(n)
for (_ <- 0 until n) {
builder += next[T]()
}
builder.result()
}
def nextWithIndex[T: ClassTag, Coll[_]](n: Int)
(implicit cbf: CanBuildFrom[Coll[(T, Int)], (T, Int), Coll[(T, Int)]]): Coll[(T, Int)] = {
val builder = cbf()
builder.sizeHint(n)
for (i <- 0 until n) {
builder += ((next[T](), i))
}
builder.result()
}
def nextMultiLine[T: ClassTag](n: Int, m: Int): Seq[Seq[T]] = {
val map = Vector.newBuilder[Vector[T]]
var i = 0
while (i < n) {
map += next[T, Vector](m)
i += 1
}
map.result()
}
private[this] def nextDouble(): Double = nextString().toDouble
private[this] def nextChar(): Char = skip.toChar
private[this] def nextString(): String = {
var b = skip
val sb = new java.lang.StringBuilder
while (!isSpaceChar(b)) {
sb.appendCodePoint(b)
b = readByte().toInt
}
sb.toString
}
private[this] def nextInt(): Int = {
var num = 0
var b = 0
var minus = false
while ( {
b = readByte().toInt
b != -1 && !((b >= '0' && b <= '9') || b == '-')
}) {}
if (b == '-') {
minus = true
b = readByte().toInt
}
while (true) {
if (b >= '0' && b <= '9') {
num = num * 10 + (b - '0')
} else {
if (minus) return -num else return num
}
b = readByte().toInt
}
throw new IOException("Read Int")
}
private[this] def nextLong(): Long = {
var num = 0L
var b = 0
var minus = false
while ( {
b = readByte().toInt
b != -1 && !((b >= '0' && b <= '9') || b == '-')
}) {}
if (b == '-') {
minus = true
b = readByte().toInt
}
while (true) {
if (b >= '0' && b <= '9') {
num = num * 10 + (b - '0')
} else {
if (minus) return -num else return num
}
b = readByte().toInt
}
throw new IOException("Read Long")
}
private[this] val inputBuffer = new Array[Byte](1024)
private[this] var lenBuffer = 0
private[this] var ptrBuffer = 0
private[this] def readByte()(implicit in: java.io.InputStream): Byte = {
if (lenBuffer == -1) throw new InputMismatchException
if (ptrBuffer >= lenBuffer) {
ptrBuffer = 0
try {
lenBuffer = in.read(inputBuffer)
} catch {
case _: IOException =>
throw new InputMismatchException
}
if (lenBuffer <= 0) return -1
}
inputBuffer({
ptrBuffer += 1
ptrBuffer - 1
})
}
private[this] def isSpaceChar(c: Int) = (c < 33 || c > 126) && c != 10 && c != 32
private[this] def skip = {
var b = 0
while ( {
b = readByte().toInt
b != -1 && isSpaceChar(b)
}) {}
b
}
}
//------------------------------------------------------------------------------------------//
// Output
//------------------------------------------------------------------------------------------//
private[this] final object Writer {
private[this] val out = new PrintWriter(System.out)
def flush(): Unit = out.flush()
def println(x: Any): Unit = out.println(x)
def print(x: Any): Unit = out.print(x)
}
} | robertoFischer/hackerrank | src/main/scala/HackerRank/Training/Regex/HackerRankLanguage.scala | Scala | mit | 7,073 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.rdd
import java.io.{FileNotFoundException, IOException}
import java.text.SimpleDateFormat
import java.util.{Date, Locale}
import scala.collection.immutable.Map
import scala.reflect.ClassTag
import org.apache.hadoop.conf.{Configurable, Configuration}
import org.apache.hadoop.io.compress.CompressionCodecFactory
import org.apache.hadoop.mapred._
import org.apache.hadoop.mapred.lib.CombineFileSplit
import org.apache.hadoop.mapreduce.TaskType
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.util.ReflectionUtils
import org.apache.spark._
import org.apache.spark.annotation.DeveloperApi
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.deploy.SparkHadoopUtil
import org.apache.spark.errors.SparkCoreErrors
import org.apache.spark.internal.Logging
import org.apache.spark.internal.config._
import org.apache.spark.rdd.HadoopRDD.HadoopMapPartitionsWithSplitRDD
import org.apache.spark.scheduler.{HDFSCacheTaskLocation, HostTaskLocation}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.util.{NextIterator, SerializableConfiguration, ShutdownHookManager, Utils}
/**
* A Spark split class that wraps around a Hadoop InputSplit.
*/
private[spark] class HadoopPartition(rddId: Int, override val index: Int, s: InputSplit)
extends Partition {
val inputSplit = new SerializableWritable[InputSplit](s)
override def hashCode(): Int = 31 * (31 + rddId) + index
override def equals(other: Any): Boolean = super.equals(other)
/**
* Get any environment variables that should be added to the users environment when running pipes
* @return a Map with the environment variables and corresponding values, it could be empty
*/
def getPipeEnvVars(): Map[String, String] = {
val envVars: Map[String, String] = inputSplit.value match {
case is: FileSplit =>
// map_input_file is deprecated in favor of mapreduce_map_input_file but set both
// since it's not removed yet
Map("map_input_file" -> is.getPath().toString(),
"mapreduce_map_input_file" -> is.getPath().toString())
case _ =>
Map()
}
envVars
}
}
/**
* :: DeveloperApi ::
* An RDD that provides core functionality for reading data stored in Hadoop (e.g., files in HDFS,
* sources in HBase, or S3), using the older MapReduce API (`org.apache.hadoop.mapred`).
*
* @param sc The SparkContext to associate the RDD with.
* @param broadcastedConf A general Hadoop Configuration, or a subclass of it. If the enclosed
* variable references an instance of JobConf, then that JobConf will be used for the Hadoop job.
* Otherwise, a new JobConf will be created on each executor using the enclosed Configuration.
* @param initLocalJobConfFuncOpt Optional closure used to initialize any JobConf that HadoopRDD
* creates.
* @param inputFormatClass Storage format of the data to be read.
* @param keyClass Class of the key associated with the inputFormatClass.
* @param valueClass Class of the value associated with the inputFormatClass.
* @param minPartitions Minimum number of HadoopRDD partitions (Hadoop Splits) to generate.
*
* @note Instantiating this class directly is not recommended, please use
* `org.apache.spark.SparkContext.hadoopRDD()`
*/
@DeveloperApi
class HadoopRDD[K, V](
sc: SparkContext,
broadcastedConf: Broadcast[SerializableConfiguration],
initLocalJobConfFuncOpt: Option[JobConf => Unit],
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int)
extends RDD[(K, V)](sc, Nil) with Logging {
if (initLocalJobConfFuncOpt.isDefined) {
sparkContext.clean(initLocalJobConfFuncOpt.get)
}
def this(
sc: SparkContext,
conf: JobConf,
inputFormatClass: Class[_ <: InputFormat[K, V]],
keyClass: Class[K],
valueClass: Class[V],
minPartitions: Int) = {
this(
sc,
sc.broadcast(new SerializableConfiguration(conf))
.asInstanceOf[Broadcast[SerializableConfiguration]],
initLocalJobConfFuncOpt = None,
inputFormatClass,
keyClass,
valueClass,
minPartitions)
}
protected val jobConfCacheKey: String = "rdd_%d_job_conf".format(id)
protected val inputFormatCacheKey: String = "rdd_%d_input_format".format(id)
// used to build JobTracker ID
private val createTime = new Date()
private val shouldCloneJobConf = sparkContext.conf.getBoolean("spark.hadoop.cloneConf", false)
private val ignoreCorruptFiles = sparkContext.conf.get(IGNORE_CORRUPT_FILES)
private val ignoreMissingFiles = sparkContext.conf.get(IGNORE_MISSING_FILES)
private val ignoreEmptySplits = sparkContext.conf.get(HADOOP_RDD_IGNORE_EMPTY_SPLITS)
// Returns a JobConf that will be used on executors to obtain input splits for Hadoop reads.
protected def getJobConf(): JobConf = {
val conf: Configuration = broadcastedConf.value.value
if (shouldCloneJobConf) {
// Hadoop Configuration objects are not thread-safe, which may lead to various problems if
// one job modifies a configuration while another reads it (SPARK-2546). This problem occurs
// somewhat rarely because most jobs treat the configuration as though it's immutable. One
// solution, implemented here, is to clone the Configuration object. Unfortunately, this
// clone can be very expensive. To avoid unexpected performance regressions for workloads and
// Hadoop versions that do not suffer from these thread-safety issues, this cloning is
// disabled by default.
HadoopRDD.CONFIGURATION_INSTANTIATION_LOCK.synchronized {
logDebug("Cloning Hadoop Configuration")
val newJobConf = new JobConf(conf)
if (!conf.isInstanceOf[JobConf]) {
initLocalJobConfFuncOpt.foreach(f => f(newJobConf))
}
newJobConf
}
} else {
conf match {
case jobConf: JobConf =>
logDebug("Re-using user-broadcasted JobConf")
jobConf
case _ =>
Option(HadoopRDD.getCachedMetadata(jobConfCacheKey))
.map { conf =>
logDebug("Re-using cached JobConf")
conf.asInstanceOf[JobConf]
}
.getOrElse {
// Create a JobConf that will be cached and used across this RDD's getJobConf()
// calls in the local process. The local cache is accessed through
// HadoopRDD.putCachedMetadata().
// The caching helps minimize GC, since a JobConf can contain ~10KB of temporary
// objects. Synchronize to prevent ConcurrentModificationException (SPARK-1097,
// HADOOP-10456).
HadoopRDD.CONFIGURATION_INSTANTIATION_LOCK.synchronized {
logDebug("Creating new JobConf and caching it for later re-use")
val newJobConf = new JobConf(conf)
initLocalJobConfFuncOpt.foreach(f => f(newJobConf))
HadoopRDD.putCachedMetadata(jobConfCacheKey, newJobConf)
newJobConf
}
}
}
}
}
protected def getInputFormat(conf: JobConf): InputFormat[K, V] = {
val newInputFormat = ReflectionUtils.newInstance(inputFormatClass.asInstanceOf[Class[_]], conf)
.asInstanceOf[InputFormat[K, V]]
newInputFormat match {
case c: Configurable => c.setConf(conf)
case _ =>
}
newInputFormat
}
override def getPartitions: Array[Partition] = {
val jobConf = getJobConf()
// add the credentials here as this can be called before SparkContext initialized
SparkHadoopUtil.get.addCredentials(jobConf)
try {
val allInputSplits = getInputFormat(jobConf).getSplits(jobConf, minPartitions)
val inputSplits = if (ignoreEmptySplits) {
allInputSplits.filter(_.getLength > 0)
} else {
allInputSplits
}
if (inputSplits.length == 1 && inputSplits(0).isInstanceOf[FileSplit]) {
val fileSplit = inputSplits(0).asInstanceOf[FileSplit]
val path = fileSplit.getPath
if (fileSplit.getLength > conf.get(IO_WARNING_LARGEFILETHRESHOLD)) {
val codecFactory = new CompressionCodecFactory(jobConf)
if (Utils.isFileSplittable(path, codecFactory)) {
logWarning(s"Loading one large file ${path.toString} with only one partition, " +
s"we can increase partition numbers for improving performance.")
} else {
logWarning(s"Loading one large unsplittable file ${path.toString} with only one " +
s"partition, because the file is compressed by unsplittable compression codec.")
}
}
}
val array = new Array[Partition](inputSplits.size)
for (i <- 0 until inputSplits.size) {
array(i) = new HadoopPartition(id, i, inputSplits(i))
}
array
} catch {
case e: InvalidInputException if ignoreMissingFiles =>
logWarning(s"${jobConf.get(FileInputFormat.INPUT_DIR)} doesn't exist and no" +
s" partitions returned from this path.", e)
Array.empty[Partition]
case e: IOException if e.getMessage.startsWith("Not a file:") =>
val path = e.getMessage.split(":").map(_.trim).apply(2)
throw SparkCoreErrors.pathNotSupportedError(path)
}
}
override def compute(theSplit: Partition, context: TaskContext): InterruptibleIterator[(K, V)] = {
val iter = new NextIterator[(K, V)] {
private val split = theSplit.asInstanceOf[HadoopPartition]
logInfo("Input split: " + split.inputSplit)
private val jobConf = getJobConf()
private val inputMetrics = context.taskMetrics().inputMetrics
private val existingBytesRead = inputMetrics.bytesRead
// Sets InputFileBlockHolder for the file block's information
split.inputSplit.value match {
case fs: FileSplit =>
InputFileBlockHolder.set(fs.getPath.toString, fs.getStart, fs.getLength)
case _ =>
InputFileBlockHolder.unset()
}
// Find a function that will return the FileSystem bytes read by this thread. Do this before
// creating RecordReader, because RecordReader's constructor might read some bytes
private val getBytesReadCallback: Option[() => Long] = split.inputSplit.value match {
case _: FileSplit | _: CombineFileSplit =>
Some(SparkHadoopUtil.get.getFSBytesReadOnThreadCallback())
case _ => None
}
// We get our input bytes from thread-local Hadoop FileSystem statistics.
// If we do a coalesce, however, we are likely to compute multiple partitions in the same
// task and in the same thread, in which case we need to avoid override values written by
// previous partitions (SPARK-13071).
private def updateBytesRead(): Unit = {
getBytesReadCallback.foreach { getBytesRead =>
inputMetrics.setBytesRead(existingBytesRead + getBytesRead())
}
}
private var reader: RecordReader[K, V] = null
private val inputFormat = getInputFormat(jobConf)
HadoopRDD.addLocalConfiguration(
new SimpleDateFormat("yyyyMMddHHmmss", Locale.US).format(createTime),
context.stageId, theSplit.index, context.attemptNumber, jobConf)
reader =
try {
inputFormat.getRecordReader(split.inputSplit.value, jobConf, Reporter.NULL)
} catch {
case e: FileNotFoundException if ignoreMissingFiles =>
logWarning(s"Skipped missing file: ${split.inputSplit}", e)
finished = true
null
// Throw FileNotFoundException even if `ignoreCorruptFiles` is true
case e: FileNotFoundException if !ignoreMissingFiles => throw e
case e: IOException if ignoreCorruptFiles =>
logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e)
finished = true
null
}
// Register an on-task-completion callback to close the input stream.
context.addTaskCompletionListener[Unit] { context =>
// Update the bytes read before closing is to make sure lingering bytesRead statistics in
// this thread get correctly added.
updateBytesRead()
closeIfNeeded()
}
private val key: K = if (reader == null) null.asInstanceOf[K] else reader.createKey()
private val value: V = if (reader == null) null.asInstanceOf[V] else reader.createValue()
override def getNext(): (K, V) = {
try {
finished = !reader.next(key, value)
} catch {
case e: FileNotFoundException if ignoreMissingFiles =>
logWarning(s"Skipped missing file: ${split.inputSplit}", e)
finished = true
// Throw FileNotFoundException even if `ignoreCorruptFiles` is true
case e: FileNotFoundException if !ignoreMissingFiles => throw e
case e: IOException if ignoreCorruptFiles =>
logWarning(s"Skipped the rest content in the corrupted file: ${split.inputSplit}", e)
finished = true
}
if (!finished) {
inputMetrics.incRecordsRead(1)
}
if (inputMetrics.recordsRead % SparkHadoopUtil.UPDATE_INPUT_METRICS_INTERVAL_RECORDS == 0) {
updateBytesRead()
}
(key, value)
}
override def close(): Unit = {
if (reader != null) {
InputFileBlockHolder.unset()
try {
reader.close()
} catch {
case e: Exception =>
if (!ShutdownHookManager.inShutdown()) {
logWarning("Exception in RecordReader.close()", e)
}
} finally {
reader = null
}
if (getBytesReadCallback.isDefined) {
updateBytesRead()
} else if (split.inputSplit.value.isInstanceOf[FileSplit] ||
split.inputSplit.value.isInstanceOf[CombineFileSplit]) {
// If we can't get the bytes read from the FS stats, fall back to the split size,
// which may be inaccurate.
try {
inputMetrics.incBytesRead(split.inputSplit.value.getLength)
} catch {
case e: java.io.IOException =>
logWarning("Unable to get input size to set InputMetrics for task", e)
}
}
}
}
}
new InterruptibleIterator[(K, V)](context, iter)
}
/** Maps over a partition, providing the InputSplit that was used as the base of the partition. */
@DeveloperApi
def mapPartitionsWithInputSplit[U: ClassTag](
f: (InputSplit, Iterator[(K, V)]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = {
new HadoopMapPartitionsWithSplitRDD(this, f, preservesPartitioning)
}
override def getPreferredLocations(split: Partition): Seq[String] = {
val hsplit = split.asInstanceOf[HadoopPartition].inputSplit.value
val locs = hsplit match {
case lsplit: InputSplitWithLocationInfo =>
HadoopRDD.convertSplitLocationInfo(lsplit.getLocationInfo)
case _ => None
}
locs.getOrElse(hsplit.getLocations.filter(_ != "localhost"))
}
override def checkpoint(): Unit = {
// Do nothing. Hadoop RDD should not be checkpointed.
}
override def persist(storageLevel: StorageLevel): this.type = {
if (storageLevel.deserialized) {
logWarning("Caching HadoopRDDs as deserialized objects usually leads to undesired" +
" behavior because Hadoop's RecordReader reuses the same Writable object for all records." +
" Use a map transformation to make copies of the records.")
}
super.persist(storageLevel)
}
def getConf: Configuration = getJobConf()
}
private[spark] object HadoopRDD extends Logging {
/**
* Configuration's constructor is not threadsafe (see SPARK-1097 and HADOOP-10456).
* Therefore, we synchronize on this lock before calling new JobConf() or new Configuration().
*/
val CONFIGURATION_INSTANTIATION_LOCK = new Object()
/** Update the input bytes read metric each time this number of records has been read */
val RECORDS_BETWEEN_BYTES_READ_METRIC_UPDATES = 256
/**
* The three methods below are helpers for accessing the local map, a property of the SparkEnv of
* the local process.
*/
def getCachedMetadata(key: String): AnyRef = SparkEnv.get.hadoopJobMetadata.get(key)
private def putCachedMetadata(key: String, value: AnyRef): Unit =
SparkEnv.get.hadoopJobMetadata.put(key, value)
/** Add Hadoop configuration specific to a single partition and attempt. */
def addLocalConfiguration(jobTrackerId: String, jobId: Int, splitId: Int, attemptId: Int,
conf: JobConf): Unit = {
val jobID = new JobID(jobTrackerId, jobId)
val taId = new TaskAttemptID(new TaskID(jobID, TaskType.MAP, splitId), attemptId)
conf.set("mapreduce.task.id", taId.getTaskID.toString)
conf.set("mapreduce.task.attempt.id", taId.toString)
conf.setBoolean("mapreduce.task.ismap", true)
conf.setInt("mapreduce.task.partition", splitId)
conf.set("mapreduce.job.id", jobID.toString)
}
/**
* Analogous to [[org.apache.spark.rdd.MapPartitionsRDD]], but passes in an InputSplit to
* the given function rather than the index of the partition.
*/
private[spark] class HadoopMapPartitionsWithSplitRDD[U: ClassTag, T: ClassTag](
prev: RDD[T],
f: (InputSplit, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false)
extends RDD[U](prev) {
override val partitioner = if (preservesPartitioning) firstParent[T].partitioner else None
override def getPartitions: Array[Partition] = firstParent[T].partitions
override def compute(split: Partition, context: TaskContext): Iterator[U] = {
val partition = split.asInstanceOf[HadoopPartition]
val inputSplit = partition.inputSplit.value
f(inputSplit, firstParent[T].iterator(split, context))
}
}
private[spark] def convertSplitLocationInfo(
infos: Array[SplitLocationInfo]): Option[Seq[String]] = {
Option(infos).map(_.flatMap { loc =>
val locationStr = loc.getLocation
if (locationStr != "localhost") {
if (loc.isInMemory) {
logDebug(s"Partition $locationStr is cached by Hadoop.")
Some(HDFSCacheTaskLocation(locationStr).toString)
} else {
Some(HostTaskLocation(locationStr).toString)
}
} else {
None
}
})
}
}
| mahak/spark | core/src/main/scala/org/apache/spark/rdd/HadoopRDD.scala | Scala | apache-2.0 | 19,373 |
package scala
package collection
import scala.language.{higherKinds, implicitConversions}
import scala.annotation.unchecked.uncheckedVariance
import scala.math.{Ordering, Numeric}
import scala.reflect.ClassTag
import scala.collection.mutable.StringBuilder
/**
* A template trait for collections which can be traversed either once only
* or one or more times.
*
* @define orderDependent
*
* Note: might return different results for different runs, unless the underlying collection type is ordered.
* @define orderDependentFold
*
* Note: might return different results for different runs, unless the
* underlying collection type is ordered or the operator is associative
* and commutative.
* @define mayNotTerminateInf
*
* Note: may not terminate for infinite-sized collections.
* @define willNotTerminateInf
*
* Note: will not terminate for infinite-sized collections.
*
* @define coll collection
*/
trait IterableOnce[+A] extends Any {
/** Iterator can be used only once */
def iterator(): Iterator[A]
/** @return The number of elements of this $coll if it can be computed in O(1) time, otherwise -1 */
def knownSize: Int
}
final class IterableOnceExtensionMethods[A](private val it: IterableOnce[A]) extends AnyVal {
@deprecated("Use .iterator().foreach(...) instead of .foreach(...) on IterableOnce", "2.13.0")
@`inline` def foreach[U](f: A => U): Unit = it match {
case it: Iterable[A] => it.foreach(f)
case _ => it.iterator().foreach(f)
}
@deprecated("Use factory.from(it) instead of it.to(factory) for IterableOnce", "2.13.0")
def to[C1](factory: Factory[A, C1]): C1 = factory.fromSpecific(it)
@deprecated("Use ArrayBuffer.from(it) instead of it.toBuffer", "2.13.0")
def toBuffer[B >: A]: mutable.Buffer[B] = mutable.ArrayBuffer.from(it)
@deprecated("Use ArrayBuffer.from(it).toArray", "2.13.0")
def toArray[B >: A: ClassTag]: Array[B] = it match {
case it: Iterable[B] => it.toArray[B]
case _ => mutable.ArrayBuffer.from(it).toArray
}
@deprecated("Use List.from(it) instead of it.toList", "2.13.0")
def toList: immutable.List[A] = immutable.List.from(it)
@deprecated("Use Set.from(it) instead of it.toSet", "2.13.0")
@`inline` def toSet[B >: A]: immutable.Set[B] = immutable.Set.from(it)
@deprecated("Use Iterable.from(it) instead of it.toIterable", "2.13.0")
@`inline` final def toIterable: Iterable[A] = Iterable.from(it)
@deprecated("Use Seq.from(it) instead of it.toSeq", "2.13.0")
@`inline` def toSeq: immutable.Seq[A] = immutable.Seq.from(it)
@deprecated("Use Stream.from(it) instead of it.toStream", "2.13.0")
@`inline` def toStream: immutable.Stream[A] = immutable.Stream.from(it)
@deprecated("Use Vector.from(it) instead of it.toVector on IterableOnce", "2.13.0")
@`inline` def toVector: immutable.Vector[A] = immutable.Vector.from(it)
@deprecated("Use Map.from(it) instead of it.toVector on IterableOnce", "2.13.0")
def toMap[K, V](implicit ev: A <:< (K, V)): immutable.Map[K, V] =
immutable.Map.from(it.asInstanceOf[IterableOnce[(K, V)]])
@deprecated("toIterator has been renamed to iterator()", "2.13.0")
@`inline` def toIterator: Iterator[A] = it.iterator()
@deprecated("Use .iterator().isEmpty instead of .isEmpty on IterableOnce", "2.13.0")
def isEmpty: Boolean = it match {
case it: Iterable[A] => it.isEmpty
case _ => it.iterator().isEmpty
}
@deprecated("Use .iterator().mkString instead of .mkString on IterableOnce", "2.13.0")
def mkString(start: String, sep: String, end: String): String = it match {
case it: Iterable[A] => it.mkString(start, sep, end)
case _ => it.iterator().mkString(start, sep, end)
}
@deprecated("Use .iterator().mkString instead of .mkString on IterableOnce", "2.13.0")
def mkString(sep: String): String = it match {
case it: Iterable[A] => it.mkString(sep)
case _ => it.iterator().mkString(sep)
}
@deprecated("Use .iterator().mkString instead of .mkString on IterableOnce", "2.13.0")
def mkString: String = it match {
case it: Iterable[A] => it.mkString
case _ => it.iterator().mkString
}
@deprecated("Use .iterator().find instead of .find on IterableOnce", "2.13.0")
def find(p: A => Boolean): Option[A] = it.iterator().find(p)
@deprecated("Use .iterator().foldLeft instead of .foldLeft on IterableOnce", "2.13.0")
@`inline` def foldLeft[B](z: B)(op: (B, A) => B): B = it.iterator().foldLeft(z)(op)
@deprecated("Use .iterator().foldRight instead of .foldLeft on IterableOnce", "2.13.0")
@`inline` def foldRight[B](z: B)(op: (A, B) => B): B = it.iterator().foldRight(z)(op)
@deprecated("Use .iterator().fold instead of .fold on IterableOnce", "2.13.0")
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = it.iterator().fold(z)(op)
@deprecated("Use .iterator().foldLeft instead of /: on IterableOnce", "2.13.0")
@`inline` def /: [B](z: B)(op: (B, A) => B): B = foldLeft[B](z)(op)
@deprecated("Use .iterator().foldRight instead of :\\\\ on IterableOnce", "2.13.0")
@`inline` def :\\ [B](z: B)(op: (A, B) => B): B = foldRight[B](z)(op)
@deprecated("Use .iterator().map instead of .map on IterableOnce or consider requiring an Iterable", "2.13.0")
def map[B](f: A => B): IterableOnce[B] = it match {
case it: Iterable[A] => it.asInstanceOf[Iterable[A]].map(f)
case _ => it.iterator().map(f)
}
@deprecated("Use .iterator().flatMap instead of .flatMap on IterableOnce or consider requiring an Iterable", "2.13.0")
def flatMap[B](f: A => IterableOnce[B]): IterableOnce[B] = it match {
case it: Iterable[A] => it.asInstanceOf[Iterable[A]].flatMap(f)
case _ => it.iterator().flatMap(f)
}
@deprecated("Use .iterator().sameElements for sameElements on Iterable or IterableOnce", "2.13.0")
def sameElements[B >: A](that: IterableOnce[B]): Boolean = it.iterator().sameElements(that)
}
object IterableOnce {
@`inline` implicit def iterableOnceExtensionMethods[A](it: IterableOnce[A]): IterableOnceExtensionMethods[A] =
new IterableOnceExtensionMethods[A](it)
}
/** This implementation trait can be mixed into an `IterableOnce` to get the basic methods that are shared between
* `Iterator` and `Iterable`. The `IterableOnce` must support multiple calls to `iterator()` but may or may not
* return the same `Iterator` every time.
*/
trait IterableOnceOps[+A, +CC[_], +C] extends Any { this: IterableOnce[A] =>
/////////////////////////////////////////////////////////////// Abstract methods that must be implemented
/** Produces a $coll containing cumulative results of applying the
* operator going left to right, including the initial value.
*
* $willNotTerminateInf
* $orderDependent
*
* @tparam B the type of the elements in the resulting collection
* @param z the initial value
* @param op the binary operator applied to the intermediate result and the element
* @return collection with intermediate results
* @note Reuse: $consumesAndProducesIterator
*/
def scanLeft[B](z: B)(op: (B, A) => B): CC[B]
/** Selects all elements of this $coll which satisfy a predicate.
*
* @param p the predicate used to test elements.
* @return a new iterator consisting of all elements of this $coll that satisfy the given
* predicate `p`. The order of the elements is preserved.
*/
def filter(p: A => Boolean): C
/** Selects all elements of this $coll which do not satisfy a predicate.
*
* @param pred the predicate used to test elements.
* @return a new $coll consisting of all elements of this $coll that do not satisfy the given
* predicate `pred`. Their order may not be preserved.
*/
def filterNot(pred: A => Boolean): C
/** Selects first ''n'' elements.
* $orderDependent
* @param n the number of elements to take from this $coll.
* @return a $coll consisting only of the first `n` elements of this $coll,
* or else the whole $coll, if it has less than `n` elements.
* If `n` is negative, returns an empty $coll.
* @note Reuse: $consumesAndProducesIterator
*/
def take(n: Int): C
/** Takes longest prefix of elements that satisfy a predicate.
* $orderDependent
* @param p The predicate used to test elements.
* @return the longest prefix of this $coll whose elements all satisfy
* the predicate `p`.
* @note Reuse: $consumesAndProducesIterator
*/
def takeWhile(p: A => Boolean): C
/** Selects all elements except first ''n'' ones.
* $orderDependent
* @param n the number of elements to drop from this $coll.
* @return a $coll consisting of all elements of this $coll except the first `n` ones, or else the
* empty $coll, if this $coll has less than `n` elements.
* If `n` is negative, don't drop any elements.
* @note Reuse: $consumesAndProducesIterator
*/
def drop(n: Int): C
/** Drops longest prefix of elements that satisfy a predicate.
* $orderDependent
* @param p The predicate used to test elements.
* @return the longest suffix of this $coll whose first element
* does not satisfy the predicate `p`.
* @note Reuse: $consumesAndProducesIterator
*/
def dropWhile(p: A => Boolean): C
/** Selects an interval of elements. The returned $coll is made up
* of all elements `x` which satisfy the invariant:
* {{{
* from <= indexOf(x) < until
* }}}
* $orderDependent
*
* @param from the lowest index to include from this $coll.
* @param until the lowest index to EXCLUDE from this $coll.
* @return a $coll containing the elements greater than or equal to
* index `from` extending up to (but not including) index `until`
* of this $coll.
* @note Reuse: $consumesAndProducesIterator
*/
def slice(from: Int, until: Int): C
/** Builds a new $coll by applying a function to all elements of this $coll.
*
* @param f the function to apply to each element.
* @tparam B the element type of the returned $coll.
* @return a new $coll resulting from applying the given function
* `f` to each element of this $coll and collecting the results.
* @note Reuse: $consumesAndProducesIterator
*/
def map[B](f: A => B): CC[B]
/** Builds a new $coll by applying a function to all elements of this $coll
* and using the elements of the resulting collections.
*
* For example:
*
* {{{
* def getWords(lines: Seq[String]): Seq[String] = lines flatMap (line => line split "\\\\W+")
* }}}
*
* The type of the resulting collection is guided by the static type of $coll. This might
* cause unexpected results sometimes. For example:
*
* {{{
* // lettersOf will return a Seq[Char] of likely repeated letters, instead of a Set
* def lettersOf(words: Seq[String]) = words flatMap (word => word.toSet)
*
* // lettersOf will return a Set[Char], not a Seq
* def lettersOf(words: Seq[String]) = words.toSet flatMap (word => word.toSeq)
*
* // xs will be an Iterable[Int]
* val xs = Map("a" -> List(11,111), "b" -> List(22,222)).flatMap(_._2)
*
* // ys will be a Map[Int, Int]
* val ys = Map("a" -> List(1 -> 11,1 -> 111), "b" -> List(2 -> 22,2 -> 222)).flatMap(_._2)
* }}}
*
* @param f the function to apply to each element.
* @tparam B the element type of the returned collection.
* @return a new $coll resulting from applying the given collection-valued function
* `f` to each element of this $coll and concatenating the results.
* @note Reuse: $consumesAndProducesIterator
*/
def flatMap[B](f: A => IterableOnce[B]): CC[B]
/** Converts this $coll of traversable collections into
* a $coll formed by the elements of these traversable
* collections.
*
* The resulting collection's type will be guided by the
* type of $coll. For example:
*
* {{{
* val xs = List(
* Set(1, 2, 3),
* Set(1, 2, 3)
* ).flatten
* // xs == List(1, 2, 3, 1, 2, 3)
*
* val ys = Set(
* List(1, 2, 3),
* List(3, 2, 1)
* ).flatten
* // ys == Set(1, 2, 3)
* }}}
*
* @tparam B the type of the elements of each traversable collection.
* @param asIterable an implicit conversion which asserts that the element
* type of this $coll is a `GenTraversable`.
* @return a new $coll resulting from concatenating all element ${coll}s.
* @note Reuse: $consumesAndProducesIterator
*/
def flatten[B](implicit asIterable: A => IterableOnce[B]): CC[B]
/** Builds a new $coll by applying a partial function to all elements of this $coll
* on which the function is defined.
*
* @param pf the partial function which filters and maps the $coll.
* @tparam B the element type of the returned $coll.
* @return a new $coll resulting from applying the given partial function
* `pf` to each element on which it is defined and collecting the results.
* The order of the elements is preserved.
* @note Reuse: $consumesAndProducesIterator
*/
def collect[B](pf: PartialFunction[A, B]): CC[B]
/** Zips this $coll with its indices.
*
* @return A new $coll containing pairs consisting of all elements of this $coll paired with their index.
* Indices start at `0`.
* @example
* `List("a", "b", "c").zipWithIndex == List(("a", 0), ("b", 1), ("c", 2))`
* @note Reuse: $consumesAndProducesIterator
*/
def zipWithIndex: CC[(A @uncheckedVariance, Int)]
/** Splits this $coll into a prefix/suffix pair according to a predicate.
*
* Note: `c span p` is equivalent to (but possibly more efficient than)
* `(c takeWhile p, c dropWhile p)`, provided the evaluation of the
* predicate `p` does not cause any side-effects.
* $orderDependent
*
* @param p the test predicate
* @return a pair consisting of the longest prefix of this $coll whose
* elements all satisfy `p`, and the rest of this $coll.
* @note Reuse: $consumesOneAndProducesTwoIterators
*/
def span(p: A => Boolean): (C, C)
/////////////////////////////////////////////////////////////// Concrete methods based on iterator()
/** The number of elements in this $coll, if it can be cheaply computed,
* -1 otherwise. Cheaply usually means: Not requiring a collection traversal.
*/
def knownSize: Int = -1
/** Apply `f` to each element for its side effects
* Note: [U] parameter needed to help scalac's type inference.
*/
def foreach[U](f: A => U): Unit = {
val it = iterator()
while(it.hasNext) f(it.next())
}
/** Tests whether a predicate holds for all elements of this $coll.
*
* $mayNotTerminateInf
*
* @param p the predicate used to test elements.
* @return `true` if this $coll is empty or the given predicate `p`
* holds for all elements of this $coll, otherwise `false`.
*/
def forall(p: A => Boolean): Boolean = {
var res = true
val it = iterator()
while (res && it.hasNext) res = p(it.next())
res
}
/** Tests whether a predicate holds for at least one element of this $coll.
*
* $mayNotTerminateInf
*
* @param p the predicate used to test elements.
* @return `true` if the given predicate `p` is satisfied by at least one element of this $coll, otherwise `false`
*/
def exists(p: A => Boolean): Boolean = {
var res = false
val it = iterator()
while (!res && it.hasNext) res = p(it.next())
res
}
/** Counts the number of elements in the $coll which satisfy a predicate.
*
* @param p the predicate used to test elements.
* @return the number of elements satisfying the predicate `p`.
*/
def count(p: A => Boolean): Int = {
var res = 0
val it = iterator()
while (it.hasNext) if (p(it.next())) res += 1
res
}
/** Finds the first element of the $coll satisfying a predicate, if any.
*
* $mayNotTerminateInf
* $orderDependent
*
* @param p the predicate used to test elements.
* @return an option value containing the first element in the $coll
* that satisfies `p`, or `None` if none exists.
*/
def find(p: A => Boolean): Option[A] = {
val it = iterator()
while (it.hasNext) {
val a = it.next()
if (p(a)) return Some(a)
}
None
}
/** Applies a binary operator to a start value and all elements of this $coll,
* going left to right.
*
* $willNotTerminateInf
* $orderDependentFold
*
* @param z the start value.
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return the result of inserting `op` between consecutive elements of this $coll,
* going left to right with the start value `z` on the left:
* {{{
* op(...op(z, x_1), x_2, ..., x_n)
* }}}
* where `x,,1,,, ..., x,,n,,` are the elements of this $coll.
* Returns `z` if this $coll is empty.
*/
def foldLeft[B](z: B)(op: (B, A) => B): B = {
var result = z
val it = iterator()
while (it.hasNext) {
result = op(result, it.next())
}
result
}
/** Applies a binary operator to all elements of this $coll and a start value,
* going right to left.
*
* $willNotTerminateInf
* $orderDependentFold
* @param z the start value.
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return the result of inserting `op` between consecutive elements of this $coll,
* going right to left with the start value `z` on the right:
* {{{
* op(x_1, op(x_2, ... op(x_n, z)...))
* }}}
* where `x,,1,,, ..., x,,n,,` are the elements of this $coll.
* Returns `z` if this $coll is empty.
*/
def foldRight[B](z: B)(op: (A, B) => B): B = reversed.foldLeft(z)((b, a) => op(a, b))
@deprecated("Use foldLeft instead of /:", "2.13.0")
@`inline` final def /: [B](z: B)(op: (B, A) => B): B = foldLeft[B](z)(op)
@deprecated("Use foldRight instead of :\\\\", "2.13.0")
@`inline` final def :\\ [B](z: B)(op: (A, B) => B): B = foldRight[B](z)(op)
/** Folds the elements of this $coll using the specified associative binary operator.
* The default implementation in `IterableOnce` is equivalent to `foldLeft` but may be
* overridden for more efficient traversal orders.
*
* $undefinedorder
* $willNotTerminateInf
*
* @tparam A1 a type parameter for the binary operator, a supertype of `A`.
* @param z a neutral element for the fold operation; may be added to the result
* an arbitrary number of times, and must not change the result (e.g., `Nil` for list concatenation,
* 0 for addition, or 1 for multiplication).
* @param op a binary operator that must be associative.
* @return the result of applying the fold operator `op` between all the elements and `z`, or `z` if this $coll is empty.
*/
def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = foldLeft(z)(op)
/** Reduces the elements of this $coll using the specified associative binary operator.
*
* $undefinedorder
*
* @tparam B A type parameter for the binary operator, a supertype of `A`.
* @param op A binary operator that must be associative.
* @return The result of applying reduce operator `op` between all the elements if the $coll is nonempty.
* @throws UnsupportedOperationException if this $coll is empty.
*/
def reduce[B >: A](op: (B, B) => B): B = reduceLeft(op)
/** Reduces the elements of this $coll, if any, using the specified
* associative binary operator.
*
* $undefinedorder
*
* @tparam B A type parameter for the binary operator, a supertype of `A`.
* @param op A binary operator that must be associative.
* @return An option value containing result of applying reduce operator `op` between all
* the elements if the collection is nonempty, and `None` otherwise.
*/
def reduceOption[B >: A](op: (B, B) => B): Option[B] = reduceLeftOption(op)
/** Applies a binary operator to all elements of this $coll,
* going left to right.
* $willNotTerminateInf
* $orderDependentFold
*
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return the result of inserting `op` between consecutive elements of this $coll,
* going left to right:
* {{{
* op( op( ... op(x_1, x_2) ..., x_{n-1}), x_n)
* }}}
* where `x,,1,,, ..., x,,n,,` are the elements of this $coll.
* @throws UnsupportedOperationException if this $coll is empty. */
def reduceLeft[B >: A](op: (B, A) => B): B = {
val it = iterator()
if (it.isEmpty)
throw new UnsupportedOperationException("empty.reduceLeft")
var first = true
var acc: B = 0.asInstanceOf[B]
while (it.hasNext) {
val x = it.next()
if (first) {
acc = x
first = false
}
else acc = op(acc, x)
}
acc
}
/** Applies a binary operator to all elements of this $coll, going right to left.
* $willNotTerminateInf
* $orderDependentFold
*
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return the result of inserting `op` between consecutive elements of this $coll,
* going right to left:
* {{{
* op(x_1, op(x_2, ..., op(x_{n-1}, x_n)...))
* }}}
* where `x,,1,,, ..., x,,n,,` are the elements of this $coll.
* @throws UnsupportedOperationException if this $coll is empty.
*/
def reduceRight[B >: A](op: (A, B) => B): B = {
val it = iterator()
if (it.isEmpty)
throw new UnsupportedOperationException("empty.reduceRight")
reversed.reduceLeft[B]((x, y) => op(y, x))
}
/** Optionally applies a binary operator to all elements of this $coll, going left to right.
* $willNotTerminateInf
* $orderDependentFold
*
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return an option value containing the result of `reduceLeft(op)` if this $coll is nonempty,
* `None` otherwise.
*/
def reduceLeftOption[B >: A](op: (B, A) => B): Option[B] = if (isEmpty) None else Some(reduceLeft(op))
/** Optionally applies a binary operator to all elements of this $coll, going
* right to left.
* $willNotTerminateInf
* $orderDependentFold
*
* @param op the binary operator.
* @tparam B the result type of the binary operator.
* @return an option value containing the result of `reduceRight(op)` if this $coll is nonempty,
* `None` otherwise.
*/
def reduceRightOption[B >: A](op: (A, B) => B): Option[B] = if (isEmpty) None else Some(reduceRight(op))
/** Tests whether the $coll is empty.
*
* Note: Implementations in subclasses that are not repeatedly traversable must take
* care not to consume any elements when `isEmpty` is called.
*
* @return `true` if the $coll contains no elements, `false` otherwise.
*/
def isEmpty: Boolean = !iterator().hasNext
/** Tests whether the $coll is not empty.
*
* @return `true` if the $coll contains at least one element, `false` otherwise.
*/
@deprecatedOverriding("nonEmpty is defined as !isEmpty; override isEmpty instead", "2.13.0")
def nonEmpty: Boolean = !isEmpty
/** The size of this $coll.
*
* $willNotTerminateInf
*
* @return the number of elements in this $coll.
*/
def size: Int = {
if (knownSize >= 0) knownSize
else {
val it = iterator()
var len = 0
while (it.hasNext) { len += 1; it.next() }
len
}
}
@deprecated("Use `dest ++= coll` instead", "2.13.0")
@inline final def copyToBuffer[B >: A](dest: mutable.Buffer[B]): Unit = dest ++= this
/** Copy elements to an array.
*
* Fills the given array `xs` starting at index `start` with values of this $coll.
*
* Copying will stop once either all the elements of this $coll have been copied,
* or the end of the array is reached.
*
* @param xs the array to fill.
* @param start the starting index of xs.
* @tparam B the type of the elements of the array.
*
* @usecase def copyToArray(xs: Array[A], start: Int): Unit
*
* $willNotTerminateInf
*/
def copyToArray[B >: A](xs: Array[B], start: Int = 0): xs.type = {
val it = iterator()
var i = start
while (i < xs.length && it.hasNext) {
xs(i) = it.next()
i += 1
}
xs
}
/** Copy elements to an array.
*
* Fills the given array `xs` starting at index `start` with at most `len` elements of this $coll.
*
* Copying will stop once either all the elements of this $coll have been copied,
* or the end of the array is reached, or `len` elements have been copied.
*
* @param xs the array to fill.
* @param start the starting index of xs.
* @param len the maximal number of elements to copy.
* @tparam B the type of the elements of the array.
*
* @note Reuse: $consumesIterator
*
* @usecase def copyToArray(xs: Array[A], start: Int, len: Int): Unit
*
* $willNotTerminateInf
*/
def copyToArray[B >: A](xs: Array[B], start: Int, len: Int): xs.type = {
val it = iterator()
var i = start
val end = start + math.min(len, xs.length - start)
while (i < end && it.hasNext) {
xs(i) = it.next()
i += 1
}
xs
}
/** Sums up the elements of this collection.
*
* @param num an implicit parameter defining a set of numeric operations
* which includes the `+` operator to be used in forming the sum.
* @tparam B the result type of the `+` operator.
* @return the sum of all elements of this $coll with respect to the `+` operator in `num`.
*
* @usecase def sum: A
* @inheritdoc
*
* @return the sum of all elements in this $coll of numbers of type `Int`.
* Instead of `Int`, any other type `T` with an implicit `Numeric[T]` implementation
* can be used as element type of the $coll and as result type of `sum`.
* Examples of such types are: `Long`, `Float`, `Double`, `BigInt`.
*
*/
def sum[B >: A](implicit num: Numeric[B]): B = foldLeft(num.zero)(num.plus)
/** Multiplies up the elements of this collection.
*
* @param num an implicit parameter defining a set of numeric operations
* which includes the `*` operator to be used in forming the product.
* @tparam B the result type of the `*` operator.
* @return the product of all elements of this $coll with respect to the `*` operator in `num`.
*
* @usecase def product: A
* @inheritdoc
*
* @return the product of all elements in this $coll of numbers of type `Int`.
* Instead of `Int`, any other type `T` with an implicit `Numeric[T]` implementation
* can be used as element type of the $coll and as result type of `product`.
* Examples of such types are: `Long`, `Float`, `Double`, `BigInt`.
*/
def product[B >: A](implicit num: Numeric[B]): B = foldLeft(num.one)(num.times)
/** Finds the smallest element.
*
* @param ord An ordering to be used for comparing elements.
* @tparam B The type over which the ordering is defined.
* @return the smallest element of this $coll with respect to the ordering `ord`.
*
* @usecase def min: A
* @inheritdoc
*
* @return the smallest element of this $coll
* @throws UnsupportedOperationException if this $coll is empty.
*/
def min[B >: A](implicit ord: Ordering[B]): A = {
if (isEmpty)
throw new UnsupportedOperationException("empty.min")
reduceLeft((x, y) => if (ord.lteq(x, y)) x else y)
}
/** Finds the smallest element.
*
* @param ord An ordering to be used for comparing elements.
* @tparam B The type over which the ordering is defined.
* @return an option value containing the smallest element of this $coll
* with respect to the ordering `ord`.
*
* @usecase def min: A
* @inheritdoc
*
* @return an option value containing the smallest element of this $coll.
*/
def minOption[B >: A](implicit ord: Ordering[B]): Option[A] = {
if (isEmpty)
None
else
Some(min(ord))
}
/** Finds the largest element.
*
* @param ord An ordering to be used for comparing elements.
* @tparam B The type over which the ordering is defined.
* @return the largest element of this $coll with respect to the ordering `ord`.
*
* @usecase def max: A
* @inheritdoc
*
* @return the largest element of this $coll.
* @throws UnsupportedOperationException if this $coll is empty.
*/
def max[B >: A](implicit ord: Ordering[B]): A = {
if (isEmpty)
throw new UnsupportedOperationException("empty.max")
reduceLeft((x, y) => if (ord.gteq(x, y)) x else y)
}
/** Finds the largest element.
*
* @param ord An ordering to be used for comparing elements.
* @tparam B The type over which the ordering is defined.
* @return an option value containing the largest element of this $coll with
* respect to the ordering `ord`.
*
* @usecase def max: A
* @inheritdoc
*
* @return an option value containing the largest element of this $coll.
*/
def maxOption[B >: A](implicit ord: Ordering[B]): Option[A] = {
if (isEmpty)
None
else
Some(max(ord))
}
/** Finds the first element which yields the largest value measured by function f.
*
* @param cmp An ordering to be used for comparing elements.
* @tparam B The result type of the function f.
* @param f The measuring function.
* @return the first element of this $coll with the largest value measured by function f
* with respect to the ordering `cmp`.
*
* @usecase def maxBy[B](f: A => B): A
* @inheritdoc
*
* @return the first element of this $coll with the largest value measured by function f.
* @throws UnsupportedOperationException if this $coll is empty.
*/
def maxBy[B](f: A => B)(implicit cmp: Ordering[B]): A = {
if (isEmpty)
throw new UnsupportedOperationException("empty.maxBy")
var maxF: B = null.asInstanceOf[B]
var maxElem: A = null.asInstanceOf[A]
var first = true
for (elem <- this) {
val fx = f(elem)
if (first || cmp.gt(fx, maxF)) {
maxElem = elem
maxF = fx
first = false
}
}
maxElem
}
/** Finds the first element which yields the largest value measured by function f.
*
* @param cmp An ordering to be used for comparing elements.
* @tparam B The result type of the function f.
* @param f The measuring function.
* @return an option value containing the first element of this $coll with the
* largest value measured by function f with respect to the ordering `cmp`.
*
* @usecase def maxBy[B](f: A => B): A
* @inheritdoc
*
* @return an option value containing the first element of this $coll with
* the largest value measured by function f.
*/
def maxByOption[B](f: A => B)(implicit cmp: Ordering[B]): Option[A] = {
if (isEmpty)
None
else
Some(maxBy(f)(cmp))
}
/** Finds the first element which yields the smallest value measured by function f.
*
* @param cmp An ordering to be used for comparing elements.
* @tparam B The result type of the function f.
* @param f The measuring function.
* @return the first element of this $coll with the smallest value measured by function f
* with respect to the ordering `cmp`.
*
* @usecase def minBy[B](f: A => B): A
* @inheritdoc
*
* @return the first element of this $coll with the smallest value measured by function f.
* @throws UnsupportedOperationException if this $coll is empty.
*/
def minBy[B](f: A => B)(implicit cmp: Ordering[B]): A = {
if (isEmpty)
throw new UnsupportedOperationException("empty.minBy")
var minF: B = null.asInstanceOf[B]
var minElem: A = null.asInstanceOf[A]
var first = true
for (elem <- this) {
val fx = f(elem)
if (first || cmp.lt(fx, minF)) {
minElem = elem
minF = fx
first = false
}
}
minElem
}
/** Finds the first element which yields the smallest value measured by function f.
*
* @param cmp An ordering to be used for comparing elements.
* @tparam B The result type of the function f.
* @param f The measuring function.
* @return an option value containing the first element of this $coll
* with the smallest value measured by function f
* with respect to the ordering `cmp`.
*
* @usecase def minBy[B](f: A => B): A
* @inheritdoc
*
* @return an option value containing the first element of this $coll with
* the smallest value measured by function f.
*/
def minByOption[B](f: A => B)(implicit cmp: Ordering[B]): Option[A] = {
if (isEmpty)
None
else
Some(minBy(f)(cmp))
}
/** Finds the first element of the $coll for which the given partial
* function is defined, and applies the partial function to it.
*
* $mayNotTerminateInf
* $orderDependent
*
* @param pf the partial function
* @return an option value containing pf applied to the first
* value for which it is defined, or `None` if none exists.
* @example `Seq("a", 1, 5L).collectFirst({ case x: Int => x*10 }) = Some(10)`
*/
def collectFirst[B](pf: PartialFunction[A, B]): Option[B] = {
// Presumably the fastest way to get in and out of a partial function is for a sentinel function to return itself
// (Tested to be lower-overhead than runWith. Would be better yet to not need to (formally) allocate it)
val sentinel: scala.Function1[A, Any] = new scala.runtime.AbstractFunction1[A, Any]{ def apply(a: A) = this }
val it = iterator()
while (it.hasNext) {
val x = pf.applyOrElse(it.next(), sentinel)
if (x.asInstanceOf[AnyRef] ne sentinel) return Some(x.asInstanceOf[B])
}
None
}
/** Displays all elements of this $coll in a string using start, end, and
* separator strings.
*
* @param start the starting string.
* @param sep the separator string.
* @param end the ending string.
* @return a string representation of this $coll. The resulting string
* begins with the string `start` and ends with the string
* `end`. Inside, the string representations (w.r.t. the method
* `toString`) of all elements of this $coll are separated by
* the string `sep`.
*
* @example `List(1, 2, 3).mkString("(", "; ", ")") = "(1; 2; 3)"`
*/
def mkString(start: String, sep: String, end: String): String =
addString(new StringBuilder(), start, sep, end).toString
/** Displays all elements of this $coll in a string using a separator string.
*
* @param sep the separator string.
* @return a string representation of this $coll. In the resulting string
* the string representations (w.r.t. the method `toString`)
* of all elements of this $coll are separated by the string `sep`.
*
* @example `List(1, 2, 3).mkString("|") = "1|2|3"`
*/
def mkString(sep: String): String = mkString("", sep, "")
/** Displays all elements of this $coll in a string.
*
* @return a string representation of this $coll. In the resulting string
* the string representations (w.r.t. the method `toString`)
* of all elements of this $coll follow each other without any
* separator string.
*/
def mkString: String = mkString("")
/** Appends all elements of this $coll to a string builder using start, end, and separator strings.
* The written text begins with the string `start` and ends with the string `end`.
* Inside, the string representations (w.r.t. the method `toString`)
* of all elements of this $coll are separated by the string `sep`.
*
* Example:
*
* {{{
* scala> val a = List(1,2,3,4)
* a: List[Int] = List(1, 2, 3, 4)
*
* scala> val b = new StringBuilder()
* b: StringBuilder =
*
* scala> a.addString(b , "List(" , ", " , ")")
* res5: StringBuilder = List(1, 2, 3, 4)
* }}}
*
* @param b the string builder to which elements are appended.
* @param start the starting string.
* @param sep the separator string.
* @param end the ending string.
* @return the string builder `b` to which elements were appended.
*/
def addString(b: StringBuilder, start: String, sep: String, end: String): b.type = {
var first = true
b.append(start)
for (x <- this) {
if (first) {
b.append(x)
first = false
}
else {
b.append(sep)
b.append(x)
}
}
b.append(end)
b
}
/** Appends all elements of this $coll to a string builder using a separator string.
* The written text consists of the string representations (w.r.t. the method `toString`)
* of all elements of this $coll, separated by the string `sep`.
*
* Example:
*
* {{{
* scala> val a = List(1,2,3,4)
* a: List[Int] = List(1, 2, 3, 4)
*
* scala> val b = new StringBuilder()
* b: StringBuilder =
*
* scala> a.addString(b, ", ")
* res0: StringBuilder = 1, 2, 3, 4
* }}}
*
* @param b the string builder to which elements are appended.
* @param sep the separator string.
* @return the string builder `b` to which elements were appended.
*/
def addString(b: StringBuilder, sep: String): StringBuilder = addString(b, "", sep, "")
/** Appends all elements of this $coll to a string builder.
* The written text consists of the string representations (w.r.t. the method
* `toString`) of all elements of this $coll without any separator string.
*
* Example:
*
* {{{
* scala> val a = List(1,2,3,4)
* a: List[Int] = List(1, 2, 3, 4)
*
* scala> val b = new StringBuilder()
* b: StringBuilder =
*
* scala> val h = a.addString(b)
* h: StringBuilder = 1234
* }}}
* @param b the string builder to which elements are appended.
* @return the string builder `b` to which elements were appended.
*/
def addString(b: StringBuilder): StringBuilder = addString(b, "")
/** Given a collection factory `factory`, convert this collection to the appropriate
* representation for the current element type `A`. Example uses:
*
* xs.to(List)
* xs.to(ArrayBuffer)
* xs.to(BitSet) // for xs: Iterable[Int]
*/
def to[C1](factory: Factory[A, C1]): C1 = factory.fromSpecific(this)
@deprecated("Use .iterator() instead of .toIterator", "2.13.0")
@`inline` final def toIterator: Iterator[A] = iterator()
def toList: immutable.List[A] = immutable.List.from(this)
def toVector: immutable.Vector[A] = immutable.Vector.from(this)
def toMap[K, V](implicit ev: A <:< (K, V)): immutable.Map[K, V] =
immutable.Map.from(this.asInstanceOf[IterableOnce[(K, V)]])
def toSet[B >: A]: immutable.Set[B] = immutable.Set.from(this)
/**
* @return This collection as a `Seq[A]`. This is equivalent to `to(Seq)` but might be faster.
*/
def toSeq: immutable.Seq[A] = immutable.Seq.from(this)
def toIndexedSeq: immutable.IndexedSeq[A] = immutable.IndexedSeq.from(this)
@deprecated("Use Stream.from(it) instead of it.toStream", "2.13.0")
@`inline` final def toStream: immutable.Stream[A] = immutable.Stream.from(this)
@deprecated("Use ArrayBuffer.from(it) instead of it.toBuffer", "2.13.0")
@`inline` final def toBuffer[B >: A]: mutable.Buffer[B] = mutable.ArrayBuffer.from(this)
/** Convert collection to array. */
def toArray[B >: A: ClassTag]: Array[B] =
if (knownSize >= 0) copyToArray(new Array[B](knownSize), 0)
else mutable.ArrayBuffer.from(this).toArray[B]
// For internal use
protected def reversed: Iterable[A] = {
var xs: immutable.List[A] = immutable.Nil
val it = iterator()
while (it.hasNext) xs = it.next() :: xs
xs
}
}
| rorygraves/perf_tester | corpus/scala-library/src/main/scala/collection/IterableOnce.scala | Scala | apache-2.0 | 42,010 |
/*
* Copyright (C) 2013-2015 by Michael Hombre Brinkmann
*/
package net.twibs.form.base
import net.twibs.util.{Request, GetMethod, PostMethod}
import net.twibs.web._
class FormResponder(makeForm: () => BaseForm) extends Responder {
lazy val actionLink = enhance(makeForm().actionLink)
def respond(request: Request): Option[Response] =
if (request.path.string == actionLink) process(request)
else None
def process(request: Request): Option[Response] =
request.method match {
case GetMethod | PostMethod => Some(enhance(parse(request)))
case _ => None
}
def parse(request: Request) = makeForm().respond(request)
def enhance[R](f: => R): R = f
}
| hombre/twibs | twibs-core/src/main/scala/net/twibs/form/base/FormResponder.scala | Scala | apache-2.0 | 690 |
package at.logic.gapt.formats.babel
import at.logic.gapt.expr.preExpr._
import at.logic.gapt.expr.{ Ty, preExpr }
import at.logic.gapt.proofs.Context
import at.logic.gapt.{ expr => real }
/**
* A signature for the Babel parser. This class decides whether a free identifier is a variable or a constant.
*/
abstract class BabelSignature {
/**
* Decides whether the symbol with the given identifier should be a variable or constant, and what its type should be.
*
* @param s The name of the symbol.
* @return Either IsVar(type) or IsConst(type).
*/
def signatureLookup( s: String ): BabelSignature.VarConst
}
/**
* Contains various methods for generating signatures.
*
*/
object BabelSignature {
/**
* The signature that the Babel parser will use if no other signature is in scope. In this signature, identifiers denote
* variables iff they start with [u-zU-Z]. The types of all identifiers are arbitrary.
*/
implicit val defaultSignature = new BabelSignature {
val varPattern = "[u-zU-Z].*".r
def signatureLookup( s: String ): VarConst =
Context.default.constant( s ) match {
case Some( c ) => IsConst( c.ty )
case None =>
s match {
case varPattern() => IsVar
case _ => IsUnknownConst
}
}
}
sealed abstract class VarConst( val isVar: Boolean )
/** Variable without known type. */
case object IsVar extends VarConst( true )
/** Constant without known type. */
case object IsUnknownConst extends VarConst( false )
/** Constant with known type. */
case class IsConst( ty: Ty ) extends VarConst( false )
}
/**
* A signature based on a map: The identifiers for which the map is defined are constants, the rest are variables.
*
* @param map A map from strings to types.
*/
case class MapBabelSignature( map: Map[String, Ty] ) extends BabelSignature {
def signatureLookup( x: String ): BabelSignature.VarConst =
if ( map contains x )
BabelSignature.IsConst( map( x ) )
else
BabelSignature.IsVar
}
object MapBabelSignature {
def apply( consts: Iterable[real.Const] ): MapBabelSignature =
MapBabelSignature( consts.view map { c => c.name -> c.ty } toMap )
}
| gebner/gapt | core/src/main/scala/at/logic/gapt/formats/babel/BabelSignature.scala | Scala | gpl-3.0 | 2,230 |
package provingground.translation
import scala.xml._
/** Stanford dependency trees and associated methods */
object NlpProse {
/** The trait for all data to be parsed to mathematics */
trait ParseData
/**Tokens*/
case class Token(word: String, idx: Int) {
/** Merge tokens by merging words and taking the first position */
def +(that: Token) = Token(word + " " + that.word, idx)
override def toString = "(" + word + "," + idx.toString + ")"
}
/** Stanford dependency relation */
case class DepRel(gov: Token, dep: Token, deptype: String) {
override def toString =
deptype + "(" + gov.toString + "," + dep.toString + ")"
}
/** Returns root of dependency tree */
def findroot(t: List[DepRel]): Token = {
val roots = t filter (_.deptype == "root")
(roots.headOption map ((d: DepRel) => d.gov)).getOrElse {
val govs = t map (_.gov)
val deps = t map (_.dep)
def notdep(g: Token) = !(deps contains g)
val top = govs filter (notdep _)
top.head
}
}
object ProseTree {
def apply(t: List[DepRel]): ProseTree = ProseTree(findroot(t), t)
}
/** Stanford Dependency tree */
case class ProseTree(root: Token, tree: List[DepRel]) extends ParseData {
val vertices = (tree.map(_.gov).toSet) union (tree.map(_.dep).toSet)
override def toString = root.toString + ":" + tree.toString
/** Dependence relations with governor a given token */
def offspring(node: Token): List[DepRel] = tree filter (_.gov == node)
/** Dependence relations with governor the root */
def heirs: List[DepRel] = offspring(root)
/** Initiates ProseTree from a list of Tokens by finding root*/
// def this(t: List[DepRel]) = this(findroot(t), t)
/**List of dependency relations descending from an initial list */
def desc(init: List[DepRel]): List[DepRel] = {
if (init.isEmpty) List()
else {
val newnodes = init map (_.dep)
val newedges = newnodes map offspring
init ::: ((newedges map desc).flatten)
}
}
/** Remove dependency relations with dependent a given token */
def -(node: Token) = ProseTree(root, (tree filter (_.dep != node)))
/** Remove all edges contained in ProseTree s and with dependent in s */
def -(s: ProseTree) = {
def notintree(edge: DepRel) =
(edge.dep != s.root) && !(s.tree contains edge)
ProseTree(root, (tree filter notintree))
}
/** Deletes in the sense of method {{-}} a list of trees*/
def --(ss: List[ProseTree]): ProseTree = ss match {
case s :: List() => this - s
case s :: sss => (this - s) -- sss
case Nil => this
}
/** The tree of all descendants of a node */
def descTree(node: Token) = ProseTree(node, desc(offspring(node)))
lazy val subTrees: Set[ProseTree] = vertices.map(descTree)
def treeAt(head: String) = subTrees.find(_.root.word == head)
def treesAt(head: String) = subTrees.filter(_.root.word == head)
/** The tree of all descendants of a node */
def -<(node: Token) = descTree(node)
/** Splits into the tree of descendants and the rest */
def split(r: DepRel) = (r, -<(r.dep), this - (-<(r.dep)))
private def depstart(r: DepRel, s: String) = r.deptype.startsWith(s)
private def depstartsome(r: DepRel, ss: List[String]) =
(ss map (r.deptype.startsWith(_))) reduce (_ || _)
/** Find Dependency Relations in heirs of (more generally starting with) a given dependency type */
def find(typ: String) = heirs find (depstart(_, typ))
/** Find Dependency Relations in heirs specifying both type and dependent word*/
def find(typ: String, word: String): Option[DepRel] = {
def depmatch(d: DepRel): Boolean =
(depstart(d, typ)) && ((d.dep.word).toLowerCase == word)
heirs find depmatch
}
/** Find Dependency Relations in heirs for type and split tree accordingly if found */
def findSplit(typ: String) = find(typ: String) map (split)
/** Find Dependency Relations in heirs for type and word and split tree accordingly if found */
def findSplit(typ: String, word: String) =
find(typ: String, word: String) map (split)
/** Find all heirs with dependency one of the given types */
def findAll(typs: List[String]): List[DepRel] =
heirs filter (depstartsome(_, typs))
/** Find all heirs with dependency the given type */
def findAll(typ: String): List[DepRel] = heirs filter (depstart(_, typ))
/**
* Mainly for convenient visualization
*/
lazy val labelMap = tree.groupBy(_.gov).view.mapValues((l) => l.map(_.deptype)).toMap
def depView(depRel: DepRel, parents: List[Token]): Elem = {
val word = s"${depRel.dep.word}(${depRel.dep.idx})"
def childViews: Seq[Elem] =
offspring(depRel.dep).filter((t) => !parents.contains(t.dep)).map {
(rel) =>
<li>{depView(rel, depRel.gov :: parents)}</li>
}
val childList =
offspring(depRel.dep).map(_.dep.word).mkString("[", ", ", "]")
<div>
<table>
<tr> <td>Word: </td> <td> <strong>{word}</strong> </td> </tr>
<tr> <td>Dep-Type: </td> <td> <strong> {depRel.deptype}</strong></td> </tr>
<tr> <td>Children: </td> <td> {childList}</td> </tr>
</table>
<ul>
{childViews}
</ul>
</div>
}
val heirsView = heirs.map { (rel) =>
<li>
{depView(rel, List(root))}
</li>
}
val pp = new scala.xml.PrettyPrinter(80, 4)
val view =
pp.format(<div>
<div>root:<strong>{root.word}</strong> </div>
<div>children:
<ul>
{heirsView}
</ul>
</div>
</div>)
}
/** Find the string of multi-word expressions starting at a token */
def mweTail(t: ProseTree, node: Token): Token = {
val nxt = t.offspring(node) find (_.deptype == "mwe")
nxt match {
case None => node
case Some(x) => mweTail(t, x.dep) + node
}
}
case class SplitTree(edge: DepRel, subtree: ProseTree, pruned: ProseTree)
/** returns Dependency Relation obtained by merging in multi-word expressions */
def mweMerge(t: ProseTree, d: DepRel) =
DepRel(mweTail(t, d.gov), mweTail(t, d.dep), d.deptype)
/** returns new tree folding together multi-word expressions */
def mweFold(t: ProseTree) = {
val foldList = (t.tree map (mweMerge(t, _))) filter (_.deptype != "mwe")
ProseTree(mweTail(t, t.root), foldList)
}
/** Generic Extractor from ProseTree*/
class ProseExtractor[A](fn: ProseTree => Option[A]) {
def unapply(t: ProseTree): Option[A] = fn(t)
def this(fn: PartialFunction[ProseTree, A]) = this(fn.lift)
}
/** Extractor matching Dependency type */
class TypeMatch(depType: String) {
def unapply(t: ProseTree): Option[(DepRel, ProseTree, ProseTree)] =
t.findSplit(depType)
}
/** Extractor matching Dependency type and Word of Dependent Token*/
class TypeWordMatch(depType: String, w: String) {
def unapply(t: ProseTree): Option[(DepRel, ProseTree, ProseTree)] =
t.findSplit(depType, w)
}
class TypeListMatch(typList: List[String]) {
def unapply(t: ProseTree): Option[(DepRel, ProseTree, ProseTree)] =
t.findAll(typList).headOption map (t.split)
}
object Conj {
def splitConj(
t: ProseTree): DepRel => (String, DepRel, ProseTree, ProseTree) =
(r) => (r.deptype drop 5, r, t -< r.dep, t - (t -< r.dep))
def unapply(t: ProseTree): Option[(String, DepRel, ProseTree, ProseTree)] =
t.find("conj").map(splitConj(t))
}
object Prep {
def splitPrep(
t: ProseTree): DepRel => (String, DepRel, ProseTree, ProseTree) =
(r) => (r.deptype drop 5, r, t -< r.dep, t - (t -< r.dep))
def unapply(t: ProseTree): Option[(String, DepRel, ProseTree, ProseTree)] =
t.find("prep").map(splitPrep(t))
}
/** Fallback for all modifiers */
object Modifier
extends TypeListMatch(
List(
"abbrev",
"amod",
"appos",
"advcl",
"purpcl",
"det",
"predet",
"preconj",
"infmod",
"partmod",
"advmod",
"mwe",
"neg",
"rcmod",
"quantmod",
"nn",
"npadvmod",
"tmod",
"num",
"number",
"prep",
"possesive",
"prt",
"aux",
"auxpass"
)) // These are not technically modifiers but behave the same way
/** Fallback for all arguments */
object Argument
extends TypeListMatch(
List("agent",
"comp",
"acomp",
"attr",
"ccomp",
"xcomp",
"complm",
"obj",
"dobj",
"iobj",
"pobj",
"mark",
"rel",
"subj",
"nsubj",
"nsubjpass",
"csubj",
"csubjpass"))
object Advcl extends TypeMatch("advcl")
object IfMark extends TypeWordMatch("mark", "if")
/** Extractor for quantmod */
object QuantMod extends TypeMatch("quantmod")
// use stringNumber()
/** Extractor for > */
object Gt extends TypeWordMatch("quantmod", "greater than")
/** Extractor for < */
object Lt extends TypeWordMatch("quantmod", "less than")
/** Extractor for "cop" relation */
object CopRel extends TypeMatch("cop")
/** Extractor for nsubj */
object Nsubj extends TypeMatch("nsubj")
/** Extractor for relative clause modifier */
object Rcmod extends TypeMatch("rcmod")
/** Extractor for Clausal complement */
object Ccomp extends TypeMatch("ccomp")
private val copFn: PartialFunction[ProseTree, (ProseTree, ProseTree)] = {
case CopRel(_, _, Nsubj(_, s, t)) => (s, t)
}
/** Extractor for "cop" identifying the subject */
object Cop extends ProseExtractor(copFn.lift)
/** Extractor for "which" */
object Which extends TypeWordMatch("nsubj", "which")
object Parataxis extends TypeMatch("parataxis")
}
| siddhartha-gadgil/ProvingGround | core/src/main/scala/provingground/translation/NlpProse.scala | Scala | mit | 10,185 |
package com.wavesplatform.it.sync.smartcontract
import com.wavesplatform.common.state.ByteStr
import com.wavesplatform.common.utils.EitherExt2
import com.wavesplatform.crypto
import com.wavesplatform.it.api.SyncHttpApi._
import com.wavesplatform.it.sync.{minFee, setScriptFee, transferAmount}
import com.wavesplatform.it.transactions.BaseTransactionSuite
import com.wavesplatform.lang.v1.estimator.v2.ScriptEstimatorV2
import com.wavesplatform.test._
import com.wavesplatform.transaction.Proofs
import com.wavesplatform.transaction.lease.{LeaseCancelTransaction, LeaseTransaction}
import com.wavesplatform.transaction.smart.script.ScriptCompiler
import org.scalatest.CancelAfterFailure
class LeaseSmartContractsTestSuite extends BaseTransactionSuite with CancelAfterFailure {
private def acc0 = firstKeyPair
private def acc1 = secondKeyPair
private def acc2 = thirdKeyPair
test("set contract, make leasing and cancel leasing") {
val (balance1, eff1) = miner.accountBalances(acc0.toAddress.toString)
val (balance2, eff2) = miner.accountBalances(thirdKeyPair.toAddress.toString)
sender.transfer(sender.keyPair, acc0.toAddress.toString, 10 * transferAmount, minFee, waitForTx = true).id
miner.assertBalances(firstAddress, balance1 + 10 * transferAmount, eff1 + 10 * transferAmount)
val scriptText = s"""
let pkA = base58'${acc0.publicKey}'
let pkB = base58'${acc1.publicKey}'
let pkC = base58'${acc2.publicKey}'
match tx {
case ltx: LeaseTransaction => sigVerify(ltx.bodyBytes,ltx.proofs[0],pkA) && sigVerify(ltx.bodyBytes,ltx.proofs[2],pkC)
case lctx : LeaseCancelTransaction => sigVerify(lctx.bodyBytes,lctx.proofs[1],pkA) && sigVerify(lctx.bodyBytes,lctx.proofs[2],pkB)
case _ => false
}
""".stripMargin
val script = ScriptCompiler(scriptText, isAssetScript = false, ScriptEstimatorV2).explicitGet()._1.bytes().base64
sender.setScript(acc0, Some(script), setScriptFee, waitForTx = true).id
val unsignedLeasing =
LeaseTransaction
.create(
2.toByte,
acc0.publicKey,
acc2.toAddress,
transferAmount,
minFee + 0.2.waves,
System.currentTimeMillis(),
Proofs.empty
)
.explicitGet()
val sigLeasingA = crypto.sign(acc0.privateKey, unsignedLeasing.bodyBytes())
val sigLeasingC = crypto.sign(acc2.privateKey, unsignedLeasing.bodyBytes())
val signedLeasing =
unsignedLeasing.copy(proofs = Proofs(Seq(sigLeasingA, ByteStr.empty, sigLeasingC)))
val leasingId =
sender.signedBroadcast(signedLeasing.json(), waitForTx = true).id
miner.assertBalances(
firstAddress,
balance1 + 10 * transferAmount - (minFee + setScriptFee + 0.2.waves),
eff1 + 9 * transferAmount - (minFee + setScriptFee + 0.2.waves)
)
miner.assertBalances(thirdAddress, balance2, eff2 + transferAmount)
val unsignedCancelLeasing =
LeaseCancelTransaction
.create(
version = 2.toByte,
sender = acc0.publicKey,
leaseId = ByteStr.decodeBase58(leasingId).get,
fee = minFee + 0.2.waves,
timestamp = System.currentTimeMillis(),
proofs = Proofs.empty
)
.explicitGet()
val sigLeasingCancelA = crypto.sign(acc0.privateKey, unsignedCancelLeasing.bodyBytes())
val sigLeasingCancelB = crypto.sign(acc1.privateKey, unsignedCancelLeasing.bodyBytes())
val signedLeasingCancel =
unsignedCancelLeasing.copy(proofs = Proofs(Seq(ByteStr.empty, sigLeasingCancelA, sigLeasingCancelB)))
sender.signedBroadcast(signedLeasingCancel.json(), waitForTx = true).id
miner.assertBalances(
firstAddress,
balance1 + 10 * transferAmount - (2 * minFee + setScriptFee + 2 * 0.2.waves),
eff1 + 10 * transferAmount - (2 * minFee + setScriptFee + 2 * 0.2.waves)
)
miner.assertBalances(thirdAddress, balance2, eff2)
}
}
| wavesplatform/Waves | node-it/src/test/scala/com/wavesplatform/it/sync/smartcontract/LeaseSmartContractsTestSuite.scala | Scala | mit | 3,972 |
package org.qcri.rheem.api
import de.hpi.isg.profiledb.store.model.Experiment
import org.apache.commons.lang3.Validate
import org.qcri.rheem.api
import org.qcri.rheem.basic.data.Record
import org.qcri.rheem.basic.operators.{CollectionSource, TableSource, TextFileSource}
import org.qcri.rheem.core.api.RheemContext
import org.qcri.rheem.core.plan.rheemplan._
import org.qcri.rheem.core.util.ReflectionUtils
import scala.collection.JavaConversions
import scala.collection.mutable.ListBuffer
import scala.language.implicitConversions
import scala.reflect._
/**
* Utility to build [[RheemPlan]]s.
*/
class PlanBuilder(rheemContext: RheemContext, private var jobName: String = null) {
private[api] val sinks = ListBuffer[Operator]()
private val udfJars = scala.collection.mutable.Set[String]()
private var experiment: Experiment = _
// We need to ensure that this module is shipped to Spark etc. in particular because of the Scala-to-Java function wrappers.
ReflectionUtils.getDeclaringJar(this) match {
case path: String => udfJars += path
case _ =>
}
/**
* Defines user-code JAR files that might be needed to transfer to execution platforms.
*
* @param paths paths to JAR files that should be transferred
* @return this instance
*/
def withUdfJars(paths: String*) = {
this.udfJars ++= paths
this
}
/**
* Defines the [[Experiment]] that should collects metrics of the [[RheemPlan]].
*
* @param experiment the [[Experiment]]
* @return this instance
*/
def withExperiment(experiment: Experiment) = {
this.experiment = experiment
this
}
/**
* Defines the name for the [[RheemPlan]] that is being created.
*
* @param jobName the name
* @return this instance
*/
def withJobName(jobName: String) = {
this.jobName = jobName
this
}
/**
* Defines user-code JAR files that might be needed to transfer to execution platforms.
*
* @param classes whose JAR files should be transferred
* @return this instance
*/
def withUdfJarsOf(classes: Class[_]*) =
withUdfJars(classes.map(ReflectionUtils.getDeclaringJar).filterNot(_ == null): _*)
/**
* Build the [[org.qcri.rheem.core.api.Job]] and execute it.
*/
def buildAndExecute(): Unit = {
val plan: RheemPlan = new RheemPlan(this.sinks.toArray: _*)
if (this.experiment == null) this.rheemContext.execute(jobName, plan, this.udfJars.toArray: _*)
else this.rheemContext.execute(jobName, plan, this.experiment, this.udfJars.toArray: _*)
}
/**
* Read a text file and provide it as a dataset of [[String]]s, one per line.
*
* @param url the URL of the text file
* @return [[DataQuanta]] representing the file
*/
def readTextFile(url: String): DataQuanta[String] = load(new TextFileSource(url))
/**
* Reads a database table and provides them as a dataset of [[Record]]s.
*
* @param source from that the [[Record]]s should be read
* @return [[DataQuanta]] of [[Record]]s in the table
*/
def readTable(source: TableSource): DataQuanta[Record] = load(source)
/**
* Loads a [[java.util.Collection]] into Rheem and represents them as [[DataQuanta]].
*
* @param collection to be loaded
* @return [[DataQuanta]] the `collection`
*/
def loadCollection[T: ClassTag](collection: java.util.Collection[T]): DataQuanta[T] =
load(new CollectionSource[T](collection, dataSetType[T]))
/**
* Loads a [[Iterable]] into Rheem and represents it as [[DataQuanta]].
*
* @param iterable to be loaded
* @return [[DataQuanta]] the `iterable`
*/
def loadCollection[T: ClassTag](iterable: Iterable[T]): DataQuanta[T] =
loadCollection(JavaConversions.asJavaCollection(iterable))
/**
* Load [[DataQuanta]] from an arbitrary [[UnarySource]].
*
* @param source that should be loaded from
* @return the [[DataQuanta]]
*/
def load[T: ClassTag](source: UnarySource[T]): DataQuanta[T] = wrap(source)
/**
* Execute a custom [[Operator]].
*
* @param operator that should be executed
* @param inputs the input [[DataQuanta]] of the `operator`, aligned with its [[InputSlot]]s
* @return an [[IndexedSeq]] of the `operator`s output [[DataQuanta]], aligned with its [[OutputSlot]]s
*/
def customOperator(operator: Operator, inputs: DataQuanta[_]*): IndexedSeq[DataQuanta[_]] = {
Validate.isTrue(operator.getNumRegularInputs == inputs.size)
// Set up inputs.
inputs.zipWithIndex.foreach(zipped => zipped._1.connectTo(operator, zipped._2))
// Set up outputs.
for (outputIndex <- 0 until operator.getNumOutputs) yield DataQuanta.create(operator.getOutput(outputIndex))(this)
}
implicit private[api] def wrap[T: ClassTag](operator: ElementaryOperator): DataQuanta[T] =
PlanBuilder.wrap[T](operator)(classTag[T], this)
}
object PlanBuilder {
implicit private[api] def wrap[T: ClassTag](operator: ElementaryOperator)(implicit planBuilder: PlanBuilder): DataQuanta[T] =
api.wrap[T](operator)
}
| jonasrk/rheem | rheem-api/src/main/scala/org/qcri/rheem/api/PlanBuilder.scala | Scala | apache-2.0 | 5,063 |
package io.iohk.ethereum.consensus.ethash.validators
import akka.util.ByteString
import io.iohk.ethereum.consensus.ethash.validators.OmmersValidator.OmmersError._
import io.iohk.ethereum.consensus.ethash.validators.OmmersValidator.{OmmersError, OmmersValid}
import io.iohk.ethereum.consensus.validators.BlockHeaderValidator
import io.iohk.ethereum.consensus.{GetBlockHeaderByHash, GetNBlocksBack}
import io.iohk.ethereum.domain.BlockHeader
import io.iohk.ethereum.utils.BlockchainConfig
class StdOmmersValidator(blockchainConfig: BlockchainConfig, blockHeaderValidator: BlockHeaderValidator)
extends OmmersValidator {
val OmmerGenerationLimit: Int = 6 // Stated on section 11.1, eq. (143) of the YP
val OmmerSizeLimit: Int = 2
/** This method allows validating the ommers of a Block. It performs the following validations (stated on
* section 11.1 of the YP):
* - OmmersValidator.validateOmmersLength
* - OmmersValidator.validateOmmersHeaders
* - OmmersValidator.validateOmmersAncestors
* It also includes validations mentioned in the white paper (https://github.com/ethereum/wiki/wiki/White-Paper)
* and implemented in the different ETC clients:
* - OmmersValidator.validateOmmersNotUsed
* - OmmersValidator.validateDuplicatedOmmers
*
* @param parentHash the hash of the parent of the block to which the ommers belong
* @param blockNumber the number of the block to which the ommers belong
* @param ommers the list of ommers to validate
* @param getBlockHeaderByHash function to obtain an ancestor block header by hash
* @param getNBlocksBack function to obtain N blocks including one given by hash and its N-1 ancestors
*
* @return [[OmmersValidator.OmmersValid]] if valid, an [[OmmersValidator.OmmersError]] otherwise
*/
def validate(
parentHash: ByteString,
blockNumber: BigInt,
ommers: Seq[BlockHeader],
getBlockHeaderByHash: GetBlockHeaderByHash,
getNBlocksBack: GetNBlocksBack
): Either[OmmersError, OmmersValid] = {
if (ommers.isEmpty)
Right(OmmersValid)
else
for {
_ <- validateOmmersLength(ommers)
_ <- validateDuplicatedOmmers(ommers)
_ <- validateOmmersHeaders(ommers, getBlockHeaderByHash)
_ <- validateOmmersAncestors(parentHash, blockNumber, ommers, getNBlocksBack)
_ <- validateOmmersNotUsed(parentHash, blockNumber, ommers, getNBlocksBack)
} yield OmmersValid
}
/** Validates ommers length based on validations stated in section 11.1 of the YP
*
* @param ommers the list of ommers to validate
*
* @return [[OmmersValidator.OmmersValid]] if valid, an [[OmmersValidator.OmmersError.OmmersLengthError]] otherwise
*/
private def validateOmmersLength(ommers: Seq[BlockHeader]): Either[OmmersError, OmmersValid] = {
if (ommers.length <= OmmerSizeLimit) Right(OmmersValid)
else Left(OmmersLengthError)
}
/** Validates that each ommer's header is valid based on validations stated in section 11.1 of the YP
*
* @param ommers the list of ommers to validate
* @param getBlockHeaderByHash function to obtain ommers' parents
*
* @return [[OmmersValidator.OmmersValid]] if valid, an [[OmmersValidator.OmmersError.OmmersNotValidError]] otherwise
*/
private def validateOmmersHeaders(
ommers: Seq[BlockHeader],
getBlockHeaderByHash: GetBlockHeaderByHash
): Either[OmmersError, OmmersValid] = {
if (ommers.forall(blockHeaderValidator.validate(_, getBlockHeaderByHash).isRight)) Right(OmmersValid)
else Left(OmmersNotValidError)
}
/** Validates that each ommer is not too old and that it is a sibling as one of the current block's ancestors
* based on validations stated in section 11.1 of the YP
*
* @param parentHash the hash of the parent of the block to which the ommers belong
* @param blockNumber the number of the block to which the ommers belong
* @param ommers the list of ommers to validate
* @param getNBlocksBack from where the ommers' parents will be obtained
*
* @return [[OmmersValidator.OmmersValid]] if valid, an [[OmmersValidator.OmmersError.OmmersUsedBeforeError]] otherwise
*/
private def validateOmmersAncestors(
parentHash: ByteString,
blockNumber: BigInt,
ommers: Seq[BlockHeader],
getNBlocksBack: GetNBlocksBack
): Either[OmmersError, OmmersValid] = {
val ancestorsOpt = collectAncestors(parentHash, blockNumber, getNBlocksBack)
val validOmmersAncestors: Seq[BlockHeader] => Boolean = ancestors =>
ommers.forall { ommer =>
val ommerIsNotAncestor = ancestors.forall(_.hash != ommer.hash)
val ommersParentIsAncestor = ancestors.exists(_.parentHash == ommer.parentHash)
ommerIsNotAncestor && ommersParentIsAncestor
}
if (ancestorsOpt.exists(validOmmersAncestors)) Right(OmmersValid)
else Left(OmmersAncestorsError)
}
/** Validates that each ommer was not previously used
* based on validations stated in the white paper (https://github.com/ethereum/wiki/wiki/White-Paper)
*
* @param parentHash the hash of the parent of the block to which the ommers belong
* @param blockNumber the number of the block to which the ommers belong
* @param ommers the list of ommers to validate
* @param getNBlocksBack from where the ommers' parents will be obtained
* @return [[OmmersValidator.OmmersValid]] if valid, an [[OmmersValidator.OmmersError.OmmersUsedBeforeError]] otherwise
*/
private def validateOmmersNotUsed(
parentHash: ByteString,
blockNumber: BigInt,
ommers: Seq[BlockHeader],
getNBlocksBack: GetNBlocksBack
): Either[OmmersError, OmmersValid] = {
val ommersFromAncestorsOpt = collectOmmersFromAncestors(parentHash, blockNumber, getNBlocksBack)
if (ommersFromAncestorsOpt.exists(ommers.intersect(_).isEmpty)) Right(OmmersValid)
else Left(OmmersUsedBeforeError)
}
/** Validates that there are no duplicated ommers
* based on validations stated in the white paper (https://github.com/ethereum/wiki/wiki/White-Paper)
*
* @param ommers the list of ommers to validate
* @return [[OmmersValidator.OmmersValid]] if valid, an [[OmmersValidator.OmmersError.OmmersDuplicatedError]] otherwise
*/
private def validateDuplicatedOmmers(ommers: Seq[BlockHeader]): Either[OmmersError, OmmersValid] = {
if (ommers.distinct.length == ommers.length) Right(OmmersValid)
else Left(OmmersDuplicatedError)
}
private def collectAncestors(
parentHash: ByteString,
blockNumber: BigInt,
getNBlocksBack: GetNBlocksBack
): Option[Seq[BlockHeader]] = {
val numberOfBlocks = blockNumber.min(OmmerGenerationLimit).toInt
val ancestors = getNBlocksBack(parentHash, numberOfBlocks).map(_.header)
Some(ancestors).filter(_.length == numberOfBlocks)
}
private def collectOmmersFromAncestors(
parentHash: ByteString,
blockNumber: BigInt,
getNBlocksBack: GetNBlocksBack
): Option[Seq[BlockHeader]] = {
val numberOfBlocks = blockNumber.min(OmmerGenerationLimit).toInt
val ancestors = getNBlocksBack(parentHash, numberOfBlocks).map(_.body.uncleNodesList)
Some(ancestors).filter(_.length == numberOfBlocks).map(_.flatten)
}
}
| input-output-hk/etc-client | src/main/scala/io/iohk/ethereum/consensus/ethash/validators/StdOmmersValidator.scala | Scala | mit | 7,380 |
package sgl
package native
import scalanative.unsafe._
import sdl2.SDL._
import sdl2.Extras._
trait NativeWindowProvider extends WindowProvider {
this: GameStateComponent with NativeGraphicsProvider =>
val frameDimension: (Int, Int)
class NativeWindow extends AbstractWindow {
override def width: Int = frameDimension._1
override def height: Int = frameDimension._2
// TODO: should refresh when Window is resized or dpis changes.
private var _xppi: Float = 0f
private var _yppi: Float = 0f
private var _ppi: Float = 0f
private def computePPIs(): Unit = {
val ddpi: Ptr[CFloat] = stackalloc[CFloat]
val hdpi: Ptr[CFloat] = stackalloc[CFloat]
val vdpi: Ptr[CFloat] = stackalloc[CFloat]
SDL_GetDisplayDPI(0, ddpi, hdpi, vdpi)
_xppi = !hdpi
_yppi = !vdpi
_ppi = !ddpi
}
override def xppi: Float = if(_xppi != 0f) _xppi else {
computePPIs()
_xppi
}
override def yppi: Float = if(_yppi != 0f) _yppi else {
computePPIs()
_yppi
}
override def ppi: Float = if(_ppi != 0f) _ppi else {
computePPIs()
_ppi
}
// TODO: rounding?
override def logicalPpi: Float = if(_ppi != 0f) _ppi else {
computePPIs()
_ppi
}
}
type Window = NativeWindow
override val Window = new NativeWindow
///** The name of the window */
//val windowTitle: String
//TODO: provide a WindowDimension object, with either fixed width/height or FullScreen
//abstract class WindowDimension
//case class FixedWindowDimension(width: Int, height: Int)
//case object FullScreen
//case class ResizableWIndowDimension(width: Int, height: Int)
//val WindowDimension: WindowDimension
}
| regb/scala-game-library | desktop-native/src/main/scala/sgl/native/NativeWindowProvider.scala | Scala | mit | 1,728 |
/**
* @author e.e d3si9n
*/
import scalaxb._
import ipo._
object PurchaseOrderIgnoreUnknownUsage {
def main(args: Array[String]): Unit = {
allTests
}
def allTests = {
testUSAddress
testItem
testItems
testPurchaseOrder
testTimeOlson
testIntWithAttr
testChoices
testLangAttr
testRoundTrip
testChoiceRoundTrip
testAny
testAnyChoice
testAnyAttribute
testDatedData
testNillable
testAll
testContentModel
testSubstitutionGroup
true
}
def testUSAddress = {
val subject = <shipTo xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO"
xsi:type="ipo:USAddress">
<street>1537 Paper Street</street>
<unknowntag1>test</unknowntag1>
<city>Wilmington</city>
<state>DE</state>
<name>Foo</name>
<unknowntag2>test</unknowntag2>
<zip>19808</zip>
</shipTo>
val Zipcode = BigInt(19808)
val address = fromXML[Addressable](subject)
address match {
case USAddress("Foo",
"1537 Paper Street",
"Wilmington",
DE,
Zipcode) =>
case _ => sys.error("match failed: " + address.toString)
}
println(address.toString)
}
def testItem = {
val subject = <item partNum="639-OS" xmlns="http://www.example.com/IPO">
<quantity>1</quantity>
<productName>Olive Soap</productName>
<unknowntag2>test</unknowntag2>
<shipDate>2010-02-06Z</shipDate>
<USPrice>4.00</USPrice>
</item>
val One = BigInt(1)
val item = fromXML[Item](subject)
item match {
case x@Item("Olive Soap",
One,
usPrice,
None,
Some(XMLCalendar("2010-02-06Z")),
_) if x.partNum == "639-OS" =>
if (usPrice != BigDecimal(4.00))
sys.error("values don't match: " + item.toString)
case _ => sys.error("match failed: " + item.toString)
}
println(item.toString)
}
def testItems = {
val subject = <items xmlns="http://www.example.com/IPO">
<item partNum="639-OS">
<quantity>1</quantity>
<unknownTag1>test</unknownTag1>
<productName>Olive Soap</productName>
<USPrice>4.00</USPrice>
<shipDate>2010-02-06Z</shipDate>
</item>
</items>
val items = fromXML[Items](subject)
items match {
case Items(_) =>
case _ => sys.error("match failed: " + items.toString)
}
println(items.toString)
}
def testPurchaseOrder = {
val subject = <purchaseOrder
xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO"
orderDate="1999-12-01Z">
<items>
<item partNum="639-OS">
<quantity>1</quantity>
<USPrice>4.00</USPrice>
<productName>Olive Soap</productName>
<shipDate>2010-02-06Z</shipDate>
</item>
</items>
<billTo xsi:type="ipo:USAddress">
<name>Foo</name>
<street>1537 Paper Street</street>
<city>Wilmington</city>
<state>DE</state>
<zip>19808</zip>
</billTo>
<shipTo exportCode="1" xsi:type="ipo:UKAddress">
<name>Helen Zoe</name>
<postcode>CB1 1JR</postcode>
<street>47 Eden Street</street>
<city>Cambridge</city>
</shipTo>
<unknowntag>test</unknowntag>
</purchaseOrder>
val purchaseOrder = fromXML[PurchaseOrderType](subject)
purchaseOrder match {
case x@PurchaseOrderType(
shipTo: UKAddress,
billTo: USAddress,
None,
Items(_),
_) if x.orderDate == Some(XMLCalendar("1999-12-01Z")) =>
case _ => sys.error("match failed: " + purchaseOrder.toString)
}
println(purchaseOrder.toString)
}
def testTimeOlson = {
val subject = <time xmlns="http://www.example.com/IPO">00:00:00</time>
val timeOlson = fromXML[TimeOlson](subject)
timeOlson match {
case x@TimeOlson(XMLCalendar("00:00:00"), _) if x.olsonTZ == "" =>
case _ => sys.error("match failed: " + timeOlson.toString)
}
println(timeOlson.toString)
}
def testIntWithAttr = {
val subject = <some foo="test" xmlns="http://www.example.com/IPO">1</some>
val intWithAttr = fromXML[IntWithAttr](subject)
intWithAttr match {
case x@IntWithAttr(1, _) if x.foo == "test" =>
case _ => sys.error("match failed: " + intWithAttr.toString)
}
println(intWithAttr.toString)
}
def testChoices = {
val subject = <Element1 xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO">
<Choice2>1</Choice2>
</Element1>
val obj = fromXML[Element1](subject)
obj match {
case Element1(DataRecord(Some("http://www.example.com/IPO"), Some("Choice2"), 1)) =>
case Element1(List(DataRecord(Some("http://www.example.com/IPO"), Some("Choice2"), 1))) =>
case _ => sys.error("match failed: " + obj.toString)
}
println(obj.toString)
}
def testLangAttr = {
val subject = <Choice1 xml:lang="en" xmlns="http://www.example.com/IPO"></Choice1>
val obj = fromXML[Choice1](subject)
obj match {
case x@Choice1(_, _) if x.xmllang == "en" =>
case _ => sys.error("match failed: " + obj.toString)
}
println(obj.toString)
}
def testRoundTrip = {
import scala.xml.{TopScope, NamespaceBinding}
val subject = <shipTo xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO"
xsi:type="ipo:USAddress">
<unknowntag>test</unknowntag>
<name>Foo</name>
<street>1537 Paper Street</street>
<state>DE</state>
<city>Wilmington</city>
<zip>19808</zip>
</shipTo>
val obj = fromXML[Addressable](subject)
obj match {
case usaddress: USAddress =>
val document = toXML[Addressable](usaddress, None, Some("shipTo"), subject.scope)
println(document)
val obj2 = fromXML[Addressable](document)
obj2 match {
case `usaddress` =>
case _ => sys.error("match failed: " + obj2.toString)
}
println(obj2.toString)
case _ => sys.error("parsed object is not USAddress")
}
}
def testChoiceRoundTrip = {
val subject = <Element1 xmlns="http://www.example.com/IPO"><Choice2>1</Choice2></Element1>
val obj = fromXML[Element1](subject)
val document = toXML(obj, Some("http://www.example.com/IPO"), Some("Element1"), subject.scope)
println(document)
val obj2 = fromXML[Element1](document)
obj2 match {
case `obj` =>
case _ => sys.error("match failed: " + obj2.toString)
}
}
def testAny = {
val subject = <choice1 xmlns="http://www.example.com/IPO"
xmlns:ipo="http://www.example.com/IPO"
xmlns:h="http://www.w3.org/1999/xhtml"
xml:lang="en"
h:href="4Q99.html">
<math xmlns="http://www.w3.org/1998/Math/MathML">
<apply>
<log/>
<logbase><cn>3</cn></logbase>
<ci>x</ci>
</apply>
</math>
<unknowntag>test</unknowntag>
</choice1>
val obj = fromXML[Choice1](subject)
obj match {
case x@Choice1(_, attributes) if (attributes("@{http://www.w3.org/1999/xhtml}href") ==
DataRecord(Some("http://www.w3.org/1999/xhtml"), Some("href"), "4Q99.html")) &&
(x.xmllang == "en") =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("choice1"), subject.scope)
println(document)
}
def testAnyChoice = {
val subject = <Element1 xmlns="http://www.example.com/IPO"
xmlns:ipo="http://www.example.com/IPO">
<math xmlns="http://www.w3.org/1998/Math/MathML">
<apply>
<log/>
<logbase><cn>3</cn></logbase>
<ci>x</ci>
</apply>
</math>
</Element1>
val obj = fromXML[Element1](subject)
val document = toXML(obj, None, Some("Element1"), subject.scope)
println(document)
val obj2 = fromXML[Element1](document)
obj2 match {
case Element1(DataRecord(Some("http://www.w3.org/1998/Math/MathML"), Some("math"), _)) =>
case Element1(List(DataRecord(Some("http://www.w3.org/1998/Math/MathML"), Some("math"), _))) =>
case _ => sys.error("match failed: " + document.toString)
}
}
def testAnyAttribute = {
val subject = <foo xmlns="http://www.example.com/IPO"
xmlns:ipo="http://www.example.com/IPO"
xmlns:h="http://www.w3.org/1999/xhtml"
h:href="4Q99.html">
</foo>
val obj = fromXML[Element2](subject)
obj match {
case Element2(attributes) if attributes("@{http://www.w3.org/1999/xhtml}href") ==
DataRecord(Some("http://www.w3.org/1999/xhtml"), Some("href"), "4Q99.html") =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("foo"), subject.scope)
println(document)
val obj2 = fromXML[Element2](document)
obj2 match {
case Element2(attributes) if attributes("@{http://www.w3.org/1999/xhtml}href") ==
DataRecord(Some("http://www.w3.org/1999/xhtml"), Some("href"), "4Q99.html") =>
case _ => sys.error("match failed: " + obj2.toString)
}
}
def testDatedData = {
val subject = <foo xmlns="http://www.example.com/IPO"
xmlns:ipo="http://www.example.com/IPO" id="foo">
<base64Binary>QUJDREVGRw==</base64Binary>
<hexBinary>0F</hexBinary>
<date>2010-02-06Z</date>
</foo>
val obj = fromXML[DatedData](subject)
obj match {
case x@DatedData(XMLCalendar("2010-02-06Z"),
HexBinary(15),
Base64Binary('A', 'B', 'C', 'D', 'E', 'F', 'G'),
_) if (x.id == Some("foo")) && (x.classValue == None) =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("foo"), subject.scope)
println(document)
}
def testNillable = {
val subject = <foo xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO">
<price xsi:nil="true" />
<tax xsi:nil="true" />
<unknowntag xsi:nil="true">test</unknowntag>
<shipTo xsi:nil="true" />
<tag xsi:nil="true" />
<tag xsi:nil="true" />
<billTo xsi:nil="true" />
<via xsi:nil="true" />
<via xsi:nil="true" />
</foo>
val obj = fromXML[NillableTest](subject)
obj match {
case NillableTest(None, Some(None), Seq(None, None),
None, Some(None), Seq(None, None)) =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("foo"), subject.scope)
println(document)
}
def testAll = {
val subject = <foo xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO">
<unknowntag>test</unknowntag>
<style></style>
<title>bar</title>
<script></script>
<unknowntag>test</unknowntag>
</foo>
val obj = fromXML[AllTest](subject)
obj match {
case x@AllTest(Some(""), Some(""), Some("bar"), _, _) if x.id == None =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("foo"), subject.scope)
println(document)
}
def testContentModel = {
val subject = <head xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO"
dir="ltr">
<unknownTag>test</unknownTag>
<script></script>
<script></script>
<title>bar</title>
<script></script>
<unknownTag>test</unknownTag>
<unknownTag>test</unknownTag>
</head>
val obj = fromXML[Head](subject)
obj match {
case x@Head(Seq(DataRecord(Some("http://www.example.com/IPO"), Some("script"), ""),
DataRecord(Some("http://www.example.com/IPO"), Some("script"), "")),
DataRecord(None, None, HeadSequence1("bar", Seq(DataRecord(Some("http://www.example.com/IPO"), Some("script"), "")) )),
_) if (x.dir == Some(Ltr)) =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("head"), subject.scope)
println(document)
}
def testSubstitutionGroup = {
val subject = <billTo xmlns="http://www.example.com/IPO"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ipo="http://www.example.com/IPO"
dir="ltr">
<gh6head2>bar</gh6head2>
<gh6sub1>foo</gh6sub1>
<unknowntag>test</unknowntag>
<city>baz</city>
</billTo>
val obj = fromXML[GH6Usage](subject)
obj match {
case GH6Usage(DataRecord(Some("http://www.example.com/IPO"),
Some("gh6sub1"), "foo"), "bar", "baz") =>
case _ => sys.error("match failed: " + obj.toString)
}
val document = toXML(obj, None, Some("billTo"), subject.scope)
println(document)
}
}
| eed3si9n/scalaxb | integration/src/test/resources/PurchaseOrderIgnoreUnknownUsage.scala | Scala | mit | 13,387 |
case class State[S, +A](run: S => (A, S)) {
def map[B](f: A => B): State[S, B] =
flatMap(a => unit(f(a)))
def map2[B,C](sb: State[S, B])(f: (A, B) => C): State[S, C] =
flatMap(a => sb.map(b => f(a, b)))
def flatMap[B](f: A => State[S, B]): State[S, B] = State(s => {
val (a, s1) = run(s)
f(a).run(s1)
})
}
object State {
def unit[S, A](a: A): State[S, A] =
State(s => (a, s))
// The idiomatic solution is expressed via foldRight
def sequenceViaFoldRight[S,A](sas: List[State[S, A]]): State[S, List[A]] =
sas.foldRight(unit[S, List[A]](List()))((f, acc) => f.map2(acc)(_ :: _))
// This implementation uses a loop internally and is the same recursion
// pattern as a left fold. It is quite common with left folds to build
// up a list in reverse order, then reverse it at the end.
// (We could also use a collection.mutable.ListBuffer internally.)
def sequence[S, A](sas: List[State[S, A]]): State[S, List[A]] = {
def go(s: S, actions: List[State[S,A]], acc: List[A]): (List[A],S) =
actions match {
case Nil => (acc.reverse,s)
case h :: t => h.run(s) match { case (a,s2) => go(s2, t, a :: acc) }
}
State((s: S) => go(s,sas,List()))
}
// We can also write the loop using a left fold. This is tail recursive like the
// previous solution, but it reverses the list _before_ folding it instead of after.
// You might think that this is slower than the `foldRight` solution since it
// walks over the list twice, but it's actually faster! The `foldRight` solution
// technically has to also walk the list twice, since it has to unravel the call
// stack, not being tail recursive. And the call stack will be as tall as the list
// is long.
def sequenceViaFoldLeft[S,A](l: List[State[S, A]]): State[S, List[A]] =
l.reverse.foldLeft(unit[S, List[A]](List()))((acc, f) => f.map2(acc)( _ :: _ ))
} | fpinscala-muc/fpinscala-LithiumTD | answerkey/state/12.answer.scala | Scala | mit | 1,848 |
Subsets and Splits
Filtered Scala Code Snippets
The query filters and retrieves a sample of code snippets that meet specific criteria, providing a basic overview of the dataset's content without revealing deeper insights.